/





























































































































































































































































































































































































Автор: Гаврилова Т.А. Хорошевский В.Ф.
Теги: компьютерные технологии специализированные и управляющие электронные вычислительные машины дискретного действия информатика интернет
ISBN: 5-272-00071-4
Год: 2000




Текст
Т. А. Гаврилова
В. Ф. Хорошевский
ЮПИТЕР
БАЗЫ ЗНАНИЙ
ИНТЕЛЛЕКТУАЛЬНЫХ
СИСТЕМ
УЧЕБНИК
т t
• студентам вузов,
изучающим вопросы
искусственного
интеллекта в рамках
соответствующих
дисциплин
• разработчикам
и нтелл ектуал ьн ых
систем
• всем интересующимся
вопросами инженерии
знаний
Т. А. Гаврилова
В. Ф. Хорошевский
БАЗЫ ЗНАНИЙ
ИНТЕЛЛЕКТУАЛЬНЫХ
СИСТЕМ
Допущено Министерством образования Российской Федерации
в качестве учебного пособия для студентов вузов, обучающихся по направлениям
«Прикладная математика и информатика», «Информатика и вычислительная техника»
и специальностям «Прикладная информатика» (по областям),
«Прикладная математика и информатика»
Санкт-Петербург
Москва • Харьков • Минск
2000
МПГПЕР'
ББК 32.973.23-018я7
УДК 681.3.016(075)
Г12
Рецензенты:
Колосов О. С., доктор технических наук, профессор, декан факультета «Автоматика и вычислительная техни-
ка» Московского энергетического института (технического университета)
Кутепов В. П., доктор технических наук, профессор, заведующий кафедрой «Прикладная математика»
Московского энергетического института (технического университета)
Кумунжиев К. В., доктор технических наук, профессор, заведующий кафедрой «Информационные системы»
Ульяновского государственного университета
Сулейманов Д. Ш., кандидат технических наук, заведующий совместной научно-исследовательской
лабораторией «Проблемы искусственного интеллекта» Академии наук Татарстана
и Казанского государственного университета
Г12 Базы знаний интеллектуальных систем / Т. А. Гаврилова, В. Ф. Хорошевский — СПб:
Питер, 2000. — 384 с.: ил.
ISBN 5-272-00071-4
Учебник для технических вузов по входящим в различные дисциплины вопросам разработки
интеллектуальных систем — развивающейся области информатики. Актуальность предмета
определяется растущим применением инженерии знаний и системного анализа в различных
областях деятельности.
Особенностью изложения является его практическая направленность: освоения имеющегося
материала достаточно для начала самостоятельной работы над созданием интеллектуальной
системы, основанной на знаниях.
В учебнике учтена все возрастающая роль Интернета, и потому подробно рассматривается
применение инженерии знаний в Сети.
. ББК 32.973.23-018я7
УДК 681.3.016(075)
ISBN 5-272-00071-4
©Т. А. Гаврилова, В. Ф. Хорошевский, 2000
© Серия, оформление. Издательский дом «Питер», 2000
Содержание
Предисловие.....................................................6
Об авторах...................................................8
От издательства..............................................8
1. Введение в интеллектуальные системы.........................9
1.1. Краткая история искусственного интеллекта...............9
1.2. Основные направления исследований в области
искусственного интеллекта................................ 15
1.3. Представление знаний и вывод
на знаниях.................................................19
1.4. Нечеткие знания........................................31
2. Разработка систем, основанных на знаниях ..................39
2.1. Введение в экспертные системы. Определение и структура.39
2.2. Классификация систем, основанных на знаниях............41
2.3. Коллектив разработчиков................................45
2.4. Технология проектирования и разработки.................49
3. Теоретические аспекты инженерии знаний.....................59
3.1. Поле знаний ............J..............................59
3.2. Стратегии получения знаний.............................67
3.3. Теоретические аспекты извлечения знаний................71
3.4. Теоретические аспекты структурирования знаний..........90
4. Технологии инженерии знаний......... ......................99
4.1. Классификация методов практического извлечения знаний..99
4.2. Коммуникативные методы................................102
4.3. Текстологические методы...............................124
4.4. Простейшие методы структурирования....................131
4.5. Состояние и перспективы автоматизированного приобретения
знаний....................................................137
4.6. Примеры методов и систем приобретения знаний..........145
4
Содержание
5. Новые тенденции и прикладные аспекты
инженерии знаний.............................................. 161
5.1. Латентные структуры знаний и психосемантика...............161
5.2. Метод репертуарных решеток............................... 176
5.3. Управление знаниями.......................................183
5.4. Визуальное проектирование баз знаний как инструмент познания.190
5.5. Проектирование гипермедиа БД и адаптивных обучающих систем... 195
6. Программный инструментарий разработки систем,
основанных на знаниях..........................................203
6.1. Технологии разработки программного обеспечения — цели,
принципы, парадигмы..........................................203
6.2. Методологии создания и модели жизненного цикла
интеллектуальных систем......................................214
6.3. Языки программирования для ИИ и языки представления знаний...218
6.4. Инструментальные пакеты для ИИ...............224
6.5. WorkBench-системы........................................ 231
7. Пример разработки системы, основанной на знаниях .... 237
7.1. Продукционно-фреймовый ЯПЗ PIL0T/2........................237
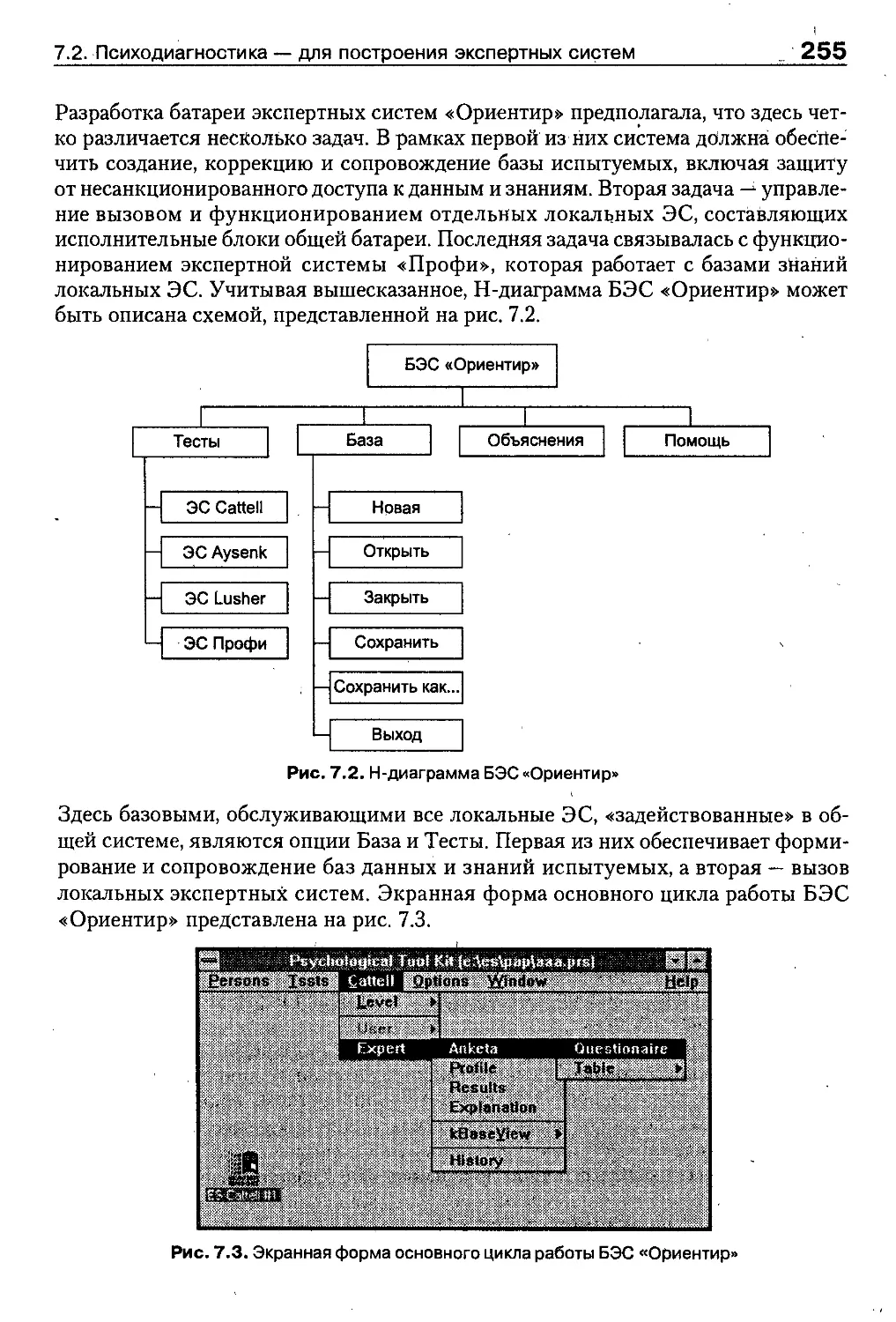
7.2. Психодиагностика — пример предметной области для построения
экспертных систем ...........................................252
7.3. Разработка и реализация психодиагностической ЭС «Cattell».256
8. Представление данных и знаний в Интернете.....................271
8.1. Язык HTML и представление знаний..........................271
8.2. Онтологии и онтологические системы........................284
8.3. Системы и средства представления онтологических знаний....301
9. Интеллектуальные Интернет-технологии..........................317
9.1. Программные агенты и мультиагентные системы...............317
9.2. Проектирование и реализация агентов и мультиагентных систем..323
9.3. Информационный поиск в среде Интернет.....................335
Заключение........................................................356
Литература
358
С любовью, учителю Д. А. Поспелову, друзьям, и близким,
всем, кто помог созданию этой версии учебника,
и, надеемся, будет сотрудничать с нами дальше
Предисловие
Вы открываете необычный учебник — учебник, предназначенный для студентов
технических университетов и их преподавателей, для аспирантов, магистров, ба-
калавров и практиков-разработчиков. Этот учебник написан для тех, кто хочет
вступить в мир науки с интригующим названием — ИСКУССТВЕННЫЙ ИН-
ТЕЛЛЕКТ.
Несмотря на обилие книг с аналогичным названием (см. список основной лите-
ратуры), на сегодняшний день нет вузовского учебника по предметам «Интеллек-
туальные системы», «Экспертные системы», «Базы знаний» и т. д. Тем не менее
практически все технические университеты совершенно справедливо включили
такого рода дисциплины в свои программы. Поскольку бум в этой науке при-
шелся на конец 70-х и 80-е, большинство книг на русском языке издано в эти
годы. И авторы приносят благодарность создателям первых отечественных мо-
нографий и справочников, а также переводчикам классических книг в этой обла-
сти — Д. А. Поспелову, Э. В. Попову, В. Л. Стефанюку, Г. С. Осипову и другим
пионерам, без работ которых создание этого учебника было бы невозможно.
Необычность этого учебника связана также с подчеркнутой междисциплинарно-
стью выбранного подхода, отказом от «клановости» отдельных научных школ и
направлений. Этот учебник могут читать инженеры и математики, экономисты и
биологи, программисты и медики. Он практически не требует предварительной
подготовки в данной области знаний и рассчитан на широкий круг читателей,
заинтересованных разработкой интеллектуальных систем, основанных на зна-
ниях.
Мы отказались от излишней специализации в пользу широты изложения, нам
хотелось представить горизонты этой науки, а не прокопать в ней глубокий, но
узкий туннель.
Другой особенностью учебника является его практическая направленность. Ос-
воив изложенный материал, студент или другой заинтересованный читатель смо-
жет самостоятельно приступить к разработке интеллектуальной системы в роли
инженера по знаниям. Акцент в учебнике сделан именно на работу со знаниями.
Фактически он ориентирован на подготовку уникальных специалистов, спрос на
которых на современном рынке высоких информационных технологий много-
кратно превышает спрос на программистов. Этих специалистов называют по-раз-
ному — системные аналитики, постановщики задач, инженеры по знаниям, инже-
неры-когнитологи. По английски это — knowledge engineers.
Предисловие
7
Рассмотренные в учебнике вопросы представляют лишь вершину айсберга срав-
нительно молодой науки — ИНЖЕНЕРИИ ЗНАНИЙ. И, надеемся, показывают
ее новые горизонты в мире информационных технологий.
Учитывая значительное число достижений и публикаций в этой области за рубе-
жом, авторы сознательно будут приводить терминологию, используемую в ориги-
налах, что существенно облегчит изучение проблемы желающим повысить свою
квалификацию через Интернет и другие источники англоязычной информации.
Материал учебника основан на курсах лекций, прочитанных авторами для сту-
дентов Санкт-Петербургского государственного технического университета (быв-
ший Политех) и Московского физико-технического института (Технического
университета). Объем курса от 32 до 64 лекционных часов плюс столько же
практических занятий. По сути дела здесь в одном учебнике собрано несколько
курсов лекций, ориентированных на разные специализации и разную базовую
подготовку,- В целом же данный учебник, по опыту авторов, содержит материал
для двухгодовых курсов с общим названием «Искусственный интеллект».
Разные категории читателей могут читать учебник по различным «сценариям».
• Сценарий 1 — для студентов-«сачков» технических вузов перед сессией. По-
метить в оглавлении параграфы, вошедшие в список вопросов для экзамена, и
читать на максимальной скорости.
• Сценарий 2 — для студентов-отличников. Внимательно прочесть весь учебник
последовательно, затем перейти к сценарию 1.
• Сценарий 3 — для студентов-непрограммистов и всех, кто просто интересует-
ся проблемой для расширения кругозора. Главы 1, 2,4,9.
• Сценарий 4 — для преподавателей вузов и тех, кто хочет овладеть инженерией
знаний. Использовать учебник как готовый конспект, расширив или сократив
материал по своему усмотрению. Варианты:
♦ минимальный курс: параграфы 1.1-1.4, 2.1-2.4, 3.2, 3.4, 4.1-4.3, 4.4, 6.3,
8.2, 9.1;
♦ главы 1-2 могут составить основу вводного курса в проблематику искус-
ственного интеллекта и систем, основанных на знаниях;
♦ аналогичный вводный курс по тематике программных средств искусствен-
ного интеллекта может дать материал главы 6, параграфа 7.1 и, при нали-
чии времени, 9.1,9.2;
♦ семестровый курс по базам знаний экспертных систем может быть прочи-
тан на основе глав 2-4, 7;
♦ базовый курс по инженерии знаний составляют главы 3,4;
♦ наконец, главы 8, 9 дают основу для курса по тематике интеллектуальных
Интернет-технологий.
• Сценарий 5 — для системных аналитиков. Главы 3-6.
, • Сценарий 6 — для программистов и разработчиков. Главы 2-4, 6-9.
Материал, набранный более мелким шрифтом, носит иллюстративный характер.
8
Предисловие
В заключение авторы благодарят заведующую редакцией технической литера-
туры издательства «Питер» Екатерину Строганову за энергию и энтузиазм при
убеждении авторов принять решение о начале работы над учебником и поддерж-
ку в ее завершении.
В параграфе 4.6. четвертой главы использованы материалы монографии «При-
обретение знаний интеллектуальными системами», любезно предоставленные
ее автором Г. С. Осиповым.
На подготовку материалов, представленных в параграфах 8.2 и 8.3 восьмой гла-
вы, а также в параграфах 9.1 и 9.3 девятой главы, в значительной мере повлияла
работа по мультиагентным системам и интеллектуальным Интернет-ориентиро-
ванным системам поиска информации, проведенная Н. В. Майкевич при подго-
товке кандидатской диссертации на тему «Исследование методов анализа Ин-
тернет-ресурсов и реализация на этой основе мультиагентной системы поиска
информации» (ИПС РАН, Переславль-Залесский, 1999). По сути дела именно
ей один из авторов данной книги обязан своей «миграцией» в эту новую, чрез-
вычайно интересную и перспективную область интеллектуальных информаци-
онных технологий из проблематики экспертных систем и программного обеспе-
чения систем искусственного интеллекта.
Отдельная благодарность должна быть высказана Е. Васильевой, Н. Нумеровой
и Н. Сташ, сотрудницам Института высокопроизводительных вычислений и баз
данных Миннауки РФ, за техническую помощь при работе над рукописью, без
которой книга могла бы так и не дойти до читателей.
Главы 1-5 написаны д. т. н„ проф. Гавриловой Т. А., главы 6-9 — д. т. н., проф.
Хорошевским В. Ф. Предисловие и заключение — результат совместной работы
авторов, которые с надеждой на дальнейшее сотрудничество выражают глубо-
кую признательность всем, кто помог выходу этой книги.
Об авторах
Т. А. Гаврилова — д. т. н., профессор кафедры компьютерных интеллектуальных
технологий Санкт-Петербургского государственного технического университета,
председатель Петербургского отделения Ассоциации искусственного интеллекта.
В. Ф. Хорошевский — д. т. н„ профессор МФТИ, ведущий научный сотрудник вы-
числительного центра РАН, член Научного Совета Российской Ассоциации ис-
кусственного интеллекта.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной по-
чты comp@piter-press.ru (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на Web-сайте издательства
http://www.piter-press.ru.
е Введение
в интеллектуальные
системы
□ Краткая история искусственного интеллекта
□ Основные направления исследований в области искусственного
интеллекта
□ Представление знаний и вывод на знаниях
□ Нечеткие знания
□ Прикладные интеллектуальные системы
1.1. Краткая история искусственного
интеллекта
1.1.1. Предыстория
Идея создания искусственного подобия человека для решения сложных задач и
моделирования человеческого разума витала в воздухе еще в древнейшие време-
на. Так, в древнем Египте была создана «оживающая» механическая статуя бога
Амона. У Гомера в «Илиаде» бог Гефест ковал человекоподобные существа-авто-
маты. В литературе эта идея обыгрывалась многократно; от Галатеи Пигмалиона
до Буратино папы Карло. Однако родоначальником искусственного интеллекта
считается средневековый испанский философ, математик и поэт Раймонд Луллий,
который еще в XIII веке попытался создать механическую машину для решения
различных задач, на основе разработанной им всеобщей классификации понятий.
В XVIII веке Лейбниц и Декарт независимо друг от друга продолжили эту идею,
предложив универсальные языки классификации всех наук. Эти работы можно
считать первыми теоретическими работами в области искусственного интеллекта.
Окончательное рождение искусственного интеллекта как научного направления
произошло только после создания ЭВМ в 40-х годах XX века. В это же время Нор-
берт Винер создал свои основополагающие работы по новой науке — киберне-
тике.
10
Глава 1 • Введение в интеллектуальные системы
Термин «искусственный интеллект» — ИИ — (Al — artificial intelligence) был
предложен в 1956 г. на семинаре с аналогичным названием в Дартсмутском
колледже (США). Семинар был посвящен разработке методов решения логи-
ческих, а не вычислительных задач. В английском языке данное словосочетание
не имеет той слегка фантастической антропоморфной окраски, которую оно при-
обрело в довольно неудачном русском переводе. Слово intelligence означает «уме-
ние рассуждать разумно», а вовсе не «интеллект», для которого есть термин intel-
lect.
Вскоре после признания искусственного интеллекта отдельной областью науки
произошло разделение его на два направления: нейрокибернетика и ^кибернети-
ка черного ящика». Эти направления развиваются практически независимо, су-
щественно различаясь как в методологии, так и в технологии. И только в настоя-
щее время стали заметны тенденции к объединению этих частей вновь в единое
целое.
1.1.2. Зарождение нейрокибернетики
Основную идею этого направления можно сформулировать следующим образом:
Единственный объект, способный мыслить, — это человеческий мозг. Поэтому лю-
бое «мыслящее» устройство должно каким-то образом воспроизводить его струк-
туру.
Таким образом, нейрокибернетика ориентирована на программно-аппаратное
моделирование структур, подобных структуре мозга. Физиологами давно уста-
новлено, что основой человеческого мозга является большое количество (до 1021)
связанных между собой и взаимодействующих нервных клеток — нейронов. По-
этому усилия нейрокибернетики были сосредоточены на создании элементов,
аналогичных нейронам, и их объединении в функционирующие системы. Эти си-
стемы принято называть нейронными сетями, или нейросетями.
Первые нейросети были созданы Розенблаттом и Мак-Каллоком в 1956-1965 гг.
Это были попытки создать системы, моделирующие человеческий глаз и его взаи-
модействие с мозгом. Устройство, созданное ими тогда, получило название пер-
септрона (perceptron). Оно умело различать буквы алфавита, но было чувстви-
тельно к их написанию. Например, буквы А, А и А для этого устройства были
тремя разными знаками. Постепенно в 70-80 годах количество работ по этому
направлению искусственного интеллекта стало снижаться. Слишком неутеши-
тельны были первые результаты. Авторы объясняли неудачи малой памятью и
низким быстродействием существующих в то время компьютеров.
Однако в 1980-х в Японии в рамках проекта «ЭВМ V поколения» был создан
первый нейрокомпьютер, или компьютер VI поколения. К этому времени ограни-
чения по памяти и быстродействию были практически сняты. Появились транс-
пьютеры — параллельные компьютеры с большим количеством процессоров.
Транспьютерная технология — это только один из десятка новых подходов к ап-
паратной реализации нейросетей, которые моделируют иерархическую структу-
ру мозга человека. Основная область применения нейрокомпьютеров сегодня —
1.1. Краткая история искусственного интеллекта
11
это задачи распознавания образов, например идентификация объектов по резуль-
татам аэрофотосъемки из космоса.
Можно выделить 3 подхода к созданию нейросетей:
1. Аппаратный — создание специальных компьютеров, нейрочипов, плат рас-
ширения, наборов микросхем, реализующих все необходимые алгоритмы.
2. Программный — создание программ и инструментариев, рассчитанных на
высокопроизводительные компьютеры. Сети создаются в памяти компьюте-
ра, всю работу выполняют его собственные процессоры.
3. Гибридный — комбинация первых двух. Часть вычислений выполняют спе-
циальные платы расширения (сопроцессоры), часть — программные сред-
ства.
Более глубокое рассмотрение этого чрезвычайно перспективного и интересного
направления исследований искусственного интеллекта выходит за рамки данной
книги. Подробнее см. работы [Соколов, Вейткявичус, 1989; Амамия, Танака, 1993].
1.1.3. От кибернетики «черного ящика» к ИИ
В основу этого подхода был положен принцип, противоположный нейрокиберне-
тике.
Не имеет значения, как устроено смыслящее» устройство. Главное, чтобы на за-
данные входные воздействия оно реагировало так же, как человеческий мозг. Сто-
ронники этого направления мотивировали свой подход тем, что человек не дол-
жен слепо следовать природе в своих научных и технологических поисках. Так,
например, очевиден успех колеса, которого не существует в природе, или самоле-
та, не машущего крыльями, подражая птице. К тому же пограничные науки о че-
ловеке не смогли внести существенного теоретического вклада, объясняющего хо-
тя бы приблизительно, как протекают интеллектуальные процессы у человека,
как устроена память и как человек познает окружающий мир.
Это направление искусственного интеллекта было ориентировано на поиски ал-
горитмов решения интеллектуальных задач на существующих моделях компью-
теров. Существенный вклад в становление новой науки внесли ее «пионеры»:
Маккарти (автор первого языка программирования для задач ИИ — ЛИСПа),
Минский (автор идеи фрейма и фреймовой модели представления знаний), Нью-
элл, Саймон, Шоу, Хант и другие.
В 1956-1963 гг. велись интенсивные поиски моделей и алгоритмов человеческо-
го мышления и разработка первых программ на их основе. Представители сущес-
твующих гуманитарных наук — философы, психологи, лингвисты — ни тогда, ни
сейчас не в состоянии были предложить таких алгоритмов. Тогда кибернетики
начали создавать собственные модели. Так последовательно были созданы и оп-
робованы различные подходы.
1. В конце 50-х годов родилась модель лабиринтного поиска. Этот подход представ-
ляет задачу как некоторое пространство состояний в форме графа, и в этом
графе проводится поиск оптимального пути от входных данных к результиру-
12
Глава 1 • Введение в интеллектуальные системы
ющим. Была проделана большая работа по разработке этой модели, но для ре-
шения практических задач эта идея не нашла широкого применения. В первых
учебниках по искусственному интеллекту [Хант, 1986; Эндрю, 1985] описаны
эти программы — они играют в игру «15», собирают «Ханойскую башню», иг-
рают в шашки и шахматы.
2. Начало 60-х — это эпоха эвристического программирования. Эвристика — пра-
вило, теоретически не обоснованное, которое позволяет сократить количество
переборов в пространстве поиска. Эвристическое программирование — разра-
ботка стратегии действий на основе известных, заранее заданных эвристик
[Александров, 1975].
3. В 1963-1970 гг. к решению задач стали подключать методы математической
логики. Робинсон разработал метод резолюций, который позволяет автомати-
чески доказывать теоремы при наличии набора исходных аксиом. Примерно в
это же время выдающийся отечественный математик Ю. С. Маслов предложил
так называемый обратный вывод, впоследствии названный его именем, реша-
ющий аналогичную задачу другим способом [Маслов, 1983]. На основе метода
резолюций француз Альбер Кольмероэ в 1973 г. создает язык логического про-
граммирования Пролог. Большой резонанс имела программа «Логик-теоре-
тик*, созданная Ньюэлом, Саймоном и Шоу, которая доказывала школьные
теоремы. Однако большинство реальных задач не сводится к набору аксиом, и
человек, решая производственные задачи, не использует классическую логику,
поэтому логические модели при всех своих преимуществах имеют существен-
ные ограничения по классам решаемых задач.
4. История искусственного интеллекта полна драматических событий, одним из
которых стал в 1973 г. так называемый «доклад Лайтхилла», который был под-
готовлен в Великобритании по заказу Британского совета научных исследова-
ний. Известный математик Д. Лайтхилл, никак с ИИ профессионально не свя-
занный, подготовил обзор состояния дел в области ИИ. В докладе были
признаны определенные достижения в области ИИ, однако уровень их опре-
делялся как разочаровывающий, и общая оценка была отрицательная с пози-
ций практической значимости. Этот отчет отбросил европейских исследова-
телей примерно на 5 лет назад, так как финансирование ИИ существенно
сократилось.
5. Примерно в это же время существенный прорыв в развитии практических при-
ложений искусственного интеллекта произошел в США, когда к середине
1970-х на смену поискам универсального алгоритма мышления пришла идея
моделировать конкретные знания специалистов-экспертов. В США появились
первые коммерческие системы, основанные на знаниях, или экспертные систе-
мы (ЭС). Стал применяться новый подход к решению задач искусственного
интеллекта — представление знаний. Созданы MYCIN и DENDRAL [Shortliffe,
1976; Buchanan, Feigenbaum, 1978], ставшие уже классическими, две первые
экспертные системы для медицины и химии. Существенный финансовый вклад
вносит Пентагон, предлагая базировать новую программу министерства обо-
роны США (Strategic Computer Initiative — SCI) на принципах ИИ. Уже вдо-
1,1. Краткая история искусственного интеллекта
13
гонку упущенных возможностей в начале 80-х объявлена глобальная програм-
ма развития новых технологий ESPRIT (Европейский Союз), в которую вклю-
чена проблематика искусственного интеллекта.
6. В ответ на успехи США в конце 70-х в гонку включается Япония, объявив о
начале проекта машин V поколения, основанных на знаниях. Проект был рас-
считан на 10 лет и объединял лучших молодых специалистов (в возрасте
до 35 лет) крупнейших японских компьютерных корпораций. Для этих специ-
алистов был создан специально новый институт ICOT, и они получили пол-
ную свободу действий, правда, без права публикации предварительных резуль-
татов. В результате они создали достаточно громоздкий и дорогой символьный
процессор, программно реализующий ПРОЛОГо-подобный язык, не получив-
ший широкого признания. Однако положительный эффект этого проекта был
очевиден. В Японии появилась значительная группа высококвалифицирован-
ных специалистов в области ИИ, которая добилась существенных результатов
в различных прикладных задачах. К середине 90-х японская ассоциация ИИ
насчитывает 40 тыс. человек.
Начиная с середины 1980-х годов, повсеместно происходит коммерциализация
искусственного интеллекта. Растут ежегодные капиталовложения, создаются
промышленные экспертные системы. Растет интерес к самообучающимся систе-
мам. Издаются десятки научных журналов, ежегодно собираются международ-
ные и национальные конференции по различным направлениям ИИ.
Искусствейный интеллект становится одной из наиболее перспективных и пре-
стижных областей информатики (computer science).
1.1.4. История искусственного интеллекта
в России
В 1954 г. в МГУ начал свою работу семинар «Автоматы и мышление» под руковод-
ством академика Ляпунова А. А. (1911-1973), одного из основателей российской ки-
бернетики. В этом семинаре принимали участие физиологи, лингвисты, психологи,
математики. Принято считать, что именно в это время родился искусственный ин-
теллект в России. Как и за рубежом, выделились два основных направления — ней-
рокибернетики и кибернетики «черного ящика».
В 1954-1964 гг. создаются отдельные программы и проводятся исследования в
области поиска решения логических задач. В Ленинграде (ЛОМИ — Ленинград-
ское отделение математического института им. Стеклова) создается программа
АЛПЕВ ЛОМИ, автоматически доказывающая теоремы. Она основана на ориги-
нальном обратном выводе Маслова, аналогичном методу резолюций Робинсона.
Среди наиболее значимых результатов, полученных отечественными учеными в
60-е годы, следует отметить алгоритм «Кора» М. М. Бонгарда, моделирующий
деятельность человеческого мозга при распознавании образов. Большой вклад в
становление российской школы ИИ внесли выдающиеся ученые Цетлин М. Л.,
Пушкин В. Н., Гаврилов М. А, чьи ученики и явились пионерами этой науки в Рос-
сии (например, знаменитая Гавриловская школа).
14
Глава 1 • Введение в интеллектуальные системы
В 1965-1980 гг. происходит рождение нового направления — ситуационного уп-
равления (соответствует представлению знаний, в западной терминологии). Ос-
нователем этой научной школы стал проф. Поспелов Д. А. Были разработаны
специальные модели представления ситуаций — представления знаний [Поспе-
лов, 1986].
При том что отношение к новым наукам в советской России всегда было насторо-
женное, наука с таким «вызывающим» названием тоже не избежала этой участи и
была встречена в Академии наук в штыки [Поспелов, 1997]. К счастью, даже среди
членов Академии наук СССР нашлись люди, не испугавшиеся столь необычного
словосочетания в качестве названия научного направления. Двое из них сыграли
огромную роль в борьбе за признание ИИ в нашей стране. Это были академики
А. И. Берг и Г. С. Поспелов.
Только в 1974 году при Комитете по системному анализу при президиуме АН
СССР был создан Научный совет по проблеме «Искусственный интеллект», его
возглавил Г. С. Поспелов, его заместителями были избраны Д. А. Поспелов и
Л. И. Микулич. В состав совета входили на разных этапах М. Г. Гаазе-Рапопорт,
Ю. И. Журавлев, Л. Т. Кузин, А. С. Нариньяни, Д. Е. Охоцимский, А. И. Поло-
винкин, О. К. Тихомиров, В. В. Чавчанидзе.
По инициативе Совета было организовано пять комплексных научных проектов,
которые были возглавлены ведущими специалистами в данной области. Проек-
ты объединяли исследования в различных коллективах страны: «Диалог» (рабо-
ты по пониманию естественного языка, руководители А. П. Ершов, А. С. Наринь-
яни), «Ситуация» (ситуационное управление, Д. А. Поспелов), «Банк» (банки
данных, Л. Т. Кузин), «Конструктор» (поисковое конструирование, А. И. Поло-
винкин), «Интеллект робота» (Д. Е. Охоцимский).
В 1980-1990 гг. проводятся активные исследования в области представления зна-
ний, разрабатываются языки представления знаний, экспертные системы (более
300). В Московском университете создается язык РЕФАЛ.
В 1988 г. создается АИИ — Ассоциация искусственного интеллекта. Ее членами
являются более 300 исследователей. Президентом Ассоциации единогласно из-
бирается Д. А. Поспелов, выдающийся ученый, чей вклад в развитие ИИ в
России трудно переоценить. Крупнейшие центры — в Москве, Петербурге, Пе-
реславле-Залесском, Новосибирске. В научный совет Ассоциации входят веду-
щие исследователи в области ИИ — В. П. Гладун, В. И. Городецкий, Г. С. Оси-
пов, Э. В. Попов, В. Л. Стефанюк, В. Ф. Хорошевский, В. К. Финн, Г. С. Цейтин,
А. С. Эрлих и другие ученые. В рамках Ассоциации проводится большое количе-
ство исследований, организуются школы для молодых специалистов, семинары,
симпозиумы, раз в два года собираются объединенные конференции, издается на-
учный журнал.
Уровень теоретических исследований по искусственному интеллекту в России
ничуть не ниже мирового. К сожалению, начиная с 80-х гг. на прикладных рабо-
тах начинает сказываться постепенное отставание в технологии. На данный мо-
мент отставание в области разработки промышленных интеллектуальных систем
составляет порядка 3-5 лет.
1.2. Основные исследования в области искусственного интеллекта
15
1.2. Основные направления исследований
в области искусственного интеллекта
Синтезируя десятки определений ИИ из различных источников, в данной книге в
качестве рабочего определения можно предложить следующее.
Искусственный интеллект — это одно из направлений информатики, целью которого яв-
ляется разработка аппаратно-программных средств, позволяющих пользователю-не-
программисту ставить и решать свои, традиционно считающиеся интеллектуальными за-
дачи, общаясь с ЭВМ на ограниченном подмножестве естественного языка.
Среди множества направлений искусственного интеллекта есть несколько веду-
щих, которые в настоящее время вызывают наибольший интерес у исследовате-
лей и практиков. Опишем их чуть подробнее.
1.2.1. Представление знаний и разработка
систем, основанных на знаниях
(knowledge-based systems)
Это основное Направление в области изучения искусственного интеллекта. Оно
связано с разработкой моделей представления знаний, созданием баз знаний, об-
разующих ядро экспертных систем. В последнее время включает в себя модели и
методы извлечения и структурирования знаний и сливается с инженерией зна-
ний. Именно исследованиям в этой области посвящена данная книга. Подробнее
см. главы 2-5.
1.2.2. Программное обеспечение систем ИИ
(software engineering for Al)
В рамках этого направления разрабатываются специальные языки для решения
интеллектуальных задач, в которых традиционно упор делается на преобладание
логической и символьной обработки над вычислительными процедурами. Эти
языки ориентированы на символьную обработку информации — LISP, PROLOG,
SMALLTALK, РЕФАЛ и др. Помимо этого создаются пакеты прикладных про-
грамм, ориентированные на промышленную разработку интеллектуальных сис-
тем, или программные инструментарии искусственного интеллекта, например
КЕЕ, ARTS, G2 [Хейес-Рот и др., 1987; Попов, Фоминых, Кисель, Шапот, 1996].
Достаточно популярно также создание так называемых пустых экспертных сис-
тем или «оболочек» — КАРРА, EXSYS, Ml, ЭКО и др., базы знаний которых мож-
но наполнять конкретными знаниями, создавая различные прикладные системы.
Подробно эти технологии рассмотрены в главе 6.
16
Глава 1 • Введение в интеллектуальные системы
1.2.3. Разработка естественно-языковых
интерфейсов и машинный перевод
(natural language processing)
Начиная с 50-х годов одной из популярных тем исследований в области ИИ яв-
ляется компьютерная лингвистика, и, в частности, машинный перевод (МП).
Идея машинного перевода оказалась совсем не так проста, как казалось первым
исследователям и разработчикам.
Уже первая программа в области естественно-языковых (ЕЯ) интерфейсов — пе-
реводчик с английского на русский язык — продемонстрировала неэффективность
первоначального подхода, основанного на пословном переводе. Однако еще долго
разработчики пытались создать программы на основе морфологического анали-
за. Неплодотворность такого подхода связана с очевидным фактом: человек мо-
жет перевести текст только на основе понимания его смысла и в контексте пред-
шествующей информации, или контекста. Иначе появляются переводы в стиле
«Моя дорогая Маша — my expensive Masha». В дальнейшем системы МП услож-
нялись и в настоящее время используется несколько более сложных моделей:
• применение так называемых «языков-посредников» или языков смысла, в ре-
зультате происходит дополнительная трансляция «исходный язык оригина-
ла — язык смысла — язык перевода»;
• ассоциативный поиск аналогичных фрагментов текста и их переводов в специ-
альных текстовых репозиториях или базах данных;
• структурный подход, включающий последовательный анализ и синтез есте-
ственно-языковых сообщений. Традиционно такой подход предполагает на-
личие нескольких фаз анализа:
1. Морфологический анализ — анализ слов в тексте.
2. Синтаксический анализ — разбор состава предложений и грамматических
связей между словами.
3. Семантический анализ — анализ смысла составных частей каждого предло-
жения на основе некоторой предметно-ориентированной базы знаний.
4. Прагматический анализ — анализ смысла предложений в реальном контек-
сте на основе собственной базы знаний.
Синтез ЕЯ-сообщений включает аналогичные этапы, но несколько в другом по-
рядке. Подробнее см. работы [Попов, 1982; Мальковский, 1985].
1.2.4. Интеллектуальные роботы (robotics)
Идея создания роботов далеко не нова. Само слово «робот» появилось в 20-х
годах, как производное от чешского «робота» — тяжелой грязной работы. Его
автор — чешский писатель Карел Чапек, описавший роботов в своем рассказе
«Р.У.Р».
1,2. Основные направления в области искусственного интеллекта
17
Роботы — это электротехнические устройства, предназначенные для автоматизации че-
ловеческого труда.
Можно условно выделить несколько поколений в истории создания и развития
робототехники:
I поколение. Роботы с жесткой схемой управления. Практически все современ-
ные промышленные роботы принадлежат к первому поколению. Фактически это
программируемые манипуляторы.
II поколение. Адаптивные роботы с сенсорными устройствами. Есть образцы та-
ких роботов, но в промышленности они пока используются мало.
III поколение. Самоорганизующиеся или интеллектуальные роботы. Это — ко-
нечная цель развития робототехники. Основные нерешенные проблемы при со-
здании интеллектуальных роботов — проблема машинного зрения и адекватного
хранения и обработки трехмерной визуальной информации.
В настоящее время в мире изготавливается более 60 000 роботов в год. Фактиче-
ски робототехника сегодня — это инженерная наука, не отвергающая технологий
ИИ, но не готовая пока к их внедрению в силу различных причин.
1.2.5. Обучение и самообучение
(machine learning)
Активно развивающаяся область искусственного интеллекта. Включает модели,
методы и алгоритмы, ориентированные на автоматическое накопление и фор-
мирование знаний на основе анализа и обобщения данных [Гаек, Гавранек, 1983;
Гладун, 1994; Финн, 1991]. Включает обучение по примерам (или индуктивное), а
также традиционные подходы из теории распознавания образов.
В последние годы к этому направлению тесно примыкают стремительно разви-
вающиеся системы data mining — анализа данных и knowledge discovery — поис-
ка закономерностей в базах данных.
1.2.6. Распознавание образов
(pattern recognition)
Традиционно — одно из направлений искусственного интеллекта, берущее нача-
ло у самых его истоков, но в настоящее время практически выделившееся в са-
мостоятельную науку. Ее основной подход — описание классов объектов через опре-
деленные значения значимых признаков. Каждому объекту ставится в соот-'
ветствие матрица признаков, по которой происходит его распознавание.
Процедура распознавания использует чаще всего специальные математические
процедуры и функции, разделяющие объекты на классы. Это направление близ-
ко к машинному обучению и тесно связано с нейрокибернетикой [Справочник
по ИИ, 1990].
18
Глава 1 • Введение в интеллектуальные системы
1.2.7. Новые архитектуры компьютеров (new
hardware platforms and architectures)
Самые современные процессоры сегодня основаны на традиционной последова-
тельной архитектуре фон Неймана, используемой еще в компьютерах первых
поколений. Эта архитектура крайне неэффективна для символьной обработки.
Поэтому усилия многих научных коллективов и фирм уже десятки лет нацелены
на разработку аппаратных архитектур, предназначенных для обработки сим-
вольных и логических данных. Создаются Пролог- и Лисп-машины, компью-
теры V и VI поколений. Последние разработки посвящены компьютерам баз
данных, параллельным и векторным компьютерам [Амамия, Танака, 1993].
И хотя удачные промышленные решения существуют, высокая стоимость, недо-
статочное программное оснащение и аппаратная несовместимость с традицион-
ными компьютерами существенно тормозят широкое использование новых архи-
тектур.
1.2.8. Игры и машинное творчество
Это, ставшее скорее историческим, направление связано с тем, что на заре иссле-
дований ИИ традиционно включал в себя игровые интеллектуальные задачи —
шахматы, шашки, го. В основе первых программ лежит один из ранних подхо-
дов — лабиринтная модель мышления плюс эвристики. Сейчас это скорее ком-
мерческое направление, так как в научном плане эти идеи считаются тупико-
выми.
Кроме того, это направление охватывает сочинение компьютером музыки [Зари-
пов, 1983], стихов, сказок [Справочник по ИИ, 1986] и даже афоризмов [Любич,
1998]. Основным методом подобного «творчества» является метод пермутаций
(перестановок) плюс использование некоторых баз знаний и данных, содержа-
щих результаты исследований по структурам текстов, рифм, сценариям и т. п.
1.2.9. Другие направления
ИИ — междисциплинарная наука, которая, как мощная река по дороге к морю,
вбирает в себя ручейки и речки смежных наук. Выше перечислены лишь те на-
правления, которые прямо или косвенно связаны с основной тематикой учебни-
ка — инженерией знаний. Стоит лишь взглянуть на основные рубрикаторы кон-
ференций по ИИ, чтобы понять, насколько широко простирается область ис-
следований по ИИ:
• генетические алгоритмы;
• когнитивное моделирование;
• интеллектуальные интерфейсы;
• распознавание и синтез речи;
• дедуктивные модели;
1,3. Представление знаний и вывод на знаниях
19
• многоагентные системы;
• онтологии;
• менеджмент знаний;
• логический вывод;
• формальные модели;
• мягкие вычисления и многое другое.
Конечно, невозможно в рамках одного учебника рассмотреть все многообразие
подходов и идей в области ИИ. Однако некоторые новые направления будут под-
робнее описаны в главах 5,8, 9.
1.3. Представление знаний и вывод
на знаниях
1.3.1. Данные и знания
При изучении интеллектуальных систем традиционно возникает вопрос — что же
такое знания и чем они отличаются от обычных данных, десятилетиями обраба-
тываемых ЭВМ. Можно предложить несколько рабочих определений, в рамках
которых это становится очевидным.
Данные — это отдельные факты, характеризующие объекты, процессы и явления пред-
метной области, а также их свойства.
При обработке на ЭВМ данные трансформируются, условно проходя следующие
этапы:
1. D1 — данные как результат измерений и наблюдений;
2. D2 — данные на материальных носителях информации (таблицы, протоколы,
справочники);
i
3. D3 — модели (структуры) данных в виде диаграмм, графиков, функций;
4. D4 — данные в компьютере на языке описания данных;
5. D5 — базы данных на машинных носителях информации.
Знания основаны на данных, полученных эмпирическим путем. Они представля-
ют собой результат мыслительной деятельности человека, направленной на обоб-
щение его опыта, полученного в результате практической деятельности.
Знания — это закономерности предметной области (принципы, связи, законы), получен-
ные в результате практической деятельности и профессионального опыта, позволяющие
специалистам ставить и решать задачи а этой области.
20
Глава 1 • Введение в интеллектуальные системы
При обработке на ЭВМ знания трансформируются аналогично данным.
1. Z1 — знания в памяти человека как результат мышления;
2. Z2 — материальные носители знаний (учебники, методические пособия);
3. Z3 — поле знаний — условное описание основных объектов предметной облас-
ти, их атрибутов и закономерностей, их связывающих;
4. Z4 — знания, описанные на языках представления знаний (продукционные язы-
ки, семантические сети, фреймы — см. далее);
5. Z5 — база знаний на машинных носителях информации.
Часто используется такое определение знаний.
Знания — это хорошо структурированные данные, или данные о данных, или метаданные.
Существует множество способов определять понятия. Один из широко приме-
няемых способов основан на идее интенсионала. Интенсионал понятия — это
определение его через соотнесение с понятием более высокого уровня абстрак-
ции с указанием специфических свойств. Интенсионалы формулируют знания
об объектах. Другой способ определяет понятие через соотнесение с понятиями
более низкого уровня абстракции или перечисление фактов, относящихся к оп-
ределяемому объекту. Это есть определение через данные, или экстенсионал по-
нятия.
Пример 1.1
Понятие «персональный компьютер». Его интенсионал: «Персональный компьютер —
это дружественная ЭВМ, которую можно поставить на стол и купить менее чем за
$2000-3000».
Экстенсионал этого понятия: «Персональный компьютер — это Mac, IBM PC, Sinkier...»
Для хранения данных используются базы данных (для них характерны большой
объем и относительно небольшая удельная стоимость информации), для хра-
нения знаний — базы знаний (небольшого объема, но исключительно дорогие
информационные массивы). База знаний — основа любой интеллектуальной си-
стемы.
Знания могут быть классифицированы по следующим категориям:
• Поверхностные — знания о видимых взаимосвязях между отдельными собы-
тиями и фактами в предметной области.
• Глубинные — абстракции, аналогии, схемы, отображающие структуру и приро-
ду процессов, протекающих в предметной области. Эти знания объясняют яв-
ления и могут использоваться для прогнозирования поведения объектов.
Пример 1.2
Поверхностные знания: «Если нажать на кнопку звонка, раздастся звук. Если болит
голова, то следует принять аспирин».
1.3. Представление знаний и вывод на знаниях
21
Глубинные знания: «Принципиальная электрическая схема зввонка и проводки. Знания
физиологов и врачей высокой квалификации о причинах, видах головных болей и методах
их лечения».
Современные экспертные системы работают в основном с поверхностными зна-
ниями. Это связано с тем, что на данный момент нет универсальных методик, по-
зволяющих выявлять глубинные структуры знаний и работать с ними.
Кроме того, в учебниках по ИИ знания традиционно делят на процедурные и дек-
ларативные. Исторически первичными были процедурные знания, то есть зна-
ния, «растворенные» в алгоритмах. Они управляли данными. Для их изменения
требовалось изменять программы. Однако с развитием искусственного интел-
лекта приоритет данных постепенно изменялся, и все большая часть знаний со-
средоточивалась в структурах данных (таблицы, списки, абстрактные типы дан-
ных), то есть увеличивалась роль декларативных знаний.
Сегодня знания приобрели чисто декларативную форму, то есть знаниями счита-
ются предложения, записанные на языках представления знаний, приближенных
к естественному и псщдгных неспециалистам.
1.3.2. Модели представления знаний
Существуют десятки моделей (или языков) представления знаний для различ-
ных предметных областей. Большинство из них может быть сведено к следую-
щим классам:
• продукционные модели;
• семантические сети;
• фреймы;
• формальные логические модели.
Продукционная модель
Продукционная модель или модель, основанная на правилах, позволяет представить зна-
ния в виде предложений типа «Если (условие), то (действие)».
Под «условием» (антецедентом) понимается некоторое предложение-образец,
по которому осуществляется поиск в базе знаний, а под «действием» (консеквен-
том) — действия, выполняемые при успешном исходе поиска (они могут быть
промежуточными, выступающими далее как условия и терминальными или це-
левыми, завершающими работу системы).
Чаще всего вывод на такой базе знаний бывает прямой (от данных к поиску цели)
или обратный (от цели для ее подтверждения — к данным). Данные — это исход-
ные факты, хранящиеся в базе фактов, на основании которых запускается маши-
на вывода или интерпретатор правил, перебирающий правила из продукцион-
ной баф! знаний (сМ. далее).
22
Глава 1 • Введение в интеллектуальные системы
Продукционная модель чаще всего применяется в промышленных экспертных
системах. Она привлекает разработчиков своей наглядностью, высокой модуль-
ностью, легкостью внесения дополнений и изменений и простотой механизма ло-
гического вывода.
Имеется большое число программных средств, реализующих продукционный
подход (язык OPS 5; «оболочки» или «пустые» ЭС — EXSYS Professional, Карра,
ЭКСПЕРТ; ЭКО, инструментальные системы ПИЭС [Хорошевский, 1993] и
СПЭИС [Ковригин, Перфильев, 1988] и др.), а также промышленных ЭС на его
основе (например, ЭС, созданных средствами G2 [Попов, 1996]) и др.
Семантические сети
Термин семантическая означает «смысловая», а сама семантика — это наука, ус-
танавливающая отношения между символами и объектами, которые они обозна-
чают, то есть наука, определяющая смысл знаков.
Семантическая сеть — это ориентированный граф, вершины которого — понятия, а ду-
ги — отношения между ними.
В качестве понятий обычно выступают абстрактные или конкретные объекты, а
отношения — это связи типа: «это» («АКО — А-Kind-Of», «is»), «имеет частью»
(«has part»), «принадлежит», «любит». Характерной особенностью семантичес-
ких сетей является обязательное наличие трех типов отношений:
• класс — элемент класса (цветок — роза);
• свойство — значение (цвет — желтый);
• пример элемента класса (роза — чайная).
Можно предложить несколько классификаций семантических сетей, связанных с
типами отношений между понятиями.
По количеству типов отношений:
• Однородные (с единственным типом отношений).
• Неоднородные (с различными типами отношений).
По типам отношений:
• Бинарные (в которых отношения связывают два объекта).
• N-арные (в которых есть специальные отношения, связывающие более двух
понятий).
Наиболее часто в семантических сетях используются следующие отношения:
• связи типа «часть — целое» («класс — подкласс», «элемент —множество»,
и т. п.);
• функциональные связи (определяемые обычно глаголами «производит»,
«влияет»...);
• количественные (больше, меньше, равно...);
1.3. Представление знаний и вывод на знаниях
23
• пространственные (далеко от , близко от, за, под, над...);
• временные (раньше, позже, в течение...);
• атрибутивные связи (иметь свойство, иметь значение);
• логические связи (И, ИЛИ, НЕ);
• лингвистические связи и др.
Проблема поиска решения в базе знаний типа семантической сети сводится к за-
даче поиска фрагмента сети, соответствующего некоторой подсети, отражающей
поставленный запрос к базе.
Пример 1.3
На рис. 1.1 изображена семантическая сеть. В качестве вершин тут выступают понятия
«человек», «т. Иванов», «Волга», «автомобиль», «вид транспорта» и «двигатель».
Красный ^4—знвчение—цвет (двигатель^
_____свойство _2имеет
частью I
[ Волга )—
принадлежит
любит
[ Иванов~^4 Н--ПРИ—еР—^Человек ]
Рис. 1.1. Семантическая сеть
Данная модель представления знаний была предложена американским психоло-
гом Куиллианом. Основным ее преимуществом является то, что она более других
соответствует современным представлениям об организации долговременной па-
мяти человека [Скрэгг, 1983].
Недостатком этой модели является сложность организации процедуры поиска
вывода на семантической сети.
Для реализации семантических сетей существуют специальные сетевые языки,
например NET [Цейтин, 1985], язык реализации систем SIMER+MIR [Осипов,
1997] и др. Широко известны экспертные системы, использующие семантичес-
кие сети в качестве языка представления знаний — PROSPECTOR, CASNET,
TORUS [Хейес-Рот и др., 1987; Durkin, 1998].
Фреймы
Термин фрейм (от английского frame, что означает «каркас» или «рамка») был
предложен Марвином Минским [Минский, 1979], одним из пионеров ИИ, в 70-е
годы для обозначения структуры знаний для восприятия пространственных
сцен. Эта модель, как и семантическая сеть, имеет глубокое психологическое обо-
снование.
24
Глава 1 • Введение в интеллектуальные системы
Фрейм — это абстрактный образ для представления некоего стереотипа восприятия.
В психологии и философии известно понятие абстрактного образа. Например,
произнесение вслух слова «комната» порождает у слушающих образ комнаты:
«жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, пло-
щадью 6-20 м2». Из этого описания ничего нельзя убрать (например, убрав окна,
мы получим уже чулан, а не комнату), но в нем есть «дырки» или «слоты» — это
незаполненные значения некоторых атрибутов — например, количество окон,
цвет стен, высота потолка, покрытие пола и др.
В теории фреймов такой образ комнаты называется фреймом комнаты. Фреймом
также называется и формализованная модель для отображения образа.
Различают фреймы-образцы, или прототипы, хранящиеся в базе знаний, и фрей-
мы-экземпляры, которые создаются для отображения реальных фактических си-
туаций на основе поступающих данных. Модель фрейма является достаточно
универсальной, поскольку позволяет отобразить все многообразие знаний о мире
через:
• фреймы-структуры, использующиеся для обозначения объектов и понятий
(заем, залог, вексель);
• фреймы-роли (менеджер, кассир, клиент);
• фреймы-сценарии (банкротство, собрание акционеров, празднование име-
нин);
• фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Традиционно структура фрейма может быть представлена как список свойств:
(ИМЯ ФРЕЙМА:
(имя 1-го слота: значение 1-го слота),
(имя 2-го слота: значение 2-го слота),
’ ’ • »
(имя N-ro слота: значение N-ro слота)).
Ту же запись можно представить в виде таблицы, дополнив ее двумя столбцами.
Таблица 1.1. Структура фрейма
Имя фрейма
Имя слота Значение слота Способ получения значения Присоединенная процедура
1.3. Представление знаний и вывод на знаниях
25
В таблице дополнительные столбцы предназначены для описания способа полу-
чения слотом его значения и возможного присоединения к тому или иному слоту
специальных процедур, что допускается в теории фреймов. В качестве значения
слота может выступать имя другого фрейма, так образуются сети фреймов.
Существует несколько способов получения слотом значений во фрейме-экзем-
пляре:
• по умолчанию от фрейма-образца (Default-значение);
• через наследование свойств от фрейма, указанного в слоте АКО;
• по формуле, указанной в слоте;
• через присоединенную процедуру;
• явно из диалога с пользователем;
• из базы данных.
Важнейшим свойством теории фреймов является заимствование из теории се-
мантических сетей — так называемое наследование свойств. И во фреймах, и в се-
мантических сетях наследование происходит по АКО-связям (A-Kind-Of == это).
Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно
наследуются, то есть переносятся, значения аналогичных слотов.
Пример 1.4
Например, в сети фреймов на рис. 1.2 понятие «ученик» наследует свойства фреймов
«ребенок* и «человек», которые находятся на более высоком уровне иерархии. Так, на
вопрос «любят ли ученики сладкое» следует ответ «да», так как этим свойством облада-
ют все дети, что указано во фрейме «ребенок». Наследование свойств может быть час-
тичным, так как возраст для учеников не наследуется из фрейма «ребенок», поскольку
указан явно в своем собственном фрейме.
Основным преимуществом фреймов как модели представления знаний является
то, что она отражает концептуальную основу организации памяти человека [Шенк,
Хантер, 1987], а также ее гибкость и наглядность.
26
Глава 1 • Введение в интеллектуальные системы
Специальные языки представления знаний в сетях фреймов FRL (Frame Repre-
sentation Language) [Байдун, Бунин, 1990], KRL (Knowledge Representation Lan-
guage) [Уотермен, 1989], фреймовая «оболочка» Карра [Стрельников, Бори-
сов, 1997] и другие программные средства позволяют эффективно строить про-
мышленные ЭС. Широко известны такие фрейм-ориентированные экспертные
системы, как ANALYST, МОДИС, TRISTAN, ALTERID [Ковригин, Перфильев,
1988; Николов, 1988; Sisodia, Warkentin, 1992].
Формальные логические модели
Традиционно в представлении знаний выделяют формальные логические модели,
основанные на классическом исчислении предикатов 1-го порядка, когда предмет-
ная область или задача описывается в виде набора аксиом. Мы же опустим описа-
ние этих моделей по следующим причинам. Исчисление предикатов 1-го порядка
в промышленных экспертных системах практически не используется. Эта логи-
ческая модель применима в основном в исследовательских «игрушечных» систе-
мах, так как предъявляет очень высокие требования и ограничения к предметной
области.
В промышленных же экспертных системах используются различные ее модифи-
кации и расширения, изложение которых выходит за рамки этого учебника.
1.3.3. Вывод на знаниях
Несмотря на все недостатки, наибольшее распространение получила продукци-
онная модель представления знаний. При использовании продукционной модели
база знаний состоит из набора правил. Программа, управляющая перебором пра-
вил, называется машиной вывода.
Машина вывода
Машина вывода (интерпретатор правил) выполняет две функции: во-первых,
просмотр существующих фактов из рабочей памяти (базы данных) и правил из
базы знаний и добавление (по мере возможности) в рабочую память новых фак-
тов и, во-вторых, определение порядка просмотра и применения правил. Этот
механизм управляет процессом консультации, сохраняя для пользователя ин-
формацию о полученных заключениях, и запрашивает у него информацию, когда
для срабатывания очередного правила в рабочей памяти оказывается недостаточ-
но данных [Осуга, Саэки, 1990].
В подавляющем большинстве систем, основанных на знаниях, механизм вывода
представляет собой небольшую по объему программу и включает два компонен-
та — один реализует собственно вывод, другой управляет этим процессом.
Действие компонента вывода основано на применении правила, называемого
modus ponens.
Правило modus ponens. Если известно, что истинно утверждение А и существует правило
вида «ЕСЛИ А, ТО В», тогда утверждение В Также истинно.
1.3. Представление знаний и вывод на знаниях
27
Правила срабатывают, когда находятся факты, удовлетворяющие их левой части:
если истинна посылка, то должно быть истинно и заключение.
Компонент вывода должен функционировать даже при недостатке информации.
Полученное решение может и не быть точным, однако система не должна останав-
ливаться из-за того, что отсутствует какая-либо часть входной информации.
Управляющий компонент определяет порядок применения правил и выполняет
четыре функции.
1. Сопоставление — образец правила сопоставляется с имеющимися фактами.
2. Выбор — если в конкретной ситуации может быть применено сразу несколько
правил, то из них выбирается одно, наиболее подходящее по заданному крите-
рию (разрешение конфликта).
3. Срабатывание — если образец правила при сопоставлении совпал с какими-
либо фактами из рабочей памяти, то правило срабатывает.
4. Действие — рабочая память подвергается изменению путем добавления в нее
заключения сработавшего, правила. Если в правой части правила содержится
указание на какое-либо действие, то оно выполняется (как, например, в систе-
мах обеспечения безопасности информации).
Интерпретатор продукций работает циклически. В каждом цикле он просматри-
вает все правила, чтобы выявить те, посылки которых совпадают с известными на
данный момент фактами из рабочей памяти. После выбора правило срабатывает,
его заключение заносится в рабочую память, и затем цикл повторяется сначала.
В одном цикле может сработать только одно правило. Если несколько правил ус-
пешно сопоставлены с фактами, то интерпретатор производит выбор по опреде-
ленному критерию единственного правила, которое срабатывает в данном цикле.
Цикл работы интерпретатора схематически представлен на рис. 1.3.
Рис. 1.3. Цикл работы интерпретатора
Информация из рабочей памяти последовательно сопоставляется с посылками
правил для выявления успешного сопоставления. Совокупность отобранных пра-
28
Глава 1 • Введение в интеллектуальные системы
вил составляет так называемое конфликтное множество. Для разрешения кон-
фликта интерпретатор имеет критерий, с помощью которого он выбирает
единственное правило, после чего оно срабатывает. Это выражается в занесе-
нии фактов, образующих заключение правила, в рабочую память или в измене-
нии критерия выбора конфликтующих правил. Если же в заключение правила
входит название какого-нибудь действия, то оно выполняется.
Работа машины вывода зависит только от состояния рабочей памяти и от состава
базы знаний. На практике обычно учитывается история работы, то есть поведе-
ние механизма вывода в предшествующих циклах. Информация о поведении ме-
ханизма вывода запоминается в памяти состояний (рис. 1.4). Обычно память со-
стояний содержит протокол системы.
Рис. 1.4. Схема функционирования интерпретатора
Стратегии управления выводом
От выбранного метода поиска, то есть стратегии вывода, будет зависеть порядок
применения и срабатывания правил. Процедура выбора сводится к определению
направления поиска и способа его осуществления. Процедуры, реализующие по-
иск, обычно «зашиты» в механизм вывода, поэтому в большинстве систем инже-
неры знаний не имеют к ним доступа и, следовательно, не могут в них ничего из-
менять по своему желанию.
При разработке стратегии управления выводом важно определить два вопроса:
1. Какую точку в пространстве состояний принять в качестве исходной? От вы-
бора этой точки зависит и метод осуществления поиска — в прямом или об-
ратном направлении.
2. Какими методами можно повысить эффективность поиска решения? Эти ме-
тоды определяются выбранной стратегией перебора — глубину, в ширину, по
подзадачам или иначе.
Прямой и обратный вывод
При обратном порядке вывода вначале выдвигается некоторая гипотеза, а затем
механизм вывода как бы возвращается назад, переходя к фактам, пытаясь найти
1.3. Представление знаний и вывод на знаниях
29
те, которые подтверждают гипотезу (рис. 1.5, правая часть). Если она оказалась
правильной, то выбирается следующая гипотеза, детализирующая первую и яв-
ляющаяся по отношению к ней подцелью. Далее отыскиваются факты, под-
тверждающие истинность подчиненной гипотезы. Вывод такого типа называется
управляемым целями, или управляемым консеквентами. Обратный поиск приме-
няется в тех случаях, когда цели известны и их сравнительно немного.
Обратный вывод
Прямой вывод
Рис. 1.5. Стратегии вывода
В системах с прямым выводом по известным фактам отыскивается заключение,
которое из этих фактов следует (см. рис. 1.5, левая часть). Если такое заключение
удается найти, то оно заносится в рабочую память. Прямой вывод часто называют
выводом, управляемым данными, или выводом, управляемым антецедентами.
Существуют системы, в которых вывод основывается на сочетании упомянутых
выше методов — обратного и ограниченного прямого. Такой комбинированный
метод получил название циклического.
Пример 1.5
Имеется фрагмент базы знаний из двух правил:
Ш. Если «отдых — летом» и «человек — активный», то «ехать в горы».
П2. Если «любит солнце», то «отдых летом».
Предположим, в систему поступили факты — «человек активный» и «любит солнце».
ПРЯМОЙ ВЫВОД — исходя из фактических данных, получить рекомендацию.
30
Глава 1 « Введение в интеллектуальные системы
1-й проход.
Шаг 1. Пробуем П1, не работает (не хватает данных «отдых — летом»).
Шаг 2. Пробуем 772, работает, в базу поступает факт «отдых — летом».
2-й проход.
Шаг 3. Пробуем П1, работает, активируется цель «ехать в горы», которая и выступает
как совет, который дает ЭС.
ОБРАТНЫЙ ВЫВОД — подтвердить выбранную цель при помощи имеющихся правил
и данных.
1-й проход.
Шаг 1. Цель — «ехать в горы»: пробуем П1 — данных «отдых — летом» нет, они стано-
вятся новой целью и ищется правило, где цель в левой части.
Шаг 2. Цель «отдых — летом»: правило П2 подтверждает цель и активирует ее.
2-й преход.
Шаг 3. Пробуем П1, подтверждается искомая цель.
Методы поиска в глубину и ширину
В системах, база знаний которых насчитывает сотни правил, желательным явля-
ется использование стратегии управления выводом, позволяющей минимизиро-
вать время поиска решения и тем самым повысить эффективность вывода. К чис-
лу таких стратегий относятся: поиск в глубину, поиск в ширину, разбиение на
подзадачи и альфа-бета алгоритм [Таунсенд, Фохт, 1991; Уэно, Исидзука, 1989;
Справочник по ИИ, 1990].
При поиске в глубину в качестве очередной подцели выбирается та, которая со-
ответствует следующему, более детальному уровню описания задачи. Например,
диагностирующая система, сделав на основе известных симптомов предположе-
ние о наличии определенного заболевания, будет продолжать запрашивать уточ-
няющие признаки и симптомы этой болезни до тех пор, пока полностью не опро-
вергнет выдвинутую гипотезу.
При поиске в ширину, напротив, система вначале проанализирует все симптомы,
находящиеся на одном уровне пространства состояний, даже если они относятся
к разным заболеваниям, и лишь затем перейдет к симптомам следующего уровня
детальности.
Разбиение на подзадачи — подразумевает выделение подзадач, решение которых
рассматривается как достижение промежуточных целей на пути к конечной цели.
Примером, подтверждающим эффективность разбиения на подзадачи, является
поиск неисправностей в компьютере — сначала выявляется отказавщая подсисте-
ма (питание, память и т. д.), что значительно сужает пространство поиска. Если
удается правильно понять сущность задачи и оптимально разбить ее на систему
иерархически связанных целей-подцелей, то можно добиться того, что путь к ее
решению в пространстве поиска будет минимален.
Альфа-бета алгоритм позволяет уменьшить пространство состояний путем уда-
ления ветвей, неперспективных для успешного поиска. Поэтому просматривают-
ся только те вершины, в которые можно попасть в результате следующего шага,
1.4. Нечеткие знания
31
после чего неперспективные направления исключаются. Альфа-бета алгоритм
нашел широкое применение в основном в системах, ориентированных на различ-
ные игры, например в шахматных программах.
1.4. Нечеткие знания
При попытке формализовать человеческие знания исследователи вскоре столк-
нулись с проблемой, затруднявшей использование традиционного математиче-
ского аппарата для их описания. Существует целый класс описаний, оперирую-
щих качественными характеристиками объектов (много, мало, сильный, очень
сильный и т. п.). Эти характеристики обычно размыты и не могут быть однознач-
но интерпретированы, однако содержат важную информацию (например, «Од-
ним из возможных признаков гриппа является высокая температура»).
Кроме того, в задачах, решаемых интеллектуальными системами, чаёто прихо-
дится пользоваться неточными знаниями, которые не могут быть интерпретиро-
ваны как полностью истинные или ложные (логические true/false или 0/1). Су-
ществуют знания, достоверность которых выражается некоторой промежуточной
цифрой, например 0.7.
Как, не разрушая свойства размытости и неточности, представлять подобные зна-
ния формально? Для разрешения таких проблем в начале 70-х американский ма-
тематик Лотфи Заде предложил формальный аппарат нечеткой (fuzzy) алгебры и
нечеткой логики [Заде, 1972]. Позднее это направление получило широкое рас-
пространение [Орловский, 1981; Аверкин и др., 1986; Яшин, 1990] и положило на-
чало одной из ветвей ИИ под названием — мягкие вычисления (soft computing).
Л. Заде ввел одно из главных понятий в нечеткой логике — понятие лингвисти-
ческой переменной.
Лингвистическая переменная (ЛП) — это переменная, значение которой определяется
набором вербальных (то есть словесных) характеристик некоторого свойства.
Например, ЛП «рост» определяется через набор {карликовый, низкий, средний,
высокий, очень высокий}.
1.4.1. Основы теории нечетких множеств
Значения лингвистической переменной (ЛП) определяются через так называе-
мые нечеткие множества (НМ), которые в свою очередь определены на некото-
ром базовом наборе значений или базовой числовой шкале, имеющей размер-
ность. Каждое значение ЛП определяется как нечеткое множество (например,
НМ «низкий рост»).
Нечеткое множество определяется через некоторую базовую шкалу В и функцию
принадлежности НМ — ц(х), хе В, принимающую значения на интервале [0...1].
Таким образом, нечеткое множество В — это совокупность пар вида (х, ц(х)), где
хе В. Часто встречается и такая запись:
32
Глава 1 • Введение в интеллектуальные системы
И V
£ н(*()
где х. — i-e значение базовой шкалы.
Функция принадлежности определяет субъективную степень уверенности экс-
перта в том, что данное конкретное значение базовой шкалы соответствует опре-
деляемому НМ. Эту функцию не стоит путать с вероятностью, носящей объек-
тивный характер и подчиняющейся другим математическим зависимостям.
Например, для двух экспертов определение НМ «высокая» для ЛП «цена автомо-
биля» в условных единицах может существенно отличаться в зависимости от их
социального и финансового положения.
«Высокая_цена_автомобиля_1» = {50000/1 + 25000/0.8 + 10000/0.6 + 5000/0.4}.
«Высокая_цена_автомобиля_2» = {25000/1 + 10000/0.8 + 5000/0.7 + 3000/0.4}
Пример 1.6
Пусть перед нами стоит задача интерпретации значений ЛП «возраст», таких как «мо-
лодой» возраст, «преклонный» возраст или «переходный» возраст. Определим «воз-
раст» как ЛП (рис. 1.6). Тогда «молодой», «преклонный», «переходный» будут значе-
ниями этой лингвистической переменной. Более полно, базовый набор значений ЛП
«возраст» следующий:
В = {младенческий, детский, юный, молодой, зрелый, преклонный, старческий}.
Рис. 1.6. Лингвистическая переменная «возраст» и нечеткие множества,
определяющие ее значения
Для ЛП «возраст» базовая шкала — это числовая шкала от 0 до 120, обозначающая ко-
личество прожитых лет, а функция принадлежности определяет, насколько мы увере-
ны в том, что данное количество лет можно отнести к данной категории возраста. На
рйс. 1.7 отражено, как одни и те же значения базовой шкалы могут участвовать в опре-
делении различных НМ.
Рис. 1.7. Формирование нечетких множеств
1.4. Нечеткие знания
33
Например, определить значение НМ «младенческий возраст» можно так:
[0.5 1 2 3 4 5 10]
jT + - + - + - + - + - + -J.
Рисунок 1.8 иллюстрирует оценку НМ неким усредненным экспертом, который ребен-
ка до полугода с высокой степенью уверенности относит к младенцам (m - 1). Дети до
четырех лет причисляются к младенцам тоже, но с меньшей степенью уверенности
(0.5< го <0.9), а в десять лет ребенка называют так только в очень редких случаях — к
примеру, для девяностолетней бабушки и 15 лет может считаться младенчеством. Та-
ким образом, нечеткие множества позволяют при определении понятия учитывать
субъективные мнения отдельных индивидуумов.
Рис. 1.8. График функции принадлежности нечеткому множеству «младенческий возраст»
1.4.2. Операции с нечеткими знаниями
Для операций с нечеткими знаниями, выраженными при помощи лингвистичес-
ких переменных, существует много различных способов. Эти способы являются в
основном эвристиками. Мы не будем останавливаться на этом вопросе подробно,
укажем лишь для примера определение нескольких операций. К примеру, опера-
ция «ИЛИ» часто задается так [Аверкин и др., 1986; Яшин, 1990]:
д(х) = тах(д1(х), д2(х))
(так называемая логика Заде) или так:
д(х) = Д1(х) + д2(х) - д1(х)* д2(х)
(вероятностный подход).
Усиление или ослабление лингвистических понятий достигается введением спе-
циальных квантификаторов. Например, если понятие «старческий возраст»
определяется как
60 70 80 90
----1------1-----1---
0.6 0.8 0.9 1
34
Глава 1 * Введение в интеллектуальные системы
то понятие «очень старческий возраст» определится как
соп(Л) = А2 = >
Т Я
то есть «очень старческий возраст» равен
60 70 80 90
0.36 0.64 0.81 . 1 ‘
Для вывода на нечетких множествах используются специальные отношения и
операции над ними (подробнее см. работу [Орловский, 1981]).
Одним из первых применений теории НМ стало использование коэффициентов
уверенности для вывода рекомендаций медицинской системы MYCIN [Shortliffe,
1976]. Этот метод использует несколько эвристических приемов. Он стал приме-
ром обработки нечетких знаний, повлиявших на последующие системы.
В настоящее время в большинство инструментальных средств разработки систем,
основанных на знаниях, включены элементы работы с НМ, кроме того, разработа-
ны специальные программные средства реализации так называемого нечеткого
вывода, например «оболочка» FuzzyCLIPS.
1.5. Прикладные интеллектуальные системы
Центральная парадигма интеллектуальных технологий сегодня — это обработка
знаний. Системы, ядром которых является база знаний или модель предметной
области, описанная на языке сверхвысокого уровня, приближенном к естествен-
ному, называют интеллектуальными. Будем называть такой язык сверхвысоко-
го уровня — языком представления знаний (ЯПЗ). Чаще всего интеллектуальные
системы (ИС) применяются для решения сложных задач, где основная сложность
решения связана с использованием слабо-формализованных знаний специалис-
тов-практиков и где логическая (или смысловая) обработка информации пре-
валирует над вычислительной. Например, понимание естественного языка, под-
держка принятия решения в сложных ситуациях, постановка диагноза и реко-
мендации по методам лечения, анализ визуальной информации, управление дис-
петчерскими пультами и др.
Фактически сейчас прикладные интеллектуальные системы используются в де-
сятках тысяч приложений. А годовой доход от продаж программных и аппарат-
ных средств искусственного интеллекта еще в 1989 г. в США составлял 870 млн
долларов, а в 1990 г. — 1,1 млрд долларов [Попов, 1996]. В дальнейшем почти
тридцатипроцентный прирост дохода сменился более плавным наращиванием
темпов (по материалам [Поспелов, 1997; Хорошевский, 1997; Попов, 1996;
Walker, Miller, 1987; Tuthill, 1994, Durkin, 1998]).
На рис. 1.9 отражены различные аспекты состояния рынка искусственного интел-
лекта: инвестиции в разработку в области ИИ (США, Европа, Япония) (рис. 1.9, а);
доля систем ИИ в информатике (программном обеспечении) (рис. 1.9, б); доходы
от продаж традиционных Языков программирования (рис. 1.9, в); инвестиции
1.5. Прикладные интеллектуальные системы
35
только в программное обеспечение (США) (рис. 1.9, г); инвестиции в аппаратное
обеспечение (США) (рис. 1.9, д); структура рынка ЭС (США, 1993) (рис. 1.9, е).
220
100
80
Прирост % гад
б
млн $
Европа
Япония
США
1984 87 89 91 93
г
Другие
приложения
Военное
депо
Рис.1.9. Состояние и перспективы рынка ИИ
Программный
инструментарий
Медицина
и образование
16%
20%
13%
Финансы
Информатика
Промышленность
16%
23%
12%
10%
Наиболее распространенным видом ИС являются экспертные системы.
Экспертные системы (ЭС) — это наиболее распространенный класс ИС, ориентирован-
ный на тиражирование опыта высококвалифицированных специалистов в областях, где
качество принятия решений традиционно Зависит от уровня экспертизы, например, ме-
дицина, юриспруденция, геология, экономика, военное дело и др.
. ЭС эффективны лишь в специфических «экспертных» областях, где важен эмпи-
рический опыт специалистов.
Только в США ежегодный доход от продаж инструментальных средств разработ-
ки ЭС составлял в начале 90-х годов 300-400 млн долларов, а от применения
ЭС — 80-90 млн долларов [Попов, 1996]. Ежегодно крупные фирмы разрабаты-
вают десятки ЭС типа «in-house» для внутреннего пользования. Эти системы ин-
тегрируют оцыт специалистов компании по ключевым и стратегически важным
технологиям. В начале 90-х гг. появилась новая наука — «менеджмент знаний»
36
Глава 1 • Введение в интеллектуальные системы
(knowledge management), ориентированная на методы обработки и управления
корпоративными знаниями (см. главу 5).
Современные ЭС — это сложные программные комплексы, аккумулирующие зна-
ния специалистов в конкретных предметных областях и распространяющие этот
эмпирический опыт для консультирования менее квалифицированных пользо-
вателей. Разработка экспертных систем, как активно развивающаяся ветвь ин-
форматики, направлена на использование ЭВМ для обработки информации в
тех областях науки и техники, где традиционные математические методы моде-
лирования малопригодны. В этих областях важна смысловая и логическая обра-
ботка информации, важен опыт экспертов.
Приведем некоторые условия, которые могут свидетельствовать о необходимо-
сти разработки и внедрения экспертных систем (частично из [Уотермен, 1989]):
• нехватка специалистов, затрачивающих значительное время для оказания по-
мощи другим;
• выполнение небольшой задачи требует многочисленного коллектива специа-
листов, поскольку ни один из них не обладает достаточным знанием;
• сниженная производительность, поскольку задача требует полного анализа
сложного набора условий, а обычный специалист не в состоянии просмотреть
(за отведенное время) все эти условия;
• большое расхождение между решениями самых хороших и самых плохих ис-
полнителей;
• наличие конкурентов, имеющих преимущество в силу того, что они лучше
справляются с поставленной задачей.
Подходящие задачи имеют следующие характеристики:
• являются узкоспециализированными;
• не зависят в значительной степени от общечеловеческих знаний или сооб-
ражений здравого смысла;
• не являются для эксперта ни слишком легкими, ни слишком сложными.
(Время, необходимое эксперту для решения проблемы, может составлять
от трех часов до трех недель.)
Экспертные системы достаточно молоды — первые системы такого рода, MYCIN
[Shortliffe, 1976] и DENDRAL [Buchanan, Feigenbaum, 1978], появились в США в
середине 70-х годов. В настоящее время в мире насчитывается несколько тысяч
промышленных ЭС, которые дают советы:
• при управлении сложными диспетчерскими пультами, например сети распре-
деления электроэнергии, — Alarm Analyser [Walker, Miller, 1987];
• при постановке медицинских диагнозов — ARAMIS [Shortliffe, Buchanan, Fei-
genbaum, J.979], NEUREX [Reggia, 1988];
• при поиске' неисправностей в электронных приборах, диагностика отказов
контрольно-измерительного оборудования — Intelligence Ware [Slagle, Gardi-
ner, Kyungsook, 1990], Plant Diagnostics [Уотермен, 1989], FOREST [Finin,
McAdams, Kleinosky, 1984];
1.5. Прикладные интеллектуальные системы
37
• по проектированию интегральных микросхем — DAA [Сойер, Фостер, 1988],
NASL [Walker, Miller, 1988], QO [Pega, Sticklen, Bond, 1993];
• по управлению перевозками — AIRPLAN [Masui, McDermott, 1983];
• по прогнозу военных действий — ANALYST [Bonasso, 1984], BATTLE [Slagle,
Gaynor, 1983];
• по формированию портфеля инвестиций, оценке финансовых рисков — RAD
[Kestelyn,1992], налогообложению — RUNE [Durkin, 1998] и т. д.
Наиболее популярные приложения ИС отображены на рис. 1.10 [Durkin, 1998].
Сейчас легче назвать области, где еще нет ЭС, чем те, где они уже применяются.
Уже в 1987 г. опрос пользователей, проведенный журналом «Intelligent Techno-
logies» (США), показал, что примерно:
• 25 % пользователей используют ЭС;
• 25 % собираются приобрести ЭС в ближайшие 2-3 года;
, • 50 % предпочитают провести исследование об эффективности их использова-
ния.
Главное отличие ИС и ЭС от других программных средств — это наличие базы
знаний (БЗ), в которой знания хранятся в форме, понятной специалистам пред-
метной области, и могут быть изменены и дополнены также в понятной форме.
Это и есть языки представления знаний — ЯПЗ.
До последнего времени именно различные ЯПЗ были центральной проблемой
при разработке ЭС. Сейчас существуют десятки языков или моделей представ-
ления знаний (см. параграф 1.3). Наибольшее распространение получили следу-
ющие модели:
• продукции (OPS5 [Forgy, 1981], ROSIE [Fain, Hayes-Roth, Sowizral, Water-
man, 1982]);
38
Глава 1 » Введение в интеллектуальные системы
• семантические сети (SIMER+MIR [Осипов, 1997]; NET [Цейтин, 1985]);
• фреймы (FRL [Байдун, Бунин, 1988; Справочник по ИИ, 1990]);
• логическое программирование (ПРОЛОГ [Макалистер, 1990; Стерлинг, Ша-
пиро, 1990]);
• объектно-ориентированные языки (SMALLTALK [Goldberg, Robson, 1983;
Буч, 1993], CLOS [Pega, Sticklen, Bond, 1993]).
Для перечисленных выше моделей существует соответствующая математическая
нотация, разработаны системы программирования, реализующие эти ЯПЗ, и
имеется большое количество реальных коммерческих ЭС. Подробнее вопросы
программной реализации прикладных ЙС рассмотрены в главе 6.
Современное состояние разработок в области ЭС в России можно охарактеризо-
вать как стадию все возрастающего интереса среди широких слоев специалис-
тов — финансистов, топ-менеджеров, преподавателей, инженеров, медиков, пси-
хологов, программистов, лиргвистов. В последние годы этот интерес имеет пока
достаточно слабое материальное подкрепление — явная нехватка учебников и
специальной литературы, отсутствие символьных процессоров и рабочих стан-
ций, ограниченное финансирование исследований в этой области, слабый отече-
ственный рынок программных продуктов для разработки ЭС.
Поэтому появляется возможность распространения «подделок» под экспертные
системы в виде многочисленных диалоговых систем и интерактивных пакетов
прикладных программ, которые дискредитируют в глазах пользователей это чрез-
вычайно перспективное направление. Процесс создания экспертной системы тре-
бует участия высококвалифицированных специалистов в области искусственно-
го интеллекта, которых пока выпускает небольшое количество высших учебных
заведений страны.
Наибольшие трудности в разработке ЭС вызывает сегодня не процесс машинной
реализации систем, а домашинный этап анализ^ знаний и проектирования базы
знаний. Этим занимается специальная наука — инженерия знаний [Гаврилова,
Червинская, 1992; Adeli, 1994; Scott, Clayton, Gibson, 1994].
Современному состоянию этой науки и посвящены последующие главы этой
книги.
е Разработка систем,
основанных
на знаниях
□ Введение в экспертные системы. Определение и структура
□ Классификация систем, основанных на знаниях
□ Коллектив разработчиков
О Технология проектирования и разработки
2.1. Введение в экспертные системы.
Определение и структура
В качестве рабочего определения экспертной-системы примем следующее.
Экспертные системы (ЭС) — это сложные программные комплексы, аккумулирующие
знания специалистов в конкретных предметных областях и тиражирующие этот эмпири-
ческий опыт для консультаций менее квалифицированных пользователей.
Обобщенная структура экспертной системы представлена на рис. 2.1. Следует
учесть, что реальные ЭС могут иметь более сложную структуру, однако блоки,
изображенные на рисунке, непременно присутствуют в любой действительно эк-
спертной системе, поскольку представляют собой стандарт de facto структуры
современной ЭС.
В целом процесс функционирования ЭС можно представить следующим обра-
зом: пользователь, желающий получить необходимую информацию, через поль-
зовательский интерфейс посылает запрос к ЭС; решатель, пользуясь базой зна-
ний, генерирует и выдает пользователю подходящую рекомендацию, объясняя
ход своих рассуждений при помощи подсистемы объяснений.
40
Глава 2 » Разработка систем, основанных на знаниях
Пользователь
Эксперт
Инженер
по знаниям
Рис. 2.1. Структура экспертной системы
Так как терминология в области разработки ЭС постоянно модифицируется, оп-
ределим основные термины в рамках данной работы.
Пользователь — специалист предметной области, для которого предназначена си-
стема. Обычно его квалификация недостаточно высока, и поэтому он нуждается в
помощи и поддержке своей деятельности со стороны ЭС. (
Инженер по знаниям — специалист в области искусственного интеллекта, высту-
пающий в роли промежуточного буфера между экспертом и базой знаний. Сино-
нимы: когнитолог, инженер-интерпретатор, аналитик.
Интерфейс пользователя — комплекс программ, реализующих диалог пользова-
теля с ЭС как на стадии ввода информации, так и при получении результатов.
База знаний (БЗ) — ядро ЭС, совокупность знаний предметной области, записан-
ная на машинный носитель в форме, понятной эксперту и пользователю (обычно
на некотором языке, приближенном к естественному). Параллельно такому «че-
ловеческому» представлению существует БЗ во внутреннем «машинном» пред-
ставлении.
Решатель — программа, моделирующая ход рассуждений эксперта на основании
знаний, имеющихся в БЗ. Синонимы: дедуктивная машина, машина вывода, блок
логического вывода.
Подсистема объяснений — программа, позволяющая пользователю получить от-
веты на вопросы: «Как была получена та или иная рекомендация?» и «Почему
сиЦт^алгриняла такое решение?» Ответ на вопрос «как» — это трассировка всего
процерсд получения решения с указанием использованных фрагментов БЗ, то
есть всех йагов цепи умозаключений. Ответ на вопрос «почему» — ссылка на умо-
заключение, Непосредственно предшествовавшее полученному решению, то есть
отход на одийчнаг назад. Развитые подсистемы объяснений поддерживают и дру-
гие типы вопросов.
Интеллектуальный редактор БЗ — программа, представляющая инженеру по
знаниям возможность создавать БЗ в диалоговом режиме. Включает в себя
систему вложенных меню, шаблонов языка представления знаний, подсказок
(«help» — режим) и других сервисных средств, облегчающих работу с базой.
2.2. Классификация систем, основанных на знаниях
41
Еще раз следует подчеркнуть, что представленная на рис. 2.1 структура является
минимальной, что означает обязательное присутствие указанных на ней блоков.
Если система объявлена разработчиками как экспертная, только наличие всех
этих блоков гарантирует реальное использование аппарата обработки знаний.
Однако промышленные прикладные ЭС могут быть существенно сложнее и до-
полнительно включать базы данных, интерфейсы обмена данными с различными
пакетами прикладных программ, электронными библиотеками и т. д.
2.2. Классификация систем, основанных
на знаниях
Класс ЭС сегодня объединяет несколько тысяч различных программных комп-
лексов, которые можно классифицировать по различным критериям. Полезными
могут оказаться классификации, представленные на рис. 2.2.
Рис. 2.2. Классификация экспертных систем
2.2.1. Классификация по решаемой задаче
Рассмотрим указанные на рисунке типы задач подробнее.
• Интерпретация данных. Это одна из традиционных задач для экспертных сис-
тем. Под интерпретацией понимается процесс определения смысла данных,
результаты которого должны быть согласованными и корректными. Обычно
предусматривается многовариантный анализ данных.
42
Глава 2 • Разработка систем, основанных на знаниях
♦ Все примеры далее из работ [Попов и Др., (ред.), 1990; Соловьев, Соловьева,
1989; Хейес-Рот и др., 1987].
♦ Обнаружение и идентификация различных типов океанских судов по ре-
зультатам аэрокосмического сканирования — SIAP;
♦ определение основных свойств личности по результатам психодиагности-
ческого тестирования в системах АВТАНТЕСТ и МИКРОЛЮШЕР и др.
• Диагностика. Под диагностикой понимается процесс соотнесения объекта с
некоторым классом объектов й/или обнаружение неисправности в некоторой
системе. Неисправность — это отклонение от нормы. Такая трактовка поз-
воляет с единых теоретических позиций рассматривать и нейсправнбсть обо-
рудования в технических системах, и заболевания живых организмов, и все-
возможные природные аномалии. Важной спецификой является здесь
необходимость понимания функциональной структуры («анатомии») ди-
агностирующей системы.
♦ Диагностика и терапия сужения коронарных сосудов — ANGY;
♦ диагностика ошибок в аппаратуре и математическом обеспечении ЭВМ —
система CRIB и др.
• Мониторинг. Основная задача мониторинга — непрерывная интерпретация
данных в реальном масштабе времени и сигнализация о выходе тех или иных
параметров за допустимые пределы. Главные проблемы — «пропуск» тревож-
ной ситуации и инверсная задача «ложного» срабатывания. Сложность этих
проблем в размытости симптомов тревожных ситуаций и необходимость уче-
та временного контекста.
♦ Контроль за работой электростанций СПРИНТ, помощь диспетчерам атом-
ного реактора — REACTOR;
♦ контроль аварийных датчиков на химическом заводе — FALCON и др,
• Проектирование. Проектирование состоит в подготовке спецификаций на со-
здание «объектов» с заранее определенными свойствами. Под, спецификацией
понимается весь набор необходимых документов — чертёж, пояснительная за-
писка и т. д. Основные проблемы здесь — получение четкого структурного
описания знаний об объекте и проблема «следа». Для организации эффектив-
ного проектирования и в еще большей степени перепроектирования необхо-
димо формировать не только сами проектные решения, но и мотивы их приня-
тия. Таким образом, в задачах проектирования тесно связываются два основ-
ных процесса, выполняемых в рамках соответствующей ЭС: процесс вывода
. решения и процесс объяснения. ; А
♦ Проектирование конфигураций ЭВМ VAX — 11/780 в системе XCON (или
R1), проектирование БИС — CADHELP;
♦ синтез электрических цепей — SYN и др.,
2.2. Классификация систем, основанных на знаниях
43
• Прогнозирование. Прогнозирование позволяет предсказывать последствия не-
которых событий или явлений на основании анализа имеющихся данных.
Прогнозирующие системы логически выводят вероятные следствия из задан-
ных ситуаций. В прогнозирующей системе обычно используется параметри-
ческая динамическая модель, в которой значения параметров «подгоняются»
под заданную ситуацию. Выводимые из этой модели следствия составляют
основу для прогнозов с вероятностными оценками.
♦ Предсказание погоды — система WILLARD;
♦ оценки будущего урожая — PLANT;
♦ прогнозы в экономике — ECON и др.
• Планирование. Под планированием понимается нахождение планов действий,
относящихся к объектам, способным выполнять некоторые функции. В таких
ЭС используются модели поведения реальных объектов с тем, чтобы логичес-
ки вывести последствия планируемой деятельности.
♦ Планирование поведения робота — STRIPS;
♦ планирование промышленных заказов — ISIS;
♦ планирование эксперимента — MOLGEN и др.
• Обучение. Под обучением понимается использование компьютера для обуче-
ния какой-то дисциплине или предмету. Системы обучения диагностируют
ошибки при изучении какой-либо дисциплины с помощью ЭВМ и подсказы-
вают правильные решения. Они аккумулируют знания о гипотетическом
«ученике» и его характерных ошибках, затем в работе они способны диагнос-
тировать слабости в познаниях обучаемых и находить соответствующие сред-
ства для их ликвидации. Кроме того, они планируют акт общения с учеником
в зависимости от успехов ученика с целью передачи знаний.
♦ Обучение языку программирования ЛИСП в системе «Учитель ЛИСПа»;
♦ система PROUST — обучение языку Паскаль и др.
• Управление. Под управлением понимается функция организованной системы,
поддерживающая определенный режим деятельности. Такого рода ЭС осуще-
ствляют управление поведением сложных систем в соответствии с заданными
спецификациями.
♦ Помощь в управлении газовой котельной — GAS;
♦ управление системой календарного планирований Project Assistant и др.
• Поддержка принятия решений. Поддержка принятия решения — это совокуп-
ность процедур, обеспечивающая лицо, принимающее решения, необходимой
информацией и рекомендациями, облегчающими процесс принятия решения.
Эти ЭС помогают специалистам выбрать и/или сформировать нужную аль-
тернативу среди множества выборов при принятии ответственных решений.
44
Глава 2 » Разработка систем, основанных на знаниях
♦ Выбор стратегии выхода фирмы из кризисной ситуации — CRYSIS;
♦ помощь в выборе страховой компании или инвестора — CHOICE и др.
В общем случае все системы, основанные на знаниях, можно подразделить на си-
стемы, решающие задачи анализа, и на системы, решающие задачи синтеза. Основ-
ное отличие задач анализа от задач синтеза заключается в том, что если в задачах
анализа множество решений может быть перечислено и включено в систему, то в
задачах синтеза множество решений потенциально не ограничено и строится из
решений компонент или под-проблем. Задачами анализа являются: интерпрета-
ция данных, диагностика, поддержка принятия решения; к задачам синтеза отно-
сятся проектирование, планирование, управление. Комбинированные: обучение,
мониторинг, прогнозирование.
2.2.2. Классификация по связи с реальным
временем
• Статические ЭС разрабатываются в предметных областях, в которых база зна-
ний и интерпретируемые данные не меняются во времени. Они стабильны.
Пример
Диагностика неисправностей в автомобиле.
• Квазидинамические ЭС интерпретируют ситуацию, которая меняется с некото-
рым фиксированным интервалом времени.'
Пример
Микробиологические ЭС, в которых снимаются лабораторные измерения с технологи-
веского процесса один раз в 4-5 часов (производство лизина, например) и анализиру-
ется динамика полученных показателей по отношению к предыдущему измерению.
• Динамические ЭС работают в сопряжении с датчиками объектов в режиме ре-
ального времени с непрерывной интерпретацией поступающих в систему дан-
ных.
Примеры
Управление гибкими производственными комплексами, мониторинг в реанимацион-
ных палатах;
программный инструментарий для разработки динамических систем — G2 [Попов,
1996].
2.2.3. Классификация по типу ЭВМ
На сегодняшний день существуют:
• ЭС для уникальных стратегически важных задач на суперЭВМ (Эльбрус,
CRAY, CONVEX и др.);
• ЭС на ЭВМ средней производительности (типа ЕС ЭВМ, mainframe); .
2.3. Коллектив разработчиков
45
• ЭС на символьных процессорах и рабочих станциях (SUN, Silicon Graphics,
APOLLO);
• ЭС на мини- и супермин-ЭВМ (VAX, micro-VAX и др.); f
• ЭС на персональных компьютерах (IBM PC, MAC II и т. п.).
2.2.4. Классификация по степени интеграции
с другими программами
Автономные ЭС работают непосредственно в режиме консультаций с пользовате-
лем для специфически «экспертных» задач, для решения которых не требуется
привлекать традиционные методы обработки данных (расчеты, моделирование
и т. д.).
Гибридные ЭС представляют программный комплекс, агрегирующий стандарт-
ные пакеты прикладных программ (например, математическую статистику, ли-
нейное программирование или системы управления базами данных) и средства
манипулирования знаниями. Это может быть интеллектуальная надстройка над
ППП (пакетами прикладных программ) или интегрированная среда для реше-
ния сложной задачи с элементами экспертных знаний.
Несмотря на внешнюю привлекательность гибридного подхода, следует отме-
тить, что разработка таких систем являет собой задачу на порядок более сложную,
чем разработка автономной ЭС. Стыковка не просто разных пакетов, а разных
методологий (что происходит в гибридных системах) порождает целый комплекс
теоретических и практических трудностей.
2.3. Коллектив разработчиков
Под коллективом разработчиков (КР) будем понимать группу специалистов, от-
ветственных за создание ЭС.
Как видно из рис. 2.1, в состав КР входят по крайней мере три человека — пользо-
ватель, эксперт и инженер по знаниям. На рисунке не видно программиста. Та-
ким образом, минимальный состав КР включает четыре человека; реально же он
разрастается до 8-10 человек. Численное увеличение коллектива разработчиков
происходит по следующим причинам: необходимость учета мнения нескольких
пользователей, помощи нескольких экспертов; потребность как в проблемных,
так и системных программистах. На Западе в этот коллектив дополнительно тра-
диционно включают менеджера и одного технического помощника.
Если использовать аналогии из близких областей, то КР более всего схож с
группой администратора базы Данных при построений интегрированных, ин-
формационных систем или бригадой программистов, разрабатывающих слож-
ный программный комплекс. При отсутствии профессионального менеджера
руководителем КР, участвующим1 во всех стадиях разработки, является инженер
по знаниям, поэтому к его квалификации предъявляются самые высокие требо-
вания. В целом уровень и численность группы зависят от характеристик постав-
ленной задачи.
46
Глава 2 • Разработка систем, основанных на знаниях
Для обеспечения эффективности сотрудничества любой творческой группы, в
том числе и группы КР ЭС, необходимо возникновение атмосферы взаимопони-
мания и доверия, которое, в свою очередь, обусловлено психологической совмес-
тимостью членов группы; следовательно, при формировании КР должны учиты-
ваться психологические свойства участников.
В настоящий момент в психологии существует несколько десятков методик по
определению свойств личности, широко используемых в вопросах профессио-
нальной ориентации. Эти психодиагностические методики, часть из которых уже
автоматизирована, различаются направленностью, глубиной, временем опроса и
способами интерпретации. В частности, система ДВАНТЕСТ (Автоматический
Анализ ТЕСТов) [Гаврилова, 1984] позволяет моделировать рассуждения психо-
лога при анализе результатов тестирования по 16-факторному опроснику Р. Кэт-
тела и выдает связное психологическое заключение на естественном русском язы-
ке, характеризующее такие свойства личности, как общительность, аналитичность,
добросовестность, самоконтроль и т. п. Модифицированная база знаний системы
АВТАНТЕСТ позднее была использована в ЭС «Cattell» (см. параграф 7.3).
Ниже приведены два аспекта характеристик членов КР: 1 — психофизиологиче-
ский, 2 — профессиональный.
Пользователь
1. К пользователю предъявляются самые слабые требования, поскольку его не
выбирают. Он является в некотором роде заказчиком системы. Желательные
качества:
а) дружелюбие;
б) умение объяснить, что же он хочет от системы;
в) отсутствие психологического барьера к применению вычислительной тех-
ники; ’
г) интерес к новому. От пользователя зависит, будет ли применяться разра-
ботанная ЭС. Замечено, что наиболее ярко качества в) и г) проявляются в
молодом возрасте, поэтому иногда такие пользователи охотнее применяют
ЭС, не испытывая при этом комплекса неполноценности оттого, что ЭВМ
им что-то подсказывает.
2. Необходимо, чтобы пользователь имел некоторый базовый уровень квалифи-
кации, который позволит ему правильно истолковать рекомендации ЭС. Кро-
ме того, должна быть полная совместимость в терминологии интерфейса к ЭС
с той, которая привычна и удобна для пользователя. Обычно требования к ква-
лификации пользователя не очень велики, иначе он переходит в разряд экс-
пертов и совершенно не нуждается в ЭС:
, Эксперт
1. Эксперт — чрезвычайно важная фигура в группе КР. В конечном счете, его под-
готовка определяет уровень компетенции базы знаний. Желательные качества:
а) доброжелательность;
б) готовность поделиться своим опытом;
2.3, Коллектив разработчиков
47
в) умение объяснить (педагогические навыки);
г) заинтересованность (моральная, а лучше еще и материальная) в успешнос-
ти разработки. Возраст эксперта обычно почтенный, что необходимо учи-
тывать всем Членам группы. Часто встает вопрос о количестве экспертов.
Поскольку проблема совмещения подчас противоречивых знаний остается
открытой, обычно с каждым из экспертов работают индивидуально, иног-
да создавая альтернативные базы.
2. Помимо безусловно высокого профессионализма в выбранной предметной об-
ласти, желательно знакомство эксперта с популярной литературой по искус-
ственному интеллекту и экспертным системам для того, чтобы эффективнее
прошел этап извлечения знаний.
Программист
1. Известно, что программисты обладают самой низкой потребностью в общении
среди представителей разных профессий. Однако при разработке ЭС необхо-
дим тесный контакт членов группы, поэтому желательны следующие его каче-
ства:
а) общительность;
б) способность отказаться от традиционных навыков и освоить новые методы;
в) интерес к разработке.
2. Поскольку современные ЭС — сложнейшие и дорогостоящие программные ком-
плексы, программисты в КР должны иметь опыт и навыки разработки про-
грамм. Обязательно знакомство с основными структурами представления зна-
ний и механизмами вывода, состоянием отечественного и мирового рынка
программных продуктов для разработки ЭС и диалоговых интерфейсов.
Инженер по знаниям
1. Существуют такие профессии и виды деятельности, для которых природные
качества личности (направленность, способности, темперамент) могут иметь
характер абсолютного показания или противопоказания к занятиям. По-ви-
димому, инженерия знаний принадлежит к таким профессиям. По различным
оценкам, это одна из самых малочисленных, высокооплачиваемых и дефицит-
ных в мире специальностей. Попытаемся дать наброски к портрету инженера
по знаниям (без претензии на полноту и точность определений).
Пол. Психологи утверждают, что мужчины более склонны к широкому охвату
явлений и в среднем у них выше аналитичность, чрезвычайно полезная инже-
неру по знаниям, которому надо иметь развитое логическое мышление и уме-
ние оперировать сложными формальными структурами^ Кроме того, при об-
щении с экспертами, которые в большинстве своем настроены скептически по
отношению к будущей ЭС, инженер по знаниям-мужчина вызывает более
высокую мотивацию успешности со стороны эксперта-женщины. С другой
стороны, известно, что у женщин выше наблюдательность к отдельным дета-
лям объектов. Так что пол не является окончательным показанием или проти-
вопоказанием к данной профессии.
48
Глава 2 » Разработка систем, основанных на знаниях
Интеллект. Это понятие вызывает самые бурные споры психологов; суще-
ствует до 50 определений интеллекта, но с прагматической точки зрения оче-
видно, что специалист в области искусственного интеллекта должен стре-
миться к максимальным оценкам по тестам как вербального, так и невербаль-
ного интеллекта.
Стиль общения. Инженер по знаниям «задает тон» в общении с экспертом, он
ведет диалог, и от него в конечном счете зависит его продуктивность. Можно
выделить два стиля общения: деловой (или жесткий) и дружеский (или мяг-
кий, деликатный). Нам кажется, что дружеский будет заведомо более успеш-
ным, так как снижает «эффект фасада» у эксперта, раскрепощает его. Дели-
катность, внимательность, интеллигентность, ненавязчивость, скромность,
умение слушать и задавать вопросы, хорошая коммуникабельность и в то же
время уверенность в себе — вот рекомендуемый стиль общения. Безусловно,
что это дар и искусство одновременно, однако занятия по психологическому
тренингу могут дать полезные навыки.
Портрет инженера по знаниям можно было бы дополнить другими характери-
стиками — широтой взглядов и интересов, артистичностью, чувством юмора,
обаянием и т. д.
2. При определении профессиональных требований к аналитику следует учиты-
вать, что ему необходимы различные навыки и умения для грамотного и эф-
фективного проведения процессов извлечения, концептуализации и формали-
зации знаний.
Инженер по знаниям имеет дело со всеми формами знаний (см. параграф 1.3).
Z1 (знания в памяти) —> Z2 (знания в книгах) —> Z3 (поле знаний) —> Z4 (модель
знаний) —> Z5 (база знаний).
Работа на уровне Z1 требует от инженера по знаниям знакомства с элементами
когнитивной психологии и способами репрезентации понятий и процессов в па-
мяти человека, с двумя основными механизмами мышления — логическим и ас-
социативным, с такими способами активизации мышления как игры, мозговой
штурм и др., с различными моделями рассуждений.
Изучение и анализ текстов на уровне Z2 подразумевает широкую общенаучную
подготовку инженера; знакомство с методами реферирования и аннотирования
текстов; владение навыками быстрого чтения, а также текстологическими мето-
дами извлечения знаний.
Разработка поля знаний на уровне Z3 требует квалифицированного знакомства с
методологией представления знаний, системным анализом, теорией познания,
аппаратом многомерного шкалирования, кластерным и факторным анализом.
Разработка формализованного описания Z4 предусматривает предварительное
изучение аппарата математической логики и современных языков представле-
ния знаний. Модель знаний разрабатывается на основании результатов глубоко-
го анализа инструментальных средств разработки ЭС и имеющихся «оболочек».
Кроме того, инженеру по знаниям необходимо владеть методологией разработки
ЭС, включая методы быстрого прототипирования.
2.4. Технология проектирования и разработки
49
И наконец, реализация базы знаний Z5, в которой инженер по знаниям участвует
вместе с программистом, подразумевает овладение практическими навыками ра-
боты на ЭВМ и, возможно, одним из языков программирования.
Так как инженеров по знаниям «выращивают» из программистов, уровень Z5
обычно не вызывает затруднения, особенно если разработка ведется на традици-
онных языках типа С или Паскаль. Специализированные языки искусственного
интеллекта Лисп и Пролог требуют некоторой перестройки архаично-алгорит-
мического мышления.
Успешность выбора и подготовки коллектива разработчиков ЭС определяет эф-
фективность и продолжительность всего процесса разработки.
2.4. Технология проектирования
и разработки
2.4.1. Проблемы разработки промышленных ЭС
Разработка программных комплексов экспертных систем как за рубежом, так и в
нашей стране находится на уровне скорее искусства, чем науки. Это связано с тем,
что долгое время системы искусственного интеллекта внедрялись в основном во
время фазы проектирования, а чаще всего разрабатывалось несколько прототип-
ных версий программ, и на их основе уже создавался конечный продукт. Такой
подход действует хорошо в исследовательских условиях, однако в коммерческих
условиях он является слишком дорогим, чтобы оправдать затраты на разработку.
Процесс разработки промышленной экспертной системы, опираясь на тради-
ционные технологии [Николов и др., 1990; Хейес-Рот и др., 1987; Tuthill, 1994],
практически для любой предметной области можно разделить на шесть более или
менее независимых этапбв (рис. 2.3).
Рис. 2.3. Этапы разработки ЭС
50
Глава 2 • Разработка систем; основанных на знания*
Последовательность этапов: дана только с целью получения общего представле-
ния о процессе создания идеального проекта. Конечно, последовательность эта
не вполне фиксированная. В действительности каждый последующий этап раз-
работки может принести новые идеи, которые могут повлиять на предыдущие
решения и даже привести к их переработке. Именно поэтому многие специалис-
ты по информатике весьма критично относятся к методологии экспертных сис-
тем. Они считают, что расходы на разработку та^сих систем очень большие, время
разработки слишком велико, а полученные в результате программы накладыва-
ют тяжелое бремя на вычислительные ресурсы.
В целом за разработку экспертных систем целесообразно браться организации,
где накоплен опыт по автоматизации рутинных процедур обработки информа-
ции, таких как:
• формирование корпоративных информационных систем;
• организация сложных расчетов;
• работа с компьютерной графикой;
• обработка текстов и автоматизированный документооборот.
Решение таких задач, во-первых, подготавливает высококвалифицированных спе-
циалистов по информатике, необходимых для создания интеллектуальных систем,
во-вторых, позволяет отделить от экспертных систем неэкспертные задачи;
2.4.2. Выбор подходящей проблемы
Этот этап определяет деятельность, предшествующую решению начать разраба-
тывать конкретную ЭС. Он включает [Николов и др., 1990]:
• определение проблемной области и задачи;
• нахождение эксперта, желающего сотрудничать при решении проблемы, и на-
значение коллектива разработчиков;
• определение предварительного подхода к решению проблемы;
• анализ расходов и прибылей от разработки;
• подготовку подробного плана разработки.
Правильный выбор проблемы представляет самую критическую часть разработ-
ки в целом. Если выбрать неподходящую проблему, можно очень быстро увяз-
нуть в «болоте» проектирования задач, которые никто не знает, как решать. Не-
подходящая проблема может также привести к созданию экспертной системы,
которая стоит намного больше, чем экономит. Дело будет обстоять еще хуже,
если разработать систему, которая работает, но неприемлема для пользователей.
Даже если разработка выполняется самой организацией для собственных целей,
эта фаза является подходящим моментом для получения рекомендаций извне,
чтобы гарантировать удачно выбранный и осуществимый с технической точки
зрения первоначальный проект.
При выборе области применения следует учитывать, что если знание, необходи-
мое для решения задач, постоянное, четко формулируемое и связано с вычисли-
тельной обработкой, то обычные алгоритмические программы, по всей вероятно-
сти, будут самым целесообразным способом решения проблем в этой области.
2.4. Технология проектирования и разработки
51
Экспертная система Ни в коем случае не устранит потребность в реляционных
базах данных, статистическом программном обеспечении, электронных таблицах
и системах текстовой обработки. Но если результативность задачи зависит от
знания, которое является субъективным, изменяющимся, символьным или выте-
кающим частично из соображений здравого смысла, тогда область может обосно-
ванно выступать претендентом на экспертную систему.
Обычно экспертные системы разрабатываются путем получения специфических
знаний от эксперта и ввода их в систему. Некоторые системы могут содержать
стратегии одного индивида. Следовательно, найти подходящего эксперта — это
ключевой шаг в созданий экспертных систем.
В процессе разработки и последующего расширения системы инженер по знани-
ям и эксперт обычно работают вместе. Инженер по знаниям помогает эксперту
структурировать знания, определять и формализовать понятия и правила, необ-
ходимые для решения проблемы.
Во время первоначальных бесед они должны решить, будет ли их сотрудничество
успешным. Это немаловажно, поскольку обе стороны будут работать совместно,
по меньшей мере в течение одного года. Кроме них в коллектив разработчиков це-
лесообразно включить потенциальных пользователей и профессиональных про-
граммистов. Подробно функции каждого члена коллектива описаны в следую-
щем параграфе.
Предварительный подход к программной реализации задачи определяется, ис-
ходя из характеристик задачи и ресурсов, выделенных на ее решение. Инженер
по знаниям выдвигает обычно несколько вариантов, связанных с использовани-
ем имеющихся на рынке программных средств. Окончательный выбор возможен
лишь на этапе разработки прототипа.
После того как задача определена, необходимо подсчитать расходы и прибыль от
разработки экспертной системы. В расходы включаются затраты на оплату труда
коллектива разработчиков. В дополнительные расходы будет включена сто-
имость приобретаемого программного инструментария, с помощью которого бу-
дет разработана экспертная система.
Прибыль может быть получена за счет снижения цены продукции, повышения
производительности труда, расширения номенклатуры продукции или услуг или
даже разработки новых видов продукции или услуг в области, в которой будет
использоваться ЭС. Соответствующие расходы и прибыль от системы определя-
ются относительно времени, в течение которого возвращаются средства, вложен-
ные в разработку. На современном этапе большая часть фирм, развивающих
крупные экспертные системы, предпочли разрабатывать дорогостоящие проекты,
приносящие значительную прибыль.
Можно ожидать развития тенденции разработки менее дорогостоящих систем,
хотя и с более длительным сроком окупаемости вложенных в них средств, так как
программные средства разработки экспертных систем непрерывно совершен-
ствуются.
После того как инженер по знаниям убедился, что:
данная задача может быть решена с помощью экспертной системы;
• экспертную систему можно создать предлагаемыми на рынке средствами;
52
Глава 2 » Разработка систем, основанных на знаниях
• имеется подходящий эксперт;
• предложенные критерии производительности являются разумными;
• затраты и срок их окупаемости приемлемы для заказчика,
он составляет план разработки. План определяет шаги процесса разработки и не-
обходимые затраты, а также ожидаемые результаты.
2.4.3. Технология быстрого прототипирования
Прототипная система является усеченной версией экспертной системы, спроек-
тированной для проверки правильности кодирования фактов, связей и стратегий
рассуждения эксперта. Она также дает возможность инженеру по знаниям при-
влечь эксперта к активному участию в процессе разработки экспертной системы,
и, следовательно, к принятию им обязательства приложить все усилия к созда-
нию системы в полном объеме.
Объем прототипа — несколько десятков правил, фреймов или примеров. На
рис. 2.4 изображено шесть стадий разработки прототипа и минимальный коллек-
тив разработчиков, занятых на каждой из стадий (пять стадий заимствовано из
работы [Хейес-Рот и др., 1987]). Приведем краткую характеристику каждой из
стадий, хотя эта схема представляет собой грубое приближение к сложному, ите-
ративному процессу.
©
Инженер по
знаниям
© @
Эксперт Программист
©
Пользователь
Рис. 2.4. Стадии разработки прототипа ЭС
2.4, Технология проектирования и разработки
53
Хотя любое теоретическое разделение бывает часто условным, осознание кол-
лективом разработчиков четких задач каждой стадии представляется целесооб-
разным. Роли разработчиков (эксперт, программист, пользователь и аналитик)
являются постоянными на протяжении всей разработки. Совмещение ролей не-
желательно.
Сроки приведены условно, так как зависят от квалификации специалистов и осо-
бенностей задачи.
Идентификация проблемы
Уточняется задача, планируется ход разработки прототипа экспертной системы,
определяются:
• необходимые ресурсы (время, люди, ЭВМ и т. д.);
• источники знаний (книги, дополнительные эксперты, методики);
• имеющиеся аналогичные экспертные системы;
• цели (распространение опыта, автоматизация рутинных действий и др.);
• классы решаемых задач и т. д.
Идентификация проблемы — знакомство и обучение членов коллектива разработчиков, а
также создание неформальной формулировки проблемы.
Средняя продолжительность 1-2 недели.
Извлечение знаний
На этой стадии происходит перенос компетентности от эксперта к инженеру по
знаниям, с использованием различных методов (см. главу 4):
• анализ текстов;
• диалоги;
• экспертные игры;
• лекции;
• дискуссии;
• интервью;
• наблюдение и другие.
Извлечение знаний — получение инженером по знаниям наиболее полного из возможных
представлений о предметной области и способах принятия решения в ней.
Средняя продолжительность 1-3 месяца.
Структурирование или концептуализация знаний
Выявляется структура полученных знаний о предметной области, то есть опреде-
ляются:
• терминология;
• список основных понятий и их атрибутов;
54
Глава 2 • Разработка систем, основанных на знаниях
• отношения между понятиями;
• ' структура входной и выходной информации; *
• стратегия принятия решений;
• ограничения стратегий и т. д.
Структурирование (или концептуализация) знаний — разработка неформального опи-
сания знаний о предметной области в виде графа, таблицы, диаграммы или текста, ко-
торое отражает основные концепции и взаимосвязи между понятиями предметной об-
ласти.
Такое описание называется полем знаний. Средняя продолжительность этапа 2-4
недели. Подробно стадия структурирования описана в главе 3.
Формализация
Строится формализованное представление концепций предметной области на
основе выбранного языка представления знаний (ЯПЗ). Традиционно на этом
этапе используются:
• логические методы (исчисления предикатов 1-го порядка и др.);
• продукционные модели (с прямым и обратным выводом);
• семантические сети;
• фреймы;
• объектно-ориентированные языки, основанные на иерархии классов, объек-
тов.
Формализация знаний — разработка базы зйанйй на языке представления знаний, ко-
торый, с одной стороны, соответствует структуре поля знаний, а с другой — позволяет
реализовать прототип системы на следующей стадии программной реализации.
Все чаще на этой стадии используется симбиоз языков представления знаний,
например, в системе ОМЕГА [Справочник по ИИ, 1990] — фреймы + семанти-
ческие сети + полный набор возможностей языка исчисления предикатов. Сред-
няя продолжительность 1-2 месяца. Подробно см. в главах 3, 4.
Реализация
Создается прототип экспертной системы, включающий базу знаний и остальные
блоки, при помощи одного из следующих способов:
• программирование на традиционных языках типа Pascal, C++ и др.;
• программирование на специализированных языках, применяемых в задачах
искусственного интеллекта: LISP [Хювянен, Сеппянен, 1991], FRL [Байдун,
Бунин, 1990], SMALLTALK [Справочник по ИИ, 1990] и др.;
• использование инструментальных средств разработки ЭС типа СПЭИС [Ков-
ригин, Перфильев, 1988], ПИЭС [Хорошевский, 1993], G2 [Попов, Фоминых,
Кисель, 1996];
2,4. Технология проектирования и разработки
• использование «пустых» ЭС или «оболочек» типа ЭКСПЕРТ [Кирсанов, По-
пов, 1990], ФИАКР [Соловьев, Соловьева, 1989] и др.
Реализация — разработка программного комплекса, демонстрирующего жизнеспособ-
ность подхода в целом. Чаще всего первый прототип отбрасывается на этапе реализации
действующей ЭС.
Средняя продолжительность 1-2 месяца. Более подробно эти вопросы рассмат-
риваются в главе 6.
Тестирование
Оценивается и проверяется работа программ прототипа с целью приведения в
соответствие с реальными запросами пользователей. Прототип проверяется на:
• удобство и адекватность интерфейсов ввода/вывода (характер вопросов в ди-
алоге, связность выводимого текста результата и др.);
• эффективность стратегии управления (порядок перебора, использование не-
четкого вывода и др.);
• качество проверочных примеров;
• корректность базы знаний (полнота и непротиворечивость правил).
Тестирование — выявление ошибок в подходе и реализации прототипа и выработка реко-
мендаций по доводке системы до-промышленного варианта.
Средняя продолжительность 1-2 недели.
2.4.4. Развитие прототипа до промышленной ЭС
При неудовлетворительном функционировании прототипа эксперт и инженер по
знаниям имеют возможность оценить, что именно будет включено в разработку
окончательного варианта системы.
Если первоначально выбранные объекты или свойства оказываются неподходя-
щими, их необходимо изменить. Можно сделать оценку общего числа эвристи-
ческих правил, необходимых для создания окончательного варианта экспертной
системы. Иногда [Хювянен, Сеппянен, 1991] при разработке промышленной и/
или коммерческой системы выделяют дополнительные этапы для перехода
(табл. 2.1).
демонстрационный прототип —> действующий прототип —> промышленная система —>
коммерческая система
Однако чаще реализуется плавный переход от демонстрационного прототипа к
промышленной системе, при этом, если программный инструментарий был вы-
бран удачно, не обязательно даже переписывать окончательный вариант други-
ми программными средствами.
Понятие же коммерческой системы в нашей стране входит в понятие «промыш-
ленный программный продукт», или «промышленная ЭС» (в этой работе).
56 Глава 2 » Разработка систем, основанных на знаниях
Основная работа на данном этапе заключается в существенном расширении базы
знаний, то есть в добавлении большого числа дополнительных правил, фреймов,
узлов семантической сети или других элементов знаний. Эти элементы знаний
обычно увеличивают глубину системы, обеспечивая большее число правил для
трудно уловимых аспектов отдельных случаев. В то же время эксперт и инженер
по знаниям могут увеличить базу знаний системы, включая правила, управляю-
щие дополнительными подзадачами или дополнительными аспектами эксперт-
ной задачи (метазнания).
Таблица 2.1. Переход от прототипа к промышленной экспертной системе
Система Описание
Демонстрационный прототип ЭС Система решает часть задач, демонстрируя жизнеспособность подхода (несколько десятков правил или понятий)
Исследовательский прототип ЭС Система решает большинство задач, но неустойчива в работе и не полностью проверена (несколько сотен правил или понятий)
Действующий прототип ЭС Система надежно решает все задачи на реальных примерах, но для сложной задачи требует много времени и памяти
Промышленная система Система обеспечивает высокое качество решений при минимизации требуемого времени и памяти; переписывается с использованием более эффективных средств представления знаний
Коммерческая система Промышленная система, пригодная к продаже, то есть хорошо документирована и снабжена сервисом .
После установления основной структуры ЭС знаний инженер по знаниям при-
ступает к разработке и адаптации интерфейсов, с помощью которых система бу-
дет общаться с пользователем и экспертом. Необходимо обратить особое внима-
ние на языковые возможности интерфейсов, их простоту и удобство для управ-
ления работой ЭС. Система должна обеспечивать пользователю возможность лег-
ким и естественным образом уточнять непонятные моменты, приостанавливать
работу и т. д. В частности, могут оказаться полезными графические представле-
ния.
На этом этапе разработки большинство экспертов узнают достаточно о вводе пра-
вил и могут сами вводить в систему новые правила. Таким образом, начинается
процесс, во время которого инженер по знаниям передает право собственности и
контроля за системой эксперту для уточнения, детальной разработки и обслужи-
вания.
2.4.5. Оценка системы
После завершения этапа разработки промышленной экспертной системы необ-
ходимо провести ее тестирование в отношении критериев эффективности. К те-
стированию широко привлекаются другие эксперты с целью апробирования ра-
2.4. Технология проектирования и разработки
57
ботоспособности системы на различных примерах. Экспертные системы оцени-
ваются главным образом для того, чтобы проверить точность работы программы
и ее полезность. Оценку можно проводить, исходя из различных критериев, ко-
торые сгруппируем следующим образом:
• критерии пользователей (понятность и «прозрачность» работы системы, удоб-
ство интерфейсов и др.);
• критерии приглашенных экспертов (оценка советов-решений, предлагаемых
системой, сравнение ее с собственными решениями, оценка подсистемы объяс-
нений и др.);
• критерии коллектива разработчиков (эффективность реализации, производи-
тельность, время отклика, дизайн, широта охвата предметной области, непро-
тиворечивость БЗ, количество тупиковых ситуаций, когда система не может
принять решение, анализ чувствительности программы к незначительным из-
менениям в представлении знаний, весовых коэффициентах, применяемых в
механизмах логического вывода, данных и т. п.).
2.4.6. Стыковка системы
На этом этапе осуществляется стыковка экспертной системы с другими программ-
ными средствами в среде, в которой она будет работать, и обучение людей, кото-
рых она будет обслуживать. Иногда это означает внесение существенных изме-
нений. Такие изменения требуют непременного вмешательства инженера по
знаниям или какого-либо другого специалиста, который сможет модифициро-
вать систему. Под стыковкой подразумевается также разработка связей между
экспертной системой и средой, в которой она действует.
Когда экспертная система уже готова, инженер по знаниям должен убедиться в
том, что эксперты, пользователи и персонал знают, как эксплуатировать и обслу-
живать ее. После передачи им своего опыта в области информационной техноло-
гии инженер по знаниям может полностью предоставить ее в распоряжение пользо-
вателей.
Для подтверждения полезности системы важно предоставить каждому из пользо-
вателей возможность поставить перед ЭС реальные задачи, а затем проследить,
как она выполняет эти задачи. Для того чтобы система была одобрена, необходи-
мо представить ее как помощника, освобождающего пользователей от обремени-
тельных задач, а не как средство их замещения.
Стыковка включает обеспечение связи ЭС с существующими базами данных и
другими системами на предприятии, а также улучшение системных факторов,
зависящих от времени, чтобы можно было обеспечить ее более эффективную ра-
боту и улучшить характеристики ее технических средств, если система работает
в необычной среде (например, связь с измерительными устройствами).
Пример 2.1
Успешно состыкована со своим окружением система PUFF — экспертная система для
диагностики заболеваний легких [Хейес-Рот и др., 1987]. После того как PUFF была
58
Глава 2 » Разработка систем, основанных на знаниях
закончена и все были удовлетворены ее работой, систему перекодировали с LISP на
Бейсик. Затем систему перенесли на ПЭВМ, которая уже работала в больнице. В свою
очередь, эта ПЭВМ была связана с измерительными приборами. Данные с измеритель-
ных приборов сразу поступают в ПЭВМ. PUFF обрабатывает эти данные и печатает
рекомендации для врача. Врач в принципе не взаимодействует с PUFF. Система пол-
ностью интегрирована со своим окружением — она представляет собой интеллектуаль-
ное расширение аппарата исследования легких, который врачи давно используют.
Пример 2.2
Другой системой, которая хорошо функционирует в своем окружении, является САТ-1
[Уотермен, 1990] — экспертная система для диагностики неисправностей дизелей ло-
комотивов.
Эта система была разработана также на LISP, а затем была переведена на FORTH с тем,
чтобы ее можно было более эффективно использовать в различных локомотивных це-
хах. Мастер по ремонту запрашивает систему о возможных причинах неисправности
дизеля. Система связана с видеодиском, с помощью которого мастеру показывают ви-
зуальные объяснения и подсказки, касающиеся более подробных проверок, которые он
должен сделать.
Кроме того, если оператор не уверен в том, как устранить неисправность, система пре-
доставляет ему обучающие материалы, которые фирма подготовила предварительно, и
показывает ему их на видеотерминале. Таким образом, мастер по ремонту может с по-
мощью экспертной системы диагностировать проблему, найти тестовую процедуру,
которую он должен использовать, получить на дисплее объяснение, как провести тест,
или получить инструкции о том, как справиться с возникшей проблемой.
2.4.7. Поддержка системы
При перекодировании системы на язык, подобный С, повышается ее быстродей-
ствие и увеличивается переносимость, однако гибкость при этом уменьшается.
Это приемлемо лишь в том случае, если система сохраняет все знания проблем-
ной области и это знание не будет изменяться в ближайшем будущем. Однако
если экспертная система создана именно из-за того, что проблемная .область изме-
няется, то необходимо поддерживать систему в ее инструментальной среде разра-
ботки. ,
Пример 2.3
Удачным примером ЭС, внедренной таким образом, является XCON (R1) — ЭС, кото-
рую фирма DEC использует для комплектации ЭВМ семейства VAX. Одной из клю-,
чевых проблем, с которой столкнулась фирма DEC, является необходимость постоян-
ного внесения изменений для новых версий оборудования, новых спецификаций и т. д.
Для этой цели XCON поддерживается в программной среде OPS5.
е Теоретические
аспекты инженерии
знаний
□ Поле знаний
□ Стратегии получения знаний
□ Теоретические аспекты извлечения знаний
□ Теоретические аспекты структурирования знаний
3.1. Поле знаний
Инженерия знания — достаточно молодое направление искусственного интел-
лекта, появившееся тогда, когда практические разработчики столкнулись с весь-
ма нетривиальными проблемами трудности «добычи» и формализации знаний.
В первых книгах по ИИ эти факты обычно только постулировались, в дальней-
шем начались серьезные исследования по выявлению оптимальных стратегий
выявления знанйй [Boose, 1990; Wielinga, Schreiber, Breuker, 1992; Tuthill, 1994;
Adeli, 1994J.
Данная глава целиком посвящена теоретическим проблемам инженерии знаний,
другими словами — проектированию баз знаний — получению и структурирова-
нию знаний специалистов для последующей разработки баз знаний. Централь-
ным понятием на стадиях получения и структурирования является так называе-
мое поле знаний, уже упоминавшееся в параграфе 1.3.
Поле знаний — это условное неформальное описание основных понятий и взаимосвя-
зей между понятиями предметной области, выявленных из системы знаний эксперта, в
виде графа, диаграммы, таблицы или текста.
3.1.1. О языке описания поля знаний
Поле знаний Pz формируется на третьей стадии разработки ЭС (см. п. 2.4) — ста-
дии структурирования.
Поле знаний, как первый шаг к формализации, представляет модель знаний о
предметной области, в том виде, в каком ее сумел выразить аналитик на некото-
60
Глава 3 * Теоретические аспекты инженерии знаний
ром «своем» языке. Что это за язык? Известно, что словарь языка конкретной на-
уки формируется путем пополнения общеупотребительного языка специальны-
ми терминами и знаками, которые либо заимствуются из повседневного языка,
либо изобретаются [Кузичева, 1987]. Назовем этот язык L и рассмотрим его же-
лаемые свойства, учитывая, что стандарта этого языка пока не существует, а каж-
дый инженер по знаниям вьщужден сам его изобретать.
Во-первых, как и в языке любой науки, в нем должно быть как можно меньше не-
точностей, присущих обыденным языкам. Частично точность достигается более
строгим определением понятий. Идеалом точности, конечно, является язык ма-
тематики. Язык L, видимо, занимает промежуточное положение между есте-
ственным языком и языком математики.
Во-вторых, желательно не использовать в нем терминов иных наук в другом, то
есть новом, смысле. Это вызывает недоразумения.
В-третьих, Язык L, видимо, будет либо символьным языком, либо языком графи-
ческим (схемы, рисунки, пиктограммы).
При выборе Языка описания поля знаний не следует забывать, что на стадии
формализации необходимо его заменить на машинно-реализуемый язык пред-
ставления знаний (ЯПЗ), выбор которого зависит от структуры поля знаний.
Существует ряд языков, достаточно универсальных, чтобы претендовать на роль
языка инженерии знаний, — это структурно-логический язык SLL, включающий
аппарат лямбда-конверсии [Вольфенгаген и др., 1979], язык К-систем [Кузнецов,
1989], УСК [Мартынов, 1977] и др. Однако они не нашли широкого применения.
В некотором смысле создание языка L очень близко к идеям разработки универ-
сальных языков науки [Кузичева, 1987]. К XVII веку сложились два подхода в
разработке универсальных языков: создание языков-классификаций гслогико-
конструктивных языков. К первому примыкают проекты, восходящие к идее
Ф. Бэкона, — это языки Вилкинса и Далгарно. Второй подход связан с исследо-
ваниями в рамках поиска универсального метода познания, наиболее четко выс-
казанного Р. Декартом, а затем в проекте универсальной характеристики Г. Лейб-
ница. Именно Лейбниц наметил основные контуры учения о символах, которые
в соответствии с его замыслами в XVIII веке развивал Г. Ламберт, который дал
имя науке «семиотика». Семиотика в основном нашла своих адептов в сфере гу-
манитарных наук. В последнее время сложилась также новая ветвь семиотики —
прикладная семиотика [Pospelov, 1995].
Представители естественных наук еще не до конца осознали достоинства семи-
отики только из-за того, что имеют дело с достаточно простыми и «жесткими»
предметными областями. Им хватает аппарата традиционной математики. В ин-
женерии знаний, однако, мы имеем дело с «мягкими» предметными областями,
где явно не хватает выразительной адекватности классического математичес-
кого аппарата и где большое значение имеет эффективность нотации (ее ком-
пактность, простота модификации, ясность интерпретации, наглядность и т. д,).
В главе 8 рассматриваются современные тенденции в этой области и вводится
понятие онотологического инжиниринга, как одного из подходов к семиотичес-
кому моделированию предметной области.
3.1. Поле знаний
61
Языки семиотического моделирования [Осипов, 1988; Поспелов, 1986] как есте-
ственное развитие языков ситуационного управления являются, как нам кажет-
ся, первым приближением к языку инженерии знаний. Именно изменчивость и
условность знаков делают семиотическую модель применимой к сложным сфе-
рам реальной человеческой деятельности. Поэтому главное на стадии концептуа-
лизации — сохранение естественной структуры поля знаний, а не выразительные
возможности языка.
Традиционно семиотика включает (рис. 3.1):
• синтаксис (совокупность правил построения языка или отношения между
знаками);
• семантику (связь между элементами языка и их значениями или отношения
между знаками и реальностью);
• прагматику (отношения между знаками и их пользователями).
Рис. 3.1. Структура семиотики
3.1.2. Семиотическая модель поля знаний
Поле знаний Pz является некоторой семиотической моделью, которая может
быть представлена как граф, рисунок, таблица, диаграмма, формула или текст в
зависимости от вкуса инженера по знаниям и особенностей предметной области.
Особенности ПО могут оказать существенное влияние на форму и содержание
компонентов структуры Pz.
62
Глава 3 * Теоретические аспекты инженерии знаний
Рассмотрим соответствующие компоненты Pz (рис. 3.2).
П
Рис. 3.2. Структура поля знаний
Синтаксис. Обобщенно синтаксическую структуру поля знаний можно предста-
вить как
П = (I, О, М),
где I — структура исходных данных, подлежащих обработке и интерпретации в
экспертной системе;
О — структура выходных данных, то есть результата работы системы;
М — операциональная модель предметной области, на основании которой про-
исходит модификация I в О.
Включение компонентов I и О в Р обусловлено тем, что составляющие и структу-
ра этих интерфейсных компонентов имплицитно (то есть неявно) присутствуют
в модели репрезентации в памяти эксперта. Операциональная Модель М может
быть представлена как совокупность концептуальной структуры Sk, отражающей
понятийную структуру предметной области, и функциональной структуры Sf, мо-
делирующей схему рассуждений эксперта:
M = (Sk,Sf).
Sk выступает как статическая, неизменная составляющая Р, в то время как Sf пред-
ставляет динамическую, изменяемую составляющую.
Формирование Sk основано на выявлении понятийной структуры предметной
области. Параграф 3.4. описывает достаточно универсальный алгоритм проведе-
ния концептуального анализа на основе модификации парадигмы структурного
анализа [Yourdon, 1989] и построения иерархии понятий (так называемая «пира-
мида знаний»). Пример Sk и Sf представлен на рис. 3.3 и 3.4.
3.1. Поле знаний
63
ЕШЕЗ-
VICONT- [NEDOSTAT.VCO]
ГПричины !-------- ,........................ч.....)Вещество)----
Ч—п-----’ — " пНедостаточность! т е>..--...7_,рд/осА'
-Недостаток белковой пищи I 7 > витамин dj (гн)
-Поносы 7 \ ,* s4
-Цирроз печени (сымптомы) \ . '
фонический алкоголизм ---- \ |саточнет потрееность|
[Поражение желудочно-кишечного тракта)
L-Понос / .’ |Н
* I—15-20 мг
[Поражение кожи)
’ -Сухость и бледность губ (внутренние болеэнй)
-Эритема / Г' -------------------------п-------
_Гияйг.илпатя'5 j ‘ it
(Лечение).
| Содержится в|
-Мясо
-Рыба
-Орехи
-Бобовые
—Хлеб
Действие)
-Обмен белков
-Обмен жиров
-Обмен углеводов
! -Сосудорасширяющее
i>—Гипотензивное
-Шелушение7
(Нервные болезни)
VНервно-мышечные боли
[Глазные болезни]
~[ в легких случаю]
_________________ '—внутрь по 0.025 г 34 раза в день
[б тяжелых случаях)
I—Парентерально 1 мл 5*4 раствора никотинамида в день
• Й
[Психические нарушения)
-Раздражительность
-Бессонница
-Подавленность
-Заторможенность
[Поражение слизистых)
ЕЯзык обложенный отечный
Язык сухой ярко-красный
Язык болезненный с трещинами
в
Рис. 3.3. Концептуальная составляющая поля знаний
Рис. 3.4. Функциональная составляющая поля знаний
64
Глава 3 • Теоретические аспекты инженерии знаний
Структура Sf включает понятия предметной области А и моделирует основные
функциональные связи RA или отношения между понятиями, образующими Sk.
Эти связи отражают модель или стратегию принятия решения в выбранной ПО.
Таким образом Sf образует стратегическую составляющую М.
Семантика. Семантика, придающая определенное значение предложениям любо-
го формального языка, определяется на некоторой области. Фактически это на-
бор правил интерпретации предложений и формул языка. Семантика L должна
быть композиционной, то есть значение предложения определяется как функция
значений его составляющих.
Семантика языка L зависит от особенностей предметной области, она обладает
свойством полиморфизма, то есть одни и те же операторы языка в разных зада-
чах могут иметь свои особенности.
Семантику поля знаний Pz можно рассматривать на двух уровнях. На первом
уровне P‘Zg есть семантическая модель знаний эксперта i о некоторой предметной
области Og. На втором уровне любое поле знаний Pz является моделью некоторых
знаний, и, следовательно, можно говорить о смысле его как некоторого зеркала
действительности. Рассматривать первый уровень в отрыве от конкретной облас-
ти нецелесообразно, поэтому остановимся подробнее на втором.
Схему, отображающую отношения между реальной действительностью и полем
знаний, можно представить так, как показано на рис. 3.5.
Mgi
Mgj
Рис. 3.5. «Испорченный телефон» при формировании поля знаний
Как следует из рисунка, поле PijZg — это результат, полученный «после 4-й транс-
ляции» (если говорить на языке информатики).
• 1-я трансляция (IJ — это восприятие и интерпретация действительности О
предметной области gi-м экспертом. В результате в памяти эксперта образу-
ется модель как семантическая репрезентация действительности и его лич-
ного опыта по работе с ней.
3.1. Поле знаний
65
• 2-я трансляция (V, ) — это вербализация опыта i-ro эксперта, когда он пытает-
ся объяснить свои рассуждения 5, и передать свои знания Z, инженеру по зна-
ниям. В результате V/ образуется либо текст Т\, либо речевое сообщение С,
• 3-я трансляция (Ij) — это восприятие и интерпретация сообщений Т( или C’J-m
инженером по знаниям. В результате в памяти инженера по знаниям образует-
ся модель мира М&.
• 4-я трансляция (Kj) — это кодирование и вербализация модели М& в форме
поля знаний PiJzg-
Более всего эта схема напоминает детскую игру в «испорченный телефон»; перед
инженером по знаниям стоит труднейшая задача — добиться максимального со-
ответствия Mgi и P'izg. У читателей не должно возникать иллюзий, что Pzg отобра-
жает Og. Ни в коем случае, ведь знания — вещь сугубо авторизованная, следовало
бы на каждой ЭС ставить четкий ярлык i-j, то есть «база знаний эксперта i в пони-
мании инженера по знаниям j». Стоит заменить, например, инженера по знаниям
j на h, и получится совсем другая картина.
Пример 3.1
Приведем пример влияния субъективных взглядов эксперта на Mgl и Vt. Реаль-
ность (Og): два человека прибегают на вокзал за 2 минуты до отхода поезда. В кассы —
очередь. В автоматических кассах свободно, но ни у того, ни у другого пет мелочи. Сле-
дующий поезд через 40 минут. Оба опаздывают на важную встречу.
Интерпретация 1-го эксперта (I,): нельзя приходить на вокзал менее чем за 10 минут.
Интерпретация 2-го эксперта (12): надо всегда иметь мелочь в кармане.
Вербализация 1-го эксперта (Vj): опоздал к нужному поезду, так как не рассчитал
время.
Вербализация 2-го эксперта (V2): опоздал, так как на вокзале неразбериха, в кассах
толпа.
Последующие трансляции еще больше будут искажать и видоизменять модель, ио те-
перь уже с учетом субъективного восприятия инженеров по знаниям.
Таким образом, если считать поле знаний смысловой (семантической) моделью пред-
метной области, то эта модель дважды субъективна. И если модель Mgi (см. рис. 3.5) —
это усеченное отображение Og, то само Pz — лишь отблеск Mgi через призму V, и Mg.
Прагматика. В качестве прагматической составляющей семиотической модели
следует рассматривать технологии проведения структурного анализа ПО, поль-
зуясь которым инженер по знаниям может сформировать Pz по результатам ста-
дии извлечения знаний.
Таким образом, под прагматикой будем понимать практические аспекты разра-
ботки и использования поля, то есть как от хаоса черновиков и стенограмм сеан-
сов извлечения знаний перейти к стройной или хотя бы ясной модели.
Подробнее эти вопросы освещены в параграфах 3.4. и 4.4. Однако поле знаний,
несмотря на все старания инженера по знаниям и эксперта, всегда будут лишь
бледным отпечатком реально существующей предметной области, ведь окружа-
ющий нас мир так изменчив, сложен и многообразен, а то, что хранится в нашем
сознании, так плохо поддается вербализации. Тем не менее с точки зрения науч-
66
Глава 3 • Теоретические аспекты инженерии знаний
ной методологии без продуманного, четкого и красивого поля знаний не может
идти и речи о создании базы знаний промышленной ЭС.
3.1.3. «Пирамида» знаний
Иерархичность понятийной структуры сознания подчеркивается в работах мно-
гих психологов [Брунер, 1971; Беккер, 1976]. Поле знаний можно стратифициро-
вать, то есть рассматривать на различных уровнях абстракции понятий. В «пира-
миде знаний» каждый следующий уровень служит для восхождения на новую
ступень обобщения и углубления знаний в предметной области. Таким образом,
возможно наличие нескольких уровней понятийной структуры Sk
Представляется целесообразным связать это с глубиной профессионального опы-
та (например, как в системе АВТАНТЕСТ [Гаврилова, Червинская, 1992]) или с
уровнем иерархии в структурной лестнице организации (рис. 4.12 главы 4).
Естественно, что и стратегии принятия решений, то есть функциональные струк-
туры Sf, на различных уровнях будут существенно отличаться.
Если попытаться дать математическую интерпретацию уровней пирамиды зна-
ний U = (Uf, U2, U3.Un ), то наиболее прозрачным является понятие гомомор-
физма — отображения некоторой системы Е, сохраняющего основные операции и
основные отношения этой системы.
Пусть
E-(E)(oi:ie I), (rj: j е J))
некоторая система с основными понятиями Of, i G I и основными отношениями
je J-
Гомоморфизмом системы Е в однотипную ей систему Е’:
Е’- (Е’, (o’j: i G I),(r’:jG J)),
называется отображение
Ф : Е => Е’>
удовлетворяющее следующим двум условиям:
Ф(о, (ер ..., enj)) = о,’ (Ф (е,),..., Ф (enj));
(е„ ..., em) G Tj => (Ф (е,),..., Ф (ет)) G г’ .
Для всех элементов ер ..., ет из Е и всех i G I, j G J.
Согласно введенным обозначениям уровни пирамиды суть гомоморфизмы моде-
лей (то есть понятий и отношений) предметной области
Ф : М => М’,
где М = (A, R, S); М’ = (A’, R’, S’), А’ — мета-понятия, или понятия более высокого
уровня абстракции; R’ — мета-отношения; S’ — мета-стратегии.
Восходя по ступеням пирамиды, мы получаем систему гомоморфизмов, что со-
ответствует результатам, полученным в когнитивной психологии об уменьше-
нии размерности семантического пространства памяти с увеличением опыта эк-
спертов.
3.2. Стратегии получения знаний
67
3.2. Стратегии получения знаний
При формировании поля знаний ключевым вопросом является сам процесс по-
лучения знаний, когда происходит перенос компетентности экспертов на инже-
неров по знаниям. Для названия этого процесса в литературе по ЭС получило
распространение несколько терминов: приобретение, добыча, извлечение, полу-
чение, выявление, формирование знаний. В англоязычной специальной литера-
туре в основном используются два: acquisition (приобретение) и elicitation (вы-
явление, извлечение, установление).
Термин «приобретение» трактуется либо очень широко — тогда он включает
весь процесс передачи знаний от эксперта к базе знаний ЭС, либо уже как способ
автоматизированного построения базы знаний посредством диалога эксперта и
специальной программы (при этом структура поля знаний заранее закладывает-
ся в программу). В обоих случаях термин «приобретение» не касается самого та-
инства экстрагирования структуры знаний из потока информации о предметной
области. Этот процесс описывается понятием ^извлечение».
Авторы склонны использовать этот термин как более емкий и более точно выра-
жающий смысл процедуры переноса компетентности эксперта через инженера по
знаниям в базу знаний ЭС. '
Извлечение знаний (knowledge elicitation) — это процедура взаимодействия эксперта с
источником знаний, в результате которой становятся явными процесс рассуждений спе-
циалистов при принятии решения и структура их представлений о предметной области.
В настоящее время большинство разработчиков ЭС отмечает, что процесс извле-
чения знаний остается самым «узким» местом при построении промышленных ЭС.
При этом им приходится практически самостоятельно разрабатывать ^етоды из-
влечения, сталкиваясь со следующими трудностями [Gaines, 1989]:
• организационные неувязки;
• неудачный метод извлечения, не совпадающий со структурой знаний в данной
области;
• неадекватная модель (язык) для представления знаний.
Можно добавить к этому [Гаврилова, Червинская, 1992]:
• неумение наладить контакт с экспертом;
• терминологический разнобой;
• отсутствие целостной системы знаний в результате извлечения только «фраг-
ментов»;
• упрощение «картины мира» эксперта и др.
Процесс извлечения знаний — это длительная и трудоемкая процедура, в кото-
рой инженеру по знаниям, вооруженному специальными знаниями по когнитив-
ной психологии, системному анализу, математической логике и пр., необходимо
воссоздать модель предметной области, которой пользуются эксперты для при-
68
Глава 3 * Теоретические аспекты инженерии знаний
нятия решения. Часто начинающие разработчики ЭС, желая упростить эту про-
цедуру, пытаются подменить инженера по знаниям самим экспертом. По многим
причинам это нежелательно.
Во-первых, большая часть знаний эксперта — это результат многочисленных на-
слоений, ступеней опыта. И часто, зная, что из А следует В, эксперт не отдает себе
отчета, что цепочка его рассуждений была гораздо длиннее, например А —> D —>
С ->В или А -> Q —э R —* В.
Во-вторых, как было известно еще Платону, мышление диалогично. И поэтому
диалог инженера по знаниям и эксперта — наиболее естественная форма изуче-
ния лабиринтов памяти эксперта, в которых хранятся знания, частью носящие
невербальный характер, то есть выраженные не в форме слов, а в форме нагляд-
ных образов, например. И именно в процессе объяснения инженеру по знаниям
эксперт на эти размытые ассоциативные образы надевает четкие словесные яр-
лыки, то есть вербализует знания.
В-третьих, эксперту труднее создать модель предметной области вследствие глу-
бины и объема информации, которой он владеет. Еще в ситуационном управле-
нии [Поспелов, 1986] было выявлено: объекты реального мира связаны более чем
200 типами отношений (временные, пространственные, причинно-следственные,
типа «часть—целое» и др.). Эти отношения и связи предметной области образуют
сложную систему, из которой выделить «скелет» или главную структуру иногда
доступнее аналитику, владеющему к тому же системной методологией.
Термин «приобретение» в рамках данного учебника оставлен за автомати-
зированными системами прямого общения с экспертом. Они действительно
непосредственно приобретают уже готовые фрагменты знаний в соответствии
со структурами, заложенными разработчиками систем. Большинство этих ин-
струментальных средств специально ориентировано на конкретные ЭС с жестко
обозначенной предметной областью и моделью представления знаний, то есть не
являются универсальными.
Приобретение знаний (knowledge acquisition) — процесс наполнения базы знаний экс-
пертом с использованием специализированных программных средств.
Например, система TEIRESIAS [Davis, 1982], ставшая прародительницей всех
инструментариев для приобретения знаний, предназначена для пополнения базы
знаний системы MYCIN или ее дочерних ветвей, построенных на «оболочке»
EMYCIN [Shortliffe, 1976] в области медицинской диагностики с использованием
продукционной модели представления знаний. Три поколения и основные тен-
денции СПЗ будут подробно описаны в параграфе 4.5. Более современные конк-
ретные системы описаны далее в параграфе 4.6.
Термин формирование знаний традиционно закрепился за чрезвычайно перспек-
тивной и активно развивающейся областью инженерии знаний, которая занима-
ется разработкой моделей, методов и алгоритмов обучения. Она включает индук-
тивные модели формирования знаний и автоматического порождения гипотез,
например ДСМ-метод [Аншаков, Скворцов, Финн, 1986] на основе обучающих
выборок, обучение по аналогии и другие методы. Эти модели позволяют выявить
3.2. Стратегии получения знаний
69
причинно-следственНые эмпирические зависимости в базах данных с неполной
информацией, содержащих структурированные числовые и символьные объекты
(часто в условиях неполноты информации).
Формирование знаний (machine learning) — процесс анализа данных и выявление
скрытых закономерностей с использованием специального математического аппарата
и программных средств.
Традиционно к задачам формирования знаний или машинного обучения отно-
сятся задачи прогнозирования, идентификация (синтеза) функций, расшифров-
ки языков, индуктивного вывода и синтеза с дополнительной информацией
[Епифанов, 1984]. В широком смысле к обучению по примерам можно отнести и
методы обучения распознаванию образов [Аткинсон, 1989; Schwartz, 1988].
Индуктивный вывод правил из фактов применен также в системах AQ,
AQUINAS, KSSI, INSTIL и некоторых других.
Наиболее продвинутыми среди методов машинного обучения являются, по-ви-
димому, методы распознавания образов, в частности, алгебраический подход, в
котором предусматривается обогащение исходных эвристических алгоритмов с
помощью алгебраических операций и построение семейства алгоритмов, гаран-
тирующего получение корректного алгоритма для решения изучаемого класса
задач, то есть алгоритма, правильно классифицирующего конечную выборку по
всем классам [Берков, 1972]. Однако применение методов формирования зна-
ний пока не стало промышленной технологией разработки баз знаний.
Для того чтобы эти методы стали элементами технологии интеллектуальных си-
стем, необходимо решить ряд задач [Осипов, 1997]:
• обеспечить механизм сопряжения независимо созданных баз данных, имею-
щих различные схемы, с базами знаний интеллектуальных систем;
• установить соответствие между набором полей базы данных и множеством
элементов декларативной компоненты базы знаний;
• выполнить преобразование результата работы алгоритма обучения в способ
представления, поддерживаемый программными средствами интеллектуаль-
ной системы.
Помимо перечисленных существуют также и другие стратегии получения
знаний, например, в случае обучения на примерах (case-based reasoning), ког-
да источник знаний — это множество примеров предметной области [Оси-
пов, 1997; Попов, Фоминых, Кисель, 1996]. Обучение на основе примеров
(прецедентов) включает настройку алгоритма распознавания на задачу по-
средством предъявления примеров, классификация которых известна [Ибер-
ла, 1980]. '
Обучение на примерах тесно связано с машинным обучением. Различие заключа-
ется в том, что результат обучения в рассматриваемом здесь случае должен
быть интерпретирован в некоторой модели, в которой, возможно, уже содержатся
факты и закономерности Предметной области, и преобразован в способ представ-
70
Глава 3 • Теоретические аспекты инженерии знаний
ления, который допускает использование результата обучения в базе знаний, для
моделирования рассуждений, для работы механизма объяснения и т. д., то есть
делает результат обучения элементом соответствующей технологии.
Например, в системе INDUCE [Коов и др., 1988] порождается непротиворечивое
описание некоторого класса объектов по множествам примеров и контр-приме-
ров данного класса. В качестве языка представления используется язык перемен-
но-значной логики первого порядка (вариант языка многозначной логики перво-
го порядка).
Следует отметить также появление двух новых «флагов» в стане сторонников
методов машинного обучения — это data mining и knowledge discovery. Оба подхо-
да базируются на анализе данных и поиске закономерностей.
Таким образом, можно выделить три основные стратегии проведения стадии по-
лучения знаний при разработке ЭС (рис. 3.6).
1. С использованием ЭВМ при наличии подходящего программного инструмен-
тария, иначе приобретение знаний.
2. С использованием программ обучения при наличии репрезентативной (то есть
достаточно представительной) выборки примеров принятия решений в пред-
метной области и соответствующих пакетов прикладных программ, иначе фор-
мирование знаний.
3. Без использования вычислительной техники путем непосредственного контак-
та инженера по знаниям и источника знаний (будь то эксперт, специальная
литература или другие источники), иначе извлечение знаний.
Рис. 3.6. Стратегии получения знаний
В учебнике подробно будут рассматриваться процессы извлечения и приобрете-
ния знаний, так как на современном этапе разработки ЭС эти стратегии являются
наиболее эффективными и перспективными. Формирование знаний, тяготеющее
в большей степени к области machine learning, то есть индуктивному обучению,
основываясь на хорошо исследованном аппарате распознавания образов [Гаек,
Гавранек, 1983] и обнаружения сходства объектов [Гусакова, Финн, 1987], выхо-
дит за рамки данного учебника. Также вне этой книги остались вопросы форми-
рования знаний из данных (data mining, knowledge discovery) и др.
3.3. Теоретические аспекты извлечения знаний
71
3.3. Теоретические аспекты извлечения
знаний
Поскольку основной проблемой инженерии знаний является процесс извлечения -
знаний, инженеру по знаниям необходимо четко понимать природу и особеннос-
ти этих процессов. Для того чтобы разобраться в природе извлечения знаний,
выделим три основных аспекта этой процедуры (рис. 3.7):
А = {Al, А2, АЗ} = {психологический, лингвистический, гносеологический}.
Рис. 3.7. Теоретические аспекты инженерии знаний
3.3.1. Психологический аспект
Из трех аспектов извлечения знаний психологический — А1 — является ведущим,
поскольку он определяет успешность и эффективность взаимодействия инжене-
ра по знаниям (аналитика) с основным источником знаний — экспертом-профес-
сионалом. Психологический аспект выделяется еще и потому, что извлечение
знаний происходит чаще всего в процессе непосредственного общения разработ-
чиков системы. А в общении психология является доминантной.
Общение, или коммуникация (от лат. communicatio — связь), — это междисцип-
линарное понятие, обозначающее все формы непосредственных контактов между
людьми — от дружеских до деловых. Оно широко исследуется в психологии, фи-
лософии, социологии, этологии, лингвистике, семиотике и других науках. Суще-
ствует несколько десятков теорий общения, и единственное, в чем сходятся все
авторы, — это сложность, многоплановость процедуры общения. Подчеркивает-
ся, что общение — не просто однонаправленный процесс передачи сообщений и
не двухтактный обмён порциями сведений, а нерасчлененный процесс циркуля-
ции информации, то есть совместный поиск истины [Каган, 1988] (рис. 3.8).
Итак, общение есть процесс выработки новой информации, общей для общаю-
щихся людей й рождающей их общность. И хотя общение — первый вид деятель-
ности, которым овладевает человек в онтогенезе, по-настоящему владеют куль-
турой и наукой общения единицы.
72
Глава 3 • Теоретические аспекты инженерии знаний
Неправильная схема Эксперт Инженер познаниям
| Послание^^»
д к
Правильная схема Эксперт / Средства \ \ общения Д Инженер по знаниям
Рис. 3.8. Структура процесса общения
Можно выделить четыре основных уровня общения [Саратовский, 1980].
1. Уровень манипулирования, когда один субъект рассматривает другого как сред-
ство или помеху по отношению к проекту своей деятельности.
2. Уровень «рефлексивной игры», когда в процессе своей деятельности человек
учитывает «контрпроект» другого субъекта, но не признает за ним -самоцен-
ность и стремится к «выигрышу», к реализации своего проекта.
3. Уровень правового общения, когда субъекты признают право на существова-
ние проектов деятельности друг друга и пытаются согласовать их хотя бы вне-
шне.
4. Уровень нравственного общения, когда субъекты внутренне принимают общий
проект взаимной деятельности.
Стремление и умение общаться на высшем, четвертом, уровне может характе-
ризовать степень профессионализма инженера по знаниям. Извлечение зна-
ний — это особый вид общения, который можно отнести к духовно-информа-
ционному типу. Согласно работе [Каган, 1988] общение делится на мате-
риально-практическое; духовно-информационное; практически-духовное. При
этом информационный аспект общения для инженера по знаниям с прагмати-
ческой точки зрения важнейший.
Известно, что потери информации при разговорном общении велики [Мицич,
1987] (рис. 3.9).
Рис. 3.9. Потери информации при разговорном общении
3.3. Теоретические аспекты извлечения знаний
73
В связи с этим рассмотрим проблему увеличения информативности общения
аналитика и эксперта за счет использования психологических знаний.
Можно выделить такие структурные компоненты модели общения при извлече-
нии знаний:
• участники общения (партнеры);
• средства общения (процедура);
• предмет общения (знания).
В соответствии с этой структурой выделим три «слоя» психологических проблем,
возникающих при извлечении знаний (рис. 3.10):
Al - {Sil, S12, S13 } - {контактный, процедурный, когнитивный}.
Рис. 3.10. Психологический аспект извлечения знаний
Контактный слой (S11)
Практически все психологи отмечают, что на любой коллективный процесс вли-
яет атмосфера, возникающая в группе участников. Существуют эксперименты,
результаты которых неоспоримо говорят, что часто дружеская атмосфера в кол-
лективе больше влияет на результат, чем индивидуальные способности отдель-
ных членов группы [Немов, 1984]. Особенно важно, чтобы в коллективе раз-
работчиков складывались кооперативные, а не конкурентные отношения. Для
кооперации характерна атмосфера сотрудничества, взаимопомощи, заинтересо-
ванности в успехах друг друга, то есть уровень нравственного общения, а для от-
ношений конкурентного типа — атмосфера индивидуализма и межличностного
соперничества (более низкий уровень общения).
В настоящее время прогнозировать совместимость в общении со 100%-й гаран-
тией невозможно. Однако можно выделить ряд факторов и черт личности, ха-
рактера и других особенностей участников общения, несомненно, оказываю-
щих влияние на эффективность процедуры.
Разработка проблематики контактного слоя позволила выявить следующие па-
раметры партнеров, влияющие на результаты процедуры извлечения знаний:
74
Глава 3 • Теоретические аспекты инженерии знаний
Sil - {sll_i} “ {пол, возраст, личность, темперамент, мотивация и др.}, часть из
которых впоследствии вошли в формирование модели пользователя.
Значения параметров пола (si 11) и возраста (sll_2) хотя и влияют на эффек-
тивность контакта, но не являются критическими. В литературе [Иванов, 1986]
отмечается, что хорошие результаты дают гетерогенные пары (мужчина/женщи-
на) и соотношение:
20 > (Ва — Ва) > 5,
где Вэ — возраст эксперта; Ва — возраст аналитика.
Под личностью (sll_3) обычно понимается устойчивая система психологичест
ких черт, характеризующая индивидуальность человека. Рекомендуемые компо-
ненты sll_3 исследованы в работе [Гаврилова, 1990] и дополнены качествами из
руководства для журналистов в работе [Schouksmith G., 1978]. sll_3 = (доброже-
лательность, аналитичность, хорошая память, внимание, наблюдательность, во-
ображение, впечатлительность, большая собранность, настойчивость, общитель-
ность, находчивость).
Со времен Галена и Гиппократа, выделивших четыре классических типа темпе-
рамента (si 14), вошли в научную терминологию понятия
sll_4= (холерик, сангвиник, меланхолик, флегматик).
Известно, что флегматики и меланхолики медленнее усваивают информацию
[Лунева, Хорошилова, 1987]. И для обеспечения психологического контакта с
ними не следует задавать беседе слишком быстрый темп, торопить их с ответом.
Зато они гораздо лучше усваивают новое, в отличие от холериков, для которых
свойственно поверхностное усваивание информации. Последних следует специ-
ально наводить на размышление и рефлексию. У меланхоликов часто занижена
самооценка, они застенчивы и в беседе их надо подбадривать. Таким образом,
наиболее успешными в рамках слоя S11 являются сангвиники и холерики.
На эффективность коллективного решения задач влияет также и мотивация
(si 15), то есть стремление к успеху. Инженер по знаниям в зависимости от ус-
ловий разработки должен изыскивать разнообразные стимулы для экспертов
(включая, разумеется, и материальные). Эксперт передает аналитику один из са-
мых дорогих в мире продуктов — знания. И если одни люди делятся опытом доб-
ровольно и с удовольствием, то другие весьма неохотно приоткрывают свои про-
фессиональные тайны. Иногда полезно оказывается возбудить в эксперте дух
соперничества, конкуренции (не нарушая, естественно, обстановки кооператив-
ности в коллективе).
Процедурный слой (S12)
Параметры процедурного слоя S12 описывают непосредственно процесс прове-
дения процедуры извлечения знаний. Фактически это профессиональные пара-
метры:
S12 - {sl2_i} - {ситуация общения (место, время, продолжительность); оборудо-
вание (вспомогательные средства, освещенность, мебель); профессиональные
приемы (темп, стиль, методы и др.)}.
3.3. Теоретические аспекты извлечения знаний
75
Инженер по знаниям, успешно овладевший наукой установления атмосферы до-
верия и взаимопонимания с экспертом (контактный слой — SI 1), должен еще су-
меть воспользоваться благоприятным воздействием этой атмосферы. Проблема
процедурного слоя касается проведения самой процедуры извлечения знаний.
Здесь мало проницательности и обаяния, полезных для решения проблемы кон-
такта, тут необходимы профессиональные знания.
Остановимся на общих закономерностях проведения процедуры.
sl2_l — ситуация общения определяется следующими компонентами:
• sl2_l_l — место проведения сеансов;
• sl2_l_2 — продолжительность проведения сеансов;
• sl2_l_3 — время проведения сеансов.
Беседу с экспертом лучше всего проводить в небольшом помещении наедине
(sl2_l_l: место), поскольку посторонние люди нарушают доверительность бесе-
ды и могут породить эффект «фасада». Рабочее место эксперта является не са-
мым оптимальным вариантом, так как его могут отвлекать телефонные звонки,
сотрудники и пр. Атмосфера замкнутого пространства и уединенности положи-
тельно влияет на эффективность.
Американский психолог И. Атватер считает, что для делового общения наиболее
благоприятная дистанция от 1,2 до 3 метров [Schouksmith, 1978]. Минимальным
«комфортным» расстоянием можно считать 0,7-0,8 метра.
Реконструкция собственных рассуждений — трудоемкий процесс, и поэтому
длительность одного сеанса (sl2_l_2: продолжительность) обычно не превыша-
ет 1,5-2 часа. Эти два часа лучше выбрать в первой половине дня, например с 10
до 12 часов, если эксперт типа «жаворонок» (sl2_l_3: время). Известно, что вза-
имная утомляемость партнеров при беседе наступает обычно через 20-25 минут
[Ноэль, 1978], поэтому в сеансе нужны паузы.
sl2_2 — оборудование включает:
• sl2_2_l — вспомогательные средства;
• sl2_2_2 — освещенность;
• sl2_2_3 — мебель.
Вспомогательные средства (sl2_2_l):
• средства для увеличения эффективности самого процесса извлечения знаний;
• средства для протоколирования результатов.
К средствам для увеличения эффективности процесса извлечения знаний прежде
всего относится наглядный материал. Независимо от метода извлечения (см. гла-
ву 4), выбранного в конкретной ситуации, его реализация возможна разными спо-
собами. Например, можно учитывать следующий фактор: широко известно, что
людей, занимающихся интеллектуальной деятельностью, можно отнести к худо-
жественному либо мыслительному типу. Термины тут условны и не имеют отно-
шения к той деятельности, которую традиционно называют художественной или
76
Глава 3 • Теоретические аспекты инженерии знаний
мыслительной. Важно, что, определив тип эксперта, инженер по знаниям может
плодотворнее использовать любой из методов извлечения, зная, что люди худо-
жественного типа легче воспринимают зрительную информацию в форме рисун-
ков, графиков, диаграмм, так как эта информация воспринимается через первую
сигнальную систему. Напротив, эксперты мыслительного типа лучше понимают
язык формул и текстовую информацию. При этом учитывается факт, что боль-
шую часть информации человек получает от зрения. Совет пользоваться актив-
нее наглядным материалом из работы [Хейес—Рот, Уотермена, Ленат, 1987]
можно считать универсальным. Такие методы, как свободный диалог и игры, пре-
доставляют богатые возможности использовать слайды, чертежи, рисунки.
Для протоколирования результатов в настоящее время используются следую-
щие способы:
• запись на бумагу непосредственно по ходу беседы (недостатки — это часто ме-
шает беседе, кроме того, трудно успеть записать все, даже при наличии навы£
ков стенографии);
• магнитофонная запись (диктофон), помогающая аналитику проанализиро-
вать весь ход сеанса и свои ошибки (недостаток — может сковывать эксперта);
• запоминание с последующей записью после беседы (недостаток — годится
только для аналитиков с блестящей памятью).
Наиболее распространенным способом на сегодня является первый. При этом
наибольшая опасность тут — потеря знаний, поскольку любая запись ответов —
это уже интерпретация, то есть привнесение субъективного понимания предмета.
Значения параметров освещенности (sl2_2_2) и мебели (sl2_2_3) очевидны и
связаны с влиянием внешних факторов на эксперта.
sl2_3 — профессиональные приемы аналитика, включают, в частности:
• S1231 — темп;
• si 2 3 2 — стиль;
• sl2_3_3 — методы.
Учет индивидуального темпа (sl2_3_l) и стиля (sl2_3_2) эксперта позволяет
аналитику снизить напряженность процедуры извлечения знаний. Типичной
ошибкой является навязывание собственных темпа и стиля.
На успешность также влияет длина фраз, которые произносит инженер по зна-
ниям. Этот факт был установлен американскими учеными — лингвистом Ингве
и психологом Миллером при проведении исследования о причинах низкой усво-
яемости команд на Военно-морском флоте США [Gammack, Young, 1985].
Причина была в длине команд. Оказалось, что человек лучше всего воспринимает
предложения глубиной (или длиной) 7+2(-2) слова. Это число (7±2) получило
название число Ингве—Миллера. Можно считать его мерой «разговорности»
речи. Опытные лекторы используют в лекции в основном короткие фразы, умень-
шая потерю информации с 20-30 % (у плохих лекторов) до 3-4 % [Горелов, 1987].
Большая часть информации поступает к инженеру по знаниям в форме предло-
жений на естественном языке. Однако внешняя речь эксперта есть воспроизведе-
ние его внутренней речи (мышления), которая гораздо богаче и многообразнее.
3.3. Теоретические аспекты извлечения знаний
77
При этом для передачи этой внутренней речи эксперт использует и невербаль-
ные средства, такие как интонация, мимика, жесты. Опытный инженер по знани-
ям старается записывать по возможности в протоколы (в форме ремарок) эту до-
полнительную интонацию.
В целом, невербальная компонента стиля общения важна и для проблем контакт-
ного слоя при установлении контакта, когда по отдельным жестам и выражению
лица эксперта инженер по знаниям может установить границу возможной «дру-
жественности» общения.
Значение параметра методов (sl2_3_3) подробно рассмотрено в следующей
главе, исходя из позиции, что метод должен подходить к эксперту как «ключ к
замку».
Когнитивный слой (S13)
Когнитивные (от англ., cognition — познание) науки исследуют познавательные
процессы человека с позиций возможности их моделирования (психология, ней-
рофизиология, эргономика, инженерия знаний). Наименее исследованы на сегод-
няшний день проблемы когнитивного слоя S13, связанные с изучением семанти-
ческого пространства памяти эксперта и реконструкцией его понятийной струк-
туры и модели рассуждений.
Основными факторами, влияющими на когнитивную адекватнбсть, будут:
S13 = {sl3_i} = {когнитивный стиль, семантическая репрезентативность поля зна-
ний и концептуальной модели}.
Под когнитивным стилем (s!3_l) человека понимается совокупность критериев
предпочтения при решении задач и познании мира, специфическая для каждого
человека. Когнитивный стиль определяет не столько эффективность деятельно-
сти, сколько способ достижения результата [Алахвердов, 1986]. Это способ по-
знания, который позволяет людям с разными способностями добиваться оди-
наковых результатов в деятельности. Это система средств и индивидуальных
приемов, к которым прибегает человек для организации своей деятельности.
Инженеру по знаниям полезно изучить и прогнозировать свой когнитивный
стиль, а также стиль эксперта. Особенно важны такие характеристики когнитив-
ного стиля, как:
• sl3_l_l — (полезависимость — поленезависимость);
• s!3_l_2 — (импульсивность — рефлективность (рефлексивность);
• sl3_l_3 — (ригидность — гибкость);
• s!3_l_4 — (когнитивная эквивалентность).
si3_i_i. Поленезависимость позволяет человеку акцентировать внимание лишь
на тех аспектах проблемы, которые необходимы для решения конкретной зада-
чи, и уметь отбрасывать все лишнее, то есть не зависеть от фона или окружаю-
щего задачу шумового поля. Эта характеристика коррелирует с такими чертами
личности, как невербальный интеллект, аналитичность мышления, способность
78
Глава 3 • Теоретические аспектыинженериизнаний
к пониманию сути. Очевидно, что помимо того, что самому аналитику необходи-
мо иметь высокое значение параметра s!3_l_l, поленезависимый эксперт — это
тоже желательный фактор. Однако приходится учитывать, что больше нуждают-
ся в общении полезависимые люди, а потому они и более контактны [Орехов,
1985].
Особенно полезны для общения гетерогенные (смешанные) пары, например «по-
лезависимый — поленезависимый» [Иванов, 1986]. В литературе описаны раз-
личные эксперименты, моделирующие общение, требующее понимания и совмест-
ной деятельности. Наиболее успешным в понимании оказались поленезависимые
испытуемые (92 % успеха), для сравнения полезависимые давали 56 % успеха
[Кулюткин, Сухобская, 1971].
Для совместной профессиональной деятельности важна также гибкость когни-
тивной организации, которая связана с поленезависимостью. Итак, большую
способность к адекватному пониманию партнера демонстрируют субъекты с вы-
сокой психологической дифференциацией, то есть поленезависимостью.
Поленезависимость является одной из характерных профессиональных черт ког-
нитивного стиля наиболее квалифицированных инженеров по знаниям. По неко-
торым результатам [Алахвердов, 1986] мужчины более поленезависимы, чем жен-
щины.
s!3_l_2. Под импульсивностью понимается быстрое принятие решения (часто
без его достаточного обоснования), а под рефлексивностью — склонность к рас-
судительности. Рефлексивность по экспериментальным данным коррелирует со
способностью к формирования понятий и продуктивностью стратегий решения
логических задач [Кулюткин, Сухобская, 1971]. Таким образом, и инженеру по
знаниям, и эксперту желательно быть рефлексивным, хотя собственный стиль
изменяется лишь частично и с большим напряжением.
sl3_l_3. Ригидность — гибкость характеризует способность человека к измене-
нию установок и точек зрения в соответствии с изменяющейся ситуацией. Ригид-
ные люди не склонны менять свои представления и структуру восприятия, напро-
тив, гибкие легко приспосабливаются к новой обстановке. Очевидно, что если
эксперт еще может себе позволить ригидность (что характерно для долго работа-
ющих над одной проблемой специалистов, особенно старшего возраста), то для
инженера по знаниям эта характеристика когнитивного стиля явно противопо-
казана. Увеличение ригидности с возрастом отмечается многими психологами
[Кулюткин, Сухобская, 1971; Орехов, 1985].
s!3_l_4. Когнитивная эквивалентность характеризует способность человека к
различению понятий и разбиению их на классы и подклассы. Чем уже диапазон
когнитивной эквивалентности, тем более тонкую классификацию способен про-
вести индивид, тем большее количество признаков понятий он может выделить.
Обычно у женщин диапазон когнитивной эквивалентности уже, чем у мужчин.
Семантическая репрезентативность (sl3_2) подразумевает подход, исключающий
традиционное навязывание эксперту некой модели представлений (например,
продукционной или фреймовой), и заставляет инженера по знаниям последова-
тельно воссоздавать модель мира эксперта, используя как неформальные методы,
3.3. Теоретические аспекты извлечения знаний
79
так и математический аппарат, например многомерное шкалирование (см. главу
4). Проблема семантической репрезентативности ориентирована на достижение
когнитивной адекватности поля знаний и концептуальной модели. В настоящий
момент она может быть сформулирована как проблема «испорченного телефона»
[Гаврилова, Червинская, 1992] (см. рис. 3.5) — возможные трансформации и по-
тери в цепи передачи информации:
(Of предметная область или реальный мир) —>
[If интерпретация i-го экспертаJ —>
(Mgf модель мира эксперта) —>
[Vf вербализация модели мира эксперта] —>
(Ti & Ci: вербальные и невербальные сообщения i-го эксперта j- му аналитику) —>
[If их интерпретация j-ым аналитиком]—>
(Mgf модель мира j-го аналитика)
[Kf кодирование при формировании поля знаний с последующей структуризацией
в концептуальную модельJ.
Круглые скобки определяют понятия, квадратные — процессы.
3.3.2. Лингвистический аспект
Лингвистический (А2) аспект касается исследований языковых проблем, так как
язык — это основное средство общения в процессе извлечения знаний.
Сразу же следует оговорить, что поскольку тема данной книги ограничена изло-
жением теории и технологии инженерии знаний, то область разработки есте-
ственно-языковых интерфейсов и весь спектр проблем, связанных с ней — лекси-
ческих, синтаксических, семантических, прагматических и т. д. [Виноград, 1976;
Мальковский, 1985; Попов, 1982], — не рассматривается.
В инженерии знаний можно выделить три слоя лингвистических проблем
(рис. 3.11):
А2 = {S21, S22, S23} = {«общий код», понятийная структура, словарь пользова-
теля}.
S21 «Общий код»
S22 Понятийная
структура
S23 Словарь
пользователя
Рис. 3.11. Лингвистический аспект извлечения знаний
80
Глава 3 • Теоретические аспекты инженерии знаний
«Общий код» (S21)
«Общий код» решает проблему языковых ножниц между профессиональной тер-
минологией эксперта и обыденной литературной речью инженера по знаниям и
включает следующие компоненты:
S21 - {s21_i} = {общенаучная терминология; специальные понятия из профессио-
нальной литературы; элементы бытового языка; неологизмы, сформированные
за время совместной работы; профессиональный жаргон и др.}.
Детализация схемы общения (см. рис. 3.8) на рис. 3.11 позволяет представить
средства общения как два потока [Горелов, 1987], в которых нас интересуют ком-
поненты VI и V2 — языки, на которых говорят аналитик и эксперт (VI’, V2’ —
невербальные компоненты). Различие языков VI и V2 и обусловливает «языко-
вый барьер» или «языковые ножницы» в общении инженера по знаниям и экс-
перта.
Эти два языка являются отражением «внутренней речи» эксперта и аналитика,
поскольку большинство психологов и лингвистов считают, что язык — это ос-
новное средство мышления наряду с другими знаковыми системами «внутрен-
него пользования» (универсальный семантический код — УСК [Мартынов, 1977],
языки «смысла» [Мельчук, 1974], концептуальные языки [Шенк, 1980] и др.).
Язык аналитика V1 состоит из трех компонентов:
• s21 _ 1 — общенаучной терминологии из его «теоретического багажа»;
• s21_2 — терминов предметной области, которые он почерпнул из специальной
литературы в период подготовки;
• s21_3 — бытового разговорного языка, которым пользуется аналитик.
Язык эксперта V2 включает:
• s21 _ 1 — общенаучную терминологию;
• s21_2 — специальную терминологию, принятую в предметной области;
• s21_3 — бытовой язык;
• s21_4 — неологизмы, созданные экспертом за время работы, то есть его про-
фессиональный жаргон.
Если считать, что бытовой и общенаучный языки у двух участников общения
примерно совпадают (хотя реально объем второго компонента у эксперта суще-
ственно больше), то некоторый общий язык или код, который необходимо выра-
ботать партнерам для успешного взаимодействия, будет складываться из пото-
ков, представленных на рис. 3.12.
В дальнейшем этот общий код преобразуется в некоторую понятийную (семан-
тическую) сеть, которая является прообразом поля знаний предметной области.
Выработка общего кода начинается с выписыванием аналитиком всех терминов,
употребляемых экспертом, и уточнения их смысла. Фактически это составление
словаря предметной области. Затем следует группирование терминов и выбор
синонимов (слов, означающих одно и то же). Разработка общего кода заканчи-
3.3. Теоретические аспекты извлечения знаний
81
вается составлением словаря терминов предметной области с предварительной
группировкой их по смыслу, то есть по понятийной близости (это уже первый
шаг структурирования знаний).
На этом этапе аналитик должен с большим вниманием отнестись ко всем специ-
альным терминам, пытаясь максимально вникнуть в суть решаемых проблем и
терминологию. Освоение аналитиком языка предметной области — первый ру-
беж на подступах к созданию адекватной базы знаний.
S21 4
Специальная
терминология
эксперта
S21 1
S21 2
Специальные
термины
из литературы
Эксперт
Инженер
по знаниям
Общенаучные
термины
Рис. 3.12. Структура общего кода
Рисунок 3.12 дает представление о процессе неоднозначности интерпретации
терминов двумя специалистами. В семиотике, науке о знаковых системах,
проблема интерпретации является одной из центральных. Интерпретация свя-
зывает «знак» и «означаемый предмет». Только в интерпретации знак получает
смысл. Так, на рис. 3.13 слова «прибор X» для эксперта означает некоторую кон-
кретную схему, которая соответствует схеме оригинала прибора, а в голове начи-
нающего аналитика слова «прибор X» вызывают пустой образ или некоторый
черный ящик с ручками.
Знак
Рис. 3.13. Неоднозначность интерпретации
82
Глава 3 • Теоретические аспекты инженерии знаний
Внимание к лингвистическому аспекту проблемы извлечения знаний способству-
ет сближению образа 1 с образом 2 и интерпретации Ис интерпретацией 12, а сло-
ва «прибор X» перейдут в действительно «общий» код.
Таким образом, слой S21 включает изучение и управление процессом разработ-
ки специального промежуточного языка, необходимого для взаимодействия ин-
женера по знаниям и эксперта.
Понятийная структура (S22)
Проблемы формирования понятийной структуры представляют следующий
слой S22 лингвистического аспекта проблемы извлечения знаний. Особенности
формирования понятийной структуры обусловлены установленным постулатом
когнитивной психологии о взаимосвязи понятий в памяти человека и наличии
семантической сети, объединяющей отдельные термины во фрагменты, фраг-
менты в сценарии и т. д. Построение иерархической .сети понятий, так называе-
мой «пирамиды знаний», — важнейшее звено в проектировании интеллектуаль-
ных систем.
Большинство специалистов по искусственному интеллекту и когнитивной пси-
хологии считают, что основная особенность естественного интеллекта и памяти
в частности — это связанность всех понятий в некоторую сеть. Поэтому для раз-
работки базы знаний и нужен не словарь, а «энциклопедия» [Шенк, Бирнбаум,
Мей, 1989], в которой все термины объяснены в словарных статьях со ссылками
на другие термины.
Таким образом, лингвистическая работа инженера по знаниям на данном слое
проблем заключается в построении таких связанных фрагментов с помощью
«сшивания» терминов. Фактически зта работа является подготовкой к этапу кон-
цептуализации, где это «шитье» (по Шенку — КОП, концептуальная организация
памяти [Шенк, Хантер, 1987]) приобретает некоторый законченный вид.
При тщательный работе аналитика и эксперта в понятийных структурах начина-
ет просматриваться иерархия понятий, подробно о которой будет говориться в
параграфах 4.4. и 8.2. Такие структуры имеют важнейшее гносеологическое и
дидактическое значение и последнее время для них используется специальный
термин — онтологии. Следует заметить, что эта иерархическая организация хо-
рошо согласуется с теорией универсального предметного кода (УПК) [Горелов,
1987; Жинкин, 1982], согласно которой при мышлении используются не языко-
вые конструкции, а их коды в форме некоторых абстракций, что в общем согла-
суется с результатами когнитивной психологии [Величковский, 1982].
Иерархия абстракций — это глобальная схема, которая может быть положена в
основу концептуального анализа структуры знаний любой предметной области.
Лингвистический эквивалент иерархии — иерархия понятий, которую необхо-
димо построить в понятийной структуре, формируемой инженером по знаниям
(рис. 3.14).
Следует подчеркнуть, что работа по составлению словаря и понятийной структу-
ры требует.лингвистического «чутья», легкости манипулирования терминами и
3.3. Теоретические аспекты извлечения знаний
83
богатого словарного запаса инженера по знаниям, так как зачастую аналитик вы-
нужден самостоятельно разрабатывать словарь признаков. Чем богаче и вырази-
тельнее получается общий код, тем более полнее база знаний.
Рис. 3.14. Пример иерархии
Аналитик вынужден все время помнить о трудности передачи образов и пред-
ставлений в вербальной форме. Полезными тут оказываются свойства многознач-
ности слов естественного языка. Часто инженеру по знаниям приходится под-
сказывать слова и выражения эксперту, и такие новые лексические конструкции
оказываются полезными.
Способность к словесной интерпретации зависит и от пола аналитика (параметр
sl_l). Установлено, что традиционно женщины придают большую значимость
невербальным компонентам общения, а в вербальных имеют более обширный ал-
фавит признаков. И вообще, существуют половые различия восприятия не толь-
ко в бытовой сфере, что очевидно, но и в профессиональной. Следовательно, у
эксперта-мужчины и у эксперта-женщины могут существенно отличаться алфа-
виты для вербализации признаков воспринимаемых объектов.
Словарь пользователя (S23)
Лингвистические результаты, соотнесенные к слоям общего кода и понятийной
структуры, направлены на создание адекватной базы знаний. Однако часто про-
фессиональный уровень конечного пользователя не позволяет ему применить
специальный язык предметной области в полном объеме.
Неожиданными для начинающих разработчиков являются проблемы формиро-
вания отдельного словаря для создания дружественного интерфейса с пользова-
телем ЭС, исследуемые в слое S23. Необходимы специальные приемы, увеличи-
вающие «прозрачность» и доступность системы. Для разработки пользователь-
ского интерфейса требуется дополнительная доработка словаря общего кода с по-
правкой на доступность и «прозрачность» системы.
84
Глава 3 • Теоретические аспекты инженерии знаний
Так, при разработке экспертной системы по психодиагностике АВТ АНТЕСТ
[Гаврилова, 1984] пришлось разработать два словаря терминов — один для психо-
логов-профессионалов, второй — для неспециалистов (испытуемых). Поскольку
результат психодиагностического тестирования всегда интересен испытуемому,
ему выдается листинг с психологическим заключением на общелитературном
языке без употребления специальных терминов. Интересно, что при внедрении
системы использовался в основном этот второй словарь; даже профессиональные
психологи предпочитали получать тексты на обыденном языке.
3.3.3. Гносеологический аспект извлечения
знаний
Гносеология — это раздел философии, связанный с теорией познания, или теорией
отражения действительности в сознании человека. Гносеологический аспект (АЗ)
извлечения знаний объединяет методологические проблемы получения нового
научного знания, поскольку при создании БЗ эксперт часто впервые формулиру-
ет некоторые закономерности, до того момента составлявшие его личный опыт.
Инженерия знаний как наука, если можно так выразиться, дважды гносеологич-
на — сначала действительность (О) отражается в сознании эксперта (Ml), а за-
тем деятельность и опыт эксперта интерпретируются сознанием инженера по
знаниям (М2), что служит уже основой для построения третьей интерпретации
(Р) — поля знаний экспертной системы (см. рис. 3.5). Процесс познания, в сущ-
ности, направлен на создание внутренней репрезентации окружающего мира в
сознании человека.
Предметом данного учебника являются в основном процессы отображения 12 и 13
(И — изучают психология и философия); подробно интерпретация 13 будет рас-
смотрена далее.
Если описать процессы 12 и 13 в терминологии, введенной в главе 1, то мы имеем
дело с превращением экспертного знания и теоретического (книжного) опыта Z1
в поле знаний Z2, которое есть материализация модели мира М2 инженера по зна-
ниям.
В процессе извлечения знаний аналитика в основном интересует компонент Z1,
связанный с неканоническими индивидуальными знаниями экспертов, посколь-
ку предметные области, требующие именно такого типа знаний, считаются наи-
более восприимчивыми к внедрению экспертных систем. Эти области обычно
называют эмпирическими, так как в них накоплен большой объем отдельных эм-
пирических фактов и наблюдений, в то время как их теоретическое обобщение —
вопрос будущего.
Если считать, что инженер по знаниям извлекает только фрагмент Z1', то есть
часть из системы знаний эксперта Z1, то его задача, во-первых, стараться, чтобы
структура Z1' соответствовала Z1, и, во-вторых, чтобы Z1’ как можно более пол-
но отражал Z1.
Познание часто сопровождается созданием новых понятий и теорий. Иногда экс-
перт порождает новые знания прямо в ходе беседы с аналитиком. Такая генера-
3.3. Теоретические аспекты извлечения знаний
85
ция знаний полезна и самому эксперту, который до того момента мог не осозна-
вать ряд соотношений и закономерностей предметной области. Аналитику может
помочь тут и инструментарий системной методологии, позволяющий использо-
вать известные принципы логики научных исследований, понятийной иерархии
науки. Эта методология заставляет его за частным всегда стремиться увидеть об-
щее, то есть строить цепочки.
Гносеологическая цепочка: факт -» обобщенный факт —> эмпирический закон —> теоре-
тический закон.
Не всегда удается дойти до последнего звена этой цепочки, но уже само стремле-
ние к движению бывает чрезвычайно плодотворным. Такой подход полностью
согласуется со структурой самого знания, которое имеет два уровня:
1. Эмпирический (наблюдения, явления).
2. Теоретический (законы, абстракции, обобщения).
Но теория — это не только стройная система обобщения научного знания, это так-
же некоторый способ производства новых знаний. Основными методологически-
ми критериями научности, позволяющими считать научным и само новое знание
и способ его получения, являются [Коршунов, Мангалов, 1988]:
АЗ = {S31, S32, S33} = {внутренняя согласованность, системность, объективность,
историзм}.
Внутренняя согласованность (S31)
Основные характеристики эмпирического знания:
S31 = {s31_i} = {модальность, противоречивость, неполнота}.
На первый взгляд критерий внутренней согласованности знания не соответству-
ет реальным характеристикам, описывающим знания с точки зрения слоя s31_i.
Эти характеристики эмпирических знаний подчеркивают его «многоуклад-
ность» — столь часто факты не согласуются друг с другом, определения противо-
речат, критерии диффузны и т. д. Аналитику, знающему особенности эмпиричес-
кого знания, — приходится сглаживать эти «шероховатости» эмпирики.
Модальность (s31_l) знания означает возможность его существования в различ-
ных категориях, то есть в конструкциях существования и долженствования. Та-
ким образом, часть закономерностей возможна, другая обязательна и т. д. Кроме
того, приходится различать такие оттенки модальности, как:
• эксперт знает, что...;
• эксперт думает, что...;
• эксперт хочет, чтобы...;
• эксперт считает, что....
Возможная противоречивость (s31_J2) эмпирического знания — естественное
следствие из основных законов диалектики, и противоречия эти не всегда долж-
86
Глава 3 » Теоретические аспекты инженерии знаний
ны разрешаться в поле знаний, а напротив, именно противоречия служат чаще
всего отправной точкой в рассуждениях экспертов.
Неполнота (s31_3) знания связана с невозможностью полного описания предмет-
ной области. Задача аналитика эту неполноту ограничить определенными рамка-
ми «полноты», то есть сузить границы предметной области либо ввести ряд огра-
ничений и допущений, упрощающих проблему.
Системность (S32)
Системно-структурный подход к познанию (восходящий еще к Гегелю) ориен-
тирует аналитика на рассмотрение любой предметной области с позиций зако-
номерностей системного целого и взаимодействия составляющих его частей.
Современный структурализм исходит из многоуровневой иерархической органи-
зации любого объекта, то есть все процессы и явления можно рассматривать как
множество более мелких подмножеств (признаков, деталей) и, наоборот, любые
объекты можно (и нужно) рассматривать как элементы более высоких классов
обобщений. Например, системный взгляд на проблематику структурирования
знаний позволяет увидеть его иерархическую организацию. Подробнее об этом
в параграфе 3.4.
Объективность (S33)
Процесс познания глубоко субъективен, то есть он существенно зависит от осо-
бенностей самого познающего субъекта. «Факты существуют для одного глаза и
отсутствуют для другого» (Виппер). Таким образом, субъективность начинается
уже с описания фактов и увеличивается по мере углубления идеализации объек-
тов.
Следовательно, более корректно говорить о глубине понимания, чем об объек-
тивности знания. Понимание — это сотворчество, процесс истолкования объекта
с точки зрения субъекта. Это сложный и неоднозначный процесс, совершающий-
ся в глубинах человеческого сознания и требующий мобилизации всех интел-
лектуальных и эмоциональных способностей человека. Всё свои усилия анали-
тик должен сосредоточить на понимании проблемы.
В психологии известен результат [Величковский, Капица, 1987], подтверждаю-
щий факт, что люди, быстро и успешно решающие интеллектуальные задачи,
большую часть времени тратят на понимание ее, в то время как плохие решатели
быстро приступают к поискам решения и чаще всего не могут его найти.
Историзм (S34)
Этот критерий связан с развитием. Познание настоящего — есть познание поро-
дившего его прошлого. И хотя большинство экспертных систем дают «горизон-
тальный» срез знаний — без учета времени (в статике), инженер по знаниям дол-
жен всегда рассматривать процессы с учетом временных изменений — как связь с
прошлым, так и связь с будущим. Например, структура поля знаний и база зна-
ний должны допускать подстройку и коррекцию как в период разработки, так и
во время эксплуатации ЭС.
3.3. Теоретические аспекты извлечения знаний
87
Рассмотрев основные критерии научности познания, попытаемся теперь описать
его структуру. Методологическая структура познания может быть представлена
как некоторая последовательность этапов [Коршунов, Манталов, 1988].
Параметры {S3i} органически вписываются в эту структуру познания, которая
может быть представлена как последовательность этапов, описанных далее с по-
зиций инженера по знаниям:
• Э_1: описание и обобщение фактов;
• Э_2: установление логических и математических связей, дедукция и индукция
законов;
• Э _3: построение идеализированной модели;
• Э_4: объяснение и предсказание явлений.
Э_1. Описание и обобщение фактов
Тщательность и полнота ведения протоколов во время процесса извлечения и
пунктуальная «домашняя работа» над ними — вот залог продуктивного первого
этапа познания и материал для описания и обобщения фактов.
На практике оказывается трудным придерживаться принципов объективности и
системности, описанных выше. Чаще всего на этом этапе факты просто собирают
и как бы бросают в «общий мешок»; опытный инженер по знаниям часто сразу
пытается найти «полочку» или «ящичек» для каждого факта, тем самым подспуд-
но готовясь к этапу концептуализации.
Э_2. Установление связей и закономерностей
В памяти эксперта все понятия увязаны и закономерности установлены, хотя ча-
сто и неявно задача инженера —^выявить каркас умозаключений эксперта. Рекон-
струируя рассуждения эксперта, инженер по знаниям может опираться на две
наиболее популярные теории мышления — логическую и ассоциативную. При
этом если логическая теория благодаря горячим поклонникам в лице математи-
ков широко цитируется и всячески эксплуатируется в работах по искусственному
интеллекту, то вторая, ассоциативная, гораздо менее известна и популярна, хотя
имеет также древние корни. Так, Р. Фейнман в своих «Лекциях по физике» отме-
чает, что в физике по-прежнему преобладающим является вавилонский, а не гре-
ческий метод построения знаний. Известно, что древневосточные математики
умели делать сложные вычисления, но формулы их не были логически увязаны.
Напротив, греческая математика дедуктивна (например, «Начала» Евклида).
Традиционная логика формирует критерии, которые гарантируют точность, ва-
лидность, непротиворечивость общих понятий рассуждений и выводов. Ее осно-
вы заложены еще в «Органоне» Аристотеля в 4 в. до н. э. Большой вклад в разви-
тие логики внес Джон Стюарт Милль (1806-1873).
Инженер по знаниям и сам использует операции традиционной логики и выде-
ляет их в схеме рассуждений эксперта. Это следующие операции:
• определение;
• сравнение и различение;
88
Глава 3 • Теоретические аспекты инженерии знаний
• анализ;
• абстрагирование;
• обобщение;
• классификация;
• категоризация;
• образование суждений;
• умозаключение;
• составление силлогизмов и т. д.
Однако красота и стройность логической теории не должны заслонять того, что
человек редко мыслит в категориях математической логики [Поспелов, 1989].
Теория ассоциаций представляет мышление как цепочку идей, связанных общи-
ми понятиями. Основными операциями такого мышления являются:
• ассоциации, приобретенные на основе различных связей;
• припоминание прошлого опыта; пробы и ошибки со случайными успехами;
• привычные («автоматические») реакции и пр.
Однако эти две теории не исчерпывают всего многообразия психологических
школ. Большой интерес для инженерии знаний может представлять гештальт-
психология. Одним из ее основателей является выдающийся немецкий психолог
М. Вертгеймер (1880-1943). Под гештальтом (нем. Gestalt) понимается прин-
цип целостности восприятия — как основа мышления. Гештальт-психологи ста-
раются во всем выделять некий целостный образ или структуру как базис для по-
нимания процессов и явлений окружающего мира. Эта теория близка теории
фреймов и объектному подходу и направлена на постижение глубинного знания,
которое характеризуется стабильностью и симметрией. При этом важен так на-
зываемый «центр ситуации», относительно которого развивается знание о пред-
метной области.
Для инженера по знаниям это означает, что, выявляя различные фрагменты зна-
ний, он не должен забывать о главном, о гештальте фрагмента, который влияет на
остальные компоненты и связывает их в некоторую структурную единицу. Геш-
тальтом может быть некий главный принцип, или идея, или гипотеза эксперта,
или его вера в силу каких-то отдельных концепций. Этот принцип редко форму-
лируется экспертом явно, он всегда как бы за «кадром», и искусство инженера по
знаниям обнаружить этот основной гештальт эксперта.
В гештальт-теории существует закон «стремления к хорошему гештальту», со-
гласно которому структуры сознания стремятся к гармонии, связности, простоте.
Это близко к старинному классическому принципу «бритвы Оккама» — «сущно-
сти не должны умножаться без необходимости» — и формулируется как принцип
прегнантности Вертгеймера [Вертгеймер, 1987]: «Организация поля имеет тен-
денцию быть настолько простой и ясной, насколько позволяют данные условия».
Рассуждения о гештальте подводят вплотную к третьему этапу в структуре позна-
ния.
3.3. Теоретические аспекты извлечения знаний
89
Э_3. Построение идеализированной модели
Для построения модели, отражающей представление субъекта о предметной об-
ласти, необходим специализированный язык, с помощью которого можно опи-
сывать и конструировать те идеализированные модели мира, которые возникают
в процессе мышления. Язык этот создается постепенно с помощью категориаль-
ного аппарата, принятого в соответствующей предметной области, а также фор-
мально-знаковых средств математикй и логики. Для эмпирических предметных
областей такой язык пока не разработан, и поле знаний, которое полуформализо-
ванным способом опишет аналитик, может быть первым шагом к созданию тако-
го языка.
Любое познавательное отражение включает в себя условность, то есть упрощение
и идеализацию. Инженеру по знаниям необходимо овладение такими специфи-
ческими гносеологическими приемами, как идеализация, огрубление, абстраги-
рование, которые позволяют адекватно отображать в модели реальную картину
мира. Эти приемы доводят свойства и признаки объектов до пределов, позволяю-
щих воспроизводить законы действительности в более лаконичном виде (без вли-
яния несущественных деталей).
На тернистом пути познания проверенный диалектический подход оказывается
лучшим «поводырем». Инженер по знаниям, который стремится познать про-
блемную область, должен быть готов постоянно изменять свои уже утвердившие1
ся способы восприятия и оценки мира и даже отказываться от них. При этом тща-
тельнее всего следует проверять правильность суждений, которые кажутся самыми
очевидными.
Э_4. Объяснение и предсказание моделей
Этот завершающий этап в структуре познания является одновременно и частич-
ным критерием истинности полученного знания. Если выявленная система зна-
ний эксперта полна и объективна, то на ее основании можно делать прогнозы и
объяснять любые явления из данной предметной области. Обычно базы знаний
ЭС страдают фрагментарностью и модульностью (несвязанностью) компонен-
тов. Все это не позволяет создавать действительно интеллектуальные системы,
которые, равняясь на человека, могли бы предсказывать новые закономерности и
объяснять случаи, не указанные в явном виде в базе. Исключением тут являются
обучающие системы, которые ориентированы на генерацию новых знаний и
«предсказание».
Предлагаемая методология вооружает аналитика аппаратом, позволяющим избе-
жать традиционных ошибок, приводящих к неполноте, противоречивости, фраг-
ментарности БЗ, и указывает направление, в котором необходимо двигаться раз-
работчикам. И хотя на сегодняшний день большинство БЗ прорабатываются
лишь до этапа Э_3, знание полной схемы обогащает и углубляет процесс проекти-
рования.
90 Глава 3 « Теоретические аспекты инженерии знаний
3.4. Теоретические аспекты
структурирования знаний
Разделение стадий извлечения и структурирования знаний является весьма ус-
ловным, поскольку хороший инженер по знаниям, уже извлекая знания, начинает
работу по структурированию и формированию поля знаний, описанному в пара-
графе 3-1.
Однако в настоящее время прослеживается тенденция опережения технологи-
ческих средств разработки интеллектуальных систем по отношению к их теоре-
тическому обоснованию. Практически сейчас существует пропасть между блес-
тящими, но несколько «постаревшими» математическими основами киберне-
тики (труды Винера, Эшби, Шеннона, Джорджа, Клира, Йордона, Ляпунова,
Глушкова и др.) и современным поколением интеллектуальных систем, которые
основаны на парадигме обработки знаний (экспертные системы, лингвистичес-
кие процессоры, обучающие системы и т. п.).
С одной стороны, это объясняется тем, что с первых шагов наука об искусствен-
ном интеллекте (ИИ) была направлена на моделирование слабоформализуе-
мых смысловых задач, в которых не применим традиционный математический
аппарат; с другой стороны, ИИ — это ветвь информатики и активно развивается
как промышленная индустрия программных средств в условиях жесткой конку-
ренции, где подчас важнее быстрое внедрение новых идей и подходов, чем их
анализ и теоретическая проработка.
Необходимость разработки теоретических основ науки о методах разработки си-
стем, основанных на знаниях — инженерии знаний, — обосновывается в работах
Поспелова Д. А., Попова Э. В., Стефанюка В. Л., Шенка Р., Минского М. — веду-
щих специалистов в области ИИ в России и зарубежом. Первые шаги в создании
методологии (работы Осипова Г. С., Хорошевского В. Ф., Яшина А. М., Wielinga,
Slagle, etc.) фактически являются пионерскими и чаще всего ориентированы на
определенный класс задач, моделируемых в рамках конкретного программного
инструментария.
В данном параграфе рассмотрена новая методология [Гаврилова, 1995], позволя-
ющая провести стадию структурирования независимо от последующей программ-
ной реализации, опираясь на достижения в области разработки сложных систем.
3.4.1. Историческая справка
Стадия концептуального анализа или структурирования знаний традиционно
является (наряду со стадией извлечения) «узким местом» в жизненном цикле
разработки интеллектуальных систем [Adeli, 1994]. Методология структурирова-
ния близка к современной теории больших систем [Гиг, 1981] или сложных сис-
тем [Courtois, 1985; Peters, 1981], где традиционно акцент делается на процессе
проектирования таких систем. Большой вклад в эту теорию внесли классики
объектно-ориентированного анализа [Буч, 1992].
3.4. Теоретические аспекты структурирования знаний
91
Разработку интеллектуальных систем с уверенностью можно отнести к данному
классу задач, поскольку они обладают основными признаками сложности (иерар-
хия понятий, внутриэлементные и межэлементные связи и пр.). Сложность про-
ектирования ИС определяется в основном сложностью предметных областей и
управления процессом разработки, а также сложностью обеспечения гибкости
конечного программного продукта и описания поведения отдельных подсистем.
Среди первых сторонников исследований по теории систем наиболее заметными
были Берталанфи [Bertalanffy, 1950], Раппопорт и Боулдинг [Boulding, 1956].
Аналогичные концепции, но связанные не с общесистемными исследованиями, а
рассматривающие информационные процессы в системах, таких как связь и уп-
равление, положили начало кибернетике как самостоятельной науке [Винер,
1958; Эшби, 1959]. Этот подход был существенно поддержан работами Шеннона
по математическому моделированию понятия информации [Шеннон, Уивер,
1963; Feinstein, 1958; Watanabe, 1969].
Позднее, в 1960-х гг. было сделано несколько попыток сформулировать и развить
математические теории систем высокого уровня общности [Mesarovic, 1964; Ар-
биб, 1975]. Существенный вклад в математическую теорию систем и основы
структурирования внесли отечественные исследователи Моисеев Н. Я. [Моисе-
ев, 1981], Глушков В. М. [Глушков, 1964], Ивахненко А. Г. [Ивахненко, 1971], По-
спелов Д. А. [Поспелов, 1986] и другие. Системный анализ тесно переплетается с
теорией систем и включает совокупность методов, ориентированных на исследо-
вание и моделирование сложных систем — технических, экономических, экологи-
ческих и т. п.
3.4.2. Иерархический подход
Проектирование сложных систем и методы структурирования информации тра-
диционно использовали иерархический подход [Месарович, Такахара, 1972] как
методологический прием расчленения формально описанной системы на уровни
(или блоки, или модули). На высших уровнях иерархии используются наименее
детализованные представления, отражающие только самые общие черты и осо-
бенности проектируемой системы. На следующих уровнях степень подробности
возрастает, при этом система рассматривается не в целом, а отдельными бло-
ками.
В теории САПР такой подход называется блочно-иерархическим (БИП) [Норен-
ков, 1983; Петров, 1991]. Одно из преимуществ БИП состоит в том, что сложная
задача большой размерности разбивается на последовательно решаемые группы
задач малой размерности.
На каждом уровне вводятся свои представления о системе и элементах. Элемент
к-го уровня является системой для уровня к-1. Продвижение от уровня к уров-
ню имеет строгую направленность, определяемую стратегией проектирования —
сверху вниз или снизу вверх.
92
Глава 3 • Теоретические аспекты инженерии знаний
Предлагаемый.ниже объектно-структурный подход позволяет объединить две,
обычно противопоставляемые, стратегии проектирования — нисходящую или
дедуктивную STRtd (top-down) с последовательной декомпозицией объектов и
процессов сверху вниз и восходящую или индуктивную STRbu (bottom-up) с по-
степенным обобщением понятий и увеличением степени абстрактности описа-
ний снизу вверх.
Синтез этих стратегий, а также включение возможности итеративных возвратов
на предыдущие уровни обобщений позволили создать дуальную концепцию, пре-
доставляющую аналитику широкую палитру возможностей на стадии структури-
рования знаний как для формирования концептуальной структуры предметной
области Sk, так и для функциональной структуры Sf.
Рисунок 3.15. иллюстрирует дуальную концепцию при проектировании Sk для ЭС
помощи оператору энергетического блока.
U1 I
процесс
Рис. 3.15. Дуальная стратегия проектирования
U2
части
процесса
из
режим
работы к
<D
га
а
U4 “
функ- га
циональ- га
ные |
состав- g
ляющие
U5
блоки
U6
действия
оператора
3.4. Теоретические аспекты структурирования знаний
93
Нисходящая концепция (top-down) декларирует движение от п => п+1, где п — п-й
уровень иерархии понятий ПО (предметной области) с последующей детализа-
цией понятий, принадлежащим соответствующим уровням.
STR^ : Р" => Р1п+|,..,Рк"+|,
где п -* номер уровня порождающего концепта;
i — номер порождающего концепта;
kj — число порождаемых концептов, сумма всех k, по i составляет общее число
концептов на уровне п+1.
Восходящая концепция (bottom-цр) предписывает движение п => п-1 с последова-
тельным обобщением понятий.
STR^P^.P^P”1,
где п — номер уровня порождающих концептов;
i — номер порождаемого концепта;
— число порождающих концептов, сумма всех k, по i составляет общее число
концептов на уровне п.
Основанием для прекращения агрегирования и дезагрегирования является пол-
ное использование словаря терминов, которым пользуется эксперт, при этом чис-
ло уровней является значимым фактором успешности структурирования (см.
«вербальные отчеты» в главе 4).
3.4.3. Традиционные методологии
структурирования
Существующие подходы к проектированию сложных систем можно разделить на
два больших класса:
• Структурный (системный) подход или анализ, основанный на идее алгорит-
мической декомпозиции, где каждый модуль системы выполняет один из важ-
нейших этапов общего процесса.
• Объектный подход, связанный с декомпозицией и выделением не процессов, а
объектов, при этом каждый объект рассматривается как экземпляр определен-
ного класса.
В структурном анализе [Yourdon, 1989; DeMarco, 1979; Gane & Sarson, 1979] раз-
работано большое число выразительных средств для проектирования, в том чис-
ле графических [Буч, 1993]: диаграммы потоков данных (DFD — data-flow diag-
rams), структурированные словари (тезаурусы), языки спецификации систем,
таблицы решений, стрелочные диаграммы «объект—связь» (ERD — entity-rela-
tionship diagrams), диаграммы переходов (состояний), деревья целей, блок-схе-
мы алгоритмов (в нотации Насси—Шнейдермана, Гамильтона—Зельдина, Фест-
ля и др.), средства управления проектом (PERT-диаграммы, диаграммы Ганта и
др.), модели окружения.
94
Глава 3 • Теоретические аспекты инженерии знаний
Множественность средств и их некоторая избыточность объясняются тем, что
каждая, предметная область, используя структурный подход как универсальное
средство моделирования, вводила свою терминологию, наиболее подходящую
для отражения специфики конкретной проблемы. Поскольку инженерия знаний
имеет дело с широким классом ПО (это «мягкие» ПО), встает задача разработки
достаточно универсального языка структурирования.
Объектный (объектно-ориентированный) подход (ООП), возникший как техно-
логия программирования больших программных продуктов, основан на следую-
щих основных элементарных понятиях [Буч, 1992]: объекты, классы как объекты,
связанные общностью структуры и свойств, и классификации как средства упо-
рядочения знаний; иерархии с наследованием свойств; инкапсуляции как сред-
ства ограничения доступа; методы и полиморфизм для определения функций и
отношений.
ООП имеет свою систему условных обозначений и предлагает богатый набор
логических и физических моделей для проектирования систем высокой степени
сложности, при этом эти системы хорошо структурированы, что порождает лег-
кость их модификации. Впервые принцип ООП установлен в 1979 [Jones, 1979],
а затем развит в работах [Shaw, 1984; Peterson, 1987; Буч, 1992].
Широкое распространение объектно-ориентированных языков программирова-
ния C++, CLOS, Smalltalk и др. успешно демонстрирует жизнеспособность и
перспективность этого подхода.
3.4.4. Объектно-структурный подход (ОСП)
Можно предложить в качестве базисной парадигмы методологии структурного
анализа знаний и формирования поля знаний Pz обобщенный объектно-стпрук-
турный подход (ОСП), последовательно разработанный от математического обо-
снования до технологии и программной реализации [Гаврилова, 1995].
Основные постулаты этой парадигмы заимствованы из ООП и расширены.
1. Системность (взаимосвязь между понятиями).
2. Абстрагирование (выявление существенных характеристик понятия, кото-
рые отличают его от других).
3. Иерархия (ранжирование на упорядоченные системы абстракций).
4. Типизация (выделение классов понятий с частичным наследованием
свойств в подклассах).
5. Модульность (разбиение задачи на подзадачи или «возможные миры»).
6. Наглядность и простота нотации.
Использование пятого постулата ОСП в инженерии знаний позволяет строить
глобальные БЗ с возможностью выделить локальные задачи с помощью горизон-
тальных и вертикальных сечений на отдельные модули пространства-описания
предметной области.
3.4. Теоретические аспекты структурирования знаний
95
Шестой постулат внесен в список последним, но не по значимости. В инженерии
знаний формирование Pz традиционно является критической точкой [Гаврилова,
Червинская, Яшин, 1988; Гаврилова, Червинская, 1992], так как создаваемая не-
формальная модель предметной области должна быть предельно ясной и лако-
ничной. Традиционно языком инженерии знаний были диаграммы, таблицы и
другие графические элементы, способствующие наглядности представлений.
Именно поэтому предлагаемый в данной работе подход к языку связан с возмож-
ной визуализацией процесса проектирования.
ОСП позволяет наглядно и компактно отобразить объекты и отношения предмет-
ной области на основе использования шести постулатов.
Объектно-структурный подход подразумевает интегрированное использование
сформулированных выше постулатов от первой до последней стадий разработки
БЗ интеллектуальных и обучающих систем. На основе ОСП предлагается алго-
ритм объектно-структурного анализа (ОСА) предметной области, позволяюще-
го оптимизировать и упорядочить достаточно размытые процедуры структури-
рования знаний.
Стратификация знаний
Основы ОСА были предложены автором еще в работах [Гаврилова, 1989; Гаври-
лова, Красовская, 1990] и успешно применялись при разработке ЭС МИКРО-
ЛЮШЕР [Гаврилова, Тишкин, Золотарев, 1989] и АВЭКС [Гаврилова, Минко-
ва, Карапетян, 1992].
ОСА подразумевает дезагрегацию ПО, как правило, на восемь страт или сло-
ев (табл. 3.1 и 3.2).
Таблица 3.1. Стратификация знаний предметной области
S_1 ЗАЧЕМ-знания Стратегический анализ: назначение и функции системы
s_2 КТО-знания Организационный анализ: коллектив разработчиков системы
s_3 ЧТО-знания Концептуальный анализ: основные концепты, понятийная структура
s_4 КАК-знания Функциональный анализ: гипотезы и модели принятия решения
s_5 ГДЕ-знания Пространственный анализ: окружение, оборудование, коммуникации
s_6 КОГДА-знания Временной анализ: временные параметры и ограничения
s_7 ПОЧЕМУ-знания Каузальный или причинно-следственный анализ: формирование подсистемы объяснений
s_8 СКОЛЬКО-энания Экономический анализ: ресурсы, затраты, прибыль, окупаемость
Объектно-структурный анализ подразумевает разработку и использование мат-
рицы ОСА (см. табл. 3.2), которая позволяет всю собранную информацию деза-
грегировать последовательно по слоям-стратам (вертикальный анализ), а затем
96
Глава 3 • Теоретические аспекты инженерии знаний
по уровням — от уровня проблемы до уровня подзадачи (горизонтальный ана-
лиз). Или наоборот — сначала по уровням, а потом по стратам.
Таблица 3.2. Матрица объектно-структурного анализа
Уровни Страты Уровень области и. Уровень проблемы и2 Уровень задачи и3 Уровень подзадачи и4 ч„
Стратегический анализ Si Е„ Е,г Е,3 Е,д ' Е,„
Организационный анализ S2 Ег,
Концептуальный анализ s3 Е3,
Функциональный анализ s4 Е4,
Пространственный анализ s5 е5,
Временной анализ s6 Ев,
Каузальный анализ s7 Е7,
Экономический анализ s6 Е6,
Sm Ёт1 Етп
При необходимости число страт может быть увеличено. В свою очередь знания
каждой страты подвергаются дальнейшему ОСА и декомпозируются на состав-
ляющие
II ,
где m — номер уровня, п — номер страты, а етп принадлежит множеству К всех
концептов (понятий) предметной области.
(1)
Матрица (1) является матрицей над К. Пусть М (К) — совокупность всех mxn
матриц над К. Тогда можно определить клеточную матрицу Е, в которой
m = ml + ... + mk,
n = nl + ... + nl,
где тип— целые положительные числа. Е G Mmn (К), и ее можно представить в
виде:
3.4. Теоретические аспекты структурирования знаний
97
(2)
где EMV е Mm(l (К), р. - 1.k; v = 1,...,1.
Матрица Е является несимметричной, так как часть клеточных элементов Ецч, мо-
гут подвергаться декомпозиции, а часть представляет некоторые базисные ато-
марные концепты из К, не подлежащие детализации.
Предлагаемый подход предполагает реализацию концёпции последовательного
генезиса ОСП через ОСА к объектно-структурной разработке (ОСР).
Алгоритм ОСА
Алгоритм ОСА (объектно-структурного анализа) предназначен для детального
практического структурирования знаний ПО. В основе ОСА заложен алгоритм
заполнения ОСА-матрицы Emn. Алгоритм содержит последовательность аналити-
ческих процедур, позволяющих упростить и оптимизировать процесс структури-
рования. Алгоритм разделяется на две составляющие:
• А_1. Глобальный (вертикальный) анализ, включающий разбиение ПО на мето-
дологические страты (чтио-знания, как-знания и т. д.) на уровне всей ПО. В ре-
зультате заполняется первый столбец матрицы (2).
• А_П. Анализ страт (горизонтальный), включающий построение многоуров-
невых структур по отдельным стратам. Число уровней п определяется особен-
ностями стратифицированных знаний ПО и может существенно отличаться
для разных страт. С точки зрения методологии п<3 свидетельствует о слабой
проработке ПО.
Первый уровень соответствует уровню всей ПО (уровень области). Второй —
уровню проблемы, выделенной для решения. Третий — уровню конкретной ре-
шаемой задачи. Дальнейшие уровни соответствуют подзадачам, если имеет
смысл их выделять.
При этом возможно как последовательное применение восходящей (bottom-up)
и нисходящей концепций (toprdown), так и их одновременное применение.
Глобальный анализ
Технология глобального анализа сводится к разбиению пространства основной
задачи структурирования ПО на подзадачи, соответствующие особенностям
ПО. Для разработки интеллектуальных систем существует минимальный набор
s-страт, обеспечивающий формирование БЗ. Минимальный набор включает три
страты:
• s3 — формирование концептуальной структуры Sk;
• s4 — формирование функциональной структуры Sf;
• s7 — формирование подсистемы объяснений S,,.
98
Глава 3 • Теоретические аспекты инженерии знаний
Формирование остальных страт позволяет существенно оптимизировать процесс
разработки и избежать многих традиционных ошибок проектирования. Страты s4
и s5 являются дополнительными и формируются в случаях, когда знания предмет-
ной области существенно зависят от временных и пространственных параметров
(системы реального времени, планирование действий роботов и т. п.).
Алгоритм А_1 глобального анализа может быть кратко сформулирован следую-
щим образом:
• А_1_1. Собрать все материалы по идентификации задачи и по результатам из-
влечения знаний.
• А_1_2. Выбрать набор страт N, подлежащих формированию (Nmin=3).
• А_1_3. Отобрать всю информацию по первой выбранной страте (i-1, где i —
номер из выбранного набора страт N).
• А_1_4. Повторить шаг А_1_3 для i+1 для всех выбранных страт до i <= N.
• А_1_5. Если часть информации останется неиспользованной, увеличить чис-
ло страт и повторить для новых страт шаг А_1_3; иначе перейти к последова-
тельной реализации алгоритмов горизонтального анализа страт А_2.
Анализ страт
Последовательность шагов горизонтального анализа зависит от номера страты,
но фактически сводится к реализации дуальной концепции структурирования
для решения конкретной подзадачи.
Ниже предлагается алгоритм ОСА для одной из обязательных страт s3 (ЧТО-ана-
лиз), результатом которого является формирование концептуальной структуры
предметной области Sk.
• А_2_3_1. Из группы информации, соответствующей ЧТО-страте, выбрать все
значимые понятия и сформулировать соответствующие концепты.
• А_2_3_2. Выявить имеющиеся иерархии и зафиксировать их графически в
виде структуры.
• А_2_3_3. Детализировать концепты, пользуясь нисходящей концепцией (top-
down).
• А_2_3_4. Образовать метапонятия по концепции (bottom-up).
• А_2_3_5. Исключить повторы, избыточность и синонимию.
• А_2_3_6. Обсудить понятия, не вошедшие в структуру Sf, с экспертом и пере-
нести их в другие страты или исключить.
• А_2_3_7. Полученный граф или набор графов разделить на уровни и обозна-
чить — согласно матрице ОСА (1).
Аналогичные алгоритмы разработаны для всех страт и апробированы при разра-
ботке экспертных систем ПРОГОР и АВЭКС.
Технологии
инженерии
знаний
□ Классификация методов практического извлечения знаний
□ Коммуникативные методы
□ Текстологические методы
□ Простейшие методы структурирования
□ Состояние и перспективы автоматизированного приобретения знаний
□ Примеры методов и систем приобретения знаний
4.1. Классификация методов практического
извлечения знаний
Подробно рассмотрев в главе 3 теоретические аспекты инженерии знаний, мы,
однако, в явном виде не определили, каким практическим методом эти знания
будут получены. В неявном виде предполагалось, что это некоторое взаимодей-
ствие инженера по знаниям и эксперта в форме непосредственного живого обще-
ния. Однако это не единственная форма извлечения знаний, хотя и довольно рас-
пространенная. В работах [Волков, Ломнев, 1989; Осипов, 1998; Boose, 1989;
Cullen, Bryman, 1988; Gammack, Young, 1985; Hart 1986] упоминается около 15
ручных (неавтоматизированных) методов извлечения и более 20 автоматизиро-
ванных методов приобретения и формирования знаний.
Рисунок 4.1 иллюстрирует предлагаемую классификацию методов извлечения
знаний, в которой используются наиболее употребительные термины, что позво-
лит инженерам по знаниям в зависимости от конкретной задачи и ситуации выб-
рать подходящий метод.
Из предложенной схемы классификации видно, что основной принцип деления
связан с источником знаний.
100
Глава 4 • Технологии инженерии знаний
Рис. 4.1. Классификация методов извлечения знаний
Коммуникативные методы извлечения знаний охватывают методы и процедуры контак-
тов инженера по знаниям с непосредственным источником знаний — экспертом, а тек-
стологические включают методы извлечения знаний из документов (методик, пособий,
руководств) и специальной литературы (стетей, монографий, учебников).
Разделение этих групп методов на верхнем уровне классификации не означает их
антагонистичности, обычно инженер по знаниям комбинирует различные мето-
ды, например сначала изучает литературу, затем беседует с экспертами, или на-
оборот.
В свою очередь, коммуникативные методы можно также разделить на две груп-
пы: активные и пассивные. Пассивные методы подразумевают, что ведущая роль
в процедуре извлечения как бы передается эксперту, а инженер по знаниям толь-
ко протоколирует рассуждения эксперта во время его реальной работы по приня-
тию решений или записывает то, что эксперт считает нужным самостоятельно
рассказать в форме лекции. В активных методах, напротив, инициатива полнос-
тью в руках инженера по знаниям, который активно контактирует с экспертом
различными способами — в играх, диалогах, беседах за круглым столом и т. д.
Следует еще раз подчеркнуть, что и активные и пассивные методы могут чередо-
ваться даже в рамках одного сеанса извлечения знаний. Например, если инженер
по знаниям застенчив и не имеет большого опыта, то вначале он может использо-
вать пассивные методы, а постепенно, ближе знакомясь с экспертом, захватывать
инициативу и переходить «в наступление».
4.1. Классификация методов практического извлечения знаний
101
Пассивные методы на первый взгляд достаточно просты, но на самом деле требу-
ют от инженера по знаниям умения четко анализировать поток сознания эксперта
и выявлять в нем значимые фрагменты знаний. Отсутствие обратной связи (пас-
сивность инженера по знаниям) значительно ослабляет эффективность этих ме-
тодов, чем и объясняется их обычно вспомогательная роль при активных методах.
Активные методы можно разделить на две группы в зависимости от числа экс-
пертов, отдающих свои знания. Если их число больше одного, то целесообразно
помимо серии индивидуальных контактов с каждым применять и методы, груп-
повых обсуждений предметной области. Такие групповые методы обычно акти-
визируют мышление участников дискуссий и позволяют выявлять весьма не-
тривиальные аспекты их знаний. В свою очередь, индивидуальные методы на
сегодняшний день остаются ведущими, поскольку столь деликатная процедура,
как «отъем знаний», не терпит лишних свидетелей.
Отдельно следует сказать об играх. Игровые методы сейчас широко используются
в социологии, экономике, менеджменте, педагогике для подготовки руководите-
лей, учителей, врачей и других специалистов. Игра — это особая форма деятель-
ности и творчества, где человек раскрепощается и чувствует себя намного свобод-
нее, чем в обычной трудовой деятельности.
На выбор метода влияют три фактора: личностные особенности инженера по зна-
ниям, личностные особенности эксперта и характеристика предметной области.
Одна из возможных классификаций людей по психологическим характеристи-
кам [Обозов, 1986] делит всех на три типа:
• мыслитель (познавательный тип);
• собеседник (эмоционально-коммуникативный тип);
• практик (практический тип).
Мыслители ориентированы на интеллектуальную работу, учебу, теоретические
обобщения и обладают такими характеристиками когнитивного стиля, как поле-
независимость и рефлексивность (см. параграф 3.3). Собеседники — это общи-
тельные, открытые люди, готовые к сотрудничеству. Практики предпочитают
действие разговорам, хорошо реализуют замыслы других, направлены на ре-
зультативность работы.
Для характеристики предметных областей можно предложить следующую клас-
сификацию:
• хорошо документированные;
• средне документированные;
• слабо документированные.
Эта классификация связана с соотношением двух видов знаний Z( и Z2, введен-
ных в п. 1.3, где Zj — это экспертное «личное» знание, a Z2 — материализованное в
книгах «общее» знание в данной конкретной области. Если представить знания
Znoпредметной области как объединение Z (И Z2, то есть Zno= Z1EZ2, то рис. 4.2 на-
глядно иллюстрирует предложенную классификацию.
102
Глава 4 • Технологии инженерии знаний
Zi Z2
Рис. 4.2. Классификация предметных областей
Кроме этого, предметные области можно разделить по критерию структуриро-
ванности знаний. Под структурированностью будем понимать степень теорети-
ческого осмысления и выявленное™ основных закономерностей и принципов,
действующих в данной предметной области. И хотя ЭС традиционно применя-
ются в слабо структурированных предметных областях, сейчас наблюдается тен-
денция расширения сферы внедрения экспертных систем.
По степени структурированности знаний предметные области могут быть:
• хорошо структурированными — с четкой аксиоматизацией, широким приме-
нением математического аппарата, устоявшейся терминологией;
• средне структурированными — с определившейся терминологией, развиваю-
щейся теорией, явными взаимосвязями между явлениями;
• слабо структурированными — с размытыми определениями, богатой эмпири-
кой, скрытыми взаимосвязями, с большим количеством «белых пятен».
Введенные в данном параграфе классификации методов и предметных областей
помогут инженеру по знаниям, четко определив свою предметную область, соот-
нести ее с предложенными типами и наметить подходящий метод или группу ме-
тодов извлечения знаний. Однако, скорее всего, реальная работа полностью
зачеркнет его выбор, и окажется, что его хорошо документированная область яв-
ляется слабо документированной, а метод наблюдений надо срочно заменят^ иг-
рами!
Такова реальная сложность процедуры извлечения знаний.
4.2. Коммуникативные методы
В соответствии с классификацией, представленной на рис. 4.1, рассмотрим под-
робнее обе разновидности коммуникативных методов: пассивные и активные.
4.2.1. Пассивные методы
Термин «пассивные» не должен вызывать иллюзий, поскольку он введен как про-
тивовес к «активным» методам. В реальности же пассивные методы требуют от
инженера по знаниям не меньшей отдачи, чем такие активные методы, как игры и
диалог.
4.2, Коммуникативные методы
103
Пассивные методы извлечения знаний включают такие методы, где ведущая роль в про-
цедуре извлечения фактически передается эксперту, а инженер по знаниям только фик-
сирует рассуждения эксперта во время работы по принятию решений.
Согласно классификации (см. рис. 4.1) к этой группе относятся:
• наблюдения;
• анализ протоколов «мыслей вслух»;
• лекции.
Наблюдения
В процессе наблюдений инженер по знаниям находится непосредственно рядом с
экспертом во время его профессиональной деятельности или имитации этой дея-
тельности. При подготовке к сеансу извлечения эксперту необходимо объяснить
цель наблюдений и попросить максимально комментировать свои действия.
Во время сеанса аналитик записывает все действия эксперта, его реплики и
объяснения. Может быть сделана и видеозапись в реальном масштабе времени.
Непременное условие этого метода — невмешательство аналитика в работу экс-
перта хотя бы на первых порах. Именно метод наблюдений является единствен-
но «чистым» методом, исключающим вмешательство инженера по знаниям и на-
вязывание им каких-то своих структур представлений.
Существуют две основные разновидности проведения наблюдений:
• наблюдение за реальным процессом;
• наблюдение за имитацией процесса.
Обычно используются обе разновидности. Сначала инженеру по знаниям по-
лезно наблюдать за реальным процессом, чтобы глубже понять предметную об-
ласть и отметить все внешние особенности процесса принятия решения. Это не-
обходимо для проектирования эффективного интерфейса пользователя. Ведь
будущая ЭС должна работать именно в контексте такого реального производ-
ственного процесса. Кроме того, только наблюдение позволит аналитику уви-
деть предметную область, а, как известно, «лучше один раз увидеть, чем сто раз
услышать».
Наблюдение за имитацией процесса проводят обычно также за рабочим местом
эксперта, но сам процесс деятельности запускается специально для аналитика.
Преимущество этой разновидности в том, что эксперт менее напряжен, чем в пер-
вом варианте, когда он работает на «два фронта» — и ведет профессиональную
деятельность, и демонстрирует ее. Недостаток совпадает с преимуществом —
именно меньшая напряженность эксперта может повлиять на результат — раз ра-
бота ненастоящая, то и решение может отличаться от настоящего.
Наблюдения за имитацией проводят также и в тех случаях, когда наблюдения за
реальным процессом по каким-либо причинам невозможны (например, профес-
сиональная этика врача-психиатра может не допускать присутствия посторонне-
го на приеме).
104
Глава 4 • Технологии инженерии знаний
Сеансы наблюдений могут потребовать от инженера по знаниям:
• овладения техникой стенографии для фиксации действий эксперта в реаль-
ном масштабе времени;
• ознакомления с методиками хронометража для четкого структурирования
производственного процесса по времени;
• развития навыков «чтения по глазам», то есть наблюдательности к жестам, ми-
мике и другим невербальным компонентам общения;
• серьезного предварительного знакомства с предметной областью, так как из-за
отсутствия «обратной связи» иногда многое непонятно в действиях экспертов.
Протоколы наблюдений после сеансов в ходе домашней работы тщательно рас-
шифровываются, а затем обсуждаются с экспертом.
Таким образом, наблюдения — один из наиболее распространенных методов из-
влечения знаний на начальных этапах разработки. Обычно он применяется не
самостоятельно, а в совокупности с другими методами.
Анализ протоколов «мыслей вслух»
Протоколирование «мыслей вслух» отличается от наблюдений тем, что эксперта
просят не просто прокомментировать свои действия и решения, но и объяснить,
как это решение было найдено, то есть продемонстрировать всю цепочку своих
рассуждений. Во время рассуждений эксперта все его слова, весь «поток созна-
ния» протоколируется инженером по знаниям, при этом полезно отметить даже
паузы и междометия. Иногда этот метод называют «вербальные отчеты» [Морго-
ев, 1988].
Вопрос об использовании для этой цели магнитофонов и диктофонов является
дискуссионным, поскольку магнитофон иногда парализующе действует на экс-
перта, разрушая атмосферу доверительности, которая может и должна возни-
кать при непосредственном общении.
Основной трудностью при протоколировании «мыслей вслух» является прин-
ципиальная сложность для любого человека объяснить, как он думает. При этом
существуют экспериментальные психологические доказательства того факта,
что люди не всегда в состоянии достоверно описывать мыслительные процессы.
Кроме того, часть знаний, хранящихся в невербальной форме (например, различ-
ные процедурные знания типа «как завязывать шнурки»), вообще слабо корре-
лируют с их словесным описанием. Автор теории фреймов М. Минский считает,
что «только как исключение, а не как правило, человек может объяснить то, что
он знает» [Minsky, 1981]. Однако существуют люди, склонные к рефлексии, для
которых эта работа является вполне доступной. Следовательно, описанная в па-
раграфе 3.3. такая характеристика когнитивного стиля, как рефлексивность, яв-
ляется для эксперта более чем желательной.
Расшифровка полученных протоколов производится инженером по знаниям са-
мостоятельно с коррекциями на следующих сеансах извлечения знаний. Удачно
4.2, Коммуникативные методы
105
проведенное протоколирование «мыслей вслух» является одним из наиболее эф-
фективных методов извлечения, поскольку в нем эксперт может проявить себя
максимально ярко, он ничем не скован, никто ему не мешает, он как б£х свободно
парит в потоке собственных умозаключений и рассуждений. Он может здесь
блеснуть эрудицией, продемонстрировать глубину своих познаний. Для большо-
го числа экспертов это самый приятный и лестный способ извлечения знаний.
От инженера по знаниям метод «мысли вслух» требует тех же умений, что и метод
наблюдений. Обычно «мысли вслух» дополняются потом одним из активных ме-
тодов для реализации обратной связи между интерпретацией инженера по знани-
ям и представлениями эксперта.
Лекции
Лекция является самым старым способом передачи знаний. Лекторское искусст-
во издревле очень высоко ценилось во всех областях науки и культуры. Но нас
сейчас интересует не столько способность к подготовке и чтению лекций, сколь-
ко способность эту лекцию слушать, конспектировать и усваивать. Уже говори-
лось, что чаще всего экспертов не выбирают, и поэтому учить эксперта чтению
лекции инженер по знаниям не сможет. Но если эксперт имеет опыт преподава-
теля (например, профессор клиники или опытный руководитель производства),
то можно воспользоваться таким концентрированным фрагментом знаний, как
лекция. В лекции эксперту также предоставлено много степеней свободы для са-
мовыражения; при этом необходимо сформулировать эксперту тему и задачу
лекции. Например, тема цикла лекций «Постановка диагноза — воспаление лег-
ких», тема конкретной лекции «Рассуждения по анализу рентгенограмм», зада-
ча — научить слушателей по перечисленным экспертом признакам ставить диаг-
ноз воспаления легких и делать прогноз. При такой постановке опытный лектор
может заранее структурировать свои знания и ход рассуждений. От инженера по
знаниям в этой ситуации требуется лишь грамотно законспектировать лекцию и
в конце задать необходимые вопросы. .
Студенты хорошо знают, что конспекты лекций одного и того же лектора у раз-
ных студентов существенно отличаются. Списать конспект лекций просят, как
правило, у одного-двух студентов из группы. Люди, умело ведущие конспект,
обычно сильные студенты. Обратное не верно. В чем же заключается искусство
ведения конспекта? В «помехоустойчивости». Записывать главное, опускать вто-
ростепенное, выделять фрагменты знаний (параграфы, под-параграфы), записы-
вать только осмысленные предложения, уметь обобщать.
Хороший вопрос по ходу лекции помогает и лектору и слушателю. Серьезные и
глубокие вопросы могут существенно поднять авторитет инженера по знаниям в
глазах эксперта.
Опытный лектор знает, что все вопросы можно условно разбить на три группы:
• умные вопросы, углубляющие лекцию;
• глупые вопросы или вопросы не по существу;
• вопросы «на засыпку» или провокационные.
106
Глава 4 • Технологии инженерии знаний
Если инженер по знаниям задает вопросы второго типа, то возможны две реак-
ции. Вежливый эксперт будет разговаривать с таким аналитиком как с ребенком,
который сейчас не понимает и все равно ничего уже не поймет. Заносчивый экс-
перт просто выйдет из контакта, не желая терять время. Если же инженер по зна-
ниям захочет продемонстрировать свою эрудицию вопросами третьего типа, то
ничего, кроме раздражения и отчуждения, он, по-видимому, в ответ не получит.
Продолжительность лекции рекомендуется стандартная — от 40 до 50 минут и
через 5-10 минут — еще столько же. Курс обычно от двух до пяти лекций.
Метод извлечения знаний в форме лекций, как и все Пассивные методы, использу-
ют в начале разработки как эффективный способ быстрого погружения инженера
по знаниям в предметную область.
В заключение несколько советов, как слушать лекции [Ребельский, 1989].
1. К лекции подготовьтесь, то есть познакомьтесь с предметной областью.
2. Слушайте с максимальным вниманием, для этого: устраните мешающие фак-
торы (скрип двери, шорохи и т. д.); удобно устройтесь; поменьше двигайтесь.
3. Учитесь отдыхать во время слушания (например, когда лектор приводит циф-
ры, которые можно взять из справочника).
4. Слушайте одновременно и лектора, и самого себя (параллельно с мыслями лек-
тора по ассоциации возникают собственные мысли).
5. Слушайте и одновременно записывайте, но записывайте текст сокращенно, ис-
пользуя условные значки (для этого вовсе не следует непременно быть стено-
графом, достаточно только установить для себя ряд условных значков и ими
неизменно пользоваться).
6. Расшифруйте записи лекции в тот же день.
7. Не спорьте с лектором в процессе лекции.
8. Рационально используйте перерывы в лекции для подведения итогов прослу-
шанного.
Сравнительные характеристики пассивных методов извлечения знаний пред-
ставлены в табл; 4.1.
Таблица 4.1. Сравнительные характеристики пассивных методов извлечения знаний
Пассивный метод извлечения знаний Наблюдения «Мысли вслух» Лекции
Достоинства Отсутствие влияния аналитика и его субъективной позиции Максимальное приближение аналитика к предметной области Свобода самовыражения для эксперта Обнаженность структур рассуждений Свобода самовыражения для эксперта Структурированное изложение. Высокая концентрация
4.2, Коммуникативные методы
107
Пассивный метод извлечения знаний Наблюдения «Мысли вслух» Лекции
Отсутствие влияния аналитика и его субъективной позиции Отсутствие влияния аналитика и его субъективной позиции
Недостатки Отсутствие обратной связи Фрагментарность полученных комментариев Отсутствие обратной связи Возможность ухода«в сторону» в рассуждениях эксперта «Зашумлен ность» деталями Слабая обратная связь Недостаток хороших лекторов среди экспертов- практиков
Требования кэксперту (типы и основные качества) Собеседник или мыслитель (способность к вербализации + мыслей + аналитичность* открытость* рефлексивность) Собеседник или мыслитель (способность к вербализации * мыслей * аналитичность* открытость* рефлексивность) Мыслитель (лекторские способности)
Требования к эксперту (типы и основные качества) Мыслитель (наблюдательность + поленезависимость) Мыслитель или собеседник (контактность* поленезависимость) Мыслитель (поле- независимость* способность к обобщению)
Характе- ристика предметной области Слабо и средне структурированные; слабо и средне документированные Тоже Слабо документированные и слабо структурированные
4.2.2. Активные индивидуальные методы
Активные индивидуальные методы извлечения знаний на сегодняшний день —
наиболее распространенные. В той или иной степени к ним прибегают при раз-
работке практически любой ЭС.
К основным активным методам можно отнести:
• анкетирование;
• интервью;
• свободный диалог;
• игры с экспертом.
Во всех этих методах активную функцию выполняет инженер по знаниям, кото-
рый пишет сценарий и режиссирует сеансы извлечения знаний. Игры с экспертом
108
Глава 4 • Технологии инженерии знаний
существенно отличаются от трех других методов. Три оставшихся метода очень
схожи между собой и отличаются лишь по степени свободы, которую может себе
позволить инженер по знаниям при проведении сеансов извлечения знаний. Их
можно назвать вопросными методами поиска знаний.
Анкетирование
Анкетирование — наиболее жесткий метод, то есть наиболее стандартизирован-
ный. В этом случае инженер по знаниям заранее составляет вопросник или анке-
ту, размножает ее и использует для опроса нескольких экспертов. Это основное
преимущество анкетирования.
Сама процедура может проводиться двумя способами:
1. Аналитик вслух задает вопросы и сам заполняет анкету по ответам эксперта.
2. Эксперт самостоятельно заполняет анкету после предварительного инструк-
тирования.
Выбор способа зависит от конкретных условий (например, от оформления анке-
ты, ее понятности, готовности эксперта). Второй способ нам кажется предпочти-
тельнее, так как у эксперта появляется неограниченное время на обдумывание
ответов.
Если вспомнить схему общения, представленную на рис. 3.8, то основными фак-
торами, на которые можно существенно повлиять при анкетировании, являются
средства общения (в данном случае это вопросник) и ситуация общения.
Вопросник (анкета) заслуживает особого разговора. Существует несколько об-
щих рекомендаций при составлении анкет. Эти рекомендации являются универ-
сальными, то есть не зависят от предметной области. Наибольший опыт работы с
анкетами накоплен в социологии и психологии, поэтому часть рекомендаций за-
имствована из [Ноэль, 1978; Погосян, 1985].
• Анкета не должна быть монотонной и однообразной, то есть вызывать скуку
или усталость. Это достигается вариациями формы вопросов, сменой темати-
ки, вставкой вопросов-шуток и игровых вопросов.
• Анкета должна быть приспособлена к языку экспертов (см. п. 3.3).
• Следует учитывать, что вопросы влияют друг на друга и поэтому последова-
тельность вопросов должна быть строго продумана.
• Желательно стремиться к оптимальной избыточности. Известно, что в анкете
всегда много лишних вопросов, часть из них необходима — это так называемые
контрольные вопросы (см. о них ниже), а другая часть должна быть минимизи-
рована.
Пример 4.1
Лишние вопросы появляются, например, в таких ситуациях. Фрагмент анкеты:
«В 12. Считаете ли вы, что лечения ангины эффективнет эритромицин?»
«В13. Какие дозы эритромицина вы обычно рекомендуете?»
4.2. Коммуникативные методы
109
При отрицательном ответе на 12-й вопрос 13-й является лишним. Его можно избежать,
усложнив вопрос.
«В 12. Применяете ли вы эритромицин для лечения ангины и если да, то в каких дозах?»
• Анкета должна иметь «хорошие манеры», то есть ее язык должен быть ясным,
понятным, предельно вежливым. Методическим мастерством составления ан-
кеты можно овладеть только на практике.
Интервью
Под интервью будем понимать специфическую форму общения инженера по зна-
ниям и эксперта, в которой инженер по знаниям задает эксперту серию заранее
подготовленных вопросов с целью извлечения знаний о предметной области.
Наибольший опыт в проведении интервью накоплен, наверное, в журналистике и
социологии. Большинство специалистов этих областей отмечают тем не менее
крайнюю недостаточность теоретических и методических исследований по тема-
тике интервьюирования [Ноэль, 1978; Шумилина, 1973].
Интервью очень близко тому способ^ анкетирования, когда аналитик сам запол-
няет анкету, занося туда ответы эксперта. Основное отличие интервью в том, что
оно позволяет аналитику опускать ряд вопросов в зависимости от ситуации,
вставлять новые вопросы в анкету, изменять темп, разнообразить ситуацию об-
щения. Кроме этого, у аналитика появляется возможность «взять в плен» экспер-
та своим обаянием, заинтересовать его самой процедурой и тем самым увеличить
эффективность сеанса извлечения.
Вопросы для интервью
Теперь несколько подробнее о центральном звене активных индивидуальных ме-
тодов — о вопросах. Инженеры по знаниям редко сомневаются в своей способно-
сти задавать вопросы. В то время как и в философии и в математике эта проблема
обсуждается с давних лет. Существует даже специальная ветвь математической
логики — эротетическая логика (логика вопросов). Есть интересная работа Бел-
напа «Логика вопросов и ответов» [Белнап, Стил, 1981], но, к сожалению, исполь-
зовать результаты, полученные логиками, непосредственно при разработке ин-
теллектуальных систем не удается.
Все вопросительные предложения можно разбить на два типа [Сергеев, Соколов,
1986]:
• вопросы с неопределенностью, относящейся ко всему предложению («Дей-
ствительно, введение больших доз антибиотиков может вызвать анафилакти-
ческий шок?);
• вопросы с неполной информацией («При каких условиях необходимо включать
кнопку?»), часто начинающиеся со слов «кто», что», «где», «когда» и т. д.
Это разделение можно дополнить классификацией, частично описанной в работе
[Шумилина, 1973] и представленной на рис. 4.3.
110
Глава 4 • Технологии инженерии знаний
Рис. 4.3. Классификация вопросов
Открытый вопрос называет тему или предмет, оставляя полную свободу экспер-
ту по форме и содержанию ответа («Не могли бы вы рассказать, как лучше сбить
высокую температуру у больного с воспалением легких?»).
В закрытом вопросе эксперт выбирает ответ из набора предложенных («Укажи-
те, пожалуйста, что вы рекомендуете при ангине: а) антибиотики, б) полоскание,
в) компрессы, г) ингаляции»). Закрытые вопросы легче обрабатывать при после-
дующем анализе, но они более опасны, так как «закрывают» ход рассуждений эк-
сперта и «программируют» его ответ в определенном направлении. При состав-
лении сценария интервью полезно чередовать открытые и закрытые вопросы,
особенно тщательно продумывать закрытые, поскольку для их составления тре-
буется определенная эрудиция в предметной области.
Личный вопрос касается непосредственно личного индивидуального опыта экс-
перта («Скажите, пожалуйста, Иван Данилович, в вашей практике вы применяете
вулнузан при фурункулезах?»). Личные вопросы обычно активизируют мышле-
ние эксперта, «играют» на его самолюбии, они всегда украшают интервью.
Безличный вопрос направлен на выявление наиболее распространенных и обще-
принятых закономерностей предметной области («Что влияет на скорость про-
цесса ферментации лизина?»).
При составлении вопросов следует учитывать, что языковые способности экс-
перта, как правило, ограничены и вследствие скованности, замкнутости, робости
4.2. Коммуникативные методы
111
он не может сразу высказать свое мнение и предоставить знания, которые от него
требуются (даже если предположить, что он их четко для себя формулирует).
Поэтому часто при «зажатости» эксперта используют не прямые вопросы, кото-
рые непосредственно указывают на предмет или тему («Как вы относитесь к ме-
тодике доктора Сухарева?»), а косвенные, которые лишь косвенно указывают на
интересующий предмет («Применяете ли вы методику доктора Сухарева? Опи-
шите, пожалуйста, результаты лечения»). Иногда приходится задавать несколь-
ко десятков косвенных вопросов вместо одного прямого.
Вербальные вопросы — это традиционные устные вопросы. Вопросы с использо-
ванием наглядного материала разнообразят интервью и снижают утомляемость
эксперта. В этих вопросах используют фотографии, рисунки и карточки. Напри-
мер, эксперту предлагаются цветные картонные карточки, на которых выписаны
признаки заболевания. Затем аналитик просит разложить эти карточки в поряд-
ке убывания значимости для постановки диагноза.
Деление вопросов по функции на основные, зондирующие, контрольные связано
с тем, что часто основные вопросы интервью, направленные на выявление знаний,
не срабатывают — эксперт по каким-то причинам уходит в сторону от вопроса,
отвечает нечетко.
Тогда аналитик использует зондирующие вопросы, которые направляют рассуж-
дения эксперта в нужную сторону. Например, если не сработал основной вопрос:
«Какие параметры определяют момент окончания процесса ферментации лизи-
на?» — аналитик начинает задавать зондирующие вопросы: «Всегда ли процесс
ферментации длится 72 часа? А если он заканчивается раньше, как это узнать?
Если он продлится больше, то что заставит микробиолога не закончить процесс
на 72-м часу?» и т. д.
Контрольные вопросы применяют для проверки достоверности и объективности
информации, полученной в интервью ранее («Скажите, пожалуйста, а москов-
ская школа психологов так же как вы трактует шкалу К опросника ММР1?» или
«Рекомендуете ли вы инъекции АТФ?» (АТФ — препарат, снятый с производ-
ства). Контрольные вопросы должны быть «хитро» составлены, чтобы не оби-
деть эксперта недоверием (для этого используют повторение вопросов в другой
форме, уточнения, ссылки на другие источники). «Лучше два раза спросить, чем
один раз напутать» (Шолом—Алейхем).
И наконец, о нейтральных и наводящих вопросах. В принципе интервьюеру
(в нашем случае инженеру по знаниям) рекомендуют быть беспристрастным, от-
сюда и вопросы его должны носить нейтральный характер, то есть не должны ука-
зывать на отношение интервьюера к данной теме. Напротив, наводящие вопросы
заставляют респондента (в данном случае эксперта) прислушаться или даже при-
нять во внимание позицию интервьюера. Нейтральный вопрос: «Совпадают
ли симптомы кровоизлияния в мозг и сотрясения мозга?» Наводящий вопрос:
«Не правда ли, очень трудно дифференцировать симптомы кровоизлияния в
мозг?»
112
Глава 4 • Технологии инженерии знаний
Кроме перечисленных выше, полезно различать и включать в интервью следую-
щие вопросы [Ноэль, 1978]:
• контактные («ломающие лед» между аналитиком и экспертом);
• буферные (для разграничения отдельных тем интервью);
• оживляющие память экспертов (для реконструкции отдельных случаев из
практики);
• «провоцирующие» (для получения спонтанных, неподготовленных ответов).
В заключение описания интервью укажем три основные характеристики вопро-
сов [Шумилина, 1973], которые влияют на качество интервью:
• язык вопроса (понятность, лаконичность, терминология);
• порядок вопросов (логическая последовательность и немонотонность);
• уместность вопросов (этика, вежливость).
Вопрос в интервью — это не просто средство общения, но и способ передачи мыс-
лей и позиции аналитика.
«Вопрос представляет собой форму движения мысли, в нем ярко выражен момент
перехода от незнания к знанию, от неполного, неточного знания к более полному
и более точному» [Лимантов, 1971]. Отсюда необходимость в протоколах фикси-
ровать не только ответы, но и вопросы, предварительно тщательно отрабатывая
их форму и содержание.
Очевидно, что любой вопрос имеет смысл только в контексте. Поэтому вопросы
может готовить инженер по знаниям, уже овладевший ключевым набором зна-
ний.
Вопросы имеют для эксперта диагностическое значение — несколько откро-
венных «глупых» вопросов могут полностью разочаровать эксперта и отбить
у него охоту к дальнейшему сотрудничеству. Известен ответ Маркса на во-
прос Прудона: «Вопрос был до такой степени неправильно поставлен, что на
него невозможно было дать правильный ответ».
Свободный диалог
Свободный диалог — это метод извлечения знаний в форме беседы инженера по
знаниям и эксперта, в которой нет жесткого регламентированного плана и во-
просника. Это определение не означает, что к свободному диалогу не надо го-
товиться. Напротив, внешне свободная и легкая форма этого метода требует
высочайшей профессиональной и психологической подготовки. Подготовка к
свободному диалогу практически может совпадать с предлагаемой в работе [Шу-
милина, 1973] подготовкой к журналистскому интервью. Рисунок 4.4 графичес-
ки иллюстрирует схему такой подготовки, дополненную в связи со спецификой
инженерии знаний. Подготовка занимает разное время в зависимости от степени
профессионализма аналитика, но в любом случае она необходима, так как не-
сколько уменьшает вероятность самого нерационального метода — метода проб
и ошибок.
4,2. Коммуникативные методы
113
Рис. 4.4. Подготовка к извлечению знаний
Квалифицированная подготовка к диалогу помогает аналитику стать истинным
драматургом или сценаристом будущих сеансов, то есть запланировать гладкое
течение процедуры извлечения: от приятного впечатления в начале беседы пере-
ход к профессиональному контакту через пробуждение интереса и завоевание
доверия эксперта. При этом для обеспечения желания эксперта продолжить бе-
седу необходимо проводить «поглаживания» (терминология Э. Берна [Берн,
1988]), то есть подбадривать эксперта и подтверждать всячески его уверенность
в собственной компетентности (фразы-вставки: «Я вас понимаю...», «...это очень
интересно» и т. д.).
Так, в одном из исследований по технике ведения профессиональных журналист-
ских диалогов [Matarozzo, Wettman, Weins, 1963] было экспериментально дока-
зано, что одобрительное и поощрительное «хмыканье» интервьюера увеличива-
ет длину ответов респондента. При этом одобрение должно быть искренним, как
показал опрос интервьюеров Института демоскопии Германии: «Лучшая улов-
ка — это избегать всяких уловок: относиться к опрашиваемому с истинным чело-
веколюбием, не с наигранным, а с подлинным интересом» [Ноэль, 1978]. Чтобы
разговорить собеседника, можно сначала аналитику рассказать о себе, о работе,
то есть поговорить самому.
Мы уже писали о профессиональной пригодности инженеров по знаниям и необ-
ходимости предварительного психологического тестирования при подготовке
инженеров по знаниям. Здесь только приведем каталог свойств идеального ин-
тервьюера [Ноэль, 1978]. На наш взгляд, это вполне подходящий образец порт-
рета инженера по знаниям перед серией свободных диалогов: «Он должен вы-
глядеть здоровым, спокойным, уверенным, внушать доверие, быть искренним,
веселым, проявлять интерес к беседе, быть опрятно одетым, ухоженным». Хоро-
114
Глава 4 • Технологии инженерии знаний
ший аналитик может личным обаянием и умением, скрыть изъяны подготовки.
Блестящая кр'аткая характеристика интервьюера приведена в той же работе —
«общительный педант».
В свободном диалоге важно также выбрать правильный темп или ритм беседы:
без больших пауз, так как эксперт может отвлечься, но и без гонки, иначе быстро
утомляются оба участника и нарастает напряженность, кроме того, некоторые
люди говорят и думают очень медленно. Умение чередовать разные темпы, на-
пряжение и разрядку в беседе существенно влияет на результат.
Подготовка к диалогу так же, как и к другим активным методам извлечения зна-
ний, включает составление плана проведения сеанса извлечения, в котором необ-
ходимо предусмотреть следующие стадии:
1. Начало беседы (знакомство, создание у эксперта «образа» аналитика, объяс-
нение целей и задач работы).
2. Диалог по извлечению знаний.
3. Заключительная стадия (благодарность эксперту, подведение итогов, договор
о последующих встречах).
Девизом для инженера по знаниям могут послужить взгляды одного из классиков
отечественного литературоведения М. М. Бахтина [Бахтин, 1975]:
«Диалог — столкновение разных умов, разных истин, несходных культурных по-
зиций, составляющих единый ум, единую истину, общую культуру».
«Диалог предполагает:
• уникальность каждого партнера и их принципиальное равенство друг другу;
• различие и оригинальность их точек зрения;
• ориентацию каждого на понимание и на активную интерпретацию его точки
зрения партнером;
• ожидание ответа и его предвосхищение в собственном высказывании;
• взаимную дополнительность позиций участников общения, соотнесение кото-
рых и является целью диалога».
Сравнительные характеристики активных индивидуальных методов извлечения
знаний представлены в табл. 4.2.
Таблица 4.2. Сравнительные характеристики активных индивидуальных методов извлечения
Активный индивидуальный метод извлечения знаний 1 Анкетирование Интервью Свободный диалог
Достоинства Возможность стандартизиро- ванного опроса нескольких экспертов Наличие обратной связи (возможность уточнений и разрешения противоречий) для эксперта Гибкость Сильная обратная связь изменения
4.2. Коммуникативные методы
115
Активный индивидуальный метод извлечения знаний Анкетирование Интервью Свободный диалог
Не требует особенного напряжения отаналитика во . время процедуры анкетирования Возможность изменения сценария и формы сеанса /
Недостатки Требует умения и опыта составления анкет Требует значительного времени на подготовку вопросов интервью Требует отаналитика высочайшего напряжения
Отсутствие контекста между экспертом, нет обратной связи. Вопросы анкеты могут быть неправильно поняты экспертом Отсутствие формальных методик проведения Трудность протоколирования результатов
Требования к эксперту (типы качества) Практик и мыслитель Собеседник или мыслитель Собеседник или мыслитель
Требования каналитику (типы и качества) Мыслитель (педантиз в составлении анкет, внимательность) Собеседник (журналистские навыки, умение слушать) Собеседник (наблюдательность умение слушать, обаяние)
Характеристика предметной области Слабо структурированные, слабо и средне документированные Тоже Тоже
4.2.3. Активные групповые методы
К групповым методам извлечения знаний относятся ролевые игры, дискуссии за
«круглым столом» с участием нескольких экспертов и «мозговые штурмы». Ос-
новное достоинство групповых методов — это возможность одновременного
«поглощения» знаний от нескольких экспертов, взаимодействие которых вносит
в этот процесс элемент принципиальной новизны от наложения разных взглядов
и позиций.
Поскольку эти методы менее популярны, чем индивидуальные (что связано со
сложностью организации), попытаемся описать их подробно.
««Круглый стол»
Метод круглого стола (термин заимствован из журналистики) предусматривает
обсуждение какой-либо проблемы из выбранной предметной области, в котором
принимают участие с равными правами несколько экспертов. Обычно вначале
116
Глава 4 • Технологии инженерии знаний
участники высказываются в определенном порядке, а затем переходят к живой
свободной дискуссии. Число участников дискуссии колеблется от трех до пя-
ти-семи.
Большинство общих рекомендаций по Извлечению знаний, предложенных ранее,
применимо и к данному методу. Однако существует и специфика, связанная с
поведением человека в группе.
Во-первых, от инженера по знаниям подготовка «круглого стола» потребует до-
полнительных усилий: как организационных (место, время, обстановка, мине-
ральная вода, чай, кворум и т. д.), так и психологических (умение вставлять уме-
стные реплики, чувство юмора, память на имена и отчества, способность гасить
конфликтные ситуации и т. д.).
Во-вторых, большинство участников будет говорить под воздействием «эффекта
фасада» совсем не то, что они сказали бы в другой обстановке, то есть желание
произвести впечатление на других экспертов будет существенно «подсвечивать»
их высказывания. Этот эффект часто наблюдается на защитах диссертаций. Чле-
ны ученого совета спрашивают обычно не то, что им действительно интересно, а
то, что демонстрирует их собственную компетентность.
Ход беседы за круглым столом удобно записывать на магнитофон, а при расшиф-
ровке и анализе результатов учитывать этот эффект, а также взаимные отноше-
ния участников.
Задача дискуссии — коллективно, с разных точек зрения, под разными углами ис-
следовать спорные гипотезы предметной области. Обычно эмпирические области
богаты таким дискуссионным материалом. Для остроты на «круглый стол» при-
глашают представителей разных научных направлений и разных поколений, это
также уменьшает опасность получения односторонних однобоких знаний.
Обмен мнениями по научным вопросам имеет давнюю традицию в истории чело-
вечества (античная Греция, Индия). До наших дней дошли литературные памят-
ники обсуждения спорных вопросов (например, Протагор «Искусство спорить»,
работы софистов), послужившие первоосновой диалектики — науки вести бесе-
ду, спорить, развивать теорию. В самом слове дискуссия (от лат. discussio — иссле-
дование) содержится указание на то, что это метод научного познания, а не просто
споры (для сравнения, полемика — от греч. polemikos — воинственный, враждеб-
ный).
Несколько практических советов по процедурным вопросам «круглого стола» из
работы [Соколов, 1980]. Перед началом дискуссии ведущему полезно:
• убедиться, что все правильно понимают задачу (то есть происходит сеанс из-
влечения знаний);
• установить регламент;
• четко сформулировать тему.
По ходу дискуссии важно проследить, чтобы слишком эмоциональные и разговор-
чивые эксперты не подменили тему и чтобы критика позиций друг друга была обо-
снованной.
Научная плодотворность дискуссий делает этот метод привлекательным и для
самих экспертов, особенно для тех, кто знает меньше. Это заметил еще Эпикур:
4.2. Коммуникативные методы
117
«При философской дискуссии больше выигрывает побежденный — в том отно-
шении, что он умножает знания» [Материалисты, 1955]. Хорошим напутствием
для проведения «круглого стола» служат слова П. Л. Капицы: «Когда в какой-
либо науке нет противоположных взглядов, нет борьбы, то эта наука идет по пути
к кладбищу, она идет хоронить себя» [Капица, 1967].
«Мозговой штурм»
Активные групповые методы обычно используются в качестве острой приправы
при извлечении знаний, сами по себе они не могут служить источником более или
менее полного знания. Их применяют как дополнительные к традиционным ин-
дивидуальным методам (наблюдения, интервью и т. д.), для активизации мышле-
ния и поведения экспертов.
«Мозговой штурм» или «мозговая атака» — один из наиболее распространенных
методов раскрепощения и активизации творческого мышления. Другие методы
(метод фокальных объектов, синектика, метод контрольных вопросов [Шепотов,
Шмаков, Крикун, 1985]) применяются гораздо реже из-за меньшей эффективно-
сти.
Впервые этот метод был использован в 1939 г. в США А. Осборном как способ
получения новых идей в условиях запрещения критики. Замечено, что боязнь
критики мешает творческому мышлению, поэтому основная идея штурма — это
отделение процедуры генерирования идей в замкнутой группе специалистов от
процесса анализа и оценки высказанных идей.
Как правило, штурм длится недолго (около 40 минут). Участникам (до 10 чело-
век) предлагается высказывать любые идеи (шутливые, фантастические, ошибоч-
ные) на заданную тему (критика запрещена). Обычно высказывается более 50
идей. Регламент до 2 минут на выступление. Самый интересный момент штур-
ма — это наступление пика (ажиотажа), когда идеи начинают «фонтанировать»,
то есть происходит непроизвольная генерация гипотез участниками. Этот пик
имеет теоретическое обоснование в работах выдающегося швейцарского психо-
лога и психиатра 3. Фрейда о бессознательном. При последующем анализе всего
лишь 10-15 % идей оказываются разумными, но среди них бывают весьма ориги-
нальные. Оценивает результаты обычно группа экспертов, не участвовавшая в
генерации.
Ведущий «мозгового штурма» — инженер по знаниям — должен свободно вла-
деть аудиторией, подобрать активную группу экспертов — «генераторов», не за-
жимать плохие идеи — они могут служить катализаторами хороших. Искусство
ведущего — это искусство задавать вопросы аудитории, «подогревая» генера-
цию. Вопросы служат «крючком» [Шепотов, Шмаков, Крикун, 1985], которым
извлекаются идеи. Вопросы также могут останавливать многословных экспер-
тов и служить способом развития идей других.
Основной девиз штурма — «чем больше идей, тем лучше». Фиксация хода сеан-
са — традиционная (протокол или магнитофон).
Достоинства и недостатки активных групповых методов извлечения знаний пред-
ставлены в табл. 4.3.
118
Глава 4 • Технологии инженерии знаний
Таблица 4.3. Сравнение активных групповых методов извлечения знаний
Активный групповой метод извлечения знаний «Круглый стол» «Мозговой штурм»
Достоинства Позволяет получить более объективные фрагменты знаний Позволяет выявлятьглубинные пласты знаний (на уровне бессознательного)
Оживляет процедуру извлечения Активизирует экспертов
Позволяет участникам обмениваться знаниями Позволяет получать новое знание (гипотезы)
Недостатки Требует больших организационных затрат Возможен только для новых интересных исследовательских проблем
Отличается сложностью проведения Не всегда эффективны (довольно низкий процент продуктивных идей)
Требования кэксперту (тип и качества) Собеседник или мыслитель (искусство полемики) Мыслитель'( креативность, то есть способность к творчеству)
Требования к инженеру по знаниям (тип и качества) Собеседник (диплома- тические способности) Собеседник или мыслитель (быстрая реакция и чувство юмора)
Характеристика предметной области Слабо структурированные и слабо документированные с наличием спорных проблем Слабо структурированные и слабо документированные с наличием перспективных «белых пятен»
Экспертные игры
Игрой называют такой вид человеческой деятельности, который отражает (вос-
создает) другие ее виды [Комаров, 1989]. При этом для игры характерны одно-
временно условность и серьезность.
Понятие экспертной игры или игры с экспертами в целях извлечения знаний вос-
ходит к трем источникам — это деловые игры, широко используемые при подго-
товке специалистов и моделировании [Борисова, Соловьева и др., 1988; Бурков,
1980; Комаров, 1989]; диагностические игры, описанные в работах [Алексеевская,
Недоступ, 1988; Гельфанд, Розенфельд, Шифрин, 1988], и компьютерные игры,
все чаще применяемые в обучении [Пажитнов, 1987].
В настоящее время в психолого-педагогических науках нет развитой теоретичес-
кой концепции деловых игр и других игровых методов обучения. Тем не менее на
практике эти игры широко используются. Под деловой игрой чаще всего понима-
ют эксперимент, где участникам предлагается производственная ситуация, а они
на основе своего жизненного опыта, своих общих и специальных знаний и пред-
4.2. Коммуникативные методы
119
ставлений принимают решения [Бурков, 1980]. Решения анализируются, и
вскрываются закономерности мышления участников эксперимента. Именно эта
анализирующая часть деловой игры полезна для получения знаний. И если уча-
стниками такой игры становятся эксперты, то игра из деловой превращается в
экспертную. Из трех основных типов деловых игр (учебных, планово-производ-
ственных и исследовательских) к экспертам ближе всего исследовательские, ко-
торые используются для анализа систем, проверки правил принятия решений.
Диагностическая игра — это та же деловая игра, но применяемая конкретно для
диагностики методов принятия решения в медицине (диагностика методов диаг-
ностики). Эти игры возникли при исследовании способов передачи опыта от
опытных врачей новичкам. В нашем понимании диагностическая игра — это игра,
безусловно, экспертная без всяких оговорок, только с жестко закрепленной пред-
метной областью — медициной.
Плодотворность моделирования реальных ситуаций в играх подтверждается се-
годня практически во всех областях науки и техники. Они развивают логическое
мышление, умение быстро принимать решения, вызывают интерес у экспертов.
В соответствии с классификацией, введенной в п. 4.1, будем разделять эксперт-
ные игры на:
• индивидуальные;
• групповые.
Кроме этого (рис. 4.5), продолжим и разовьем эту классификацию введением
других критериев:
• использование специального оборудования;
• применение вычислительной техники.
Рис. 4.5. Классификация экспертных игр
120
Глава 4 • Технологии инженерии знаний
Игры с экспертом
В этом случае с экспертом играет инженер по знаниям, который берет на себя ка-
кую-нибудь роль в моделируемой ситуации. Например, одному из авторов часто
приходилось разыгрывать с экспертом игру «Учитель и ученик», в которой ин-
женер по знаниям берет на себя роль ученика и на глазах у эксперта выполняет
его работу (например, пишет психодиагностическое заключение), а эксперт по-
правляет ошибки «ученика». Эта игра — удобный способ разговорить застенчи-
вого эксперта.
Пример 4.2
Другая игра (заимствована из работы [Гельфанд, Розенфельд, Шифрин, 1988]) застав-
ляет инженера по знаниям взять на себя роль врача, который знает хорошо больного, а
эксперт играет роль консультанта. Консультант задает вопросы и делает прогноз о це-
лесообразности применения того или иного вида лечения (в описанной игре это был
прогноз целесообразности электростимульной терапии при сердечной аритмии). Игра
«двух врачей» позволила выявить, что эксперту понадобилось всего 30 вопросов для
успешного прогноза, в то время как первоначальный вариант вопросника, составлен-
ный медиками для той же цели, содержал 170 вопросов.
Пример.4.3
Сначала эксперта просят написать обоснование для собственного прогноза. Например,
почему он считает, что язва у больного X заживает. Накапливается несколько таких
обоснований [Гельфанд, Розенфельд, Шифрин, 1988], а через некоторое время экспер-
ту зачитывают только его обоснование и просят сделать прогноз. Как правило, этого он
сделать не может, то есть обоснование (или его знания) было неполным. Эксперт до-
полняет обоснование, тем самым выявляются скрытые (для самого эксперта) пласты
знаний. Так, в играх «Обоснование прогноза рецидива язвенного кровотечения» уда-
лось выявить, что значимыми для прогноза являются всего три правила. Причем два
правила входили в традиционно-диагностический вопросник, а третье было сформу-
лировано во время игры.
Пример 4.4
Игра «фокусировка на контексте»: эксперт играет роль ЭС, а инженер по знаниям —
роль пользователя. Разыгрывается ситуация консультации. Первые вопросы эксперта
выявляют наиболее значимые понятия, самые важные аспекты проблемы. Роль
пользователя может взять на себя и другой эксперт [Rabbits, Wright, 1987].
Основные советы инженеру по знаниям по проведению индивидуальных игр:
• играйте смелее, придумывайте игры сами;
• не навязывайте игру эксперту, если он не расположен;
• в игре «не давите»,на эксперта, не забывайте цели игры;
• играйте весело, нешаблонно;
• не забывайте о времени и о том, что игра утомительна для эксперта.
Ролевые игры в группе
Групповые игры предусматривают участие в игре нескольких экспертов. К такой
игре обычно заранее составляется сценарий, распределяются роли, к каждой роли
4.2. Коммуникативные методы
121
готовится портрет-описание (лучше с девизом) и разрабатывается система оце-
нивания игроков [Борисова, Соловьева и др., 1988].
Существует несколько способов проведения ролевых игр. В одних играх игроки
могут придумать себе новые имена и играть под ними. В других все игроки пере-
ходят на «ты». В третьих роли выбирают игроки, в четвертых роли вытягивают по
жребию. Роль — это комплекс образцов поведения. Роль связана с другими роля-
ми. «Короля играет свита». Поскольку в нашем случае режиссером и сценаристом
игры является инженер по знаниям, то ему и предоставляется полная свобода в
выборе формы проведения игры.
Пример 4.5
Так, в работе [Лазарева, Пашинин, 1987] описана игра «План», предназначенная для
извлечения знаний из специалистов предприятия, разрабатывающих производствен-
ные планы выпуска для цехов и принимающих различные решения по управлению
производством.
В игре экспертов разбили на три игровые группы: ЛПР, — группа планирования;
ЛПР2 — группа менеджеров; Э — группа экспертизы по оцениванию действия ЛПР, и
ЛПР2. Группам ЛПР, и ЛПР2 задавались различные производственные ситуации и
тщательно протоколировались их споры, рассуждения, аргументы по принятии реше-
ний. В результате игры был создан прототип базы знаний экспертной системы плани-
рования.
Обычно в игре принимает участие от трех до шести экспертов, если их больше, то
можно разбить всех на несколько конкурирующих игровых бригад. Элемент со-
стязательности оживляет игру. Например, чей диагноз окажется ближе к истин-
ному, чей план рациональнее использует ресурсы, кто быстрее определит причи-
ну неисправности в техническом блоке.
Создание игровой обстановки потребует немало фантазии и творческой выдумки
от инженера по знаниям. Ролевая игра, как правило, требует некоторых простей-
ших заготовок (например, табличек «Директор», «Бухгалтерия», «Плановый от-
дел», специально напечатанных инструкций с правилами игры). Но главное, ко-
нечно, чтобы эксперты в игре действительно «заиграли», раскрепостились и
«раскрыли свои карты».
Игры с тренажерами
Игры с тренажерами в значительной степени ближе не к играм, а к имитацион-
ным упражнениям в ситуации, приближенной к действительности.
Наличие тренажера позволяет воссоздать почти производственную ситуацию и
понаблюдать за экспертом. Тренажеры широко применяют для обучения (напри-
мер, летчиков или операторов атомных станций). Очевидно, что применение тре-
нажеров для извлечения знаний позволит зафиксировать фрагменты «летучих»
знаний, возникающих во время и на месте реальных ситуаций й выпадающих из
памяти при выходе за пределы ситуации.
Компьютерные экспертные игры
Идея использовать компьютеры в деловых играх известна давно. Но только
когда компьютерные игры взяли в плен практически всех пользователей пер-
122
Глава 4 • Технологии инженерии знаний
сональных ЭВМ от мала до велика, стала очевидной особая притягательность
такого рода игр.
Традиционная современная классификация компьютерных игр из журнала
GAME.EXE:
• Action/Arcade games (экшн/аркады). Игры-действия. Требуют хорошего
глазомера и быстрой реакции.
• Simulation games (симуляторы). Базируются на моделировании реальной
действительности и отработки практических навыков, например в вождении
автомобиля, пассажирского самолета, поезда, авиадиспетчера и даже симу-
ляторы рыбной ловли. Также популярны спортивные симуляторы — теннис,
бокс и др.
• 3D Action games (-«стрелялки»). То же, что и экшн, но с активным использо-
ванием трехмерной графики.
• Strategy games (стратегические игры). Требуют стратегического планирова-
ния и ответственности при принятии решений, например развитие цивилиза-
ций, соперничество миров, экономическая борьба. Особый класс стратегичес-
ких игр — wargames (военные игры). В последнее время упор в 3D Action
делается на многопользовательский режим (игру по сети).
• Puzzles (настольные игры-головоломки). Компьютерные реализации различ-
ных логических игр.
• Adventure/Quest (приключенческие игры). Обычно обладают разветвленным
сценарием, красивой графикой и звуком. Управляя одним или несколькими
персонажами, игрок должен правильно вести диалоги, разгадывать множество
загадок и головоломок, замечать и правильно использовать предметы, спря-
танные в игре.
• Role-playing games RPG (ролевые игры). Распространенный жанр, берущий
свое начало в старых английских настольных играх. Существует один или не-
сколько персонажей, обладающих индивидуальными способностями и харак-
теристиками. Им приходится сражаться с врагами, решать загадки. По мере
выполнения этих задач, у героев накапливается опыт, и по достижении опреде-
ленного значения их характеристики улучшаются...
Следует отметить, что многие игры могут быть отнесены сразу к нескольким
классам, и в целом, эту классификацию нельзя считать строгой. Игры иногда по-
лезны для развлечения экспертов перед сеансом извлечения знаний. Кроме того,
очевидно, что экспертные игры, сочетая элементы перечисленных выше классов,
могут успешно применяться для непосредственного извлечения знаний. Однако
разработка и программная реализация такой игры потребуют существенных вло-
жений временных и денежных ресурсов.
Пример 4.6
Одна из первых отечественных экспертных компьютерных игр описана в работе [Гин-
кул, 1989]. Основной принцип игры «Зоосад» состоит в создании игровой ситуации
при организации диалога с экспертом. При этом задача извлечения знаний маскиру-
ется нацеленностью на решение чисто игровой задачи: необходимо определить содер-
жимое «черного ящика», в котором находится некое животное, при этом надо набрать
4.2. Коммуникативные методы
123
наибольшее количество очков, не истратив выделенного ресурса денег. В ходе игры
эксперт делает ставки на различные гипотезы, указывая при этом, какими признака-
ми обладает то или иное животное. После каждого ответа он получает необходимую
информацию о результатах. По ходу игры невидимо для эксперта формируются пра-
вила, отражающие знания эксперта на основании сделанных им ходов. В данной
игре — зто знания о том, какими признаками обладают те или иные животные. Таким
образом, выявляется алфавит значимых признаков для диагностики и классифика-
ции животных.
Сравнительные характеристики экспертных игр приведены в табл. 4.4.
Таблица 4.4. Сравнительные характеристики экспертных игр
Экспертные игры Индивидуальные Групповые Компьютерные
Достоинства Дают возможность сравнительно быстро получить качественную картину принятия решения Реалистично воссоздают атмосферу конкретной задачи Вызывают интерес у эксперта
Позволяют выяснить, какую информацию и как использует эксперт Раскрепощают экспертов Привлекают дизайном и динамикой
«Г рупповые» знания более объективны
Выявляют логику и аргументацию экспертов
Недостатки Отсутствие методик стандартного набора игр Требует от аналитика знания основ игротехники Сложность и высокая цена создания специализированных игр в конкретной ПО
Высокие профессиональные требования к аналитику Сложность создания игр для конкретных предметных областей
Требования к эксперту (тип и качества) Собеседник или практик (раскованность и актерское мастерство) Тоже Практик без психологического барьера к ЭВМ
Требования каналитику (тип и качества) Собеседник (режиссерские способности + умение создавать сценарии + актерское мастерство) Собеседник (способность к ведению конферанса + режиссерские способности + сценарист ч актерское мастерство) Мыслитель (контакт с программистом)
Требования к предметной области Средне и слабо структурированные и слабо документированные Тоже Тоже
124
Глава 4 • Технологии инженерии знаний
4.3. Текстологические методы
Группа текстологических методов объединяет методы извлечения знаний, осно-
ванные на изучении специальных текстов из учебников, монографий, статей, ме-
тодик и других носителей профессиональных знаний.
В буквальном смысле текстологические методы не относятся к текстологии — на-
уке, которая родилась в русле филологии с целью критического прочтения лите-
ратурных текстов, изучения и интерпретации источников с узкоприкладной за-
дачей — подготовки текстов к изданию. Сейчас текстология расширила свои гра-
ницы включением аспектов смежных наук — герменевтики (науки правильного
толкования древних текстов — библии, античных рукописей и др.), семиотики,
психолингвистики и др.
Текстологические методы извлечения знаний, безусловно, используя основные
положения текстологии, отличаются принципиально от ее методологии, во-пер-
вых, характером и природой своих источников (профессиональная специальная
литература, а не художественная, живущая по своим особым законам), а во-вто-
рых, жесткой прагматической направленностью извлечения конкретных профес-
сиональных знаний.
Среди методов извлечения знаний эта группа является наименее разработанной,
по ней практически нет никакой библиографии, поэтому Дальнейшее изложение
является как бы введением в методы изучения текстов в том виде, как это пред-
ставляют авторы.
Задачу извлечения знаний из текстов можно сформулировать как задачу понима-
ния и выделения смысла текста. Сам текст на естественном языке является лишь
проводником смысла, а замысел и знания автора лежат во вторичной структуре
(смысловой структуре или макроструктуре текста), настраиваемой над есте-
ственным текстом [Величковский, Капица, 1987], или, как сформулировано в
работе [Файн, 1987], «текст не содержит и не передает смысл, а является лишь ин-‘
струментом для автора текста».
При этом можно выделить две такие смысловые структуры:
М1 — смысл, который пытался заложить автор, это его модель мира, и М2 — смысл,
который постигает читатель, в данном случае инженер по знаниям (рис. 4.6), в
процессе интерпретации I. При этом Т — это словесное одеяние Мр то есть резуль-
тат вербализации V.
Сложность процесса заключается в принципиальной невозможности совпадения
знаний, образующих М1 иМ2, из-за того, что М1 образуется за счет всей совокуп-
ности представлений, потребностей, интересов и опыта автора, лишь малая часть
которых находит отражение в тексте Т. Соответственно, и М2 образуется в процес-
се интерпретации текста Тза счет привлечения всей совокупности научного и че-
ловеческого багажа читателя. Таким образом, два инженера по знаниям извлекут
из одного Тдве различные модели vlM‘2 .
4.3. Текстологические методы
125
Текст
книги
Рис. 4.6. Схема извлечения знаний из специальных текстов
Встает задача: выяснить, за счет чего можно достичь максимальной адекватности
М1 и М2, помня при этом, что понимание всегда относительно, поскольку это син-
тез двух смыслов «свое—чужое» [Бахтин, 1975].
Рассмотрим подробнее, какие источники питают модель М1 и создают текст Т.
В работе [Сергеев, 1987] указаны два компонента любого научного текста. Это пер-
вичный материал наблюдений а и система научных понятий Р в момент создания
текста. В дополнение к этому, на наш взгляд, помимо объективных данных экспе-
риментов и наблюдений, в тексте обязательно присутствуют субъективные взгля-
ды автора у, результат его личного опыта, а также некоторые «общие места» или
«вода» 8. Кроме этого, любой научный текст содержит заимствования из других
источников (статей, монографий) и т. д. При этом все компоненты погружены в
языковую среду L. Можно записать:
T = (a,p,y,8,0)L.
Таким образом, компоненты научного текста можно представить в виде следую-
щей схемы (рис. 4.7). При этом компоненты Р, у, часть а входят и в модель Мг
Рис. 4.7. Компоненты научного текста
При извлечении знаний аналитику, интерпретирующему текст, приходится решать
задачу декомпозиции этого текста на перечисленные выше компоненты для выделе-
ния истинно значимых для реализации базы знаний фрагментов. Сложность интер-
претации научных и специальных текстов заключается еще и в том, что любой текст
126
Глава 4 • Технологии инженерии знаний
приобретает смысл только в контексте, где под контекстом понимается окружение,
в которое «погружен» текст.
Различают микро- и макроконтекст. Микроконтекст — это ближайшее окруже-
ние текста. Так, предложение получает смысл в контексте абзаца, абзац в контек-
сте главы и т. д. Макроконтекст — это вся система знаний, связанная с предмет-
ной областью (то есть знания об особенностях и свойствах, явно не указанных в
тексте). Другими словами, любое знание обретает смысл в контексте некоторого
метазнания.
Теперь несколько подробнее о центральном звене процедуры извлечения зна-
ния — о понимании текста. Классическим в текстологии является определение
немецкого философа и языковеда В. фон Гумбольдта [Фон Гумбольдт, 1984]:
«...Люди понимают друг друга не потому, что передают собеседнику знаки пред-
метов, и даже не потому, что взаимно настраивают друг друга на точное и полное
воспроизведение идентичного понятия, а потому, что взаимно затрагивают друг
в друге одно и то же звено цепи чувственных представлений и зачатков внутрен-
них понятий, прикасаются к одним и тем же клавишам инструмента своего духа,
благодаря чему у каждого вспыхивают в сознании соответствующие, но не тож-
дественные смыслы.»
Говоря на языке современного языкознания, понимание — это формирование
«второго текста», то есть семантической структуры (понятийной структуры)
[Сиротко-Сибирский, 1968]. В нашей терминологии — это попытка воссоздания
семантической структуры М1 в процессе формирования модели М2, то есть это
первый шаг структурирования знаний.
Как происходит процесс понимания I? Одна из возможных схем изложена в ра-
боте [Соколов, 1947; Соколов, 1968]. Мы внесли несколько изменений в эту схе-
му в связи с тем, что в ней трактуется понимание текста на иностранном языке, а
нас интересует понимание текста в новой для познающего субъекта предметной
области. Кром? этого, дополним ее некоторыми положениями герменевтики.
В целом полученная схема согласуется со стратегией изучения всего нового.
Основными моментами понимания текста являются:
• Выдвижение предварительной гипотезы о смысле всего текста (предугадыва-
ние).
• Определение значений непонятных слов (то есть специальной терминоло-
гии).
• Возникновение общей гипотезы о содержании текста (о знаниях).
• Уточнение значения терминов и интерпретация отдельных фрагментов текста
под влиянием общей гипотезы (от целого к частям).
• Формирование некоторой смысловой структуры текста за счет установления
внутренних связей между отдельными важными (ключевыми) словами и
фрагментами, а также за счет образования абстрактных понятий, обобщаю-
щих конкретные фрагменты знаний.
4.3. Текстологические методы
127
• Корректировка общей гипотезы относительно содержащихся в тексте фраг-
ментов знаний (от частей к целому).
• Принятие основной гипотезы, то есть формирование М}. <
Следует отметить наличие как дедуктивной (от целого к частям), так и индук-
тивной (от частей к целому) составляющей процесса понимания. Такой двуе-
диный подход позволяет охватывать текст как смысловое единство особого рода,
с его основными признаками, такими как связность, цельность, законченность
и др. [Сиротко-Сибирский, 1968].
Центральными моментами процесса I являются шаги 5 и 7, то есть формирование
смысловой структуры или выделение «опорных», ключевых, слов или «смысло-
вых вех» [Сиротко-Сибирский, 1968], а также заключительное связывание
«смысловых вех» в единую семантическую структуру.
При анализе текста важно выявление внутренних связей между отдельными эле-
ментами текста и понятиями. Традиционно выделяют два вида связей в тексте —
эксплицитные (или явные связи), которые выражаются во внешнем дроблении
текста, и имплицитные (скрытые связи). Эксплицитные связи делят текст на па-
раграфы с помощью перечисления компонентов, вводных слов (или коннекто-
ров) типа «во-первых..., во-вторых..., однако и т. д.». Имплицитные, или внут-
ренние, связи между отдельными «смысловыми вехами» вызывают основное
затруднение при понимании.
Итак, семантическая структура текста образуется в сознании познающего субъек-
та с помощью знаний о языке, знаний о мире, а также общих (фоновых) знаний
в той предметной области, которой посвящен текст. «Тексты пишут для посвя-
щенных». Другими словами, если текст не является научно-популярным, то для
его адекватного прочтения требуется некоторая подготовка.
Таким образом, путь к знаниям удлиняется еще на одно звено. Если мы раньше
говорили, что сами текстологические методы редко употребляются как самостоя-
тельный метод извлечения, а обычно используются как некоторая подготовка к
коммуникативному взаимодействию, то теперь утверждаем, что и для прочтения
текстов нужна подготовка. Какая же?
Подготовкой к прочтению специальных текстов является выбор совместно с эк-
спертами некоторого «базового» списка литературы, который постепенно введет
аналитика в предметную область. В этом списке могут быть учебники для начи-
нающих, главы и фрагменты из монографий, популярные издания. Только после
ознакомления с «базовым» списком целесообразно приступать к чтению специ-
альных текстов.
Таким образом, на процесс понимания (или интерпретации) I и модель М2 вли-
яют следующие компоненты (рис. 4.8):
• экстракт компонентов (а, Р, у, 6)’, почерпнутый из текста Т;
• предварительные знания аналитика о предметной области со;
• общенаучная эрудиция аналитика е;
• его личный опыт ср.
128
Глава 4 • Технологии инженерии знаний
М2= [(а, Р, у, 6)', со, е, ф].
Процесс I — это сложный, не поддающийся формализации процесс, на который
существенным образом влияют такие чисто индивидуальные компоненты, как
когнитивный стиль познания, интеллектуальные характеристики и др.
Рис. 4.8. Компоненты формирования смысла текста
Но процедура разбивки текста на части («смысловые группы»), а затем сгущение,
сжатие содержимого каждого смыслового куска в «смысловую веху» является,
видимо, основой для любого индивидуального процесса понимания. Такая комп-
рессия (сжатие) текста в виде набора ключевых слов, передающих основное со-
держание текста, может служить удобной методологической основой для прове-
дения текстологических процедур извлечения знаний.
В качестве ключевого слова может служить любая часть речи (существительное,
прилагательное, глагол и т. д.) или их сочетание. Набор ключевых слов (НКС) —
это набор опорных точек, по которым развертывается текст при кодировании в
память и осознается при декодировании, это семантическое ядро цельности [Си-
ротко-Сибирский, 1968].
Пример 4.7
В качестве примера приведем результаты эксперимента по формированию НКС. Зна-
ния извлекались из следующего текста [Уэно, Исидзука, 1989].
«Теория фреймов относится к психологическим понятиям, касающимся понимания
того, что мы видим и слышим. Эти способы восприятия трактуются с последователь-
ной точки зрения, на их основании осуществляется концептуальное моделирование,
целесообразность полученных моделей исследуется вместе с различными проблемами,
возникающими в этих двух областях.
Для осознания того факта, что заданная информация в этих областях имеет единствен-
ный смысл, человеческая память прежде всего должна быть способна увязывать эту
информацию со специальными концептуальными объектами. В противном случае не
удается систематизировать информацию, которая выглядит разрозненной. В основе
теории фреймов лежит восприятие фактов посредством сопоставления полученной
извне информации с конкретными элементами и значениями, а также с рамками, опре-
4.3. Текстологические методы
129
деленными для каждого концептуального объекта в нашей памяти. Структура, пред-
ставляющая эти рамки, называется фреймом. Поскольку между различными концеп-
туальными объектами имеются некоторые аналогии, то образуется иерархическая
структура с классификационными и обобщающими свойствами. Собственно, она пред-
ставляет собой иерархическую структуру отношений типа «абстрактпое-конкретное».
•Сложные объекты представлены комбинацией нескольких фреймов, другими словами,
они соответствуют фреймовой сети. Кроме того, каждый фрейм дополняется связан-
ными с ним фактами и процедурой, обеспечивающей выполнение запросов к другим
фреймам.
Причиной, по которой представление знаний фреймами выглядит достаточно
точным, является возможность более полного описания процесса мышления че-
ловека посредством определения крупной и структурированной основной едини-
цы представления знаний и более тесной связи знаний, основанных на фактах, и
процедурных знаний. Тем не менее, как было отмечено ее автором, теорию фрей-
мов следует скорее отнести к теории постановки задач, чем к результативной тео-
рии. Можно считать, что она существенно повышает уровень и детализирует ме-
ханизм памяти человека, выводов, понимания и обучения.»
В группе из 34 испытуемых не было получено ни одного совпадающего НКС и,
соответственно, все структуры существенно отличались. Для примера приведем
две работы (рис. 4.9, а, б).
Интересно, что одна из гипотез лингвостатистики о том, что наиболее употребля-
емые слова являются наиболее важными с точки зрения содержания текста, то
есть отражают его тематическую структуру, частично подтвердилась.
Следует сказать несколько слов о том, почему мы выделяем три вида текстологи-
ческих методов (см. рис. 4.1):
• анализ специальной литературы;
• анализ учебников;
• анализ методик.
Перечисленные три метода существенно отличаются, во-вторых, по степени кон-
центрированности специальных знаний, и, во-вторых, по соотношению специ-
альных и фоновых знаний. Наиболее простым методом является анализ учеб-
ников, в которых логика изложения обычно соответствует логике предмета
и поэтому макроструктура такого текста будет, наверное, более значима, чем
структура текста какой-нибудь специальной статьи. Анализ методик затруднен
как раз сжатостью изложения и практическим отсутствием комментариев, то есть
фоновых знаний, облегчающих понимание для неспециалистов. Поэтому мож-
но рекомендовать для практической работы комбинацию перечисленных мето-
дов.
В заключение предложим одну из возможных практических методик анализа тек-
стов с целью извлечения и структурирования знаний.
130
Глава 4 • Технологии инженерии знаний
а
<теория фреймов ТФ
(ISA — теория постановки задач),
(АКО — психологическое понятие),
(НАЗНАЧЕНИЕ — систематизация*
описание мышления),
(ПРИНЦИП — восприятие внешних факторов
и сопоставление с фреймами),
(ОСНОВНОЕ ПОНЯТИЕ — фрейм, сеть фреймов)*
<фрейм
(ISA — понятие ТФ),
(ОПРЕДЕЛЕНИЕ -...),
(... )>
Рис. 4.9. Примеры смысловых структур, извлеченных из текста
, 4.4. Простейшие методы структуирования
131
Алгоритм извлечения знаний из текста
1. Составление «базового» списка литературы для ознакомления с предмет-
ной областью и чтение по списку.
2. Выбор текста для извлечения знаний.
3. Первое знакомство с текстом (беглое прочтение). Для определения зна-
чения незнакомых слов — консультации со специалистами или привле-
чение справочной литературы.
4. Формирование первой гипотезы о макроструктуре текста.
5. Внимательное прочтение текста с выписыванием ключевых слов и выра-
жений, то есть выделение «смысловых вех» (компрессия текста).
6. Определение связей между ключевыми словами, разработка макрострук-
туры текста в форме графа или «сжатого» текста (реферата).
7. Формирование поля знаний на основании макроструктуры текста.
4.4. Простейшие методы структурирования
Методы извлечения знаний, рассмотренные выше, являются непосредственной
подготовкой к структурированию знаний. Данный параграф посвящен изучению
практических методов структурирования знаний.
4.4.1. Алгоритм для «чайников»
В качестве простейшего прагматического подхода к формированию поля зна-
ний начинающему инженеру по знаниям можно предложить следующий алго-
ритм для «чайников» (рис. 4.10).
1. Определение входных {X} и выходных {Y} данных. Этот шаг совершенно необ-
ходим, так как он определяет направление движения в поле знаний — от X к Y.
Кроме того, структура входных и выходных данных существенно влияет на
форму и содержание поля знаний. На этом шаге определение может быть до-
статочно размытым, в дальнейшем оно будет уточняться.
2. Составление словаря терминов и наборов ключевых слов N. На этом шаге про-
водится текстуальный анализ всех протоколов сеансов извлечения знаний и
выписываются все значимые слова, обозначающие понятия, явления, процес-
сы, предметы, действия, признаки и т. п. При этом следует попытаться разоб-
раться в значении терминов. Важен осмысленный словарь.
3. Выявление объектов и понйтий {А}. Производится «просеивание» словаря N и
выбрр значимых для принятия решения понятий и их признаков. В идеале на
этом шаге образуется полный систематический набор терминов из какой-либо
области знаний.
4. Выявление связей между понятиями. Все в мире связано. Но определить, как
направлены связи, что ближе, а что дальше, необходимо на этом этапе. Таким
132
Глава 4 • Технологии инженерии знаний
образом, строится сеть ассоциаций, где связи только намечены, но пока не по-
именованы. Например, понятия «день», «ночь», «утро» и «вечер» явно как-то
связаны, связаны также и понятия «красный флаг» и «красный галстук», но
характер связи тут существенно отличен.
5. Выявление метапонятий и детализации понятий. Связи, полученные на пре-
дыдущем шаге, позволяют инженеру по знаниям структурировать понятия и
как выявлять понятия более высокого уровня обобщения (метапонятия), так и
детализировать на более низком уровне.
6. Построение пирамиды знаний. Под пирамидой знаний мы понимаем иерар-
хическую лестницу понятий, подъем по которой означает углубление понима-
ния и повышения уровня абстракции (обобщенности) понятий. Количество
уровней в пирамиде зависит от особенностей предметной области, профессио-
нализма экспертов и инженеров по знаниям.
7. Определение отношений {RA}. Отношения между понятиями выявляются как
внутри каждого из уровней пирамиды, так и между уровнями. Фактически на
этом шаге даются имена тем связям, которые обнаруживаются на шагах 4 и 5, а
также обозначаются причинно-следственные, лингвистические, временные и
другие виды отношений.
8. Определение стратегий принятия решений (Sf). Определение стратегий при-
нятия решения, то есть выявление цепочек рассуждений, связывает все сфор-
мированные ранее понятия и отношения в динамическую систему поля зна-
ний. Именно стратегии придают активность знаниям, именно они «пе-
ретряхивают» модель М в поиске от X к Y.
Рис. 4.10. Стадии структурирования знаний — алгоритм для «чайников»
4.4. Простейшие методы структурирования
133
Однако на практике при использовании данного алгоритма можно столкнуться с
непредвиденными трудностями, связанными с ошибками на стадии извлечения
знаний и с особенностями знаний различных предметных областей. Тогда воз-
можно привлечение других, более «прицельных» методов структурирования.
При этом на разных этапах схемы (рис. 4.10) возможно использование различных
методик.
4.4.2. Специальные методы структурирования
Используя представленный на рис. 4.10 алгоритм, инженер по знаниям может
испытывать необходимость в применении специальных методов структурирова-
ния на разных шагах алгоритма. При этом, естественно, для таких простых и оче-
видных шагов, как определение входных и выходных понятий или составление
словаря, никаких искусственных методов предлагаться не будет.
Методы выявления объектов, понятий и их атрибутов
Понятие или концепт — это обобщение предметов некоторого класса по их спе-
цифическим признакам. Обобщенность является сквозной характеристикой всех
когнитивных психических структур, начиная с простейших сенсорных образов.
Так, понятие «автомобиль» объединяет множество различных предметов, но все
они имеют четыре колеса, двигатель и массу других деталей, позволяющих пере-
возить на них грузы и людей. Существует ряд методов выявления понятий пред-
метной области в общем словаре терминов, который составлен на основании се-
ансов извлечения знаний. При этом важно выявление не только самих понятий,
но и их признаков.
Возвращаясь к терминологии, введенной в параграфе 1.3, на этом этапе опреде-
ляются также интенсионалы и экстенсионалы понятий предметной области. Ин-
тенсионал очерчивает пбнятие через взаимосвязь значимых признаков, а эк-
стенсионал — через перечисление конкретных экземпляров объекта.
Если задача выделения реальных объектов А связана только с наблюдательнос-
тью и лингвистическими способностями эксперта и инженера по знаниям, то оп-
ределение метапонятий В требует от них умения проводить операции обобщения
и классификации, которые никогда не считались тривиальными.
Поспелов Д. А. [Поспелов, 1986] предложил ряд подходов к созданию основ тео-
рии обобщения и классификации применительно к ситуационному управле-
нию и искусственному интеллекту в целом, а также выделил ряд особенностей
задач формирования понятий. Среди них особое место занимает выявление
прагматически значимых признаков для формирования понятий, способствую-
щих решению задачи.
Сложность заключается в том, что для многих понятий практически невозможно
однозначно определить их признаки, это связано с различными формами репре-
зентации понятий в памяти человека.
134
Глава 4 • Технологии инженерии знаний
Все методы выявления понятий мы разделили на:
• традиционные, основанные на математическом аппарате распознавания обра-
зов и классификации;
• нетрадиционные, основанные на методологии инженерии знаний.
Если первые достаточно хорошо освещены в литературе, то вторые пока менее из-
вестны.
Пример 4.8
Интересный эксперимент по выявлению понятий описан в работе [Кук, Макдональд,
1986].
Тридцати студентам, имеющим права на вождение автомобиля, предложили составить
словарь терминов предметной области с помощью четырех методов:
1. Формирование перечня понятий (17 %).
2. Интервьюирование специалистов (35 %).
3. Составление списка элементарных действий (18 %).
4. Составление оглавления учебника (30 %).
Цифры в скобках характеризуют продуктивность соответствующего метода,
то есть показывают, какой процент понятий из общего выявленного списка (702 тер-
мина) был получен соответствующим методом. Для классификации понятий были
привлечены еще два участника эксперимента, которые разделили 702 выявленных по-
нятия на семь категорий (методом сортировки карточек). Таблица 4.5 отражает чис-
ленные данные концептуализации.
Таблица 4.5. Данные концептуализации
Категории Процент Процент от общего числа терминов, полученный
от общего соответствующим
числа терминов методом
Перечень понятий Интервью- ирование Список операций Составление оглавления
Объяснение 6 5,5 7,2 7,0 4,9
Общие правила 22,0 43,6 18,9 36,8 4,9
Режимные правила 9,0 9,8 8,4 11,6 6,6
Понятия 42,0 18,4 38,9 8,5 77,7
Процедуры 9,0 5,1 9,5 25,6 1,2
Факты 9,0 15,0 12,5 8,9 1,2
Прочие понятия 3,0 2,6 4,6 1,6 3,5
В целом результаты показали, что для выявления непосредственно концептов
наиболее результативными оказались методы интервьюирования и составления
оглавления учебника. Однако наибольшее число общих правил было порождено
в методе списка действий. Таким образом, еще раз подтвердилось утверждение о
том, что нет «лучшего» метода, есть методы, подходящие для тех или иных ситуа-
ций и типов знаний.
4.4. Простейшие методы структурирования 135
Интересно, что число правил — продукций «если — то» — составило небольшой
процент во всех четырех методах. Это говорит о том, что популярная продукци-
онная модель вряд ли является естественной для человеческих моделей репрезен-
тации знаний.
Методы выявления связей между понятиями
Концепты не существуют независимо, они включены в общую понятийную
структуру с помощью отношений. Выявление связей между понятиями при раз-
работке баз знаний доставляет инженеру по знаниям немало проблем. То, что зна-
ния в памяти — это некоторые связные структуры, а не отдельные фрагменты,
общеизвестно и очевидно. Тем не менее основной упор в существующих моделях
представления знаний делается на понятия, а связи вводят весьма примитивные
(в основном причинно-следственные).
В последних работах по теории ИИ все больше внимания уделяется взаимосвя-
занности структур знаний. Так, в работе [Шенк, Бирнбаум, Мей, 1989] введено
понятие сценария (script) как некоторой структуры представления знаний. Ос-
нову сценария составляет КОП (концептуальная организация памяти) и мета-
КОПы — некоторые обобщающие структуры.
Сценарии, в свою очередь, делятся на фрагменты — или сцены (chunks). Связи
между фрагментами — временные или пространственные, внутри фрагмента —
самые различные: ситуативные, ассоциативные, функциональные и т. д.
Все методы выявления таких связей можно разделить на две группы:
• Формальные.
• Неформальные (основаны на дополнительной работе с экспертом).
Неформальные методы выявления связей придумывает инженер по знаниям для
того, чтобы вынудить эксперта указать явные и неявные связи между понятиями.
Наиболее распространенным является метод «сортировка карточек» в группы
[Волков, Ломнев, 1989; Rabbits, Wright, 1987], широко применяемый и для фор-
мирования понятий. Другим неформальным методом является построение замк-
нутых кривых. В этом случае эксперта просят обвести замкнутой кривой свя-
занные друг с другом понятия [Olson, Reuter, 1987]. Этот метод может быть
реализован как на бумаге, так и на экране дисплея. В этом случае можно говорить
о привлечении элементов когнитивной графики [Зенкин, 1991].
После того как определены связи между понятиями, все понятия как бы распада-
ются на группы. Такого рода группы представляют собой метапонятия, присвое-
ние имен которым происходит на следующей стадии процесса структурирования.
Методы выделения метапонятий и детализация понятий
(пирамида знаний)
Процесс образования метапонятий, то есть интерпретации групп понятий, полу-
ченных на предыдущей стадии, как и обратная процедура — детализация (разук-
рупнение) понятий, — видимо, принципиально не поддающиеся формализации
операции. Они требуют высокой квалификации экспертов, а также наличия спо-
собностей к «наклеиванию» лингвистических ярлыков. Если на рис. 4.11 показа-
136
Глава 4 • Технологии инженерии знаний
ны схемы обобщения и детализации на тривиальных примерах, то в реальных
предметных областях эта задача оказывается весьма трудоемкой. При этом неза-
висимо от того, формальными или неформальными методами были выявлены
понятия или детали понятий, присвоение имен которым или интерпретация их —
всегда неформальный процесс, в котором инженер по знаниям просит эксперта
дать название некоторой группе понятий или отдельных признаков.
Рис. 4.11. Обобщение и детализация понятий
Это не всегда удается. Так, в системе АВТАНТЕСТ [Гаврилова, Червинская,
1992] при образовании метапонятий, полученных методами кластерного анализа,
интерпретация заняла несколько месяцев и не может считаться удовлетворитель-
ной. Это связано с тем, что формальные методы иногда выделяют «искусствен-
ные» концепты, в то время как неформальные обычно — практически исполь-
зуемые и потому легко узнаваемые понятия.
Методы построения пирамиды знаний обязательно включают использование на-
глядного материала — рисунков, схем, кубиков. Уровни пирамиды чаще возника-
ют в сознании инженера по знаниям именно как некоторые образы.
Построение пирамиды знаний может быть основано и на естественной иерархии
предметной области, например связанной с организационной структурой пред-
приятия или с уровнем компетентности специалистов (рис. 4.12).
из
U2
U1
из
U2
U1
Рис. 4.12. Пирамиды знаний
4.5. Состояние и перспективы автоматизированного приобретения знаний 137
Методы определения отношений
Если на стадии 4 (см. рис. 4.10) мы выявили связи между понятиями и использо-
вали их на стадиях 5 И 6 для получения пирамиды знаний, то на стадии 7 мы даем
имена связям, то есть превращаем их в отношения.
В работе [Поспелов, 1986] указывается на наличие более 200 базовых видов раз-
личных отношений, существующих между понятиями. Предложены различные
классификации отношений [Келасьев, 1984; Поспелов, 1986]. Следует только
подчеркнуть, что помимо универсальных отношений (пространственных, вре-
менных, причинно-следственных) существуют еще и специфические отноше-
ния, присущие той или иной предметной области [Гаврилова, Червинская,
Яшин, 1988].
Интересные возможности к структурированию знаний добавляют системы ког-
нитивной графики. Так, в системе OPAL [Oiton., Muser, Combs et al., 1987] экс-
перт может манипулировать на экране дисплея изображениями простейших по-
нятий и строить схемы лечения заболеваний, обозначая отношения явными
линиями, которые затем именуются.
Предлагаемая в данном учебнике методология структурирования опирается на
современные представления о структуре человеческой памяти и формах репре-
зентации информации в ней [Величковский, 1982].
Скудность методов структурирования объясняется тем, что методологическая
база инженерии знаний только закладывается, а большинство инженеров по зна-
ниям проводит концептуализацию, руководствуясь наиболее дорогими и неэф-
фективными способами — «проб и ошибок» и «по наитию», то есть исходя из со-
ображений здравого смысла.
4.5. Состояние и перспективы
автоматизированного
приобретения знаний
В данном параграфе мы рассмотрим автоматизированный подход к проблеме из-
влечения и структурирования знаний, традиционно называемый приобретением
знаний (knowledge acquisition).
Поскольку основную трудность в создании интеллектуальных систем представ-
ляет домашинный этап проектирования, выполняемый инженером по знаниям
(или аналитиком), — анализ предметной области, получение знаний и их струк-
турирование, — эти процедуры традиционно считаются «узким местом» (bottle-
neck) проектирования экспертных систем [Gaines, 1987; Boose, 1990]. Последние
5-6 лет усилия разработчиков направлены на создание инструментальной про-
граммной поддержки деятельности инженера по знаниям и эксперта именно на
этих этапах.
138 Глава 4 • Технологии инженерии знаний
4.5.1. Эволюция систем приобретения знаний
Первое поколение таких систем появилось в середине 80-х — это так называемые
системы приобретения знаний (СПЗ) (TEIRESIAS [Davis, 1982], SIMER+
MIR [Осипов, 1988], АРИАДНА [Моргоев, 1988]). Это средства наполнения так
называемых «пустых» ЭС, то есть систем, из БЗ которых изъяты знания (напри-
мер, EMYCIN — EMPTY MYCIN, опустошенная медицинская ЭС MyCIN со спе-
циальной диалоговой системой заполнения базы знаний TEIRESIAS). Их авто-
ры считали, что прямой диалог эксперта с компьютером через СПЗ поможет
сократить жизненный цикл разработки. Однако опыт создания и внедрения СПЗ
продемонстрировал несовершенство такого подхода.
Основные недостатки СПЗ I поколения:
• Слабая проработка методов извлечения и структурирования знаний.
• Жесткость модели представления знаний, встроенной в СПЗ и связанной с
привязкой к программной реализации.
• Ограничения на предметную область.
Таким образом, традиционная схема разработки СПЗ I поколения:
создание конкретной ЭС -» опустошение БЗ -» разработка СПЗ для новых
наполнений БЗ -» формирование новой БЗ для другой ЭС
оказалась несостоятельной для промышленного применения.
Второе поколение СПЗ появилось в конце 80-х и было ориентировано на более
широкий модельный подход [Gaines, 1989; Борисов, Федоров, Архипов, 1991] с
акцентом на предварительном детальном анализе предметной области. Так, в Ев-
ропе широкое применение получила методология KADS (Knowledge Acquisition
and Documentation Structuring) [Wielinga et al., 1989], в основе которой лежит
понятие интерпретационной модели, позволяющей процессы извлечения, струк-
турирования и формализации знаний рассматривать как «интерпретацию» линг-
вистических знаний в другие представления и структуры.
KADS-методология
Рисунок 4.13 демонстрирует преобразование знаний согласно методологии KADS
[Breuker, Wielinga, 1989] через спецификацию пяти шагов анализа ^идентифика-
ция — концептуализация — гносеологический уровень — логический уровень — уро-
вень анализа выполнениям и стадии или пространства проектирования.
Результатом анализа является концептуальная модель экспертизы, состоящая из
четырех уровней {уровня области — уровня вывода — уровня задачи — стратеги-
ческого уровня), которая затем вводится в пространство проектирования и преоб-
разуется в трехуровневую модель проектирования (рис. 4.14).
При решении реальных задач KADS использует библиотеку интерпретацион-
ных моделей, описывающих общие экспертные задачи, такие как диагностика,
мониторинг (см. классификацию 1 из п. 2.2) и пр., без конкретного наполнения
объектами предметной области. Интерпретационная модель представляет собой
4.5. Состояние и перспективы автоматизированного приобретения знаний 139
концептуальную модель без уровня области. На основании извлеченных лингви-
стических данных происходит отбор, комбинация и вложение верхних уровней
модели, то есть уровней вывода и задачи, которые наполняются конкретными
объектами и атрибутами из уровня области и представляют в результате концеп-
туальную модель рассматриваемой задачи. На рис. 4.15 представлена модель
жизненного цикла KADS.
Рис. 4.13. Методология KADS
Первые системы программной поддержки KADS-методологии представлены на-
бором инструментальных средств KADS PowerTools [Schreiber G., Breuker J. et al.,
1988]. В этот набор входят следующие системы: редактор протоколов PED (Pro-
tocol Editor); Редактор системы понятий (Concept Editor); Редактор концепту-
альных моделей СМЕ (Conceptual Model Editor) и ИМ-библиотекарь IML (Inter-
pretation Model Librarian).
Редактор протоколов — программное средство, помогающее инженеру по знани-
ям в проведении анализа знаний о предметной области на лингвистическом уров-
не. При работе со знаниями на этом уровне исходным-материалом являются тек-
сты (протоколы) — записи интервью с экспертом, протоколы «мыслей вслух» и
любые другие тексты, полезные с точки зрения инженера знаний. Редактор про-
токолов реализован как гипертекстовая система, обеспечивающая выделение
фрагментов в анализируемом тексте, установление связей между фрагментами,
группирование фрагментов, аннотирование фрагментов. Фрагменты могут иметь
любую длину — от отдельного слова до протокола в целом. Фрагменты могут пе-
рекрывать друг друга.
140
Глава 4 • Технологии инженерии знаний
Рис. 4.14. Основные модели KADS
Возможны следующие типы связей между фрагментами:
• аннотация (связь между фрагментом протокола и некоторым текстом, введен-
ным инженером знаний для спецификации этого фрагмента);
• член группы (связь между фрагментом и названием — именем группы фраг-
ментов; объединение фрагментов в группу позволяет инженеру знаний струк-
турировать протоколы, при этом группа фрагментов получает уникальное
имя);
• поименованная связь (связь между двумя фрагментами, имя связи выбирает-
ся инженером знаний);
• понятийная связь (поименованная связь между фрагментом и понятием; обыч-
но используется, если фрагмент содержит определение понятий).
Редактор понятий помогает инженеру знаний организовывать предметные зна-
ния в виде набора понятий и связывающих их отношений. Каждое понятие име-
ет имя и может иметь атрибуты; каждый атрибут может иметь значение. Какие
именно атрибуты используются — это определяет инженер знаний с учетом спе-
цифики предметной области. С помощью Редактора понятий инженер знаний
может вводить произвольные отношения между понятиями и создавать иерар-
хические структуры по тому или иному отношению. Существует единственное
отношение (ISA), семантика которого «встроена» в Редактор. Если инженер зна-
ний устанавливает это отношение между двумя понятиями, то имеет место на-
следование атрибутов.
4.5. Состояние и перспективы автоматизированного приобретения знаний 141
Рис. 4.15. Жизненный цикл KADS
ИМ-библиотекарь помогает инженеру знаний проводить анализ предметных зна-
ний на эпистемологическом уровне. Основное назначение Библиотекаря состоит
в том, чтобы помочь инженеру знаний выбрать одну или более ИМ, подходящих
для исследуемой проблемной области (ПО). Помощь Библиотекаря проявляется
в чисто информационном аспекте. Вначале Библиотекарь демонстрирует пользо-
вателю иерархию типов задач, для которых в библиотеке имеются ИМ. После
того как пользователь выбрал интересующую его ИМ, ему демонстрируется ее
краткое описание и список атрибутов, включающий в себя следующие атрибуты:
«краткое описание», «определение», «структура задачи», «стратегии», «ПО-зна-
142
Глава 4 • Технологии инженерии знаний
ния». Выбрав атрибут «определение», пользователь сможет увидеть на экране
графическое изображение структуры вывода, элементами которой являются ис-
точники знаний и метаклассы. Как источники знаний, так и метаклассы имеют
свои наборы атрибутов; инженер знаний может просмотреть их, указывая на со-
ответствующий элемент.
Психосемантика
Помимо идеологии KADS на разработку СПЗ II поколения большое влияние
оказали методы смежных наук, в частности психосемантики, одного из молодых
направлений прикладной психологии [Петренко, 1988; Шмелев, 1983], перспек-
тивного инструмента, позволяющего реконструировать семантическое простран-
ство памяти и тем самым моделировать глубинные структуры знаний эксперта
(см. параграф 5.1). Уже первые приложения психосемантики в ИИ в середине
80-х годов позволили получить достаточно наглядные результаты [Кук, Макдо-
нальд, 1986]. В дальнейшем развитие этих методов шло по линии разработки
удобных пакетов прикладных программ, основанных на методах многомерно-
го шкалирования, факторного анализа, а также специализированных методов
обработки репертуарных решеток [Франселла, Баннистер, 1987] (параграф 5.2).
Примерами СПЗ такого типа являются системы KELLY [Похилько, Страхов,
1990], MADONNA [Терехина, 1988], MEDIS [Алексеева и др., 1989]. Специфи-
ка конкретных приложений требовала развития также «нечисленных» методов,
использующих парадигму логического вывода. Примерами систем этого направ-
ления служат системы ETS [Boose, 1986] и AQUINAS [Boose, Bradshaw, Schema,1988].
Успехи СПЗ II поколения позволили значительно расширить рынок ЭС, кото-
рый к концу 80-х оценивался в 300 млн долларов в год [Попов, 1991]. Тем не менее
и эти системы были не свободны от недостатков, к важнейшим из которых можно
отнести:
• несовершенство интерфейса, в результате чего неподготовленные эксперты не
способны овладеть системой и отторгают ее;
• сложность настройки на конкретную профессиональную языковую среду;
• необходимость разработки дорогостоящих лингвистических процессоров для
анализа естественно-языковых сообщений и текстов.
Третье поколение СПЗ — KEATS [Eisenstadt et al., 1990], MACAO [Aussenac-
Gilles, Natta, 1992], NEXPERT-OBJECT [NEXPERT-OBJECT, 1990] - перенес-
ло акцент в проектировании с эксперта на инженера по знаниям [Гаврилова,
1988; Gruber, 1989]. Новые СПЗ — это программные средства для аналитика,
более сложные, гибкие, а главное использующие графические возможности со-
временных рабочих станций и достижения CASE-техйологии (Computer-Aided
Software Engineering). Эти системы позволяют не задавать заранее интерпрета-
ционную модель, а формировать структуру БЗ динамически.
Существуют различные классификации СПЗ — по выразительности и мощнос-
ти инструментальных средств [Попов, 1988]; по обобщенным характеристикам
[Boose, 1990]; в рамках структурно-функционального подхода [Волков, Ломнев,
1989]; интегрированная классификация предложена в работе [Гаврилова, Чер-
винская, 1992].
4.5. Состояние и перспективы автоматизированного приобретения знаний 143
Учитывая новейшие тенденции в инженерии знаний можно предложить следую-
щую схему таксономии СПЗ, представленную на рис. 4.16.
Рис. 4.16. Классификация систем приобретения знаний
Однако и современные СПЗ не полностью лишены серьезных недостатков СПЗ
I и II поколений, большая часть которых обусловлена отсутствием теоретической
концепции проектирования БЗ. В результате эта область до настоящего времени
справедливо считается скорее «искусством», чем наукой и основана на «ad hoc»
технологии (то есть применительно к случаю).
4.5.2. Современное состояние
автоматизированных систем
приобретения знаний
Анализ современного состояния программных средств приобретения знаний и
поддержки деятельности инженера по знаниям позволяет выявить две группы
проблем, характерных для существующих СПЗ:
• Методологические проблемы.
• Технологические проблемы.
144
Глава 4 • Технологии инженерии знаний
А. Методологические проблемы
Основная проблема, встающая перед разработчиками, — отсутствие теорети-
ческого базиса процесса извлечения и структурирования знаний — порождает
дочерние более узкие вопросы и казусы на всех этапах создания интеллектуаль-
ных систем. Даже тщательно проработанная методология KADS, описанная в пре-
дыдущем параграфе, страдает громоздкостью и явной избыточностью. Ниже пе-
речислены наиболее общие из возникающих проблем в последовательности,
соответствующей стадиям жизненного цикла (см. рис. 2.4):
• размытость критериев выбора подходящей задачи;
• слабая проработанность теоретических аспектов процессов извлечения зна-
ний (философские, лингвистические, психологические, педагогические, ди-
дактические и другие аспекты), а также отсутствие обоснованной классифи-
кации методов извлечения знаний и разброс терминологии;
• отсутствие единого теоретического базиса процедуры структурирования зна-
ний;
• жесткость моделей представления знаний, заставляющая разработчиков обед-
нять и урезать реальные знания экспертов;
• несовершенство математического базиса моделей представления знаний (дес-
криптивный, а не конструктивный характер большинства имеющихся матема-
тических моделей);
• эмпиричность процедуры выбора программного инструментария и процесса
тестирования (отсутствие критериев, разрозненные классификации, etc.).
Б. Технологические проблемы
Большая часть технологических проблем является естественным следствием ме-
тодологических и порождена ими. Наиболее серьезными из технологических
проблем являются;
• отсутствие концептуальной целостности и согласованности между отдельны-
ми приемами и методами инженерии знаний;
• недостаток или отсутствие квалифицированных специалистов в области ин-
женерии знаний;
• отсутствие технико-экономических показателей оценки эффективности ЭС
(в России);
• несмотря на обилие методов извлечения знаний (фактически более 200 в обзо-
ре [Boose, 1990]), практическая недоступность методических материалов по
практике проведения сеансов извлечения знаний;
• явная неполнота и недостаточность имеющихся методов структурирования
знаний [Кук, Макдональд, 1986; Гаврилова, Червинская, 1992], отсутствие
классификаций и рекомендаций по выбору подходящего метода;
• несмотря на обилие рынка программных средств, недостаток промышленных
систем поддержки разработки и их узкая направленность (зависимость от
платформы, языка реализации, ограничений предметной области), разрыв
между ЯПЗ и языками, встроенными в «оболочки» ЭС;
4.6, Примеры методов и систем приобретения знаний
145
• жесткость программных средств, их низкая адаптивность, отсутствие индиви-
дуальной настройки на пользователя и предметную Область;
• слабые графические возможности программных средств, недостаточный учет
когнитивных й эргономических факторов;
• сложность внедрения ЭС, обусловленная психологическими проблемами пер-
сонала и неприятия новой технологии решения задач.
4.6. Примеры методов и систем
приобретения знаний
Данный параграф посвящен обзору некоторых наиболее известных методов и си-
стем приобретения знаний, на основе переработки материалов из работ [Осипов,
1990; Молокова, 1992; Осипов, 1997].
4.6.1. Автоматизированное структурированное
интервью
Впервые структурированное интервью применено при создании системы TEI-
RESIAS [Davis, 1982] для формирования новых правил и новых понятий. Для
этих целей в системе использованы следующие соображения: в случае неудачи в
режиме консультации (или тестирования) система предлагает эксперту выде-
лить причины неудачи. Контекст, полученный в результате этого, позволяет сис-
теме сформировать некоторые «ожидания», характеризующие содержание ново-
го правила, которое будет вводиться экспертом для устранения неудачи.
Система ROGET [Bennet, 1985] — это первая попытка заменить инженера знаний
программной системой на начальном этапе приобретения знаний. Эта система
беседует с экспертом как инженер по знаниям, стремящийся понять, как концеп-
туально могут быть организованы экспертные знания, необходимые для создания
диагностической ЭС.
В системе MOLE [Eshelman, 1987] приобретение знаний осуществляется в два
этапа: на первом этапе используется структурированное интервью и эксперту
(или инженеру по знаниям) предлагается ввести список событий предметной об-
ласти и определить связи между ними; на втором этапе выполняется контекстное
приобретение знаний, как это сделано в системе TEIRESIAS.
Система состоит из двух частей: интерпретатора базы предметных знаний и
подсистемы приобретения знаний. Последняя поддерживает как процесс первое
начального заполнения БЗ, так и процесс отладки и уточнения БЗ.
Интерпретатор БЗ ориентирован на класс диагностических задач и осуществляет
вывод решения путем сопоставления заранее определенного множества гипотез
(о причине неисправности, о заболевании и т. д.) с совокупностью наблюдений
(симптомов, показаний приборов и т. д.). Иными словами, интерпретатор систе-
мы MOLE реализует некоторый вариант метода эвристической классификации.
146
Глава 4 • Технологии инженерии знаний
В базе знаний MOLE первоначально существуют знания о том, какие типы .когни-
тивных структур необходимы для осуществления вывода и как распознать зна-
ния того или иного типа в информации, сообщаемой экспертом. MOLE запраши-
вает у эксперта список объектов, играющих роли гипотез и наблюдений. Эксперт,
кроме того, должен указать, какие пары «наблюдение — гипотеза» и «гипотеза —
гипотеза» ассоциативно связаны.
Результатом этого этапа извлечения знаний является сеть объектов. Затем MO-
LE пытается получить дополнительную информацию: о типе объекта (является
объект наблюдаемым или выводимым); о природе ассоциативной связи (какой
тип знаний лежит в основе ассоциации — объясняющие, предсказывающие или
иные); о направлении ассоциативной связи, о численной оценке «силы» ассоциа-
тивной связи. Однако MOLE понимает, что эксперт не всегда может предоста-
вить такую информацию. Поэтому на этом этапе MOLE использует стратегию
ожиданий: она пытается вывести необходимую информацию из сообщений экс-
перта на основе своих ожиданий.
На этапе начального формирования базы знаний MOLE назначает численные
веса ассоциативных связей по умолчанию на основе следующих посылок:
• каждое наблюдение должно быть объяснено некоторой гипотезой;
• только одна из гипотез, объясняющих данное наблюдение, является в каждом
конкретном случае наиболее вероятной;
• сумма оценок для связей данного наблюдения с объясняющими его гипотеза-
ми равна единице.
Тогда по умолчанию MOLE назначает для каждой связи данного наблюдения
оценку, полученную как частное от деления единицы на число гипотез, объясня-
ющих данное наблюдение. MOLE предполагает, что если эксперт сообщил не-
сколько объяснений для одного и того же объекта, то, вероятно, он может сооб-
щить и знания, позволяющие различать эти объяснения.
Система приобретения знаний SALT [Markus, 1987] создана в университете Car-
negie Mellon. Система SALT — система приобретения знаний для задач конструи-
рования. Система SALT разрабатывалась в предположении, что решение этой за-
дачи осуществляется методом пошагового распространения ограничений.
Для решения задач конструирования методом пошагового распространения огра-
ничений необходимы знания следующих типов:
• процедуры установления значений параметров;
• процедуры проверки ограничений;
• процедуры коррекции значений параметров с указанием «цены» каждого кор-
ректирующего действия.
Важно, чтобы все эти знания составляли целостную и непротиворечивую БЗ.
Наибольшую трудность для эксперта представляет необходимость последова-
тельно, шаг за шагом описать все свои действия при разработке проекта. Работая
с системой SALT, эксперт избавлен от этой необходимости.
4.6. Примеры методов и систем приобретения знаний 147
Исходя из того, как именно экспертные знания будут использоваться в ЭС при
составлении конкретных проектов, SALT анализирует текущее состояние БЗ и
предлагает эксперту-пользователю ввести или пересмотреть тот или иной фраг-
мент знаний. Диалог с пользователем в SALT ведется либо посредством вопро-
сов-подсказок, либо посредством меню. Инициатива в диалоге принадлежит си-
стеме.
Система приобретения знаний OPAL [Musen, Fagan, et al., 1987] была создана в
начале 80-х годов в Стэнфордском университете. Эта система обеспечивает
формирование и наращивание базы знаний для ЭС ONCOCIN, дающей советы
по лечению онкологических больных. Система приобретения знаний OPAL ос-
нована на детально проработанной модели медицинских знаний, используемых
врачами-онкологами для рекомендации лечения.
Системой используется девять типов знаний:
• схема лечения (порядок и длительность режимов лечения);
• критерий выбора протокола;
• химиотерапия (описание комбинаций лекарств, назначаемых в том или ином
режиме, их дозировка);
• радиотерапия (локализация и дозировка радиотерапии);
• изменения в составе крови, требующие модификации дозировки;
• негативные реакции на лечение, выявленные путем лабораторных исследова-
ний;
• другие отрицательные последствия проводимого лечения, требующие моди-
фикации дозировки лекарств;
• перерыв или прекращение лечения;
• лабораторные исследования, необходимые для обнаружения токсичности ле-
чения и для сохранения истории течения болезни.
Эти типы медицинских знаний связаны в иерархическую структуру.
Для ввода каждого типа знаний разработан специальный графический интер-
фейс, учитывающий то, как принято фиксировать соответствующие знания. Так,
например, для записи схемы лечения онкологи используют диаграммы перехо-
дов с условиями на дугах. В системе OPAL ввод таких знаний осуществляется с
помощью графического языка программирования. Схема лечения создается как
программа на этом языке.
Схемы протоколов и заполненные формы транслируются системой OPAL во
внутреннее представление БЗ ЭС ONCOCIN. Этот процесс осуществляется без
участия пользователя. По схемам протоколов порождаются диаграммы перехо-
дов, называемые генераторами; по формам-бланкам порождаются правила про-
дукций, присоединяемые к соответствующим состояниям в диаграмме.
Система KNACK создана в 1989 г. в университете Carnegie Mellon. Она представ-
ляет собой ориентированный на экспертов предметной области инструмент для
создания ЭС, помогающих оценивать и улучшать различные виды проектов.
148
Глава 4 • Технологии инженерии знаний
Единственными знаниями, изначально встроенными в систему KNACK, явля-
ются знания о процессе оценки проектов вообще, то есть независимо от конкрет-
ного содержания проектов. Все остальные знания приобретаются системой
KNACK на основе диалога и анализа документов, называемых отчетами. Отчет
описывает процесс оценки какого-либо конкретного проекта.
Приобретение знаний, необходимых для оценки проектов определенного класса,
система KNACK осуществляет в два этапа. Первый этап — это настройка на класс
проектов. На этом этапе система KNACK с помощью эксперта создает предвари-
тельную модель. Расширенная с помощью специальных процедур модель пред-
метной области автоматически транслируется в программу на языке OPS-5.
К методам структурированного интервью примыкают и использованные при по-
строении системы МЕДИКС [Ларичев, Мечитов и др., 1989] процедуры эксперт-
ной классификации. Задача экспертной классификации формулируется в работе
[Ларичев, Мечитов и др., 1989] для:
• множества независимых свойств Р;
• множества признаков Q;
• множества Q™ возможных значений m-го признака;
• множества А всех возможных состояний.
Эксперту (или группе экспертов) предлагается идентифицировать наличие свойств
из множества Р и тем самым построить классификацию множества А = UK,, та-
кую, что состояние а О А относится к некоторому классу К? если, по мнению экс-
перта, это состояние обладает свойством POP. Повысить эффективность экспер-
тной классификации в этом случае удается благодаря использованию априорно
заданного отношения линейного порядка на множестве состояний.
4.6.2. Имитация консультаций
Этот метод реализован в системе АРИАДНА [Моргоев, 1988]. В основе этого ме-
тода — многократное решение экспертом проблемы классификации в режиме
последовательной вопросно-ответной консультации «клиент — эксперт». При
этом роль клиента моделируется всеми участниками работы, а эксперт выполня-
ет функции, близкие к его профессиональной консультативной деятельности.
С появлением персональных компьютеров связано появление игр эксперта с
компьютером [Андриенко Г., Андриенко Н., 1992]. В системе ЭСКИЗ реализо-
ван набор игр для приобретения знаний, являющихся той или иной модифика-
цией принципа репертуарных решеток. Например, в игре «Регата» объектами,
для которых эксперт должен указать различающие признаки, являются яхты.
В ходе гонок яхты должны проходить в пролеты мостов; в один и тот же пролет
проходят яхты, соответствующие сходным по какому-либо атрибуту объектам.
Рассмотренные выше системы поддержки процессов приобретения знаний, как
правило, ориентированы на отдельные фазы всего технологического цикла.
В связи с вышесказанным интересно хотя бы кратко рассмотреть интегрирован-
ные средства поддержки определенных методологий.
4.6. Примеры методов и систем приобретения знаний
149
4.6.3. Интегрированные среды
приобретения знаний
Интегрированная среда приобретения знаний AQUINAS [Boose, Bradshaw, Sche-
ma, 1988] представляет собой набор программных средств для извлечения экс-
пертных знаний различных типов различными методами. В состав AQUINAS
входят:
• система Dialog Manager для помощи новичкам в работе с AQUINAS;
• система ETS для извлечения и анализа репертуарных решеток с последующим
преобразованием их в базу продукционных правил;
• средства конструирования различных иерархических структур знаний;
• средства извлечения, представления и использования неточных знаний;
• средства тестирования и коррекции БЗ;
• средства, позволяющие эксперту оценивать конструкторы по наиболее подхо-
дящим шкалам;
• средства работы с несколькими экспертами;
• средства автоматического пополнения и коррекции БЗ.
Dialog Manager представляет собой ЭС, специально созданную для того, чтобы
консультировать эксперта о возможностях, представляемых AQUINAS, и руко-
водить экспертом при работе с AQUINAS. Возможны три режима взаимодей-
ствия с Dialog Manager:
• автоматический, при котором Dialog Manager полностью берет на себя руко-
водство процессом извлечения знаний;
• ассистирующий, при котором хотя эксперту и даются рекомендации относи-
тельно его дальнейших действий, но он может им не следовать;
• режим наблюдения за действиями эксперта и сохранения истории.
Выбрав автоматический или ассистирующий режим, экспрет должен выбрать
степень подробности подсказок и объяснений, даваемых системой («полностью»,
«на среднем уровне», «кратко»),
В БЗ Dialog Manager имеются эвристики, которые позволяют этой системе при
накоплении экспертом достаточного опыта перейти от автоматического режима
к ассистирующему. Dialog Manager информирует эксперта о переключении ре-
жимов. Работая в ассистирующем режиме, Dialog Manager оставляет за экспер-
том выбор деятельности, но на основе своих эвристик рекомендует наиболее
подходящую. В частности, если Dialog Manager считает, что эксперту следует
заняться анализом БЗ, то в рекомендации обычно указывается, какой именно
аспект нуждается в анализе. Так, эксперту может быть рекомендовано обратить-
ся либо к процедурам анализа сходства элементов (конструкторов), либо к про-
цедурам кластеризации элементов (конструкторов), либо к разбиению исходной
решетки на несколько иерархически связанных.
150
Глава 4 • Технологии инженерии знаний
Интегрированная среда приобретения знаний KITTEN (Knowledge Initiation &
transfer Tools for Experts and Novices) [Show, Woodward, 1988], подобно AQUI-
NAS, основана на построении и анализе репертуарных решеток. Отличие KIT-
TEN от AQUINAS заключается в том, что в KITTEN обеспечивается извлечение
элементов и конструкторов из текстов, а кроме того, имеются процедуры, анали-
зирующие примеры решения задач экспертом и генерирующие по ним продук-
ционные правила. Продукционные правила, порождаемые из примеров и реше-
ток, могут быть загружены в БЗ оболочки NEXPERT, с помощью которой про-
водится тестирование БЗ.
Завершая обзор прямых методов приобретения знаний, суммируем проблемы,
которые этими методами не решаются:
• эти методы не устраняют посредника между системой и экспертом;
• автономное использование описанных методов не решает таких проблем ин-
женерии знаний, как устранение «пробелов» в знаниях, выявление «глубин-
ных», невербальных знаний; сохраняется большая «время-емкость» и субъек-
тивность интервью;
• фаза приобретения знаний идеологически и теоретически не связывается со
следующими фазами инженерии знаний.
4.6.4. Приобретение знаний из текстов
Как было указано в параграфе 4.3, даже ручные методы выявления знаний из тек-
ста крайне слабо разработаны. В тех же немногих случаях, когда применяются
автоматизированные методики, речь, как правило, идет о методах лексико-семан-
тического анализа, а также о моделях понимания текста.
Наибольшую известность имеют модели понимания на лингвистическом уровне.
Системы, основанные на них, состоят в большинстве случаев из двух частей:
• первая — морфологический и синтаксический анализ;
• вторая — семантический анализ, который использует результаты работы пер-
вой части, а также словарную или справочную информацию для построения
формализованного образа текста.
Говоря о семантическом анализе текста, надо иметь в виду, что всякие отношения
текста с его семантикой начинаются после того, как в нашем распоряжении ока-
зывается некоторая модель действительности. Объектами этой модели, в частно-
сти, могут являться индивиды и отношения.
Таким образом, первая проблема, возникающая при попытках автоматического
извлечения знаний из текста, — это выявление свойств элементов текста для со-
отнесения этих элементов с объектами модели. Крайне редко эти свойства при-
сутствуют в тексте эксплицитно, то есть явно.
Вторая особенность существующих систем анализа текста — это, как правило,
необходимость использования словаря предметной области для выполнения
4.6. Примеры методов и систем приобретения знаний
151
морфологического анализа, выделения имен и словосочетаний и т. д. Однако тре-
бование Предварительного создания словаря предметной области одновременно
сильно осложняет задачу и уменьшает степень универсальности получаемой сис-
темы.
Понимание текста на семантическом уровне предполагает выявление не только
лингвистических, но и логических отношений между языковыми объектами
[Апресян, 1974]. Среди подходов к пониманию текста на семантическом уровне
следует выделить модели типа «смысл — текст», в частности, модель семантик
предпочтения [Wilks, 1976], модель концептуальной зависимости [Хейес-Рот и
др., 1987]. В модели «смысл — текст» [Мельчук, 1974] предлагается семантичес-
кое представление на основе семантического графа и описания коммуникатив-
ной структуры текста.
В системе KRITON [Diderich, Ruchman, May, 1987] анализ текста используется
для выявления хорошо структурированных знаний из книг, документов, описа-
ний, инструкций. Основанный на контент-анализе метод протокольного анализа
используется для выявления процедурных знаний. Он осуществляется в пять
шагов.
1. Протокол делится на сегменты на основании пауз, которые делает эксперт в
процессе записи.
2. Семантический анализ сегментов, формирование высказываний для каждого
сегмента.
3. Из текста выделяются операторы и аргументы.
4. Делается попытка поиска по образцу в БЗ для обнаружения переменных в
высказываниях (переменная вставляется в высказывание, если соответствую-
щая ссылка в тексте не обнаружена).
5. Утверждения упорядочиваются в соответствии с их появлением в протоколе.
В системе ТАКТ (Tool for Acquisition of Knowledge from Text) [Kaplan, Berry-Rog-
ghe, 1991] предполагается предварительная подготовка (разметка посредством
введения явной скобочной структуры) предложений текста до начала работы тек-
стового анализатора. В результате анализа выделяются объекты, процессы и от-
ношения каузального характера.
4.6.5. Инструментарий прямого приобретения
знаний SIMER + MIR
Программная система SIMER + MIR, разработанная в ИПС РАН под руководством
Осипова Г. С. [Осипов, 1997], представляет собой совокупность программных
средств для формирования модели и базы знаний предметной области. Система
ориентирована преимущественно на области с неясной структурой объектов, с
неполно описанным множеством свойств объектов и богатым набором связей
различной «связывающей силы» между объектами.
152
Глава 4 • Технологии инженерии знаний
Одна из особенностей системы состоит в том, что ее использование на заключи-
тельном этапе не предполагает участия специалистов-разработчиков экспертных
систем. Это означает, что система SIMER + MIR представляет собой технологию
создания систем, основанных на знаниях о предметной области, причем техноло-
гию, ориентированную на экспертов.
Архитектура. Система SIMER + MIR включает модуль прямого приобретения
знаний SIMER, систему моделирования рассуждений типа аргументации MIR,
программу адаптации системы MIR к базе знаний, сформированной с помощью
SIMER + и программной среды поддержки базы знаний, над которой работают
все названные модули. Конструкции базы знаний создаются и просматриваются с
помощью языка инженера знаний FORTE, который включается в технологию в
специальных случаях (рис. 4.17).
Рис. 4.17. Создание конструкции базы знаний с помощью языка FORTE
Представление и база знаний. Одним из наиболее распространенных видов экс-
пертизы являются высказывания (сообщения) эксперта об объектах (событиях)
предметной области. Эти высказывания имеют вид:
< имя объекта > < имя отношения > < имя объекта >.
Для ряда областей — медицины, экологии, политики, социологии — можно выде-
лить формы сообщений, показанные в табл. 4.6:
Таблица 4.6. Формы сообщений
Номер формы Имя формы Номер формы Имя формы
Ф, а характерно для р Фе При а нередко присутствует р
Ф2 а наблюдается при р Ф9 а может наблюдаться при Р
Фз а отмечается при Р Ф,о а обычно сопровождается Р
Фд а есть проявление р Ф„ При а как правило р
ф5 а есть признак р Ф,г При «обычно р
Фб а сопровождает р Ф,з а иногда сопровождается р
ф7 а нередко сопровождается р Фн «часто сопровождается р
4.6. Примеры методов и систем приобретения знаний
153
Номер формы Имя формы Номер формы Имя формы
Ф,5 а исключает р Фго С а начинается р
Ф,6 а приводит к р Ф2( Р развивается при а
Ф,7 При а возникает р Ф22 Р может развиваться при а
Ф,8 а может привести к р Фгз Р может начаться с а
Ф,9 а может развиваться в р
Этот список не является исчерпывающим, однако дает представление о тех ког-
нитивных структурах, которые необходимо представлять и обрабатывать в базе
знаний.
Каждая из этих форм может иметь различный смысл; уточнение смысла можно
получить при рассмотрении «прямого» сообщения с «обращенным». Иными сло-
вами, если для некоторых фиксированных а или 0 справедливо сообщение фор-
мы Ф10, то необходимо попытаться установить, какое из сообщений Ф; — Ф23
справедливо при замене а на 0, 0 на а. Так, для сообщения «Гром наблюдается при
грозе» справедливо «обращенное» сообщение «Гроза сопровождается гро-
мом», а для сообщения «Воспалительный процесс может наблюдаться при повы-
шенной температуре» справедливо сообщение «Повышенная температура ха-
рактерна для воспалительного процесса». Таким образом, смысл сообщений
уточняется построением «конъюнкций» форм Ф; — Ф23 Такие «конъюнкции»
форм сообщений будут называться типами сообщений. Возможные типы сообще-
ний приведены в табл. 4.7.
С каждым типом сообщения из табл. 4.7 связывается формальная конструкция
базы знаний, то есть бинарное отношение на множестве объектов (событий). Эти
конструкции можно проиллюстрировать следующим образом: если каждый
объект (событие) представить в виде «двухмерного» множества, по первому из-
мерению которого можно откладывать атрибуты этого объекта, а по второму —
множества значений соответствующих атрибутов, то каждый объект представ-
ляется в виде фигуры:
АТР 1 АТР 2 АТРЗ АТРп
Теблица 4.7. Типы сообщений
Тип Сообщение
т, Т2 Т3 т4 Т5 L а есть проявление р, и р может сопровождать а а есть проявление р, и р сопровождается а а может увеличивать возможность р, и р увеличивает возможность а а может сопровождаться Р, и р может быть проявлением а а сопровождается р, и р может быть проявлением а а есть проявление р, и р есть проявление а
продолжение&
154
Глава 4 • Технологии инженерии знаний.
Таблица 4.7. {продолжение)
Тип Сообщение
Т7 а может увеличивать возможность Р, и Р может увеличивать возможность а
Т8 а может протекать с Р, и Р может протекать с а
Т9 а увеличивает возможность Р, и р увеличивать возможность а
Т,о а сопровождается Р, и р может сопровождает а
Т,, а сопровождается р, и р сопровождаться а
Т,2 а исключает Р,. и Р исключает а
Т,3 а приводит к р
Т,4 а может привести к р
Т,5 а увеличивает возможность развития р
Т,о а может увеличить возможность развития р
Т, 7 а исключает возможность развития р
Если считать множества всех атрибутов равновеликими, то можно рисовать пря-
моугольники.
Тогда типу сообщения Tt можно поставить в соответствие диаграмму (пересече-
ние аир всюду далее заштриховано).
В качестве примера приведем интерпретации некоторых диаграмм. Так, диаграм-
му, соответствующую сообщению типа Т3, можно интерпретировать следующим
образом: для всякого примера объекта Р качестве примера приведем интерпрета-
ции некоторых диаграмм. Так, диаграмму, соответствующую сообщению типа Т3,
можно интерпретировать следующим образом: для всякого примера объекта Р
найдутся такие примеры объекта а, в которых равны совпадающие имена и значе-
ния атрибутов.
Для остальных типов сообщений получим диаграммы, представленные в табл. 4.8.
Таблица 4.8. Диаграммы для различных типов сообщений
4.6. Примеры методов и систем приобретения знаний
155
Для сообщения типа Т8: для всякого имени атрибута примера объекта а найдется
совпадающее с ним имя атрибута из примера объекта (3, и наоборот; при этрм со-
ответствующие значения атрибутов равны. Найдутся такие примеры объекта а, в
которых равны совпадающие имена и значения атрибутов.
Каждой из изображенных диаграмм можно дать такую теоретйко-множествен-
ную интерпретацию, связав с каждым из типов сообщений Т; некоторое бинарное
отношение Rk примеров объектов (при k = i).
Способ представления с определенными так отношениями называется неодно-
родной семантической сетью.
В реализации базы знаний основными элементами структур данных являются
элементы «вершина», «элемент кортежа», «атрибут», «цепь», «стрелка». Элемент
«вершина» соответствует объекту (событию), он содержит имя, списки входных
и выходных «стрелок» и список типа «элемент кортежа». Список «элементов кор-
тежа» соответствует совокупности атрибутов события.
Для обеспечения простого способа определения указателя «вершины» существу-
ют элементы типа «цепь». Элемент типа «цепь» содержит указатель на «верши-
ну» и указатель на следующий элемент типа «цепь». Указатель на первый элемент
списка «цепь» входит в описание элемента типа «атрибут». «Атрибут» характе-
ризуется также именем, множеством значений и единицей измерения.
Отношения на множестве объектов реализованы в элементах типа «стрелка».
Каждый такой элемент содержит имя, сорт, вес, тип веса, указатель на «вершину»
и указатель на следующий элемент типа «стрелка». Отношения на двух объектах
описываются парой элементов типа «стрелка», один из которых входит в список
156
Глава 4 • Технологии инженерии знаний
входящих стрелок одного объекта, другой — в список входящих стрелок другого
объекта.
Процедурная компонента системы содержит функции создания структур дан-
ных, поддержки корректности базы знаний, наследования свойств и ряд других
функций. Для обеспечения поиска по именам элементов типа «вершина» и «ат-
рибут» в системе реализовано В-дерево. Доступ ко всем элементам базы осуще-
ствляется через виртуальную память. Каждый элемент имеет внутренний иден-
тификатор, по значению которого однозначно определяется его размещение в
оперативной или внешней памяти. Для работы с объектами, отсутствующими в
оперативной памяти, осуществляется их динамический перенос из внешней па-
мяти в оперативную. Это позволяет системе работать на компьютере с ограничен-
ным объемом оперативной памяти. .
Прямое приобретение знаний в системе SIMER
Для выявления структурных знаний о предметной области используются страте-
гии разбиения на ступени и репертуарных решеток. Подробнее о репертуарных
решетках см. параграф 5.2.
Стратегия разбиения на ступени направлена на выявление структурных и клас-
сификационных свойств событий (понятий, объектов), области и таксонометри-
ческой структуры событий предметной области.
Стратегия разбиения на ступени реализуется в одном из двух сценариев, который
выбирается экспертом
1. «Имя — свойство».
2. «Множество имен — свойство».
Сценарий «Имя — свойство»
1. Вопрос системы об имени события.
2. Сообщение эксперта об имени события.
3. Вопрос системы об имени свойства.
4. Сообщение эксперта об имени свойства.
5. Вопрос системы о существовании множества значений свойства.
6. Ответ эксперта (Да/Нет).
7. В случае отрицательного ответа имя свойства воспринимается как имя
события.
8. Если имя события, образованного на шаге 3, отсутствует в базе знаний,
то это событие рассматривается как новое, и для него выполняются шаги
2-7.
9. Вопрос системы о типе множества значений свойства (непрерывноб/дис-
кретное).
10. Ответ эксперта.
4.6, Примеры методов и систем приобретения знаний 157
»
11. Вопрос системы о единице измерения свойства.
12. Сообщение эксперта о единице измерения.
13. Вопрос системы о множестве значений свойства.
14. Сообщения эксперта о множестве значений свойства.
15. В процессе выполнения шагов 2—6 создается глобальный объект «имя
свойства» и область его значений. Совокупность таких объектов будем
называть базисом свойств области.
16. Вопрос системы о подмножестве значений свойства, характерного для
описываемого события.
17. Сообщение эксперта о подмножестве значений свойства.
В результате выполнения шага 7 один из элементов базиса свойств связывается с
описываемым событием (с указанием подмножества области значений элемента
базиса, характеризующего описываемое событие).
Сценарий «Множество имен — свойство»
При работе сценария шаг 1 многократно повторяется, а затем выполняются
шаги 2—7 для каждого имени события.
Стратегия репертуарных решеток направлена на преодоление когнитивной за-
щиты эксперта. Механизм преодоления основан на выявлении его личностных
конструктов. Каждый конструкт описывается некоторой совокупностью шкал, а
каждая шкала образуется оппозицией свойств.
Наиболее эффективный способ выявления противоположных свойств — предъяв-
ление эксперту триад семантически связанных событий с предложением назвать
свойство, отличающей одно событие от двух других [Kelly, 1955]. На следующем
шаге эксперту предлагается назвать противоположное свойство. Таким способом
выявляются элементы множества личностных психологических конструктов кон-
кретного эксперта.
С другой стороны, свойства, различающие события, — это те свойства, которые
влияют на формирование решения. Так как при этом не ставится задача выявле-
ния когнитивной организации индивидуального сознания эксперта, то описан-
ная процедура используется для формирования базиса свойств области, а не для
построения личностных конструктов. Пополнение базиса свойств области осу-
ществляется путем повторения этой процедуры с другими триадами.
Пример 4.9
Например, эксперту в области представления знаний предъявляется триада понятий,
описывающих способы представления: семантические сети, фреймы, системы продук-
ций. Эксперту предлагается ответить на следующие вопросы:
Какой из указанных способов представления отличается от двух других?
158
Глава 4 • Технологии инженерии знаний
системы продукций;
Какое свойство отличает системы продукций от семантических сетей и фреймов?
легкость описания динамики;
Назовите противоположное свойство свойству «легкость описания динамики»-?
трудность описания динамики;
Дайте имя свойству, имеющему значения «легкость описания динамики» и «трудность
описания динамики»?
возможность описания динамики.
В результате формируется шкала с именем «возможность описания динамики» и со
значением «легкость описания динамики» для объекта «системы продукций»; «труд-
ность описания динамики» для объектов «семантические сети» и «фреймы».
Предлагая эксперту аналогичные вопросы об отличии семантических сетей от систем
продукций и фреймов, можно выявить и другие свойства базиса областй.
Еще один пример — выявление каузальных знаний о предметной области. К кау-
зальным знаниям о предметной области в соответствии с работой [Поспелов,
1986] относятся:
• связи между следствиями и необходимыми и достаточными причинами;
• связи между следствиями и достаточными причинами;
• связи между следствиями и необходимыми co-причинами; связи между след-
ствиями и возможными со-причинами.
Будем понимать каузальные знания несколько шире, включив в рассмотрение,
кроме связей событий настоящего с будущим и событий прошлого с настоящим,
и связи между событиями настоящего. В соответствии с этим отнесем к каузаль-
ным знаниям все типы сообщений из табл. 4.6.
Тогда задача выявления каузальных знаний сведется к установлению соответ-
ствия между множеством типов сообщений и множеством отношений Rt—R17, то
есть к поиску отображения Т в R. Для поиска этого отображения используется
стратегия выявления сходства [Осипов, 1989]. Она основана на выявлении в ин-
терактивном режиме алгебраических свойств сообщений Tj (таких как симмет-
ричность — ассимметричность, рефлексивность — иррефлексивность и других)
и появлении на основании этого гипотез о принадлежности сообщений тем или
иным отношениям Rk (именно эти свойства оказываются нужными при работе
механизма рассуждений).
Пример 4.10
Например, относительно двух событий: «рост заработной платы» и «повышение уров-
ня жизни» эксперт сообщил, что «рост заработной платы» обычно сопровождается
«повышением уровня жизни». Тогда возникают вопросы:
а) повышение уровня жизни всегда сопровождается ростом заработной платы?
б) повышение уровня жизни обычно сопровождается ростом заработной платы?
в) повышение уровня жизни может сопровождаться ростом заработной платы?
4,6. Примеры методов и систем приобретения знаний
159
Ответ эксперта а) будет свидетельствовать о том, что исходное сообщёнйе относится к
типу Т2табл. 4.6; ответ в) — исходное сообщение относится к типу Т10той же таблицы.
Далее появляются гипотезы о том, что сообщение эксперта интерпретируется отноше-
нием R2 или R10 в зависимости от ответа а) или в). Повышение степени достоверности
такой гипотезы возможно при использовании стратегии подтверждения сходства
[Осипов, 1989].
Стратегия подтверждения сходства является комбинированной, основанной на
взаимодействии стратегий разбиения на ступени и выявления сходства, а также
на анализе свойств событий (если они определены).
Например, в результате работы стратегии выявления сходства установлена при-
надлежность предыдущего примера отношению R2. На основании определения
отношения R2 для всякого свойства первого события найдется единственное
свойство второго события, и наоборот, так что область значения свойства перво-
го события является подобластью области значений соответствующего свойства
второго события. В случае выполнения этого условия гипотеза о принадлежнос-
ти предыдущего примера отношению R2 считается достоверным утверждением,
в противном случае запускается стратегия разбиения на ступени с целью выявле-
ния новых свойств событий, для которых было бы верно это условие. Если, не-
смотря на это, условие достоверности не выполняется, то статус гипотезы сохра-
няется, однако в базе знаний системы появляется информация о некорректности
соответствующей связи между событиями. Эта информация ограничивает воз-
можность использования построенной связи, например, с точки зрения механиз-
ма наследования свойств. При работе стратегий выявления и подтверждения
сходства сценарий работы называется системой.
Моделирование рассуждений в системе MIR
Введем следующие обозначения:
• О — опрос признаков из множества S;
• П — порождение множества гипотез Г;
• И — исключение множества гипотез Г.
Элементы данных типа «стрелка», соответствующие отношению R]2, будем назы-
вать отрицательными связями, остальные — положительными.
Работа системы MIR начинается с работы модуля О, затем модуль П строит мно-
жество гипотез Г на основе анализа положительных связей S с Г для подтвержден-
ных признаков S. Множество гипотез Г используется модулем О для порождения
нового множества признаков Sp связанных с гипотезами из Г положительными
связями, и осуществления их тестирования. К подтвержденным признакам из S,
применяется модуль П для порождения нового множества гипотез Гр Выполня-
ются операции Г: = Г и Гр S: = S и Sv Этот процесс продолжается итеративно до
стабилизации множества S и Г. Затем выполняется модуль И исключения гипотез
из Г на основе анализа отрицательных связей для подтверждения симптомов и
анализа положительных связей для обусловленных признаков, то есть таких не-
160
Глава 4 • Технологии инженерии знаний
подтвержденных признаков, отсутствие которых имеет большее значение для
принятия решения, чем их присутствие.
Если в результате выполнения модуля И во множестве гипотез осталось более
одной гипотезы, то выполняется поиск дифференциальных признаков для под-
множеств множества гипотез (дифференциальным признаком для некоторого
множества гипотез называется значение свойства, характерное для одной гипо-
тезы из множества и нехарактерное для других, или событие, связанное положи-
тельной связью с одной гипотезой из множества и не связанное таковой с други-
ми). В результате этого процесса происходит исключение соответствующих
гипотез. При необходимости процедура повторяется для оставшегося множества
гипотез до его стабилизации.
После выполнения еще нескольких модулей осуществляется анализ полученного
множества гипотез с целью поиска его минимального подмножества, связанного
положительными связями со всеми подтвержденными признаками и тем самым
объясняющего их. Это последнее множество и считается окончательным резуль-
татом.
5
Новые тенденции
и прикладные
аспекты инженерии
знаний
□ Латентные структуры знаний и психосемантика
□ Метод репертуарных решеток
□ Управление знаниями
□ Визуальное проектирование баз знаний как инструмент познания
□ Проектирование гипермедиа БД и адаптивных обучающих систем
5.1. Латентные структуры знаний
и психосемантика
Большинство систем приобретения знаний (обзор в п. 4.5) облегчают сложный и
трудоемкий процесс формирования баз знаний и реализуют прямой диалог с эк-
спертом. Однако выявляемые таким образом структуры знаний часто отражают
лишь поверхностную составляющую знаний эксперта, не затрагивая их глубин-
ной структуры. Этим же недостатком обладает большинство методов непосред-
ственного извлечения знаний (параграфы 4.1.-4.3).
Для извлечения глубинных пластов экспертного знания можно воспользоваться
методами психосемантики — науки, возникшей на стыке когнитивной психоло-
гии, психолингвистики, психологии восприятия и исследований индивидуаль-
ного сознания. Психосемантика исследует структуры сознания через моделиро-
вание индивидуальной системы знаний [Петренко, 1988] и выявление тех
категориальных структур сознания, которые могут не осознаваться (латентные,
имплицитные или скрытые) [Петренко, 1983; Терехина, 1988; Шмелев, 1983].
162 Глава 5 » Новые тенденции и прикладные аспекты инженерии знаний
5.1.1. Семантические пространства
и психологическое шкалирование
Основным методом экспериментальной психосемантики является метод рекон-
струкции субъективных семантических пространств. Здесь психосемантика тес-
но сплетается с психолингвистикой и лингвистической семантикой — с методо-
логией выявления значений слов, лексикографией, «падежной грамматикой» и
структурными исследованиями [Апресян, 1977; Мельчук, 1974; Соссюр, 1977;
Филлмор, 1983; Щерба, 1974]. Однако лингвистические методы в основном на-
правлены на анализ текстов, отчужденных от субъекта, от его мотивов и замыс-
лов.
Психолингвистические методы обращаются непосредственно к испытуемому.
Большинство из них связано с различными формами субъективного шкалирова-
ния. Перед испытуемым ставится задача оценить «сходство знаний» с помощью
некоторой градуированной шкалы, например от 0 до 5 или от 0 до 9. В этом случае
исследователь получает в руки численно представленные стандартизированные
данные^ легко поддающиеся статистической обработке.
Психосемантика — как одно из молодых направлений современной психологии
[Петренко, 1988; Шмелев, 1983] — сразу была оценена специалистами в области
искусственного интеллекта как перспективный инструмент, позволяющий ре-
конструировать семантическое пространство памяти как психологическую мо-
дель глубинной структуры знаний эксперта. Уже первые приложения психосе-
мантики в ИИ в середине 80-х годов позволили получить достаточно наглядные
результаты. В психологии семантические пространства выступают как модель
категориальной структуры индивидуального сознания. При концептуальном
анализе знаний структуру семантического пространства эксперта можно считать
основой для формирования поля знаний. При этом отдельные параметры семан-
тического пространства соответствуют различным компонентам поля (размер-
ность пространства соотносится со сложностью поля, выделенные понятийные
структуры с метапонятиями, содержательные связи между понятиями-стиму-
лами — это суть отношения и т. д.).
Легче всего познакомиться с экспериментальной психосемантикой на примере,
связанном с выявлением структуры и размерности семантического пространства
знаний из некоторой предметной области [Петренко, 1988].
В основе построения семантических пространств, как правило, лежит статисти-
ческая процедура (например, факторный анализ [Аверкин, Батыршин, Блишун
и др., 1986], многомерное шкалирование [Тиори, Фрай, 1985] или кластерный
анализ [Дюран, Оделл, 1977]), позволяющая группировать ряд отдельных при-
знаков описания в более емкие категории-факторы. Говоря на языке поля знаний,
это — построение концептов более высокого уровня абстракции. При геометри-
ческой интерпретации семантического пространства значение отдельного при-
знака отображается как точка или вектор с заданными координатами внутри
n-мерного пространства, координатами которого выступают выделенные факто-
5.1. Латентные структуры знаний и психосемантика
163
ры. Построение семантического пространства, таким образом, включает переход
к описанию предметной области на более высоком уровне абстракции, то есть пе-
реход от языка, содержащего большой алфавит признаков описания, к более ем-
кому языку концептуализации, содержащему меньшее число концептов и вы-
ступающему своеобразным метаязыком по отношению к первому.
В зависимости от опыта и профессиональной компетентности испытуемых раз-
мерность пространства и расположение в ней первичных понятий может суще-
ственно варьироваться. Эта особенность семантических пространств может быть
использована на стадии контроля в процессах обучения, при тестировании экс-
периментов и пользователей.
Пример 5.1
Так, для проверки знаний и понимания английского языка в работе [Терехина, 1988]
были взяты десять наиболее распространенных предлогов, достаточно трудно перево-
димых. На экране дисплея испытуемому предъявлялась пара предлогов и спрашива-
лось, часто ли у него вызывает затруднения выбор одного из этих предлогов. Степень
затруднения оценивалась в баллах от 1 до 9. На этих данных методами многомерного
шкалирования была построена структура сложности употребления английских пред-
логов с точки зрения носителя русского языка. Эта модель существенно зависит
от уровня знаний. Так, модель новичка не представляет организованной структуры.
У людей, имеющих определенные навыки, проявилась некоторая структурирован-
ность семантического пространства, в нем отчетливо обозначились пары и тройки
сходных предлогов.
Рис. 5.1. Семантическое пространство близости английских предлогов
Наиболее четкая и связная структура приведена на рис. 5.1. По ней можно объяснить
особенности дифференциации предлогов в английском языке. Основа структуры пред-
ставляется в виде окружности, близкие точки на которой соответствуют трудно диф-
ференцируемым предлогам. Структура опирается на две ортогональные оси. Ось абс-
цисс соответствует предлогам направления движения, а ось ординат — предлогам цели —
средства.
164 Глава 5 » Новые тенденции и прикладные аспекты инженерии знаний
На основании получаемых методами психосемантики моделей^ можно проводить
контроль знаний. При анализе индивидуальных семантических пространств вы-
являются вопросы, которые не усвоены и не уложились в систему. Контроль
структуры знаний проводится на основе сопоставления семантических про-
странств хороших специалистов и новичков (студентов, слушателей, молодых
специалистов). Степень согласованности семантических пространств (их размер-
ности, признаки и конфигурации понятий) будет определять уровень знаний но-
вичка.
Однако здесь необходимо учесть, что семантические пространства двух квалифи-
цированных специалистов могут быть разными, так как содержат индивидуаль-
ные различия восприятия, отражающие опыт и характер деятельности человека.
Поэтому не всегда можно формально сравнить семантические пространства экс-
перта и новичка, следует предварительно изучить семантические Пространства
нескольких специалистов, а затем уж производить сравнение.
В работе [Кук, Макдональд, 1986] описан подобный эксперимент. Были получе-
ны когнитивные структуры знаний опытного летчика-истребителя и пилота-но-
вичка, с использованием двух методов: многомерного шкалирования (алгоритм
MDS — Alscal) и сетевого шкалирования со взвешенными связями (алгоритм
Pathfinder). Оба алгоритма основаны на использовании оценок психологичес-
кой близости. Опытный пилот и пилот-новичок оценивали все возможные пар-
ное сочетания 30 связанных с полетом понятий, приписывая числа от 0 до 9 каж-
дой паре, где 0 обозначал самую слабую степень связи между понятиями, а 9 —
самую сильную. Эти оценки затем обрабатывались с применением обоих алго-
ритмов шкалирования.
В соответствии с алгоритмами MDS каждый концепт, выражающий некоторое
понятие, помещается в к-мерное пространство таким образом, что расстояние
между точками отражает психологическую близость соответствующих кон-
цептов. Алгоритм Pathfinder строит семантическую сеть [Schvaneveldt, Durso,
Dearholt, 1985]. Дуги могут быть либо ориентированными (несимметричное
отношение), либо неориентированными (симметричное отношение). Оба мето-
да обеспечивают сжатия больших объемов данных (в форме попарных оценок)
к меньшему набору параметров; однако нацелены они на выявление разных
свойств исследуемых структур. Если в алгоритме Pathfinder центром внимания
являются локальные отношения между концептами, то алгоритм MDS обеспечи-
вает более широкое понимание свойств метризуемого пространства концептов.
Результирующие когнитивные структуры оказались близкими для летчиков-ис-
требителей с одинаковым уровнем опыта, но были различными для разных групп
испытуемых. Авторы экспериментов обнаружили, что по когнитивной структуре,
характерной для летчика-истребителя, можно установить, новичок он или опыт-
ный пилот. Наконец, проведенный ими же анализ когнитивных структур выявил
наличие концептов и отношений, общих для представлений опытного специали-
ста и новичка, и, кроме того, ряд концептов и отношений, которые появились
5.1. Латентные структуры знаний и психосемантика 165
только в одном из представлений. Прямым развитием рассмотренной работы ста-
ла экспертная система управления воздушным боем ACES [Goldsmith, Schvane-
Veldt, 1985].
Аналогичное исследование механизмов накопления опыта было проведено в об-
ласти программирования на ЭВМ [Cooke, 1985]. С помощью методов шкалиро-
вания было показано, что один из аспектов программистского опыта включает в
себя организацию знаний соответственно замыслу программы, или семантике, а
не в соответствии с синтаксисом.
Пример 5.2
Сетевое представление абстрактных понятий программирования на основе оценок
связности концептов у программистов показано на рис. 5.2. Эксперимент показал, что
всех программистов на основе анализа структуры семантического пространства можно
разбить на три группы: новички, неопытные специалисты среднего уровня, опытные
специалисты. Это заключение совпадает с результатами, полученными в работе [Гав-
рилова, 1984]. Кроме того, исследовалась эволюция когнитивной структуры програм-
миста по мере его продвижения от иовичка до опытного специалиста.
Рис. 5.2. Ассоциативная сеть структуры знаний эксперта-программиста
Интерпретация выявленных отношений (связей) между понятиями требует дополни-
тельных усилий от коллектива разработчиков ЭС. Так, например, означивание дуг на
рис. 5.2. потребовало дополнительного эксперимента, участникам которого была пред-
ложена пара понятий и поставлена задача дать словесное описание связи между поня-
тиями пары. Результаты представлены в табл. 5.1. Таким образом, ассоциативная сеть
на рис. 5.2 может быть превращена в семантическую.
166
Глава 5 « Новые тенденции и прикладные аспекты инженерии знаний
Таблица 5.1. Описание связи между понятиями
Связанные пвры понятий Отношение между связанной парой понятий
Подпрограмма — программа Симаольные данные — выход Параметр — программа Программа — выход Сортировка — поиск Численные данные — параметр Функция — оператор Функция — программа Отладка — программа Выход — численные данные Массив — символьные данные Функция — подпрограмма / Присваивание значений — параметр Массиа — глобальная перемена Массив — численные данные Повторение — сортировка Программа — алгоритм Сортировка—алгоритм Сортировка — численные данные Присваивание — оператор Естьчасть Естьтип Используется Производит Включает в себя Может быть Есть Естьчасть Подвергается Состоит из Может состоять из Есть Используется для Может быть Может состоять из Естьчасть Есть выполнение Есть Делается на Есть
Все упомянутые выше методы (включая кластерный анализ) можно отнести к
методам психологического шкалирования. Их основу составляют алгоритмы
преобразования сложных структур данных в более понятную форму, которая
предполагается психологически содержательной. Результирующее представле-
ние зависит от метода:
• кластерный анализ порождает древовидную структуру [Дюран, Оделл, 1977];
• многомерное шкалирование и факторный анализ — пространственную [Окунь,
1974; Терехина, 1986];
• алгоритм MDS — сетевую [Кук, Макдональд, 1986];
• репертуарные решетки (см. параграф 5.2 и работу [Франселла, Баннистер,
1987]) порождают конструкты или метаизмерения [Kintsch, 1974].
Формальная методология психосемантического шкалирования позволяет час-
тично автоматизировать процесс структурирования знаний и получать «когни-
тивный разрез» его представлений о предметной области. Методология шкалиро-
вания позволяет выявлять структуры знания косвенным путем при получении
ответов от экспертов на довольно простые вопросы (например, «насколько близ-
ки понятия X! и Х2» вместо «скажите, какова связь между X, и Х2 как они влияют
друг на друга»).
5.1. Латентные структуры знаний и психосемантика
167
Почти все эксперименты позволили выявить одну закономерность. Размерность
семантического пространства с повышением уровня профессионализма умень-
шается. Этот вывод согласуется с известными положениями когнитивной психо-
логии о том, что процесс познания сопровождается обобщением.
Построение семантического пространства обычно включает три последователь-
ных шага [Петренко, 1983].
1. Выбор и применение соответствующего метода оценки семантического сход-
ства. Этот шаг включает в себя эксперимент с испытуемыми, которым предла-
гается оценить общность предъявляемых стимульных признаков на некото-
рой шкале.
2. Построение структуры семантического пространства на основе математичес-
кого анализа полученной матрицы сходства. При этом происходит уменьше-
ние числа исследуемых понятий за счет обобщения и получения генерализо-
ванных осей.
3. Идентификацию, интерпретацию выделенных факторных структур, кластеров
или групп объектов, осей и т. д. На этом шаге необходимо найти смысловые
эквиваленты, языковые «ярлыки» для выделенных структур. Здесь большое
значение приобретает лингвистическое чутье и профессионализм специалис-
та, проводящего исследование, и экспертов-испытуемых. Часто к интерпрета-
ции привлекают группу экспертов.
5.1.2. Методы многомерного шкалирования
В дальнейшем развитие методов психосемантики шло по линии разработки
удобных пакетов прикладных программ, основанных на методах многомерного
шкалирования (МШ), факторного анализа, а также специализированных мето-
дов (статистической) обработки репертуарных решеток [Франселла, Баннистер,
1987]. Примерами пакетов такого типа являются системы KELLY [Похилько,
Страхов, 1990], MADONNA [Терехина, 1988], MEDIS [Алексеева, Воинов и др.,
1989]. С другой стороны, специфика ряда конкретных приложений, прежде все-
го — в инженерии знаний, требовала также развития иных (не численных) мето-
дов обработки психосемантических данных, использующих — в той или иной
форме — парадигму логического вывода на знаниях. Ярким примером этого на-
правления служит система AQUINAS [Boose et al., 1989; Boose, 1990]. Однако
анализ практического применения систем обоих типов к задачам инженерии
знаний приводит к выводу о несовершенстве имеющихся методик и необходимо-
сти их развития в соответствии с современными требованиями инженерии зна-
ний. Наибольшие перспективы в этой области, по-видимому, у методов много-
мерного шкалирования).
Многомерное шкалирование (МШ) сегодня — это математический инструмен-
тарий, предназначенный для обработки данных о попарных сходствах, связях
или отношениях между анализируемыми объектами с целью представления этих
объектов в виде точек некоторого координатного пространства. МШ представ-
ляет собой один из разделов прикладной статистики, научной дисциплины, раз-
168
Глава 5 » Новые тенденции и прикладные аспекты инженерии знаний
рабатывающей и систематизирующей понятия, приемы, математические методы
и модели, предназначенные для сбора, стандартной записи, систематизации и
обработки статистических данных с целью их лаконичного представления, ин-
терпретации и получения научных и практических выводов.
Традиционно МШ используется для решения трех типов задач:
1 . Поиск и интерпретация латентных (то есть скрытых, непосредственно не на-
блюдаемых) переменных, объясняющих заданную структуру попарных рассто-
яний (связей, близостей).
2. Верификация геометрической конфигурации системы анализируемых объек-
тов в координатном пространстве латентных переменных.
3. Сжатие исходного массива данных с минимальными потерями в их информа-
тивности.
Независимо от задачи МШ всегда используется как инструмент наглядного
представления (визуализации) исходных данных. МШ широко применяется в
исследованиях по антропологии, педагогике, психологии, экономике, социологии
[Дэйвисон, 1988].
В основе данного подхода лежит интерактивная процедура субъективного шка-
лирования, когда испытуемому (то есть эксперту) предлагается оценить сходство
между различными элементами П с помощью некоторой градуированной шкалы
(например, от 0 до 9, или от -2 до +2). После такой процедуры аналитик распола-
гает численно представленными стандартизованными данными, поддающимися
обработке существующими пакетами прикладных программ, реализующими раз-
личные алгоритмы формирования концептов более высокого уровня абстракции
и строящими геометрическую интерпретацию семантического пространства в ев-
клидовой системе координат.
Основной тип данных в МШ — меры близости между двумя объектами (i, j) —
dij. Если мера близости такова, что самые большие значения dij соответствуют
парам наиболее похожих объектов, то dij — мера сходства, если, наоборот, наиме-
нее похожим, то dij — мера различия.
МШ использует дистанционную модель различия, используя понятие расстоя-
ния в геометрии как аналогию сходства и различия понятий (рис. 5.3).
Для того чтобы функция d, определенная на парах объектов (а, Ь), была евклидо-
вым расстоянием, она должна удовлетворять следующим Четырем аксиомам:
d(a,b) > О,
d(a,a) = О,
d(a,b) = d(b,a),
d(a,b)+d(b,c) > d(a,c).
Тогда, согласно обычной формуле евклидова расстояния, мера различия двух
объектов i и j со значениями признака к у объектов i и j соответственно
X. их.:
ik jk
5J. Латентные структуры знаний и психосемантика
169
Рис. 5.3. Расстояние в евклидовой метрике
Дистанционная модель была многократно проверена в социологии и психологии
[Monahan, Lockhead, 1977; Петренко, 1988; Шмелев, 1983], что дает возможность
оценить ее пригодность для использования.
В большинстве работ по МШ используется матричная алгебра. Геометрическая
интерпретация позволяет представить абстрактные понятия матричной алгебры
в конкретной графической форме. Для облегчения интерпретации решения за-
дачи МШ к первоначально оцененной матрице координат стимулов X применя-
ется вращение.
Среди множества алгоритмов МШ широко используются различные модифика-
ции метрических методов Торгерсона [Torgerson, 1958], а также неметрические
модели, например Крускала [Kruskal, 1964].
При сравнении методов МШ с другими методами анализа, теоретически приме-
нимыми в инженерии знаний (иерархический кластерный анализ [Дюран, Оделл,
1977] или факторный анализ [Иберла, 1980]), МШ выигрывает за счет возможно-
сти дать наглядное количественное координатное представление, зачастую более
простое и поэтому легче интерпретируемое экспертами.
5.1.3. Использование метафор для выявления
«скрытых» структур знаний
Несмотря на кажущуюся близость задач, инженерия знаний и психосемантика
существенно отличаются как в теоретических основаниях, на которых они бази-
руются, так и в практических методиках. Но главное отличие заключается в том,
что инженерия знаний направлена на выявление — в конечном итоге — модели
рассуждений [Поспелов, 1989], динамической или операциональной составляю-
щей ментального пространства (или функциональной структуры поля знаний
Sf), в то время как психосемантика, пытаясь представить ментальное простран-
ство в виде евклидова пространства, позволяет делать видимой статическую
структуру взаимного «расположения» объектов в памяти, в виде проекций скоп-
лений объектов (концептуальная структура Sk).
170 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
Помимо этого следует отметить ряд недостатков методов психосемантики с точ-
ки зрения практической инженерии знаний.
1. Поскольку в основе психосемантического эксперимента лежит процедура из-
мерения субъективных расстояний между предъявляемыми стимулами, то и
результаты обработки такого эксперимента, как правило, используют геомет-
рическую интерпретацию — евклидово пространство небольшого числа изме-
рений (чаще всего — двумерное). Такое сильное упрощение модели памяти
может привести к неадекватным базам знаний.
2. Естественность иерархии как глобальной модели понятийных структур созна-
ния служит методологической базой ОСП. Кроме того, и в естественном языке
понятия явно тяготеют к различным уровням обобщения. Однако в большин-
стве прикладных пакетов не предусмотрено разбиение семантического про-
странства на уровни, отражающие различные степени общности понятий, вклю-
ченных в экспериментальный план. В результате получаемые кластеры
понятий, пространственно изолированные в геометрической модели шкали-
рования, носят таксономически неоднородный характер и трудно поддаются
интерпретации.
3. Единственные отношения, выявляемые процедурами психосемантики, — это
«далеко — близко» по некоторой шкале. Для проектирования и построения баз
знаний выявление отношений является на порядок более сложной задачей, чем
выявление понятий. Поэтому семантические пространства, полученные в ре-
зультате шкалирования и кластеризации, должны быть подвергнуты дальней-
шей обработке на предмет определения отношений, особенно функциональ-
ных и каузальных.
Нельзя ожидать, что эти противоречия могут быть разрешены быстро и безболез-
ненно, в силу того, что математический аппарат, положенный в основу всех паке-
тов прикладных программ по психосемантике, имеет определенные границы
применимости. Однако одним из возможных путей сближения без нарушения
чистоты процедуры видится расширение пространства конкретных объектов-
стимулов предметной области за счет добавления некоторых абстрактных объек-
тов из мира метафор, которые заставят эксперта-испытуемого выйти за рамки
объективности в мир субъективных представлений, которые зачастую в большей
степени влияют на его рассуждения и модель принятия решений, чем традицион-
ные правильные взгляды.
Ниже описан подход, разработанный совместно с Воиновым А. В. [Voinov, Gav-
rilova, 1993; Воинов, Гаврилова, 1994] и позволяющий вывести эксперта за гра-
ницы традиционной установки и тем самым выявить субъективные, часто скры-
ваемые или скрытые структуры его профессионального опыта.
Большинство результатов, полученных в когнитивной психологии, подтвержда-
ют, что у человека (в том числе и у эксперта) формальные знания о мире (в част-
ности, о той предметной области, где он является экспертом) и его личный пове-
денческий опыт не могут существовать изолированно, они образуют целостную,
стабильную структуру. В западной литературе за этой структурой закрепилось
5,1.. Латентные структуры знаний и психосемантика
171
название «модель (или картина) мира». Принципиальным свойством модели
мира является то, что ее структура не дана человеку — ее носителю — в интрос-
пекции, она работает на существенно латентном, неосознаваемом уровне, зачас-
тую вообще ничем не отмеченном (в символической форме) на поверхности вер-
бального сознания.
Изучение модели мира человека является задачей когнитивной психологии, пси-
хосемантики и прочих родственных дисциплин. Что же касается эксперта как
объекта пристального внимания инженерии знаний, то здесь одна из проблем,
в решении которых может помочь психосемантика, связана с необходимостью
(и неизбежностью) отделения опыта эксперта от его объективных знаний в про-
цессе формализации и структурирования последних для экспертных систем.
Строго говоря, невозможно указать ту грань, за которой знания (которые можно
формализовать и извлечь) переходят в опыт (то есть в то, что остается уникаль-
ной, неотчуждаемой собственностью эксперта). Более корректно, по-видимому,
говорить о неком континууме, детальность градации которого может зависеть от
конкретной задачи.
Например, можно выделить следующие три уровня:
1. Знания, предназначенные для изложения или доказательства (аргументации),
например, на междисциплинарном уровне или для популярной лекции (вер-
бальные).
2. Знания, которые применяются в реальной практике, — знания еще вербализу-
емые, но уже нерефлектируемые.
3. Собственно опыт, то есть знания, лежащие на наиболее глубоком, неосознава-
емом уровне, отвечающие за те решения эксперта, которые внешне (в том чис-
ле и для него самого) выглядят как мгновенное озарение или «инсайт», интуи-
тивный творческий акт (интуитивные).
Классическая методика психосемантического эксперимента также не позволяет
выделить из его результатов интуитивный уровень. Это видно из самой тестовой
процедуры. Просят ли испытуемого оценить сходство-различие стимулов напря-
мую или же предлагается оценить их соответствие некоторым «конструктам» — в
любом случае испытуемый вольно или невольно настраивается на необходимость
доказательности своего ответа в терминах объективных свойств стимулов.
Большинство методов извлечения знаний ориентировано на верхние — вербаль-
ные или вербализируемые — уровни знания. Необходим косвенный метод, ори-
ентированный на выявление скрытых предпочтений практического опыта или
операциональных составляющих опыта. Таким методом может служить метафо-
рический подход. Метафорический подход, впервые описанный с чисто лингвис-
тических позиций [Black, 1962; Ricoeur, 1975], а также с позиций практической
психологии [Гордон, 1987], был видоизменен для нужд инженерии знаний. На-
пример, в экспериментах по объективному сравнению языков программирова-
ния между собой были также использованы два метафорических «мира» — мир
животных и мир транспорта.
172 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
В рамках этого подхода удалось экспериментально доказать следующие тезисы:
• метафора работает как фильтр, выделяющий, посредством подбора адекват-
ного объекта сравнения, определенные свойства основного объекта (то есть
того, о котором собственно и идет речь). Эти выделяемые свойства имеют су-
щественно операциональный характер, проявляющийся на уровне полимор-
физма методов, так как метафора по самой своей сути исключает возмож-
ность сравнения объектов по их внутренним, объективным свойствам;
• метафора имеет целью скорее не сообщить что-либо о данном объекте (то есть
ответить на вопрос «что это?»), а призвать к определенному отношению к
нему, указать на некую парадигму, говорящую о том, как следует вести себя по
отношению к данному объекту;
• субъективному сдвигу в отношении к основному объекту (например, к Языку
программирования) сопутствует также и сдвиг в восприятии объекта сравне-
ния (например, к конкретному животному) в силу вышеуказанной специфики
фильтруемых метафорой свойств. Поэтому объект сравнения выступает в ме-
тафоре не по своему прямому назначению, то есть это не просто «лев» как
представитель фауны, а воплощение силы, ловкости и могущества;
• в том случае, когда метафора сопоставляет не единичные объекты, а некоторые
их множества, в которых объекты связаны осмысленными отношениями, про-
странство объектов сравнения должно быть изоморфно пространству основ-
ных объектов по системе указанных отношений.
На эти тезисы опирается предлагаемая модификация классической методики со-
поставления объектов, применяемой, например, в оценочной решетке Келли
[Kelly, 1955]. При проведении эксперимента была использована система MEDIS
[Алексеева, Воинов и др., 1989; Воинов, Гаврилова, 1994]. Эта система позволяет
планировать, проводить и обрабатывать данные произвольного психосеманти-
ческого эксперимента. Помимо классической парадигмы многомерного шкалиро-
вания, система MEDIS включает в себя некоторые возможности теста репертуар-
ных решеток. В частности, она позволяет работать со стимулами двух сортов —
так называемыми элементами и конструктами (с единственным исключением:
конструкты в системе MEDIS — в отличие от классического теста репертуарных
решеток — монополярны). Естественно, выбор базового инструментария суще-
ственно повлиял на описываемую экспериментальную реализацию методики.
В качестве предметной области был выбран мир языков программирования. В про-
странство базовых понятий (выступавших в методике в качестве элементов) бы-
ло включено несколько более или менее популярных языков программирова-
ния, принадлежащих к следующим классам:
• языки искусственного интеллекта;
• традиционные процедурные языки
• так называемые «макроязыки», обычно реализуемые в оболочках операцион-
ных систем, текстовых редакторах и т. д.
В качестве метафорических пространств выбраны мир животных и мир транс-
порта. Объекты этих миров выступали в методике в качестве (монополярных)
конструктов. На первом этапе эксперимента каждый из респондентов выпол-
5.1. Латентные структуры знаний и психосемантика
173
нял классическое попарное субъективное шкалирование элементов. На воп-
рос, «Есть ли что-либо общее между данными языками программирования», рес-
понденту предлагалось ответить одной из следующих альтернатив.
ДА! 1 Объекты очень близки
Да ' 2 Между объектами есть что-то общее
??? 3 Неопределенный ответ
Нет 4 Объекты различны
НЕТ! 5 Объекты совершенно несовместимы
Данные этого этапа (отдельно для каждого из респондентов) подвергались об-
работке методами многомерного шкалирования (см. выше) и представлены на
рис. 5.4.
Результатом такой обработки является некоторое евклидово пространство не-
большого числа измерений, в котором исходные оценки различий представлены
геометрическими расстояниями между точками. Чем лучше эти расстояния соот-
ветствуют исходным различиям, тем более адекватным считается результат обра-
ботки в целом. При этом буквальное совпадение расстояний и числовых кодов
ответов, естественно, не является обязательным (хотя оно и возможно в некото-
рых модельных экспериментах). Более важным оказывается ранговое соответ-
ствие расстояний исходным оценкам. А именно, в идеальном случае все расстоя-
ния между точками, соответствующие (например) ответам «ДА!» в исходных
данных, должны быть меньше (хотя бы и на доли процента масштаба шкалы) всех
расстояний, соответствующих ответам «Да», и т. д.
В реальном эксперименте идеальное соответствие невозможно в принципе, так
как целью обработки является сжатие, сокращение размерности данных, что ог-
раничивает число координатных осей результирующего пространства. Тем не
менее алгоритм шкалирования пытается — насколько это возможно — миними-
зировать ранговое несоответствие модели исходным данным.
Геометрическую модель шкалирования можно интерпретировать по-разному:
• во-первых, можно выяснить смысл координатных осей результирующего про-
странства. Эти оси по сути своей аналогичны факторам в факторном анализе,
что позволяет использовать соответствующую парадигму интерпретации, де-
тально разработанную в экспериментальной психологии. В данном случае
можно считать, что выявленные факторы играют роль базовых категорий, или
базовых (латентных) конструктов, с помощью которых респондент (как пра-
вило, неосознанно) упорядочивает свою картину мира (точнее, ее проекцию на
данную предметную область);
• во-вторых, можно проанализировать компактные группировки стимулов в
этом пространстве, отождествив Их с некоторыми существенными (хотя й
скрытыми от интроспекции) таксономическими единицами, реально при-
сутствующими в модели мира эксперта. Существенно, что делается попытка
интерпретировать кластеры, полученные по модели шкалирования, а не по
исходным числовым кодам различий. Это вытекает из предположения, что
174 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
информация, не воспроизводимая главными (наиболее нагруженными) фак-
торами, является «шумом», сопутствующим любому (а особенно психологи-
ческому) эксперименту.
Рисунок 5.4 отражает традиционную классификацию языков программирова-
ния и легко поддается вербальной интерпретации. Например, на рисунке грри-
зонтальная ось соответствует делению языков программирования на «языки ис-
кусственного интеллекта» (левый полюс шкалы) и «традиционные языки
программирования» (правый полюс). Вертикальная ось отражает классифика-
цию языков программирования в зависимости от уровня — языки высокого
уровня (нижний полюс) и языки низкого уровня или системные языки (верхний
полюс).
Y
- •z • C++ Assembler • Pascal • C • Fortran
• Prolog • Smalltalk • LISP • Dbaselll+ • Clipper • Basic • Multi-Edit Macro • DOS Batch
Рис. 5.4. Классификация языков программирования
Основная экспериментальная процедура — попарное сравнение некоторых объек-
тов и выражение степени их сходства (несходства) на числовой оси или выделе-
ние пар близких объектов из предъявленной триады — сама по себе накладывает
большое количество ограничений на выявляемую структуру, в частности:
1. Из-за выбора стимульного материала (выбор объектов остается за инженером
по знаниям).
2. Из-за несовершенства шкалы измерений.
3. В связи с рядом допущений математического аппарата. Но главное, что полу-
ченная структура знаний чаще всего носит академический характер, то есть
отражает объективно существующие, но легко объяснимые, как бы лежащие
на поверхности закономерности.
Это связано с психологической установкой самого эксперимента, во время кото-
рого эксперта как бы проверяют, экзаменуют й он, естественно, стремится давать
правильные ответы.
На следующем этапе эксперимента респонденту предлагалось сопоставить каж-
дый из языков программирования с каждым из метафорических персонажей. Как
и на первом этапе, пары предъявлялись в равномерно-случайном порядке (анало-
5.1/Латентные структуры знаний и психосемантика
175
гичном расписанию кругового турнира в спортивных играх). Инструкция для со-
поставления выглядела следующим образом:
Попробуйте оценить выразительную силу данной метафоры: «ЛИСП — это слон»
или «C++ — это яхта». f
Результирующая таблица числовых кодов оценок (идентичная оценочной решет-
ке Келли) была также обработана методами многомерного шкалирования про-
граммы МЕДИС. Результаты представлены на рис. 5.5 и 5.6.
Y
• Multi-Edit Место • Assembler
□ Кот • Prolog ° Лиса
LISP • Pascal
• DOS Batch * * □ Павлин
□ Осел Петух Ф3аяц аТигр
> Basic • Smalltalk________рВолк
□ Лев Х
4 Fortran
• DbaselII+ (, С
□ Обезьяна □ Слон
□ Конь е C++
• Clipper
Рис. 5.5. Метафорическая классификация языков программирования (мир животных)
Basic
□ Телега
з Велосипед
□ Поезд
• Pascal
□Автомобиль
□ Пароход
• DOS Batch
Smalltalk
• C++
□ Яхта
• С
» Dbaselll+
• Fortran
• Prolog
• Clipper е LISP □Самолет
• Multi-Edit Macro
□ Метро _
□Автобус аСлон
□ Грузовик
• Clipper
X
Рис. 5.6. Метафорическая классификация языков программирования (мир транспорта)
При интерпретации удалось выявить такие латентные понятия и структуры, как
«степень изощренности языка» (шкала X рис. 5.5), «сила» (шкала Y рис. 5.5),
«универсальность» (шкала Y рис. 5.6), «скорость» (шкала X рис. 5.6) и др.
Кроме этого, полученные рисунки позволили выявить скрытые предпочтения эк-
сперта и существенные характеристики объектов, выступавших в виде стиму-
лов — «силу» языка С («слон»); скорость C++ («яхта»); «старомодность» Форт-
рана («телега») и пр.
176 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
В применении к реальному процессу извлечения знаний это обстоятельство ста-
новится принципиальным, так как позволяет на самом деле отделить те знания,
благодаря которым эксперт является таковым (уровень В), от общезначимых, ба-
нальных (для экспертов в данной предметной области) знаний (уровень А), кото-
рые возможно и не стоят того, чтобы ради них создавать собственно экспертную
систему.
Однако можно ожидать, что во многих (если не в большинстве) случаях выявлен-
ные латентные структуры могут полностью перевернуть представления инжене-
ра по знаниям о предметной области и позволить ему существенно углубить базу
знаний. Введение мира метафор — это некая игра, а игра раскрепощает сознание
эксперта и, как все игровые методики извлечения знаний (п. 4.2), является хоро-
шим катализатором трудоемких серий интервью с экспертом, без которых сегод-
ня невозможна разработка промышленных интеллектуальных систем.
5.2. Метод репертуарных решеток
5.2.1. Основные понятия
Среди методов когнитивной психологии — науки, изучающей то, как человек по-
знает и воспринимает мир, других людей и самого себя, как формируется целост-
ная система представлений и отношений конкретного человека, особое место за-
нимает такой метод личностной психодиагностики, как метод репертуарных ре-
шеток («repertory grid» ).
Впервые метод был сформулирован автором теории личностных конструктов
Джорджем Келли в 1955 г. Чем шире набор личностных конструктов у субъекта,
тем более многомерным, дифференцированным является образ мира, человека,
других явлений и предметов^ то есть тем выше его когнитивная сложность [Гав-
рилова, 1988].
Репертуарная решетка представляет собой матрицу, которая заполняется либо
самим испытуемым, либо экспериментатором в процессе обследования или бесе-
ды. Столбцу матрицы соответствует определенная группа объектов, или, иначе,
элементов. В качестве объектов могут выступать люди, предметы, понятия, отно-
шения, звуки, цвета — все, что интересует психодиагноста. Строки матрицы
представляют собой конструкты -г биполярные признаки, параметры, шкалы,
альтернативные противоположные отношения или способы поведения.
Конструкты либо задаются исследователем, либо выявляются у испытуемого с
помощью специальных приемов и процедур выявления. Вводя понятие конст-
рукта, Келли объединяет две функции: функцию обобщения (установления
сходства) и функцию противопоставления. Он предлагает несколько определе-
ний понятия «конструкт». Одно из них:
Конструкт — зтонекоторый признак или свойство, по которому два или несколько объек-
тов сходны между собой и, следовательно, отличны от третьего объекта или нескольких
других объектов.
5,2. Метод репертуарных решеток
177
Например,, выделение из трех предметов «диван, кресло, стул» двух «диван и
кресло» выявляет конструкт «мягкость мебели». Келли в своих работах подчер-
кивает биполярность конструктов. Он считает, что, утверждая что-нибудь, мы
всегда одновременно что-то отрицаем. Именно биполярность конструктов делает
возможным построение репертуарной решетки. Например, север — юг — это ре-
ферентная ось: элементы, которые в одном контексте являются «севером», в дру-
гом становятся «югом».
Возможности конструкта ограничены. Они могут быть применены только к неко-
торым объектам. Это нашло свое отражение в понятии «диапазона пригодности»
конструкта. Английские психологи Франселла и Баннистер [Франселла, Бан-
нистер, 1987] считают правило «диапазона пригодности» отличительной чертой
техники репертуарных решеток. Под диапазоном пригодности можно понимать
область представлений человека о мире, понятия которой можно соотнести с
конкретной референтной осью выделяемого конструкта. Психологически осмыс-
ленный результат получится только в том случае, если элементы, используемые в
репертуарной решетке; будут попадать в «диапазон пригодности» конструктов
испытуемого.
Конструкты — не изолированные образования. Они взаимодействуют друг с дру-
гом, причем характер этого взаимодействия не случаен, а носит целостный сис-
темный характер.
В процессе заполнения репертуарной решетки испытуемый должен оценить каж-
дый объект по каждому конструкту или каким-то другим образом поставить в
соответствие элементы конструктам.
Определение репертуарная означает, что элементы выбираются по определен-
ным правилам так, чтобы они соответствовали какой-либо одной области и все
вместе были связаны осмысленным образом (контекстом) аналогично репертуа-
ру ролей в пьесе. Предполагается, что, изменяя репертуар элементов, можно «на-
страивать» Методики на выявление конструктов разных уровней общности и от-
носящихся к разным системам.
При переводе с английского языка термин матрица не используется, поскольку
репертуарная решетка не всегда является матрицей в строгом смысле этого тер-
мина: в ней на пересечении строк и столбцов не обязательно стоят числа, не все-
гда выдерживается прямоугольный формат, строки могут быть разной длины.
Второй смысл этого определения заключается в том, что в технике репертуарных
решеток часто элементы задаются в виде обобщенных инструкций, репертуара
ролей, на место которых каждый конкретный человек мысленно подставляет сво-
их знакомых людей или конкретные предметы, если в качестве элементов заданы
названия предметов.
По всей видимости, репертуарные решетки лучше считать специфической разно-
видностью структурированного интервью. Обычно мы исследуем систему конст-
руктов другого человека в ходе разговора с ним. В процессе беседы мы постепенно
начинаем понимать, как он видит мир, что с чем связано, что из чего следует, что
для чего важно, а что нет, как он оценивает других людей, события и ситуации.
178
Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
Решетка формализует этот процесс и дает математическоеобоснованиесвязей
между конструктами данного человека, позволяет более детально изучить от-
дельные подсистемы конструктов, подметить индивидуальное, специфическое в
структуре и содержании мировоззрения человека.
Важное положение техники репертуарных решеток: ориентация на выявление
собственных конструктов испытуемого, а не навязывание их ему извне.
Гибкость и эффективность репертуарных решеток, качество и количество полу-
чаемой информации делают их пригодными для решения широкого круга задач.
Методики этого типа используются в различных областях практической деятель-
ности: в педагогике и социологии, в медицине, рекламе и дизайне. Репертуарные
решетки оказались методом, идеально приспособленным для реализации в виде
диалоговых программ на компьютере, что также способствовало их широкому
распространению. Достоинства и преимущества данного метода полностью рас-
крываются тогда, когда есть возможность, проведя исследование, быстро обрабо-
тать результаты и проанализировать их с тем, чтобы уже при следующей встрече
с испытуемым можно было уточнить и проверить возникшие предположения, со-
ставить и провести репертуарную решетку другого типа, а если это необходимо, и
дополнить прежнюю, изменив репертуар элементов или выборку конструктов.
5.2.2. Методы выявления конструктов
Метод минимального контекста
Метод минимального контекста или метод триад наиболее часто используется
для выявления конструктов. Элементы представляются в группах по три. Это
минимальное число, которое позволяет определить сходство и различие.
Испытуемому предъявляются три элемента из всего списка и предлагается на-
звать какое-нибудь важное качество, по которому два из них сходны между собой
и, следовательно, отличны от третьего. После того как экспериментатор запишет
ответ, испытуемого просят назвать, в чем конкретно состоит отличие третьего
элемента от двух других (если испытуемый не указал, какие именно два элемента
были оценены как сходные между собой, то его просят сделать это). Ответ на этот
вопрос и представляет собой противоположный полюс конструкта. Испытуемо-7
му предъявляется столько триад элементов, сколько сочтет нужным эксперимен-
татор. Специфических правил не существует. Все зависит лишь от величины вы-
борки, то есть от числа конструктов, подлежащих исследованию.
Пример 5.3
Имеется список из названий фруктов. Берется триада «яблоко-груша-апельсин». Рес-
пондент выделяет два сходных объекта — «яблоко и груша»; качество, определяющее
сходство, — «отсутствие аллергической реакции у респондента», отличие третьего
объекта — «аллергичность». Так выявлен личностный конструкт «аллергичность/от-
сутствие таковой».
5.2. Метод репертуарных решеток
179
Другие методы выявления конструктов
Франселла и Баннистер {Франселла, Баннистер, 1987] описывают методы, кото-
рые также? используют триады:
• последовательный метод;
• метод самоидентификации;
• метод ролевой персонификации.
В двух последних методах в триаду включается элемент «я сам».
Келли предложил использовать триады для выявления конструктов, посколь-
ку этот метод отражал его теоретические представления о том, как конструкты
впервые возникают. Однако в связи с тем, что у испытуемого выявляются уже
сложившиеся конструкты, не обязательно использовать непременно три элемен-
та. Триада не является единственным способом выявления противоположного
полюса.
Для выявления конструктов можно использовать два элемента (выявление кон-
структов при помощи диад элементов) или более, чем три, как это делается в ме-
тоде полного контекста [Франселла, Баннистер, 1987].
Часто используемый метод — техника лестничного спуска Хинкла:
• конструкты извлекаются стандартным методом;
• по поводу отдельного конструкта задается вопрос «К какому полюсу данного
конструкта вы бы хотели быть отнесены?»;
• затем: «Почему вы предпочитаете этот полюс?», «Что противостоит этому?».
Таким образом, получается новый конструкт, более обобщенный, чем исходный.
Процесс повторяется, и выделяется иерархия конструктов.
5.2.3. Анализ репертуарных решеток
Анализ репертуарных решеток позволяет определить силу и направленность
связей между конструктами респондента, выявить наиболее важные и значимые
параметры (глубинные конструкты), лежащие в основе конкретных оценок и от-
ношений, построить целостную подсистему конструктов, позволяющую описы-
вать и предсказывать оценки и отношения человека.
Анализ единичной репертуарной решетки
Можно использовать форму кластерного анализа для группировки конструктов.
Этот алгоритм структурирует конструкты в линейный порядок, так что конст-
рукты, находящиеся близко в пространстве, также оказываются близки в порядке.
Этот алгоритм имеет преимущество при демонстрации, так как представление
просто реорганизует решетку, доказывая соседства конструктов и элементов.
Таким образом, формируются две матрицы — одна для элементов, другая для
конструктов. Кластеры определяются выбором наибольших значений в этих мат-
180 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
рицах — то есть наиболее связанных составляющих матрицу, — до т^х пор пока
все элементы и конструкты не оказываются включенными в кластерное дерево.
Программа производит иерархическую кластеризацию системы конструктов экс-
перта и представляет извлеченные знания.
Кроме того, для каждого конструкта имеются численные значения в решетке как
вектор величин, связанных с расположением элементов относительно полюсов
данного конструкта. С этой точки зрения каждый конструкт может быть пред-
ставлен как точка в многомерном пространстве, а его плоскость определяется
числом связанных с ним элементов. Естественной мерой отношений между кон-
структами является, следовательно, расстояние между ними в этом многомерном
пространстве. Два конструкта с нулевым расстоянием между ними — это конст-
рукты, по отношению к которым элементы структурируются совершенно одина-
ково. Следовательно, можно считать, что они используются одинаково. В каком-
то смысле это эквивалентные конструкты.
Для неэквивалентных конструктов можно анализировать их пространственные
отношения, определяя ряд осей как проекцию каждого конструкта на ось, наи-
более удаленную от них, проекцию на вторую ось, связанную с оставшимися
расстояниями, и т. д. Это метод анализа главных компонент пространства
конструктов. Он связан с факторным анализом семантического пространства,
использованного в изучении семантического дифференциала. Метод анализа
главных компонент позволяет представить элементы и конструкты так, что меж-
ду ними могут быть выявлены взаимосвязи. Возможно построить логический
анализ репертуарной решетки, используя конструкты как предикаты относи-
тельно элементов.
Анализ нескольких репертуарных решеток
'Довольно часто возникает ситуация, когда требуется сравнить несколько репер-
туарных решеток. Анализ серии репертуарных решеток, заполняемых одним и
тем же человеком в разные моменты времени, позволяет следить за динамикой
конструктов и оценок, строить траектории изменения состояния человека в сис-
теме его собственных субъективных шкал.
Проанализируем несколько репертуарных решеток, заполняемых разными людьми.
Анализ пар системных конструктов используется для измерения согласия и по-
нимания между людьми. Для этого два эксперта, имеющие разные точки зрения,
создают и заполняют решетки по общей области знаний. При этом каждый неза-
висимо от другого выбирает элементы, выявляет конструкты и оценивает их. За-
тем каждый делает две пустые копии своей решетки, оставляя элементы и конст-
рукты без значений их оценки. Обе эти решетки заполняются партнерами. При
этом одна заполняется так, как он сам себе это представляет, а вторая так, как он
представляет себе заполнение оригинальной решетки ее автором. Сравнение пар
решетбк помогает достигнуть соглашения и понимания между двумя людьми.
Существуют три способа сравнения двух решеток.
1. Сцепление решеток, имеющих общие элементы, и их последующая обработка
одним из описанных алгоритмов, как если бы они составляли одну большую
5.2. Метод репертуарных решеток 181
решетку. Таким образом, можно исследовать взаимодействие идей через про-
верку смешанных кластеров конструктов из разных решеток.
2. Данный путь требует наличия двух решеток с одинаковыми именами элемен-
тов и конструктов и показывает расхождения между ними через измерение рас-
стояния между одними и теми же именами. Результаты показывают согласие
в понимании и выявляют различия между двумя решетками, основанными на
одинаковых именах и конструктах.
3. Данный способ также использует две решетки с одинаковыми именами эле-
ментов и конструктов, находит наиболее сильно изменяющиеся элементы и
конструкты и удаляет их из решетки. Таким образом, определяются базовые
элементы и конструкты, которые показывают согласие и понимание.
Анализ групп системных конструктов. Анализируется серия репертуарных реше-
ток, полученная от группы людей, использовавших одинаковые элементы. Срав-
нивается каждая пара и показывается «групповая сеть», которая отражает связи
сходных конструктов внутри группы. Создается решетка, отражающая конструк-
ты, которые понимаются большинством группы, и это служит основанием даль-
нейшего анализа. Каждый конструкт, неиспользованный в рамках группы, оцени-
вается по силе связанности с другими конструктами.
5.2.4. Автоматизированные методы
Данный параграф посвящен обзору некоторых наиболее известных методов и
систем приобретения знаний на основе метода репертуарных решеток, частично
из работ [Осипов, 1990; Молокова, 1992; Осипов,1997].
Впервые автоматизированное создание репертуарных решеток и извлечение из
экспертов конструктов было реализовано в системе PLANET [Gaines, Shaw, 1984;
Shaw, Woodward, 1988]. Дальнейшим развитием системы PLANET является ин-
тегрированная среда KITTEN, поддерживающая ряд методов извлечения знаний.
Буза Д. в системе ETS [Boose, 1985] использовал метод репертуарных решеток
для выявления понятийной системы предметной области. Потомками ETS явля-
ются система NeoETS и интегрированная среда для извлечения экспертных зна-
ний AQUINAS [Boose, Bradshaw, Shema, 1988].
Известно большое число прототипов ЭС, для создания которых использовалась
ETS. Среди них:
1. Советчик по выбору инструментария для разработчиков ЭС.
2. Консультант по языкам программирования.
3. Анализатор геологических данных.
4. Советчик по отладке Фортран-программ.
5. Консультант по СУБД и др.
Однако область применения ETS ограничена извлечением экспертных знаний
для таких несложных задач анализа, которые не требуют для своего решения про-
цедурных, каузальных и стратегических знаний.
182 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
ETS взаимодействует с экспертом в диалоговом режиме, интервьюируя его и по-
могая анализировать создаваемую БЗ. В архитектуре ETS могут быть выделены
подсистемы: извлечения элементов; выявления конструктов; построения репер-
туарной решетки; построения графа импликативных связей; генерации продук-
ционных правил; тестирования БЗ; коррекции БЗ; генерации БЗ для различных
инструментальных средств создания ЭС.
В диагностической системе MORE [Kahn, Nowlan, McDermott, 1985} использо-
ваны принципы, сходные с теми, которые лежат в основе обеих описацных выше
систем. Здесь впервые использовано несколько различных стратегий интервью.
Техника интервью, использованная в MORE, направлена на выявление следую-
щих сущностей:
• гипотезы — подтверждение которых имеет своим результатом диагноз;
• симптомы — наблюдение которых приближает последующее принятие гипо-
тезы;
• условия — некоторое множество событий, которое не является непосредствен- ,
но симптоматическим для какой-либо гипотезы, но которое может иметь диаг-
ностическое значение для некоторых других событий;
• связи — соединение сущностей;
• пути — выделенный тип связи, который соединяет гипотезы с симптомами.
В соответствии с этим в системе используются следующие стратегии интервью:
дифференциация гипотез, различение симптомов, симптомная обусловленность,
деление пути и некоторые другие.
Стратегия дифференциации гипотез направлена на поиск симптомов, которые
обеспечивают более точное различие гипотез. Наиболее мощными в этом смысле
являются те симптомы, которые наблюдаются при одном диагностируемом собы-
тии.
Стратегия различения симптомов выявляет специфические характеристики симп-
тома, которые, с одной стороны, идентифицируют его как следствие некоторой
гипотезы, с другой — противопоставляют другим.
Стратегия симптомной обусловленности направлена на выявление негативных
симптомов, то есть симптомов, отсутствие которых имеет больший диагностичес-
кий вес, чем их присутствие.
Стратегия деления пути обеспечивает нахождение симптоматических событий,
которые лежат на пути к уже найденному симптому. Если такой симптом суще-
ствует, то он имеет большее диагностическое значение, чем уже найденный.
В системе KRITON [Diderich, Ruhman, May, 1987] (см. п. 4.6.4) для приобретения
знаний используются два источника: эксперт с его знаниями, полученными на
практике; книжные знания, документы, описания, инструкции (эти знания хоро-
шо структурированы и фиксированы традиционными средствами). Для извлече-
ния знаний из первого источника в KRITON применена техника интервью, ис-
пользующая стратегии репертуарной решетки разбиения на ступени. Стратегия
разбиения на ступени направлена на выявление наследственной структуры пред-
5.3. Управление знаниями
183
метной области. Акцент делается на выявлении структуры родовых и видовых
понятий (супертипов). При этом типы, выявленные на очередном шаге работы
стратегии, становятся базисом для последующего ее применения.
В системе применен прием переключения стратегий: если при работе стратегии
репертуарной решетки при предъявлении тройки семантически связанных поня-
тий эксперт не в состоянии назвать признак, отличающий два из них от третьего,
система запускает стратегию разбиения на ступени и, задавая эксперту вопросы о
понятиях, связанных с предыдущими отношениями «род — вид», предпринимает
попытку выяснения таксономической структуры этих понятий с целью выявле-
ния признаков; их различающих.
В России существенные результаты в применении репертуарных решеток в ин-
женерии знаний бь!ли получены под руководством Г. С. Осипова в рамках про-
екта SIMER+MIR (см. п. 4.6.5).
5.3. Управление знаниями
5.3.1. Что такое «управление знаниями»
Следует иметь в виду, что знаниями в контексте данного параграфа называют не
только знания, но и данные по определениям в главе 1 данного учебника.
Понятие «управление знаниями* (КМ — Knowledge Management) появилось в се-
редине 90-х годов в крупных корпорациях, где проблемы обработки информа-
ции приобрели особую остроту и стали критическими. При этом стало очевид-
ным, что основным узким местом является обработка знаний, накопленных
специалистами компании, так как именно знания обеспечивают преимущество
перед конкурентами. Часто информации в компаниях накоплено даже больше,
чем они в состоянии обработать. Различные компании пытаются решать этот
вопрос по-разному, но при этом каждая компания стремится увеличить эффек-
тивность обработки знаний [Macintosh, 1997].
Ресурсы знаний различаются в зависимости от отраслей индустрии и приложе-
ний, но, как правило, включают руководства, письма, новости, информацию о
заказчиках, сведения о конкурентах и данные, накопившиеся в процессе разра-
ботки. Для применения КМ-систем используются разнообразные технологии:
• электронная почта;
• базы и хранилища данных (Data Wharehouse);
• системы групповой поддержки;
• броузеры и системы поиска;
• корпоративные сети и Интернет;
• экспертные системы и базы знаний; интеллектуальные системы.
Традиционно проектировщики систем КМ ориентировались лишь на отдельные
группы потребителей — главным образом менеджеров. Более современные КМ-
системы спроектированы уже в расчете на целую организацию.
184
Глава 5 * Новые тенденции и прикладные аспекты инженерии знаний
Хранилища данных, которые работают по принципу центрального склада, были
одним из первых инструментариев КМ. Как правило, хранилища содержат, мно-
голетние версии обычной БД, физически размещаемые в той же самой базе. Ког-
да все данные содержатся в едином хранилище, изучение связей между отдель-
ными элементами может быть более плодотворным.
При этом активы знаний могут находиться в различных местах: в базах данных,
базах знаний, в картотечных блоках, у специалистов и могут быть рассредоточе-
ны по всему предприятию. Слишком часто одна часть предприятия повторяет
работу другой части просто потому, что невозможно найти и использовать зна-
ния, находящиеся в других частях предприятия.
Управление знаниями — это совокупность процессов, которые управляют созданием,
распространением, обработкой и использованием знаний внутри предприятия.
Необходимость разработки систем КМ обусловлена следующими причинами:
• работники предприятия тратят слишком много времени на поиск необходи-
мой информации;
• опыт ведущих и наиболее квалифицированных сотрудников используется
только ими самими;
• ценная информация захоронена в огромном количестве документов и данных,
доступ к которым затруднен;
• дорогостоящие ошибки повторяются из-за недостаточной информированнос-
ти и игнорирования предыдущего опыта.
Важность систем КМ обусловлена также тем, что знание, которое не использует-
ся и не возрастает, в конечном счете становится устаревшим и бесполезным, так
же, как деньги, которые сохранены без того, чтобы стать оборотным капиталом, в
конечном счете теряют свою стоимость, пока не обесценятся. Напротив, знание,
которое распространяется, приобретается и обменивается, генерирует новое зна-
ние.
5.3.2. Управление знаниям и корпоративная
память
Большинство обзоров концепции управления знания (КМ) уделяет внимание
только первичной обработке корпоративной информации типа электронной по-
чты, программного обеспечения коллективной работы или гипертекстовых баз
данных (например [Wiig, 1996]). Они формируют существенную часть из необхо-
димой, но определенно не достаточной технической инфраструктуры для управ-
ления знаниями.
Одним из новых решений по управлению знаниями является понятие корпора-
тивной памяти (corporate memory), которая по аналогии с человеческой памятью
позволяет пользоваться предыдущим опытом и избегать повторения ошибок.
Корпоративная память фиксирует информацию из различных источников предприятия и
делает зту информацию доступной специалистам для решения производственных задач.
б.З. Управление знаниями
185
Корпоративная память не позволяет исчезнуть знаниям выбывающих специали-
стов (Уход на пенсию, увольнение и пр.). Она хранит большие объемы данных,
информации и знаний из различных источников предприятия. Они представ-
лены в различных формах, таких как базы данных, документы и базы знаний
(рис. 5.7).
Неявные данные и знания
Явные данные и знания
Рис. 5.7. Данные и знания в системах корпоративной памяти
Введем два уровня корпоративной памяти (так называемые явные и неявные зна-
ния [Nonaka, Takeuchi, 1995]).
Уровень 1. Уровень материальной или явной информации — это данные и знания,
которые могут быть найдены в документах организации в форме сообщений, пи-
сем, статей, справочников, патентов, чертежей, видео- и аудиозаписей, про-
граммного обеспечения и т. д.
Уровень 2. Уровень персональной или скрытой информации — это персональное
знание, неотрывно связанное с индивидуальным опытом. Оно может быть пере-
дано через прямой контакт — «с глазу на глаз», через процедуры извлечения зна-
ний (см. главу 3). Именно скрытое знание — то практическое знание, которое яв-
ляется ключевым при принятии решения и управлении технологическими про-
цессами.
В действительности эти два типа информации, подобные двум сторонам одной и
той же медали, одинаково важны в структуре корпоративной памяти (см. рис. 5.7).
При разработке систем КМ можно выделить следующие этапы:
1. Накопление. Стихийное и бессистемное накопление информации в организа-
ции.
186
Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
2. Извлечение. Процесс, идентичный традиционному извлечению знаний для ЭС
(см. главы 2 и 3). Это один из наиболее сложных и трудоемких этапов. От его
успешности зависит дальнейшая жизнеспособность системы.
3. Структурирование. На этом этапе должны быть выделены основные понятия,
выработана структура представления информации, обладающая максималь-
ной наглядностью, простотой изменения и дополнения.
4. Формализация. Представление структурированной информации в форматах
машинной обработки, то есть на языках описания данных и знаний.
5. Обслуживание. Под процессом обслуживания понимается корректировка фор-
мализованных данных и знаний (добавление, обновление): «чистка», то есть
удаление устаревшей информации; фильтрация данных и знаний для поиска
информации, необходимой пользователям.
Если первые четыре этапа обычны для инженерии знаний, то последний являет-
ся специфичным для систем управления знаниями.
Как уже было сказано, он распадается на три более мелких процесса:
• Корректировка формализованных знаний (добавление, обновление).
• Удаление устаревшей информации.
• Фильтрация знаний для поиска информации, необходимой пользователю, вы-
деляет компоненты данных и знаний, соответствующие требованиям конкрет-
ного пользователя. При помощи той же процедуры пользователь может узнать
местонахождение интересующей его информации.
Рассмотренная выше классификация не является единственной, но она позволя-
ет понять, что происходит в реальных системах управления знаниями.
5.3.3. Системы OMIS
Автоматизированные системы КМ, или Organizational Memory information Sys-
tems (OMIS), предназначены для накопления и управления знаниями предприя-
тия [Kuehn and Abecker, 1998]. OMIS включают работу как на уровне 1 — с явным
знанием компании в форме баз данных и электронных архивов, так и на уровне
2 — со скрытым знанием, фиксируя его в некотором (более или менее формаль-
ном) представлении в форме экспертных систем [Wiig, 1990] или БД.
OMIS часто используют вспомогательные справочные системы, так называемые
helpdesk-приложения.
Основные функции OMIS:
• Сбор и систематическая организация информации из различных источников в
централизованное и структурное информационное хранилище.
• Интеграция с существующими автоматизированными системами [Conklin,
1996]. На техническом уровне это означает, что корпоративная память должна
быть непосредственно связана с помощью интерфейса с инструментальными
5.3. Управление знаниями
187
средствами, которые в настоящее время используются в организации (напри-
мер, текстовые процессоры, электронные таблицы, системы).
• Обеспечение нужной информации по запросу (пассивная форма) и при необхо-
димости (активная форма). Слишком частые ошибки — это следствие недо-
статочной информированности. Этого невозможно избежать с помощью пас-
сивной информационной системы, так как служащие часто слишком заняты,
чтобы искать информацию, или просто не знают, что нужная информация
существует. Корпоративная память может напоминать служащим о полезной
информации и быть компетентным партнером для совместного решения за-
дач.
Конечная цель OMIS состоит в том, чтобы обеспечить доступ к знанию всякий
раз, когда это необходимо. Чтобы обеспечить это, OMIS реализует активный под-
ход распространения знаний, который не полагается на запросы пользователей, а
автоматически обеспечивает полезное для решения задачи знание. Чтобы предот-
вращать информационную перегрузку, этот подход должен быть совмещен с вы-
сокой выборочной оценкой уместности. Законченная система должна действо-
вать как интеллектуальный помощник пользователю.
Использование корпоративной памяти часто преследует более умеренные цели,
чем использование ЭС. Это связано с тем, что технологии обработки данных (баз
данных и гипертекстовых систем) применяются гораздо шире, чем технологии
систем, основанных на знаниях. OMIS сохраняют и обеспечивают выдачу по за-
просу нужной информации, но оставляют ее интерпретацию и оценку в специ-
фическом контексте задачи главным образом пользователю.
С другой стороны, корпоративная память расширяет эти технологии работой со
знаниями, чтобы улучшить качество решения задач. Так OMIS включает под-
системы объяснений, которые позволяют непосредственно отвечать на вопросы:
«Почему?» и «Почему нет?». В простой базе данных или гипертекстовой системе
пользователи должны были бы искать нужную информацию для ответа на такие
вопросы непосредственно, а для этого необходимо отфильтровать большое коли-
чество потенциально нужной информации, которая, однако, не будет применять-
ся в специфическом случае.
Наконец, OMIS не только выдает информацию, но должна также быть всегда го-
товой воспринимать новую информацию от ее пользователей.
Рисунок 5.8 представляет архитектуру для OMIS и корпоративной памяти (част-
ично из работы [Borghoff and Pareschi, 1998]). Ядром системы является Информа-
ционное хранилище (Information Depository). Рисунок также дает представление о
некоторых видах информации, которая включается в корпоративную память.
Если хранилища данных содержат в основном количественную информацию, то
хранилища знаний больше ориентированы на качественный материал. КМ-сис-
темы генерируют системы из широкого диапазона данных, хранилищ данных,
статей новостей, внешних баз, WWW-страниц.
188 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
Интерфейс пользователя
Информационное хранилище
Данные
Документы
Знания
Онтологический уровень
Структура БЗ,
понятийные
структуры
Фактографические
БД,
реляционные БД-
справочники
Документальные
БД, чертежи,
рефераты и т. д.
' БЗ с правилами,
фреймами,
семантическими
сетями, правила
k вывода
Содержательный уровень
Интерфейс разработчиков
Рис. 5.8. Архитектура OMIS
Программный инструментарий для OMIS включает как оригинальные разра-
ботки, например KARAT [Tschaitschian, 1997], так и стандартные средства, на-
пример, LOTUS NOTES обеспечила один из первых инструментариев хранения
качественно и документальной информацией. Однако сегодня в связи с бурным
развитием Интернета, КМ-сйстемы все чаще используют Web-технологию.
5.3.4. Особенности разработки OMIS
Так как разработка систем корпоративной памяти — это прежде всего программ-
ный проект, то для нее применимы традиционные технологии разработки боль-
ших программных систем. В каждом программном проекте первым шагом в раз-
работке является анализ требований, в котором должны быть найдены ответы на
следующие вопросы:
• Какие задачи должны поддерживаться?
• Какая информация необходима, чтобы решить эти задачи?
• Какой тип поддержки желателен пользователями?
• Каков уровень затрат на разработку?
• Какие изменения ожидаются в будущем?
5.3. Управление знаниями
189
При поиске ответов на эти вопросы следует учитывать:
1. Человеческий фактор. Основная причина неудач ранних опытных проектов
OMIS заключалась в том, что разработчики игнорировали реальные потреб-
ности, способности и цели пользователей системы [Malsch et al., 1993; Kuehn
et al., 1994].
2. Стоимостной анализ. Во-первых, ядро проекта должно ориентироваться на
критические процессы, «страдающие» от недостатка информационной поддерж-
ки. Во-вторых не следует перегружать начальную систему слишком большим
количеством услуг, которые могут быть желательны, но не обещают быстрое
возвращение инвестиций.
3. Эволюция знаний. Электронная поддержка особенно ценна в областях, под-
вергающихся быстрым изменениям, так как на таких предприятиях трудно
обеспечить доступ к оперативной современной информации. В системах OMIS
часто используют различные новые технологии обработки знаний, не имею-
щие пока общепринятых русскоязычных терминов и связанные с получением
нового знания из анализа данных, например «открытие или разведка знаний»
(Knowledge Discovery) и «разработка данных» (Data Mining). Разведка зна-
ний представляет собой новое и быстро развивающееся направление, занима-
ющееся «нетривиальным извлечением точной, ранее неизвестной и потенци-
ально полезной информации из данных» [Piatetsky-Shapiro, Frawley, 1991].
В методах разведки данных используются различные подходы к анализу тек-
ста и числовых данных, плюс специальный инструментарий статистического
анализа.
4. Чувствительность к контексту для естественно-языковых запросов.
5. Система должна «понимать» контекст поступающих запросов. К примеру, она
должна различать термины «размножение животных» и «размножение доку-
ментов».
6. Гибкость.
7. Система должна иметь возможность обрабатывать знания в различной форме
и по разным темам в контексте работы данного предприятия.
8. Интеллектуальность.
9. Система должна накапливать информацию о своих пользователях и о знани-
ях, которые она получает во время работы. Таким Образом, со временем ее воз-
можность «продуманно» предоставлять пользователям знания должна совер-
шенствоваться.
До последнего времени при разработке OMIS остается целый ряд исследователь-
ских вопросов [Kuehn and Abecker,1998],
• Проблема обобщения моделей данных, словарей понятий или тезаурусов, онто-
логий. Основание для объединенной эксплуатации данных, документов и фор-
мального знания — построение объединенных метамоделей данных и знаний.
Полезны были бы процедуры автоматического порождения тезауруса из суще-
ствующих массивов документов. Объединенная онтология/тезаурус может
использоваться, чтобы улучшить поиск, фильтрацию и маршрутизацию до-
кументов.
190 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
• Проблема объединения логического вывода и информационного поиска. Объеди-
ненная эксплуатация формальных и неформальных представлений знаний и
данных — это последовательное сближение логических методов и методов ин-
формационного поиска и индексации данных.
• Соединение деловых процессов и управления знаниями. Окончательная цель со-
стоит в том, чтобы обнаруживать информационную потребность в течение
выполнения производственного процесса и определять уместное знание в спе-
цифическом контексте задачи. Первый прагматический шаг в этом направле-
нии описан в работе [Hinkelmann и Kieninger, 1997], где авторы предлагают
использовать информацию контекста задачи для информационной фильтра-
ции.
Корпоративная память интегрирует знания, чтобы в решении новых задач опе-
реться на предварительно накопленный опыт. Таким образом, можно избегать
повторения ошибок, опыт может расширяться систематически, и. информацион-
но-емкие процессы работы могут быть выполнены более эффективными спосо-
бами. В отличие от экспертных систем первичная цель систем OMIS — не под-
держка одной специфической задачи, а лучшая эксплуатация необходимого об-
щего ресурса — знаний.
В настоящее время существует значительный интерес к КМ со стороны промыш-
ленных компаний, которые осознают высокий прикладной потенциал корпора-
тивной памяти для решения целого ряда практических задач обработки инфор-
мации. С другой стороны, не многие из проектов идут далее стадии прототипа,
что очевидно показывает, что компании стараются избегать затрат и риска вло-
жения капитала в новые технологии, которые еще не нашли широкого распрост-
ранения.
5.4. Визуальное проектирование баз знаний
как инструмент познания
Визуальные методы спецификации и проектирования баз знаний и разработка
концептуальных структур являются достаточно эффективным гносеологическим
инструментом или инструментом познания [Jonassen, 1993]. Использование ме-
тодов инженерии знаний в качестве дидактических инструментов и в качестве
формализмов представления знаний способствует более быстрому и более полно-
му пониманию структуры знаний данной предметной области, что особенно ценно
для новичков на стадии изучения особенностей профессиональной деятельности.
Методы визуальной инженерии знаний можно широко использовать в различ-
ных учебных заведениях — от школ до университетов — как для углубления Про-
цесса понимания, так и для контроля знаний. Большинство учеников и студен-
тов овладевают навыками визуального структурирования в течение нескольких
часов.
5.4. Визуальное проектирование баз знаний как инструмент познания
191
5.4.1. От понятийных карт к семантическим сетям
В параграфе 3.1 было предложено определение поля знаний, которое позволяет
инженеру по знаниям трактовать форму представления поля достаточно широ-
ко, в частности семантические сети или понятийные карты (concept maps) (см,
параграф 1.3) являются возможной формой представления. Это означает, что
сам процесс построения семантических сетей помогает осознавать познаватель-
ные структуры.
Рис. 5.9. Пример понятийной карты
Программы визуализации являются инструментом, позволяющим сделать види-
мыми семантические сети памяти человека. Сети состоят из узлов и упорядочен-
ных соотношений или связей, соединяющих эти узлы. Узлы выражают понятия
или предположения, а связи описывают взаимоотношения между этими узлами.
Поэтому разработка семантических сетей подразумевает анализ структурных
взаимодействий между отдельными понятиями предметной,области.
В процессе создания семантических сетей эксперт и аналитик вынуждены анали-
зировать структуры своих собственных знаний, что помогает им включать новые
знания в структуры уже имеющихся знаний. Результатом этого является более
осмысленное использование приобретенных знаний.
Визуальные спецификации в форме сетей могут использоваться новичками и эк-
спертами в качестве инструментов для оценки изменений, произошедших в их
мышлении. Если согласиться, что семантическая сеть является достаточно пол-
ным представлением памяти человека, то процесс обучения с этой точки зрения
можно рассматривать как реорганизацию семантической памяти.
192
Глава 5 « Новые тенденции и прикладные аспекты инженерии знаний
Kozma [Kozma, 1992], один из разработчиков программы организации семанти-
ческой сети Learning Tool, считает, что эти средства являются инструментами
познания, усиливающими и расширяющими познания человека. Разработка се-
мантических сетей требует от учеников:
• реорганизации знаний;
• исчерпывающего описания понятий и связей между ними;
• глубокой обработки знаний, что способствует лучшему запоминанию и извле-
чению из памяти знаний, а также повышает способности применять знания в
новых ситуациях;
• связывания новых понятий с существующими понятиями и представлениями,
что улучшает понимание;
• пространственного изучения посредством пространственного представления
понятий в изучаемой области [Fisher, Faletn, Paterson, Lipson, Thorton &
Spring, 1990].
Полезность семантических сетей и карт понятий, пожалуй, лучше всего демонст-
рируется их связями с другими формами мышления высшего порядка. Они тес-
но связаны с формальным обоснованием в химии [Schreiber & Abeg, 1991] и спо-
собностью аргументировать свои высказывания в биологии [Briscoe & LeMaster,
1991; Mikulecky, 1987].^Гакже было показано, что семантические сети имеют
связь с выполнением исследований [Goldsmith, Johnson & Acton, 1991].
5.4.2. База знаний как познавательный
инструмент
Когда семантическая сеть создается как прообраз базы знаний, разработчик дол-
жен фактически моделировать знания эксперта. Особенно глубокого понимания
требует разработка функциональной структуры.
Определение структуры ЕСЛИ-TO области знаний вынуждает чётко форму-
лировать принципы принятия решения. Нельзя считать, что просто разработка
поля знаний системы обязательно приведет к получению полных функциональ-
ных знаний в данной области.
Разработка экспертных систем стала использоваться как инструмент познания
сравнительно недавно. Lippert [Lippert, 1988], который является одним из пио-
неров применения экспертных систем в качестве инструментов познания, ут-
верждает, что задания по созданию небольших базисов правил являются очень
полезными для решения педагогических проблем и структурирования знаний
для учеников от шестого класса до взрослых. Изучение при этом становится
более осмысленным, так как ученики оценивают не только сам процесс мышле-
ния, но также и результаты этого процесса, то есть полученную базу знаний. Со-
здание базы знаний требует от учеников умения отделять друг от друга факты,
переменные и правила, относящиеся к связям между составляющими области
знаний.
5.4. Визуальное проектирование баз знаний как инструмент познания
193
Например, Lai [Lai, 1989] установил, что после того, как студенты-медики созда-
дут медицинскую экспертную систему, они повышают свое умение в плане аргу-
ментации и получают более глубокие знания по изучаемому предмету. Шесть
студентов-первокурсников физического факультета, которые использовали экс-
пертные системы для составления вопросов, принятия решений, формулировки
правил и объяснений относительно движения частицы в соответствии с законами
классической физики, получили более глубокие знания в данной области благо-
даря тщательной работе, связанной с кодированием информации и обработкой
большого материала для получения ясного и связного содержания, а следователь-
но, и большей семантической глубины [Lippert & Finley, 1988].
Таким образом, создание базы знаний экспертной системы способствует более
глубокому усвоению знаний, а визуальная спецификация усиливает прозрач-
ность и наглядность представлений.
Когда компьютеры используются в обучении как инструмент познания, а не как
контрольно-обучающие системы (обучающие компьютеры), они расширяют воз-
можности автоматизированных обучающих систем (АОС), одновременно раз-
вивая мыслительные способности и знания учеников. Результатом такого со-
трудничества учащегося и компьютера является значительное повышение эф-
фективности обучения. Компьютеры не могут и не должны управлять Процессом
обучения. Скорее, компьютеры должны использоваться для того, чтобы помочь
ученикам приобрести знания.
В данном параграфе будет описываться автоматизированное рабочее место (АРМ)
инженера по знаниям KEW (Knowledge Engineering Workbench) [Гаврилова,
1995; Гаврилова, Воинов, 1995-1997], который наряду с такими программами,
как SemNet [Fisher 1990, 1992], Learning Tool [Kozma, 1987], TextVision
[Kommers, 1989] или Inspiration, дает возможность ученикам, экспертам или
аналитикам связать между собой изучаемые ими понятия в многомерные сети
представлений и описать природу связей между всеми входящими в сеть поня-
тиями.
Последняя версия KEW, созданная совместно с Воиновым А. В., получила пер-
вую премию на выставке программных систем IV Национальной конференции
по искусственному интеллекту в 1994 г. в разделе программных инструментари-
ев разработки интеллектуальных систем. KEW демонстрирует жизнеспособ-
ность технологии автоматизированного проектирования интеллектуальных сис-
тем (АПРИС) или CAKE (Computer Aided Knowledge Engineering), впервые
описанной в работе [Гаврилова, 1992].
KEW предназначен для интеллектуальной поддержки деятельности инженера по
знаниям на протяжении всего жизненного цикла разработки экспертной системы,
включая стадии — идентификации проблемы, получения знаний, структурирова-
ния знаний, формализации, программной реализации, тестирования.
Центральным блоком KEW является графический структуризатор знаний KNOST
(KNOwledge STucturer). Система KNOST поддерживает последовательную
графическую реализацию ОСА (см. параграф 3.4) и автоматическую компиля-
цию БЗ из графической спецификации.
194
Глава 5 . Новые тенденции и прикладные аспекты инженерии знаний
[Материоя]
— Панель
концептуальной
структуры
— Панель
гипертекста
[Морское
[Нарушения] [—Существенное
т х I—Несущественное
[Входные факторы |
[Внешние факторь^
стеврация
онсервация
(колебания температур]
Сейсмическая активность] ---------
—Высокая ^-Небольшие
Пл |н - Капитальный ремонт
АО
«а в 2DD4 году.
-Камень
-Керамике
-Дерево
-Низкая
—Нет
[Решение)
Камень
Керами»
[Механические 1 [рас,)тельНые|
-Трещины '1 —
-Раскол
1лесень
4ет
(Капитальный ремонт)
-Укрепление конструкций
-Снос
-Защитные сооружения
—Цементирование
-Ремонт фундамента
[Косметический ремонт]
-Защит а от воды
-Заделка щелей
-Чистка
—Штукатурка
—Окрашивание
Трещины
Раскол
Плесень
:Нет
'Несущественное; Есть
:Существенное ;Нет
Средняя
Средняя
Небольшие
Небольшие
"Г
[Реставрация Штукат<
консервация Окрашкф
......
%
Панель
функциональной
структуры
Рис. 5.10. Интерфейс АРМа инженера познаниям
Интерфейс KNOST состоит из трех основных частей (рис. 5.10):
• панель концептуальной структуры;
• панель гипертекста;
• панель функциональной структуры.
Панель концептуальной структуры предназначена для графического структури-
рования знаний. Она позволяет определить понятия и обозначить связи между
ними в форме концептуальной структуры Sk.
В панель гипертекста можно поместить любой комментарий, связанный с объек-
том, определенным на панели концептуальной структуры понятий.
Основное назначение панели функциональной структуры Sf — представить на-
глядно в форме строк таблицы причинно-следственные и другие функционалы
5.5. Проектирование гипермедиа БД и адаптивных обучающих систем
195
ные взаимосвязи между понятиями концептуальной структуры, на основании
которых эксперт принимает решения. Столбцы таблицы формируются простей-
шей операцией drag-and-drop из понятий на панели концептуальной структуры.
После того как модели Sk и Sf созданы, KNOST автоматически компилирует базу
знаний на ПРОЛОГе из созданной графической спецификации и моделирует ра-
боту экспертной системы. Это удобно для быстрого наглядного прототипирова-
ния ЭС и для отладки БЗ совместно с экспертом.
5.5. Проектирование гипермедиа БД
и адаптивных обучающих систем
5.5.1. Гипертекстовые системы
Первые информационные системы на основе гипертекстовых (ГТ) моделей по-
явились еще в середине 60-х [Engelbart, 1968], но подлинный расцвет наступил в
80-е годы после появления первых коммерческих ГТ систем для ПЭВМ —
GUIDE (1986 г.) и HyperCard (1987 г.). В настоящее время ГТ технология явля-
ется стандартом de facto в области АОС и сверхбольших документальных БД
[Nielsen, 1990; Агеев, 1994].
Под гипертекстом понимают технологию формирования информационных массивов в
виде ассоциативных сетей, элементами или узлами которой выступают фрагменты тек-
ста, рисунки, диаграммы и пр.
Навигация по таким сетям осуществляется по связям между узлами. Основные
функции связей [Conklin, 1987]:
• перейти к новой теме;
• присоединить комментарий к документу;
• соединить ссылки на документ с документом, показать на экране графическую
информацию (рисунок, чертеж, график, фотографию и пр.);
• запустить другую программу и т. д.
Учитывая широкое использование графовых структур в моделировании, ГТ мо-
жет приобретать черты более сложных моделей, например сетей Петри, диаграмм
состояний и др.
В настоящее время не существует стандартизированной технологии разработки
«хорошо структурированного» ГТ, хотя важность когнитивно-наглядной и «про-
зрачной» структуры ГТ очевидна.
196 Глава 5 « Новые тенденции и прикладные аспекты инженерии знаний
В качестве рабочего упрощенного алгоритма составления ГТ можно предложить
следующий (в п. 5.5.3 будет представлен более сложный вариант).
Инструкция по разработке гипертекстового приложения
1. Дайте название воображаемому документу, например «Учебник по ку-
линарии», «Справочник абитуриента» и пр.
2. Представьте, что вся информация должна быть сгруппирована как в хо-
рошем учебнике, то есть в виде глав и параграфов. Основное условие
для глав, параграфов и подпараграфов — сбалансированность, то есть
примерно равная величина.
3. Проставьте перекрестные ссылки между понятиями внутри параграфов,
придерживаясь принципа «чем меньше — тем лучше».
4. Добейтесь баланса аудио, видео и графической информации.
5. Предоставте возможность возвращения на шаг назад или на более высо-
кий уровень иерархии.
6. Отобразите иерархическое положение текущей страницы. Например,
если мы находимся в подпараграфе, то необходимо вывести название
текущей главы и параграфа.
7. Еще раз проверьте гипертекстовое содержание, в котором отражены все
главы, параграфы и подпараграфы. Из любой страницы приложения дол-
жен быть доступ к этому содержанию.
8. Все необходимые гипертекстовые ссылки лучше располагать не в самом
тексте, а разместить их в одном месте на странице, например в конце
страницы.
9. Ссылки, по которым пользователь уже заходил, должны выделяться дру-
гим цветом.
5.5.2. От мультимедиа к гипермедиа
Мультимедиа (ММ) сегодня понимается как интегрированная компьютерная среда, по-
зволяющая использовать наряду с традиционными средствами взаимодействия человека
и ЭВМ (алфавитно-цифровой и/или графический дисплей, принтер, клавиатура) новые
возможности: звук (живой человеческий голос, музыку и др.), видеоролики (цветные ху-
дожественные и документальные клипы), озвученную мультипликацию и т. д.
Когда элементы ММ объединены на основе сети гипертекста, можно говорить о
гипермедиа (ГМ). Основной сферой применения ГМ сегодня являются автомати-
зированные обучающие системы (АОС) или электронные учебники. Размещение
в узлах сети не только текстовой и цифровой информации, но и графиков, видео-
клипов, фото и музыки обогащает гипертекст и увеличивает занимательность и
наглядность электронных учебников. В последние годы ММ активно внедряется
5.5. Проектирование гипермедиа БД и адаптивных обучающих систем
197
и в интеллектуальные системы [Nielsen, 1990], особенно в системы-консультанты,
как эффективное средство увеличения наглядности и понятности рекомендаций,
выдаваемых системой. Использование анимации, звука и видео существенно об-
легчает усвоение учебного материала по структурированию знаний и снижает
уровень когнитивных усилий учащихся при одновременном уменьшении време-
ни, необходимого на изучение данной проблематики.
Основной предпосылкой интереса к гипермедиа-системам является фактически
беспрецедентный успех глобальной сети Интернет и WWW-технологии.
Другим фактором появления ГМ можно считать мощный прорыв на рынке
машинных носителей информации со стороны фирм, производящих компакт-
аудиодиски (PHILIPS, SONY, NIMBUS) в виде CD-ROM (Compact Disc Read
Only Memory), позволяющих хранить до 600 Мб информации, тем самым от-
крывая дверь для обработки BLOB (Binary Large Objects) — больших двоичных
объектов, например оцифрованных видеоизображений.
Тем не менее существует целый ряд проблем, с которыми сталкиваются разра-
ботчики ММ-систем, независимо от того, ориентированы они на Интернет-при-
ложения или на автономные учебники на CD-ROM:
• отсутствие методологии и технологии структурирования разнородной ин-
формации;
• отсутствие единых стандартов на системы кодирования и обработки;
• сложные аппаратные и программные решения проблем аналого-цифровых
преобразований и синхронизации полноэкранного видео.
Сейчас не существует единой методологии, а тем более технологии разработки
ГМ систем, такое состояние характеризуется как «по science, rather art», то есть
«не наука, а искусство». Однако первые подступы к созданию технологии уже
сделаны [Кирмайкл, 1994; Reisman, 1991], и разработки в этой области продол-
жают активно развиваться.
Традиционно процесс разработки ГМ включает:
Фаза 1 — проектирование и разработка структуры и отдельных фрагментов ги-
пермедиа-приложения, включая звуковые и видеоролики, программное окруже-
ние. 1 фаза — наиболее трудоемкий по времени и человеческим ресурсам период.
Эту фазу осуществляет команда, состоящая из:
• менеджера;
• специалиста по системам обучения;
• эксперта предметной области;
• дизайнера-графика; ,
• системного аналитика;
• сценариста; •
• программиста.
Фаза 2 зависит от того, на какой вариант приложения рассчитана система.
198
Глава 5 « Новые тенденции и прикладные аспекты инженерии знаний
Для Интернет-приложений разрабатываются Web-страницы на языке HTML с
включением оцифрованных в специальных форматах звука, изображений, ани-
мации и видео. При этом могут использоваться специальные пакеты, например
Dreamwever или FrontPage.
Для изготовления CD-дисков используется как HTML-формат, так и специаль-
ные программные средства (authoring languages and systems), как, например
Toolbook или Macromedia Director.
Фаза 3 включает прототипирование CD-ROM на специальном устройстве WORM
(Write Once Read Many) и его тестирование либо размещение приложения на
Интернет-сайте.
Фаза 4 — это тиражирование и производство готовых CD ROM.
5.5.3. На пути к адаптивным обучающим
системам
Инструментом познания согласно концепции параграфа 5.4 можно считать и про-
цесс проектирования структуры гипертекста. Ранее нами [Гаврилова, 1996-99]
был предложен подход, трактующий структуру (граф) гипертекста (ГТ) как «ске-
лет» поля знаний, то есть наиболее информационно-нагруженный элемент поля
знаний. Именно этот граф отражает структуру знания, которую можно назвать
гиперзнания. Усвоение этой структуры является важнейшим компонентом про-
цесса обучения. Очевидно, чем более будет конкретная структура ГТ соответство-
вать индивидуальной когнитивной структуре, тем эффективнее будет идти про-
цесс обучения. Фактически это означает, что обучение и тренинг будут организо-
ваны не через навязывание конкретных когнитивных структур обучаемому и
ломку старых представлений, а через проекцию нового знания на каркас индиви-
дуального опыта и наращивание уже имеющихся когнитивных структур. Такая
адаптация к индивидуальным познавательным структурам может существенно
повысить эффективность обучающих систем.
Предлагаемый подход позволяет представить поле знаний предметной области в
виде релевантной гиперструктуры HS, узлами которой являются концепты А,
выделяемые экспертами как «опорные», то есть принципиально значимые. Свя-
зи или отношения R используются для переходов между узлами. Такая трактов-
ка является естественным развитием моделей представления знаний типа семан-
тических сетей, которые на современном этапе считаются наиболее адекватными
человеческой структуре памяти [Величковский, 1982; Шенк, Хантер, 1987]. Ес-
тественно, что такие концептуально-когнитивные структуры отличаются резкой
индивидуальностью, связанной с личностными, интеллектуальными и профес-
сиональными различиями носителей знаний. В некотором смысле такая (Струк-
тура является когнитивной моделью индивида.
Предлагаемый подход согласуется с концепцией мультидеревьев [Furna, Zacks,
1994], реализующей множественное представление ПО. Модель пользователя,
сформированная по этому принципу, будет отражать «модель мира» данного
конкретного пользователя в виде гиперграфа, узлы которого, в свою очередь, мо-
гут быть раскрыты в виде гиперструктур более низкого уровня. Фактически это
5.5. Проектирование гипермедиа БД и адаптивных обучающих систем
199
соответствует субъективным концептуальным структурам в памяти. Часто в про-
блематике АОС используют понятие «сценария». Традиционно под сценарием
понимается описание содержательного, логического и временного взаимодей-
ствия структурных единиц программы, с помощью которых реализуется автор-
ская цель [Бойкачев, Конева, Новик, 1994].
Очевидно, что в гипермедиа учебных приложениях естественным представлени-
ем сценария является граф гипертекста. При этом важно добиваться, чтобы этот
сценарий соответствовал (был релевантным) представлениям как учителей, так
и учеников.
Релевантная ГТ-структура представляет стратифицированную сеть HS=<A,R>, отража-
ющую иерархию понятий предметной области в форме, соответствующей профессио-
нальным представлениям экспертов и не вызывающей когнитивного диссонанса у
пользователя.
Для формирования стратифицированного множества вершин А можно исполь-
зовать модификацию алгоритмов объектно-структурного анализа ОСА (пара-
граф 3.4).
Алгоритм «ОСА-гипер»
1. Сформулировать цель и собрать от экспертов всю доступную информа-
цию.
2. Определить количество страт N, подлежащих формированию.
3. Из информации, полученной от экспертов и из литературы, выбрать всё
значимые основные объекты и понятия {А} и разместить их по стратам,
сформировав опорные метаузлы ГТ структуры.
4. Детализировать концепты, пользуясь нисходящей концепцией (top-
down).
5. Образовать метапонятия по концепции (bottom-up).
6. Исключить повторы, избыточность и синонимию.
7. Обсудить понятия, не вошедшие в структуру ГТ с экспертом и включить
их или исключить.
8. Выявить основные отношения {R} и спроектировать эскиз ГТ структу-
ры.
9. Провести обследование потенциальных пользователей с целью выявле-
ния их когнитивных представлений о данной ПО, а также формирова-
ния модели пользователя.
10. Привести в соответствие эскиз ГТ и представления пользователя.
И. Сформировать ряд сценариев обхода ГТ с целью упрощения навигации
и учета необходимых сценарных связей и включить их в структуру.
200
Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
Данный алгоритм выявляет канонический или основной сценарий, альтернатив-
ные сценарии формируются на основании либо иного опыта преподавания, либо
с учетом категории пользователей.
Последовательное применение данного подхода и визуальных методов проекти-
рования позволило сформировать ГРАФИТ-технологию и реализовать ее в ряде
программных продуктов ВИКОНТ (ВИзуальный Конструктор Онтологий), ПЕ-
ГАС (ПроЕктирование Гипер-Активных Схем) [Гаврилова и др., 1998-2000]
(рис. 5.11).
Графические технологии
(ГРАФИТ)
Эксперт
в предметной
области
Рис. 5.11. ГРАФИТ-технология визуального проектирования ГТ
При разработке гипермедиа-приложений необходимо также учитывать фактор
сбалансированности звуковых и видеоузлов опорной ГТструктуры, то есть
аудио- и видеофрагменты должны равномерно распределяться на сети. Для это-
го в технологию ГРАФИТ введено понятие «раскраски» узлов, что позволяет на-
глядно оценить сбалансированность сети по аудио- и видеонагрузке. Алгоритм
«ОСА-гипер» учитывает необходимость анализа не только исходной информа-
ции, но и навигационных возможностей:
• перемещение на экран назад;
• возврат к началу;
• возврат к началу секции;
'5.5. Проектирование гипермедиа БД и адаптивных обучающих систем 201
• просмотр структуры;
• озвучивание экрана;
• включение видео;
• помощь;
• перемещение на экран вперед. s
Особенно ценно в реализации графической навигации то, что в произвольный
момент пользователь может посмотреть структуру сценария и понять, в каком
месте он сейчас находится.
Данный подход использован при создании ГТ АОС в области инженерии знаний
для систем дистанционного обучения (Gavrilova, Stash, Udaltsov, 1998). Системы
обучения в области ИИ имеют пока небольшую историю, хотя при отсутствии
учебников по данным дисциплинам эти электронные учебники особенно необхо-
димы. Известны лишь единичные работы в нашей стране и за рубежом — «База
знаний для разработчиков ЭС» [Молокова, Уварова, 1992] и KARTT (Knowledge
Acquisition Research and Teaching Tool) [Liebovitz, Bland, 1994].
При проектировании любой ГТ структуры нетривиальной задачей является вы-
деление «опорных» концептов — вопрос, практически не освещенный в литера-
туре. В работе [Гаврилова, Червинская, 1993] представлен обзор различных ме-
тодов извлечения знаний, частично включающих и исследования по выявлению
значимых концептов. Можно предложить использовать для этой цели методы
многомерного шкалирования, позволяющие выявлять структуру индивидуаль-
ных ментальных пространств, анализируя попарные связи понятий предметной
области (см. п. 5.1).
Эти методы использовались и ранее для изучения семантических пространств
памяти [Терехина, 1988; Петренко, 1988; Cook, 1985], однако можно использовать
новый подход, ориентированный на анализ не только осей ментальных про-
странств с выявлением соответствующих конструктов, но и точек сгущения поня-
тий, называемых «аттракторами» для выявления метапонятий или концептов.
В дальнейшем эти концепты образуют узлы {А} релевантной ГТ структуры, кото-
рую можно фактически трактовать как модель пользователя UM (user model):
UM - {A, R}.
Более широкие исследования [Voinov, Gavrilova, 1993; Воинов, Гаврилова, 1994]
показали, что психосемантические методики (см. п. 5.1), обогащенные новыми
элементами (использование метафорических планов), могут способствовать вы-
явлению имплицитных структур знаний, не поддающихся выявлению другими
методами.
202 Глава 5 • Новые тенденции и прикладные аспекты инженерии знаний
Использование UM как гиперструктуры в гипертекстовых АОС позволяет созда-
вать «гибкие» релевантные сценарии, ориентированные на когнитивные особен-
ности определенных групп пользователей. Последнее замечание можно также от-
нести к разработке систем гипермедиа. Очевидно, что глубокое и конструктивное
изучение человеческого фактора в области computer science может существенно
раздвинуть ограничения современных интеллектуальных и обучающих систем.
Программный
инструментарий
разработки систем,
основанных
на знаниях
□ Технологии разработки программного обеспечения — цели, принципы,
парадигмы
□ Методологии создания и модели жизненного цикла интеллектуальных
систем
□ Языки программирования для ИИ и языки представления знаний
□ Инструментальные пакеты для ИИ
□ WorkBench-системы
6.1. Технологии разработки программного
обеспечения — цели, принципы,
парадигмы
6.1.1. Основные понятия процесса разработки
программного обеспечения (ПО)
Как известно, технология (от греческого технос — мастерство, логос — слово, на-
ука) — это наука о мастерстве.
Под технологией программирования понимается [Брукс, 1979] совокупность знаний о
способах и средствах достижения целей в области программного обеспечения ЭВМ, в
том числе и таких, которые ранее никем не достигались.
В широком смысле технология разработки ПО должна обеспечивать последова-
тельный подход к созданию программных систем. Наиболее очевидная цель в
204 Глава 6 • Программный инструментарий разработки систем
»
разработке ПО состоит в соблюдении установленных заказчиком требований
при реализации системы. Однако у заказчика редко имеются полные и последова-
тельные определения требований. Обычно и заказчик и разработчик не до конца
понимают проблему, и требования совершенствуются в процессе разработки сис-
темы. Необходимо отметить и факт изменения требований в течение жизненного
цикла программной системы.
Изменения являются постоянным фактором разработки ПО. Для того чтобы
преодолеть их разрушающий эффект, в качестве целей технологии разработки
ПО принимаются следующие четыре свойства программных систем [Ross et al.,
1975]:
1. Модифицируемость. Необходимость модификации ПО обычно возникает по
двум причинам: чтобы отразить в системе изменение требований или чтобы
исправить ошибки, внесенные ранее в процессе разработки.
2. Эффективность системы подразумевает, что при функционировании опти-
мальным образом используются имеющиеся в ее распоряжении ресурсы: вре-
мя и память.
3. Надежность системы ПО означает, что она должна предотвращать концепту-
альные ошибки, ошибки в проектировании и реализации, а также ошибки, воз-
никающие при функционировании системы.
4. Понимаемость. Последняя цель технологии ПО — понимаемость — является
мостом между конкретной проблемной областью и соответствующим решени-
ем. Для того чтобы система была понимаемой, она должна быть «прозрачной».
Цели технологии разработки ПО, рассмотренные выше, не могут лишь пассивно
признаваться. Наоборот, по мере выполнения работ необходимо придерживаться
определенного набора принципов, которые обеспечивают достижение этих це-
лей. В качестве таких принципов обычно выделяют [Ross et al., 1975; Буч, 1992]
абстракцию, сокрытие информации, модульность, локализацию, единообразие,
полноту и подтверждаемость.
Абстракция является одним из основных средств для управления сложными сис-
темами ПО. Суть абстракции состоит в выделении существенных свойств с игно-
рированием несущественных деталей. По мере декомпозиции решения на отдель-
ные компоненты каждая из них становится частью абстракции на соответствующем
уровне. Абстрагирование применяется и к данным, и к алгоритмам. На любом
уровне абстракции могут фиксироваться абстрактные типы данных, каждый из
которых характеризуется множеством значений и множеством операций, приме-
нимых к любому объекту данного типа.
Сокрытие или упрятывание информации имеет целью сделать недрступцыми де-
тали, которые могут повлиять на остальные, более существенные части системы.
Упрятывание информации обычно скрывает реализацию объекта или операции
и, таким образом, позволяет фиксировать внимание на более высоком уровне
абстракции. Кроме того, сокрытие проектных решений нижнего уровня оберега-
ет стратегию принятия решений верхнего уровня от влияния деталей.
6.1. Технологии разработки программного обеспечения
205
Абстракция и сокрытие информации способствуют модифицируемости и пони-
маемости систем ПО, На каждом уровне абстракции допускается применение
лишь определенного набора операций и делается невозможным применение лю-
бых операций, нарушающих логическую концепцию данного уровня, за счет чего
повышается надежность программной системы.
Модульность является следующим фундаментальным свойством, помогающим
управлять сложностью систем ПО. Она реализуется целенаправленным конст-
руированием. В самом общем плане модули могут быть функциональными (про-
цедурно-ориентированными) или декларативными (объектно-ориентирован-
ными). Связность модулей определяется как мера их взаимной зависимости.
В идеале должны разрабатываться слабо связанные модули. Другой мерой, при-
менимой к модульности, является прочность, которая определяет, насколько
сильно связаны элементы внутри модуля.
Локализация помогает создавать слабо связанные и весьма прочные модули. По
отношению к целям технологии разработки ПО принципы модульности и лока-
лизации прямо способствуют достижению модифицируемости, надежности и
понимаемости.
Абстракция и модульность считаются наиболее важными принципами, исполь-
зуемыми для управления сложностью систем ПО. Но они не являются достаточ-
ными, потому что не гарантируют получения согласованных и правильных сис-
тем. Для обеспечения этих свойств необходимо привлекать принципы едино-
образия, полноты и подтверждаемости.
Принципы технологии разработки ПО не должны применяться случайно — не-
обходимо выполнять структуризацию системы определенным образом и, что са-
мое важное, поскольку происходит Деление системы на модули, применять со-
гласованные критерии декомпозиции. Можно выделить три основных подхода к
разработке ПО, обеспечивающие такие критерии: нисходящее структурное про-
ектирование [Йордан, 1979]; проектирование, структурированное по данным
[Jackson, 1975], и объектно-ориентированное проектирование [Booch, 1986].
Нисходящее структурное проектирование определяет декомпозицию системы
путем оформления каждого шага этого процесса в виде модуля. Это приводит к
созданию функциональных программных модулей.
Проектирование, структурированное по данным, является альтернативой нисхо-
дящей методологии. При этом сначала определяются структуры данных, а затем
на их основе определяется структура программных модулей. Таким образом,
здесь делается попытка сначала четко определить реализацию объектов, а за-
тем сделать их структуру видимой в функциональных модулях, обеспечиваю-
щих операции над объектами.
Методы нисходящего проектирования императивны по своей природе. Они зас-
тавляют концентрировать внимание на операциях, мало заботясь о проектирова-
нии структур данных. Методы проектирования, основанные на структурирова-
нии по данным, находятся как бы на другом конце спектра. Они концентрируют
внимание на объектах, а операции трактуют глобальным образом.
206 Глава 6 • Программный инструментарий разработки систем
В идеале разработчикам ПО хотелось бы использовать подход, позволяющий
строить решения прямо в соответствии с имеющимся представлением проблемы.
Кроме того, как и в естественном языке, желательна сбалансированность объек-
тов и операций на уровне принимаемых решений.
Такой подход получил название объектно-ориентированного [Booch, 1986]. Здесь
учитывается важность трактовки объектов ПО как активных элементов, причем
каждый объект наделен своим собственным набором допустимых операций. Лег-
ко убедиться, что объектно-ориентированная парадигма поддерживает основные
принципы технологии разработки ПО.
6.1.2. Модели процесса разработки ПО
Под жизненным циклом разработки ПО традиционно понимается упорядоченная со-
вокупность этапов, обеспечивающих создание качественного программного продукта.
В общем случае в жизненный цикл разработки включаются следующие стадии: техни-
ческое задание, эскизный проект, технический проект, рабочий проект и внедрение.
В литературе существует множество нареканий на несовершенство данного раз-
биения [Липаев и др., 1983], но смысл его в целом достаточно ясен — борьба со
сложностью процесса разработки программных продуктов за счет структуриза-
ции этапов и локализации на каждом из них только тех задач, которые могут и
должны решаться именно здесь. Если перечисленные выше этапы укрупнить,
останутся стадии проектирования, реализации и сопровождения.
Проектирование предполагает составление формальных и/или формализован-
ных спецификаций.
Реализация — преобразование этих спецификаций в программный код (автома-
тическое и/или автоматизированное).
Сопровождение — тестирование разработанной системы, ее внедрение и последу-
ющую модификацию, которая, в свою очередь, может вернуть весь процесс к ста-
дии проектирования .(перепроектирование).
Ключевой стадией в жизненном цикле процесса разработки ПО является проек-
тирование. Ошибки и просчеты, допущенные здесь, — самые «дорогие». Поэтому
основные усилия в области технологии программирования направлены на авто-
матизацию проектирования программных комплексов. При этом базисными по-
нятиями являются модель программы и модель системы.
Существуют различные подходы к разработке таких моделей [Миллс, 1970].
Однако с точки зрения целей настоящей книги нас будут интересовать, в первую
очередь, те из них, которые имеют непосредственное продолжение в инструмен-
тальных средствах и интегрированных инструментальных средах. Поэтому
ниже основное внимание будет уделено моделям программ, которые использу-
ются в так называемых WorkBench-системах (наиболее близким по семантике к
этому термину является словосочетание «станок для производства ПО»).
Одну из таких моделей предлагает W/O (Wamier/Orr) методология [Огг et al.,
1977]. Она объединяет методологию Warnier по использованию логических
6.1. Технологии разработки программного обеспечения
207
структур данных и логических конструкций программ и систем и методологию
DSSD (Data Structured System Development) Oppa, базисом которой является
аксиома о логическом соответствии между эвристической структурой программ
и данных, обрабатываемых этими программами. На практике такая методология
предполагает, что в распоряжении проектировщика системы имеется представи-
тельный набор процедурных шаблонов для достаточно широкого класса програм-
мируемых задач.
В настоящее время DSSD-методология «переросла» из методологии разработки
программ в методологию разработки систем. При этом выделены явно уровень
программирования (programming level) и системный уровень (system level).
Применяются в DSSD два концептуальных представления — диаграммы входов
(Entity diagrams), обеспечивающие определение системного контекста, и моди-
фицированные W/O-диаграммы (Assembly-line Diagrams), специфицирующие
функциональное развитие системы [McClure, 1979].
Следующим подходом к созданию моделей программ (по идее достаточно близ-
ким к W/O-методологии) является логическое моделирование Гэйна [Cane et al.,
1979]. Сам метод ориентирован на создание систем обработки данных. Логичес-
кая модель системы проектируется в процессе последовательного применения
следующих семи этапов: описание природы предметной области с помощью диа-
грамм потоков данных (Data Flow Diagram); выделение первичной модели дан-
ных (списка элементов данных в каждом информационном узле); проверка того,
что DFD действительно отражает структуру данных, хранимых в системе; сведе-
ние полученной на предыдущем этапе информации в двумерные таблицы, кото-
рые в дальнейшем нормализуются; коррекция DFD с учетом результатов норма-
лизации предыдущего этапа; разбиение полученной в результате выполнения
предыдущих этапов модели на «процедурные единицы» (procedure units), а так-
же определение деталей каждой процедурной единицы. После выполнения этих
этапов принимается решение о необходимости прототипирования системы на
целевом языке.
И наконец, третьим в ряду подходов к созданию модели проектируемой про-
граммы является метод Йордана (Yourdon) [Yourdon et al., 1979; Yourdon, 1989].
Он включает два компонента: инструментальные средства и методики. Ориенти-
рована методология Йордана на проектирование систем обработки данных. Под
инструментальными средствами здесь понимаются различные диаграммы, ис-
пользуемые при описании моделей требований и моделей архитектуры проекти-
руемой информационной системы. Самые известные из таких диаграмм — диа-
граммы потоков данных DFD. Однако их недостатком является отсутствие
средств описания отношений между данными и их «поведения» во времени. Вот
почему в инструментальные средства метода Йордана на сегодняшний день кро-
ме DFD включены ERD-диаграммы (Entity Relationship Diagrams) и STD-диа-
граммы (State Transition Diagrams).
Методики в методе Йордана помогают перейти от бланка на бумаге и/или экран-
ной формы к хорошо организованной системной модели. Первоначально эти ме-
тодики базировались на традиционном top-down проектировании. В настоящее
208
Глава 6 • Программный инструментарий разработки систем
время здесь используется метод событийного разбиения (event partitioning). При
этом сначала создается контекстная диаграмма верхнего уровня (top level context
diagram), где определяются системные ограничения и интерфейсы с внешним
«миром». Затем с помощью техники интервью формируется список событий из
внешней среды, на которые система должна реагировать. Такой подход обеспечи-
вает простой базис для формирования «сырой» DFD. Несколько DFD-реакций
могут быть объединены в реакцию более высокого уровня. Критерием такого
объединения является наличие узлов, связанных общими данными. По существу,
событийное разбиение не что иное, как метод объектно-ориентированного проек-
тирования.
Проблемы, возникающие при использовании метода ERD-диаграмм, связаны,
прежде всего, с трудностями интеграции компонентов при разработке всей систе-
мы. Вот почему в последнее время этот метод был обобщен за счет введения ин-
тегрированной базы данных. При этом ERD-метод трансформируется в струк-
турную методологию, основные этапы которой сводятся к разработке ERD
(здесь выделяются как собственно сущности с их типами, так и связи, тоже с их
типами); определению кардинальности (cardianality) — однозначности-много-
значности типов связей; преобразованию ERD по определенным правилам в со-
ответствующий файл и структуру БД. В процессе такого преобразования каж-
дый тип сущности трансформируется в отношение, а тип связи — в особое (stand
alone) отношение или объединяется с другими отношениями в зависимости от
кардинальности типа связи. Разработка прикладных программ на основе сфор-
мированного файла и структуры базы данных является заключительным этапом
в этом подходе.
Последним методом, который кратко рассматривается в данном подразделе, яв-
ляется метод структурного проектирования (Structured Design) [Yourdon et al.,
1979]. Структурное проектирование сделалось действительно мощным и активно
используемым на практике подходом за счет того, что к моделям и методам были
добавлены оценки результатов проектирования. Здесь предлагаются все проект-
ные решения располагать в 3-мерном пространстве (содержание — сложность —
связность). И утверждается, что хорошими проектными решениями будут лишь
те, которые при заданном содержании имеют минимальную сложность и макси-
мальную связность. По существу, этот критерий отражает уже обсуждавшиеся
выше понятия абстрагируемости, модульности, сокрытия информации, связнос-
ти и т. п. Конкретным примером воплощения структурного подхода является
«водопадная» или «каскадная» (waterfall) модель разработки систем ПО [Balzer
et al., 1983].
Технология программирования уже прошла достаточно долгий путь развития, и
сейчас происходит переоценка ее фундаментальных исходных посылок. Первым
кандидатом для такой переоценки стала традиционная точка зрения на процесс
разработки ПО, как на процесс, основанный на понятии жизненного цикла. Рас-
тущее единодушие специалистов состоит в том, что данная точка зрения должна
быть заменена такой, которая в большей степени соответствовала бы разработ-
кам, поддерживаемым автоматизированными средами.
6.1. Технологии разработки программного обеспечения
209
В качестве примера смены парадигм можно отметить спиральную модель процес-
саразработки МО (рис. 6.1), предложенную Боэмом [Boehm, 1986], суть которой
состоит в том, что отдельные фазы процесса «прокручиваются» на постепенно
повышающихся уровнях иерархии.
*k Увеличение стоимости
Определение ситуации,
альтернатив, ограничений
Оценка альтернатив,
разрешение рисков
Рис. 6.1. Спиральная модель Боэма
/
Результатом разработки при этом становится не только программный код, но и
его представление на более высоком уровне, что особенно важно в тех случаях,
когда ПО эволюционизирует. Естественно, что такая модель предполагает нали-
чие более гибких механизмов взаимодействия между потребителями и разработ-
чиками и соответствующих инструментальных средств.
В Европе это направление ассоциируется, прежде всего, с проектированием ПО
на основе объектно-ориентированных методологий, среди которых наиболее по-
пулярными являются технология MERISE и методология Шлайера—Мэллора
(Shlaer-Mellor) [Andre et al., 1994; Shlaer et al., 1992].
В рамках данного подхода проектирование рассматривается как процесс, проте-
кающий в пространстве трех измерений: «статика»—«динамика»—«алгоритмы»
(рис. 6.2).
Жизненный цикл при этом похож на виток в спирали Боэма, но включает другие
стадии. Первая из них связана с осью «Статика» и предполагает идентифйкацию
и описание объектов, атрибутов и отношений, которые требуются для специфи-
кации проектируемой системы. Вторая стадия служит для описания поведения
каждого объекта в ответ на внешние запросы и дает в качестве результата сово-
купность жизненных циклов всех введенных объектов. Затем проектируются ал-
210
Глава 6 • Программный инструментарий разработки систем
горитмы реализации действий, специфицированных на предыдущей стадии, и,
наконец, на четвертой стадии осуществляется валидация спроектированной сис-
темы на полноту и функциональное соответствие исходной задаче. Последняя
стадия может потребовать нового витка в модели жизненного цикла.
Рис. 6.2. Проектирование в методологии Shlaer-Mellor
Таким образом, мы рассмотрели основные модели процессов разработки систем
«традицонного» программного обеспечения и теперь переходим к анализу соот-
ветствующего инструментария.
6.1.3. Инструментальные средства
поддержки разработки систем ПО
Технология программирования в целом и средства поддержки разработки ПО, в
частности, развиваются настолько быстро, что даже простое перечисление основ-
ных инструментальных систем заняло бы в этой книге слишком много места. Вот
почему ниже мы остановимся кратко лишь на нескольких проектах в области тех-
нологии программирования, которые интересны в контексте данного издания.
Любая развитая технологическая система должна поддерживать все основные
этапы создания проектируемого программного комплекса. Для достижения этой
цели в общей структуре типовой технологической системы поддержки разработ-
ки (рис. 6.3) обычно выделяют базу данных проекта; подсистему автоматизации
проектирования и программирования; подсистемы отладки, документирования и
сопровождения, а также подсистему управления ходом выполнения проекта.
6.1. Технологии разработки программного обеспечения
211
Исходные и промежуточные спецификации
программы, тесты, задания и т. д.
&
Рис. 6.3. Общая структура типовой технологической системы поддержки разработки
Развитые библиотечные системы поддержки разработки используются в настоя-
щее время во всем мире во всех сколько-нибудь серьезных программных проек-
тах. Но в подавляющем большинстве случаев такие системы достигли уровня
удобства работы с ними квалифицированных программистов. Нас же, прежде
всего, интересуют системы и проекты, в которых имеются тенденции к экспли-
цитному представлению технологических знаний, даже если они и не базируют-
ся на идеях и методах ИИ. .
Один из таких проектов — Gandalf [Haberman et al., 1986] — ориентирован на ав-
томатизированную генерацию систем разработки программного обеспечения.
Исследования, выполняемые в рамках проекта Gandalf, касаются трех аспектов
поддержки проектирования ПО: управление проектом, контроль версий и инкре-
ментное программирование, а также интеграция их в единую среду. Управление в
Gandalf-среде базируется на предположении, что разрабатываемый проект дол-
жен трактоваться как множество абстрактных типов данных, над которыми могут
выполняться лишь определенные операции. Средством, реализующим данную
концепцию, явилась система SDC (Software Development Control), представляю-
щая собой набор программ, первоначально реализованных на языке Shell в систе-
ме UNIX, а позднее переведенная на язык С.
212
Глава 6 • Программный инструментарий разработки систем
Исследования в области контроля версий были начаты еще Л. Коопридером на
базе проекта FAFOS [Habermann et al., 1976], где изначально анализировались
возможности создания семейства операционных систем. Была разработана нота-
ция для описания взаимодействия между подсистемами, для описания различ-
ных версий подсистем (исходного и объектного кода, документации и т. п.) и для
описания действующих на этапе разработки механизмов (компиляция, редакти-
рование связей и т. п.). Затем был создан специальный язык Intercol как средство
описания взаимосвязи и версий модулей в системе. И наконец, в систему были
встроены знания о том, как конструировать систему из частей, не заставляя зани-
маться этим пользователя. В развитие этих работ была создана система SUCE, в
рамках которой отслеживались различия между реализациями (версиями, кото-
рые действительно дают код для ряда спецификаций) и композициями (версия-
ми, определяющими новые подсистемы как группы существующих подсистем).
В системе LOIPE (Language-Oriented Incremental Programming Environment) ин-
крементная компиляция выполняется на уровне отдельной процедуры. Достоин-
ством такого подхода является то, что при коррекции процедуры на уровне ло-
кальных объектов или типов перекомпилируется только она. Если же меняется
спецификация, то перекомпилируются и все зависящие от нее процедуры. Поль-
зовательский интерфейс с LOIPE-системой базируется на подсистеме синтакси-
чески-ориентированного редактирования ALOE (A Language-Oriented Editor).
Целью разработки этой подсистемы было исследование возможности создания и
использования синтаксически-ориентированных редакторов в качестве базиса
для сред программирования.
Анализ литературы последних лет по технологии программирования показыва-
ет, что новой ветвью в технологии промышленной разработки и реализации
сложных и значительных по объему систем программного обеспечения явля-
ется CASE-технология (Computer Aided Software Engineering) [BYTE, 1990].
Первоначально CASE-технология появилась в проектах создания промышлен-
ных систем обработки данных. Это обстоятельство наложило свой отпечаток и
на инструментальные средства CASE-технологии, где самое серьезное внимание
уделялось, по крайней мере в ранних CASE-системах, поддержке проектирова-
ния информационных потоков. В настоящее время наблюдается отход от ориен-
тации на системы обработки данных, и инструментальные средства CASE-тех-
нологии становятся все более универсальными.
Все средства поддержки CASE-технологии делятся на две большие группы: СА-
SE-ToolKits и CASE-WorkBenches. Хороших русских эквивалентов этим терми-
нам нет. Однако первые часто называют «инструментальными сундучками» (па-
кетами разработчика, технологическими пакетами), а вторые — «станками для
производства программ^ (технологическими линиями).
По определению [BYTE, 1990]. CASE-ToolKit — коллекция интегрированных программ-
ных средств, обеспечивающих аатоматическое ассистирование в решении задач одно-
го типа в процессе создания программ.
6,1. Технологии разработки программного обеспечения
213
Такие пакеты используют общее «хранилище» для всей технической и управля-
ющей информации по проекту (репозиторий), снабжены общим интерфейсом с
пользователем и унифицированным интерфейсом между отдельными инстру-
ментами пакета. Как правило, CASE-ToolKit концентрируются вокруг поддерж-
ки разработки одной фазы производства программ или на одном типе приклад-
ных задач.
Все вышесказанное справедливо и по отношению к CASE-WorkBench. Но здесь,
кроме того, обеспечивается автоматизированная поддержка анализа решаемых
задач по производству программного обеспечения, которая базируется на общих
предположениях о процессе и технологии такой деятельности; поддерживается
автоматическая передача результатов работ от одного этапа к другому, начиная со
стадии проектирования и кончая отчуждением созданного программного продук-
та и его сопровождением. \
Таким образом, CASE-WorkBench является естественным «замыканием» технологии
разработки, реализации и сопровождения программного обеспечения.
В настоящее время «типовая» система поддержки CASE-технологии имеет функци-
ональные возможности, представленные на рис. 6.4.
Рис. 6.4. Функциональные возможности типовой системы поддержки CASE-технологии
Как следует из этой Н-диаграммы, в CASE-среде должны поддерживаться все ос-
новные этапы разработки и сопровождения процессов создания программных
систем. Однако уровень такой поддержки существенно различен. Так, например,
если говорить об этапах анализа и проектирования, большинство инструмен-
тальных пакетов поддерживает экранные и отчетные формы, создание прототи-
214
Глава 6 • Программный инструментарий разработки систем
пов, обнаружение ошибок. Значительная часть этих средств предназначена для
ПЭВМ. Многие поддерживают такие широко используемые методологии, как
структурный анализ DeMarco или Gane/Sarson, структурное проектирование
Yourdan/Jackson и некоторые другие. Существуют специализированные пакеты
разработчиков для создания информационных систем, например AnaTool (Ad-
vanced Logical Software) для Macintosh; CA-Universe/Prototype (Computer Asso-
ciates International) для ПЭВМ. Имеются CASE-среды и для поддержки разра-
ботки систем реального времени.
В среде разработчиков ПО существуют две оценки данного подхода: часть из них
считает, что CASE-технология кардинально меняет процессы разработки и эксп-
луатации ПО, другие отрицают это и оставляют за инструментальными сред-
ствами CASE лишь функцию автоматизации рутинных работ [BYTE, 1989]. Од-
нако анализ литературы показывает, что CASE средства все-таки «сдвигают»
технологии разработки ПО с управления выполнением проектов в сторону мето-
да прототипизации. И этот сдвиг, на наш взгляд, чрезвычайно важная тенденция
в современной технологии программирования.
6.2. Методологии создания и модели
жизненного цикла интеллектуальных
систем
В настоящее время в области разработки и реализации интеллектуальных систем
сложилось следующее положение: с одной стороны, квалификация коллективов
разработчиков здесь, как правило, достаточно высока, чтобы считать классичес-
кие положения технологии разработки ПО, обсуждавшиеся выше, естественным
компонентом работы. С другой стороны, жизненно важными технологические ас-
пекты создания интеллектуальных систем становятся, лишь когда такие системы
выходят на уровень промышленных разработок. Создание и внедрение интеллек-
туальных систем общения с промышленными базами данных, систем машинного
перевода нового поколения, интеллектуальных систем автоматического синтеза
программ и особенно экспертных систем, по существу, и выдвинуло проблему
технологической поддержки разработок в области ИИ на передний план [SIG-
SOFT, 1986].
На фоне вышеописанной ситуации обращает на себя внимание тот факт, что име-
ются только единичные примеры инструментальных систем, которые бы поддер-
живали некоторую четко провозглашенную технологию разработки ПО и опира-
лись бы на достаточно развитые системы представления знаний [Ramamoorthy
et al., 1987]. Учитывая это, в данном параграфе рассматриваются'технологичес-
кие аспекты и методологии создания интеллектуальных систем в свете введен-
, ных выше понятий технологии программирования, а в следующих — инструмен-
тарий для разработки систем ИИ.
Стиль программирования систем искусственного интеллекта существенно отли-
чается от стиля программирования с использованием обычных алгоритмических
6.2, Методологии создания жизненного цикла интеллектуальных систем
215
языков. При этом почти каждая подобласть области ИИ характеризуется своим
собственным стилем программирования, не всегда адекватным для других прило-
жений. В табл. 6.1 приведены некоторые характерные отличия между обычными
программными системами и системами ИИ [Ramamoorthy et al., 1987].
Таблица 6.1. Отличия систем ИИ от обычных программных систем
Характеристика программирование Программирование в СИИ Традиционное
Тип обработки Символьная Числовая
Методы Эвристический поиск Алгоритм
Задание шагов решения Неявное Точное
Искомое решение Удовлетворительное Оптимальное
Управление и данные Перемешаны Разделены
Знания Неточные Точные '
Модификации Частые Редкие
Но ввиду все возрастающего использования систем ИИ в конкретных приложе-
ниях, к ним начинают предъявляться практически те же требования, что и к тра-
диционным программным комплексам и системам. В связи с этим становится
весьма актуальной поддержка жизненного цикла программ в ИИ. К основным
этапам в этом случае относятся инженерия требований, тестирование на прото-
типах и сопровождение.
Как и в случае обычных программных систем, разработка системы ИИ должна
начинаться с формулирования полных, непротиворечивых и однозначных требо-
ваний к ней [Basili et al., 1984]. При проектировании должны использоваться
принципы технологии разработки ПО — такие, например, как сокрытие инфор-
мации, локализация и модульность. Предполагается, что система должна проек-
тироваться как композиция уровней. Любой уровень должен быть чувствителен
лишь к нижележащим уровням. Такое проектирование упрощает не только реа-
лизацию, но и тестирование.
Тестирование ПО ИИ отличается от тестирования обычных систем, так как для
первых характерно недетерминированное поведение вследствие использования
стратегии разрешения конфликтов, зависящей от параметров периода исполне-
ния программы. Поэтому единственным эффективным способом тестирования
систем ИИ является прототипизация.
Фаза сопровождения, включающая выполнение самых различных модификаций
системы, является важнейшим этапом процесса разработки любой системы, но
имеет свою специфику для систем ИИ. Здесь база знаний — наиболее динамич-
ный компонент и меняется в течение всего жизненного цикла. Поэтому сопро-
вождение интеллектуальных систем — серьезная проблема. Но именно вопросам
сопровождения уделяется мало внимания, хотя в обычном программировании
имеются средства, которые могли бы быть адаптированы и для случая ПО ИИ.
Это, например, системы управления версиями, системы управления конфигура-
цией и системы модифицирующих запросов.
216 Глава 6 « Программный инструментарий разработки систем
Таким образом, создание ПО систем, основанных на знаниях, имеет как общие
моменты с разработкой традиционных систем ПО, так и свою специфику, кото-
рая явным образом должна отражаться в соответствующих моделях жизненного
цикла.
В недавнем прошлом полигоном для создания и испытания таких моделей явля-
лись экспертные системы (ЭС).
В ходе работ по созданию ЭС практически сложилась определенная технология,
включающая следующие основные этапы: идентификацию, концептуализацию,
формализацию, реализацию и тестирование [Попов, 1987; Уотерман, 1989].
На этапе идентификации определяются задачи, подлежащие решению, выявля-
ются цели разработки, ресурсы, наличие экпертов, готовых и способных передать
свои знания проектируемой ЭС, категории и требования будущих пользователей.
Концептуализация необходима для проведения содержательного анализа пред-
метной области, в процессе которого выделяются используемые понятия и их взаи-
мосвязи, определяются методы решения задач, и подробно обсуждалась в преды-
дущих главах.
На этапе формализации определяются способы представления всех типов знаний,
специфицируются выделенные ранее понятия, фиксируются способы интерпре-
тации знаний, моделируется работа системы, и оцениваются полученные резуль-
таты.
Этап реализации предполагает создание программной обстановки, в которой бу-
дет функционировать будущая система, и наполнение экспертом базы знаний, а
на этапе тестирования эксперт и инженер по знаниям в интерактивном режиме,
используя, в частности, объяснения, проверяют компетентность ЭС.
В заключение на этапе тестирования проверяется пригодность ЭС для конечных
пользователей.
Понятно, что процесс создания ЭС не сводится к строгой последовательности
выполнения вышеперечисленных этапов. В ходе разработки происходят много-
численные возвраты к предыдущим этапам и решения, принятые там, пересмат-
риваются. Все это существенно снижает общую эффективность разработки конк-
ретной системы и позволяет сделать вывод о том, что модель жизненного цикла,
соответствующая такой технологии, имеет мало шансов на промышленное ис-
пользование.
Это, конечно, не означает, что ЭС, разработанные в рамках такой методологии,
практически бесполезны или их проектирование вообще невозможно. Обычно
таким образом создаются небольшие автономно функционирующие ЭС первого
поколения.
Промышленная технология создания ЭС включает три фазы (или, если быть
точнее, технологии): проектирование, реализацию и внедрение. Жизненный цикл
разработки, охватываемый этой технологией или совокупностью технологий,
состоит из 6 этапов: исследование выполнимости проекта;разработка общей кон-
цепции ЭС;разработка и тестирование серии прототипов; разработка и испыта-
ние головного образца; разработка и проверка расширенных версий системы; при-
вязка системы к реальной рабочей среде.
9
6,2. Методологии создания жизненного цикла интеллектуальных систем
217
На фазе проектирования проект инициализируется, формируется группа разра-
ботчиков, определяются требования к будущей ЭС, проводятся исследования
выполнимости проекта и вырабатывается общая концепция будущей системы.
Остальные фазы данной технологии, по мнению [Микулич, 1990], ближе к тех-
нологии Уотермана (Waterman) и направлены на реализацию разработанной
концепций в виде серии прототипов, последовательно приближающихся к тре-
буемой ЭС. Последний из прототипов и приобретает статус головного образца,
который устанавливается будущим пользователем в реальную операционную
среду.
Нетрудно понять, что первые два этапа промышленной технологии соответству-
ют этапу идентификации; следующие три — этапам концептуализации, форма-
лизации, реализации и тестирования. Новым и вместе с тем естественным для
промышленной технологии является здесь этап привязки системы к реальной
рабочей обстановке.
Недостатком и той и другой технологии является то, что в действительности это
лишь более или менее структурированный набор методических рекомендаций, к
отдельным элементам которого, в лучшем случае, привязаны те или иные инст-
рументальные средства. И можно сказать, что сегодняшнее состояние здесь бли-
же к описательному, чем к естественно-научному. А это влечет за собой наличие
интерпретаций методологических рекомендаций, которые могут быть настолько
различными, что теряется сама идея технологии. Таким образом, самым важным
на данном этапе является создание операциональных моделей технологии разра-
ботки интеллектуальных систем. И здесь, по нашему мнению, хорошим приме-
ром могут послужить модели экспертизы, уже разработанные в рамках исследо-
ваний по приобретению знаний.
Приобретение знаний, как уже неоднократно отмечалось выше, является ключе-
вой задачей во всех технологиях построения систем, основанных на знаниях
(СОЗ). Существует распространенный принцип, согласно которому производи-
тельность СОЗ находится в прямой зависимости от количества знаний, содержа-
щихся в системе [Feigenbaum, 1977]. Более 15 лет, с момента появления извест-
ной программы TIERESIAS [Davis, 1984], исследователи в области ИИ рассмат-
ривают приобретение знаний как задачу переноса знаний эксперта в БЗ системы,
что чрезвычайно важно для создания действующей системы. Но в настоящее
время работы в области приобретения зцаний становятся важными и с точки
зрения использования полученных здесь результатов для создания интеллекту-
альных технологий разработки самих СОЗ.
Первое поколение методик для СОЗ базировалось на подходах двух типов: по-
этапном и прототипном.
Поэтапный подход связан с представлениями о жизненном цикле [Buchanan
et al., 1983; Guida et al., 1989] и соответствующей поддержке его основных стадий.
В прототипном подходе первого поколения [Grover, 1983; Wielinga et al., 1988]
процесс приобретения знаний может не отрабатывать все стадии, так как основ-
ным предположением здесь была возможность раскрытия структуры области экс-
пертизы на раннем этапе проектирования на основе сравнительно небольшого
218
Глава 6 • Программный инструментарий разработки систем
анализа. Во втором поколении СОЗ-методик признана сложность процесса при-
обретения знаний, преодоление которой видится в моделировании экспертизы.
В данной области были предложены такие методики, как онтологический анализ
[Alexander et al., 1987], концептуальные графы Sowa [Clancey, 1985], подходы, ос-
нованные на обобщенных (родовых) задачах [Chandrasekaran, 1985], и концепту-
альное моделирование, например KADS-методология [Breuker et al., 1986]. Мё-
тодики приобретения знаний обсуждаются в огромном числе работ и, в част-
ности, в предыдущих главах настоящей книги. Не имея места для их сколько-
нибудь полного анализа, сошлемся здесь лишь на обзоры [Wielinga et al., 1988;
Молокова, 1992; Осипов, 1993] и перейдем к инструментальным средствам под-
держки разработки интеллектуальных систем.
6.3. Языки программирования для ИИ
и языки представления знаний
Обсуждение технологических аспектов разработки сложных программных сис-
тем, проведенное выше, показывает, что наиболее проработанным этапом здесь
является реализация программных проектов. По идеям и методам этот этап бли-
зок к автоматизации программирования — одной из основных проблем использо-
вания средств вычислительной техники. Здесь уже в течение многих лет приме-
няется обширный арсенал языков программирования высокого уровня, ориен-
тированных на удобную и эффективную реализацию различных классов задач, а
также широкий спектр трансляторов, обеспечивающих получение качественных
исполнительных программ. Все шире используются на современном этапе и ме-
тоды автоматического синтеза программ. Уже стало обычным применение языко-
во-ориентированных редакторов и специализированных баз данных. И можно
сказать, что в рамках технологии программирования уже практически сформиро-
валась концепция окружения разработки сложных программных продуктов, ко-
торая и определяет инструментальные средства, доступные разработчикам.
Необходимость использования средств автоматизации программирования при-
кладных систем, ориентированных на знания, и в частности ЭС, была осознана
разработчиками этого класса программного обеспечения ЭВМ уже давно. По су-
ществу, средства поддержки разработки интеллектуальных систем в своем разви-
тии прошли основные стадии, характерные для систем автоматизации програм-
мирования.
Оценивая данный процесс с сегодняшних позиций, можно указать в этой области
две тенденции. Первая из них как бы повторяет «классический» путь развития
средств автоматизации программирования: автокоды — языки высокого уровня —
языки сверхвысокого уровня — языки спецификаций. Условно эту тенденцию мож-
но назвать восходящей стратегией в области создания средств автоматизации
разработки интеллектуальных систем. Вторая тенденция, нисходящая, связывает-
ся со специальными средствами, уже изначально ориентированными на опреде-
ленные классы задач и методов ИИ. В конце концов, обе эти тенденции, взаимно
6.3. Языки программирования для ИИ и языки представления знаний
219
обогатив друг друга, должны привести к созданию мощного и гибкого инструмен-
тария интеллектуального программирования. Но для настоящего этапа в этой
области, по нашему мнению, характерна концентрация усилий в следующих на-
правлениях:
1. Разработка систем представления знаний (СПЗ) путем прямого использоват
ния широко распространенных языков обработки символьной информации и,
все чаще, языков программирования общего назначения.
2. Расширение базисных языков ИИ до систем представления знаний за счет спе-
циализированных библиотек и пакетов.
3. Создание языков представления знаний (ЯПЗ), специально ориентированных
на поддержку определенных формализмов, и реализация соответствующих
трансляторов с этих языков.
На начальном этапе развития ИИ языков и систем, ориентированных специально
на создание прикладных систем, основанных на знаниях, не существовало.
С одной стороны, в то время еще не оформился сам подход, в котором централь-
ное место отводилось бы изложению теории в форме программ, а с другой — сама
область ИИ только зарождалась как научное направление. Немаловажным было
и то, что появившиеся к тому времени универсальные языки программирования
высокого уровня казались адекватным инструментом для создания любых, в том
числе и интеллектуальных, систем. Однако сложность и трудоемкость разработ-
ки здесь настолько велики, что практически полезные интеллектуальные системы
становятся недоступными для реализации. Учитывая вышесказанное, были раз-
работаны языки и системы обработки символьной информации, которые на не-
сколько десятилетий стали основным инструментом программирования интел-
лектуальных систем.
До недавнего времени наиболее популярным базовым языком реализации сис-
тем ИИ вообще и ЭС, в частности, был ЛИСП [McCarthy, 1978]. Ниже кратко
рассматривается эволюция ЛИСПа, а затем обсуждаются альтернативы этому
языку, существовавшие и существующие в области реализации систем, ориенти-
рованных на знания. Результаты этого краткого обзора суммированы в виде схе-
мы развития средств автоматизации программирования интеллектуальных сис-
тем на рис. 6.5. Подробнее эти вопросы обсуждаются в работе [Хорошевский,
1990а, Хорошевский, 1990Ь].
Как известно, язык ЛИСП был разработан в Стэнфорде под руководством Дж. Мак-
карти в начале 60-х годов и не предйазначался вначале для программирования
задач ИИ. Это был язык, который должен был стать следующим за ФОРТРАНОМ
шагом на пути автоматизации программирования.
По первоначальным замыслам новый язык должен был иметь средства работы с
матрицами, указателями и структурами из указателей и т. п. Предполагалось, что
первые реализации будут интерпретирующими, но в дальнейшем будут созданы
компиляторы. Как отмечает сам автор языка в обзоре [McCarthy, 1978], к счастью,
для столь амбициозного проекта не хватило средств. К тому же к моменту созда-
220
Глава 6 • Программный инструментарий разработки сйстем
ния первых ЛИСП-интерпретаторов в практику работы на ЭВМ стал входить
диалоговый режим, и режим интерпретаций естественйо вписался в общую струк-
туру диалоговой работы.
Рис. 6.5. Эволюция средств представления знаний
Примерно тогда же окончательно сформировались и принципы, положенные
в основу языка ЛИСП: использование единого спискового представления для
6.3. Языки программирования для ИИ и языки представления знаний 221
программ и данных; применение выражений для определения функций; скобоч-
ный синтаксис языка. Процесс разработки языка завершился созданием версии
ЛИСП 1.5 [McCarthy, 1978], которая на многие годы определила пути его разви-
тия;
На протяжении всего существования языка было много попыток его усовершен-
ствования за счет введения дополнительных базисных примитивов и/или управ-
ляющих структур. Однако, как правило, все эти изменения не прививались в ка-
честве самостоятельных языков, так как их создатели оставались в «лисповской»
парадигме, не предлагая нового взгляда на программирование.
После разработки в начале 70-х годов таких мощных ЛИСП-систем, как MacLisp
и Interlisp .[Moon, 1973; Teitelman, 1974], попытки создания языков ИИ, отлич-
ных от ЛИСПа, но на той же парадигме, по-видимому, сходят на нет. И дальней-
шее развитие языка идет, с одной стороны, по пути его стандартизации (таковы,
например, Standart Lisp, Franz Lisp и Common Lisp), а с другой — в направлении
создания концептуально новых языков для представления и манипулирования
знаниями, погруженных в ЛИСП-среду [Barr et al., 1982].
К концу 80-х годов ЛИСП был реализован на всех классах ЭВМ, начиная с пер-
сональных компьютеров и кончая высокопроизводительными вычислительны-
ми системами. Новый толчок развитию ЛИСПа дало создание ЛИСП-машин,
которые и в настоящее время выпускаются рядом фирм США, Японии и Запад-
ной Европы.
Из предыдущего может сложиться впечатление, что язык ЛИСП (а вернее его
современные диалекты) — единственный язык ИИ. В действительности, конеч-
но, это не так. Уже в середине 60-х годов, то есть на этапе становления ЛИСПа,
разрабатывались языки, предлагающие другие концептуальные основы. Наибо-
лее важными из них в области обработки символьной информации являются, по
нашему мнению, СНОБОЛ [Griswold, 1978], разработанный в лабораториях
Белла, и язык РЕФАЛ [Турчин, 1968], созданный в ИПМ АН СССР.
Первый из них (СНОБОЛ) — язык обработки строк, в рамках которого впервые
появилась и была реализована в достаточно полной мере концепция поиска по
образцу. С позиций сегодняшнего дня можно сказать, что язык СНОБОЛ был
одной из первых практических реализаций развитой продукционной системы.
Наиболее известная и интересная версия этого языка — СНОБОЛ-IV [Грисуолд
и др., 1980]. Здесь, на наш взгляд, техника задания образцов и работа с ними суще-
ственно опередили потребности практики. Может быть именно это, а также поли-
тика активного внедрения ЛИСПа помешали широкому использованию языка
СНОБОЛ в области ИИ.
В основу языка РЕФАЛ положено понятие рекурсивной функции, определенной
на множестве произвольных символьных выражений. Базовой структурой дан-
ных этого языка являются списки, но не односвязные, как в ЛИСПе, а двунаправ-
ленные. Обработка символов ближе, как мы бы сказали сегодня, к продукционно-
му формализму. При этом активно используется концепция поиска по образцу,
характерная для СНОБОЛа. Таким образом, РЕФАЛ вобрал в себя лучшие чер-
222
Глава 6 • Программный инструментарий разработки систем
ты наиболее интересных языков обработки символьной информации 60-х годов.
В настоящее время можно говорить о языке РЕФАЛ второго [Климов и др., 1987]
и даже третьего поколения. Реализован РЕФАЛ на всех основных типах ЭВМ и
активно используется для автоматизации построения трансляторов, для построе-
ния систем аналитических преобразований, а также, подобно ЛИСПу, в качестве
инструментальной среды для реализации языков представления знаний [Хоро-
шевский, 1983].
В начале 70-х годов появился еще один новый язык, способный составить конку-
ренцию ЛИСПу при реализации систем, ориентированных на знания, — язык
ПРОЛОГ [Clocksin et al., 1982]. Он не дает новых сверхмощных средств програм-
мирования по сравнению с ЛИСПом, но поддерживает другую модель организа-
ции вычислений. Подобно тому, как ЛИСП скрыл от программиста устройство
памяти ЭВМ, ПРОЛОГ позволил ему не заботиться (без необходимости) о пото-
ке управления в программе. ПРОЛОГ предлагает такую парадигму мышления, в
рамках которой описание решаемой задачи представляется в виде слабо структу-
рированной совокупности отношений. Это удобно, если число отношений не
слишком велико и каждое отношение описывается небольшим числом альтерна-
тив. В противном случае ПРОЛОГ-программа становится весьма сложной для
понимания и модификации. Возникают и проблемы эффективности реализации
языка, так как в общем случае механизмы вывода, встроенные в ПРОЛОГ, обеспе-
чивают поиск решения на основе перебора возможных альтернатив и декларатив-
ного возврата из тупиков. ПРОЛОГ разработан в Марсельском университете в
1971 г. [Colmerauer, 1983]. Однако популярность он стал приобретать лишь в на-
чале 80-х годов, когда благодаря усилиям математиков был обоснован логичес-
кий базис этого языка, а также в силу того, что в японском проекте вычислитель-
ных систем V поколения ПРОЛОГ был выбран в качестве базового для машины
вывода. В настоящее время ПРОЛОГ завоевал признание и на американском кон-
тиненте, хотя уступает в популярности ЛИСПу и даже специальным продукци-
онным языкам, широко используемым при создании ЭС.
Мы рассмотрели языки общего назначения для задач ИИ. Вместе с тем в рамках
развития средств автоматизации программных систем, ориентированных на зна-
ния, были языки, сыгравшие важную роль в эволюции основных языков ИИ.
В первую очередь среди , них необходимо выделить языки, ориентированные на
программирование поисковых задач. Это ПЛЭНЕР и различные его модифика-
ции [Пильщиков, 1983], КОННАЙВЕР [Sussman et al., 1976], а также языки, вы-
росшие из потребностей известной планирующей системы QA4 [Sacerdoti et
al., 1976]. Все эти языки функционируют в ЛИСП-среде и создавались как расши-
рения базового языка. Для них, кроме свойств ЛИСПа, характерны следующие
черты: представление данных в виде произвольных списковых структур; разви-
тые методы сопоставления образцов; поиск с возвратами и вызов процедур по об-
разцу. Заметим, что в конечном счете ни один из них не стал универсальным язы-
ком программирования ИИ. Однако выработанные здесь решения были
использованы и в ЛИСПе, и в ПРОЛОГе, и в современных продукционных язы-
ках. Важно и то, что языки этой группы способствовали переосмыслению самого
6.3. Языки программирования для ИИ и языки представления знаний
223
понятия программы. В области ИИ это послужило толчком к развитию объектно-
ориентированного программирования и разработке языков представления зна-
ний первого поколения.
В 70-х годах в программировании вообще и программировании задач ИИ, в част-
ности, центр тяжести стал смещаться от процедурных к декларативным описа-
ниям. К этому же времени в ИИ сформировались и концепции представления
знаний на основе семантических сетей и фреймов. Естественно, что появились и
специальные языки программирования, ориентированные на поддержку этих кон-
цепций. Но из десятков, а может и сотен языков представления знаний (ЯПЗ)
первого поколения лишь несколько сыграли заметную роль в про-
граммной поддержке систем представления знаний. Среди таких ЯПЗ явно вы-
деляются KRL, FRL, KL-ONE и некоторые другие [Хорошевский, 1990]. Харак-
терными чертами этих ЯПЗ были: двухуровневое представление данных (абст-
рактная модель предметной области в виде иерархии множеств понятий и
конкретная модель ситуации как совокупность взаимосвязанных экземпляров
этих понятий); представление связей между понятиями и закономерностей
предметной области в виде присоединенных процедур; семантический подход к
сопоставлению образцов и поиску по образцу.
Суммируя вышесказанное, можно отметить, что на первом этапе была сформи-
рована значительная коллекция методов представления знаний и соответствую-
щих ЯПЗ. Все это способствовало формированию новой стадии исследований в
области ИИ, которая характеризуется переходом от экспериментальной про-
граммной проверки идей и методов к созданию практически значимых инстру-
ментов.
В силу ограниченного объема книги мы не сможем здесь рассмотреть даже наи-
более распространенные языки и системы представления знаний. Поэтому ниже
приведены лишь некоторые замечания относительно одного из самых распрост-
раненных ЯПЗ — OPS5 (Official Production System, version 5) [Brownston et al.,
1985], который претендовал в начале 80-х годов на роль языка-стандарта в обла-
сти представления знаний для ЭС.
OPS5 — один из многочисленных на сегодняшний день ЯПЗ для ЭС, поддержи-
вающих продукционный подход к представлению знаний. OPSS-программа, в
общем случае, содержит секцию деклараций, где описываются используемые
объекты и определяются введенные пользователем функции, и секцию продук-
ций, основу которой составляют правила. OPSS-объекты описываются с помо-
щью фреймов-экземпляров, прототипы которых задаются в виде определенных
структур данных, опирающихся на небольшое число встроенных типов. Во вре-
мя исполнения программы обрабатываемые данные помещаются в рабочую па-
мять, а правила — в память продукций. Модуль вывода решений в ОР85-системе
состоит из трех основных блоков: отождествления, где осуществляется поиск
подходящих правил; выбора исполняемого правила из конфликтного множества
правил и собственно исполнителя выбранного правила. Непосредственно в OPS5
поддерживается единственная стратегия вывода решений — вывод, управляе-
мый целями. Вместе с тем OPS5 — достаточно гибкий язык, в котором имеются
224
Глава 6 » Программный инструментарий разработки систем
явные средства не только для описания данных, но и средства определения уп-
равления над этими данными.
Анализ формализмов представления знаний и методов вывода решений позво-
ляет сформулировать следующие требования к ЯПЗ:
• наличие простых и вместе с тем достаточно мощных средств представления
сложно структурированных и взаимосвязанных объектов;
• возможность отображения описаний объектов на разные виды памяти ЭВМ;
• наличие гибких средств управления выводом, учитывающих необходимость
структурирования правил работы решателя;
• «прозрачность» системных механизмов для программиста, предполагающая
возможность их доопределения и переопределения на уровне входного языка;
• возможность эффективной реализации.
Конечно, перечисленные требования во многом противоречивы. Но удачные язы-
ки и системы представления знаний, как правило, появляются лишь тогда, когда в
рамках разумного компромисса учтены все эти требования.
6.4. Инструментальные пакеты для ИИ
Развитые среды автоматизации программирования на базе языков символьной
обработки являются необходимым технологическим уровнем систем поддержки
разработки прикладных интеллектуальных систем. Как правило, такие среды
покрывают (и то частично) подсистему автоматизации проектирования и про-
граммирования. Вот почему следующим этапом в развитии инструментальных
средств стала ориентация на среды поддержки разработок интеллектуальных
систем.
Анализ существующих инструментальных систем показывает, что сначала в об-
ласти ИИ более активно велись работы по созданию интеллектуальных систем
автоматизированного синтеза исполнительных программ. И это естественно,
если иметь в виду, что инструментарий ИИ является, по существу, эволюцион-
ным развитием систем автоматизации программирования. При этом основная
доля мощности и интеллектуальности такого инструментария связывалась не с
его архитектурой, а с функциональными возможностями отдельных компонен-
тов той или иной технологической среды. Большое значение при разработке ин-
струментария для ИЙ уделялось и удобству сопряжения отдельных компонен-
тов. Пожалуй, именно здесь были получены впечатляющие результаты и именно
здесь наиболее широко использовались последние достижения теории и прак-
тики программирования, такие, например^ как синтаксически-ориентирован-
ное редактирование и инкрементная компиляция. Вместе с тем подавляющее
большинство современных инструментальных систем «не знают», что проекти-
рует и реализует с их помощью пользователь. И с этой точки зрения можно ска-
зать, что все такие системы являются не более чем «сундучками» с инструмента-
ми, успех использования которых определяется искусством работающего с ними
мастера. Примерами подобных сред служит подавляющее большинство инстру-
6.4. Инструментальные пакеты для ИИ
225
ментальных пакетов и систем-оболочек для создания экспертных систем типа
EXSYS [EXSYS, 1985], GURU [MDBS, 1986] и др. [Harmon, 1987]. Однако не
они определяют на сегодняшний день уровень достижений в этой области.
К первому эшелону большинство специалистов относит системы ART [ART,
1984], КЕЕ [Florentin, 1987] и Knowledge Craft [CARNEGIE, 1987]. Заметим, что
в последнее время в класс самых мощных и развитых систем вошла и среда G2
[CATALYST, 1993]. Все эти системы, во-первых, отличает то, что это, безусловно,
интегрированные среды поддержки разработки интеллектуальных (в первую
очередь, экспертных) систем. И вместе с тем для этих систем характерно не эклек-
тичное объединение различных полезных блоков, но тщательно сбалансирован-
ный их отбор, что позволило сделать первые шаги от автоматизации програм-
мирования систем ИИ к технологическим системам поддержки проектирования
сначала экспертных, а затем и других интеллектуальных систем.
Остановимся чуть подробнее на двух системах из «большой тройки» — ART и
КЕЕ, а в заключение кратко охарактеризуем систему G2. Сравнение основывает-
ся, главным образом, на работах [Wall et al., 1986; Richer, 1986; Gillmore et al.,
1985] и на информации, полученной от дилеров этих систем.
В середине 80-х годов система ART была одной из самых современных интегри-
рованных сред (ИС), поддерживающих технологию проектирования систем, ос-
нованных на правилах. В ней существует ясное и богатое разнообразие типов пра-
вил. Различные типы правил элегантно вводятся с помощью мощного механизма
«точек зрения» (Viewpoint). Этот механизм фактически является очень близким
к системе, основанной на истинности предположений (truth maintanance system)
[de Kleer, 1989], которая, по-видимому, является развитием идей KEEWorlds+ в
системе КЕЕ. По существу, ART является пакетом разработчика. При этом воз-
можные ограничения в использовании ART вызваны не свойствами самой систе-
мы, а философией базового метода представления знаний.
ART объединяет два главных формализма представления знаний: правила для
процедурных и фреймоподобные структуры для декларативных знаний. Глав-
ным является формализм продукционных правил. Декларативные знания опи-
сываются через факты и схемы [schemata] и в некоторых случаях через образцы
[patterns]. Кроме факторов числовой неопределенности, которые связываются с
индивидуальными фактами, в ART различаются факты, которые явно принима-
ются за ложные, и факты, истинность которых неизвестна. Возможно использо-
вание логических зависимостей, которые позволяют изменить факты позже,
если обнаружится, что онш на самом деле оказались ложными. Механизм View-
point допускает образование нескольких конкурирующих миров, где пробуются
альтернативные решения.
Схема предусматривается в ART в качестве макроформы для выражения таксо-
номических знаний в структурированном виде, но ни метод, ни активные значе-
ния или выход в базовый язык в этом декларативном представлении не допус-
каются. ART обеспечивает 11 системно-определенных свойств, наследование
которых поддерживается системой автоматически. Допускается множествен-
ное наследование. Однако средства задания активных значений, указания ограни-
226
Глава 6 • Программный инструментарий разработки систем
чений на слот и привязки процедурных знаний к слотам здесь отсутствуют. Та-
ким образом, роль компонента, основанного на фреймах, является чисто опи-
сательной. Ограничения и значения по умолчанию могут быть обеспечены в
правилах, хотя их было бы легко установить непосредственно с помощью процедур-
но-ориентированного фреймового, формализма. Наследование, определяемое
пользователем, не допускается, но тоже может быть смоделировано посред-
ством правил [Wall et al., 1986]. Согласно концепции фирмы Inference Corpora-
tion это является преимуществом, так как статическое наследование предус-
матривает мощную прекомпиляцию эффективного кода.
Продукционные знания описываются с помощью правил пяти видов: правила
выводов, продукционные правила, гипотетические правила, правила ограниче-
ний и правила полаганий. Правила вывода добавляют факты в базу знаний, в то
время как продукционные правила изменяют факты в рабочей памяти (напри-
мер, значение атрибута объекта). Гипотетические правила позволяют в ART ис-
пользовать возможности формирования гипотез и представляются в следующей
форме: «ЕСЛИ это случилось, ТО рассматривать это как гипотезу». Правила ог-
раничений описывают ситуацию, которая никогда не может появиться при пра-
вильной точке зрения на действительность. Правила полаганий используются
для предположений (которые принимаются за правильные) о точках зрения (ги-
потезах). При подтверждении гипотезой некоторого условия она принимается за
правильную, объединяется со всеми породившими ее гипотезами и становится
новым корнем в древовидной структуре. Другие, несовместимые, гипотезы отбра-
сываются.
Вызов процедур, определенных пользователем, может быть использован как в ле-
вых, так и в правых частях правил ART. Образцы (patterns) используются в ус-
ловной части правил. Они должны быть сопоставлены с фактами рабочей памя-
ти. Образцы могут включать переменные и логические связки, обеспечивающие
сочетание фрагментов модели (И, ИЛИ, НЕ, СУЩЕСТВУЕТ, ДЛЯ ВСЕХ).
ART предлагает традиционные модели вывода: «от фактов к цели» и «от цели к
фактам». Они могут объединяться в мощный механизм истинности, основанный
на предположениях, который допускает аргументацию типа ЧТО ЕСЛИ. Кроме
того, в составе ART используются и классические правила типа OPS.
Графическое окружение ART хорошо развито. Интерфейс ARTStudio включает в
себя базу знаний с демонстрацией гипотез, утилиты отладчика запускаемых про-
грамм, систему подсказок, доступную в любое время, систему меню и графичес-
кий пакет ARTist (ART Image Syntesis Tool ) с оконным редактором. ART предла-
гает редактор базы знаний, но не дает редактора схем, подобного внутреннему
графическому редактору КЕЕ [Wall et al., 1986; Richer, 1986], обсуждаемому
ниже. Как указывается в работе [Gillmore et al., 1985], это может стать причиной
ошибок при «глубоком» редактировании разрабатываемых баз знаний.
ARTist позволяет создавать доступные правилам меню и управлять окнами поль-
зовательского интерфейса, а также создавать сами окна. Графические конструк-
ции описываются с помощью схем и ссылаются на правила. Это обеспечивает
функционирование по принципу управления обращениями к данным.
6.4. Инструментальные пакеты для ИИ
227
ART часто представляют в качестве лучшей ИС для создания экспертных сис-
тем, но следует понимать, что хорошо эта среда отвечает лишь всем требованиям
подхода поверхностных знаний. Благодаря компилятору правил система вывода
в ART является быстрой по своей природе. Главные стратегии структуры управ-
ления поиском решений обеспечиваются, и некоторая гибкость в управлении по-
иском остается инженеру по знаниям. Чисто декларативные таксономические
фреймы языка интегрируются с системой правил, но в ART не существует дей-
ствительно процедурных фреймов, которые могли бы позволить объединить
предметные описания с продукционными. В этом отношении объектно-ориенти-
рованное программирование с образцами и возможностями моделирования мог-
ло бы быть более полезным. Нельзя сказать, что подход, основанный на моделях,
не осуществим в ART. Однако кажется, что другие ИС более эффективны для
этих целей.
Первые версии ART опирались на язык ЛИСП, последние реализованы непо-
средственно на С. Это увеличивает эффективность периода исполнения ART.
Введены в новые версии и некоторые другие усовершенствования. Они касаются
в основном выразительной силы формализма, основанного на фреймах, и увели-
чивают адекватность ART по отношению к методу аргументации, основайному
на модели. Имеется информация, что в ART включен и объектно-ориенти-
рованный подход.
Теперь рассмотрим основные свойства системы КЕЕ и типы задач, которые
«подходят?» для этой среды. КЕЕ фактически является большим набором хоро-
шо интегрированных ИИ-парадигм. Этот пакет включает продукционные пра-
вила, основанный на фреймах язык с наследованиями, логически-ориентирован-
ные утверждения, объектно-ориентированные парадигмы с сопутствующими
сообщениями и обеспечивает доступ в базовую LISP-систему. Кроме того, КЕЕ
предлагает средства для организации и объединения знаний в специфические
компоненты и явного структурирования процесса аргументации. Преимущества
КЕЕ заключаются также в мощности и дружественности пользовательского ин-
терфейса.
Главное отличие между формализмом представления знаний КЕЕ и ART заклю-
чается в способе, которым эти ИС связывают фреймы и правила. КЕЕ является
средой, в основе которой лежат фреймы, в то время как в ART — правила. Фрей-
мы в КЕЕ называются элементами (units) и вводятся в более широком смысле,
чем в ART. Здесь фреймы могут иметь процедурную роль и дают возможность
построения поведенческих моделей объекта и моделей экспертизы. С этой целью
к слотам могут привязываться активные значения и методы. Активные значения
могут выборочно активизировать системы правил. Таким образом, язык фрей-
мов КЕЕ позволяет представлять поведение независимых сложных компонент в
рамках подхода, основанного на модели, что обеспечивает разделение знаний на
проблемно-ориентированные фрагменты. При этом каждый компонент знаний
может быть активирован по требованию.
Описание объектов и правил в КЕЕ представляется в виде иерархий фреймов.
Доступны два основных отношения: классы/подклассы и классы/примеры. Каж-
228
Глава 6 • Программный инструментарий разработки систем
дый объект представляется слотами; в системе различаются индивидные (соб-
ственные) и коллективные слоты. Первые используются для описания атрибутов
и свойств класса, рассматриваемого в качестве объекта, а вторые описывают родо-
вые свойства членов класса. Слоты могут иметь различные аспекты, которые, в
свою очередь, могут иметь множественные значения. На них могут накладывать-
ся ограничения, которые могут использоваться в качестве автоматических утилит
для проверки целостности знаний. Этим КЕЕ отличается от ART, где ограниче-
ния могут выражаться только с помощью правил. Со слотами могут быть связаны
активные значения. Формализм продукционных правил в КЕЕ тоже хорошо раз-
работан. Использование переменных и вызов LISP-функций допускается как в
исполняемых, так и в условных частях.
КЕЕ предлагает несколько методик для моделирования рассуждений. Конечно,
при этом имеется базовый поисковый механизм, но КЕЕ позволяет также транс-
формировать неявные знания во фреймы и в решетки наследования, что дает
средства для моделирования операций аргументации.
КЕЕ (версия 3.0) обеспечивается системой, основанной на предположении ис-
тинности выполнения, называемой KEEWorld. Согласно заявлениям фирмы
IntelliCorp, она обеспечивает поддержку фундаментальных методов поиска в
пространстве состояний. Мощность КЕЕ проявляется при решении задач, где
процесс аргументации может трансформироваться, выполняться и управляться
с помощью фреймовых компонент. Решетка наследования фреймов позволяет
установить несколько видов зависимостей между объектами. Система снабжена
возможностями автоматического восстановления неявной информации. Утверж-
дается, что эта информация может быть представлена фреймами [Fikes et al.,
1985]. КЕЕ обеспечена эффективными возможностями восстановления и авто-
матической проверки информации. Для этой цели существует логический язык
TellandAsk, который используется для определения и восстановления фактов в
базе знаний КЕЕ.
Пользовательский интерфейс КЕЕ очень гибкий и тщательно проработанный.
Он включает мощный редактор, программу просмотра базы знаний, поясняющие
сообщения и т. д. Известно, что он превосходит по мощности интерфейс ART
[Wall et al., 1986; Richer, 1986]. КЕЕ обеспечивает пользователя графическими
средствами KEEpictures и Activelraages для построения графических представле-
ний. Последние могут быть привязаны к фреймовым слотам, и тогда изменение
значения слота приводит к изменению «картинки».
Следует отметить и недавнюю эволюцию системы. КЕЕ 2.1 не имел гипотети-
ческой системы или системы, основанной на предположении об истинности вы-
полнения. В КЕЕ 3.0 эти новые возможности доступны. А его открытая архитек-
тура является важным фактором в процессе настройки и расширения, так как
части КЕЕ написаны в самом КЕЕ. С одной стороны, это полезно для подтверж-
дения гибкости КЕЕ и способности к развитию. С другой — это может привести
к неэффективности исполняющей системы. Дополнительно фирма IntelliCorp
уже разработала пакет специализированных программ для КЕЕ. Одна из таких
программ — SIMKIT. Она спроектирована для поддержки моделирования в КЕЕ.
6.4. Инструментальные пакеты для ИИ
229
Таким образом, КЕЕ является развитой системой, основанной на фреймах, где
хорошо сбалансированы формализмы представления как декларативных, так и
процедурных знаний. Доступны в системе и методы явного управления и струк-
турирования процесса аргументации. Благодаря этому КЕЕ является подходя-
щим для решения задач в рамках подхода, основанного на модели.
Важнейшими при разработке интеллектуальных прикладных систем являются
вопросы формирования и отладки баз знаний. Но здесь КЕЕ, ART и многие дру-
гие инструментальные пакеты, к сожалению, идут по пути обычных систем авто-
матизации программирования. Пользователю предоставляется мощный графи-
ческий редактор правил, используемый для начального ввода продукций и
коррекции их в процессе отладки, и средства графической трассировки вывода
решений, которые должны позволить инженеру знаний ориентироваться во взаи-
модействии сотен и тысяч правил.
Инструментальная среда G2 — разработка фирмы Gensym Corp. — является раз-
витием известной экспертной системы реального времени PICON. По утвержде-
нию официального дилера этой фирмы в России Э. В. Попова, G2 является самой
мощной из сред для систем реального времени среди всех инструментов данного
класса. Система G2 реализована на всех основных вычислительных платформах,
включая рабочие станции Sun, НР9000, RS/6000 и ПЭВМ, работающие под уп-
равлением Windows NT. Возможна работа с системой в режиме клиент—сервер в
сети Ethernet.
Основные функциональные возможости G2 связаны с поддержкой процессов сле-
жения за множеством (порядка тысяч) одновременно изменяющихся параметров
и обработкой изменений в режиме реального времени; проверкой нештатных си-
туаций на управляемых объектах и принятием решений как в режиме ассистиро-
вания оператору, так и в автоматическом режиме. Функциональные возможнос-
ти системы обеспечиваются быстрым выполнением распараллеливающихся
операций, доступными в режиме on-line данными, блоками темпорального выво-
да (включая ссылки на прошлое поведение и поведение управляемого объекта во
времени, интеграцию с подсистемами динамического моделирования и проце-
дурными знаниями о времени), специальной техникой вывода решений в режиме
реального времени (включая стандартные forward и backward рассуждения, а так-
же event-driven выводы, сканирование датчиков для определения ситуаций, тре-
бующих немедленного вмешательства в процесс управления, механизмы фокуси-
рования на определенном подмножестве знаний с использованием метазнаний и
мощной подсистемой real-time truth maintenance). Все это дает возможность при-
кладным системам, разработанным с использованием G2, поддерживать на RISC-
архитектурах обработку 1000 правил/с реального уровня сложности.
Указанные параметры производят серьезное впечатление, и, хотя доступной тех-
нической информации по системе G2 явно недостаточно для окончательных
выводов о ее применимости во всем спектре заявленных приложений, можно
предположить, что система G2 действительно была одной из первых инструмен-
тальных сред, поддерживающих разработку интегрированных интеллектуальных
систем.
230
Глава 6 • Программный инструментарий разработки систем
В заключение настоящего параграфа остановимся на первых попытках интел-
лектуализации инструментальных средств. Следует сразу сказать, что здесь дос-
таточно четко просматриваются два направления: снизу (применение методов
ИИ для разработки программного обеспечения) и сверху (переход к системам
поддержки разработки баз знаний, основывающихся, в свою очередь, на метазна-
ниях).
Результаты, полученные с использованием методов ИИ в различных областях
человеческой деятельности, привели разработчиков МО к идее использования
интеллектуальных систем в программировании. Проект «Ассистент программи-
ста» в Массачусетском технологическом институте и проект «Пси» в Стэнфорд-
ском университете были первыми шагами в этом направлении [Waters, 1985;
Green, 1977]. В этих проектах предпринимались попытки промоделировать зна-
ния программиста, используемые для понимания, проектирования, реализации
и сопровождения ПО. Предполагалось, что эти знания могут быть использованы,
например, экспертной системой для частичной автоматизации процесса разра-
ботки ПО, однако существенных результатов в этой части, по-видимому, получе-
но не было.
Методы ИИ могут значительно увеличить мощность существующих инструмен-
тальных средств и в области разработки, оценки и проверки требований. Дей-
ствительно, часто пользователь не знает тех возможностей и особенностей, кото-
рые он хотел бы иметь от программной системы, и процесс разработки требований
напоминает процесс приобретения знаний. Понятно, что при этом соответствую-
щие инструментальные средства могут использоваться при формировании
пользователем своих требований. Вот почему ниже приводится краткий обзор
средств приобретения знаний и сопровождения баз знаний, дополняющий анало-
гичный материал предыдущих глав, но с акцентом на инструментальных компо-
нентах.
Исторически впервые автоматическое извлечение из экспертов конструктов и
создание репертуарных решеток, необходимых для построения поля знаний [Гав-
рилова и др., 1988], было реализовано в системе PLANET [Shaw, 1982; Shaw et al.,
1984]. Ряд алгоритмов и программ PLANET был впоследствии использован при
создании системы ETS [Boose, 1985а; Boose, 1985b; Boose, 1985с; Boose, 1986],
обеспечивающей не только автоматическое создание репертуарной решетки, но и
преобразование ее в традиционные для ЭС формы представления БЗ. Потомками
ETS являются система NeoETS [Boose et al., 1986] и интегрированная среда для
извлечения экспертных знаний AQUINAS [Boose et al., 1987]. Дальнейшим раз-
витием системы PLANET является интегрированная среда KITTEN [Gaines et al.,
1986; Gaines et al., 1987], поддерживающая ряд методов извлечения знаний.
Перечисленные выше системы поддержки процессов приобретения знаний, как
правило, ориентированы на отдельные фазы всего технологического цикла. Од-
ной из методологий, ориентированных на «интегрированные» средства поддержки
разработки, справедливо считается KADS, рассмотренная в параграфе 4.5. В этой
системе сделана, пожалуй, первая попытка объединения достижений «клас-
сической» технологии программирования и методов ИИ. В дальнейшем эта
6.5. WorkBench-системы
231
тенденция стала проявляться все более определенно, и лидерство, в конечном
счете, перешло к инструментальным системам нового поколения, основное отли-
чие которых состоит в том, что они опираются на знания о технологии проекти-
рования, реализации и сопровождения интеллектуальных систем. В настоящее
время попытки создания таких инструментальных систем наблюдаются в Work-
Bench, рассматриваемых ниже.
6.5. WorkBench-системы
Системы типа WorkBench в контексте автоматизации программирования — это интег-
рированные инструментальные системы, поддерживающие весь цикл создания и со-
провождения программ.
К основным характеристикам WorkBench-систем относятся:
1. Использование определенной технологии проектирования на протяжении всего
жизненного цикла целевого продукта.
2. Вертикальная интеграция инструментальных средств, обеспечивающая связи
и совместимость по данным между различными инструментами, используе-
мыми на разных стадиях создания целевой системы.
3. Горизонтальная интеграция моделей и методов, используемых на одной и той
. же стадии проектирования.
4. Сбалансированность инструментария, то есть отсутствие дублирующих ком-
понентов, «необходимость и достаточность» каждого инструмента.
Одна из систем данного типа разрабатывалась в рамках проекта VITAL [VITAL,
1990]. Отдельные стадии методологии поддерживаются здесь следующими сред-
ствами: анализ — подсистемой КАТ (Knowledge Acquisition ToolKit); проекти-
рование — подсистемой FTDT (Functional and Technical Design Tool); кодирова-
ние знаний — языком представления знаний; проверка и верификация — V&VT
(Validation and Verification Tool); поддержка и отладка — VT (Visualization
Tool).
WorkBench VITAL — тесно связанная с методологией система, пригодная для
промышленного применения. Обеспечивается это средствами трансформации
баз знаний в процедурное представление и развитыми средствами визуализации
для поддержки навигации по большим базам знаний.
В целом проект VITAL был достаточно амбициозным по своим целям и задачам,
но, учитывая финансирование его в рамках европейской научной программы
ESPRIT и задел основных исполнителей, вполне реальным.
Проект VITAL, если так можно сказать, определил философию разработки
WorkBench-систем. Ниже, в качестве примеров, рассматриваются две Work-
Bench-системы, KEATS [Motta et al., 1988] и Shelly [Bouchet et al., 1989], где эта
философия нашла некоторое реальное воплощение.
232
Глава 6 • Программный инструментарий разработки систем
Система KEATS (Knowledge Engineer’s Assistant); [Motta et al., 1988; Motta et al.,
1989} первоначально представляла собой набор инструментов, созданных для по-
мощи инженерам знаний в проведении анализа предметных знаний и разработки
концептуальной модели ПО (вот тут говорится про предметную область!!!).
В первой версии системы, Называемой KEATS-1 [Motta et al., 1988], были реали-
зованы редактор текстов CREF (Cross Reference Editing Facility) и графический
редактор GIS (Graphical Interface System), а также фрейм-ориентированный язык
описания знаний KDL (Knowledge Description Language) и интерпретатор про-
дукционных правил COPS (Context Oriented Production System).
Редактор текстов CREF помогает инженерам знаний провести анализ докумен-
тов, имеющих текстовую форму, и допускает установление связей между фраг-
ментами типа «ссылается», «обобщает», «заменяет», «предшествует».
Графический редактор GIS позволяет инженеру знаний быстро построить пред-
ставление концептуальной модели ПО (то же самое). Элементами графического
представления могут быть как фрагменты, выделенные посредством компонента
CREF, так и произвольные объекты исследуемой ПО (то же самое). Различаются
два вида графических элементов: классы (изображаются овалом) и примеры
(изображаются прямоугольником). Разные типы отношений между элементами
показываются разными стрелками. В KEATS-1 такое графическое представление
автоматически транслируется в текст на языке KDL. Поддерживается и обратное
отображение.
В работе [Motta et al., 1989] были проанализированы ограничения CREF и GIS
как инструментальных средств приобретения знаний. Анализ текстовых доку-
ментов в CREF и построение концептуальной модели ПО (то же самое), поддер-
живаемое GIS, являются хотя и разными, но тесно связанными видами деятель-
ности. Но поскольку в KEATS-1 они обеспечиваются разными программными
системами и автоматического интерфейса между ними нет, то построение кон-
цептуальной модели, элементами которой были бы сущности, выделенные в про-
цессе анализа, требует от инженера по знаниям дополнительных усилий. Поэто-
му естественно иметь такую инструментальную поддержку, которая позволяла
бы инженеру знаний строить концептуальную модель, исходя из информации, со-
держащейся в текстовых документах. Требуемая инструментальная поддержка
была реализована в подсистеме ACQUIST системы KEATS-2 [Motta et al., 1989].
Рассмотрим функциональные возможности ACQUIST подробнее. Выделение
фрагментов здесь реализуется посредством указания (с помощью мыши) на
область текста и задания имени понятия, релевантного отмеченному тексту. Име-
на понятий высвечены в виде элементов меню на том же экране, что и анализиру-
емый текст. Нескольким фрагментам может быть поставлено в соответствие одно
и то же понятие. Понятия могут быть заранее перечислены инженером знаний
или генерироваться непосредственно в процессе анализа текста. В последнем слу-
чае возможно «заводить» имена понятий вручную либо воспользоваться лекси-
ческим анализатором.
6.5. WorkBench-системы
233
В ACQUIST лексический анализ может выполняться над множеством указанных
пользователем текстов. Имеется возможность задать фильтр для отсеивания
слов, не представляющих интереса, который реализуется как обычный текстовый
файл, где перечислены такие «неинтересные» слова. На понятиях может быть за-
дана иерархическая структура. Пользователь ACQUIST может объединить в
одну группу близкие с его точки зрения понятия и дать название этой группе.
Группы понятий, в свою очередь, могут быть подвергнуты дальнейшему обобще-
нию.
ACQUIST позволяет связывать фрагменты, понятия, группы с помощью встро-
енных связей и связей, определенных самим пользователем. Для того чтобы ин-
женер знаний имел целостное представление о той структуре, которую он, уста-
навливая связи, создает, в ACQUIST имеется возможность построить «карту»
текущей структуры. Для одного и того же множества понятий, групп и фрагмен-
тов может быть построено много карт, каждая из которых соответствует некото-
рому «взгляду» на отношения между элементами. Пользователь имеет возмож-
ность не только просмотреть графическое представление, но и непосредственно
манипулировать его элементами. В частности, можно определять связи, переме-
щать графические объекты и подструктуры и т. п.
Сохраняемые версии результатов анализа называются здесь теориями. ACQUIST
позволяет одновременно загрузить несколько теорий и при необходимости пере-
ключаться от одной теории к другой. По желанию пользователя различные тео-
рии могут быть слиты. ACQUIST создан с использованием методологии объект-
но-ориентированного программирования: фрагменты, понятия и группы реали-
зованы как объекты.
Новая версия системы KEATS, которая была развитием предыдущей, разработа-
на в лаборатории когнитологии Открытого университета Великобритании и
финансировалась British Telecom. Corp. По определению авторов, KEATS — про-
граммное окружение, поддерживающее построение систем, основанных на знани-
ях. Основное назначение — поддержка разработки ЭС на критических стадиях —
приобретение и кодирование знаний, отладка БЗ [Motta et al., 1989].
Данная система поддерживает не только отдельные методы моделирования, но и
обеспечивает интегрированную программную поддержку взаимосвязанных мо-
делей знаний. Основные компоненты KEATS: ACQUIST — средство фрагмен-
тирования текстовых источников знаний, которое позволяет разбить текст или
протокол беседы с экспертом на множество взаимосвязанных, аннотирован-
ных фрагментов (гипертекст) и создать концепты (понятия); FLIK — фреймово-
ориентированный язык представления знаний; GIS — графический интерфейс,
используемый как для создания гипертекстов и концептуальных моделей с по-
мощью ACQUIST, так и для проектирования фреймовых систем на основе языка
FLIK; ERI — базисный интерпретатор правил, обеспечивающий прямой и об-
ратный вывод по продукциям; TRI — визуализирующий интерпретатор правил,
демонстрирующий трассу выполнения продукций в виде мозаичной таблицы, а
234 Глава 6 « Программный инструментарий разработки систем
также графически отражающий активные правила, фреймы и конфликтное мно-
жество; Tables — интерфейс манипулирования таблицами, который может ис-
пользоваться вместе со всеми моделями знаний, поддерживаемыми в KEATS;
CS — язык описания и распостранения ограничений; TMS — немонотонная сис-
тема сопровождения истинности, тесно связанная с ERI, FLIK и CS, а также
TMV — графический интерфейс «подсистемы TMS, обеспечивающий визуализа-
цию на И/ИЛИ дереве значения истинности или ложности заключений в зави-
симости от посылок.
В системе KEATS концептуальные модели могут создаваться с помощью методов
«сверху—вниз» и «снизу—вверх». Первый подход используется при четко опре-
деленной задаче и наличии специфической модели в ПО (то же самое), например
в задачах диагностики. Специфическая модель может быть сразу же отражена в
виде таблиц и концептуальных моделей и имплантирована в будущую ЭС с помо-
щью GIS и Tables. Когда приобретение знаний основывается не на четко опреде-
ленной модели ПО, а, например, на протоколе опроса эксперта, используется вто-
рой подход. Текстовые данные анализируются и фрагментируются с помощью
ACQUIST, и выделяются концепты. Созданная модель затем визуализируется с
помощью GIS.
Интеллектуальная система Shelly [Bouchet et al., 1989] является представителем
следующего поколения программной поддержки KADS-методологии. Она спо-
собна не только обеспечивать выполнение работ, предусматриваемых методоло-
гией, но и советовать инженеру знаний, когда и как выполнять ту или иную рабо-
ту, а также объяснять, почему это необходимо. Система Shelly разрабатывалась
как интегрированная программная среда, поддерживающая весь процесс созда-
ния ЭС, если он осуществляется в соответствии с KADS-методологией. И про-
цесс разработки самой системы Shelly является примером практического ее при-
менения.
Согласно KADS-методологии, рассмотренной в п. 4.5, необходимо провести анализ
четырех типов знаний, относящихся соответственно к уровням стратегий, задач,
выводов и предметной области. К уровню стратегий относятся знания, обеспечи-
вающие гибкость разрабатываемой системы, ее способность решать разнообраз-
ные проблемы, выбирая или формируя подходящие стратегии. Для системы
Shelly такими проблемами являются: управление деятельностью инженера зна-
ний, разрабатывающего прикладную ЭС; слежение за процессом разработки ЭС;
выдача советов, подсказок, объяснений по требованию пользователя.
Знания стратегического уровня, необходимые для решения этих проблем, пред-
ставляют собой набор правил, задающих условия начала и завершения каждого
вида работы, предусмотренной KADS-методологией. Иерархия видов работ, а
также описания тех работ, выполнение которых поддерживается Shelly, состав-
ляют знания уровня задач. К уровню выводов относятся знания о конкретных
действиях, с помощью которых может быть выполнена та или иная работа. Уро-
вень предметной области составляют описания тех объектов, над которыми мо-
гут выполняться действия, относящиеся к уровню выводов. При этом различа-
6.5. WorkBench-системы
235
ются объекты, используемые в KADS-методологии («понятие», «метакласс»
и т. п.), объекты, обусловленные программной реализацией методологии («фраг-
мент», «связь» и т. п.), и объекты, обусловленные природой интерфейса («окно»,
«текст» и т. п.).
Основное проектное решение при создании системы Shelly состоит в том, что
каждому виду деятельности здесь соответствует свое инструментальное средство
AST (Activity Support Tool).
Центральным модулем в Shelly является управляющий модуль «Advice & Gui-
dance». Он предназначен для информирования пользователя о текущем состоя-
нии разработки его прикладной ЭС; обеспечивает ответы на конкретные вопросы
пользователя; рекомендует пользователю дальнейшие действия и активирует со-
ответствующий модуль AST; предупреждает пользователя о нарушении им
KADS-методологии.
Модуль «Advice & Guidance» может функционировать в двух режимах, различа-
ющихся степенью сложности. Первый, простой режим, «локального совета», ак-
тивируется посредством явного запроса, поступившего от пользователя. Во вто-
ром режиме пользователь может получить рекомендации относительно того, как
наиболее эффективно работать с Shelly. Система будет постоянно следить за дея-
тельностью пользователя и при необходимости предупредит его и объяснит,
почему рекомендуется выполнять ту или иную работу.
Рабочую память Shelly составляют база знаний, базы данных о разработках ЭС и
база внешних форм. В.базе знаний хранятся описания объектов KADS-методо-
логии и соответствующих видов деятельности. Каждый вид деятельности пред-
ставлен фреймом со следующим набором слотов
Пример 6.1
описание: <текст>
цель: <текст>
когда: <текст>
как: <текст>
вход: <объект КАВ5-методологии>
выход: <объект КАВ5-методологии>
связан с: <вид деятельности>
поддерживается: AST
Кроме того, в базе знаний имеется набор правил, позволяющих управлять про-
цессом разработки прикладной ЭС.
Пример 6.2
ЕСЛИ Деятельность 1> по проекту X = «завершена» И
Деятельность2> по проекту X = «завершена»
ТО возможно начать <деятельностьЗ> по проекту X.
236 Глава 6 • Программный инструментарий разработки систем
В базах данных о разработках ЭС представлены примеры объектов KADS-мето-
дологии, построенные на конкретном предметном материале, а также информа-
ция о текущем статусе каждого вида деятельности («завершена», «начата», «не
начата»).
Понятно, что фрагментарный обзор WorkBench-систем, приведенный выше, не
дает полного представления обо всех их функциональных возможностях. Одна-
ко для нас важна, прежде всего, тенденция развития инструментальных средств
поддержки разработки интеллектуальных систем, состоящая в том, что уже име-
ются положительные примеры WorkBench-инструментария, ориентированного
на весь жизненный цикл создания систем, основанных на знаниях.
в Пример разработки
системы,
основанной
на знаниях
□ Продукционно-фреймовый ЯПЗ PILOT/2
□ Психодиагностика — пример предметной области для построения
экспертных систем
□ Разработка и реализация психодиагностической ЭС «Cattell»
7.1. Продукционно-фреймовый ЯПЗ PILOT/2
В любом языке программирования можно выделить три составляющие: декла-
ративную (описания данных), процедурную (правила преобразования данных)
и инференциалъную (правила управления компонентами процедурной, а иногда
и декларативной составляющих). Не исключение в этом смысле и языки пред-
ставления знаний, но их специфика в том, что описания здесь в основном струк-
турные, а данные могут быть активными за счет присоединенных процедур, обес-
печивающих «вычисление» их значений; правила преобразования данных ориен-
тированы скорее на то, чтобы явно специфицировать, что должно быть получено,
не концентрируя без необходимости внимание программиста на том, как дости-
гается результат. Но самое большое отличие ЯПЗ от других языков в инферен-
циальной компоненте, которая реализует некоторую (чаще всего встроенную)
стратегию поиска решения. Такой подход предполагает, что при выполнении
ЯПЗ-программ всегда существует «арбитр», функцией которого является оцен-
ка «текущей ситуации» и выбор пути движения от нее к целевой.
В разных ЯПЗ имеются различные средства определения декларативной, проце-
дурной и инференциальной составляющих. Отличия же здесь связаны, в первую
очередь, с использованием того или иного подхода к представлению знаний.
В качестве примера развитых средств продукционно-фреймового программиро-
вания баз знаний ниже обсуждается ЯПЗ PILOT/2, разработанный в рамках про-
екта PiES WorkBench [Khoroshevsky, 1994b], Его специфика в том, что здесь вве-
238
Глава 7 • Пример разработки системы, основанной на знаниях
дены явно достаточно мощные средства программирования инференциальной
составляющей и выразительные описания образцов, а также удобный и открытый
для расширения набор операторов преобразования данных в основной и внешней
памяти.
%
7.1.1. Структура ПИЛОТ-программ и управление
выводом
В общем случае PILOT-программа содержит две основные (декларативная и про-
цедурная) и две вспомогательные (включение файлов и переопределение строк)
компоненты. Декларативная часть состоит из элементов, специфицирующих пе-
ременные, прототипы функций и/или процедур, а также необходимые базы зна-
ний. Продукционная часть состоит из секций, которые, в свою очередь, содержат
продукции. Инференциальная составляющая присутствует в ЯПЗ PILOT/2 не-
явным образом в виде встроенного «арбитра», алгоритм работы которого описы-
вается ниже, и, кроме того, определяется средствами настройки и перепрограмми-
рования такого «арбитра».
Разбиение на секции и правила и специальные условия в виде секционных и пра-
виловых разрешений необходимы для того, чтобы обеспечить многоуровневое
управление выполнением PILOT-программ. Как известно [Форсайт, 1987], «ар-
битр» продукционной системы функционирует следующим образом: сначала для
всех продукций проверяются условия применимости и из тех продукций, для ко-
торых эти условия истинны, формируется конфликтное множество. Из этого
множества по определенному критерию выбирается исполняемая продукция; она
реализуется (то есть отрабатывается ее правая часть), и цикл управления работой
«арбитра» повторяется, пока конфликтное множество на некотором шаге не ста-
нет пустым (тогда работа продукционной системы завершается естественным об-
разом) или функционирование не будет прервано явным образом, например с
помощью специального действия из правой части исполняемой продукции
(в этом случае работа продукционной системы завершается принудительно).
Понятно, что работа такого «арбитра» имеет смысл лишь в тех случаях, когда про-
дукций немного (десятки), а в конфликтном множестве продукций мало (едини-
цы). В противном случае функционирование системы неэффективно и требуют-
ся специальные алгоритмы, чтобы «арбитр» не тратил все время только на себя.
К настоящему времени разработаны и опробованы на практике различнее стра-
тегии увеличения эффективности работы «арбитра» [de Kleer, 1989], которые
используются и в данном случае. Но не менее важно иметь гибкие средства описа-
ния этих стратегий с уровня входного языка. Тогда пользователь, в зависимости
от требований его задачи, сможет отказаться от стандартных стратегий и описать
свою собственную, которая адекватна его конкретному случаю.
Для описания стратегий управления выводом решений в ЯПЗ PILOT/2 служат
секционное и правиловое разрешения. Каждое из них является последовательно-
стью фильтров, с помощью которых формируется и/или изменяется конфликт-
ное множество продукций. Для понимания того, как пользоваться этими фильт-
7.1. Продукционно-фреймовый ЯПЗ PILOT/2
239
рами, необходимо знать стратегию встроенного «арбитра» PILOT/2. Поэтому
ниже приводится алгоритм его работы, специфицирующий схему, представлен-
ную на рис. 7.1.
Алгоритм работы встроенного «арбитра» ЯПЗ PILOT/2
while (уровень-0 != NULL ) {
«выбрать из «повестки-дня» секцию для выполнения»;
«сформировать на уровне-1 мн-во правил этой секции»;
«выполнить фильтрацию мн-ва правил на уровне-1 по флагу активна/
неактивна»;
«выполнить фильтрацию мн-ва оставшихся правил на основании вычисления
истинности секционного разрешения»;
«сформировать на уровне-2 множество активных правил»;
for (каждого правила на уровне-2) {
«вычислить значение истинности левой части»;
if ( значение истинности правила == TRUE )
«добавить правило в конфл. мн-во на уровне-3»;
}
«выполнить фильтрацию мн-ва оставшихся на уровне-3 правил на основании
вычисления истинности правиловых разрешений»;
«сформировать на уровне-4 множество готовых к выполнению правил»;
if ( на уровне-4 осталось одно правило )
«выполнить данное правило»;
else{
«выполнить случайный выбор исполняемого правила из множества
правил на уровне-4»;
«выполнить данное правило»;
}
}
Приведенный алгоритм прозрачен и не нуждается в особых комментариях. Заме-
тим лишь, что фильтр «активна/неактивна» реализован как встроенная проверка
флагов активности продукций текущей секции. Первоначально (при запуске сек-
ции) «арбитр» считает, что все продукции секции активны, но в процессе вы-
полнения их состояние может измениться за счет применения соответствующих
действий. Фильтр секционного разрешения тоже программируется с уровня
входного языка. В результате применения этих двух фильтров формируется мно-
жество продукций, которые принципиально могут войти в конфликтное множе-
ство. Этап фильтрации продукций по истинности левых частей — традиционный,
240
Глава 7 • Пример разработки системы, основанной на знаниях
в результате получается традиционное конфликтное множество (правда, уже усе- -
ченное за счет предыдущих двух фильтров). На этом множестве в ЯПЗ PILOT/2
может быть организовано дополнительное управление за счет программируемых
правиловых разрешений. Если все усечения не привели к однозначному выбору
исполняемой продукции, она выбирается случайным образом и цикл работы «ар-
битра» повторяется.
Section Main Si
Уровень О
Точек «влияния» на работу «арбитра» PILOT/2 всего четыре: активность/неак-
тивность продукций; секционное разрешение; истинность левых частей продук-
ций; правиловое разрешение. Существует и пятая точка — алгоритм случайного
выбора, но она инженеру по знаниям недоступна.
Секционные и правиловые разрешения суть последовательность операторов
if-then-else и действий разрешения. При этом сами условия секционного и пра-
вилового разрешений — логические формулы в базисе И-ИЛИ-НЕ с общепри-
нятым старшинством операций. А специфика ЯПЗ PILOT/2 состоит в том, как
определяются элементарные разрешения. Семантика действий разрешений (при
условии, что через КМ обозначено конфликтное множество) — следующая:
7,1, Продукционно-фреймовый ЯПЗ PILOT/2 241
set (Rl, R2,Rk)
insert (Rl, R2,Rk)
remove (Rl, R2,..., Rk)
removeall
break
KM = Rl, R2,..., Rk
KMH - KMC + Rl + R2 + ... + Rk
KMH = KMC - Rl - R2 - ... - Rk
KM = пустое множество
Прерывает выполнение оставшихся элементов
секционного или правилового разрешения
Семантика элементарных секционных (продукционных) разрешений— опреде-
ляется правилами вида:
1. Элементарное секционное разрешение active(Rl,R2,...,Rk) истинно, если все
продукции Rl, R2,..., Rk имеют включенные флаги активности.
2. Элементарное секционное (продукционное) разрешение used(Rl,R2,...,Rk) ис-
тинно, если все продукции Rl, R2,..., Rk применялись ранее.
3. Элементарное продукционное разрешение ready(Rl,R2,...,Rk) истинно, если
все продукции Rl, R2,..., Rk готовы к выполнению, что, в свою очередь, спра-
ведливо, если их левые части (условия) истинны.
Понятно, что практически все элементарные разрешения работают с именами
продукций, так что проверка соответствующих условий выполняется «арбит-
ром» достаточно быстро. И этих средств (в подавляющем большинстве случаев)
достаточно для существенного увеличения гибкости управления продукцион-
ной системой и сохранения в то же время приемлемой эффективности ее работы.
Вместе с тем в ЯПЗ PILOT/2 инженеру по знаниям предоставлена возможность
управления работой продукционной системы и на основе анализа базы знаний.
Нужно лишь понимать, что это управление «дорогое», так что пользоваться им
следует лишь в тех случаях, когда соответствующие условия невозможно (или
нецелесообразно) проверять в левых частях продукций.
7.1.2. Декларативное представление данных
и знаний
Декларативная часть PILOT-программы состоит из элементов, специфицирую-
щих типы данных, прототипы функций и/или процедур, переменные, а также не-
обходимые базы знаний.
Спецификация типов — мощное средство конструирования новых типов данных,
которые поддерживаются системой автоматически на основании базовых типов.
В ЯПЗ PILOT/2 фиксированы следующие базовые типы: int, float, char, string,
имя-фрейма, prototype, frame, func, proc. Без учета спецификации ограничения это
дает почти те же возможности, что и спецификация typedef в языках С и C++.
Однако в ЯПЗ PILOT/2 существуют и множественные типы, симметричные по
отношению к базовым, а также усечение вновь вводимых типов с помощью огра-
242 Глава 7 • Пример разработки системы, основанной на знаниях
ничений. Последние задают в базисе И-ИЛИ-НЕ ограничения, которым должны
удовлетворять значения соответствующего типа. Так, например, спецификация
Child is_a Age restr_by (>0 && <12);
вводит подтип типа Age, значения которого должны быть положительными целы-
ми в интервале [0, 12].
Спецификации
Persons is_a {frame};
Friends is_a Persons restr_by (>={Петр, Иван} );
определяют, что элементами типа Friends являются элементы типа Persons, вклю-
чающие в себя, по крайней мере, два указанных явно элемента.
Обработка сложно структурированных данных во внешней памяти является от-
личительным свойством всех ЯПЗ. Но помимо этого нужны и «обычные» пе-
ременные. Вот почему в ЯПЗ PILOT/2 введены регистры и стеки. Семантика
регистров такая же, как у простых переменных традиционных языков програм-
мирования. Иначе обстоит дело со стеками. Для явной спецификации поведения
стеков в ЯПЗ PILOT/2 введены префиксы и постфиксы, которые являются од-
номестными операторами, аналогичными по синтаксису унарным операторам
(++) и (—) современных языков программирования. Семантика их зафиксиро-
вана в табл. 7.1. Одна и та же переменная, в зависимости от наличия или отсут-
ствия префикса (постфикса), трактуется либо как регистр, либо как стек. Для
выделения имен переменных в текстах PILOT-программ им предшествует сим-
вол «$».
Таблица 7.1. Семантика переменных в языке PILOT/2
Стековые переменные
GET-переменные
PUT-переменные
Слева
Взять
с сохранением
<
Взять без
сохранения
Добааить
новое значение
Заменить верхушку
на новое значение
Справа
Ядром декларативного представления данных и знаний в ЯПЗ PILOT/2 является
спецификация баз — временных и постоянных. Все базы в ЯПЗ PILOT/2 фрей-
мовые и поддерживаются на этапе выполнения продукционных программ специа-
лизированным пакетом FRAME/2 [Sherstnew et al., 1994].
Спецификация временной базы предполагает, что определенные здесь фреймы
имеют «время жизни», совпадающее с периодом выполнения PILOT-програм-
мы, а ее имя — встроено в систему и не может быть изменено. Типичный пример
определения временной базы — следующий:
base = { спецификация-фрейма, .... спецификация-фрейма };
Иначе обстоит дело с постоянными базами. Их «время жизни» никак не связано с
конкретной PILOT-программой, а имена выбирает сам пользователь. Такие базы
7.1. Продукционно-фреймовый ЯПЗ PILOT/2
243
могут создаваться и/или использоваться в данной PILOT-программе. Примера-
ми определения постоянных баз могут быть следующие спецификации:
base system = { фрейм-1....... фрейм-N };
extern base person = { фрейм-1, фрейм-2, фрейм-3 };
base new;
base ( a1, a2, ... aN ) = { фрейм-1, фрейм-2.......фрейм-L };
И в случае временных, и в случае постоянных баз основным элементом определе-
ния является спецификация фрейма:
спецификация-фрейма ::= || спецификация-прототипа ||
|[спецификация-экземпляра ||
спецификация-прототипа ::= [ имя-фреймаis_a prototype
{{; спецификация-демона }} {{; декларация-слота }}]
г
спецификация-экземпляра ::= [
|| имя-фрейма || is_a имя-фрейма
|| ( имя-фрейма {{ , имя-фрейма }} ) ||
{{;спецификация-демона}} {{;спецификация-слота }}]
спецификация-слота ::=
|| || имя-слота
|| || ( имя-слота {{, имя-слота }} )
|| without имя-слота {{, имя-слота }}
11 декларация-слота
|| = значение
декларация-слота ::= || имя-слота || тип
|| ( имя-слота {{ , имя-слота }} ) ||
{{ ; дополнительная-спецификация }}
дополнительная-спецификация ::= || спецификация-демона ||
11 спецификация-умолчания 11
|| спецификация-ограничения ||
спецификация-демона ::= || if_added || имя-демона ( )
11 if_deleted | |
11 Unchanged | |
спецификация-умолчания by_default значение
спецификация-ограничения ::= restr_by спецификатор
Из этих определений следует, что ЯПЗ PILOT/2 является сильно типизирован-
ным языком и, следовательно, обеспечивает строгую проверку правильности ис-
244
Глава 7 • Пример разработки системы, основанной на знаниях
пользования типов на этапе трансляции. Такой подход повышает надежность
проектирования продукционных программ и увеличивает их эффективность.
Теперь рассмотрим примеры спецификации фреймов. Первый из них — специ-
фикация прототипа вида:
[Person is_a prototype;
Name string, if „changed ask_why () ;
Age int, restr_by >= 0 ;
Sex string, restr_by (==«male>> || ==«female»),
by_default «male» ;
Children {frame}];
Из этого описания следует, что у фрейма Person, заданного как корневой прото-
тип, имеются четыре слота с именами Name, Age, Sex и Children. Каждый слот мо-
жет иметь значение определенного типа. Значениями слотов Name и Sex могут
быть строки, слота Age — число, а слота Children — множество ссылок на другие
фреймы. Кроме обязательной спецификации типа слот может иметь дополни-
тельную спецификацию. Так, чтобы показать, что значение слота Age должно
быть не меньше 0, а слот Sex может принимать только два значения, «male» или
«female», использована дополнительная спецификация restr_by. Конструкция,
следующая за этим ключевым словом, называется спецификатором и представ-
ляет собой логическое выражение особого вида. Другая дополнительная специ-
фикация, by_default, определяет значение слота по умолчанию. Например, если
в экземпляре фрейма Person не будет указано конкретное значение слота Sex, оно
будет равно «male».
Кроме этих дополнительных спецификаций имеются в ЯПЗ PILOT/2 и специ-
фикации демонов. Они определяют присоединенные процедуры, которые «запус-
каются» при добавлении (if_added), удалении (if_deleted) или изменении значе-
ний (if_changed).
Любой фрейм может стать прототипом для других фреймов:
[ John is_a Person; if_deleted bury();
Name = «Johnson» ;
Age = 32 ;
Children = {Ann, Tom} ];
[ Mary is_a Person;
without Age ;
Name = «Smirnova» ;
Sex = «female» ;
Children = empty];
Приведенные выше фреймы John и Mary — экземпляры фрейма Person. Их сло-
ты получают конкретные значения. Фрейм-экземпляр может не иметь некото-
рых слотов своего прототипа (имена таких слотов перечисляются после ключе-
вого слова without) и может иметь дополнительные слоты, специфицируемые
так же, как и в прототипе.
7.1. Продукционно-фреймовый ЯПЗ PILOT/2
245
7.1.3. Процедурные средства языка
При обсуждении примеров спецификаций фреймов мы пользовались интуи-
тивным пониманием значения. Спецификация этого понятия в ЯПЗ PILOT/2
следующая. Значения могут быть простыми (единичными) и множественными.
Множественные значения — списки простых значений одного типа, заключен-
ные в фигурные скобки. В качестве простых значений в PILOT/2 выступают вы-
ражения.
Введение префиксов и постфиксов к именам переменных является первым шагом
на пути определения выражений. Но в ЯПЗ PILOT/2 есть и более мощные сред-
ства этого типа. Здесь используются традиционный набор арифметических опе-
раций и общепринятое их старшинство, а специфика ЯПЗ на уровне первичного
выражения:
перв-арифм
| число 11
| GET-переменная ||
| VAR-переменная ||
| - перв-арифм | |
| вызов-функции ||
| ( арифметическое ) ||
| слот-фрейма ||
вызов-функции ::= имя-функции ( значение {{, значение }} )
Первые шесть вариантов вполне традиционны, а последний имеет следующее оп
ределение:
слот-фрейма ::= [ имя-фрейма : имя-слота ]
Учитывая вышесказанное, следующие примеры суть правильно построенные вы-
ражения ЯПЗ PILOT/2:
empty
“а"
«qwerty»
Person
$NameFrame
$AgeValue>
10 * ( $var1 + 2 ** 4 )
[John : Age]
пустое выражение
ASCII-символ char
строка string
имя-фрейма frame
VAR-переменная frame
GET-переменная int
арифметическое int
слот-фрейма int
my_func («events.kb»; [Event : Value])вызов-функции bool
Теперь вернемся к основному средству построения конфликтного множества —
к условиям. Напомним, что в ЯПЗ PILOT/2 две точки, где, согласно синтаксису
языка, возможно использование условий: конструкция if в секционных и прави-
ловых разрешениях и левые части продукционных правил. И в том и в другом
случае инженер по знаниям может сформулировать произвольную условную
246
Глава 7 • Пример разработки системы, основанной на знаниях
конструкцию в базисе И-ИЛИ-НЕ с общепризнанным старшинством логичес-
ких операций. Кроме того, на уровне первичных условий возможно использова-
ние отношений и образцов.
Образцы являются наиболее важной и мощной конструкцией языка PILOT/2,
так как они позволяют находить и фиксировать интересующую инженера по зна-
ниям ситуацию в базе знаний. По синтаксису образец похож на слот-фрейма, но у
него существенно большие возможности и другая семантика. Образец — это пре-
дикат на базе знаний, принимающий значения «истина» или «ложь», тогда как
слот-фрейма возвращает значение конкретного слота конкретного фрейма. Обра-
зец определяет некий шаблон, которому могут удовлетворять фреймы из базы
знаний. Образец состоит из синтаксического обрамления «?[...]» и тела. Тело
представляет собой шаблон фрейма, которому, быть может, предшествует конст-
рукция «захвата» результатов отождествления в переменную, и список слотов-
образцов, который может быть пустым. Каждый слот-образец также имеет шаб-
лон слота в качестве базы отождествления и, быть может, конструкцию «захвата»
результатов. Таким образом, тело определяет структуру, которую должны иметь
фреймы базы знаний, чтобы успешно сопоставиться с образцом. Шаблон фрейма
определяет множество фреймов базы, на которых будет происходить отождеств-
ление. Это множество может состоять из единственного фрейма (при этом указы-
вается имя фрейма или его отрицание); всей базы (тогда шаблоном фрейма явля-
ется символ «*»); фрейма (фреймов), имена которых хранятся в переменных типа
VAR или GET, а также фиксироваться с помощью конструкции явного задания
множества, образованного из элементов и стандартных теоретико-множествен-
ных операций one_of (пересечение); all_of (объединение); - (вычитание). Пус-
той префикс соответствует операции one_of. При этом семантика операции
one_of — «первый из сопоставленных». Операция «вычитание» может использо-
ваться только с именами фреймов, заданными явно. Результаты успешных сопо-
ставлений могут запоминаться в переменных с помощью операции присваивания
(в случае префикса one_of или его отсутствия запоминается результат первого
успешного сопоставления, а в случае префикса all_of — результаты всех успеш-
ных сопоставлений). Шаблон слота практически тот же, что и шаблон фрейма.
Однако для слотов есть еще один способ указания объединения — перечисление
нужных слотов через разделитель «;». Отличие шаблона слота от шаблона фрей-
ма в том, что здесь добавляется значение-образец. Как и в предыдущих случаях,
найденные значения могут «захватываться» в переменные. Шаблон значения мо-
жет фиксировать, что оно произвольно, но существует (в этом случае использует-
ся символ «*», либо определить возможные значения более точно с помощью эле-
ментов (значение-первичного-спецификатора) и логических операций в базисе
И-ИЛИ. Заметим, что отрицание здесь не требуется, так как его функцию берет
на себя отношение «!=« в первичном-спецификатора. Спецификаторы задают
декларативно ограничения на значения. Синтаксис спецификаторов следую-
щий:
спецификатор ::= терм-спецификатора {{ || терм-спецификатора }}
терм-спецификатора ::= первичное-спецификатора
{{ && первичное-спецификатора }}
7.1. Продукционно-фреймовый ЯПЗ PILOT/2
247
первичное-спецификатора::=
|| || < || значение-первичн-спецификатора||
II II <= II II
II II == II II
II II != II II
II II >= II II
II II > II II
11 ( спецификатор ) 11
значение-первичн-спецификатора ; : =
|| значение
II II пусто ||
|| || one_from 11
|| || all_from | |
|| VAR-переменная
|| GET-переменная
Знаки отношений имеют стандартную семантику для чисел и семантику сравне-
ния ASCI-кодов для символов и строк. В тех случаях, когда значение в первич-
ном-спецификатора является множеством, все знаки отношений имеют следую-
щую интерпретацию:
• < — строгое включение множества значений спецификатора во множество
значений слота;
• <= — нестрогое включение множества значений спецификатора во множество
значений слота;
• == — совпадение множества значений спецификатора с множеством значений
слота;
• != — несовпадение множества значений спецификатора с множеством значе-
ний слота;
• >= — нестрогое покрытие множества значений спецификатора множеством
значений слота;
• > — строгое покрытие множества значений спецификатора множеством зна-
чений слота.
Дополнительно к этому значение-первичного-спецификатора может быть VAR-
или GET-переменной, которым предшествует префикс one_from (один из эле-
ментов в переменной должен быть использован); all_from (все элементы пере-
менной должны быть использованы). Пустой префикс соответствует операции
one_from.
Возможности образцов лучше рассмотреть на примерах. Пусть в текущей базе
имеются следующие фреймы, причем порядок их расположения в базе такой, как
описано ниже:
[, F1 is_a prototype; [ F2 is_a F1; [ F3 is_a F1;
S1 int, by_default 8 ; S2 = "x" ]; S1=0];
S2 char];
248
Глава 7 • Пример разработки системы, основанной на знаниях
Имеются также переменные $V 1 (типа frame) и $V2 (типа char), которые до при-
менения каждого из образцов содержат следующие значения:
$V1 = IF1 IF2 IF3 I $V2 = I’a’ !’b’ I
Примеры образцов с их значениями и значениями переменных $V1 и $V2 после
применения этих образцов к описанной базе представлены ниже.
N/N Образец Результат
1 ?[F : S] false
2 ?[F1 : S2] true
3 ?[F2 : S1 {== 8}] true
4 ?[ »$V1 = all_of *: S1{==8}] true
5 ?[* : S2 {== <<$V2} ] true
6 ?[one_of $V1>> : S1{== one_from {1,0}} ] true
6а ?[one_of $V1>> : S1 {== all. .from {1,0}} ]false
7 ?[$V1«: S1 {==8}; >$V2=S2] true
8 ?[* : *] true
Образцы 1 и 2 представляют собой запросы на наличие в базе соответствующих
слотов-фреймов. Поскольку [F:S] в базе нет, a [FLS2] — есть, значения образцов 1
и 2 соответственно false и true. Образец 3 более избирателен, он проверяет базу на
наличие в ней фрейма F2 со слотом S1, имеющим значение 8. Такой фрейм в оп-
ределенной нами базе имеется (вспомним, что фрейм-экземпляр наследует слоты
своего прототипа), поэтому значение образца — true. Образец 4 ищет все (all_of)
фреймы со слотами S1, равными 8, записывая при этом их имена в переменную
$V1. Префикс этой переменной предписывает заносить в нее значения слева с
сохранением. В образце 5 значение слота S2 берется из переменной $V2 (слева без
сохранения), причем имя фрейма может быть любым (*). Но фрейм со слотом S2
= "а" в базе один (F2). Ключевое слово one_of в образце 6, явно указывающее на
поиск только первого подходящего фрейма, — не обязательно, такая стратегия
подразумевается по умолчанию. Для успешного сопоставления с этим образцом
фрейм F3, имя которого взято справа без сохранения из переменной $V1, должен
иметь слот S1, значением которого может быть одно из (one_from) чисел: 1 или 0.
Условие соблюдается, и значение образца — true. Вместо one_from может быть
указано all_from (образец 6а), в этом случае значением слота должно быть все
множество {1,0}. Образец 7 показывает, что можно проверять значения несколь-
ких слотов сразу. Семантика его следующая: найти первый фрейм со слотами
S1 = 8 и S2; если такой фрейм будет найден, записать его имя в переменную $V1
справа, протолкнув верхушку стека справа, а значение слота S2 — в переменную
$V2 слева, без сохранения значения в верхушке стека. С помощью образца 8 про-
веряется, есть ли вообще в текущей базе какие-нибудь фреймы.
Таким образом, мы обсудили конструкции ЯПЗ PILOT/2, которые могут пот-
ребоваться при формировании левых частей продукционных правил. Все они
предназначены для выделения в БЗ системы интересующих нас ситуаций. Такое
выделение не самоцель, а средство для преобразования таких ситуаций для полу-
чения решений. Сами преобразования описываются в основном, в правых частях
продукционных правил ЯПЗ-программы и сводятся к выполнению определен-
ных действий над БЗ и/или значениями переменных.
7.1, Продукционно-фреймовый ЯПЗ PILOT/2
249
В ЯПЗ PILOT/2 все действия делятся на стандартные (системные) и нестандарт-
ные (пользовательские). Все они могут использоваться не только в правых час-
тях продукционных правил, но и в аннотациях, что позволяет реализовывать в
ЯПЗ PILOT/2 развитые модели объяснений [Clancey, 1983]. Синтаксис нестан-
дартных действий определяется спецификацией прототипов процедур, рассмот-
ренной выше, и синтаксисом обращений к процедурам, а семантика и реализа-
ция — целиком в руках пользователя ЯПЗ PILOT/2.
Классификация стандартных действий проста. Это обработка переменных, обра-
ботка базы знаний, процедурное управление и ввод/вывод.
Как указывалось выше, в ЯПЗ PILOT/2 имеются три вида переменных (VAR,
GET, PUT). С учетом этого:
/
обработка-переменных ::= || оператор-присваивания ||
11 PUSH-оператор | |
|| POP-оператор ||
|| CLEAR-оператор ' ||
оператор-присваивания ::= || VAR-переменная || = значение
|| PUT-переменная 11
Примерами присваивания значений переменным могут служить конструкции
вида:
$var1=<$a+$b;
>$var2=[FrameName : SlotName] * $var1;
$var3« =empty;
Заметим, что с помощью присваивания можно реализовать и «проталкивание»
стека, например, так:
»$var2 = empty; $var3« = ;
или даже так
$var«;
Однако более общим будет действие вида
push ( left, $var2, $var3 ); push ( right, $var2, $var3 );
так как здесь с помощью одного действия можно обработать несколько стеков,
причем одно и то же имя может многократно повторяться в качестве параметра.
В этом случае в соответствующем стеке появится несколько пустых позиций-
уровней. Выталкивание значений из стеков производится аналогичным образом.
Для очистки стеков следует использовать стандартное действие CLEAR. При
этом не важно, с какой стороны (слева или справа) начнет очищаться стек.
Присваивания и операторы обработки стеков, рассмотренные выше, конечно,
важны, но не они составляют суть обработки данных в языках представления зна-
ний. В дополнение к этому, а вернее, в первую очередь, здесь должны быть сред-
ства изменения базы знаний, текущее состояние которой и определяет, какие ре-
шения уже были приняты и что будет происходить дальше.
250
Глава 7 » Пример разработки системы, основанной на знаниях
Выше уже обсуждалась конструкция образца ЯПЗ PILOT/2, которая использу-
ется для выделения интересующих инженера по знаниям ситуаций. Почти та же
конструкция применяется и для преобразования ситуаций. Действительно, для
выполнения любого преобразования в конечном счете нужно найти некоторую
ситуацию и либо удалить ее, либо скорректировать соответствующим образом.
Для полноты нужны и средства формирования новых ситуаций. Все эти дей-
ствия выполняются в ЯПЗ PILOT/2 с помощью конструкции обработка-базы-
знаний, которую для краткости и преемственности с языком ПИЛОТ [Хоро-
шевский и др., 1990] будем также называть манипулятором. Итак, манипулятор,
или обработка базы знаний, — это удаление фреймов, создание фреймов, замена
фреймов или коррекция фрейма.
Операции удаления, создания и замены фреймов в текущей базе знаний манипу-
лируют с фреймами как с целыми и неделимыми единицами. При этом благодаря
использованию образцов можно за одно обращение к соответствующему манипу-
лятору провести множественные изменения в базе знаний:
[?[*:*] \ ]; [ ?[ * : *{==«обработан»} ] \ ];
[ ?[ »$DeletedFrameNames=all_of * : *{==«обработан>>} ] \ ];
Создание новых фреймов в ЯПЗ PILOT/2 для пользователя языка тоже простая
операция. Здесь нужно дать определение нового фрейма или совокупности фрей-
мов аналогично тому, как это делалось в рамках декларативной компоненты ЯПЗ
PILOT/2:
[ \ [ Framel : Slotll = «Mother»;
Slot12 = «Father»;
Slot13 = «Children»;
Slot14 = 21];
[ Frame2 : Slot21 = empty];
[ Frame3 :]
]
Замена одних фреймов на другие — не что иное, как объединение уже рассмотрен-
ных конструкций удаления и вставки:
[.?[*:*] \ [ Frame : Slot = «End Of Job» ] ]
Так в ЯПЗ PILOT/2 осуществляется коррекция баз знаний на уровне отдельных
единиц-фреймов. Вместе с тем часто требуется скорректировать некоторый
фрейм или группу фреймов более «тонким» способом. Например, это может быть
изменение значений некоторых слотов определенных фреймов, удаление «не-
нужных» слотов и/или добавление новых слотов в уже существующие фреймы.
Все эти манипуляции с базой знаний осуществляются в ЯПЗ PILOT/2 на уровне
конструкции коррекция-фрейма. Примеры использования манипуляторов в слу-
чае коррекции базы знаний на уровне отдельных фреймов и/или групп фреймов
приводятся ниже:
[ *: \ S1 int] - К первому фрейму в базе знаний добавить слот с
именем S1.
7.1, Продукционно-фреймовый ЯПЗ PILOT/2
251
[all_of *:$del\ ] - Во всех фреймах, имеющих слот с именей,
хранящимся в $del, удалить этот слот.
[all_of * : S1=+1] - Во всех фреймах, имеющих слот S1, изменить
значение последнего, увеличив его на 1.
При обсуждении общей структуры управления PILOT-программой были введе-
ны мощные, но «дорогие» средства управления выводом. Вместе с тем инженер
по знаниям иногда может быть уверен, что надо выполнить определенную про-
дукцию или секцию; он может знать, что определенные продукции пока не нуж-
ны, но зато необходимо включить в рассмотрение другие продукции. Наконец,
иногда требуется осуществить принудительное завершение работы PILOT-npo-
граммы. Все такие действия в ЯПЗ PILOT/2 объединены в группу действий про-
цедурного управления на уровне управление-активностью-правил, управление-
активностью-секций, вызов-секции или выход.
Фильтр «активности/неактивности» продукций — первый из используемых «ар-
битром». Поэтому, явно активируя или деактивируя некоторые из продукций,
можно существенно сократить его работу и увеличить производительность всей
продукционной системы. В случае секций фильтр активности, конечно, не столь
эффективен, но у инженера по знаниям появляется возможность более точной
структуризации правил продукционной системы и за счет этого увеличения эф-
фективности ее функционирования.
Одними из уже упоминавшихся действий являются переключения флагов актив-
ности продукций (rule_on/rule_off), с помощью которых можно устанавливать
их как в текущей, так и любой другой секции. Возможно манипулирование флага-
ми сразу всех продукций одной секции (section_on/section_off).
Особым действием является вызов (invoke) секции. В результате его выполнения
текущая активная секция «проталкивается» в управляющий стек, а ее место на
следующем шаге занимает вызываемая секция. Так как за вызовом секции могут
следовать другие действия (в частности, другие вызовы), после полной отработки
этого вызова «арбитр» на некотором шаге, минуя формирование КМ и выбор из
него продукции, возвращается к применению данной продукции, причем в той ее
части, которая непосредственно следует за вызовом.
Выполнение действия exit прерывает работу «арбитра» и таким образом завер-
шает работу продукционной системы. В качестве «побочного» эффекта это дей-
ствие позволяет передать во внешнюю среду информацию о том, как завершилась
PILOT-программа. По «умолчанию» выход происходит с нулевым кодом воз-
врата.
Мы рассмотрели обработку переменных и баз знаний, а также действия, связан-
ные с управлением выполнением PILOT-программ. Вместе с тем понятно, что
сколько-нибудь сложные задачй требуют удобного ввода/вывода. Вот почему в
ЯПЗ PILOT/2 включена совокупность стандартных действий, поддерживаю-
щих ввод/вывод информации. При этом основное внимание уделяется действи-
ям по работе с базами знаний. Что же касается средств работы с файлами, то в
ЯПЗ PILOT/2 используется лишь последовательный доступ и простые формат-
ные преобразования, а также специализированный обмен с экраном на уровне
252
Глава 7 • Пример разработки системы, основанной на знаниях
сообщений и вопрос-ответных цепочек [Khoroshevsky, 1994]. Все более развитые
средства этого типа, которые могут потребоваться пользователю, должны под-
ключаться на уровне нестандартных действий.
Выше мы обсудили основные аспекты представления знаний на базе ЯПЗ PI-
LOT/2. Примеры его использования будут рассматриваться в следующих пара-
графах данной главы.
7.2. Психодиагностика — пример
предметной области для построения
экспертных систем
В настоящем параграфе вписывается пример использования тех теоретических
знаний, которые, как надеются авторы, уже усвоены читателем этой книги.
Для конкретности мы взяли в качестве предметной области проектирования и
реализации экспертных систем область психодиагностики. И на этом примере
попытаемся вместе с читателем пройти по пути разработки и реализации соот-
ветствующей экспертной системы — одной из спектра реализованных на основе
методов и средств, рассматриваемых в данной книге.
7, 2.1. Особенности предметной области
Современная психодиагностика предоставляет практикующим психологам ши-
рокий спектр методик, тестов и опросников для диагностирования и прогноза
личностных особенностей человека и позволяет получать развернутое психоло-
гическое заключение («портрет» испытуемого). Такие заключения могут ис-
пользоваться специалистами, желающими оценить свои способности и, возмож-
но, изменить род своей деятельности в соответствии с рекомендациями; пре-
подавателями, занятыми обучением и переобучением специалистов — с целью
выбора адекватных методов и средств обучения; руководителями организаций,
подбирающими работоспособные коллективы и/или анализирующими деятель-
ность малых коллективов; сотрудниками органов управления трудовыми ресур-
сами и бирж труда и т. д. Можно использовать результаты и для стимулирова-
ния личностного роста испытуемых, а также для профилактики психологи-
ческих срывов и повышения адаптивных свойств человека в условиях стресса.
Таким образом, сама предметная область психодиагностики и профориентации
является значимой и представляет интерес для создания соответствующих сис-
тем автоматизации. Важно и то, что тиражировать в компьютерных системах
имеет смысл лишь опыт ведущих специалистов в этой области, которые,-как пра-
вило, заняты и не могут обеспечить все потребности общества в соответствую-
щих консультациях.
Современное состояние автоматизации психодиагностики и профконсульти-
рования характеризуется наличием достаточно большого числа отдельных про-
грамм, автоматизирующих стадию предъявления тестов и дешифрацию резуль-
7.2. Психодиагностика — для построения экспертных систем
253
татов по ключу. На выходе такие системы, как правило, выдают числовой вектор
результатов либо шаблонные заготовки интерпретации этих векторов, не отра-
жающие индивидуальных особенностей испытуемых. Такое положение связано
с объективной сложностью индивидуальных психологических заключений, по-
лучение которых требует привлечения профессиональных экспертов, способных
и готовых поделиться своим опытом и мастерством.
Следует отметить, что психодиагностика является классической предметной об-
ластью для разработки систем, основанных на знаниях. И именно здесь методоло-
гия и технология создания экспертных систем могут принести значительный эф-
фект.
Оставшаяся часть главы построена следующим образом: сначала кратко обсужда-
ется сама проблематика психодиагностики и профконсультирования, затем ста-
вится задача разработки интеллектуальной системы «Ориентир» и перечисляют-
ся основные требования к этой системе. В заключение рассматриваются вопросы
разработки и реализации одной из ЭС, входящих в состав системы «Ориентир».
7. 2.2. Батарея психодиагностических ЭС
«Ориентир»
Представления человека о себе и система его ценностей могут быть выявлены с
помощью различных психологических методов, однако возможность влиять на
их формирование в ситуации консультации очень ограничена. Обычно особен-
ности психики исследуются в трех направлениях — анализ перцептивных осо-
бенностей, исследование интеллекта и личностных особенностей. Факторов, вли-
яющих на построение рекомендаций, так много, что для того, чтобы прийти к
какому-либо заключению (например, о выборе профессии), необходимо провес-
ти полное психологическое обследование с целью получения психологического
портрета испытуемого, обеспечить сопоставление его психологи-
ческих черт и требований, которые предъявляет желаемая сфера деятельности, и
сообщить ему полученные результаты. При этом под результатами имеется в виду
не однозначная короткая ицформация о том, подходит ли избранная профессия
человеку. Испытуемому необходимо сообщить его психологический портрет,
какие перспективы открывают перед ним его психологические черты в плане
выбора деятельности, и о том, как они сочетаются с его планами на будущее. Для
этого, очевидно, нужно использовать не один тест, а сбалансированную систему
тестов.
Содержательные классификации тестов — это, в первую очередь, классифика-
ции по психическим функциям, и, практически, они совпадают с классификаци-
ей способностей по тому же. основанию. С этой точки зрения тесты делятся на
сенсомоторные; перцептивные; тесты на особенности внимания; мнестические
(особенности памяти); тесты на интеллектуальный уровень и интеллектуальные
особенности; личностные тесты. Каждый из этих классов тестов может быть, в
свою очередь, разделен на подклассы в зависимости от конкретной особенности
им измеряемой [Анастази, 1982].
254
Глава 7 • Пример разработки системы, основанной на знаниях
По стимульному материалу тесты делятся на вербальные и невербальные. По
сути, компьютеризация никак не связана с этой характеристикой методики. Но
зрительное изображение, сложное по форме и/или цвету, может привести к труд-
ностям как на этапе компьютеризации методики, так и при тиражировании ее на
разные, типы ЭВМ и, в частности, дисплеев.
Личностные тесты направлены на выявление присущих человеку личностных
черт, осознаваемых и бессознательных особенностей и проблем. Многие из них
(например, прожективные) относятся к объективным нестандартизованным тес-
там. Но с точки зрения компьютерного тестирования способностей гораздо боль-
ший интерес представляют личностные опросники, особенно опросники, охваты-
вающие широкий круг личностных черт и особенностей личности. К наиболее
широко используемым личностным опросникам (в том числе и в нашей стране)
относятся Миннесотский мультифазный личностный опросник (MMPI), 16-фак-
торный тест Кеттелла, опросник У СК (уровень субъективного контроля), опрос-
ник Айзенка и некоторые другие.
Количество тестов, используемых в конкретной работе для психодиагностики,
может быть различным. Возможно, для диагностики одной, узконаправленной
способности в некоторых случаях можно ограничиться и одним тестом. Однако
почти всегда широта и значимость диагностической задачи заставляют использо-
вать тест, позволяющий определить сразу несколько показателей, или батарею
(многофакторных) тестов.
Учитывая вышесказанное, в рамках проекта «Ориентир», выполнявшегося сов-
местно специалистами из ВЦ РАН (Москва) и СПбГТУ (Санкт-Петербург) в се-
редине 90-х годов и связанного с созданием программных средств, обеспечиваю-
щих функционирование соответствующей интеллектуальной интерактивной
среды, была разработана и реализована батарея ЭС, работающих на получение
следующих общих результатов:
1. Психологическая диагностика основных свойств личности, мотивации, интел-
лекта, темперамента с получением психологического заключения в виде тек-
ста на естественном языке.
2. Прогнозирование профессиональной успешности в различных видах деятель-
ности с учетом возраста, пола и психологических особенностей испытуемых.
3. Выдача рекомендаций по созданию научных, творческих, учебных и производ-
ственных малых Коллективов на основе диагностики ролевой и психологичес-
кой совместимости отдельных членов коллектива.
4. Профессиональный подбор и отбор специалистов для переподготовки в рам-
ках специального заказа. '
5. Изучение психологических особенностей испытуемых с целью выбора наибо-
лее подходящих методов обучения, средств адаптации, индивидуального под-
хода, способствующих профессиональному и личностному росту.
Отличительные особенности проекта были связаны с тем, что здесь в рамках еди-
ной интеллектуальной системы объединялись результаты, получаемые от отдель-
ных диагностических ЭС различной модальности. Реализация проекта осуществ-
лялась в среде Windows с использованием методов объектно-ориентированного
проектирования и программирования, а базисом послужила технология разра-
ботки систем, основанных на знаниях. *
7.2. Психодиагностика — для построения экспертных систем
255
Разработка батареи экспертных систем «Ориентир» предполагала, что здесь чет-
ко различается несколько задач. В рамках первой из них система должна обеспе-
чить создание, коррекцию и сопровождение базы испытуемых, включая защиту
от несанкционированного доступа к данным и знаниям. Вторая задача управле-
ние вызовом и функционированием отдельных локальных ЭС, составляющих
исполнительные блоки общей батареи. Последняя задача связывалась с функцио-
нированием экспертной системы «Профи», которая работает с базами зйаний
локальных ЭС. Учитывая вышесказанное, Н-диаграмма БЭС «Ориентир» может
быть описана схемой, представленной на рис. 7.2.
Рис. 7.2. Н-диаграмма БЭС «Ориентир»
Здесь базовыми, обслуживающими все локальные ЭС, «задействованные» в об-
щей системе, являются опции База и Тесты. Первая из них обеспечивает форми-
рование и сопровождение баз данных и знаний испытуемых, а вторая — вызов
локальных экспертных систем. Экранная форма основного цикла работы БЭС
«Ориентир» представлена на рис. 7.3.
Рис. 7.3. Экранная форма основного цикла работы БЭС «Ориентир»
256 Глава 7 * Пример разработки системы, основанной на знаниях
7.3. Разработка и реализация
психодиагностической ЭС «Cattell»
Одной из подсистем БЭС «Ориентир» является психодиагностическая ЭС «Cat-
tell», в рамках которой, в частности, выполняется тестирование испытуемых по
тесту Кеттелла.
Как известно, тест Кеттелла измеряет 16 личностных черт, характеризующих
эмоциональную, социальную и интеллектуальную сферы испытуемого. Шкалы
теста сведены в табл. 7.2.
Таблица 7.2. Шкалы теста Кеттелла и их интерпретация
Шкала Характеристики полюсов шкалы
А Легкость эмоциональных контактов — эмоциональная отстраненность
В Способность к логическому мышлению
С Интегрированность поведения, эмоциональная устойчивость —
эмоциональная неустойчивость
Е Доминантность — подчиняемость
F Легкость, эмоциональность поведения — серьезность, ограниченность
эмоциональных проявлений
G Глубокая усвоенность социальных норм и правил — отсутствие внутренней
необходимости соответствовать в своих поступках социальным нормам
Н Настойчивость, решительность в достижении цели — робость, ранимость
I Чувствительность, «витание в облаках» — трезвость, реалистичность
L Подозрительность—доверчивость
М Индивидуалистичность, развитое воображение — склонность применяться
к коллективу, прагматичность
N Склонность следовать воспитанным формам поведения —
непосредственность поведения
О Готовность к самообвинению, пессимистичность — уверенность в себе,
оптимистичность
Q1 Потребность в переменах, новшествах — консерватизм
Q2 Ориентация на собственные Мнения, взгляды —
ориентация на мнения и взгляды окружающих
03 Высокий сознательный контроль поведения — низкий сознательный контроль
поведения
04 Энергичность, высокий уровень напряжения — Расслабленность,
низкий уровень напряжения
Тест существует в нескольких формах. В данном проекте использовалась форма А.
7.3.1. Архитектура системы и ее база знаний
Анализ предметной области и требований, предъявляемых к системе «Cattell»
специалистами по социальной психологии, с одной стороны, и условиями работы
7.3. Разработка и реализация психодиагностической ЭС «Cattell
257
ее в рамках общей системы «Ориентир», с другой, позволил специфицировать
архитектуру и функциональные возможности этой ЭС Н-диаграммой, представ-
ленной на рис. 7.4.
Собственное меню системы «Cattell» располагается в виде дополнительных оп-
ций основного меню. *
Работа всех функциональных модулей в ЭС «Cattell» базируется на знаниях о
«мире» испытуемых, Соответствующей методики психологического тестирова-
ния и правилах анализа его результатов. Знания об испытуемом содержатся в об-
щей БЗ системы «Ориентир», а знания о самом тесте — в БЗ ЭС «Cattell». В об-
щую базу знаний добавляется лишь та информация, которая описывает
результаты тестирования.
ЭС «Cattell»
—г— Уровень
—г- Испытуемый
Тестирование
Результаты
Ч— Эксперт
I—г- Анкетирование
Профилирование
Портретирование
---По вопроснику
—г- По таблице
---Создание
---Редактирование
---Объяснения
—>- Анализ знаний
___На уровне правил
— Количественное
(сырые баллы)
---Из расчета
---По таблице
Ч— Качественное
---Невербализованное
---Вербализованное
(семантические станы)
----Из расчета
---По шкалам
На уровне объектов
---- Ретроспектива
--- Помощь
Рис. 7.4. Н-диаграмма ЭС «Cattell»
Основные знания о тесте «Cattell» представляются совокупностью фреймов-эк-
земпляров, формируемых с использованием следующих прототипов:
[cattell is_a prototype; [portret is_a prototype;
a_status int; anketa frame; not_verbf rame;
n_status int; n_prfl frame; verbframe ];
258
Глава 7 » Пример разработки системы, основанной на знаниях
s_status int; s_prfl frame;
p_status int; port ret frame ];
[not_verb is_a prototype; [verb is_a prototype;
order {string}; order {string};
Ы {string}; b1_valn {int}; b1_vals {string}; Ы, b1_txt {string};
b2 {string}; b2_valn {int}; b2_vals {string}; b2, b2_txt {string};
b3 {string}; b3_valn {int}; b3_vals {string}; b3, b3_txt {string};
b4 {string}; b4_valn {int}; b4_vals {string} ];
b4,b4_txt{string}];
[ n_prfl is_a prototype;
А, В, С, E, F, G, H, I, L, M, N, 0, Q1, 02, 03, 04 int ];
[ s_prfl is_a prototype;
А, В, С, E, F, G, H, I, L, M, N, 0, QI, 02, 03, 04 string ];
[ anketa is_a prototype;
ansi, ans2, ans3...... ans187 string ];
Кроме того, в БЗ ЭС «Cattell» содержится совокупность фреймов-экземпляров,
поддерживающих технологические знания о том, как осуществляется переход от
ответов в анкете испытуемого к «сырым баллам» в числовом профиле, а от него к
семантическому профилю и затем к невербализованному и вербализованному
портретам.
7.3.2. Общение с пользователем
и опрос испытуемых
Как следует из Н-диаграммы, представленной на рис. 7.4, подопции Cattell-меню
различны для режима «Испытуемый» и режима «Эксперт».
Активация первого режима приводит к последовательному выполнению проце-
дур диалогового анкетирования испытуемого, подсчета «сырых баллов» по каж-
дому из 16 кеттелловских факторов и формирования на этой основе числового, а
затем и семантического профиля испытуемого. Весь диалог в рамках этой опции
ведется на языке, близком к естественному. При этом лингвистический процес-
сор для анализа ответов испытуемого, конечно, не используется, а «взаимопони-
мание» обеспечивается тем, что инициатива во всех диалогах здесь всегда у сис-
темы. Таким образом, она всегда «знает», каков должен быть ответ испытуемого
в данной точке и в случае ошибки «добивается» правильного ответа с помощью
переспросов и подсказок.
7.3. Разработка и реализация психодиагностической ЭС «Cattell
259
Единственной точкой перехвата инициативы от системы к пользователю явля-
ется вызов «помощи», к которой можно обратиться нажатием функциональной
клавиши F1 или через соответствующую опцию в меню. При этом на экране по-
является специальное окно, где высвечивается соответствующая контексту обра-
щения к «помощи» информация. Отсутсвие на этом уровне объяснений — не
случайно. Испытуемый не должен «понимать», почему (как) получен его лично-
стный портрет. В противном случае он будет осознанно или подсознательно от-
ступать от «естественных» для себя ответов на вопросы анкеты и в конечном
счете «научится» получать желаемый, а не действительный личностный порт-
рет.
Противоположная ситуация в опции «Эксперт». Во-первых, на этом уровне все
выводы системы должны (по желанию экперта) сопровождаться объяснениями
и обоснованиями и во-вторых, у психолога должны быть средства анализа зна-
ний системы и данных по конкретному испытуемому. Защита от несанкциони-
рованного доступа к данным и знаниям обеспечивается всей системой «Ориен-
тир», если база помечена как личная (ее «владельцем» указан статус PRIVATE).
Опции режима «Эксперт» перечислены в Н-диаграмме на рис. 7.4. Анализ дан-
ных и знаний системы, а также объяснения вынесены на уровень основного меню
и активируются из соответствующих опций.
Ввиду небольшой компьютерной подготовки психологов-экспертов в данном ре-
жиме диалог в подавляющем большинстве случаев идет на уровне меню и/или
семантически значимых клавиш. Кроме того, в любой точке, где требуется реак-
ция пользователя, он может вместо ответа обратиться к блоку «помощь» уже об-
суждавшимся выше способом.
Из приведенной выше Н-диаграммы ЭС «Cattell» следует, что опрос испытуемых
может осуществляться двумя способами: на основе ответов на ЕЯ-формулировки
вопросов теста и путем заполнения таблиц. Первый вариант удобен при индиви-
дуальном тестировании, а второй — при массовом вводе результатов анкетирова-
ния, предварительно зафиксированных на бумажных носителях.
Но и в том и в другом случае результатом работы блока анкетирования является
фрейм-экземпляр прототипа «anketa», приведенного выше.
7.3.3. Вывод портретов и генерация
их текстовых представлений
Для удобства работы психолога-эксперта результаты профилирования выдают-
ся в специальное окно в виде графика, на оси абсцисс которого указаны факторы,
а на оси ординат — «сырые баллы», набранные испытуемым по каждому из фак-
торов. Существует в системе и возможность табличной визуализации числового
профиля. Несколько иначе визуализируется результат построения качественно-
го профиля испытуемого. Здесь психологу-эксперту выдается 16 семантических
шкал.(по числу факторов), на каждой из которых отмечается числовое значение
соответствующего фактора.
260
Глава 7 * Пример разработки системы, основанной на знаниях
Процедуры обработки данных анкетирования в рамках предыдущих опций бази-
руются на знаниях. Но знания эти доведены до алгоритмов, реализация которых в
виде продукционной системы нецелесообразна. Поэтому в ЭС «Cattell» все такие
процедуры реализуются на языке C++, а затем подключаются в нужных точках.
Вместе с тем сами технологические знания представлены эксплицитно совокуп-
ностью следующих фреймов прототипов и экземпляров:
[ a_n_tbl is_a prototype;
f_A {frame}; /* ответы по фактору А с весами */
f_B {frame}; /* ответы по фактору В с весами */
f_Q4{frame}; /* ответы по фактору 04 с весами */];
[ a_n_elem is_a prototype;
ans_dsc string; /* имя фрейма-экземпляра ответа на анкету */
weight a, weight_b, weight_c int; /* веса ответа типа «а», «б» и «с»
*71;
[ answer is_a prototype;
prt_name, exmjiame, slot_name string];
[ ankjiumb is_a a_n_tbl;
f_A={q_3, q_4, q_26, q_27, q_51, q_52, q_76, q_101, q_.126, q_151, q_176 };
f_B={q_28,q_53,q_54,q_77,q_78,q_102,...q_152,q_153,q_177,q_178};
f_Q4={q_25,q_49,q_50,q_74,q_75,q_99,q_100,...q_150,q_174,q_175} ];
[ q_3 is_a a_n_elem;
ans_dsc = «ans_003»;
weight_a= 2;
weight_b= 1;
weight_c= 0 ];
[ ans_003 is_a answer;
prt_name= «anketa»;
exm_name= «anketa0037»;
slot_name= «ans3» ];
Запускаются процедуры получения числового и семантического профилей испы-
туемого как демоны при выборе соответствующих опций в меню ЭС «Cattell».
1.3. Разработка и реализация психодиагностической ЭС «Cattell
261
В опции «портретирование» осуществляется психологическая интерпретация
полученный на предыдущих этапах профилей испытуемого с целью построения
его словесного личностного портрета. Здесь уровень алгоритмизации знаний пси-
холога-эксперта существенно иной. Разные школы психологов несколько по-раз-
ному оценивают роль и вес разных факторов, приписывают им различные тексто-
вые отображения. Поэтому реализация вывода словесного портрета испытуемого
в ЭС «Cattell» базируется на продукционно-фреймовом формализме. Собствен-
но вербализация портрета — нисходящая (от цели), а подготовка его структури-
рованного невербализованного описания — восходящая (от данных).
Наиболее сложным и интересным является этап вывода невербализованного
портрета, реализованный в виде продукционной системы, предложенной в рабо-
те [Гаврилова и др., 1992]. Правила этой системы служат для выявления и устра-
нения противоречий двух типов. Первый связан, в конечном счете, с анализом
ответов на определенные вопросы анкеты и позволяет фиксировать ситуации,
когда построение сколько-нибудь достоверного личностного портрета на осно-
вании имеющихся данных нецелесообразно. Возникновение таких ситуаций
обычно связывается либо с невнимательным заполнением анкеты испытуемым,
либо с попыткой преднамеренного искажения результатов тестирования за счет
противоречивых ответов на дублирующиеся по семантике вопросы теста. И в
том и в другом случае анкета помечается как «плохая» и из дальнейшей обработ-
ки исключается. Второй тип противоречий связан с выявлением и устранением
контекстной зависимости и доминирования значений разных факторов, что по-
зволяет получить более «гладкий» личностный портрет.
Но и в том и в другом случае исходными данными для работы продукционной
системы являются числовой и семантический профили испытуемого, прототи-
пы которых (n_prfl и s_prfl) приведены выше. Примеры словесных формулиро-
вок правил разрешения противоречий выглядят следующим образом:
Если
значение фактора «F» в семантическом профиле испытуемого «Очень Низкий», а
значение фактора «03» - «Низкий»,
то
фактор «03» поглощается фактором «F».
Если
значения факторов «01» и «02» в семантическом профиле испытуемого «Очень
Высокий»,
то
для принятия решения о поглощении нужно сравнить значения этих факторов в
числовом профиле испытуемого. Кандидатом на поглощение будет тот фактор, у
которого числовое значение меньше.
На уровне ЯПЗ PILOT/2, обсуждавшегося выше, описание этих правил транс-
формируется во фрагмейт продукционной программы вида:
7.3. Разработка и реализация психодиагностической ЭС «Cattell
263
Н={«Не имеет навыка решения логических задач, довольно медленно
обучается новым понятиям.»};
СР={«Имеет определенные навыки в решении логических задач.»};
В={«Умеет абстрактно мыслить, хорошо решает логические задачи,
довольно быстро обучается новым понятиям.»};
0В={«Умеет абстрактно мыслить, очень хорошо решает логические
задачи, быстро обучается новым понятиям.»};
[ Q4 is_a factor;
ОН={«В настоящий момент самоуспокоен, расслаблен, не напряжен.»};
Н={«В настоящий момент находится в спокойном расслабленном состоянии.»};
СР=;
В={«В настоящий момент человеку присуще высокое рабочее
напряжение, собранность, энергичность.»};
ОВ={«В настоящий момент человек напряжен, собран и даже
несколько «взвинчен».»};
Учитывая то, что генерация текстовых представлений портретов осуществляется
в ЭС «Cattell» на уровне целых предложений и групп предложений, здесь исполь-
зуется простая продукционная система со следующими правилами:
section PORTRET-GEN
removeall;
if (?[ $curr_port : $curr_not_verb = not_verb ] &&
?[ $curr_port : $curr_verb = verb ] &&
?[ $curr_not_verb : $curr_order = all_of order ;
$curr_b1 = all_of Ы;
$curr_b2 = all_of b2;
$curr_b3 = all_of b3;
$curr_b4 = all_of b4 ] ) insert (COPY);
rule COPY
==> [ $curr_verb order ] = $curr_order;
[ $curr_verb Ы ] = $curr_b1;
[ $curr_verb b2 ] = $curr_b2;
[ $curr_verb b3 ] = $curr_b3;
[ $curr_vprb b4 ] = $curr_b4;
rule_off (COPY);invoke (B1);invoke (B2);invoke (B3);invoke (B4);
264
Глава 7 » Пример разработки системы, основанной незнаниях
section В1
if ( ?[ $curr_not_verb : $curr_b1_vals = all_of b1_vals ] );
rule A
:: <$curr_b1 == «А»
==> <<$curr_b1;
$curr_txt = all_of [ A : <<$curr_b1_vals ];
[ $curr_verb ; ,b1_txtJ = tcurrjrxt;
clear ($curr_txt);
rule E
:: <$curr_b1 == «Е»
==> <<$curr_b1;
$curr_txt = all_of [ E : <<$curr_b1_vals ];
[ $curr_verb : b1_txt ] = $curr_txt;
clear ($curr_txt);
rule N
:: <$curr_b1 == «Н»
==> <<$curr_b1;
$curr_txt = all_of [ N : <<$curr_b1_vals ];
[ $curr_verb : b1_txt ] = $curr_txt;
clear ($curr_txt);
section B4
if ( ?[ $curr_not_verb : ,$curr_b4_vals = all_of b4_vals ] );
rule В
:: <$curr_b4 == «В»
==> «$curr_b4;
$curr_txt = all_of [ В : <<$curr_b4_vals ];
[ $curr_verb : b4_txt ] = $curr_txt;
clear ($curr_txt);
rule 01
:: <$curr_b4 == «01» .
==> <<$curr_b4;
7.3. Разработка и реализация психодиагностической ЭС «Cattell
265
$curr_txt = all_of [ Q1 : <<$curr_b4_vals ];
[ $curr_verb : b4_txt ] = $curr_txt; clear ($curr_txt);
Результатом работы этой продукционной программы является фрейм-экземпляр
прототипа verb, слоты order и Ы-Ь4 которого содержат ту же информацию, что и
в невербальном портрете, а слоты bl_txt—b4_txt — собственно текстовое пред-
ставление портрета испытуемого.
7.3.4. Помощь и объяснения в ЭС «Cattell»
Помощь в ЭС «Cattell» обеспечивается стандартным гипертекстовым Help. В на-
шем случае топиками и подтопиками такого гипертекста являются общее описа-
ние системы и подсказки для работы внутри блоков системы. Последние, в свою
очередь, делятся на описания действий пользователя в рамках ввода и/или редак-
тирования анкет испытуемых и их числовых (семантических) профилей и полу-
чения вербальных портретов. Во всех случаях акцент в текстах помощи делается
на описании доступных пользователю способов получения нужных ему результа-
тов.
Объяснения в ЭС «Cattell» строятся на основе модели [Clancey, 1983; Khoro-
shevsky, 1985]. При этом система поддерживает два типа запросов: общие и спе-
циальные. Последние, в свою очередь, делятся на запросы типа «Почему», «Как»
и «Что». Модель объяснений опирается не на трассу вывода решения, а на клю-
чевые темы, связанные с функционированием системы. Таких тем — три: вер-
бальный портрет испытуемого, его профиль и заполненная анкета. Типичные
примеры запросов на объяснения — следующие:
Случай общих запросов
При построении данного портрета были нёинтерпретируемые факторы ?
Сколько противоречий было при построении данного портрета?
Какие факторы при построении данного портрета не интерпретировались?
Как разрешались противоречия при построении данного портрета? и т. и.
Случай специальных запросов
Почему в портрете испытуемого присутствует фраза «...»?
Как в профиле испытуемого получено значение фактора «...»? и т. д.
Для устранения непониманий все запросы на объяснения после анализа перефра-
зируются и выдаются эксперту в виде эхо-вопросов. И только в случае, если его
«устраивает» интерпретация запроса, данная системой, происходит формирова-
ние текста объяснения. Так, например, эхо-запрос для последнего из общих во-
просов — Вас интересуют правила поглощения противоречивых факторов в дан-
ном портрете?, а для последнего из специальных вопросов — Вы хотели бы
узнать, каким образом сформировано значение фактора «...» = «...»?
266
Глава 7 • Пример разработки системы, основанной на знаниях
Примеры объясняющих текстов для тех же запросов, к которым приведены эхо-
вопросы системы — следующие:
Фактор «...» = «...» поглощен фактором «...» = «...», так как на шкале «ОН-Н-СР-
В-ОВ» значение «...» выражено «сильнее» значения
Общая формула, которая является ключом теста, выглядит следующим образом:
F _value( factor) = £ omeem(q)* вес - omeetna(q)'
qc. factor
Для фактора она трансформируется в формулу:
F_value («...») - ответ (цЗ)*вес-ответа (q3) + ...+ ответ (ц176)*вес-ответа (ql76);
С учетом ответов испытуемого эта формула приводится к выражению вида;
F_value («...») = 2+...+2 = «...»
Таким образом сформировано значение фактора
Как следует из приведенных примеров, объяснения в ЭС «Cattell» достаточно
подробные и позволяют получить психологу-эксперту практически всю инте-
ресующую его информацию. Понятно, что поддержка объяснений такого уровня
существенно сложнее, чем выдача аннотаций к трассе вывода решения и требует
своей базы знаний (согласованной с предметной БЗ) и своей программы вывода.
Основные моменты построения этих компонентов и рассматриваются ниже.
В целом подсистема объяснения системы «Cattell» строится по «полной» схеме:
прием запроса от пользователя; анализ запроса; генерация эхо-вопроса; прием
подтверждения на системную интерпретацию запроса и вывод собственно текста
объяснения.
Формирование запросов на объяснения осуществляется на основе меню, в корне-
вых опциях которого находятся темы объяснений, а на листьях — ЕЯ-шаблоны
конкретных вопросов. В зависимости от типа запроса он может сопровождаться
параметрами, которые выбираются пользователем непосредственно из портрета
или профиля испытуемого. Система, «зная» описание текущего испытуемого, до-
полняет запрос пользователя и формирует структуру вида
«тема» «тип-запроса» «имя объясняемого фрейма-экземпляра»
«контекст»),
которая, по существу, является внутренним представлением запроса на объясне-
ние. Таким образом, удается избежать построения Л-процессора для анализа за-
просов и вместе с тем обеспечить естественное общение.
Айализ внутреннего представления осуществляется параллельно с генерацией
эхо-вопроса. При этом сама внутренняя структура является управляющей це-
почкой, которая задает поверхностную структуру эхо-вопроса. Фрагмент соот-
ветствующего множества ATN показан на рис. 7.5.
7.3. Разработка и реализация психодиагностической ЭС «Cattell
267
CAT 'portrpf
'Вы хотели
бы понять,'
CAT 'profile' Т
EXPL-A
'Вас интересует,'
TST
'Вы хотели
бы понять то,"
TST
CATyco^que’ Т
САТ ’1' T»(^PUSH
—-У 'идентифицирован '---ZF-VALUE т \-----
значением'
'почему
фактор’
EX-PR )
'что система пока не может объяснить!'
CAT 'Г Т
/ 'имелись ли в профиле
/испытуемого факторы, которые'
ЕХ-СМ)...
TST
,РОР
POP
□1-2-2
POP
/----\ TST
>(Q1-2-3)-------------:-------X Q1-2-6
4 У 'не дали при построении
портрета никакой вербальной
составляющей?'
'что система пока не может объяснить!'
POP
□ 1-2-4
'Данная тема пока системе недоступна.'
POP
Q1*2
Т
Т
Т
Т
Рис. 7.5. Фрагмент ATN-представления анализатора запросов и генератора эхо-вопросов
В результате анализа запросов на объяснения и генерации эхо-вопросов, а также
уточнений, которые отражают процесс согласования мнений системы и пользова-
теля, в базе знаний ПОЭС (подсистемы объяснений ЭС) «Cattell» формируется
окончательная редакция запроса — фрейм-экземпляр следующего прототипа:
[ expl_request is_a prototype;
rq_team frame; rq_type int; rq_context {string};
expl_fr frame; expl_sl {string}; expl_fun string;
echo_txt{string}; expl_txt{string} ];
В начальный момент вывода текста объяснения в этом экземпляре заполнены
слоты rq_team (тема объяснения из БЗ ПОЭС); rq_type (тип запроса, — WHY,
HOW или WHAT, — сформированный анализатором); rq^context (параметры
запроса, если они требуются) и echo_txt (поверхностное представление «согла-
сованного» эхо-вопроса). Слоты expl fr (объясняемый фрейм-экземпляр из
предметной БЗ теста); expl_sl (объясняемые слоты объясняемого фрейма-экземп-
ляра) и expl_fun (имя процедуры вывода текста объяснения) заполняются самой
ПОЭС. Значение слота expl_txt представляет результат работы.
Собственная БЗ ПОЭС — статическая и содержит совокупность поддерживае-
мых моделей объяснений, определяемых как экземпляры следующих основных
прототипов:
[ explain is_a prototype;
expl_slt {string}; expl_fncstring; expl_knw frame ];
268 Глава 7 » Пример разработки системы, основанной на знаниях
[ v_expl is_a prototype; .. . , ,
why_slt {string}; why (frame);
how_slt {string}; how (frame);
what_slt{string}; what(frame) ];
[ p_expl is_a prototype;
why {frame}; how {frame} ];
[ c_expl is_a prototype;
noneframe; contra frame ];
[ wh is_a prototype;
path{frame}; process string ];
[ path is_a prototype;
typeint; nm_f ramestring; nm_slot {string} ];
[ rule is_a prototype;
r_fact {string}; r_part {string} ];
В нашем случае это множество экземпляров представляется следующими фреймами:
[ port is_a explain;
expl_slt= { «Ь1», «Ь2», «ЬЗ», «Ь4» };
expl_fnc= «portret»; '
expl_knw= portret ];
[ prfl is_a explain;
expl_slt
={«А»,«В»,«С»,«Е»,«F»,“G”,“И*,«I»,«L»,«М»,«N»,«0»,«01»,«02»,«03»,«04» };
expl_fnc=«profile»;
expl_knw=profile ];
[comn is_a explain;
expl_slt={ };
expl_f nc =«com_que»;
expl_knw=common];
Анализ их показывает, что в ЭС «Cattell» поддерживаются модели объяснения
всех групп интерпретируемых в вербальном портрете факторов, всех факторов в
профиле испытуемого и модели общих запросов.
7,3. Разработка и реализация психодиагностической ЭС «Cattell
269
Так, например, знания, необходимые для объяснения вербального портрета конк-
ретизируются фреймом-экземпляром portret, где заданы ссылки на объясняемые
тексты («bl_txt>, «b2_txt», «b3_txt>, «b4_txt») и способы доступа к релевантной
информации из предметной БЗ теста (whl, wh2, wh3, wh4):
[ portret : v_expl;
why_slt ={ «b1_txt», «b2_txt», «b3_txt», «b4_txt» };
why ={ wh1, wh2, wh3, wh4 };
how_slt ={ «b1_txt», «b2_txt», «b3_txt», «b4_txt» };
how ={ wh1, wh2, wh3, wh4 };
what_slt={ «b1_txt», «b2_txt», «b3_txt», «b4_txt>> };
what={ wh1, wh2, wh3, wh4 } ];
При такой модели процессор объяснений интерпретирует последовательно опи-
сания экземпляров типа wh, где описываются пути, ведущие от запроса на объяс-
нение к тем данным, которые и составляют внутреннее представление ответа.
Наиболее сложной является модель объяснения поглощения факторов, активи-
руемая подмножеством общих вопросов. В этом случае ПОЭС должна иметь
в своей БЗ модели всех правил поглощения и объяснять рассуждения машины
вывода «Cattell». Для конкретности дальнейшего обсуждения предположим, что
обрабатывается запрос вида «Как разрешались противоречия при построении
данного портрета?» и пользователь согласился с интерпретацией системы, спе-
цифицированной в эхо-вопросе «Вас интересуют правила поглощения противо-
речивых факторов в данном портрете?» Пусть также, для определенности, един-
ственным поглощенным фактором при выводе вербального портрета был фактор А.
Для этого фактора в модели существуют два правила объяснения поглощения,
соответствующие очень низкому (ОН) и очень высокому (ОВ) значению этого
фактора в семантическом профиле испытуемого:
[ АОН is_a rule; [ АОВ is_a rule;
r_fact ={«Е», «L»}; r_fact ={«E», «L»};
r_part ={«EOH»,»LOH»} ]; r_part ={«EOB»,«LOB»} ];
Однако реально поглощение фактора А наблюдается лишь тогда, когда значения
факторов Е и L тоже ОН или ОВ. Понятно, что в такой ситуации подсистема
объяснения должна сравнивать не семантические профили по вышеуказанным
факторам, а их числовые профили. Учитывая вышесказанное, продукционная
система вывода объяснения поглощений содержит 98 правил, аналогичных пра-
вилам для фактора А:
section EXPL-COLLAPSE-A
removeall; '
if ( [$curr_s_prfl : A] == [$curr_s_prfl : E] ){
if ( [$curr_s_prfl : A] == «ОН» ) insert (AOH-COLLAPSED-E);
270
Глава 7 • Пример разработки системы, основанной на знаниях
if ( [$curr_s_prfl : А] == «ОВ» ) insert (AOB-COLLAPSED-E);
break };
if ( [$curr_s_prfl : A] == [$curr_s_prfl : L] ){
if ( [$curr_s_prfl : A] == «ОН» ) insert (AOH-COLLAPSED-L);
if ( [$curr_s_prfl : A] == «0В» ) insert (AOB-COLLAPSED-L);
break };
rule AOH-COLLAPSED-E
:: ( ?[$curr_n_prfl : $curr_A = A]) &&
( ?[$curr_n_prfl : $curr_E = E]) &&
($curr_A <= $qurr_E)
==> [expl_request_001 : expl_txt]=
{«Фактор A = «, $curr_A>>, «(ОН) поглощен »,
«фактором E = «, $curr_E, «(ОН), т.к. числовое»,
«значение E выражено сильнее значения А.»} ];
rule AOB-COLLAPSED-L
:: ( ?[$curr_n_prfl : $curr_A = A] ) &&
( ?[$curr_n_prfl : $curr_L = L] ) &&
($curr_A <= $curr_L)
==> [expl_request_001 : expl_txt]= , z
{«Фактор A = «, $curr_A>>, «(OB) поглощен »,
«фактором L = «, $curr_E, «(OB), т.к. числовое»,
«значение L выражено сильнее значения А.»} ];
Таким образом, осуществляется генерация объяснений в ЭС «Cattell». В данной
версии каждый запрос на объяснение приводит к генерации одного и того же эк-
земпляра прототипа expl request. Однако нетрудно модифицировать обсуж-
давшуюся продукционную программу так, чтобы в БЗ объяснений сохранялась
история работы с ней пользователя. В таком случае БЗ объяснений может ис-
пользоваться для обучения специалистов интерпретации результатов по тесту
Кеттелла.
Выше описаны основные проектные решения, использованные при создании
психодиагностической ЭС «Cattell». Однако читателям должно быть ясно, что
эти решения являются достаточно общими и характерными не только для дан-
ной экспертной системы, но и для большинства ЭС диагностики.
е Представление
данных и знаний
в Интернете
□ Язык HTML и представление знаний
□ Онтологии и онтологические системы
□ Системы и средства представления онтологических знаний
8.1. Язык HTML и представление знаний
8.1.1. Историческая справка
Очевидно, что для представления информации в среде Интернет нужен был язык,
который бы был «понимаем» всеми компьютерами в сети и вместе с тем обеспечи-
вал бы достаточные выразительные средства для удобного описания разных
типов документов. Таким языком публикаций для WWW и стал HTML (Нурег-
• Text Markup Language) [WAI, 1999]: Этот язык предоставляет авторам Интернет-
публикаций средства:
• представления документов, включающих заголовки, тексты, таблицы, списки,
«картинки» и т. п. элементы;
• осуществления навигации по отдельным документам и множеству документов
путем использования гиперссылок;
• конструирования диалоговых форм для взаимодействия с удаленными серви-
сами, доступными в сети, а также:
• включения в документы вычисляемых форм (spread-sheets), видео и звука,
равно как и разнообразных приложений.
HTML — «авторский» язык. Первая его версия была разработана Т. Бернерс-Ли
(Tim Berners-Lee) из Европейского Центра ядерных исследований (CERN). Ак-
тивно поддерживался этот язык компанией NCSA, где был реализован один из
первых Web-броузеров — Mosaic. Победное шествие HTML по Интернету все
90-е годы объясняется, в первую очередь, взрывным ростом Web и потребностя-
ми в единообразном представлении информации. За это время язык претерпел
272
Глава 8 « Представление данных и знаний в Интернете
существенные изменения. И уже к середине 90-х годов произошла стандартиза-
ция его версий, которая стала курироваться международными организациями.
Версия HTML 2.0 (ноябрь 1995 г.) была разработана под эгидой Internet Engi-
neering Task Force (IETF) для фиксации уже сложившейся практики использо-
вания этого языка до 1994 г. включительно [Berners-Lee et al., 1995]. В версиях
HTML+ (1993 г.) и HTML 3.0 (1995 г.) описательные возможности языка были
существенно расширены. Практика использования новых конструкций усилия-
ми World Wide Web Consortium’s (W3C) HTML Working Group была зафикси-
рована в HTML 3.2 (январь 1997 г.) [Raggett, 1997]. В настоящее время наиболее
развитой является версия языка HTML 4.0 [HTML 4,1998], в которой представ-
лены новые возможности аппаратуры и требования производителей программ-
ного обеспечения броузеров, а также пожелания Интернет-авторов.
8.1.2. HTML — язык гипертекстовой разметки
Интернет-документов
Целью настоящей главы в целом и данного параграфа в частности, безусловно, не
является описание языка HTML или изложение приемов создания Интернет-до-
кументов с использованием этого языка. Для этого в настоящее время имеется
достаточное число книг, пособий и Интернет-сайтов, в том числе и русскоязыч-
ных (например, http://www.citforum.ru/). Вместе с тем для обсуждения возмож-
ностей HTML по представлению в Интернет знаний, а не данных основные поня-
тия этого языка нам потребуются. Вот почему ниже приводится краткое описание
структуры HTML-текстов и некоторых основных конструкций самого языка.
HTML — язык разметки Интернет-документов с помощью специальных конст-
рукций, называемых тегами (tag). Для выделения тегов в HTML-текстах эти
конструкции берутся в угловые скобки. Различают теги «открытия» размечае-
мого фрагмента (они задаются ключевым словом и, быть может, множеством до-
пустимых параметров) и теги его «закрытия» (такие теги суть то же ключевое
слово, которому предшествует символ «/»). В отличие от начальных конечные
теги параметров не имеют. Некоторые из начальных тегов не имеют парных ко-
нечных. Регистр, в котором представлены ключевые слова тегов и их параметров,
роли не играет. Пожалуй, этими соглашениями и исчерпываются основные пра-
вила, которым следуют все спецификации языка HTML. Отметим лишь, что
полное и строгое его описание базируется на специальной системе специфика-
ции языков разметки SGML [Goldfarb, 1991], одним из примеров использования
которой и является HTML.
Общая структура HTML-документа может быть представлена следующим фор-
матом:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN"
"http://www.w3.org/TR/REC-htmL40/strict.dtd">
<HTML>
<HEAD>
8.1. Язык HTML и представление знаний
273
<Т1Т1.Е>Наименование документа</ПТ1Е>
<МЕТА name=keywords •сопбепб=’,Представление знаний,
Мультиагентные системы">
</HEAD>
<BODY>
Собственно текст документа
</BODY>
</HTML>
Как следует из приведенного формата, комментарий <!DOCTYPE ...> фиксирует
текущее состояние спецификации версии языка HTML. Кроме того,,в HTML-до-
кументе выделяются две основные структурные единицы — «голова» документа
(между тегами <HEAD> и </HEAD>) и его «тело» (между тегами <BODY> и
</BODY>).
Один из элементов головы документа — это заголовок произвольный текст меж-
ду тегами <TITLE> и </TITLE>. Не менее, а быть может и более важным элементом
головы документа является тег <МЕТА... >. В приведенном выше примере этот тег
с помощью параметров name и content фиксирует значение первого атрибута как
keywords, а второго — как ключевые слова «Представление знаний» и «Мульти-
агентные системы». Этот и некоторые другие теги типа <МЕТА ... > ориентирова-
ны на аннотирование Интернет-документов и, кроме того, существенно облегча-
ют задачу индексирования их, например, с помощью сетевых роботов.
Собственно содержание документа находится в теле. Как правило, оно состоит из
последовательности структурных единиц, базисными среди которых являются
заголовки разного уровня (текст, заключенный между тегами <Hi> и </№>) и па-
раграфы — текст между тегами <Р> и </Р>. По существу, это минимальные сред-
ства форматирования Интернет-документов. Естественно, что в HTML, особенно
в его последней версии HTML 4.0, такие средствазначительно богаче. Здесь и
всевозможные выравнивания, и табуляция, и несколько типов списков, и т. д.
Но более важными базовыми конструкциями языка HTML, которые, собственно,
и дают основание ввести в его название термин «гипертекст», являются якоря
(anchors).
Синтаксически эти конструкции представлены тегами <А> и </А> с атрибутами
NAME и HREF.
Собственно якорем является конструкция вида
<А МАМЕ="Метка">текст</А>,
которая обеспечивает уникальное (в пределах документа) имя начала определен-
ного фрагмента HTML-текста. При этом текст, заключенный между тегами <А> и
</А>, как правило, задает семантически значимое наименование заголовка.
Для ссылок на помеченные таким образом части Интернет-документа использу-
ются конструкции
<А НАЕЕ=”#Метка">текст</А> или <А HREF=”URL">TeKCT</A>.
274
Глава 8 » Представление данных и знаний в Интернете
Первая из них задает локальную ссылку на часть документа, начинающуюся с
указанной метки. Вторая — глобальную ссылку на документ в сети, однозначно
идентифицируемый с помощью URL (Unified Resource Locator). По существу,
URL — это Интернет-адрес: имя домена, уточненное названием протокола и
собственное имя документа, включая путь к нему в пределах данного домена.
В качестве примера URL можно привести следующую ссылку вида http://www.
anywhere.ru/anywhat.html.
Использование в Интернет-публикациях ссылок позволяет организовать логи-
ческое структурирование информации и обеспечивает удобную и единообразную
навигацию как в пределах одного документа, так и в целом по множеству доку-
ментов, которые, по мнению автора данного HTML-текста, связаны между собой.
Важными конструкциями HTML, особенно в его последней версии, являются
также таблицы с богатыми возможностями задания многоуровневых заголовков
и формы, с помощью которых в язык введены средства обеспечения диалога с чи-
тателями Интернет-документов. Базисными конструкциями форм являются ре-
дактируемые текстовые поля, элементы выбора, кнопки и т. п.
Примеры форматов спецификации таблиц и форм приведены ниже.
<TABLE>
<TR>
<TD> Столбец-1, строка-1 </TD>
<TD> Столбец-1, строка-2 </TD>
</TR>
</TABLE>
<FORM METHOD="POST" ...>
<P>
Вы можете ввести в поле одну строку:
<INPUT NAME="entry">
</Р>
<Р>
Для обработки результатов ввода нажмите кнопку:
cINPUT TYPE="submif УАП1Е="Принять запрос”>
</Р>
</FORM>
Заметим, что именно на уровне форм в HTML появились возможности ввода ин-
формации в просматриваемый документ и ее обработки с помощью специальных
программ, выполняемых на сервере. В последних версиях языка эта идея получи-
ла дальнейшее развитие и в настоящее время присоединенные процедуры могут
быть подключены к HTML-документу не только в формах, но и в других конст-
рукциях, а их выполнение может осуществляться как на сервере, так и на клиенте.
8.1. Язык HTML и представление знаний
275
Следующей важной конструкцией, которая появилась уже в версии языка
HTML 2.0, являются кадры (frames). Часто их называют также рамками или
фреймами. С использованием кадров стало возможным разделить документ на
части и представлять их в отдельных, правда неперекрывающихся, областях эк-
рана. По существу, с кадрами в язык HTML были введены в ограниченном объе-
ме средства представления информации, характерные для многооконных при-
ложений. Экранная форма с примером структуризации документа с помощью
кадров приведена на рис. 8.1.
.--Ц Российская ассоциация искусственного интеллекта - Microsoft Internet Explorer
£* £» ]». М ИЛ
J 2) 4
h(lp//raai.botik.ru:8101/RAAl.ru.html
ЯНИЙЙММИа^11Г»-
жим
УСТАВ
ifoiia£
сргазм.
Лригламекне
££/£&•&
С&ЯЗ№
UU за
Свймбия
Школа YZc-fe- ^
общественной организации
"Российская ассоциация искусственного интеллекта”
(РАИИ)
1, Общие положения
1. Общественная организация ’Российская Ассоциация искусственного
интеллекта" (РАИИ), далее "Ассоциация", является добровольной творческой
профессиональной общественной организацией деятелей науки.
2. Ассоциация является научным сообществом специалистов в области теории
и методологии искусственного интеллекта, создания и применения
программного и аппаратного обеспечения компьютерных систем,
Д. Ассоциацня осуществляет свою деятельность в соответствин с действующим
законодательством н настоящим Уставом на принципахравноправня своии
членов, гласности, законности, самоуправления. :
Рис. 8.1. Использование кадров для структуризации Интернет-документа
На наш взгляд, концепция кадров получила естественное развитие в конструк-
циях HTML 4.0, названных слоями (layers). Основными достоинствами слоев
являются возможность их «привязки» по месту на экране, динамическое «всплы-
вание» и «схлопывание» слоев, а также их перекрытие.
Кроме слоев в HTML 4.0 появились и другие конструкции, расширяющие воз-
можности разметки Интернет-документов, среди которых следует отметить ин-
тернационализацию (использование стандарта ISO/IEC:10646 в качестве базо-
вого множества допустимых символов, а также появление специальных тегов,
фиксирующих кодировку; документа); более четкое разделение между структу-
рой документа и его представлением за счет таблиц стилей (style sheets); скрип-
ты (scripts), поддерживающие, в частности, создание динамических страниц; но-
вый механизм интеграции текстовых и графических ссылок, исполняемый на
276
Глава 8 • Представление данных и знаний в Интернете
стороне клиента (client-side image map mechanism) и, безусловно, стандартиза-
цию механизма подключения к HTML-документам базисных медиаобъектов и
приложений (embedding generic media objects and applications).
Справедливости ради следует отметить, что интерпретация некоторых конструк-
ций последних версий языка HTML разными броузерами различна. Однако, как
представляется, это не принципиальные, а технологические трудности совмести-
мости программных продуктов разных фирм, в первую очередь Microsoft и Net-
scape. >
В целом же можно констатировать, что текущая версия языка HTML является
мощным средством разметки Интернет-документов. Но ориентирован этот язык
скорее на «разметку визуализации», чем на семантическую разметку, доступную
для восприятия не только читателями-людьми, но и программами (в первую оче-
редь, агентами, функционирующими в среде Интернет, которые обсуждаются в
следующей главе настоящей книги). И тем не менее некоторые, правда ограни-
ченные, возможности для представления знаний имеются в этом языке и сейчас.
Вот почему в следующем подразделе данного параграфа эти вопросы обсужда-
ются подробнее.
8.1.3 . Возможности представления знаний
на базе языка HTML
Выше были рассмотрены основные конструкции HTML. Теперь обсудим, каким
образом они могут быть использованы для семантической разметки Интернет-
документов и насколько это вообще возможно и эффективно.
Для этого выделим те конструкции языка, которые могут быть полезными для
решения данной задачи.
Очевидно, что к их числу, прежде всего, относятся теги типа <TITLE>, <МЕТА... > и
<А... >.
Первый важен для фиксации семантики всего HTML-документа, так как текст,
заключенный между тегами <TITLE> и </TITLE>, чаще всего отражает его назначе-
ние и/или содержание.
Теги типа <МЕТА... >, по существу, вводят имена атрибутов и их значения с помо-
щью параметров пате=«...» и content=«...», а ссылки и якоря фиксируют отноше-
ния между частями одного документа и/или отдельными документами.
Но если теги типа <МЕТА... > явно вводят семантику значений атрибутов, одина-
ково интерпретируемых броузерами за счет ключевых слов (например, keywords,
author и др.), которые могут быть значениями параметра name, то теги типа <А... >
лишь фиксируют факт наличия отношения между ссылкой и ее якорем. В некото-
рых случаях этому отношению можно «приписать» имя SeeAlso, в других — Isa,
ConsistOf, PartOf или иное подходящее имя, но в целом семантика данной конст-
рукции имплицитна, а встроенная интерпретация ее связана лишь с переходом по
ссылке и визуализацией начала соответствующего фрагмента документа или за-
грузкой нового документа для просмотра.
8.1. Язык HTML и представление знаний
277
Из других конструкций HTML полезными для последующей обработки на пред-
мет эксплицитного представления семантики соответствующих частей докумен-
та могут быть заголовки разделов и подразделов (тексты между тегами <Hi> и
</Hi>), списки, таблицы и другие элементы языка.
Но в целом можно отметить, что выделение значимых для семантической интер-
претации конструкций является экспертной задачей, решаемой каждый раз авто-
ром соответствующей Интернет-публикации по-своему. Правда, уже существуют
определенные стереотипы, особенно заметные на коммерческих сайтах. Так, на-
пример, при анализе сайтов Интернет-магазинов, проведенном Н. В. Майкевич,
было зафиксировано, что каталоги товаров в настоящее время в большинстве слу-
чаев представляются таблицами и/или списками либо «зашиты» в чувствитель-
ные для щелчка мышью графические образы. Аналогичная ситуация характерна
и для индексов на сайтах машин поиска.
Для примера на рис. 8.2 приведена экранная форма известного электронного ма-
газина, функционирующего в сети по адресу http://amazon.com/.
•3 Аяыгоп.соп»: 5оНи<де / Operating Systems & Utilities / Operating Systems - Microsoft internet Explorer
В'ЕЗЕЗ
, й £* ft- I* w • El
. «“* ' Sw RrtMh .Bom ; Sawh Ftwwto tfetw W ftrt, •' .
aiTiaZOn.COm. r----.-------—s .............
SEARCH
< AHGi'iRIES
FOR
«ILERS
UVA & EUWRt
RELEASES
GAMES
s.«a>< I Software *]l ©
| All Categories Ц©
ЮС5
Scflwarg. > I^£catina£ysi.emSi.&litiliii8S > operating Systems
Browse Operating Systems
• beOS • Macintosh
• ROS • Microsoft Windows
♦ Linux & Unix • 0S2
Windows 2000 Is Here!
Trying to decide whether to upgrade to
Windows 2000? See, what other people are
buymg or get expert recommendations from
our editorial staff
Hacker’s Heritage
Debian GNUIJnux
by Loki Publishing Company
Our T op Severs
Updated Dally
1. Microsoft Windows 98 Second Edition
Ujjflradg
’•*Г r 1*1"**' -
Рис. 8.2. Экранная форма секции «Электроника» магазина Amazon.com
Фрагмент соответствующего HTML-текста представлен ниже:
<html>
<head>
<title>
Amazon.com: Electronics/Software/Operating Systems
278
Глава 8 » Представление данных и знаний в Интернете
</title>
</head>
cbody ... >
ctable ...>
<tr>
<td colspan=2 bgcolor=#EEEECC>
<font ... >Browse <8>0perating Systems</B></font>
</td>
</tr>
<tr>
<td bgcolor="FFFFFF" valign="top" width=50%>
<ul>
<li><a href=/exec/obidos/tg/electronics/...> D0S</a>
<li><a href=/exec/obidos/tg/electronics/...> Linux & Unix</a>
clixa href=/exec/obidos/tg/electronics/... > Macintosh</a>
</ul>
</td>
<td valign="top” width=50%>
<ul>
clixa href=/exec/obidos/tg/electronics... > Microsoft Windows</a>
clixa href=/exec/obidos/tg/electronics/... > 0S2</a>
</ul>
</td>
</tr>
</ table>
Как следует из сравнения экранной формы (см. рис. 8.2) и приведенного HTML-
текста, каталог товаров организован в виде таблицы (тег <table>), в ячейках ко-
торой (тег <td>) с помощью конструкции списка (тег <li>) перечислены продук-
ты (в данном случае это операционные системы DOS, Linux & Unix, Macintosh,
Microsoft Windows и OS2). Собственно описания этих продуктов и их характе-
ристики заданы в виде ссылок на отдельные документы (теги <а href=/exec/
obidos/tg/electronics...>). При этом из анализа HTML-текста следует, что его се-
мантически значимые характеристики могут быть «закопаны» достаточно глу-
боко. И более того, разбросаны по разным частям одного документа и даже раз-
ным документам. Все вышесказанное существенно затрудняет семантический
анализ Интернет-документов, независимо от того, выполняется ли он людьми-
экспертами или специальными программами.
Решение проблемы семантического анализа Интернет-документов в настоящее
время связывается с использованием двух подходов. В рамках первого из них
8.1. Язык HTML и представление знаний
279
предполагается, что семантическая разметка HTML-текста выполняется вруч-
ную (или полуавтоматически, с применением соответствующих инструменталь-
ных средств) его автором на основе специальных метатегов. По существу, ре-
зультатом такой разметки является семантическая сеть, отражающая знания,
представленные в документе. Второй подход связан с автоматическим и/или по-
луавтоматическим преобразованием исходного текста в специальное семанти-
ческое представление, как правило, в онтологию или ее фрагмент.
Подробнее эти подходы обсуждаются ниже. Но и в том и в другом случае для
выполнения указанных преобразований целесообразно конвертирование HTML-
текстов в более удобное для дальнейшей обработки представление. Для иллюст-
рации возможностей применения к решению этой задачи средств представления
знаний, описанных в предыдущих главах, рассмотрим интеллектуальный HTML-
конвертор [Maikevich et al., 1998].
Для сокращения объема материала обсудим подмножество языка HTML, которое
может быть задано следующими BNF-определениями:
HTML-текст ::= <HTML> HEAD BODY </HTML>
HEAD ::= TITLE { HEAD } | ...
TITLE ::= <TITLE> строка </TITLE>
BODY ::= <BODY> HTML-BODY </BODY>
HTML-BODY ::= PARAGRAPH { HTML-BODY } |
HEADER { HTML-BODY } | LIST { HTML-BODY } | ...
HEADER ::= <H1> TEXT </H1> | <H2> TEXT </H2> | ...
PARAGRAPH ::= <P> TEXT </P>
LIST ::= <UL> LIST-ATOM { LIST-ATOM } </UL> |
<0L> LIST-ATOM { LIST-ATOM } </0L> |
<MENU> LIST-ATOM { LIST-ATOM } </MENU> | ...
ANCHOR ::= <A HREF= LINK > TEXT </A> |
<A NAME= метка > TEXT </A>
TEXT : := ...
LIST-ATOM ::= ...
LINK : := ...
Некоторые из синтаксических диаграмм, соответствующих приведенным выше
правилам, представлены на рис. 8.3 и 8.4.
Как следует из приведенных правил и диаграмм, с теоретической точки зрения
HTML — это простой язык программирования с контекстно-свободной грамма-
тикой. Нетрудно показать, что для анализа HTML-текстов можно использо-
вать, например, нисходящие распознаватели, реализуемые на базе метода рекур-
280
Глава 8 » Представление данных и знаний в Интернете
сивного спуска. При этом возможны разные подходы. Ниже для этого используй
ется продукционно-фреймовый формализм представления знаний и показыва-
ется, как на этой основе может быть разработан интеллектуальный HTML-кон-
вертор.
Рис. 8.3. Синтаксическая диаграмма понятия HTML
Рис. 8.4. Синтаксическая диаграмма понятия LINK
Прежде всего зададим регулярное отображение каждого правила спецификации
HTML-конструкций в соответствующий объект базы знаний на уровне фрейма-
прототипа. Система таких прототипов даст нам описание языка, а множество
8.1. Язык HTML и представление знаний
281
фреймов-экземпляров — спецификацию конкретных и синтаксически правиль-
ных HTML-текстов. Основные правила такого отображения следующие:
• каждому концепту из левой части BNF-определения поставим в соответствие
имя фрейма-прототипа;
• альтернативам из правой части BNF-определения при этом должны соответ-
ствовать имена слотов этого фрейма;
• для концептов-нетерминалов соответствующий слот должен иметь тип frame;
• для концептов-терминалов соответствующие слоты будут, как правило, иметь
типы numb или string,
• рекурсия в BNF-определениях заменяется итерацией, а соответствующие сло-
ты становятся множественными.
Применение сформулированных выше правил к BNF-определениям языка HTML
приводит нас к следующему множеству фреймов-прототипов:
[htmlis_aprototype, if_added HTML ();
HEADframe, restr_by head;
BODYframe, restr_by body ];
[headis_aprototype, if_added HEAD ();
BODY{frame}, restr_by one_of {title, ...} ];
[title is_aprototype, if_added TITLE ();
BODYstring ];
[bodyis_aprototype, if_added BODY ();
SENT{frame},restr_by one_of {header, paragraph, list, ...} ];
[header is_aprototype;
BODYframe, restr_by text ];
[hi is_aheader, if_added H1()l;...[h6 is_aheader, if_added H6()J;
[paragraph is_aprototype, if_added PARAGRAPH ();
BODYframe, restr_by text ];
[listis_aprototype;
ATOM{frame}, if_added LI () ];
[textis_aprototype;
ATOM{frame},restr_by one_of {br,hr,image,anchor....line} ];
[br is_aprototype; if_added BR () ];
[hr is_aprototype; if_added HR () ];
[image is_aprototype; if_added IMG ();
SRC frame, restr_by link ];
[anchor is_aprototype;
BODYframe, restr_by text ];
282
Глава 8 • Представление данных и знаний в Интернете
[linkis_aprototype;
URL frame, restr_by one_of {http, ftp, ...} ];
MAILframe, restr_by mail ];
[url is_alink;
without_slot MAIL];
[httpis_aurl,if_added HTTP ();
SERVER string;
DIR {string};
FILEstring ];
[ftp is_aurl,if_added FTP ();
SERVER string;
DIR {string};
FILEstring ];
Теперь, в соответствии с приведенными фреймами-прототипами и синтаксичес-
кими диаграммами, можно специфицировать процедурную часть конвертора как
систему демонов, присоединенных к фреймам и/или их слотам. Для примера
ниже приводится спецификация одного из таких демонов на языке Java [Нортон
и др., 1998]:
public class HTML extends FramePrototype {
HEAD head = null;
BODY body = null;
String keyword;
public void HTML (String name) {
super (name);
keyword = getToken ();
if (keyword.compareTo ("<HTML>") == 0) {
head = new HEAD (getNewName ());
body = new BODY (getNewName ());
};
keyword = getToken ();
if (keyword.compareTo ("</HTML>") == 0) return;
}
}
По существу, такой демон не что иное, как конструктор класса HTML, а запуск
конвертора осуществляется с помощью оператора создания нового объекта этого
класса:
HTML currPage = new HTML (get_new_name ());
При этом будут рекурсивно вызываться конструкторы других классов (на верх-
нем уровне это HEAD и BODY), что, в конечном счете, приведет к построению
8.1. Язык HTML и представление знаний
283
множества фреймов-экземпляров, представляющих анализируемую HTML-стра-
ницу (currPage).
Понятно, что в общем случае такой подход дает нам средства синтаксически-ори-
ентированного конвертирования HTML-текста во фреймовое представление. Но
получение полезной для дальнейшей работы базы знаний предполагает его даль-
нейшую семантическую интерпретацию и построение в конечном счете семанти-
ческой сети, отражающей смысл исходного Интернет-документа.
Для примера, фрагменты такой семантической сети для HTML-текста описания
секции «Электроника» магазина Amazon.com, обсуждавшегося выше, приведены
на рис. 8.5.
Рис. 8.5. фрагмент семантической сети для секции «Электроника» магазина Amazon.com
284
Глава 8 • Представление данных и знаний в Интернете
По сути дела, эта семантическая сеть представляет фрагмент онтологии предмет-
ной области «Электронная коммерция», которая может быть базйсом для ре-
шения разнообразных практических задач. Так, например, с ее помощью могут
решаться задачи поиска определенных товаров по запросу пользователя, осуще-
ствляться маркетинговый анализ запросов и т. п. Во всех этих и многих других
случаях онтологии играют ключевую роль как один из перспективных подходов к
представлению знаний в среде Интернет.
Вместе с тем, несмотря на важность понятия онтологии для теории и практики
современных интеллектуальных систем, общепринятого понимания этого тер-
мина нет, хотя различные определения, предложенные разными авторами й на-
учными коллективами [Gruber, 1991; Guarino, 1996; Fridman et al., 1997], ра-
спространяются и медленно конвергируют. Поэтому в следующем параграфе
обсуждается само понятие онтологии и вводится соответствующая система мо-
делей [Maikevich et al., 1999], затем приводится классификация онтологий, по-
лезная для последующего сравнения известных в этой области проектов. В за-
ключительных разделах главы обсуждаются примеры онтологий и специальные
системы аннотирования Интернет-ресурсов на основе онтологий.
8.2. Онтологии и онтологические системы
8.2.1. Основные определения
Онтология (от др.-греч. онтос — сущее, логос — учение, понятие) — термин, опре-
деляющий учение о бытии, о сущем, в отличие от гносеологии — учения о позна-
нии. Уже у X. Вольфа (1679-1754), автора самого термина «онтология», учение о
бытии было отделено от учения о познании. Введен же термин в философскую
литературу немецким философом Р. Гоклениусом (1547-1628). При этом онтоло-
гия являлась частью метафизики, наукой самостоятельной, независимой и не свя-
занной с логикой, с «практической философией», с науками о природе. Ее пред-
мет составляет изучение абстрактных и общих философских категорий, таких
как бытие, субстанция, причина, действие, явление и т. д., а сама онтология как
наука претендовала на полное объяснение причин всех явлений [Розенталь и др.,
1951].
Понятно, что такое определение мало пригодно для практического использова-
ния, но дает отправную точку для дальнейшей конкретизации и обсуждения с
точки зрения целей настоящего издания. В этом смысле интереснее определение
онтологии, предложенное в рамках разработки системы стандартов на мульти-
агентные системы международным сообществом FIPA (Foundation for Intelli-
gent Physical Agents). В работе [FIPA, 1998] утверждается, что
В философском смысле можно ссылаться на онтологию как на определенную систему ка-
тегорий, являющихся следствием определенного взгляда на мир.
8.2. Онтологии и онтологические системы
285
При этом сама система категорий не зависит от конкретного языка: онтология
Аристотеля всегда одна и та же, независимо от языка, использованого для ее опи-
сания.
С другой точки зрения, более близкой к понятиям, связанным с ИИ, онтология —
это формально представленные на базе концептуализации знания. Концептуали-
зация, как уже обсуждалось выше, предполагает описание множества объектов и
понятий, знаний о них и связей между ними. Таким образом,
Онтологией [Gruber, 1993] называется эксплицитная спецификация концептуализации.
Формально онтология состоит из терминов, организованных в таксономию, их опреде-
лений и атрибутов, а также связанных с ними аксиом и правил вывода.
Часто набор предположений, составляющих онтологию, имеет форму логичес-
кой теории первого порядка, где термины словаря являются именами унарных и
бинарных предикатов, называемых соответственно концептами и отношениями.
В простейшем случае онтология описывает только иерархию концептов, связан-
ных отношениями категоризации. В более сложных случаях в нее добавляются
подходящие аксиомы для выражения других отношений между концептами и
для того, чтобы ограничить их предполагаемую интерпретацию. Учитывая вы-
шесказанное, онтология представляет собой базу знаний, описывающую факты,
которые предполагаются всегда истинными в рамках определенного сообщества
на основе общепринятого смысла используемого словаря.
Еще более конкретно понятие онтологии в Известном проекте Ontolingiia [Far-
quhar et al., 1996], который активно ведется в Стэнфордском университете. Здесь
предполагается, что
Онтология — это эксплицитная спецификация определенной темы.
Такой подход предполагает формальное и декларативное представление некото-
рой темы, которое включает словарь (или список констант) для отсылки к тер-
минам предметной области, ограничения целостности на термины, логические
утверждения, которые ограничивают интерпретацию терминов и то, как они со-
относятся друг с другом.
Резюмируя вышесказанное, можно констатировать, что в настоящее время пони-
мание термина «онтология» различно, в зависимости от контекста и целей его ис-
пользования. В работе [Guarino, et al., 1995а] дано достаточно содержательное и
интересное обсуждение этих вопросов, которое сводится в конечном счете к
тому, что здесь выделяются следующие аспекты интерпретации этого термина:
1. Онтология как философская дисциплина.
2. Онтология как неформальная концептуальная система.
3. Онтология как формальный взгляд на семантику.
4. Онтология как спецификация «концептуализации».
286
Глава 8 • Представление данных и знаний в Интернете
5. Онтология как представление концептуальной системы через логическую тео-
рию, характеризуемую:
♦ специальными формальными свойствами или
• только ее назначением.
6. Онтология как словарь, используемый логической теорией.
7. Онтология как (метауровневая) спецификация логической теории.
Следует отметить, что первая интерпретация радикально отличается от осталь-
ных и связана, как предлагают авторы вышеуказанной работы, с тем, что здесь
мы говорим об Онтологии (с большой буквы) и имеем в виду философскую дис-
циплину, изучающую, согласно Аристотелю, природу и организацию сущего.
В этом смысле Онтология пытается ответить на вопрос: «Что есть сущее?» или, в
другой формулировке, на вопрос: «Какие свойства являются общими для всего
сущего?» Когда же мы говорим об онтологии (с маленькой буквы), то ссылаемся
на объект, природа которого может быть различной, в зависимости от выбора
между интерпретациями 2-7. Согласно второй интерпретации онтология явля-
ется концептуальной системой, которую мы можем предполагать в качестве ба-
зиса определенной БЗ. Согласно интерпретации 3 онтология, на основе которой
построена БЗ, выражается в терминах подходящих формальных структур на се-
мантическом уровне. Таким образом, эти две интерпретации рассматривают он-
тологию как концептуальную «семантическую» сущность, неважно, формаль-
ную или неформальную, в то время как интерпретации 5-7 трактуют онтологию
как специальный «синтаксический» объект. Оставшаяся, четвертая интерпрета-
ция, которая была предложена Грубером [Gruber, 1993] в качестве определения
онтологии для использования в рамках ИИ-сообщества, — одна из наиболее про-
блематичных, так как точный смысл ее зависит от понимания терминов «специ-
фикация» и «концептуализация». И вместе с тем именно это определение чаще
всего и используется в настоящее время в работах по проектированию и исследо-
ванию онтологий.
Для определенности дальнейшего изложения мы будем считать, что
Онтологии — это БЗ специального типа, которые могут «читаться» и пониматься, отчуж-
даться от разработчика и/или физически разделяться их пользователями.
При этом онтологический инжиниринг — ветвь инженерии знаний, использую-
щий Онтологию (с большой буквы) для построения онтологий (с маленькой
буквы). Понятно, что любая онтология имеет под собой концептуализацию, но
одна концептуализация может быть основой разных онтологий, и две разные БЗ
могут отражать одну онтологию.
8.2.2. Модели онтологии и онтологической
системы
Выше уже отмечалось, что понятие онтологии предполагает определение и ис-
пользование взаимосвязанной и взаимосогласованной совокупности трех компо-
8.2. Онтологии и онтологические системы
287
нент: таксономии терминов, определений терминов и правил их обработки. Учи-
тывая это, введем следующее определение понятия модели онтологии:
Под формальной моделью онтологии О будем понимать упорядоченную тройку вида:
О = <Х,Й, Ф>,
где
X — конечное множество концептов (понятий, терминов) предметной области, кото-
рую представляет онтология О;
91 — конечное множество отношений между концептами (понятиями, терминами)
заданной предметной области;
Ф — конечное множество функций интерпретации (аксиоматизация), заданных на
концептах и/или отношениях онтологии О.
Заметим, что естественным ограничением, накладываемым на множество X, яв-
ляется его конечность и непустота. Иначе обстоит дело с компонентами Ф и SR в
определении онтологии О. Понятно, что и в этом случае Ф и 91 должны быть ко-
нечными множествами. Рассмотрим, однако, граничные случаи, связанные с их
пустотой.
Пусть 91 = 0 и Ф= 0. Тогда онтология О трансформируется в простой словарь:
O = V = <X, {}, {}>.
Такая вырожденная онтология может быть полезна для спецификации, попол-
нения и поддержки словарей ПО, но онтологии-словари имеют ограниченное ис-
пользование, поскольку не вводят эксплицитно смысла терминов. Хотя в не-
которых случаях, когда используемые термины принадлежат очень узкому
(например, техническому) словарю и их смыслы уже заранее хорошо согласова-
ны в пределах определенного (например, научного) сообщества, такие онтологии
применяются на практике. Известными примерами онтологий этого типа явля-
ются индексы машин поиска информации в сети Интернет.
Иная ситуация в случае использования терминов обычного естественного языка
или в тех случаях, когда общаются программные агенты. В этом случае необ-
ходимо характеризовать предполагаемый смысл элементов словаря с помощью
подходящей аксиоматизации, цель использования которой — в исключении не-
желательных моделей и в том, чтобы интерпретация была единой для всех учас-
тников общения.
Другой вариант соответствует случаю 91 = 0, но Ф * 0. Тогда каждому элементу
множества терминов из X может быть поставлена в соответствие функция интер-
претации f из Ф. Формально это утверждение может быть записано следующим
образом.
Пусть
Х = Х1иХ2,
причем
Xt п Х2 = 0,
где Xt — множество интерпретируемых терминов;
Х2 — множество интерпретирующих терминов.
288
Глава 8 • Представление данных и знаний в Интернете
Тогда
3(хе Xt, у1, у2,...» укб Х2),
такие что
x = f(y1.y2....»Ук),
где f 6 Ф.
Пустота пересечения множеств Xi и Х2 исключает циклические интерпретации, а
введение в рассмотрение функции к аргументов призвано обеспечить более пол-
ную интерпретацию. Вид отображения f из Ф определяет выразительную мощ-
ность и практическую полезность этого вида онтологии. Так, если предположить,
что функция интерпретации задается оператором присваивания значений (Xf := Х2,
где Xt — имя интерпретации Х2), то онтология трансформируется в пассивный
словарь V₽:
О = V1’= < Xfu Х2, {}, {:=}>.
Такой словарь пассивен, так как все определения терминов из Xt берутся из уже
существующего и фиксированного множества Х2.. Практическая ценность его
выше, чем простого словаря^ но явно недостаточна, например, для представления
знаний в задачах обработки информации в Интернете в силу динамического ха-
рактера этой среды.
Для того чтобы учесть последнее обстоятельство, предположим, что часть интер-
претирующих терминов из множества Х2 задается процедурно, а не декларативно.
Смысл таких терминов «вычисляется» каждый раз при их интерпретации.
Ценность такого словаря для задач обработки информации в среде Интернет
выше, чем у предыдущей модели, но все еще недостаточна, так как интерпретиру-
емые элементы из Xt никак не связаны между собой и, следовательно, играют
лишь роль ключей входа в онтологию.
Для представления модели онтологии, которая нужна для решения задач обра-
ботки информации в Интернете, очевидно, требуется отказаться от предположе-
ния 91= 0.
Итак, предположим, что множество отношений на концептах онтологии не пусто,
и рассмотрим возможные варианты его формирования.
Для этого введем в рассмотрение специальный подкласс онтологий — простую
таксономию следующим образом:
О = Т° = < X, {is_a}, {}>.
Под таксономической структурой будем понимать иерархическую систему понятий, свя-
занных между собой отношением is_a («бытьэлементом класса»).
Отношение is_a имеет фиксированную заранее семантику и позволяет организо-
вывать структуру понятий онтологии в виде дерева. Такой подход имеет свои
преимущества и недостатки, но в общем случае является адекватным и удобным
для представления иерархии понятий.
8:2. Онтологий и онтологические системы
289
Результаты анализа частных случаев модели онтологии приведены в таблице 8.1. Таблица 8.1 • Классификация моделей онтологии
Компоненты модели 91 = 0 Ф=0 О® «4 9t={is_a) Ф=0
Формальное определение <Х, {}, {}> <Х,иХ2, {},ф> <Х,<Х,и (Х2ир2-),{),Ф> < X, is_a), {}>
Пояснение Словарь ПО Пассивный словарь ПО Активный словарь ПО Таксономия понятий ПО
Далее можно обобщить частные случаи модели Онтологии таким образом, чтобы
обеспечить возможность:
• представления множества концептов X в виде сетевой структуры;
• использования достаточно богатого множества отношений % включающего
не только таксономические отношения, но и отношения, отражающие специ-
фику конкретной предметной области, а также средства расширения множе-
ства 91;
• использования декларативных и процедурных интерпретаций и отношений,
включая возможность определения новых интерпретаций.
Тогда можно ввести в рассмотрение модель расширяемой онтологии и исследовать
ее свойства. Однако, учитывая техническую направленность данной книги, мы не
будем делать этого здесь, а желающих познакомиться с такой моделью отсылаем к
работе [Maikevich et al., 1999]. Как показано в этой работе, модель расширяемой
онтологии является достаточно мощной для спецификации процессов формиро-
вания пространств знаний в среде Интернет. Вместе с тем и эта модель является
неполной в силу своей пассивности даже там, где определены соответствующие
процедурные интерпретации и введены специальные функции пополнения онто-
логии. Ведь единственной точкой управления активностью в такой модели явля-
ется запрос на интерпретацию определенного концепта. Этот запрос выполняется
всегда одинаково и инициирует запуск соответствующей процедуры. А собствен-
но вывод ответа на запрос и/или поиск необходимой для этого информации оста-
ется вне модели и должен реализовываться другими средствами.
Учитывая вышесказанное, а также необходимость эксплицитной спецификации
процессов функционирования онтологии, введем в рассмотрение понятие онто-
логической системы
Под формальной моделью онтологической системы!}0 будемпонимать триплет вида:
Х° = <о "’•*•, {О “*}, S “ >,
где
п meta . .
О — онтология верхнего уровня (метаонтология);
{О d&t) — множество предметных онтологий и онтологий задач предметной области;
Е — модель машины вывода, ассоциированной с онтологической системой X °.
290
Глава 8 • Представление данных и знаний в Интернете
Использование системы онтологий и специальной машины вывода позволяет ре-
шать в такой модели различные задачи. Расширяя систему моделей {О d4t}i можно
учитывать предпочтения пользователя, а изменяя модель машины вывода, вво-
дить специализированные критерии релевантности получаемой в процессе поис-
ка информации и формировать специальные репозитории накопленных данных,
а также пополнять при необходимости используемые онтологии.
о
В модели £ имеются три онтологические компоненты:
• метаонтология;
• предметная онтология;
• онтология задач.
Как указывалось выше, метаонтология оперирует общими концептами и отно-
шениями, которые не зависят от конкретной предметной области. Концептами
метауровня являются общие понятия, такие как «объект», «свойство», «значе-
ние» и т. д. Тогда на уровне метаонтологии мы получаем интенсиональное опи-
сание свойств предметной онтологии и онтологии задач. Онтология метауровня
является статической, что дает возможность обеспечить здесь эффективный вы-
вод.
Предметная онтология Odom,in содержит понятия, описывающие конкретную
предметную область, отношения, семантически значимые для данной предмет-
ной области, и множество интерпретаций этих понятий и отношений (деклара-
тивных и процедурных). Понятия предметной области специфичны в каждой
прикладной онтологии, но отношения — более универсальны. Поэтому в каче-
стве базиса обычно выделяют такие отношения модели предметной онтологии,
как part_of, kind_of, contained_in, member_of, seealso и некоторые другие.
Отношение part_of определено на множестве концептов, является отношением
принадлежности и показывает, что концепт может быть частью других концеп-
тов. Оно является отношением типа «часть-целое» и по свойствам близко к от-
ношению is_a и может быть задано соответствующими аксиомами. Аналогич-
ным образом можно ввести и другие отношения типа «часть-целое».
Иначе обстоит дело с отношением see also. Оно обладает другой семантикой и
другими свойствами. Поэтому целесообразно вводить его не декларативно, а
процедурно, подобно тому, как это делается при определении новых типов в язы-
ках программирования, где поддерживаются абстрактные типы данных;
X see_also Y:
see_also member_of Relation {
if ( (X is_a Notion) & (Y is_a Notion) & (X see_also Y) )
if (Operation connected_with X)
Operation connected_with Y
};
Заметим, что и отношение see_also «не вполне» транзитивно. Действительно,
если предположить, что (XI see also Х2) & (Х2 see_also ХЗ), то можно считать,
что (XI see also ХЗ). Однако по мере увеличения длины цепочки объектов, свя-
8.2. Онтологии и онтологические системы
291
занных данным отношением, справедливость транзитивного переноса свойства
connected_ with падает. Поэтому в случае отношения see also мы имеем дело не с
отношением частичного порядка (как, например, в случае отношения is_a), а с
отношением толерантности. Однако для простоты это ограничение может' быть
перенесено из определения отношения в функцию его интерпретации.
Анализ различных предметных областей показывает, что введенный выше набор
отношений является достаточным для начального описания соответствующих
онтологий. Понятно, что этот базис является открытым и может пополняться в
зависимости от предметной области и целей, стоящих перед прикладной систе-
мой, в которой такая онтология используется.
Онтология задач в качестве понятий содержит типы решаемых задач, а отноше-
ния этой онтологии, как правило, специфицируют декомпозицию задач на подза-
дачи. Вместе с тем, если прикладной системой решается единственный тип задач
(например, задачи поиска релевантной запросу информации), то онтология задач
может в данном случае описываться словарной моделью, рассмотренной выше.
Таким образом, модель онтологической системы позволяет описывать необхо-
димые ДЛЯ’ ее функционирования онтологии разных уровней. Взаимосвязь меж-
ду онтологиями показана на рис. 8.6.
Рис.. 8.в. Взаимосвязь между онтологиями онтологической системы
Машина вывода онтологической системы в общем случае может опираться на се-
тевое представление онтологий всех уровней. При этом ее функционирование
будет связано:
• с активацией понятий и/или отношений, фиксирующих решаемую задачу
(описание исходной ситуации);
• определением целевого состояния (ситуации);
• выводом на сети, заключающемся в том, что от узлов исходной ситуации рас-
пространяются волны .активации, использующие свойства отношений, с ними
связанных. Критерием остановки процесса является достижение целевой си-
туации или превышение длительности исполнения (time-out).
292
Глава 8 • Представление данных и знаний в Интернете
8.2.3. Методологии создания
и «жизненный цикл» онтологий
Как уже отмечалось выше, разработчики систем, основанных на знаниях, сталки-
ваются с проблемой «узкого горлышка» приобретения знаний. Аналогичная про-
блема существует и при создании онтологий. Но, в отличие от разработчиков
интеллектуальных систем, создателей онтологий ждут и дополнительные про-
блемы, связанные с отсутствием сколько-нибудь общих ц верифицированных ме-
тодологий, определяющих, какие «процедуры» должны выполняться в процессе
разработки и на каких стадиях разработки онтологий они должны выполняться.
В настоящее время существует лишь несколько предметно-независимых методо-
логий, ориентированных на построение онтологий [Gruninger et al., 1995; Ushold,
et al., 1996; Fernandez et al., 1997].
Следует сразу отметить, что эти подходы и методологии базируются на следую-
щих принципам проектирования и реализации онтологий, предложенных Грубе-
ром [Gruber, 1993]:
1. Ясность (Clarity) — онтология должна эффективно передавать смысл вве-
денных терминов. Определения должны быть объективными, хотя моти-
вация введения терминов может определяться ситуацией или требования-
ми вычислительной эффективности. Для объективизации определений
должен использоваться четко фиксированный формализм, при этом целе-
сообразно задавать определения в виде логических аксиом.
2. Согласованность (Coherence) — означает, что по крайней мере все определения
должны быть логически непротиворечивы, а все утверждения, выводимые в
онтологии, не должны противоречить аксиомам.
3. Расширяемость (Extendibility) — онтология должна быть спроектирована так,
чтобы обеспечивать использование разделяемых словарей терминов, допуска-
ющих возможность монотонного расширения и/или специализации без необ-
ходимости ревизии уже существующих понятий.
4. Минимум влияния кодирования (Minimal encoding bias) — концептуализация, ле-
жащая в основе создаваемой онтологии, должна быть специфицирована на
уровне представления, а не символьного кодирования. Этот принцип связан с
тем, что агенты, разделяющие онтологию, могут быть реализованы в различ-
ных системах представления знаний. (
5. Минимум онтологических обязательств (Minimal ontological commitment) — он-
тология должна содержать только наиболее существенные предположения о
моделируемом мире, чтобы оставлять свободу расширения и специализации.
Отсюда следует, что онтологии базируются на «слабых» теориях, так как цель
их создания и использования состоит, прежде всего, в том, чтобы «говорить» о
предметной области, в отличие от БЗ, которые могут содержать знания, необ-
ходимые для решения задач и/или ответов на вопросы.
Методологию и «жизненный цикл» создания онтологий обсудим на примере под-
хода METHONTOLOGY, разработанного Гомез-Перезом (Gomez-Perez) с колле-
8.2. Онтологии и онтологические системы
293
гами, в рамках которого реализуются принципы Груберу а также разработано
программное окружение спецификации онтологий ODE. (Ontology Design Envi-
ronment) [Blazquez et al., 1998].
В рамках этого подхода выделяются следующие процедуры в «жизненном цик-
ле» создания онтологии: управление проектом, собственно разработка и поддерж-
ка разработки.
Процедуры управления проектом включают планирование, контроль и гарантии
качества. Планирование определяет, какие задачи должны быть выполнены, как
они организуются, как много времени и какие ресурсы нужны для их выполнения.
Контроль гарантирует, что запланированные задачи выполнены и именно так, как
это предполагалось. Гарантии качества нужны для того, чтобы быть уверенным в
том, что компоненты и продукт в целом находятся на заданном уровне.
Собственно разработка включает спецификацию, концептуализацию, формали-
зацию и реализацию. Спецификация определяет цели создания онтологии, ее
предполагаемое использование и потенциальных пользователей. Концептуали-
зация обеспечивает структурирование предметных знаний в виде значимой экс-
плицитной модели. Формализация трансформирует концептуальную модель в
формальную или «вычислительную». Наконец, в процессе реализации вычисли-
тельная модель программируется на соответствующем яз^ке представления зна-
ний.
Процедуры поддержки включают действия, выполняемые одновременно с разра-
боткой, без которых онтология не может быть построена. Они представлены про-
цедурами приобретения знаний, оценки, интеграции, документирования и управ-
ления конфигурациями. Приобретение знаний аккумулирует знания в заданной
предметной области. Оценка дает технические решения по оценке онтологии, со-
ответствующего программного обеспечения и документации как в процессе вы-
полнения каждой фазы, так и между фазами. Интеграция требуется, когда стро-
ится новая онтология с использованием уже существующих. Документирование
дает детальную, понятную и исчерпывающую информацию о каждой фазе и про-
дукте в целом. Управление конфигурациями необходимо для архивации всех вер-
сий документации, программного обеспечения и кода онтологии, а также для кон-
троля за изменениями.
Общая схема «жизненного цикла» создания онтологий в рамках подхода MET-
HONTOLOGY представлена на рис. 8.7.
Заметим, что процесс построения онтологии здесь распадается на серию подпро-
цессов по созданию промежуточных представлений. При этом выполнение от-
дельных подпроцессов не последовательное (в смысле «водопадной» модели жиз-
ненного цикла,, обсуждавшейся в предыдущей главе), а определяется полнотой и
точностью уже накопленных знаний. Однако, как показывает опыт, сначала стро-
ится глоссарий терминов (Glossary of Terms), затем деревья классификации
концептов (Concept Classification Trees) и диаграммы бинарных отношений
(Binary Relations Diagrams). И только после этого — остальные промежуточные
представления.
294
Глава 8 • Представление данных и знаний в Интернете
Концептуализация
Рис. 8.7. «Жизненный цикл» создания онтологий в рамках подхода METHONTOLOGY
Для иллюстрации результатов, получаемых на разных этапах создания онтоло-
гий в рамках подхода METHONTOLOGY, будем предполагать, следуя работе
[Blazquez et al., 1998], что предметной областью разработки является сообщество
специалистов по приобретению знаний, работающих в контексте инициативы
(КА)2 [Benjamins et al., 1998].
Согласно обсуждаемой методологии сначала здесь строится глоссарий терми-
нов, включающий все термины (концепты и их экземпляры, атрибуты, действия
и т. п.), важные для предметной области, и их естественно-языковые описания.
Фрагмент такого глоссария представлен в табл. 8.2.
Таблица 8.2. Фрагмент глоссария
Термин Описаниетермина
Academic Staff «Он\она может быть лектором или исследователем.
Одна из возможных обязанностей — руководство аспирантами»
Researcher «Он\она является членом Academic Staff, может быть членом
исследовательской группы и кооперироваться с другими исследователями»
8.2. Онтологии и онтологические системы
295
Термин Описание термина
Nicola Guarino «Он является исследователем CNR National Research Council. Его исследования связаны с онтологиями. Он работает по проекту OntoSeek»
Weight «Вес человека. Измеряется в килограммах»
Когда глоссарий терминов достигает «существенного» объема, строятся деревья
классификации концептов. Как правило, при этом используются отношения ти-
па subclass-of и некоторые другие таксономические отношения. Таким образом,
идентифицируются основные таксономии предметной области, а каждая таксо-
номия, согласно рассматриваемой методологии, дает в конечном счете цитоло-
гию. В рамках инициативы (КА)2 идентифицировано несколько таксономий, ос-
новные из которых people, publications, events, organizations и research topics.
Фрагменты некоторых из них представлены на рис. 8.8.
People
Employee
Academic-Staff
Lecturer
Researcher
Publication
Article
Article-ln-Bbok
Conference-Paper
Project
Development-Project
Software-Project
Research-Project
Student
PhD-Student
Book
Journal
IEEE-Expert
Рис. 8.8. фрагменты таксономий, выделяемых в рамках инициативы (КА)2
Следующим шагом является построение «Ad hoc» диаграмм бинарных отноше-
ний, целью создания которых является фиксация отношений между концептами
одной или разных онтологий. Заметим, что в дальнейшем эти диаграммы могут
послужить исходным материалом для интеграции разных онтологий. Пример
одной из таких диаграмм приведен на рис. 8.9.
Рис. 8.9. Фрагмент диаграммы бинарных отношений, выделяемых в рамках инициативы (КА):
296
Глава 8 • Представление данных и знаний в Интернете
После построения представлений, фиксированных выше, для каждого дерева
классификации,концептов строятся:
1. Словарь концептов (Concept Dictionary), содержащий все концепты предмет-
ной области, экземпляры таких концептов, атрибуты экземпляров концептов,
отношения, источником которых является концепт, а также (опционально) си-
нонимы и акронимы концепта. Фрагмент такого словаря представлен в табл. 8.3.
2. Таблица бинарных отношений (Table of Binary Relations) для каждого «Ad hoc»
отношения, исходный концепт которого содержится в классификационном де-
реве. Для каждого отношения фиксируется его имя, имена концепта-источни-
ка и целевого концепта, инверсное отношение и т. п. характеристики. Пример
двух таблиц этого типа представлен в табл. 8.4, 8.5.
3. Таблица атрибутов экземпляра (Instance Attribute Table) для каждого экземп-
ляра из словаря концептов. Основные характеристики здесь следующие: имя
атрибута, тип значения, единица измерения, точность, диапазон изменения,
значение «по умолчанию», атрибуты, которые могут быть выведены с исполь-
зованием данного, формула или правило для вывода атрибута и др. Пример
описания атрибутов экземпляра Weight показан в табл. 8.6.
4. Таблица атрибутов класса (Class Attribute Table) для каждого класса из слова-
ря концептов с аналогичными характеристиками.
5. Таблица логических аксиом (Logical Axioms Table), в которой даются опреде-
ления концептов через всегда истинные логические выражения. Определение
каждой аксиомы включает ее имя, естественно-языковое описание, концепт, к
которому аксиома относится, атрибуты, используемые в аксиоме, логическое
выражение, формально описывающее аксиому, и др. Пример описания аксио-
мы приведен в табл. 8.7.
6. Таблица констант (Constants Table), где для каждой константы указывается ее
имя, естественно-языковое описание, тип значения, само значение, единица из-
мерения, атрибуты, которые могут быть выведены с использованием данной
константы, и т. п.
7. Таблица формулы (Formula Table) для каждой формулы, включенной в таб-
лицу атрибутов экземпляра. Каждая таблица этого типа, помимо собственно
формулы, должна специфицировать ее имя, атрибут, выводимый с помощью
этой формулы, естественно-языковое описание, точность, ограничения, при ко-
торых возможно использовать формулу, и др.
8. Деревья классификации атрибутов (Attribute Classification Trees), которые гра-
фически показывают соответствующие атрибуты и константы, используемые
для вывода значения корневого атрибута и формулы, применяемые для этого.
По сути дела, эти деревья используются для проверки того, что все атрибуты,
представленные в формуле, имеют описания и ни один из атрибутов не пропу-
щен.
9. Таблица экземпляров (Instance Table) для каждого входа в словарь концептов.
Здесь специфицируется имя экземпляра, его атрибуты и их значения. Пример
фрагмента таблицы экземпляров представлен в табл. 8.8.
8.2. Онтологии и онтологические системы
297
Таблица 8.3. Фрагмент словаря концептов
Имя концепта ... Экземпляр Атрибуты экземпляра 'Отношение
Academic-Staff Person — Age first-Name Last-Name Photo Weight Supervises Has-Publications Editor-of
Researcher Gomez-Perez — Cooperates-with Research-Interest Member-of-Research-Group
Таблица 8.4. Фрагмент описания отношения Employs
Имя отношения Employs
Исходный концепт Organization
Кардинальность d.n)
Целостный концепт Employee
Математические свойства —
Инверсные отношения Affiliation
Ссылки —
Таблица 8.5. Фрагмент описания отношения Affiliation
Имя отношения Affiliation
Исходный концепт Employee
Кардинальность d.n)
Целостный концепт Organization
Математические саойства —
Инверсные отношения Employs
Ссылки —
Таблица 8.8. Фрагмент описания атрибутов экземпляра Weight
Имя атрибута экземпляра Weight
Тип значения Mass-Quantity
Единица измерения Kilogram
Точность 0.001
Диапазон [0,200]
Значение «по умолчанию» —
Кардинальность (1.1)
Выводится из атрибута экземпляра —
Выводится из атрибута класса —
Выводится из констант —
формула —
298
Глава 8 • Представление данных и знаний в Интернете
Таблица 8.7. Фрагмент описания аксиомы The-Head-Of-Project-Works-ln-The-Project
Имя аксиомы The-Head-Of-Project-Works-ln-The-Project
Описание «Работник, являющийся руководителем проекта, работает в проекте»
Концепт Ссылочные атрибуты Переменные Определение Employee Е, Р Forall (Е, Р) Employs (Е) and Head-Of-Project (Е, Р) => Works-At-Project (Е, Р)
Таблица 8.8. фрагмент таблицы экземпляров
Экземпляр Атрибут Значение
Gomez-Perez Full Name First Name Last Name E-Mail «Asuncion Gomez-Perez» «Asuncion» «Gomez-Perez» «asun@fi.upm.es»
Как показывает анализ приведенных выше процедур, выполняемых при создании
онтологий в подходе METHONTOLOGY, все они хорошо коррелируют с теми
стадиями, которые выделены и используются при построении баз знаний. И это
не случайное совпадение, а закономерность, связанная с тем, что онтология — это,
по существу, БЗ специального вида. Поэтому, как и в случае построения баз зна-
ний, здесь используется концепция быстрого прототипирования, а специфика
проявляется в тех конкретных процессах, которые реализуют рассмотренные
выше процедуры. При этом:
• планирование выполняется до начала собственно разработки;
• контроль и гарантии качества осуществляются в процессе разработки;
• большая часть операций по накоплению знаний и их оценке выполняется на
стадии концептуализации для того, чтобы предотвратить распространение
ошибок на фазу реализации;
• интеграция не должна рассматриваться как интеграция на стадии реализации.
Напротив, она выполняется в процессе разработки.
8.2.4. Примеры онтологий
В настоящее время исследования в области онтологий и онтологических систем
являются «горячими точками» не только в ИИ, но и в работах по интеллектуали-
зации информационного поиска, в первую очередь, в среде Интернет; в работах
по мультиагентным системам; в проектах по автоматическому «извлечению» зна-
ний из текстов на естественном языке; в проектах, ведущихся в смежных облас-
тях.
8.2. Онтологии и онтологические системы
299
При этом разные авторы вводят различные типизации онтологий [Gruber, 1995;
Guarino, 1996], суммируя которые можно выделить классификации по:
• степени зависимости от конкретной задачи или предметной области;
• уровню детализации аксиоматизации;
• «природе» предметной области и т. д.
Дополнительно к этим измерениям можно ввести и классификации, связанные с
разработкой, реализацией и сопровождением онтологий, но такая типизация бо-
лее уместна при обсуждении вопросов реализации онтологических систем.
По степени зависимости от конкретной задачи или предметной области обычно
различают:
• онтологии верхнего уровня;
• онтологии, ориентированные на предметную область;
• онтологии, ориентированные на конкретную задачу;
• прикладные онтологии.
Онтологии верхнего уровня описывают очень общие концепты, такие как про-
странство, время, материя, объект, событие, действие и т. д., которые независимы
от конкретной проблемы или области. Поэтому представляется разумным, по
крайней мере в теории, унифицировать их для больших сообществ пользовате-
лей.
Примером такой общей онтологиии является CYC® [Lenat, 1995]. Одноименный
проект — CYC® — ориентирован на создание мультиконтекстной базы знаний и
специальной машины вывода, разрабатываемой Сусогр. Основная цель этого ги-
гантского проекта — построить базу знаний всех общих понятий (начиная с та-
ких, как время, сущность и т. д.), включающую семантическую структуру терми-
нов, связей между ними и аксиом. Предполагается, что такая база знаний может
быть доступна разнообразным программным средствам, работающим со знания-
ми, и будет играть роль базы «начальных знаний». В онтологии, по некоторым
данным, уже представлены 106 концептов и 105 аксиом. Для представления зна-
ний в рамках этого проекта разработан специальный язык CYCL.
Другим примером онтологии верхнего уровня является онтология системы Gene-
railized Upper Model [Braetman et al., 1994], ориентированная на поддержку про-
цессов обработки естественного языка: английского, немецкого и итальянского.
Уровень абстракции этой онтологии находится между лексическими и концепту-
альными знаниями, что определяется требованиями упрощения интерфейсов с
лингвистическими ресурсами. Модель Generalized Upper Model включает таксо-
номию, организованную в виде иерархии концептов (около 250 понятий) и от-
дельной иерархии связей. Фрагмент системы понятий этой онтологии приведен
на рис. 8.10.
В целом же можно констатировать, что, несмотря на отдельные успехи, создание
достаточно общих онтологий верхнего уровня представляет собой очень серьез-
ную задачу, которая еще не имеет удовлетворительного решения.
300
Глава 8 • Представление данных и знаний в Интернете
Рис. 8.10. Фрагмент системы понятий онтологии Generalized Upper Model
Предметные онтологии и онтологии задач описывают, соответственно, словарь,
связанный с предметной областью (медицина, коммерция и т. д.) или с конкрет-
ной задачей или деятельностью (диагностика, продажи и т. п.) за счет специали-
зации терминов, введенных в онтологии верхнего уровня. Примерами онтологий,
ориентированных на определенную предметную область и конкретную задачу,
являются TOVE и Plinius соответственно [TOVE, 1999; Van der Vet et al., 1994].
Онтология в системе TOVE (Toronto Virtual Enterprise Project) [TOVE, 1999]
предметно ориентирована на представление модели корпорации. Основная цель
ее разработки — отвечать на вопросы пользователей по реинжинирингу бизнес-
процессов, извлекая эксплицитно представленные в онтологии знания. При этом
система может проводить дедуктивный вывод ответов. В онтологии нет средств
для интеграции с другими онтологиями. Формально онтология описывается с
помощью фреймов. Таксономия понятий онтологии TOVE представлена на
рис. 8.11.
Прикладные онтологии описывают концепты, зависящие как от конкретной
предметной области, так и от задач, которые в них решаются. Концепты в таких
онтологиях часто соответствуют ролям, которые играют объекты в предметной
области в процессе, выполнения определенной деятельности. Пример такой он-
тологии — онтология системы Plinius [Van der Vet et al„ 1994], предназначенная
для полуавтоматического извлечения знаний из текстов в области химии. В от-
личие от других, упомянутых выше онтологий, здесь нет явной таксономии
понятий. Вместо этого определено несколько множеств атомарных концептов,
таких как, например, химический элемент, целое число и т. п., и правила конст-
8.3. Системы и средства представления онтйлогических знаний 301
руирования остальных концептов. В онтологии описано около 150 концептов и
6 правил. Формально онтология Plinius тоже описывается с помощью фреймов.
Как показывает анализ работ в этой области, научными сообществами и колекти-
вами создаются онтологии разных типов, но в целом в настоящее время наиболее
активно разрабатываются и используются на практике предметные онтологии.
Вместе с тем, независимо от типа онтологии, для их представления и использова-
ния требуются Специальные алгоритмические средства, к обсуждению которых
мы и переходим в следующем параграфе.
8.3. Системы и средства представления
онтологических знаний
8.3.1. Основные подходы
В настоящее время во всем мире исследования по пространствам знаний в среде
Интернет [Khoroshevsky, 1998] ведутся широким фронтом. И одним из ключевых
аспектов в таких исследованиях являются алгоритмические и программные сред-
ства представления онтологических знаний и работы с онтологиями.
В качестве примеров исследовательских проектов по данной тематике можно
указать Co-operative Information Gathering Project из лаборатории Распределен-
ного ИИ университета Массачусет; проект экстрактирования знаний из гипер-
текстов на основе использования методов машинного обучения, выполняемого в
университете Карнеги Мэллон; работы Knowledge Technology Group лаборато-
рии Sun Microsystems по технологии обработки знаний (проект «Precision Con-
tent Retrieval»), целью которого является построение концептуальной таксоно-
302 Глава 8 • Представление данных и знаний в Интернете
мии фраз, выделяемых из индексированных материалов, и многие другие [Lesser
et al., 1998; Luke et al., 1996; Woods et al., 1999]. Общей целью практически всех
таких проектов является разработка новых подходов к построению пространств
знаний и средств работы с ними, где бы обеспечивались:
• использование семантики для управления процессом ответа на запросы;
• возможность построения ответов с хорошо определенной семантикой и про-
стым синтаксисом, которые могли бы быть «поняты» и обработаны программ-
ными агентами или другими программными средствами;
• возможность гомогенного доступа к информации, которая физически распре-
делена и гетерогенно представлена в Интернете;
• получение информации, которая явно не присутствует среди фактов, получен-
ных из сети, но может быть выведена из других фактов и базовых знаний.
Впечатляющая коллекция ссылок на такие проекты представлена в Интернете по
адресу http://www.tzi.org/grp/i3/, но наиболее интересными с точки зрения темы
данного раздела, по-видимому, являются инициатива (КА)2 [Benjamins et al.,
1998] и проект SHOE [Heflin et al., 1998], которые и обсуждаются ниже.
8.3.2. Инициатива (КА)2 и инструментарий
Ontobroker
Аннотация знаний в рамках инициативы (КА)2
Аннотация знаний сообществом приобретения знаний (Knowledge Annotation
Initiative of the Knowledge Acquisition Community) — так расшифровывается аббре-
виатура (KA)2. Целью работ по этому международному проекту является, в ко-
нечном счете, интеллектуальный поиск в среде Интернет и автоматическое на-
копление новых знаний.
В рамках инициативы (КА)2 выделяются три основных направления исследова-
ний:
• онтологический инжиниринг (ontological engineering);
• аннотация WebTCTpaHHn;
• запросы к информации на Web-страницах и вывод ответов на базе онтологи-
ческих знаний.
Онтологический инжиниринг — одно из основных направлений, в рамках кото-
рого предполагается, что сообщество (КА)2 должно создать свою собственную и
достаточно общую систему онтологий на основе использования средств Onto-
lingua [Farquhar et al., 1996]. В настоящее время уже разработано воесемь онтоло-
гий, которые могут рассматриваться как разделы общей онтологии — онтоло-
гия организации (organization ontology), проекта (project ontology), личности
(person ontology), направления исследований (research-topic ontology), публика-
ций (publication ontology), событий (event ontology), исследовательских про-
8.3. Системы и средства представления онтологических знаний
303
дуктов (research-product ontology) и исследовательских групп (research-group
ontology). При этом разработка примеров онтологий осуществляется и управля-
ется участниками проекта — так называемыми провайдер-агентами («provider
agents»), а размещаются эти онтологии на их Web-страницах. Такие страницы
аннотируются с использованием нового типа HTML-тегов (ONTO), информа-
ция в пределах которых обрабатывается специальной компонентой, работающей
на основе онтологий, — системой Ontocrawler. В рамках этой компоненты, в за-
висимости от «богатства» используемой онтологии, может выводиться новая
информация, релевантная запросам, но не присутствующая явно на Web-стра-
ницах в сети Интернет.
Сама система Ontocrawler разрабатывается в рамках отдельного проекта инициа-
тивы (КА)2 — проекта Ontobroker [Fensel et al., 1998], который, собственно, и
интересен с точки зрения обсуждения средств представления и обработки онто-
логических знаний.
Средства спецификации онтологий в проекте Ontobroker
В Ontobroker имеются три основные подсистемы: интерфейс формулирования
запросов (query interface), машина вывода ответов (inference engine) и собствен-
но машина доступа к Интернет-ресурсам — «червяк» (Webcrawler), используе-
мый для накопления требуемых знаний из этой среды.
Для спецификации онтологий разработан специальный язык представления зна-
ний. Подмножество этого языка служит и для формулировки запросов, а язык
аннотирования — для «обогащения» Web-документов онтологической информа-
цией. Все эти компоненты и обсуждаются ниже.
Формализм запросов
Формализм запросов ориентирован на фреймовое представление онтологий, в
рамках которого, как и обычно, определены понятия экземпляров, классов, атри-
бутов и значений.
Схема O:C[A-»V] означает, что объект О является экземпляром класса С с ат-
рибутом А, имеющим значение V. Важно, что в каждой позиции такой схемы мо-
гут использоваться не только константы, но и переменные или выражения.
Для примера, запрос вида
FORALL R <- R:Researcher
предполагает поиск всех объектов, являющихся экземплярами класса Researcher.
Если предположить, что идентификатором объекта служит URL домашней стра-
ницы специалиста, в качестве результата по этому запросу будет выдан список
соответствующих Интернет-ссылок.
Понятно, что это простейший запрос. Обычно же в запросе определяется поиско-
вый образ объектов, обладающих определенными свойствами. Так, если необхо-
димо найти всех специалистов по фамилии Иванов и при этом выдать в качестве
304
Глава 8 • Представление данных и знаний в Интернете
результата их имена и электронные адреса,, то приведенный выше запрос можно
модифицировать следующим образом:
FORALL Obj, FN, ЕМ <- > ,
Obj :Researcher[firstName-»FN;
1азТМате-»"Иванов"; email-»EM].
В качестве ответа при этом могут быть получены значения переменных:
Obj = http://www.anywhere.ru/~ivanov/
FN = Иван
ЕМ’ = mailto:ivanov@anvwhere.ru '
Имеются в языке Ontobroker и средства вывода значений свойств. Так, некоторые
из атрибутов объекта могут задавать отношения, свойства которых известны ма-
шине вывода. Для примера, в запросе вида
FORALL Obj,СР <-
Obj :Researcher[lastName -»"Иванов"; cooperatesWith-»CP],
атрибут cooperatesWith является отношением, обладающим свойством симмет-
ричности. Это означает, что даже если у объекта, описывающего специалиста по
фамилии Иванов, свойства cooperatesWith нет, Ontobroker выведет»его, если в
онтологии представлен объект, описывающий другого специалиста, который
имеет такое свойство со значением «Иванов».
В рассматриваемом языке представления онтологических знаний присутствуют
и другие правила вывода значений атрибутов, эксплицитно не представленных в
Web-документах. При этом понятно, что язык запросрв Ontobroker может ис-
пользоваться и для формирования репозиториев с информацией, удовлетворяю-
щей заданным ограничениям. И более того, с помощью запросов можно получать
и метаинформацию: запрос вида
FORALL Att, Т <- Researcher[Att=»T]
вернет в качестве результата имена всех атрибутов класса Researcher и связанных
с ним классов.
В самой системе Ontobroker поддерживаются два типа интерфейсов при форми-
ровании запросов — текстовый (для экспертов) и графический (для пользовате-
лей). Первый из них предполагает, что запросы формулируются непосредственно
во входном языке описания онтологий. Понятно, что при этом знание синтаксиса
языка Ontobroker и знакомство с онтологией, для которой запрос формулирует-
ся, должны у эксперта присутствовать.
Проблема знания синтаксиса решается в данном случае, как, впрочем, и в боль-
шинстве других инструментальных средств нового поколения, за счет диалогов,
управляемых системой (system-driven dialogue). Пользователю выдается соответ-
8.3. Системы и средства представления онтологических знаний 305
ствующая панель, где могут быть определены (путем выбора из меню) компонен-
ты запроса и связки между ними. Такой подход обеспечивает синтаксическую
корректность и однозначность интерпретации запроса.
Сложнее преодолеть разрыв в знаниях эксперта и пользователя, особенно нович-
ка, об используемой онтологии. Ведь для правильной формулировки запроса не-
обходимо знать, по крайней мере, какие концепты в онтологии присутствуют и
какие атрибуты имеются у концептов. Поэтому все системы представления онто-
логических знаний предоставляют своим пользователям средства виуализации
онтологий и навигации по онтологии.
В Ontobroker для визуализации онтологий используется подход, основанный на
идеях гиперболической геометрии (Hyperbolic Geometry) [Lamping et al., 1995].
В случае обсуждаемой системы эти идеи реализуются следующим образом:
класс, интересующий пользователя в данный момент, представляется «большим
шаром», а классы, с ним непосредственно связанные, — «маленькими шарами» и
располагаются по границе круга, «очерчивающего» соответствующий слой. Ис-
пользуя данный интерфейс, и эксперт и пользователь могут легко и эффективно
включать в свой запрос нужные концепты и их атрибуты, а система Ontobroker
переведет их в текстовое представление автоматически. Реализован интерфейс
онтологий Ontobroker как Java»-апплет, что обеспечивает работу с Web-броузе-
рами на любых платформах, где поддерживается Java-технология.
Формализм представления и машина вывода
Как уже отмечалось выше, онтология определяется через концепты (классы),
связанные отношениями, атрибуты и аксиомы. И адекватный язык представле-
ния должен обеспечить удобные средства для описания всех перечисленных
компонентов. В Ontobroker базисом представления являются так называемые
логики фреймов (Frame-Logic) [Kifer et al., 1995].
Базисными конструкциями в данном подходе являются:
• Подклассы (Subclassing) — запись Cl:: С2 означает, что класс С1 является
подклассом С2.
• Экземпляры (Instance of) — запись О : С означает, что О является экземпля-
ром класса С.
• Декларации атрибутов (Attribute Declaration) — запись С1[А=»С2] означа-
ет, что для экземпляра класса С1 определен атрибут А, значением которого
должен быть экземпляр С2.
• Значения атрибутов (Attribute Value) — запись O[A-»V] означает, что эк-
земпляр О имеет атрибут А со значением V.
• Часть-целое (Part-of) — запись О1 <: 02 означает, что О1 Является частью 02.
• Отношения (Relations) — предикаты вида р(а1,...,а2) могут использоваться,
как и в обычных логических формализмах, но с тем расширением, что в каче-
стве аргументов здесь могут выступать не только термы, но и выражения.
306
Глава 8 • Представление данных и знаний в Интернете
Из базисных конструкций строятся более сложные — факты (facts), правила (ru-
les), «двойные» правила (double rules) и запросы (queries). Запросы уже обсужда-
лись выше. Факты, по сути, являются элементарными выражениями,
Правила, как и обычно, имеют левую и правую части, причем левая часть (здесь
она называется «головой») является конъюнкцией элементарных выражений, а
правая («тело») сложная формула, термами которой являются элементарные
выражения, связанные обычными предикатными символами типа implies: —> ,
implied by: <—, equivalent: <—>, AND, OR и NOT. Отличие между обычными и
«двойными» правилами в симметричности последних. Важное достоинство
формализма — возможность использования переменных в «голове» правил
(с квантором FORALL) или в его «теле» (с кванторами FORALL и EXISTS).
Пример фрагмента онтологии в формализме Ontobroker, адаптированный из
работы [Fensel et al., 1998], приводится ниже.
Определения атрибутов
Person [firstName =» STRING;
lastName =» STRING;
eMail =» STRING;
publication =» Publication],
Employee [affiliation =» Organization; ...].
Researcher [researchinterest =» ResearchTopic;
memberOf =» ResearchGroup; /
cooperatesWith. =» Researcher],
Publication [ author =» Person;
title =» STRING;
year =» NUMBER;
abstract =» STRING],
Правила
FORALL Person"!, Person2
Person"!: Researcher [cooperatesWith-» Person2] <-
Person2:Researcher [cooperatesWith -» Person!].
FORALL Person!, Publication!
Publication!:Publication [author-» Person!] <->
Person!: Person [publication-» Publication!].
По-видимому, в пояснениях здесь нуждаются только правила. Первое из них
фиксирует симметричность отношения cooperatesWith. Второе утверждает, что
если конкретная личность (экземпляр класса Person) имеет публикацию, то по-
следняя имеет автора, который тоже является экземпляром класса Person, и об-
ратно.
8.3. Системы и средства представления онтологических знаний
307
Машина вывода Ontobroker состоит из двух основных компонентов: транслятора
с расширенного языка представления в ограниченный и собственно вычислителя
выражений ограниченного языка, который является обычным языком логическо-
го программирования.;
Аннотация Web-страниц онтологической информацией
Поскольку, как уже отмечалось выше, Web-информация чаще всего представле-
на на языке HTML, в рамках проекта Ontobroker разработано простое его расши-
рение для аннотации Web-страниц. Основная идея этого расширения состоит в
следующем: в язык HTML добавлено несколько релевантных для решения по-
ставленных задач тегов, использование которых позволяет Ontobroker ин-
терпретировать аннотированные фрагменты HTML-текста как факты языка
представления онтологических знаний. При этом Web-страницы остаются при-
емлемыми для стандартных броузеров типа Netscape Navigator или MS Explorer;
В язык введены три эпистемологически различных примитива:
• Идентификация объекта, который может быть определен как экземпляр опре-
деленного класса, с помощью URL.
• Установка значения атрибута объекта.
• Определение отношений между объектами.
Все примитивы синтаксически расширяют тег <а ...> языка HTML. Так, напри-
мер, если специалист Иванов захочет определить себя как объект обсуждавшей-
ся выше онтологии, он может на своей домашней странице ввести конструкцию
вида:
<а onto=" "http://www.anywhere.ru/'ivanov/" : Researcher"> </a>
Теперь для объекта Иванов класса Researcher можно ввести атрибут email и его
значение с помощью следующей конструкции:
<а onto=" "http://www. anywhere.ru/'ivanov/"
remail="mallto: ivanov(s>anvwhere. ru"l "> </a>
Аналогичным образом вводятся и отношения:
<а onto= "REL(0bj1, 0bj2, Obj3.. Objn)" > ... </a>
Имеются в языке и средства, которые обеспечивают уменьшение сложности ан-
нотирования: например, возможности именования «длинных» конструкций и
последующего использования этих имен.
При таком подходе Ontocrawler — компонент системы Ontobroker — простой
CGI-скрипт, который периодически проверяет аннотированные страницы на
Web. Для поиска таких страниц он обращается к индексным страницам провай-
деров, которые зарегистрированы в рамках инициативы (КА)2.
308
Глава 8 • Представление данных и знаний в Интернете
8.3.3. Проект SHOE — спецификация онтологий
и инструментарий
Общая характеристика проекта
Проект SHOE {Simple HTML Ontology Extensions) ориентирован на решение про-
блемы добавления к Web-страницам семантической информации и соотнесения
ее с онтологиями соответствующих предметных областей. Предполагается, что,
используя эту информацию, поисковые системы смогут обеспечивать более реле-
вантные ответы на запросы, чем это возможно сейчас на базе использования ма-
шин поиска, функционирующих в Интернете.
Для поддержки процессов аннотирования в рамках проекта SHOE разрабатыва-
ется специальный набор инструментальных средств (suite of tools), а основой их
является язык Интернет-совместимого представления знаний, который, собствен-
но, и дал название всему проекту.
В настоящее время в проекте SHOE выделены следующие главные направления
исследований:
• Разработка множества повторно используемых онтологий (reusable ontolo-
gies) для концептов, которые наиболее частотны для Web-ресурсов.
• Создание средств проектирования онтологий — аннотаторов знаний (Know-
ledge Annotator), которые бы упростили этот процесс.
Предполагается также, что в SHOE-инструментарий будет включена «неслож-
ная» обработка естественного языка (lightweight natural language processing te-
chniques), которая обеспечит представление пользователям аннотаций докумен-
тов.
Спецификации онтологий и инструментарий SHOE
В данном подразделе мы сосредоточимся не столько на самих онтологиях, разра-
батываемых в рамках проекта SHOE [Luke et al., 1996], сколько на языке пред-
ставления онтологических знаний и средствах поддержки процессов проектиро-
вания онтологий.
Формализм представления и машина вывода
Следует сразу отметить, что SHOE по своей идее близок к уже обсуждавшейся
выше инициативе (КА)2. Но концепция языка представления знаний здесь дру-
гая, хотя и она лежит в русле расширения HTML специальными тегами. А основ-
ное отличие языка SHOE в том, что здесь, по существу, предлагается «полномасш-
табное» расширение HTML. Для этого SHOE вводит в HTML-стандарт
следующие новые теги для спецификации онтологий: ONTOLOGY, USE-
ONTOLOGY, DEF-CATEGORY, DEF-RELATION, DEF-ARG, DEF-RENAME, DEF-CON-
STANT, DEF-TYPE, DEF-INFERENCE, INF-IF, INF-THEN,COMPARISON, CATEGORY,
RELATION, ARG и некоторые другие. Для аннотирования HTML-документов ис-
8.3. Системы и средства представления онтологических знаний 309
пользуется часть из уже перечисленных тегов и, кроме того, вводятся новые, на-
пример INSTANCE. И наконец, в SHOE вводится метатег вида <МЕТА НТТР-
EQUIV =...">.
Для определенности в рамках спецификации языка SHOE предполагается, что
онтология представляется в виде is_a иерархии классов/категорий, множества
атомарных отношений между категориями и множества правил вывода В форме
простых клауз Хорна.
Термами языка являются термы HTML и дополнительно к этому понятия Cate-
gory (Class), Data (причем с типами STRING, NUMBER, DATE, TRUTH),Element, In-
stance, Instance Key., Name, Ontology, Relation (Relationship), Rule и некоторые дру-
гие.
Декларации онтологий задаются внутри тела HTML-документа и не могут пере-
крываться с другими тегами HTML. В одном документе может быть определено
несколько онтологий, но такие определения тоже не может перекрываться или
быть вложенными. Общая схема определения онтологии следующая:
<ONTOLOGY ID="идентификатор-онтологии"
VERSION="sepcKfl"
[BACKWARD-COMPATIBLE-WITH="cnncoK-eepc^"]
[DESCRIPTION="reKcr"]
[DECLARATORS2^'список-деклар. -экземпляров" ]>
собственно-декларация-онтологии
</ONTOLOGY>
Для указания того, что данная онтология расширяет другую, уже существующую,
используется специальный тег:
' <USE-ONTOLOGY ID="идентификатор-онтологии"
VERSION2”версия" PREFIX2''префикс" [URL="URL"]>
Внутри определения онтологии могут специфицироваться новые категории, для
чего используется специальный тег вида:
<DEF-CATEGORY NAME2"имя-категории"
[ISА=”список-родительских-кате торий"]
[DESCRIPTION2"текст" ] [SHORT=''TeKCT"]>
Аналогичный подход применяется и для определения отношений:
<DEF-RЕLATION NAMЕ="имя-отношения"
[DESCRIPTION2''текст” ] [5Н0РТ="текст” ]>
список-аргументов
</DEF-RELATION>
Возможно определение тех же понятий и с помощью тега ONTDEF с парамет-
рами.
310
Глава 8 • Представление данных и знаний в Интернете
Одним из важнейших компонентов определения онтологии являются правила
вывода. В SHOE такие правила «похожи» на Хорновские клаузы по сути, но от-
личаются от них по форме:
<DEF-INFERENCE [DESCRIPTION^’текст”]>
<INF-IF> тело </INF-IF>
<INF-THEN> голова </INF-THEN>
</DEF-INFERENCE>
Для примера, ниже обсуждается фрагмент определения онтологии в формализме
SHOE, коррелирующий с уже обсуждавшимся фрагментом определения-анало-
гичной онтологии в формализме Ontobroker.
Пусть нас интересуют исследователи, имеющие в Интернете свои домашние стра-
ницы. Для работы с такими страницами можно воспользоваться уже существую-
щей в рамкдх SHOE онтологией общих понятий (organization-ontology ver-
sion 2.1) по адресу http://www.ont.org/orgont.html. Однако предположим для
определенности, что существующую онтологию необходимо расширить понятия-
ми Person и Organization. Тогда спецификация фрагмента новой онтологии (Но-
mePageOntology) может быть представлена в формализме SHOE следующим об-
разом:
<ONTOLOGY ID="HomePageOntology" VERSION="1. 0">
<ONTOLOGY-EXTENDS "organization-ontology"
VERSI0N="2.1" PREFIX="orp”
\JR{.="http://www. ont. org/orgont. html">
<ONTDEF CATEGORY=’’Person” ISA="org. Thing">
<ONTDEF RELATION="IastWaffle" ARGS=”Person STRING">
<ONTDEF RELATION^’ firstName" ARGS="Person STRING">
<ONTDEF RELATI0N="fflarried7b” ARGS="Person Person">;
<ONTDEF RELATION="e/npj!oyee" ARGS=”orp. Organization Person">
</ONTOLOGY>
Аннотация Web-документов на базе онтологий
Аннотация HTML-документов в SHOE осуществляется также с использованием
тегов. В частности, для этого служат теги USE-ONTOLOGY, INSTANCE, CATEGORY,
RELATION. Последние три тега имеют следующие форматы:
cINSTANCE KEY="значение-ключа"
[0Е1ЕСАТЕ-Т0=’’список-примерое”]> ... </INSTANCE>
cCATEGORY N№E="префикс, категория" [FOR="ключ"]>
<RELATION NAMЕ="префикс, отношение">список-аргументов </RELATION>
Для поиска и обработки домашних страниц с помощью специфицированной вы-
ше онтологии необходимо, чтобы авторы Web-публикаций сами (или на основе
инструментария SHOE) проаннотировали свои документы.
8.3; Системы и средства представления онтологических знаний
311
Так, например, фрагмент аннотации персональной страницы исследователя Ива-
нова в формализме SHOE выглядит следующим образом: : 5
<BODY>
«МЕТА HTTP-EQUIV="Instance"
CONTENT="rtttp://Mtw. anywhere. ru/~ivanov">
«USE-ONTOLOGY "HomePageOntology"
VERSIONS. 0" PREFIX="our"
URL= "http://www. ont. org/HomePageOntology. html”>
<CATEGORY "our. Person">
<RELATION "our. firstName" T0="Ivan">
«RELATION "our. lastName" 10="Ivanov">
«RELATION "our.marriedTo"
T0="http://www. somewhere. ru/'Mariya">
«RELATION -"our. employee" FROM="http://www. ocas. ru">
</BODY>
Анализ приведенного HTML-текста показывает, что даже в таком, казалось бы,
простом случае задача аннотации Web-документа достаточно сложна. Ситуация
становится еще более сложной при аннотировании реальных HTML-документов.
Во-первых, уже выбор объектов текста, подлежащих аннотированию, не три-
виален, особенно если Web-документ представляет объекты реального мира. Во-
вторых, гиперссылки часто фиксируют лишь наличие определенных отношений
между объектами, но не их семантику. И наконец можно, конечно, аннотировать
каждую именную группу в естественно-языковом представлении HTML-страни-
цы, но для реальных документов это слишком трудоемкая задача, которая к тому
же чревата большим количеством ошибок.
Поэтому в рамках проекта SHOE для автоматизации процессов аннотирования
Web-доку ментов разработана специальная система Knowledge Annotator [КА,
1999], одна из экранных форм которой представлена на рис. 8.12.
BE
<**
.........if
УСТ АВ
а6нп<*п>«ш»й »ргммх>М9т
"Расшносм ассецнацмя мсжусстанмогв юггмлектж’
(РАИН)
Рис. 8.12. Экранная форма системы Knowledge Annotator
акяялех»' (РАЩЬ; д«яи дсгёрякмым*
Адоцаацкяжмккя научным сшммиепж » убахчн ««рам
я: ыьтфдоясгйк мидоимяньго я*«ллта;4я»д*«я* мсрнжжепс • .
зр»эграмм>м* » япаярияйгй : ••
М«дынр»кода анпллиптлввае apcflectk
учреживмия; ® кмчасас «
312
Глава 8 » Представление данных и знаний в Интернете
Основными информационными блоками в приведенной выше экранной форме
являются экземпляры (instances), онтологии (ontologies) и утверждения (claims).
Пользователь может добавлять, редактировать и/или удалять любой из элемен-
тов этих блоков. При создании новых объектов пользователю выдаются соответ-
ствующие подсказки в виде, например, списка доступных онтологий, описанных
в них категорий, отношений и т. п.
Для визуализации знаний, содержащихся в обрабатываемом документе, Know-
ledge Annotator использует различные методы, начиная с аннотированного
HTML-текста и заканчивая описаниями утверждений на естественном (англий-
ском) языке. Кроме того, система осуществляет проверку корректности действий
пользователя и транслирует его выборы в синтаксически правильные конструк-
ции SHOE.
Формализм запросов
В настоящее время существуют различные примеры языков запросов к докумен-
там, проаннотированным на основе формализмов SHOE, рассмотренных выше.
Так, в университете Мэрилэнд (University of Maryland at College Park) разрабо-
тан робот Expos, который обрабатывает SHOE-документы и добавляет их в свою
базу знаний, используя систему представления знаний PARKA [Stoffel et al.,
1997].
Пример PARKA-запроса для поиска домашних страниц может быть специфици-
рован следующим образом:
(query! "(:and
(#! instanceOf ?Х it! Person) (#! instanceOf ?Y #! Person)
(#!instanceOf ?Z #!Organization)
(#!lastName ?X ''Ivanov”) (#!lastName ?Y "Ivanova")
(#!employee ?Z ?X) (#!employee ?Z ?Y)
(#!marriedTo ?X ?Y)
(#!involvedln ?Z "РФФИ-проекты")))
По существу, это достаточно простой SQL-запрос, расширенный за счет исполь-
зования понятий онтологии, переменных и ограниченных по мощности образцов.
Оценивая формализм представления онтологических знаний SHOE и поддержку
процессов аннотирования Web-ресурсов в этом проекте в целом, можно конста-
тировать, что это достаточно мощная система методов и средств, которая вместе с
тем сложнее для пользователя, чем Ontobroker.
8.3.4. Другие подходы и тенденции
В заключение настоящего параграфа необходимо, хотя бы в общих чертах, рас-
смотреть усилия World Wide Web Consortium (W3C) по созданию и внедрению
средств маркировки Интернет-ресурсов.
До недавнего времени в распоряжении Интернет-авторов для этого почти исклю-
чительно использовался уже обсуждавшийся выше язык HTML. Однако с точки
8,3. Системы и средства представления онтологических знаний
313
зрения семантической разметки Интернет-документов этот язык обладает рядом
недостатков, основными среди которых являются следующие [Johnson, 1999]:
• жесткая ориентация на визуализацию;
• единственная «точка зрения» на данные;
• нерасширяемость;
• весьма ограниченные средства спецификации семантической структуры доку-
ментов.
Справедливости ради следует заметить, что еще в конце 60-х годов в рамках ис-
следований по представлению документов компанией IBM был разработан язык
SGML (Standard Generalized Markup Language), который лишен многих из пере-
численных недостатков. К середине 80-х годов этот язык стал стандартом для
многих промышленных компаний и правительственных учреждений США, но,
по мнению специалистов рабочей группы SGML W3C [Bosak, 1997], он слишком
сложен для широкого использования Интернет-авторами. Вот почему в рамках
W3C, начиная с 1996 года, предпринимаются усилия по разработке средств раз-
метки документов, сравнимых по мощности с SGML, а по простоте использова-
ния — с HTML. И среди работ данного направления в первую очередь следует
отметить язык XML (extensible Markup Language) [XML, 1998].
В языке XML «сняты» многие ограничения HTML, язык разметки стал суще-
ственно мощнее. И одновременно XML-тексты остаются понятными для всех, кто
работал с языком HTML. Отличительные свойства XML и в том, что здесь фикси-
руется стандарт на определение синтаксиса и единообразные средства введения в
языки разметки (Markup Language) новых тегов. А это, в свою очередь, позволяет
конструировать на основе XML новые языки маркировки Web-документов и,
кроме того, обеспечивает возможность различным приложениям (и, в частности,
программным агентам) «понимать» и обрабатывать XML-документы.
Каждый XML-документ обладает определенной логической и физической струк-
турой. Физически это композиция элементов, называемых единицами (entities),
которые могут быть связаны взаимными ссылками. Логически документ состоит
из деклараций, единиц, комментариев, собственно текстов и инструкций обработ-
ки, причем каждая конструкция XML маркируется специальными тегами явным
образом. Все теги XML — парные, а конструкции могут быть вложены друг в дру-
га, образуя правильно построенное дерево. Так, например, конструкция <ltem
Attribute1=«Value1»> </ltem> определяет единицу с именем Item и списком пар ат-
рибут-значение, который в нашем случае представлен единственным атрибутом
с именем Attributel, имеющим значение «Valuel».
Для иллюстрации возможностей этого языка рассмотрим содержательный при-
мер XML-документа, описывающего домашнюю страницу исследователя Ивано-
ва.
<?xml version="1.0”?>
<Homepage>
<Мате>Домашняя страница Иванова</Мате>
314
Глава 8 « Представление данных и знаний в Интернете
<Person>
<firstName>Ivan«/firstName >
<lastName>Ivanov</lastName >
cmarriedTo Homepage="http://www.anywhere.ru">
Mariya Ivanova</marriedTo>
«employee Homepage="http://www.ccas. ru">
CCAS of Russia«/employee>
<publications>
«book title="First Book"/>
«book title="Second Book"/>
</publications>
</Person>
</Homepage>
Этот XML-документ структурирован существенно лучше, чем был бы аналогич-
ный ему HTML-текст, но пока не имеет «смысла», так как из него не следует, как
интерпретируются единицы типа Person, publications, book и т. п. Для решения
этого вопроса используется специальная спецификация определения типа доку-
мента DTD (document type definition). По сути дела, это грамматика языка раз-
метки, в рамках которой определяются, какие элементы могут присутствовать в
документе, какие атрибуты они имеют и как элементы соотносятся друг с другом.
Понятно, что для стандарта XML такие спецификации уже разработаны самими
авторами языка, но в нашем случае используется специальный его диалект, и по-
тому именно мы должны специфицировать DTD нашего документа. Такая спе-
цификация может быть следующей:
<!ELEMENT Homepage (Name, Person)>
<!ELEMENT Name (#PCDATA)>
<!ELEMENT Person (firstName, lastName, marriedTo?,
employee?, publications?, Homepage?)>
<!ATTLIST Person Homepage xml:link CDATA>
<!ELEMENT firstName, (#PCDATA)>
<! ELEMENT lastName (#PCDATA)>
<!ELEMENT marriedTo (Person)>
<! ELEMENT employee (organization^
<!ATTLIST organization Homepage xml:link CDATA>
<!ELEMENT publications (book*, paper*, report*)>
«IATTLIST book title CDATA «REQUIRED, coauthor Person,
publisher CDATA, year CDATA)>
<! ELEMENT paper (title, coauthor*, journal, year, vol?,
number?)>
<!ELEMENT report (title, coauthor*, organization, year)>
8.3. Системы и средства представления онтологических знаний 315
Как следует из приведенного описания, в DTD специфицировано «сведение»
конструкций нашего XML-документа к стандартным XML-конструкциям, пони-
маемым броузерами нового поколения.
В настоящее время уже разработаны DTD для различных предметных областей,
и каждая такая спецификация, по сути дела, определяет новый язык разметки.
Известным примером развития DTD для спецификации общих ресурсов являет-
ся RDF (Resource Description Framework) [RDF, 1999], разрабатываемый W3C.
Этот формат может использоваться для добавления в документы метаинформа-
ции, которая, в частности, может быть представлением семантики документа.
Использование собственных диалектов XML является важным шагом на пути
формирования пространств знаний в сети Интернет. Но, по сути дела, это лишь
первый шаг в этом направлении. Действительно, какие средства дает язык XML
для представления знаний? Очевидно, что это, в первую очередь, средства специ-
фикации декларативной компоненты развитых систем представления знаний.
И то в ограниченном объеме. Каким же образом авторы этого языка и его расши-
рений предполагают подключение процедур обработки XML-конструкций? На
сегодняшний день в предложениях W3C явно прослеживается лишь одна идея:
поскольку XML-документы не что иное, как портабельные данные, а язык Java
имеет портабельный код, следует их использовать совместно. Для этого предла-
гаются специальные интерфейсы, например SAX {Simple API for XML), которые
уже сейчас могут поддерживать многие Java-анализаторы. Основная идея здесь
достаточно проста — анализатор просматривает узлы дерева документа из XML-
файла и вызывает соответствующие методы, определенные пользователем. Для
того чтобы этот механизм работал, программист должен создать класс, реализу-
ющий соответствующий интерфейс. Методы этого класса будут вызываться вся-
кий раз, когда на входе распознавателя появляется нужная конструкция (тег,
входная строка и т. п.). Собственно обработка информации при этом целиком в
руках программиста, а среда лишь поддерживает общее функционирование и об-
работку исключительных ситуаций.
Такой подход имеет много общего и с подходом Ontobroker, и с подходом SHOE.
Авторы обоих этих проектов активно приветствуют усилия W3C, но вместе с тем
отмечают, что в предложениях соответствующих рабочих групп еще много недо-
статков. В первую очередь — это отсутствие стандартов на интеллектуальную об-
работку XML-конструкций, сравнительно небольшой практический опыт семан-
тической разметки Интернет-документов и достаточно ограниченные
средства логической обработки, используемые при этом.
Вот почему, как показывает анализ литературы и Интернет-ресурсов по данной
тематике, в настоящее время:
• эффективная обработка информации на Web связывается, в первую очередь, с
использованием ИИ-технологий;
• основные подходы в этой области ориентированы на решение проблемы из-
влечения из Web-ресурсов эксплицитных знаний на основе семантического
маркирования таких ресурсов;
316
Глава 8 » Представление данных и знаний в Интернете
• во всех исследовательских и многих коммерческих проектах данного направ-
ления активно используются (или, по крайней мере, декларируется использо-
вание) агентно-ориентированные вычисления и технологии.
Учитывая вышесказанное, в следующей главе обсуждаются мультиагентные сис-
темы и системы интеллектуальных агентов.
Интеллектуальные
Интернет-
технологии
□ Программные агенты и мультиагентные системы
□ Проектирование и реализация агентов и мультиагентных систем
□ Информационный поиск в среде Интернет
9.1. Программные агенты и мультиагентные
системы
9.1.1. Историческая справка
Проблематика интеллектуальных агентов и мультиагентных систем (МАС) име-
ет уже почти 40-летнюю историю [Городецкий и др., 1998; Тарасов, 1998] и сфор-
мировалась на основе результатов, полученных в рамках работ по распределенно-
му искусственному интеллекту (DAI), распределенному решению задач (DPS) и
параллельному искусственному интеллекту (PAI) [Demazeau et al., 1990; Пэра-
нек, 1991; Rasmussen et al., 1991]. Но, пожалуй, лишь в последнее 10-летие
она выделилась в самостоятельную область исследований и приложений и все
больше претендует на одну из ведущих ролей в рамках интеллектуальных инфор-
мационных технологий. Спектр работ по данной тематике весьма широк, интег-
рирует достижения в области компьютерных сетей и открытых систем, искусст-
венного интеллекта и информационных технологий и ряда других исследований,
а результаты уже сегодня позволяют говорить о новом качестве получаемых ре-
шений.
Понятно, что в рамках данного издания мы не сможем даже обозреть все направ-
ления и результаты в области МАС. Поэтому далее сконцентрируемся лишь на
тех разделах, которые имеют непосредственное отношение к теме настоящей
книги. С учетом сделанных замечаний и с позиций сегодняшнего дня все иссле-
дования в этой области можно выделить в две основные фазы: первая охватывает
период с 1977 г. по настоящее время, а вторая — с начала 1990 г. по настоящее
время.
318
Глава 9 » Интеллектуальные Интернет-технологии
Работы первого периода концентрировались на исследовании так называемых
«смышленых.» (smart) агентов, которые были начаты в конце 1970-х годов и
продолжаются все 1980-е годы вплоть до наших дней. Первоначально эти работы
были сосредоточены на анализе принципов взаимодействия между агентами, на
декомпозиции решаемых задач на подзадачи и распределении полученных задач
между отдельными агентами, координации и кооперации агентов, разрешении
конфликтов путем переговоров и т. п. Цель таких работ — анализ, спецификация,
проектирование и реализация систем агентов. На этом же уровне активно велись
работы по теории, архитектурам и языкам для программной реализации агентов.
Примерно с 1990 г. стало ясно, что программные агенты могут использоваться в
широком спектре применений. Однако потенциал агентных технологий, по-ви-
димому, стал в значительной мере осознан не только разработчиками)-но и инвес-
торами после известного отчета консультативной фирмы Ovum [Ovum, 1994],
которая предсказала, что сектор рынка для программных агентов в США и Евро-
пе вырастет, по крайней мере, до $3,9 billion к 2000 г. в противовес 1995 г., когда он
оценивался в $476 million.
В настоящее время множество исследовательских лабораторий, университетов,
фирм и промышленных организаций работают в этой области, и список их посто-
янно расширяется. Он включает мало известные имена и небольшие коллекти-
вы, уже признанные исследовательские центры и организации (например, уни-
верситет Карнеги Мэллон (CMU) и фирма General Magic), а также огромные
транснациональные компании (такие как Apple, AT&T, ВТ, Daimler-Benz, DEC,
HP, IBM, Lotus, Microsoft, Oracle, Sharp и др.).; Областями практического ис-
пользования агентных технологий являются управление информационными по-
токами (workflow management) и сетями (network management), управление воз-
душным движением (air-traffic control), информационный поиск (information
retrieval), электронная коммерция (e-commerce), обучение (education), электрон-
ные библиотеки (digital libraries) и многие-многие другие приложения.
Существует несколько причин, почему необходимы и полезны программные
агенты, МАС и, более общо, агентные технологии. Основная из них в том, что
агенты автономны и могут выполняться в фоновом (background) режиме от лица
пользователя при решении разных задач, наиболее важными из которых являют-
ся сбор информации, ее фильтрация и использование для принятия решений.
Таким образом, основная идея программных агентов — делегирование полномо-
чий. Для того чтобы реализовать эту идею, агент должен иметь возможность взаи-
модействия со своим владельцем или пользователем для получения соответ-
ствующих заданий и возвращения полученных результатов, ориентироваться в
среде своего выполнения и принимать решения, необходимые для выполнения
поставленных перед ним задач.
К построению агентно-ориентированных систем можно указать два подхода: реа-
лизация единственного автономного агента или разработка мультиагентной сис-
темы. Автономный агент взаимодействует только с пользователем и реализует
весь спектр функциональных возможностей, необходимых в рамках агентно-ори-
9.1. Программные агенты и Мультиагентные системы
319
вотированной программы. В противовес этому МАС являются программно-вы-
числительными комплексами, где взаимодействуют различные агенты для реше-
ния задач, которые трудны или недоступны в силу своей сложности для одного
агента. Часто такие мультиагентные системы называют агентствами (agencies), в
рамках которых агенты общаются, кооперируются и договариваются между со-
бой для поиска решения поставленной перед ними задачи.
Агентные технологии обычно предполагают использование определенных типо-
логий агентов и их моделей, архитектур МАС и опираются на соответствующие
агентные библиотеки и средства поддержки разработки разных типов мульти-
агентных систем.
9.1.2. Основные понятия
Существует несколько подходов к определению понятий в данной предметной
области. -По-видимому, одним из наиболее последовательных в этом вопросе
является международная ассоциация FIPA (Foundation for Intelligent Physical
Agents), каждый документ которой содержит толковый словарь терминов, реле-
вантных данному документу [FIPA, 1998]. И вместе с тем практически во всех
работах, где даются, например, определения понятия агента и ето базисных
свойств, общим местом стало замечание об отсутствии единого мнения по этому
поводу [Franklin et al., 1996; BelgraVe, 1996; Nwana, 1996]. Фактически, используя
понятие «агент», каждый автор или сообщество определяют своего агента с кон-
кретным набором свойств в зависимости от целей разработки, решаемых задач,
техники реализации и т. п. критериев. Как следствие, в рамках данного направле-
ния появилось множество типов агентов, например: автономные агенты, мобиль-
ные агенты, персональные ассистенты, интеллектуальные агенты, социальные
агенты и т. д. [Nwana, 1996], а вместо единственного определения базового аген-
та — множество определений производных типов.
Учитывая вышесказанное, понятие агента целесообразно трактовать как мета-
имя или класс, который включает множество подклассов. Ряд определений аген-
тов, данных разными исследователями, представлен в работе [Franklin et al.,
1996]. В настоящем издании будем придерживаться следующей концепции по
этому поводу.
Агент — это аппаратная или программная сущность, способная действовать в интересах
достижения целей, поставленных перед ним владельцем и/или пользователем [Wool-
dridge etal., 1995].
Таким образом, в рамках МАС-парадигмы программные агенты рассматривают-
ся как автономные компоненты, действующие от лица пользователя.
В настоящее время существует несколько классификаций агентов [Nwana, 1996],
одна из которых, представлена в табл. 9.1.
320_________________________Глава 9 » Интеллектуальные Интернет-технологии
Таблица 9.1. Классификация агентов
^'"'"^Типы агентов Характеристики'"''-^- Простые Смышленые (smart) Интел- лектуальные (intelligent) Действительно (truly) интел- лектуальные
Автономное выполнение + + +
Взаимодействие + + + +
с другими агентами и/или пользователями
Слежение за окружением + + + +
Способность использования абстракций + + +
Способность использования предметных знаний + +
Возможность адаптивного поведения для достижения целей + ' +
Обучение из окружения Толерантность к ошибкам и/или + +
неверным входным сигналам Real-time исполнение +
ЕЯ-взаимодействие +
Как следует из приведенной таблицы, собственно целесообразное поведение по-
является только на уровне интеллектуальных агентов [Пономарева и др., 1999;
Хорошевский, 1999]. И это не случайно, так как для него необходимо не только
наличие целей функционирования, но и возможность использования достаточно
сложных знаний о среде, партнерах и о себе. С точки зрения целей настоящей
книги, наибольший интерес представляют интеллектуальные и действительно
интеллектуальные (см. табл. 9.1) агенты. Понятно, что все характеристики бо-
лее «простых» типов агентов при этом наследуются.
Иногда агентов определяют через свойства, которыми они должны обладать.
Учитывая то, что нас в данной книге, в первую очередь, интересуют интеллекту-
альные агенты, приведем типовой список свойств, которыми такие агенты долж-
ны обладать [Wooldridge et al., 1995; FIPA, 1998]:
• автономность (autonomy, autonomious functioning) — способность функцио-
нировать без вмешательства со стороны своего владельца и осуществлять кон-
троль внутреннего состояния и своих действий;
• социальное поведение (social ability, social behaviour) — возможность взаимо-
действия и коммуникации с другими агентами;
• реактивность (reactivity) — адекватное восприятие среды и соответствующие
реакции на ее изменения;
• активность (pro-activity) — способность генерировать цели и действовать ра-
циональным образом для их достижения;
9.1. Программные агенты и мультиагентные системы
321
• базовые знания (basic knowledge) — знания агента о себе, окружающей среде,
включая других агентов, которые не меняются, в рамках жизненного цикла
агента;
• убеждения (beliefs) — переменная часть базовых знаний, которые могут ме-
няться во времени, хотя агент может об этом не знать и продолжать их исполь-
зовать для своих целей;
• цели (goals) — совокупность состояний, на достижение которых направле-
но текущее поведение агента;
• желания (desires) — состояния и/или ситуации, достижение которых для аген-
та важно;
• обязательства (commitments) — задачи, которые берет на себя агент по просьбе
и/или поручению других агентов;
• намерения (intentions) — то, что агент должен делать в силу своих обяза-
тельств и/или желаний.
Иногда в этот же перечень добавляются и такие свойства, как рациональность
(rationality), правдивость (veracity), благожелательность (benevolence), а также
мобильность (mobility), хотя последнее характерно не только для интеллекту-
альных агентов.
ЧВ зависимости от концепции, выбранной для организации МАС, обычно выде-
ляются три базовых класса архитектур [Wray et al., 1994; Wooldridge et. al., 1995;
Nwana, 1996]:
• архитектуры, которые базируются на принципах и методах работы со знания-
ми (deliberative agent architectures);
• архитектуры, основанные на поведенческих моделях типа «стимул-реакция»
(reactive agent architectures);
• гибридные архитектуры (hybrid architectures).
Наиболее «трудными» терминологически в этой триаде являются архитектуры
первого типа. Прямая калька — делиберативные архитектуры — неудобна для
русскоязычного произношения и не имеет нужной семантической окраски для
русскоязычного читателя. Сам термин был введен в работе [Genesereth et al.,
1987] при обсуждении архитектур агентов.
Архитектуру или агентов, которые используют только точное представление картины
мира в символьной форме, а решения при этом (например, о действиях) принимаются
на основе формальных рассуждений и использования методов сравнения по образцу,
принято определять как делиберативные.
Таким образом, в данном случае мы имеем дело с «разумными» агентами и архи-
тектурами, имеющими в качестве основы проектирования и реализации модели,
методы и средства искусственного интеллекта. В работе [Тарасов, 1998] таких
агентов предлагается называть когнитивными, что не вполне правильно, так как
при этом неявно предполагается, что «рассуждающие» агенты познают мир, в ко-
тором они функционируют. Нам представляется, что для русского языка более
322
Глава 9 « Интеллектуальные Интернет-технологии
удобным и адекватным были бы термины «агент, базирующийся на знаниях» или
«интеллектуальный агент», а также «архитектура интеллектуальных агентов».
Именно этих терминов мы и будем придерживаться в данном издании. Первона-
чально идея интеллектуальных агентов связывалась практически полностью с
классической логической парадигмой ИИ. Однако по мере развития исследова-
ний в этой области стало ясно, что такие «ментальные» свойства агентов, как, на-
пример, убеждения, желания, намерения, обязательства по отношению к другим
агентам и т. п„ невыразимы в терминах исчисления предикатов первого порядка.
Поэтому для представления знаний агентов в рамках данной архитектуры были
использованы специальные расширения соответствующих логических исчисле-
ний [Поспелов, 1998], а также разработаны новые архитектуры, в частности архи-
тектуры типа BDI (Belief-Desire-Intention). Один из конкретных примеров архи-
тектуры этого класса обсуждается ниже.
Принципы реактивной архитектуры возникли как альтернативный подход к ар-
хитектуре интеллектуальных агентов. Идея реактивных агентов впервые возник-
ла в работах Брукса, выдвинувшего тезис, что интеллектуальное поведение может
быть реализовано без символьного представления знаний, принятого в класси-
ческом ИИ [Brooks, 1991]. Таким образом [Connah, 1994]:
Реактивными называются агенты и архитектуры, где нет эксплицитно представленной
модели мира, а функционирование отдельных агентов и всей системы осуществляется по
правилам типа ситуация—действие. При этом под ситуацией понимается потенциально
сложная комбинация внутренних и внешних состояний.
Вообще говоря, данный подход ведет свое начало с работ по планированию пове-
дения роботов, которые активно велись в ИИ в 70-х годах. Простым примером
реализации реактивных архитектур в этом контексте можно считать системы, где
реакции агентов на внешние события генерируются соответствующими конечны-
ми автоматами. Широко известным примером системы с реактивной архитекту-
рой является планирующая система STRIPS [Fikes et al., 1971], где использовался
логический подход, расширенный за счет ассоциированных с действиями пред-
условий и пост-условий. Позже в рамках реактивных архитектур были разрабо-
таны и другие системы, но, как правило, они не могли справиться с задачами ре-
ального уровня сложности.
Учитывая вышесказанное, многие исследователи считают, что ни первый, ни вто-
рой подходы не дают оптимального результата при разработке агентов и МАС
[Wray et al., 1994]. Поэтому попытки их объединения предпринимаются постоян-
но и уже привели к появлению разнообразных гибридных архитектур. По сути
дела, именно гибридные архитектуры и используются в настоящее время во всех,
сколько-нибудь значимых проектах и системах.
Мы рассмотрели основные подходы к разработке мультиагентных систем. Архи-,
тектуры МАС и их характеристики, широко используемые в настоящее время,
представлены в табл. 9.2.
9.2. Проектирование и реализация агентов и мультиагентных систем
323
Таблица 9.2. Архитектуры МАС и их характеристики
Архитектура Представление знаний Модель мира Решатель
Интеллектуальная Символьное Исчисление Логический
Реактивная Автоматное Граф Автомат
Гибридная Смешанное Гибридная Машина вывода
Организация МАС на принципах ИИ имеет преимущества с точки зрения удоб-
ства использования методов и средств символьного представления знаний, разра-
ботанных в рамках искусственного интеллекта. Но в то же время создание точной
и полной модели представления мира, процессов и механизмов рассуждения в
нем представляют здесь существенные трудности, уже неоднократно обсуждав-
шиеся в данной книге в связи с рассмотрением вопросов приобретения знаний.
Реактивный подход позволяет наилучшим образом использовать множество дос-
таточно простых образцов поведения для реакции агента на определенные стиму-
лы для конкретной предметной области. Однако применение этого подхода ог-
раничивается необходимостью полного ситуативного анализа всех возможных
активностей агентов.
Недостатки гибридных архитектур связаны с «непринципиальным» проектиро-
ванием МАС. со всеми вытекающими отсюда последствиями. Так, например,
многие гибридные архитектуры слишком специфичны для приложений, под ко-
торые они разрабатываются. Но несмотря на указанные недостатки, гибридные
архитектуры позволяют гибко комбинировать возможности всех подходов. Вот
почему в последнее время явно прослеживается тенденция разработки и исполь-
зования именно гибридных МАС-архитектур и систем агентов [Sloman, 1996].
9.2. Проектирование и реализация агентов
и мультиагентных систем
9.2.1. Общие вопросы проектирования агентов
и МАС
Идеи программных агентов вообще и интеллектуальных агентов, в частности,
привлекательны, так как позволяют людям делегировать им свои полномочия по
решению сложных задач. Однако разработка МАС и действительно интеллекту-
альных агентов требует специальных знаний и является сложной ресурсоемкой
задачей. Ведь программные агенты — новый класс систем программного обеспе-
чения (ПО), которое действует от лица пользователя. Они являются мощной аб-
стракцией для «визуализации» и структурирования сложного. Но если процеду-
ры, функции, методы и классы — известные абстракции, которые разработчики
ПО используют ежедневно, то программные агенты — это принципиально новая
парадигма, неизвестная большинству из них даже сегодня.
324
Глава 9 « Интеллектуальные Интернет-технологии
Вместе с тем развитие и внедрение программных агентов было бы, по-видимому,
невозможно без предыдущего опыта разработки и практического освоения кон-
цепции открытых систем [Орлик, 1997], которые характеризуются свойствами:
• расширяемости/масштабируемости (возможность изменения набора состав-
ляющих системы);
• мобильности/переносимости (простота переноса программной системы на
разные аппаратно-программные платформы);
• интероперабельности (способность к взаимодействию с другими системами);
• дружелюбности к пользователю/легкой управляемости.
Одним из результатов внедрения концепции открытых систем в практику стало
распространение архитектуры «клиент—сервер» [Орлик, 1997]. В настоящее вре-
мя выделяются следующие модели клиент-серверного взаимодействия:
• «Толстый клиент — тонкий сервер». Наиболее часто встречающийся вариант
реализации архитектуры клиент—сервер. Серверная часть реализует только
доступ к ресурсам, а основная часть приложения находится на клиенте.
• «Тонкий клиент — толстый сервер». Модель, активно используемая в связи с
распространением Интернет-технологий и, в первую очередь, Web-броузеров.
В этом случае клиентское приложение обеспечивает реализацию интерфейса,
а сервер объединяет остальные части приложений.
При создании МАС могут с успехом использоваться обе модели, хотя в настоя-
щее время чаще применяется вторая. Но независимо от используемой модели
средства разработки и исполнения распределенных приложений, которыми, как
правило, являются МАС, опираются на статический подход (позволяют переда-
вать только данные приложений) или динамический подход (обеспечивают воз-
можности передачи исполняемого кода).
При динамическом подходе МАС-приложения используют парадигму мобиль-
ных агентов. '
Мобильные агенты — это программы, которые могут перемещаться по сети, например
по WWW. Они покидают клиентский компьютер и перемещаются на удаленный сервер
для выполнения своих действий, после чего возвращаются обратно.
Часть исследователей считают, что мобильные агенты обеспечивают более про-
грессивный метод работы в сетевых приложениях. Другие авторы отмечают, что
мобильные агенты привносят опасность с точки зрения обеспечения секретности
информации и загруженности сети [Chess et. al. 1995].
Понятно, что одни и те же функциональные возможности в большинстве случаев
могут быть реализованы как посредством мобильных, так и статических агентов.
Использование мобильных агентов может быть целесообразным, если они:
• уменьшают время и стоимость передачи данных (например, при больших
объемах данных вместо передачи всей необработанной информации по сети
на хост-источник посылается агент, который выбирает только необходимую
информацию и передает ее пользователю);
9.2, Проектирование и реализация агентов и мультиагентных систем
325
• позволяют преодолеть ограничение локальных ресурсов (например, если воз-
можности процессора и объем памяти клиентскогб компьютера малы, то, мо-
жет быть, целесообразнее использование мобильных агентов, выполняющих
вычисления на сервере);
• облегчают координацию (например, запросы к удаленным серверам выпол-
няются мобильными агентами как отдельные задачи, а потому не нуждаются
в координации);
• позволяют выполнять асинхронные вычисления (например, запустив агента,
можно переключиться на другое приложение и даже отсоединиться от сети, а
результат будет доставлен агентом адресату после выполнения задания).
Мобильные агенты являются перспективными для МАС, но в настоящее время
нет единых стандартов их разработки и все еще остается нерешенным ряд про-
блем, таких как легальные способы перемещения агентов по сети, верификация
агентов (в частности, защита от передаваемых по сети вирусов), соблюдение
агентами прав частной собственности и сохранение конфиденциальности ин-
формации, которой они обладают, перенаселение сети агентами, а также совмес-
тимость кода агента и программно-аппаратных средств сетевой машины, где он
исполняется [Wayner, 1995].
В настоящее время наиболее известными технологиями реализации статических
и динамических распределенных приложений являются программирование со-
кетов, вызов удаленных процедур — RPC (Remote Procedure Call), DCOM (Mic-
rosoft Distributed Component Object Model), Java RMI (Java Remote Method In-
vocation) и CORBA (Common Object Request Broker Architecture) [Maurer et al.,
1998]. Вместе с тем с точки'зрения разработки и реализации МАС наиболее
важными, по-видимому, являются последние три — DCOM, Java RMI и CORBA
[Gopalan, 1999].
Модель Microsoft DCOM является объектной моделью, которая поддерживается
Windows 95, Windows NT, Sun Solaris, Digital UNIX, IBM MVS и др. Основная ее
ценность — в предоставлении возможностей интеграции приложений, реализо-
ванных в разных системах программирования.
Java RMI-приложения обычно состоят из клиента и сервера. При этом на сервере
создаются некоторые объекты, которые можно передавать по сети, либо методы
их определяются как доступные длЯ вызова удаленными приложениями, а на
клиенте реализуются приложения, пользующиеся удаленными объектами. Отли-
чительной чертой RMI является возможность передачи в сети не только методов,
но и самих объектов, что обеспечивает в конечном счете реализацию мобильных
агентов.
CORBA является частью ОМА (Object Management Architecture), разработанной
для стандартизации архитектуры и интерфейсов взаимодействия объектно-ори-
ентированных приложений. Интерфейсы между CORBA-объектами определя-
ются через специальный язык IDL (Interface Definition Language), который явля-
ется языком описания интерфейсов. Сами интерфейсы могут при этом быть
реализованы на любых других языках программирования и присоединены к
326
Глава 9 • Интеллектуальные Интернет-технологии
CORBA-приложениям. В рамках стандартов предполагается, что CORBA-объек-
ты могут коммуницировать с DCOM-объектами через специальные CORBA-
DCOM мосты (Bridges).
Технологии Java RMI и CORBA являются, по-видимому, на сегодняшний день
самыми гибкими и эффективными средствами реализации распределенных при-
ложений [Gopalan, 1999]. Эти технологии очень близки по своим характеристи-
кам. Основным преимуществом CORBA является интерфейс IDL, унифицирую-
щий средства коммуникации между приложениями и интероперабельность с
другими приложениями. С другой стороны, Java RMI является более гибким и
мощным средством создания распределенных приложений на платформе Java,
включая возможность реализации мобильных приложений.
В настоящее время еще не вполне ясно, какая из этих концепций «победит» в
борьбе за мультиагентные системы. Вмешаться в этот процесс может и модель
DCOM, активно «продвигаемая» компанией Microsoft. Но анализ существую-
щих реализаций МАС показывает, что пока более распространенным здесь явля-
ется подход Java RMI.
Выше кратко обсуждались вопросы стратегии программного обеспечения распре-
деленных приложений. Если же вернуться к проблематике МАС, то все про-
граммные средства для их разработки и реализации на современном этапе можно
разделить на два больших класса: МАС-библиотеки и МАС-среды. Впечатляю-
щий список сайтов, где представлена информация о том и другом программном
обеспечении, как из коммерческих, так и из исследовательских организаций,
представлен в Интернет по адресу http://www.reticular.com/.
Оставляя в стороне вопросы проектирования и реализации МАС-библиотек, ко-
торые, конечно, являются базисом для создания мультиагентных приложений,
но выходят за рамки данного издания, в оставшейся части настоящего параграфа
мы сосредоточимся на обсуждении инструментария для построения МАС. При
этом нас будут интересовать, в первую очередь, модели, методы и средства под-
держки процессов проектирования агентов и мультиагентных систем.
Одним из удачных примеров систем данного класса является, на наш взгляд, ин-
струментарий AgentBuilder компании Reticular Systems, Inc. [AgentBuilder, 1999] —
одного из лидеров в этой области, к обсуждению которого мы и переходим.
9.2.2. Инструментарий AgentBuilder
Инструментарий для построения МАС компании Reticular Systems, Inc. состоит
из двух компонентов: средств разработки (development tools) и окружения перио-
да исполнения (run-time execution environment). Первый компонент ориентиро-
ван на поддержку процессов анализа предметной области создаваемой МАС и
проектирование агентов с заданным поведением. Второй — обеспечивает эффек-
тивную среду для выполнения агентно-ориентированных программ. И тот и дру-
гой компоненты реализованы на языке Java, что позволяет им работать на всех
платформах, где установлена Java-среда. Агентные программы, проектируемые в
рамках AgentBuilder, тоже являются Java-программами и могут исполняться на
любом компьютере, где установлена виртуальная Java-машина JVM (Java
virtual machine).
9.2. Проектирование и реализация агентов и мультиагентных систем
327
Общая схема Процесса проектирования и реализации агентно-ориентированных
приложений на основе AgentBuilder ToolKit представлена на рис. 9.1.
Этот инструментарий имеет средства для организации и предметной области со-
здаваемой МАС, средства спецификации архитектуры агенства и поведения аген-
тов, а также средства отладки агентных приложений и наблюдения за поведением
созданных агентов.
Модель «жизненного цикла» агентов, разрабатываемых в рамках AgentBuilder,
представлена на рис. 9.2. Как следует из данной схемы, стандартный «жизненный
цикл» агента включает следующие основные шаги:
• обработка новых сообщений;
• определение, какие правила поведения применимы в текущей ситуации;
• выполнение действий, специфицированных этими правилами;
• обновление ментальной модели в соответствии с заданными правилами;
• планирование.
Собственно ментальные модели (начальная и текущая) включают описания ис-
ходных (текущих) намерений, полаганий, обязательств и возможностей, а также
спецификации правил поведения.
Рис. 9.1. Технологическая схема процесса разработки агентно-ориентированных
приложений на базе AgentBuilder ToolKit
328
Глава 9 • Интеллектуальные Интернет-технологии
Данная модель получила название Reticular Agent Mental Model (RAMM) и яв-
ляется развитием модели Шохама (Shoham) [Shoham, 1993], где все действия вы-
полняются только как результат определенных обязательств. В рамках RAMM
эта идея расширена до уровня общих правил поведения, которые определяют
причину действия агента в каждой точке его функционирования. При этом пра-
вила поведения фиксируют множество возможных «откликов» агента на те-
кущее состояние среды так, как это предписывается полаганиями.
Для спецификации поведения агентов в системе AgentBuilder используется спе-
циальный объектно-ориентированный язык RADL (Reticular,Agent Definition
Language). Правила поведения в этом языке могут рассматриваться как конструк-
ции вида WHEN-IF-THEN.
WHEN-часть правила адресована новым событиям, возникающим в окружении
агента и включает новые сообщения, полученные от других агентов.
IF-часть сравнивает текущую ментальную модель с условиями применимости
правила. Образцы в IF-части работают на намерениях, полаганиях, обязатель-
ствах и возможностях, определенных в ментальной модели.
Рис. 9.2. Модель «жизненного цикла» агента в системе AgentBuilder
THEN-часть определяет действия в ответ на текущие события и состояния мен-
тальной модели и внешнего окружения. Они могут включать обновление мен-
тальной модели, коммуникативные и внутренние действия.
9.2. Проектирование и реализация агентов и мультиагентных систем
329
Общий формат правил поведения следующий:
NAME имя правила :
WHENMessage Condition(s)
IF Mental Condition(s)
THENPrivate Action(s); Mental Change(s); Message Action(s)
Для иллюстрации возможностей этого языка рассмотрим пример правила «Дви-
жение-Вперед-На-Зеленый-Свет» из предметной области «Управление автомо-
билем», взятый из руководства пользователя [AgentBuilder, 1999].
NAME "Greenlight Move Forward Rule"
WHEN
?KQMLMessage.Performative EQUALS TELL
?KQMLMessage.Sender EQUALS "stoplight-agent"
?KQMLMessage.Content EQUALS String
?KQMLMessage.Ontology EQUALS "Stoplight"
IF
?KQMLMessage.Content EQUALS "stoplight-green"
?KQMLMessage.Status EQUALS "stoppedAtRedLight”
currentMotion.Content EQUALS "stoplight-green"
currentLocation EQUALS nextintersection
NOT(currentLocation EQUALS destination)
FOR_A'LL (?BlockedIntersection,
NOT(?BlockedIntersection.Location EQUALS currentLocation))
THEN
DO (Go(trafficSpeed))
DO ($nextlntersection =
getNextlntersection (currentLocation,
currentMotion.Direction))
ASSERT (SET_VALUE_OF currentMotion.Status TO moving)
ASSERT (SET_VALUE_OF nextintersection TO $nextlntersection)
SEND (performative = REPLY, receiver = "stoplight-agent",
content = "acknowledged",
in-reply-to = ?KQMLMessage.Reply-with)
Как следует из данного примера, в языке RADL активно используются образцы,
имеются достаточно развитые средства работы с переменными и представитель-
ный набор действий, включающий формирование перформативов языка KQML
[Labrou et al, 1997]. Структуры данных, на которых «работает» данный язык, яв-
ляются, по существу, фреймами, а сами правила — суть продукции специального
вида. Язык поддержан на инструментальном уровне системой специальных язы-
ково-ориентированных редакторов.
Спецификация поведения агентов и их ментальных моделей составляет специ-
альный файл (agent definition file), который используется совместно с классами
и методами из библиотеки действий агентов и библиотеки интерфейсов. Этот
файл интерпретируется в рамках компонента Reticular’s Run-Time Agent Engine,
являющегося частью окружения периода исполнения AgentBuilder.
330
Глава 9 « Интеллектуальные Интернет-технологии
Оценивая подход к спецификации моделей поведения агентов, используемый в
AgentBuilder, можно констатировать, что в целом это серьезная система представ-
ления и манипулирования знаниями, ориентированная на описание моделей
типа RAMM. Вместе с тем в данной модели отсутствуют средства эксплицитного
управления выводом, которые могли бы существенно увеличить функциональ-
ную мощность языка. Нет в модели и средств явной фиксации состояния агента,
отличных от флагов и/или значений переменных. Не вполне ясно и то, как в спе-
цификации моделей поведения могут быть учтены разные, но одновременно сосу-
ществующие «линии поведения», что характерно для действительно интеллекту-
альных агентов. Не вполне обоснованным представляется и использование режи-
ма интерпретации для реализации поведения агентов.
Но в целом можно еще раз отметить, что инструментарий AgentBuilder является
современным и мощным средством проектирования и реализации МАС.
9.2.3. Система Bee-gent
Инструментарий AgentBuilder, обсуждавшийся выше, базируется на концепции
среды разработки, принятой в технологии программирования. Отличный от это-
го подход применяется в системе Bee-gent [Bee-gent, 1999]. Здесь для проектиро-
вания и реализации МАС используется специальная МАС-библиотека, реализо-
ванная на языке Java, а собственно технология, на наш взгляд, представлена
методологией спецификации поведения агентов распределенной системы. При
этом в систтеме Bee-gent используется множество базовых агентов (generic
agents), среди которых можно выделить упаковщики (agent wrappers) и медиато-
ры (mediation agents).
Поведение всей системы, направленное на достижение определенных целей, ба-
зируется на спецификации «бесед» (message exchanges) через протоколы взаимо-
действия (interaction protocols).
Такие протоколы представляются специальными графами (рис. 9.3), основными
понятиями которых являются состояния (states) и переходы (transitions). При
этом переходы, по сути дела, лишь специфицируют смещение «фокуса» в следую-
щее состояние с помощью специальных правил перехода, а ядро формализма со-
ставляют состояния. Именно здесь проверяются предусловия перемещения в сле-
дующее состояние и в случае их удовлетворения выполняются действия, в основе
которых обмен XML/ACL сообщениями. Возможны правила, результатом вы-
полнения которых является выбор следующего состояния из множества подходя-
щих.
Как и обычно в таких случаях, в качестве базиса сообщений декларируется ис-
пользование теории речевых актов [Austin, 1965; Searle, 1985]. Однако в случае
Bee-gent для этого используется специальный язык ACL, разработанный на осно-
ве KQML [Labrou et al„ 1997]. Интересно здесь то, что логическая структура ACL-
выражений представляется в формализме XML [XML, 1998]. Поэтому язык опи-
сания поведения агентов в Bee-gent называется XML/ACL. Основное отличие его
от, например, языка RADL в том, что в XML/ACL введены перформативы пред-
ставления намерений (intentions), а также средства спецификации потоков раз-
9.2. Проектирование и реализация агентов и мулыиагентных систем
331
вертывания беседы (conversation flows). Вместе с тем в языке спецификации по-
ведения агентов системы Bee-gent нет правил, определяющих, в каких случаях
какие перформативы должны использоваться. И, следовательно, нет типовых
сценариев диалогов. Пример перформатива в формализме XML/ACL приведен
ниже:
<!DOCTYPE request SYSTEM "request.dtd">
<request>
<sender>Mediation Agent</sender>
<receiver>Agent Wrapper</receiver>
<content>
<action>act1</action>
<actor>Agent Wrapper</actor>
<args>null</args>
</content>
<protocol>Request-inform</protocol>
<reply-with>MSG-ID:1</reply-with>
<ontology>default</ontology>
</request>
Рис. 9.3. Общая структура протоколов взаимодействия в системе Bee-gent
332
Глава 9 • Интеллектуальные Интернет-технологии
Как следует из данного примера, для спецификации перформативов использует-
ся система специальных тегов, что хорошо коррелирует с предложениями FIPA
по созданию языка SKDL (Structured Knowledge Description Language) [SKDL,
1998]. Вместе с тем реализация поведения агентов лежит на специальной систе-
ме Java-классов и практически никак Не связана с внешним представлением пер-
формативов в языке XML/ACL.
Для иллюстрации подхода Bee-gent к описанию поведения агентов рассмотрим
модельную задачу брокера [Bee-gent, 1999], обслуживающего потенциального
покупателя, который находит продавца определенного товара, обсуждает с ним
цены и информирует покупателя о возможных вариантах покупки.
Контрактная сеть верхнего уровня для данной задачи представлена на рис. 9.4.
Рис. 9.4. Контрактная сеть верхнего уровня для задачи брокера
С точки зрения системы представления знаний AgentBuilder, она наиболее близ-
ка к спецификации агентства (Agency). Однако в данном случае, по нашему мне-
нию, в контрактной сети Bee-gent более детально специфицируются не только
типы взаимодействий между агентами в агентстве, но и их реализация.
Собственно спецификацию поведения агентов в системе Bee-gent можно проил-
люстрировать на примере протокола взаимодействия для продавца, показанного
на рис. 9.5
Такая спецификация достаточно прозрачна и в дополнительных комментариях
не нуждается. Поэтому, на наш взгляд, интереснее рассмотреть, как реализуется
поведение агента в формализме системы Bee-gent.
9.2. Проектирование и реализация агентов и мультиагентных систем
333
Ожидание запроса
Ответ о наличии
товаров и ценах
Ответ:
Sorry,
Refuse,
Propose,
V"......
(Согласи^
> Ожидание запроса
Рис. 9.5. Граф протокола взаимодействия для поведения продавца
Собственно инициация агента здесь осуществляется стандарным для Java-при-
ложений образом:
import com.Toshiba.beegent. *;
import com.Toshiba.beegent.xml. *;
import com.Toshiba.beegent.util.*;
public class AW2 extends AgentWrapper {
public static void main (String[] argv) throws Exception {
AW2 aw = new AW2();
aw.setName ("bidder”);
aw.printLog (true);
aw.setPassword ("kawamura");
aw.addPublicIPStates ();
aw.startIP ();
}
Каждое состояние в протоколе взаимодействия является экземпляром класса
AwrIPState, фрагмент описания которого приведен ниже.
334
Глава 9 • Интеллектуальные Интернет-технология
class AwrIPStatel extends AwrIPState {
AwrIPStateSI () { super ("INIT"); }
public void action () {
XmlAcl xa = null;
while ( waitXML (0) ){
xa = getXML ();
pe.rf = xa.getTag2Value ("performative");
sender = xa.getTag2Value ("sender");
action = xa.getTag2Value ("action");
if (perf.equals ("cfp")) break;
// Send XML/ACL
int rand = new Random (System.currentTimeMillis()).nextlnt ();
int dice = Math.abs (rand) % 3;
switch (dice) {
case 0: // generate Refuse performative
setPostcond ("INIT");
break;
default:
setPostcond ("INIT");
return;
if ( !sendXML (xa) )
Debug. printLog (getMyname (), "Failed to send XML/ACL”);.
Наиболее интересны и важны здесь «петля» ожидания сообщений и оператор
switch, в теле которого собственно и специфицируется поведение как последова-
тельность действий, направленных в данном случае на формирование соответ-
ствующего перформатива.
Анализ этого фрагмента и других примеров реализации поведения агентов в си-
стеме Bee-gent позволяет сделать следующие выводы. Агентная библиотека фир-
мы Toshiba является достаточно развитой и отвечает основным требованиям к
компонентам программного обеспечения данного класса. Перформативы XML/
ACL более высокого, по сравнению с KQML, уровня. Для спецификации прото-
колов взаимодействия предлагается использовать язык программирования, а не
представления знаний. На уровне технологии имеется достаточно четкая струк-
тура представления поведения агентов. Учитывая то, что языком реализации
поведения в данном случае является Java, система Bee-gent ориентирована на
компиляцию программ, а не интерпретацию спецификаций, как это происходит
в случае системы AgentBuilder.
9.3. Информационный поиск в среде Интернет
335
Выше мы обсудили два подхода к разработке и реализации МАС, которые отра-
жают разные концы спектра инструментов, используемых в этой области.
Суммируя все вышесказанное, можно отметить, что в настоящее время в работах
по созданию инструментария явно фиксируется тенденция использования мето-
дов и средств ИИ, ориентированных на поддержку процессов проектирования
программных агентов и МАС в целом.
При этом задача построения технологий нового поколения для создания МАС
может быть решена на основе совместного использования опыта разработчиков
МАС и методологий обработки знаний, заимствованных из ИИ [Guarino et al.,
1995Ь]. Для этого прежде всего необходимо адаптировать методы и средства
проектирования и реализации прикладных интеллектуальных систем в новую
проблемную область: разработку мультиагентных систем нового поколения.
Очевидно, что спецификация процесса разработки МАС на основе методов про-
ектирования баз знаний в такой технологии предполагает:
• эксплицитное представление в БЗ архитектуры проектируемой МАС;
• явную спецификацию архитектуры отдельных типов агентов, «задействован-
ных» в рамках проектируемой МАС;
• описание в виде специальных баз знаний модели (схемы) всех знаний, необхо-
димых каждому агенту для реализации поставленных перед ним целей;
• анализ используемых в настоящее время при реализации МАС систем классов
и соответствующих программных библиотек с целью явной спецификации со-
ответствия между элементами архитектуры проектируемой МАС и ее компо-
нентами и программными единицами, реализующими их;
• формальную спецификацию (на уровне соответствующей системы представ-
ления и манипулирования знаниями) специальной машины вывода (решате-
ля), целью которой является переход от спецификации МАС к ее реализации.
Учитывая вышесказанное, можно констатировать, что процесс разработки МАС
при этом хорошо коррелирует с соответствующим процессом создания сложных
программных систем, но отличается дополнительными фазами, связанными с
наличием независимых компонентов (агентов), взаимодействующих с пользова-
телем и друг с другом.
По существу, при таком подходе мы получаем специализированную экспертную
систему, предметной областью которой является автоматизация проектирования
и реализации определенного класса мультиагентных систем. Создание такой ме-
тодологии разработки МАС обсуждается, например, в работе [Iglesias et. all,
1996], где приводится, в частности, спецификация процесса разработки МАС на
базе CommonKADS.
9.3. Информационный поиск
в среде Интернет
По-видимому, не будет большим преувеличением утверждение о том, что конец
XX века — это время новых информационных технологий, «живущих» в гло-
336
Глава 9 • Интеллектуальные Интернет-технологии
бальных и локальных сетях, наиболее яркими представителями которых явля-
ются Интернет и интранет. В настоящее время уже ни у кого нет сомнений в том,
что Интернет является de facto всемирным хранилищем информации практи-
чески по всем аспектам жизни человечества. Так же как и то, что эффективный
доступ к этой информации в связи с экспоненциальным ростом объема Интер-
нет-ресурсов становится все более сложным и трудоемким [Cowie et al., 1996].
И не столько с технической точки зрения, сколько с точки зрения поиска и ана-
лиза информации.
С другой стороны, как уже отмечалось в предыдущем параграфе, важнейшими из
областей практического использования агентных технологий являются сбор ин-
формации, ее фильтрация и использование для принятия решений.
Учитывая вышесказанное, цель данного параграфа в обсуждении проблем пред-
ставления и обработки информации в сети Интернет на основе использования
парадигмы многоагентных систем, а также обзор уже существующих в этой обла-
сти приложений.
Авторы отдают себе отчет, что при этом за рамками такого обсуждения остаются
многие важные применения агентных технологий, но вынуждены ограничиться
данной тематикой в силу ограничений на объем данного издания и время его под-
готовки.
/
9.3.1. Машины поиска
Пространство WWW уже сегодня содержит огромное количество HTML-доку-
ментов, причем не только тексты, но и графику, видео, звук и т. д. Гипертексто-
вые связи между Web-документами и/или их частями отражают отношения
между отдельными информационными фрагментами, представленными в сети.
Броузеры, поддерживающие HTML-стандарты, обеспечивают представление
материалов пользователям и навигацию по ссылкам для доступа к документам,
распределенным по сети. Однако поиск информации в настоящее время поддер-
жан существенно слабее и в большинстве случаев базируется на использовании
ключевых слов и ограниченного числа типов машин поиска.
Машины поиска, по-видимому, являются в Интернете самым распространенным
и доступным ресурсом для извлечения информации. При этом, как правило, ис-
пользуются два типа сетевых роботов: спайдеры (spiders) и индексы (indexes).
Спайдеры, иногда называемые также ботами (bots, от робот-robots), перемеща-
ются по Web от сайта к сайту. Некоторые из них перемещаются от сервера к сер-
веру беспорядочно, другие используют приоритеты, такие, например, как посе-
щаемость сайта. Оказавшись на сайте, спайдер посылает отчет поисковой
машине и продолжает индексирование. Индексы используются для ускорения
поиска и сбора информации. Некоторые поисковые механизмы индексируют со-
держание страниц полностью, другие — только отдельные их части, такие, на-
пример, как заголовки документов.
Основными характеристиками машин поиска являются язык запросов пользова-
теля, представление исходных и выходных документов, время индексации и пр-
9.3. Информационный поиск в среде Интернет
337
иска, объем индекса. Существенной характеристикой машин поиска является
также качество представления результатов. Наиболее популярные поисковые
машины в настоящее время — AltaVista (http://www.altavista.com и/или http:
//altavista.ru), Exite (http://www.excite.com), Infoseek (http://www.infoseek.
com), Lycos (http://www.lycos.com), WebCrawler (http://www. webcrawler,
com), Yahoo! (http://www.yahoo.com) и некоторые другие. Примером полно-
текстовой системы поиска с учетом морфологии русского языка является систе-
ма Япс1ех (http://www.yandex.ru). Сравнительный анализ достоинств ц/недо-
статков машин поиска можно найти в работе [CompTek, 2000а], а русскоязычных
машин поиска — в работе [CompTek, 2000b],
Как правило, поисковые машины обеспечивают интерфейс типа меню, с помо-
щью которого пользователь может скомпоновать запрос на поиск информации,
используя ключевые слова и/или фразы и логические связки И-ИЛИ-НЕ. Боль-
шинство машин поиска находят огромное количество «релевантных» страниц по
запросу пользователя. Каждый найденный документ обычно ранжируется по
степени его корреляции с запросом. Релевантность каждого документа оценива-
ется с помощью различных технологий, например учета частоты появления на'
странице искомых слов. Некоторые поисковые механизмы используют дополни-
тельно другие факторы, такие как частота посещения страницы и/или близость
расположения друг к другу искомых терминов.
Типичную организацию машин поиска можно рассмотреть на примере системы
WebCrawler (рис. 9.6), разработанной в университете Вашингтон (Сиэтл, США).
Интернет
Механизм
поиска
Рис. 9.6. Общая архитектура системы WebCrawler
WebCrawler начинает процесс поиска новых сайтов с известных ему документов
и переходит по ссылкам на другие страницы. Он рассматривает сетевое простран-
ство как ориентированный граф и использует алгоритм обхода графа, работая в
следующем цикле [Cheong, 1996]:
• найти новый документ;
• отметить документ как извлеченный;
♦ расшифровать ссылки с этого документа;
♦ проиндексировать содержание документа.
Поисковый механизм работает в двух режимах: поиск документов в реальном
времени и индексирование документов.
338
Глава 9 * Интеллектуальные Интернет-технологии
Этим сервисом определяется, какие документы и какие типы документов нужно
найти и извлечь из сети. Звуковые файлы, картинки, двоичные файлы и т. п. —
не извлекаются. Ошибочно извлеченные файлы будут проигнорированы на ста-
дии индексирования. В режиме индексирования система строит индекс инфор-
мации из найденных документов, в режиме поиска — находит документы, мак-
симально соответствующие запросу пользователя.
Агенты в системе WebCrawler отвечают за извлечение документов из сети. Для
выполнения этой работы поисковый механизм находит свободного агента и пере-
дает ему задание на поиск. Агент приступает к работе и возвращает либо содержа-
ние документа, либо объяснение, почему данный документ нельзя доставить.
Агенты запускаются как отдельные процессы, что позволяет изолировать основ-
ной процесс работы системы от ошибок и проблем с памятью. Одновременно ис-
пользуется до 15 агентов.
В базе данных хранятся метаданные документов, связи между документами, пол-
нотекстовый индекс, другая служебная информация. База обновляется каждый
раз, когда поступает новый документ. Для отсечения семантически незначимых
слов используется стоп-словарь, словам из документа приписывается вес, рав-
ный частоте их появления в данном тексте, деленной на частоту появления слова
в ссылках на другие документы. Такой индекс позволяет быстро находить по за-
данному слову ссылки на документы его содержащие. Целиком URL (ссылки на
документы в сети) не запоминаются. Вместо этого вся нужная информация по-
мещается в специальные объекты. Каждый объект запоминается в отдельном В-
дереве: документы — в одном, серверы — в другом, а ссылки — в третьем. Такое
разделение данных позволяет быстро определить неиспользуемые или часто ис-
пользуемые серверы.
Аналогичным образом устроены и другие машины поиска. Характеризуя их в це-
лом, можно отметить, что это глобальные поисковые механизмы, охватывающие
до 90 % ресурсов Интернета. Они не могут настраиваться на предпочтения пользо-
вателя и не имеют средств анализа информации, а их сетевым роботам становится
все труднее справляться с постоянным ростом ресурсов Интернета. Главной зада-
чей машин поиска, по сути, является индексация ресурсов глобальной сети, а так-
же поддержка и расширение соответствующих баз данных. Фактически в базах
данных машин поиска хранится информация о том, где и что лежит в сети. Поэто-
му можно считать, что существующие машины поиска обеспечивают низкоуров-
невый сервис для клиентских поисковых программ более высокого уровня.
9.3.2. Неспециализированные
и специализированные
поисковые агенты
Первым уровнем надстройки над поисковыми машинами являются, по-видимо-
му, неспециализированные поисковые агенты. По сути дела, эти компоненты
имеются в настоящее время практически у всех машин поиска. Такие агенты, в
9.3. Информационный поиск в среде Интернет
339
первую очередь, обеспечивают поиск по ключевым словам и устойчивым слово-
сочетаниям [Delgado, 2000]. Кроме поиска они поддерживают различные и мно-
гочисленные сервисы, такие, например, как передача запроса пользователя сразу
на множество машин поиска, настройка на личные предпочтения пользователя,
формирование тематической базы данных на основе результатов поиска пользо-
вателя, а некоторые — и обучение агентов. Не менее важно и то, что такие системы
агентов объединяют ссылки на сайты, найденные множеством машин поиска,
исключая повторные и неработающие ссылки. Но ни одна из систем данного
класса не в состоянии самостоятельно отобрать полезную информацию и остав-
ляет это пользователю. Конечно, используя такие программы, можно уменьшить
число результирующих документов, доставляемых обычными машинами поис-
ка. Но степень «попадания ответа в запрос» практически та же, что и у машин
поиска. Важно и то, что неспециализированные агенты опыта по поиску в опре-
деленной предметной области не накапливают. А обучение, если вообще допус-
кается, занимает много времени.
Специализированные агенты поиска, как следует уже из их названия, приспособ-
лены искать информацию, например, только про музыку, или только про книги,
или только про котировки акций и т. д. Большинство таких агентов устроено же-
стко. Они «умеют» очень хорошо работать на определенных сайтах с фиксиро-
ванным форматом данных. При этом даже адреса этих сайтов могут быть «заши-
ты» в агента, например сайты с котировками акций на биржах мира.
Системы, построенные на базе специализированных агентов, кроме поиска пре-
доставляют пользователям определенный пакет средств для организации и уп-
равления найденной информацией. Как правило, такие системы содержат набор
агентов, каждый из которых ориентирован на поиск информации только по од-
ной теме. Они могут иметь доступ к сотням ресурсов Интернета, включая специа-
лизированные базы данных. Основные специализации агентов в таких систе-
мах в настоящее время — новости, конференции и группы по интересам, книги,
программное обеспечение, электронные магазины и другая бизнес-информация,
часто задаваемые вопросы и некоторые другие. Обычно пользователь здесь мо-
жет сфЬрмировать запрос к системе, используя естественный язык, а результаты
сопровождаются аннотациями содержания найденных документов, списками
ключевых слов и некоторой другой дополнительной информацией, облегчаю-
щей пользователю выделение интересующих его ресурсов.
В развитых системах этого класса имеются возможности:
• сохранения параметров поиска для повторного использования, а часто и пол-
ной «истории» запросов пользователя;
• параллельного поиска на множестве ресурсов Интернета;
• оформления результатов в виде отчетов (HTML-файлов) и сохранения их в
базе данных;
• слежения за обновлением информационных ресурсов Интернета, в том числе с
частотой, задаваемой пользователем.
340
Глава 9 » Интеллектуальные Интернет-технологии
Недостатки у специализированных агентов те же, что и у неспециализированных,
но есть и серьезный плюс — четкое срабатывание на хорошо структурированных
данных в известном формате.
9.3.3. Системы интеллектуальных
поисковых агентов
Сегодня в развитии систем поиска и обработки Интернет-ресурсов наметился
явный сдвиг в сторону использования средств ИИ, в частности представления
знаний и вывода на знаниях, интеллектуальных механизмов обучения, анализа
естественно-языковых текстов и некоторых других.
Как правило, системы интеллектуального поиска разрабатываются либо в серь-
езных фирмах, владеющих технологиями разработки и реализации интеллекту-
альных агентов, либо в исследовательских лабораториях университетов. Спра-
ведливости ради следует заметить, что коммерческие версии таких систем часто
декларируют больше, чем реализовано в действительности, а исследовательские
разработки обычно существуют в виде демонстрационных версий с ограничен-
ными возможностями, хотя в теоретическом плане последние интереснее.
Для конкретизации дальнейшего изложения остановимся сначала более подроб-
но на нескольких, интересных на наш взгляд, коммерческих системах интеллек-
туального поиска и обработки информации в сети Интернет, а завершим обсуж-
дение рассмотрением нескольких исследовательских проектов в этой области,
использующих онтологии.
Autonomy и Webcompass — системы интеллектуального
поиска и обработки информации
Обсуждаемые ниже версии агентных поисковых систем Autonomy [Autonomy,
1998] и Webcompass [Webcompass* 1999] созданы во второй половине 90-х годов.
Цели их разработки практически одинаковые — обеспечить пользователе интег-
рированными средствами поиска релевантной его интересам информации в сети
Интернет, организация найденных документов в рамках определенных тем, а так-
же автоматизация процессов самого поиска. Вместе с тем проектные решения,
принятые разработчиками, здесь существенно разные.
Первое различие между этими системами в ориентации на разные категории
пользователей.
Система Autonomy представляет собой совокупность программных агентов для
интеллектуального поиска и обработки информации, организованных в рамках
специализированной оболочки, предназначенной скорее для конечных пользо-
вателей, чем предметных специалистов. Такая установка влечет за собой специ-
альную организацию интерфейсов, интуитивно понятную и прозрачную для но-
вичков. По сути, пользователю здесь предлагается парадигма «антропоморфного»
9.3, Информационный поиск в среде Интернет
341
общения со всеми компонентами системы и «игровой» подход к решению доста-
точно сложных задач (рис. 9.7).
Рис. 9.7. Главная панель системы Autonomy
Система Webcompass архитектурно тоже состоит из агентно-ориентированных
компонентов, поддерживающих все основные процессы, которые должны быть
реализованы в полномасштабном программном комплексе поиска и анализа ин-
формации. Но ориентирована эта система, прежде всего, на «продвинутых»
пользователей, которые хотят и могут сформировать структурное описание об-
ласти своих интересов. Коммуникационный центр Webcompass (рис. 9.8) пред-
лагает пользователю парадигму многооконного интерфейса, характерную для
современных офисных приложений, и систему структурных редакторов для спе-
цификации предметной области, поисковых запросов и управляющей информа-
ции.
Второе различие между системами Autonomy и Webcompass — в подходе к описа-
нию предметной области поиска.
В первых версиях системы Autonomy использовалась технология нейросетей и
специальный метод представления, разработанный для фирмы AgentWare (так
тогда называлась фирма, выпустившая релиз системы Autonomy) коллективом
Neurodynamics из Кембриджа. В основе технологии лежат методы распознава-
ния образов и обработки сигналов. При этом системой формируется представле-
ние о том, какими должны быть релевантные документы, используемые в даль-
нейшем на этапе поиска информации.
В системе Webcompass описание предметной области основано на использовании
таксономии понятий, связанных между собой отношениями типа is a, part of, has
part, is a kind of и некоторых других. Ограничением такого представления являет-
ся то, что между понятиями не может быть больше одного отношения.
342
Глава 9 • Интеллектуальные Интернет-технологии
*• WebCompass - (computational tirnjuistic$|
♦ 3» fe* й« _«* a*
*1*121
1.'Пл*» Гй
о lngus*rs
the science ci language
*L»MflTl Min-rt»r I -1
*vwW+ VjUcnct®
Z A qje^ iurrfeXui
•?> ф A part of artificial inteSgence
&'ф A specific kind it expert system
Э^ф See also logic programmng
®"ф A specific kind is pattern recognition
:A specific kind is robotics
Has part fuzzy set theory
Й ф Has part knowledge representation
& ф Has part natural language p > es<v »
1
*L
Topic:
Query Terms:
Definition:
Category:
: ф See also natural language
ф-ф H as part neural network
^ф See abo SIGART
«1
J
computational linguistics
computational linguistics, computer linguistics, language data processing
the application or implementation of linguistic theory by computers
General
M
Рис. 9.8. Коммуникационный центр системы Webcompass
Третье различие между обсуждаемыми системами состоит в используемых сред-
ствах спецификации запросов.
В системе Autonomy запрос на поиск представляется на естественном языке. Си-
стема анализирует текст автоматически и извлекает из него смысловое содержа-
ние, которое помещается в специальный конфигурационный файл. При этом
внутреннее представление запроса тоже представляется нейросетью, в узлах ко-
торой располагаются ключевые слова и выражения.
Запрос к системе Webcompass базируется на «прямом» использовании сформи-
рованного пользователем описания предметной области. Поскольку здесь такое
описание представлено таксономией понятий (ключевые слова и выражения), то
для формирования запроса достаточно просто промаркировать интересующие
пользователя темы. На основании этих пометок система сама формирует запрос
на поиск релевантной информации.
Собственно поиск релевантной информации в системе Autonomy ведется с ис-
пользованием методов нечеткой логики. В основе поискового алгоритма лежит
«Механизм динамических рассуждений» (МДР), разработанный уже упоминав-
шимся коллективом Neurodynamics. Базовые функции МДР — сравнение кон-
цептов (по входному тексту определяются ссылки на документы из заранее со-
ставленного списка с наиболее релевантной информацией для поиска); создание
агента (формируются концепты из тренировочного текста и из других подходя-
щих источников для использования их агентом); стандартный поиск слов в тек-
сте.
9.3. Информационный поиск в среде Интернет
343
Поиск в системе Webcompass ведется на основе ключевых слов. При этом он осу-
ществляется сразу на 35 машинах поиска, которые задаются списком. Этот спи-
сок можно изменять, а кроме того, добавить адреса для поиска в интранет,
Usenet, FTP и Gopher ресурсах. Система проверяет каждую найденную ссылку
на доступность и, анализируя найденную информацию, составляет краткое ре-
зюме документов, а также определяет степень соответствия сайта запросу
пользователя, ранжируя найденные документы от 1 до 100.
Остальные функциональные возможности рассматриваемых систем скорее сход-
ны, чем различны. Это формирование репозиториев результатов, наличие фоно-
вого режима поиска информации и некоторые другие.
Из интересных особенностей системы Autonomy, отсутствующих в системе Web-
compass в явном виде, можно отметить режим обучения поисковых агентов.
Оценивая рассмотренные выше системы и класс агентных систем данного типа
можно отметить их следующие достоинства:
• возможность простой модификации используемых машин поиска;
• использование словарей терминов для обработки запросов;
• создание кратких аннотаций найденных документов;
• поддержка настраиваемых баз данных по темам поиска и результатам;
• классифицикация результатов поиска по темам, запоминание и автоматичес-
кое обновление ссылок на источники;
• использование результатов поиска для улучшения его качества в той же обла-
сти в будущем.
Недостатком таких систем является, как правило, слабая обучаемость агентов.
Поэтому такие системы являются полезными инструментами при поиске инфор-
мации в Интернете, но не могут сделать этот поиск полностью автоматическим и
эффективным с точки зрения пользователя.
Справедливости ради отметим, что в последнее время фирмы, выпускавшие сис-
темы Autonomy и Webcompass, рассмотренные выше, а также многие другие фир-
мы, работающие на рынке информационных технологий, активно используют
последние наработки в этой области, полученные в исследовательских лаборато-
риях и проектах, связанных с проблематикой искусственного интеллекта.
Учитывая вышесказанное, сейчас на авансцену развития агентных технологий
вообще и использования их при поиске информации в частности выходят про-
блемы представления знаний, механизмы вывода новых знаний, описание модели
мира, моделирование рассуждений в рамках агентного подхода. По существу,
именно эти аспекты и являются ключевыми при создании интеллектуальных си-
стем поиска информации в сети Интернет в разных исследовательских проектах,
к обсуждению которых мы и переходим.
Проект системы MARRI
Система MARRI [Villemin, 1999]'разработана для поиска Web-страниц, релевант-
ных запросам в определенной предметной области. Для решения поставленных
344
Глава 9 • Интеллектуальные Интернет-технологии
задач система использует знания, представленные в виде онтологии, которая в
данном случае понимается как множество концептов и связей между ними. Ба-
зисное предположение разработчиков состоит в том, что релевантные тексты со-
стоят из значимых для предметной области предложений, содержащих фрагмен-
ты, «сопоставимые» с онтологией предметной области. Предполагается, что одни
агенты — агенты сети — для предварительного отбора используют стандартные
машины поиска, а другие — специализированные агенты — осуществляют поверх-
ностный анализ полученных Web-страниц, затем проверяют их на соответствие
так называемому онтологическому тесту и возвращают пользователю лишь те
страницы, которые успешно прошли данный тест.
Суть онтологического теста состоит в следующем. Сначала осуществляется мор-
фологический и синтаксический анализ предложений полученного от агентов
сети текста и строится его синтаксическое дерево; затем осуществляется опреде-
ление типа предложения (утвердительное, отрицательное и т. п.) и тип речевого
акта, который это предложение отражает. Для дальнейшего анализа выбираются
только простые утвердительные предложения со структурой NP VP NP, где NP —
именная группа, a VP — глагольная группа. При этом неявно предполагается, что
структура знаний о предметной области отражена в структуре предложений,
описывающих концепты. Поэтому, если анализируемое предложение действи-
тельно описывает некоторый концепт, значимые для предметной области слова
уже присутствуют в онтологии.
С учетом всего вышесказанного, онтологический тест выполняется следующим
образом:
• существительные (или, в общем случае, именные группы) отображаются на
концепты онтологии, а глаголы (или, в общем случае, глагольные группы) —
на роли;
• в глагольной группе выделяется для дальнейшей обработки основной глагол
(V). Если он отсутствует в онтологии, тест возвращает «неудачу», иначе:
• в левой «верхней» именной группе выделяется базисное существительное (N).
Если оно отсутствует в онтологии, тест возвращает «неудачу», иначе:
• проверяется ограничение (семантическое отношение) S между N и V. При
этом возможны следующие варианты:
♦ N и V действительно связаны отношением S, которое представлено в онто-
логии;
♦ в онтологии отношением S связаны существительное N' и глагол V, причем
N' является подклассом N, а V — подклассом V;
♦ если же предыдущие два варианта не имеют места, тест возвращает «неуда-
чу»;
♦ аналогичная процедура выполняется и для правой «верхней» именной
группы.
Таким образом, онтологический тест в случае успеха поволяет «наложить» ана-
лизируемый текст на онтологию предметной области.
9.3. Информационный поиск в среде Интернет
345
Архитектурно система MARRI (рис. 9.9) является сетью специализированных
агентов четырех типов: агент пользователя (User Agent), агент-брокер (Broker
Agent), агент сети (Connection Agent) и агент обработки текста (Text Processing
Agent). Каждый из агентов обладает следующими свойствами:
• это автономная Java-программа с собственным сетевым адресом (URL);
• он взаимодействует с другими агентами с помощью языка ACL (Agent Com-
munication Language), функционирующего над HTTP-протоколом;
• агент является потребителем и поставщиком информации, в зависимости от
того, с какими агентами системы он общается;
• он может взаимодействовать с автономными программными компонентами —
такими как, например, Web-броузеры, анализаторы ЕЯ' или онтологические
БД;
• агент обладает специальными знаниями и возможностями вывода для оп-
ределения того, доступна ли нужная Web-страница, содержит ли она тек-
стовую информацию и релевантна ли эта информация определенной пред-
метной области.
Рис. 9.9. Архитектура системы MARRI
Интерфейсный агент (ИА) поддерживает интеллектуальное взаимодействие с
пользователем. Он ассистирует при формулировке запросов и представляет ре-
зультаты поиска в виде списка релевантных URL или Web-страниц. Когда поль-
зователь выбирает интересующую его предметную область, ИА запрашивает со-
ответствующую онтологию из онтологической БД, а также информирует других
агентов сети о том, какая онтология будет использоваться.
Задачей агента сети (АС) является подключение к заданной URL Web-странице,
ее считывание и анализ. В силу того, что нужная страница может быть недоступна
346
Глава 9 • Интеллектуальные Интернет-технологии
или неинтересна по содержанию, АС должен «уметь» обрабатывать исключи-
тельные ситуации, а также анализировать собственно текст, представлен-
ный на считанной странице.
В системе MARRI задействованы два типа агентов-брокеров: брокер URL и бро-
кер HTML. Первые предназначены для «сопровождения» списков Интернет-ад-
ресов, поставляемых броузером, а вторые — для запоминания полученных Web-
страниц и распределения их между агентами обработки текста (АОТ) для
дальнейшего анализа.
Целью функционирования АОТ является семантический анализ Web-страниц
для проверки их релевантности на базе соответствующей онтологии. Предвари-
тельно эти же агенты преобразуют HTML-текст к определенному структурному
представлению, с которым работают морфологический и синтаксический ана-
лизаторы. Результат обработки текста представляется в виде синтаксического
дерева, которое должно отождествиться с определенным фрагментом используе-
мой онтологии.
С архитектурной точки зрения система MARRI, по сегодняшним меркам, явля-
ется почти традиционной. Ее отличительная черта — представление агентов ав-
тономными Java-программами с собственными сетевыми адресами, что неявно
предполагает их мобильность и/или распределенность по сети. Такое решение
было бы весьма интересным, если бы не политика контроля за безопасностью
сервера, которая не допускает в настоящее время регистрацию и запуск Java-npo-
грамм, не сертифицированных на данном сервере.
Прототип системы реализован на языке Java (версия 1.1.3). Для тестирования
его разработаны две (очень грубых) онтологии — одна в области электронной
коммерции (около 200 элементов), а вторая — в области Интернет-безопасности
клиентских приложений (около 450 элементов). Предполагается развитие этих
онтологий и интеграция их с соответствующими онтологиями, уже существую-
щими на онтологических серверах.
Прототип системы OntoSeek
Разработка и реализация прототипа системы «содержательного» доступа к
WWW-ресурсам OntoSeek — результат 2-летней работы, выполненной в коопе-
рации Corinto (Consorzio di Ricerca Nazionale Tecnologia Oggetti — National Re-
search Consortium for Object Technology) и Ladseb-CNR (National Research
Council — Institute of Systems Science and Biomedical Engineering), как части про-
екта по поиску и повторному использованию программных компонентов [Gua-
rino, et al., 1999].
Система OntoSeek разработана для содержательного извлечения информации из
доступных в режиме on-line «желтых» страниц (yellow pages) и каталогов. В рам-
ках системы совместно используются механизмы поиска по содержанию, управ-
ляемые соответствующей онтологией (ontology-driven content-matching mecha-
nism), и достаточно мощный формализм представления.
9.3. Информационный поиск в среде Интернет
347
При создании OntoSeek были приняты следующие проектные решения:
• использование ограниченного числа ЕЯ-терминов для точного описания ре-
сурсов на фазе кодирования;
• полная «терминологическая свобода» в запросах за счет управляемого онтоло-
гией семантического отображения их на описания ресурсов;
• интерактивное ассистирование пользователю в процессе формулировки за-
проса, его обобщения и/или конкретизации, а также приняты во внимание:
♦ текущее состояние исследований в области Интернет-архитектур;
♦ необходимость достижения высокой точности и приемлемой эффективно-
сти на больших массивах данных;
♦ важность хорошей масштабируемости и портабельности принимаемых ре-
шений.
Система работает как с гомогенными, так и с гетерогенными каталогами продук-
тов. Понятно, что второй вариант сложнее. Поэтому в системе OntoSeek для пред-
ставления запросов и описания ресурсов используется модификация простых
концептуальных графов Дж. Совы [Sowa, 1984], которые обладают существенно
более мощными выразительными возможностями и гибкостью по сравнению с
обычно используемыми списками типа «атрибут-значение». Для концептуаль-
ных графов проблема контекстного отождествления редуцируется до управляе-
мого онтологией поиска в графе. При этом узлы и дуги сопоставимы, если онтоло-
гия «показывает», что между ними существует заданное отношение, вместе с тем,
поскольку система базируется на! использовании лингвистической онтологии,
узлы концептуального графа должны быть привязаны к соответствующим лекси-
ческим единицам, причем для этого должны выполняться определенные семанти-
ческие ограничения.
На этапе планирования проекта вместо разработки собственной лингвистичес-
кой онтологии были проанализированы доступные Интернет-ресурсы и выбра-
на онтология Sensus [Knight et al., 1994], которая обладает простой таксономи-
ческой структурой, имеет объем около 50 000 узлов, в основном выделенных из
тезауруса WordNet [Beckwith et al., 1990], а также доступна для исследователь-
ских целей в свободном режиме.
Функциональная структура системы OntoSeek представлена на рис. 9.10.
На фазе кодирования описание ресурсов конвертируется в концептуальный
граф. Для этого «поверхностные» узлы и дуги, отмеченные пользователем, с по-
мощью лексического интерфейса трансформируются в смыслы, заданные в сло-
варе. Таким образом, «граф слов» транслируется в «граф смыслов», причем каж-
дому понятию последнего сопоставляется соответствующий узел онтологии.
После семантической валидации концептуального графа на основе использова-
ния онтологии он запоминается в БД.
348
Глава 9 • Интеллектуальные Интернет-технологии
Интернет
Рис. 9.10. Функциональная структура системы OntoSeek
Наиболее интересным моментом этапа кодирования ресурсов в системе Onto-
Seek является формализм представления помеченных концептуальных графов
(ПКГ), который базируется на том, что заданы словари существительных и глаго-
лов, а собственно ПКГ определяется как связный ориентированный граф, удов-
летворяющий следующим синтаксическим ограничениям:
• Дуги могут быть помечены только существительными из словаря (любой
граф, содержащий дугу, помеченную транзитивной конструкцией вида
[<URLl>man] —> [love) —> [women], может быть конвертирован в базисный
ПКГ вида [<URLl>man] <— (agent) <— [love] —> (patient) —> [women]).
• В общем случае узлы помечаются строками вида concept [instance], где con-
cept — с уществительное или глагол из словаря, а необязательная ссылка ins-
tance — управляющий идентификатор.
• Для каждого графа существует в точности один узел, называемый «головой».
Этот узел маркируется URL в угловых скобках, идентифицирующим файл
описания ресурса, который описывает данный граф, и маркерной строки,
представляющей понятие онтологии.
Понятно, что прежде, чем использовать этот граф, должна быть устранена поли-
семия, что может позволить однозначно отразить существующие метки в поня-
9.3. Информационный поиск в среде Интернет
349
тия онтологии. После выполнения этой процедуры семантическая интерпрета-
ция ПКГ происходит следующим образом:
• каждый узел, помеченный «словом» А, представляет класс экземпляров соот-
ветствующего концепта. При наличии в описании идентификатора экземпля-
ра узел определяет синглетон, содержащий этот экземпляр. Если А — глагол,
узел фиксирует его номинализацию (например, узел с пометкой «love» опре-
деляет класс событий «любить»);
• каждая дуга с пометкой С из узла А в узел В определяет соответствующее непу-
стое отношение;
• в целом граф с «головой» А и URL U определяют класс экземпляров А, описы-
ваемых ресурсом, помеченным U.
Процесс поиска осуществляется следующим образом. Пользователь представля-
ет свой запрос тоже в виде концептуального графа, который после устранения
лексической неоднозначности и семантической валидации передается компонен-
те отождествления, работающей с БД. Здесь ищутся графы, удовлетворяющие
запросу и ограничениям, заданным в онтологии, после чего ответ представляется
пользователю в виде HTML-отчета.
Семантика графа запроса и процедура его построения аналогичны рассмотрен-
ной выше процедуре кодирования ресурсов, но имеет следующие отличия:
• на месте URL может быть задана переменная;
• переменными может быть помечено произвольное число узлов.
Так, например, запрос вида [<Х> саг] -> (part) —> [radio] вернет множество URL
на документы, описывающие автомобили с радиоприемниками в качестве части,
а запрос вида [car] —> (part) —> [<Х> radio] — множество URL на документы, опи-
сывающие радиоприемник как часть автомобиля. И более того, композиция этих
запросов вида [<Х> car] —> (part) —> [<Y> radio] может быть использована для
получения документов обоих типов.
Таким образом, предполагается, что граф запроса Q отождествляется с графом
описания ресурса R, если:
• Q изоморфен подграфу графа R;
• пометки графа R соответствуют пометкам графа Q,
• «голова» графа R соответствует узлу, помеченному переменной в графе Q.
Последнее условие необходимо, если мы хотим «сосредоточиться» на ресур-
сах, соответствующих запросу в точности.
Реализация системы OntoSeek выполнена в парадигме «клиент-сервер». Архи-
тектурным ядром ее является сервер онтологий, обеспечивающий для приложе-
ний интерфейсы доступа и/или манипулирования данными модели онтологии,
а также поддержки БД концептуальных графов. Заметим, что последняя может
строиться й пополняться не только в интерактивном режиме, но и за счет ском-
пилированных описаний ПКГ, представленных на языке XML. Компонента БД в
системе OntoSeek выделена в отдельный блок, что позволяет легко заменить при
необходимости используемую СУБД.
350
Глава 9 • Интеллектуальные Интернет-технологии
Проект начался зимой 1996 г. — на заре эры языка Java. Поэтому прототип был
реализован на языке C++. В настоящее время авторы предполагают провести ре-
инжиниринг системы на основе использования новейших Интернет-технологий.
Таким образом, использование онтологий для интеллектуальной работы с Интер-
нет-ресурсами является в настоящее время «горячей» точкой исследований и
практических применений.
Специалистам в этой области хорошо известны Интернет-сайты организаций и
проектов, связанных с созданием и использованием онтологий, но даже у них при
выборе онтологии, «подходящей» для конкретного приложения, возникают опре-
деленные проблемы. Основные из них: отсутствие стандартного набора свойств,
характеризующих онтологию с точки зрения ее пользователя; уникальность ло-
гической структуры представления релевантной информации на каждом «онто-
логическом» сайте; высокая трудоемкость поиска подходящей онтологии.
Учитывая вышесказанное, в заключение данного параграфа рассмотрим пример
интеллектуального агента, который демонстрирует онтологический подход к
поиску на Web и выбору для использования собственно онтологий.
(ONTO)2 — агент поиска и выбора онтологий
Целью разработки интеллектуального WWW-брокера выбора онтологий на Web
[Vega et aL, 1999] было решение проблемы ассистирования при выборе онтоло-
гий. Для этого потребовалось сформировать перечень свойств, которые позволя-
ют охарактеризовать онтологию с точки зрения ее будущего пользователя и пред-
ложить единую логическую структуру соответствующих описаний; разработать
специальную ссылочную онтологию (Reference Ontology), в рамках которой
представлены описания существующих на Web онтологий; реализовать интел-
лектуального агента (ONTO)2, использующего ссылочную онтологию в качестве
источника знаний для поиска онтологий, удовлетворяющих заданному множе-
ству ограничений.
Для решения первой из перечисленных задач авторы (ONTO)2 детально проана-
лизировали онтологии, представленные на Web, и построили таксономию
свойств, используемых для описания онтологий (табл. 9.2). Для удобства даль-
нейшего использования все свойства сгруппированы в категории идентифика-
ции, описания и функциональности.
Как следует из приведенной таксономии, идентификация дает информацию об
онтологии, как таковой, ее разработчиках и дистрибьюторах; описание — общую
информацию, аннотацию онтологии, некоторые детали проектирования и реали-
зации, требования к аппаратуре и программному обеспечению, ценовые характе-
ристики и перечень применений; функциональность — представление о том, как
использовать онтологию в приложениях.
9.3. Информационный поиск в среде Интернет
351
При решении задачи разработки ссылочной онтологии авторы (ONTO)2 исполь-
зовали уже обсуждавшуюся выше технологию METHONTOLOGY и инструмен-
тарий ODE [Blazquez et al., 1998]. При этом, в соответствии с общими тенденци-
ями по созданию разделяемых онтологий и, по-видимому, в силу того, что один из
авторов обсуждаемой работы (Gomez-Perez) является провайдер-агентом меж-
дународного проекта по построению разделяемых баз знаний [Benjamins et al.,
1998], Reference Ontology была «имплантирована» в онтологию Product инициа-
тивы (КА)2.
В качестве источников знаний для построения ссылочной онтологии была ис-
пользована уже обсуждавшаяся таксономия свойств, концептуальная модель
(КА)2 и свойства, выделенные в рамках разработки онтологии исследовательских
тем (Research-Topic) инициативы (КА)2. Критерии, которые применялись при
имплантации ссылочной онтологии в онтологию (КА)2, — следующие:
• модульность (онтология должна была быть модульной, чтобы обеспечить гиб-
кость и различные варианты использования);
• специализация (концепты определялись таким образом, чтобы обеспечить их
классификацию по общим свойствам и гарантировать наследование таких
свойств);
• разнообразие (знания представлялись в онтологии таким образом, чтобы ис-
пользовать преимущества множественного наследования и облегчить добав-
ление новых концептов);
• минимизация семантических расстояний (аналогичные концепты группиро-
вались и представлялись как подклассы одного класса на базе одних и тех же
примитивов);
• максимизация связей между таксономиями;
• стандартизация имен (везде, где это было возможно, для именования отноше-
ний использовалась конкатенация имен концептов, которые ими связыва-
лись).
Анализ концептуальной модели (КА)2 онтологии с точки зрения перечисленных
выше критериев и ссылочной онтологии показал, что:
• некоторые важные классы отсутствуют (например, классы Server и Languages,
которые должны быть подклассами класса Computer-Support в онтологии Pro-
duct);
• некоторые важные отношения опущены (например, отношение Distributed-by
между понятиями продукта и организации);
• некоторые важные свойства не представлены (например, Research-Topic-Web-
pages, Type-of-Ontology и некоторые другие).
352
Глава 9 • Интеллектуальные Интернет-технологии
Таблица 9.2. Таксономия свойств, используемых для описания онтологий
Основные характеристики
Иденти- Онтологии Имя, сайт-сервер, сайт-зеркало, Web-страницы,
фикация Разработчиков доступность FAQ, ЕЯ-описание, дата окончания разработки ФИО, Web-страницы, e-mail, контактное лицо,
Описание Дистрибьюторов Общая телефон, факс, почтовый адрес ФИО, Web-страницы, e-mail, контактное лицо, телефон, факс, почтовый адрес Тип онтологии; предметная область;
Функцио- нальность информация Обзорная информация Информация о проектировании Требования ценовые Использование назначение; онтологические обязательстаа; список концептов верхнего уровня; статус реализации; наличие on-line и «бумажной» документации Количество концептов, представляющих классы; количество концептов, представляющих экземпляры; количествоаксиом; количество отношений; количество функций; количество классов концептов . на первом, втором и третьем уровнях; количество классов на листьях; среднее значение фактора ветвления; среднее значение фактора глубины; максимальная глубина Методология разработки; формальный уровень методологии; подход к разработке; уровень формализации спецификации; типы источников знаний; достоверность источников знаний; техники приобретения знаний; формализм; список онтологий, с которыми осуществлена интеграция; перечень языков, в рамках которых доступна онтология К аппаратуре; программному обеспечению цена; стоимость сопровождения; оценка характеристики стоимости необходимой аппаратуры; оценка стоимости необходимого программного обеспечения Количество приложений; список основных приложений Описание использованных инструментальных средств; качество документации; обучающие курсы; on-line помощь; руководства по использованию; возможность модульного использования; возможность добавления новых знаний
Поэтому был проведен реинжиниринг (КА)2 онтологии, который позволил рас-
ширить ее новыми концептами, отношениями и свойствами, с одной стороны, и
специализировать уже представленные знания таким образом, чтобы использо-
вать их для сравнения различных онтологий.
Для реализации интеллектуальных WWW-брокеров поиска онтологий была
предложена архитектура Onto Agent, представленная на рис. 9.11.
9.3. Информационный поиск в среде Интернет
353
В рамках Данной архитектуры выделяются брокер построения модели предмет-
ной области (Domain Model Builder Broker) и WWW-брокер поиска модели
(WWW Domain Model Retrieval Broker).
Первый из них ориентирован на формирование концептуальной структуры он-
тологий, которые будут в поле зрения будущей экспертизы. Этот модуль вклю-
чает:
• Коллекционера онтологической информации (Ontology Information Collec-
tor) — WWW-интерфейс, ориентированный на сбор информации от распре-
деленных по сети агентов (программных агентов и собственно пользователей).
• Концептуализатора экземпляров (An Instance Conceptualizer) — преобразова-
тель данных от WWW-интерфейса в экземпляр онтологии, специфицирован-
ный на уровне формализма представления знаний.
• Генератора/Транслятора онтологий (Ontology Generator/Translator) — ком-
поненты отображения концептуального представления онтологий на целевые
языки реализации, что обеспечивает доступ к ним из удаленных приложений.
Целью второго модуля является обеспечение доступа к накопленной информа-
ции и представление ее наилучшим для пользователя образом. Этот модуль
включает:
• Формирователя запросов (A Query Builder) — компоненту построения запро-
сов с использованием словаря брокера и при необходимости переформулиро-
вания и/или уточнения запросов пользователя.
354
Глава 9 » Интеллектуальные Интернет-технологии
• Транслятор запросов (A Query Translator) — преобразователя запроса в пред-
ставление, совместимое с языком реализации онтологии.
• Машину вывода (An Inference Engine) — блок поиска ответа на запрос. *'
• Формирователя ответов (An Answer Builder) — компоненту, которая служит
для представления информации, найденной машиной вывода.
По сути дела, рассмотренные выше компоненты составляют технологию построе-
ния WWW-брокеров для поиска информации на основе онтологий. А примером
ее использования является интеллектуальный (ONTO)2 агент. Его брокер пост-
роения модели предметной области работает со ссылочной онтологией, а входной
запрос строится как соответствующая HTML-форма. Брокер поиска ответов реа-
лизован в настоящее время как Java-апплет и как автономное Java-приложение.
Результаты поиска онтологий, удовлетворяющих запросу, возвращаются пользо-
вателю в виде HTML-формы.
Оценивая представленный подход в целом, можно отметить, что он хорошо кор-
релирует по своим идеям и целям с уже обсуждавшейся системой Ontobroker.
Однако в случае (ONTO)2 агента для хранения формализаций онтологий исполь-
зуется база данных, а для поиска — стандартные средства на основе SQL. Само-
стоятельную ценность данного проекта представляет ссылочная онтология, кото-
рая может использоваться не только для целей поиска, но и для стандартизации
описаний онтологий вообще.
Все вышесказанное показывает, что использование агентов и особенно интеллек-
туальных агентов при сборе, поиске и анализе информации имеет ряд преиму-
ществ, основные из которых сводятся к следующему [Pagina Н., 1996]:
• они могут обеспечить пользователю доступ ко всем Интернет-сёрвисам и сете-
вым протоколам;
• отдельный агент может быть занят одной или несколькими задачами парал-
лельно;
• преимущества агентов в том, что они могут осуществлять поиск по заданию
пользователя после его отключения от сети;
• мобильность (если она присутствует) позволяет агентам искать информацию
сразу на сервере, что увеличивает скорость и точность поиска, уменьшая за-
грузку сети;
• они могут создавать собственную базу информационных ресурсов, которая об-
новляется и расширяется с каждым поиском;
• возможность агентов сотрудничать друг с другом позволяет использовать на-
копленный опыт;
• агенты могут использовать модель пользователя для корректировки и уточне-
ния запросов;
• они могут адаптироваться под предпочтения и желания пользователя и, изу-
чив их, искать полезную информацию заранее;
9.3. Информационный поиск в среде Интернет
355
• агенты способны искать информацию, учитывая контекст. Они могут вывести
этот контекст из запроса, например построив модель мира пользователя;
• агенты могут искать информацию интеллектуально, например используя сло-
вари, тезаурусы и онтологии, а также средства вывода релевантной информа-
ции, не представленной явно ни в запросе, ни в найденных документах.
Именно поэтому с применением и развитием агентных технологий на основе ме-
тодов и средств искусственного интеллекта связываются самые серьезные перс-
пективы перехода от пространств данных к пространствам знаний в глобальных и
локальных сетях.
Заключение
Итак, уважаемый читатель, вы завершаете чтение книги по базам знаний интел-
лектуальных систем. Авторы отдают себе отчет в том, что за ее рамками остались
целые континенты планеты Искусственный Интеллект, которые еще ждут своих
исследователей, толкователей, методистов и, конечно, читателей. Но дорогу оси-
лит идущий... И, наверное, именно это, а также понимание, что в данный момент в
нашей стране практически нет литературы, которая не то чтобы закрыла тему, но
хотя бы зафиксировала полученные в одном из ее важнейших разделов результа-
ты, подвигло нас на работу по написанию этой книги.
Материал данного учебника показывает, что в настоящее время в области баз
знаний интеллектуальных систем уже имеется серьезный теоретический базис,
существует достаточно широкий спектр соответствующих методов и техноло-
гий разработки. Многие из них поддержаны адекватным программным инстру-
ментарием. И основная цель авторов была в том, чтобы сделать эту информацию
достоянием читателей. Понятно, что в силу многих причин, в частности ограни-
чений на объем издания, дать полномасштабное и логически замкнутое описа-
ние теории, методов проектирования и средств реализации баз знаний, а также
соответствующих систем, основанных на знаниях, в одной книге практически
невозможно. Отчасти поэтому список рекомендованной литературы у нас зна-
чительно шире, чем это обычно бывает в учебниках. Кроме того, в списке литера-
туры достаточно много ссылок на релевантные тематика Интернет-ресурсы, что,
по нашему мнению, должно привить читателю вкус к самостоятельному плава-
нию в океанах уже (или еще) доступной в сети информации.
Вместе с тем, авторы надеются, что читатели этой книги не будут воспринимать
представленные в ней материалы как истину в последней инстанции, но будут
относиться к ним творчески, а иногда и критически. Ведь не секрет, что для пост-
роения и использования баз знаний, на которых основываются современные ин-
теллектуальные системы, требуются исследовательские коллективы, работаю-
щие вместе долго и имеющие опыт разработки такого рода систем. Для
получения действительно хороших результатов необходимы дорогостоящие
людские и материальные ресурсы — специалисты, лицензионные инструмента-
рии, документация. Кроме того, разработка их достаточно трудоемкий (годы) и
дорогостоящий (десятки, если не сотни тыс. долларов) процесс. Вот почему в на-
стоящее время действующие интеллектуальные системы ориентированы в ос-
новном на поддержку работы постоянно работающих групп пользователей для
Заключение
357
достаточно специализированных задач. Следует отметить и то, что в настоящее
время почти нет действительно интеллектуальных систем, удобных для работы
широкого круга пользователей в сети Интернет.
Таким образом, разработка теории, методов и технологий представления и ис-
пользования знаний остается актуальной задачей для дальнейшего развития ин-
теллектуальных систем. Особую актуальность, по нашему мнению, приобретают,
на современном этапе развития науки и общества в целом Интернет-ориентиро-
ванные технологии и распределенный искусственный интеллект. Уже сейчас яс-
но, что применение систем, основанных на знаниях, компонентом которых явля-
ются, например, онтологии, а реализация базируется на мультиагентных техно-
логиях, должно привести к рассмотрению и использованию Всемирной паутины
как организованного и структурированного пространства знаний.
И в заключение, авторы надеются, что их собственный скромный вклад в методо-
логию, технологию и программные средства создания баз знаний, также отражен-
ный в данной книге, позволит молодым специалистам в области искусственного
интеллекта пойти дальше по тернистому пути этой молодой науки, которой так
хочется стать индустрией!
Литература
1. Агеев В. Н., 1994. Примеры гипертекстовых и гипермедиа систем (обзор) //
Компьютерные технологии в высшем образовании: Сб. статей. М.: Изд-во МГУ.
С. 225-229.
2. Аверкин А. Н„ Батыршин И. 3., Блишун А. Ф., Силов В. Б., Тарасов В. Б., 1986.
Нечеткие множества в моделях управления и искусственного интеллекта //
Под ред. Д. А. Доспелова. М.: Наука.
3. Алахвердов В. М., 1986. Когнитивные стили в контурах процесса познания.
Когнитивные стили // Под ред. В. Колги. —Таллинн. С. 12-23.
4. Александров Е. А., 1975. Основы теории эвристических решений. М.: Наука.
5. Алексеева И. А., Воинов А. В., Сейсян А. Р., Эткинд А. М., 1989. Психосеман-
тическая реконструкция картины мира подростков, употреблявших токсичес-
кие вещества // Сб. Конструктивная психология — новое направление разви-
тия психологической науки. Под ред. А. Г. Копытова. Красноярский гос. ун-т.
С. 36-41.
6. Алексеевская М. А., Недоступ А. В., 1988. Диагностические игры в медицин-
ских задачах. Вопросы кибернетики // Задачи медицинской диагностики и
прогнозирования с точки зрения врача. № 112. С. 128-139.
7. Амамия М., Танака Ю., 1993. Архитектура ЭВМ и ИИ. М.: Мир.
8. Анастази А., 1982. Психологическое тестирование. Т. 1. М. С. 96-162.
9. Андриенко Г. Л., Андриенко Н. В., 1992. Игровые процедуры сопоставления в
инженерии знаний // Сборник трудов III конференции по искусственному
интеллекту. Тверь. С. 93-96.
10. Аншаков О. М., Скворцов Д. П., Финн Д. К., 1986. Логические средства экс-
пертных систем типа ДСМ // Семиотика и информатика. Вып. 28. С. 5-15.
И. Апресян Ю. Д., 1977. Экспериментальное исследование семантики русского
языка. М.: Наука.
12. Апресян Ю.Д., 1974. Лексическая семантика. Семиотические средства языка.
М.: Наука.
13. Арбиб М., 1975. Алгебраическая теория автоматов. М.: Статистика.
14. Аткинсон Р„ 1980. Человеческая память и процесс обучения // Пер. с англ. М.:
Прогресс.
15. Байдун В. В., Бунин А. И., 1990. Средства представления и обработки знаний в
системе FRL/PS // Всесоюзная конференция по искусственному интеллекту:
тез. докл. Т. 1. Минск. С. 66-71.
Литература
359
16. Бахтин М. М., 1975. Вопросы литературы и эстетики: Исследования разных
лет. М.: Художественная литература.
17. Белнап Н., Стил Т., 1981. Логика вопросов и ответов. М.: Прогресс.
18. Берков В. Ф„ 1972. Вопрос как форма мысли. Минск, Изд-во БГУ.
19. Берн Э., 1988. Игры, в которые играют люди. Люди, которые играют в игры//
Пер. с англ. М.: Прогресс.
20. Бойкачев К. К., Конева И. Г., Новик И. 3., 1994. «Сценарий» — инструмент
визуальной разработки компьютерных программ // Компьютерные техноло-
гии в высшем образовании: Сб. статей. М.: Изд-во МГУ. С. 167-178.
21. Борисов А. Н„ Федоров И. П., Архипов И. Ф., 1991. Приобретение знаний
для интеллектуальных систем. Рижский технический университет.
22. Борисова Н. В., Соловьева А. А. и др., 1988. Деловая игра «Методика конст-
руирования деловой игры». М.: ИПКИР.
23. Брунер Дж., 1971. Исследование развития познавательной деятельности //
Пер. с англ. М.: Педагогика.
24. Бурков В. И. и др., 1980. Деловые игры в принятии управленческих решений.
М.: МИСИС.
25. Брукс Ф. П.( 1979. Как проектируются и создаются программные комплексы.
Мифический человеко-месяц: очерки по системному программированию. М.:
Наука.
26. Буч Г., 1992. Объектно-ориентированное проектирование с примерами при-
менения. М.: Конкорд.
27. Веккер Л. М., 1976. Психические процессы // В 3-х томах. Т. 2. Л.: ЛГУ.
28. Величковский Б. М., 1982. Современная когнитивная психология. М.: МГУ.
29. Величковский Б. М., Капица М. С., 1987. Психологические проблемы изуче-
ния интеллекта // Интеллектуальные процессы и их моделирование. М.:
Наука. С. 120-141.
30. Вертгеймер М., 1987. Продуктивное мышление // Пер с нем. М.: Прогресс.
31. Винер Н., 1958. Кибернетика или управление и связь в животном и машине.
М.: Сов. радио.
32. Виноград Т., 1976. Программа, понимающая естественный язык // Пер. с англ.
М.: Мир.
33. Воинов А., Гаврилова Т., 1994. Инженерия знаний и психосемантика: Об од-
ном подходе к выявлению глубинных знаний // Известия РАН Техническая
кибернетика. № 5. С. 5-13
34. Волков А. М., Ломнев В. С., 1989. Классификация способов извлечения опыта
экспертов // Известия АН СССР. Техническая кибернетика. № 5. С. 34-45.
35. Вольфенгаген В. Э., Воскресенская О. В., Горбанев Ю. Г., 1979. Система пред-
ставления знаний с использованием семантических сетей // Вопросы кибер- •
нетики: Интеллектуальные банки данных. М.: АН СССР. С. 49-69.
360
Литература
36. Гаврилова Т. А., 1984. Представление знаний в экспертной диагностической
системе АВТАНТЕСТ // Изв. АН СССР. Техническая кибернетика. № 5.
С. 165-173.
37. Гаврилова Т. А., 1988. Как стать инженером по знаниям // Доклад на Всесо-
юзной конференции по искусственному интеллекту. М.: ВИНИТИ. С. 332-
338.
38. Гаврилова Т. А., Минкова С. П„ Карапетян Г. С., 1988. Экспертные системы
для оценки качества деятельности летного состава // Тез. докладов научно-
практической школы-семинара «Программное обеспечение и индустриаль-
ная технология интеллектуализации разработки и применения ЭВМ». — Ро-
стов н/Д, ВНИИПС. С. 23-25.
39. Гаврилова Т. А., Червинская К. Р., Яшин А. М., 1988. Формирование поля
знаний на примере психодиагностики // Техническая кибернетика. № 5.
С. 72-85.
40. Гаврилова Т. А., 1989. От поля знаний к базе знаний через формализацию //
Статья в сб. «Представление знаний в экспертных системах». Л.: ЛИИАН.
С. 16-24.
41. Гаврилова Т. А., 1989. Подготовка коллектива разработчиков экспертной си-
стемы // Доклад на школе-семинаре «Проблемы применения ЭС в народном
хозяйстве». Кишинев. С. 59-62.
42. Гаврилова Т. А., Тишкин А. И., Золотарев А. Ю., 1989. МИКРОЛЮШЕР:
экспертная система интерпретации данных // Доклад на школе-семинаре
«Проблемы применения ЭС в народном хозяйстве». Кишинев. С. 17-23.
43. Гаврилова Т. А., Красовская М. Р„ 1991. О концептуальном анализе знаний
при разработке экспертных систем // Доклад на Всесоюзной научно-практи-
ческои конференции «ТиЬридные интеллектуальные системы».Гостов нД.
С. 110-113.
44. Гаврилова Т. А., 1922. Спецификация знаний через структурирование: введе-
ние в САКЕ-технологию // Сборник трудов III конференции по искусствен-
ному интеллекту. Т. 2. Тверь. С. 113-116.
45. Гаврилова Т. А., Червинская К. Р., 1992. Извлечение и структурирование зна-
ний для экспертных систем. М.: Радио и связь.
46. Гаврилова Т. А., 1995. Объектно-структурная методология концептуального
анализа знаний и технология автоматизированного проектирования баз зна-
ний // Труды Междунар. конф. «Знания — диалог-решение 95». Т. 1. Ялта.
С. 9.
47. Гаврилова Т. А., Котова Е. Е., Писарев А. С., 1999. Активные схемы как инстру-
мент семантического анализа //Труды международного семинара «ДИАЛОГ
99». Таруса. С. 26-27.
48. Гаврилова Т. А., Лещева И. А., 1999. ВИКОНТ: Визуальный Конструктор
ОНТологий для структурирования семантической информации // Труды
Первой Всероссийской научной конференции «Электронные библиотеки:
перспективные методы и технологии, электронные коллекции». СПб. С. 97-98.
Литература
361
49. Гаек П., Гавранек Т., 1983. Автоматическое образование гипотез: математи-
ческие основы общей теории// Пер. с англ. М.: Наука.
50. Гельфанд И. И., Розенфелвд Б. И., Шифрин М. А. Структурная организация
данных в задачах медицинской диагностики и прогнозирования // Вопросы
кибернетики. Задачи медицинской диагностики и прогнозирования с точки
зрения врача. М.: АН СССР. С. 5-64.
51. Гиг Дж., ван., 1981. Прикладная общая теория систем // В 2-х кн. М.: Мир.
52. Гинкул Г. П., 1989. Игровой подход к приобретению знаний и его реализация
в системе КАПРИЗ // Проблемы применения экспертных систем в народ-
ном хозяйстве: тез. докл. респ. школы-семинара. Кишинев. С.71-74.
53. Гладун В. П., 1994. Процессы формирования новых знаний. София.
54. Глушков В. М., 1964. Введение в кибернетику. Киев: Издательство АН У ССР.
55. Гордон Д., 1987. Терапевтические метафоры // Личная рукопись М. М. Кага-
на.
56. Горелов И. Н., 1987. Разговор с компьютером. М.: Наука.
57. Городецкий В. И., Грушинский М. С., Хабалов А.В., 1988. Многоагентные си-
стемы (обзор) // Новости искусственного интеллекта. № 2.
58. Грисуолд Р., Поудж Дж., Полонски И., 1980. Язык программирования СНО-
БОЛ-4. М.: Мир.
59. Гусакова С. М., Финн В. К., 1987. Сходства и правдоподобный вывод // Из-
вестия АН СССР. Техническая кибернетика. № 5. С. 42-63.
60. Дэйвисон, 1988. Многомерное шкалирование. Методы наглядного представ-
ления данных. — М.: Финансы и статистика.
61. Дюран Б., Оделл П., 1977. Кластерный анализ // Пер. с франц. М.: Статисти-
ка.
62. Епифанов М. Е., 1984. Индуктивное обобщение в ассоциативных сетях // Из-
вестия АН СССР. Техническая кибернетика. № 5. С. 132-146.
63. Жинкин Н. И., 1982. Речь как проводник информации. М.: Наука.
64. Заде Л., 1972. Лингвистическая переменная. М.: Физматгиз.
65. Зарипов Р. X., 1983. Машинный поиск вариантов при моделировании твор-
ческого процесса. М.: Наука.
66. Зенкин А. А., 1991. Основы когнитивной компьютерной графики. М.: Наука
67. Иберла К., 1980. Факторный анализ // Пер. с нем. М.: Статистика.
68. Иванов П. И., 1986. Влияние некоторых индивидуально-психологических осо-
бенностей на процесс обобщения // Автореферат дис. канд. психол.
наук. М.
69. Ивахненко Г. И., 1971. Системы эвристической самоорганизации в техничес-
кой кибернетике. Киев, Техшка.
70. Йодан Э., 1979. Структурное проектирование и конструирование программ //
Пер. с англ. М.: Мир.
362
Литература
71. Каган М. С., 1988. Мир общения: проблема межсубъектных отношений. М.:
Политиздат.
72. Капица П. Л., 1967. Приглашение к спору // Юность. — № 1. С. 79-82.
73. Келасьев В. И., 1984. Структурная модель мышления. Л.: ЛГУ.
74. Кирсанов Б. С., Попов Э. В., 1990. Отечественные оболочки экспертных сис-
тем // Справочник по искусственному интеллекту. Т. 1 М.: Радио и связь.
С. 369-388.
75. Климов Анд. В., Романенко С. А., 1987. Система программирования РЕФАЛ-2
для ЕС ЭВМ. Описание входного языка // Препринт ИПМ АН СССР. М.
76. Ковригин О.В., Перфильев К. Г., 1988. Гибридные средства представления
знаний в системе СПЭИС // Всесоюзная конференция по искусственному
интеллекту: тез. докл. Т. 2. Переславль-Залесский. С. 490-494.
77. Комаров В. Ф., 1989. Управленческие имитационные игры. Новосибирск: На-
ука.
78. Коов М. И., Мацкин М. Б., Тыугу Э.Х., 1988. Интеграция концептуальных и
экспертных знаний в САПР // Известия АН СССР. Техническая кибернети-
ка. № 5. С. 108-118.
79. Коршунов А. М., Манталов В. В., 1988. Диалектика социального познания.
М.: Политиздат.
80. Кузичева 3. А., 1987. Языки науки, языки логики, естественные языки // Ло-
гика научного познания. Актуальные проблемы. М.: Наука. С. 57-73.
81. Кузнецов В. Е., 1989. Представление в ЭВМ неформальных процедур. М.:
Наука.
82. Кук Н. М., Макдональд Дж., 1986. Формальная методология приобретения и
представления экспертных знаний // ТИИЭР. Т. 74, № 10. С.145-155.
83. Кулюткин Ю. И., Сухобская Г. С., 1971. Индивидуальные различия 'в мысли-
тельной деятельности взрослых учащихся. М.: Педагогика.
84. Лазарева Т. К., Пашинин Н. Д., 1987. Деловые имитационные игры в эксперт-
ных системах // Деловые игры и их программное обеспечение: тез. докл. Пу-
щино. С. 63-64.
85. Ларичев О. И., Мечитов А. И., Мошкович Е. И., Фуремс Е. М., 1989. Выявле-
ние экспертных знаний. М.: Наука.
86. Лимантов Ф. С., 1971. О природе вопроса // Вопрос. Мнение. Человек. Уч.
записки ЛГПИ им. Герцена. Т. 497. С. 4-20.
87. Липаев В. В., Серебровский Л. А., Галаганов П. Г. и др., 1983. Технология про-
ектирования комплексов программ АСУ. М.: Радио и связь.
88. Лунева О. В., Хорошилова Е. А., 1987. Психология делового общения. М.:
ВКШ при ЦК ВЛКСМ.
89. Любич Д. Л., 1998. 1000 афоризмов. СПб:, Издательство Буковского.
Литература
363
90. Макалистер Дж., 1990. Искусственный интеллект и ПРОЛОГ на микроЭВМ.
М.: Машиностроение.
91. Мальковский М. Г., 1985. Диалог с системой искусственного интеллекта. М.:
МГУ.
92. Мартынов В. В., 1977. Универсальный семантический код. Минск: Наука и
техника.
93. Маслов С. Ю., 1986. Теория дедуктивных систем и ее применение. М.: Радио
и связь.
94. Материалисты древней Греции, 1955. Собрание текстов Гераклита, Демокрита
и Эпикура.: М.: Политиздат.
95. Мельчук И. А„ 1974. Опыт теории лингвистических моделей «Смысл-Текст».
Семантика, синтаксис. М.: Наука.
96. Месарович М., Такахара Я., 1978. Общая теория систем: математические
основы. М.: Мир.
97. Микулич Л. И., 1990. Промышленная технология создания систем, основан-
ных на заниях //В сб.: Экспертные системы на персональных компьютерах.
М.: МДНТП им. Ф. Э. Дзержинского.
98. Миллс X., 1970. Программирование больших систем по принципу сверху
вниз // В книге: Средства отладки больших систем. М.: Статистика.
99. Минский М.: 1979. Фреймы для представления знаний. М.: Энергия.
100. Мицич П. П., 1987. Как проводить деловые беседы. М.: Экономика.
101. Моисеев Н. Н., 1981. Математические задачи системного анализа. М.: Наука.
102. Молокова О. С., 1992. Методология анализа предметных знаний // Новости
искусственного интеллекта. № 3. С. 11-60.
103. Молокова О. С., Уварова Т. Г., 1989. База знаний для разработчиков экспертных
систем // Тез. доклада Всесоюзного научно-технического семинара «Програм-
мное обеспечение новых информационных технологий». Калинин. С. 23-28.
104. Моргоев В. К., 1988. Метод структурирования и извлечения экспертных зна-
ний: имитация консультаций. Человеко-машинные процедуры принятия ре-
шений. М.: ВНИИСИ. С. 44-57.
105. Немов Р. С., 1984. Социально-психологический анализ эффективной деятель-
ности коллектива. М.: Педагогика.
106. Николов С. А. и др., 1990. Анализ состояния и тенденции развития информа-
тики. Проблемы создания экспертных систем // Исследовательский отчет.
Под ред. С. А. Николова. София: Интерпрограмма.
107. Норенков И. П., 1986. Введение в автоматизированное проектирование тех-
нических устройств и систем. М.: Высшая школа.
108. Нортон П., Станек У., 1998. Программирование на Java // В 2-х кн. СКПресс.
109. Ноэль Э„ 1978. Массовые опросы // Пер. с нем. М.: Прогресс.
364
Литература
110. Обозов И. И., 1986. Психологическая культура взаимных отношений. М.:
Знание.
111. Окунь Я., 1974. Факторный анализ. М.: Статистика.
112. Орехов А. И., 1985. Формирование приемов эффективного решения твор-
ческих задач // Автореферат дис. канд. психол. наук. М.
113. Орлик С., 1997. Многоуровневые модели в архитектуре клиент-сервер, http://
www.citforum.ru/database/osbd/glava_95.shtml.
114. Орловский С. А., 1981. Проблемы принятия решения при нечеткрй исход-
ной информации. М., Наука.
115. Осипов Г. С., 1988. Метод формирования и структурирования модели зна-
ний для одного типа предметных областей // Известия АН СССР. Техни-
ческая кибернетика. № 2. С. 3-12.
116. Осипов Г. С„ 1989. Принципы прямого приобретения знаний // Сборник
трудов Второго международного семинара «Теория и применение искусст-
венного интеллекта». Созополь. С. 56-59.
117. Осипов Г. С., 1993. Информационные технологии, основанные на знаниях //
Ж. Новости искусственного интеллекта. №1. С. 7-41.
118. Осипов Г. С., 1997. Приобретение знаний интеллектуальными системами.
М.: Наука.
119. Осуга С., Саэки Ю. (ред.), 1990. Приобретение знаний. М.: Мир.
120. Петренко В. Ф., 1983. Введение в экспериментальную психосемантику: ис-
следование форм репрезентации в обыденном сознании. М.: МГУ.
121. Петренко В. Ф., 1988. Психосемантика сознания. М.: Издательство МГУ.
122. Петров А. В. ( ред.), 1991. Разработка САПР // В 10 кн. Т. 4. М.: Высшая
школа.
123. Пильщиков В. Н., 1983. Язык ПЛЭНЕР. М.: Наука.
124. Погосян Г. А., 1985. Метод интервью и достоверность социологической ин-
формации. Ереван, АН Арм. ССР.
125. Пономарева С. М„ Хорошевский В. Ф., 1999. Методы и модели коммуника-
ции в профессиональных группах и группах интеллектуальных агентов //
В сб. трудов 4-го международного семинара по прикладной семиотике, семи-
отическому и интеллектуальному управлению ASC/IC’99. М.
126. Попов Э. В., Фоминых И. Б., Кисель Е. Б., Шапот М. Д., 1996. Статические и
динамические экспертные системы. М.: Финансы и статистика.
127. Попов Э. В. (ред), 1996. Динамические интеллектуальные системы в управ-
лении и моделировании. М.: МИФИ.
128. Попов Э. В., 1982. Общение с ЭВМ на естественном языке. М.: Наука.
129. Попов Э.В., 1987. Экспертные системы: Решение неформализованных задач
в диалоге с ЭВМ. М.: Наука.
130. Попов Э. В., 1988. Экспертные системы. М.: Наука.
131. Попов Э- В., 1991. Экспертные системы 90-х гг. Классификация, состояние,
проблемы, тенденции // Новости искусственного интеллекта. № 2. С. 84-101.
Литература
365
132. Поспелов Д. А., 1989. Моделирование рассуждений. Опыт анализа мысли-
тельных актов. М.: Радио и связь.
133. Поспелов Д. А., 1986. Искусственный интеллект: фантазия или наука? М.:
Радио и связь.
134. Поспелов Д. А., 1986. Ситуационное управление: Теория и практика. М.:
Наука.
135. Поспелов Д. А., 1998. Многоагентные системы — настоящее и будущее //
Информационные технологии и вычислительные системы. № 1.
136. Поспелов Д. А., 1997. Три шага на пути к официальному признанию // Но-
вости искусственного интеллекта. № 1. С. 99-115.
137. Похилько В. И., Страхов Н.Н., 1990. Система KELLY. М.: МГУ; МП «Гума-
нитарные технологии» (на магнитном носителе).
138. Пэранек Г. В., 1991. Распределенный искусственный интеллект // В кн.: Ис-
кусственный интеллект: применение в интегрированных производственных
системах, Э. Кьюсиак (ред.). М.: Машиностроение.
139. Ребельский И. В., 1989. Азбука умственного труда // ЭКО. №7. С. 43-150.
140. Розенталь М., Юдин П., 1951. Краткий философский словарь. М.: Полит-
издат.
141. Справочник по искусственному интеллекту в 3-х т., 1990 // Под ред. Э. В. По-
пова и Д. А. Поспелова. М.: Радио и связь.
142. Сагатовский В. И., 1980. Социальное проектирование // Прикладная этика
и управление нравственным воспитанием. Томск. С. 84-86.
143. Сергеев В. М., 1987. Когнитивные модели в исследовании мышления: струк-
тур и онтология знания // Интеллектуальные процессы и их моделирова-
ние^М.: Наука. С.179-195.
144. Сергеев К. А., Соколов А. Н., 1986. Логический анализ форм научного поис-
ка. Л.: Наука.
145. Сиротко-Сибирский С. А., 1968. Смысловое содержание текста и его отра-
жение в ключевых словах // Автореферат дис. канд. филол. наук. Л.
146. Скрэгг Г., 1983. Семантические сети как модели памяти // Новое в зарубеж-
ной лингвистике. Вып. 12. М.: Радуга. С. 228-271.
147. Сойер Б., Фостер Д., 1989. Построение экспертных систем на ПАСКАЛЕ. —
М.: Финансы и статистика.
148. Соколов А.Н., 1947. Психологический анализ понимания иностранного тек-
ста // Изв. АПН РСФСР. Вып. 7. С. 163-190.
149. Соколов А. Н., 1968. Внутренняя речь и мышление. М.: Просвещение.
150. Соколов А. Н., 1980. Проблемы научной дискуссии. Л.: Наука.
151. Соколов Е. Н., Вейткявичус Г. Г., 1989. Нейроинтеллект. От нейрона к ней-
рокомпьютеру. М.: Наука.
152. Соловьев С. Ю., Соловьева Г.М., 1989. Вопросы организации баз знаний в
системе ФИАКР // Экспертные системы: состояние и перспективы. Под ред.
Д. А. Поспелова. М.: Наука. С. 47-54.
366
Литература
153. Соссюр Ф., де, 1977. Труды по языкознанию // Пер. с франц. М.: Прогресс.
154. Стерлинг Л., Шапиро Э., 1990. Искусство программирования на языке ПРО-
ЛОГ. М.: Мир.
155. Стрельников Ю. Н., Борисов Н. А., 1997. Разработка экспертных систем сред-
ствами инструментальной оболочки в среде MS Windows. Тверь, ТГТУ.
156. Тарасов В. Б., 1998. Агенты, многоагентные системы, виртуальные сообще-
ства: стратегическое направление в информатике и искусственном интеллек-
те // Новости искусственного интеллекта. № 2.
157. Таунсенд К., Фохт Д., 1991. Проектирование и реализация экспертных сис-
тем на ПЭВМ. М.: Финансы и статистика.
158. Терехина А. Ю., 1986. Анализ данных методами многомерного шкалирова-
ния. М.: Наука.
159. Терехина А.Ю., 1988. Представление структуры знаний методами многомер-
ного шкалирования. М.: ВИНИТИ.
160. Тиори Т., Фрай Дж., 1985. Проектирование структур баз данных //Пер. с
англ. В 2-х кн. М.: Мир.
161. Турчин В. Ф., 1968. Метаалгоритмический язык // Кибернетика. № 4.
С. 45-54.
162. Уотермен Д., 1989. Руководство по экспертным системам // Пер. с англ. М.:
Мир.
163. Уэно X., Исидзука М. (ред.), 1989. Представление и использование знаний.
М.: Мир.
164. Файн В. С., 1987. Машинное понимание естественного языка в рамках кон-
цепции реагирования // Интеллектуальные процессы и их моделирование. —
М.: Наука. С. 375-391.
165. Филлмор И., 1983. Основные проблемы лексической семантики // Новое в
зарубежной лингвистике. Вып. 12. М.: Радуга. С. 74-122.
166. Финн В. К., 1991. Правдоподобные рассуждения в интеллектуальных систе-
мах типа ДСМ // Итоги науки и техники. Серия «Информатика». Т. 15: «Ин-
теллектуальные информационные системы». ВИНИТИ. С. 54-101.
167. Фон Гумбольдт В., 1984. Избранные труды по языкознанию // Пер. с нем.
М.: Прогресс.
168. Форсайт Ф., 1987. Экспертные системы. Принципы работы и примеры. М.:
Радио и связь.
169. Франселла Ф., Баннистер Д., 1987. Новый метод исследования личности:
руководство по репертуарным личностным методикам // Пер. с англ. М.:
Прогресс.
170. Хант Д., 1986. Искусственный интеллект. М.: Мир.
171. Хейес-Рот и др., 1987. Построение экспертных систем // Под ред. Ф. Хейес-
Рота, Д. Уотермена, Д. Лената. М.: Мир.
Литература
367
172. Хорошевский В. Ф., 1983. ATNL-машина — вопросы программной и аппа-
ратной реализации // В сб. трудов I Международного симпозиума ИФИП и
ИФАК, 4-6 сентября 1983 г. Л.: С. 156-174.
173. Хорошевский В. Ф., 1990а. Языковые средства программиования // В кн.:
Искусственный интеллект. Книга 3. Программные и аппаратные средства.
М.: Радио и Связь. С. 7-17.
174. Хорошевский В. Ф., 1990b. Программные средства представления знаний:
состояние исследований и проблемы // В кн.: Искусственный интеллект.
Книга 3. Программные и аппаратные средства. — М.: Радио и Связь. С. 72-
82.
175. Хорошевский В. Ф., 1993. Управление проектами в интеллектуальной сис-
теме PIES Workbench // Изв. РАН Серия «Техническая кибернетика». № 5.
С. 71-98.
176. Хорошевский В. Ф., Щенников С. Ю., 1990. Инструментальная поддержка
процессов приобретения знаний в системе ПиЭС // Изв. АН СССР. Техни-
ческая кибернетика. № 4. С. 206-215.
177. Хорошевский В. Ф., 1995 и PIES-технология и инструментарий PIES
WorkBench для разработки систем, основанных на знаниях, Новости Искус-
ственного интеллекта, № 2. С. 7-64
178. Хорошевский В. Ф., 1999. Поведение интеллектуальных агентов: модели и
методы реализации // В сб. трудов 4-го международного семинара по при-
кладной семиотике, семиотическому и интеллектуальному управлению ASC/
IC’99. М.
179. Хювянен Э., Сеппянен Й., 1991. Мир ЛИСПа // В 2-х т. М.:Мир.
180. Цейтин Г. С., 1985. Программирование на ассоциативных сетях // ЭВМ в
проектировании и производстве. Вып. 2. Л.: Машиностроение. С. 16-48.
181. Шенк Р., 1980. Обработка концептуальной информации // Пер. с англ. М.:
Энергия.
182. Шенк Р., Бирнбаум Л., Мей Дж., 1989. К интеграции семантики и прагмати-
ки // Новое в зарубежной лингвистике. Компьютерная лингвистика. Вып.
14. М.: Прогресс.
183. Шенк Р., Хантер Л., 1987. Познать механизмы мышления // Реальность и
прогнозы искусственного интеллекта. М.: Мир.
184. Шеннон К., Уивер У., 1963. Математическая теория связи. М.: ИЛ.
185. Шепотов Е. Г., Шмаков Б. В., Крикун П. Д., 1985. Методы активизации мыш-
ления. Челябинск, ЧПИ.
186. Шмелев А. Г., 1983. Введение в экспериментальную психосемантику. М.;
МГУ.
187. Шумилина Т. В., 1973. Интервью в журналистике. М.: МГУ.
188. Щерба Л. В., 1974. Языковая система и речевая деятельность. Л.: Наука.
189. Эшби У. Р., 1959. Введение в кибернетику. М.: ИЛ.
368
Литература
190. Эндрю А., 1985. Искусственный интеллект. М.: Мир.
191. Яшин А. М„ 1990. Разработка экспертных систем. Л: ЛПИ.
192. Adeli Н., 1994. Knowledge Engineering. McGraw-HillPublishing Company, N. Y.
193. Alexander J. H., Freiling MJ., Shulman S.J., Rehfuss S., Messick S.L., 1987.
Ontological analysis: an ongoing, experiment // Int. Journal of Man-Machine
Studies. Vol. 26. P. 473-485.
194. Andre J., Delpech P.-M., 1994. Moving from Merise to Shlaer-Mellor // Objects
in Europe. Vol. 1, No. 3. P. 7-11.
195. Anjewierden A., 1987. Knowledge Acquisition Tool // Al Communications. —
Vol. 0, No. l.-P. 29-38.
196. ART, 1984. ART User’s Manual // Inference Systems Inc., Ca.
197. AgentBuilder, 1999. AgentBuilder An Integrated Toolkit for Constracting
Intelligent Software Agents //Revision 1.3, February 18,1999. Reticular Systems,
Inc. ,
198. Austin J. L., 1965. How to Do Things with Words. Oxford.
199. Autonomy, 1998. Autonomy Technology Whitepaper. — http://www.autonomy.
com/tech/wp.html
200. Aussenac-Gilles N., Natta N., 1992. Making the Method Solving Explicit with
MACAO: the SIZYPHUS case-study in Sisyphus’92: Models of problem solving. —
Ed. by M.Linster, GMD.
201. Balzer R., Cheatham T.E., Green C., 1983. Software Technology in the 1990s:
Using a New Paradigm // Computer J. — November. P. 39-45.
202. Barr A., Feigenbaum E.A., 1982. The Handbook of Artificial Intelligence // Vol.
II. — Los Altos, California: Kaufmann Inc.
203. Basili V.R., Perricone B.T., 1984. Software Errors and Complexity: An Empirical
Investigation // Communications. ACM. — Vol. 27, No. 1. — P. 42-52.
204. Beckwith R., Fellbaum C., Gross D., Miller G., 1990. WordNet: A Lexical Database
Organized on Psycholinguistic Principles // In Zernik, U. (Ed.), Using On-line
Resources to Build a Lexicon. Chapter 9. Hillsdale, NJ: Erlbaum. P. 211-231.
205. Bee-gent, 1999. Bee-gent Home Page. — http://www2.toshiba.co.jp/beegent.
206. Belgrave M., 1996. The Unified Agent Architecture: A White Paper. — http://
www.ee.mcgill.ca/-belmarc.
207. Benjamins V. R., Fensel D., et. al., 1998. Community is Knowledge! // In KA2, In:
Proc. KAW’98, Banff, Canada.
208. Bennet J. S., 1985. A Knowledge-Based System for Acquiring the Conceptual
Structure of a Diagnostic Expert System //Journal of Automated Reasoning. —
No. 1. P. 49-74.
209. Berners-Lee T., Connolly D„ 1995. HyperText Markup Language 2.0. November.
210. Bertalanffy L., 1950. An Outline of General Systems Theory // British Journal of
the Philosofy of Science. Vol. 1. P. 134-164.
Литература 369
211. Black М., 1962. Models and Metaphor. Studies in Language and Philosophy. —
Ithaca-London, Cornell University Press. P. 25-47.
212. Blazquez M., Fernandez M., Garcia-Pinar J. M„ Gomez-Perez A., 1998. Building
Ontologies at the Knowledge Level using the Ontology Design Envirnoment //
Knowledge Acquisition Workshop, KAW98, Banff.
213. Boehm B.W., 1986. A Spiral Model of Software Development and Enhancement //
ACM SIGSOFT Software Engineering Notes. Vol. 11, No. 4.
214. Bonasso Jr., 1984. ANALYST, an Expert System for processing sensor Returns //
Report MTP-83W00002, MITRE Corp.
215. Boose J.H., 1985. A Knowledge Acquisition Program for Expert Systems Based
on Personal Construct Psychology // Int. Journal of Man-Machine Studies. —
Vol. 23. P. 495-525.
216. Boose J.H., 1985a. Personal construct theory and the transfer of human expertise //
Proc. 6-th Eur. Conf. Artif. Intell. Amsterdam. P. 51-60.
217. Boose J. H., 1985b. A knowledge acquisition program to expert systems based oh
personal construct psychology // Int. Journal of Man-MachineJStudies. Vol. 23,
No. 5. P. 499-525.
218. Boose J. H., 1985c. Rapid acquisition and combination of knowledge from multiple
experts in the same domain // Proc, of 2-nd Conf. Artif. Intell. Appl. Eng.
Knowledge-Based Syst. Amsterdam. P. 461-466.
219. Boose J. H., 1986. ETS: a PCP — based program for building knowledge-based
systems // Proc. WESTEX-86: IEEE West. Conf. Knowledge-Based Eng. And
Expert Syst., Anaheim, Calif. June 24-26. Washington: D. C.
220. Boose J. H., 1989. A research framework for knowledge acquisition echniques and
tools // Proc, of 3-rd European Knowledge Acquisition for Knowledge-based
Systems Workshop: EKAT’89. Paris.
221. Boose J. H., 1990. Knowledge Acquisition Tools, Methods, and Mediating
Representations // In Motoda H., Mizogochi R., Boose J., Gaines B. (Eds.)
Knowledge Acquisition for Knowledge-Based Systems. IOS Press, Ohinsha Ltd.,
Tokyo.
222. Boose J. H., Bradshaw J. H., Shema D. B., 1988. Transforming repertory grids to
shell-based knowledge bases using AQUINAS, a knowledge acquisition workbench
// Proceedings of the AAAI-88 Integration of Knowledge Acquisition and
Performance Systems Workshop. St. Paul.
223. Boose J. H., Bradshaw J. M., 1986. NEOETS: Capturing expert system knowledge
in hierarchical rating grids // Proc. Expert Syst. Gov.Symp. Washington. P. 34-45.
224. Boose J. H„ Bradshaw J. M., 1987. Expertise transfer and complex problems: using
AQUINAS as a knowledge-based systems // Int. Journal of Man-Machine
Studies. Vol. 26, No. 1. P. 3-28.
225. Borghoff U., Pareschi R., 1998. Information Technology for Knowledge
Management. — Springer-Verlag, Bln.
226. Bosak J., 1997. XML, Java, and the future of the Web // Sun Microsystems. —
http://sunsite.unc. edu/pub/sun-info/standards/xml/why/xmlapps.htm
370
Литература
227. Bouchet С., Brunet С., Anjewierden А., 1989. SHELLY: an integrated .workbench
for KBS development // Proc, of 9th Int. Workshop Expert Syst. and their Appl. —
France, Avignon. Vol. 1. P. 303-315.
228. Boulding K. L., 1956. General Systems Theory // The Skeleton of Science.
Management Science. No. 2. P. 197-208.
229. Braetman J. A., Magnini B., Rinaldi F., 1994. The Generalized Italian, German,
English Upper Model // ЕСАГ94, Amsterdam.
230. Breuker J. A., Wielinga B.J., 1989. Models of Expertise in Knowledge Acquisi-
tion // In Guida G., Tasso C. (ed.) Topics in expert system design. — Amsterdam,
North-Holland. P. 165-295.
231. Breuker J. A., Wielinga B. J., Hayward S.A., 1986. Structuring of knowledge-based
systems development -// ESPRIT“85: Status Report of Cont. Work. North-
Holland. P. 771-784.
232. Briscoe C. & LeMaster S. U„ 1991. Meaningful learning in college biology through
concept mapping // American Biology Teacher, 53(4),>P. 214-219.
233. Brooks R. A., 1991. Intelligence without Representation // Artificial Intelligence.
No. 47. P. 139-159.
234. Brownston L., Farrell R., et al., 1985. Programming Expert Systems in OPS5: An
introduction to Rule-Based Programming // Addison-Wesley Publ. Comp. Inc.
235. Buchanan B., et al., 1983. Constructing an Expert System // Building Expert
Systems.
236. BYTE, 1989. April. P. 206-246.
237. BYTE, 1990. CASE New Approach to Software Engineering // August.
238. Caines B. R., Shaw M. L., 1984. Cognitive and Logical foundation of Knowledge
Acquisition // Proceedings of the 5-th Banff Knowledge Acquisition for
Knowledge-Based Workshop. November. Banff, Canada. P. 82—101.
239. Cane C., Sarson T., 1979. Structured System Analisis // Englewood Cliffs:
Prentice-Hall.
240. CARNEGIE, 1987. CARNEGIE GROUP INC. // Expert Systems. Vol. 4, No. 2.
241. CATALYST, 1993. — Gensym Corp., G2 // In Object-Oriented Technology on
Sun Workstations. Catalyst, January.
242. Chandrasekaran B., 1985. Generic tasks in knowledge-based reasoning: expert
systems at the right level of abstraction // Proceedings of the Expert Syst. in
Government. P. 62-65.
243. Cheong Fan-Chun, 1996. Internet Agents: Spiders, Wanderers, Brokers, and Bots.
New Riders Publishing, USA.
244. Chess D., Harrison C., Kershenbaum A., 1995. Mobile Agents: Are They a Good
Idea? // IBM Research Division. — http://www.research.ibm.com/iagents/paps/
mobile_idea_abstr.html.
245. Clancey W.J., 1983. The epistemology of a rule-based expert system — a framework
for explanation // Artificial Intelligence. Vol. 20. P. 215-251.
Литература
371
246. Clancey W.J., 1985. Review of J.F.Sowa’s Conceptual Structures // Artificial
Intelligence. P. 13-128.
247. Clocksin W., Mellish C„ 1982. Programming in PROLOG // Berlin, Springer
Verlag.
248. Colmerauer A., 1983. PROLOG in 10 Figures // Proceedings of IJCAI-83. P. 488-
499.
249. CompTek, 2000a. Сравнительный анализ машин поиска по материалам жур-
налов «Мир ПК», «PC Magazine/RE», «Планета Интернет». — http://
www.comptek.ru/arcadia/review/review.html.
250. CompTek, 2000b. Сравнительный анализ русскоязычных машин поиска по
материалам журнала «Планета Интернет». — http://www.comptek.ru/arcadia/
review/review_rus.html.
251. Conklin J., 1987. Hypertext: An Introduction and Survey// Computer. Vol. 20,
No. 9. P. 17-41.
252. Conklin J., 1996. Designing organizational memory: Preserving intellectual assets
in a knowledge economy // Electronic Publication by Corporate Memory Systems,
Inc.
253. Connah D., 1994. The Design of Interacting Agents for Use in Interfaces //In
Brouwer-Janse, D. & Harringdon, T. L. (eds.), Human-Machine Communication
for Educational Systems Design, NATO ASI Series, Series F, Computer and
Systems Sciences 129. Heidelberg: Springer Verlag.
254. Cook N. M., 1985. Computer Programming Expertise: Vanation of Cognitive
Structure: vanations of cognitive structures in FT durso, chair, human expertise //
Papers in Honor of W.Chaise, Meeting of Southern Psychological Association. —
Austin: TX. P. 73-89.
255. Courtois P., 1985. On Time and Space Decomposition of Complex Structures //
Communinications of the ACM. Vol. 28, No. 6. P. 596-610.
256. Cowie J., Lehnert W.G., 1996. Information Extraction // Comm. ACM. —
No. 39(1).
257. Cullen J., Bryman A., 1988. The knowledge acquisition bottleneck: time for
reassessment // Expert Systems. Vol. 5, No. 3.
258. Davis R., 1982. TEIRESIAS: Applications of meta-level knowledge // Knowledge-
based systems in Artificial Intelligence. N.Y.: McGraw-Hill.
259. Davis R., 1984. Interactive Transfer of Expertise // In: Rule-Based Expert Systems
/ Buchanan B. G., Shortliffe E. H. London, Addison-Wesley. P. 171-205.
260. Kleer de J., 1989. Problem solving with the ATMS // Artifitial Intelligence. Vol. 28,
No. 2. P. 197-224. >
261. Delgado R., Joaquin A., 2000. Agent-Based Information.
262. DeMarco T., 1979. Structured Analysis and System Specification. — Englewood
Cliffs, NJ: Prentice Hall.
372
Литература
263. Demazeau Y., Muller J.-P. (eds.), 1990. Decentralized Artificial Intelligence.
Amsterdam: Elsevier North-Holland, 1990.
264. Diderich J., Ruhman I., May M„ 1987. KRITON: a knowledge acquisition tool for
expert systems // Int. Journal of Man-Machine Studies. Vol. 26, No. 1. P. 9-40.
265. Durkin J., 1998. Expert Systems: Catalog of Applications. — ICS, USA.
266. Eisenstadt M., Domingue J., Rajan T., Motta E., 1990. Visual Knowledge
Engineering // IEEE Transactions on Software Engineering. Vol. 16, No. 10.
P. 1164-1177.
267. Engelbart O., 1986. Hypertext as a New Form of Non-linear Documentation //
Communication of ACM. Vol. 3, No. 5. P. 143-155.
268. Eshelman L., 1987. MOLE. A Knowledge Acquisition Tool That Buries Certainty
Factors // Int. Journal of Man-Machine Studies. Vol. 26, No. 1. P. 563-577.
269. EXSYS, 1985. Exsys User Manual // EXSYS Inc.
270. Fain J., Hayes-Roth F., Sowizral H., Waterman D., 1982. Programming in ROSIEA
an Introductionby Means of Examples // Report N-1646-APRA. — Rand
Corporation.
271. Farquhar A., Fikes R., Rice J., 1996. The Ontolingua Server: A Tool for
Collaborative Ontology Construction // Knowledge Systems Laboratory, KSL-
96-26, September, 1996.
272. Feigenbaum E., 1977. The art of artificial intelligence: themes and case studies of
knowledge engineering // Proceedings of IJCAI-77.
273. Feigenbaum E., Buchanan B. Dendral and Meta-Dendral // Artificial
Intelligence. Vol. 11, No. 1-2.
274. Feinstein A., 1958. Foundations of Information Theory. McGraw-hill, N. Y.
275. Fensel, D., Decker S., Erdmann M., Studer R., 1998. Ontobroker: How to enable
intelligent access to the WWW // In AAAI-98 Workshop on Al and Information
Integration. Madison, WI.
276. Fernandez M., Gomez-Perez A., Juristo N., 1997. METHONTOLOGY: From
Ontological Art Toward Ontological Engineering // Spring Symposium Series
on Ontological Engineering. AAAI-97, Stanford. USA.
277. Fikes R. Kehler T., 1985. The role of frame-based representation in resoning //
Com. ACM. P. 904-920.
278. Fikes R.E., Nillson N., 1971. STRIPS: A New Approach to the Application of
Theorem Proving to Problem Solving // Artificial Intelligence. Vol. 5, No. 2.
279. Finin T., McAdams J., Kleinosky P., 1984. FOREST: an expert system for automaic
Test Equipment _// Proceedings of the First Conference on Artificial Intelligence
Applications. IEEE computer Society. P. 689-702.
,280. FIPA, 1998. Ontology Service. FIPA 98 Specification. Part 12. October, 1998.
http://www.cset.it/fipa.
281. Fisher К. M., Faletti J., Patlerson H., Thornton R., Lipson J. & Spring, C., 1990.
Computer assisted concept mapping // Journal of College Science Teaching.
No. 19 (6). P. 347-352.
.Литература
373
282. Fisher К. М., 199,0,. Semantic networking: New kid on the block //Journal of
Research in Science Teaching. No. 27(10). P. 1001-1018.
283. Fisher К. M., 1992. SemNet: 'A tool for personal knowledge construction // In
< P. Kommers, D. Jonassen, & T. Mayes (Eds.) Cognitive tools for learning. Berlin:
Springer Verlag. P. 63-76.
284. Flprentin J. J., 1987. Software Review: KEE // Expert Systems. Vol. 4, No. 2.
P. 118-120,.
285. Forgy C. L„ 1981. OPS5 User’s Manual. — Pittsburg, Pa: Carnegie-Mellon
University.
286. Franklin S. , Graesser A., 1996. Is it an Agent, or just a Program?: A Taxonomy for
Autonomous Agents // Proceedings of the Third International Workshop on
Agent Theories, Architectures, and Languages, Springer-Verlag.
287. Fridman N., Hafner, 1997. Ontology Design: A Survey and Comparative Review
//Al Magazine. No. 18 (3). P. 53-74.
288. Furna G. W., Zacks J., 1994. Multitrees: Enriching and Reusing Hierarchical
Structure // Human Factors in Computing Systems. Conference Proceedings.
Boston, Ms. P. 330-334
289. Gruber T. R., 1995. Toward Principles for the Design of Ontologies Used for
Knowledge Sharing // International Journal of Human and Computer Studies. -
No. 43(5/6). P. 907-928.
290. Gaines B. R., 1987. An Overview of Knowledge Acquisition and Transfer // Special
issue on the 1st Knowledge Acquisition for Knoweledge-Based Systems Workshop.
Part 3, International Journal of Man-Machine Studies, 26. P. 453-472.
291. Gaines B. R., 1989. Second Generation Knowledge Acquisition Systems //
Proceedings of the Second European Knowledge Acquisition Workshop. Vol. 17.
Bonn. P. 1-14.
292. Gaines B. R., Shaw M.L.G., 1986. Knowledge Engineering Techniques //
Proceedings of AUTOFACT86. Detroit. P. 79-96.
293. Gaines B. R., Shaw M. L. G., 1987. KITTEN: Knowledge initiation and transfer
tools for experts and novices // International Journal of Man-Machine Studies. —
Vol. 27, No. 3,P. 251-280.
294. Gammack J. G., Young R. M., 1985. Psychological Techniques for Eliciting Expert
Knowledge // Research and Development in Expert Systems. Cambridge:
University Press.
295. Gane C., and Sarson.T., 1979. Structured System Analysis. — Englewood Cliffs,
NJ: Prentice Hall.
296. Gavrilova T., Chernigovskaya T., 1999. Cognitive Aspects of Visual Knowledge
Base Design // Proceedings of the International Conference PEG, Intelligent
Computer and communications technology (Teaching & Learning for the 21-st
Century), Great Britain. P. 174-181.
297. Gavrilova T., Kotova E., Stash N., 1999. Adaptive Distance Learning Course on
Artificial Intelligence, ICL99, Austria.
374
Литература
298. Genesereth М. R., Fikes R. E„ 1987. Knowledge interchange format, version 3.0.
Reference manual // Technical report, Logic-92-1. Computer Science Dept.,
Stanford University, http://www.cs.umbc. edu/kse/.
299. Gillmore J.F., Pulaski K„ 1985. A survey of expert system tools // Proc, of the
Second IEEE Conf, on Al Applications. P. 498-502.
300. Goldberg F., Robson D., 1983. SMALLTALK-80: the Language and its
Implementation. Reading, Mass: Addison Wesley.
301. Goldfarb C. F„ 1991. The SGML Handbook. Clarendon Press.
302. Goldsmith T. E., Schvaneveldt R. W *1985. ACES: Air combat Expert Simulation
// Memo. In Comput. And Cogn. Sci„ MCCS-85-34, Comput. Res. Lab. New
Mexico: State Univ.
303. Goldsmith T. E, Johnson P. J., & Acton W. H., 1991. Assessing structural
knowledge //Journal of Educational Psychology, 83, P. 88-96.
304. Gopalan, 1999. A Detailed Comparison of CORBA, DCOM and Java/RMI (with
specific code examples). — http://www.execpc. com/~gopalan/index.html.
305. Green C. A., 1977. Summary of PSI program synthesis system // Proc, of IJCAI-
77. P. 380-381.
306. Griswold R„ 1978. A History of the SNOBOL Programming Language //
SIGPLAN Notices. Vol. 13, No. 8. P. 275-308.
307. Grover M., 1983. A Pragmatic Knowledge Acquisition Methodology // Proceeding
of IJCAI. P. 436-438.
308. Gruber T. R., 1991. The role of common ontology in achieving sharable, reusable
knowledge bases // In J. A. Allen, R.Fikes, and E. Sandewell, editors, Principles of
Knowledge Representation and Reasoning, In: Proceedings of the Second
International Conference. Morgan Kaufmann. P. 601-602.
309. Gruber T. R., 1993. A translation approach to portable ontologies // Knowledge
Acquisition. No. 5 (2). P. 199-220.
310. Gruber T., 1989. The Acquisition of the strategic Knowledge. Academic Press.
311. Gruninger M., Fox M., 1995. Methodology for the Design and Evaluation of
Ontologies // Proceedings of IJCAI-95 Workshop on Basic Ontological Issues in
Knowledge Sharing.
312. Guarino N., 1996. Ontologies: What Are They, and Where’s The Research? // A
panel held at KR’96, the Fifth International Conference on Principles of
Knowledge Representation and Reasoning, November 5, 1996, Cambridge,
Massachusetts, http://www-ksl.stanford.edu/KR96/Panel.html.
313. Guarino N., Giaretta P., 1995a. Ontologies and Knowledge Bases. Towards a
Terminological Clarification // In: Towards Very Large Knowledge Bases. — N.J.I.
Mars (ed.), IOS Press, Amsterdam.
314. Guarino N., Masolo C., Vetere G., 1999. OntoSeek: Content-Based Access to the
Web // IEEE INTELLIGENT SYSTEMS. - May/June 1999.
315. Guarino N., Poli R., 1995b. The role of ontology in the information technology //
International Journal of Human-Computer Studies. No. 43(5/6). Special issue
on ontology. P. 623-965.
Литература 375
316. Guida G., Tasso C., 1989. Buldung Expert Systems: From Life Cycle to
development methodology // Topics in Expert Systems Design, Metodologies
and Tools. Amsterdam, North Holland. P. 3-24.
317. Haberman A. N., Notkin D., 1986. Gandalf: Software Development Environments
// IEEE Trans. Software Eng. Vol. SE-12, No. 12. P.1117-1127.
318. Habermann N., Flon F., Cooprider L., 1976' Modularization and Hierarchy in a
Family of Operating Systems // CACM. Vol. 19, №5. P.266-272.
319. Harmon P., 1987. Review in Expert Systems // Expert Systems Strategies. Vol. 3,
No. 6. P.11-18.
320. Hart A., 1986. Knowledge Acquisition for expert systems. London, Kogan Page.
321. Heflin J., Hendler J„ Luke S., 1998. Reading Between the Lines: Using SHOE to
Discover Implicit Knowledge from the Web //In AAAI-98 Workshop on Al and
Information Integration.
322. Hinkelmann K. and Kieninger Th., 1997 Task-oriented web-search refinement
and information filtering. DFKI GmbH.
323. HTML4, 1998. HTML 4.0 Specification, W3C Recommendation, revised on 24
April 1998. http://www.w3.org/TR/REC-html40.
324. Jackson M., 1975. Principles of Program Design. N. Y.: Academic Press.
325. Jonassen D.H., 1993. Changes in knowledge structures from building semantic
net versus production rule representation of subject content. Journal of Computer
Based Instruction, 20 (4), P. 99-109.
326. Jonassen D.H., Mandi H. (Eds), 1999. Designing Hypermedia for Learning, —
Springer-Verlag N. Y., Incorporated.
327. Jones A., 1992. The Object Model: a Conceptual Tool for Structuring Software.
Operating Systems. N. Y.: Springer-Verlag. P. 8.
328. Kahn G., Nowlan S., McDermott J., 1985. MORE: An Intelligent Knowledge
Acquisition Tool // The proceedings of the Ninth Joint Conference on Artificial
Intelligence. — August. Los Angeles, CA. P. 581-584.
329. Kaplan R. M., Berry-Rogghe G., 1991. Knowledge-based acquisitions of causal
relationships in text // Knowledge Acquisition. № 3. P.317-337.
330. Kelly G.A., 1955. The Psychology of Personal Constructs. — N. Y.: Norton.
331. Kestelyn J., 1992. Application Watch // The International Jour. Of Knowledge
Engineering. Vol. 8, No. 2. P. 123-129.
332. Khoroshevsky V.F., Situation Control Software: From Symbol Manipulation
Languages Through Knowledge Representation Systems to Semiotic Technologies,
Proc. Of the 1995 ISIC Workshop, — 10 IEEE International Symposium on
Intelligent Control, 127-129 (1995).
333. Khoroshevsky V. F., Knowledge V.S., 1998. Data Spaces: How an Applied
Semiotics to Work on Web // In: Proceedings 3rd Workshop on Applied
Semiotics, National Conference with International Participation (САГ98),
Pushchino, Russia.
376
Литература
334. Khoroshevsky V. F., 1985; ATN-based Explanation Subsystems: Design and
Implementation // Computers and Artificial Intelligence. Vol. 4 (1985), No. 4,
P. 289-311.
335. Khoroshevsky V. F., 1994. Knowledge Based Design of Intelligent Interfaces ih
PiES WorkBench '// Proc, of the Sixth International Conference oil Artificial
Intelligence and Information-Control Systems of Robots. — Smolenice,
Slovakia. September 21-25, World Scientific. P. 159-168.
336. Khoroshevsky V. F., 1994b. Knowledge Based,Design of Knowledge Based Systems
in PiES WorkBench // Proc, of JCKBSE’94, Japan-CIS Symposium on
Knowledge Based Software Engineering'94. P. 256-261.
337. Kifer M., Lausen G., Wu J., 1995. Logical Foundations of Object-Oriented and
Frame-Based Languages //Journal of the ACM.
338. Kintsch W., 1974. The representation of meaning in memory. N. Y.
339. Kitto С. M., Boose J. H., 1987a. Heuristics for expertise transfer: an implementation
of a dialog manager for knowledge acquisition // International Journal of Man-
Machine Studies. Vol. 26, No. 2. P. 183-202.
340. Kitto С. M., Boose J. H., 1987b. Choosing knowledge acquisition strategies for
application tasks//Proc, of WESTEX’87. P. 96-103.
341. Knight K., Luk S., 1994. Building a Large Knowledge Base for Machine
Translation, Proc. Amer. Assoc // Artificial Intelligence Conf. (AAAI-94). AAAI
Press, Menlo Park, Calif. P. 773—778.
342. Kommers P. A. M., 1989. Texlvision. Eachede, Netherlands: University of Twente,
Educational Instrumentation Department.
343. Kozma R. B., 1992. Constructing knowledge with learning tool. In P. Kommers,
D. Jonassen, A T. Mayes (Eds.), Cognitive tools for learning (P. 23-32). Berlin:
Springer-Verlag.
344. Kozma R. B., 1987. The implications of cognitive psychology for computer-based
learning tools. Educational Technology, (11). P. 20-24.
345. Kruskal J. B., 1964. Nonmetric multidimensional scaling: a numerical method,
Psychometrika 29, P. 115-129.
3,46 . Kbhn O., Abecker A., 1998. Corporate Memories for Knowledge Management in
Industrial Practice: Prospects and Challenges.
347. Kbhn 0., Becker V., Lohse V. and Ph. Neumann, 1994. Integrated Knowledge
Utilization and Evolution for the Conservation of Corporate Know-How //
ISMICK’94: Int. Symposium on the Management of Industrial and Corporate
Knowledge.
348. Labrou Y., Finin T., 1997. A Proposal for a new KQML Specification // TR CS-
97-03. February 3,1997.
349. Lai K. W., 1989. Acquiring expertise and cognitive skills in the process of
constructing an expert system: A preliminary study. Paper presented at the annual
meeting of the American Educational Research Association, San Francisco. CA
(ERIC Document No. ED 312986).
Литература
377
350. Lamping L., Rao R., Pirolli P., 1995. A Focus+Context Technique Based on
Hyperbolic Geometry for Visualizing Large Hierarchies // In Proceedings of the
ACM SIGCHI Conference on Human Factors in Computing Systems.
351. Leibowitz J., Bland K., 1994. Using Multimedia to Help Students Learn Knowledge
Acquisition // Multimedia Computing — Preparing for the 21-th Century ed.
Reisman S. — USA: Idea Group Publishing. P. 537-556.
352. Lenat, D. B., 1995. CYC: A Large-Scale Investment in Knowledge Infrastructu-
re // Communications of the ACM 38. № 11. http://www.cyc. com.
353. Lesser V., Horning B., Klassner F., Raja A., Wagner T„ Zhang S., 1998. A Next
Generation Information Gathering Agent // Umass Computer Science Technical
Report 1998-72, May, 1998.
354. Lippert R.C. & Finley F., 1988. Student’s refinement of knowledge during the
development of knowledge for expert systems // Paper presented at the annual
meeting of the National Association for Research in Science Teaching, Lake of
the Olarks, MO. (ERIC Document No. ED 293872).
355. Lippert R.C., 1988. An expert system shell to teach problem solving. Teach Trends,
33(2). P. 22-26.
356. Lowe D., Hall W.,1999. Hypermedia and the Web: An Engineering Approach.
Wiley, John & Sons, Incorporated.
357, Luke S., Spector L., Rager D., 1996. Ontology-Based Knowledge Discovery on
the World-Wide Web // In: Proc. Of the Workshop on Internet-based
Information Systems, AAAI-96, Portland, Oregon.
358. Macintosh A., 1997. Knowledge asset management // Airing. No. (20), April.
359. Maikevich N. V., Khoroshevsky V. F., 1998. Knowledge Driven Processing of
HTML-Based Information for Intellectual Spaces on Web // In: Proceedings of
the Third Joint Conference on Knowledge-Based Software Engineering,
Smolenice, Slovakia.
360. Maikevich N. V„ Khoroshevsky V. F., 1999. Intelligent Processing of Web
Resources: Ontology-Based Approach and Multiagent Support // In: Proceedings
of 1st International Workshop of Central and Eastern Europe on Multi-agent
Systems (CEEMAS’99). — 1-4 June, 1999, St.-Petersburg, Russia.
361. Malsch Th., Bachmann R., Jonas M., MillU., and Ziegler S., 1993. Expertensysteme
in der Abseitsfalle? — Fallstudien aus der industriellen Praxis, edition sigma, Reiner
Bohn Verlag, Berlin.
362. Markus S., 1987. Taking Backtracking with a Grain of SALT // Int. Journal of
Man-Machine Studies. Vol. 26, No. 4. P. 383-398.
363. Masui S., McDermott J., 1983. Decision-making in Time-critical Situations //
Proceedings IJKAI-83. P. 233-235.
364. Matarozzo J.D., Wettman M., Weins A.N., 1963. Interviewer influence on duration
of interview speech //J. Verbal Learning and Verbal Behavior. No. 1.
365. Maurer F., Dellen B., 1998. A Concept for an Internet-based Process-Oriented
Knowledge Management Environment // Proceedings of the KAW’98, Banff,
Canada.
378
Литература
366. McCarthy J., 1978. History of LISP// SIGPLAN Notices. Vol.l3(1978). P. 217-
223.
367. McClure C. A., 1979. CASE Workshop // BYTE. - April.
368. MDBS, 1986. Guru User Manual // MDBS Inc.
369. Mesarovic M.D. (ed), 1964. Views on General Systems Theory. N. Y., Wiley.
370. Mikulescky L., 1988. Development of Interactive computer programs to help
students transfer basic skills to college level science and behavioural sciences
courses. Bloomingion IN: Indiana University.
371. Minsky M.A., 1981. Theory of memory // Perspectives in Cognitive Science.
Norwod, N. S., Ablex.
372. Monahan J.S., Lockhead G.R., 1977. Identification of integral stimuli // Journal
off Experimental Psychology. General 106. P. 94-110.
373. Moon D., 1973. MACLISP Reference Manual. MIT Press, Cambridge, Mass.
374. Motta E., Eisenstadt M., Pitman K., West M., 1988. Support for knowledge
acquisition in the Knowledge Engineers Assistant (KEATS) // Expert Systems.
Vol. 5. P. 6-27.
375. Motta E., Rajan T., Eisenstadt M., 1989. A methodology and tool for knowledge
acquisition in KEATS-2 // Proc, of Int. Summer Sch. Top. Expert Syst. Des.:
Methodol. and Tools. Amsterdam. P. 297-323.
376. Motta E., Rajan T., Dominigue J., Eisenstadt M., 1990. Visual Knowledge Engine-
ering // IEEE Transactions on software engineering. Vol. 16, No. 10. P. 151-164.
377. Motta E., Rajan T., Dominigue J., Eisenstadt M., 1991. Methodological foundations
of KEATS, the Knowledge Engineer’s Assistant // Knowledge Acquisition. No. 3.
P. 21-47.
378. Musen M. A., Fagan L- M., Combs D. M„ Shortliffe E. N., 1987. Use of a Domain
Model to Drive an Interactive Knowledge-Editing Tool // Int. Journal of Man-
Machine Studies. Vol. 26, No. 1. P. 105-121.
379. NEXPERT OBJECT, 1990 // Tutorial. Nexpert Co.
380. Nielsen J., 1990. HyperText & HyperMedia. Academ. Press Inc
381. Nonaka I. and Takeuchi L, 1995. The Knowledge-Creating Company. N. Y.:
. Oxford: Oxford University Press.
382. Nwana H. S., 1996. Software Agents: An Overview // Knowledge Engineering
Review. Vol.ll, №3. Cambridge University Press. P. 1-40.
383. Olson J. R., Reuter H. H., 1987. Extracting expertise from experts: methods for
knowledge acquisition // Expert systems. Vol. 4, No. 3.
384. Olton J.D., Muser M.A., Combs D.M. et al., 1987. Graphical access to medical
expert systems // Methods of Information in Medicine. Vol. 26, № 3.
385. Orr D, Kenneth T., 1977. Structured System Development. N. Y.: Academic Press.
386. Orr D, Kenneth T., 1977. Structured System Development. N. Y.: Academic Press.
387. Ovum, 1994. Intelligent agents: the new revolution in software. Ovum.
Литература
379
388. Pagina Н., 1996. Intelligent Software Agents on the Internet, http://
www.hermans.org/agents/index.html.
389. Pega M., Sticklen J., Bond W„ 1993. Functional Representation and Reasoning //
IEEE Expert. April. P. 65-78.
390. Peters L., 1981. Software Design. N. Y.: Yourdon Press.
391. Piatetsky-Shapiro G. and Frawley W., eds., 1991. Knowledge Discovery in
Databases. AAAI/MIT Press.
392. Pospelov D.A., Basic concepts of Situational Languages and formal means of
analysis and control of natural systems, Presented at the QAT Teleconference,
New Mexico State University and the Army Research Office, December 13, (1996).
393. Pospelov D.A., Semiotic Models in Control Systems, In. Proc, of the 1995 ISIC
Workshop — the 10th IEEE International Symposium on Intelligent Control,
6-12 (1995).
394. Rabbits L., Wright G., 1987. Card tricks for small players // Expert Systems User.
Vol. 22, No. 11.
395. Raggett D., 1977. HTML 3.2 Reference Specification. — http://www.w3.org/TR/
REC-html32.
396. Ramamoorthy С. V., Shekhar S., Garg V., 1987. Software Development Support
for Al Programs // Computer. Vol. 20, No. 1. P. 30-40.
397. Rasmussen J., Brehmer B., Leplat J., (eds.), 1991. Distributed Decision-Making.
Cognitive Models for Cooperative Work. N. Y.: J. Wiley & Sons.
398. RDF, 1999. Resource Description Framework (RDF) Data Model and Syntax //
W3C Recommendation. — http://www.w3.org/TR/WD-rdf-syntax.
399. Reggia J. A., 1988. Representing and using medical knowledge for the neurological
localization // Report TR-693, Computer Science Dept., University of Maryland.
400. Reisman S., 1991. Developing Multimedia Applications // IEEE Computer
Graphics & Applications. P. 58-66.
401. Richer M., 1986. An evaluating of expert system development tools // Expert
Systems. P. 166-183.
402. Ricoeur P., 1975. La metaphore vive. — Paris, Editions du Seuil.
403. Ross D.T., Goodenough J.B., Irvine C. A., 1975. Software Engineering: Process,
Principles and Goals // Computer. VqI. 8, No. 5. P. 17-28.
404. Sacerdoti E., et al., 1976. Qlisp: a Language for the Interactive Development of
Complex Systems // SRI, Tech, note 120.
405. Schlenker D. A. & Abegg G. L., 1991. Scoring student-generated concept maps in
introductory college chemistry. Paper presented at the annual meeting of National
Association for Research in Science Teaching, Lake Geneva. WI.
406. Schoucksmith G., 1978. Assessment through interviewers. Oxford.
407. Schreiber G., Breuker J., Bredeweg B., Wielinga B., 1988. Modeling in KBS
Development // Proceedings of the Second European Knowledge Acquisition
Workshop (EKAW-88). Bonn. P. 1-15.
380
Литература
408. Schvaneveldt R. W., Durso F. T., Dearholt D. W., 1985. Pathfinder. Scaling with
network structure//MCCS-85-9. ' ,
409. Schwartz T„ 1988. Scoping// IEEE Expert? Vol. 3, No. 1.
410. Scott A., Clayton J. E., Gibson E. L., 1994. A practical Guide to Knowledge
Acquisition. Addison-Wesley Publ.
411. Searle J. R., Vanderveken D., 19851 Foundations of Illocutionary Logic.
Cambridge Univ. Press: Shoham Y„ 1993. Agent-oriented programming //
Artificial Intelligence. № 60(1).
412. Shaw M. L., Woodward J. B., 1988. Validation of a Knowledge Support System //
Proceedings of the 2-th Knowledge Acquisition for.Knowledge-Based
Workshop. Banff, Canada.
413. Shaw M., 1984. Abstraction Technique in Modern Programming Languages //
IEEE Software. Vol. 1(4).
414. Shaw M. L. G„ 1982. PLANET: some experience in creating an integrated system
for repertory grid application on a microcomputers // International Journal of
Man-Machine Studies. Vol. 17, No. 3. P. 345-360.
415. Shaw M. L. G., Gaines B. R„ 1984. Deriving the constructs underlying decision //
Fuzzy Sets and Decis. Anal, Amsterdam. P. 335-355.
416. Sherstnew W.Yu., WorfolomeexV A.N., Aleshin A. Yu., 1994. FRAME/2 —
Application Program Interface for Frame Knowledge Bases // Proc, of
JCKBSE’94, Japan-CIS Symposium on Knowledge Based Software
Engineering’94. P. 168-170.
417. Shlaer S., Mellor S., 1992. Object Life Cycles: Modelling the World in
States. Englewood Cliffs, NJ: Yourdon Press.
418. Shortliffe E., 1976. Computer based medical consultations: MYCIN. N. Y.,
American Elsevier.
419. Shortliffe E.H., Buchanan B.G., Feigenbaum E.A., 1979. Knowledge engineering
for medical decision-making: a review of computer-based clinical decision aids //
Proceedings of the IEEE. Vol. 67, No. 9. P. 1207-1224.
420. SIGSOFT, 1986. ACM SIGSOFT Software Engineering Notes. Vol. 11, No. 4,
August.
421. Sisodia R., Warkentin M., 1992. Al in business and management // PC Al. Jan/
Feb. P. 32-34.
422. SKDL, 1998. Human Agent Interaction // FIPA98 Draft Specification: Part 8. —
http://www.cset.it/fipa/fipa8713.doc
423. Slagle J. R., Gardiner O. A., KyungsookN., 1990. Knowledge Specification on an
Expert System // IEEE Expert. August. P. 29-38.
424. Slagle J. R., Gaynor M., 1983. Expert System Consultation Control Strategy //
Proceedings AAAI-83. P. 369-272.
425. Sloman A., 1996. What sort of architecture is required for a human-like agent? //
Invited talk at Cognitive Modeling Workshop, AAAI-96, Portland Oregon, August
1996.
Литература
381
426. Sowa, J., 1984. Conceptual Structures: Information Processing in Mind and
Machine. - Addison-Wesley, Ready, Massachussets.
427. Stoffel K., Taylor M., Hendler J., 1997. Efficient Management of Very Large
Ontologies // In Proceedings of American Association for Artificial Intelligence
Conference (AAAI-97). AAAI/MIT Press.
428. Sussman GJ., McDermot D.U., 1976. From PLANNER to CONNIVER — A
Genetic Approach // Proc, of 1976 Joint Computer Conference. AFIPS Press.
P. 271-278.
429. Teitelman W., 1974. INTERLISP Reference Manual // XEROX PARC.
430. Torgerson W. S., 1958. Theory and methods of scaling. N. Y.: Wiley.
431. TOVE, 1999. TOVE Manual. — Department of Industrial Engineering, University
of Toronto. — http://www.ie/utoronto.ca/EIL/tove.
432. Tschaitschian B., Abecker A. and Schmalhofer, 1997. A. Putting Knowledge Into
Action: Information Tuning With KARAT // In 10th European Workshop on
Knowledge Acquisition, Modeling, and Management (EKAW-97).
433. Tuthill G.S., 1994. Knowledge Engineering. — TAB Books Inc.
434. Uschold M., Gruninger M., 1996. ONTOLOGIES: Principles, Methods and
Applications, // Knowledge Engineering Review. Vol. 11, No. 2.
435. Van der Vet P.E., Mars NJ., Speel P.H., 1994. The Plinius Ontology of Ceramic
Materials // ЕСАГ94, Amsterdam.
436. Villemin F.-Y., 1999. Ontologies-based relevant information retrieval. — http://
www.cnam.fr/f-yv.
437. VITAL, 1990. VITAL: A Methodology-Based Workbench for KBS Life Cycle
Support // ESPRIT-II Project 5365.
438. Voinov A., Gavrilova T., 1993. Knowledge Acquisition through Elicitation of
Latent Cognitive Structures: Metaphor — Based Approach // Proc, of East-West
International Conference on Artificial Intelligence: From Theory to Practice
EWAIC’93. Moscow, P. 113-119.
439. WAI, 1999. Web Accessibility Initiative (WAI) Web site. — http://www.w3.org/
WAI/
440. Walker С. T., Miller K.R., 1988. Expert Systems 1987: An Assessment of
Technology and Applications. Madison.
441. Wall R., Apon A. Beal J. at al., 1986. An evaluation of commercial expert system
building tools // Data Knowledge Eng. P. 279-304.
442. Watanabe S., 1969. Knowing and Guessing. N. Y.: Wiley.
443. Waters R.C., 1985. The Programmer’s Apprentice: A Session with KBEmacs //
Trans. Software Eng. Vol. SE-11, No. 11.
444. Wayner P., 1995. Free Agents // BYTE. March. P. 105-114.
445. WebCompass, 1999. WebCompass Page. — http://www.symantec. com/
techsupp/webcompass/kbase_webcompass.html.
382
Литература
- 446. Wielinga В., Akkermans Н., Schreiber G., Balder J., 1989. A Knowledge Acquisition
Perspective on Knowledge-Level Models // Proceedings of the Fourth Knowledge
Acquisition for Knowledge-Based Systems Workshop. — Banff, 36. P. 1-22.
447. Wielinga B., Schreiber G.,Breuker J., 1992. A Modelling Approach to Knowledge
Engineering // Knowledge Acquisition. 4 (1). Special Issue.
448. Wielinga B.J., Bredeweg B„ Breuker J. A., 1988. Knowledge Acquisition for Expert
-• Systems // Proceedings of ACAI88.
449. Woods W. A., Bookman L. A., Houston A., Kuhns R. J., Martin P., Green S.,
1999. Linguistic Knowledge Can Improve Information Retrieval // Knowledge
Technology Group, Sun Microsystems, TR-99-83. — http://www.sun.com/
research/techrep/1999.
450. Wooldridge M., Jennings N., 1995. Intelligent Agents: Theory and Practice //
Knowledge Engineering Review. No. 10 (2).
451. Wray R. Ron C. et. al., 1994. A Survey of Cognitive and Agent Architecture. —
http://krusty.eecs.umich.edu/cogarchO/
452. Wiig, 1990. Expert Systems: A manager’s guide. Geneva: The International Labour
Office of the United Nations.
453. Wiig K., 1996. Knowledge management is no illusion! // Proc, of the First
International Conference on Practical Aspects of Knowledge Management. Zurich,
Switzerland: Swiss Informaticians Society
454. Wilks Y., 1976. Parsing English II // Computational Semantics. Eds. Y. Wilks,
E. Sharniak. N. Y.: North-Holland. P. 155-184.
455. XML, 1998. Extensible Markup Language (XML) // W3C Recommendation. —
http://www. w3.org/TR/l 998/REC-xml-19980210.
456. Yourdon E. Constantine L., 1979. Structured Design. — Englewood Cliffs, NJ:
Yourdon Press / Prentice-Hall.
457. Yourdon E., 1989. Modern Sructured Analysis. — Prentice-Hall Int. Ed.
Т. А. Гаврилова, В. Ф. Хорошевский
Базы знаний интеллектуальных систем
Главный редактор В. Усманов
Ответственный редактор Е. Строганова
Руководитель проекта И. Корнеев
Литературный редактор Н. Дубнова
Художник Н. Биржаков
Иллюстрации М. Жданова
Верстка М. Жданова
Корректор В. Листова
Лицензия ЛР № 066333 от 23.02.99.
Подписано в печать 31.07.00. Формат 70х100‘/16.
Усл. п. л. 30,96. Тираж 5000 экз. Заказ № 1382.
Издательство «Питер».
196105, Санкт-Петербург, Благодатная ул., д. 67.
Отпечатано с диапозитивов в ГПП «Печатный двор»
Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций.
197110, Санкт-Петербург, Чкаловский пр., 15.