/




































































































































































































































































Текст
Введение
в системный
анализ:
применение
в экологии
An Introduction to
Systems Analysis:
with ecological applications
John N. R. Jeffers
F. I. S., F. I. Biol., м. в. I. M.
Director of the Institute of Terrestrial Ecology,
Natural Environmental Research Council, Grange-over-Sands,
Cumbria
Edward Arnold
Дж. Джефферс
Введение
в системный
анализ:
применение
в экологии
Перевод с английского
канд. физ.-мат. наук
Д. О. ЛОГОФЕТА
под редакцией
д-ра физ-мат. наук
Ю. М. СВИРЕЖЕВА
Издательство «Мир». Москва 1981
ББК 28.08
Д40
УДК 575.3/7
Д40
Джефферс Дж.
Введение в системный анализ: применение в эко-
логии: Пер. с англ. / Перевод Логофета Д. О.; Под
ред. и с предисл. Ю. М. Свирежева. — М.: Мир,
1981. — 256 с. с ил.
Книга, написанная известным английским ученым, убеди-
тельно показывает, что системный анализ представляет собой не
простую совокупность математических методов и моделей, а ши-
рокую программу исследования сложных систем, в которой постро-
ение математических моделей сочетается с конкретными экологи-
ческими исследованиями. Большим достоинством книги является
рассмотрение преимуществ и недостатков в применении того или
иного математического аппарата.
Для биологов различных специальностей (экологов, зоологов,
ботаников), математиков и инженеров, занимающихся проблемами
экологии, студентов соответствующих специальностей.
21004-117
041(01)—81
117—81, 2001050000
ББК 28.08
Редакция литературы по биологии
В John N. R. Jeffers
Перевод па русский язык, «Мир», 1981
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
Предлагаемая вниманию читателя книга известного
английского эколога Дж. Джефферса не претендует на
роль некоего стандартного учебника или сборника рецеп-
тов — как строить модели и т. п. Скорее это хорошо и ув-
лекательно написанный рассказ о методах системного
анализа, о том, что они дают в применении к экологичес-
ким проблемам, и о реальной «кухне» системного исследо-
вания — последнее в очень многих книгах и работах тща-
тельно скрывается от читателя или во всяком случае не
разъясняется.
Дж. Джефферс — представитель пока еще немногочис-
ленного отряда экологов, которые выступают как энтузи-
асты применения системных методов и не только ратуют
за это, но используют их при решении конкретных проб-
лем. Хорошо известна его редакторская работа над книга-
ми по математическому моделированию в экологии. В дан-
ной книге он счастливо избегает Сциллы неоправданных
надежд, когда считают, что системный апализ — это пана-
цея от всех «экологических» бед, и Харибды глобального
скептицизма, который полагает экологические системы
настолько сложными, что их невозможно исследовать ко-
личественными методами, а остается только инвентаризи-
ровать и описывать.
Я думаю, что прежде всего данное издание ориентиро-
вано на экологов, ранее не сталкивавшихся ни с матема-
тическими моделями, пи с машинными имитациями.
А необходимо заметить, что сейчас отсутствие модели в
экологических публикациях считается чуть ли не дурным
тоном (особенно это характерно для работ западных уче-
ных). Очень распространено в экологической литературе
использовапие алгоритмических языков типа «системной
динамики» Форрестера, языков, специально ориентиро-
ванных на моделирование. Даже в интерпретации резуль-
татов моделирования, т. е. в той области, которая всегда
6
Предисловие редактора перевода
считалась вотчиной конкретных исследователей — экологов
и биологов, все шире используется понятийный ряд, ха-
рактерный скорее для математиков (например, теория ка-
тастроф). Можно заключить, что тот набор концепций,
методов, рецептов, который сейчас принято называть
«системным анализом», все шире и шире используется в
экологии — науке по существу также «системной». Ко-
нечно эта книга не может служить учебником для профес-
сионалов-«системщиков», по она и не претендует на эту
роль. Ее задача — дать непрофессионалам представление
о том, что может и чего не может системный анализ, кото-
рый отнюдь не является философским камнем, но пред-
ставляет собой достаточно мощный аппарат исследования.
Теперь коротко о содержании книги. Книга написана
предельно просто и в то же время четко и достаточно стро-
го. Очень помогает в понимании и организации материала
большое количество диаграмм и дендрограмм, по которым
легко представить себе структуру предмета и его иерар-
хическую организацию. Начинается она с главы под наз-
ванием «Что такое системный анализ?». И хотя можно
не во всем согласиться с автором, его попытка дать опре-
деление этому весьма аморфному предмету может быть
отнесена к числу удачных: ее достоинство в ее прагматич-
ности — системный анализ — это метод, а не философия
науки.
Вторая глава — «Модели и математика» на простых
примерах рассказывает читателю, какого типа модели це-
лесообразно использовать в экологии, знакомит с особен-
ностями математического языка и дает классификацию
типов математических моделей в экологии. Заметим, что
все рассуждения автора применимы не только к экологии,
по и к биологии вообще. Особенно полезен параграф о
достоинствах и недостатках математических моделей — что
может и чего не может математика, применяемая в таких
естественных науках, как биология.
Последующие главы более подробно знакомят нас с
уже описанными типами моделей. Книга построена так,
что если читатель хочет получить лишь общее представле-
ние о предмете, он без всякого для себя ущерба может
перейти сразу к главе восьмой «Процесс моделирования»,
однако для углубленного знакомства необходимо прочесть
Предисловие редактора перевода
1
и остальные главы книги — с третьей по седьмую. В седь-
мой главе, по-видимому, впервые в учебной экологической
литературе проиллюстрирована теория катастроф — в со-
четании с имитационными моделями она образует одно из
новых и перспективных направлений в математической
экологии.
В главе о процессах моделирования большое внимание
уделено исключительно важному в моделировании вопро-
су об идентификации и верификации моделей, а также
проблеме анализа чувствительности.
Заканчивается книга главой о роли ЭВМ в моделиро-
вании и, более широко, вообще в экологических исследо-
ваниях. Автор с полной убежденностью подчеркивает, что
ЭВМ должна быть таким же распространенным инстру-
ментом, как и традиционные биологические методы. Важ-
ную роль играет в каждом конкретном случае умелый вы-
бор типа ЭВМ — с тем, чтобы обеспечить возможность вы-
полнения планируемой работы и в то же время сделать
это наиболее целесообразно экономически.
Чтение книги не требует от читателя специальной
математической подготовки. Удачно подобранные приме-
ры делают понятными и наглядными даже весьма слож-
ные математические абстракции.
Ю. М. Свирежев
ПРЕДИСЛОВИЕ
Росту интереса экологов к системному анализу мешает,
пожалуй, лишь отсутствие ясного понимания многими из
них смысла термина «системный анализ». В самом деле,
ряд экологов испытывает сильное предубеждение против
применения концепции системного анализа (в том виде,
как они ее понимают) к задачам исследования экологиче-
ских систем и управления ими. Поскольку эта новая ветвь
экологии относительно молода, дело осложняется отсутст-
вием стандартного учебника, в котором студент или науч-
ный работник могли бы почерпнуть необходимые сведе-
ния. Правда, имеется ряд книг, где описаны результаты
применения системного анализа к частным задачам эко-
логии, но эти книги по-разному трактуют термин «систем-
ный анализ» и сферу применения данного подхода.
Настоящее издание не претендует на роль некоего
стандартного учебника. Оно задумано как практическое
введение в системный анализ в применении к самым раз-
ным экологическим проблемам. Автор надеется, что в та-
кой роли данная книга будет полезна и студентам-эколо-
гам — как учебное пособие, и молодым ученым, специали-
зирующимся в этой области, которые недостаточно владе-
ют математическими методами или впервые прибегли к
использованию математических систем, — как рабочий
инструмент в их научной и практической деятельности.
Она может заинтересовать не только биологов, но и всех
тех, кто хочет ознакомиться с теорией и практикой сис-
темного анализа.
Поэтому в книге содержится довольно мало математи-
ческих выкладок, и для ее понимания не требуется специ-
альных знаний по математике или статистике. Некоторый
математический аппарат все же используется, и читателю
понадобится немного поупражняться в выполнении прос-
тых статистических вычислений. Еще более полезным
окажется знакомство с машинным программированием
Предисловие
9
на одном из языков высокого уровня, как, например,
ФОРТРАН, АЛГОЛ пли БЭЙСИК. Если же читатель бу-
дет удручен тем объемом математики, что содержится в
книге, введение в системный анализ можно считать несос-
тоявшимся, по крайней мере для этого читателя.
В конце каждой главы помещены дендрограммы, по-
дытоживающие содержание данной главы. Эти дендро-
граммы следуют идеям книги Тони Бьюзепа [9], вышед-
шей в 1974 г. Как отражение структуры и содержания
глав они могут служить основой для построения более
детальных дендрограмм и дополнительным средством
повторения и усвоения материала.
Грейндж-овер-Сэндз
1978 Дж. Джефферс
Системный анализ:
применение в энологии
Концепции
и определение
Модели
и математика
Динамические
Г* модели
_Матричные
модели
____>. Стохастические
модели
Многомерные
модели
г Оптимизационные
и другие модели
Предметный указатель
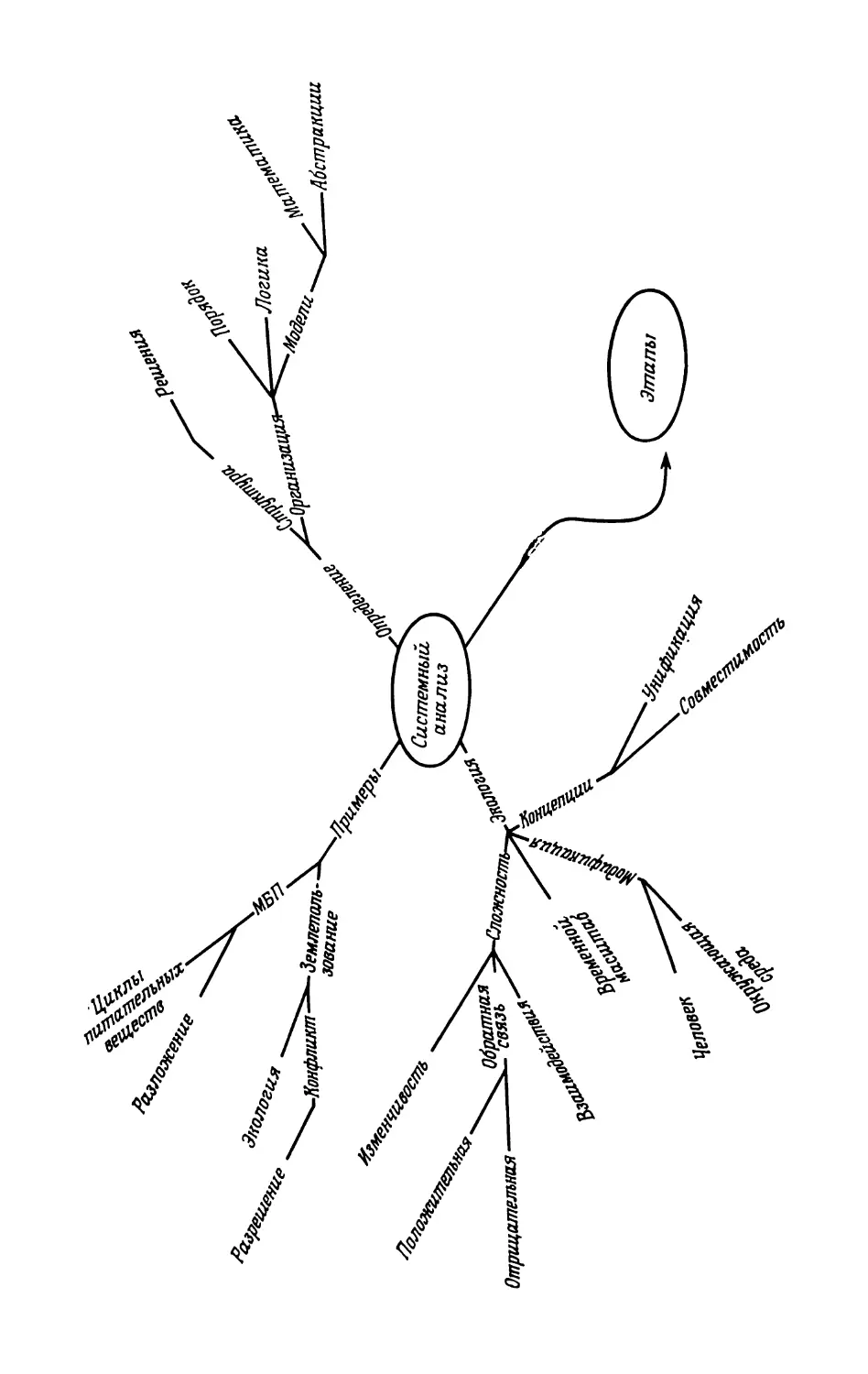
ЧТО ТАКОЕ СИСТЕМНЫЙ АНАЛИЗ?
Вопреки представлениям многих экологов, системный
анализ не есть какой-то математический метод и даже не
группа математических методов. Это широкая стратегия
научного поиска, которая, конечно, использует математи-
ческий аппарат и математические концепции, но в рамках
систематизированного научного подхода к решению слож-
ных проблем. По существу системный анализ организует
наши знания об объекте таким образом, чтобы помочь вы-
брать нужную стратегию или предсказать результаты
одной или нескольких стратегий, которые представляются
целесообразными тем, кто должен принимать решения.
В наиболее благоприятных случаях стратегия, найденная
с помощью системного анализа, оказывается «наилучшей»
в некотором определенном смысле.
В данной книге мы будем понимать под системным
анализом упорядоченную и логическую организацию дан-
ных и информации в виде моделей, сопровождающуюся
строгой проверкой и анализом самих моделей, необходи-
мыми для их верификации и последующего улучшения.
Определение термина «модель» будет дано в гл. 2, а пока
мы можем рассматривать модели как формальные описа-
ния основных элементов естественнонаучной проблемы
в физических или математических терминах. Ранее основ-
ной упор при объяснении тех или иных явлений делался
па использование физических аналогий биологических и
экологических процессов. Системный анализ также иногда
обращается к физическим аналогиям подобного рода, од-
нако чаще применяемые здесь модели математические и в
своей основе абстрактные.
При использовании системного анализа в решении
практических задач экологии мы прежде всего выделяем
семь этапов. Эти этапы и их взаимосвязь схематически
представлены па рис. 1.1 и вкратце описаны ниже. Более
подробно они будут рассмотрены в гл. 7, где обсуждаются
14 Глава 1
соотношения между указанными этапами и решением
практических проблем. Тем не менее, прежде чем рас-
сматривать различные типы моделей, которые составляют
ядро системного анализа, весьма целесообразно получить
представление об указанных этапах.
Выбор проблемы
Постановка задачи
L_> и ограничение
~ степени ее ’
сложности
/
Установление
иерархии
целей и задач
/
^Выбор путей
решения задачи
\
/
—Моделирование -
Оценка
__ возможных
стратегий
Внедрение
результатов
Рис. 1.1. Этапы системного анализа и их взаимосвязь.
1, Выбор проблемы
Осознание того, что существует некая проблема (или
совокупность взаимосвязанных проблем), которую можно
исследовать с помощью системного анализа и которая
достаточно важна для детального изучения, не всегда ока-
зывается тривиальным шагом. Как показывает горький
Что такое системный анализ?
15
опыт, удивительно легко просмотреть какие-то практиче-
ские аспекты экологии, которые необходимо было учесть,
и не менее легко поверить, что общепринятые представле-
ния об экологических процессах и системах истинны уже
потому, что они широко распространены. Однако осозна-
ние того, что исследование действительно необходимо,
столь же важно, как и выбор правильного метода исследо-
вания. С одной стороны, можно взяться за решение проб-
лемы, не поддающейся системному анализу, а с другой —
выбрать проблему, которая не требует для своего решения
всей мощи системного анализа и изучать которую данным
методом было бы неэкономично. Такая двойственность
первого этапа делает его критическим для успеха или
неудачи всего исследования.
2. Постановка задачи и ограничение степени ее сложности
Коль скоро существование проблемы осознано, требу-
ется упростить задачу настолько, чтобы она скорее всего
имела аналитическое решение, сохраняя в то же время
все те элементы, которые делают проблему достаточно
интересной для практического изучения. Здесь мы вновь
имеем дело с критическим этапом любого системного ис-
следования. Вывод о том, стоит ли рассматривать тот или
иной аспект данной проблемы, а также результаты сопос-
тавления значимости конкретного аспекта для аналитиче-
ского отражения ситуации с его ролью в усложнении за-
дачи, которое вполне может сделать ее неразрешимой,
часто зависит от накопленного опыта в применении сис-
темного анализа. Именно на этом этапе опытный специа-
лист по системному анализу может внести наиболее весо-
мый вклад в решение проблемы. Успех или неудача всего
исследования во многом зависят от топкого равновесия
между упрощением и усложнением — равновесия, при ко-
тором сохранены все связи с исходной проблемой, доста-
точные для того, чтобы аналитическое решение поддава-
лось интерпретации. Не один заманчивый проект оказы-
вался в конце концов неосуществленным из-за того, что
принятый уровень сложности затруднял последующее
моделирование, не позволяя получить решение. И напро-
тив, в результате многих системных исследований, выпол-
16 Глава 1
ценных в самых разных областях экологии, были получе-
ны тривиальные решения задач, которые на самом деле
составляли лишь подмножества исходных проблем.
3. Установление иерархии целей и задач
После постановки задачи п ограничения степени ее
сложности можно приступать к установлению целей и за-
дач исследования. Обычно эти цели и задачи образуют не-
кую иерархию, причем основные задачи последовательно
подразделяются па ряд второстепенных. В такой иерархии
необходимо определить приоритеты различных стадий и
соотнести их с теми усилиями, которые необходимо при-
ложить для достижения поставленных целей. Таким обра-
зом, в сложном исследовании специалист но системному
анализу может присвоить сравнительно малый приоритет
тем целям и задачам, которые, хотя и важны с точки зре-
ния получения научной информации, довольно слабо вли-
яют на вид решений, принимаемых относительно воздей-
ствий на экосистему и управления сю. В иной ситуации,
когда данная задача составляет часть программы какого-
то фундаментального исследования, исследователь заведомо
ограничен определенными формами управления и концен-
трирует максимум усилий на задачах, которые непосред-
ственно связаны с самими экологическими процессами. Во
всяком случае, для плодотворного применения системного
анализа очень важно, чтобы приоритеты, присвоенные
различным задачам, были четко определены.
4. Выбор путей решения задачи
На данном этапе исследователь обычно может выбрать
несколько путей решения проблемы. Эти пути подробно
рассмотрены в гл. 2, однако, как правило, опытному спе-
циалисту по системному анализу сразу видны семейства
возможных решений конкретных задач. В общем случае
он будет искать наиболее общее аналитическое решение,
поскольку это позволит максимально использовать резуль-
таты исследования аналогичных задач и соответствующий
математический аппарат. Каждая конкретная задача
обычно может быть решена более чем одним способом.
Что такое системный анализ?
17
И вновь выбор семейства, в рамках которого следует ис-
кать аналитическое решение, зависит от опыта специалис-
та по системному анализу. Неопытный исследователь мо-
жет затратить много времени и денег в бесплодных
попытках применить решение из какого-то семейства, не
сознавая, что это решение получено при допущениях, не
справедливых для того частного случая, с которым он
имеет дело. Аналитик же часто разрабатывает несколько
альтернативных решений и только позже останавливается
на том из них, которое лучше подходит для его задачи.
5. Моделирование
После того как проанализированы подходящие аль-
тернативы, можно приступать к важному этапу моделиро-
вания сложных динамических взаимосвязей между раз-
личными аспектами проблемы. При этом необходимо пом-
нить, что моделируемым процессам, а также механизмам
обратной связи присуща внутренняя неопределенность, а
это может значительно усложнить как понимание систе-
мы, так и ее управляемость. Кроме того, в самом процессе
моделирования нужно учитывать сложный ряд правил,
которые необходимо будет соблюдать при выработке ре-
шения о подходящей стратегии. На этом этапе математи-
ку очень легко увлечься остроумием и изяществом модели,
и в результате будут утрачены все точки соприкосновения
между реальным процессом принятия решений и матема-
тикой, призванной определить возможные последствия
этих решений.
6. Оценка возможных стратегий
Как только моделирование доведено до стадии, па ко-
торой модель можно (по крайней мере, предварительно)
использовать, начинается этап оценки потенциальных
стратегий, полученных из модели. В ходе этой оценки
исследуется чувствительность результатов к допущениям,
сделанным при построении модели, поскольку правомоч-
ность этих допущений можно проверить лишь в процессе
использования модели. Если окажется, что основные до-
пущения некорректны, возможно, придется вернуться к
18 Глава 1
этапу моделирования, но часто удается улучшить модель,
незначительно модифицировав исходный вариант. Обычно
необходимо также исследовать «чувствительность» моде-
ли к тем аспектам проблемы, которые были исключены из
формального анализа на втором этапе, т. е. когда стави-
лась задача и ограничивалась степень ее сложности.
7. Внедрение результатов
Заключительный этап системного анализа представля-
ет собой применение па практике результатов, которые
были получены па предыдущих этапах. Если исследова-
ние проводилось по вышеописанной схеме, то шаги, кото-
рые необходимо для этого предпринять, будут достаточно
очевидны. Тем не менее системный анализ нельзя считать
завершенным, пока исследование не дойдет до стадии
практического применения, и именно в этом отношении
многие выполненные ранее работы оказывались неполны-
ми. В то же время как раз на последнем этапе может вы-
явиться неполнота тех или иных стадий или необходимость
их пересмотра, в результате чего понадобится еще раз
пройти какие-то из уже завершенных этапов.
Поскольку системный анализ представляет собой ско-
рее способ мышления, нежели определенный набор рецеп-
тов, приведенный выше перечень должен рассматриваться
только как руководство к действию. При решении конк-
ретных задач некоторые из этапов могут быть исключены
или изменен порядок их следования; иногда придется по-
вторить эти этапы в различных комбинациях. Папример,
может оказаться необходимым пересмотреть роль исклю-
ченных из рассмотрения факторов, что потребует пройти
несколько раз стадии моделирования и оценки возможных
стратегий. Аналогичным образом может периодически
проверяться адекватность целевой структуры исследова-
ния, для чего придется время от времени возвращаться к
одному из ранних этапов даже после выполнения значи-
тельной части работы па более поздних этапах анализа.
Самые плодотворные модели будут «копировать» реаль-
ную ситуацию с той точностью, которая позволит получить
Что такое системный анализ?
19
широкий спектр решений и удовлетворит широкий круг
людей, принимающих решения. Стадия принятия реше-
ния, таким образом, не всегда бывает четко определена;
окончательное решение может приниматься уже после
завершения формального научного исследования.
Цель описанного выше многоэтапного системного ана-
лиза состоит в том, чтобы помочь выбрать правильную
стратегию при решении практических задач, в данном
случае в области экологии. Структура этого анализа на-
правлена па то, чтобы сосредоточить главные усилия па
сложных и, как правило, крупномасштабных проблемах,
не поддающихся решению более простыми методами ис-
следования, например наблюдением и прямым экспери-
ментированием. Из-за сложности проблем, для решения
которых обычно применяется системный анализ, послед-
ний часто предполагает использование ЭВМ для обработ-
ки и анализа данных, а также сложного математического
аппарата для проведения выбора между альтернативными
решениями. Однако ни использование ЭВМ, пи привле-
чение математического аппарата, ни то и другое, вместе
взятое, не является основной особенностью системного
анализа, как такового. И действительно, его структура
может подчас быть лучше всего проиллюстрирована на
примере задач, решение которых не требует их использо-
вания.
Особый вклад системного анализа в решение различ-
ных проблем обусловлен тем, что он позволяет выявить
те факторы и взаимосвязи, которые впоследствии могут
оказаться весьма существенными, что он дает возмож-
ность так видоизменять методику наблюдений и экспери-
мент, чтобы включить эти факторы в рассмотрение, и
освещает слабые места гипотез и допущений. Как науч-
ный метод системный анализ с ого акцептом па проверку
гипотез через эксперименты и строгие выборочные проце-
дуры создает мощные инструменты познания физического
мира и объединяет эти инструменты в систему гибкого, но
строгого исследования сложных явлений. Успехов в его
приложении к практическим задачам чаще всего удастся
достичь небольшим группам ученых, работающих в одном
институте и занимающихся четко очерченной и достаточ-
но узкой проблемой. Некоторые детали этого вопроса об-
20 Глава 1
суждаются в гл. 7, а сейчас достаточно подчеркнуть, что
для плодотворности работы этих групп необходимо с са-
мого начала обращать особое внимание па связь этапа
моделирования с тщательно отработанной стратегией ис-
следования п строгой проверкой всех используемых в
анализе данных.
Определив в общих чертах, что такое системный ана-
лиз, выясним, почему мы вынуждены использовать его в
экологии. Отчасти дело здесь в относительной сложности
экологии как науки, имеющей дело с разнообразными
взаимодействиями между огромным множеством организ-
мов. Почти все эти взаимодействия динамические в том
смысле, что они зависят от времени и постоянно изменя-
ются. Более того, взаимодействия часто имеют ту особен-
ность, которую в технике называют «обратной связью»,
т. е. характеризуются тем, что некоторые эффекты процес-
са возвращаются к своему источнику или к предыдущей
стадии, в результате чего эти эффекты усиливаются или
видоизменяются. Обратные связи бывают положительны-
ми (усиление эффекта) и отрицательными (ослабление
эффекта). Сама обратная связь может быть достаточно
сложной, включая в себя ряд положительных и отрица-
тельных эффектов, а последствия могут зависеть от фак-
торов внешней среды.
Сложность экосистем, однако, не ограничивается нали-
чием разнообразных взаимодействий между организмами.
Живые организмы сами изменчивы — это одна из важней-
ших их особенностей. Указанная изменчивость может
проявляться либо при взаимодействии организмов друг с
другом (например, в процессе конкуренции или хищниче-
ства), либо в реакции организмов (коллективной или ин-
дивидуальной) па условия окружающей среды. Эта реак-
ция заключается в изменении скорости роста и воспроиз-
ведения или даже в различной способности к выживанию
в сильно различающихся условиях. Когда к этому добав-
ляются происходящие независимо изменения таких факто-
ров среды, как климат и характер местообитания, иссле-
дование и регулирование экологических процессов и эко-
логических систем превращаются в трудную задачу.
В результате анализ даже относительно неизменной
экологической системы весьма сложен. Традиционная
Что такое системный анализ?
21
стратегия эколога в таких условиях состоит обычно в том,
что он сосредоточивает свое внимание па малых подмно-
жествах реальной проблемы. Так, многие исследователи
ограничивались анализом поведения отдельных организмов
в относительно простых местообитаниях (например, муч-
ных хрущаков в мешочках с мукой или червей сем.
Enchytraeidae в селективных средах) либо конкуренции
между двумя пли тремя видами (по-прежнему в относи-
тельно простых местообитаниях).
Особенно популярный тип экологического исследова-
ния — это анализ отношений между одним хищником и
одной жертвой, папример между оленьей мышью
Peromyscus leucopus и личинками пилильщика в лабора-
тории [36] или же между Paramecium и Didinium [53].
Во всех этих примерах была предпринята попытка упрос-
тить задачу настолько, чтобы ее можпо было исследовать
традиционными методами, исключая потенциальные ис-
точники изменчивости. Но даже после этого взаимоотно-
шения между рассматриваемыми организмами оставались
достаточно трудными для моделирования и анализа [55].
Когда в экологическом исследовании рассматриваются
эффекты намеренного воздействия па экологические сис-
темы, тем самым вводится еще одно измерение изменчи-
вости и взаимодействия. В принципиальных вопросах
прикладной экологии лесоводства и земледелия для неко-
торого упрощения обычно рассматривают поведение лишь
одной культуры, однако подобные исследования почти
ничего не говорят нам о том, как будет вести себя система
как целое в ответ на изменения, вызванные хозяйствен-
ной деятельностью человека. В частности, влияние данной
культуры на почву и на другие виды, входящие в состав
той экосистемы, в пределах которой произрастает даппая
культура, изучается довольно редко в основном из-за
трудностей проведения экспериментов, которые пужпо
поставить, чтобы проверить правильность гипотез необхо-
димой степени сложности. Еще труднее распространить
идеи комплексного подхода па экологические эффекты
землепользования, где рассматривается несколько альтер-
нативных стратегий развития и управления средой. Столь
же редко изучение результатов намеренного воздействия
па природные и «полупрнродпые» экосистемы, папример
22
Глава 7
при таком управлении природными ресурсами, которое
обеспечивает их охрану; все это опять-таки обусловлено
тем, что трудно учесть всю сложность и изменчивость
множества видов, от которых зависит устойчивость или
неустойчивость данной экосистемы.
Но всем этим причинам, т. е. из-за внутренней сложно-
сти экологических взаимосвязей, характерной для живых
организмов изменчивости и очевидной непредсказуемости
результатов постоянных воздействий па экосистемы со
стороны человека, экологу необходимо упорядочить и ло-
гически организовать свои исследования, которые уже
выходят за рамки последовательной проверки гипотез, хо-
тя «тяга к природе», порождаемая экспериментом, по-
прежнему остается в центре всей этой организации. При-
кладной системный анализ дает возможную схему такой
организации — схему, в которой экспериментирование
является составной частью процесса моделирования сис-
темы, так что сложность и изменчивость сохраняются в
той форме, в которой опи поддаются анализу. Специалис-
ты по системному анализу не объявляют свой подход к
решению сложных проблем единственно возможным, но
они, разумеется, считают, что это самый эффективный
подход — если бы существовало более эффективное реше-
ние, они бы им воспользовались!
Есть, однако, и еще одно основание для применения
системного анализа в экологии. По самой своей природе
экологическое исследование часто требует больших масш-
табов времени. Например, исследования в области земле-
делия и садоводства связаны главным образом с определе-
нием урожайности, а урожай собирается раз в год, так что
один цикл эксперимента занимает год или более. Чтобы
найти оптимальное количество удобрений и провести дру-
гие возможные мероприятия по окультуриванию, может
понадобиться несколько лет, особенно когда необходимо
рассматривать взаимосвязь между экспериментальными
результатами и погодой. В лесоводстве из-за длительного
круговорота урожаев древесины самый непродолжитель-
ный эксперимент занимает 25 лет, а долговременные
эксперименты могут длиться от 40 до 120 лет. Аналогич-
ные масштабы времени часто необходимы и для проведе-
ния исследований по управлению природными ресурсами.
Что такое системный анализ?
23
Все это требует извлекать максимальную пользу из каж-
дой стадии экспериментирования, и именно системный
анализ позволяет построить нужную схему эксперимента.
Далее, современное состояние экологии как пауки с
ее крайней рассредоточенностью научных усилий настоя-
тельно требует введения некой объединяющей концепции.
Необходимо отметить не только очевидную несовместимость
многих существующих теорий, по и то, что, как правило,
не изучена правомочность допущений, стоящих за этими
теориями, — отчасти потому, что сами допущения никогда
не формулировались в явном виде. Аналогичное состояние
характерно и для многих других областей пауки, по эко-
логия, несомненно, является одной из тех областей, где
системный анализ может действовать как фильтр (хотя
и не только как фильтр) существующих идей. Несовмес-
тимые теории можно рассматривать как альтернативные
гипотезы, при этом сам системный анализ часто будет
подсказывать, какие контрольные эксперименты необхо-
димо провести, чтобы сделать выбор.
Наконец, нам нужно внимательно рассмотреть приро-
ду тех моделей, которые мы собираемся строить для опи-
сания экологических отношений. Обычно мы не осознаем,
как велика роль функциональных моделей физики и тех-
ники в формировании наших представлений о взаимосвя-
зях различных физических явлений. На самом деле, как
будет показано в следующей главе, многие семейства
моделей, которые мы можем пытаться применить в сис-
темном анализе, окажутся моделями функционального
и детерминистского типа, полученными из причинно-след-
ственных отношений физики, а математический аппарат,
использованный для описания этих моделей, есть не что
иное, как традиционная прикладная математика, которую
мы все изучали в школе и которая, строго говоря, являет-
ся математикой, примененной к физике. Однако далеко
не все экологические отношения являются отношениями
такого тина, поскольку включают, как мы заметили, из-
менчивость организмов и местообитаний, а также взаимо-
действие между организмами и местообитаниями. Здесь
уже трудно применять методы прямого исследования и
экспериментирования и необходим более сложный мате-
матический аппарат стохастических или вероятностных
24 Глава 1
связей, чтобы моделировать изменчивость биологических
процессов и связи между переменными, которые зависят
от ряда независимых факторов.
Число опубликованных работ в области применения
системного анализа в экологии сравнительно невелико,
так что привести практические примеры не так просто.
Рассмотрим все же два таких примера, чтобы проиллюст-
рировать, каким именно образом системный анализ может
использоваться в экологии. Во-первых, мы остановимся на
применении системного анализа для исследования циклов
питательных веществ и разлагателей в проектах Между-
народной Биологической Программы (МБП) и, во-вторых,
вкратце рассмотрим роль системного анализа в изучении
экологических последствий землепользования.
Исследование циклов питательных веществ и разлага-
телей в экологических системах далеко не просто. Прямой
анализ процессов, составляющих эти циклы, затруднен
сложностью самих циклов — одновременное определение
многих включенных в анализ параметров может даже
оказаться невозможным без некоего искажения самих
процессов, особенно если учесть, что для обнаружения
сезонных п периодических изменений необходимы боль-
шие времена. Не всегда можно признать удовлетворитель-
ным и определение параметров отдельных составляющих
этих процессов в последовательных фазах — вследствие
сезонных или годичных изменений от одной фазы к дру-
гой и в результате отсутствия какого-либо эффективного
способа оценки взаимодействия между этими составляю-
щими в последовательных фазах. Тем пе менее при работе
в рамках МБП с помощью системного анализа был дос-
тигнут значительный прогресс в синтезе моделей циклов
питательных веществ и разлагателей для конкретных
биомов. Многие из этих моделей первоначально были по-
строены па основе данных, собранных ранее, а прямая
имитация процессов выявляла необходимость проведения
критических тестов, т. е. вела к дальнейшему сбору дан-
ных и моделированию. В Англии, например, значитель-
ные успехи были достигнуты в моделировании «природ-
ных» листопадных лесов и болот на возвышенностях,
причем в последнем случае предварительный синтез для
тундровых систем привел международные исследования к
Что такое системный анализ?
25
той стадии, па которой стало возможно изучение эффек-
тов управления и эксплуатации тундры.
Исследование результатов существенных изменений
в землепользовании также почти пе предпринималось из-
за больших размеров земельных площадей и необходимо-
сти проведения длительных экспериментов. И вновь син-
тез экологических моделей, построенных по результатам
более ранних исследований, и последующие ключевые
эксперименты позволили предсказывать результаты изме-
нений в управлении и, следовательно, результаты опреде-
ленных стратегий землепользования. Одна интересная
особенность раппих попыток синтеза подобного рода со-
стояла в осознании того, что пет необходимости строить
подробные модели экологии каждого компонента экосис-
темы. Нужнее всего как раз сравнительно простые моде-
ли, которые способны отразить потенциальный конфликт
между стратегиями землепользования, применяемыми
различными организациями, эксплуатирующими данный
земельный участок. Часто оказывается возможным сфор-
мулировать эти модели таким образом, что между различ-
ными организациями устанавливается некая «игровая»
ситуация; это позволяет выявить конфликтность их стра-
тегий и испробовать пути разрешения этого конфликта —
своего рода «монополия» в землепользовании.
Применение системного анализа к задачам, подобным
приведенным здесь, будет более детально проанализиро-
вано в гл. 7, когда мы вернемся к рассмотрению стратегии
процесса моделирования. Однако, прежде чем обратиться
к этому аспекту системного анализа, мы должны будем
изучить роль моделей как важнейшего элемента всего
здания системного анализа и рассмотреть наиболее типич-
ные семейства моделей.
2
МОДЕЛИ И МАТЕМАТИКА
В предыдущей главе мы описали модели как формаль-
ные выражения основных элементов проблемы в физиче-
ских или математических терминах. Теперь необходимо
уточнить это описание с тем, чтобы понять, что кроется
за важнейшим этапом системного анализа — этапом по-
строения модели — и за выбором подходящей модели для
решения данной проблемы. Рассмотрим вначале, что под-
разумевается под термином «формальные выражения» и
почему при этом используются именно физические или
математические термины.
Словесные модели
Читатель, не получивший достаточного математическо-
го образования, вполне может спросить: «Почему основ-
ным элементам задачи нужно давать формальное выраже-
ние и почему мы используем для этого именно физические
или математические термины? Нельзя ли с таким же успе-
хом начать с чисто словесного описания и избежать этого
пристрастия к математике?» Разумеется, нет сомнений, что
при первом знакомстве с проблемой мы будем скорее всего
пользоваться вербальными терминами, и поиск наиболее
точного вербального описания поможет найти решение
задачи, которой мы занимаемся. И действительно, некото-
рые специалисты но системному анализу считают построе-
ние «словесной модели» важным предшествующим моде-
лированию этапом, па котором объединяется все, что свя-
зано с решаемой проблемой, с целью выделения той части
системы, которую с их точки зрения необходимо исследо-
вать. Удивительно, как часто даже четверо пли пятеро
ученых, занимающихся одной и той же проблемой, не со-
глашаются с описаниями своих коллег, предложенными
для данной экологической системы; разногласия же по по-
воду частных элементов системы, которые прямо или кос-
28
Глава 2
всппо связапы с практическими задачами исследования,
возникают еще чаще. Что же касается больших групп ис-
следователей, занимающихся сложными проблемами, к
которым применим системный анализ, то здесь эти раз-
ногласия бывают весьма глубокими и трудноразрешимыми.
Поэтому есть все основания потратить определенное вре-
мя па то, чтобы найти описание, удовлетворяющее всех
заинтересованных исследователей, даже если в нем будут
некоторые пробелы, отражающие те моменты, по которым
не удалось прийти к общему мнению. Такое описание мо-
жет во многом помочь па стадиях постановки задачи и
ограничения степени ее сложности и установления иерар-
хии целей и задач исследования. В такой роли «словесная
модель» — хотя и не включенная в определение «модели»,
используемое в этой книге,— может принести неоценимую
пользу.
Меллапби [57] возражает против термина «словесная
модель». Он совершенно справедливо указывает, что все,
что подразумевается под этим термином, есть некое описа-
ние и потому пет никакой нужды присваивать обычному
процессу описания какое-то сложное название. Однако,
поскольку определение модели, использованное в настоя-
щем учебнике, предполагает формальное выражение, по-
лезно делать различие между этими формальными выра-
жениями и чисто словесными описаниями явлений, про-
цессов и взаимодействий.
Стоит все же заметить, что опытные исследователи в
области системного анализа не считают нужным делать
упор па «словесные модели», когда исследование уже выхо-
дит из стадий постановки задачи и ограничения степени
ее сложности и установления иерархии целей и задач.
Отчасти это обусловлено тем, что опытный аналитик спо-
собен быстро перейти к построению целого ряда матема-
тических моделей и считает, что быстрее всего к решению
проблемы его приведет выбор наиболее подходящей из них.
Отчасти разочарование в словесных моделях обусловлено
трудностями, внутренне присущими самим моделям, и
именно па этих трудностях мы должны сейчас остано-
виться.
В сущности указанных трудностей две, а все осталь-
ные вытекают непосредственно из них. Во-первых, с по-
Модели и математика
29
мощью словесных моделей легко вникнуть в проблему,
когда нужно определить сложные связи. И в самом деле,
даже самые тонкие связи часто молено описать словами —
подтверждением тому служат целые горы литературы на
многих языках, по одновременное действие многих слож-
ных связей, имеющих место в экологических системах,
очень трудно представить при помощи последовательных
отношений между словами. Суть этих связей быстро теря-
ется в множестве слов, необходимых для их описания,
причем быстрее всего — при описании обратной связи, ко-
торую мы уже определили как возвращение некоторых
эффектов процесса к своему источнику пли к предыдущей
стадии, приводящее к усилению или ослаблению самого
эффекта. Если какой-либо эколог сомневается в справедли-
вости нашего утверждения о том, как трудно использовать
словесные модели для описания биологических процессов,
он может попробовать описать словами взаимосвязь между
фотосинтезом и дыханием у растений в газообмене О2 и
С02.
Во-вторых, одно и то же слово нс всегда, к сожалению,
имеет одинаковый смысл в устах различных членов груп-
пы ученых, занимающихся одной проблемой. Прежде чем
пользоваться такими терминами, как «биомасса», «при-
рост», «урожай на корню», необходимо дать им строгое
определение. Будучи определенным, слово превращается в
символ, по если с моделью начнет работать человек, не
входивший ранее в данную группу исследователей, он
вполне может интерпретировать это слово в более широ-
ком смысле, чем то узкое значение, которое присвоено
данному символу.
Математические модели
Сила математики заключается в ее способности
выражать идеи и особенно сложные связи с помощью симво-
лической логики, сохраняя в то же время простоту и ра-
циональность выражения. Вероятно, пематематику «прос-
тота выражения» может показаться как раз таким свой-
ством, которое менее всего присуще математике. И все же
целое здание математической системы обозначений поко-
ится па экономичном выражении связей через символиче-
скую логику, и это выражение является «формальным» в
30
Глава 2
том смысле, что пз него можно формальными способами
получить некие предсказания. Не будь этой способности
предсказывать результаты изменений одного или более
элементов связей, мы не могли бы считать эти выражения
научной, а не просто метафизической или литературной
записью.
Поэтому паше использование математических обозначе-
ний в моделировании сложных систем является попыткой
дать содержательную символическую логику, которая уп-
рощает, по не слишком искажает основные взаимосвязи.
Логики иногда говорят об этом использовании символиче-
ской логики как об «отображении» системы с помощью
гомоморфа, т. е. несовершенного изображения действи-
тельности, некой карикатуры па нее.
Различные математические правила манипулирования
со связями системы позволяют нам делать предсказания
относительно тех изменений, которые могут произойти в
экологических системах, когда изменяются их составляю-
щие. Такие предсказания в свою очередь позволяют срав-
нивать модельные системы с темп реальными объектами,
которые они должны представлять, и проверять тем самым
адекватность модели наблюдениям и экспериментальным
данным,— это именно та «тяга к природе», которая обя-
зательна для приложений всякого научного метода. В сущ-
ности даже манипуляции с самой модельной системой мо-
гут подсказать, какие реальные эксперименты необходи-
мо поставить для проверки адекватности модели.
Мэйнард Смит (56] делает различие между «моделя-
ми» и «имитациями». «Имитацией» он считает максималь-
но подробное математическое описание с какой-то практи-
ческой целью, а под термином «модель» понимает описа-
ние общих идей, содержащее как можно меньше деталей.
В пашем учебнике мы не будем делать этого различия,
считая моделью любое формальное описание связей между
определенными символами; эти модели мы будем приме-
нять, как правило, для того, чтобы имитировать реакцию
экологической системы в ответ на различные воздействия.
Таким образом, в прикладном системном анализе мы бу-
дем стремиться к слиянию понятий «модель» и «имитация»
в том смысле, какой вкладывает в эти термины Мэйнард
Смит.
Модели и математика
31
Детерминистские модели
Прежде чем двигаться дальше, нам нужно дать некото-
рые рабочие определения, отражающие основные концеп-
ции. Однако сделать это целесообразно на примере каких-
либо простых моделей, которые мы сейчас и рассмотрим.
Одной из простейших моделей роста популяции организ-
мов является модель, заданная дифференциальным урав-
нением
dy
где у — плотность популяции в момент £, а г - констан-
та. Один из примеров биологического процесса, который
может быть представлен подобной моделью,— это рост
бактериальной культуры до того, как начнет истощаться
среда; здесь скорост г» роста в любой момент времени рав-
на постоянной доле от плотности популяции в этот мо-
мент. Выражая эту связь в такой форме, мы можем ис-
пользовать свойства частного вида символической логики,
представленной дифференциальными уравнениями, чтобы
показать, что плотность популяции в любой момент вре-
мени может также выражаться уравнением
У = уоег‘.
где по-прежнему у — плотность популяции в момент t,
у о — плотность в момент t — Q, г — константа, а е — осно-
вание натурального логарифма !.
Эта простая экспоненциальная модель имеет довольно
ограниченное применение, поскольку плотность популя-
ции организмов будет по мере исчерпания питательных ве-
ществ достигать некоторого стационарного значения. Аль-
тернативной моделью, обладающей данным свойством, яв-
ляется дифференциальное уравнение
4т
1 Читатель, незнакомый с теорией дифференциальных уравне-
ний, должен будет принять это утверждение па веру. Главное же
состоит в том, что существует четко установленная логическая
связь между двумя этими уравнениями и написание модели в од-
ной из этих форм автоматически предполагает и другую.
32
Глава 2
где у — вновь плотность популяции в момент £, а а и b —
константы. Аналогично предыдущему эта модель может
быть также представлена уравнением
а
________Ъ
У ~ 1 + ’
где у и уо — плотность популяции в момент t и t = 0 соот-
ветственно, а и b — константы, е — основание натурально-
го логарифма. Эта логистическая модель достаточно хоро-
шо описывает рост бактериальных популяций в условиях,
когда запасы питательных веществ ограничены. Сначала
рост популяции поспт экспоненциальный характер, а за-
тем, по мере исчерпания ресурсов, постепенно замедляет-
ся, пока плотность популяции не достигнет постоянного
уровня, или асимптоты. Более того, предсказать, что этот
постоянный уровень равен а/6, мы можем при помощи
простых алгебраических манипуляций с исходной моделью,
т. е. посредством логической дедукции в рамках формаль-
ной символической логики математического выражения на-
шей модели. Иными словами, выражая модель в абстракт-
ных математических терминах вместо слов, мы сразу же
приобретаем возможность получать из модели дальнейшую
информацию.
Стохастические модели
Обе упомянутые выше модели являются детерминист-
скими в том смысле, что при заданных значениях кон-
стант плотность популяции в данный момент времени t
всегда одна и та же — величина у однозначно определяет-
ся значением £, т. е. в обычном физическом смысле причи-
ны, всегда порождающей одно п то же следствие. И дей-
ствительно, модели, задаваемые дифференциальными урав-
нениями, были разработаны вначале в приложениях
математики к физике — этой классической области при-
кладной математики — п естественно, что в поисках мо-
делей для экологии пам прежде всего следует посмотреть,
нельзя ли использовать то, что было развито в других об-
ластях.
Модели и математика
33
Мы можем, однако, строить наши модели совершенно
иным способом, положив в их основу изменчивость живых
организмов; тогда это будут вероятностные, или стохасти-
ческие модели. В подобных моделях используется совсем
иная область математики, развившаяся позже, чем диффе-
ренциальное исчисление и дифференциальные уравнения.
Один простой пример такой модели, соответствующей де-
терминистской модели экспоненциального роста, задается
уравнением
4г = [« + Y(W,
СП
где у — плотность популяции в момент t, а — константа,
а у(/) — случайная переменная с нулевым средним. Это
значит, что величина у(/) меняется, принимая значения
из некоторого случайного распределения так, что между
флуктуациями в последовательные моменты пет никакой
корреляции. Допущение об отсутствии систематической
корреляции может показаться нереалистичным, однако
все это означает лишь то, что флуктуации коррелируют
только на отрезках времепи, которые малы по сравнению
с другими временными масштабами, характерными для
системы.
Легко видеть, что если основой для имитации служит
стохастическая модель, то результаты имитации могут
различаться, даже если константы и начальные условия
одинаковы. Эту вариабельность обеспечивают вероятно-
стные элементы модели; назначение таких моделей имен-
но в том и состоит, чтобы отразить изменчивость, харак-
терную для живых организмов и экологических систем. Что
же касается постановки реального эксперимента, то обыч-
но бывает необходимо провести целую серию имитаций, с
тем чтобы определить, как система реагирует па различ-
ные воздействия.
Рабочие определения
Итак, выше мы вкратце рассмотрели два типа моделей,
или наборов правил для вычисления предсказываемых зна-
чений величин, с которыми можно сравнить значения наб-
людаемые:
2-843
34
Глава 2
1) детерминистские модели, в которых предсказывае-
мые значения могут быть точно вычислены;
2) стохастические модели, в которых предсказываемые
значения зависят от распределения вероятностей.
Это различие важно иметь в виду, и далее мы рассмот-
рим, как с помощью распределения вероятностей осущест-
вляется подгонка моделей, т. е. выбор таких значений па-
раметров, при которых предсказанные величины достаточ-
но близки к результатам наблюдений. Оценка таких
параметров требует применения статистических методов,
которые опираются на теорию вероятностей, и, чтобы луч-
ше разобраться в моделях, нам понадобятся некоторые
рабочие определения.
Во-первых, мы все время должны различать популяцию
и выборку, извлеченную из этой популяции. Под популя-
цией мы будем понимать полное множество индивидов,
свойства которого мы хотим исследовать. Эти индивиды
могут быть организмами, экосистемами или даже мерой
или любой характеристикой организмов либо экосистем.
Выборка — это любое конечное множество индивидов, из-
влеченное из популяции; при этом считается, что выборка
делается таким образом, что вычисленные но пей величи-
ны являются показательными (репрезентативными) для
всей популяции и могут поэтому рассматриваться как оцен-
ки соответствующих величии для этой популяции. Здесь
мы не будем описывать методы, которыми делаются выбор-
ки, необходимые для получения несмещенных оценок по-
пуляционных величии,— их можно пайти в любом хоро-
шем руководстве по статистике,— ио примем, что приме-
няются методы, позволяющие получить выборки, которые
являются pei 1 резей гативпыми для данной популяции. Ве-
личины, характеризующие популяцию в целом, определим
как параметры (в отличие от соответствующих величин
для выборок, которые будут считаться оценками для этих
параметров) либо как константы или коэффициенты в
уравнениях модели. Необходимо все время помнить о раз-
нице между параметрами и выборочными оценками.
Во-вторых, паши уравнения, задающие модель, будут
содержать два типа переменных. По краб пей мере одна из
переменных будет зависимой в том смысле, что она ме-
няется при изменении других переменных. В рассмотрен-
Модели и математика
35
ных выше примерах такой величиной является плотность
у. Другие переменные4 считаются независимыми на языке
дифференциального ' исчисления — независимыми в том
смысле, что именно их изменение влечет за собой измене-
ние зависимых переменных. Такое употребление термина
«независимые» может, однако, ввести в заблуждение, по-
скольку две пли более независимые переменные на самом
деле иногда сильно коррелируют. Когда при получении
оценок параметров модели мы будем применять методы
регрессионного анализа, те величины, изменения которых
приводят к изменению зависимой переменной, будут назы-
ваться регрессионными переменными.
В-третьих, определим подгонку модели как выбор та-
ких значений параметров, при которых предсказанные зна-
чения величин достаточно близки к наблюдаемым. В дей-
ствительности вероятность того, что параметры отвечают
данным наблюдений, мы будем рассматривать как мате-
матическую функцию этих параметров и определим ее как
функцию правдоподобия. Эта функция является мерой со-
ответствия между моделью и данными, а те значения
параметров, для которых правдоподобие максимально, на-
зываются оценками максимального правдоподобия.
На самом деле наши модели подразделяются еще на
две категории, а именно па аналитические и имитацион-
ные. Аналитические модели — это те, в которых для опре-
деления значений предсказываемых величин получаются
выражения в явном виде; сюда относятся регрессионные и
многомерные модели, модели планирования эксперимента
и стандартные теоретические статистические распределе-
ния. Имитационные модели — это модели, которые могут
быть описаны с помощью набора определенных матема-
тических операций, таких, как решение дифференциаль-
ных уравнений, повторное применение переходной матри-
цы пли использование случайных либо псевдослучайных
чисел. Преимущество имитационных моделей состоит в том,
что их легче построить пематематику, по подогнать их
под данные наблюдений обычно труднее, чем аналитиче-
ские модели.
2*
36
Глава 2
Простые примеры
В свете данных определений остановимся еще на не-
скольких примерах сравнительно простых математических
моделей в экологии. Вольтерра [88] описывал взаимодей-
ствия между хищниками с плотностью у и их жертвами с
плотностью х с помощью дифференциальных уравнений
1 о
---= ах — Ьх“ — сху,
ей
(1г/ I /
— = еу + с ху,
ей
где а, Ь, с, е и с' — коэффициенты, х — плотность популя-
ции жертв, у — плотность популяции хищников, t — время.
Ясно, что эта модель детерминистская в том смысле,
что при заданных начальных значениях х и у и при задан-
ных значениях коэффициентов мы всегда будем получать
одни и те же результаты. Зависимыми переменными яв-
ляются х и у, а независимой — t (заметим, что вид
дифференциальных уравнений, как правило, ничего не го-
ворит о природе переменных), но предсказанные значения
х и. у всегда зависят также от предыдущих значений х и
у, и о такой модели говорят, что она «рекурсивна».
Поведение данной модели поддается математическому
анализу и довольно хорошо изучено, так что это скорее
аналитическая, нежели имитационная модель. В отсутст-
вие хищничества численность жертв описывалась бы ло-
гистическим уравнением и характеризовалась собственной
скоростью прироста а и емкостью среды а/b. Скорость, с
которой поедаются жертвы, пропорциональна произведе-
нию плотностей хищника и жертвы. Используя одни лишь
математические методы, можно показать также (см., на-
пример, книгу Мэйнарда Смита [56]), что если емкость
среды для жертв достаточно велика, чтобы выдержать дав-
ление хищника, то численности и жертвы, и хищника ко-
леблются с убывающей амплитудой, причем колебания
численности хищника отстают по фазе от колебаний чис-
ленности жертвы.
Разумеется, точные значения популяционных парамет-
ров а, р, у, г) и у' удается определить не для всякой попу-
ляции жертвы и хищника (условимся обозначать популя-
Модели и математика
37
циоппые параметры греческими, а выборочные оценки —
малыми латинскими буквами), и нам нужно будет найти
способ получения оценки популяционных параметров по
данным для выборок. Позже мы рассмотрим пример под-
гонки модели такого рода.
Интересный пример стохастической модели был пред-
ложен Скелламом [72] как возможное объяснение вариа-
ции числа видов, принадлежащих одному роду, для об-
ширного множества групп живых организмов. Он сформу-
лировал гипотезу, состоящую в том, что эволюционное дре-
во есть результат стохастического процесса, в котором с
каждой ветвью время от времени происходит одно из трех
взаимоисключающих событий:
1) ветвь остается перазветвлеппой;
2) разветвляется на две;
3) исчезает из рода, к которому опа принадлежит, в
результате
а) вымирания вида,
б) образования нового рода (т. е. смены своего ро-
дового названия).
Из этой гипотезы можно вывести уравнение
Фп+1 («) = Фп + М ,
где Ф есть производящая функция факториальных момен-
тов 1 для числа видов одного рода, который возник в точ-
ности п лет назад. Можно показать, что решение этого
уравнения приводит к геометрическому распределению с
аномальным пулевым классом. Интегрируя это распреде-
ление по п, мы приходим к выводу, что число видов од-
ного рода должно следовать логарифмическому распреде-
лению, и действительно, число видов известных родов
описывается этим распределением довольно хорошо. Заме-
тим, что в этом примере нам даже не пришлось оценивать
значения параметров аир — как только была установле-
на форма модели, все рассуждение проходило на основе
дедуктивной логики математики. Если же, однако, мы за-
хотели бы предсказать число видов какого-то конкретного
рода, нам понадобился бы некий метод для оценки этих
популяционных параметров.
1 В отечественной литературе она часто называется просто
производящей функцией. — Прим, персе.
38
Глава 2
Семейства математических моделей
Мы остановились сейчас лишь на некоторых общих
свойствах математических моделей; в последующих гла-
вах этой книги конкретные семейства моделей будут рас-
смотрены более подробно. Еще одно преимущество ис-
пользования математических моделей состоит в том, что
опытный аналитик способен распознавать «семейства» мо-
делей аналогично тому, как опытный ботаник часто может
отнести данное растение к определенному роду, даже когда
ему неизвестен этот вид. В рамках вводного курса, каким
является данный учебник, невозможно рассмотреть все су-
ществующие семейства моделей, поэтому мы остановимся
лишь на тех из них, с которыми «пользователи» систем-
ного анализа сталкиваются наиболее часто, а именно:
1) динамические модели; 2) компартмептальпые моде-
ли; 3) матричные модели; 4) многомерные модели; 5) оп-
тимизационные и друтие модели.
Как мы увидим, этот список далеко пе полон, а его ка-
тегории к тому же пе взаимоисключающие. Но этой клас-
сификации достаточно, чтобы дать представление о неко-
торых математических моделях, применимых для реше-
ния практических задач, и проиллюстрировать основные
требования, предъявляемые к моделям прикладного сис-
темного анализа.
Преимущества и недостатки математических моделей
Прежде чем обратиться к рассмотрению различных се-
мейств математических моделей, подытожим все-таки от-
носительные преимущества и недостатки применения ма-
тематических моделей в прикладном системном анализе.
Преимущества математических моделей состоят в том,
что эти модели точны и абстрактны, что они передают
информацию логическим однозначным образом. Модели
точны, поскольку они позволяют делать предсказания, ко-
торые можно сравнить с реальными данными, поставив
эксперимент или проведя необходимые наблюдения. Мо-
дели абстрактны, так как символическая логика матема-
тики извлекает те и только те элементы, которые важны
для дедуктивной логики рассуждения, исключая, таким
образом, все посторонние значения, которые могут быть
Модели и математика
39
приданы словам. Математические модели позволяют ис-
пользовать всю совокупность накопленных знаний о пове-
дении взаимосвязей, так что логически связанные сужде-
ния об изучаемой системе можно вывести, не повторяя
все предыдущие исследования. Математические модели
дают нам важное средство коммуникации благодаря одно-
значности символической логики, используемой в матема-
тике,— средство, которое в значительной степени лишено
недостатков, свойственных обычному языку.
Недостатки математических моделей заключаются во
внешней сложности (но крайней мере, для нематематика)
символической логики. Эта сложность отчасти неизбеж-
на — если изучаемая проблема сложна, вполне возможно
(по все же не обязательно), что сложным окажется и ма-
тематический аппарат, необходимый для ее описания. Ма-
тематика вообще наука сложная, и трудности при перево-
де результатов с языка математики па язык реальной
жизни испытывают не только пематематики. Отсутствием
корректной интерпретации результатов сложных методов
анализа страдают многие научные статьи, быть может,
вследствие того, что этот вопрос обсуждается намного ре-
же, чем соответствующие математические аспекты исследо-
вания. По мнению Бросса [8], «псевдонаука процветает
потому, что сравнительно мало людей утруждают себя пе-
реводом с языка алгебры па повседневный язык, легко поз-
воляющий выявить абсурдность того или иного суждения».
Но, пожалуй, самый большой недостаток математиче-
ских моделей связан с тем искажением, которое можно
привнести в саму проблему, упорно отстаивая конкретную
модель, даже если в действительности она не соответствует
фактам, а также с теми трудностями, которые возникают
иногда при необходимости отказаться от модели, оказав-
шейся неперспективной. Математическое моделирование
настолько опьяняющее занятие, что «модельеру» очень
легко отойти от реальности и увлечься применением ма-
тематических языков к искусным абстрактным формам.
Именно поэтому необходимо помнить, что моделирование
в прикладном системном анализе — это лишь один из эта-
пов широкой стратегии исследования. Мы должны внима-
тельно следить за тем, чтобы моделирование не преврати-
лось в самоцель!
“*Фор&а
Средство
°nip6f/t коммуникации
^S” X
•хсХ
Символическое
»’»”•"
\ X
Недостатки
Основа
Компартментальные
Xх
с””’ ✓ »
♦’ /
VnpolUeHH
X
мейХ
Cei*e*
X
»*> ^ett^
/
4 »rt^
4>
/ «/
Zcp^ X
—Модели
Сми/п
,4 .X
/
/
< X
Модели и \__/7римеры —^вероятность
математика J г л
&
/У
*%. Г, rt8UcU~
\^е^н' ^jejbie
?/§"§. %. ----Популяция
$ «Зч
* *? \
Регрессионные
•Данные наблюдений
ч______п
-----Оценки
3
ДИНАМИЧЕСКИЕ МОДЕЛИ
Наш обзор некоторых семейств математических моде-
лей мы начнем с рассмотрения одного из недавних дости-
жений в области моделирования. Изучение динамики сис-
тем базируется па теории сервомеханизмов, разработанной
тоже сравнительно недавно, а всякое практическое исполь-
зование динамических моделей зависит от способности
современных быстродействующих вычислительных машин
решать большое число (сотни) уравнений за короткие про-
межутки времени. Эти уравнения являются более или ме-
нее сложными математическими описаниями того, как
функционирует имитируемая система, и даются они в фор-
ме выражений для «уровней» различных типов, «темп»
изменения которых регулируется управляющими функция-
ми. Уравнения для уровней описывают накопления в сис-
теме таких величии, как вес, численность организмов или
количество энергии, а уравнения для темпов управляют
изменением этих уровней во времени. Управляющие функ-
ции отражают правила, явные или неявные, которые, как
предполагается, регулируют функционирование системы.
Как подчеркивалось в предыдущей главе, математиче-
ские модели данной системы могут отображать эту систе-
му лишь с той степенью точности, с какой уравнения, опи-
сывающие свойства компонентов модели, отображают
свойства компонентов реальной системы. Популярность
динамических моделей обязана большой гибкости мето-
дов, применяемых для описания динамики систем, которая
включает нелинейные реакции компонентов па регули-
рующие переменные, а также положительные и отрица-
тельные обратные связи. Как мы увидим, однако, такая
гибкость имеет и свои недостатки. Например, обычно не-
возможно учесть уравнения для всех компонентов систе-
мы, так как даже при наличии современных ЭВМ имита-
ция быстро становится слишком сложной. Поэтому необ-
ходимо иметь некоторую абстракцию, основанную на здра-
42
Глава 3
вом смысле п на допущениях относительно того, какие из
многих компонент системы в действительности управляют
ее функционированием.
При использовании системной динамики в моделирова-
нии мы выделяем три главных этана. Во-первых, нужно
установить, какое именно динамическое свойство системы
представляет интерес, и сформулировать гипотезы о взаи-
модействиях, порождающих данное свойство; этот шаг
можно отождествить с этапом постановки задачи; он, оче-
видно, тесно связан с темп стадиями системного анализа,
которые предшествуют самому этапу моделирования, хотя
мы и имеем дело уже с детализированным поведением и
взаимодействиями переменных системы. Во-вторых, ма-
шинная имитационная модель должна быть построена та-
ким образом, чтобы она дублировала элементы поведения
и взаимодействий, определенные как существенные для
системы. В-третьих, когда мы убедимся в том, что поведе-
ние модели достаточно близко к поведению реальной сис-
темы, мы используем модель, чтобы попять последова-
тельность изменений, наблюдаемых в реальной системе, и
предложить эксперименты, которые можно поставить на
стадии оценки потенциальных стратегий, т. е. на следую-
щем этапе системного анализа.
Одна из привлекательных особенностей динамических
моделей заключается в возможности использовать диаграм-
мы связей для представления основных взаимодействий в
Рис. 3.1. Условные обозначения, предложенные Форрестером для
изображения взаимодействий в системе.
Динамические модели
43
сложной системе. На рис. 3.1 показаны условные обозна-
чения, введенные Форрестером [24] и используемые при
построении таких диаграмм, и, хотя эти обозначения пер-
воначально были приняты для промышленных систем, они
столь же удобны и применимы в экологии. Во всяком слу-
I
П
Рис. 3.2. Простые примеры диаграмм для представления экспонен-
циального (7) и логистического роста (77) (объяснения см. в тек-
сте).
чае, они дают те преимущества, которые несет установле-
ние стандартного набора символов для широкого круга
практических задач.
Форрестер приписал специальные символы различным
типам элементов, которые можно выделить в системах,
полностью определяемых переменными состояния. Сами
переменные состояния, или «содержимое» интегралов,
изображаются прямоугольниками, темпы изменения —
специальными символами (см. рис. 3.1), а вспомогательные
переменные — кружками. Параметры пли константы изоб-
ражаются маленькими кружками па липни. Потокам ве-
щества соответствуют сплошные стрелки, а потокам ин-
формации — штриховые. Рис. 3.2 иллюстрирует пример ис-
пользования этих символов для представления экспонен-
циального и логистического роста. При экспоненциальном
44
Глава 3
росте количество (К) регулируется темпом роста (ТР),
который в свою очередь зависит от относительного темпа
роста (ОТР), считающегося константой, и текущего зна-
чения количества (К). При логистическом росте К регу-
лируется ТР, который зависит от текущего значения К и
двух копстапт — ОТР и емкости среды (ЕС).
Следует заметить, что диаграммы связей пе дают ис-
черпывающего описания взаимодействий. Такое описание
легче получить с помощью математических уравнений или
машинных алгоритмов — однозначных инструкций, кото-
рые необходимо написать, чтобы ЭВМ смогла решить эти
уравнения. Однако многие считают, что диаграммы полез-
ны для символического изображения основных связей как
контроль допущений, заложенных в математические урав-
нения, и потому эти диаграммы чаще рисуют после, а не
до того, как определены уравнения.
Как приступают к построению динамической модели
для той или иной практической проблемы? Однозначного
ответа на этот вопрос пе существует, многое зависит от
квалификации людей, запятых данной проблемой, и осо-
бенно от того, обладают ли те, кто имеет необходимые
экологические познания, также и математическими позна-
ниями, достаточными для полного использования возмож-
ностей математики. Чаще всего динамические модели кон-
струируют небольшие группы исследователей, состоящие
из экологов, математиков и специалистов по управлению
ресурсами.
Наиболее удобной отправной точкой часто бывает по-
строение относительно простой словесной модели, служа-
щей основой для тех множеств уравнений, которые в ко-
нечном счете определят систему. Математики будут стре-
миться как можно скорее формализовать взаимодействия
с помощью уравнений, связывающих переменные состоя-
ния системы, тогда как экологи и специалисты по ресур-
сам будут пытаться соотнести эти уравпения со своим по-
ниманием проблемы, используя диаграммы связей и пере-
осмысливая уравнения как описания, с которыми нужно
сравнить построенную ранее словесную модель. Весь про-
цесс является итеративным, проходящим через несколько
стадий последовательных приближений. В одних случаях
модель с большим трудом придется составлять из постро-
Динамические модели
45
енпых ранее моделей отдельных частей системы (напри-
мер, экспоненциального или логистического роста), в дру-
гих построение начнется с модификации уже существую-
щей модели. При этом математическая основа выступает
как удобный объект для обмена опытом, а также как сред-
ство общения между математиком и экологом, что и было
отмечено в предыдущей главе.
Необходимо, однако, подчеркнуть, что набор формаль-
ных уравнений — это то, что нужно для следующей стадии
процесса моделирования, который должен имитировать
экологическую систему па ЭВМ, используя быстродейст-
вие последней для итеративного решения при многих проб-
ных значениях параметров. Многие из параметров (кон-
стант) модели бывают неизвестны, и потому для отыска-
ния подходящих значений этих параметров ЭВМ работает
в итеративном режиме поиска, начинающегося с некото-
рых предугаданных или произвольно взятых значений.
В тех случаях, когда есть основания полагать, что две или
более переменные связаны между собой, нужно будет най-
ти вид и коэффициенты этих взаимосвязей, чтобы подо-
гнать модель к данным наблюдений.
Многих экологов привлекает к динамическим моделям
и наличие специально ориентированных языков для их
машинной реализации. Чтобы дать исследователю возмож-
ность умозрительно использовать ЭВМ, не обучаясь специ-
ально современным методам программирования, были
разработаны такие языки, как ДИНАМО (DINAMO), язык
имитации непрерывных систем (КССЛ) [Continuous
Sistem Simulation Language (CSSL)], программа для мо-
делирования непрерывных систем (КСМП) [Continuos
Modelling Program (CSMP)]. Эти программирующие сис-
темы призваны облегчить общение пе только между
исследователем и ЭВМ, по и между самими исследователя-
ми. Важной чертой указанных имитационных программи-
рующих систем является, кроме того, то, что все процес-
сы и их детали могут быть представлены в концептуальной,
а не в вычислительной форме. Сама программирую-
щая система включает некую процедуру сортировки, ко-
торая упорядочивает все расчеты и процессы интегриро-
вания в эффективный алгоритм. В результате этого
программа имитации может быть представлена в более по-
46
Глава 3
мятной форме, а ряд концептуальных ошибок и ошибок
программирования выявляется самой системой.
Тем не менее многие исследователи, пе только знако-
мые с программированием, но и в совершенстве владею-
щие этим методом, предпочитают записывать свои про-
граммы имитации па языках высокого уровня, таких, как
ФОРТРАН, БЭЙСИК пли АЛГОЛ. Из этих языков самым
легким для работы является, пожалуй, БЭЙСИК, посколь-
ку он разработан как диалоговый язык, а эта его особен-
ность значительно упрощает подгонку констант и коэффи-
циентов, а также проверку имитации. Более того, работая
на машинном языке общего назначения, мы заведомо из-
бавляемся от ограничений и правил, присущих любому
специально ориентированному языку. Сравните сами раз-
личные записи программ для приведенных ниже примеров.
Пример 3.1. Рост дрожжей в монокультурах
и в смешанной культуре
В качестве первого примера применения динамических
моделей к экологической (точнее говоря, биологической)
проблеме мы рассмотрим относительно простую ситуацию,
впервые описанную Гаузе [26], который выращивал два
вида дрожжей (Saccharomyces cerevisiae и Schizosaccharo-
myces ’’Kephir”) в среде с определенным содержанием
сахара. Дрожжи, растущие в аэробных условиях при до-
статочном количестве сахара и некоторых других необхо-
димых веществ, потребляют сахар как источник энергии,
необходимой для роста новых клеток и для поддержания
культуры. Конечные продукты превращения сахара в про-
цессе дыхания — углекислый газ и вода — не загрязняют
культуральную среду. Если же дрожжи растут в анаэроб-
ных условиях, образуется еще один конечный продукт —
спирт, который может накапливаться в среде, замедляя и
в конечном счете полностью подавляя почкование дрож-
жей, даже если в среде содержится достаточное для роста
культуры количество сахара.
Гаузе выращивал эти виды дрожжей в моно- и сме-
шанных культурах; сравнение роста дрожжей в смешан-
ной культуре с ростом в монокультуре позволяло сделать
вывод о взаимном влиянии их друг на друга. Гаузе пред-
Динамические модели
47
положил, что ого влияние обусловлено образованием обои-
ми видами дрожжей одного и того же продукта жизнедея-
тельности — спирта, который подавляет почкование. Для
того чтобы проверить эту гипотезу, мы должны смодели-
ровать независимый рост двух видов и их рост в смешан-
ной культуре в предположении, что единственной причи-
ной взаимного влияния служит образование одного и того
же вредного продукта.
Диаграмма связей для этого примера показана на
рис. 3.3. Здесь мы имеем три основные переменные (пе-
ременные состояния): количество дрожжей первого и вто-
рого видов и количество спирта. Штриховые стрелки, от-
ражающие поток информации, указывают па то, что рост
дрожжей зависит от их количества, относительного темпа
роста и вспомогательной переменной (ВП1 пли ВП2), от-
ражающей замедление роста. Эта переменная является в
свою очередь функцией количества содержащегося в куль-
Фактпор!, влияющий
на образование спирта
Фактор Zr влияющий
на образование спирта
Рис. 3.3. Диаграмма связей для роста и взаимного влияния двух
видов дрожжей [17].
48 Глава 3
туральпой среде спирта. Основные связи одинаковы для
обоих видов дрожжей, хотя значения параметров и вид
функций могут различаться. Количество спирта регули-
руется темпами его образования дрожжами обоих видов,
а сами эти темпы зависят от темпов роста видов и от
других факторов, влияющих па образование спирта.
Де Вит и Гудриап [17] предлагают для этой модели
программу на КСМП, которая воспроизведена в табл. 3.1.
Эквивалентная программа па БЭЙСИКе приведена в
табл. 3.2, а результаты, полученные по этой программе
Таблица 3.1
Программа на КСМП для имитации роста
и взаимодействия двух видов дрожжей [17]
TITLE MIXED CULTURE OF YEAST
Y1 = INTGRL (lYl, RYl)
y2 = INTGRL (iy2, ry2)
incon iyI = 0.45, iy2 = 0.45
ryI = rgrI • y1 • (1. - redI)
ry2 = rgr2 • y2 • (1. - red2)
parameter rgrI = 0.236, rgr2 = 0.049
RED1 = AFGEN (RED1T, ALC/,MALC)
RED2 = AFGEN (REd2t, ALC/MALC)
FUNCTION RED1T = (0., 0.), (1., 1.)
FUNCTION red2t = (0., 0.), (1., 1.)
PARAMETER MALC =1.5
ALC = INTGRL (ALC, ALCP1 + ALCP2>
alcpI = alpfI * ryI
alcp2 = alpf2 • ry2
parameter alpfI = 0.122, alpf2 = 0.270
INCON IALC = 0.
FINISH ALC = LALC
LALC « 0.99 * MALC
TIMBER FINTIM = 150., OUTDEL 2.
PRTPLT Yl, Y2, ALC
END
STOP
Динамические модели
49
при оцененных значениях параметров, приведены в
табл. 3.3 и представлены па рис. 3.4 вместе с эксперимен-
тальными значениями, измеренными Гаузе.
Таблица 3.2
Программа на ВЭЙСИКе для имитации роста дрожжей
в смешанной культуре и монокультурах
10 REM MIXED CULTURE OF YEASTS *
20 PRINT “INITIAL AMOUNTS: Y0,Y2“J
30 INPUT Y1»Y2
40 PRINT “RELATIVE GROWTH RATES: RbR2"J
50 INPUT RI*R2
60 PRINT “ALCOHOL PROD RATES: F1>F2“J
70 INPUT F1>F2
80 PRINT "MAX ALCOHOL LEVEL: M"l
90 INPUT M
95 PRINT
100 LET A=0
110 LET DI=0
120 LET D2 = 0
130 FOR 1=1 TO 60
140 FOR J=1 TO 10
150 LET Si=R1•Y1•(I-DI)*0•1
160 LET S2=R2«Y2*(1-D2)*0.1
170 LET Y1=Y1♦S1
180 LET Y2=Y2*S2
190 LET PI=F1*S1
200 LET P2=F2*S2
210 LET A=A*P1*P2
230 LET D1=A/M
240 LET D2=A/M
2 50 NEXT J
260 PRINT I>Y1*Y2>A
280 NEXT I
290 STOP
300 END
Как были получены оценки для параметров? Посколь-
ку Гаузе выращивал эти два вида дрожжей в монокульту-
рах, можно было, во-первых, оценить скорость роста и
образования спирта для каждого вида в отдельности, а во-
вторых, сравнить их со скоростью роста дрожжей при сов-
местном их культивировании при известных начальных
количествах и некоторой максимальной концентрации
спирта, при которой, по оценкам, полностью подавляется
формирование почек.
Если относительным темпам роста и переменным, влия-
ющим на образование спирта, придать значения, при ко-
торых они наиболее близко соответствуют эксперимеп-
50
Глава 3
Таблица 3.3
Наблюдаемые и расчетные значения для роста двух видов
дрожжей в монокультурах и смешанной культуре
S ch izosa ccharom у ces „ К о ph i г“
Часы Объем дрожжевой культуры (произвольные единицы)
монокультура смешанная культура
наблюдаемый расчетный наблюдаемый расчетный
0 0,45 0,45 0,45 0,45
6 — 0,60 0,291 0,59
16 1,00 0,95 0,98 0,81
24 — 1,34 1,47 0,88
29 1,70 1,64 1,46 0,89
48 2,73 3,04 1,71 0,89
53 — 3,44 1,84 0,89
72 4,87 4,72 — —
93 5,67 5,51 — —
117 5,80 5,86 — —
141 5,83 5,96 — —
Saccharotnyces cerevisiae
Часы Наблюдаемый Расчетный Наблюдаемый Расчетный
0 0,45 0,45 0,45 0,45
6 0,37 1,72 0,375 1,70
16 8,87 8,18 3,99 7,56
24 10,66 11,83 4,69 10,86
29 12,50 12,46 6,15 11,47
40 13,27 12,73 — 11,75
48 12,87 12,74 7,27 11,77
53 12,70 12,74 8,30 11,77
Динамические модели
51
тальным данным для монокультур, то, сравнив теорети-
ческие и экспериментальные результаты для смешанной
культуры, мы получим, что реальный темп роста Saccharo-
myces заметно ниже ожидаемого, тогда как темп роста
Рис. 3.4. Сравнение наблюдаемых и вычисленных значений пара-
метров для роста дрожжей в монокультурах и смешанной культуре.
О — смешанная культура, ф — монокультура, ф—ф —имитация
роста монокультуры, X — X —имитация роста смешанной культуры.
А —Schizosaccharomyces “Kephir”, Б — Saccharomyces cerevisiae.
Б
Schizosaccharomyces выше. Отсюда следует, что указанные
виды дрожжей оказывают взаимное влияние на рост друг
друга не только путем образования спирта. Вероятно, один
из видов (или каждый из них) продуцирует еще какие-то
вещества, стимулирующие или подавляющие рост другого
вида, и, чтобы продолжить процесс моделирования, нам
нужны дополнительные сведения о биологии данных видов.
Пример 3.2. Ячмень и овес, растущие в условиях конкуренции
Для второго примера динамических моделей мы ис-
пользуем уравнения Лотки — Вольтерра:
= х (а — Ъх — су),
52
Глава 3
— = г/ (е — /.г — gyj,
(U
где а, Ъ, с, е, f и g — положительные константы, отражаю-
щие конкуренцию между видами растений при смешан-
ном посеве. В отличие от первого примера численность
растений каждого вида в смешанном посеве этих сель-
скохозяйственных культур определяется во время посева.
В пашей модели конкуренция между культурами будет
выражаться в терминах «относительного пространства» —
безразмерной переменной, которая характеризует влияние
плотности растений на пространство, доступное для кор-
ней и листьев, па количество получаемых растениями пи-
тательных веществ, солнечного света и прочих факторов.
Действительная продукция сухого вещества получается
затем как произведение «относительного пространства»
на максимально возможную продуктивность в монокульту-
ре с высокой плотностью посева. Таким образом, все три
величины оказываются функциями времени.
Мы будем имитировать рост и конкуренцию овса и яч-
меня при смешанном посеве. Дифференциальные уравне-
ния, в которых Гя — это относительное пространство для
Таблица 3.4
Относительные скорости роста овса и ячменя
Сутки Относительная скорость роста
ячмень овес
0 0,4286 0,7143
7 0,1071 0,1190
14 0,0441 0,0634
21 0,0225 0,0431
28 0,0064 0,0242
35 —0,0036 0,0511
42 —0,0065 0,0491
Динамические модели
53
Таблица 3.5
Программа на КСМП для имитации роста овса и ячменя
в условиях конкуренции
TITLE BARLEY AND OATS — COMPETING FOR THE SAME SPACE
INITIAL
RSO1 = 3.0 * DO
RSB1 = 9.0 * DB
DYNAMIC
* EQUATIONS FOR OATS
RSO = INTGRL (RSOl, RATEO)
RATEO = RSO * (1. - RSO - RSB) * AFGEN (RGRO, TIME)
* EQUATIONS FOR BARLEY
RSB s INTGRL (RSB1, RATEB)
RATEB = RSB * (1. - RSO - RSB) * AFGEN (RGRB, TIME)
FUNCTION RGRB = (0.0, 0.4286), ....
(7.0, 0.1071), ....
(42.0, -0.0065),
FUNCTION RGRO = (0.0, 0.7143), .
(7.0, 0.1190), ,
(42.0, 0.0491), ...
METHOD MILNE
PRINT RBS, RSO, DELT
TIMBER FINTIM = 42.0, PRDEL = 7.0
• DENSITY OF SOWING ON ROW/cM
PARAMETER DB s 0.02, DO a 0.02
END
STOP
54
Глава 3
ячменя, а го —относительное пространство для овса, имеют
следующий вид:
(гя— Гя —Гяго),
CU
-77- = Go (ГО — Го — Гяго).
Для того чтобы смоделировать изменения конкуренции
со временем, мы воспользуемся приемом, который часто
применяется в подобных ситуациях, а именно будем рас-
сматривать коэффициенты Ся и Go как эмпирические
Таблица 3.6
Программа на БЭЙСИКе для имитации роста овса и ячменя
в условиях конкуренции
10 REM COMPETITION BETWEEN BARLEY AND OATS
20 PRINT "SOWING DENSITIES IN ROW/CM’4
30 INPUT D1»D2
35 PRINT\PRINT\PRINT
40 LET S1=3.0*D1
50 LET S2=9.0*D2
60 DIM P(7)*R1(7), R2( 7)
70 FOR 1=1 TO 7
60 READ P(I)*R1 (I ) *R2(I)
90 NEXT I
100 LET T=0
! 10 FOR 1=1 TO 42
120 FOR J=1 TO 100
1 30 FOR K=2 TO 7
140 IF T>P(K) THEN 180
150 LET G1 = R I ( К- 1 )♦ ( T-P( K-1))♦(R1(К)-RI(K-1) )/7
160 LET G2=R2(K-1)♦(T-P(K-1))♦(R2<К)-R2(К-I))/7
170 GO TO 190
180 NEXT К
190 LET S3=S1*(1-S1-S2)*G1*0.01
200 LET S4=S2*(1-S2-SI)*G2*0.01
205 LET Sl=Sl+S3
207 LET S2=S2+S4
210 LET T=T+0.01
220 NEXT J
230 PRINT bGI/G2/Sl»S2
240 NEXT I
2 50 STOP
251 DATA 0*0.7143*0.4286
2 52 DATA 7*0.1190*0.1071
253 DATA 14*0.0634*0.0441
254 DATA 21*0.0431*0.0225
255 DATA 28*0.0242*0.0064
256 DATA 35*0.051l*-0.0036
257 DATA 42*0.0491*-0.0065
300 END
Динамические модели
55
функции времени, значения которых заданы в табл. 3.4.
Обе эти функции представляют собой относительные ско-
рости роста растений в отсутствие конкуренции и были
определены из данных мо росту растений при очень низ-
ких плотностях посева [3].
Эмпирические функции, подобные относительным ско-
ростям роста, легко моделируются посредством специаль-
Таблица 3.7
Результаты имитации с помощью, программы на БЭЙСИКе,
представленной в табл. 3.6
SOWING DENSITIES IN ROW/СМ? 0.02/0.02
I .6301076 .3831307 .09 683289 .2403713
2 .5450647 .3372021 .1387513 .299701
3 .4600219 .2912736 . 1 79684 .3522976
A .3749791 .2453451 . 2 1 48 7 5 .3952106
5 .2899363 .1994165 .2421353 .4280727
6 .2048936 .153488 . 261 29 1 3 . 4519494
7 .1198508 . 107559 5 .2730962 . 468282
8 .1111366 .09819005 .28102 . 4803851
9 .1031938 .08919006 .2880248 .4908378
10 .09 52 509 1 .08019006 .2941902 . 4997922
1 1 .08730806 .07119007 .2995939 .5073929
12 .07936521 .06219008 .3043083 .5137725
13 .07142236 .05319009 .3083993 .5190492
14 .063479 51 .0441901 .3 1 19251 .5233257
15 .06052903 .04104518 . 3 1 50599 .5269338
16 .05762904 .03795947 .3179564 .5301679
17 .05472904 .03487376 .3206301 .5330534
18 .05182904 .03178805 . 3230954 .5356136
19 .04892904 .02870233 .3253657 . 5378698
20 .04602905 .02561662 . 327453 I . 5398408
21 .04312905 .02253091 . 3293688 .5415438
22 .04042705 .02022304 .331127 .5430206
23 .03772705 .01792304 .33274 .5443099
24 .03502706 .01562305 .3342153 .5454211
25 .03232706 .01332305 .3355593 .5463624
26 .029 62706 .01102305 .336778 .547141’
27 .02692706 8.723054E-3 .3378765 .5477632
28 .02422707 6.423056E-3 .3388594 .5482341
29 .02800433 4.985750E-3 .3398535 . 548 58 4 6
30 .03184718 3.557180E-3 .3409836 .5488441
31 .03569004 2. 128 610E-3 .3422469 . 5 49 0 1 4 6
32 .039 53289 7.000401E-4 .3436406 .5490982
33 .04337584 - 7.28 5637E-4 .3451618 .5490972
34 .04721878 -2.157168E-3 . 3468074 .5490141
35 .05106173 -3. 585772E-3 .3485743 .5488512
36 .05081713 -4. 0101 69E-3 . 3 5038 68 . 5486391
37 .0505314 - 4. 424464E-3 . 3521704 .5484076
38 .05024568 -4.838759E-3 .3539257 .5481573
39 .0499599 6 -5.253055E-3 .3556533 .5478888
40 .049 67424 -5.667350E-3 .3573538 .5476027
41 .04938852 -6.081645E-3 .3590278 .5472996
42 .0491028 -6. 495940E-3 .360676 .5469798
56
Глава 3
но ориентированных языков моделирования — в сущности
возможность использования таких функций является од-
ним из главных преимуществ этих языков. Бреннан и др.
[7] предлагают для этой модели программу па КСМП,
Рис. 3.5. Рост овса и ячменя при начальном расстоянии между се-
менами в 2 см.
часть которой приведена в табл. 3.5. В этой программе
упомянутые функции получаются с помощью линейной
интерполяции между табличными точками, однако КСМП
допускает также п квадратичную интерполяцию данных,
когда такой уровень точности оправдан.
В табл. 3.6 дана эквивалентная программа на
БЭЙСИКе с эмпирическими функциями, полученными так-
же с помощью линейной интерполяции. Соответствующие
результаты записаны в табл. 3.7 и представлены графиче-
ски на рис. 3.5. Поскольку ячмень сначала растет гораз-
до быстрее, чем овес, при совместном выращивании этих
культур ячмень на ранних стадиях занимает непропор-
ционально много доступного пространства, и к моменту,
когда начинает расти овес, последнему уже не хватает
места.
Сезонный подход лосося
Пороговый уровень
высокой воды
Рис. 3.6. Диаграмма связей для миграции лосося вверх по течению [65].
/ Высота воды
"V---у заграждения
I
Скорость течения
воды у заграждения
Исток реки
58
Глава 3
Пример 3.3. Миграция лосося вверх по течению
Третий пример динамических моделей, который мы рас-
смотрим,— это имитация миграции лосося вверх по тече-
нию, обсуждавшаяся Рэдфордом [65]. Основные компо-
ненты системы представлены на диаграмме связей
рис. 3.6. Постулируется, что миграция зависит от количе-
ства пресной воды в эстуарии, а не от уровня воды возле
учетного заграждения, где измеряются темп миграции ло-
сосей и уровень воды. Сплошная линия в верхней части
диаграммы соответствует миграции лосося из моря к вер-
ховьям реки через эстуарий и заграждение. Сплошная ли-
ния в ппжпей части диаграммы соответствует течению во-
ды от истока реки к морю. Три интересующих нас пере-
менных состояния — это число лососей в эстуарии, число
лососей в верховьях реки и число лососей, ожидающих
низкой воды. Четвертой переменной состояния служит ко-
личество пресной воды в эстуарии. Модель зависит от не-
скольких констант, главным образом от высоты воды у за-
граждения, порогового уровня высокой воды, общего числа
лососей и фактора задержки для темпа перемешивания
пресной и морской воды.
Таблица 3.8
Часть программы на ДИНАМО, моделирующей миграцию
лосося вверх по течению
NOTE UPSTREAM MIGRATION OF SALMON
NOTE PROGRAMMED FOR AN IBM S/360 COMPUTER
L NSE.K • NSE.J + DT * (RASE.JK-RSMW.JK-RSER.JK) NO OF SALMON IN ESTUARY
R RMS.KL s FWE.K/DELAY RATE OF MIXING OF SEAWATER
R RASE.KL s TNSTY * SIS.K/100 RATE OF ARRIVAL OF SALMON
A SIS.К a TABHL (TDRSI, TIME, 15, 201, 31) SEASONAL INFLUX SALMON
T .tdrsi - .083/.131/.129/.133/.323/1.370/1.108 TABLE SIS
A PRSM.K = TABHL (TPRSM, FWE, K, .6, 1.6, 1.) POTENTIAL RATE MIGRATION
T tprsm = 0.0/0.95 TABLE PRSM
L FWE.К « FWE.J + DT • (RWFW.JK - RMS.JK) FRESHWATER IN ESTUARY
Динамические модели
59
Для построения модели необходима также информа-
ция о величине сезонного подхода лососей и потенциаль-
ной скорости их миграции. 13 отсутствие эксперименталь-
ных данных но конкретному заграждению представление
о том, как функционирует вся система, можно получить
при разумных оценках существующих в системе связей.
В табл. 3.8 приведена часть предложенной Рэдфордом [65]
программы па ДИНАМО, в которую такие оценки вклю-
чены просто как таблицы. Число лососей в эстуарии в дан-
ный момент времени (NSE.K) определяется через зна-
чение этого числа за некий предшествующий малый про-
межуток времени (DT) и темпы прихода (RASE.JK) и
ухода (RSMW.JK, RSERJK) лососей, характерные для
данного промежутка времени. Предполагается, что величи-
на DT выбрала достаточно разумно, чтобы эти темпы мож-
но было считать постоянными на всем коротком проме-
жутке времени. Аналогичные уравнения выписываются
для каждой переменной состояния, и в каждом случае про-
грамма задает те темпы, которые должны быть учтены.
Уравнения для темпов также могут быть выписаны как
функции переменных состояния и произвольных функций,
введенных как допущения. Например, теми перемешива-
ния воды эстуария с морской водой за короткий промежу-
ток времени (RMS.KL) зависит от количества пресной
воды в эстуарии в момент К (FWE.K), деленного на фак-
тор задержки. Темп захода лосося в эстуарий зависит
от сезонного подхода лосося согласно функции TABHL
(TDRSI, TIME, 15, 201, 31). Эта запись па ДИНАМО по-
казывает, что данные зависят от времени (TIME) и эта
зависимость описывается некоей функцией, затабулиро-
ванной в точках с интервалом в 31 день, начиная с 15-го
и кончая 201-м днем. Между табличными значениями пред-
полагается линейная интерполяция; в процессе имитации
берется первое значение таблицы, когда TIME меньше
15 дней, и ее последнее значение, когда TIME больше
201 дня.
Как и в КСМП, каждый символ структурной схемы
кодируется обычно с помощью одной строки программы, а
порядок, в каком записаны эти строки, не существен, так
как система ДИНАМО способна пересортировать уравне-
ния в нужную вычислительную последовательность. Не
60
Глава 3
трудно, однако, перевести связи диаграммы и па язык
общего назначения (например, ВЭЙСПК) с представлени-
ем табличных величин в виде кривых, построенных с по-
мощью ортогональных полиномов. Данный пример иллю-
стрирует применение динамической модели к довольно
сложной экологической проблеме, для решения которой
может не хватать многих данных. Преимущество исполь-
зования такой модели состоит в том, что можно достаточ-
но подробно изучить чувствительность системы к измене-
ниям включенных в рассмотрение параметров и функций.
Тогда в дальнейших исследованиях можно сделать упор па
прямые измерения тех параметров, которые, как показал
анализ, наиболее важны для определения механизма функ-
ционирования системы.
Пример ЗЛ. Таблица хода роста ели ситхииской
В качестве четвертого примера мы рассмотрим получен-
ную Кристи [11] эмпирическую модель для построения
таблиц хода роста лесных деревьев. Эта работа иллюстри-
рует одно из ранних приложений динамических моделей—
в сущности применение метода еще до того, как он стал
широко известен под названием ’’динамическое моделиро-
вание”. Пример будет особенно полезен как иллюстрация
того, что основные идеи метода неновы; он также проде-
монстрирует чисто эмпирический подход. Таблица хода
роста является традиционным в лесоводстве способом отоб-
ражения постепенного развития древостоя за постоянные
интервалы времени, охватывающие большую часть полез-
ной жизни леса в данном месте. В такую таблицу обычно
включены значения среднего диаметра и высоты деревьев,
их площади оснований (т. е. суммы площадей поперечно-
го сечения деревьев на уровне груди) и объема.
На начальных этапах развития научного лесоводства
таблицы хода роста составлялись в основном с помощью
графических методов сглаживания кривыми данных изме-
рений, полученных на пробных площадях. По мере появ-
ления новых статистических методов были предприняты
попытки усовершенствовать характеристику лесного дре-
востоя, основанную па сглаживании данных. Однако, по-
скольку различные части таблицы хода роста взаимозави-
Динамические модели
61
симы, важно быть уверенным, что связи полученных кри-
вых отражают действительную взаимозависимость между
их переменными. Принципиальной особенностью этого
процесса в Англии было использование «смотровой табли-
цы», в которой связи всех основных характеристик уро-
жая строились по отношению к «высоте модельного дере-
ва» (т. е. средней высоте 100 деревьев наибольшего
диаметра на одном гектаре). Таблицы хода роста, соот-
ветствующие различным категориям бонитета или типам
условий местообитания, получали затем из связей смотро-
вой таблицы подстановкой возраста вместо высоты из
вспомогательного соотношения между высотой модельного
дерева и возрастом.
Диаграмма связей для простой таблицы хода роста по-
казана на рис. 3.7. 13 табл. 3.9 приведена БЭЙСИК-про-
грамма для построения таблицы хода роста ели ситхин-
ской, Picea sitchensis (Bong) Carr. Для каждого из воз-
растных классов, задаваемых рядом приращений возрас-
Рис. 3.7. Диаграмма связей для простой таблицы хода роста.
62
Глава 3
та, среднегодовой прирост (СГП) и средняя модельная
высота насаждения вычисляются из сложных соотноше-
ний (С1, ..., 06), зависящих от заданных параметров (ха-
рактеристик древостоя). Переменная состояния, соответ-
ствующая общему запасу, определяется из соотношения,
связывающего ее с возрастом и среднегодовым приростом;
аналогичным образом коэффициент формы и запас по диа-
метру определяются из средней высоты модельного дерева.
Наконец, общая площадь оснований определяется уже из
другого множества параметров, связывающих общий запас
с коэффициентом формы.
Таблица 3.9
Программа на БЭЙСИКе для имитации хода роста
ели ситхинской
LIST
10 REM SHORT YIELD TABLE FOR SITKA SPRUCE
20 FOR A=20 TO 80 STEP 5
30 LET H= ( ( 5.6580760E-I 4*A-2•3814098E- I 1)♦A*3.7952208E-9)♦A
31 LET H = ( ( ( H - 2 • 9 5 63399 E-7 ) ♦ A* 1.30 488 57 E-5) ♦ A-4 • 7 67 1 98 1 E-4) ♦ A
32 LET H=((H* 1.5601327E-2)*A*1.9162451E-1)♦A*9.8037440E-2
40 LET M«((-4.9693779E-13*A*2.0023260E-10)*A-3.4496064E-8)*A
41 LET M=(((M*3.2853312E-6)*A-1.8590905E-4)♦A*6.2650400E-3)♦A
42 LET M=((M- 1.2572190E- 1)♦A*1.8334816)♦A-1. 1562462E*1
50 LET V=M*A
60 LET F = - 0.600441*0.468491*H-0.003619*H*H
70 LET G=V/F
80 LET D=1.673873*0.087942*H - 0.000 7 19 *H *H
81 LET D=EXP(D)
90 PRINT A,I NT(H♦ 1 0*0.5)/10,INT(G*10*0.5)/10,INT(V*0.5),INT(D*10*0•5)0
100 NEXT A
110 STOP
120 END
READY
RUN
20 7. 7 26.8 75 10. I
25 10.2 38 1 44 12.1
30 12.7 47.9 228 1 4.5
35 1 5. 1 56. 6 320 17.1
40 17.4 64. 1 413 19.8
45 19.4 70.5 503 22.4
50 21.2 76 58 5 24.9
55 22.7 80. 5 657 27. I
60 23.9 84.3 720 29
65 25 87.5 774 30.6
70 25.9 90.3 821 32. 1
75 26. 7 92.7 8 64 33.4
80 27.3 9 4.8 901 34. 5
READY
Динамические модели
63
Следует подчеркнуть, что табл. 3.9 составляет лишь
часть полной программы, необходимой для построения
таблицы хода роста. Для решения всей задачи лесоводу
необходимо учитывать число деревьев, которые остаются
после последовательных прореживаний, и делать различие
между запасом стволов па корню и урожаем, изъятым на
разных стадиях жизни древостоя в результате прорежива-
ния. Заметим, однако, что уже в такой простой форме
таблицы хода роста имеется шесть функциональных соот-
ношений и пять групп параметров. Кроме того, хотя мо-
дель и нелинейна, она не содержит (по крайней мере, в
данном простом варианте) никаких нетель обратной связи.
Как же определяются взаимосвязи в моделях подобно-
го типа? Обычно для этого используют подгонку кривых к
данным наблюдений на постоянных участках, где измере-
ния проводятся через регулярные интервалы времени.
Подгонка основана на статистической методике подбора
ортогональных полиномов, которые должны проходить че-
рез небольшое число теоретически «фиксированных» то-
чек. В отдельных случаях, когда из-за сильного разброса
данных не удается подобрать никакой единой кривой да-
же при высоких порядках полиномов, стоит использовать
сплайновые псевдокривые. Следует, однако, подчеркнуть,
что этот процесс независимого подбора кривых для мно-
гих отдельных взаимосвязей не всегда приводит к состоя-
тельным и совместимым соотношениям, и в задачу модели-
рования входит проверка этой внутренней состоятельнос-
ти. Необходимо отметить также ряд важных вопросов,
касающихся чувствительности соотношений к небольшим
изменениям формы кривых и оценок параметров; эти во-
просы мы подробнее обсудим, когда перейдем к рассмот-
рению относительных преимуществ и недостатков семей-
ства динамических моделей в целом.
Подобные модели урожая древесины широко использу-
ются в практике лесоведения и лесоустройства. Идея пред-
ставления роста популяции деревьев с помощью краткой
табличной записи долгое время рассматривалась лесово-
дами как нечто само собой разумеющееся, тогда как в
смежных дисциплинах аналогичные подходы к описанию
развития биологических популяций расценивались как но-
ваторство. Гамильтон и Кристи [31] описывают иримепе-
64
Глава 3
пне моделей запаса, сходных с моделями рис. 3.7 и
табл. 3.9, по более сложных, для составления прогнозов,
оценки древостоя и эффективности различных способов
обработки площадей, для управления продуктивностью ле-
са. Такие модели обычно легче строить и легче использо-
вать, чем модели, основанные па имитации роста отдель-
ных деревьев; эти модели в настоящее время не могут
быть использованы для предсказания урожаев на едини-
цу площади.
Теперь, рассмотрев несколько простых примеров дина-
мических моделей, мы можем обсудить относительные пре-
имущества и недостатки данного семейства математиче-
ских моделей. Ясно, что подобные модели кажутся эколо-
гам весьма привлекательными, особенно если последние
получили некоторое математическое образование. При по-
строении этих моделей допускается значительная свобода
в выборе ограничений и допущений, а также введение не-
линейностей и обратных связей, которые весьма харак-
терны для экологических систем. Эколог в состоянии отоб-
разить или скопировать поведение экосистемы в соответ-
ствии со своими представлениями об этом поведении и по-
лучить некие дополнительные представления о поведении
экосистемы при изменении параметров и управляющих
переменных модели. Способность ЭВМ выполнять огром-
ное число точных элементарных вычислений дает экологу
возможность заменять аналитические способы интегриро-
вания менее точными, но более простыми методами раз-
ностных уравнений. Более того, даже когда значения па-
раметров неизвестны, можно относительно просто оцепить
их методом последовательных приближений или с помощью
интерполяции функций, заданных в виде таблиц. В наи-
более благоприятных случаях удается даже проверить раз-
личные предположения относительно параметров или
функций.
Отсутствие строго обязательной структуры моделей и
свобода в выборе ограничений могут оказаться и недостат-
ками. С одной стороны, не всегда легко предсказать пове-
дение даже совсем простых динамических моделей. Доста-
точно лишь одной нелинейности и двух нетель обратной
связи, чтобы поведение модели стало «коптриитуитивным»,
т. е. противоречило нашим интуитивным представлениям
Динамические модели
65
о системе. С другой стороны, ничего пе стоит построить
модель, характеризующуюся неустойчивым или не совпа-
дающим с действительностью поведением даже в рамках
практических ограничений, налагаемых на входные пере-
менные. Еще одна трудность связана с тем, что для выяс-
нения механизма функционирования модельной системы
часто бывает необходимо провести много специальных экс-
периментов с моделью. Например, почти всегда приходит-
ся проверять поведение модели в ответ на одновременное
изменение двух или более входных переменных и только
в редких случаях достаточно проверить реакцию на изме-
нение в данный момент времени лишь одной переменной.
Трудности, связанные с предсказанием поведения ди-
намических моделей, заметно снижают их роль в дальней-
шем развитии теории. Как мы увидим, поведение некото-
рых других семейств моделей более предсказуемо, так что,
сделав вместо одних допущений другие, быть может менее
очевидные, бывает легче выяснить реакцию модели на из-
менения переменных. Естественно, что наибольшие труд-
ности в построении математических моделей связаны с
проверкой основных допущений, необходимых для приме-
нения модели, по эта проверка часто оказывается более
легкой и математически более строгой, нежели поиск слож-
ных типов поведения и разрывностей в динамических мо-
делях.
Пожалуй, самый большой недостаток динамических мо-
делей заключается в том, что они не всегда дают оценки
значений основных параметров, особенно когда их число
достаточно велико. Упомянутые выше способы получения
оценок методом последовательных приближений требуют
слишком много времени и могут оказаться весьма трудоем-
кими, несмотря па использование ЭВМ. Кроме того, даже
для относительно простых моделей не всегда можно полу-
чить сходящиеся оценки, и многие другие семейства мате-
матических моделей были построены специально для того,
чтобы упростить процедуру оценки основных параметров,
иногда даже в ущерб «реалистичности» этих моделей. Си-
туация нередко осложняется наличием слишком большого
числа связей, переменных и параметров, что обычно харак-
терно для динамических моделей из-за их достойной похва-
лы тенденции имитировать реальность как можно точнее.
3-843
66
Глава 3
Ученому всегда следует стремиться к построению наибо-
лее простой из возможных моделей и пе приумножать без
нужды их элементы и связи, однако эту простоту доволь-
но трудно совместить с гибкостью динамических моделей.
Динамические модели по своей природе и математиче-
ской структуре нацелены в основном па получение детер-
министских решений. Правда, в них могут включаться
стохастические элементы, но иногда это сопряжено с опре-
деленными трудностями. В результате модели данного се-
мейства обычно не отражают той изменчивости, которая
внутренне присуща экологическим и биологическим систе-
мам. Как будет показано позже, особенно важно уметь
моделировать изменчивость экологических систем (как,
впрочем, и их общие тенденции) — в сущности, от этой
изменчивости порой зависит устойчивость таких систем.
Наконец, хотя заведомо известно, что работа с дина-
мическими моделями требует использования ЭВМ, следует
особо подчеркнуть, что создание и анализ таких моделей
сопряжены обычно с очень большими затратами машинно-
го времени и (особенно когда используются специально
ориентированные имитационные языки) с необходимостью
располагать ЭВМ высокого класса. Из сказанного ясно,
что подобные модели обходятся слишком дорого и поэтому
по средствам лишь крупным лабораториям и фирмам.
Итак, динамические модели могут быть особенно полез-
ны на ранних стадиях системного анализа сложных эколо-
гических систем, поскольку они направлены па выявление
основных связей в системе и тех переменных и подсистем,
которые, по мнению исследователя, являются ключевыми.
На более поздних этапах целесообразнее, однако, сосре-
доточить основные усилия па использовании какого-либо
другого семейства моделей; именно поэтому в системном
анализе выделена стадия получения альтернативных ре-
шений проблемы.
Модели, рассмотренные в данной главе, иллюстрируют
тот факт, что трудности, с которыми приходится сталки-
ваться при оценке параметров, могут быть выражены в
разной степени. Пример 3.1 представляет собой классиче-
ский случай, когда эти трудности минимальны. В основе
модели лежат простые, четко определенные связи, а пара-
метры оцениваются по результатам экспериментов на моно-
Динамические модели
67
культурах. Из этих оценок логически вытекают результа-
ты для смешанной культуры. Пример 3.2 более сложный:
хотя основные связи остаются четко определенными, оце-
нить параметры становится труднее. Относительные темпы
роста оцениваются с помощью интерполяции между фи-
ксированными значениями эмпирических функций для
темпов роста двух видов во времени. Насколько чувстви-
тельна модель к изменениям формы указанных функций?
Эту чувствительность в принципе можно было бы четко
проверить, по существует бесконечное множество возмож-
ных комбинаций форм для двух видов, и окончательного
ответа па вопрос мы так никогда и не получим.
Пример 3.3 еще сложнее; здесь мы имеем большее чис-
ло параметров, подлежащих оценке, менее простые связи
и большее число функций, которые нуждаются в опреде-
лении. Главной задачей, занимающей больше времени, чем
любой другой этап процесса моделирования, становится
проверка чувствительности модели к изменениям лежащих
в ее основе допущений. И наконец, пример 3.4 чисто эмпи-
рический. Эта модель целиком зависит от набора произ-
вольных функций, полученных путем различного рода про-
цедур подгонки кривых к экспериментальным данным, но
моделирование уже полностью сводится к способу провер-
ки внутренней состоятельности включенных в модель соот-
ношений.
3:
Легкость формулирования
Гибкость
Обратная связь
Нелинейность
Отсутствие жесткой структуры
Возможная непредсказуемость поведения
Трудности оценки основных параметров
Детерминизм
'’Ч,.
Выводы -------
Дрожжи
Рост в условиях
конкуренции
Миграция лосося
Таблицы хода роста
модели
£
1
а сло^Чь1-
/
срррМ»7
F
X
Л*
/
Z
инамические\-Дл.а.грам1ль''
ч
Связи
/. Гипотеза,
2. Имитация
3. Понимание
^споненциал»ный
рост
Уровни
Вспомогательные
переменные
Уравнения темпов
ноток вещества
Параметры (константы)
Поток информации
Сток
Ч?*,
БЭЙСИК
ДИНАМО
КСМП
КССЛ
4
МАТРИЧНЫЕ МОДЕЛИ
Рассмотренное в предыдущей главе семейство динами-
ческих моделей — это пример лишь одного из возможных
подходов к моделированию экологических систем. Такие
модели предоставляют исследователю почти полную сво-
боду при описании тех элементов системы, которые он
считает существенными для понимания основных взаимо-
связей между переменными и блоками, выделенными при
описании системы. Эти модели стремятся обычно к макси-
мальной «реалистичности» — к тому, чтобы как можно точ-
нее описать языком математики те или иные физические,
химические или биологические процессы, иногда даже в
ущерб математической простоте и элегантности. Платой за
это часто оказывается необходимость увеличивать число
блоков модели (с тем, чтобы учесть относительно малые
изменения в поведении системы) и те трудности, с кото-
рыми приходится сталкиваться при получении несмещен-
ных и достоверных оценок модельных параметров. Матрич-
ные модели представляют собой семейство таких моделей,
реалистичность которых в известной мере принесена в
жертву тем преимуществам, которые дает специфика ма-
тематического описания модели. При этом дедуктивная
логика чистой математики позволяет «модельеру» прове-
рить следствия принятых им допущений без всякого «экс-
периментирования» с моделью, требующего затрат машин-
ного времени, хотя ЭВМ и могут использоваться для неко-
торых вычислений.
Термин «матрица» применяется математиками для обо-
значения прямоугольной таблицы чисел; так, матрица
’10 3
А = 2 4 8
.13 2
— 6'
16
— 5.
— это матрица из трех строк и четырех столбцов, пли ма-
трица 3X4. Каждое из двенадцати записанных в пей чисел
70
Глава 4
называется элементом, и если матрица как целое есть А,
то ац — это элемент I- строки и /-го столбца А. Поэтому
символическая запись матрицы А выглядит следующим
образом:
«И «12 «13 «14
«21 «22 «23 «24
-«31 «32 «33 «34-
Условимся использовать для обозначения матрицы за-
главные латинские буквы, выделенные жирным шрифтом,
а для обозначения отдельных элементов этой матрицы —
соответствующие строчные буквы с надлежащими индек-
сами. В матричной алгебре, оперирующей этими таблицами
чисел, часто встречаются матрицы специального вида. На-
пример, матрица с одинаковым числом строк и столбцов
называется квадратной, а следующим трем видам квадрат-
ных матриц
1 0'
0
0 0
0 1
’ 3 —2’
—2 5
присвоены специальные названия: I называется единичной
матрицей, О — нулевой, А — симметричной матрицей. Осо-
бую роль играют элементы матрицы, стоящие на пересече-
нии первой строки и первого столбца, второй строки и вто-
рого столбца и т. д.; они образуют так называемую главную
диагональ матрицы. В единичной, или тождественной, ма-
трице главная диагональ состоит из единиц, а все осталь-
ные элементы — пули. В симметричной матрице элементы
главной диагонали могут принимать любые значения, а
недиагопальные элементы связаны соотношением ajj = aji.
Наконец, матрицы только из одной строки или одного
столбца
Г21
а = [1
2]
или b = 4
L6J
3
называют соответственно вектор-строкой и вектор-столб-
цом. Условимся обозначать такие матрицы строчными ла-
Матричные модели
71
типскими буквами, выделенными жирным шрифтом. Ма-
трица, состоящая лишь из одного элемента, например
D = 3,
называется скаляром.
Записывать массивы чисел в виде матриц удобно пото-
му, что это позволяет оперировать с ними так же, как и с
обычными числами, т. е. скалярами. Например, сложение
или вычитание двух матриц состоит в сложении или вычи-
тании всех соответствующих элементов этих матриц. Ум-
ножение и деление матриц не столь просты, но тоже пред-
ставляют собой вполне определенные математические
операции. Матричная алгебра является одпой из важней-
ших областей современной математики, и экологам, кото-
рые намереваются применять в своих исследованиях си-
стемный анализ, стоит прочесть какой-либо учебник по
этому предмету (например, [2, 66, 71]) \ чтобы ближе
познакомиться с системой обозначений и операциями в
данной области математики.
Квадратные матрицы обладают одним важным свой-
ством, а именно: для любой такой матрицы существуют
собственные числа и собственные векторы, которые удов-
летворяют уравнению
Av = Xv,
где А — квадратная матрица, v — вектор-столбец, а Л —
скаляр. В общем случае, если А есть матрица «Xw, сущест-
вует п собственных чисел Z, причем среди них могут быть
повторяющиеся, отрицательные и мнимые.
Каждому собственному числу X соответствует собст-
венный вектор v, и, как мы увидим ниже в данной главе,
эти числа и векторы играют важную роль при выяснении
специфических свойств исходной матрицы. Для нахожде-
ния собственных чисел и собственных векторов существу-
ют различные методы — с некоторыми из них мы познако-
мимся, когда перейдем к рассмотрению примеров матрич-
ных моделей.
1 Из учебников, изданных па русском языке, можно рекомендо-
вать следующие: Веллман Р. Введение в теорию матриц. Пер. с
англ. — М.: Паука, 1969; Ланкастер П. Теория матриц. Пер. с
англ. — М.: Паука, 1978. — Прим, перев.
72
Глава 4
Один из ранних вариантов матричной модели был раз-
работан Льюисом [50] и Лесли [49] как детерминистская
модель, предсказывающая будущую возрастную структу-
ру популяции самок по известной структуре в настоящий
момент времени и гипотетическим коэффициентам выжива-
ния и плодовитости. Популяцию разбивают на гг+1 воз-
растных групп (т. е. 0, 1, 2, 3, гг, причем каждая груп-
па состоит из особей одного возраста), так что самая
старшая группа, или группа, в которой все доживающие до
данного возраста животные вымирают, имеет номер п. Мо-
дель представляется матричным уравнением
/о /1/2 ’ ’ ’ Ai-l fn
р0 о о • •. о о
0 д О • •. о о
0 0 р2 . • • о о
nt,o 0
nt, 1 nH-i, 1
nt, 2 n/-H, 2
nt, 3 nt+\, 3
Согласно этому уравнению, численности животных возраст-
ных классов в момент времени t + i можно получить, умно-
жив численности возрастных классов в момент t на матри-
цу, элементами которой являются коэффициенты плодо-
витости и выживания для каждого возрастного класса.
Величины = 1, 2, ..., п) представляют число самок,
производимых одной самкой г-го возрастного класса, а
/ъ(г = О, 1, 2, ..., и —1) — вероятность того, что самка г-го
возрастного класса доживет до возраста г + 1.
Менее очевидно то, что поведение этой модели можно
предсказать, анализируя некоторые формальные свойства
матрицы А в уравнении
Аа( = а,+1)
где а/ — вектор-столбец, представляющий возрастную
структуру популяции в момент t, а аг-н — вектор-столбец,
Матричные модели
73
представляющий возрастную структуру в момент t+1.
Во-первых, последовательно умножив уравнение на матри-
цу А, легко получить более общее уравнение для числен-
ности возрастных классов к моменту времени t + k:
at+k = •
Во-вторых, поскольку матрица А квадратная с п + 1 стро-
ками и столбцами, опа имеет п + 1 собственных чисел и соб-
ственных векторов. Элементы А суть положительные числа
либо нули, так как ни Д-, пи pL пе могут принимать отри-
цательных значений, и можно показать, что в этом случае
наибольшее собственное число и все координаты соответ-
ствующего ему собственного вектора также положительны
и имеют определенный экологический смысл1.
Чтобы понять, почему так важны именно это собствен-
ное число и соответствующий ему собственный вектор,
лучше всего рассмотреть какой-либо простой пример, ска-
жем одну из простейших моделей, предложенную Уильям-
соном [97]. Он рассматривает такую модель:
"О 9 12“
— о о
з
1
0—0
2
пЖ.о
П^+1,2
Исходная популяция состоит из одной самки старшего
возраста, что отражено в вектор-столбце в левой части
уравнения. По прошествии одного временного интервала в
популяции будет уже 12 самок младшего возраста, по-
скольку
1 Имеется в виду наибольшее по абсолютной величине собст-
венное число, которое называется главным. — Прим, перев.
74
Глава 4
Повторное применение модели, когда вектор для предшест-
вующей популяции умножается на коэффициенты плодо-
Рис. 4.1. Предсказанные численности самок младшего, среднего и
старшего возраста.
Матричные модели
75
Каждое животное старшего возраста, прежде чем уме-
реть, успевает произвести в среднем 12 потомков; каждое
животное среднего возраста, прежде чем умереть или пе-
рейти в следующий возрастной класс (вероятности этих
событий одинаковы), производит в среднем 9 потомков.
Молодые животные не производят потомства и с вероят-
ностью 7з попадают в среднюю возрастную группу.
На рис. 4.1 в логарифмическом масштабе нанесены чис-
ленности каждой возрастной группы для первых 20 вре-
менных интервалов. Начиная с какого-то момента време-
ни, до которого наблюдаются колебания численностей,
предсказанные численности экспоненциально возрастают,
причем соотношение между численностями животных
младшего, среднего и старшего возрастов остается посто-
янным.
Главное собственное число и собственный вектор матри-
цы можно найти относительно простым методом последо-
вательных приближений. Главное собственное число дает
скорость, с которой возрастает размер популяции1; в на-
шем случае это число равно 2, т. е. за каждый временной
интервал размер популяции удваивается. В общем случае,
если X — главное собственное число,
Av = Av,
где v — устойчивая возрастная структура популяции, при-
чем численности разных возрастных классов представлены
в виде относительных величин. Если построить график за-
висимости логарифма размера популяции от времени, то
наклон этого графика после достижения устойчивой струк-
туры популяции будет равен InZ — внутренней (intrinsic)
скорости естественного прироста. Зная главное собственное
число, можно, воспользовавшись уравнением
н = ,
оцепить также число особей, которых необходимо изъять
из популяции, чтобы размер ее стал равен исходному
[здесь Н — доля особей (в %), изымаемых из популяции].
1 Когда возрастная структура популяции стабилизировалась.—
Прим, перев.
76
Глава 4
В свою очередь, соответствующий главному собствен-
ному числу собственный вектор отражает устойчивую воз-
растную структуру популяции. В пашем примере этот век-
тор равен
Г24
4
_ 1_
и указывает на то, что между численностями животных
младшего, среднего и старшего возрастных классов в по-
пуляции, достигшей устойчивой возрастной структуры,
имеется определенное соотношение.
Данный пример показывает, что формулировка мате-
матической модели должна быть как можно более простой,
поскольку тогда даже относительно несложные вычисления
выявляют принципиальные свойства модели. Наш пример
страдает таким же недостатком, что и детерминистская
экспоненциальная модель роста популяции: мы допускаем,
что размер популяции может неограниченно расти. Можно,
однако, построить и более реалистичную модель, считая
все элементы матрицы некоторыми функциями размера
популяции. Ниже в этой главе мы рассмотрим пример по-
добной модификации модели.
С помощью матричных моделей, используя относитель-
но простую связь между размером популяции и выжива-
нием, можно описать также системы хищник — жертва,
для поведения которых бывают характерны заметные ко-
лебания. Аналогичным образом могут быть учтены сезон-
ные и случайные изменения среды, а также эффекты вре-
менных задержек, хотя модель при этом, конечно, услож-
нится.
Описанная выше основная матричная модель может
быть видоизменена далее тем или иным образом. Все эти
изменения состоят в модификации элементов исходной ма-
трицы пли включении новых элементов, и одним из простей-
ших тому примеров служит изучение эффектов сбора уро-
жая в различных частях популяции. Лсфкович [48], на-
пример, дает весьма полезное введение в математический
аппарат моделей сбора урожая, которые он построил на
основе своих моделей для иммиграции. Матричная модель
может быть легко распространена и на случай учета обоих
Матричные модели
77
полов; Уильямсон [96] дает простой пример такой моде-
ли для популяции, разделенной па три возрастных класса:
о /то 0 fmt 0 /m2 nt, mO nt+l, mO
0 //0 0 tfl 0 //2 nt, to re/+i, to
Pma 0 0 0 0 0 nt+l, ml
0 pf0 0 0 0 0 nt, fl nt+l, fl
0 0 pmi 0 0 0 nt, m2 nr+l, m2
_0 0 0 Pfi 0 0 _ ni, f2_ _ ”<+1. f2 _
Здесь fmi и ffi — соответственно число самцов и самок, про-
изводимых одной самкой i-го возрастного класса за один
временной интервал, pmi и рц — вероятности того, что соот-
ветственно самец или самка доживут до следующего воз-
растного класса, a nt,mi и nt,fi — численности соответствен-
но самок и самцов i-го возрастного класса в момент t.
Но, пожалуй, наиболее известные модификации матри-
чных моделей относятся все же к рассмотрению размерных
классов или дискретных стадий внутри популяции. Ашер
[78, 79, 80, 81], например, применял такие модели для
анализа управления и эксплуатации лесов, где деревья
классифицировались не только по возрасту, но и по разме-
ру. В отличие от него Лефкович [46, 47, 48] использовал
матричные модели для анализа популяций насекомых-вре-
дителей; при этом структура популяций насекомых опре-
делялась различными стадиями жизненного цикла насеко-
мого.
Матричные модели могут применяться и для анализа
таких динамических процессов, как круговорот питатель-
ных веществ и поток энергии в экосистемах; предпосылкой
для такого моделирования служит естественная подразде-
ленпость экосистемы па компартменты — входящие в ее
состав виды пли трофические уровни. Потери экосистем
трактуются при этом как разность между суммой входов
и выходов и запасом для каждого отдельного компартмен-
та системы. Наконец, мы встретимся с распространением
концепции матричных моделей, когда в главе, посвящен-
ной стохастическим моделям, перейдем к рассмотрению
марковских моделей.
78
Глава 4
Марковские модели отличаются тем, что сумма элемен-
тов в каждой строке матрицы равна единице.
Пример 4.1. Выживание и плодовитость синего кита
Наш первый пример практического применения матрич-
ных моделей аналогичен основной модели Лесли. Он был
построен Ашером [82] на основе данных по синему киту
(Balaenoptera musculus), собранных Лоузом [45] и Эрен-
фельдом [18] в 30-е годы еще до того, как произошли рез-
кие изменения коэффициентов выживания и вид фактиче-
ски вымер [45, 92].
Самки синего кита достигают половой зрелости в воз-
расте между четырьмя и семью годами, а продолжитель-
ность беременности составляет примерно один год. Рожда-
ется единственный детеныш, которого самка выкармливает
в течение семи месяцев и за это время не может забере-
менеть вновь. Учитывая это обстоятельство, а также то,
что киты совершают миграции, можно сделать вывод, что
самка рождает не более одного детеныша за два года. Чис-
ленности самцов и самок примерно одинаковы, и это отно-
шение почти не меняется с возрастом. Предполагается,
что синие киты живут не более 40 лет. Для первых десяти
лет жизни коэффициенты выживания по оценкам равны
87% популяции за каждый год \
Если шаг по времени положить равным двум годам, то
матрица Лесли для популяции синего кита будет иметь
вид:
"0 0 0,19 0,44 0,50 0,50 0,45“
0,87 0 0 0 0 0 0
0 0,87 0 0 0 0 0
А = 0 0 0,87 0 0 0 0
0 0 0 0,87 0 0 0
0 0 0 0 0,87 0 0
_0 0 0 0 0 0,87 0,80_
1 Приведенная ниже матрица соответствует оценке 87% за
каждые два года. — Прим. ред.
Матричные модели
79
Как и прежде, элементы первой строки равны среднему
числу потомков женского пола, производимых одной сам-
кой за два года, причем максимальная плодовитость ха-
рактерна для возрастных классов 8—9 и 10—11 лет. Для
возрастных классов 12 лет и старше плодовитость несколь-
ко пиже — опа уменьшается в среднем до 0,45 на одну сам-
ку. Естественная смертность принимается равной 13% по-
пуляции за каждый двухлетний период в течение первых
десяти лет жизни. Коэффициент выживания китов возраст-
ной группы 12 лет и старше полагается равным 80%.
Главное собственное число и соответствующий ему соб-
ственный вектор данной матрицы, вычисленные, как и
прежде, с помощью итеративной процедуры, равны:
к (за один год) = V 1,0072 = 1,0036
а = [1000, 764, 584, 447, 341, 261, 885]'Л
Это собственное число указывает па то, что численность
популяции способна возрастать, а натуральный логарифм
его дает оценку внутренней скорости прироста:
Г = In % = In 1,0036 = 0,0036.
Аналогично доля популяции, которую можно изъять,
оценивается как
Н = 100 (% = 100 ( 1,0072 — 1 V
\ л J 1,0072 )
= 0,71% за каждые два года, или примерно 0,35% за год.
Поскольку это собственное число близко к 1, внутренняя
скорость прироста, а следовательно, и доля животных, ко-
торых можно отлавливать каждый год, довольно малы.
Если при эксплуатации Н превысит указанное значение,
то численность вида неизбежно будет убывать, за исклю-
чением случаев, когда гомеостатические механизмы изме-
няют соответствующим образом параметры выживания и
плодовитости [62].
Ашер [84] проанализировал результаты малых измене-
ний коэффициентов выживания и плодовитости и показал,
1 Штрих означает транспонирование, т. е. замену строки на
столбец. — Прим, перев.
80
Глава 4
что уменьшение всех коэффициентов выживания на 0,115
(с 0,87 до 0,755) приводит к уменьшению собственного
числа от 1,0072 до 1,0000. Аналогичный эффект оказывает
и уменьшение всех коэффициентов плодовитости на 48,6%.
Вообще говоря, если Х + бЛ — собственное число возмущен-
ной матрицы А + бА и если максимальный элемент б А по
абсолютной величине не превосходит е, то влияние малых
изменений элементов матрицы А па значение X оценивает-
ся как
| 8Z | <пе/(у', х),
где х и у' — соответствующие X, нормированные 1 собствен-
ные вектор-столбцы матрицы А и транспонированной мат-
рицы. Это неравенство нередко дает слишком грубую оцен-
ку, особенно когда у матрицы много пулевых элементов,
как в данном примере. Тем не менее установить макси-
мально возможный эффект возмущений весьма полезно;
это позволяет еще раз проиллюстрировать преимущество
использования определенных ограничений при построении
модели.
Пример 4.2. Структура популяции благородного оленя
В качестве примера применения матричной модели к
двуполой популяции мы рассмотрим различные попытки
моделирования динамики популяций благородного оленя.
Благородный олень (Cervas elaphus) — это животное, ко-
торое расселилось по Англии в атлантическом интервале
(примерно 7500—4500 лет назад) и сыграло важную роль
в общей экологии острова как самое крупное из диких ко-
пытных Англии. Вначале численность популяции этих
животных регулировалась различного рода хищниками, в
том числе и человеком. С тех пор как земли Англии нача-
ли усиленно возделываться, все эти хищники были либо
взяты под контроль, либо отстрелены, поскольку они ме-
шали земледелию и лесоводству, а также угрожали без-
опасности самого человека. Все более интенсивная вырубка
лесов, которые ранее покрывали значительную часть Шот-
ландии, привела к тому, что характер пригодных для оле-
1 Таким образом, х'х=у'у = 1. — Прим. перев.
Матричные модели
81
пей местообитаний существенно изменился и они все боль-
ше стали конкурировать с овцами и крупным рогатым
скотом за пастбища. В прошлом веке землевладельцы со-
держали большие стада оленей для охоты, нанося урон
сельскохозяйственным и лесным угодьям, — как собствен-
ным, так и своих соседей. В настоящее время, в связи с
ростом потребностей в продуктах земледелия и лесоводства
и уменьшением интереса к оленьей охоте, со всей серьез-
ностью встал вопрос о регуляции численности популяций
благородного оленя.
Лоув [51] изучал динамику популяции благородного
оленя па острове Рам с 1957 г. Его оценка структуры этой
популяции в начале исследований подытожена в табл. 4.1.
Таблица выживания построена для условий, когда эксплуа-
тация была весьма незначительной и составляла примерно
Таблица 4.1
Структура популяции благородного оленя
на острове Рам в 1957 г. [51]
Численности животных Коэффициенты выживания
самцы самки самцы самки
1 107,0 129,4 0,718 0,863
2 74,9 113,5 0,990 0,902
3 79,4 113,1 0,990 0,882
4 70,1 81,4 0,990 0,879
5 85,9 78,2 0,990 0,862
6 78,4 59,3 0,991 0,840
*7 79,2 64,6 0,734 0,808
L8 59,1 55,1 0,496 0,507
9 29,5 25,0 0,370 0,326
10 11,3 8,7 0,848 0,864
И 9,3 8,3 0,821 0,824
12 8,7 6,7 0,781 0,810
13 3,5 2,0 0,720 0,735
14 5,7 1,1 0,611 0,680
15 1,5 4,2 0,364 0,529
16 0,7 2,2 0,000 0,000
17 0,3 0
М глрла рля сСсгх гсгсв гсЕулягг.и благорс^вого олевя
Таблица 4.2
А = 0 0 0 0 202 0 0 419 0 0 434 0 0 362 0 0 363 0 0 355 0 0 376 0 0 422 0 0 417 0 0 464 0 0-464 0 0464 0 0 464 0 0 464 0 0-464
0 0 0 0 214 0 0 444 0 0 459 0 0 589 0 0 589 0 0-576 0 0-612 0 0 353 0 0 348 0 0 388 0 0-388 0 0 388 0 0 388 0 0 388 0 0 388
0 718 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 863 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 990 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 902 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 990 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 882 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 990 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 879 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 990 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 862 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 G 0 0 0 0 0 0 0 0 0-991 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 840 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 734 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 808 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 496 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 507 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 370 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 326 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 8480 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0-864 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 821 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 824 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 781 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 810 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 720 0 0 0 0 0 0 0
0 0 0 0 0 0 0 с 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 735 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 611 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 680 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 364 0 0 О'
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 529 0 0
Матричные модели
83
40 самцов и 40 самок в год, так что популяция оказыва-
лась недоэксилуатируемой и ее численность регулирова-
лась в основном естественной смертностью. После первого
года жизни естественная смертность постепенно возраста-
ла до максимальных значений, которые достигались (как
у самцов, так и у самок) в восьми- и девятилетнем возрас-
те. Наблюдалось заметное различие в смертности самцов
и самок возрастных классов со второго по шестой: коэф-
фициент смертности самцов составлял лишь один процент,
тогда как для самок он лежал между 10 и 20 процентами.
Ашер [83] оцепил коэффициенты рождаемости самцов
и самок, используя данные Лоува о доле молодняка в по-
пуляции и беря взвешенные средние для возрастных групп.
Предполагалось, что благородные олени производят лишь
одного детеныша в год.
В табл. 4.2 приведена матрица для обих полов популя-
ции благородного оленя. Эта матрица неизбежно оказы-
вается весьма громоздкой и насчитывает в данном случае
32 строки и столбца. Главное собственное число X рав-
но 1,1636.
Соответствующий собственный вектор, отражающий
возрастную структуру стабильной популяции оленя и по-
строенный так, чтобы численность однолетних самцов была
равна 1000, приведен в табл. 4.3. Поскольку
н = 100 % = 100 ( 1,1636-1 % = 14,1 %,
\ X / 1,1636 )
из неэксплуатируемой в сущности популяции можно изы-
мать 14,1% особей в год в предположении, что из каждой
возрастной группы берется одип и тот же процент. Модель,
однако, с равным успехом можно использовать и для опре-
деления таких стратегий эксплуатации, когда изымаются
особи не всех, а только определенных возрастных классов.
Беддипгтоп [5] рассматривал отстрел благородного оле-
ня в Шотландии просто как эксплуатацию возобновимого
ресурса и исследовал его влияние па динамику популяции.
Он пришел к выводу, что элементы матрицы А следует
рассматривать как функции плотности популяции п раз-
личных факторов среды. Как выживание, так и плодови-
тость каждого класса зависят не только от погодных усло-
вий, но и от плотности популяции, причем с увеличением
84
Глава 4
Таблица 4.3
Собственный вектор матрицы для благородного оленя
Возраст (годы) Самцы Самки Возраст (годы) Самцы Самки
1 1000 1239 9 74 66
2 617 919 10 24 18
3 525 712 И 17 14
4 447 540 12 12 10
5 380 408 13 8 7
6 323 302 14 5 4
7 275 218 15 3 2
8 174 151 16 1 1
последней они уменьшаются. Поэтому Беддингтон предпо-
ложил, что матричная модель для популяции благородного
оленя должна иметь вид
n<+i = ’
где индекс при матрице М указывает на то, что ее элемен-
ты являются функциями суммарной плотности популяции
Nt = ^nt.
i
В отсутствие эксплуатации существует равновесная
плотность популяции N *, задаваемая решением детерми-
нантпого уравнения
| Мт -I | =0.
Многочисленные машинные имитации популяцион-
ного процесса показали, что, анализируя локальную устой-
чивость, можно описать и глобальную устойчивость и что
в отсутствие эксплуатации популяция должна будет приб-
лижаться к равновесию, а флуктуации вблизи этого равно-
весия будут угасать. После введения диагональной матри-
цы D, элементы которой 0/ есть вероятности того, что i-й
Матричные модели
85
возрастной класс выживает после отстрела, уравнение Леф-
ковича [48] принимает вид:
П(И = М(^) Dn,.
Если 0г поддерживаются постоянными и не настолько ма-
лы, что при некоторой данной численности популяции по-
следняя пе может возрастать, то популяция достигнет рав-
новесия, определяемого уравнением
| MmD-I | -О’
Пример 4.3. Размерные классы сосны обыкновенной
Деревья в лесу обычно классифицируют по размеру, а
не по возрасту. Ашер [78] модифицировал основную мо-
дель Лесли для выборочных лесов, которые характеризуют-
ся неоднородной возрастной и размерной структурой де-
ревьев и в которых нет четко выраженной фазы восстанов-
ления. Каждое дерево в таких лесах за данный интервал
времени либо остается в том же размерном классе, либо
переходит в следующий класс, если только этот интервал
достаточно мал, чтобы не произошел переход более чем на
один класс.
Основная трудность при построении модели леса — это
найти аналог членов плодовитости основной модели. Если
допустить, что лес восстанавливается естественным путем,
то всякое свободное пространство, образовавшееся в ре-
зультате гибели или вырубки дерева, будет заполняться
либо естественным восстановлением, либо разрастанием
кроны соседних деревьев. Поэтому элементы матрицы, опи-
сывающие плодовитость, зависят не от общей численности
популяции, а от числа изъятых деревьев. Если в размер-
ном классе i в момент t имеется гы деревьев, то при устой-
чивой структуре популяции в момент £ + 1 в этом классе
будет Хгц деревьев, и (X—1)м/ из них будет изъято, чтобы
свести численность к гы. Таким образом, элементы первой
строки матричной модели, отражающие восстановление,
необходимо умножить на (Z—1).
Модель Ашера [80] имеет вид:
86
Глава 4
ao+ro(^ 1) 1) 1)* ’ *^п-1(^ -О сп(^ ^п)
О II о о • • о О о о о о • •
1 о о . . о О О . о е • • о о
где at(i = O, 1, ..., /г--1)—вероятность того, что дерево оста-
нется в £-м размерном классе; bi(i = 0, 1, ..., п—1) —веро-
ятность того, что дерево перейдет в следующий размерный
класс; c£(Z = O, 1, ..., п) —число деревьев размерного клас-
са 0, заполняющего свободное пространство, которое по-
явилось в результате изъятия одного дерева г-го класса.
Величина ап — это управляющее решение: она зависит от
числа деревьев, которые необходимо оставить в самом
крупном классе, и часто бывает равна 0. Это, в свою оче-
редь, влияет на член, описывающий восстановление, кото-
рый становится равным — 1 + Ьп) и, поскольку &п =
= 1—ап, упрощается, таким образом, до cn(Z—ап). Чтобы
найти решение задачи о главном собственном числе
и собственном векторе для матрицы, отдельные
элементы которой являются функциями того же самого
числа, необходим более сложный метод, чем приме-
нявшаяся до сих пор итеративная процедура. Ашер [80,
81] предлагает простой и довольно быстрый метод реше-
ния этой задачи и показывает, что модель имеет лишь одно
собственное число, большее единицы, и соответствующий
собственный вектор, все координаты которого неотрица-
тельны. В модели, таким образом, существует лишь одна
размерная структура леса, имеющая биологический смысл
и максимизирующая продукцию древесины.
Ашер [78] дает также пример применения этой модели
к лесу сосны обыкновенной, основанный на данных по
конкретному лесу и па вычислении размеров площадей,
занятых соснами разного размера [37]. Основная матрица
модели имеет следующий вид:
Матричные модели
87
“0,72 0 0 3,6 (Л — 1) 5,1 (А—1) 7,5Х”
0,28 0,69 0 0 0 0
0 0,31 0,75 0 0 0
А = 0 0 0,25 0,77 0 0
0 0 0 0,23 0,63 0
0 0 0 0 0,37 0
Собственное число и собственный вектор этой матрицы
равны
X = 1,204266,
а = [1000, 544, 372, 214, 86, 26]'.
Шаг по времени равен шести годам и, поскольку
н = 100 р'-20^~1А % = 16,96% ,
1,204266 /
каждые шесть лет можно изымать примерно 17% деревьев.
Лшер [84] распространил эту конкретную модель на
случай восьми размерных классов (вместо шести) для ана-
лиза стратегий эксплуатации и, в частности, для определе-
ния того максимального размера, до которого следует остав-
лять дерево расти. Он пришел к предварительному выводу,
что короткие обороты рубки дают меньший ежегодный
прирост, чем более длительные.
Пример 4.4. Цикл фосфора в экосистеме
из трех компартментов
В этом заключительном примере данной главы, посвя-
щенной матричным моделям, мы рассмотрим использова-
ние последних для имитации потока энергии и цикла пи-
тательных веществ в экосистемах. Это, несомненно, дина-
мические процессы, и для того, чтобы описать поступление
энергии или питательных веществ в экосистему и их пере-
нос внутри экосистемы, необходимо несколько модифици-
ровать основную матрицу. Весьма удобно считать, что эко-
система подразделена на компартменты — виды или тро-
фические уровни либо функциональные части этих видов
88 Глава 4
или уровнен. Наконец, в пашей модели не нужно специ-
ально описывать потери экосистемой вещества и энергии:
мы можем считать, что потерн для каждого компартмента
равны разности между поступлениями и суммой запаса и
выходов вещества или энергии из данного компартмента.
Как Лшер [78], так и Гудман [28] отмечали тот факт,
что основная матрица Лесли может рассматриваться как
сумма двух матриц:
/о /1 /2 ‘ ‘ ’
ООО-.
О 0 0 •••
Ро О
О Pi
о ... О'
О ... О
О ... о
ООО... О ООО..*0
или
A = F+P,
где матрица F отражает пополнение популяции новыми
членами, а матрица Р — переход членов из одного возраст-
ного класса в другой в пределах популяции. При описании
Рис. 4.2. Схематическое представление цикла фосфора в экосистеме
из трех компартментов.
Матричные модели
89
динамических процессов мы тоже можем использовать та-
кое разбиение исходной матрицы.
Смит [73] построил модель для цикла фосфора в сис-
теме из трех компартмептов; диаграмма этой системы при-
ведена на рис. 4.2. В модели определено пять категорий
параметров:
Xi — количество фосфора в г-м компартменте в данный
момент времени;
at — скорость поступления фосфора в г-й компартмент;
Zi — скорость ухода фосфора из j-го компартмента;
fij — ноток фосфора из г-го компартмента в /-й;
fa — относительное количество фосфора, накапливаю-
здесь два вектор-столбца дают запас энергии и питатель-
ных веществ в трех компартмептах системы в моменты
t и £ + 1. Элементы матрицы, не лежащие па главной диаго-
нали, соответствуют переходам между z-м и J-м компарт-
ментами. Элементы главной диагонали состоят из двух
слагаемых: количества энергии или питательных веществ,
не переносимых из одного компартмента в другой, и их
количества, поступающего в j-ii компартмент; последнее
не зависит от уже накопленного в этом компартменте коли-
чества вещества или энергии и потому представлено в виде
(Lilxt,i.
По данным Смита [73] для модели с шагом по време-
ни, равным 1 сут, Ашер [82] пересчитал параметры для
модели, приведенной к шагу, равному 4 ч. Эти параметры
90
Глава 4
Таблица 4.4
Параметры модели цикла фосфора
Параметры Функции
9,5
1,4
хз 9,0
/12 0,10417ярГ2
/г1 0,05208г2
/23 0,10417х2х3
/31 0,05208г3
Z1 0,02083^
Z3 0,01042^3
/11 (1—0,02083—0,10417*,)*!
/22 (1—0,05208—0,1041 7x3)i2
/33 (1—0,05208—0,01042z3)x3
представлены в табл. 4.4. Все потоки приведены к потокам
на единицу вещества путем деления их на количество ве-
щества в том компартменте, откуда исходит поток, т. е. на
Xi. Основная матрица в этом случае имеет вид
‘0,94298 0,05208 0,05208"
0,14584 0,01042 0
_0 0,93753 0,85417.
Главное собственное число этой матрицы равно 1, а соот-
ветствующий собственный вектор— [9,5; 1,4; 9,0]'. Иначе
говоря, анализ показывает, что система находится в ста-
ционарном состоянии, т. е. общее количество фосфатов пе
возрастает.
Стоит, пожалуй, подчеркнуть, что при работе с матрич-
ными моделями циклов веществ пли энергии могут иногда
возникать затруднения в вычислении главного собственно-
го числа н собственного вектора. Эти трудности обычно
Матричные модели
91
можно обойти, выбрав подходящий шаг по времени. В ра-
боте Ашера [82] приводится несколько дополнительных
примеров.
В данной главе о матричных моделях мы рассмотрели
одно семейство моделей, «реализм» которых частично при-
несен в жертву тем выгодам, которые дает использова-
ние данного математического формализма. Тот же самый
формализм накладывает ограничения и на область приме-
нения моделей, однако эти ограничения компенсируются
удобством вычислений и сравнительной легкостью отыска-
ния значений основных параметров модели.
Матричная алгебра является одним из мощных и дей-
ственных инструментов современной математики. Она об-
ладает четырьмя главными преимуществами.
1. Очень компактно записывает уравнения и выра-
жения.
2. Облегчает запоминание этих выражений.
3. Существенно упрощает процедуру нахождения реше-
ний для сложных задач.
4. Машинные языки высокого уровня имеют удобные
инструкции для выполнения матричных вычислений.
Несмотря на то, что матричные вычисления иногда ока-
зываются весьма громоздкими (особенно при обращении
матрицы и нахождении собственных чисел и собственных
векторов), их обычно гораздо легче запрограммировать,
чем расчеты по динамическим моделям. Кроме того, свой-
ства основных матриц этих моделей позволяют модельеру
использовать дедуктивную логику чистой математики.
В данной главе мы сосредоточили внимание лишь на глав-
ном собственном числе и соответствующем ему собственном
векторе как характеристиках основных матриц. Остальные
собственные числа и собственные векторы могут характе-
ризовать устойчивость или колебательные тенденции в мо-
делях, по мы не рассматривали их здесь из-за относитель-
ной сложности программы для вычисления всех собствен-
ных чисел и собственных векторов матрицы.
В системном анализе матричные модели образуют важ-
ное, но не оцененное по достоинству семейство. До сих пор
в экологии это семейство было «педоэксплуатировапо» и
92 Глава 4
число опубликованных работ сравнительно невелико. Не-
дооценка матричных моделей объясняется отчасти тем, что
биологи и экологи не знакомы с матричной алгеброй, хотя
дифференциальные и разностные уравнения динамических
моделей требуют от модельера гораздо больших матема-
тических способностей. Широкое распространение ЭВМ и
понимание того, что даже па малых ЭВМ (т. е. на совре-
менных микро- и мипикомттьтотерах) можно запрограмми-
ровать по крайней мере вычисление главного собственного
числа и собственного вектора, приведет, вероятно, к более
широкому применению матричного формализма.
£
1
/
лгр'
$
Прямоугольная
Квадратная
Диагональная
Тождественная
Векторы
Строка
Столбец
Скаляры
х°
сХ
/1римеРь1
Благородный олень
/
Применение
_ ^ппеоМи-л
шпемалшка
модели
Собственный вектор
об»п°л
Матрица Лесли
Сложение
Вычитание
Умножение
Обращение
Темп росгпа
5
СТОХАСТИЧЕСКИЕ МОДЕЛИ
Все семейства моделей, которые мы рассматривали до
сих пор, были детерминистскими. Это значит, что при од-
них и тех же начальных условиях результат моделирова-
ния одинаков и предсказывается математическими соотно-
шениями, задающими модель. Детерминистские модели —
это закономерное развитие той ветви математики, которую
мы изучали еще на первых курсах институтов, в частно-
сти, так называемой «прикладной математики», т. е. мате-
матики, применяемой в физике. Такие модели являются
необходимыми аналогами тех физических процессов, где
имеет место взаимно однозначное соответствие между при-
чиной и следствием.
Существует, однако, и более позднее направление ма-
тематики, которое позволяет описывать связи с помощью
вероятностей, в результате чего исход моделируемой реак-
ции определен неоднозначно. Модели, которые оперируют
вероятностями, называют стохастическими; такие модели
особенно важны при учете изменчивости и сложности эко-
логических систем. Разумеется, вероятностные элементы
можно ввести почти в любой тип моделей, например в ди-
намические модели, описанные в гл. 3, и, в частности, в
исследование устойчивости этих моделей к вариациям их
основных параметров. Но в данной главе мы остановились
на моделях, которые стохастичны изначально. Поскольку
развитие статистической теории прошло уже долгий исто-
рический путь, нам придется остановиться лишь на неко-
торых типах моделей.
Пространственные распределения организмов
Одним из простейших применений стохастических мо-
делей к решению экологических проблем является описа-
ние пространственных распределений живых организмов.
Конечно, это можно сделать с помощью очень многих ста-
Стохастические модели
95
тистических распределений, по здесь мы рассмотрим лишь
самые простые из них.
В экологии часто возникает необходимость предсказать
число организмов, обитающих па какой-то определенной
площади или на данном объекте (например, на дереве,
листе или семени). При этом средняя плотность организ-
мов, вообще говоря, неизвестна, и потому нам нужна мате-
матическая модель, которая давала бы эффективную меру
среднего числа встречаемых особей, а также меру вариа-
бельности встречаемости и структуру этой вариабельности.
Если мы забудем па время о существовании полностью
равномерного распределения, т. е. распределения, при ко-
тором каждый выборочный объект содержит одно и то же,
без вариаций, число особей, простейшая гипотеза, которую
мы сможем сформулировать, будет состоять в том, что каж-
дый организм имеет постоянную, хотя и неизвестную, ве-
роятность встретиться в выборке и что особи никак не
влияют друг на друга, или, иными словами, что вероятно-
сти встречаемости организмов независимы. Не вдаваясь в
детали вывода (который на самом деле можно найти в
большинстве учебников по элементарной теории вероятно-
стей, например [93] *), заметим, что при сделанных допу-
щениях вероятности обнаружения в выборке 0, 1, 2, 3 ...,
х особей задаются последовательностью
p-/n p-m m arm 171,2 р-m т3 р-/и тХ
с • и • и — • и ' • .... и ,
1! 21 3! xl
где е — основание натурального (неперова) логарифма.
Эта последовательность широко известна в статистиче-
ской литературе как ряд (или распределение) Пуассона.
Согласно этому распределению, среднее число особей в
выборке и их дисперсия равны т. Проверить пригодность
распределения Пуассона для описания пространственного
распределения организмов (а следовательно, и справедли-
вость гипотезы, что вероятность встречаемости отдельного
организма постоянна и не зависит от присутствия осталь-
ных особей) можно либо путем сравнения наблюдаемой
1 Из учебников, перо веденных на русский язык, можно реко-
мендовать: Феллер В. Введение в теорию вероятностей и ее прило-
жения. Т. I —М.: Мир, 1967. — Прим, персе.
96
Глава 5
частоты встречаемости с частотой, которая задается теоре-
тическим распределением, либо сравнением среднего и
дисперсии наблюдаемых частот с соответствующими тео-
ретическими значениями.
Если пуассоновское распределение отвергается, это да-
ет основание формулировать какие-то альтернативные ги-
потезы относительно распределения. Хотя при этом мы и
руководствуемся тем, что уже известно о данной системе,
всегда существует бесконечное множество вероятных гипо-
тез, и потому наш поиск адекватной математической моде-
ли должен опираться прежде всего па экологию проблемы,
а не на удобство математического описания. Кроме того,
модель пе должна быть переопределенной и содержать
больше параметров, чем можно оценить исходя из разум-
ной совокупности данных. Многие распределения, отличные
от пуассоновского, порождают модели, предполагающие
весьма специфические отклонения от «чистой» случайно-
сти, и их применимость зависит, таким обрзом, от экологи-
ческой сути задачи.
Если особи стремятся избегать тесных контактов, осо-
бенно когда число их возрастает, характерной особенно-
стью распределения будет его регулярность и равномерная
распространенность особей, причем дисперсия числа особей
оказывается меньше его среднего значения. Относительно
равномерное распространение часто бывает обусловлено,
например, территориальным поведением животных, а рас-
селение прикрепленных беспозвоночных может быть ре-
гулярным лишь на небольших участках дна реки или
озера. Такого рода регулярные распределения можно ап-
проксимировать (положительным) биномиальным распре-
делением, для которого ожидаемое распределение частот
задается разложением бинома
П (q + Р)к,
где п — число выборочных объектов;
р — вероятность того, что данная точка выборочного
объекта занята какой-то особью;
д = 1—р;
к — максимально возможное число особей, которое
способен содержать выборочный объект.
Стохастические модели
97
На практике параметры к, р и q оценивают по выбор-
кам из популяций. Чтобы проверить соответствие между
фактическими результатами и положительным биноми-
альным распределением, сравнивают наблюдаемые и ожи-
даемые частоты, используя критерий %2.
Когда пространственное распределение особей не явля-
ется ни чисто случайным, пи регулярным, а дисперсия
числа особей в выборке больше среднего их числа в вы-
борке, распределение обычно называют «контагиозным»,
подразумевая, что в пространственной структуре имеются
скопления, или «пятна» организмов, и нерегулярные «пус-
тоты». Разумеется, неравномерности распределения особей
может способствовать множество факторов внешней среды,
а некоторые виды стремятся к агрегации, образуя скопле-
ния даже независимо от влияния этих факторов. Резуль-
тирующая структура распределения зависит от размера
групп и расстояния между ними, от пространственного
распределения групп и распределения особей внутри
группы.
Для неравномерных распределений предлагалось не-
сколько математических моделей, и, пожалуй, наиболее из-
вестной из них является отрицательное биномиальное рас-
пределение. Оно задается разложением бинома
(д — р)Л
где р = р/к,
Q = 1 + Р-
Параметрами этого распределения служат арифмети-
ческое среднее ц и показатель степени к. Этот показатель
связан с характером пространственного распределения осо-
бей, а его обратное значение 1/к служит мерой избыточной
дисперсии, или сгруппироваппости особей в популяции.
Когда к стремится к бесконечности, 1/к приближается к
нулю, а распределение сходится к ряду Пуассона, т. е. к
чисто случайной встречаемости особей. Если же к прибли-
жается к пулю, а 1/к стремится к бесконечности, то рас-
пределение сходится к логарифмическому ряду, свойства и
применение которого были описаны Уильямсом [94].
Имеются различные критерии для подбора отрицатель-
ного биномиального распределения, причем эффектив-
4-843
98
Глава 5
ность этих критериев зависит от размера выборки, сред-
него числа особей на одну выборку и от того, насколько
трудно оценить параметр к. Сложные вопросы выбора под-
ходящих методов увели бы нас в сторону от основной темы
книги; достаточно подробное их обсуждение можно найти
в работе Эллиотта [19].
Недостатком отрицательного биномиального распреде-
ления является то, что оно может быть получено в самых
разных биологических моделях. Это распределение может
иметь место, например, в модели, где есть истинная копта-
гиозность в том смысле, что присутствие в выборке одной
особи повышает вероятность обнаружить в ней и другую
особь. Можно показать, что к отрицательному биномиаль-
ному распределению размера популяции приводит также
рост популяции с постоянными коэффициентами рождае-
мости и смертности особей и постоянной скоростью имми-
грации. Отрицательному биномиальному распределению
подчиняются и случайно распределенные группы особей,
с числом индивидов в группах, распределенным по лога-
рифмическому закону, а также популяции, состоящие из
нескольких подпопуляций, внутри которых распределение
случайно, но с различной вероятностью встречаемости.
Таким образом, отрицательное биномиальное распреде-
ление можно с успехом применять к самым разным рас-
пределениям организмов. Однако невозможность связать
его с каким-то конкретным набором начальных условий
уменьшает полезность этого распределения — пример мо-
дели, универсальность которой оказывается недостатком!
По этой причине был разработан ряд других контагиозных
распределений. В работе [1], папример, как возможные
альтернативы для распределений с дисперсией, большей,
чем среднее значение, и с положительной ассиметрией
(скошенностью вправо) предлагались распределения То-
мас [77], Неймана [58] (типа А), Пойа [63], а также
дискретное логарифмически-пормалыюе распределение.
Распределения Томас и Неймана очень похожи, но по-
лучаются они при наличии разных допущений. Распреде-
ление Неймана предназначено для описания распростране-
ния из случайно распределенных скоплений; при этом ог-
раничение на размер скоплений определяется диапазоном,
на котором рассеяны организмы. Распределение Томас
Стохастические модели
99
является в сущности двойным пуассоновским, поскольку
одно пуассоновское распределение описывает число скоп-
лений, а второе — численность особей в скоплениях. Обе
эти модели способны описывать распределения с более чем
одной модой, тогда как у отрицательного биномиального
распределения есть только одна мода.
Распределение Пойа получается в предположении одно-
временной и случайной колонизации родительскими орга-
низмами некоторого конкретного местообитания. Эти роди-
тельские организмы производят скопления (кластеры) по-
томков, численность особей в которых следует геометриче-
скому распределению. Дискретное логарифмпчески-нор-
мальпое распределение получается просто прямым
логарифмированием числа организмов, обнаруженных в
каждой выборке.
По мере роста числа организмов па выборку или, на-
оборот, по мере увеличения числа выборок все эти распре-
деления приближаются к нормальному, которое лежит в
основе многих основных идей и критериев математической
статистики. Даже при довольно малом числе выборок при-
ближение к нормальному распределению можно получить
сравнительно простым преобразованием данных наблюде-
ний, а отыскание нужного преобразования само по себе
может дать представление о природе изучаемого распреде-
ления организмов. Следует упомянуть, что существуют и
другие подходы к исследованию пространственных распре-
делений, основанные на измерении расстояний между со-
седними особями. Эти методы выходят за рамки нашей
книги; обзор некоторых из них содержится в книгах Пиелу
[61] и Грейг-Смита [30].
Пример 5.1. Численность Helobdella в выборках
из озера
В табл. 5.1 приведено число пиявок Helobdella в 103 вы-
борках, взятых из пресноводного озера, а в табл. 5.2 —
соответствующие этим выборкам частоты.
Общее число обнаруженных особей равно 84, так что
среднее их число па выборку есть
х = = 0,8155.
103
4*
100 Глава 5
Таблица 5.1
Численность Helobdella в 103 выборках из пресноводного озера
0 0 1 0 0 1 3 0 0 1
3202220002
0 1 0 0 0 0 0 1 0 1
1 1 0 0 0 0 6 2 2 0
1 0 2 0 1 0 1 2 1 0
01400 0 1040
2 1 1 1 5 0 0 0 0 0
00002 1 1002
0 0 0 1 0 2 1 0 0 1
0180 100000
010 — — — — — — —
Таблица 5.2
Сравнение наблюдаемых частот Helobdella с частотами,
ожидаемыми по распределению Пуассона
Число особей Наблюдаемая частота Ожидаемая частота Разность
0 58 45,57 — 12,43
1 25 37,16 + 12,16
2 13 15,15 +2,15
3 2 4,12 +2,12
4 2 0,84
5 1 0,14
6 1 0,02 1 —4
7 0 0,00
8 1 0,00
В предположении, что вероятность встретить любую
особь в выборке остается постоянной и независимой, час-
тота встречаемости 0, 1, 2, 3, ..., х организмов задается со-
ответствующим членом ряда Пуассона
Стохастические модели
101
... П1Л
Pw - е-"1 — ,
X !
где т = х.
Отсюда ожидаемая частота отсутствия индивидов в
выборке есть
пе~т = 103 (0,442418) = 45,57 ,
а для остальных частот последующие члены ряда дают зна-
чения:
пе~тт = 103 (0,442418) (0,8155) = 37,16,
по’"1 = 103 (0,442418) (0,3325) = 15,15,
пе~т^- = 103 (0,442418) (0,0904) = 4,12,
пе-"1 = 103 (0,442418) (0,0184) = 0,84,
пе'"1 = 103 (0,442418) (0,0030) = 0,14,
пе’"1 = 103 (0,442418) (0,0004) = 0,02.
Эти частоты приведены в табл. 5.2 вместе с их откло-
нениями от наблюдаемых частот. Исходы выборок с ма-
лыми значениями ожидаемых частот объединены, чтобы
минимальное значение ожидаемой частоты было равно 1.
Адекватность пуассоновского распределения как модели
распределения Helobdella в озерных выборках проверяет-
ся затем с помощью критерия %2, описанного в любом учеб-
нике по элементарной статистике (см., например, [4]) *.
Этот критерий вычисляется как
У2 = У <°' ~ Е-)2
где к — число классов,
1 Из отечественных учебников можно рекомендовать: Ур-
бах В. Ю. Статистический анализ в биологических и медицинских
исследованиях. — М.: Медицина, 1975. — Прим, персе.
102 Глава 5
Oi — наблюдаемая частота, характерная для класса г,
Et — ожидаемая частота, характерная для класса i.
Для рассматриваемого нами примера
2 = (- 12,43)2 (12,16)2 (2,15)2 (2,12)2
Х 45,57 37,16 15,15 4,12
+ 24,77 .
1
Сравнение этой величины с табличными значениями
для (к—1)=4 степеней свободы показывает, что вероят-
ность получить выборку, которая в такой степени отлича-
лась бы от ожидаемых значений для популяции особей с
постоянной вероятностью встречаемости, меньше, чем 0,001
(в действительности близка к 0,0003), и практически мо-
жет считаться равной нулю.
Другая проверка адекватности распределения состоит
в сравнении дисперсии наблюдаемой численности организ-
мов со средним числом особей на выборку.
2 = *2 (п-1)
Л. >
т
где s2 — дисперсия,
п — число выборок,
тп — среднее число организмов на выборку.
Для рассматриваемого нами примера
2 = 1,7990(103—1) = 225
0,8155
со 102 степенями свободы.
Вероятность достижения столь высокого значения х2
по-прежнему много меньше, чем 0,001, и потому модель
постоянной вероятности встречаемости индивида должна
быть отвергнута.
Читатель мог заметить, что в последних параграфах
было дано два разных толкования вероятностей — обстоя-
тельство, которое может привести к некоторой путанице.
Прежде всего мы определили стохастическую модель, в
которой вероятность встречаемости особи постоянна и ко-
торая давала в среднем 0,8155 особи на выборку. Чтобы
проверить справедливость этой модели, мы применили ста-
Стохастические модели
103
тистический критерий согласия наблюдаемых частот с
частотами, ожидаемыми исходя из модели. Результаты
этой проверки выражаются как вероятность (пе путать с
вероятностью встречаемости отдельного организма!) того,
что подобные выборочные данные могли бы получиться
для популяции, если бы та обладала свойствами, присущи-
ми модели. По соглашению, любая гипотетическая модель,
для которой эта найденная по данным наблюдений вероят-
ность оказывается меньше 0,05, отвергается.
Для того, чтобы к данным нашего примера подобрать
отрицательное биномиальное распределение, нам нужно
прежде всего оцепить параметр к в выражении
|i \—k (к х—1) ! / |i у
к) х ! (к—1) ! \ |i + к /
где Р(х) есть вероятность обнаружения х особей в выбор-
ке, а параметры ц и к оцениваются по распределению
выборочных частот и с помощью статистик х и к. Предва-
рительную оценку k можно получить из уравнения.
х2 _ (0,8155)2
S2_7 (1,7990 — 0,8155)
но затем эта оценка должна использоваться как начальное
значение для подстановки в уравнение максимального
правдоподобия
п In (1 + xlk) = V (—(х)
х \ к + Х
где п — общее число выборок, In — натуральный логарифм,
Л(Х) — общее число выборок с исходом, превосходящим х.
Опробуются различные значения к до тех пор, пока равен-
ство не будет приближенно выполняться; для нашего при-
мера разумным решением оказывается к = 0,8.
Отдельные члены частотного распределения последова-
тельно вычисляются по этанам, представленным ниже:
104
Глава 5
К Р(х)/ — ftP (х)
0 Р(х=0) = (* + -f )~/г = 0,5699 58,70
1 Р(х-1) = ( к \ ( ыи —р (х=0) = 0,2302 23,71
2 Р(х=2) = | 1 \ ^2 ) ’ 1 X \ X + к } Р(х=\) = 0,1046 10,77
3 Р(х=3) = | / /с + 2 \ \ 3 / / х \ \ х + к ) Р(=2) = 0,0493 5,07
4 •Р(лг=4) — < fc + 3 \ (4 / 1 1 х \ х + к ) Р(х=3) = 0,0236 2,43
5 Р(х=5) = | fc + 4\ । к 5 / ' ( х \ х + к j Р(х=4) = 0,0114 1,18
6 Р(х=6) = ( 'к + 5 \ < 6 / ( х I х + к у Р(х=5) = 0,0056 0,58
7 Р(х=7) = | А + б\ । к 7 / \ х \ х + к j Р(х=б) = 0,0027 0,28
8 Р(х=8) = < 8 / ( х \ 1 х + к 1 Р(х=7) = 0,0013 0,14
Полученные значения ожидаемых частот приведены в
табл. 5.3; здесь же даны наблюдаемые частоты и разность
между ними и ожидаемыми значениями. Едва ли нужно
доказывать, что данная модель дает лучшие результаты,
чем предыдущая, по вычислим все же критерий %2 как
2 = (-0,70)2 (1,29)2 (2,23)2 (—3,07)2
• ~ 58,70 + 23,71 ' 10,77 + 5,07 +
(-О,43Р (0,68)2 = 2
"Г 2,43 "Г 2,32
с четырьмя степенями свободы (т. е. п—2, поскольку мо-
дель содержит теперь два параметра, ц п к). Вероятность
того, что величина х2 достигает такого значения для вы-
Стохастические модели
105
Таблица 5.3
Сравнение наблюдаемых частот с частотами,
ожидаемыми исходя из отрицательного биномиального
распределения
Число особей Наблюдаемая частота Ожидаемая частота Разность
0 58 58,70 —0,70
1 25 23,71 1,29
2 13 10,77 2,23
3 2 5,07 —3,07
4 2 2,43 —0,43
5 1 1,18 \
6 1 0,58
7 0 0,28 2,18 0,82
8 1 0,14 J
Сумма 103 103 0,14
борки из популяции, подчиняющейся отрицательному би-
номиальному распределению, равна приблизительно 0,70
и заведомо пе настолько мала, чтобы можно было отверг-
нуть эту гипотезу.
В результате проделанных вычислений, которые выгля-
дят весьма громоздкими, поскольку полностью воспроизве-
ден каждый их этап, мы можем утверждать, что отрица-
тельное биномиальное распределение
(9 — PTk
является адекватной моделью распределения численности
Helobdella в выборках из конкретного пресноводного озе-
ра, причем
к = 0,8,
р = х/к = 1,0194 ,
g = 1 4-р.
Члены распределения задаются выражением
106 Глава 5
р (1 I —V’ft + * — 1) ! / X у
W \ Л / х ! (к — 1) ! х + k ) ’
где 1\х) — это вероятность обнаружения х особей в выбор-
ке и где по-прежнему
к -0,8,
х - 0,8155.
Дисперсионный анализ
Одной из наиболее широко применяемых в научном
исследовании статистических моделей является модель,
которая лежит в основе статистической методики диспер-
сионного анализа, хотя многие из тех, кто применяет ста-
тистические методы, вряд ли сознают, что они используют
какую-то модель, быть может, потому, что данный аспект
дисперсионного анализа нередко ие рассматривается в
элементарных учебниках статистики. Тем пе менее линей-
ные факторные модели, лежащие в основе дисперсионного
анализа, сыграли важную роль в развитии пауки и, веро-
ятно, сохранят свое важное значение, несмотря па огра-
ничительный характер их основных допущений. Разработ-
ка этих моделей в области планирования и оценки экспе-
риментов и наблюдений является одним из главных дости-
жений последних пятидесяти лет, и мы рассмотрим, как
и ранее, лишь один из наиболее простых примеров их при-
менения.
Основная модель рассматривает ограниченное число
независимых факторов или эффектов, которые, будучи при-
бавлены к среднему, способны описать моделируемую ре-
альную ситуацию. Так, простой эксперимент из t опытов,
повторенных в г отдельных сериях (блоках), можно опи-
сать с помощью модели
Уа — И + Pi + »
где ц —среднее,
Р/ — эффект i-ro блока (i = l, 2, ..., г),
Tj — влияние /-го опыта (/ = 1, 2, ..., t),
Sij — случайные ошибки, значения которых распреде-
Стохастические модели 107
лены независимо и нормально с пулевым средним
и дисперсией о2.
Модель можно значительно упростить, предположив да-
лее, что
Pi + Рг + Рз 4“ * * ' + Рг = 0
и Т1 + + Т3 Н----4-^=0.
Вообще говоря, мы, конечно, не знаем значений различ-
ных параметров модели; их нужно получать по выборкам
из данной популяции таким образом, чтобы они оказыва-
лись несмещенными оценками популяционных параметров.
Одно из необходимых условий получения несмещенных
оценок подобного рода заключается в том, чтобы в плане
нашего эксперимента присутствовал элемент случайности;
в описанной выше модели, папример, t опытов должны
быть случайным образом распределены между конкретны-
ми участками (или другими единицами эксперименталь-
ного материала) внутри каждой серии.
При таком условии оценки популяционных параметров
обычно получают методом наименьших квадратов, т. е. на-
ходят те значения параметров модели ц, рг-, т/, которые да-
ют наименьшую сумму квадратов отклонений от наблюдае-
мых значений. Это достаточно сложная теория, и ее мож-
но найти в любом учебнике по статистике, например [4].
Проиллюстрируем применение дисперсного анализа к ре-
шению практических задач на простом примере.
Пример 5.2. Рост сеянцев ели ситхинской на стерилизованной
и нестерилизованной почве
Очень часто рост сеянцев па первом году жизни за-
медляется в результате воздействия других организмов,
даже когда конкуренция между этими сеянцами и уже обо-
сновавшимися растениями отсутствует. Например, одно-
летние сеянцы ели ситхинской, Picea sitchensis (Bong.)
Сагг, могут оказаться весьма слабыми, низкорослыми и с
небольшим диаметром ствола даже па специально подго-
товленной почве; это дает возможность определить влияние
других организмов, сравнивая рост сеянцев па почвах, под-
готовленных обычным способом, и на предварительно сте-
108 Глава 5
рилизовапных почвах. Усложним немного ситуацию, пред-
ставив, что мы хотим проверить два альтернативных мето-
да стерилизации, а именно — стерилизацию паром и форма-
лином. Тогда наша схема предполагает постановку опытов
трех типов, а именно:
= контроль, без стерилизации ,
О2 = стерилизация формалином,
О3 = стерилизация паром .
Чтобы определить значения параметров для какой-то
конкретной популяции почвы, мы должны сравнить резуль-
таты этих опытов (тщательно рандомизированных) по
крайней мере в двух отдельных случаях или в двух отдель-
ных выборках почвы из одной и той же популяции. (На
самом деле условия постановки корректных экспериментов
несколько сложнее, по этот вопрос выходит за рамки дан-
ной книги; см. по этому поводу работы [20, 22, 60].)
В нашем примере эксперимент повторяется на восьми от-
дельных выборках почвы, каждая из которых разделяется
затем па три части для проведения опытов трех типов,
Таблица 5.4
Средний диаметр однолетних сеянцев ели ситхинской,
выращенных на стерилизованной и нестерилизованной почвах
Блок Средний диаметр, мм Сумма в блоке
контроль стерилизация формалином стерилиза- ция паром
1 0,84 1,09 1,16 3,09
2 0,84 1,03 1,66 3,53
3 0,97 0,88 1,50 3,35
4 1,06 0,94 1,50 3,50
5 1,00 1,13 1,59 3,72
6 0,81 1,00 1,31 3,12
7 0,75 1,06 1,44 3,25
8 0,91 0,56 1,50 2,97
Сумма в опыте 7,18 7,69 11,66 26,53
Стохастические модели
109
причем части выбираются случайным образом. Представим
далее, что через год средние диаметры сеянцев, выросших
на каждом участке, будут такими, какие приведены в
табл. 5.4.
Среднее для всего эксперимента оценивается как сред-
нее всей выборки, представленной таблицей 5.4, которое
получается сложением всех 24 значений и делением на
24, т. е.
пг = 26,53/24 - 1,105 мм.
Аналогично, эффект блоков 1, 2, 3, ..., 8 можно оценить
по средним для соответствующих блоков; так, папример,
эффект блока 1 оценивается как
Ба = (3,09/3) — 1,105 = 1,030 - 1,105 = - 0,075 мм.
Вспомним, что мы успростили модель, сделав допущение,
что сумма эффектов всех блоков равна нулю, и потому мы
вычитаем из каждого блочного эффекта среднее по всему
эксперименту. Аналогично, эффект второго блока оцени-
вается как
Б2 = (3,53/3) — 1,105 = 1,177 — 1,105 = 0,072 мм
и т. д. для всех остальных блоков.
Таким же образом вычисляются эффекты опытов трех
типов. Так,
О£ = (7,18/8) — 1,105 = 0,898 — 1,105 = — 0,208,
О2 = (7,69/8) — 1,105 = 0,961 — 1,105 = — 0,144,
О3 = (11,66/8) — 1,105 = 1,458 — 1,105 = 0,353,
и
01 + О2 + О3 = (— 0,208) 4- (— 0,144) + (0,353) = 0,001,
т. е. почти нуль !.
(Заметим, что оценки эффектов блока и опыта можно
получить столь простым путем только при условии, что
план эксперимента обладает свойством ортогональности.
Эта простота послужила одной из причин широкого приме-
нения ортогональных планов экспериментов, особенно в то
1 Отличие от пуля обусловлено здесь ошибками округления
при вычислении Оь Ог, О3. — Прим, персе.
110 Глава 5
время, когда вычислительная техника не была столь раз-
вита. Ортогональные планы сохраняют свое значение и
сейчас далее прп наличии ЭВМ, поскольку они существен-
но облегчают анализ сложных моделей и экспериментов.)
Теперь мы можем вычислить ожидаемые величины для
каждого участка и найти разницу между ожидаемыми и
наблюдаемыми значениями. Для трех опытов первого бло-
ка, например, ожидаемые значения таковы:
Уи = т Bj + Oi 9
У12 — т + В4 + О2,
У13 = т + Bj + О3,
т. е.
Уп = 1,105 + (— 0,075) + (— 0,208) = 0,822 мм,
У12 = 1,105 + (— 0,075) + (— 0,144) = 0,886 мм,
У13 = 1,105 + (— 0,075) + (0,353) = 1,383 мм,
а отклонения наблюдаемых значений от ожидаемых состав-
ляют:
dn = 0,84 — 0,822 = 0,018 мм ,
d12 = 1,09 — 0,886 = 0,204 мм ,
d13 = 1,16 — 1,383 = — 0,223 мм .
В табл. 5.5 и 5.6 приведены программы на БЭЙСИКе
для вычисления аддитивных эффектов в широком диапазо-
не планов экспериментов и для комбинации этих эффектов
при получении искомых значений. Два этих процесса на-
столько фундаментальны в исследовании аддитивных мо-
делей, что они образуют ядро широкого мноя^ества про-
цедур и в ортогональных планах могут применяться даже
для оценки отсутствующих величин. В табл. 5.7 приведены
результаты счета по этим программам с использованием
данных нашего примера.
Стохастические модели
111
Таблица 5.5
Программа на БЭЙСИКе для вычисления аддитивных
эффектов в ({акторных планах
5 DIM NC6)> YС 72)>ЕС 24)>С С 6)
15 READ D
20 LET M-l
25 FOR 1-1 TO D
30 READ NCI)
35 LET M-M*NCI)
40 NEXT I
45 FOR I-i TO M
50 READ YCI)
55 NEXT I
60 LET K-0
65 LET P-1
70 FOR 1-1 TO D
75 LET CCI)-l
80 LET L-NCI)
85 LET P-P*L
90 LET K-K*L
95 NEXT I
100 FOR 1-1 TO К
101 LET EC 1*1)-0
105 NEXT I
110 LET T-0
115 FOR 1-1 TO P
120 LET Q-YCI )
125 LET T-T*Q
130 LET L»1
135 FOR J-l TO D
140 LET K-L+CCJ)
145 LET ECK)-ECK)*Q
150 LET L-L+NCJ)
155 NEXT J
160 LET J-D
165 IF C(J)-NCJ) THEN 160
170 LET CCJ)«CCJ)*1
175 GO TO 195
180 LET CCJ)-1
185 LET J-J-l
190 IF J<>0 THEN 165
195 NEXT I
200 LET R-l/M
205 LET EC 1)-T*R
206 PRINT EC 1)
210 LET K-l
215 FOR 1-1 TO D
220 LET L-NCI)
225 LET Q-L*R
230 FOR J-l TO L
235 LET K-K*l
240 LET EC К)С EC К)*Q)“EC 1)
245 PRINT ECK),
250 NEXT J
255 PRINT
260 NEXT I
265 STOP
400 END
Таблица 5.6
Программа на БЭЙСИКе для табулирования аддитивных
эффектов в факторных планах
5 REM PROGRAM ТО CONSTRUCT ADDITIVE TABLE
10 DIM N(6)#Y(72),E(24)#C(6)#V(6)
15 READ D
20 LET M-l
25 FOR I«1 TO D
30 READ N(I)
35 LET M-M*N(I)
40 NEXT I
45 FOR 1-1 TO M
50 1 READ EC I)
55 I NEXT I
265 LET P-1
270 LET K-l
275 LET A-EC1)
280 FOR 1-1 TO D
285 LET L-NCI)
290 LET CC I )-L
295 LET P-P*L
300 LET K-K*L
305 LET VCD-K
310 LET B-ECK)
315 LET A-A+B
320 LET J-K
325 IF L-l THEN 350
330 LET ECJ)-E(J-l)-ECJ)
335 LET J-J-l
340 LET L-L-l
345 GO TO 325
350 LET ECJ)-B-ECJ)
355 NEXT I
360 LET T-P
365 LET Y(P)-A
370 LET I-D
375 LET A-0
380 LET J-VCI )
385 LET A-A*E(J)
390 LET CCI)-CCI )- I
395 LET VCI)-V(I)-l
400 IF C(I)<>0 THEN 425
405 LET CCI)-NCI )
410 LET VCI)-VCI)*C<I)
415 LET I-I-l
420 IF 1-0 THEN 440
422 GO TO 380
425 LET T-T-l
430 LET Y<T)-YCT*1 )*A
435 GO TO 370
440 LET J-0
442 FOR 1-1 TO P
445 PRINT Y( I
446 LET J-J*l
447 IF J<>NCD) THEN 450
448 PRINT
449 LET J-0
450 NEXT I
470 STOP
600 END
Стохастические модели
113
Таблица 5.7
Данные и результаты счета по программам, приведенным
в табл. 5.5 п 5.6
NEW OR OLD--OLD
OLD PROGRAM NAME--ADDEFF
READY
300 DATA 2#8# 3
301 DATA 0.84#1 .09#1.16
302 DATA 0.84#1.03#1.66
30 3 DATA 0.97,0.88#1.50
30 4 DATA 1 .06,0.94# 1 . 50
30 5 DATA 1.00#1.13#1.59
30 6 DATA 0.81#1.00#1.31
30 7 DATA 0.75#1.06#1.44
308 DATA 0.91#0.56#1.50
READY
RUN
1.105417
- .07541665 .07125001 .01125 .061 25 .1345833
- .06541666 -.02208333 - . 1 1 541 67
- .2079166 -.1441667 .3520833
READY
OLD
OLD PROGRAM NAME--ADDTAB
READY
500 DATA 2*8*3
501 DATA 1.105
502 DATA -0.075*0.071*0.01 1*0.061,0.135#-0•065#-0•022#-0•115
503 DATA -0•208#-0.144,0.352
RUN
<8220001 .8860001 1.382
•9680001 1 .032 1.528
•9080001 .9720001 1.468
•9580001 1 .022 1.518
1 <032 1 .096 1 . 592
• 832 .896 1 . 392
• 875 .9 39 1 . 435
• 782 .846 1.342
READY
114 Глава 5
Основное значение описанной выше аддитивной модели
заключается, однако, в возможности дальнейшего развития
методики дисперсионного анализа, которая определена
этой моделью. Сколько параметров действительно необхо-
димо для описания реакции сеянцев на условия, при кото-
рых проводятся опыты трех типов (будем считать, что
отсутствие стерилизации — контроль — также является от-
дельным типом опыта)? На практике пас, как правило, не
интересует эффект блоков, поскольку блоки вводятся для
того, чтобы обеспечить необходимую повторность при срав-
нен пн опытов, и, кроме того, они могут повышать надеж-
ность сравнений. Например, в некоторых блоках может
использоваться почва, собрапная в различное время из
остальных блоков; иногда серии опытов ставятся при раз-
личном затенении. Эти различия несущественны постоль-
ку, поскольку все участки в пределах одной серии макси-
мально одинаковы, за исключением условий проводимого
на них опыта. Поэтому для всех реальных ситуаций мы
можем свести нашу модель к соотношению
= ц + +
где е; — случайные ошибки, взаимно независимые и нор-
мально распределенные с нулевым средним и дисперси-
ей о 2.
Метод дисперсионного анализа состоит в определенном
разбиении общей суммы квадратов отклонений наблюдае-
мых значений от значений, ожидаемых исходя из теоре-
тической модели. Это разбиение соответствует числу оце-
ниваемых параметров и позволяет выявить соответствую-
щую вариабельность. Результаты анализа данных табл. 5.4
приведены в табл. 5.8. Общей суммой квадратов отклоне-
ний является сумма, полученная в предположении, что
ожидаемым значением для каждого опыта служит среднее
по всему эксперименту. Сумма квадратов отклонений по
блокам получается при вычислении ожидаемого значения
для каждого участка как экспериментального среднего
плюс эффект соответствующего блока, а сумма квадратов
отклонений по опытам — при вычислении ожидаемого зна-
чения для участка как экспериментального среднего плюс
эффект соответствующего опыта. Сумма квадратов откло-
нений для ошибки получается, как и следовало ожидать,
Стохастические модели
115
Таблица 5.8
Дисперсионный анализ данных табл. 5.4
Источник дис- персии Степени сво- боды Сумма квад- ратов от- клонений Средний квадрат F □
Блоки Опыты Ошибка 7 2 14 0,1525 1,5038 0,3295 0,0218 0,7519 0,0235 0,93 32,00
Сумма 23 1,9858
Средние квадраты являются оценками следующих параметров:
Блоки
Опыты
а2+гаЗ
Ошибка а2
при вычислении ожидаемых значений для участков как
экспериментальных средних плюс эффекты соответствую-
щего блока и опыта. На самом деле существуют укорочен-
ные методы вычисления этих сумм квадратов отклонений;
выкладки для данного примера полностью приведены в
книге Джефферса [38].
Некоторого пояснения требует термин «степени свобо-
ды» (табл. 5.8.). В каждой из трех рассмотренных в
табл. 5.8 моделей оценивается различное число параметров.
Хотя число блоков равно восьми, мы связаны условием, со-
стоящим в том, что эффекты блоков в сумме должны да-
вать нуль, так что в действительности независимы лишь
семь из этих эффектов — восьмой уже фиксирован, т. е.
имеется 7 = 8—1 степеней свободы. Аналогично, вследствие
допущения о том, что в сумме должны давать нуль и эф-
фекты опыта, в распределении этих эффектов существует
лишь 2 = 3—1 степеней свободы. Число степеней свободы
116 Глава 5
для модели с обоими типами эффектов получается пере-
множением степеней свободы для блоков и опытов, т. е.
равно
2 х 7 = 14 .
Заметим, что сумма степеней свободы для всех трех
моделей равна числу степеней свободы для общей суммы
квадратов отклонений, т. е. 23 = 24—1, поскольку каждому
из 23 участков мы можем приписать любое значение, но
тогда значение для последнего участка определится из
условия, что усредненное ожидаемое значение должно быть
равно экспериментальному среднему.
Средние квадраты, или дисперсии, получаются делени-
ем сумм квадратов отклонений на соответствующие числа
степеней свободы. Средние квадраты для трех моделей,
отражающие дисперсии для различных составляющих, так-
же приведены в табл. 5.8, а деление средних квадратов
для блоков и опытов па средний квадрат ошибки дает кри-
терий достоверности (значимости) эффектов соответствен-
но блоков и опытов, отвечающий стандартному F-критерию
математической статистики. Искомый уровень значимости
дает сравнение вычисленных отношений с табличными
значениями F (для соответствующего числа степеней сво-
боды) и в пашем случае столь большое отношение для
опытов не появилось бы и в одном случае па сотню, будь
эффект опытов нулевым. Эффект же блоков, с другой сто-
роны, вполне мог оказаться большим даже для популяции,
где он па самом деле нулевой. Поэтому для всех реальных
ситуаций паша модель сводится к выражению
Yj = I* + Х1 + е >
параметры которого оцениваются как
Y j = т Ь О7- -4- е,
где т = 1,105,
О, = —0,208,
О2= —0,144,
О3 = 0,353,
а е — случайная ошибка, значения которой распределены
Стохастические модели 117
независимо и нормально с нулевым средним и дисперсией
0,0235/8 = 0,00294.
Далее по этой модели мы можем оценить эффект стери-
лизации формалином:
dQ { = (1,105 — 0,144) — (1,105 — 0,208) = 0,064 .
Стандартная ошибка равна
S- = |/ 2 х =± 0,077.
Аналогично эффект стерилизации паром оценивается
как
d0 2 = (1,105 + 0,353) — (1,105 — 0,208) = 0,561
со стандартной ошибкой, равной по-прежпему+0,077. Та-
ким образом из модели следует, что средний диаметр сеян-
цев увеличивается на 0,561+0,077 мм, и это увеличение
является статистически значимым. Увеличение же средне-
го диаметра сеянцев на 0,064+0,077 мм, вызываемое стери-
лизацией формалином, статистически незначимо. Выявле-
ние причины этого интересного различия может составить
предмет дальнейшего исследования.
Пример 5.2 представляет собой весьма простое приме-
нение линейной аддитивной модели, лежащей в основе дис-
персионного анализа, и тем, кто намерен применять сис-
темный анализ и математические модели в экологии,
настоятельно рекомендуется прочесть какой-нибудь общий
учебник статистики, где разбирается дисперсионной и ко-
вариационный анализ. Методы, разработанные в анализе
этого типа, оказываются исключительно плодоторными, не-
смотря на очевидную жесткость лежащих в его основе
допущений, которые формулируются так:
1. Эффекты опытов и блоков предполагаются аддитивны-
ми.
2. Остаточные эффекты считаются независимыми от на-
блюдения к наблюдению и распределенными с нулевым
средним и одинаковой дисперсией.
3. При вычислении критериев значимости и оценке до-
верительных интервалов остаточные ошибки считаются
нормально распределенными.
118 Глава 5
Даже если указанные допущения выполняются лишь
приблизительно или если данные еще нужно преобразо-
вать, чтобы добиться этого, дисперсионный анализ дает
конкретный метод построения моделей экологических по-
пуляций, а также метод оценки параметров моделей по вы-
борочным наблюдениям. Эти модели могут быть довольно
сложными и содержать линейные взаимосвязи и взаимосвя-
зи более высокого порядка между многими факторами. На-
пример, с помощью тщательно спланированных экспери-
ментов и последующей обработки результатов можно вы-
явить влияния различных элементов при внесении
удобрений и одновременно проверить, оказывается ли ре-
зультат введения каждого элемента одним и тем же при
наличии и в отсутствие какого-то одного или всех осталь-
ных элементов. Аналогично, путем проведения столь же
тщательно спланированных экспериментов и применения
факторных моделей, можно определить, как следует менять
управление в луговой системе по числу укосов и количест-
ву удобрений, чтобы учесть годичные изменения климата.
Рассмотрение более сложных аддитивных моделей выхо-
дит, однако, за рамки данной книги.
Множественный регрессионный анализ
Описанные выше линейные модели представляют собой
частный случай более общих регрессионных моделей, ко-
торые задаются выражением
У = Ро + + Рг^г 4" • • • 4" Рр^р 4" е ,
где 0о — константа,
0/ — коэффициент при г-й переменной,
xt — i-я. переменная, а е является случайной ошибкой,
значения которой распределены нормально и не-
зависимо с пулевым средним и дисперсией о2.
В этом выражении у рассматривается как случайная
величина, которая распределена в окрестности некоторого
среднего, зависящего от значений р переменных ..., хр.
Считается, что эти переменные влияют лишь па среднее у
и, в частности, что дисперсия постоянна. Когда нужны
критерии значимости, предполагают далее, что у распреде-
лена нормально в окрестности этого среднего. И наконец,
Стохастические модели
119
считают, что у можно рассматривать как линейную функ-
цию переменных .г, хотя функциональная зависимость мо-
жет иметь место и между самими х, так что более общие
модели оперируют полиномиальными и другими нелиней-
ными функциями.
В частном случае аддитивных моделей экспериментов,
аналогичных описанным выше, параметры модели
оцениваются обычно путем минимизации остаточной сум-
мы квадратов 2(У—у) 2 для выборки из определенной по-
пуляции. В книге Спрента [75] обсуждается применимость
различных регрессионных моделей, а рекомендации и про-
граммы для подбора таких моделей по фактическим дан-
ным можно найти у Дэвиса [16]. Чтобы получить некото-
рое представление о применении регрессионных моделей
в экологических исследованиях, рассмотрим один конкрет-
ный пример.
Пример 5.3. Скорости разложения листового опада
В серии экспериментов по определению скорости раз-
ложения листового опада точно взвешенные образцы вы-
сушенного па воздухе опада по 0,25 г разлагали па поверх-
ности мулля (лесной почвы) в стеклянных пробирках
диаметром 28 мм и длиной 15 см, помещенных в полевые
условия, но защищенных от животных. Опад и почву пред-
варительно обрабатывали, чтобы уничтожить животных и
их покоящиеся стадии. Пробирки выставляли в поле в спе-
циальных коробках, не доступных для животных, по про-
пускавших дождь и воздух. Время от времени проводили
выборочное обследование пробирок, причем каждая вы-
борка состояла из двух пробирок. Опад взвешивали в спе-
циальных респираторных колбах, а дыхание измеряли в
респирометрах по поглощению кислорода в течение вось-
ми часов с момента установления темнового равновесия.
Поглощение кислорода измеряли при трех или четырех
температурах, в том числе при 10°С, в течение нескольких
последовательных дней. Выбранный диапазон температур
соответствовал диапазону, характерному для полевых ус-
ловий в данное время года. Предварительные исследования
показали, что извлечение листьев из пробирок не вызывает
заметных изменений в дыхании и что результаты, получен-
120 Глава 5
ные при различных температурах в последовательные дни,
одинаковы независимо от того, повышалась температура
в эти дни или понижалась. После измерения дыхания об-
разцы высушивали в печи при 105°С и взвешивали. Полное
описание обработки данных этого эксперимента приведено
в работе Джефферса и др. [39]. Данные представляли в
виде графика зависимости поглощения кислорода от тем-
пературы. Оказалось, что связь между температурой и по-
глощением кислорода нелинейна и что разброс показателей
поглощения при высоких температурах больше, чем при
низких. Последнее обстоятельство указывало на что, что
нужно перейти от абсолютных значений поглощения кис-
лорода к их логарифмам и прибавить константу 1, чтобы
скорректировать нулевые значения. Построение графика
в новых координатах подтверждало, что логарифмирование
действительно устраняет нелинейность и дает примерно
одинаковые дисперсии во всем диапазоне температур.
Уравнение
lg (Y + 1) == 0,561 — 8,701 Д • 10’4 +
+ 3,935Д2 • 10’7 + 7,187В • 10'4 + 0,0398? ,
где Y — поглощение кислорода, измеренное в
мкл• (0,25 г)-1-ч~1, Д — число дней, в течение которых
выдерживались образцы, В — процентное содержание вла-
ги в образцах, Т — температура, измеренная в °C, дает
несмещенные оценки для поглощения кислорода во всем
диапазоне дней, температур и влажностей, охваченном в
этом эксперименте, со средним отклонением в поглощении
кислорода, равном 0,319 ±0,321.
Применение регрессионной модели во многом способ-
ствовало пониманию биологической природы изменения по-
глощения кислорода в ответ на изменения факторов среды.
Для описания связи между температурой и скоростью ка-
кого-либо биологического процесса биологи применяют в
настоящее время две основные модели. Первая и более
ранняя из них — это уравнение Аррениуса, которое запи-
сывается обычно в экспоненциальной форме, содержащей
множитель Больцмана:
я = ле-£/(ЛГ>,
где К — константа скорости данной реакции, А — постояп-
Стохастические модели
121
пая, Е — константа, характерная для данной реакции и
определяющая влияние температуры па ее скорость, R —
газовая постоянная и Т — абсолютная температура. Лога-
рифмируя это уравнение, получаем
In Я-In А + (-E/R) (1/Г),
т. е. логарифм константы скорости реакции является ли-
нейной функцией обратного значения температуры.
В основе второй модели лежит использование темпера-
турного коэффициента (?ю, который можно записать как
Qlo (^2//<1)10/(^-7'1).
Когда разность температур составляет 10°С, значение (?ю
равно отношению констант скоростей данной реакции при
двух этих температурах. Отсюда следует соотношение типа
К = Серг,
где С — константа, а Р= (Iii(?io)/Ю. Логарифмируя это
соотношение, получаем
In Д’ —In С ±РТ,
т. е. логарифм константы скорости реакции оказывается
линейной функцией температуры.
Различие между этими двумя моделями состоит в том,
что при заданной разности температур (?ю пе зависит от
абсолютной температуры, тогда как для уравнения Арре-
ниуса величина
K2/Kt = exp {- E/R(Т21 - гг1)}
при заданной разнице температур изменяется с изменени-
ем абсолютного значения температуры.
Исследование свойств листового опада в дубовом лесу
привело к модели, основанной па использовании коэффи-
циента (?10, поскольку Р= (ln(2io)/lO пе зависело от абсо-
лютного значения температуры п равнялось 0,09158, отку-
да следовало, чго (>ю = 2,5.
122
Глава 5
Марковские модели
Последний из типов стохастических моделей, которые
мы рассмотрим в данной книге, — это марковские модели;
они состоят в близком родстве с матричными моделями,
обсуждавшимися в гл. 4. Основной конструкцией в этих
моделях служит матрица, элементы которой равны вероят-
ностям перехода из одного состояния в другое за опре-
деленные промежутки времени. Эта матрица, таким обра-
зом, весьма похожа па матрицы, использующиеся в мат-
ричных моделях, за исключением того, что суммы вероят-
ностей по всем строкам равны 1.
Марковская модель первого порядка — это модель, в
которой будущее развитие системы определяется ее теку-
щим состоянием и пе зависит от того, каким путем система
пришла в это состояние. Последовательность результатов,
получаемых из такой модели, часто называют марковской
цепью. Применение этой модели к практическим ситуациям
требует выполнения трех основных условий:
1. Система должна допускать классификацию на конечное
число состояний.
2. Переходы должны происходить в дискретные моменты
времени, правда, эти моменты могут быть достаточно
близкими, чтобы для моделируемой системы время мож-
но было считать непрерывным.
3. Вероятности пе должны меняться со временем.
Возможны и некоторые модификации этих условий,
однако ценою возрастания математической сложности мо-
дели. Иногда используют вероятности, зависящие от вре-
мени, и непостоянные промежутки времени между пере-
ходами, а в марковских моделях более высокого порядка
вероятности перехода зависят не только от текущего со-
стояния, по и от одного или нескольких предшествующих.
Особенно велико потенциальное значение марковских
моделей, которые не нашли еще широкого применения в
экологии. Проведенные предварительные исследования по-
казывают, что в тех случаях, когда изучаемые системы
проявляют марковские свойства и, в частности, свойства
стационарности и «марковости» первого порядка, из ана-
лиза модели можно получить ряд интересных и важных
выводов, например:
Стохастические модели
123
1. Алгебраический анализ переходной матрицы выявляет
существование переходных множеств состояний, замк-
нутых множеств состояний или поглощающих состоя-
ний. Дальнейший анализ позволяет разбить переходную
матрицу па блоки, которые исследуются по отдельно-
сти, что упрощает изучение экологической системы.
2. Анализ переходной матрицы позволяет вычислить сред-
нее время перехода от одного состояния к другому и
среднюю длительность пребывания в конкретном со-
стоянии, если оно достигается.
3. Когда существуют замкнутые или поглощающие состоя-
ния, можно вычислить вероятность пребывания в замк-
нутом множестве или среднее время поглощения.
Экологический смысл этих понятий схематически иллю-
стрируется рис. 5.1, где показала типичная сукцессия;
каждая стадия этой сукцессии определяется характеристи-
ками доминирующих на дайной стадии типов растений.
Как показывает диаграмма, переходным множеством со-
стояний является множество, каждое состояние которого
может в конце концов быть достигнуто из любого другого
состояния этого множества, по которое покидается навсег-
да, если система переходит в замкнутое множество состоя-
ний либо в поглощающее состояние.
Замкнутое множество состояний отличается от пере-
Рис. 5.1. Схематическое изображение переходных, замкнутых и по-
глощающих состояний.
124 Глава 5
ходного тем, что оно не может быть покинуто, если систе-
ма перешла в одно из состояний замкнутого множества.
Поглощающим является состояние, которое, будучи достиг-
нуто, уже пе покидается, т. е. в нем происходит полное
самозамещение. Среднее время первого достижения соот-
ветствует тогда среднему времени, необходимому для на-
ступления конкретной стадии сукцессии, а среднее время
поглощения — среднему времени достижения устойчивой
композиции.
Марковские модели можно обобщить па уровни второго
и третьего порядков с известной степенью пестациопар-
ности и другими формами нелинейности, по это значитель-
но усложняет последующий анализ. Имеются также фор-
мальные методы проверки существования зависимостей
второго и третьего порядков, однако в ближайшем буду-
щем подобные модели вряд ли найдут широкое применение
и признание в экологии.
Для построения моделей марковского типа необходимо
следующее:
1. Некая разумная классификация состояний сукцессии
по определимым категориям (в выявлении этих состоя-
ний часто оказываются полезными многомерные модели
следующей главы).
2. Данные для определения переходных вероятностей или
скоростей, с которыми состояния переходят со временем
из одной категории данной классификации в другую.
3. Данные о начальных условиях, сложившихся в некото-
рый фиксированный момент времени, обычно после из-
вестного возмущения.
Выбор между марковскими и другими моделями часто
зависит от целей исследования, по там, где можно при-
менить прямой марковский подход, появляется возмож-
ность провести дальнейший алгебраический анализ, позво-
ляющий лучше понять стохастический характер многих
экологических процессов и вычислить средние времена до-
стижения и поглощения, а также степени стабильности и
сходимости для определенного состояния, что дает допол-
нительную информацию, имеющую непосредственное от-
ношение к экологии и управлению.
Таким образом, преимущества моделей марковского ти-
па сводятся к следующему:
Стохастические модели
125
1. Такие модели довольно легко строить па основе данных
по сукцессиям.
2. Марковские модели пе требуют глубокого понимания
внутренних механизмов динамических изменений в сис-
теме, но могут помочь выявить те области, где такое
понимание имело бы важное значение, и, следовательно,
выступают как ориентир и стимул для дальнейшего ис-
следования.
3. Основная матрица переходных вероятностей отобража-
ет главные параметры динамических изменений в сис-
теме таким образом, который доступен лишь немногим
моделям других типов.
4. Результаты анализа марковских моделей легко пред-
ставить графически, что делает их более наглядными и
попятными специалистам по управлению ресурсами.
5. Вычислительные потребности при исследовании марков-
ских моделей довольно скромны и легко удовлетворяют-
ся с помощью малых ЭВМ либо — при небольшом числе
состояний — с помощью ручных калькуляторов.
У марковских моделей имеются, однако,,и определен-
ные недостатки, в том числе:
1. Отсутствие зависимости от функциональных механиз-
мов снижает их привлекательность для экологов, склон-
ных к функциональному подходу.
2. Отклонение от стационарности, в предположении кото-
рой получены марковские цепи первого порядка, в слу-
чае прямых марковских моделей в принципе хотя и
возможно, но приводит к непомерно большим трудно-
стям в анализе и вычислениях.
3. В отдельных случаях имеющихся данных недостаточно
для того, чтобы достоверно оцепить вероятности или
скорости переходов, особенно если эти переходы редки.
4. Как и в других моделях, выяснение адекватности моде-
ли зависит от возможности предсказать поведение сис-
темы; сделать же это для процессов, охватывающих
достаточно длительные периоды времени, довольно
трудно.
Эти трудности обязывают к большой осторожности в
применении марковских цепей к экологическим проблемам.
Главная задача состоит здесь в сборе данных для вычисле-
ния переходных вероятностей и построения переходных
126 Глава 5
матриц, для чего требуется подробная документация об
изменениях, происходящих за определенные интервалы
времени, п реакциях на различные типы возмущений. Но
когда такого рода данные существуют как исторические
либо экспериментальные записи, подобные модели оказы-
ваются весьма полезными и, вероятно, они найдут более
широкое применение в будущем.
Пример 5.4. Сукцессионные изменения на верховом болоте
На верховых болотах часто можно наблюдать интерес-
ные сукцессионные изменения в результате усиления дре-
нирования; в табл. 5.9 приведены оценки вероятностей пе-
Таблица 5.9
Переходные вероятности для сукцессионных изменений
на верховом болоте (временной шаг = 20 годам)
Начальное состояние Вероятность перехода в конечное состояние
1. Болото 2. Calluna 3. Лес 4. Участок, спорадически выедаемый крупными травоядными
1. Болото 0,65 0,29 0,06 0,00
2. Calluna 0,30 0,33 0,30 0,07
3. Лес 0,00 0,28 0,69 0,03
4. Участок, спородичес- ки выедаемый круп- ными травоядными 0,00 0,40 0,20 0,40
реходов между четырьмя возможными состояниями за пе-
риод в двадцать лет. Состояние 1 соответствует наиболее
влажной фации, в которой доминирует Sphagnum, а также
представители сосудистых растений — в основном Calluna
vulgaris, Erica tetralix и Eriophorum vaginatum. Состояние
2 отвечает более сухой фации с ассоциацией Calluna —
Cladonia и проростками Betula и Pinus sylvestris. Состоя-
ние 3 соответствует более или менее укоренившемуся ле-
су из Betula и Pinus sylvestris, причем для более зрелого
леса типично сообщество V actinium myrtillus с гипновыми
Стохастические модели
127
мхами. Состояние 4 соответствует стадии, на которой бо-
лее сухие фации спорадически выедаются крупными тра-
воядными, в результате чего закрепляется ассоциация, где
доминирует Molinia — Pteridium.
Итак, участки, характеризующиеся вначале типичным
для болота комплексом растительности, с вероятностью
0,65 остаются по прошествии 20 лет в том же состоянии и
с вероятностями 0,29 и 0,06 превращаются в сообщество,
где доминирует Calluna, и в лес соответственно. Участки,
на которых вначале доминирует Calluna, имеют примерно
равные вероятности остаться в том же состоянии, вернуть-
ся к болоту из-за флуктуаций уровня грунтовых вод или
превратиться в лес; с малой вероятностью (0,07) опи пре-
вращаются в участки, спорадически выедаемые крупными
травоядными. Лесные участки с вероятностью 0,69 сохраня-
ются как лес, с вероятностью 0,28 из-за вымирания деревьев
возвращаются к состоянию, для которого типичным явля-
ется Calluna, и по-прежнему с малой вероятностью (0,03)
превращаются в участки, спорадически выедаемые круп-
ными травоядными. Выедаемые участки с равной вероят-
ностью подвергаются дальнейшему выеданию или возвра-
щаются в состояние, где доминирует Calluna, и с вероят-
ностью 0,20 превращаются в лес в результате развития
невыеденных проростков.
Таким образом, ни одно из указанных четырех состоя-
ний не является замкнутым или поглощающим: в целом
набор этих состояний отражает переход от болота к ле-
су — переход, па который накладываются внешние воз-
мущения, обусловленные выеданием растительности тра-
воядными. Хотя возврат от состояния, где доминирует
Calluna, к болоту вследствие изменения уровня грунтовых
вод возможен, прямой переход от леса к болоту не проис-
ходит. Когда поглощающие состояния отсутствуют, мар-
ковский процесс является эргодической цепью, и все след-
ствия из матрицы переходных вероятностей мы можем по-
лучить, используя основные свойства марковской модели.
Прежде всего заметим, что, как и в матричных моде-
лях, обсуждавшихся в гл. числа, приведенные в табл. 5.9,
представляют собой вероятности переходов из состояний в
состояния за один временной шаг (20 лет). Вероятности
переходов за два временных шага можно легко получить,
128 Глава 5
умножая «одношаговую» переходную матрицу самое на се-
бя, так что в простейшем случае двух состояний соответ-
ствующие вероятности задаются матрицей
Гп(2) п(2Л
Р\\ Р\2
п(2) п(2)
L Р21 Р22 J
Р11 Pi2 v Al Pi2
A
_Ai Рл\ LAi P22.
В сжатой форме мы можем записать эту операцию в виде
р(2) = р р.
Аналогично «трехшаговые» переходы описываются мат-
рицей
Гп(3) п(3)1
Ai А2
п(3) п(3)
L Р21 Р22 J
Ai Р\2 Ра Pi2
(2) (2)
Р21 Р22] [P2l Р22
ИЛИ
р(3) _ р(2) ' р
В общем случае для п шагов мы можем записать
р(>0 __ р (п~ О , р
Для матрицы табл. 5.9 вероятности переходов за два шага
таковы:
"0,5095 0,3010 0,1674 0,0221"
0,2940 0,3079 0,3380 0,0601
0,0840 0,2976 0,5661 0,0523
0,1200 0,3480 0,3380 0,1940
а для четырех временных шагов они равны:
"0,3648 0,3035 0,2893 0,0424"
0,2759 0,3048 0,3649 0,0543
0,1841 0,3056 0,4528 0,0595
_0,2151 0,3114 0,3946 0,0789_
Если матрицу вероятностей переходов последовательно
возводить в степень до тех пор, пока каждая ее строка пе
Стохастические модели
129
станет такой же, как и все остальные, образуя некоторый
фиксированный вектор вероятностей, мы получим в ре-
зультате так называемую регулярную переходную матри-
цу. Эта матрица показывает, до какой степени вероятность
перехода из одного состояния в другое не зависит от на-
чального состояния, а фиксированный вектор вероятностей
t дает стационарное распределение вероятностей всех со-
стояний. В нашем примере этот вектор равен
[0,2177 0,2539 0,3822 0,1462].
Таким образом, если вероятности переходов оценены
правильно и остаются постоянными, данная экосистема
достигнет в конце концов состояния равновесия, в котором
примерно 22% площади занято болотами и приблизитель-
но по 25, 38 и 15% занимают сообщество Calluna, лес и
выедаемые крупными травоядными участки соответствен-
но. Если, как в пашем примере, поглощающие состояния
отсутствуют, пас смогут заинтересовать также средние
времена первого достижения любого состояния, т. е., на-
пример, среднее время, необходимое для того, чтобы боло-
то превратилось в участок, где доминирует Calluna, в лес
либо выедаемый травоядными участок. С другой стороны,
мы можем задаться вопросом, сколько времени понадобит-
ся для того, чтобы случайно выбранный участок превра-
тился в болото, сообщество Calluna, в лес или выедаемый
крупными травоядными участок; для этого пам понадо-
бится найти средине времена первого достижения в рав-
новесии.
В результате пе очень сложных вычислений мы полу-
чим следующую матрицу средних времен первого дости-
жения:
" 0 3,561 7,197 31,688”
9,566 0 5,237 28,755
13,672 4,107 0 29,178
_18,673 9,107 5,000 0
Поскольку каждый временной шаг равен 20 годам,
среднее время, необходимое для того, чтобы участок, где
преобладает Calluna, превратился в болото, составляет
5-843
130 Глава 5
9,566 Х20=191 г. Аналогично среднее время, необходимое
для превращения леса в участок, на котором преобладает
Calluna, составляет 4,107X20 = 82 г; таким же образом
можно вычислить и все другие времена.
Наконец, зная матрицу времен и вектор вероятностей,
легко найти вектор средних времен первого достижения в
равновесии:
[10,385 3,676 3,627 25,351].
И вновь, поскольку каждый временной шаг равен двад-
цати годам, среднее время, необходимое для того, чтобы
случайно выбранный участок превратился в болото, со-
ставляет 10,385X20 = 208 лет, а чтобы он превратился в
участок, па котором преобладает вид Calluna, в лес или
участок, выедаемый травоядными, требуется в среднем
74 г., 73 г. и 507 лет соответственно.
Здесь, как и во многих других математических моде-
лях, основные свойства модели дают дополнительную ин-
формацию о поведении моделируемо]'! системы и тем са-
мым позволяют избежать проведения длительных экспе-
риментов, которые в противном случае было бы необходимо
поставить для определения свойств эмпирической модели
динамики.
Исторически первыми среди математических моделей
были разработаны детерминистские модели. Большинство
из пих, однако, разрабатывалось применительно к прило-
жениям физических и химических законов для условий,
когда вариабельность реакции моделируемых систем бы-
ла сравнительно мала или по крайней мере относительно
легко контролировалась. Наиболее полного расцвета эти
физические аналоги достигли, пожалуй, с развитием нью-
тонова исчисления, хотя неуклонный прогресс в исследо-
вании фундаментальных математических свойств детер-
министских систем наблюдается и сейчас. Первую попытку
применить подобный детерминистский образ мышления к
биологическим и экологическим системам представляют
собой динамические модели, описанные в гл. 3. По, как
подчеркивалось в гл. 1, экологические связи неизбежно
несут в себе изменчивость, внутренне присущую живым
организмам и их местообитаниям, а также взаимодейст-
виям живых организмов с окружающей средой; при моде-
Стохастические модели
131
лировапии этой изменчивости мы должны использовать
также соответствующие стохастические связи.
Именно осознание того, что биологические объекты об-
ладают внутренней изменчивостью, явилось одной из дви-
жущих сил развития современной статистики. Порожден-
ное стремлением предсказать исход игры случая, изуче-
ние вероятностей, начатое в восемнадцатом и девятнадца-
том столетиях, было продолжено затем в трудах повой
школы статистиков, запятых поисками формальных ана-
логий биологических процессов и моделирования экспери-
ментов в земледелии и лесоводстве. В этой области ста-
тистики также достигнут поразительный прогресс, в
результате которого математика стала более изящной, чет-
че выявляя основные свойства моделей. В дайной главе мы
коснулись лишь некоторых преимуществ использования
этих хорошо разработанных семейств математических мо-
делей, чтобы дать представление о различных аспектах,
интересных как с научной точки зрения, так и с точки зре-
ния управления. Чтобы основные свойства модели стали
более понятными, мы приняли, как и в предыдущей гла-
ве, более высокий уровень формализации моделей, хотя и
пе отказывались от необходимости проверять, являются
ли математические допущения справедливыми для той кон-
кретной проблемы, которая пас интересует. Мы еще вер-
немся к этой теме в последней главе данной книги.
Есть два момента, из-за которых детерминистские мо-
дели ие способны адекватно описывать реальные экологи-
ческие системы. Во-первых, они допускают, что размер
популяций может быть бесконечен, и, во-вторых, не учиты-
вают флуктуации свойств среды со временем. Следователь-
но, применение детерминистских моделей вместо стохасти-
ческих можно оправдать лишь тем, что они удобнее с
точки зрения математики. Если, например, детерминист-
ская модель указывает па устойчивое равновесие, то соот-
ветствующая стохастическая модель почти наверняка
предскажет длительное существование, а если детермини-
стская модель указывает па отсутствие равновесия либо
его неустойчивость, стохастическая модель скорее всего
предскажет вымирание с высокой вероятностью. Однако,
несмотря па то что, как мы ожидаем, детерминистские и
стохастические модели должны иметь близкие свойства,
5*
132 Глава 5
предсказания кажущихся справедливыми альтернативных
моделей оказываются иногда противоположными, и имен-
но это противоречие представляет наибольший интерес.
Вот почему в системном анализе придается особое значе-
ние одновременному исследованию нескольких альтерна-
тивных моделей — решений одной практической задачи.
Когда используется детерминистская модель, по-видимо-
му, лучше всего сопоставлять ее результаты с результата-
ми одной или нескольких стохастических моделей. Но
даже тогда, когда детерминистская модель является единст-
венно приемлемой, оценивать ее параметры часто прихо-
дится с привлечением математической статистики и стоха-
стических процессов. Вот почему эти методы имеют фун-
даментальное значение в применении системного анализа
к экологии.
Пример^Марков-/5лОТО.С!ПичеС>^.ос^я
ские т,„ ипЯо„„ веи»^,,
струв^УР11
Поглощение
кислороои
днали3
»3&г ^,, ?✓
* ^^^^-Модельу*
лЯ Стерилизация
е
/. я.
// I
// |
I
Нормальное
л
кие модели
/
Р^ер.
4
%*.
0^<SSJe
_____
__Другие ——х
/ о мае
Неймана
Пойа
•HyaccoHOG-^^
СКОР
Блоки "%
Vofcop
6
МНОГОМЕРНЫЕ МОДЕЛИ
В предыдущих главах мы называли переменной любую
величину, которая принимает различные значения для
разных индивидов или же различные значения для одного
и того же индивида в разное время. В статистике термин
«переменная» определяется как «величина, которая может
принимать любое значение из некоторого заданного мно-
жества значений», а сами значения могут быть непрерыв-
ными, как в случае измерения высоты, или дискретными,
как при подсчете индивидов. В некоторых случаях приня-
то использовать это слово для обозначения пеколичест-
вепных характеристик. Например, «пол» в этом смысле
можно рассматривать как переменную, поскольку любой
индивид может принимать одно из двух значений — «са-
мец» или «самка».
В гл. 2 мы делали различие между зависимыми и неза-
висимыми, или регрессионными переменными. Зависимые
переменные — это те переменные, которые, как ожидается,
будут изменяться в ответ па изменения других перемен-
ных, тогда как регрессионные переменные обусловливают
изменения, приводящие к вариациям зависимых перемен-
ных. С различием между двумя этими классами перемен-
ных мы уже сталкивались в регрессионных моделях пре-
дыдущей главы.
В статистике различаются далее переменные и случай-
ные переменные. Случайная переменная — это величина,
которая может принимать любое значение из определен-
ного множества с какой-то определенной относительной
частотой пли вероятностью. Такие случайные переменные
иногда называются также случайными величинами, и их
можно считать определенными, если задано не просто
множество их допустимых значений, как для обычной ма-
тематической переменной, по и соответствующая частот-
ная или вероятностная функция, показывающая, сколь
часто данная переменная принимает то или иное значение
Многомерные модели
135
в исследуемой ситуации. Почти все рассмотренные до сих
пор модели были определены с помощью только одной слу-
чайной переменной, по в экологии и других приложениях
системного анализа есть масса ситуаций, где модели долж-
ны учитывать поведение более чем одной переменной
Все такие модели называют «многомерными»; они связа-
ны с методами, которые в совокупности именуются «мно-
гомерным анализом» — выражение, достаточно широко
используемое для обозначения метода обработки данных,
которые являются многомерными в том смысле, что каж-
дый представитель порождает значения р переменных.
Математический аппарат, применяемый при построе-
нии многомерных моделей, в основном пе нов. Например,
фундаментальные распределения вероятностей, связанные
с многомерными нормальными распределениями, были по-
лучены в 30-е годы, и методы, разработанные в ту пору,
служат основой большинства многомерных методов, при-
меняемых по сей день. Однако, когда число переменных
велико, вычисления, необходимые для многомерного анали-
за и построения многомерных моделей!, становятся крайне
громоздкими — их практически невозможно выполнить да-
же на электрических счетных машинках, если число пере-
менных превышает четыре или пять. Поэтому до тех пор,
пока пе получили широкого распространения ЭВМ, уда-
лось провести лишь очень небольшое число исследований
методом многомерного анализа, и почти во всех учебни-
ках приводились одни и те же примеры.
В настоящее время, когда ЭВМ стали общедоступны-
ми, это положение в корне изменилось, в результате чего
многомерные модели стали важным дополнением к тому
кругу моделей, с которым оперирует системный анализ.
Большинство необходимых вычислений запрограммирова-
но сейчас для многих имеющихся ЭВМ, и в литературе
появляется все больше и больше соответствующих при-
меров. Тем пе менее, применяя системный анализ в эко-
логии и других областях, многомерными моделями часто
пренебрегают.
На рис. 6.1 приведена простая классификация много-
мерных моделей. Прежде всего эти модели можно разде-
лить на две основные категории, а именно: модели, в ко-
торых одни случайные величины используются для пред-
13() Глава 6
сказания значений других, и модели, где все переменные
одного типа и не делается попыток предсказать одно мно-
жество значений по другому. Последнюю категорию моде-
лей, которые в целом называются описательными, можно
далее подразделить па модели, у которых все входы коли-
чественные п которые используют анализ главных ком-
понент и кластерный анализ, и модели, у которых по
крайней мере некоторые из входов пе количественные, а
качественные. Для последних больше подходит модель
взаимного осреднения. Прогностические модели, в свою
очередь, могут быть подразделены по числу предсказывае-
мых случайных величин, а затем по тому, являются ли
все прогнозы количественными. Если предсказывается не-
сколько величин, наиболее приемлемой является модель
канонического анализа. Если же предсказываемая вели-
чина только одна и a priori имеется две группы индиви-
дов, наиболее подходящей из имеющихся моделей оказы-
вается модель дискриминантного анализа, в то время как
для более чем двух априорных групп индивидов наиболее
Рис. 6.1. Простая классификация многомерных моделей.
Многомерные модели
137
плодотворным оказывается подход, основанный па приме-
пенни анализа канонических переменных. Ниже описаны
простые примеры применения всех этих моделей.
Описательные модели
Анализ главных компонент
Анализ главных компонент является, пожалуй, наибо-
лее известным и, несомненно, одним из самых простых
способов изучения многомерных вариаций. Этот метод
можно применять к любым данным, отвечающим следую-
щим основным требованиям.
1. В каждой из некоторого ряда выборок индивидов изме-
ряются и записываются значения одних и тех же пере-
менных. Измерения должны проводиться по всем инди-
видам; индивиды, для которых они проведены пе пол-
ностью, исключаются из рассмотрения, пока пе найдена
некая подходящая методика для восполнения недостаю-
щих значений.
2. Предполагается, что выбранные для анализа перемен-
ные непрерывны, а если они дискретны, то изменяются с
такими приращениями, которые достаточно малы, что-
бы величины можно было приближенно считать непре-
рывными.
3. К отношениям между переменными или их линейным
функциям, исходно включенным в анализ, не добавля-
ется никаких других отношений или линейных функ-
ций, так же как исходные переменные не заменяются
их отношениями или линейными функциями.
В задачу анализа главных компонент может входить
исследование одного или нескольких вопросов:
1. Анализ корреляций между отдельными переменными.
2. Сведение исходной размерности вариабельности, пред-
ставленной в отдельных выборках, к наименьшему чис-
лу существенных для анализа измерений вариабель-
ности.
3. Исключение тех переменных, которые песут сравни-
тельно мало дополнительной информации по изучаемой
проблеме.
138 Глава в
Выявление наиболее информативных сочетаний отдель-
ных выборок или какой-либо структуры, a priori зало-
женной в выборках.
5. Определение подходящих весов переменных при по-
строении индексов вариабельности.
6. Установление подлинности тех выборок, происхождение
которых неизвестно пли вызывает сомнения.
7. Распознавание ошибочно идентифицированных выборок.
В конкретном исследовании наиболее существенны
лишь некоторые из этих задач; отдельные из них могут
вообще не ставиться. В целом же метод главных компо-
нент дает одно из возможных решений всех перечислен-
ных выше задач.
Анализ главных компонент подробно описан в книгах
[41], [64] и [70]. Этот метод довольно широко использу-
ется при решении экологических проблем и особенно за-
дач таксономии; примеры анализа подобного рода можно
найти сейчас почтя в каждом номере любого экологиче-
ского журнала.
В сущности анализ главных компонент основан иа оты-
скании собственных чисел и соответствующих собственных
векторов матрицы коэффициентов корреляции между ис-
ходными переменными. Получающиеся собственные числа
и собственные векторы определяют компоненты полной
вариабельности (заложенной в исходных переменных) как
линейные функции этих переменных с коэффициентами,
выбранными так, что функции оказываются математиче-
ски независимыми, пли ортогональными друг другу. У этих
компонент не обязательно должен быть определенный эко-
логический смысл, однако, как показывает опыт работы
с данным методом, те компоненты, которые учитывают
значительную часть полной вариабельности, обычно этот
смысл имеют. Более того, вычисление значений указанных
компонент для каждого исследуемого индивида дает го-
товый способ учета основной изменчивости индивидов, вы-
явления их связей друг с другом и обнаружения неизвест-
ных пли неверно классифицированных индивидов. Лучше
всего проиллюстрировать этот метод простым примером.
Многомерные модели
139
Пример 6.1. Физическая среда в заливе Моркам и обитающие
в нем беспозвоночные
В ходе исследования возможных последствий для ок-
ружающей среды, к которым могло привести возведение
дамбы в заливе Моркам, были предприняты наблюдения в
течение августа и сентября 196(8 г. В каждой из 274 выбо-
рочных точек в различных частях залива было взято по
десять 10-саптпметровых колонок грунта; выборочный
материал тут же обрабатывали, а одпу четверть его остав-
ляли для химического и физического анализа. Для каждой
из выборок определяли значение следующих восьми пере-
менных:
1. Долю частиц размером >250 мкм.
2. Долю частиц размером 125—250 мкм.
3. Долю частиц размером 62,5—125 мкм.
4. Долю частиц размером < 62,5 мкм.
5. Потери в результате прокаливания при 550°С.
6. Содержание кальция.
7. Содержание фосфора.
8. Содержание азота.
Выбор указанных переменных был основан на резуль-
татах обработки данных предварительных наблюдений,
точнее говоря, это число переменных в основном исследо-
вании было подсказано анализом главных компонент.
В табл. 6.1 подытожены основные результаты наблюде-
ний для 274 выборочных точек, а в табл. 6.2 приведены
коэффициенты корреляции между исходными переменны-
ми. Применение обычного критерия значимости корреля-
ции между двумя переменными с числом степеней свобо-
ды п—2 = 274—2 = 272 (едва ли справедливого для корре-
ляционной матрицы подобного рода) показало, что доли
частиц крупнее 250 мкм и частиц размером 125—250 мкм
значимо и положительно коррелируют между собой и отри-
цательно коррелируют с долей частиц размером 62,5—
125 мкм и мельче 62,5 мкм. Последние показатели также
значимо и отрицательно коррелируют между собой. В про-
тивоположность этому все четыре переменные, характери-
зующие химические свойства грунта, были значимо и по-
ложительно взаимно коррелироваиы. Потери при прокали-
вании положительно коррелировали с долями частиц раз-
140
Глава (j
Таблица G.l
Переменные, характеризующие свойства среды
в заливе Моркам
Переменная Мини- мум, % Среднее, % Макси- мум, % Стандарт- ное от- клонение
1. Доля частиц размером > 250 мкм 0,100 1,207 43,0 4,479
2. Доля частиц размером 125—250 мкм 0,050 20,31 94,0 23,27
3. Доля частиц размером 62,5—125 мкм 0,100 53,67 97,0 21,36
4. Доля частиц размером <62,5 мкм 0,500 24,74 88,0 20,77
5. Потери в результате про- каливания при 550сС 0,440 1,504 3,72 0,555
6. Содержание кальция 1,500 2,401 9,00 0,704
7. Содержание фосфора 0,016 0,028 0,048 0,0056
8. Содержание азота 0,001 0,013 0,054 0,0093
Таблица 6.2
Коэффициенты корреляции между переменными среды
Х1
0,147' Хг
—0,283' -0,565' *3
—0,095 —0,572' —0,330' х.
—0,001 -0,402' 0.1272 0,388' *5
0,713' -0,253' —0,051 0,175' 0,359х Хв
-0,148- —0,405' 0,217' 0,204' 0,566х 0,167' х.
0,072 -0,420' 0,005 0,453' 0,735х 0,421' 0,436 X,
1 Значимо на уровне 0,01.
2 Значимо на уровне 0,05.
мором 62,5—125 мкм и мельче 62,5 мкм и отрицательно
коррелировали с долей частиц размером 125—250 мкм.
Содержание кальция положительно коррелировало с долей
Многомерные модели
141
частиц крупнее 250 и мельче 62,5 мкм и отрицательно кор-
релировало с долей частиц размером от 125 до 250 мкм.
Содержание фосфора отрицательно коррелировало с долей
частиц размером свыше 125 мкм и положительно корре-
лировало с долей частиц размером менее 125 мкм. Содер-
жание азота отрицательно коррелировало с долей частиц
размером 125—250 мкм и положительно — с долей частиц
мельче 62,5 мкм.
Из простого рассмотрения корреляционной матрицы,
т. е., в сущности, самих данных, трудно извлечь что-либо,
кроме утверждения, что между этими восемью переменны-
ми существует тесная взаимная корреляция. Анализ глав-
ных компонент начинается с вычисления такой линейной
функции восьми переменных, которая дает как можно
большую часть всей вариабельности, содержащейся в
274 выборках; эта функция обозначается через Zj. После
этого переходят к отысканию второй линейной функции
исходных переменных, которая не зависит от первой и да-
ет максимально возможную часть оставшейся вариабель-
ности; эта линейная функция обозначается через Z2. За-
тем находят Z3, Z4 и т. д. до тех пор, пока не исчерпается
вся вариабельность. На деле эта процедура эквивалентна
нахождению собственных чисел и соответствующих собст-
венных векторов корреляционной матрицы табл. 6.2 [44],
[41], [42], [70].
Таким образом,
= ^11^1 4“ ^21^2 + <?зЛ 4" ^41^4 4"
+ ^51^5 + ^61^6 4“ ^71^7 4" ^81^8 ’
где Zj — первая главная компонента,
Cij — коэффициент при г-й переменной в /-й компо-
ненте,
Xi — i-я переменная;
^2 = ^12^1 4" ^22^2 4“ £*32^3 4" ^*42^4 4“ ^52^5 4"
+ £*62^6 4" + С82Х8;
Zt = С1Д1 + c2ix2 + C3iX3 + С4/Х4 + cbix5 +
С6/Х6 + С7/Х7 -j- C8jX8.
142 Глава 6
частиц крупнее 250 и мельче 62,5 мкм и отрицательно кор-
реляционной матрицы табл. 6.2. Собственное число первой
компоненты равно 3,12; это число, выраженное как про-
Таблица 6.3
Собственные числа для первых четырех компонент
переменных, характеризующих свойства среды
Компонента Собственное число Доля вариабель- ности, % Кумулятивная доля вариабель- ности, %
3,12 39,0 39,0
1,87 23,4 62,4
Z3 1,26 15,7 78,1
*4 0,83 10,3 88,4
цент от общего числа переменных, показывает, какую до-
лю полной вариабельности учитывает данная компонента.
Аналогично остальные собственные числа отражают те до-
ли вариабельности, которые учитываются соответствующи-
ми компонентами, а в сумме они дают кумулятивные доли
полной вариабельности, учитываемые независимыми по
определению линейными функциями. Из табл. 6.3, таким
образом, видно, что первая линейная функция восьми пе-
ременных отвечает за 39% полной вариабельности, а сле-
дующие три компоненты — за 23,4, 15,7 и 10,3% соответ-
ственно. В сумме четыре компоненты дают 88,4% вариа-
бельности, содержащейся в восьми исходных переменных.
Анализ также показывает, что вычислять следующие ком-
поненты, по-видимому, пе стоит, так как вряд ли компо-
ненты с собственными числами, меньшими примерно 0,8,
будут иметь какое-то практическое значение, хотя мы и
не прибегали, как мог заметить читатель, к обычным кри-
териям значимости. Причина, но которой мы не можем
воспользоваться этими критериями, состоит в том, что все
такие критерии для многомерных задач основаны на ги-
потезе многомерного нормального распределения, которой
редко удовлетворяют экологические данные.
В табл. 6.4 приведены собственные векторы, элементы
которых есть коэффициенты линейных функций, опреде-
Многомерные модели
143
Таблица 6.4
Собственные векторы для первых четырех компонент
переменных среды
Переменная Коэффициенты для компонент
z2 z3 z4
0,05 1,00 0,49 0,17
х2 —0,90 0,40 -0,23 — 1,00
х3 0,25 —0,72 1,00 0,24
X. 0,74 0,07 —0,87 0,84
Хь 1,00 0,01 —0,03 -0,64
Хв 0,61 0,79 0,53 0,24
Х7 0,80 —0,27 0,04 —0,86
X» 0,97 0,17 —0,16 —0,42
ляющих компоненты полной вариабельности. Эти коэффи-
циенты можно использовать для интерпретации экологи-
ческого смысла компонент, используя знак и относитель-
ную величину коэффициентов как показатели веса, который
следует присвоить каждой переменной в этих четы-
рех индексах вариабельности. Первая компонента отража-
ет в основном противоположность фактора Х$ (потери при
прокаливании образца) и факторов Xq и Xg (содержание
фосфора и азота), с одной стороны, и фактора Х% (доля
частиц размером 125—250 мкм), с другой, и представляет
собой некоторую меру общего «плодородия» песка и ила.
Вторая компонента является показателем доли самых
крупных частиц (т. е. частиц >250 мкм) и содержания
кальция и служит мерой количества разбитых раковин.
Третья компонента отражает противоположность факторов
Х3 (доля частиц размером 62,5—125 мкм) и Х^ (доля
частиц, размер которых меньше 62,5 мкм) и рассматри-
вается как мера накопления морского ила. Четвертая ком-
понента вновь отражает противоположность факторов, но
в данном случае факторов X? (доля частиц размером 125—
250 мкм) и X? (содержание фосфора), с одной стороны, и
фактора Х4 (число частиц мельче 62,5 мкм), с другой, и
интерпретируется как мера речных наносов.
144 Глава 6
Анализ показывает, что для учета основной изменчи-
вости химических и физических свойств песка и ила в
заливе Моркам достаточно ограниченного числа измерений
вариабельности. В данном случае было достаточно четы-
рех компонент, чтобы учесть 88% полной вариабельности,
а сами компоненты легко интерпретировались через вполне
конкретные тины изменчивости, поддающиеся определе-
нию. В действительности нахождение отдельных компо-
нент для отдельных выборок и нанесение их значений па
карту залива помогают выявить области высокой продук-
тивности, границы распространения морских осадков и
речных наносов, а также области с высоким содержанием
кальция, указывающим па наличие большого количества
разбитых раковин. Получающиеся при этом карты помо-
гают выявить источник вариабельности, который в против-
ном случае остался бы неизвестным.
Помимо определения размера частиц и химического со-
става песка и ила, проводились выборочные исследования
для определения численностей 22 видов или видовых
групп беспозвоночных, обитающих в заливе. В табл. 6.5
Таблица G.5
Численности различных видов беспозвоночных
в заливе Моркам
Вид Численность на I м» Стандартное отклонение
минимум среднее максимум
Л Масота balthica 0 2325 56 325 5966
Tellina tenuis 0 49,2 9 800 544
^3 Hydrobia ulvae 0 374,2 8 525 1014
Yt Corophium volutator 0 540,5 8 700 1180
Nereis diversicolor 0 63,5 750 116
Y, Arenicola marina 0 16,7 222 26
к, Nephthys hombergii 0 4,94 100 17
приведены численности па квадратный метр только семи
из этих видов, поскольку остальные виды беспозвоночных
встречались слишком редко, чтобы анализировать их чис-
Многомерные модели
145
ленпость. Общее число выборок, по которым составлена
эта таблица, равно 329, так как помимо выборок для оп-
ределения физических и химических свойств среды дела-
лись некоторые дополнительные выборки с целью уяснить
распределение видов, поскольку считалось, что число ви-
дов более вариабельно, чем переменные среды. Как пока-
зывает анализ табл. 6.5, это предположение было, несом-
ненно, справедливым, поскольку число отдельных орга-
низмов семи видов в выборках ила действительно очень
сильно варьировало.
В табл. 6.6 приведены коэффициенты корреляции
между численностями видов в отдельных выборках.
Таблица 6.6
Коэффициенты корреляции между численностями
различных видов беспозвоночных
—0,028 ^2
0,358i 0,032 ^3
0,051 0,054 0,3131
0,569х 0,009 0,302i 0,1621
0,174х —0,003 0,081 —0,095
—0,170х —0,000 —0,099 —0,1182
У 5
0,084 Ув
—0,092 —0,011 У7
1 Значимо на уровне 0,01.
2 Значимо на уровне 0,05.
И вновь обычный критерий значимости для коэффициен-
тов корреляции между двумя переменными здесь едва ли
применим — пе только потому, что мы проверяем несколь-
ко коэффициентов одновременно, по и потому, что распре-
деление исходных данных далеко от нормального. Тем пе
менее, согласно обычному критерию значимости, числен-
ность Масота balthica положительно коррелировала с чис-
ленностями Hydrobia ulvae, Nereis diversicolor и Arenicola
marina и отрицательно коррелировала с численностью
Nephthys hombergii. Численности Hydrobia ulvae, Corophi-
um volutator и Nereis diversicolor взаимно коррелировали,
а численность Corophium volutator отрицательно коррели-
ровала с численностью Nephthys hombergii. Численность
146 Глава 6
Tellina tenuis не обнаруживался заметных корреляций с чис-
ленностями всех остальных видов.
Таблица 6.7
Собственные числа первых пяти компонент для численностей
различных видов беспозвоночных
Компонента Собственное число Доля вариабель- ности, % Кумулятивная доля вариабель- ности, %
1,98 28,3 28,3
w2 1,20 17,1 45,4
1,00 14,3 59,7
0,95 13,6 73,3
0,85 12,2 85,5
Как и прежде, главные компоненты для корреляцион-
ной матрицы табл. 6.6 определяются по собственным чис-
лам и собственным векторам этой матрицы. Первые пять
собственных чисел корреляционной матрицы приведены в
табл. 6.7, которая показывает, что пять соответствующих
компонент учитывают почти 86% полной вариабельности.
Остальные две компоненты, которые можно вычислить,
Таблица 6.8
Собственные векторы первых пяти компонент
для численностей различных видов беспозвоночных
Переменная Коэффициенты для компонент
и/2 ^з и/4
Y1 1,00 -0,48 -0,01 0,13 -0,43
У2 0,04 0,40 1,00 —0,20 —0,41
У3 0,89 0,32 0,04 0,11 0,59
Y, 0,51 1,00 —0,05 0,13 0,71
Уз 0,99 —0,22 —0,01 0,19 —0,59
у« 0,29 —0,86 0,25 -0,54 1,00
У7 —0,32 —0,44 0,34 1,00 0,47
Многомерные модели
147
соответствуют, по-видимому, лишь случайным вариациям.
Согласно приведенным в табл. 6.8 собственным векторам
первая компонента, отвечающая за 28,3% полной вариа-
бельности численности видов, является показателем чис-
ленностей Масота balthica, Hydrobia ulvae и Nereis diversi-
color. Вторая компонента, учитывающая 17,1% вариабель-
ности, отражает противоположность изменений численно-
стей Corophium volutator и Arenicola marina. Остальные
компоненты, отвечающие за 14,3, 13,6 и 12,2% соответст-
венно, являются прямой мерой численностей Tellina tenuis,
Nephthys hombergii и Arenicola marina соответственно.
Таким образом, с помощью анализа вновь удается пред-
ставить всю массу информации в относительно простом ви-
де, где пять компонент учитывают около 86% полной ва-
риабельности. Как и при анализе физических и химических
свойств песка и ила, вычисление значений отдельных ком-
понент для различных выборок и нанесение этих значений
на карту залива дает ясную картину распределения орга-
низмов в рамках этих пяти независимых компонент.
И вновь получающиеся карты помогают выявить источ-
ник вариабельности, который в противном случае оставал-
ся бы неизвестным.
Еще более интересным оказалось, однако, рассмотре-
ние корреляций между значениями компонент для среды
и для численности беспозвоночных. Эти корреляции были
Таблица 6.9
Коэффициенты корреляции между компонентами для среды
и компонентами для численности беспозвоночных
Коэффициент корреляции с компонентой для среды
Компонента для численности беспозвоночных 23 23 24
0,408i -0,029 0,039 —0,031
—0,047 —0,1641 —0,097 0,1532
—0,078 —0,007 0,1202 0,000
W4 —0,029 —0,1871 0,062 —0,101
—0,004 0,042 0,095 0,1561
* Значимо на уровне 0,01 .
Значимо на уровне 0,05.
148 Глава 6
прослежены по тем 272 выборкам, по которым имелись
оба набора компонент; соответствующие данные приведе-
ны в табл. 6.9. С прежними оговорками ио поводу обосно-
ванности обычных критериев значимости для подобных
корреляций мы можем сделать вывод, что, судя по дан-
ным таблицы, между компонентами для среды и компо-
нентами для численности беспозвоночных существуют ин-
тересные взаимосвязи. Первая компонента, относящаяся к
популяции беспозвоночных, — показатель численностей
Масота balthica, Hydrobia ulvae и Nereis diversicolor — по-
ложительно коррелирует с первой из компонент для сре-
ды — общей продуктивностью. Противоположность между
численностями Corophium volutator и Arenicola marina
отрицательно коррелирует со второй компонентой для сре-
ды и положительно коррелирует с четвертой компонентой,
т. е. отрицательно коррелирует с наличием разбитых ра-
ковин и положительно — с речными наносами. Числеп-
Рис. G.2. Корреляции между численностями беспозвоночных и свой-
ствами среды обитания.
Многомериы-с модели
149
ность Tellina tenuis положительно коррелирует с третьей
компонентой для среды, которая служит мерой накопления
морского ила, а численность Nephthys hombergii отрица-
тельно коррелирует с наличием разбитых раковин. Чис-
ленность Arenicola marina положительно коррелирует с
количеством осадочного материала морского происхожде-
ния. Схематически все эти корреляции изображены па
рис. 6.2.
Два рассмотренных выше исследования дают пример
интересного описательного анализа взаимосвязей между
физико-химическими свойствами песка и ила и численно-
стью популяций беспозвоночных в заливе Моркам. К это-
му примеру мы вернемся позже при рассмотрении еще од-
ной альтернативной модели — модели канонических кор-
реляций.
Кластерный анализ
Когда все входы количественные, альтернативной мно-
гомерной описательной моделью является модель, осно-
ванная на кластерном анализе. Кластерный анализ сопут-
ствует самым разнообразным методам обнаружения струк-
тур, присущих сложным совокупностям данных. Как и
при анализе главных компонент основу данных чаще все-
го составляет выборка объектов, каждый из которых опи-
сывается набором отдельных переменных. Задача заклю-
чается в объединении переменных или элементов данной
группы в такие кластеры, чтобы элементы внутри одного
кластера обладали высокой степенью «естественной бли-
зости» между собой, а сами кластеры были «достаточно
отличны» одни от другого. И подход к проблеме, и полу-
чаемые результаты принципиально зависят от того, какой
смысл вкладывает исследователь в выражения «естествен-
ная близость» и «достаточно отличны».
В общем случае кластерный анализ предполагает, что
о структуре, внутренне присущей совокупности данных,
ничего не известно или известно лишь немногое. Все, что
имеется в пашем распоряжении, это совокупность данных.
Целью анализа в этом случае является обнаружение неко-
ей категорной структуры, которая соответствовала бы
наблюдениям, и проблема часто формулируется как задача
150 Глава 6
отыскания «естественных групп». Сущностью кластерного
анализа можно было бы с равным успехом считать и оты-
скание подходящего смысла для терминов «естественные
группы» и «естественные ассоциации».
Кластерный анализ представляет собой попытку сгруп-
пировать выборочные точки многомерного пространства в
отдельные множества, которые, как мы надеемся, будут
соответствовать наблюдаемым свойствам выборки. Группы
точек могут быть в свою очередь сгруппированы в более
крупные множества, так что в конечном счете все точки
оказываются иерархически классифицированными. Эту
иерархическую классификацию можно представить схема-
тически, и обычно в такие схемы вводится некий масштаб,
чтобы указать степень подобия различных групп. Одним
из простейших типов кластерного анализа является анализ
по методу «одного звена», который был предложен Спи-
том [74] как удобный способ представления таксономиче-
ских связей в форме дендрограмм. Связи между п выбор-
ками выражаются через таксономические расстояния меж-
ду каждой парой выборок, измеренные в некотором разум-
ном масштабе. Метод заключается в такой сортировке
выборок, которая определяет кластеры по возрастающему
набору пороговых расстояний (dj, Й2, dn). Кластеры
уровня di строятся следующим образом.
1. Выборки группируются путем объединения всех отрез-
ков длины di или менее. Говорят, что каждое такое
множество образует кластер уровня d/, а длина всех от-
резков, которые соединяют два кластера, определенных
па уровне di, будет больше dz.
2. После проведения сортировки при пороговом расстоя-
нии di+\>di все кластеры уровня dz сохраняются, но не-
которые из них могут сливаться в большие кластеры.
В действительности два кластера будут сливаться, ког-
да между ними существует хотя бы одно звено такой
длины d, что dz<d^dz-i-i. (Это свойство достаточности
лишь одного звена для слияния кластеров и объясняет
выражение «кластерный анализ по методу одного
звена».)
Дендрограмма показывает, как кластеры уровня dj
объединяются на уровне d2 и т. д. на последующих уров-
нях, пока все выборки не сольются в единый кластер.
Многомерные модели
151
На практике кластерный анализ но методу одного звена
лучше всего провести, опираясь па понятие «дерева мини-
мальной протяженности», т. е. дерева, соединяющего все
точки набором прямолинейных отрезков между некоторы-
ми нарами точек таким образом, что:
(1) пе возникает замкнутых петель;
(2) каждая точка лежит хотя бы па одной прямой;
(3) дерево является связным;
(4) сумма длин отрезков минимальна.
На рис. 6.3 показан простой пример дерева с целочислен-
ными длинами отрезков и общей длиной в 22 единицы.
Обзор различных методов кластерного анализа, кото-
рые были развиты за последние годы, сделан в работе [14],
где описаны также принципы многих методов эмпириче-
ской классификации и обсуждаются возможности их даль-
нейшего развития и применения. Вообще применять клас-
терный анализ данных следует с определенной осторож-
ностью, а сами методы должны опираться па строгую
математическую формулировку задачи. Наметившаяся же
тенденция рассматривать кластерный анализ как приемле-
мую альтернативу традиционным методам биологических
наук достойна осуждения, а для обобщения данных вмес-
Рис. 6.3. Дерево минимальной протяженности с целочисленными
длинами отрезков.
152 Глава 6
то самого кластерного анализа и классификации можно
применять н другие методы. Но когда кластерный анализ
используется лишь как одна из моделей системного ана-
лиза, он иногда оказывается весьма полезным и помогает
прояснить некоторые свойства исходных данных. И вновь,
как и ранее, лучше всего проиллюстрировать метод на
простом примере.
Пример 6.2. Почвы Лейк-Дистрикта
В качестве примера применения кластерного анализа,
основанного на методах одного звена и дерева минималь-
ной протяженности, мы рассмотрим анализ свойств 25 почв
из национального парка Лейк-Дистрикт, применявшихся
при исследовании реакции платана п березы па содержа-
ние питательных веществ в почве. Почвы были выбраны
так, чтобы перекрыть как можно более широкий диапазон
химических свойств и, в частности, свойств, связанных с
содержанием фосфатов. Прежде чем использовать почвы
в экспериментах по выяснению реакция платана и березы
различного происхождения, необходимо было установить
диапазон изменчивости свойств почв и возможность их
объединения в кластеры.
В табл. 6.10 приведены определенные для каждой из
25 почв значения семи переменных, а именно: потерь при
прокаливании, количества фосфора, участвующего в изо-
топном обмене, фосфатазной активности, количества экс-
трагируемого железа, общего содержания фосфора, общего
содержания азота и pH. Далее эти данные обобщены в
табл. 6.11. Между каждыми двумя почвами можно вычис-
лить расстояние в евклидовом пространстве по формуле
da = [(®п — xtJ)2 + (x2i — x2j)2 + (х3/ — аг3>)2 +
+ (xit — *4;)2 + (x5i — х^)2 + (x6i — жб;)2 +
+ (хц — ^у)2]7’ =
_/г=1
где dij — евклидово расстояние между Z-й и /-й почвами,
Xki — значение fc-й случайной переменной для г-й почвы,
нормализованное путем вычитания среднего по 25 почвам
СЛ4^С0ЬОн^О^>ОО-<1СЭСЛ4^С01Сн^О^)ОО-<1СЭСЛ^хгоЮ^
ОО С\Э ЬЭ t000b^^ab3CHI\500©^.C5c©^OcDO^Cn©03X>IS500CCwi ь*^ЗСССЛ©©ОС0^3ООО*ЛООС©СО^©СЛ^*ОООО©ЬХСО О 00 О 4^ СС СО ~Л 1-». ц.\ to н. С04^СПСЛС0©©-Л©© —J — Потери при прока- ливании, % сухого веса
ь* ь* СО СО to •-* -Л О О СП ~Л о 00 О СО о 00 О Си СП со О О СО О О О с: —1 4^j-jo^cooceoo-q^jooco^j^oo — co^oocococoooo^jo ^1©С000О0Э-<1к&чС0г0с0--30000£чСЛ£ч£чОСЛ<1н^С0СЛ© Количество фосфора, принявшего участие в изотопном обмене, мкг на 1 г сухого веса
O^CHCOCOCOCnlOCOCOO^^OtOCOCOCOCOCO СО СО 3 Ох С5 оо сп х © о о сп оо о -л со о оо о со -л to го го ~л W ОО ОО Л 02 О JS JX W ОО W'О Л <) W tv СО О W С Л ОС — Фосфатазная актив- ность1
t-* —мл ia СО СО <-л л k-ь. t-i. to I-* осогроооо’Сооого^лоосо спооосогоО^о^- го ОООООООО'ООООСлОООООООООСОО Количество экстра- гируемого железа, мг на ICO г сухого веса
СО'ООООООООООООООООООООООО о о О О О О о О О о О СО — ^CilOCnQOOCnOOW^OOOOh*CnOM^^OOt^*3QCTM Общее количество фосфора, % сухого веса
м ООО оо 0000000-^0000000-^СО-^0 00с©00ЬЗ£*СЛ0500£*£*00С>ЬэЬ000С>£*С>00СЛ^ЗЬЗС0|-*О со го ooJ^cccoi-^cocnoocoi-^^ -xj o<j со со coco оосо Общее количество азота, % сухого веса
COCO^x^^Js^J^^CnCOJ^COCO^jSCn^^CO^JS^^^ СС^^ЧО^»^*ЗСЛООфОООЧ^^ь».СЛ*ЗСОООО'ОСЛ cc-jO’— Ослсоо^огосо^госпососооососо^соосо pH
Таблица 6.10
Значения семи переменных для 25 почв Лейк-Дистрикта
154 Глава 6
/ 70,6— 191,48 _ 67,5— 191,48 \2
+ \ 321,37 321,37 /
/467,1 — 608,96 _ 1059,8 — 608,96\2
+ \ 653,68 653,68 J +
/ 1400 — 1247 _ 460 — 1247 \2
Ц 644,44 644,44 / +
/ 0,12 — 0,108 _ 0,15 —0,108\2
0,065 0,065 / +
/ 0,63 — 0,820______1,19 — 0,820 \2 ,
+ \ 0,634 0,634 / '
/4,53 — 4,51 _ 4,90-4,51 \2Р/2 =
0,909 0,909 /. —
= (0,602859 + 0,000093 + 0,822128 +
+ 2,127604 + 0,213018 Ц- 0,780185 +
Ч-ОДбббЗЗ)1^ = (4,711569)^2 = 2,17.
Таблица 6.11
Обобщение данных для почв Лейк-Дистрикта
Переменная Минимум Среднее Максимум Стандарт- ное откло- нение
Потери при прокаливании, % сухого веса 7,54 25,50 88,78 23,26
Количество фосфора, при- нявшего участие в изо- топном обмене, мкг на 1 г сухого веса 9,80 191,48 1700,30 321,37
Фосфатазная активность, мкг фенола на 1 г сухо- го веса почвы, 13°С, 3 ч 71,3 608,96 3309,70 653,68
Количество экстрагируемо- го железа, мг на 100 г сухого веса 95 1247 2800 644,44
Общее содержание фосфора, % сухого веса 0,01 0,108 0,36 0,065
Общее содержание азота, % сухого веса 0,21 0,820 2,32 0,634
pH воды 3,19 4,510 7,93 0,909
Многомерные модели
155
Поскольку это вычисление нужно проделать для всех
возможных пар почв, т. е. для п(п—1)/2 (в данном слу-
чае для 300) пар, ясно, что без ЭВМ здесь не обойтись.
По половине матрицы расстояний между каждой па-
рой почв можно найти дерево минимальной протяженнос-
ти, также с помощью ЭВМ, применяя один из нескольких
алгоритмов, среди которых наиболее удобным представля-
ется алгоритм Гувера и Росса [29]. Результаты расчетов
представлены в табл. 6.12 и схематически изображены па
рис. 6.4. Большинство почв несомненно довольно близки
по своим свойствам, однако некоторые (и в особенности
почва № 3) существенно от них отличаются.
Таблица 6.12
Дерево минимальной протяженности для почв Лейк-Дистрикта
Порядковый номер почвы Порядковый но- мер почвы, «граничащей» с данной Расстояние Порядковый номер почвы Порядковый но- мер почвы, «граничащей» с данной Расстояние
2 17 2,09 14 8 0,92
3 4 6,83 15 14 1,27
4 23 1,93 16 18 1,35
5 16 2,62 17 7 0,55
6 20 0,96 18 7 0,52
7 9 0,85 19 21 0,72
8 10 0,68 20 10 0,75
9 1 0,80 21 20 0,41
10 1 0,65 22 18 0,51
И 8 0,82 23 8 0,62
12 2 2,44 24 25 1,84
13 22 1,84 25 12 1,11
Метод дерева минимальной протяженности является
весьма ценным как сам по себе, так и при интерпретации
156 Глава 6
результатов кластерного анализа, позволяя судить об адек-
ватности кластеров по числу близких соседей, отнесенных
к разным кластерам. Особенно полезен он при построении
векторных диаграмм, которые иллюстрируют маломерные
Рис. 6.4. Схематическое представление дерева минимальной протя-
женности для почв Лейк-Дистрикта.
приближения для конфигураций в пространстве многих
измерений. В рассмотренном выше примере вариабельность
семимерна и всякая попытка изобразить ее в пространстве
меньшей размерности будет неизбежно вносить некоторое
искажение — о степени этого искажения можно судить пу-
тем наложения дерева минимальной протяженности на ма-
ломерное представление вариабельности. Так, па рис. 6.5
показано распределение 25 почв па двумерной плоскости
{pH; количество экстрагируемого железа}. Видно, что
диаграмма дает неверное положение почвы № 3 — можно
счесть, что она близка но своим свойствам к почвам № 1,
9 и 19. Еще более убедителен, пожалуй, рис. 6.6, изобра-
жающий распределение 25 почв на двумерной плоскости
{pH; потери при прокаливании}. Если бы пе было дерева
Многомерные модели
157
минимальной протяженности, можно было бы сделать вы-
вод, что почвы 2 н 4 сходны между собой, тогда как по
всей совокупности признаков почва 2 ближе к почвам
7, 12 п 17, а почва 4 — к почве 23.
Результаты кластерного анализа по методу одного зве-
на, полученные выделением кластеров на дереве минималь-
ной протяженности при пороговых расстояниях 0,75, 1,00,
1,25, 1,50 и т. д., приведены на рис. 6.7. Выявляется не-
сколько тесно связанных кластеров (например, почвы 1,8,
10 и 23), почвы 7, 17, 18 и 22 и почвы 19, 20 и 21), сли-
вающихся через отдельные почвы в основную группу почв
Лейк-Дистрикта, для которой почва 3 и в мепыпей степе-
ни почва 5 пе типичны. Способ, которым следует выби-
рать почвы для экспериментального исследования реакции
платана и березы па содержание в почве питательных ве-
ществ, определяется целями этого исследования. Если
нужно, чтобы группы почв были достаточно однородны,
Рис. 6.5. Проекция дерева ми-
нимальной протяженности па
Двумерную плоскость {pH; ко-
личество экстрагируемого же-
леза}.
Переменная 7
Рис. 6.6. Проекция дерева ми-
нимальной протяженности на
двумерную плоскость {рП; по-
тери при прокаливании}.
158 Глава в
используют лпшь те почвы, которые связаны на низком
уровне пороговых расстояний (т. е. почвы 1, 8, 10, 23, 7,
17, 18, 22, 9, 11, 14, 6, 19, 20 и 21). Если стремятся охва-
тить весь диапазон изменений свойств почвы, то берут
Рис. 6.7. Дендрограмма кластерного анализа почв Лейк-Дистрикта,
лишь некоторые из почв, принадлежащих разным клас-
терам, почвы, более пли менее от пих отличающиеся, и,
разумеется, почву 3.
Взаимное осреднение
Когда в описательных моделях некоторые из перемен-
ных являются качественными, метод главных компонент
теряет свою ценность. Кластерный анализ, правда, можно
применять, даже если качественный характер носят все
данные. В этом случае строят индексы подобия, которые
переводят затем в расстояния по формулам типа
dpq = 1 Spq ,
М ногомерные модели
159
где подобие Spq между индивидами р и q измеряется как
отношение числа «совпадений» к общему числу сравнивае-
мых признаков, причем «совпадение» имеет место тогда,
когда признак присутствует или отсутствует у обоих ин-
дивидов одновременно.
Существуют, однако, многомерные модели, разработан-
ные специально для качественных данных, и важное место
среди них занимает модель взаимного осреднения, описан-
ная Хиллом [34]. Эта модель особенно ценна для анализа
данных типа «наличие — отсутствие», которые часто встре-
чаются в экологии, например, при регистрации наличия
или отсутствия конкретных видов в квадратах. Геометри-
чески такие данные можно представить как набор точек,
расположенных в некоторых вершинах единичного гипер-
куба, хотя ордпнация (упорядочение) этих точек и пе за-
висит явным образом от геометрических расстояний между
ними.
В основе метода лежит построение последовательных
приближений, которое начинается с того, что индивидам
приписывается произвольный набор начальных показате-
лей (обычно от 0 до 100), выбранных — в идеальном слу-
чае — так, что они отражают некий градиент, a priori
ожидаемый исходя из собранных данных. Затем вычисляют
средние показатели для каждого признака, по которым, в
свою очередь, определяют новые средние для индивидов,
взятые в таком масштабе, чтобы сохранить первоначаль-
ный размах показателей. После достаточного числа итера-
ций округленные показатели признаков будут сходиться
к одному и тому же вектору, который и дает первую ось
ордипации !.
Получив первую ось, переходят к нахождению второй;
хорошим начальным приближением для показателей вто-
рой оси служит одна из промежуточных итераций первой
оси, преобразованная па основе результатов первой про-
цедуры. В работе Хилла [34] приведен простой пример
1 Процедура может быть формализована алгебраически, с по-
мощью специального преобразования, приводящего матрицу наблю-
дений к симметричной форме, и тогда собственное число единично-
го собственного вектора будет показывать, насколько уменьшается
размах показателей при одной итерации. — Прим, персе.
160
Глава С)
подобных вычислений, которые для всякой практической
задачи являются весьма трудоемкими и должны выпол-
няться на ЭВМ.
В сущности процесс представляет собой повторную пе-
рекрестную калибровку, которая позволяет получить одно-
мерную ординацию одновременно как по признакам, так
и по индивидам. Модель названа «взаимным осреднением»,
поскольку показатели признаков получаются в пей как
средние значения показателей для индивидов и наоборот,
показатели для индивидов являются средними показате-
лен для признаков. Конечные значения показателей пе
зависят, вообще говоря, от начальных приближений, одна-
ко удачный выбор начальных значений может существен-
но уменьшить необходимое число итераций. Вся процеду-
ра в целом очень близка к анализу главных компонент и
может быть распространена па случай не только качест-
венных, по и количественных данных.
В экологических исследованиях взаимное осреднение
обычно применяется к задачам, которые с недавних пор
стали называться «анализом индикаторных видов». В этом
анализе отдельные квадраты упорядочивают методом вза-
имного осреднения вдоль первой оси ординацпи, а затем
относительно центра тяжести ординацип подразделяют их
па две группы. Пять «индикаторных» видов выбирают с
помощью функции
Л ~ I ^1/^1---7П2/М2 I >
где Ij — индикаторное значение вида / (в предположении,
что это значение равно 1, если вид служит совершенным
индикатором, и 0, если вид пе играет никакой роли в ин-
дикации) ;
т\ — число квадратов с видом /, расположенных но
отрицательную сторону дихотомии;
7^2 — число квадратов с видом /, расположенных по
положительную сторону дихотомии;
М\ — общее число квадратов по отрицательную сто-
рону дихотомии;
М2 — общее число квадратов по положительную сто-
рону дихотомии.
Пять видов с наивысшими индикаторными значениями
используются затем при построении «индикаторного по-
Многомерные модели
161
казателя» для всего множества квадратов и при определе-
нии «порога индикации», соответствующего данной дихо-
томии.
Весь процесс можно повторить для второй и последую-
щих осей взаимного осреднения, вновь подразделяя квад-
раты тем же самым методом и продолжая эту операцию
до тех пор, пока это возможно. Никакого Четкого критерия
для установления момента, когда следует прекратить раз-
биение, пока не получено, так что выбор и порогов, и чис-
ла разбиений более или менее произволен. Индикаторные
показатели можно рассматривать как средство ордипации
по шеститочечной шкале — ординации, разумеется, грубой,
но зато легко выполнимой даже в полевых условиях пу-
тем регистрации пяти избранных видов в конкретных
квадратах. Задача состоит в том, чтобы достаточно точно
воспроизвести результаты первоначальной ординации по
методу взаимного осреднения, и тогда анализ индикатор-
ных видов может служить критерием для классификации
квадратов.
Пример 6.3. Естественные сосняки Шотландии
В работе Хилла с соавторами [35] рассмотрен пример
применения метода взаимного осреднения и анализа ин-
дикаторных видов для классификации естественных сос-
няков Шотландии. Для анализа использованы данные
обследования 26 основных сосновых лесов, описанных в ра-
боте [76]. В этом обследовании внутри каждого из кар-
тографических контуров, обозначенных па картах как сос-
няки, случайно выбирали 16 площадок по 200 м2. Каждую
площадку подразделяли затем на пять вложенных квад-
ратов площадью 4, 25, 50, 100 и 200 м2. На этих квадра-
тах (начиная с самого маленького) была проведена куму-
лятивная перепись всех сосудистых растений. После того,
как были собраны первичные данные но растительности,
на каждой площадке замеряли деревья и кустарники, со-
ставляли список характерных особенностей местообитания
и отмечали основные свойства почвы, взятой из неглубо-
кого разреза в центре площадки.
Для описательной классификации применялись лишь
данные по наличию—отсутствию видов — считалось, что
6—843
162 Глава 6
на каждой площадке имеется такое число видов, которого
достаточно, чтобы о флористическом сходстве между пло-
щадками можно было судить, опираясь только па эти наб-
людения. Все данные представляли собой записи по
416 площадкам (26 сосняков X16 площадок) и насчиты-
вали 176 видов с частотою более трех.
Диапазон вариаций среди сосняков оказался довольно
небольшим и вполне удовлетворительно представлялся с
помощью двумерной ординации. Первая ось этой ордина-
ции была связана с мощностью органических слоев поч-
вы, а вторая — с ее кислотностью. В табл. 6.13 показаны
Т а б л’и ц а 6.13
Классификация данных для пробных площадок в естественных
сосняках Шотландии
Разбиение 1
Отрицательные индикаторные Deschampsia jlexuosa
виды:
Положительные индикаторные Drosera rotundifolia, Erica tet-
виды: ralix, Narthecium ossifragum,
Sphagnum papillosum
Если индикаторный показатель < 0, то переходим к разбие-
нию 2
Если индикаторный показатель > 0, то переходим к разбие-
нию 3
Разбиение 2
Отрицательные индикаторные
виды:
Положительные индикаторные
виды:
Если индикаторный показатель
Если индикаторный показатель
Разбиение 3
Нет
Agrostis canina, Anthoxanthum
odoratum, Galium saxatile, Oxa-
Us acetosella, Viola riviniana
<2, то группа AB
>2, то группа CD
Отрицательные индикаторные Нет
виды:
Положительные индикаторные Agrostis canina, Galium saxatile
виды: Luzula multiflora, Succtsa pra-
te nsis, Viola riviniana
Если индикаторный показатель <2, то группа EF
Если индикаторный показатель > 2, то группа GH
Многомерные модели
163
первые два уровня иерархии, порождаемой анализом ин-
дикаторных видов по данным для площадок. Классифика-
ционную иерархию можно представить с помощью следую-
щей схемы:
{(АВ) (CD)} {(EF) (GH)} .
Она показывает, что первое разбиение выделяет из всех
видов группы А, В, С и D, второе разбиение делит под-
группу, состоящую из А, В, С и D, па две более мелкие
группы — А, В и С, D и т. д. Связь между классификаци-
ей площадок по группам и ординацией представлена на
рис. 6.8, где изображены средние показатели и стандарт-
ные отклонения для площадок данных типов.
Оказалось, что для всех восьми типов площадок, ко-
торые были выделены с помощью описательной модели,
характерна сильная корреляция и с другими факторами
среды. Модель, таким образом, давала некую ’’точку от-
Первая ось - мощность органического слоя
Рис. 6.8. Связь между классификацией площадок по группам и ор-
динацией по методу взаимного осреднения для естественных сос-
няков Шотландия.
6*
164 Глава 6
счета” для дальнейших детальных исследований, а не ре-
шение проблем динамики самих сосновых лесов. В част-
ности, классификация, которую легко провести в полевых
условиях, позволила описать основные типы местообита-
ний, и это описание пе только подтвердило наличие опре-
деленных групп местообитаний, выявленных ранее [76],
но и обнаружило различия, которые требовали дальнейше-
го изучения, т. е. выполнило одну из главных задач любо-
го системного исследования.
Прогностические модели
Рассмотрим теперь прогностические модели. Обратив-
шись к рис. 6.1, мы увидим, что, согласно приведенной
классификации, модели, в которых по двум пли более пере-
менным предсказывается только одпа случайная перемен-
ная, отличаются от моделей, где таких случайных пере-
менных несколько. Множественный регрессионный анализ,
о котором мы уже говорили в гл. 5, когда речь шла о сто-
хастических моделях, несомненно, представляет собой один
из типов прогностических моделей, позволяя предсказать
значение одной случайной величины но значениям двух
или более переменных, обычно именуемых регрессионны-
ми переменными. Для случаев, когда регрессионные пере-
менные являются па самом деле случайными величинами,
т. е. переменными, характеризующимися определенной
относительной частотой или вероятностью, можно пока-
зать, что математически процедуры оценки остаются экви-
валентными; они применимы даже тогда, когда модель
оперирует одновременно и регрессионными случайными
величинами, и регрессионными переменными. Поэтому при
решении практических задач обычно пе стоит задаваться
вопросом, с какой моделью мы имеем дело — классической
регрессионной моделью для переменных, моделью, опери-
рующей случайными величинами или обоими типами пе-
ременных одновременно,— нужно лишь, чтобы эти пере-
менные были достаточно верными измерениями необходи-
мых нам величин.
Таким образом, имея дело с одной предсказываемой
случайной величиной, мы будем придерживаться в данной
главе классической модели дискриминантного анализа, тео-
Многомерные модели
165
ретические основы которой разработаны Фишером более
сорока лет назад [21]. Согласно рпс. 6.1, мы будем отли-
чать модель, позволяющую сделать выбор между двумя
группами и известную под названием дискриминантной
функции, от модели, дающей разбиение на более чем две
группы и именуемой моделью канонических величин.
Дискриминантная функция
В классической модели дискриминантной функции Фи-
шера рассматривается задача, как паплучшпм образом сде-
лать выбор (дискриминацию) между двумя априорными
группами, когда для каждого индивида измеряется не-
сколько показателей (переменных). Модель дает такую
линейную функцию измерений по каждой переменной, что
индивида можно отнести к той или иной из двух групп с
наименьшей вероятностью ошибиться. Дискриминантная
функция записывается как
% = -р ^2^2 “Ь * * ’ 4“ Vw >
где a=(fli, ..., ат) — вектор дискриминантных коэффици-
ентов, х= (j?i, ..., Хщ) — вектор наблюдений или измерений,
сделанных для индивида, которого нужно отнести к той
или иной группе. Заметим, что в этой модели предполага-
ется существование лишь двух групп и пе считается, что
если данный индивид пе может быть с достаточной сте-
пенью определенности отнесен ни к одной из двух групп,
то существуют еще какие-то группы. И вновь для иллю-
страции применения модели лучше всего рассмотреть кон-
кретный пример.
Пример 6.4. Сосудистые растения Сигни-Айленда
Сигни-Айлепд принадлежит к группе Южных Оркней-
ских островов, расположенных в одном из морских регио-
нов Антарктиды. Ближайшая материковая точка находится
на Антарктическом полуострове и удалена примерно па
640 км, но иммиграция животных происходит с острова
Южная Георгия, лежащего примерно в 900 км к северо-
востоку, и с острова Огненная Земля, расположенного при-
мерно в 1440 км к северо-западу.
166 Глава в
При изучении растительности острова па карту Спгпи-
Айленла масштабом 1 : 25 000 наносили произвольную сет-
ку из квадратов по 500 м2. По картам, составленным науч-
ными экспедициями, оценивали переменные, характери-
зующие свойства среды в квадратах. Далее определяли
площади внутри каждого квадрата, запятые различными
типами растительности, и, в частности, отмечали, произ-
растают ли в данном квадрате сосудистые растения.
Предварительная обработка данных по переменным
среды показывала, что полная вариабельность данных при-
близительно семимерна п что число переменных среды
можно поэтому уменьшить до семи без особых потерь ин-
формации. Значения этих семи переменных для 104 квад-
ратов сетки сведены в табл. 6.14. Сосудистые растения бы-
Таблица 6.14
Переменные, характеризующие свойства среды на острове
Сигнп-Айленд
Переменная Минимум Среднее Максимум Стандарт- ное от- клонение
1. Максимальная высота (в метрах) 5 140,0 280 79,3
2. Число контуров, разре- занных трансектой вос- ток—запад 0 7,5 22 5,44
3. Склоны, обращенные на юг, % 4. Площадь, занятая озе- рами, % 0 19,2 100 25,0
0 1,2 20 3,47
5. Площадь, занятая, со- гласно карте, скалами 0 13,3 45 9,12
6. Площадь, запятая, со- гласно карте, осыпями и оползнями, % 7. Расстояние до моря на восток (в метрах) 0 27,2 91 25,8
0 1026 4100 1084
ли обнаружены па 22 квадратах. Возникает интересный
вопрос: можно ли использовать семь переменных среды
или некое их подмножество для того, чтобы предсказать
Многомерные модели
167
наличие или отсутствие сосудистых растений в каком-то
квадрате.
Для обеих групп квадратов измерялись одни и те же
переменные, так что исходные данные можно представить
в виде двух матриц, одна из которых имеет порядок
а вторая — п2Хт. Так как сосудистые растения
были обнаружены па 22 квадратах,
п{ = 22 , п2 = 82 , т = 7 .
В табл. 6.15 приведена правая верхняя половина сим-
метричной объединенной матрицы ковариаций 1 для обеих
Таблица 6.15
Объединенная матрица ковариаций для наборов данных
1 2 3 4 5 6 7
5310,961 199,8022 194,8896 -32,94015 -16,05446 62,73615 12569,94
26,88293 -25,31391 1,559248 12,8375 42,83095 4,190566
578,6623 -4,799063 —36,08125 -116,5440 —315,8835
11,96896 3,166493 15,54125 62,82278
83,73383 44,49558 1250,437
667,5128 2087,470 1175,907
матриц данных. Вектор дискриминантных коэффициен-
тов а задается решением совместной системы уравнений,
которая в матричной форме записывается как
Sa = d,
где S обозначает объединенную матрицу ковариаций, a d
является разностью между векторами средних для двух
групп. Это уравнение легко разрешить, умножив слева
обе его части па матрицу, обратную ковариационной, т. е.
а = SM .
Матрица, обратная объединенной матрице ковариаций,
1 В литературе по математической статистике матрицу ковари-
аций часто называют матрицей рассеяния. — Прим, перев.
Таблица 6.16
Матрица, обратная объединенной матрице ковариаций
3.236548Е—4 —2.98233Е—3 —1,895112Е—3 9,9986822Е- -4 4.140633Е—4 8.999152Е—5 —4.153426Е—6
0,07199744 2,899737Е—3 —0,01020711 —9.022103Е—3 —3.144589Е—3 4.812380Е—6
1,965440Е—3 —4,002193Е— -4 2,661735Е—4 1,602335Е—4 1,997326Е—6
0,0897032 —8,298558Е—4 —1,504498Е—3 —1,198577Е—5
0,01397195 —2,672139Е—4 —1,866131Е—5
1,783831Е—3 —3,709850Е—6
9.222408Е—7
Многомерные модели
169
приведена в табл. 6.16, где для удобства использована
экспоненциальная форма записи чисел; эта матрица также
симметрична относительно главной диагонали. Векторы
средних, вектор разностей между ними и вектор дискри-
минантных коэффициентов приведены в табл. 6.17.
Таблица 6.17
Векторы средних, разностей между ними и вектор дискриминантных коэффициентов
Переменная Среднее для площадок, на которых произрастают сосудистые растения Среднее для площадок, на которых сосудистые растения отсутствуют Разность Дискриминант- ная функция
1 78,1818 123,5096 —45,3278 —8,799238Е—3
2 4,2273 6,6538 —2,4265 —0,1421932
3 5,6818 18,0385 —12,3567 —0,0301576
4 0,3182 1,1250 —0,8068 —0,1312235
5 14,2273 10,2596 3,9677 0,02264888
6 30,0000 20,8558 9,1442 0,01204919
7 825,0000 851,9232 —26,9232 —1.693091Е—4
Далее определяется критерий Хотеллинга Т2 по фор-
муле
Т2 П!П2 d,a = 35,90,
(^1 + п2)
а значимость для Т2 оценивается по критерию отношения
дисперсий согласно выражению
р___ ~1~ ^2 m 1 . ^2___4 83
+ п2 — 2) m,
со степенями свободы ш = 7 и (ni + n2—ш—1) =96. Если
бы обе группы принадлежали одной и той же популяции,
то вероятность получить столь высокое значение F была
бы равна примерно 0,00011.
Таким образом, функция
Z = — 0,00880*! — 0,142х2 — 0,0302*3 — 0,131*4 +
+ 0,0226*5 + 0,0120*в — 0,000169*7
1 70 Глава 6
дает значимую дискриминацию между квадратами по
500 м2, на которых произрастают сосудистые растения, и
квадратами, где они пе произрастают. Значения функции Z
(дискриминантные показатели) вычисляются для каждого
квадрата из двух групп, а центры дискриминантных пока-
зателей оказываются равными —0,959 и —3,029 для групп
с сосудистыми растениями и без них соответственно.
Разность между дискриминантными центрами групп
называется «обобщенным расстоянием» между группами;
его можно вычислить, используя значение Г2, по формуле
JJ2 _ П1 п2 .
или более прямо из соотношения
D2 = d'SM = 2,070 .
Мера эффективности, с которой вычисляемая дискри-
минантная функция может использоваться для классифи-
кации произвольного индивида, задается стандартным
нормальным отклонением
— = 0,719.
2
Табличные значения нормального распределения вероят-
ностей, соответствующего такому отклонению, показыва-
ют, что примерно 76% индивидов будут правильно отне-
сены к своим группам с помощью данной дискриминант-
ной функции.
Вычисление дискриминантных показателей позволяет
рассматривать исходно выбранные квадраты как два клас-
тера точек, рассеянных по одной прямой, с центрами, соот-
ветствующими средним показателям для кластеров. Цен-
ность дискриминантной функции состоит в том, что опа,
во-первых, позволяет определить влйяпие основных пере-
менных на дискриминацию, а во-вторых — вычислить
дискриминантный показатель для любого нового квадра-
та и либо отпести последний к одной из двух групп, либо
решить, что он пе принадлежит ни к одной из них. Нам
может понадобиться определить, например, какова вероят-
ность того, что в каком-то произвольном квадрате пло-
Многомерные модели
171
щадью 500 м2, наложенном па карту Сигни-Лйленда, бу-
дут обнаружены сосудистые растения, с тем чтобы решить,
стоит ли затрачивать усилия на поиски этих растений в
довольно суровых полевых условиях.
Если две группы, ио которым вычислялись дискрими-
нантные коэффициенты, одинаково представлены в попу-
ляции, откуда извлечены выборки, то границей, по кото-
рой мы будем относить неклассифицированный индивид к
одной из двух групп, разумно считать середину расстоя-
ния между центрами групп. Так, квадраты с дискрими-
нантным показателем меньше —1,994 нужно было бы от-
нести к группе, где сосудистых растений нет, тогда как
квадраты с дискриминантным показателем больше
— 1,994 — к группе, где такие растения произрастают.
Когда две группы представлены в популяции неодина-
ково, граница разбиения должна быть смещена от сере-
дины между центрами в сторону меньшей группы на рас-
стояние
In Д
D ’
где R равно отношению числа индивидов в большей груп-
пе к их числу в меньшей группе. Если мы можем считать,
что рассматриваемые квадраты представляют собой несме-
щенную выборку из популяции всевозможных квадра
тов, то
R = 3,727
и
_!И =2211 = 0,914,
D 1,430
т. е. границу разбиения следует перенести из —1,994 в
— 1,080.
Канонические величины
Дискриминантная функция дает мощный практический
метод дискриминации между двумя априорными группа-
ми. Но в экологии часто встречаются ситуации, когда чис-
172 Глава 6
ло груш г, между которыми нужно сделать выбор, больше
двух. В простейшем случае третья группа может быть об-
разована гибридами, полученными при скрещивании осо-
бей из двух исходных групп (папример, при скрещива-
нии благородного и пятнистого олепя [52]). При таксоно-
мических исследованиях (например, при изучении прямо-
крылых [6] пли анализе экологии насекомых, обитающих
на ракитнике [89]) возникают и более сложные задачи
дискриминации.
Как и во всех других многомерных моделях, мы вновь
имеем матрицу наблюдений, р столбцов которой дают зна-
чения р переменных для каждого из п индивидов, соот-
ветствующих строкам матрицы. В отличие от метода глав-
ных компонент, у матрицы возникает определенная струк-
тура вследствие того, что индивиды извлекаются из т
(<п) отдельных групп. Поскольку нам по-прежнему нуж-
но найти представление р переменных в пространстве как
можно меньшего числа размерностей, мы, как и прежде,
будем выделять межгрупповую вариабельность из внутри-
групповой. Необходимо различать объединенную матрицу
внутригрупповых сумм квадратов и произведений отклоне-
ний от групповых средних, W, и матрицу межгрупповых
сумм квадратов и произведений отклонений групповых
средних от общих средних — В.
Задача заключается теперь в том, чтобы получить пе
одну дискриминантную функцию, а набор таких функций
вида
d = aixi + а2х2 + а3х3 + • • • + архр,
где аь «2, «з, dp являются дискриминантными коэффи-
циентами, вычисленными так, что они минимизируют сме-
шение между различными группами. Довольно легко по-
казать (см., папример, работу [44]), что эти коэффициен-
ты задаются собственными числами и собственными
векторами произведения двух матриц W-IB. Элементы нор-
мированных собственных векторов служат весами аь аг,
аз, ..., ар, а собственные числа являются показателями
дискриминационной способности по соответствующим ка-
ноническим величинам, или осям дискриминации.
Многомерные модели
173
Пример 6.5. Форма листьев у отдельных разновидностей
тополя
Для исследования свойств отдельных разновидностей
тополя были, в частности, собраны коллекции листьев этих
деревьев и проведен ряд стандартных измерений. Для по-
следующего анализа были выбраны следующие девять ха-
рактеристик:
1) длина черешка;
2) длина пластинки листа;
3) ширина пластинки листа в ее самой широкой части;
4) ширина пластинки листа в ее средней части;
5) ширина пластинки листа па расстоянии 1/3 ее длины;
6) ширина пластинки листа па расстоянии 2/3 ее длины;
7) расстояние от основания листа до точки, где черешок
прикрепляется к пластинке;
8) угол между средней жилкой и первой боковой жил-
кой первого порядка;
9) угол между средней жилкой и первой боковой жилкой
второго порядка.
Все линейные размеры округлялись до миллиметров, а
два угловых — до градусов.
В табл. 6.18 приведены основные размеры пяти листь-
ев с разных деревьев каждой из шести разновидностей то-
поля. Эти разновидности представляют, таким образом,
шесть априорных группировок листвы, для которых мы
отыскиваем эффективные дискриминаторы, опирающиеся
па девять измерений.
В табл. 6.19 приведена половина матрицы межгруппо-
вых сумм квадратов и произведений отклонений. (Заме-
тим, что, поскольку матрица симметрична, нам нужна лишь
главная диагональ, соответствующая межгрупповым сум-
мам квадратов отклонений, и верхние или нижние педиа-
гопальные элементы, соответствующие суммам произведе-
ний отклонений). Аналогичная половина объединенной
матрицы внутригрупповых сумм квадратов и произведе-
ний отклонений приведена в табл. 6.20. Матрица, обратная
этой симметричной матрице, умноженная справа па меж-
групповую матрицу, дает так называемую детерминапт-
ную матрицу, которая приведена в табл. 6.21. Заметим,
нто детерминаптная матрица уже не симметрична.
Таблица 6.18
Основные размеры листьев тополя
Разновидность Номер переменной
1 2 3 4 5 6 7 8 9
Populus serotina VB 39 98 95 55 88 76 110 90 100
39 96 95 58 92 80 95 90 92
43 100 84 54 80 70 100 70 97
54 123 117 72 ИЗ 94 105 85 110
47 114 105 69 102 90 92 72 95
Populus gelrica HA 47 108 121 95 118 110 110 87 110
56 90 120 95 117 110 105 80 100
65 130 140 95 140 125 115 90 110
50 114 118 85 ИЗ 108 ПО 85 108
47 ИЗ 125 87 121 110 110 90 108
Populus gelrica VB 60 120 132 90 122 114 115 85 110
44 87 101 67 97 88 100 75 97
45 94 100 66 88 86 105 85 108
59 115 125 84 118 106 110 70 НО
49 90 107 75 103 96 110 90 108
Populus TXT32 24 117 84 60 84 76 80 60 90
30 134 105 73 104 92 65 50 87
31 150 114 73 110 96 70 60 85
23 140 90 64 95 87 60 50 85
27 126 98 75 96 90 77 60 92
Populus TXT37 12 118 61 43 59 52 60 50 70
15 136 95 55 89 75 55 65 90
16 145 101 63 97 64 90 60 90
17 161 118 64 112 94 85 65 90
18 155 105 60 100 83 70 70 95
Populus serotina 58 130 124 64 114 84 90 50 90
erecta 53 124 118 60 110 94 95 55 90
67 134 130 80 126 103 95 50 85
57 124 120 72 114 100 93 65 92
56 122 124 70 120 100 95 65 93
Таблица 6 19
Половина матрицы межгрупповых сумм квадратов и произведений отклонений
Переменная 1 2 3 4 5 6 7 8 9
Р 1 6992,73
L 2 —5031,18 6896,12
3 4616,37 —2147,25 4244,50
1Г2 4 3112,37 —2580,44 3070,87 3683,06
ir3 5 4119,93 —1765,49 3940,25 3115,75 3790,87
6 3826,18 —2572,25 3676,00 3744,56 3615,62 3993,31
Ь 7 6237,19 —6589,62 3909,50 3477,56 3375,12 3792,75 7593,50
vr 8 2616,40 —4863,69 1308,68 2255,43 1126,75 2010,06 5035,19 4732,56
и, 9 2467,59 —3483,37 1560,87 2064,62 1387,75 2006,37 3708,37 2980,56 2147,62
Таблица 6.20
Половина матрицы внутригрупповых сумм квадратов и произведений отклонений
Переменная 1 2 3 4 5 6 7 8 9
1 808,40
2 1227,40 4189,59
3 1332,39 3664,59 4251,19
4 361,80 1661,20 2128,61 1522,40
5 1344,79 3533,62 4069,18 2123,40 4046,81
6 1013,00 2677,81 3116,20 1765,59 3110,79 2614,00
7 266,61 832,42 1103,59 556,20 997,02 867,00 1615,61
8 — 118,80 207,59 611,00 138,00 513,41 518,80 503,20 1298,40
9 254,20 1022,01 1131,57 503,98 1013,18 813,61 597,81 551,00 835,61
Таблица 6.21
Детерминантная матрица для разновидностей тополя
Переменная 1 2 3 4 5 6 7 8 9
1 680,664 —570,221 386,839 236,172 326,647 300,492 649,240 307,849 259,044
2 —347,187 293,287 —217,448 — 159,342 — 188,698 — 189,260 —338,606 —165,818 — 147, 135
3 301,905 —179,680 201,352 72,422 157,388 120,518 244,195 53,144 76,830
4 —490,526 332,712 —277,978 — 105,947 —224,159 — 170,362 —403,467 —122,630 — 128,989
5 —263,822 202,724 —179,153 — 111,376 —144,730 —142,457 —242,703 —89,089 — 103,355
6 361,501 —286,830 242,426 191,883 214,392 223,842 327,599 137,036 147,628
7 54,913 —54,648 29,868 17,315 23,828 21,749 64,801 41,007 27,250
8 —40,764 —15,374 —39,973 — 12,537 —35,114 —24,556 6.423 47,899 12,943
9 130,949 —163,570 74,260 92,256 66,186 92,650 160,506 110,427 90,137
178
Глава 6
Таблица 6.2
Собственные числа детерминаптной матрицы
Каноническая величина Собственное число Доля вариабель- ности, % Кумулятивная доля, %
I 1097,34 81,21 81,21
II 168,50 12,47 93,68
III 58,42 4,32 98,00
IV 16,39 1,21 99,21
В табл. 6.22 представлены первые четыре собственных
числа детерминаптной матрицы; процент вариабельности
вычисляется по отношению к сумме элементов главной
диагонали матрицы, которая равна 1351,30. Первые три
канонические величины несут 98% полной вариабельнос-
ти детерминаптной матрицы, причем на долю первой из
них приходится 81,21%. Соответствующий критерий зна-
чимости показывает, что для дискриминации между груп-
пами практически важны лишь первые три канонические
величины.
Присвоенные девяти переменным веса приведены в
табл. 6.23; они представляют собой элементы нормиро-
ванных собственных векторов, отвечающих первым четы-
рем собственным числам детерминаптной матрицы. Первая
каноническая величина приписывает наибольший вес дли-
не черешка и общей форме листа, присваивая положитель-
ный вес ширине листовой пластинки в ее самой, широкой
части и на расстоянии 2/3 длины и отрицательный — дли-
не листа и ширине его посредине и па расстоянии 1/3 дли-
ны. Таким образом, для листьев с высоким значением
данной канонической величины характерны длинные че-
решки и короткие широкие и резко сужающиеся листовые
пластинки, а для листьев с низким ее значением — корот-
кие черешки и длинные, узкие, плавно сужающиеся плас-
тинки.
Все остальные канонические величины отражают ва-
риации ширины листовой пластинки. Вторая канониче-
ская величина в основном противопоставляет ширину лис-
товой пластинки в ее средней и самой широкой частях,
Многомерные модели
179
Таблица 6.23
Веса переменных в канонических величинах
Переменная Нормированные веса IV
I И Ш
1. Длина черешка 1,000 0,428 0,189 0,158
2. Длина пластинки —0,507 0,011 0,287 0,089
3. Ширина пластинки (auj 0,423 0,716 -0,448 —0,829
4. Ширина пластинки (w2) —0,697 —1,000 0,107 0,209
5. Ширина пластинки (ш3) —0,384 -0,183 0,631 1,000
6. Ширина пластинки (ш4) 7. Расстояние от основания листа до точки, где че- решок прикрепляется к 0,513 -0,059 -1,000 -0,357
пластинке 8. Угол между средней жилкой и первой боко- вой жилкой первого по- 0,087 0,003 0,196 0,026
рядка 9. Угол между средней жилкой и первой боко- вой жилкой второго по- -0,035 -0,255 0,622 0,198
рядка 0,211 -0,384 —0,118 -0,271
третья — ширину на расстоянии 2/3 длины с шириной
на расстоянии 1/3 и углом между средней и первой боковой
жилкой первого порядка. Четвертая каноническая величи-
на противопоставляет ширину листа на расстоянии 1/3 дли-
ны ширине в самой широкой его части. Три этих меры
Таблица 6.24
Средние значения канонических величин для отдельных разно-
видностей тополя
Средние значения канонических величин
Разновидность I II Hi IV
Populus serotina VB 5,51 —10,18 8,18 0,80
Populus gelrica HA 6,53 -13,95 4,94 1,05
Populus gelrica VB 8,40 -11,72 5,21 -1,11
Populus TXT32 -4,22 -11,28 4,05 0,68
Populus TXT37 -7,25 —10,04 6,43 -0,22
Populus serotina erecta 6,90 -6,10 4,43 0,58
180 Глава 6
Рис. 6.9. Проекция дерева мини-
мальной протяженности для раз-
новидностей тополя на двумер-
ную плоскость {каноническая ве-
личина 2; каноническая величи-
на 1}.
копусообразности листа добавляют, однако, лишь 18%
различий к 81%, учтенному первой канонической вели-
чиной.
И наконец, в табл. 6.24 приведены средние значения
четырех канонических величин для каждой из шести
групп. Два гибрида ТХТ
сразу же идентифициру-
ются по низким значени-
ям первой канонической
величины, хотя по исход-
ным данным выделить их
пе так-то легко. Из трех
оставшихся разновидно-
стей по сравнительно вы-
сокому значению второй
канонической величины
сразу выделяется Populus
serotina erecta:, два варие-
тета Populus gelrica разли-
чаются но четвертой кано-
нической величине, и оба
они отличаются от Populus
serotina по третьей величи-
не. Как и прежде, интер-
претации сходства всех
шести разновидностей по-
могает дерево минималь-
ной протяженности, осно-
ванное в данном случае на
канонических величинах
(см. рис. 6.9).
Многомерная модель анализа канонических величин
оказывается весьма мощным и гибким инструментом для
изучения возможности дискриминации между нескольки-
ми априорными группами и является логическим обобще-
нием дискриминантной функции.
Многомерные модели
181
Канонические корреляции
Наконец, мы подходим к рассмотрению многомерной
модели, применяющейся при решении одной из самых
трудных статистических проблем, — определении связей
между двумя или более множествами величин. Как мы
уже говорили, один из возможных путей решения этой
проблемы состоит в использовании модели анализа глав-
ных компонент. Вычисляя главные компоненты для каж-
дого множества переменных и корреляции между полу-
чившимися компонентами, часто удается обнаружить
сложные взаимосвязи между этими множествами. Иссле-
дование, применяющее данный подход к изучению связей
между ростом сосны черной калабарийской и физико-геог-
рафическими условиями, и физико-химическими свойства-
ми почвы тех мест, где она произрастает па юге Англии,
описано в работе [25].
В качестве альтернативы допущению о наличии апри-
орной структуры, присущей индивидам (т.е. строкам ис-
ходной матрицы данных), мы предположим теперь, что
случайные переменные, т. е. столбцы матрицы, можно
разбить на два множества из г и q переменных, так что
r+q = p. Это эквивалентно записи матрицы данных в виде
X = [XjX2],
где Xi имеет п строк и г столбцов, а Х2 — п строк и q
столбцов. Тогда ковариационную либо корреляционную
матрицу, вычисляемую по основпой матрице данных,
можно представить в виде блоков:
$ _ Агг Crq
^qr ^qq _
По этой матрице требуется найти линейные комби-
нации1
Ut = Ipq,
= ni/X2 ,
1 Неявно введено обозначение: Xi = х2=(х, н,...
—,хг+<7)'.—Прим, перев.
182 Глава 6
где /=1, 2, 3, s таковы, что наибольшая корреляция
имеет место между ti\ и z?i, наибольшая корреляция
среди всевозможных линейных комбинаций, не коррели-
рующих с U\ и имеет место между Иг и v2 и т. д. для
всех s возможных нар.
Можно показать, что эти канонические корреляции и
векторы, определяющие веса переменных из обоих мно-
жеств, задаются собственными числами и собственными
векторами двух матриц,
СД-1С — В
и
СВ-ЧУ — А.
Обе матрицы имеют одинаковые собственные числа, а их
собственные векторы дают коэффициенты линейных ком-
бинаций для левой и правой групп переменных соответст-
венно.
Пример 6.6. Физическая среда в заливе Моркам и обитающие
в нем беспозвоночные
В примере 6.1 мы устанавливали корреляцию между
главными компонентами двух множеств переменных, од-
но из которых характеризует физические и химические
свойства песка и ила в заливе, а другое — численность
семи видов беспозвоночных, обнаруженных в пробах грун-
та. Ясно, что в данной ситуации может оказаться полез-
ной и модель канонических корреляций.
В табл. 6.25 приведены коэффициенты корреляции
между восемью переменными среды и численностями се-
ми видов для 272 проб, по которым имелись оба набора
переменных. Эта таблица соответствует в обозначениях,
приведенных выше, матрице Crq с семью строками, соот-
ветствующими разным видам беспозвоночных (г), и во-
семью столбцами для физических и химических перемен-
ных (q). Из этой матрицы, а также из матриц Агг и В^,
элементы которых близки к значениям величин, приве-
денных в табл. 6.6 и 6.2 соответственно (близки, но пе
совпадают, так как число проб, для которых измерялись
оба набора переменных, было равно только 272), можно
вычислить необходимые нам собственные числа и соответ-
Таблица 6.25
Коэффициенты корреляции между численностями различных видов беспозвоночных и переменными
для среды в заливе Моркам1
Вид Коэффициенты корреляции с переменными среды
>250 мкм 125-250 мкм 62,5-125 мкм <62,5 мкм потери при про- каливании кальций фосфор азот
Масота balthica —0,040 —0,2394 0Л594 0,113 0,4024 0,1583 —0,023 0,5164
Tellina tenuis —0,016 0,022 0,055 —0,077 —0,016 —0,035 —0,006 —0,063
Ну dr obi a ulvae —0,068 —0,2324 0,2014 0,071 0,1713 0,038 —0,022 0,1943
Corophium volutator —0,064 —0,2654 0,087 0,2244 0,092 0,060 -0,024 0,1332
Nereis diversicolor —0,011 —0,1522 0,056 0,114 0,2994 0,106 0,006 0,4014
Nrenicola marina 0,244 —0,048 —0,027 0,032 0,096 0,2304 0,083 0,1392
Nephthys hombergii —0,050 0,095 0,113 —0,2094 —0,068 —0,090 —0,020 —0,110
1 Подробнее смысл переменных см. в примере 6.1.
* Значимо на уровне 0,05.
3 Значимо на уровне 0,01.
4 Значимо на уровне 0,001.
184
Глава 6
ствующие им канонические корреляции (они приведены
в табл. 6.26). В работе [54] предложен простой критерий
Таблица 6.26
Собственные числа и канонические корреляции
Порядковый номер Собственное число Каноническая корреляция Доля дисперсии
виды беспозво- ночных среда
1 0,312523 0,559 0,25 0,24
2 0,111680 0,334 0,13 0,18
3 0,080338 0,283 0,16 0,19
4 0,044555 0,211 0,13 0,13
значимости этих корреляций, по которому значимыми
оказываются лишь первые две из них, а третья близка к
значимости. Согласно грубому эмпирическому правилу
канонические корреляции, меньшие 0,3, вряд ли окажутся
значимыми, по обычно стоит рассматривать и корреляции,
близкие к этому порогу, чтобы выяснить, пе поддаются ли
они содержательной интерпретации.
Первые три канонические корреляции отражают 54%
вариабельности численности различных видов беспозво-
ночных и 61% вариабельности переменных, характеризу-
ющих свойства среды. В отличие от корреляций между
главными компонентами для двух множеств в примере 6.1
анализ канонических корреляций дает непосредственную
меру того, какая часть вариабельности двух множеств
обусловлена взаимосвязями между ними—в данном при-
мере степень этой взаимосвязи оказывается удивительно
высокой. Собственные векторы для численностей различ-
ных видов беспозвоночных и для переменных, характери-
зующих свойства среды в заливе, взятые в соответству-
ющем масштабе, приведены в табл. 6.27 и 6.28 соответст-
венно. Среди численностей видов первая каноническая
корреляция приписывает наибольший вес численности
Масота balthica, а среди переменных среды — доле час-
Многомерные модели
185
Таблица 6.27
Собственные векторы для численностей видов, взятые
в определенном масштабе
Векторы для корреляций,
взятые в определенном масштабе
1 2 3
Масота balthica 1,000 -0,326 -0,230
у2 Tellina tenuis -0,067 -0,431 0,016
У3 Hydrobia ulvae 0,012 —0,474 —0,674
У4 Corophium volutator 0,146 1,000 —1,000
Y6 Nereis diver sic olor 0,194 0,007 0,725
Ув Arenicola marina 0,067 0,786 0,964
Yi Nephthys hombergii 0,007 —0,910 -0,099
Таблица 6.28
Собственные векторы для переменных среды, взятые в
определенном масштабе
Переменная среды Векторы для корреляций, взятые в определенном масштабе
1 2 3
Доля частиц размером >250 мкм, % 0,060 0,253 0,104
A'2 Доля частиц размером 125—250 мкм, % Доля частиц размером 62,5— 125 мкм, % 0,913 0,765 -0,616
Xs 1,000 0,720 -0,997
Доля частиц размером < 62,5 мкм, % 0,666 1,000 —1,000
Потери при прокаливании при 550сС 0,015 -0,126 0,124
X. Содержание кальция, % 0,052 0,105 0,039
X, Содержание фосфора % -0,005 0,062 0,174
X, Содержание азота, % 0,936 -0,023 0,160
18G Глава 6
тиц размером от 62,5 до 250 мкм и содержанию азота.
Вторая из корреляций противопоставляет численности
Corophium volutator и Arenicola marina численностям
Nephthys hombergii и в меньшей степени численностям
Масота balthica, Telllna tenuis и Hydrobia ulvae. Эта ком-
бинация коррелирует в основном с долей частиц мельче
62,5 мкм, но помимо этого и с долей частиц размером от
62,5 до 250 мкм. Наконец, третья корреляция связывает
противоположность между численностями Corophium
volutator и Arenicola marina с отсутствием частиц мельче
125 мкм.
Многомерная модель канонических корреляций пред-
ставляет собой мощиый инструмент исследования и обоб-
щения сложных взаимосвязей между двумя множествами
переменных. Данной моделью редко пользуются в основ-
ном пз-за трудностей вычислений, однако сейчас, когда
для проведения этих вычислений составлены эффективные
алгоритмы, пет никаких особых оснований пренебрегать
этим методом и дальше.
Наш обзор многомерных моделей был, естественно,
весьма поверхностным — об этом потенциально важном
классе моделей, которые ведут прямое наступление на мно-
гомерную природу многих экологических проблем, можно
было бы сказать гораздо больше. Читатели, желающие
ближе познакомиться с этим вопросом, найдут соответст-
вующие примеры в работах [70, 32, 41].
Рассмотренные модели опираются па математические
свойства матриц данных, учитывают некую внутренне
присущую этим данным структуру и используют соответ-
ствующее разбиение матриц. Как и в некоторых других
математических моделях, мы отказываемся здесь от сво-
боды динамической имитации ради знания свойств и по-
ведения математических конструкций определенного типа.
Ограниченность этих конструкций компенсируется более
четким пониманием логики модели как некоего прибли-
жения реальной действительности.
«А * , <t Ч \ а \ -о *L \ ^\х ***&, ?п к \ ^\к> ^П/Г^лщ >\ \ ч: Форма листьев ^^^^онрнические -Пример '^величиньГЛ л'^ с< тг Си^а' ^качественные—— Q / х\ <лЛ Приблизительный $ 4>* Ч а#* > Ч | / Ч // ^/’ / X I # #' / Xе’ 1 / X / </ 7 X i У х* ч / ^5—4^Z"«"’"' ,-^СГ (Многомерные'х'ю^' ^^^еСп„ \модели ) ^7— ^чогвмерное 1/ Пддв6ие Минимальной ^1\ Хи протяженности. £ Х^ ^ъ -% "%. S % ‘ ? \ -%- 1* '**"*«./’ <*Z$* °с"^ Ц/о
7
ОПТИМИЗАЦИОННЫЕ И ДРУГИЕ
МОДЕЛИ
Эта глава является последней из глав, рассматрива-
ющих основные семейства математических моделей, кото-
рые чаще всего используются в приложениях системного
анализа к экологии. Опа будет короче остальных, так как
модели, описанные в пей, либо считаются обычно менее
приемлемыми для решения экологических задач, либо бы-
ли построены сравнительно недавно и пе проявили еще
всех своих возможностей. Тем пе менее для специалиста
по системному анализу очень важно представлять себе
возможности максимально широкого круга моделей, и
описанные в этой главе модели следует иметь в виду, ког-
да работа находится па стадии выбора пути решения за-
дачи. Если настоящая книга будет когда-либо переизда-
ваться, то скорее всего потребуется расширить именно
данную главу, включив в нее новые разработки и приме-
ры применения данных моделей.
Оптимизационные модели
Столь странное слово «оптимизация» придумано для
того, чтобы обозначить отыскание максимума либо мини-
мума какого-то математического выражения пли функции,
когда некоторые их переменные мы можем изменять в оп-
ределенных пределах. Если бы мы хотели найти только
максимум, мы могли бы назвать этот процесс максимиза-
цией-словом, которое в конце концов более приемлемо.
И наоборот, отыскивая только минимум, мы могли бы
использовать слово минимизация. Математически одну
из этих операций всегда можно превратить в другую, так
что в том, что оба процесса рассматриваются как один,
есть определенная логика. Когда грамматика непонятна,
выручает логика!
Заметим, что почти все модели, которые мы уже рас-
смотрели в этой книге, в принципе могут быть использо-
Оптимизационные и другие модели
189
ваны при отыскании тех или иных максимумов или ми-
нимумов. Будет ли это использование иметь смысл,
целиком зависит от конкретной задачи, но такие ситуации,
когда необходимо изучить возможность увеличения про-
дуктивности некоторой экологической системы путем из-
менения окружающей среды или смены методов управле-
ния, возникают в экологии довольно часто. Одна из глав-
ных причин применения моделей в том и состоит, что мы
должны уметь предвидеть результаты этих изменений.
С помощью динамической модели роста дрожжей в
смешанной культуре (см. гл. 3, пример 3.1) мы можем
попытаться, например, определить соотношение между
исходными количествами обоих видов (дрожжей), при ко-
тором продуцируется максимум дрожжевых клеток. Ана-
логичный вопрос может возникнуть и в отношении роста
овса и ячменя при совместном посеве: каково оптимальное
исходное соотношение между этими культурами, дающее
максимальный общий урожай? Определив эксперимен-
тально основные параметры моделей, мы можем последу-
ющие эксперименты с целью отыскания нужных соотно-
шений проводить уже па моделях.
В матричных моделях, экспериментируя с нескольки-
ми различными возрастными структурами популяции и
интенсивностями ее эксплуатации, мы можем определить
оптимальное значение некоторой целевой функции, хотя
сами матричные методы при заданных начальных услови-
ях определяют стационарные состояния и коэффициенты
сбора урожая. Интересные возможности для эксперимен-
тирования предоставляют и стохастические модели. Так,
используя их для исследования разложения листового
опада (пример 5.3), можно попытаться определить число
дней выдерживания образцов в поле, содержание влаги и
температуру, при которых поглощение кислорода макси-
мально. Точно так же, моделируя поведение верхового бо-
лота, можно исследовать влияние изменения переходных
вероятностей па продолжительность времени, в течение
которого данный участок остается в каком-то конкретном
состоянии.
Труднее, пожалуй, предусмотреть оптимизацию в мно-
гомерных моделях, по по крайней мере в одном смысле
эти модели уже обнаруживают оптимальные условия,
190 Глава Т
определяющие связи. Так, например, дискриминантные
функции представляют собой линейные функции исходных
переменных, которые обеспечивают панлучшую (т. е. оп-
тимальную) дискриминацию между априорными группами.
Аналогичным образом, канонические корреляции опреде-
ляют такие линейные функции двух наборов переменных,
которые обладают наибольшими корреляциями.
Совершенно естественным, однако, является желание
сформулировать модель так, чтобы облегчить отыскание
оптимальной комбинации ключевых переменных, и основ-
ные математические формулировки такого рода были раз-
работаны независимо в тех ранних приложениях матема-
тических методов к практическим задачам, которые извест-
ны сейчас под названием «исследование операций». Здесь
возникают терминологические трудности из-за того, что
нахождение общего класса решений таких задач называ-
лось «математическим программированием» еще до того,
как слово «программирование» вошло в обиход в смысле
написания инструкций для ЭВМ. Тот факт, что большая
часть математического программирования сейчас тесно
связана с ЭВМ, вносит лишь дополнительную путаницу!
В наиболее простой для описания форме математиче-
ское программирование известно под названием «линейное
программирование». В этой модели мы начинаем с линей-
ной целевой функции
Y d^X^ -J- "Т * * * ~Ь
i
и хотим найти максимум или минимум этой функции при
одном или более ограничениях, которые также выражены
в виде линейных функций, хотя исходно это могут быть
просто неравенства, например,
^1*^1 4“ &3^3 •
Часто имеются неявные ограничения, состоящие в том, что
Xi не могут быть отрицательными.
Когда переменных только две, задачи оптимизации та-
кого рода довольно легко решаются графическими мето-
дами. Для более чем двух переменных задача сильно ус-
ложняется, и обычный подход к ее решению предполагает
использование так называемого «симплекс-метода». Преж-
Оптимизационные и другие модели
191
де всего путем введения вспомогательных переменных ог-
раничения, выраженные в виде неравенств, заменяются
линейными уравнениями L Затем ищется любое допусти-
мое решение задачи, и, как только оно найдено, итератив-
ным методом пытаются улучшить это решение, т. е. при-
близить его к определенному оптимуму целевой функции
с помощью малых изменений значений переменных. Эта
итеративная процедура продолжается до тех пор, пока
нельзя будет получить никакого дальнейшего улучшения.
Одно из преимуществ оптимизационных моделей со-
стоит в том, что они всегда освещают два немаловажных
аспекта проблемы. Полученное решение дает значения пе-
ременных целевой функции, при которых эта функция
достигает максимума или минимума, в зависимости от того,
как поставлена задача. Одпако, помимо этого, метод ука-
зывает и то ограничение, которе нужно ослабить, чтобы
улучшить оптимальное значение целевой функции. В ре-
зультате этого экспериментатор может тщательнее прове-
рить постановку задачи и, в частности, свои оценки коэф-
фициентов при переменных в целевой функции и природу
указанного ограничения. Если окажется, что можно улуч-
шить оценки или ослабить ограничение, то оп сможет най-
ти еще лучшее решение.
Как и прежде, проиллюстрировать структуру модели и
ее применение, по-видимому, легче всего на простом при-
мере.
Пример 7.1. Оптимальные стратегии хищника
Частон [10] предлагает простую экологическую задачу,
которую можно сформулировать в виде модели линейного
программирования. Он постулирует существование хищни-
ка, гнездо которого находится в точке А, и двух потенци-
альных источников пищи, расположенных на участках В
и С. Время, необходимое хищнику для того, чтобы добрать-
ся до участков В и С и возвратиться с единицей добычи,
полагается равным двум и трем минутам соответственно.
С другой стороны, на участке В хищник затрачивает на
1 Ограничения, состоящие в том, что все переменные должны
быть больше пуля, остаются прежними. — Прим, перев.
192
Глава 7
поимку единицы добычи rri две минуты, тогда как на
участке С ему требуется лишь одна минута, чтобы пой-
мать единицу добычи #2. Энергетическая ценность одной
единицы ГГ1 оценивается в 25 Дж, а единицы х% — в 30 Дж.
Если мы введем теперь ограничение, состоящее в том,
что па путь из гнезда в любой из участков и обратно хищ-
ник может затрачивать не более 120 мин в сутки и что на
поиск жертв он может тратить не более 80 мин в сутки, то
мы придем к классической задаче линейного программи-
рования. Упомянутые ограничения записываются в виде
неравенств
2xi + 3^2 <120
(для времени в пути) и
2xi + 1^2 < 80
(для времени поиска пищи). Нужно записать также не-
явные ограничения
xt > 0 , х2 > 0,
так как хищник не может поймать отрицательное число
жертв. При этих ограничениях мы хотим максимизировать
целевую функцию
Z = (25^ 30л*2) Дж .
Эту частную задачу довольно легко решить графически,
воспользовавшись записанными в виде неравенств ограни-
чениями. Ограничение по времени в пути показывает, что
если х\ равно нулю, то Х2 может быть не более 40 единиц.
Точно так же, если Х2 равно нулю, то х\ может быть не
более 60 единиц. Комбинации предельных значений яд и
#2 можно представить в виде прямой, соединяющей две
точки— (^1 = 60; #2 = 0) и (#1 = 0; £2 = 40) (см. рис. 7.1).
Применив аналогичные рассуждения к ограничению по
времени поиска пищи, мы получим, что если #1 равно ну-
лю, то Х2 не может превышать 80 единиц, а если Х2 равно
пулю, то х\ не может быть больше 40 единиц.
Все имеющие смысл решения лежат, таким образом, в
четырехугольнике OPQR па рис. 7.1, а максимум целевой
функции достигается в точке, которая наиболее удалена
Оптимизационные и другие модели
193
от начала координат в направлении, показанном стрелкой.
Эта точка имеет координаты {.zi = 30; #2 = 20}, так что мак-
симальное значение целевой функции равно
Z = 25^ 30;г2 = 25 х 30 + 30 х 20 = 1350 Дж .
Читатель может самостоятельно проверить, как влияет
ослабление одного или обоих ограничений на целевую
функцию, имея в виду, что самым важным при оптимиза-
ции часто является нахождение того ограничения, ослаб-
ление которого позволяет найти еще лучшее решение.
Данный пример, разумеется, очень прост, и графиче-
ский метод решения обычно можно применять лишь в том
случае, когда целевая функция и ограничения зависят от
двух переменных; правда, такие решения нередко можно
найти и для случая нескольких ограничений. Имеются, од-
нако, эффективные алгоритмы для решения задач линей-
ного программирования, и особенно для тех задач, которые
Рис. 7.1. Графическое решение простои задачи линейного програм-
мирования
7—843
194 Глава 7
могут быть сформулированы как задачи о перевозках. По-
пулярное введение в линейное программирование читатель
может найти в книге Вайды [85]
Существует множество экологических проблем, кото-
рые можно выразить через модели линейного программи-
рования. Большинство этих проблем связано с управлени-
ем природными ресурсами в сельском хозяйстве и лесовод-
стве. Линейное программирование применяется в исследо-
ваниях по управлению [90] и планированию [23] лесных
запасов, прп экономическом анализе мероприятий по улуч-
шению качества древесных лесных пород [86] и при ана-
лизе развития сельскохозяйственных предприятий [59].
На основе линейного программирования разрабатываются
также итеративные системы для отбора проектов научных
исследований, результаты которых смогли бы указать та-
кие новые направления в развитии сельского хозяйства,
которые принесли бы наибольшую пользу общественному
благосостоянию [67].
Несмотря на всю ценность линейного программирова-
ния, ясно, что далеко пе все задачи можно представить
через линейные целевые функции и линейные ограничения,
нелинейность же этих функций или ограничений — либо и
того, и другого — очень сильно затрудняет отыскание ре-
шений. К таким же трудностям приводят и постановки
задач, при которых накладываются определенные ограни-
чения па размеры скоплений, в которых могут быть сосре-
доточены единицы каких-то конкретных ресурсов. В связи
с этим была разработана теория нелинейного программи-
рования, хотя экологических моделей, построенных исклю-
чительно на основе этой теории, довольно мало. Некоторые
последние достижения на пути применения методов опти-
мизации в управлении природными ресурсами, а также
задачи, где могут понадобиться подобные методы, рассмот-
рены в обзоре [87].
Иногда крупномасштабные проблемы оптимизации
можно подразделить па ряд более мелких задач, образую-
щих последовательность во времени пли в пространстве
1 Из опубликованных на русском языке книг можно рекомен-
довать: Гасс С. И. Путешествие в страну линейного программирова-
ния. Пер. с англ. — М.: «Мир», 1973. — Пр им. ред.
Оптимизационные и другие модели
195
либо и в пространстве, н во времени. Подобные постановки
задач часто позволяют упростить процедуру отыскания
решения, при этом, правда, нужно специально проверять,
дает ли последовательность оптимальных решений подза-
дач приближение оптимального решения полной пробле-
мы. Такой поиск наилучшего решения па каждом этапе
известен пол названием «динамического программирова-
ния». Математический аппарат, использующийся в таких
моделях, довольно сложен, и потому примеры их успешно-
го применения в экологии весьма немногочисленны. Хил-
борп [33] описывает использование стохастического ди-
намического программирования для определения оптималь-
ных интенсивностей лова для смешанных популяций рыб.
В работе Уатта [91] предлагается пример применения
динамического программирования для определения страте-
гий борьбы с вредителями, а Шрайдер [69] описывает мо-
дель, которая дает рекомендации по капиталовложениям
для всей совокупности процессов в лесоводстве — от посад-
ки деревьев до получения готовой продукции одной или
нескольких первичных деревообрабатывающих отраслей.
Для читателей, которые захотят поближе познакомить-
ся с методами оптимизации, весьма полезной окажется
книга Конверса [13]. В ней не только достаточно полно
изложена теория оптимизации, по и содержится ряд полез-
ных программ для ЭВМ на БЭЙСИКе.
Теоретико-игровые модели
С моделями математического программирования тесно
связаны модели, которые основаны па теории игр. Простей-
шая из этих моделей — так называемая игра двух лиц с
нулевой суммой. При этом имеется два множества интере-
сов, одно из которых может представлять природу или ка-
кую-то другую внешнюю силу, а сама игра «замкнута» в
том смысле, что все, что проигрывает один из игроков, вы-
игрывает другой. Теорию можно распространить и на слу-
чай игры многих лиц с нулевой суммой, но этот случай
выходит за рамки нашей книги.
В той разновидности игры, с которой мы будем иметь
Дело, в центре анализа стоит простая матрица, показываю-
щая, какие стратегии могут применять оба игрока, и исхо-
7*
196 Глава 7
ды всевозможных комбинаций этих стратегий. Пример та-
кой матрицы приведен в табл. 7.1, которая дает возмож-
ные исходы игры с точки зрения человека, который не
может вспомнить, является ли сегодняшний день днем
рождения его жены! Он может применить две стратегии,
а именно: либо купить цветы, либо прийти домой без цве-
тов. У природы здесь тоже две стратегии, т. е. день рожде-
ния жены либо сегодня, либо в другой день.
Таблица 7.1
Матрица игры, указывающая стратегии и исходы для задачи
«Не сегодня ли день рождения жены?»
Стратегия Природа
День рождения нс сегодня День рождения сегодня
Муж Без цветов 0 — 10
С цветами 1 1,5
Числа в таблице показывают исход игры с точки зрения
мужа для каждой комбинации стратегий двух игроков.
В соответствии с ними, если муж приходит домой без цве-
тов и день рождения жены пе сегодня, исход игры для
пего пулевой — оп ничего пе выигрывает и ничего не про-
игрывает. Если же оп приходит без цветов, но день рож-
дения жены именно сегодня, муж проигрывает достаточ-
но много ( — 10), так как оп забыл нечто, о чем следовало
бы хорошо помнить. Если муж приходит домой с цветами,
по день рождения пе сегодня, имеется весьма скромный
выигрыш, ценность которого, быть может, слегка умень-
шается из-за ощущения, что он сделал нечто, чего мог бы
и не делать. Если муж приходит домой с цветами и день
рождения его жены именно сегодня, выигрыш несколько
больше (1,5), так как муж вспомнил о том, чего в общем-
то и пе должен был забывать.
Можно показать, что данная игра обладает той харак-
терной особенностью, которая в теории игр называется
«седловой точкой». Попросту говоря, когда наибольший из
Оптимизационные и другие модели
197
минимумов по строке совпадает с наименьшим из макси-
мумов по столбцу, игра имеет седловую точку и игрокам
всегда следует придерживаться той чистой стратегии, кото-
рая стоит па пересечении соответствующих строки и столб-
ца. В данной игре мужу в любом случае следует прийти
домой с цветами!
Поиск седловых точек является весьма важным мо-
ментом теории игр; вероятность того, что эти седловые точ-
ки будут существовать у случайно выбранной матрицы,
велика для матриц невысоких порядков. В тех же случаях,
когда никакой седловой точки пе существует, можно пока-
зать, что решение следует искать в смешанных стратегиях.
Это означает, что должны применяться две или более стра-
тегии и что вероятности, с какими данные стратегии при-
меняются, могут быть вычислены но матрице игры. Каж-
дый раз во время игры выбор стратегии должен осущест-
вляться случайно, по с фиксированными вероятностями
для соответствующих стратегии.
Уместно, конечно, спросить, почему мы рассматриваем
природу как злостного противника, стремящегося миними-
зировать выигрыш партнера, будь то человек, животное
или растение. И все же в ситуациях, когда у нас не хва-
тает знаний о реакции живых организмов или внешней
среды на выбор стратегий, которые будут давать наилуч-
ший результат хотя бы в среднем, стоит применять некую
комбинацию стратегий, консервативную в том смысле, что
она минимизирует ущерб, причиняемый при наихудших
стратегиях, которые может применить природа.
Описанный выше пример взят из книги Вильямса [95].
Эта книга служит прекрасным введением в теорию игр,
написанным в увлекательной п остроумной форме с мно-
жеством практических примеров. Простой пример из обла-
сти экологии, рассмотренный ниже, является измененным
вариантом одного из примеров, приведенных в этой книге.
Пример 7.2. Стратегии ловли на удочку и питания
Представим себе, что существование некоего вида рыб»
питающихся у поверхности воды, зависит главным образом
от наличия трех видов летающих насекомых. Эти виды —
обозначим их через х\, х% и х^ — у поверхности воды пред-
198 Глава 7
ставлены не одинаково, а с частотами соответственно 15дг,
Ьп и п. Иными словами, насекомых Х2 в пять раз больше,
чем #3, а х\ — в три раза больше, чем х%.
Допустим, что некто ловит рыбу на один из этих трех
видов насекомых, насаживая их па крючок. Тогда исходы
игры с точки зрения рыбы для каждого из возможных со-
четаний стратегий питания и применяемой наживки могут
быть такими, как приведенные в табл. 7.2.
Таблица 7.2
Матрица игры для стратегий ловли на удочку и питания
Стратегия Рыболов использует в качестве наживки
Х1 Хз
Х1 -2 0 0
Рыба питается х2 0 -6 0
х3 0 0 -30
Можно показать, что данная матрица игры не имеет
седловой точки, а как рыболову, так и рыбе следует при-
менять одну и ту же смешанную стратегию ужения и пи-
тания — х\: Х2: х^ = 15 : 5 : 1. При этом цена игры для ры-
бы оказывается отрицательной и равной —10/7, указывая
на то, что в конце концов рыба будет поймана, по что опти-
мальная стратегия питания уменьшает вероятность поим-
ки в каждом конкретном случае.
Таблица 7.3
Матрица игры для измененных стратегий ловли на удочку
и питания
Стратегия Рыболов использует в качестве наживки
Xi х2 Хз приманку
Х1 —2 0 -0 —1
Рыба питается т ^2 0 -6 0 -3
х3 0 0 -30 -15
Оптимизационные и другие модели
199
Если мы предположим теперь, и то рыболов иногда ис-
пользует приманку, которая может быть принята по ошиб-
ке за любое из трех насекомых, по которая вдвое чаще вы-
зывает подозрение у рыбы, то матрица игры изменится так,
как это показано в табл. 7.3. Новая матрица по-прежнему
не имеет седловой точки, а оптимальная смешанная стра-
тегия для рыбы выражается теперь пропорцией 3:1:0 —
насекомые хз стали слишком опасны для жизни! Оптималь-
ная смешанная стратегия рыболова выражается пропор-
цией 7:2:0: 1, и ему тоже никогда не следует использо-
вать хз в качестве наживки. Цепа игры для рыбы равна
теперь —30/20, что несколько меньше, чем в исходном ва-
рианте.
Модели, основанные па теории игр, представляют собой
интересный и пока еще малоизученный подход к решению
стратегических задач. Разработка теории для более слож-
ных игр с ненулевой суммой и игр многих лиц, где между
игроками могут создаваться коалиции, представляет собой
область исследований, заслуживающую особого внимания,
в частности в экологических проектах, связанных с плани-
рованием и оценкой воздействий па окружающую среду.
Модели теории катастроф
Теория катастроф является весьма элегантным резуль-
татом применения топологии к системам, которые облада-
ют четырьмя основными свойствами: бимодальностью,
разрывностью, гистерезисом и дивергенцией. О бимодаль-
ности говорят, когда для системы характерно одно из двух
(или более) состояний, а свойство разрывности предпола-
гает, что между этими двумя состояниями оказывается
сравнительно мало индивидов или наблюдений. Хороший
пример как бимодалыюсти, так и разрывности дает харак-
терное деление организмов на самцов и самок. Наличие
случайных организмов неопределенного пола не создает
серьезных препятствий для распознавания этих двух со-
стояний, а теория предполагает такой разрыв между со-
стояниями, что любой индивид может быть без труда отне-
сен лишь к одной из категорий. О разрывности говорят и
тогда, когда малые изменения какой-либо переменной, в
том числе времени, вызывают большие изменения в пове-
200 Глава 7
дении или состоянии системы. Гистерезис проявляется в
том, что система обладает четко выраженной замедленной
реакцией на некое воздействие, причем эта реакция идет
по одному пути, когда воздействие возрастает, и по дру-
гому, когда оно убывает.
Труднее описать свойство дивергенции, характерной
особенностью которого является то, что близкие начальные
условия эволюционируют к значительно удаленным друг
от друга конечным состояниям. В приложениях таких мо-
делей к динамике популяций, например, начальные усло-
вия чуть выше и чуть ниже вполне определенных порогов
часто расходятся к принципиально разным конечным со-
стояниям.
Простейший тип катастрофы иллюстрируется рис. 7.2,
на котором изображена катастрофа, именуемая складкой.
Предполагается, что сначала система находится в точке Л
на нижней ветви складчатого многообразия. С ростом пе-
ременной р переменная х тоже возрастает, так что система
проходит через точку В и достигает точки С. В данной точ-
ке переменная р пересекает особенность 5j, и система
совершает «катастрофический» скачок на верхнюю ветвь
Рис. 7.2. Изображение катастрофы «складка».
Оптимизационные и другие модели 201
многообразия в точку С'. Дальнейшее возрастание пере-
менной р уводит систему далее, за точку D.
Если же переменная р начинает теперь убывать, то
система продолжает следовать вдоль верхней ветви много-
образия, через точку Е к точке F. В этой точке перемен-
ная р пересекает особенность S2, и система совершает «ка-
тастрофический» возврат на пижшою ветвь многообразия
в точку F', после чего дальнейшие изменения переменной
р ведут систему либо к точке А, либо к точке В до тех
пор, пока она вновь не пересечет особенность Si.
Простая катастрофа «складка» довольно хорошо иллю-
стрирует свойство бимодалыюсти, представленное двумя
ветвями складчатого многообразия, и свойство разрывно-
сти, представленное резкими скачками с одной ветви на
другую в особенностях Si и S2. Гистерезис иллюстрируется
тем, что траектория системы при уменьшении р после пе-
ресечения особенности отличается от траектории, по кото-
Рис. 7.3. Изображение катастрофы «сборка».
202 Глава 7
рой движется система лрп увеличении р. Следует, пожалуй,
отметить, что конкретная форма функции, связывающей
х и р на многообразии, пе важна — лишь бы в проекции х
иа р сохранялась особенность типа складки. Простейшая
из эквивалентных функций, представляющих катастрофу
«складка», задается многочленом третьей степени:
/(*; р) = — (я3 — * + р)-
Более сложный тип катастрофы — сборка — изображен
па рис. 7.3. Допустим, что данная система описывается пе-
ременной х, которая зависит от двух переменных, р и q.
Благодаря наличию складки па поверхности, изображаю-
щей эту зависимость, поведение системы варьирует в со-
ответствии со значениями р и q. Например, при измене-
нии р от точки Pi к Рг система движется из точки А, пока
не встретится с особенностью и пе совершит «катастрофи-
ческий» скачок иа нижнюю часть поверхности, вдоль
Рис. 7 А Иллюстрация дивергенции при сборке.
Оптимизационные и другие модели 203
которой будет продолжать двигаться к точке В. С другой
стороны, при движении системы от С к D то же самое
изменение значений р пе встречается с особенностью. Про-
исходит или нет встреча с особенностью, зависит от отно-
сительных значений р и q.
Катастрофа «сборка» хорошо иллюстрирует свойство
дивергенции, что ясно видно па рис. 7.4, где показаны тра-
ектории системы из двух близких состояний Е и F. Если
значение q уменьшается, система движется к точкам G и Н
соответственно. При одном и том же изменении параметра
q и даже при том, что обо траектории могут начинаться
из сколь угодно близких точек, они приводят систему в
весьма далекие друг от друга конечные состояния. Благо-
даря наличию складки траектории из двух этих близких
точек расходятся, причем траектория EG оказывается на
верхнем, а траектория FH — па нижнем листе многооб-
разия L
Всем, кто хотел бы получить простое и ясное представ-
ление о приложении теории катастроф к экологическим
системам, лучше всего обратиться к работе Джонса [40].
Помимо популярного введения в теорию катастроф и фор-
мулировки основных условий, необходимых для ее при-
менения, в ней демонстрируется применение этой теории
при моделировании системы еловой листовертки-почкоеда
в лесах восточной Канады.
Пример 7.3. Заболевание голландского вяза
В качестве интересного, хотя и весьма умозрительного
примера возможного применения моделей, основанных па
теории катастроф, к экологическим системам мы рассмот-
рим вспышку заболевания голландского вяза в Англии.
Возбудителем этого заболевания, вызывающего высыхание
верхушек деревьев и их гибель, является гриб Ceratocystis
ulmi, который переносится от дерева к дереву жуками-ко-
роедами рода Scolytus. В Англии заболевание было впер-
вые зарегистрировано в 1927 г., хотя почти наверняка оно
существовало и ранее. После 1927 г. произошло несколько
1 Приведенные здесь примеры отнюдь не исчерпывают все из-
вестные в настоящее время типы катастроф. — Прим, пер ев.
204 Глава 7
серьезных вспышек этого заболевания, когда оно, очевид-
но, переходило от эндемической стадии к эпидемической.
Недавние исследования позволяют утверждать, что по
крайней мере последняя эпидемическая вспышка болезни
вызвана агрессивным штаммом Ceratocystis ulmi, и предпо-
лагается, что заметная региопалыюсть в распространении
заболевания есть результат независимого появления аг-
рессивного штамма в различных местах. Считается, что
слабо пораженные деревья, — особенно в местах, удален-
ных от основных очагов заболевания, — заражены неагрес-
сивным штаммом, который образует остаточную популя-
цию Ceratocystis ulmi, сохранившуюся после спада преды-
дущей эпидемии.
Альтернативная гипотеза состоит в том, что как гибель
значительной части зараженных вязов, так и наличие аг-
рессивного штамма являются отражением эпидемической
фазы заболевания и что оба эти фактора связаны с попу-
Рис. 7.5. Модель, основанная на теории катастроф, для заболевания
голландского вяза.
Оптимизационные и другие модели
205
ляцией жуков-короедов Scolytus п числом вязов на едини-
цу площади так, как это показано па рис. 7.5. Типичный
путь развития эпидемии начинается в точке А, для кото-
рой характерно большое число вязов па единицу площади
и низкая численность популяции жуков. Если популяция
неуков увеличивается (например, вследствие того, что в
течение нескольких лет была мягкая зима), этот путь пере-
секает складчатую особенность в точке Т и скачком пере-
ходит в току В эпидемической стадии, для которой харак-
терны наличие агрессивного штамма и гибель значитель-
ной части зараженных деревьев.
Из точки В система может двигаться двумя различны-
ми путями. Если в результате эпидемии или выборочной
рубки число вязов па единицу площади существенно
уменьшается и параллельно уменьшается численность жу-
ков, то заболевание постепенно возвращается к эндемиче-
скому уровню. Если, однако, вследствие соответствующей
обработки или неблагоприятных условий популяция жуков
резко сокращается прежде, чем существенно уменьшается
численность вязов, то «путь» заболевания проходит через
складку, совершая резкий переход в точку С эндемического
уровня, причем скорость перехода зависит от размаха
складки.
О динамике популяций жуков-короедов известно до-
вольно мало. В работе Гиббса и Хоуэлла [27], однако,
приведены оценки численности вязов на 1 км2 в южных
графствах Англин наряду с оценками доли зараженных
вязов и доли вязов с явными признаками заболевания по
данным 1971 г. Если считать долю зараженных вязов гру-
бым показателем численности популяции жуков, то мож-
но провести предварительную оценку справедливости гипо-
тезы теории катастроф, опираясь па соотношения между
долями вязов с явными признаками заболевания и зара-
женных вязов. Для графств с плотностью менее 200 вязов
на 1 км2 и более 200 вязов па 1 км2 они представлены па
рис. 7.6. Эти данные пе противоречат гипотезе многообра-
зия со сборкой где-то между 100 и 200 вязами на 1 км2
при доле зараженных деревьев примерно 10%. Ясно, одна-
ко, что для проверки этой гипотезы необходимы дальней-
шие исследования.
Модели, основанные па теории катастроф, впервые по-
206
Глава 7
явились в 1970 г. и с тех пор вызывают большой интерес.
Эти модели привлекают стройностью своей теории и на-
глядностью изображения, но их трудно применять к ситуа-
циям с большим числом измерений. Серьезные трудности
Рис. 7.6. Соотношения между долями зараженных вязов и вязов
с явными признаками заболевания.
приходится преодолевать и при оценке параметров много-
образий по экологическим данным. Тем не менее, можно
почти не сомневаться, что в ближайшем будущем эти моде-
ли получат дальнейшее развитие и применение.
Мы завершаем обзор основных семейств математиче-
ских моделей, встречающихся в приложениях системного
анализа к экологическим проблемам. Для конкретных за-
дач могут оказаться приемлемы все либо некоторые из этих
семейств моделей, и па этапе выбора путей решения сле-
дует использовать — по крайней мере в предварительной
форме — как можно большее их число. В следующей главе
мы подробнее остановимся на самом процессе моделиро-
вания.
8
ПРОЦЕСС МОДЕЛИРОВАНИЯ
В предыдущих главах мы описали основную идеологию
системного анализа и применения математических моде-
лей и рассмотрели семейства математических моделей, ко-
торые чаще всего используются в решении экологических
проблем. Но от знакомства с идеологией и примерами мо-
делей конкретных типов еще весьма далеко до практиче-
ского применения математических моделей к реальным
задачам, и в данной главе мы рассмотрим, как в сущности
протекает процесс, в ходе которого специалист по систем-
ному анализу должен вникнуть в проблему и начать ра-
ботать над ее решением. Математика — наука точная, но,
как мы увидим, приложение математики к проблемам ре-
альной действительности требует большой интуиции, прак-
тического опыта, воображения и того, что можно назвать
«чутьем». Эти качества особенно важны, когда сама проб-
лема, как это часто случается, изучена довольно слабо.
Постановка задачи и ограничение степени
ее сложности
Если следовать этапам системного анализа, выделенным
в гл. 1, то первым шагом после того, как осознано сущест-
вование проблемы, которую стоит исследовать, должна
быть постановка задачи и ограничение уровня ее слож-
ности. В сущности именно данный этап является решаю-
щим для всего исследования. Только осознавая это, мы
можем быть уверены в том, что те ограниченные научные
силы, которыми мы должны вести наступление па проб-
лему, будут правильно распределены, а не растрачены па
выяснение вопросов, не имеющих прямого отношения к
стоящей перед нами проблеме. Хотя ученые по традиции
считают, что их изыскания не должны быть стеснены
рамками практической выгоды, системный анализ не при-
держивается этой традиции.
Процесс моделирования
209
Важно, однако, подчеркнуть, что нам вряд ли удастся
правильно поставить задачу и ограничить степень ее слож-
ности с первой же (или даже с тг-й!) попытки и что не
стоит поэтому стремиться к завершению этой стадии в
один прием. Главное — это начать, и хотя, конечно, же-
лательно начать в верпом направлении, если потом выяс-
нится, что направление нужно сменить, это нестрашно —
ведь мы к этому подготовлены.
Наши описания экологических систем должны быть
ограничены некоторыми пределами — пространственными,
временными, а также в смысле подразделения на подсис-
темы, по которым должны приниматься решения. Статис-
тики всегда подчеркивают, что первым этапом любой фор-
мы экспериментирования или выборочного обследования с
необходимостью является определение популяции, относи-
тельно которой делаются какие-то выводы, и это требова-
ние, несомненно, распространяется и па моделирование
экологических систем. Наша модель направлена па то, что-
бы помочь получить определенные выводы о некоторой по-
пуляции, и исходная постановка задачи, и ограничение
степени ее сложности должны быть достаточно ясными,
чтобы идентифицировать эту популяцию.
Интересный пример возникающих здесь трудностей
дает проводимое в Англии исследование по обработке пло-
щадей, которые были покрыты распыленной золой — от-
ходами электростанций, работающих на угле. Распыленная
зола почти инертна, содержит весьма незначительное ко-
личество органических веществ (или не содержит их во-
обще), а также различные количества вредных для рас-
тений и животных элементов. Поскольку зола проникала
в производительные экосистемы на глубину до нескольких
метров, возникла задача создать новые системы, которые
были бы способны выживать и развиваться при таких ус-
ловиях. Эксперименты с различными видами обработки
почвы и управления неизбежно придется проводить на пло-
щадях, уже покрытых золой, однако применимость полу-
ченных здесь результатов к площадям, которые еще толь-
ко могут быть покрыты золой в будущем, вызывает сомне-
ние, поскольку вполне вероятно, что технологический про-
цесс или сырье, на котором работают электростанции,
изменятся со временем. В данном случае экосистемы оп-
210 Глава 8
ределены и ограничены в пространстве и как подсистемы,
но не во времени. Поэтому в системном анализе восста-
новления таких экосистем путем внесения удобрений и
органических веществ, а также путем заселения почвы
дождевыми червями и другими беспозвоночными потребу-
ется дополнительный этап проверки применимости полу-
ченных результатов для другого состава золы. Аналогич-
ные требования к плану исследований предъявляет и воз-
можное влияние климатических и погодных циклов на
оздоровительные мероприятия в нарушенных экосистемах.
Последовательные методики для таких исследований и по-
строения соответствующих моделей созданы уже много лет
назад, по используются довольпо редко.
Обычно, однако, легче ограничить задачу в простран-
стве и времени, чем идентифицировать экологические под-
системы, которые должны включаться в модель,— ограни-
чения первого типа более очевидны. Во многих проектах
Международной Биологической Программы (МБП) счи-
талось, что нужно моделировать экосистему в целом и по-
тому нет необходимости идентифицировать ее подсистемы.
Когда же предпринимались попытки синтеза, то обнару-
живалось, что многие проекты МБП содержат в модели су-
щественные пробелы, которые нельзя заполнить пи экспе-
риментальными результатами, пи данными наблюдений и
которые часто были обусловлены отсутствием какого бы
то ни было предварительного синтеза. Опыт работы в рам-
ках МБП заставил экологов усомниться в целесообразно-
сти моделирования экосистемы в целом и привел к необ-
ходимости сосредоточиться на анализе тщательно сплани-
рованных наборов подсистем. В изучении экосистем
тундры, например, основное внимание уделялось циклам
разлагателей и питательных веществ как основе для пред-
сказания последствий различных воздействий па среду.
Сложность и модели
Системный анализ в экологии стал применяться срав-
нительно недавно, и потому готовых рецептов построения
математических моделей довольпо мало. В результате при
разработке модели в пее часто включаются непроверенные
гипотезы, а оптимальное число необходимых подсистем
Процесс моделирования
211
трУДн0 предопределить достаточно точно. Можно предполо-
жить, что более сложная модель полнее учитывает слож-
ности реальной системы, по, хотя это предположение ин-
туитивно кажется вполне корректным, необходимо принять
во внимание дополнительные факторы. Рассмотрим, напри-
мер, гипотезу о том, что более сложная модель дает и бо-
лее высокую точность, с точки зрения неопределенности,
присущей модельным прогнозам. Вообще говоря, система-
тическое смещение, возникающее при разложении систе-
мы на несколько подсистем, связано со сложностью моде-
ли обратной зависимостью, но налицо и соответствующее
возрастание неопределенности из-за ошибок измерения
отдельных параметров модели. Те новые параметры, кото-
рые вводятся в модель, должны определяться количест-
венно в полевых и лабораторных экспериментах, и в их
оценках всегда есть некоторые ошибки. Пройдя через ими-
тацию, эти ошибки измерений вносят свой вклад в неопре-
деленность полученных прогнозов. По всем этим причинам
в любой модели выгодно уменьшать число включенных в
рассмотрение подсистем.
В то же время некоторые экологи подчеркивают важ-
ность структуры экологических ниш в динамике экосистем
и полагают, что те модели, которые игнорируют видовые
различия, рискуют потерять важные элементы их дина-
мики. Пока можно прямо сравнить поведение упрощенной
модели с поведением репрезентативного набора экосистем,
принятие упрощенной модели должно основываться на
демонстрации того факта, что се отличия от поведения моде-
ли, более полно учитывающей сложность биологической
системы, несущественны для целей данного исследования.
Отыскание компромисса между сложностью и простотой
при выборе подсистем и видов, учитываемых в модели, —
это одна из самых трудных задач, с которыми специалист
по системному анализу сталкивается в любой практиче-
ской ситуации. Как уже отмечалось выше, ему вряд ли
удастся с первого раза сформулировать модель п ограни-
чить уровень ее сложности.
212 Глава 8
Воздействия
Определить разумный уровень сложности подсистем —
задача немаловажная, но, пожалуй, еще важнее определить
те воздействия, которым будет подвергаться система. Ни-
какая модель или научная программа не смогут предви-
деть все (или хотя бы многие) вероятные экологические
воздействия, и любое исследование должно быть организо-
вано в соответствии с некоторым набором гипотез о при-
менимости тех или иных мер управления и воздействий.
В идеальном случае основная структура исследования поз-
воляет анализировать взаимодействие различных факто-
ров. При планировании экспериментов, которые необходи-
мо поставить, можно учесть факторную структуру воздей-
ствий так, чтобы эффекты различных факторов не накла-
дывались друг на друга. Многочисленные схемы управле-
ния факторными структурами в экспериментах позволяют
провести эти исследования экономично и с достаточной
степенью точности. Даже когда прямое экспериментирова-
ние невозможно, все равно нужно перечислить вероятные
воздействия и подвергнуть определенную нами систему
такому выборочному обследованию, при котором эффекты
этих воздействий по возможности пе накладывались бы
друг на друга. По-видимому, пе стоит продолжать иссле-
дование, в котором невозможно разделить эффекты двух
пли более воздействий.
Весьма типичный пример подобных затруднений мож-
но найти в недавних работах по моделированию связей
между распределением и концентрацией кислых осадков
и ростом дерева. Хотя и с некоторыми трудностями, но все
же удается измерить кратковременные флуктуации роста
отдельных деревьев, однако лишь сравнительно малую до-
лю полной вариабельпости роста за период времени, ска-
жем, в один час, можно объяснить изменением климатиче-
ских условий (температуры, влажности, скорости ветра)
и эвапотрапспирацией. Неудивительно поэтому, что про-
стые модели роста, учитывающие только возможные запаз-
дывания реакции деревьев па климатические изменения,
оказываются пе очень, результативными. Если же ввести в
модель концентрацию кислых осадков, то мы столкнем-
ся с новой трудностью — сами кислые осадки будут сильно
Процесс моделирования
213
коррелировать с темп же климатическими переменными,
которые используются для характеристики роста деревьев.
Отсюда следует, что регистрация роста и климатических
условий па ограниченном числе участков вряд ли даст нам
какое-либо представление о сложном взаимодействии меж-
ду .климатом, кислыми осадками и ростом деревьев, пока
не будет найден способ разделения налагающихся друг на
друга эффектов климата и кислых осадков.
Мы так долго говорим о трудностях, возникающих в
самом начале работы на этане постановки задачи и ограни-
чения степени ее сложности, что многие исследователи,
пожалуй, и не решатся начать! Лучше, однако, в полной
мере осознать всю сложность проблемы, чем пытаться ре-
шить малую ее часть и думать, что решено уже все. У спе-
циалистов по системному анализу бывает один серьезный
недостаток: абстрагируя какую-то часть проблемы, удоб-
ную для решения, они претендуют затем на то, что выбран-
ная ими часть лучше всего представляет систему в целом.
Словесные модели
Сделав несколько попыток определить задачу и огра-
ничить уровень ее сложности, большинство аналитиков, ве-
роятно, будут пытаться сформулировать словесную модель
той проблемы, пад которой они работают. Мы уже обсуж-
дали пользу построения подобных моделей, а также право
вербального описания называться своего рода моделью.
Ничего, кроме пользы, это пе принесет, если прежде, чем
приступать к каким-либо математическим операциям, ма-
тематик или специалист по системному анализу запишет
как можно более простыми словами то, как оп понимает
проблему, и согласует это описание с экологами и теми
практиками, которые, как оп надеется, будут в конечном
счете использовать его модели. Приняв эту простую меру
предосторожности, можно будет избежать многих после-
дующих дискуссий. Разумеется, математик будет сомне-
ваться, можно ли словами отразить все изящество той мо-
дели, которую ои в конце концов построит, а эколог будет
Удивляться тому, что математик собирается определить
проблему в какой-то еще, лучшей, чем слова, форме, —
однако именно в этом взаимодействии и состоит вся цен-
214 Глава 8
пость предстоящего исследования. Определенные трудно-
сти будут возникать также из-за того, что различные груп-
пы людей, занимающихся решением одной йроблемы, ред-
ко будут иметь возможность вполне свободно обменивать-
ся своими идеями — независимо от того, используют ли
они при этом слова, математические выражения, диаграм-
мы или просто интуицию. Поэтому иаилучпшй выход —
применять как можно большее число различных способов
описания.
Выбор путей решения
На данном этапе нам предстоит «выдать» список воз-
можных альтернативных путей решения задачи. Сколько
таких путей следует искать? На этот вопрос нет простого
ответа, если, конечно, не рассматривать ситуации, когда
человек, воображающий себя аналитиком, выписывает под-
ряд все различные подходы к решению задачи, которые он
только может себе представить. При дальнейшем рассмот-
рении из-за трудностей — математических либо концепту-
альных — некоторые пути решения покажутся бесперспек-
тивными, однако не следует отвергать их по этой причине,
по крайней мере на первых порах. В дальнейшем может
оказаться также, что многие из предложенных альтерна-
тивных путей решения требуют такой информации, кото-
рой либо нет вообще, либо ее трудно собрать. И вновь из-за
этого не следует сразу же отвергать альтернативы: часто
обнаруживается, что данные, которые считались несущест-
вующими или которые казалось трудно собрать, в действи-
тельности можно извлечь из каких-то неожиданных источ-
ников или получить — по крайней мере в каком-то прибли-
жении — из других данных. Поэтому при первом просмотре
возможных альтернатив даже самые невероятные пути
решения следует включать в список. Часто сама возмож-
ность использовать определенный математический аппарат
выявляется лишь после нескольких недель обдумывания
вероятных путей решения — человеческий мозг работает
медленно, а ход мысли предсказать нельзя!
Как только готов список возможных путей решения,
следует посмотреть, какими способами можпо было бы объ-
единить эти пути по два, по три или более. На ранних эта-
Процесс моделирования
215
пах системного анализа подобные комбинации могут по-
казаться неразумными, однако не следует упускать их из
виду, поскольку целесообразность такого объединения по-
прежнему может стать очевидной лишь после того, как мы
затратим значительное время па ее обдумывание. Факти-
ческое же объединение возможно лишь после того, как на-
чата работа над несколькими моделями. Важно только под-
готовить себя к тому, что пути решения проблемы могут
быть самыми разными и что их можно комбинировать.
Гипотезы
В сущности, всякое исследование экосистем, которое
претендует па научность и которое пытается применить
системный анализ в качестве метода исследования, требует,
чтобы постановка задачи и ограничение уровня ее слож-
ности были сформулированы в виде гипотез, которые мо-
гут быть формально проверены, — пусть даже эта проверка
сводится к цепочке дедуктивных рассуждений, построен-
ных на одной или нескольких гипотезах, пе поддающихся
прямой верификации. Можно выделить три основных клас-
са гипотез, которые будут использоваться при реализации
различных альтернативных путей решения, фигурирующих
в составленном исследователями списке.
1. Гипотезы о пригодности, идентифицирующие и опреде-
ляющие переменные, виды и подсистемы, имеющие
отношение к данной проблеме.
2. Гипотезы о процессах, связывающих подсистемы в рам-
ках данной проблемы и определяющие воздействия, ко-
торым подвергается система.
3. Гипотезы о соотношениях и их формальном представле-
нии посредством линейных, нелинейных и интерактив-
ных математических выражений.
Эти три классг! гипотез могут быть объединены в рам-
ках одной формальной схемы рассуждений, представляе-
мой с помощью таблицы решений, где перечисляются все
гипотезы и их комбинации, которые должны быть четко
определены для решения конкретной проблемы. Для каж-
дой комбинации таблица решений указывает, какие дей-
ствия необходимо предпринять, чтобы быть уверенным в
правильности полученного решения. Поскольку таблицы
216 Глава 8
решении дают ясный способ описания сложного набора
гипотез и разнообразных стратегий, они часто служат иде-
альным средством и для описания условий взаимодействия
между составными частями модели. По такой же методике
перечисляются и комбинации гипотез, необходимые для
таких стратегий, в ходе осуществления которых могут про-
изойти неуправляемые события, так что предсказать или
регулировать их с полной определенностью невозможно.
Именно па этом делается основной упор в последних иссле-
дованиях по методам принятия решений.
Подчеркивая необходимость принятия формальных ги-
потез при постановке задачи и ограничении степени ее
сложности, мы хотим опровергнуть бытующее представле-
ние о том, что системный анализ является чем-то вроде
высшей магии, которая с помощью абстракций и алгорит-
мов математики позволяет решать задачи без особых раз-
мышлений! В действительности же необходимость форму-
лировать гипотезы таким образом, чтобы их можно было
проверить (обычно статистическими методами), уже сама
по себе направляет основные усилия исследователей па
логические рассуждения, а пе на математические манипу-
ляции, программирование и вычисления. И если в этих
рассуждениях будет не хватать логики, то никакие вычис-
ления пе спасут модель от неминуемого провала.
Построение модели
Мы переходим теперь к наиболее приятной для мате-
матика стадии системного анализа, т. е. к фактическому
построению модели и математическому манипулированию
различными идеями, которые выражены в виде гипотез.
Здесь суммируются и тщательно проверяются данные, с
тем чтобы установить, удовлетворяют ли они сформулиро-
ванным гипотезам. Вручную либо на ЭВМ строятся графи-
ки для проверки всевозможных соотношений и для выясне-
ния, являются ли эти соотношения линейными, нелиней-
ными или интерактивными. Для основных индивидов про-
сматриваются существующие наборы данных и опробуются
различные статистические критерии, причем для одного и
того же множества данных иногда используются несколько
критериев. Нематематпку, а в сущности, и «чистому» мате-
Процесс моделирования
217
матику, большая часть этой работы может показаться
«игрой». Вполне понятно, что большинству прикладных
математиков правится именно этот этап и они пе будут
слишком торопиться завершить его или хотя бы проанали-
зировать, как далеко они продвинулись в поисках альтер-
нативных решений исходной проблемы. Они могут даже
забыть, в чем состоит эта проблема, если время от времени
не напоминать им о необходимости сверяться со словесной
моделью, формулировкой проблемы и принятым уровнем
сложности. У них будет постоянно возникать желание ис-
пробовать все разновидности существующих идей, которые
примыкают к основной цели исследования. Найдутся самые
разные причины, почему в данный момент рано подводить
итоги и оценивать результат всей работы. Для математика
это игра — и хорошо, что это может быть игрой!
Тем не менее должен наступить момент, когда выби-
рается ряд альтернативных моделей, которые нужно дове-
сти до получения окончательного решения проблемы.
По тем или иным причинам какие-то альтернативы из рас-
смотрения исключаются. Быть может, слишком сложен
математический аппарат; возможно, отсутствуют необходи-
мые данные; не исключено, что идея, казавшаяся па пер-
вый взгляд вполне приемлемой, теряет адекватность при
рассмотрении ее с учетом имеющейся информации и целей
исследования. В конце концов приемлемым подходом к ре-
шению исходной проблемы оказываются две, три или даже
одна из исходных альтернатив и их комбинаций. Тогда
приходит пора собирать воедино все ресурсы исследования,
вновь уточнять формулировку задачи и степень ее слож-
ности, поскольку они почти наверняка видоизменились в
ходе интенсивной и лихорадочной математической работы,
и объединять выводы, полученные из всех вычислений,
графиков и просто упорных размышлений. Здесь мы вплот-
ную подходим к тому, что является, пожалуй, самым труд-
ным этапом работы — верификации и подтверждению сис-
темной модели.
Верификация и подтверждение
Сделанный памп акцепт па формулировке гипотез помо-
жет выяснить разницу между верификацией и подтвержде-
218 Глава 8
нием 1 модели. Хотя употребление этих терминов пе всег-
да согласовано, верификацией можно считать процесс вы-
яснения, является ли общее поведение модели «разумным»
отображением изучаемой части реальной системы и совпа-
дают ли механизмы, включенные в модель, с известными
механизмами явлений, происходящих в данной системе.
Таким образом, верификация — это весьма субъективная
оценка успешности моделирования, а не точная проверка
гипотез, лежащих в основе модели. Поэтому неудивитель-
но, что отдельные моменты верификации неизбежно воз-
никают на этапе лихорадочной математической работы,
когда «разумность» результатов служит одним из крите-
риев, по которым модельер может судить об успехе или
неудаче своих усилий. Однако то, что разумно для каких-
то составляющих модели, может оказаться менее разум-
ным, когда эти составляющие объединяются в единое
целое. Иногда бывает необходимо подвергнуть взаимосвя-
зи между различными воздействиями на систему и ее реак-
циями последовательному факторному анализу, чтобы га-
рантировать охват всего диапазона возможных условий и
чтобы можно было утверждать, что в рамках данной фор-
мулировки задачи и в свете поставленных целей исследо-
вания поведение модели воспроизводит поведение реальной
системы. При этом, разумеется, мы должны быть достаточ-
но осторожны и пе отказываться от модели только потому,
что ее поведение контринтуитивно. Известны многочислен-
ные примеры решений, которые противоречили тому, что
считалось здравым смыслом, и пе следует отвергать модель
лишь по Toil причине, что она приводит к неожиданным
результатам. Когда же модель ведет себя совершенно иным
образом, чем реальная изучаемая система, нужно искать
объяснение этому рассогласованию. Вот в чем заключает-
ся роль верификации.
В отличие от верификации, подтверждение модели —
это количественное выражение того, в какой степени вы-
ход модели согласуется с поведением реальной системы.
1 В оригинале — validation. Для обозначения различных сторон
сложного процесса анализа адекватности модели реальному объек-
ту применяются термины, имеющие разные смысловые оттенки:
идентификация, верификация, подтверждение, калибровка. Устой-
чивая терминология здесь еще нс сложилась. — Прим, персе.
Процесс моделирования
219
Подтверждение подразумевает точную и объективную про-
верку основных гипотез, которая проводится с помощью
специальных, в первую очередь статистических, процедур,
облегчающих выяснение адекватности модели. В большин-
стве экологических приложении системного анализа этот
процесс подтверждения редко доводился до конца — в ос-
новном из-за неадекватности исходной формулировки за-
дачи. Чаще всего к подтверждению модели, если опо вооб-
ще проводится, подходят прямым и очевидным образом, а
именно, наблюдая поведение моделируемой системы при
регулируемых или измеряемых нагрузках и прочих фикси-
рованных условиях и сравнивая затем наблюдения с соот-
ветствующими предсказаниями имитационного аналога
системы. Модель считается подтвержденной, если при всех
испробованных условиях наблюдения в известных преде-
лах согласуются с предсказаниями.
Эта процедура обладает рядом недостатков, немаловаж-
ный из которых заключается в неопределенности, связан-
ной с получением общего вывода из конечного (и, как
правило, небольшого) числа экспериментов. Эта неопреде-
ленность приобретает особое значение при подтверждении
тех моделей системного анализа, в которых делаются по-
пытки предсказать эффекты того же порядка величины,
что и случайные флуктуации (иначе говоря «шум»), при-
сущие всем измерениям в реальных системах. В подобных
случаях целесообразно применять методы статистического
планирования и анализа экспериментов, как для умень-
шения числа экспериментов, необходимых при заданном
уровне достоверности, так и для выяснения статистической
значимости измеренных эффектов и эффектов, полученных
из модели. К счастью, за последние пятьдесят лет разра-
ботаны весьма эффективные методы планирования экспе-
риментов; если вначале эти методы применялись к экспе-
риментам над объектами реального мира, то сейчас они
приобретают все большее значение в анализе поведения
имитационных аналогов этих объектов. Подробное рассмот-
рение этих методов выходит за рамки нашей книги, а
интересующийся данным вопросом читатель может обра-
титься к работам [68] и [43].
Наиболее важный аспект, который должен учитываться
при подтверждении модели, заключается в том, что мы
220 Глава 8
заведомо допускаем возможность изменения более чем од-
ного параметра одновременно. К сожалению, многие науч-
ные работники были воспитаны в совершенно ошибочном
убеждения, что все корректные научные исследования
могут быть выполнены при изменении лишь одного пара-
метра. Как справедливо отмечал еще Р. Фишер в 20-х го-
дах, в подобных исследованиях никогда не будут адекват-
но изучены взаимодействия двух или более факторов. По-
этому подтверждение системных моделей почти наверняка
потребует факторных экспериментов для определения эф-
фектов изменения модельных параметров и эффектов взаи-
модействия этих изменений. Когда число параметров вели-
ко, полезными окажутся лишь достаточно сложные планы
экспериментов, которые содержат только некоторые из
огромного числа факторных комбинаций изменений этих
параметров. В отличие от экспериментов в полевых усло-
виях, эксперименты на моделях проводятся в системном
анализе последовательно и к ним особенно удобно приме-
нять многочисленные методы последовательного экспери-
ментирования, в том числе циклические планы и построе-
ние поверхности реакций систем па воздействия. Иногда
для подтверждения моделей системного анализа оказыва-
ются подходящими методы экспериментирования, приме-
няемые на опытных предприятиях в промышленности.
Достаточно полные обзоры всех этих методов можно найти
в обычных учебниках по планированию экспериментов
(см., например [12, 15]).
Анализ чувствительности
Анализом чувствительности часто называют исследова-
ние тех эффектов, которые вызываются изменениями вход-
ных переменных и параметров модели и, в частности, вы-
яснение того, как сильно при этом меняется поведение мо-
дели. В идеале такой анализ должен начинаться, как
только сделаны первые шаги в построении модели, и со-
ставлять часть того, что выше было названо «лихорадоч-
ной» математической работой. Параметры, к изменению
которых модель наиболее чувствительна, подвергаются
затем более тщательному изучению и последующей моди-
Процесс моделирования
221
фпкацип, и тогда может выясниться, что для более точного
моделирования соответствующих механизмов необходима
дополнительная экспериментальная работа или анализ дать
ных. Анализ чувствительности (особенно на ранних стади-
ях осуществления научного проекта) может во многом по-
мочь при распределении ресурсов между различными час-
тями научной программы.
С помощью анализа чувствительности можно исследо-
вать также неопределенности в работе модели, и посколь-
ку приходится оценивать фактическую неопределенность
в значениях параметров, пробные вариации этих парамет-
ров подходящего порядка величины могут специально вво-
диться при каждом просчете. Для больших и сложных
моделей анализ чувствительности и проверка пригодности
модели в целом может оказаться весьма длительным и до-
рогостоящим процессом, однако важно выяснить поведение
модели во всем диапазоне изменений основных парамет-
ров, а изучение эффектов изменения только одного пара-
метра пе даст никакой информации о взаимодействиях.
Планирование и интеграция
В результате развития методов системного анализа и
широкого применения вычислительных машин и машин-
ных языков (этой теме посвящается следующая глава)
сейчас стало возможным планирование научных стратегий
экологических исследований, в которых фигурируют мно-
гие взаимодействующие компоненты. Создание междисцип-
линарных групп исследователей все больше способствует
объединению усилий представителей различных дисцип-
лин, участвующих в осуществлении той или иной научной
программы. Такие программы часто направлены на реше-
ние проблем, имеющих принципиальную важность с точки
зрения долговременных перспектив и весьма небольшое
значение с точки зрения сиюминутных практических це-
лей. С другой стороны, административные органы управ-
ления постоянно озабочены решением частных (но неот-
ложных) практических задач и проявляют потому замет-
ный прагматизм. Для того, чтобы при разработке новых
подходов к решению проблем добиться интеграции науч-
222 Глава 8
кого и управленческого отношения к делу, нужно объеди-
нить точность и обособленность науки с прагматизмом
управления. Как показывает опыт применения системного
анализа в экологии и других областях, формулировка гипо-
тез и сбор информации, а также планирование и выполне-
ние вспомогательных исследований и планов по управле-
нию очень часто предпринимаются разными группами и
организациями. Их неадекватная интеграция приводит к
потере связи между:
а) экспериментальными данными и разработкой моделей;
б) имитационными моделями, общим анализом систем и
внедрением моделей в практику управления;
в) проверкой предсказаний системного анализа и внедре-
нием моделей в практику управления;
г) практикой управления и разработкой новых гипотез;
д) применением результатов вспомогательных исследова-
ний и разработкой новых гипотез.
Разработка моделей часто идет по некоему стандартно-
му пути, па котором каждая составляющая модели после-
довательно разбивается на более детальные блоки, легче
поддающиеся научному анализу. Из практики системных
исследований вытекают обычно следующие выводы.
1. Качество имеющихся данных оставляет желать много
лучшего, а представление о природе причинных свя-
зей — особенно связей в экологии — как правило, до-
вольно слабое.
2. Системный анализ и сбор данных должны осущест-
вляться взаимосвязанно, это позволяет извлечь макси-
мальную пользу для принятия решений.
3. Чтобы в практике исследований утвердилась широкая
междисциплинарная проблемно-ориентированная мето-
дология, необходимо обучение системному анализу.
4. Системные модели могут быть улучшены лишь в ходе
их построения и исправления слабых мест.
5. Группы, занимающиеся системным анализом, должны
состоять из специалистов различных областей науки.
6. Исследование, не использующее методов системного
анализа, нередко требует большого объема высокока-
чественных данных, что делает его дорогостоящим.
Процесс моделирования
223
В данной главе указаны лишь основные этапы процес-
са моделирования. Специалисты по системному анализу
или модельеры, по-видимому, идут каждый в какой-то ме-
ре своим путем, по-разпому расставляя акценты на разных
этапах работы. Важно было лишь подчеркнуть, что весь
процесс моделирования регулируется — или должен регу-
лироваться — исходной формулировкой задачи и ограниче-
нием уровня ее сложности и что системный анализ не есть
группа приемов или методов, ищущих практического при-
ложения. Эти методы существуют, многие математики име-
ют богатый опыт их применения, п задача специалиста по
системному анализу — использовать ту информацию, ко-
торую мы имеем о применении математических моделей,
при решении экологических проблем. Как уже отмеча-
лось в этой книге, можно начать с попытки определить
экологическую систему на таком уровне сложности, кото-
рый только можно вообразить, и искать затем для всего
этого математические выражения. Бесперспективность та-
кого подхода в том, что модель сама становится слишком
сложной, чтобы быть инструментом рационального мыш-
ления и управления. Альтернативный подход состоит в
определенном снижении сложности до уровня, допускаю-
щего моделирование, и последующем использовании мате-
матических свойств хорошо изученных логических систем.
То, как происходит моделирование, со стороны — и особен-
но нематематику — может показаться хаосом, по этот про-
цесс проходит все же четко различимые стадии, которые
способствуют концентрации теоретических и эксперимен-
тальных усилий на достижении приемлемого практического
решения. В следующей главе мы остановимся па роли
ЭВМ и машинных языков в системном анализе вообще и
в процессе моделирования в частности.
сх. н ч % * *4 \ \Ч * '-Х х, ’“s*4^ ЙЕ“''ЧЛ’Т"“" V Ресурсы Х Xе графинов , .X иХ 1 м“ г# з 1 5 _> в. £ 4^ § X t 4 / 1 /%мерь1 "Тл^х / 1Г^* / 1 # ^пр°и / / _/ ^яклаЗыг«м>»1есЯ $ /‘С. V—2 К^ели/шгния/ задачи "%. ^\? ^^ние /</ J4 х. У < >< Ч лригойио®-^—- Переменные ' X Г / 5 / X 4 \ X
9
РОЛЬ ЭВМ
Хотя до сих пор мы не уделяли особого внимания воп-
росу о роли ЭВМ в системном анализе, ясно, что приме-
нение ЭВМ подразумевалось как при общем описании
системного анализа и семейств математических моделей
в первых главах книги, так и при обзоре процесса модели-
рования в предыдущей главе. Мы сознательно не обраща-
ли внимание читателей па этот вопрос, чтобы пе возника-
ло впечатления, что системный анализ отличается от дру-
гих теоретических и экспериментальных исследований
лишь применением ЭВМ. Тем не менее есть три очень важ-
ные причины использования ЭВМ в системном анализе:
а) большая скорость вычислений;
б) способность обеспечить быстрый доступ к большим мас-
сивам данных;
в) важная роль алгоритмических языков в передаче ин-
формации.
Рассмотрим подробнее каждую из трех этих причин.
Тот факт, что ЭВМ выполняют вычисления с почти не-
вероятной скоростью, конечно, общеизвестен, и в этом
самая очевидная причина их применения. Не так-то просто
объяснить, какова эта скорость, человеку, у которого нет
опыта работы па ЭВМ, — это только добавит масла в огонь
пепрекращающихся дебатов о применении ЭВМ в повсе-
дневной жизни. Укажем, однако, что объем вычислений,
который обычный человек мог бы проделать за год с по-
мощью лишь карандаша и бумаги, пе отвлекаясь на еду,
сон и отдых, можно было бы выполнить за два или три
месяца с помощью простейшей вычислительной машинки,
какая продается в любом большом писчебумажном мага-
зине. Даже самая медленная из имеющихся сейчас ЭВМ
проделает этот объем работы за несколько минут, а самым
мощным ЭВМ сегодняшнего дня понадобятся для этого
лишь считанные секунды. Без ЭВМ невозможны были бы
почти все вычисления, необходимые в системном анализе.
8—843
226 Глава 9
Почему же нужны такие невероятные скорости вычис-
лений? Во-первых, они нужны просто потому, что многие
из тех математических методов, которыми мы хотим вос-
пользоваться, нельзя применять, если пет возможности
проводить быстрые и точные вычисления. Такие задачи,
как нахождение обратных матриц, перемножение матриц,
отыскание собственных чисел и собственных векторов, ока-
зываются весьма трудоемкими и требуют много времени,
когда решаются вручную или с помощью простейших каль-
куляторов, а вероятность допустить ошибку, которая если
и обнаружится, то лишь после того, как вычисления уже
почти закончены, при этом весьма велика. От идеи прове-
сти вручную подбор даже совсем простых кривых или
регрессионных соотношений придется сразу же отказаться,
как только представишь, что даже одно такое вычисление
займет несколько недель. Поэтому без ЭВМ многие мате-
матические методы были бы практически неприменимыми,
несмотря на их очевидную ценность.
Однако то, что вместе с ЭВМ мы получаем доступ к
более мощному арсеналу методов, оказывается далеко не
единственной причиной важности высокого быстродействия
ЭВМ. Хотя современные ЭВМ редко допускают ошибки в
арифметике как таковой (а когда такие ошибки все же
происходят, машина сама сообщает об этом), ошибки час-
то допускаются пользователями ЭВМ — в значениях, при-
писанных параметрам модели, в принятой форме соотно-
шений между двумя или более переменными и в количест-
ве и качестве данных, участвующих в обработке. Очень
часто мы обнаруживаем эти ошибки лишь к концу вычис-
лений или когда уже просматриваем окончательные ре-
зультаты. Если бы само вычисление заняло у пас несколь-
ко недель, то вряд ли мы с большим удовольствием отнес-
лись бы к перспективе повторить его для других значений
параметров, других допущений пли данных. Л сознание
того, что мы можем за считанные секунды легко и безбо-
лезненно повторить всю операцию, побуждает к более
тщательной проверке и оценке результатов на каждой ста-
дии исследования. Лишь те, кто в научных разработках
никогда пе имел дела с ЭВМ, верят, что достаточно с одно-
го конца заложить в машину данные, как опа, единожды
Роль ЭВМ
227
проделав все необходимые вычисления, выдаст иа другом
конце готовый результат!
Одна из возможностей, возникающих благодаря высо-
кому быстродействию ЭВМ, заключается в анализе наших
данных, первичных либо уже обработанных, с помощью
построения графиков или иными методами. Когда объем
данных невелик, ученому довольно легко их критически
просматривать, рисовать графики зависимости одной пере-
менной от другой, искать основные показатели, которые
могли бы говорить о наличии аномалий и ошибок, и вооб-
ще приобретать «чувство» данных. Еще до широкого распро-
странения ЭВМ статистики, в том числе и автор этих строк,
которым приходилось обрабатывать данные на настольных
электрических вычислительных машинах, прекрасно пони-
мали, что такому общему представлению о данных и обна-
ружению аномальных значений помогает то, что они само-
лично и порой неоднократно вводят данные через клавиа-
туру этих машин. Обработка же больших массивов
информации па таких машинах сразу становится невозмож-
ной или по крайней мере непроизводительной для ученого,
в связи с чем ввод данных в ЭВМ пли их перевод в другие
формы хранения поручается операторам, которые могут
и не иметь никакого представления о целях и задачах об-
работки, и у них нет критического отношения к вводимой
информации. К счастью, быстродействие ЭВМ позволяет
ученому тщательно проверять все свои данные, прежде чем
приступать к какому-либо формальному анализу.
Все эти рассуждения призваны объяснить одно обстоя-
тельство, которое по понимается людьми, далекими от ис-
следовательской работы: девять из десяти аналитических
вычислений оказываются «отходами» в том смысле, что
они фактически пе используются в окончательных резуль-
татах. Разумеется, эти вычисления проведены не впустую,
так как они способствовали лучшему пониманию проблемы
и решению задачи. Это важное отличие научных вычисли-
тельных операций от автоматической обработки данных
(применяющейся, папример, при составлении платежной
ведомости или учете товаров на складе) часто приходится
объяснять администраторам вычислительных центров, для
которых «производительность» измеряется долей «успеш-
ных» просчетов.
8*
228 Глава 9
Хотя быстродействие существенно и само по себе, оно
менее важно, нежели вторая нз причин применения ЭВМ
в системном анализе — их способность обеспечивать быст-
рый доступ к большим массивам данных. Использование
ЭВМ всегда предполагает, что основная паша информация
представлена в такой форме, которая может воспринимать-
ся машиной, т. е. что данные нанесены па некоторый но-
ситель, откуда они могут быть прочитаны ЭВМ. Простей-
шим и самым первым из таких носителей является перфо-
карта, содержащая 80 колонок, где может быть пробито
множество числовых и буквенных символов. Затем эти дан-
ные считываются ЭВМ и запасаются в какой-либо форме,
удобной для храпения в памяти ЭВМ. Иногда носителем
служит бумажная перфолента, на которой также можно
пробить числовые и буквенные символы и которая также
может быть прочитана ЭВМ. У перфокарт и перфолент
есть свои преимущества и недостатки, хотя на деле выбор
между этими двумя носителями редко логически обосно-
ван, а связан чаще с привычкой. С развитием интерактив-
ных методов использования ЭВМ данные все чаще стали
вводиться с клавиатуры непосредственно па один из основ-
ных машинных носителей информации — магнитную лен-
ту либо магнитные диски.
Какая бы форма ввода пн применялась, как только дан-
ные прочитаны ЭВМ или нанесены на носитель, с которо-
го они могут быть прочитаны и тщательно проверены, их
можно подвергать любой необходимой обработке. Ими мож-
но обмениваться с другими специалистами, переносить на
другую ЭВМ либо непосредственно, либо через какой-то
из имеющихся носителей — перфокарты, перфоленту, маг-
нитную ленту или взаимозаменяемые магнитные диски.
Данные можно редактировать, представлять в нескольких
альтернативных формах, делать общедоступными, но за-
щищать от любых изменений пли же защищать так, что
их нельзя будет ни прочитать, ни изменить без предвари-
тельного разрешения. С данными можно проводить сорти-
ровку и другие вспомогательные операции без всякой необ-
ходимости вникать в них заново, так что коль скоро дан-
ные однажды проверены, то маловероятно, что в них вкра-
дутся какие-то ошибки. Худшее, что может случиться, —
это утрата данных в результате какого-либо сбоя в работе
Роль ЭВМ
229
ЭВМ, по чтобы защитить данные от подобных неожидан-
ностей, принято обычно организовывать хранение инфор-
мации иа двух отдельных носителях и в разных местах.
Простота введения данных в ЭВМ и накопления их
привела к возникновению концепции «банка данных», по-
нимаемого как банк информации, доступной широкому
кругу людей, — будь то «банкиры» или «клиенты» банка.
Применять эту концепцию нужно осторожно! Во-первых,
все данные содержатся в ЭВМ в предопределенной форме.
Важно поэтому, чтобы каждый, кто хочет воспользоваться
данными из “банка”, был проинформирован об этой
форме и ее особенностях. Например, данные ио числу орга-
низмов с каким-то конкретным заболеванием могли быть
собраны лишь в малой выборке из общего числа организ-
мов, и «процент больных» может иметь весьма невысокую
точность. Сравнивая эти данные с данными самых разных
уровней точности, можно получить результаты, вводящие
в заблуждение. Еще важнее учитывать возможный резуль-
тат тех ограничений, которые связаны со способом сбора
данных, когда эти ограничения пе выполняются в самих
данных.
Мы пе должны также поддаваться соблазну использо-
вать все данные в полном объеме только потому, что они
есть. Часто для конкретных целей нам нужна будет лишь
весьма малая выборка из имеющейся в ЭВМ информации,
и тогда следует применять обширную теорию выборочных
обследований, которая особенно интенсивно разрабаты-
валась за последние пятьдесят лет. С небольшой, правиль-г
но сделанной выборкой легче обращаться в ходе вычисле-
ний, опа снижает затраты машинного времени и часто
помогает уяснить как ход рассуждений, так и результаты
исследования.
Существует и другая веская причина, чтобы всюду, где
это возможно, работать с выборками. Поскольку логически
недопустимо и формулировать, и проверять гипотезы на
одном и том же множестве данных, обычно предпочитают
Детально проанализировать лишь некоторую выборку из
всей совокупности данных и по результатам этого анализа
сформулировать новые гипотезы, которые можно объектив-
но проверить затем па остальных данных. Если множество
Данных действительно обширно, этот процесс анализа,
230 Глава 9
формулировки гипотез и их перепроверки можно последо-
вательно расширять, чтобы добиться эффективного и ло-
гически безупречного решения экологических проблем.
Не менее очевидна и третья причина использования
ЭВМ в системном анализе. Поскольку ЭВМ могут работать,
лишь руководствуясь набором точных и совершенно одно-
значных инструкций, эти инструкции обеспечивают точную
и логическую запись всех вычислений и вспомогательных
операций, которые применялись в анализе наших данных
и построении модели. На профессиональном языке эти
инструкции называются «программой» (program) — наме-
ренно используется североамериканский вариант написа-
ния этого слова, что позволяет, во всяком случае в Европе,
отличать специальное употребление обычного слова «про-
грамма» (programme) от его общего значения в смысле
планируемой последовательности каких-либо событий.
Большинству начинающих пользователей ЭВМ написание
программы, или программирование, покажется лишь до-
садной необходимостью, однако вскоре станет ясно, какую
исключительную пользу приносит однозначное описание
процесса вычислений. Если программы при первом состав-
лении были соответствующим образом аннотированы, то
часто оказывается возможным совершенно точно восста-
новить, что было сделано в ходе вычислений несколько
месяцев или даже лет тому назад.
На ранних этапах развития вычислительной техники
все программы для ЭВМ писались на так называемых «ма-
шинных языках», и такие языки были специфичны для
каждого конкретного типа машины, а иногда и для отдель-
ных машин. На написание программы в машинных кодах
уходило много сил и времени, трудно было передать про-
граммы с одной машины па другую, а следовательно, и
от одного ученого к другому, если оказывалось, что они
работают па разных марках ЭВМ. Очень скоро, однако,
появилась возможность писать программы более простым
способом — в первую очередь па так называемых «авто-
кодах» и затем па нескольких языках высокого уровня.
Наиболее известные из таких языков — это, несомненно.
ФОРТРАН (FORTRAN - от FORmula TRANslation.
«трансляция формул») и АЛГОЛ (ALGOL — от ALGOritli-
mic Language, «алгоритмический язык»); па этих двух
Роль ЭВМ 231
языках написано очень большое число машинных про-
грамм для научных целей. Позже к списку наиболее упот-
ребительных языков добавился БЭЙСИК—«универсаль-
ный символически]”! инструктивный код для начинаю-
щих» \ главные преимущества которого заключаются в
том, что им легко овладеть и oir особенно подходит для
интерактивного способа общения с ЭВМ через терминалы.
Некоторые пользователи ЭВМ предпочитают применять
такие специально ориентированные языки, как ДИНАМО
и КСМП, которые упрощают программирование для дина-
мических моделей. Действительно, с помощью таких язы-
ков программировать для ЭВМ некоторые семейства мо-
делей проще, но, вообще говоря, для каждого семейства
пользователю понадобится знание своего специального
языка, и даже если бы он знал все эти языки, то все рав-
но обнаружил бы, что их возможности не удовлетворяют
его потребности полностью. Каждому, кто хочет занимать-
ся системным анализом в том виде, как он описан в на-
стоящей книге, мы настоятельно рекомендуем про делывать
вычисления на одном из языков высокого уровня — таких,
как ФОРТРАН, АЛГОЛ или БЭЙСИК. Эти языки гибки,
исключительно мощны и открывают доступ к широкому
кругу программ, подпрограмм и алгоритмов. Овладение
одним из них (а лучше всеми тремя!) откроет новую и
поистине неисчерпаемую сокровищницу знания и мастер-
ства, которую едва ли можно описать. Более того, сам
опыт, который вы приобретете в процессе обучения, преоб-
разит то, что раньше казалось утомительным и скучным,
в свете новых взглядов и возможностей. Кто-то сказал,
что этот опыт более всего похож на озарение, снизошед-
шее на путника по дороге в Дамаск.
Сами машинные программы образуют важную сферу
обмена информацией. В сущности установить контакт с
Другим специалистом по системному анализу часто бывает
проще всего, посмотрев, каким образом написаны програм-
мы для его модели. Если мы хотим попять, как он моде-
лировал такие биологические процессы, как фотосинтез
Или дыхание, пли как он учел генетическую изменчивость
1 В оригинале BASIC (Beginner’s All-purpose Symbolic Instruc-
tional Cod). — Прим, перса.
232 Глава 9
в процессе размножения того пли иного организма, то са-
мое полное и точное описание мы найдем в его машинной
программе. Мы можем затем использовать этот же кусок
программы или изменить его так, как нам представляется
необходимым. Если мы сообщаем о своих результатах авто-
ру программы, то в этом последовательном процессе наши
модели будут взаимно обогащаться и улучшаться как при-
ближения реальной действительности. Язык слов часто
неадекватен, иное дело — язык ЭВМ, которые к тому же
открывают доступ к нужным нам данным и обладают до-
статочным быстродействием, чтобы выполнить практиче-
ски любой необходимый нам вид вычислений.
Машинные программы — и особенно программы грамот-
но написанные — допускают также определенную свободу
в их применении. Одна и та же программа может работать
много раз с различными значениями входных данных и
и даже в тех целях, для которых первоначально она нс
предназначалась. Из исходной программы часто могут из-
влекаться более мелкие, автономные части большой про-
граммы — пользователи ЭВМ называют их подпрограмма-
ми — и применяться к таким расчетам, какие и не преду-
сматривались авторами программы; эти подпрограммы
могут объединяться также в различные последовательно-
сти для выполнения новых типов вычислений. Ту гибкостт
и свободу, с которой ученый может оперировать языком
программирования, трудно представить тому, кто сам нс
занимался этим. С уверенностью можно сказать, что немно-
гие из исследователей, постигших премудрость программи
ровапия, откажутся от тех возможностей, которые откры
вает перед ними эта паука.
Последняя особенность грамотно написанных программ
состоит в их способности вводить последующих пользова
телей программы в круг тех ограничений, которые пеиз
бежны при любом вычислении или моделировании в эко
логии. Включая операции разнообразных проверок данных
фигурирующих в вычислениях, можно добиться того, что
бы модель начинала работать лишь с данными, которые ьг
противоречат допущениям, лежащим в ее основе. Пожа
луй, пе все машинные программы настолько пзощреппь
по умелый модельер может гарантировать, что с его мс
делыо не произойдут две вещи, чаще всего подрывающи
Роль ЭВМ 233
репутацию моделирования: экстраполяция модели па слу-
чаи, для которых она пеприемлема, и использование совер-
шенно непригодных данных.
Основной вывод данной главы состоит в том, что ЭВМ
играют важную роль в системном анализе и моделирова-
нии. В сущности без применения ЭВМ нельзя выполнить
ни одной серьезной работы, особенно в экологии, и каж-
дому, кто хочет заниматься исследованиями в этой обла-
сти, придется научиться работать с машиной. Использовать
же ЭВМ, не зная, как на пей программировать, это все
равно, что иметь «Ролс-Ройс» или «Ягуар-Е» и пе уметь
водить машину. Важно поэтому знать один или несколько
таких языков программирования высокого уровня, как
ФОРТРАН, АЛГОЛ или БЭЙСИК. Изучение первого язы-
ка до стадии активного применения потребует стольких же
усилий, как и обучение вождению машины, по это заня-
тие стоит того, так как, во-первых, умея программировать,
вы сможете проделать работу, которая в противном случае
просто пе будет выполнена, а во-вторых, приобщитесь к
опыту многих людей, заключенному в других машинных
программах. На овладение вторым машинным языком уй-
дет уже гораздо меньше времени — наверняка меньше
половины того, что затрачено па изучение первого, а для
третьего языка понадобится еще меньше времени.
Практическое использование программирования су-
щественно повысит гибкость моделирования, которая мо-
жет понадобиться в любом приложении системного анализа
к экологическим проблемам. Это позволит разрабатывать
сразу несколько типов моделей, испытывать их и, если
нужно, отвергать без особых сожалений со стороны модель-
ера о том, что он посвятил модели так много времени, что
не следовало бы от нее отказываться. На самом деле, в
моделировании и системном анализе возникают вечные
трудности, когда приходится убеждать научных работни-
ков отказаться от модели, которая уже устарела, особенно
если потрачены месяцы пли даже годы па ее разработку.
Применение же ЭВМ для любых вычислительных нужд
анализа и моделирования упрощает подход к задаче и
Позволяет, когда нужно, сосредоточивать усилия па кон-
цептуальных аспектах работы.
Кроме того, применение ЭВМ существенно облегчает
234 Глава 9
обмен информацией между учеными и открывает доступ
к накопленным результатам работ, выполненных ранее.
Представляется вероятным, что в будущем результаты ис-
следовании все чаще будут передаваться в виде моделей,
аналогичных тем, которые мы строим в системном анализе,
и что эти модели легче и точнее всего смогут сообщаться
через машинные программы, позволяющие реализовывать
их на ЭВМ. Вместо того, чтобы говорить о «байке данных»,
мы будем говорить о «банке моделей», и нашим первым
шагом в решении каждой повой проблемы будет проверка,
не содержится ли в «банке моделей» аналогичных задач,
способных служить хотя бы первым приближением к ис-
ходной проблеме. В идеале мы, конечно, хотели бы по-
строить для каждой новой проблемы свою модель, но в ми-
ре так много проблем и они столь разнообразны, что нет
никакой надежды, что нам удастся разработать их все с
самого начала. Информация о том, что уже достигнуто в
прошлом, приобретает поэтому очень важное значение.
Одно из самых интенсивных направлений развития пау-
ки и техники наблюдается сейчас в области ЭВМ и вычис-
лительной математики. Сами ЭВМ становятся мощнее, но
меньше размерами и дешевле в эксплуатации. Тот тип
ЭВМ, которые называют сейчас «минпкомиьютерами», в
работе во много раз мощнее машин, которые всего лишь
десять лет назад считались большими компьютерами.
Л стоят они меньше тех машин, которым пришли на сме-
ну. Но сегодня даже эти мппикомиыотеры уже заменяются
«микрокомпыотерами» такой же мощности и быстродей-
ствия. В то же время конструируются и поистине боль-
шие ЭВМ — это машины, позволяющие решать такие за-
дачи, о которых еще несколько лет назад можно было
только мечтать. Комбинированное применение новых ма-
лых ЭВМ для повседневных вычислений и больших ЭВМ,
когда нужно получить доступ к главным массивам дан-
ных и необходимо особо высокое быстродействие, станет
еще более мощным орудием в руках специалиста по сис
темному анализу и позволит исследовать более сложные
модели, которые полнее учитывают изменчивость физиче
ского и экологического мира и их взаимодействие.
Интенсивное развитие ЭВМ стимулирует также не ме
нее интенсивную разработку алгоритмов, необходимых для
Роль ЭВМ
235
практического применения ЭВМ. Когда человеческий ум
начинает осознавать возможности, появляющиеся в резуль-
тате способности ЭВМ вычислять и выполнять логические
действия со скоростями, которые еще несколько лет назад
казались невероятными, то новые представления о пашем
мире и пашем воздействии па пего «конденсируются» в тех
алгоритмах, которые мы готовим для проверки этих идей на
ЭВМ. История языков программирования коротка, по она
уже может похвастаться одними из самых значительных те-
оретических достижений человечества. В свою очередь, эти
теоретические достижения ведут к развитию самой матема-
тики — не той классической математики, которую мы изу-
чаем в школах и университетах, п, конечно, пе той клас-
сической прикладной математики, которая есть в сущности
математика в приложении к физике восемнадцатого и де-
вятнадцатого столетий. Эта новая математика, появившая-
ся благодаря ЭВМ и стимулируемая практическими про-
блемами современного мира, способна рассматривать —
пожалуй, впервые — динамику, вариабельность, неопреде-
ленность и катастрофы нашего мира и пашей Вселенной.
Однако мы не можем закончить эту главу без напоми-
нания, что системный анализ в том виде, как оп описан в
данной книге, является функцией человеческого интеллек-
та. Несмотря на то, что ЭВМ и машинные языки позволя-
ют осуществить многие этапы системного анализа, нельзя
забывать, что они служат лишь инструментами мышления.
Как и всякий инструмент, их можно использовать непра-
вильно или даже злоупотреблять ими. Никакой объем вы-
числительной работы пе спасет пас, если ложны допуще-
ния модели или ошибочна ее логика. Точность описания
не имеет смысла, когда сама модель базируется иа ложных
предпосылках пли ложной логике, по эта точность сможет
Помочь другому исследователю разглядеть ошибки в пред-
посылках и погрешности в логике. Наибольшая опасность
таится, пожалуй, в том, что модели, взлелеянные повой
«магией» ЭВМ и ее языка, слишком часто выдаются за
самое реальную действительность, приближением которой
ОНИ служат. Модели системного анализа недолговечны
Или, во всяком случае, должны быть таковыми, чтобы с
ростом наших знаний па смену им приходили новые моде-
ли, новые приближения действительности.
Послесловие
Данное введение в системный анализ в применении
его к экологии преследует единственную цель. Оно направ-
лено на то, чтобы ввести читателя в круг идей и концеп-
ций системного анализа и математических моделей и
объяснить, почему эти модели нужны в экологии. Значи-
тельная часть книги посвящена описанию наиболее важ-
ных семейств математических моделей и простым приме-
рам их практического применения в экологических иссле-
дованиях, а заканчивается книга обзором процесса модели-
рования и обсуждением роли ЭВМ в системном анализе.
Заинтересованный читатель вправе спросить теперь
автора: «А почему вы не взяли конкретную экологическую
проблему и па ее примере не показали разработку всех
альтернативных моделей — как они выбирались и отверга-
лись, какие предлагались рекомендации по применению
результатов и как им следовали на практике?» Когда автор
только обдумывал, как писать эту книгу, он рассматривал
и такой подход, по после долгих размышлений отказался от
него. Во-первых, это сделало бы объем книги слишком
большим для «введения». Во-вторых, рассмотрение какой-
то одной конкретной проблемы почти наверняка сузило бы
круг потенциальных читателей книги, а большая часть
аргументации и выводов относилась бы к данному приме-
ру, а не к общим принципам и концепциям, которые здесь
обсуждались. И в-третьих, литература, посвященная при-
менению системного анализа для решения практических
проблем, уже начинает появляться, и некоторые из работ
вполне можно расширить, чтобы показать, каким образом
общая идеология системного исследования увязывается с
потребностями конкретной проблемы.
Любому читателю, иожелающему продолжить изучение
аспектов системного анализа, затронутых в данном ввод-
ном курсе, понадобятся специальные руководства. Совер-
шенно ясно, что никакой эколог никогда не будет знать
«слишком много» математики и никакой математик никог-
238
Послесловие,
да не будет знать «слишком много» экологии, если они
хотят работать в области системного анализа. Если вы эко-
лог, начинайте читать учебники по математике. Их сотни
на выбор, поэтому читайте математические пособия так,
как будто это романы — если книга пе заинтересовала вас,
отложите ее и поищите другую. Начинайте с достаточно
простых учебников алгебры, аналитической геометрии, ана-
лиза или статистики и выстраивайте прочный фундамент
знаний. Не пытайтесь проштудировать учебник — пропу-
скайте те места, которые окажутся слишком трудными при
первом чтении, и возвращайтесь к ним позже — читайте
ради удовольствия познавать новые идеи.
Если вы математик, начинайте читать что-нибудь из
многих сотен книг по общей или специальной экологии.
И тоже не стремитесь во что бы то ни стало проработать
книгу, которая наскучила вам, — быть может, позже она
заинтересует вас или вы решите, что возвращаться к ней
не стоит. Вас будет раздражать неумение многих экологов
пользоваться символическим представлением, в результате
чего объем большинства их книг гораздо больше необхо-
димого. Если вы сможете усмотреть способы, которыми
ваши математические знания можно «адаптировать» к опи-
санию экологических явлений и процессов, значит, вы сде-
лаете свои первые шаги в системном анализе.
Но главное — если вы еще пе умеете программировать
для ЭВМ, начинайте учиться! Это обучение не будет лег-
ким — оно потребует точности мышления, строгости выра-
жений, определенной доли прагматизма. После того, как
вы овладеете начальными этапами, программирование ско-
рее всего покажется вам более увлекательным и захваты-
вающим занятием, чем разгадывание кроссвордов, игра в
бридж или шахматы. Умение, которое вы приобретете, от-
кроет вам двери в ту многочисленную «литературу» по
системному анализу, которая никогда пе будет опублико-
вана, но которая существует в виде машинных программ
и алгоритмов.
Список литературы
1. Anscombe F. J. Sampling theory of the negative binomial and
logarithmic series distributions, Biometrika, 37, 358—382 (1950).
2. Anton 11. Elementary Linear Algebra, 2nd edn. Wiley, New York
and London.
3. Baeumer K., De Wit С. T. Competitive interference of plant spe-
cies in monocultures and in mixed stands, Noth. J. agric. Sci.,
16, 103-122 (1968).
4. Balaam L. N. Fundamentals of Biometry, Allen and Unwin, Lon-
don (1972).
5. Beddington J. R. Economic and ecological analysis of red deer
harvesting in Scotland, J. environ. Management, 3, 91 — 103 (1975).
6. Blackith R. E., Blackith R. M. Variation of shape and of discrete
anatomical characters in the morabine grasshoppers, Aust. J. Zool,.
17, 697—718 (1969).
7. Brennan R. D., De Wit С. T., Williams W. A., Quattrin E. V. The
utility of a digital simulation language for ecological modelling,
Oecologia, 4, 113—132 (1970).
8. Bross I. D. J. Comment, J. Am. statist. Ass., 66, 562 (1971).
9. Buzan A. Use your Head, BBC, London (1974).
10. Chaston I. Mathematics for Ecologists, Butterworths, London
(1971).
11. Christie J. M. The characterization of the relationships between
basic crop parameters in yield table construction, Proc. 3rd Conf.
Adv. Grp. Forest Statisticians, Jouy-en-Josas, IUFRO, 37—54
(1972).
12. Cochran W. G., Cox G. M. Experimental Designs, Wiley, New
York and London (1957).
13. Converse A. 0. Optimization, Holt, Rinehart and Winston, New
York (1970).
14. Cormack R. M. A review of classification, J. R. statist. Soc. (A),
134, 321-367 (1971).
15. Davies O. L. Design and Analysis of Industrial Experiments.
Hafner, New York (1960).
16. Davies R. G. Computer Programming in Quantitative Biology,
Academic Press, London and New York (1971).
17. De Wit С. T., Goudriaan J. Simulation of Ecological Processes,
Centre For Agricultural Publishing and Documentation, Wagenin-
gen (1974).
18. Ehrenfeld D. W. Biological Conservation, Holt, Rinehart and Win-
ston, New York (1970). [Имеется перевод: Эренфелд Д., Приро-
да и люди. — М.: Мир, 1973.]
19. Elliott J. М. Some methods for the statistical analysis of samples
of benthic invertebrates, Scient. Pubis. Freshwat. biol. Ass., No.
25 (1973).
20. Federer W. E. Experimental Design, MacMillan, New York (1955).
240
Список литературы
21. Fisher R. Л. The use of multiple measurements in taxonomic
problems, Ann. Eugen., 7, 179—188 (1930).
22. Fisher R. A. The Design of Experiments, 5th edn. Oliver and
Boyd, London (1949).
23. Fornstad B. F. The linear programming planning system of the
Swedish Forest Service, Bull. For. Comm., Lond., 44, 124—130
(1971).
24. Forrester J. W. Industrial Dynamics, Massachusetts Institute of
Technology Press (1961). [Имеется перевод: Форрестер Дж.
Основы кибернетики предприятия.— М.: Прогресс, 1971.]
25. Fourt D. F., Donald D. G. M., Jeffers J. N. R., Binns W. 0. Corsican
Pine (Pinus nigra var. maritima (Ait.) Melville) in southern
Britain —a study of growth and site factors, Forestry, 44, 189—
207 (1971).
26. Gause G. F. The Struggle for Existence, Williams and Wilkins,
Balitmore (1934).
27. Gibbs J. N., Howell R. S. Dutch elm disease survey, 1971, Forest
Rec., No. 82 (1972).
28. Goodman L. A. The analysis of population growth when the birth
and death rates depend upon several factors, Biometrics, 25,
659-681 (1969).
29. Gower C., Ross G. J. Minimum spanning trees and single linkage
cluster analysis, Appl. Statist., 18, 54—64 (1969).
30. Greig-Smith P. Quantitative Plant Ecology, 2nd edn., Butter-
worths, London (1964). [Имеется перевод: Грейг-Смит. Количе-
ственная экология растений. — М.: Мир, 1967.]
31. Hamilton G. Christie J. М. Construction and application of
stand yield models. In: Growth Models for Tree and Stand Simu-
lation, ed. Fries J., Research Notes, 30, Institutionen for Skogspro-
duktion, Stockholm (1974).
32. Harris R. J. A Primer of Multivariate Statistics, Academic Press,
London (1974).
33. Hilborn R. Optimal exploitation of multiple stocks by a common
fishery: a new methodology, IIASA Research Report RR—75—28
(1975).
34. Hill M. O. Reciprocal averaging: an eigenvector method of ordi-
nation, J. Ecol., 61, 237—249 (1973).
35. Hill M. O., Bunce R. G. II., Shaw M. W. Indicator species analy-
sis, a divisive polythetic method of classification, and its appli-
cation to a survey of native pinewoods in Scotland, J. Ecol., 63,
597-613. (1975).
36. Rolling C. S. Tne functional response of predators to prey density
and its role in mimicry and population regulation, Mem. ent. Soc.
Can., 45, 1—60 (1965).
37. Hummel F. C., Christie J. M. Revised yield tables for conifers in
Great Britain, Forest Rec., No. 24 (1953).
38. Jeffers J. N. R. Experimental Design and Analysis in Forest Re-
search, Almqvist and Wiksell, Stockholm (1959).
39. Jeffers J. N. R., Howard D. M., Howard P. J. A. An analysis of
litter respiration at different temperatures, Appl. Statist., 25, 139—
146 (1976).
Список литературы
241
40. Jones D. D. The application of catastrophe theory to ecological
systems, 11 ASA Research Report RR-75-15 (1975).
41. Kendall M. G. Multivariate Analysis, Griffin, London (1975).
42. Kendall M. G., Stuart A. The Advanced Theory of Statistics, Vol.
Ill, 3rd edn., Griffin, London (1976). [Имеется перевод: Кен-
далл M., Стьюарт Л. Многомерный статистический анализ и
временные ряды. — М.: Наука, 1976.]
43. Kleijnen J. Р. С. Statistical Techniques in Simulation, Dekker,
New York (1975).
44. Krzanowski W. J. The algebraic basis of classical multivariate
methods, Statistician, 20, 51—61 (1971).
45. Laws R. M. Some effects of whaling on southern stocks of baleen
whales. In: The Exploitation of Natural Animal Populations, ed.
Le Cren E. D., Holdgate M. W., Elackwells, Oxford, 242—259 (1962).
46. Lejkovitch L. P. The study of population growth in organisms
grouped by stages, Biometrics, 21, 1—18 (1965).
47. Lefkovitch L. P. The effects of adult emigration on populations of
Lasioderma serricorne (F.) (Coleoptera: Anobiidae), Oikos, 15,
200—210 (1966).
48. Lejkovitch L. P. A theoretical evaluation of population growth
after removing individuals from some age groups, Bull. ent. Res.,
57, 437-445 (1967).
49. Leslie P. II. On the use of matrices in certain population mathe-
matics, Biometrika, 33, 183—212 (1945).
50. Lewis E. G. On the generation and growth of a population,
Sankhya, 6, 93—96 (1942).
51. Lowe V. P. W. Population dynamics of Red deer (Cervus elaphus
L.) on Rhum, J. Anim. Ecol., 38, 425—457 (1969).
52. Lowe V. P. W., Gardiner A. S. Hybridization between Red deer
(Cervus elaphus) and Sika deer (Cervus nippon) with particular
reference to stocks in N. W. England, J. Zool., Lond., 177, 553—
566 (1975).
53. Luckinbill L. S. Co-existence in laboratory populations of Para-
mecium aurelia and its predator Didinium nasutum, Ecology, 54,
1320—1327 (1973).
54. Marriott F. II. C. Tests of significance in canonical analysis, Bio-
metrika, 39, 58-64 (1952).
55. May R. M. Simple mathematical models with very complicated
dynamics, Nature, Lond., 261, 459—467 (1976).
56. Maynard Smith J. Models in Ecology, Cambridge University Press,
London and Cambridge (1974). [Имеется перевод: Смит Дж. М.
Модели в экологии. — М.: Мир, 1976.]
57. Mellanby К. Mistaken models, Nature, Lond., 259, 523 (1976).
58. Neyman J. On a new class of “contagious” distributions, appli-
cable in entomology and bacteriology, Ann. math. Statist., 10,
35-57 (1939).
59. Olsson R. A multiperiod linear programming model for studies of
the growth problems of the agricultural firm, Swed. J. agric. Res.,
1, 139-178 (1971).
60. Pearce S. C. Biological Statistics: an Introduction, McGraw-Hill,
New York (1965).
242
Список литературы
61. Pielou S. С. An Introduction to Mathematical Ecology, Wiley-In-
terscience, New York and London (1969).
62. Pollard J. II. On the use of direct matrix product in analysing
certain stochastic population models, Biometrika, 53, 397—415,
(1966).
63. Polya G. Sur quelques points de la theorie des probabilites, Annis
Inst. Henri Poincare, 1, 117—161 (1931).
64. Quenouille M. II. Associated Measurements, Butterworths, London,
(1952).
65. Radjord P. J. The simulation language as an aid to ecological
modelling. In: Mathematical Models in Ecology, ed. Jeffers J. N. R.,
Blackwells, Oxford, 277—295 (1972).
66. Rorres C., Anton II. Applications of Linear Algebra, Wiley, New
York and London (1977).
67. Russell D. G. Resource allocation system for agricultural research,
Res. Monograph in Technological Economics 1, University of
Stirling, Scotland (1973).
68. Schatzo/f M., Tillman С. C. Design of experiments in simulator
validation, IBM J. Res. Dev., 19, 252-262 (1975).
69. Schreider G. F. Optimal forest investment decisions through dy-
namic programming, Bull. Sch. For. Yale Univ. No. 72 (1968).
70. Seal H. Multivariate Statistical Analysis for Biologists, Methuen,
London (1964).
71. Searle S. R. Matrix Algebra for Biological Sciences, Wiley, New
York (1966).
72. Skellam J. G. Phylogeny as a stochastic process, Biometrics, 7,
121 (1951).
73. Smith F. E. Analysis of ecosystems. In Analysis of Temperate
Forest Ecosystems, ed. Reichle D. E., Springer, Berlin, 7—18
(1970).
74. Sneath P. H. Computers in taxonomy, J. gen Microbiol., 17, 201—
226 (1957).
75. Sprent P. Models in Regression and Related Topics, Methuen, Lon-
don (1969).
76. Steven II. M., Carlisle A. The Native Pinewoods of Scotland, Oli-
ver and Boyd, Edinburg (1959).
77. Thomas M. A generalization of Poisson’s binomial limit for use in
ecology, Biometrika, 36, 18—25 (1949).
78. Usher M. B. A matrix approach to the management of renewable
resources, with special reference to selection forests, J. appl. Ecol.,
3, 355—367 (1966).
79. Usher M. B. A structure for selection forests Sylva, Edinb., 47,
6—8 (1967/68).
80. Usher M. B. A matrix model for forest management, Biometrics,
25, 309—315 (1969 a).
81. Usher M. B. A matrix approach to the management of renewable
resources, with special reference to selection forests — two exten-
sions, J. appl Ecol., 6, 347—348 (1969).
82. Usher M. B. Developments in the Leslie matrix model. In: Mathe-
matical Model in Ecology, ed. Jeffers J. N. R., Blackwells, Oxford,
29-69 (1972).
Список литературы
243
83. Usher М. В. Biological Conservation and Management, Chapman
and Hall, London (1973).
84. Usher M. B. Extensions to models, used in renewable resource
management, which incorporate an arbitrary structure. J. environ.
Management, 4, 123—140 (1976).
85. Vajda S. An Introduction to Linear Programming and the Theory
of Games, Methuen, London (1960).
86. Van Buijtenen J. P., Saitta W. W. Linear programming applied to
the economic analysis of forest tree improvement, J. For., 70,
164—167 (1972).
87. Van Dyne G. M., Fray er W. E., Bledsoe L. J. Some optimization
techniques and problems in the natural resource sciences. In:
Studies in Optimization 1, 95—124. Symposium on Optimization,
Society for Industrial and Applied Mathematics, Philadelphia,
Pennsylvania (1970).
88. Volterra V. Variazione e fluttuazini del numero d’individui in
specie animali conviventi, Atti. Accad. naz. Lincei Memorie
(ser. 6), 2, 31—113 (1926).
89. Walojf N. Scotch broom [Sarothamnus scoparius (L.) Wim-
mer] and its insect fauna introduced into the Pacific northwest of
America, J. appl. Ecol., 3, 293—311 (1966).
90. Wardle P. Forest management and operational research. A linear
programming study, Management Sci. (USA), И, В 260—270
(1965).
91. Watt К. E. F. Dynamic programming, “Look ahead programming”,
and the strategy of insect pest control, Can. Ent., 95, 525—536
(1963).
92. Watt К. E. F. Ecology and Resource Management, McGraw-Hill,
New York (1968). [Имеется перевод: Уатт К. Экология и управ-
ление природными ресурсами. — М.: Мир, 1971.]
93. Weatherburn С. Е. A First Course in Mathematical Statistics,
Cambridge University Press, London and Cambridge (1952).
94. Williams С. B. Patterns in the Balance of Nature, Academic Press,
London and New York (1964).
95. Williams J. D. The Complete Strategist, McGraw-Hill, London,
and New York (1966). [Имеется перевод: Вильямс Дж. Д. Со-
вершенный стратег или букварь по теории стратегических
игр. — М.: Советское радио, i960.]
96. Williamson М. Н. Some extensions in the use of matrices in po-
pulation theory, Bull. math. Biophys., 21, 13—17 (1959).
97. Williamson M. H. Introducing students to the concepts of popu-
lation dynamics. In: The Teaching of Ecology, ed. Lambert J. M.,
Blackwells, Oxford, 169—175 (1967).
Предметный указате./6
Автокод 230
Агрегация 97
Адекватность 18, 101—102, 156,
218
АЛГОЛ 46, 230-231, 233
Алгоритм 44, 234—235, 238
Анализ главных компонент
136, 137-149
— данных 227
— дискриминантный 136
— дисперсионный 106—118
— индикаторных видов 160—
161, 163
— канонический 136
— канонических корреляций
181—186
---переменных 136—137
— кластерный 136, 149—158
— ковариационный 117—118
— многомерный 135
— регрессионный 118—121
— факторный 218
— чувствительности 220—221
Аррениуса уравнение 120—
121
Атлантический интервал 80
— собственный 71, 73, 87, 138,
141-143, 146, 184-185
---столбец 70—73
---строка 70—71
Верификация 13, 217—218
Вероятность встречаемости 95,
100-101
— переходная 124—125, 126—
129, 189
Внедрение результатов 18
Воздействия 21, 212—213
Возрастная группа 72
— структура 72—73
Возрастной класс 61—62, 72,
75
Выбор проблемы 14—15
— путей . решения 16—17,
214-215
Выборка 34, 97, 137, 229
— репрезентативная 34
Выборочное обследование 229
Выборочные процедуры 19
Выживание 72—76
— благородного оленя 82—84
— синего кита 78—79
Вычитание матриц 71
Банк данных 229, 234
— моделей 234
Бимодальность 199, 201
БЭЙСИК 46, 49, 54, 62, Hi-
ll 3, 231, 233
Вариабельность в выборках
137-138
— встречаемости 95, 102
— данных 166
— индекс 138
— роста 211
Вектор дискриминантных ко-
эффициентов 165, 167, 169
Гипотезы 215—217, 219, 222,
229
— альтернативные 23, 96
— используемые при реализа-
ции альтернативных путей
решения 215
— проверка 19, 22, 219
Гистерезис 199, 200, 201—202
Главные компоненты 141—142
Гомоморф 30
Дендрограмма 9, 150, 157—158
Дерево минимальной протя-
Предметный указатель
245
женности 151, 155—157, 180
Дерево модельное 61
Диагональ матрицы 70
Диаграмма связей 42—44, 47,
57-60
Дивергенция 199, 200, 203
Динамика систем 41—42
ДИНАМО 45, 59, 231
Дискриминатор 173
Дискриминация 165, 171—172
Емкость среды 36, 44
Игра двух лиц с нулевой сум-
мой 195—196
— многих лиц 199
— с ненулевой суммой 199
Иерархия целей 16
Изменчивость 20—24, 33, 130—
131, 138
Имитация 24, 30, 33, 41, 45—
46, 211
Индекс вариабельности 138
— подобия 158—159
Индикаторное значение 160
Индикаторный показатель
160-161
Интеграция 221—222
Интегрирование 64
Интерполяция 56, 59
Исследование операций 190
Исход игры 196
Итеративный процесс 44—45
Канонические величины 172,
178—180
— корреляции 181—186, 190
Катастрофа «сборка» 201—203
— «складка» 200—202, 203
Кислые осадки 212—213
Классификация иерархическая
150
— многомерных моделей 135—
137
— описательная 161
Кластер 149, 150, 157—158
Компартмент 77, 87—88
Конкуренция 20, 51—56, 81
Константы в уравнениях моде-
ли 34
— изображение на диаграммах
43-44
Контагиозность 98
Конфликт 25
Коэффициент выживания 72,
74, 78—80
— дискриминантный 165, 167—
169, 171—172
— корреляции 139—140
— плодовитости 72, 74—75,
78-80
— сбора урожая 189
— смертности 83
— формы 62
Критерий значимости 116—118
--- корреляций 139
— согласия 103
— F 116
- х2 97, 101-102, 104-105
КСМП 45, 48, 53, 56, 59, 231
КССЛ 45
Лист, мера конусообразности
179-180
Листовой опад, разложение
119-121
Магнитная лента 228
Магнитный диск 228
Максимизация 188
Марковская цепь 122—125
---эргодическая 127
Матрица 69—70
— возмущенная 80
— данных 153, 181, 186
— дстермипантпая 173, 177—
178
— единичная 70
— игры 195—198
— квадратная 70—71
— ковариаций 167, 181
— коэффициентов корреляции
138, 140, 145, 147, 181
— Лесли 72, 78, 88
— нулевая 70
— переходная 123, 125—126
---регулярная 129
246
Предметный указатель
Матрица симметричная 70
— средних времен первого до-
стижения 129
— тождественная 70
Матрицы, вычитание 71
— деление 71
— сложение 71
— элемент 70, 73, 76, 89
Матричная алгебра 71, 91
Международная биологическая
программа (МБП) 24, 210
Метод главных компонент 137,
141
— дисперсионного анализа
114-118
— наименьших квадратов 107
— одного звена 150—158
Миграция лосося 58—60
Микрокомпьютер 234
Миникомпьютер 234
Минимизация 188
Многообразие 206
— складчатое 200
Множество состояний замкну-
тое 123-124, 127
---переходное 123—124
Моделирование 17, 39, 208—223
Модель 13—14, 27, 30, 235
— абстрактная 38—39
— аддитивная 110, 111, 117—
119
— адекватная 96, 105
— альтернативная 132, 217, 237
— аналитическая 35
— вероятностная 33
— взаимного осреднения 136,
159-160, 161
— детерминистская 23, 31—32,
34, 94, 130-132
— динамическая 38, 41—67
---недостатки 64—66
---преимущества 64
— дискриминантного анализа
164-165
— имитационная 35, 42
— канонических величин 165,
180
---корреляций 181—186
— компартментальная 38
— Лесли 72—76
— линейного программирова-
ния 190, 194
— логистическая 31—32
— марковская 77—78, 122—130
--- более высокого порядка
122, 124
--- недостатки 125
---первого порядка 122,
126-130
---преимущества 124—125
— математическая 29—30, 39,
208
— матричная 38, 69—92, 189
---модификация 76—91
— многомерная 38, 134—186,
189-190
---классификация 135—137
— описательная 136—164
— оптимизационная 38, 188—
199
— поведение 64—65
--- «контринтуитпвное» 64—
65, 218
— подтверждение 217—220
— построение 216—217
— прогностическая, 136, 164—
186
— регрессионная 118—121
— рекурсивная 36
— словесная 27—29, 44, 213—
214
— стохастическая 32—33, 34,
37, 94-132, 189
— теоретико-игровая 25, 195—
199
— теории катастроф 199—206
— точная 38
— факторная 106
— функциональная 23
— экспоненциальная 31
Монокультура 46—51
Носители информации 228—
229
Обратная связь 20, 2$, 63
Оптимизация 188—190
Ординация 159—160
Ось дискриминации 172
— ординации 159, 162—163
Предметный указатель
247
Относительное пространство
52-54
Оценка выборочная 34, 37
— максимального правдоподо-
бия 35
— несмещенная 107
— параметров 34—35, 49—51,
63, 65-67, 69
— связей 59
— стратегий 17—18
Параметр 34, 36—37, 63
— распределения 97
Переменная 34, 134
— вспомогательная 43, 47—48
— дискретная 137
— зависимая 34—35, 134
— независимая 35
— непрерывная 137
— регрессионная 35, 134, 164
— случайная 134, 164
— состояния 42—43, 47, 58, 62
Перфолента 228
План эксперимента 109, 220
---ортогональный 109—110
Планирование эксперимента
106, 212, 219-220
Плодовитость 72—75, 85
— благородного оленя 82—84
— синего кита 78—80
Плотность популяции 31
Поглощающее состояние 123—
124, 127
Подгонка кривых 63, 67
— модели 34—35
Подобие 159
Подпрограмма 232
Подтверждение модели 217—
220
Популяция 34
Постановка задачи 15—16
Построение модели 216—217
Потери (вещества и энергии)
для компартмепта 88
-------экосистемы 77
Поток вещества 43
— информации 43, 47
— энергии 87
Почвы Лейк-Дистрикта 152—
158
Прагматизм 221, 238
Принятие решений 17, 19, 216,
222
Программа 230—232, 238
Программирование 190, 232—
233, 238
— динамическое 195
— линейное 190—194
— математическое 190, 195
Пуассона ряд 95, 97, 100—101
Равновесие 85, 131
Разложение листового опада
119-121
Размерные классы сосны обык-
новенной 85—87
Разновидности тополя 173—180
Разрывность 199—201
Распределение биномиальное
96-97
— геометрическое 37, 99
— контагиозное 97—99
— логарифмически - нормаль-
ное 98—99
— логарифмическое 37
— Неймана 98
— нормальное 99, 135
— отрицательное биномиаль-
ное 97-99, 103—106
— Пойа 99
— пространственное 94—99
— Пуассона 95—96, 99—101
— равномерное 95—96
— с положительной асиммет-
рией 98—99
— Томас 98—99
— частот 97
Расстояние в евклидовом про-
странстве 152—154
Рост бактериальной популяции
31-32
— дерева 212—213
— дрожжей 46—51, 189
— ели ситхинской 60—63,
107-118
— логистический 43—44
— овса 51—56, 189
— экспоненциальный 43—44
— ячменя 51—56, 189
Ряд Пуассона 95, 97, 100—101
248
Предметный указатель
Сбор урожая 76
Сглаживание данных 60
Седловая точка 196—198
Семейство моделей 38
Симплекс-метод 190—191
Синтез моделей 25, 210
Системное исследование 15—
16, 222, 237
Системный анализ 13, 18—25,
208, 216, 222-223, 225, 237
---этапы 13—20, 208—223
Скаляр 71
Скорость прироста 36
---внутренняя 75, 79
— разложения опада 119—121
— реакции 120—121
— роста, относительная 52, 55
Сложность 15—16, 20—22, 39,
211, 217, 223
Смешанная культура 46—51
Смешанный посев 52, 56
Собственное число 71, 73, 138,
141-142, 146, 184
---главное 73—76, 86
Собственный вектор 71, 73, 87,
138, 141-143, 146, 184-185
---главный 73, 75, 86
Сосна обыкновенная, размер-
ные классы 85—87
Сосняки Шотландии 161—163
Сосудистые растения 126—130,
165-171
Среднее время первого дости-
жения 124, 129
---перехода 123, 129—130
---поглощения 123
---пребывания 123
Стадия эндемическая 204—205
— эпидемическая 204—205
Степени свободы 102, 104, 115
---число 115—116
Стратегии землепользования
25
— исследования 19, 20—21
— ловли 197—199
— оптимальные 191—193
— питания 197—199
— смешанные 197—199
— чистые 197
— эксплуатации 87
Структура возрастная 72—73
--- устойчивая 75
— данных 149, 186
--- априорная 181
— популяции 77, 81—84
— пространственная 97
— размерная 85—86
— факторная 212
— экологических ниш 211
Сукцессия 123
— на верховом болоте 125—130
Таблица решений 215—216
— смотровая 61
— хода роста 60—63
Темп 41, 43-44, 47-48, 58
— роста 44, 47—48, 51
Территориальное поведение 96
Тополь, разновидности 173—
180
Умножение матриц 71
Уравнение Аррениуса 120—121
— для темпов 42
— логистическое 31, 36
— Лотки —Вольтерра 51—52
— максимального правдоподо-
бия 103
Уровень 41—43
Устойчивость 66, 84, 131
ФОРТРАН 46, 230-231, 233
Функция дискриминантная
165, 169-171, 190
— правдоподобия 35
— производящая 37
— табличная 59—60
— целевая 189—194
— эмпирическая 54—55
Хищничество 20, 36
Цена игры 198—199 t
Цикл питательных веществ 24,
87, 210
— фосфора 87—90
Частота встречаемости 96, 100
П редметный указатель 249
Численность беспозвоночных
144-156, 182—186
— вязов 204—206
— жуков-короедов 204—206
— пиявок 99—101
Чувствительность 17—18, 60,
63, 67, 220-221
Экологическое исследование 22
Экология 20, 23
Эксплуатация популяции 78,
81-84
Экстраполяция 232—233
Элемент матрицы 70, 73, 76, 89
Эндемическая стадия 204—205
Эпидемическая стадия 204—205
Шум 219
ЭВМ 19, 45, 135, 225-235
— быстродействие 225—226
Эволюционное древо 37
Экологические отношения 23
Язык высокого уровня 46, 91
— машинный 230, 235
— программирования 232—233,
235
— специально ориентирован-
ный 45
Оглавление
Предисловие редактора перевода........................... 5
Предисловие ............................................. 8
Глава 1. Что такое системный анализ? 13
1. Выбор проблемы............................... 14
2. Постановка задачи и ограничение степени ее
сложности....................................... 15
3. Установление иерархии целей и задач .... 16
4. Выбор путей решения задачи................... 16
5. Моделирование................................ 17
6. Оценка возможных стратегий................... 17
7. Внедрение результатов........................ 18
Глава 2. Модели и математика............................ 27
Словесные модели..................................... 27
Математические модели................................ 29
Детерминистские модели............................... 31
Стохастические модели................................ 32
Рабочие определения.................................. 33
Простые примеры...................................... 36
Семейства математических моделей..................... 38
Преимущества и недостатки математических моделей . 38
Глава 3. Динамические модели............................ 41
Пример 3.1. Рост дрожжей в монокультурах и в
смешанной культуре.............................. 46
Пример 3.2. Ячмень и овес, растущие в условиях
конкуренции..................................... 51
Пример 3.3. Миграция лосося вверх по течению . 58
Пример 3.4. Таблица хода роста ели ситхинской . 60
Глава 4. Матричные модели........................ . 69
Пример 4.1. Выжпванпе п плодовитость синего кита 78
Пример 4.2. Структура популяции благородного
оленя........................................... 60
Пример 4.3. Размерные классы сосны обыкновен-
ной ............................................ 65
Оглавление
251
Пример 4.4. Цикл фосфора в экосистеме из трех
компартментов................................
Глава 5. Стохастические модели.......................
Пространственные распределения организмов . . . .
Пример 5.1. Численность Helobdella в выборках из
озера .............................................
Дисперсионный анализ..............................
Пример 5.2. Рост сеянцев ели ситхинской на стери-
лизованной и нестерилизованной почве . . . .
Множественный регрессионный анализ................
Пример 5.3. Скорости разложения листового опада
Марковские модели.................................
Пример 5.4. Сукцессионные изменения на верховом
болоте ......................................
Глава 6. Многомерные модели..........................
Описательные модели...............................
Анализ главных компонент.....................
Пример 6.1. Физическая среда в заливе Моркам и
обитающие в нем беспозвоночные...............
Кластерный анализ............................
Пример 6.2. Почвы Лейк-Дистрикта.............
Взаимное осреднение..........................
Пример 6.3. Естественные сосняки Шотландии . .
Прогностические модели............................
Дискриминантная функция .....................
Пример 6.4. Сосудистые растения Сигни-Айленда .
Канонические величины .......................
Пример 6.5. Форма листьев у отдельных разновид-
ностей тополя ...............................
Канонические корреляции......................
Пример 6.6. Физическая среда в заливе Моркам и
обитающие в нем беспозвоночные...............
Глава 7. Оптимизационные и другие модели.............
Оптимизационные модели............................
Пример 7.1. Оптимальные стратегии хищника . .
Теоретико-игровые модели..........................
Пример 7.2. Стратегии ловли на удочку и питания
Модели теории катастроф...........................
Пример 7.3. Заболевание голландского вяза . . .
Глава 8. Процесс моделирования ......................
Постановка задачи и ограничение степени ее сложности
Сложность и модели................................
Воздействия ......................................
87
94
94
99
106
107
118
119
122
126
134
137
137
139
149
152
158
161
164
165
165
171
173
181
182
188
188
191
195
197
199
203
208
208
210
212
252
Оглавление
Словесные модели.................................... 213
Выбор путей решения................................. 214
Гипотезы............................................ 215
Построение модели................................... 216
Верификация и подтверждение......................... 217
Анализ чувствительности............................. 220
Планирование и интеграция........................... 221
Глава 9. Роль ЭВМ...................................... 225
Послесловие............................................ 237
Список литературы...................................... 239
Предметный указатель................................... 244
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги,
се оформлении, качестве перевода и дру-
гие просим присылать ио адресу: 129820,
Москва, И-110, ГСП. 1-й Рижский пор., д. 2,
издательство «Мир».
Дж. Джефферс
ВВЕДЕНИЕ В СИСТЕМНЫЙ АНАЛИЗ:
ПРИМЕНЕНИЕ В ЭКОЛОГИИ
Ст. научн. редактор Н. Н. Шафрановская
Мл. редактор 3. Е. Кожанова
Художник А. Ф. Смеляков
Художественный редактор Б. Н. Юдкин
Технический редактор 3. И. Резник
Корректор А. В. Щербакова
ИБ № 2373
Сдано в набор 27.10.80. Подписано к печати
25.03.81. Формат 84х108,/32. Бумага типографская
№ 2. Гарнитура обыкновенная. Печать высокая.
Объем 4 бум. л. Усл. печ. л. 13,44. Усл. кр.-
отт. 13,63. Уч.-изд. л. 12,33. Изд. № 4/0971.
Тираж 7000 экз. Зак. 843. Цена 95 коп.
Издательство «Мир»
Москва, 1-й Рижский пер., 2.
Ярославский полиграфкомбинат Союзполиграф-
прома при Государственном комитете СССР по
делам издательств, полиграфии и книжной тор-
говли. 150014, Ярославль, ул. Свободы, 97.
Московский дом книги
121019 Москва, проспект Калинина, 26, п/я 42
имеет в продаже книги зарубежных ученых по биологии
Воллеман М. Биохимия опухолей мозга. 1977. 2-10.
Джекобсон М. Половые феромоны насекомых. 1976.
2-92.
Пост X. Физиология клетки. 1975. 5-93.
Лархер В. Экология растений. 1978. 2-10.
Миллер Дж. Эксперименты в молекулярной генетике.
1976. 3-07.
Свободные радикалы в биологии, т. 1 и 2. 1979. 7-00.
Спелл Дж. Совместимость тканей. 1979. 2-80.
Тамар Г. Основы сенсорной физиологии. 1976. 2-79.
Тарр С. Основы патологии растений. 1975. 5-10.
Фаг лямбда. 1975. 3-12.
УВАЖАЕМЫЕ ТОВАРИЩИ!
Если вы хотите приобрести какую-либо из перечис-
ленных книг, отправьте открытку с заказом по адресу ма-
газина. Книга будет выслана вам наложенным платежом
(без задатка).
Издательство «Мир» выпустило в свет в 1981 году
Пиапка Э. Эволюционная экология. Пер. с апгл., 28 л.,
2 р. 40 к.
В монографии известного эколога из США центральное
место отведено принципам популяционной экологии, ана-
лизу взаимодействия популяций (главным образом конку-
ренции и хищничеству) и экологической нише. Рассмотре-
ны также эволюционное значение дрейфа континентов, ста-
рение организма, воздействие климата па растительность,
биогеография островов.
Книга предназначена для биологов всех специально-
стей, в первую очередь для экологов, зоологов, ботаников
и эволюционистов, для студентов и преподавателей биоло-
гических специальностей, а также для широкого круга
лиц, соприкасающихся с проблемами окружающей среды.
Издательство «Мир» выпустит в свет в 1982 году
Молекулы и клетки. Сборник статей, вып. 7. Пер. с
англ., 25 л., 3 р. 50 к.
Очередной выпуск серии «Молекулы и клетки» (вып.
1 — 6 выходили в 1966—1977 гг.). В данный сборник во-
шли статьи, посвященные биокристаллам, фактору сна,
биологической фиксации азота, клеточным мембранам, пе-
ресадке гепов, заданному синтезу полезных белков бакте-
риями, старению клеток человека и другим интересным
вопросам биологии. Сборник хорошо иллюстрирован.
Книга предназначена для биологов, медиков, химиков,
физиков, математиков, инженеров, преподавателей вузов
и средней школы, а также для студентов и аспирантов всех
этих специальностей.