/

















































































































































































































































































































Текст
ПРИОБРЕТЕНИЕ ЗНАНИЙ
*Р»1Э*Ш 3
# - А #
ПРИОБРЕТЕНИЕ ЗНАНИЙ
Под редакцией С. ОСУГИ, Ю. САЭКИ
Перевод с японского
канд. техн. наук Ю. Н. Чернышова
под редакцией
д-ра физ.-мат. наук Н. Г. Волкова
Москва «Мир» 1990
ББК 32.973.1
П76
УДК 007.001.33
Авторы: Осуга С, Саэки Ю., Судзуки X
Кобаяси X., Оцуки С, Китихаси Т., Танака
Арикава С, Синохара Т., Мияхара Т., Хараг]
Ю.,
арагути М.
Приобретение знаний: Пер. с япон./Под ред.
П76 С. Осуги, Ю. Саэки.—М.: Мир, 1990.—304 с, ил.
ISBN 5-03-001263-Х
Книга является переводом третьего тома 10-томной
серии по инженерии знаний, написанной крупными японскими
специалистами. Посвящена методике приобретения знаний
и обучения с точки зрения построения экспертных систем
и баз знаний. Рассмотрены психологические аспекты
обучения, методы и проблемы, связанные с извлечением
знаний. Обсуждены вопросы представления знаний для работы
в режиме диалога и способы ведения диалога. Много
внимания уделено проблемам построения баз знаний.
Проанализированы прикладные аспекты автоматического синтеза
программ на Лиспе.
Для студентов университетов и специалистов по
созданию обучающих систем и тренажеров.
^ 1402070000-444
11 043@1)-90 5"90 ББК 32-973-J
Редакция литературы по информатике и робототехнике
ISBN 5-03-001263-Х (русск.) © С. Осуга, Ю. Саэки. «Ол
ISBN 4-274-07346 (япон.) Токио, 1987
© перевод на русский язэж,
Ю. Н. Чернышов 1990
ОТ ПЕРЕВОДЧИКА
Среди многочисленных проблем искусственного интеллекта
исследования по представлению и использованию знаний
занимают особое место. И не столько потому, что они тесно связаны
с самым загадочным явлением природы — мышлением человека,
сколько потому, что результаты этих исследований первыми -
начали приносить ощутимую пользу, воплотившись во множестве
экспертных систем.
Экспертные системы, ассимилируя знания ведущих
специалистов самых разнообразных профилей, играют важную роль в
распространении этих знаний, в повышении квалификации
пользователей, а в последние годы благодаря развитию
международных сетей связи способствуют созданию общедоступных баз
знаний в различных сферах деятельности человека.
Как известно, компьютеры пятого поколения, первые образцы
которых, по оценке экспертов, должны появиться в 90-е гг.,
будут в максимальной степени использовать результаты
исследований в области инженерии знаний. Вспомним, что универсальность
существующих компьютеров достигается за счет определенного
набора команд и независимого механизма их обработки, а
проблема — лишь в преобразовании решаемой задачи в
последовательность таких команд. Точно так же в компьютерах пятого
поколения универсальность должна быть достигнута за счет
представления знаний в некотором унифицированном формате и
создания механизма их обработки (машины логических выводов).
При этом любая поставленная человеком задача может быть
решена компьютером, естественно, при условии, что он
(компьютер) имеет необходимые для ее решения знания.
Таким образом, очевидно, что будущее вычислительной
техники и международных коммуникационных сетей во многом
связывают с системами, основанными на знаниях.
Развитие экспертной системы, как и интеллектуальная жизнь
человека, складывается из двух процессов: накопления знаний
и их использования. Но если человек приобретает знания из
опыта в течение всей жизни, то экспертная система на первом
этапе получает свои знания от эксперта и, будучи переданной
пользователям, в большинстве случаев может лишь
систематизировать имеющиеся знания, скажем проверять их
непротиворечивость и надежность, (Хотя более развитые экспертные системы
имеют функции приобретения новых знаний в диалоге с
опытными пользователями.)
Развитие работ в области создания интеллектуальных систем
во многом сдерживается нехваткой соответствующих
специалистов— инженеров по знаниям. Они должны владеть методами
представления и использования знаний, методами
программирования, а также обладать достаточной эрудицией для общения со
специалистами других профилей, в частности хорошо представ-
8
Предисловие
смысле — проблема обучения. Именно так можно назвать функ-
i*iiii извлечения информации из окружающей среды и их
накопление в памяти с целью использования.
Проблема обучения имеет несколько аспектов: 1 — функции
обучающегося, 2 — свойства среды — источника информации, 3 —
взаимодействие обучающегося и среды. В принципе уровень
знаний повышается постоянно по мере абстрагирования их смысла,
поэтому функции, которыми должен обладать обучающийся,
различны в зависимости от уровня необходимой ему информацп i.
То же можно сказать и о среде, которая дает информацию
обучающемуся, а уровень представления исходной информации
зависит от уровня, достигнутого обучающимся. Кроме того,
наличие взаимосвязи между обучающимся и средой обусловливается
его способностями и эффективностью обучения. После
получения информации низкого уровня сам обучающийся может
повысить ее уровень, следуя соответствующим инструкциям.
Итак, при обучении ставятся по крайней мере две цели.
Первая — извлечение информации из среды, вторая — повышение
ее уровня и структурирование. Пока не получена вся
информация, она не может стать знанием, и данные низкого уровня,
например исходные данные, могут быть использованы также на
низком уровне. С повышением уровня данных возрастает их
универсальность в плане применения. Вторая цель достигается с
помощью различных средств. Следовательно, необходимо
обсуждать обе цели проблемы обучения с учетом указанных выше
трех аспектов. Более того, помимо функций обучающегося,
связанных с получением информации об объекте и повышением ее
уровня, необходимы функции управления процессом обучения.
При изучении проблемы обучения необходимо применять
различные подходы, взятые из жизни. Функции обучения присущи
живым существам по их природе, поэтому предложены такие
подходы, как наблюдение и моделирование функций обучения
животных и человека, изучение модели обучения с помощью
математики или символической логики, моделирование процесса
обучения при обработке образов, выполняемой чисто с практической
точки зрения, и другие подходы. Короче говоря, проведено
множество исследований функций обучения, но по сравнению со
сложностью проблемы обучения полученные результаты
недостаточны для систематического обсуждения. Тем не менее при
рассмотрении инженерии знаний нельзя пройти мимо проблемы
обучения, охватывающей почти половину задач обработки знаний.
В данной книге важное место занимает систематическое
изложение современного состояния исследований этой проблемы, и
сторонники различных подходов к ее решению во многих областях
могут обсудить ее с соответствующих точек зрения.
Издание книги—во многом заслуга сотрудников
издательства «Омся», без помощи которых выход книги в свет был бы
невозможен
Февраль 1987
С. Осуга
Ю. Сажи
ГЛАВА 1
ВВЕДЕНИЕ
С. Осуга (Токийский университет)
По мере развития и практического применения
техники обработки знаний повышался интерес к таким
функциям, как обучение и приобретение знаний с
помощью компьютеров. Поскольку объектом обработки
являются знания, то неизбежно появляется
стремление к созданию систем с функциями приобретения,
хранения и применения знаний. Однако большинство
обучающихся систем, разработанных до настоящего
времени, ориентированы на анализ механизма
приобретения информации человеком и его
воспроизведения в машине, а сложное эвристическое обучение,
свойственное человеку, практически не реализовано.
Если это предел возможностей обучения с помощью
машин, то каким бы большим ни был вклад
подобных систем в исследования способности человека к
обучению и исследованию процесса обучения как
науки, написанные человеком программы
по-прежнему будут лучше созданных самими машинами
в процессе обучения.
Разумеется, существование этого предела не
предсказано никакой теорией, и цель современных
исследований процесса обучения — повысить уровень
функций, имеющих прикладное значение. Кроме того,
обучение с помощью машин важно не только в
практическом плане, но и в плане объяснения способности
человека к обучению и как фундамент научного
направления, так что в этом смысле ценность подобных
исследований огромна. В то же время при
разработке систем, рассчитанных на получение логических
выводов на порядок более высокого уровня, чем
предложенные до сих пор, желательно не только
принимать во внимание ценность этих исследований,
но и уточнить сами цели исследований.
13
Глава 1
Ниже после общих замечаний о том, что такое
обучение, рассмотрены приобретение знаний и
обучение с практической точки зрения.
1.1. ОБУЧЕНИЕ
1.1.1. КАК ОПРЕДЕЛИТЬ ФУНКЦИИ ОБУЧЕНИЯ!
Обучение — широкое понятие, поэтому этот термин
часто используют, не задумываясь о его глубоком
смысле. Итак, прежде всего начнем с определения.
Общепринятый смысл обучения можно пояснить так:
в процессе повторения однотипных экспериментов
методом проб и ошибок или экспериментов с одной
и той же исходной совокупностью данных происходит
модификация системы, которая при этом
демонстрирует на каждом этапе экспериментов лучшие
результаты, чем на предыдущем этапе. Подобное
определение не что иное, как наблюдение со стороны
действий обучающейся системы в конкретной среде,
т. е. обобщенное определение, и, опираясь на него,
сложно реализовать обучение с помощью машины —
необходимо превратить это определение в более
конструктивное.
1.1.2. ПОДХОДЫ К ИССЛЕДОВАНИЮ ОБУЧЕНИЯ
Существуют различные аспекты исследования
функций обучения, поэтому необходимо уточнить
различия между целями и подходами к исследованиям.
Здесь можно выделить три направления. Первое —
изучение функций мышления и обучения человека
и их моделирование на компьютерах, второе —
изучение функций информационно-логического обучения,
третье—исследования процесса обучения в области
обработки образов. Все эти направления в будущем
должны слиться, но пока до этого еще далеко.
1. Когнитивный подход. Обучение — это функция,
свойственная животным по их природе, поэтому по
традиции исследования процесса обучения животных
и человека главным образом проводились в психо-
Введение
11
логии, а в последнее время в биологии и
нейрофизиологии в связи с изучением механизма памяти,
С другой стороны, развитие компьютеров
стимулирует исследования, связанные с моделированием
процесса обучения человека и объяснением функций
обучения на основе результатов моделирования. Это
одна из важных целей исследования процесса
обучения. При этом нет необходимости принимать во
внимание, превышает ли она возможности человека,
есть ли в ней практическая ценность? В общем
случае обучение и для человека нелегкий процесс; как
правило, обучение проходит медленно и не очень
эффективно. Объяснение причин этого явления еще
сыграет свою роль в разработке новых методов
обучения. При подобном подходе моделирование
функций обучения человека и животных выполняют
посредством наблюдения и анализа результатов. В
настоящее время такое моделирование выполняют
многие исследователи, поэтому для успешного
использования предложенных ими методов прежде всего
необходимо знать, в чем состоит моделирование и
какие ограничения оно имеет. Это обсуждается
в гл. 2.
Кстати, как связан когнитивный подход с
инженерией знаний, имеющей важное прикладное
значение? Сегодня для многочисленных систем (точнее,
для их экспертных оболочек), если их рассматривать
в качестве систем инженерии знаний как таковой,
связи не усматривается. Область применения
большинства существующих систем ограничена, на что
указывают многие специалисты, но если начать
выяснять причины этого факта, то как раз и
обнаруживается связь между инженерией знаний и когни-
тивизмом. Например, для современных систем нет
принципиальной разницы между специалистом и
начинающим, просто предполагается, что есть различие
в объеме специальных знаний, имеющихся у того
и у другого, но специалист может описать свои
знания. Кроме того, предполагается, что специалист,
решая задачи с использованием знаний, вызывает и
обрабатывает их последовательно. Однако с
позиций когнитивизма эти допущения не всегда верны,
12
Глава \
Следовательно, системы, созданные при этих
допущениях, ведут себя не так, как человек. Эти
проблемы рассматриваются в гл. 3.
Исследования функций обучения имеют глубокую
связь с разработкой и исследованиями систем
обучения с помощью компьютеров. Такие системы
развиваются в направлении синтеза моделей приобретения
знаний через диалог и тесно связаны с проблемами
понимания языков. Наиболее интересное направление
в этой области — исследования способностей к
обучению, при которых модель учащегося выводится из
результатов наблюдения. Приобретению знаний в
диалоге посвящена гл. 4.
Можно ожидать, что в процессе этих исследований
появятся новые методы машинного обучения.
2. Информационно-логический подход. Вместе с
прогрессом вычислительной техники развиваются
исследования, в которых функции обучения
рассматриваются с позиций информатики с целью
теоретического объяснения обобщенного механизма
обучения. Центральной темой исследований здесь является
не психологический, а математический анализ и
моделирование функций; акцент делается на
классификацию и анализ традиционных методов обучения,
а также на объяснение функций сбора информации
и других функций. В последние годы при
классификации методов обучения особое внимание уделяют
их связи с функциями логических выводов, в
частности с индукцией, аналогией и другими разделами
логики. Об этом будет идти речь в гл. 7 и
последующих главах.
Классификация по взаимосвязи со средой,
например обучение с преподавателем и без него, играет
важную роль в исследовании индивидуального
обучения. В настоящее время ведется много
исследований, но все они рассматривают обучение с
преподавателем, когда человек подготавливает среду
обучения, используя уже известные факты, либо само
обучение проходит под руководством человека.
Обучение без преподавателя более сложно.
Введение
13
3. Подход с позиций обработки образной информации
и другие подходы. С практической точки зрения
эффективность обучения машины можно обнаружить
в одном из двух случаев; 1 — обучение приведет
к результатам, которые не могли быть
запрограммированы человеком (не известным человеку); 2
—обучение более простым способом приведет к
результатам, которые, вообще говоря, мог бы непосредственно
запрограммировать человек, и в этом состоит их
практическая ценность.
В первом случае в процессе обучения открываются
новые факты. Хотя обучение и открытие не одно
и то же. Открытие — это процесс, при котором,
например, из совокупности экспериментальных данных
выводится физический закон, а в процессе
обучения— решение очередной задачи может быть найдено
на основе полученных до этого результатов
благодаря запоминанию данных и автоматическому
составлению указателей для их поиска. Оба этих
процесса в сочетании могли бы дать поразительный
эффект, но, как отмечено выше, это функции эври*
стического обучения без преподавателя. В настоящее
время пока не существует системы, в которой эти
функции были бы реализованы на практическом
уровне, хотя можно привести ряд примеров
исследований, связанных с логическими выводами по
аналогии, индукции и обучением на основе примеров.
Эвристическое обучение, которое может привести к
открытию неизвестных фактов, имеет большое
значение для человека, поэтому в будущем определенные
надежды возлагают на исследования систем
поддержки открытий, работающих в сотрудничестве
с человеком. Эвристическое обучение — это не совсем
открытие новых общих физических законов или
обнаружение специфичных объектов со структурой,
удовлетворяющей заданным требованиям, как в
проблемах проектирования, тем не менее оно включает
функции систематизации информации. В
практическом плане в системах поддержки открытий на
основе примеров не обойтись без баз данных.
Добавление, обновление и удаление данных — это самые
примитивные функции баз данных, но при реализа-
14
Глава 1
ции машинного обучения их нельзя игнорировать.
Об этом говорится в гл. 6.
Во втором случае человек сам может
запрограммировать результаты, но обучение эффективнее по
сравнению с той рутинной работой, включая
подготовительные операции, которую придется делать
человеку, в частности особенно заметен эффект при
работе с образной информацией. Например, при
распознавании речи обучение сводится к запоминанию
образцов голоса конкретных лиц и последующему их
использованию; важно обучение при обработке
изображений и т. д. Можно привести много примеров
обучения такого рода, отметим лишь, что для
успешной работы подобных систем необходимо дать им
практическую направленность, в том числе и
результатам обучения.
Выше были рассмотрены три подхода к
исследованиям обучения в их взаимодействии. Как уже было
отмечено, важными функциями обучения являются
получение новой информации из среды и ее
систематизация для последующего использования.
1.1.3. ПРИОБРЕТЕНИЕ ЗНАНИЙ
И ОВЛАДЕНИЕ МАСТЕРСТВОМ
Следует остановиться и на третьей точке зрения на
обучение, которая складывается из двух аспектов:
1—приобретение и структуризация знаний; 2 —
овладение мастерством и квалификация. Первый аспект,
как уже отмечалось выше, состоит в получении
кодированной информации из внешнего мира и ее
систематизации. При этом приобретаются
разнообразные знания, начиная от простейших исходных
данных типа измерений в физической системе или
данных изображений и кончая переработанной,
структурированной и проверенной информацией типа
физических законов и экспертных знаний; функции
обучения в зависимости от типа знаний будут
различаться. Само обучение каждого типа можно
оценить по тому, насколько широко и полно будут
описаны среда и объекты.
Овладение мастерством достигается благодаря
непрерывным упражнениям, как, например, в игре в
Введение
15
гольф или игре на фортепиано, но полученные при
этом знания нельзя представить в виде кодов, и
подобный процесс называют подсознательным
обучением. Это обучение имеет непосредственное
отношение к строению физических органов, отвечающих за
движение и мышление. С позиции информатики это
обучение низкого уровня, и компьютер в этом случае
чрезвычайно сложно сделать объектом обучения.
Таким образом, в понятие «обучение» можно
вкладывать различный смысл. В следующих разделах
ограничимся знаниями, которые представляют
объекты в виде кодов, и рассмотрим функции обучения,
обращая основное внимание на практическую
сторону проблемы обучения.
1.2. МЕТОДЫ ПРИОБРЕТЕНИЯ ЗНАНИЙ
1.2.1. ЭТАПЫ ПРИОБРЕТЕНИЯ ЗНАНИЙ
Приобретение знаний реализуется с помощью двух
функций: получения информации извне и ее
систематизации. При этом в зависимости от способности
системы обучения к логическим выводам возможны
различные формы приобретения знаний, а также
различные формы получаемой информации. Форма
представления знаний для их использования определяется
внутри системы, поэтому форма информации, которую
она может принимать, зависит от того, какие
способности имеет система для формализации
информации до уровня знаний. Если обучающаяся система
совсем лишена такой способности, то человек должен
заранее подготовить все, вплоть до формализации
информации, т. е. чем выше способности машины к
логическим выводам, тем меньше нагрузка на
человека.
Функции, необходимые обучающейся системе для
приобретения знаний, различаются в зависимости от
конфигурации системы. В дальнейшем при
рассмотрении систем инженерии знаний предполагается, что
Существует система с конфигурацией, показанной на
рис. 1.1, которая включает базу знаний и механизм
16
Глава 1
логических выводов, использующий эти знания при
решении задач. Если база знаний пополняется
знаниями о стандартной форме их представления, то
этими знаниями также можно воспользоваться.
Следовательно, от функций обучения требуется
преобразование полученной извне информации в знания и
пополнение ими базы знаний.
Можно предложить следующую классификацию
этапов обучения, соответствующих способностям
компьютеров к формализации.
A. Получение информации без логических
выводов.
1. Ввод программ.
2. Ввод фактических данных.
Б. Получение извне информации, уже
представленной в форме знаний.
1. Получение готового набора знаний,
представленных во внутреннем формате,
2. Получение знаний, представленных во
внутреннем формате, в режиме диалога,
3. Получение знаний, представленных во
внешнем формате, и их понимание.
B. Обучение по примерам.
1. Параметрическое обучение.
2. Обучение на основе выводов по аналогии.
3. Обучение на основе выводов по индукции —
эвристическое обучение.
Г. Приобретение знаний на метауровне.
Компьютер
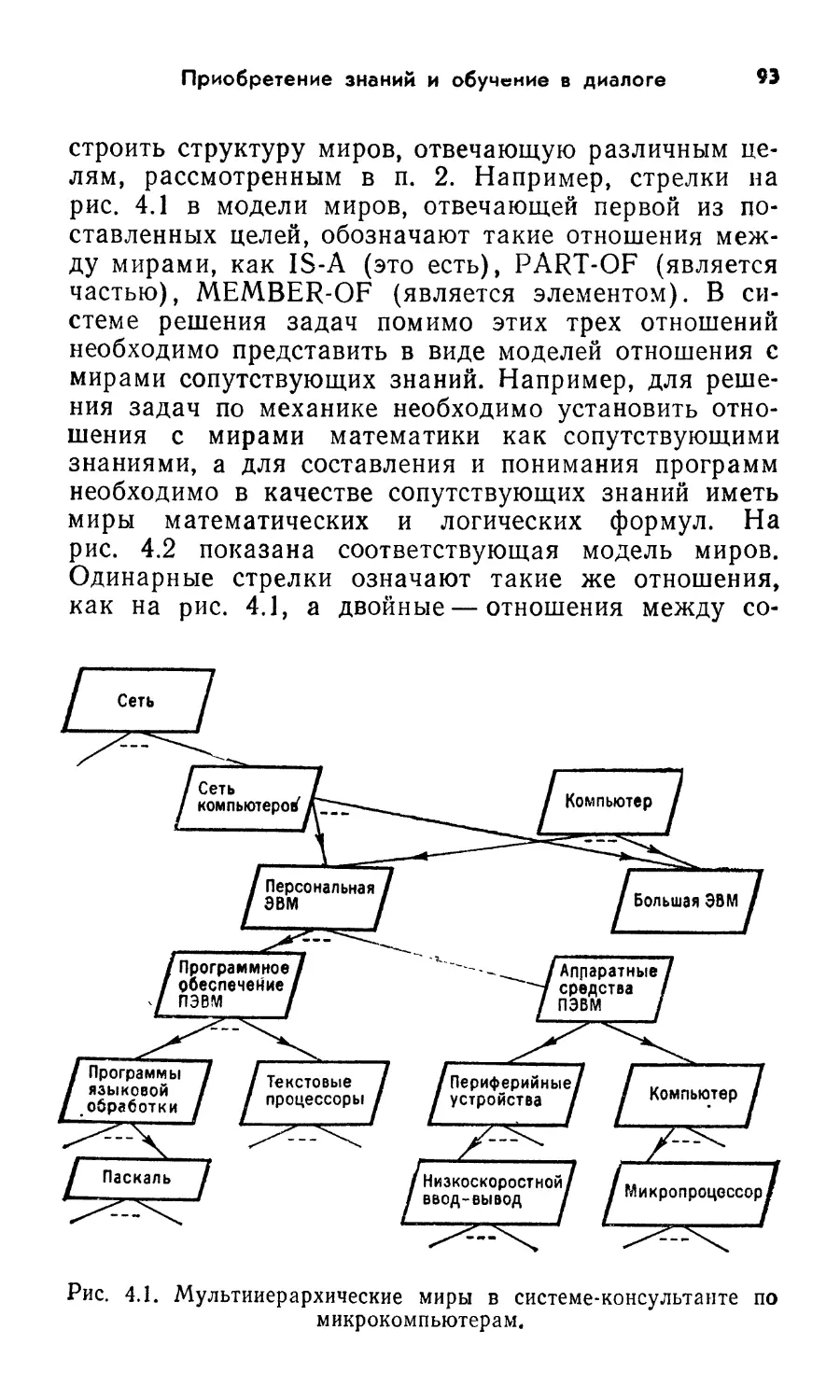
Рис. 1.1. Базовая структура систем обработки знаний.
Введение
17
1.2.2. ОБУЧЕНИЕ БЕЗ ВЫВОДОВ И ОБУЧЕНИЕ
С ВЫВОДАМИ НА НИЗКОМ УРОВНЕ
Категорию А молено назвать обучением без выводов
или механическим запоминанием, это простой
процесс получения информации, при котором
необязательны функции выводов, а полученная информация
в виде программ или данных используется для
решения задач в неизменном виде. Другими словами, это
способ получения информации, характерный для
существующих компьютеров.
Категория Б — это получение информации извне,
представленной в форме знаний, т. е. в форме,
которую можно использовать для выводов. Обучающейся
системе необходимо иметь функцию преобразования
входной информации в формат, удобный для
дальнейшего использования и включения в базу знаний.
Приобретение знаний на этом этапе происходит в
наиболее простой форме: это знания, предварительно
подготовленные человеком во внутреннем формате,
какими являются большинство специальных знаний,
изначально заданных в экспертных системах. В
случае прикладных систем инженерии знаний
необходимо преобразовать специальные знания из какой-либо
области в машинный формат, но для этого нужен
посредник, хорошо знающий как проблемную
область, так и инженерию знаний. Таких посредников
называют инженерами по знаниям; в последние годы
началась специализация таких инженеров, но по
прогнозам подготовка их в достаточном числе окажется
сложной задачей. Для улучшения положения ничего
не остается, как перепоручить эти функции самим
системам. В общем случае для этого необходимо
иметь функции выводов достаточно высокого уровня,
но можно ограничиться и выводами на сравнительно
низком уровне, а остальное доверить человеку — в
этом и состоит приобретение знаний в диалоге.
Примером служит хорошо известная система TEIRESIAS.
Это система-консультант в области медицины,
разработанная на базе системы MYCIN. Специалисты в
проблемной области являются преподавателями
обучающейся системы, а ученик — система инженерии
знаний — изучает ответы на поставленные задачи и
18
Глава f
корректирует те правила в базе знаний, которые
ранее приводили к ошибкам. Для подготовки знаний
в экспертной системе необходимы вспомогательные
средства типа редактора знаний, причем в процессе
приобретения знаний в диалоге не только
редактируются отдельные правила и факты, но и
восполняются недостатки существующих правил, т. е.
ведется редактирование базы знаний.
Если знания заданы во внешнем формате,
например на естественном языке, то следует преобразовать
их во внутренний формат. Для этого необходимо
понимать внешнее представление, т. е. естественный
язык, графические данные и т. п. Фактически
приобретение знаний и их понимание тесно связаны.
Проблема понимания сводится не только к преобразованию
структуры предложений — необходимо получить
формат, удобный для применения.
Аналогичная проблема — преобразование во
внутренний формат советов, подсказок по решению
задач, что называется «операционализацией» знаний.
В этом заключается центральная проблема
искусственного интеллекта; она, в частности, изучает
преобразование советов, подсказок, представленных в
терминах проблемной области, в процедуры.
Например, система UNDERSTAND выполняет операциона-
лизацию представления задачи о ханойской башне 1}
на английском языке путем построения
соответствующих состояний и операций, приводящих к этим состоя*
ниям.
1.2.3. ОСНОВНЫЕ ПРИНЦИПЫ ПРИОБРЕТЕНИЯ
ЗНАНИЙ ИЗ ПРИМЕРОВ
Проблемы категории Б возникают из-за того, что
описания, или, что то же самое, представления знаний,
задаются извне в некотором формате. При этом
необходимо всего лишь преобразование форматов
представления информации, но функция открытия не
требуется. Напротив, в категории В есть свои особей*
ности приобретения знаний: здесь выполняется сбор
1} Задача о ханойской башне — известная логическая голо-*
воломка. — Прим. ред.
Введение
t9
отдельных фактов, их обобщение и использование в
качестве знаний. Для этого уже необходимо выявить
общие понятия, вытекающие из примеров, и выбрать
формат или структуру информации для их
представления. В зависимости от уровня функций выводов
могут возникать как сравнительно простые, так и
сложные представления.
Категория В отличается от категории Б еще и тем,
что входная информация — это набор
несистематизированных примеров, поэтому внешне здесь есть
много общего с категорией Б. Например, чтобы получить
фактические данные во внешнем представлении,
необходимо их понимать, а это аналогично
категории Б.З.
Высший уровень категории В — эвристическое
обучение, рассмотренное в разд. 1.1.2; в этом случае
представление знаний наиболее сложное.
Практически эвристическое в полном смысле слова обучение
не реализовано.
По сравнению с категориями А и Б методы
обучения категории В имеют большую степень свободы.
Поэтому уточним общие принципы такого обучения.
1. Языки представления. Обучение по примерам —
это процесс сбора отдельных фактов, их обобщение
и систематизация, поэтому необходим
унифицированный язык представления примеров и общих правил.
Эти правила, будучи результатом обучения, должны
стать объектами для использования знаний, поэтому
и образуют язык представления знаний. И наоборот,
язык представления знаний должен учитывать и
определять указанные выше условия приобретения
знаний.
2. Способы описания объектов. В случае обучения
по примерам из описаний отдельных объектов
создаются еще более общие описания объектов некоторого
класса, при этом возникает важная проблема: как
описать данный класс объектов. В полном классе
некоторых объектов следует определить меньший
класс объектов, обладающих общим свойством
(объекты только в этом классе обладают заданным
20
Глава 1
свойством), но в действительности проще
определить список объектов и убедиться, что все объекты
в нем обладают общим свойством. Для
некоторого типа задач можно эффективно использовать
ложные примеры или контрпримеры, убедительно
показывающие, что данные объекты не входят в этот
класс. Однако в общем случае обработка ложных
примеров сложна. Иллюстрацией применения
контрпримеров может служить понятие «почти то»,
введенное Уинстоном 1}.
3. Правила обобщения. Для сбора отдельных
примеров и создания общих правил необходимы правила
обобщения. Предложено несколько способов их
описания: замена постоянных атрибутов языка на
переменные, исключение описаний с ограниченным
применением и т. п. Очевидно, что эти способы тесно
связаны с языком представления знаний.
Функция обучения — это выводы в широком
смысле слова, т. е. функция, порождающая из
заданного представления частные представления. Однако
то, что мы здесь называем выводами, существенно
отличается от дедуктивных выводов, лежащих в основе
современных экспертных систем, предназначенных для
использования знаний. Диапазон, в котором
представление, порожденное дедуктивным выводом, служит
объектом описания, ни в коем случае не больше
диапазона, заданного априори. Например, пусть в
формуле вывода
А, А->В
В'
А — высказывание «Сократ — человек», или в
формализованном виде ЧЕЛОВЕК (Сократ), а А->В
высказывание «все люди смертны», или (V.v)
[ЧЕЛОВЕК(*)-* СМЕРТЕН (*)]. Отсюда по
дедукции получаем высказывание В': «Сократ смертен»,
СМЕРТЕН (Сократ). Предикат СМЕРТЕН в
высказывании В имеет переменную и подходит ко всем
]) См. Уинстон П. Искусственный интеллект.— М.: Мир,
1980. — Прим. первв%
Введение
21
объектам в мире, тогда как высказывание В'
ограничивается только конкретным объектом — Сократом.
В отличие от этого выводы при обучении
обладают совсем другим свойством: диапазон объектов
описания порожденных представлений больше, чем
диапазон, заданный изначально. Однако этот
диапазон не бесконечен, его можно расширять в
определенных пределах. Это и есть правило обобщения.
Возможны различные типы выводов в зависимости
от способа обобщения, один из примеров обобщения
описан ниже. По образцу приведенной выше
формулы построим общее выражение вывода, включающего
обобщение:
Р, н-»Р
Н
Здесь Р — множество известных тезисов, Н —
гипотеза. Смысл этого выражения заключается в
следующем. Пусть задано множество тезисов Р. Если
предложить некую гипотезу Н и показать, что Р
выводится из Н, то будем считать Н истинной. Например,
пусть задано множество Р:
(ДОМ (Киёмори) ^
ДОМ (СигэмориП.
ДОМ (Ацумори) J
Выдвинем гипотезу Н!
Hi: (Vjc) ДОМ (х), т. е.
„каждый человек имеет дом".
При этом из Hi получаем Р и делаем вывод, что Н\
истинна. В данном примере диапазон объектов, к
которым применим предикат ДОМ, ограничен
множеством Р, состоящим из Киёмори, Сигэмори и
Ацумори; заменим их на переменную и расширим
множество до объектов во всем мире.
В результате, если впоследствии появляется новый
объект Корэмори, которого не было в Р, то сразу же
делаем вывод ДОМ (Корэмори). Априори из Р
этого не следует. Отличие выводов при обучении от
дедуктивных выводов как раз и состоит в том, что
диапазон объектов расширяется и создается несколько
22
Глава 1
гипотез Н. За счет расширения из гипотезы Я
выводятся другие высказывания. Это можно представить
следующим образом:
Г Р, Н^р-т - . „ о
—п ^Q : из гипотезы Нь которой
— 1 — удовлетворяет Р, следует Q.
С другой стороны, есть риск совершить ошибку,
расширив таким образом класс объектов. Если
появится новый объект Цуруги (не человек1)), то мы
придем к странному выводу ДОМ (Цуруги).
Выбранная нами гипотеза имеет очень большой диапазон
объектов, но гипотез может быть много, поэтому
выберем гипотезу с наименьшим множеством объектов.
В нашем обсуждении указанная выше формула
вывода в плане обучения слишком упрощена, исполь->
зуем более реальную формулу
Р("{Рь Р2}), {Рь Н}->Р2
Н
т. е. «гипотеза Н истинна, если подмножество Р2
множества Р можно вывести из гипотезы Н и оставше^
гося подмножества Pi». Рассмотрим следующий
пример множества Р:
P«={Pi, Р2}
/ \/х [ДОМ (х) -> ЧЕЛОВЕК (*)]
I (Каждый, кто имеет дом — человек)
Pl | Vjc [ДОМ (*)-> ВЛАДЕЛЕЦ (*)]
v (Каждый, кто имеет дом — владелец)
!ДОМ (Киёмори)
ДОМ (Сигэмори)
ДОМ (Ацумори)
В примере, приведенном ранее, гипотеза Н\
создавалась непосредственно из Р2, теперь же
учитываются предикаты из Рь поэтому выдвинем следующую
гипотезу Н2:
1} Цуруги (япон.) —меч самурая. Смысл примера в том, что
это слово не может быть фамилией человека. — Прим. перев%
Введение
23
Н2; (V*) [ЧЕЛОВЕК (х)-+ ДОМ (х)]
(Каждый человек имеет дом = если нет
дома, то не человек).
Здесь условие ЧЕЛОВЕК(я) ограничивает
диапазон ДОМ (я) множеством людей, поэтому указанный
выше вывод о том, что Цуруги имеет дом, не
подтверждается.
Если после определения такой гипотезы вновь
добавить факт
ЧЕЛОВЕК (Корэмори) (Корэмори —- человек),
то путем дедукции сразу же получим
ДОМ (Корэмори) (Корэмори имеет дом).
Подобная связка обучение — дедукция может быть
представлена следующим образом:
Вывод при обучении ...
/Р(={Рь Р2}), {Рь H(=Q->R)}->R2,
V H(=Q->R), Q \
R ) ' '•
... Вывод при дедукции
Но и при таком ограниченном диапазоне гипотеза
Н2 еще неверна. Если задано, что
ЧЕЛОВЕК (Есицунэ)Д~ ДОМ(Есицунэ)
(Есицунэ — человек, но бездомный),
то опятб получаем противоречие. Поэтому еще
ограничим диапазон:
Н3; (V*) [ВЛАДЕЛЕЦ (*)-> ДОМ (*)].
На этот раз (на какое-то время) мы получили
правильную формулу. Таким образом, традиционный
метод обобщения состоит в выборе минимальной
гипотезы среди большого числа возможных гипотез
обобщения, в которых объекты из заданного набора
примеров (Р2) заменены переменной и которые
расширяют диапазон применения логических формул.
Полученная гипотеза называется минимальным обобще-
24
Глава 1
нием. Метод минимального обобщения особенно
важен при выводах в случае машинного обучения.
Приведенные выше примеры облегчают
понимание читателем идеи, но чтобы использовать
минимальное обобщение на формальном уровне, этого
недостаточно. Во всяком случае, компьютер только по
множеству Pi не сможет оценить, какое из
ограничений ЧЕЛОВЕК(х) или ВЛАДЕЛЕЦ^) сильнее.
Здесь нужна, например, такая оценка:
(V*) [ВЛАДЕЛЕЦ (х) -* ЧЕЛОВЕК (*)]
(Если владелец, то и человек).
Определив в общих чертах описание обобщения,
сравнительно легко в соответствующем диапазоне
выбрать постоянные, которые следует заменить на
переменные, и описания, которые нужно исключить.
Например, заменяя часть или все постоянные в
наборе предикатов, таких, как Р\ и Р2 в приведенном
выше примере, на переменные, легко исключить
предикаты, не отвечающие примерам. Сложнее то, что
помимо заранее заданных предикатов необходимо
создавать новые, но соответствующих правил для
этого, даже исходя из общих соображений, не
придумано. В первом случае подобные правила называют
правилами альтернативного обобщения, во втором —
правилами структурного обобщения. Обучающихся
систем, пользующихся первыми правилами, много, а
пользующихся вторыми — мало.
4. Управление обучением. В процессе обучения по
примерам можно применять различные стратегии
структуризации информации и необходимо управлять
этим процессом в ответ на входные данные.
Существуют два классических метода: метод «снизу-вверх»,
при котором последовательно выбираются и
структурируются отдельные сообщения, и метод «сверху-
вниз», при котором сначала выдвигается гипотеза, а
затем она корректируется по мере поступления
информации. На практике эти методы комбинируются, хотя
управление обучением с максимальным эффектом не
такая уж простая проблема.
Введение
25
1.2.4. ЗТЛПЫ ОБУЧЕНИЯ ПО ПРИМЕРАМ
1. Параметрическое обучение. Наиболее простая
форма обучения по примерам или наблюдениям состоит
в определении общего вида правила, которое должно
стать результатом вывода, и последующей
корректировки входящих в это правило параметров в
зависимости от данных. При этом используют
психологические модели обучения, системы управления
обучением и другие методы.
Примером обучающейся системы этой категории
в области искусственного интеллекта является
система Meta-Dendral. Эта система выводит новые
правила путем коррекции правил продукций в процессе
обучения или на основе исходных масс-спектральных
данных 1\ параметрическое обучение в ней
представлено в несколько специфичном виде, но все же она
относится к указанной выше категории, поскольку
в системе задана основная структура знаний,
которая корректируется последовательно по отдельным
данным.
2. Обучение на основе выводов по аналогии.
Приобретение новых понятий возможно путем
преобразования существующих знаний, похожих на те, которые
собираются получить. Это важная функция, которую
называют обучением на основе выводов по аналогии
или просто обучением по аналогии. В нашей жизни
много примеров, когда новые понятия или
технические приехмы приобретаются с помощью аналогии.
Выводы по аналогии — один из важных объектов
исследования искусственного интеллекта, наиболее
интересные результаты здесь получены П. Уинстоном.
Он использует выводы по аналогии, основываясь на
следующей гипотезе: «Если две ситуации подобны
по нескольким признакам, то они подобны и еще по
одному признаку». Подобие двух ситуаций распо-
1) Системы Dendral и Meta-Dendral предназначены для
построения структуры сложных молекул на основе данных масс-
спектралыюго анализа и правил классификации фрагментов
органических молекул. — Прим. ред.
36
Глава 1
знается путем обнаружения наилучших совпадений
по наиболее важным признакам.
Недавно Ацукути и Арикава предложили
формализацию выводов по аналогии и, развивая теорию
аналогии, получили алгоритм выводов, органично
использующий дедуктивные выводы. Благодаря этому
был сделан еще один шаг к практическому
применению теории аналогии. Подробнее об этом будет
сказано в гл. 8.
Рассмотрим две ситуации: S\ и S2. Пусть в S\
справедливо утверждение: «г\ — причина
возникновения г2», что запишем как n(a, b)->- r2(c, d). Пусть
также в S2 известно г\(а\ Ь'). С помощью
традиционной дедукции только из этих условий никакого
вывода получить нельзя, но при выводе по аналогии
благодаря открытию1) подобия п(а, Ь) и Г\(а\ Ь')
можно сделать вывод о том, что в S2 возникнет
r2{c\ d'). Подобие rx (a, b) и Г\(а\ Ь') оценивается
путем открытия некоторого третьего выражения
(W, и). W — это некоторое выражение, позволяющее
сравнивать обе ситуации, оно включает переменные.
Через и обозначена пара значений, которые можно
подставить вместо переменных в W: если в W
подставить одно значение, то получится Su если
второе— то S2. В приведенном выше примере (W, и) =
= ({/-!(*, У)}, {Х-<а, а'>, {У-{6, 6'»). Таким
образом, получается своего рода правило обобщения.
Если определить такое выражение (W, и), то r\ (a, b)
и r\(a\ br) будут подобны и, как следствие этого,
выводится r2(c\ d').
3. Обучение на основе выводов по индукции —
эвристическое обучение. Среди всех форм обучения особо
выделим обучение на основе выводов по индукции —
это обучение с использованием выводов высокого
уровня, как и при обучении по аналогии. В процессе
этого обучения путем обобщения совокупности
имеющихся данных выводятся общие правила. Возможно
1) Открытие как результат логических выводов следует
отличать от обнаружения как результата поиска. Подробнее об
этом см. в гл. 7. — Прим. перев.
Введение
27
обучение с преподавателем, когда входные данные
задает человек, наблюдающий за состоянием
обучающейся системы, и обучение без преподавателя,
когда данные поступают в систему случайно. И в том
и в другом случае выводы могут быть различными,
они имеют и различную степень сложности в
зависимости от того, задаются ли только корректные
данные или в том числе и некорректные данные
и т. п. Так или иначе, обучение этой категории
включает открытие новых правил, построение теорий,
создание структур и другие действия, причем модель
теории или структуры, которые следует создать,
заранее не задаются, поэтому их необходимо
разработать так, чтобы можно было объяснить все
правильные данные и контрпримеры. Исследование
структурированных выводов активно ведется
многими специалистами, но такие выводы еще не
реализованы, это проблема будущего.
Индуктивные выводы возможны в случае, когда
представление результата вывода частично
определяется из представления входной информации. В
последнее время обращают на себя внимание
программы генерации программ по образцу с
использованием индуктивных выводов. Ожидается, что
исследования в этом направлении будут развиваться.
Т.2.5. ПРИОБРЕТЕНИЕ ЗНАНИЙ НА МЕТАУРОВНЕ
Выше было рассмотрено обучение на объектном
уровне, а еще более сложная проблема —
приобретение знаний на метауровне, т. е. знаний, основой
которых является информация по управлению
решением задач с использованием знаний на объектном
уровне. Для знаний на метауровне пока не
установлены ни формы представления и использования,
ни связь со знаниями на объектном уровне, ни
другая техника их систематизации. Поскольку не
определена форма их представления с точки зрения
использования, то трудно говорить о приобретений
знаний на метауровне. Тем не менее с этой
проблемой связаны многие надежды в инженерии знаний.
ГЛАВА 2
ВОЗМОЖНОСТИ ТЕХНОЛОГИЧЕСКИХ
подходов в психологии
Ю. Сажи, X. Судзуки (Токийский университет)
В данной главе рассмотрены формальные
механистические подходы к изучению процессов обучения
в бихевиористической 1} психологии и науке о
мышлении, которые помогут понять, какими особенностями
обладает такая превосходная самообучающаяся
система, как человек. Используя имеющиеся знания,
человек перерабатывает огромный объем
информации, поступающей из окружающей среды, и тем
самым обучается. Другими словами, обучение
человека зависит от знаний, которые не отражают
формальную структурную сторону среды обучения, а
являются откликом на смысловую функциональную
сторону. Следовательно, будучи зависимым от
знаний, процесс обучения проходит как осмысление
человеком среды, а такое обучение не базируется
на каком-либо формальном процедурном механизме.
2.1. ВВЕДЕНИЕ
Прежде всего ознакомимся с тем, как трактуется
термин «обучение» в психологии. Учитывая, что
читатели имеют естественно-техническое образование,
по возможности сконцентрируем их внимание на
различиях понятия обучения, рассматриваемого с
естественно-технических и психологических
концепций, и приблизимся к точке зрения на обучение,
принятой в современной науке о мышлении. Соб-
стсенно говоря, термин «естественно-техническая
концепция» предложен авторами; практически все
исследователи естественно-технических систем не подо-
вревают, что имеют дело с такой концепцией. Один
из авторов (Саэки), заинтересовавшись проблемами
1} От английского слова behavior (поведение). — Прим. перев.
Возможности технологических подходов в психологии 29
обучения, стал студентом факультета естествознания
и техники. Позже, изучая психологию в аспирантуре
одного из университетов США, он существенно
пересмотрел свои взгляды па обучение. Это было время
превращения психологии из бихевиористической в
когнитивистскую, появились технологические подходы
к обучению. Другими словами, возникли разногласия
г.:ежду методологией, которая, исходя из естественно-
технической концепции, привязывает такое
психологическое явление, как обучение, к парадигме техники,
н психологическим мировоззрением, считающим пер-
гоосновой обучения разум человека, который не
пассивно реагирует на внешние стимулы, а постоянно
ожидает внешних событий, осмысливает их и
управляет внешним миром. Вот почему
естественно-техническая концепция оказалась тесно связанной с когни-
тивистской парадигмой, которая обсуждает проблемы
мышления человека и познания им мира. Именно это
дало повод для зарождения и развития психологии
мышления и ее связи с исследованиями
искусственного интеллекта и способствовало уточнению
дальнейших исследований.
В этой главе мы акцентируем внимание на
метаморфозах естественно-технической концепции
обучения, на том, что такое когнитивистская концепция,
а также на том, что нас ожидает в будущем.
2.2. ОТ НАИВНОГО ЭМПИРИЗМА
К ПСИХОЛОГИИ ОБУЧЕНИЯ
Но хватит о специалистах. Что представляет простой
человек, услышав слово «обучение»? Нет ли в его
точке зрения на обучение крайне наивного
эмпиризма? Скорее всего, он считает, что обучение — это
когда по мере накопления опыта поведение
становится более разумным. Причем под опытом он
понимает повторение одних и тех же действий в ответ
на одни и те же стимулы либо действия, как пишут
в статьях, методом проб и ошибок, т. е.
первоначально бессистемные действия, действия наугад.
А слова «становится более разумным» означают, что
30
Глава 2
если после нескольких попыток находится правильное
решение, то соответствующие этому решению
действия будут повторяться все чаще, а неудачные
действия — все реже и реже. Если же сложные
действия повторять неоднократно, тренироваться, то они
будут легче получаться, а если вслед за действием
последует наказание, то пропорционально этому
наказанию обучающийся будет избегать таких
действий. Если что-то привлечет внимание и оставит
неизгладимое впечатление, то это хорошо
запомнится, а все, что изучалось в состоянии рассеянности,
будет забыто.
Подобный взгляд на обучение до какой-то
степени оправдывается. Как правило, все, что мы
называем словами «учиться», «тренироваться»,
приблизительно соответствует такой «теории».
В начале 20-х годов нашего столетия благодаря
работам в сфере психологии обучения Э. Л. Торн-
дайка, Э. Р. Гасри, Э. С. Толмана, К. Л. Халла,
Б. Ф. Скиннера и других ученых, которые принимали
за основу некоторые из подобных взглядов, из
результатов строгих экспериментов были найдены
«законы» обучения всех животных в разнообразных
условиях.
Э. Л. Торндайк A874—1948). После многочисленных
экспериментов по обучению животных Торндайк
пришел к убеждению, что этот процесс можно объяснить
через бессознательную непосредственную
ассоциацию действия и места. Сравнивая кривые
обучаемости животных и человека, он пришел к
заключению, что обучение человека строится на базе чисто
механических, а не сознательных принципов.
Поэтому он пытался описать обучение человека с
помощью простых правил, справедливых одновременно
и для животных, и ввел три закона: готовности,
тренировки и эффекта.
Закон готовности — первое условие обучения:
получение результата при некотором действии приводит
животное в состояние удовлетворенности, а
неполучение—в состояние неудовлетворенности. (Кстати,
сегодня педагоги иногда называют «готовностью»
Возможности технологических подходов в психологии 31
врожденные способности к обучению, но Торндайк
имел в виду совсем другое.)
Закон тренировки: при повторяющихся действиях
усиливается связь места и действия, а прекращение
тренировки приводит к ослаблению связи (в
последние годы жизни Торндайк считал, что обучение не
достигается лишь простой тренировкой, необходим
эффект удовлетворенности результатом).
Закон эффекта: если результат, который достигнут
некоторым действием, приводит к состоянию
удовлетворенности, то связь между действием и местом
усиливается, а если к состоянию неудовлетворенности,
то ослабевает (в последние годы он рассматривал и
обратный эффект неудовлетворенности).
Зачастую Торндайк наблюдал и публиковал то,
что не всегда следовало из его собственной теории
обучения. Например, весьма оригинальные
эксперименты убеждают, что поведение животного в случаях,
когда оно зевает или ухаживает за собой, находится
вне рамок закона эффекта. Кроме того, в эти годы
возрос интерес к обучению в широком смысле слова,
акцентировалось внимание на таких вопросах, как
важность стимулов, заинтересованность в решении
задачи, развитие способностей, восприятие смысла
обучения, отношение к исследованию задачи,
концентрация внимания и т. п.
Э. Р. Гасри A886—1959). Принцип обучения Гасри:
«В некоторый момент комбинация стимулов и
движение сливаются воедино»; при этом не нужны ни
тренировки, ни повод, ни удовлетворенность, ни
наказание, просто неожиданно совпадают движение и
сущность стимулов, изредка сопровождающих это
движение. То, что здесь названо сущностью стимулов, не
ограничивается их физическими свойствами, а
предполагает нечто, подготовленное экспериментаторами.
Другими словами, есть некая модель стимулов,
которые воспринимают животные при опытах, и это всего
лишь часть стимулов, существующих во внешнем
мире. Следовательно, в каждый момент
воспринимается модель стимулов, чуть отличная от той, что
была за секунду до этого, эта модель подобна преды-
32
Глава 2
дущей, но и отлична от нее и совпадает с движением.
Таким образом, на практике для обучения какому-
либо поведению необходимо путем различных
тренировок добиться, чтобы многочисленные побуждения
(модель стимулов) совпадали с желаемым
движением.
Например, нам надо научиться правильно
печатать на пишущей машинке. Для того чтобы ранее
сформированные ошибочные дзижения были
заменены на комбинацию правильных движений в
сочетании с правильными стимулами, необходимы
многочисленные тренировки. Еще пример: когда животное
в результате правильного действия получает корм,
вероятность нужного поведения возрастает, что
объясняется совсем не действием «закона эффекта», а
просто тем, что поведение животного, которое видит
корм и набрасывается на него, имеет совершенно
иную природу, нежели поведение, которому его до
этого учили. Поэтому, для того чтобы поведение было
обусловлено моделью стимулов, не имеющей ничего
общего со стимулом «корм», следует поддерживать
сильную связь между этой моделью и обусловлен*
кыми ею движениями, с одной стороны, и
стремлением животного к корму — с другой (если нет корма,
то животное теряется, и результативность обучения
постепенно сводится на нет).
Теория обучения Гасри слишком проста, и
возникает вопрос, до какой степени обучение можно
объяснять такими простыми принципами? Кстати,
какими бы явлениями не пытались опровергнуть Гасри,
он все ловко объяснял по-своему. Даже действие
«программы поведения», «внимания» и других
факторов, объяснение которых все другие психологи
считали очевидным, он трактовал по-своему, исходя из
яринципа мгновенного слияния стимулов и реакции,
что можно назвать последовательным
механистическим подходом.
Э. К. Толман A886—1959). Оригинальность теории
рэучения Гасри заключается в том, что нечеткость
понятия «модель стимулов» позволяла ему давать
^объяснения» всем явлениям, исходя из последова-
Возможности технологических подходов ¦ психологии 33
тельных механистических принципов, но эта теория
не гадится для подтверждения экспериментальных
гипотез. Короче говоря, причина в том, что она
«объясняет» любые результаты. В отличие от нее
методика экспериментов Толмана строго следует «бихе-
виористическим» принципам (это научная методика,
которая позволяет выдвигать экспериментальные
гипотезы о зависимости между стимулом и реакцией,
поддающейся измерению и подтверждению путем
строгого управления экспериментом), и такая
«теория» обучения подтверждает рациональность и
целенаправленность поведения животных, а именно:
обучение животных не есть механическое слияние модели
стимулов и действий, а скорее влияние среды,
органичная связь цели и средства.
Рассмотрим, например, следующий эксперимент.
Заставим крысу искать корм в лабиринте,
показанном на рис. 2.1. Если в целевой ящик положить корм,
то крыса сразу побежит по пути 1. Если этот путь
перекрыть блоком А, то она побежит по пути 2, а по
старому пути уже никогда не побежит, т. е. очень
быстро будет выбран более короткий путь. Это пока-
Корм I Целевой ящи*
блок 3
БлокА
Место старта
Рис. 2.1. Эксперимент по латентному обучению и приобретению
мысленных схем у крыс (Толман и Гонзик),
2 С. Осуга, Ю. Саэки
34
Глава 2
зывает, что при свободном поиске корма возможно
«скрытое» обучение, несмотря на то что обучение не
сопровождается каким-либо эффектом, скажем,
получением корма. В эксперименте, где вместо блока А
установлен блок Б, крыса, пройдя путь 1, натыкается
на блок Б и, не обращая внимания на путь 2, сразу
выбирает путь 3. Это говорит о том, что она «знает»,
что путь 2 не годится, если путь 1 загорожен
блоком Б. Если следовать Толману, то крыса
приобретает «мысленную схему» среды и каждый раз
совершает целенаправленные действия (Толман вместо
«действие» говорит «поступок»).
^Теорию обучения Толмана можно назвать теорией
когнитивного обучения. Она оказала заметное
влияние на раздел психологии, изучающий мышление,
начиная с 50-х гг. (например, X. А. Саймон, предлагая
модель процесса принятия решения, указывал, что
идеи своих исследований он почерпнул из теории
обучения Толмана).
К. Л. Халл A884—1952). Халл считал, что
психология, так же как и физика или геометрия, должна
быть построена на основе нескольких аксиом и
системы гипотез, которые могут быть дедуктивно
выведены из аксиом. В 1943 г. он опубликовал
монографию «Принципы поведения». Он также считал, что
«телеологические»1) гипотезы Толмана не научны,
что все следует объяснять через ассоциацию
стимулов и реакции. В результате он дал определения и
Строгие критерии измерения таких понятий, как
«побуждение» — биологически активное состояние
животного, «привычка» — автоматическое возникновение
реакции и другие, установил принципы «усиления» —
условий формирования привычки (при которых
результаты поведения связываются с ослаблением
побуждений), ввел и строго обосновал гипотезу связи
внутренних стимулов и реакции, которая играет роль
посредника между непосредственно предшествующим
*> Телеология — идеалистическое учение, приписывающее
процессу целесообразность. Этому учению противопоставляют де«
термкнизм, — Йрим. перев.
Возможности технологических подходов в психологии 35
внешним стимулом и поведением, и ряд других
гипотез. Воспользовавшись такими понятиями, Халл
подверг резкой критике объяснения Толмана и его
эксперименты.
В течение нескольких десятков лет после Халла
психология в основном развивалась по намеченному
им пути; возродилась традиция считать «научными»
только гипотезы, представленные в виде
алгебраических формул с переменными, которые можно точно
измерить, получила заметное развитие физическая
психология, о которой еще пойдет речь далее.
Обращает на себя внимание то, что наука, которую Халл
считал «идеальной», фактически обрела систему
аксиом по типу ньютоновой механики. Следовательно,
именно количественные алгебраические зависимости,
которые Халл называл «не очень строгими
описаниями», впоследствии благодаря ему были безусловно
подтверждены математической дедукцией исходя из
«механистических» определений и принципов.
Б. Ф. Скиннер A904—). Позиции Скиннера очень
близки к позициям Торндайка и носят
последовательный описательный характер. Его точка зрения на
психологию как науку резко отличалась от точки
зрения Халла, который считал, что психология должна
быть наукой, описывающей все через количественные
зависимости на основе точных измерений. По Халлу,
психология должна образоваться из
систематизированной научной теории, а эта теория в свою очередь
должна пройти по пути экспериментальной проверки
гипотез. Скиннер же отрицал и «теорию», и
«гипотезы». Он считал, что для науки о поведении
животных и человека достаточно, если будут понятны
правила метаморфоз их поведения, а эти правила не
теория, а скорее описание. Иначе говоря, проблема
только в связи входов и выходов, а для уточнения
такой связи предпринимать ничего не нужно
(например, задаваться вопросом о внутреннем механизме:
«Почему возникла такая связь?»). Торндайк также
придерживался описательной точки зрения и,
невозмутимо манипулируя понятием «удовлетворение»,
постулировал внутреннее состояние животного — он
2*
36
Глава 2
еще не был столь же последователен, как бихевио-
ристы.
Скиннер изобрел так называемый «ящик Скинне-
ра» — устройство для экспериментов и наблюдения
за животными с целью выяснения правил метаморфоз
их поведения. Это ящик со стеклянной дверцей, кото-!
рый устроен так, что, когда крыса или голубь нажмут
рычаг или клюнут в маленький кружок внутри ящика,
им автоматически выдается корм. Правила
метаморфоз поведения, которые выявляются с помощью
такого устройства, в основном можно описать понятием
«усиление».
Усиление — это увеличение вероятности появления
нужного поведения при условии, что результаты
поведения сопровождаются какими-то действиями.
Большая часть исследований Скиннера была
посвящена проблеме влияния на поведение различий в
способах усиления (сопровождаемости усиления),
проблеме поведения в условиях, когда сопровождение
усиления отсутствует, и другим проблемам. Скиннер
нашел применение подобным правилам метаморфоз
поведения, создал обучающуюся машину и предложил
методику «модификации поведения» для лечения
психических расстройств, которую использовал в своей
клинике. Эта методика называется техникой обучения;
или техникой поведения. , {
Наука и техника обучения. Торндайк, Гасри, Тол-
ман, Халл и Скиннер, столь активно работавшие
в. 1930—1940-х гг., стремились к тому, чтобы была
построена теория психологии обучения, чтобы она во-,
шла в один ряд с другими науками, такими, как
физика и химия, а ее приложения можно было назвать
техникой психологии, так же как вычислительная,
техника или химическая технология. Другими словами,
они хотели создать некоторую технику, подкреплен^
ную научной теорией. Деятельность этих людей
происходила в начале XX века. Разве она не повлияла
на веру людей в науку и технику, когда начались
бурные перемены в нашем мире в связи с
современной технической революцией?
Возможности технологических подходов в психологии 1?
2.3. РАСЦВЕТ И ПАДЕНИВ
МАТЕМАТИЧЕСКОЙ ПСИХОЛОГИИ
Два направления в психологии обучения 50—
60-х гг. — курс на измерения, поддерживаемый Хал-
лом, и техника поведения Скиннера — развивались
независимо, каждое направление привело к открытию
и применению различных теорий, правил поведения.
В частности, одна из таких новых теорий —
математическая психология.
Попытки использовать математику в
психологических исследованиях предпринимались очень давно;
например, еще в середине XIX века Дж. Т. Фегинар
один из первых начал исследования в области
психофизики. Позже в начале нашего столетия Л. Л. Са-
стон, К. Е. Спирмен, С. С. Стивене и другие ученые
разработали различные математические методы
формализации психологических критериев. Однако в этих
исследованиях математика использовалась
исключительно как средство анализа данных, а не для
моделирования психологических процессов, таких, как
рассуждение или принятие решений животными и
человеком.
Вообще говоря, представить поведение человека
в виде математической модели пытались достаточно
давно в области обществоведения и, в частности,
в экономике. Мощный импульс этому направлению
дала монография Дж. фон Неймана и О. Морген-
штерна «Теория игр и экономическое поведение»
,A944). Однако в области психологии теорию игр
стали применять лишь во второй половине 50-х гг.
До этого в начале 50-х гг. были начаты
исследования, в которых для объяснения процесса обучения
животных применялась модель переходов из
состояния в состояние, основанная на теории вероятности и,
в частности, марковских процессах. Видимо, в этот
период и появилась так называемая математическая
психология.
Математическая психология, унаследовав мощные
средства описания из теории вероятности и
статистики, прежде всего послужила бурному развитию
психологии обучения. При этом были сохранены ос-
38
Глава 2
новные принципы обучения бихевиоризма Толмана,
Гасри, Халла и Скиннера, предложенные в 40-х гг.,
а каких-либо новых принципов не было предложено.
Тем не менее достоверность описаний в плане их
детализации резко возросла, появилась возможность
полностью предсказать и экспериментально проверить
вплоть до подсчета средних значений и дисперсий,
например влияния, которые оказывают на кривую
обучаемости различия в условиях экспериментов.
И как новая парадигма стали доминировать новые
формы экспериментов по так называемому
вероятностному обучению.
При подобных экспериментах используют
несколько (обычно две) ламп, и обучающемуся дается
несколько попыток угадать, какая из ламп загорится.
Каждая лампа загорается случайно с постоянной
вероятностью. Специалисты по математической
психологии, построив сложную вероятностную модель
процесса обучения, предположили, что вероятность
ожидаемой реакции обучающегося (относительная
частота угадываний) на каждую лампу должна быть
равна вероятности загорания этой лампы в
действительности, если усреднить данные ожидаемой
реакции обучающихся на вопрос о том, какая лампа
загорится, по количеству обучающихся. По существу
это будет вероятность реакции обучающегося,
которая точно отражает вероятность появления внешнего
события.
Почему же подобные эксперименты, как сказано
выше, стали доминировать? На это есть несколько
причин.
Во-первых, то, что вероятность реакции совпадает
с вероятностью появления события, можно
предсказать только в ходе вероятностного процесса
механического слияния стимула и реакции, а совсем не
через приобретение чего-то, что можно представить
через какое-либо вероятностное понятие.
Во-вторых, когда человек стремится к
«максимальной вероятности угадывания», тогда его
оптимальным поведением было бы предсказание
загорания лампы, которая включается чаще других.
Впрочем, при этом предполагается, что задачу, как еде-
Возможности технологических подходов в психологии ЗФ
лать вероятность угадывания максимальной во всех
попытках, можно решить только путем вычислений,
хотя существуют различные мнения по поводу того,
есть ли что-либо «рациональное» в толковании
ответов на вопрос: «Как вы думаете, какая лампа
загорится?». Однако с бихевиористической точки зрения
нет необходимости говорить, что действия человека —
это результат мышления или сознания, бессмысленно
спорить о том, должна ли реакция быть другой, если
действие — результат мышления, а нужно с
готовностью признать это раз и навсегда.
В-третьих, подобные эксперименты можно
проводить с кем угодно и где угодно, причем если
вычислить параметры обучаемости на основе полученных
данных, то, правильно нарисовав кривую
обучаемости, можно точно предсказать и экспериментально
проверить различные особенности вероятностных
явлений, например вероятность того, что лампа А
загорится три раза подряд. Таким образом, бихевиори-
стический научный взгляд на обучение стал
доминирующей парадигмой.
В области психологии есть еще одно направление,
которое образовалось чуть позже рассмотренной
выше математической теории обучения — во второй
половине 50-х гг. Это психология принятия решений,
ведущая свое начало с теории игр фон Неймана и
Моргенштерна, а именно: теорию игр и теорию
вероятности (в частности, теорему Байеса) стали
использовать для построения эталонной модели
рациональных рассуждений человека и сравнивать ее с
реальным процессом рассуждений. Следовательно, сданной
точки зрения человек — это не машина, в которой
происходит слияние стимулов и реакций, а существо,
способное к выбору оптимального поведения и
имеющее свои цели и намерения. Подобные исследования
в настоящее время называют байесовской
психологией, ведутся исследования многоальтернативной
оценки, группового принятия решения, вероятностных
рассуждений, поведения в многовариантных играх с
выбором и другие исследования, а в целях развития
прикладной теории — фундаментальные исследования
теории измерений. Внедрение математики в психоло-
40
Главе 2
гию с целью теоретического моделирования породило
две противоположные точки зрения. Первая
предполагает описание механического слияния стимула и
реакции с помощью марковских процессов так, как
в математической теории обучения, вторая ведет свое
начало от теории игр и предполагает моделирование
целенаправленных разумных сторон человека.
Честно говоря, каждая из этих двух точек зрения
зашла в тупик. Тем не менее каждая из них является
результатом добросовестного накопления опыта
в строгих психологических экспериментах, и навряд
ли эти точки зрения изменятся. Но в данной книге
придется отложить знакомство с данными
исследованиями и ограничиться формулировкой ряда проблем,
которые дали повод говорить о возрождении «эпохи
науки о мышлении».
В математической психологии это следующие
проблемы.
1. Часто параметры, поясняющие данные какого-
либо эксперимента, не могут объяснить данные
других экспериментов, в которых по теоретическим
расчетам действуют аналогичные процессы.
2. Начали разрабатываться модели переходов из
состояния в состояние, учитывающие внимание,
память, тактику и другие способности человека, созданы
модели, выходящие за рамки чистой теории слияния
стимула и реакции.
3. С одной стороны, исходя из психологических
гипотез, очень трудно построить какие-либо общие
закономерности для внимания, памяти, тактики и
т. д., поскольку условия экспериментов определяются
ad hoc lK С другой стороны, в байесовской или иной
психологии принятия решений появляются
следующие проблемы.
1) Человек не всегда придерживается
рациональных взглядов, он может достигнуть
удовлетворяющего его уровня при минимальной умственной
нагрузке.
2) Так называемой тактики общих рассуждений
не существует; оценки, как правило, связываются со
*> На данный случай (лат.). — Прим. перев.
Возможности технологических подходов в психологии 41
смыслом объектов и условий; поэтому крайне сложно
представить эту тактику в виде простых
математических формул.
С подобными проблемами психология вступила
в 60-е гг. навстречу эпохе науки о мышлении.
2.4. ВЗГЛЯДЫ НА ОБУЧЕНИЕ
В НАУКЕ О МЫШЛЕНИИ
Уже говорилось о том, с чего начались исследования
науки о мышлении, поэтому коснемся ниже понятия
«обучение».
Характерно, что в период с 1956 по 1972 г., когда
становилась наука о мышлении, ученые не
использовали слова «обучение». Оно было чуть ли не
запретным словом, во всяком случае, если кто-нибудь по
рассеянности спросит: «А как быть с проблемой
обучения?», то разговоры немедленно прекращались, и
вопрошающий чувствовал себя неловко. Дело в том,
что слово «обучение» слишком долго использовали
бихевиористы, как бы приобретя патент на его
применение, поэтому в разговоре об обучении возникали
ассоциации со слиянием стимула и реакции, а
специалисты в области мышления питали к этому чуть
ли не отвращение.
Наука о мышлении до 1972 г. — это главным
образом исследования по решению задач и механизму
памяти, а также исследования по психологической
интерпретации результатов моделирования с
помощью компьютеров процессов доказательства теорем
и решения головоломок, исследования кратковремен*
ной памяти в экспериментах по запоминанию списка
слов, экспериментальные исследования
психологической адекватности лингвистики Хомского и т. п.
После выхода книги «Системы, понимающие
естественный язык» Т. Винограда 1} в 1972 г. начали
обсуждать связь исследований долговременной памяти и
представления знаний с исследованиями решения
задач и мышления. Вступив с такими идеями в 80-е гг.,
*> Русский перевод вышел в издательстве «Мир» в 1976 г.—
Прим. перев»
42
Глава 2
ученые в области мышления вновь начали поднимать
проблему обучения.
В книге «Умение мыслить и как его приобрести»
под редакцией Андерсона (Cognitive Skills and Their
Acquisition. Hillsdale, N. J., 1981) впервые в самом
общем виде указано, что в науке о мышлении
центральной является проблема обучения и приобретения
знаний. В современной науке о мышлении энергично
ведутся теоретические и практические исследования
обучения и приобретения знаний 1К
2.5. ТЕОРИЯ ОБУЧЕНИЯ ACT *
Андерсон в книге «Архитектура познания» (Кэм-
бридж, 1983J) существенно улучшил известную
теорию ACT и предложил теорию ACT*. Эта теория
основана на своего рода системе продукций, состоящей
из рабочей памяти, памяти продукций и
декларативной памяти, а также на обобщенной модели
мышления человека, которая объясняет память и знания
человека, принятие решений, обучение и другие
аспекты мышления. Общее представление о
процедурном обучении в теории ACT * дает рис. 2.2. Как
показано на этом рисунке, в теории ACT * обучение
делится на два этапа в зависимости от состояния зна-
Декларативный этап Процедурный этап
(declarative stage) (procedural stage)
Компиляш 9ВД1Г
wledfo QQfflpUftlfeA]
(know
процвдуращшй
(proceduralliatfOh)
Композиция j Разделение
Координация знаний
(knowledge tuning)
Обобщение
(generalization}
Композиция < Разделение
(composition) (discrimination)
Усиление
(strengthening}
Рис. 2.2. Этапы обучения и механизм преобразовании в теории
Х) В данной книге среди различных теорий обучения не
упомянута теория обучения на основе параллельной распределенной
обработки, которая бурно развивается в последние годы.
2> Anderson, J. R.s The Architecture of Cognition, Cambridge,
M. A., Harvard, 1983.
Возможности технологических подходов в психологии 43
ний. Переход с одного этапа на другой
осуществляется с помощью механизма компиляции знаний,
дальнейший процесс обучения объясняется
механизмом координации знаний. Ниже теория ACT *
рассмотрена более детально.
2.5.1. ДЕКЛАРАТИВНЫЙ ЭТАП И КОМПИЛЯЦИЯ ЗНАНИЯ
Рассмотрим сначала декларативный этап. Например,
представим себе ситуацию, когда мы только что
изучили три теоремы сложения тригонометрических
функций (типа sin (а + Р) = sin а-cos р +
+ cosaesinp) в курсе математики. Допустим, нужно
решить задачу определения значения sin 105°.
Причем нас не учили, когда и какую формулу
использовать (как правило, это действительно не проходят
в школе), так что нам не понятно, что здесь делать.
Поэтому попытаемся использовать одну из
выученных формул. Например, проверим, подойдет ли
формула cos(a-j-P)- Повторяя эти проверки, к счастью,
обнаруживаем, что можно использовать формулу
sin(a+ р). На этот раз обратим внимание на то, что
105 нужно представить как a + р, и начнем
подбирать значения аир. Естественно, эти значения можно
определять произвольно. Скажем, пусть это 100 и 5;
тогда получаем sin 100-cos 5 + cos 100-sin 5, но
значение такого выражения найти сложно, поэтому
подумаем над тем, какие же числа взять в качестве a
и р, чтобы получить удобное выражение. Если
обратиться к долговременной памяти, то нетрудно
вспомнить, что мы уже получали значения sin и cos для
30, 45, 60 и 90 градусов. Поэтому разобьем 105 на 60
и 45 и положим a = 60, р = 45. Подставим аир
в левую часть соответствующей формулы и получим
искомое значение через значения sin 60, cos 45, sin 45
и cos 60.
На первом этапе обучения даже при решении
задачи с использованием единственной формулы
необходима достаточно сложная обработка данных, и
ученик, выполняя эту работу, испытывает большие
затруднения и тратит много времени. Андерсон
называет этот этап декларативным, он имеет следующие
44
Глава 2
особенности. Прежде всего на декларативном этапе
учебная процедура (формула) представляете^
в кратковременной памяти в виде «то-то есть то-то»,
т. е. в декларативном фактическом виде. В
приведенном выше примере формула будет представлена
в виде «sin(a+p) есть sin a cos р + cos a sin р (где
а и р— переменные)», без информации о том, при
каких условиях ее использовать. Таким образом,
знания на этом этапе имеют форму высказываний, их
нельзя непосредственно использовать при решении
задачи. В чем же особенность обработки с помощью
декларативных знаний? Андерсон утверждает, что
обработка ведется сверху-вниз путем интерпретации
знаний. Как видно из приведенного примера,
начинающий проделал рассуждения в обратном
направлении от цели задачи, скажем, таким образом:
«Чтобы получить sin 105, необходима формула sin(a + P),
а при использовании этой формулы необходимо,
чтобы a + р было равно 105, и т. д.» Когда поставлена
задача, то содержащаяся в ней информация
поочередно заменяется на знания из долговременной
памяти. Это легко понять, если читатель знаком с
обработкой на языке Бейсик или других языках, которые
основаны на принципах интерпретации. Другими
словами, декларативные знания сами по себе
использовать нельзя, для их выбора необходима
интерпретация и сопоставление информации в запомненных
формулах и информации в тексте задачи. Что же такое
интерпретация в случае решения задачи человеком?
В теории ACT* интерпретатором является множество
продукций, которые, как правило, можно
использовать при решении задачи. В приведенном примере
управление решением задачи и рассуждения типа
«Видимо, можно применить какую-либо формулу,
попробую их одна за другой», «Разобью это число на
два числа, для которых я знаю значения sin и cos»—¦
все это основано на универсальных продукциях,
пригодных для решения задач. Данная обработка играет
важную роль в рабочей памяти. Именно в рабочей
памяти во время обработки должны находиться цель
и подходящие формулы. По наблюдению Андерсона,
в самом начале обучения человек в процессе решения
Возможности технологических подходов в психологии 45
задачи каким-то образом облекает в слова заученные
формулы. Благодаря этому данные формулы
остаются в рабочей памяти. Замечено также, что на
такую обработку требуется время. Дело в том, что
заданную информацию необходимо последовательно
преобразовать с помощью универсальных продукций
трчно так же, как при обработке на языках
интерпретаторов.
Однако с течением времени решение задач,
подобных указанной выше, будет получаться мгновенно, а
именно: лишь взглянув на условие, можно записать
и решить sin 105 = sin60 • cos45 + cos60 . sin45= V^/
/2 • V2/2+ 1/2. V2/2 = л/б/4 + V2/4= (Уб + V2 )/4.
На этом этапе время, требуемое для решения,
значительно сокращается, и формулы уже не будут
представляться чем-то абстрактным. Андерсон назвал этот
этап процедурным.
На каких же знаниях базируются эти действия?
С помощью какого механизма преобразуются знания?
В теории ACT* подобные преобразования
инициируются благодаря компиляции знаний. Возможны два
механизма компиляции. Первый называется проце-
дурализацией. Он состоит в замене переменных в пер*
воначально используемых универсальных продукциях
на некоторые специальные значения, подходящие для
решения задачи. Для того чтобы эти продукции были
общими или универсальными, многое в них
представлено в виде переменных. Следовательно, для
определения из условия задачи конкретных значений этих
переменных необходима обработка, называемая
интерпретацией, при выполнении которой происходит
обращение к знаниям в долговременной памяти.
Неоднократное обращение к такой памяти рано или
поздно приведет к тому, что все переменные будут
заменены на значения, подходящие для данной
проблемной области.
Второй механизм — композиция. Это слияние
независимых продукций и преобразование их в одну
обобщенную продукцию. Следовательно, то, что ранее
выполнялось за несколько часов, теперь будет
выполняться за один шаг.
46
Глава 2
Допустим, есть три продукции:
Р1: если нужно получить значение некоторого
тригонометрического выражения, то найдите
подходящую формулу;
Р2: если нужно получить значение некоторого
тригонометрического выражения и найдена
подходящая формула, то подставьте число из
задачи вместо переменной в формуле;
РЗ: если переменная в формуле представлена как
сумма двух переменных (а + р), то разбейте
число в задаче на подходящие значения и
определите две переменные.
Сначала благодаря процедурализации продукцию
Р1 преобразуем к виду
Р1*: если нужно получить значение sin, то
используйте формулу sin (а + Р)-
Аналогично преобразуем продукцию РЗ:
РЗ*: если переменная в формуле представлена как
сумма двух переменных (а + р), то разбейте
число в задаче на сумму каких-либо из чисел
30, 45, 60, 90.
Теперь благодаря механизму композиции продукций
Р1*, РЗ*, Р2 окончательно получим
Р*: если нужно получить значение sin, то
используйте формулу sin(a+P), разбейте число
в задаче на сумму из каких-либо чисел 30,
45, 60, 90 и подставьте их в формулу.
Как видно из этого примера, композиционная
продукция имеет одно условие, которое в исходных
продукциях повторялось. Перед композицией в условие
Р2 вставлен результат выполнения Р1, а после
композиции часть этого условия исключена. Таким
образом, обработка, состоящая из трех шагов, стала
выполняться за один шаг.
Благодаря действию этого механизма значительно
повышается скорость обработки, уменьшается
нагрузка на долговременную память, обработка выпол-
Возможности технологических подходов в психологии 47
няется более «гладко». Кроме того, как показали
многочисленные исследования, которые сравнивали
новичков со специалистами, последние логические
выводы делают «снизу-вверх» по типу образного
мышления, работая непосредственно на оснобе исходных
данных.
2.5.2. ПРОЦЕДУРНЫЙ ЭТАП
И КООРДИНАЦИЯ ЗНАНИЙ
Благодаря компиляции знаний обучение переходит
на следующую ступень, становится более адаптивным.
По Андерсону, это обеспечивается координацией
знаний. Она осуществляется с помощью трех механизмов.
Обратимся вновь к уже знакомому примеру. Если
задан угол 105°, то мы его делим на углы 60 и 45°, а
если угол кратен степени 2, то при вычислении
пользуемся формулой 2 sin a cos а. Другими словами,
иногда обычные продукции преобразуются в более
специализированные, отвечающие условию задачи. Это
называется специализацией. В теории ACT*
специализация возникает в случае неудачной попытки
применения известных продукций, при этом сравниваются
условия успешного применения и условия, при
которых применение было неудачным, выявляются их
различия и создается новая продукция на основе
полученной информации.
Однако успехи в специализации возможны лишь
при создании продукций, соответствующих условию
данной задачи, а к этому вся система мышления
приспосабливается с трудом. Ведь число продукций
может быть огромно. Например, теоремы о сложении
можно использовать не только для получения sinx,
cosjc и других значений, но и при решении
тригонометрических уравнений, доказательстве неравенств,
равенств и т. д. Специалист в процессе обучения
должен не только вырабатывать большое число
специализированных продукций, но и, как правило,
генерировать такие продукции, которые можно
использовать для решения задач в различных областях.
Подобное расширение области применения продукций и
обеспечение их применения в более широком
контексте называется обобщением. Механизм обобщения в
48
Глава 2
теории ACT* включает две составляющие:
исключение несовпадающих высказываний в условиях
продукций в случае, когда эти продукции имеют одно и
то же действие, а также замена постоянных в
условиях на переменные. Для координации знаний в
теории ACT* предусмотрен еще один механизм,
называемый стабилизацией. Он заключается в усилении
продукций для того, чтобы при сопоставлении
преимущественно использовались часто используемые
продукции.
< С помощью четырех указанных выше механизмов
Андерсон смог достаточно строго объяснить преобра*
зование знаний человека, возникающее в процессе
обучения, и изменения в его поведении на основе
этих знаний. Например, в случае многократной
проверки памяти по Стенбергу (испытуемому
показывают список букв, затем одну букву, затем он
вспоминает, была ли эта буква в списке) отсутствие
пропорциональной зависимости между временем
реакции и числом букв можно объяснить с помощью
механизма процедурализации в теории ACT*. А
обнаруженная Лачинсом функциональная приверженность
(явление, состоящее в том, что после неоднократного
решения задач одним и тем же методом его же ста*
раются применить и для других задач, которые можно
решить более простым способом) может быть
объяснена с помощью механизмов композиции и
стабилизации. Теория Андерсона подтверждена
многочисленными исследованиями и экспериментами.
2.5.S. ЗНАЧЕНИЕ И ПРОБЛЕМЫ ТЕОРИИ ACT *
Создание теории ACT* подвело черту под бихевиори^
стической теорией обучения. В основе подходов Хал-
ла и других идеологов научного мира в эпоху бихе*
виоризма лежит описание изменений поступков в
соответствии с математически формализованной
теорией, а внутреннее состояние используется всего лишь
в виде параметров (сила привычки, побуждение и
т. п.) в формулах, допускаемых теорией. Однако мы
приобретаем знания именно благодаря обучению, да
и к изменению поведения нас также ведут знания.
Возможности технологических подходов в психологии 49
В теории ACT* различные изменения поведения,
возникающие в процессе обучения, описываются как
качественные изменения состояния наших знаний. По*
этому можно точно описать, какие ограничения
налагают на систему обработки знаний человеком
особенности знаний на декларативном и процедурном
этапах и как возникают изменения поведения.
Однако очевидно, что механизмы изменения в
теории ACT* приводят к большему числу проблем.
Будучи введенными в теорию, эти механизмы
ориентированы на оптимизацию системы мышления,
которая описывается с помощью продукций. Другими
словами, предполагается, что успехи в обучении
обусловлены механизмом исключения избыточности,
который предназначен для уменьшения нагрузки на
рабочую память (процедурализация), механизмом,
который позволяет все, что можно, сделать за один
раз (композиция), и механизмом объединения
процедур, которые порождают один результат
(обобщение). При таком обучении система (человек,
компьютер) может обрабатывать поставленную задачу с
очень высокой эффективностью. Тем не менее на
практике процесс обучения человека не всегда
идеальный. Например, сколько раз мы встречались с
тем, что ученик не понимает материал даже
при,неоднократном повторении. Проблема в
индивидуальных различиях: один ученик — способный, а
другой — тугодум. Короче говоря, в одной ситуации
механизмы изменения работают, а в другой — нет. Это
нельзя объяснить в рамках теории ACT*.
В процессе обучения мы не только стремимся
делать как можно меньше ошибок, быстро все
обработать, но и дать точные объяснения, установить связь
с задачами в других областях. Здесь необходима
тесная связь со структурированием знаний, а такая
проблема совершенно не затронута в этой теории.
2.6. ОБУЧЕНИЕ ЧЕЛОВЕКА
В данном разделе на примере развития - ребенка
уточним особенности обучения человека и обсудим
проблемы, которые обходит молчанием теория ACT*.
50
Глава 2
2.6.1. ПРОБЛЕМА: ПОЧЕМУ ТАК ПОЗДНО
НАЧИНАЕТ УЧИТЬСЯ ЧЕЛОВЕК!
Одна из известных проблем в психологии развития —
это так называемая проблема сохранения Пиаже.
Существует несколько версий этой проблемы.
Рассмотрим одну из них. Расположим несколько камешков
в два ряда, как на рис. 2.3, а. Если спросить четырех-
пятилетних детей: «Равно ли число камешков в
верхнем и нижнем рядах?», то получим ответ: «Да, равно».
Но если изменить расположение камешков так, как
показано на рис. 2.3, б, и задать тот же вопрос, то
большая часть детей ответит: «Внизу больше» (хотя
экспериментаторам встречались и дети, которые
ответили: «Камешков немного, но вверху их больше»).
Когда детей спрашивали, почему они так думают, то
их реакция была самой разнообразной: «Потому что
нижний ряд шире», «Потому что внизу растянуто»,
«Потому что вверху теснее» и т. п. Более того, дети
в зависимости от возраста и ситуации часто меняют
свое мнение. Некоторые читатели, наверное, уже
спрашивают: «Разве эти дети не умеют считать?»
Успокойтесь, они могут считать и указывать, что в
каждом ряду по четыре камешка (как правило, в че-
тырех-пятилетнем возрасте большая часть детей
может считать вслух до 20 и пересчитать до 10
предметов). И тем не менее, как это ни удивительно,
некоторые говорят: «Внизу четыре камешка, поэтому
внизу больше»,
0 о о о
й
б
Рйо, 2,3. а— начальная расстановка; 0 — измененная расста*
новка.
Возможности технологических подходов в психологии 51
Даже с такой на первый взгляд простой задачей
ребенок может справиться лишь в пяти-шестилетнем
возрасте. Опять кое-кто из читателей подумал:
«Разве не будет все понятно, если сосчитать камешки?»
Но если попросить детей сосчитать камешки, это
приводит к противоположному результату — ребенок не
может правильно ответить даже после нескольких
упражнений. Например, если ребенку несколько раз
давать эту задачу и каждый раз подсказывать ответ,
то вскоре он начнет отвечать правильно. Однако, если
проверить его через некоторое время, то снова
столкнемся с прежней ситуацией. Более того, если в
момент, когда нам покажется, что обучение дает
эффект, мы с помощью какой-либо уловки, так чтобы
не заметил ребенок, уберем камешек из какого-либо
ряда, то он будет механически отвечать: «Одинаково»,
а если ему подсказать: «Ну что ты, внизу меньше!»,
то мы неожиданно снова вернемся к старому
результату. Даже при целенаправленных упражнениях
каких-либо успехов в обучении не будет достигнуто.
Рассмотрим другой пример. В школе учат
различные законы, правила. Среди них — теорема сложения
тригонометрических функций, которую мы
использовали при объяснении теории ACT*. Кстати, как
правило, подобные теоремы никак не удается заучить
даже при многократном повторении: многие ученики,
испытывая трудности, занимаются у репетиторов.
Даже если они на какое-то время запомнят эти
формулы, то возникнут новые трудности: как их
использовать на практике. И совсем не. важно, может ли
ученик наизусть прочитать эти формулы, важно то,
что ученики ясно себе их представляют. Если бы
однажды объясненное сразу же можно было
выучить, то учитель не испытывал бы никаких
трудностей, и исчезла бы большая часть проблем в учебных
заведениях. Не только дети, но и взрослые многого
не могут выучить, и для них выпускают
разнообразные учебники, справочники, пособия, а учителя по-
прежнему с трудом составляют учебные планы.
Приведенные здесь примеры разительно
отличаются от обучения, формализованного теорией ACT*.
В процессе обучения человека, конечно, возникают
52
Глава 2
процедурализация, композиция, обобщение и
специализация. Однако все это далеко не всегда работает,
а если и работает, то требует много времени. Никогда
процесс обучения не идет автоматически, как это
утверждает теория ACT*. Быть может, люди глупы?
(Например, ограничен объем рабочей и
долговременной памяти? Есть ограничения на доступ к памяти?
Нелогичны механизмы специализации и обобщения?
и т. д.) Но если это так, то вы, уважаемые
исследователи инженерии знаний, совсем не интересовались
обучением человека, а выбрали себе в партнеры
«высокоодаренные» компьютеры и просто
рассматриваете алгоритмы высокоэффективного обучения и их
применение.
Однако может быть и другая точка зрения.
Можно ведь считать, что при обучении человека
существуют внешние ограничения, которые ни в чем не
совпадают с ограничениями при обучении
компьютеров (и которые нельзя учесть в современных
компьютерах), а человек выполняет специфичную обработку
с целью хоть как-то преодолеть эти ограничения, что
требует большего времени. Попытаемся обсудить
отставание в обучении человека с этой точки зрения.
2.6.2. НОВАЯ ПРОБЛЕМА: СЛОЖНОСТЬ СРЕДЫ
Среда, в которой проходит обучение человека,
вопреки нашим ожиданиям, достаточно сложна. В мире*
где мы учимся, потенциально существует
неограниченно много информации. Рассмотрим такой случай»
Студент, изучающий язык Лисп, собирается решить
задачу вывода на печать треугольника Паскаля 1) при
любом N. Он определил функцию с именем PASCAL,
запрограммировал ее и запустил на решение. Снача*
ла он пробует вычислить треугольник при N = 3, но
на экране дисплея появляется странная картинка, и
какую бы клавишу он не нажимал, от компьютера нет
никакой реакции (обратите внимание на то, что при
J) В алгебре треугольником Паскаля называют записанные в
форме треугольника коэффициенты полиномов (х + у)ы.~-Прим9
перев.
Возможности технологических подходов в психологии S3
обычной ошибке такая ситуация не возникает). Он
думает, что при запуске программы нажал не ту
клавишу, нажимает клавишу «сброс» и пытается
выполнить программу еще раз. Но вновь тот же результат.
Делать нечего, он начинает все сначала. На этот раз
внимательно проверяет, нет ли в тексте программы
ошибки. Но как он ни ломал голову, ничего не нашел
(разумеется, ошибка-то была) и пробует выполнить
программу при N = 2. Теперь все кончается
выходом в операционную систему. Тут рассеянного
студента осенило: «Разве можно присваивать этой
функции имя PASCAL? Это же название языка
программирования! Как же неосмотрительно я поступил!» Он
проверяет имена функций по каталогу OBLIST и, не
очень задумываясь, заменяет имя функции на
PASTRI и корректирует программу (при этом
случайно исправляя ошибку). Затем робко набирает
«PASTRI 3» и, разумеется, получается 1, 3, 3, 1.
После нескольких попыток с другими числами он
делает заключение: «Нельзя использовать
привилегированные имена типа PASCAL» 1).
Этот случай рассказан не как анекдот для
разрядки. Он приведен как пример того, что среда, в
которой обучается человек, содержит самую
разнообразную информацию. По мнению эксперта по
компьютерам, эффект обучения такого студента поистине
абсурдный: разве можно подумать, что ошибка
возникла из-за имени функции, а тем более из-за
привилегированного имени? Начинающий программист не
может понять, что это информация к тому, чтобы
обдумать свою неудачу (если все понятно, то это уже
не новичок). Другими словами, в принципе можно
было бы искать причину неудачи среди той
информации, которая окружает нашего студента (говорят
ведь про неудачу, что, мол, ворона накаркала; до сих
пор в Японии много людей, которые верят, что
свадьба в день «буцумэцу»2* приведет к несчастному бра-
1) Этим студентом был один из авторов (Саэки), подобная
ситуация возникла при работе с программным обеспечением на
микрокомпьютере mu-LISP.
2> День кончины Будды,— Прим. перев.
54
Глава 2
ку). И дело совсем не в том, что информация в среде,
где мы живем, постоянно меняется, а в том, что
нередко одну информацию мы подменяем другой. А раз
так, то чрезвычайно сложно формально механически
определить, из-за какой информации наше поведение
оказалось ошибочным, а из-за какой — успешным.
Поэтому-то для обучения человека требуется время.
С другой стороны, дело не в том, что человек,
сталкиваясь с подобной средой, теряется. Просто
независимо от сложности среды система обработки
информации, какой является человек, выбирает
соответствующие действия, исходя из ограниченного опыта,
и успешно адаптируется к среде. Почему это
происходит? Как человек обучается и приобретает знания,
когда механические формальные методы непригодны?
В настоящее время есть теория обучения машин, но
большинство обучающихся систем не учитывает
сложность среды. Информация, которую можно вложить
в систему, определяется заранее, ее объем крайне
мал, а взаимосвязь между различной информацией
определяется априорно (в некоторых системах
запоминается все, что выполнялось ранее). Такая среда
качественно отличается от среды, в которой
происходит обучение человека (по крайней мере
начинающего). Следовательно, при дальнейшем расширении
области применения существующих обучающихся
систем обязательно необходимо учитывать методы
обработки всевозможных видов информации.
2.6.3. РЕШЕНИЕ: ЗАВИСИМОСТЬ ОБУЧЕНИЯ
ОТ ЗНАНИЙ
Раскрывая затронутую здесь тему, нельзя не
упомянуть исследования понятий, выполненные Морфи и
Медином. Эти исследования в каком-то смысле
охватывают проблемы, аналогичные проблеме обучения.
В большинстве современных исследований понятия
представляют в виде списка атрибутов,
характеристик. Однако, если у некоторого объекта существует
неограниченное число атрибутов, всех их перечислить
невозможно. Часто каждому атрибуту приписывают
вес и таким образом выделяют среди них самые важ-
Возможности технологических подходов в психологии $5
ные. Однако очевидно, что такой подход не очень
эффективен. Например, для понятия «собака» атрибуты
«четырехногое животное» и «лает» должны быть
самыми важными, но достаточно взглянуть на собаку,
лишившуюся ноги из-за несчастного случая, чтобы
сразу сказать, что это собака, и нам не нужно
заставлять ее лаять. Опыт показывает, что критериев
оценки важности атрибутов не существует.
Ну, а как определить понятие «человек», какие
особенности он имеет? Рассмотрим следующий
пример. Вот ряд слов: рукопись книги, ребенок,
сберегательная книжка, драгоценности — едва ли найдется
человек, который сразу же ответит, к какой единой
категории отнести эти понятия. Однако, услышав
ответ «спасенное при пожаре», каждый с ним
согласится. Кстати, найдется ли человек, который на вопрос
об атрибуте понятий «рукопись книги» или
«ребенок» приведет категорию «спасенное при пожаре»?
Вряд ли. Однако мы можем экспромтом прийти к
такой категории (особенно если самому пришлось
пережить пожар). Другими словами, понятия, которыми
мы оперируем, очень и очень гибкие. Человек в
зависимости от ситуации сразу же может извлечь и
обобщить важные и общие атрибуты. Рассмотрим
понятие «птица»: «имеет крылья», «летает», «имеет клюв»,
«клюет корм» — все это атрибуты птицы. Увидев
объект, которому присущи эти атрибуты, человек
однозначно определит: это птица. Но только ли это
делает человек? Например, на вопрос: «Почему
птица летает?» мы можем ответить: «Потому что у нее
есть крылья», а на вопрос: «Как ест птица?» —
ответим: «Она клюет корм клювом». Таким образом, все
атрибуты можно представить не только по
отдельности, но и в их взаимосвязи.
Морфи и Медин утверждают, что понятия,
которыми оперирует человек,— это не множество простых
атрибутов, они имеют внутреннюю структуру,
скрепленную знаниями. Как только в предыдущих
примерах нам сообщали ответ, мы сразу же улавливали
связь, поскольку, например, благодаря знаниям о
пожаре смогли выбрать важнейшие из атрибутов
весьма далеких друг от друга понятий «рукопись книг軧
56
Глава 2
«ребенок» и других и образовать иа них единый ряд.
В примере «птица летает» благодаря знаниям о мире
полет мы ассоциировали с крыльями и представили
причинно-следственную цепочку. Другими словами,
благодаря знаниям человек строит некую
взаимосвязь между атрибутами понятия, объединяет их
семасиологически и охватывает их как единое целое с
позиции теории мышления. Атрибуты и особенности
нельзя подбирать по отдельности, как и нельзя
фиксировать.
Но вернемся к проблеме обучения. Подобно тому
как человек связывает и обобщает атрибуты далеких
друг от друга понятий, используя знания о структуре
понятий, при обучении он также на основе
имеющихся знаний выбирает среди потенциально
неограниченной информации, поставляемой ему средой,
наиболее важную информацию для соответствующей
деятельности. Короче говоря, разве ради успеха в
обучении ему не требуются знания для
упорядочивания и систематизации информации из среды
обучения?
. Вспомним реакции детей в опытах по сохранению
чисел Пиаже. Когда детей расспрашивают о причине
их ответа, они называют самые различные причины.
Кто главной считает длину ряда, кто — плотность,
хотя одновременно учитывает и число камешков.
Видимо, это говорит о том, что для подобной ситуации
у них не хватает знаний, которые бы
систематизировали различную информацию, присутствующую в
условиях эксперимента. Другими словами, от случая
к случаю в качестве причины приводятся наиболее
заметные атрибуты: детям не хватает знаний, которые
устанавливают связь этих атрибутов с целью задачи.
Поэтому они не могут однозначно определить причину
своих ошибок, и обучение не дает результатов даже
при неоднократных подсказках. Это полностью
относится и к студенту, изучающему язык Лисп. Он
ничему не научился, хотя получал от компьютера
различные ответы, поскольку у него не было знаний,
достаточных для того, чтобы идентифицировать
причину ошибки, да и вы, дорогой читатель, смеетесь над
этим студентом только потому, что обладаете доста*-
Возможности технологических подходов в психологии $7
точным запасом знаний о Лиспе или общих
принципах программирования. Короче говоря, информация,
позволяющая понять причину неудачи, глубоко
скрыта от студента, а вы благодаря соответствующим
знаниям можете наперед сказать, какой информацией
разумно воспользоваться в данном случае.
Сказанное выше справедливо не только для
людей, но и для животных. Гарсия и Келинг
экспериментально проверили, при каких из указанных ниже
четырех условий крысы могут научиться избегать
неприятных для них ситуаций.
Условие 1. В момент, когда крыса пьет воду,
даются световой и звуковой сигналы, а
затем — удар током.
Условие 2. В момент, когда крыса пьет воду,
даются световой и звуковой сигналы, а
затем у нее вызывается рвота.
Условие 3. В момент, когда крыса пьет воду, в
воду добавляют сахар, а затем дается
удар током.
Условие 4. В момент, когда крыса пьет воду, в
воду добавляют сахар, а затем у нее
вызывается рвота.
Урок не прошел даром (крысы перестали на
следующий день пить воду) только для крыс,
прошедших обучение при условиях 1 и 4.
Смысл такого результата очевиден. Просто в
рамках тех знаний, которыми обладают крысы, им
становится ясно, что после светового и звукового
сигналов будет дан ток, а причину рвоты при этом же
условии им понять трудно (если человек, выпив
воды из-под крана, получит удар током, он, как
правило, будет искать, нет ли рядом оголенной
электрической проводки, и, конечно, не подумает, что
это связано с водой). С другой стороны, рвота после
выпитой сладкой воды — это та информация, которая
вполне «доступна» крысам на уровне их знаний, но
связать вкус воды с ударом током им уже трудно.
В свете этого обсуждения становится очевидным
ответ на проблему, указанную в начале данного раз-
18
Глава 2
дела. Люди (и даже животные) через опыт
приобретают разнообразные знания о мире и с их помощью
строят предположения о том, какая часть из
огромного объема информации в условиях обучения
является наиболее важной. Связав воедино
информацию, важную для их деятельности в данный момент,
и осмыслив ее, они самостоятельно моделируют
окружающую среду1}. Поэтому даже в очень
сложной среде (по меньшей мере сложнее, чем среда
вокруг компьютера) можно с успехом обучаться и
соответствующим образом реагировать на новые
ситуации. И наоборот, без систематизации
разнообразной информации внутри среды (без построения
соответствующей модели) обучение не даст результата
даже при некотором опыте.
Обобщим сказанное. Люди учатся через опыт.
Однако они не впитывают в себя всю информацию.
Восприятие информации и ее систематизация
осуществляются через знания. Поэтому, даже имея опыт,
в одной и той же ситуации каждый человек в разное
время (т. е. в зависимости от состояния знаний
обучающегося) может по-разному осмысливать
информацию. Кроме того, человек, опираясь на свои
знания, либо изменяет среду для получения
необходимого опыта, либо избегает накопления случайного
опыта. В этом смысле наше обучение можно назвать
обучением, зависимым от знаний. Компиляция
знаний в теории ACT* не отрицает того, что в
результате обучения возникает упорядочивание знаний, но
в такой замкнутой в себе области мышления, как
обучение, это происходит не автоматически, а лишь
благодаря динамическому взаимному использованию
разнообразных знаний человека. Обучение
человека— это совсем не накопление порция за порцией
информации в пустой голове и не упорядочивание ее
с помощью каких-то самоконтролирующихся
механизмов. В пустую голову информация никак не попадет,
а если бы даже она туда попала, то ее
упорядочивание было бы невозможным. В теории ACT* нельзя
0 Иногда полученный таким образом упорядоченный
символический мир называют мысленной моделью,
Возможности технологических подходов в психологии 59
объяснить, как влияют на обучение индивидуальные
особенности людей и различия в решаемых задачах,
поскольку эта теория не рассматривает свойства и
функции накопленных знаний.
2.7. ЗНАНИЯ ЧЕЛОВЕКА
Итак, из сказанного выше стало очевидно, что
обучение главным образом возможно благодаря
знаниям. Но в какой форме представлены наши знания?
Для ответа на этот вопрос мы должны понять
особенности зависящего от знаний обучения человека.
Существуют две точки зрения на то, как
представляются знания человека. Первая — знания
представляются в абстрактной форме и имеют высокую
степень универсальности. Вторая — знания
специфичны в зависимости от места их приобретения и
использования, имеют низкую степень общности и
универсальности.
Например, знание «1 + 1=2» можно применять
вне зависимости от объектов, а знание «отец — это
мужчина, имеющий ребенка» можно истолковать вне
связи с каким-либо событием. Считается, что
общность подобных знаний — это необходимое условие
адаптации к сложной среде. Но так ли это?
2.7.1. ПРОБЛЕМА: СПЕЦИФИЧНОСТЬ ОБЛАСТИ ЗНАНИЙ
Вернемся к задаче Пиаже. Вы помните, что четы-
рех-пятилетние дети ошибаются в простой задаче.
Но ведь они уверены, что не ошибаются! Хотя,
например, по сообщению самого Пиаже, если в
качестве атрибутов для эксперимента выбрать не
камешки, а вазы с цветами или подставки с яйцами, то
ребенок, не справлявшийся с простой задачей, будет
отвечать правильно. Более того, некоторые
исследователи отмечают, что вероятность правильного
ответа повышается, если каждый раз при расстановке
или сжатии ряда камешков объяснять свои действия
ребенку. Однако если через какое-то время вновь
вернуться к прежнему заданию, то ребенок, который
давал правильный ответ в задании с объяснениями,
60
Глава 2
опять не сможет ответить. В чем же дело? Формально
вроде бы два одинаковых задания, но в одном
случае ребенок дает ответ без труда, а в другом —
ошибается. Почему же нельзя во втором задании
применить знания, которые однажды уже помогли ему?
Может быть, потому, что это ребенок? Но
аналогичные явления неоднократно наблюдались и в
экспериментах со взрослыми.
Посмотрим на результаты экспериментов Вейсона,
изучающих дедуктивные выводы человека. Пусть
тезис «если Р, то Q» истинен, тогда, как правило,
истинен и антитезис «если не Q, то не Р». Студенты
университета уже приобрели это знание, но могут ли
они использовать его в подходящих условиях для
логических выводов? Эти ожидания оказались
ошибочны. Вейсон провел следующий эксперимент.
Показав студентам четыре карточки (рис. 2.4), он сказал:
«На лицевой стороне этих карточек написаны
цифры, а на обратной — буквы. Какое наименьшее число
карточек необходимо перевернуть, чтобы подтвердить
истинность тезиса: на обратной стороне четных
карточек всегда написана гласная?» Свыше 80 %
испытуемых (студентов) решили, что достаточно
перевернуть карточки с четными цифрами и гласными
(разумеется, правильное решение иное: необходимо
перевернуть карточки с четными цифрами и
согласными).
Здесь, уважаемые читатели, вы наверное
подумали так: «Разве дело в том, что, как было сказано»
человек учится? Имеет ли значение его умение
рассуждать логически? Видимо, и ошибочные выводы
человека могут быть представлены в некоторой
форме». Например, в задании с четырьмя карточками
скорее всего человек не пользуется правилом: «об*
ратное также истинно». Другими словами, у человека
есть своя логика, но только она чисто случайно от-.
в
ш
Рис. 2,4. Задача с четырьмя картами Вейсона,
Возможности технологических подходов в психологии 61
личается от правил логики как науки. Поэтому
можно считать, что человек преимущественно
пользуется своими пусть ошибочными правилами, но
которые также можно формально описать. Кстати,
и эта ситуация не так проста.
Например, Румельхарт провел следующий
эксперимент, несколько видоизменив задание с четырьмя
карточками. Испытуемым сообщили: «В некотором
универмаге на обороте чека на покупку стоимостью
свыше десяти тысяч долларов должна стоять печать
заведующего. Какие из чеков следует перевернуть
и проверить это?» Затем показали четыре чека: чек
с печатью, чек без печати, чек на сумму свыше
десяти тысяч долларов и чек на меньшую сумму.
В результате свыше 60 % испытуемых смогли выбрать
правильные чеки. Разумеется, это задание формально
полностью аналогично заданию с четырьмя
карточками, приведенному выше. Однако в первом задании
вероятность правильного ответа была чуть выше
10%, а во втором — свыше 60%. Следовательно,
человек не может делать соответствующие выводы при
решении такого рода задач, и дело совсем не в том,
что он при этом безрассудно использует ошибочные
правила ^
На практике подобных примеров можно привесМ
множество. Например, даже студенты факультета
естествознания и техники Массачусетского
технологического института (США), сидя перед дисплеем
компьютера, игнорировали закон инерции и
совершали промахи раз за разом. Разумеется, если бы эти
студенты пользовались бумагой и карандашом, они
без труда решили бы задачи, связанные с законом
инерции. Кстати, в своей автобиографии Фейнман2^
писал, что он восторгался каждый раз, когда
студенты этого же института указывали, что
касательные к волнообразным неровностям облачных
образований параллельны земле (другими словами, что
1} Об ограничениях формальных подходов к исследованиям
такого рода см. гл. 4, 5.
2) «Вы, конечно, шутите, мистер Фейнман!» — Нью-Йорк,
1985. Главы из этой книги опубликованы в журнале «Наука и
жизнь», 1986, № 10, 12; 1987, № 2, 8; 1988, № 8. — Прим. пере в.
62
Глава 2
значение производной в точках экстремума равно
нулю). Кроме того, исследования равнозначности
задач и аналогий показали, что нельзя так просто
применять знания, приобретенные при решении
испытуемыми одних задач, к структурно идентичным им
другим задачам.
Явление, когда знания то работают, то не
работают в зависимости от контекста формально и
структурно идентичных задач, называют специфичностью
области. Другими словами, наши знания
специализируются в зависимости от контекста, в котором они
были приобретены, и от ситуации, в которой они
чаще всего использовались, поэтому такие знания
не работают в ситуации, содержащей иную
информацию. Следовательно, знания человека не слишком
универсальны, а существенно ограничиваются
конкретным опытом. Результаты приведенных
экспериментов и их интерпретация, очевидно, поддерживают
вторую точку зрения.
Тем не менее и подобный вывод достаточно
сомнителен. Только этим невозможно объяснить многое
в поведении человека. Например, в эксперименте
Румельхарта испытуемые не могли использовать
прошлый опыт (никак не предполагалось, что
испытуемые имеют опыт работы в универмаге с подобным
правилом). Итак, среда, которая окружает нас,
постоянно изменяется, и каждый момент времени
неповторим. Люди в такой среде не могут
существовать, не опираясь на свой опыт и не получая
типичные для данной ситуации знания.
2.7.2. РЕШЕНИЕ: ПОЛУАБСТРАКТНОСТЬ ЗНАНИЙ
Как же представить знания человека, которые и
неуниверсальны и нетипичны для опыта? Какое
отношение имеют к нашему мышлению особенности
представления знаний и какую роль играют эти
особенности? Для решения этих проблем прежде всего
обсудим, как человек может заставить работать
знания в процессе логических выводов.
Не так давно Чен и Холиок опубликовали
результаты исследований, в которых много намеков на эту
Возможности технологических подходов в психологии 63
тему. Они выяснили, что человек может делать
надлежащие выводы тогда, когда есть «допустимый»
контекст. При выполнении некоторого действия и при
оценке, выполняются ли условия этого действия,
человек может делать выводы практически интуитивно.
Знания для таких выводов исследователи назвали
«схемой прагматических выводов». Эти знания можно
представить в форме следующих правил.
Правило 1. Если выполняется некоторое действие,
то должны удовлетворяться условия
для этого действия.
Правило 2. Если некоторое действие не будет
выполняться, то могут не
удовлетворяться и его условия.
Правило 3. Если удовлетворяются условия, то
можно выполнить действие.
Правило 4. Если условия не удовлетворяются, то
действие выполнять не нужно.
Эти правила и схема выводов точно соответствуют
формальным правилам оценки условий. Вспомним,
ведь и мы бессознательно используем такую схему
в повседневной жизни. Например, давайте поставим
себя на место полицейского, которому нужно
выявлять водителей без прав. Он проверяет выполнение
правила «Для вождения автомобиля необходимы
водительские права». Ему могут встретиться четыре
типа людей: человек, сидящий в автомобиле,
ребенок (т. е. человек, который не может вести
автомобиль), человек с правами и человек без прав. Кого
из них следует подвергнуть полицейской проверке?
Естественно, проверим человека, сидящего в
автомобиле, и человека без прав. Но как быть с
остальными людьми, имеющими права (другими^.словами,
надо ли проверять правило, противоположное
правилу «Если сидишь за рулем, то должен иметь права»)?
Чен, проведя несколько экспериментов, доказал,
что мы правильно делаем выводы по условиям с
использованием указанных выше правил. Кроме того,
оказалось, что эти схемы можно применять не только
64
Глава 2
в конкретной области, они действуют всегда при
условии, что есть «допустимый» контекст, и выдают
соответствующие оценки. Итак, знания, успешно
работающие в некоторой задаче, иногда не работают
в другой задаче, формально и структурно
аналогичной первой. Но, с другой стороны, соответствующие
знания работают всегда при наличии допустимого
контекста. Что может рассказать это явление о
характере человеческих знаний? Что такое
«допустимый» контекст в утверждении, что знания работают
при наличии допустимого контекста? Это
утверждение не содержит ни формы, ни структуры. Речь идет
о смысле, который мы, люди, извлекаем из задачи
(или строим из контекста). Следовательно, может
быть, следует сделать вывод о том, что вопрос
«Можно ли применять знания?» подразумевает не
формальную, структурную сторону задачи, а
смысловую, содержательную? Если смысл идентичен, то
человек может применять соответствующие знания в
достаточно широкой области. Такое свойство знаний
мы будем называть «полуабстрактностью». Это
означает, что с позиции формализации наши знания
не являются абстрактными и универсальными, а й
позиции осмысления — они в высшей степени
универсальны. Короче говоря, человеку очень сложно
с помощью одних и тех же знаний решать задачи,
формально и структурно аналогичные, но по смыслу
и содержанию полностью различные. Или еще
короче: человек не считает идентичными две задачи
с различным смыслом и содержанием (или ему
крайне трудно признать этоI).
Давайте еще раз вернемся к проблеме сохранения
Пиаже, которую мы уже неоднократно упоминали
в данной главе. Ребенок ошибается в простом
задании, поскольку он не может установить взаимно одно-
1) Идея полуабстрактных знаний имеет много общего с идеей
смысловой чувствительности, которую высказал японский иссл^
дователь Андзаи. Однако эта идея обсуждалась с точки зрения
совместного использования целей и состояния субъекта, а мы,
говоря «знания полуабстрактны», имеем в виду, что в основа
всего лежит; смысловая связь как основной конструктивный
элемент знаний,
Возможности технологических подходов в психологии 65
значное соответствие между объектами в каждом
ряду. Однако нельзя сказать, что у ребенка совсем
нет знания о взаимно однозначном соответствии. Это
следует из ряда экспериментов, описанных выше.
В какой форме ребенок приобретает это знание?
Один из авторов данной главы в качестве атрибутов
для экспериментов выбрал предметы, имеющие некую
функциональную смысловую связь, и провел те же
эксперименты (например, один ряд — куклы,
другой— стулья). И что же? Ребенок, который в
простом задании оценивал длину или плотность ряда,
смог сделать правильную оценку, не запутавшись
в полученной информации. Но самое интересное то,
что такая функциональная смысловая связь носит
стимулирующий эффект лишь в случае, когда задан
вопрос: «Все ли куклы рассядутся по стульям?», и
не дает эффекта, когда задан вопрос: «Равно ли
число кукол и стульев?» И уже при любой замене
атрибутов получается аналогичный результат.
Посмотрим, как поддерживает эти результаты
выдвинутая выше гипотеза «полуабстрактности
знаний». Вообще говоря, у ребенка нет абстрактного
знания о взаимно однозначном соответствии, а есть
функционально эквивалентное ему знание
(прагматичная схема) типа «с каждым предметом можно что-
то сделать» или «с каждым предметом можно
установить функциональную связь (например, усадить на
стул)». Таким образом, если это знание работает
и предметы имеют функциональную смысловую связь,
то в результате будет установлено взаимно
однозначное соответствие между ними. С точки зрения нас,
взрослых, нет особого различия в том, какие
предметы выстраиваются в ряд, какие вопросы задаются.
Форма и структура задачи непременно приводятся
к взаимно однозначному соответствию. Однако с
точки зрения смысла и содержания задачи различия
в форме вопросов вызывают существенные сдвиги в
сознании. С одной стороны, вопросы равнозначны,
а с другой — появляется задача прагматического
осмысления: «Рассядутся ли?» Знание ребенка о
взаимно однозначном соответствии очень
чувствительно к подобной смысловой стороне условия за-
3 С. Осуга, Ю. Саэки
66
Глава 2
дачи, поэтому это знание успешно работает в случае,
когда в задаче спрашивается о смысловой связи,
и не работает ? других случаях.
В заключение рассмотрим, какое значение имеет
утверждение о том, что обучение зависит от
подобных полуабстрактных знаний. Из сказанного выше
можно сделать следующий вывод: знание,
приобретенное в некотором контексте, с не очень высокой
вероятностью можно применить в контексте,
отличающемся от прежнего в смысловом отношении, но
аналогичном в функциональном. Поэтому некоторые
из читателей, может быть, придут к заключению:
«Все-таки человек глуп! В компьютерах следует по
возможности представлять знания абстрактно и
формально, обеспечить их универсальность. Иначе
компьютер будет поступать так же странно, как и
человек». Однако можно ли так думать всерьез? Так ли
просто понять, что задачи, подобные по смыслу,
однотипны? Например, в исследованиях Чена
приводились задачи о служащих государственных
учреждений, о персонале почтового отделения, о юристах,
контролирующих выполнение законов, и другие
задачи. Понять, что столь разнообразные задачи имеют
допустимый контекст,, не так просто (по крайней
мере, существующие системы, понимающие
естественный язык, не могут охватить столь обширную
область 1)). Итак, такая обучающаяся система, как
человек, нечувствительна к понятию «формальность»,
но очень податлива к понятию «смысл», и при этом
может в полной мере адаптироваться к среде даже
без особых тренировок. При обучении человека
крайне важно путем смысловой интерпретации
условий задачи (т. е. надо понять, что требуется)
установить связь с существующими знаниями.
Обучающаяся система, какой является человек, имеет
слабую универсальность по отношению к форме, но
может адаптироваться к сложной среде благодаря
универсальности по отношению к смыслу.
,} Для решения этой проблемы, видимо, будут эффективны
идеи, предложенные Шенком в книге «Динамическая память—>
теория запоминания и обучения компьютеров и людей». —
Кембридж, 1982.
Возможности технологических подходоо в психологии 67
2.8. ЗАКЛЮЧЕНИЕ
В данной главе проведена (нестрогая)
систематизация исследований обучения на основе «технических»
подходов с формальных механистических позиций и
уточнены проблемы и ограничения этих подходов
в сравнении с процессом обучения человека. Это
настолько нестрогая систематизация, что, по мнению
авторов, среди читателей найдутся такие, кто
вспыхнет негодованием. Для этого, чтобы исключить
неверное понимание, отметим, что авторы считают
возможным формальное представление мышления и
обучения человека. Думаем, что и среди обучающихся
систем немало таких, обучение которых считается
плодотворным и эффективным, благодаря удачным
алгоритмам обучения, и применение этих систем
позволит уточнить решение проблем обучения. Считаем
также, что в системы должно быть встроено как
можно меньше средств так называемой технической
эстетики; лучше, чтобы эти средства были более
универсальными.
Существует также точка зрения, что приведенные
здесь идеи необходимо высоко ценить, что в систему
мышления человека с рождения встроено множество
знаний. И такая система не будет обучаться, если не
будет осмысливать мир с помощью этих знаний. Но
на это требуется время, и как бы мы ни старались,
«технически» оптимальным такое осмысление сделать
нельзя. Несомненный факт, что универсальных
обучающихся систем, совершенных, как человек, не
существует. Такие системы не только должны быстро
работать в процессе обучения и выбирать
соответствующие действия, но и осмысливать, понимать мир
объектов, создавать органичное представление этого
мира. Не выбрать ли нам на первый взгляд окольный
путь анализа подобной формы обучения, сравнения
ее с формой обучения компьютеров, другими словами,
путь исследования обучения с позиций теории
мышления? В результате чего это должно способствовать
и созданию совершенных систем, и проникновению
в тайны нашей «души».
3*
ГЛАВА 3.
МЕТОДЫ И ПРОБЛЕМЫ ИЗВЛЕЧЕНИЯ
ЗНАНИЙ
X. Кобаси
(Токийский университет естественных наук)
Методы, с помощью которых программы
автоматически вводят знания, не имеют прямого отношения
к взглядам на процесс обучения человека — образца
для изучения проблем приобретения знаний и
обучения. Работа, связанная с получением знаний,
имеющихся у конкретного лица, называется извлечением
знаний, в инженерии знаний эта работа имеет
немаловажное значение. Необходимостью извлечения
знаний специалиста разработчиком экспертной системы
нельзя пренебрегать не только из-за того, что пол-
костью автоматизировать этот процесс необычайно
сложно, но и из теоретических соображений. В
данной главе подняты проблемы извлечения знаний,
исходя из этой точки зрения. Кроме того, эта глава
знакомит с некоторыми из методов, предложенных к
настоящему времени для извлечения знаний, хотя цель
главы состоит не в том, чтобы тут же предложить
каталог практических методов. Скорее в ней
уточняется методика извлечения знаний как объект
исследований, требующих серьезных усилий, и отмечается
целесообразность таких методов.
3.1. МАССА ПРОБЛЕМ
Не понимаем ли мы превратно, что такое теория
экспертных систем? Литературы об этих системах очень
много, в том числе и хорошей, и плохой. Одному не-
ьозможно даже бегло просмотреть всю эту
литературу. Экспертные системы — это хорошо известное
приложение систем искусственного интеллекта. О них
написано столько, что невольно возникает иллюзия
существования теории экспертных систем. Большая
часть исследований экспертных систем решает
частные проблемы при заданных ограничениях компью-
Методы и проблемы извлечения знаний 69
терной техники, времени, стоимости и других
ресурсов без применения какой-либо теории, построенной
вне области исследований. Следовательно,
стандартная методология создания экспертных систем так и
не установлена.
Что же могут предложить исследования
искусственного интеллекта? Это изучение конкретных
случаев, включая несколько прототипов экспертных
систем, а также технику программирования. Многие из
исследований и разработок собственно экспертных
систем следует назвать эвристическими, часто эти
исследования дублируют друг друга и не выдерживают
критической оценки.
В каких же областях применяют экспертные
системы и как они взаимодействуют с пользователями?
Какую экспертизу они проводят? Где граница между
экспертными способностями специалиста и обычными
знаниями? Можно ли отделить экспертные
способности от других знаний и передать их неспециалистам?
Если можно, то какой полезный эффект создаст это
для неспециалиста и его окружения? В каких случаях
и какие методы следует использовать при извлечении
специальных знаний эксперта? Какую роль при этом
играет эксперт? Теории, отвечающей на эти вопросы,
и систематической методологии для поиска ответов
пока не существует.
Указанные проблемы теоретических основ
проектирования экспертных систем — одна из причин,
препятствующих проектированию адаптивных человеко-
машинных систем и затрудняющих надлежащий
выбор аппаратных и программных средств. Попытки
построения многочисленных экспертных систем,
предпринятые до настоящего времени, имеют не только
практическую ценность, но и предоставляют данные
для подготовки названной здесь теории.
3.2. ИНЖЕНЕРИЯ ЗНАНИЙ
Приобретение знаний в узком смысле слова — это
работа по наполнению баз знаний. Но ведь кто-то
должен выбрать знания, которые следует поместить
в базу знаний и соответствующим образом закодиро-
70
Глава 3
вать. В этом случае данными являются форма
представления знаний и методы их использования
(например, формулы выводов).
Приобретение знаний в этом смысле само по себе
сложная работа, на практике в ходе этой работы
часто выявляются недостатки базового понимания
проблемной области, в которой будет применяться
система, недостатки формы представления знаний и
методов их использования. Это также следствие
отсутствия теории. Поэтому на основе существующих баз
данных осуществляют пересмотр понятий проблемных
областей и повторное изучение систем, включая базы
знаний. Эту работу, выполняемую в дополнение к
приобретению знаний в узком смысле, можно назвать
приобретением знаний в широком смысле слова. На
практике эта работа тесно связана со всем процессом
разработки экспертных систем — от возникновения
замысла до ее реализации и совершенствования. Этот
процесс, за исключением нескольких примеров,
также обсуждался лишь эпизодически. Процесс
организации знаний в базу и построения экспертных систем
называют также инженерией знаний.
Примечание. Д. Мичи считает главными
элементами инженерии знаний использование операций
типа обобщение, генерацию гипотез для индуктивных
выводов, подготовку новых программ самими
компьютерными программами и т. п. Слово engineering
в английском языке означает искусная обработка
предметов, изобретение или создание чего-либо.
Следовательно, работу по оснащению программ
специальными экспертными знаниями из проблемной
области, выполняемую либо человеком, либо
компьютером (программой), можно назвать инженерией
знаний.
3.3. УРОВНИ ПРИОБРЕТЕНИЯ ЗНАНИИ
Существует по меньшей мере три уровня методов
оснащения программ экспертными знаниями.
Первый уровень (наиболее простой). Это этап
создания алгоритма, взятого из литературы или
придуманного специалистом или проектировщиком си*
Методы и проблемы извлечения знаний 71
стемы, и преобразование его в программу самими
проектировщиками. На практике трудноосуществим.
Второй уровень. Программа может заполнить
пробелы в знаниях, например из литературы, описывая
объекты или формируя этапы (план) работ.
Третий уровень. Программа самостоятельно
приобретает алгоритмические знания, «читая» книги.
Разумеется, способность «чтения» книг, как мы
увидим из примеров систем второго уровня,
подразумевает несовершенство того, что мы называем книгой.
Это интеллектуальные способности высокого уровня,
которые позволят не только каким-то образом усвоить
содержание книг, подобно тому как загружаются
программы в компьютер, но и использовать
информацию как подсказку или совет.
В настоящее время большинство компьютерных
программ — это программы первого уровня.
Например, в случае программ численных расчетов или
диагностических систем, базирующихся на логических
операциях, проектировщики программ, включая тех,
кого называют системными аналитиками, должны
путем изучения теорий в проблемной области,
анализа работ или через разговоры со специалистами
сами преобразовывать знания в программы.
Наиболее просто программировать то, что заранее
систематизировано и для чего определены правила
обработки, скажем, коммерческие расчеты на
предприятиях. Вполне реально, регламентированно можно
вычислять без ошибок — вот аргументы для
обоснования компьютеризации коммерческих расчетов,
например начисления заработной платы. А будь все
хоть немного сложнее, то, как известно, потребуется
специальный подготовительный этап — анализ работ.
Для того, что не систематизировано, не поддается
описанию, например для стратегии игр на досках
(шахматы, го и др.), невозможно заранее определить
алгоритм, гарантирующий решение. Поэтому
проектировщик программ под свою ответственность должен
представить разрозненные знания в виде программы,
которую можно выполнить. Стратегию игры в
шахматы, как и других игр на доске, часто представляют
в виде дерева, но такой алгоритм основан на способ-
72
Глава 3
иости человека к перебору вариантов, и для его
реализации в программе проектировщику придется
интерпретировать и детализировать описания этих
вариантов. К первому уровню принадлежит также
программа Dendral для интерпретации
масс-спектрограмм.
Усовершенствованная программа Meta Dendral
относится ко второму уровню, поскольку она
расширяет теорию стабильности молекулярных соединений,
осуществляя открытие конкретных соединений. Но
если бы программа сама изучала учебники по химии
и развивалась, оперируя новыми группами
химических соединений, то она принадлежала бы к третьему
уровню. Например, чтобы принадлежать к третьему
уровню, шахматная программа должна сама читать
шахматные руководства и совершенствовать свое
мастерство через обучение.
Процесс получения знаний от человека с целью
их передачи программам первого уровня называется
извлечением знаний. Что считать извлечением знаний
на втором и третьем уровне? Сторонники того или
иного направления формулируют это по-разному. Что
такое знания? Что значит «хорошо знать»? Эти
вопросы — одни из основных в теории мышления, они
тесно связаны с еще нерешенными проблемами,
поэтому об этом, естественно, надо говорить.
3.4. ЭКСПЕРТНЫЕ СИСТЕМЫ
Об успехах в исследовании экспертных систем уже
говорилось в первых двух книгах 1) данной серии,
поэтому повторим лишь основные моменты. Не
вдаваясь в детали появления термина «экспертные
системы», отметим только, что, согласно классификации
Джонсона, это разновидность систем, основанных на
знаниях (рис. 3.1). К таким системам относятся
также системы обработки естественных языков, которые
в процессе работы используют знания, но не требуют
!) Осуга С. Обработка знаний. — М: Мир, 1989;
Представление и использование знания/Под ред. X. Уэно, М. Исидзука. —
М.: Мир, 1989. — Прим. перев.
Методы и проблемы извлечения знаний 73
так называемых экспертных знаний. Экспертные
системы предполагают активное участие
человека-эксперта и, используя главным образом основные
положения конкретной проблемной области, извлеченные
из эксперта, решают сложные задачи, обычно не
решаемые неспециалистами, и общаются с последними
на естественном языке. Исследования и разработки
экспертных систем не ограничиваются сферой
компьютерных систем, а имеют отношение к
проектированию человеко-машинных систем, обладающих
экспертными знаниями, и должны решать проблему
извлечения экспертных знаний из человека. Некоторые
особенности экспертных систем приведены в табл. 3.1.
Таблица 3.1. Особенности экспертных систем
1. Перерабатывают большое количество знаний.
2. Представляют знания в простой унифицированной форме.
3. Обладают независимым механизмом логических выводов.
4. Могут объяснить результаты, полученные в процессе
обработки знаний.
Рассматривая эффективность экспертных систем,
удобно выделить их практическую и
методологическую ценность.
Медицинская
диагностика
Обнаружение
неисправностей
Оценка
месторождении
Другие
Рис. 3.1. Классификация компьютерных систем с акцентом на
системы применения знаний.
74
Глава 3
1. Практическая ценность. Расширение экспертной
системы в процессе применения и другие ее
модификации еще только в проекте, а сам факт внедрения
системы как законченного программного продукта
совместно с пользователем на его рабочем месте уже
несет в себе положительный эффект, обусловленный
качественным улучшением деятельности
пользователя.
В самом начале разработки должна быть
поставлена следующая задача: какие функции будет
выполнять система. В дополнение к основным функциям,
видимо, можно считать практической ценностью и те
разнообразные побочные эффекты, которые не всегда
предусматриваются и к которым приводит работа
системы в специфичной среде пользователя.
Экспертная система, взаимодействуя с
пользователем и решая задачи, которые пользователь, не
будучи экспертом, решить не в состоянии, выполняет
сложные работы, поэтому наряду со следующими
основными функциями:
1.) оказание помощи (полу-)экспертам в их
деятельности по специальной тематике (например,
помощь в принятии решений);
2) восполнение нехватки экспертов в конкретной
проблемной области;
и другими функциями система может проявлять,
например, такие побочные эффекты:
1) исключение нежелательных последствий
излишней специализации человека благодаря
предоставлению и накоплению экспертных знаний;
2) эффект обучения-, обусловленный
приобретением пользователем опыта в умственной
деятельности (например, принятия решений высокого уровня).
Подобного опыта без системы пользователь бы не
накопил 1).
2. Методологически ценность. Собственно говоря,
разработка экспертных систем — это один из методов
1) Система при этом не выступает в роли учителя, просто
происходит эвристическое обучение самого пользователя за счет
предоставления ему новых возможностей.
Методы и проблемы извлечения знаний 75
исследования принципов построения теории
экспертных способностей и теории принятия решений.
Примечание. Методологией, как правило,
называют цели исследований в некоторой проблемной
области, используемые понятия, исследование
принципов выводов и структуры проблемной области.
Исследование методов исследований также входит в
методологию.
Готовые системы в тесном контакте с
пользователями, будучи моделью эксперта и специалиста, могут
помочь, например, в исследованиях надежности
больших систем и исследованиях принципов организации
разработок. Понятие «поддержка принятия решений»
в смысле применения экспертных систем как
альтернатива понятию «поддержка принятия решений» на
основе существующих теорий субъективного
ожидаемого выбора и теории многовариантного выбора,
видимо, способствует расширению теории принятия
решений. Кроме того, психологи говорят, что знания,
к которым приходит человек через опыт решения
задач, становятся знаниями для решения задач.
А нельзя ли и это отнести к пользователю экспертной
системы, который часть решения задачи возлагает на
программу? Утверждают также, что человек, выделяя
самое важное для достижения цели, реагирует не
только на ситуацию вокруг него, но и на смысл этой
ситуации для человека. Таким образом, возникает
новая проблема исследований: снижается ли смысловая
чувствительность пользователя экспертной системы,
который всего лишь дает ответы на вопросы системы.
Так же, как и в других научных направлениях,
в которых особый интерес представляют
универсальные законы и преобладает тенденция к накоплению
данных экспериментов и наблюдений, в проблемной
области психологии мышления, темой исследований
которой является решение задач, главное место
занимают задачи со сравнительно строго определенным
«правильным решением» типа задач арифметики,
элементарной физики, головоломок. Исследования
обработки и использования экспертных знаний в нечетких
сложных областях, определение которых также
проблематично, имеют недавнюю историю. Исключением
751
Глава 3
можно считать исследования шахматного мастерства,
начатые А. Д. де Гротом.
В настоящее время известно много публикаций об
исследованиях в области медицинской диагностики,
проектирования программного обеспечения
компьютеров, изобразительного искусства и т. д. Все это
исследования того, как специалист решает сложные
нечеткие задачи, как описать различие между
специалистом и начинающим. Однако на вопрос, кто из них
может лучше обработать и использовать знания, пока
ответа не получено, не считая нескольких намеков.
Как видно из приведенных выше примеров,
методологическая ценность готовых систем состоит в том,
что они предлагают новые темы и методы
исследований. Вместе с тем ожидается, что методы извлечения
знаний для построения экспертных систем как
альтернатива известным разнообразным методам
«получения того, что знает человек» обогатит методологию
благодаря совместным применениям всех этих
методов.
3.5. ИЗВЛЕЧЕНИЕ ЗНАНИЙ
В чем же особенность извлечения знаний для
экспертных систем? Ответ можно получить, ответив на
другой вопрос: «Откуда, что и как извлекать?».
Источниками знаний в общем случае можно считать
эксперта, разработчика системы и пользователя. На
практике один и тот же человек может играть
несколько ролей. Вопрос «Что извлекать и откуда?»
трудно отделить от вопроса «Как?», но для того,
чтобы извлечение знаний не было сведено к простой
процедуре, прежде всего необходимо ответить на
первый вопрос. Ответ на второй вопрос должна дать
соответствующая техника, моделирование и
планирование всего процесса извлечения знаний.
3.5.1. ОТКУДА ИЗВЛЕКАТЬ ЗНАНИЯ!
Источниками знаний для экспертных систем могут
быть учебники, справочники, материалы конкретных
исследований в проблемной области и т. п. Кроме
того, нередко сами разработчики системы уже имеют
Методы и проблемы извлечения знаний 77
знания в соответствующей области. Хотя
классический источник знаний — это эксперт в данной
области, знания от которого получает разработчик систем,
выступающий в роли инженера по знаниям.
Кто же такой эксперт? Это либо специалист в
отличие от обычного инженера, либо человек с опытом
в отличие от новичка. Как правило, психологов
интересует эксперт в последнем смысле.
На сравнительно ранних этапах исследований
экспертом считали любого человека. Качественного
различия между новичком и экспертом не
предполагалось, просто эксперт знает больше и может
работать лучше и быстрее. Подобное различие может
быть обусловлено разницей во времени обучения и
занятий по подготовке эксперта, достигающего по
продолжительности пяти тысяч часов. Последние десять
лет при исследованиях в области психологии
мышления чаще всего и эксперту и новичку давали одни и
те же задания, а затем сравнивали различия в их
реакции. Подразумевалось, что понять особенности
эксперта как объекта сравнения на контрастных
примерах легче, чем изучать только его выдающиеся
способности в конкретной области. В частности,
преобладало мнение, что новичок — это тот же эксперт,
знания которого не наполнены содержанием, и
выдвигали гипотезу, что эксперт может "получиться из
новичка, если последнему дать недостающие знания.
Сегодня существует аналогичная точка зрения о том,
что экспертная система с незаполненной базой
знаний — это система-новичок, из нее образуется
настоящая экспертная система, если в нее вложить модули-
знания, например правила продукций.
Кстати, когда чуть более детально изучали
поведение новичка, то стало очевидным, что его
особенности качественно отличаются от особенностей
эксперта. Есть классический образ поведения новичка,
который можно выразить тремя словами: торопится
выдать решение. Например, когда задана задача по
элементарной физике, он как можно быстрее найдет
подходящую на вид формулу и, не записывая ее на
бумаге, сразу же подставит значения переменных, по
возможности в уме произведет вычисления, выдаст
78
Глава 3
ответ и лишь после этого первый раз напишет на
бумаге. Человек нередко может быть новичком в чем-то
одном, а в другом подняться выше его уровня; даже
при логических выводах он имеет опыт применения
прямых и обратных выводов. Но, несмотря на это,
часто новичок проявляет себя как псевдоэксперт;
например, в процессе рассуждений, когда до решения
сложной задачи необходимо добраться через
несколько шагов, то, выполняя поиск метода, то
проводя вычисления, он имитирует, что может найти
решение с первого взгляда, что его сложные действия
не разбиваются на этапы, что он может все делать
словно на одном дыхании и т. д. Такой псевдоэксперт
как бы не принимает во внимание то, что он по сути
новичок. Это поведение нельзя считать оптимальным
с точки зрения обучения решению задач.
Следовательно, и новичков можно разделить на тех, кто
приобретает опыт именно как новичок, и тех, кто не
способен к этому.
Инженер по знаниям и сама экспертная система
на этапе извлечения знаний, а также пользователи на
этапе внедрения системы находятся в положении
новичков. Как показывают исследования экспертов и
новичков, более желательно по возможности быть
хорошим новичком.
Изучение общих особенностей эксперта — это не
только одна из возможных целей, к которой следует
стремиться в человеко-машинных системах,
состоящих из экспертной системы и пользователя, это
важно для тогр, чтобы заранее знать особенности
партнера, от которого мы будем получать знания.
Известно, что чем выше способности эксперта
в проблемной области, тем более он не способен к
описанию знаний, используемых им для решения
задачи. Уотерман это назвал парадоксом инженерии
знаний. Если спросить у эксперта, что он конкретно
делает, решая задачу, то он объяснит наиболее
правдоподобный, по его мнению, но совершенно отличный
от реального процесс рассуждений, поэтому здесь
нужно быть осторожным. Необходимо по
возможности выдвинуть гипотезу о том, что эксперт считает
своим процессом рассуждения, и проверить ее каким-
Методы и проблемы извлечения знаний Т)
либо способом. Это же относится и к случаю, когда
эксперт извлекает собственные знания. По мнению
Уотермана, лучше избегать совмещения функций
инженера по знаниям и эксперта (совет Уотермана), но
разумность этого совета еще не подтверждена.
Существует мнение, что знания эксперта
систематизируются вместе с внешней моделью задачи и
мгновенно выбираются из памяти в ответ на каждую
конкретную ситуацию, и лишь в ситуации, с которой
эксперт сталкивается впервые, порядок их выборки
будет определяться сознательно по наиболее общим
закономерностям. Не всегда можно гарантировать, что
поведение эксперта будет именно таким, но если
считать это советом для успешного извлечения знаний, то
в такой гарантии нет необходимости. Если данное
мнение верное, то не будет ли легче извлекать общие
закономерности, ставя каждый раз эксперта в
сравнительно новую ситуацию? Этот новый совет появился
экспромтом, остается только проверить его
эффективность на практике.
Эксперт, как правило, может точно указать, что
находится в центре его внимания, но не даст
разумного объяснения действия этого центра на процесс
рассуждений, а когда его спрашивают, о чем он
думал, он не может дать точного ответа. Существуют
заметные индивидуальные различия способностей
человека к так называемому самонаблюдению, когда
он следит и анализирует собственный процесс
мышления, причем эта способность совсем не зависит от
того, является ли он экспертом.
Разумеется, пользователь, как и эксперт, также
важный источник знаний. Понятие «пользователь» на
самом деле достаточно нечеткое: оператор системы,
исполнитель, получатель — все они пользователи в
широком смысле слова. Однако их обязанности носят
различный характер, поэтому по сути их следовало
бы изучать по отдельности. А пока временно
ограничимся людьми, которые благодаря непосредственному
общению с экспертной системой демонстрируют
способности, аналогичные способностям эксперта.
Для того чтобы экспертные системы не остались
Э лабораториях, а использовались на промышленных
80
Глава 3
предприятиях, необходимо получить от пользователей
ответы на разнообразные вопросы об эффективности,
удобстве пользования и т. п.
В заключение хотелось бы напомнить
общеизвестное: интерфейс в смысле хорошего понимания
действий системы и легкости операций — очень важный
элемент системы; многие системы оснащены
функциями объяснения своих действий, в некоторых
системах коды, связанные с интерфейсом пользователя, —
это свыше 60 % всех кодов программ. Тем не менее
условия повышения эффективности интерфейса как
проблемы принятия решений при разработке системы
еще в полной мере не изучены. Инженеру по знаниям
необходимо в кратчайший срок уточнить гипотезы о
будущем пользователе.
3.5.2. ЧТО ИЗВЛЕКАТЬ!
Независимо от выбранных методов извлечения знаний
специалисты по построению экспертных систем будут
переносить в них знания, надеясь получить их от
экспертов. Если функции системы уже определены, то,
естественно, самое важное — получить правила
выводов, которые необходимы для реализации этих
функций. Остановимся на этом подробнее.
1. Базовая структура. Очень важно перечислить
объекты, понятия и атрибуты, которые формируют
базовую структуру проблемной области, и знать
свойства области. Связь между объектами, понятиями и
атрибутами организуется через правила вывода.
Следовательно, адресуя эксперту вопросы о том, что
должна советовать система, какие блоки образуют
систему и из каких блоков состоят эти блоки, можно
уточнить язык описания правил, например, подобных
правилам, встроенным в систему EMYCIN.
2. Критерии разумности. Почему эксперт решает
некоторую проблему именно данным способом? Может
быть, этот способ имеет высокую эвристическую
ценность, а может, подготовлен на случай неудачи?
Какая этому способу необходима поддержка?
Методы и проблемы извлечения знаний 81
3. Средства, используемые экспертом. Гипнограммы,
используемые экспертом по расстройствам сна,
модели принятия решений, используемые экспертом по
принятию решений, и т. п. — все это средства,
которые доступны только экспертам, они являются как
бы продолжением рук экспертов. Одна из целей
реализации экспертных систем — облегчить применение
таких средств неспециалистам, поэтому желательно
получить от экспертов знания по их использованию.
Но это, естественно, еще не все знания, которые
необходимо извлекать, здесь не упомянуты знания и
правила выводов, которые непосредственно
помещаются в базу знаний системы. Более детальное
обсуждение хотелось бы продолжить в книге о
методологии построения экспертных систем.
3.5.3. КАК ИЗВЛЕКАТЬ ЗНАНИЯ)
В литературе по построению экспертных систем
обсуждаются методы извлечения знаний, которые
подчеркивают преимущества выбора того или иного
подхода к разработке системы. Ознакомимся с тремя
подходами: долговременная рабочая группа,
оперативное создание прототипа и подход «особое
внимание анализу знаний», и рассмотрим кратко один из
современных методов извлечения знаний,
используемых в проекте ESPRIT, известного как европейский
проект создания компьютеров пятого поколения.
Долговременная рабочая группа. Эксперты и
инженеры по знаниям организуют долговременную
группу с целью совместного создания моделей и
программ решения задач. Можно ли это назвать
специфичным подходом? Во всяком случае, именно так
создано несколько уникальных программ:
INTERNIST, PROSPECTOR и др.
Оперативное создание прототипа. При этом
подходе образуется инициативная группа экспертов, и
после того, как инженеры по знаниям усваивают
первоначальные знания о проблемной области,
экспертов подробно расспрашивают и в сжатые сроки
завершают разработку программы, которая считается
прототипом. Затем в основном ведутся работы по
82
Глава 3
оценке и модификации полученной экспертной
системы. При этом подходе, если можно так сказать,
создается эскиз системы, и при необходимости иногда
приходится отказываться от всего. Прототип
разрабатывается как своего рода полигон для того, чтобы
вызвать у экспертов достаточный интерес и энтузиазм
к построению экспертной системы, поэтому этим
подходом не следует слишком увлекаться.
Особое внимание анализу знаний. В основе этого
подхода лежит по возможности подробный
предварительный анализ знаний и методов решения задач
в проблемной области. За проектирование и
реализацию системы принимаются только после
всестороннего анализа знаний.
Цель анализа состоит в уменьшении риска и
затрат на построение экспертной системы. Подробно
указать функции системы трудно, если не принимать
во внимание идеи проектирования и реализации,
поэтому с целью подтверждения возможности,
полезности и реализуемости системы собирают информацию
для уточнения ограничений при принятии важных
проектных решений, не создавая какую-либо прото-
типную систему. Такие решения связаны, например,
с глубиной и формой представления знаний.
Еще один стимул к серьезному анализу знаний
связан с тем, что, как правило, очень трудно
заинтересовать экспертов на долгое время. Если заранее
собрать и проанализировать важнейшую
информацию, то зачастую можно принять решение о
проектировании и реализации на основе собранной
информации, уже не поддерживая связи с экспертами.
Все эти подходы взаимно не противоречат друг
другу, но отличаются расстановкой акцентов. В
настоящее время трудно дать ответ на вопрос, какой
подход является оптимальным. Однако по мере
технического совершенствования и распространения
экспертных систем изменятся критерии для сравнения
подходов, и, не исключено, что границы для их
классификации и выбора станут нечеткими. Тем не менее
уже сегодня, исходя из здравого смысла, видны
слабости таких подходов, как оперативное создание
прототипа и методов постепенной разработки. Давайте
Методы и проблемы извлечения знании S3
несколько подробно остановимся на подходе «особое
внимание анализу знаний», предложив конкретный
план его реализации. Для того чтобы компенсировать
недостаток теоретической базы, упомянутый в начале
этой главы, будем считать, что пока нам не
понадобятся специальные знания, знания, использование
которых впоследствии может быть пересмотрено, и
извлечение знаний как один из конкретных этапов
разработки.
Процесс анализа знаний удобно разбить на два
больших этапа. Цель первого этапа — определение
ролей, которые будут играть проектируемая
экспертная система и пользователь. Следовательно, здесь
необходимо провести анализ проблемной области,
определить решаемые задачи и собрать информацию о
рабочей среде экспертов и экспертной системы.
Цель второго этапа — подробное указание работ,
которые должна выполнять экспертная система при
условии, что определены функции человеко-машинной
системы, состоящей из самой системы и
пользователя. В эти указания включают также знания для
реализации экспертных способностей и правила
логических выводов.
После завершения определения функций создают
так называемую интерпретационную модель,
предназначенную для интерпретации данных, полученных при
извлечении знаний. Теперь уже можно описывать
в терминах интерпретационной модели информацию
от экспертов и других источников.
3.5.4. ТЕХНИКА ИЗВЛЕЧЕНИЯ ЗНАНИЙ
Технику извлечения знаний можно . разделить на
шесть основных классов: опрос с наводящими
вопросами, структурированный опрос, самонаблюдение,
самоотчет, диалог, критический обзор. Каждый класс
в свою очередь состоит из нескольких технических
методов, но подробную классификацию опустим и
укажем только, что цель извлечения знаний может быть
достигнута различными способами в зависимости от
того, как эти знания будут анализироваться.
84
Глава 3
1. Опрос с наводящими вопросами. Это метод,
наиболее близкий к традиционному диалогу. Главное
отличие в том, что инициатива в этом опросе
принадлежит одному из партнеров, который и подготавливает
предварительно тему разговора. Основные
структурные элементы опроса — предложение темы и поиск
информации.
Цели. Ключевыми считаются вопросы, ответ на
которые дать сравнительно просто, поэтому можно
привести следующие примеры информации, которую
можно извлечь:
— фактические знания, которые не
систематически описаны в литературе;
— типы задач, решаемых экспертом, и
особенности проблемной области;
— способности, которые может проявить эксперт
в проблемной области;
— объекты и посредники действий эксперта в его
рабочей среде;
— характеристика людей, получающих помощь
эксперта, и т. п.
Начальные условия. Необходимые условия для
проведения опроса такого рода не очень жесткие,
поэтому они соответствуют первому этапу извлечения
знаний. Главное условие — достаточный
терминологический запас у ведущего опрос, другими словами,
эксперт должен более или менее понимать, о чем
идет речь.
Возможное управление. Ведущий опрос может в
какой-то степени управлять извлечением знаний,
используя заданную последовательность выбора тем.
Кроме того, можно применять различную технику
«зондирования» в диалоге для получения
информации.
2. Структурированный опрос. В опросе с наводящими
вопросами инженер по знаниям использовал вопросы
только в целях «зондирования», а здесь с помощью
заранее подготовленных разнообразных вопросов он
узнает о каких-либо понятиях и моделях, или, говоря
образно, о корнях и листьях. Вопросы об ожидаемом
влиянии, достоверности, просьбы об объяснении, при-
Методы и проблемы извлечения знаний 85
меры и контрпримеры — все это может стать очень
полезным для глубокого прослеживания структуры
понятий. Однако есть риск, что эксперт будет
отвечать не думая.
Начальные условия. Условия проведения
структурированного опроса более жесткие, чем опроса с
наводящими вопросами. Инженер по знаниям должен
хорошо владеть терминологией, используемой
экспертами, а если уже просит разъяснений, то должен их
понимать. Техника опроса также должна быть
доведена до определенного уровня, а эксперту
необходимо быть готовым к ответам даже на неприятные
вопросы.
Цели. Подробно обсуждаются следующие вопросы:
— структура нескольких понятий;
— содержание и функции моделей решения задач;
— разумность, обоснованность, причины выбора
действий экспертом и т. п.
3. Самонаблюдение. Эксперта просят говорить все,
что приходит ему в голову, о том, какую задачу он
решает и как он это делает. Это своего рода
размышления вслух, хотя эксперт вряд ли будет делать
это при решении задач на практике.
Цели. Извлекается следующая информация:
— описание в общих чертах стратегии, которой, по
мнению эксперта, он придерживается при решении
некоторой задачи;
— рассуждения о разумности решений и идей,
появившихся в процессе логических выводов;
— общая информация о типе знаний, которые, как
считает эксперт, он использует в процессе решения
задачи.
Начальные условия. Не должно быть препятствий
для размышления вслух.
4. Самоотчет. Это так называемые ортодоксальные
рассуждения вслух, когда одновременно с
выполнением некоторой работы эксперт самому себе дает
отчет о том, что он делает и что думает. Этот процесс
не требует пояснений, не нужно доискиваться до
причин и определять разумность действий.
86
Глава 3
Цели:
— выясняется, где и для чего эксперт использует
специальные знания в процессе решения задачи;
— уточняются подробности стратегии решения
задач и управления выводами;
— получаются критерии и материалы для оценки
готовой экспертной системы;
— определяется, из каких шагов состоит процесс
решения задачи.
Начальные условия:
— инженер по знаниям должен понимать, до
какого момента он не смог повторить решение задачи
эксперта;
— необходимо создать условия для успешного
решения типичных задач экспертом;
— эксперт должен привыкнуть к рассуждению
вслух;
— эксперту должна быть понятна необходимость
сбора данных самоотчета до тех пор, пока не будет
получена более четкая информация.
5. Диалог. Нередко служба консультаций, созданная
при вычислительном центре, не понимая важности
своей работы, отсылает задающего вопросы к
справочникам. Опытный консультант, сам выдвинув
несколько гипотез о полученной задаче, задает
пришедшему на консультацию наводящие вопросы и дает
советы. Он может также вносить поправки в
пояснительные схемы, которые рисует неспециалист, и даже
давать готовые решения, но в терминах, понятных
неспециалисту.
Консультант, мысленно разобравшись с задачей,
не думает решать ее вместо своего собеседника. Он
поддерживает с ним разговор, дает советы и помогает
ему самому решить задачу.
Экспертные способности по существу и
демонстрируются в процессе диалога с неспециалистом.
Любая консультация — это обмен информацией между
экспертом и неспециалистом. Для получения
информации о процессе совместного решения задачи
недостаточно одного лишь опроса эксперта или его само*
отчета, для этого предназначен метод непосредствен-
Методы и проблемы извлечения знаний 87
ного наблюдения и регистрации основных моментов
диалога.
Добавим к этому, что необходимым условием
удобного интерфейса между создаваемой экспертной
системой и пользователем является возможность
делать выводы на основе информации, полученной из
наблюдений за диалогом. Заметна тенденция вначале
создавать систему решения задач (ядро экспертной
системы), а уже потом добавлять к ней
человеко-машинный интерфейс, хотя во многих системах,
внедряемых на предприятиях, например в системе
финансовых расчетов, большая часть усовершенствований
по просьбе пользователей касается именно
ввода-вывода, а правильность сопутствующих вычислений
почти всегда считается очевидной.
Инженер по знаниям либо непосредственно ведет
запись диалога эксперта с неспециалистом, либо сам
выступает в роли неспециалиста.
6. Критический обзор. Обычно критический обзор
используется для извлечения так называемых
метазнаний— это повторное изучение знаний, извлеченных
другими методами, совместно с экспертом —
источником информации. При этом нередко заполняются
пробелы в уже извлеченных знаниях, случается, что
ставится под сомнение качество извлечения знаний.
План критической оценки и совершенствования
прототипа системы с участием экспертов в этом смысле
также можно назвать разновидностью критического
обзора.
3.6. ЗАКЛЮЧЕНИЕ
В этой главе рассмотрена работа по извлечению зна*
ний как первого этапа построения экспертных систем.
Для извлечения знаний необходимо учиться не только
экспертной системе. Инженер по знаниям также
должен учиться у эксперта или с помощью других
источников информации, имея дело с новой проблемной
областью. Поэтому извлечение знаний можно
назвать учебной деятельностью инженера по знаниям.
Проблема извлечений знаний, следовательно,
83
Глава 3
сводится к тому, как эффективно реализовать такое
обучение.
Общепризнанного решения поставленной здесь
проблемы пока не существует. Однако одно то, что
мы правильно понимаем эту проблему, уже первый
шаг к ее решению. Приобретение знаний — еще очень
молодая область исследований, можно сказать, она
находится в положении новичка. Автор считает, что
сегодня важно понимать эту проблему именно как
проблему, а не становиться псевдоэкспертом.
ГЛАВА 4,
ПРИОБРЕТЕНИЕ ЗНАНИЙ
И ОБУЧЕНИЕ В ДИАЛОГЕ
С. Оцуки (Университет Кюсю)
Рассмотрим, какую роль в процессе приобретения
знаний и обучения играет диалог между
интеллектуальной информационной системой и человеком из
внешнего мира.
Прежде всего, введем мультииерархическую
модель как структуру знаний, необходимую для
представления технически и лингвистически допустимого
диалога, и обсудим связь этой модели с внешним,
в частности естественным, языком. Далее объясним
технику диалога на естественном языке. Укажем
также методы представления диалога на естественном
языке, основанные на введении в
мультииерархическую модель грамматики определенных
предложений 1\ основанной на понятии падежа Филмора и
мирах с предысторией Хомского.
В заключение изучим смысл приобретения знаний
в диалоге и рассмотрим процесс обучения в диалоге
на примере построения модели пользователя.
4.1. ПРЕДСТАВЛЕНИЕ ЗНАНИЙ
ДЛЯ ДИАЛОГА
Исследуем, при каком представлении знаний можно
уменьшить неестественность, скованность человека и
построить как технически, так и лингвистически
правильную систему.
4.1.1. ВВЕДЕНИЕ МУЛЬТИИЕРАРХИЧЕСКОЙ
МОДЕЛИ
Описать знания для диалога, как правило, очень
трудно. Если задаться целью, чтобы машина понима-
1} Здесь слово «определенные» имеет смысл «подчиняющиеся
правилам Хорна», поэтому иногда соответствующие
предложения называют хорновскими предложениями. — Прим. перев.
90
Глава 4
ла предложения на естественном языке, сказанные
нами в обычной разговорной манере, то очевидно,
придется подготовить в виде знаний самые неожиданные
факты, правила, результаты вычислений и т. п.
Например, для понимания простого диалога: «К какому
микрокомпьютеру можно подключить этот
принтер?» — «К этому».— «А он печатает в цвете?» —
«Да»,— необходимо иметь технические знания о
микрокомпьютерах и принтерах, а также
лингвистические знания о местоимениях «этот», «он», о том, на
что указывают опущенные слова, необходимо также
уметь пользоваться этими знаниями.
Для понимания этого диалога достаточно
представить такие технические знания: можно передавать
информацию между данным микрокомпьютером и
принтером; существуют два типа принтера: с обычной
и цветной печатью; микрокомпьютер обладает
функцией указания цвета. Однако как быть, если мы
продолжим серию вопросов: «Этот микрокомпьютер
можно подключить к большой ЭВМ?», «Можно ли
воспользоваться общедоступными каналами связи?»,
«Поставляется ли программное обеспечение для
текстового процессора?»," «Где продается программное
обеспечение?» и т. д. Здесь уже необходимо
позаботиться о том, чтобы сменить тему разговора на
«большие ЭВМ», «общедоступные каналы связи», т. е. на
темы, которые не имеют смысла в среде
микрокомпьютеров, а также связать с главной темой
разговора знания, которые нельзя обработать в среде
технических знаний, но которые нужны для ответов на два
последних вопроса.
1. Уточнение предметной области. По мере
продолжения подобного разговора среда необходимых
знаний постепенно расширяется. Однако при организации
знаний в рамках технической системы, естественно,
придется ограничиться лишь знаниями, в
определенной среде. Например, необходимы знания об
аппаратных средствах и программном обеспечении
микрокомпьютеров, о способах их использования. Кроме
этого, видимо, следует ввести косвенные знания,
связанные с микрокомпьютерами: знания о сети, знания об
11рисбретение знаний и обучение в диалоге 51
аппаратуре, подключаемой к микрокомпьютерам,
знания о производстве, сбыте и обслуживании и т. п.
Таким образом, предметной областью будем
называть область в некоторой среде, технические знания
в которой мы хотим представить. Если такая область
определена, то содержание знаний уже достаточно
строго ограничено, но необходимо еще решать, какую
форму представления выбрать. Дело в том, что
представление знаний зависит от того, для чего и как они
будут использоваться.
2. Для чего используются знания? Большая часть
интеллектуальных систем в настоящее время
использует знания в следующих пяти целях. Во-первых, для
помощи в понимании и интерпретации фактов.
¦Пример — все вопросы о микрокомпьютерах,
приведенные выше. В эту категорию входят различные
консультационные системы и системы запросов в базы
данных. Во-вторых, для решения задач. В этом случае
центральной проблемой является поиск метода,
удовлетворяющего заданным условиям, и определение
плана решения. В эту категорию входят также
системы планирования. В-третьих, для идентификации
источника и причины. Это связано с проблемами
идентификации источника несовместимости вновь
полученных знаний с уже существующими, проблемами
идентификации причины получения или неполучения
решения в системах второй категории и другими
проблемами. В-четвертых, для составления вопросов и
ответов самой системой. Например, системе
необходимо спросить о недостающих условиях в случае,
когда подтверждается, что неудача в решении задачи
возникла вследствие неполноты заданных условий.
Кроме того, в обучающих системах, например
системах компьютерного обучения, после идентификации
ошибки ученика с целью подтверждения, понимает ли
он данную тему, необходимо составить и предложить
ему задачу, в которой представлен источник ошибки.
В-пятых, для усвоения новых знаний, исправления
противоречивых знаний и систематизации избыточных
знаний.
92
Глава 4
Для первой цели свойства, правила, отношения
между разнообразными фактами, входящие в область
можно описать с помощью семантической сети,
фреймов, продукционных правил, логики или другими
способами представления знаний. Но уже для решения
задач (вторая цель) необходимо наделить сами
знания функциями построения пространства поиска и
выводов, отвечающих задаче, т. е. функциями
моделирования процесса решения. Это можно сделать
путем представления знаний как отношений между
целью и промежуточными целями. Для
идентификации причин и ошибок (третья и четвертая цели) и
составления задач с использованием результатов
идентификации необходимо иметь метазнания, чтобы
интерпретировать процесс поиска решения.
Метазнания необходимы также для хранения и обработки
зианий (пятая цель).
3. Структурирование знаний. Знания удобно по
возможности описывать по модульному принципу. Однако
модульные знания должны правильно отражать
структуру объектной области в целом и отвечать
поставленной цели. Один из предложенных методов
описания — иерархическая модель миров. С помощью
такого метода определяется структура миров (миром
в этой модели называется модуль), обусловленная
отношениями понятий, типичных для каждого мира.
Например, систему консультаций, по
микрокомпьютерам, упомянутую выше, можно представить в виде
иерархической модели миров, указанной на рис. 4.1.
Достоинства этого метода заключаются в следующем.
Во-первых, есть возможность наследовать знания из
миров верхних уровней. Во-вторых, можно сузить
класс объектов поиска, ограничившись только
центральными тематическими мирами со знаниями,
которые будут объектами при логических выводах, и
мирами верхнего уровня, из которых первые миры
наследуют знания. В-третьих, по мере раскрытия темы
миры объектов выводов будут сменять друг друга,
поэтому раскрытие темы можно представить через
слежение за мирами. В-четвертых, благодаря
указанию множества отношений между мирами можно по-
Приобретение знаний и обучение в диалоге М
строить структуру миров, отвечающую различным
целям, рассмотренным в п. 2. Например, стрелки на
рис. 4.1 в модели миров, отвечающей первой из
поставленных целей, обозначают такие отношения
между мирами, как IS-A (это есть), PART-OF (является
частью), MEMBER-OF (является элементом). В
системе решения задач помимо этих трех отношений
необходимо представить в виде моделей отношения с
мирами сопутствующих знаний. Например, для
решения задач по механике необходимо установить
отношения с мирами математики как сопутствующими
знаниями, а для составления и понимания программ
необходимо в качестве сопутствующих знаний иметь
миры математических и логических формул. На
рис. 4.2 показана соответствующая модель миров.
Одинарные стрелки означают такие же отношения,
как на рис. 4.1, а двойные — отношения между со-
/1???ДТ' / /текстовые / /периферийные/ / „ ~ йп I
/ оТрабоТи / /процессоры/ / устройства / /Компьютер/
IJT I /ввТвьГдСТН0Й/ /микропроцессор^
Рис. 4.1. Мультииерархические миры в системе-консультанте по
микрокомпьютерам.
п
Глава 4
/—"" ' -у /Программное/ /Аппаратные/
Математические / / обеспечение/ / средства /
формулы / А j l I /п п /
Операционные/
системы /
Рис. 4.2. Наследование знаний в мультииерархшеских мирах.
путствующими знаниями, необходимыми при
решении задач.
4. Интерфейс с внешним миром. Внешний мир — это
мир пользователей системы, или, другими словами,
мир, в котором мы живем. Использование терминов,
близких к терминам, принятым во внешнем мире, не
только удобно пользователям при общении с
системой, но и способствует реальному представлению
предметной области. Но для этого необходимо
преобразование между внешним (естественным языком,
изображением и т. п.) и внутренним (язык
представления знаний) языками. Как сказано выше, если
внутренние знания правильно отражают и представ-
Рис. 4.3. Мультииерархическая модель.
Приобретение знаний и обучение в диалоге 95
ляют в виде моделей структуры внешней предметной
области, то можно считать, что результат разбиения
на модули в иерархических мирах согласован с
семантической структурой внешнего языка. Кроме того,
диалог с внешним миром ведется только в мирах,
связанных с темой диалога. Следовательно, если
интерфейс представить в виде модели миров,
однозначно соответствующих иерархическим мирам, так, как
на рис. 4.3, то при удачном соответствии можно
получить массу удобств в случае использования
естественного языка в качестве внешнего языка системы,
о чем еще будет идти речь далее. Модель на рис. 4.3
называется мультииерархической моделью (МИМ),
блок интерфейса — областью языка, а блок
внутренних знаний — областью понятий.
4.1.2. ЛОГИЧЕСКИЕ ЯЗЫКИ
И МУЛЬТИИЕРАРХИЧЕСКАЯ МОДЕЛЬ
Для описания такой мультииерархической модели по
следующим пяти причинам удобно выбрать
логический язык и, в частности, язык Пролог.
1. Логические языки по своему назначению — это
языки для моделирования процесса логических
выводов человека, поэтому они дают более естественнее
представление знаний, чем другие языки
программирования.
2. Логические языки представляют тезисы,
выраженные на естественном языке, в виде высказываний
логики предикатов первого порядка, поэтому они
обеспечивают лучшую согласованность с естественными
языками, нежели другие языки.
3. Представление высказываний просто и унифи*
цировано, поэтому в одном и том же формате можно
описывать знания, определенные внутри миров,
знания, формирующие структуру миров, и метазнания,
использующие в качестве объектов знания в
высказываниях. А это означает, что логические языки имеют
гибкую структуру как языки описания знаний.
4. В настоящее время легко приобрести систему
обработки Пролог (если ограничиться только правил
лами Хорна), причем ее может освоить каждый.
5. Пролог имеет мощный механизм обратных вы«
96
Глава 4
водов, называемый отождествлением, поэтому
знания, описанные на Прологе, уже оснащены
функциями моделирования процессов; обеспечивается не
только дедукция, но и индукция, импликация, аналогия и
другие выводы.
Достоинства Пролога — вот причина его
успешного использования в настоящее время как языка
описания знаний, несмотря на некоторые его недостатки,
скажем, низкую эффективность процедуры перебора
с возвратами. Во всех примерах в этой главе
используется Пролог. Имена, начинающиеся со знака *,—
это переменные, в квадратных скобках указываются
списки.
4.1.3. СМЫСЛ МУЛЬТИИЕРАРХИЧЕСКОЙ МОДЕЛИ
1. Естественные языки и мультииерархическая
модель. В области понятий мультииерархической
модели на языке Пролог описываются факты и действия,
правила и отношения между фактами, подробное
содержание правил и действий для их реализации и т. п.
Например, в мире применения пишущих машинок
системы консультации по микрокомпьютерам знание
«для установки бумаги в пишущую машинку TW-38
необходимо взять бумагу, откинуть рычаг вперед, отрегулировать
ограничители в соответствии с шириной бумаги и вставить
бумагу»
можно описать в виде следующего предложения
Пролога:
как (установить(*агент, бумага, TW-38),
(взять(*агент, бумага), откинуть(*агент, рычаг, вперед),
отрегулировать(*агент, ограничители, ширина-бумаги,
рука),
вставить(*агент, бумага, в, каретка)))
«-агент указывает человека, устанавливающего
бумагу, это переменная, следовательно, при таком
способе описания можно заменять действующее лицо,
«Как» — это предикат с аргументами-предикатами.
Имена и обозначения предикатов в предложении
Пролога будем называть понятиями. В данном
примере понятиями являются: как (^действие, *метод),
Приобретение знаний и обучение в диалоге 97
установить(«агент, «объект, «место), бумага, TW-33,
взять («агент, «объект), откинуть («агент, «объект,
«направление), рычаг, вперед, отрегулировать («агент,
«объект, «цель, «инструмент), ограничители, ширина-
бумаги, рука, вставить («агент, «объект, «отношение,
«место), в, каретка.
Область языка — это блок для выполнения
взаимных преобразований между понятиями из области
понятий и естественным языком, поэтому здесь
необходимы две функции: функция преобразования
между понятиями и семантикой естественного языка и
функция либо синтеза предложений из простых слов
в соответствии с грамматикой естественного языка,
либо разбора предложений. Мир грамматики на
верхнем уровне области языка на рис. 4.3 включает
грамматические знания, необходимые для синтеза
или разбора предложений, и знания о словах,
совместно используемых во всех мирах: например,
предлоги английского языка, большая часть служебных
слов, вспомогательных глаголов и прилагательных
японского языка и другие грамматические формы.
Миры области языка, расположенные ниже мира
грамматики, представляют собой блоки преобразования слов
и понятий, т. е. это миры словаря. Разделение
словаря в соответствии с мирами объектов имеет
следующие достоинства.
1. Можно сократить число объектов словаря до
уровня числа объектов области понятий, что
обеспечивает хорошую эффективность обработки.
2. Как показано на рис. 4.4, в области объектов
семантический диапазон многозначных слов
ограничен, поэтому легко идентифицировать их смысл.
Например, фрейм в мире представления знаний
означает модель фрейма Минского, в мире обучения с
помощью компьютеров — модель обучения с
последовательным выводом кадров на дисплей, в мире
строительной механики — каркас 1).
3. Как показано на рис. 4.5, синонимы (параметры
и аргументы) могут определяться парами, что
исключает неверное понимание.
l> Frame (англ.) — фрейм^ кадр, каркас. — Прим. перев.
4 С. Осуга, Ю, Саэкн
98 Глава 4
Область понятий | Область языка
Рис. 4.4. Идентификация смысла многозначных слов с помощью
мультииерархической модели. СКО — система компьютерного
обучения.
Рис. 4.5. Обработка синонимов в мультииерархической модели.
Приобретение знаний и обучение в диалоге $9
4. В области языка необходимо строить несколько
уровней для каждого используемого естественного
языка, а область понятий должна быть описана так,
чтобы ее можно было использовать совместно
несколькими языками. Например, уже упоминавшаяся
система консультаций по микрокомпьютерам в качестве
внешнего языка может использовать английский или
японский язык, но обрабатывает одни и те же знания
в области объектов.
5. Грамматический мир в области языка можно
описать один раз и использовать во всех
интеллектуальных системах, а область понятий и словарные
миры составляются с учетом области объектов и
конкретных знаний, определенных в зависимости от це-
лей обработки, рассмотренных в разд. 4.1.1.
2. Рисунки и мультииерархическая модель. Рис. 4.6 —
пример взаимосвязи между рисунками, терминами,
которые придают смысл этим рисункам, и мульти-
иерархической моделью. Преимущества и неудобства
хранения рисунков в области языка заключаются в
следующем.
1. В области понятий можно полностью описать
отношения между целым и частями, порядок и
взаимное расположение деталей при сборке изделия, метод
сборки и другие знания. Следовательно, рисунки удоб*
но использовать при указании пользователю
конкретных образов.
2. Диалог об указанном рисунке ведется на
естественном языке. Этот язык и рисунки имеют взаимно
однозначное соответствие благодаря понятиям
(рис. 4.6, в), поэтому-можно легко описывать знания
о рисунке, о котором идет речь.
3. Иерархическая реализация сложных чертежей и
подробных графических данных в крупных системах,
говоря откровенно, еще далека до совершенства,
следовательно, на практике, видимо, можно
ограничиться системами, в которых можно эффективно ис*
пользовать лишь простые рисунки, связав их с
диалогом на естественном языке, например, так, как в
справочных системах или в системах компьютерного
обучения
4*
ICO Глвва 4
Экран А
Конфигурация
персонального компьютера
Экргн А1
Экран Периферийные
А11 устройства
А
1 Экран А111'
/
Цифровой
дисплей
• • •
Мышь
Высокоскоростной Экран
ввод-вывод AU
Экран А121
/
Гибкий
диск
А
Экран А122
\
Жесткий
диск
Название I
Компьютер
1 Дисплей
1 Телетвйа
I Клавиатура
1 Принтер
Обозначение
1 (Память, I
1 блок питания,, 1
1 выключатели, I
I микропроцессор, I
1 интерфейс) 1
О
сэ
с=3
сз
Название
.Жесткий ДИСК
1 Гибкий Диск;
Магнитные
ленты
[ Мышь
Обозначение 1
CD
^
б
Приобретение знаний и обучение в диалоге
101
Рис. 4.6. а — дерево редактирования для отображения любого
блока из рис. 4.7. В узлах дерева на каждом экране
находятся знания об относительных координатах, коэффициенте
увеличения, цвете и т. п.; б — основной экран для рис. 4.7. Рисунки
располагаются и отображаются в соответствии с деревом
редактирования на рис. 4.6, а; в — взаимосвязь между
мирами-рисунками, мирами словаря и мирами понятий в мультииерархи-
ческой модели.
4. В современных версиях Пролога нельзя
обрабатывать рисунки, поэтому необходимо ввести в
систему обработки Пролога какие-либо средства или
добавить блоки обработки рисунков. Это один из
недостатков Пролога как языка обработки знаний.
4.2. МЕТОДЫ ДИАЛОГА
Рассмотрим методы описания знаний на языке
Пролог в области языка мультииерархической модели.
102
Глава 4
4.2.1. ВНЕШНИЕ И ВНУТРЕННИЕ ЯЗЫКИ
Обычно для передачи мыслей мы используем
различные средства. Естественный язык — наиболее
типичное из них, хотя мы пользуемся также рисунками,
кодами и т. д. Для передачи математических понятий
используем математические и логические формулы,
для передачи алгоритмов — языки программирования,
блок-схемы, диаграммы анализа задач1) и другие
средства. Все это можно считать внешними языками,
ниже в качестве внешних языков мы рассмотрим
естественный язык, математические и логические
формулы и языки программирования.
Среди последних математические и логические
формулы, а также языки программирования имеют
общее свойство — они согласованы семантически с
компьютерами, поэтому не подумайте, что проблема
построения интерфейса с мультииерархической
моделью состоит в преобразовании формул и программ
как внешнего языка в машинный язык,
определяющий семантику компьютера. Цель обработки формул
и программ в инженерии знаний заключается в
выполнении того, что недостижимо путем
непосредственных вычислений, записанных на существующих
процедурных языках, в частности в автоматическом
синтезе программ, в идентификации ошибок в
программах, в понимании программ, т. е. в помощи
человеку. Все это в инженерии знаний реализуется с
использованием механизма выводов так, как это
делает сам человек. Следовательно, математические и
логические формулы и языки программирования
также необходимо преобразовывать во внутреннее
представление, удобное для получения выводов.
С рисунками будем иметь дело только в случае,
когда объективно смысл их очевиден. Например, в
структурной схеме компьютерной системы на рис. 4.7
объективно определен смысл каждого обозначения,
1) Разновидность блок-схем, разработанных в Японии (Ни-
мура и др.) для языка Паскаль. См. Микрокомпьютеры.
Справочное руководство/Под ред. С. Ватанабэ и др. — М.: Мир,
1990. — Прим. перев.
Приобретение знаний и обучение в диалоге 133
поэтому такую схему можно обрабатывать как
внешний язык, но все то, смысл чего объективно
механически не определен, скажем, пейзажи, абстрактные
картины, мы исключим из категории внешних
языков.
Естественный язык — наиболее важный из
внешних языков. В согласованности естественного языка
и области понятий, образно говоря, заключена жизнь
или смерть' диалоговой системы. Ответственность за
это несет представление знаний в области языка.
Следуя понятию падежа Филмора, все "глаголы
образуют предложения, изменяясь по типам и
падежам. Рассмотрим, например, глагол break (разби*
вать).
I Телетайп L
Магнитные
Компьютер
(Память,
блок питания,
выключатели t
микропроцессор,
интерфейс)
Принтер
Г Мышь ]
— Ч
Жесткий диск J
2.
Гибкий диск
Рис. 4 7. Конфигурация микрокомпьютера-
104
Глава 4
® The window broke. Окно разбито.
B) A hammer broke the window. Окно разбито молотком.
ф John broke the window with a hammer. Джон разбил окно
молотком.
С точки зрения поверхностной (грамматической)
структуры эти три предложения имеют различные
подлежащие и дополнения, но с точки зрения
глубинной (семантической) структуры их можно
унифицировать в следующем виде:
E) Разбивать({агент}, объект, {инструмент}).
Запись @ показывает, что глагол «разбивать»
обязательно сопровождается дополнением, т. е.
объектом, который разбивают, а агентивный падеж, т. е.
тот, кто разбивает, и инструментальный падеж, т. е.
то, чем разбивают, в предложении могут быть или не
быть. Для машинного преобразования предложений
0 — @ в виде ф необходимо учитывать
предысторию выбора, введенную Хомским. Например, для
глагола «разбивать» предысторией выбора называют еле-»
дующие свойства: агентивный падеж этого глагола
ограничивается словами с предысторией
«одушевленный», объективный падеж — словами с предысторией
«хрупкий», а инструментальный падеж — словами с
предысторией «твердый».
Если сказанное выше представить на Прологе, то
получим
Разбивать(*агент, *объект, *инструмент)
<- не(переменная(*объект), с-вид(*агент,
одушевленный), с-вид(*объект, хрупкий),
с-вид(*инструмент, твердый).
С-вид — это предикат, обозначающий предысторию
выбора 1). Если помимо предыстории выбора, общих
для всех миров, типа одушевленный, хрупкий,
твердый, можно было бы определять предыстории,
специфичные для каждого мира, то это способствовало
бы пониманию смысла. Например, в мире руководства
по микрокомпьютеру удобно определить в качестве
предыстории выбора команды и параметры. Дчя пред-
*> «С» от слова «существительное». — Прим. перев^
Приобретение знаний и обучение в диалоге 105
ложений © — ® необходимы следующие
предыстории выбора:
с-вид(окно, хрупкое), с-вид(молоток, твердый).
с-вид(Джон, одушевленный).
Вот как их можно использовать: несмотря на то,
что в поверхностной структуре предложения © окно
является подлежащим, из того, что нет дополнения и
что предыстория выбора даёт нам свойство «хрупкое»,
мы заключаем, что окно — это объектный падеж.
Точно так же преобразуем предложения © — C) в
предикаты © — ©.
© Разбивать(*агент, окно, «инструмент)
F) Разбивать(*агент, окно, молоток)
ф Разбивать(Джон, окно, молоток)
Из предиката E) ясно, что разбито окно, но ничего
не говорится о том, кто это сделал и чем. В ©
представлена законченная сцена: Джон разбил окно
молотком. В® акцентируется то, что окно разбито
молотком.
В подобной ситуации совершенно безразлично,
каким будет внешний язык—английским или японским.
Другими словами, это представление не зависит от
вида внешнего языка. Таким образом, предикат @
определяет понятие «разбивать». Далее мы
рассмотрим способы машинного преобразования между
естественным языком и понятиями, способы машинной
идентификации смысловых атрибутов типа времени и
образа действия и смысловую идентификацию
предложений на естественном языке.
Вернемся еще раз к предикату с-вид (^экземпляр,
^имя-мира). Миры с именами *имя-мира фактически
являются отдельными мирами в области понятий, в
них описаны знания с общей предысторией набора,
а ^экземпляр, как экземпляр таких миров, наследует
их свойства, но, как указано выше, в техническую
систему с ограниченной областью объектов невозможно
включить все миры предыстории выбора.
Следовательно, предикат с-вид будем использовать как
специальный предикат в области языка.
106
Глава 4
4.2.2. ПРЕОБРАЗОВАНИЕ ВНЕШНЕГО ЯЗЫКА
ПРЕДСТАВЛЕНИЯ ЗНАНИЙ
Перейра и Уоррен с помощью Пролога формализо^
вали способ преобразования двух языков с
различными поверхностными структурами. Этот способ
называется грамматикой определенных предложений
(ГОП), в принципе математические и логические
формулы, а также языки программирования можно
описать и с использованием форм Бекуса — Наура
(БНФ) (или контекстно-свободной грамматики
(КСГ)), но языки с правилами, зависящими от
контекста, и грамматикой с ограничивающими условиями,
какими являются естественные языки, можно
обработать только с помощью методов, аналогичных ГОП.
В статье Перейры и Уоррена 1) приведены примеры
преобразования между предложениями естественного
языка и деревом грамматического разбора, а также
преобразования между естественным языком и
нормальной формой логики предикатов первого порядка.
Ниже прежде всего опишем ГОП на примере
преобразования предложения естественного языка в дерево
грамматического разбора и обратно. Затем для того,
чтобы мы могли оперировать с представлением зна- .
ний в области понятий, введенной в предыдущем
разделе, как с глубинной структурой естественного
языка, опишем метод преобразования между понятиями
и предложениями английского языка.
Рассмотрим представление с помощью ГОП
подмножества английского языка, представленного на
рис. 4.8. На каждом этапе разбора предложения
слева-направо участвуют три последовательности
символов.
Первая — входная последовательность символов
для разбора; вторая образуется из нескольких слов
(или ни из одного слова), начиная с левой части
входной последовательности, при успешном разборе эта
последовательность формирует частичную
последовательность, для которой очевидна ее принадлежность
•> Pereira F. С. N. and Warren D. H. D. Definite Clause
Crammer for Language Analysis, Artif. IntelL, 13, 3, pp. 231—278
A980).
Приобретение знаний и обучение в диалоге 107
некоторой категории заданной грамматики. Третья
последовательность — это символы, оставшиеся после
исключения второй последовательности в случае
успешного разбора, она является входной
последовательностью для последующего этапа
грамматического разбора.
При образовании из КСГ в ГОП особую роль
играют первая и третья последовательности, а
именно: первая последовательность является объектом
разбора, а третья — переходит в следующий этап,
поэтому она необходима независимо от цели
преобразования. Вторая последовательность используется в
соответствии с целью преобразования. Например, на
рис. 4.9 представлена ГОП для преобразования
между предложением английского языка и деревом
грамматического разбора. Первый и второй параметры
каждого предиката соответствуют первой и третьей
последовательностям. В ГОП эти параметры
определяются, если они, безусловно, существуют, поэтому
их опускают и не записывают. Но нас здесь
интересует процесс выполнения, поэтому будем записывать
эти два параметра в предложениях Пролога не
опуская. Для того чтобы было видно, к какой
грамматической категории принадлежит вторая
последовательность, в третьем параметре к этой последовательности,
заключенной в скобки, добавим первую букву (буквы)
категории. Например, ГС (*имя) означает, что *имя
принадлежит Группе Существительного. Для грамма-
A) предложение -^группа-существительного, группа-глагола
B) группа-существительного -> артикль, существительное
C) группа-существительного -> имя-собственное
D) группа-глагола -> глагол, группа-существительного
E) группа-глагола -> глагол
F) артикль -> [the]
G) артикль -> [а]
(8) существительное -> [window]
(9) существительное —> [hammer]
A0) имя-собственное-> [John]
A1) глагол -> [broke]
Рис. 4.8. КСГ, представляющая подмножество английского
языка.
108
Глава 4
тического разбора предложения «John broke the
window» («Джон разбил окно») с помощью ГОП на
рис. 4.9 можно определить следующую цель:
Предложение{[Зо\т broke the window], [ ],
• дерево-разбора).
Грамматический разбор реализуется как процесс
выполнения, приведенный на рис. 4.10. В результате
получается дерево грамматического разбора как
значение параметра ^дерево-разбора:
n(rC(HC(John)), ЩГ(Ьгоке), rC(A(the), C(window)))).
Это полностью аналогично дереву разбора,
приведенному на рис. 4.11.
A) предложение (*целое, *остаток, П(«группа-существитель-
ного, *группа-глагола)) <- группа-существитель-
ного(*целое, *остаток1, «группа-существитель-
ного), группа-глагола(*остаток1, *остаток,
*группа-глагола).
B) группа-существительного (*целое, «остаток, ГС(*артикль,
¦существительное)) <- артикль(*целое, «остаток!,
¦артикль), существительное(*остаток1, «остаток,
¦существительное).
C) группа-существительного (*целое, «остаток, ГС(*имя-соб-
ственное)) <- имя-собственное(«целое, «остаток,
«имя-собственное).
D) группа-глагола («целое, «остаток, ГГ(«глагол, «группа-
существительного)) <т- глагол(*целоз, «остатокI,
«глагол), группа-сущестзительного(*остаток1,
¦остаток, «группа-существительного).
E) группа-глагола («целое, «остаток, ГТ(*глагол)) «- глагол
(«целое, «остаток, «глагол).
F) артикль ([Ше|*остаток], «остаток, A(the)).
G) артикль ([а]*остаток], «остаток, А(а)).
(8) существительное ([window|*ocTaTOKJ, «остаток,
C(window)).
(9) существительное ([паттег|*остаток], «остаток,
C(hammer)).
A0) имя-собственное ([John|*ocTaTOK], «остаток, HC(John)).
(И) глагол ([Ьгоке|*остаток], «остаток, Г(Ьгоке)).
1'ас. 4.9. Программа грамматического разбора,
соответствующая грамматике на рис. 4.8,
• <- предложение ([John broke the window], пусто, *дерево-разбора).
*дерево-разбора = П(*группа-существительного, *группа-глагола)'
A) • <- группа-существительного ([John broke the window], *остаток1, *группа-сушествительного)
группа-глагола(*остаток1, пусто, *группа-глагола).
*группа-существительного = ГС(*имя-собственное)
(з) :
<- имя-собственное ([John broke the window], *остаток1, *имя-собственное),
группа-глагола(*остаток1, пусто, *группа-глагола).
*имя-собственное == HC(John), *остаток1 = [broke the window]
A0) • <- группа-глагола ([broke the window], пусто, *группа-глагола).
*группа-глагола = ГГ(*глагол, *группа-существительного)
D) • -<- глагол ([broke the window], *остаток1, *глагол),
группа-существительного(*остаток1, пусто, *группа-существителыюго).
глагол = Г(Ьгоке), *остаток1 = [the window]
A1) • <- группа-существительного ([the window], пусто, *группа-существительного).
¦группа-существительного = ГС(*артикль, «существительное)
B) • <- артикль ([the window], *остаток1, *артикль),
существительное(*остаток1, пусто, «существительное).
*артикль = A(the), *остаток1 = [window]
(б) • <- существительное ([window], пусто, «существительное).
«существительное = C(window)
(8) ?
Рис. 4.10. Процесс разбора предложения «John broke the window» (подчеркнуты объекты вызова
следующих процедур. Числа слева — номера грамматических правил, выбранных путем сопоставления с
образцом).
=3
¦о
о
о\
т>
ф
110
Глава 4
Информацию, зависящую от контекста, можно
распознать либо путем добавления параметров, либо
путем введения правил, не включенных в ГОП.
Например, для добавления в ГОП на рис. 4.9 лица и числа
к параметрам предикатов B) и C) добавим *лицо,
к параметрам предикатов D) и E)—*лица, а
параметрам предикатов (8) — A0)—параметр Зеу
указывающий на третье лицо единственного числа. После
добавления к A1) параметра [1е, 1м, 2е, 2м, Зе, Зм],
указывающего все лица и числа, предикат A)
преобразуем в следующий вид:
Предложение(*целое, достаток, П(*группа-существительного,
*группа-глагола)) <- группа-существительного(*целое,
*остаток1, *лицо, *группа-существительного),
группа-глагола(*остаток1, ^остаток, *лица,
* группа-глагола),{член(*лицо, *лица).}
В фигурных скобках указано ограничение, не
включенное в ГОП (лицо и число подлежащего и
предиката совпадают).
Пролог не различает входные и выходные
переменные, поэтому ГОП на рис. 4.9 можно
использовать также для генерации предложений на
английском языке по дереву грамматического разбора.
Пример— рис. 4.12. Строки с A) по E) на рис. 4.9
называются грамматическими правилами, а строки с
F) по A1)—блоком словаря. В мультииерархиче-
ской модели словарь, используемый во всех
грамматических правилах, находится на верхнем уровне, а
специальный словарь включается в миры словаря.
Предложение
Группа Группа
существительного глагола
Ммя Глагоа Группа
собственное
существительного
Артикль Существительное
I I
Зопп broks 1he window
Рис. 4.11. Дерево грамматического разбора предложения «John
broke the window».
Приобретение знаний и обучение в диалоге 111
Для того чтобы ГОП играла роль интерфейса
между естественным языком и представлением знаний в
области понятий, необходимо естественный язык
преобразовывать не только в указанное выше дерево
грамматического разбора, по и в формат предиката
для области понятий. А именно, как следует из
примера с глаголом «разбивать», необходимо
преобразовывать поверхностную структуру, полученную с
помощью дерева грамматического разбора, в понятия,
I
• <- предложение (*целое, пусто, П(ГС(ИС(тоИ:1)),
I ГТ(Г(Ьгоке), rC(A(the), C(window))))).
A) • <- группа-существительного (*целое, *остаток1,
| rC(HC(John))),
| группа-глагола (*остаток1, пусто, ГТ(Г(Ьгоке),
rC(A(the), C(window)))).
C) • <- имя-собственное (*целое, *остаток1, MC(John)),
группа-глагола (*остаток1, пусто, ГГ(Г(Ьгоке),
rC(A(the), C(window)))).
*целое = [John | достаток 1]
A0) • <- группа-глагола (*остаток1, пусто, ГТ{Г(Ьгоке),
I fC(A(the), C(window)))).
D) • <- глагол (*остаток1, остаток2, Г(Ьгоке)),
, группа-существительного (*остаток2, пусто,
TC(A(the), C(window))).
*остаток1 = [broke | *остаток2]
A1) • <- группа-существительного (*остаток2, пусто,
| rC(A(the), C(window))).
B) • <- артикль (*остаток2, *остатокЗ, A(the)),
существительное (*остатокЗ, пусто, C(window)),
*остаток2 = [the | *остатокЗ]
F) • <- существительное (*остатокЗ, пусто, C(window)).
*остатокЗ = [window]
(8) D
Рис. 4.12. Процесс генерации предложения «John broke the win*
dow» из дерева грамматического разбора (П(ГС(ИСEопп)),
ГГ(Г(broke), rC(A(the), C(window)))).
112
Глава 4
В этом случае, к примеру, можно воспользоваться
следующей формулой преобразования. Здесь *л:—•
подлежащее поверхностной структуры, а *у —
дополнение.
® Преоор(разбивать, разбивать (*х, *у, *z)t разбивать
(-=*, *#, *z)) <- не(переменная(*х)), не(переменная(*#)),
с-вид(*л;, агент), с-вид(*#, хрупкий).
® Преобр(разбивать, разбивать(*лг, **/, *z)t разбивать
(*#, *x, *г)) <- переменная(*#), с-вид(*л;, хрупкий).
® Преобр(разбивать, разбивать(**, *#, *г), разбивать
(*z, *#, **) <- не(переменная(**))> не(переменная(*#)),
с-вид(*л;, твердый), с-вид(*#, хрупкий).
Исходная ГОП проста, поэтому правила
преобразования достаточно записать в таком виде, но в
действительности все более сложно. Используя ® — ®,
покажем, как КСГ на рис. 4.8 преобразуется в ГОП.
Здесь учитываются лицо, число, время. Время по
отношению к входному английскому предложению —
выходная переменная и входная при синтезе
предложения. Аналогично можно обрабатывать атрибуты
предложения, получаемые из поверхностной
структуры, такие, как продолженные и совершенные
времена, вспомогательные глаголы, вид, форма и залог
предложения, а также предложные группы, то есть
существительные с предлогом, которые не
обусловливают пассивный падеж данного глагола, скажем,
инструментальный падеж для глагола «разбивать»
(например, «вчера», определяющее время, «в
Японии», определяющее место).
Предикат A) на рис. 4.13 используется в случае
преобразования понятий в предложение, а (Г)—в
случае преобразования предложения в понятия. То
же справедливо для E) и E'). Таким образом, для
преобразования предложения в понятия прежде всего
получается дерево грамматического разбора, а после
того, как станет очевидной поверхностная структура,
она преобразуется в понятия, и, наоборот, при
синтезе предложения из понятий последние прежде всего
преобразуются в поверхностную структуру, а затем
Приобретение знаний и обучение в диалоге 113
синтезируется предложение. На рис. 4.14 показан
процесс получения из предложения «The window
broke» («Окно разбито») понятия разбивать (*у, окно,
*z) и ^прошедшее-время, а на рис. 4.15 — процесс
синтеза этого же предложения из понятия разби*
вать(*#, окно, *г) и ^прошедшее-время.
A) предложение («целое, «остаток. *время, «понятие)
<- {переменная(*целое),}
группа-глагола (*остаток1, достаток, ?-время,
*лица, «подлежащее, «понятие), группа -су щест-
вительного(«целое, достаток 1, *лицо, «подлежа-
щее), {член («лицо, «лица).}
(Г) предложение (*целое, «остаток, «время, «понятие)
«<- группа-существительного («целое, *остаток1,
«лицо, «понятие), группа-глагола (достаток!,
«остаток, «время, «лица, «подлежащее, «понятие),
{член («лицо, «лица).}
B) группа-существительного («целое, «остаток, «лицо,
«понятие)
<- артикль («целое, *остаток1), существительное
(*остаток1, «остаток, «лицо, «понятие).
E) группа-глагола («целое, «остаток, «время, «лица,
«подлежащее, «понятие)
<- {переменная («целое),} преобр(*основа,
«поверхностная, «понятие), глагол («целое, «остаток,
«основа, «время, «лица, «подлежащее,
«дополнение, «поверхностная).
E') группа-глагола («целое, «остаток, «время, «лица,
«подлежащее, «понятие)
<- глагол («целое, «остаток, «основа, «время, «лица,
«подлежащее, «дополнение, «поверхностная),
преобр («основа, «поверхностная, «понятие).
F) артикль ([the | «остаток], «остаток).
(8) (существительное ([window | «остаток], «остаток,
Зе, window).
A1) глагол ([broke | «остаток], «остаток, break, прошедшее,
[1е, 1м, 2е, 2м, Зе, Зм], «подлежащее,
«дополнение, break («подлежащее, «дополнение,
«понятие)).
Рис» 4.13. Программа преобразования английского предложения
в понятие с учетом времени, лица и числа.
114
Глава 4
F)
«- предложение ([the window broke], пусто, *время,
¦понятие).
О ) • <- группа-существительного ([the window broke],
*остаток1, *лиИ.о, ^подлежащее),
группа-глагола (*остаток1, пусто, *время, #лица,
¦подлежащее, ¦понятие), член (¦лицо, ¦лица).
B) • <- артикль ([the window broke], ¦остаток),
существительное (¦остаток!, ¦остаток!, *лицо,
¦подлежащее), группа-глагола (*остаток1, пусто,
¦время, ¦лица, ¦подлежащее, ¦понятие),
члены (*лицо, ¦лица).
достаток = [window broke]
<- существительное ([window, broke], »остаток1,
¦лицо, ^подлежащее),
группа-глагола (¦остаток!, пусто, ¦время, ¦лица,
¦подлежащее, ¦понятие), член (¦лицо, ¦лица).
достаток 1 — [broke], ¦лицо = Зе,
¦подлежащее = window
C) . <- группа-глагола ([broke], пусто, ¦время, ¦лица,
window, ¦понятие),
член (Зе, *лица).
E') • <- глагол ([broke], пусто, *основа, ¦время, ¦лица,
window, ¦дополнение, *п),
преобр (*основа, *п, ¦понятие),
член (Зе, *лица).
¦основа == break, ¦время = прошедшее,
¦лица = [1е, 1м, 2е, 2м, Зе, Зм], *п = break
(window, ¦дополнение, ¦понятиеЗ)
A1) - <- преобр (break, break (window, ¦дополнение,
¦понятиеЗ), ¦понятие),
членCе, [1е, 1м, 2е, 2м, Зе, Зм]).
¦понятие = break (¦#, window, *z)
(9) • «- c-вид(window, хрупкое), переменная(чдополнение),
I членCе, [1е, 1м. 2е, 2м, Зе, Зм]).
Рис. 4.14. Процесс преобразования предложения The window
broke в понятие разбивать (*у, окно, *z) и ^время-прошедшее.
Приобретение знаний и обучение в диалоге 115
i
• <- предложение (¦целое, пусто прошедшее,
break(*#, window, *z)).
A) • <- переменная (*целое), группа-глагола(*остаток,
пусто, прошедшее, ¦лица, ^подлежащее,
breaker/, window, ¦?)),
группа-существительного (¦целое, ¦остаток, ¦лицо,
¦подлежащее), член(*лицо, ¦лица).
E) . <- переменная (достаток), преобр(*основа, ¦п,
Ьгеак(*г/, window, *г),
глагол (достаток, пусто, ¦основа, прошедшее,
¦лица, ¦подлежащее, дополнение, *п),
группа-существительного (¦целое, достаток, ¦лицо,
¦подлежащее), член (¦лицо, ¦лица).
¦основа == break, ¦п =» break(window, *y, *z)
(9) • <- глагол (достаток, пусто, break, прошедшее, *ляцач
window, ¦дополнение, break(window, ¦ */, *г)),
группа-существительного (¦целое, ¦остаток, ¦лицо,
window), член (*лицо, ¦лица)
¦остаток = [broke], *лица = [1е, 1м, 2е, 2м,
Зе, Зм]
A1) • <- группа-существительного (¦целое, [broke], *лицо,
window),
член (*лицо, [1е, 1м, 2е, 2м, Зе, Зм]).
B) • <- артикль (¦целое, *остаток1),
существительное (*остаток1, [broke], ¦лицо,
window), член (¦лицо, [1е, 1м, 2е, 2м, Зе, Зм]),
¦целое = [the | ¦остаток!]
F) : **~ существительное (*остаток1, [broke], ¦лицо
window),
член (¦лицо, [1е 1м, 2е, 2м, Зе, Зм]).
¦остаток! = [window broke], ¦лицо = Зе
(8) J <- членCе, [1е, 1м, 2е, 2м, Зе, Зм]).
а
Рис. 4.15. Процесс синтеза предложения The window broke из
понятия разбивать [*у, окно, *) и *время-прошедшее^
116
Глава 4
Формулы и языки программирования точно так же
с использованием ГОП можно преобразовать в
понятия. ГОП описывается на базе КСГ с помощью
правил Хорна, но если в КСГ включены рекуррентные
слева правила, то возможно образование бесконечных
циклов, поэтому необходимо переписать КСГ в
грамматику без таких правил.
4.2.3. ДИАЛОГ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
4.2.3.1. СМЫСЛ ПРЕДЛОЖЕНИЙ
НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
Как указано выше, предложения на естественном
языке можно преобразовать в информационное
множество, содержащее помимо понятий, выраженных в
виде предикатов, информацию о времени
(настоящее, прошедшее, будущее), видовременной
характеристике (континуальное, перфектное, несовершенное),
залоге (активный, страдательный), модальности
(разрешительная, запретительная, потенциальная,
сослагательная, облигаторная, недостоверная и т. п.), типе
предложения (вопросительное, повествовательное,
восклицательное), независимых членах (время, место,
причина, результат, степень, цель, уступка и т. п.).
Подобное информационное множество помогает
уточнить различия в предложениях, которые неразличимы
при использовании предикатов. ВозьмехМ, например,
предложения
John broke the window with a hummer.
Did John break the window with a hammer?
John has broken the window with a hammer,
John can break the window with a hammer.
(Джон разбивал окно молотком.
Джон разбивал окно молотком?
Джон разбил окно молотком.
Джон может разбить окно молотком).
Все они преобразуются в одно и то же понятие
«разбивать» (Джон, окно, молоток), но имеют различный
смысл, который можно понять с помощью указанного
выше информационного множества. Следовательно,
такое множество определяет формальный смысл
Приобретение знаний и обучение в диалоге 117
предложения на естественном языке. Этот смысл
можно идентифицировать только в области языка.
Смысл предложения на естественном языке
идентифицируется благодаря знаниям из области
понятий, соответствующей области языка, в которую
преобразуется входное предложение, знаниям из миров
связей, с помощью которых область понятий
наследует свойства, а также знаниям из миров
предыстории выбора, которые из чисто технических
соображений ограничены, но с помощью которых слова из
области понятий наследуют свойства.
Определительные отношения независимых членов,
как правило, можно идентифицировать несколькими
способами. Например, в предложении
John broken the window in the church.
(Джон разбил окно в церкви.)
формально не понятно, что определяют слова in the
church (в церкви): window (окно) или John broken
the window (Джон разбил окно). Из формального
смысла выясняется, что предлог in (в), судя по
предыстории выбора понятия church (церковь),
означает место, но никак не время. В результате это
предложение в области языка можно
идентифицировать как одно из следующих двух понятий:
Л7> Где(разбивать(Джон, окно, ^инструмент), в, церковь)
fT^\ Разбивать(Джон, окно, *инструмент) Л где (окно, в,
церковь)
Где — предикат, выражающий место. Кроме него
можно аналогично представить другие понятия
(обстоятельства), используя предикаты когда (время),
почему (повод, результат, цель, причина), как
(средство, степень), но (уступка) и другие. Формат этих
предикатов — суть формат сложного предложения.
Знания об этих форматах играют важную роль при
идентификации вопросов, ответов и ошибок в диалоге.
Определить, какое из понятий (jT) или 1(п) верное,
можно с помощью знаний в области понятий,
а если нет таких знаний, то нет другого способа,
кроме как обучение из внешнего мира в диалоге.
118
Глава 4
Определить понятие можно из контекста диалога,
что мы и делали до сих пор, а также с помощью
знаний из области понятий. Поскольку, как будет
указано ниже, в мультииерархическои модели в процессе
диалога создается модель пользователя, то
содержание диалога, о котором шла речь, будучи знаниями
из этой модели, можно считать объектом для выводов
в области понятий.
4 2 3 2. МЕТОДЫ ВЕДЕНИЯ ДИАЛОГА
НА ЕСТЕСТВЕННОМ ЯЗЫКЕ
Диалог на естественном языке можно разбить на три
этапа: грамматический разбор, понимание и выводы,
а также синтез. Грамматический разбор и синтез
выполняются с помощью знаний в области языка, а
понимание и выводы — с помощью знаний в области
понятий. На рис. 4.16 приведен пример такого диалога.
*вывод — это сообщение для поддержания диалога,
т. е. ответ, вопрос пользователю или другой текст.
^¦ввод-пользователя — это предложение на
естественном языке, введенное пользователем после вывода
vвывод. Это предложение формально преобразуется
благодаря предикату идентифицировать-язык с
помощью знаний из области языка и отождествляется
как значение переменных *формальный-смысл и
^понятие. Формальный смысл служит входной
переменной для следующего предиката идентифициро-
вать-понятие, здесь с помощью знаний из области
понятий делается вывод, который отождествляется как
значение переменной ^сообщение. Сообщение
преобразуется в предложение на естественном языке с
помощью следующего предиката проверить-сообщение,
диалог (*вывод)
<- ввод (*вывод, *ввод-пользователя),
идентифицировать-язык (*ввод-пользователя,
^остаток, *формальный-смысл, ^понятие),
идентифицировать-понятие (*понятие,
*формальный-смысл, *сообщение),
проверить-сообщение (*сообщение, пусто,
*вывод'),
диалог (*вывод').
Рис. 4 16. Программа верхнего уровня диалога.
Приобретение знаний и обучение в диалоге 119
и это предложение выдается пользователю.
Подобный диалог может продолжаться бесконечно.
Прекращение диалога обусловливается идентификацией
входных предложений пользователя в области
понятий. Например, если пользователь ввел предложение
«Конец этой системы», то в области языка
синтезируется понятие достаточно (*агент, тот-же-самый) и
формальный смысл вид-предложения (императив).
В области языка существует правило, которое
считает это понятие наиболее приоритетным и может
порождать вызов программы обработки конца диалога.
Пример программы идентификации формального
смысла в области языка приведен на рис. 4.17, а
именно: при успешном завершении грамматического
разбора всего предложения будет успешной и
идентификация формального смысла, но если чтение и
понимание частичной последовательности символов
будет неудачным, то вызывается подпрограмма
уточнить, которая выполняет соответствующую
обработку. Она первым делом выполняет идентификацию
смысла той частичной последовательности, разбор
которой завершился успешно, а затем выдает фразу
«Я никак не могу понять смысл ^остаток» и передает
идентифицировать-язык («ввод-пользователя, пусто,
«формальный-смысл, «понятие) <- предложение
(«ввод-пользователя, пусто, «формальный-смысл,
«понятие),
идентифицировать-язык («ввод-пользователя, «остаток,
«формальный-смысл, понятие) <- предложение
(«ввод-пользователя, «остаток,
«формальный-смысл, «понятие),
уточнить («остаток, «формальный-смысл, «понятие),
идентифицировать-язык («ввод-пользователя, «остаток,
«формальный-смысл, «понятие) <- сменить-мир
(«ввод-пользователя),
идентифицировать-язык (*ввод-пользователя,
«остаток, «формальный-смысл, «понятие/,
идентифицировать-язык («ввод-пользователя, «остаток,
«формальный-смысл, «понятие) <- спросить-сноса
(«ввод-пользователя, «вывод), диалог («вывод).
Рис. 4.17. Программа верхнего уровня области языка.
120
Глава 4
переменные *формальный-смысл и ^понятие на
следующий этап. В случае неудачи идентификации
формального смысла входного предложения с помощью
предиката сменить-мир происходит переход в другие
миры, соответствующие словарю входного
предложения, и вновь повторяется его грамматический анализ.
Если и с помощью этого предиката не удается
идентифицировать смысл, то в предикате спросить-снова
переменной *вывод присваивается фраза «Я не знаю
значения слова w, пожалуйста, используйте другое
выражение», где w — неидентифицированное слово.
В области понятий обрабатывается значение *яо-
нятие, при этом к модели пользователя добавляется
значение *формальный-смысл. Эта модель, как будет
указано ниже, представляет собой содержание диалога
с пользователем, то есть миры, в которых
регистрируется, как система интерпретирует диалог. В случае
когда результат обработки ^понятие сводится не к
синтезу предложения на естественном языке, а к
действию, то подпрограмма, соответствующая этому
действию, присваивает значение переменной ^сообщение.
Например, если в ходе диалога обнаружилось, что
пользователь сменил тему, то в момент завершения
обработки в текущей области понятий необходимо
заменить модель пользователя. Если в подобных
случаях переменную ^сообщение отождествить с целью,
которая изменит среду пользователя, то после
завершения обработки в области понятий будет, например,
выполняться программа проверить-сообщение
/рис. 4.18).
проверить-сообщение (пусто, *вывод, *вывод).
проверить-сообщение ([отобразить *сообщение| *остаток],
*вывод1, вывод2) <- синтезировать (*сообщение,
¦предложение), вывести (*предложение),
проверить-сообщение (достаток, *вывод1, *вывод2).
проверить-сообщение ([действовать ^сообщение | *остаток],
*вывод1, *выводЗ) <- вызвать (^сообщение
(*вывод1, *вывод2)), проверить-сообщение
(¦остаток, *вывод2, *выводЗ).
Рис, 4.18. Программа верхнего уровня «проверка-сообщения».
Приобретение знаний и обучение в диалоге $21
4.2.3.3. НЕЧЕТКИЕ ПРЕДЛОЖЕНИЯ
В процессе диалога нередко появляются нечеткие
предложения, предложения с опущенными словами,
предложения с местоимениями, предложения с
многозначными словами и т. п. Смысл подобных
предложений с неточными словами идентифицируется
в мультииерархической модели с помощью
следующих пяти методов.
1. Метод иерархической организации знаний. Как уже
было отмечено, многозначные слова обычно
выражают различные понятия, поэтому часто
принадлежат различным мирам в области языка. В
мультииерархической модели миры, служащие темой
разговора, наследуют нужные знания из миров верхнего
уровня и благодаря унификации определяют понятия
слов, что играет существенную роль при
идентификации.
Иерархическая организация миров также
эффективна для обработки нечетких предложений.
Например, если в диалоге с системой-консультантом по
микрокомпьютерам был задан вопрос: «Где
находится выключатель?», а темой диалога был принтер,
то можно идентифицировать расположение
выключателя принтера; если разговор шел о
микрокомпьютере, то указать, как он включается, а если о
системе, включающей и то и другое, то расположение
обоих выключателей.
2. Метод изучения нескольких вариантов. При
идентификации формального смысла нечеткого
предложения в области языка можно выдвинуть несколько
вариантов (гипотез). Число гипотез можно уменьшить
в результате вывода в области понятий.
Например, на этапе разбора формального смысла
приведенного выше предложения
Джои разбил окно в церкви
в области языка формально нельзя оценить,
относятся ли слова «в церкви» к слову «окно» или к фра-
m
Глета 4
зе «Джон разбил окно». Однако если в модели
пользователя уже находится предложение
Джон вошел в церковь
и идентифицировано, что церковь — это место, где
сейчас находится Джон, то уже можно сделать
вывод, что «в церкви» относится к оставшейся фразе.
3. Метод отождествления переменных. Опущенные
имена и местоимения можно обрабатывать в области
языка как переменные (см. примеры ©, (§)
разд. 4.2.1).
4. Идентификация смысла с помощью вопросов,
В случае понимания нечетких предложений
указанными выше тремя методами можно в диалоге на
естественном языке спросить пользователя или попросить
его ввести более понятные предложения и приобрести
тем самым новые знания.
5. Метод запоминания нечетких знаний. Если
знание X нечеткое, можно обрабатывать его с введением
нечеткости в само знание, например, используя
представление типа возможность (X, вероятность (О, 3)).
Но в этом случае необходимо определять
непротиворечивые правила выводов.
4.3. ПРИОБРЕТЕНИЕ ЗНАНИЙ
И ОБУЧЕНИЕ В ДИАЛОГЕ
4.3.1. ЗНАЧЕНИЕ ДИАЛОГА
В ПРИОБРЕТЕНИИ ЗНАНИЙ
Приобретение знаний в интеллектуальных
информационных системах можно разбить на два этапа: этап
генерации системы и этап добавления знаний в
готовую систему. Ввод знаний в процессе диалога на
естественном языке при генерации системы, видимо,
наиболее интересная тема исследований процесса
приобретения знаний, но технические методы ввода
знаний в системы пока не освоены. Предлагают
вводить знания в словарь и область понятий через
диалоговые редакторы Пролога, в виде рисунков, таблиц
Приобретение знаний и обучение в диалоге 123
и т. п. Поэтому ниже будем рассматривать приобре-
теыие знаний существующими системами.
1. Уточнение нечетких знаний. Как отмечено в конце
предыдущего раздела, в случае когда в системе
недостаточно знаний, трудно правильно
идентифицировать нечеткие входные предложения на естественном
языке. Приобретая правильные знания в диалоге с
пользователем, система обеспечивает такую
идентификацию, если, конечно, знания в системе
непротиворечивы. Следует также обратить внимание на то, что
недостаточно высокая надежность модели
пользователя (см. далее) снижает надежность системы.
2. Полнота знаний, а также обнаружение и обработка
противоречивых знаний. В процессе выполнения про*
грамм на Прологе, идентифицирующих смысл в
области понятий, неудачи возможны в двух случаях, а
именно: когда в состав знаний не включены правила,
соответствующие обозначениям предикатов
некоторой цели или подцели, и когда, несмотря на наличие
таких правил, возникает несоответствие параметров
или несогласованность условий. Неудача в первом
случае преодолевается благодаря отождествлению с
новыми знаниями, как указано в п. 1, но при неудаче
во втором случае уже необходимо идентифицировать
ее причины. Обсуждение проблем идентификации
ошибок не входит в задачи данной книги, поэтому не
будем останавливаться на этом, хотя, например, об
идентификации ошибок в знаниях при диалоге с
помощью индуктивных выводов можно узнать в гл. 7,
Если в результате такой идентификации окажется,
что ошибка не связана с пользователем, а вызвана
знаниями самой системы, то необходима коррекция
этих знаний.
При избыточных знаниях, т. е. в случае, когда
идентификация входного предложения в области
понятий завершена успешно и в диалоге на
естественном языке на это предложение получен ответ «да»,
но пользователю выдается предложение с тем же
смыслом, в коррекции знаний системы нет
необходимости.
124
Глава 4
3. Роль контрпримеров. Взаимосвязь между средой
пользователя системы обработки интеллектуальной
информации и средой приобретения знаний
осуществляется благодаря выводам на основе гипотез об
открытых мирах. Поясним это на примере. В области
понятий системы-консультанта по микрокомпьютерам
заложены знания о том, что к микрокомпьютеру
COMP-XyZ можно подключиться через интерфейсы
AAA-111 и ВВВ-222:
возможность(подключение(*агент, COiAP-XYZ, *объект,
ААА-111), имеется)
возможность(подключение(*агент, COh\P-XYZ, *объект,
ВВВ-222), имеется)
Допустим, что пользователь спрашивает, можно
ли подключиться через другой интерфейс АВС-333.
Гели миры замкнуты, то вследствие неудачной
идентификации система может ответить «АВС-333 не
используется». В открытых мирах создаются другие
правила, например правило, описывающее все
подключаемые интерфейсы:
таблица-интерфейсов(СОМР-*Г?, [ААА-1И, ВВВ-222])
Теперь можно проверить возможность подключения
с помощью предиката
возможность(подключение(*агент, номер-компьютера,
¦объект, *интерфейс), имеется) <- таблица-интерфейсов
(*номер-компьютера, *список-иитерфейсов),
член(*интерфейс, список-интерфейсов).
Однако в случаях, когда заранее не определен
^список-интерфейсов, либо этот список неограниченно
большой-, либо выводы делаются путем сложных
вычислений и т. д., очень важную роль играют
контрпримеры. Например, если знание о том, что через
интерфейс АВС-333 подключаться нельзя, представить
в виде
возможность(подключение(*агент, COMP-XYZ, *объект,
АВС-333), не-имеется),
то на заданный выше вопрос можно ответить. Если
же этот факт неизвестен, то его можно усвоить как
новое знание.
Приобретение знаний и обучение в диалоге 125
4.3.2. ЗНАЧЕНИЕ ДИАЛОГА ПРИ ОБУЧЕНИИ
Обучение системы обработки интеллектуальной
информации включает также усвоение новых знаний
(как и в случае приобретения знаний, о чем шла речь
выше), но ниже рассмотрим вопросы создания новых
знаний с помощью диалога. Классический пример —
создание знаний в диалоге и использование модели
пользователя. В этом разделе изучим модели
пользователя для современных систем обработки
интеллектуальной информации, а также их роль в диалоге.
4.3.2.1. ПРИМЕРЫ МОДЕЛЕЙ ПОЛЬЗОВАТЕЛЯ
Если партнером по диалогу является человек, то, как
правило, содержание и терминология диалога
зависят от того, кто этот человек: ребенок, специалист
или студент. Соответствующую среду можно
реализовать через построение модели пользователя.
Исследования таких моделей активно ведутся в области
систем обучения с помощью компьютеров и систем для
диалога на естественном языке. Дело в том, что при
компьютерном обучении необходимо оценивать
степень понимания студентом предметной области и
выбирать содержание учебного материала.
I. Оверлейные модели. Термин «оверлейная модель»
введен Голдштайном в 1981 г., но фактически этот
термин употреблялся пользователями системы
компьютерного обучения географии еще в 1970 г.
Модель ученика строится следующим образом.
К узлам семантической сети системы компьютерного,
обучения, описывающей знания по географии, в
качестве атрибутов добавляются числа, показывающие,
в какой степени ученик понимает содержащиеся
в каждом узле знания.
Подобная оверлейная модель строится в
предположении, что знания ученика и знания системы
имеют полностью аналогичную структуру, но первые
являются подмножеством последних.
Кранси, используя систему медицинской
диагностики инфекционных заболеваний MYCIN, создал
ш
Глава 4
обучающую систему GUIDON, в которой использовал
оверлейную модель для той же предметной области.
Система MYCIN описывает знания с помощью
продукционных правил, поэтому в модели пользователя
GUIDON накапливаются правила, 'распределяемые
по следующим трем группам в зависимости от
степени их понимания. Первая группа — правила, из
которых с точки зрения системы пользователь может
делать вывод, если задана предпосылка
продукционного правила. Вторая группа — правила, которые
учащийся может правильно использовать и приходить
к правильным выводам, если заданы данные
(состояние пациента). В последнюю группу собираются
правила, которые пользователь может применять для
разъяснений при получении обоснования ответа.
2. Разностные модели. Такая модель использована
в игре «Запад», созданной Хартом. Это игра типа
сугороку1}, в которой игрок передвигает фургон от
старта до финиша, но вместо костей используются
формулы с четырьмя арифметическими операциями.
Если умело подобрать формулы, то цель достаточно
быстро достигается кратчайшим путем. Эта игра
используется для обучения, причем ученика заставляют
решать предварительно составленные задачи, но
предсказать его способности невозможно. Зная лишь
предыдущие ходы ученика на доске, нельзя получить
информацию для построения модели пользователя.
Точно так же нельзя категорически утверждать, что
мы совсем не знаем, какие способы решения он
использует. Даже если он делает не наилучший ход,
это не означает, что данный ход ошибочен. Чтобы
учитывать всевозможные ситуации, и предложена
разностная модель.
Что же такое разностная модель? Сравнивая зна-
ния, которые лежат в основе хода, сделанного
учеником в некоторой позиции на доске, с описанными
в программе знаниями, которые использует эксперт
в такой же позиции, определяют различия между
*> Сугороку — японская игра, при которой, бросая кости,
передвигают фигурки по доске. — Прим. перев.
Приобретение знаний и обучение в диалоге 127
ними, которые и накапливаются в модели
пользователя. Следовательно, разностная модель — это
модель, которая подчеркивает различия между тем, чего
не знает ученик или знает, но не обращает
внимания, т. е. между мастерством игры, которым не может
в должной мере овладеть ученик, и мастерством,
которым он должен овладеть и понять.
3. Пертурбационные модели. Оверлейные и
разностные модели — это модели пользователя, построенные
в предположении, что знания пользователя об
объектной области являются подмножеством знаний
системы. Пертурбационная модель строится, исходя из
того, что знания пользователя частично расходятся
со знаниями системы. Хотя если не совсем ясно,
в чем заключаются эти расхождения, построить
модель пользователя нельзя. Следовательно, важной
предпосылкой построения такой модели является
идентификация причин расхождения.
При обработке знаний предполагается, что могут
существовать следующие пять причин расхождения:
1) недостаток знаний;
2) имеются ошибочные знания;
3) имеются верные знания, но пользователь не
знает способа их применения или неправильно их
применяет;
4) ошибка из-за невнимательности;
5) пользователь умышленно дает «взятый с
потолка» ответ.
Последнюю причину можно легко исключить, если
задать несколько очень легких вопросов. Степень
доверия к таким пользователям помечается самым
низким значением, и лучше не допускать приобретения
знаний из входных предложений, полученных от них<
Для учета причин 1—4 достаточно иметь
следующие функции:
1) функцию выявления расхождений в ответах
пользователя;
2) функцию идентификации, по какой из причин
A—4) возникла ошибка в правилах или действии,
использованных в процессе выводов при решении
задачи;
128
Глава 4
3) функцию объяснения расхождения путем его
повторного выявления в процессе решения задачи
с учетом результата функции 2.
В последнем случае необходимо решить ту же
задачу, добавив возмущение (пертурбацию) в сами
знания, используемые для ее решения, и в знания
о том, как применять первое знание. (Термин
«пертурбация» до сих пор употреблялся по отношению
к небесным телам, но в последнее время его стали
употреблять и в сфере информационных систем.)
Сказанное выше подразумевает необходимость
построения модели процесса решения задачи и
метазнаний, которые помогут интерпретировать этот
процесс. Предложенные до настоящего времени модели
пользователя нередко удовлетворяют лишь части
этих требований.
DEBUGGER — система для обучения
хирургическим операциям, созданная Бартоиом. Знания в
эгой системе называются сетью процедур, на основе
богатого клинического опыта хирургические функции
разбиваются на несколько десятков основных
приемов и создается сеть от узла, в котором операция
противопоказана, до узла, в котором воможно
хирургическое вмешательство в полном объеме, и к
каждому узлу добавляется процедура выполнения
частных приемов. Модель пользователя в системе
DEBUGGER генерируется путем накопления ошибок,
идентифицированных после пертурбации такой сети
процедур. Проще говоря, ошибка идентифицируется
благодаря замене части узлов в сети на заранее
подготовленные ошибочные процедуры, известные из
клинического опыта. Потенциально огромное число
комбинаций, обусловленное тем, какие процедуры
заменять, ограничивается с учетом специфических
для данной области приемов и их повторяемости.
Шапиро предложил метод индуктивных выводов,
названный им MIS (Model Inference System), для
интеллектуальной системы диагностики программ,
написанных на Прологе. Этот метод подробно
объясняется в гл. 7, отметим лишь, что после
идентификации в ходе диалога блока, в котором возникла
ошибка, ее причина идентифицируется путем пертур-
Приобретение знаний и обучение в диалоге 129
бационных вычислений с использованием оператора
уточнения (refinement). В настоящее время в
некоторых интеллектуальных системах компьютерного
обучения, разработанных в Японии, этот метод
используется для идентификации ошибок.
4.3.2.2. МОДЕЛЬ ПОЛЬЗОВАТЕЛЯ
В МУЛЬТИИЕРАРХИЧЕСКОЙ МОДЕЛИ
Какая модель пользователя наиболее подходит для
мультииерархической модели? Особенность последней
состоит в том, что она имеет связанные мультииерар-
хические миры с внутренними знаниями, в
зависимости от темы диалога происходит перемещение
миров и наследование ими необходимых знаний из
взаимосвязанных миров. Если система будет иметь
возможность свободно без каких-либо ограничений
переходить от мира к миру, то возникнет следующее
неудобство. Кто бы ни был партнером по диалогу —
ребенок или эксперт, диалог будет вестись с
использованием одних и тех же знаний, а система, не
учитывающая уровень партнера, будет неудобной. Кроме
того, свободное перемещение мультииерархических
миров обеспечит решение задач с использованием
знаний эксперта, гораздо более глубоких, чем знания
из курса какого-либо предмета, поэтому такая
система не пригодна как обучающая.
По этим причинам в качестве модели
пользователя, подразумевающей существование миров, удобна
оверлейная модель, а именно: в модель пользователя
не включаются миры, которые не были затронуты
в теме диалога с пользователем, тем самым
запрещается переход к другим мирам, если не считать
миры, необходимые как сопутствующие знания. При
таком методе не нужно заботиться о том, что в
процессе диалога когда-нибудь «всплывут» знания, не
доступные пользователю. Со знаниями,
накапливаемыми внутри миров, и со связями между мирами
поступают следующим образом. В ходе диалога
идентифицируются причины ошибок и нечеткие знания,
и, если пользователь прав, корректируются знания
внутри миров, в противном случае ошибочные знания
5 С. Осуга, Ю. Саэкн
ио
Глава 4
необходимо накапливать в модели пользователя*
Следовательно, если учитывать структуру миров и
содержащиеся в них знания, то эффективнее строить
модель пользователя как пертурбационную.
Но как же определить исходные значения в
модели пользователя при первом диалоге с ним?
Например, знания, необходимые
пользователю-учащемуся, который пришел проконсультироваться по
библиотеке программ, и эксперту по программному
обеспечению, существенно отличаются. Для этого
существуют два способа:
1) использовать собеседование, а именно: при
первой встрече с пользователем определить миры его
модели, задав несколько вопросов и получив ответы
о его потребностях;
2) сразу определить уровень пользователя,
выделив из них студентов, экспертов и детей, и установить
усредненные начальные миры пользователя.
Определив, таким образом, начальные значения
миров пользователя и впоследствии ведя с ним
диалог, постепенно строится модель пользователя,
наиболее полно отражающая уровень его понимания.
4.3.2.3. РОЛЬ МОДЕЛИ ПОЛЬЗОВАТЕЛЯ
Модель пользователя — это модель процесса диалога,
которую создает система, интерпретируя способности
и уровень понимания пользователем предмета
разговора. Следовательно, с помощью этой модели, как
и с помощью знаний самой системы, можно решать
задачи (в среде знаний пользователя) и отвечать
на вопросы. Система может применять эту модель,
чтобы:
1) создавать усредненную модель,
соответствующую уровню пользователя, о чем уже
говорилось выше;
2) при правильном создании модели решать
задачи и задавать вопросы на уровне пользователя;
т. е. объяснять ошибки пользователя;
3) быстро обнаруживать индивидуальные
различия пользователей благодаря применению моделей
пользователей в процессе идентификации ошибок.
Например: «.Это человек, который путает при вводе
Приобретение знаний и обучение в диалоге 131
английского текста буквы г и I»1) или «Это человек,
который часто делает ошибки в четырех арифмети-
ческих действиях». На первом этапе идентификации
ошибки можно проверить знания, которые
зарегистрированы в модели пользователя как знания,
наиболее часто приводящие к ошибке;
4) стимулировать взаимный инициативный диалог.
В справочных системах инициатор диалога —
пользователь, т. е. система только получает решение и
дает ответы на вопросы пользователя. При этом
в случае ошибочного или нечеткого вопроса после
идентификации этого факта с помощью модели
пользователя необходимо, чтобы инициатором диалога
стала система; например, она может указать ему:
«Вы не знаете о...». Если в системе решения задач
либо недостаточно входных данных, либо в них
обнаружено противоречие, этот факт идентифицируется
в ходе диалога с пользователем, а результаты
идентификации накапливаются в модели пользователя и
используются как справочный материал при
идентификации последующих ошибок. В системах
компьютерного обучения взаимная инициатива в диалоге
имеет гораздо большее значение, а именно: система
должна в педагогических целях указывать
пользователю на его ошибки и составлять задачи, в которых
учитываются причины этих ошибок, для того чтобы
убедиться, что пользователь понял весь материал,
С этой же целью необходимы метазнания
(называемые учебными знаниями), которые помогают
интерпретировать процесс решения задачи по модели
пользователя и вызывать действия в соответствии
с возникшей ситуацией.
Эти примеры показывают, что модель
пользователя, построенная системой в ходе диалога, дает
повод для перехвата системой инициативы в диалоге.
Диалог со сменой инициативы в системе
компьютерного обучения пониманию программы, приведенной
на рис. 4.19, а, можно посмотреть на рис. 4.19,6
1) В японском языке звук «1» отсутствует, и в словах
иностранного происхождения он заменяется на «г». — Прим, ред%
5*
132 Глава 4
program
var a,
begin
a '. =
b: -
x' =
P20403 (output);
b, x ' real;
2.5; j
2e-14;
a + b;
writeln(x)
end.
a
С. Есть вопросы?
* П. Я не могу понять смысл Р20403 в первой строке.
С. Р20403 в первой строке — это имя программы.
П. Для чего используется имя программы?
С. Хорошо. Я покажу вам страницу с объяснением
имени программы. (После вывода объяснения система
вновь возвращается к этой сцене.)
* С Есть вопросы?
П. Нет.
С. Тогда, пожалуйста, ответьте, каковы значения В и X?
П. 2е-14, 2е-11.5.
С. Ваш ответ некорректен. Каково значение В?
* П. Что означает 2е-14?
С. е-14 в выражении означает -14 степень 10, а 2е-14
означает 2, уменьшенное на е-14.
* С. Каково значение В?
П. 0.00000000000002.
С. Правильно. Вы можете вычислить значение X?
П. Да. X равно 2.50000000000002.
С. Нет. Знаете ли вы, сколько цифр содержит вещественная
переменная?
П. Нет,
С. Вещественная переменная содержит 14 цифр. Число
значащих цифр вещественной переменной — 14. Теперь укажите
значение X.
П. 2.5.
С. Хорошо. Теперь давайте решим другую задачу.
б
Рис. 4.19. а — программа для обучения; б — пример взаимного
инициативного диалога о программе а.
(С — система, П — пользователь, * помечены строки,
где меняется инициатива),
ГЛАВА 5.
ОБУЧЕНИЕ ПРИ РАСПОЗНАВАНИИ
ОБРАЗОВ
Т. Китахаси (Осакский университет)
В этой главе рассмотрены конструкции и функции
перцептрона и неокогнитрона — классических систем
с механизмом распознавания образов и функциями
параметрического обучения — аналогов системы
зрения животных. Обсуждаются современные тенденции
обработки изображений на основе описания
понятий— объектов обучения как одного из примеров
непараметрического обучения. Кроме того, приводится
пример адаптивного к среде автомата как еще один
пример непараметрического обучения несколько
другого рода и анализируется его работа.
5.1. ВВЕДЕНИЕ
Среди обучающихся систем, связанных с
распознаванием образов, прежде всего следует назвать
систему зрения животных и моделирующие ее
экспериментальные системы.' Из экспериментов Хабела и
Визела по физиологии нервной системы, объектом
которых была зрительная система кошек, стало
очевидным, что эта система простирается от сетчатки
глаз до коры головного мозга и состоит из
многослойной сети нервных волокон, а образы,
распознаваемые нервными клетками — элементами структуры
этой системы, становятся все более сложными на
каждом слое. Одновременно и параллельно с ними Розен-
блатт и Блок построили модель зрительных нервных
цепей на основе знаний о физиологии известных в то
время нервов, а также экспериментально и
теоретически изучили процесс распознавания образов и
функции обучения в такой модели. Сравнение
поведения смоделированных нервных цепей и
поведения зрительной системы животных позволило
сделать еще один шаг в так называемом структурном
134
Глава 5
исследовании, цель которого — объяснение базовой
структуры зрительной нервной системы. В данной
главе будет детально описана система, называемая
перцептроном, а также неокогнитрон, созданный по
проекту Фукусима как модель с развитой
самоорганизацией.
Неокогнитрон — это экспериментальная система,
реализованная на базе мини-компьютера, после
обучения она за несколько секунд может распознавать
знаки, написанные с помощью специального
устройства ввода. Если ограничиться только способностью
к распознаванию, то эта система может послужить
превосходной основой для создания механизмов
считывания почтовых индексов и другого подобного
применения. Более того, благодаря исследованиям
стала очевидной связь между структурой нервной
системы или подобной модельной системы и
функциями обучения и распознавания. Так, неокогнитрон
демонстрирует не только способность к
классификации по внешним признакам, как перцептрон, но и
способность к самообучению, другими словами, если
неоднократно показывать неокогнитрону один и тот
же знак до тех пор, пока реакция на него не будет
стабильной, а затем повторять этот процесс при
переходе к следующему знаку, то автоматически будет
приобретена способность к распознаванию образов.
Кроме того, благодаря добавлению цепей обратной
связи эта система может приобрести способность
к ассоциации. Это привело к новым идеям о
структуре и функциях зрительной системы животных.
Далее в процессе обучения перцептрона, неокогнит-
рона и нервной системы обнаруживаются общие
моменты— это параметрическое обучение, которое
заставляет меняться параметры связи между
элементами их структуры.
Распознавание образов и главным образом
распознавание знаков — это одна из тем исследований в
области искусственного интеллекта. В частности,
успешно ведутся исследования распознавания
предметов, связанные с необходимостью развития техники
обработки, скажем, рентгеновских снимков и
автоматизации современных технологических процессов
Обучение при распознавании образов 135
изготовления и контроля изделий; от распознавания
двумерных форм переходят к трехмерным объектам
и даже к трехмерным движущимся объектам.
Одновременно эти исследования ассимилировали идеи
описания понятий в стремительно развивающейся
инженерии знаний, причем результаты распознавания
не ограничиваются лишь установлением соответствия
с обозначениями понятий, а получили дальнейшее
развитие вплоть до требования установить связь
с описаниями структурных понятий. Уинстон1} на
примере тел простой структуры определил методы
обучения простым понятиям, и благодаря его
исследованиям проблемы обучения были возрождены и
в других областях. Об этом подробно рассказано
в гл. 9. Опубликованы сообщения о системах, которые
ориентированы на приобретение описаний понятий
через обработку черно-белых изображений. Подобные
системы можно назвать первыми системами, которые
непараметрически обучаются общим понятиям,
связанным с несколькими объектами-телами. Об этом
также будет подробно рассказано.
5.2. МОДЕЛИ СЕТИ НЕРВНЫХ ЦЕПЕЙ
Как указано в разд. 5.1, Хабел и Визел установили,
что зрительная система кошек имеет структуру,
состоящую из более чем трех слоев, от зрительного
нерва эта система простирается до зоны зрения в
коре головного мозга, а нервные клетки как
структурные элементы каждого слоя реагируют на
сложные черно-белые образы, отображающиеся на
сетчатке глаза. В отличие от подобных аналитических
методов, с помощью которых шаг за шагом
анатомически и психологически пытались объяснить
структуру зрительной нервной системы животных,
рассмотренные ниже перцептрон, когнитрон и неокогнит-
рон — это все проекты исследования тех же проблем
конструктивными методами, которые одновременно
предполагалось применить и к реальным объектам,
{) См.: Психология машинного зрения/Под ред. П. Уинсто-
на. — М.: Мир, 1978. —Прим. перев.
136
Глава 5
например для распознавания знаков, а именно:
благодаря выдвижению гипотез о неизвестных элементах
зрительной системы в дополнение к полученным в
эти годы результатам анатомических и
психологических исследований были построены модели и
проведено сравнение их работы с функциями реальной
зрительной системы, а затем через проверку
правильности или недоработки этих гипотез была уточнена
структура зрительной системы.
5.2.1. ОБУЧАЮЩАЯСЯ СИСТЕМА
С УЧИТЕЛЕМ— ПЕРЦЕПТРОН
В 1958 г. Розенблатт построил систему, которая
обучается образам и построена на основе модели
нервных цепей с трехслойной структурой, схематично
показанной на рис. 5.1, назвал ее перцептроном и дал
теоретическое обоснование ее работы. Особенность
этой системы состоит в том, что между элементами
первого и второго слоев фиксированы случайным
образом линии связи, ведущие от нескольких элементов
первого слоя к одному из элементов второго слоя и
имеющие неизменные коэффициенты связи, а гибкость
структуры обеспечивается за счет изменения
коэффициентов связей между элементами второго и третьего
слоев (от одного к нескольким). Выходы каждого
элемента имеют два значения (например, 1 и 0).
Для обучения этой системы распознаванию образов
первому слою поочередно показывают эти образы,
и для каждого из них извне указывают тот образ-
реакцию, который должен выдать третий слой, а пер-
цептрон в соответствии с заданными правилами обу-
Входная модель
•Входйой
«лои
Второй
слои
Выходной
слой
Рис, 5.1. Структура трехслойного перцептропа.
Обучение при распознавании образов 127
чения заставляют менять коэффициенты связей до
тех пор, пока не будет получена нужная реакция.
Согласно классификации по внешним признакам, это
система, обучающаяся с учителем.
1. Механизм обучения. Данный процесс можно
назвать обучением с акцентом на коррекцию ошибок,
причем коррекция коэффициентов связей выполняется
только в случаях ошибочной реакции. Коррекция
затрагивает все коэффициенты входных связей, которые
подключены к элементам с ошибочной реакцией*
Испытаны различные правила коррекции, и почти
при всех правилах обучение шло успешно. Наиболее
простое правило устанавливает следующую
зависимость между входом хц i-ro элемента, желаемым
выходом di и величиной коррекции коэффициента
связи Л:
если Хц = dh то а,ц + Д,
если xi} Ф dh то йц — Л.
В экспериментальном перцептроне первый слой
состоял из 20 X 20 = 400 элементов, второй — также
из 400, а третий — из 8 элементов. Соответствующее
устройство могло правильно распознавать заданные
буквы, показанные в определенном месте. Кроме
того, сообщалось о возможности обучения
классификации нечетных и четных цифр.
2. Система с внутренними связями. Была предложена
усовершенствованная система с еще одним слоем,
имеющим связи с первым и вторым слоями. Выходы
четвертого слоя в такой системе определяются двумя
элементами: входным набором и реакцией элементов
взаимосвязи, поэтому возникают временные
зависимости. Следовательно, предоставилась возможность
обучения не только распознаванию отдельных
образов, но и выявлению временных последовательностей
типа движения образа. При моделировании в
реальных условиях был получен следующий результат:
после того как систему научили давать одну и ту же
реакцию на некоторый образ, а также параллельный
138
Глаза 5
перенос и вращение этого образа, ее обучили
реакции на второй образ, а затем показали параллельный
перенос и вращение второго образа, при этом
наблюдалась тенденция к появлению той же реакции, что
и на. второй образ. Это, видимо, означает, что
достигнуто обучение форме движения, представленного
во времени такого, как двухмерное движение. Однако
подобный способ обучения еще недостаточно
теоретически обоснован.
3. Логические функции нервных клеток. Действие
модели нервных клеток как минимальных
конструктивных элементов перцептрона можно описать
следующим образом. Клетки первого слоя возбуждаются
или не возбуждаются в зависимости от того,
попадает ли на них свет. При возбуждении с выхода
клеток выдается сигнал 1, который достигает второго
слоя. Во втором и последующих слоях действует
следующая зависимость между входным сигналом х1%
принимающего два значения в зависимости от
возбуждения t-й клетки предыдущего слоя,
коэффициентом связи ац (между i-n клеткой и /-й клеткой
данного слоя), порогового значения 9 для /-й клетки
и ее выходом у}-:
если Yjaiixi -— 6, > О, то уj = 1;
(здесь Хц = 1 или 0);
если Yjauxi — 9/ < 0> т0 У\
дологический механизм с такой логикой называют
пороговой логикой.
Пороговая логика исследована достаточно полно.
Очевидно, что пороговые элементы с наиболее
простой структурой можно реализовать с помощью
логических элементов И, ИЛИ, а также, если допустить
отрицательные значения коэффициентов связи,
элемента НЕ. Известно также, что с помощью
комбинации таких элементов можно реализовать
произвольную логику. Кроме того, каждый элемент имеет
запаздывание, используя которое можно реализовать
функцию запоминания. Следовательно, можно со-
Обучение при распознавании образов 139
здать арифметическо-логическое устройство
компьютеров по аналогии с сетью нервных цепей.
Рассмотрим логические функции отдельной клетки
геометрически. Если число входов в клетку равно п9
а входные значения — только 1 или 0, то множество
входных образов образует м-мерный единичный куб.
Если мы распределим по вершинам этого куба
образы, которые должны возбуждать, и образы,
которые не должны возбуждать клетки, так, чтобы при
этом множество образов можно было разбить на 2
подмножества с помощью n-мерного сечения
п
которое определяется коэффициентами связи ац и
пороговыми значениями 0;, т. е. так, чтобы оба
подмножества были выпуклыми, то клетки могут
осуществлять распознавание. Если на процесс обучения пер-
цептрона взглянуть как на процесс возбуждения
клеток, то видно, что при изменении значений а-ц в
соответствии с реакцией на входной образ меняется
наклон такого сечения. Перцептрон и описанный далее
неокогнитрон — это механизмы, способные к такому
параметрическому обучению.
О способности перцептрона к распознаванию
образов подробно рассказано в книге Минского и Пей*
перта «Перцептроны. Введение в вычислительную
геометрию», изданному Массачусетским
технологическим институтом, США, в 1969 г.1)
5.2.2. СИСТЕМА, ОБУЧАЮЩАЯСЯ
БЕЗ УЧИТЕЛЯ — НЕОКОГНИТРОН
Метод, при котором одновременно с входным
образом показывается результат его распознавания, так
как при обучении трехслойного перцептрона, назьь
вается методом обучения «с учителем». В отличие от
этого метода обучение, при котором выходная
реакция при распознавании каждого образа в процессе
1) Имеется перевод: Минский М, Пейперт С.
..Перцептроны.—М.: Мир, 1971. — Прим. персе.
140
Глава 5
обучения анализируется автономно, называется
обучением «без учителя». Предложено несколько
моделей сетей нервных цепей (с многослойной
структурой), которые обучаются без учителя. В целом их
структура аналогична структуре перцептрона.
Рассмотрим один из примеров — неокогнитрон.
Поскольку методы обучения перцептрона и не-
окогнитрона различны, то различны и правила их
обучения, и модели нервных клеток как основных
элементов (рис. 5.2), и структура сети нервных
цепей. Основные отличия неокогнитрона заключаются
в следующем:
1) реакция клеток не дискретна (два значения),
а непрерывна;
2) в качестве принципа обучения использована
«гипотеза обнаружения максимальных значений». Ее
можно сформулировать следующим образом:
«Усиливаются сигналы клеток, локально показывающих
максимальный выход. Правило усиления:
коэффициенты связей клеток, у которых входные сигналы,
поступающие от клеток с максимальным выходом, не
равны нулю, увеличиваются на величину, сравнимую
с входным значением»;
3) введены контрольные клетки, это клетки с
отрицательными коэффициентами связей.
Приведенная выше гипотеза исходит из
предпосылки, что модель клетки имеет вид, показанный на
рис. 5.2, причем свойства 1 и 2 неразделимы. Следуя
правилу обучения 2, усиление затрагивает все
элементы, которые случайно дают сильную реакцию на
некоторый входной образ, т. е. впоследствии они
начнут избирательно реагировать на этот образ, бла-
Возбужр,аемыв(
входы
Управляющие
.К
w=(pi>]
*-о Выход
Рис. 5.2. Модель нервной клетки
«рМ={о 5<
Аналоговый
пороговый элемент: /че,п) = е-п
' ^v*4-' i Шунтирующий 14-е *
^С? ] управляющий элемент. rtв/п^~Y+^[","*
Обучение при распознавании образов 141
годаря чему реализуется независимое обучение без
учителя. В реальном неокогнитроне введено
несколько дополнительных усилений, в частности усиливаются
не только элементы с максимальным выходом, но и
группа элементов в окрестности последних.
И еще об отличиях в структуре: неокогнитрон по
сравнению с перцептроном имеет много слоев, и
главное отличие состоит в том, что после слоев с
изменяемыми коэффициентами связи (слои клеток 5,
или просто — слои S), расположены дополнительные
слои с фиксированными связями (слои клеток С, или
слои С). Фиксированные связи, как показано на
рис. 5.3, ведут к определенным участкам слоя S и
устанавливают связь типа ИЛИ, при которой
возбуждение хотя бы одного из элементов слоя S приводит
к возбуждению элементов слоя С.
Кстати, в неокогнитроне, так же как и в перцепт-
роне, соединения между входным слоем и следующего
за ним слоем Usi отличаются от соединения между
другими слоями, это не гибкие соединения, а, если
можно так сказать, искусственные. Другими словами,
элементы слоя USl соединяются так, чтобы они
реагировали на несколько заранее подобранных базовых
образов на входном слое (Т-образные образы на
рис. 5.4), причем элементы, реагирующие на
конкретный образ, локализуются и создают группу
в слое Usu Элементы слоя UC\ — слоя С,
примыкающего к слою Usu— соединяются в соответствии с
правилами соединения слоев 5 и С, приведенными
выше, поэтому каждый элемент слоя Uci также
реагирует на любой из базовых образов из некоторой
области входного слоя. Вследствие такой структуры
неокогнитрону присущи допуски на смещение
образов.
Второй слой 5 и последующие слои имеют
структуру, описанную в начале раздела, они
самоорганизуются по правилам обучения, поэтому
допуски на смещение усиливаются с каждым слоем.
Одновременно гарантируется, что неокогнитрон
может обучаться комбинации базовых образов,
образующих целый образ для обучения, а также сможет
142
Глава 5
правильно отреагировать на их смещение
относительно друг друга.
Если ранее извлекались пространственные
особенности, которые возбуждаемые элементы строили в
зависимости от обучаемого образа, то эти слои,
содержащие контрольные элементы 3, уже играют
новую роль: они извлекают особенности, характерные
для участков вне образа.
Авторы неокогнитрона (Фукусима и Миякэ)
показали, что благодаря введению цепей обратной
связи в соответствующие места двух систем можно
реализовать процесс автореакции с ассоциативными
функциями. Другими словами, экспериментально
установлено, что если сразу показать «кучу» образов,
которым система уже обучена, то будут выданы
непрерывно изменяющиеся образы, а среди них
последовательно один за другим будут показаны все
образы из этой кучи. Аналогичные эксперименты так-
Рис. 5.3. Структура неокогнитрона.
Рис. 5.4. Фиксированные связи между входным и первым
слоями неокогнитрона.
Обучение при распознавании образов 143
же показали, что даже при вводе части запомненных
образов можно восстановить все изображение. Таким
образом, очевидно, что неокогнитрон обладает
ассоциативными функциями.
5.2.3. НОВОЕ НАПРАВЛЕНИЕ — КОННЕКТИОНИСТ
В последнее время, когда стала возможной
реализация крупных параллельных систем, обусловленная
развитием интегральной технологии, был предложен
проект системы, аналогичной перцептрону, под
названием коннектионист 1\ Как отмечено выше, перцептрон
и неокогнитрон — это модели зрительной системы,
в основном выполняющие распознавание образов,
тогда как коннектионист создан с целью
всеобъемлющей обработки информации вплоть до
символьной обработки. Распознавание образов в этой системе
предполагалось реализовать с использованием
элементов, похожих на нервные клетки. Для обработки
на символьном уровне предложен набор различных
базовых схем, в частности правило вида «если-то»
реализуется с помощью двухкаскадной схемы И-ИЛИ,
реализованы схемы выбора максимального значения,
схемы просмотра таблиц и другие схемы. Путем
комбинации этих схем предполагалось встраивать в
систему разнообразные алгоритмы, таким образом
были предложены идеи, отсутствующие у перцеп-
трона. Даже в распознавании образов есть новые
идеи: в структуру цепей введено понятие обработки
сверху-вниз, к элементам для распознавания букв
добавлены входы обратной связи, указывающие
связность последовательности букв в слове.
5.3. ОБУЧЕНИЕ ПОНЯТИЯМ
ПО ИЗОБРАЖЕНИЯМ
Об обучении понятиям подробно рассказано в
разд. 5.1. Предложенные до сих пор методы обучения
понятиям связаны с понятиями объектов, а
идентификация этих понятий осуществлялась через
показ нескольких конкретных физических объектов,
1} От английского слова connectionist (связист),™-Прим*
пере в,
144
Глава 5
принадлежащих к данной категории (понятию), и из*
влечение общего в отдельных частях и структуре
объектов. Такое обучение отличается от параметриче*
ского обучения, рассмотренного выше.
Идея на первый взгляд проста, однако прежде
всего не понятно, возможно ли определение понятия
через показ каких-либо предметов? Кроме того,
возникает проблема: следует ли при обучении
отбрасывать все элементы, которые с виду не имеют ничего
общего, и не будут ли они иметь что-то общее в
случае некоторых отличий на следующих этапах
обучения? На эти вопросы в проекте обучения понятиям
дан однозначный ответ. Уинстон предложил ввести
понятие «почти-то». Это пример, не принадлежащий
к той категории, которой обучают, из-за некоторых
несоответствий, например отсутствия одной из
связей между частями объекта. Важность понятия
«почти-то» состоит в том, что с его помощью можно
установить свойства, содержащиеся во всех
подтверждающих их примерах, но не включенные при онре-
делении «почти-того» объекта, другими словами,
свойства, которые обязательно должны
присутствовать при определении данного понятия.
5.3.1. ОТ ЧЕРНО-БЕЛОГО ИЗОБРАЖЕНИЯ
К ОПИСАНИЮ ПОНЯТИЯ
Теория обучения Уинстона1) возникла из описания
заданных понятий в виде несложных контурных
рисунков, которые были придуманы всего лишь для
облегчения понимания человеком содержания
описания понятия, а в результате Уинстон пришел к
обучению понятия с помощью их графического
представления, данного вместе с рисунком. Изображение и
рисунки — самое подходящее средство с точки
зрения человека не только для того, чтобы дать примеры,
но и для представления и понимания предметов.
Поэтому можно ожидать их широкого использования
как одной из форм ввода-вывода в системах обработ-
*> Уинстон Г. П. Построение структурных понятий по
примерам.—В кн.: Психология машинного зрения, -—М.: Мир,
1978. -«- Прим, перев%
Обучение при распознавании образов 145
ки информации. Однако исследование такого
применения изображений — дело будущего. Бреди,
используя молоток как пример входного изображения,
указал метод его разделения на рукоятку и головку,
определения в результате обработки изображения
соединительных связей между ними и символьного
представления структуры молотка. Применяя этот
метод к трем изображениям молотка, он получил
соответствующие описания понятия, сформировал
некое обобщенное описание из общих частей, указал
процесс получения символьного описания понятия
по примерам изображений и тем самым получил
ответы на указанные в конце предыдущего раздела
проблемы.
Прежде при распознавании образов сначала
выполняли распознавание объекта по его внешним
формам — контуру, плоскостям и т. п. или по его
особенностям, а затем устанавливали соответствие с
понятием. Позже стали использовать знания о
сопоставлении образов (обработка сверху-вниз, управление по
инициативе моделей). Классический метод —
предварительное ограничение класса объектов, которые
предстоит распознавать, запоминание внутри системы
их моделей и распознавание объектов путем выбора
способа и процедуры обработки изображения с
использованием таких моделей. Система ACRONYM,
разработанная Бруксом и Бинфордом в Станфорд-
ском университете (США),— типичная система,
использующая этот метод. Пример модели в этой
системе приведен на рис. 5.5. Если распознавание
прошло успешно, то с помощью модели, заложенной
в систему, и трехмерной структуры объекта можно
Рис, 5.5» Модель в систем ACRONYM (цилиндрическое пред*
ставление).
146
Глава 5
одновременно определить положение и угол зрения
объекта на изображении. Этот метод применим не
только к распознаванию простых предметов, он
может служить основой для различной обработки,
следующей за распознаванием образа.
Упомянутые выше исследования Бреди — это шаг
назад по сравнению с системой ACRONYM в том
смысле, что они ограничивались пониманием
двухмерной структуры, а в последней системе внутренняя
структура предмета, заранее заданная в виде
модели, определялась из изображения путем анализа
снизу-вверх, и в принципе не стоит считать
недостатком тот факт, что класс объектов обработки
ограничивался встроенными моделями. Системы, которые
позволяют закодировать указанные им объекты до
уровня, позволяющего использовать их для обучения
и выводов, играют важную роль, поскольку они
связывают существующие методы обработки
изображений с методами искусственного интеллекта.
Рассмотрим далее суть исследований Бреди.
1. Анализ структуры предмета на основе его
изображения. Для того чтобы получить описание
нескольких предметов, принадлежащих одной
категории по их черно-белым изображениям, необходимо
прежде всего уметь извлекать предметы из заданного
изображения. Однако выделить их из общей сцены
крайне сложно, поэтому Бреди использует лишь
изображения, включающие только изучаемые объекты.
При анализе структуры предмета на первом этапе
необходимо разбить его на части, имеющие четкие
формы и функции. Если удастся получить подобное
разбиение, то второй этап — получение абстрактного
описания понятия как описания взаимосвязей между
частями — уже сравнительно простая операция.
Бреди, Асада и Коннел для первого этапа ввели
понятие сглаженной локальной симметрии, провели
разбиение на частичные структуры, а на втором
этапе использовали взаимосвязи полученных структур и
создали окончательное представление в виде сети.
Если с помощью такой обработки получить описание
структур из черно-белого изображения нескольких
Обучение при распознавании образов 147
объектов, представляющих одно и то же понятие, то
можно применить указанный выше метод обучения
понятию Уинстона (см. рис. 5.9, 5.10).
2. Сглаженная локальная симметрия (СЛС).
Понятие СЛС — это интересное предложение для анализа
структуры предмета на основе его формы. Если
локальная или глобальная симметрии предмета
отражают особенности его конструкции, то это повышает
эффективность анализа структуры.
Определение 5.1. Если внешние нормали (или
касательные) к двум точкам контура и отрезок,
соединяющий эти точки, имеют равные смежные углы, то
говорят, что контур между этими двумя точками
имеет СЛС (рис. 5.6).
Примеры СЛС всем известных предметов
приведены на рис. 5.7. Выявление СЛС для контуров,
полученных при обработке реальных изображений,
весьма сложная операция из-за ошибок в выделении
форм и влияния помех. Поэтому на предварительном
этапе обработки необходимо сглаживание, т. е.
глобальная обработка форм.
Понятие СЛС очень похоже на геометрическое
место центров вписанных окружностей, которое
прежде использовали для выделения центральной линии
предмета, но между ними есть и различия (рис. 5.8).
3. Выделение частичной структуры. Для изучения
особенностей СЛС введем два определения.
«^s
<F^t
Рис. 5.7, СЛС в моделях,
В2«*
Рис. 5.6. Определение СЛС.
148
Глава 5
Определение 5.2. Покрытием называется часть
контура, образованная линиями продолжения
СЛС.
Определение 5.3. Вложение между линиями
продолжения СЛС определяется через вложение между
покрытиями.
С помощью вложений определяется
полуупорядоченная связь между фрагментами с СЛС. СЛС с
большим покрытием можно рассматривать как
глобальную симметрию, поэтому максимальные
элементы полуупорядоченного множества вложений
являются кандидатами на частичную структуру. Такая
структура образуется из элементов, начиная с
элемента с максимальным покрытием; процесс
образования структур прекращается, когда будет покрыт
весь контур.
4. Взаимосвязи между подструктурами. Взаимосвязи
между подструктурами, полученными в процессе
указанной выше обработки, образуются в зависимости
от наличия или отсутствия соединений, эта
взаимосвязь имеет два атрибута. По внешнему виду такие
соединения можно разбить на соединения — сторона-
конец и конец-конец. Первое соединение — это
соединение конца одной СЛС с серединой другой СЛС.
В случае соединения сторона-конец используются два
параметра, качественно выражающие вид
соединения: угол пересечения двух СЛС и расположение
точки соединения, а в случае соединения
конец-конец — только угол пересечения. Как видно из рис. 5.9,
на практике разбиение можно выполнять и по форме
концевой части.
5. Отношения соединений частичных подструктур и
описание понятия. Если каждую подструктуру
представить вершиной, а отношение соединения —
ориентированной ветвью, пометив ее параметрами
соединения, то получим представление в виде сети.
Пример представления приведен на рис. 5.9. Из этого
рисунка видно, что две части предмета изначально и,
может быть, слишком поспешно поименованы как
головка и рукоятка, но при последующем тщательном
Обучение при распознавании образов
Е
Рис. 5.8. Центральные линии, а — геометрическое место центров
вписанных окружностей; б — СЛС.
ЩЮПвТОК-1
изогнутый Имеет
Прямой
удлиненный
средней-
длины ~
отделяю* прямой
щиис" f уамнфнныЪ
Сторона
быпуклыв
ровны* 1/^~~~7"Х***^\
(сторона-t конец тупой сторона-2 сторонл— сторона-} конец ровный сторонИ-4
спрэва-от
слева-от
гконец-2
/ \ сторона
конец роСный Р°0ный "V^T^^/ I N ьн й°6НШ
ровный расположен-в-центоаКО"е</ <М10й Р° Ь'й
сторШ
расположен-в-центра
Рис. 5,9. Описание понятия, выведенное из одного молотка.
150
Глава 5
анализе структуры предмета на изображении
становится очевидно, что такое сетевое представление
понятия имеет глубокий смысл.
5.3.2. ОБУЧЕНИЕ ПОНЯТИЮ
Если выполнить обработку, рассмотренную выше,
для нескольких примеров, принадлежащих одному
понятию, то окажется, что полученные сетевые
представления имеют много общего в своей основной
структуре. Коннелл и Бреди, используя этот метод
при обучении понятию только по подтверждающим
примерам, вывели представление понятия «молоток»
(рис. 5.10).
К этим исследованиям еще только приступили, и
едва ли методы разбиения изображения на элементы
ill
^^
ID
молоток-!
отделяющийся
отделяющийся прямой
удлиненный
длинный
\слвеа-от спрааа-о^
-конец-2
7 \
нонец ровный
сторон*
ровный Конец роОиый
Paz, 5.10. Описание понятия, выведенное из трех молотков.
Обучение при распознавании образов 151
ограничиваются только СЛС, нужно разрабатывать
и другие методы. Например, предложены методы,
которые также используют локальную симметрию.
В дальнейшем, видимо, объектами разбиения будут
трехмерные рисунки.
5.4. СИСТЕМЫ, АДАПТИРУЮЩИЕСЯ
К СРЕДЕ
Мир объектов обучения разнообразен, и кроме
области, в которой объекты на этапах,
предшествующих пониманию, можно представить в виде
конструктивной модели, строго описывающей структуру об-
екта, существуют и миры, объекты в которых суть
абстрактные данные. В этом разделе мы рассмотрим
область так называемой теории игр и ознакомимся
с дискуссией о связи структуры и действия. Цетлин 1)
поместил систему в среду, характеризующуюся
вероятностной реакцией, провел анализ связи ее
структуры и поведения и рассмотрел с позиции теории
игр адаптацию системы к такой среде. В качестве
модели среды он выбрал случайную информацию, т. е,
рассматривал систему, которая возвращает ответ
случайным образом в зависимости от своей реакции, и,
противопоставив такой среде конечный автомат как
адаптирующуюся к среде систему, впервые
формализовал эту проблему. Позже Крылов 2), Фу и Ли, Та-
кэути и Китахаси и другие исследователи попытались
найти обобщение путем превращения среды в
нестационарную, заменой обучающейся системы па
изоморфные автоматы, и сформулировали в общем
случае эту проблему как игры между несколькими
людьми. В каждом случае предлагались
усовершенствованные автоматы, представляющие собой
обучающиеся системы, и изучалось их поведение. Ниже
кратко рассмотрим эти исследования.
1} Цетлин М. Л. О поведении конечных автоматов в
случайной среде. — Автоматика и телемеханика, 1961, Т. 22, № 10.
2> Крылов В. Я., Цетлин М. Л. Игры между автоматами,—
Автоматика и телемеханика, 1963, Т. 24, № 7.
152 Глава 5
8.4.1. АВТОМАТЫ, АДАПТИРУЮЩИЕСЯ К СРЕДЕ
Основы поведения автоматов, адаптирующихся к
среде, можно представить следующим образом.
Автомат имеет несколько цепочек состояний, отвечающих
стратегии адаптации, и если он сталкивается с
ситуацией (/ = 0), к которой стремится адаптироваться,
•"о переходит к состоянию в направлении, из которого
эта стратегия не позволяет выбраться, и, наоборот,
если в качестве реакции возвращается ситуация
(/ = 1), к которой не следует адаптироваться, то
осуществляется переход к состоянию в направлении, в
котором эту стратегию можно изменить.
Цетлин предложил автомат с наиболее простой
структурой, удовлетворяющей этим условиям,
который имеет механизм смены состояний (рис. 5.11).
Назовем его автоматом А\.
Такэути и Китахаси предложили несколько
вероятностных автоматов со структурой, такой, что в
ситуации, к которой нужно адаптироваться, стратегию
изменить чуть более трудно, чем в автомате Л1, а
функции адаптации более общие. Один из таких
автоматов показан на рис. 5.12, назовем его
автоматом ЛИ.
Фу и Ли предложили автомат Л1П, отличающийся
от Л1, как показано на рис. 5.13, только переходами
из состояния в состояние при / = 0, его поведение
лучше, чем у Л1. Ознакомимся с некоторыми типовыми
рассуждениями.
% Г /Р %г Г /¦"
«.•.-J—О5*" О—--- *~--*»05A-li О*-—-
Рис, 5.11, Схема переходов из состояния в состояние
адаптирующегося к среде автомата Л1,
Обучение при распознавании образов
15*
%,,
••v-v>< *tifc «A
«a+fc-l
Рис, 6,12. Схема переходов из состояния в состояние автомата
All: в —случай / = 0; б —случай / «= 1,
JN0 ^^
Рис. 5.13. Схема переходов из состояния в состояние автомата
А\\\\ при / = 0.
154
Глава 5
5.4.1.1. СТРУКТУРА И ПОВЕДЕНИЕ АВТОМАТОВ,
АДАПТИРУЮЩИХСЯ К СРЕДЕ
В отличие от случайной среды, введенной Цетлиным,
адаптируемость к среде автомата ЛИ, предложенного
Такэути и Такэхаси, означает выбор оптимальной
стратегии в смысле минимизации ожидаемого
значения потерь. Рассмотрим это более подробно.
1. Структура автомата. В случайной среде С с
вероятностью pi в ответ на выходной сигнал О/
автомата, подключенного к этой среде, подается отклик
/ = 1 (для автомата это вход, указывающий потери)
и с вероятностью qt = 1 — /?, — отклик / = 0
(прибыль для автомата).
Автомат ЛИ— это конечный вероятностный
автомат, определяемый следующим образом:
автомат ЛИ; ({5}, {/}, {О}, Ф, /);
S(/+1) = <P(S@, /(/+1));
O@ = /(S@).
Здесь S(t)—внутреннее состояние автомата в
момент t\ I(t)—вход автомата в момент / (выход
среды С); Ф — функция перехода из состояния
в состояние {S} X {/} -*• {S}; O(t) — выход автомата
в момент /, т. е. его стратегия; / — функция выхода
{S} - {О}.
2. Анализ поведения автомата. Пусть для простоты
рассуждений число стратегий равно 2, а цепочки
состояний, представляющих стратегии, состоят из п
состояний. Если подключить входы и выходы автомата
ЛИ к случайной среде С, как показано на рис. 5.14,
то переходы из состояния в состояние в этом
автомате можно представить таблицей Р\\ приведенной
на рис. 5.15.
Это вероятностная таблица, поэтому поведение
системы, которое можно представить как взаимные
действия случайной среды С и автомата ЛИ, можно
описать с помощью конечного марковского процесса.
В целом можно считать, что вся система образует
самоконтролирующий автомат.
Обучение при распознавании образов 155
Следовательно, если я,-/ — вероятность того, что
внутреннее состояние АН в стационарном режиме
равно 5//, то вектор состояний я = (яи, пи, ..., яы,
Я2ь ..., Я2п) имеет следующие свойства. Если обозна-
Ш
Случайная среда С
Автомат А]*
Alrt
Рис. 5,14, Система, состоящая из случайной среды и автомата.
Sn Sn 5i3—«•
Snt ч{ vl о
Sn
S22
'Sin ^2i $22"
•0 0
4{ 0 Vl
0 4i' 0. ft'
4Л 6
\ \ \ • I
%/V\; о
О д/ 0 0 0»»»'
«а Я3' 0"
V 0 J>a##
9 92' 0./'
0
• 0 vl
— 0 p2' 0
где, vir-biPivb24t
Vi:=zl'-V'r*iPi+a24t
4t ' 0 pi
Рис. 5.15. Таблица переходов Pl2l для автомата ЛИ.
156
Глава 5
чить р\ = bxpt + b2qif q\ =* 1 - р\ = a{pi + a2qt (/=1, 2),
го из соотношений
тс = пР\1
получим следующую систему уравнений
относительно лц:
пп = я\ (ян + я12); я21 = ?2 (я21 + я22);
пи = Р\пц-\ + Я'Рц+1? я2/ = ^я2/-1 + ^2/ + р
ят = Р1я|Я-1 + ^«ai! я2« = Ргя2«-1 + ^2Я1Л-
Если допустить, что решение есть пи = а[~1, я2/=»
= а^", то для щ/, П2/ в этой системе уравнений
получим
A-р;)а*-а, + />; = 0(/=1. 2).
Разложив на множители, получим корни этого
уравнения
__ Pi __,
ап—~ 7» а/2—*•
Следовательно, считая Ки Li произвольными
постоянными, можно определить общее решение
2
в виде
При /=1 получим L,==0 (/=1, 2), из выражений
для яд и я/я определим значения Ki, а ожидаемое
значение потерь в нормальном состоянии р(АЩ
Обучение при распознавании образов 157
можно задать следующей формулой:
у Pi [Pi) -W
P(AU) =4Li^
i ViY-WtY
fcl(p'i)n p't-i'i
3. Гарантия адаптируемости, В соответствии со
структурой ЛИ переход из состояния в состояние в случае
/ = 0 следует выполнять в направлении,
сохраняющем текущую стратегию, а в случае / = 1 —
наоборот. Следовательно, справедлива следующая
гипотеза:
Ь\ > Ь2.
В действительности, если Ь\ > Ь2у то справедливо
следующее соотношение между р\ и pt\
Р\ = Pib\ + ? А = Pi (b\ — h) + К
Ь\ и b2— положительные постоянные, по
предположению Ъ\ — Ь2 > 0, поэтому если
min {Pi} = Рй9
то соответствующая им вероятность р'а равна
min{p'}. Справедливо также обратное соотношение.
Если, используя эти соотношения,
минимизировать потери ЛИ, то, в результате мы придем к самой
длинной из стратегий, в соответствии с которой
существует наименьшее число состояний, к которым не
следует адаптироваться.
Если длины п цепочек состояний, представляющих
каждую стратегию, имеют предел, то при min{p/} <i
< 1/2 получим
lim р (ЛИ) = min {/?'}.
При этом из формул для р\, рр q( имеем
P'i — у== P*bi + 4fi2 — у
= Pi(bl - j) + <li{b2- j)>
158
Глаза 5
поэтому если Ь{ < 1/2, то, как правило, независимо
от значения pt справедливо р\ < 1/2. Следовательно,
если автомат АН имеет структуру, удовлетворяющую
условию
^>b{>b2>Qy
то независимо от ограничений на параметры
случайной среды ожидаемое значение потери автомата All
обеспечивает стратегию минимизации потерь. А это
означает, что вероятность выбора этой стратегии
равна 1.
В автомате Л1, предложенном Цетлиным, для
выбора оптимальной стратегии поведения в случайной
среде в указанном выше смысле придется вводить
ограничение pi < 1/2. Таким образом, можно
считать, что All обладает более совершенной
способностью к адаптации, чем А1.
Этот вывод, приведенный для двух стратегий,
можно распространить и на общий случай.
4. Скорость адаптации. Цетлин, Фу и Ли предложили
аналогичные идеи адаптации к среде, но для
определения скорости адаптации написали программы
моделирования автоматов на компьютерах. Такэути и
Китахаси показали, что эту скорость можно
количественно оценить путем введения производящей
функции. И в этом смысле АН имеет лучшие
характеристики.
5.4.2. ДРУГИЕ ИДЕИ
До сих пор предполагалось, что случайная среда как
объект изучения была стационарной, хотя изучается
также адаптируемость автоматов, находящихся в
нестационарной среде. Кроме того, Цетлин и Крылов
сформулировали проблему игр с нулевой суммой
между двумя автоматами. Чандрасекаран и Шен
ввели изменения в структуру автомата. Однако в
любом случае с точки зрения структуры поведение
автоматов приводит к состоянию, не имеющему
отношения к значениям фон Неймана в теории игр.
Обучение при распознавании образов 159
Усовершенствование структуры автоматов,
приведенное Крыловым, Фу и Ли, Такэути и Китахаси, как
описано в предыдущем разделе, привело к
улучшению их поведения в случайной среде. Одновременно
было показано, что аналитически можно указать ряд
автоматов, ожидаемое значение прибыли для
которых в момент стационарного состояния при игре с
нулевой суммой двух лиц совпадает со значением фон
Неймана.
Выше была рассмотрена адаптивность при
заданной структуре. Кроме того, было изучено применение
в процессе адаптации различных структурных
элементов и предложены идеи фиксации в механизме
адаптации тех элементов, которые дают наилучшие
результаты. Это так называемая теория развивающихся
автоматов.
ГЛАВА 6.
ПРИОБРЕТЕНИЕ ЗНАНИЙ.
ХРАНЯЩИХСЯ В БАЗАХ ДАННЫХ
Ю. Танака (Университет Хоккайдо)
Приобретение знаний, хранящихся в базах данных,
осуществляется в процессе обновления данных
пользователем. Но если такое обновление оставить без
внимания, то может, скажем, оказаться, что возраст
человека 500 лет, либо появятся два студента с одним
номером зачетки, либо возникнет избыточность, либо
будет неверным содержание базы данных. Для того
чтобы предотвратить это, необходимо избегать
нежелательных изменений. В данной главе прежде всего
рассмотрим базы данных, на примерах объясним
термин «запрос по образцу» (ЗПО) в языке
манипуляции данными, поясним, как записывать с помощью
ЗПО ограничения для исключения нежелательных
обновлений, прокомментируем проблемы
предотвращения изменений, ведущих к противоречиям и
избыточности, проблемы обновления с использованием
неполной информации и другие проблемы.
6.1. БАЗЫ ДАННЫХ И ЯЗЫК
МАНИПУЛИРОВАНИЯ ДАННЫМИ
6.1.1. БАЗЫ ДАННЫХ
Базы данных — это средство для упорядочивания
взаимосвязанной информации и унификации
управления ее хранением. Пользователь баз данных может
либо получать информацию, удовлетворяющую
некоторым условиям, либо добавлять новую информацию.
Основной элемент информации, хранящейся в базе
данных, называется записью. Каждая запись имеет
несколько атрибутов и соответствующих им значений.
Пример: {«имя>, Ямада Таро), ((место жительства),
префектура ОО, город ЛЛ, район XX,
квартал , номер дома ++)}• Эта запись с атрибу-
Приобретение знаний, хранящихся в базах данных 161
тзми <имя> и (место жительства), она содержит
информацию о том, что Ямада Таро живет в доме
номер + + "т. д.
Про записи с одним и тем же множеством данных
и однотипной информации говорят, что они имеют
один формат. Множество записей с одним форматом
называют файлом. Множество файлов называют
базой данных. В модели отношений, являющейся одним
из способов представления баз данных 1\ записи
называют кортежами, а файлы — отношениями. На
рис. 6.1 приведен пример базы данных. Каждое
отношение на этом рисунке представлено в виде таблицы,
каждая строка которой — запись или кортеж, а
колонки — атрибуты. База данных определяется как
множество отношений.
Операция извлечения различной специфичной
информации из базы данных называется поиском. В
модели отношений для поиска определяются операции
выделения части таблицы, операции создания носой
таблицы через слияние таблиц и другие операции
добавления в базу данных новой информации,
операции изменения старой информации, существующей в
базе данных, или ее исключения, последние операции
называют обновлением. Создают язык
манипулирования данными, с помощью которого можно свободно
описывать поиск и обновление в системе баз данных
и указывать системе управления базами данных,
какие операции выполнять^ Ознакомимся далее с
запросами по образцу как одним из таких языков.
6.1.2. ЗАПРОС ПО ОБРАЗЦУ (ЗПО)
На рис. 6.2, а приведен пример описания на языке
ЗПО поиска в базе данных на рис. 6.1. Используя
шаблон отношений, как в этом примере на языке
ЗПО, можно описать поиск и обновление. В графе
<имя> шаблона вписано П. Танака, в графе (место
рождения) — Кусиро2). «П.» означать «печатать»,
т. е. следует выдать на принтер все значения колонки
1) Речь идет о реляционных базах данных. — Прим. персе.
2) Город на острове Хоккайдо. — Прим. персе.
6 С. Осуга, Ю. Саэки
162
Глава б
<имя> в кортежах, полученных в результате поиска.
Слова Танака и Кусиро подразумевают следующее
условие: если в колонке <имя> записано Танака, то
в графе (место рождения) этой же записи должно
быть Кусиро. Подчеркивание фамилии Танака
означает «например», это не только условие <имя> =
Танака, но и условие «если в графе (имя), например,
стоит Танака, то эта запись удовлетворяет такому-то
и такому-то условиям»; таким образом, Танака
играет роль переменной. Кусиро здесь не подчеркнуто,
что соответствует условию «(место рождения) —
Кусиро».
Запись «П.» не в графе <имя>, а под названием
отношения, как на рис. 6.2,6, означает вывод всех
атрибутов. На рис. 6.3, а в графе (возраст) записано
«>20». Это означает: получить только кортежи,
в графе (возраст) которых значение больше 20. На
рис. 6.3,6 в одной строке с П. Танака в графе (ме-
{Студенты |
L. mmmwJ
Имя
Судзуки
Ямада
Я мзда
Накамура
[Накамура
Накамура
Сатй
Сато
Хобби I
Теннис |
Бейсбол I
Теннис 1
Настольный |
теннис 1
Теннис |
бейсбол
Теннис
бейсбол
Студенты
Имя
Судзуки
Ямада
Накамура
Танака
; Сато
Возраст
19
20
23
22
22
Место 1
рождения|
Иокогама
Кусира
Кобэ
Киото
Киото
Рис. 6.1, База данных^
Студенты
Имя
П Танака
Возраст
Место
рождения
Кусиро
Студенты
П.
Имя
Возраст
Место[
рождения f
Кусиро 1
& 5
Рис о 2. Поиск в базе данных на рис. 6.1: а — «Выдаше имена
студглтов, родившихся в Кусиро»; б — «Выдайте записи о сту«
дентах, родившихся в Кусиро».
Приобретение знаний, хранящихся в базах данных 163
сто рождения) указано Кусиро, а в одной строке с
П. Накамура в графе (возраст) указано «>20». Это
поиск студентов, родившихся в Кусиро и/или
имеющих возраст больше 20 лет. На рис. 6.3,6 записаны две
строки: (П. Танака, бейсбол) и (П. Танака, теннис).
Это запрос па поиск людей, интересующихся
одновременно бейсболом и теннисом.
На рис. 6.4, а использованы шаблоны двух
отношений и запелнены две графы: графа <имя>
отношения «студенты», в которой записано Танака, и это же
имя записано в графе (имя) отношения «хобби». Так
обозначается поиск по двум отношениям: некто
имеет, например, фамилию Танака и возраст больше
20 лет, требуется найти все имена и хобби. На
рис. 6.4,6 использован знак «с—1» (отрицание), это
поиск имен, возраста и мест рождения всех
студентов, не интересующихся бейсболом.
На рис. 6.5, а использована переменная ВСЕ
в значении ВСЕХ Такая запись во второй строке
означает перечень всех хобби Танака. А эта же
запись в первой строке указывает вывод имен всех
студентов, имеющих такое же хобби, как в этом
перечне. На рис. 6.5,6 запись ВСЕ.Х, относящаяся
к Накамура в примере а, заменена на набор «ВСЕ.Х
и точка». Эта точка указывает, что Накамура может
иметь хобби. Следовательно, будет идти поиск имен
студентов, имеющих по крайней мере все те же
хобби, что и Танака, включая самого Танака.
В качестве переменных для выбора значений типа
ВСЕ.Х можно использовать СУМ (сумма), СРД
(среднее), МАК (максимум), МИН (минимум) КЛЧ
(количество) и другие. На рис. 6.6, а дан пример
использования КЛЧ, это запрос о количестве хобби у
Танака. На рис. 6.6,6 — пример использования
переменной УН (уникум), исключающей дубликатные
значения из множества значений, это запрос о
количестве всех хобби в базе данных.
Операции, связанные со вставкой, удалением или
заменой записей в некотором отношении выполняются
при указании в графе с названием отношения отме-
6*
164
Глаза 6
j Студенты
ИУ|Я
П Тагзка
Всзраст
>20
Место
рождения
Студенты
Имя
П.Танака
П.Иакзм/ра
Возраст
>20
Место j
рождения
Кусиро
, Хобби
И «л я
П.Точака
П.Танака
Хобби
Бейсбол
Теннис
Рис. 6 3. Поиск в базе данных на pic. 6.1: а — «Выдайте имена
студсчтов старте 20 лет», б — «Выдайте имена студентов
старше 20 лет и/или родившихся в Кусиро»; в — «Выдайте имена
студентов, интересующихся бейсболом и теннисом».
i Студенты
Имя
Танзка
Возраст
>20
Место
рождения
Хобби
П.
Имя
Танака
Хобби
Студенты
П.
Имя
Танака
Возраст
Хобби
~1
Имя
Танака
Хобби:
бейсбол
Рис. 6.4. Поиск в базе данных на рис. 6.1: а — «Выдайте имена
и хобби студентов старше 20 лет»; б—«Выдайте имена,
возраст и место рождения студентоз, не интересующихся
бейсболом»*
Приобретение знаний, хранящихся в базах данных 165
Хобби
Имя
П.Накамура
Танака
Хобби
ВСЕ.Х/
ВСЕ.Х_
Хобби
Имя
П.Накзмура
. Танака
Хобби
ГвСЕ.^Х "I
ВСЕ.Х
а 6
Рис. 6.5. Поиск в базе данных на рис. 6.1: а —«Выдайте имена
студентов, все хобби которых полностью совпадают с хобби
Танака»; б — «Выдайте имена студентов, интересующихся тем
же, что и Танака».
1 Хобби
Имя
Танака
*
Хобби
1ШЧ.ВСЕ.Х,
> """ J
Хобби
Имя
Хобби1
1ШЧ,УН»ВСЕ.*
•
Рис, 6.6. Поиск в базе данных на рис. 6.1: а— «Выдайте,
сколько хобби имеет Танака»; б — «Выдайте, сколько всего хобч
би появилось в базе данных».
Студенты
У,
Имя
Возраст
>20
Место
рождения
а
Студенту
е,
Има
Ямакэва
Возраот
18
Медто |
рождения
КобЗ !
Студенты
3.
Имя
Ямада
Возраст
21
Место
рождения
Рис. 6.7. Обновление базы данных на рис. 6.1: а — «Исключите
записи о студентах старше 20 лет; б — «Вставьте запись (Яма-
кава, 18, Кобэ)»; в —«Замените возраст Ямада на 21 год». 4
ш
Глава 6
ток В, У, 3 соответственно. На рис. 6.7, а указано
удаление из отношения «студенты» записи о студентах
старше 20 лет, на рис. 6.7,6 — вставку записи (Яма-
гава, 18, Кобэ), а на рис. 6.7, в — изменение возраста'
Ямада на 21 год.
6.2. НЕЖЕЛАТЕЛЬНЫЕ ОБНОВЛЕНИЯ
Если базу данных рассматривать как знания, то
приобретение знаний в базе данных осуществляется
благодаря обновлению данных. С этой точки зрения,
каким бы ни был запрос на обновление от
пользователя, необходимо проверить целесообразность его
выполнения. Например, следует ли принимать
обновление, если возраст человека заменяется на 500 лет?
Необходимо предотвращать подобные нежелательные
обновления для того, чтобы сохранять практическую
Студечты
L, , ,
Номер
зачетки
8401001
В502321
3404105
8510249
Имя
Ямада
Судэуки
Накамура
Тзнака
Возраст
18
1?
гь
п
'%ес,о
рождения
Киото
Иокогама
Кобэ
Киото
Хобби
Hoiv-j
зачегки
94010 01
8510249
8510249
8404105
8404105
8404105
—"•-¦ -'i
Хобби
Теннис I
бейсбол 1
Теннис I
Настольный!
теннис 1
Теннис I
бейсбол I
Рис. 6.8. База данных,
Студенты
В.
Номер
зачетки
8604123
Имя
Сато
Возраст
500
Место
рождения
Токио
а
Студенты
В.
Номер
вачетки
94010Q1
Имя
Кэвакэми
Возраст
2Q
Место"*"-*!
рождения
Нагоя
i
б
Нис. 6.9. Нежелательные обновления базы данных на рис. 6.8s
а — добавление записи с нереальным возрастом; б —
обновление вносит второго студента с номером 8401001,
Приобретение знаний, хранящихся в базах данных 167
Студенты
В.
Номер
Зачетки
8401001
Имя
Ямада
Возраст
18
Место
рождения
Аомори
Рис. 6.10. Запись, которая при добавлении в базу данных на
рис. 6.8 приводит к противоречию
Студенты
В.
Номер
зачетки
8401001
Имя
Ямада
Возраст
18
Место
рождения
Киото
Рис. 6.11. Избыточное обновление базы данных на рис. 6.8.
ценность информации, накопленной в базе данных.
Поэтому давайте рассмотрим, какие обновления
нежелательны. Разобьем их на следующие четыре класса:
1) обновления, не удовлетворяющие ограничениям
целостности;
2) обновления, приводящие к противоречию;
3) избыточные обновления;
4) обновления на основе неполной информации.
Покажем примеры таких нежелательных обновлений
на примере базы данных на рис. 6.8.
Примеры обновлений, не удовлетворяющих
ограничениям целостности, приведены на рис. 6.9, а, б.
В первом примере вводятся нереальные значения:
возраст — 500 лет, во втором — в результате
обновления появляются два студента с одним номером
8401001. Такие обновления нежелательны, для их
предотвращения необходимо, чтобы системе бьпи
известны ограничения «возраст человека менее 130 лет»
и «номер зачетки студента однозначно определяет'
его», кроме того, система должна иметь механизм
проверки этих условий.
На рис. 6.10 — пример обновления, приводящего
к противоречию. В результате обновления местом
рождения студента Ямада с номером 8401001
оказывается и Киото, и Аомори, что противоречит друг
другу. На рис. 6.11 — пример избыточного
обновления. Информацию в этом примере можно получить из
уже существующей информации.
Пример нежелательного обновления на основе
неполной информации —это случай ввода в базу
163
Глйза 6
данных на рис. 6.8 таких данных: «Хобби Сато —
вождение машины». Ясно, что Сато любит водить
машину, но такого студента в базе нет, поэтому
обновить рис. 6.8 невозможно.
В следующем разделе рассмотрим, как
описываются и предотвращаются нежелательные
обновления.
6.3. ОГРАНИЧЕНИЯ ЦЕЛОСТНОСТИ
ПРИ ОБНОВЛЕНИИ БАЗ ДАННЫХ
К ограничениям целостности при обновлении баз
данных относятся ограничения, представленные
равенствами или неравенствами и справедливые для
значений, вычисленных по одному или нескольким
атрибутам так, как в случае, когда возраст оказывается
равным COG ло1, а также ограничения, связанные со
структурой атрибутов так, как в примере, когда по
номеру зачетки студента однозначно определялось
его имя и место рождения.
Необходимо уметь как описывать ограничения
целостности, так и указывать метод их проверки. Для
таких описаний используют расширенный язык
манипуляции данными, предназначенный изначально для
поиска и обновления б'азы данных. Приведем ниже
расширение языка описания ограничений на базе
языка ЗПО на примерах конкретных ограничений.
В языке ЗПО для описания ограничений
целостности используются шаблоны отношений, вслед за
названием отношения можно записать
а) Ц.ТИП.Ц
б) Ц.ДЛИНА.Ц
в) Ц.КЛЮЧ.Ц
г) Ц.КОНСТР.Ц
д) Ц.КОНСТР. «список условий».Ц
Буква Ц в записи Ц...Ц — первая буква слова
«целостность» {). Ограничение а используется для
определения типа значения каждого атрибута, например
символьные или целочисленные. Ограничение б — для
определения длины значения, например для символь-
1} В оригинале «I» от слов Integrity Constraint
(ограничение целостности). — Прим. перев.
Приобретение знаний, хранящихся в базах данных 169
ных значений—не более некоторого числа знаков,
для целочисленных — не более некоторого числа
разрядов. Ограничение в указывает атрибуты, включая
основной ключевой атрибут. Ключом отношения
называют подмножество множества атрибутов этого
отношения, это минимальное множество,
удовлетворяющее следующему условию: не существует
кортежей, все значения атрибутов которых одинаковы.
Ключей может быть несколько, тогда один из них
называется основным. Ключи отражают физическую
структуру хранения отношений. Описания г и д
используются в случае других ограничений целостности.
Во время обновления проверяются первые четыре
ограничения, а последнее ограничение проверяется
только в случае обновления типа В (вставка), У
(удаление), 3 (замена), в которых указан список
ограничений.
На рис. 6.12 приведены примеры ограничивающих
условий для базы данных на рис. 6.8. Ограничение а
описывает «возрастной ценз» от 15 до 40 лет для
студентов, записанных в базе данных. Ограничение б
указывает, что не должно быть студентов с одним
именем и фамилией. Ограничение в говорит о том,
что при обновлении возраст, как правило, должен
возрастать. Ограничение г — добавление информации
о хобби студентов выполняется только для студентов,
зарегистрированных в отношении «студенты».
Пусть в некотором отношении X и У —
подмножества его атрибутов, тогда скажем, что существует
функциональная подчиненность из X в У, которое
обозначим как Х-+У, если из того, что в X
определены все значения атрибутов, следует, что определены
все значения атрибутов в У. В отношении «студенты»
на рис. 5.8 существует следующая функциональная
подчиненность: «номер зачетки)} ->- «имя,
(возраст), (место рождения». Кроме функциональной
подчиненности известны многозначная подчиненность,
гепочечная подчиненность и др. Все это разновид-
i-ости ограничений целостности в том смысле, что
обновление подчиненных отношений допускается только
в случае, когда это обновление не противоречит
ограничениям целостности. Приведенная выше подчинен-
i:o
Глава 6
ность в отношении «студенты» сохраняется при
указании основного ключа — атрибута (номер зачетки).
Функциональную подчиненность можно представить
с помощью описания на рис. 6.12,6. Этот пример
аналогичен добавлению функциональной подчиненности
«имя» ->- «номер зачетки)}.
Некоторые ограничения целостности можно
проверить только с помощью значений обновляемого
кортежа, так, как на рис. 6.12, а, другие, как, например,
б, с, г, для проверки требуют нового поиска, и время
выполнения таких проверок, разумеется, различное.
Одна из проблем, которую еще предстоит решить, —
как с наилучшей эффективностью обрабатывать
подобные сложные ограничения целостности
Студенты
Ц.КЯЮЧ.Ц.
Ц.КОНСТР(В.Д).Ц,
Ц.КОНСТР(М.).Ц,
Ц.КОНСТР@./3.).Ц.
Ц.КОНСТР(В.).Ц.
ч.
Номер
зачетки
К
ьсвл
н
hi
(все.hi)
Имя
«к
ИМЯ X
Возраст
NK
>15
<40
>АХ-"
Я
Место
рождения
кк
Г Хобби
Ц.КОНСТР(З). Ц
Номер
зачетки
&CE..NZ
Хобби
БЛОК УСЛ05ИЙ
Ш.ВСЕ.г1Х=1
Рис. 6 12. Ограничения целостности базы данных на рис. 6.8»
Приобретение знаний, хранящихся в Сазах данных 171
6.4. НЕПРОТИВОРЕЧИВОСТЬ
И УПРАВЛЕНИЕ ОБНОВЛЕНИЕМ
Примеры противоречий в базе данных можно найти
на рис. 6.13, 6.14. На первом рисунке приведено
отношение с атрибутами (номер зачетки), (имя),
(хобби). В таблице встречаются два одинаковых номера,
под которыми зарегистрированы два студента с
различными фамилиями. Это противоречие можно
устранить благодаря введению в качестве ограничения
целостности функциональной подчиненности (номер
зачетки)-»- (имя). На языке ЗПО это записывают гак,
как на рис. 6.15. Но можно избежать противоречия
более непосредственным способом: разделив это
отношение на два: R{ ((номер зачетки), (имя)) и /?2
((номер зачетки), (хобби)) и указав в R\ как основной
ключ (номер зачетки). Такое разбиение называют
формализацией. Использование формализации
приводит к лучшим результатам, чем введение ограничений
целостности, поскольку в последнем случае
необходимо выполнять программу проверки этого
ограничения, а в первом — ограничение вводится
автоматически за счет физической организации файлов, в
которых хранятся отношения.
На рис. 6.16 — пример противоречия, с которым
нельзя справиться через формализацию; око сгязано
с тем, что во множестве простых отношений
невозможно полностью описать смысловую структуру
информации. Этот пример содержит такое
противоречие: а одновременно является и родителем, и сыном
Ь. Это можно предотвратить путем введения
ограничения на рис. 6.17. Противоречия такого рода
возникают в базах данных, содержащих негативную
информацию. На рис. 6.18 приведен пример ограничения
целостности для исключения противоречий в
отношениях «приятели» и «враги».
Расширенная система, в которой к базе данных
добавлены дедуктивные функции и которая может
обрабатывать не только фактические знания и факты
в правилах, но и сами правила, называется
дедуктивной базой данных. В последние годы ведется
активное изучение таких баз данных. Пусть в базе данных
172
Глаза 6
Хобби
Номер
зачетки
8401231
8402311
8401231
Имя
Судзуки
Сато
Судзуки
Ямада
Хобби 1
i
Теннис j
Бейсбол
Настольный
теннис
Теннис
1
Противоречие
Рис. 6.13. Противоречие, обусловленное подчиненностью.
Родители
| и дети
Родители
а
а
d
d
b
Дети ]
b
с
d
с
а
Противоречив
Рис. 6.14. Смысловое противоречие.
Хобби
Ц.К0НСТР(В.,3.).Ц..
Номер
зачетки
Ж
Имя
BCE.NMX
Хобби ]
|
Блок условий
КЛЧ, УН. BCg. NMX=1
Рис. 6.15. Описание ограничения целостности для функциональ*»
ной подчиненности (номер зачетки) ->- (имя)А
Приобретение знаний, хранящихся в базах данных 173
есть кортеж (vu v2, ..., vn) в отношении
R(AU Л2, ..., Ап) с атрибутами Аи А2, ..., Ап,
тогда можно рассматривать логические формулы
R(v\, v2, ..., vn), где R — имя предиката. Базу
данных, которая состоит, из логических формул логики
предикатов первого порядка и единственного
предиката, можно принять за систему аксиом, состоящих
из логических формул без предиката, т. е. только из
фактов.
Ri
ц ключ, ц
Номер
зачетки
К
Имя |
NK |
стн
Номер
зачетки
Хобби I
\
Рис. 6.16. Разбиение отношения на рис. 6.13 и указание основа
чого ключа.
Родители и дети
Ц.К0НОТР(в.,3.).Ц.
В.
Родители
1
1
Дети
*1 '
1
Рис. 6.17, Описание ограничения целостности, исключающее про-*
тиворечие на рис. 6.14.
Приятели
Ц.К0НСТРC,В.),Ц.
Be
Человек
V
Человек
Враги
Ц.К0НСТРC.,В.). Ц.
0.
Человек
Человек
Рис. 6.18. Исключение противоречия в базе данных, содержа*
щей негативную информацию,
174
Глава 6
Пусть л — такая система аксиом, тогда при
обычном поиске выдвигается гипотеза, которую можно
назвать гипотезой закрытых миров, а именно: если
произвольную логическую формулу w невозможно
доказать с помощью А^ то допускается, что справедтизо
отрицание w, т. е. I w. В базе данных А есть
множество фактов, поэтому условие «w можно доказать
в А» эквивалентно условию «w содержится в базе
данных в виде факта». Следовательно, гипотеза
закрытого мира равнозначна допущению, что для
фактов, не содержащихся в базе данных, эта гипотеза не
справедлива.
В дедуктивной базе данных информацию
представляют не только с помощью фактов, но и с помощью
множества аксиом Л, включающего также логические
формулы с переменными, т. е. множества правил.
В подобной базе ситуация, когда добавление новой
информации ведет к противоречию, эквивалентна
тому, что из A U {w} можно доказать ложную гипотезу.
Для проверки, приводит ли обновление к
противоречию, необходим поиск в базе данных. Проверка
противоречия в дедуктивной базе — это уже
обработка, требующая времени. В настоящее время для
реализации такой обработки необходимы новые, еще
неизвестные практические методы. Это проблема
будущих исследований.
6.5. ИСКЛЮЧЕНИЕ ИЗБЫТОЧНОСТИ
В отношении на рис. 6.19 в двух местах появились
значения (номер зачетки) и (имя) одного и того же
человека. Подобно противоречию на рис. 6.13,
подобная избыточность также зависит от функциональной
подчиненности (номер зачетки)->-(имя). По
аналогии с предыдущим примером формализуем отношение
к укажем в R\((номер зачетки), (имя)) как основной
ключ атрибут (номер зачетки). Это позволит
исключить избыточность. Однако известно, что в общем
случае избыточность такого рода не всегда можно
исключить, даже введя какую-либо формализацию.
Вообще говоря, нельзя предупреждать появление
избыточности, запрещая обновление, вносящее эту
избыточность. Дело в том, что кроме избыточной ин«
Приобретение знаний, хранящихся в базах данных 175
формации при обновлении добавляется также и
полезная информация.
Избыточность в базах данных возникает также
при определении представления. Представление
это механизм, который рассматривает описание
запроса на поиск, не требуя его выполнения, а
определяя виртуальное отношение. На рис. 6.20 приведен
пример определения представления Ц. ПРЕДСТ
дедушки и бабушки Ц. Буква Ц указывает, что этот
шаблон определяет новое представление с именем
«дедушки и бабушки». В нем содержатся атрибуты
«дедушка и бабушка» и «внук», х и у в шаблоне —
это ссылки на записи в отношении «родители и дети»,
существующем в базе данных, с помощью этой ссылки
можно сделать вывод: если х — это некто в
отношении «дедушки и бабушки», то, получив из отношения
«родители и дети» сведения о том, что z— сын х, а
у — сын г, заключаем, что у — внук х. ~~
Пусть теперь в самом деле существует отношение
«дедушки и бабушки», такое, как на рис. 6.21, и
определим виртуальное представление «5 — дедушки и
бабушки» так, как на рис. 6.22. В этом случае
информация в кортеже (a, d)y вставленная в существующее
отношение «дедушки и бабушки», может быть
получена из отношения «родители и дети», и поэтому
является избыточной.
| Хобби
Номер
зачетки
8401112
6402321
8503221
84Q11U
!
Имя
Яма/\а
Сато
Судауки
Ям ада
•
Хобби
Теннис
бейсбол
Теннис
настольный
Теннис
1
-*—1
*-
Включаег
избыточную
информации
Рис. 6.19. Избыточность, вызванная подчиненностью.
176
Глава 6
Ц. ПРЕДСТ дедушки И бабушки
Дедушки и бабушки
х^
Внуки
х
|Родители и дети
Родители
2.
Дети
х
Рис, 6.20. Определение представления «дедушки и бабушки» с
помощью существующих отношений.
Родители"
[и дети
Родители
а
а
b
Дети
b
с
d
Дедушки
и бабушки
Дедушки
и бабушки
а
ь
Внуки
е
f
Рис. 6.21. База данных с отношениями «родители и дети» и
«дедушки и бабушки»,
Ц. ПРЕДСТ дедушки и бабушки Ц.
Дедушки
и бабушки
V
Внуки
X
Л
Родители
| и дети
Родители
X
Дети
7_
х
Дедушки
и бабушки
Дедушки
и бабушки
х
Внуки
W
Рис. 6.22. Определение представления «В—дедушки и
бабушки» в случае, когда существует и отношение «дедушки и
бабушки».
Приобретение знаний, хранящихся в базах данных Ш
Представления можно считать своего рода
правилами в дедуктивной базе данных. В общем случае
пусть А — система аксиом в дедуктивной базе
данных, a до — предикат, определяемый вновь вводимой
записью; тогда если из Л можно доказать до, то до —
избыточна. Кроме того, пусть до' аксиома,
включенная в Л, тогда до' избыточна при внесении до, если из
(Л — {до'}) (J {до} можно доказать до'.
Не всякую избыточность можно исключить, в
частности избыточность, возникающую при
использовании представлений, исключить можно, но для ее
проверки необходимо организовать поиск. В дедуктивной
базе данных такая проверка особенно сложна, и пока
неизвестны методы ее реализации. Это тема будущих
исследований.
6.6. ОБРАБОТКА НЕПОЛНОЙ ИНФОРМАЦИИ
Примеры нежелательного обновления неполной
информации сложно приводить не только в случае
обновления существующих отношений, но и при
обновлении представлений. На рис. 6.23 — пример базы
данных с отношением «родители и дети» и
представлением «дедушки и бабушки». Рассмотрим внесение
в последнее представление кортежа (a, g)\ из него
не ясно, кто сын а или родитель g (назовем этого
человека *0), поэтому обновлять существующее
отношение «родители и дети» нельзя. Иначе это
обновление вызовет противоречие до тех пор, пока не будет
проверено, кто же д:0: а, Ъ или кто другой.
Примеры нежелательного обновления
представлений можно обнаружить и при удалении записей.
Пусть из отношения «дедушки и бабушки»
удаляется кортеж (а, е), т. е. из отношения «родители и
дети» подлежит удалению либо (а, Ь), либо (Ь, е).
Однако трудно сказать, какое из удалений
правильное. Если удалить первый кортеж, то из отношения
.«дедушки и бабушки» придется удалить информацию
t(a, h)y а если удалить второй — то (d, e).
Аналогичная проблема возникнет вследствие
частичного отсутствия информации, необходимой для
преобразования базы данных, когда обновление
f78 Глава 6
Родители
*и дети
Родители
а
а
d
b
b
•
Дети-
b
с
b
е
h
•
Дедушки
и бабушки
X
Внуки
У,
Родители
I и дети
Родители
?
?
Дети
Z
Рис. 6.23. База данных с отношением «родители и дети» и
определение представления «дедушки и бабушки».
представлений приводит к преобразованию
существующих отношений.
Проблема обновления представлений одно время
была успешно исследована в части автоматического
преобразования обновлений представления в
обновление существующих отношений. Однако, как видно из
приведенных примеров, автоматическое
преобразование по существу невозможно, и в дальнейшем, видимо,
необходимы еще исследования того, какую
опущенную информацию система должна запрашивать у
пользователя.
ГЛАВА 7.
ТЕОРИЯ ИНДУКТИВНЫХ ВЫВОДОВ
С. Арикава, Т. Синохара, Т. Мияхара
(Университет Кюсю)
Индуктивный вывод — это вывод из имеющихся
данных объясняющего их общего правила. Было время,
когда под индуктивным выводом понимали
доказательство гипотез, но в настоящее время принято
указанное выше определение. Следовательно,
обнаруживается глубокая связь с различными процессами
обучения, процессом овладения языками человеком,
извлечением особенностей множества данных,
автоматическим синтезом программ по примерам
ввода-вывода, полуавтоматическим приобретением знаний в
экспертных системах, отладкой программ и
другими процессами. В данной и следующих главах дан
общий обзор современного состояния теории
индуктивных выводов с точки зрения указанных
прикладных проблем. В частности, в данной главе
рассмотрены результаты математических исследований,
связанных с индуктивными функциями и индуктивными
выводами в грамматике.
7.1. ОСНОВНЫЕ ПОНЯТИЯ ТЕОРИИ
ИНДУКТИВНЫХ ВЫВОДОВ
Как уже было сказано, индуктивный вывод — это вы*
вод из заданных данных объясняющего их общего
правила. Например, пусть известно, что есть
некоторый многочлен от одной переменной. Давайте
посмотрим, как выводится /(х), если последовательно
задаются в качестве данных пары значений @, /@)),
,A, /A)), Вначале задается @, 1), и естественно,
что есть смысл вывести постоянную функцию
f(x)= 1. Затем задается A, 1), эта пара удовлетво<
ряет предложенной функции f{x)= 1. Следовательно
в этот момент нет необходимости менять вывод. На*
конец, задается B, 3), что плохо согласуется с наши*
180
Глава 7
выводом, поэтому откажемся от него и после
нескольких проб и ошибок выведем новую функцию
f(x) = x2 — х + 1, которая удовлетворяет всем
заданным до сих пор фактам @, 1), A, 1), B, 3). Далее
мы убедимся, что эта же функция удовлетворяет
фактам C, 7), D, 13), E, 21) ..., поэтому нет
необходимости менять этот вывод. Таким образом, из
последовательности пар переменная-функция можно
вывести многочлен второй степени f(x) = x2 — х+1.
Грубо говоря, такой метод вывода можно назвать
индуктивным.
Как видно из этого примера, при выводе в каждый
момент времени объясняются все данные, полученные
до этого момента. Разумеется, данные, полученные
позже, уже могут и не удовлетворять этому выводу.
В таких случаях приходится менять вывод.
Следовательно, в общем случае индуктивный выврд — это
неограниченно долгий процесс. И это не удивительно,
если вспомнить процесс освоения человеком языков,
процесс совершенствования программного
обеспечения и т. п.
Для точного определения индуктивного вывода
необходимо уточнить: 1) множество правил —
объектов вывода, 2) метод представления правил,
3) способ показа примеров, 4) метод вывода и
5) критерий правильности вывода.
В качестве правил — объектов вывода — можно
рассматривать главным образом индуктивные
функции, формальные языки, программы и т. п. Кроме
того, эти правила могут быть представлены в виде
машины Тьюринга для вычисления функций,
грамматики языков, операторов Пролога и другим
способом. Машина Тьюринга — это математическая
модель компьютера, ее в принципе можно считать
программой. В случае когда объектом вывода является
формальный язык, он сам определяет правила, а его
грамматика — метод представления правил, поэтому
говорят о грамматическом выводе.
Для показа примеров функции / можно
использовать последовательность пар (x,f(x)) входных и
выходных значений так, как указано выше,
последовательность действий машины Тьюринга, вычисляющей
Теория индуктивных выводов
ш
/, и другие данные. Задание машине выводов пары
входных и выходных значений (х, f(x)) функции f
соответствует заданию системе автоматического
синтеза программ входных значений х и выходных
значений /(#), которые должны быть получены
программой вычисления / в ответ на х. В этом смысле
автоматический синтез программ по примерам также
можно считать индуктивным выводом функции f.
Формальные языки — это множество слов; поэтому,
например, для языка L можно рассматривать два
типа слов, принадлежащих и не принадлежащих
этому языку. Первые назовем положительными, а
вторые — отрицательными данными. Другими
словами, есть два способа показа примеров формального
языка: с помощью положительных и отрицательных
данных. Когда объектом служат сами программы,
тогда то же самое можно говорить о функциях языка
Лисп, но для'Пролога показ примеров осуществляется
в виде фактов. Например, <3 ^ 4, истина), <2 ^ 1,
ложь). В этом случае положительным данным
соответствуют данные с атрибутом «истина», а
отрицательным — данные с атрибутом «ложь».
Вывод реализуется благодаря неограниченному
повторению основного процесса
запрос входных данных -> предположение -> выходные
данные.
Другими словами, при выводе последовательно
получают примеры как входные данные, вычисляют
предположение на данный момент и выдают
результат вычислений. Предположение в каждый момент
времени основано на ограниченном числе примеров,
полученных до сих пор, поэтому обычно в качестве
метода вывода используют машину Тьюринга,
вычисляющую предположение по ограниченному числу
примеров. Такую машину назовем машиной выводов.
Учитывая, что индуктивный вывод, как уже было
отмечено, это неограниченно продолжающийся
процесс, критерием правильности вывода, как правило,
считают понятие идентификации в пределе. Это
понятие введено Голдом, оно используется почти всегда
в теории индуктивных выводов. Говорят, что машина
182
Глава 7
вывода М идентифицирует в пределе правило /?, если
при показе примеров R последовательность выходных
данных, генерируемых М, сходится к некоторому
представлению т, а именно: все выходные данные,
начиная с некоторого момента времени, совпадают с т,
при этом т называют правильным представлением R.
Кроме того, говорят, что множество правил Г
позволяет сделать индуктивный вывод, если существует
некоторая машина выводов М, которая
идентифицирует в пределе любое правило R из множества Г.
Обратите внимание на то, что слова «позволяет
сделать индуктивный вывод» не имеют смысла для
единственного правила, а относятся только к множеству
правил.
В данной главе рассмотрены вывод рекурсивных
функций и грамматический вывод как типичные
примеры в теории индуктивных выводов.
7.2. ИНДУКТИВНЫЙ ВЫВОД ФУНКЦИЙ
Автоматический синтез программ . по примерам
компьютерами можно рассматривать как
индуктивный вывод функций. Возможности компьютеров в
последние годы резко возросли, поэтому естественно
задать следующий вопрос: «Допустим, что в будущем
мы сможем использовать любое количество ресурсов
компьютера. Можно ли при этом построить систему,
которая будет автоматически синтезировать по
примерам произвольно заданные программы, не имеющие
бесконечных циклов?»
Математическая теория индуктивных выводов,
основу которой заложил Голд, формализовала
выводы на основе теории вычислений и дала строгий
ответ на этот вопрос. Ознакомимся с некоторыми из
многочисленных результатов, полученных до
настоящего времени, начиная с отрицательного ответа на
поставленный вопрос.
Прежде всего формализуем основополагающее
понятие теории индуктивных выводов —
идентификацию в пределе и обсудим его связь с методом
перечисления и понятием экстраполяции,
предположенными на ранних этапах исследований.
Теория индуктивных выводов
183
В процессе индуктивного вывода функции f
машине вывода М последовательно задаются дгнные
/@), /A), ..., а М каждый раз при получении данных
выдает программу. Формализуем этот процесс на
основе теории вычислений. Если использовать
соответствующий метод кодирования, то в качестве лан-
ных достаточно рассмотреть только натура;ьные
числа 0, 1, 2, ..., поэтому объектом изучения будем
считать функции, отображающие натуральные числа
в натуральные числа. В частности, если это особо не
оговорено, в качестве функции возьмем функцию
одной переменной. Назовем частичной рекурсивной
функцию, которая вычисляется программой,
возвращающей значение не для всех натуральных чисел.
НазовехМ рекурсивной функцию, которая вычисляется
программой, возвращающей значение для всех
натуральных чисел. Множество всех частичных
рекурсивных функций обозначим через 5*, а множество всех
рекурсивных функций — через Я. Если фиксировать
язык программирования и рассматривать программу
как последовательность символов, то все программы
можно однозначно перенумеровать. При такой
нумерации можно отождествить р-ю программу с ее
номером р. Для конкретной рекурсивной функции f
нельзя однозначно определить программу,
вычисляющую /, поэтому данные /@), /A), fB), ... можно
рассматривать как примеры спецификаций программ,
вычисляющих /. Выходные данные машины вывода
назовем предположением. Если использовать
соответствующий метод кодирования, то машину выводов М
можно считать частичной рекурсивной функцией, а
именно: в каждый момент времени k M задаются
примеры /[&], представляющие собой перекодированный
в натуральные числа ограниченный набор данных
f@), /A), ..., f(k), и предположениями машины М
являются также натуральные числа. Предположение
машины М в момент k обозначим как M(f[k]).
Определение 7.1. Скажем, что машина выводов М
идентифицирует в пределе рекурсивную функцию f,
если неограниченная последовательность
предположений M(f[0])9 M(f[l]), ..., выдаваемых машиной Af,
сходится к некоторому натуральному числу р, т. е.
184
Глзва 7
все предположения, начиная с некоторого момента,
есть р, при этом р назовем программой,
вычисляющей /.
Помимо идентификации в пределе можно
рассматривать и другие критерии успеха индуктивного вывода.
Для того чтобы отличать данный критерий от других,
обозначим идентификацию в пределе как ЕХ-иден-
тифпкацию, подчеркивая этим, что предположения
сходятся в программе, вычисляющей
(объясняющей— по-английски Explain) рекурсивную функцию.
Все рекурсивные функции, которые ЕХ-идентифици-
руег машина выводов М, обозначим через ЕХ(М).
Если машина выводов М ЕХ-идентифицирует любую
функцию из множества рекурсивных функций U, то
скажем, что М ЕХ-идентифицирует (идентифицирует
в пределе) множество U. Если существует машина
выводов, которая ЕХ-идентифицирует множество
рекурсивных функций U, то скажем, что U позволяет
делать ЕХ-идентификацию (позволяет делать
идентификацию в пределе). Само множество, которое
позволяет делать hX-идентификацию, т. е. множество
рекурсивных функций, также обозначим через EX.
Понятие идентификации в пределе ввел Голд;
точно так же формализовано и понятие индуктивный
вывод. В литературе вместо ЕХ иногда пишут LIM
или GN.
Ниже рассмотрим различные критерии успеха и
сравним возможности машин вывода,
удовлетворяющих таким критериям. Считают, что семейство
множеств рекурсивных функций, которые позволяют
делать индуктивные выводы на основе соответствующих
критериев, определяет возможности машины вывода,
удовлетворяющей этому критерию. Подобное
семейство называют методом вывода (или типом
идентификации). Например, ЕХ, определенный выше, это
метод вывода, определяющий возможности машины
выводов, удовлетворяющей критерию ЕХ-идентифи-
кации. Ниже по аналогии с ЕХ-идентификацией
определим критерий успеха, который назовем
ID-идентификацией, и введем обозначение ID(M),
гонятие «позволяет сделать ID-идентификацию» и
соответствующий метод вывода ID. Хотелось бы обра-
Теория индуктивных еьшодоа
185
тить внимание на то, что для ID-идентификации и
метода вывода ID использовано одно и то же
обозначение ID. Для сравнения возможностей машин
выводов, удовлетворяющих различным критериям успеха,
можно изучать вложение методов вывода. Ведется
много исследований, объясняющих иерархию
методов вывода с этой точки зрения. Такая иерархия
отражает различия в возможностях машин вывода,
удовлетворяющих тем или иным критериям, в теории
формальных языков это соответствует иерархии
классов языков типа иерархии Хомского, которая вводит
различия в возможностях устройств ввода и
обработки. Пусть есть два критерия успеха: Шгиденти-
фикация и ГО2-идентификация. Если, например,
метод вывода ID2 строго лучше метода вывода IDi,
т. е. ID, ^ ID2, то скажем, что ГО2-идентификация
имеет строго большие возможности, чем IDi-иденти-
фикация.
При реализации индуктивных выводов па
действующих компьютерах перечисляют все возможные
предположения, и основной стратегией считают
обнаружение правильного предположения путем проверки
того, объясняет ли оно полученные до этого момента
данные. Эту стратегию обычно называют методом
генерации и проверки, а в теории индуктивных
выводов — методом перечисления или идентификации
путем перечисления. Система вывода моделей MIS,
созданная Шапиро, в своей основе использует метод
перечисления, а улучшение сходимости при такой
стратегии обеспечивается за счет использования
логики предикатов первого порядка (см. разд. 8.4).
Пусть U — множество рекурсивных функций.
Если есть некоторая рекурсивная функция /2, и
множество всех функций, вычисляемых по программам
/г@), h(l), ..., совпадает с ?/, то множество U
назовем перечисляемым. При этом h перечисляет U.
Как следует из теоремы 7.1, подмножество
перечисляемого множества рекурсивных функций позволяет
сделать индуктивный вывод с помощью метода
перечисления, поэтому такое подмножество само
определяет отдельный метод вывода, отражающий
возможности метода перечисления.
186
Глава 7
Определение 7.2. Подмножество перечисляемого
множества рекурсивных функций обозначим через
NUM.
В данной области самым первым получен
следующий результат.
Теорема 7.1 (Голд). Подмножество перечисляемого
множества рекурсивных функций позволяет сделать
ЕХ-идентификацию. Другими словами, NUM ^ EX.
Доказательство. Пусть U — подмножество
перечисляемого множества рекурсивных функций. Тогда
есть некоторая рекурсивная функция А, такая, что U
есть подмножество, которое перечисляет h. Построим
следующим образом машину выводов М,
использующую метод перечисления. Пусть / — любая функция
(/, и в момент k машине М даны данные f[k].
М — это машина, которая ведет поиск программы,
способной вычислить все полученные до этого
момента данные, последовательно проверяя программы
/г@), АA), ..., перечисленные с помощью h.
Выходом машины будет являться первая обнаруженная
при этом программа.
Пусть р — первая программа, вычисляющая f,
обнаруженная среди программ, перечисленных с
помощью h. Программы, которые при перечислении
следовали раньше р, не позволяют вычислить /,
поэтому есть момент, когда М, отбросив все такие
программы, выдаст р. Но если М выдала р, то р может
вычислить все данные, полученные до этого момента,
поэтому М и в дальнейшем продолжает выдавать р.
Другими словами, если заданы данные о /, то
неограниченная последовательность предположений,
выдаваемых М, сходится к р. Следовательно, М может
ЕХ-идентифицировать любую функцию / множе-
жества U.
Пример. Пусть U множество многочленов с
целочисленными коэффициентами от одной переменной.
Путем перечисления комбинаций целочисленных
коэффициентов можно перечислить программы для всех
функций множества Uy поэтому U — это
перечисляемое множество рекурсивных функций. Следовательно,
U e NUM. На основании метода перечисления в
теореме 7.1 машина выводов М будет ЕХ-идентифициро-
Теория индуктивных выводов
187
вать любую функцию f из U. Другими словами, М
выполняет ЕХ-идентификацию U. Следовательно,
{/€= EX.
Можно ли всегда при ЕХ-идентификации
применять стратегию, основанную на таком самом простом
методе перечисления? Для ответа на этот вопрос
проверим, истинно ли вложение NUM и ЕХ, о
котором упоминалось выше. Следующая теорема дает
отрицательный ответ на этот вопрос.
Теорема 7.2 (Бардин). Существует множество
рекурсивных функций, для которых нельзя применить
метод перечисления, но которые позволяют делать
ЕХ-идентификацию. То есть NUM +1 EX.
Подготовим термины и обозначения, а затем
приступим к доказательству. В дальнейшем определения
терминов и обозначений, используемых в процессе
доказательства теорем, будем выделять скобками
(и). Целесообразно дать строгое объяснение уже
введенных терминов и обозначений.
( Обозначим через срр частичную рекурсивную
функцию, вычисляемую программой р. При этом
{фо, Фь ф2, ...} совпадает с множеством частичных
рекурсивных функций <Р. Точнее, пусть ф0, фь ф2> ¦..
есть ^-воспринимающая программная система.
Назовем р программой /, если срр = /. Обратим внимание
на то, что для любой рекурсивной функции /
существует счетное неограниченное число программ,
вычисляющих / и отличающихся хотя бы одним
символом, поэтому существует счетное неограниченное
число программ /. ^-воспринимающая программная
система — это система абстрактного представления
частичных рекурсивных функций, которые можно
вычислить на традиционных языках программирования,
но с точки зрения теории важно то, что для таких
программных систем справедлива указанная ниже
теорема о рекурсии.
Теорема о рекурсии. Для любой рекурсивной
функции / существует натуральное число /, такое, что
Фж) = ф;-
Такое число i называют неподвижной точкой.
Процедура, которая останавливается после конечного
числа операций и выдает результат в ответ на любое
186
Глава 7
Определение 7.2. Подмножество перечисляемого
множества рекурсивных функций обозначим через
NUM.
В данной области самым первым получен
следующий результат.
Теорема 7.1 (Голд). Подмножество перечисляемого
множества рекурсивных функций позволяет сделать
ЕХ-идентификацию. Другими словами, NUM ^ EX.
Доказательство. Пусть U — подмножество
перечисляемого множества рекурсивных функций. Тогда
есть некоторая рекурсивная функция ft, такая, что U
есть подмножество, которое перечисляет ft. Построим
следующим образом машину выводов М,
использующую метод перечисления. Пусть / — любая функция
(/, и в момент k машине М даны данные f[k].
М — это машина, которая ведет поиск программы,
способной вычислить все полученные до этого
момента данные, последовательно проверяя программы
Л@), ft(l), ..., перечисленные с помощью ft.
Выходом машины будет являться первая обнаруженная
при этом программа.
Пусть р — первая программа, вычисляющая /,
обнаруженная среди программ, перечисленных с
помощью ft. Программы, которые при перечислении
следовали раньше р, не позволяют вычислить /,
поэтому есть момент, когда М, отбросив все такие
программы, выдаст р. Но если М выдала р, то р может
вычислить все данные, полученные до этого момента,
поэтому М и в дальнейшем продолжает выдавать р.
Другими словами, если заданы данные о /, то
неограниченная последовательность предположений,
выдаваемых М, сходится к р. Следовательно, М может
ЕХ-идентифицировать любую функцию / множе-
жества U.
Пример. Пусть U множество многочленов с
целочисленными коэффициентами от одной переменной.
Путем перечисления комбинаций целочисленных
коэффициентов можно перечислить программы для всех
функций множества f/, поэтому U — это
перечисляемое множество рекурсивных функций. Следовательно,
U e NUM. На основании метода перечисления в
теореме 7.1 машина выводов М будет ЕХ-идентифициро-
Теория индуктивных выводов
187
вать любую функцию f из U. Другими словами, М
выполняет ЕХ-идентификацию U. Следовательно,
U <=е EX.
Можно ли всегда при ЕХ-идентификации
применять стратегию, основанную на таком самом простом
методе перечисления? Для ответа на этот вопрос
проверим, истинно ли вложение NUM и ЕХ, о
котором упоминалось выше. Следующая теорема дает
отрицательный ответ на этот вопрос.
Теорема 7.2 (Бардин). Существует множество
рекурсивных функций, для которых нельзя применить
метод перечисления, но которые позволяют делать
ЕХ-идентификацию. То есть NUM +: EX.
Подготовим термины и обозначения, а затем
приступим к доказательству. В дальнейшем определения
терминов и обозначений, используемых в процессе
доказательства теорем, будем выделять скобками
(и). Целесообразно дать строгое объяснение уже
введенных терминов и обозначений.
( Обозначим через фр частичную рекурсивную
функцию, вычисляемую программой р. При этом
{фо, Фь ф2, ...} совпадает с множеством частичных
рекурсивных функций Ф% Точнее, пусть ср0, фь ф2, ...
есть ^-воспринимающая программная система.
Назовем р программой /, если фр = /. Обратим внимание
на то, что для любой рекурсивной функции /
существует счетное неограниченное число программ,
вычисляющих / и отличающихся хотя бы одним
символом, поэтому существует счетное неограниченное
число программ /. ^-воспринимающая программная
система — это система абстрактного представления
частичных рекурсивных функций, которые можно
вычислить на традиционных языках программирования,
но с точки зрения теории важно то, что для таких
программных систем справедлива указанная ниже
теорема о рекурсии.
Теорема о рекурсии. Для любой рекурсивной
функции / существует натуральное число /, такое, что
Ф/@ = ф/-
Такое число i называют неподвижной точкой.
Процедура, которая останавливается после конечного
числа операций и выдает результат в ответ на любое
188
Глава 7
входное слачение, называется рекурсивной. С
помощью соответствующего кодирования входных и
выходных значений рекурсивную процедуру можно
представить как рекурсивную функцию. Теорема о
рекурсии указывает, что если есть рекурсивная
процедура /ь которая преобразует программу р в
программу f(P)> T0 существует программа i, которая при
преобразовании / не меняет своего смысла как
программа. На самом деле для любой рекурсивной функции
f существует счетное неограниченное число
неподвижных точек (вторая теорема о рекурсии Клини).
Теорема о рекурсии важна как средство построения
функций других типов. Обозначим
множество-натуральных чисел через N, а множество ограниченных
последовательностей (длины больше 0) натуральных
чисел— через TV*. Рекурсивная функция — это
частичная рекурсивная функция, область определения
которой есть N. Функцию рекурсивного
взаимно-однозначного отображения из N* в N назовем рекурсивным
кодированием, обозначим ее как < >. Натуральные
числа, которые в результате некоторого рекурсивного
кодирования < > поставлены в соответствие
ограниченной последовательности натуральных чисел ао,
аи ..., ak, обозначим через <а0, аи ..., а&> или
<a0ai ... ak). Для удобства формализации лучше
использовать кодированные числа <а0, аь ..., а^>, но
на практике ничто не препятствует рассмотрению
ограниченной последовательности а0, аь ..., #?•
Область определения частичной рекурсивной
функции / обозначим через dom(f). Определение
частичной рекурсивной функции / для натурального числа х
будем записывать как f(x)\, а определение ее значений
/@), /A), .... f(k) F^0)-как /[А]в=</@),/A),...
...,/(&)>. Скажем, что неограниченная
последовательность натуральных чисел {hk}ksN сходится к р, если
существует некоторое число ko e N, такое, что для
любого k ^ k0 справедливо hk = р, и запишем это
как Y\mkhk = р. Ниже для простоты изложения фразу
«для всех (произвольных) х е S справедливо...»
будем обозначать как VxeS ..., а фразу
«существует x^S такое, что справедливо...» — как
ELrsS ... .
Теория индуктивных вь'водов
18$
Скажем, что Me? ЕХ-идентифицирует /ей?,
если Vk е Л;, М (/ [k]) |, и существует р =
= Нт*Л1(/[?]) такое, что фр = f. При этом ЕХ(Л1)г=
е== {/е$?|Л1 е^ ЕХ-идентифицирует /}, определим
метод вывода ЕХ как EX = {U ? 31 \ ЗМ е ?;
t/e=EX(M)}.
Число шагов, необходимых для того, чтобы
программа i, получив входное число х, вычислила q>i(x)t
обозначим через Ф/(х). Точнее, {Ф?}геЛ/есть мера
сложности {ф;}/ е JV, а именно: каждая Ф*, являясь
частичной рекурсивной функцией, удовлетворяет двум
условиям (система аксиом Блюма).
1) Для любого /gA/ области определения ф; и
Ф, равны;
2) 50, а:, у) = < л
(О в других случаях,
причем предикат S трех переменных рекурсивный.
Предикат —это функция, которая принимает только
два значения: 0 или 1. Условие 1) означает, что число
шагов, требуемое для вычисления, определяется тогда
и только тогда, когда вычисления закончатся. Уело*
вне 2) означает, что процедура, оценивающая число
шагов для вычисления, является рекурсивной.
Система аксиом Блюма, таким образом, получается
естественной и достаточно строгой.
Отождествим рекурсивную функцию / с
неограниченной последовательностью натуральных чисел
/@)/A)... и введем обозначение / =/@)/(i) ... .
Например, запись f = ig (i^N, g^9l) обозначает
Д0)=/, f(k)=g(k—1)(?^1). Кроме того, запись
f = abcQ°°(a,byc e N) обозначает /@)=а, f(l)=b,
fB)=c,f(k) = 0 (A>3).)
Доказательство теоремы 7.2. Пусть U ^ {/ е
€Е 5?|фдо) =/}. То есть функция / во множестве U
содержит собственную программу как значение /@),
Такая функция называется функцией с автооппеа-
нием, ее удобно использовать для указания того, что
вложение методов вывода является истинным.
Попробуем показать, что существует рекурсивная
функция / такая, что ф/@> = f. Рассмотрим постоянную
функцию \(х)=р. Процедура построения fp из р
190
Глава 7
является рекурсивной, поэтому За е &\ для Vp ^ N
справедливо <pa(p) = fp. Из теоремы о рекурсии hi e
^/V; Фа(/> = ф/ = /«. Кроме того, из fi@)= i следует,
что // е [/. Следовательно, V ф 0. Аналогичным
образом можно доказать существование различных
функций с автоописанием, используемых в
приведенных далее доказательствах. И на самом деле, в
каждом процессе доказательства строится функция с ав-
тооппсанием, поэтому существование таких функций
можно считать очевидным.
Покажем, что U e EX. Рассмотрим машину
выводов М0 такую, что для [ей, k <= N будет M0{f lIc]) =
= /@). V/e(/, limkM0(f[k]) = f@)9 поэтому U <=
?=EX(Mo).
Покажем методом от противного, что f/^KUM.
Допустим, что f/eNUM. Для ^ЕЙ, /еА'
процедура, строящаяся /g из /, является рекурсивной,
поэтому
VgEEi%, ЗЛееЙ; V/e=tf, <pm = ig.
Из теоремы о рекурсии
V?E=i%, ЗЛее$; E/eiV; Фл (/) = ф/=/g.
Здесь из ф/@) = / следует ф/ <= (/, а именно:
VgE^, Э/е=ЛГ; Ф/ = у^Е=?/.
При этом
поэтому можно перечислить произвольные функции
/g такие, что ф/ = jg (ge52, j^N). Если к такому
перечислению /g применить рекурсивную функцию,
а роющую g из jg, то можно перечислить
произвольные рекурсивные функции g, а Й будет перечисли-
мым множеством. Но 31 неперечислимое, что приводит
нас к противоречию.
Покажем, что Si— неперечислимое множество.
Допустим, что оно перечислимое. Тогда 3h ^Я\ ?2 =
— {фад|/е#}. Определим e(j) = Фод(/) + 1- Из
того, что е^&у следует ЗА е iV; e(j)= Фл(*>(/). Здесь
если у = А, то ej/г) = Фм*I*) = срл(л)_(Л)гК *» А эт0
Теория индуктивных выводов
111
противоречит допущению, что е = фА(Л) е 31. (Конец
доказательства.)
Приведенная выше теорема показывает, что
понятие «позволяет делать ЕХ-идентификацию» гораздо
более широкое, чем мы его себе представляли.
Программы без бесконечных циклов представляются
рекурсивными функциями —правилами. Следовательно»
множество таких программ соответствует множеству
31 рекурсивных функций. Но 31 неперечислимое
множество, поэтому, например, нельзя применить метод
перечисления в задаче автоматического синтеза по
примерам всех программ без бесконечных циклов.
Но позволяют ли саЫи такие программы делать
ЕХ-идентификацию? Следующая теорема дает
отрицательный ответ на поставленный в начале этого
раздела вопрос, поэтому сегодня значение этой
теоремы очень велико.
Теорема 7.3 (Голд). Не существует машины
выводов, выполняющей ЕХ-идентификацию всех
рекурсивных функций, а именно 31 ф EX.
Доказательство. Используем метод от противного.
Допустим, что 3Mg^; 3t^EX{M). Для У/<ееЙ,
Vk^N имеем M(f[k])\, поэтому отметим, что Ме
ей. Рассмотрим функцию / == totit2 ...,
определенную следующей процедурой.
Шаг 0: определим U = 0, перейдем к шагу 1.
Шаг k (k^l): пусть определены /0, *ь •••> tk-u
Перечислим последовательности знаков, поочередно
состоящих только из 0 или 1: / = 0, 1, 00, 11, 000»
111, ... . Самое первое в этом перечислении ty
удовлетворяющее неравенству
м№х.. -'*-!» фмцы.. ./*_,/», (*)
определим как /*. Перейдем к шагу k+ 1.
Покажем, что /ей. Это можно сделать, если по*
казать, что на каждом шаге k данная процедура
всегда обнаруживает tk после конечного числа
операций. Если gEs/0*i ... f*-i0°°, h = tot\ ... f*-il°°, то
из того, что g, Лей^ЕХ(Л1), следует, что
существуют limkM(g[k] ) и limkM(h[k]). Из того, что
цф1г, имеем limkM(g[k]) ф limkM(h[k]). Поскольку
в противном случае, задавая М данные о различных
192
Глава 7
рекурсивных функциях g, А, мы придем к
заключению, что предположения, выдаваемые М, будут
сходиться к одной и той же программе, что противоречит
допущению. Следовательно, не должно быть, что
М(Шх ... tk-l))=limkM(g[k])=UmkM(h[k}), a
именно: по крайней мере одно из значений
\\mkM(g[k\) или \\mkM(h[k\) отлично от M((tot\ ...
... tk-v>). Пусть, например, M((t0t\ ... tk-\))?=
Ф lim* M (g [k]). Поэтому 3/ ^ 1; М «*<,* i ... 'л-i» Ф
фМ({Мх ... tk-iOO). Существует по крайней мере
одно /, удовлетворяющее условию (*), поэтому,
перечисляя на каждом шаге k значения t = 0, 1, 00, 11,
000, 111, ... и проверяя условие (*), можно всегда
обнаружить tk после конечного числа операций.
Таким образом, процедура определения / является
рекурсивной, а именно: fe?
Однако последовательность чисел {M(f[k])}k<-N
колеблется неограниченное число раз, поэтому $ф
^ЕХ(М). Это противоречит допущению о том, что
{е 31 s ЕХ(М). (Конец доказательства.)
Очень похожим на идентификацию в пределе
является понятие экстраполяции. Это понятие
встречается в задачах типа
„продолжите ряд чисел 1, 3, 5, 7",
которые часто встречаются в тестах на интеллект.
Если целью индуктивных выводов является
получение правила, объясняющего примеры, то целью
экстраполяции является прогнозирование следующего
элемента заданного ограниченного ряда. Экстраполя-
ционной машиной называется машина, которая
выдает прогнозируемое значение /(&+1) рекурсивной
функции / на основе данных /@), /A), ..., f(k).
Такую машину по аналогии с машиной выводов можно
рассматривать как частичную рекурсивную функцию,
которая в каждый момент времени k выдает
прогнозируемое значение /(/г + 1) на основании данных
f[k] о рекурсивной функции /.
Определение 7.3. Если экстраполирующая машина
М, которую будем считать рекурсивной функцией
Теория индуктивных выводов
193
(т. е. она выдает прогнозируемое значение, какое бы
входное значение ни получила), правильно
предсказывает следующее значение f(k+l) в каждый
момент, начиная с некоторого момента, то скажем, что
М NV-экстраполирует1) функцию /.
Если экстраполирующая машина М, которую
будем считать частичной рекурсивной функцией, выдает
прогнозируемое значение во все моменты времени,
когда заданы данные об /, и начиная с некоторого
момента в каждый момент k правильно прогнозирует
следующее значение /(?+1), то скажем, что М
NV-экстраполирует /. Если экстраполирующая
машина М, которую будем считать частичной
рекурсивной функцией, правильно прогнозирует следующее
значение /(&+ 1) во все моменты, начиная с
некоторого момента, когда заданы данные об /, то скажем,
что М NV'-экстраполирует /. Если существует
экстраполирующая машина, которая
NV-экстраполирует (NV'-экстраполирует, МУ"-экстраполирует)
любую функцию множества рекурсивных функций Uy то
скажем, что U позволяет делать NV-экстраполяцию
(NV-экстраполяцию, МУ"-экстраполяцию). Само
множество рекурсивных функций, которое позволяет
делать NV-экстраполяцию (NV-экстраполяцию, NV*
экстраполяцию), обозначим через NV(NV, NV"). Из
определения очевидно, что NV s NV7 г NV", но
известно, что NV ^ N V ? N V".
Определение экстраполирующей машины очень
похоже на определение машины выводов, поэтому,
используя первую машину, можно строить вторую
и, наоборот, используя вторую, можно построить
первую. Кстати, равнозначны ли возможности
экстраполяции и индуктивных выводов? Для строгого
обсуждения можно разместить NV, NV, NV" в
иерархии методов вывода (см. рис. 7.1, 7.2).
Для того чтобы уточнить особенности множеств,
которые позволяют делать NV-экстраполяцию,
введем понятие /г-простоты. Пусть /г — рекурсивная
и NV — сокращение слоз Next Value (следующее значе*
ние). — Прим. перев.
7 С. Осуга, Ю. Саэки
194
Глава 7
функция. Скажем, что рекурсивная функция / яв*
ляется /i-простой, если среди программ, вычисляющих
/, существует такая, которая почти для всех
натуральных чисел х, то есть для всех натуральных
чисел х, за некоторыми исключениями, заканчивает
вычисление f(x) за менее чем h(x) шагов.
Использование этого понятия позволяет указать следующие
особенности NV.
Теорема 7.4 (Бардин и Фрейволд, Блюм Л. и
Блюм М). Для множества рекурсивных функций V
следующие три условия равнозначны:
1) для некоторой рекурсивной функции h(x) все
функции множества (//г-просты;
2) U позволяет делать NV-экстраполяцию;
3) U есть подмножество перечисляемого
множества.
Доказательство. (Пусть P(k) — некоторое
суждение о натуральном числе k. Если 3ko^N, V& > &о
справедливо P(k), то скажем, что Р справедливо
почти лля всех натуральных чисел (почти всюду в N),
и запишем Р (п. в.). Скажем, что / /z-простая, если
3*e.V; ф/= f и Ф; ^ h (п. в.). Скажем, что
экстраполирующая машина Мей? NV-экстраполирует
рекурсивную функцию /, если З&о ^ N и для Vk ^ ko
справедливо M(f[k] ) = f(k + 1). Запишем это в виде
NV(M) as {/ е Я\М <= / NV-экстраполирует /}, что
обозначим так. NV = {UsSl\ ЗМ е=$; U с NV(Af)},
Кроме того, определим NUM = { U s 31 \ За е 52;
Используя введенные обозначения, представим
данную георему в виде {?/^52| ЗЛ е52; V/e?/,
3/f=iV; ф/ = [ и ф,-^ А (п .в.)} = NV = NUM.
A)=^B). Пусть ЗА ^52; любая функция /
множества U ft-проста. Тогда построим следующим
образом экстраполирующую машину М. В доказательстве
обозначение <jc, у} представляет собой рекурсивно
закодированные пары натуральных чисел (х,у).
Пусть /@) ... f(x—1)(х^1) — ограниченная
произвольная последовательность натуральных чисел
длины более 1. М перечисляет все пары натуральных
чисел (/, я), начиная с меньшего </, п>, и среди пар
[i9 я), удовлетворяющих условию
Теория индуктивных выводов
195
Vу < х, Ф{ (у) < max {ny h (у)},
V#<x— 1, <Pi(y) = f(y)
отыскивает пару (/0, ло)> появившуюся первой (т. е.
с наименьшим <i, п>) при таком перечислении, затем
выводит М (/ [п — 1]) = ф/0 (х).
Покажем, что М е 5?. Это можно сделать, если
показать, что при задании ограниченной
последовательности /@) ... f(x—1) в качестве входных
данных М всегда будет выдавать M(f[x—1]) после
конечного числа операций. При проверке (*) для
каждого (i,n) может и не быть ф/(*/Н, но число шагов
Ф/(у) вычисления ф/(г/) ограничено сверху числом
max{n, h(y)}, поэтому проверка (*) всегда
закончится через конечное число операций. Кроме того,
пусть ро — некоторая программач для ограниченной
последовательности /@) ...f(x—1), например /@)...
... f(x— 1H°°, если s0 = max {ФРо(#)(#<*}, то
(ро, So) удовлетворяет условиям (*) для (i9n)9
поэтому существует по крайней мере одна пара (/, п),
удовлетворяющая (*). Следовательно, благодаря
перечислению всех пар натуральных чисел (/, п) в
порядке, начиная с наименьшего </, п}у и благодаря
проверке (*) можно всегда обнаружить требуемую пару
(io, п0). При этом из Ф/0 (х) ^ max {я, h(x)} следует
Ф/о {х) |. Следовательно, M(f[x— 1 ]) = ф/0 (х) всегда
выдается после конечного числа операций.
Возьмем Vfei/. / /i-проста, поэтому 3/ <= N) Ф/ —
= / и 3yoe=N\ Vy^yo, ®i(yXh{y). Пусть m =
= гпах{Ф](у) \у < г/о}» тогда (/, т) удовлетворяет
условию (**):
Vys=N, Ф/(г/)<тах{т, h{y)} и <Pj(y) = f(y). (**)
Существует по крайней мере одна пара (/, т),
удовлетворяющая (**), поэтому среди всех таких пар су*
ществует (/о, т0) с наименьшим </, т>. Пусть х0 —
наименьшее х, при котором М, прочитав f[x— 1],
выбирает (jo1m0I тогда М для Ух^х0г прочитав
f[x— 1], выбирает (/о, т0), поэтому М(/[л:—1]) =
= Ф/о(*1=/(*). Поэтому /e=NV(iW),To есть ?/eNV.
(*)
7*
196
Глава 7
B)=^C). Пусть ?/e=NV, а именно: ЭМе=М;
U ?NV(M). Конечная начальная функция — это
функция из N в N с областью определения {О, I, ...
..., п} (пбЛ/).[о, /ь .-• — перечисление всех
конечных начальных функций. Определим gi по М и /г
следующим образом:
)ава( М*) ПРИ *€=dom(/,),
^ ^ \ M(gi [x — 1]) в остальных случаях.
Из МеЯ следует V/ е #, g* е 52. Кроме того,
процедура построения gi из i рекурсивна, поэтому
За е $!; V/ е N, фв(«) = g"/. Для любой функции /,
которую М NV-экстраполирует, 3/gM, f — gi и,
наоборот, для Vi^N M NV-экстраполирует gi,
поэтому NV(Af)= {gi\i^N}. Таким образом, Зоей;
?7^NV(A!) = {?;|/ееЛ/} = {фв@|/еЛ/}^Я, а
именно: (У ее NUM.
C)=ф-A). Пусть ?/ее NUM. То есть За е= Я; U ?
s {фа(о | ? е jV} ? 52. Пусть А (х) ss max {Фа(о (*) | i <
<4- Из Vi^N, фа(о^52 следует Фв^еЯ.
Поэтому ЛЕЙ, а именно: ЗЛ е ?2; 'V[e(), 3a(i)^N;
фа(/) = / и 3t'EJV; Vx^ /, Фа(о(*)^ Л(*)- Другими
словами, любая f из U /i-проста. (Конец
доказательства.)
Из этой теоремы очевидно, что возможности NV-
экстраполяции и метода перечисления равнозначны, и
то и другое можно применять для множества, все
функции которого /i-просты. Блюм в качестве
критерия объема вычислений использовал понятия /г-уме-
ренный и О-умеренный, выяснил особенности методов
вывода и показал, что существует тесная связь между
возможностями вывода и объемом вычислений. На
основе теории объема вычислений Блюма аналогичные
исследования были продолжены группой математиков
из ФРГ, которые получили интересные результаты.
Из этого раздела мы узнали, что NUMVEX,
Й^ЕХ. В разд. 7.3 будет введен еще один критерий
успеха индуктивного вывода, слабее, чем
идентификация в пределе (ЕХ-идентификация); мы ознакомимся
с иерархией методов вывода, главным образом выше
Теория индуктивных выводов
197
уровнем, чем EX. В разд. 7.4 будет введен критерий
успеха, сильнее ЕХ-идентификации, и объяснена
иерархия методов вывода между NUM и EX.
7.3. РАСШИРЕНИЕ ИДЕНТИФИКАЦИИ
В ПРЕДЕЛЕ
В разд. 7.2 показано, что множество рекурсивных
функций 01 не позволяет делать ЕХ-идентификацию.
Если ослабить условия сходимости неограниченной
последовательности предположений, которые выдает
машина выводов, то возможности вывода, как правило,
повышаются. На основе работ Кейса и Смита введем
критерий успеха индуктивных выводов, слабее
идентификации в пределе (ЕХ-идентификации), и обсудим
иерархию расширенных методов вывода. Давайте
уточним, до каких пор можно ослаблять критерий
вывода для множества рекурсивных функций 01 и
существуют ли какие-либо критерии между новым
критерием и ЕХ-идентификацией. Иерархия будет
представлена на рис. 7.1 в конце этого раздела.
7.3.1. КРИТЕРИЙ, ДОПУСКАЮЩИЙ ИСКЛЮЧЕНИЯ,
И КРИТЕРИЙ, ИМЕЮЩИЙ ОГРАНИЧЕНИЯ
НА КОЛИЧЕСТВО ИЗМЕНЕНИЙ ПРЕДПОЛОЖЕНИЙ
При ЕХ-идентификации машине выводов М задаются
данные о рекурсивной функции / и требуется, чтобы
предположения, выдаваемые М, сходились в
программе /. Ослабим этот критерий успеха и рассмотрим
критерий, в соответствии с которым предположения
могут сходиться к программе, вычисляющей /, за
исключением конечного числа случаев. Пусть m, n —
натуральные числа или знак *.
Определение 7.4. Скажем, что машина выводов
М ЕХ^-идентифицирует рекурсивную функцию /, если
при задании данных об / предположения, выдаваемые
М, сходятся к программе, правильно вычисляющей /,
за исключением не более чем п случаев (при п = *,
за исключением конечного числа случаев).
Очевидно, что при увеличении максимального
числа исключений п становятся лучше
соответствующие методы вывода ЕХ" (см. рис. 7.1),
198
Глава 7
Кроме метода Блюма, приведенного выше, в ка- т
честве критерия измерения объема вычислений при
индуктивных выводах можно рассмотреть количество
изменений предположений машиной выводов.
Определение 7.5. Скажем, что машина выводов
М EXm-идентифицирует рекурсивную функцию /, если
при задании данных от f M ЕХ"-идентифицирует
функцию / после максимально m изменений
предположений (при m = * после некоторого количества
изменений).
Понятие ЕХ*-идентификации совпадает с
понятиями идентификации почти всюду (Блюм) и
субидентификации (Миникоччи).
Обратим внимание, что по определению ЕХ =¦
=ЕХ = ЕХ*, ЕХП=*ЕХ*. Очевидно также, что при
уменьшении максимального числа изменений
предположений критерий успеха усиливается, а
соответствующие методы вывода - EXW становятся хуже.
ЕХо-идентификация — это критерий выдачи
правильной программы только при одном изменении
предположения. Этот критерий аналогичен так называемой
конечной идентификации (FIN), при которой можно
определять конечный набор данных, необходимых^
для выдачи машиной выводов правильного
предположения. Таким образом метод вывода ЕХо можно
обозначить как FIN. Пусть а, Ь, с, d — натуральные
числа или знак #. Кроме того, определим, что для
любого натурального числа k ^ -*. При этом очевидно,
что
EXt<=EXcd<=>a^c и 6<rf
(см. рис. 7.1).
7.3.2. КРИТЕРИЙ, ОСНОВАННЫЙ НА СХОДИМОСТИ
С ТОЧКИ ЗРЕНИЯ ДЕЙСТВИЙ ПРОГРАММЫ
В критериях, рассмотренных до сих пор, требовалась
сходимость неограниченной последовательности
предположений, выдаваемых машиной выводов, как
последовательности натуральных чисел. Это
соответствует посимвольной сходимости неограниченной по-
Теория индуктивных выводов
199
следовательности программ, представляющих собой
предположения. Рассмотрим критерий, при котором
нет такой сходимости, но, начиная с некоторого
момента, можно корректировать действие программы.
Определение 7.6. Скажем, что машина выводов М
ВС-идентифицирует J> рекурсивную функцию f, если
предположения, выдаваемые М во все моменты
времени, начиная с некоторого момента, есть не что иное,
как программа, вычисляющая f. Кроме того, скажем,
что М ВО-идентифицирует f, если предположения,
выдаваемые М, во все моменты времени, начиная с
некоторого момента, за исключением максимально
п случаев (при п = *, за исключением конечного
числа случаев), есть программа, вычисляющая /.
Обратим внимание, что по определению ВС = ВС0.
Если критерий успеха индуктивных выводов
ослаблен до ВС-идентификации, то 91 будет позволять
делать выводы.
Теорема 7.5 (Кейс и Смит). Существует машина
выводов, которая ВС*-идентифицирует все
рекурсивные функции, т. е. 91 е ВС*.
Доказательство. ( Пусть р — программа, а / —
рекурсивная функция. Если Ц)р{х) определяется, но
отличается от }(х) или Цр(х) не определяется, то
запишем Ц)Р(х)ф f{x). При этом такое х назовем
исключением, при котором программа р не может вычислить
/. Если {х е N | фр (х) Ф f (х)} — конечное множество,
то запишем фр = */. Скажем, что М е 9*
ВС-идентифицирует [еЯ, если Vk^N, M(f[k])\ и 3k0 e N*
Vk ^ k0, фМ (f[k)) = *f.)
Пусть e(f[k])—программа, определенная ниже.
Покажем, что для V/еЙ, Vk&N машина выводов,
определенная как M(f[k] )e= e{f[k]),
ВС—идентифицирует /.
Программа e(f[k]), получив входное значение
xeAf, действует следующим образом.
f Среди р, таких, что 0 ^ р ^ ky отыскивает ми-
фр (у) ^ х. Если такое р существует, то для входного
значения х запускается программа р, и если фр(х)
нимальное р, такое, что 0 ^ Vy ^ k> yp(y) = f(y) и
1> От английских слов Behaviorally Correct. — Прим. ред.
200
Глава Т
вычисляется, то возвращается его значение. Если
такого р не существует, то возвращается 0. J
ФР в общем случае — частичная рекурсивная
функция. Кроме того, если изменить k, то изменится что-
то внутри f J, т. е. изменятся символы в
программе е (/[&]), поэтому следует обратить внимание
на то, что последовательность натуральных чисел
{e(f[k])}k^N не сходится.
Возьмем любую рекурсивную функцию /. Пусть
pf программа, вычисляющая /, с минимальным
номером, а именно: pf = min{/? e N|<рр = /}. Если взять
достаточно большое натуральное число kf
(например, пусть kf — максимальное из чисел pf и
max{min{y&N\<(p(y)=?f(y)}\0^p<pf})t то
выполняется
Pf<kf, 0<Vp<pf, 0<3z/<?f; <pp(y)?>f(y).(*)
Здесь показано, что yk^zkf, Фм(И?]) = 7« Если взять
достаточно большое натуральное число Xftk
(например, пусть Xf, k = niax {<hpf(y) |0 ^ у ^ к), то
выполняется
0<V*/<6, Opf(y)^xUk. (**)
По определению M(jl[k] )== e(f [k]). Для любого
входного значения х ^ xf} k, как следует из (*) и (**),
программа e(f[k]) отбросит все р, такие, что
О < р < pf, выберет pf и выдаст Фв(п*п(х) = Ф/?г (х) =
= /(*)• ПОЭТОМУ Vx^ZXf k, <PM(f[k\){x) = (pe{flk])(x) =
-fix).
В результате V/еЯ, 3kf^N; Vk^kf, флмм*:) = 7»
а именно: Л1 ВС*-идентифицирует любую
рекурсивную функцию /. (Конец доказательства.)
Критерий ВС*-идентификации не реализуем, но
из определения возможности делать выводы из
множества следует, что любое подмножество 52
позволяет делать ВС*-идентификацию, поэтому метод
вывода ВС* совпадает с семейством всех мно^ еств
рекурсивных функций. Следовательно, пока объектом
индуктивных выводов являются рекурсивные функции,
метода вывода «сильнее», чем ВС*, не существует.
Теория индуктивных выводов
201
Кейс и Смит показали, что методы вывода
ЕХт, ВС" образуют следующую красивую иерархию
(рис. 7.1). Обозначим через +U, ^, ^ отношения
строгого вложения, а именно: метод вывода, лежащий
вверху или слева, строго лучше, чем методы вывода,
лежащие внизу или справа. Эта иерархия отражает
связь между методами вывода EXo, EX, EX*, ВС,
ВС*, отличающимися по максимальному числу
исключений, допускаемых в сходящихся
предположениях, или максимальному числу изменений
предположений. Иерархия методов вывода, допускающих
исключения, кроме того, подробно проанализирована
и исследована в работах Чена, Смита, Дэйли и
других математиков.
^€ЕВС*
\)
•
•
ю
ВС1
V
BC=NV"
KJ
ЕХ*2 • •
(U ^
KJ
ЕХ1 2 . .
и
EX Q • •
\
• РЕХГ?ЕХ1
и ю
• •
?*J V
• 2EXl2EXi
U 0 «J
• РЕХ?2ЕХ!
NV
Рис. 7.1. Иерархия методов вызода ЕХ^ ВС" по Кейсу и
Смиту
202
Глава 7
7.4. ИНДУКТИВНЫЕ ВЫВОДЫ,
УДОВЛЕТВОРЯЮЩИЕ ЕСТЕСТВЕННЫМ КРИТЕРИЯМ
В разд. 7.3 рассмотрены критерии, более слабые по
сравнению с ЕХ-идентификацией, в которых либо
допускалось конечное число исключений при
предположениях, либо сходимость заменялась действиями
программы, и предложена иерархия методов вывода,
главным образом лежащих выше метода EX. С
практической точки зрения, естественно, более
желательны критерии, при которых предположения,
выдаваемые машиной вывода, в любой момент времени не
противоречат заданным до этого времени данным.
Допустим, что ЕХ-идентификация имеет свойства,
естественные с практической точки зрения;
рассмотрим критерии сильнее, чем ЕХ-идентификация, и
выясним иерархию методов вывода, лежащих ниже
ЕХ-идентификации. Результаты, с которыми мы
ознакомимся далее, получены группой математиков из
ФРГ (Вихаген, Янтке, Бейк).
7.4.1. КРИТЕРИЙ С ОГРАНИЧЕНИЕМ
НА ОБЛАСТЬ ПАМЯТИ
Машина выводов, которая обсуждалась до сих пор,
делала предположения на основе всех данных
f@)> /40» •••> /(&)> заданных до момента времени k.
Индуктивный вывод — это процесс неограниченной
продолжительности, поэтому со временем объем
данных, к которым должна обращаться машина
выводов, неограниченно возрастает. Для изучения
возможностей индуктивных выводов, выполняемых на
реальных компьютерах, необходимо вводить
ограничения на область памяти. Поэтому рассмотрим
критерий, при котором правильный вывод делается
благодаря итеративному (ITeratively working)
определению предположения hk+\ в момент &+ 1, только на
основе предыдущего предположения hk на момент k
и полученных в текущий момент данных (k, f(k)).
Определение 7.7. Скажем, что машина выводов М,
которую будем рассматривать как частичную
рекурсивную функцию трех переменных, 1Т-идентифици-
рует рекурсивную функцию /, если неограниченная
Теория индуктивных выводов
203
последовательность предположений {hk}kGN, опреде-»
ляемых следующим образом: Л0 == 0, hk+\ == М(Л*,
k, f(k)), сходится к программе, вычисляющей /.
IT-идентификацию можно назвать критерием с
ограничением на область памяти при реализации
процесса «запрос входных значений —> вычисление
предположения -> выходное значение».
Теорема 7.6 (Вихаген). IT-идентификация имеет
возможности строго слабее, чем ЕХ-идентификация,
а именно: IT?EX.
Доказательство. По определению IT s EX,
поэтому достаточно показать, что 3?/еЕХ\1Т. Пусть
U0 =з {аО°°|аеЕЛ/*}, V\ = {/ е= Я\ут = f, VxeeN,
Если построить следующим образом машину
вывода Af0, то ?/ ^ ЕХ(Мо).
л:0 при 0^{% лгь ..., л;*},
некоторая программа
рекурсивной функции
#о*1 • • • **0°° — в других
случаях.
Af0«*o, *ь • •> я*»^
Покажем методом от противного, что /7 0 1Т<
Обозначим через 9>г множество частичных рекурсив*
ных функций трех переменных. Допустим, что
ЗМ e^3;C/=[/oU[/ig iT(Af). Определим
следующим образом ft для любого / е М
МО)-*,
Г 1 при Af(AA^), /t, \)?>hk{h),
Ы*)Н 2 При M(hk(fi), k, \)~hk(ft) it
Здесь А,(/,)и0, Л*+,(М=М(М//), А;, /*(*))
(/г^О), \i^.3i. Это потому, что не существует
k e N такого, что
M(hk{fil Ь l) = M(hk(fi), ky 2) = А*(Л), (*)
поэтому //(Л) определяется для любого k&N. А раз
(гак, то возьмем минимальное среди ky удовлетворяю-
204
Глава 7
щих (*). Пусть g e 01 — функция, определяемая
следующим образом:
!/,• (х) при х < k,
1 при x = k,
0 при х > ky
a g' е 91 — функция, определяемая следующим
образом:
( ft (х) при х < k,
g'(x) = < 2 при x = k,
I 0 при х > k.
Пусть {hk{g)}k^N, {hk(g')}k&N соответственно
последовательности предположений при задании М данных
о g, g'. По допущению для Yk&N, hk{g) = hk{g').
Но это противоречит тому, что g", g' <= t/0 S IT (M)
и g =И= ?'. Таким образом, не существует *eJV,
удовлетворяющего (*).
По теореме о рекурсии За > 0; <рв = fa e ?/ь
При задании машине выводов Л1 данных о /а
последовательность предположений {hk(fa)}k&N
неограниченно колеблется, поэтому fa ^ 1Т(М). Это
противоречит тому, что fae f/i s t/s IT(M). (Конец
доказательства.)
7.4.2. НЕПРОТИВОРЕЧИВЫЕ КРИТЕРИИ
Критерий, при котором предположения, выдаваемые
в каждый момент времени машиной выводов, не
противоречат всем полученным до этого момента
данным,— естественный и часто используется в системах
автоматического синтеза программ. Фактически
систему модельных выводов MIS, созданную Шапиро,
можно рассматривать как машину выводов,
удовлетворяющую этому критерию. Метод вывода CONS °
позволяет представить возможности этого критерия.
Определение 7.8. Скажем, что машина выводов М
CONS-идентифицирует рекурсивную функцию /, если
1) От английского слова Consistent (состоятельный,
логичный). — Прим. перев.
Теория индуктивных выводов
205
М ЕХ-идентифицирует /ив любой момент времени k
может вычислить предположение М (/[&]) по всем
полученным до этого момента данным /@), /A), ..«
...,/(?)•
Очевидно, что машина вывода, которая выдает
только предположения, объясняющие все
полученные до некоторого момента данные, не может делать
выводы для множества рекурсивных функций,
которое позволяет делать IT-идентификацию (а
следовательно, и ЕХ-идентификацию).
Теорема 7.7 (Вихаген). CONS-идентификация
имеет строго лучшие возможности, чем метод
перечисления, но строго худшие возможности, чем IT-
идентификация, а именно: NUM ^ CONS ^ IT.
Доказательство. (Скажем, что машина выводов
М е 31 CONS-идентифицирует рекурсивную функцию
/, если /<ее ЕХ(М) и V&ge N, Фм<п*]) = /[А].)
1) NUM^CONS.
la) Покажем, что NUMeCONS.
Пусть 3h^9l\ U ^{cpk{i)\i<z=N} ?#.
Основываясь на методе перечисления из теоре*
мы 7.1, машину выводов М^& можно представить
следующим образом:
М((х0> хи ..., xk))-
h(mm{ie=N\q>h{i)[k] =
= (xQi хь ..., xk)}),
если такое / существует,
не определена в других
случаях.
Когда задаются данные о любой функции / из ?/,
машина выводов М, выдавая только предположения,
не противоречащие всем полученным до сих пор
данным, ЕХ-идентифицирует /, поэтому U s CONS(Af).
16) Покажем, что CONS\NUM^0.
Если определить множество рекурсивных функций
U и машину выводов Л10 так, как в доказательстве
теоремы 7.2, то станет очевидным, что U S
c=CONS(A!o) и f/^NUM.
2) CONS ^ IT.
Соб
Глава 7
M'(k9 x, у) i
2а) Покажем, что CONS s IT.
Пусть ЗМе^; GsCONS(Af). Тогда построим
иашнну выводов ЛГ е ^3 следующим образом:
М((у)) при ? = л; = 0,
М«Ф*@)...Ф*(^-1)у» при х>0
и Фл @ i Для 0 ^ V/ ^ л: ~ 1,
не определено в других случаях.
Пусть {hk}k(-N — последовательность предположений
при задании М' данных об V/ е I/, тогда Нпий* =
~= lim*M (f [k]). Таким образом, U s IT(М').
26) Покажем, что IT\CONS^0.
Пусть ?/ ss {at/1 а е Л/*, t ^2, f — рекурсивный
предикат, ср,- = aif]. Построим машину выводов
М е ^3 следующим образом:
.... , Г У при */>2,
v ' ' *' ( ft при у < 2.
Последовательность предположений при задании М
данных об Vcp; e= ?/ сходится к /, поэтому ф* е IT(Af).
Следовательно, U e IT.
Покажем методом от противного, что [/ ^ CONS.
Допустим, что Ме^; ?/^CONS(Af). Определим
* для любого i е ДО следующим образом:
//@)-/,
•
(при к^О)
0 при М«М0)...Ы*H»=*
^М«/,@)..
1 при М«Ы0)...М*H» =
= М«/,@).
и М«М0)...Ы*I»=*
•м*)>),
../,(*)»
.//(*)».
fi s й. Поскольку не существует ftsiV такого,
что Л!«МО) ". М*)О»=М«М0) ... fi(k)\)) =
==M«//@) ...//(*)», поэтому ft (А) определяется
для любого натурального числа k. Пусть существует
k такое, что k e ДО, тогда существует функция в ?/,
которая для любой ограниченной последовательности
а натуральных чисел»начинается с а, поэтому суще-
Теория индуктивных выводов
207
ствуют g^U такая, что g[k + 1] « <//@) ...
... /|(АH>, и feU такая, что g'[k+l] — <М0) ...
.../,(&) 1>. Следовательно, можно определить
М(#[&+!]) и M(g'[?+1]). По допущению для
любого k они равны. Из того, что g, g' s 0 е
^CONS(M) имеем g[? + 1] = ?'[**+ 1]» что
противоречит способу определения g, g'. To есть не
существует fteJV.
По теореме о рекурсии За ^2; фа = fa q С/.
Числовая последовательность {Af (/д [k])}ke.N
неограниченно колеблется, поэтому fa0CONS(Af). А это
противоречит тому, что fa e ?/ г CONS(Al). '(Конец
доказательства.)
7.4.3. ПОРЯДОК УКАЗАНИЯ ДАННЫХ
В приведенных до сих пор критериях способ показа
примеров рекурсивной функции Д а именно порядок
указания данных, ограничивался только
последовательностью /@), /A), ... . Ниже опишем критерий
задания данных в произвольном (ARBitrary)
порядке. Неограниченный ряд, в котором все
натуральные числа появляются только один раз, называется
перестановкой N.
Определение 7.9. Скажем, что машина выводов М,
которую будем считать частичной рекурсивной
функцией трех переменных, 1ТагЬ-идентифицирует
рекурсивную функцию f, если для любой перестановки
N X гэ {хо, хи .. } — неограниченная
последовательность предположений {hk+l(f, X)}k^Ni определяемая
как h0 (f, X) ш* 0, hk+l (/, X) = М (hk (/, X), xk, f (xk))
(k^O), сходится к программе, вычисляющей /.
По аналогии с IT-идентификацией назовем IDarb-
идентификацией критерий, определяемый при задании
данных в произвольном порядке, а соответствующий
метод вывода обозначим через IDarb. Очевидно, что
IDarb s ID, поэтому есть два случая: IDarb ^ ID или
IDarb = ID. В последнем случае возможности вывода
при ID-идентификации не зависят от порядка
задания данных. Поэтому ID-идентификацию и метод
вывода ID называют независимыми от порядка.
208
Глава 7
Легко понять, что не зависит от порядка ЕХ-иден-
тификация, поскольку из любой машины выводов М
можно построить следующую машину выводов М\
для которой ЕХ(М) ^ ЕХагЬ(М').
Если для любой перестановки N X = {х0, *i, ...}
заданы данные (х0) /(лг0)), (х\, f{xi)), ..., то М'
запоминает эти данные, выдает соответствующее
предположение до момента, пока не будут заданы все
данные @, /@)), A, /A)), ..., F, f(k)) Для
некоторого kt и выдает предположение M(f[k]), когда все
эти данные будут заданы. Посмотрим, для всех ли
машин выводов эффективен этот метод, ведь пока
мы без ограничения общности считали критерии
успеха независимыми от порядка. В такой ситуации
Янтке и Бейк показали, что IT-идентификация не
является независимой от порядка.
Теорема 7.8 (Янтке и Бейк). IT-идентификация
зависит^от порядка, а именно: ITarb ^ IT.
Доказательство. Достаточно показать, что 1Т\
\ITarb Ф 0. Пусть Uoi = {/ е= 91\\ — рекурсивный
предикат, такой, что / = 0 (п. в.) или /= 1 (п. в.)}.
t/0i — перечислимое множество, по теореме 7.7 U0\ e
geNUMcz IT..
Покажем методом от противного, что ?/oi Ф- ITarb.
Допустим, что 3Mg^3; U0\ s ITarb(M). Пусть f0 =
= 0, X = {0, 1, 2, ...} — перестановка. f0 e ?/0ь
поэтому есть начальный момент s e Nt при котором
последовательность предположений {hk(f0, X)}k(_N при
задании М данных о /о в порядке X сходится к
правильной программе f0, а именно:
3ss=N; A^tfo, X)?*h3{f0,xy9
Mk > s, hk (/0, X) = hs (/0, Xy Ф,5 (foi X) = /0.
Для простоты будем писать hk^hk{fof X) (k^O).
Рассмотрим предикат /ь определенный следующим
образом:
( 0 При X ^5,
Теория индуктивных выводов
209
fi <= Uoi s 1ТагЬ(Л1), поэтому по аналогии с /о
3tz=N; ht_{(fuX)^ht(fb X);
\tk>f, ht(fi,X) = ht(fl,X)}%t{fvX) = fl. (*)
Здесь для / s 52 и перестановки К = {г/0> */ь .. •}
будем записывать (/, Y) [k] = <J(y0), f(yx), ...
..., /Ы>. Из (/0,Х) [s] = (fuX) [s] имеем ft, =
= hs+i = hs+i (fu X). Из того, что /0 Ф fu получаем,
что hs+\(fuX) не является программой fu поэтому
t>s+L
Рассмотрим перестановку Хи = {*о, *ь • • •}>
определяемую числовой последовательностью xt\
( I ПрИ /<!s,
k ПрИ / = 5+1,
/ — 1 При 5 + 1 < / ^ k,
V. i при / > k.
Кроме того, рассмотрим следующий предикат gki
xt^
0 при x = k9
ftw—I fiW при хфкт
= 1°
Возьмем k такое, что k ^ t{> s-\- 1). Из того, что
(/,, X) [s] = (gu Хк) [s] = (/о, X) \s], имеем
0<V/О + 1, h,(fu X) = h,(gk, Хк) = h}.
Кроме того,
A,+2(g*, Xk) = M(hs+i(gk, Xk), xs+u gb(xt+l)),
= M(hs+l,k,0),
= ht.
Теперь из условий k ^ / и (*) имеем
Vj>s,hl(fl,X) = hi+1(gk,Xk).
Следовательно,
а именно: существует lim/ft/(^, Zft), и программа ft
отлична от g/e. Поэтому gk^lTarb(M). Это противо-
210
Глава 7
речит тому, что gk& ?/<и sJTarb(M J. (Конец
доказательства.)
Очевидно, что на практике кроме 1Т-идентифика-
ции есть несколько других естественных критериев,
зависящих от порядка (см. рис. 7.2).
7.4.4. ДРУГИЕ ЕСТЕСТВЕННЫЕ КРИТЕРИИ
Кроме указанных выше можно рассмотреть много
других критериев, имеющих естественную природу.
В частности, среди них выделим критерий
оптимального (BEST) объема данных, требуемого для
индуктивного вывода.
Определение 7.10. Скажем, что множество
рекурсивных функций U позволяет сделать BEST-иденти-
фикацию, если существует машина выводов М,
которая ЕХ-идентифицирует U, но не существует машины
выводов, которая идентифицирует любую функцию из
U по данным, объем которых тот же, что нужен для
Му а некоторую функцию идентифицирует по данным,
объем которых строго меньше объема, требуемого
для М.
Перечислимое множество рекурсивных функций
обозначим через NUM!. Голд показал, что метод
перечисления, который на первый взгляд имеет плохую
эффективность, оптимально с точки зрения объема
данных идентифицирует множество функций, которое
можно перечислить. Этот факт запишем как NUM! s
s BEST.
Если при идентификации функции из множества
рекурсивных функций U предположение, которое
выдала машина выводов, не является программой
функции, принадлежащей U, то такое предложение нельзя
считать правильным. Следовательно, можно считать
естественным свойство сохранения класса (Class
Preserving), состоящее в том, что машина выводов в
качестве предположения всегда выдает только программы
функций, принадлежащих U. Скажем, что машина
выводов М с таким свойством СР-идентифицирует
множество рекурсивных функций U, если М
ЕХ-идентифицирует U. Скажем также, что ведется WCP-
идентификация, если машина выводов М обладает
свойством сохранения класса в слабом смысле
Теория индуктивных выводов
211
(Weakly Class Preserving), состоящим в том, что М
выдает только программы функций, принадлежащих
ЕХ(Л1), или ведется TOTAL-идентификация, если
машина выводов обладает свойством выдавать только
программы рекурсивных функций (TOTAL recursive
function).
Итак, мы рассмотрели много критериев с
естественными свойствами. Можно изучить критерии,
обладающие несколькими из этих свойств. Например, если
машина выводов М, обладающая свойствами
сохранения класса и непротиворечивости, ЕХ-идентифици-
рует множество рекурсивных функций [/, то скажем,
что М CP-CONS-идентифицирует U. При этом
соответствующий метод вывода CP-CONS назовем
комбинацией методов СР и CONS. Такие комбинации
будем отмечать знаком «-». Аналогично можно
определить другие комбинации методов вывода.
Используя их, можно уточнить особенности метода вывода
BEST, оптимального по отношению к объему данных.
Теорема 7.9 (Янтке и Бейк). Возможности BEST-
идентификации равнозначны возможностям СР-
CONS-идентификации, а именно: BEST-CP-CONS.
Доказательство. (min{/e e N\ V/^ k, M{f[k]) =
= M (/[/]) назовем точкой стабилизации при задании
М данных о /, обозначим ее через Stab (Л!,/).
Скажем, что множество рекурсивных функций U
позволяет сделать BEST-идентификацию, если существует
машина выводов М е 91, удовлетворяющая двум
условиям. Запишем это как ?/^BEST(M). Эти
условия:
1) t/sEX(AI);
2) для любой машины вывода Гей такой, что
U ? ЕХ(Г), справедливо утверждение
V/ е= U, Stab (Г, /) < Stab (М, f)
**Vf e?/, Stab (Г, /) = Stab(M, f).
Метод вывода BEST определим как BEST = {U s
cz Я\ ЗМ €= 9\ U s BEST(M)}.
Скажем, что множество рекурсивных функций
позволяет сделать CP-CONS-идентификацию, если ЗМ е
е=^; U<=EX(M) н?/е?/, Vk<=Nt умцт&и (со*
212
Глава 7
хранение класса), <pvf(f [k]) = f[k] (непротиворечивость).
Запишем это как U s CP-CONS (M). Метод вывода
CP-CONS определим как CP-CONS = {U s Я\ ЗМ е=
<ее^; t/s CP-CONS(М)}.)
1) Покажем, что BEST = CP-CONS.
Пусть 3Ale^; t/sBEST(Al). Покажем методом
от противного, что U s CP-CONS (M).
1а) Допустим, что Bg €Е /7; 3s е= ЛГ; <p.w(gisu ^ ?/.
При этом Stab(Af, g) > 5. Пусть р одна из программ
#. Построим следующим образом М' е 3* для / е ^,
А*'(/Ш) = {
/? ПрИ S<& И #(&) = /[&]•
Л1 (/[&]) в других случаях.
U ^ЕХ(М'), кроме того, очевидно, что Vfe[/,
Stab (Af'f /) < Stab (М, /) и Stab (M\ g) = s <
< Stab(Af, g"). Это обратно тому, что (ZsBEST(jM).
16) Допустим, что 3gs=U; 3se=Af; q>w(s[S])[s]?=g[s].
При этом Stab(M, g) > s, поэтому можно прийти
к противоречию тем же способом, что и в 1а.
2) Покажем, что CP-CONS s BEST.
Пусть 3Mg^; t/ s CP-CONS (M). Построим
следующим образом ЛГ е ^:
для f <=$, k^N
M(f[k]) при & = 0 или
<*)*¦/(A),
M ('l*" — ] Д1'(/[А- 1]) приЬОи
V(M*-i]>W = fW'
не определено в других случаях.
U ? CP-CONS (ЛГ), обратим также внимание на то,
чго М' обладает свойством не изменять второй раз
предположение, если хотя бы один раз она выдала
правильное предположение.
Покажем методом от противного, что U s
S BEST(M'). Допустим, что
ЭЛ1"€=^, ?/<=ЕХ(Л1") и
VAetf, Stab (M77, A)<Stab(Af, /г),
3/ е= ?/; Stab (ЛГ, /) < Stab (М'9 /).
Теория индуктивных выводов
213
Пусть gsEstpAnnstaMM", f)]), тогда / Ф gy а из того,
что М' сохраняет класс, имеем g ^ [/. Кроме того,
из непротиворечивости ЛГ имеем
/[Stab(M", f)] = VM,{f[siabm,,tf)])[SUb(M", /)] =
= g[Stab(M", /)].
Поэтому ? = фЖ(?jstab(лг, f)]). Af, прочитав g[Stab(AT,
f)], выдает программу g, поэтому из свойств М
Stab(M', g)<Stab(M", /).
Из того, что /lStab(M"J)] = ?[Stab(M",/)] и /,?е
eI7, f Ф g, имеем
Stab (ЛГ, /) < Stab (Л1", g).
Следовательно,
Stab(Af', g)<Stab(M", g).
Это противоречит допущениям о М". (Конец доказа-
тельства.)
Для методов вывода, естественных с практической
точки зрения, известна следующая иерархия. Это
главным образом иерархия ниже чем EX. Пусть ID —
некоторый метод вывода, тогда обозначим через
52-ID метод вывода, определяемый, в частности, тогда,
когда машина вывода является рекурсивной
функцией. На рис. 7.2 показано, что методы вывода,
лежащие выше непрерывной линии, строго лучше, чем
методы, лежащие под ней. Например, Ю{ указывает
вложение ID2ctID[. Знак «=» означает, что методы
справа и слева от него равнозначны, а знак «||» — что
равнозначны методы сверху и снизу от этого знака.
В разд. 7.2—7.4 были приведены теоретические
результаты в области индуктивных выводов над
рекурсивными функциями. Основным среди критериев
успеха индуктивных выводов считают понятие
идентификации в пределе, но были приведены и многие
другие критерии, а для того чтобы сравнить
возможности машин выводов, удовлетворяющих тому или
иному критерию, была построена иерархия соответст-
214
Глава 7
вующих методов вывода. Благодаря этому стало
очевидно, что возможности метода перечисления и
NV-идентификации равнозначны. Кроме того,
обратившись к иерархии методов выводов, лежащих выше
ЕХ и возникших путем ослабления основного
критерия, мы видим, что множество всех рекурсивных
функций 91 позволяет делать выводы до тех пор, пока
критерий не будет ослаблен до ВС*.
Кроме того, допустив существование свойств,
естественных с практической точки зрения, таких как
«использование метода перечисления», «выдача
только предположений, непротиворечащих всем
полученным до сих пор данным» и других, мы увидели, что
CQNS=CPN8*IT
^-CONS=^-CONS-IT
ICONS'A
* CONS'*
^-TOTAL,rb
? -TOTAL
NUM=NV ^
CP-IT^CP~CPrb
CONS-ГГ*
«•CONS-IT*.*
TOTAL-TOTAL***WCP«WCPurb
TOTAL4T^WCP-CONS4*
II
TOTAL-CONS
TOTAL -IT,rb
CP-CONS=CP-CONS-IT=BEST
CP-CONSiA
num:
CP-CONS-IT,rb FIN^FIN'*
Рис. 7.2. Иерархия основных методов вывода, лежащих ниже
ЕХ,
Теория индуктивных выводов
215
усиление критериев приводит к ухудшению
возможностей вывода. Другими словами, метод вывода,
раскрывающий возможности метода перечисления,
находится на достаточно низкой ступени иерархии
методов вывода, рассмотренных в данных разделах. Таким
образом, метод перечисления может удовлетворять
всем свойствам, которые можно затребовать от
методов вывода на более высоких ступенях. Это хорошо
согласуется с действительным положением дел, когда
при реализации системы индуктивных выводов на
компьютере изначально используют метод
перечисления, а эффективность системы повышают за сч-ет
рационального выбора стратегии поиска кандидатов.
Достаточно полное общее изложение теории
индуктивных выводов сделали Англюн и Смит.
Тенденции исследований индуктивных выводов в ФРГ
подробно отписали Клетт и Вихаген. Все они включили
подробное описание иерархии методов вывода.
Вообще говоря, исследования иерархии методов
индуктивных выводов для рекурсивных функций
ведутся около 10 лет, создана полная и подробная
иерархия. Если сравнить с первыми результатами
Голда, полученными еще в 1965 г., то хорошо
заметен прогресс в этой области. Читатели,
заинтересовавшиеся этой областью, могут обратиться к
соответствующей литературе.
7.5. ИНДУКТИВНЫЕ ВЫВОДЫ В ЯЗЫКАХ
В данном разделе в качестве объекта индуктивных
выводов выбраны языки. Основное отличие
индуктивных выводов в языках от случая функций сводится
к представлению данных. Если представление данных
о функции / — это последовательность входных и
выходных значений, то для представления данных о
языке L можно рассматривать два метода. Первый —
задается последовательность, состоящая только из
слов языка L, это представление называется
положительным. Второй — задается последовательность,
состоящая из пар, в которых есть любое слово w и
информация о том, принадлежит ли w языку L; такое
представление называется полным. Пусть f — харак-
216
Глава 7
теристическая функция языка L, при этом если w e
е L, то f(w) = 1, а если — нет, то f(w) = О, поэтому
индуктивные выводы в языке L при полном
представлении можно рассматривать как индуктивные выводы
для этой характеристической функции.
Следовательно, все проблемы в теории индуктивных выводов,
объектом в которой являются языки, сводятся к
индуктивным выводам при положительном
представлении. Поэтому в данном разделе мы будем обсуждать
в основном такие выводы.
Прежде всего дадим основные определения,
связанные с индуктивными выводами в языках,
необходимые для дальнейшего обсуждения.
Пусть 2 — конечное множество символов.
Конечная любая последовательность, состоящая из
символов 2, называется словом. Длину слова w обозначим
через \w\. Пустая (длины 0) последовательность
символов также является словом, обозначим ее
через е. Через 2* обозначим множество всех слов в 2.
Любое подмножество множества 2* называется
языком в 2. Например, пусть 2 = {0, 1}, тогда 2* есть
множество ограниченных последовательностей,
состоящих из 0 и 1, а {00, 01, 10} —это язык в 2.
Язык L называется рекурсивным, если для любого
слова w можно вычислить суждение, принадлежит ли
оно L, Семейство Г языков, состоящее из L\9 L2, ...,
называется индексированным семейством
рекурсивных языков, если можно вычислить функцию
следующего вида:
{1, если w e Lu
0 — в противном случае.
Если T = Li, L2, ... — индексированное семейство
рекурсивных языков, то для любого целого
положительного / и любого слова w, используя указанную
выше функцию /, можно непосредственно построить
машину Тьюринга, оценивающую, включает ли язык
L слово w. Следовательно, обратите внимание на то,
что целое положительное число i можно считать
представлением языка наряду с грамматикой и автоматом.
Ниже без особого напоминания будем говорить о се-
Теория индуктивных выводов
217
мействе языков как о индексированном семействе
рекурсивных языков.
Теперь давайте введем определение представления
данных о языке.
Определение 7.11. Полным представлением языка
L называется неограниченная последовательность
пар, состоящих из слов и 0 или 1: (w\, t\),
(о>2,/2), ...» т.е. {w\w — witti=l}=L u{w\w=*
— Wi, ti = 0} = L° (=2* — L). Положительным
представлением языка L называется неограниченная
последовательность слов w\, w2, ..., т. е. {w\w = wt) =*
= L. При этом допускается повторение слов в
неограниченной последовательности.
Если полное представление может предоставить
информацию о том, какому из языков принадлежит
каждое слово, то правильное представление такой
информации не дает.
Понятие машины выводов и сходимости
(идентификации в пределе) определим так, как в разд. 7.2.
Определение 7.12. Скажем, что семейство языков
Г = Lu L2t ... позволяет'делать индуктивный вывод
из полных (положительных) данных, если существует
машина выводов, которая для любого полного
(положительного) представления любого языка
обеспечивает сходимость к /, такому, что L/ = L/.
Голд показал, что индексированное семейство
рекурсивных языков, как правило, позволяет делать
выводы из полных данных, но не всегда позволяет
делать выводы из правильных данных. Очевидно, что
индексированное семейство рекурсивных языков Г =
= Lb L2> ... позволяет делать выводы из полных
данных с помощью машины выводов, использующей
метод перечисления, объясненный в разд. 7.2.
Семейство языков Г называется сверхограниченным, если
среди всех ограниченных языков, включенных в Г,
есть по крайней мере один неограниченный язык на 2.
Следующая теорема, доказанная Голдом, — наиболее
важный результат, полученный на раннем этапе
исследований.
Теорема 7.10 (Голд). Сверхограниченное
семейство языков не позволяет делать индуктивные выводы
из правильных данных.
218
Глава 7
Доказательство. Используем метод от противного.
Пусть Г = Lb L2, ... — сверхограниченное семейство
языков, а М — машина выводов, делающая
индуктивные выводы в Г из положительных данных. Пусть
L — неограниченный язык в Г, а=Шь w2, ... —
перечисление языка L, Fn — ограниченный язык,
состоящий из первых п слов а. Обозначим через х[п]
ограниченную подпоследовательность, состоящую из
первых п членов неограниченной последовательности т.
Определим следующим образом положительное
представление о/ каждого языка Ft.
F\ = {^1}, поэтому о\ составим из бесконечного
числа только w\. Пусть С\ — наименьшее целое число,
при котором M(ai[Ci]) = «некоторое выражение
(индекс) F\», а именно: если М долгое время давать
только w{, то выход М будет сходиться к некоторому
положительному целому числу /, и L/ = Fu поэтому
пусть С\ — число данных, заданных до момента, когда
М выдаст индекс / языка, равного F\. Пусть а2 —
представление, состоящее из С\ подряд идущих слов
W\ и бесконечного числа &>2. Пусть С2— наименьшее
целое число, большее Сь при котором М(о2[С2]) =
= «некоторое выражение F2». Затем аналогично
определим On И С п.
Тогда предел оПУ который обозначим через Ооо,
есть положительное представление L. При этом М
для сгоо генерирует бесконечное число различных вы-
выходных данных М{о<х>[С\]) = М(о\[С\]),
Л1(аоо[С2]) = Л4(а2[С2]), ..., но все они не являются
выражениями L. Следовательно, М для о<х> не
обеспечивает сходимость. Это противоречит допущению о
том, что М делает индуктивные выводы в Г из
положительных данных. (Конец доказательства.)
Из этой теоремы следует, что семейства языков,
которые позволяют делать индуктивные выводы из
положительных данных, ограничиваются семействами,
не являющимися сверхограниченными. Очевидно
также, что даже семейства регулярных языков,
находящиеся на верхнем уровне иерархии Хрмского, не
позволяют делать выводы из положительных данных.
Этот факт считают отрицательным с точки зрения
применения индуктивных выводов. Однако ухудшение
Теория индуктивных выводов
219
возможностей индуктивных выводов из
положительных данных по сравнению с выводами из полных
данных и возможность делать выводы в некоторых
интересных семействах — это различные проблемы. Так,
Англюн не только доказал теоремы об особенностях
семейств, которые позволяют делать выводы из
положительных данных, но и показал существование не
очевидных, но очень интересных семейств. Например,
он открыл, что семейство образных языков позволяет
делать выводы из положительных данных, что
является очень важным результатом. Продолжая
исследования Англюна, Синохара, Нике, Янтке получили
результаты, связанные с применением индуктивных
выводов. Об индуктивных выводах из положительных
данных подробно рассказано в следующем разделе.
7.6. ИНДУКТИВНЫЕ ВЫВОДЫ
ИЗ ПОЛОЖИТЕЛЬНЫХ ДАННЫХ
Индуктивные выводы из положительных данных —
это выводы из слов, принадлежащих некоторому
языку, т. е. только из положительных примеров, эти
выводы естественней, чем индуктивные выводы из
полных данных, из которых можно использовать
информацию о принадлежности слов языку. Это
закономерно, хотя бы потому, что, скажем, при обучении по
примерам совсем не обязательно давать ошибочные
примеры. Однако, как следует из теоремы 7.10, при
некоторых условиях существенно необходимы
ошибочные примеры.
Прежде всего рассмотрим сложность индуктивных
выводов из положительных данных. Пусть объектом
выводов является семейство языков Г = Lb L2, ... .
Рассмотрим два следующих случая, когда
предположение g, выданное в процессе индуктивных выводов
из положительных данных о языке L, неверное, т. ^
Li ф Lg:
I. Ц — Ь8Ф0,
II. Ц — L8 = 0.
Назовем их ошибками первого и второго рода.
При ошибке первого- рода в положительном
преломлении Lj обязательно обнаруживаются несколько
220
Глава 7
контрпримеров со е Ц — Lgl которые показывают, что
Lg — ошибка, поэтому можно сменить предположение
на другое. В случае ошибки второго рода
предположение назовем сверхобобщенным по сравнению с
целевым предположением, другими словами, Lt +1 Lg. Lg
противоречит какому-либо положительному
представлению L/, поэтому, исходя только из положительного
представления, нельзя оценить, что g— ошибка.
В отличие от этого полное представление позволяет
указать такие ошибки, которые могут быть ошибками
не только первого, но и второго рода. Следовательно,
сложность индуктивных выводов из положительных
данных обусловливают именно ошибки второго рода.
Ознакомимся с результатами, полученными Анг-
люном.
Определение 7.13. Пусть Г = L\, L2>... —
семейство языков. Конечным свидетельством L/ называется
множество Ti, удовлетворяющее условиям:
1) Ti — ограниченное подмножество L/,
2) не существует L/, включающего 7\- и
являющегося строгим подмножеством Ц.
Обратим внимание на то, что Ti— ограниченное
подмножество L/, причем Li является наименьшим
языком, включающим 7\.
Определение 7.14. Скажем, что семейство языков
Г = Li, L2, ... удовлетворяет условию 1, если
существует процедура, которая для любого / перечисляет
элементы конечного свидетельства Ц.
Теорема 7.11 (Англюн). Необходимым и
достаточным условием того, что семейство языков Г = Lu
L2, ... позволяет делать индуктивные выводы из
положительных данных, является условие 1.
Доказательство. Прежде всего покажем, что
условие 1 является необходимым условием для того,
чтобы Г позволяло делать индуктивные выводы из
положительных данных. Допустим, что машина
выводов М делает выводы из положительных данных
в Г. Используя М, построим процедуру Q,
удовлетворяющую условию 1. Пусть шь w2, ... — перечисление
элементов L/, а Фь Ф2, ... — все ограниченные
последовательности, состоящие из элементов Ц.
Процедура Q начинается с шага 0.
'Теория индуктивных выводов
221
Шаг 0: пусть gq—пустая последовательность,
переходим к шагу 1.
Шаг п (п^1): выдаем wn, пусть an = an-\Wn.
Проверяем, для всех ли k=l, 2, ... равны М(оп)
и М(опФк). Если обнаруживаем, что они не равны,
то выдаем все элементы Ф*, принимаем ап = оЛфЛ и
переходим к шагу п-\- 1.
Если предположить, что Q выполняет бесконечное
число шагов, то Ооо — положительное представление
Ц, что противоречит тому, что М не обеспечивает
сходимость для Goo. Следовательно, пусть
выполнение Q закончится на N шаге (при этом Q для всех
k= 1, 2, ... проверит, равны ли M(oN) и М(омфк),
и зациклится). Выходными данными Q будет
ограниченная последовательность а#. Множество, состоящее
из слов, включенных в oN, является конечным
свидетельством Li. Дело в том, что в противном случае
будет существовать /, такое, что Т{ ? Lf ^ Lh и аы
нельзя связывать с положительным представлением
L/, но, с другой стороны, есть такое представление
L/, причем какие бы слова языка Li вне aN ни
задавались, выходные данные М не будут изменяться,
начиная с г\ такого, что Lr = Lh и поэтому в конце
концов М не сможет правильно делать выводы о L/,
что приводит нас к противоречию.
Наоборот, пусть справедливо условие 1.
Построим машину выводов М. Пусть s\, s2, ..., sn —
входные данные, полученные М до некоторого
момента; представим их в виде S,* = {s|s = S/, /=!,
2, ..., я}. М выдаст наименьшее целое число /,
удовлетворяющее условию
Sns=L, и T,czsn. (a)
При этом Tj — перечислимое множество, но его не
всегда можно вычислить (другими словами, нельзя
оценить, когда закончится перечисление Г;), поэтому
пока еще нельзя утверждать, что М можно
реализовать. Однако для облегчения понимания рассуждений
допустим, что Tj можно вычислить, и покажем, что
М делает правильные индуктивные выводы из
правильных данных о Г. При этом ясно, что важную
222
Глаза 7
роль для устранения ошибок второго рода играет
множество конечных свидетельств, а именно: пусть
при выводе Sn достаточно большое и включает 7\,
тогда в этот момент уже нет ошибок второго рода.
А ошибки первого рода полностью исключены, если
Sn большое, поэтому М обеспечивает сходимость к
правильному предположению.
Для того чтобы не вводить допущение о
возможности вычисления Г/, обозначим через Tf} множество,
полученное при ограничении числа шагов вычислений
методом перечисления Г/ числом входных данных п,
и используем Т^ вместо Г/. При этом может
случиться, что не существует /, удовлетворяющее
нашему условию, поэтому ограничим диапазон поиска /
до числа п, и если до п такого / найдено не будет,
то не будем заботиться о каких-либо выходных
данных, но будем выдавать только то, что не
противоречит, например, Sn. В результате, если заменить
условие (а) на следующее условие (а'), то можно
получить искомую машину выводов М:
Sn^Lj и (Tj^Sn или }>п). (а')
(Конец доказательства.)
Англюн рассмотрел несколько условий
возможности делать индуктивные выводы из правильных
данных. Ниже мы рассмотрим' условие 2. Другие
условия можно узнать из его работ.
Определение 7.15. Скажем, что семейство языков
Г = L\, L2, ... удовлетворяет условию 2, если для
любого непустого ограниченного множества S число
языков в Г, включающих 5, ограничено, а именно:
C(S) = {L\S<=L и Э* L = Lt)
состоит из конечного числа языков.
Теорема 7.12 (Англюн). Если семейство языков
r = Li, L2, ... удовлетворяет условию 2, то Г
позволяет делать индуктивные выводы из правильных
данных.
Доказательство. Достаточно показать, что
семейство языков Г, удовлетворяющее условию 2,
удовлетворяет и условию 1. Как правило, для любых /, / не
Теория индуктивных выводов
221
всегда можно вычислить, выполняется ли условие
L/ +1 Lt. Для того чтобы облегчить рассуждения,
допустим, что оценку Li ^ Lt можно вычислить.
Рассмотрим следующую процедуру Q. Пусть для Q
заданы входные данные L Процедура начинается
с шага 0.
Шаг 0: выдаем любое слово wx языка Li и
принимаем А\ = {w\}. Переходим к шагу 1.
Шаг п (п ^ 1): организуем поиск /, такого, что
Ап s Lf +" Lh если / найдено, то выдаем любое слово
wn из Li — L/, принимаем Ап+\ = Ап\] {wn} и
переходим к шагу п+ 1.
Покажем, что такая процедура Q выполняет
перечисление элементов конечного свидетельства L/.
Очевидно, что на некотором шаге Q терпит неудачу
при поиске / (т. е. зацикливается), при этом она не
переходит к следующему шагу. Дело в том, что Г
удовлетворяет условию 2, ц поэтому в Г существует
только конечное число языков, включающих wn,
которое Q выдала в самом начале. Пусть последним
процедура Q выполняла шаг N, тогда ясно, что AN —
конечное свидетельство L/.
В этом рассуждении мы считали, что возможно
вычисление оценки Lf +1 Lh и для снятия этого
допущения можно следующим образом изменить шаг а
процедуры (я^1). Пусть s\, s2y ...— рекурсивное
перечисление элементов 2*, что обозначим в виде
Шаг п (/г^1): организуем поиск пары целых
положительных чисел (/, /и), таких, что An^L/ и
L/m) ? Lim); если j найдено, то выдаем любое слово
wn из L/m)—¦ L{im\ принимаем Ап+\ = An\j {wn} и
переходим к шагу м+1.
Здесь L(f> — ограниченное множество; которое
можно вычислить, и если обратить внимание^на то,
что порядок поиска пар (/, т) позволяет найти все
такие пары, то легко показать, что процедура Q
правильно перечисляет элементы конечного
свидетельства I/. (Конец доказательства.)
224
Глава 7
Условие 2— это достаточное условие возможности
делать индуктивные выводы из правильных данных,
можно также доказать, что необходимого условия не
существует. Однако условие 2 в отличие от условия 1
легко использовать из-за того, что оно не связано
с индексами. На практике, используя теорему 7.12,
можно показать возможность делать индуктивные
выводы из правильных данных о многих семействах
языков, например о семействе образных языков,
В этом смысле условие 2 достаточно важно.
Рассмотрим кратко индуктивные выводы из
правильных данных о семействе образных языков. Среди
всех семейств, которые позволяют делать
индуктивные выеоды из правильных данных, семейство
образных языков — наиболее важное; это семейство было
введено Англюном.
Прежде всего дадим основные определения.
Пусть X = {хи х2, ...}—счетное множество,
состоящее из символов, отличных от 2. Элементы 2
назовем константами, а элементы X — переменными.
Образ — это последовательность символов длины
больше 1, состоящая из констант и переменных.
Языком L(p), отражающим образ р, назовем набор
последовательностей констант, полученных путем
замены всех переменных в р на произвольные непустые
последовательности констант.
Например, пусть 2 = {0,1}, Х= {ху у, ...}. р =
= 00л: — образ, a L(p)—набор последовательностей
длины более 3, в начале которых находится 00, а
затем идет последовательность из 0 и 1. Если q = хх,
то L{q) — это набор последовательностей, в которых
дважды повторяется непустая последовательность,
состоящая из 0 и 1.
Покажем, что семейство образных языков
позволяет делать индуктивные выводы из правильных
данных.
Теорема 7.13 (Англюн). Семейство образных
языков позволяет делать индуктивные выводы из
правильных данных.
Доказательство. Покажем, что удовлетворяется
условие 2. Пусть w — произвольное слово, р —
произвольный образ. Переход к переменным только огра-
Теория индуктивных выводов
225
ничивает непустые последовательности констант,
поэтому если w^L(p), то |р|<|о>|. Здесь \р\
обозначает длину образа р, включая переменные. Если
при замене имен переменных образ р будет равен
образу qy то L(p)= L(q) (например, если р = 0x1*,
q = 0yly, то L(p)= L(q)). Следовательно, число
образов длины, меньшей |ш|, ограничено, и если
игнорировать замены имен переменных, то, очевидно,
будет ограничено число слов, которые эти образы
выражают. Поэтому для любого непустого ограниченного
множества слов S ограничено число слов-образов,
которые включены в S. Другими словами, семейство
образных языков удовлетворяет условию 2. По
теореме 7.12 это семейство позволяет делать
индуктивные выводы из правильных данных. (Конец
доказательства.)
Об образных языках написано очень много, и
поэтому подробное их обсуждение невозможно,
отметим лишь, что они не только позволяют делать
индуктивные выводы, но и имеют важное значение с точки
зрения различных применений. Частично об их
применении мы ознакомимся в следующей главе.
Читатели, интересующиеся этими проблемами, могут
посмотреть работы Синохара и Янтке.
7.7. ИНДУКТИВНЫЕ ВЫВОДЫ
В ФОРМАЛЬНЫХ СИСТЕМАХ
В разд. 7.6 мы увидели, что образные языки,
введенные Англюном, позволяют делать индуктивные
выводы из правильных данных. Существуют ли помимо
этих языков другие интересные семейства языков,
обладающих таким свойством? Разумеется,
теоретически существует бесконечно много семейств языков,
удовлетворяющих условию 1, проблема лишь в том,
как указать их примеры. Такие примеры указал и сам
Англюн, а в последние годы Синохара предложил
естественное расширение образных языков до языков,
определяемых с помощью формальных систем, и
показал, что и они позволяют делать индуктивные
выводы из правильных данных. В данном разделе
ознакомимся с его результатами.
8 С. Осуга, Ю. Саэкн
216
Глава 7
Формальные языки в большинстве случаев
определяются с использованием грамматики и автоматов,
но можно также их определять с помощью
формальных систем, введенным Смаллианом. Понятие
формальной системы основано на следующем способе
математического определения множеств:
1) а есть элемент S;
2) если х — элемент S, то f(x) также элемент S;
3) элементом S является то и только то, что после
конечного применения операций A) и B) остается
элементом S.
Арикава теоретически рассмотрел языки с
позиций такой формальной системы. Он ввел простую
формальную систему (SFS) как формальную систему
с ограничениями, и показал, что семейство языков,
определяемое через SFS, больше, чем семейство
контекстно свободных языков, но меньше, чем семейство
контекстно-зависимых языков.
Кроме того, им введена примитивная формальная
система (PFS), которая добавляет к SFS новые
ограничения; было показано, что семейство языков,
определяемое через PFS, также позволяет делать
индуктивные выводы из правильных данных. PFS — это
формальная система, состоящая только из двух
шагов: основного шага и шага индукции. Образные
языки Англюна можно определить с помощью
наиболее простой PFS, состоящей только из основного
шага, поэтому семейство языков, определяемого
таким образом, является естественным расширением
образных языков.
7.7.1. ФОРМАЛЬНЫЕ СИСТЕМЫ И ЯЗЫКИ
Пусть 2 ограниченное множество символов, X и D —
счетные множества символов и пусть 2, X и D не
имеют общего подмножества. Элементы 2, X и D
назовем соответственно константами, переменными и
предикатами, для их обозначения используем буквы
а, Ь, с, ..., х, г/, г, хи х2, ... и Р, Q, /?, Ри Л>, ... .
Элементы B(J^0*> а именно ограниченные
последовательности, состоящие из переменных и констант,
назовем термами (терм — это понятие, совпадающее
Теория индуктивных выводов
227
с образом, введенным в разд. 7.6). Если Р, Р\у ...
..., Рп — предикаты, a t, t\, t2l ..., tn — термы, то
запись P(t)^-P{(ti)& ... &Pn(tn) назовем формулой.
P(t) назовем заключением, а все
Pi(ti)—предусловиями. Формулу при п = О назовем атомарной
формулой и сократим ее до знака «-<-». Формальная
система есть ограниченное множество формул.
Пусть 0 — гомоморфное отображение (в смысле
сцепления последовательностей символов) терма
в терм. Отображение t с помощью 0 обозначим как
/0. Отображение, которое для любой константы а
дает а = а0, т. е. заменяет только переменные,
назовем подстановкой. Для формулы F = P(t)+-
+-Pi(ti)& ... &Pn{tn) определим ^ FQ = P(tQ)+~
*-Pi(txQ) ...Pn(tnQ).
Определение 7.16. Пусть Е = {Fu ..., Fm} —
формальная система. Формула F = P(t)+-P\(t\)& ...
... &Pn-\(tn-\) называется доказуемой из ?, если
справедливо любое из следующих условий:
1) F является элементом Е\
2) существует некоторая подстановка 9 и
формула F\ доказуемая из ?, такие, что Р = Р'0;
3) две формулы P(t)+-Pi(tx)& ... &P„-i(^-i}-
-&Pn(tn) и Pn(tn) одновременно доказуемы из Е
(метод трехэтапного вывода).
Определение 7.17. Определим следующим образом
язык с помощью- формальной системы Е и
предиката Р:
L(E, P) = {t\t слово, Р(t) — доказуема из Е}.
В случае когда Е содержит только один предикат,
для краткости введем обозначение Ь(Е).
Если формальные системы Е и Е' совпадают с
точностью до замены переменных и перестановки
предусловий, то назовем их эквивалентными. Как следует
из определения, если Е и Ег эквивалентны, то для
любого предиката Р L(?, Р) = L(E\ P).
Пример 1
1) Пусть Е= {P(axbx)}. L(E) = {cd|cd = axbx,
*eS*}—образный язык, расширенный за счет
подстановки пустых последовательностей вместо
переменных в образе axbx (Синохара).
8>
223
Глава 7
2)Е={Р(г); Р(ах)+-Р(х)у Q{bxbxbx)+-P(x)}.
L(E,P) = {an\n^O, L(E,Q\= {banbanban\n^O}.
7.7.2. ОГРАНИЧЕНИЯ ФОРМАЛЬНЫХ СИСТЕМ
Рекурсивно перечисляемый язык можно определить
с помощью формальной системы. Следовательно, для
того чтобы обсуждать возможность выводов из
правильных данных, необходимо ограничить понятие
формальной системы. Арикава предложил простую
формальную систему (SFS), в которой аргументы
предусловий формулы и только они появляются в
качестве переменных в заключении.
Определение 7.18. Формальная система Е
называется простой, если все формулы Е имеют вид
P(t(xu ..., Хп))-4-Рх(хх)& ... &Рп(Хп). Здесь t(xu ...
..., хп)—терм, содержащий по крайней мере п
переменных Х\9 . ., Хп-
Арикава показал, что язык, определяемый с
помощью SFS, рекурсивный, а также что с помощью
SFS можно определить контекстно-свободные языки.
Семейство последних является сверхограниченным,
поэтому семейство языков, определяемых с помощью
SFS, также сверхограничено, но не позволяет делать
индуктивные выводы из правильных данных.
Следовательно, дадим новые ограничения и введем
примитивную формальную систему, затем обсудим
возможность индуктивных выводов из правильных
данных для таких систем.
Определение 7.19. Пусть Е — это SFS. E
называется примитивной, если она состоит из двух
формул: P(tX) И P(t2(Xu ..-, Xn))+-P{Xi)& ... &Р(ХП).
Первая называется базовым шагом, а вторая —
шагом индукции.
PFS содержит только один предикат, поэтому
ниже этот предикат будем обозначать просто Р.
Кроме того, в PFS введено ограничение на подстановки
в переменные пустой последовательности. В связи с
этим обратите внимание на то, что в определении
образного языка также были запрещены
подстановки в переменные пустой последовательности.
Теория индуктивных выводов
229
Определение 7.20. Пусть X = {хи х2, ...}.
Определим следующим образом канонические формы термов,
формул и PFS:
1) скажем, что терм / имеет каноническую форму,
если он включает п переменных хи •••» *п и для
любого / = 1, ..., п — 1 самый левый Xi появляется
левее, чем левый лгн-г,
2) скажем, что формула P(t(xi[y ..., xin))<-
<- Р (хп) &... &Р (xin) имеет каноническую форму,
если терм t(xi[f ..., xin) имеет каноническую форму
и 1 ^ ix < ... < in;
3) скажем, что PFS E имеет каноническую форму,
если формулы Е имеют каноническую форму.
Из этого определения ясно, что для любой PFS
Е существует единственная каноническая форма,
тождественная ?.
Пример 2
Пусть 2 = {а, &}, X = {х, у, ...}. Следующие
системы являются PFS:
1) Ег = {Р(ахЬх)9 Р(ух)+-Р(х)&Р(у)};
2) Е2 = {Р(а), Р(хх)<-Р(х)};
3) Е3 = {Р(ахЬу), Р(хх)<-Р(х)}.
Е{ не имеет канонической формы. Е\ = {P(axbx)>
Р (ху) <- Р (х) &Р (у)} — уже имеет каноническую
форму и тождественна Е. L(E{) включает aaba, abbb,
aabbab, aabaaaba, aabaabbb, abbbaaba, abbbabbb, ....
Подстановки пустой последовательности в
переменные запрещены, поэтому ab не принадлежит L(?1).
Е2 и ?3 имеют каноническую форму. L(E2)= {а, аау
аааау аааааааа, ...} = {а2 \п^0} не является
контекстно-свободным языком. Ь(ЕЪ) = L({P(axby)}) —
образный язык, определяемый образом axby.
В случае когда шаг индукции в PFS E имеет
вид Р(х)+- Р(х), этот шаг, избыточен в том смысле,
что L(E) можно определить только с помощью
базового шага Е. Кроме того, если шаг индукции
избыточен, то соответствующий язык является образным.
В данном примере L(E2) не является образным
языком. Следовательно, ясно, что семейство языков,
определяемое с помощью PFS, строго включает
образные языки.
230
Глава 7
7.7.3. ИНДУКТИВНЫЕ ВЫВОДЫ ИЗ ПОЛОЖИТЕЛЬНЫХ
ДАННЫХ О ФОРМАЛЬНЫХ СИСТЕМАХ
Покажем, что семейства языков, определенных выше
с помощью PFS, позволяют делать индуктивные
выводы из положительных данных.
Прежде всего покажем, что подобные выводы
позволяют делать семейства языков, определенные с
помощью PFS, которая не содержит переменных в
базовом шаге. Для доказательства используем
условие 2', которое получим из условия 2 — достаточного
условия возможности выводов из правильных данных.
Условие 2 имело вид «Для любого непустого
ограниченного множества S число языков, включенных в Sf
ограничено», а это по существу требует, чтобы «Для
любого слова до число языков, включающих до, было
ограничено». Несколько ослабим это условие: «Для
любых различных слов wx и до2 число языков,
одновременно включающих wx и до2, ограничено»,— это и
есть условие 2'.
Определение 7.21. Скажем, что семейство языков
Г = Lb L2, ... удовлетворяет условию 2', если для
любых различных последовательностей символов w\
и до2
С(доь ^2) = {L|^e L и w2^L и 3i L = Lt}
состояло из ограниченного числа языков.
Лемма 6.14. Если семейство Г = L\, L2, ...
удовлетворяет условию 2', то Г позволяет делать
индуктивные выводы из правильных данных.
Доказательство. Аналогично теореме 7.12.
Теорема 7.15. Семейство языков, определенных с
помощью PFS, базовый шаг которой не содержит
переменных, позволяет делать индуктивные выводы из
правильных данных.
Доказательство. Пусть Е — PFS, P(w)—ее
базовый шаг. до— слово (не содержащее переменных).
Пусть L(E) включает два различных слова w\ и до2.
Есть только базовый шаг, поэтому Р (до) не доказуемо;
если по крайней мере для одного из доь w2 не
использовать шаг индукции, то недоказуемо, что они есть
элементы L(E). Подстановка пустой
последовательности в переменные невозможна, в связи с этим дли-
Теория индуктивных выводов
2М
на аргументов в заключениях базового шага и шага
индукции меньше длин w{ и w2> а число предусловий
также меньше длин wx и w2. Если игнорировать
тождественные системы, то таких PFS существует
ограниченное число, поэтому семейство языков,
определенное с помощью PFS, базовый шаг которой не
содержит переменных, удовлетворяет условию 2'.
Следовательно, по лемме 7.14 теорема доказана.
Приведем теперь доказательство целевой теоремы.
Для этого используем теорему 7.11, доказательства
которой очень похоже на доказательство того, чта
семейство сумм образных языков позволяет делать
индуктивные выводы из правильных данных (Сино-
хара). Используем также следующие две леммы,
доказательства которых опустим.
Лемма 7.16. Пусть Е — PFS, P(t) — ее базовый
шаг, тогда если S0(E)— это множество самых
коротких слов, принадлежащих L(E), то S0(E)=L({P(t)})(\,
nZmo.
Лемма 7.17. Пусть Еи Е2 — PFS. Если S0(?i)s
^ L(E2)^ L(Ei)y то базовые шаги Ех и ?2, если не
считать замены имен переменных, совпадают.
Теорема 7.18. Семейство языков, определенных с
помощью PFS, позволяют делать индуктивные
выводы из правильных данных.
Доказательство. Можно сделать, если показать,
что следующая процедура Q перечисляет элементы
конечного свидетельства PFS. Входными данными для
Q служит PFS, a P(t)—ее базовый шаг. Пусть ш^
w2i ...— перечисление непустых слов.
procedure Q (Е)
begin
выдать все элементы из S0 (E)
T:=S0(E)
while Wie=L(E)-L ({P (/)}) do /:= / + 1
выдать Wi
T:=T{J{wi}
l) \t\ —длина терма, 2И1— последовательность символов
длиной /. — Прим. ред.
232
Глава 7
В^ {F | F = Р (/' (хи ..., хп)) <- Р (*0 &..ЛР (хп),
F — каноническая форма, | /' (xi} ..., хп) | ^ | wt [,
T^L({P (О, Z7})}
for /:= 1 to oo do
if ш/s L(?) then
begin
iB':={FeB|^EL({P@, F})}
if В' Ф 0 then
begin
выдать до*
Г:-и{и>/}
?:= В - В'
end
end
end
Процедура Q прежде всего выдает все короткие
слова Sq(E) языка L{E)y по лемме 7.16 S0(E)
—ограниченное множество, которое можно вычислить.
Следующий оператор while оценивает, избыточен ли mai
индукции ?; если избыточен, то процедура
зацикливается, но в этом случае S0(E)— конечное
свидетельство языка L(E)\ если не избыточен, то оператор
while всегда закончится, будет выдано слово wiy про
которое, не используя шаг индукции, нельзя доказать,
что оно принадлежит L(?), затем вычислится В. Если
язык L{E') PFS Ef будет включать все слова,
которые выдаст процедура Q до этого момента, то
базовый шаг его системы будет тождественен P{t)y как
следует из леммы 7.17. Следовательно, введем в В все
такие шаги индукции Е'. Обратим внимание на то,
что В ограничено, поэтому легко показать, что
процедура Q будет перечислять элементы конечного
свидетельства. (Конец доказательства.)
7.8. ЭФФЕКТИВНОСТЬ ОТРИЦАТЕЛЬНЫХ ДАННЫХ
В разд. 7.5—7.7 главным образом обсуждались
индуктивные выводы из правильных данных. Как
показывает теорема 7.10, из полных данных, использующих
и положительные и отрицательные данные, можно
делать индуктивные выводы, но существуют семей-
Теория индуктивных выводов
233
ства языков, которые не позволяют делать
индуктивные выводы только из положительных данных.
В этом смысле следует считать отрицательные данные
полезными для индуктивных выводов, поэтому ниже
несколько более подробно остановимся на роли слов,
которые не .принадлежат языкам. Индуктивные
выводы из отрицательных данных можно определить
по аналогии с выводами из положительных данных,
но можно ли с помощью семейства языков, которые
позволяют делать индуктивные выводы из
положительных данных, делать то же самое из
отрицательных данных? Существуют ли семейства языков,
которые не позволяют делать выводы из
положительных данных, но позволяют делать выводы, когда к
положительному представлению добавляется
некоторое число отрицательных данных? Приведем решения
подобных проблем. Для этого прежде всего
рассмотрим индуктивные выводы из отрицательного
представления, определяемого следующим образом.
Определение 7.22. Отрицательным представлением
языка L называется неограниченная
последовательность слов wu w2j ..., или {w\w = Wi] = Lc.
Возможность делать индуктивные выводы из
отрицательных данных определим по аналогии с
выводами из положительных данных.
Для семейства языков Г = Lu L2, ... обозначим
через Гс семейство, состоящее из дополнительных
множеств Lb L2, Тогда индуктивный вывод из
отрицательных данных о языке L можно
отождествить с индуктивным выводом из положительных
данных о его дополнении Lc. Короче говоря, если
семейство Г позволяет делать индуктивный вывод из
отрицательных данных, то Vе позволяет делать
индуктивный вывод из положительных данных, обратное
также справедливо. Следовательно, для того чтобы
показать, что некоторое семейство языков Г
позволяет делать индуктивные выводы из отрицательных
данных, очевидно, достаточно показать, что
семейство Гс, состоящее из дополнений языков,
удовлетворяет условиям 1 или 2.
Но может ли семейство языков, которое позволяет
лелать индуктивные выводы из положительных дан-
234
Глава 7
ных, делать выводы и из отрицательных данных?
Следующая теорема показывает, что это не так.
Теорема 7.19. Семейство языков Ф = {L ^ 2*|L —
непустые ограниченные} позволяет делать
индуктивные выводы из положительных данных, но не
позволяет делать индуктивные выводы из отрицательных
данных.
Доказательство. Очевидно, что ф позволяет делать
индуктивные выводы из положительных данных.
Фактически, каждый язык является собственным
множеством конечных свидетельств.
Пусть Ф позволяет делать индуктивные выводы
из отрицательных данных. Тогда Фс позволяет делать
индуктивные выводы из положительных данных.
Пусть L — любой непустой ограниченный язык. По
теореме 7.11 для языка Lc должно существовать
конечное свидетельство Г, удовлетворяющее условиям:
1) Т есть ограниченное подмножество Lc\
2) в Фс не существует L'c, которое включало бы
Т и являлось подмножеством Lc.
Пусть Т — любое множество, удовлетворяющее
A). L ограничено, поэтому Lc неограничено. Lc — Г
не пустое. Пусть w любое слово из Lc — Т. Тогда
U = L U {w} ограничен, и поэтому является языком
в Ф, при этом
Следовательно, Т не удовлетворяет условию B). (Ко*
нец доказательства.)
Далее рассмотрим проблему: существует ли
семейство языков, которое позволяет делать
индуктивные выводы и из положительных, и из отрицательных
данных? Очевидно, что ответ на этот вопрос «Да»„
поскольку таким семейством является семейство,
состоящее из ограниченного числа языков. Как было
сказано сразу после доказательства теоремы 7.12,
большинство семейств языков, которые позволяют
делать индуктивные выводы из положительных
данных, и прежде всего образные языки, удовлетворяют
условию 2. Следующая теорема показывает, что
большинство таких языков позволяет делать индуктивные
выводы и из отрицательных данных.
Теория индуктивных выводов
235
Теорема 7.20. Если семейство Г, состоящее из
языков не над 2*, удовлетворяет условию 2, то Г
позволяет делать индуктивные выводы из отрицательных,
данных.
Доказательство. Пусть семейство языков Г = Lu
L2, ... (L/^=2*) удовлетворяет условию 2. Тогда
Достаточно показать, что Гс удовлетворяет условию К
Другими словами, покажем, что для любого i
существует процедура, которая перечисляет элементы
множества Ti (конечного свидетельства Lf, которое
удовлетворяет следующим условиям:
1) Ti — ограниченное подмножество Lc\
2) не существует /, такого, что Ц включает Ti
и является строгим подмножеством Ц.
Рассмотрим процедуру Q, определенную
следующим образом. Q начинается с шага 0.
Шаг 0: пусть v, w — любые элементы
соответственно Li, Lb Выдаем w, принимаем Ах = {w} и
переходим к шагу 1.
Шаг п (n ^ 1): организуем поиск целого
положительного / и слова х, таких, что v e L/, An s L],x e
е L°i — L/, если они найдены, то выдаем х, принимаем
Ап+{ = An U {х} и переходим к шагу п + 1.
Л/г —это элемент L/, который Q выдает до шага
п. Если Ап еще слишком мало, чтобы быть конечным
свидетельством L?, то существует /,
удовлетворяющее условию Ап^ L/^ L?. Не всегда можно
вычислить, будет ли L) ^ L?, но такое / удовлетворяет
условию
Lci-Lci^0.
Кроме того, из того, что yet/? L/, имеем
v e Lj.
Г удовлетворяет условию 2, поэтому существует
ограниченное число языков, включающих v. Если на
это обратить внимание, то легко показать, что будут
перечислены элементы множества конечных
свидетельств L°i. (Конец доказательства.)
Непосредственным стимулом дискуссии о возмож-
135
Глава 7
ности индуктивных выводов из отрицательных данных
послужила проблема: «Насколько возрастут
возможности вывода по сравнению со случаем только
положительного представления, если к нему добавить
только одно отрицательное данное?» Определим
следующим образом представление, в котором к
положительному представлению добавлено несколько
отрицательных данных, и аналогично определим
индуктивный вывод из такого представления.
Определение 7.23. Положительным
представлением с добавлением по крайней мере п отрицательных
данных (ниже сокращенно РРп) называется
неограниченная последовательность пар из слов и 0 или 1
(wu ti), (w2, t2), ... или {w\w = wi, ti=l} = L,
{w\w = wi9 ti = 0} s Lc и #{w\w = Wi, ti = 0} ^ n.
Здесь #S означает число элементов множества S.
Теорема 7.21. Если семейство языков Г = Lu L2>...
позволяет делать индуктивные выводы из РРпу то Г
яозволяет делать индуктивные выводы из
положительных данных.
Доказательство. Допустим, что машина выводов
М делает индуктивные выводы из РРп для Г.
Покажем, что, используя Af, можно построить машину
выводов Af', которая будет делать индуктивные
выводы из положительных данных о Г. Пусть входные
данные в М' — w\, ш2, ..., wm. Af строится
следующим образом:
[обнаружим наименьшее t, при котором для всех
k = 1, 2, ..., m Wk e Lt, и получим п различных слов
¦Хи х2, ..., хп, не принадлежащих Lt. Зададим М п
отрицательных данных (хи 0), (х2} 0), ..., (хп, 0),
а вслед за ними m положительных данных (wu 1),
(i02, 1), •¦•> (wm, 1). При этом выходные данные g
машины М будем считать выходными данными М'. J
Пусть o = W\, w2, ... — положительное
представление языка Li. Если доказать, что АР обеспечивает
сходимость а к /, такому, что L/ = Li, то теорема
будет доказана.
Зададим М' в качестве выходных данных
o[m]=Wu W2, .., wm. Г — индексированное
семейство рекурсивных функций, поэтому при вычислении
можно обнаружить Lt, включающий все входные дан-
Теория индуктивных выводов
23Г
ные. Кроме того, Г позволяет делать индуктивные
выводы из РРп, поэтому существует по крайней мере
п слов, не принадлежащих Lr, следовательно, при
вычислении можно получить хи х2, ..., хп. Данные,
которые М' передает в М,— это начальная часть
некоторой последовательности РРп языка Lty поэтому
выходные данные М определяются как обычно.
Следовательно, и выходные данные М' будут определяться
как обычно. При этом М' добавляет к полученным
положительным данным непротиворечащие им
отрицательные данные, но не передает их в М, поскольку
есть вероятность, что выходные данные М будут не
определены в случае, когда входные данные,
поступившие в М, не являются представлением РРп языка
в Г. Пусть t — наименьшее целое число,
удовлетворяющее условию Li ^ Lt. Тогда если соответствующим,
образом увеличить т, то и W обнаружит такое t.
Различные слова хи х2, ..., хп, не принадлежащие
Lt, не принадлежат также и Liy поэтому о'=(хи 0),
(х2,0), ...> (хп,0), (шь1), (^2,1), ... будут
являться представлением РРп языка L/, и М для о'
обеспечит сходимость к /, такому, что L/ = Li.
Следовательно, ЛГ для а также обеспечит сходимость к /,
такому, что L\ = Li. (Конец доказательства.)
Из теоремы 7.21 следует, что ограниченное числа
отрицательных данных не эффективно для
индуктивных выводов. Это доказательство основано на факте,,
что п отрицательных данных можно построить (в
пределе) из положительного представления. Известно,
что возможность делать индуктивные выводы не
означает, что всегда можно делать непротиворечивые
и сохраняющие свойства языков индуктивные выводы
(Англюн). Построение машины выводов М' в
теореме 7.21 сохраняет непротиворечивость и свойства
машины М, поэтому ясно, что в случае
непротиворечивых и сохраняющих свойства языков индуктивных
выводов ограниченное число отрицательных данных
также не эффективно. Однако объем вычислений
в машине выводов М' больше, чем в М, поэтому
отрицательные данные вряд ли эффективны и с этой
точки зрения. Хотя эту проблему еще предстоит
обсудить.
ГЛАВА 8
СИНТЕЗ ПРОГРАММ ПО ПРИМЕРАМ
С. Арикава, М. Харагути (Университет Кюсю)
Использовать теорию индуктивных выводов,
рассмотренную в предыдущей главе, в чистом виде зачастую
неэффективно. Поэтому предложены специальные
подходы для конкретных применений. Выберем
примеры таких подходов из области автоматического
синтеза программ и ознакомимся с результатами
исследований в этой области. Особое внимание уделим
теоретическим результатам, полученным Шапиро,
поскольку есть возможность их практического
применения. Кроме того, кратко затронем вопросы
совершенствования этой теории.
8.1. АВТОМАТИЧЕСКИЙ СИНТЕЗ
ЛИСП-ПРОГРАММ
Автоматическим синтезом программ по примерам
(программированием по примерам) называется
процедура создания программ по примерам входных и
выходных выражений и процесса выполнения
(трассировки). Примеры, которые задаются такой
процедуре в качестве входных данных, называют
спецификацией. В общем случае примеры содержат только
«частично ограниченную информацию» о целевой
программе, поэтому благодаря «показу» подобной
процедуре синтеза неограниченного числа примеров
можно делать индуктивные выводы в смысле,
объясненном в предыдущей главе.
При грамматическом выводе примерами служат
последовательности символов. С другой стороны,
в проблеме автоматического синтеза ЛИСП-программ
примеры имеют структуру данных, которая
называется 5-выражением. Главная цель данного
раздела — изучение методологии индуктивных выводов
по таким примерам.
Синтез программ по примерам
239
Прежде всего поясним указанную выше проблему
на простейшем примере. Допустим, существует пара
<Х, У>5-выражений, таких, что X =ф- У. Здесь X
интерпретируется как входное, а У — как выходное
выражение. Пусть
(ABCD)^((A)(B)(C)(D))
— пара S-выражений; тогда рассмотрим задачу
вывода «?», если в паре S-выражений
(А В С D E)=4>?
неизвестно выходное выражение. С. Харди создал
компьютерную модель GAP (обобщенный
автоматический программист), предназначенную для подобных
выводов, т. е. для решения задачи, с чем
ассоциировать «?» после просмотра нескольких примеров. В
общем случае для индуктивных выводов необходимо
иметь две процедуры: процедуру генерации гипотезы
из множества примеров, являющихся предпосылками
вывода, и процедуру проверки, выводятся ли эти
предпосылки логически из гипотезы. GAP также
построена из этих двух процедур.
Прежде всего GAP, используя эвристический
метод, генерирует из пары заданных S-выражений в
качестве программы-гипотезы скиммер 1\
ассоциирующийся с некоторой «подсказкой». При этом
предполагается, что подсказки — это априорные знания об
S-выражениях и ЛИСП-программах, которые
предварительно накапливаются в некоторой базе данных.
Затем благодаря проверке этой программы-гипотезы
с помощью дедуктивной ЛИСП-системы она
преобразуется в окончательную ЛИСП-программу. Поясним
действия GAP в случае приведенных выше
S-выражений.
Инициируется подсказка, которая обращает
внимание на то, что длины списков (А В CD) и ((А) (В)
(С) (D)) в паре
(А В CD)^((A)(B)(C)(D))
]) От английского глагола to skim (скользить, бегло
просматривать).— Прим. перев.
240
Глава 8
равны и генерируется программный скиммер
(LABEL SELF (LAMBDA (X)
(COND ((ATOM(FARTOF X» NIL)
(T (CONS(FORM X) (SELF (CDR X))))
)))
Здесь SELF — имя целевой программы, a <FORMX>,
<PARTOFX> — неизвестные части. Используя
дедуктивную ЛИСП-систему, GAP оценивает этот скиммер
для конкретного S-выражения (А В CD).
Обнаружение неизвестных символов, скажем <FORMX>, с
помощью традиционной ЛИСП-системы заканчивается
неудачей или ошибкой, а в ЛИСП-системе GAP эта
операция активно используется, при этом
приобретается информация о неопределенных частях.
Например, для
X = (А В С D)
путем сопоставления с образцом уточняется, что
<FORMX) = (A),
SELF[(BCD)] = ((B)(C)(D)).
Продолжая генерацию скиммеров на основе подобных
подсказок до тех пор, пока не будут оценены
неопределенные части, получаем окончательную ЛИСП-про-
грамму. В данном примере
(LABEL SELF (LAMBDA (X)
(COND ((ATOM X) NIL)
(T (CONS (LIST (CAR X))
(SELF (CDR X)) ))
)))
Применив эту программу к еще одному S-выра-
жению (ABCDE), GAP возвращает результат
вывода
? = ((A)(B)(C)(D)(E)).
Возможности системы GAP главным образом зависят
от набора подсказок. Однако в отличие от
традиционных индуктивных выводов эта система может
рассматривать подсказки, тесно связанные с конкретной
Синтез программ по примерам
241
предметной областью (ПО), например, S-выраже-
ниями, в чем ее главная особенность. В этом смысле
GAP является системой индуктивных выводов,
использующей специфичные знания ПО.
В случае когда заданы несколько примеров,
естественно рассматривать выводы о структуре
управления ЛИСП-программы на основе анализа
структурных связей между примерами, другими словами,
методом «управления от данных». С помощью этой
стратегии Саммерс создал систему синтеза ЛИСП-
программ по примерам THESYS. В этой системе
основные операторы ЛИСПа ограничены операторами
cons, cdr, car, atom, запрещено использовать eq,
поэтому рассматриваются только ЛИСП-программы,
преобразующие структуры (S-выражения) в другие
структуры. Кроме того, с целью упрощения анализа
структур примеров допускается, что в ограниченном
множестве пар S-выражений, заданных системе
THESYS,
множество, состоящее из входных s-выражений,
?' = {а,: 1</</г},
строго упорядочено: s-выражения в нем связаны
отношением «<». Например, входные s-выражсния
в множестве
Е = {( ) =* ( ), А => ((A)), (В А) => ((В) (А))}
удовлетворяют следующему отношению порядка:
()<(А)<(ВА).
Используя подобное строго упорядоченное множество
примеров, THESYS сначала генерирует предикаты
ЛИСПа для распознавания каждого входного
S-выражения. В данном примере для ( ), (А), (В А)
генерируются
Pi [х] = atom [x],
р2[х] = atom [cdr [*]],
Рз Iх] = atom [cdr [cdr [x] ] ].
9 С. Ocvra. Ю. Саэки
242
Глава 8
Далее для каждого входного и выходного выражения
множества Е рассматривается представление
выходного S-выражения через входное S-выражение.
Например, в случае (А)=^((А)) обращается внимание
на то, что
((A))-cons [(A); nil],
кроме того, заменяя (А) на переменную, генерируется
М-выражение
f2[x] = cons[x; nil].
Выражения /,- называются фрагментами. Для ( ),
(В А) аналогично образуются фрагменты
M*] = nil;
/з М = cons [cons [car [x]\ nil];
cons [cdr [x]\ nil]].
Используя pi[x], fi[x], можно получить программу
/M = [Pi М-->Ы*];
РзМ">/з1*]]>
которая строго соответствует данному множеству
примеров Е. Итак, THESYS обнаруживает
рекуррентные отношения между // [х], /; [х], кодирует их в виде
рекурсивных вызовов функций ЛИСПа. Для
обнаружения рекуррентных отношений используется метод,
подобный вычислению разности между натуральными
числами. Поскольку объектами вычисления разности
являются М-выражения, используется операция
унификации подвыражений выражений F и G.
Например, для
/2 W = cons [x\ nil],
h М = cons tcons tcar М; п^]»
cons [cdr [x]; nil]]
/2 [cdr \x\) совпадает с подвыражением cons [cdr [x]\
nil] фрагмента /з[*], поэтому в результате вычислен
Синтез программ по примерам
243
ния разности получаем
/зМ = cons [cons [car [х]\ nil];
/2 [cdr [*]]].
Для предикатов используется аналогичная операция,
например, получаем
РзМ = Р2[сс1г[л:]].
Принцип вывода THESYS. Пусть для фрагментов
Pi[x], fi[x] {k ^ i ^ п) справедливы рекуррентные
отношения
fM[x] = F[xifi[x]l
Pt + \[x]=P[x, PlM].
Тогда делается вывод, что указанные выше равенства
справедливы и для i = k, ..., /г, ... . При этом
F> P — М-выражения, не зависящие от L
В соответствии с этим принципом вывода
рекуррентные отношения представляются через функцию и
и получается ЛИСП-программа
f[x] = [atom [x] -> nil;
t-+u[x]]\
и [х] = [atom [cdr [x] ] -> cons [x; nil];
/-> cons [cons [car [x]]; nil];
u[cdr [x]]].
Таким образом, используя разность натуральных
чисел и подобие, THESYS реализует синтез программ
по примерам как вполне обоснованный логический
вывод. В случае когда не удается найти разность
выражений, THESYS прекращает обработку и не
приходит к какому-нибудь выводу. В связи с этим
невозможно делать вывод сложнее, чем структура
управления программы, использованная в принципе вывода.
8.2. ИДЕНТИФИКАЦИЯ ЛИСП-ПРОГРАММ
В ПРЕДЕЛЕ
Системы выводов Харди и Саммерса, с которыми мы
познакомились в предыдущем разделе, не дают
отвита на вопрос, какой будет результирующая про-
9'
244
Главг» 8
грамма при увеличении хмножества примеров. Как
указано в гл. 7, математической основой индуктивных
выводов служит понятие идентификации в пределе,
введенное Голдом. Ниже мы рассмотрим регулярные
ЛИСП-программы и их вывод, предложенный Бир-
манном, который свел задачу автоматического синтеза
ЛИСП-программ по примерам к идентификации
программ в пределе.
Основные функции регулярных ЛИСП-программ
Бирманна, так же, как и в системе THESYS Сам-
мерса, ограничиваются только функциями саг, cdr,
cons, atom. Кроме того, Саммерс из входных и
выходных выражений строил М-выражения, которые он
назвал фрагментами, а затем, вычисляя разность
фрагментов, создавал ЛИСП-программу с
рекурсивными вызовами. Синтез регулярных ЛИСП-программ
в основном осуществляется аналогичным образом, а
именно: операциям генерации фрагментов и
получения разности соответствуют операции трассировки и
слияния.
Трассировка показывает, как можно построить
выходное S-выражение из входного S-выражения в
случае, когда пара заданных S-выражений
рассматривается как вход и выход некоторой программы. В
качестве примера возьмем пару S-выражений
<(А.В).С)=ИС.(В.А))
Если записать их в виде фрагмента, получим
/М = (С.(В.А))
= cons [cdr [x];
cons [cdr [car [*]];
car [car [x] ] ] ],
* = ((A.B).C)
Дважды подчеркнутая здесь функция саг[х]
указывает на то, что для конструирования подвыражения
(В.А) из х достаточно применить функцию саг к
начальному выражению ((А.В).С) и получить
(А. В)=>(В.А).
Синтез программ по примерам
245
Таким образом, в системе синтеза регулярных ЛИСП-
программ предпочтение отдается делению выражений
с помощью функций саг и cdr, особенно в случаях,
когда выходное выражение конструируется из
входного или входное выражение можно предварительно
разделить на части. Введем обозначения для каждой
новой функции, представим их в виде следующих
выражений и назовем это трассировкой.
Трассировка F:
M*] = cons[M*]; /зМ1.
/2M = Mcdr[x]],
/з[*1 = Ысаг[л]],
/5M = cons[/6[x]; fi[x]]>
h[x] = f *№*[*]],
/7 W=/9 [car [a:]],
h[x] = *>
h[x] = *>
fo[x] = x.
Обратите внимание на подчеркнутый оператор,
который отражает указанный выше «принцип
предпочтения». Собственно регулярной ЛИСП-программой
называется программа, для которой трассировка,
построенная указанным выше способом из пары входного
и выходного выражений, совпадает с трассировкой
реальных вычислений.
Для того чтобы далее рассмотреть метод слияния,
предварительно укажем целевую регулярную
программу G.
Программа G:
g{ [х] = [atom [л:] -> х\
Т-> cons [&[*]; g3 [*Ш;
^*l = gi[cdr[*]];
g3M=ffi[carM].
Трассировка Ту показывающая, как эта программа
выполняется для входного S-выражения ((А.В).С),
имеет следующий вид.
246
Глава 8
Трассировка Т вычисления по программе G:
gi,i М = cons [g2fl [x]; g3>l [х] ],
g2,i[x] = gifi[cdr[x]],
g3,i[x] = gi,z[cav[x]],
gi,3 [x] = cons [g2<2 [x], g3< 2 [x] ],
g-2,2 [X] = gl,4 [Cdr [X] ],
g3,2[*] = gi,e[car[x]],
glfi M = X,
gl>4[x] = x,
glfi[x] = X
Здесь git / обозначает j-e применение функции gt во
время выполнения. Если сравнить трассировки F и Т,
то, например, /б и gi,3 совпадают, а именно: /5 — это
третье применение g[. Соответствие F и Т можно
представить в табл. 8.1. Из этой таблицы видно, что
Таблица 8.1
Имя функции
g\
g2
Появление в T
ft,/(Ki<2)
8г, /(К/<2)
Появление в F
/ь /г> /4. fe. /9
h, h
h, U
для вывода G из Т7, если G неизвестна, достаточно
разделить обозначения функций в F на некоторые
равнозначные классы и отождествить обозначения
функций, принадлежащих одному классу. Операция
отождествления обозначений называется слиянием.
В нашем примере в соответствии с приведенной выше
таблицей отождествим /ь /б, /4, /в с /9, /г с /6 и /3 с /7;
в результате получим
|cons[/2W; /зМ], если ((А. В.). С), (А. В);
'i[xi \x, если А, В, С
M*] = UcdrM];
/з [х] = /i [car [x]].
Синтез программ по примерам
147
При этом выполнена генерация предиката с условием
«если» с целью разделения двух типов S-выражений.
В данном случае для разделения достаточно
применить atom[x], поэтому оператор «если» перепишем
в виде условного оператора ЛИСПа и получим
/i M = [atom [x] -> х\
T->cons[f2[x]\ /3 [*]]];
/2M = fi[cdrM];
/зМ = Мсаг[дг]].
Обратите внимание на то, что эта программа
идентична G, за исключением имен функций.
При выводе программы с помощью слияния
необходимо решить задачу, как вычислять равнозначные
классы функций. Для ее решения Бирманн
использовал стратегию поиска программы минимального
размера, а именно: перечислив функции в порядке,
начиная с функции наименьшего размера, он один за
другим просматривал возможные равнозначные классы
до тех пор, пока не будет синтезирована программа,
которая может реализовать заданную трассировку.
Следовательно, гарантируется, что полученная в
результате вывода программа — это программа
наименьшего размера, которая может выполнить
заданную трассировку. Кроме того, очевидно, что
это свойство дает возможность делать
идентификацию в пределе так, как рассказано в предыдущем
разделе.
Итак, синтез регулярных ЛИСП-программ по
примерам имеет большое преимущество в том смысле,
что его объектом является реальный язык
программирования — ЛИСП и он имеет теоретическое
подтверждение. Однако сложность синтеза в том, что
объем вычислений для получения программы
минимального размера экспоненциально возрастает.
Бауэр, используя метод слияния, описал метод вывода,
при котором вывод осуществляется за разумное
время. С этим методом мы кратко познакомимся
в следующем разделе.
248
Глава 8
8.3. CDL —РЕАЛЬНЫЕ ПРОБЛЕМЫ
Как уже отмечалось, в системе THESYS Саммерса
невозможен вывод программ со сложной структурой
управления, а при выводе регулярных
ЛИСП-программ Бирманна серьезной проблемой становится
объем вычислений. Что же необходимо, чтобы
подобные методы автоматического синтеза программ по
примерам стали действенным инструментом
программистов? Система синтеза программ по
трассировке, которую Бауэр использовал как
экспериментальную систему, наметила идею решения этой
проблемы.
Принимая за основу метод слияния Бирманна,
Бауэр спроектировал язык описания вычислений CDL
и построил систему синтеза программ на
процедурных языках по трассировкам, записанным на CDL.
Трассировка ЛИСП-программ, о которой шла речь
в предыдущем разделе, состояла из операторов
ЛИСПа (М-выражений), а рассматриваемая ниже
трассировка формально включает ограниченный
набор операторов процедурного языка. Основная идея
синтеза программ по такой трассировке заключается
в использовании системой синтеза в качестве знаний
различных условий (договоренностей) о способах
применения переменных, констант и других
элементов программ. Предполагается, что трассировка на
языке CDL удовлетворяет таким условиям.
На практике в написанной программистом
программе появляются имена процедур, аргументы
процедур, локальные и глобальные переменные, массивы,
записи, имена процедур и другие элементы. При
записи трассировки на языке CDL также можно
вводить все имена, появляющиеся в программе, за
исключением операторов управления (например,
оператора GOTO). При этом используются следующие
условия для более точного отражения в трассировке
замысла программиста:
1) появляющиеся в программе константы не
записываются в виде переменных;
2) переменные, за исключением входных
параметров, не записываются в виде констант;
Синтез программ по примерам
249
3) переменные, принимающие в качестве значения
часть структуры (например, АA) для переменной А
типа массива), не записываются в виде отдельной
переменкой;
4) входные параметры процедур задаются в виде
констант, а после изменения входного значения в
результате вычислений вместо этого входного
параметра должна использоваться константа.
Когда системе синтеза программ задается
написанная на языке CDL трассировка, допускается, что
она удовлетворяет условиям 1—4. Например, в
трассировке записана константа 5, при этом из
трассировки должно четко следовать, что эта константа не
входит в какой-либо список входных параметров.
Тогда система синтеза расценивает константу 5 как
обозначение константы, используемой в целевой
программе.
Синтез программ осуществляется структурными
методами с использованием слияния на основе
трассировки, представляющей собой набор операторов,
удовлетворяющих указанным условиям. Прежде всего
все операторы в трассировке разбиваются на
«подобные» классы операторов, и формируются
равнозначные операторы. Затем проверяется,
удовлетворяют ли операторы в этих классах условиям
1—4. В заключение равнозначные операторы
сливаются в один, и составляется программа,
содержащая циклы.
Обратите внимание на то, что оценка подобия двух
каких-либо операторов выполняется полностью на
основе их структуры. В зависимости от их свойств
можно в трассировке записывать неопределенные
имена процедур, что позволяет синтезировать
иерархические программы.
Синтез программ по описанию трассировки на
языке CDL позволяет получить разнообразную
дополнительную информацию о примерах вычислений.
Однако проблема определения уровня такой
дополнительной информации в трассировке — это крайне
сложная проблема выбора, чему отдать предпочтение:
увеличить время ввода пользователем трассировки
или повысить возможности и надежность системы
250
Глава 8
синтеза. Для решения этой проблемы, видимо,
необходимы особые исследования разнообразных языков
программирования.
8.4. ВЫВОД МОДЕЛЕЙ
Объектами индуктивных выводов до сих пор были
функции, формальные языки и программы. Причем
все они рассматривались по отдельности. Трудность
здесь в том, что при расширении класса объектов
становятся неэффективными методы вывода, а
эффективные методы действуют только в узком классе
объектов.
В последние годы Шапиро предложил
унифицированные и достаточно эффективные методы
индуктивных выводов, объектами которых выбраны
формальные языки первого порядка и, в частности, хорнов-
ские предложения. Эти методы он назвал
методами вывода моделей, причем они могут
применяться не только для функций, формальных
языков и программ, но и как средство
полуавтоматической отладки при разработке программного
обеспечения.
Ниже мы познакомимся с общей концепцией
вывода моделей Шапиро и усовершенствованием его
методов, полученным недавно Исидзака.
В основе концепции вывода моделей Шапиро
лежит высказывание Поппера о том, что теория должна
опровергаться фактами. Этот принцип нашел
отражение в понятии идентификации в пределе как критерия
правильности вывода, который уже был рассмотрен.
Шапиро начал с перевода понятий «теория», «факт»
и «опровержение», упомянутых в этом высказывании,
в термины логики предикатов первого порядка.
Кроме того, отличие его подхода от других методов
индуктивных выводов заключается в том, что в качестве
объектов он выбрал логику предикатов и ее модель.
В этом причина практической ценности его теории.
В частности, логика предикатов отличается
следующими достоинствами:
1) имеет естественный смысл. Можно легко
обнаруживать места возникновения несоответствия;
Синтез программ по примерам
251
2) дает тесную связь между грамматикой и
семантикой. Это позволяет просто ослабить опровергающие
предположения;
3) имеет свойства монотонности и модульности.
Это позволяет в общих чертах прогнозировать
возможности вывода в зависимости от смены
предположений и диапазон их влияния;
4) его можно рассматривать как язык
программирования, например как язык логического
программирования типа Пролог.
8.4.1. ПРОБЛЕМА ВЫВОДА МОДЕЛЕЙ
Рассмотрим в качестве языка множество операторов
L логики предикатов первого порядка, состоящее из
операторов с конечным числом предикатов и
функций, а именно: операторы в L имеют вид
{/>, p,}*-{Qu •••> Qk) (и k>0).
Здесь Pm, Qn — атомы. Такие операторы назовем
предложениями. В частности, при / = 0 или / = 1
назовем их хорновскими предложениями.
Эти операторы можно интерпретировать как вывод
PiV ... VPj из Qi& ... &Qk. {Qi, ..., Qk} назовем
предпосылкой, а {Рь ..., Pj} — заключением.
Оператор с пустой предпосылкой означает, что по крайней
мере один атом в выводе истинен, а оператор с
пустым заключением — что по крайней мере один атом
в предпосылке ложный. Пустой оператор обозначим
через П. При любой интерпретации он ложен.
Оператор {Р}+- запишем просто как Р.
Рассмотрим два подмножества L0, Lh множества L
таких, что
Допустим также, что L0 и Lh — определяемые, то есть
для любого оператора Р существует алгоритм,
определяющий, принадлежит ли Р Lh или L0. Lo назовем
языком наблюдений, a Lh — языком гипотез,
операторы в Lo — операторами наблюдения, а операторы
в Lh — гипотезами.
Рассмотрим непустое множество Я, которое
назовем областью (так называемая область Эрбрана),
251
Глава 8
Представление P(tu ..., tn) {U^H), в котором
аргументы предиката Реп переменными,
принадлежащего L, заменены на элементы Я, назовем
порождающим атомом (ground atom). Образ М, в котором
каждому порождающему атому в L поставлено в
соответствие значение «истина» или «ложь», назовем
моделью. Образ М распространяется на оператор в L
с переменными х\, ..., хп (п ^ 0)
(Л, ..., Pt)*-{Qu •••> Qn)
следующим образом:
"истина, если для
любых хи..., хп е
мир Р)<-(о о \\-\м(р1)У—УМ(Р()<
истинно;
ложь—в противном
случае.
Скажем, что оператор а в L истинен в М9 если
М(а) = истина, и ложный в М, если М(а) — ложь.
Пусть задан оператор наблюдения а, допустим,
что существует механизм, который выдает ответ
«истина», если а истинен в М, и «ложь», если а
ложный в М. Такой механизм назовем
предсказателем. Операции задания предсказателю входных
данных и чтения его ответа назовем экспериментом
в Л1 Кроме того, пару данных <а, v}, которые
описывают результат эксперимента, назовем фактом. Здесь
«gL0 — оператор наблюдения, aye {истина, ложь}.
Обозначим через L^ множество операторов
наблюдения, истинных в модели М. Например, пусть
существует принцип вывода, или некая полная процедура
вывода, и Т есть ограниченное подмножество L.
Тогда запишем Т \— р, если оператор р выводится из
7, и Т\-/-р, если не выводится. Пусть S — множество
операторов; запишем Т Н 5, если для любого peS
имеет место ГНр, и TtyS— в противном случае. ^
Определение 8.1. Допустим, что множество
операторов Т cz Lh является полным набором аксиом L0
в М, если все операторы в Т истинны в М и Т н La *
Синтез программ по примерам 253
Теперь можно строго сформулировать проблему
вывода модели.
Пусть заданы язык предикатов первого порядка L
и два его подмножества L0 и Lh, а также
предсказание о некоторой неизвестной модели М языка L.
Тогда проблема вывода модели состоит в
нахождении конечного полного набора аксиом L0 модели М.
Алгоритм решения такой проблемы назовем
алгоритмом вывода модели. Он соответствует машине выводов
из гл. 7. Обнаружение любого aei0 в некотором
факте Ft = (ay v) из неограниченной
последовательности фактов Fu F2, •¦. о М назовем перечислением
М. Алгоритм вывода модели сводится к просмотру
перечисления модели для заданного языка
наблюдения L0f другими словами, к чтению одного из
фактов и выдаче время от времени ограниченного
множества операторов языка гипотез Lh. Полученное
при этом ограниченное множество гипотез будем
называть наблюдениями этого алгоритма. Другие
понятия, например сходимость и идентификация в
пределе, определяются так же, как в гл. 7.
Как уже было отмечено, в основе вывода моделей
Шапиро лежит методология Поппера: «Теория
должна опровергаться фактами». Факт уже определен
выше, а теория — это наблюдения Г, а именно:
ограниченное множество гипотез. Следовательно, для
опровержения в соответствии с принципом Поппера
необходимо наложить на L0 и Lh некоторые
допустимые ограничения.
Определение 8.2. Назовем пару <L0> Lh}
допустимой, если для любой модели М языка L и любого
множества Т a Lh такого, что {а е L0 \ T Ь- а} = L^9
Т истинно в М.
Пусть <L0, Lh) — пара, удовлетворяющая этому
условию, тогда принцип Поппера можно реализовать,
указав доказательство того, что в теории с ложным
Lh множество, удовлетворяющее L^9 ложно для всех
языков наблюдения L0.
В качестве пар <LG> LA>, удовлетворяющих
условию допустимости, можно рассматривать такие парьп
1) L0 = {порождающие автомы L}, Lh = {хорнов*
ские операторы L}\
254
Глава 8
2) L0 = {порождающие простые операторы L},
Lh = L.
Здесь простым оператором назван оператор,
состоящий только из одного атома. Ниже рассмотрим
только случай 1.
8.4 2. АЛГОРИТМЫ ВЫВОДА МОДЕЛЕЙ
Зафиксируем одно из перечислений всех конечных
множеств операторов в Lh\ пусть это будет Гь Г2, ... .
Рассмотрим простой алгоритм вывода, указанный на
рис.* 8.1. В общем случае окончание цикла while не
поддается оценке, поэтому этот алгоритм может
зациклиться. Следовательно, существует вероятность
того, что после чтения некоторого факта следующий
факт так и не будет прочитан, и этот алгоритм будет
действовать неверно.
В этом случае будем управлять числом циклов
вывода с помощью некой вычисляемой функции h.
Обозначим через Т \- па(Т\-/-па) ситуацию, когда Т
может (не может) вывести а не более чем через
п шагов вывода. Затем фиксируем перечисление аь
а2, ... множества L0. Тогда этот алгоритм можно
улучшить так, как указано на рис. 8.2. В новом
алгоритме вывод может быть прерван через п или h(i)
шагов, и все Tk будут ограниченными множествами,
поэтому выход из цикла while обеспечивается в любом
случае.
k<-b 5fa-se«-{a};
repeat
read следующий
Sv <- Sv U {a}
while Эр ее 5faIse
3p^5true:
k<-k+\
output Tk
forever
5true *~
факт F =
:7*r-P
{}
= <<x, v)
или
Гл^Мо |
Рис. 8.1. Простой алгоритм вывода моделей на основе
перечисления.
Синтез программ по примерам
255
k<-b Sfalse <-{?};
repeat
read следующий
Sv <- Sv U {a}
while 3peSfalse
3a. € Strue
k<-k + 1
output Tk
forever
5*rue <- i }
факт Fn = (a, v)
:Г*|-лРи.™
:7"feb^ft(i)a.do
Рис. 8.2. Алгоритм вывода, использующий /i-простоту.
Скажем, что ограниченное множество Tk Л-просто,
если для почти всех п > О (т. е. за исключением
конечного числа случаев), при которых Tk^an, имеет
место
min {Л ГЛГ-/ая}< А ДО-
Скажем также, что модель М /г-проста, если для
некоторого k > О Т является /i-простым полным
набором аксиом Lo модели М. Тогда можно показать, что
если М /i-простая модель языка L, то указанный выше
алгоритм идентифицирует в пределе эту модель, и,
наоборот, модель, которую идентифицирует в пределе
этот алгоритм, является Л-простой.
Примеры фактов:
<0<0', true)
(plus @, 0', 0), false)
(times @', 0", 0""), true)
Теория:
Х^Х
X^Y"+-X^Y
plus (X, 0, X)
plus(X, Г, Z')<-plus(*, Г, Z)
times (X, 0, 0)
times (X, Y\ Z) <- times (X, У, M), plus (IF, X, Z)
Рис. 8.З. Вывод операций над числами.
Ш
Глава 8
Примеры фактов:
(append([a, b]. [с, d, e], [ ]), false)
(append([a, b], [c, d, e], [a, b, c, d, e]), true)
(reverse([a, b, с], [а, с, b), false)
(reverse(a, b, с], [с, b, a], true)
Теория:
append([ ], Xt X)
аррегкЩЛ | X, У], [A | Z]) <- append(A', Y, Z)
reversed ], [ ])
reverse^ | X], Y) <- reverse(X, Z), append(Z,
[A]. Y)
Рис. 8.4. Вывод логических программ.
Выше приведены два примера вывода моделей.
В примере на рис. 8.3 областью является множество
всех натуральных чисел, а язык состоит из 0,
функции X' (число, следующее за X), p!us(X, У, Z) (X 4-
L+Y = Z), times (Л, У, Z) (X X Y = Z).
На рис. 8.4/Приведен пример вывода логических
ррограмм. Область — списки, язык — константа []
(пусто), append(X, У, Z) (если к X присоединить У,
то получится Z), reverse(X, У) (У-получен путем
обратной перестановки элементов X).
8.4.3. ОПРОВЕРЖЕНИЕ И УТОЧНЕНИЕ ГИПОТЕЗ
Подобные* примеры могут быть выведены с помощью
алгоритма вывода на рис. 8.2, но и в нем не все
можно реализовать. В частности, между текущим
предположением Tk и следующим за ним кандидатом
в предположение Tk+\ при традиционном
перечислении какой-либо связи не возникает. Другими
словами, перечисление кандидатов в предположение
определяется вне всякой связи с моделью, которую
предстоит из них вывести, и, кроме того, вне всякой связи
с примерами фактов, которые получил алгоритм до
текущего момента. Из-за этого, например, даже если
в данный момент мы пришли к предположению, очень
близкому к правильному, иногда кандидатуры,
проверяемые сразу вслед за ним, никак с ним не свя-
Синтез программ по примерам
257
заны. С целью улучшения алгоритма вывода с
помощью перечисления Шапиро предложил следующие
два важных метода.
А. Опровержение с помощью решающих экспери*
ментов
Когда предположение усиливается, т. е. когда вы*
водится оператор, ложный в М, по крайней мере
одна из гипотез в этом предположении ложна. Для
поиска такой гипотезы используются эксперименты,
соответствующие решающим экспериментам в
философии, и плохая гипотеза отвергается. Эта операция
называется слежением за противоречивыми точками.
При таком эксперименте в случае научной теории
можно только указать, что все предположение
ошибочно, но в случае вывода модели можно выделить
по крайней мере одну ошибочную гипотезу в
предположении.
Прежде всего приведем пример логики
высказываний и объясним алгоритм слежения за
противоречивыми точками. Этот алгоритм можно применять, если
возникает противоречие между некоторой гипотезой и
фактом, а входом в этот алгоритм является дерево
вывода, в котором корнем служит пустой оператор ?,
а листьями — гипотезы и операторы наблюдения,
истинные в М, то есть S = Г&и^истина. В этом дереве
установлен следующий порядок листьев: атомы,
используемые при выводе влево приходят к
предусловиям, а вправо — к заключениям. Данный алгоритм
выдает предсказания, на основе которых можно узнать
истинность порождающих атомов языка L и выдать
операторы а, истинные в М и такие, что a^Tk. На
рис. 8.5 указано дерево в случае
S = {P<-Q&R, Q<-R, «-P, #«-}.
Допустим, что P+-Q&R ложно. Отправимся от
пустого оператора ? в корне дерева и будем
последовательно проверять атомы, используемые при выводе,
выясняя, истинны ли они в модели М, в неясных
случаях «прислушаемся» к предсказанию, если оно
истинно, то пойдем по левой ветви, если ложно, то по
правой. Если таким образом придем к листу, то вы-
253
Глава 8
<2<-Я
Рис. 8.5. Слежение за противоречивыми точками в случае
суждений.
дадим оператор, записанный в этом месте. Это
позволяет исключить ложные операторы.
В данном примере заметим, что исходный R
истинный, поэтому идем налево, используемый
далее атом Р ложный, поэтому -идем направо.
Истинность в М атома Q, используемого при выводе, .не
ясна, поэтому «прислушиваемся» к предсказанию и
получим ответ, что оно истинно, поэтому пойдем
налево и достигнем листа P+-Q&R. Так можно
обнаружить противоречие. Достоинство этого алгоритма
заключается в том, что по результатам текущей
проверки можно однозначно определить исход
следующей проверки.
Данный алгоритм слежения за противоречивыми
точками можно использовать и в случае логики
предикатов. При этом перед проверкой необходимо
конкретизировать предикат в порождающем атоме.
Например, изучим введение аксиомы отношения ^ для
натуральных чисел. Если в момент, когда нам
встретился факт {s@)^ s(s@)), истина}», предложена
гипотеза s(X)^Y+-X < У, то можно построить
дерево вывода, аналогичное дереву в случае суждений
(рис. 8.6). Здесь, для того чтобы выбрать ложную
гипотезу среди трех гипотез, находящихся в листьях,
]> Авторы ввели новое обозначение s(X) для функции X'
(см. рис, 8.3), — Прим. перев?
Синтез программ по примерам
159
+-*(Z)U0 $(X)UY*-X?Y.
*-Х?0 Q^W<r<
а
Рис. 8.6. Слежение за противоречивыми точками для логики
предикатов,
используем алгоритм слежения за противоречивыми
точками. Атом, используемый при выводе в корне
D, — это атом 0^0. Обратимся к предсказанию с
этим оператором и получим ответ «истина». Поэтому
пойдем по левой ветви. Здесь для вывода
использовался атом s(X)^:0, конкретизируем его в
предсказании, определим истинность оператора s@)^0 и
получим ответ «ложь». Поэтому пойдем по правой
ветви и обнаружим ложную гипотезу s(X)^LY+~
<-Х^ Y. Вспомнив все замены переменных, которые
мы использовали до достижения этого листа, можно
получить пример, показывающий, что эта гипотеза
ложная, т. е. одновременно получим контрпример для
этой гипотезы: 5@)^0-^-0^0. Таким образом,
алгоритм вывода исключает из предположения эту
гипотезу.
Б. Уточнение гипотез
С помощью приведенного выше алгоритма
слежения за противоречивыми точками можно исключить
гипотезу, которая стала причиной вывода оператора
наблюдения, ложного в Му и ослабить слишком
сильное предположение. Но есть еще одна проблема — что
еще можно сделать для ослабления предположения?
Для ее решения Шапиро ввел оператор уточнения.
С его помощью не только решается настоящая
проблема, но и устраняется недостаток алгоритма
перечисления, упомянутый в начале раздела. Данный
оператор пригоден для гипотез, исключенных с помощью
указанного выше алгоритма слежения за противоре-
260
Глава 8
чивыми точками, в случае, когда предположение
ослабляется, т. е. когда нельзя вывести оператор
наблюдения, истинный в М.
Определение 8.3. Оператор q назовем уточнением
оператора -р, если справедливо одно из следующих
условий:
1) р = П, q=a(xu ..., хп), где а — предикат п
переменных, все xi — попарно различные переменные;
2) р = Р, q = P{u/v), где {u/v} указывает
замену, и, v — различные переменные Р;
3) р = Р, q = P{v/f(xu ..., Хп)}, где / —
функция п переменных, xt различные переменные, не
встречающиеся в Р;
4) р==а(/ь ..., tn), q = a(tu ...» tn)+-a(xu ...
,.., Хп)у где U — термы, а — предикат п переменных,
xi — различные переменные, встречающиеся в /*.
Оператором уточнения называется операция
построения оператора q по такому оператору р. Кроме
этого оператора Шапиро рассмотрел более общий
оператор уточнения, а именно: он доказал, что,
отправляясь от пустого оператора ?, применение
оператора уточнения конечное число раз позволяет по-
Т<-{П)
repeat
! Считать следующий факт Fn = (a, v) |
Sv<-
while
while
until
Sv U {a}
3Р е 5false
:T[-Jdo
Используя алгоритм слежения за
противоречивыми точками,
щую гипотезу
Э«* е 5tme:
исключить из Т опровергаю-
TW-h(t)*td0
Добавить в Т уточнение для удаленной выше
гипотезы
VP е 5false:
V«< e Strue:
Вывести наблюдение Т
forever
Т У/- р, а также
T\-h{i)ar
Рис, 8.7. Обобщенный алгоритм вывода моделей.
Синтез программ по примерам WI
лучить любое предположение Tk. Итак,
окончательный уточненный алгоритм вывода моделей приведен
на рис. 8.7,
8.4.4. СОВЕРШЕНСТВОВАНИЕ СИСТЕМЫ
ВЫВОДА МОДЕЛЕЙ
В системе вывода моделей Шапиро есть немало
достоинств, но она ставит и ряд следующих проблем:
1) для указания адекватности предположений,
полученных просто перечислением, используются
только положительные факты, то есть факты типа {а,
истина};
2) перечисление ограничивается только простыми
операторами, и при достаточно большом
пространстве поиска нельзя генерировать сложные операторы;
3) индуктивные выводы следуют от общего к
конкретному, хотя более естественно рассматривать
выводы от конкретного к общему.
В последние годы Исидзака решил эти проблемы
с помощью понятия минимального обобщения,
введенного Плоткиным. Его метод ориентирован на хор-
новские операторы, причем логический вывод
предложений осуществляется с использованием обобщения
из множества положительных фактов, этот метод
эффективен, поскольку перечисление предложений
можно ограничить до уровня объектов.
ГЛАВА 9
ТЕОРИЯ АНАЛОГИЙ
С. Арикава, М. Харагути (Университет Кюсю)
Аналогия — это метод выводов, при которых
обнаруживается подобие между несколькими заданными
объектами; благодаря переносу фактов и знаний,
справедливых для одних объектов, на основе этого
подобия на совсем другие объекты либо определяется
способ решения задач, либо предсказываются
неизвестные факты и знания. Следовательно, когда
человек сталкивается с неизвестной задачей, он на первых
порах использует этот естественный метод вывода.
В данной главе мы познакомимся с исследованиями
аналогии, проведенными до сих пор, а также с ее
математической формализацией и исследованиями по
реализации метода аналогии, выполненными
авторами.
9.1. НАПРАВЛЕНИЯ ИССЛЕДОВАНИИ
АНАЛОГИИ
Одна из важнейших проблем инженерии знаний —
приобретение знаний. Под приобретением здесь
понимается получение знаний в виде, пригодном для их
использования компьютерами, поэтому многие
исследователи указывают, что ключом к знаниям является
теория и методология машинного обучения. В общем
случае машинное обучение включает приобретение
новых декларативных знаний, систематизацию и
хранение новых знаний, а также обнаружение новых
фактов. Среди указанных форм обучения аналогия,
о которой будет идти речь в данной главе, связана,
в частности, с проблемой машинного обнаружения
новых фактов.
Под новыми фактами мы будем понимать факты,
которые дедуктивно не выводятся из некоторых
существующих знаний. О некоторых аспектах
обнаружения новых фактов в исследованиях машинного
Теория аналогий
161
обучения можно посмотреть в гл. 7, 8, посвященных
индуктивным выводам. В общем случае при
индуктивных выводах по заданным данным создается
гипотеза, их объясняющая, а с помощью дедукции из
этой гипотезы можно вывести новые факты. С
другой стороны, при аналогии новые факты
предсказываются путем использования некоторых
преобразований уже известных знаний.
Индукция и аналогия крайне необходимы при
обработке интеллектуальной информации, и поэтому
желательно изложить основы их совместного
применения. Как было указано в гл. 8, Шапиро ввел
строгую формализацию индуктивных выводов в части
вывода моделей с использованием логики предикатов
первого порядка; в теории индуктивных выводов есть
заметные успехи. В данной главе с указанной выше
точки зрения дадим формализацию аналогии также
с помощью логики предикатов и укажем
теоретические основы для автоматизации аналогии.
Познакомимся также с реализацией машины аналогий,
использующей логические программы.
Прежде всего в данном разделе дадим краткий
обзор исследований аналогии, выполненных главным
образом Уинстоном. В разд. 9.2 формально
определим аналогию, опираясь на результаты исследований
Уинстона, и рассмотрим связь между аналогией и
дедукцией. Кроме того, введем логику первого
порядка для аналогии на основе частичного тождества'
как одного из видов подобия. В разд. 9.3 укажем
метод изучения свойств частичного тождества и
реализации аналогии с помощью логических программ.
С целью обзора исследований аналогии,
проведенных до настоящего времени, выделим два типа
аналогии: для решения задач и для предсказаний.
Аналогия первого типа применяется главным образом
для повышения эффективности решения задач,
которые, вообще говоря, можно решить и без аналогии.
Например, благодаря использованию решений
аналогичных задач в областях программирования и
доказательства теорем можно прийти к выводам о
программах или доказательствах. О другой стороны,
используя аналогию для предсказаний, благодаря
ш
Ггявэ 9
преобразованию знаний на основе подобия между
объектами можно сделать заключение о том, что,
возможно, справедливы новые факты. Например, если
объектами аналогии является некая система аксиом,
то знаниями могут быть теоремы, справедливые в
этой системе. При этом, используя схожесть между
системами аксиом, можно преобразовать теорему
в одной из систем в логическую формулу для другой
системы и сделать вывод о том, что эта формула есть
теорема. Другими словами, аналогия используется и
для решения некоторых строго сформулированных
задач и для предсказаний, а также для приобретения
не заданной ранее информации.
9.1.1. АНАЛОГИЯ ПРИ РЕШЕНИИ ЗАДАЧ
1. Из системы аналогий для решения задач с
помощью компьютеров первой была создана система
для доказательства теорем с помощью правил
вывода]) (Клинг, 1971 г.). Подобие по Клингу — это
образ А во втором из следующих условий для двух
заданных теорем Т\ и Т2 (Т\ — доказана, а Т2— нет):
1) Т\ и Т2 имеют грамматически одинаковые
структуры;
2) существует образ Л, который сохраняет
словарные значения в обозначениях Т\ и Т2
(обозначениях предикатов, функций, переменных).
Работа системы Клинга начинается с получения
А, который расширяется до образа А* для
используемых аксиом, затем с помощью А* доказательство Т\
по правилам вывода преобразуется в доказательство
Т2. Однако большинство примеров успешного
применения этой системы было связано с Т\ и Т2у которые
были почти идентичными, система оказалась
недостаточно аргументированной и унифицированной, что
нельзя сказать об используемых понятиях и методах.
2. Танвансон применял аналогию для задач
программирования роботов. Аналогия проводилась за
счет преобразования и использования законченных
программ на основе подобия команд, задаваемых
1 В этом разделе под выводом понимается математический
вывод формул.— Прим. перев.
Теория аналогий
245
роботу. Причем для более эффективной аналогии
непосредственное подобие команд не учитывалось.
Вместо этого в базе данных сохранялись группы команд
из уже составленных программ, преобразованных
методом абстрагирования в форму абстрактных команд
и программ. Танзансон определял подобие благодаря
смысловому сопоставлению текущих команд и
абстрактных команд в базе данных. Преимущество
определения подобия через абстрагирование состоит
в том, что можно организовать доступ в базу данных
для выбора подобных команд. Как известно, метод
абстрагирования эффективен и для традиционного
программирования без использования подобия, но в
случае аналогии он также полезен.
Система Танвансона, используя соответствие
между текущими командами и абстрактными командами,
найденными благодаря смысловому сопоставлению,
преобразует абстрактную программу в
незавершенную программу для текущего набора команд, и этот
процесс повторяется до полного завершения про-
граммы. Таким образом, эта система
программирования совсем не использует традиционные способы
составления программ, а извлекает подобные
команды путем смыслового сопоставления и использует
аналогию в том смысле, что абстрактные программы
преобразуются с помощью им подобных. Однако в
большинстве случаев более важным представляется
решение задач путем органичного сочетания
существующих методов решения с аналогией. Например,
Карбонел в качестве специальных операторов
обобщенного решателя задач рассматривал так
называемые Г-операторы, основанные на подобии, и
утверждал, что возможно органичное применение аналогии
и существующих операторов.
3. Область доказательства теорем одновременно
с Клингом исследовал Плейстид. Его исследования
были связаны с процедурами для нахождения
доказательств актуальных в данный момент теорем с
использованием доказательств абстрактных теорем.
Существенное отличие от указанных выше исследований
] и 2 состоит в том, что получается соответствие
(подобие) уже доказанной теоремы Т\ и недоказанной
ш
Глава 9
теоремы Г2, никакого вывода на основе этого подобия
не делается, а с целью упрощения задачи из Т2
строится абстрактная теорема Т'г Следовательно,
соответствие между Т2 и Т'2 полностью известно с
самого начала, поэтому, получив «абстрактное
доказательство» Р2 абстрактной теоремы Т2, можно из Р2
получить доказательство Р2 теоремы Т2, Подобный
метод доказательства теорем по правилам вывода
называется стратегией абстрагирования, он показан на
рис. 9.1.
В случае решения задач по этой стратегии можно
упростить процесс поиска подобных задач,
рассмотренный Танвансоном. Вместо проблемы поиска
возникает новая проблема: до какого уровня
абстрагировать решение исходной задачи? Плейстид
математически определил абстрагирование логических
формул и дал одно из решений этой проблемы.
Продемонстрируем на простом примере основную идею
его решения.
Пусть G — ограниченное множество
высказываний, а С — высказывание; будем записывать G Ь-С,
если из G по правилам вывода можно вывести С.
Давайте определим вывод GHC с помощью стратегии
абстрагирования. Например, рассмотрим 1)
G = {~P(x)V~QWR(x), P(x), Q(a)}y C = R(a).
Для абстрагирования высказываний используем
пропозициональное2) абстрагирование, при котором
Абстрагирование
Задача *- Абстрактная задача
(доказал^) (доказать Т?)
I
I
t
f
i
I
I
Решение ?г•*-< "" ' ¦ ¦¦ ¦ Абстрактное решениеР?
Решение задачи/ < дерево вывода к пустому
выводимое из Р? предложению)
Рис. 9.1. Стратегия абстрагирования.
Традиционное
решение задачи
(принцип вывода)
1) Знак «~» означает отрицание. — Прим. ред.
2> От английского proposition (высказывание). — Прим. пе*
рев.
Теория аналогии
267
остаются только обозначения предикатов, а
остальное отбрасывается. При абстрагировании G и С
получим
G' = {~PV~QV/?, Я, Q}, С' = Я.
В логике высказываний это есть множество
высказываний и высказывание. Очевидно, что вывод
С \- С сделать легче, чем вывод G \- С. Вывод
Gf Y- С делается так, как на рис. 9.2.
Теперь укажем способ вывода G \— С исходной
задачи из вывода G/ h С. ~ Р(х) V ~ Q{x)V R(x)t
Р{х), Q(a) благодаря пропозициональному
абстрагированию связывается соответственно с ~ Р V ~ Q V /?,
Р, Q; поэтому рассмотрим метод построения вывода
GY- С, при котором сохраняется каждый вывод,
обусловленный абстрагированием (рис. 9.3). При
построении выводимых высказываний Сх и С2 сначала
перейдем к выводу Ср С2 и C'v
В данном примере начнем с вывода
Р9 ~PV~QVR I Q V/?,
затем, проверив выводР(л:), ~P{x)V ~ Q (х) V R (х)\
получим
/>(*), ~P(x)V~Q(x)VR(x)\ Q(x)VR(x).
Обратим внимание на то, что здесь ~QVR — это
~ Pv-QVR
QVR
Рис. 9.2. Пример вывода.
С/
с2'
\ /
•Сз >-^с3'
Рис, 9.3. Перенос вывода на другое множество.
253
Глава 9
пропозициональное абстрагирование выводимого
высказывания ~Q(x) V R(x). Далее сделаем вывод
~QV#, Qh-P
и получим
~Q(x)VR(x), Q(a)\-R(a).
Таким образом, отправляясь от дерева вывода
G' |— С, можно получить дерево вывода G Р С.
Принимая за основу эту идею, Плейстид дал
общее определение абстрактных образов и предложил
стратегию для получения дерева вывода с помощью
абстрагирования.
9.1.2. АНАЛОГИЯ ДЛЯ ПРЕДСКАЗАНИЙ
Как один из примеров аналогий для предсказаний
можно привести аналогию, основанную на причинных
отношениях Уинстона. Аналогия, рассмотренная в
данном разделе, главным образом относится к
этому направлению. Прежде всего кратко опишем
принцип аналогии, использованный Уинстоном.
Объектом аналогии служат простые предложения
на английском языке; будучи введенными в систему
аналогий, они преобразуются в структуру фреймов.
При этом с целью приобретения информации об
отношениях, выходящих за рамки отношений между
фреймами, делаются различные дедуктивные выводы
с помощью демонов1}, ассоциирующихся с именем
отношения. Например, из входного предложения
Lady Macbeth persuades [Macbeth wants to be a king]
(Леди Макбет убеждает Макбета, что он хочет быть
королем)
генерируется сеть фреймов, показанная на рис. 9.4.
Знак «^—» на этом рисунке отмечает «поясняющий
фрейм», дополнительно объясняющий отношения
между фреймами.
Пусть из описания двух заданных английских
предложений сгенерирована сегь фреймов N\ и 7V2.
Проблема состоит в обнаружении подобия между ни-
1> Присоединенные процедуры. — Прим% перев.
Теория аналогий
269
ми. Подобие, рассматриваемое Уинстоном,
указывает пары фреймов N\ и N2 (исключая поясняющие
фреймы) с максимальным числом совпадающих
отношений. Под совпадением отношений здесь
понимается равенство значений слотов, принадлежащих
фреймам, или равенство, за исключением пары значений
слотов отношений. Способ определения таких пар
иллюстрирует рис. 9.5. Запись п\ -> п2 на этом
рисунке указывает, что слот г фрейма п\ есть /г2,
пунктирная линия указывает пары фреймов. Обратите
внимание на то, что определение пар
распространяется и на определение пар поясняющих фреймов.
Если таким образом определить пары фреймов, то
на их основе можно делать выводы. Уинстон,
проводя аналогию, следовал основной гипотезе о том, что
подобие сохраняет причинные отношения, другими
словами, подобные причины приводят к подобным
заключениям. Для строгого представления этой
гипотезы обратимся к рис. 9.6. На этом рисунке а, Ъ, а',
??', ... — объектные фреймы, г\, г2, ... — отношения
между фреймами. Пунктирные линии указывают
пары фреймов. В S\ r\(a, b) является причиной
r2(c, d)\ благодаря определению пары к n(a, b)
известно, что в S2 справедливо подобное отношение
r\(a\ b'). При этом ссылаясь на причинные
отношения в Si, делаем вывод о существовании аналогично-^
контролирует
хочет-быть
Леди-Макбет -- *- хочет-быть t -
убеждает
король
Рис. 9.4 Часть фреймового представления объекта аналогии.
Рис, 9.5. Парное соответствие фреймов.
270
Глава 9
Рис. 9.6. Принцип аналогии Уинстона.
го отношения r2{c\ d') в S2 (прослеживая пары
отношений). Кроме того, Уинстон допускает
существование закона Перехода в причинных отношениях и
использование сцепления принципа аналогии.
Как легко видеть, условием для того, чтобы
подобная система аналогий вела себя достаточно
разумно, является способность процедуры преобразования,
которая извлекает причинные отношения из описаний
входных предложений, к дедуктивным выводам на
основе богатого набора знаний. Кроме того,
сущностью выводов по принципу аналогии является
использование причинных отношений как логических
правил. Исходя из этих соображений, в следующем
разделе рассмотрим принцип аналогии, основанный
на отношениях логической импликации, и обсудим
способы органичного сочетания в дедуктивной
системе аналогии и дедукции.
9.2. ТЕОРИЯ АНАЛОГИИ
В общем случае аналогия — это вывод подобного
заключения, если справедливы подобные
предпосылки. Уинстон, исследуя аналогию, считал
предпосылкой и заключением причину и следствие в причинных
отношениях. В этом разделе рассмотрим
предпосылки и заключения в отношениях логической
импликации и сформулируем аналогию с помощью хорновской
логики. Кроме того, обсудим отношение между ана-
Теория аналогий
271
логией и дедукцией с использованием понятия суммы
аналогий. Укажем также, что аналогию, основанную
на подобии как-частичном тождестве, можно описать
с помощью логики первого порядка.
9.2.1. ФОРМАЛИЗАЦИЯ АНАЛОГИИ
Прежде всего поясним принцип аналогии на
примере рис. 9.7.
На рисунке а» и а — факты, справедливые в Si, a
Р/ — факты, справедливые в S2. ср — образ или
отношение между объектами, определяющее подобность —
назовем его подобием. Ситуацию, при которой
тождественность предпосылок можно рассматривать как
подобие ф, будем записывать в виде а,фР; A^/^п)«
Тогда аналогия — это вывод р в S2, такого, что асрр.
Для строгого определение аналогии необходимо
задать:
1) определение подобия ф;
2) метод получения ф из заданных объектов Si
и S2;
3) операцию для вывода |3, такого, что асрР
(рис. 9.7), на основе ф.
Прежде всего определение подобия ф должно
зависеть от представления объектов и их смысла. В дан«
ном разделе допустим, что объекты аналогии
представляются через ограниченные множества Si
определенных предложений и представляют собой
минимальные модели Mi множеств S«, определяемые
следующим образом. Здесь под определенными
предложениями понимаются правила «если — то», которые
будем записывать в виде
А*-Ви ..., Вп,
где Л, В,— положительные литералы. Для простоты
ниже будем называть эти предложения правилами.
Объект St*№§ДП0СЫЛК8 eft,"*, <tn. *~ Заключение #
Подобие <р
Объект S2:предпосылка Д,«", Д, -~->- Заключение ]} ?
Рис 9.7, Принцип аналогии.
гп
Глава 9
Термы, не содержащие переменных в S/,
представляют собой отдельные элементы объектов, предикаты
р — отношения между элементами, а
порождающие атомы p(tu ..., tn)y не содержащие
переменных,— отношение р между элементами //. В
дальнейшем порождающие атомы, не содержащие
переменных, будем называть просто атомами. Обозначим
через Bi множество, состоящее из всех атомов Si.
Тогда минимальная модель Mi множества Si—это
множество атомов, логически выводимых из Sr.
Ml = {a<=Bl:Si\-a),
где h обозначает вывод в логике предикатов. Кроме
того, элементы Mi назовем фактами в S/.
Для определения аналогии между Mi необходимо
рассмотреть отношение пар Mi. С этой целью еле-
дующим образом определим пары термов Si.
Определение 9.1. Пусть U(Si)— множество
термов, не содержащих переменных, в St. Тогда
конечное множество ф, такое, что ф^ f/(Si)X ^(^2),
назовем парным соответствием. Здесь знак «X»
означает прямое произведение множеств.
Термы представляют собой отдельные элементы
S/, поэтому парное соответствие можно
интерпретировать как некое парное отношение между элементами.
Si в общем случае имеет функции без переменных,
поэтому парное соответствие ф можно следующим
образом распространить на парное отношение ф*
между U(Si).
Определение 9.2. Отношение термов ф+^ ?/(Si)X
X ^(^2), порождаемое ф, определим как минимальное
отношение термов, удовлетворяющее формулам (9.1)
и (9.2).
Ф^Ф+> (9.1)
</,, /;>€=ф+=></(/,, .... tn), fit и ..., 0>е=Ф+.
(9.2)
Здесь / — функция, содержащаяся одновременно в
Si и S2.
Для заданных Si и S2 в общем случае существует
несколько возможных парных соответствий ф. Для
Теория аналогий
273
каждого из них можно следующим образом
определить подобие как совпадение отношений, т. е.
совпадение предикатов.
Определение 9.3. Пусть tf^U(S[)J /Je=t/(S2)f
ф—парное соответствие, а, о! — соответствующие
факты в Si, S2. Тогда возможность отождествить а и
рс' с помощью ф для некоторого предиката р можно
ваписать в виде
<* = р(*ь •••> tn)t
af==zP(t[> •••> Q*
причем (tj, t'j} e ф+. Кроме того, отождествление а и
а' с помощью ф будем записывать как осфа'.
После соответствующей подготовки определений
принцип аналогии (рис. 9.7) можно переписать так,
как указано ниже.
Аналогия на основе парного соответствия ф
Пусть в Si факты рь ..., prt служат условиями того,
что факт а справедлив, а именно: в Si справедливо
a-*-Ei, ..., p«. Тогда, если существует факт
р'< в S , такой, что Р;фР^, то в S2 выводится атом а',
такой, что афа'.
Обратите внимание на то, что атом а/ в S2 не
обязательно является фактом в S2. Следовательно,
такая аналогия наводит с помощью ф на мысль о
возможности существования атома а', который
дедуктивно не выводится из S2.
Для определения атома а', который можно
вывести по аналогии, прежде всего из правила
R • a*-Pi, • • •, Ря
с помощью ф построим правило
/?':а'<-р;,..., р;,
затем рассмотрим вывод а' из а'<-$[, ..., Р^ и
известных фактов рр ..., р'Л с помощью правила
«модус поненс». Построение R' из R называется
преобразованием правила (на основе ф), а процесс вывода а'
обозначается следующей графической формой (на-
Ю С. Осуга, Ю. Сазкн
274
Глава 9
зываемой основной графической формой) i
(конкретизация) А<-Вь ,.., Вп
(преобразование правила
с помощью ф) a^nPi»_*j_--L?{L
(модус поненс) р{, ..., $'п а'<-Рр . .¦, р'„.
а'
В основной графической форме конкретизация и
«модус поненс» — это выводы в дедуктивной системе,
поэтому если в этой системе можно будет
реализовать часть, указанную пунктирной чертой, т. е.
преобразование правила, то будет возможным
органичное использование аналогии и дедукции.
Факт а', который получен как следствие такой
аналогии, как отмечено выше, не обязательно
является логическим следствием S2. Однако парное
соответствие ф по крайней мере дает основание полагать, что
а' справедлив. Поэтому, предположив существование
а', можно продолжить процесс вывода, а именно:
пусть в основной графической форме pt- — факт в Su
а $\ — факт в S2; если есть атом, который
выведен по аналогии из этих фактов, то допустим, что он
является также фактом, и на основе того же парного
соответствия ф из рр р^ выведем новый а'.
Множество атомов, которые можно вывести таким образом,
будем обозначать через М,(*). Преобразование
правил и определение М{(*) можно строго дать так, как
указано ниже.
Определение 9.4. Пусть ф — парное соответствие,
Ji (i = 1, 2)—множества фактов в Si. Тогда скажем,
что два правила без переменных
/? = a<TPi, ..., ря>
я'^а'^-р;,..., р;
являются (ф, Л, /2)-подобными, если
Руе=/Р A}е/2(К/<й), acpa', р/Фр;.
Кроме того, для заданного RY построение R\ и
(ф, 1и /2)-подобного R2 назовем преобразованием
Теория аналогий
275
правила, обозначим его в виде следующей
графической формы:
/?1 = а«-Рь ..., Рл,
(Ф, Л, /2),
R2 = a'«-pl9 .... р;.
Преобразование в соответствии с определением
9.4, когда в качестве Ri выбирается конкретизация
предложений Sb а в качестве // — минимальные
модели Mf множества S/, является преобразованием
правила с использованием указанной выше основной
графической формы. В приведенном ниже
определении М;(*) допускается, что правила S2 преобразуются
в правила S\.
Определение 9.5. Пусть М/ — минимальные
модели S/, а ф — парное соответствие, тогда множество
фактов Af/(») определяется следующим образом:
Mi (*) = U nMi (n)
Mi@) = Mi
Mi(n+l) = {a:/?,(^UAf/(/i)US,l-a}
R. (n) = {R' = of <- Pp ..., p^: для конкретизации R
некоторого правила Sj(i^j) существуют
R' и (ф, М{{п), М2(д))-подобное правило R)
Кроме того, атом а в М,(*) назовем фактом,
выводимым по аналогии на основе парного соответствия ф.
Пример 9.1: Sx = {f(b, c)y
т(а, Ь)у
gf(X, Z)<-p(X, К), f(Y, Z),
р(Х, Y)<-f(X9 Y\
p(X, Y)+-m(X, Y)}
S2 = {m(a', b%
f(b\ c')}
Здесь прописные буквы обозначают переменные, а
строчные — предикаты без переменных. Кроме того,
рассмотрим парное соответствие
<P = {<a, a'X (t>, b'), {с, с')}.
10*
276
Глава 9
Фактами в 52 являются только т(а', &') и ](Ъ\сг) +
Прежде всего из основной графической формы
р(Х, Y)*-f(X, Y)
f(b\ с') р(Ь'9 c')<-f(b', с')
р{Ь\ с')
получим, что р(Ь',с') еЛ1г(*). Аналогично получим,
что p(a'f b') еА1г(*). Допустим, что р(а\Ь') —факт
в 52, и получим следующую основную графическую
форму:
gf(X, Z)*-p(X, Г), f(Y, Z)
s[La± ?bz L&Jl'JAb-L .f)
p(a\ П f(b\ c') gfjcf, c')+-ptft b% /(ft7, c').
gf(a', C)
Следовательно, g\{a\c') e Af2(*).
9.2.2. АНАЛОГИЯ И ДЕДУКЦИЯ
В предыдущем разделе использовано понятие
преобразования правил и объяснен принцип аналогии в
дедуктивной системе. С точки зрения заданных
объектов Si, S2 выведенные атомы а е М/(*) в общем
случае логически не следуют из 5/, поэтому вывод,
заданный в предыдущем разделе, если так можно
сказать, находится строго «над» дедуктивными выводами.
Однако случай известного парного отношения ф
можно считать своего рода дедукцией. На самом деле
атом абМ,-(*) логически выводится из суммы
аналогий S\ и 52, определенной ниже.
Сумма аналогий — это ограниченное множество
правил, состоящее из следующих подмножеств:
(R\) множества правил, определяющих парное
соответствие ф,
(R2) «копий» S\ и S2,
[R3) множества правил, выполняющих
преобразование правил.
Теория аналогия
27/
Прежде всеги для определения (RI) введем
предикат ~.
Для каждого элемента </, О, принадлежащего ф,
имеет место t ~ t'. (9.3)
Для функции /, существующей одновременно в Si, S2,
f(Xu ...9Xn)~f(Yu ...,ГЯ)<-
<-X{~Yu ...tXn~Yn. (9.4)
РА1И(ф)—это множество, состоящее из
правил (9.3) и (9.4).
Лемма 9.1. Для парного соответствия ф, терма t
в Si и терма /' в S2 следующие два утверждения
эквивалентны: </, О еф+ и РАЩ(ф) r-t~t\
Затем построим копии S/. Для того чтобы
подчеркнуть принадлежность каждого предиката р
множеству Sit присвоим ему индекс I и будем писать рь.
Тогда copy(Sj)—это множество правил, которые
дают возможность применить эту операцию к S,.
Правила, которые делают выводы, основанные на
преобразованиях правил, можно задать следующим
образом: используя предикат ~ и введенный выше
предикат присвоения индексов copy(S<).
Для каждого правила
действующего для непустого Si, построим новое пра«
вило суммы аналогий, состоящее из правил
ti~Wl9 ..., tn~Wn9
S\~Vi9 ..., sk~Vk9
q{{S\> ..-, sk),
iAVl..., vk),
. . . (9.5)
Для каждого правила
p(tu ..., tn)<-..., q(sit ..., sk), ...
действующего для непустого S2, по аналогии с (9.5)
278
Глава 9
поставим в соответствие правило
г,-/,,..., wa~tM
Vi~sb ..., Vk~sk,
q2(su .... sk),
di(Vlt...t Vk),
- • • (9.6)
Определение 9.6. Сумма аналогий для парного
соответствия ф между Si и S2 — это сумма множества
правил, определенных в (9.5), (9.6), и множеств
copy (Si), copy(S2), РАЩ(ф). Обозначим эту сумму
аналогий через S^52.
Пример 9.2. Пусть
St = {p(a, Ъ),
p(f(X), b)*-p(X, b)h
S2 = {p(f(c), d)},
Ф = {<<*, /(c)), Ф, d)}.
Тогда Si(fS2 — это множество
{Pi(a, b),
Pl(f(X), b)+-Pl(X, b),
pAWu WJ<r-f(X)~Wu b~W2>
X~VU b~V2,
Pi(X, b),
IhiVu V2),
p2(/(c), d),
a ~ / (c),
b~d,
f(X)~f(Y)+-X~Y).
Аналогии в случае известного ф можно приписать
свойства дедукции из суммы аналогии.
Теорема 9.1. Для атома p{tu ..., /„) утверждения
1) р(/ь ...,/„) еМ(И,
2) Si<fSa Ь piih, .... Ц
равнозначны.
Теория аналогий
279
Доказательство интересующиеся читатели могут
найти в статье Х).
9.2.3. ЛОГИКА ПЕРВОГО ПОРЯДКА
ДЛЯ АНАЛОГИИ
Если для заданных Si и S2 парное соответствие ср
«обнаружено» и известно, то теорема 9.1 утверждает,
что аналогия с помощью ф — это дедукция из суммы
аналогий S^S2. Следовательно, наиболее важной
проблемой при аналогии следует считать метод
обнаружения ф.
Следуя определению парного соответствия,
данного в предыдущем разделе, под ф можно было бы
понимать простое ограниченное отношение между
термами. Но в действительности на ф зачастую
накладываются дополнительные ограничения. В данном
разделе мы рассмотрим частичную эквивалентность
термов как одно из таких ограничений, а парное
соответствие ф, удовлетворяющее такому ограничению,
назовем частичным тождеством. Кроме того,
определим логику первого порядка (множество логических
формул), включающих как параметр частичное
тождество ф, и покажем, что проблему обнаружения ф.
можно свести к проблеме получения ф, не
противоречащего такой логике первого порядка.
Как следует из определения 9.1 парного
соответствия ф и леммы 9.1, необходимо, чтобы ф+
удовлетворяла аксиоме
A0:f(Xlf ..., Xn)~f{Yl9 ..., Yn)<-
<-Xi~Yu ¦.., Xn~Yn.
Соответствующее отношение ф+ не всегда является
взаимно однозначным. Например, пусть в Si a, b —
обозначения констант, a on — обозначение функции
двух переменных, в S2 — константы а\ Ь\ с', функция
on, тогда рассмотрим парное соответствие
Ф = {(а, а'), (Ь, Ь'\ {ct on (а', &')>}•
l) -Haraguchi M., Arikawa S. A Foundation of Reasoning by
Analogy. Analogical Union of Logic Programs. — Proc. Logic
Programming Ccnf. —1986, June> Tokyo, pp. 103—110.
280
Глава 9
Для такого ф <с, оп(а\ ft')>, <on(a, b), on(a', b')) &
?ф+, т. е. два различных терма в U(S\) поставлены
в соответствие одному терму в f/E2). Это означает,
что отношение между областями, в которых
определено подобие, не то же самое, что эквивалентность
между областями.
Определение 9.7 (Харагути). Если для парного
соответствия ф отношение ф+ является взаимно
однозначным, то ф назовем частичным тождеством.
Для того чтобы ф являлось частичным
тождеством, необходимо в дополнение к Л0 ввести следующие
новые аксиомы:
AX\Y*=2Z+-X~Y9 X~Z,
A2:Y = XZ<-Y ~Х9 Z~X.
Здесь «=,» обозначение предиката структурной
эквивалентности термов (в смысле возможности
унификации). Более строго в соответствии со следующей
логикой первого порядка EQ/ (теории
эквивалентности), введенной Кларком, «=,» можно определить
так, как указано ниже.
Логика первого порядка EQr.
1) для различных констант с, d(c=?id),
2) для различных функций /, g
f(Xu ..., Xn)?*ig(Yi9 ..., Ут),
3) для константы с и .функции /
/№, .... Xn)?>tc,
4) для терма t[X] с переменной X, отличного от X
([Х]ФЬХ,
5) для функции /
Xj = iYj*-f(Xu ..., Хп) — J (Yu ..., Yn),
6) X = tX9
7)f(Xu ..., Xn) = if(Yu ..., Yn)+-
<r~X\ = iY\y ..., Xn = iYn,
8) p{Xx *„)<-*1 = «У„ .... Xn = tYa,
p(Xu .-., Yn).
Теория аналогий
281
При этих условиях для термов /, s в S*, не
содержащих переменных, утверждения «EQ; h s = t» й
«s и / структурно равны» равнозначны. С помощью
EQ/ можно следующим образом определить логику
первого порядка СТ(ф), которая дает условия того,
что ф является частичным тождеством.
CT(9) = EQ1UEQ2U{^o, Аи Л2}и<р.
Здесь U означает сумму множеств логических формул.
Теорема 9.2. Для парного соответствия ф
следующие два условия равнозначны:
1) ф — частичное тождество,
2) СТ(ф) — непротиворечивая логика.
Если модель СТ(ф) существует, то она
определяется однозначно, с точностью до обозначений,
в этом смысле частичное тождество ф можно назвать
моделью СТ(ф). Из приведенных выше рассуждений
можно следующим образом построить механизм
аналогии на основе частичного тождества.
Для заданных представлений объектов S\ и 5^
проблема выводов по аналогии разбивается на две
подпроблемы. Первая — проблема обнаружения
подобия, а именно: это проблема получения ф, для
которого СТ(ф) непротиворечива. Вторая — вывод
новых фактов по дедукции из суммы аналогии S\yS2
для полученного ф.
В общем случае оценка непротиворечивости
логики — алгоритмически нерешаемая проблема.
Однако, к счастью, если частичное тождество ф
определено, то сразу же можно рассмотреть процедуру
вывода из S\(pS2- В следующем разделе мы изучим
свойства частичного тождества и приведем процедуру
выводов из суммы аналогии.
9.3. РЕАЛИЗАЦИЯ МЕХАНИЗМА АНАЛОГИИ
Выше было введено понятие частичного тождества
(определение 9.7) и показано, что проблема
обнаружения частичного тождества ф равнозначна
обнаружению непротиворечивости логики СТ(ф). В данном
разделе дадим условия обеспечения частичного
тождества заданных парных соответствий. Кроме того,
282
Глава 9
рассмотрим метод реализации механизма аналогии,
выполняющего выводы на основе ф, если с помощью
этих условий обнаружено частичное тождество ф.
Основные этапы реализации состоят в следующем.
PL Предварительно получим парное соответствие
между моделями множеств определенных
предложений, затем будем не только преобразовывать правила,
но и одновременно с преобразованием проверять
согласование частичных тождеств, частично определив
тем самым ф.
Р2. Объекты аналогии описываются в виде
множества определенных предложений, поэтому для
преобразования правил воспользуемся конкретизацией и
правилом «модус поненс» в системе обработки
логических программ (в данном случае интерпретатором
Пролога).
В процессе преобразования правил для выводов
по аналогии на основе подобия как «структурного
частичного тождества» (Харагути) накладывались
условия согласования правил на основе некоторого
частичного тождества. Кроме того, в системе выводов
по аналогии Уинстона, использующей фреймовые
структуры как внутреннее представление объектов,
априори вводились условия, соответствующие
максимальному частичному тождеству ф, а уже затем
делалась аналогия. В рассматриваемом ниже методе ф
определяется так, как указано в Р1, поэтому нет
необходимости заранее знать ф." Отметим также, что
Уинстон, используя входной интерфейс,
предварительно обрабатывал структуры с целью получения
дедуктивных выводов, а в данном методе дедукция
делается только при необходимости. В этом состоят
наиболее явные отличия этих методов.
9.3.1. ПОДОБИЕ КАК ЧАСТИЧНОЕ ТОЖДЕСТВО
Частичное тождество ф, введенное выше, — это
отношение термов, задающее частичную тождественность
областей Эрбрана С/E«). В общем случае парное со*
ответствие ф задает отношение а1фос2 атомов он в Si
(определение 9.3), а частичное тождество — взаимно
однозначное отношение атомов.
Теория аналогий
233
Лемма 9.2. Для частичного тождества ср
Ю(Ф) = {(а, p)|aeAflf p s M2t аФр}
является взаимно однозначным отношением атомов
в Mi и М2.
Из этой леммы следует, что частичное тождество ф
задает частичную тождественность Mi и М2. Если
использовать обобщенное графическое представление
(Плоткин), то этот факт можно иллюстрировать так,
как на рис. 9.8. На этом рисунке переменные X/
введены для представления пар (tp ф из ф+. Кроме
того, с помощью Xj запись p(tv ..., /л)фр(^, ..., ^)
представляется в виде логической формулы
р(Хи • •., Хп).
Для реализации аналогии на основе такого
частичного тождества рассмотрим условие,
гарантирующее, что заданное парное соответствие ф является
частичным тождеством.
Определение 9.8. Следующее условие для парного
соответствия ф s U(S\) X U(S2) назовем
расширенным условием частичного тождества и обозначим его
как EPIC о.
Условие: пусть (/, ОеФ» ('/» */)еФ> а term(Xp
..., Хп) — терм, не содержащий констант. Тогда не
существует (/, /'), (tp ty, term^, ...,Xn) таких, что
/ = term (/р ...9^)&?Ф term (t'x, ..., Q,
t Ф term (fp ..., tn) & f = term (t[y ..., Q.
M\ M2
Рис. 9.8. Частичное тождество М\ и М2.
!> Сокращение слов Extended Partial Identity Condition
(расширенное условие частичного тождества). — Прим. перев*
284
Глава 9
Теорема 9.3. Необходимым и достаточным
условием для того, чтобы ф было частичным тождеством,
является EPIC.
EPIC по существу обеспечивает возможность
унификации и играет важную роль при реализации
системы выводов, но об этом мы узнаем в следующем
разделе.
9.1.2. РЕАЛИЗАЦИЯ СИСТЕМЫ АНАЛОГИИ
В данном разделе будет дана процедура вывода от
цели к фактам факта аеД(*) для некоторого
частичного тождества ф. По определению Mi(*)
включает минимальную модель Mi множества Si и
является минимальным множеством, замкнутым
относительно применения правил, полученных при их
преобразовании. Следовательно, искомая процедура
вывода состоит из двух процедур:
RI) интерпретатора, который считает Si
логической программой и выполняет ее процедурную
интерпретацию;
R2) процедуры, выполняющей преобразование
правил от цели к фактам.
В качестве интерпретатора рассмотрим
интерпретатор чистого Пролога. Тогда указанную выше процедуру
вывода можно считать логической программой,
расширяющей этот интерпретатор. Для преобразования
правил в процедуре R2 необходимо определить,
на основе какого частичного тождества выполнять
это преобразование. С этой целью сначала априори
зададимся некоторым частичным тождеством ф и
рассмотрим метод выводов с фиксированным ф.
Однако это не эффективно в следующих случаях:
1) для заданных S\ и S2 может существовать
несколько ф, поэтому для определения подходящего ф,
следуя некоторому порядку действий, потребуется
большой объем вычислений;
2) подходящих для аналогии ф также может быть
несколько, поэтому выбор только одного из них
суживает возможности выводов.
Процедура вывода, приведенная в данном разделе,
одновременно с определением некоторого частичного
тождества ф для атома а в Si показывает с помощью
Теория аналогий
285
механизма выводов от цели к фактам, используемого
Прологом, что аеЛ1(*), Объясним действия этой
процедуры на простом примере. Зададим этой
процедуре следующие S\ и S2:
Si = {f(b, с), т(а, Ь),
gf(X, Z)<-p(X9 У), /(У, Z),
P(X, Y)+-f(X, У),
p(X, Y)+-m(X9 У)},
S2 = {m{a\ П f{b'9 c')>.
Зададимся для этих S{ и S2 и некоторого частичного
тождества ф начальной целью
В этот момент никакой информации о ф не задано.
Процедура вывода прежде всего проверяет
безотносительно ~ф, является ли gf{a\c') логическим
следствием S2i то есть атомом в М2. В случае неудачи
процедура пытается преобразовать правила Si.
gf(a\c')<?M2i поэтому конкретизируем правило S\:
gf{X9 Z)<-p(X, У), /(У, Z)
и преобразуем его. Для конкретизации сгенерируем
подцель:
+-[р(Х9 У), /(У, Z) в SJ,
получим решение 6= {а/Ху b/Yy c/Z}, с помощью
некоторого ф выполним преобразование
g/^Vj-Pdi, x2), f(xZtYA)
По определению преобразования правила для
а = «а, а'), (с, О, (fl9 *!>, (bt Х2\ (b, Х3), (с, ХА)}
должно быть справедливо
ЭчВХхЭХ2ЗХ3ЗХ4 [or s ф+]. (9.7)
Благодаря определению достаточности формулы (9.7)
частично получаем ф. С этой целью используем
следующую лемму.
285
Глава 9
Лемма 9.3. Пусть о — ограниченное множество пар
термов, не содержащих переменных. Тогда
необходимым и достаточным условием существования
некоторого частичного тождества, такого, что о ?= ф+,
является условие EPIC для а.
По этой лемме формулу (9.7) можно привести
к виду
ЭХ{ЗХ2ЗХгЗХ4[а удовлетворяет EPIC]. (9.8)
Процедура вывода, определив Х\у Х2, Хз, Х4, для
которых а удовлетворяет EPIC, частично получает ф,
используемое для преобразования правил. Поставив
в соответствие а' и Х\ для терма а в Si, EPIC задает
(частичную) эквивалентность областей Эрбрана Si и
S2, поэтому в S2 должно быть справедливо о! = Х\.
Аналогично для термов Ъ и с в Si должны быть
справедливы Х2 = ХЪ и с' = ХА. В конце концов
утверждения «существует некоторое частичное тождество,
которое делает возможным преобразование исходных
правил» и «множество равенств
{а' = Хи Х2 = Х2У с' = Ха} (9.9)
имеет решение» равнозначны. Здесь знак «=»
означает отношение структурного равенства термов,
поэтому через возможность унификации можно
проверить существование решения. В данном случае
решение дает замена
Q={a'/Xu X3/X2i c'IX&
а формулу (9.8) можно привести к виду
3*3[ав={(а, а'\ (Ь, Х3>> (с, с')} удовлетворяет EPIC].
Таким образом, получаем преобразование правила
gf(a, c)+-p(a, b),J_(b,_c) (g
gf(a~?)«-р(а\ х5, f(*з, С)
Далее, для получения Хг генерируем подцель
+-[p(a't X3)} f(XZt сОеЛМ*)].
Здесь р{а\ Х3) ф Мг, поэтому по аналогии с
вышесказанным выполним преобразование правила, а именно:
Теория аналогий
287
конкретизируем
р(Х9 Y)<-f(X, Y)
и проверим преобразование правила
р?, c)+-f(b, с}
р(а', x5«-f(Xi, Й'
Далее, аналогично сформируем парное соответствие
Oi = {(b, a'\ <*, Х3), (Ь, Х4), (с, Хь)}.
Здесь необходимо проверить, что это и предыдущее
преобразования выполнялись на основе одного и того
же частичного тождества ф (это назовем проверкой
согласования). Для этого используем следующую
лемму.
Лемма 9.4. Пусть ть t2 — ограниченные множества
пар термов. Тогда необходимым и достаточным
условием для существования некоторого парного
соответствия ф такого, что Ti ? ф+ и t2 ? ф+, является
условие EPIC для Ti Ut2-
По этой лемме для текущего преобразования о\ и
предыдущего преобразования об можно получить
Х3у Х4 и Х5, для которых
aeU(Xi = {<a, a\ {Ь, Х3\ (с, с'\ {Ь, а'\ (с, Х3\
(bf XA), (с, Х5)}
удовлетворяет EPIC. В данном случае а' ставится
в соответствие а и Ь, но а = Ь не справедливо,
поэтому указанных выше Хг, Х4, Х5 не существует, и
введенные преобразования правил отвергаются как
неподходящие. В этом случае процедура вывода
осуществляет возврат управления и конкретизирует еще
одно правило для р
р(Х, Y)+-m(X, Y)
и проверяет преобразование
р (a, b)<-m (a, b)
У{^7х1)"^Сх"%)
Далее, аналогично выполняется унификация для
rj = {(a, a')> (Ь, Хъ), (с, *')> (<>> *а\ {Ь, Х5)}
28»
Глава 9
и получается преобразование
р (а, Ь)<-т(а, Ь)
р(а"х5)"т\а'~~Х~)'
Далее, для получения Х5 генерируется подцель
<-[т(а', Хъ) в S2],
из решения Ъ'/Хь следует, что т{а\ Ь')&Ми поэтому
г) приведем к виду
4' = {<а, а'>, F, П {с, с')}.
Множество ц' удовлетворяет EPIC, поэтому очевидно,
что
gf(a't OgM2(*)
справедливо для частичного тождества ф, такого, что
Г)' ?= Ф+.
Таким образом, процедура вывода процедурно
интерпретирует программу на чистом Прологе,
выполняет преобразования правил и проверку их
согласования, идя от цели к фактам. Преобразование
.правил и проверка согласования по существу
заменяют унификацию термов. На рис. 9.9 приведена
основная часть программы на Прологе, реализующая
указанную выше процедуру вывода.
Прежде всего предполагается, что факт А и
правило С*-Ви ..., Вп множества Si накоплены в базе
данных Пролога, преобразованные с помощью
предиката facti в вид
iact{(A)<-
fact2 (С) +- factt (Bi), ..., factx (Bn).
Точно так же факты и правила Sa g помощью fact2
преобразованы в предложения Пролога. Цель (Goal)
aGM/(*) для процедуры вывода представляется
через предикат fact/(a) и передается основному
предикату ana программы на рис. 9.9,
Вторая переменная Epic и третья переменная
Epic' предиката reason (причина) принимают в
качестве значения множество пар терминов,
представленных в виде списков, первая переменная Goal
принимает значение цели процедуры вывода. Предложения
Теория аналогий
289
с С2 по С4 — блок интерпретатора чистого Пролога,
Prematch (подбор) в теле предложения СЪ этой
программы — это предикат поиска возможных правил
для преобразования правил. Предикат
trans(преобразование) вводит новые переменные и выполняет
преобразования правил, полученных с помощью prematch.
Как указано в примере, преобразование правил с
помощью унификации и других методов заканчивается
в четвертом литерале предложения СЪ и далее.
Предикат Epic получает множество равенств из списка
(множества) пар терминов и осуществляет
унификацию в соответствии с леммой 9.3. Проверка
согласования на основе леммы 9.4 выполняется в пятом и
шестом литералах в теле предложения С5.
В результате reason (Goal, Epic, Epic') наряду с
преобразованием правил для заданных Goal и Epic
в соответствии с леммами 9.3 и 9.4 конкретизирует
список пар терминов Epic, получая как множество
(С1)
(С2)
(СЗ)
(С4)
(С5)
ana (Goal)
:— reason (Goa1, [ ], Epic).
reason (true, Epic, Epic)
. i
reason (Goal, Goal), Epic, Epic2)
. |
reason (Goal, Epic, Epicl),
reason (Goal, Epicl, Epic2).
reason (Goal, Epic, Epicl)
:— clause (Goal, Goals),
reason (Goals, Epic, Epicl).
reason (Goal, Epic, Epic3)
:— prematch (Goal, Sgoal, Sgoals),
-> reason (Sgoals, Epic, Epicl),
trans (Goal, Sgoal, Sgoals, Tgoal, Bind),
epic (Bind),
append (Epicl, Bind, Epic2),
epic (Epic2),
reason (Tgoals, Epic2, Epic3)f;
epic (Epic3).
Рис. 9,9. Программа на Прологе для аналогии.
290
Глава 9
пар расширенный список терминов Epic7 и рекурсив-*
но вызывает предикат reason. Частичное тождество ф
получается поэтапно благодаря рекурсивному вызову
этого предиката. Данная система аналогий
реализована с помощью С-Пролога на компьютере DCL.
В заключение приведем достаточно сложный
пример аналогии. Приведенные ниже S\ и S2 взяты из
примера, который Уинстон составил по трагедии
Шекспира «Макбет». Аргументы предикатов, начи«
нающиеся с прописной буквы,— это переменные, а
начинающиеся со строчной — константы. Системе
аналогий задан вопрос: убил (X, придворный-.а) в Si?
а именно, кто убил придворного_а? Строго говоря,
вопрос имеет вид: аналогия {факт2 (убил (X, придвор*
иый-а)))? Выполняя аналогию с использованием S\9
система примерно через 20 секунд получила ответ:
X = придворный-b, т. е. мог убить придворный-Ь.
Si = {корыстолюбивая(ледимак), женат(мак, ледимак),
безвольный(мак), хбкоролевой1)(ледимак), король
(дункан), преданный(макдуфф, дункан),
злой(мак) <- безвольный(мак) & женат(мак, X) &
корыстолюбивый (X),
убийца (X, Y) <- женат (У, X) &
безвольный (Y) & корыстолюбивый (X)
хбкоролем(мак)<-убеждает(ледимак, мак) &
хбкоролевой(ледимак),
убийца(Убийца, Король) ч-король
(Король) & хбкоролем(Убийца)& злой(Убийца),
убил(Преданный, Убийца) <- убийца(Убийца, Ктото) &
преданный(Преданный, Ктото)}
52= {придворный(придворный_а), леди(леди_а),
король(король_а), придворный(придворный_Ь),
преданный(придворный_Ь, король_а),
женат(придворный_а, леди_а),
безвольный(придворный_а),
корыстолюбивая(леди_а), хбкоролевой(леди_а)
вопрос:<-убил(Х, придворный_а) (в S3)
ответ: X = придворный_Ь
*)Хочет быть королевой — Прим. перев.
Теория аналогий
291
9.3.3. ПРОБЛЕМЫ, КОТОРЫЕ ПРЕДСТОИТ
РЕШИТЬ В БУДУЩЕМ
В данном разделе рассмотрены принципы аналогии
для логической импликации, и показана возможность
унифицированной реализации аналогии и дедукции
благодаря формализации аналогии в рамках хорнов-
ской логики. В частности, существенное достоинство
реализации механизма аналогии на основе частичного
тождества с помощью логических программ
заключается в том, что этот механизм создает естественное
расширение интерпретатора Пролога и его
унификацию. Вместе с тем в процессе теоретических
исследований и практической реализации, начало которому
положила связь логики равенств и аналогии, возникло
немало проблем. Кратко познакомимся с некоторыми
из них.
1. Здесь были рассмотрены только принципы
аналогии для импликации, но желательно изучить также
аналогию для логических отношений более высокого
уровня, чем импликация. Для обсуждения принципов
аналогии на таком уровне, сохраняющих
согласование с дедуктивными выводами, необходима теория
типов отношений.
2. Аналогия была формализована в рамках хор-
новской логики, поэтому не была описана обработка
негативных знаний, но в общем случае можно
рассмотреть устранение избыточной аналогии с помощью
негативных знаний. Проблема аналогии и
негативных знаний имеет глубокую связь с выводом М-опе-
раторов в немонотонной логике, что можно считать
расширением теории аналогии, которая обсуждалась
в данной главе.
- 3. Одна из главных целей исследования
аналогии — ее приложение к автоматическому синтезу и
преобразованию программ. Это также тесно связано с
проблемой создания пакетов программ и их
повторного использования. На практике повторно
используемые программы можно рассматривать как
программы, в которых абстрагируются некоторые общие
стороны нескольких программ. Следовательно, теория
и методология абстрагирования подобных программ
(в данном случае логических программ) будет
292
Глава 9
строиться на основе теории аналогии между
моделями, рассмотренной в данной главе.
4. Еще одна из целей исследования аналогии —
изучение связи аналогии с другими выводами и
построение единой системы выводов. Для этого
необходимо, в частности, обсудить связь индуктивных
выводов и аналогии. Более конкретно, видимо, можно
повысить эффективность системы индуктивных
выводов благодаря тому, что при генерации гипотез
с помощью индуктивных выводов производить
частичный отбор (множества) правил, используя
преобразование правил. А в качестве операции отбора правил
достаточно рассмотреть некоторое расширение
принципа преобразования правил, указанного в данной
главе (Арикава).
Таким образом, можно привести ряд
разнообразных проблем как с теоретической, так и с
практической точки зрения. В будущем необходимо
продолжить эти исследования.
9.4. ПРИМЕНЕНИЕ ИНДУКТИВНЫХ ВЫВОДОВ
И АНАЛОГИИ
Как следует из материалов этой главы, индуктивные
выводы и аналогия — это сравнительно новые
методы обработки интеллектуальной информации, а для
человека — это естественные выводы, и их
теоретические исследования в настоящее время ведутся
достаточно активно. Следовательно, сейчас можно
рассматривать разнообразные приложения этой теории в
плане повышения уровня использования компьютеров, в
основе которого лежит обработка интеллектуальной
информации. В данном разделе хотелось бы
ознакомить читателя с некоторыми областями применения
этой теории и обсудить новые формы применения
индуктивных выводов и аналогии.
9.4.1. ПРИМЕНЕНИЕ ИНДУКТИВНЫХ ВЫВОДОВ
Среди типичных областей применения индуктивных
выводов отметим полуавтоматическое приобретение
знаний в экспертных системах, автоматический синтез
программ по примерам в области интеллектуального
Теория аналогий
193
программирования, полуавтоматическую отладку и
другие области.
Применение для приобретения знаний имеет два
основных аспекта: систематизация данных, при
которой из собранных данных и данных наблюдения
извлекается некоторое общее правило, и передача
знаний, суть которой — в получении знаний от эксперта.
В первом случае индуктивные выводы, которые
рассматривались до сих пор, можно использовать в
неизменном виде. Примерами служат экспертная
система Meta-Dendral и система обработки
интеллектуальной информации на базе Пролога в проекте
ICOT 1). Во втором случае теорию индуктивных
выводов нельзя применять в чистом виде, но в
последние годы исследования Англюна в Иельском
университете, США, теоретически развили это направление,
и с этими исследованиями связызают определенные
надежды.
Применение индуктивных выводов к
автоматическому синтезу программ по примерам, как видно из
первой части гл. 8, было исследовано еще несколько
лет назад. Однако этим исследованиям не хватает
последовательности в части формализации выводов
и разнообразия объектов, хотя развитие системы
вывода моделей Шапиро, рассмотренной во второй части
гл. 8, позволяет надеяться на практическую
реализацию автоматического синтеза логических программ.
Однако следует отметить, что до поистине широкого
применения остается решить еще немало проблем,
таких, как разработка способов сужения
пространства поиска, необходимого при перечислении
предположений (в данном случае логических программ),
проблема введения так называемых теоретических
терминов, и других проблем. Кроме синтеза программ
с помощью системы вывода моделей за последние
годы опубликованы два примера применения
индуктивных выводов в редакторах, являющихся
средством общения человека с компьютером. Один из
примеров— система ввода данных, разработанная Си-
1) Проект ЭВМ пятого поколения Токийского института
вычислительной техники новых поколений (ICOT).— Прим. перев*
294
Глава 9
нохара. В ней применены методы вывода образных
языков, объясненные в гл. 7, но практически время,
необходимое для вывода, должно расти не быстрее,
чем полином от времени характерной реакции
человека. Второй пример — система редактирования по
примерам, предложенная Никсом; она автоматически
синтезирует программы для размещения в
реляционной базе данных конкретных входных данных.
Особенность этих двух систем состоит в том, что они
реализованы на основе теоретических результатов.
Разработка программ всегда сопровождается
отладкой, для частичной ее автоматизации можно
применять систему вывода моделей Шапиро. Это
главная тема его докторской диссертации, ее основной
результат — алгоритм слежения за противоречивыми
точками — изложен во второй части гл. 8, а именно:
если в логической программе, которую предстоит
разработать, оказались ошибки, то эти ошибки
вкрались в программу в какой-то момент. Следовательно,
считая разработчика программ предсказателем и
спрашивая его об истинности операторов наблюдения,
можно обнаружить предложение с ошибкой. Это
новый интересный пример применения индуктивных
выводов.
9.4.2. ПРИМЕНЕНИЕ АНАЛОГИИ
Аналогия в каком-то смысле более естественный
метод вывода для человека, нежели индукция, поэтому
можно рассматривать ее различные применения.
Классический пример — прогнозы и решение задач,
именно они стимулируют теоретические исследования
аналогии, рассмотренной в данной главе. Кроме того,
аналогию можно применять для преобразования
знаний человека в знания для экспертных систем. В
настоящее время еще только подходят к исследованиям
машинного перевода на основе аналогии, объектом
которой служат оригинальные тексты и их переводы
на другой язык — как естественный, так и
технический, но, видимо, скоро и это будет возможным.
Аналогию можно применять также при разработке
программ. Как правило, при разработке значительная
Теория аналогий
195
часть работ сводится к повторному применению
существующих программ. С этой целью часто
используются программы, подобные программе, которую
предстоит разработать. Ниже приведем пример такой
программы. Допустим, что уже разработаны
(логическая) программа обратной перестановки элементов
списка rev:
S\ = \СЬ С2},
С,: rev ([], И),
C2:rev([X\Xs], W)+-rev(Xs, Zs),
append {Zs, [X], W)
и программа append конкатенации списков. Поставим
себе целью составить программу fullrev обратной
перестановки элементов списка, которые в свою очередь
являются списками. Это программа, которая,
например, с успехом выполняет следующие действия:
С3: fullrev ([], []),
С4: fullrev ([1, 2], [2, 1]),
С5: fullrev ([1, 2], 3, [4, [5, 6]]],
[[[6, 5], 4], 3, [2, 1]]).
Для простоты с самого начала будем использовать
С3 как часть целевой программы:
52 = {С3}.
Для текущего S2 результат С4, разумеется, не
может быть получен. Поэтому выведем С4 с помощью
преобразования правил Si. Практически на основе
Парного соответствия
Ф = {<[], []>, О, 0,B, 2),
(append, append), (rev, fullrev)}
с помощью преобразования правил
rev([J|Xs], W)*-rev(Xs, Zs), append (Zs, [X], W)
fulireval, 2], [2, I])*-fullrev([2], [2]),
append ([2], [1], [2, 1])
296
Глава 9
а также преобразования
rev(J2]L[2])^rev([], []), append^ U21jJ2|) _
fullrev([2], [2])<-fulirev« ], П), append ([ ], И, [2D
очевидно получим
fullrev([l, 2], [2, l])e=Af2(*).
Таким образом, добавив в S2 с помощью ф правило Sj,
выполняющее преобразование правила, получим
S2 = {C6:fullrev([], [ ]).
С7 :fullrev ([X\Xs], W)<-iullvev(Xs, Zs),
append (Zs, [X], W).}
Но это S2 приводит к неудаче для С5. Кроме того,
неудачно введение нового правила, полученное только
что с помощью преобразования правила. При этом
впервые вспомним о том, что можно вызвать атом
условия и процедуру генерации новых предложений
программы для индуктивных выводов. Действительно,
добавив в тело Ci атом условия atom(X) и вновь
сгенерировав
C8:fullrevPUs], W)+-
fullrevCY, Y), f ullrev №?, Zs), append (Zs, [Y], W),
можно получить целевую программу
S2 = {C6:f ullrev ([], { ]).
C7:ful\rev([X\Xs], W)+-atom(X),
Mlrev(Xs, Zs), append(Zs, [X], W).
C8: fullrev ([X \Xs], W <- fullrev (X, Y),
fullrev(Xs, Zs), append (Zs, [Y], W).}
Таким образом, применяя индуктивные выводы к
аналогии, по группе известных программ можно
разработать новую требуемую программу. Эта проблема
к настоящему времени еще недостаточно изучена, но
является актуальной прикладной проблемой.
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
Абстрагирование пропозицион-
ное 266
Автомат 152
Аналогия 262
Атом 251, 272
— порождающий 252
База данных 160
дедуктивная 171
реляционная 161
— знаний 15
Вложение 148
Вывод грамматический 180
— индуктивный 179, 217
— логический 16
— моделей 250
— правил 179
— функций 182
Гипотеза 251
— закрытых миров 174
—открытых миров 124
Грамматика определенных
предложений 106
— контекстно-свободная 106
Данные отрицательные 181
— положительные 181
Дедукция 20
Демон 268
Диалог 86
Заключение 251
Избыточность 174
Извлечение знаний 72
Идентификация в"-пределе 183
— конечная 198
Кодирование рекурсивное 188
Компиляция знаний 45
Композиция знаний 45
Коннектионист 143
Конкретизация 274
Координация знаний 47
Кортеж 161
ЛИСП-программа 238
регулярная 245
Логика пороговая 138
Машина выводов 181
— Тьюринга 180
— экстраполяционная 192
Мера сложности 189
Миры грамматики 97
— предыстории выбора 117
— связей 117
— словаря 97
Множество перечисляемое 183
Модель 252
— интерпретационная 93
— минимальная 272
— мультииерархическая 92
— оверлейная 125
— пертурбационная 127
— пользователя 125
— разностная 126
Модус поненс 274
Наблюдение 253
Неокогнитрон 134, 140
Область понятий 95
— предметная 91
— Эрбрана 251
— языка 95
Обобщение 47
— минимальное 23
Образ 224
298
Предметный указатель
Обучение параметрическое 24,
134
— по аналогии 25
— понятиям 143
— по примерам 19
— эвристическое 13, 26
Ограничение целостности 168
Оператор наблюдения 251
— уточнения 129
Операционализация знаний 18
Опрос критический 87
— с наводящими вопросами
84
— структурированный 84
Открытие 13
Отношение 161
— виртуальное 175
Отождествление 96, 273
Падеж агентивный 104
— инструментальный 104
— объектный 105
Перестановка 207
Перечисление 185, 253
Перцептрон 136
Подобие 271
Подстановка 227
Подчиненность многозначная
169
— функциональная 169
— цепочечная 169
Поиск 161
Покрытие 148
Полуабстрактность знаний 64
Понятие 96
«Почти то» 144
Правило 271
— обобщения 20
альтернативного 24
структурного 24
Предложение 251
— определенное 271
— хорновское 251
Предположение 183
— сверхобобщенное 220
Предпосылка 251
Предсказатель 252
Представление 175
— полное 215
— положительное 215
— правильное 182
Предыстория выбора 104
Преобразование правил 273
Процедура рекурсивная 187
Процедурализация знаний 45
Психология байесовская 39
— бихевиористическая 28
— математическая 37
Самонаблюдение 85
Самоотчет 85
Свидетельство конечное 220
Семейство языков 216
индексированное 216
сверхограниченное 217
Симметрия глобальная 148
— сглаженная локальная 147
Система вопросов и ответов 91
— компьютерного обучения
91
— распознавания образов
133
— формальная 226
примитивная 228
эквивалентная 227
— экспертная 72
— ACRONYM 145
— DEBUGGER 128
GAP 239
— Meta-Dendral 25, 72, 293
— TEIRESIAS 17
— THESYS 241
— UNDERSTAND 18
Скиммер 239
Слежение 257
Слово 216
Соответствие парное 272
Специализация 47
Спецификация 238
Стабилизация 48
Стратегия абстрагирования 266
Структурирование знаний 92
Сумма аналогий 276
Схема прагматических выводов
63
Терм 226
Тождество частичное 280
Точка неподвижная 187
— стабилизации 211
Трассировка 245
Предметный указатель
ж
Уточнение 260
Файл 161
Факт 252, 272
Форма каноническая 228
— основная графическая 274
Формализация 171
Формула 227
Фрагмент 242
Функция рекурсивная 183
— обучения 20
— с автоописанием 189
— частичная рекурсивная 183
— /ипростая 194
Шаг базовый 228
— индукции 228
Эквивалентность
280
Эксперимент 252
Экстраполяция 192
структурная
Язык 216
— гипотез 251
— запроса по образцу 161
— логический 95
— наблюдений 251
— образный 224
— описания вычислений CDB
248
— Пролог 95
— рекурсивный 216
— формальный 181
ВС-идентификация 199
ВЕСТ-идентификация 210
CONS-идентификация 204
СР-идентификация 210
ЕХ-идентификация 184
ЕХп-идентификация 197
ЕХ^-идентификация 198
LD-идентификация 184
ШагЬ-идентификация 207
IT-идентификация 202
1ТагЬ-идентификация 207
М-выражение 242
NV-экстраполяция 193
S-выражение 238
TOTAL-идентификация 211
WCP-идентификация 210
ОГЛАВЛЕНИЕ
От переводчика ....... б
Предисловие 7
ГЛАВА 1. ВВЕДЕНИЕ
С. Осуга
1.1. Обучение . , < 10
1.1.1. Как определить функции обучения? 10
1.1.2. Подходы к исследованию обучения 10
1.1.3. Приобретение знаний и овладение мастерством . 14
1.2. Методы приобретения знаний 15
1.2.1. Этапы приобретения знаний 15
1.2.2. Обучение без выводов и обучение с выводами на
низком уровне 17
1.2.3. Основные принципы приобретения знаний из
примеров 18
1.2.4. Этапы обучения по примерам ........ 24
1.2.5. Приобретение знаний на метауровне 27
ГЛАВА 2. ВОЗМОЖНОСТИ ТЕХНОЛОГИЧЕСКИХ
ПОДХОДОВ В ПСИХОЛОГИИ
Ю. Сажи, X. Судзуки
2.1. Введение 28
2.2. От наивного эмпиризма к психологии обучения ... 29
2.3. Расцвет и падение математической психологии ... 37
2.4. Взгляды на обучение в науке о мышлении 41
2.5. Теория обучения ACT * 42
2.5.1. Декларативный этап и компиляция знаний . . 43
2.5.2. Процедурный этап и координация знаний ... 47
2.5.3. Значение и про]блемы теории ACT * 48
2.6. Обучение человека 49
2.6.1. Проблема: почему так поздно начинает учиться
человек? 50
2 6.2. Новая проблема: сложность среды 52
2.6.3. Решение: зависимость обучения от знаний ... 54
2.7. Знания человека 59
2.7.1. Проблема: специфичность области знаний ... 59
2.7.2. Решение: полуабстрактность знаний 62
2.8. Заключение 67
Оглавление
301
ГЛАВА 3. МЕТОДЫ И ПРОБЛЕМЫ ИЗВЛЕЧЕНИЯ
ЗНАНИЙ
X. Кобаси
3.1. Масса проблем 68
3.2. Инженерия знаний , 69
3.3. Уровни приобретения знаний 70
3.4. Экспертные системы 72
3.5. Извлечение знаний 76
3.5.1. Откуда извлекать знания? 76
3.5 2. Что извлекать? 80
3.5.3. Как извлекать знания? 81
3 5.4. Техника извлечения знаний 83
3.6. Заключение 87
ГЛАВА 4. ПРИОБРЕТЕНИЕ ЗНАНИИ И ОБУЧЕНИЕ
В ДИАЛОГЕ
С. Оцуки
4.1. Представление знаний для диалога 89
4.1.1. Введение мультииерархической модели .... 89
4.1.2. Логические языки и мультииерархическая модель 95
4.1.3. Смысл мутииерархической модели 96
4.2. Методы диалога 101
4.2.1 Внешние и внутренние языки 102
4.2.2. Преобразование внешнего языка представления
знаний 106
4.2.3. Диалог на естественном языке ....... 116
4.3. Приобретение знаний и обучение в диалоге 122
4.3.1. Значение диалога в приобретении знаний . . . 122
4.3.2. Значение диалога при обучении 125
ГЛАВА 5. ОБУЧЕНИЕ ПРИ РАСПОЗНАВАНИИ ОБРАЗОВ
Т. Китахаси
5.1. Введение 133
5.2. Модели сети нервных цепей 135
5 2.1. Обучающаяся система с учителем — перцептрон 136
5.2.2. Система, обучающаяся без учителя — неокогни-
трон 139
5.2.3. Новое направление — коннектионист , . , . . 143
5.3. Обучение понятиям по изображениям ....... 143
5.3.1. От черно-белого изображения к описанию
понятия 144
5.3.2. Обучение понятию 150
5.4. Системы, адаптирующиеся к среде 151
5.4.1. Автоматы, адаптирующиеся к среде 152
5.4.2. Другие идеи ё 158
Ш
Оглавление
ГЛАВА 6. ПРИОБРЕТЕНИЕ ЗНАНИЙ, ХРАНЯЩИХСЯ
В БАЗАХ ДАННЫХ
Ю. Танака
6.1. Базы данных и язык манипулирования данными . . . 160
6.1.1. Базы данных 160
6.1.2. Запрос по образцу (ЗПО) 161
6.2. Нежелательные обновления 166
6.3. Ограничения целостности при обновлении баз данных 168
6 4. Непротиворечивость и управление'обновлением . . .171
6.5. Исключение избыточности 174
6.6. Обработка неполной информации 177
ГЛАВА 7. ТЕОРИЯ ИНДУКТИВНЫХ ВЫВОДОВ
С. Арикава, Т. Синохара, Т. Мияхара
7.1. Основные понятия теории индуктивных выводов . . .179
7.2. Индуктивный вывод функций 182
7.3. Расширение идентификации в пределе 197
7.3.1. Критерий, допускающий исключения, и критерий,
имеющий ограничения на количество изменений
предположений 197
7.3.2. Критерий, основанный на сходимости с точки
зрения действий программы 198
7.4. Индуктивные выводы, удовлетворяющие естественным
критеримя 202
7.4.1. Критерий с ограничением на область памяти . . 202
7.4.2. Непротиворечивые критерии 204
7.4.3. Порядок указания данных 207
7.4.4. Другие естественные критерии 210
7.5. Индуктивные выводы в языках 215
7.6. Индуктивные выводы из положительных данных . . .219
7.7. Индуктивные выводы в формальных системах .... 225
7.7.1. Формальные системы и языки 226
7.7.2. Ограничения формальных систем 228
7.7.3. Индуктивные выводы из положительных данных о
формальных системах 230
7.8. Эффективность отрицательных данных 232
ГЛАВА 8. СИНТЕЗ ПРОГРАММ ПО ПРИМЕРАМ
С. Арикава, М. Харагути
8.1. Автоматический синтез ЛИСП-программ 238
8.2. Идентификация ЛИСП-программ в пределе 243
8.3. CDL — реальные проблемы 248
8.4. Вывод моделей 250
8 4.1. Проблема вывода моделей 251
8.4.2. Алгоритмы вывода моделей 254
8.4.3. Опровержение и уточнение гипотез 256
8.4.4. Совершенствование системы вывода моделей . . 261
Оглавление 3t?
ГЛАВА 9. ТЕОРИЯ АНАЛОГИЙ
С. Арикавау М. Харагути
9.1. Направления исследований аналогии 263
9.1.1. Аналогия при*. решении задач 264
9.1.2. Аналогия для предсказаний ,.,,,,, 268
9.2. Теория аналогии 270
9.2.1. Формализация аналогии , , . . , 271
9.2.2. Аналогия и дедукция «... 276
9.2.3. Логика первого порядка для аналогии ¦ ¦ ¦ . 279
9.3. Реализация механизма аналогии ...,,<•». 281
9.8.1. Подобие как частичное тождество 282
9.3.2. Реализация системы аналогии ...,,.. 284
9.3.3. Проблемы, которые предстоит решить в будущем 290
9.4. Применение индуктивных выводов и аналогии , # . . 292
9.4.1. Применение индуктивных выводов . . f f t . 292
9.4.2. Применение аналогии .•*«*. 294
Предметный указатель . •¦•••. 297
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги,
ее оформлении, качестве перевода и другие
прочим присылать по адресу: 129820,
Москва, .И-110, 1-й Рижский пер., д. 2, изд-во
«Мир».
Учебное издание
Сэцуо Осуга, Ютака Саэки, X. Судзуки и др.
ПРИОБРЕТЕНИЕ ЗНАНИЙ
Под. ред. С. Осуги, Ю. Саэки
Заведующий редакцией д-р техн. наук А. Л. Щерс
Зам. заведующего редакцией Э. Н. Бадиков
Научный редактор С. В. Богдасаров
Мл. редактор Ю. Л. Евдокимова
Художник В. С. Стуликоз
Художественный редактор Н. М. Иванов
Технический редактор И. И. Володина
Корректор Т. И. Стифеева
ИБ № 7071
Сдано в набор 12.05.89. Подписано к печати 29.11.89.
Формат 84ХЮ8'/з2. Бумага книжн.-журн. Печать высокая.
Гарнитура литературная. Объем 4,75 бум. л. Усл. печ. л. 15,96.
Усл. кр.-отт. 16,20. Уч.-изд. л. 15,43. Изд. Кя 6/6601. Тираж
25 000 экз. Зак. 179. Цена 1 р. 10 к.
Издательство „Мир" В/О „Совэкспорткнига"
Государственного комитета СССР по печати. 129820. ГСП, Москва,
1-й Рижский пер., 2
Ленинградская типография № 2 головное предприятие
ордена Трудового Красного Знамени Ленинградского
объединения «Техническая книга» им. Евгении Соколовой
при Государственном комитете СССР по печати 198052.
г. Ленинград, Л-52, Измайловский проспект, 29.