/














































































































































































































































































































Автор: Шмидт Дуглас Хьюстон Стивен
Теги: языки программирования компьютерные технологии программирование c++
ISBN: 978-5-9518-0362-7
Год: 2009




Текст
Программирование
сетевых приложений
на । ।
Том 1
Профессиональный подход к проблеме
сложности: АС£ и паттерны
Дуглас Шмидт
Стивен Хьюстон
БИНОМ
Серия C++ In-Depth ♦ Бьерн Страуструп
Программирование сетевых
приложений на C++
Том1
C++ Network Programming
Volume 1
Mastering Complexity with ACE and Patterns
Douglas C. Schmidt
Stephen D. Huston
A Addison-Wesley
Boston • San Francisco • New York • Toronto • Montreal
London • Munich • Paris • Madrid
Capetown • Sydney • Tokyo • Singapore • Mexico City
Дуглас С. Шмидт
Стивен Д. Хьюстон
Программирование
сетевых приложений
на C++
Том 1
Перевод с английского
под редакцией
А. П. Караваева
*
Москва
Издательство БИНОМ
2009
УДК 004.43
ББК 32.973.26-018.1
Ш73
Д. Шмидт, С. Хьюстон
Прсираммирование сетевых приложений на C++. Том 1. — М.: ООО «Би-
ном-Пресс», 2009. — 304 с.: ил.
В книге излагается один из самых перспективных подходов к профессиональному
программированию сетевых приложений па C++. Рассматриваются основные причины
сложности разработки сетевых приложений, а также паттерны проектирования и АСЕ
ПО промежуточного слоя я открытыми исходными кодами, которое можно свободно за-
грузить с сайта в Интернет и которое является одним из наиболее переносимых и широко
используемых инструментальных средств сетевого программирования на C++ в мире.
Книга адресована разработчикам-практикам, которым необходимо в сжатые сроки
и без головоломных трудностей создавать гибкие и эффективные сетевые приложения.
Кроме того, книга будет полезна студентам старших курсов, аспирантам и всем заинте-
ресованным в изучении и систематизации материала, связанного с применением языка
C++, объектно-ориентированного подхода и паттернов проектирования при разработке
сетевого программного обеспечения.
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic
or mechanical, including photocopying, recording or by any information storage retrieval system, without per-
mission from Pearson Education, Inc.
Russian language edition published by Binom Publishers. Copyright © 2009 by Binom Publishers.
Все права защищены. Никакая часть этой книги не может быть воспроизведена в любой форме или любыми
средствами, электронными или механическими, включая фотографирование, магнитофонную запись или
иные дюдства копирования или сохранения информации без письменного разрешения издательства.
Authorized translation from the English language edition
ISBN 978-5-9518-0362-7 (pyc.) © Original Copyright. Addison-Wesley, 2009
ISBN 0-201-60464-7 (англ.) © Издание на русском языке. Издательство Бином, 2009
Научно-техническое издание
Дуглас С. Шмидт, Стивен Д. Хьюстон
Программирование сетевых приложений на C++. Том 1
Компьютерная верстка К. А. Свиридова
Подписано в печать 15.05.2009. Формат 70 х 100/16. Усл. печ. л. 24,7
Бумага газетная. Печать офсетная.
Тираж 500 экз. Заказ 110
Издательство «Бином-Пресс», 2009
141077, Королев, Московской обл., ул. 50 лет ВЛКСМ, 4-Г
Отпечатано в ОАО «ИПК „Ульяновский Дом печати"»
432980, г. Ульяновск, ул. Гончарова, 14
Содержание
Предисловие................................................9
Об этой книге..............................................12
Глава 0. Проблемы проектирования, решения
промежуточного слоя и АСЕ..........................21
0.1 Проблемы сетевых приложений........................21
0.2 Аспекты проектирования сетевых приложений..........25
0.3 Решения, связанные с объектно-ориентированным
промежуточным слоем............................. 27
0.4 Обзор инструментальной библиотеки АСЕ..............32
0.5 Пример: сетевая служба регистрации.................36
0.6 Резюме.............................................38
ЧАСТЬ I. Объектно-ориентированное программирование
сетевых приложений.................................41
Глава 1. Аспекты проектирования: коммуникации...............43
1.1 Протоколы без установления и с установлением соединения. . 43
1.2 Синхронный и асинхронный обмен сообщениями.........46
1.3 Передача сообщений и общая память..................48
1.4 Резюме.............................................51
Глава 2. Обзор Socket API...................................53
2.1 Обзор механизмов IPC операционных систем...........53
2.2 Socket API.........................................54
2.3 Ограничения Socket API.............................57
2.4 Резюме.............................................63
6
Программирование сетевых приложений на C++. Том 1
Глава 3. Интерфейсные фасады АСЕ: сокеты....................65
3.1 Обзор..............................................65
3.2 Классы ACE_Addr и АСЕ JNET_Addr....................69
3.3 Класс АСЕ JPC.SAP..................................72
3.4 Класс ACE_SOCK.....................................73
3.5 Класс ACE_SOCK_Connector...........................74
3.6 Классы ACE_SOCK_IO и ACE_SOCK_Stream...............79
3.7 Класс ACE_SOCK_Acceptor............................83
3.8 Резюме.............................................86
Глава 4. Реализация сетевой службы регистрации..............89
4.1 Обзор..............................................89
4.2 Класс ACE_Message_Block............................90
4.3 Классы ACE_InputCDR и ACE_OutputCDR................94
4.4 Первоначальный вариант сервера регистрации.........98
4-5 Клиентское приложение.............................112
4.6 Резюме............................................115
ЧАСТЬ П. Программирование параллельных
объектно-ориентированных сетевых приложений . . . 117
Глава 5. Аспекты проектирования: параллелизм...............119
5.1 Последовательные, параллельные и
взаимно-согласованные серверы..................119
5.2 Процессы и потоки.................................125
5.3 Стратегии создания процессов/потоков..............128
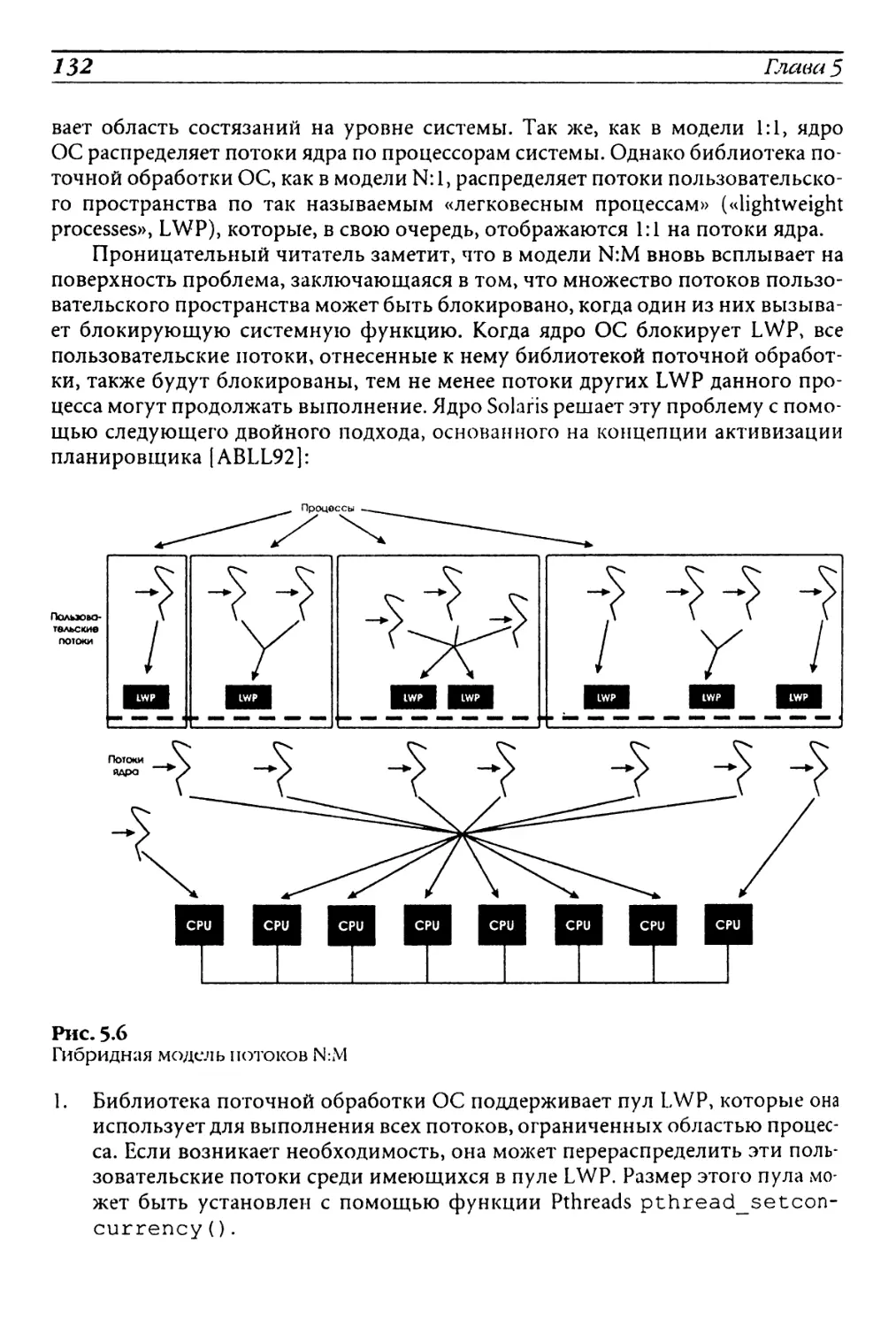
5.4 Модель пользовательских потоков, потоков ядра
и гибридная модель.............................129
5.5 Классы планирования с разделением времени и в реальном
времени........................................134
5.6 Архитектуры, ориентированные на задачи и на сообщения. . 136
5.7 Резюме............................................138
Глава 6. Обзор механизмов параллелизма операционных
систем...........................................139
<6.1 Демультиплексирование синхронных событий..........139
6.2 Механизмы многозадачности.........................141
6.3 Механизмы многопоточности.........................143
6.4 Механизмы синхронизации...........................144
6.5 Ограничения механизмов параллелизма ОС............148
6.6 Резюме............................................150
Содержание
7
Глава 7. Интерфейсные фасады АСЕ: демультиплексирование
синхронных событий................................153
7.1 Обзор.............................................153
7.2 Класс ACE_Handle_Set............................ 155
7.3 Класс ACE_Handle_Set_Iterator.....................161
7.4 Методы ACE::select()..............................164
7.5 Резюме......................•.....................170
Глава 8. Интерфейсные фасады АСЕ: процессы.................171
8.1 Обзор.............................................. . 171
8.2 Класс ACEJProcess.................................173
. 8.3 Класс ACE_Process_Options.........................177
8.4 Класс ACE_Process_Manager.........................180
8.5 Резюме............................................192
Глава 9. Интерфейсные фасады АСЕ: потоки...................195
9.1 Обзор.............................................195
9.2 Класс ACE_Thread_Manager..........................197
9.3 Класс ACE_Sched_Params............................207
9.4 Класс ACE_TSS.....................................210
9.5 Резюме............................................214
Глава 10. Интерфейсные фасады АСЕ: синхронизация............215
10.1 Обзор.............................................215
10.2 Классы ACE_Guard..................................217
10.3 ACE-классы мьютексов............................ 220
10.4 ACE-классы блокировок «читдтели/писатель».........226
10.5 ACE-классы семафоров..............................229
10.6 ACE-классы условных переменных . . . ............236
10.7 Резюме........................................... 240
Приложение А Принципы проектирования интерфейсных
фасадов АСЕ на C++...........................................243
А.1 Обзор.............................................243
А.2 Используйте интерфейсные фасады для повышения
типовой безопасности.............:..............244
А.З Упрощайте наиболее общие случаи применения........247
А.4 Используйте иерархические представления для
повышения ясности и расширяемости проекта.......254
А.5 Скрывайте, где только можно, платформенные различия. . . 256
А.6 Повышайте эффективность...........................262
А.7 Резюме............................................265
8 Программирование сетевых приложений на C++. Тем 1
Приложение В. Прошлое, настоящее и будущее АСЕ..............267
ВЛ Эволюция АСЕ.................................... 267
В.2 Дорога в будущее..................................275
В.З Заключительные замечания..........................276
Словарь терминов.........................................277
Англо-русский указатель терминов.........................291
Литература...............................................297
Предисловие
Пока я писал это предисловие, я путешествовал по Европе, полагаясь на ве-
ликолепную инфраструктуру европейского общественного транспорта. Я —
американец, возможно, поэтому я восхищаюсь этой инфраструктурой и удив-
ляюсь ей. Где бы я ни приземлился, в любом аэропорту, везде я мог свободно
пользоваться поездами и автобусами: быстрые, чистые, надежные,—они отхо-
дили и приходили вовремя и, что, может быть, самое главное, шли именно
туда, куда мне было нужно. Объявления об отправлении и прибытии — на не-
скольких языках. Следовать знакам и указателям легко даже таким как я, не
знающим языка, иностранцам.
Я живу и работаю в районе Бостона и, как большинство американцев, что-
бы попасть из одного места в другое, почти полностью полагаюсь на свою ма-
шину. За исключением отдельных поездок в бостонском метро, я везде езжу на
машине, так как инфраструктура общественного транспорта слишком ограни-
чена, чтобы помочь мне добраться именно туда, куда требуется. Миллионы
других жителей Бостона, и не только Бостона, находятся в таком же затрудни-
тельном положении, что создает большой объем автомобильного трафика,
с которым не справляется инфраструктура наших автомагистралей. Я знаю, что
пришел бы в ужас, если бы точно знал какую часть своей жизни я потерял, сидя
в дорожных «пробках».
Существует несколько интересных аналогий между сетевыми компьютер-
ными и транспортными системами, самая важная из которых заключается
в том, что успешная работа, и тех, и других, зависит от масштабируемой ин-
фраструктуры. Масштабируемые транспортные системы включают в- себя не
только такие видимые элементы инфраструктуры, как поезда и рельсы или са-
молеты и аэропорты. Они также требуют составления расписаний, выбора мар-
шрутов, технического обслуживания, продажи билетов и диспетчерского
управления — и все это должно быть согласовано с самой транспортной систе-
мой в ее материальном воплощении. Сетевые вычисления тоже требуют нали-
чия не только хост-компьютеров и сетей — материальной компьютерной и
коммуникационной инфраструктуры, — но и реализуемого программными
средствами планирования, маршрутизации, диспетчеризации^ конфигуриро-
вания, управления версиями, аутентификации, авторизации и мониторинга,
которые позволяют сетевым системам по мере необходимости изменять свой
масштаб.
Ирония с инфраструктурой заключается в том, что ее очень трудно сделать
такой как нужно, и, несмотря на это, чем меньше замечает ее пользователь, тем
более удачной ее следует считать. Несмотря, например, на пересеченную мест-
ность швейцарских Альп, несколько архитекторов, инженеров и строителей
употребили свои профессиональные знания на то, чтобы обеспечить эффек-
тивную транспортную систему, которой миллионы людей в Швейцарии с лег-
костью пользуются каждый день. Эта система, в сущности, так надежна и так
проста в обращении, что ее очень быстро начинаешь принимать, как должное и
перестаешь замечать. Например, когда пользуешься в Швейцарии железной до-
рогой, внимание сосредоточено только на том, чтобы попасть из одного места
10
Программирование сетевых приложений на C++. Там 1
в другое, а не на используемых для доставки средствах. Если только вы не ту-
ристы, вы, вероятно, не обратите никакого внимания на то, что пересекаете тон-
нель, на проектирование и строительство которого ушли годы, или поднимае-
тесь по наклонной плоскости такой крутой, что железнодорожный путь ис-
пользует фуникулер, чтобы поезду было легче подниматься. Рельсовая
инфраструктура четко делает то, что должна делать, и, как следствие, вы ее про-
сто не замечаете.
Эта книга об инфраструктуре программного обеспечения (ПО) сетевых
компьютерных систем, называемого обычно промежуточным слоем (middle-
ware). Это ПО называется промежуточным слоем потому, что оно, как «горло-
вина песочных часов», размещается между операционной системой и сетью —
внизу и приложением — вверху. Существует большой выбор ПО промежуточ-
ного слоя разных видов, масштабов и возможностей, в диапазоне от серверов
приложений J2EE, систем обмена асинхронными сообщениями и брокеров
ORB CORBA до программ, которые управляют сокетами в небольших встроен-
ных системах. Промежуточный слой должен поддерживать постоянно расши-
ряющийся набор приложений, операционных систем, сетевых протоколов',
языков программирования и форматов данных. Без промежуточного слоя, для
того чтобы справиться с постоянно растущим разнообразием и разнородно-
стью сетевых компьютерных систем, потребовалась бы кропотливая и дорого-
стоящая работа, чреватая к тому же ошибочными решениями.
Несмотря на многообразие типов промежуточного слоя .и разнообразие
проблем, которые он решает, различные типы промежуточного слоя имеют
тенденцию использовать одни и те же общие абстракции и паттерны, чтобы
справиться со сложностью решаемых задач. Если вы когда-нибудь заглядывали
в исходный код, например, масштабируемого сервера приложений, системы
передачи сообщений или CORBA QRB, то вам, вероятно, известно, что в них
применяются похожие методы для решения таких задач, как управление соеди-
нениями, организация параллельного выполнения, синхронизация, демульти-
плексирование событий, диспетчеризация обработчиков событий, регистрация
ошибок и мониторинг. Как количество пассажиров швейцарских железных до-
рог неизмеримо превышает число тех, кто эти дороги проектировал и строил,
так и количество потребителей успешно работающего промежуточного слоя
значительно превышает количество тех, кто его разрабатывал и создавал. Если
вы занимаетесь проектированием, созданием или использованием промежу-
точного слоя, то ваш успех зависит от знания, понимания и применения этих
общих абстракций и паттернов.
Хотя многие понимают, что промежуточный слой должен быть масштаби-
руемым и гибким, немногие могут сделать это так же эффективно, как это сде-
лано в ADAPTIVE Communication Environment (АСЕ), адаптивной коммуника-
ционной среде, которую Дат Шмидт и Стив Хьюстон описывают в своей книге.
АСЕ—это популярная инструментальная библиотека C++, в которой собраны
абстракции и паттерны общего характера, применяемые во многих успешно
работающих программных средствах промежуточного слоя и в сетевых прило-
жениях. АСЕ стала основой цногих сетевых компьютерных систем, от прило-
Предисловие
11
жений реального времени в авиационных электронных системах до брокеров
CORBA ORB и до поддержки однорангового взаимодействия мэйнфреймов.
Как любой промежуточный слой, хорошо выполняющий свои функции,
АСЕ скрывает в себе сложность, создаваемую разнообразием гетерогенных
сред, поверх которых она функционирует. Что, однако, выделяет АСЕ из боль-
шинства других инфраструктур промежуточного слоя, так это то, что даже пре-
доставляя максимум гибкости'там, где это требуется приложению, она в то же
время делает это не за счет производительности и масштабируемости системы.
Я сам в течение долгого времени был разработчиком промежуточного слоя, и я
знаю очень хорошо, что достичь и высокой производительности, и гибкости
в одном пакете программ — это трудное дело.
И все же то, что в АСЕ достигнуты такая гибкость и производительность,
в некотором отношении, меня не удивляет. Я знаю Дата давно, и мне хорошо
известно, что он в этой области — первопроходец. Множество масштабируе-
мых, высокопроизводительных и гибких решений промежуточного слоя/су-
щесгвующих сегодня, несут на себе отчетливый отпечаток его влияния. Его со-
авторство со Стивом, одаренным разработчиком, использующим C++, и авто-
ром, работа которого в течение нескольких лет способствовала значительному
усовершенствованию АСЕ, привело к созданию труда, с которым обязан озна-
комиться любой специалист, участвующий в разработке, создании или хотя бы
даже в использовании промежуточного слоя. Возрастающая вездесущность
World Wide Web и взаимосвязанных встроенных систем означает^ что количе-
ство, масштабы и значение сетевых компьютерных систем будут постоянно
возрастать. Только усвоив основные паттерны, методы, классы и накопленные
знания, которыми Дат и Стив делятся в предлагаемой вашему вниманию кнцге,
мы можем надеяться на создание такой инфраструктуры промежуточного
слоя, которая сделает все эти системы прозрачными, эффективными и надеж-
ными.
Стив Виноски
Главный архитектор & вице-президент, Platform Technologies
IONA Technologies
Сентябрь 2001 г.
Об этой книге
За последние десять лет параллельное объектно-ориентированное сетевое
программирование сформировалось в эффективную парадигму разработки
приложений, взаимодействующие объекты которых могут быть:
1. Совмещены в одном процессе или на одном компьютере.
2. Распределены по множеству компьютеров, соединенных сетью, такой как,
внутреннее соединение встроенных систем, локальная сеть (LAN), корпо-
ративная интрасеть (intranet) или Internet.
Различные составляющие распределенных объектов должны эффективно
взаимодействовать и координировать свою работу. Более того, они должны это
делать и в том случае, если сами приложения в течение срока службы изменя-
ются. Размещение объектов, имеющаяся сетевая инфраструктура и варианты
параллельной обработки на платформе, должны предусматривать значитель-
ную степень свободы, обеспечивать перспективу.
При правильном проектировании, возможности параллельного объект-
но-ориентированного сетевого программирования могут значительно повы-
сить гибкость приложений. Например, в соответствии с требованиями и имею-
щимися у проекта ресурсами, вы можете использовать:
• Встроенные или карманные системы реального времени.
• Персональные или портативные компьютеры.
• Ассортимент разного рода UNIX или Linux систем.
• «Большое железо» мэйнфреймов и даже суперкомпьютеров.
Однако скорее всего, вы столкнетесь с большими проблемами при разра-
ботке и переносе сетевых приложений на множество платформ различных опе-
рационных систем (ОС). Эта проблемы предстанут в виде несовместимых сете-
вых протоколов или библиотек компонентов, у которых на разных аппаратных
и программных платформах разные API и разная семантика, а также в виде
«случайной» сложности, которая связана с ограничениями самих внутренних
механизмов ОС межпроцессного взаимодействия (IPC) и параллелизма. Чтобы
решить эта проблемы ADAPTIVE Communication Environment (АСЕ) предлага-
ет объектно-ориентированное инструментальное средство, которое может ра-
ботать на многих аппаратных платформах и платформах ОС, включая боль-
шинство версий Win32 и UNIX, многие ОС реального времени и встроенные
ОС.
Кто-то станет вас убеждать, что стандарты ОС, де-факто или де-юре, такие
как POSIX, UNIX98, или Win32, это все, что нужно программистам, чтобы за-
щитить свои приложения от проблем с переносимостью. К сожалению, афо-
ризм «в стандартах хорошо то, что их много — есть из чего выбирать» [Тап96]
сегодня даже более актуален, чем десять лет назад. Сегодня существует множе-
ство различных платформ ОС, используемых в коммерческих, академических
и правительственных проектах, и целый ряд модификаций, число которых рас-
тет с каждой новой версией или вариантом.
Об этой книге
13
За последние два десятилетия мы, авторы этой книги, разработали большое
количество кросс-платформенных, параллельных сетевых систем. Поэтому мы
можем говорить с уверенностью, что производители ОС часто реализуют то
одни стандарты, то другие. Кроме того, стандарты изменяются и развиваются.
Так что вам придется работать с множеством платформ, в разное время по-раз-
ному реализующих разные стандарты. Поэтому, программирование API ОС
порождает следующие две проблемы:
1. Программирование API связано с ошибками, так как в API ОС, написан-
ных на языке С, часто недостаточно внимания уделяется типовой безопас-
ности, переносимости, реентерабельности и расширяемости интерфейсов
системных функций и библиотек функций. Например, конечные точки со-
единения в широко используемом Sockets API (см. главу 2) определяются
слабо типизированными целочисленными значениями или указателя-
ми-дескрипторами ввода/вывода, что повышает вероятность возникнове-
ния неочевидных ошибок программирования в процессе выполнения.
2. Программирование API способствует применению неадекватных мето-
дов проектирования, так как многие сетевые приложения, написанные
с использованием API ОС, основаны на алгоритмическом, а не на объект-
но-ориентированном, проектировании. При алгоритмическом проектиро-
вании декомпозиция структуры приложения осуществляется в соответст-
вии с конкретными функциональными требованиями, которые не являют-
ся неизменными и могут с течением времени эволюционировать.
Следовательно, эта парадигма проектирования приводит к программным
структурам, которые трудно расширять и быстро перестраивать в соответ-
ствии с изменением требований, предъявляемых к приложению [Воо94].
В наш век экономических потрясений, сокращения объема регулирования
экономики со стороны государства и беспощадной глобальной конкурентной
борьбы, разрабатывать приложения почти с нуля, используя только API ОС и
методы алгоритмического проектирования, — непомерно дорого и долго.
Если вы разрабатываете сетевые программные системы много лет, то вы,
наверное, научились принимать некоторые из этих проблем как «жизненные
реалии». И все же есть лучший путь. В этой книге мы показываем как C++ и
АСЕ обеспечивают объектно-ориентированные возможности, позволяющие
избежать многих ошибок и ловушек, по-прежнему, следуя стандартам — и
даже, в отдельных случаях, используя некоторые возможности, зависящие от
платформы. Объектно-ориентированные решения демонстрируют более вы-
сокую стабильность во времени, чем алгоритмические, что делает их более
предпочтительными при разработке многих типов сетевых приложений.
Конечно, эта гибкость дается не просто так: возможно, придется осваивать
новые концепции, методы, паттерны, инструментальные средства и методы
проектирования. В зависимости от подготовки, кривая обучения может ока-
заться для вас как тривиальной, так и достаточно крутой поначалу. Основной
момент, тем не менее, заключается в том, что объектно-ориентированная пара-
дигма способна предложить совокупность продуманных методов, которые по-
зволяют преодолеть многие проблемы разработки сетевых приложений. В этой
14
Программирование сетевых приложений на C++. Там 1
книге, с целью проиллюстрировать объектно-ориентированные методы, ис-
пользуемые при разработке и применении классов инструментальной библио-
теки АСЕ, приведен ряд конкретных примеров. Вы можете использовать эти
методы и классы АСЕ для того, чтобы упростить свои собственные приложе-
ния.
Кому адресована эта книга
Эта книга адресована, в первую очередь, разработчикам-практикам, сту-
дентам старших курсов и аспирантам, а также всем заинтересованным в изуче-
нии стратегии и тактики применения C++ и объектно-ориентированного про-
ектирования при программировании параллельных сетевых приложений. Мы
рассматриваем основные аспекты, принципы и паттерны проектирования, не-
обходимые для того, чтобы в сжатые сроки и без больших проблем разрабаты-
вать гибкие и эффективные параллельные сетевые приложения. Многочислен-
ные примеры кода на C++ дополняют излагаемые принципы проектирования
и показывают на конкретных примерах как сразу начать использовать основ-
ные классы АСЕ. Мы переносим вас «за кулисы», чтобы показать, как и почему
механизмы IPC и параллелизма разработаны именно такими, какими вы их ви-
дите в инструментальной библиотеке АСЕ. Этот материал поможет вам упоря-
дочить накопленный опыт проектирования и более эффективно использовать
C++ и паттерны в собственных объектно-ориентированных сетевых приложе-
ниях.
Эта книга не является всеобъемлющим учебником объектно-ориентиро-
ванного проектирования, паттернов, UML, C++, системного программирова-
ния или компьютерных сетей. Мы полагаем, что читатели этой книги в той или
иной степени знакомы со следующими темами:
• Объектно-ориентированные методы проектирования и программиро-
вания, например, каркасы приложений [Joh97, FJS99b, FJS99a], паттерны
(GHJV95, BMR+96, SSRBOO], модульный принцип организации [Меу97],
сокрытие информации [Раг72] и моделирование [Воо94].
• Объектно-ориентированные нотации и процессы, такие как Unified Mo-
deling Language (UML) [RJB98], экстремальное программирование (extre-
me Programming) [BecOO] и Rational Unified Process (RUP) [JBR99].
• Фундаментальные свойства языка C++, такие как классы, наследование,
динамическое связывание и параметризованные типы [BjaOO],
• Основные механизмы системного программирования, такие как де-
мультиплексирование событий, управление процессами и потоками,
виртуальная память и механизмы IPC, а также API, которые, как правило,
имеются на платформах UNIX [Ste98, Ste99, Ste92, Lew95, KSS96, But97] и
Win32 [Ric97, Sol98, JO99].
• Сетевые концепции и терминология, такие как TCP/IP [Ste93], удален-
ный вызов процедур [ObjOl] и архитектура клиент/сервер [CS92].
Об этой книге
15
Мы рекомендуем использовать обширную библиографию для поиска ис-
точников информации по темам» о которых вы захотите узнать больше.
Эта книга не является также руководством программиста АСЕ; это значит,
что мы не приводим описание всех методов и классов АСЕ. Если вам требуется
такой уровень детализации, то вы можете обратиться к обширной онлайновой
документации по АСЕ, предоставляемой справочной системой Doxygen (DimOlJ
по адресам http: //ace.ece.uci.edu/Doxygen/ и http: //www. rivera-
ce . сот/docs/. Взамен всего этого, материал книги сосредоточен на:
• основных концепциях, паттернах и возможностях C++, которые форми-
руют дизайн успешно работающих объектно-ориентированных прило-
жений и промежуточного слоя;
• обосновании и основных применениях наиболее часто используемых
классов интерфейсных фасадов АСЕ, связанных с TCP/IP и параллельной
обработкой.
Структура и содержание
Книга показывает каким образом C++ и промежуточный слой помогают
решать проблемы, связанные с разработкой сетевых приложений. Мы приво-
дим обзор основных механизмов ОС, реализованных на известных платфор-
мах, и показываем каким образом АСЕ использует язык C++ и паттерны для
инкапсуляции этих механизмов в библиотеке классов интерфейсных фасадов,
которые улучшают переносимость и отказоустойчивость приложений. Глав-
ным примером приложения в книге является сетевая служба регистрации, ко-
торая передает регистрационные записи от клиентских приложений серверу
регистрации по TCP/IP. Мы используем эту службу в качестве рабочего приме-
ра на всем протяжении книги, чтобы:
• показать на конкретном примере, чем C++ и АСЕ могут помочь в разра-
ботке эффективных, прогнозируемых и масштабируемых сетевых при-
ложений;
• продемонстрировать процесс анализа и решения ключевых вопросов
проектирования и реализации, возникающих перед вами в процессе раз-
работки собственных параллельных объектно-ориентированных сете-
вых приложений.
В книге 11 глав. Они организованы следующим образом:
• Введение—Глава 0—это введение в программирование сетевых прило-
жений на C++. Она начинается с перечисления задач и описания про-
блем, которые возникают при расширении приложений за пределы по-
токов и процессов. Затем приводится классификация уровней промежу-
точного слоя и объясняется, как можно использовать промежуточный
слой инфраструктуры хоста и инструментальные средства АСЕ для ре-
шения общих проблем сетевого программирования.
• Часть I — Главы с 1 по 4 описывают аспекты проектирования, связанные
с коммуникациями, и объектно-ориентированные методы, используе-
16
Программирование сетевых приложений на C++. Там 1
мые в АСЕ для эффективного программирования механизмов IPC ОС.
Результатом являются классы, которые закладывают основу первой, вер-
сии сетевой службы регистрации, играющей в этой книге роль рабочего
примера.
• Часть П — Главы с 5 по 10 описывают аспекты проектирования, связан-
ные с механизмами параллелизма, и объектно-ориентированные мето-
ды, используемые в АСЕ, для эффективного программирования этих ме-
ханизмов.
При изложении материала частей I и II мы приводим ряд все более слож-
ных реализаций нашей сетевой службы регистрации, чтобы проиллюстриро-
вать возможности практического применения интерфейсных фасадов АСЕ,
связанных с механизмами IPC и параллелизма.
Приложение А суммирует принципы проектирования и реализации клас-
сов, лежащих в основе интерфейсных фасадов АСЕ IPC и параллелизма. При-
ложение В прослеживает, с самого начала, десятилетнюю эволюцию открытого
исходного кода АСЕ и намечает пути его развития в будущем. Книга завершает-
ся словарем технических терминов (в том числе ключевых терминов данной
книги)1 и обширным списком источников для дальнейшего изучения.
Дополнительный материал
Материал этой книги посвящен преодолению сложности разработки сете-
вых приложений за счет использования возможностей языка C++, паттернов и
АСЕ. Второй том из этой серии — C++ Network Programming: Systematic Reuse
with ACE and Frameworks [SH] — расширяет границы нашего исследования,
включая, предлагаемые АСЕ, объектно-ориентированные сетевые программ-
ные каркасы приложений (frameworks). Эти каркасы являются реализациями
популярных паттернов, используемых в классах интерфейсных фасадов АСЕ,
представленных в данной книге, призванными обеспечить более основатель-
ную поддержку и расширение уровня систематического повторного использо-
вания. Отличительной особенностью классов интерфейсных фасадов АСЕ, из-
лагаемых в данной книге, и классов каркасов, рассматриваемых во 2-ом томе,
является то, что в классах интерфейсных фасадов АСЕ виртуальных методов не-
много, тогда как классы каркасов содержат, в основном, виртуальные методы.
Эта книга использует АСЕ версии 5.2, выпущенной в октябре 2001 г. Про-
граммное обеспечение АСЕ и все примеры приложений, описанные в нашей
книге являются открытым ПО и могут быть загружены с сайтов
http: / /асе .есе .uci. edu и http: //www. riverace. com. Эти сайты со-
держат много материалов, касающихся АСЕ: учебных пособий, технических
статей и обзор интерфейсных фасадов АСЕ механизмов IPC и синхронизации,
которые не вошли в эту книгу. Мы рекомендуем вам получить копию АСЕ, что-
бы вы могли использовать ее вместе с книгой, изучать реальные классы и карка-
При переводе нами был добавлен также Англо-русский указатель терминов. — Прим. ред.
Об этой книге
17
сы АСЕ во всех подробностях и выполнять примеры кода в процессе чтения
этой книги. Предварительно скомпилированные версии АСЕ также можно
приобрести на сайте http: Z/www. riverace. com по номинальной цене.
Для получения дополнительной информации по АСЕ или при желании со-
общить о любых ошибках, которые вы найдете в этой книге, мы рекомендуем
вам подписаться на список рассылки АСЕ ace-users@cs.wustl.edu. Вы
можете подписаться, послав письмо по электронной почте серверу рассылки
Majordomo по адресу ace-users-request@cs.wustl .edu. В тело письма
(строка темы игнорируется) включите следующую команду:
subscribe ace-users [emailaddress@domain]
Вы должны включить адрес электронной почты в формате add-
ress@domain, но только в том случае, если адрес вашего сообщения в поле
From не является тем адресом, на который вы хотите получать сообщения.
Почтовые отправления в список рассылки АСЕ, передаются также в группы
новостей USENET comp. sof t-sys. асе. Архивы почтовых отправлений в спи-
сок рассылки АСЕ доступны по адресу http://groups.yahoo.com/gro-
up/ace-users.
Благодарности
Чемпионские медали за рецензирование получают Кристофер Аллен
(Christopher Allen), Томер Эймиаз (Tomer Amiaz), Ален Декамп (Alain Decamps),
Дон Хинтон (Don Hinton), Сузан Либескинд (Susan Liebeskind), Деннис Манкл
(Dennis Mancl), Патрик Рабо (Patrick Rabau), Эймонн Сандерз (Eamonn Saun-
ders) и Джонни Уиллемзен (Johnny Willemsen), которые прочитали всю книгу и
дали обширные комментарии, значительно улучшившие ее форму и содержа-
ние. За все оставшиеся ошибки ответственность несут, естественно, авторы.
Многие пользователи АСЕ со всего мира прислали свои соображения по
поводу первых вариантов этой книги, к ним относятся Марк Аппел (Mark
Appel), Шахзад Аслам-Мир (Shahzad Aslam-Mir), Кевин Бейли (Kevin Bailey),
Барри Беновиц (Barry Benowitz), Эммануэль Крозе (Emmanuel Croze), Ясир
Фейз (Yasir Faiz), Гилмар Дерге (Gillmer Derge), Иан Хансон (Iain Hanson), Брэд
Хоскинз (Brad Hoskins), Боб Хьюстон (Bob Huston), Кристофер Колхофф
(Christopher Kohlhoff), Сердж Колган (Serge Kolgan), Энди Марчевка (Andy
Marchewka), Джефф Макнил (Jeff McNiel), Фил Меснир (Phil Mesnier), Артуро
Монтес (Arturo Montes), Эрон Нилсен (Aaron Nielsen), Джефф Парсонс (Jeff
Parsons), Пирн Филипз(Рип Philipse), Ярон Пинто (Yaron Pinto), Стефан Пион
(Stephane Pion), Ник Пратт (Nick Pratt), Пол Рабел (Paul Rubel), Шурья Саркар
(Shourya Sarcar), Лео Штуцманн (Leo Stutzmann), Томми Свенссон (Tommy
Svensson), Ален Тотуом (Alain Totouom), Роджер Трейджин (Roger Tragin) и Ру-
вен Ягел (Reuven Yagel).
Мы признательны всем членам, прошлым и настоящим, групп DOC в Was-
hington University, St. Louis и University of California, Irvine, а также сотрудникам
18
Программирование сетевых приложений на C++. Том 1
Object Computing Inc. и Riverace Corporation, которые разрабатывали, совер-
шенствовали и оптимизировали многие из возможностей АСЕ, представлен-
ных в этой книге. В эту группу входят Эверетт Андерсон (Everett Anderson),
Алекс Аруланту (Alex Arulanthu), Шон Аткинс (Shawn Atkins), Джон Огей (John
Aughey), Даррелл Бранш (Darrell Brunsch), Лютер Бейкер (Luther Baker), Дон
Буш (Don Busch), Крис Клиланд (Chris Cleeland), Анджело Корсаро (Angelo
Corsaro), Чад Эллиот (Chad Elliot), Серджио Флорес-Гайтан (Sergio Flores-Gai-
tan), Крис Джилл (Chris Gill), Прейдип Гор (Pradeep Gore), Энди Гокхейл (Andy
Gokhale), Приянка Гонтла (Priyanka Gontla), Мирна Харбибсон (Myrna Harbib-
son), Тим Гаррисон (Tim Harrison), Джон Хеннан (Shawn Hannan), Джон Хейт-
манн (John Heitmann), Джо Гофферт (Joe Hoffert), Джеймс Хью (James Hu),
Франк Ханлет (Frank Hunleth), Прашант Джейн (Prashant Jain), Вишел Кейчру
(Vishal Kachroo), Рэй Кифстад (Ray Kiefstad), Китти Кришнакумар (Kitty Krish-
nakumar), Ямуна Кришнамурти (Yamuna Krishnamurthy), Майкл Керчер (Mi-
chael Kircher), Фред Кунс (Fred Kuhns), Дейвид Левин (David Levine), Чанака
Лиянааракчи (Chanaka Liyanaarachchi), Майкл Моран (Michael Moran), Эбра-
хим Мошири (Ebrahim Moshiri), Сумедх Манги (Sumedh Mungee), Бала Натара-
ян (Bala Natarajan), Оссама Отхман (Ossama Othman), Джефф Парсонс (Jeff Par-
sons), Киртика Парамесваран (Kirthika Parameswaran), Криш Патаяпура (Krish
Pathayapura), Ирфан Пейрали (Irfan Pyarali), Сумита Рао (Sumita Rao), Карлос
О’Райен (Carlos O'Ryan), Рич Сибел (Rich Siebel), Малколм Спенз (Malcolm
Spence), Марина Спивак (Marina Spivak), Нага Сурендран (Naga Surendran),
Стив Тоттен (Steve Totten), Брюс Траск (Bruce Trask), Нанбор Ванг (Nanbor
Wang) и Сет Уидофф (Seth Widoff).
Мы хотим также поблагодарить тысячи разработчиков, использующих язык
C++, из почти пятидесяти стран, которые внесли свой вклад в АСЕ за последние де-
сять лет. Достижения и успех АСЕ—это памятник мастерству и щедрости многих
талантливых разработчиков и дальновидных компаний, которые были так про-
зорливы, что приняли участие в создании основы открытого исходного кода АСЕ.
Без их поддержки, постоянной обратной связи и содействия, мы никогда бы не на-
писали эту книгу. В знак признания за работу, проделанную сообществом откры-
того исходного кода АСЕ, мы ведем список всех, кто участвовал в этой работе; спи-
сок находится по адресу http: / /асе. есе. uci. edu/ACE-members. html.
Мы признательны также за поддержку коллегам и спонсорам нашей иссле-
довательской работы, связанной с паттернами, и разработкой инструменталь-
ной библиотеки АСЕ, особый вклад внесли Рон Акерс (Ron Akers, Motorola),
Стив Бакинский (Steve Bachinsky, SAIC), Джон Бэй (John Bay, DARPA), Детлиф
Беккер (Detlef Becker, Siemens), Дейв Бусиго (Dave Busigo, DARPA), Джон Бут-
титто (John Buttitto, Sun), Бекки Каллисон (Becky Callison, Boeing), Вэй Чианг
(Wei Chiang, Nokia), Джо Кросс (Joe Cross, Lockheed Martin), Лу ДиПалма (Lou
DiPalma, Raytheon), Брайан Доерр (Bryan Doerr, Boeing), Карлхайнц Дорн (Karl-
heinz Dorn, Siemens), Матт Эмерсон (Matt Emerson, Escient Convergence Group,
Inc.), Силвестер Фернандес (Sylvester Fernandez, Lockheed Martin), Никки Форд
(Nikki Ford, DARPA), Андреас Гейслер (Andreas Geisler, Siemens), Хелен Джилл
(Helen Gill, NSF), Боб Грошадл (Bob Groschadl, Pivotech Systems, Inc.), Джоди Xa-
гинс (Jody Hagins, ATD), Энди Харвей (Andy Harvey, Cisco), Сю Келли (Sue Kelly,
Об этой книге
19
Sandia National Labs), Гари Кооб (Gary Koob, DARPA), Петри Коскелайнен (Petri
Koskelainen, Nokia Inc), Шон Ландис (Sean Landis, Motorola), Патрик Лардьери
(Patrick Lardieri, Lockheed Martin), Даг Ли (Doug Lea, SUNY Oswego), Хикью Ли
(Hikyu Lee, SoftLinx), Джо Лойелл (Joe Loyall, BBN), Майк Мастерс (Mike Mas-
ters, NSWC), Эд Мейз (Ed Mays, U.S. Marine Corps), Джон Меллби (John Mellby,
Raytheon), Джейнетт Милос (Jeanette Milos, DARPA), Стен Мойер (Stan Moyer,
Telcordia), Расс Ноусворти (Russ Noseworthy, Object Sciences), Дитер Кель (Dieter
Quehl, Siemens), Виджей Рагха-ван (Vijay Ragha-van, Vanderbilt U.), Люси Робил-
лард (Lucie Robillard, U.S. Air Force), Крэг Родригес (Craig Rodrigues, BBN), Рик
Шантц (Rick Schantz, BBN), Стив Шаффер (Steve Shaffer, Kodak), Том Шилдс
(Tom Shields, Raytheon), Дэйв Шарп (Dave Sharp, Boeing), Навал Сода (Naval
Sodha, Ericsson), Пол Стефенсон (Paul Stephenson, Ericsson), Тат-суйя Суда
(Tat-suya Suda, UCI), Умар Сейид (Umar Syyid, Hughes), Янос Штипанович
(Janos Sztipanovits, Vanderbilt U.), Гаутам Тейкер (Gautam Thaker, Lockheed Mar-
tin), Лотар Верзингер (Lothar Werzinger, Krones) и Дон Винтер (Don Winter,
Boeing).
Особая благодарность Сюзан Купер (Susan Cooper), редактору, за улучше-
ние написанного нами материала. Кроме того, мы благодарны за сотрудничест-
во и терпение редактору Дебби Лафферти (Debbie Lafferty), координатору из-
дания Элизабет Райан (Elizabeth Ryan), редактору серии и автору языка C++
Бьерну Страуструпу (Bjarne Stroustrup) и всем остальным сотрудникам изда-
тельства Addison-Wesley, которые сделали возможной публикацию этой книги.
В заключение, мы хотели бы также выразить нашу признательность и от-
дать дань уважения покойному Ричарду Стивенсу (W. Richard Stevens) родона-
чальнику литературы о сетевом программировании. Его книги подняли яс-
ность изложения искусства и науки сетевого программирования до прежде не-
ведомого уровня. Мы пытаемся стоять на его виртуальных плечах и расширять
то понимание, которое книги Ричарда принесли в мир объектно-ориентиро-
ванного проектирования и программирования на C++.
Благодарности Стива
Я хотел бы поблагодарить Бога, подарившего мне радость заниматься ком-
пьютерами и сетями. Надеюсь, что Он мной доволен. Мою жену Джейн; спаси-
бо тебе, что любишь меня и радуешь каждый день. Я не смог бы закончить эту
работу без твоей поддержки — ты мое благословение. Спасибо покойному Дей-
виду Драммонду (David N. Drummond), который рискнул принять неродного
ребенка. И спасибо Дагу Шмидту, ученому и джентльмену, интуиция которого,
энтузиазм и творчество, каждый день и удивляют меня, и придают новые силы.
Благодарности Дата
Я писал эту книгу около десяти лет. Большое потрясение (и облегчение) —
увидеть ее, наконец, в печати! Я благодарен за это Стиву Хьюстону (Steve
Huston), Дебби Лафферти (Debbie Lafferty) и Бьерну Страуструпу (Bjarne Strou-
strup) за их огромное терпение и помощь в работе над этим проектом вплоть до
20 Программирование сетевых приложений на C++. Том 1
его воплощения. Я хотел бы также поблагодарить мою жену Соню за любовь и
за поддержку, пока я писал эту книгу—теперь, когда она закончена, у нас будет
больше времени для бальных танцев! Наконец, спасибо моим многочисленным
друзьям и коллегам по College of William and Mary; Washington University, St.
Louis; University of California, Irvine; DARPA; и Siemens — и тысячам разработ-
чиков и пользователей АСЕ и ТАО по всему миру — вы очень обогатили мою
интеллектуальную и межличностную жизнь в последние два десятилетия.
Глава О
Проблемы проектирования,
решения промежуточного слоя
и АСЕ
Краткое содержание
Глава описывает сдвиг парадигмы проектирования, который произошел
при переходе от архитектур автономных приложений к архитектурам сетевых
приложений. Этот сдвиг привел к появлению новых проблем двух типов.
Во-первых, в пространстве задач, это проблемы, связанные с проектированием
и архитектурой программного обеспечения. И, во-вторых, в пространстве ре-
шений, это проблемы, связанные с инструментальными программными сред-
ствами и методами, используемыми при реализации сетевых приложений.
В этой главе сначала анализируются аспекты проектирования, влияющие на
проблемы первого типа, а затем дается представление о промежуточном слое,
создание которого диктуется проблемами второго типа и который применяется
для их решения. Кроме того, глава знакомит с инструментальной библиотекой
АСЕ и с примером сетевого приложения, который используется на протяжении
всей книги в качестве иллюстрации предлагаемых решений.
0.1 Проблемы сетевых приложений
Большинству разработчиков программного обеспечения хорошо знакомы
архитектуры автономных приложений, в которых один компьютер содержит
все необходимые программные компоненты: графический пользовательский
интерфейс (GUI), прикладную сервисную обработку и средства хранения ин-
формационных ресурсов. Например, автономная прикладная архитектура,
представленная на рис. 0.1, объединяет GUI, прикладную обработку и хранение
информационных ресурсов на одном компьютере, к которому напрямую под-
22
Глава О
Рис. 0.1
Архитектура автономных
приложений
ключены периферийные устройства. Поток управления автономного прило-
жения реализуется исключительно на том компьютере, на котором выполне-
ние началось.
Архитектуры сетевых приложений разделяют прикладную систему на
службы (services), которые могут совместно и многократно использоваться мно-
жеством приложений. Чтобы повысить эффективность и полезность служб, их
распределяют по множеству вычислительных устройств, подключенных
к сети, как показано на рис. 0.2. Обычные сетевые услуги, которые предоставля-
ются клиентам (clients) в такого рода средах, включают распределенную систе-
му именования, сетевые файловые системы, управление таблицами маршрути-
зации, регистрацию, печать, электронную почту, дистанционный вход в систе-
му, передачу файлов, службы электронной коммерции на базе Web, обработку
платежей, организацию взаимосвязей с клиентами, системы «справочных сто-
лов», обмен MP3, потоковое медиа, обмен сообщениями в реальном времени,
групповые чаты.
Архитектура сетевых приложений, показанная на рис. 0.2, распределяет
реализацию интерактивного GUI, обработку запросов на обслуживание и хра-
нение информационных ресурсов среди множества независимых хостов сети.
Во время выполнения сетевого приложения поток управления реализуется или
на одном, или на нескольких хостах. Все компоненты такой системы обменива-
ются информацией; передавая друг другу данные и управление потоком по
мере необходимости. Если использовать совместимые протоколы обмена ин-
формацией, то можно добиться взаимодействия отдельных компонент, даже
если базовые сети, операционные системы, аппаратные средства и языки про-
граммирования являются неоднородными [HV99]. Такое разделение ответст-
венности за реализацию прикладной сетевой службы, среди множества хостов
может иметь следующие преимущества:
1. Усовершенствованные взаимосвязь и взаимодействие способствуют бы-
строму распространению информации большему числу потенциальных
пользователей. Наличие взаимосвязи освобождает от необходимости пере-
носить информацию вручную и создавать дубликаты.
2. Улучшенные производительность и масштабируемость дают возмож-
ность легко, не нарушая устойчивости, изменять конфигурации систем
Проблемы проектирования, решения промежуточного слоя и АСЕ
23
с целью балансировки вычислительных ресурсов в соответствии с текущи-
ми и прогнозируемыми системными требованиями.
3. Сокращение затрат за счет того, что пользователи и приложения могут со-
вместно использовать дорогостоящие периферийные устройства и про-
граммное обеспечение, например, сложные системы управления базами
данных.
Ваша работа в качестве разработчика сетевых приложений заключается
в том, чтобы понять какие службы будут обеспечивать работу ваших приложе-
ний и в какой, или каких, из существующих сред они могут быть реализованы, а
затем:
1. Спроектировать механизмы, которые будут использоваться службами для
организации взаимодействия между собой и с клиентами.
2. Выбрать архитектурные решения и способы организации служб такие, что-
бы они наиболее эффективно использовали существующие среды.
3. Реализовать эти решения, испол$>зуя методы и средства, которые исключают
сложность и позволяют разрабатывать корректное, расширяемое, высоко-
производительное, не требующее значительных усилий на сопровождение
программное обеспечение, необходимое для достижения стоящих перед
вами целей.
Эта книга предоставляет информацию и средства, необходимые вам для
того, чтобы преуспеть в решении этих задач.
24
Глава О
Ваша работа не будет легкой. Сетевые приложения, как правило, гораздо
сложнее проектировать, программировать, отлаживать, оптимизировать и кон-
тролировать, чем их автономные аналоги. Нужно научиться преодолевать собст-
венную и «случайную» сложность [Вго87], которые связаны с разработкой и кон-
фигурированием сетевых приложений. Собственная сложность (inherent
complexities) связана с ключевыми проблемами предметной области (domain),
затрудняющими разработку сетевого приложения, включая:
• Выбор подходящих механизмов коммуникаций и создание протоколов
для их эффективного использования.
• Проектирование сетевых служб, которые рационально используют дос-
тупные вычислительные ресурсы и снижают затраты на последующее со-
провождение.
• Эффективное использование параллелизма (concurrency) для достиже-
ния предсказуемой, надежной и высокой производительности вашей
системы.
• Размещение и конфигурирование служб, увеличивающее, насколько это
возможно, работоспособность и гибкость системы.
Преодоление собственной сложности требует опыта и основательного по-
нимания самой предметной области. Существует много альтернатив проекти-
рования, имеющих отношение к проблемам собственной сложности, мы будем
их рассматривать в главах 1 и 5.
«Случайная» сложность (accidental complexities) вытекает из ограничений,
связанных с инструментальными средствами и методами, применяемыми для
разработки программного обеспечения сетевых приложений, включая:
• Отсутствие в ОС собственных типобезопасных (type-safe), переносимых
и расширяемых API.
• Широко распространенное применение алгоритмической декомпозиции,
что делает неоправданно трудными поддержку и развитие сетевых при-
ложений.
• Непрерывный процесс открытий и изобретений основных концепций и
возможностей сетевых приложений удерживает затраты, связанные
с жизненным циклом программного обеспечения, на излишне высоком
уровне.
Разработчики сетевых приложений должны понимать эти проблемы и
применять эффективные методы борьбы с ними. На всем протяжении этой
книги мы показываем на примерах как АСЕ использует объектно-ориентиро-
ванные методы и возможности языка C++, чтобы справиться с этой «случай-
ной» сложностью.
Проблемы проектирования, решения промежуточного слоя и АСЕ
25
0.2 Аспекты проектирования сетевых
приложений
Можно научиться программировать API и интерфейсы, не вникая в ключе-
вые аспекты проектирования предметной области. Тем не менее, как следует из
нашего опыта, разработчики с более глубоким знанием предметной области се-
тевого приложения гораздо лучше подготовлены к эффективному решению
ключевых проблем, связанных с проектированием, реализацией и производи-
тельностью. Поэтому, в первую очередь, мы исследуем основные архитектур-
ные аспекты проектирования, связанные с разработкой сетевых приложений.
Больше внимания мы уделяем серверам, которые поддерживают множество
служб или множество экземпляров одной службы и обслуживают одновремен-
но множество клиентов, как в показанной на рис. 0.2 среде сетевых приложе-
ний.
Аспекты проектирования, обсуждаемые в этой книге, были определены пу-
тем всестороннего анализа предметной области (domain analysis), основанного
на реальных проектах и опыте реализации сотен корпоративных сетевых при-
ложений и систем, разработанных за последнее десятилетие. Анализ предмет-
ной области является индуктивным процессом с обратными связями, система-
тически исследующим предметную область с целью выявления ее основных
проблем и аспектов проектирования и выработки на этой основе эффективных
методов решения. Этот процесс дает следующие преимущества:
• Определяет общий словарь абстракций предметной области, что позво-
ляет разработчикам более эффективно общаться друг с другом [Fow97].
В свою очередь, уточнение словаря предметной области упрощает его
отображение на соответствующий набор паттернов и программных аб-
стракций в области решений. Например, общее понимание сетевых про-
токолов, стратегий демультиплексирования событий и архитектур па-
раллелизма позволяет нам применить эти концепции к обсуждению ин-
терфейсных фасадов (wrapper facades) и каркасов (frameworks) АСЕ
в [-SH].
• Улучшает повторное использование путем разделения анализа проекта
на две составляющие:
1. Специфичную для конкретных типов приложений.
2. Общую для всех приложений данной предметной области.
Сосредоточившись на общих для предметной области вопросах проекти-
рования, разработчики приложений и промежуточного слоя могут выявить
возможности для адаптации или для создания библиотек классов повторно ис-
пользуемого программного обеспечения. После разложения канонических по-
токов управления по библиотекам классов и их реинтеграции, они могут соз-
дать каркасы промежуточного слоя, такие как в АСЕ, которые могут существен-
но снизить объем работы при разработке приложений в дальнейшем.
В сформировавшейся предметной области задачи проектирования, отра-
жающие специфику приложения, могут решаться на систематической основе
26
Глава О
Рис. 0.3
Аспекты проектирования сетевых
приложений
путем расширения и настройки существующих каркасов промежуточного слоя
средствами объектно-ориентированного языка, такими как наследование, ди-
намическое связывание, параметризованные типы и исключения.
В области сетевых приложений разработчики встречаются с проектными
решениями каждого из четырех аспектов, изображенных на рис. 0.3. Эти аспек-
ты проектирования касаются, в основном, борьбы с собственной сложностью
предметной области. Поэтому они в значительной степени независимы от про-
цессов, связанных с жизненным циклом, от методов и нотаций проектирова-
ния, от языков программирования, от платформ операционных систем и от се-
тевых аппаратных средств. Каждый из этих аспектов проектирования состоит
из набора относительно независимых альтернатив. Хотя они по большей части
независимы друг от друга, изменение одной или нескольких альтернатив сете-
вого приложения могут соответственно изменить всю его «форму». Следова-
тельно, изменения дизайна не могут осуществляться изолировано. Имейте это
в виду, анализируя следующие аспекты проектирования:
1. Аспекты коммуникаций касаются правил, формы и уровня абстракции,
которые сетевые приложения используют при взаимодействии.
2. Аспекты параллелизма касаются механизмов и стратегий правильного ис-
пользования процессов и потоков для представления множества экземпля-
ров служб, а также того, каким образом каждый экземпляр службы может
внутри себя использовать множество потоков.
3. Аспекты служб касаются ключевых свойств сетевых прикладных служб,
таких как время существования и структура каждого экземпляра службы.
4. Аспекты конфигурации касаются идентификации сетевых служб, а также
того, в какой момент времени они объединяются для формирования закон-
ченных приложений. Аспекты конфигурации часто затрагивают несколько
служб, а также связи между ними.
Мы рассмотрим первые две группы аспектов более подробно в главах 1 и 5
соответственно, а третью и четвертую обсудим в [ SH ]. Сначала мы рассмотрим
основной словарь, альтернативы проектирования и абстракции решений, за-
тем возможности платформ относительно каждого аспекта, связанную с ними
«случайную» сложность, и решения, которые предлагает АСЕ. Как вы увидите,
АСЕ использует апробированную объектно-ориентированную декомпозицию,
дизайн интерфейсов, паттерны, инкапсулирующие данные, и возможности язы-
ка C++, чтобы дать возможность аспектам проектирования ваших сетевых при-
Проблемы проектирования,решения промежуточного слоя и АСЕ
21
ложений изменяться настолько независимым и переносимым образом, насколь-
ко это возможно.
0.3 Решения, связанные
с объектно-ориентированным
промежуточным слоем
Некоторые из наиболее удачных методов и инструментальных средств,
созданных, чтобы справиться со «случайной» и собственной сложностью сете-
вых приложений, объединились в объектно-ориентированном промежуточ-
ном слое, который помогает преодолевать проблемы, связанные со сложно-
стью и разнородностью сетевых приложений. Объектно-ориентированный
промежуточный слой предлагает повторно используемые программные ком-
поненты и каркасы (framework) служб/протоколов, функциональность кото-
рых заполняет пробел между:
1. Задачами, которые решают целевые приложения.
2. Низкоуровневыми возможностями операционных систем, стеков сетевых
протоколов и аппаратных средств.
Объектно-ориентированный промежуточный слой предоставляет такие
возможности, которые играют решающую роль в упрощении и согласовании
процессов соединения и взаимодействия сетевых приложений.
0.3*1 Уровни объектно-ориентированного
промежуточного слоя
Стеки сетевых протоколов, такие как TCP/IP [Ste93], можно разделить на
несколько уровней, например, на физический, передачи данных, сетевой,
транспортный, сеансовый, представления и прикладной уровни, определенные
в эталонной модели OSI [В1а91 ].
Аналогичным образом и объектно-ориентированный промежуточный
слой можно разделить на несколько уровней [SS01], приведенных на рис. 0.4.
Обычно иерархия объектно-ориентированного промежуточного слоя включа-
ет уровни, описанные ниже:
Промежуточный слой инфраструктуры хоста (host infrastructure middleware)
инкапсулирует механизмы параллелизма и межпроцессного взаимодействия
(IPC) с целью создания возможностей для объектно-ориентированного сетево-
го программирования. Эти возможности исключают многие трудоемкие, под-
верженные ошибкам и непереносимые действия, связанные с разработкой сете-
вых приложений с использованием собственных API ОС, таких как Sockets или
API поточной обработки POSIX (Pthreads). Известными примерами промежу-
точного слоя инфраструктуры хоста являются Java Packages [ AGH00] и АСЕ.
Распределительный уровень промежуточного слоя (distribution middleware)
использует и расширяет промежуточный слой инфраструктуры хоста с целью
28
Глава О
общие службы промежуточного слоя
приложения
прикладные службы
промежуточного слоя
распределительный уровень
промежуточного слоя
промежуточный слой
инфраструктуры хоста
аппаратные средства
Рис. 0.4
Уровни объекшо-ориентированного промежуточного слоя и их окружение
автоматизации решения общих задач сетевого программирования, таких как
управление соединениями и памятью, маршалинг и демаршалинг, демультип-
лексирование запросов и данных, синхронизация и многопоточность. Разработ-
чики, использующие распределительный промежуточный слой, могут про-
граммировать распределенные приложения почти как автономные, просто вы-
зывая операции целевых объектов, не заботясь об их местоположении, языке,
ОС или аппаратуре [HV99]. Ядром распределительного промежуточного слоя
являются брокеры (посредники) объектных запросов, Object Request Brokers (ORB),
такие как COM4- [Вох97], Java RMI [Sun98] и CORBA [ObjO 1 ].
Общие службы промежуточного слоя (common middleware services) дополняют
распределительный уровень, определяя высокоуровневые, независимые от
приложений сервисы, такие как уведомление о событиях, регистрация, воз-
можность долговременного хранения, безопасность и обратимые транзакции.
Поскольку, в соответствии с объектно-ориентированной распределенной мо-
делью программирования, распределительный промежуточный слой в значи-
тельной степени нацелен на управлении ресурсами конечных систем, общие
службы промежуточного слоя сосредоточены на выделении, планировании и
Проблемы проектирования, решения промежуточного слоя и АСЕ
29
координации различных ресурсов всей распределенной системы. Без общих
служб промежуточного слоя, возможности сквозной координации пришлось
бы создавать специально (ad hoc) для каждого сетевого приложения.
Прикладные службы промежуточного слоя (domain-specific middleware services)
удовлетворяют специфическим требованиям конкретных предметных областей,
таких как телекоммуникации, электронная коммерция, здравоохранение, авто-
матизация технологических процессов или авиационная электроника. Посколь-
ку другие уровни объектно-ориентированного промежуточного слоя предостав-
ляют широко и повторно используемые «горизонтальные» сервисы и механиз-
мы, прикладные службы нацелены на «вертикальные» решения. С позиции
«есть в продаже» («commercial off-the-shelf», COTS), прикладные службы явля-
ются сегодня наименее сформировавшимся из уровней промежуточного слоя.
Частично это происходит из-за исторически сложившегося отсутствия стан-
дартов промежуточного слоя, необходимых, чтобы обеспечить стабильную
базу для создания прикладных служб.
Объектно-ориентированный промежуточный слой является важным инст-
рументом разработки сетевых приложений. Он предлагает три глобальных на-
правления совершенствования процессов разработки и эволюции сетевых при-
ложений:
1. Стратегический подход, который освобождает разработчика приложения
от низкоуровневых забот, связанных с API параллелизма и сетевого взаи-
модействия, встроенных в ОС. Фундаментальный охват концепций и воз-
можностей, лежащий в основе этих API, является основой любого процесса
разработки сетевых приложений. Задача промежуточного слоя скрыть
многочисленные детали этих API, представить их в виде более высокоуров-
невых абстрактных объектов, которыми легче пользоваться. Освободив-
шись от необходимости уделять слишком много внимания низкоуровне-
вым деталям, разработчики могут сосредоточиться на более стратегиче-
ских вопросах, касающихся самого приложения.
2. Эффективное повторное использование, которое снижает объем работ,
связанных с жизненным циклом ПО, путем использования накопленных
экспертами знаний и создании на основе имеющихся реализаций ключе-
вых паттернов [SSRBOO, GHJV95] экземпляров повторно используемых
каркасов промежуточного слоя. В будущем, большинство сетевых прило-
жений будет собираться из специализированных компонентов и общих
«сменных» компонентов служб промежуточного слоя путем написания
сценариев их взаимодействия, а не путем программирования с нуля
[Joh97].
3. Открытые стандарты, обеспечивающие создание множества переносимых
и взаимодействующих программных продуктов. Эти продукты способству-
ют тому, чтобы внимание разработчиков было направлено на архитектуру
высокоуровневых программных приложений и на такие проблемы проекти-
рования, как безопасность взаимодействия, управление многоуровневыми
распределенными ресурсами и отказоустойчивые сервисы. Возрастающе
важную роль играет открытое и/или коммерческое (COTS) объектно-ори-
30
Глава О
ентированное ПО промежуточного слоя, такое как CORBA или виртуаль-
ные машины Java и АСЕ, которое можно приобрести или получить через
источники открытого ПО. COTS ПО промежуточного слоя имеет особенно
важное значение для организаций с ограниченными ресурсами на разра-
ботку программного обеспечения, для которых большое значение имеет
«время продажи» (time-to-market).
Хотя распределительный уровень, общие и прикладные службы промежу-
точного слоя являются важными темами, в дальнейшем в этой книге они не
рассматриваются по причинам, которые будут изложены в следующеиразделе.
С дальнейшим изложением этих тем, можно познакомиться или на сайте
[http://ace.ece.uci.edu/middleware.html], или по книге Advanced
CORBA Programming with C++ [HV99].
0.3.2 Преимущества промежуточного слоя
инфраструктуры хоста
В том случае, если на разработчиков накладываются строгие ограничения,
связанные с качеством обслуживания (quality of service, QoS) и/или сдерживанием
затрат, то предпочтение следует отдать уровню промежуточного слоя инфра-
структуры хоста, а не уровням расположенным выше. Этот уровень является
также наиболее динамично развивающимся уровнем промежуточного слоя.
Области применения этого уровня и их обоснование обсуждаются ниже.
Соответствие строгим требованиям QoS. Некоторым типам приложений
требуется доступ к внутренним механизмам IPC ОС и протоколам, чтобы соот-
ветствовать повышенным требованиям QoS, связанным с эффективностью и
прогнозируемостью. Например, мультимедийные приложения требуют ком-
муникационного сервиса, связанного с длительной двунаправленной переда-
чей потока байтов, что плохо согласуется с синхронной парадигмой типа за-
прос/ответ, реализуемой распределительным уровнем промежуточного слоя
[NGSY00]. Несмотря на существенные достижения [GS99, POS+00] в методах
оптимизации, многие традиционные реализаций распределительного уровня
промежуточного слоя все еще имеют значительные издержки, связанные с про-
изводительностью и временем ожидания (latency), и не имеют достаточных
средств влияния на другие связанные с QoS характеристики, такие как флуктуа-
ции и надежность.
Часто промежуточный слой инфраструктуры хоста больше подходит для
того, чтобы гарантировать QoS сквозной передачи, так как он предоставляет
приложениям возможность:
• Исключать избыточные операции, например, маршалинг и демарша-
линг в однородных средах.
• Осуществлять многоуровневый контроль за характером связи, в том
числе осуществлять поддержку групповой IP-передачи и асинхронного
ввода/вывода.
Проблемы проектирования, решения промежуточного слоя и АСЕ
31
• Модифицировать сетевые протоколы с целью оптимизации использова-
ния полосы пропускания сети или с целью замены сетевого взаимодейст-
вия с обратной связью на взаимодействие через общую память.
Мы ожидаем, что к концу текущего десятилетия исследования и разработ-
ки в области распределительного уровня и общих служб промежуточного слоя
достигнут таких возможностей качества обслуживания (QoS), что они смогут
соперничать или даже превысят возможности промежуточного слоя инфра-
структуры хоста и сетевых приложений, написанных «вручную». В эти десять
лет, тем не менее, надо написать и установить много корпоративного ПО.
Именно в этом контексте промежуточный слой инфраструктуры хоста играет
важную роль, повышая уровень абстракции при разработке сетевых приложе-
ний, и не оказывая негативного влияния на их QoS.
Сдерживание затрат. Чтобы выжить в глобально конкурентном окруже-
нии, многие организации переходят на технологические процессы и методы
объектно-ориентированной разработки. В этом контексте, промежуточный
слой инфраструктуры хоста предлагает действенные и проверенные временем
решения, способствующие снижению затрат на собственную и «случайную»
сложность, речь о которых шла в разделе 0.1.
Например, освоение новых компиляторов, сред разработки, отладчиков и
инструментальных средств может стоить дорого. Обучение программистов-
разработчиков может стоить еще дороже, учитывая объем того, что нужно изу-
чить, чтобы стать знатоком новых технологий. Начиная программные проек-
ты, в которых должны оцениваться или применяться новые технологии, важно
эти затраты ограничить. Промежуточный слой инфраструктуры хоста может
быть эффективным средством повышения квалификации, знаний и опыта в об-
ласти ОС и сетей в процессе переноса разработки на новые платформы и подъема
по кривой обучения в направлении более новаторских, сдерживающих затраты
программных технологий.
Больше практических результатов за счет повышения качества базовых
знаний. Основательное понимание промежуточного слоя инфраструктуры
хоста помогает разработчикам выявлять высокоуровневые паттерны и службы,
что повышает их продуктивность в собственных прикладных областях. Поми-
мо современных технологий промежуточного слоя, ориентированных на мето-
ды и сообщения, существует много новых технологических проблем, требую-
щих решения. Промежуточный слой инфраструктуры хоста обеспечивает важ-
ный строительный блок для будущих исследований и разработок по
следующим причинам:
• Разработчики с глубоким пониманием проблем проектирования и паттер-
нов, лежащих в основе промежуточного слоя инфраструктуры хоста, смо-
гут быстрее усваивать достижения в области программных технологий.
В будущем они смогут стать, внутри коллектива или организации, ини-
циаторами освоения более развитых возможностей промежуточного слоя.
• Разработчики с основательным знанием того, что происходит «под капо-
том» промежуточного слоя, лучше подготовлены к поиску новых путей
совершенствования своих сетевых приложений.
32
Глава О
Уровень компонентов
сетевых служб
JAWS ADAPTIVE
WEB SERVER
Уровень
каркасов
приложений
Стандартный
промежуточный слой
THE АСЕ ORBCTAO)
С API
STREAMS
Уровень р
интерфейс- U
PROCESS/ l<
TREADS
ных фаса-
дов C++
АССЕР- ь
TOR J?1
SERVER t
HANDLER I
3
WIN32
NAMED PIPES
REACTOR/
PRO-
SYNCH
WRAPPERS
SPIPESAP
SOCK
SAP/TLI SAP
CONNEC-
TOR
Уровень адаптации к ОС
SERVICE
CONFI-
GURATOR
CORBA
HANDLER
МЕМ МАР
FILE SYS
APIS
A RED
XLLOC
FILE SAP
SOCKETS/
1U
UNIX FIFOS
SF.LECT/
IO COMP
DYNAMIC
UNKING
SHARED
MEMORY
$1
Подсистема
процессов/потоков
Подсистема
коммуникаций
Подсистема виртуальной
памяти и файлов
Общие сервисы операционной системы
Рис. 0.5
Многоуровневая архитектура АСЕ
0.4 Обзор инструментальной библиотеки АСЕ
ADAPTIVE Communication Environment (АСЕ) — это пример широко ис-
пользуемого ПО промежуточного слоя инфраструктуры хоста. Библиотека
АСЕ содержит -240000 строк кода на C++ и -500 классов. Программный дист-
рибутив АСЕ содержит также сотни автоматизированных регрессивных тестов
и примеров приложений. АСЕ является ПО с открытыми исходными текстами
и его можно свободно загрузить с сайта http://ace.ece.uci.edu/ или http://www.ri-
verace.com.
Чтобы разделить уровни ответственности, уменьшить сложность и сделать
возможной функциональную декомпозицию, АСЕ спроектирован с использо-
ванием многоуровневой архитектуры [BMR+96], показанной на рис. 0.5. Фун-
даментом инструментальной среды АСЕ является объединение уровня адапта-
ции к ОС и интерфейсных фасадов, написанных на языке C++ [SSRBOO], кото-
рые инкапсулируют основные механизмы ОС, связанные с параллельным
сетевым программированием. Уровни АСЕ, расположенные выше, строятся на
этом фундаменте, и обеспечивают повторно используемые каркасы
(frameworks), компоненты сетевых служб и стандартный промежуточный слой.
Взятые вместе, эти уровни промежуточного слоя упрощают создание, объеди-
Проблемы проектирования, решения промежуточного слоя и АСЕ 33
нение, конфигурирование и перенесение сетевых приложений, без заметного
снижения их производительности.
Материал данной книги сосредоточен на интерфейсных фасадах механиз-
мов IPC и параллелизма ОС. Дополнительные преимущества, связанные с кар-
касами приложений, и исчерпывающее описание ACE-каркасов представлены
во втором томе C++ Network Programming [SH]. Далее в данной главе описыва-
ются структура и функции различных уровней АСЕ. В разделе В. 1.4 описаны
стандартный промежуточный слой (TAO [SLM98] и JAWS [HS99]), которые ба-
зируются на АСЕ и непосредственно связаны с ней.
0Д.1 ACE-уровень адаптации к ОС
АСЕ-уровень адаптации к ОС составляет приблизительно 10 процентов от
всего объема АСЕ (около 27000 строк кода). Этот уровень состоит из класса
с именем ACE_OS, который включает более 500 статических методов, написан-
ных на C++. Эти методы инкапсулируют внутренние, ориентированные на
язык С, API ОС, которые скрывают зависящие от платформы детали и предос-
тавляют унифицированный интерфейс механизмов ОС, используемых более
высокими уровнями АСЕ. Уровень адаптации ACE_OS упрощает переноси-
мость и сопровождение АСЕ и гарантирует, что только разработчики АСЕ — а
не разработчики приложений — должны владеть знанием скрытых, зависимых
от платформы подробностей, лежащих в основе интерфейсных фасадов АСЕ.
Абстракция, обеспечиваемая классом ACE_OS, позволяет использовать единое
дерево исходных кодов для всех платформ ОС, приведенных в блоке 1.
1; Платформы ОС, поддерживаемые АСЕ
«АСЕможЗт работать на мнопкоперациснниг системах, включая:
рС персональных компьютеров (PC) например Win^'-'-ws гВсе 32/64-разряд-
версии), WlnCE; Redhat Debion и SuSE i ini те а также Macintosh OS X;
Большинстве версий UNIX, например, SunOS4.x и Sbiaris, SGI IRIX, HP-UX Digital
;y ,pNIX(Gpihp>lqIru64), AIX DG/UXSCO OpenSeiver, UnixWare, NetBSD и FreeBSD:
'У>:0пер<1Цйоннь1ё сйс.темь! реального времени например, VxWorks, OS/9, Cho-
U/WUyrixOS. Pharlap. 1 NT. ONX Neu'trino и RTP, PTF.MS и pSoS:
•M.QCбольших корпоратив! ibix систем, например. Open VMS: MVSOpenFdition,
'Nph^tbp^i'iCrdy’UFilCbS-
&СЕМ0Й40 использовать co зсеМи осровными компиляторами C++ для указан--
йж nocsnui энный,АСЕ, который находился по адресу
/УаДе- ece+uci; Дай; содержи! полный, обновляемыйсписок платформ,
^аюкё'йнструкцйи пб загрузке и компоновке АСЕ.
0Д.2 Уровень C++ интерфейсных фасадов АСЕ
Интерфейсный фасад состоит из одного или нескольких классов, инкапсу-
лирующих функции и данные внутри типобезопасного объектно-ориентиро-
ванного интерфейса [SSRB00]. Уровень интерфейсных фасадов АСЕ, написан-
ных на C++, располагается поверх уровня адаптации к ОС и обеспечивает поч-
34
Глава О
ти такую же функциональность, которая показана на рис. 0.5. Организация
этой функциональности в виде C++ классов, а не автономных С-функций, су-
щественно сокращает объем работы, связанный с изучением и правильным ис-
пользованием АСЕ. Интерфейсные фасады АСЕ тщательно проектировались
так, чтобы минимизировать или исключить издержки производительности,
возникающие как следствие повышения безопасности и улучшения повторно-
го использования. Принципы, которыми руководствовались при разработке
АСЕ, изложены в приложении А.
В АСЕ предусмотрен большой набор интерфейсных фасадов, составляю-
щих почти 50 процентов от общего объема исходного кода. Приложения ком-
бинируют и конкретизируют эти интерфейсные фасады путем их избиратель-
ного наследования, агрегирования и/или создания экземпляров. В этой книге
мы показываем каким образом интерфейсные фасады сокетов, файлов, парал-
лельной обработки и синхронизации, используются для разработки эффектив-
ных, переносимых сетевых приложений.
04.3 Уровень каркасов АСЕ
! Остальные ~40 процентов АСЕ — это объектно-ориентированные каркасы
приложений (object-oriented frameworks), представляющие собой интегрирован-
ные наборы классов, объединенные с целью создания инфраструктуры повтор-
но используемого ПО для семейства родственных приложений [ FS97]. Объект-
но-ориентированные каркасы — это ключ к успешному систематическому по-
вторному использованию. Они дополняют и развивают другие методы
повторного использования, такие как библиотеки классов, компоненты и пат-
терны [ Joh97]. Делая акцент на интеграции и совместной работе специализиро-
ванных и универсальных классов, каркасы АСЕ позволяют осуществлять более
масштабное повторное использование ПО, чем в случае повторного использо-
вания отдельных классов или автономных функций. В АСЕ каркасы приложе-
ний интегрируют и дополняют интерфейсные фасады на C++, за счет примене-
ния расширенных паттернов параллельного и сетевого программирования
[BMR+96, SSRB001 для конкретизации (reify) канонического управляющего по-
тока и объединения семейств взаимосвязанных классов АСЕ.
Перечисленные далее каркасы АСЁ поддерживают эффективную, надеж-
ную и гибкую разработку и настройку параллельных сетевых приложений и
служб:
Каркасы демультиплексирования и диспетчеризации событий. АСЕ-карг
касы Reactor и Proactor являются соответственно реализациями паттернов Re-
actor и Proactor [SSRB00]. Каркасы Reactor и Proactor автоматизируют в при
кладных программах демультиплексирование и диспетчеризацию различных
типов событий, связанных с вводом/выводом, таймером, сигналами и синхро-
низацией.
Каркас установления соединений и инициализации сервисов. АСЕ-кар-
кас Acceptor-Connector является реализацией паттерна Acceptor-Connector
[SSRBOOJ. Этот каркас отделяет активно-пассивные роли при инициализации
Проблемы проектирования, решения промежуточного слоя и АСЕ 35
от прикладной обработки» выполняемой взаимодействующими одноранговы-
ми службами, после завершения инициализации.
Каркас параллелизма. АСЕ предлагает каркас Task, который можно ис-
пользовать при реализации основных паттернов параллелизма [ SSRBOO, Lea99],
таких как Active Object и Half-Sync/Half-Async, которые упрощают параллель-
ное программирование, отделяя, соответственно, выполнение методов от их
вызовов, и синхронную обработку от асинхронной.
Каркас конфигуратора сервисов. Данный каркас реализует паттерн Com-
ponent Configurator [SSRBOO] с целью поддержки конфигурации приложений,
службы которых могут быть скомпонованы динамически в более позднее вре-
мя, на одном из этапов их реализации, например, во время инсталляции. Этот
каркас поддерживает также динамическую реконфигурацию служб приложе-
ния во время выполнения.
Каркас потоков (streams). Данный каркас реализует паттерн Pipes and Filters
[BMR+96], в котором каждый этап обработки инкапсулируется в модуле-
фильтре. Модуль-фильтр имеет доступ к потоку данных, которые передаются
через модули, и может манипулировать ими. ACE-каркас Streams упрощает
разработку иерархически упорядоченных служб, которые могут быть гибко
скомбинированы для создания некоторых типов сетевых приложений, таких
как стеки протоколов пользовательского уровня и агенты управления сетью
[SS94].
Детальное обсуждение обоснования, структуры и использования каркасов
в АСЕ войдет в C++ Network Programming: Systematic Reuse with ACE and Frame-
works [SH]. Дополнительная информация об интерфейсных фасадах и каркасах
АСЕ имеется также в The АСЕ Programmer’s Guide [HJS].
04.4 Уровень компонентов сетевых служб АСЕ
В дополнение к описанным ранее интерфейсным фасадам и каркасам про-
межуточного слоя инфраструктуры хоста, АСЕ также предоставляет библиоте-
ку сетевых служб, которые организованы в виде компонентов. Компонент —
это инкапсулированная часть программной системы, которая реализует кон-
кретную службу или совокупность служб [Szy98]. Хотя эти компоненты не
включены в саму библиотеку АСЕ, они входят в программный дистрибутив
АСЕ, чтобы обеспечить следующие возможности:
• Продемонстрировать типичные примеры использования возможно-
стей АСЕ — Компоненты показывают, как можно использовать основ-
ные каркасы и классы АСЕ для разработки гибких, эффективных и на-
дежных сетевых служб.
• Разложить сетевые приложения на повторно используемые стандарт-
ные блоки — Эти компоненты обеспечивают повторно используемые
реализации сетевых прикладных служб общего назначения, таких как
присваивание имен, маршрутизация событий [SchOO], регистрация, вре-
менная синхронизация [SSRBOO] и блокировка сети.
36
Глава О
0.5 Пример: сетевая служба регистрации
На всем протяжении этой книги мы используем один и тот же пример сете-
вой службы регистрации, в качестве вспомогательного средства, наглядно ил-
люстрирующего ключевые моменты и возможности АСЕ. Эта служба собирает
и фиксирует регистрационную информацию, отправленную одним или не-
сколькими клиентскими приложениями. Своего рода вариант обычно исполь-
зуемого в Windows NT/2000 журнала регистрации событий (отсутствует в Win-
dows 95/98). Если же вы опытный UNIX-программист, то можете подумать, что
все это пустая трата времени, так как эту задачу решает SYSLOGD. Тогда приве-
дем решающий довод в пользу предлагаемого нами сервиса регистрации: он яв-
ляется переносимым, так что приложения смогут регистрировать сообщения
на всех платформах, которые поддерживает АСЕ.
Пример службы регистрации — это реально имеющаяся в АСЕ служба ре-
гистрации Logging Service, но в миниатюре. Служба регистрации АСЕ может
конфигурироваться динамически с помощью паттерна Component Configura-
tor [SSRBOO] и каркаса АСЕ Service Configurator [SH]. Если применить паттерн
Adapter [GHJV95], то записи можно перенаправлять в UNIX SYSLOGD или
в журнал регистрации событий Windows NT/2000 или и туда, и туда — даже
Рис. 0.6
Элементы службы сетевой регистрации
Проблемы проектирования, решения промежуточного слоя и АСЕ 37
если исходное приложение работает на платформе другой ОС. Пример службы
регистрации, рассматриваемый в этой книге, сознательно сокращен, чтобы
можно было сосредоточиться на решении проблем, связанных со сложностью.
На рис. 0.6 показаны прикладные процессы и сервер нашей сетевой, службы ре-
гистрации. Ниже мы рассмотрим основные блоки, изображенные на рис. 0.6.
Процессы клиентских приложений работают на хостах-клиентах и гене-
рируют регистрационные записи в диапазоне от отладочной информации до
критических сообщений об ошибках. Регистрационные записи, которые посы-
лает клиентское приложение содержат следующую информацию:
1. Время создания регистрационной записи.
2. Идентификатор процесса данного приложения.
3. Уровень приоритета регистрационной записи.
4. Строку, которая содержит текст регистрационного сообщения и может из-
меняться в пределах от 0 байтов до максимума, устанавливаемого при на-
стройке, например, 4 Кб.
Серверы регистрации принимают и сохраняют регистрационные записи,
полученные от клиентских приложений. У сервера регистрации есть возмож-
ность определить какой из клиентских Хостов отправил данное сообщение бла-
годаря адресной информации, которую он получает от Socket API. Обычно сис-
тема имеет один сервер регистрации, хотя серверы регистрации могут дублиро-
ваться с целью повышения отказоустойчивости.
На всем протяжении книги мы ссылаемся на пример сетевой службы региг
страции, чтобы сделать наши рассуждения об аспектах анализа предметной об-
Блок 2: Компоновка АСЕ и программ, использующих АСЕ
АСЕ — это программное обеспечение с открытыми исходными кодами, его
можно загрузить с сайта http://ace.ece.uci.edu и скомпоновать самостоятель-
но. Вот несколько советов, которые помогут вам разобраться с примерами
программ, которые мы демонстрируем, а также в том как скомпоновать АСЕ,
примеры и свои собственные приложения:
• Установите АСЕ в свободный каталог. Корневой каталог дистрибутива назы-
вается ACE_wrappers. Мы ссылаемся на этот корневой каталог как на
$ACE_ROOT. Создайте переменную окружения с этим именем и присвойте
;ейзначение полного пути к корневому каталогу АСЕ.
«♦. Исходные тексты и заголовочные файлы АСЕ находятся в $ACE_ROOT/ асе.
. '* * Исходные тексты и заголовочные файлы для примеров сетевой службы реги-
' страции этой книги находятся в $ACE_ROOT/examples/c++NPv'l.
♦ При компиляции ваших программ каталог SACE.ROOT должен быть включен
.. в список путей к заголовочным файлам в вашем компиляторе, обычно это де-
к лается с помощью опций компилятора -I или /I.
А Файл'$АСЕ_РООТ/ACE-INSTALl.html содержит полный набор инструкций по
[• к компоновке й установке АСЕ и программ, использующих АСЕ.
^ы можете приобрести уже скомпонованную версию АСЕ в компании Riverace
/пономинальной цене,.Со списком компиляторов и платформ ОС, поддержи-
ваемых предварительно скомпонованными версиями от Riverace можно озна-
'^бйитьбянасййтеьъьр://www. rivsrace.com.
38
Глава О
ласти сетевых приложений более конкретными. Архитектура рассматриваемой
нами службы регистрации определялась по результатам анализа предметной
области. Как реальные продукты изменяются в объеме по мере их развития
в соответствии с жизненным циклом, так же и структура, функциональность,
масштабируемость и надежность службы регистрации будут развиваться по
мере того, как мы будем продвигаться по этой книге и по [SH]. Мы будем про-
должать, шаг за шагом, разработку этой службы, чтобы продемонстрировать
решение обычных задач проектирования с использованием ключевых паттер-
нов, реализованных с помощью классов из библиотеки АСЕ. В блоке 2 приведе-
на информация о том, как скомпоновать библиотеку АСЕ, чтобы можно было
экспериментировать с примерами, которые мы приводим в этой книге.
0.6 Резюме
В данной главе рассмотрены проблемы, связанные с разработкой сетевых
приложений и промежуточного слоя, которые могли бы эффективно функ-
ционировать в распределенных вычислительных средах. Мы познакомились
с собственной и «случайной» сложностью, проявляющимися при разработке
ПО в диапазоне от систем реального времени и встроенных систем [SLM98],
имеющих строгие ограничения, до вновь создаваемых абстракций промежу-
точного слоя [MSKS00] и сетевых приложений следующего поколения
[SKKK00], которые имеют строгие требования по качеству обслуживания QoS.
Мы систематизировали многоуровневую структуру промежуточного слоя, под-
черкнув выгоды использования промежуточного слоя инфраструктуры хоста,
который является центральной темой этой книги.
В этой главе представлены также результаты предметного анализа основ-
ных аспектов проектирования архитектур сетевых приложений. Эти аспекты
были сгруппированы в четыре категории:
1. Коммуникационные протоколы и механизмы.
2. Архитектуры параллелизма.
3. Архитектуры служб.
4. Стратегии конфигурации служб.
Эти результаты анализа предметной области уточнялись в процессе разра-
ботки сотен сетевых приложений и компонентов промежуточного слоя в тече-
ние последних десяти лет. Этими результатами мы руководствовались также
при разработке инструментальной библиотеки АСЕ, предназначенной для па-
раллельного сетевого программирования. АСЕ является иллюстрацией прин-
ципов и преимуществ, достигаемых при рефакторинге (refactoring) [FBB+99] по-
вторяющихся структур и моделей поведения сетевых приложений в структуры
промежуточного слоя инфраструктуры хоста. Архитектура ПО АСЕ, ориенти-
рованная на паттерны проектирования, является примером корпоративного
уровня, показывающим что правильное объектно-ориентированное проекти-
рование и применение возможностей языка C++ могут привести к существен-
Проблемы проектирования, решения промежуточного слоя и АСЕ 39
ному совершенствованию планирования разработок, а также к повышению ка-
чества, гибкости и производительности сетевых приложений и промежуточно-
го слоя.
В заключение мы представили сетевую службу регистрации, которая фик-
сирует регистрационную информацию, отправляемую одним или нескольки-
ми клиентскими приложениями. Мы используем этот пример на протяжении
всей книги, чтобы проиллюстрировать общие проблемы проектирования и их
эффективное решение с помощью АСЕ. Следующие две части книги организо-
ваны следующим образом:
• Часть I — В главах с 1 по 4 перечислены альтернативы проектирования,
связанные с коммуникациями, и приведено описание объектно-ориен-
тированных методов, используемых в АСЕ, для эффективного програм-
мирования механизмов IPC ОС.
• Часть II—В главах с 5 по 10 перечислены альтернативы проектирования,
связанные с параллелизмом, и приведено описание объектно-ориенти-
рованных методов, используемых в АСЕ, для эффективного программи-
рования механизмов параллелизма ОС.
На всем протяжении книги, мы демонстрируем общие проблемы, возни-
кающие в процессе проектирования сетевых приложений и при их программи-
ровании с использованием API ОС IPC и параллелизма. Мы также показываем
каким образом АСЕ использует объектно-ориентированные методы проекти-
рования, возможности языка C++ и паттерны проектирования для решения
этих проблем.
Часть I
Объектно-ориентированное
программирование сетевых
приложений
Глава 1
Аспекты проектирования:
коммуникации
Краткое содержание
Коммуникации играют фундаментальную роль в проектировании сетевых
приложений. В данной главе представлен предметный анализ коммуникацион-
ных аспектов проектирования, касающихся правил, формы и уровня абстрак-
ции, используемых сетевыми приложениями для взаимодействия друг с дру-
гом. В этой главе мы рассматриваем следующие аспекты проектирования:
• Протоколы без установления и с установлением соединения.
• Обмен синхронными и асинхронными сообщениями.
• Передача сообщений и общая память.
1.1 Протоколы без установления
и с установлением соединения
Любой протокол — это набор правил, которые устанавливают каким обра-
зом взаимосвязанные объекты, например, прикладные процессы, взаимодейст-
вующие в сетевой вычислительной среде, обмениваются управляющей инфор-
мацией и данными. В общем случае протоколы делятся на протоколы без уста-
новления и с установлением соединения. Основные альтернативы этого
аспекта касаются времени ожидания (latency), масштабируемости (scalability) и
надежности (reliability).
Протоколы без установления соединения обеспечивают сервис ориенти-
рованный на сообщения, при котором каждое сообщение передается и мар-
шрутизируется независимо. Протоколы без установления соединения часто ис-
пользуют семантику доставки по принципу «максимального усилия» (best-
effort). Такая семантика не гарантирует, что последовательность сообщений
44
Глава 1
придет в том же порядке, в каком была передана, не гарантируется даже то, что
сообщения будут доставлены вообще.
Широко распространенными примерами протоколов без установления со-
единения являются протоколы User Datagram Protocol (UDP) и Internet Protocol
(IP). Эти протоколы могут быть использованы непосредственно мультимедий-
ными приложениями, такими как IP-телефония или потоковое видео
[MSKS00], которые допускают частичную потерю данных. UDP/IP поддержива-
ет также возможность ненадежного группового вещания (multicast) [DC90] и
широковещания, что позволяет отправителю обмениваться информацией
с группами получателей.
Протоколы с установлением соединения обеспечивают надежную, упоря-
доченную доставку без дублирования, которая подходит приложениям, не до-
пускающим потери данных. С целью улучшения производительности и гаран-
тии надежности, протоколы с установлением соединения поддерживают ин-
формацию о состоянии на стороне отправителя и/или получателей и
обмениваются ею. Протокол Transmission Control Protocol (TCP) является про-
токолом с установлением соединения, который используется во многих сеансо-
вых Internet-приложениях, например, в web-сервисах и в электронной почте.
При использовании протоколов с установлением соединения, разработчи-
ки приложений и промежуточного слоя должны также выбирать следующие
альтернативы проектирования:
• Стратегии кадрирования данных. Протоколы с установлением соедине-
ния предлагают различные стратегии кадрирования данных. Например,
стратегии доставки, ориентированные на сообщения, поддерживаются
некоторыми протоколами с установлением соединения, такими как ТР4
и ХТР. В отличие от них TCP является протоколом передачи потока бай-
тов, который не сохраняет границы прикладных сообщений. Таким об-
разом, если приложение выполняет четыре вызова send (), чтобы пере-
дать четыре отдельных сообщения по TCP, то получателю будет передан
один или несколько (и может быть больше, чем 4) TCP-сегментов. По-
этому, если приложению требуется доставка, ориентированная на сооб-
щения, отправитель и получатель должны выполнить дополнительную
обработку, чтобы кадрировать четыре сообщения, передаваемых по TCP.
Если сообщения всегда имеют одинаковый размер и гарантируется от-
сутствие ошибок при передаче данных по сети, то кадрировать данные
относительно просто; иначе это может превратиться в нетривиальную
задачу.
* Стратегии мультиплексирования соединений. Две основных стратегии
передачи данных по протоколу с установлением соединения показаны на
рис. 1.1, а их описание приведено ниже:
1. Мультиплексированные, если все клиентские запросы, создаваемые пото-
ками одного процесса, передаются серверному процессу по одному
TCP-соединению, как показано на рис. 1.1(1). Преимущество мультиплек-
сирования соединений заключается в том, что при этом экономятся комму-
никационные ресурсы ОС, такие как дескрипторы сокетов и блоки управ-
Аспекты проектирования: коммуникации
45
Мультиплексированное соединение
Немулыиплексированные соединения
Рис. 1.1
Альтернативные стратегии мультиплексирования соединений
ления соединением. Недостатки этой стратегии заключаются в том, что ее
труднее программировать [AOS+00], она менее эффективна [СВ01] и менее
детерминирована [SMFGG01]. Проблемы возникают из-за механизмов
синхронизации и переключения контекстов, необходимых при сопоставле-
нии друг другу запросов и ответов, передаваемых по мультиплексирован-
ному соединению.
2. ^мультиплексированные, если каждый клиент использует отдельное со-
единение для обмена информацией с одноранговым партнером, как пока-
зано на рис. 1.1(*2). Основным преимуществом демультиплексированных
соединений является более четкое управление приоритетами передачи дан-
ных. В дизайне с демультиплексированными соединениями приоритет ка-
ждого соединения может быть установлен индивидуально, так что данные
с высоким приоритетом будут передаваться быстрее, даже если между дру-
гими потоками существуют большие объемы трафика данных с низким
приоритетом. Такое решение устраняет инверсию приоритетов (priority
inversion), когда потоки с низким приоритетом монополизируют единст-
венное мультиплексированное соединение. Кроме того, благодаря раздель-
ному использованию соединений, эта стратегия имеет низкие накладные
расходы на синхронизацию, так как чтобы посылать и получать двусторон-
ние запросы, дополнительные блокировки не'нужны. По сравнению со
стратегиями с мультиплексированием соединений, в стратегиях без муль-
типлексирования потребляется больше ресурсов ОС и поэтому в некото-
рых средах такого рода решения плохо масштабируются, например, в сер-
верах электронной коммерции в Internet, с большим числом пользовате-
лей.
Дополнительную информацию о проектировании и альтернативах страте-
гий мультиплексирования соединений можно найти в [SMFGG01, SSRBOO].
Служба регистрации^ Предлагаемые нами реализации сетевой службы ре-
гистрации используют протокол TCP/IP с установлением соединения для пере-
дачи регистрационных записей от клиентских приложений серверу регистра-
ции. Издержки, связанные с установлением соединения, компенсируются тем,
что соединение устанавливается только один раз и тем, что оно кэшируется
в течение всего процесса обмена информацией между клиентом и сервером. Ус-
танавливаемые соединения не мультиплексируются, каждое регистрирующее-
46
Глава 1
ся клиентское приложение открывает отдельное TCP-соединение с сервером
регистрации.
Выбор TCP требует от нас реализации механизма кадрирования данных по-
верх потока байтов TCP (этот механизм показан в блоке 9). Тем не менее, то, что
протокол TCP существует практически на всех платформах, делает это решение
окупаемым за счет интероперабельности и переносимости как относительно
платформ ОС, так и относительно сетевого уровня передачи данных. Более
того, транспортный уровень сети, а не приложение, отвечает за управление по-
токами и перегрузками, за повторную передачу утерянных данных и за гаран-
тию доставки данных в правильной последовательности. Эти возможности
важны для тех сетевых приложений, которые не могут допустить утрату реги-
страционных данных.
1.2 Синхронный и асинхронный обмен
сообщениями
Во многих сетевых приложениях клиент посылает запрос серверу, который
обрабатывает этот запрос и затем возвращает ответ. Такие протоколы типа за-
прос/ответ могут быть реализованы поверх протоколов как без установления,
так и с установлением соединения. Двумя альтернативными стратегиями орга-
низации обмена по протоколам типа запрос/ответ являются синхронный и
асинхронный обмен, изображенные на рис. 1.2. На выбор стратегий обмена
синхронными или асинхронными сообщениями влияют следующие два фак-
тора:
Клиент Сервер
Зопрос 1
Ответ 1
Запрос 2»
ф .Ответ 2. _
•
Запрос Зг
* .Ответ 3__
(1) Синхронная
Клиент Сервер
Запрос 11
Запрос 2 (
•
Запрос Зг
« _9™_ет 2__
4 .Ответ 3__
т* М
(2) Асинхронная
Рис. 1.2
Синхронная и асинхронная стратегии передачи сообщений
1. Взаимозависимость запросов.
2. Задержка в нижерасположенных протоколах или каналах передачи.
Аспекты проектирования: коммуникации
47
Далее мы рассматриваем каким образом эти факторы влияют на выбор
стратегии.
Синхронные протоколы запрос/ответ реализовать проще всего. В этих
протоколах обмен запросами и ответами осуществляется в последовательно-
сти, определяемой принципом строгой очередности (lock-step). На каждый за-
прос, синхронно, должен быть получен ответ, до того, как будет послан следую-
щий запрос, см. рис. 1.2(1). Синхронные протоколы типа запрос/ответ подхо-
дят в следующих ситуациях:
• Когда от результата запроса зависят результаты следующих запросов, на-
пример, приложение, которое предусматривает обмен информацией
с аутентификацией, не станет отвечать на запросы, связанные с выдачей
секретной информации, пока не будет успешно завершен обмен серти-
фикатами безопасности.
• Когда приложения обмениваются сообщениями, требующими кратко-
временной обработки в сетях с незначительной задержкой, например,
операции NFS read() и write () в высокоскоростных локальных се-
тях.
• Когда простота реализации или небольшое число обменов по протоколу
перекрывают любое возможное улучшение производительности, кото-
рое может быть достигнуто с помощью асинхронных протоколов за-
прос/ответ, описанных далее.
Асинхронные протоколы запрос/ответ передают запросы от клиента
к серверу, не ожидая синхронных ответов [AOS+00] . Множество клиентских за-
просов может быть послано до того, как ответы придут с сервера, см. рис. 1.2(2).
Тем не менее, асинхронным протоколам типа запрос/ответ часто требуются ме-
тодики обнаружения утраченных или некорректных запросов и их повторной
передачи позже.
Асинхронные протоколы типа запрос/ответ подходят в следующих ситуа-
циях:
• Когда от ответа не зависит выбор следующих запросов. Например,
web-браузеры могут использовать асинхронные стратегии для выборки
с того же сервера множества встроенных изображений. Так как каждый
запрос является независимым, все они могут быть посланы асинхронно,
не ожидая промежуточных ответов. Каждый ответ включает информа-
цию, которую браузер может использовать для сопоставления с соответ-
ствующим запросом даже в том случае, когда порядок поступления отве-
тов отличается от того порядка, в котором были посланы запросы.
• Когда время передачи запроса больше, чем время, которое требуется для
его обработки. Стратегии асинхронных запросов способствуют эффек-
тивному использованию сети, нивелируя последствия большой задерж-
ки. Результирующее увеличение производительности значительно Пере-
вешивает дополнительную сложность, связанную с сопоставлением от-
ветов и запросов и корректной реализацией стратегий повторной
передачи.
48
Глава 1
Служба регистрации => Предлагаемый нами сервер сетевой регистрации
использует односторонний вариант асинхронного протокола типа запрос/от-
вет, который не требует ответов на прикладном уровне. Регистрационные запи-
си пересылаются только от клиентских приложений серверу регистрации; при-
ложения не требуют от сервера подтверждений. Сервер регистрации самостоя-
тельно записывает каждую регистрационную запись на диск сразу после ее
получения, считая, что каждая отправленная регистрационная запись составле-
на правильно. Такого решения достаточно пока клиентские приложения не
требуют от сетевой службы регистрации предпринимать героические усилия
с целью гарантировать, что все регистрационные записи сохраняются надежно,
даже в случае катастрофических отказов. Если бы нужно было удовлетворить
такое требование, то нам пришлось бы разрабатывать сервис регистрации, ори-
ентированный на транзакции, что гораздо сложнее и требует значительно
больших затрат времени.
1.3 Передача сообщений и общая память
В наших рассуждениях о протоколах до сих пор предполагалось, что ин-
формацией обмениваются одноранговые процессы, выполняющиеся на раз-
ных компьютерах. Такой тип обмена информацией называется передачей сооб-
щений. Другой тип информационного обмена имеет место тогда, когда взаимо-
действующие одноранговые процессы имеют доступ к общей области памяти.
В данном разделе описываются эти два механизма и связанные с ними альтер-
нативы.
При .передаче сообщений осуществляется обмен потоками байтов и данны-
ми в виде записей непосредственно с помощью механизмов IPC, которые мы
рассмотрим в главе 2. Разработчики приложений обычно определяют формат и
содержание этих сообщений, также как прикладной протокол, которому участ-
ники должны следовать при обмене сообщениями. Этот протокол определяет
также количество возможных участников каждой процедуры обмена информа-
цией (например, однонаправленная (unicast) передача «точка-точка» (point-to-
point), групповое вещание (multicast) или широковещание (broadcast)) и каким об-
разом участники начинают, ведут и завершают сеанс передачи сообщений.
Механизмы передачи сообщений по IPC передают данные в виде сообще-
ний от одного процесса или потока другому посредством канала IPC, см.
рис. 1.3(1).
Если передается большой объем данных, их можно разбивать на фрагмен-
ты и посылать в виде последовательности сообщений. Если данные должны по-
лучать несколько процессов, то каждое сообщение может посылаться несколь-
ко раз, по числу получателей. Многие известные архитектуры промежуточного
слоя, такие как RPC, CORBA и промежуточный слой, ориентированный на со-
общения, МОМ, внутри используют коммуникационную модель передачи со-
общений.
Аспекты проектирования: коммуникации
49
Рис. 1.3
Передача сообщений и общая память
Общая память позволяет нескольким процессам на одном или разных хос-
тах получать доступ к данным и обмениваться ими так, как если бы это были
локальные данные, расположенные в адресном пространстве соответствующих
процессов. Если у сетевых приложений есть данные, с которыми должны рабо-
тать несколько процессов, то такое средство как общая память может оказаться
более эффективным коммуникационным механизмом, чем передача сообще-
ний. Вместо определения метода передачи информации между участниками
обмена, приложения, которые используют механизм общей памяти ОС, долж-
ны определить, как выделять и отображать область(и) общей памяти и какие
структуры данных там размещать.
Общая память может иметь локальный и распределенный характер.
• Локальная общая память позволяет процессам на одном компьютере
иметь одну или несколько областей общей памяти, отображенной на раз-
личные диапазоны виртуальных адресов. Два распространенных меха-
низма общей памяти включают:
1. Общая память в System V UNIX, где системный вызов s hinge t ()
создает новую область разделяемой памяти или возвращает указа-
тель на уже существующую. Процесс подключает область разделяе-
мой памяти к своему виртуальному адресному пространству с помо-
щью системного вызова shmat ().
2. Файлы, отображаемые в память, где весь файл или его часть отобра-
жается на область виртуальной памяти, совместно используемой не-
сколькими процессами. Содержимое, отображаемых в память фай-
лов можно сбрасывать надиск для постоянного хранения, что являет-
ся удобным способом сохранения и восстановления информации во
время выполнения программы.
И в том, и в другом случаях ОС предоставляет возможность нескольким
процессам отображать области общей памяти в их собственные адресные про-
странства, см. рис. 1.3(2). Все процессы, в адресные пространства которых ото-
бражаются области общей памяти, могут непосредственно читать содержимое
общей памяти и записывать в него данные.
Не смотря на гибкость, обМен информацией между несколькими процесса-
ми через общую память требует внимательного программирования. Напри-
мер, разработчики приложений должны гарантировать, что совместно исполь-
50 Глава 1
зуемые данные не будут повреждены в результате гонок. Механизмы синхро-
низации с областью действия на уровне системы (system-scope), описанные
в главе 10, могут осуществлять сериализацию областей общей памяти, таким
образом, что к совместно используемой информации организуется упорядо-
ченный доступ. Приложения следует более тщательно проектировать и в том
случае, если они сохраняют в общей памяти объекты C++, см. информацию
в блоке 3.
Блок 3: Объекты C++ и общая память
В C++ оператор, выделения памяти new может инициализировать объекты С++
в общей памяти.- Такая возможность существует для конкретных классов
(BJaOO), так как каждый из них содержит все операции, необходимые для рабо-
ты с ним. Все методы конкретного класса не являются виртуальными: го есть
они могут вызываться не косвенно, через указатель на функцию, а непосредст-
венно. Многие интерфейсные фасады АСЕ являются конкретными классами,
по причинам, изложенным в разделе А.6.
Наоборот, абстрактные типы, которые содержат виртуальные методы, трудно |
программировать в переносимом стиле, если они размещаются в общей па- |
мяти. Виртуальные методы вызывают обычно косвенно, с помощью таблицы
указателей на функции (viable), расположенной в памяти объекта. Область
общей памяти может располагаться в разных областях виртуальной памяти
того процесса, который ее отображает (ВС94, Jor91). Более того, компиля-
тор/компоновщик C++ не обязан располагать таблицы viable по одним и тем
же адресам в разных процессах. Поэтому viable, также как и функции, на ко-
торые она ссылается, могут отображаться по разным виртуальным адресам
в каждом процессе, что «гарантирует» проблемы во время выполнения.
• Распределенная общая память (DSM) является программной абстрак-
цией, которая предоставляет приложениям расширенные механизмы
виртуальной памяти ОС [JM98]. Виртуальная память обеспечивает сово-
купность стратегий выборки, размещения и замены набора страниц по
требованию, с целью создания для программ иллюзии того, что они рас-
полагают гораздо большим адресным пространством, чем реально суще-
ствующая физическая память. DSM расширяет концепцию виртуальной
памяти на случай сети, чтобы дать процессам возможность прозрачно
взаимодействовать, используя данные в глобальной/общей памяти. DSM
представляет собой гибрид двух вычислительных парадигм: общей па-
мяти в многопроцессорной обработке и распределенной системы
[РТМ97].
Например, существуют аппаратно-программные платформы, объединяю-
щие несколько компьютеров в кластер, в логически единую систему, в которой
память совместно используется всеми компьютерами кластера. Приложе-
ния-участники обмениваются информацией через распределенную общую па-
мять, организуемую «между» сетевыми компьютерами. DSM-системы обеспе-
чивают механизмы для координации обновления данных в процессах и узлах
сети. Эта коммуникационная модель часто использует механизмы передачи со-
Аспекты проектирования: коммуникации
общений на нижних уровнях для координации обмена данными и для синхро-
низации процессов, осуществляющих чтение и запись.
Служба регистрации => Предлагаемая нами служба регистрации использу-
ет модель IPC с передачей сообщений, реализованную поверх TCP/IP. Меха-
низм IPC с передачей сообщений обычно более практичен, чем механизм DSM,
при реализации которого необходимо управлять сложными распределенными
кэшами с помощью когерентных протоколов. Так как DSM — это тема для пер-
спективных исследований, редко применяемая на практике, то в этой книге мы
ее больше рассматривать не будем. Хорошие обзоры исследований по DSM
можно найти в [NL91, РТМ97].
1.4 Резюме
Изолированные объекты, расположенные в едином адресном пространстве
автономного приложения, часто взаимодействуют, передавая параметры через
вызовы функций и/или через глобальные переменные. Но объектам, располо-
женным в адресных пространствах разных сетевых приложений, нужны другие
механизмы межпроцессного взаимодействия. В этой главе было показано, что
механизмы IPC затрагивают несколько коммуникационных аспектов, которые
следует учитывать при разработке сетевых приложений. Мы привели описание
режимов соединений, протоколов запрос/ответ и альтернатив обмена инфор-
мацией, а также отметили факторы и компромиссы, которые оказывают влия-
ние на выбор разработчика.
В следующей главе обсуждается Socket API. Это самое распространенное из
средств IPC, которые используются при реализации проектов, поэтому важно
понять его возможности и недостатки, а также решения, предлагаемые АСЕ.
Инструментальная библиотека АСЕ предлагает ряд классов, которые помогают
управлять выбранными вами вариантами коммуникаций в соответствии с ас-
пектами проектирования, рассмотренными в этой главе. Например:
• Интерфейсные фасады АСЕ, инкапсулирующие функции установления
соединения и синхронной передачи сообщений, представлены в главе 3.
• Асинхронное установление соединений и передача данных рассматрива-
ются в [SH].
• ACE-механизм файлов, отображаемых в память, описан в блоке 7, АСЕ-
механизмы общей памяти изложены в [HJS].
Применение перечисленных возможностей АСЕ в сетевых приложениях
помогает уменьшить их собственную и «случайную» сложность.
Глава 2
Обзор Socket API
Краткое содержание
Материал предыдущей главы касался в основном оценки аспектов проек-
тирования, связанных с взаимодействием сетевых приложений, которые пре-
доставляют много возможностей для преодоления собственной сложности.
Данная глава является исходной точкой в исследовании пространства решений,
начиная с наиболее известного механизма межпроцессных коммуникаций
(IPC): сокетов. Мы рассматриваем Socket API и его применение с TCP/IP, затем
анализируем наиболее распространенные варианты «случайной» сложности,
возникающие в процессе программирования разработчиками сетевых прило-
жений с использованием API ОС.
2.1 Обзор механизмов IPC операционных
систем
Сетевые приложения нуждаются в механизмах межпроцессных коммуни-
каций (IPC), чтобы клиенты и серверы могли обмениваться информацией. Ме-
ханизмы IPC, предоставляемые операционными системами можно разделить
яа две основные категории:
• Локальные IPC — Некоторые механизмы IPC, такие как общая память,
каналы, сокеты UNIX-домена или сигналы, позволяют обмениваться ин-
формацией только между объектами, которые размещены на одном ком-
пьютере [Ste99],
• Удаленные IPC — Другие механизмы IPC, такие как сокеты Intemet-до-
мена [Ste98], каналы Х.25, именованные каналы Win32, поддерживают
коммуникации между объектами, которые могут находится в любом
узле сети.
54
Глава 2
Хотя сетевые приложения в значительной мере связаны с механизмами
удаленных IPC, паттерны и интерфейсные фасады АСЕ, которые мы предлага-
ем, применимы также к большинству механизмов локальных IPC.
Всестороннее обсуждение механизмов IPC ОС и их API выходит за рамки
этой книги. Мы рекомендуем для более полного рассмотрения этой темы обра-
титься к [Rag93, MBKQ96, Ric97, Sol98, Ste98, Ste99]. Данная глава посвящена
Socket API и TCP/IP, так как они являются наиболее распространенным IPC API
и наиболее популярным сетевым протоколом, соответственно. Мы показыва-
ем, как трудно полагаться на Socket API при написании переносимых и надеж-
ных программ в гетерогенной среде. Затем главы 3 и 4 иллюстрируют каким об-
разом АСЕ использует C++ и паттерны для решения этих проблем.
2.2 Socket API
Программный интерфейс Socket API был разработан в BSD UNIX
[MBKQ96], чтобы обеспечить интерфейс прикладного.уровня со стеком прото-
колов TCP/IP. Этот API с тех пор был перенесен на большинство операционных
систем, включая все, поддерживаемые АСЕ. Сегодня, де-факто, это стандарт
программирования межпроцессного взаимодействия по TCP/IP.
Приложения могут использовать С-функции из Socket API для создания
локальных конечных точек соединения, которые называются сокетами, и
управления ими. Доступ к каждому сокету осуществляется по его идентифика-
тору (handle), который в литературе по UNIX называется также дескриптором.
Дескриптор сокета определяет одну конечную точку соединения, поддерживае-
мую ОС, скрывая от приложений различия в низкоуровневых деталях реализа-
ции ядра ОС и снимая с них зависимость от этих деталей, таких как:
• В UNIX дескрипторы сокетов и другие дескрипторы ввода/вывода, на-
пример, дескрипторы файлов, каналов, терминальных устройств, могут
использоваться взаимозаменяемо для большинства операций.
• В Microsoft Windows дескрипторы сокетов не могут использоваться взаи-
мозаменяемо с дескрипторами ввода/вывода для большинства операций,
хотя они служат похожим целям.
Каждый сокет может быть связан с локальным и удаленным адресом. Эти
адреса определяют связь между двумя и более одноранговыми процессами, ко-
торые через этот сокет обмениваются информацией.
Socket API содержит приблизительно два десятка системных функций, ко-
торые могут быть отнесены к следующим пяти категориям:
1. Управление локальными контекстами. Socket API предоставляет функции
для управления информацией о локальных контекстах, которая обычно
хранится внутри ядра ОС или в системных библиотеках.
Обзор Socket API
55
Функция Описание
socket () Функция фабрики, создающая дескриптор сокета и возвращающая его вызывающей программе.
bind О. Ассоциирует дескриптор сокета с локальным или удаленным адресом.
getsockname () Возвращает локальный адрес, с которым связан сокет.
getpeername() Возвращает удаленный адрес, с которым связан сокет.
close () Освобождает дескриптор сокета, делая его доступным для повторного использования.
2. Установление и закрытие соединений. Socket API предоставляет функции
для установления и закрытия соединений.
Функция Описание
connect () Активно устанавливает соединение, используя дескриптор сокета.
listen () Указывает на готовность пассивно воспринимать входящие запросы клиентского соединения.
accept () Функция фабрики, создающая новую конечную точку соединения для обслуживания клиентских запросов.
shutdown () Избирательно закрывает поток на передающей (read-side) и/или на приемной (write-side) стороне двунаправленного соединения.
3. Механизмы передачи данных. Socket API обеспечивает функции, с помо-
щью которых можно посылать и получать данные, используя дескрипторы
сокетов.
Функция Описание
send () recv () Передают из буфера и принимают в буфер данные, через заданный дескриптор ввода/вывода.
sendto () recvfrom () Обмениваются дейтаграммами без установления соединения; при каждом вызове sendto () указывается сетевой адрес получателя.
В UNIX эти функции можно также использовать для других типов деск-
рипторов ввода/вывода, например, файлов и терминалов. Платформы на базе
UNIX предоставляют также следующие механизмы передачи данных.
56
Глава 2
Функция Описание
read () write () Принимают в буфер и передают из буфера данные через заданный дескриптор.
readv() writev() Поддерживают чтение-с-разнесением данных (scatter-read) и запись-со-слиянием данных (gather-write), соответственно, чтобы оптимизировать переключение режимов и упростить управление памятью.
sendmsg() recvmsg() Универсальные функции, которые являются обобщением возможностей других функций передачи данных.
4. Управление опциями. В Socket API определены функции, позволяющие
программистам изменять поведение сокета по умолчанию, чтобы сделать
возможным групповое вещание, широковещание и модификацию/запрос
размера буферов передаваемых данных.
Функция — Описание
setsockopt() Модифицирует опции различных уровней стека протоколов.
getsockopt() Запрашивает опции различных уровней стека протоколов.
5. Сетевая адресация. Дополнительно к функциям, описанным выше, сете-
вые приложения часто используют функции, преобразующие удобные для
человека имена, например, tango.ece.uci.edu, в низкоуровневые сетевые ад-
реса, например, 128.195.174.35.
Функция Описание
gethostbyname() gethostbyaddr() Преобразуют сетевые адреса из имен хостов в адреса IPV4 и обратно.
getipnodebyname() getipnodebyaddr() Преобразуют сетевые адреса из имен хостов в адреса IPV4/IPv6 и обратно.
getservbyname() Идентифицирует сервисы по их «дружественным» именам.
Хотя Socket API чаще всего используют, когда пишут приложения TCP/IP,
он достаточно универсален и может поддерживать многие коммуникационные
домены. Коммуникационный домен определяется семейством протоколов и
семейством адресов следующим образом:
• Семейство протоколов. Современные сетевые среды включают большое
количество протоколов, которые могут предлагать многообразные ком-
муникационные сервисы, такие как надежная доставка с установлением
соединения, ненадежная групповая доставка и т.д. Семейство протоко-
лов — это совокупность протоколов, которые предлагают определенный
Обзор Socket API
57
набор взаимосвязанных сервисов. При создании сокета с помощью Soc-
ket API, протокол задается комбинацией следующих двух параметров:
1. Семейство протоколов — например, UNIX-домен (PF_UNIX), Internet-до-
мен IPv4 (PF_INET) и IPv6 (PF_INET6), ATM (PF_ATMSVC), X.25
(PF_X25), Appletalk (PF_APPLETALK) И т.д.
2. Тип сервиса — например, упорядоченный надежный поток байтов
(SOCK_STREAM), ненадежная дейтаграмма (SOCK_DGRAM), и т.д.
Например, можно задать протокол TCP/IP, если передать функции soc-
ket () параметры PF_INET (или PF_INET6) и SOCK_STREAM.
• Семейство адресов. Семейство адресов определяет формат, который за-
дает размер адреса в байтах, а также количество, тип и порядок располо-
жения его полей. Кроме того, семейство адресов определяет набор функ-
ций, которые воспринимают данный формат адреса, например, чтобы
определить подсеть, которой предназначена данная IP-дейтаграмма. Се-
мейство адресов тесно связано с семейством протоколов, например, се-
мейство адресов IPv4 a f_ine t работает только с семейством протоколов
IPv4 pf_inet.
2.3 Ограничения Socket API
Встроенный в ОС Socket API имеет несколько ограничений: он подвержен
ошибкам, слишком сложен и непереносим/неоднороден. Хотя следующие рас-
суждения касаются, в первую очередь Socket API, эти замечания можно отнести
и на счет других встроенных в ОС IPC API.
2.3.1 Подверженные ошибкам API
Как отмечалось в разделе 2.2, Socket API использует дескрипторы для иден-
тификации конечных точек сокетов. В общем случае, операционные системы
используют дескрипторы для идентификации других механизмов ввода/выво-
да, таких как файлы, каналы и терминалы. Эти дескрипторы реализованы
в виде слабо типизированных (weakly typed) целочисленных и указательных ти-
пов, которые могут привести к появлению неявных ошибок во время выполне-
ния. Чтобы проиллюстрировать эти и другие проблемы, которые могут иметь
место, рассмотрим следующую функцию echo_server ():
О // В этом примере "баги"! Не копируйте его!
1 #include <sys/types.h>
2 #include <sys/socket.h>
3
4 const int PORT_NUM = 10000;
5
6 int echo server ()
7 <
58
Глава 2
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
struct sockaddr_in addr;
int addr_len;
char buf[BUFSIZ];
int n_handle;
// Создаем локальную конечную точку.
int s_handle = socket (PFJJNIX, SOCK_DGRAM, 0) ;
if (s_handle == -1) return -1;
// Задаем адрес, который прослушивается сервером.
addr.sin_family » AF_INET;
addr.sin_port = PORT_NUM;
addr.sin_addr.addr = INADDR_ANY;
if (bind (s_handle, (struct sockaddr *) &addr,
sizeof addr) »= -1)
return -1;
// Создаем новую конечную точку содинения.
if (n_handle = accept (s_handle, (struct sockaddr *) &addr,
&addr_len) != -1) {
int n;
while ((n = read (s_handle, buf, sizeof buf)) > 0)
write (n_handle, buf, n);
close (n_handle);
}
return 0;
Эта функция содержит по меньшей мере 10 ошибок как неочевидных, так и
самых обычных, встречающихся при использовании Socket API. Посмотрите
код, представленный выше. Попробуйте найти 10 ошибок, а затем ознакомь-
тесь с нашим разбором этих «дыр». Числа в круглых скобках — это номера
строк функции echo_server (), в которых есть ошибки.
1. Забыли проинициализировать критическую переменную. (8-9) Перемен-
ная addr_len должна быть проинициализирована значением size-
of (addr). Если не проинициализировать эту переменную, то вызов ac-
cept () в строке 26 завершится во время выполнения с ошибкой.
2. Использовали непереносимый тип данных для дескриптора. (11-14) Хотя
эти строки выглядят достаточно безобидно, они также скрывают потенци-
альную опасность. Этот код не получится перенести на платформы Win-
dows Sockets (WinSock), где дескрипторы сокетов имеют тип SOCKET, а не
тип int. Более того, ошибки WinSock отображаются с помощью нестан-
дартного макроса INVALID_SOCKET_HANDLE, а не с помощью возвращае-
мого значения -1. Другие ошибки во фрагменте кода, представленного
выше, будут непонятны, пока мы не рассмотрим оставшуюся часть функ-
ции. Следующие три ошибки, связанные с сетевой адресацией, неочевидны
и проявляются только во время выполнения.
Обзор Socket API
59
3. He обнулили неиспользуемые члены структуры. Вся структура add г
должна быть обнулена до присваивания значений каждому из членов, со-
держащих адреса. Socket API использует одну базовую адресную структуру
(sockaddr) с различными «оверлеями», зависящими от семейства адре-
сов, например, sockaddr_in для IPv4. Без инициализации всей структуры
нулевыми значениями, часть полей может содержать неопределенные зна-
чения, что может привести во время выполнения к появлению случайных
ошибок.
4. Несоответствие семейств адрес/протокол. (17) Поле addr. sin_family
было установлено в AF_INET, что означает семейство Internet-адресации.
Это поле будет использоваться с сокетом (s_handle), созданного
с UNIX-семейством протоколов, что одно другому не соответствует. Вме-
сто этого, тип семейства протоколов, передаваемый функции socket ()
должен был быть PF_INET.
5. Неправильный порядок байтов. Значение, присвоенное addr. sin_port,
не соответствует сетевому порядку байтов; программист забыл использо-
вать htons () для преобразования номера порта из того порядка байтов,
который принят на хосте, в сетевой порядок байтов. При выполнении на
компьютере с прямым порядком расположения байтов, эта программа бу-
дет выполняться без ошибок, но клиенты не смогут подключиться по ука-
занному номеру порта.
Если эти ошибки с сетевой адресацией исправить, то строки 21-23 на самом
деле заработали бы!
В строках 25-27 присутствует набор взаимосвязанных ошибок. Они пока-
зывают как трудно бывает локализовать ошибки до выполнения, если програм-
мировать С Socket API напрямую.
6. Отсутствует важный API-вызов. (25) Была случайно пропущена функция
listen (). Эту функцию нужно вызывать до accept (), чтобы устано-
вить дескриптор сокета в так называемый «пассивный режим».
7. Неправильный тип сокета при API-вызове. (26) Функция accept () была
вызвана с параметром s_handle, именно так как нужно. Однако
s_handle был создан для сокета типа SOCK_DGRAM, который является не-
правильным типом сокета при использовании с accept (). Первоначаль-
ный вызов socket () в строке 13 должен был, поэтому, передать параметр
SOCKJSTREAM.
8. Ошибка приоритета операторов. (26-27) Есть еще одна ошибка, связанная
с вызовом accept (). В соответствии с текстом программы, n_handle бу-
дет принимать значение 1, если accept () завершится успешно, и О,
если — нет. Если эта программа будет выполняться в UNIX (и все осталь-
ные ошибки будут исправлены), то данные будут записаны или в stdout,
или в stdin, соответственно, но не в сокет, с которым установлено соеди-
нение. Большинства из ошибок этого примера можно избежать, если ис-
пользовать ACE-классы интерфейсных фасадов, но данная ошибка — это
просто ошибка в приоритете операторов, и ее нельзя обойти, используя
60
Глава 2
АСЕ или любую другую библиотеку. Это ошибка [Кое88], характерная для
С и C++ программ, которая излечивается только хорошим знанием при-
оритетов операторов. Чтобы ее исправить, заключите выражение присваи-
вания в круглые скобки, вот так:
if((n_handle = accept(s_handle, (struct sockaddr *) &addr,
&addr_len)) != -1) {
Еще лучше следовать соглашению, которое мы используем в АСЕ, и помес-
тить оператор присваивания n_handle в отдельной строке:
n_handle = accept (s_handle,
(struct sockaddr *) &addr, &addr_len);
if (n_handle != -1) {
В этом случае вам не нужно беспокоиться о том, чтобы помнить сокровен-
ные правила приоритетов операторов C++! Мы уже почти закончили с функ-
цией echo_server (), но есть еще несколько ошибок.
9. В API-вызове использован неправильный дескриптор. (29) Функция
read () вызывается, чтобы принять до sizeof buf байтов из s_handle,
сокета, работающего в режиме пассивного прослушивания. Вместо этого
мы должны были вызвать read () с n_handle. Эта проблема сама прояви-
лась бы как скрытая ошибка времени выполнения, ее нельзя определить во
время компиляции, так как дескрипторы сокетов являются слабо типизи-
рованными.
10. Возможна потеря данных. (30) Возвращаемое функцией write () значе-
ние не было проверено, чтобы убедиться, что были записаны все п байтов
(или что вообще были записаны какие-то байты), что является возможным
источником потери данных. Из-за буферизации сокетов и управления по-
током, запись, с помощью функции write (), в сокет, работающий в ре-
жиме потока байтов, может привести к передаче только части из запрошен-
ного числа байтов, в этом случае остаток должен быть передан позже.
Обжегшись не раз, опытные программисты сетевых приложений будут
бдительны по отношению к большинству проблем отмеченных выше. Более
фундаментальной проблемой проектирования, однако, является отсутствие
адекватного контроля типов и подходящих абстракций данных в существую-
щих Socket API. Исходный текст, приведенный выше, на некоторых платфор-
мах ОС пройдет компиляцию без ошибок и предупреждений, но не на всех. Тем
не менее, ни на одной из платформ он не будет работать правильно!
Через несколько лет программисты создадут многочисленные приемы,
чтобы обойти эти проблемы, и используют их в новых библиотеках. Общим
решением было бы использовать операторы typedef, чтобы программистам
было ясно какие типы задействованы. Хотя такого рода решения могут смяг-
чить некоторые проблемы переносимости, они не решают других проблем, пе-
речисленных выше. В частности, разнообразие схем адресации IPC дает больше
вариантов, чем простой typedef сможет вместить.
Обзор Socket API
61
2.3.2 Слишком сложные API
Socket API предоставляет один интерфейс, поддерживающий множество:
• Семейств протоколов, таких как TCP/IP, IPX/SPX, Х.25, ISO OSI, ATM и
сокеты UNIX-домена.
• Режимов связи/соединения, таких как установление активных и пассив-
ных соединений, передача данных.
• Стратегий оптимизации соединений, таких как функция записи-со-
слиянием writev (), которая в одном вызове осуществляет запись не-
скольких буферов.
• Опций для менее часто используемых функций, таких как широковеща-
ние, групповое вещание, асинхронный ввод/вывод и срочная доставка
данных.
Socket API объединяет всю эту функциональность в одном API (см. табли-
цы в разделе 2.2). Результат — проблемы при разработке приложений. Тем не
мене, если вы внимательно проанализируете Socket API, то увидите, что в его
интерфейсе можно выделить следующие три измерения:
I. Тип коммуникационного сервиса, например, потоки, дейтаграммы с уста-
новлением и без установления соединения.
2. Роль в связи/соединении, например, клиенты чаще активно инициируют
соединения, а серверы чаще пассивно принимают запросы клиентов.
3. Коммуникационный домен, например, исключительно локальный хост по
сранению с либо локальным, либо удаленным хостом.
Рис. 2.1 группирует родственные функции Socket API в соответствии с ука-
занными тремя измерениями. Эта естественная группировка, однако, скрыта
в Socket API, так как вся эта функциональность втиснута в одну библиотеку
функций. Более того, в Socket API не заложено возможности проверить пра-
вильность использования ее функций во время компиляции для разных ролей
в связи и соединении, таких как установление активных и пассивных соедине-
ний или обмен потоками или дейтаграммами.
2.33 Непереносимые и неоднородные API
Несмотря на вездесущность, Socket API не является переносимым. Вот не-
которые из отличий между платформами:
• Имена функций — Функции read (), write () и close () в функции
echo_server () не являются переносимыми на все платформы ОС. На-
пример, в Windows определен другой набор функций (ReadFileO,
WriteFile () и closesocket ()), обеспечивающих выполнение тех
же действий.
• Семантика функций — Некоторые функции ведут себя по-разному на
разных платформах. Например, в UNIX и на Win32 функции accept ()
можно передавать null-указатели в поле адреса клиента и в поле размера.
62
Глава 2
Коммуникационный домен
Локальный Локальный/удаленный
cet (PF_Ul|lX)/bind (
socket (PF_UNIX)/bind
q
i1
send () /freci
send О /recv
.L
socket (PF_UNIX)
bind J) /connect ()
S
I
I
1,------
’socket (tPF_INET)[
ibind О У connect, О
socket (PFJJNIX) bint} ()
/listen () 1 /accept, (Дх
soccet (PFjnflX) ,
bini () /connect () >
sdndto () |/re
--------4--------1—
OX'sdcket (PFuINET)/b!Lnd
sendto () /rtevfrom (,)
Jioc) et(PF_Ib ET)/bind
svfrom (
•socket(PF_IЛЕТ)
[bind () /copnect ()
T
send () /recv ()
socket (PF_UNIX)
bind () /connect ()
socket (PFJJNIX)
bind () /connect ()
send () /rec
socket(PF_
/listen ()
JNIX)binc
/accept
1
Рис. 2.1
Таксономия аспектов проектирования, связанных с сокетами
На некоторых платформах реального времени, например VxWorks, пере-
дача null-указателей функции accept () может привести к полному от-
казу компьютера.
• Типы дескрипторов сокетов — Разные платформы используют разное
представление для дескрипторов сокетов. Например, на платформах
UNIX-дескрипторы сокетов имеют целочисленный тип, тогда как
в Win32 они, на самом деле, реализуются как указатели.
• Заголовочные файлы — Разные платформы ОС/компиляторов исполь-
зуют разные имена заголовочных файдов, которые содержат прототипы
функций Socket API.
Еще одна проблема с Socket API заключается в том, что у нескольких десят-
ков его функций отсутствует единое соглашение об именовании, что затрудня-
ет определение области действия данного API. Например, ниоткуда не следует,
что функции socket () ,bind (), accept () и connect () принадлежат одно-
Обзор Socket API
63
му API. Другие сетевые API решают эту проблему, используя для всех своих
функций общий префикс. Например, префикс t_ предшествует каждой функ-
ции из TLI API [Rag93].
2.4 Резюме
Необходимым условием качественного выполнения любой работы являет-
ся эффективное владение инструментом. Многие полезные инструменты мо-
гут причинить вред, если их неправильно использовать. И хотя еще никто не
получал по голове UNIX-каналом или сокетом, время и ресурсы, потраченные
на излишнюю разработку и отладку стоят, конечно, уйму денег, вызывают
преждевременное выпадение волос и наводят тоску на многих социальных ин-
дивидуумов. Кроме того, в отличие от таких инструментов как гаечные ключи и
молотки, обучение использованию низкоуровневых инструментальных
средств одной платформы иногда не помогает перенести сетевое приложение
на новую платформу.
Разработчики программ, создающие сетевые приложения, должны овла-
деть концепциями и инструментальными средствами, связанными с межпро-
цессным взаимодействием (IPC). В этой главе был представлен Socket API. Рас-
смотрен круг возможностей, которые предоставляет этот вездесущий API, а
также множество, связанных с ним «случайных» сложностей. Один короткий
фрагмент программы продемонстрировал диапазон ошибок, обычно совер-
шаемых из-за этих сложностей. Следующая глава показывает как АСЕ, исполь-
зуя возможности языка C++ и паттерн Wrapper Facade [SSRB00] решает эти
проблемы.
Глава 3
Интерфейсные фасады, АСЕ:
сокеты
Краткое содержание
В этой главе представлены паттерны и классы интерфейсных фасадов
(wrapper facade), предлагаемые АСЕ для решения рассмотренных в главе 2 про-
блем, связанных со «случайной» сложностью Socket API. Мы описываем классы
АСЕ, которые используют паттерн Wrapper Facade для инкапсуляции ориенти-
рованных на соединение функций Socket API в переносимые классы C++. Мы
также иллюстрируем применение этих классов на небольших, хорошо извест-
ных примерах web-сервера и web-клиента, прежде чем перейти, в главе 4, к бо-
лее глобальному примеру сетевой службы регистрации.
3.1 Обзор
АСЕ определяет набор классов C++, которые нацелены на снятие ограниче-
ний Socket API, описанных в разделе 2.3. Эти классы созданы в соответствии
; паттерном проектирования Wrapper Facade (SSRBOO].' Поэтому они инкапсу-
лируют функции и данные, реализованные существующими не объектно-ори-
ентированными API, в более сжатые, надежные, переносимые, удобные в экс-
плуатации и связанные между собой интерфейсы объектно-ориентированных
классов. Классы интерфейсных фасадов АСЕ Socket, представленные в этой гла-
ве, включают:
В остальной части этой книги мы применяем термин интерфейсные! фасад АСЕ (АСЕ wrapper
facade), чтобы сослаться на класс АСЕ, созданный с использованием паттерна Wrapper Facade.
66
Глава 3
Класс АСЕ Описание 1
ACE_Addr Корень иерархии сетевой адресации АСЕ.
ACE_INET_Addr Инкапсулирует семейство адресов Internet-домена.
АСЕ_IPC_SAP Корень иерархии интерфейсных фасадовАСЕ IPC.
ACE_SOCK Корень иерархии интерфейсных фасадов АСЕ Socket. |
ACE-SOCK-Connector Фабрика, которая соединяется с одноранговым процессом-акцептором и затем инициализирует новую конечную точку соединения в объекте ACE_socK_stream.
ACE—SOCK—10 ACE-SOCK—Stream Инкапсулирует механизмы передачи данных, поддер- живаемые сокетами передачи данных (data-mode).
ACE-SOCK-Acceptor Фабрика, которая инициализирует новую конечную точку соединения в объекте ACE_socK_stream в ответ на запрос о соединении от однорангового процесса-коннектора.
Рис. 3.1 показывает основные взаимосвязи между этими классами. Интер-
фейсные фасады АСЕ Socket обеспечивают следующие преимущества:
• Улучшают типовую безопасность за счет быстрого выявления многих
неочевидных ошибок, касающихся типов в приложениях; например, у
фабрик пассивного и активного установления соединений отсутствуют
методы передачи и получения данных, поэтому ошибки, связанные с ти-
пами, обнаруживаются на этапе компиляции, а не во время выполнения.
• Гарантируют переносимость за счет независимых от платформы клас-
сов C++.
* Упрощают общие случаи применения за счет снижения объема кода
приложения и объема работ, связанного с низкоуровневыми деталями
программирования сетевых приложений. Это позволяет разработчикам
сосредоточиться на высокоуровневых проблемах, относящихся к самому
приложению.
Кроме того, в интерфейсных фасадах АСЕ Socket, с целью сохранения эф-
фективности, используются подставляемые функции. Это позволяет и обеспе-
чить перечисленные выше качества программного обеспечения, и сохранить,
производительность. Принципы проектирования АСЕ, касающиеся эффектив-
ности рассматриваются в разделе А.6.
Структура интерфейсных, фасадов АСЕ Socket соответствует таксономии
коммуникационных сервисов, ролям в соединении/связи и коммуникацион-
ным доменам, показанным на рис. 3,.2. Классы, показанные на этом рисунке,
обеспечивают следующие возможности:
• Классы ACE_SOCK_* инкапсулируют функции Socket API, относящиеся
к Internet-домену.
• Классы ACE_LSOCK_* инкапсулируют функции Socket API, относящие-
ся к UNIX-домену.
Интерфейсные фасады АСЕ: сокеты
67
Рис. 3.1
Взаимосвязь классов АСЕ Socket, ориентированных на установление соединений
Поучительно сравнить структуру классов АСЕ на рис. 3.2 с функциями на
рис. 2.1. Классов на рис. 3.2 гораздо меньше, поскольку они используют интер-
о
ф
о
о
8
о
И
S
О
о
SOCK_Dgram
о
&
0
8
о
Коммуникационный домен
Локальный Локальный/удаленный
>5 Я
о
LSOCK__Dgram
LSOCK__CODgram
• SOCK_CODgram•
LSOCK_Acceptor
LSOCK Stream
SOCK Stream
LSOCK Connector
SOCK Connector
;SOCKJDgram_Bcast
SOCKJOgram^Mcaat
SOCK_Accepto r
Рис. 3.2
Таксономия интерфейсных фасадов АСЕ Socket
68
Глава 3
фейсные фасады АСЕ Socket, чтобы инкапсулировать поведение множества
функций сокетов в связанные наследованием классы C++. Дополнительно
к классам, поддерживающим установление соединений и обмен информацией,
в АСЕ также предусмотрен соответствующий набор классов адресации. Мы
рассмотрим их характеристики в разделе 3.2, а лежащие в их основе принципы
проектирования в разделе А.4.2. Рис. 3.1 изображает связи между этими и дру-
гими классами АСЕ семейства Socket API ориентированных на соединение.
Остальная часть материала данной главы сосредоточена на ориентирован-
ных на соединение интерфейсных фасадах АСЕ Internet-домена, так как они
наиболее популярны из АСЕ IPC. Классы организованы в иерархическую
структуру, показанную на рис. 3.1. Чтобы избежать дублирования кода, общие
методы и структуры вынесены в абстрактные классы, которые сами по себе реа-
лизации не имеют. Добавляют соответствующие методы и способствуют пра-
вильному применению паттернов производные классы. Например, сетевые
приложения с установлением соединения характеризуются асимметричностью
ролей клиентов и серверов в установлении соединений. Серверы пассивно вос-
принимают клиентов, которые активно [SSRBOO] устанавливают соединения
с серверами (см. рис. 3.3).
АКТИВНАЯ РОЛЬ
ПАССИВНАЯ РОЛЬ
В СОЕДИНЕНИИ
В СОЕДИНЕНИИ
Рис. з.з
Роли интерфейсных фасадов в АСЕ Socket
Даже у одноранговых приложений (peer-to-peer applications), которые могут
играть роль и клиента, и сервера, соединения должны быть активно иницииро-
ваны одним из партнеров и пассивно приняты другим.
С-функции Socket API можно разделить по трем разным ролям, которые
они играют для протоколов с установлением соединения, таких как TCP:
1. Активную роль в установлении соединения (коннектор) играет одноранго-
вое приложение, которое инициирует соединение с удаленным партнером.
2. Пассивную роль в установлении соединения (акцептор) играет одноранго-
вое приложение, которое принимает соединение от удаленного партнера.
3. Роль передачи данных (поток данных, stream) играют оба одноранговых
приложения с целью обмена данными после установления соединения.
Интерфейсные фасады АСЕ: сокеты
69
В этой главе приведено обоснование и описание функциональных возмож-
ностей классов АСЕ Socket, которые коллективно исполняют указанные выше
роли в установлении соединений и передаче данных. Примите во внимание мо-
менты, отмеченные в блоке 4, относительно UML-диаграмм и C++ программ
этой книги.
3.2 Классы ACEAddr и ACEINETAddr
Обоснование
Сетевая адресация — это слабое место Socket API. Механизмы сетевой адре-
сации Socket API используют структуры С и приведения типов, что связано
с трудоемким и чреватым ошибками программированием. Семейство адресов
является первым членом обобщенной адресной структуры sockaddr. Другие
адресные структуры, такие как sockaddr_in для адресов Internet-домена и
sockaddr_un для адресов UNIX-домена, также имеют член, определяющий
семейство адресов, который занимает то же самое место и имеет тот же размер,
что и в структуре sockaddr. Приложения используют эти специфические
структуры адресных семейств путем:
1. Выделения памяти под структуру для нужного семейства адресов, напри-
мер, структуру sockaddr_in.
Блок 4: Изображение классов АСЕ и программ на C++
Как правило, мы приводим UML диаграмму и таблицу, которые описывают основ-
ные методы для каждого используемого в этой книге C++ класса АСЕ. Полные ин-
терфейсы C++ классов АСЕ доступны в онлайн на http: //асе. -зсе. uci. edu и
jhttp: Z/ww. riverace. com. Полные реализации C++ классов и примеры се-
левой службы регистрации находятся в каталогах $АСЕ_иоит/асе и
'$АСЕ ROOTZexamples.Zc++Ni?vl соответственно. Мы рекомендуем иметь под
•рукой копикхисходного кода АСЕ, чтобы можно было быстро навести справку.
;С целью экономии места, в приводимых нами UML-диаграммах классов выде-
лены атрибуты и операции, которые используются в примерах наших про-
грамм. Диаграммы классов не содержат раздела атрибутов, если ни один из
.атрибутов этого класса не имеет отношения к обсуждаемой теме. Если вам
нужна вводная информация по UML, или нужно освежить эту информацию в па-
мяти, мы рекомендуем книгу UML Distilled (wKSOO).
jfa'ioKe с .целью экономии места мы используем некоторые сокращения про-
граммного кода, которых нет в оригинале АСЕ, например:
& Мы опустили В'примерах на C++ большую часть кода обработки ошибок.
;М AQE, конечно, всегда осуществляется проверка на наличие ошибок, и
£. предпринимаются соответствующие действия, как раз такие, какие нужны
вашим приложениям.
Й Внекоторых из наших примеров на C++ реализации методов представлены
в определениях классов. ВАСЕ, тем не менее, сделано не так, поскольку это
й^агромождает интерфейсы классов и замедляет компиляцию.
Кководящие указания по программированию АСЕ находятся в $ace_ro-
K/docs7.ACE--gu'idel ines; html.
10
Глава 3
2. Заполнения члена структуры, определяющего семейство адресов, чтобы
указать Socket API какого именно типа этот адрес на самом деле.
3. Задания адресов, например IP, и номеров портов.
4. Привидения к типу sockaddr *, для передачи функциям Socket API.
Чтобы уменьшить сложность всех этих низкоуровневых деталей, в АСЕ оп-
ределена иерархия классов, которая обеспечивает единый интерфейс для всех
объектов АСЕ, связанных с сетевой адресацией.
Функциональные возможности класса
Класс ACE_Addr является корнем ACE-иерархии сетевой адресации. Ин-
терфейс этого класса показан на рис. 3.4. Его основные методы обеспечивают
следующие, общие для всех ACE-классов, связанных с сетевой адресацией, воз-
можности:
Рис. 3.4
Диаграммы классов ACE_Addr и ACE_lNET_Addr
Метод Описание |
operator== () Проверяет адреса на совпадение.
operator!=() Проверяет адреса на несовпадение.
hash () Вычисляет значение хэш-функции адреса. |
В классе ACE_Addr определен также статический член данных sap_any,
который и клиенты, и серверы могут использовать в качестве «группового сим-
вола» (wildcard), если им безразличен задаваемый ими адрес. Например:
Интерфейсные фасады АСЕ: сокеты
71
• Клиентские приложения могут использовать sap_any с целью создания
временных, назначаемых ОС, номеров портов, известных как «эфемер-
ные порты» («ephemeral ports»), которые возвращаются операционной
системе для дальнейшего использования после завершения соединений.
• Серверные приложения могут использовать sap_any для выбора номе-
ров портов, если они экспортируют эти номера клиентам посредством
некоторого механизма локализации, типа служб именования или трей-
динга.
Конкретные адресные классы для каждого механизма IPC, например, соке-
тов Intemet-домена или UNIX-домена, являются производными от ACE_Addr
и добавляют к нему что-то от своих потребностей, связанных с адресацией. На-
пример, адресная информация TCP/IP и UDP/IP представлена в классе
ACE_INET_Addr, приведенном на рис. 3.4. Дополнительно к реализации базо-
вого интерфейса ACE_Addr, ACE_INET_Addr реализует следующие основные
методы:
Метод Описание I
ACE_INET_Addr() set () Инициализирует ACE_iNET_Addr именами хостов, IP-адресами и/или номерами портов.
string_to_addr() Преобразует СТРОКУ В ACE_INET_Addr.
addr_to_string () Преобразует ACE_iNET_Addr в строку.
get_port_number() Возвращает номер порта с порядком байтов, принятом на хосте.
get_host_name() Возвращает имя хоста. |
Применение интерфейсных фасадов АСЕ Socket для сетевой адресации по-
могает избежать обычных ловушек и ошибок, которые могут появляться при
использовании С-структур данных типа sockaddr. В качестве примера рас-
смотрим конструктор ACE_INET_Addr, приведенный на рис. 3.4. Этот конст-
руктор создает ACE_INET_Addr по номеру порта и имени хоста, исключая та-
ким образом часто встречающиеся ошибки программирования за счет:
• Инициализаций всех байтов базовой sockaddr_in нулем.
• Преобразования номера порта и IP-адреса в сетевой порядок байтов.
Класс ACE_INET_Addr позволяет разработчикам писать сетевые прило-
жения, не беспокоясь о низкоуровневых деталях инициализации адресов. Су-
ществует много других перегруженных конструкторов и методов set ()
в ACE_lNET_Addr, которые могут быть использованы для инициализации
объектов сетевой адресации Intemet-домена, с помощью различных комбина-
ций имен хостов, IP-адресов и/или имен и номеров портов TCP/UDP.
72
Глава 3
3.3 Класс ACE IPC SAP
Обоснование
В разделе 2.3.1 отмечались проблемы с переносимостью, вытекающие из
использования дескрипторов ввода/вывода, IPC API встроенных в ОС. АСЕ ре-
шает проблему переносимости дескрипторов ввода/вывода за счет:
• Определения типа ACE_HANDLE, который обозначает соответствующий
тип дескриптора каждой платформы ОС.
• Создания переносимого макроса ACE_INVALID_HANDLE, который при-
ложения могут использовать в качестве теста на наличие ошибок.
Эти простые изменения: тип, определенный в АСЕ, и абстрагирование зна-
чений — помогают улучшить переносимость приложений.
Разработчики программного обеспечения, сведущие в объектном подходе,
скажут, тем не менее, что дескриптор — даже переносимый — это не тот уро-
вень абстракции, который нужен объектно-ориентированному сетевому при-
ложению. Более подходящей программной абстракцией был бы какой-нибудь
класс дескрипторов ввода/вывода. Поэтому в АСЕ предусмотрен класс
ACE_IPC_SAP.'
Функциональные возможности класса
Класс ACE_IPC_SAP является корнем ACE-иерархии интерфейсных фаса-
дов IPC и обеспечивает основные возможности манипулирования дескрипто-
рами ввода/вывода для других интерфейсных фасадов АСЕ. Его интерфейс по-
казан на рис. 3.5 (вместе с классом ACE_SOCK, описанным в разделе 3.4), а его
основные методы приведены в таблице:
Метод Описание
enable () disable{) Устанавливает или снимает различные опции дескрипторов ввода/вывода, например, разрешая/запрещая неблокируемый ввод/вывод.
set_handle () get-handle () Устанавливает и получает базовый дескриптор ввода/вывода. --
Хотя ACE_I PC_SАР определяет полезные методы и данные, он не предна-
значен для прямого использования приложениями. Вместо этого, он использу-
ется производными классами, такими как интерфейсные фасады АСЕ для фай-
лов, каналов STREAM, именованных каналов и интерфейса System V Transport
Layer Interface (TLI). Чтобы осуществить это проектное ограничение и защи-
тить ACE_I PC_S АР от непосредственного создания экземпляров на его основе,
мы сделали ACE_IPC_SAP абстрактным классом, определив его конструктор
в защищенной части этого класса. Мы используем это соглашение вместо опре-
I
В литературе по сетевым стандартам [В1а91], акроним «SAP» означает «service access point;
(точка доступа к сервису).
Интерфейсные фасады АСЕ: сокеты
73
ЛСВ_1РС_ЗАР
- handle_ : ACE_HANDLE
+ enable (value : int)
+ disable (value : int)
+ get_handle () : ACE—HANDLE
+ set-handle (h : ACE-HANDLE)
ACE SOCK
+ open (type : int, photO-family : int)
protocol : int; reuse_addr : int) :int
+ close () : int
+ get—option (level : int, option : int;
optval : void *, optlen : int *) : int
+ set—option (level : int, option : int;
optval : void *, optlen : int *) : int
+ get—local—addr (addr : ACE_Addri) : int
+ get-remote—addr (addr : ACE_Addr&) : int
Рис. 3.5
Диаграммы классов ace_ipc_sap и ace_sock
деления чисто виртуального метода, чтобы исключить необходимость наличия
виртуального указателя в каждом экземпляре производных классов.
34 Класс ACESOCK
Обоснование
Как отмечалось в разделе 2.3, основной причиной «случайной» сложности
в Socket API является неспособность компиляторов обнаружить неправильное
использование дескрипторов сокетов в процессе компиляции. Класс
ACE_IPC_SAP, описанный в разделе 3.3, — это первый шаг на пути к решению
этой проблемы. В остальной части данной главы описываются другие интер-
фейсные фасады АСЕ Socket, которые решают другие проблемы, отмеченные
в разделе 2.3. Мы начинаем перемещаться вниз по иерархии наследования на
рис. 3.1 и обсуждать действия, имеющие смысл для каждого из уровней, начи-
ная с класса ACE_SOCK.
Функциональные возможности класса
Класс ACE_SOCK является корнем иерархии интерфейсных фасадов АСЕ
Socket. Дополнительно к экспортированию методов, унаследованных от
ACE_IPC_SAP, ACE_SOCK обеспечивает возможности, общие для других ин-
терфейсных фасадов АСЕ Socket, в том числе и для классов, обсуждаемых позже
в этой главе. Эти возможности включают:
74
Глава 3
• Создание и удаление дескрипторов сокетов.
• Получение сетевых адресов локальных и удаленных одноранговых про-
цессов.
• Установление и получение опций сокетов, таких как размеры очередей
сокетов, разрешение широковещательной/групповой передачи данных и
отключение алгоритма Нейгла (описанного в блоке 6).
Интерфейс ACE_SOCK и его связи с базовым классом ACE_IPC_SAP показаны на
рис.3.5, а его основные методы представлены в следующей таблице:
Метод Описание
open () close () Создают и закрывают конечную точку соединения сокета.
get_local_addr() get_remote_addr() Возвращают адрес локального и удаленного однорангового процесса, соответственно.
set_option() get_option() Устанавливают и считывают опции сокетов. |
Чтобы предотвратить случайное неправильное использование, АСЕ SQCK
определен как абстрактный класс; то есть его конструктор объявлен в защищен •
ной части класса. Поэтому также как у ACE_IPC_SAP, экземпляры объектов
ACE_SOCK не могут быть созданы непосредственно, они доступны только про-
изводным классам, таким как ориентированные на соединение интерфейсные
фасады, описанные в разделах с 3.5 по 3.7.
В класс ACE_SOCK предусмотрен метод close (), так как в деструкторе
класса дескриптор сокета не закрывается. Как отмечено в разделе А.6.1, такая
конструкция является осознанной и защищает от возможных ошибок при пе-
редаче ACE_SOCK_Stream по значению или при его копировании вдругие
объекты. Опытные разработчики АСЕ используют более высокоуровневые
классы, чтобы автоматически закрывать вложенный дескриптор/сокета. На-
пример, класс Logging_Handler, описанный в разделе 4.4.2, закрывает свои
сокеты, когда закрывается объект с дескриптором более высокого уровня. Класс
ACE_Svc_Handler, рассматриваемый в [SH], также закрывает дес'криптор со-
кета нижнего уровня автоматически.
3.5 Класс ACE_SOCK_Connector
Обоснование
Хотя в протоколах с установлением соединений для сокетов существуют
три разных роли, Socket API поддерживает только два следующих режима рабо-
ты сокетов:
1. Сокет передачи данных (data-mode) используется одноранговыми прило-
жениями, независимо от той роли, которую они играют в установлении со-
Интерфейсные фасады АСЕ: сокеты
75
единения, для обмена данными между одноранговыми процессами по ус-
тановленному между ними соединению.
2. Сокет пассивного режима (passive-mode) — это фабрика, используемая од-
норанговыми приложениями, играющими пассивную роль в установле-
нии соединения, которая возвращает дескриптор на подсоединенный сокет
передачи данных.
Не существует сокета, который играет исключительно активную роль в ус-
тановлении соединения. Просто сокет передачи данных исполняет и эту роль,
по совместительству. Поэтому предполагается, что приложение не может вы-
зывать send () или recv () до того, как функция connect () успешно завер-
шит процесс установления соединения.
Асимметрия в Socket API между ролями, исполняемыми в установлении
соединения, и видами сокетов сбивает с толку и может приводить к появлению
ошибок. Например, приложение может случайно вызвать recv () или
send (), используя дескриптор сокета передачи данных до того, как по нему ус-
тановлено соединение. К сожалению, эту проблему нельзя обнаружить до вре-
мени выполнения, так как дескрипторы сокетов являются слабо типизирован-
ными (weakly-typed) и, поэтому, двойственная роль сокетов передачи данных
реализуется за счет соглашения о том, как надо программировать, а не за счет
возможностей компилятора проверять правильность типов. Поэтому в АСЕ
определен класс ACE_SOCK_Connector, который не допускает случайного не-
правильного использования, только за счет того, что реализует в явном виде
методы активного установления соединений.
Функциональные возможности класса
Класс ACE_SOCK_Connector — это фабрика, активно создающая новую
конечную точку соединения. Он обеспечивает следующие возможности:
• Инициирует соединение с одноранговым процессом-акцептором и затем, по-
сле установления соединения, инициализирует объект ACE_SOCK_Stream.
• Соединения могут быть инициированы в блокируемом и неблокируе-
мом режимах, а также в режиме с контролем времени.
• Используются «характеристики» (traits) C++ для поддержки методов обоб-
щенного программирования, позволяющих полностью изменять функ-
циональность с помощью параметризованных типов C++ (см. блок 5).
Интерфейс класса ACE_SOCK_Connector показан на рис. 3.6. Два основ-
ных метода ACE_SOCK_Connector приведены в следующей таблице:
Метод Описание |
connect () Активно устанавливает соединение ACE_socK_stream с конкретным сетевым адресом, используя блокируемый, неблокируемый или временной режимы.
complete () Пытае гея завершить неблокируемое соединение и инициализировать ace_sock_s tream. |
76
Глава 3
Рис. 3.6
Диаграмма класса ACE_SOCK_Connector
Блок 5: Использование «характеристик» в интерфейсных
фасадах АСЕ Socket,л .
Чтобы упростить массовую замену классов IPC и связанных- с ними Ьд^ефных'
классов, интерфейсные фасады АСЕ Socket юпрёДёляют^с^акГ^'йртик^»..
(.traits). «Характеристики»» - это идиома. обобщенного1 прс!гр^^^Ш10й'йя.-
(AleOl). которую можно использовать для определенияи объединения Множе-
ства характеристик, изменяющих реакцию(й) шаблонных классов (Jc»s99). Ин-"
„терфёйсные фасады АСЕ Scckpl используют «характеристики» для определе-
ния следующих ассоциаЧий\<лассов: ’ , " < J. . . ' . ’
•-р££Ж.-Atxr Эт-ц' ,>хдрахтерис'т'ика»>- определяет'.',адресный;. класс’.
асе- i’NS?_Addr. ;«ж рый ассоциирован с классами интёрфейсНЬ^<фФСа-’‘
доэ’АСЕ Socke!. *• ; v"
• peep._str.pam — Это «характеристика» определяет класс передачи данных
ACE_.SQCK_TTLream, который ОССОЦИЙрОВаН Сфабриками ACE_sdcK_Xc$ep- .
tor ... . ; .
АСЕ реализует эти «характеристики»» как определения типдв-.С++, которые
приведены в виде заметбк в UML диаграммах в Этой главе.,Раздел’А. 5.3; пока-
зывает кек использовать эти «характеристики», чтобы писать лаконичные па-
раметризованные функции и классы.. Мы рассматриваем Другие применения
«характеристик» АСЕ и классов «’характеристик» в (SH).- -
Класс ACE_SOCK_Connector поддерживает блокируемое, неблокируемое
и временное соединения, причем блокируемое устанавливается по умолчанию.
Неблокируемое и временное соединения полезны тогда, когда соединения уста-
навливаются по линиям связи с большими задержками с помощью однопоточ-
ных приложений или инициализируется много одноранговых процессов, кото-
рые могут подключаться в произвольном порядке. Три типа значений
ACE_Time_Value может быть передано методу connect (), для управления
его поведением:
Интерфейсные фасады АСЕ: сокеты
77
Значение Поведение
NULL-указатель на ACE_Time_Value Указывает методу connect (), что нужно перейти в режим бесконечного ожидания, то есть блокироваться до того момента, пока будет установлено соединение или пока ОС не примет решение о недоступности данного серверного хоста.
Не NULL-указатель на АСЕ_Т ime_Va 1 ue, методы которого sec () и usee () возвращают 0 Указывает методу connect (), что нужно осуществить неблокируемое соединение, то есть если соединение не установлено сразу, вернуть -1 и установить errno в ewouldblock.
Не NULL-указатель на ACE_Time_Value, Метод которого sec () или usee () возвращают >0 Указывает методу connect (), что нужно при установлении соединения ждать определенное время и вернуть-1 с errno, установленным в etime, если к тому времени установить данное соединение не получится.
Существующая в ACE_SOCK_Connector поддержка тайм-аута соедине-
ния особенно полезна с практической точки зрения, так как способы, которыми
Socket API реализуют тайм-ауты соединений очень отличаются на разных плат-
форм ОС.
Так как базовый API сокетов не использует фабрику сокетов для соедине-
ния с сокетами передачи данных, то классу ACE_SOCK_Connector не требуется
наследование от класса ACE_SOCK, рассмотренного в разделе 3.4. Поэтому он не
имеет своего собственного дескриптора сокета. Вместо этого, ACE_SOCK_Con-
nector заимствует дескриптор у ACE_SOCK_Stream, который передается его
методу connect () и использует его для активного установления соединения.
В результате, экземпляры ACE_SOCK_Connector не сохраняют состояние, так
что их можно использовать реентерабельно в многопоточных программах, при
этом не требуется дополнительных блокировок.
Пример
В блоке 2 было описано как скомпоновать библиотеку АСЕ так, чтобы можно
было экспериментировать с теми примерами, которые мы приводим в этой книге.
Наш первый пример показывает как можно использовать ACE_SOCK_Con-
nector, чтобы подключить клиентское приложение к web-серверу. Мы начи-
наем с включения необходимых заголовочных файлов АСЕ Socket:
♦include "ace/INET_Addr.h"
♦include "ace/SOCK_Connector.h"
♦ include '’ace/SOCK_Stream.h"
Затем мы определяем функцию main (), которая устанавливает соедине-
ние с web-сервером прослушивающим порт 80. Это стандартный номер порта,
который используют web-серверы, поддерживающие Hypertext Transport Pro-
tocol (HTTP) [Ste96j. HTTP — это простой протокол расположенный поверх
TCP и используемый клиентами для загрузки содержимого с web-сервера.
78
Глава 3
int main (int
{
const char
argc > 1
const char
argc > 2
argc, char *argv[])
*pathname =
? argvfl] : "index.html";
*server_hostname «
? argv(2] : "ace.ece,uci.edu";
ACE_SOCK_Connector connector;
ACE_SOCK_Stream peer;
ACE_INET_Addr peer_addr;
if (peer_addr.set (80, server_hostname) == -1)
return 1;
else if (connector.connect (peer, peer_addr) == -1)
return 1;
// ...
Мы завершим этот пример в разделе 3.5 после того, как сначала опишем
функциональные возможности класса передачи данных ACE_SOCK_Stream.
Учтите, что приведенный выше вызов connector. connect () является
синхронным, то есть будет заблокирован до того момента, когда или соедине-
ние будет установлено, или запрос соединения завершится неудачей. Как пока-
зано в таблице в разделе 3.5, интерфейсные фасады АСЕ Socket упрощают пере-
носимое выполнение неблокируемых или временных соединений. Например,
следующий код иллюстрирует как изменить наше клиентское приложение,
чтобы выполнить connect () с web-сервером в неблокируемом режиме.
// Устанавливает неблокируемое соединение,
if (connector.connect(peer,
peer_addr,
&ACE_Time_Value::zero) == -1) {
if (errno == EWOULDBLOCK) (
// Делаем что-нибудь другое ...
// Теперь,пытаемся завершить установление соединения,
// но не блокируемся, если оно еще не завершено.
if (connector.complete (peer,
0,
&ACE_Time_Value::zero) == -1)
// ...
Аналогично connect () с контролем времени может быть выполнен сле-
дующим образом:
ACE_Time_Value timeout (10); // Устанавливаем тайм-аут 10 секунд
if( connector.connect (peer, peer_addr,&timeout)==-l){
if (errno == ETIME)
// Тайм-аут, делаем что-нибудь другое ...
}
Интерфейсные фасады АСЕ: сокеты 79
3.6 Классы ACE SOCK IO и ACESOCKStream
Обоснование
К области «случайной» сложности, которая была определена в разделе 2.3,
относится неспособность обнаружить неправильное использование сокета
в момент компиляции. В разделе 3.1 отмечалось, что в управлении соединением
задействованы три роли: роль активного соединения, роль пассивного соединения
и роль обмена данными. В Socket API, однако, определены только два вида соке-
тов: передачи данных и пассивного режима. Следовательно, разработчики могут
неправильно использовать сокеты, причем так, что это нельзя будет обнару-
жить во время компиляции. Класс ACE_SOCK_Connector делает первый шаг
на пути решения этой «случайной» сложности; класс ACE_SOCK_St ream дела-
ет следующий шаг. ACE_SOCK_Stream определяет объект передачи данных
(data-mode) как «только для передачи» («transfer-only»). Объект
ACE_SOCK_S tream не может быть использован ни в одной другой роли, кроме
передачи данный, без сознательного нарушения его интерфейса.
Рис. 3.7
Диаграммы классов ACE_SOCK_Stream и ACE_SOCK_IO
Функциональные возможности класса
Класс ACE_SOCK_Stream инкапсулирует механизмы передачи данных,
поддерживаемые сокетами передачи данных. Данный класс обеспечивает сле-
дующие функциональные возможности:
80
Глава 3
• Поддерживает передачу и получение вплоть до п байтов или точно п бай-
тов.
• Поддерживает операции «чтения-с-разнесением» («scatter-read»), кото-
рые заполняют несколько буферов, предоставленных вызывающей сто-
роной, а не один непрерывный буфер.
• Поддерживает операции «записи-со-слиянием» («gather-write»), которые
передают содержимое нескольких независимых буферов одной операцией.
• Поддерживает блокируемые, неблокируемые и временные операции.
• Поддерживает методы обобщенного программирования [AleOl], кото-
рые допускают массовую замену функциональности с помощью пара-
метризованных типов C++ (см. в блок 5).
Экземпляры ACE_SOCK_Stream инициализируются фабриками АСЕ_
SOCK_Acceptor или ACE_SOCK_Connector. Интерфейс классов АСЕ_
SOCK_Stream и ACE_SOCK_IO показан на рис. 3.7. Класс ACE_SOCK_Stream
является производным от класса ACE_SOCK_IO, который, в свою очередь, яв-
ляется производным от ACE_SOCK и определяет основные методы передачи
данных, которые повторно используются интерфейсными фасадами АСЕ UDP.
Основные методы, экспортируемые ACE_SOCK_Stream приведены в сле-
дующей таблице:
Метод Описание |
send() recv() Передают и принимают буферы с данными. Могут записать или прочитать меньше запрошенного количества байтов из-за буферизации в ОС и управления потоком в транспортном' протоколе. 1
send_n () recv_n() Передают и принимают буферы ровно с п байтами данных, чтобы | упростить прикладную обработку коротких сообщений («short-writes» и «short-reads»).
recvv_n() Эффективно и полностью принимает несколько буферов с данными, используя системную функцию ОС чтения-с-разнесением («scatter-read»).
sendv_n() Эффективно и полностью отправляет несколько буферов с данными, используя системную функцию ОС записи-со-слиянием («gather-write»). |
Класс ACE_SOCK_Stream поддерживает блокируемый, неблокируемый и
временной ввод/вывод, причем блокируемый ввод/вывод используется по
умолчанию. Ввод/вывод, зависимый от времени, полезен при взаимодействии
с одноранговыми процессами, которые могут зависать или блокироваться на
неопределенное время. Два типа значений ACE_Time_Value могут переда-
ваться методам ввода/вывода ACE_SOCK_Stream с целью управления их реак-
цией на тайм-аут:
Интерфейсные фасадыАСЕ: сокеты
Значение Поведение
NULL-указатель на ACE_T i me_Va 1 ue Указывает, что метод ввода/вывода должен блокироваться до того момента, когда будут переданы данные или возникнет ошибка.
He NULL-указатель HQ ACE_Time_Value Указывает, что метод ввода/вывода должен ждать соответствующее время, пока будут передаваться данные. Если время тайм-аута истечет до того, как будут переданы или получены данные, возвращается -1 с errno установленным в etime.
Неблокируемый ввод/вывод полезен для тех приложений, которые не мо-
гут позволить себе блокироваться, если данные не посылаются или не прини-
маются немедленно. Блокируемый и неблокируемый ввод/вывод можно кон-
тролировать с помощью методов enable () и disable (), унаследованных от
ACE_IPC_SAP:
peer.enable(ACE_NONBLOCK); //Разрешает неблокируемый I/O.
peer.disable(ACE_NONBLOCK); //Запрещает неблокируемый I/O.
Если метод ввода/вывода вызывается экземпляром ACE_SOCK_Stream,
который работает в неблокируемом режиме и этот вызов блокируется, то воз-
вращается-1 и errno устанавливается в EWOULDBLOCK.
Пример
Теперь, когда мы рассмотрели функциональные возможности
ACE_SOCK_St ream, мы можем продемонстрировать ту часть нашего примера
web-клиента (см. раздел 3.5), в которой передаются данные. В этой части про-
граммы посылается HTTP-запрос GET на ресурс, заданный своим URL и затем
распечатывается содержимое загруженного с web-сервера файла.
II... пропущенная часть примера из раздела- 3.5 ...
char buf[BUFSIZ];
iovec iov[3];
iov[0].iov_base = "GET
iov[0].iov_len =4; //Длина "GET ".
iov[1].iov_base = pathname;
iov[l].iov_len = strlen (pathname);
iov[2].iov_base = " HTTP/1.0\r\n\r\n";
iov[2].iov_len = 13; //Длина " HTTP/1.0\r\n\r\n";
if (peer.sendv_n (iov, 3) == -1)
return 1;
for (ssize_t n; (n = peer.recv (buf, sizeof buf)) > 0; )
ACE::write_n (ACE_STDOUT, buf, n) ;
return peer.close();
82
Глава 3
Мы используем массив структур iovec для рациональной передачи
HTTP-запроса GET web-серверу с использованием метода записи-со-слиянием
ACE_SOCK_Stream: : sendv_n (). Это позволяет обойти проблемы с произ-
водительностью, связанные с алгоритмом Нейгла [Ste93], который описывает-
ся в блоке 6. На платформах UNIX/POSIX этот метод реализован в wr itev (), а
на платформах WinSock2 — в WSASend ().
Методы ввода/вывода в функции client_download_f ile () будут за-
блокированы, если обнаружатся проблемы с управлением потоком TCP или
если web-сервер будет работать некорректно. Чтобы защитить клиента от бес-
конечного зависания, мы можем добавить к вызовам этих методов тайм-ауты.
Например, в следующем фрагменте программы, если сервер не получает дан-
ные в течение 10 секунд, то возвращается значение -1 с errno, установленным
BETIME:
//Ждет не более 10 секунд при отправке или приеме данных
ACE_Time_Value timeout (10);
peer.sendv_n (iov, 3, &timeout) ;
while (peer.recv (buf, sizeof buf, &timeout) > 0)
//...обрабатываем содержимое загруженного файла
Блок 6: Алгоритм Нейгла
По умолчанию, большинство реализаций -TCP/IP используют алгоритм Нейгла
(Nagle's:qigorithrh)j'(Std93)/. ко|брЙй осуществляет буферизацию небольших,
. Последовательно отправляемых пакетов TCP/IP в стеке отправителя. Хотя этот
алгоритм минимизируёт'перегрузку сети, он может увеличить время ожидания
и снизить производительность, если не знать когда и как он действует. Такого
рода проблемы могут возникнуть, если несколько небольших буферов после-
довательно отправлятьодносторонним'и операциями; например, следующий
код запустит алгоритм Нейгла: , . :
peerisendjr ("GET ", 4).‘
peer.send_n (pathname,"’strlen (pathname^)/;'
peer.send_n (" flTTP/1.0\r\n\r\n", .13);-’/ .
Разработчики приложений могут отключатьрлгоритм Нейгла с помощью вызо-
ва peer .enable () С флагом TCP_NODELAY, -4TO'3aCTaBHT TCP сразу ОТПрОВЛЯТЬ
пакеты. Функция с 1 леп t_downioad_f lie () демонстрирует еще более эффек-
тивное решение с использованием sendv п.О . для передачи всех буферов
с данными одной системной функцией. Этому Методу передается массив
структур iovec, которые определяются следующим образом:
Struct iovec { .
. "'// Указатель на буфер. , дЛ'.у'Д ’ ' ' '
char *icv base;
*- // Длина буфера, н.х который .ука^ёв’ае'т '^iov base>.
.i'Ot iov Рг; . . •:". /
Интерфейсные фасадыАСЕ: сокеты
83
Некоторые платформы ОС сами определяют iovec, за других это делает АСЕ.
Имена членов в любом случае одни и те же, но не всегда в одном и том же по-
рядке, поэтому присваивайте им значения явно, а не путем инициализации
всей структуры.
3.7 Класс ACE_SOCK_Acceptor
Обоснование
Классы ACE_SOCK_Connector и ACE_SOCK_Stream решают проблемы
сложности, возникающие из-за неправильного использования ролей в обмене
данными и функций Socket API. Хотя в Socket API задан один набор функций
для исполнения роли пассивного установления соединения, существуют до-
полнительные проблемы.
АСЕ INET Addr
АСЕ SOCK
АСЕ SOCK Stream
т
I
тг
Т
------------
PEER ADDR
------------Ц
PEER_STREAM
Ji_______________________
ACE_SOCK_Acceptor
open (local_addr : ACE_Addr&) : int
+ accept (stream : ACE_SOCK_Streams) : int
Рис. 3.8
Диаграмма класса ACE_SOCK_Acceptor
С-функции Socket API являются слабо типизированными, что делает воз-
можным их неправильное использование.
Например, функция accept () может быть вызвана с дескриптором соке-
та передачи данных, который предназначен для передачи данных с помощью
операций ввода/вывода recv () и send (). Аналогично, операции ввода/выво-
да могут быть вызваны для фабрики дескрипторов сокетов пассивного режима,
которая должна только принимать соединения. К сожалению, такие ошибки
Могут обнаружиться только во время выполнения. АСЕ решает эти проблемы
с помощью строго типизированного класса ACE_SOCK_Acceptor. В отличие
от прямых вызовов Socket API, компилятор может легко обнаружить непра-
вильное использование ACE_SOCK_Acceptor во время компиляции.
Функциональные возможности класса
Класс ACE_SOCK_Acceptor — это фабрика [GHJV95], которая пассивно
устанавливает новую конечную точку соединения. Он обеспечивает следую-
щие функциональные возможности:
• Он принимает соединение от однорангового процесса-коннектора, за-
прашивающего соединение, и затем инициализирует объект
ACE_SOCK_Stream, когда соединение установлено.
84
Глава 5
• Соединения могут быть установлены в любом режиме: блокируемом» не-
блокируемом или с контролем времени.
• «Характеристики» (traits) C++ используются для поддержки методов
обобщенного программирования, которые дают возможность массовой
замены функциональности с помощью параметризированных типов
C++ (см. блок 5).
Интерфейс класса ACE_SOCK_Acceptor показан на рис. 3.8, а два его ос-
новных метода представлены в следующей таблице:
Метод Описание
open () Инициализирует сокет-фабрику пассивного режима для пассивного прослушивания назначенного ACE_iNET_Addr адреса.
accept () Инициализирует параметр ACE_socK_stream для вновь принятого клиентского соединения.
Методы open () и accept () ACE_SOCK_Acceptor используют дескрип-
тор сокета, унаследованный от ACE_IPC_SAP. Такое решение использует сис-
тему типов C++ для защиты разработчиков приложений от перечисленных да-
лее источников случайного неправильного использования:
• Низкоуровневые функции socket (), bind () и listen () всегда вы-
зываются в нужной последовательности с помощью метода open ()
класса ACE_SOCK_Acceptor.
• Эти функции вызываются только с тем дескриптором сокета, который
был инициализирован в качестве фабрики дескрипторов сокетов пассив-
ного режима.
Принципы, лежащие в основе этих и других интерфейсных фасадов АСЕ,
рассмотрены в Приложении А.
Пример
Мы проиллюстрируем применение ACE_SOCK_Acceptor, показав уста-
новление пассивного соединения и загрузку частей содержимого последова-
тельного web-сервера, который обрабатывает клиентские запросы следующим
образом:
1. Принимает новое соединение, инициированное клиентом, порт 80.
2. Читает имя пути из запроса GET и загружает затребованный файл.
3. Закрывает соединение.
4. Возвращается обратно к шагу 1.
Для рационального чтения файла мы используем АСЕ_Меш_Мар (см.
блок 7). А чтобы использовать функциональные возможности АСЕ_Меш_Мар,
мы подключаем ace/Mem_Map. h вместе с другими заголовочными файлами
интерфейсных фасадов АСЕ Socket, необходимых для написания нашего web-
сервера.
Интерфейсные фасады АСЕ: сокеты
85
♦include "ace/Auto_Ptr.h"
♦include "ace/INET_Addr.h"
♦include "ace/SOCK_Acceptor.h"
^include "ace/SOCK_Stream.h"
♦include "ace/Mem_Map.h"
// Возвращает динамически выделенный буфер для имени пути,
extern char *get_url_pathname (ACE_SOCK_Stream *);
Hain web-сервер поддерживает HTTP версии 1.0, поэтому каждый клиент-
ский запрос будет иметь отдельное TCP соединение. В приведенной далее про-
грамме web-сервера мы сначала инициализируем фабрику ACE_SOCK_Accep-
tor для прослушивания запросов на соединение по порту 80. Затем мы запус-
каем цикл обработки событий, который периодически принимает новое
клиентское соединение, отображает запрошенный файл в память, выгружает
его клиенту и закрывает соединение после завершения передачи файла.
int main ()
( >
ACE_INET_Addr server_addr;
ACE_SOCK_Acceptor acceptor;
ACE_SOCK_Stream peer;
if (server_addr.set (80) == -1) return 1;
if (acceptor.open (server_addr) == -1) return 1;
for (;;) {
if (acceptor.accept (peer) == -1) return 1;
peer->disable (ACE_NONBLOCK) ; // Обеспечивает блокировку
<recv>s.
auto_ptr <char *> pathname = get_url_pathname (peer);
ACE_Mem_Map mapped_file (pathname.get ());
if (peer.send_n (mapped_file.addr (),
mapped_file.size ()) -1) return 1;
peer.close ();
1
return acceptor.close() == -1 ? 1 : 0;
}
Основной недостаток нашего последовательного web-сервера проявится
тогда, когда множество клиентов пошлет запросы одновременно. В этом слу-
чае, пока web-сервер будет обрабатывать текущий запрос, реализация
ОС Socket поставит в очередь небольшое число запросов на соединение (напри-
мер, 5-10). В условиях реальной работы web-сервера очередь ОС будет быстро
переполнена. Когда это произойдет, клиенты начнут получать сообщения об
ошибках, связанные с тем, что ОС, на базе которой работает данный web-cep-
86
Глава $
Блок 7: Класс АСЕ Мет^Мар; i
Интерфейсный фасад •АСЕ_Мет£мар; инкапсулирует механизмы огображае- I
мых в память файлов/существующие на платформах Win32 и POSIX. Эти вызовы
используют механизмы виртуальной памяти ОС Для отображения файлов в ад-
ресное просгранство процесса. Получить доступ к содержимому отобоа- I
женного в память файла можно напрямую, через указатель, что более удобно j
и эффективно, чем доступ к блокам Данных с помощью функций чтения и запи- ;
си системного ввода/вывода Кроме того, «одержимое отображенных в па-
мять файлов могут ,со8мёстт|0.использс>врть несколько процессов, работаю-
щих на одном компьютере, как ^ыдр отмечено.,^ разделе 1.3.
Собственные Wip32 и f-Q.SIX API охображения.файлов в память являются непе-
реносимыми и сл15жйы$и. Например!, разработчики должны самостоятельно
отслеживать многие детали, связаннырс учетом использования системных ре-
сурсов, таких как открытие файла, ойр^лёНИё его размера и выполнения
многочисленных отображений,Напротив, интерфейсный фасад АСЕ_мет .чар
предлагает интерфейс, который. упрощает обычное использование отобра-
жаемых в память файлов с помощью значений, устанавливаемых по умолча-
нию, и 6 помощью' многочисленных: кбнртрУкторЬв с несколькими вариантами
сигнатур, например,'> «отображение по’ дескриптору открытого файла» или I
«отображение по имени'фа^а»,.^,' , |
вер, начнет отклонять их запросы на установление соединения. В главах 8 и 9
рассмотрены паттерны и интерфейсные фасады АСЕ, которые устраняют этот
недостаток.
3.8 Резюме
В этой главе было продемонстрировано каким образом АСЕ использует
возможности C++ и паттерн Wrapper Facade для того, чтобы упростить кор-
ректное и переносимое программирование механизмов TCP/IP с установлени-
ем соединения в сетевых приложениях. Мы сосредоточились на интерфейсных
фасадах АСЕ Socket, которые упрощают использование:
• Сетевых адресов, дескрипторов ввода/вывода и базовых операций с соке-
тами.
• Соединений TCP и операций передачи данных.
В следующей главе будет показано как эти интерфейсные фасады АСЕ
Socket используются для разработки первой итерации нашей сетевой службы
регистрации.
Интерфейсные фасады АСЕ Socket решают следующие проблемы Socket
API, рассмотренные в разделе 2.3:
• Подверженные ошибкам API — Интерфейсные фасады АСЕ Socket га-
рантируют типовую безопасность всех аргументов, передаваемых Socket
API. Должны быть урегулированы также проблемы с расположением
байтов, в процессе прозрачной ACE-обработки функций поиска адрес-
ной информации.
Интерфейсные фасады АСЕ: сокеты
87
• Слишком сложные API — Путем разделения Socket API на отдельные
классы активного соединения, пассивного соединения и передачи дан-
ных, интерфейсные фасады АСЕ Socket уменьшают сложность разработ-
ки сетевых приложений. Разработчикам не нужно знать все интерфейс-
ные фасады АСЕ Socket для того, чтобы писать сетевые приложения, а
нужно знать только те, которые они используют.
• Непереносимые и неоднородные API — Исходный код клиентского,
приложения и web-сервера компилируется и выполняется без ошибок и
эффективно на всех платформах, которые поддерживают АСЕ.
Объектно-ориентированное проектирование интерфейсных фасадов АСЕ
Socket упрощает также изменение механизма IPC приложения, не требуя при
этом изменять аргументы API и «вручную» изменять адресные структуры и
функции. Например, классы каждого варианта коммуникационного сервиса
(поток, дейтаграмма или дейтаграмма с соединением) на рис. 3.2 предлагают
общий набор методов, который позволяет им легко взаимозаменять друг друга
с помощью методов обобщенного программирования [А1е01]. Как отмечено
в блоке 5, обобщенное программирование и идиома C++ характеристика (trait)
допускают комплексную замену функциональности с помощью параметризо-
ванных типов. Эти методы применимы и к другим классам интерфейсных фа-
садов АСЕ IPC, которые представлены на web-сайте, посвященном АСЕ по ад-
ресу http://ace.ece.uci.edu.
Глава 4
Реализация сетевой службы
регистрации
Краткое содержание
В этой главе представлена первая реализация нашей сетевой службы реги-
страции. Мы показываем как передавать и принимать регистрационные записи
переносимым, корректным и эффективным образом путем объединения ин-
терфейсных фасадов АСЕ Socket, рассмотренных в главе 3, с другими классами
АСЕ, которые управляют буферизацией и маршалингом/демаршалингом сооб-
щений. Мы уточняем этот пример на всем протяжении остальной части книги,
чтобы продемонстрировать обычные проблемы, которые приходится решать
при разработке объектно-ориентированных сетевых приложений.
4.1 Обзор
Большинство сетевых приложений выполняет следующие действия:
• Устанавливают соединения, активно и пассивно.
• Обмениваются данными с одноранговыми партнерами.
• Управляют буферами данных.
• Осуществляют маршалинг и демаршалинг данных так, чтобы их можно
было правильно обрабатывать в гетерогенных системах.
В этой главе будет показано как интерфейсные фасады АСЕ Socket, рас-
смотренные в главе 3, могут быть дополнены ACE-классами буферизации и
(де) маршалинга сообщений с целью упрощения первого варианта реализации
нашей сетевой службы регистрации. Составные части этой службы изображе-
ны на рис. 0.6.
90
Глава 4
4.2 Класс ACE_Message_Block
Обоснование
Многим сетевым приложениям требуются средства эффективного управ-
ления сообщениями [SS93]. Стандартные операции управления сообщениями
включают:
• Запись сообщений в буферы при их получении из сети или от других
процессов того же хоста.
• Добавление или удаление заголовков и трейлеров сообщений при их
прохождении через стек протоколов.
• Фрагментацию и сборку сообщений для согласования их размера с мак-
симальным размером передаваемого блока данных сети (MTU).
• Запись сообщений в буферы для передачи или ретрансляции.
• Переупорядочение сообщений, полученных не в том порядке.
С целью повышения эффективности, эти операции должны минимизиро-
вать издержки динамического управления памятью и исключить избыточное
копирование данных, поэтому в АСЕ предусмотрен класс ACE_Messa-
ge_Block.
Функциональные возможности класса
Класс ACE_Message_Block позволяет эффективно управлять сообще-
ниями фиксированной и переменной длины. ACE_Message_Block является
реализацией паттерна Composite [GHJV95] и обеспечивает следующие функ-
циональные возможности:
• Каждый ACE_Message_Block содержит указатель на ACE Da-
ta_Block, в котором ведется подсчет ссылок и который, в свою очередь,
указывает на реальные данные, связанные с сообщением. Такая структу-
ра позволяет гибко и эффективно совместно использовать данные и ми-
нимизировать излишние издержки копирования памяти.
• Класс позволяет объединить события в односвязный список для под-
держки составных сообщений, которые могут быть использованы в по-
лиморфных списках и в многоуровневых стеках протоколов, которые
требуют эффективных вставки/удаления заголовков/трейлеров.
• Класс позволяет объединить множество сообщений в двусвязный спи-
сок, который создает основу класса ACE_Message_Queue, который
подробно рассматривается в [SH].
• Класс рассматривает свойства синхронизации и управления памятью как
аспекты {aspects) [Kic97, СЕОО], которые приложения могут видоизме-
нять, без изменения базовой реализации ACE_Message_Block.
Интерфейс класса ACE_Message_Block показан на рис. 4.1. Его структура
представляет собой неточную копию механизма буферизации сообщений
в System V STREAMS [Rag93] и поддерживает два вида сообщений:
Реализация сетевой службы регистрации
91
ACEJMess&gaJBlock
# rd_ptr_ : size_t
# wr_ptr_ : size_t
# cont_ : ACE__Message_Block *
# next_ : ACE_Message_Block *
# prev_ : ACE_Message_Block *
# data_block_ : ACE_Data_Block *
+ init (size : size_t) : int
+ msg_type (type : ACE_Message_Type)
+ msg_type () : ACE_Message_Type)
+ msg_j?riority (prio : u_long)
+ msg_priority () : u_long
+ clone () : ACE_Message_Block *
+ dublicate () : ACE_Message_Block *
+ release () : ACE_Message__Block *
+ set_flags (flags : u_long) : u_long
+ clr_flags (flags : u_long) : u_long
+ copy (buf : const char *,n : size_t) : int
-r rd_ptr (n : size_t)
+ rd_ptr () : char *
+ wr_ptr (n : size_t)
+ wr_ptr () : char *
+ len^ht () : size_t)
total_lenght () : size_t
+ size () : size_t
ACE_Data_Block
# base_ : char *
# refcnt : int
>
1
Рис. 4.1
Диаграмма класса ACE_Message_Block
• Простые сообщения содержат один ACE_Mes s age_Bloc к, см. рис. 4.2 (1).
• Составные сообщения содержат несколько ACE_Message_Block, со-
единенных вместе в соответствии с паттерном Composite [GHJV95], кото-
рый предлагает структуру для создания рекурсивных объединений, как
показано на рис. 4.2 (2). Составные сообщения часто состоят из управ-
ляющей информации, которая включает учет использования системных
ресурсов, таких как адреса назначения, за которыми следуют одно или
несколько информационных сообщений, которые включают реальное
содержимое данного сообщения.
Основные методы ACE_Message_Block приведены в следующей таблице:
Метод Описание 9
ACE_Message_Block () init() ........ .... .. jl Инициализирует сообщение.
msg_type () Устанавливает и возвращает тип сообщения.
msg_priority() Устанавливает и возвращает приоритет сообщения.
clone () Возвращает точную «детальную копию» всего сообщения. ;
duplicate () Возвращает дубликат сообщения, который ц увеличивает счетчик ссылок на 1.
92
ГЛава 4
Метод Описание
release() Уменьшает счетчик ссылок на 1 и освобождает ресурсы сообщения, если счетчик обнуляется.
set_flags() Поразрядное ИЛИ (OR) заданных битов в существующем наборе флагов, которые определяют семантику сообщений, например, нужно ли удалять буфер после того как сообщение отправлено и т.д.
clr_flags () Сбрасывает и устанавливает биты флагов.
copy о Копирует п байтов из буфера в сообщение.
rd_ptr () Устанавливает и возвращает указатель «на чтение» (read pointer).
wr_ptr () Устанавливает и возвращает указатель «на запись» (write pointer).
cont () Устанавливает и возвращает поле продолжения сообщения, которое объединяет составные сообщения.
next() prev () Устанавливает и возвращает указатели на двухсвязный список сообщений В ACE_Message_Queue.
length () Устанавливает и возвращает текущий размер сообщения, которое определено как wr_ptr () - rd_ptr().
total_length () Возвращает размер сообщения, включая все связанные блоки сообщения.
size () Устанавливает и возвращает общий объем сообщения, который включает количество памяти, выделенной до и после блока (rd_ptr (), wr_ptr ()). |
Каждый ACE_Message_Block содержит указатель на подсчитывающий
ссылки ACE_Data_Block, который, в свою очередь, указывает на реальные
данные, см. рис. 4.2 (1). Заметьте, что rdjptr () и wr_ptr () указывают соответ-
ственно на начало и на конец активной.части полезных данных. Рис. 4.2 (2) пока-
зывает как можно использовать метод ACE_Message_Block::duplicate (),
для создания «упрощенной копии» («shallow сору») сообщения. Это позволяет им
совместно использовать одни и те же данные гибко и эффективно, минимизи-
руя объем выделения памяти и издержки копирования. Если копируется сам
блок сообщения, различные rd_ptr () и wr_ptr () могут указывать на раз-
ные части одних и тех же совместно используемых полезных данных.
Пример
Следующая программа читает все данные из стандартного ввода и записы-
вает в односвязный список динамически выделяемых блоков ACE_Messa-
ge_Block, которые объединяются с помощью имеющихся у них указателей
Реализация сетевой службы регистрации
93
полезные донные
0) структура простого сообщения
Рис. 4.2
Два вида ACE__Message_Block
(2) структура составного сообщения
продолжения. Затем она выводит содержимое всех связанных блоков сообще-
ний на стандартный вывод и освобождает выделенную им динамическую па-
мять.
Iinclude "ace/OS.h"
finclude ”ace/Message_Block.h"
int main (int argc, char *argv[])
(
ACE_Message__Block *head - new ACE__Message_Block (BUFSIZ) ;
ACE_Message_Block *mblk « head;
for (;;) {
ssize_t nbytes « ACE::read_n (ACE_STDIN,
mblk->wr_ptr (),
mblk->size ());
if (nbytes <« 0)
break; // Выходим, если EOF или ошибка.
// Смещаем указатель write на конец буфера.
mblk->wr_ptr (nbytes);
// Размещаем блок сообщения и связываем его
// с концом списка.
mblk->cont (new ACE_Message_Block (BUFSIZ));
mblk » mblk->cont ();
}
// Выводим содержимое списка на стандартный вывод.
for (mblk = head; mblk != 0; mblk = mblk->cont ())
ACE::write_n (ACE_STDOUT, mblk->rd_ptr(), mblk->length()) ;
head->release (); // Освобождаем всю память цепочки,
return 0;
94
Глава 4
Цикл for, который выводит содержимое списка на стандартный вывод мо-
жет быть заменен одним вызовом АСЕ: :write_n (head). Этот метод выво-
дит все блоки сообщения, связанные их cont () указателями, с применением
высокоэффективной операции записи-со-слиянием. Похожая оптимизация
используется в методе Logging_Handler: : wri.te_log_record ().
Мы используем методы АСЕ: : read_n () и АСЕ: : write_n (), а не функ-
ции ввода/вывода C++, так как не все платформы ОС, на который работает АСЕ
реализуют эти функции так как нужно. Они могут, например, быть причиной
лишнего копирования данных из-за внутренней буферизации и не могут ис-
пользовать преимущество оптимизированной записи-со-слиянием, рассмот-
ренной в предыдущем разделе.
4.3 Классы ACE_InputCDR и ACE_OutputCDR
Обоснование
Сетевым приложениям, отправляющим и принимающим сообщения, час-
то нужна поддержка для:
• Линеаризации при осуществлении преобразования производных типов
данных, таких как массивы, связные списки или графы в/из буферов ли-
нейной памяти.
• Маршал инга/демаршалинга для корректного взаимодействия в средах
с неодинаковыми ограничениями на выравнивание данных компилято-
рами и аппаратными командами с разными правилами расположения
байтов.
Так как «вручную» трудно без ошибок и эффективно выполнять линеари-
зацию, маршалинг и демаршалинг, то лучше эти операции инкапсулировать
в повторно используемые классы, вот почему в АСЕ предусмотрены классы
ACE_OutputCDR и ACE_InputCDR.
Функциональные возможности классов
Классы ACE_OutputCDR и ACE_InputCDR предоставляют высоко опти-
мизированные, переносимые и удобные средства маршалинга и демаршалинга
данных на основе стандартного формата CORBA Common Data Representation
(CDR) [ObjOl]. ACE_OutputCDR создает CDR-буфер из структуры данных
(маршалинг), a ACE_InputCDR извлекает данные из CDR-буфера (демарша-
линг).
Классы ACE_OutputCDR и ACE_InputCDR поддерживают следующие
функциональные возможности:
• Реализуют операции (де)маршалинга следующих типов:
Простые типы, например, логические; 16-, 32- и 64-разрядные целые;
8-разрядные октеты; числа с плавающей точкой одинарной и двой-
ной точности; символы; и строки.
Массивы простых типов.
Реализация сетевой службы регистрации
95
• Операторы ввода (<<) и вывода (») могут быть использованы для мар-
шалинга и демаршалинга простых типов с тем же синтаксисом что и у
функций ввода/вывода C++.
• Используют внутренние цепочки ACE_Message_Block, чтобы избе-
жать излишнего копирования памяти.
• Используют преимущество CORBA CDR выравнивания и правил упоря-
дочения байтов, чтобы избежать излишнего копирования памяти и опе-
раций перестановки байтов, соответственно.
• Предоставляют оптимизированный код перестановки байтов, который
использует подставляемый ассемблерные команды для распространен-
ных аппаратных платформ, таких как Intel х86, и стандартные макро-
сы/функции htons (), htonl (), ntohs () и ntohl () для других плат-
форм.
• Поддерживают маршалинг и демаршалинг буферов октетов без копиро-
вания.
• Пользователи могут определить преобразования собственных наборов
символов для платформ, которые не используют ASCII или UNICODE
в качестве внутренних наборов символов.
Интерфейсы потоковых классов АСЕ CDR показаны на рис. 4.3. Основные
методы класса ACE_OutputCDR приведены в следующей таблице:
Метод Описание
ACE_Ou tputCDR () Создает пустой CDR-поток ввода.
write_* () Записывает простой тип в поток, например, write_ushort().
.write_*_array () Записывает массив простых типов в поток, например, writG-long_array().
operator<< () Оператор ввода определен для каждого простого типа.
•gaod_bit () Возвращает 0, если в потоке обнаружена ошибка.
total_length () Возвращает количество байтов в потоке.
begin () Возвращает указатель на первый блок сообщения в цепочке.
'end () Возвращает указатель на последний блок сообщения в цепочке.
Аналогично, основные методы класса ACE_InputCDR приведены в сле-
дующей таблице:
96
Глава 4
Метод Описание
ACE_InputCDR() Создает пустой CDR-поток вывода.
read_*() Извлекает простой тип из потока, например. read_char().
read_*_array () Извлекает массив простых типов из потока, например, read_octet_array()
operator» () Оператор вывода определен для каждого простого типа.
good_bit () Возвращает 0, если поток обнаружил ошибку.
steal—contents () Возвращает КОПИЮ базового ACE_MessageJBlock. содержащего текущий CDR-поток. |
Классы АСЕ_1 при tCDR и ACE_Ou tpu tCDR преобразуют типизированные
данные в нетипизированные буферы и наоборот. Как следствие, программисты
должны быть внимательны при использовании этих классов, чтобы не допус-
тить нарушений системы типов. Одним из способов общего решения этих про-
блем является программирование с использованием распределительного уров-
ня промежуточного слоя, например, CORBA [ObjOl] и The АСЕ ORB (TAO)
[SLM98], рассмотренных в разделе В. 1.4.
Пример
Потоковые классы АСЕ CDR предопределяют операторы « и » для про-
стых типов и массивов. АСЕ-приложения несут ответственность за определе-
ние этих операторов для их собственных типов данных.1 Чтобы проиллюстри-
ровать эти операторы, мы показываем операторы АСЕ CDR ввода и вывода для
ACI_InputCDR
ACKjOutputCDR
- start- : АСЕ_Message-Block
- good_bit— : int
- start- : ACE Message-Block
- current— : ACE_Message—Block *
- good—bit— : int
+ read_char (x : Char &)
: Boolean
+ read_octet_array (x : Octet*,
size : ULong)
: Boolean
+ operator» (s: ACE_InputCDRS,
x : Char)
: Boolean
+ good_bit () : int
+ steal-Contents ()
: ACE—Message—Block *
+ writO-Ushort (x : UShort)
: Boolean
+ write-long array (x : Long *,
~ size : ULong)
: Boolean
+ operator« (s : ACE OutputCDRi,
x : UShort)
: Boolean
+ good bit () : int
+ total-length () : size_t
+ begin () : ACE Message Block *
+ end () : ACE_Message-BTock *
Рис. 4.3
Диаграммы классов ACE_IприtCDR И ACE_OutputCDR
1
Эти операторы могут быть также сгенерированы автоматически с помощью таких средств,
как компилятор CORBA Interface Definition Language (IDL) [AOSKOO], предоставляемый
TAG.
Реализация сетевой службы регистрации
97
класса ACE_Log_Record, который используется и клиентским приложением
И сервером регистрации. Этот класс C++ содержит несколько полей и буфер со-
общений изменяемого размера. Таким образом, наш оператор ввода осуществ-
ляет маршалинг каждого поля, преобразуя его в объект ACE_OutputCDR, как
показано ниже:
int operator<< (ACE_OutputCDR &cdr,
const ACE_Log_Record &log_record)
(
size_t msglen = log_record.msg_data_len ();
// Записывает каждое поле <log_record> в CDR-поток вывода.
cdr << ACE_CDR::Long (log_record.type ());
cdr << ACE_CDR::Long (log_record.pid ()) ;
cdr << ACE_CDR::Long (log_record.time_stamp ().sec ());
cdr << ACE_CDR::Long (log_record.time_stamp O.usec ());
cdr << ACE_CDR::ULong (msglen);
cdr.write_char_array (log_record.msg_data (), msglen);
return cdr.good bit ();
1
Наш оператор вывода осуществляет демаршалинг каждого поля объекта
&CE_InputCDR и заполняет, соответственно, объект ACE_Log_Record.
int operator>> (ACE_InputCDR &cdr,
ACE Log Record &log record)
(
ACE_CDR::Long type;
ACE—CDR::Long pid;
ACE_CDR::Long sec, usee;
ACE—CDR::ULong buffer_len;
// Извлекаем каждое поле из CDR-потока ввода в <log_record>.
if ((cdr » type) && (cdr » pid) && (cdr » sec)
&& (cdr >> usee) && (cdr >> buffer_len)) {
ACEJTCHAR log_msg[ACE_Log_Record::MAXLOGMSGLEN+1];
log_record.type (type);
log_record.pid (pid);
log_record.time_stamp (ACE_Time_Value (sec, usee));
cdr.read_char_array (log_msg, buffer_len);
log_msg[buffer_len] = ’\0';
log_record.msg data (log_msg);
)
return cdr.good bit ();
98
Глава 4
Мы используем эти два оператора ввода и вывода, чтобы немного упро-
стить наше приложение сетевой регистрации.
4.4 Первоначальный вариант сервера
регистрации
Наша первая реализация сетевой службы регистрации определяет исход-
ную структуру и реализации основных повторно используемых классов. Сер-
вер регистрации прослушивает TCP порт, номер которого определен в файле
сетевых сервисов операционной системы как ace_logger, что является обыч-
ной практикой, применяемой многими сетевыми серверами. Например, сле-
дующая строка может присутствовать в файле UNIX /etc/services :
ace_logger 9700/tcp # Connection-oriented Logging Service
Клиентские приложения могут факультативно задавать TCP-порт и 1Р-ад-
рес, по которым клиентское приложение и сервер регистрации должны обме-
ниваться регистрационными записями. Однако если эта информация не опре-
делена, то номер порта находится в базе данных соответствующих служб, и
Рис. 4.4
Классы, которые используются в примерах с сервером регистрации
Реализация сетевой службы регистрации
99
предполагается, что имя хоста определяется параметром ACE-DEFAULT-SER-
VER-HOST, который определен на большинстве платформ ОС как ”local-
host ”. После установления соединения клиент посылает регистрационную за-
пись серверу регистрации, который каждую запись заносит в файл. В данном
разделе представлен набор повторно используемых классов, которые управля
ют установлением пассивного соединения и передачей данных для всех серве-
ров регистрации, представленных в этой книге.
44.1 Базовый класс Logging server
Теперь, после того как в предыдущих разделах были рассмотрены
ACE__Mes sage_Block, ACE_Output_CDR и ACE_InputCDR, мы можем ис-
пользовать эти классы в новом базовом классе, который упростит те реализа-
ции нашего сервера регистрации, которые демонстрируются на всем протяже-
нии этой книги. На рис. 4.4 показаны абстрактный базовый класс Log-
ging-Server , класс Logging_Handler, который мы разработаем в разделе
4.4.2 и конкретные классы сервера регистрации, которые мы создадим в еле
дующих главах. Мы поместили определение базового класса Logging-Ser-
ver в следующий далее заголовочный файл с именем Logging_Server. hr
linclude "ace/FILE_IO.h"
If inc lode "ace/ SOCK_Acceptor . h”
// Предварительное объявление.
class ACE—SOCK—Stream;
class Logging Server
public:
// Метод шаблона выполняет цикл обработки событий
// сервера регистрации.
virtual int run (int argc, char *argv[]);
protected:
// Следующие четыре метода - это "hook-методы"1, которые
// могут быть подменены производными классами.
virtual int open (u_short port = 0);
virtual int wai t_for _inultiple_events () { return 0; }
virtual int handle_connections () 0;
virtual int handle_data (ACE_SOCK_Stream * = 0) = 0;
// Вспомогательный метод, может использоваться hook-методами,
int rnake_log_f i Le (ACE_FILE_IO &, ACE_SOCK_Stream * = 0) ;
hook (хук) — компьютерный жаргон, означающий «аппаратно или программно реализован-
ную возможность, которая в дальнейшем позволяет пользователю легко вводить дополне-
ния или изменения». (Реймонд Э. Новый словарь хакера.— М.:ЦенрКом, 1996.) Прим.рсд
100
Глава 4
// Закрывает конечную точку сокета и отключает АСЕ.
virtual ~Logging_Server () {
acceptor_.close ();
}
// Аксессор.
ACE_SOCK_Acceptor ^acceptor () {
return acceptor_;
}
private:
// Конечная точка сокета-акцептора.
ACE_SOCK_Acceptor_acceptor_;
};
Все последующие примеры сетевой службы регистрации будут включать
эти заголовочные файлы, наследовать Logging_Server и подменять и по-
вторно использовать его методы, каждый из которых мы опишем ниже. Файл
реализации Logging_Server. срр включает следующие заголовочные фай-
лы АСЕ:
♦include "ace/FILE_Addr.h"
♦include "ace/FILE_Connector.h"
♦include "ace/FILE_IO.h"
♦include "ace/INET_Addr.h"
♦include "ace/SOCK_Stream.h"
♦include "Logging_Server.h"
Шаблонный метод Logging-ServernrunO
Этот общедоступный метод выполняет канонические этапы инициализа-
ции и цикла обработки событий, применяемые большинством вариантов
службы регистрации в этой книге.
int Logging Server::run (int argc, char *argv[])
{
if (open (argc > 1 ? atoi (argvfl]) : 0) == -1)
return -1;
for (;;) {
if (wait_for_multiple_events () == -1) return -1;
if (handle_connections () == -1) return -1;
if (handle_data () == -1) return -1;
}
return 0;
}
Код, приведенный выше, — это пример паттерна Template Method
[GHJV95], который определяет структуру алгоритма операции, перекладывая
некоторые этапы на hook-методы, которые могут быть заменены производны-
Реализация сетевой службы регистрации
101
ми классами. Все вызовы open (), wait_for_multiple_events (), hand-
le_data() и handle_connections () в шаблонном методе run () пред-
ставляют собой hook-методы, которые могут быть заменены производными
классами.
Hook-методы класса LoggingServer
У каждого hook-метода класса Logging_Server есть своя роль и сцена-
рий действий по умолчанию, которые вкратце описаны ниже.
Logging_Server::open(). Этот метод устанавливает адрес сервера и создает
конечную точку-акцептор для пассивного прослушивания назначенного номе-
ра порта. Хотя метод может быть изменен производными классами, показан-
ной ниже реализации по умолчанию достаточно для всех примеров этой книги:
int Logging_Server::open (u_short logger_port)
// Увеличиваем количество доступных дескрипторов сокетов до
// максимума, поддерживаемого данной платформой ОС.
АСЕ::set_handle_limit ();
ACE_INET_Addr server_addr;
int result;
if (logger_port ! = 0}
result = server_addr.set (logger_port, INADDR_ANY);
else
result = server_addr.set ("ace_logger"-, INADDR_ANY);
if.(result == -1)
return -1;
// Начинаем прослушивание и разрешаем повторное использование
// адреса прослушивания при быстрых рестартах.
return acceptor_.open (server_addr, 1);
}
Хотя конструктор ACE_INET_Addr принимает в качестве аргументов но-
мер порта и имя хоста, здесь мы этого не делаем по следующим причинам:
1. Мы даем возможность пользователю или передавать номер порта, или ис-
пользовать имя сервиса по умолчанию, а это требует разных вызовов.
2. Могут быть вызваны сетевые адресные функции, такие как gethostby-
name (), что может оказаться неожиданным для программистов, не пред-
полагающих, что конструктор будет ждать определения адреса серверного
хоста.
3. Если произошла ошибка, нам нужно «выдать» правильную диагностику.
В разделе А.б.З объяснено почему в АСЕ для передачи сообщений об ошиб-
ках не используется механизм исключений C++.
Обратите внимание на второй аргумент в вызове acceptor_. open. Его
действие приводит к тому, что для сокета-акцептора устанавливается опция
SOJREUSEADDR, которая разрешает программе осуществлять рестарт сразу по-
102
Глава 4
еле того как она была остановлена. Это помогает избежать конфликтов с сокета-
ми, которые остались от предыдущих запусков и находятся в состоянии TI-
ME_WAIT, иначе могло бы случиться так, что новый сервер регистрации не смог
бы принимать запросы клиентов на регистрацию в течении нескольких минут.
Loggmg_Serven:wait_for_multiple _events(). Роль, которую играет этот ме-
тод, —ждать наступления различных событий. Реализацией по умолчанию яв-
ляется пустая инструкция; то есть метод просто возвращает 0. Это поведение по
умолчанию заменяется реализациями сервера регистрации, которые использу-
ют основанные на select () механизмы демультиплексирования синхронных
событий, рассмотренные в главе 7.
Logging_Serven:handle_connections(). Роль этого hook-метода — прини-
мать одно или несколько соединений от клиентов. Мы определяем его как «чис-
то» виртуальный метод, чтобы переложить его реализацию на производные
классы.
Logging_Serven:handle_data(). Роль этого hook-метода — получать регист-
рационную запись от клиента и записывать ее в файл регистрации. Этот метод
мы также определяем как «чисто» виртуальный, чтобы обеспечить его реализа-
цию производными классами.
Блок 8: Интерфейсные фасады АСЕ File
АСЕ инкапсулирует зависящие от платформы механизмы небуферизованных
операций с файлами в соответствии с паттерном Wrapper,Facade. Как и боль-
шинство классов семейства интерфейсных фасадов АСЕ IPC, классы АСЕ File
отделяют
• инициализирующие фабрики, например, ace_fi tE_Connector, которые от-
крывают и/или создают файлы, от • . . ,~ ' г
• классов передачи данных, например, асе File_io, которые приложения
используют для чтения и записи данных в файл, открытый с пбмЬщью асе_ f i -
I.E_CONNECTOR. *’ ’ л' • '
Симметрия интерфейсных фаебдов АСЕ IPC и файлов демонстрирует универ-
сальность проектных решений АСЕ и обеспечивает оенр.ву дляабобщения ме-
ханизмов IPC в более высокоуровневые каркасы АСЕ, рассмотренные в (SH).
Метод Logging_Server::make_log_fileO
Этот вспомогательный метод может быть использован hook-методами для
инициализации регистрационного файла с помощью интерфейсных фасадов
АСЕ File, рассмотренных в блоке 8.
int Logging_Server::make_log_file (ACE_FILE_IO &logging_file,
ACE_SOCK_Stream *logging_peer)
{
char filename[MAXHOSTNAMELEN + sizeof (".log")];
if (logging_peer != 0) { // Используем имя клиента
// в качестве имени файла.
ACE_INET_Addr logging_peer_addr;
logging_peer->get_remote_addr (logging_peer_addr);
Реализация сетевой службы регистрации
103
logging_peer_addr.get_host_name (filename, MAXHOSTNAMELEN);
strcat (filename, ".log");
)
else
strcpy (filename, "logging_server.log");
ACE_FILE_Connector connector;
return connector.connect (logging_file,
ACE_FILE_Addr (filename),
0, // Без тайм-аутов.
ACE_Addr::sap_any, // Пропускаем.
0, // He пытаемся использовать
// тот же адрес еще раз.
OJRDWR | O_CREAT I O_APPEND,
ACE_DEFAULT_FILE_PERMS);
По умолчанию регистрационному файлу присваивается имя "log-
ging_server . log”. Это имя можно заменить, используя имя хоста клиента,
i которым установлено соединение. Мы это продемонстрируем в разделе 7.4.
Блок 9: Протокол кадрирования сообщений для службы
регистрации
Гак как ГОР является протоколом управления потоком байтов, то на приклад-
ном уровне нам потребуется протокол для разбиения сообщения на кадры,
чтобы в потоке данных можно было выделять отдельные регистрационные за
писи Мы используем 8-ми байтовый заголовок в виде CDR-кода. который со-
держи! индикатор порядка байтов и размер полезных данных, за которыми
следует содержимое регистрационных записей, как показано ниже:
44.2 Класс Logging Handler
Этот класс используется в службах регистрации для инкапсуляции вво-
ла/вывода и обработки регистрационных записей в соответствии с протоколом
кадрирования сообщений, рассмотренным в блоке 9. Сторона отправителя
ватой реализации протокола показана в методе Logging_Client: : send (), а
104
Глава4
сторона получателя показана в методе Logging_Handler: : recv_log_re*-
cord().
Определение класса Logging_Handler помещено в заголовочный файл,
который называется Logging_Handler. h.
«include "ace/FILE_IO.h"
«include ”ace/SOCK_Stream.h"
class ACE_Message_Block; // Предварительное объявление.
class Logging Handler
{
protected:
// Ссылка на регистрационный файл.
ACE-FILE-IО Slog_file—;
// Подключенный к клиенту.
АСЕ—SOCK—Stream logging—peere-
public:
// Методы инициализации и завершения.
Logging.—Handler (ACE_FILE-IO &log_file)
: log—file— (log—file) {}
Logging-Handler (ACE—FILE—10 Slog-file,
ACE-HANDLE handle)
: log—file— (log—file)
{ logging—peer-.set—handle (handle); }
Logging—Handler (ACE—FILE—10 Slog_file,
const ACE-SOCK-Stream Sldgging-peer)
: log—file— (log—file), logging—peer_ (logging-peer) {}
Logging-Handler (const ACE—SOCK—Stream slogging—peer)
: log—file— (0), logging—peer_ (logging—peer) {}
int close () { return logging—peer_.close (); }
// Получает одну регистрационную запись от подключенного
// клиента.
// Возвращает длину записи в случае успеха и <mblk> содержит
// имя хоста, <mblk->cont()> содержит заголовок регистрационной
// записи (порядок байтов и длину) и данные. Возвращает -1
// в случае ошибки или при закрытии соединения.
int reeV—log_record (ACE—Message—Block *Smblk);
// Записывает одну запись в регистрационный файл. <mblk>
// содержит имя хоста, a <mblk->cont> содержит
// регистрационную запись.
// Возвращает длину записанной в файл записи; -1 при ошибке,
int write—log—record (ACE_Message—Block *mblk);
// Регистрирует одну запись вызовом <recV—log_record> и
// <write—log—record>. Возвращает 0 при успехе и -1 при
// ошибке.
int log—record ();
ACE-SOCK—Stream Speer (). { return logging—peer_; } // Аксессор.
};
Реализация сетевой службы регистрации
105
Ниже мы показываем реализацию методов recv_log_record (), wri-
te_log_record() иlog_record().
Logging_Handler::recv_log_record(). Этот метод реализует протокол кадри-
рования сообщения службы сетевой регистрации на принимающей стороне
(см. блок 9). Он использует классы ACEjSOCK_Stream, ACE_Messa-
ge_Block и АСЕ_1 приtCDR совместно с оператором вывода operator>>,
определенным ранее, для чтения одной полной регистрационной записи от
подключенного клиента. Этот код является переносимым и интероперабель-
ным, так как мы осуществляем демаршалинг содержимого, полученного из
сети с помощью класса АСЕ_1приtCDR.
1 int Logging Handler::recv_log_record (ACE Message_Block *&mblk)
2 {
3 ACE_INET_Addr peer_addr;
4 logging_Jpeer_. get_remote_addr (peer_addr) ;
5 mblk = new ACE_Message_Block (MAXHOSTNAMELEN + 1);
6 peer__addr. get_host__name (mblk->wr_ptr (), MAXHOSTNAMELEN);
7 mblk->wr_ptr (strlen (mblk->wr_ptr ()) + 1); // Смещаемся
//за имя.
8
9 ACE_Message_Block *payload =
10 new ACE_Message_Block (ACE_DEFAULT_CDR_BUFSIZE);
11 // Выравниваем блок сообщения для CDR-потока.
12 ACE_CDR::mb_align (payload);
13
14 if (logging_peer_.recv_n (payload->wr_ptr (), 8) ~ 8) {
15 payload->wr_ptr (8); // Учитывает добавление 8 байтов.
16
17 ACE_IприtCDR cdr (payload) ;
18
19 ACE—CDR::Boolean byte_order;
20 // Используем вспом.метод для устранения
неоднознач.битов символов.
21 cdr >> АСЕ______InputCDR::to_boolean (byte_order) ;
22 cdr. reset_byte__order (byte_order) ;
23
24 ACE_CDR::ULong length;
25 cdr » length;
26
27 payload->size (length + 8);
28
29 if (logging_peer_.recv_n (payload->wr_ptr(), length) > 0) {
30 payload->wr_ptr (length); // Учитывает
// дополнительные байты.
31 mblk->cont (payload);
32 return length; // Возвращает длину регистрационной
// записи.
33 )
34 )
35 payload->release ();
106
Глава 4
36 mblk->release ();
37 payload = mblk = 0;
38 return -1;
39 }
40
Строки 3-7 Выделяем память под новый ACE_Mes sage_Block для хране-
ния имени хоста logging_peer_. Мы внимательны к деталям: завершаем имя
хоста нулем и следим, чтобы только имя хоста включалось в текущую длину
блока сообщения, которая определяется как wr_ptr () - rd_ptr ().
Строки 9-12 Мы создаем отдельный ACE_Message_Block для фиксации
регистрационной записи. Размер заголовка, который мы получаем первым, из-
вестен (8 байтов). Затем, после его получения, мы используем возможности
CDR для демаршалинга заголовка, предпринимая относительно нового блока
сообщения некоторые предосторожности, связанные с CDR. Чтобы CDR мог
осуществлять переносимый демаршалинг данных нужно, чтобы данные, про-
шедшие маршалинг, выравнивались по 8-ми байтовой границе. ACE_Messa-
ge_Block не дает никаких гарантий выравнивания, поэтому мы вызываем
ACE_CDR: : mb_align (), чтобы обеспечить правильное выравнивание до вы-
зова payload->wr_ptr () с целью получения заголовка. Выравнивание мо-
жет вылиться в наличие неиспользуемых байтов в начале блока внутреннего
буфера, поэтому мы должны сначала установить размер pay load больше, чем
8 байтов, которые мы собираемся получить (ACE_DEFAULT_CDR_BUFSIZE
имеет значение по умолчанию 512).
Строки 14-15 После успешного вызова recv_n () с целью получения заго-
ловка фиксированного размера, указатель записи payload сдвигается, чтобы
учесть добавление 8-ми байтов к блоку сообщения.
Строки 17-25 Мы создаем CDR-объект для демаршалинга 8-ми байтного
заголовка, расположенного в блоке сообщения payload. CDR-объект копиру-
ет заголовок, избегая любых изменений блока сообщения payload, так как за-
головок прошел демаршалинг. Так как указателем.порядка байтов является
ACE_CDR: : Boolean, он может быть извлечен независимо от порядка байтов,
принятого у клиента. Порядок байтов CDR-потока устанавливается затем в со-
ответствии с порядком, определяемым вводом и извлекается длина регистра-
ционной записи payload, которая может иметь переменную длину.
Строки 27-32 Теперь, когда мы знаем длину полезных данных регистраци-
онной записи, изменяем размер блока сообщения payload, так чтобы в него
поместилась вся запись. Следующий вызов recv_n () добавляет оставшуюся
часть регистрационной записи к блоку сообщения payload, сразу за заголов-
ком. Если все проходит нормально, мы добавляем указатель записи в payload
в соответствии с добавленными данными, присоединяя payload к mblk с по-
мощью его поля продолжения, и возвращаем длину регистрационной записи.
Строки 35-38 Ситуации, которые могут привести к ошибкам на этом кон-
чаются, и нам нужно освободить память в mblk и payload, чтобы предотвра-
тить ее утечку.
Реализация сетевой службы регистрации
107
Метод recv_log_record () рационально использует CDR-поток и блок
сообщения для эффективно-переносимого приема регистрационной записи.
Он использует элемент продолжения блока сообщения для хранения имени
хоста клиентского приложения, за которым следует блок сообщения с регист-
рационной записью.
Рис. 4.5
Цепочка блоков сообщения с информацией о регистрационной записи
Эти два элемента хранятся отдельно, но передаются в приложении в виде
одного блока, как показано на рис. 4.5.
Logging_Handler.:write_log_record(). Этот метод использует классы
ACE_FILE_IO, ACE_Message_Block и ACE_InputCDR вместе с оператором
вывода operator» для форматирования и записи имени хоста и регистраци-
онной записи, полученных от клиента, в регистрационный файл.
1 int Logging_Handler::write_log_record (ACE_Message_Block *mblk)
2 {
3 if (log_file_->send_n (mblk) == -1) return -1;
4
5 if (ACE::debug ()) (
6 ACE_InputCDR edr (mblk->cont ());
7 ACE-CDR: .‘Boolean byte_order;
8 ACE_CDR::ULong length;
9 edr » ACE_InputCDR::to_boolean (byte_order) ;
10 edr.reset_byte_order (byte_order);
11 edr » length;
12 ACE_Log_Record log_record;
13 edr » log_record; // Выделяем <ACE_log_record>.
14 log_record.print (mblk->rd_ptr (), 1, cert);
15 }
16
17 return mblk->total_length ();
18 >
Строка 3 Имя хоста находится в mblк, а регистрационная запись — в звене
продолжения цепочки mblk. Мы используем метод send_n () из ACE_FI-
LE_IO, чтобы записать все блоки сообщения, соединенные в цепочку их указа-
телями cont (). Внутри этот метод использует операцию ОС запись-со-слия-
нием для снижения затрат на междоменные переходы (domain-crossingpenalty).
Так как регистрационный файл записывается в CDR-формате, нам нужно будет
108
Глава 4
написать отдельную программу для чтения и отображения его информации
в приемлемом для человека формате.
Строки 5-18 В отладочном режиме мы создаем CDR-поток из данных реги-
страционной записи и выводим его содержимое в сегг. Так как заголовок ре-
гистрационной записи по-прежнему находится в ее блоке сообщения, нужно
извлечь байты, чтобы убедиться, что демаршалинг самой регистрационной за-
писи выполнен правильно. Хотя мы и не используем поле заголовка length,
мы его извлекаем, чтобы убедиться, что CDR-поток позиционирован правиль-
но, на начало регистрационной записи, при вызове оператора вывода для де-
маршалинга данных. Данный метод возвращает количество байтов, записан-
ных в регистрационный файл.
Loggmg_Handler::log_recordO. Этот метод использует методы recv_log_
record () и write_log_record () для чтения регистрационной записи из
сокета и ее записи в регистрационный файл, соответственно.
int Logging_Handler::log record ()
{
ACE_Message_Block *mblk = 0;
if (recv_log_record (mblk) == -1)
return -1;
else (
int result = write_log_record (mblk);
mblk->release (); // Освобождаем все содержимое,
return result =- -17-1: 0;
}
)
Вызов release () удаляет имя клиентского хоста из mblk и регистраци-
онную запись из mblk->cont ().
44.3 Класс Iterative Logging Server
Следующий код показывает как с помощью интерфейсных фасадов АСЕ
Socket реализовать последовательный (iterative) сервер регистрации. Этот при-
мер наследует различные hook-методы из базового класса Logging_Server
для последовательной обработки клиентских запросов на регистрацию в сле-
дующем порядке:
1. Hook-метод handle_connections () принимает новое соединение от
клиента.
2. Hook-метод handle_data () читает и обрабатывает регистрационные за-
писи от клиента до тех пор, пока не закроется соединение или пока не про-
изойдет ошибка.
3. Возвращаемся на шаг 1.
Сначала мы включаем заголовочные файлы, которые нам нужны для этого
примера.
Реализация сетевой службы регистрации
109
♦include "ace/FILE_IO.h"
♦include "ace/INET_Addr.h"
♦include "ace/Log_Msg.h"
♦include ”Logging_Server.h"
♦include "Logging_Handler. h"
Затем мы создаем класс lterative_Logging_Server, который насле-
дует от Logging_Server, и помещаем этот класс в заголовочный файл Ite-
rative_Logging_Server .h. Мы определяем члены-данные, которые при-
нимают регистрационные записи от клиента, и записываем данные в регистра-
ционный файл.
class Iterative_Logging_Server : public Logging_Server
{
protected:
ACE_FILE_IO log_file_;
Logging_Handler logging_handler_;
public;
Iterative_Logging_Server (): logging_handler_ (log_file_) {}
Logging_Handler &logging_handler (} {
return logging_handler_;
}
protected:
11 Другие методы, показанные ниже...
);
Hook-метод open () создает и/или открывает регистрационный файл с по-
мощью вспомогательного метода make_log_file (). Если вызов та-
ke_log_file () завершается неудачей, мы используем макрос ACEJER-
ROR_RETURN, описанный в блоке 10, чтобы вывести пояснительное сообщение
ввернуть номер ошибки. Если же вызов завершается успешно, то мы вызываем
родительский hook-метод open () для инициализации сетевого адреса
ACE_INET_Addr, на котором сервер регистрации прослушивает клиентские
запросы на соединение.
virtual int open (u_short port) {
if (make_log_file (log_file_) == -1)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "make_log_file()"),-1);
return Logging Server::open (port);
}
Деструктор закрывает регистрационный файл:
virtual ~Iterative_Logging_Server () {
log_file_.close ();
}
110
Глава 4
Блок 10: ACE-макросы вывода отладочной информации
и сообщений об ошибках
В АСЕ предусмотрен набор макроопределений (макросов), которые объеди-
няют вывод отладочной информации и сообщений об ошибках в формате по-
хожем на printf (). Макросами наиболее общего характера являются
ACE_DEBUG, ACE_ERROR И ACE_ERROR_RETURN, Которые инкапсулируют метод
ACE_Log_Msg:: log ().’Этот метод принимает переменное количество аргу-
ментов, таким образом, что первый аргумент во всех этих макросах на самом
деле является составным аргументом, заключенным в еще одну пару круглых
скобок, чтобы C++ препроцессор воспринимал его как один аргумент.
Первый аргумент метода ACE_Log_Msg:: log О показывает насколько ошибка
является «серьезной», например, lm_error для ошибок общего характера и
lm_debug для диагностической информации. Следующий параметр — это
форматирующая строка, которая принимает большинство спецификаторов
преобразований printfО. В АСЕ определены несколько дополнительных
спецификаторов форматов, полезных для операций трассировки и вывода
служебной информации; включая
Формат Действие __i
%l Выводит номер строки, в которой произошла ошибка __ _
%N Выводит имя файла, в котором произошла ошибка
%n Выводит имя программы
%P Выводит ID текущего процесса j!
Гр • Принимает аргумент const char * и выводит его значение и । сообщение об ошибке, соответствующее errno (типа per гог ().).
%T Выводит текущее время
Iff - Выводит ID вызывающего потока.
Макрос ace_error_return является сокращенной командой регистрации
сообщения об ошибке и передачи возвращаемого значения из текущей функ-
ции. Поэтому он принимает два аргумента: первый такой же, как и у других мак-
росов, а второй — возвращаемое функцией после регистрации сообщения
значение.
Поскольку мы создаем последовательный сервер, мы можем повторно ис-
пользовать унаследованный метод wait_for_multiple_events (). Таким
образом, метод handle_connect ions () просто блокируется до тех пор, пока
сможет принять следующее клиентское соединение.
virtual int handle_connections () {
ACE_INET_Addr logging_peer_addr;
if (acceptor ().accept (logging_handler_.peer (),
&logging_peer_addr) == -1)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "accept()"), -1);
Реализация сетевой службы регистрации
111
ACE_DEBUG ((LM_DEBUG, "Accepted connection from %s\n",
logging_peer_addr.get_host_name ()));
return 0;
}
После того, как сервер принимает новое клиентское соединение, его
hook-метод handle_data () продолжает принимать регистрационные записи
от этого клиента до тех пор, пока не закрывается соединение или пока не проис-
ходит ошибка.
virtual int handle_data (ACE_SOCK_Stream *) {
while (logging_handler_.log_record () != -1)
continue;
logging_handler_.close (); // Закрываем дескриптор сокета,
return 0;
I
Функция main () создает экземпляр объекта Iterative_Logging_Ser-
ver и передает управление его методу run () для циклической обработки всех
клиентских запросов. Этот код находится в файле Iterative_Log-
ging_Server. срр.
♦include "ace/Log_Msg.h"
♦include "Iterative_Logging_Server.h"
int main (int argc, char *argv(])
(
Iterative_Logging_Server server;
if (server.run (argc, argv) == -1)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "server.run()") , 1) ;
return 0;
Этот пример показывает насколько проще программировать сетевые при-
ложения, используя АСЕ, а не вызовы Socket API, написанных на языке С. Вся,
свойственная Socket API, «случайная» сложность, о которой шла речь в разде-
ле 2.3, устранена, благодаря применению классов интерфейсных фасадов АСЕ.
Поскольку эта сложность устранена, разработчики могут сосредоточиться на
стратегических задачах приложения. Заметьте, что большая часть показанного
нами кода касается специфических для приложения задач маршалинга/демар-
шалинга и ввода/вывода в методах Logging_Handler, рассмотренных в раз-
деле 4.4.1, а не «традиционных» задач управления сокетами, буферами или по-
рядком байтов, как это бывает в приложениях с программированием Socket
API.
Однако не смотря на многочисленные усовершенствования, возможности
нашей первой реализации сервера регистрации ограничены самим дизайном
112
Глава 4
последовательного сервера. Следующие примеры в этой книги показывают как
паттерны параллелизма и интерфейсные фасады АСЕ помогают снять и эти
проблемы. Так как в сервере регистрации роли Logging_Server и
Logging_Handler разделены, мы сможем изменять детали его реализации,
не изменяя его дизайн в целом.
4.5 Клиентское приложение
Представленное далее клиентское приложение показывает как использо-
вать интерфейсные фасады АСЕ для установления соединений, маршалинга ре-
гистрационных записей и передачи данных серверу регистрации. В данном
примере читаются строки стандартного ввода, каждая строка передается серве-
ру регистрации в отдельной регистрационной записи, работа завершается по-
сле получения из стандартного ввода символа EOF. Сначала мы включаем заго-
ловочные файлы, необходимые классам, которые использует эта программа.
Неплохая мысль включить, в частности, заголовочные файлы АСЕ, относящие-
ся к используемым классам. Например, ace/OS.h включает определение
ACE_DEFAULT_SERVER_HOST, которое мы используем в качестве имени хоста
по умолчанию.
♦include "ace/OS.h"
#include "ace/CDR_Stream.h"
♦include "ace/INET_Addr.h"
♦include "ace/SOCK_Connector.h"
♦include "ace/SOCK_Stream.h"
♦include "ace/Log_Record.h"
♦include "ace/streams.h"
♦include <string>
Мы включаем ace/streams.h, который содержит условные директивы,
повышающие переносимость функций ввода/вывода C++. Основываясь на
конфигурационных установках АСЕ, они подключают нужный заголовочный
файл (например, <iostream> вместо <iostream.h>). Если функции вво-
да/вывода поставляются со стандартной (std) областью видимости имен, файл
ace/streams . h подключает те классы, которые используются в глобальном
пространстве имен.
Мы начинаем с определения класса Logging_Client, метод которого
send () передает одну запись ACE_Log_Record по соединению
ACE_SOCK_Stream. В этом классе реализованы также вспомогательный ме-
тод,. который возвращает ссылку на принадлежащий ему экземпляр
ACE_SOCK_Stream, и деструктор, который закрывает дескриптор базового со-
кета.
class Logging Client
{
public:
Реализация сетевой службы регистрации
ИЗ
// Передает серверу <log__record>.
int send (const ACE_Log_Record &log_record);
// Метод-аксессор.
ACE_SOCK_Stream &peer () { return logging_peer_; }
// Закрывает соединение с сервером.
~Logging_Client () { logging_peer_.close (); )
private:
ACE_SOCK_Stream logging__peer_; // Соединенный с сервером.
I;
Метод Logging_Client: : send () реализует механизм кадрирования
сообщений, описанный в блоке 9, на передающей стороне. Этот метод является
переносимым и интероперабельным, так как он использует оператор вывода
(operator<<) для маршалинга содержимого регистрационной записи в поток
ACE_jDutputCDR.
1 int Logging_Client::send (const ACE_Log_Record &log_record) {
2 const size_t max_payload_size =
3 4 И type ()
4 + 8 / / временная метка
5 + 4 // id процесса
6 + 4 // размер данных
7 + MAXLOGMSGLEN // данные
8 + ACE_CDR::MAX_ALIGNMENT; // заполнение;
9
10 ACE_0utputCDR payload (max_payload_size);
11 payload << log_record;
12 ACE_CDR::ULong length = payload.total_length ();
13
14 ACE_OutputCDR header (ACE_CDR: :MAX_ALIGNMENT 4-8) ;
15 header << ACE_0utputCDR: : from__boolean (ACE_CDR_BYTE_ORDER) ;
16 header << ACE__CDR: :ULong (length);
17
18 iovec iov [2] ;
19 iov[0].iov_base = header.begin ()->rd_ptr ();
20 iov[0].iov_len= 8;
21 iov[l].iov_base = payload.begin ()~>rd_jptr ();
22 iov[l] . iov__len= length;
23
24 return logging_peer_.sendv_n (iov, 2);
25 }
Строки 2-12 Мы выделяем объем памяти, достаточный для всей записи
ACE_Log_Record, помещаем содержимое log_record в payload CDR-no-
тока и получаем количество байтов, занимаемых потоком.
114
Глава 4
Строки 14-16 Затем мы создаем заголовок в виде CDR-кода, так чтобы при-
нимающая сторона могла определить порядок байтов и размер входящего
CDR-потока.
Строки 18-24 Мы используем iovec для рациональной передачи заголов-
ка и полезных данных CDR-потока одним вызовом метода записи-со-сл иянием
sendv_n().
В заключение, мы приводим функцию main () клиентского приложения.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
int main (int argc, char *argv[])
{
u_short logger_port =
argc > 1 ? atoi (argv[l]> : 0;
const char *logger_host «
argc > 2 ? argv[2] : ACE_DEFAULT—SERVER—HOST;
int result;
ACE_INET_Addr server_addr;
if (logger_port ’= 0)
result = server_addr.set (logger_port, logger_host) ;
else
result = server—addr.set ("ace_logger’’, logger_host);
if (result == -1)
ACE_ERROR_RETURN((LM—ERROR,
"lookup %s, %p\n",
logger_port == 0 ? "ace—logger” : argv[l],
logger—host), 1);
ACE—SOCK—Connector connector;
Logging—Client logging—client;
if (connector.connect (logging—client.peer (),
server—addr) < 0)
ACE-ERROR-RETURN ((LM—ERROR,
”%p\n",
"connect ()"),
1) ;
// Ограничивает число читаемых символов каждой записи,
cin.width (АСЕ—Log_Record::MAXLOGMSGLEN);
for (;;) {
std::string user—input;
getline (cin, user—input, ’\n’);
if (!cin || cin.eof ()) break;
ACE—Time—Value now (ACE—OS::gettimeofday ());
ACE—Log—Record log—record (LM—INFO, now,
ACE-OS::getpid ());
Реализация сетевой службы регистрации
115
42 log_record.msg_data (user_input.c_str ());
43
44 if (logging_client.send (log_record) == -1)
45 ACE_ERROR_RETURN ((LMJERROR,
46 "%p\n", "loggihg client.send()"), 1);
47 }
48
49 return 0; // Деструктор клиента закрывает TCP-соединение.
50 }
Строки 3-19 Если в качестве аргументов командной строки передаются TCP
порт и имя хоста, то мы используем их для инициализации конечной точки се-
тевого соединения, на которой сервер регистрации пассивно прослушивает за-
просы на соединение. Иначе мы используем установки по умолчанию.
Строки 21-29 Затем мы пытаемся установить соединение с сервером реги-
страции, используя ACE_INET_Addr, проинициализированный выше. По-
пытка установить соединение осуществляется посредством ACE_SOCK_Con-
nector. Если она удается, то подключается сокет объекта logging_client.
Строки 31-47 В заключение, мы показываем основной цикл обработки со-
бытий клиентского приложения, который осуществляет чтение буферов стан-
дартного ввода и их передачу серверу регистрации, пока-не появится EOF. Класс
ACE_Log_Record хранит информацию, необходимую для регистрации одной
записи и поддерживает методы записи и чтения данных регистрационной запи-
си. Мы используем метод Logging_Client: : send () для упрощения марша-
линга и передачи ACE_Log_Record.
Данное клиентское приложение сетевой регистрации представляет собой
упрощенный вариант сетевой службы регистрации, реализованной в АСЕ. Ре-
альная служба регистрации АСЕ основывается на классе ACE_Lotj_Msg. Мак-
росы, рассмотренные в блоке 10, используют класс ACE_Log_Msg (в частности
его метод ACE_Log_Msg: : log ()). Сам код клиента службы регистрации, по-
сле устранения «случайной» сложности, является относительно простым. По-
этому, по мере того как мы будем продолжать разработку сервера регистрации
в этой книге, примеры будут касаться серверов, а не клиентов, так как, именно,
серверы демонстрируют решения наиболее интересных проблем демультип-
лексирования, параллелизма и синхронизации.
4.6 Резюме
В данной главе мы применили интерфейсные фасады АСЕ Socket и
ACE-классы буферизации и маршалинга/демаршалинга сообщений для пер-
вой клиент/серверной реализации нашей сетевой службы регистрации. Мы и
дальше будем использовать эти ACE-классы на всем протяжении книги, чтобы
обеспечить переносимость, лаконичность и эффективность реализаций нашей
сетевой службы регистрации. Служба регистрации в полном объеме представ-
ляет собой подмножество компонентов сетевых служб АСЕ, которые рассмот-
рены в разделе 0.4.4.
Часть II
Программирование
параллельных
объектно-ориентированных
сетевых приложений
Глава 5
Аспекты проектирования:
параллелизм
Краткое содержание
Для разработки масштабируемых и надежных сетевых приложений, осо-
бенно серверов, параллелизм является важнейшим аспектом. Эта глава посвя-
щена предметному анализу аспектов проектирования, связанных с параллелиз-
мом, которые определяют стратегии и механизмы организованного использо-
вания процессов, потоков и их синхронизации. В этой главе мы рассматриваем
следующие аспекты проектирования:
• Последовательные, параллельные и взаимно-согласованные серверы.
• Процессы и потоки (thread).
• Стратегии создания процессов/потоков.
• Модель пользовательских потоков, потоков ядра и гибридная модель.
• Классы планирования с разделением времени и в реальном времени.
• Архитектуры, ориентированные на задачи и на сообщения.
5.1 Последовательные, параллельные
и взаимно-согласованные серверы
Серверы можно классифицировать на последовательные (iterative), парал-
лельные (concurrent) и взаимно-согласованные (reactive). Первый вариант со-
четает простоту программирования со способностью масштабироваться при
увеличении объема услуг и нагрузки хоста.
Последовательные серверы обрабатывают каждый клиентский запрос пол-
ностью, прежде чем обслуживать следующие запросы. Поэтому в процессе обра-
ботки запроса последовательный сервер ставит дополнительные запросы в оче-
редь или игнорирует их. Последовательные серверы лучше всего подходят для:
120
Глава 5
(1) Пос\вдо«лельмый/»эаимн^ сервер
(2) Параллельный сервер
Рис. 5.1
Последовательный/взаимно-согласованный и параллельный серверы
• Краткосрочных услуг, таких как стандартные сервисы Internet ECHO и
DAYTIME, которые имеют минимальный разброс времени выполнения.
• Редко используемых служб, таких как служба резервного копирования
удаленной файловой системы, которая работает по ночам, когда загрузка
комплексов минимальна.
Разрабатывать последовательные серверы относительно просто. Как пока-
зано на рис. 5.1 (1), такие серверы часто обрабатывают запросы на обслужива-
ние в пределах адресного пространства одного процесса, что демонстрирует
следующий псевдокод:.
void iterative_server ()
{
инициализировать конечную(ые) точку(и) прослушивания
for (каждого нового клиентского запроса) {
получить следующий запрос от источника ввода
выполнить запрос на обслуживание
if (требуется ответ) отправить ответ клиенту
)
)
Вследствие такой итеративной структуры, обработка каждого запроса се-
риализуется на уровне относительно крупных модулей, например, на уровне
интерфейса между приложением и демультиплексором синхронных событий
ОС, таким как select () или WaitForMultipleObjects (). Однако на та-
ком «крупно-модульном» уровне параллелизма возможно неполное использо-
вание некоторых ресурсов обработки (например, нескольких процессоров), а
также всех возможностей ОС (таких как поддержка параллельной DMA-переда-
чи к/от устройствам I/O), которые имеются на платформе хоста.
Аспекты проектирования: параллелизм
121
Последовательные серверы могут также препятствовать успешной работе
клиентов, заставляя их ждать, пока сервер обработает их запросы. Продолжи-
тельные задержки на сервере усложняют приложение и расчет тайм-аутов
ретрансляции на уровне промежуточного слоя, что может привести к избыточ-
ному сетевому трафику. В зависимости от типов протоколов, используемых
для обмена запросами между клиентом и сервером, сервер может также полу-
чать дубликаты запросов.
Параллельные серверы обрабатывают множество запросов от клиентов
одновременно, см. рис. 5.1 (2). В зависимости от аппаратной платформы и
ОС параллельный сервер реализует свои сервисы, используя или несколько по-
токов, или несколько процессов. Если сервер реализует один сервис, то одно-
временно может выполняться несколько копий этого сервиса. Если же сервер
реализует несколько сервисов, то несколько копий разных сервисов также мо-
гут выполняться одновременно.
Параллельные серверы хорошо подходят службам, связанным с вво-
дом/выводом, и/или с продолжительным и разным по времени обслуживани-
ем. В отличие от последовательных, параллельные серверы дают возможность
использовать более сложные методы синхронизации, которые сериализуют за-
просы на прикладном уровне. Такое решение требует использования механиз-
мов синхронизации, связанных с блокировками типа семафоров или мьютексов
[ЕКВ+92], чтобы гарантировать надежное взаимодействие и совместное исполь-
зование данных одновременно работающими процессами и потоками. Мы рас-
смотрим эти механизмы в главе 6, а в главе 10 приведем примеры их использо-
вания.
Как мы узнаем в разделе 5.2, параллельные серверы могут быть устроены
по-разному, например, они могут использовать или множество процессов, или
множество потоков. Распространенным вариантом организации параллельно-
го сервера является модель поток-на-запрос (thread-per-request), в которой ос-
новной (master) поток создает отдельный рабочий (worker) поток для парал-
лельной обработки каждого клиентского запроса:
void master_thread ()
(
инициализировать конечную(ые) точку(и) прослушивания
for (каждого нового клиентского запроса) (
принять запрос
создать новый рабочий поток и передать запрос этому потоку
)
)
Основной поток продолжает прослушивание новых запросов, пока рабо-
чий поток обрабатывает клиентский запрос, следующим образом:
void worker_thread ()
{
выполнить запрос на обслуживание
122
Глава 5
if (требуется ответ) отправить ответ клиенту
завершить поток
)
Модель поток-на-запрос можно легко модифицировать, чтобы реализо-
вать другие модели параллельных серверов, такие как поток-на-соединение
(thread-per-connection):
void master_thread ()
{
инициализировать конечную(ые) точку(и) прослушивания
for (каждого нового клиентского запроса) (
принять соединение
создать новый рабочий поток и передать соединение
этому потоку
)
)
В этой модели основной поток продолжает прослушивать новые запросы
на соединение, пока рабочий поток обрабатывает клиентские запросы от дан-
ного соединения, следующим образом:
void worker_thread ()
{
for (каждого запроса на соединение) (
принять запрос
выполнить запрос на обслуживание
if (требуется ответ) отправить ответ клиенту
)
)
Модель поток-на-соединение обеспечивает хорошую поддержку для рабо-
ты с приоритетами клиентских запросов. Например, соединения с клиентами
с высоким приоритетом могут быть ассоциированы с высокоприоритетными
потоками. Запросы от клиентов с более высоким приоритетом будут, поэтому
обслуживаться раньше запросов от клиентов с меньшим приоритетом, так как
у ОС есть возможность вытеснять потоки с более низким приоритетом.
В разделе 5.3 демонстрируются также некоторые другие модели параллель-
ных серверов, такие как пул потоков (threadpool) и пул процессов.
Взаимно-согласованные серверы обрабатывают множество запросов
практически одновременно, хотя вся обработка на самом деле выполняется од-
ним потоком. До того как получили широкое распространение платформы ОС
с поддержкой многопоточности, параллельная обработка часто осуществля-
лась на основе стратегии демультиплексирования синхронных событий, при
которой множество запросов на обслуживание обрабатывалось в цикличе-
ски-круговом порядке однопоточным процессом. Например, таким образом
работает стандартный сервер X Windows.
Аспекты проектирования: параллелизм.
123
Взаимно-согласованный сервер может быть реализован за счет явного
квантования времени, выделяемого на каждый запрос, посредством механиз-
мов демультиплексирования синхронных событий, таких как select () и
WaitForMultipleObjects () .рассмотренных вглаве6. Следующий псевдо-
код иллюстрирует типичный стиль программирования, используемый во вза-
имно-согласованный сервере, использующем select ():
void reactive server ()
{
инициализировать конечную(ые) точку(и) прослушивания
// Цикл обработки событий.
for (;;) {
select () на множестве конечных точек для клиентских запросов
for (каждого активного клиентского запроса) {
принять соединение
выполнить запрос на обслуживание
if (требуется ответ) отправить ответ клиенту
)
J
)
Хотя такой сервер может обслужить множество клиентов за некоторый
промежуток времени, по своей сути, как серверный процесс он является после-
довательным. Поэтому по сравнению с теми преимуществами, которые дает
использование реализованной в полном объеме многопоточности, приложе-
ния, разработанные с помощью данного подхода имеют следующие ограниче-
ния:
• Увеличение сложности программирования. Некоторые типы сетевых
приложений, такие как серверы, связанные с вводом/вы во дом, трудно
программировать в модели взаимно-согласованного сервера. Разработ-
чики должны, например, отвечать за все детали создания потока обработ-
ки событий и сохранять и восстанавливать «вручную» информацию о
контексте. Поэтому, чтобы клиенты ощутили, что их запросы обрабаты-
ваются параллельно, а не последовательно, каждый запрос должен вы-
полняться за относительно короткий промежуток времени. Длительные
операции, такие как загрузка большого файла, также должны програм-
мироваться в явном виде как конечные автоматы, которые отслеживают
этапы обработки одного объекта, реагируя в то же время на события
с другими объектами. Такой дизайн может стать громоздким по мере
увеличения числа состояний.
• Снижение надежности и производительности. Может «зависнуть» весь
серверный процесс, если произойдет сбой одной операции, например,
если обслуживающий процесс попадает в бесконечный цикл или в тупи-
ковую ситуацию (deadlock). Кроме того, даже если процесс продолжает
функционировать, его производительность будет падать, если ОС бло-
кирует весь процесс, пока одна из служб вызывает системную функцию
124
Глава 5
или обращается к несуществующей странице памяти. Если же использо-
вать только неблокируемые методы, то будет трудно повысить произво-
дительность за счет таких эффективных методов, как DMA, которые
обеспечивают выигрыш за счет локальности ссылок в кэшах данных и ко-
манд. Как следует из главы 6, механизмы многопоточности ОС могут
преодолевать эти ограничения производительности путем автоматиза-
ции вытесняющего и параллельного выполнения независимых служб,
работающих в отдельных потоках. Одним из способов урегулировать
эти проблемы, не прибегая к решению в виде полнофункционального
параллельного сервера, является использование асинхронного ввода/вы-
вода, рассмотренного в блоке 11.
Блок 11: Асинхронный ввод/вывод и активные (proactive)
серверы' ' .-У’?.4.."
Еще одним механизмом обработки множества потоков ввода/вывода однопо-
точным сервером является асинхронный I/O. Этот механизм позволяет серве-
ру инициировать запросы на ввод/вывод через один или нёсколькодескрипто-
ров.ввода/вывода, не дожидаясь завершения. Вместо блокировки, ОС сооб-
щает серверу, когда запросы выполнены, и сервёр может продолжить
обработку для тех дескрипторов, которые завершили процедуры ввода/выво-
да. Асинхронный ввод/вывод реализован на следующих платформах ОС:
• Асинхронный ввод/вывод поддерживается в Win32 через ввод/выврд спере-
крытием (overlapped) и портами расширенного (completion) вёоДа/вывода
(Ric97,Sol98). ' ' ' ' .
• На некоторых POSIX-совместимых платформах: реализовано семейство
функций асинхронного ввода/вывода aio_* О (P.OS95, Gal95).
Однако поскольку асинхронный ввод/вывод не имеет таких же переносимых
реализаций как многопоточность или демультиплексирование синхронных
событий, то мы не будем его рассматривать в дальнейшем в этой книге.
Асинхронный ввод/вывод обсуждается в (SH). при рассмотрении АСЕ-карка-
са Proactor, который является реализацией паттерна Proactor (SSRBOO). Этот
паперн позволяет приложениям с управлением по событиям эффективно осу-
ществлять демультиплексирова ние и диспетчеризациюзапросрв на обслужи-
вание, когда они инициируются по завершении асинхрфн.нь)Х операций, дос-
тигая, таким образом, преимуществ в производитёльн6рти,!хф^1аёрнь1х для
параллельного выполнения, и избегая некоторых .ero'rie^,TCTdfr<OB. АСЕ-кар-
кас Proactor реализован в Win32 и на POSIX-совместймыХ'ПХатформах, кото-
рые поддерживают семейство функций асинхронного ввода/вывода a io_* ().
Служба регистрации => Для простоты, в первой реализации нашей службы
сетевой регистрации в главе 4 использована модель последовательного сервера.
В следующих главах возможности и масштабируемость нашего сервера ре-
гистрации расширятся: в главе 7 демонстрируется расширение сервера в соот-
ветствии со взаимно-согласованной моделью, в главе 8 показана параллельная
модель, использующая множество процессов, а в главе 9 показано несколько
параллельных моделей, использующих множество потоков.
Аспекты проектирования: параллелизм
125
Процесс
s Локальный IPC
Ж®
Процесс Процесс
X
(2) многопоточность
(1) многозадачность
Рис. 5.2
Многозадачность и многопоточность
5.2 Процессы и потоки
В разделе 5.1 были изложены преимущества параллельных серверов, кото-
рые могут быть реализованы на базе множества процессов или множества пото-
ков. Основные варианты этого аспекта затрагивают надежность, эффектив-
ность и масштабируемость.
Многозадачность. Процесс — элемент ОС, обеспечивающий контекст для
выполнения программы. Каждый процесс располагает некоторыми ресурсами,
такими как виртуальная память, дескрипторы ввода/вывода и обработчики
сигналов, и защищен от других процессов ОС на аппаратном уровне посредст-
вом блока управления памятью (memory management unit, MMU). Процессы,
созданные с помощью fork () в UNIX и CreateProcess () в Win32, выпол-
няются параллельно в отдельных адресных пространствах, не связанных с соз-
давшими их процессами. Подробно эти механизмы рассматриваются в главе 8.
Операционные системы более ранних поколений, например, BSD UNIX
[MBKQ96], могли создавать процессы только с одним потоком управления.
Модель однопоточных процессов может быть более надежной, так как процес-
сы не могут повлиять друг на друга без прямого вмешательства программиста.
Процессы могут работать совместно только через общую память или локаль-
ные механизмы IPC, см. рис. 5.2 (1).
Однако однопоточные процессы трудно использовать для разработки не-
которых типов приложений, особенно высокопроизводительных серверов или
серверов реального времени.
Серверы, которым нужно взаимодействовать друг с другом или отвечать на
запросы по обслуживанию должны использовать какую-то форму IPC, что
приводит к их усложнению. Кроме того, при использовании многозадачности,
трудно осуществлять эффективный, детальный контроль за планированием и
приоритетами процессов.
Многопоточность. Чтобы смягчить проблемы с процессами, отмеченные
выше, большинство платформ ОС в настоящее время поддерживает множест-
во потоков внутри одного процесса. Поток — это одна из последовательностей
126
Глава 5
команд, выполняемая в контексте защищенного пространства процесса, см.
рис. 5.2 (2). Кроме указателя команд, поток управляет такими ресурсами, как
стек (времени выполнения) записей активизации функций, набор регистров,
сигнальные маски, приоритеты и принадлежащие потоку данные. Если имеется
несколько процессоров, то обслуживание в многопоточных серверах может
осуществляться параллельно [ЕКВ+92]. Во многих версиях UNIX потоки созда-
ются вызовом pthread_create (); в Win32 — вызовом CreateThread ().
Реализация параллельных сетевых приложений, которые выполняют мно-
жество операций в отдельных потоках, а не в отдельных процессах, может
уменьшить следующие источники издержек, связанных с параллельным вы-
полнением:
• Создание потоков и переключение контекстов. Так как потоки поддер-
живают меньше информации о состоянии, чем процессы, то накладные
расходы на создание потоков и переключение контекстов могут быть
меньше, чем на соответствующие действия, связанные с жизненным
циклом процессов. Например, ресурсы, относящиеся к уровню процесса,
такие как отображения виртуальных адресов и кэши, не нужно менять
при переключении с одного потока процесса на другой.
• Синхронизация. При планировании и выполнении прикладного потока,
переключение между режимом ядра и пользовательским режимом мо-
жет оказаться не нужным. Также как синхронизация внутри процесса
часто является менее накладной, чем синхронизация между процессами,
поскольку синхронизируемые объекты внутри процесса являются ло-
кальными и, поэтому, могут не требовать вмешательства ядра. Напро-
тив, синхронизация потоков разных процессов в общем случае требует
вмешательства ядра ОС.
• Копирование данных. Потоки имеют возможность работать с общей ин-
формацией, используя локальную память процесса, что дает следующие
преимущества:
1. Часто это эффективнее, чем использование для взаимодействия меж-
ду процессами общей памяти или локальных механизмов IPC, по-
скольку не нужно копировать данные с участием ядра.
2. Проще использовать объекты C++ в локальной памяти процесса, так
как нет проблем с размещением виртуальных таблиц классов (см.
блок 3 на стр. 30).
Например, сервисы взаимосвязанных баз данных, обращающиеся к общим
структурам, расположенным в локальной памяти процесса, проще и эффек-
тивнее реализовать в виде нескольких потоков, чем нескольких процессов.
Как следствие такого рода оптимизации, многопоточность зачастую может
способствовать значительному повышению производительности приложения.
Например, приложения, ориентированные на ввод/вывод, могут выиграть за
счет многопоточности, так как операции, требующие интенсивных вычисле-
ний, могут выполняться параллельно с дисковыми и сетевыми операциями.
Однако то, что некоторая платформа ОС поддерживает потоки, не означает,
что все приложения должны быть многопоточными. В частности, использова-
Аспекты проектирования: параллелизм
127
ние многопоточности при реализации параллельных приложений приводит
к следующим ограничениям:
• Снижение производительности. Широко распространенным является
заблуждение, что поточная обработка сама по себе улучшает производи-
тельность приложения. Часто, тем не менее, поточная обработка не улуч-
шает производительность по цёлому ряду причин, включая:
1. Приложения, ориентированные на вычисления, на однопроцессор-
ной системе не получат преимуществ от введения поточной обработ-
ки, поскольку вычисления и обмен информацией не могут выпол-
няться параллельно.
2. Многоуровневые стратегии блокировки могут привести к большим
непроизводительным издержкам, связанным с синхронизацией, что
не позволяет приложениям полностью использовать преимущества
параллельной обработки [SS95].
• Снижение надежности. С целью сокращения переключений контекстов и
издержек синхронизации, потоки или имеют незначительную защиту
MMU одного потока от другого или вообще ее не имеют. Выполнение всех
задач на основе потоков в адресном пространстве одного процесса может
снизить надежность приложения по нескольким причинам, включая:
1. Отдельные потоки внутри адресного пространства одного процесса
не достаточно хорошо защищены друг от друга. Одна некорректно
работающая в процессе служба может, следовательно, разрушить
глобальные данные, совместно используемые службами, которые
выполняют другие потоки этого же процесса. Это, в свою очередь,
может привести к некорректным результатам, аварийному отказу
процесса в целом или к бесконечному зацикливанию приложения.
2. Некоторые функции ОС, вызванные в одном потоке, могут привести
к нежелательным побочным эффектам для всего процесса; например,
функции UNIX exit () и Win32 ExitProcess () в качестве «побоч-
ного» эффекта приводят к завершению всех потоков процесса.
• Отсутствие на уровне потоков управления доступом. В большинстве
операционных систем процесс является единицей управления доступом.
Поэтому еще одним ограничением, связанным с многопоточностью, яв-
ляется то, что потоки внутри процесса имеют один и тот же ID пользова-
теля и одинаковые привилегии доступа к файлам и другим защищенным
ресурсам. Чтобы предотвратить случайный иди преднамеренный несанк-
ционированный доступ к ресурсам, сетевые службы, например, TELNET,
которые основывают свои механизмы защиты на владении процессами,
часто работают в отдельных процессах.
Служба регистрации => Параллельные реализации сервера нашей сетевой
службе регистрации могут быть реализованы разными способами. В главах 8 и
9, для реализации параллельных серверов регистрации, используются, соответ-
ственно, множество процессов и множество потоков.
128
Глава 5
5.3 Стратегии создания процессов/потоков
Существуют различные стратегии создания процессов и потоков. Эти стра-
тегии могут быть использованы с целью оптимизации производительности па-
раллельных серверов в зависимости от условий, позволяя, таким образом, раз-
работчикам настраивать уровни параллелизма, чтобы согласовать их с требова-
ниями клиентов и имеющимися в ОС ресурсами обработки. Как показано
ниже, выбор других стратегий снизил издержки, связанные с запуском, и уве-
личил потребление ресурсов.
Активное создание (eager spawning). При этой стратегии в момент созда-
ния серверного процесса в режиме упреждения создаются один или несколько
процессов ОС или потоков. Эти исполнительные ресурсы, создаваемые в режи-
ме «горячего запуска» («warm-started»), образуют пул, улучшающий время от-
клика за счет накладных расходов в момент запуска службы, еще до начала об-
служивания запросов. Этот пул может быть развернут или создан статически
и/или динамически в зависимости от различных факторов, таких как количест-
во доступных процессоров, текущая загруженность машины или длина очере-
ди клиентских запросов. На рис. 5.3(1) изображена стратегия активного порож-
дения для потоков. Такой дизайн использует паттерн Half-Sync/Half-Async
[SSRBOO], который передает запросы с уровня ввода/вывода рабочему потоку
пула.
Альтернативной стратегией активного создания является стратегия управ-
ления пулом потоков с помощью паттерна Leader/Followers [SSRBOO], см.
рис. 5.3 (2). Этот паттерн определяет эффективную модель параллелизма, при
которой множество потоков работают, совместно используя множество источ-
ников событий, чтобы обнаруживать, демультиплексировать, диспетчеризиро-
вать и обрабатывать запросы на обслуживание, которые возникают в источни-
ках событий. Паттерн Leader/Followers может быть использован вместо паттер-
на Half-Sync/Half-Async для улучшения производительности в случае
Предварительно созданные потоки
Предварительно созданные потоки
Лоток-лидер
Ведомые потоки
(2) стратегия Leodef/Followers
Рис. 5.3
Стратегии активного создания пула потоков
Аспекты проектирования: параллелизм
129
отсутствия синхронизации или ограничений на очередность обработки запро-
сов пулом потоков.
Создание по требованию порождает новый процесс или поток в ответ на
новое соединение с клиентом и/или на поступление запросов на данные, также
как в моделях поток-на-запрос и поток-на-соединение, рассмотренных в разде-
ле 5.1. На рис. 5.4 показана эта стратегия для потоков. Основное преимущество
стратегий создания по требованию заключается в меньшем потреблении ресур-
сов. Недостатком, однако, является то, что эти стратегии могут снижать произ-
водительность сильно загруженных серверов и детерминизм систем реального
времени из-за издержек на создание процессов/потоков и запуск служб.
3:recv(msg)
4 cprocexx(mag)
Поток по
требованию
Другие работающие
потоки по требованию
Поток по
требованию
Поток по
требованию
Демультиплексор
г?; событий •
Поток-
диспетчер
Рис. 54
Стратегия создания потоков по требованию типа поток-на-запрос
Служба регистрации => В разделе 9.2 представлен сервер регистрации, реа-
лизованный в соответствии со стратегией создания по требованию типа по-
ток-на-соединение. Примеры, иллюстрирующие стратегии активного созда-
ния, представлены в [SH]. Там мы показываем как ACE-каркасы могут быть
применены для реализации обеих моделей пула потоков и half-sync/half-async,
и leader/followers.
5 А Модель пользовательских потоков, потоков
ядра и гибридная модель
Планирование является основным механизмом, с помощью которого
ОС гарантирует корректное использование приложениями процессорных ре-
сурсов хоста. Потоки являются единицами планирования и выполнения в мно-
гопоточных процессах. Платформы современных ОС реализуют различные
модели планирования потоков, создаваемых приложениями. Основным отли-
чием этих моделей является область состязаний (contention scope), в которой по-
токи конкурируют за системные ресурсы, в частности за процессорное время.
Существуют две разные области состязаний:
130
Глава 5
• Область состязаний на уровне процесса, в которой потоки одного процес-
са конкурируют друг с другом (но не непосредственно с потоками других
процессов) за распределяемое процессорное время.
• Область состязаний на уровне системы, в которой потоки конкурируют
с другими потоками в области действия системы, независимо от того,
к какому процессу они относятся.
Три модели планирования потоков реализованы в наиболее распростра-
ненных операционных системах:
• модель пользовательских потоков N: 1;
• модель потоков ядра 1:1;
• гибридная модель потоков N:M.
Ниже мы описываем эти модели, обсуждаем связанные с ними альтернати-
вы и показываем каким образом они поддерживают различные области состя-
заний.
Модель пользовательских потоков N:l. Ранние реализации поточности
создавались поверх механизмов управления процессами и управлялись биб-
лиотеками, расположенными в пользовательском пространстве. Ядро ОС, по-
этому, вообще ничего не знало о потоках. Ядро планировало процессы, а биб-
лиотеки управляли п потоками одного процесса, см. рис.5.5 (1). Отсюда назва-
ние модели пользовательских потоков «N:!», а потоки назывались «потоками
пользовательского пространства» или просто «пользовательскими потоками».
В модели поточности N:1 все потоки работают в области состязаний на уровне
процесса.
HP-UX 10.20 и SunOS 4.x являются примерами платформ, реализующих
модель пользовательских потоков N:l.
Процессы Процессы
(1) Модель пользовательских потоков N: 1 (2) Модель потоков ядра 1:1
Рис. 5.5
Модели ПОТОКОВ N:1 и 1:1
Аспекты проектирования: параллелизм
131
В модели поточности Ы:1, ядро не участвует ни в событиях жизненного
цикла потоков, ни в переключении контекстов в том же процессе. Создание,
уничтожение и переключение контекстов потоков, поэтому, может быть очень
эффективным. Ирония заключается в том, что и две основные проблемы моде-
ли N:1, также вытекают из факта, что ядру ничего неизвестно о потоках:
1. Независимо от количества процессоров хоста, каждый процесс планирует-
ся только на одном. Все потоки процесса борются за этот процессор, совме-
стно используя все выделенные кванты времени, которые ядро может ис-
пользовать при планировании процессов.
2. Если какой-то из потоков выполняет операцию, требующую блокировки,
например, чтение из файла read () или запись в файл write (), то все по-
токи этого процесса блокируются до момента завершения указанной опе-
рации. Многие реализации N:l, наиболее известная из них DCE Threads,
* предусматривают оболочки для системных функций ОС, чтобы смягчить
это ограничение. Однако эти оболочки не являются полностью прозрачны-
ми и у них есть свои ограничения, касающиеся поведения программ. Тем не
менее, это нужно знать, чтобы избежать их негативного влияния на прило-
жение.
Модель потоков ядра 1:1. Ядра большинства современных ОС обеспечива-
ют прямую поддержку потоков. В модели потоков ядра «1:1» каждый поток,
созданный приложением, непосредственно управляется потоком ядра. Ядро
ОС распределяет каждый поток ядра по процессорам, имеющимся в системе,
см. рис. 5.5 (2). Однако в модели «1:1» все потоки действуют в области состяза-
ний на уровне системы. Примерами платформ, обеспечивающих модель пото-
ков ядра «1:1», являются HP-UX 11, Linux и Windows NT/2000.
Модель 1:1 решает следующие две проблемы модели N:l, отмеченные
выше:
• Приложения с поддержкой многопоточности могут извлечь пользу из
наличия нескольких процессоров, если они имеются в системе.
• Если ядро блокирует один из потоков при выполнении им системной
функции, другие потоки могут продолжать выполняться..
Тем не мене, поскольку в создании й планировании потоков участвует ядро
ОС, операции, связанные с жизненным циклом потоков, могут стоить «доро-
же», чем в модели N:l, хотя в общем случае остаются более «дешевыми», чем
операции, связанные с жизненным циклом процессов.
Гибридная модель потоков N:M. Некоторые операционные системы, на-
пример Solaris [ЕКВ+92], предлагают комбинацию моделей N: 1 и 1:1, которая на-
зывается гибридной моделью потоков «N:M». Эта модель поддерживает смесь
пользовательских потоков и потоков ядра. Гибридная модель показана на
рис. 5.6. При создании потока приложение может указать в какой области состя-
заний должен действовать этот поток (по умолчанию в Solaris область состяза-
ний назначается на уровне процесса). Библиотека поточной обработки ОС соз-
дает поток в пользовательском пространстве, а поток ядра создается только
в том случае, если это необходимо или если приложение в явном видезапраши-
132
Глава 5
вает область состязаний на уровне системы. Так же, как в модели 1:1, ядро
ОС распределяет потоки ядра по процессорам системы. Однако библиотека по-
точной обработки ОС, как в модели N: 1, распределяет потоки пользовательско-
го пространства по так называемым «легковесным процессам» («lightweight
processes», LWP), которые, в свою очередь, отображаются 1:1 на потоки ядра.
Проницательный читатель заметит, что в модели N:M вновь всплывает на
поверхность проблема, заключающаяся в том, что множество потоков пользо-
вательского пространства может быть блокировано, когда один из них вызыва-
ет блокирующую системную функцию. Когда ядро ОС блокирует LWP, все
пользовательские потоки, отнесенные к нему библиотекой поточной обработ-
ки, также будут блокированы, тем не менее потоки других LWP данного про-
цесса могут продолжать выполнение. Ядро Solaris решает эту проблему с помо-
щью следующего двойного подхода, основанного на концепции активизации
планировщика | ABLL92]:
Рис. 5-6
Гибридная модель потоков N:M
1. Библиотека поточной обработки ОС поддерживает пул LWP, которые она
использует для выполнения всех потоков, ограниченных областью процес-
са. Если возникает необходимость, она может перераспределить эти поль-
зовательские потоки среди имеющихся в пуле LWP. Размер этого пула мо-
жет быть установлен с помощью функции Pthreads pthread_setcon-
currency().
Аспекты проектирования: параллелизм
133
2. Если ядро ОС замечает, что все потоки ядра в процессе блокированы, оно
посылает сигнал SIGWAITING тем процессам, которых это касается. Биб-
лиотека поточной обработки перехватывает этот сигнал и может создать
новый LWP. Затем она может перераспределить поток, ограниченный об-
ластью процесса, на новый LWP, давая приложению возможность продол-
жить выполнение.
Не все платформы ОС позволяют влиять на то, каким образом потоки соз-
даются и как им выделяются системные ресурсы. Вы должны знать что, кон-
кретно, позволяет делать ваша платформа(ы) и как функционируют потоки,
чтобы сделать максимум того, что вы должны сделать. Подробное обсуждение
механизмов параллелизма ОС можно найти в [Lew95, But97, Ric97, Sol98,
Sch94]. Неправильное использование потоков, как и любого мощного много-
функционального инструмента, может принести вред. Например, какую об-
ласть состязаний выбрать? Ответ зависит от того, по какой из перечисленных
далее причин вы создали поток, а также от того насколько он должен быть неза-
висимым от других потоков вашей программы:
* Создание потоков с целью ограничить влияние других задач. Некото-
рые задачи требуют, чтобы в процессе их выполнения вмешательство
других потоков процесса или даже всех потоков системы, было мини-
мальным. Вот некоторые из примеров:
Поток, который должен быстро реагировать на какой-нибудь сигнал,
например, отслеживать движение мыши или отключение рубильни-
ка электростанции.
Задача, которую нужно изолировать от других задач потому, что она
интенсивно использует процессор.
Задача с интенсивным вводом/выводом в многопроцессорной системе.
В этих случаях, каждый поток должен планироваться автономно и иметь
минимальное взаимодействие с другими потоками приложения. Чтобы
достичь этой цели, используйте поток с областью состязаний на уровне
системы, чтобы избежать планирования нового потока относительно
других потоков одного и того же потока ядра и разрешить ОС использо-
вать несколько процессоров. Если ваша система поддерживает модель
N:M, запрашивайте область состязательности на уровне системы в явном
виде. Если ваша система предлагает модель 1:1, вам повезло, вы получите
область состязаний на уровне системы в любом случае. На системах Nd,
впрочем, вам, возможно, не так повезет.
• Создание потоков с целью упростить структуру приложения. Чаще
всего бывает разумным сохранять имеющиеся ресурсы ОС на случай
трудных ситуаций. Основным побуждением при создании потоков мо-
жет быть упрощение структуры приложения путем декомпозиции на от-
дельные логические задачи, типа операций технологического процесса,
которые выполняют отдельную операцию с данными и передают их сле-
дующей операции. В этом случае, вы избавляетесь от издержек на поток
ядра, еслц вам достаточно возможностей потоков с областью действия на
134
Глава 5
уровне процесса, которые создаются по умолчанию в системах N:1 или по
запросу в модели N:M. Использование потоков с областью действия на
уровне процесса имеет следующие последствия:
Оставаясь самостоятельными элементами приложения, эти потоки
не требуют дополнительного вовлечения ядра в создание, планиро-
вание и синхронизацию потоков.
Поскольку потоки с областью действия на уровне процесса находят-
ся в состоянии ожидания в связи с решением задач синхронизации,
например, ожиданием освобождения мьютекса, а не в связи с вызо-
вом блокируемых системных функций, то процессу в целом или по-
току ядра не грозит внезапная блокировка.
Хотя многопоточность может, особенно поначалу, казаться пугающей, по-
токи способны упростить проекты ваших приложений как только вы освоите
паттерны синхронизации [SSRBOO] и механизмы параллелизма ОС. Например,
вы можете выполнять синхронный I/O из одного или нескольких потоков, что
приведет к более простым решениям по сравнению с синхронными или асин-
хронными паттернами обработки событий, такими как Reactor или Proactor, со-
ответственно. Мы обсудим механизмы параллелизма ОС в главе 6, а интер-
фейсные фасады АСЕ, связанные с поточностью и синхронизацией, которые
инкапсулируют эти механизмы в главах 9 и 10.
Служба регистрации =ф Наши реализации сервера регистрации в остальной
части этой книги демонстрируют различные интерфейсные фасады АСЕ, свя-
занные с параллельной обработкой. Эти примеры-используют потоки с обла-
стью состязаний на уровне системы, то есть потоки ядра 1:1, в том случае, если
назначение потока выполнять I/O, например, получение регистрационных за-
писей от клиентов. Такое решение гарантирует, что блокируемый вызов при
получении данных от сокета не приведет к непреднамеренному блокированию
каких-то других потоков или всего процесса.
5.5 Классы планирования с разделением
времени и в реальном времени
Дополнительно к областям состязаний и моделям поточности, рассмотрен-
ным в разделе 5.4, платформы ОС часто определяют политики и уровни при-
оритетов, которые оказывают дополнительное влияние на характер изменения
планирования [But97]. Эти функциональные возможности позволяют совре-
менным операционным системам выполнять совокупность приложений с уни-
версальным диапазоном и потребностями планирования в реальном времени.
Ядра ОС могут относить потоки к различным классам планирования и плани-
ровать эти потоки, используя несколько критериев, таких как приоритет и по-
требность в ресурсах. Различные стратегии классов планирования, описанные
ниже, нарушают принцип равноправия для повышения предсказуемости и
управляемости.
Аспекты проектирования: параллелизм
135
Класс планирования с разделением времени. Универсальные планировщи-
ки ОС традиционно ориентированы на интерактивные среды с разделением
времени. Планировщики этих операционных систем обычно являются:
• Основанными на приоритетах — готовый к выполнению поток с самым
высоким приоритетом будет первым в очереди на выполнение.
♦ Справедливыми (fair) — приоритеты потоков в планировщике с разде-
лением времени могут изменяться в зависимости от частоты использова-
ния процессора. Например, в зависимости от того, как много процессор-
ного времени использует связанный с вычислениями и уже долгое время
работающий поток, планировщик с разделением времени может про-
грессивно уменьшать его приоритет пока не будет достигнут нижний
предел.
• Вытесняющими — если выполняется поток с более низким приорите-
том в момент когда готов к работе поток с более высоким приоритетом,
планировщик должен вытеснить поток с более низким приоритетом и
дать возможность выполняться потоку с более высоким приоритетом.
• С квантованием времени, которое используется для передачи управле-
ния потокам с одинаковым приоритетом. В соответствии с этим методом
каждый поток выполняется не больше конечного периода времени (на-
пример, 10 миллисекунд). Когда квант времени работающего в данный
момент потока заканчивается, планировщик выбирает следующий из
имеющихся потоков, выполняет переключение контекста и помещает
вытесненный поток в очередь.
Класс планирования в реальном времени. Хотя планирование с разделе-
нием времени подходит традиционным сетевым приложениям, оно редко
удовлетворяет потребностям приложений реального времени. Например, не
существует фиксированного порядка выполнения для потоков, относящихся
к классу планирования с разделением времени, так как планировщик может из-
менять приоритеты с течением времени. Более того, планировщики с разделе-
нием времени не пытаются ограничить количество времени, необходимое для
вытеснения потока с более низким приоритетом, когда поток с более высоким
приоритетом готов к выполнению.
Поэтому операционные системы реального времени (такие как VxWorks
или LynxOS) и некоторые универсальные операционные системы (такие как
Solaris и Windows NT) предусматривают класс планирования в реальном време-
ни [Kha92], который ограничивает время выполнения в наихудшем случае при
диспетчеризации пользовательских потоков и потоков ядра. Любая ОС с клас-
сом планирования в реальном времени часто поддерживает одну или обе из
следующих политик планирования [Gal95]:
• Циклическую (round-robin) политику, при которой квант времени зада-
ет максимальное время выполнения потока до его вытеснения другим
потоком реального времени с тем же приоритетом.
• Политику очереди (FIFO), при которой поток с более высоким приори-
тетом может работать столько, сколько ему нужно, пока он добровольно
136
Глава 5
не передаст управление или пока не будет вытеснен потоком реального
времени с более высоким приоритетом.
Если ОС поддерживает классы планирования и с разделением времени, и
в реальном времени, то потоки реального времени всегда работают с более вы-
соким приоритетом, чем потоки с разделением времени.
Программы реального времени с большим объемом вычислений могут мо-
нополизировать систему и подавить любую другую деятельность. Большинство
универсальных операционных систем, поэтому, регламентируют эту нежела-
тельную ситуацию, ограничивая применение класса планирования в реальном
времени приложениями, выполняющимися с полномочиями привилегирован-
ного пользователя.
Служба регистрации => Так как служба регистрации не является критичной
ко времени, большинство наших примеров в этой книге используют класс, ус-
танавливаемый ОС по умолчанию, а именно, класс планирования с разделением
времени. Тем не менее, для полноты картины, вариант сервера сетевой регистра-
ции из раздела 9.3 показывает как использовать АСЕ, чтобы написать переноси-
мый сервер регистрации, работающий с классом планирования в реальном вре-
мени.
5.6 Архитектуры, ориентированные на задачи
и на сообщения
Архитектура параллелизма устанавливает связь между:
1. Процессорами (CPU), которые обеспечивают контекст выполнения для
прикладного кода.
2. Управляющими и информационными сообщениями, которые посылают
и принимают одно или несколько приложений и сетевых устройств.
3. Заданиями на обслуживание, которые службы выполняют, когда получа-
ют сообщения и когда отправляют их.
Архитектура параллелизма сетевых приложений является одним из не-
скольких факторов, в наибольшей степени влияющих на их производитель-
ность, поскольку воздействует на переключение контекстов, синхронизацию,
планирование и издержки пересылки данных. Существуют два классических
типа архитектур параллелизма: ориентированные на задачи и на сообщения
[SS93]. Основные компромиссы этого аспекта касаются простоты программи-
рования и производительности.
Архитектуры параллелизма ориентированные на задачи структурируют
множество процессоров в соответствии с отдельными служебными функция-
ми приложения. В этой архитектуре задания являются активными, а сообще-
ния, обрабатываемые заданиями, являются пассивными, см. рис. 5.7 (1). Парал-
лельность достигается путем выполнения заданий на обслуживание на разных
процессорах и передачи информационных и управляющих сообщений между
заданиями/процессорами. Архитектуры параллелизма, ориентированные на
Аспекты проектирования: параллелизм,
137
задачи, могут быть реализованы с помощью паттернов типа producer/consumer
(производитель/потребитель), таких как Pipes and Filters [BMR+96] и Active
Object [SSRBOO], которые мы демонстрируем в [SH].
Архитектуры параллелизма, ориентированные на сообщения структури-
руют процессоры в соответствии с сообщениями, полученными от приложе-
ний и сетевых устройств. В этой архитектуре сообщения являются активными,
азадачи пассивными, см. рис. 5.7 (2).
(1) архитектура параллелизма,
ориентированная на задачи
(2) архитектура параллелизма,
ориентированная на сообщения
Рис. 5.7
Архитектуры параллелизма, ориентированные на задачи и на сообщения
Параллелизм достигается путем одновременного сопровождения множест-
ва сообщений на разных процессорах через стек заданий на обслуживание. Мо-
дели поток-на-запрос, поток-на-соединение и пул потоков могут быть исполь-
зованы для реализации архитектур параллелизма, ориентированных на сооб-
щения. Глава 9 иллюстрирует использование модели поток-на-соединение, а
модель пула потоков показана в [ SH ].
Служба регистрации => В этой книге мы интегрируем поточную обработку
в сетевую службу регистрации, используя архитектуры параллелизма, ориен-
тированные на сообщения, в частности модель поток-на-соединение, которые
часто являются более эффективными, чем архитектуры, ориентированные на
задачи [НР91, SS95]. Архитектуры, ориентированные на задачи, тем не менее,
часто легче программировать, так как синхронизация в пределах задачи или
уровня часто не нужна, поскольку параллелизм сериализуется в точке доступа
138
Глава 5
к задаче, а также между уровнями стека протоколов. Наоборот, архитектуры,
ориентированные на сообщения, бывает труднее реализовать, из-за необходи-
мости более сложного управления параллелизмом.
5.7 Резюме
Сетевые серверы могут ассоциировать один или несколько процессов
ОС или потоков с одной или несколькими прикладными службами. Это требу-
ет принятия решений по нескольким аспектов проектирования, которые влия-
ют на использование потоков и процессов, а также процессорных ресурсов, на
характер планирования и на производительность приложений. В этой главе
приведен анализ многих аспектов параллелизма, которые могут быть исполь-
зованы при проектировании сетевых приложений. Остальные главы этой кни-
ги описывают интерфейсные фасады АСЕ, которые являются результатом про-
веденного анализа. В них мы рассматриваем доводы «за и против» инкапсуля-
ции и использования демультиплексирования синхронных событий,
многозадачности, поточности и механизмов синхронизации, имеющихся в со-
временных операционных системах.
Глава 6
Обзор механизмов параллелизма
операционных систем
Краткое содержание
Сетевым приложениям, особенно серверам, часто приходится обрабаты-
вать запросы параллельно, чтобы соответствовать предъявляемым к ним тре-
бования качества обслуживания. Глава 6 описывает основные варианты про-
ектных решений, связанные с альтернативами параллельной обработки. В гла-
ве приведен обзор демультиплексирования синхронных событий,
многозадачности, многопоточности и механизмов синхронизации, которые
можно использовать при реализации соответствующих проектных решений.
Мы также рассмотрим основные проблемы переносимости и программирова-
ния, которые возникают при разработке сетевых приложений с использовани-
ем АР! ОС С-функций, реализующих параллельную обработку.
6.1 Демультиплексирование синхронных
событий
Демультиплексор синхронных событий — это функция, поддерживаемая
ОС, которая ждет наступления заданных событий на множестве источников со-
бытий. Когда один или несколько источников событий активизируются, эта
функция передает возвращаемое значение вызвавшему ее процессу. Вызвав-
ший ее процесс может, таким образом, обрабатывать события, исходящие от
многих источников. Демультиплексоры синхронных событий часто использу-
ются в качестве основы для реализации циклов обработки событий взаим-
но-согласованного сервера, который отслеживает события от клиентов и реаги-
рует на них последовательным и согласованным образом.
Большинство операционных систем поддерживают одну или несколько
функций демультиплексирования синхронных событий, например:
140
Глава 6
• Функция pol1 () [Rag93], которая ведет свое происхождение из System V
UNIX.
• Функция WaitForMultipleObjects () [Sol98], которая реализована
в Win32.
• Функция select () [Ste98], которая демультиплексирует источники со-
бытий для дескрипторов I/O1.
Мы рассмотрим select (), поскольку это самая распространенная функ-
ция. Сетевые приложения с управлением по событиям могут использовать
select!), чтобы определить для каких дескрипторов можно вызывать опера-
ции I/O синхронно, не блокируя вызвавший их поток приложения. С API для
функции select () приведены ниже:
int select (int width,
fd_set *read_fds,
fd_set *write_fds,
fd_set *except_fds,
struct timeval *timeout);
// Максимальный дескриптор + 1
// Набор "read''-дескрипторов
// Набор "write’’-дескрипторов
// Набор "exception"-дескрипторов
// Время ожидания событий
Структура fd_set представляет собой набор дескрипторов для проверки
событий ввода/вывода (набора дескрипторов). Три параметра fd_set, адреса
которых передаются в read_fds, write_fds и except_fds, проверяются
функцией select (), чтобы узнать какие из ее дескрипторов активизированы
для чтения, для записи или в связи с исключительными ситуациями (такими
как выход данных за пределы диапазона). Функция select () информирует
вызвавший ее процесс об активных и неактивных дескрипторах, изменяя свои
аргументы f d_set указанным ниже образом:
• Если значение дескриптора неактивное fd_set, такой дескриптор игно-
рируется, а его значение будет неактивным в fd_set, возвращаемой
select().
• Если значение дескриптора активно в f d_set, соответствующий деск-
риптор проверяется на наличие событий. Если у данного дескриптора
есть необработанное событие, соответствующее ему значение будет ак-
тивным в fd_set, возвращаемой из select () .Если у данного дескрип-
тора нет необработанного события, его значение будет неактивным
в возвращаемой f d_set.
Каждая платформа ОС предоставляет базовый набор операций, которые
позволяют приложению опрашивать структуры fd_set и оперировать
с ними. И хотя эти операции являются макросами на одних платформах и
функциями на других, они имеют похожие имена и поведение:
Win32 версия функции select)) работает только с дескрипторами сокетов.
Обзор механизмов параллелизма операционных систем
141
Функция Описание |
FD_ZERO() Отмечает все значения дескрипторов в f d_set как неактивные. |
FD_CLR() Устанавливает дескриптор в f d_set в неактивное состояние. •
FD_SET () Устанавливает дескриптор в f d set в активное состояние.
FD_ISSET() Проверяет активность заданного дескриптора в td_set. |
Последний параметр select () является указателем на struct timeval,
которая содержит следующие два поля:
struct timeval
(
long tv_sec;
long tv_usec;
);
/* секунды */
/* микросекунды */
Следующие три типа значений timeval могут быть переданы select ()
для управления ее поведением относительно тайм-аутов:
Значение Поведение |
NULL-указатель на timeval Указывает, что select () должна ждать без ограничения времени, пока наступит, по крайней мере, одно событие I/O или пока сигнал прервет этот вызов.
Не NULL-указатель на timeval, ПОЛЯ tv sec И tv_usec которой = 0 Указывает, что select () должна выполнять опрос, то есть проверять все дескрипторы и немедленно возвращать результаты опроса.
timeval, ПОЛЯ tv_sec И tv_usec которой > 0 Указывает, что select () должна ждать наступления события I/O указанное время. |
6.2 Механизмы многозадачности
Все современные универсальные операционные системы обеспечивают ме-
ханизмы создания множества процессов и управления их выполнением. Про-
цесс является единицей управления ресурсами и защиты. Некоторые встроен-
ные операционные системы, такие как многие версии VxWorks и pSoS, поддер-
живают только одно адресное пространство, что похоже на наличие одного
процесса. Такое ограничение чаще всего является разумным; например, компь-
ютеру, встроенному в сотовый телефон нет необходимости выполнять не-
сколько процессов. Тем не менее, большинство систем встроенного типа все
таки поддерживают многопоточность, которую мы будем рассматривать в раз-
деле 6.3.
142
Глава 6
Функции управления процессами, предлагаемые различными операцион-
ными системами, сильно отличаются. Однако в многозадачных операционных
системах перечисленные далее возможности являются общими:
Операции, связанные с жизненным циклом процессов. Процессы созда-
ются тогда, когда ОС или прикладные программы вызывают функции созда-
ния и выполнения процессов, такие как fork() или семейство функций
ехес*() (POSIX), или CreateProcess () (Win32). Эти функции создают но-
вое адресное пространство для выполнения конкретной программы. Иниции-
рующий процесс может также задать аргументы командной строки новой про-
граммы и переменные окружения, чтобы передать новому процессу такую ин-
формацию, как команды, параметры, расположение файлов или каталогов.
Процесс выполняется до своего завершения:
• По собственной инициативе, например, достигнув конца функции
main () или вызвав API-функцию завершения процесса, ExitPro-
cess () (Win32) или exit () (POSIX), которые дают процессу возмож-
ность установить в заданное значение свой статус выхода.
• Принудительно, например, при принудительном завершении сигналом
kill (POSIX) или внешней операцией завершения, такой как Termina-
teProcessO (Win32).
Операции синхронизации процессов. Большинство операционных сис-
тем при завершении процесса сохраняют его идентификатор и статус заверше-
ния, что позволяет его родительскому процессу синхронизироваться с ним и
получить от него статус его завершения. Распространенные примеры функций
синхронизации процессов включают:
• Функции POSIX wait () и waitpid ().
• Функции Win32 WaitForSingleObject () и WaitForMultipleOb-
jects().
Многие операционные системы поддерживают также внутреннюю связь
типа предок/потомок между создающим и создаваемым процессами. Эта связь
используется некоторыми операционными системами, чтобы содействовать
уведомлению, возможно заинтересованного в этом родительского процесса, о
том, что один из порожденных им процессов завершился. В POSIX-системах,
например, ОС посылает сигнал SIGCHLD родительскому процессу, когда один
из его процессов-потомков завершается.
Операции, относящиеся к свойствам процессов. Большинство операци-
онных систем предусматривают функции, возвращающие и устанавливающие
различные свойства процессов. Свойства, которые могут быть установлены на
уровне процесса включают права доступа к файлам по умолчанию, идентифи-
кацию пользователя, ограничения на ресурсы, приоритет при выделении вре-
мени и текущий рабочий каталог. Некоторые операционные системы позволя-
ют процессу также блокировать области его виртуальной памяти, чтобы избе-
жать ошибок из-за отсутствия страницы или чтобы разрешить обмен данными
с устройствами I/O через память.
Обзор механизмов параллелизма операционных систем
143
63 Механизмы многопоточности
Поток является исполняемой единицей внутри процесса. Большинство со-
временных операционных систем обеспечивают механизмы, которые управля-
ют жизненным циклом потоков, синхронизацией и другими относящимися
к потокам характеристиками, такими как приоритеты или выделяемая потоку
память. Мы перечисляем каждый из этих механизмов ниже.
Операции, связанные с жизненным циклом потоков. Основной (main)
поток программы создается неявным образом, когда начинает выполняться
процесс. Большинство остальных потоков создаются с помощью явных вызо-
вов функций создания потоков, таких как pthread_create () (Pthreads)
или CreateThread () (Win32). Эти функции создают и запускают новый
поток, выполняя одну из функций точки входа (entry-point function), которая
задается вызывающим процессом. Так же, как и в случае процессов, потоки вы-
полняются пока не завершатся:
• По собственной инициативе, например, достигнув конца своей функ-
ции точки входа или вызвав функцию завершения потока, такую как
pthread_exit () (Pthreads) или ExitThread () (Win32), которые дают
потоку возможность установить статус выхода в конкретное значение.
• Принудительно, например, при уничтожении сигналом kill или опе-
рацией завершения асинхронного потока, такой как pthread_can-
cel () (Pthreads) или TerminateThread () (Win32).
Операции синхронизации потоков. Многие механизмы поточности
ОС предоставляют возможность создать поток:
• Обособленным (detached) — Когда обособленный поток завершается,
ОС автоматически восстанавливает память, используемую для хранения
состояния потока и статуса его завершения.
• Объединяемым (joinable) — Когда объединяемый поток завершается,
ОС запоминает его идентификатор и статус завершения, так чтобы дру-
гой поток мог позже синхронизироваться с ним и получить статус его за-
вершения.
Примеры распространенных механизмов синхронизации включают:
• Функцию pthread_j oin () в Pthreads.
• Функции Win32 WaitForSingleObject () и WaitForMultipleOb-
jects ().
На некоторых платформах ОС имеются функции синхронизации, которые
позволяют потокам приостанавливать и возобновлять друг друга. Другие по-
зволяют потокам посылать сигналы другим потокам того же процесса. Однако
в общем случае, эти операции являются непереносимыми и их трудно исполь-
зовать корректно [But97]; поэтому в дальнейшем мы не будем их рассматри-
вать, хотя АСЕ все же инкапсулирует их на тех платформах, на которых они су-
ществуют.
144
Глава 6
Операции, относящиеся к свойствам потоков. Большинство операцион-
ных систем предусматривают функции, которые возвращают и устанавливают
различные свойства потоков. Например, свойство потока может быть провере-
но и изменено с помощью функций pthread_getschedparam.() и
pthread_setschedparam () в Pthreads, а также GetThreadPriority () и
SetThreadPriority () в Win32. Многие операционные системы позволяют
также приложениям выбирать более фундаментальные свойства, такие как
класс планирования потока. Например, Solaris поддерживает классы планиро-
вания в реальном времени и с разделением времени [Kha92], рассмотренные
в разделе 5.5.
Локальная память потока. Локальная память потока (thread-specific stora-
ge, TSS)1 по области действия похожа на глобальные данные; то есть она не явля-
ется локальной для какой-то конкретной функции или объекта. Однако в отли-
чие от глобальных данных, каждый поток, на самом деле, имеет собственную
копию TSS-данных. TSS может быть использована приложениями для хране-
ния данных, доступ к которым необходим многим функциям или объектам, но
которые являются частными данными определенного потока. Обычный при-
мер — errno, где хранится статус ошибки системных функций. Каждый эле-
мент TSS связан с ключом, который является глобальным для всех потоков про-
цесса. Эти ключи создаются функцией-фабрикой, такой как pthre-
ad_key_create() (Pthreads) или TlsAlloc () (Win32). Любой поток может
использовать этот ключ для обращения, через указатель, к связанной с ним ко-
пии памяти. Связь ключ/указатель управляется TSS-функциями, таким как
pthread_setspecif ic () и pthread_getspecific<) в Pthreads или
TlsGetValue () иTlsSetValue() в Win32.
6.4 Механизмы синхронизации
Как отмечалось в разделах 6.2 и 6.3, платформы ОС обеспечивают зачаточ-
ные механизмы синхронизации, которые дают возможность процессам и пото-
кам ждать завершения других процессов и потоков. Этих механизмов доста-
точно для относительно простых приложений, которые выполняют параллель-
но несколько независимых ветвей. Многие параллельные приложения, однако,
требуют более сложных механизмов синхронизации, чтобы дать возможность
процессам и потокам координировать порядок их выполнения и доступа к со-
вместно используемым ресурсам, таким как файлы, записи баз данных, сетевые
устройства, данные объектов и разделяемая память. Доступ к этим ресурсам
должен синхронизироваться для предотвращения эффекта гонок (race conditi-
ons).
Эффект гонок может иметь место, когда порядок выполнения двух или не-
скольких параллельных потоков дает непредсказуемые и ошибочные результа-
Более привычный и распространенный синоним этого термина— thread local storage (TLS).
Это сокращение присутствует и в названиях упоминаемых далее функций, например,
TlsGetValue (). — Прим. ред.
Обзор механизмов параллелизма операционных систем
145
ты. Один из способов предохранения от эффекта гонок — использовать меха-
низмы синхронизации, который сериализуют доступ к критических секциям
кода, содержащим обращения к совместно используемым ресурсам. Обычные
механизмы синхронизации ОС включают мьютексы, блокировки читатели/пи-
сатель (readers/writer), семафоры и условные переменные (condition variables).
Чтобы проиллюстрировать потребность в такого рода механизмах, рас-
смотрим следующее дополнение к методу Iterative_Logging_Ser-
ver:: handle_data (), определенному в разделе 4.4.3.
typedef u_long COUNTER;
// Глобальная переменная с областью видимости на уровне файла,
static COUNTER reguest_count;
// ...
virtual int handle_data (ACE_SOCK_Stream *} (
while (logging_handler_.log_record () != -1)
// Подсчитываем количество запросов.
++request_count;
ACE_DEBUG ((LM_DEBUG,
"request_count = %d\n", request_count));
logging_hdndler_.close ();
return 0;
1
Метод handle_data () ждет поступления регистрационных записей от
клиента. Когда запись поступает, она выводится и обрабатывается. В перемен-
ной request_count ведется подсчет количества входящих клиентских реги-
страционных записей.
Код, представленный выше, прекрасно работает до тех пор, пока hand-
le_data () выполняется только в одном потоке Процесса. Однако на многих
платформах могут быть получены неверные результаты, когда в одном процес-
се несколько потоков выполняют handle_data () одновременно. Проблема
заключается в том, что этот код не является поддерживающим многопоточность
(thread-safe) из-за эффекта гонок при доступе к глобальной переменной ге-
quest_count. В частности, различные потоки могут инкрементировать и вы-
водить «устаревшие» значения переменной request_count на тех платфор-
мах, на которых:
• Операции автоинкремента компилируются в несколько ассемблерных
команд load, add и store.
• Нет поддержки управления всей памятью на аппаратном уровне.
Операционные системы предлагают некоторую совокупность механизмов
синхронизации, чтобы обеспечить правильные результаты в этой и похожих
ситуациях. Далее перечислены наиболее распространенные механизмы син-
хронизации.
146
Глава 6
6.4.1 Блокировки «взаимное исключение» (мьютекс)
Блокировки «взаимное исключение» (мьютекс) могут использоваться для
защиты целостности совместно используемого ресурса, к которому одновре-
менно обращаются несколько потоков. Мьютекс сериализует выполнение не-
скольких потоков путем введения критической секции кода, которая может вы-
полняться только одним потоком одновременно. Семантика мьютекса — это
семантика «скобок»; то есть поток, владеющий мьютексом является ответствен-
ным за его освобождение. Простота семантики способствует созданию эффек-
тивных реализаций мьютексов, например, посредстврм аппаратных спин-бло-
кировок.' Существуют два основных типа мьютексов:
• Нерекурсивный мьютекс, который будет блокироваться или как-то иначе
отказывать в работе, если поток, в текущий момент владеющий мьютею
сом, попытается завладеть им повторно, предварительно не освободив
его.
• Рекурсивный мьютекс, который позволяет потоку, владеющему мьютек-
сом вновь и вновь завладевать им, не приводя при этом к самоблокиров-
ке, если только этот поток, в конечном итоге, освобождает мьютекс
столько же раз, сколько раз он им завладел.
6.4.2 Блокировки «читатели/писатель »
Блокировки типа «читатели/писатель» (readers/writer) позволяют обра-
щаться к совместно используемому ресурсу двумя способами:
• Нескольким потокам одновременно осуществлять доступ на чтение, не
модифицируя его.
• Только один поток одновременно изменяет ресурс, запрещая при этом
другим потокам доступ как на чтение, так и на запись.
Блокировка этого типа может повысить производительность тех парал-
лельных приложений, в которых чтение ресурсов осуществляется гораздо
чаще, чем запись. Блокировки «readers/writer» могут быть реализованы таким
образом, чтобы отдать предпочтение или чтению, или записи [ВА90].
Некоторые свойства блокировок «readers/writer» совпадают со свойствами
мьютексов; например, поток, который завладел блокировкой, должен и освобо-
дить ее. Когда «писатель» хочет завладеть блокировкой, то он ждет пока все ос-
тальные владельцы блокировки («читатели») освободят ее, а затем он завладева-
ет этой блокировкой в эксклюзивном режиме. В отличие от мьютексов, однако,
несколько потоков могут одновременно владеть блокировкой «readers/writer»,
осуществляя параллельное чтение.
Хотя спин-блокировки имеют небольшие собственные накладные расходы, они могут по-
треблять много процессорных ресурсов, если поток долго находится в состоянии активного
ожидания момента выполнения конкретного условия.
Обзор механизмов параллелизма операционных систем 147
6.4.3 Семафоры
Концептуально, семафор — это неотрицательное целое число, которое
можно автоматически инкрементировать и декрементировать. Поток блокиру-
ется, если он пытается декрементировать семафор, значение которого равно 0.
Блокированный поток освобождается только после того, как другой поток ос-
вободит семафор, увеличивая при этом его значение до величины большей,
чем 0.
Семафоры сохраняют состояние, чтобы отслеживать значение счетчика и
количество блокированных потоков. Они часто реализуются с помощью
«слип-блокировок» (sleep locks), которые вызывают переключение контекста,
что позволяет другим потокам продолжать выполнение. В отличие от мьютек-
сов, они не требуют, чтобы их освобождал тот же поток, который завладел ими
первоначально. Это свойство позволяет использовать семафоры в большом
диапазоне контекстов выполнения, например, в обработчиках сигналов или
прерываний.
6.4.4 Условные переменные
Условная переменная (condition variable) обеспечивает иную, чем мьютекс,
«readers/writer» или семафор, разновидность синхронизации. Три перечислен-
ных механизма заставляют другие потоки ждать, пока поток, владеющий бло-
кировкой, выполняет код в критической секции. В отличие от этого, поток мо-
жет использовать условную переменную, чтобы координировать и планиро-
вать свое собственное функционирование.
Например, условная переменная может заставить ждать пока условное вы-
ражение, включающее данные, совместно используемые другими потоками,
примет конкретное значение. Когда взаимодействующий поток указывает, что
состояние совместно используемых данных изменилось, поток, блокирован-
ный на условной переменной, активизируется. После активизации поток снова
вычисляет свое условное выражение и может возобновить выполнение, если
совместно используемые данные, достигли нужного состояния. Так как с услов-
ной переменной можно использовать произвольно сложные условные выраже-
ние, то они допускают более сложное планирование, чем другие механизмы
синхронизации, перечисленные выше.
Условные переменные обеспечивают основные механизмы синхронизации
для улучшенных паттернов параллелизма, таких как Active Object и Monitor
Object [SSRBOO] и внутренних коммуникационных механизмов процесса, таких
как очереди синхронных сообщений. Pthreads и UNIX International (UI) threads
(реализованные на Solaris) поддерживают условные переменные за счет внут-
ренних механизмов, но другие платформы, такие как Win32 и многие операци-
онные системы реального времени, их не поддерживают.
В блоке 12 оцениваются относительные характеристики качества механиз-
мов синхронизации ОС, перечисленных выше. В общем случае вы должны пы-
таться использовать наиболее эффективный механизм синхронизации из тех,
которые обеспечивают нужную вам семантику. Если эффективность имеет зна-
148
Глава 6
чение, ищите справочную информацию по платформам, на которых будет ра-
ботать ваше приложение. Вы можете настроить приложение так, чтобы извлечь
преимущество из особенностей платформ, варьируя ACE-классы синхрониза-
ции. Более того, ваш код может оставаться переносимым при использовании
паттерна Strategized Locking [SSRBOO] и в соответствии с сигнатурой метода псев-
докласса ACE_LOCK*, рассмотренного в разделе 10.1.
Блок 12: Оценка качества механизмов синхронизации
Операционные системы поддерживают набор механизмов синхронизации,
чтобы удовлетворить потребности различных приложений. Хотя качество функ-
ционирования механизмов синхронизации варьируется в зависимости от реа-
лизаций ОС и аппаратных средств, далее перечислены те общие вопросы, ко-
торые следует учитывать:
• У семафоров и условных переменных издержки часто выше, чем у мьютек-
сов, так как их реализации являются более сложными. Тем не менее, внут-
ренние механизмы ОС почти всегда действуют лучше, чем создаваемые
пользователями заменители, так как они могут использовать преимущество
внутренних характеристик ОС и настройки на конкретную аппаратуру.
• У мьютексов, в общем случае, издержек меньше, чем у блокировок «rea-
ders/writer», так как мьютексам не нужно управлять многочисленными ожи-
дающими потоками. Однако мнржество потоков, осуществляющих чтение,
может действовать в параллель, поэтому блокировки «readers/writer» лучше
масштабируются в мультипроцессорных системах, когда используются для
обращений к данным, которые значительно чаще читают, чем изменяют.
• Нерекурсивные мьютексы более эффективны, чем рекурсивные. Вместе
с тем, рекурсивные мьютексы могут быть,причиной неочевидных ошибок,
если программисты забывают освободить их (But97), тогда как нерекурсив-
ные мьютексы сразу выявляют эти проблемы за счет тупиковых ситуаций.
6.5 Ограничения механизмов параллелизма ОС
Разработка сетевых приложений с использованием собственных механиз-
мов параллелизма ОС, перечисленных выше, может создавать проблемы с пе-
реносимостью и надежностью. Чтобы проиллюстрировать некоторые из этих
проблем, рассмотрим функцию, которая использует мьютекс UI threads для ре-
шения проблемы автоинкрементной сериализации, которую мы наблюдали
с request_count в разделе 6.4:
typedef u_long COUNTER;
static COUNTER request_count; // Глобальная на уровне
// файла переменная
static mutex_t m; // Защищает request_count
// (инициализированную нулем).
// . . .
virtual int handle_data (ACE_SOCK_Stream *) (
Обзор механизмов параллелизма операционных систем 149
while (logging_handler_.log_record () != -1) {
// Отслеживает количество запросов.
mutex_lock (&m); // Получаем блокировку
++request_count; // Счетчик запросов
mutex_unlock (&m); // Снимаем блокировку
}
mutex_lock (&m);
int count = request_count;
mutex_unlock (&m);
ACE_DEBUG ((LM_DEBUG, "request_count = %d\n", count));
logging_handler_.close ();
return 0;
)
В коде, представленном выше, m является переменной типа mutex_.t, кото-
рая автоматически инициализируется 0. В UI threads любая синхронизирующая
переменная, которая установлена в 0, неявно инициализируется в соответствии
с ее семантикой по умолчанию [ЕКВ+92]. Например, переменная mutex_t яв-
ляется статической переменной, то есть по умолчанию инициализируется раз-
блокированным состоянием. При первом вызове функции mutex_lock(),
она будет, следовательно, пытаться завладеть блокировкой. Любой другой по-
ток, который попытается завладеть этой блокировкой, должен будет ждать
пока поток, владеющий блокировкой m освободит ее.
Хотя код, представленный выше, решает исходную проблему синхрониза-
ции, у него имеются следующие недостатки:
• Требует кропотливой работы. Это решение требует изменения исходно-
го кода с целью добавления мьютекса и связанных с ним С-функций. При
разработке большой программной системы, выполнение этих измене-
ний вручную приведет к проблемам с сопровождением, если изменения
окажутся несогласованными.
• Подвержен ошибкам. Хотя метод handle_data () является относи-
тельно простым, программисты могут легко забыть вызвать mutex_un-
lock () в более сложных методах. Отсутствие этого вызова может при-
вести к голоданию (starvation) других потоков, которые блокируются при
попытке завладеть мьютексом. Более того, так как мьютекс mutex_t яв-
ляется нерекурсивным, возникнет тупиковая ситуация, если поток, вла-
деющий мьютексом m попробует завладеть им повторно, предваритель-
но не освободив его. Кроме того, мы пренебрегли проверкой возвращае-
мого значения mutex_lock(), не убедились, что он завершился
успешно. Это может привести к неочевидным проблемам в создаваемых
приложениях.
• Имеет неочевидные побочные эффекты. Возможно также, что програм-
мист забудет проинициализировать переменную мьютекса. Как упоми-
налось выше, статическая переменная mutex_t является неявно ини-
циализированной в UI threads. Однако такие гарантии отсутствуют для
150
Глава 6
полей mutex_t объектов размещаемых динамически. Кроме того, дру-
гие реализации потоков ОС, такие как Pthreads и потоки Win32, не под-
держивают эту семантику неявной инициализации; то есть все объекты
синхронизации должны быть явно проинициализированы.
• Не является переносимым. Этот код будет работать только с механизма-
ми синхронизации UI threads. Чтобы перенести метод handle_da.ta ()
на Pthreads и Win32 и использовать другие API синхронизации в полном
объеме, потребуется, следовательно, изменение блокирующего кода.
Вообще, многие проблемы, которые демонстрируют API параллелизма ОС,
аналогичны проблемам Socket API, рассмотренным в разделе 2.3. К тому же, API
параллелизма на разных платформах ОС еще менее стандартизованы, чем Soc-
ket API. Даже если API похожи, все равно часто существуют неочевидные син-
таксические и семантические отклонения от одной реализации к другой. На-
пример, функции в различных проектах стандарта Pthreads, реализованные
разными поставщиками операционных систем имеют разные списки парамет-
ров и разную индикацию ошибок.
В блоке 13 перечислены некоторые из различий в стратегиях передачи со-
общений об ошибках в разных API параллелизма. Отсутствие переносимости
увеличивает «случайную» сложность параллельных сетевых приложений. По-
этому важно создавать высокоуровневые программные абстракции, такие как
в АСЕ, чтобы помочь разработчикам избежать проблем, связанных с неперено-
симыми и неоднородными API.
Блок 13: Стратегии передачи сообщений об ошибках в API J
параллелизма . < .|
Разные API параллелизмагю-разному сообщают об ошибках вызывающим их |
процессам..Например, некоторые API.'-такие как UI threads и Pthreads. возвра- I
щают 0 при успешном завершении и ненулевое значение ошибки при неуда- 1
че. Другие API, такие как потоки Win32, возвращаю! О при ошибке и передают
соответствующее значение ошибки через локальную память потока. Это раз-
ница в поведении вносит путаницу и цё способствует переносимости. Интер-
фейсные фасады АСЕ, связаннее с параллелизмом, наоборот, определяют и
осуществляют единый подход. Он заключается в том, что при ошибке всегда
возвращается -1 и набор значений errno, которые зависят от конкретного по-
тока и указывают на причину ошибки, ।
6.6 Резюме
Операционные системы обеспечивают механизмы параллелизма, которые
управляют множеством процессов на хосте и множеством потоков внутри про-
цесса. Любая хорошая универсальная ОС дает возможность множеству процес-
сов работать параллельно. Современные универсальные операционные систе-
мы и ОС реального времени позволяют также работать одновременно множе-
ству потоков. Параллелизм, когда он используется в сочетании с подходящими
Обзор механизмов параллелизма операционных систем
151
паттернами и конфигурациями приложений, способствует улучшению произ-
водительности и упрощает структуру программ.
Классы интерфейсных фасадов, относящиеся к параллелизму, предлагае-
мые АСЕ, рассматриваются в следующих четырех главах:
• В главе 7 рассматриваются ACE-классы демультиплексирования синх-
ронных событий.
• В главе 8 рассматриваются ACE-классы для механизмов ОС работы с про-
цессами.
• В главе 9 рассматриваются ACE-классы для механизмов ОС работы с по-
токами.
• В главе 10 рассматриваются ACE-классы для механизмов ОС, связанных
с синхронизацией.
На всем протяжении этих четырех глав мы исследуем каким образом АСЕ
использует возможности C++ и паттерн Wrapper Facade, чтобы преодолевать
проблемы с API параллелизма ОС и улучшать функциональность, переноси-
мость и отказоустойчивость параллельных сетевых приложений. Где нужно мы
показываем реализации интерфейсных фасадов АСЕ, связанных с параллелиз-
мом, чтобы проиллюстрировать как они связаны с базовыми механизмами па-
раллелизма ОС. Мы также показываем чем отличаются возможности плат-
форм ОС и каким образом АСЕ защищает разработчиков от этих отличий.
Глава 7
Интерфейсные фасады АСЕ:
демультиплексирование
синхронных событий
Краткое содержание
В главе описаны интерфейсные фасады АСЕ, инкапсулирующие механиз-
мы ОС, связанные с демультиплексированием синхронных событий, в перено-
симые классы C++. Мы представим также несколько новых улучшенных вер-
сий нашего сервера сетевой регистрации, которые используют эти интерфейс-
ные фасады АСЕ.
7.1 Обзор
В разделе 5.1 обсуждались аспекты параллельной работы серверов, причем
одним из проектных решений был взаимно-согласованный сервер. Модель вза-
имно-согласованного сервера может быть представлена в виде упрощенного
варианта многозадачности (lightweight multitasking), при котором однопоточ-
ный сервер взаимодействует с множеством клиентов по алгоритму кругового
обслуживания (round-robin), исключая издержки и сложность механизмов по-
точной обработки и синхронизации. В стратегию параллелизма такого сервера
входит использование цикла обработки событий, в котором сервер непрерыв-
но проверяет наличие событий у своих клиентов и реагирует на эти события.
Цикл обработки событий демультиплексирует входные сигналы от различных
источников событий таким образом, что появляется возможность их упорядо-
ченной обработки.
Источниками событий в сетевых приложениях являются, в основном, деск-
рипторы сокетов. Наиболее переносимым вариантом демультиплексора син-
хронных событий является функция select О и ее наборы процедур обработ-
154
Глава 7
ки, рассмотренные в разделе 6.1. В данной главе рассматриваются классы (см.
далее в таблице), которые могут быть применены для упрощения и оптимиза-
ции использования этих возможностей во взаимно-согласованных серверах:
Класс/Мвтод АСЕ Описание
ACE_Handle_Set Инкапсулирует f d_set и основные процедуры для работы с ней.
ACE_Handle_Set_Iterator Обеспечивает переносимые и эффективные механизмы циклического перебора множества активных обработчиков объекта ACE_Handle._set.
АСЕ::select() Упрощает наиболее распространенные варианты использования select () и улучшает ее переносимость. |
ACE__Handle_8et
- mask_ : fd_ set
+ + reset () clr_bit (h : ACE-HANDLE)
+ + + ♦ + + set_bit (h is__set (h : num__set () maX-Set () fdse t () : sync (max : : ACE-HANDLE) : ACE HANDLE) : int : int : ACE-HANDLE fd set * : ACE-HANDLE)
ACB_Bandle__Se t_I terator
- handles_ : ACE_Handle_Set& - handle__indeX- : int
+ operator () : ACE_HANDLE
Рис. 7.1
Диаграммы классов ACE_Handle_Set и ACE_Handle_Set_I terator
Интерфейсы классов ACE_Handle_Set и ACE_Handle_Set_Iterator
показаны на рис. 7.1. Эти интерфейсные фасады имеют следующие преимуще-
ства:
• Обеспечивают кросс-платформенную переносимость. Классы АСЕ_Нап-
dle_Set и ACE_Handle_Set_I terator могут использоваться на всех
платформах ОС, которые поддерживают select () и f d set. Эти клас-
сы упрощают корректное использование процедур обработки ввода/вы-
вода для демультиплексирования синхронных сетевых событий.
• Обеспечивают эффективное сканирование по множеству активных де-
скрипторов без ущерба для переносимости. Эффективное циклическое
сканирование множества активных дескрипторов является важным фак-
тором в улучшении производительности цикла обработки событий вза-
имно-согласованных серверов. Необходимость повышения производи-
тельности цикла обработки событий часто побуждает программистов
исследовать внутреннее устройство fd_set, чтобы отыскать более эф-
фективные способы ее просмотра. Класс ACE_Handle_Set_Iterator
тщательно оптимизирован таким образом, чтобы сетевым приложениям
не нужно было полагаться на внутренние представления f d_set.
Интерфейсные фасады АСЕ: демультиплексирование событий
155
Интерфейсные методы АСЕ:: select () инкапсулируют системную функ-
цию select () и используют класс ACE_Handle_Set, чтобы упростить пере-
дачу дескрипторов. Взаимно-согласованная версия сервера регистрации ис-
пользуется, чтобы показать каким образом эти интерфейсы АСЕ могут упро-
стить программирование сетевых приложений.
7.2 Класс ACE Handle Set
Обоснование
В разделе 2.3 были описаны проблемы, связанные с прямым использовани-
ем дескрипторов ввода/вывода. Структура f d_set является еще одним источ-
ником «случайной» сложности, которая проявляется в следующем:
• Макроопределениями или функциями, которые платформы предостав-
ляют для манипулирования f d_set и ее сканирования, нужно пользо-
ваться осторожно, чтобы избежать обработки неактивных дескрипторов
и случайно не повредить f d_set.
• Код, осуществляющий сканирование активных дескрипторов, часто пред-
ставляет собой критический участок программы, так как он все время вы-
полняется в непрерывном цикле. Поэтому этот код является явным кан-
дидатом на оптимизацию с целью улучшения производительности.
• Структура f d_set определена в поставляемых с системой заголовочных
файлах: ее представление открыто для программистов. Заманчиво, ко-
нечно, творчески использовать это знание внутреннего устройства плат-
формы. Тем не менее, если воспользоваться этим знанием, то это может
привести к проблемам с переносимостью, так как эти представления
сильно меняются от платформы к платформе.
• В fd_set есть неочевидные аспекты, негативно влияющие на переноси-
мость, которые проявляются при использовании в сочетании с функцией
select().
Чтобы проиллюстрировать последнее положение, давайте вернемся к сиг-
натуре функции select ():
int select (int width,
fd_set *read_fds,
fd_set *write_fds,
fd_set *except_fds,
struct timeval *timeout) ;
// Максимальный дескриптор плюс 1
// Набор "read''-дескрипторов
// Набор "write''-дескрипторов
// Набор "exception’’-дескрипторов
// Время ожидания событий
Три аргумента fd_set задают дескрипторы, которые используются при
выборе событий соответствующего типа. Аргумент t imeou t используется для
задания предельного времени ожидания событий. Конкретные детали, касаю-
щиеся этих параметров, лишь незначительно меняются от платформы к плат-
форме. Тем не менее, так как от платформы к платформе меняется природа де-
156
Глава 7
скрипторов ввода/вывода (и, соответственно, f d_set), значение первого аргу-
мента (width) существенно зависит от операционной системы:
• В UNIX, дескрипторы I/O начинаются с 0 и увеличиваются до максималь-
ного значения, определяемого ОС. Следовательно, параметр width
в UNIX показывает «предел сканирования дескрипторов в f d_set»; то
есть определяется как самый большой номер дескриптора в любом из
трех параметров f d_set плюс 1.
• В Win32 дескрипторы сокетов реализуются не в виде небольших целых
чисел, а в виде указателей. Поэтому аргумент width в select () игно-
рируется совсем. Вместо этого, каждая fd_set содержит свой собствен-
ный счетчик дескрипторов.
• На других платформах, где дескрипторы могут быть целыми, но начи-
наться не с 0, смысл параметра width опять-таки может быть не таким,
как в первых двух случаях.
Значения f d_se t, связанные с размерами, еще и по-разному вычисляются,
в зависимости от особенностей платформенного представления и принятой на
данной платформе семантики select (). Любые приложения, написанные
с непосредственным использованием API ОС, должны, следовательно, учиты-
вать все эти мелкие отличия, и каждый проект может заканчиваться перепроек-
тированием и повторной реализацией кода, обеспечивающего корректные зна-
чения параметра width. Разрешение этих противоречий, связанных с перено-
симостью, в каждом приложении утомительно и приводит к ошибкам, вот
почему АСЕ предлагает класс ACE_Handle_Set.
Функциональные возможности класса
Класс ACE_Handle_Set при инкапсуляции структур f d_set использует
паттерн Wrapper Facade [SSRBOO]. Этот класс предоставляет следующие воз-
можности:
• Улучшает переносимость, облегчает использование и повышает типовую
безопасность событийно-управляемых приложений, упрощая кросс-
платформенное применение fd_set и select ().
• Автоматически отслеживает и настраивает значения fd_set, относя-
щиеся к размерам, по мере добавления и удаления дескрипторов.
Так как различия в представлениях f d_set скрыты в реализации АСЕ_Нап-
dle_Se t, код приложения может быть написан только один раз, а затем просто
перекомпилироваться при переносе на новую платформу.
Интерфейс ACE_Handle_Set показан на рис. 7.1, а его основные методы
приведены в следующей таблице:
Интерфейсные фасады АСЕ; демультиплексирование событий
157
Метод Описание
ACE_Handle_Set () reset () Инициализирует набор дескрипторов значениями по умолчанию. ।
clr_bit () Освобождает один дескриптор набора.
set_bit () Устанавливает один дескриптор набора. •_
is_set () Проверяет является ли заданный дескриптор активным ., дескриптором набора. i
num_set () Возвращает количество активных дескрипторов совокупности.
max_set () Возвращает значение максимального дескриптора набора.
fdset () Возвращает указатель на базовую f d_set или NULL-указатель, если в наборе нет активных указателей.
sync () Осуществляет повторную синхронизацию набора дескрипторов, чтобы определить новый максимальный активный дескриптор и количество активных дескрипторов, что бывает полезно после изменения набора дескрипторов в результате внешней операции, например, вызова select ().
Пример
В разделах 4.4.3 и 5.1 были отмечены некоторые, из проблем, связанных
с последовательными серверами. Использование демультиплексирования син-
хронных событий при реализации модели взаимно-согласованных серверов —
это один из способов обойти эти проблемы. Теперь мы продемонстрируем
пример, который улучшает реализацию последовательного сервера регистра-
ции из главы 4 с помощью select () и класса ACE_Handle_Set. Этот сервер
демультиплексирует следующие два типа событий:
1. Поступление новых соединений от клиентов.
2. Поступление регистрационных записей по клиентским соединениям.
Мы помещаем нашу реализацию в заголовочный файл с именем React i-
ve_Logging_Server. h, который начинается с включения заголовочного фай-
ла АСЕ Handle_Set.h и заголовочного файла Iterative_Logging_Ser-
ver.h. Создаем новый класс Reactive_Logging_Server на базе класса
Iterative_Logging_Server. Повторно используем его члены-данные и оп-
ределяем еще два члена, которые используются для управления клиентами.
♦include "ace/Handle_Set.h"
♦include "Iterative_Logging_Server.h"
class Reactive_Logging_Server : public Iterative_Logging_Server
(
protected:
I/ Следит за дескриптором сокета-акцептора и за всеми
158
Глава 7
// дескрипторами подключенных сокетов потоков.
ACE_Handle_Set master_handle_set_;
// Следит за дескрипторами, помеченными <select> как активные.
АСЕ_Handle_Set active_handles_;
// Другие методы, приведенные ниже...
};
Для реализации семантики взаимно-согласованного сервера, мы заменяем
hook-методы Iterative__Logging_Server, начиная с open () :*
virtual int open (u_short logger_port) {
Iterative_Logging_Server::open (logger_port);
master_handle_set_.set_bit (acceptor ().get—handle ());
acceptor ().enable (ACE_NONBLOCK);
return 0;
}
После вызова метода open () родительского класса с целью инициализа-
ции сокета-акцептора, мы вызываем метод set_bit() из master-hand-
lers е t_, чтобы следить за дескриптором этого сокета. Мы устанавливаем так-
же для этого сокета-акцептора неблокируемый режим по причинам, которые
изложены в блоке 14.
Затем мы реализуем метод взаимно-согласованного сервера wa-
it_for__multiple__events (). Мы копируем master_handle_set_ в ас-
tive_handles_, которая будет изменяться функцией select (). Нам нужно
вычислить аргумент width для select (), путем приведения к виду, который
должен компилироваться на Win32 (на этой платформе конкретное значение
передаваемое в select () игнорируется). Второй параметр, передаваемый se-
lect (), является указателем на базовую fd_set в active_handles_, обра-
щение к которой осуществляет метод ACE__Handle.__Set: : fdset ().
virtual int wait_for_multiple_events () {
active_handles_ = master_handle—set_;
int width = (int) active_handles_.max_set () + 1;
if (select (width,
active_handles_.fdset (),
0, // без write-fds
0, // без except_fds
0)) // без тайм-аута
return -1;
active_handles_.sync
( (ACE__HANDLE) active_handles_.max_set () + 1);
return 0;
}
С целью экономии места, мы опускаем код обработки ошибок, объем которого здесь даже
больше, чем в первой реализации сервера регистрации.
Интерфейсные фасады АСЕ: демультиплексирование событий 159
Блок 14: Обоснование неблокируемых сокетов-акцепторов
При передаче сокета-акцептора в select (), он, после того как принимается
соединение, помечается как «активный». Многие серверы используют это со-
бытие, чтобы сообщить, что.поддерживается вызов accept о без блокирова-
ния. К сожалению, существует эффект гонок, который является результатом
асинхронной работы TCP/IP. В частности, после того, как select о сообщит,
что сокет-акцептор является активным (но до вызова accept ()), клиент может
закрыть соединение, из-за чего accept () может блокировать, а потенциально
и «подвеси гь» все приложение. Чтобы избавиться от этой проблемы, сокегы-ак-
цепторы, при использовании select (), всегда должны устанавливаться в не-
блокируемый режим. В АСЕ это решается просто, в переносимом стиле, пуюм
передачи флага ace_nonblock методу enable о, экспортируемому
АСЕ IPC SAP и, соответственно, ACE_SOCK_Acceptor.
Если происходит ошибка, select () возвращает -1, которую мы исполь-
зуем в качестве возвращаемого значения этого метода. Если выполнение завер-
шается успешно, возвращается количество активных дескрипторов и изменя-
ется active_handles_ fd_set, чтобы отметить каждый активный, на дан-
ный момент, дескриптор. Вызов ACE_Handle_Set; : sync () возвращает
в начальное состояние счетчик дескрипторов и значения, связанные с размера-
ми, в active_handles_, чтобы отразить изменения сделанные select ().
Теперь мы продемонстрируем реализацию hook-метода handle_con-
nections (). Если дескриптор сокета-акцептора является активным, мы при-
нимаем все соединения, заявки на которые поступают, и добавляем их к mas-
ter_handle_set_. Так как мы устанавливаем сокет-акцептор в неблокируе-
мый режим, он возвращает -1 и устанавливает errno в значение
EWOULDBLOCK, когда все запрашиваемые соединения приняты, как описано
в блоке 14. Поэтому, мы можем не беспокоиться о том, что процесс «зависнет»
на неопределенное время.
virtual int handle_connections () {
if (active_handles_.is_set (acceptor ().get_handle ())) {
while (acceptor ().accept (logging_handler ().peer ()) == 0)
master_handle_set_.set_bit
(logging_handler ().peer (),get_handle ());
// Исключаем дескриптор акцептора из дальнейшего рассмотрения.
active_handles_.clr_bit (acceptor ().get_handle О);
)
return 0;
)
Обратите внимание на то, как мы используем здесь метод get_handle (),
а также set_handle() в методе handle_data () ниже. Такое прямое ис-
пользование низкоуровневого дескриптора сокета возможно благодаря прин-
ципу проектирования Allow Controlled Violations of Type Safety, разрешающему
контролируемое нарушение типовой безопасности; этот принцип поясняется
в разделе А.2.2.
160
Глава 7
Ноок-метод handle_data () циклически опрашивает множество деск-
рипторов, которые могут быть активными; для каждого активного дескрипто-
ра он вызывает метод log_record (). Этот метод обрабатывает одну регист-
рационную запись от каждого активного соединения.
// Этот метод содержит ошибки. Не копируйте этот пример!
virtual int handle_data (ACE_SOCK_Stream *) {
for (ACE_HANDLE handle = acceptor ().get_handle () + 1;
handle < active_handles_.max_set () + 1;
handle++) {
if (active_handles_.is_set (handle)) {
logging_handler ().peer ().set_handle (handle);
if (logging_handler ().log_recprd () == -1) (
// Обрабатываем закрытие соединения или сбой СОМ-порта.
master_handle_set_.clr_bit (handle);
logging_handler ().close ();
}
)
)
return 0;
)
В handle_data () мы используем методы ACE_Handle_Set, чтобы:
• Проверить является ли дескриптор активным.
• Освободить дескриптор в mas ter_handle_set_, после того как клиент
закроет соединение.
Хотя это достаточно небольшой метод, все же есть несколько проблем с ис-
пользованием ACE_Handle_Set в стиле, приведенном выше. В следующем
разделе описывается каким образом ACE_Handle_Set_I terator решает эти
проблемы, поэтому на всякий случай прочтите его прежде, чем применять ре-
шение, приведенное выше, в вашей собственной программе!
Функция main () почти не отличается от аналогичной функции последо-
вательного сервера из раздела 4.4.3. Единственное отличие заключается в том,
что определяется экземпляр Reactive_Logging_Server, а не Iterati-
ve_Logging_Server.
#include "ace/Log_Msg.h"
♦include "Reactive_Logging_Server.h"
int main (int argc, char *argv[])
(
Reactive_Logging_Server server;
if (server.run (argc, argv) == -1}
ACE_ERROR_RETURN ( (I,M_ERROR, "%p\n", "server. run () "), 1) ;
return 0;
Интерфейсные фасадыАСЕ: демультиплексирование событий
161
73 Класс ACE_Handle_Set_Iterator
Обоснование
Предыдущий пример показал как взаимно-согласованный сервер демуль-
типлексирует события, распределяя их по программам обработки событий
с помощью следующих шагов:
1. Функция select () возвращает количество дескрипторов, значение кото-
рых активно в их измененном(ых) наборе(ах) дескрипторов.
2. Сервер, выполняя цикл обработки событий, сканирует наборы дескрипто-
ров, определяет активные дескрипторы и выполняет код обработки собы-
тия для каждого дескриптора.
Хотя эти действия выглядят простыми, на практике возникают осложне-
ния, так как select () возвращает общее количество активных значений деск-
рипторов, но не указывает в каком наборе(ах) дескрипторов они находятся.
Один из способов просканировать набор дескрипторов — вызвать ACE_Hand-
le_Set: : is_set () для каждого дескриптора, который может быть в актив-
ном состоянии, как мы это делали в методе handle_data (). Тем не менее, та-
кой подход имеет две проблемы:
• Цикл for, который используется для обхода дескрипторов, работает
только на платформах тех ОС, у которых дескрипторы сокетов имеют
вид непрерывной последовательности беззнаковых целых чисел. В то
время как POSIX/UNIX поддерживает именно такой подход, в Win32 это
не работает, поэтому приведенный код не является переносимым. Кроме
того, такой цикл подразумевает, что сокет-акцептор имеет наименьший
из дескрипторов сокетов. В сложных приложениях это свойство может
не выполняться, если дескрипторы открывались до открытия рассматри-
ваемого сокета-акцептора и позже были закрыты, в этом случае значения
их дескрипторов могут использоваться повторно.
• Даже на тех платформах, которые все-таки поддерживают непрерывную
последовательность значений дескрипторов, каждая операция
is_set () вызывается последовательно для всех возможных значений
дескрипторов. В сетевых приложениях часто бывает, тем не менее, так,
что, в каждый данный момент времени, только некоторые из множества
доступных дескрипторов сокетов являются активными. Последователь-
ный перебор прореженных наборов дескрипторов является неэффектив-
ным, особенно если потенциальное количество дескрипторов велико; на-
пример, на многих платформах UNIX по умолчанию возможно до 1024
дескрипторов на f d_set. Хотя методы ACE_Handle_Set max_set () и
num_set () могут быть использованы для ограничения области поиска,
все же остается недостаток, связанный с неэффективным последователь-
ным просмотром набора дескрипторов, который является избыточным.
Решение указанных проблем с переносимостью и оптимизация узких мест
в каждом приложении является утомительным и связанным с ошибками заня-
тием, вот почему в АСЕ предусмотрен класс ACE_Handle_Set_Iterator.
162
Глава 7
Функциональные возможности класса
Класс ACE_Handle_Set_Iterator использует паттерн Iterator [GHJV95],
который предоставляет методы последовательного доступа к элементам со-
ставного объекта, не раскрывая его внутренней структуры. Этот класс обеспе-
чивает эффективный перебор дескрипторов в ACE_Handle_Set, возвращая
только активные дескрипторы, по одному дескриптору за каждое обращение
к методу operator (). Интерфейс ACE_Handle_Set_Iterator и его связь
с классом ACE_Handle_Set изображены на рис. 7.1. Его основные методы
приведены в следующей таблице:
Метод Описание I
AC£_Handle_Set_I ter a tor () Инициализирует итератор набора дескрипторов для перебора ACE_Handle_set.
operator() Возвращает следующий новый дескриптор из набора дескрипторов или ace_invali d_hand- le, если просмотрены все дескрипторы. |
Так как ACE_Handle_Set_Iterator спроектирован не как «надежный
итератор» ("robust iterator") [Kof93], то важно не освобождать те дескрипторы
из ACE_Handle_Set, которые уже просмотрены.
Хотя у ACE_Handle_Set_Iterator простой интерфейс, его реализация
выглядит более солидной, чем у интерфейсных фасадов АСЕ Socket, рассмот-
ренных в главе 3. В частности, ACE_Handle_Set_Iterator инкапсулирует
все зависящие от платформы детали представления f d_set, что способствует
эффективному и переносимому просмотру всех активных дескрипторов
в ACE_Handle_Set, следующим образом:
• В структуре f d_set в Winsock есть поле, которое содержит количество
значений дескрипторов в наборе. Сами дескрипторы хранятся в смежных
элементах массива значений дескрипторов. В ACE_Handle_Set_Ite-
rator этот факт учитывается при организации доступа к каждому деск-
риптору таким образом, что не нужно искать следующий дескриптор и
не нужно искать все возможные значения активных дескрипторов.
• В большинстве представлений fd_set в UNIX каждому возможному
значению дескриптора отводится один бит. Соответственно, f d_set со-
держит массив целых чисел, который достаточно велик, чтобы охватить
весь диапазон битовых значений. Класс ACE_Handle_Set_Iterator
устроен так, чтобы быстро пропускать большие последовательности де-
скрипторов с неактивными значениями, пропуская элементы целочис-
ленного массива с нулевыми значениями. Ненулевые элементы массива
могут быть быстро просмотрены путем сдвига и маскирования битов,
используя закрытые члены класса для запоминания элемента массива и
позиции сдвига между вызовами operator ().
• Адаптация к разным размерам и порядку битов базовой fd_set осуще-
ствляется применением более подходящих сдвигов и стратегий доступа
Интерфейсные фасадыАСЕ: демультиплексирование событий 163
к элементам массива. Например, ACE_Handle_Set_Iterator можно
настроить на использование высоко оптимизированного алгоритма ма-
нипулирования битами, основанного на следующих двух допущениях:
Структура fd_set представлена массивом слов (на большинстве
UNIX платформ это так и есть).
Если п—слово, выражение п (п - 1) убирает самый младший зна-
чащий бит (Isb) п.
Суть оптимизации в этом алгоритме заключается в том, что количество
тестируемых битов каждого слова в f d_set точно равно количеству ак-
тивных битов, а не общему количеству битов в слове. Когда активных де-
скрипторов немного, этот алгоритм может существенно улучшить про-
изводительность сервера. В этом алгоритме ACE_Handle_Se t_I tera-
tor начинает с поиска первого слова с активным битом в fd_set. Так
как выражение word &~(word -1) тестирует в слове активный Isb, мы
должны найти п таких, у которых Isb = 2". Для каждого слова в f d_set
мы будем иметь затраты равные О (количество активных битов в слове).
Таким образом, если в слове 64 бита и только один активный, затраты
времени выполнения будут 1, а не 64.
• ACE_Handle_Set можно настроить так, чтобы использовать другой
быстрый алгоритм, который формирует количество активных дескрип-
торов, после того как select () их устанавливает. Он поддерживает
символьный массив из 256 элементов, каждый элемент которого содер-
жит количество активных битов нужных, чтобы получить данное значе-
ние индекса. Например, 5-ый элемент содержит значение 2 (2 бита, 0-ой и
2-ой, установлены в «1» в двоичном коде числа 5). Бегло просматривая
элементы f d_set и суммируя соответствующие значения массива,ко-
личество активных битов в fd_set может быть подсчитано быстро, не
перебирая их все последовательно.
• Так как ACE_Handle_Set_Iterator является дружественным клас-
сом ACE_Handle_Set, то он может использовать подсчитанное количе-
ство активных дескрипторов и максимальное значение дескриптора для
ограничения пространства их поиска. Такой подход позволяет
ACE_Handle_Set_Iterator просматривать минимально необходи-
мое подмножество значений дескрипторов, которые могут быть актив-
ными.
Скрывая все эти детали оптимизации в ACE_Handle_Set_Iterator,
АСЕ может значительно повысить производительность основных операций де-
мультиплексирования синхронных событий, не подвергая риску переноси-
мость приложения. Этот класс показывает, что подходящие уровни абстракции
могут существенно повысить производительность приложения.
Пример
Этот пример показывает, как можно использовать ACE_Handle_Set_I te-
rator для устранения недостатков взаимно-согласованного сервера регистра-
164
Глава 7
ции, упоминаемого в разделе 7.2. Мы концентрируем наше внимание на мето-
де handle_data (), заменяя большую часть его кода на код ACE_Hand-
le_Set_Iterator, который осуществляет последовательный обход
active_handles_ следующим образом:
virtual int handle_data (ACE_SOCK_Stream *) (
ACE_Handle_Set_Iterator peer_iterator (active_handles_);
for (ACE_HANDLE handle;
(handle = peer_iterator ()) != ACE_INVALID_HANDLE;
) {
logging_handler O.peer ().set_handle (handle);
if (logging_handler ().log_record () == -1) (
// Обрабатываем закрытие соединения или сбой СОМ-порта
master_handle_set_.clr_bit (handle);
logging_handler ().close ();
)
)
)
Этот код является не только более лаконичным и переносимым, но и более
эффективным благодаря оптимизации ACE_Handle_Set_Iterator.
74 Методы ACE::selectO
Обоснование
Функция select () присутствует на большинстве платформ ОС. Но даже
у этой общеизвестной функции есть тонкости, которые больше, чем следует,
осложняют ее применение. Посмотрите, например, как select () использует-
ся в разделе 7.2. Даже если самый распространенный вариант использования
select () во взаимно-согласованном сервере — это бесконечное ожидание
ввода от множества дескрипторов сокетов, программисты должны не забыть
поставить NULL-указатели для структур fd_set записи и исключений и для
указателя тайм-аута. Кроме того, программисты должны не забыть вызвать ме-
тод sync () для active_handles_, чтобы отразить изменения, сделанные
select ().
Решение этих проблем в каждом приложении может быть утомительно и
приводит к ошибкам, вот почему в АСЕ предусмотрены интерфейсные методы
АСЕ::select().
Функциональные возможности методов
АСЕ определяет перегруженные статические интерфейсные методы для ис-
ходной функции select (), которые упрощают ее использование для боль-
шинства распространенных случаев. Эти методы определены во вспомогатель-
ном классе АСЕ следующим образом:
Интерфейсные фасадыАСЕ: демультиплексирование событий
165
class АСЕ {
public:
static int select (int width,
ACE_Handle_Set &rfds,
const ACE_Time_Value *tv = 0);
static int select (int width,
ACE_Handle_Set *rfds,
ACE_Handle_Set *wfds = 0,
ACE_Handle_Set *efds = 0,
const ACE_Time_Value *tv = 0);
// ... Остальные методы опущены
};
В первом перегруженном методе select () в классе АСЕ опущены некото-
рые параметры и задано значение 0 по умолчанию для тайм-аута, что значит:
ждать неограниченное время. Второй метод добавляет значения 0 по умолча-
нию для нечасто используемых ACE_Handle_Set записи и исключений. Оба
они автоматически вызывают ACE_Handle_Set: : sync (), когда базовый ме-
тод select () возвращает значения для восстановления числа дескрипторов и
значений, связанных с размерами в наборе дескрипторов, чтобы отразить изме-
нения, сделанные select ().
Мы изобрели эти интерфейсные функции, уделив внимание деталям про-
ектирования и распространенным случаям применения, чтобы упростить про-
граммирование и снизить вероятность ошибок в коде приложения. Замысел
мотивировался следующими соображениями:
• Упростить распространенные случаи применения. Как упоминалось
выше, самым типичным случаем применения select () во взаимно-со-
гласованном сервере является неограниченное по времени ожидание
ввода от множества дескрипторов сокетов. Методы АСЕ:: select () уп-
рощает данный случай типового применения. Данный принцип проек-
тирования мы будем обсуждать в разделе А.З.
• Инкапсулировать платформенные отклонения. Все версии select ()
принимают аргумент тайм-аута; но только версия из Linux изменяет зна-
чение тайм-аута при возврате, чтобы отразить сколько времени прошло
в период тайм-аута, до выбора одного из дескрипторов. Интерфейсные
функции АСЕ: : select () объявляют тайм-аут с квалификатором
const, чтобы однозначно задать его значение и включить внутренний
код, чтобы урегулировать необычное изменение тайм-аута в Linux. Дан-
ный принцип проектирования мы будем обсуждать в разделе А.5.
• Обеспечить переносимость типов. Класс ACE_Time_value использу-
ется вместо встроенного временного типа, принятого на конкретной
платформе, так как временные типы не являются согласованными для
всех платформ.
166
Глава 7
Рис. 7.2
Архитектура взаимно-согласованного сервера регистрации
Пример
Чем более полезным и переносимым делаем мы наш сервер регистрации,
тем больше будут стремиться клиентские приложения его использовать и тем
больше будет его загрузка. Поэтому мы хотим спроектировать наши следую-
щие серверы регистрации так, чтобы избежать появления узких мест. В следую-
щих нескольких главах мы проанализируем механизмы параллелизма ОС и
связанные с ними интерфейсные фасады АСЕ. Однако по мере того как мы все
больше будем осваивать параллелизм, единственный файл регистрационных
записей, который мы использовали до сих пор, будет превращаться в узкое ме-
сто, так как в него записываются все регистрационные записи.
Поэтому, чтобы подготовиться к добавлению различных форм паралле-
лизма, мы расширяем наш последний пример взаимно-согласованного сервера
так, чтобы записывать регистрационные записи от разных клиентов в разные
регистрационные файлы, по одному на каждое клиентское соединение. Рис. 7.2
показывает потенциально более масштабируемую архитектуру взаимно-согла-
сованного сервера регистрации, которая основана на двух предыдущих приме-
рах этой главы и является их развитием. Как показано на рисунке, эта реализа-
ция взаимно-согласованного сервера поддерживает контейнер отображений
(map container), который позволяет серверу вести отдельные файлы регистра-
ции для каждого из клиентов. Рисунок также показывает, как мы используем
интерфейсный метод АСЕ: : select () и класс ACE_Handle_Set для обслу-
живания множества клиентов в модели взаимно-согласованного сервера.
Реализацию начнем с включения нескольких новых заголовочных файлов,
обеспечивающих новые возможности, которыми мы будем пользоваться в на-
шем сервере регистрации.
Интерфейсные фасадыАСЕ: демультиплексирование событий 467
♦include "ace/ACE.h"
♦include "ace/Handle_Set.h"
♦include ”ace/Hash_Map_Manager.h"
♦include "ace/Synch.h"
♦include "Logging_Server.h"
♦include "Logging_Handler.h"
Затем мы определяем тип шаблона ACE_Hash_Map_Manager, объяснение
которого приведено в блоке 15.
typedef ACE_Hash_Map_Manager<ACE_HANDLE,
ACE_FILE_IO *,
ACE_Null_Mutex> LOG_MAP;
Мы будем использовать экземпляр этого шаблона, чтобы эффективно ото-
бражать активное соединение сокета ACE_HANDLE на объект ACE_FILE_IO,
который соответствует своему регистрационному файлу. Используя
ACE_HANDLE в качестве ключа отображения, мы решаем важную проблему пе-
реносимости: дескрипторы сокетов в UNIX небольшие беззнаковые целые чис-
ла, а в Win32 — указатели.
Мы создаем новый заголовочный файл Reactive_Logging_Ser-
ver_Ex. h, который содержит производный класс Reactive_Logging_Ser-
ver_Ex, наследующий от Logging_Server. Основное различие между этой
реализацией и реализацией из раздела 7.2 заключается в том, что мы создаем
log_map для эффективного сопоставления активных дескрипторов с соответст-
вующими им указателями ACE_FILE_IO. Чтобы предупредить любые сомне-
ния, что активный дескриптор является потоковым сокетом, ACE_SOCK_Ac-
ceptor не добавляется к log_map.
class Reactive_Logging_Server_Ex : public Logging_Server
(
protected:
// Связывает активный дескриптор с указателем <ACE_FILE_IO>.
LOG_MAP log_map_;
/I Следит за дескрипторами сокета-акцептора и
// всех присоединенных потоковых сокетов.
ACE_Handle_Set master_handle_set_;
// Следит за дескрипторами чтения, отмеченных как
// активные <select>.
ACE_Handle_Set active_read_handles_;
// Остальные методы, приведенные ниже...
168
Клава 7
Блок 15: Контейнерные классы АСЕ
АСЕ предусматривает набор контейнерных классов, включая:
• Односвязные и двухсвязные списки.
• Множества и мультимножества.
• Стеки и очереди.
• Динамические массивы.
• Классы для работы со строками.
Где возможно, эти классы создаются в соответствии с классами стандартной
библиотеки C++ так, чтобы можно было легко переходить от одних к другим по
мере развития компиляторов C++.
ACE_Hash_Map_Manager определяет абстракцию множества, рационально
связывающего~<лючи и их значения.
Мы используем этот класс вместо «стандартного» std: :map (Aus98) по не-
скольким причинам:
1. std:: map не так уж стандартен—не все компиляторы, с которыми работа-
ет АСЕ, его реализуют, а те, которые реализуют, не заботятся о том, чтобы
реализовать его по общему образцу.
2. ACE_Hash_Map_Manage г выполняет эффективный поиск, основанный на хэ-
шировании, которое пока не поддерживает std: :map.
Более полное изложение контейнерных классов АСЕ приводится в (HJS).
Hook-метод open () просто выполняет шаги, необходимые для инициали
заЦии взаимно-согласованного сервера.
virtual int open (u_short port) {
Logging_Server::open (port) ;
master_handle_set_.set_bit (acceptor ().get_handle ());
acceptor ().enable (ACE_NONBLOCK);
return 0;
Ноок-метод wait_for_multiple_events() этого взаимно-согласо-
ванного сервера похож на метод из раздела 7.2. Однако в этом методе мы вызы-
ваем АСЕ:: select (), статический интерфейсный метод АСЕ, в котором пре-
дусмотрены аргументы по умолчанию для наиболее часто используемых пара-
метров функции select ().
virtual int wait_for_multiple_evencs () {
active_read_handles_ = master_handle_set_;
int width - (int) active_read_handles_.max_set () + 1;
return ACE::select (width, active_read_handles_);
Реализация hook-метода handle_connections () похожа на реализа-
цию в Reactive_Logging_Server. Мы принимаем новые соединения и об-
новляем log_map_ и master_handle_set_.
Интерфейсные фасады АСЕ: демультиплексирование событий 169
virtual int handle_connections () {
ACE_SOCK_Stream logging_peer;
while (acceptor ().accept (logging_peer) != -1) {
master_handle_set_.set_bit (logging_peer,get_handle ());
ACE_FILE_IO *log_file » new ACE_FILE_IO;
// Используем имя хоста клиента в качестве имени
// регистрационного файла.
make_log_file (*log_file, &logging_peer);
// Добавляем новый дескриптор <logging_peer> к отображению
// и к набору дескрипторов, выбранных (<select>) для ввода
log_map_.bind (logging_peer.get_handle (), log_file);
master_handle_set_.set_bit (logging_peer.get_handle ());
}
return 0;
)
Обратите внимание, что мы используем метод make_log_f i le (), произ-
водный от базового класса Logging_Server, описанного в разделе 4.4.1.
Hook-метод handle_data () последовательно обходит только активные
соединения, получает от каждого регистрационную запись и сохраняет запись
в регистрационном файле, связанном с данным клиентским соединением.
virtual int handle_data (ACE_SOCK_Stream *) {
ACE_Handle_Set_Iterator peer_iterator (active_read_handles_);
for (ACE_HANDLE handle;
(handle » peer_iterator ()) != ACE_INVALID_HANDLE;
) (
ACE_FILE_IO *log_file;
log_map_.find (handle, log_file);
Logging_Handler logging_handler (*log_file, handle);
if (logging_handler.log_record () == -1) {
logging_handler.close ();
master_handle_set_.clr_bit (handle);
log_map_.unbind (handle);
log_file->close ();
delete log_file;
)
}
return 0;
)
Когда клиент закрывает соединение, мы закрываем соответствующий Log-
ging_Handler, освобождаем дескриптор из master_handle_set_, удаля-
170
Глава 7
ем связь дескриптор-файл из log_map_ и удаляем динамически размещенный
объект ACE_FILE_IO. Хотя В этом примере мы показываем мало кода, связан-
ного с обработкой ошибок, готовый продукт должен выполнять положенные
действия в случае возникновения ошибок.
В завершение, мы приводим программу main (), которая, по сути, иден-
тична тем, которые приводились раньше, с тем исключением, что на этот раз
мы определяем экземпляр Reactive_Logging_Server_Ex.
int main (int argc, char *argv[])
(
Reactive_Logging_Server_Ex server;
if (server.run (argc, argv) == -1)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "server, run ()"), 1);
return 0;
}
7.5 Резюме
В этой главе были рассмотрены моменты, связанные со «случайной» слож-
ностью, являющиеся источниками снижения производительности и проблем
с переносимостью, которые возникают при проектировании сетевого приложе-
ния в соответствии с моделью взаимно-согласованного сервера. Интерфейсные
фасады ACE_Handle_Set и ACE_Handle_Set_Iterator были представле-
ны в качестве одного из способов решения этих проблем. Эти классы помогают
обеспечить программирование переносимого и надежного сервера, не ухудшая
производительность сетевых приложений.
Вз'аимно-согласованные серверы являются общепринятой программной
моделью, которая позволяет одному серверу взаимодействовать с несколькими
одноранговыми процессами или клиентами одновременно. Хотя новые версии
сервера сетевой регистрации в этой главе показали как просто делать это в пере-
носимом стиле, по-прежнему остается возможность дальнейшего усовершен-
ствования. В примере из раздела 7.4 осуществляется выбор: принять новое со-
единение или принять регистрационные записи в зависимости от того является
дескриптор сокета в ACE_Handle_Set активным или нет. Хотя такой подход
работает, он тесно связывает код демультиплексирования событий и управле-
ния соединением. Разработчикам приложений, поэтому, придется переписы-
вать этот код. На самом деле это универсальный подход и поэтому должен быть
реализован в виде повторно используемого каркаса.
Фундаментальным вопросом здесь является то, что select () и fd_set
создают основу для мощных возможностей, связанных с демультиплексирова-
нием и обработкой событий, которые трудно инкапсулировать в простом ин-
терфейсном фасаде. Поэтому в АСЕ предусмотрен каркас, основанный на пат-
терне Reactor [SSRBOO], чтобы выделять и повторно использовать обобщенное
поведение, связанное с демультиплексированием и диспетчеризацией, более
гибко. Мы будем подробно рассматривать каркас АСЕ Reactor в [SH].
Глава 8
Интерфейсные фасады АСЕ:
процессы
Краткое содержание
В главе описаны интерфейсные фасады АСЕ, инкапсулирующие механиз-
мы многозадачности ОС в переносимые классы C++. Показано большое разно-
образие средств многозадачности в популярных операционных системах и ме-
тоды, которые использует АСЕ, для абстрагирования концепций переносимо-
сти в виде удобных классов. Наконец, в ней показано как применять эти классы
в многозадачной версии нашей сетевой службы регистрации.
8.1 Обзор
Для сетевых приложений важно, чтобы ОС поддерживала многозадач-
ность, так как это способствует:
• Возможности параллельного выполнения, позволяя ОС планировать и
выполнять отдельные процессы на разных CPU.
• Повышению отказоустойчивости путем использования аппаратных
средств управления блоками памяти (MMU) для защиты адресных про-
странств изолированных процессов от случайного или злонамеренного
повреждения другими активными процессами системы.
• Усилению защиты, позволяя каждому процессу контролировать или ре-
гулировать информацию, связанную с защитой и аутентификацией, на
уровне пользователя или на уровне сеанса.
Эта глава описывает следующие ACE-классы, которые сетевые приложения
могут использовать для создания одного или нескольких процессов и управле-
ния ими:
172
Глава 8
Класс АСЕ Описания
ACE_Process Создает и синхронизирует процессы в переносимом стиле.
ACE_Process_Options Задает независимые и зависимые от платформы опции.
ACE_Process_Manager Создает и синхронизирует выполнение групп процессов переносимым образом.
На рис. 8.1 показаны взаимосвязи между этими классами. Эти интерфейс-
ные фасады имеют следующие преимущества:
• Улучшают кросс-платформенную переносимость в гетерогенной сре-
де. Возможности управления процессами сильно различаются на разных
платформах ОС. Интерфейсные фасады АСЕ, относящиеся к многоза-
дачности, предлагают переносимый вариант использования общего под-
множества этих возможностей. Например, классы ACE_Process и
ACE_Process_Options дают возможность единообразно создавать,
координировать и синхронизировать процессы, независимо от базовых
механизмов многозадачности ОС.
• Делают более удобным доступ к механизмам, зависящим от ОС. Неко-
торые платформы предлагают мощные механизмы создания процессов,
например POSIX fork(). Интерфейсные фасады АСЕ, описываемые
в данной главе, предоставляют разработчикам возможность обращаться
к этим механизмам, без изменения кода их приложений в различных
проектах.
• Позволяют управлять группами процессов как единым целым. Сете-
вые приложения, использующие многозадачность, часто требуют, чтобы
несколько процессов начинали и завершали работу группой. Класс
ACE_Process_Manager добавляет эту возможность к управлению от-
дельными процессами, за которое отвечает ACE_Process.
Рис. 8.1
Взаимосвязь классов АСЕ, относящихся к управлению процессами
В данной главе приведено обоснование и описание возможностей классов
АСЕ, связанных с многозадачностью. Мы приводим примеры каждого из клас-
сов, чтобы показать каким образом они могут упростить нашу сетевую службу
регистрации и повысить надежность различных ее аспектов.
Интерфейсные фасадыАСЕ: процессы
173
8.2 Класс ACE_Process
Обоснование
Создание процессов и управление ими является основной составляющей
большинства универсальных операционных систем (в разделе 6.2 объяснялось,
почему некоторые встроенные операционные системы не предоставляют воз-
можностей для работы с процессами). Операционные системы, которые все же
поддерживают одновременное выполнение процессов, обеспечивают набор
функций для:
• Создания процесса с целью выполнения конкретной программы.
• Добровольного или вынужденного завершения процесса.
• Синхронизации с завершением другого процесса.
Принимая во внимание уровень развития возможностей управления про-
цессами в ОС, можно было бы предположить, что существует некоторый уни-
фицированный стандарт, регулирующий эту область. Для многих аспектов,
к сожалению, это не так. Например, в следующей таблице перечислены основ-
ные отличия управления процессами в POSIX/UNIX и Win32:
POSIX/UNIX Win32
fork () создает копию вызывающего процесса, включая открытые дескрипторы ввода/вывода; последующий (необязательный) вызов функции ехес* () замещает текущий программный образ новым образом. CreateProcess() ВОДНОМ системном вызове и порождает новый процесс и выполняет назначенный образ программы.
Функция ki 11 () посылает процессу сигнал останова. Процессы могут перехватывать некоторые сигналы и интерпретировать их как требования завершения и завершаться как положено, с выполнением всех необходимых промежуточных действий. TerminateProcess() вынуждает процесс завершиться, не давая процессу возможности сделать это самостоятельно.
Функцию waitpido можно использовать для ожидания завершения порожденных процессов. Родительский процесс может также перехватывать сигнал sigchld, который выдает ОС родительскому процессу при завершении порожденного им процесса. Любая из двух функций, WaitForMultipleObjects() ИЛИ WaitForSingleObject О, может быть использована для ожидания того момента, когдЬ дескриптор некоторого процесса сообщит о своем завершении.
Хотя исчерпывающий анализ механизмов многозадачности ОС выходит за
рамки данной книги (дополнительную информацию см. в [Sch94, Ste92, Ric97]),
приведенные сопоставления показывают основные различия между двумя по-
пулярными операционными средами. Вы видите, что механизмы ОС управле-
ния процессами отличаются и синтаксически и семантически. Урегулирование
174
Глава 8
этих платформенных отклонений в каждом приложении является трудным,
утомительным, подверженным ошибкам и ненужным, так как в АСЕ преду-
смотрен класс ACE_Process.
Функциональные возможности класса
Класс ACE_Process инкапсулирует вариации различных API ОС, связан-
ных с многозадачностью, в соответствии с паттерном Wrapper Facade. В этом
классе определены единообразные переносимые методы, возможности кото-
рых позволяют приложениям:
• Создавать и завершать процессы.
• Осуществлять синхронизацию при завершении процессов.
• Получать доступ к свойствам процессов, таким как ID процесса.
Интерфейс класса ACE_Process показан на рис. 8.2; его основные кросс-
платформенные методы перечислены в следующей таблице:
Метод Описание
prepare() Вызывается функцией spawn () перед тем, как создавать порожденный процесс. Допускает проверку и/или модификацию опций, которые будут использоваться новым процессом; удобный способ задать зависящие от платформы опции.
spawn() Создает адресное пространство нового процесса и выполняет заданный образ программы.
unmanage () Вызывается ACE_Process_Manager, при завершении управляемого им процесса.
getpidO Возвращает id нового порожденного процесса.
exit_code() Возвращает код завершения порожденного процесса.
wait () Ждет завершения порожденного процесса.
terminate() Прерывает выполнение процесса, не давая ему возможности завершить начатую работу (используйте осторожно).
Класс ACE_Process обеспечивает переносимый доступ к общим возмож-
ностям создания нового процесса и выполнения нового образа программы
в э^ом новом процессе. Тем не менее, управление процессами — это одна из не-
скольких функциональных областей, в которой интерфейсные фасады не мо-
гут инкапсулировать все отличия ОС в одном объединенном классе, который
обеспечивал бы переносимость по всему диапазону платформ, поддерживае-
мых АСЕ. Например, в блоке 16 приводятся некоторые основные проблемы пе-
реносимости, связанные с серверами, которые используют уникальную семан-
тику механизма POSIX fork ().
Интерфейсные фасады АСЕ: процессы
175
ACE_₽roc«ss
# exit_code_ : int
# proceS3_info_ : PROCESS_INFORMATION (Win32)
# child_id_ : pid_t (POSIX)
+ prepare (options : ACE_Process_Optionsi) : int
+ spawn (opt : ACEJProcess_Options) : pid_t
+ unmanage ()
+ getpid () : pid_t
+ exit_code () : int
+ wait (status : ACE_exitcode *, options : int) : pid_t
+ terminate () : int
+ parent (child : pid_t)
+ child (parent : pid__t)
+ kill (signum : int ) : int
Рис. 8.2
Диаграмма класса ACE_Process
Так как UNIX является основной платформой для сетевых приложений,
класс ACE_Process предлагает несколько методов, работающих только в сре-
де POSIX/UNIX. Эти методы полезны (на самом деле, необходимы) во многих
проектных ситуациях. Чтобы исключить путаницу,'эти функции перечислены
ниже в таблице отдельно от тех переносимых методов, которые предлагает
ACE_Process.
Метод Описание
parent() Может быть перегружен, чтобы обеспечить нужное приложению функционирование; вызывается в контексте родительского процесса после вызова fork (), если процесс-потомок был порожден успешно.
child() Может быть перегружен, чтобы обеспечить нужное приложению функционирование; вызывается в контексте порожденного процесса после fork о и до ехес ().
kill () Посылает сигнал процессу. Переносим только на те операционные системы UNIX/POSIX которые могут посылать сигналы конкретным процессам.
Пример
Данный пример показывает, как использовать ACE_Process для перено-
симого создания нового процесса, который выполняет заданный образ про-
граммы. Программа, которую мы создаем, «рекурсивно» вычисляет факториа-
лы по следующей схеме:
1. Имея родительский процесс, создающий процесс-потомок, который сам
выполняет программный образ вычисления факториала числа, переданно-
го в переменной окружения факториала, по умолчанию вычисляя факто-
риал 10 (10!), если переменная окружения не задана.
2. Каждый родительский процесс затем ждет завершения порожденного им
процесса, используя код завершения процесса-потомка для вычисления
176
Глава 8
Блок 16; Проблемы переносимости POSIX
Многие UNIX-приложения используют системную функцию POSIX fork о для
создания, параллельных серверов, реализуемых на основе процесса. Пере-
нести эти серверы может оказаться трудно, если они используют любую из
следующих двух возможностей fork ():
1. Иметь родительский процесс, создающий (forkо) порожденный про-
цесс с крпиёй адресного пространства родительского процесса и копия-
ми всех Дескрипторов I/O родительского процесса (включая сокеты).
2. Иметь и родительский процесс, и порожденный, с помощью fork о, про-
цесс на одном и том же месте, но с разными возвращаемыми значениями,
которые затем выполняют разные фрагменты серверной обработки одного
и того же программного образа.
Не существует средства для дублирования адресного пространства на плат-
формах без функции fork (). Однако большинство популярных платформ ОС,
включая Win32, поддерживают более важную возможность получения нужных
дескрипторов I/O в порожденном процессе. Класс ACE_Process_options
Обеспечивает переносимый способ использования этой возможности, как
можно видеть в примере сервера регистрации в разделе 8,4.
факториала п и возвращает вычисленное значение в качестве кода заверше-
ния данного процесса.
Хотя очевидно, что это не самый эффективный способ вычисления факто-
риалов, он является, как показано ниже, выразительной иллюстрацией воз-
можностей ACE_Process.
♦include "ace/OS.h"
♦include "ace/Process.h"
int main (int argc, char *argv(])
(
ACE_Process_Options options;
char *n_env = 0;
int n;
if (argc == 1) ( // Процесс верхнего уровня.
n_env - ACE_OS::getenv ("FACTORIAL");
n = n_env == 0 ? 0 : atoi (n_env);
options.command line ("%s %d", argv[0], n == 0 ? 10 : n);
)
else if (atoi (argv[lj) == 1) return 1; // Основной случай,
else (
n = atoi (argv['l]);
options.command_line ("%s %d", argv[0], n - 1);
)
ACE_Process child;
child.spawn (options); // "Рекурсивный" вызов.
chiId.wait ();
return n * child.exit_code (); // Вычисляем n!.
Интерфейсные фасадыАСЕ: процессы
177
Вызов ACE_Proces s: : wa i t () будет работать независимо от, того был ли
порожденный процесс завершен до этого вызова или нет. Если он уже завер-
шен, вызов завершится немедленно, если нет, метод ждет завершения порож-
денного процесса. Этот метод является переносимым на все многозадачные
операционные системы.
Пример, приведенный выше, показывает наиболее основное и переноси-
мое использование ACE_Proce'ss_Options: для задания командной строки
порожденной программы. В следующем разделе обсуждается, почему нам ну-
жен отдельный класс опций и демонстрируется диапазон его возможностей.
8.3 Класс ACE_Process_Options
Обоснование
Операционные системы предлагают ряд методов для установки свойств
вновь создаваемых процессов. Свойства нового процесса затрагивают его связи
с другими процессами и условия его выполнения. Некоторые из распростра-
ненных свойств включают:
• Образ программы. Какую программу должен выполнять новый про-
цесс?
• Открытые дескрипторы I/O. Должен ли порожденный процесс наследо-
вать открытые дескрипторы I/O или другие объекты ОС? Должен ли он
закрывать некоторые или все из унаследованных им открытых дескрип-
торов?
• Доступ к дисплею. Должен ли порожденный процесс иметь доступ к тер-
миналу или к дисплею пользователя?
• Рабочий каталог. Должен ли порожденный процесс выполняться в том
же каталоге, что и его родительский процесс или в другом каталоге?
• Связь с процессами. Должен ли порожденный процесс выполняться
в фоновом режиме как независимый процесс-демон или как часть взаи-
мосвязанной группы?
• Атрибуты защиты. Должны ли быть изменены атрибуты защиты или
установки защиты файлов по умолчанию порожденного процесса, что-
бы расширить или ограничить его возможности?
Эти альтернативы касаются возможностей и API, которые часто бывают не-
переносимыми, даже на родственные платформы. Требуется большой опыт и
знание специфики платформ, чтобы гарантировать, что свойства каждого при-
кладного процесса выражены правильно. Класс ACE_Process_Options фик-
сирует это знание в переносимом виде.
Функциональные возможности класса
Класс ACE_Process_Options унифицирует способ передачи свойств
процессов классам ACE_Process и ACE_Process_Manager, которые ис-
178
Глава 8
пользуют эти свойства для выбора базовых механизмов ОС, связанных с созда-
нием и условиями выполнения процессов, и воздействия на эти механизмы.
ACE_Process_Options предоставляет следующие возможности:
• Позволяет приложению задать нужную для управления процессом ин-
формацию.
• Позволяет расширять возможности управления процессами при измене-
нии платформы.
• Обеспечивает механизм автономизации, который позволяет АСЕ пре-
доставлять эти возможности без изменения интерфейса создания про-
цессов.
Интерфейс класса ACE_Process_Options показан на рис. 8.3, а его ос-
новные кросс-платформенные методы перечислены в следующей таблице:
Метод Описание
command_line() Использует форматную строку типа printf, чтобы задать команду и ее аргументы, и использовать их при запуске новой программы в порожденном процессе.
setenv() Задает переменные окружения, добавляемые к окружению порожденного процесса.
working_directory () Задает новый каталог, на который порожденный процесс должен переключиться прежде, чем запустить новый образ программы.
set_handles() Устанавливает дескрипторы файлов, которые порожденный процесс должен использовать для своих потоков STDIN, STDOUT и STDERR.
pass-handle() Указывает дескриптор, который должен быть передан порожденному процессу.
АСК—Proсе»«—Option»
+ + command_line (format : const char *,...): int setenv (envp : char *(])
+ + working directory (dir : const char *) set-handles (in : ACE_HANDLE, out : ACE-HANDLE, err : ACE_HANDLE) : int
+ + pass_handle (h : ACE_HANDLE) s int creation—flags (flags : u_long) avoid_zombies (on_off : int)
+ + + setruid (id : uid_t) seteuid (id : uid_t) set—process-attributes () : LPSECURITY-ATTRIBUTES
Рис. 8.3
Диаграмма класса ACE_Process_Options
Интерфейсные фасады АСЕ: процессы
В разделе 8.2 объясняется, почему ACE_Process предлагает:
1. Методы, которые можно перенести на все операционные системы, поддер-
живающие процессы.
2. Методы, которые работают только на некоторых платформах.
Класс АСЕ_Ргосеss_Opt ions также использует этот подход. Его методы,
перечисленные выше, предлагают переносимый набор свойств для всех много-
задачных платформ. Методы, перечисленные ниже, предоставляют доступ
к свойствам, которые зависят от конкретной платформы:
Метод Описание |
creation_flags () Определяет выполнять или нет новый образ 1 программы в порожденном процессе (POSIX). |
avoid_zombies () У Позволяет ACE_Process принять меры, чтобы ? гарантировать, что порожденный процесс не превратится, после завершения, в зомби (больше несуществующий) (POSIX).
setruidO seteuid () Устанавливает ID реального и эффективного пользователя, для порожденного процесса (POSIX).
set_process_attributes() Предоставляет доступ к установкам атрибутов процессов для порожденного процесса (Win32).
Эти методы позволяют приложениям, управляющим несколькими одно-
временно выполняющимися процессами, извлечь преимущество из тех воз-
можностей, которые нельзя перенести на другие платформы, не требуя перепи-
сывать код, управляющий свойствами процессов, для каждой платформы.
Пример
Этот раздел обобщает код примера из раздела 8.2 следующим образом:
• Использует переменную окружения WORK ING_DIR для задания рабочего
каталога программы, в котором находится файл factorial. log.
• Передает имя программы порождаемым процессам через переменную
окружения.
• Выводит диагностические сообщения в файл factorial. log, который
содержит имя программы и ID процесса.
♦include "ace/OS.h"
♦include "асе/ACE.h"
♦include "ace/Process.h"
int main (int argc, char *argv(])
(
ACE_Process_Options options;
180
Глава 8
FILE *fp = 0;
char *n_env = 0;
int n ;
if (argc == 1) { // Процесс верхнего уровня.
n_env = ACE-OS::getenv ("FACTORIAL");
n = П—env == 0 ? 0 : atoi (n_env);
options.command_line ("%s %d", argv[0], n == 0 ? 10 : n);
const char *working_dir = ACE—OS::getenv ("WORKING—DIR");
if (working_dir) options.working—directory (working—dir);
fp = fopen ("factorial.log", "a");
options.setenv (”PROGRAM=%s", ACE::basename (argv[0]));
}
else {
fp = fopen ("factorial.log", "a");
if (atoi (argvfl]) == 1) {
fprintf (fp, ”[%s|%d]: base case\n",
ACE-OS::getenv ("PROGRAM"), ACE-OS::getpid ());
fclose (fp);
return 1; // Основной вариант.
} else {
n = atoi (argv[l]);
options.command line ("%s %d", argv[0], n - 1);
)
}
ACE—Process child;
child.spawn (options); // Делаем "рекурсивный" вызов.
child.wait ();
int factorial = n * child.exit—code (); // Вычисляем n!.
fprintf (fp, "[%s|%d]: %d! == %d\n",
ACE-OS::getenv ("PROGRAM"), ACE-OS::getpid (),
n, factorial);
fclose (fp);
return factorial;
}
Хотя системные функции, вызываемые в коде ACE-ProcesS-Options и
АСЕ—Process значительно различаются для разных платформ ОС, таких как
Win32 и POSIX, код, представленный выше, будет компилироваться и выпол-
няться переносимо и корректно на всех этих платформах.
8.4 Класс ACE_Process_Manager
Обоснование
Сложные сетевые приложения часто требуют создания групп процессов
для координации предоставления конкретной услуги. Например, многоуров-
Интерфейсные фасады АСЕ: процессы
181
невое приложение автоматизации документооборота может создавать несколь-
ко процессов для работы на разных участках этой большой задачи. Один основ-
ной процесс может ждать завершения всей группы рабочих процессов, прежде
чем перейти к следующему этапу деловой операции. Это является настолько
общим принципом, что в АСЕ предусмотрен класс ACE_Process_Manager.
ACX__Proc«sa_Manag«r
- process_table_ : ACE_Process * []
- current_count_ : size_t
+ open (start_size : size_t) ! int
+ close () : int
+ spawn (proc : ACE_Process *, opt : ACE_Process_Options) : pid_t
+ spawn__n (n : size_t, opts : ACE_Process_Options, pids : pid_t []
: int
+ wait (timeout : ACE_Time_Value) : int
+ wait (pid : pid_t, status : ACE_exitcode *) : pid_t
+ instance () : ACE Process Manager *
Рис. 84
Диаграмма класса ACE_Process_Manager
Функциональные возможности класса
Класс ACE_Process_Manager использует паттерн Wrapper Facade для
объединения переносимости и больших возможностей ACE_Process со спо-
собностью управлять группами процессов как одним целым. Этот класс имеет
следующие функциональные возможности:
• Обеспечивает ведение внутренних записей для контроля и управления
группами процессов, порожденных классом ACE_Process.
• Позволяет процессу порождать группу процессов и ждать их завершения
до того, как продолжить свою собственную работу.
Интерфейс класса ACE_Process_Manage г показан на рис.8.4, а его основ-
ные методы приведены в следующей таблице:
Метод Описание |
open () Инициализирует ACE_Process_Manager.
close () Освобождает все ресурсы (не ждет завершения процессов). |
spawn () Создает процесс и присоединяет его к управляемой группе процессов.
spawn_n () Создает п новых процессов, принадлежащих к одной группе процессов.
wait () Ждет завершения всех или некоторых процессов из группы процессов.
instance () Статический метод, возвращающий указатель на синглтон (singleton) ACE_Process_Manager.
182
Глава 8
Класс ACE_Process_Manager можно использовать двумя способами:
• Как синглтон [GHJV95] через его метод instance ().
• Создавая один или несколько экземпляров. Эту возможность можно
использовать для поддержки нескольких групп процессов внутри про-
цесса.
Рис. 8.5
Архитектура многозадачного сервера регистрации
Пример
Пример из раздела 7.4 продемонстрировал дизайн и реализацию взаим-
но-согласованного сервера, который несколько смягчает недостатки последо-
вательной модели сервера. Еще одной моделью сервера, обрабатывающего за-
просы клиентов, является модель создания нового процесса для управления ка-
ждым клиентом. Модели параллелизма на основе процессов часто оказываются
полезными, если решения, связанные с многопоточной обработкой или:
• Невозможны, например, первые UNIX-системы, в которых отсутствуют
эффективные реализации потоков или в которых вообще отсутствует
поддержка поточной обработки.
• Нежелательны, например, из-за ограничений, связанных с нереентера-
бельными библиотеками, поставляемыми сторонними производителя-
ми, или из-за требований надежности, связанных с пространствен;
но-временной декомпозицией аппаратных средств.
В разделе 5.2 представлены другие «за и против» реализации серверов на ос-
нове многозадачности, а не многопоточности.
Структура нашего многозадачного сервера регистрации показана на
рис. 8.5. Этот вариант сервера регистрации использует модель параллелизма
типа процесс-на-соединение и во многом похож на первую версию из раздела
Интерфейсные фасады АСЕ: процессы
183
4.4.3, которая использует дизайн последовательного сервера. Основное разли-
чие здесь заключается в том, что основной процесс порождает новый рабочий
процесс для каждого установленного с портом службы регистрации соедине-
ния. Затем основной процесс продолжает принимать новые соединения. Каж-
дый рабочий процесс обрабатывает все заявки на регистрацию, посылаемые
клиентом по одному соединению; процесс завершается при закрытии этого со-
единения.
Метод процесс-на-соединение имеет два основных преимущества:
1. Повышает надежность сервера регистрации относительно проблем, свя-
занных с разрушением одним экземпляром службы других ее экземпляров.
Это может случиться, например, из-за внутренней ошибки или из-за дейст-
вий злоумышленника, обнаружившего способ использовать уязвимое ме-
сто, связанное с переполнением буферов.
2. Это следующий шаг расширения сервера регистрации в направлении, по-
зволяющем каждому процессу проверять или контролировать информа-
цию, касающуюся защиты и аутентификации на уровне пользователя или
на уровне сеанса. Например, начало каждого ориентированного на пользо-
вателя сеанса регистрации может включать обмен типа пользователь/па-
роль. Используя многозадачный сервер, а не взаимно-согласованный или
многопоточный, обработка информации, зависящей от пользователя, в ка-
ждом процессе не может быть случайно (или злонамеренно!) нарушена
другими пользователями, так как каждый процесс имеет свое собственное
адресное пространство и свои привилегии доступа.
Сервер типа процесс-на-соединение, показанный ниже, работает правиль-
но и на платформах POSIX, и на Win32. Это впечатляющее достижение, если
учесть платформенные различия, изложенные в разделе 8.2 и блоке 16. Благода-
ря четкой декомпозиции задач в нашем примере-проекте сервера регистрации
и благодаря разумному использованию в АСЕ интерфейсных фасадов, отли-
чия, необходимые коду сервера оказываются минимальными и хорошо скры-
тыми. В частности, бросается в глаза явное отсутствие в приложении условно
компилируемого кода.
Тем не менее, из-за разных моделей создания процессов, мы должны, в пер-
вую очередь, решить как выполнять POSIX-процесс. Win32 принудительно за-
гружает образ программы во вновь созданный процесс, в то время как POSIX
этого не делает. В Win32 мы локализуем в одной программе всю логику сервера
ивыполняем этот программный образ и в рабочем, и в основном процессах, ис-
пользуя различные аргументы командной строки. На платформах POSIX, мы
можем или:
• Использовать ту же модель, что и в Win32 и выполнять новый образ про-
граммы.
• Повысить производительность, не вызывая функцию ехес* () после за-
вершения вызова fork ().
184
Глава 8
Чтобы добиться преимущества в производительности и показать как про-
сто, с помощью АСЕ корректно реализовать оба способа, мы не будем выпол-
нять новый образ программы в рабочих процессах на платформах POS1X.
Код сервера регистрации в варианте процесс-на-соединение не особенно
сложен, хотя он и работает по-разному в POSIX и Win32. Тем не менее, объясне-
ния последовательностей событий и деталей реализации интерфейсных фасадов
АСЕ, которые способствуют этой простоте, являются довольно замысловатыми.
Чтобы это легче воспринималось, мы разделяем объяснение класса Рго-
cess_Per_Connection_Logging_Server, управление процессами в при-
мере и класс Logging_Process.
Класс Process_Per_Connection_Logging_Server. Также как и в случае с по-
следовательным сервером регистрации в разделе 4.4.3, мы определяем класс,
представляющий наш сервер. Мы начинаем с включения необходимых заголо-
вочных файлов АСЕ:
♦include "ace/Log_Record.h"
♦include "ace/Process.h"
♦include "ace/Process_Manager.h"
♦include "ace/Signal.h"
♦include "Logging_Server.h"
Мы создаем класс Process_Per_Connection_Logging_Server на ос-
нове класса Logging_Serveг, определенного в разделе 4.4.1. Мы перегружаем
метод run (), чтобы реализовать два разных способа, которыми программа мо-
жет быть выполнена в Win32: как основной процесс, чтобы принимать соеди-
нения и порождать рабочие процессы, и как рабочий процесс, чтобы обслужи-
вать клиента регистрации. Это различие задается аргументами командной
строки:
• Основной процесс начинается с необязательного номера порта в команд-
ной строке, точно также как и другие наши реализации сервера сетевой
регистрации.
• Рабочий процесс начинается с двух аргументов: (1) +Н (опция "handle",
которую АСЕ добавляет к переданному дескриптору) и (2) числовое зна-
чение дескриптора сокета, унаследованного от основного процесса.
Рис. 8.6 и 8.7 изображают взаимодействие основного процесса с рабочими
для POSIX и Win32, соответственно.
Мы увидим, как параметры командной строки передаются на самом деле,
когда будем исследовать класс Logging_Proces s. Но сначала мы рассмотрим
определение нашего серверного класса:
class Process_Per_Connection_Logging_Server
: public Logging_Server
(
protected:
char prog_name_[MAXPATHLEN +1] ;
Интерфейсные фасадыАСЕ: процессы
185
Основной процесс
Рабочий процесс
Рис. 8.6
Последовательность создания основного и рабочего процессов в POSIX
Член данных prog_name_ принимает имя серверной программы из аргу-
мента командной строки argv [ 0 ]. Мы используем это имя при создании рабо-
чих процессов, которые обрабатывают новые соединения. Метод run () прове
ряет счетчик аргументов командной строки, чтобы принять решение как дол-
жен выполняться сервер: как основной процесс или как рабочий. Если
в командной строке два аргумента, то это рабочий процесс, иначе» — основной.
virtual int run (int argc, char *argv[]) {
strncpy (prog_name_, argv[0], MAXPATHLEN);
prog_name_[MAXPATHLEN] = ’\0'; // Обеспечиваем NUL-символ.
if (argc == 3)
return run_worker (argc, argv); // Только в Win32.
else
return runjnaster (argc, argv);
Основной процесс
Рабочий процесс
Рис. 8.7
Последовательность создания основного и рабочего процессов в Win32
186
Глава 8
Метод run_master () похож на метод Logging_Server: : run (); на-
пример, он открывает порт сервера регистрации для прослушивания и вызыва-
ет handle_connections(), чтобы принимать новые клиентские соедине-
ния. Однако он не вызывает hook-метод handle_data (), который всегда вы-
зывается в рабочем процессе.
Главный сервер порождает новый рабочий процесс для обработки регист-
рационных записей каждого клиента, как показано на рис. 8.5.
int run_master (int argc, char *argv[J) {
u_short logger_port = 0;
if (argc == 2) logger_port = atoi (argv(lj);
if (open (logger_port) == -1) return -1;
for (;;)
if (handle_connections () == -1) return -1;
return 0;
}
Мы наследуем реализацию метода open () из базового класса Log-
ging_Server, который инициализирует конечную точку акцептора для пас-
сивного прослушивания указанного порта. Так как реализация wait_f or_mul-
tiple_events () представляет собой холостую команду, мы просто ее здесь
опускаем и вызываем непосредственно handle_connections (), для выпол-
нения цикла обработки событий главного сервера.
Метод run_wor ker () выполняется только в Win32. При создании рабоче-
го процесса, основной процесс запрашивает дескриптор сокета, который был
передан рабочему процессу в командной строке. Метод run_worker () преоб-
разует аргумент командной строки обратно в дескриптор, создает объект
ACE_SOCK_Stream с эти дескриптором и вызывает handle_data () для об-
работки регистрационных записей клиента. Так как тип входящих данных фик-
сирован, он должен быть преобразован с помощью операции приведения типа.
Чтобы сделать это настолько безопасно, насколько позволяет C++ компи-
лятор платформы, АСЕ предлагает набор переносимых макроопределений
приведения типа (включая используемый ниже ACE_static_cast), которые
рассмотрены в блоке 17.
int run_worker (int argc, char *argv[]) (
ACE_HANDLE socket_handle =
ACE_static_cast (ACE_HANDLE, atoi (argv[2]>);
ACE_SOCK_Stream logging_peer (socket_handle);
handle_data (&logging_peer);
logging_peer.close ();
return 0;
Интерфейсные фасады АСЕ: процессы
187
Блок 17: Переносимое приведение типов на всех
компиляторах C++
Большинство программистов, изучавших до языка C++ язык С. знакомы с опе-
ратором приведения типа (type) expression. Это сильнодействующее
средство, но его леп<о применить неправильно, поскольку он i юрушает типо-
вую безопасность и может привести к ошибкам, особенно при перенесении
программ на новые плртфррмы. Хотя в ртан^арте C++ было введено несколько
ключевых слов допускающих приведение, типов без утраты их смысла, они не
реализованы в тех компиляторах, которые появились раньше, чем было введе-
но это свойство. Поэтому АСЕ поставляет набор макросов, которые позволяют
написать код в.переносимом стиле. Они используют, где можно, преимущест-
во новых операторов приведения типа; а где необходимо — оператор приве-
дения типа в С-стиле;. Наиболее часто используемые операторы приведения
типа, поставляемые вместе с АСЕ, перечислены в нижеследующей таблице:
АСЕ-макросы приведения тйпа .. Оператор приведения C++, используемый, если доступен
ACE_cOnst_cast (TYPE, EXPR) , COnst^Cast<TYPE>(EXPR) ;
stotic_cast<TYPE>(EXPR)
ACE_dynamic_cast (TYPE, EXPR) ACE_re i n terp re t(T Y PE fEXPR) d у n ami c_ca st <TY PE >(EXPR> r e i n t e r p r e u _ c a s L < 1' Y E Ч7. > (E X P R)
Главный серверный процесс пассивно прослушивает запросы на новые
клиентские соединения. Как и в наших предыдущих серверах регистрации,
метод handle_connections () принимает новые соединения. В сервере ре-
гистрации типа процесс-на-соединение, однако, handle_connectionsО
порождает новый рабочий процесс для работы с каждым новым клиентским
соединением. Рис. 8.6 иллюстрирует последовательность событий, которая
происходит, когда handle_connections () принимает новое соединение и
порождает рабочий процесс в POSIX. Рис. 8.7 показывает ту же последователь-
ность в Win32 (на обоих рисунках имя Process_Per_Connection_Log-
ging_Server, чтобы его поместить в отведенное пространство, сокращено до
Logging_Server). И рисунки, и пояснения ссылаются на класс Log-
ging_Process. Блок 18 перечисляет шаги на указанных рисунках, а следую-
щие фрагменты кода C++ иллюстрируют как эти шаги программируются с по-
мощью ACE_Process_Manager.
Ниже показана реализация метода handle_connections () класса Рго-
cess_Per_Connection_Logging_Server:
1 virtual int handle_connections () {
2 ACE_SOCK_Stream logging_peer;
3 if (acceptor ().accept (logging_peer) == -1)
4 return -1;
5
6 Logging_Process * logger =
188
Глава 8
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
new Logging_Process (prog_name_, logging_peer);
ACE_Process_Options options;
pid_t pid = ACE_Process_Manager:’.instance ()->spawn
(logger, options);
if (pid == 0) {
acceptor(}.close ();
handle_data (&logging_peer);
delete logger;
ACE_OS::exit (0) ;
)
logging_peer.close ();
if (pid == -1)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "spawn ()"), -Dr-
return ACE_Process_Manager::instance ()->wait
(0, ACE Time Value::zero);
Мы проанализируем реализацию метода handle_connections (), ссы-
лаясь на шаги на рис. 8.6 и 8.7, поясненные в блоке 18.
Строки 2-4 (Шаг 1) Вызываем acceptor () . accept (); вызов блокирует-
ся до момента подключения клиента.
Строки 6-10 (Шаги 2-4) Порождаем новый процесс для работы с приня-
тым клиентским соединением. Работа по правильной установке опций для ка-
ждой платформы выполняется методом Logging_Process: :prepare ().
ACE_Process:: spawn () вызывает подходящий платформенный механизм
создания нового процесса.
Строки 11-15 (POSIX Шаг 5w)' В Win32 значение возвращаемое spawn ()
не может быть равно 0, так как возвращается или PID нового процесса или -1
в случае ошибки. Поэтому эти строки всегда выполняются в контексте POSIX
процесса, порожденного вызовом f or к (). Рабочий процесс закрывает свой
унаследованный объект-акцептор, так как рабочий процесс использует только
установленное клиентское соединение, а новых соединений не принимает. Ме-
тод handle_data () вызывается для обработки всех регистрационных запи-
сей клиента, затем объект Logging_Process освобождается, а рабочий про-
цесс завершается. Основной процесс обнаружит, что рабочий процесс завер-
шен при следующем вызове ACE_Process_Manager:: wait () в строке 21.
Строка 17 Если вызов spawn () возвращается в родительский процесс (для
Win32 это всегда так), объект logging_peer больше не нужен, и он закрыва-
ется. Реальное TCP-соединение не закрывается, поскольку описанное далее за-
висящее от платформы поведение инкапсулировано в интерфейсные фасады
АСЕ для работы с процессами:
• В POSIX рабочий процесс наследовал копию всего объекта, включая от-
крытый дескриптор. ОС подсчитывает ссылки на дескрипторы, так что
соединение не может быть разорвано пока и родительский и рабочие
процессы ни закроют свои копии этого дескриптора.
Шаг 5w в Win32 выполняется методом run_worker ()
Интерфейсные фасадыАСЕ: процессы
189
Блок 18; Как создаются рабочие процессы
Пронумерованные шаги; изображенные на рис. 8.6 и 8.7 похожи. Они осуще-
ствляются методом.handle_conriectior!s () и перечислены ниже:
1. Принять новое соединение от клиента регистрации.
2. Чтобы начать создание нового рабочего процесса, вызвать лсе_р,..,-
vcess_Mana<jer:: spawn (). Дон вызовет АСЕ Process: :spawn().
3. ACE_Process:: spawn ( j осуществляет обратный вызов метода i.,og-
gingCServer,:; prepare () . чтобы установить атрибуты нового процесса.
4., Метод ACE_process:: spawn о вызывает платформенный механизм соз-
дания процесса. Например, в POSIX функция fork о создает рабочий
процесс в виде точной копии основного процесса. Новый процесс начина-
' ет выполняться в методе handie_connections() с точки возврата fcrko.
BWin32, тёмно менее, функция cr eateProcess о создает новый процесс
который не дублирует основной процесс. Новый процесс наследует де-
скриптор сдкёта нового клиента как показано в методе Logging_Pro - !
cess::prepare (). Новый процесс выполняет тот жз образ программы. '
что и основной процесс, но с новым значением дескриптора, передан i
ным в командной строке.
5. Дескриптор сокета регистрирующегося, однорангового процесса за
. крываётся’В основном процессе; в то врем как копия рабочего процесса
\. остается открытой и обслуживаетрегистрацию клиента.
5w, В рабочем процессе вызывается ”hodk-MeTOA.handie_data о. В POSIX он
' вызывается•’^m^^.i«<jMeTO^ia,handle_.g$nnecti0ns(). В Win32 метод
' . Process P.er^Conni&ti'pn_Logging_Server• :run() принимает дескрип-
• ' торхИз командной сфоки й вызывает метод rji~_workc-r (), который вызы-
BoeTh&hdijardata'f). Рабочий процесс завершается одновременно с за-
кбытиеМ ^^нтскогр соединения.,
& Основной П^цёсс'периодически вызывает ACE_₽rocess_Man3geг: : * *<•••
i.t (ьчтобы выяснить? не заверщилсяли рабочий” процесс.
7. После’ЗаверШен'йЯ-рабоЧего Процесса ACE_Process..Manager: : wall, г :
' Bbl3biBaeTjLoggi'ng_Process : :unnianage .(). Это дает возможность основ-
•• т^ному прбцёсбу освободить все ресурсы, связанные с этим рабочим про-
. цессом. Затем объектLoggingjprocess удаляет сам себя.
• В Windows NT/2000 дескрипторы управляются также как в POSIX; то есть
соединение закрывается только после того, как оба процесса закроют де-
скрипторы.
• В Windows 95/98 ссылки на дескрипторы автоматически не подсчитыва-
ются. Однако ACE_Process_Options: :pass_handle (), вызванный
из метода Logging_Process :: prepare (), дублирует дескриптор со-
кета, содержащийся в logging_peer. Родительский процесс может, по-
этому, без риска закрыть свой дескриптор, не влияя на соединение.
Как всегда, интерфейсные фасады АСЕ защищают разработчиков прило-
жений от необходимости вникать в тонкости и нюансы каждой платформы ОС!
Строки21-22(Шагиби7)МетодАСЕ_Ргосезз_Мападег: :wait() про-
веряет, завершились ли рабочие процессы, получая их статус и освобождая все
открытые ими дескрипторы.
Метод handle_data (), показанный ниже, идентичен для всех платформ.
Он переводит клиентский сокет в режим блокирования, открывает регистраци-
190
Глава 8
онный файл, чтобы сохранить регистрационные записи и обрабатывает регист-
рационные записи до тех пор, пока клиент регистрации не закроет сокет или
пока не произойдет ошибка. В заключение, закрывается файл регистрационных
записей.
virtual int handle_data (ACE_SOCK_Stream *logging_peer) {
// Обеспечиваем блокировку <recv>.
logging_peer->disable (ACE_NONBLOCK);
ACE_FILE_IO log_file;
make_log_file (log_file, logging_peer);
Logging_Handler logging_handler (log_file,
*logging_peer) ;
while (logging_handler.log_record () != -1)
continue;
log_file.close ();
return 0;
}
Класс Logging_Process. Чтобы правильно создать новый рабочий процесс,
мы определяем класс Logging_Process, который является производным
классом класса ACE_Process, рассмотренного в разделе 8.2. Так как требова-
ния, связанные с созданием, часто меняются от платформы к платформе и от
приложения к приложению, в ACE_Process предусмотрены hook-методы
prepare () и unmanage (). Наш класс Logging_Process использует метод
prepare () для передачи дескриптора сокета нового клиента регистрации ра-
бочему процессу. Это также то место, где мы локализуем любые изменения,
если нам нужно пересмотреть решение не выполнять новый образ программы
в POSIX.
class Logging_Process : public ACE_Process
{
private:
Logging_Process (); // Вынуждаем использовать нужный
// конструктор.
char prog_name_[MAXPATHLEN + .1J ;
ACE_SOCK_Stream logging_peer_;
public:
Logging_Process (const char *prog_name,
const ACE_SOCK_Stream &logging_peer)
: logging_peer_ (logging_peer.get_handle ())
( strcpy (prog_name_, prog_name); }
Параметры, необходимые для настройки нового рабочего процесса переда-
ются конструктору класса Logging_Process. Эти параметры включают имя
команды, используемое для создания нового процесса, и ACE_SOCK_Stream
клиента службы регистрации, который будет использовать рабочий процесс.
Интерфейсные фасадыАСЕ: процессы
191
Оба эти параметра используются в следующем далее hook-методе prepare (),
который вызывается методом ACE_Process : : spawn () до создания нового
процесса.
virtual int prepare (ACE_Process_Options &options) |
if (options.pass_handle (logging_peer_.get_handle (j) -- -I)
ACE_ERROR_RETURN ( (LM_ERROR, ”ip\n", "pass_handle()"), -1);
options.command_line ("%s", prog_name_);
options.avoid_zombies (1);
options.creation_f lags (ACE_Process_Options::NO_EXEC);
return 0;
)
Метод prepare () представлен как «шаг 3» на рис.8.6 и 8.7. Его единствен-
ный аргумент является ссылкой на объект ACE_Process_Options, который
ACE_Process : : spawn () использует для создания нового процесса. Это дает
prepare () возможность изменять опции или добавлять по мере необходимо-
сти. Мы используем prepare () для установки опций следующим образом:
• Передача дескриптора сокета клиента. Элементы ACE_Process и
ACE_Process_Options выполняют все зависящие от платформы дета-
ли корректного получения дескриптора сокета рабочим процессом,
включая его дублирование в Windows 95/98, и закрытие дубликата деск-
риптора при завершении процесса. Мы используем метод pass_hand-
1е () для передачи значения дескриптора в командную строку рабочего
процесса, что является признаком того, что клиент регистрации требует
обслуживания.
• У становка имени программы. Это нужно и при вызове POSIX f о г к (), и
при выполнении, по желанию, образа программы.
• Предупреждение появления процессов-зомби. Это флаг нужен только
в POSIX и игнорируется в Win32.
• Установка флага NO_EXEC, так чтобы POSIX-системы только создавали,
с помощью fork (), новый рабочий процесс и не запускали на выполне-
ние, с помощью ехес (), новый образ программы. Этот флаг в Win32 иг-
норируется.
Хотя некоторые методы в Win32 не действуют, мы их вызываем все равно,
так чтобы процедура настройки рабочего процесса была переносимой на все
АСЕ-платформы, поддерживающие многозадачность. Доводы в пользу такого
решения (и рассуждения о том, в каком случае подобное решение неправильно)
см. в разделе А.5.
ACE_Process_Manager инкапсулирует зависящие от платформы дета-
ли, определяющие когда процесс завершается и вызывает hook-метод unmana-
ge () для всех объектов уже завершившегося процесса. Метод Logging_Pro-
cess : : unmanage () показан как «шаг 7» на рис. 8.6 и 8.7 и приведен ниже:
192
Глава 8
virtual void unmanage () {
delete this;
)
Он просто удаляет объект Logging_Process, который был создан дина-
мически в процессе установления соединения с клиентом службы регистрации.
Дескриптор сокета регистрирующегося однорангового процесса может быть,
впрочем, продублирован при передаче рабочему процессу в Windows 95/98.
Благодаря инкапсуляции поведения и состояния в классе ACE_Process, такой
дескриптор будет закрыт в деструкторе ACE_Proces s, так что наш код «очист-
ки» является переносимым на все платформы, поддерживаемые АСЕ.
Наконец, мы показываем функцию main (), которая является небольшим
расширением наших предыдущих серверов.
static void sigterm_handler (int /* знак */) { /* No-op. */ }
int main (int argc, char *argv[J)
{
// Регистрируемся на получение сигнала <SIGTERM>.
ACE_Sig_Action sa (sigterm_handler, SIGTERM);
Process_Per_Connection_Logging_Server server;
if (server.run (argc, argv) == -1 && errno != EINTR)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "server.run()"), 1);
// Барьерная синхронизация.
return ACE_Process_Manager::instance ()->wait ();
)
Класс ACE_S ig_Act ion регистрирует процесс на получение сигнала SIG-
TERM, который администраторы могут использовать для закрытия родитель-
ского серверного процесса. Перед завершением, родительский процесс вызыва-
ет ACE_Process_Manager:: wait () для синхронизации по выходу всех ра-
бочих процессов регистрации до того как завершиться самому. Эта
возможность барьерной синхронизации может быть полезной, если родитель-
скому процессу нужно записать метку времени завершения в выходное устрой-
ство или файл регистрации.
8.5 Резюме
Большинство многозадачных операционных систем было создано тогда,
когда в моде были патентованные системы, и каждый разрабатывал свои собст-
венные механизмы управления обработкой. Так как важно поддерживать со-
вместимость версий ОС, многие из этих патентованных механизмов обработки
и библиотек API остаются до наших дней. В этой главе было показано, как ис-
Интерфейсные фасады АСЕ: процессы
193
пользовать возможности управления обработкой, имеющиеся в АСЕ, что по-
зволяет осуществлять переносимое кросс-платформенное программирование
многозадачных серверов. Мы применили ACE_Process_Manager к новой
реализации сервера регистрации, в которой совокупность создаваемых процес-
сов объединяется в группу. Группировка позволяет основному процессу ждать
завершения всех рабочих процессов, прежде чем завершиться самому.
Из-за внутренних различий в логике управления процессами, разработчи-
ки сетевых приложений должны тщательно оценивать требования, связанные
с параллелизмом их систем. Предыдущие главы в значительной степени фоку-
сировались на преодолении «случайной» сложности, вносимой низкоуровневы-
ми API. Данная глава расширяет предмет рассмотрения на проблемы разработки
кросс-платформенных программ. В ней показано, каким образом переносимые
интерфейсные фасады АСЕ значительно упрощают программирование много-
задачных приложений. Кроме того из нее становится ясно, что возможности се-
годняшних и завтрашних прикладных платформ должны основательно анализи-
роваться при оценке проектных решений, связанных с параллельным выполнени-
ем процессов. Например, интерфейсные фасады АСЕ, связанные с процессами,
могут скрыть от приложений многие детали ОС, но они не могут обеспечить
абстракцию процессов на тех платформах, на которых процессов нет вообще.
Глава 9
Интерфейсные фасады АСЕ:
потоки
Краткое содержание
В главе рассматриваются интерфейсные фасады АСЕ, которые инкапсули-
руют механизмы многопоточной обработки ОС в переносимые классы C++.
Мы применяем эти интерфейсные фасады АСЕ, относящиеся к поточной обра-
ботке, чтобы проиллюстрировать серию прогрессирующе гибких и эффектив-
ных усовершенствований нашей сетевой службы регистрации.
9.1 Обзор
Многие сетевые приложения естественным образом вписываются в много-
поточную схему, так как задачи обработки могут быть отделены от задач вво-
да/вывода. Многопоточность особенно удобна в серверах, которые управляют
связью с установлением и без установления соединений с множеством клиен-
тов одновременно. Все более мощная современная поддержка многопоточно-
сти в ОС помогает сетевым приложениям:
• Использовать достоинства аппаратуры, такие как симметричная много-
процессорная обработка, которая открывает возможность истинного па-
раллелизма при выполнении программ.
* Повышать производительность путем совмещения вычислений и об-
мена данными.
• Улучшать время отклика для GUI и сетевых серверов, чтобы гарантиро-
вать, что задачи чувствительные ко времени будут спланированы как
нужно.
• Упрощать структуру программ, позволяя приложениям использовать
интуитивно понятные механизмы синхронного программирования, а не
более сложные механизмы асинхронного программирования.
196
Глава 9
В данной главе рассматриваются следующие классы АСЕ, которые сетевые
приложения могут использовать для создания внутри процесса и организации
одного или нескольких потоков управления:
Клосс АСЕ Описание
ACE_Thread_ Manager Позволяет приложениям переносимым образом создавать потоки и управлять их временем жизни, синхронизацией и свойствами.
ACE_Sched_ Params Переносимая инкапсуляция возможностей классов планирования ОС, которая используется совместно С интерфейсным методом ACE_OS: : sched_params () для управления различными свойствами потоков реального времени.
ACE-TSS Инкапсулирует механизмы локальной памяти потоков, чтобы дать возможность обращаться к объектам, которые «физически» являются приватными объектами потока, так, как если бы они были «логически» глобальными для программы.
Эти интерфейсные фасады предоставляют следующие преимущества:
• Обеспечивают кросс-платформенную переносимость в гетерогенной
среде. АСЕ, с помощью своих интерфейсных фасадов, скрывает, что опе-
рационные системы различаются синтаксисом и логикой многопоточно-
сти. Например, класс ACE_Thread_Manager обеспечивает идентич-
ность поведения обособленных/объединяемых потоков, независимо от
базовых механизмов поточной обработки ОС.
• Управляют группами потоков как связной совокупностью. Параллель-
ным сетевым приложениям часто бывает нужно начинать и завершать
работу нескольких потоков как единого целого. Класс ACE_Thread_Ma-
nager предоставляет возможность работы с группой потоков, что по-
зволяет другим потокам ждать завершения всей группы потоков, прежде
чем продолжать собственную работу.
• Влияют на политики и приоритеты планирования потоков. Многие се-
тевые приложения требуют жесткого контроля за приоритетами их пото-
ков. Операционные системы реального времени и универсальные ОС
часто отличаются своими возможностями планирования, и кросс-плат-
форменным сетевым приложениям нужен способ переносимого управле-
ния несопоставимыми свойствами планирования. Класс ACE_Sched_Pa-
rams создан, чтобы предоставить доступ к информации планирования
в реальном времени унифицированным, переносимым и удобным для
использования образом.
• Эффективно используют локальную память потока (TSS) и управляют
ею. TSS является механизмом, который позволяет множеству объектов и
методов управлять информацией, которая является специфической для
каждого потока. Класс интерфейсного фасада АСЕ TSS нивелирует син-
таксические различия, также как отличия в возможностях платформ.
Интерфейсные фасадыАСЕ: потоки
197
В главе приведено обоснование и описание возможностей классов АСЕ
многопоточной обработки. Мы приводим примеры каждого класса, чтобы по-
казать каким образом они могут упростить и оптимизировать различные ас-
пекты нашей сетевой службы регистрации.
9.2 Класс ACE_Thread_Manager
Обоснование
Разные операционные системы используют разные API для создания,
управления и синхронного завершения потоков. Современные механизмы
многопоточности страдают от «случайной» сложности, похожей на ту, которая
рассматривалась в предыдущих главах. Два типа «случайностей» осложняют
написание переносимых приложений:
• Синтаксические—Внутренние API ОС, связанные с поточностью, часто
оказываются непереносимыми из-за синтаксических различий, даже
если они реализуют одинаковую функциональность, например, функ-
ции Win32 CreateThread () и Pthreads pthread_create () предлага-
ют похожие возможности создания потоков, хотя их API синтаксически
отличаются.
• Семантические — Интерфейсные фасады, которые экспортируют син-
таксически одинаковый интерфейс программирования на C++, не обяза-
тельно учитывают различие в логике механизмов многопоточности раз-
ных ОС, например, и Pthreads, и UI threads поддерживают обособленные
(detached) потоки, тогда как Win32 их не поддерживает, a VxWorks под-
держивает только их.
Один особенно часто дискутируемый аспект многопоточных приложе-
ний — это определение того, как завершать потоки переносимым образом. Не-
которые платформы ОС сами обеспечивают поддержку завершения потоков,
например:
• Pthreads определяет мощный набор API, которые позволяют завершать
потоки асинхронно или согласованно с помощью функций pthre-
ad_cancel () и pthread_testcancel().
• На некоторых платформах UNIX можно также завершать потоки с помо-
щью сигналов, например, с помощью функций Pthreads pthre-
ad_kill () и UI threads thr_kill ().
• Функция Win32 TerminateThreadO реализует асинхронное заверше-
ние.
К сожалению, собственные механизмы ОС завершения потоков, перечис-
ленные выше, не являются переносимыми и могут приводить к появлению
ошибок. Например, сигналы UNIX и функция Win32 TerminateThread ()
могут тут же завершить зависший поток, не дав ему освободить ресурсы, кото-
рыми он владел. Механизмы асинхронного завершения потоков в Pthreads
198
Глава 9
обеспечивают лучшую поддержку для освобождения ресурсов, которыми вла-
деет поток, но и их трудно понять и запрограммировать корректно, и они непе-
реносимы на платформы отличные от Pthreads.
Поскольку решать все эти проблемы переносимости для каждого приложе-
ния и утомительно, и может приводить к ошибкам, АСЕ предлагает класс
ACE_Thread_Manager.
Функциональные возможности класса
Класс ACE_Thread_Manager использует паттерн Wrapper Facade для ор-
ганизации инкапсуляции синтаксических и семантических отличий многопо-
точных API разных ОС. Этот класс обеспечивает следующие возможности, свя-
занные с переносимостью:
• Создает один или сразу несколько потоков, каждый из которых парал-
лельно выполняет одну из функций, реализуемых приложением.
• Изменяет атрибуты потока общего характера, например, приоритет при
выделении времени и размер стека, для каждого из созданных потоков.
• Создает и управляет набором потоков как связной совокупностью, назы-
ваемой группой потоков.
• Управляет потоками в классе ACE_Tas к, который мы представим в [SH].
• Упрощает совместное завершение (cooperative cancelation) потоков.
• Позволяет ждать завершения одного или нескольких потоков.
Интерфейс класса ACE_Thread_Manager показан на рис. 9.1, а его основ-
ные кросс-платформенные методы перечислены в следующей таблице:
Метод Описание
spawn() Создает новый поток управления, передавая ему функцию для выполнения в качестве входной точки потока и ее параметры.
spawn_n() Создает п новых потоков, принадлежащих одной группе. Другие потоки могут ждать завершения всей этой группы потоков.
wait () Ждет завершения всех потоков в менеджере потоков и принимает статусы завершения всех объединенных потоков.
join () Ждет завершения конкретного потока и получает его статус завершения.
cancel_all() Требует завершения все потоков, управляемых объектом ACE_Thread_Manager.
testcancel () Выясняет можно ли потребовать завершения указанного потока.
exit () Завершает поток и освобождает ресурсы этого потока.
close() Закрывает и освобождает все ресурсы всех управляемых потоков.
instance () Статический метод, который возвращает указатель на СИНГЛТОН (Singleton) ACE_Thread_Manager.
Интерфейсные фасадыАСЕ: потоки
199
ACE__Thraad_JManagar
* grp_id_ : int:
+ spawn (func : ACE THR_FUNC, args : void * e 0, flags : long - THR_NEW_LWP | THR_JOINABLE, id: ACE_thread_t * « 0, handle : ACE_hthread_t * = 0, priority : long - ACE_DEFAULT_THREAD_PRIORITY, grp_id : int « -1, stack : void * - 0, stack_size : size_t «0) : int
+ spawn_n (n : size_t, func : ACE_THR_FUNC, args : void * = 0, flags : long - THR_NEW_LWP | THR_JOINABLE, priority : long « ACE_DEFAULT THREAD-PRIORITY, grp_id : int » -1, task : ACE_Task_Base * - 0, handles : ACE_hthread_t [ ] « 0, stacks : void * [ ] « 0 stack_sizes : size_t [ ] 0) : int
+ + + + + + + wait (timeout : const ACE_Time_Value * - 0) : int join (id : ACE_thread_t, status : void ** * 0) : int cancel_all (async_cancel : int -0) : int testcancel (id : ACE_thread_t ) : int exit (status : void * e 0, do_thread_exit : int =1) : int close ( ) : int .instance L.) .;...AGE Thread Manager *
+ + suspend (id : ACE_thread_t) : int resume (id : ACE_thread_t) : int kill (id ; ACE_thread_t, signum : int) : int
Рис. 9.1
Диаграмма класса ACE_Thread_Manager
Методу ACE_Thread_Manager: : spawn () может быть передан набор
флагов для задания свойств создаваемого потока. Это значение является пораз-
рядным включающим «ИЛИ» флагов, приведенных в следующей таблице:
Флаг Описание
THR_SCOPE_SYSTEM Новый поток создается с областью состязаний на уровне системы, и закрепляется на постоянной основе за вновь создаваемым потоком ядра.
THR_SCOPE_PROCESS Новый поток создается с областью состязаний на уровне процесса то есть он выполняется как пользовательский поток.
THR_NEW_LWP Этот флаг влияет на атрибут, связанный с параллельным выполнением процесса. Желательный уровень параллелизма для несвязанных потоков увеличивается на единицу, что обычно приводит к добавлению нового потока ядра к пулу, готовых к выполнению, пользовательских потоков. На тех платформах ОС, которые не поддерживают модель поточности N:M пользователь/ядро, этот флаг игнорируется. |
200
Глава 9
Флаг Описание
THRJ3ETACHED Новый поток создается обособленным (detached). Это означает, что его статус завершения недоступен другим потокам. Его ID и другие ресурсы высвобождаются ОС как только он завершается. Этот флаг противоположен флагу thr_joinable.
THR_JOINABLE Новый поток создается объединяемым (lolnable). Это означает, что его статус завершения может быть получен другими потоками с помощью метода ACE_Thread_Manager:: join (). Его ID И другие ресурсы не высвобождаются ОС пока к другие потоки не присоединятся к нему. Этот флаг противоположен флагу thr_detached. По умолчанию для всех методов создания потоков АСЕ используется флаг THR_JOINABLE.
Класс ACE_Thread_Manager не только создает потоки с различными
свойствами, он также поддерживает безопасный, удобный в использовании и
переносимый механизм совместного завершения потоков. При использовании
этого механизма поток, завершающий свое выполнение, с помощью
ACE_Thread_Manager: : cancel () устанавливает флаг, указывающий, что
обозначенный поток должен завершиться сам. Завершенный поток в этой схе-
ме также отвечает за взаимодействие, периодически вызывая ACE_Thre-
ad_Manager: : testcancel (), чтобы проверить, не поступил ли к нему за-
прос на завершение.
Так как поток завершается не сразу, свойство АСЕ совместного завершения
потоков аналогично применению политики отложенного завершения (deferred
cancelation), принятой в Pthreads, в которой точкой завершения является вызов
ACE_Thread_Manager: : testcancel (). Совместное завершение потоков
в АСЕ отличается от отложенного завершения в Pthreads в следующем:
• Освобождение ресурсов потока в АСЕ должно'программироваться в яв-
ном виде после точки завершения.
• После получения запроса на завершение поток в АСЕ может принять ре-
шение о завершении всей выполняемой работы или даже проигнориро-
вать запрос на завершение вообще.
Таким образом, завершение потока в АСЕ является делом строго добро-
вольным, и это единственная возможность завершать поток переносимым и
безопасным образом.
Так же как ACE_Process_Manager, рассмотренный в разделе 8.4,
ACE_Thread_Manager можно использовать двумя способами:
• Как синглтон [GHJV95], обращение к которому осуществляется с помо-
щью его метода instance (). Этот метод реализован с помощью пат-
терна Double-Checked Locking Optimization, в соответствии с изложен-
ным в блоке 19.
Интерфейсные фасадыАСЕ: потоки
201
• Путем создания одного или нескольких экземпляров. Эту возможность
можно использовать для поддержки нескольких наборов групп потоков
внутри процесса. Хотя такое применение допустимо всегда, оно особо ре-
комендуется при разработке разделяемых библиотек (shared library), DLL,
которые используют класс ACE_Thread_Manager. Такой подход по-
зволяет избежать пересечений с экземпляром синглтона, который может
использовать вызывающее приложение.
Пример
Многопоточные серверы являются обычным решением в тех операцион-
ных системах, где создание потоков, связано с меньшими издержками, чем соз-
дание процессов. В следующем примере используется ACE_Thread_Manager
для реализации нашего первого многопоточного сервера регистрации, постро-
енного в соответствии с моделью параллелизма поток-на-соединение. Как по-
казано на рис. 9.2, основной поток выполняется в непрерывном режиме и игра-
ет роль фабрики, которая:
1. Принимает соединение и динамически создает объект ACE_SOCK_Stream.
2. Создает рабочий поток, который использует этот объект для управления
сеансом регистрации клиента.
Рабочий поток выполняет всю последующую обработку регистрационной
записи объекта ACE_SOCK_Stream и удаляет его, после закрытия соединения.
Такой дизайн параллелизма похож на пример из раздела 8.4, в котором для каж-
дого клиентского соединения создавался новый процесс. Этот сервер регистра-
ции типа поток-на-соединение отличается, однако, от реализации сервера про-
цесс-на-соединение в следующем:
• Он создает новый поток для каждого соединения, а не новый процесс,
следовательно, должен быть более эффективным.
• Он является более переносимым, так как работает на всех платформах,
поддерживающих потоки.
• Он является существенно более простым, поскольку переносимые много-
поточные серверы легче программировать, чем многозадачные серверы.
В разделе 5.2 приводится более общее описание всех «за и против» реализа-
ции многопоточных серверов, а не многозадачных.
Мы начинаем, как всегда, с включения нужных заголовочных файлов АСЕ:
♦include "ace/SOCK_Stream.h"
♦include "ace/Thread_Manager.h"
♦include "Logging_Server.h"
♦include "Logging_Handler.h"
202
Глава 9
Блок 19: Сериализация синглтонов в АСЕ .
Паттерн Singleton (GHJV95) гарантирует, что класс будет иметь только один эк-
земпляр и предоставляет глобальную точку для доступа к этому экземпляру.
Синглтоны, определенные, в АСЕ, используют паттерн Double-Checked Locking
Optimization (38РВ00) для снижения издержек, связанных с состязаниями и син-
хронизацией, когдб критические секции кода должны запрашивать блокиров-
ки в потокобезопЬснбм стиле только один раз за все время выполнения про-
граммы. Следующий далее код показывает каким образом статический метод
ACE_Thread_Manager:: instance' () использует этот паттерн:
АСЕ Tbredd_Managet *ACE^Thre'ad_Manager:: instance () (
.if (ACE^Threa^Manager: 0) (
ACE_GUARD_RETURN(ACE_Recursive_Thread_Mutex, acejnon,
*ACE Static_Gbject_IaOck: : instance () z
- '5 . \ ’
•if (ACE_Thxead_M^rjager:.:t:hr_mgr__. 0).- ? ‘
... : ;thr_mgr
hew. ACEJTh.read^Manager;
} ’ ' ; Г 'л • -
return ACE_Thread_Managert: thrjngr_;
J ' > U.v, r-Г' J ". . . ’
Метод ACE_staticfcHg'b^ect^t6ck; :lnstari'ceО возвращает предварительно
инициализиррванн^|о‘бХркйррв1<у> которая создается до выполнения функции
main’О - как отмечено в^лбкё^23: / \ ' ’ . . ’ ‘
Рис. 9-2
Архитектура сервера регистрации типа поток-на-соединение
Мы определяем класс Thread_Per_Connect i on_Logging_Server, ко-
торый является производным от Logging_Server.
Интерфейсные фасадыАСЕ: потоки 203
class Thread_Per_Connection_Logging_Server : public
Logging_Server
private:
class Thread_Args {
public:
Thread_Args (Thread_Per_Conenction_Logging_Server *lsp)
: this_ (Isp) {}
Thread__Per_Connection__Logging_Server *this__;
ACE_SOCK_Stream logging_peer_;
// Передается в качестве параметра
// в <ACE_JThread__Manager::spawn>.
static void *run_svc (void *arg);
protected:
// Остальные методы, приведенные ниже...
Также как в случае Process_Per_Connection_Logging_Server
в разделе 8.4, мы наследуем и повторно используем методы open () и
wait_for_multiple_events ().
Блок 20: ЬшЙбки иловушкй смешения потоков и объектов
"*' * ..«и.. I—. t ж. и. -------------------------------------------------------------------------------------------------------------------------------------- -----------------
параметров функциям, с кото-
рых, начйнает^фп^ёк^потбков^жнд тщательно конгролироват ь Мно-
гие программисты рут<з^ поток иобъёкт, когда говорят что-нибудь вроде «этот
объект..выпрдняется 6^Ьг§кеж Важнд различать следующее:
• ПотЪК—это. эЛёмейтЬрная составляющая, процесса выполнения.
♦ рбъею^'этр участрк''п^х^М СИЗрнные р^имметодь!.
Таким. ,рб[таздм^Иё‘.суШ^ствуе^.внрй связи междупотоком и каким бы то ни
былЬ объектом', К коТЬрому этот^гюток обращается в процессе выполнения.
Поэтому важно убедиться, что никакой поток не будет'обращаться к объекту,
который Уже удален,' * ? . .• , - .
Наприйор, был создан/удален в области действия
• ци10\ахр.х,.впотока будетлерезаписан следующим кли-
онтскимсоединением.
ПоэТОму,?^Трбь1: избежать этйх: неприятностей, мы создаем объекты гыо-
ad Агд^|Нбмйчфски и поручаем функции run s vc () перед завершением ее
работы их/-
Метод handle_connections () принимает соединение в элемент дан-
ных ACE_SOCK_Stream объекта thread_args. (Блок 20 объясняет почему
мы выделяем память под thread_args динамически). Затем мы используем
синглтон (singleton) ACE_Thread_Manager для создания нового потока, кото-
рый управляет вновь подключенным клиентом.
204
Глава 9
virtual int handle_connections () (
Thread_Args *thread_args » new Thread_Args (this);
if (acceptor ().accept (thread_args->logging_peer_) == -1)
return -1;
else if (ACE_Thread_Manager::instance ()->spawn (
// Указатель на функцию-точку-входа.
Thread_Per_Connection_Logging_Server::run_svc,
11 Параметр <run_svc>.
ACE_static_cast (void *, thread_arg.s),
THR_DETACHED | THR_SCOPE_SYSTEM) == -1)
return -1;
else
return 0;
}
Статический метод run_svc () является точкой входа каждого нового по-
тока. Базовая функция создания потоков ОС передает указатель thread_args
методу run_svc (), который должен управлять временем жизни объектов
logging_peer. Так как мы не ждем завершения потока, чтобы получить его
статус завершения, мы передаем флаг THR_DETACHED, который указывает
ACE_Thread_Manager и базовой реализации поточной обработки в ОС, что
ресурсы нужно освободить сразу после завершения потока. Всеми потоками,
созданными синглтоном ACE_Thread_Manager можно управлять как еди-
ным целым. Следовательно, мы можем ждать их завершения, даже если они не
были отмечены как объединяемые (joinable) с помощью флага THR_ JOINABLE
при их создании. Блок 21 показывает, как создаются потоки с применением
этих флагов.
Метод run_svc (), показанный ниже, служит точкой входа для каждого
нового потока, созданного для обработки регистрационных записей клиента.
void *Thread_Per_Connection_Logging_Server::run_svc (void *arg)
Thread_Args *thread_args ACE_static_cast (Thread_Args *, arg);
thread_args->this_->handle_data (&thread_args->logging_peer_);
thread_args->logging_peer_.close ();
delete thread_args;
return 0; // Возвращаемое значение игнорируется.
)
Как показано в блоке 21, методу ACE_Thread_Manager: : spawn () пере-
дается указатель Thread_Args, используемый функцией run_svc (). Этот
указатель должен быть приведен к типу void * для согласования с API поточ-
ной обработки АСЕ, которая может переноситься на другие операционные сис-
темы. После того, как функция run_s vc () вызывается библиотекой поточной
обработки ОС, она выполняет обратное приведение указателя к Th read_Args
*. Макроопределение АСЕ ACE_static_cast () (см. блок 17) упрощает one-
Интерфейсные фасадыАСЕ: потоки
205
Блок 21: Как создаются потоки в АСЕ
Ниже на рисунке показана последовательность вызовов, которая совершает-
ся при вызове ACE^Thread_Manager:: spawn () на платформенной конфигура-
ции, которая использует системную функцию UI Threads t ’.r_ reace ();
стек потока
времени выполнения
1. ACEJThreadJdarrager : : spawn
(run_$vc,
thread ax*gs, ' -
THRJDETACHED’г THR_SCOPE_SYSTEM);
2. thr^create \ >
(0, Or •
run_svc, thread_args,
3. run_svc (thread_args)
THRJ)ETACHED Г THR_SCOPE_SYSTEMr &thread_id) ;
Независимо от ОС, для создания потока выполняются следующие шаги:
1. ОС создает контекст выполнения потока.
2. ОС выделяет память под стек потока.
3. Готовится набор регистров нового потока так, что когда он будет направ-
лен на выполнение, он вызовет функцию-точку-входа потока, передавае-
мую в качестве параметра в spawn ().
4. Поток помечается как «готовый к выполнению» (runnable) так, чтобы ОС мог-
ла начать’ его выполнение.
рацию приведения указателя, делая ее настолько безопасной, насколько позво-
ляет используемый компилятор. Заметьте, что поскольку мы вызываем
run_svc () в обособленном (detached) потоке, возвращаемое ею значение иг-
норируется.
Статический метод run_svc () использует члены-данные параметра
Thread_Args для передачи управления обратно следующему методу hand-
le_data(), так чтобы обработка регистрационных записей могла продол-
жаться.
protected:
virtual int handle_data (ACE_SOCK_Stream *logging_peer) {
ACE_FILE_IO log_file;
// Имя хоста клиента используется в качестве имени log-файла.
make_log_file (log_file, logging_peer);
// Переводим соединение в блокируемый режим.
client->disable (ACE_NONBLOCK);
Logging_Handler logging_handler (log_file, *logging_peer);
ACE_Thread_Manager *tm = ACE_Thread_Manager::instance ();
ACE_thread_t me = ACE_OS::thr_self ();
// Продолжаем обработку log-записей до тех пор, пока клиент
// закроет соединение или поток получит запрос с
206
Глава 9
// требованием завершиться самостоятельно.
while (!tm->testcancel (me)
&& logging_handler.log_record () != -1)
continue;
log_file.close ();
return 0;
}
Данная версия handle_data () похожа на версию из примера процесс-
на-соединение. Тем не менее, в этой версии поток handle_data (), который
обрабатывает клиентские регистрационные записи, может получить запрос
с требованием завершиться самому, что является одни из примеров совместно-
го завершения (cooperative cancelation). С целью согласования, каждый поток
handle_data (), прежде чем обрабатывать регистрационную запись, вызыва-
ет ACE_Thread_Manager: :testcancel (), чтобы проверить не поступил
ли от основного потока запрос на завершение.
Одним из недостатков такого размещения вызова testcancel () и такого
дизайна метода Logging_Handler: : log_record () является то, что такой
поток «заметит» запрос на завершение только после того, как получит следую-
щую регистрационную запись. Если клиенты посылают регистрационные за-
писи достаточно часто, то это может и не будет проблемой. Чтобы устранить
этот недостаток, можно использовать ACE-каркасы Reactor и Task, рассмотрен-
ные в [SH].
В завершение, программа main() выполняет цикл обработки событий
сервера регистрации в своем шаблонном методе run ().
int main (int argc, char *argv[])
{
// Регистрируемся на получение сигнала <SIGTERM>.
ACE_Sig_Action sa (sigterm_handler, SIGTERM);
‘ Thread_Per_Connection_Logging_Server server;
if (server.run (argc, argv) == -1)
ACE_ERROR_RETURN ((LM_ERROR, "%p\n", "server.run()"), 1);
// Совместное завершение потоков.
ACE_Thread_Manager::instance ()->cancel_all ();
// Барьерная синхронизация, ожидание не больше минуты.
ACE_Time_Value timeout (60);
return ACE_Thread_Manager::instance ()->wait (&timeout);
)
Реализация сервера регистрации типа поток-на-соединение перехватывает
сигнал SIGTERM, чтобы дать возможность системному администратору завер-
шить его работу штатно. Но вместо того, чтобы ждать завершения сеансов все-
Интерфейсные фасады АСЕ: потоки
207
ми клиентами службы регистрации, что может занять неизвестно сколько вре-
мени, основной поток использует механизм совместного завершения
ACE_Thread_Manager, чтобы потребовать завершения от всех потоков служ-
бы, созданных синглтоном ACE_Thread_Manager.
Вызов wait () в конце main (), позволяет серверу регистрации ждать до
одной минуты, чтобы синхронизировать процесс окончания всех завершаемых
потоков. Это один из примеров барьерной синхронизации, помогающей избе-
жать проблем, которые могут иметь место на платформах тех ОС, где ситуация,
в которой основной поток завершается до завершения других потоков, может
иметь нежелательные последствия. Тем не менее, ограничивая время ожидания
с помощь)» аргумента, задающего величину тайм-аута, мы гарантируем, что
сервер регистрации не будет ждать бесконечно.
9.3 Класс ACE_Sched_Params
Обоснование
Все потоки, создаваемые классом Thread_Per_Connection_Log-
ging_Server работают с тем приоритетом, который установлен по умолча-
нию в предопределенном макросе ACE_DEFAULT_THREAD_PRIORITY. Неко-
торые типы сетевых приложений, особенно требующие выполнения в реаль-
ном времени, нуждаются в более тщательном контроле за приоритетами* их
потоков. В АСЕ можно задавать приоритет вновь создаваемого потока путем
передачи параметра методам ACE_Thread_Manager:: spawn () или
spawn_n (). С этим подходом, однако, связаны две проблемы:
• Непереносимость—Платформы разных ОС задают приоритеты по-раз-
ному, например, в некоторых операционных системах более высокие
приоритеты имеют большее числовое значение, тогда как в других —
меньшее.
• Выполнение не в реальном времени — Большинство операционных
систем требуют дополнительных (и нестандартных) мер, чтобы обеспе-
чить выполнение потоков с классом планирования в реальном времени,
изложенным в разделе 5.5.
Урегулирование этих проблем в каждом приложении утомительно и при-
водит к ошибкам, вот почему в АСЕ предусмотрен класс интерфейсного фасада
ACE_Sched_Params и интерфейсный метод ACE_OS: : sched_params ().
Функциональные возможности класса
Класс ACE_Sched_Params использует паттерн Wrapper Facade для орга-
низации инкапсуляции API классов планирования ОС, рассмотренных в разде-
ле 5.5. Этот класс можно использовать вместе с методом ACE_OS: : sched_pa-
rams (), чтобы обеспечить следующие функциональные возможности:
208
Глава 9
• Переносимый способ задания политик планирования, таких как FIFO
(первым пришел — первым обслужен) и циклическое (round-robin) пла-
нирование.
• Способ задать шаг квантования времени для политики циклического
планирования.
• Способ задать область действия данной политики, например, текущий
процесс или текущий поток.
• Согласованный способ представления приоритетов планирования. Это
необходимо, так как на платформах некоторых ОС более высокие при-
оритеты задаются более низкими значениями приоритетов.
Метод ACE_OS: : sched_params () инкапсулирует зависящую от кон-
кретной ОС функцию(и), которая оперирует классом планирования и
ACE_Sched_Params обеспечивает значения, используемые этим методом.
Интерфейс класса ACE_Sched_Params показан на рис. 9.3, а его основные
методы приведены в следующей таблице:
Метод Описание
ACE_Sched_Params() Устанавливает политику планирования, приоритет, область действия и шаг квантования для потока реального времени.
priority_min() Возвращает минимальный приоритет для данной политики планирования и области действия.
priority__max () Возвращает максимальный приоритет для данной политики планирования и области действия.
next_priority() Для заданной политики, приоритета и области действия, возвращает следующий более высокий приоритет, где слова «более высокий» относятся к приоритету планирования, а не к самому значению приоритета. Если данный приоритет уже является самым большим приоритетом для данной политики, тогда он и является возвращаемым значением.
previous^priority() Для заданных политики, приоритета и области действия, возвращает предыдущий более низкий приоритет, где слова «более низкий» относятся к приоритету планирования, а не к самому значению приоритета. Если данный приоритет уже является самым низким приоритетом для данной политики, тогда он и является возвращаемым значением.
Метод ACE_OS: : sched_params () вызывается обычно из main () до
того как будет создан хоть один из потоков. Так как порождаемые потоки на-
следуют класс и приоритет планирования родительского потока, то этот вы-
зов устанавливает базовый приоритет, задаваемый по умолчанию. Приорите-
ты конкретным потокам могут быть назначены при создании с помощью ме-
Интерфейсные фасады АСЕ: потоки
209
ACB_8ch«d_Params
- policy_ : int
- priority_ : int
- scope_ : int
- quantum : ACE Time Value
+ ACE_Sched Params {policy : int, priority : int,
scope : int - ACE_SCOPE_THREAD,
quantum : ACE_Time_Value « ACE_Time_Value: : zero)
+ priority min (policy : int. scope : int - ACE SCOPE THREAD) : int
+ priority max (polity; _1п£^лмр.е..in.t-“_ACE-.a£QPE THREAP) ; int
+ next priority {policy ; int, int priority,.
scope ; int. -ACE, SCOPE,THREAP).;.lnt
+ previous priority (policy : int. priority : int.
scope : int - ACE SCOPE THREAD) : int
Рис. 9.3
Диаграмма класса ACE_Sched_Params
тода ACE_Thread_Manager: : spawn () или установлены с помощью
ACE_OS::thr_prio().
Пример
Чтобы продемонстрировать каким образом можно использовать АСЕ для
переносимого программирования классов планирования ОС реального време-
ни, мы модифицируем пример нашего сервера регистрации типа поток-на-со-
единение из .раздела 9.2. После тщательного эмпирического анализа опыта экс-
плуатации нашей сетевой службы регистрации, мы решили отдать преимуще-
ство подключенным клиентам, а не новым запросам на установление
соединения. Тот поток, который принимает соединения, будет, соответственно,
работать с более низким приоритетом реального времени, чем потоки, которые
мы создаем, чтобы принимать и обрабатывать регистрационные записи.
В файле RT_Thread_Per_Connection_Logging_Server. h мы насле-
дуем от класса Thread_Per_Connection_Logging_Server для создания
сервера сетевой регистрации, потоки которого будут работать с классом плани-
рования ОС в реальном времени.
class RT_Thread_Per_Connection_Logging_Server
: public Thread_Per_Connection_Loggin_Server
{
public:
Затем мы перегружаем hook-метод open (), что разрешить планирование
типа FIFO для всех потоков, созданных в данном процессе. По умолчанию, соз-
данные потоки будут работать с самым низким приоритетом потока реального
времени. Если приложение не имеет достаточных полномочий, приоритет на-
ших потоков будет понижен и они будут выполняться с классом планирования
разделения времени.
virtual int open (u_short port) {
ACE_Sched_Params f i fo_sched_params
210
Глава 9
(ACE_SCHED_FIFO,
ACE_Sched_Params::priority_min (ACE_SCHED_FIFO),
ACE_SCOPE_PROCESS);
if (ACE_OS:: sched_params (fifo_sched_jparams) == -1) {
if (errno — EPERM || errno -- ENOTSUP)
ACE_DEBUG ((LM_DEBUG,
"Warning: user's not superuser, so "
"we'll run in the time-shared class\n"));
else
ACE_ERROR_RETURN ((LM_ERROR,
"%p\n", ”ACE_OS::sched_params ()"), -1);
)
// Инициализирует родительские классы.
return Thread_Per_Connection_Logging_Server::open (port);
)
В заключение, мы перегружаем метод handle_data (), так чтобы он по-
вышал приоритет каждого потока, который обрабатывает регистрационные за-
писи от подключенных клиентов.
virtual int handle_data (ACE_SOCK_Stream *logging_client) {
int prio »
ACE_Sched_Params::next_priority
(ACE_SCHED_FIFO,
ACE_Sched_Params::priority_min (ACE_SCHED_FIFO),
ACE_SCOPE_THREAD);
ACE_OS::thr_setprio (prio);
return Thread_Per_Connection_Logging_Server::handle_data
(logging client);
}
Использование объектно-ориентированного проектирования, возможно-
стей C++ и интерфейсных фасадов АСЕ позволяет нам добавить к нашему сер-
веру регистрации типа поток-на-соединение возможность планирования в ре-
альном времени, не изменяя ни одного из существующих классов и не добавляя
код, зависящий от специфики платформы. Функция main () похожа на анало-
гичную из раздела 9.2, с экземпляром класса RT_Thread_Per_Connecti-
on_Logging_Server вместо Thread_Per_Connection_Logging_Ser-
ver.
94 Класс ACETSS
Обоснование
Хотя глобальные переменные C++ время от времени бывают нелишними,
связанная с ними возможность опасных побочных эффектов и не до конца яс-
Интерфейсные фасады АСЕ: потоки
211
ная семантика их инициализации [LGSOO] могут приводить к скрытым пробле-
мам. Эти проблемы обостряются в многопоточных приложениях. В частности,
когда несколько потоков одновременно обращаются к несинхронизируемым
глобальным переменным, существует риск потери информации или использо-
вания неправильной информации.
Рассмотрим, например, переменную С errno. Сериализация доступа
к единственной в процессе errno нецелесообразна, так как errno может быть
изменена одновременно, например, в промежутке между ее установкой систем-
ной функцией и тестированием прикладным кодом. Поэтому механизмы син-
хронизации, перечисленные в разделе 6.4 здесь не подходят. Каждому потоку
нужна своя собственная копия errno, именно поэтому реализуются механиз-
мы, обеспечивающие поддержку локальной памяти потока (TSS). Благодаря
механизму TSS, не один поток не может получить доступ к экземпляру errno
другого потока.
К сожалению, библиотеки С API TSS операционных систем имеют следую-
щие проблемы:
• Ненадежность—В большинстве С API TSS указатели на локальные объ-
екты потока хранятся как указатели на void *, что является наиболее ра-
зумным подходом для API общего пользования. Однако это еще один ис-
точник «случайной» сложности, так как подверженные ошибкам указате-
ли на void ухудшают типовую безопасность. Кроме того, их нужно
приводить к конкретному типу, что добавляет источник возможной
ошибки программиста.
• Непереносимость — В дополнение к различиям API, возможности и ис-
пользование TSS также отличаются на разных платформах. Например,
Win32, в отличие от Pthreads и UI Threads, не предоставляет надежного
способа освобождения памяти, выделенной под локальные объекты пото-
ка по завершении потока. В UI Threads, наоборот, не существует API для
удаления ключа. Эти различия в логике делают проблематичным написа-
ние кода, который может устойчиво работать на платформах разных ОС.
Решение этих проблем в каждом приложении утомительно и приводит
к ошибкам, вот почему в АСЕ включен класс ACE_TSS.
Функциональные возможности класса
Класс ACE_TSS реализует паттерн T/jrra^-Specz/ic Storage, который инкапсу-
лирует и улучшает TSS API ОС [SSRB00]. Этот класс предоставляет следующие
возможности:
• Поддерживает данные, которые принадлежат потоку «физически», то
есть являются собственными данными потока, но позволяют осуществ-
лять доступ к ним так, как если бы «логически» они были глобальными
для программы.
• Использует оператор делегирования C++, operator-> (), чтобы обес-
печить локальные интеллектуальные указатели (smart pointers) потока
[Меу96].
212
Глава 9
-----------------------------| TYPE !
Ad-TSS '----
- keylock^ : ACE__Thread__Mutex
- once_ : int
- key_ : ACE_thread_key_t
+ operator -> () : TYPE *
+ gleanup_..(ptx r.vpicl *)
Рис. 9-4
Диаграмма класса ace_tss
• Инкапсулирует управление ключами, связанными с TSS объектами.
• Для платформ, в которых отсутствует адекватная внутренняя поддержка
TSS, например, VxWorks, ACE_TSS осуществляет ее эффективную эму-
ляцию.
Интерфейс класса ACE_TS S показан на рис.9.4, а его основные методы при-
ведены ниже:
Метод Описание
operator->() Получает локальный объект потока, ассоциированный с ключом TSS.
cleanup() Статический метод, который удаляет объект TSS по завершении потока.
Шаблон ACE_TSS является посредником (proxy), который преобразует
обычные C++ классы в классы, обеспечивающие типовую безопасность, экзем-
пляры которых располагаются в локальной памяти потока. Он объединяет ме-
тодделегированияорегаЬог-> () с другими возможностями C++, такими как
шаблоны, подстановка и перегрузка. Дополнительно он использует распро-
страненные паттерны синхронизации и идиомы [SSRBOO], такие как
Double-Checked Locking Optimization и Scoped Locking, как показано в реализа-
ции operator-> () ниже:
template <class TYPE> TYPE *
ACE_TSS<TYPE>::operator-> () (
if (once_ == 0) {
// Проверяем сериализацию.
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, keylock_, 0);
if (once_ == 0) {
ACE_OS::thr_keycreate (&key_, &ACE_TSS<TYPE>::cleanup);
once_ = 1;
)
j
TYPE *ts_obj = 0;
Интерфейсные фасадыАСЕ: потоки
213
II Инициализируем <ts_obj> в локальной памяти потока.
АСЕ_OS::thr_getspecific (key_, (void **) &ts_obj);
// Проверяем был ли этот метод вызван в этом потоке.
if (ts_obj ==0) {
// Выделяем память из кучи.
ts_obj = new TYPE;
// Сохраняем динамически выделенный указатель в TSS.
АСЕ OS::thr setspecific (key_, ts_obj);
}
return ts_obj;
)
Дополнительные подробности, связанные с реализацией на C++ посредни-
ка локальной памяти потока, изложены при рассмотрении паттерна Thread-
Specific Storage в [SSRB00].
Пример
Этот пример показывает, как можно применить ACE_TSS к нашему приме-
ру сервера регистрации типа поток-на-соединение из раздела 9.2. В этой реали-
зации каждый поток получает свой собственный счетчик запросов, не требуя
наличия мьютекса. Он также позволяет нам использовать локальную память
потока, без внесения «случайной» сложности, связанной с подверженными
ошибкам и непереносимыми С API.
Мы начинаем с определения простого класса, который следит за счетчика-
ми запросов:
class Request—Count {
public:
Request_Count (): count- (0) {}
void increment () { ++count_; }
int value () const { return count_; }
private:
int count— ;
I;
Заметьте, что Request_Count ничего не знает о локальной памяти пото-
ка. Затем мы используем этот класс как параметр типа шаблона ACE_TSS, сле-
дующим образом:
static АСЕ—TSS<Request—Count> request—count;
Теперь каждый поток имеет отдельную копию Request-Count, обраще-
ние к которой осуществляется через request-Count. Хотя этот объект выгля-
дит «логически глобальным», то есть обращение к нему осуществляется также,
как к любому другому объекту в области видимости файла, его состояние явля-
214
Глава 9
ется «физически локальным» для потока, в котором он используется. Мы пока-
зываем, как просто интегрировать reques t_count в метод handle_data ():
virtual int handle_data (ACE_SOCK_Stream *) {
while (logging_handler_.log_record () ! -1)
// Подсчитываем количество запросов.
request_count->increment ();
ACE_DEBUG ((LM—DEBUG, "requ6st_count - %d\n",
request count->value ()));
}
При использовании интерфейсного фасада ACE_TSS, нам не требуется
блокировать вызовы increment () и value (), что исключает состояния со-
стязаний и гонок.
9.5 Резюме
Разные операционные системы не только предлагают API с разным синтак-
сисом, но и логика этих API также изменяется неочевидным образом. Чтобы
компенсировать эту сложность, интерфейсные фасады АСЕ, связанные с по-
точной обработкой, реализуют переносимый набор возможностей, который
экспортирует единообразный синтаксис и семантику многопоточности. В этом
разделе представлены еще несколько редакций нашего примера сервера регист-
рации, в которых мы показали, как управлять сеансами нескольких клиентов
с помощью нескольких потоков, а не процессов, а также как управлять приори-
тетами планирования в реальном времени потоками сервера.
АСЕ предлагает также каркас параллелизма ACE_Task, который позволяет
разработчикам использовать поточную обработку в мощной и расширяемой
объектно-ориентированной манере. Кроме того, каркас параллелизма
ACE_Task не только обеспечивает средство создания'потоков в контексте объек-
та, но также гибкий и мощный механизм организации очередей для передачи
данных и объектов между задачами в архитектурах, ориентированных на сооб-
щения и на задачи. Как описано в [SH], каркас ACE_Tasк может быть применен
к реализации следующих распространенных паттернов параллелизма [SSRBOO]:
• Паттерн Active Object, который разделяет вызов и выполнение метода.
Его назначение — улучшить параллельную обработку и упростить син-
хронизированный доступ к объектам, которые находятся в своих собст-
венных потоках.
* Паттерн Half-Sync/Half- Async, который разделяет, в параллельных сис-
темах, синхронную и асинхронную обработку, чтобы упростить про-
граммирование, не снижая заметно производительность. Этот паттерн
вводит два коммуникационных уровня: один для синхронного и один
для асинхронного обслуживания. Уровень организации очередей служит
связующим звеном между синхронным и асинхронным уровнями.
Глава 10
Интерфейсные фасады АСЕ:
синхронизация
Краткое содержание
б данной главе приведено описание интерфейсных фасадов АСЕ, инкапсу-
лирующих механизмы синхронизации ОС в переносимые классы C++. Мы по-
кажем ряд взаимосвязанных примеров, чтобы проиллюстрировать каким обра-
зом эти классы могут применяться на практике. Кроме того, мы покажем, как
можно объединять основные интерфейсные фасады АСЕ, связанные с синхро-
низацией, и эмулировать механизмы синхронизаций, которые не поддержива-
ются самими операционными системами.
10.1 Обзор
Особенности аппаратуры могут оказывать существенное влияние на функ-
ционирование механизмов поточной обработки ОС. Несколько потоков, на-
пример, могут выполняться одновременно на нескольких процессорах. В одно-
процессорной системе, хотя потоки могут то направляться на выполнение, то
сниматься с выполнения, создавая впечатление одновременной работы, в каж-
дый момент времени активным является только один поток. И в том, и в дру-
гом сценарии, тем не менее, разработчики должны пользоваться механизмами
синхронизации, чтобы избежать состояний гонок и обеспечить, чтобы их при-
ложения согласовывали свои обращения к совместно используемым ресурсам.
Разные операционные системы предлагают разные механизмы синхрони-
зации с различной семантикой, используют разные API. Некоторые из этих API
соответствуют международным стандартам, например, Pthreads [1ЕЕ96]. Дру-
гие API соответствуют стандартам де-факто, например, Win32 [Sol98]. В данной
главе описаны приведенные в таблице классы АСЕ, которые сетевые приложе-
ния могут использовать для переносимого программирования механизмов
синхронизации потоков и/или процессов:
216
Глава 10
Класс АСЕ Описание |
ACE_Guard AC E_Re ad_Guard AC E_Wr i t e_Gua rd Используя идиому Scoped Locking (SSRBOO). обеспечивают автоматический захват и снятие блокировки, при входе в блок C++ и, соответственно, при выходе и? него.
ACE_Thread__Mutex ACE_Process_Mutex ACE_Null_Mutex Обеспечивают простой и эффективный механизм, которым могут пользоваться параллельные приложения для сериализации доступа к совместно используемым ресурсам.
ACE_RW_Thread_Mutex ACE_RW_Process_Mutex Обеспечивают эффективный одновременный доступ к ресурсам, содержимое которых гораздо чаще считается, чем изменяется.
ACE_Thread_Semaphore ACE_Process_Semaphore ACE_Nu 1 l_Semapho re Реализуют вычислительный семафор (counting semaphore), распространенное средство синхронизации нескольких потоков управления.
ACE_Condition_Thread_Mutex ACE_Null_Condition Позволяет потокам эффективно коорд инировать и планировать свою работу.
Эти интерфейсные фасады обеспечивают следующие преимущества:
• Повышают типовую безопасность.
Автоматизируя инициализацию объектов синхронизации, напри-
мер, в том случае если они выступают в качестве членов-данных
классов C++.
Предотвращая неправильное использование, например, копирова-
ние одного мьютекса в другой.
Гарантируя автоматический захват и снятие блокировок при входе
в области их действия и выходе из них, даже при возникновении ис-
ключительных ситуаций и ошибок.
• Обеспечивают кросс-платформенную переносимость в гетерогенной
среде. Например, АСЕ обеспечивает переносимые реализации блокиро-
вок типа «читатели/писатель» и условные переменные на платформах,
которые сами по себе не поддерживают эти механизмы синхронизации.
• Повышают уровень абстракции и модульности, не снижая эффектив-
ности. Использование возможностей языка C++, таких как подставляе-
мые функции и шаблоны, гарантируют, что интерфейсные фасады АСЕ,
связанные с синхронизацией, не повлекут дополнительных издержек
или, если повлекут, то небольшие.
• Предоставляют унифицированный интерфейс синхронизации, позво-
ляющий приложениям устанавливать и снимать различные типы блоки-
ровок. Например, интерфейс ACE_LOCK*, показанный на рис.10.1, под-
держивает все механизмы блокировок АСЕ: мьютексы, «читатели/писа-
Интерфейсные фасадыАСЕ: синхронизация
217
тель», семафоры и захват файлов. Интерфейс ACE_LOCK* представляет
собой «псевдокласс», в АСЕ такого класса нет. Мы используем его только
для того, чтобы продемонстрировать единообразие сигнатур, поддержи
ваемых многими из классов синхронизации АСЕ, такими как
ACE_Thread_Mutex, ACE_Process_Mutex и ACE_Thread_Sema-
phore.
• Снижают количество изменений необходимых для создания кода, под-
держивающего поточную обработку. Единообразие интерфейсов АСЕ,
связанных с синхронизацией, позволяет с единственным шаблонным
классом ACE_Guard обеспечить установку и снятие большинства типов
блокировок при входе в контролируемые ими области и выходе из них,
соответственно.
АСЕ_ХОСХ*
+ remove ( ) : int
+ acquire ( ) : int
+ tryacquire ( ) : int
+ release ( ) : int
+ acquire_read ( ) : int
+ acquire_write ( ) : int
+ tryacquire-read ( ) : int
♦ tryacquire—write ( ) : int
+ tryacquire—write— upgrade ( ) : int
Рис. 10.1
Псевдокласс ace_lock*
В данной главе приведено обоснование и описание возможностей основ-
ных классов интерфейсных фасадов АСЕ. Мы приводим примеры для каждого
класса, чтобы показать каким образом они могут упростить решение общих
проблем синхронизации, характерных для параллельных сетевых приложений.
10.2 Классы ACE_Guard
Обоснование
Единообразие интерфейсных фасадов АСЕ, связанных с синхронизацией,
упрощает их корректное использование и содействует преодолению некоторых
проблем несистемного характера, возникающих при сетевом кросс-платфор-
менном программировании. Отдельная, часто встречающаяся, проблема отно-
сится к области действия блокировок. Ошибки при запросах блокировок и их
освобождении могут привести к зависанию системы в результате тупиковой
ситуации (deadlock) или случайному переходу в состояниетонок. При реализа-
ции запросов и освобождений блокировок в явном виде, может оказаться, что
трудно обеспечить снятие установленной блокировки, проследив при этом все
возможные пути выполнения кода, особенно в случае обработки исключитель-
218
Глава 10
--------------! АСЕ LOCK!
ла Guard *—--“i—1
# LOCK- : ACE-LOCK
♦ owner_ : int
+ ACE-Guarde (lock : ACE—LOCK £)
+ acquire ( ) : int ~
4- release ( ) : int
4- locked ( ) : int
--------------5------------------
г.......1
---------- ACE LOCK»
Aa_RaadjGuard ‘,
ла Write Guard
Г.....
{ ACE-LOCK I
4- acquire-read ( ) ; int
+ acquire-Write ( ) : int
Рис. 10.2
Диаграммы семейства классов ACE_Guard
ных ситуаций C++. В АСЕ предусмотрен класс ACE_Guard и его производные
классы, чтобы обеспечить правильный захват и освобождение блокировок.
Функциональные возможности классов
Классы ACE_Guard, ACE_Read_Guard и ACE_Write_Guard реализуют
идиому Scoped Locking [SSRBOO], которая использует семантику конструкторов
и Деструкторов классов C++, чтобы гарантировать автоматический захват и
снятие блокировок при входе в блок кода C++ и, соответственно, при выходе из
него. На рис. 10.2 показан интерфейс этих классов и их взаимосвязи друг с дру-
гом.
Следующий фрагмент исходного кода C++ из класса ACE_Guard показы-
вает, как в этом классе реализуется идиома Scoped Locking:
template <class LOCK>
class ACE_Guard
{
public:
// Неявным и автоматическим образом запрашивает блокировку.
ACE_Guard (LOCK &lock): lock_ (&lock) { acquire (); )
// Неявным образом освобождает блокировку.
~ACE_Guard () { release (); }
// Явном образом запрашивает блокировку.
int acquire () {
return owner_ = lock_->acquire ();
}
// Явном образом снимает блокировку.
int release () {
Интерфейсные фасадыАСЕ: синхронизация
219
if (owner_ -1)
return -1;
else {
owner_ “ -1
return lock ->release ();
)
)
int locked () const { return owner_ != -1; }
// ... Остальные методы опущены
protected:
// Используется подклассами для сохранения указателя.
ACE_Guard (LOCK *lock): lock_ (lock) {}
// Указатель на LOCK (блокировку), которой мы владеем.
LOCK *lock_;
// Отслеживает получена запрошенная блокировка или нет.
int owner_;
);
Экземпляр ACE_Guard задает участок кода, для которого блокировка за-
прашивается, а затем освобождается автоматически, при создании и удалении
объекта, защищаемого блокировкой. ACE_Guard является шаблоном класса,
который работает для любого класса LOCK, открытые методы которого совпа-
дают с сигнатурами, включенными в псевдокласс ACE_LOCK*, приведенный на
рис. 10.1. Как показано позже, этот псевдокласс включает большинство интер-
фейсных фасадов АСЕ, представленных в данной главе.
У шаблонных классов ACE_Read_Guard и ACE_Write_Guard такой же
интерфейс, как и у класса ACE_Guard. Однако их методы acquire () запра-
шивают блокировки считывания и записи с помощью методов acqui-
re_read() и acquire_write(), соответственно, определенных шаблон-
ным параметром LOCK, как показано ниже:
template <class LOCK>
class ACE_Write_Guard : public ACE_Guard<LOCK>
(
public:
// Автоматически запрашивает блокировку для записи.
ACE_Write_Guard (LOCK &lock): ACE_Guard (Slock)
( owner_ = lock_.acquire_write (); )
// ... Те же операции, что и в <ACE_Guard>.
);
template cclass LOCK>
class ACE_Read_Guard : public ACE_Guard<LOCK>
220
Глава 10
public:
// Автоматически запрашивает блокировку для считывания.
ACE_Read_Guard (LOCK block) : ACE_Guard (block)
( owner_= lock_.acquire_read (); )
// ... Те же операции, что и в <ACE_Guard>.
);
Применение классов ACE_Write_Guard и ACE_Read_Guard иллюстри-
рует реализация Atomic_Op.
10.3 ACE-классы мьютексов
Обоснование
Большинство операционных систем предлагают какую-нибудь форму ме-
ханизма мьютексов, который параллельные приложения могут использовать
для сериализации доступа к совместно используемым ресурсам. Также как и
большинство других возможностей, зависящих от платформы, которые мы ви-
дели в данной книге, и эти имеют тонкие различия в синтаксисе и семантике на
разных платформах ОС. У мьютексов также разные требования к инициализа-
ции. Интерфейсные фасады АСЕ, связанные с мьютексами, создавались с це-
лью преодолеть все эти проблемы подходящим способом.
Функциональные возможности классов
АСЕ использует паттерн Wrapper Facade для инкапсуляции внутренних ме-
ханизмов синхронизации ОС, относящихся к мьютексам, с помощью классов
ACE_Process_Mutex и ACE_Thread_Mutex, которые переносимым обра-
зом реализуют семантику нерекурсивных мьютексов с областью действия на
уровне системы и на уровне процесса, соответственно.1 Поэтому они могут
быть использованы для сериализации доступа потоков к критическим секциям
в одном процессе или в разных процессах. Интерфейс класса ACE_Thre-
ad_Mutex идентичен интерфейсу псевдокласса ACE_LOCK*, показанному на
рис. 10.1. Следующий фрагмент класса C++ показывает как ACE_Thre-
ad_Mutex может быть реализован в Pthreads:
class ACE_Thread_Mutex
(
public:
ACE_Thread_Mutex (const char * = 0, ACE_mutexattr_t *attrs = 0)
{ pthread_mutex_init (block_, attrs); }
~ACE_Thread_Mutex () ( pthread_mutex_destroy (block_); )
int acquire () { return pthread_mutex_lock (block_) ; }
int acquire (ACE_Time_Value *timeout) {
Рекурсивные мьютексы с областью действия на уровне процесса реализованы в классе
ACE_Recursive_Threaci_Mutex, представленном в разделе 10.6.
Интерфейсные фасады АСЕ: синхронизация
221
return pthread_mutex_timedlock
(&lock_, timeout == 0 ? О : *timeout);
)
int release О { return pthread_mutex_unlock (&lock_); )
// ... Остальные методы опущены ...
private:
pthread mutex_t lock ; // Механизм мьютексов Pthreads.
}:
Все вызовы метода acquire () объекта ACE_Thread_Mutex будут бло-
кироваться до тех пор, пока поток, владеющий этой блокировкой в данный мо-
мент, не покинет свою критическую секцию. Чтобы выйти из критической сек-
ции, поток должен вызвать метод release () для объекта мьютекс, которым
он владеет, разрешая, таким образом, другому потоку, блокированному на
этом же мьютексе, войти в его критическую секцию.
На платформе Win32 класс ACE_Thread_Mutex реализован с CRITI-
CAL_SECTION, которая является упрощенной (lightweight) блокировкой
Win32, которая сериализует потоки внутри одного процесса. Наоборот, реали-
зация ACE_Process_Mutex использует в Win32 мьютекс на базе HANDLE, ко-
торый может работать как в одном процессе, так и между процессами на одной
машине:
class ACE_Process_Mutex
(
public:
ACE_Process_Mutex (const char *name, ACE_mutexattr_t *)
{ lock_ = CreateMutex (0, fALSE, name); )
~Thread_Mutex () { CloseHandle (lock_); }
int acquire ()
{ return WaitFo.rSingleObject (lock_, INFINITE); )
int acquire (ACE_Time_Value ‘timeout) (
return WaitForSingleObject
(lock , timeout == 0 ? INFINITE : tim£out->msec ());
}
int release () { return ReleaseMutex (lock_); }
// ... Остальные методы опущены ...
private:
HANDLE lock ; // Механизм сериализации Win32.
);
Класс ACE_Thread_Mutex реализован с использованием собственных ме-
ханизмов мьютексов с областью действия на уровне процесса для всех плат-
форм ОС. В зависимости от характеристик платформы данной ОС, однако,
ACE_Process_Mutex может быть реализован на основе разных механизмов,
например:
• Используется мьютекс ОС Win32, как было показано выше.
• Некоторые реализации потоковой обработки в UNIX, такие как Pthreads
и UI Threads, требуют, чтобы межпроцессные мьютексы размещались
222
Глава 10
в совместно используемой памяти. На этих платформах, АСЕ предпочи-
тает использовать, если возможно, UNIX System V семафор, так как это
обеспечивает более надежный механизм восстановления системных ре-
сурсов, чем собственные межпроцессные мьютексы ОС.
• Некоторым приложениям нужно больше семафоров, чем позволяют па-
раметры ядра System V IPC, или им требуется возможность выполнять
операцию acquire () с привязкой по времени. В этих случаях АСЕ мож-
но настроить так, чтобы использовать встроенные мьютексы ОС в совме-
стно используемой памяти, что возлагает больше ответственности на
разработчиков приложения, которые должны обеспечить правильную
очистку.
Независимо от того, какой базовый механизм использует АСЕ, интерфейс
классов идентичен, что позволяет разработчикам приложений эксперименти-
ровать с разными конфигурациями, не изменяя их исходный код.
Еще одним типом мьютекса, поддерживаемым АСЕ, является ACE_Nul l_Mu-
tex. Часть его интерфейса и реализации показаны ниже:
class ACE_Null_Mutex
{
public:
ACE_Null_Mutex (const char * = 0, ACE_mutexattr_t * = 0) {}
int acquire () { return 0; }
int release () { return 0; }
// . . .
};
Класс ACE_Null_Mutex реализует все свои методы как подставляемые
функции, не содержащие инструкций («по-ор»), которые могут быть полно-
стью удалены оптимизирующим компилятором. Этот класс обеспечивает реа-
лизацию с, нулевыми накладными расходами интерфейса псевдокласса
ACE_LOCK*, совместно используемого другими интерфейсными фасадами
АСЕ на C++, относящимися к поточной обработке и синхронизации.
ACE_Null_Mutex является примером паттерна Null Object [Woo97]. Его
можно использовать вместе с паттерном Strategized Locking [SSRBOO] так, чтобы
приложения могли параметризовать нужный им тип синхронизации, не изме-
няя кода приложения. Эта возможность полезна в тех случаях, когда взаимное
исключение не требуется, например, если прикладная конфигурация работает
в одном потоке и/или никогда не конкурирует с другими потоками за доступ
к ресурсам.
Пример
Следующий код показывает как для снятия некоторых проблем с решения-
ми в виде мьютексов в UNIX International, показанном в разделе 6.5., может
быть применен ACE_Thread_Mutex.
Интерфейсные фасадыАСЕ: синхронизация
223
linclude "ace/Synch.h”
typedef u_long COUNTER;
static COUNTER request_count; // Глобальная переменная на
// уровне файла.
// Защищенный мьютексом request—count
//(инициализирует конструктор)
static ACE_Thread—Mutex m;
// ...
virtual int handle_data (ACE_SOCK_Stream *) {
while (logging_handler_.log_record () != -1) {
// Пробуем запросить блокировку.
if (m.acquire () s= -1) return 0;
++request—count; // Счетчик запросов.
m,release () ; // Снимаем блокировку.
}
m.acquire ();
int count = request—count;
m. release ();
ACE_DEBUG ((LM_DEBUG, "request_count = %d\n”, count));
)
Использование интерфейсного класса C++ ACE__Thread_Mutex до неко-
торой степени улучшает первоначальный код, улучшает его переносимость, а
также осуществляет автоматическую инициализацию при создании экземпля-
ра базового объекта мьютекс.
И все же, интерфейсные фасады АСЕ, связанные с параллельной обработ-
кой, не решают всех проблем, перечисленных в разделе 6.5. Например, про-
граммисты, по-прежнему, должны «вручную» освобождать мьютекс, что при-
водит к ошибкам, как из-за невнимательности программиста, так и из-за нали-
чия исключений C++. Кроме того, специально проверять был ли мьютекс
получен на самом деле — это и утомительно для программистов, и чревато
ошибками. Например, обратите внимание, что мы пренебрегли проверкой ус-
пешного завершения метода АСЕ—Thread—Mutex: : acquire (), прежде чем
присвоить count значение request—count. Мы можем упростить этот при-
мер, применив идиому Scoped Locking [SSRB00] посредством макроса
ACE-GUARD*, рассмотренного в блоке 22.
virtual int handle_data (АСЕ—SOCK—Stream *) {
while (logging—handler—.log—record () != -1) {
// Запрос блокировки в конструкторе.
ACE-GUARD-RETURN (ACE_Thread_Mutex, guard, m, -1);
++request_count; // Счетчик запросов
// Освобождаем блокировку в деструкторе.
224
Глава 10
Блок 22: Обзор макроса ACE GUARD>
АСЕ определяет набор макросов, упрощающих использование классов
>/< Gii^Ld, ACE^Writej^uard и ACE_Kead_Guar<J, Эти макросы тестируют на
наличие гупиковых ситуаций и ситуаций, в которыхрперайии с нижележащими
блокировками приводят к ошибку. Как показа^бйй^^ про-,
верку, чтобы убедиться, что данная блокировка' дёйЙтвйте/^йо блокирована/
прежде чем продолжать выполнение; ’ а '
define ZiCE__GUARD (MUTEX,; OBJ, LOCK) A
ACE_Guard< MUTEX 9 OB J (LOCK)'f \
if (CBJ. locked () '=«= 0) returri;’’
define ACE_GUARD_RETURN (MUTEX, pBJ,^LOCK,kRETURN) \ "
ACE„Guard< MUTEX >. OBJ .(LOCK),;- * *
if (OBJ.locked () — oj ’re^urq -ВЕТишЛр^.^.,. ’ > C. .
del. .c /\CE_WRITE_GUARD (MUTEX,’’OBJ,-' LQCK)' СЛССЛ'-' ?
АГЕ лх ice Guardk MUTEX ->
(oS.-oetei 0. -
AC E _WR I TE_GUARD_RRTURN\/;(MUTEX^Qfe^Kr'I^W^V'^
:i te_Guard< MUTEX •>; OfcF .(LOCK)X Л i- '
(OBJ. locked (). == Qj. <^tdr.n .• i.M/ ,
у
#
лЛ
if
aerine ACE_READ_GOARD (MUTEX,’WjJ
ACE_Read_Guatd< .-MUTEX > OBJ
if (obj.locked ‘o •-« o.) -return’;:5'
define ACE_REAB_GUARD_RETyRN-' (MUTEX,OBJ,,LCtC?^ETURN) -?
• ACE_ReadjGuard< MUTEX > OBJ (LOCK); \ •’ '
if ..(OBJ.locked- () =.;=->.0)Return
г"%
int count;
{
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, m, -1);
count = request_count;
}
ACE_DEBUG ((LM_DEBUG, "request_count = %d\n", count));
)
Внеся небольшое изменение в код, мы добились того, что Ace_Thre-
ad_Mu tex теперь запрашивается и освобождается автоматически, а также того,
что ошибки при работе с мьютексами будут обрабатываться должным образом.
Хотя мы уже решили многие проблемы, перечисленные в разделе 6.5, сле-
дующие две проблемы, по-прежнему, остаются:
• Предложенное решение, по-прежнему, требует кропотливой работы:
мы должны вставлять макрос ACE_GUARD вручную внутри области дей-
ствия нового оператора, ограниченной фигурными скобками. В разделе
10.4 показано как исключить необходимость такой работы.
• Кроме того, предложенное решение чревато ошибками: Статический
глобальный объект ACE_Thread_Mutex m должен быть соответствую-
Интерфейсные фасады АСЕ: синхронизация
225
щим образом инициализирован до вызова метода handle_data ().
Удивительно, но это достаточно трудно сделать, так как C++ не гаранти-
рует порядок инициализации глобальных и статических объектов в раз-
ных файлах. В блоке 23 показано как АСЕ решает эту проблему с помо-
щью класса ACE_Object_Manager.
Класс ACE_Object_Manager предлагает глобальный рекурсивный мью-
текс, который мы можем использовать в нашем примере сервера регистрации:
// ...
while (logging_handler_.log_record О != -1) (
/I Запрашиваем блокировку в конструкторе.
ACE_GUARD_RETURN (ACE_Recursive_Thread_Mutex, guard,
ACE_Static_Object_Lock::instance (),
-1) ;
++request_count; // Счетчик запросов
I/ Освобождаем блокировку в деструкторе.
}
И ...
Так как экземпляр ACE_Static_Object_Lock контролируется объек-
том ACE_Object_Manager, то это гарантирует, что экземпляр инициализи-
руется при начале работы программы и удаляется одновременно с ее заверше-
нием.
Блок23. Класс ACE„Qbject .Manager л.
4трбь1 обеспечить гюоледо'зспельный порядок инициализации ‘глобальных и
статических объектов. в АСЕ предусмотрен класс ACE_obiect Manager, хото-
рь$ д^яется р^^чзаДи^Й Каперпа Objoc t Life-tic те Manager (L'GSOOj, Этот пат-
тёрн управляёгрбъе!<трм на всём протяжении его времени жизни от создания
и первого использования до своевременного удаления при завершении про-
граммы. Класс асе'Qbj»3ct_j’anager предоставляет следующие возможно-
-.•СГй, способстзуювАиё. замёно ста • йческбгс создат 1иЯ/удЬления‘ объектов ав--
томатичес^игддинамическймвыделеыием/сю'врботкд^чием: ... .
• УправляетудаЛеЙйем объектов (обычно синглтонов) при завершении про-
грамм,. |{роме управления удалением объектов библиотеки АСЕ. он рбеспё-
V чйвае^брйАРжениям интерфейс для регистрации объектов, которые должны'
быть удалены. ' А . .
• Прёкрффает-оабот.у служб''библиотеки АСЕ при завершении программы,
. так чтобйэти службы могли освободить заг гимаемую г тми память. Это. рабо-
л^ет^ё^срзданйя статического экземпляра, деструктор котороговызыва-
• ется .ййё’сте с деструкторами всех остальных статических объектов. При-
’: Л<лад^рмуд<рДу Предоставляются hook-методы для регистрации объектов и
<;.массйврв,: к6т<эрь|р должны, быть удалены при. завершении программы, По-.
>. 'рЯДЬ|<ётйх«ыз6вЬв очистки является обратным (LIFO) по отношению к поряд-
, ку их регистраций;"а именно, объект/массив, зарегистрировавшийся по7
слёднйм, удаляется первым.
•. Предварительно инициализирует некоторые объекты, такие как ACE_sta-
-А ’.'tic^cbj^ctjEock,так/чтобы они создавались до начала работы функции
main (, ' /'.7 •: '
8 Программирование сетевых
приложений на C++. Том 1
226
Глава 10
10.4 ACE-классы блокировок
«читатели/писатель»
Обоснование
Блокировки «читатели/писатель» (readers/writer) позволяют организовать
эффективный одновременный доступ к ресурсам, содержимое которых гораз-
до чаще считывается, чем изменяется. Многие операционные системы поддер-
живают семантику «читатели/писатель» в своих API блокировки файлов. Во-
влечение файловой системы в действия, связанные с синхронизацией, однако,
является и неэффективным, и необязательным, и может блокироваться в не-
предвиденных ситуациях, например, при использовании памяти, подключае-
мой по сети, для хранения блокируемого файла. Кроме того, механизмы блоки-
ровки файлов работают только с областью действия на уровне системы, а не на
уровне процесса.
Удивительно, но лишь в немногих из операционных систем реализованы
блокировки «читатели/писатель» с областью действия на уровне процесса. На-
пример, Pthreads (без расширений UNIX98), потоки Win32 и многие операци-
онные системы реального времени сами по себе их не поддерживают. UI threads
поддерживают блокировки «читатели/писатель» с помощью типа rwlock_t.
Согласование всех этих вариантов, связанных с переносимостью,, утомительно
и чревато ошибками, вот почему в АСЕ предусмотрены интерфейсные фасады
блокировок «читатели/писатель».
Функциональные возможности классов
АСЕ инкапсулирует внутренние механизмы ОС, связанные с блокировка-
ми «читатели/писатель», в классах ACE_RW_Thread_Mutex и ACE_RW_Pro-
cess_Mutex. Эти классы, с целью обеспечения переносимой реализации бло-
кировок «читатели/писатель» с областями действия на уровне процесса и на
уровне системы, применяют паттерн Wrapper Facade. Интерфейс этих классов
идентичен сигнатуре псевдокласса ACE_LOCK*, показанной на рис.10.1.
Если платформа поддерживает блокировки «читатели/писатель» с обла-
стью действия на уровне процесса, класс ACE_RW_Thread_Mutex просто ин-
капсулирует собственные переменные ОС, связанные с синхронизацией. Одна-
ко на платформах тех ОС, в которых отсутствуют блокировки «читатели/писа-
тель», АСЕ обеспечивает их реализацию, используя те низкоуровневые
механизмы синхронизации, которые существуют в этих ОС, такие как мьютек-
сы, условные переменные или семафоры. Реализация блокировок «читате-
ли/писатель» в АСЕ отдает предпочтение «писателям». Таким образом, если
имеется несколько «читателей» и единственный «писатель» ожидающие осво-
бождения одной и той же блокировки, «писатель» получит эту блокировку
в первую очередь.
Пример
Хотя реализация handle_data () на базе ACE_Guard решает некоторые
проблемы, но, по-прежнему, требуется кропотливое изменение кода, а именно,
Интерфейсные фасадыАСЕ: синхронизация
227
добавление внутри цикла xACE_GUARD_RETURN. Решение, которое менее чре-
вато ошибками и требует меньше изменений, использует:
• Перегрузку операторов C++.
• ACE_RW_Thread_Mutex.
• Идиому Scoped Locking, посредством использования макросов
ACE_WRITE_GUARD И ACE_READ_GUARD.
Мы используем эти возможности ниже для создания класса Atomic_Op,
который поддерживает поточную обработку арифметически# операций.
class Atomic__Op
(
public:
// Инициализируем <count_> значением <count>.
Atomic_Op (long count = 0)
: count_ (count) {}
// Атомарное предварительное инкрементирование <count_>.
long operator++ () {
// Используем метод <acquire_write> для запроса блокировки
// записи.
ACE_WRITE_GUARD_RETURN (ACE_RW_Thread_Mutex, guard, lock_,
-1) ;
return ++count_;
}
/I Атомарно возвращает <count__>.
operator long () {
// Используем метод <acquire_read> для запроса блокировки
// чтения.
ACE_READ_GUARD_RETURN (ACEJW_Thread_Mutex, guard, lock_,
0) ;
return count_;
}
// ... Остальные арифметические операторы опущены.
private:
// Блокировка ’’читатели/писатель” (readers/writer).
ACE_RW_Thread_Mutex lock_;
// Значение счетчика <Atomic_Op>.
long count_;
);
Класс Atomic_Op перегружает стандартные арифметические операторы,
такие как ++, += и т.д., для данных типа long. Так как эти методы модифи-
цируют count_, то они получают эксклюзивный доступ, запрашивая блоки-
228
Глава 10
ровку записи. Напротив, оператору long () будет достаточно блокировки чте-
ния, так как он допускает одновременное чтение count_ несколькими потока-
ми.
Применяя класс Atomic_Op, мы можем теперь написать следующий код,
который почти совпадает с исходным, не приспособленным к поточной обра-
ботке, кодом. Изменен только оператор typedef для COUNTER:
typedef Atomic_Op COUNTER;
static COUNTER request_count; // Глобальная переменная
// на уровне файла.
virtual int handle_data (ACE_SOCK_Stream *) {
while (logging_handler_.log_record () != -1)
// Подсчитываем количество запросов.
++request_count; // На самом деле вызывается
// <Atomic_Op::operator++>.
ACE_DEBUG ((LM_DEBUG, "request_count = %d\n",
// На самом деле вызывается <Atomic_Op::operator long>.
(long) request_count));
)
Оба вызова operator++ () и operator long () используют методы
ACE_RW_Thread_Mutex acquire_write () и acquire_read (), соответ-
ственно. Таким образом, арифметические операции с объектами создаваемых
экземпляров классов Atomic_Op теперь правильно инкрементируют/декре-
ментируют счетчики в многопроцессорной системе, не требуя серьезных изме-
нений существующего прикладного кода!
Класс Atomic_Op, представленный выше является на самом деле упро-
щенным вариантом шаблонного класса ACE_Atomic_Op, часть которого при-
ведена ниже:
template cclass TYPE, class LOCK>
class ACE_Atomic_Op {
public:
// ... Конструкторы и арифметические операторы опущены,
private:
LOCK lock_;
TYPE type_;
);
Класс ACE_Atomic_Op создает простую и удивительно выразительную
абстракцию параметризованного класса, объединяя:
• Идиому Scoped Locking и паттерн Strategized Locking.
• Использование шаблонов и перегруженных операторов C++.
Этот шаблонный класс корректно выполняет операции с теми типами, ко-
торые требуют атомарных операций. Чтобы обеспечить такую же функцио-
нальность, с поддержкой поточной обработки, например, для других арифме-
Интерфейсные фасады АСЕ: синхронизация
229
тических типов, мы можем просто создать экземпляры новых объектов шаб-
лонного класса ACE_Atomic_Op следующим образом:
ACE_Atomic_Op<double, ACE_Null_Mutex> double_counter;
ACE_Atomic_Op<Complex, ACE_RW_Thread_Mutex> complex_counter;
10.5 ACE-классы семафоров
Обоснование
Семафоры являются действенным механизмом, используемым для блоки-
ровки и/или синхронизации доступа к совместно используемым ресурсам в па-
раллельных приложениях. Семафор содержит счетчик, отражающий состоя-
ние совместно используемого ресурса. Разработчики приложений определяют
семантику счетчика семафора и его начальное значение. Семафоры, поэтому,
можно использовать в качестве посредников доступа к пулу ресурсов.
Так как освобождение семафора приводит к инкременту его счетчика неза-
висимо от наличия ожидающих, то семафоры полезны при отслеживании со-
бытий, которые изменяют состояние совместно работающих программ. Пото-
ки могут принимать решения, основываясь на этих событиях, даже если они
уже произошли. Хотя в той или иной форме механизм семафоров имеется
в большинстве операционных систем, интерфейсные фасады АСЕ, связанные
с семафорами, решают проблемы, возникающие из-за неочевидных отличий
в синтаксисе и семантике семафоров в разных средах.
Функциональные возможности классов
Классы ACE_Thread_Semaphore и ACE_Process_Semaphore инкап-
сулируют в переносимой форме семафоры с областью действия на уровне про-
цесса и на уровне системы, в соответствии с паттерном Wrapper Facade. Интер-
фейсы этих классов в значительной степени совпадают с псевдоклассом
ACE_LOCK*, показанным на рис. 10.1. Конструктор все же немного отличается,
так как инициализация у семафоров более содержательна, чем у мьютексов и
блокировок «читатели/писатель», допуская установку начального значения
счетчика семафора. Соответствующая часть ACE_Thread_Semaphore API
показана ниже:
class ACE_Thread_Semaphore
{
public:
// Инициализирует семафор с начальным значением <count>,
// максимальным значением <тах> и по умолчанию разблокированным.
ACE_Thread_Semaphore (u_int count = 1,
const char ‘name = 0,
void *arg = 0,
int max = Ox7FFFFFFF);
11 ... то же, что и в сигнатуре псевдокласса <ACE_LOCK>.
};
230
Глава 10
У класса ACE_Process_Semaphore такой же интерфейс, хотя он осуще-
ствляет синхронизацию потоков на уровне системы, а не на уровне процесса.
Эти два ACE-класса инкапсулируют, где это можно сделать, внутренние ме-
ханизмы семафоров ОС, и эмулируют их, если сама платформа ОС семафоры
не поддерживает. Это дает возможность приложениям использовать семафо-
ры, и оставаться переносимыми на новые платформы независимо от того, под-
держиваются на этих платформах семафоры или нет. В разделе А.5.2 показана
эмуляция ACE_Thread_Semaphore на платформах, не поддерживающих се-
мафоры.
В классе ACE_Null_Semaphore все его методы реализованы в виде пус-
тых («по-ор») подставляемых функций. Ниже мы приводим реализацию двух
из его методов acquire ():
class ACE_Null_Semaphore
{
public:
int acquire () { return 0; }
int acquire (ACE_Time_Value *) { errno = ETIME; return -1; }
// ...
};
Обратите внимание, что версия acquire () с контролем времени возвра-
щает-1 и устанавливает errno в ETIME, чтобы обеспечить корректное взаимо-
действие ACE_Null_Semaphore в сочетании с паттерном Strategized Locking
[SSRBOO]. Что касается не-null семафоров АСЕ, то блокируемая версия acqui-
re () часто используется для сериализации доступа к критической секции, а
версия с контролем времени чаще используется, чтобы ждать обновления дру-
гим потоком некоторого условия или изменения совместно используемого со-
стояния. Однако при использовании ACE_Null_Semaphore, других потоков,
участвующих в изменении состояния или условия, нет. Иначе, нельзя было бы
использовать null-семафор. Возвращение значения ошибки означает, что со-
стояние или условие не было (и не может быть) изменено, что соответствует
поведению потоков в том случае, когда тайм-аут истекает до того, как условие
или состояние изменено.
Пример
Хотя семафоры могут координировать работу нескольких потоков, сами
по себе они не передают от потока к потоку никаких данных. Обмен данными
между потоками является, тем не менее, обычной техникой параллельного про-
граммирования, а значит нечто типа облегченного внутрипроцессного меха-
низма очереди сообщений может оказаться достаточно полезным. Поэтому мы
демонстрируем реализацию класса Message_Queue, которая обеспечивает
следующие возможности:
• Позволяет помещать сообщения (объекты ACE_Message_Block) в ко-
нец очереди и выводить из очереди в ее начале.
Интерфейсные фасадыАСЕ: синхронизация
231
• Поддерживает регулируемое управление потоком, которое не позволяет
быстродействующим потокам-источникам сообщений перегружать ре-
сурсы менее быстродействующих потоков-потребителей сообщений.
• Позволяет задавать тайм-ауты операций постановки в очередь и вывода
из очереди, чтобы исключить, при необходимости, неограниченное по
времени блокирование.
Ниже мы показываем основные фрагменты реализации класса Messa-
ge_Queue и пример использования ACE_Thread_Semaphore. Чтобы упро-
стить создание и развитие этого кода, мы применяем также следующие паттер-
ны и идиомы из POSA21 [SSRBOO]:
• Monitor Object — Открытые (public) методы Message_Queue ведут
себя как синхронизированные методы в соответствии с паттерном проек-
тирования Monitor Object [SSRBOO], который гарантирует, что в каждый
Момент времени внутри объекта выполняется только один метод и по-
зволяет методам объекта совместно планировать последовательность их
выполнения.
• Thread-Safe Interface — Открытые (public) методы Message_Queue за-
прашивают блокировки и делегируют функции организации очередей
закрытым методам реализации в соответствии с паттерном Thread-Safe
Interface. Этот паттерн проектирования минимизирует издержки блоки-
ровки и гарантирует, что вызовы методов внутри объекта не приведут
к тупиковой ситуации («self-deadlock»), пробуя запросить блокировку,
уже занятую объектом.
• Scoped Locking — Макрос ACE_GUARD* гарантирует, что любой интер-
фейсный фасад синхронизации, сигнатура которого соответствует сиг-
натуре псевдокласса ACE_LOCK* запрашивается и освобождается авто-
матически в соответствии с идиомой Scoped Locking [SSRBOO].
Большинство паттернов из книги POSA2 могут быть реализованы с помо-
щью ACE-классов синхронизации и параллелизма.
Мы начинаем с определения класса Message_Queue:
class Message_Queue
(
public:
// Уровни "малой воды" (LWM) и "полной воды" (HWM)
//по умолчанию.2
enum {
DEFAULT_LWM =0, // 0 - отметка уровня "малой воды".
Аббревиатура POSA означает Pattern-Oriented Software Architecture (архитектура программ-
ного обеспечения ориентированного на паттерны). — Прим. ред.
Нижний и верхний уровни очереди в программе обозначаются как Low-Water Mark (LWM),
отметка уровня малой воды, и High-Water Mark (HWM), отметка уровня полной воды. По-
скольку эти обозначения используются в именах внутри программы, мы сохраняем эту тер-
минологию. — Прим. ред.
Глава 10
DEFAULT—HWM =16* 1024 // 16К - отметка уровня ’’полной
// воды”.
};
// Инициализирует.
Message_Queue (size_t = DEFAULT__HWM, size_t = DEFAULT_LWM) ;
// Уничтожает.
~Message_Queue ();
Il Проверка очереди: полна/пуста.
int is__full () const;
int is_empty () const;
// Интерфейс постановки в очередь и извлечения из очереди
// ACE_Message_Blocks.
int enqueue_tail (ACE_Message_Block *, ACE_Time_Value * = 0) ;
int dequeue_head (ACE_Message_Block *&, ACE_Time_Value * = 0) ;
private:
7/ Реализация постановки в очередь и извлечения из очереди
// ACE_Message_Blocks.
int enqueue_tail_i (ACE_Message_Block *, ACE_Time_Value * = 0);
int dequeue_head_i (ACE_Message_Block *&, ACE_Time_Value * = 0);
// Реализация проверки граничных условий.
int is_empty_i () const;
int is_fuli_i () const;
// Наименьшее число, после которого блокировка снимается,
int low_water_mark_;
// Наибольшее число байтов до блокировки.
int high_water_mark__;
// Текущее количество байтов в очереди.
int cur_bytes_;
// Текущее количество сообщений в очереди.
int cur_count_;
// Количество потоков, ожидающих извлечения сообщения
//из очереди.
size_t dequeue__waiters__;
// Количество потоков, ожидающих постановки сообщения
//в очередь.
size_t enqueue_waiters_;
// Интерфейсные фасады C++, координирующие параллельный
// доступ.
mutable ACE_Thread_Mutex lock_;
ACE_Thread_Semaphore notempty__;
ACE_Thread_Semaphore notfull_;
// Остальные детали реализации очередей опущены...
);
Интерфейсные фасады АСЕ: синхронизация
233
Конструктор Message_Queue, показанный ниже, создает пустой список
сообщений и инициализирует ACE_Thread_Semaphore, чтобы начать счи-
тать с 0 (мьютекс locк_ инициализируется автоматически своими конструкто-
рами по умолчанию).
Message_Queue::Message_Queue (size_t hwm, size_t Iwm)
: low_water_mark_ (Iwm),
high_water_mark (hwm),
cur_bytes_ (0),
cur_count_ (0) ,
dequeue_waiters_ (0) ,
enqueue_waitbrs_ (0),
notempty_ (0),
notfull_ (0)
{ /* Остальная часть реализации конструктора опущена... */ I
Следующие методы проверяют, является ли очередь «пустой», то есть не
содержит сообщений, или «полной», то есть содержит больше, чем high_wa-
ter_ma г k_ байтов. Эти методы, как и другие представленные ниже, спроекти-
рованы в соответствии с паттерном Thread-Safe Interface [SSRBOO].
Мы начинаем с интерфейсных методов is_empty () и is_full ():
int Message_Queue::is_empty () const {
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, lock_, -1);
return is_empty_i ();
)
int Message_Queue::is_full () const {
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, lock_, -1) ;
return is_full_i ();
)
Эти методы запрашивают lock_ и затем передают вызов одному из сле-
дующих методов реализации:
int Message_Queue::is_empty_i () const {
return cur_bytes_ <= 0 && cur_count_ <= 0;
)
int Message_Queue::is_full_i () const (
return cur_bytes_ >= high_water_mark_;
)
Эти методы предполагают, что захватывается и реально выполняет работу
1оск_.
Метод enqueue_tail () вставляет новый элемент в конец очереди и воз-
вращает счетчик количества сообщений в очереди. Что касается метода dequ-
eue_head (), если параметр тайм-аута равен 0, вызывающая сторона будет
блокирована до того момента, когда действие станет возможным. Иначе, вызы-
234
Глава 10
вающая сторона будет блокирована только на то время, которое указано в * t i -
meout. Блокируемый вызов может завершиться, если поступит сигнал или ис-
течет время отведенное на тайм-аут. В этом случае errno устанавливается
в значение ewouldblock.
int Message_Queue::enqueue_tail (ACE_Message_Block *new_mblk,
ACE_Time_Value *timeout)
{
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, lock-, -1) ;
int result » 0;
// Ждем пока освободится место в очереди.
while (iS—full—i () && result != -1) {
++enqueue_waiters—;
guard.release () ;
result « notfull—.acquire (timeout);
guard.acquire () ;
}
if (result «« -1) {
if (enqueue—waiters— > 0)
--enqueue—waiters—;
if (errno «« ETIME)
errno ~ EWOULDBLOCK;
return -1;
}
// Ставит сообщение в конец очереди.
int queued—messages = enqueue—tail—i (new—mblk) ;
// Сообщает всем блокированным потокам, что в очереди
// появилось место!
if (dequeue—waiters— > 0) {
—dequeue—waiters—;
notemptУ—.release () ;
}
return queued—messages; // деструктор защиты снимает
// блокировку.
}
Метод enqueue-tail () освобождает семафор no tempt У-, когда суще-
ствует по крайней мере один поток, ожидающий извлечения сообщения из оче-
реди. Сама логика помещения в очередь находится в enqueue_tail_i О, ко-
торый мы здесь не приводим, так как это относится к деталям низкоуровневой
реализации. Обратите внимание на возможность состояния гонок в промежут-
ке времени между вызовом not-full-. acquire () и повторным запросом
защитной блокировки. Возможна ситуация, в которой в этот небольшой про-
межуток времени другой поток вызывает dequeue_head (), декрементируя
enqueue_waiterS-. Поэтому после повторного запроса блокировки, осуще-
Интерфейсные фасадыАСЕ: синхронизация
235
ствляется проверка счетчика для предотвращения ситуации, в которой, в ре-
зультате декрементирования, значение enqueue_waiters_ может стать
меньше 0.
Метод dequeue_head () удаляет первый элемент из очереди, отправляет
его обратно, вызвавшей стороне, и возвращает значение счетчика количества
элементов, остающихся в очереди, следующим образом:
int Message—Queue: .-dequeue—head (ACE_Message_Block *&first_item,
ACE_Time_Value *timeout)
{
ACE_GUARD_RETURN (ACEJThread-Mutex, guard, lock-, -1) ;
int result = 0;
// Ждем появления в очереди первого элемента.
while (is_empty i () && result != -1) {
++dequeue—waiters—;
guard.release ();
result = notempty_.acquire (timeout);
guard.acquire ();
}
if (result == -1) {
if (dequeue—waiters— > 0)
--dequeue_waiters—;
if (errno == ETIME)
errno = EWOULDBLOCK;
return -1;
)
// Удаляем первое сообщение из очереди.
int queued—messages - dequeue—head—i (first—item);
// Подаем сигнал, только если опускаемся ниже нижнего уровня.
if (cur—byteS— <~ low—water—mark— && enqueue—waiters— >0) {
enqueue—waiters—
notfull—.release ();
}
return queued—messages; // Деструктор <guard>
// освобождает clock—>
)
Класс Message—Queue, приведенный выше, реализует часть возможно-
стей АСЕ—Message-Queue и ACE-Message_Queue_Ex, представленных
в [SH]. Эти АСЕ-классы очередей сообщений отличаются от реализации Mes-
sage-Queue, приведенной выше, в следующих направлениях:
• В дополнение к очередям FIFO, они позволяют также помещать сообще-
ния в начало очереди (то есть в порядке LIFO) или в соответствии с при-
оритетом.
236
Глава 10
• Они используют «характеристики» (traits) C++ и паттерн Strategized Loc-
king с целью параметризации своих механизмов синхронизации, кото-
рые позволяют программистам, с целью повышения эффективности, за-
менять синхронизацию со строгой поддержкой поточности на конфигу-
рации с очередями одиночных потоков.
• Они предоставляют распределители памяти, которые позволяют выде-
лять память под сообщения из различных источников, таких как совме-
стно используемая память, куча, статическая память или локальная па-
мять потока.
• Их можно настраивать с целью планирования порядка выполнения по-
токов через их ACE_Thread_Semaphore или ACE_Condition_Thre-
ad_Mutex, чтобы выбирать между большей эффективностью и боль-
шими возможностями, соответственно.
• ACE_Message_Queue_Ex является строго типизированной версией
ACE_Message_Queue, которая помещает в очередь и извлекает из очере-
ди экземпляры шаблонного параметра MESSAGE_TYPE, а не ACE_Mes-
sage_Block.
10.6 ACE-классы условных переменных
Обоснование
Условные переменные (condition variables) позволяют потокам эффектив-
но координировать и планировать свою работу. Хотя условные переменные
входят в стандарт Pthreads, некоторые распространенные платформы ОС, такие
как Win32 и VxWorks, сами по себе условные переменные не поддерживают.
Хотя условные переменные могут быть эмулированы с помощью других
имеющихся в ОС механизмов синхронизации, таких как семафоры и мьютек-
сы, создавать такие эмуляции слишком расточительно для разработчиков при-
ложений и может привести к ошибкам. АСЕ предлагает интерфейсный фасад
ACE_Condition_Thread_Mutex для работы с условными переменными,
чтобы избежать этих проблем.
Функциональные возможности классов
Класс ACE_Condition_Thread_Mutex использует паттерн Wrapper Fa-
cade для организации инкапсуляции семантики условных переменных с обла-
стью действия на уровне процесса. Интерфейс класса ACE_Conditi-
on_Thread_Mutex показан на рис.10.3, а в следующей таблице перечислены
основные его методы:
Интерфейсные фасадыАСЕ: синхронизация
Метод Описание
wait () В рамках атомарной операции освобождает мьютекс, связанный с условной переменной, и блокируется на время тайм-аута или до получения последующего сообще: :ия от другого потока с помощью методов signal () или broadcast().
signal() Передает сообщение одному из потоков, ждущих на данной условной переменной.
broadcast() Передает сообщение всем потокам, ждущим; га данной j условной переменной. Д
Если временной параметр, передаваемый ACE_Conditior._Thread_Mu-
tex: : wait (), не равен 0, то этот метод будет блокироваться до того момента
времени, исчисляемого в абсолютных единицах, которое указано в ACE_Ti-
me_Value. Если это время истекает до того, как условная переменная получает
сообщение, этот метод возвращает-1 вызывающей стороне с errno, установ-
ленным в ETIME, что означает истечение срока тайм-аута. Незавлсп.ло от ре-
зультата завершения wait (), мьютекс, связанный с данной условной перемен-
ной, будет оставаться в заблокированном состоянии.
ACE__Condi tion_Thread_Mu tex
- cond_ : ACE_cond_t
- mutex_ : ACE_Thread_Mutex&
+ ACE_Condition_Thread_Mutex (mtx : const ACE_Thread_Mucex&,
name : const char *,
arg : void *)
+ wait (time : ACE_Time_Value*) int
+ signal ( ) : int
+ broadcast {) : int
Рис. 10.3
Диаграмма класса ACE_Condition_Thread_Mutex
Если требуется управлять изменениями, связанными с вычислением слож-
ных условных выражений или с планированием, то условные переменные под-
ходят больше, чем мьютексы или семафоры. Например, условные переменные
часто используются для реализации очередей синхронных сообщений, кото-
рые обеспечивают связь типа «производитель/потребитель» («producer/consu-
тег») для передачи сообщений между потоками. Условные переменные блоки-
руют потоки-источники при переполнении очереди сообщений и блокируют
потоки-потребители, если очередь пуста. Так как хранить историю событий не
требуется, то условные переменные не требуют записи, находясь в сигнальном
состоянии.
Класс ACE_Null_Condition является реализацией с нулевыми наклад-
ными расходами, соответствующими интерфейсу ACE_Condition_Thre-
ad_Mutex. Этот класс аналогичен классу ACE_Nu 1 l_Mutex, представленному
238
Глава 10
в разделе 10.3; то есть все реализации его методов не содержат операций, явля-
ются пустыми, в соответствии с паттерном Null Object [Woo97]. Класс
ACE_Null_Condition представлен ниже:
class ACE_Null__Condition
{
public:
ACE_Null_Condition (const ACE_Null_Mutex&, int =0, void* =0) {}
~ACE_Null__Condition () {}
int remove () { return 0; }
int wait (ACE_Time_Value* =0) const (errno = ETIME; return -1;}
int signal () const { return 0; }
int broadcast () const { return 0; }
AC3BJEtecursiv«_Thr«ad_Mutax
- nesting_level_ : int
- owner_id_ : ACE_thread_t
- lock_ : ACE_Thread_Mutex
- lock_available_ : ACE_Condition_Thread_Mutex
+ ACE-Recursive_Thread_Mutex (name : const char ♦)
+ acquire ( ) : int
+ release ( ) : int
Рис. 104
Диаграмма класса ACE_Recursive_Thread_Mutex
Метод wait () возвращает -1 c errno установленным в ETIME так, что
ACE_Null_Condition работает правильно при использовании в сочетании
с паттерном Strategized Locking в классах типа Mes sage_Queue, который пред-
ставлен в разделе 10.5
Пример
По умолчанию реализация мьютексов в UI threads является нерекурсивной;
то есть поток, владеющий мьютексом, не может повторно завладеть тем же
мьютексом, не создав для самого себя тупиковой ситуации.1 Хотя нерекурсив-
ные мьютексы эффективны, в некоторых обстоятельствах они слишком огра-
ничивают. Например, рекурсивные мьютексы особенно полезны для каркасов
приложений на C++, управляемых обратными вызовами (callback-driven), где
цикл обработки событий каркаса выполняет обратный вызов кода, определяе-
мого пользователем. Так как код, определяемый пользователем, может позднее
повторно войти в код каркаса через точку входа метода, то рекурсивные мью-
тексы помогают предотвратить возникновение тупиков (deadlock) на мьютек-
сах, в процессе обратного вызова.
I
Заметим, что Pthreads и Win32 обеспечивают поддержку рекурсивных мьютексов на систем*
ном уровне.
Интерфейсные фасадыАСЕ: синхронизация
239
Чтобы содействовать и такому развитию событий, АСЕ, с помощью класса
ACE_Recursive_Thread_Mutex, предлагает поддержку рекурсивных мью-
тексов с областью действия на уровне процесса. Интерфейс этого класса пока-
зан на рис. 10.4. Общедоступный интерфейс этого класса соответствует псевдо-
классу ACE_LOCK* на рис. 10.1. Следующий код показывает как можно исполь-
зовать ACE_Condition_Thread_Mutex, чтобы реализовать семантику
рекурсивного мьютекса на платформах, которые сами по себе рекурсивные
мьютексы не поддерживают.
Сколько раз поток с owner_id_ завладел рекурсивным мьютексом отсле-
живает nesting_level_. Сериализует доступ к nesting_level_ и ow-
ner_id_ — lock_. Условная переменная lock_available_ используется,
чтобы приостановить потоки, не владеющие мьютексом и ожидающие того
момента, когда уровень вложенности опуститься до 0 и мьютекс будет освобо-
жден. Конструктор ACE_Recursive_Thread_Mutex инициализирует эти
члены-данные:
ACE_Recursive_Thread_Mutex::ACE_Recursive_Thread_Mutex
(const char *name, void *arg)
: nesting_level_ (0), owner_id_ (0), lock_ (name, arg),
// Инициализирует условную переменную.
lock_available_ (lock_, name, arg) { }
Далее мы показываем как запрашивать рекурсивный мьютекс.
1 int ACE_Recursive_Thread_Mutex::acquire ()
2 {
3 ACE_thread_t t_id = ACE_OS::thr_self ();
4
5 ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, lock_, -1) ;
6
7 if (nesting_level_ == 0) {
8 owner_id_ = t_id;
9 nesting_level_ 1;
10 }
11 else if (t_id owner_id_)
12 nesting_level_++;
13 else {
14 while (nesting_level_ > 0)
15 lock_available_.wait ();
16
17 owner_id_ = t_id;
18 nesting_level =1;
19 }
20 return 0;
21 )
Строки 3-5 Мы начинаем с выяснения того, из какого потока мы вызваны и
затем запрашиваем lock_mutex с помощью идиомы Scoped Locking.
240
Глава 10
Строки 7-12 Если конфликтной ситуации нет, сразу же передаем мьютекс
владельцу. Иначе, если у мьютекса уже есть владелец, просто уменьшаем уро-
вень вложенности на единицу и продолжаем выполнение, чтобы избежать са-
моблокировки (self-deadlock).
Строки 13-20 Если мьютексом владеет другой поток, мы используем услов-
ную переменную lock_available_ для ожидания того, когда уровень вло-
женности опустится до нуля. Когда метод wait () вызван clock_availab-
1е_, он автоматически освобождает lock_mutex и приостанавливает работу
вызывающего потока. Когда уровень вложенности, наконец, опускается до
нуля, мы можем запросить 1оск_ и получить рекурсивный мьютекс в свое вла-
дение. Деструктор guard освобождает 1оск_ посредством идиомы Scoped
Locking.
Далее мы приводим метод ACE_Recursive_Thread_Mutex:: release ():
int ACE_Recursive_Thread Mutex::release ()
{
ACE_thread_t t_id = ACE_OS::thr_self ();
// Автоматически запрашиваем мьютекс.
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, lock_, -1);
nesting_level_—;
if (nesting_level_ == 0)
lock_available_.signal О; // Сообщаем ожидающим, что
// блокировка свободна.
return 0; // Деструктор <guard> освобождает <lock_>.
)
Когда метод signal () вызывается с lock_available_, он запускает
один из потоков, ожидающих сигнала от условной переменной.
10.7 Резюме
Платформы ОС предлагают разработчикам сетевых приложений различ-
ные механизмы синхронизации, которыми можно пользоваться при проекти-
ровании параллельных приложений. В дополнение к «случайной» сложности,
связанной с переносимостью и использованием API, продемонстрированной
в предыдущих главах, применение механизмов синхронизации связано еще и
с другой проблемой: не все из них поддерживаются современными операцион-
ными системами. В этой главе мы показали, как решать эти проблемы путем
создания классов синхронизации, которые помогают разработчикам совер-
шать меньше ошибок и использовать существующие механизмы синхрониза-
ции для эмуляции отсутствующих. Результатом является совокупность интер-
фейсных фасадов синхронизации АСЕ, которые разработчики приложений мо-
гут использовать переносимым и надежным образом с целью удовлетворения
многих потребностей в синхронизации.
Интерфейсные фасадыАСЕ: синхронизация
241
Интерфейсы синхронизации АСЕ адаптируют синтаксически несовмести-
мые механизмы синхронизации ОС так, что они выглядят унифицированными
с точки зрения классов C++. Эти интерфейсные фасады обеспечивают синхро-
низацию процессов и потоков в сетевых приложениях. В главе было приведено
описание наиболее широко используемых, объектно-ориентированных интер-
фейсных фасадов АСЕ, связанных с синхронизацией. На web-сайте, посвящен-
ном АСЕ (http: //асе. есе. uci. edu), есть описания и других интерфейс-
ных фасадов синхронизации, которые предлагает АСЕ.
Приложение А
Принципы проектирования
интерфейсных фасадов АСЕ
на C++
Краткое содержание
Это приложение продолжает наши рассуждения относительно «случай-
ной» сложности, связанной с использованием API ОС, а также относительно
того, каким образом АСЕ преодолевает ее с помощью паттерна Wrapper Facade.
Мы суммируем здесь принципы проектирования, лежащие в основе классов
интерфейсных фасадов АСЕ, связанных с IPC и параллелизмом, так, чтобы вы
могли им следовать и применять в собственных проектах. Хотелось бы наде-
яться, что вы используете их, чтобы спроектировать и разработать новые клас-
сы, которые можно было бы включить в АСЕ!
А.1 Обзор
В этом приложении мы приводим описание следующих принципов, при-
менявшихся в процессе разработки интерфейсных фасадов АСЕ:
• Используйте интерфейсные фасады для повышения типовой безопасно-
сти.
• Упрощайте наиболее общие случаи применения.
• Используйте иерархическое представление с целью повышения ясности
и расширяемости проектов.
• Инкапсулируйте, где только можно, платформенные различия.
• Повышайте эффективность.
В этом приложении мы документируем эти принципы в сжатой образной
форме так, чтобы вы могли понять под-влиянием каких мотивов формировал-
244
Приложение A
ся АСЕ и применить их к собственным каркасам и приложениям. Контекстом
для всех этих принципов является разработка интерфейсных фасадов для сис-
темных механизмов IPC и параллелизма.
Главными задачами АСЕ являются переносимость и эффективность, по-
этому мы принимаем компромиссные решения, которые могут быть ненужны-
ми или неподходящими для высокоуровневых объектно-ориентированных
каркасов приложений.
А.2 Используйте интерфейсные фасады
для повышения типовой безопасности
Языки программирования высокого уровня, такие как C++ и Java, обеспе-
чивают повышенную типовую безопасность, что должно служить гарантией
того, что к объектам не будут применяться действия, которых они не поддер-
живают. В идеальном случае ошибки, связанные с неправильным использова-
нием типов, должны обнаруживаться во время компиляции. Однако библиоте-
ки ОС, такие как С-библиотеки времени выполнения, Sockets или Pthreads, не-
часто открывают свои внутренние структуры данных, так как это:
• Подорвало бы усилия по обеспечению совместимости снизу вверх.
• Сделало бы трудной, на некоторых платформах, поддержку нескольких
языков программирования.
• Открыло бы доступ к скрытым деталям, которые не должны использо-
ваться приложениями.
Поэтому API ОС часто предоставляют интерфейс в стиле С, используя низ-
коуровневое непрозрачное представление структур внутренних данных, на-
пример, дескрипторов ввода/вывода и сокетов. Такие непрозрачные типы за-
трудняют для компиляторов обнаружение ошибок, связанных с неправильным
применением типов. Эти ошибки, следовательно, могут быть обнаружены
только во время выполнения, что увеличивает объем работ, связанных с разра-
боткой и отладкой, усложняет обработку ошибок и снижает отказоустойчи-
вость приложений. В данном разделе описан принцип проектирования, кото-
рый повышает типовую безопасность во время компиляции и обеспечивает
люк (escape hatch) для тех случаев, в которых строгая типовая безопасность явля-
ется неоправданно жестким требованием.
А.2.1 Создавайте классы C++, которые не допускают
неправильного использования
Проблема: Многие ограничения Socket API, рассмотренные в разделе 2.3,
вытекают из следующих проблем, связанных с отсутствием в них типовой безо-
пасности:
1. Трудно переносить — Имена типов и базовые представления дескрипто-
ров ввода/вывода различаются на разных платформах, делая их неперено-
Принципы проектирования интерфейсных фасадов АСЕ на C++245
самыми. Например, дескрипторы сокетов являются целыми числами на
платформах UNIX и указателями в Win32.
2. Легко неправильно использовать—Низкоуровневые представления дают
возможность неправильно использовать дескрипторы ввода/вывода таким
образом, что это может быть обнаружено только во время выполнения. На-
пример, Socket API можно легко использовать неправильно, если вызвать
функцию accept () с дескриптором сокета передачи данных (data-mode
socket), который предназначен для передачи данных с помощью recv () и
send().
Решение => Создать классы C++, которые не допускают неправильного
использования. Слабо типизированные дескрипторы ввода/вывода могут
быть инкапсулированы в классах C++, которые предоставят своим пользовате-
лям строго типизированные методы. При использовании прикладной про-
граммой этих новых классов, компиляторы C++ могут обеспечить вызов толь-
ко разрешенных методов.
Следующий код на C++ иллюстрирует применение этого принципа
к функции echo_server (), приведенной в разделе 2.3.1:
int echo_server (const ACE_INET_Addr &addr)
{
ACE_SOCK_Acceptor acceptor; // Фабрика соединений.
ACE_SOCK_Stream peer_stream; // Объект передачи данных.
ACE_INET_Addr peer_addr; // Объект адреса.
// Инициализируем пассивный акцептор и принимаем новое
// соединение.
if (acceptor.open (addr) != -1
&& acceptor.accept (peer_stream, &peer_addr) != -1) (
char buf[BUFSIZ);
for (size_t n; (n = peer_stream.recv (buf, sizeof buf)) > 0;)
// send_n() управляет записью коротких сообщений.
II ("short writes").
if (peer_stream.send_n (buf, n) 1= n)
// Обработка ошибок опущена...
}
Этот вариант решает многие проблемы Socket API и использования С. На-
пример, класс ACE_SOCK_Acceptor предоставляет только методы, примени-
мые к пассивному установлению соединений. Так как эти классы интерфейс-
ных фасадов являются строго типизированными, некорректные операции об-
наруживаются во время компиляции, а не вовремя выполнения. Вследствие
этого, невозможно вызвать recv () /send () для ACE_SOCK_Acceptor или
accept () для ACE_SOCK_Stream, так как указанные методы отсутствуют
в этих интерфейсных фасадах.
246
Приложение A
А.2.2 Разрешайте контролируемые нарушения
типовой безопасности
Проблема: Как отмечено выше, интерфейсные фасады могут скрывать от
сетевых приложений детали реализации, связанные с особенностями плат-
форм и возможностью появления ошибок, например, представление дескрип-
тора сокета как целого числа или как указателя. Возникают, однако, ситуации,
в которых этот дополнительный уровень абстракции и типовой безопасности
на самом деле мешает разработчикам использовать интерфейсный фасад в бла-
городных целях, но непредусмотренных его первоначальным разработчиком.
Неудача в одном случае может привести к тому, что разработчики совсем отка-
жутся от внесения и других важных улучшений, связанных с интерфейсными
фасадами.
Решение => Разрешить контролируемые нарушения с помощью люков
(«escape hatches»). Назначение этого принципа упростить правильное исполь-
зование интерфейсных фасадов, затруднить их неправильное использование,
но не запрещать совсем использовать их таким образом, который разработчики
класса первоначально не предполагали. Иллюстрацией этого принципа явля-
ются методы get_handle () иset_handle() в ACE_IPC_SAP, который яв-
ляется корневым базовым классом интерфейсных фасадов АСЕ IPC, рассмот-
ренных в разделе 3.3. Наличие этих двух метод получения и установки дескрип-
тора ввода/вывода позволяет приложениям обойти проверку типа
интерфейсным фасадом АСЕ IPC, когда приложению нужно использовать сис-
темные функции, ориентированные на дескрипторы.
Например, может оказаться необходимым получить дескриптор сокета для
использования с классом ACE_Handle_Set и функцией select (), как пока-
зано ниже:
ACE_SOCK_Acceptor acceptor;
ACE_Handle_Set ready_handles;
И ...
if (ready_handles.is_set (acceptor.get_handle ())
ACE::select ((int)acceptor.get_handle () + 1, ready_handles ());
Разумеется механизм люков должен применяться с умом, так как он ослож-
няет переносимость и повышает вероятность ошибок, тем самым, сводя на нет
основные преимущества паттерна Wrapper Facade. Ситуации, в которых требу-
ется соединить объектно-ориентированные и не объектно-ориентированные
абстракции, как в случае с реализацией некоторых уровней самого АСЕ, нужно,
в идеальном варианте, убирать внутрь реализаций классов и редко показывать
пользователям классов. Если потребность в люкахчасто возникает у потребите
лей классов, лучше всего переосмыслить дизайн интерфейсов классов: нельзя
ли их рефакторизовать (refactor) или перепроектировать (redesign) с целью вос-
становления типовой безопасности.
Принципы проектирования интерфейсных фасадов АСЕ на C++
247
А.З Упрощайте наиболее общие случаи
применения
Разработчики API отвечают за реализацию механизмов, которые позволя-
ют разработчикам приложений использовать любые функции, поддерживае-
мые данным API. Современные операционные системы, файловые системы,
стеки протоколов, и средства поточной обработки предлагают широкий спектр
возможностей. Поэтому современные API часто являются громоздкими и
сложными, предлагая несметное число функций, которые могут требовать
множества аргументов для выбора нужной функциональности.
К счастью, принцип Парето, известный также как закон «80:20»', действует
и в случае программных API, это значит, что большая часть того, что обычно
требуется, может быть ограничена небольшим подмножеством всего имеюще-
гося набора функций [ PS90]. Более того, одни и те же наборы функций исполь-
зуются часто в одной и той же последовательности для достижения тех же или
похожих целей. Хорошо спроектированные программные средства могут из-
влечь выгоду их этого принципа путем выделения и упрощения этих общих
случаев применения. Интерфейсные фасады АСЕ упрощают общие случаи
применения следующими способами.
А.3.1 Объединяйте несколько функций в одном методе
Проблема: API системных функций ОС уровня С часто содержат целый ряд
функций, которые используются относительно редко. Как отмечалось в разде-
ле 2.3.2, например, Socket API поддерживает много семейств протоколов, таких
как TCP/IP, IPX/SPX, Х.25, ISO OSI и сокеты домена UNIX. С целью поддержки
всех семейств протоколов, авторы-разработчики определили в Socket API от-
дельные С-функции, которые:
1. Создают дескриптор сокета.
2. Привязывают дескриптор сокета к конечной точке соединения.
3. Обозначают конечную точку соединения как фабрику, работающую в пас-
сивном режиме (passive-mode).
4. Принимают соединение и возвращают дескриптор режима передачи дан-
ных (data-mode).
Следовательно, создание и инициализация сокета домена Internet, рабо-
тающего в пассивном режиме, требует, как показано ниже, нескольких вызо-
вов:
sockaddr_in addr;
int addr_leri = sizeof addr;
int n_handle, s_handle = socket (PF_INET, SOCK_STREAM, 0);
Одна из самых известных трактовок этого закона звучит так: «20% населения выпивает 80%
пива». — Прим. ред.
248
Приложение A
memset (&addr, 0, sizeof addr);
addr.sin_family = AF_INET;
addr.sin_port = htons (port);
addr.sin_addr.s_addr = INADDR_ANY;
bind (s_handle, &addr, addr_len);
listen (s_handle);
H ...
n_handle = accept (s_handle, &addr, &addr_len);
Многие серверы TCP/IP имеют набор этих, или аналогичных, функций, ко-
торые осуществляют активное соединение с сокетом. Существуют небольшие
отличия в том как выбираются номера портов, но в своей основе это один и тот
же,код, который переписывается для каждого нового ТСР/1Р-приложения. Как
показано в разделе 2.3.1, это повторение, без которого любые проекты могли бы
обойтись, является основным источником возможных ошибок программиро-
вания и увеличения времени отладки. Превращение этого набора операций
в повторно используемый код, простым и типобезопасным образом, экономит
время и усилия при разработке каждого сетевого приложения.
Решение => Объединяйте несколько функций в одном методе. Такое уп-
рощение уменьшает необходимость писать или переписывать в каждом проек-
те, возможно с ошибками, один и тот же код, такой как код инициализации со-
единения в пассивном режиме, приведенный выше. Выгоды такого подхода
растут с ростом количества строк кода, которые объединяются в одном методе.
Не нужно делать специальных вызовов, что снижает вероятность ошибок при
использовании параметров. Главное преимущество такого подхода, однако, за-
ключается в инкапсуляции знаний о совокупности вызываемых функций и по-
рядке их вызова, что устраняет главный источник потенциальных ошибок.
Например, класс ACE_SOCK_Acceptor является фабрикой для установле-
ния пассивных соединений. Его метод open () вызывает функции socket (),
bind () и listen () для создания конечной точки соединения, работающей
в пассивном режиме. Следовательно, чтобы добиться функциональности,
представленной ранее, в приложениях можно просто написать следующее:
ACE_SOCK_Acceptor acceptor;
ACE_SOCK_Stream stream;
acceptor.open (ACE_INET_Addr (port));
acceptor.accept (stream);
// ...
Аналогичным образом конструктор ACE_INET_Addr минимизирует час-
то встречающиеся ошибки программирования, связанные с непосредственным
использованием семейств С-структур данных. Например, он автоматически
обнуляет адресную структуру (inet_addr_) sockaddr_in и преобразует но-
мер порта в сетевой порядок байтов, следующим образом:
Принципы проектирования интерфейсных фасадов АСЕ на C++ 249
ACE_INET_Addr::ACE_INET_Addr (u_short port, long ip_addr) {
memset (&this->inet_addr_, 0, sizeof this->inet_addr_);
this->inet_addr_.sin_family = AF_INET;
this->inet_addr_.sin_port - htons (port);
memcpy (&this->inet_addr_.sin_addr, &ip_addr, sizeof
ip_addr);
)
В общем случае, такой подход приводит к созданию кода, который является
более лаконичным, более ясным и менее подверженным ошибкам, так как он
использует паттерн Wrapper Facade, чтобы избежать проблем, связанных с ти-
повой безопасностью.
А3.2 Объединяйте функции в унифицированный
интерфейсный фасад
Проблема: Современные компьютерные платформы часто предоставляют
типовую функциональность, но доступ к ней обеспечивают по-разному. Это
могут быть разные имена функций, которые делают, по большей части, одно и
то же. Это могут быть также совершенно разные функции, которые на разных
платформах нужно вызывать в разной последовательности. Этот изменяю-
щийся набор основных API и разная семантика, усложняют перенос приложе-
ний на новые платформы.
Многопоточность — это хороший пример того, как API и семантика изме-
няются от платформы к платформе. Этапы создания потока с разными свойст-
вами значительно отличаются для потоков POSIX (Pthreads), потоков UNIX
International (UI threads), потоков Win32 и операционных систем реального
времени. В следующем списке перечислены некоторые из основных отличий:
• Имена функций — Функция создания потоков называется pthre-
ad_create () в Pthreads, thr_create () в UI threads и CreateThre-
ad () в Win32.
* Возвращаемые значения—Некоторые API поточной обработки возвра-
щают ID потока (или дескриптор) в случае успешного завершения, тогда
как другие возвращают 0. Что касается ошибок, некоторые возвращают
особое значение (при сохранении кода ошибки в другом месте), а другие
возвращают непосредственно код ошибки.
• Количество функций — Для задания свойств потока, таких как объем
стека или приоритет, любые атрибуты передаются в CreateThread ()
в Win32 или thr_create () в UI threads. В Pthreads, однако, отдельные
функции используются для создания, модификации и последующего
удаления структур данных с атрибутами потоков, которые затем переда-
ются функции pthread_create ().
• Порядок вызовов функций — Когда требуется несколько вызовов
функций, то иногда их требуется выполнять в разных последовательно-
стях. Например, API Pthreads draft 4 требует, чтобы поток, после созда-
250
Приложение A
ния, был отмечен как объединяемый (joinable), тогда как другие реализа-
ции Pthreads, требует сделать это до создания потока.
Решение => Объединяйте функции в унифицированный интерфейсный
фасад для правильной координации изменений необходимых при переходе на
другие платформы. Например, метод ACE_Thread_Manager: : spawn (),
чтобы удовлетворить кросс-платформенным требованиям создания потоков,
принимает через аргументы всю необходимую ему информацию (см. раздел
А.3.3 по поводу важного принципа относящегося к аргументам) и осуществля-
ет все вызовы системных функций ОС в нужной последовательности. Различ-
ные соглашения, существующие на платформах, относительно возвращаемых
значений учтены и унифицированы в рамках единого соглашения о возвра-
щаемых значениях, используемого для всей библиотеки АСЕ, а именно, 0 в слу-
чае успешного завершения, -1 при ошибке с указанием причины ошибки
в errno. Это решение позволяет осуществлять создание всех потоков в самой
АСЕ и в приложениях пользователей с помощью единственного метода, вызы-
ваемого на всех платформах.
Ваша задача при унификации функций — выбрать степень детализации
интерфейса и какие низкоуровневые функции объединять. Не забудьте об этом
в процессе принятия решений:
• Переносимость — Метод интерфейсного фасада должен стремиться
к воплощению одной и той же логики на всех платформах. Это не всегда
возможно; например, не все платформы ОС допускают создание потоков'
с областью действия на уровне системы, как следует из материала раздела
5.4. Во многих случаях, тем не менее, такой метод помогает скрыть эти
отличия, эмулируя те возможности, которые не поддерживаются, или,
игнорируя затребованные возможности или атрибуты, которые не явля-
ются существенными. См. в разделе А.5 дополнительную информацию
на эту тему.
• Простота использования — Вызывающая сторона должна иметь воз-
можность определить, как использовать метод интерфейсного фасада,
какую подготовку нужно выполнить до вызова, например, сформиро-
вать атрибуты, и что представляют собой возвращаемые значения и ка-
ков их смысл. Легче использовать небольшое количество методов, чем
большое число взаимосвязанных методов. Кроме того, остерегайтесь по-
бочных эффектов, таких как выделение внутренней памяти, об управле-
нии которой должна помнить вызывающая сторона.
А.3.3 Переупорядочивайте параметры и назначайте
значения по умолчанию
Проблема: Библиотеки ОС содержат системные функции, которые долж-
ны удовлетворять большому количеству возможных применений и предостав-
лять доступ ко всей функциональности системы. Эти функции, поэтому, часто
имеют много аргументов, которые редко используются, но их значения по
умолчанию должны задаваться в явном виде. Кроме того, последовательность
Принципы проектирования интерфейсных фасадов АСЕ на C++
251
параметров в прототипе функции не всегда соответствует частоте, с которой
приложения передают значения, отличные от значений по умолчанию, в эту
функцию, что увеличивает вероятность ошибок кодирования. Библиотеки ОС
также часто реализуются на С таким образом, чтобы их можно было вызвать из
разных языков, что предохраняет от использования возможностей языка и аб-
стракций проектирования, которые могли бы помочь избавиться от этих про-
блем.
Например, функция thr_create () из UI threads принимает шесть пара-
метров:
1. Указатель стека.
2. Объем стека.
3. Функцию-точки-входа.
4. Аргумент void * для функции-точки-входа.
5. Флаги, используемые для создания потока.
6. Идентификатор созданного потока.
Так как большинство приложений требует семантики стека, задаваемой по
умолчанию, параметры 1 и 2 обычно равны 0. Разработчики должны не забыть
передать эти нулевые значения, что обременительно и чревато ошибками. Для
параллельных приложений типично создавать потоки с семантикой «объеди-
няемый», это означает, что другой поток будет согласовывать с ним свои дейст-
вия и получать статус этого потока при его завершении. Поэтому параметр 5
имеет обычное значение, но он все-таки изменяется в зависимости от конкрет-
ного случая. Параметры 3 и 4 изменяются чаще всего. Параметр б устанавлива-
ется методом thr_create (), поэтому он должен предоставляться вызываю-
щей стороной.
Решение => Переупорядочивайте параметры и назначайте значения по
умолчанию для того, чтобы упростить использование в наиболее распростра-
ненных случаях. При проектировании классов интерфейсных фасадов вы мо-
жете извлечь выгоду из двух важных факторов:
• Вам известны наиболее распространенные случаи применения, и вы мо-
жете спроектировать интерфейс таким образом, чтобы упростить разра-
ботчикам приложений использование этих случаев.
• Вы можете выбрать и использовать для реализации объектно-ориенти-
рованный язык, такой как C++, и извлечь выгоду из возможностей этого
языка и тех высокоуровневых абстракций, которые доступны при объ-
ектно-ориентированном проектировании.
Что касается изложенной выше проблемы, то вы можете переупорядочить
параметры так, чтобы сначала разместить часто используемые параметры, а
редко используемые параметры разместить в конце, где им можно назначить
значения по умолчанию.
Например, параметры ACE_Thread_Manager:: spawn () упорядочены
так, что те параметры, которые изменяются чаще всего, такие как функция по-
тока и ее аргумент void *, стоят первыми. За ними задаются значения по
умолчанию всем остальным параметрам; например, модель синхронизации по-
252
Приложение A
тока по умолчанию будет thr_joinable. В результате большинство прило-
жений сможет передавать минимальное количество информации, необходи-
мой для наиболее распространенных случаев применения.
Параметры, устанавливаемые в C++ по умолчанию могут также использо-
ваться для других целей. Например, метод connect () класса ACE_SOCK__Con-
nector имеет следующую сигнатуру:
int ACE_SOCK_Connector::connect
(ACE—SOCK—Stream &new_stream,
const ACE_SOCK_Addr &remote—sap,
ACE_Time__Value * timeout = 0,
const ACE_Addr &local__sap = ACE_Addr: : sap_any,
int reuse—addr = 0,
int flags s0,
int perms « 0,
int protocol-family = PF—INET,
int protocol e 0);
А метод connect () класса ACE_TLI_Connector имеет несколько иную
сигнатуру:
int АСЕ—TLI—Connector::connect
(ACE—TLI—Stream &new_stream,
const ACE—Addr &remote_sap,
ACE—Time—Value *timeout « 0,
const ACE-Addr &local_sap » ACE—Addr::sap_any,
int reuse—addr « 0,
int flags e 0_RDWR,
int perms « 0,
const char device[] = ACE-TLI_TCP_DEVICE,
struct t—info *info = 0,
int rW—flag « 1,
struct netbuf *udata « 0,
struct netbuf *opt « 0);
На практике, только несколько первых параметров connect () изменяют-
ся от вызова к вызову. Следовательно, чтобы упростить программирование,
значения, устанавливаемые по умолчанию, используются в методах con-
nect () этих классов так, чтобы разработчикам не нужно было назначать их
постоянно. В результате, наиболее распространенный случай применения и
в том, и в другом классах почти идентичны. Например, ACE-SOCK-Connec-
tor выглядит следующим образом:
ACE-SOCK-Stream stream;
ACE-SOCK—Connector connector;
// Компилятор назначает значения по умолчанию,
connector.connect (stream, АСЕ_INET_Addr (port, host));
// ...
Принципы проектирования интерфейсных фасадов АСЕ на C++253
A ACE_TLI_Connector выглядит следующим образом
ACE_TLI_Stream stream;
ACE_TLI_Connector connector;
// Компилятор назначает значения по умолчанию,
connector.connect (stream, ACE_INET_Addr (port, host));
// ...
Общая сигнатура, обусловленная наличием параметров назначаемых по
умолчанию, может использоваться в сочетании с параметризованными типа-
ми, рассматриваемыми в [SH], для улучшения порождающего программирова-
ния (generative programming) [СЕОО] и для обеспечения изменчивости с помо-
щью параметризованных типов, в соответствии с изложенным в разделе А.5.3.
А.3.4 Явно связывайте объекты, образующие единое
целое
Проблема: Из-за универсального характера библиотек, используемых опе-
рационной системой, между многочисленными функциями и структурами
данных существуют зависимости. Однако так как эти зависимости имеют
скрытый характер, их трудно выявить и автоматически привести в действие.
Раздел 2.3.1 иллюстрирует этот факт, используя связи между функциями soc-
ket (), bind (), listen () и accept (). Эта проблема обостряется в тех слу-
чаях, когда в какие-то моменты времени несколько объектов данных использу-
ется совместно, а в другие моменты — раздельно.
Например, при использовании средств поточной обработки, мьютекс явля-
ется обычным механизмом синхронизации. Мьютекс используется также вме-
сте с условной переменной; это значит, что условная переменная и мьютекс
обычно ассоциируются со временем жизни условной переменной. Pthreads API
с этой точки зрения подвержен ошибкам, поскольку не реализует эту связь
явно. Сигнатуры функций pthread_cond_* () принймают pthread_mu-
tex_t *. Тем не менее, только синтаксически нельзя выразить тесную взаимо-
связь между pthread_cond_t и специфическим pthread_mutex_t. Кроме
того, использование условной переменной Pthreads API осложнено тем, что
мьютекс нужно передавать в качестве параметра при каждом вызове функции
pthread_cond_wait().
Решение => Явно связывайте объекты, представляющие собой единое це-
лое, чтобы свести к минимуму количество деталей, которые разработчики при-
ложений должны помнить. Ваша задача как разработчика интерфейсных фаса-
дов заключается в том, чтобы упростить для пользователей правильное созда-
ние классов и затруднить (или сделать невозможным) неправильное создание
классов. Создание одного класса, который инкапсулирует несколько взаимо-
связанных объектов, — это один из способов достижения этой цели, так как он
явно представляет связь между объектами, составляющими единое целое,
в виде краткой записи.
254
Приложение A
Этот принцип идет на один шаг дальше, чем использование интерфейсных
фасадов для улучшения типовой безопасности, рассмотренное в разделе А.2.
Там целью являлось применение системы типов C++ для обеспечения строгого
контроля типов. Здесь цель — использовать возможности C++, чтобы усилить
зависимость между строго типизированными объектами. Например, чтобы ук-
репить связь между условной переменной и ее мьютексом, класс ACE_Condi-
t ion_Thread_Mu tex, рассмотренный в разделе 10.6 включает ссылки и на пе-
ременную состояния, и на мьютекс:
class ACE_Condition_Thread_Mutex {
// ....
private:
ACE_cond_t cond_; // Экземпляр условной переменной.
АСЕ Thread Mutex &mutex ; // Ссылка на: мьютекс.
);
Конструктор этого класса требует ссылки на объект ACE_Thread_Mutex,
вынуждая пользователя ассоциировать мьютекс правильно, как показано
ниже:
ACE_Condition_Thread_Mutex::ACE_Condition_Thread_Mutex
(const ACE_Thread_Mutex &m): mutex_ (m) {/*...*/)
i
Любая попытка иного использования будет обнаружена компилятором
C++ и отвергнута.
АД Используйте иерархические представления
для^ повышения ясности и расширяемости
проекта
Наследование является определяющим свойством объектно-ориентиро-
ванных методов проектирования и языков программирования [Меу97]. Хотя
опыт показывает, что многоуровневые иерархии наследования могут оказаться
громоздкими [GHJV95], есть, как показано ниже, и преимущества в разумном
использование наследования для моделирования иерархий программных абст-
ракций.
АД.1 Заменяйте «одномерные» API на иерархические
представления
Проблема: Сложность библиотеки Socket API частично является следстви-
ем ее громоздкой «одномерной» структуры [Маг64]. Например, все функции
находятся на одном уровне абстракции, как показано на рис. А. 1. Эта «одномер-
ная» структура увеличивает объем работы, необходимой для изучения и пра-
вильного использования Socket API. Например, чтобы писать сетевые прило-
Принципы проектирования интерфейсных фасадов АСЕ на C++
255
ооу У
°9eif«
>« X s S Р с
и и и
OOOOOJD
Рис. АЛ
Функции Socket API
жения, программисты должны знать большую часть Socket API, даже если они
используют меньшую ее часть. Кроме того, функциональность является децен-
трализованной, что приводит к дублированию кода.
Решение => Заменяйте «одномерные» API иерархическим представления-
ми, чтобы максимизировать повторное и совместное использование кода. Этот
принцип добавляет использование иерархически связанных классов к реструк-
туризации существующих одномерных API. Например, интерфейсные фасады
АСЕ Socket были спроектированы путем преобразования функций Socket API,
показанных на рис. А.1, в иерархически упорядоченные классы, представлен-
ные на рис. 3.1. Наследование способствует повторному использованию кода и
повышает модульность АСЕ, следующим образом:
• Базовые классы являются отражением общего. Иерархические структу-
ры исключают ненужное дублирование кода, так как базовые классы вы-
ражают общие механизмы, реализуемые в корне иерархии наследования.
Например, интерфейсные фасады АСЕ IPC совместно используют все
механизмы, реализованные сверху, в направлении к корню иерархии на-
следования, например, в базовых классах ACE_IPC_SAP и ACE_SOCK.
Эти механизмы включают методы открытия/закрытия и уСтановки/по-
лучения дескрипторов ввода/вывода нижнего уровня, также как некото-
рые функции управления опциями, которые являются общими для всех
производных классов интерфейсных фасадов.
* Производные классы являются отражением различий. Подклассы, рас-
полагаемые по направлению к листьям иерархии наследования, реализу-
ют специализированные методы, которые настроены на реализуемый
тип связи. Например, подклассы ACE_SOCK обеспечивают и потоковую
и дейтаграммную связь, и локальный и удаленный обмен данными.
А.4.2 Заменяйте псевдонаследование наследованием
в стиле C++
Проблема: Многие API, связанные с С-программированием на системном
уровне, подвержены ошибкам из-за неудовлетворительной иерархии абстрак-
ций. Например, механизмы сетевой адресации Socket API используют С-струк-
256
Приложение A
Рис.А.2
Иерархия адресации АСЕ IPC
туры и приведение типов, предлагая неудобную для работы форму «наследова-
ния» для адресов Internet и UNIX доменов.
Наиболее общей адресной структурой сокетов является sockaddr, кото-
рая определяет псевдо «базовый класс» для задания адресной информации. Ее
первый член указывает на нужное семейство адресов, а второй член—квазине-
прозрачный (quasi-opaque) массив байтов. Конкретные структуры адресного
семейства задают затем адресную информацию, заполняя этот массив байтов.
Такая структура с псевдонаследованием приводит, как следует из изложенного
в разделах 2.3.1 и 3.2, к большому количеству неочевидных ошибок. В частно-
сти, использование приведения типов — в сочетании со слабо типизированны-
ми ориентированными на дескрипторы Socket API — затрудняет компилято-
рам обнаружение ошибок программирования во время компиляции.
Решение => Заменяйте псевдонаследование на наследование C++. Вместо
того, чтобы заставлять разработчиков приложений возиться с приведением и
перегрузкой типов, этот принцип нацелен на использование возможностей
объектно-ориентированного языка программирования C++, Например, в АСЕ
определена иерархия классов ACE_Addr, рассмотренная в разделе 3.2, чтобы
обеспечить типобезопасные интерфейсные фасады для различных форматов
сетевой адресации, таких как адреса Internet и UNIX доменов, каналы STREAM,
файлы и устройства, показанные на рис А.2. Каждый производный класс скры-
вает специфичные для данного семейства адресов детали за общим API.
А.5 Скрывайте, где только можно,
платформенные различия
Разработка многоплатформенных программ преподносит множество про-
блем разработчикам классов, так как функциональные возможности платформ
могут сильно отличаться. Эти отличия часто принимают одну из следующих
форм:
• Отутствует и не может быть реализована — Некоторые платформы
просто не предоставляют той возможности, которая имеется на других
Принципы проектирования интерфейсных фасадов АСЕ на C++
257
платформах; например, на некоторых платформах отсутствует концеп-
ция зомби (из главы 8), поэтому там нет возможности появления зомби и
нет необходимости предлагать способ борьбы с появлением зомби.
• Отсутствует, но может быть эмулирована — Некоторые платформы не
предоставляют возможности, которая имеется на других платформах, но
предоставляют достаточно других функциональных возможностей для
эмуляции той, которая отсутствует, например, условная переменная и
блокировки «читатели/писатель», рассмотренные в главе 10, на платфор-
мах некоторых ОС эмулируются.
• Отсутствует, но существует другая, не менее хорошая, возможность —
Некоторые платформы не предоставляют какой-то возможности, такой
как Socket API, но предоставляет эквивалентную возможность, такую как
TLI. В других случаях, могут существовать обе возможности, но одна из
платформенных реализаций больше подходит, чем другая. Например,
одна из них может быть более производительной или иметь меньше не-
достатков.
В данном разделе описано, что делать в таких ситуациях, чтобы в итоге по-
лучить набор классов C++, которце позволяют без особых проблем разрабаты-
вать переносимые сетевые приложения.
А.5.1 Дайте возможность исходному коду
скомпоноваться по оптимальному варианту
Проблема: Функциональные возможности платформ иногда отличаются
в такой степени, что интерфейсные фасады не способны скрыть эти отличия.
Например, интерфейсный фасад не может, как по волшебству, создать семан-
тику потоков ядра, если это не входит в состав функциональных возможностей
данной платформы. Вот проблема, которую должен решить создатель классов:
нужно ли создавать класс, в котором отсутствует метод (или совокупность ме-
тодов), соответствующий этой возможности?
Программа, которая переносится на большое количество платформ, в ко-
нечном счете, столкнется с такой, в которой какая-то важная функция не под-
держивается. Первая реакция на эту проблему — отказ от создания класса или
метода класса, соответствующего этой функции. Заставить компилятор обна-
ружить эту проблему во время компиляции. Это правильное решение в том
случае, если отсутствующая возможность имеет первостепенное значение для
данного приложения. Например, способность создавать новый процесс являет-
ся основополагающей возможностью для многих сетевых приложений. Если
платформа не поддерживает многозадачность, то лучше узнать об этом во вре-
мя компиляции. Возможны, однако, случаи, в которых приложению лучше
дать возможность поработать и «пореагировать» на любые возможные пробле-
мы во время выполнения. В режиме выполнения можно опробовать альтерна-
тивные подходы.
Решение => Дать возможность исходному коду скомпоноваться цо опти-
мальному варианту. Существуют ситуации, в которых лучше дать возмож-
258
Приложение A
ность исходному коду скомпилироваться без ошибок, даже тогда, когда функ-
циональные возможности, к которым этот код пытается получить доступ, от-
сутствуют и не могут быть эмулированы. Это может быть полезно вот по каким
причинам:
• Способность обнаружить проблему во время выполнения и дать воз-
можность приложению выбрать альтернативный план действия. Этот
случай часто возникает в проекте библиотеки классов, так как разработ-
чики не могут предвидеть все ситуации, в которых данный класс может
использоваться. В таких случаях, возможно, лучший вариант реализо-
вать метод, который возвращает вызывающей стороне сообщение «не
поддерживается» («not implemented»). Тогда вызывающая сторона сво-
бодна выбрать другой метод или возможность, сообщить об ошибке и
попробовать продолжить выполнение или завершиться. В АСЕ опреде-
лен макрос с названием ACE_NOTSUP_RETURN, который служит этой
цели.
• Игнорирование отсутствующей возможности дает тот же эффект, что
и ее наличие. Для этого случая, рассмотрим приложение UNIX, которое
использует метод ACE_Process_Options: : avoid_zombies (), что-
бы избежать появления процессов зомби. Если это приложение перено-
сится на Win32, то там не существует понятия процесса-зомби. В этом
случае, совершенно приемлемо вызвать метод avoid_zombies () и по-
лучить сообщение об успешном завершении, так как исходным намере-
нием этого метода и было завершить выполнение ничего не сделав.
А.5.2 Эмулируйте отсутствующие возможности
Проблема: Из-за большого диапазона возможностей и стандартов, реали-
зованных в современных компьютерных платформах, между ними часто суще-
ствует расхождение в наборе функциональных возможностей. При переносе на
новую платформу, это расхождение порождает некоторую область недостаю-
щих функциональных возможностей, на которые проект полагался на преды-
дущей платформе. Тщательный анализ концепций, на которых базируются эти
возможности, однако, часто выявляет альтернативные возможности, которые
могут быть объединены с целью эмуляции недостающих функциональных
возможностей.
Вопреки распространенному представлению, стандарты не являются пана-
цеей для переносимых программ. Существует огромное множество стандартов
и платформ, реализующих различные наборы стандартов, часто изменяющие-
ся от версий к версии ОС. Даже в рамках стандарта бывает так, что некоторые
возможности являются необязательными. Например, семафор и класс плани-
рования в реальном времени являются необязательными составляющими
Pthreads.
Работа по перенесению на новую платформу программы, разработанной
для другой платформы, или ряда платформ, часто показывает, что те возмож-
ности, которые использует программа, отсутствуют на новой платформе. Вне-
Принципы проектирования интерфейсных фасадов АСЕ на C++
259
сение изменений, с целью компенсировать отсутствующую возможность, мо-
жет привести к Вол новому эффекту (ripple effect) всего проекта. Однако если
тщательно проанализировать возможности новой платформы, то можно най-
ти такие, которые, если их объединить, можно использовать для эмуляции от-
сутствующей возможности. Поэтому, если проект использует C++ классы ин-
терфейсных фасадов разумно, то можно избежать дорогостоящих изменений
проекта и кода.
Решение => Эмулируйте отсутствующие возможности. Классы, спроекти-
рованные в соответствии с паттерном Wrapper Facade могут инкапсулировать
собственные возможности платформы удобными и типобезопасными спосо-
бами. Они могут также содержать код, который использует существующие воз-
можности платформы для эмуляции некоторых отсутствующих возможно-
стей. Например, следующий код на C++ показывает как ACE-классы условной
переменной и мьютекса могут быть использованы для реализации интерфейс-
ного фасада семафора с областью действия на уровне процесса для тех плат-
форм ОС, на которых его реализация отсутствует.
class ACE_Thread_Semaphore
!
private:
ACE_Thread_Mutex mutex_; // Сериализует доступ.
// Ждет когда <count_> примет ненулевое значение.
ACE_Condition_Thread_Mutex count_nonzero_;
u_long count_; // Следит за счетчиком семафора.
u_long waiters_; // Следит за количеством ожидающих.
public:
ACE_Thread_Semaphore (u_int count = 1)
: count_nonzero_ (mutex_), // Связывает мьютекс и условие.
count_ (count),
waiters_ (0) {}
Обратите внимание как инициализатор count_nonzero_ связывает объ-
ект mutex_ с самим собой, в соответствии с принципом явного связывания
объектов, представляющих собой единое целое, рассмотренным в разделе А.3.4.
Метод acquire () блокирует вызывающий поток до тех пор, пока счетчик
семафора станет больше, чем 0, как показано ниже.
int acquire () {
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, mutex_, -1);
int result = 0;
// Считает число ожидающих, чтобы мы могли сообщить
// им в <release()>.
waiters_++;
// Переводим вызывающий поток в состояние ожидания семафора.
while (count_ == 0 && result == 0)
// Освобождаем и вновь запрашиваем <mutex_>
260
Приложение A
result = count_nonzero_.wait ();
--waiters_;
if (result == 0) —count_;
return result;
)
Для полноты картины мы приводим ниже реализацию метода release ()
класса ACE_Thread_Semaphore, который инкрементирует счетчик семафо-
ра, потенциально блокируя поток, ждущий условной переменной со-
unt_nonzero_.
int release () {
ACE_GUARD_RETURN (ACE_Thread_Mutex, guard, mutex_, -1);
// Сообщаем ожидающим, что семафор свободен,
if (waiters_ > 0) count_nonzero_.signal ();
++count_;
return 0;
)
// ... Остальные методы опущены ...
};
Обратите внимание как оба метода acquire () и release () класса
ACE_Thread_Semaphore используют макрос ACE_GUARD_RETURN (описа-
ние которого приведено в блоке 22), который инкапсулирует идиому Scoped
Locking [SSRBOO], чтобы обеспечить автоматическую блокировку и освобожде-
ние mutex_. Такой дизайн — это еще один пример принципа простоты ис-
пользования в наиболее общих случаях применения (рассмотренном в разделе
А.З).
А.5.3 Управляйте изменчивостью с помощью
параметризованных типов
Проблема: Сетевым приложениям и промежуточному слою часто прихо-
дится работать на самых разных платформах, которые сильно отличаются и по
возможностям ОС и по эффективности. Например, платформы могут иметь
разные сетевые API: одни имеют Sockets, но не имеют TLI, другие наоборот.
Точно так же, реализации этих API на разных платформах могут быть более
или менее эффективными. При написании повторно используемых программ
в такой гетерогенной среде, должны быть учтены следующие факторы:
• Разным приложениям нужны разные формы стратегий промежуточного
слоя, например, разные механизмы синхронизации или IPC. Добавление
новых или улучшенных стратегий должно быть непосредственным.
В идеале, каждая функция или класс приложения должны ограничивать-
ся одной копией, чтобы избежать несоответствия версий.
Принципы проектирования интерфейсных фасадов АСЕ на C++
261
* Механизм, выбранный для внесения изменений должен не слишком вли-
ять на производительность времени выполнения. В частности, наследо-
вание и динамическое связывание могут привести к дополнительным из-
держкам во время выполнения из-за косвенного характера обращения
к виртуальным методам [HLS97].
Решение =» Управляйте изменчивостью с помощью параметризованных
типов, а не через наследование или динамическое связывание. Параметризо-
ванные типы делают приложения независимыми от конкретных стратегий, та-
ких как API синхронизации или IPC и не вносят дополнительных издержек во
время выполнения. Хотя параметризованные типы могут увеличить издержки
времени компиляции и компоновки, после компиляции они дают обычно эф-
фективный код [BjaOO].
Например, инкапсуляция Socket API в классы C++ (а не в автономные
С-функции) способствует повышению переносимости, допуская массовую за-
мену механизмов сетевого программирования с помощью параметризованных
типов. Следующий код иллюстрирует этот принцип путем применения мето-
дов порождающего (generative) [СЕОО] и обобщенного (generic) [ AleOl] про-
граммирования для модификации echo_server () таким образом, что он
становится шаблоном C++ функции.
template <class ACCEPTOR>
int echo_server (const typename ACCEPTOR::PEER ADDR &addr)
{
// Фабрика соединений.
ACCEPTOR acceptor;
// Объект передачи данных.
typename ACCEPTOR::PEER_STREAM peer_stream;
// Объект адреса однорангового процесса.
typename ACCEPTOR::PEER_ADDR peer_addr;
int result - 0;
// Инициализируем сервер в пассивном режиме и принимаем
// новое соединение.
if (acceptor.open (addr) != -1
&& acceptor.accept (peer_stream, &peer_addr) != -1) (
char buf[BUFSIZ];
for (size_t n; (n = peer_stream.recv (buf, sizeof buf))
> 0;)
if (peer_stream.send_n (buf, n) != n) (
result = -1;
break;
I
peer_stream.close ();
)
return result;
262
Приложение A
Используя шаблоны АСЕ и C++, приложения могут быть написаны так,
чтобы они были прозрачно параметризуемыми интерфейсными фасадами
C++ Socket или TLI, в зависимости от свойств базовой платформы ОС:
//В зависимости от условия выбираем механизм IPC.
#if defined (USEJSOCKETS)
typedef ACE_SOCK_Acceptor ACCEPTOR;
#elif defined (USE_TLI)
typedef ACE_TLI_Acceptor ACCEPTOR;
#endif /* USE_SOCKETS. ♦/
int driver_function (u_short port_num)
{
H ...
// Вызываем <echo_server()> с соответствующим сетевым API.
// Обратите внимание на использование характеристик (traits)
// шаблона для <addr>.
typename ACCEPTOR::PEER_ADDR addr (port_num);
echo_server<ACCEPTOR> (addr);
)
Эта методика работает по следующим соображениям:
• C++ классы интерфейсных фасадов АСЕ Socket и TLI предлагают объект-
но-ориентированный интерфейс с общей сигнатурой. В тех случаях, ко-
гда интерфейсы изначально не согласованы, чтобы сделать их такими,
можно применить паттерн Adapter [GHJV95], как показано в разделе
А.3.3.
• Шаблоны C++ поддерживают согласование типов по сигнатурам, при
котором, чтобы охватить все потенциальные функциональные возмож-
ности, параметры типов не нужны. Вместо этого, шаблоны параметризу-
ют код приложения, который спроектирован -таким образом, что вызы-
вает только подмножество методов, таких как open (), close (),
send() и recv ().
Вообще, параметризованные типы являются менее агрессивными и более
расширяемыми, чем возможные альтернативы, такие как реализация несколь-
ких версий функции echo_server () или включение большого количества
директив условной компиляции по всему исходному коду приложения.
А.6 Повышайте эффективность
Принципы проектирования, используемые для высокоуровневых прило-
жений и оболочек GUI, необязательно подходят для низкоуровневых инстру-
ментальных средств сетевого программирования. В частности, как мы покажем
в данном разделе, соображения, связанные с производительностью, препятст-
вуют использованию некоторых языковых возможностей, идиом и паттернов.
Принципы проектирования интерфейсных фасадов АСЕ на C++
263
А.6.1 Повышайте эффективность интерфейсных
фасадов
Проблема: Несмотря на годы успешных внедрений, в отдельных областях
применения существует устойчивое представление, что объектно-ориентиро-
ванные методы и C++ не подходят для систем критичных к произвЬдительно-
сти. Например, динамическое связывание и такие возможности объектно-ори-
ентированных языков программирования как обработка исключений, могут
быть проблематичны во встроенных приложениях реального времени, кото-
рые требуют прогнозируемого отклика в реальном времени, небольшого вре-
мени ожидания и последействия. Однако во многих прикладных областях, тре-
бующих работы в реальном времени, таких как аэрокосмические приложения,
обработка вызовов, управление процессами и распределенное, интерактивное
моделирование, гибкий и переносимый промежуточный слой инфраструкту-
ры хоста может принести пользу. Поэтому важно, чтобы объектно-ориентиро-
ванные программы, предназначенные для этих областей применения были
спроектированы так, чтобы исключить те возможности языка и паттерны, ко-
торые вносят дополнительные издержки производительности.
Решение => Повышайте эффективность интерфейсных фасадов. В АСЕ
для обеспечения эффективности его интерфейсных фасадов используются сле-
дующие методы:
• Многие интерфейсные фасады АСЕ представляют собой конкретные
классы; то есть их методы не являются виртуальными. Такой дизайн ис-
ключает издержки, связанные с динамической диспетчеризацией связы-
вания методов, увеличивает возможность подстановки методов и позво-
ляет размещать объекты там где целесообразнее, в общей памяти.
• Все интерфейсные фасады АСЕ IPC содержат в явном виде методы
open () ис1оэе(),аих деструкторы не закрывают дескрипторы. Такой
дизайн предохраняет от неочевидных ошибок, возникающих в том слу-
чае, если дескрипторы ввода/вывода закрываются преждевременно при
передаче по значению от одного объекта другому. В интерфейсных фаса-
дах АСЕ сознательно не используется паттерн Bridge [GHJV95], так как
это связано с динамическим выделением памяти и не повышением, а
снижением эффективности. Вместо этого, принцип, который мы приме-
няем в АСЕ, заключается в том, чтобы не выполнять некоторые типы не-
явных операций классов, расположенных выше в иерархии. Лучше, эти
возможности, если нужно, обеспечат абстракции более высоких уровней.
Например, класс 'Logging_Server в разделе 4.4.1, закрывает дескрип-
тор сокета-акцептора в своем деструкторе, что на этом уровне абстрак-
ции является обычной практикой.
264
Приложение A
А.6.2 Подставляйте методы, критичные к времени
выполнения
Проблема: Интерфейсные фасады повышают переносимость и типовую
безопасность существующих С API за счет создания дополнительного уровня
абстракции. Однако если реализация интерфейсных фасадов неэффективна,
вряд ли разработчики сетевых приложений станут их использовать вместо при-
вычных сетевых С API. Сетевые приложения чувствительны ко времени вы-
полнения. Уже сама сеть обостряет эти проблемы. Так как системные вызовы
ОС часто находятся на критичных к времени выполнения участках процессов,
разработчики сетевых приложений стремятся избегать любых издержек, ухуд-
шающих производительность.
Решение => Подставляйте методы критичные к времени выполнения,
чтобы свести к минимуму или исключить любые непроизводительные издерж-
ки, являющиеся результатом повышения типовой безопасности. В АСЕ широ-
ко используется такая возможность языка C++ как подстановка, чтобы избе-
жать издержек, связанных с вызовом методов, возникающих из-за наличия
в АСЕ дополнительных уровней абстракции, в том числе уровня адаптации
к ОС и интерфейсных фасадов C++. Методы в критичных по времени ветвях
выполнения, такие как методы recv () и send () класса ACE_SOCK_Stream
заданы в виде подставляемых функций C++. Подстановка является эффектив-
ным средством и по времени, и по объему, так эти методы являются небольши-
ми (1-2 строки на метод). Кроме того, виртуальные методы используются рас-
четливо, в критичных ко времени выполнения участках АСЕ, так как многие
оптимизирующие компиляторы C++ не полностью исключают издержки, свя-
занные с виртуальными методами [HLS97].
А.6.3 Избегайте обработки исключений
в инструментальных средствах системного
уровня
Проблема: Опытные C++ программисты заметят, что определения классов
на всем протяжении книги и в АСЕ не содержат спецификаций исключитель-
ных ситуаций. На первый взгляд это может показаться недостатком, так как об-
работка ошибочных ситуаций в цепи вызовов может оказаться сложной и явля-
ется основным мотивом создания в C++ механизмов обработки исключитель-
ных ситуаций. Однако с использованием встроенной в C++ обработки
исключений в инструментальных средствах системного уровня, связано две
проблемы:
1. Переносимость—работа над АСЕ началась в 1991 году, задолго до того, как
исключения были включены в стандарт C++. Даже сегодня, компиляторы
не являются унифицированными относительно поддержки исключитель-
ных ситуаций, а все конечные пользователи .не могут перейти на новые
компиляторы из-за зависимости от уже существующих решений. Так как
библиотека АСЕ должна работать на многих платформах со многими ком-
Принципы проектирования интерфейсных фасадов АСЕ на C++
265
пиляторами, любая зависимость от языковых механизмов исключений мо-
жет стать препятствием для ее переносимого использования в некоторых
средах.
2. Производительность — Непроизводительные издержки времени и памя-
ти, вносимые многими компиляторами, неприемлемы для некоторых ти-
пов приложений. Например, дополнительный объем памяти и затраты
времени, связанные со встроенной в язык обработкой исключений являют-
ся недопустимо высокими для приложений реального времени во встроен-
ных системах. Поэтому, даже если платформа поддерживает обработку ис-
ключений, встроенные приложения и приложения реального времени, воз-
можно, не смогут ее использовать.
Решение => Избегайте обработки исключительных ситуаций в инстру-
ментальных средствах системного уровня. АСЕ не вызывает исключительных
ситуаций по причинам, изложенным выше. Для передачи внутренней инфор-
мации о статусе ошибки между портами исходящего и входящего вызовов
в АСЕ используется паттерн Thread-Specific Storage [SSRBOO]. Этот паттерн по-
зволяет осуществлять последовательные операции внутри потока для автома-
тического доступа к общим данным без дополнительных затрат на блокировку
При каждом обращении. Помещая информацию об ошибке в локальную па-
мять потока, каждый поток может выполнять надежную установку и тестиро-
вание статуса операций в рамках этого потока, без использования дополни-
тельных блокировок или сложных протоколов синхронизации.
Для тех систем, которым нужно использовать исключения в своих при-
кладных программах, АСЕ можно скомпилировать с поддержкой встроенной
обработки исключений C++. На платформах, использующих предварительно
скомпонованную библиотеку АСЕ, просто добавьте exceptions=l к команд-
ной строке или к файлу platf orm_macros . GNU.
А.7 Резюме
В этом приложении изложены принципы проектирования, которым следу-
ет АСЕ для достижения поставленной цели: реализовать преимущества проме-
жуточного слоя инфраструктуры хоста, рассмотренные в разделе 0.3.1. Некото
рые из этих принципов хорошо известны тем, кто знаком с порождающим
(generative) программированием [CE00], но вряд ли широко известны всем се-
тевым программистам. Другие принципы изложены в более общем виде в опи-
сании паттерна Wrapper Facade в [SSRBOO]. Благодаря продуманным и прове-
ренным временем фундаментальным принципам проектирования, заложен-
ным в АСЕ, эта библиотека является гибким, мощным и переносимым
инструментальным средством, которое помогает в тысячах проектов избежать
ловушек, связанных со «случайной» сложностью, рассмотренной в этой книге.
Приложение В
Прошлое, настоящее
и будущее АСЕ
Краткое содержание
В данном приложении приведена краткая история АСЕ, объясняющая про-
исхождение и эволюцию открытых исходных текстов этой инструментальной
библиотеки за последнее десятилетие. Потом мы перечисляем стандартное ПО
промежуточного слоя, основанное на АСЕ и поставляемое с АСЕ. Заканчиваем
мы соображениями о том, в каком направлении, с нашей точки зрения, будет
развиваться АСЕ в будущем.
ВЛ Эволюция АСЕ
Эрик Реймонд (Eric Raymond), пионер движения за открытые исходные
тексты [O'R98], любит повторять, что «Любая хорошая программа начинается
с удовлетворения собственной потребности разработчика» [RayOl]. Хотя это и
не всегда так, для АСЕ это полностью соответствует действительности. В этом
разделе излагается эволюция АСЕ—от истоков, в качестве средства, упрощаю-
щего жизнь отдельного исследователя, до одного из наиболее переносимых и
широко используемых инструментальных средств сетевого программирова-
ния на C++ в мире.
В.1.1 Собственная потребность
В 1990 году Даг Шмидт (Doug Schmidt) прервал свою исследовательскую ра-
боту в University of California, Irvine (UCI), связанную с получение докторской
степени, ради работы в Кремниевой долине (Silicon Valley) в начинающей ком-
пании Independence Technologies Inc. (ITI), которая в конечном счете была при-
обретена компанией BEA Systems, Inc. ITI специализировалась на оперативной
268
Приложение В
обработке транзакций (OLTP) в UNIX-системах; в 1990 г. это было новинкой.
Именно в ITI на Дата оказала большое влияние классическая книга Ричарда
Стивенса (Richard Stevens) UNIX Network Programming («Программирование се-
тевых приложений в UNIX»), которую Даг впитал и постарался применить
к разработке инструментальных средств промежуточного слоя OLTP, написан-
ных на С и C++.
В 1991 г. Даг вернулся в UCI, чтобы закончить работу над диссертацией, по-
священной параллельной обработке данных с использованием сетевых прото-
колов [SS95]. Цель его докторской диссертации заключалась в разработке и оп-
тимизации A Dynamically Assembled Protocol Transformation, Integration, and e Valu-
ation Environment (ADAPTIVE)1 [SBS93]. ADAPTIVE обеспечила настраиваемые
упрощенные и адаптивные машины протоколов, которые помогли улучшить
сквозную производительность приложений и снизить издержки транспортной
системы [SS93].
В начале 1990-х существовало два досадных источника «случайной» слож-
ности, связанной с созданием системного ПО, такого как ADAPTIVE:
1. Код протоколов в ADAPTIVE был написан с помощью методов объект-
но-ориентированного проектирования и C++. Однако при обращении
к ресурсам ОС, таким как процессы, потоки, блокировки, сокеты, общая па-
мять, библиотеки DLL и файлы, необходимо было возвращаться к API, со-
стоящим из С-функций и процедурному стилю проектирования.
2. Один и тот же «стереотипный» код приходилось писать снова и снова при
решении задач сетевого программирования общего характера, таких как
установление соединений, демультиплексирование и диспетчеризация
синхронных событий, синхронизация и архитектуры параллелизма.
Среда ADAPTIVE Communication Environment (АСЕ)2 была создана, чтобы
решить эти две проблемы. Первая общедоступная версия АСЕ появилась
в 1992 г. и работала на SunOS 4.x и 5.x. Приблизительно 10 тыс. строк ее кода
объединяли возможности C++, передовые механизмы ОС и паттерны, чтобы
обеспечить расширяемое и эффективное инструментальное средство для раз-
работки объектно-ориентированного сетевого программного обеспечения.
Если бы Даг не выпустил АСЕ на основе модели распространения открытых
исходных Текстов, то, возможно, АСЕ постепенно сошла бы на нет после того,
как он закончил свою докторскую диссертацию. К счастью, Даг многие годы
участвовал в работе сообщества в поддержку открытого программного обеспе-
чения, написал GNU GPERF генератор хэш-функций [Sch90] и отдельные части
библиотеки GNU LIBG++ вместе с Дагом Ли (Doug Lea) [Lea88]. Поэтому ему
были известны преимущества объединения специалистов [SP01 ] для совмест-
ной работы над инструментальными средствами на основе открытых исходных
текстов. Основным достоинством моделей разработки на основе открытых ис-
ходных текстов является то, что они подходят для работы с большими коллек-
тивами пользователей, когда разработчики приложений и конечные пользова-
Динамически компонуемая среда преобразования, интеграции и апробации протоколов. —
Прим. ред.
Адаптивная коммуникационная среда. — Прим. ред.
Прошлое, настоящее и будущее АСЕ
269
тели могут принять участие в большой работе, связанной с проверкой качества,
документированием и сопровождением.
В.1.2 Решающий момент
К 1994 г. развитие АСЕ достигло той-точки, когда библиотека использова-
лась в нескольких десятках коммерческих проектов, включая управление сетя-
ми Ericsson (SS94] и Indium [SchOO]. В то время Даг стал доцентом Washington
University, St. Louis. Этот переход совпал со всплеском коммерческого интереса
к использованию промежуточного слоя в качестве вспомогательного средства
для улучшения переносимости и гибкости сетевых приложений.
Среда АСЕ была неплохо позиционирована для того, чтобы суметь исполь-
зовать первую волну интереса к промежуточному слою. В результате, Даг и его
исследовательская группа в Washington University получили финансирование
от многих предусмотрительных спонсоров, включая ATDesk, BBN, Boeing, Cis-
co, DARPA, Ericsson, Hughes, Icomverse, Iridium, Kodak, Krones, Lockheed Martin,-
Lucent, Motorola, Nokia, Nortel, NSF, Raytheon, SAIC, Siemens MED, Siemens SCR,
Siemens ZT, Sprint и Telcordia. Эти спонсоры осознали, что для них было бы
слишком дорого, как в смысле денежных средств, так и в смысле затрат време-
ни, самостоятельно переоткрывать и переизобретать специализированные ре-
шения проблем, связанных с их основными сетевыми приложениями. К сча-
стью, участники проекта АСЕ, для решения этих проблем, уже определили, за-
документировали и реализовали основные паттерны и каркасы, которые
спонсоры Дага могли применить, чтобы сэкономить на многих трудоемких и
дорогостоящих аспектах разработки и сопровождения своих сетевых приложе-
ний.
За следующие шесть лет почти 7 миллионов долларов спонсорских средств
позволили Дагу нанять множество аспирантов и штатных сотрудников. Мно-
гие из них в течение долгих лет работали в Distributed Object Computing (DOC)
Groups в Washington University в St.Louis, а теперь в UCI, куда Даг вернулся в ка-
честве штатного адъюнкт-профессора факультета электронной и вычисли-
тельной техники. Группы DOC сообща:
1. Значительно расширили возможности АСЕ, которая теперь почти в 25 раз
превышает первоначальный объем и содержит сотни дополнительных
классов и каркасов.
2. Перенесли АСЕ на множество новых платформ ОС/компиляторов, кото-
рые были перечислены в блоке 1.
3. Написали множество статей в журналах и технических отчетов, в которых
приведено описание паттернов и характеристик интерфейсных фасадов и
каркасов инструментальной библиотеки АСЕ. Возможность загружать эти от-
четы с http://www.cs.wustl.edu/~schmicit/publications.htinl
позволила разработчикам во всем мире оценивать область применения и
качество АСЕ, чтобы понять, как ее можно использовать в своих целях.
Члены DOC Group и сообщество пользователей АСЕ стали инструментом
преобразования АСЕ из индивидуального хобби отдельного исследователя
270
Приложение В
в одну из наиболее широко используемых инфраструктур на базе языка C++,
предназначенной для разработки параллельных объектно-ориентированных
сетевых приложений на множестве платформ с разными аппаратными и про-
граммными средствами.
В. 1.3 Преодоление пропасти
В 1996 г. пока Даг и его группа в Washington University работали над версией
АСЕ 3.x, Стив Хьюстон (Steve Huston) занимался тем, что консультировал и раз-
рабатывал сетевые приложения. В одном из проектов ему понадобились сете-
вые программные средства на C++, которые бы удовлетворяли жесткому гра-
фику разработки. Результатом поиска в Web стал АСЕ. К сожалению, АСЕ не
был перенесен на ту платформу, для которой разрабатывался проект (Unix-
ware). Однако проект, без использования тех возможностей, которые предос-
тавлял АСЕ, был обречен, поэтому Стив начал работу по переносу АСЕ на
UnixWare. За время работы по переносу АСЕ на новую платформу, Стив освоил
АСЕ достаточно, чтобы выполнить эту работу, а последующая разработка за-
казной системы заняла меньше времени, чем понадобилось бы Стиву для раз-
работки необходимого сетевого ПО с нуля. Новая система функционировала
эффективно и это достижение стало первым из многих успешных случаев вне-
дрения АСЕ [Gro].
Осознав те преимущества, которые дает применение АСЕ, Стив стал одним
глазом следить за работой DOC Group и списком рассылки АСЕ. Хотя АСЕ не-
прерывно совершенствовалась, ее, все также, использовали, в основном, науч-
но-исследовательские и промышленные опытно-конструкторские группы.
Несмотря на то, что АСЕ была слишком полезной, чтобы оставлять ее исклю-
чительно в руках исследователей, Стив понял, что требуется высококвалифи-
цированная поддержка для того, чтобы АСЕ преодолела пропасть, отделяю-
щую ее от поддержки разработчиками основного коммерческого ПО. Колеса
закрутились к концу 1996 г., середине 1997 г. Стив переименовал свою компанию
в Riverace Corporation (http: //www.riverace.com) и сосредоточил ее дея-
тельность на услугах, связанных с поддержкой в освоении и применении АСЕ.
Сегодня Riverace обеспечивает услуги по технической поддержке и кон-
сультированию, которые помогают компаниям лучше использовать АСЕ в сво-
их опытно-конструкторских работах. Компания продолжает работать над по-
вышением качества АСЕ, как продукта с открытыми исходными текстами,
обеспечивая поддержку на коммерческом уровне, который помогает расши-
рять сферу внедрения АСЕ в разработку корпоративного ПО по всему миру. Те-
перь АСЕ, имеет все достоинства коммерческого ПО, но все ее преимущества
доступны без каких-либо лицензионных отчислений, связанных с использова-
нием или разработкой. В блоке 24 приведена лицензия ПО с открытыми исход-
ными текстами, которую использует АСЕ.
Прошлое, настоящее и будущее АСЕ
271
Блок 24: Лицензия открытого исходного кода АСЕ
Лицензия АСЕ. как открытого ПО, похожа на так называемую BSD UNIX лицен-
зию ПО с открытыми исходными кодами. Пользователи могут свободно исполь-
зовать, модифицировать, копировать и распространять, без ограничения сро-
ка и без возможности отмены этого соглашения, исходный код АСЕ и объект-
ный код, созданный с использованием исходного кода АСЕ, также как
копировать и распространять модифицированные версии этого ПО. В частно-
сти, АСЕ можно использовать в патентованном ПО и пользователи не обязаны
распространять любые исходные коды, которые были скомпонованы с АСЕ
или разработаны на основе АСЕ. Вся информация о лицензировании АСЕ и ко-
пирайте находится в файле $ace_root/copying в пакете АСЕ.
В.1.4 Стандарты промежуточного сдоя
Ближе ко второй, половине 1990-х гг., стало ясно, что информационные
технологии превращаются в потребительский товар; то есть в предсказуемые и
постоянно сокращающиеся сроки, основные аппаратные и программные сред-
ства становились быстрее, дешевле и лучше. В прошедшее десятилетие все мы
выиграли от того, что аппаратура, такая как процессоры, запоминающие уст-
ройства, сетевые компоненты, например IP-маршрутизаторы, стала потреби-
тельским товаром. В наше время многие программные средства и компоненты
также превращаются в потребительский товар, благодаря развитию следую-
щих стандартов:
• Языков программирования, таких как Java и C++.
• Операционных сред, такие как POSIX и виртуальные машины Java.
• Промежуточного слоя, например, CORBA, Enterprise Java Beans и Web-
службы .NET [SS01 ].
Результатом превращения этих программных продуктов в товар является
то, что отрасли промышленности, которые долгое время были защищены вы-
сокими порогами вхождения в них, такие как телекоммуникационная и аэро-
космическая отрасли, стали более уязвимы для разрушительных технологий
[Chr97] и глобальной конкурентной борьбы, что может снизить цены до уров-
ня маргинальной стоимости.
Как только Даг понял, что долгосрочный успех в индустрии ПО зависит от
освоения удобных открытых стандартов, он начал два сопутствующих проекта,
которые сосредоточились на преобразовании исследований, связанных с АСЕ
в открытые стандарты промежуточного слоя. Данный раздел излагает резуль-
таты этих сопутствующих работ, которые привели к созданию двух, основан-
ных на стандартах, инструментальных средств промежуточного слоя — ТАО и
JAWS — приведенных на рис. В.1. ТАО и JAWS были разработаны, как изложе-
но ниже, с использованием интерфейсных фасадов и каркасов АСЕ.
272
Приложение В
Объект I
(сервант) |
out агдо * return value
Singtalon
Strategy
Rckiw Froiictoc
I'O Slreu$y
Framework
in ага*
o----------►
Клиент operation ()
ЮР
Ядро ОС
Ядро ОС
Active Object
Strategy
Pipes «nd Fillers
Piotocoi pipelMo
Ргжтипмгк
Cooournency
S»*ugy
FramMrorit
(1)The ACE ORB (TAO)
(2) JAWS Adaptive Web Server (JAWS)
< IOL-ГЛ [ORBiun-Hrne ______
( стабы J рланирошдик) Л • реального времени
Ядро ORB реального
времени
Сменные
протоколы
ORB &
XPORT
адаптер
Asyccluuom Солфйюп Token
Semico Configurator
moirw
{СхрапОн
btm видом
Рис. ВЛ
Промежуточный слой на базе АСЕ, совместимый со стандартами
The АСЕ ORB (TAO)
TAO — это высокопроизводительная реализация спецификации CORBA
| SLM98], работающая в реальном времени. Она включает возможности сетево-
го интерфейса, ОС, сетевого протокола и промежуточного слоя CORBA, пока-
занных на рис. В.1 (I). Многие паттерны, используемые в ТАО, описаны
в [SC00]. Как и АСЕ, ТАО является открытым ПО, которое можно свободно за-
грузить с URL http://асе.есе.uci.edu/TAO.
Работа DOC Group над ТАО, сыграла важную роль в разработке нескольких
стандартов:
• ТАО оказал влияние на спецификацию OMG CORBA реального времени
[ObjOl], особенно в том, что касается явного связывания и возможности
переносимой синхронизации.
• ТАО был включен в DII СОЕ1 в качестве одного из двух ORB, отобранных
для архитектуры Joint Tactical Architecture (JTA) агентства DISA2.
• 'ГАО был использован в качестве основы для стандарта распределенного
интерактивного моделирования DMSO HLA/RTI [OSLN99].
Сегодня ТАО используется в сотнях научно-исследовательских и коммер-
ческих проектов в аэрокосмической области, в телекоммуникациях, моделиро-
вании, здравоохранении, научных расчетах и финансовых операциях по всему
миру. Его отличает то, что он является первым CORBA ORB успешно полетав-
Defense Information Infrastructure Common Operating Environment — общее операционное
окружение оборонной информационной инфраструктуры (США, D1SA). — Прим. ред.
Defence Information System Agency — агентство по оборонным информационным системам
(США). — Прим. ред.
Прошлое, настоящее и будущее АСЕ
273
шим в истребительной авиации [Lac98]. TAO поддерживается OCI (http:
I /www. theaceorb. com), на основе лицензии открытого ПО и бизнес моде-
ли, аналогичной компании Riverace.
JAWS Adaptive Web Server (JAWS)
JAWS является высокопроизводительным, адаптивным web-сервером
[HS99], который создан с применением каркасов АСЕ. Он является реализацией
спецификации HTTP 1.0. На рис. В. 1 (2) показаны главные структурные компо-
ненты и паттерны в JAWS. Структура JAWS представляет собой каркас каркасов
(framework of frameworks). Общий каркас JAWS содержит следующие компо-
ненты и каркасы:
• Concurrency strategies (стратегии параллелизма) реализуют механизмы
параллелизма, такие как поток-на-соединение и пул потоков, которые
могут выбираться адаптивно во время выполнения или предварительно
во время инициализации;
• I/O strategies (стратегии ввода/вывода) реализуют различные механиз-
мы ввода/вывода, такие как асинхронный, синхронный и взаимно-согла-
сованный (reactive) ввод/вывод;
• Event dispatcher (диспетчер событий) координирует обработку событий
между вводом/выводом JAWS и стратегиями параллелизма;
• Protocol handlers (обработчики протоколов) реализуют синтаксический
анализ и обработку НТТР-запросов;
• Protocol pipeline (конвейер протоколов) позволяет легко включать опе-
рации фильтрации в состав данных, обрабатываемых обработчиками
протоколов;
• Cached virtual filesystem (кэшируемая виртуальная файловая система)
улучшает производительность web-сервера путем снижения издержек,
связанных с обращениями к файловой системе с использованием страте-
гий кэширования, таких как least recently used (LRU), замещение элемента
с наиболее давним использованием, и least frequently used (LFU), замеще-
ние наименее часто используемого элемента.
Структура каждого из этих каркасов представляет собой совокупность
взаимодействующих объектов, реализованную путем объединения и расшире-
ния компонентов АСЕ. Описание паттернов, составляющих JAWS, приведено
в [SSRBOO]. Также как АСЕ и TAO, JAWS используется во многих коммерческих
проектах. Он также является открытым ПО — распространяемым с пакетом
АСЕ в каталоге $ ACE_ROOT / apps /.
Библиотека АСЕ является основой успеха ТАО и JAWS. Более того, техно-
логический процесс был синергическим. Например, процесс реализации и по-
вторного разложения на классы [FBB+99] ТАО и JAWS привел к созданию мно-
гих новых классов, а также к переопределению и оптимизации многих классов
и каркасов АСЕ.
274
Приложение В
В.1.5 Влияние открытых исходных кодов
Сообщество открытых исходных кодов АСЕ включает тысячи разработчи-
ков и конечных пользователей. Без их поддержки вряд ли АСЕ смогла бы дос-
тичь тех успехов, которых она достигла, по следующим причинам:
Отсутствие достаточных капиталовложений. Более 100 человеко-лет тру-
да было затрачено на разработку АСЕ+ТАО. Полагая, что каждый человеко-год
стоит обычной компании около 200 тыс. долларов США на оклад и льготы, эта
работа потребовала бы около 20 миллионов долларов финансирования при
традиционной модели разработки с закрытыми исходными кодами. Спонсо-
рам групп DOC разработка АСЕ+ТАО обошлась в треть этой суммы. Большая
часть разницы была возмещена временем и работой сообщества специалистов,
работавших над открытыми исходными кодами АСЕ+ТАО.
Отсутствие быстрого возмещения инвестиций. АСЕ потребовалось не-
сколько лет, чтобы достичь той степени развития, когда ее можно было исполь-
зовать в производственных системах. Создание многих каркасов АСЕ, например,
потребовало множества итераций для определения подходящих API, паттернов
и связей между ними. Немногие компании или. венчурные предприниматели
захотели бы инвестировать в проект промежуточного слоя на столь длительное
время, особенно если конечный результат раздавался бы даром!
Недостаток времени, интереса и доступных платформ. Разработка высоко
переносимого промежуточного слоя требует большого объема «черновой» ра-
боты, типа проверки того, что программа компонуется и работает без ошибок
на множестве компиляторов и платформ ОС. Даже если основная группа разра-
ботчиков имеет достаточно времени и интереса (что не соответствует действи-
тельности в хронически недофинансируемых высококвалифицированных науч-
но-исследовательских коллективах), было бы недопустимо дорогим удовольст-
вием приобретать все необходимые для работы аппаратно-программные
платформы, и все это содержать. К счастью, модель разработки с открытым ис-
ходным кодом позволила группам DOC использовать огромные человеческие
и вычислительные ресурсы, имеющиеся в Web, чтобы обеспечить выполнение
большой «черновой» работы с экономией времени и материальных ресурсов
(SPOIL
Недостаточно широкая техническая экспертиза. АСЕ значительно выиг-
рала благодаря распространению ПО и участию экспертов в области промежу-
точного слоя по всему миру. Даг в свое время участвовал в проектах GNU С и
C++ в конце 1980-х вместе с пионерами движения за открытое ПО, такими как
Ричард Столмен (Richard Stallman), Даг Ли (Doug Lea) и Майкл Тиманн (Michael
Tiemann). Поэтому когда он начал разработку АСЕ, он понимал ценность соз-
дания сообщества технических экспертов для развития и поддержки возмож-
ностей программного инструментального средства.
Как только первая работающая версия АСЕ была завершена в 1991 г. она
стала доступна по анонимному ftp — HTTP и Web, как известно, тогда еще не
существовало. Благодаря этому сразу же образовался небольшой коллектив
пользователей, помогавших исправлять ошибки и переносить АСЕ на новые
Прошлое, настоящее и будущее АСЕ
275
платформы, повышая, таким образом, ценность этого ПО — термина «откры-
тый исходный код» (open source) тогда тоже еще не существовало!
В.2 Дорога в будущее
Что касается АСЕ, то мы планируем работать в будущем по следующим на-
правлениям:
Улучшение документации. Отсутствие в АСЕ исчерпывающей документа-
ции, которую было бы легко использовать, отчасти препятствует успешному
внедрению самой АСЕ. Большая, многогранная работа по решению этой про-
блемы уже ведется, и она будет оставаться в центре внимания в будущем. В 2000
г. Карлос О’Райен (Carlos O'Ryan) и Даррелл Бранш (Darrell Brunsch) возглави-
ли в UCI работу по преобразованию генератора справочных материалов АСЕ
в Doxygen [DimOl]. Doxygen обеспечивает более выразительное описание пра-
вил пользования АСЕ, а результирующие справочные материалы гораздо легче
использовать. Улучшенный справочный материал и предстоящая публикация
книг The АСЕ Programmer's Guide [HJS] и C++ Network Programming, Volume 2:
Systematic Reuse with ACE and Frameworks [SH] помогут гораздо большему числу
разработчиков на C++ использовать возможности и гибкость АСЕ наилучшим
образом.
Новые и обновленные платформы. Мы продолжим улучшать и расши-
рять АСЕ с целью поддержки новых версий тех операционных систем, которые
уже включены в АСЕ. Будут рассматриваться новые платформы, в первую оче-
редь, в соответствии с интересами и потребностями коллектива пользователей
АСЕ и клиентов Riverace. Будет также расширяться способность АСЕ использо-
вать возможности C++. АСЕ работает с большинством компиляторов C++. По
мере того, как идет время, и все большее число компиляторов поддерживает
стандарт C++, диапазон поддерживаемых АСЕ компиляторов будет не расши-
ряться, а смещаться. Такой вариант развития позволит АСЕ использовать но-
вые возможности стандарта C++, такие как встроенная обработка исключений,
частичная специализация шаблонов (partial template specialization), функции-
члены шаблонов (template member functions) и стандартная библиотека C++
(Standard C++ Library).
Повышение надежности. В АСЕ имеется большой набор тестов регрессив-
ных испытаний, которые работают постоянно, каждый день, на множестве плат-
форм. Эти тесты автоматически обнаруживают ошибки компиляции, ошибки
конфигурации, ошибки времени выполнения и ошибки при работе с памятью.
В любой момент времени вы можете проследить за статусом АСЕ, ознакомив-
шись с результатами этих регрессионных тестов на http://ace.ece.uci.edu/sco-
reboard/. Так как АСЕ представляет собой программный продукт большого
объема, мы будем расширять его регрессионные испытания, чтобы гарантиро-
вать, что его качество и надежность продолжают улучшаться.
Уменьшение необходимого объема памяти. Объем ядра библиотеки АСЕ
колеблется в диапазоне от 700КВ до 1.5МВ на платформах наиболее распростра-
ненных ОС, но требует значительно большего объема памяти при компоновке
276 Приложение В
со всей отладочной информацией. В некоторых, средах, особенно во встроен-
ных системах с ограниченным объемом памяти [NW01], объем памяти, зани-
маемый АСЕ может стать помехой. Поэтому мы уже начали работу, которая по-
зволит использовать при компоновке только те части АСЕ, которые требуются
приложениям, снижая соответственно необходимый объем памяти, который
теперь будет определяться не всей библиотекой АСЕ, а только той ее частью, ко-
торую использует приложение. Дополнительную информацию о работе по
разделению АСЕ на части смотрите в файле $ACE_ROOT/docs /АСЕ-sub-
sets . html в программном пакете АСЕ.
Сообщите нам, если вы хотите принять участие в этих проектах!
В.З Заключительные замечания
В последние десятилетие мы работали по многим направлениям, связан-
ным с исследованиями и разработкой сетевых приложений, от чисто теорети-
ческих академических исследований до разработки конкретных продуктов и
консультирования. Из нашего опыта следует, что наиболее действенный спо-
соб внедрения возможностей передовых методов, связанных с исследованием и
разработкой программного обеспечения, в разработку основного коммерче-
ского ПО это:
1. Разрабатывать высококачественное повторно используемое ПО, основан-
ное на самых современных результатах исследования систем.
2. С самого начала работать с пользователями своего продукта с целью его
внедрения в приложения, связанные с решением реальных задач.
3. Обеспечивать коммерческую услуги и поддержку, чтобы содействовать пе-
реходу на новые методы и их освоению разработчиками серийного ПО.
Значительные внедрения в коммерческие рынки редко происходят раньше,
чем исследователи продемонстрируют преимущества своих методов на реаль-
ных операционных системах. Полное отделение технологии от исследований,
тем не менее, может сдерживать работу, связанную с передовыми исследова-
ниями и разработками, которая нужна для улучшения и расширения новых
технологий. Тесное сотрудничество исследовательских и коммерческих групп
помогает сочетать опережающее развитие продукта с плавным вхождением
в серийное производство. Совместная «коммерческо-академическая» работа,
как в случае с Riverace и DOC Group, требует терпения и коллективной работы,
чтобы сохранить то лучшее, что есть в каждой из этих областей деятельности.
Достигнутые результаты могут стать достаточным вознаграждением всем уча-
стникам команды, а также пользователям, которые от такого сотрудничества
только выигрывают.
Словарь терминов
ЛИ (Application
Programming Interface)
Callback-объект (callback)
CORBA
Internet
Intranet
LFU (Least Frequently Used)
LRU (Least Recently Used)
Unicode
Абстрактный класс
(abstract class)
Активное ожидание (busy
wait)
Активный объект (active
object)
Алгоритмическая деком-
позиция (algorithmic
decomposition)
Анализ предметной облас-
ти (domain analysis)
Архитектура автономных
приложений (stand-alone
application architecture)
Архитектура сетевых при-
ложений (networked
application architecture)
Интерфейс прикладного программирования. Внешний ин-
терфейс программной платформы, например, операци-
онной системы, который используется реализованными
на этой платформе системами или приложениями.
Объект, зарегистрированный у диспетчера, осуществ-
ляющего обратный вызов метода этого объекта в момент
наступления определенного события.
Архитектура общего посредника (брокера) объектных
запросов (Common Object Request Broker Architecture,
CORBA), стандарт распределенного объектного проме-
жуточного слоя вычислительных систем, разработанный
Object Management Group (OMG).
Всемирная «сеть сетей», основанная на протоколе IP (Inter-
net ProtocoQ. Рассматривается многими как самое значи-
тельное изобретение человечества после огня и MTV.
Компьютерная сеть внутри компании или иной организации.
Такая сеть может быть защищена от доступа извне и обес-
печивает платформу для обмена информацией, совместной
работы и документооборота в пределах компании, исполь-
зуя технологии Internet для обмена информацией.
Стратегия кэширования, при которой в первую очередь
замещается наименее часто используемый элемент.
Стратегия кэширования, при которой в первую очередь
замещается наиболее давно использовавшийся элемент.
Стандарт представления символов, который включает ал-
фавиты большинства письменных языков, а также знаки
пунктуации, математические и другие символы.
Класс, в котором отсутствует реализация определенных
в его интерфейсе методов. Абстрактный класс определя-
ет общий интерфейс производных классов.
Используемый потоком способ ожидания снятия блоки-
ровки, который заключается в зацикливании потока и в вы-
полнении проверки снятия блокировки на каждой итера-
ции цикла, в отличие от ожидания снятия блокировки пу-
тем перехода в пассивный режим (sleeping), что дает
возможность продолжать выполнение другим потокам.
Объект, который является реализацией паттерна Active
Object (ср. Пассивный объект).
Парадигма проектирования, в соответствии с которой
разбиение программ осуществляется по функционально-
му принципу.
Индуктивный, управляемый обратными связями процесс,
связанный с системным исследованием проблемной об-
ласти, с целью определения основных проблем и аспек-
тов проектирования, чтобы, опираясь на них, создать эф-
фективные методы решения.
Архитектура, которая требует, чтобы все ресурсы и ком-
поненты автономного приложения находились на одном
компьютере. Этому компьютеру для выполнения приложе-
ния не нужны другие компьютеры.
Архитектура, способствующая использованию программ-
ных компонентов и ресурсов, которые могут располагать-
ся в любом узле распределенной системы и использо-
ваться для выполнения сетевых приложений.
278
Программирование сетевых приложений на C++. Том 1
Асинхронный ввод/вывод
(asynchronous I/O)
Аспекты (aspects)
Барьерная синхронизация
(barrier synchronization)
Блок управления памятью
(MMU, memory
management unit)
Блокировка (lock)
Блокировка «читатели/пи-
сатель» (readers/writer lock)
Брокер объектных запро-
сов (Object Request Broker,
ORB)
Виртуальная машина
(virtual machine)
Виртуальная память (virtual
memory)
Волновой эффект (rippie
effect)
Время ожидания (latency)
Голодание (starvation)
Механизм передачи данных, при котором инициировав-
шая операцию ввода-вывода сторона не приостанавли-
вает свою работу и не ждет завершения операции вво-
да/вывода.
Качественные характеристики программы, такие как
управление памятью, синхронизация, отказоустойчивость,
которые выходят за границы модулей.
Механизм синхронизации потоков, который позволяет за-
данной группе потоков синхронизировать свою работу
в тот момент, когда каждый из этих потоков достигает неко-
торого состояния, например, завершения общей опера-
ции или задачи. «Барьер» представляет собой особую tO4-
ку в выполняемой ветви. Каждый поток, достигающий барь-
ерной точки (барьера) ждет, когда другие потоки также
достигнут этой точки. После того как все потоки заданной
совокупности достигают барьера, барьер «падает» и все
потоки одновременно продолжают свое выполнение.
MMU защищает адресные пространства автономных про-
цессов от случайного или злонамеренного разрушения
другими активными процессами системы.
Механизм, используемый для реализации разновидности
критической секции. Блокировка, которую можно перио-
дически занимать и освобождать, например, статический
мьютекс (static mutex), может быть включена в состав
класса. Если множество потоков пытается одновременно
занять блокировку, сможет это сделать только один, а все
остальные будут блокированы до момента снятия блоки-
ровки. Другие механизмы блокировки, такие как семафо-
ры или блокировки типа «читатели/писатель» (readers/wri-
ter), определяют другую логику синхронизации.
Блокировка, которая позволяет нескольким потокам осу-
ществлять параллельный доступ к ресурсу, но изменять
этот ресурс в каждый данный момент времени может
только один поток, при этом другим потокам и параллель-
ный доступ, и внесение изменений запрещается.
Один из иерархических уровней промежуточного слоя,
который позволяет клиентам вызывать методы распреде-
ленных объектов, не заботясь о расположении объекта,
языке программирования, платформе операционной сис-
темы, сетевых протоколах или аппаратных средствах.
Абстрактный посредник, который предлагает набор ус-
луг приложениям более высокого уровня или другим вир-
туальным машинам.
Механизм операционных систем, позволяющий разработ-
чикам создавать приложения, адресное пространство ко-
торых больше, чем объем физической памяти компьютера.
Феномен необходимости внесения изменений, вызванных
побочными эффектами предыдущих изменений. Образ
расходящихся кругов от камня, брошенного на неподвиж-
ную поверхность озера.
Задержка выполнения операций.
Риск сбоя при выделении процессорного времени, кото-
рый происходит тогда, когда один или несколько потоков
постоянно вытесняются потоками с более высоким при-
оритетом и не выполняются вообще.
Словарь терминов
279
Групповое вещание
(multicast)
Дейтаграмма (datagram)
Демаршалинг
(demarshaling)
Демон (daemon)
Демультиплексирование
(demultiplexing)
Дескриптор (handle)
Динамическое связывание
(dynamic binding)
Домен (domain)
Запись-со-слиянием
(gather-write)
Зомби (zombie)
Идиома (Idiom)
Идиома Scoped Locking
(Scoped Locking Idiom)
Инверсия приоритетов
(priority Inversion)
Интеллектуальный указа-
тель (smart pointer)
Интерфейс (Interface)
Сетевой протокол который позволяет отправителю ра<
циональным образом передавать сообщения группе по-
лучателей (ср. Однонаправленная передача).
Автономный, независимый блок данных, в котором доста-
точно информации, чтобы проложить маршрут от хос-
та-источника к хосту-приемнику, независимо от предыду-
щих операций обмена данными между указанными хоста-
ми или в сети в целом.
Преобразование данных, подвергнутых маршалингу, из
стандартного (host-independent) формата, независимого
от хоста, во внутренний (host-specific) формат хоста.
Серверный процесс, постоянно работающий в фоновом ре-
жиме и оказывающий различные услуги по запросу клиентов.
Механизм доставки входных данных из порта ввода к полу-
чателям, которым они предназначены. Между входным
портом и получателями существует связь 1:N. Демультип-
лексирование обычно применяется к входящим событиям
и потокам данных. Обратная операция называется мулти-
плексированием.
Дескриптор — это идентификатор ресурсов, управляе-
мых ядром операционной системы. Эти ресурсы обычно
включают, помимо прочего, сетевые соединения, откры-
тые файлы, таймеры и объекты синхронизации.
Механизм, который откладывает ассоциацию имени опе-
рации (сообщение) с соответствующим кодом (метод) до
времени выполнения. Используется при реализации поли-
морфизма в объектно-ориентированных языках.
Домен в Internet—это элемент системы доменной адре-
сации, например, ucl.edu или rlverace.com.
Операция вывода, которая одной операцией передает
содержимое множества независимых буферов данных.
Процесс, который завершен, но продолжает занимать
место в таблице процессов. Зомби остается в этом со-
стоянии до получения рт него родительским процессом
статуса завершения.
Идиома—это низкоуровневый паттерн, характерный для
языка программирования. Идиома описывает способ реа-
лизации отдельных аспектов компонентов или взаимосвя-
зей между ними, используя возможности данного языка.
Идиома C++, которая гарантирует, что блокировка будет
переведена в состояние «занят» при вхождении потока
управления в область действия (scope) и автоматически
освобождена при выходе из этой области действия, неза-
висимо от пути выхода.
Сбой системы планирования, который происходит тогда,
когда поток или запрос с более низким приоритетом бло-
кирует выполнение потока или запроса с более высоким
приоритетом.
Интеллектуальный указатель является объектом C++, кото-
рый выглядит и действует как обычный указатель, но может
выполнять некоторые дополнительные действия, которые
обычные указатели не поддерживают, например, кэши-
рование, долговременное хранение или доступ к локаль-
ной памяти потока.
Общедоступная часть класса, компонента или подсистемы.
280
Программирование сетевых приложений на C++. Том 1
Интерфейс транспортного
уровня (Transport Layer
Interface, TLI)
Интерфейсный фасад
(wrapper facade)
Каркас (framework)
Качество обслуживания
(Quality of Service, QoS)
Клиент (client)
Компонент (component)
Конечная точка (endpoint)
Конкретизация (reify)
Конкретный класс
(concrete class)
Критическая секция
(critical section)
Критическая точка (hot
spot)
Кеши данных и команд
(data and Instruction
caches)
Линеаризация (linearization)
Люк (escape hatch)
TLI представляет собой набор вызовов функций, преду-
смотренный в System V UNIX и используемый сетевыми
приложениями для установления соединений и обмена
данными через соединенные конечные точки транспорт-
ного уровня.
Один или несколько классов, которые инкапсулируют
функции и данные внутри типобезопасного объектно-ори-
ентированного интерфейса.
См. Объектно-ориентированный каркас.
Совокупность политик и механизмов, созданных для улучше-
ния связи и управления ее характеристиками, такими как по-
лоса пропускания, время ожидания и флуктуации (jitter).
В этой книге «клиент» — это роль, исполняемая компонен-
том или подсистемой, которые вызывают или используют
функции, реализуемые другими компонентами.
Инкапсулированная часть программных средств, реали-
зующая определенный сервис или совокупность серви-
сов. Компонент имеет один или несколько интерфейсов,
которые обеспечивают доступ к его сервисам. В конст-
рукции системы компоненты являются строительными бло-
ками. На уровне языка программирования компоненты
могут быть представлены в качестве модулей, классов,
объектов или совокупности взаимосвязанных функций.
Компонент, в котором отсутствует реализация элементов
его интерфейса, называется абстрактным.
Точка подключения соединения.
Акт создания конкретного экземпляра некоторой абст-
рактной сущности. Например, конкретная реализация
«реактора» (reactor) конкретизирует паттерн Reactor, а
объект конкретизирует класс.
Класс, на основе которого могут быть созданы экземпляры
объектов. В отличие от абстрактных классов, в конкретном
классе присутствует реализация всех методов. Данный
термин используется для того, чтобы отличить конкретные
производные классы от их абстрактных суперклассов.
Программный код, который не должен выполняться в неко-
тором объекте параллельно, или с помощью критической
секции можно синхронизировать подсистему. Критиче-
ская секция — это последовательность команд, которая
подчиняется следующему неизменному правилу: пока
один поток или процесс выполняется в критической сек-
ции, ни один другой поток или процесс не могут выпол-
няться в этой критической секции.
Часто выполняющийся участок программного кода (обыч-
но небольшой).
Специальная быстродействующая память, соединенная
с процессором (CPU), которая способна улучшить об-
щую производительность системы.
Процесс маршалинга данных со сложной структурой
(richly typed), таких как массивы, списки или графы, в ли-
нейный буфер памяти.
Средство, позволяющее использовать некоторое систем-
ное свойство таким способом, который непредусмотрен
разработчиками.
Словарь терминов
281
Маршалинг (marshaling)
Межпроцессное взаимо-
действие (Interprocess
Communication, IPC)
Механизм синхронизации
(synchronization mechanism)
Мьютекс (mutex)
Наследование (inheritance)
Ненадежный транспортный
протокол (unreliable
transport protocol)
Нерекурсивный мьютекс
(nonrecurslve mutex).
Номер порта (port number)
Обеспечивающий под-
держку исключений
(exception safe)
Область состязаний
(contention scope)
Область состязаний на
уровне процесса
(process-scope contention)
Область состязаний на
уровне системы
(system-scope contention)
Обобщенное представле-
ние данных (Common Data
Representation, CDR)
Преобразование набора данных из внутреннего
(host-specific) формата хоста в стандартный
(host-independent) формат.
Обмен данными между процессами, располагающимися
в отдельных адресных пространствах. Примеры механиз-
мов IPC включают общую память, каналы UNIX, очереди
сообщений и связь через сокеты.
Механизм блокировки, координирующий порядок выпол-
нения потоков.
Мьютекс — механизм блокировки типа «взаимное исклю-
чение» (mutual exclusion), который гарантирует, что в дан-
ный момент времени только один поток является одновре-
менно активным внутри критической секции, чтобы избе-
жать состояния гонок.
Свойство объектно-ориентированных языков, которое по-
зволяет создавать новые классы на базе существующих.
Наследование определяет повторное использование
реализаций, взаимосвязь подтипов, или и то, и другое.
В зависимости от языка программирования возможно еди-
ничное или множественное наследование.
Транспортный протокол, который не дает гарантии дос-
тавки передаваемых данных; данные могут быть никогда
не доставлены, доставлены не в той последовательности
или доставлены несколько раз.
Мьютекс, который должен быть освобожден прежде, чем
он будет вновь занят любым потоком. Ср. Рекурсивный
мьютекс.
16-битовый номер, который используется для идентифика-
ции конечной точки соединения в TCP протоколе.
Компонент обеспечивает поддержку исключительных си-
туаций, если исключение вызванное в данном компоненте
или переданное от компонента, вызванного данным ком-
понентом, не приводит к утечкам ресурсов или к неустой-
чивому состоянию.
Домен (domain), в котором потоки конкурируют за обла-
дание ресурсами (например, процессорным временем).
См. Область состязаний на уровне процесса и Область
состязаний на уровне системы.
Политика параллелизма, в соответствии с которой область
состязаний (scope of contention) или синхронизации пото-
ков ограничена процессом, выполняющимся на некотором
хосте (ср. Область состязаний на уровне системы).
Политика параллелизма, при которой область состязаний
и синхронизации потоков находится на уровне процессов
хоста, (ср. Область состязаний на уровне процесса)
Стандартный формат, определенный в CORBA, для выпол-
нения маршалинга и демаршалинга данных. Он использу-
ет каноническое представление «приемник упорядочива-
ет», которое заключается в том, что дополнительная обра-
ботка проводится только тогда, когда порядок байтов,
принятый отправителем отличается от порядка байтов,
принятого получателем.
282 Программирование сетевых приложений на C++. Том 1
Обобщенное программи- рование (generic programming) Методика программирования, объединяющая паттерны проектирования и параметризованные типы C++, что дает разработчикам возможность создавать выразительный, гибкий, эффективный программный код специально при- способленный для повторного использования.
Общая память (shared memory) Механизм операционной системы, который позволяет не- скольким процессам, работающим на компьютере, со- вместно использовать общий сегмент памяти (ср. Переда- ча сообщений).
Общие службы промежу- точного слоя (common middleware services) Этот уровень иерархии промежуточного слоя определяет службы, независящие от области применения, например, уведомление о событиях, регистрация, организация муль- тимедийных потоков данных, долговременность, безопас- ность, привязка к глобальному времени, планирование в реальном времени и управление распределенными ре- сурсами, отказоустойчивость, управление параллельным выполнением операций и обратимые транзакции,—кото- рые выделяют, планируют и координируют различные ре- сурсы всей распределенной системы.
Объектно-ориентирован- Объединенная группа классов, совместно обеспечиваю-
ный каркас (object-oriented щая архитектуру повторно используемого программного
framework) обеспечения для семейства родственных приложений. В объектно-ориентированном окружении каркас состоит из абстрактных и конкретных классов. Создание экземп- ляра такого каркаса заключается в композиции сущест- вующих классов и в создании на их основе производных классов.
Однонаправленное веща- ние (unicast) Сетевой протокол, который позволяет отправителю пере- давать сообщения одному получателю (ср. Групповое ве- щание).
Одноранговое взаимодей- ствие (peer-to-peer) В распределенной системе одноранговые приложения являются процессами, взаимодействующими друг с дру- гом. В отличие от компонентов в архитектуре клиент-сер- вер, одноранговые приложения могут действовать как кли- енты, как серверы, или как и те, и другие, а также могут менять свои роли в динамике.
Односторонний вызов ме- тодов (one-way method Invocation) Отложенное завершение (deferred cancelation) Вызов метода, который передает параметры серверному объекту, но не получает от сервера никаких результатов. (Ср. Двусторонний вызов методов). Механизм завершения потоков, в соответствии с которым завершение откладывается до того момента, когда поток, который должен быть завершен, сам проверяет наличие отложенных сигналов на завершение, которые следует выполнить.
Параллелизм (parallelism) Способность объекта, компонента или системы выполнять операции, которые являются «физически одновременны- ми» (ср. Параллельное выполнение).
Параллельное выполнение (concurrency) Способность объекта, компонента или системы выполнять «логически одновременные» (logically simultaneous) опе- рации (ср. Параллелизм).
Параметризованный тип (parameterized type) Особенность языка программирования, которая позволя- ет классам быть параметризованными другими различны- ми типами (ср. Шаблон)
Пассивный объект (passive object) Объект, который заимствует поток у вызывающего процес- са для выполнения своих методов (ср. Активный объект).
Словарь терминов
283
Паттерн (pattern)
Паттерн
Acceptor-Connector
(Acceptor-Connector
pattern)
Паттерн Active Object
(Active Object pattern)
Паттерн Component
Configurator (Component
Configurator pattern)
Паттерн Double-Checked
Locking Optimization
(Double-Checked Locking
Optimization pattern)
Паттерн
Hatf-Sync/Half-Async
(Haff-Sync/Half-Async
pattern)
Паттерн Leader/Foflower»
(Leader/Followers pattern)
Паттерн Monitor Object
(Monitor Object pattern)
Паттерн Pipet and Filter»
(Pipes and Filters pattern)
Паттерн Proactor (Proactor
pattern)
Паттерн Reactor (Reactor
pattern)
Паттерн представляет собой описание некоторой повто-
ряющейся проблемы проектирования, возникающей
в конкретных проектных ситуациях, и предлагает хорошо
апробированное положительное решение этой пробле-
мы. Спецификация этого решения включает описание
структуры компонентов, их функций, взаимосвязей и спо-
собов взаимодействия.
Паттерн проектирования, разделяющий подключение и
инициализацию взаимодействующих одноранговых сер-
висов сетевой системы и обработку, которую они осуще-
ствляют после подключения и инициализации.
Паттерн проектирования, разделяющий выполнение и вы-
зов метода, с целью повышения параллелизма и упроще-
ния синхронного доступа к объектам, которые принадле-
жат разным потокам управления.
Паттерн П|эоектирования, который позволяет присоеди-
нять и отключать реализации его компонентов во время вы-
полнения, не требуя модификации, повторной компиляции
или статической перекомпоновки приложения.
Паттерн проектирования, который снижает издержки, свя-
занные с состязаниями и синхронизацией каждый раз, ко-
гда критические секции кода должны запрашивать блоки-
ровки безопасным с точки зрения многопоточности спосо-
бом непосредственно во время выполнения программы.
Архитектурный паттерн, который разделяет синхронную и
асинхронную обработку в параллельных системах, чтобы
упростить программирование без значительного сниже-
ния производительности. Этот паттерн вводит два взаимо-
связанных иерархических уровня, один для синхронной и
один для асинхронной сервисной обработки. Уровень
организации очередей служит связующим звеном для
коммуникаций между сервисами синхронного и асин-
хронного уровней.
Архитектурный паттерн, обеспечивающий эффективную
модель параллелизма, в которой множество потоков по
очереди совместно используют множество источников
событий д ля того, чтобы обнаруживать, распределять, ко-
ординировать и обрабатывать запросы на обслуживание,
которые появляются в этих источниках.
Паттерн проектирования, синхронизирующий выполнение
параллельных методов так. чтобы в каждый момент време-
ни внутри объекта выполнялся только один метод. Он так-
же позволяет методам объекта совместно планировать
последовательности их действий.
Архитектурный паттерн проектирования, который обеспечи-
вает структуру для систем, обрабатывающих поток данных.
Архитектурный паттерн, который позволяет приложениям
с управлением по событиям эффективно демультиплекси-
ровать и д испетчеризировать запросы на обслуживание
инициируемые завершением асинхронных операций, что-
бы достичь выигрыша в производительности за счет одно-
временного выполнения операций, избегая некоторых
связанных с этим недостатков.
Архитектурный паттерн, который позволяет приложениям
с управлением по событиям демультиплексировать и дис-
петчеризировать запросы на обслуживание, передавае-
мые приложению от одного или нескольких клиентов.
284 Программирование сетевых приложений на C++. Тем 1
Паттерн Strategized Locking
(Strategized Locking pattern)
Паттерн Thread-Safe
Interface (Thread-Safe
Interface pattern)
Паттерн Thread-Specific
Storage (Thread-Specific
Storage pattern, TSS pattern)
Паттерн проектирования
(design pattern)
Передача сообщений
(message passing)
Планировщик (scheduler)
Платформа (platform)
Паттерн проектирования, который осуществляет парамет-
ризацию механизмов синхронизации, защищающих кри-
тические секции компонентов от параллельного доступа.
Паттерн проектирования, минимизирующий издержки
блокировки и гарантирующий, что вызов методов внутри
компонента не приведет к самоблокировке
(self-deadlock) из-за попытки повторно занять блокировку,
которая уже занята этим компонентом.
Паттерн проектирования, который позволяет множеству
потоков использовать одну «логически глобальную»
(logically global) точку доступа для извлечения локального
объекта одного из потоков, не приводя к дополнительным
издержкам на блокировку при каждом доступе к объекту.
Паттерн проектирования предлагает схему усовершенст-
вования компонентов программной системы или взаимо-
связей между ними. Он представляет собой описание
наиболее часто применяемой структуры взаимодейст-
вующих компонентов, которая решает одну из общих про-
блем проектирования в некотором конкретном контексте.
Механизм IPC, используемый для обмена сообщениями
между потоками или процессами (ср. Общая память).
Механизм, который определяет порядок обработки пото-
ков или событий.
Подстановка (Inlining)
Полоса пропускания
(bandwidth)
Порождающее програм-
мирование (generative
programming)
Потери переключения
(domain-crossing penalty)
Сочетание аппаратных и программных средств, исполь-
зуемых при создании системы. Программные платформы
включают операционные системы, библиотеки и каркасы
(frameworks). Платформа реализует виртуальную машину,
на которой выполняются приложения.
Способ оптимизации во время компиляции, который заме-
няет вызов функции или метода телом программы функции
или метода. Подстановка тела функции/метода большого
объема может привести к «раздуванию» кода, с сопутст-
вующими негативными последствиями, связанными с по-
треблением памяти и подкачкой.
Пропускная способность передающей среды, напри-
мер, сети или шины.
Методика программирования, нацеленная на разработку
и реализацию программных компонентов, которые могут
объединяться с целью создания (порождения)4 специали-
зированных и высоко оптимизированных систем, удовле-
творяющих специфическим требованиям.
Потеря производительности, которая происходит, когда
вызовы системных функций приводят к переключению из
режима пользовательский приложений в режим ядра. До-
полнительно к прерыванию, связанному с переключени-
ем в привилегированный режим доступа, операции вво-
да/вывода часто требуют копирования данных в область
памяти, отведенную приложениям, и из нее, что также уве-
личивает задержку.
I
По аналогии с порождающими грамматиками (generative grammar). — Прим, ред.
Словарь терминов
285
Поток (thread)
Поток-на-соединение
(thread-per-connectlon)
Поток-на-запрос
(thread-per-request)
Потокобезоласный
(thread-safe)
Предметная область
(domain)
Прикладные службы про-
межуточного слоя
(Domain-specific
Middleware Services)
Промежуточный слой
(middleware)
Независимая последовательность команд которая вы-
полняется в совместно используемом с другими потоками
адресном пространстве. Каждый поток имеет свой собст-
венный стек времени выполнения и регистры, что позволя-
ет ему выполнять синхронный ввод/вывод без блокировки
других параллельно выполняющихся потоков. По сравне-
нию с процессами, потоки поддерживают минимум ин-
формации о состоянии, требуют относительно меньше из-
держек при создании, синхронизации и планировании, и
обычно взаимодействуют с другими потоками с помощью
объектов в области памяти процесса, которому они при-
надлежат, а не через общую память.
Модель параллелизма, которая ассоциирует с каждым
сетевым соединением отдельный поток. Эта модель рас-
сматривает каждого клиента, соединяющегося с серве-
ром, в виде отдельного потока действующего пока суще-
ствует соединение. Такая модель подходит серверам, ко-
торым приходится поддерживать продолжительные
сеансы (session) с множеством клиентов. Но не подходит
клиентам, таким как HTTP 1.0 web-браузеры, которые вы-
полняют каждый запрос в отдельном соединении, им
больше подходит модель логок-на-залрос (thread per
request).
Модель параллелизма, в которой для каждого запроса
создается новый поток. Эта модель подходит серверам,
которым приходится обрабатывать долговременные за-
просы от множества клиентов, например, запросы к базе
данных. Эта модель подходит меньше при краткосрочных
запросах, из-за издержек, связанных с созданием нового
потока для каждого запроса. Эта модель может также по-
треблять большое количество ресурсов операционной
системы, если множество клиентов посылают запросы
одновременно.
Защищенный от любых нежелательных побочных эффектов
(состояний гонок, конфликтов из-за данных и т.д.), порож-
даемых параллельным выполнением одного и того же уча-
стка программы несколькими потоками.
Объединяет концепции, знания и другие элементы, отно-
сящиеся к конкретной проблемной области. Часто ис-
пользуется в сочетании «область применения»
(application domain), чтобы выделить ту проблемную об-
ласть, к которой относится приложение.
Этот уровень иерархии промежуточного слоя реализует
специализированные службы, удовлетворяющие требо-
ваниям конкретных прикладных областей, таких как теле-
коммуникации или электронная коммерция (e-commer-
се). Прикладные службы промежуточного слоя нацелены
на узкоспециализированные вертикальные решения, в от-
личие от более широко и многократно используемых
служб, реализуемых более низкими уровнями в иерархии
промежуточного слоя.
Совокупность уровней и компонентов, которые обеспечи-
вают повторно используемые общие службы и механизмы
сетевого программирования. Промежуточный слой рас-
полагается над операционной системой и ее стеком про-
токолов, но ниже структурных и функциональных состав-
ляющих любого отдельно взятого приложения.
286
Программирование сетевых приложений на C++. Том 1
Промежуточный слой ин-
фраструктуры хоста (host
Infrastructure middleware)
Протокол (protocol)
Протокол IP (Internet
Protocol)
Протокол пользователь-
ских дейтаграмм (User
Datagram Protocol UDP)
Протокол управления пере-
дачей (Transmission Control
Protocol TCP)
Процесс (process)
Пул потоков (thread pool)
Распределение
(distribution)
Распределительный уро-
вень промежуточного слоя
(distribution middleware)
Данный уровень иерархии промежуточного слоя инкапсу-
лирует имеющиеся на хостах механизмы параллельной
обработки и IPC, с целью интеграции возможностей ОО и
сетевого программирования, что исключает многие тру-
доемкие, подверженные ошибкам и непереносимые ас-
пекты, связанные с разработкой сетевых приложений на
базе API ОС, таких как Socket API или Pthreads.
Набор правил, который описывает каким образом осуще-
ствляется обмен сообщениями между взаимодействую-
щими одноранговыми процессами, а таюке синтаксис и
семантику этих сообщений.
Протокол сетевого уровня, который осуществляет фраг-
ментацию, сборку и маршрутизацию пакетов по принципу
«максимального усилия» (best-effort).
Ненадежный транспортный протокол без установления со-
единения, который организует обмен дейтаграммными сооб-
щениями между локальной и удаленной конечными точками..
Транспортный протокол с установлением соединения, ко-
торый обеспечивает надежный, упорядоченный и не дуб-
лируемый обмен байтовыми потоками данных между ло-
кальной и удаленной конечными точками.
Процесс предоставляет ресурсы, такие как виртуальная
память, и возможности защиты, такие как идентификаторы
пользователя/группы и аппаратно защищенное адресное
пространство, которое может использоваться одним или
несколькими потоками процесса. Однако по сравнению
с потоком, процесс поддерживает больше информации о
состоянии, требует больше накладных расходов при соз-
дании, синхронизации и планировании, и часто взаимо-
действует с другими процессами посредством передачи
сообщений или общей памяти.
Модель параллелизма, в которой создается несколько по-
токов, обрабатывающих запросы одновременно. Эта мо-
дель является разновидностью модели поток-на-запрос, со
снижением издержек на создание потоков путем упреж-
дающего порождения пула потоков. Эта модель подходит
серверам, для которых желательно ограничить количество
потребляемых ими системных ресурсов. Запросы клиентов
могут обрабатываться одновременно пока количество од-
новременных запросов не превысит количество потоков в
пуле. С этого момента дополнительные запросы должны до-
жидаться в очередь пока не освободится один из потоков.
Действия, связанные с размещением объекта в другом
процессе или на другом хосте, по отношению к клиентам,
которые к этому объекту обращаются. Распределение
часто применяется, чтобы повысить отказоустойчивость
или с целью улучшения доступа к удаленным ресурсам
(ср. Совмещение).
Этот уровень иерархии промежуточного слоя автоматизиру-
ет решение задач сетевого программирования общего ха-
рактера, таких как: управление соединениями и памятью,
маршалинг и демаршалинг, демультиплексирование дан-
ных и запросов, синхронийация и многопоточность—так, что-
бы разработчики могли программировать распределенные
приложения в значительной степени также, как автономные
приложения, то есть вызывая процедуры целевых объектов,
независимо от их расположения, языка, ОС и аппаратуры.
287
Словарь терминов
Рекурсивный мыотвкс
(recursive mutex)
Рефакторинг (refactoring)
Семафор (semaphore)
Сериализация (serialization)
Синхронный ввод/вывод
(synchronous I/O)
Система (system)
Слабо типизированный
(weakly typed)
Слип-блокировка
(sleep-lock)
Служба (service)
«Случайная» сложность
(accidental complexity)
Собственная сложность
(inherent complexity)
Событие (event)
Блокировка, которая может быть повторно занята потоком,
уже владеющим этим мьютексом, без риска самоблоки-
ровки (self-deadlock) потока. Ср. Нерекурсивный мьютекс.
Последовательно-поступательные действия по абстрагиро-
ванию универсальных функций существующего программ-
ного обеспечения с целью улучшения структуры и повторно-
го использования компонентов и каркасов (frameworks).
Механизм блокировки, использующий счетчик. Пока зна-
чение счетчика больше нуля, любой поток может запро-
сить семафор и не быть заблокированным. Но после того
как счетчик обнуляется, потоки блокируются на этом се-
мафоре до того момента, когда значение счетчика этого
семафора станет больше нуля в результате инкремента
счетчика при освобождении семафора другим потоком.
Механизм, который с целью предотвращения состояния
гонок, гарантирует, что внутри критической секции одно-
временно выполняется только один поток.
Механизм передачи и получения данных, при котором
инициированная операция ввода/вывода приостанавли-
вает работу вызывающего потока на время завершения
этой операции.
Совокупность программных и/или аппаратных средств,
реализующая одну или несколько служб (service). Система
может быть платформой, приложением или и тем, и другим.
Элемент данных, объявленный тип данных которого не
полностью отражает его предполагаемое использование
или целевое назначение.
Вариант синхронизации, при котором поток ждет освобо-
ждения блокировки в режиме ожидания (sleeping), пре-
доставляя другим потокам возможность выполняться (ср.
Спин-блокировка).
В контексте программирования в сетевой среде служба
может быть (1) четко определенной функцией, реализуе-
мой сервером, например, служба echo, предоставляемая
суперсервером inetd, (2) совокупностью возможностей,
предлагаемых сервером-демоном, например, сам супер-
сервер inetd, или (3) совокупность серверных процессов,
взаимодействующих при решении общей задачи, напри-
мер, совокупность демонов rwho в подсети локальной сети
(LAN), которые периодически рассылают широковещатель-
ные пакеты и получают информацию о состоянии с уведом-
лением о действиях пользователей на других хостах.
Сложность, которая является следствием побочных огра-
ничений, накладываемых применяемыми инструменталь-
ными средствами и методами, такими как API, не обеспе-
чивающие типовую безопасность, и процедурное проек-
тирование, используемое при разработке программного
обеспечения в некоторых прикладных областях.
Сложность, являющаяся следствием фундаментальных
свойств предметной области, которые усложняют разра-
ботку приложения (см. «Случайная» сложность).
Сообщение, которое передает информацию о появлении
существенного события, а также все данные, связанные
с этим событием.
288
Программирование сетевых приложений на C++. Том 1
Совместно используемая
библиотека (shared library)
Совместное завершение
(cooperative cancelation)
Совмещение (collocation)
Соединение (connection)
Сокет (socket)
Сокет пассивного режима
(passive-mode socket)
Сокет передачи данных
(data-mode socket)
Сообщение (message)
Состояние гонок (race
condition)
Спин-блокировка
(spin-lock)
Сток протоколов (protocol
stack)
Библиотека, совместно используемая несколькими про-
цессами, подключаемая к адресному пространству про-
цесса и отключаемая от него, динамически, с целью по-
вышения гибкости и расширяемости приложения вр время
выполнения. Известна также как динамически подключае-
мая библиотека (Dynamically Linked Library, DLL).
Механизм завершения потоков, реализованный в АСЕ, по-
средством которого поток, осуществляющий завершение,
требует от одного или нескольких потоков самостоятель-
но завершиться. Предполагается, что указанные потоки
удовлетворят это требование в под ходящий момент, но их
не принуждают это делать.
Действия, связанные с размещением объекта в том же
процессе, или на том же хосте, на котором расположены
клиенты, которые к нему обращаются. Совмещение часто
применяют, чтобы использовать преимущества локальных
ссылок (ср. Распределение).
Полнодуплексная связь, которая используется одноран-
говыми процессами для обмена данными между конечны-
ми точками сетевого приложения.
Многозначный термин, относящийся к программирова-
нию в сетевой среде. Сокет представляет собой конеч-
ную точку соединения, которая задает конкретный сете-
вой адрес и номер порта. Socket API является библиоте-
кой функций, которую поддерживает большинство
операционных систем и которую используют сетевые
приложения для установления соединений и обмена ин-
формацией через конечные точки сокетов. Сокет переда-
чи данных (data-mode socket) может быть использован
для обмена данными между соединенными одноранговы-
ми процессами (peers). Сокет пассивного режима (passi-
ve-mode socket) является фабрикой, которая возвращает
дескриптор присоединенного сокета передачи данных.
См. Сокет.
См. Сокет.
Сообщения используются для обмена информацией между
объектами, потоками или процессами. В объектно-ориенти-
рованной системе термин «сообщение» используется что-
бы описать выбор и активизацию некоторой операции или
метода объекта. Этот тип сообщения является синхронным,
то есть отправитель ждет пока получатель завершит активи-
зированную операцию. Потоки и процессы чаще обменива-
ются информацией асинхронно, то есть отправитель про-
должает свою работу, не дожидаясь ответа получателя.
Состояние гонок представляет собой риск сбоя при Па-
раллельном выполнении, который может произойти, если
несколько потоков выполняются одновременно в непра-
вильно сериализованной критической секции.'
Способ синхронизации, при котором поток ждет снятия бло-
кировки в режиме непрерывного цикла с проверкой снятия
блокировки на каждой итерации, (ср. Слип-блокировка).
Группа иерархически упорядоченных протоколов.
Словарь терминов
289
Строгая очередность (lock-step) Принцип проектирования протоколов, который требует, чтобы на запрос был получен ответ до того, как будет сде- лан следующий запрос.
Типобезопасный (type safe) Свойство, принудительно обеспечиваемое системой ти- пов языка программирования, чтобы гарантировать, что только корректные операции могут быть вызваны при об- ращении к экземплярам типов.
Транспортный уровень (transport layer) Тупик (deadlock) Уровень в стеке протоколов, который отвечает за сквозную (end to end) передачу данных и управление соед инением. Тупик’—это ситуация, связанная с одновременным выполне- нием операций, которая может возникнуть тогда, когда не- сколько потоков пытаются захватить несколько блокировок и попадают в тупик, в состояние бесконечного ожидания.
Управление потоком (flow control) Механизм сетевых протоколов, который предохраняет от- правителя, имеющего высокую скорость передачи, от пе- реполнения буферной памяти и перегрузки вычислитель- ных ресурсов менее мощного получателя.
Уровень (layer) Уровень (level) абстракции, определяющий конкретный набор служб в иерархии. Уровень Ц является потребите- лем услуг уровня 1^., и поставщиком услуг уровню Ц.,.
Условная переменная (condition variable) Условная переменная является механизмом синхрониза- ции, используемым совместно работающими потоками, чтобы временно приостанавливать свою работу до того момента, когда условное выражение, включающее со- вместно используемые этими потоками данные, достигнет заданного значения. Условная переменная всегда ис- пользуется вместе с мьютексом, которым сначала поток должен завладеть, а потом вычислять условное выраже- ние. Если условное выражение принимает значение «ложь» (false), то поток автоматически приостанавливает свою работу на этой условной переменной и освобожда- ет мьютекс, чтобы другие потоки могли изменять совмест- но используемые данные. Когда один из совместно рабо- тающих потоков изменяет эти данные, то он может «уведо- мить» об этом условную переменную, которая атомарно возобновляет работу приостановленного на этой услов- ной переменной потока и снова запрашивает мьютекс.
Установление активного соединения (active connection establishment) Роль, которую играет в установлении соединения одно- ранговое приложение, инициирующее соединение с удаленным партнером (ср. Установление пассивного соединения).
Установление пассивного соединения (passive connection establishment) Роль в установлении соединения, которую играет одно- ранговое приложение, принимая запрос на установле- ние соединения от удаленного однорангового приложе- ния (ср. Установление активного соединения).
Фабрика (factory) Метод или функция, которые создают и монтируют ресур- сы, необходимые для создания и инициализации объекта или экземпляра компонента.
Флуктуации (litter) Стандартное отклонение времени ожидания для серии операций.
Характеристики (traits) Тип, который передает информацию, используемую дру- гим классом или алгоритмом для определения политик или деталей реализации на этапе компиляции.
Хост (host) Компьютер, который подключен к сети и имеет адрес.
Широко используется также термин «взаимоблокировка». — Прим. ред.
290
Программирование сетевых приложений на C++. Тем 1
Цикл обработки событий
(event loop)
Чтение-с-разнесением
(scatter-read)
Шаблон (template)
Шина (bus)
Широковещание
(broadcast)
Экстренные данные
(out-of-band data)
Язык паттернов (pattern
language)
Программная конструкция, которая непрерывно отслежи-
вает и обрабатывает события.
Операция ввода, сохраняющая данные в нескольких пре-
доставляемых вызывающей стороной буферах, а не в од-
ном непрерывном буфере.
Свойство языка программирования C++, которое делает
возможной параметризацию классов и функций различ-
ными типами, константами или указателями на функции.
Шаблон часто называют родовым (generic) или парамет-
ризованным (parameterized) типом.
Высокоскоростной канад связи, соединяющий элементы
вычислительной системы, такие как процессоры, диски и
сетевые интерфейсы.
Широковещание является специальной формой группово-
го вещания (.multicast), в которой сообщения отправителя
передаются всем узлам данного домена.
Данные, которые доставляются вне трафика обычного
байтового потока; известны также как срочные данные
(urgent data).
Семейство взаимосвязанных паттернов проектирования,
которое, на систематической основе, определяет про-
цесс решения проблем проектирования программного
обеспечения.
Англо-русский указатель терминов
abstract class
Acceptor-Connector pattern
accidental complexity
active connection establishment
active object
Active Object pattern
algorithmic decomposition
aspects
asynchronous I/O
bandwidth
barrier synchronization
broadcast
bus
busy wait
callback
client
collocation
Common Data Representation (CDR)
common middleware services
component
Component Configurator pattern
concrete class
concurrency
condition variable
connection
contention scope
cooperative cancelation
critical section
daemon
data and instruction caches
data-mode socket
datagram
deadlock
deferred cancelation
абстрактный класс
паттерн Acceptor-Connector
«случайная» сложность
установление активного соединения
активный объект
паттерн Active Object
алгоритмическая декомпозиция
аспекты
асинхронный ввод/вывод
полоса пропускания
барьерная синхронизация
широковещание
шина
активное ожидание
callback-объект
клиент
совмещение
обобщенное представление данных
общие службы промежуточного слоя
компонент
паттерн Component Configurator
конкретный класс
параллельное выполнение
условная переменная
соединение
область состязаний
совместное завершение
критическая секция
демон
кэши данных и команд
сокет передачи данных
дейтаграмма
тупик
отложенное завершение
292
Программирование сетевых приложений на C++. Том 1
demarshaling
demultiplexing
design pattern
distribution
distribution middleware
domain
domain analysis
domain-crossing penalty
domain-specific middleware services
Double-Checked Locking
Optimization pattern
dynamic binding
endpoint
escape hatch
event
event loop
exception safe
factory
flow control
framework
gather-write
generative programming
generic programming
Half-Sync/Half-Async pattern
handle
host
host infrastructure middleware
hot spot
idiom
inherent complexity
inheritance
inlining
interface
Internet Protocol
демаршалинг
демультиплексирование
паттерн проектирования
распределение
распределительный уровень
промежуточного слоя
предметная область, домен
анализ предметной области
потери переключения
прикладные службы
промежуточного слоя
паттерн Double-Checked Locking
Optimization
динамическое связывание
конечная точка
люк
событие
цикл обработки событий
обеспечивающий поддержку
исключений
фабрика
управление потоком
каркас
запись-со-слиянием
порождающее программирование
обобщенное программирование
паттерн Half-Sync/Half-Async
дескриптор
хост
промежуточный слой
инфраструктуры хоста
критическая точка
идиома
собственная сложность
наследование
подстановка
интерфейс
протокол IP
Англо-руссжий указатель терминов
293
Interprocess Communication (IPC)
jitter
latency
layer
Leader/Followers pattern
linearization
lock
lock-step
marshaling
Memory Management Unit (MMU)
message
message passing
middleware
Monitor Object pattern
multicast
mutex
networked application architecture
nonrecursive mutex
object-oriented framework
Object Request Broker (ORB)
one-way method invocation
out-of-band data
parallelism
parameterized type
passive connection establishment
passive-mode socket
passive object
pattern
pattern language
peer-to-peer
Pipes and Filters pattern
platform
port number
priority inversion
Proactor pattern
process
process-scope contention
межпроцессное взаимодействие
флуктуации
время ожидания
уровень
паттерн Leader/Followers
линеаризация
блокировка
строгая очередность
маршалинг
блок управления памятью
сообщение
передача сообщений
промежуточный слой
паттерн Monitor Object
групповое вещание
мьютекс
архитектура сетевых приложений
нерекурсивный мьютекс
объектно-ориентированный каркас
брокер объектных запросов
односторонний вызов методов
экстренные данные
параллелизм
параметризованный тип
установление пассивного соединения
сокет пассивного режима
пассивный объект
паттерн
язык паттернов
одноранговое взаимодействие
паттерн Pipes and Filters
платформа
номер порта
инверсия приоритетов
паттерн Proactor
процесс
состязания на уровне процесса
294
Программирование сетевых приложений на C++. Тем 1
protocol
protocol stack
Quality of Service (QoS)
race condition
Reactor pattern
readers/writer lock
recursive mutex
refactoring
reify
ripple effect
scatter-read
scheduler
Scoped Locking idiom
semaphore
serialization
service
shared library
shared memory
sleep-lock
smart pointer
socket
spin-lock
stand-alone application architecture
starvation
Strategized Locking pattern
synchronization mechanism
synchronous I/O
system
system-scope contention
template
thread
thread-per-connection
thread-per-request
thread pool
протокол
стек протоколов
качество обслуживания
состояние гонок
паттерн Reactor
блокировка «читатели/писатель»
рекурсивный мьютекс
рефакторинг
конкретизация
волновой эффект
чтение-с-разнесением
планировщик
идиома Scoped Locking
семафор
сериализация
служба
совместно используемая библиотека
общая память
слип-блокировка
интеллектуальный указатель
сокет
спин-блокировка
архитектура автономных
приложений
голодание
паттерн-образец Strategized Locking
механизм синхронизации
синхронный ввод/вывод
система
область состязаний на уровне
системы
шаблон
поток
поток-на-соединение
поток-на-запрос
пул потоков
Англо-русский указатель терминов
295
thread-safe
Thread-Safe Interface pattern
Thread-Specific Storage (TSS) pattern
traits
Transmission Control Protocol (TCP)
transport layer
Transport Layer Interface (TLI)
type safe
unicast
unreliable transport protocol
User Datagram Protocol (UDP)
virtual machine
virtual memory
weakly typed
wrapper facade
zombie
обеспечивающий поддержку
поточности
паттерн Thread-Safe Interface
паттерн Thread-Specific Storage
характеристики
протокол управления передачей
транспортный уровень
интерфейс транспортного уровня
типобезопасный
однонаправленное вещание
ненадежный транспортный протокол
протокол пользовательских
дейтаграмм
виртуальная машина
виртуальная память
слабо типизированный
интерфейсный фасад
зомби
Литература
[ABLL92] Thomas Е. Anderson, Brian N. Bershad, Edward D. Lazowska, and Henry M. Levy.
Scheduler Activation: Effective Kernel Support for the User-Level Management
of Parallelism. ACM Transactions on Computer Systems, pages 53-79, February
1992.
(AGHOO] Ken Arnold, James Gosling, and David Holmes. The Java Programming
Language. Addison-Wesley, Boston, 2000.
(AleO 1 ] Andrei Alexandrescu. Modem C++ Design: Generic Programming and Design
Patterns Applied. Addison-Wesley, Boston, 2001. (Русский перевод: Александ-
реску А. Современное проектирование на C++. Серия C++ In-Depth. — М.:
Вильямс, 2002.)
[AOS+OOJ Alexander В. Arulanthu, Carlos O'Ryan, Douglas C. Schmidt, Michael Kircher,
and Jeff Parsons. The Design and Performance of a Scalable ORB Architecture
for CORBA Asynchronous Messaging. In Proceedings of the Middleware 2000
Conference. ACM/IFIP, April 2000.
(AOSKOO) Alexander B. Arulanthu, Carlos O'Ryan, Douglas C. Schmidt, and Michael
Kircher. Applying C++, Patterns, and Components to Develop an IDL Compiler
for CORBA AMI Callbacks. C++ Report, 12(3), March 2000.
(Au$98] Matt Austern. Generic Programming and the STL: Using and Extending the C++
Standard. Addison-Wesley, Reading, Massachusetts, 1998.
[BA90] M. Ben-Ari. Principles of Concurrent and Distributed Programming. Prentice Hall
International Series In Computer Science, 1990.
[BC94] Arlndam Banerjl and David L. Cohn. Shared Objects and vtbl Placement —
Revisited. Journal of C Language and Translation. 6(1):44-60, September 1994.
[BecOO] Kent Beck. Extreme Programming Explained: Embrace Change.
Addison-Wesley, Boston, 2000.
[BjaOO] Bjarne Stroustrup. The C++ Programming Language. 3е Edition. Addison-Wesley,
Boston, 2000. (Русский перевод: Страуструп Б. Язык программирования C++.
3-е изд.—СПб.: М.: Невский диалект—Бином, 1999.)
(Bla91 ] U. Black. OSI: A Model for Computer Communications Standards. Prentice-Hall,
Englewood Cliffs, New Jersey, 1991.
[BMR+96] Frank Buschmann, Reglne Meunier, Hans Rohnert, Peter Sommerlad. and
Michael Stal. Pattern-Oriented Software Architecture-A System of Patterns. Wiley
and Sons, New York, 1996.
[Boo94] Grady Booch. Object Oriented Analysis and Design with Applications (2a
Edition). Benjamin/Cummings, Redwood City, California, 1994. (Русский пере-
вод: Буч Г. Объектно-ориентированный анализ и проектирование с приме-
рами приложений на C++. 2-е изд. — СПб.: М.: Невский диалект—Бином,
1999.)
[Вох97] Donald Box. Essential COM. Addison-Wesley, Reading, Massachusetts. 1997.
[Bro87] Frederick P. Brooks. No Silver Bullet: Essence and Accidents of Software
Engineering. IEEE Computer. 20(4): 10-19, April 1987.
[But97] David R. Butenhof. Programming with POSIX Threads. Addison-Wesley, Reading,
Massachusetts, 1997.
[CBO1 ] G. Coulson and S. Balchoo. Implementing the CORBA GIOP In a
Hlgh-Perfo|mance Object Request Broker Environment. ACM Distributed
Computlrigdournal, 14(2), April 2001.
(CEOOj Krzysztof Czarnecki and Ulrich Elsenecker. Generative Programming: Methods.
Tools, and Applications. Addison-Wesley, Boston, 2000.
(Chr97j Clayton Christensen. The Innovator's Dilemma: When New Technologies Cause
Great Firms to Fail Harvard Business School Press, Cambridge, Massachusetts,
1997.
298
Программирование сетевых приложений на C++. Том 1
[CS92] Douglas Е. Comer and David L. Stevens. Internetworking with TCP/IP Vol III: Client
— Server Programming and Applications. Prentice Hall, Englewood Cliffs, NJ,
1992.
[DC90] Stephen E. Deering and David R. Cheriton. Multicast routing In datagram
Internetworks and extended LANs. ACM Transactions on Computer Systems,
8(2):85-110, May 1990.
[DlmOl] Dimitri van Heesch. Doxygen. http://www.doxygen.org, 2001.
[EKB+92] J.R. Eykholt, S.R. Kleiman, S. Barton, R. Faulkner, A Shlvallnglah, M. Smith, D. Stein,
J. Voll, M. Weeks, and D. Williams. Beyond Multiprocessing... Multithreading the
SunOS Kernel. In Proceedings of the Summer USENIX Conference. San Antonio,
Texas, June 1992.
(FBB+99] Martin Fowler, Kent Beck, John Brant, William Opdyke, and Don Roberts.
Refactoring—Improving the Design of Existing Code. Addison-Wesley, Reading,
Massachusetts, 1999.
[FJS99a] Mohamed Fayad, Ralph Johnson, and Douglas C. Schmidt, editors.
Object-Oriented Application Frameworks: Applications & Experiences. Wiley &
Sons, New York, 1999.
[FJS99b] Mohamed Fayad, Ralph Johnson, and Douglas C. Schmidt, editors.
Object-Oriented Application Frameworks: Problems & Perspectives. Wiley &
Sons, New York, 1999.
[Fow97] Martin Fowler. Analysis Patterns. Addison-Wesley, Reading, Massachusetts, 1997.
[FS97] Mohamed E. Fayad and Douglas C. Schmidt. Object-Oriented Application
Frameworks. Communications of the ACM. 40(10), October 1997.
(Gal95] Bill Gallmelster. POSIX.4 Programming for the Real World. O'Reilly, Sebastopol,
California, 1995.
[GHJV95] Erich Gamma, Richard Helm, Ralph Johnson, and John Vllssldes. Design Patterns:
Elements of Reusable Object-Oriented Software. Addison-Wesley, Reading,
Massachusetts, 1995. (Русский перевод: Гамма Э., Хелм Р., Джонсон Р., Влис-
сидес Дж. Приемы объектно-ориентированного проектирования. Паттерны
проектирования. — СПб.: Питер, 2001.)
[Gro] DOC Group. АСЕ Success Stories.
http://www.cs.wustl.edu/~schmldt/ACE-users.html.
[GS99] Anlruddha Gokhale and Douglas C. Schmidt. Optimizing a CORBA HOt>
Protocol Engine for Minimal Footprint Multimedia Systems. Journal on Selected
Areas in Communications special Issue on Service Enabling Platforms for
Networked Multimedia Systems. 17(9), September 1999.
[HJS] Stephen D. Huston, James C.E. Johnson, and Umar Syyld. The ACE Programmer's
Guide. Addison-Wesley, Boston (forthcoming).
[HLS97] Timothy H. Harrison, David L. Levine, and Douglas C. Schmidt. The Design and
Performance of a Real-time CORBA Event Service. In Proceedings ofOOPSLA
97. pages 184-199, Atlanta, GA, October 1997. ACM.
[HP91J Norman C. Hutchinson and Larry L. Peterson. The x-kernei: An Architecture for
Implementing Network Protocols. IEEE Transactions on Software Engineering.
17(0:64-76, January 1991.
[HS99] James Hu and Douglas C. Schmidt. JAWS: A Framework for High Performance
Web Servers. In Mohamed Fayad and Ralph Johnson, editors, Domain-Specific
Application Frameworks: Frameworks Experience by Industry. Wiley 8c Sons, New
York, 1999.
[HV99] Michi Henning and Steve Vlnoskl. Advanced CORBA Programming With C++.
Addison-Wesley, Reading, Massachusetts, 1999.
[IEE96] IEEE. Threads Extension for Portable Operating Systems (Draft 10). February 1996.
Литература
299
[JBR99] Ivar Jacobson, Grady Booch, and James Rumbaugh. Unified Software
Development Process. Addison-Wesley Object Technology Series.
Addison-Wesley, Reading, Massachusetts, 1999.
JJM98] Bruce Jacob and Trevor Mudge. Virtual Memory: Issues of Implementation. IEEE
Computer. 31(6):33-43, June 1998.
(JO99] Anthony Jones and Jim Ohlund. Network Programming for Microsoft Windows.
MS Press, 1999.
[Joh97] Ralph Johnson. Frameworks = Patterns + Components. Communications of the
ACM. 40(10), October 1997.
(Joi91 ] David Jordan. Instantiation of C++ Objects In Shared Memory. Journal of
Object-Oriented Programming. March-April 1991.
[Jos99] Nicolai Josuttls. The C++ Standard Library: A Tutorial and Reference.
Addison-Wesley, Reading, Massachusetts, 1999.
(Kha92J Khanna, S., etal. Realtime Scheduling In SunOS 5.0. In Roceedllngs of the USENIX
Winter Conference, pages 375-390. USENIX Association, 1992.
[Klc97] Gregor Klczales. Aspect-Oriented Programming. In Proceedings of the 11th
European Conference on Object-Oriented Programming. June 1997.
[Koe88] Andrew Koenig. C Traps and Pitfalls. Addison-Wesley, 1988.
(Kof9?) Thomas Kofier. Robust Iterators for ET++. Structured Programming. 14(2):62-85,
1993.
[KSS96] Steve Kleiman, Devang Shah, and Bart Smaalders. Programming with Threads.
Prentice Hall, Upper Saddle River, NJ, 1996.
[Lac98] Ralph Lachenmaler. Open Systems Architecture Puts Six Bombs on Target,
http://www.cs.wustl.edu/~schmldt/TAO-boelng.html, December 1998.
[Lea88] Doug Lea. Ilbg++, the GNU C++ Library. In Proceedings of the 1* C++
Conference, pages 243-256, Denver, CO, October 1988. USENIX.
JLea99] Doug Lea. Concurrent Java: Design Principles and Patterns, Second Edition.
Addison-Wesley, Reading, Massachusetts, 1999.
(Lew95J Bil Lewis. Threads Primer: A Guide to Multithreaded Programming. Prentice-Hall,
Englewood Cliffs, NJ, 1995.
[LGSOO] David L. Levine, Christopher D. Gill, and Douglas C. Schmidt. Object Lifetime
Manager—A Complementary Pattern for Controlling Object Creation and
Destruction. C++ Report, 12(1), January 2000.
[Mar64] Herbert Marcuse. One Dimensional Man: Studies In Ideology of Advanced
Industrial Society. Beacon Press, Boston, 1964. •
[MBKQ96] Marshall Kirk McKusIck, Keith Bostic, Michael J. Karels, and John S. Quarterman.
The Design and Implementation of the 4.48SD Operating System. Addison
Wesley, Reading, Massachusetts, 1996.
[Mey96] Scott Meyers. More Effective C++. Addison-Wesley, Reading, Massachusetts,
1996. (Русский перевод: Мейерс С. Наиболее эффективное использование
C++. —М:ДМК, 2000.)
[Mey97j Bertrand Meyer. Object-Oriented Software Construction, Second Edition.
Prentice Hall, Englewood Cliffs, NJ, 1997.
[Moo91] Geoffrey Moore. Crossing the Chasm: Marketing and Selling High-Tech Products
to Mainstream Customers. HarperCollins, New York, 1991.
[MSKSOO] Sumedh Mungee, Nagarajan Surendran, Yamuna Krlshnamurthy, and Douglas
C. Schmidt. The Design and Performance of a CORBA Audlo/VIdeo Streaming
Service. InMahbubur Syed, editor. Design and Management of Multimedia
InformatiatfSystems: Opportunities and Challenges. Idea Group Publishing,
Hershey, PA, 2000.
300
Программирование сетевых приложений на C++. Там 1
[NGSYOO] Balachandran Natarajan, Anlruddha Gokhale, Douglas C. Schmidt, and Shallnl
Yajnlk. Applying Patterns to Improve the Performance of Fault-Tolerant CORBA.
In Proceedings of the T* International Conference on High Performance
Computing (HIPC 2000), Bangalore, India, December 2000. ACM/IEEE.
[NL91 ] Bill Ntlzberg and Virginia Lo. Distributed Shared Memory: A Survey of Issues and
Algorithms. IEEE Computer, pages 52-60, August 1991.
[NW01] James Noble and Charles Weir. Smail Memory Software: Patterns for Systems
with Limited Memory. Addison-Wesley, Boston, 2001.
[ObjOl ] Object Management Group. The Common Object Request Broker: Architecture
and Specification, 2.5 edition, September 2001.
[O'R98] Tim O'Reilly. The Open-Source Revolution. Release 1.0. November 1998.
http;//www.orellly.com/catalog/open$ource$/.
[OSLN99] Carlos O'Ryan, Douglas C. Schmidt, David Levine, and Russell Noseworthy.
Applying a Scalable CORBA Events Service to Large-scale Distributed
Interactive Simulations. In Proceedings of the 5" Workshop an Object-oriented
Real-time Dependable Systems. Montery, CA, November 1999. IEEE.
[Par72] David L. Pamas. On the Criteria To Be Used In Decomposing Systems Into
Modules. Communications of the ACM. 15(12), December 1972.
(POS95J Information Technology—Portable Operating System Interface (POSIX) — Part
1: System Application: Program Interface (API) (C Language), 1995.
[POS+OOj Irfan Pyarali, Carlos O'Ryan, Douglas C. Schmidt, Nanbor Wang, Vishal Kachroo,
and Anlruddha Gokhale. Using Principle Patterns to Optimize Real-time ORBs.
Concurrency Magazine. 8(1), 2000.
[PS90] Adam Porter and Richard Selby. Empirically Guided Software Development
Using Metric-Based Classification Trees. IEEE Software. March 1990.
[PTM97] Jeiica Protic, Milo Tomaevlc, and Veljko Mllutlnovlc. Distributed Shared Memory
Concepts and Systems. IEEE Computer Society Press, 1997.
[Rag9P] Steve Rago. UNIX System V Network Programming. Addison-Wesley, Reading,
Massachusetts, 1993.
[RayOl ] Eric Raymond. The Cathedral and the Bazaar: Musings on Linux and Open
Source by an Accidental Revolutionary. O'Reilly, February 2001.
http://www.orellly.com/catalog/cathbazpaper/.
[Rlc97] Jeffrey Richter. Advanced Windows. Third Edition. Microsoft Press, Redmond,
WA, 1997.
(RJB98J James Rumbaugh, Ivar Jacobson, and GradyBooch. The Unified Modeling
Language Reference Manual. AddlsOn-Wesley Object Technology Series.
Addison-Wesley, Reading, Massachusetts, 1998.
[SBS9<’j Douglas C. Schmidt, Donald F. Box, and Tatsuya Suda. ADAPTIVE: A Dynamically
Assembled Protocol Transformation, Integration, and evaluation Environment.
Journal of Concurrency: Practice and Experience. 5(4):269-286, June 1993.
jSCOO] Douglas C. Schmidt and Chris Cleeland. Applying a Pattern Language to
Develop Extensible ORB Middleware. In Linda Rising, editor, Design Patterns In
Communications. Cambridge University Press, 2000.
(Sch90j Douglas C. Schmidt. GPERF: A Perfect Hash Function Generator. In Proceedings
of the 2° C++ Conference, pages 87-102, San Francisco, California, April 1990.
USENIX.
[Sch94] Curt Schimmel. UNIX Systems for Modem Architectures: Symmetric
Multiprocessing and Caching for Kernel Programmers. Addison-Wesley,
Reading, Massachusetts, 1994. -
[SchOO] Douglas C. Schmidt. Applying a Pattern Language to Develop Application-level
Gateways, in Linda Rising, editor. Design Patterns in Communications.
Cambridge University Press, 2000.
Литература
301
[SH] Douglas C. Schmidt and Stephen D. Huston. C++ Network Programming,
Volume 2: Systematic Reuse with ACE and Frameworks. Addison-Wesley, Boston
(forthcoming).
[SKKKOO] Douglas C. Schmidt, Vishal Kachroo, Yamuna Krishnamurthy, and Fred Kuhns.
Applying QoS-enabled Distributed Object Computing Middleware to
Next-generation Distributed Applications. IEEE Communications Magazine,
38(10): 112-123, October 2000.
[SLM98] Douglas C. Schmidt, David L. Levine, and Sumedh Mungee. The Design and
Performance of Real-Time Object Request Brokers. Computer Communications.
21(4): 294-324, April 1998.
[SMFGG01] Douglas C. Schmidt, Sumedh Mungee, Sergio Flores-Gaitan, and Aniruddha
Gokhale. Software Architectures for Reducing Priority inversion and
Non-determlnlsm In Real-time Object Request Brokers. Journal of Real-time
Systems, special Issue on Real-time Computing In the Age of the Web and the
Internet. 21(2), 2001.
(Soi98J David A. Solomon. Inside Windows NT. 2nd Ed. Microsoft Press, Redmond,
Washington, 2nd edition, 1998.
(SPOT] Douglas C. Schmidt and Adam Porter. Leveraging Open-Source Communities
to Improve the Quality and Performance of Open-Source Software. In First
Workshop on Open-Source Software Engineering, 23” International Conference
on Software Engineering, May 2001.
[SS9?] Douglas C. Schmidt and Tatsuya Suda. Transport System Architecture Services
for High-Performance Communications Systems. IEEE Journal on Selected Areas
In Communication, 11(4):489-506, May 1993.
[SS94J Douglas C. Schmidt and Tatsuya Suda. An Object-Oriented Framework for
Dynamically Configuring Extensible Distributed Communication Systems. IEE/BCS
Distributed Systems Engineering Journal (Special Issue on Configurable
Distributed Systems). 2:280-293, December 1994.
[SS95] Douglas C. Schmidt and Tatsuya Suda. Measuring the Performance of Parallel
Message-based Process Architectures. In Proceedings of the Conference on
Computer Communications (INFOCOM), pages 624-633, Boston, April 1995. IEEE.
[SSO1J Richard E. Schantz and Douglas C. Schmidt. Middleware for Distributed Systems:
Evolving the Common Structure for Network-centric Applications, in John
Marclnlak and George Teleckl, editors. Encyclopedia of Software Engineering.
Wiley &. Sons, New York, 2001.
[SSRBOO] Douglas C. Schmidt, Michael Stal, Hans Rohnert, and Frank Buschmann.
Pattern-Oriented Software Architecture: Patterns for Concurrent and Networked
Objects, Volume 2. Wiley & Sons, New York, 2000.
[Ste92] W. Richard Stevens. Advanced Programming In the UNIX Environment.
Addison-Wesley, Reading, Massachusetts, 1992.
[Ste9?J W. Richard Stevens. TCP/IP Illustrated, Volume 1. Addison-Wesley, Reading,
Massachusetts, 1993.
[Ste96] W. Richard Stevens. TCP/IP llustrated. Volume 3. Addison-Wesley, Reading,
Massachusetts, 1996.
[Ste98] W. Richard Stevens. UNIX Network Programming, Volume 1: Networking APIs:
Sockets and ХП, Second Edition. Prentice-Hall, Englewood Cliffs, NJ, 1998.
[Ste99] W. Richard Stevens. UNIX Network Programming, Volume 2: Interprocess
Communications, Second Edition. Prentice-Hall, Englewood Cliffs, NJ, 1999.
[Sun98] Sun Microsystems, inc. Java Remote Method Invocation Specification (RMI),
October 1998.
[Szy98] Clemens Sz^jerskl. Component Software—Beyond Object-Oriented
Programming. Addison-Wesley, Reading, Massachusetts, 1998.
Программирование сетевых приложений на C++. Таи 1
302
[Tan96]
[wKSOO]
[Woo97]
Andrews. Tanenbaum. Computer Networks. Prentice-Hall, Upper Saddle River,
New Jersey, 3rd edition, 1996. (Русский перевод: Таненбаум Э. Компьютер-
ные сети.—СПб.: Питер, 2002.)
Martin Fowler with Kendall Scott. UML Distilled—A Brief Guide to the Standard
Object Modeling Language (2nd Edition). Addison-Wesley, Boston, 2000.
Bobby Woolf. The Null Object Pattern. In Robert Martin, Frank Buschmann, and
Dirk Rlehle, editors. Pattern Languages of Program Design. Addison-Wesley,
Reading, Massachusetts, 1997.
Программирование сетевых приложений на
Том 1
Дуглас Шмидт, Стивен Хьюстон
По мере того, как сети, устройства и системы продолжают развиваться, разработчики программного
обеспечения сталкиваются с уникальной проблемой создания надежных распределенных приложений
в непрерывно изменяющейся среде. Программирование сетевых приложений на C++, Том 1,
предлагает практические решения, связанные с разработкой и оптимизацией сложных распределенных
систем, на основе использования ADAPTIVE Communication Environment (АСЕ), революционной
инфраструктуры сетевых приложений, работающей на многих аппаратных платформах и операционных
системах.
Эта книга поможет профессионалам в области программного обеспечения избежать ошибок и ловушек
при разработке эффективных, переносимых и гибких сетевых приложений. В ней исследуется
свойственная параллельным сетевым приложениям сложность проектирования и те компромиссные
решения, которые должны рассматриваться в процессе работы по преодолению сложностей.
Программирование сетевых приложений на C++ начинается с обзора тем и инструментальных среда?
вовлеченных в процесс создания распределенных параллельных приложений. Затем в книге излагаются
основные аспекты проектирования, паттерны и принципы, необходимые для разработки гибких и
эффективных параллельных сетевых приложений. Экспертная команда авторов этой книги, демонстрируя
эффективное применение C++ и паттернов при разработке объектно-ориентированных сетевых
приложений, показывает вам путь к усовершенствованию накопленного опыта проектирования.
Читатели найдут в этой книге изложение следующих тем:
• Программирование сетевых приложений на C++, включая обзор общих проблем разработки
и стратегии их решения
• Инструментальная библиотека АСЕ
• Протоколы соединений, обмен сообщениями и сравнительный анализ механизмов передачи сообщений
и обшей памяти
• Методы реализации повторно используемых прикладных сетевых служб
• Параллелизм в объектно-ориентированном сетевом программировании
• Принципы и паттерны проектирования, используемые в интерфейсных фасадах АСЕ
Вместе с этой книгой разработчики, использующие язык C++, получают в свое распоряжение наиболее
совершенное из имеющихся инструментальных средств, предназначенных для того, чтобы эффективно
и без больших проблем создавать успешно работающие, кросс-платформенные, параллельные сетевые
приложения.
Д-р Дуглас Шмидт — автор-разработчик АСЕ, профессор University of California, Irvine, где занимается
исследованием паттернов и критериев оптимизации распределенного промежуточного слоя встроенных
систем и систем реального времени. Он бывший главный редактор C++Report, постоянный обозреватель
C/C++ Users Journal и соредактор книги Pattern Languages of Program Design (Addison-Wesley. 1995).
Стивен Д. Хьюстон — президент и генеральный директор компании Riverace Corporation, которая
оказывает техническую поддержку и консультирует компании, стремящиеся быть в курсе разработки
программных проектов с применением АСЕ. Стив имеет опыт работы с АСЕ более пяти лет и более
двадцати лет разрабатывает программное обеспечение — в основном сетевые протоколы и приложения
на C++ в самых разных аппаратных и программных средах.
http://www.aw.com/cseng/series/lndepth/
http://ace.ece.uci.edu/
http://www.riverace.com/
Дизайн обложки Скотт Камазин,
Photo Researchers, Inc.
ISBN 5-9 9 78595 518-0024-2 800244