/







































































































































































Текст
ТЕОРИЯ И МЕТОДЫ
СИСТЕМНОГО АНАЛИЗА
РЕДАКЦИОННАЯ КОЛЛЕГИЯ СЕРИИ
академик Д.М. ГВИШИАНИ
(председатель)
член-корреспондент АН СССР СВ. ЕМЕЛЬЯНОВ
(заместитель председателя)
член-корреспондент АН СССР С.С. ШАТАЛИН
доктор экономических наук Б.З. МИЛЬНЕР
доктор технических наук Ю.С ПОПКОВ
МОСКВА "НАУКА"
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ
1982
СВ. ЧЕСН0К0В
ДЕТЕРМИНАЦИОННЫИ
АНАЛИЗ
СОЦИАЛЬНО-
ЭКОНОМИЧЕСКИХ
ДАННЫХ
МОСКВА"НАУКА"
ГЛАВНАЯ РВДАКЦИЯ
ФИЗИКО-МАТКМАТИЧКСКОЙ ЛИТЕРАТУРЫ
19 82
32.81
461
УДК 33:301:311.2
Детерминационный анализ социально-экономических данных. Чесноков СВ. -
М.: Наука. Главная редакция физико-математической литературы, 1982. - 168 с.
Монография посвящена одному из направлений в методах обработки
качественных социологических и социально-экономических данных — детерминационному
анализу. Метод предназначен для решения задач, связанных с поиском и описанием
взаимозависимостей между отдельными переменными, фигурирующими в рабочих
документах эмпирических обследований, или группами таких переменных. Он
представляет собой вариант исчисления обычных эмпирических условных частот
(процентов) , которые содержатся в таблицах сопряженности признаков. Последовательная
ориентация на манипулирование условными частотами отличает его от многих других
методов решения сходных задач. В книге изложены основания метода, даны
примеры его приложений, описано вычислительное обеспечение, необходимое для
пользования методом.
Табл. 20, илл. 43, библ. 66 назв.
Сергей Валерианович Чесноков
ДЕТЕРМИНАЦИОННЫЙ АНАЛИЗ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ СИСТЕМ
Серия: "Теория и методы системного анализа"
М., 1982 г., 168 стр. с нлл.
РедакторЯ.С. Райская. Технический редактор Н.В. Семенчинекая
Корректор Т.В. Обод
ИБ№ 12154
Подписано к печати 06.07.82. Т - 11127. Фор мат 60 X 90 1/16.
Бумага офсетная М° 1. Печать офсетная. Усл. печ.л. 10,5.Уч.-издл. 10,96.
Тираж 2500экз. Тип. зак.244 Цена 1 р. 60 к.
Издательство "Наука"
Главная редакция физико-математической литературы.
Москва, В-71, Ленинский проспект, 15
4-я типография издательства "Наука"
630077, Новосибирск, 77, ул. Станиславского, 25
1502000000-104
Ч : 166*2
053 @2) -82
.© Издательство "Наука"
Главная редакция
физико-математической литературы,
1982
ОГЛАВЛЕНИЕ
Предисловие 7
Глава I. Некоторые особенности эмпирического описания социальных
явлений на микроуровне . 11
§ 1.1. Формальный образ первичных эмпирических данных.
Матрица данных, веер отображений 11
§ 1.2. Номинальность 14
§ 1.3. Конкретность 17
§ 1.4. Ограниченная статистичность • 21
Г л а в а И. Основные понятия детерминационного анализа 23
§ 2.1. Детерминация 24
§ 2.2. Эквивалентные преобразования таблиц сопряженности и
произведение переменных 27
§ 2.3. Равенство переменных по заданному основанию 29
§ 2.4. Непустые и пустые значения переменных 31
§ 2.5. Нулевая и единичная переменные 33
§ 2.6. Уточнения. Понятие существенности 36
§ 2.7. Контекст т 40
§ 2.8. Нормальные функции .' . *. 44
§ 2.9. Детерминационные функции С13-функции) 51
§ 2.10. Стандартное разложение *D-функции 55
ГлаваЩ. Практический детерминационный анализ . . '. 59
§ 3.1. Базовые задачи. Типы исследовательских вопросов .... 60
§ 3.2. Диалоговая вычислительная система 65
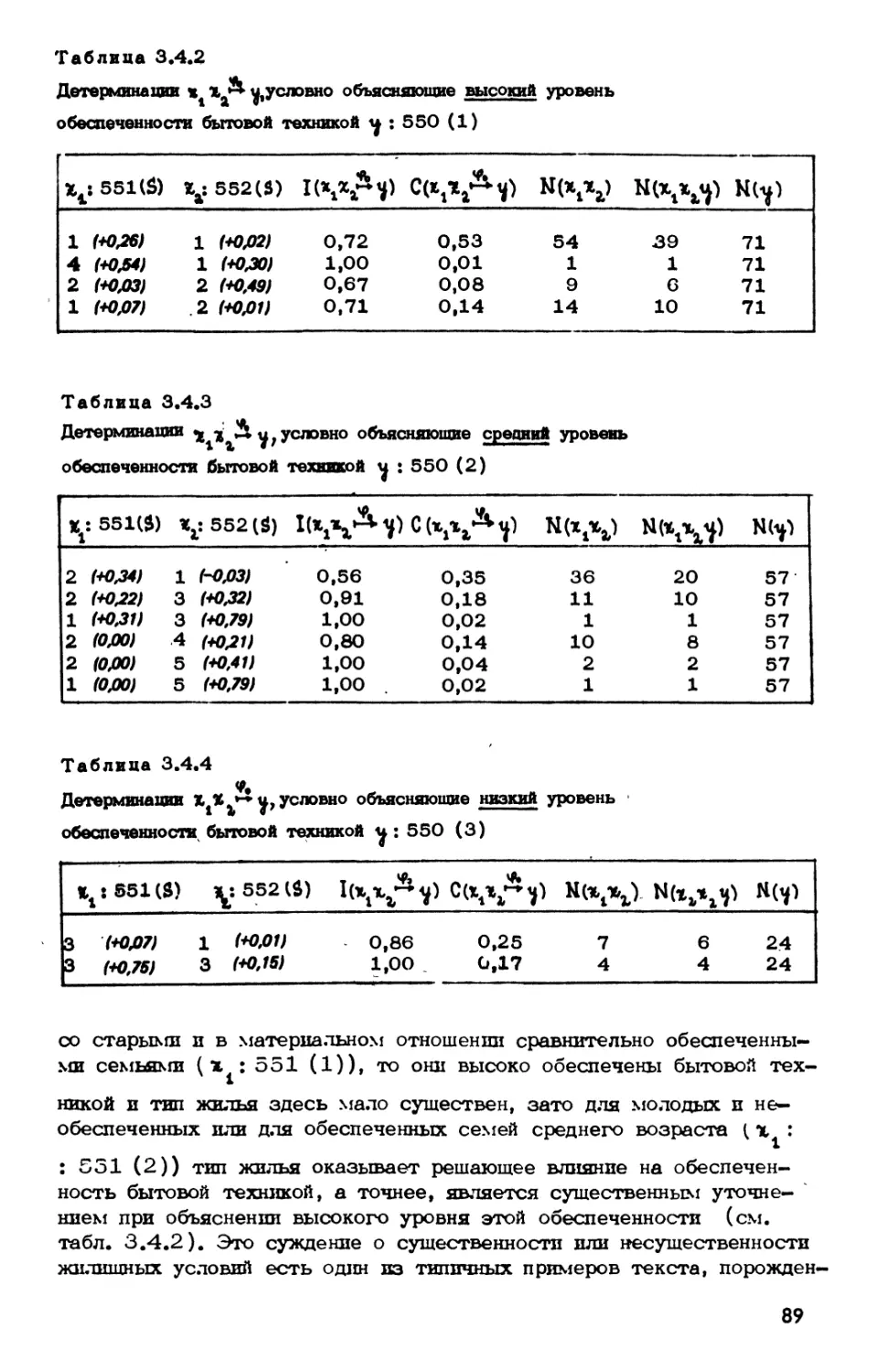
§ 3.3. Пример 1. Читательское поведение 76
§ 3.4. Пример 2. Объяснительная типологизация семей и
жилищных условий 83
Глава1у. Детерминационный анализ и элементы моделирования
социальных процессов 92
8 4.1. Ъ -функция как модель языкового понятия 93
§ 4.2. Моделирование коммуникаций 96
4.3. Моделирование элементов макроописания на микроуровне . 103
4.4. Моделирование отношения между первичными
(качественными) и вторичными (количественными)
закономерностями 106
5
Глава Y. Место аетерминационного анализа в системе математичес-
ких методов обработки данных . 116
§ 5.1. Статистическая детерминация и статистическая связь ... 117
§ 5.2. Детерминационный анализ и методы исследования связей
4
на основе критерия уС 125
§ 5.3. <D -функции и расстояние по Хеммингу между разбиениями
объектов 134
§ 5.4. Уравнение регрессии и метод главных компонент как
способы описания D -функций 142
Приложение 154
Литература 165
"Кто дал ему облик?Кто - рост, имя, движение?
Кто нацелил способностью различать?..."
Атхарваведа, х , 2.
*Но мы, те, кто понимает, что такое жизнь, мы,
конечно, смеемся над номерами и цифрами! ¦ • т*
Антуан де Сент-Экзюпери,
"Маленький принц*.
ПРЕДИСЛОВИЕ
Предлагаемая вниманию читателя монография посвящена вопросам
анализа качественных социологических и социально-экономических
данных.
Арсенал методов, предназначенных для обработки и анализа
таких данных, в настоящее время весьма разнообразен. Наиболее
разработаны методы, применимые к результатам количественных
измерений или измерений, которые приближаются к количественным. Сюда
относятся всевозможные модели регрессионного, факторного,
дисперсионного, компонентного анализа, многие методы таксономии и
классификации и ряд других. Достаточно полный обзор на эту тему
можно найти в работах [1, 2, 14, 17]. Гораздо менее изучена
проблематика анализа качественных данных.
В массе социологических и социально-экономических исследований
качественные данные преобладают. Много лет назад B0-е годы или
около того) казалось, что с развитием техники и теории измерений
произойдет постепенная замена качественных данных
количественными. Опыт эмпирических исследований, накопленный в мировой
практике за последние десятилетия, заставляет, однако, думать, что для
большинства социальных индикаторов их качественная природа
обусловлена фундаментальными свойствами социального объекта [51].
В первом приближении задачи анализа социологических и
социально-экономических данных подразделяются на два класса: изучение
структуры связей между переменными и построение вторичных
агрегированных показателей [35, 6 1]. Основное направление усилий по
созданию методов, предназначенных для анализа качественных данных,
характеризуется использованием всевозможных интегральных
показателей, описывающих либо тесноту связи между переменными
(эмпирическими индикаторами), либо "расстояние" ("близость") между
эмпирическими объектами или их разбиениями. Набор показателей
довольно широк: от коэффициентов Юла, Кендалла, Пирсона, Чупрова,
Крамера до энтропии [32], метрики Хемминга [34] и других
(соответствующий обзор см. в монографиях [33, Зб] ). Однако
использование подобных интегральных показателей, обеспечивая
возможность получать суждения общего характера, вместе с тем уводит
исследователей-предметников от видения объекта через призму конкрет-
7
ных свойств, представленных значениями качественных
(номинальных) признаков в рабочих документах эмпирических обследований.
Видимо, в первую очередь этим обстоятельством следует объяснить
тот факт, что на практике критерием истинности результатов,
полученных с помощью таких интегральных показателей, для социолога
и социо-экономиста служит, как правило, итог прямого визуального
анализа таблиц сопряженности.
Непосредственное изучение процентных распределений,
содержащихся в таблицах сопряженности, образует основу так назьюаемого
содержательного анализа эмпирических данных в обыденной научной
деятельности специалистов-предметников. Когда такие таблицы-распр«
деления имеют небольшое число измерений - одно, два, три - их
изучение не представляет особых затруднений. Но стоит
незначительно увеличить размерность (до четырех, пяти, шести измерений),
как появляются существенные трудности: осложняется представление
материала в удобной визуально обозримой форме, в таблицах
появляется большое число пустых или почти пустых клеток, становится
трудно прослеживать интересующие исследователя тенденции и
закономерности. Преодоление подобных трудностей путем введения показателей,
характеризующих содержащиеся в таблицах распределения "в целом4",
интегрально, дает в ряде случаев положительный эффект, но зато,
как отмечалось, уменьшает возможности содержательного
манипулирования конкретными свойствами - значениями качественных
признаков (переменных). В то же время техника локального,
фрагментарного анализа таблиц сопряженности, которая могла бы
способствовать преодолению возникающих трудностей, в научной литературе
практически не обсуждается. Детерминационный анализ, теория и
практика которого составляют основное содержание этой монографии,
представляет собой вариант именно такого рода техники.
Задача, которую решает детерминационный анализ, неоригинальна.
Это задача поиска и описания ситуаций, в которых по конкретным
значениям одних социальных индикаторов можно было бы достаточно
определенно предсказывать значения других индикаторов. Речь идет,
таким образом, о выяснении своеобразных микрозакономерностей,
характеризующих функционирование социальной системы. Главной
характеристикой, описывающей возможность предсказания, служит обыч-i
ная эмпирическая условная частота. Другими словами, если 8
предсказывается на основе & по правилу ¦"если а, то 6 f, то мерой
точности полагается величина условной частоты РF1а),Само правило
''если СЦ то 8 " обозначается символом а»-* в и называется
детерминацией (отсюда и название метода).
Детерминации можно трактовать как логические импликации,
порожденные, индуцированные, эмпирическими условными частотами.
Имеется связь между понятием детерминации и так называемыми
секвенциальными высказываниями (высказываниями, квантифицирован-
ными частотными кванторами) (см. [1б]).
Термин 'детерминацияг происходит от латинского deterininatto -
ограничение, определение и используется, как правило, для
обозначения ситуации, когда одно свойство, событие, явление, оказывает
8
определяющее влияние на другое свойство, событие, явление.
Термин был впервые введен в области биологии немецким ученым Гай-
дером в 1900 г. (БСЭ, 2-е изд., т. 14, с. 132), Безотносительно
к биологии он часто используется в философских работах (см., к
примеру, [25], с. 125 и далее), встречается и в работах по
методам анализа данных (см. монографию [501, с. 103 - 105). В
этой книге понятию детерминации придается точный и несколько
более широкий (чем принято обычно) смысл (детальнее см. ниже §2.1).
Детерминационный анализ позволяет так организовать процесс
обработки качественных данных, чтобы, манипулируя сочетаниями
отдельных элементарных свойств, можно было получать достаточно
точные и полные детерминации. В его задачу входит дифференциация
различных свойств по степени существенности их вклада в аргументы
детерминаций, измеряемой величинами соответствующих приращений
условных частот. Важным элементом детерминационного анализа
является активное формирование контекстов, в которых изучаются
детерминации, а также включение в аналитический процесс априорных
и апостериорных типологий, агрегированных показателей, индексов.
Детерминационный анализ есть, таким образом, метод
систематического исследования условных частот или, попросту говоря,
процентов, которые содержатся в обычных статистических таблицах
сопряженности различных признаков. Для его практического
использования необходима специальная вычислительная диалоговая система.
Детерминационная техника в режиме диалога позволяет в
значительной мере автоматизировать процесс изучения многомерных таблиц
сопряженности, преодолеть упоминавшиеся выше трудности, которые
возникают при переходе от двух-, трехмерных таблиц к таблицам
большей размерности. Она дает возможность чрезвычайно гибко и
оперативно манипулировать качественными признаками,
характеризующими процессы и явления в социально-экономической системе.
Детерминационный анализ предназначен для описания ряда
практических ситуаций, на описание которых претендует также так
называемая теория нечетких множеств [19]. Сходство и различие
между этими двумя подходами определяется в основном следующей
аналогией между понятием детерминации и понятием принадлежности
нечеткому множеству. Фраза "имеется детерминация а*+6 с
интенсивностью РF|а) * допускает в терминах теории нечетких множеств
такой аналог: "имеется элемент &, принадлежность которого
нечеткому множеству 6 характеризуется значением функции
принадлежности jU/g(Q/) = Pt&lOb)". Однако, если функция принадлежности это
некий априори заданный формальный объект, то аналог функции
принадлежности - интенсивность детерминации - это всегда самая обычная
условная частота (условная вероятность). Благодаря этому расчетный и
понятийный аппарат детерминационного анализа существенно
отличается от расчетного и понятийного аппарата теории нечетких множеств.
Сама по себе идея анализировать условные частоты ненова. Одним
из первых вопрос о необходимости методов такого типа поднял Бон-
гард [4] (см. также [7, 11, 18, 27,28]). От прочих направлений
в этой области детерминационный анализ отличается прежде всего
9
последовательной ориентацией на непосредственное манипулирование
прямыми и обратными условными частотами и их приращениями.
Оказывается, что математические формулировки задач при таком
подходе естественно приводят к понятию так называемой детерминадионно?
(индуцированной) функции, образованной детерминациями, а сам
метод становится методом анализа подобных функций.
Книга состоит из пяти глав. Гл. I - вводная. Б ней изложены осо
бенности ситуации, сложившейся в практике эмпирического описания
социальных явлений, которые можно рассматривать как
содержательные предпосылки, ведущие к схеме детерминационного анализа. Гл.и
содержит описание основных понятий детерминационного анализа, пост
роенное на простых примерах. Практические процедуры анализа
рассматриваются в гл. Ш. Здесь же описывается диалоговая
вычислительная система, обеспечивающая необходимые расчеты. Гл. и/ посвя
щена -элементам моделирования социальных процессов на основе
понятий, фигурирующих в детерминационном анализе. Взаимоотношение
рассматриваемого метода с другими математическими методами
анализа данных обсуждается в последней, V главе. Завершает книгу
математическое приложение, где представлена формальная схема,
лежащая в основе детерминационного анализа.
Работа над материалом, вошедшим в книгу, велась в течегие 10
лет. Я считаю своим приятным долгом выразить признательность тем,
кто в разные периоды этой работы способствовал ее проведению и
завершению: P.M. Фрумкиной, М.С. Мацковскому, В.В. Сазонову,
Б.А. Грушину, Д.Ю. Панову (ныне покойному), Ю.Н. Живлюку, и мно
гим другим, чье доброжелательное и заинтересованное отношение
помогло мне довести ее до относительного завершения. Я особо
благодарен С. 3. Богатырь и Г.Д. Брускину, а также К. Б. Соколову,
О. С. Пчелинцеву, С. С. Шаталину, В. И. Данилову-Данильяну, В.Г.
Гребенникову, Н. И. Лапину, Г. В. Сухановой, А. А. Веселову, В. Н. Деза,
А. Я. Подрабиновичу за помощь и поддержку, без которых написание
этой книги вряд ли оказалось бы возможным или было бы отложено
на неопределенный срок. Ценные дискуссии и обсуждения с
А.Н.Алексеевым, П. Ф. Ацдруковичем, О. Б. Божковым, Ю. Вооглайдом, Л.А.Гор
доном, А. Г. Здравомысловым, Я. С. Капелюшем, М. Ю. Лауристин,
Ю. И. Маниным, Б. Г. Миркиным, И. Б. Мучником, Н. Ф. Наумовой,
Б.В. Сазоновым, Н.М. Римашевской, В.Й. Ядовым в немалой степени
способствовали прояснению многих из затронутых в книге вопросов.
В работе над материалом монографии для меня много значили также
поддержка и участие С.С. Артемьева, И.В. Вознесенской, Н.Б.
Косаревой, Н.Н. Ноздриной, В.А. Павлова, М.Ю. Рю, Т.А. Сычевой, Е.М.
Щербаковой, М.Ю. Щукина и других сотрудников отдела системного
исследования социально-экономических проблем развития народного хозяйства
ВНИИСИ ГКНТ и АН СССР. Всем им я глубоко признателен.
Одно мелкое замечание. Написание ряда буквенных символов на
рисунках отличается от написания соответствующих символов в
основном тексте. Наиболее выразительно это различие прослеживается
на букве а (си), хотя и для некоторых других прописных и строчных
букв оно довольно заметно. Это объясняется техническими причинами.
10
Глава I
НЕКОТОРЫЕ ОСОБЕННОСТИ ЭМПИРИЧЕСКОГО ОПИСАНИЯ
СОЦИАЛЬНЫХ ЯВЛЕНИЙ НА МИКРОУРОВНЕ
Эмпирическое описание социальных явлений осуществляется на
базе специальных эмпирических исследований. Основой таких
исследований служат социальные измерения. Можно констатировать, что
практика социальных измерений сложилась как практика получения
эмпирических данных о том, что происходит в жизни отдельных
людей, независимо от того, идет ли речь об аспектах собственно
социальных или экономических. Уровень рассмотрения социальной и
социально-экономической проблематики, на котором явно
учитываются индивидуальные жизненные ситуации, индивидуальные проявления
воли людей, их устремления и надежды, - это по определению
микроуровень описания социальных (социально-экономических) явлений.
Социальные измерения привязаны к микроуровню, хотя их элементы
могут встречаться и на других уровнях.
В этой главе мы рассмотрим некоторые особенности
эмпирического описания социальных явлений, которые диктуются свойствами
социальных измерений. Цель такого рассмотрения - получить
компактные, ясные и конструктивные требования к математическим
методам анализа и интерпретации эмпирических данных.
§ 1.1. Формальный образ первичных эмпирических данных.
Матрица данных, веер отображений
Тезис. Первичные эмпирические данные, получаемые в ходе
социальных исследований, представляют собой веер, отображений, т.е.
совокупность отображений вида Е^Х. i€ 1,п,где Е - множество
объектов, Х-~ множество значений переменной %. i - индекс, нумерую-
ir *
щий переменные, участвующие в эмпирическом обследовании.
Математические методы анализа данных должны быть методами
оперирования такими совокупностями отображений.
Первичный результат социальных измерений - это, попросту
говоря, пачка заполненных анкет. Конечно, это могут быть не анкеты,
11
а бланки интервью, или иные типы рабочих документов. Тем не
менее пачка заполненных анкет - наиболее простой и точный образ
первичных эмпирических данных, получаемых путем социальных
измерений в ходе эмпирического обследования.
Каков формальный образ пачки заполненных анкет? Здесь мы по
существу интересуемся вопросом о том, каков исходный формальный
объект, с которым должны иметь дело математические методы анаг-
лиза и интерпретации данных. Наиболее Общеупотребительная
интерпретация этого формального образа - матрица данных. В ней
строки - объекты, столбцы - переменные, а каждый отдельный элемент .
на пересечении строки и столбца - значение соответствующей
переменной для соответствующего объекта (см., например, [24, 35]).
Обратимся к примеру. Допустим, в анкете всего два вопроса.
1. Сколько лет Вы состоите в браке?
1) до 3 лет,
2) от 3 до 10 лет,
3) более 10 лет,
4) в браке не состою.
2. Есть ли у Вас сбережения на сберкнижке?
1) есть,
2) нет,
3) нет ответа.
Это значит, что имеются всего две переменные. Первая
(обозначим ее через X) - длительность брака, вторая (обозначим ее
через и) - наличие сбережений на сберкнижке. Переменная X имеет
множество значении из четырех элементов: л = \ х , X ; х ,х Jf
где X - длительность брака до 3 лет, X - длительность брака
от 3 до 10 лет, X - длительность брака более 10 лет, % - рее-!
пондент в браке не состоит.
В множестве значений переменной и три элемента
u } где и - есть сбережения на сберкнижке, и - нет
сбережений на сберкнижке, и - респондент не ответил на вопрос.
Предположим, опрошено три человека, и, судя по ответам,
оказалось, что один из них состоит в браке более 10 лет ( х = х ) и
имеет сбережения на сберкнижке Ы - \j ), другой состоит в браке
до трех лет (Xs х ) и сбережений не имеет ( у = \j ), & третий
е,1>
еB>
е<3'
- анкета 1
— анкета 2
- анкета 3
X
хC)
хA)
хD»
V
у<1>
у<2>;
yd» I
Рис. 1.1,1. Пример матрицы данных. Три объекта, две переменные.
12
х-{
(D)
,<3>
Х<2>^
,Н)
-4-
-Ф
-Ф-
еA) е<2» еC)
,C>
/B)
A)
-Ф-
-Ф-
еA1еB)еC)
У '
Е
Рис. 1.1.2. Графики отображений Е* X (слева) и E"*Y(справа).
Точки графиков отмечены кружками.
в браке не состоит (X - х )и имеет сбережения (и - и ).
Матрица данных в этом случае будет иметь вид, изображенный на рис. 1.1.1
На практике в матрице данных бывает в среднем от нескольких
сотен до нескольких тысяч строк (объектов) и от нескольких
десятков до нескольких сотен столбцов (переменных) - таковы
размеры матриц, описывающих обычные массивы социологических и
социально-экономических данных в типичных случаях.
Элементы матрицы данных в социальных исследованиях имеют,
как правило, нечисловую природу. Это обстоятельство отражает
одну из важнейших специфических особенностей социальных измерений
(см. ниже § 1.2). В этих условиях термин "матрица" теряет свое
формальное математическое содержание и превращается в
математическую метафору, обозначающую произвольное, вообще говоря,
нечисловое множество, элементы которого расположены в клетках
прямоугольной таблицы. Ничего, кроме возможности записать данные в
виде такой таблицы, здесь термин "матрица" не означает.
Это вынуждает искать некое более основательное
математическое понятие, стоящее за образом матрицы данных, которое
позволило бы удовлетворительно описывать формальную структуру
эмпирических данных и операции над ними. "Таким понятием оказывается
понятие отображения, или функции.
Посмотрим на рис. 1.1.1. Каждый столбец изображенной на нем
матрицы - не что иное, как табличная запись функции, которая
отображает множество объектов (строк) в множество значений
переменной, соответствующей этому столбцу. Матрица данных на рис. 1.1.1
представляет собой запись двух отображений (функций), которые
показаны на рис. 1.1.2.
Здесь множество строк матрицы на рис. 1.1.1. (т.е. множество
объектов) обозначено через Е. Оно содержит три элемента: Е = \ С ,
€ , е }, где е - анкета 1, в - анкета 2, е - анкета 3.
Отображения Е"*Х и Е"* Y можно изобразить совместно в виде
диаграммы следующим образом:
X Y
Е
13
В общем случае, когда имеется к переменных X. Л € 1,Н,и каждая
переменная X. имеет множество значений Л., эта диаграмма будет
иметь вид веера отображений;
Xi Х2 Х3 ... Хп
Е
Отображения, образующие веер, мы будем называть компонентами.
В рассмотренном выше примере веер отображений имеет две
компоненты, в общем случае - п компонент. Множество Е называется
основанием веера.
Таким образом, совокупность первичных данных описывается
веером отображений, имеющим столько компонент, сколько
альтернативных переменных фигурирует в эмпирическом исследовании.
Переменная х называется альтернативной, если всякому
конкретному объекту из обследуемой совокупности Е может соответствовать
только одно ее значение. Общеизвестно, что в рабочих документах
обследований довольно часто встречаются вопросы, которым
соответствуют неальтернативные переменные. Это вопросы, в которых
респондент может одновременно выбрать не один, а два или более
вариантов ответа. Сюда относится, например, часто встречающаяся
форма вопросов-списков. Однако любые неальтернативные переменные,
встречающиеся в практике социальных измерений, всегда можно
преобразовать в переменные альтернативные, причем такое
преобразование всегда может быть проведено так, чтобы любая
содержательная или формальная проблема анализа данных, допускающая
постановку и решение в терминах неальтернативных переменных, имела
эквивалентную постановку и решение в терминах альтернативных
переменных.
Утверждение, что совокупность первичных эмпирических данных,
получаемых в результате социальных измерений, описывается веером
отображений (т.е. совокупностью отображений вида ока-
зывается, таким образом, справедливым для довольно широкого
класса эмпирических данных. Отсюда вытекает очевидное требование к
математическим методам анализа подобных данных: эти методы
должны быть методами оперирования веерами отображений.
§ 1.2. Номинальность
Тезис. Дискретность и конечность - вот все свойства множеств
Е,Х. ,i€ i,tt, на которые можно опираться при проведении
преобразований над веерами отображений вида Е~*Х^? 161,11. Ограниченность
набора этих свойств - прямое следствие принципа номинальности в
социальных измерениях (см. ниже).
14
Социальный измерения не могут существовать вне общения с
людьми, вне коммутшкативных процессов. Это основная причина того,
почему социальные измерения являются по руществу измерениями
номинальными илщ качественными.
Большая част|> социальных переменных, используемых в
конкретных исследования^, - это переменные номинальные, т.е. такие,
значениями которых выступают, вообще говоря, нечисловые, символы.
Номинальные измерения суть акты идентификации объектов
исследования со значениями подобных номинальных переменных.
'Затрудняюсь ответить' - подчеркивает респондент в анкете, и этот его
ответ - типичный пример номинального измерения. В роли
нечислового символа (знака) здесь выступает вся конструкция 'затрудняюсь
ответить' как целое. Мнения, установки, ценностные ориентации,
вербальное и невербальное поведение - все основные социлогические
характеристики измеряются на основе номинальных индикаторов
(номинальных переменных), фигурирующих в рабочих документах
обследований. Пол, тип семьи, профессия, любой вопрос с закрытиями 'да',
"нет', 'затрудняюсь ответить', практически любой открытый вопрос
в анкете или интервью - общеизвестные примеры номинальных
переменных.
Номинальные переменные возникают всегда, когда объектами
исследования становятся люди, их сознание и поведение. Это
обусловлено тем, что социальное не может формироваться, существовать и
проявлять себя вне язьща, вне словесности в широком смысле. И
социолог—исследователь, и те, кто выразил добрую волю выступить в
роли респондентов, предпочитают представлять свои реакции и
описывать внешний для них мир образами и понятиями, выражаемыми
словами, а не числами . Именно поэтому используемые в
социологии номинальные переменные всегда представляют собой
семантические конструкции, изображаемые словами и сочетаниями слов
живого языка, а методы формирования таких номинальных переменных
образуют ядро методической культуры эмпирических социологических
исследований.
j Можно было бы предположить, что обилие номинальных
переменных - это своего рода издержки, проистекающие от неразвитости
теории и техники социальных измерений, и в будущем положение
изменится: номинальные переменные перестанут играть главенствующую
роль в социальных измерениях, уступив место переменным
количественным или близким к ним по уровню. Такая точка зрения вьодвигает
Существуют, разумеется, слова, обозначающие числа. Однако,
во-первых, сфера их использования ограничена. Во-вторых, за
редкими (быть может, патологическими) исключениями, они
используются в обыденной языковой практике точно так же, как все
прочие слова, а не так, как, скажем, используются значения
числовых переменных в узкоспециализированной практике
естественных наук.
15
на передний план проблему квантификации как проблему поиска
чисел, стоящих за словами обычного человеческого языка .
В социологии, однако, эта точка зрения давно ассоциируется со
своего рода болезнью, получившей название квантофрении ([51],
с. 175). Весь* содержательный опыт социальных исследований
позволяет утверждать как раз обратное: нет никаких оснований
рассчитывать на то, что в будущем с развитием техники ^ теории социальных
измерений преобладанию номинальных переменных здесь будет
положен конец. До тех пор, пока слово будет служить человеку в его
обыденной жизни главным инструментом познания и отражения себя и
внешнего мира, до тех пор, пока человек сохранит за собой
активную роль в порождении значений, формирующих его собственное
отражение социального мира в используемых им словах, этого не про-
изойдет . Тем самым утверждается, что основополагающая роль
номинальности в социальных измерениях обусловлена
фундаментальными свойствами самой социальной реальности и не может
измениться с течением времени. Это утверждение составляет суть принципа
номинальности, который мы принимаем как априори очевидный и не
требующий дальнейших объяснений. Имеется тесная взаимосвязь
между принципом номинальности и специфической функцией активности,
которой наделен социальный объект в социологических исследованиях
(см. t61]).
Обратимся к требованию, которое вытекает из принципа
номинальности применительно к математическим методам анализа
данных. Мы пришли к тому, что это должны быть методы
оперирования совокупностями отображений вида E~*X.,i€ i,tt.Согласно
принципу номинальности переменные, на базе которых строится веер
отображений Е -,,X.?i € 1,П,суть в общем случае переменные номинальные.
Отсюда следует жесткое требование: математические методы анализа
и интерпретации эмпирических данных должны в общем случае
предполагать полную произвольность природы элементов, из которых со-
Отметим, что по существу именно эта позиция прямо
предшествует концепции, трактующей измерение как гомоморфное отображение
эмпирической системы с отношениями в числовую систему с
отношениями [39, 473.
**)
В частности, представление о том, что во всякой науке
описательный этап (т.е. этап классификаций или номинальных
измерений) должен быть рано или поздно преодолен и затем замещен
этапом установления величин и математическим моделированием,
наподобие того, как это произошло в физике [13], для социологических и
социально-экономических исследований не годится в принципе -
альтернатива ведет к образу сообщества людей как роботоподобных
существ со стрелками приборов вместо языка и электродами вместо
волос.
16
стоят множества X», i € 1,п. Фактически множества X. являются
дискретными и конечными - это все, что в соответствии с принципом
номинальности допустимо предполагать относительно свойств
множеств, фигурирующих в веерах отображений.
Попытки следовать этому требованию приводят к трудностям,
которые весьма вьфазительно описываются в монографии Саганенко (см.
[41], с. 130): гНа\ основании нашего опыта при измерении чисто
соииологических переменных, таких, как установки, мнения,
удовлетворенность, целенаправленность и пр., мы знаем, что получаем
либо шкалы классификаций (т.е. номинальные шкалы - С.Ч.), либо
полуупорядоченные шкалы*..
Наши данные обладают настолько малым количеством свойств,
что самое надежное иметь дело с исходными (лучше с негруппиро-
ванными) данными и разве лишь считать для них те или иные
проценты . • •
Практически все способы обработки данных в наших случаях
являются некорректными... *,
Итак, следование принципу номинальности приводит нас к
чрезвычайно бедным расчетным возможностям: обрабатывая данные, нам
остается 'разве лишь считать для них те или иные проценты*.
Возможности эти кажутся специалистам по математическим методам в
социологии столь ничтожными, что использовать их - все равно что
не применять никаких методов:
'Итак, мы стоим перед проблемой: либо применять строгие
методы к нестрогим данным, либо не применять никаких методов. Мы
выбираем первое, так как только таким способом можно
осуществлять по крайней мере предварительное упорядочение материала,
только так можно попытаться нащупать какие-то наиболее общие
закономерности и связи между данными. Другого пути перехода от
констатирующих описаний к содержательно-объяснительному анализу
пока не видно* ([41], с. 134).
Приведенные цитаты удачно оттеняют научное направление в
анализе социологических и социально-экономических данных,
развиваемое в настоящей книге. Это направление по существу возникает
всецело на базе подсчетов тех или иных процентов, т.е. там, где по
бытующей традиции никакого серьезного продвижения в области
методов анализа социологической и социально-экономической
информации ожидать не пшходится.
§ 13. Конкретность
Тезис. Принцип конкретности. Содержательные социальные
значения всегда привязываются к конкретным свойствам, которые
выступают как отдельные значения признаков (первичных и вторичных
переменных). Реальные установки, ценностные ориентации, мотивации
людей строятся на основе связей между отдельными свойствами, т.е.
между отдельными значениями признаков, а не признаками в целом,
о этом смысле понимаемая конкретность является внутренним свойст-
17
вом социального объекта. Описание социальных закономерностей
базируется на описании связей между отдельными значениями
признаков, а не признаками в целом. /
Одна из основных задач, решаемых при обработке
социально-экономических данных, - задача выяснения и описания связей между
переменными. Наиболее простой типичный случа^ - случай, когда
задана матрица, подобная изображенной на рис. 1.3.1, и по ней
необходимо оценить, насколько связаны переменные х,и.
У<
У
у<3>
уB)
уA)
42
0
58
х<1)
0
58
42
хB)
58
42
0
хC)
X
X
Рис. 1.3.1. Таблица сопряженности между признаками
(переменными) х,у (вариант 1).
Здесь переменные (в дальнейшем будем считать, что переменная
и признак - синонимы) х,и имеют по три значения, а в клетках,
таблицы сопряженности указаны числа респондентов, давших
соответствующие сочетания ответов; всего в выборке, как нетрудно
подсчитать, 300 человек.
Имеется свыше 100 моделей оценки величины статистической
связи между переменными х; ц в подобной ситуации [34]. Подсчи-
таем, например,. коэффициент Пирсона
П-л —*—: '
N+/*
где
/*-N
НЕ
N(x,y)'
- I
Здесь N(X,U)- число, которое в таблице сопряженности находится
; То, что это именно коэффициент Пирсона, в данном случае не
имеет особого значения. Мы здесь приводим его для примера
только потому, что он принадлежит к числу наиболее известных. В
принципе аналогичный пример можно было бы привести, используя любую
из множества подобных мер связи (более детально этот вопрос
разбирается в гл. v).
18
на пересечении столбца х и строки U,N(ij)- сумма всех чисел в
строке ц, N(x)- сумма всех чисел в столбце х;Ы - полное число
элементов в выборке.
Подсчет показывает, что коэффициент Пирсона для. этой таблицы
равен 0,59. Мы можем утверждать: связь между признаками х, и
довольно высока и измеряется величиной коэффициента Пирсона,
равной 0,59.
Попробуем теперь взглянуть на ситуацию с позиции людей, которые
скрываются за числами, проставленными в таблице сопряженности.
Переменные х,и для этих людей суть вопросы анкеты, а значения
переменных - варианты ответов на эти вопросы. В пределах
каждого отдельного вопроса социальная информация, получаемая
эмпирически, полностью определяется тем, какой ответ на данный вопрос
выбрал опрашиваемый. При выборе ответа человек опирается на
различение конкретных значений социальных переменных. Кроме того,
он учитывает связи между социальными переменными,
представляющие собой следования (условные суждения), в которых и посылки
и следствия выражены опять-таки через отдельные значения
определенных социальных переменных.
Каждая переменная сама по себе (точнее, имя переменной,
заключенное в формулировке вопроса) определяет только класс объектов
(ответов на вопрос), среди которых человек делает выбор. После
того как этот класс зафиксирован в сознании, мышление отвечающего
строится на основе оперирования конкретными вариантами ответов -
объектов из этого класса. Для опрашиваемых есть мужчины и есть
женщины, а признак "пол* - лишь знак, показывающий, что
речь должна идти о мужчинах и женщинах и о различениях
между ними.
Изучаемые в эмпирических исследованиях социальные нормы,
вербальные и невербальные установки, ценностные ориентации,
мотивации людей строятся на базе связей между отдельными свойствами,
т.е. между отдельными значениями признаков, а не признаками в
целом. В этом проявляется конкретность мышления на уровне
обыденной жизнедеятельности. Так понимаемая конкретность выступает не.
как внешнее требование, а как внутреннее свойство социального
объекта. Из констатации этого свойства мы будем исходить как из
принципа, который для краткости назовем принципом конкретности.
Применительно к изучению связей между социальными
переменными (признаками) принцип конкретности требует, чтобы описание
этих связей в ходе обработки и анализа эмпирических данных
базировалось на описании связей между отдельными конкретными
значениями признаков, а не признаками в целом. При этом использование
общих, интегральных, 'усредненных* показателей связи между
признаками в целом, вообще говоря, допустимо. Однако всякий подобный
показатель может быть признан удовлетворяющим принципу
конкретности лишь в той мере, в какой по значениям этого показателя можно
Установить, как связаны между собой отдельные конкретные
значения признаков.
19
У
У<
у<3)
уB)
у<1)
0
0
50
х<1>
0
50
0
хB)
60
70
70
х<3)
X
X
Рис. 1.3.2. Таблица сопряженности между признаками
(переменными) х,^ (вариант 2).
Вернемся к таблице сопряженности (см. рис. 1.3.1). Описание
связи между признаками хгц, которое содержится во фразе: * Связь
между признаками х7 у измеряется величиной коэффициента Пирсона,
равной 0,59*, не удовлетворяет принШшу конкретности. Величина
коэффициента Пирсона, равная 0,59, не позволяет нам сказать
ничего определенного ни о том, какие значения х связаны с какими
значениями у.7 ни о величине этих связей. Действительно,
рассмотрим рис. 1.3.2. На нем показана таблица сопряженности между теми
же признаками х,ч; которая весьма отличается в содержательном
плане от таблицы на рис. 1.3.1, где значения и следовали из значен^
х с максимальной вероятностью, которая оценивается величиной
P(^lx) - 58/E8 +42) -0,58;
таковы соответствия
ветствия х^1*-*^ и х(г>'
И) и) т
X ~\f ,Х -М
„(*>
f^V^t^.Ha рис. 1.3.2 соот-
у предельно жесткие - в mat значения и
следуют из значений х с условной вероятностью, которая оцениваете^
KaKP(V<4)|x{i,) = P(V
(г),Х(ЗЛ)= 50/50 = 1.
Между тем связь в таблице сопряженности на этом рисунке
описывается, как легко убедиться, величиной коэффициента Пирсона, такн
же равной 0,59, т.е. коэффициент Пирсона не отличает эти две табл^
цы одну от другой.
Аналогичные примеры можно привести и для любой другой из
множества моделей, которыми пользуются для измерения связи между
признаками в целом, интегрально. Все они не удовлетворяют
принципу конкретности и поэтому непригодны при анализе социальной
информации.
В этой книге мы будем развивать только такие подходы к ана~
лизу взаимосвязей между переменными, которые удовлетворяют принн
ципу конкретности. Забегая вперед, скажем, что наиболее приемле- i
мой мерой статистического взаимодействия между свойствами
(конкретными значениями признаков) оказываются обычные оценки
условных вероятностей (условные эмпирические частоты, т.е. все те
же проценты).
20
§ 1.4. Ограниченная статистичность
Тезис. Сощшльные закономерности представляют собой
закономерности статистические и в общем случае не являются жестко
детерминированными. Однако статистичность социальных закономерностей
выступает лишь как ограниченное по своим масштабам нарушение
детерминизма.
В эмпирическом исследовании данные о наличии тех или иных
социальных закономерностей возникают всегда как данные о связях
между переменными, фигурирующими в обследовании. В простейшем
случае, если в обследуемой совокупности действует жесткая норма
(природа ее нас не интересует), которая предписывает каждому
индивиду, оказавшемуся в ситуации (V, действовать способом 8, то
эмпирически действие этой нормы мы отметим тем, что условная
частота свойства i при условии, что имеет место свойство О/, окажется
равной P(S|d)- 1 (разумеется, если свойства а и 6 попали в рабочий
документ обследования как значения определенных эмпирических
индикаторов). Строгое равенство условной частоты единице означает,
что социальная закономерность, представленная упомянутой нормой
поведения, жестко детерминирована. Как правило, однако, жесткий
детерминизм не имеет места. Жесткость связей, которыми
представлены социальные закономерности, может быть различной в разных
социальных группах. Детерминизму здесь противопоставляется
статистичность, увеличение которой равносильно размытию
закономерности и в конечном итоге - ее исчезновению.
Социальные закономерности не являются в общем случае жестко
детерминированными, они по своей природе статистичны . Однако
статистичность социальных закономерностей выступает лишь как
ограниченное по своим масштабам нарушение детерминизма. Это
утверждение мы будем называть принципом ограниченной
статистичности.
Принцип ограниченной статистичности предъявляет к
математическим методам анализа данных определенные требования. В
частности^ всякий метод описания статистических связей между
социальными переменными должен позволять исследователю обнаруживать
жесткие связи между значениями переменных, характеризующиеся
ограниченной статистичностью, коль скоро такие жесткие связи
существуют в действительности. Метод, позволяющий это делать,
можно признать удовлетворяющим требованиям, которые вытекают из
принципа ограниченной статистичности. Если же де-факто связи та-
; Обращаем особое внимание на то, что статистичность здесь
понимается в весьма узком смысле как мера отличия эмпирических
условных частот (интенсивностей детерминаций) от единицы, т.е. как
мера нарушения детерминизма (понимаемого опять-таки достаточно
узко). Тем самым вопрос о том, являются ли вероятностные
описания адекватными моделями социальных явлений, здесь не
обсуждается.
21
кого типа есть или могут быть, но метод ле позволяет их
обнаружить, подобный метод должен считаться не удовлетворяющим
принципу ограниченной статистичности. В таком случае следует
подвергнуть сомнению возможность достаточно эффективного анализа
социальных закономерностей данным методом.
Теперь кратко подытожим сказанное в этой главе. Мы
рассмотрели некоторые особенности эмпирического описания социальных
явлений на микроуровне. Используемые здесь измерительные
процедуры, поставляющие эмпирический материал для такого описания, всегда
строятся на базе коммуникативных процессов - в конечном итоге это
всегда вопросы, обращенные к отдельным людям, высказанные в слог-
вах, которые должны быть им понятны, и ответы на вопросы,
записанные на обычном живом человеческом языке.
С формальной точки зрения итог социальных измерений можно без
ущерба для общности записать в виде веера отображений
Е-Х., сеМц
где Е - множество респондентов, X. - множество значений переменной
X. I - индекс, нумерующий переменные, фигурирующие в эмпиричес-
v
ком обследовании.
Прежде чем двигаться дальше, нам важно было установить
следующие положения:
1. Множества Е, Х-, фигурирующие в веере отображений, являются
дискретными, вообще говоря, конечными множествами произвольной
природы. Это обстоятельство имеет глубокий непреходящий смысл и
выражает принцип номинальности.
2. Социальные закономерности предстают в эмпирических
исследованиях в форме связей между переменными, фигурирующими в
обследовании. Важно, что основой описания таких связей должно быть
описание связей между отдельными значениями переменных, а не
между переменными в целом. Всякое описание связей между
переменными в целом приемлемо лишь тогда, когда его можно
конкретизировать до описания связей между конкретными значениями
переменных - таково требование принципа конкретности.
3. Связи, описывающие социальные закономерности, не являются в
общем случае жестко детерминированными. Но статистичность,
размывающая детерминизм, здесь ограничена. Методы обнаружения и
описания статистических связей должны быть рассчитаны на анализ
случаев, когда статистичность выступает как более или менее
ограниченное нарушение детерминизма - таково требование принципа ог-
раниченной статистичности.
Глава II
ОСНОВНЫЕ ПОНЯТИЯ ДЕТЕРМИНАЦИОННОГО АНАЛИЗА
Не будет, по всей видимости, большим преувеличением сказать,
что основная трудность в создании эффективных математических
методов анализа эмпирической информации в социальных
исследованиях - это качественный характер данных, подлежащих обработке.
Основную массу информации в социологии составляют результаты
измерений в неупорядоченных (синонимы: номинальных,
классификационных) или полуупорядоченных шкалах. Многие авторы отмечают, что
даже тогда, когда измерение осуществляется в шкалах порядковых
или более высокого уровня, все равно анализ данных разумно
строить так, как будто мы имеем дело с номинальными шкалами [41,
51]. В социально-экономических исследованиях положение во
многом сходное.
Для анализа качественных данных в социологии используется
целый ряд методов [2, 22, 33, 36]. Однако следует признать, чгго
до сих пор, как и много лет назад, самым надежным для социолога
остается визуальный анализ условных и безусловных частот
(процентов), содержащихся в таблицах сопряженности признаков.
Используемая здесь техника, как правило, тривиальна - она сводится к
подсчету условных частот, связывающих значения переменных, и, далее,
к сравнению этих условных частот между собой. Выводам которые
при этом делаются, основываются на интерпретации величин
условных частот как показателей направленной связи между значениями
признаков (переменных). Например, если среди мужчин процент
часто читающих книг заметно выше, чем среди женщин, то отсюда
выводится заключение, что пол влияет на чтение книг, причем
мужчины более склонны к частому чтению, чем женщины. Как метод,
детерминационный анализ представляет собой прямое развитие этой
тривиальной техники. Для обычных двумерных таблиц его отличие
от подобной техники выглядит как чисто терминологическое, по
существу же можно* считать, что он с ней совпадает. В случае
многомерных таблиц сопряженности детерминационный анализ дает
возможность так организовать расчеты и процедуры содержательной
интерпретации, что анализировать, скажем, четырех-, пяти-,
шестимерные таблицы становится в принципе столь же легко, как и двумерные,
23
тогда как применение обычной тривиальной техники наталкивается
в таких случаях на существенные трудности в организации анализа
и способах содержательной интерпретации результатов.
Примеры реализации детерминационного анализа рассмотрены в
следующей, Ш гл. Прежде, однако, необходимо описать основные
понятия, лежащие в основе метода, и привязать их к реальностям, с
которыми практический исследователь сталкивается в своей
каждодневной практике. Это и составляет содержание настоящей главы.
§ 2.1. Детерминация
Допустим, социолог по некоторому свойству а выделил из
обследуемой совокупности группу всех тех респондентов, которые
обладают данным свойством, и обнаружил, что какая-то доля
респондентов из выделенной группы, скажем, 70%, демонстрирует
определенный тип поведения 8. На языке детерминационного анализа это
означает, что имеется детерминация а/~& с интенсивностью U а»-» в) =
- 70%. Детерминация а>*Й - это не что иное, как высказывание
"если а;то 6", или "из а следует 8", которому приписывается
интенсивность Ца-* Ь),отражающая его точность, или истинность.
Допустим теперь, что среди респондентов, демонстрирующих тип
поведения 6; доля тех, кто обладает свойством а, составляет, скажем, 40%.
На языке детерминационного анализа это означает, что
детерминация &*-+ в имеет емкость С (&ь""'&) ~ 40%. Она измеряет долю случаев
реализации поведения 8, которая "объясняется" высказыванием "из
а следует 6". Емкость С (а, *+Ь) отражает, таким образом, насколько
всеобъемлюще объяснение, построенное на детерминации а*-*6,т.е.
полноту этой детерминации.
Детерминационный анализ начинается, как мы видим, с
приписывания некоторой дополнительной смысловой нагрузки самым
обычным понятиям - процентам, или условным частотам (условным
вероятностям), причем сама детерминация как самостоятельный объект
вводится априори, ее существование постулируется.
У
у^Ь
у = Ь
60
140
х = а
590
210
х Ф а
X
Рис. 2.1.1. Таблица сопряженности 2*2 по переменным x,ti.
Объем выборки (сумма чисел в клетках) - 1000 человек.
На рис. 2.1.1 изображена простейшая таблица сопряженности по
переменным X,U, в клетках которой проставлены числа
респондентов. Каждая клетка характеризуется здесь абсолютной величиной
числа, которое в ней находится, его долей (в %) относительно суммы
чисел в столбце (условная частота в столбце) и долей (в %) того же
числа относительно суммы чисел в строке (условная частота в строке).
24
В детерминашюнном анализе предлагается рассматривать каждую
клетку такой таблицы сопряженности (и вообще любой произвольного
размера шхн) как изображение двух - прямой и обратной -
детерминаций, а соответствующие условные частоты (проценты по строке и
столбцу) - как исчерпывающие характеристики этих детерминаций -
их интенсивности и емкости. При этом интенсивность прямой
детерминации является емкостью обратной, а емкость прямой -
интенсивностью обратной. Например, клетка на пересечении столбца х = О,
и строки ^ в Ь соответствует двум детерминациям а* 8 и S-1, О/.Для
первой интенсивность и емкость равны соответственно
С(а~*)-Р(а|1)-14У?210-о,4.
Интенсивность и емкость детерминации Iй* й равны тем же числам,
но их надо поменять местами:
С(*-»)-РE|*)-5^^-35--0.7.
Как измерять частоты - в процентах или долях единицы -
безразлично, но мы везде в дальнейшем будем предпочитать доли единицы, а
не проценты. Очевидно, что
I(a~6) e СF~ со),
С(о,~Ь) - Ш~а).
Зрительный образ всякой пары детерминаций а-* 6, Ь*+ а удобно
связывать либо, как отмечено, с определенной клеткой таблицы
сопряженности (точнее, с определенным столбцом и строкой, на пересечении
которых она находится), либо с диаграммой Венна (рис. 2.1.2).
Здесь множество Е всех обследуемых не очерчено - очерчены
только группы обладающих свойством а, (левый эллипс) и свойством I
(правый эллипс), которые обозначены соответственно через Е (ои) и
?F).
Всякая детерминация может существовать лишь тогда, когда
определены ее интенсивность и емкость. Отсюда следует, что нам
необходимо немного исправить утверждение о том, что всякую клетку
(вместе со столбцом и строкой, на пересечении которых она
находится) нужно рассматривать как изображение двух взаимно
обратных детерминаций. Не всякую, разумеется, но лишь такую, которая
находится на пересечении строки и столбца, соответствующих
ненулевым по численности группам респондентов. Детерминация a •*¦* Ь (в t-*
^а)существует лишь тогда, когда N (&M* О и NF) 5* О, где N(a),
NF)-. числа респондентов соответственно в группах Е(а) и ЕF).
25
Рис. 2.1.2. Диаграмма Венна, изображающая пару взаимно
обратных детерминаций а»* в и l^d(ср. с рис. 2.1.1).
ai—э*-Ь ai—^b ai—^b a<—^b
Da и хз хз
1 2 3 4
1*0 1 = 1 l«0 I* 1
C«0 C*0 C = 1 C«1
Рис. 2.1.З. Различные варианты сочетаний точности и полноты
детерминаций. Неполная и неточная детерминация а* 8 A), точная, но
неполная B), неточная, но полная C), точная и полная D).
Интенсивность и емкость детерминации а*-* & суть условные
частоты w % при условии a " и *а при условии Ь *. Они изменяются от
нуля до единицыг
0<CU~*l)< 1.
Если какая-нибудь из этих характеристик равна нулю, то и
другая также равна нулю. Но если нулевое значение исключить, то
интенсивность и емкость - независимые характеристики: при любом
ненулевом значении одной из них может быть в принципе любое
ненулевое значение другой (если; разумеется, не накладывать
дополнительных ограничений на числа заполнения в таблице сопряженности),
На рис. 2.1.3 показаны четыре диаграммы Венна, соответствующие
в известной мере крайним вариантам сочетаний интенсивности
(точности) и емкости (полноты) детерминации а-*4. Для упрощения здесь
группа респондентов, обладающая свойством а, и группа, обладают
щая свойством Ь, обозначены символами flu, 6 (вместо Е(<ь) и ЕF),
как было бы правильнее).
Рассмотренное выше понятие "детерминация* являетдя в детер-
минационном анализе основным. Оно представляет собой*
расширение обычного понятия, обозначаемого тем же словом. Совпадение
общепринятого и введенного нами понятий имеет место, когда
интенсивность детерминации либо строго равна единице, либо отлича-
26
ется от единицы, но лишь незначительно, т*е. когда
детерминация в нашей терминологии - точная или почти точная (см.
также [42 - 46] , где рассматривается один из вариантов детер-
минационного анализа и понятие детерминации используется в
смысле, близком к нашему).
§ 2.2. Эквивалентные преобразования таблиц
сопряженности и произведение переменных
Выше мы уже отмечали, что основное подспорье в
содержательном анализе эмпирических данных для социолога - таблицы
сопряженности. Понятие детерминации, рассмотренное в предыдущем параграфе,
аккумулирует в себе представление о клетках таких таблиц, а
также о записанных в них числах респондентов и процентных
соотношениях этих чисел по соответствующим строкам и столбцам. Мы
имели в виду двумерные таблицы, но реально случаем двумерных
таблиц ограничиться невозможно: более или менее интересные
содержательные результаты получаются, как правило, только при анализе
таблиц сопряженности большего числа измерений. Следует иметь в.
виду, однако, что всякую многомерную таблицу сопряженности
можно без каких-либо потерь преобразовать в двумерную таблицу и
анализировать как двумерную. Для проведения таких преобразований -
они называются эквивалентными - используется свертка или
произведение переменных.
Рассмотрим конкретный пример перехода от трехмерной
таблицы к двумерной путем эквивалентного преобразования (рис. 2.2.1).
Показанные на рисунке две таблицы, очевидно, эквивалентны,
только левая таблица трехмерна (правда, она представлена в виде
двумерной) и переменные х,и,х понимаются как отдельные переменные,
тогда как в правой таблице участвуют всего две переменные ху,%,
поскольку значки Cub, 5.6, а 6, fob здесь выступают не как сочетания
значений двух отдельных переменных х*и, а как отдельные
значения одной переменной, обозначенной символом хи. Переменная хи
называется произведением переменных X,U. Из рис. 2.2.1 следует,
что таблица сопряженности по переменным xu,x,u должна иметь
вид, представленный на рис. 2.2.2.
Произведение хи есть, таким образом, взаимно однозначная
функция от переменных X, и.. Если ввести обозначение xu - f (х,и), то,
очевидно, f @/7Ь) sd6;f(a,o) «5,0 и т.д. Как мы видим,
соответствия {х?u) •->xu,образующие эту функцию, являются точными и
полными детерминациями:
Ш*,и) — хи) »С((х,и) ~ ху) -1.
Всякое конкретное значение переменной ху есть произведение
соответствующих значений переменных х, и-. Так, xu e a6 есть
произведение значений X s a, и u « ft. Произведение значений
эквивалентно логической связке "ъ" (конъюнкции): а1*(ал1) = (а и 6). Если
21
7
С
С
0
100
х = а
у = Ь
200
100
х =а
у = Ь
300
100
х = а
у = Б
0
200
х = а
у = 5
X
У
z
с
с
0
100
ab
200
100
ab
300
100
ab
0
200
аБ
ху
Рис. 2.2.1. Эквивалентное преобразование трехмерной таблицы по
переменным х9Ц 9% (слева) в двумерную по переменным ху, %
(справа).
ху
ab
ab
ab
ab
0
0
0
100
x = a
y = b
0
0
300.
0
x = a
y = b
0
400
0
0
x =a
y = b
200
0
0
0
x = a
у = Б
X
У
Рис. 2.2.2. Трехмерная таблица сопряженности по переменным ос^,
м-
говорить на языке групп респондентов, то свойству а
соответствует группа Е (а) обладающих этим свойством (на рис. 2.2.1 эта группа
содержит IE (а) Is 100 + 100 + 300 - 500 человек), свойству Ь -
группа ЕF) (на том же рисунке ее численность 1Е(ЬI = 100 + 100 +
+ 200 « 400 человек).JB таком случае произведению а 6
соответствует группа Е(а6)= Е (а) ПЕF) респондентов, которые обладают и
свойством &, и свойством 6 одновременно (на рисунке численность
этой группы представлена суммой чисел в столбце 0.6 и составляет
100 человек). Обозначая для краткости группы Е(оО и E(i)
символами а, Б можно было бы записать сив^апб.Операция произведения
значений переменных изоморфна, как видим, обычному пересечению
множеств.
Трехмерную таблицу по переменным х^ъ, показанную на
рис. 2.2.1, можно эквивалентно преобразовать к двумерной не
единственным способом. На рис. 2.2.3 представлены еще два
эквивалентных двумерных варианта той же таблицы.
Распределение респондентов по переменной х ^ * есть одномерная
таблица, эквивалентная исходной трехмерной таблице по переменным
X, и, X. Иными словами, от трехмерной таблицы мы можем с помощыд
эквивалентного преобразования перейти не только к двумерной, но
и к одномерной таблице сопряженности. Произведение переменных
коммутативно (для любых х7^ имеет место %-у в ^х) и ассоциативно
(для любых X0J%1 выполняется xlijfc)-Ubij)fc), и поэтому построить
переменную ХЦЪ (а значит, и провести эквивалентное преобразование трехч
мерной таблицы в одномерную) можно одним-единетвенным способом.
28
X
а
а
100
100
cb
200
0
cb
200
100
cb
0
300
сБ
zy
У
b
b
100
100
ас
200
100
ас
300
0
ас
0
200
ас
Х2
Рис. 2.2.3. Двумерные таблицы сопряженности по переменным х ,
1ц (слева) и -и , Х*^ (справа) как эквивалентные представления
трехмерной таблицы по х , у , ъ на рис. 2.2.1.
u; v
и = р
v = q
Q. lO-
ll II
3 >
u = p
v = q
u = P
v = q
0
0
100
0
x = a
y = b
0
200
100
0
x =a
y = b
0
300
100
0
x =a
y = b
0
0
200
0
x =a
y = b
X
Y
Рис. 2.2.4. Один из многочисленных вариантов эквивалентного
представления трехмерной таблицы по х, ^ , X в виде четырехмерной
таблицы по переменным X, j,u,v,
С помощью эквивалентных преобразований можно не только
уменьшать, но и увеличивать размерность таблицы сопряженности.
Например, трехмерную таблицу по xt^,x, показанную на рис. 2.2.1,
можно преобразовать в четырехмерную по переменным х, u» u*9v так,
как изображено на рис. 2.2.4.
Вообню, любую таблицу сопряженности произвольной размерности
можно всегда представить в виде эквивалентной таблицы
сопряженности любой меньшей или большей размерности. Понятие
многомерности становится, таким образом, сугубо относительным,
зависящим в известной мере от точки зрения: мы вольны выбирать для
всякой конкретной таблицы представление такой размерности, какая
нам удобнее по каким-либо дополнительным соображениям.
§ 23. Равенство переменных по заданному основанию
Кроме произведения переменных, в детерминационном анализе
систематически используется понятие равенства переменных по
заданному основанию. В качестве основания выступает конкретное
множество респондентов, на котором осуществляются социальные из-
МеРения. Две переменные х,и считаются равными па заданному ос-
29
У
у<2»
yd)
1
0
1000
х<1>
х = у
0
0
х<2)
0
0
хC>
X
У
у<2>
yd»
и
0
800
хA>
х = у
200
0
хB)
0
0
хC)
X
У
у,2)
yd)
III
100
900
XA)
х?=у
0
0
хB)
0
0
хC)
X
у B)
yd)
IV
0
799
хA)
хФу
200
0
хB)
0
1
х<3>
X
Рис. 2.3.1. Примеры таблиц сопряженности, соответствующих рав-
_ ным (варианты I, В )и неравным (варианты Н»1-) переменным х,т^.
нованию, если в результате измерений они одинаково классифици-
руют множество респондентов, выступающее в качестве основания.
Это значит, что для любого х *=мдолжно найтись такое у в Ь, что
группы респондентов по a, ft совпадают, т.е. Е(а>)=Е(&). Тогда (и
только тогда) мы говорим, что х - у.
Факт равенства переменных легко устанавливается с помощью
таблицы сопряженности по переменным, которые "проверяются* на пред-*
мет установления равенства. Для того чтобы переменные х, ^ были
равны по заданному основанию, необходимо и достаточно, чтобы
таблица сопряженности по переменным x,tj. удовлетворяла следующему
требованию: в каждом столбце и в каждой строке этой таблицы
должно быть не более одной заполненной клетки (т.е. клетки, в которой
стоит число, отличное от нуля).
Возьмем в качестве основания множество, содержащее 1000
респондентов. Если переменные х,у (пусть для определенности первая
имеет три, а вторая - два значения) равны по этому основанию (или
'равны на этом множестве"), то варианты таблиц сопряженности по
х,^ могут быть подобны вариантам 1,11 на рис. 2.3.1 и не могу!
быть такими, как варианты (и,Ту.
Равенство х * у означает, что существует взаимно однозначная
функция ^ e i (X),определенная для тех значений х, которым
соответствуют ненулевые группы респондентов, причем она состоит из
точных и полных детерминаций, т.е.
I(x~f(x)) = C(x~ f(x))-l.
Когда мы пишем у в х вместо функциональный записи аа sf (х),
то подразумеваем, что, каково бы ни было значение х» a, которому
соответствует ненулевая группа респондентов, значение у e a сов-
30
падает со значением у e f ((b). Иными словами, если х s \j, тоЕ (х) в
=* E(t^) и I(x~4j)eC(x»-^)= 1.
Обратим внимание на следующие специфические особенности
определенного нами понятия равенства:
1. Равенство Xst|no заданному основанию не имеет смысла,
если не задано само основание, т.е. множество, на котором
измеряются переменные эс, ^.
2. Возможность равенства х в и никак не связана с совпадением
или несовпадением числа значений переменных х, и. Переменные
могут быть равными или неравными по заданному основанию вне
зависимости от того, имеют ли они одинаковое или различное число
значений. Все определяется только тем, совпадают или не совпадают
классификации множества, выступающего в качестве основания,
полученные отдельно по каждой из переменных в результате измерений.
3. Возможность равенства х « и никак не связана с природой
знаков, которыми описываются сами значения переменных х,и.
Значения х могут быть обозначены числами, а Значения ч - словами (или
наоборот), ими могут быть буквы или вообще какие угодно символы-
для определения равенства это соврешенно безразлично; все упирается
только в совпадение (несовпадение) классификаций, т.е. опять-таки
в процедуры измерений и их реализацию .
Если х - <Ц у в В - конкретные значения переменных х, и, то
равенство ou e Ь эквивалентно равенству конкретных групп
респондентов Е @/)в ЕF), выделенных по этим значениям.
На протяжении всей книги мы будем систематически
использовать (и использовали уже ранее, например, при определении
коммутативности ху**цъ) понятие равенства между переменными и
отдельными значениями переменных именно в указанном выше смысле,
т.е. как равенство по заданному основанию.
Отметим, что если x=t^ tox^sx«i^, Так, любая степень
переменной есть та же переменная: xn s x при любом п > 1.
§ 2.4. Непустые и пустые, значения переменных
Выберем некоторую переменную х ^и рассмотрим какое-либо ее*
значение х « 0/. Если в массиве респондентов имеется хоть один
человек, который обладает свойством <ь, то свойство ои называют
непустым или наполненным, значением переменной х. Если 4во всем
массиве никто этим свойством не обладает, то значение х - Q/
называют пустым, или ненаполненным. На рис. 2.4.1 значения x(i> и
х непустые - им соответствуют ненулевые группы респондентов,
а значения X F» - пустые, потому что численности соответст*-
вующих им групп равны нулю.
Независимость от природы представления социальных
переменных характерна вообще для всех процедур и операций детерминацион-
н°го анализа.
31
X*
хC)
х
0
100
хA)
0
0
хB)
900
.0
хC>
0
0
хD)
X
N(x)
100
хA)
0
хB)
900
хC)
0
хD)
X
Рис. 2.4.1. Распределение численностей групп N (х) « IE (x)l по
значениям переменной X.
Рис. 2.4.2. Таблица сопряженности по переменным X , X .
Понятия наполненности и ненаполненности относительны: в
пределах одного обследования значению X = 0/ может соответствовать
нулевая группа, в другом обследовании - ненулевая.
Численность N (Q/)группы респондентов, обладающих свойством Xя*
= 0/7 определяет числовую меру для значения Q/ переменной х. Таким
образом, пустые (ненаполненные) значения переменной х - это
значения нулевой меры.
Множество значений переменной х на рис. 2.4.1 имеет четыре
элемента:
Исключим из него пустые значения X tx и полученное в
результате множество обозначим через X :
Переменную, которая имеет множество значений X , обозначим
через х и-построим таблицу сопряженности по переменным х,х
(рис. 2.4.2).
Как мы видим, переменные х, х равны. Отбросив пустые
значения, мы получим переменную, эквивалентную первоначальной, т.е. по
существу переменная х после отбрасывания пустых значений не
изменилась. Добавление новых пустых значений также не изменило бы
переменную х. Вообще, добавление или отбрасывание пустых
значений не меняет какую бы то ни было переменную.
В детерминационном анализе необходимость различать непустые
и пустые значения обусловлена прежде всего тем, что само понятие
детерминации определено только для непустых значений переменных
(см. § 2.1): для существования детерминации а*¦* 6 необходимо и
достаточно, чтобы N@/) ?* О, NF)?* О. Воспользовавшись тем, что
отбрасывание пустых значений не' может изменить какую бы то ни
было переменную, мы в дальнейшем будем, где это возможно,
исключать их из. рассмотрения.
32
§ 2.5. Нулевая и единичная переменные
Среди множества переменных, которые фигурируют в
эмпирических социальных и социально-экономических исследованиях, выделяют*-
ся две, обладающие замечательными свойствами. Одна из них
называется нулевой или индивидуальной и обозначается символом е.
Множество ее значений совпадает с множеством обследуемых индивидов "Е .
Другая носит название единичной или универсальной. Она
обозначается символом со и имеет множество значений, состоящее из
одного элемента {со} (т.е. единичная переменная со принимает
единственное непустое значение, обозначаемое тем же символом со).
Нулевая переменная имеет столько значений, сколько индивидов
содержится в обследуемой совокупности. Ее конкретными
значениями выступают имена индивидов, отличающие каждого из них от всех
других. Она дает максимально детальное, строго
индивидуализированное описание объектов, откуда и эпитет 'индивидуальная* в ее
названии. Переменная 6 называется также "нулевой", так как в
операции умножения переменных она играет роль, которую при обычном
умножении чисел выполняет нуль. Какова бы ни была переменная х,
результат ее умножения на индивидуальную переменную е есть
снова индивидуальная переменная е, т.е. имеет место равенство
хе » е.
Проиллюстрируем это на элементарном примере. На рис. 2.5.1
показана простейшая матрица данных. Выделим в ней столбцы е,ехи
построим таблицу сопряженности по этим переменным (рис. 2.5.2).
Равенство еу ¦» 6 непосредственно подтверждается этой таблицей.
Нетрудно видеть, что совершенно не важно, сколько индивидов в
обследуемой совокупности, сколько значений у переменной х, и какие
значения переменной х ставятся в соответствие конкретным
значениям переменной е. В любом случае таблица сопряженности по
переменным е, ех устроена так, что в каждой ее строке и каждом
столбце находится одна (и только одна) заполненная клетка, причем
число заполнения в ней в точности равно единице.
Если зафиксировать е e e , то равенство е vx ¦ е
представляет собой уравнение относительно х. Оно имеет единственное ре-#
шение - значение переменной х, которым обладает данный индивид eU).
анкета 1
анкета 2
анкета 3
анкета 4
е
ви»
е<2>
в<3>
в'4»
X
хA)
хB)
х<2>
хA)
СО
СО
со
со
со
ех
вA)х<1)
вB,хB)
еC)хB)
еD)хA)
сох
«х*1»
ых121
сох'2'
<oxA>J
рис. 2.5.1. Матрица данных, полученных в результате измерений
по переменным е , х , со , ех и сох.
33
ex
e<4)xm
eC)xB)
eB)xB)
e(DxA)
0
0
0
1
e<1>
0
0
1
0
e<2>
o.
1
0
0
e<3>
1
0
0
0
e<4>
e
Рис. 2.5.2. Таблица сопряженности по переменным е , ех (пустые
значения ех опущены).
X
х<2>
х<1>
0
1
еA)
1
0
е<2>
1
0
е<3)
0
1
е<4)
е
B)
A)
X
* (е)
вП) еB) еC)
.И)
Рис. 2.5.3. Таблица сопряженности по переменным х, е (слева) и
график нормальной функции Xs ср(е) (справа; точки графика
отмечены кружками).
(к) (Ю
Если зафиксировать X e x f то равенство ех вб есть
уравнение относительно е, которое имеет столько решений, сколько* ин-
дивидов в группе е,(х ).
Рассмотрим столбцы по х, е в матрице данных (см. рис. 2.5.1)
и построим таблицу сопряженности, как показано на рис. 2.5.3. В
каждом ее столбце заполнена лишь одна клетка, и число заполнения
в ней равно единице. Заполненные клетки представляют график
функции, которую мы обозначим через if (в более привычной форме ее
график показан справа на том же рисунке). Функция ч состоит из де—
терминаций е *-* х (знак е *+ х эквивалентен знаку е »-*чЧе) или е-*х,где
x=cf(e)), имеющих единичную интенсивность и отличную от
единицы емкость; иными словами, эти детерминации являются точными,
но не полными. Например, Цес4)~хA))= 1, С{еA)~ х(°)= 1/2, 1(еA)~
•^х )=1,С(е »-* х )= 1/2 и т.д. Функция, состоящая из точных,
но не обязательно полных детерминаций, называется нормальной .
Таким образом, переменная х является нормальной функцией от ин—
Запись равенства типа х = \ф является записью взаимно
однозначной нормальной функции, состоящей из детерминаций, не только
точных, но и полных (см. § 2.3). О нормальных функциях см.
также § 2.8.
34
CJX
<ox,2>
<OXA>
0
2
XID
2
0
xB)
X
CO
CO
2
XID
2
x<2>
X
Рис. 2.5.4. Таблица сопряженности по переменным со»,».
Рис. 2.5.5. Таблица сопряженности по переменным со,х.
дивидуальной переменной е. Легко видеть, что само по себе наличие
функциональной зависимости х от е не обусловлено видом
переменной х. Любая переменная, какой бы она ни была, есть нормальная
функция от индивидуальной переменной в. В этом лишь проявляются
элементарные свойства, присущие измерениям - в ходе измерений по
переменной х каждому индивиду е u ставится в соответствие
значение х = ср (е ), Если X - альтернативная переменная, то каждому ин-
с.1)
дивиду е ставится в соответствие только одно значение
переменной х, т.е. <f есть функция. Не совсем очевидно, может быть, лишь
то, что функция ср состоит из точных детерминаций, т.е. нормальна.
Это видно из рис. 2.5.3. В общем виде нормальность функции <р
нетрудно усмотреть из равенства е х = е. При любом фиксированном
это есть уравнение, которому, как отмечалось, удовлетворяет
единственное значение переменной х, а именно х - <f (e ), С
другой стороны, из него следует, что NF х )=N(,€ 1 ),т.е.
Не
и)Д,
х)-
N(ecl)xw)
MUU))
- 1.
Если индивидуальная переменная е играет роль нуля в операции
умножения переменных, то универсальная переменная со играет в той
же операции роль единицы: какова бы ни была переменная х,
результат ее умножения на универсальную переменную со есть та же
переменная х, т.е. справедливо равенство
хсо в х.
Этим объясняется эпитет 'единичная* в названии переменной со. Вер-»
немея к матрице на рис. 2.5.1 с целью проиллюстрировать
указанное равенство. Выделим в ней столбцы osx,x и построим таблицу
сопряженности по переменным со», х. Результат представлен на
Рис. 2.5.4. Как мы видим, равенство сох « х действительно справедливо,
причем факт равенства,, как легко убедиться, не обусловлен ни
видом переменной х и распределением ее значений по строкам матри-
иы данных на рис. 2.5.1, ни количеством строк в самой матрице.
Он обусловлен лишь тем, что переменная со имеет одно—единствен—
35
ное значение, которое присваивается каждому индивиду из
обследуемой совокупности.
Группа Eto) представляет собой всю обследуемую совокупность Е,
поэтому очевидно, что, каким бы ни было свойство х - си,
группа Е @/) полностью включена вЕ sE(Co) Отсюда следует, что
всегда справедливо соотношение
Е(а»ЛЕ(х)-Е(х),
которое эквивалентно равенству со Xе х, записанному на языке групп
индивидов, обладающих свойствами со,».
На рис. 2.5.5 изображена таблица сопряженности по переменным
со, х, построенная на основе данных, содержащихся в матрице на
рис. 2.5.1.
Отсюда видно, что со является тривиальной нормальной функцией от
переменной х: всякое (непустое) значение х детерминирует со с
интенсивностью, равной единице. Это обстоятельство также
непосредственно следует из равенства сох« х, которое влечет за собой
соотношение N(cox) = N (х), и тем самым
N(cox)
I (х •-+ со^ m :— = 1.
4 ; N(x)
В итоге получаем следующее. Каждая переменная х есть
нормальная функция от индивидуальной переменной е. Вместе с тем
переменная х есть аргумент нормальной функции, имеющей единственное
значение - универсальное свойство со.
Известно, что всякая переменная в социальном обследовании
реферирует некоторое понятие. Каково бы ни было понятие,'
реферируемое переменной х; оно в пределах заданного обследования всегда ока-ч
зывается более общим, чем понятие 'конкретный индивид",
реферируемое индивидуальной переменной е, и менее общим, чем понятие
'обследуемая совокупность как целое', реферируемое универсальной
переменной со. Отмеченные выше свойства переменных е, со есть
формальное выражение этого обстоятельства. Индивидуальная (нулевая)
и универсальная (единичная) переменные определяют, таким образом,
предельные границы диапазона общности в описании эмпирического
объекта: минимальная ('нулевая') общность ассоциируется с
индивидуальной переменной еэ максимальная ('единичная') общность - с
универсальной переменной со.
§ 2.6. Уточнения. Понятие существенности
Рассмотрим две детерминации а^1и ас•* Ь. Вторая отличается от
первой наличием дополнительного детерминирующего свойства с. Ее
интенсивность може* быть как больше или равна, так и меньше
интенсивности детерминации а^Ь.В детерминашюнном анализе это
интерпретируется в любом случае как уточнение, которое свойство с
вносит в детерминацию а*-* 6 (или как уточнение с в детерминации
ас ь-»-6). Уточнение называется позитивным или положительным, если
36
У
Б
ь
0
100
ас
60
40
ас
I
100
0
ас
40
60
ас
У
Б
b
uv
II
100
100
а
100 1
100 1
а |
60
140
140
60
u I c I c I v
рис. 2.6.1. Таблицы сопряженности по переменным ti,t*tf (T); u,u(fi)'
I(ac•-¦ 6)>I(ou>-¦ 8),и негативным или отрицательнымр если Нас*-* Ь)<
<1 @/^6). Когда Цас ~ Ь)e I (a |-> Ь), уточнение с называется
несущественным или нулевым.
На рис. 2.6.1 показаны три таблицы сопряженности.
Семантика фигурирующих здесь переменных u,u/,v описывается
следующим словарем (пример вымышленный):
и- любовь к шоколаду,
6 - любит,
?- не любит;
К, - любовь к леденяам,
О/- любит,
а- не любит;
xf - возрастная группа,
С - ребенок,
G- взрослый.
Согласно таблицам l(a*-*8)e 0,5, 1(CUC •-* В)в 1. Детерминация а*-+6
равнозначна утверхщению: кто любит леденцы, тот любит и шоколад.
Его точность сравнительно невелика и равна 0,5. Значительно
более точно утверждение: дети, которые любят леденцы, любят и
шоколад. Свойство с (быть ребенком) позитивно уточняет
детерминацию а»-*8. Мерой существенности уточнения служит приращение
интенсивности, которое происходит благодаря включению с в
детерминацию а»-* 8,т.е. величина
S(ac*«-*l) - i(a,c~fc) -I(a-4) -l - 0,5 « 0,5 >о.
Символ S везде в дальнейшем будет использоваться для
обозначения* существенности, так что, напр|1мер, S(а^*-и*)следует читать
как существенность уточнения V-, вносимого в детерминацию и »-* и,
причем
S (***•-* у) - I(av -¦у) ~ I(u/*-*^).
Свойство, производящее уточнение, существенность которого
определяется здесь и в дальнейшем (в скобках, следующих за символом
S) отмечается звездочкой.
37
Примером негативного уточнения детерминации а»-* 8 может служит!
свойство с" (быть взрослым). Нетрудно подсчитать (см. рис. 2.6.1),
что
$(ас*~ 8) - I(ouс ^Ь) ~1(а —6)«0-.0,5=-0,5<0.
Детерминация ас1"* 8 равнозначна утверждению: взрослые, которые
любят леденцы, любят и шоколад. Это предельно неверное
утверждение: интенсивность детерминации здесь в точности равна нулю, .т.е.
свойство С в качестве антиуточнения разрушило первоначальную
детерминацию а ¦** 6.
Рассмотрим теперь детерминацию a^fc U(ctv*t) « 0,5; см. рис.2.6.1)
и получим ее уточнение с помощью свойства С. Здесь это свойство
выступает позитивным уточнением:
S (ас *~ ?) e I lac ~ 8) - Ца~ 8) -1 - 0,5 - 0,5.
Детерминация ас»-* 8 (взрослые, которые любят леденцы, не любят
шоколад), полученная с помощью уточнения с, абсолютно точна, ее
интенсивность равна единице, свойство с здесь выступает
позитивным уточнением. Обратим внимание на соотношение
$(o,c*~fc)--S(ac*^8).
Здесь мы имеем дело с общим правилом: существенности одного и тог-
го же уточнения в детерминациях вида a *-+ 8, а*"* 8,где 6 - строгое
отрицание 6, равны по величине и противоположны по знаку. Если
некоторое свойство выступает как позитивное (негативное) уточнение
детерминации а»-* 6,то оно является негативным (позитивным)
уточнением детерминации a *-*8.
Существенность есть мера значимости, "влиятельности', свойств,
которые выступают в качестве уточнений. Подсчет и последующее
сопоставление существенностей различных уточнений играет важную
роль в детерминационном анализе. Вернемся, например, к
Детерминации аС^в.До сих пор мы о свойстве с в этой детерминации
говорили как об уточнении, вносимом в детерминацию а** 8. В такой трак«
товке детерминация ас»8 представлялась нам как результат
добавления, привнесения, свойства с в детерминацию а*-* 6. С тем же
успехом, однако, можно детерминацию a~g мыслить как результат
изъятия, отбрасывания! свойства с из детерминации ас^в.В таком случа
существенность S(aC**+ 8) показывает, как изменится интенсивность
детерминации ас**8 при отбрасывании свойства с. Величину
существенности S(ouc*^8) можно, таким образом, трактовать не только как
существенность уточнения с,,вносимого в детерминацию а>^В,но и
как существенность свойства с в детерминации ас~6.С этой точки
зрения свойство с достаточно существенно - мы нашли, что $(<vc**+8)«
«0,5, т.е. отбрасывание С заметно уменьшает интенсивность детер-
38
минации ас»+ б.Теперь подсчитаем для сравнения существенность
свойства а (см. рис. 2.6.1):
$(о,*с ~ Ь) * Icao— 6) -1(с ~ В) - 1-- 0,7 = 0,3.
Отбрасывание свойства Q/ меньше разрушает детерминацию <ьс»-»6,
чем отбрасывание свойства с ; следовательно, свойство с здесь
более существенно @,5), чем свойство ъ @,3). Напомним:
содержание детерминации ас»-8 в том, что ребенок (свойство с), который
любит леденцы (свойство ои), любит и шоколад (свойство 6), Таким
образом, формальное сравнение существенностей свойств 0/.и с
приводит нас к следующему содержательному выводу. Если мы
объясняем любовь к шоколаду тем, что имеем дело с детьми, любящими
леденцы, то важнее здесь то, что это дети, чем то, что они любят
леденцы.
Поставим такой вопрос: как определить существенность
свойства х в детерминации х*-*и? Чтобы на него ответить, необходимо
понять, каким должен быть результат отбрасывания х из
детерминации х *-»у.Вспомним, что всегда х « со», так что отбросить х из
детерминации х ь-* и - это то же, что отбросить х из детерминации
сох v-»- u. В итоге искомая существенность определится как
существенность уточнения, вносимого свойством х в детерминацию со*+ц ,
т.е. как
S(cox *-*y) ~Hcy>x*-*y)-I(oo»-«-tpt
Таким образом, подсчет существенности х в детерминации х1-*^
есть частный случай разобранного выше подсчета существенности х в
детерминации вида хх»-*^,а именно, когда % в со. Отметим также,
что в данном частном случае существенность, если ее представить
в вероятностных обозначениях, запишется так:
S(w**-*y).-Plyl*)-P(y>.
Если разность в правой части обращается в нуль, то это принято
интерпретировать как отсутствие статистической связи между
свойствами (событиями) х, и. В детерминащюнном анализе интерпретация
равенства правой части нулю другая: свойство х вносит несущест—
*)
венное уточнение в детерминацию w^|
Универсальное свойство со всегда вносит несущественное
уточнение в любую детерминацию вида х*-*^«
&(со*х *-*у) - 1(сох»-*у)- Цх»-*^) в0.
Ни одно содержательное утверждение в пределах заданного
обследования не может быть существенно (позитивно либо негативно) уточ-
Одновременно, как нетрудно увидеть, свойство и вносит
несущественное уточнение в детерминацию со +~ х.
39
нено с помощью со. Эта глобальная несущественность универсальной
переменной является формальным эквивалентом предельной общности
и бессодержательности (внутри данного обследования!) понятия,
которое ею реферируется (см. § 2,5). Несущественность со позволяет
опускать ее во всех обозначениях и расчетах, относящихся к массив|
данных, в котором она сохраняет универсальность.
В противовес универсально несущественной единичной переменной
«, нулевая переменная е может быть названа "универсально сущест*
венной". Какова бы ни была детерминация х*-*и,переменная е
уточняет ее с предельно допустимой положительной или отрицательной
существенностью. Введем обозначение
1(х -"у) в <*»•
Любое уточнение детерминации х^чне может иметь существенное!
меньше, чем-л, и больше, чем 1 - с*,. Рассмотрим детерминацию
еэс^ц.Если она существует (т.е. если еос непусто), то
Jl. y.-q><e),
1(ех~ у) Н
[О, у*ч>(е),
где <р(е)~ нормальная функция, указывающая значение переменной и
для данного индивида е (см. § 2.5). Отсюда непосредственно
получаем
«, Г1"*, ?ш<Р(е),
S(e х~у)-|
[ -*, у*<р(е),
т.е. уточнения, вносимые в детерминацию х>~*^ значениями
переменной е, действительно имеют предельно допустимые положительное
A - ос) либо отрицательное (~оо) значения. Это обстоятельство мож^
но рассматривать как формальное вьфажение предельной конкретности
понятия, которое реферируется нулевой переменной.
§ 2.7. Контекст
Всякое утверждение справедливо лишь в определенном контексте.
Даже если контекст не указан явно, он подразумевается. В предьщун!
щем параграфе для иллюстрации использовалось утверждение: дети,
любящие леденцы, неравнодушны также и к шоколаду. Точность
соответствующей ему детерминации а С»-* 6 равна, как видно из таблицы
сопряженности I на рис. 2.6.1, единице. Очевидно, это справедливо
только в пределах выборки, которая распределена по клеткам ука-
занной таблицы . Свойство, на основе которого данная выборка сфор|
мирована, есть универсальное свойство со. Оно незримо присутствует*
Может оказаться, конечно; что наше утверждение справедливо
и для какой-то более широкой совокупности, но нам это неизвестно.
Обсуждением того, как распространять результаты детерминационногч^
анализа на более широкую совокупность, мы не занимаемся.
40
0 в групде тех, кто обладает свойством сьс (действительно, ведь ас =¦
^ а С со), и в группе тех, кто обладает свойством 6(8 « 6 со).
Поэтому правильнее было бы детерминацию ас и- ft записывать как
детерминацию ассо^всо, но упоминание свойства со можно опустить, поскольку его
формальное включение или исключение ничего не меняет. Оно в
данном случае выполняет роль подразумеваемого контекста,
называемого универсальным. Таким образом, универсальное свойство со есть
одновременно и универсальный контекст.
Когда эмпирическое социальное исследование только
проектируется, реальные свойства, на основе которых формируется затем
свойство сд, никогда не претендуют на универсальность. Никто не проводил
обследование всех людей на Земле. В конкретных обследованиях
универсальное свойство со всегда конкретно и перестает быть
универсальным (становясь обычным свойством наряду с любыми другими),
как только мы выходим за пределы обследуемой совокупности.
Таковы, например, свойства "жители города" или "жители деревни",
"школьники" или "молодежь в возрасте до стольких-то лет",
"аудитория телевидения", "читатели Литературной газеты" и т.д. и т.п.
Универсальность контекста всегда относительна. При обследовании
сельских жителей данного региона универсальным контекстом со
служит универсальное свойство, которое есть "сельский житель данного
региона". Но если мы переходим к обследованию всех жителей
данного региона (и городских, и сельских), то роль универсального
контекста берет на себя свойство со' "житель данного региона", а
бывшее универсальное свойство to перестает быть универсальным и
становится рядовым значением обычной неуниверсальной переменной,
описывающей тип поселения (город - село). Всякий универсальный
контекст есть сужение некоторого более универсального контекста:
чтобы от обследования в контексте всех жителей региона перейти к
обследованию в контексте сельских жителей того же региона,
необходимо, очевидно, оставить в обследуемой совокупности только
сельских жителей, а городских исключить. Будет ли в таком случае
свойство "сельский житель данного региона" определять универсальный
контекст? Ответ зависит от точки зрения: да, будет, если мы не будем
в своих суждениях выходить за пределы массива сельских жителей;
нет, не будет, если суждения о сельских жителях мы будем
соотносить с суждениями, в которых фигурируют и не жители села. В
последнем случае мы должны считать, что в универсальном контексте
жителей данного региона сформирован обычный, неуниверсальный, контекст
сельских жителей и в зтом контексте справедливы такие-то утверждения.
Рассмотрим массив данных с универсальным контекстом со.
Любое непустое свойство к может служить здесь обычным (неуниверсаль-
?НЯ)_контекстом, который представляет собой сужение
универсального контекста со. Чтобы перейти из контекста со в контекст к = 1<со,
необходимо выделить группу респондентов ЕA<), обладающих свойст-
°м к; и затем вести анализ только внутри нее, абстрагировавшись
т °стальной части массива.
Рассмотрим некоторую детерминацию а »-*Ь. Что с ней произойдет
рй переходе в контекст к ? На рис. 2.7.1 представлена диаграмма
41
Граница а
Граница b
Граница со
Рис. 2.7.1. Диаграмма Венна, показывающая,что в контексте 1<
детерминация a**i становится детерминацией ь\с*+Ък & к(а,*+Ь).
Венна» где показан один из возможных вариантов взаимодействия
групп Е(а),Е(Ь), Е(к) в массиве респондентов Е вЕ(со) (эти группы
обозначены на рисунке просто символами а, Ь, к, со).
Перейти в контекст 'к - значит перейти к рассмотрению только
группы Е(к),а все прочее из рассмотрения исключить. В таком
случае вместо а получим а к, свойство 6 перейдет в свойство Ьк и де-*
терминация а>-* Ь преобразуется в детерминацию ak*-* Некоторую моя
но также обозначить через k (a•-*&).Таким образом, детерминация
Ь~Ь в контексте к - это детерминация к (а »-*¦ 6).
Обратим внимание, что трактовка и запись детерминации 4<(cv«-*
зависят от контекста: в контексте со это к(а^&),в контексте к это*
a^ fe.Предположим, что детерминацию а»-* 6,понимаемую как детерм]
нацию в контексте к, необходимо записать в. контексте со', более ун
версальном чем контекст со. Искомая запись будет иметь вид to'cot
-¦6). Свойство с^ как универсальное,можно отбросить, но свойство
со, которое теперь (в контексте со') уже не универсально,
отбрасывать нельзя: в контексте со' детерминации сок(а^Ь)и к (a»-* 6),boo6l
говоря, различны, тогда как в контексте со они совпадают.
Вернемся к рис. 2.7.1. Если использовать свойство к не как к
текст, а как уточнение, вносимое в детерминацию a*•+ 6, то в резу!
тате получим детерминацию ak^ 6. Зададимся вопросом: чем отлича
использование некоторого свойства в качестве контекста от испол*
зования того же свойства в качестве уточнения? Чтобы ответить \
него, сравним интенсивность и емкость детерминаций ak-4k и ськ*-*
Непосредственно из рис. 2.7.1 видно, что интенсивности у них ра*
ны. Формально это также очевидно:
I(a*~fcfc)-
N(aUk) „ N(ak&) _
N(ak)
N(ak)
=4(ak^6).
B.7.
Здесь учтено, что произведение ak6k коммутативно и к = к. Так*
образом, перевод контекста в уточнение и обратно не меняет инте
*^ Обозначения ак~8ки к (а*
эквивалентные.
42
>6) используются в дальнейшем как
сивности детерминаций. На этом основаны расчеты уточнений,
вносимых контекстом, а также расчеты существенности контекста. Все они
сводятся к подсчетам существенности уточнений, которые вносит
свойство, выполняющее роль контекста. Действительно, существенность
уточнения, вносимого контекстом к в детерминацию ь*-+ lf или
существенность контекста к в детерминации ак*-*вк естественно
определить как разность
S(k%~6))eI(ak~ 6^-1@,^ 6).
Поскольку IlakH^6k)ssI(a/k»-^6),To эта разность просто совпадает
с величиной S(Glk *-*¦ 6 O измеряющей существенность уточнения,
вносимого свойством к в детерминацию а~ Ь (см. § 2.6).
При вычислении интенсивности понятия 'контекст* и ^уточнение"
можно не различать; но в случае емкости такое различие необходимо: емкоо»
ти детерминаций ak~J и аЖ-> tk, вообще говоря, различны, причем
C(ak^Mr) > C(ak~6). B.7.2)
Перевод уточнения на роль контекста (т.е. переход от детерминации
ak^fc к детерминации ak*-*fck) может только увеличить полноту
объяснения или оставить ее неизменной. В справедливости неравенства B.7.2)
легко убедиться, если подставить туда численности схютветствующих
групп: оно эквивалентно очевидному соотношению (см. также рис. 2.7.1)
N(S) > М*Ю.
В частности, если в детерминации а* 8 свойство а перевести в
контекст, то получим детерминацию а^ В(Ь, которая имеет ту же
интенсивность, что и О,** 6,тогда как емкость ее равна единице:
КЦоЛои)
C@,~*a)- N(ftt) -l>C(tt~b).
Мы обсудили, что происходит, если в контекст перевести
свойство k B детерминации ка»-*6,а теперь посмотрим, что будет, если
проделать ту же процедуру, но уже с детерминацией
Пользуясь тем, что , нетрудно из уже
полученных соотношений B.7.1) и B.7.2) получить
C(aki-*Mo-C(a~Uo,
I(ak~6k) >I(a~6k).
При переводе в контекст свойства, уточняющего функцию (т.е. высту-
^Щего сомножителем в свойстве, на которое направлено острие детер—
Мйнаиионной стрелки), остается неизменной полнота (емкость), а точ-
°Сть (интенсивность) может либо возрасти, либо остаться прежней.
Ж)" "
Если в детерминации k a* 8 свойство к выступает как обычное
Чнение, или уточнение по аргументу, то в детерминации а ++Ь к
выступает как уточнение по функции.
43
Среди всех контекстов, в которых может рассматриваться
детерминация а >* 6, самым широким является универсальный контекст
со. Его существенность всегда равна нулю:
$(оЛа~ Ь))e IU* (а—Ь» - 1(а~ 6) - 0.
Самый узкий из всех возможных контекстов - контекст отдельно
го индивида, или индивидуальный контекст. Если детерминация а*"*
существует в контексте индивида е, то ее интенсивность в данном
индивидуальном контексте равна* единице, т.е.
Nice)
I(ela ~6» eI(e ~е)« —— -1.
N(e)
Это значит, что, какой бы контекст k ни выбрать для
детерминации а**в,его существенность не может превышать существенност!
индивидуального контекста:
$(с*(а^1))>8(к*(а~&))-
Индивидуальный контекст имеет, таким образом, максимальную
существенность. Всякое условное объяснение в нем имеет
максимальные точность и полноту: в индивидуальном контексте детермин
ция а** ((как и любая другая) обладает не только единичной интен
ностью, но (что легко проверить) и единичной емкостью. Однако у^
ловное объяснение, построенное на детерминации a^8,имеет в
контексте одного индивида мало смысла, так как она (как и любая др
гая детерминация) в индивидуальном контексте е эквивалентна
детерминации е~е (поскольку cue *¦ е, 8е « е) и, хотя последняя имее
единичные интенсивность и емкость, она представляет собой тавтоя
гию 'если е,то е*. Мы приходим, таким образом, к выводу,
который содержательно априори очевиден: изучать связи между свойств
вами имеет смысл только в достаточно широких контекстах. Чем
уже контекст, тем менее осмыслено такое изучение, а в пределе,
когда контекст замыкается на одного индивида, оно вообще
бессодержательно. Заметим, что этот довольно жесткий вывод относите
только к контексту и не распространяется, вообще говоря, на случаи,;
когда индивидуальная переменная выступает в качестве аргумента.
§ 2.8. Нормальные функции
Переменные, которые фигурируют непосредственно в рабочих до
кументах обследований, дают, как правило, довольно подробное, д«
тализированное, приземленное (если можно так выразиться) описай
ние. Это естественно. Социальные измерения основаны на общений
на коммуникации, и слова, с которыми социолог обращается к лки
дям (в виде вопросов, в виде предлагаемых вариантов ответов, в
де свободной беседы или как-нибудь иначе), должны быть пс
строены так, чтобы они были им понятны, чтобы они соотносили
с теми знаками и значениями, в которых респонденту привычно с
44
ить свои отношения с внешним миром. В процеосе анализа
необходимо проводить содержательную агрегацию, обобщение, чтобы увязать
эмпирические результаты с теоретическим уровнем, где описание
социального объекта должно быть освобождено от излишних
подробностей, излишней детализации. С этой целью обычно и используются
нормальные функции, которые в практике социальных и социально-
экономических исследований называют по-разному: теоретические
типологии, таксономии, вторичные переменные, агрегированные
показатели, индексы, содержательные классификации и т.д.
Рассмотрим простейший пример. Пусть необходимо определить
уровень обеспеченности бытовой техникой на основании обследования,
в котором фигурируют три переменные:
эс' Наличие холодильника
а- есть,
а- нет.
*»•Наличие стаРальной-машины
R - есть,
8- нет.
X : Наличие швейной машины
С- есть,
?- нет.
Введем четвертую переменную:
•и: Уровень обеспеченности бытовой техникой
и - высокий,
yN - средний,
у*5)- низкий.
Чтобы перейти от достаточно детального описания, которое
дается совместно переменными х , х , эс , к более агрегированному,
* те *
обобщенному описанию в терминах уровней обеспеченности бытоЛвой
техникой, необходимо задать функцию
Примем, что если есть и холодильник, и стиральная и швейная
машины, то уровень обеспеченности высокий, если есть два из трех
названных предметов, то средний, а если есть только какой-либо
°ДИн предмет или все они отсутствуют - низкий. Определенную
таким образом функцию можно представить в виде табл. 2.8.1.
Ее запись как логической функции выглядит так:
уD)- йл^лс,
^г)а(ал Ьло)у(ал1ло)у(лл 6л о),
^C)*(алЬл o)v(Sa 6aT5)v(? л Та c)v (Ъл Ь а с).
45
Таблица 2.8.1.
Функция, отражающая уровень обеспеченности
бытовой техникой *
Холодильник
«1
| а
а
1 ^
1 ^
1 ^
Стиральная
машина
в
в
&
6
I
в
&
6
Швейная
машина
С
С
с
с
с
с
с
1
Уровень
обеспеченности
A) *, 1
ij - высокий
I
^ - средний
I
i
i
i
if - низкий
Функция f позволяет избежать излишней детализации и перейти
к содержательно более агрегированному описанию в терминах
уровней обеспеченности бытовой техникой (со всеми,разумеется,
оговорками относительно ее интерпретации, которые в данном случае
необходимо сделать). Чтобы, однако, действительно воспользоваться
функцией f как инструментом такой агрегации, необходимо предположить,
что если для некоторого индивида е переменные х , хо , X равны X (е)
* it О \
X (е), ХДе), то значение переменной и для того же индивида равно
уф-Кх^е), хг(е), х5(е».
Это предположение тривиально. Оно означает, что о каждом
индивиде, о котором точно известно, есть ли у него холодильник (х
),стиральная машина (х,)и швейная машина (хх), можно на основании функ-
нии и = ?(х , Х0 , Х~ ) точно сказать, какой у него уровень обеспе-
ч 1 и Ъ
ченности бытовой техникой. Обычно такое предположение
принимается неявно, как само собой разумеющееся. Но именно оно
представляет собой тот решающий шаг, который следует сделать, чтобы
функция f стала нормальной функцией.
Итак, пусть задана некоторая функция u = f(x)n для любого в€Б
определены значения функций и = ср(е), Х-ф(е). Если всегда (для
всех е из Е) справедливо равенство ф(б)= f (Ц/(е)),то функция f
называется нормальной. Нормальная функция U = I (х) определена
только для непустых значений аргумента х, т.е. только для тех значений
переменной х, для которых N(X)^|E(X)| Ф О.
Попросту говоря, если по переменной х какой-либо объект
обладает данным свойством х = а, то по переменной и тот же объект
46
У
уC)
у<2>
уA)
0
0
X
abc
0
X
0
abc
0
X
0
abc
0
X
0
abc
X
0
0
abc
X
0
0
abc
X
•0
0
abc
X
0
0
abc
X = X1X2X3
Рис. 2.8Д. Таблица сопряженности по переменным Х,Ц.
должен обладать свойством, которое можно отыскать (вычислить)
по формуле u « f (a), - это и есть требование, при выполнении
которого функция f оказывается нормальной.
Вернемся к нашему примеру с нормальной функцией us Цх^х^х^).
Предположим, что все значения переменной X в »^ »^ Лз ""
непустые. Тогда, как бы ни распределялись респонденты по
значениям переменной х, таблица сопряженности по переменным зь;^
будет иметь вид, изображенный на рис. 2.8.1, где заполненные клетки
помечены крестиком (число респондентов, лопавших в заданную
помеченную клетку, для нас не имеет значения, важно только, что оно
отлично от нуля)»
Отсюда видно, что соответствия х x^ac»-*u есть детерминации с
единичной интенсивностью, т.е. точные. Мы уже сталкивались (см.
§ 2.5) с определением нормальной функции как функции, состоящей
из точных детерминаций. В данном параграфе нормальная функция
определена несколько по-иному. Приведенная таблица
иллюстрирует эквивалентность обоих определений.
Подчеркнем: обычная и нормальная функции суть различные
формальные объекты. Соответствия (точечные), образующие
нормальную функцию, - точные детерминации, а соответствия (также
точечные), из которых состоит обычная функция, детерминациями не
являются. Важно также и то, что функции, используемые при
анализе социальных и социально-экономических данных в виде типологий,
индексов, таксономии, агрегированных^похазателей и т.д., есть
именно нормальные, а не обычные функции.
В детерминационном анализе нормальные функции систематически
используют для преобразования переменных; подобные преобразования
называются нормальными. Простейшим преобразованием такого рода
является равенство (по заданному основанию): и « V есть запись
взаимно однозначной нормальной функции t* в <р(яг) = v, для кото-
рой 1(и»-иг)«С(и^ tr)e 1. Если и, = V, то для любого X в 0и
детерминации ги*а и \7«*а эквивалентны, т.е. имеют одинаковые интенсивность и
емкость. То же, очевидно, справедливо и для детерминаций 0,^*1*,a»-*tr.
При Произвольных нормальных преобразованиях переменных
детерминации преобразуются следующим образом. Пусть задана некоторая
47
нормальная функция u* ?(v), т.е. известны интенсивности I(v~u)« 1
и емкости C(v-* u) образующих ее детерминаций. Предположим, при
некотором фиксированном значении переменной х = Q/ определены
детерминации вида агн* а. Функция ! осуществляет, очевидно,
нормальное преобразование от переменной v к переменной^. Спрашивается,
как найти детерминации вида ил-»а?Это так называемая задача о
нормальном преобразовании аргумента (или источника) в произвольной
детерминации. Ответ дается следующими формулами:
I(u~a)e ZZ I(u-* v)I(tr^a),
B.8Д)
С(
Здесь знак f" (u) означает, как обычно, прообраз и относительно 1,
т.е. множество всех значение V, которые при фиксированном
значении а удовлетворяют уравнению u- f(tf).
Чтобы проверить первую формулу, подставим в нее численности
..-t.
соответствующих групп и учтем, что если ve f" (t*),ToH(tfU/) = N(v).
В итоге получим
_ N(tfu) N(tfOb) ЩиоЛ_
что и требовалось. Вторая формула также проверяется непосредственно:
_ N(va) N(i*a)
Обратим внимание, что формула для интенсивности остается
справедливой, если в ней интенсивности заменить емкостями; после
такой замены' получим
C(tt~ a) = XI G (t*~ v) С (v *-**),
что в точности совпадает с формулой для емкости, поскольку при
vef"x(u) в силу нормальности C(u^V)s Ци1-*а) - 1. Но такая
замена равнозначна замене всех стрелок детерминаций на обратные, так
как для любой детерминации х•->и имеет местоТф^^ССи-» х).Это
дает возможность сразу решить и вторую задачу - задачу о
нормальном преобразовании стока (или цели) в произвольной детерминации,
которая ставится так. Пусть задана нормальная функция, u s ;f(tr).npen-j
положим, при некотором фиксированном х - 0/ определены
детерминации вида Q,»-* и. Спрашивается, как найти детерминации вида а»-*и?
48
Ответ дается формулами
I(a>-u,)- XI I(a^v),
V6rV) - B.8.2)
C(a~u)e ]C C(a~v)C(t/~u).
vcf^di)
В заключение рассмотрим вопрос об уравнении, которому
подчиняются нормальные функции. Мы видели, что для нормальности
некоторой функции u s <K%) необходимо и достаточно, чтобы
выполнялось условие
I(x~v)-1.
До сих пор мы рассматривали это равенство как следствие
нормальности, как определенное свойство, которым обладает
нормальная функция. Однако при обработке социальных и
социально-экономических данных первичным формальным объектом выступает веер
отображений (см. § 1.1). Это значит, что, как бы ни определялись
правила измерения переменных х,и на объектах из множества Е,
выступающего основанием веера, исходная информация о наличии
(отсутствии) функции <f:X""*Y содержится в двух отображениях
(компонентах веера)оО:Е-*Х hj*:E~*Y. Как мы можем, например, узнать,
существуют ли для данного и - 6 такие значения х,что
детерминация х*+1 является точной? Следует, очевидно, пользуясь
компонентами веера <*., а, подсчитать величину
N(xft)
и посмотреть, как она зависит от х. Все значения х, для которых
Кх^б)88 1» мы можем считать прообразом некоторой нормальной
функции ср относительно и - 8. Таким образом, мы воспользовались
соотношением
Л(х~В) = 1
как уравнением относительно х, решения которого определяют
прообраз нормальной функции ср относительно 6, если строение
отображений ее, jj допускает существование такой функции. Перебрав все
значения u e Y, мы в конечном итоге построим нормальную функцию <р
(если она существует) как функцию, удовлетворяющую уравнению
1(х?^) = 1. B.8.3)
Это и есть уравнение нормальной функции. В нем переменные х, у,
считаются заданными вместе со своими компонентами <>с, j* веера
отображений.
Если уравнение B.8.3) имеет решение, то оно единственно.
Покажем это. Пусть tf>, ^ - два решения такие, что для некоторого
49
значения ХбХ <р (х)^ ^ (х). Тогда
I(x~ ф(х)) + 1(х*-^(х))=*1 +1 = 2,
что невозможно, поскольку при фиксированном значении х всегда
Отметим, что функция, удовлетворяющая уравнению B.8.3),
удовлетворяет и уравнению
I(kx~ ky)-i B.8.4)
при всех непустых кх (т.е. значениях х, непустых в контексте к).
Иными словами, переход к более узкому контексту сопровождается
только, быть может, сужением 'области определения нормальной
функции, но не нарушает нормальность. Вместе с тем, если на данном
веере отображений решение уравнения B.8.3) отсутствует, то для
уравнения B.8.4) оно может существовать. Функция, нормальная в
контексте к, может не иметь нормального расширения на более
широкий контекст (в частности, на универсальный контекст).
Уравнение B.8.4) есть в известном смысле обобщение уравнения B.8.3):
оно переходит в B.8.3) в частном случае k e со.
Нормальная функция <р, удовлетворяющая уравнению B.8.4),
удовлетворяет также неравенству
C(kx*^kif)>0. B.8.5)
Поэтому вместо B.8.4) следовало бы записать уравнение для
нормальной функции в виде системы, в которую входит равенство по
интенсивности B.8.4) и неравенство по емкости B.8.5):
I(k(x~^)) = l,
Ф B.8.6)
[C(k(X-*y))>0
Неравенство для емкости всегда можно опустить, если нас не
интересуют какие-либо ограничения, налагаемые на вид нормальной
функции. Но, например, уравнение (точнее, система уравнений) для
взаимно однозначной нормальной функции имеет вид
Кк(х^Ц))=Ч,
B.8.7)
[С(к(хД^))=1.
50
Здесь уже без условия, налагающего ограничение на емкость, не
обойтись.
При заданных значениях переменных х, и соотношение B.8.7)
может выполняться только в случае
k^* cf (kx) = кх,
т.е. когда в контексте к переменные х, и совпадают.
Уравнения B.8.6) и B.8.7) можно объединить в более общее
уравнение, записав его в виде системы
B.8.8)
CAt(x^))€ М,
где М- некоторое подмножество из отрезка [О, ll.
В случае B.8.6) М= (О, 1], в случае B.8.7) множество М
стоит из одной точки, соответствующей единице. Если множество М
состоит из точки, соответствующей нулю, то уравнение B.8.8) не имеет
ни одного решения в классе всех функций от X к ^ (т.е. функций
вида u s (р (х))в любом контексте 4<.
§ 2.9. Детерминационные функции (D-функции)
Нормальные функции состоят из детерминаций, на которые
наложено одно ограничение: они должны быть точными, т.е. иметь
единичную интенсивность. Снимем ограничение, налагаемое на
интенсивность: пусть она будет произвольной. Тогда получим класс
функций, которые называются детерминащюнными или D -функциями.
Итак, детерминационная, или D-функция, - это функция, в
которой все точечные соответствия суть произвольные детерминации.
Класс нормальных функций образован Б-функциями в частном
случае точных детерминаций.
На рис. 2.9.1 показана простейшая таблица сопряженности 2*2
по переменным х, и , имеющим соответственно множества значений
XSU » 0uj,Y~iO , О I. Все значения переменных х,и здесь,
очевидно, непустые. Интенсивности и емкости детерминаций от * к j
имеют следующие значения:
Детерминация
а -* Ь
а *-+ I
а -* 1
а •- Ь
Интенсивность
0,8
0,2
0,4
0,6
Емкость
0,67
0,25
0,33
0,75
Из них можно составить всего восемь D-функций, изображенных
на том же рисунке. Они образуют полный класс В-фунций от х к и.
В случае, когда переменные х, ty имеют соответственно кит
непустых значений, полный класс D-функций содержит число функций,
51
У
Б
ь
У
Б
ь
20
ВО
а
60
40
I
5
X
Рис. 2.9.1. Таблица сопряженности по переменным
X , ^ (вверху) и функции <f j, t » 1, 8, образующие
полный класс В --функций от X к U.
У *г
Б • 9
ь—
У
Б
ь
</>з
*4
*5
У
Б
ь
</>б
^7
*8
равное Т(п,т),которое определяется выражением
п
T(n,m)-ZImlT
i-i
!(n-i)!
Полный класс D -^ункний от X к ц включает все отображения
вида Х^Уи все отображения вида В^У,где ВсХ.
Процедуры детерминационного анализа начинаются с решения
следующей основной задачи: в полном классе Ъ -функций от х к у в
контексте к найти все D -функции, которое удовлетворяют ограничениям
B.9.1)
где L, М - зависящие, вообще говоря, от X , ^ подмножества из от*-
резка [О, 1] на вещественной оси. Система ограничений B.9.1)
называется основным уравнением детерминационного анализа.
Решить его - значит в контексте к указать все D -функции из полного
*)
класса D -функций от х к U, которые ему удовлетворяют . В случае,
когда множество L состоит из одной точки, соответствующей
единице, уравнение B.9,1) переходит в уравнение, решением которого
'Веер отображений, а значит, и таблица сопряженности по х и
считаются заданными.
52
0,8
0,6
0,4
0,2
1
\
1 ^7
1
1
*l
*l
<?l < S^6
> "гГ'^Ь'^Ь
^7
«01
^1/S^6
^1,^6
—
^7
*l
01
<01
^4
^4
^4
L^to*
0,25 0,33 0,67 0,75 1 о
Рис. 2.9.2. Решения основного уравнения B.9.2) в различных
областях значений параметров У, 6*.
могут быть только нормальные функции. В дальнейшем мы будем
иметь дело с основным уравнением в форме
UMx~tj))>5,
B.9.2)
где У , ff - некоторые константы 04 8*4 1, 04^4 1 •
На рис. 2.9.2 в качестве примера представлены все возможные
варианты его решения для таблицы сопряженности пох,| и полного
класса D -функций, изображенных ранее на рис. 2.9.1. Контекст к -
я со. Граничные точки, отделяющие области различных решений по оси
б', взяты для графического удобства не в масштабе. Принадлежность
граничных точек по У и б1 указана стрелками - острие стрелок, как
обычно, обозначает открытый конец полуинтервала, в котором
расположена стрелка. Ъ -функции, являющиеся решениями B.9.2),
проставлены в соответствующих областях значений параметров У , в и
показаны на рис. 2.9.1. Остутствие решений показано прочерком.
Мы видим, что если 5 > 0,33, 5 > 0,4, то решение основного
уравнения единственно. В этом лишь отчасти проявляется специфика
конкретной таблицы сопряженности, на основе которой рассчитаны
решения и граничные точки, отделяющие области различных решений.
Существует общее правило, справедливое вне зависимости от
конкретного веера отображений и таблицы сопряженности (теорема
единственности).
Пусть параметр У в основном уравнении B.9.2) больше половины.
Тогда, если решение этого уравнения существует, оно единственно.
Формальное доказательство данного положения тривиально: если
у, (f '- два разных решения, не совпадающие при каком-то кх,то,
поскольку & > 0,5,
I(fcx~v(kx))+I(kx— *'(*%))» &+»>!.
53
Но это невозможно, потому что интенсивности суть условные
частоты (проценты) и такая сумма никогда не превышает единицы A00%).
Точно так же несложно показать, что когда оба параметра 8, 6 в
уравнении B.9.2) больше половины, то, если существует В
-функция, служащая его решением, она не только единственна, но еще и
взаимно однозначна.
Аналогично тому, как мы определили Ъ -функции, можно
определить В -отношения. Пусть X , Y - множества значений переменных
Рис. 2.9.3. Графики Б готношений, эквивалентных совокупностям В«
функций { Cflf Срг , Cf5,q>e}(справа) и{ Vtt^} (слева).
X t u соответственно; подмножество R 6 X*Y называется детермина-
ционным отношением или Б "Отношением от ос к и 7 если каждой
паре (х, u)cR поставлена во взаимно однозначное соответствие
детерминация х»-*у.С такой точки зрения уравнение B.9.2) есть
уравнение относительно Б -отношения. Всякая совокупность Б -функций,
являющихся решением этого уравнения, определяет некоторое Б
-отношение. Например, совокупности В -функции [ ф. , ср , ср5,(р6} ^(р,
tp }, указанные на рис. 2.9.2, представляют собой Б-отношения,
графики которых изображены на рис. 2.9.3.
В терминах В-отношений любое решение уравнения B.9.2), если
оно существует, единственно при любых значениях параметра У. В
таком случае эквивалентом теоремы единственности служит
следующее утверждение: если существует Б -отношение, удовлетворяющее
уравнению B.9.2) при значении параметра S> 0,5, то это Б
-отношение есть Б-функция.
Язык В -отношений удобен для обсуждения решений этого
уравнения при ?< 0,5. При 5 > 0,5 все Б -отношения, дающие его
решение, есть В-функции, и тогда более предпочтительным становится
язык В-функций.
Практическая процедура поиска решений основного уравнения B.9.2]
крайне проста: если идти 'со стороны хг (возможен и иной путь, а
именно, *со стороны у"), то для каждого непустого х - о, следует
подсчитать I (а*ь,ф^)|С((Х,-*у)как функции от и, и те значения ц, при
которых названные величины превышают соответственно S , G , будут
значениями (при Xs си) искомого Б-отношения, дающего решение
уравнения B.9.2). Когда 5 > 0,5, процедура еще более
облегчается тем, что если найдено какое-либо одно значение \j e в, для
которого 1(а,^6)>У, то дальше можно не искать: других значений \^ф
54
? 6, детерминируемых значением х - сь с интенсивностью,
превышающей 1/2, не существует. Следует просто положить в в<г(а), т.е. счи-
<р
тать, что при заданном Xs О/ детерминация **+Ч, принадлежащая
искомой "D-функции v, дающей единственное решение уравнения B.9.2),
найдена, и перейти к повторению алгоритма с другим значением х.
Здесь D-функции и D-отношения как бы порождаются, индуцируются,
числами заполнения в таблицах сопряженности, на основе которых
подсчитываются интенсивности и емкости. Но этом основании в
ряде работ (например, [60 - 63] и некоторых других) Ъ -функции,
появляющиеся как решения B.9.2) при 8 > 0,5, назывались
индуцированными функциями (а детерминации х~^ определялись как
индуцированные соответствия).
Если понятие детерминации не определено, то говорить о детер-
минационных функциях нет смысла. Обычные функциональные
зависимости - это не D -функции. Однако детерминационная функция ^ в
» <р(х) (если абстрагироваться от интенсивностей и емкостей соот-
ф
ветствий ЭС*"*^,считая их просто точечными соответствиями) есть,
очевидно, обычная функция от х к и. Обычные функции называть D-
функциями, вообще говоря, нельзя, но о последних можно всегда
говорить как о самых обычных функциях.
§ 2ДО. Стандартное разложение D-функции
Рассмотрим таблицу сопряженности по переменным х, у,
изображенную слева на рис. 2.10.1. Очевидно, группы похD),ха)
практически однородны по и , а группы по х , х - по ц- ¦
Поэтому естественно столбец х склеить" со столбцом х( } а столбец
XW - со столбцом х1 .В итоге получим таблицу, которая
показана слева на рис. 2.10.2. Здесь р* - результат "склейки",
объединения, xw с хсг> (т.е. Р D) = х (i)v эс(г)), р(г) - результат
объединениях*5^ x(l° (T.e.p^LxUVx(l4)).
"Склейка" означает нормальное преобразование р - ф (х)
переменной х в переменную р ; таблица сопряженности по переменным х , р и
график преобразования приведены на рис. 2.10.3.
Процедура склейки по значениям переменной х, изображаемая
нормальной функцией р = Ч*.1*Ь©сть-простейший пример так называемой
стандартной объяснительной (объясняющей) типологии.
"Объяснительной" ("объясняющей") она называется потому, что основанием для
типологизашга значений переменной х выступает здесь то, как сами
эти значения "объясняют",.детерминируют, значения другой
переменной и. Эпитет "стандартная" обусловлен стандартным характером
процедуры такой типологизапии в детерминационном анализе. Она
систематически используется именно как стандартная процедура при
построении всевозможных объяснительных типологий.
55
У
уB)
уA)
20
80
х<1>
10
90
хB)
80
20
хC>
90
10
х<4)
X
B)
A)
хA) хB) х.З. х.4) „
Рис, 2.10.1. Таблица сопряженности по х,и (слева).и график
])-функции ij« <Р(Х) (справа).
,B)
,И)
30
170
J.D
170
30
А2)
А2)
,П!
р<1> р<2> р
Рис. 2.10.2. Таблица сопряженности по u7 p (слева) как результат
объединения столбцов на рис. 2.10.1 и график Ъ Н^ушшии u= <f(p)
(справа).
• р
р,2)
Рт
0
100
хA)
0
100
хB)
100
0
хC)
100
0
х<4)
X
J2)
JD
т ¦ Я О
к L
хA) хB) х<3) хD) х
Рис. 2.10,3. Таблица сопряженности по переменным X, р (слева)
и график нормальной функции р в ЦЧХ) (справа).
Вернемся к таблице сопряженности на рис. 2.10.1. Основанием
для объединения первых двух (слева направо) столбцов для нас
послужило то, что большая часть респондентов в них сосредоточена на
пересечении со строкой по и , т.е. близостью интенсивности
детерминаций хA)ь+у( , х( >*t^(i)K единице. Аналогично, столбцы по х(г ,
X объединены были потому, что их , и* х детерминируют одно
и то же значение ij = ^ с интенсивностью, также близкой к
единице. Перечисленные детерминации образуют D-функцию ^ =
<?(х),график которой расположен справа* на том же рисунке. После склейки,
т.е. после проведения нормального преобразования р = Ц»(х),мы
получили функцию и-^(р), показанную справа на рис. 2.10.2.
56
X
уD)
хC)
х<2>
хA)
1
1
0
0
хA)
1
1
0
0
хB)
0
0
1
1
х<3>
0
0
1
1
х<4>
X
Рис, 2.10.4. Матрица расстояний между точками в пространстве
значений переменной х.
Поскольку у « <р (х)« у(р),в р « ф (х), то I)-функции ^Р, <р , Ф связаны,
очевидно, соотношением
Ф(х) s <МФ(х)).
Иными словами, функция <р есть композиция D -функций <р и ф,т.е.
Обратим внимание на то, что функция *р является взаимно
однозначной. Таким образом, тривиальная процедура склейки столбцов
в таблице сопряженности привела нас к разложению D -функции <р в
композицию двух D-функций, одна из которых (Ф) есть нормальная
функция, а другая (ф)- взаимно однозначная .
Справедливо следующее положение: какой бы ни была "D-функция
/\
ср,ее разложение у = <роф в композицию нормальной (ф) и взаимно
-А
однозначной (ф) функций всегда существует и единственно.
Разложение (р я(роф называется стандартным разложением D-
функции <р на нормальную (ф) и взаимно однозначную (Q) Ъ -функции.
Нормальная функция ф называется также стандартной объяснительной
(объясняющей) типологией на основе Ъ -функции <р или просто
нормальной компонентой D-функции <р.
Стандартное разложение ср = <роф изображается диаграммой
*) /ч
В общем случае образ функции «f (т.е. множество ее значений)
не обязательно совпадает с множеством значений переменной и.
Иными словами, термин "взаимно однозначная" здесь следует понимать
как "взаимно однозначная на образе". Более строгая терминология
приведена в пункте 6.3 приложения.
57
где стрелки следует понимать как знаки отображений (функций) от
одной• переменной к другой.
Стандартное разложение аналогично каноническому разложению
отображений, используемому в алгебре и теории множеств (см.,
например, [3, 6]): нормальная компонента играет здесь роль
канонической сюръекшш, а взаимно однозначная компонента выступает как
композиция канонической биекции и канонической инъекции.
Вернемся снова к таблице сопряженности на рис. 2.10.1. Введем "рао
стояние* между значениями % , % ,i,ka 1,2, 3, 4, следующим образом:
pu'Wi
О, ЧЧХ1") = Ч»СХ(|°),
1 <<(xliV <KXA°).
Матрица значений функции расстояния показана на рис. 2.10.4.
Расстояние между значениями переменной х определяется видом
D-функции и- (f(x).Алгоритм получения стандартной
объяснительной типологии р s у (х) прост: все значения х детерминирующие
одно и то же значение и, находятся друг от друга на расстоянии,
равном нулю, и попадают в один класс (тип, таксон), который есть
ф~ (у). Расстояние между любым значением х из одного класса и
любым значением х из другого класса всегда равно единице. Таким
образом, получение стандартной объяснительной (объясняющей)
типологии по Б -функции и- <р(х)опирается на элементарную
метризацию пространства значений аргумента х, которая "наводится" D-
функпией <р (конкретный пример см. в § 3.4).
Глава III
ПРАКТИЧЕСКИЙ ДЕТЕРМИНАЦИОННЫЙ АНАЛИЗ
Получение эмпирических данных в виде заполненных рабочих
документов - это лишь завершающая стадия весьма сложного
процесса, куда включаются и теоретическая проработка собственно социаль-"
ной и социально-экономической проблематики, покрываемой
обследованием, и длительные, кропотливые процедуры поиска эмпирических
референтов для понятий, в которых формулируется эта проблематика,
и формирование рабочего документа, и проведение пилотажа, и
проектирование выборки, и многое, многое другое. Но вместе с тем
массив заполненных рабочих документов, полученных по завершении
'полевого этапа1', знаменует только начало большой работы.
Необходимо затем провести контент-анализ открытых вопросов по некоторой
подвыборке, с тем чтобы преобразовать их из открытых в закрытые.
Необходимо закодировать информацию и отперфорировать ее. Затем
следует ввод данных в ЭВМ с итеративными процедурами контроля
и редактирования, и лишь после всего этого (если подготовлено
соответствующее программное обеспечение) может быть реализован
этап расчетов с их последующим (или параллельным) анализом.
Именно здесь и включается в эмпирическое обследование детерми-
нашюнный анализ, практическая реализация которого возможна
только на базе специальной вычислительной системы,
предусматривающей (как обязательное или почти обязательное)
условие режим^ диалога, осуществляемого
исследователем-предметником, с ЭВМ.
В данной главе дается представление о практической стороне де-
терминационного анализа. Она начинается с изложения основных
типов исследовательских вопросов (элементарных задач), образующих
базис детерминадионных расчетов. Затем описывается диалоговая
вычислительная система, обеспечивающая расчеты. После этого
следуют иллюстративные примеры практического приложения детермина-
нионных расчетов к анализу материалов конкретного исследования.
Здесь разбирается, в частности, совместное влияние* ряда факторов
(таких, как квалификация труда и образование, преобладающие в
семье, пол респондента, собственное его образование) на
вербальную оценку читательского поведения. Еще один пример посвящен сов-
59
местному построению двух объяснительных типологий, одна из
которых типологизирует жилищные условия по характеру жилья
(отдельная квартира, коммунальная квартира, отдельный дом и т.д.) и
количеству жилых комнат, а другая дает типологию семей по
продолжительности брака и по уровню материальной обеспеченности.
Объясняемой переменной служит априорная типология по уровню
обеспеченности бытовой техникой, уже рассмотренная нами ранее в § 2.8, где
разбиралось понятие нормальной функции.
§ 3.1. Базовые задачи. Типы исследовательских вопросов
В сущности, детерминадионный анализ сводится к получению
условных частот или процентов (интенсивности и емкости суть только
лишь самые обычные условные частоты) и анализу приращений,
которые получают условные частоты, при изменениях состава свойств,
фигурирующих в них (эти приращения суть существенности
соответствующих свойств). Поэтому детерминадионный анализ, строго
говоря, можно всегда свести к двум элементарным задачам: 1) найти
условные частоты, коль скоро заданы фигурирующие в них свойства,
и 2) найти разность между заданными условными частотами. При
таком подходе, однако, очень трудно проследить связь названных
задач с содержательными постановками многих проблем, которые
обычно стоят перед исследователем-предметником, хотя, как
правило, связь, несомненно, имеется. Смысл таких понятий, как
детерминация, уточнение, существенность уточнений (или существенность
свойств), контекст, существенность контекста, нормальная функция,
В -функция и т.д., состоит прежде всего в том, что с их помощью
связь содержательных постановок в привычных
специалисту-предметнику терминах с подсчетами условных частот можно проследить
легче, чем без использования подобных понятий.
Итак, в детерминащюнном анализе выделяются с учетом
сделанных выше оговорок следующие десять базовых задач. Для каждой
задачи приведены ее название и содержательная постановка.
Задача 1. Получение объяснений. Задано некоторое свойство
(назовем его объясняемым, т.е. подлежащим объяснению). Какие
люди и в каких условиях им обладают? Дать описание этих людей и
условий, т.е. указать свойства (назовем их объясняющими), которые
объясняли бы первоначально заданное свойство.
Задача 2. Получение уточнений. Имеется некоторый признак.
Позволяют ли его значения уточнить объяснение, полученное в
качестве решения задачи 1? Если да, то указать, искомые значения при*-
знака и как они уточняют это решение*
Задача 3. Получение дополнений. Имеется некоторый
признак. Позволяют ли его значения дополнить объяснение, полученное в
качестве решения задачи 1? Если да, то указать искомые значения
признака и как они позволяют это сделать.
Задача 4. Существенность контекста. Допустим, решение
задачи 1 получено в некотором контексте. Существен ли он? Указать
степень существенности.
60
Задача 5, Существенность объясняющих свойств.
Допустим, имеется решение задачи 1. Насколько существенны в нем
объясняющие свойства, которые входят в описание людей и условий,
дающее само решение?- Указать их существенность.
Задача 6. Существенность объясняемых свойств.
Допустим, имеется решение задачи 1. Насколько существенны в нем
свойства, которые в сочетании образуют объясняемое свойство?
Указать их существенность.
Задача 7. Построение объясняющей типологии. Пусть
изначально имеется набор свойств, каждое из которых по
отдельности объясняет одно и то же свойство R , может быть, не очень
полно, но зато достаточно точно. Требуется построить обобщающее
типологическое свойство, которое обобщало €ы все объясняющие
свойства изначального набора и давало бы также достаточно точное
объяснение свойства 6, но при этом, чтобы полнота данного объяснения
была заведомо выше, чем у отдельных объяснений свойства 6
свойствами из упомянутого набора.
Задача 8. Построение объясняемой типологии. Пусть
изначально имеется набор свойств, каждое из которых можно объяснить,
пусть не очень точно, но зато достаточно полно, с помощью одного
и того же свойства а. Требуется построить обобщающее
типологическое свойство, которое обобщало бы все объясняемые свойства
изначального набора, и при этом, чтобы само оно объяснялось свойством
а не только достаточно полно, но и заведомо точнее, чем каждое из
отдельных свойств из упомянутого набора.
Задача 9. Проверка объяснительных возможностей
типологии. Пусть задано некоторое типологическое свойство,
выступающее как содержательное типологическое обобщение рада более
простых (менее общих) свойств. Требуется определить, насколько
оно существенно при объяснении некоторого третьего свойства.
Задача 10. Проверка объясняемости типологии. Пусть
задано некоторое типологическое свойство, выступающее как
содержательное типологическое обобщение ряда более простых (менее
общих) свойств. Требуется определить, насколько оно может быть
объяснено с помощью ряда третьих свойств.
Как легко заметить, элементарность по крайней мере некоторых
приведенных задач носит достаточно, условный характер. Они не
являются независимыми, многие из них, например, предполагают
существование решения задачи 1. Но они тем не менее дают удовлет>-
ворительное представление о спектре исследовательских вопросов,
на которые детерминационный анализ ориентирован как на базовые.
Практически любую задачу в детерминационном анализе можно
свести либо к одной из перечисленных, либо к суперпозиции
нескольких из них. Обратимся теперь к формальной постановке базовых
задач (практические иллюстрации содержатся в следующих параграфах
данной главы).
Формальной основой базовых задач являются следующие три
задачи:
61
1. Решение основного уравнения для D-функций.
2. Определение существенности различных свойств (переменных)
в детерминациях (D -функциях).
3. Преобразования D-функций путем нормальных преобразований
переменных.
Ниже представлены формальные постановки перечисленных выше
десяти базовых задач. Предполагается, что веер отображений (т.е.
исходный массив в виде матрицы данных) фиксирован.
Задача 1. Получение объяснений.
Задано:
1) объясняемое свойство 6;
2) объясняющая переменная х;
3) контекст It;
4) минимально допустимая точность объяснения У;
5) минимально допустимая полнота объяснения 64
Требуется указать все D -функции, дающие решение основного
уравнения
<
СA((х?б)) >ff.
L
Всякое решение ^(а1-* 8) этого уравнения есть по определению
искомое объяснение свойства 6 свойством а в -контексте к с точностью
1A<(а~В)) и полнотой С(к1а^6)).
Задача 2. Получение уточнений для определенного решения
задачи 1.
Задано:
1) решение 1< (а-* 6) задачи 1;
2) уточняющая переменная Ъ.
Требуется отыскать величины
5(а,** —в)-1(ах-- &)-1({ь~ 6)s&I(x).
Искомые уточнения определяются одним из трех неравенств:
д1(г)>0, д1(г)*0, д1(%)<0
в зависимости от того, требуется ли отыскать позитивные,
несущественные или негативные уточнения. Величина 1д1(ХI измеряет
степень существенности.
Задача 3. Получение дополнений для совокупности решений
задачи 1.
Задано:
1) совокупность решений k(x»-*b),X€ А, задачи 1;
2) дополняющая переменная %.
62
Требуется отыскать все решения основного уравнения
в которых Х^А.Эти решения и являются искомыми дополнениями.
Задача 4. Существенность контекста*
Задано
решение k (а *~* Ь) задачи 1.
Требуется отыскать существенность контекста
$(к*(а,~6))= 1A<(а,>4))- Ца->6у
Задача 5. Существенность объясняющих свойств.
Задано;
1) решение fc^^ 8) задачи 1;
2) разложение & = Get.
Требуется отыскать существенность свойства С'
«Г
Задача 6. Существенность объясняемых свойств.
Задано:
1) решение к(а»-*8) задачи 1;
2) разложение 6 = С А.
Требуется отыскать существенность свойства с:
Задача 7. Построение объясняющей типологии.
Задано:
1) объясняемая переменная ц\
2) объясняющая переменная х;
3) минимально допустимая точность ? > 0,5;
4) минимально допустимая полнота G.
Требуется построить стандартное разложение (см. § 2.10)
4>(х)= ?(Ф (х))
цля D -функции у - v(x), являющейся решением уравнения
ч.
Нормальная функция р - ^(х) будет искомой объясняющей
типологией. Для всякого объясняемого свойства и = 8 уравнение
63
e if (p) определяет единственное типологическое свойство
робъясняющее 6 (vp взаимно однозначна!).
Задача 8. Построение объясняемой типологии.
Задано:
1) объясняемая переменная и;
2) объясняющая переменная х;
3) минимально допустимая точность объяснения У;
4) минимально допустимая полнота объяснения <$ > 0,5.
Требуется построить стандартное разложение
для D-функции х e <p(u), являющейся решением уравнения
Нормальная функция р в ф (и) будет искомой объясняемой
типологией. Для всякого объясняющего свойства х « <Ь уравнение си «
= ^>(р) определяет единственное типологическое свойство р,
объясняемое свойством О/.
Задача 9. Проверка объяснительных возможностей
типологии.
Задано:
1) объясняемое свойство I;
2) переменная х;
3) нормальная функция (типология) рв ф(эс);
4) контекст к;
5) минимально допустимая точность объяснения S>;
6) минимально допустимая полнота объяснения 6Г.
Требуется решить задачу 1, положив в качестве объясняющей
переменной переменную р.
Задача 10« Проверка объясняемости типологии.
Задано:
1) нормальная функция (типология) р s ф(х);
2) объясняемое свойство 𠦻 Ь; v
3) объясняющая переменная х ;
4) контекст к;
5) минимально допустимая точность объяснения 5;
6) минимально допустимая полнота объяснения б.
Требуется решить задачу 1.
Перейдем теперь к описанию диалоговой вычислительной системы,
обеспечивающей расчеты, необходимые для решения базовых задач
и задач, которые сводятся к базовым.
64
§ 3.2. Диалоговая вычислительная система
Описываемая ниже диалоговая система создана и функционируют
во ВНИИ системных исследований ГКНТ и АН СССР в двух
вариантах: базовом (на основе ЭВМ ЕС типа Ряд-40) и пилотажном (на
основе ЭВМ PDP 11-70). Система позволяет обрабатывать данные,
представленные в виде веера отображений (матрицы данных)
где Е - обследуемое множество объектов (множество строк в
матрице данных), X.- множество значений переменной X. л - индекс
(имя) переменной х. и множества ее значений (индекс или имя
столбца в матрице данных), я, - число переменных (число столбцов в
матерние данных).
Технические ограничения на размеры обрабатываемого массива
4 3
данных: число объектов N -IEI ? 10 ; число переменных п 4г 10 ;
число значений каждой переменной практически неограничено.
Система предназначена для обработки в первую очередь качественных
данных, но может применяться также и для обработки данных
количественных. Она функционирует в режиме диалога с многократной
оперативной реализацией элементарного акта "запрос-ответ". Диалог
осуществляется через дисплей непосредственно самим
исследователем-социологом без посредничества программистов. Инструкция по
использованию системы не предполагает владения языками
программирования или иных специальных формальных знаний. Опыт
показывает, что для овладения инструкцией до такой степени, чтобы
можно было самостоятельно начать практическую работу с системой,
сшециалйслу-лредметнику без специальной
формально-математической подготовки требуется время порядка одного-двух часов. Язык
запросов и ответов включает только те понятия, с которыми
исследователь, работающий с эмпирическим материалом, сталкивается в
своей каждодневной практике. Время, необходимое для введения
запроса с пульта дисплея и получения ответа на экране телевизора, -
около минуты. Вопросы и ответы распечатываются параллельно на
бумажной ленте практически синхронно с ходом диалога и
предоставляются исследователю для последующего визуального анализа.
Основным документом при работе с системой является словарь
переменных - перечень эмпирических индикаторов, включенных в
обследование и преобразованных к форме, в которой все они
представлены как закрытые и альтернативные. Каждая переменная в словаре
имеет свой код (номер). Код имеется также у каждого значения
переменной. Значения числовых переменных могут кодироваться самими
числовыми значениями, но это не обязательно. Вот для примера
небольшой фрагмент такого словаря .
Обследование, которому относится приведенный фрагмент,
используется ниже для иллюстрации. Его авторы - Б.М. Л^вин и
65
Словарь переменных (фрагмент)
. • • 9. Уровень образования в семье респондента (измеряется
уровню образования ведущей брачной пары) .
1. Высокий (у обоих супругов образование среднее и выше).
2. Низкий (у обоих супругов образование ниже среднего).
3. Средний (у одного из супругов образование среднее и выше,
у другого - ниже среднего).
... 451. Частота чтения книг (вербальная оценка).
1. Часто (несколько раз в неделю и чаще).
2. Не очень часто (примерно один раз в неделю).
3. Редко (примерно раз в месяц и реже).
4. Очень редко, практически никогда.
5. Затрудняюсь ответить.
... 488. Пол.
1. Мужской.
2. Женский.
Указанные в словаре коды переменных и их значений играют роль
'слов* в языке, на котором система воспринимает вопросы и выдает
ответы исследователю. То, что кодами выступают числа, не имеет
принципиального значения. Числа здесь играют только роль
различающих меток, вместо них могли бы с тем же успехом
использоваться обычные слова или любые буквенные символы.
Детерминации - это клетки таблиц сопряженности, и их анализ
есть анализ клеток в таких таблицах. Большая часть расчетов,
производимых диалоговой системой, падает на подсчет и распечатку таблиц
сопряженности. В этом смысле описываемая диалоговая система есть
лишь естественное развитие систем, позволяющих получать таблицы
сопряженности. Техника и терминология детерминационного анализа
не меняют существа дела, которое остается простым. Но они
требуют несколько иной формы представления таблиц сопряженности,
чем принято обычно: таблицы сопряженности превращаются здесь в
таблицы детерминаций.
Продолжение сноски
Я.С. Капелюш. В нем изучались потребительские ориентации и
потребительское поведение сельского населения. Данные относятся к
Воронежской области, измерения были проведены в 1977 г. Обследование имело
пилотажный характер, поэтому выборка небольшая - в основании
веера всего N -/152 человека. Мы приводим здесь лишь три
переменные, тогда как всего в обследовании фигурировало к - 527
переменных (т.е. число компонент веера или содержательных разрезов здесь
весьма велико). Коды (номера) переменных сохранены такими же,
что и в рабочем варианте словаря. Другие его фрагменты
воспроизводятся в дальнейшем по мере необходимости.
*' Если в семье несколько брачных пар, то отмечается ^младшая
пара; если в семье нет брачных пар, то отмечается образование
одиночек или младшего из взрослых членов семьи.
66
Таблица 3.2.1
Таблица сопряженности
по переменным х: 9, и: 451
(значения переменных обозначены
кодами из словаря)
X: 9
1
2
3
29
9
17
—
1
16 кз
1
1
8 | 8
i
3 6
2 i 3
3
26
7
4
2
4
1
5
1i:45l
Обратимся, например, к таблице сопряженности по переменным
9 : 4?>1 из приведенного фрагмента словаря (табл. 3.2.1).
Система (если она получает соответствующий запрос)
распечатывает такую таблицу в виде пяти таблиц, каждая из которых
содержит сведения только об одном из столбцов таблицы.
В качестве примера ниже, приведена одна из них (табл. 3.2.2).
Эта таблица содержит данные из первого столбца табл. 3.2.1 -
ряд цифр в вертикальной колонке N (х ^), ограниченной
вертикальными линиями. Свойство, определяющее первый ее столбец, вынесено
в заголовок табл. 3.2.2 в виде символа ц :451A), который
читается так: 'переменная ц есть переменная № 451; значение
переменной и фиксировано и равно значению № 1 переменной № 451*.
Переменная № 9 здесь выступает как переменная х. Символ х : 9 чи-
тается так: 'переменная х есть переменная №9' * Каждая строка
этой таблицы соответствует одной клетке в первом столбце табл. 3.2.1
или одной детерминации х~*у: в первой строке заключены данные о
верхней клетке первого столбца табл. 3.2.1 с числом заполнения
N(x^)s 29 (т.е. сведения о детерминации х»-*у,где х : 9A), ц. :
:451 A)), во второй - данные о клетке с числом заполненияNCat^
¦» 9 и т.д. Кроме самого числа заполнения N (хи) в строке таблицы
детерминаций указан полный 'джентльменский набор', обычно
используемый в социлогической практике при анализе клеток в
таблицах сопряженности: 'процент по строке' (интенсивность U*1-*^)) и
'процент по столбцу' (емкость С(х*-*^));интенсивность и емкость
выражены здесь в долях единицы, а не в процентах (только поэтому мы
и ставим кавычки), затем число N (%) респондентов в целом по
строке (т.е. численность группы тех, кто обладает свойством х), число
заполнения N(xu) и, наконец, число Nty) респондентов в целом по
столбцу (т\е. численность группы тех, кто обладает свойством ^ )•
*^В дальнейшем знак № у номера переменной мы будем опускать.
67
Таблица 3.2.2
Таблица детерминаций ivCx»-*^);
к= и; ц: 451 A); X: 9;
У= О; <* = О
х: 9 I(x»-y) C(x~tj) N(x)
1 0,46 0,53 63
2 0,16 0,16 55
3 0,50 0,31 34
N(Xtj)
29
9
17
*М
55 !
55
55 !
Все эти сведения обычно содержатся и в таблицах сопряженности с
тем лишь отличием, что процент по строке не называется
интенсивностью, а процент по столбцу не связывается с емкостью
определенных детерминаций. В этом смысле таблицы детерминаций - это
буквально то же, что и таблицы сопряженности. Разница между ними
становится очевидной лишь при переходе к анализу многомерных
группировок. Теоретически рассматривать многомерные таблицы
сопряженности (как формальный объект) легко, а практически их анализировать
трудно - они имеют очень негибкую форму представления. Что же
касается таблиц детерминаций, то в случае многомерности их
рассматривать в принципе столь же несложно, как и в случае двух
измерений, нужно только, сообразуясь с содержательной постановкой
задачи, решить заранее, какие переменные будут объясняемыми (ц),
*)
какие объясняющими (X), а какие войдут своими значениями в
контекст к.
Множество значений объясняющей переменной х называется
содержательной сферой, на которой система отыскивает детерминации.
Ввести (добавить) какую-либо переменную в содержательную сферу
по х - это значит включить ее в число сомножителей х. В табл. 3.2.2
содержательная сфера состоит из одной переменной 9. Добавим в
нее, например, переменную 488 (пол). Результат такого добавления
представлен в табл. 3.2.3 (здесь, как и далее в данной главе, мы
приводим в качестве примеров результаты реальных расчетов,
проведенных на материалах упоминавшегося выше конкретного обследования).
Эта таблица описывает влияние образования (переменная 9) и
пола (переменная 488) на частое чтение книг (значение 1
переменной 451) в универсальном контексте k e со. Ее расшифровка
элементарно производится с помощью словаря: в первой строке
представлены мужчины 488A), проживающие в семье с высоким уровнем
образования 9A); их 34 человека, среди них 20 человек (что
составляет I (х — ^)*100 = 59%) читают книги часто; всего читающих часто
55 человек, среди них те же 20 человек составляют С(х»-»у)* 100 «
= 36% и т.д.
*^ Переменная v "входит" в переменную х, если х есть произведе*-
ние ряда переменных, среди которых фигурирует v.
68
Таблица 3.2.3
Таблица детерминаций к(х~у); к=со; у: 451 A); X: 488; 9;
У- О; 6-= О
х: 488;
! 1
2
: 1
2
1
2
9
1
1
2
2
3
3
1(*"Ч)
0,59
0,31
0,23
0,12
0,47
0,53
С(*-у)
0,36
ОД 6
0,09
0,07
0,13
0,18
К(х)
34
29
22
33
15
19
N(xtj)
20
9
5
4
7
10
Щ) |
55
55
55
55
55
55
В универсальном контексте У в со вычислительная система
позволяет получать таблицы детерминаций, в которых содержится до 14
измерений - до 7 измерений по х (т.е. в содержательной сфере
может быть до 7 переменных из словаря) и до 7 переменных по ^-
Реально это обеспечивает практически неограниченную ''глубину"¦
просматривания материала, поскольку в словарь можно всегда ввести
новую переменную как нормальную функцию от набора переменных, уже
имеющихся в словаре (см. далее о запросе NF), т.е. каждая из 14
переменных может сама быть многомерным образованием.
Если увеличивать число переменных в содержательной сфере (т.е.
увеличивать размерность х),то группы по х будут становиться все
более дробными, из-за чего количество строк в таблице
детерминаций будет, вообще говоря, возрастать и может сделаться весьма
большим, В системе предусмотрена возможность ограничить объем
таблицы детерминаций путем отбрасывания строк, которые соответствуют
детерминациям с недостаточно большой интенсивностью или емкостью.
Табл. 3.2.2 и 3.2.3 содержат детерминации, которые удовлетворяют
/равнению
\ С (х- у > 6-,
где У в 6" « о. Величины $, б" представляют соответственно
минимально допустимые точность и полноту. Чтобы освободиться от
детерминаций с низкими точностью и полнотой, необходимо сделать %,
J отличными от нуля, повысив каждую из них до нужной величины.
Положив, например, в табл. 3.2.3 V = 0,4, <э - 0,1, получим
габл. 3.2.4, которая представляет собой фрагмент табл. 3.2.3.
Может показаться, что таблицы детерминаций дают более
громоздкую запись многомерных распределений, чем обычные таблицы
сопряженности: действительно, вместо одной таблицы сопряженности
(см. табл. 3.2.1) мы должны получить, как отмечалось, целых пять
таблиц детерминаций, а при многомерных и число таких таблиц,
описывающих полностью таблицу сопряженности, может оказаться
69
Таблица 3.2.4
Таблица детерминаций k{x*-*y)\ Vv= Q • ^: 451 A); х: 488; 9;
5"= 0,4;" в» 0,1
х : 488
1
1
2
9
1
3
3
I(x»-*yl
0,59
0,47
0,53
е(Хн^)
0,36
0,13
0,18
N(x)
34
15
19
Ы(х^) Nty)
20 55 !
7 55
10 55
значительно больше. Однако на деле запись в форме таблиц
детерминаций оказывается в конечном итоге более компактной, более экономично
и (что весьма важно) значительно более удобной для анализа, чем
запись в виде таблиц сопряженности. Исследователя-предметника
интересует, как правило, возможность объяснить отдельные конкретные
свойства,.а не переменные в целом. Тогда, фиксируя объясняемые
свойства в виде конкретных значений переменной ^, а также
отсекая заведомо недостаточно точные или недостаточно полные
объяснения, пользователь может с помощью таблиц детерминаций
анализировать только те фрагменты многомерных распределений, которые
содержат интересующую его информацию, а все прочие части этих
распределений, коль скоро они неинтересны, во внимание не
принимать. В случае двумерных распределений эти преимущества детер-
минационных таблиц не столь заметны. Но с увеличением
размерности они становятся все более очевидными.
Мы рассмотрели таблицы детерминаций, полученные в
универсальном контексте У и со. В общем случае вычислительная система
позволяет пользователю формировать контекст в виде любых отдельных
свойств или сочетаний свойств из словаря переменных. В качестве
простейшего примера приведем табл. 3.2.5, где в контексте одних
только женщин (У в 488B)) строится объяснение очень редкого
чтения книг (у: 451 D)) на содержательной сфере, ограниченной
образованием в семье респондента (х:9), при ? - <э « О.
Пусть t(M)~ размерность контекста к,*Ци") - размерность
объясняемого свойства u,ifr(x)- размерность объясняющей переменной X
(т.е. количество переменных в содержательной сфере, на которой
Таблица 3.2.5
Таблица детерминаций V (Х"Ц)\ к5* 488 B); \j: 451 D); х: 9;
{Г= О; б*» О
^х : 488
2
2
2
9
1
2
3
I(k(x~y»
0,03
0,67
0,16
C(k(x~yfl
0,04
0,81
0,11
Nftx)
29
33
19
ШЬхц) R[\iy) 1
1 27
22 27
3 27
70
отыскиваются объяснения). Общие ограничения на эти величины в
описываемой вычислительной системе таковы:
Г%(к) + г(у) + ч(х)< i*i,
|г(к) + %(ц) < 7,
[%(*) + х(х) < 7.
В случае, когда М = со , имеем. i(k)~#0 и мы приходим к
ограничениям на размерность таблиц сопряженности, уже
упоминавшимся ранее.
Диалоговая вычислительная система позволяет получать
всевозможные таблицы детерминаций по специальному запросу SD. В
запросе, который набирается на клавиатуре дисплея, указываются:
1) код запроса (символ S), показывающий, что мы хотим
получить именно таблицу или таблицы детерминаций, а не что-либо иное);
2) имена переменных, входящих своими значениями в контекст -к
(коды имен по словарю);
3) значения этих переменных, образующие в сочетании
конкретный контекст к (коды по словарю);
4) имена переменных, входящих своими значениями в
объясняемое свойство и (коды имен по словарю);
5) значения этих переменных, образующие в сочетании
конкретное объясняемое свойство и (коды по словарю; в одном запросе
таких свойств может 5ыть указано до десяти; по каждому из них в
ответе фигурирует отдельная таблица детерминаций);
6) имена переменных, входящих в объясняющую переменную ж (т.е.
словарные коды переменных, образующих содержательную сферу);
7) минимально допустимая точность У;
8) минимально допустимая полнота 6\
Запрос 2> в диалоге с системой эквивалентен следующему
словесному вопросу: 'Кто в контексте к обладает свойством и ? Перечислить
все*достаточно точные и полные ответы, имеющиеся на заданной
содержательной сфере*.
В ответ на такой вопрос, коль скоро указаны необходимые
параметры k , u , зс , V, б* , система выдает на экране телевизора и
параллельно распечатывает на бумажной ленте все детерминации,
которые образуют D-отношение <f, удовлетворяющее уравнению
Ик(х~у))> У,
С(к(х~у)) У/ ft
Для каждого значения ^ распечатывается своя таблица
детерминаций, как мы показали выше.
*) Для любой переменной х должно выполняться равенство t(x)H
s г((ох)« t(u>)+ %(х),откуда г(со) « О.
71
Таблица 3.2.6
Таблица детерминаций to (x^ij); ft я со; ^ - <tf ; х : 9; 451;
У» О; ОТ» О
Гх : 9
1
1
1
1
1
2
2
2
2
2
3
3
3
3
3
451
1
2
3
4
5
1
2
3
4
5
1
2
3
4
5
Их—1J)
1.0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
1,0
С(х~у)
0,191
0,105
0,086
0,019
0,013
0,059
0,053
0,053
0,171
0,026
0,112
0,020
0,039
0,046
0,007
Щх)
29
16
13
3
2
9
8
8
26
4
17
3
6
7
1
N(xt^)
29
16
13
3
2
9
8
8
26
4
17
3
6
7
1
N(t*)
152 j
152
152 " I
152
152
152 ,
152
152
152
152 1
152
152
152
152
152 J
Такой запрос обеспечивает чрезвычайно большую гибкость в
манипуляции данными: с его помощью можно исследовать структуру
детерминационных связей между любыми переменными или наборами
переменных из словаря, получая необходимую для анализа
информацию в удобной, легко визуально обозримой форме. Всю информацию
о линейных, парных, тройных и т.д. распределениях, обычно
необходимую специалисту-предметнику на начальном этапе анализа данных,
очевидно, легко получить по этому запросу, причем даже в
пределах одного и того же распределения имеется достаточно широкий
выбор в форме организации выходных таблиц (несмотря на то, что
общая структура таблиц детерминаций всегда жестко фиксирована).
Например, если форма представления парного распределения по
образованию (переменная 9) и частоте чтения книг (переменная 451) в
виде совокупности таблиц типа 3.2.2 почему-либо не устраивает
специалиста, можно, поменяв местами переменные 9 и 451, получить
таблицы детерминаций 1<(х*+у),где х : 451, у: 9A, 2, 3). Если же
необходимо визуально просмотреть скопления респондентов в
"пространстве* переменных 9 и 451, то разумно, положив к = <*>, ^ - со,
X : 9; 451, У *? G* « О, получить сведения о том же парном
распределении в виде табл. 3.2.6. Поскольку для непустых х всегда Их-*-
-*о))в 1, У можно взять любым между нулем и единицей. Емкости
в этой таблице суть частоты совместного распределения по перемен-'
ным 9 и 451. Положив здесь х: 9, мы получили бы линейное рас-
72
Таблица 3.2.7
Таблица детерминаций 1<(х->ц)\ 1<« со ; у : 9 A); 451 D); х = е
сГ« 1; в= О
х:е
067
105
128
I(x~tp
1
1
1
С (х-у)
0,007
0,007
0,007
Nix)
1
1
1
N(xy)
1
1
1
Щ) |
3
3
3
пределение по уровню образования в семье респондента, а при х: 9;
451; 488 имели бы совместное (тройное) распределение по
переменным 9; 451; 488. Таким образом, в предельном случае u= cof
запрос ft обеспечивает режим работы системы, когда она работает
как источник всевозможных распределений, которые можно получить
в нормировке на любой контекст.
В другом предельном случае, который реализуется при условии
Xs e(fc7u - произвольные, 1Гв 1,6 « О), вычислительная система
работает в режиме информационного поиска. Например, если
положить в этом режиме fc в со, ц : 9 A); 451 D), то система выдаст
табл. 3.2.7, которая показывает, что группа живущих в семьях с
высоким образованием (переменная 9, значение 1) и практически
никогда не читающих книги (переменная 451, значение 4) состоит
из трех человек, представленных анкетами под номерами 067, 105
и 128.
Мы видели в § 3.1, что все десять базовых задач детерминацион-
ного анализа покрываются списком, куда входят формальные задачи:
решение основного уравнения, определение существенности и
преобразование детерминаций (Ъ -функций) путем нормальных
преобразований переменных. i
Первая из них, очевидно, решается системой на основе запроса
2) (или серии таких запросов). Вторую также можно решить на
основе запроса®. Скажем, сравнивая интенсивности детерминаций х*-+у,
у которых в одном случае X: 9 (образование в семье), а в
другом случае X: 488; 9 (пол и образование в семье), получим
сведения о существенности уточнений, вносимых свойствами " мужчина f
'женщина' в объяснение свойства и с помощью уровня образования
в семье (см., например, табл. 3.2.2 и 3.2.3). Тем не менее в
системе предусмотрен специальный запрос S ? (детерминация плюс
существенность), который решает'вторую задачу, позволяя
автоматически подсчитывать существенности отдельных свойств,
фигурирующих в объясняющем (детерминирующем) свойстве х и контексте 1с.
Он набирается на клавиатуре дисплея точно так же, как запрос 8),
только вместо кодового символа fD в нем фигурирует символ 2>S. В
случае, например, табл. 3.2.3 этот запрос позволяет получить
точно такую же таблицу, но с проставленными величинами
существенности пола D88) и уровня образования в семье (9) для каждой из
73
Таблица 3.2.8
Таблица детерминаций и существенностей.
1< - со; ^: 451 A); х : 488; 9; 5« О; в - О
Гх : 488(g)
1 (+0,13)
2 (-0,15)
1 (+0,07)
2 (-0,04)
1 (-0,03)
2 (+0,03)
9(8}
1 WW
1 (+0,03)
2 Г-^22;
2 К/й
3 (+0,02)
3 ^25;
Ц*~у)
0,59
0,31
0,23
0,12
0,47
0,53
C(x~ij)
0,36
0,16
0,09
0,07
0,13
0,18
N(x)
34
29
22
33
15
19
N(xtp
20
9
5
4
7
10
Hty
55
55
55
55
55
55
указанных в ней детерминаций (см. табл. 3.2.8, где величины
существенностей • показаны курсивом в скобках рядом с каждым
значением кода, обозначающим одно из объясняющих свойств). Здесь
видно, что при объяснении частого чтения книг пол практически
несуществен в группах семей со средним или низким уровнем
образования, тогда как в семьях с высоким уровнем образования мужской
пол имеет не очень значительную, но все же заметную позитивную
существенность, женский пол - негативную существенность. На
женщин наибольшее позитивное влияние оказывает средний уровень
образования в семье (а не высокий, как можно было бы ожидать), а
наибольшее негативное влияние связано с низким уровнем
образования. Для мужчин, напротив, наибольшее позитивное влияние
оказывает высокий уровень образования в семье, тогда как средний его
уровень в группе мужчин практически несуществен. Низкий уровень
образования в семье для мужчин оказывается при объяснении
частого чтения книг более существенным негативным фактором, чем для
женщин, т.е. мужчин низкий уровень образования в семье более
активно отвращает от частого чтения книг, чем женщин (хотя, как мы
видим, в семьях с низким уровнем образования .среди мужчин
интенсивность частого чтения книг выше, чем у женщин, - 23% против
12%). Обратим здесь внимание на то, что хотя мы и говорим о
влиянии пола или влиянии уровня образования в семье, но всегда речь
идет только о существенности конкретных свойств в детерминациях,
объясняющих некоторое другое конкретное свойство. В одном
сочетании объясняющих свойств на одной и той же содержательной сфере
величины существенности одни, в другом - другие. Одно и то же
свойство может иметь высокую существенность в объяснении
свойства, выраженного одним значением какой-либо переменной, и вместе
с тем быть практически несущественным при объяснении свойства,
выраженного другим значением той же переменной (при неизменной
содержательной сфере). Эта игра существенностей, отражающая
важные стороны социальных явлений и процессов, в принципе не может
быть обнаружена с помощью способов анализа данных, не
удовлетворяющих принципу конкретности (например, таких, которые опираются
74
на всевозможные интегральные меры связи типа метрики Хемминга,
информационных мер, коэффициентов Пирсона, Чупрова, Крамера, Юла,
Кендалла и т.д.).
Третья и последняя задача из списка основных решается в
системе при помощи запроса МТ{М7 - нормальная функция). Этим
запросом состав словаря переменных можно расширить за счет вторичных
переменных, реферирующих содержательные обобщения, необходимые
исследователю. Вторичные переменные (содержательные типологии,
агрегированные показатели, индексы) вводятся как нормальные
функции от уже имеющихся в словаре (не обязательно первичных)
переменных. Значения вновь вводимых, переменных кодируются, сами они
получают каждая отдельный номер и затем используются наравне со
всеми другими переменными из словаря. При вводе запроса в
систему на клавиатуре дисплея набирается следующая информация:
1) код запроса - символ JVT;
2) имена переменных xt, х^ ,..., х , выступающих аргументами
вводимой переменной;
3) новая переменная как нормальная функция и = ?(х ,х , . ..,x.)j
4) код новой переменной в словаре.
Нормальная функция f может быть задана либо в логической
форме (см., например, логическую запись нормальной функции u = f (х<,
х, , X.) в § 2.8), либо в виде алгебраической функции от числовых
символов, которыми закодированы значения переменных.
Практически преобразование детерминаций, куда включена
переменная X, к детерминациям, куда вместо X включена переменная ъ
как нормальная функция 1 = ф (,х), осуществляется вводом
новой переменной ъ в словарь и затем заменой в
анализируемых детерминациях ( D -отношениях, Ъ -функциях) переменной
Хна переменную ъ.
Кроме ©,S)S и UТ система позволяет реализовать еще ряд
других запросов. Например, есть запрос, позволяющий в аргументах
детерминаций автоматически отбрасывать несущественные уточнения,
запрос, осуществляющий стандартное разложение произвольной
D-функции, выделение нормальной компоненты и ряд других. Они образуют
естественное развитие библиотеки запросов, и мы их здесь касаться
не будем, полагая, что читатель уже получил достаточное
представление о диалоговой вычислительной системе, обеспечивающей
необходимые расчеты в детерминадионном анализе.
Алгоритмы, по которым работает система, в
формально-математическом отношении просты. Они с достаточной очевидностью
демонстрируются разобранными выше примерами. В плане собственно
вычислительном их реализация в программном обеспечении
системы уже менее тривиальна. Возникающие здесь проблемы
обсуждаются, например, в работах [8 - 10].
Перейдем теперь непосредственно к демонстрации фрагментов
диалога, имевших место при анализе конкретных детерминашюнных
зависимостей.
75
§ 33. Пример 1. Читательское поведение
Ниже следует фрагмент диалога с вычислительной системой, в
котором решалась задача: исследовать, как на данной выборке
осуществляется влияние (совместное или порознь) пола, образования и
квалификации труда на читательское поведение. Образование взято
в двух аспектах: уровень образования, преобладающего в семье, и
уровень собственного образования респондента. Референтом
читательского поведения служит вербальная оценка частоты чтения.
Внимание в диалоге сосредоточено на крайних случаях, когда люди
отвечают, что они читают книги часто, и когда они говорят, что не
читают книг практически никогда.
Текст диалога очищен от технических деталей. В реальном
режиме детерминациоиного анализа каждый из указанных ниже вопросов
диалога предстает как один из конкретных запросов (в этом
диалоге — только запросов © и 2)?»)к системе, обсуждавшихся в
предыдущем параграфе, и каждый ответ выглядит как определенная таблица
детерминаций. Но в приводимом тексте диалога все запросы
сформулированы в словесной форме и ответы даны также в этой форме,
разве лишь с вкраплением (по мере необходимости) цифровых сведений
о точности и полноте ответов (точнее, детерминаций, на которых
построены ответы), о существенности фигурирующих в них уточнений
и о численностях участвующих в них групп. В контексте каждого
ответа обычно понятно, о какой детерминации' или о каком уточнении
идет речь, и поэтому вместо символов I (fc^), С (эь^), S(xx*»-Mj)
точность, полноту, существенность мы будем обозначать, как
правило, просто символами I , С , S .
Ответы в диалоге, записанные в словесной форме, представляют
собой текст, по форме мало отличающийся от обычного. По
существу же это не обычный текст. Слова и понятия, образующие его
основу, суть слова и понятия, фигурирующие в словаре переменных,
либо в виде имен переменных, либо в виде их отдельных значений.
Грамматическая структура здесь порождена детерминациями. Таким
образом, текст вопросов и ответов, представленный ниже, это
реферированный текст, порожденный результатами социальных
измерений (сокращенно - R -текст).
Словарь переменных, участвующих в диалоге
• ..9. Уровень образования в семье респондента (измеряется по
ведущей брачной паре).
1. Высокий (у обоих супругов образование среднее или выше).
2. Низкий (у обоих супругов образование ниже среднего).
3. Средний (у одного из супругов образование среднее или выше,
у другого - ниже среднего).
... 10. Уровень квалификации труда в семье респондента
(измеряется по ведущей брачной паре).
1. Высокий (оба или один из супругов специалисты).
2. Средний (оба или один из супругов, не будучи по статусу
специалистами, занимаются квалифицированным умственным или
физическим трудом).
76
3. Низкий (оба супруга занимаются неквалифицированным трудом)
4. Прочий.
... 399, Уровень образования самого респондента.
1. Высокий (образование среднее специальное или выше).
2. Средний (образование среднее или неполное среднее).
3. Низкий (образование ниже неполного среднего).
... 451. Частота чтения книг (вербальная оценка).
1. Часто (несколько раз в неделю и чаще).
2. Не очень часто (примерно один раз в неделю).
3. Редко (примерно раз в месяц и реже).
4. Не читаю практически никогда.
5. Затрудняюсь ответить.
... 488. Пол.
1. Мужской.
2. Женский.
Собственно диалог
Вопрос 1. Кто более склонен часто читать книги, мужчины или
женщины?
Ответ 1. Мужчины ( 1= 0,45, С = 0,58).
Вопрос 2. Насколько существенно, что это именно мужчины?
Ответ 2. Существенно, но не очень; S ~ +0,09.
Вопрос 3. Остановимся на мужчинах (т.е. положим к-488A)).
Можно ли условно объяснить их склонность к чтению образованием
в семье?
Ответ 3. Да, имеются три различных условных объяснения.
3.1. Мужчины читают часто, когда у них в семье преобладает
высокий уровень образования (I *» 0,59, С= 0,63).
3.2. Мужчины читают часто, когда у них в семье преобладает
средний уровень образования ( 1 = 0,47, С « 0,21).
3.3. Мужчины читают часто, когда у них в семье преобладает
низкий уровень образования (I « 0,23, С = 0,16).
Комментарий к ответу 3. Наиболее точным и полным является
ответ 3.1. Остановимся на нем подробнее.
Вопрос 4. Какую роль в ответе 3.1. играет высокое
образование в семье?
Ответ 4. Сравнительно существенную; S= +0,14.
Вопрос 5. А насколько существенно то, что речь в ответе 3.1
идет о мужчинах?
Ответ 5. Сравнительно существенно S « +0,13.
Комментарий к ответу 5. Обратим внимание, что здесь
существенность свойства "мужской пол" выше, чем в ответе 2.
Вопрос 6. Нельзя ли уточнить ответ 3.1, если ввести в
рассмотрение уровень квалификации труда в семье?
Ответ 6. Мужчины читают часто, когда у них в семье
преобладает и высокий уровень образования, и высокий уровень
квалификации труда ( I - 0,76, С « 0,50).
Вопрос 7. Насколько существенным здесь оказалось уточнение
"высокий уровень квалификации труда"?
77
Ответ 7. Довольно существенным; S = +0,19.
Вопрос 8. А как с введением уточнения изменилась
существенность высокого уровня образования, которая согласно ответу 4
была равна S = +0,14?
Ответ 8. На фоне высокой квалификации труда она уменьшилась
практически до нуля и стала равной S = +0,02.
Вопрос 9. В чем причина этого? Может быть в том, что
высокая квалификация труда влечет за собой высокий уровень
образования?
Ответ 9. Да, если в семье преобладает
высококвалифицированный труд, то в ней и высокий уровень образования (I * 0,91, С -
= 0,62, контекст * = 488A)).
Комментарий к ответу 9. В детерминахдаонном анализе имеет
место теорема: для того чтобы в детерминации vx**y уточнение v было
несущественным, достаточно, чтобы Icx^ir) = 1. В ответе 9 мы,
очевидно, столкнулись со случаем, демонстрирующим более сильный
вариант,этой теоремы: если 1 — I(x**v)s l, то существует такая
непрерывная неотрицательная функция ц - ц ( &), стремящаяся к нулю
при ?-*0, что I(vx»-*y)- 1(х*-цL*1*
Вопрос 10. Отбросим в ответе 6 свойство 'уровень
образования в семье'. Какое объяснение получим в итоге?
Ответ 10. Мужчины читают книги, когда у них в семье
преобладает труд высокой квалификации (I - 0,74, С = 0,53).
Вопрос 11. Насколько изменилась существенность высокой
квалификации труда при переходе от ответа 6 (где она согласно
ответу 7 равна $= +0,19) к ответу 10?
Ответ 11. Существенность заметно возросла и стала равной S -
- +0,29.
Вопрос 12. Какова в ответе 10 существенность контекста
'мужчины' в сравнении с ответом 1 (где по ответу 2 Й=+0,09)и
ответом 3.1, где по ответу 5 3- +0,13?
Ответ 12. Существенность контекста 'мужчины' здесь выше,
чем в ответах 1 и 3.1, и равна S= +0,17.
Вопрос 13. Мы видели, что уровень образования в семье не
позволяет заметно уточнить ответ 10 (ср. его с ответом 6). А как
здесь может сказаться собственное образование респондента?
Может ли оно внести существенное позитивное уточнение в ответ 10?
Ответ 13. Нет. Единственное позитивное уточнение ответа 10
может быть получено, если ввести в него 'высокий уровень
образования самого респондента'. Но оно будет столь же несущественно,
как и уточнение, вносимое переменной 9; его существенность 3 -
- +0,02.
Вопрос 14. Состоит ли причина этого в том, что, как и уровень
образования в семье, уровень образования самого респондента
также определяется высокой квалификацией труда в семье?
Ответ 14. Да. В семьях, где преобладает
высококвалифицированный труд, члены семьи мужчины имеют высокое образование (Iе
- 0,74, С= 0,77).
78
Вопрос 15. Существуют ли на содержательной сфере,
включающей переменные 9; 10; 399, ответы, дающие в контексте
"мужчины" дополнительные к ответу 10 объяснения с точностью, не
меньшей, чем У = 0,7?
Ответ 15. Нет, если не считать нескольких уникальных в
обследуемом массиве случаев.
Вопрос 16. Какие по численности группы определяют
детерминацию из ответа 10?
Ответ 16. Мужчин, проживающих в семьях, где преобладает
высокая квалификация труда, N(a)= 23 человека, из них N@,6)= 17
человек читают книги часто. Всего часто читающих мужчин NA)=
= 32 человека. Как указано в ответе 10, I Id»-* 4} = 0,74,
СЛМ-* i) = 0,53.
Краткие выводы. В группе мужчин нам удалось получить
достаточно точное условное объяснение частого чтения книг с интенсив?-
ностью I ~ 0,74 (ответ 10). Оказалось, что оно обусловлено жизнью
в семьях, где преобладает труд высокой квалификации. При
попытках уточнить этот результат с помощью образования оказывается,
что лишь высокий уровень образования (либо собственного, либо в
семье) может служить его позитивным уточнением. Однако это
уточнение чрезвычайно слабое - в обоих случаях S - +0,02. Его
практическая несущественность объясняется тем, что в группе мужчин
высокая квалификация труда, если она преобладает в семье, с
высокой точностью определяет также и высокий уровень образования как
у ведущей брачной пары (I = 0,91; см.. ответ 9), так и у членов
семьи ( I = 0,74; см. ответ 14). Полученное объяснение имеет
полноту С = 0,53, т.е. оно объясняет 53% всех случаев частого чтения
книг среди мужчин. На данной содержательной сфере это так
называемая социализированная компонента поведения, т.е. компонента,
подчиняющаяся локальной микрозакономерности, обнаруженной в
ответе 10. Остальные 47% случаев поведения не социализированы,
поскольку, как видно из ответа 15, для них здесь (т.е. на той же
содержательной сфере) согласно ответу 15 нет неуникальных
объяснений.
Продолжим диалог. Попробуем теперь получить сколько-нибудь
точное объяснение частого чтения книг*для женщин.
Вопрос 17. Каковы точность и полнота детерминации
"женщины читают книги часто"?
Ответ 17 Детерминация "женщины читают книги часто"
характеризуется точностью I = 0,28 и полнотой *С « 0,41.
Вопрос 18. Возьмем группу женщин- и будем работать только
с ней (т.е. в дальнейшем положим к * 488B)). Можно ли
объяснить их склонность к чтению квалификацией труда,
преобладающего в семье?
Ответ 18. Да, имеются три раз личных объяснения.
18.1.Женщины читают часто, когда у них в семьях преобладает
труд высокой квалификации (I ~ 0,35, С =* 0,26).
18.2. Женщины читают часто, когда у них в семье преобладает
труд средней квалификации (I - 0,36, С - 0,70).
79
18.3. Женщины читают часто, когда у них в семье преобладает
труд низкой квалификации (Is 0,06, С= 0,04).
Комментарий к ответу 18. Мы видели, что для мужчин высокая
квалификация труда в семье весьма строго обусловливает частое
чтение книг (Is5 0,74; см. ответ 10). Для женщин это не так, что
и демонстрируют ответы 18.1 - 18.3. Первые два ответа имеют
невысокие (хотя и заметно отличные от нуля) почти одинаковые
интенсивности и в совокупности дают практически полное объяснение
с емкостью С s 0,26 + 0,70 » 0,96. Последний ответ отличается
точностью и полнотой, близкими к нулю. Попробуем уточнить
ответы 18.1, 18.2.
Вопрос 19. Можно ли позитивно уточнить ответы 18.1, 18.2
так, чтобы в итоге получить неуникальные объяснения частого чте^-
ния с точностью, превышающей 0,5, если в содержательную сферу
включить как образование в семье респондента, так и его
собственное образование? В уточненных ответах указать существенность
объясняющих свойств.
Ответ 19. Что касаемся ответа 18.1 - нет. Ответ 18.2
допускает два уточнения, результатом которых являются следующие
объяснения:
19.1.Женщины (S = О) читают книги-часто в тех случаях,
когда они проживают в семьях, где преобладает труд средней
квалификации B = +0,43) и средний уровень образования ( S - +0,50),
при условии, что сами они имеют высокий уровень образования (S -
= +0,42). Здесь точность Is 1 и полнота С = 0,13.
19.2. Женщины (S» +0,15) читают книги часто в тех случаях,
когда они проживают в семьях, где преобладает труд средней
квалификации (S= -0,03) и средний уровень образования (S = +0,13),
при условии, что сами они имеют также средний уровень образования
(S s +0,02), Здесь точность I « 0,6, полнота С = 0,13.
Вопрос 20. В ответе 19.1 существенность контекста "женщины"
равна нулю при том, что мужчины с аналогичным набором свойств
нам ранее не встречались. Возникает подозрение, что в семьях, где
преобладает средний уровень образования и труд средней
квалификации, высокий уровень собственного образования имеют только
женщины. Так ли это?
Ответ 20. Да, в контексте 1<:9C); 10 B) это так с
точностью I = 0,75 и полнотой С я 0,25.
Таблица 3.3.1.
Таблица детерминаций и существенностей к ответу. 24; to e 488 B);
кх:488
Ответ 24.1
Ответ 24.2
Ответ 24.3
1 ,
2 (+0,25)
2 (+022)
2 (+0,30)
9tS)
2 (+0,09)
2 (-0,01)
2 (+0,13)
10 W)
2 @,00)
3 @,00)
3 (+0,15)
399 (S)
3 (+0,36)
3 (+0,03)
2 h0,06)
80
Вопрос 21. В ответе 19.2 есть негативное уточнение. Если
его отбросить, как изменятся параметры ответа I, С , S ?
Ответ 21. Отбросив в ответе 19.2 негативное уточнение
"средний уровень квалификации труда в семье", получим следующее
условное объяснение: женщины (S - +0,10) читают книги часто в тех
случаях, когда они проживают в семьях, где уровень образо-
.вания средний ($ = +0,27), и сами они имеют образование
среднего уровня ( S s +0,10). Точность ответа I = 0,63,
полнота t« 0,22.
Краткие выводы. В группе женщин условное объяснение частого
чтения книг более разнообразно, плюралистично, чем у мужчин.
Если там было одно объяснение (ответ 10), то здесь - два (ответы
19.1 и 21). Если там образование на фоне квалификации труда
было несущественно, то здесь образование (и собственное, и в семье)
всегда в той или иной мере существенно, а квалификация труда в
одном случае (ответ 19.1) весьма существенна, а в другом
(ответы 19.2 и 21) не существенна вовсе. Суммарная полнота
условного объяснения в группе женщин равна всего С = 0,13 + 0,22 =
в 0,35. Это значит, что на рассматриваемой содержательной сфере
вербальное поведение, выраженное в оценке "часто читаю книги",
менее социализировано, чем у мужчин, где полнота условного
объяснения была равна С - 0,53.
Продолжим диалог и попробуем получить условное объяснение,не
чтения книг.
Вопрос 22. Если ограничиться только полом, кто не читает
книг?
Ответ 22.1. Мужчины (I «0,14, С =0,28, S «-0,10).
Ответ 22.2. Женщины (I « 0,32, С - 0,72, S e +0,08).
Вопрос 23. Если включить в содержательную сферу переменные
9; 10; 399, можно ли уточнить ответ 22.1 так, чтобы в итоге
можно было получить объяснения, точность которых больше, чем 0,5?
Ответ 23. Нет.
Комментарий к ответу 23. На данной содержательной сфере
поведение "не чтение книг" в группе мужчин не социализировано,
достаточно точных объяснений ему здесь (на этой сфере) дать
невозможно.
Вопрос 24. Повторим вопрос 23, только теперь уже
применительно к ответу 22.2.
у: 451 D); х : 9; 10; 399; Г- 0,5; S = о,1
>-
Ц*(х~^)
0,89
0,89
0,80
i СA<(х~уУ)
0,31
0,31
0,15
! N(f<oc)
9
9
5
Nltcxy)
8
.8
4
[NAop
26
26
26
81
Таблица 3.3.2.
Результат диалога. 13 -функция 1с u e <f(kx)
Контекст к
488
1
2
2
2
2
2
Аргумент х
9
-
3
3
2
2
* 2
10
1
2
2
3
3
399
-
1
2
3
3
2
Функция^
451
1
1
1
4
4
4
Точность
1
0,74
1,00
0,63
0,89
0,89
0,80
Полнота
С
0,53
0,13
0,22
0,31
0,31
0,15
№
ответа в
тексте диалога
10
19.1
21
24.1
24.2
24.3 |
Ответ 24. Можно. Имеются три уточненных ответа, приведенные
в табл. 3.3.1.
Краткие выводы» Поведение, условно объясняемое таблицей к
ответу 24, весьма сильно социализировано: суммарная полнота
представленных здесь условных объяснений равна С = 0,31 +0,31 +
+ 0,15- 0,77, т.е. необъясненными на данной содержательной
сфере остаются всего 23^ случаев не чтения. Все объяснения весьма
точны; интенсивности их не ниже 0,80. Видно, что пол везде
оказывается существенным (обратим внимание, что согласно ответу 22.2
в целом женский пол при объяснении не чтения имеет низкую
существенность, S = +0,08). Как. и в случае частого чтения, в группе
женщин квалификация труда 10 B) или 10 C) в большинстве случаев
(С я 0,31 + 0,31) несущественна.
Подведем итог. Он частично представлен в табл. 3.3.2, где
приведена D -функция ku= <?(кх),обнаруженная и проанализированная в
ходе диалога. Значения аргументов, контекста и функции записаны с
использованием кодов из словаря переменных. Прочерк показывает,
что соответствующее уточнение опущено. Содержательная сторёна
дела раскрывается достаточно подробно в тексте самого диалога,
и мы на ней останавливаться не будем.
D-функция, представленная в таблице, служит одним из
типичных примеров локальных микрозакономерностей, описывающих
социальные явления. Подчеркнем, что результаты диалога, строго
говоря, относятся только к той выборке, которая подвергалась
обследованию. Распространение их на более широкую совокупность связано
со статистическим оцениванием доверительных интервалов для
величин точности, полноты и существенности, фигурирующих в диалоге.
82
§ 3.4. Пример 2. Объяснительная типологизация семей
и жилищных условий
В предыдущем параграфе обсуждался пример практического
диалога, в котором не фигурировали какие-либо интегральные переменные
в виде нормальных функций от переменных из словаря. Здесь мы
рассмотрим задачу, в которой итогом выступают две совместные
типологии - типология семей по продолжительности брака и
среднедушевому доходу и типология жилищных условий по характеру жилья
и количеству комнат. Они возникают как определенные нормальные
функции, построенные так, чтобы с их помощью можно было
достаточно точно и полно объяснить обеспеченность бытовой техникой.
Формальная постановка задачи такова. Имеется Б -функция и =
= ф( х , х^). Ее взаимно однозначная компонента ^ = <р(р) в стан- .
дартном разложении M^vityix , X )) характеризуется точностью
и полнотой, которые связаны с детерминациями, образующими
исходную функцию 9, выражениями (см. § 2.8)
хххге ч~1(Н)
C.4.1)
С(р~у)~ Ц ССх4х~у).
х^еср ор
Требуется построить D -функцию «р0 и нормальные функции ф ,
Ш , связанные соотношениями
\Ш Ч»! ^*г). C.4.2)
V W>
исходя из того, что функция <fe Должна удовлетворять условию
|l(p0^V)-l(p^V)|4^7
^ ~ C.4.3)
где оС , jb - неотрицательные числа, и = vf0 (ро") - взаимно однознач-
ная компонента в стандартном разложении U = cf0(vY0v*'1'O) функции
Ч>0. Точность и полнота детерминаций ро**"* Ч определяются по при-
83
веденным выше формулам C.4.1), где вместо р , Ч , ф следует вез-
де подставить р0 , ф0 , ф0. Условие C.4.3) означает, что ф0
аппроксимирует D -функцию vf. Задачу, таким образом, можно
сформулировать так: найти Ф0 , Ф , ф связанные соотношениями C.4.2),
исходя из того, что <f0 должна аппроксимировать <f,
В этой задаче U- объясняемая переменная, * - ЦЛх*) -
искомая объяснительная типология по X , *& = ф~ (хз)- искомая
объяснительная типология по Хп . В случае х «со решение задачи будет
доставляться любыми D-функцией <f0 и нормальной функцией ф удов-!
летворяющими уравнению
В общем случае при произвольных х„, X, существует по край-
ней мере одно решение поставленной задачи:
\= Ч»
. Ч" Ч*
удовлетворяющее условию C.4.3) с 4 = J* = О. Нам неизвестен
регулярный алгоритм обнаружения всех решений поставленной задачи,
когда об , jb заданы заранее. Но мы укажем путь, приводящий в
ряде случаев к нахождению по крайней мере одного из возможных
решений в условиях, когда оО , р заранее не заданы и определяются
"задним числом", апостериори. Он позволяет находить решения,
которые приводят к достаточно близким к нулю значениям левых частей
в неравенствах C.4.3). Перейдем к практической стороне дела.
Словарь первичных переменных, задействованных в задаче
... 4. Продолжительность брака (возраст семьи) измеряется по
ведущей брачной паре.
1. До 3 лет.
2. От 3 до 10 лет.
3. Более 10 лет.
4. Трудно определить.
... 6. Среднемесячный душевой доход в семье от всех
поступлений.
1. До 40 р.
2. От 40 до 60 р.
3. От 60 до 80 р.
*)
84
При сС = JS = О выполнение C.4.3) означает <& = cf0
4. От 80 до 100 р.
5. От 100 до 120 р.
6. Свыше 120 р.
.. • 64. Наличие холодильника.
1. Есть.
2. Нет.
... 65. Наличие стиральной машины.
1. Есть.
2. Нет.
... 66. Наличие швейной машины.
1. Есть.
2. Нет.
... 223. Вид жилья.
1. Отдельная квартира.
2. Коммунальная квартира.
3. Отдельный дом.
4. Половина дома.
...'224. Количество жилых комнат.
1. 1 комната.
2. 2 комнаты.
3. 3 комнаты.
4. 4 и более комнат.
5. Нет ответа.
Начнем с того, что введем в словарь априорную типологию
по переменным 64, 65, 66, фиксирующую уровень
обеспеченности бытовой техникой, присвоив ей один из свободных
номеров, например 550.
... 550 (^). Уровень обеспеченности бытовой техникой.
1. Высокий.
2. Средний.
3. Низкий.
Определим ее как нормальную функцию с помощью табл. 3.4.1.
Эта функция уже рассматривалась нами ранее (табл. 2.8.1). Она
определяет объясняемую переменную у* Чтобы ввести ее в словарь,
необходимо воспользоваться запросом *№$¦, как описано в § 3.2.
Обозначим произведение переменных 4 и 6 через »г (т.е.
положим %х: 4; 6), а произведение переменных 223 и 224 - через
Х^Ог.е. положим » : 223; 224). Переменная %г описывает
возраст семьи D) в сочетании со среднемесячным душевым доходом
F); х, описывает вид жилья B23) в сочетании с количеством
жилых комнат B24). Искомая типология семей представляет собой
нормальную функцию »1= 4>t(xt),a искомая типологии ,лищных
условий - нормальную функцию %х = Ф(эс^).
Функции Ц/ , ф- неизвестны, задача состоит в том, чтобы их най-
ти. ЕЬступим следующим образом. Попросим вычислительнную систему
85
Таблица 3.4.1
Переменная 550 как нормальная функция
от переменных 64; 65; 66
Аргументы
64
(холодильник)
1. Есть
1. Есть
1. Есть
2. Нет
1. Есть
2. Нет
2. Нет
2. Нет
65
(стир.
машина)
1. Есть
1. Есть
2. Нет
1. Есть
2. Нет
1. Есть
2. Нет
2. Нет
66
(швейн.
машина)
1. Есть
2. Нет
1. Есть
1. Есть
2. Нет
2. Нет
1. Есть
2. Нет
Функция
550
(уровень обесп.
бытовой
техникой)
1. Высокий
2. Средний
3. Низкий
(по запросу Й) рассчитать Ъ-функцию ^^ ф(х1,Х^')^
удовлетворяющую уравнению
Г Кхгхг^^) >0,5,
С<Х1ХГ" V> >0-
Получим три таблицы детерминаций, образующих функцию cf (для
каждого уровня обеспеченности -и- своя таблица). Ввиду
громоздкости мы их здесь приводить не будем. Вместо этого приведем
распределение значений функции tf по области ее определения в
пространстве переменных X , X. (рис. 3.4.1).
Здесь столбцы и строки перетасованы так, чтобы в двумерном
поле четырехмерной переменной X х образовались более или менее ком-
пактные скопления одинаковых значений объясняемой переменной ^.
Искомые типологии должны представлять собой аппроксимацию этих
скоплений сеткой прямоугольников, получаемых объединением
столбцов и строк в классы: объединения столбцов есть значения
переменной X , объединения строк - значения переменной х..
Аппроксимировать скопления одинаковых значений сеткой прямоугольников -
значит добиться того, чтобы внутри каждого прямоугольника
содержались преимущественно одинаковые значения. Тривиальная идеальная
86
*2 |
224 223
4 1
3 1
2 1
1 1
*\ 3
4 4
3 3
3 4
2 3
2 4
1 3
1 4
1 2
2 2
5 3
21=3
0
1
6
О
о
о
1
3
о
о
2
1
X
л
о
о
0
0
3
1
zi=2
О
L2L
|х"
2
5
X
1
1
X
X
1
2
Л
X
X
0
X
л
2
2
?
д
X
X
X
0
X
X
X
X
X
2
3
л
л
0
X
X
X
1
4
Л
D
X
X
2
4
О
Д
X
X
X
О
0
X
3
2
z,=1
X
д
д
D
Д
D
Д
3
3
д
д
д
д
д
д
X
3
4
д
д
D
Д
X
3
5
Д
д
X
3
6
II
N
д
4
5
z2=2
Zo = 1
*-2 '
гА = 3
V4
«#=5
:ь
Рис. 3.4.1. Значения функции ^= Ч (Х^х^). Треугольники - ^~ 1,
крестики - Ч = 2, кружки ^ = 3, квадратики - непустые значения
% х2; не попавшие в область определения <f. Сверху и справа
-значения функций Х± = yt(oc ), х = Ц; (х^).Слева и снизу - значения
переменных 223, 224, 4, 6. Пустые строки и столбцы опущены.
аппроксимация такого рода всегда возможна - она осуществляется,
если положить х = х±, %г= х,^. На рис. 3.4.1 изображен один из
нетривиальных вариантов аппроксимации. Им определяются типологии
xt= t|/ (х ), X » Ф^Схг), показанные отдельно на рис. 3.4.2.
Искомые типологии получены, но задача пока не доведена до
конца. Необходимо еще проверить, как эти типологии объясняют
обеспеченность бытовой техникой, а также проверить выполнение
условия C.4.3У. Понятно, что если бы в каждом прямоугольнике,
состоящем из значений переменной XX, на рис. 3.4.1, содержались бы
только одинаковые значения ^> т° полученные типологии давали бы
в известном смысле идеальное объяснение. В этом случае условие
C.4.3) выполнялось бы при ы, « J* = О. Однако в силу неполной
однородности (например, в прямоугольнике с координатами ** в2, ъ е1
содержатся в основном крестики, но имеются также треугольники
87
d
a
6 I 2 {©1 2
Э
223
4
3
2
1
f5!
la)
(i.
(г'
1
p
II
_4_
12
2
1
j_
4
2
3
1)
jj
.4)
2)
4
Pi
u
u
Ы"
5
| 224
Рис. З.4.2. Типология семей (слева) и жилищных условий
(справа). Номера (коды) типов проставлены в клетках.
и кружки) объяснительные типологии X , X будут давать не наи-
1 А
лучшее из возможных совместное объяснение *}.
Введем типологии X , X в словарь переменных, присвоив
переменной х. номер 551, а переменной х, - номер 552.
... 551 (Х^. Типы семей (названия типов условные).
1. Старые и сравнительно обеспеченные семьи.
2. Молодые необеспеченные или среднего возраста обеспеченные
семьи.
3. Молодые обеспеченные или немолодью необеспеченные семьи.
4. Прочие семьи.
... 552 ( Х^)# Типы жилищных условий (названия типов
условные).
1. Дом или полдома со многими комнатами.
2. Отдельная квартира.
3. Дом или полдома из одной комнаты.
4. Коммунальная квартира.
5. Прочие.
Теперь имеется непосредственная возможность оценить
объяснительные возможности типологий Х4, х. семей и жилищных условий.
Для этого получим, пользуясь запросом S&S, таблицы детерминаций
3.4.2 - 3.4.4, образующих D -функцию ^ = 4>0(*txt>'
Как мы видим, представляющая условное объяснение функция ц
состоит из детерминаций, имеющих сравнительно высокую точность,
и по каждому типу обеспеченности суммарная полнота дополняющих
друг друга ответов также достаточно велика. Обратим внимание на
полученную "игру существенностей": когда мы имеем дело, например,
** Обратим внимание, что однородность заполнения
аппроксимирующих прямоугольников на рис. 3.4.1 должна определяться и
определялась с учетом численностей групп, представленных в клетках,
а также с учетом интенсивностей детерминаций, образующих
функцию *f.
88
Таблица 3.4.2
Детерминации * % & у,условно объясняющие высокий уровень
обеспеченности бытовой техникой у : 550 A)
*tiS8HS) х>: 552E) Кус^у) С(гхгг&ц) Щх^) Щххг^) Nty
1 (+026)
4 (+0&)
2 (+0ДЗ)
1 ПОД?)
1 (+0J02)
1 (+от
2 (+0,49)
.2 (+0J01)
0,72
1,00
0,67
0,71
0,53
0,01
0,08
0,14
54
1
9
14
39
1
G
10
71
71
71
71
Таблица 3.4.3
Детерминации ^ *: Л у; условно объясняющие средний уровень
обеспеченности бытовой техникой ч : 550 B)
^: 55KS) «х: 552 (S)
2 (+0Д4) 1 ДОДО
2 (+0,22) 3 f+0,3fl
1 WWW 3 (+0,79)
2 «WW 4 (+021)
2 f0,OV 5 W?,4/i
1 @J00) 5 W#W
Кх^Л
0,56
0,91
1,00
0,80
1,00
1,00
?)C(
хг&
0,35
0,18
0,02
0,14
0,04
0,02
V
N<W
36
11
1
10
2
1
N<W*)
20
10
1
8
2
1
Щ) 1
57
57
57
57
57
57
Таблица 3.4.4
*
Детерминации X.**-* и, условно объясняющие низкий уровень
обеспеченности бытовой техникой и: 550 C)
V55KS) \:552CS) 1(у,г~у) C(xtx^4) ИС»^), N(t»»^ Ktyl
|3 7*MW 1 (+0,01) 0,86 0,25 7
|3 (+0,75) 3 WW 1,00 0Д7 4
24
24
со старыми и в материальном отношении сравнительно
обеспеченными семьями (V: 551 A)), то они высоко обеспечены бытовой
техникой и тип жилья здесь мало существен, зато для молодых и
необеспеченных или для обеспеченных семей среднего возраста (% :
: 551 B)) тип жилья оказывает решающее влияние на
обеспеченность бытовой техникой, а точнее, является существенным
уточнением при объяснении высокого уровня этой обеспеченности (см.
табл. 3.4.2). Это суждение о существенности или несущественности
жилищных условий есть один из типичных примеров текста, порожден-
89
Таблица 3.4.5
Сравнение близости функций ц и у0
в плане выполнения условия C.4.3)
UH
C(P-V)
1 ^
*
1дс1
Значения ^ = ?(р ) « vf 0 (р0)
у :550A)
0,88
0,72
0,16
0,75
0,76
0,01
tj: 550B)
0,88
0,69
0,19
0,74
0,74
0,00
\1 :550C)
0,94
0,91
0,03
0,71
0,42
0,29
ного обследованием, т.е. R -текста. Внимательно просмотрев таблицы
детерминаций 3.4.2 - 3.4.4, можно без труда перевести их
содержимое в текстовую форму, но, поскольку наша задача здесь - лишь
демонстрация детерминашюнной техники и приемов, а не
собственно содержательный анализ проблем обеспеченности бытовой техникой,
мы этого делать на будем.
В табл. 3.4.5 приведены данные, показывающие, в какой мере
продемонстрированное выше решение задачи удовлетворительно в
плане выполнения условия C.4.3). Фигурирующие в нем модули
разностей обозначены здесь через | дЦи|лС| соответственно.
Отсюда видно, что полученное нами решение исходной задачи
удовлетворяет условию C.4.3), если
Л > </,* = max |a-I| я 0,19,
f> >f>*= жах|дС1 - 0,2,9.
О
Мы уже отмечали, что всегда существует тривиальное решение,
которое дает cL « р «* О. Оно соответствует случаю Ъ » х , % -
~ Х- 9 т.е. при таком решении типологизация, как таковая,
отсутствует. Существуют ли в каждом конкретном случае нетривиальные ре—
90
шения, которые дают высокую степень содержательного обобщения
при малых 4 , А , - это вопрос, который упирается в разработку
регулярных алгоритмов поиска наилучших (по минимуму <** , р )
решений. Такие алгоритмы в настоящее время пока отсутствуют.
Однако ясно, что если накладываются достаточно жесткие ограничения
на искомые типологии (а ограничение C.4.2), состоящее в том, что
искомая D-функция должна быть найдена при рассечении пространо-
*)
ва значений хл х. на цилиндрические , а не какие-либо иные мно-
жества, является весьма жестким), то за возможность типологиза-
ции (обобщения) всегда, вообще говоря, приходится платить
потерями в точности и полноте объяснений.
В заключение заметим, что обычно алгоритмы таксономии
(классификации), используемые в социально-экономических исследованиях,
требуют введения метрики, определяющей понятие близости в
пространстве типологизируемых переменных (см., например, [49] )#
Ввиду номинальности социальных переменных метризация часто
превращается в проблему, которую, кдк правило, пытаются решать путем
перехода от номинальных шкал к шкалам более высокого порядка,
что часто сопровождается определенным насилием над обследуемой
социальной реальностью. В алгоритмах типологизации, основанных
на детерминационном анализе, 'такое насилие исключается полностью,
поскольку метризация, на которой они базируются, не обусловлена
природой шкал. Используемые здесь метрики естественно
порождаются понятием D-функции, наподобие того, как это было указано в
§ 2.10. Задача типологизации оказывается, таким образом,
подчиненной целям объяснения, ради достижения которых, собственно, она
обычно и ставится. Можно предоолагать, что процессы,
сопровождающие типологизацию (классификацию, содержательное обобщение)
понятий в естественном языке, имеют сходную природу.
*^ Пусть задано множество X*Y. Подмножество L этого
множества называется цилиндрическим, если оно представимо а, форме
L « А*У,где А - подмножество X,либо в форме L - X*В,где В -
подмножество Y. В первом случае L будет цилиндрическим множеств
вом с основанием А и образующей "вдоль" V, во втором -
цилиндрическим множеством с основанием В и образующей "вдоль" X.
91
Глава IV
ДЕТЕРМИНАЦИОННЫЙ АНАЛИЗ
И ЭЛЕМЕНТЫ МОДЕЛИРОВАНИЯ
СОЦИАЛЬНЫХ ПРОЦЕССОВ
Значениями индикаторов (переменных) в социальном эмпирическом
обследовании выступают слова и сочетания слов обычного
человеческого языка, и это обстоятельство отражает фундаментальные
свойства сохшального объекта, зафиксированные в принципе номинальности.
Собирая эмпирические данные, исследователь, в сущности, подобен
журналисту: он общается с людьми (непосредственно, либо при
посредничестве интервьюера, либо просто получая "письма"
респондентов в виде заполненных анкет), чтобы затем по материалам
обобщения написать текст, посредством которого частные разговоры и
переписка с отдельными людьми социализируются, приобретают
социальное звучание. Статус "научности" появляется здесь лишь
благодаря тому, что исследователь, в отличие от журналиста (по
крайней мере - традиционного, классического журналиста),
систематически пользуется специальными приемами "работы со словом",
основанными на особой технике рефлексивного реконструирования
процессов порождения и функционирования понятий, существующих в
социальной среде как на обыденном, так и на теоретическом уровне.
Естественно поэтому, что в любых математических методах и
приемах, используемых для анализа социальных данных, всегда скрыто
или явно присутствуют элементы моделирования социальных
процессов и явлений в форме моделирования языковых понятий, в которых
эти процессы и явления получают свое отражение (см. [61], где
приведенный тезис раскрывается более подробно). Как видно из
предыдущей главы, детерминационный анализ сам по себе может
рассматриваться как математическая модель перехода от процедур
наклеивания языковых ярлыков (социальные измерения) к языковым текстам
(К -тексты). Этим обусловлены возможности детерминационного
анализа при моделировании таких важных элементов социальной
реальности, как языковые понятия, социальные коммуникации, отношение между
качественными и количественными закономерностями и т.д. Настоящая
глава содержит обсуждение связанных с этим вопросов.
92
§ 4.1. D-функция как модель языкового понятия
Услышав какое-нибудь новое слово или понятие, мы задаемся
вопросом: что оно означает? Обычно объяснения даются в форме
примеров, из которых становится ясно, что имеет в виду наш собеседник.
Если объединение таких примерных поясняющих ситуации в одном слове
нас устраивает, мы, не задерживаясь на этом, продолжаем беседу.
Если же слово кажется нам неподходящим для выражения смысла,
который следует из конкретных примеров, то мы либо фиксируем для
себя факт необычного словоупотребления и временно принимаем его
как данное , либо начинаем "спорить", доказывая, что собеседник
"ошибается", называя ситуации не теми обобщающими именами,
какими следовало бы их называть. Обратимся к иллюстративному
примеру, который должен пояснить, что мы здесь имеем в виду.
В § 3.4 мы говорили об обеспеченности бытовой техникой. Это
понятие реферировалось переменной и.
у. Уровень обеспеченности бытовой техникой.
1. Высокий.
2. Средний.
3. Низкий.
Каждый вправе, однако, спросить: что означает, например,
"высокий" уровень обеспеченности бытовой техникой и чем он
отличается от "среднего" или "низкого"? В рамках разбиравшейся нами
задачи на этот вопрос был дан совершенно четкий ответ: высокий
уровень означает наличие в доме холодильника, стиральной машины и
швейной машины, средний - наличие только двух из названных
предметов, низкий - либо наличие в доме только одного из этих
предметов, либо их отсутствие. Это и есть полный перечень конкретных
примеров, поясняющих смысл понятия "уровень обеспеченности
бытовой техникой". Все названные конкретные примеры описываются
нормальной функцией ^ = f(x , х^,х3), где х - наличие
холодильника (есть - нет), х - наличие стиральной машины (есть - нет),
х - наличие швейной машины (есть - нет), а сама функция х
определяется табл. 3.4.1. Она есть лишь точный формальный
эквивалент ответа, только что данного на вопрос о том, что означает
"уровень обеспеченности бытовой техникой", только там это - обычный
текст, а здесь - формальный объект детерминациоыного анализа.
Функция я* = f(xlf X^ , Х^ ) выступает, таким образом, моделью
понятия, которое реферируется переменной и : переменная Х = х х^х.
реферирует горизонт значений этого понятия, а сама функция ? опре-
'Так, например, употребление слова "уравнение" применительно
к выражению B.9.2) не совсем обычно: можно ли называть
уравнением систему неравенств? Мы полагаем, что в данном случае
такое словоупотребление оправдано и не приводит к недоразумениям,
однако известная условность здесь налицо.
93
деляет его смысловое наполнение в рамках заданного горизонта
значений \
Слова 'уровень обеспеченности бытовой техникой' могут, однако,
показаться неподходящими, если их смысл понимается так, как мы
его определили с помощью функции i. Она, очевидно, дает слишком
узкое смысловое наполнение этих слов, тогда как в них заключена
как бы претензия на определение уровня обеспеченности бытовой
техникой вообще. Если такая претензия есть, то почему, на каком
основании допустимо ограничиваться холодильником, стиральной машиной
и швейной машиной? Почему, например, не включить в рассмотрение
кухонный комбайн, пылесос, полотер, автомат для чистки обуви,
электрический фен, утюг с увлажняющим устройством и множество
других предметов, которые также разумно считать 'бытовой техникой'?
Обычная схема ответа здесь .такова: 'Мы не претендуем на общность^
Для наших целей достаточно учесть только холодильник, стиральную
и швейную машины, остальное нас не интересует. Если Вам важно
учесть что-либо дополнительно - предложите свой вариант
смыслового наполнения и давайте его проанализируем'. Дальше все зави-*-
сит от обсуждения вопроса о том, насколько выбранное
эмпирическое наполнение горизонта значений адекватно задачам, которые
ставит исследователь. Если исследователь убедит критика, что
принятое им огрубление понятия оправдано, то их коммуникация может
быть продолжена дальше, если же нет - возникает
'коммуникационный разрыв* и нужен третейский суд.
Нормальные функции моделируют понятия, которые вводятся
исследователем с целью построения обобщений, позволяющих
перекинуть мостик между теоретическим и эмпирическим уровнями. В
примере с обеспеченностью бытовой техникой это обобщение носит, по
сути, априорный, теоретический, как принято говорить, характер.
Рассмотренные в § 3.4 варианты типологизации семей и жилищных
условий дают пример обобщений, которые носят квазиаприорный,
если можно так выразиться, характер: здесь волевое решение о виде
нормальной функции заменено опять-таки волевым решением о
необходимости получить условное объяснение, из-за чего искомая
нормальная функция получается как бы 'объективно', на основе
применения формального метода, а на самом деле, конечно, мы имеем
дело лишь с превращенной формой построения опять-таки априорного
обобщения. Аналогично следует расценивать как квазиаприорные все
обобщения и классификации, которые получаются с помощью
таксономии, кластер-анализа и иных методов построения 'объективных'
классификаций и типологий: в них всегда можно указать то место, где
Для каждого конкретного у = о горизонт значений
определяется как совокупность значений переменной х, удовлетворяющих
условию f (Х)= &, т.е. как f "*(*) ¦ {* :Uxh Ь). Отметим, что
сходным образом моделирование понятий осуществляется в теории
информационно поисковых языков.
94
волевое решение исследователя диктует, по сути, итоговый
результат (как правило, это решения о виде метрики, о критерии, по
которому строится разбиение на классы, и о необходимом числе классов).
Априорные и квазиаприорные модели понятий всегда содержат
элемент огрубления реальных, живых понятий, которые служат их
прототипом. Корректное использование таких моделей достигается лишь
скрупулезной фиксацией этого огрубления и четким определением
контекста, в котором оно несущественно или не очень существенно.
Кроме априорных и квазиаприорных в практике эмпирических
исследований используются также и апостериорные модели. Для
примера рассмотрим все ту же обеспеченность бытовой техникой.
Допустим, что в рабочем документе имеется прямой вопрос:
U0« Какой уровень обеспеченности бытовой техникой в Вашей семье?
1. Высокий.
2. Средний.
3. Низкий.
4. Затрудняюсь ответить.
Сравним переменные и , и 0. Если для каждого респондента
семантика понятия ''уровень обеспеченности бытовой техникой" в
точности совпадает с семантикой, отраженной в рассмотренной выше
априорной модели и = f (x , Х^, «5), то и должно равняться Ч0,т.е.
должна существовать взаимно однозначная нормальная функция \l0 -
в Ф (и),Удовлетворяющая уравнению
нУЧ.)-1»
_С(уЦ,)-1.
Проверить, так ли это, можно, очевидно, просто послав
вычислительной системе соответствующий запрос. Заранее очевидно, однако,
что наиболее вероятна ситуация, когда Ч? Ч0> T«e» смысловое
наполнение респондентами понятия "уровень обеспеченности бытовой
техникой * не только отличается от наполнения, которое представлено
нормальной функцией Ч^Цх^Х-.Х^), но изменяется также от
респондента к респонденту. В таком случае естественно попытаться
проанализировать D -функцию Чо"^30!' хг* xa ^» показывающую,
как наличие или отсутствие холодильника (х.), стиральной машины
(х,) и швейной машины (х,) определяет реальную семантику
понятия "уровень обеспеченности бытовой техникой". Ъ -функция tQ
выступает как апостериорная модель понятия, априорная модель которого
есть нормальная функция у ~ ?(xt, x^,X^ ). Подбирая различные
контексты и различные референты для горизонта значений, можно,
таким образом, анализировать структуру смыслового наполнения
понятий, характерную для социальной среды.
95
§ 4.2. Моделирование коммуникаций
Сразу оговоримся: мы не претендуем на построение модели
коммуникативных процессов в социальной системе. Наша задача
значительно проще - показать, что некоторые понятия детерми-
национного анализа можно использовать с целью такого
моделирования.
Отчасти это иллюстрируется диалогом, приведенным в § 3.3, в
известной степени приближающимся к естественным диалогическим
построениям в языковой среде. Рассмотрим теперь некоторые
элементы коммуникативных процессов, в описании которых могут быть
полезны понятия детерминашюнного анализа.
1. Допустим, вышел новый фильм, и Вы хотите решить: пойти на
него или нет. Ваш приятель сообщил Вам, что фильм плохой, и Вы,
поверив ему, решили, что не пойдете его смотреть. Другой Ваш
приятель сказал, что фильм хороший, и Вы еще более укрепились в
мнении, что фильм плохой и что смотреть его не стоит. Что произошло?
Дело в том, что горизонты значений (или, в обыденном варианте,
смысл) оценок, даваемых фильму, в контексте, связанном с первым
приятелем, совпадают с Вашими и Вы это знаете. Горизонты
значений, которые связывает с оценкой фильма второй приятель, с
Вашими не совпадают, но Вам они также хорошо известны, и поэтому
Вы без лишних слов понимаете: то, что в контексте, связанном с
ним, хорошо, - в контексте, связанном с Вами, либо неинтересно,
либо плохо.
Пусть у - референт понятия, служащего предметом коммуникации
(например, оценка качества фильма). Рассмотрим элементарный акт
коммуникации - передачу знака ^= в (хороший фильм) от индивида
р к индивиду (^ # Прием и передача знака всегда осуществляются в
неком контексте к, поэтому реально мы имеем дело не со знаком
о,а со знаком к в. Связь между понятием, рефериуемым перемен--
ной ^,и его горизонтом значений моделируется функциями 161}
Ь^* Чр 1^зс) Для индивида р, , - - .
^У= 4V(.kx) для индивида <у
Здесь X - референт горизонта значений понятия и, общий для
индивидов р , с^. Обозначим горизонты значений знака для
индивидов р , (j, через Hp(fcЬ),HftA<6)соответственно. Согласно D.2.1)
Это предположение не ограничивает общности рассуждений:
если для одного .индивида референт U горизонта значений не совпадает
с референтом v горизонта значений для другого индивида, то всегда
можно прийти к соотношениям D.2.1), положив X°itir, Отметим
также, что используемая нами запись 1<^ = <f (kx) означает, что
функция ср имеет область определения в множестве {to}*X и область
значений в множестве {V} * Y, гдеХ,^ - множества значений
переменных X , ty соответственно.
96
они имеют вид
р р р D.2.2)
H^cltb) -^*{1|»)-11с»:^1кх)-1сП.
Полное понимание знака , посланного индивидом р индивиду (L,
возможно лишь тогда, когда
H^k&)~Hp(kft), D.2.3)
т.е. когда горизонт значений знака о в контексте к для индивида р
совпадает с горизонтом значений того же знака в том же контексте
для индивида (L, Горизонты Hp(tc6) и НлкЬ) суть подмножества
одного и того же множества {к}*Х,где Х- множество значений
переменной х. Если D.2.3) не выполняется, но НЛ1<о)все же имеет
общие элементы с Н (к&),то возможны лишь различные виды
частичного (либо одностороннего) понимания.
В рассматриваемом элементарном акте социальной коммуникации
механически передается и принимается знак к р, но фактически
передается и принимается совокупность сведений, образующая горизонт
значений знака 1с Ь. В этом важнейшая специфическая особенность
социальных коммуникаций. Следует иметь в виду, что модели связи
D.2.1) между понятием и горизонтами значений для каждого
индивида в течение его жизни меняются, причем целенаправленное их
изменение с ограничениями вида D.2.3) составляют одну из важных
функций социальных коммуникаций.
Возможности изучения и моделирования такого рода элементарных
актов коммуникации на основе понятий детерминапионного анализа
обусловлены тем, что функции D.2.1), моделирующие связь между
референтом понятия и горизонтом его значений, можно практически
получить как D -функции. Скажем, D-функцию к^ = ^р(кх)можно
найти, если задан веер
X Y Z
ХЬ< , D.2.4)
F*{p}
где Z - множество значений переменной %, одним из значений
которой является контекст k , F - эталонное множество ситуаций,
классифицируемое индивидом р по значениям переменных X, ^ , % . В
упомянутой ситуации с оценкой кинокартины содержательная
интерпретация элементов этого веера может быть, например, такой: у, -
общая оценка фильма (типа 'очень хороший*, "хороший", "средний",
"плохой", "очень плохой"), X - характеристика горизонта значений
общей оценки и, включающая идентификацию фильма по таким
параметрам, как жанр, характер сюжета, характер музыкального оформле-
97
ния и т.д., % - переменная, включающая показатели, описывающие
собственно ситуацию оценивания каждого фильма (идет ли речь о
сугубо личной оценке или об оценке с позиций некоторой референтной
группы, выступает ли оценивающий в жестко заданной ролевой
ситуации или нет и т.д.), F - эталонное множество фильмов.
Веера, подобные D,2.4), весьма часто встречаются в разного рода
эмпирических процедурах, используемых, в частности, в экспертных
опросах. Такие опросы характерны при исследовании в области кино, театра,
конъюнктуры потребительского спроса и т.д.
Если необходимо установить существование общих горизонтов
значений для группы индивидов (или установить, для каких подгрупп
индивидов имеются общие горизонты значений), то в качестве
основания веера D.2.4) должно быть использовано множество F * Е, где
Е - обследуемая совокупность индивидов. В этом случае переменная
% может включать параметры, характеризующие индивидов (в веере
D.2.4) такие параметры также могут фигурировать в X, но,
поскольку там множество Е состоит всего из одного индивида р, они
совпадают с единичной переменной со и потому неинформативны).
Апостериорная модель понятия "уровень обеспеченности бытовой
техникой ", рассмотренная в конце §4,1, предполагает использование
подобного веера с основанием F < Е (там неявно предполагалось, что
множество F состоит из "одной эталонной ситуации, а именно той, в
которой находится сам респондент).
2. Рассмотрим следующий фрагмент диалога между двумя лицами
А и Б, в котором обсуждается поступок u s &, совершенный неким
индивидом р.
А. Вам известно, что р совершил поступок и - Ь ?
Б. Да.
А. Как Вы думаете, почему он так поступил?
Б. Разве Вам непонятно?
А. Нет.
Б. Разумеется, потому, что он попал в ситуацию х - CU.
А. Я знаю о том, что р оказался в ситуашш X ~ Q/, но мне все
равно непонятен его поступок. Помните случай с <^?Он был в точно
такой же ситуации, но поступил по-иному.
Б. Но ведь для (^ было еще и % + к ?
А. Да, но разве в случае с р было X в к?
Б. Конечно.
А. Вот как! Тогда, пожалуй, Вы правы, это действительно все
объясняет.
Легко себе предствить,' как можно небольшие формальные
вкрапления в этом диалоге заменить словами так, чтобы сделать из него
обычный текст. > Достаточно все назвать обычными именами:
индивидов р , <L , поступок и « в, ситуацию х в си, обстоятельство х =1<.
Для наших целей, однако, удобно оставить формальные обозначения.
Ниже следует один из возможных вариантов интерпретации
коммуникативного процесса, представленного этим диалогом, в терминах
детерминащюнного анализа.
98
Исходная ситуация. В контексте, который в данном диалоге
считается универсальным, прошлый опыт участников диалога фиксирован
веером
X Y 2
Д/ЗоДо
D.2.5)
Ео
Основное уравнение
Ф
1(*х»-* 24) > У,
<р D.2.6)
С (XX—>гу) >0
при ч т 6, X s U , У > 0,5 имеет на веере D.2.5) решение,
которое включает, в частности, детерминацию fca»—*fc8 с интенсивностью,
близкой к единице. Эта детерминация достаточно точно объясняет
поступок R в контексте к наличием ситуации Q/.
Задача диалога. Она диктуется участником А. Ему известно, что
поступок и « Ь индивида р характеризуется веером
X V
I D.2.7)
{Р}
X Y
где х=вб(р)«а, у *-J» Ср > " t . Сравнивая D.2.7) с D.2.5),
он оперирует только той частью веера D.2.5), где представлены
переменные х, -и , т.е. веером
X Y
J^Jh <4-2-8)
На этом веере детерминация а»-* 8 имеет низкую интенсивность,
т.е. прошлый опыт'в форме D.2.8) не позволяет объяснить
поступок и « о наличием ситуации X в О/. Задача, которая решается в
диалоге участником А , - найти такое объяснение.
Ход диалога. Диалог начинается констатацией поступка у -
6,совершенного индивидом р, и формулировкой задачи, которую перед Б
ставит А (Как Вы думаете, почему ...?). Затем следует решение,
предлагаемое Б, в котором поступок у, в & объясняется наличием
ситуации х - О/. А отвергает это объяснение. Приведенный им
контрпример с индивидом а позволяет Б осознать, что А в разговоре с
ним не учитывает дополнительного обстоятельства k, которое имело
место в обсуждаемом случае. Б сообщает об этом А. Тем самым
99
выявляется, что вместо веера D.2.7) А необходимо рассматривать
более полный веер
X Y Z
«М?/? D.2.9)
где х =г(р) s 1с. Обращаясь теперь к прошлому опыту,
изображаемому веером D.2.5), А убеждается, что детерминация сь~& в
контексте к действительно имеет высокую интенсивность *'; объяснение,
данное Б, его теперь удовлетворяет, цель диалога достигнута.
Приведенный выше диалог можно трактовать как обсуждение его
участниками проблемы включения нового опыта D.2.9) в старый
D.2.5). Рассмотрим этот вопрос более подробно. Формально
присоединяя веер D.2.9) к вееру D.2,5), получим веер
X Y Z
Е,
D.2.10)
где Е.я Е 1/{р},а компоненты *ь , j^ , у определяются через
компоненты «б0 , jse , jp0 веера D.2.5) и компоненты 4. , ь , f веера
D.2.9) следующим образом:
*t(e) -
Л«Н
г»(«>-
*<«),
/,«•).
fr(«>.
1
ее Е
€clp},
eelp},
••е..
D.2.11)
Мы фактически определили процедуру 'сложения*' для вееров.
Веер D.2.10) есть результат добавления к вееру D.2.5)
'элементарного' веера D.2.9) (элементарность проявляется в том, что в
основании последнего лежит одноэлементное множество).
Вычислим приращения интенсивности и емкости, которые получает
детерминация к а*-* Ф(кй) при переходе от веера D.2.5) к дополненно-
'См. рис. 2.7.1, где позитивное уточнение, вносимое контекстом
V в детерминацию а,-*8, иллюстрируется диаграммой Венна.
100
му вееру D.2.10). Мы полагали ранее, что <fAcа) « кЬ. Назовем
это случаем 1 и рассмотрим наряду с ним еще и случай 2, когда
«f(fcfc) ? кв. Обозначим интенсивность и емкость детерминации fca»-*
^?(к<ъ)на веере D.2.5) через I0, CQ , Они равны
NA(fca(fUa))
'• N0Hca.)
N.tto,»(fc»)) D-2Д2)
°~ N0(<fA<a,)) *
где Ne(') - численность группы Е (•) в множестве Е .
Соответствующие величины на веере D.2.10) равны
Ne(K0i,<fA<<b)) + 8
I
1 N0t1ta) + i
N01* o^f (*<*)) + 8
D.2.13)
где в зависит от того, какой случай мы рассматриваем, а именно,
fl, <fA<a) = к6(случай 1),
Но, ч(ко.)? к8 (случай 2). D.2.14)
V
Искомые приращения А I = lt ~ I^haC^C-C^ согласно
D.2.12), D.2ДЗ) имеют вид
е-10
**" i+N (**) '
D.2.15)
• d-cj
в + NQ(<p(t<a))
Допустим теперь (как и предполагалось ранее), что
детерминация 1iCL>-»cp(ica) имеет на веере D.2.5) интенсивность 10, достаточно
близкую к единице. Тогда случай 1 интерпретируется как
подтверждение старого опыта новым, случай 2 - как неподтверждение. В
первом .случае ((p(ku/) s 1* Ь) , 8 = 1 и приращения D.2.15)
неотрицательны: новый опыт, будучи включен в старый, увеличивает (в
крайнем случае оставляет неизменным) его точность и полноту. Во
втором случае (vttoCL)?4 УЬ) , 6 = О и приращения D.2.15) таковы,
чтод I < О, дС= О: здесь новый опыт, будучи включен в старый,
101
приводит к его разрушению, уменьшению его точности. Обращает на
себя внимание несимметрия: отношение д I в случае 2 к ДI в случае
1 равно по абсолютной величине 10/A-1)и при стремлении I к
единице становится весьма большим. Разрушающая сила нового
опыта при его несогласии со старым выше, чем его укрепляющая сила
в случае согласия (хотя абсолютные величины д1,дС сами по
себе могут быть небольшими).
Представляет интерес зависимость приращений ДI, Д С от числа
наблюдений N0(feu),NL(tp(ka)), содержащихся в прошлом опыте. Если
Ne(fc?») eN0(фtkСЬ))~ 1, то характеристики 1&, С равны обе либо нулю,
либо единице. Положим IQ» C0S1. Тогда согласно D.2.15) имеем
д1 в —?—> ь С - 0.
В этом предельном случае, когда детерминашюнная связь в
старом опыте построена на единичном совпадении, т.е. столь же
"элементарна " % как и связь, демонстрируемая новым опытом,
подкрепление (случай 1,ф({с&)81<К, 8=1) оставляет интенсивность^ без
изменения (ДА s О), тогда как неподкрепление (случай 2, (p(ka)9*
9*1F , 9 * О) приводит к заметному разрушению первоначальной
детерминации ka*-*<p(ka): приращение интенсивности при включении
нового веера в старый здесь д I » -1/2. С увеличением N0(ka),M0(<Kka))
значения приращений д1 ,дС согласно D.2,15) уменьшаются по
абсолютной величине. Чем богаче становится прошлый опыт (т.е. чем
больше величины N A(a), N(V(ka)),тем менее он чувствителен к
подтверждению или неподтверждению новыми фактами.
Приведенные несложные модельные построения качественно
согласуются с эмпирическими исследованиями коммуникативных
отношений и процессов переработки информации у человека (см. [30],
гл. Ш - 2011, в частности, с. 448-459). Их, очевидно, можно
было бы продолжить. Скажем, любопытно рассмотреть различные
варианты последовательных добавлений к вееру D.2.5) не одного, а
целой серии вееров типа D.2.9), или проанализировать способы
включения в веер D.2.5) веера, уже отличного от элементарного
(т.е. веера, в основании которого лежит множество с произвольным
числом элементов), или, наконец, построить модель
коммуникативных отношений в случае, когда прошлый опыт участников
представлен неодинаковыми веерами, и т.д. и т.п. Однако собственно
моделирование коммуникаций, как сказано ранее, не входит в нашу
задачу. Мы пытались лишь привести аргументы в пользу того, что
на основе понятий детерминационного анализа такое моделирование
действительно возможно. у ^>*у-**и,,М(>
3. Заметим, что возможность объяснить некоторый поступок}
*не трактовать как возможность включить его в систему социальных
отношений для тех, кто его объясняетАкаю. социализированность по-
102 С™)
ведения, выраженного данным поступком. Необъяснимые для членов
данного социального коллектива поступки весьма часто получают
статус аномальных и тем самым вытесняются из системы социальных
отношений в данном коллективе, т.е. не социализируются. Если для
объяснения поступка ^ = 6 в контексте к используется Ъ -функция
ku = <f(kx) (как в приведенном выше примере), то мерой
возможности дать вообще какое бы то ни было объяснение поведению,
выраженному этим поступком, выступает величина
С<Лк1)« XI C(kx~<p(kx)). D.2.16)
kxecp-^kl)
Она может интерпретироваться как показатель социализирован-
ноети (степень социализации) определенного поведения (поступка)
у я Ь в контексте к на содержательной сфере, определяемой
переменной X (см. также ниже § 4.4), и представляет собой долю
получивших объяснение (на данной содержательной сфере) случаев
рассматриваемого поведения среди всех случаев поведения,
встречавшихся в прошлом в указанном контексте. Величина D.2.16) есть
<р о
полнота детерминации р»-* о,принадлежащей взаимно однозначной
компоненте (р стандартного разложения D -функции ф. В -функция к^ =
s^lktx) позволяет в принципе объяснить одно и то же поведение ^= &,
вообще говоря, многими способами. Их число определяется величиной
Н(кв)«1<р"*0АI, D.2.17)
т.е. количеством элементов в прообразе к Ч -к» относительно ср. Это
величина характеризует разнообразие предпосылок для поведения ^ =
= 6 в заданном контексте на заданной содержательной сфере.
Большие ее значения соответствуют видам поведения, которые можно
было бы назвать полисоциальными или плюралистичными по числу
предпосылок. Малые значения этой величины относятся, напротив, к
моносоциальным, или монистичным, видам поведения. Степень сошализи-
рованности D.2.16) и разнообразие предпосылок D.2.17) одного
и того же вида поведения могут оказаться весьма различными в
различных социальных группах. Их эмпирическое исследование (в
разных контекстах и на разных содержательных сферах) представляет
самостоятельный интерес.
§ 43. Моделирование элементов макроописания
на микроуровне
Различение микро- и макроуровней, вообще говоря, относительно:
один и тот же уровень с одной точки зрения может расцениваться
как *микро*, с другой - как 'макро*. При описании
социально-экономических процессов и явлений к микроуровню обычно относят все,
что связано с различениями индивидуальных ситуаций. Социально-
экономические эмпирические исследования, построенные на
индивидуальных контактах с отдельными людьми, с этой точки зрения есть
103
У
у<3>
у B)
y(i)
10
20
®
хA)
10
10
0
хB.
0
®
10
хC)
®
10
20
хD)
®
20
0
хE)
®
10
0
х<6)
Q
0
0
хG)
X
Рис. 4.3Д. Таблица сопряженности по переменным х, и.Кружками
отмечены клетки, образующие график D-функции 14= cj (X),
исследования, определяющие собой микроуровень. Такое понимание,
однако, нуждается в уточнении. Элементы макроописания
органически вплетаются в микроуровень, и их необходимо уметь в нем
различать.
Рассмотрим, к примеру, таблицу сопряженности по переменным
X, и, изображенную на рис. 4.3.1.
Клетки, соответствующие детерминациям с точностью, достаточно
близкой к единице, отмечены здесь кружочками. В совокупности они
образуют график D -функции, которую мы обозначим через ц = <f (х).
Приведенная таблица (как и любая другая) состоит из многих
отдельных элементов. В клетках находятся числа заполнения N(x у),которые
дают распределение респондентов по значениям переменной хи. Не
указаны, но подразумеваются числа заполнения N(x),N(tp, представ-
ляющие результат суммирования по столбцам и по строкам:
N(x)~ZN(xu},
D.3 Д)
Отмеченные кружочками клетки таблицы соответствуют детермина-
циям видах>-»и. Не указаны, но также подразумеваются
детерминации, образующие веер отображений
Y X*Y
7
Е
X Y Х>
D.3.2)
Они скрываются за числами заполнения, которые представляют собой
результат отождествления всех детерминаций из веера D.3.2),
попадающих в одну и ту же клетку таблицы. Какие из названных
элементов следует отнести к. микроуровню, а какие нет? Или, быть мо-
104
жет, все они относятся к микроуровню? Попытка ответить на эти
вопросы сразу приводит к необходимости более точно определить,
что есть микроуровень, выработать более ясное понимание того, как
из описания на микроуровне можно строить описание на'более
высоких по иерархии уровнях. Чтобы хоть как-то продвинуться в
попытках получить ответы на эти вопросы, разберем каждый из названных
выше элементов.
1, Веер отображений D.3.2). Он позволяет точно установить
состояние каждого индивида из множества Е по переменным X , и ,
хи. Это, очевидно, и есть в чистом виде полное микроописание
совокупности индивидов Е.
^# Р -функция u = <f (*) (см« Рис- 4.3.1). Она удовлетворяет урав-
нению(рля значительной части объектов из Б)
Jb(«) -»(*(*)). D.3.2)
Иными словами, <1 можно трактовать как результат обобщения
компоненты веера u-Jb(%) путем нормального преобразования х = «с(е),
т.е. путем такого разбиения всех индивидов на типологические
группы по отдельным значениям переменной х, что внутри каждой группы
индивиды частично теряют индивидуальность, перестают быть
различимыми. В-функция u e 9W уже не есть микроописание, коль
скоро х ? е. Она выступает по отношению к микроуровню в роли
обобщающей закономерности, которая представляет собой шаг в сторону
более агрегированного описания.
Отметим, что функция Ф определяет правила измерения
переменной и на объектах X , т.е. что мы го> существу получаем новый веер
отображений, состоящий по меньшей мере из одной компоненты «f :X
-*Yt роль основания (т.е. роль множества Е в веере D.3.2)) здесь
играет множество X, а роль объектов выполняют теперь уже не
индивиды, а значения переменной х, которые тем самым подверглись
объективации. Таким образом, мы имеем дело здесь с простейшим
примером того, как внутри одного первичного веера отображений
порождается новый, вторичный веер, свойства которого определяются
свойствами первичного. Переход к более высоким уровням
(макроуровням) описания связан прежде всего с процедурами объективации
и порождения вторичных вееров. D -функция <? по отношению к
первичному вееру есть элемент макроописания, но по отношению к
порожденному ею вторичному вееру она есть, очевидно, микроописание
индивидуальных состояний объектов х по переменной и. Здесь
проявляется относительность понятий микро- и макроописания.
3. Число заполнения п » Ы(ху).Это нормальная функция от
переменной х и, которая определена на множествеXхYи принимает
значения на множестве неотрицательных целых чисел Jf в{п1 Н>0}.
Число заполнения IV = N(xy) при фиксированном х^ есть число всех
** Мы полагаем очевидным, что в данном случае описание по
переменной ху (компонента f веера D.3.2)) однозначно определяется
описаниями, по переменным х , и (компонентами «с#, р того же веера).
105
детерминаций видав~хив веере отображений D,3.2). Чтобы
получить число заполнения N(xu),необходимо, очевидно, принять гипоте-
Т
зу равномерности, qorviacHO которой всякая детерминация в |-ху
априори наделяется числовой мерой, равной единице.
Числа заполнения представляют собой элемент описания,
относящийся к макроуровню, если задачей является описание совокупности
индивидов Е. Функция N(x^) определяет, однако, вторичный одноком-
лонентный веер N(xi^)l X* г*#,в котором объектами служат значения
переменной хи. На этом вторичном веере числа заполнения
выступают как первичное описание. С помощью D.3.1) легко построить
еще две компоненты вторичного веера:
N(x):X*Y-^t№ и N(tp: X xY^Jt.
В итоге получим веер
XxY
Объективация, приводящая ко вторичным веерам указанного типа,
играет фундаментальную роль в моделировании
социально-экономических процессов: она порождает макроскопическое количественное
описание над уровнем социальных измерений, где господствует
описание качественное.
§.4.4. Моделирование отношения между
первичными (качественными) и вторичными (количественными)
закономерностями
Вернемся к рис. 4.3.1 и попытаемся понять, какую роль играет
показанная на нем Ъ -функция ц = <Р(х) в вопросе о связи
распределения N(u) респондентов по значениям переменной и с распре деле- ,
нием Ы(Х) по значениям переменной х. Числа заполнения Nty) hN(xu|
связаны очевидным, уже приводившимся в § 4.3 соотношением *
НЫ) aEN(xu), D.4.1)
X
D -функция Ц = <р(Х) ставит в соответствие каждому значению и,
множество <р (tj) значений X, которые условно объясняют или являются
предпосылками данного и. Например, для Ч = ^ имеем Cf (u ) -
и т.д. (см. рис. 4.3.1). Разобьем сумму в правой
части D.4.1) на два слагаемых, первое из которых есть сумма по
всем X, которые являются предпосылками *f, а второе содержит
106
сумму по всем остальным значениям х :
N(y)« XI N(xu)+ Л N(xy). D.4.2)
Воспользовавшись определением емкости
N(XU)
и тождеством
ЦС(х~у) =1,
х
приведем вторую сумму в D.4.2) к виду
II N(x4)-(i-Cwiu))N(u). D.4.3)
%*ч> (у)
Здесь С (г») - степень социализации, которой характеризуется
закономерность, описываемая В-функцией (р (см. §§ 3.3, 4.2),
СЫ)" XI С(Х~и). D.4.4)
V ХбГ(^) "
С учетом определения интенсивности
- Ы(ХЦ)
первая сумма в D.4.2) примет вид
Л N(xy)= Л I(x~y)N(x,). D.4.5)
xeqT4(y) xc<pty)
Подставив D.4.3) и D.4.5) в D.4.2), получим окончательно
Щ*Г~^7 5Z 4 1(Х~^)Ь1(х). D.4.6)
Vl} Х€фЛ^)
Эта формула показывает, как закономерность микроуровня,
выраженная D-функцией и » 9 (х), определяет отношение между
макроскопическими характеристиками - распределением респондентов по
и и распределением по х. Связь между распределениями NfX^Nty),
описываемая здесь, есть сама по себе одна из разновидностей
количественных закономерностей, используемых в модельных построе-
107
ниях на макроуровне. Таким образом, формула D.4.6) показывает,
как осуществляется один из вариантов взаимодействия между
первичной (качественной) закономерностью микроуровня, описываемой
детерминациями, образующими D -функцию u - <f (х), и вторичной
(количественной) закономерностью, характеризующей макроуровень.
Эпитет 'первичная* по отношению к качественной закономерности, в
противовес эпитету 'вторичная* по отношению к закономерности
количественной, используется нами потому, что качественные
классификационные различения, которые в обобщенной форме описываются
закономерностью и в9(х)> являются в прямом смысле, первичными,
тогда как количественные переменные N(x),N(tj)B D.4.6) суть
результат объективации %,ч , т.el вторичны в буквальном смысле.
Обратимся к выражению D.4.6). Если закономерность ц^щх)
(будем ее называть микрозакономерностью, в отличие от
макрозакономерности, описываемой самим выражением D.4.6)), точна и
полностью социализирована, то
Nty) = 21 N(X), D.4.7)
т*е. распространенность и в социальной системе определяется
только распространенностью предпосылок х 6 ср (ij), предопределяющих 14 •
Реально, однако, закономерности, как правило, не бывают ни
абсолютно точными, ни абсолютно социализированными. Например,
точность рассмотренной в § 3.4 закономерности ч в (р (х ^объясняющей
высокий уровень обеспеченности бытовой техникой, определялась для
различных предпосылок х - X X величинами 0,72; 1,00; 0,67;
0,71 (см. табл. 3.4.2), а степень социализации была равной 0,76
А
ф
(величина Сф (<f )eC (p0»-*U) в табл. 3.4.5 при у:550 A)). Но
если, как в указанном случае, социализация и точность все же
достаточно высоки, то формула D.4.7) может служить (и обычно служит)
нулевым приближением при оценке распространенности того или иного
явления и, коль скоро известна распространенность его предпосылок.
Число Й(ч) слагаемых в сумме D.4.7) характеризует
разнообразие предпосылок, предопределяющих явление и (см. формулу D.2.17) )#
Это число есть вместе с тем показатель уровня обобщения, которым
характеризуется закономерность у = <f(x): чем больше R (у),тем более
дробным, менее обобщенным предстает объяснение явления U с
помощью микроэакономерности ^= 9 (х). Предельный случай
минимального обобщения достигается, когда R^) вМ(и),т.е. когда объясне- '
ние полностью распадается на индивидуальные случаи. Он
реализуется, когда для объяснения используется непосредственно компонента
веера, определяющая и как нормальную функцию от индивидуальной
переменной е. Действительно, возьмем в качестве
микрозакономерности D -функцию u «¦ J*F),T.e. непосредственно компоненту JS веера
108 \
отображений (см. D.3.2)). Это нормальная функция, т.е. Це^у)*8 1.
Степень социализации здесь максимальна:
v^'.-S,.^6^)'
eejs (у)
Формула D.4.7) мля этого случая точна и принимает вид
N(y» 21 N(e).
ecjb^)
Здесь N (в) «¦ 1, сумма содержит ровно N (и) слагаемых, степень
разнообразия предельно велика:
ЪЦ) -ljT4ly)l-N(y>
й уровень обобщения тем самым предельно низок.
Сравним, например, точность, степень социализации и уровень
обобщения микрозакономернос^ей \i e JV(e) и ^ в <р(х),исходя из ситуации,
изображенной на рис. 4.3.1 при и = у .
1. Микрозакономерность u s ft (в). Разнообразие предпосылок пре-
дельно велико:
Rlyw)-N(ytt))
3G0.
Уровень обобщения предельно низок. Точность предельно высока
и равна единице. Степень социализации предельно высока и также
равна единице.
2. Микрозакономерность и « <р (х).Разнообразие предпосылок
невелико:
(в 90 раз меньше, чем для и я Jb(e)). Уровень обобщения весьма
значителен. Точность для разных предпосылок Ос , х1 , х( , X
различна и определяется рядом чисел 0,7; 0,8; 0,9; 1,0. Степень
социализации немного ниже предельно возможной и равна
Х€ф (Ч )
Таким образом, переход от предельно подробного описания у в
^Jbte),заложенного непосредственно в результатах измерений, к
обобщенному описанию и = if (х) сопровождается здесь резким
повышением уровня обобщения, но зато наличием потерь в точности и
степени социализации. Отсюда вытекает еще одна интерпретация
цетерминационного анализа: он представляет собой систему
методов, направленных на получение и анализ обобщений первичной
информации, которые сопровождаются значительным сокращением раз-
109
нообразия предпосылок обследуемого явления при не очень больших
потерях в точности условных объяснений и степени социализации.
Рассмотрим еще одну модель связи между первичными и
вторичными закономерностями, когда вторичная закономерность предстает
на макроуровне в виде уравнения регрессии между числовыми
переменными, а первичная закономерность есть D -функция, связывающая
на микроуровне качественные имена переменных. Довольно широко
распространены ситуации, в которых числовые переменные,
используемые в количественных макромоделях социальных и социально-
экономических процессов, получают имена, задаваемые через
определенные свойства, наличие которых устанавливается путем
качественных идентификаций, т.е. социальных измерений. Количественные
переменные, такие как рождаемость, смертность, уровень
образования, миграционные потоки, определяемые в целом для некоторой
территориальной единицы, предполагают существование индивидуальных
качественных различий, позволяющих устанавливать такие свойства,
как факт рождения или смерти, наличие определенного
индивидуального образования, факт отъезда или приезда, которые "дают имя" упо-^
мянутым количественным переменным.
Пусть в 10 городах % = 1, 2, ..., 10 обследовано N~ 1000
респондентов по анкете с двумя закрытыми альтернативными вопросами
х (ответы 0/, а ) и ^ (ответы Ь, Ь ) и результат обследования таков*,
как показано в таблице сопряженности по переменным х, U на
рис. 4,4.1.
Рис. 4.4.1. Таблица
сопряженности по х, и.
Предположим, что эта таблица сопряженности расслоилась по 10
городам так, как показано на рис, 4.4.2: наложив друг на друга все
приведенные в нем таблицы сопряженности и сложив числа
заполнения в соответствующих клетках, мы получим таблицу на рис. 4.4.1.
Зафиксируем внимание на ответах а, 6 . Введем обозначения N(a)=
s u; Ntb) e V. Величины u, xf есть функции от х: в первом городе
(см. рис. 4.4.2) a - 5 + 5 = 10, tf= 5 + 35 = 40, во втором и -
= 5 + 45 * 50, V я 45 + 40 s 85 и т.д. Построенный таким
образом ряд значений чисел a, V по городам показан в табл. 4.4.1.
Этот ряд задает корреляционное поле в плоскости ч*, V,
изображенное на рис. 4.4.3.
Судя по этому рисунку, между переменными ги , \f имеется
довольно тесная зависимость. О том же говорит коэффициент
корреляции, который, как нетрудно подсчитать, равен j> =» 0,91. Точки
корреляционного поля хорошо группируются около точек прямой
линии регрессии переменной tf по переменной tu, которая, как опять
же несложно подсчитать, задается уравнением регрессии V = 0,89 и*
+ 37,3.
110
У
Б
ь
50
150
а
400
400
а
X
z=1
V
Б
b
5
5
a
55
35
a
X
z=2
У
Ъ
b
5
45
a
10
40
a
X
Y
Б
b
0
15
a
55
30
a
X
z=4
Y
Б
b
5
15
a
30
50
a
X
z=5
У
b
b
10
20
a
15
55
a
,
X
z = 6
У
Б
b
0
5
a
55
40
a
X
z=7
У
Б
b
0
40
a
35
25
a
X
z=8
Y
cri
20
5
a
25
50
a
X
Y
b
b
0
0
a
65
35
a
X
z=10
У
cri
b
5
0
a
55
40
a
X
Рис. 4.4.2. Таблицы сопряженности по X, ч в каждом из городов
*» 1, 2, ... , 10.
Рис. 4.4.3. Корреляционное поле в плоскости tutv .и линия регрео*
сии V по гд>.
111
Таблица 4.4Д
Рад значений переменных и, и по городам %» 1, 2, ..., 10
г
Ивги(Х)
J tr c 1Г(Ю
1
10
40
2
50
85
3
15
45
4
20
65
5
30
75
6
5
45
7
40
65
8
25
55
9
0
35
10
5
40 J
Детерминация а*•+ 6,имеющая точность I » 150/200 - 0,75 и
полноту С - 150/550 - 0,27 (см. рис. 4.4.1), представляет собой
элементарный пример микрозакономерности, в которой качество а
выступает как предпосылка (условное объяснение) качества в.
Если, например, о, - высокий уровень образования, 6 - наличие
установки на миграцию, то а*-* о условно объясняет наличие у
респондента установки на миграцию высоким уровнем его образования
с довольно высокой точностью, I я 0,75, и сравнительно невысокой
полнотой, С я 0,27.
Линия регрессии на рис. 4.4.3 - это типичный пример
макрозакономерности. Если интерпретировать а, 6 , как сказано выше, то
переменная МХ)= М(ах),обозначающая количество лиц с высоким
уровнем образования в выборке из города t,есть, уровень
образования в городе %, а переменная tr(x) nN(ix), обозначающая
количество лиц с выраженной установкой на миграцию в той же выборке,
есть уровень потенциальной миграции в этом городе. Линия
регрессии на рис. 4.4.3 в таком случае показывает, что уровень
потенциальной миграции возрастает с ростом уровня образования tf.
Корреляционное поле в плоскости u , if образовано объектами, в
роли которых выступают значения переменной %,т.е. города. Таким
образом, макрозакономерность в форме линии регрессии получена
кар результат объективации значений переменной X,имеющей на
микроуровне, в сущности, тот же статус, что и переменные *, ^;
переменная % соответствует вопросу *в каком городе Вы живете?* с
десятью альтернативными ответами.
Детерминация а~8есть вариант закономерности на первичном
веере с основанием Е (респонденты). Функция регрессии tfe 0,89 и +
+ 37,3 есть вариант закономерности на вторичном веере с
основанием Z (города). Отношение между первичным и вторичным веерами
имеет вид {'№ - множество неотрицательных целых чисел)
v«AMbz\ /u«/V(az)
D.4.8)
112
Рассмотрим теперь общий случай, когда в множестве Е имеется
произвольное число индивидов N, а множество 2 содержит
произвольное число ш^ N непустых (относительно Е) городов. Предположим,
что детерминация а*-* о имеет точность I и полноту С и
распределение индгвидов пот непустым городам носит произвольный характер.
Положим, как и ранее, а s U/(X)sN(ax), v s VCX)88 NF%).Cnpaiim-
вается, можно ли при этих исходных предположениях описать в
достаточно общем виде отношение, которое имеется между первичной
качественной закономерностью а**Ь и вторичной количественной
закономерностью, заданной в виде точной функции регрессии V я ф (а) ?
Ответ положителен, и мы сейчас покажем, как это сделать.
Рассмотрим средний квадрат отклонений (вдоль направления и)то-
точек корреляционного поля в плоскости а, V от точек функции
регрессии Vе ф A*);
L*= — HU(г)- фЫ%)))г>0. D.4.9)
ж x
Прежде всего отметим, что если I = С - 1, то Lia О и
функция регрессии есть просто t/ » ip(\b) ¦ <u. Действительно, из I s С я 1
следует, что N (&&) a N (&) « NF). Как бы ни распределялись
индивиды из Е по городам, это условие, очевидно, сохранится, т.е. в
любом городе % будет и,(%)- Н{&%)= Н(Ь%)~ V(%).Bce города, таким
образом, будут расположены строго на прямой Ve U/, которая и
будет идеальной функцией регрессии..
Если I Ф 1, Сф 1, то, по всей видимости, должна существовать
функция ?A, С), которая производит оценку
L*<f(I,C) D.4.10)
и обращается в нуль при I Я,С в 1. Эта функция (если она
существует) описывает искомое отношение между качественной и
количественной закономерностями. Получим ее в явном виде - тем самым
задача будет решена.
Введем обозначения
^s—Hu,(%),
m х
_ 4 D.4.11)
v - — Ц v(x).
m г
Заменим в D.4.9) точную функцию регрессии линейной, т.е.
положим
0(t*) т и, + г? ~ги.
Поскольку для точной функции регрессии сумма в правой части
D.4.9) минимальна, то вследствие такой замены она может лишь
Hi
возрасти. После простых преобразований получим
Заметим-, что
щ%)-и(х) »N(ouftx)-Nca^x). D.4.13)
Подставляя это соотношение в сумму по ъ, находим
^Z[vrtO-al*)l4^SN(EbL^IlN(aW
t*v % Ж г Hi г
D.4.14)
Оценку сумм в последнем выражении следует производить с
учетом того, что
ZN(a&x)-N(aft)«m?(i-C),
* D.4.15)
IlN(€ui*)-N(ab)-nvaD-I).
г
Кроме того, необходимо учесть, что слагаемые в этих суммах
не превышают величины
со = ntax N (г). D.4.16]
X
Оценка сумм в D,4.14) сводится, таким образом, к задаче: otiP
кать оценку сверху суммы квадратов/^ р. при условиях z^p.* A*
- Const и р. ^ со . Максимальное значение оцениваемой суммы достю-
гается, когда все р. принимают значения либо О, либо со. Значений
р. -со может быть не больше, чем А/со. Итоговая оценка имеет вид
У пЪ s • сог« А со,
А-*Р\ ч со
Применяя сказанное к оценке сумм в D.4.14), при выполнений
D.4Д5), D.4.16) находим
— 51[и(г)~и/(г)]г<со[аA-1) + v(l-C)]. D.4.11
ж %
Теперь осталось только преобразовать в D.4.12) квадрат разнос*!
I V- а) к виду, при котором явно видна его зависимость от I , С.
С учетом D.4.11) и D.4.13) нетрудно получить
(V-ti)X~[Mi-I)-V(i-C)]*. 14.4.14
114
Подставляя D.4.17) и D.4.18) в D.4.12), приходим к
окончательному результату
L4 a>[w(l-I)^V(i-C)]-[tZ(l-I)-V(l-C)r. D.4.19)
Правая часть этого неравенства и есть искомая функция f(I,C);
производящая оценку D.4.10).
При равномерном стремлении точности I и полноты С к единице
величина L равномерно стремится к нулю, а функция регрессии Vя
- ф (U)- к линейной функции V = а. Коэффициент корреляции при этом
также равномерно стремится к единице.
Таким образом, мы приходим к выводу: если первичная
микрозакономерность в виде детерминации а* 6 имеет достаточно высокую
точность и полноту, то между количественными переменными 14, хг
именами которых являются соответственно а, в , имеется тесная,
близкая к линейной корреляционная зависимость, выступающая как
закономерность макроуровня.
Глава V
МЕСТО ДЕТЕРМИНАЦИОННОГО АНАЛИЗА В СИСТЕМЕ
МАТЕМАТИЧЕСКИХ МЕТОДОВ ОБРАБОТКИ ДАННЫХ
Детерминашюнный анализ удовлетворяет требованиям, вытекающий
из принципов номинальности, конкретности и ограниченной статистич*»
ности. Он применим в случае, когда используемые, в обследовании
переменные номинальны (требование, диктуемое принципом
номинальности), и дает возможность анализировать связи между отдельными
значениями переменных (требование, определяемое принципом
конкретности). И, наконец, он позволяет анализировать связи детер-
минашюнного типа, что гарантирует систематическое обнаружение
и описание ситуаций, когда статистичность ограничена (требование,
исходящее из принципа ограниченной статистичности). Если последо-
вательно удовлетворять всем названным требованиям, то мы
придем к схеме детерминационного анализа с точностью до
терминологических условностей. Это облегчает проведение параллелей и
разграничений между детерминашюнным анализом и иными
математическими методами.^вё^ТВодится, в сущности, к установлению того,,
каким из приведенных выше требований тот или иной метод анализа
данных не удовлетворяет и почему.
Практически оказывается, однако, что существует лишь
небольшое число общих причин, ответственных за невыполнение
упомянутых принципов. Поэтому для выяснения места, которое
детерминашюнный анализ занимает среди других математических методов, не*
нужды перебирать вообще все возможные методы — достаточно
назвать эти причины и проиллюстрировать их действие отдельными при**
мерами, что и сделано ниже. Выбранные нами примеры имеют
условный характер. Как правило, это простейшие/ таблицы
сопряженности, типичные в известном смысле для практики эмпирических об
следований. Их условность носит намеренный характер и не вызван
недостатком конкретного эмпирического материала. Она отвечает
стилю, принятому в данной книге, и позволяет, на взгляд автора,
добиться большей рельефности и простоты в обсуждении
поднимаемой проблематики.
Детерминашюнный анализ представляет собой описательный мето>
Собственно статистические проблемы, связанные с его приложенияк
116
нами были затронуты лишь вскользь, они в предлагаемой читателю
книге практически не обсуждаются. Отчасти это обусловлено тем, что
собственно статистическое обеспечение детерминационного анализа
сводится по существу к известным схемам выборочного
оценивания условных частот и их приращений и (с учетом некоторой
специфики, привносимой близостью условных частот к единице; см. [59])
не представляет особенных проблем. Вероятностно-статистические
методы, с которыми сравнивается детерминашюнный анализ,
трактуются здесь как описательные. Сравнение в таком ключе
представляет для нас наибольший интерес.
Все исследуемые нами величины типа условных или безусловных
частот могут с равным правом рассматриваться как
соответствующие точные вероятности. По крайней мере один тип случайного
процесса, описываемого определенными таким образом вероятностями,
очевиден: это случайный отбор с возвращением, проводимый из
совокупностей, представленных числами в клетках таблиц
сопряженности, по которым рассчитываются интересующие нас частоты. Для
изложения обсуждаемых ниже вопросов безразлично, имеется ли в
виду чисто частотная схема или стохастическая схема указанного
типа, в которой частоты в точности равны соответствующим
вероятностям. Понятия 'частота* и 'вероятность* используются в
приводимом ниже тексте с учетом сделанных оговорок.
§ 5.1. Статистическая детерминация
и статистическая связь
Одно из ключевых отличий детерминационного анализа от иных
математических методов определяется тем, как эти методы
соотносятся с требованиями, вытекающими из принципа ограниченной ста-
тистичности.
Рассмотрим две таблицы сопряженности, изображенные на
рис. 5.1.1. Зависимость свойства «аВот свойства х в А
характеризуется в левой таблице довольно высокой статистичностыо 1 -
-Р(В1А)в 1 - 0,4 » 0,6. В правой таблице статистичность той же
зависимости равна 1 - Р(В1А)Я 1 - 1 в О, т.е. полностью
отсутствует. Группа индивидов, обладающих свойством А, в левой
таблице разнородна по значениям переменной и. В правой таблице
аналогичная группа полностью однородна по значениям той же
переменной: все индивиды в ней обладают только одним значением: u e Ъ.
Применительно к математическим методам анализа социальных
данных принцип ограниченной статистичности требует, чтобы случаи
зависимости свойства В от свойства А, показанные на рис. 5.1.1,
были различимы. Утверждается, что всякий метод, который позволяет
распознавать случаи малой статистичности и отличать их от случаев,
когда статистичность заведомо немала, более адекватен задачам
анализа социальных данных, чем любой другой метод, который этого
делать не позволяет.
Детерминашюнный анализ описывает два случая связи между
свойствами А и В на рис. 5.1.1 следующим образом.
117
V
в
30
40
30
А
90
10
0
0
10
90
X
У
В
0
240
0
А
30
0
0
0
0
30
X
Рис. 5.1.1. Две таблицы сопряженности по х,^, В обоих случаях
разность Р(В1А)-Р(В)'равна 0,2.
Левая таблица. Детерминация А** В имеет интенсивность 1(А*-» В)*
~ Р(В1А) = 40/100 - 0,4. Ее дефект, численно совпадающий со ста-**
тистичностью, описывается величиной 1 ~Р(В1А) = 1 - 0,4 = 0,6.
Емкость детерминации А* В есть С(А"» В) » Р (А1 В) в 40/60 = 0,67.
Существенность свойства А в детерминации (А•¦* В) = 1о>А***В)(или
существенность, которую вносит свойство А в детерминацию оъ*+ В, где
Сд - универсальное свойство) равна
$(соА*-* В) - I (с*А~ В) - I (go ~ В) -
-Р(В|А)-р(В)- 0,й - 0,а «0,2
Правая таблица. Детерминация А1-* В имеет интенсивность 1(Аь»
ь-В)« Р(В1А)« 240/240 - l.Ee дефект 1 - р(В1А) равен нулю(т.е«
*) * *
статистичность отсутствует ). Емкость этой детерминации есть
С(А^В)=Р(А1В)« 240/240 » 1. Существенность свойства А в
детерминации (А** В)« (<*>А** В)равна
-P(BIA)-PIB)-1-0,8 - ОД.
Таким образом, различие в статистичности, которой
характеризуется зависимость В от А в двух приведенных случаях, детермина-
ционный анализ обнаруживает автоматически. Это происходит потому
что интенсивность, используемая здесь в качестве одной из основнь!
характеристик направленного влияния одного свойства на другое,
есть прямая мера статистичности этого влияния: статистичность влис
ния А на В (зависимости В от А ^ определяется величиной 1 - К А** В
т.е. как дополнение соответствующей интенсивности до единицы. КрС
ме интенсивности, направленное влияние одного свойства на другое
описывается также величиной емкости, или полноты. Мы видим, чтоц
обсуждаемые случаи зависимости В от А различаются также и по этс^
му параметру: для левой таблицы полнота равна 0,67, для правой \
она равна 1. Эти случаи не различаются, однако, по тому, насколь*
ко существенным оказывается уточнение, вносимое свойством А в
Очевидно, что речь идет только о той совокупности индивидов
которая представлена в клетках обсуждаемой таблицы сопряженност
118
зависимость свойства В от универсального свойства со. В случае
левой таблицы интенсивность этой зависимости 1(<о»-»В) = Р(В) «
~ G0/300 » 0,2, т.е. не слишком велика. Для правой таблицы
указанная интенсивность существенно выше: 1(со»*В)в Р(В) - 240/300 »
- 0,8. Но и в том, и в другом случае внесение уточнения с помощью
свойства А приводит к увеличению интенсивности на одну и ту же
величину:
1(соА - В) - Ко» — В) - Р(В|А) - Р(В) = 0,2
Остановимся более подробно на концепции связи между
отдельными свойствами (событиями), которая лежит в хэснове детерминацион-
иого анализа. В сущности, эта концепция сводится к следующему:
1. Статистическая связь между свойствами (событиями) А,В
всегда имеет направленный характер. Направлений два: от А к В и от В к
А. Связь в обоих направлениях исчерпывающе характеризуется двумя
величинами**: Р(В)А) « 1(А->В)и Р(А1В) - 1(В-*А).В частотной
интерпретации это условные частоты (соответственно частота В при
условии А и частота А при условии В),в вероятностной
интерпретации - условные вероятности, в интерпретации детерминационного
анализа - интенсивности двух взаимно обратных детерминаций, причем
интенсивность связи в одном направлении интерпретируется как
емкость в обратном направлении.
2. Понятие связи между свойствами (событиями) не является
абсолютным. Связь всегда определяется относительно некоторого
контекста. Вне какого бы то ни было контекста понятие связи теряет
смысл. В частности, если особо не оговорено обратное,
направленная связь между свойствами А, В мыслится как связь в
универсальном контексте со. Направленная связь от _Д к В эквивалентна
направленной связи от со А к В (или направленно^ связи ото) А к со В , или
направленной связи от~А к gJB ) • Если здесь Поменять местами А и
В э то эквивалентность сохраняется. Она обусловлена тем, что
всегда А = са А, В = сдВ(см. § 2.5).
3. Рассматривая направленную связь от А к Ь, которая
характеризуется интенсивностью Р(В1А) « 1(А^В)= НсоА^В), мы можем
отбросить свойство А и перейти к рассмотрению направленной связи
от со к В (со - универсальное свойство), характеризующейся
интенсивностью Р (В ) s I(«о*"* В). Приращение интенсивности
Р(В1А)-Р(В) = 1(соЛ~В)-1(со~В)
в детерминапионном анализе рассматривается как мера
существенности свойства А в детерминации (А-*В) ~(<оАь*В) или как мера
существенности уточнения, вносимого свойством А в
детерминацию (д)-*В. Более подробно понятие существенности изложено
выше (см. § 2.6).
Если какая-либо из них не определена, то указанное понятие
связи теряет смысл. Это имеет место, в частности, тогда, когда
либо А, либо В оказывается пустым (см. § 2.1).
119
Мы намеренно подчеркнули специфическое определение понятия
статистической связи между свойствами А , В , из которого исходит де-
терминашюнный анализ, и сделали это по той простой причине, что
в широком классе вероятностнс>-статистических методов
используется иное определение статистической связи и именно здесь детерми-
национный анализ расходится с рядом традиционных методов
обработки данных.
В детерминационном анализе, как отмечено выше, связь между
свойствами (событиями) А , В описывается двумя условными
частотами (условными вероятностями) Р(В I А}, Р (АIВ ), рассматриваемыми
каждая сама по себе, что автоматически обеспечивает распознавание
ситуаций ограниченной статистичности, при которых либо Р(В1А)
»либо Р(А|Ь) , либо обе эти величины достаточно близки к единице.
Рассмотрим теперь в качестве меры связи между свойствами А ,
В величину
Rt«P(BIA)-P(b). E.1.1)
Если
Кт°> E.1.2)
то согласно обычной интерпретации имеет место статистическая не-^
зависимость свойств А , В. Мера связи E.1.1) определяет связь
как альтернативу статистической независимости: связь тем больше
(по абсолютной величине), чем сильнее нарушается условие
статистической независимости E.1.2). Спрашивается, можно ли, пользуясь
мерой связи E.1.1), построить методы анализа связей,
удовлетворяющие требованиям, предъявляемым принципом ограниченной
статистичности? Ответ вполне определенный: нет. Мера связи E.1.1) не
позволяет всегда отличать случаи, в которых статистичность
достаточно мала, от случаев, когда статистичность нельзя считать малой.
Например, для обеих таблиц сопряженности, показанных на рис. 5.1.1
сйязь между свойствами А я В характеризуется одной и той же
величиной Л « 0,2, т.е. мера связи E.1..1) не позволяет различать
указанные здесь ситуации. Представляется очевидным, что подобных
примеров можно привести много.
Рассмотрим другую меру связи
R2« Р(АВ) ~Р(А)Р(В). E.1.3)
Условие R" О также определяет статистическую независимость и
при P(A)l* О совпадает с условием E.1.2). А%не позволит ли ме-
**Величины Р(В|А),Р(В) рассматриваются здесь как точные
значения, не подверженные статистическому разбросу. В цротивном
случае статистическая независимость становится гипотезой, подлежащей
проверке.
120
У
в
30
50
40
А
60
25
0
0
25
70
X
У
В
0
20
0
А
70
60
0
0
70
80
X
Рис, 5,1.2. Две таблицы сопряженности по х,и. В обоих случаях
разность R «Р (АВ)-Р(АЖВ) равна 0,033.
ра связи R. удовлетворить требованиям принципа ограниченной
статистичности? Ответ опять-таки отрицательный: нет. В качестве
примера, иллюстрирующего сказанное, на рис. 5.1.2 приведены две
таблицы сопряженности, в которых величины статистичности зависимостей
В от А резко различны (для левой таблицы 1 - 1( A~B)s 0,58, для
правой 1 - ДА*-*В)» О), и тем не менее значения Т^для обеих
таблиц одинаковы и равны 0,033. Как и в случае меры R , для R,
также можно привести целый ряд подобных примеров, показывающих, что
мера связи Rfc часто не позволяет распознавать ситуации жестких
связей, характеризующихся ограниченной статистичностью.
Можно было бы, как нередко делается, предположить, что неудачи с
мерами связи R- f ^% обусловлены видом зависимости этих мер от
величин P(AB)tP(A),P(В). В таком случае следует, видимо,
попытаться искать меру связи в форме более общей, чем E.1.1), E.1.3),
функции вида
R&- Ф(Р(АВ),Р(А),Р(В)), E-1.4)
наложив на нее ограничение, состоящее в том, чтобы эта функция
обращалась, например, в нуль при
Р(АВ)-Р(А)Р(В)-0, EД.5)
т.е. при статистической независимости свойств А,В. Этот путь
порождает множество всевозможных моделей связи (см., например, ?2,
33J), но не приводит к успеху в том смысле, что,какой бы нк была
функция Ф, принимающая постоянное значение (не обязательно нуль)
при условии E.1.5), она при ее использовании в качестве меры
связи не позволяет распознавать случаи ограниченной статистичности
тогда и только тогда, когда они имеют место. Чтобы
убедиться в этом, достаточно рассмотреть всего один какой-нибудь
пример, когда мера R. фиксирует одинаковые величины связи
в двух различных случаях, заведомо резко отличающихся один
от другого величиной статистичности, которой характеризуется
зависимость между свойствами К и В . Такой пример показан
на рис. 5.1.3.
121
У
в
0
100
0
А
0
100
0
0
100
0
X
У
в
30
20
50
А
30
20
50
30
20
50
X
Рис. 5.1.3. Две таблицы сопряженности по переменным X, t^. В
-обоих случаях R3e Ф(Р(АВ),Р(А),Р(В)) - О.
Для левой Таблицы статистичность зависимости В от А велика и
равна 1 -ЦА^В)8* 1 - 0,2 = 0,8. Ситуация здесь далека от
детерминизма. Для правой таблицы статистичность 1 - КА^В) я 1 -
-1 = 0, т.е. предельно мала. Здесь зависимость В от А имеет строго
детерминистический характер. Вместе с тем мера связи R.b обоих
случаях одинакова и равна нулю, поскольку и там и там имеет место
статистическая независимость свойств А, В и выполнено условие
E.1.5).
Мы приходам, таким образом, к следующему выводу: если
определять статистическую связь как меру нарушения условия
статистической независимости, то требованиям, проистекающим из принципа
ограниченной статистичности, удовлетворить нельзя ни при каком
виде функции, выбранной в качестве конкретной меры связи. Пример
на рис. 5.1.3 отчетливо показывает основную причину, порождающую
этот вьюод: представление о статистической связи как о мере
приближения к статистическому детерминизму (к которому ведет принцип
ограниченной статистичности и из которого исходит детерминашон-
ный анализ) оказывается несовместимым с представлением о
статистической связи как о мере нарушения условия статистической
независимости (которое лежит в основе большого числа вероятностно-
статистических методов анализа данных, используемых в социальных
и социально-экономических исследованиях). Эта несовместимость
выражается в том, что наличие или отсутствие полного
статистического детерминизма может иметь место как в отсутствие, так и при
наличии статистической незвисимости. На рис. 5,1.1 и 5.1.2
показаны случаи, когда статистической независимости между свойствами
А, Ъ нет, но в одних условиях влияние А на В носит строго
детерминистический характер, а в других - нет. На рис. 5.1.3 как нали- -
чие детерминизма (правая таблица), так и его отсутствие (левая
таблица) реализуются при наличии статистической независимости.
Степень приближения к детерминизму и степень приближения к
статистической независимости - две самостоятельные, несводимые
одна к другой характеристики статистической связи. Обе они важны
в практических приложениях. Однако, если определять связь как
альтернативу статистической независимости, то создать
непротиворечивую схему анализа ситуаций, характеризующихся ограниченной ста-
тистичностью (т.е. близостью к детерминизму), невозможно. Если
же определять связь как меру приближения к детерминизму, то та-
122
кая схема оказывается возможной и тогда мы приходим к детермина-
ционному анализу.
Здесь следует упомянуть об одном важном обстоятельстве.
Характеристики связи как меры нарушения статистической независимости
органически входят в схему детерминационного анализа. Однако
условие статистической независимости, записанное в виде E.1.2) или
E.1.5), получает здесь иную интерпретацию, отличную от
общепринятой. Используя стандартные обозначения интенсивностей,
перепишем условие E,1.2) в форме
P(BlA)-P(B) - I(»A^B)-I(to^B)-0. E.1.6)
Оно интерпретируется так: свойство А является несущественным
уточнением универсального свойства &> в детерминации соА^Вили
свойство А вносит несущественное уточнение в детерминацию (й*+ В.
С позиций детерминационного анализа условие E.1.6) не имеет
отношения к *независимости событий А, В f оно означает лишь
независимость интенсивности ICcftA*"* В) (т.е. величины Р(В 1Ю)от
наличия или отсутствия свойства А, что и отражено в приведенной выше
трактовке этого условия. Если встать на такую точку зрения, то
интерпретацию E.1.6) как условия, отражающего независимость
событий А, В, следует считать семантическим казусом, который
исторически возник, видимо, из-за интуитивно, казалось бы,
естественного, но тем не менее неверного отождествления независимости
вероятности одного события (В) от наступления (ненаступления)
другого события (А),с одной стороны, и независимости просто одного
события (В) от другого события (А) - с другой.
Корни определения статистической связи как альтернативы
статистической независимости лежат в интерпретации условия Р (АВ) =
SP(A)P(B) как условия, определяющего статистическую
независимость свойств, событий А, В. Она принята по крайней мере со
времен Лапласа и отражена в формулировках теоремы о возможности
представить вероятность появления нескольких событий в виде
произведения вероятностей каждого из этих событий в отдельности,
приводимых классическими руководствами по теории вероятностей и
математической статистике. Вот, например, формулировка Лапласа ([26],
с. 17): 'Если события независимы друг от друга (подчеркнуто мной -
С.Ч.), вероятность существования их совместности есть
произведение вероятностей". Аналогичная формулировка приведена у
А.А.Маркова ( [313, с. 19): "... вероятность случиться нескольким
независимым событиям (подчеркнуто мной - С.Ч.) вместе равна произведению
их вероятностей". А.Н. Колмогоров ([.23], с. 19) придерживается
той же интерпретации, лишь подчеркивая, что в формальном
определении статистической независимости первично само формальное
условие Р(АВ)-Р(А)Р(Ь).
Отметим формулировки указанной теормы, которые не содержат
семантического казуса. Такоца, например, формулировка,
представленная П. Л. Чебышевым ([52], с. 9): "В частном случае, когда
одно событие не имеет влияния на вероятность другого (подчеркнуто
мной - С.Ч.) » ..., вероятность случиться им вместе определится через
123
произведение их вероятностей-'. Укажем также формулировку, данную
Э. Борелем ([5], с, 45): "... Теорема. Когда событие, вероят-
ность которого огаскивается, состоит в последовательном
наступлении двух событий, то искомая вероятность равна произведению
вероятности первого события на вероятность наступления второго
события при уже совершившемся первом событии. Вообще, если
необходимо последовательное наступление нескольких событий, надо
перемножить различные вероятности этих событий, вычисляя каждую
из них в предположении, что предшествующие события уже имели
место.
Ограничиваясь случаем двух событий, мы видим, что если
вероятность второго события не зависит от выполнения первого (под-
черкнуто мной - С.Ч.), то это последнее ограничение излишне*.
В сравнении с приведенными выше формулировками Лапласа и
А. А. Маркова здесь утверждение о независимости событий
замещено утверждением о независимости вероятности одного события от
наступления (ненаступления) другого события. Это отражает только
то, что фактически имеет место и тем самым ведет к большей
интерпретационной точности, исключая возможные недоразумения.
М.Кац [21] пишет: "Понятие независимости, хотя и является
центральным по важности в теории вероятностей, не есть чисто
математическое понятие. Правило умножения вероятностей независимых
событий представляет собой попытку формализовать это понятие и на
этой основе построить некоторое исчисление ... Существует, таким
образрм, независимость в расплывчатом, интуитивном понимании и
'независимость* в том узком, но точно определенном смысле, что
применимо правило умножения вероятностей". Именно правило
умножения вероятностей играет первостепенную роль в теории вероят-
ностей и математической статистике. Его интерпретация для
большого круга задач имеет сугубо второстепенное значение: в
аналитических расчетах важны фактические операции, а не слова,
которыми они называются. По этой причине отмеченный выше
семантический казус во многих вероятносл^омл'атистических построениях
и расчетах никакой роли не играет. Он совершенно неважен и тогда,
когда при обработке данных ставятся и решаются задачи анализа
связей между переменными, связей, понимаемых в смысле нарушения
условий, описывающих статистическую независимость. Здесь
определение статистической связи входит не только в метод решения
задачи, но и определяет саму задачу, в силу чего оно, естественно, не
может породить каких-^пибо противоречий и сомнений.
Однако, как только заходит речь о задачах, возникающих прежде
всего в социологических исследованиях, в которых требуется
обнаруживать и анализировать зависимости между отдельными
значениями дискретных нечисловых переменных, характеризующиеся
ограниченной статистичностью, семантический казус начинает играть
негативную роль, сдерживая развитие методов эффективного решения таких
задач и стимулируя разработку методов, имеющих принципиальные
недостатки. К этим последним относятся все вероятностные и
статистические методы, в которых используются интегральные меры
124
связи между признаками, такие, как известные коэффициенты Юла и
Кендалла, коэффициенты Пирсона, Чупрова, Крамера (основанные на
критерии ? ), всевозможные информационные меры и т.д. В
формальную структуру подобных мер заложено определение связи между
свойствами, событийми, как степени нарушения условия статистической
независимости (т.е. собственно семантический казус) - это
оказывается достаточным, чтобы с их помощью было практически
невозможно выполнить более или менее детальное исследование
социальных микрозакономерностей. Последний тезис подробно
разворачивается в следующем параграфе на примере методов, использующих кри-
%
терий $ и основанные на нем коэффициенты Пирсона, Чупрова,
Крамера.
§ 5.2. Детерминационный анализ
и методы исследования связей на основе критерия -у
Пусть имеются две переменные х , ^ с дискретными
множествами значений X , Y соответственно. Количества элементов в множесл>-
вах X , Y обозначим через IX I e m, I Yle W. Предположим, ч^го на
X*Y задана функция плотности f * f(x,t|), удовлетворяющая условию
нормировки
EEt-i.
В практических задачах обработки социально-экономических
данных прямое произведение X*Y есть таблица сопряженности размером
m*tv,a величины i суть частоты, заполняющие клетки этой таблицы
и рассчитываемые по некоторой выборке объемом N единиц. В
большом числе алгоритмов анализа связей между переменными х , ух в
этих условиях используется величина, обозначаемая f, \
Hie QS 9(*)я^-* f - функция плотности распределения объектов в
точках множества X ,Н 2 Н (ц)~ }L» f - функция плотности распре—
1 хеХ
деления объектов в точках множества Y.
Если выборка случайная, то величина $ подчиняется
стандартному X -распределению с (ж- 1)(п- 1) степенями свободы. Значе-
ние )С , вычисленное по определенной выборке, позволяет с фиксиро-
125
ванным заранее уровнем значимости принять или отвергнуть
гипотезу о наличии статистической независимости между переменными х,ц.
Нас, однако, будет здесь интересовать использование )С не как
статистического критерия, а как показателя, описывающего величину
статистической связи между х, и , В таком чисто описательном клю-
че величина X используется обычно для вычисления по ней значений
неких стандартных мер связи, среди которых наиболее
употребительны коэффициент Пирсона П, коэффициент Чупрова Т и коэффициент
Крамера К. Зная величины f ,Ш , п , N , эти коэффициенты можно
вычислить, пользуясь формулами [33].
П=,1 — ^, E.2.2)
ГЦ
1 N + /5
/—
1 Nt/сЙГ
J__
-1
Г'
хг
-1)(п-
/г
г
-1)
1 '¦ " ' *
E.2.3)
К « \\ ~ ' E.2.4)
Nmmlm-ljtv-i)
Если статистическую связь изначально понимать как отклонение
от статистической независимости, то использование критерия ^г,а
также приведенных выше коэффициентов как мер связи
представляется естественным и при наличии известных оговорок вполне
оправданным. Наша цель, однако, состоит в том, чтобы сопоставить
методы, основанные на использовании таких мер связи, с детермина-
ционным анализом. Для этого следует прежде всего ответить на
вопрос: в какой степени величину JC и названные выше
коэффициенты можно использовать для обнаружения случаев, в которых по
конкретным значениям одних переменных можно достаточно хорошо
предсказать конкретные значения других переменных?
Рассмотрим простую модельную ситуацию, когда IXI ^lYl85 TV и
функция плотности f на Xх Y имеет вид
I - Ь
{ «f(Xfy)«j E.2.5)
где 0-4 &•? 1, (f> - произвольная функция из X в Y.
126
Вычисляя величины f(ijlX) = i(x,y)/u(x), получим (как легко
показать из E.2.5), J(x)= 1/tv)
i-t , u = <p(x),
lU|*)"i с _, E.2.6)
Иными словами, зная X я 0/, мы всегда в выбранной модельной
ситуации будем иметь возможность утверждать, что из X я &
следует U « 6 e (jpW c вероятностью !""•?, а любое другое значение
U^ о - с вероятностью &/(n-i)# Величина Ъ играет роль ошибки
предсказания, осуществляемого по правилу 'если х~0Ь, тоив t =
s 9 WJ ПРИ этом величина 1 - & есть точность такого предсказания.
Зная t , мы в нашей модельной ситуации будем иметь полную
информацию о возможности предсказывать значения переменной ч по
конкретным значениям переменной X.
Предположим теперь, что в нашем распоряжении имеется двух-
лараметрическое семейство таблиц сопряженности по переменным х,ц,
в которых числа заполнения N(x,i^)« Nf(x,tj); где f (x,^)
определяется выражением E.2.5). Таблицы сопряженности этого
семейства различаются по двум параметрам: по значениям I и по
виду функции <f. Величину п будем считать фиксированной. Поставим
задачу: расклассифицировать эти таблицы по принципу возможности
в каждой из них по значениям переменной х предсказывать
значения переменной ^ по правилу ^ s <кх).Она решается тривиально:
таблицы должны быть расклассифицированы по значениям параметра Ь.
Вид функции <р какую-либо роль в такой классификации играть не
может, поскольку возможность предсказывать по правилу 'если X - <Л/ 7
то у - в « Vta*)" зависит только от Ь и не зависит от вида
функции ц . Очевидность этого решения делает рассматриваемое семейство
таблиц сопряженности удобным полигоном для апробации
различных методов описания связи между переменными, в частности,
для сравнения детерминашюнного анализа и методов
исследования связей с помощью коэффициентов, построенных на основе
критерия у .
В рамках рецептурной схемы детерминационного анализа
различение таблиц двухпараметрического семейства по значениям параметра
Ь обеспечивается автоматически. Действительно, функция у - ф(х)
есть D-функция, образованная детерминациями Х^Фф.Интенсивность
каждой из них равна 1 - &. Вычисляя ее, исследователь всегда
может определить величину I, которая есть дополнение интенсивности
до единицы, т.е. статистичность. То, что в данном случае
вычисление интенсивности тривиально, не должно вводить в заблуждение.
Обратимся теперь к схеме различения (классификации) таблиц со-
пряженности того же семейства по значениям величины у и
коэффициентов Пирсона, Чупрова, Крамера. Возьмем для примера
коэффициент Чупрова E.2.3), который в данном случае (поскольку hv =
в П ) совпадает с коэффициентом Крамера E.2.4). Обозначим ка-
127
кую-либо произвольную таблицу сопряженности рассматриваемого
семейства через А(&, ф ;Пг ). Она характеризуется значением
коэффициента Чупрова Т, которое мы обозначим черезТ (&,ср ). Чтобы
найти его в явной форме, подставим функцию плотности E.2.5) в
E.2.1), а результат - в выражение E.2.3). Проделав
необходимые вычисления, получим
Здесь ф\Х}- область значений функции <р , А« А(^)в1ф~ Ы)\ - число
элементов множества X в прообразе и относительно <р.
Величина Т F, <р ) есть мера связи между переменными х, и в
таблице сопряженности А (&, <р ; IV ). Она определяет классификацию
таблиц сопряженности рассматриваемого семейства по степени
выраженности связи. В понимании связи как возможности делать
предсказания на основе условных высказываний вида "если X - Ь, той -
а i - tf(Cb)*1 наилучшая классификация осуществляется по величине
параметра t. Поэтому качество классификации, определяемой на
основе коэффициента Чупрова Т, разумно оценивать по тому, насколько
таблицы сопряженности с фиксированным значением Т ( Б, cf ) в *с ,
н
которые в совокупности образуют класс
VnU)-{а(*,ф;*): Tn(e,<f)e«c}, E.2.8)
различаются по величине Ь (напомним, что п, считается
фиксированным). Если они различаются незначительно, то классификацию,
осуществляемую по величине коэффициента Чупрова, можно признать
приемлемой. Если разброс величины ? для таблиц класса V («О
велик, то классификацию таблиц по значению Т следует считать
менее приемлемой, поскольку в таком случае по нему нельзя получить
определенное суждение о величине &.и, следовательно, нельзя
оценить ошибку, которая совершается при предсказаниях, опирающихся
на упомянутые выше условные высказывания. Вопрос о качестве
классификации таблиц сопряженности по величине коэффициента Чупрова
сводится, таким образом, к вопросу о том, в каких пределах может
изменяться величина I при фиксированном значении коэффициента
Чупрова Т. Чтобы выяснить это, обратимся к формуле E.2.7). Она
показывает, что Т зависит не только от ?,но йот вида функции ф
которая представлена здесь набором значений [As A (u): y€Y]» В
таблицах сопряженности рассматриваемого семейства представлены (по
построению) все возможные функции, осуществляющие отображение
из множества X в множество Y. Поэтому при заданном I величина
Т( I, <Р ) будет изменяться в зависимости от вида функции ср (т.е.
от конкретного набора -значений А.). Нетрудно показать, что пределы
128
1 T=Tn(e,<p)
Рис. 5.2.1. Область совместимых значений I и Тн(& ,tf )
(заштрихована). Ее пересечение с прямой Т « oL дает диапазон изменения
? в классе таблиц сопряженности, характеризующихся одинаковыми
величинами Т (&,сМ я вС.
этих изменений таковы:
0<TnU,o)<
1-
6»
н-1
E.2.9)
В самом деле, функция
i(A)
Л(*-Л)
(н-1)Л + еп»11-л)
удовлетворяет при t < 1 неравенству
f(U + tJ)< !Ы + Н*),
где tt> О, tf > О, 0< u + tf^H/ (это проверяется непосредственным
вычислением). Отсюда следует, что максимальное (в пространстве
отображений из X в Y ) значение суммы под знаком радикала в
E.2.7) достигается при Лн Л(^)в 1 (<р - взаимно однозначное
отображение), минимальное - при Х? А Су)» tv (ср — постоянное
отображение или отображение в точку). Подставив указанные, значения в
E.2.7), получим E.2.9).
Обращая неравенство E.2.9) относительно Ь9 найдем искомые
пределы изменений величины Ь7 которые могут иметь место для
таблиц сопряженности рассматриваемого семейства, характеризующихся
фиксированным значением коэффициента Чупрова. Результат в данном
случае нагляднее представить в графической форме, как показано на
рис. 5.2.1.
Для таблиц, характеризующихся значением коэффициента Чупрова
Т (EtV ) e *» (см. E.2.8) У, величина t может быть заключена в
пределах от О до ? («С), как изображено на рисунке. При Т F, <р )?
^ l/(tl- 1) область допустимых значений имеет разрыв. Здесь яс-
129
но видно, что классы таблиц сопряженности по одинаковым
значениям Ъ, о одной стороны, и-по одинаковым значениям коэффициента
Чупрова - с другой, совпадают только в единственном случае,
когда Т1&» ? ) ™ 1. Чем больше отличается коэффициент Чупрова от
TV
единицы, тем меньше информации он несет о величине I. Тем
менее он пригоден для обнаружения ситуаций, в которых можно
пользоваться условными высказываниями ''если Xs5 (Цто ^ = 8а(р(аГ
с достаточно малой ошибкой 6. Тем более неконкретными будут
суждения о влиянии одних свойств на другие, которые можно получить
на базе коэффициента Чупрова, в сравнении с суждениями, которые
можно сделать в тех же случаях на базе детерминащюнного
анализа, В рассматриваемом примере коэффициент Крамера совпадает с
коэффициентом Чупрова, так что этот вывод полностью применим и
к нему. Для коэффициента Пирсона вместо E.2.9) имеем
| SlV I I ,
It
Форма области, заштрихованной на рис. 5.2.1, для коэффициента
Пирсона, как видно отсюда, будет несколько иной (ее границы уже
не являются линейными), но, как нетрудно убедиться, вывод и здесь
качественно остается тем же, что и в случае коэффициентов
Чупрова и Крамера.
Итак, обсуждаемые коэффициенты несут в себе более или менее
определенную информацию о возможностях осуществлять
предсказание на базе условных высказываний вида 'если Xs d, то^во ¦*
в у(Ъ)* лишь тогда, когда величины этих коэффициентов более или
менее близки к предельно возможным. Представляет интерес
произвести оценку области, в которой названные коэффициенты
информативны в указанном смысле. Для этого уточним задачу: пусть нам
необходимо, зная конкретное значение коэффициента Чупрова Т* (?,ф),
выяснить, имеется ли в таблице сопряженности АД&, tf ; н)
какая-либо D -функциональная зависимость, для которой статистичность
Ь меньше некого заранее заданного порога у. Мы находимся в
ситуации, когда известно значение Т (& , if ) e Л коэффициента
Чупрова, но неизвестны величина Ь и вид функции <р, характеризующие
распределение в таблице сопряженности, для которой Т^ (Ь» Ф ) =
оС.Обратимся к рис. ,5.2.1. Линия 5 s f пересекает границу
заштрихованной области в точке, которая (см. E.2.9)) на горизонтальной оси
имеет координату
Tn*<r)-|*-^l|- E-2Д1)
130
Рассмотрим сначала случай у < 1 - 2/tv, Если при этом ее >
>Т Чг),то(см. рис. 5.2.1) заведомо 6 < у. Значения Т (t, tf) ,
лежащие правее точки Т (у), позволяют, таким образом, сделать
определенные суждения о величине Ъ. Они образуют область
информативных (в указанном смысле) значений коэффициента Чупрова. Если «С <
<Т (у), то, напротив,определенного суждения о том, превышает ли
величина Ь пороговое значение или она меньше него, сделать нельзя,
поскольку, как видно из рис. 5.2.1 (где изображен именно такой
случай), значение Ь «¦ у лежит внутри области допустимых значений 6 и
в принципе может иметь место как &< у, так и I > у. Значения Т {I, ср),
лежащие левее *%Ду)> в этом смысле неинформативны. В
совокупности* они составляют область неинформативных значений
коэффициента Чупрова. Формула E.2.11) определяет границу, отделяющую
эту область от области информативности при у < 1 - 2/tv. В
случае, когда у > 1 - 2/tv, неинформативными, как видно из рис. 5.2.1,
оказываются (независимо от у) все значения Т (&, Ф L 1/(Н- 1).
Пользуясь E.2.11),вычислим, к примеру; границу Т (у)в
довольно типичном для социальных исследований случае, когда размерность
таблиц сопряженности It- 5. При у= 0,2 получаем Т (у)- 0,75.
Иными словами, если из семейства таблиц размером 5*5 нам
необходимо отобрать таблице, в которых заведомо имеется возможность
сделать прогностические высказывания с ошибкой, не превышающей
20%, то коэффициент Чупрова может оказаться полезным только в
том случае, когда его величина не меньше, чем 0,75. Большая часть
G5%) диапазона возможных изменений этого коэффициента
оказывается областью неинформативности.
Среди всевозможных функций вида Ч^^Х),
характеризующихся статистичностью Ь$ у, существуют такие, для которых
значение коэффициента Чупрова всегда оказывается в области
неинформативности. Пользуясь коэффициентом Чупрова, их. обнаружить
невозможно.
Получим соотношение, описывающее класс таких нераспознаваемых
функций в явной форме. Из формулы E.2.7) следует, что при I < 1 -
- 1/л значение Т [Ь,<р ) с уменьшением Ь возрастает. Для любой
фиксированной функции if величина Т^ (?,, у ) не может, таким
образом, превышать Т (О, <р ). Полагая в E.2.7) t s 0,~находим
TV
где l<f$C)l~ число элементов в области значений функции (f>. Если
131
функция ip такова, что
ТК@'«° <Тп(Т>> E.2.13)
то значение Т (&, ф ), которое всегда не больше, чем Т (О, <р ),
оказывается согласно этому соотношению в области неинформатавнос-
ти при любых значениях Ь. Неравенство E.2.13) и есть искомое
соотношение, определяющее класс нераспознаваемых функций.
Подставляя сюда E.2.11) и E.2.12), получим в итоге следующее
неравенство:
|<р(Х)| < 1 + lH-i)(l- -^Zjf E.2.14)
Оно представляет собой ограничение на число элементов в
области значений <р (X) функции <р.
Условие E.2.14) определяет класс нераспознаваемых с помощью
коэффициента Чупрова функций при у < 1 - 2/ft. Если у > 1 - 2/Vt, то
класс нераспознаваемых функций также определяется этим условием,
где следует положить у я 1 - 2/ri.
В рассмотренном выше примере, когда tie 5, p0,2, в класс
нераспознаваемых согласно E.2.14) попадают все функции, у
которых область значений содержит! <f(X)l<3,25, т.е. до трех
элементов включительно. Из общего числа 5 «3125 всех функций,
отображающих одно пятиэлементное множество в другое, также пяти-
элемеятное множество, нераспознаваемых оказывается, как можно
подсчитать, 405.
Приведенные выше рассуэкдения автоматически переносятся не •
только на коэффициент Крамера (что очевидно), но и на коэффициент
Пирсона, а также на величину )С ,если ее рассматривать как меру
связи. При этом условие E.2.14), характеризующее класс
нераспознаваемых функций, остается неизменным. Меняются лишь значения
порога информативности: для коэффициента Пирсона он равен
г*
ПпФ
1 TV 1 |
E.2.15)
(ср. с E.2.10)). Для величины jC аналогичный порог есть
<*T>-N(»-i)(i-;^?- E.2.16)
В примере с tt« 5, у» 0,2 область неинформативности для
коэффициента Пирсона занимает полуинтервал [6, 0,83 ) (соответствен-
132
но область информативных значений - отрезок [0,83*0,89}), для
величины X неинформативными оказываются значения в
полуинтервале t О, 2.25N) (область информативности [2,25N, 4N1).
При обработке социологических и социально-экономических
данных одной из важнейших является задача предсказания. Требования,
диктуемые принципами номинальности, конкретности и ограниченной
статистичности, приводят к тому, что эта задача ставится как
задача поиска ситуаций, когда допустимы условные утверждения вида
'если а, то S *, для которых условная частота P(Md) достаточно
близка к единице. Приведенный выше анализ показывает, что методы
исследования связей между социально-экономическими переменными,
опирающиеся на критерий /* и коэффициенты Пирсона, Чупрова,
Крамера, обладают рядом особенностей, препятствующих использованию
их в качестве методов решения подобной задачи. Это
подтверждается значительными по размеру областями неинформативности, а
также наличием класса нераспознаваемых зависимостей, что можно
рассматривать как фактическое рассогласование названных методов с
требованиями, вытекающими из принципов конкретности и
ограниченной статистичности. Одна из главных причин этого состоит в том,
что приведенные выше методы опираются на представления о связи
между переменными как на меру нарушения условия статистической
независимости (такой мерой, в частности, и является величина )Сг).
Поэтому обсуждавшиеся коэффициенты не позволяют распознавать
зависимость <р e COKst (см. условие E.2.14)), для которой при
любом t имеет место ситуация статистической независимости. Это
обстоятельство достаточно тривиально. Оно выражается в том, что
функция <f ° СОЛВ^для которой |<Р(ХIв 1* всегда удовлетворяет
условию E.2.14) и, следовательно, образует ядро класса
нераспознаваемых функций. Несколько менее тривиально то, что в таком
классе содержатся также функции, отличные от постоянных, которые в
принципе могут нести в себе практически интересные сведения о
социальных микрозакономерностях. Эти функции оказываются
"близкими' к константе, если смотреть на них через призму
обсуждавшихся коэффициентов. Мера такой 'близости* задается
условием E.2.14).
Ориентация на определение связи как на альтернативу
статистической независимости не является единственной причиной
обсуждавшихся особенностей методов, построенных на использовании
коэффициентов Пирсона, Чупрова, Крамера. Другая важнейшая причина
состоит в интегральности подхода к описанию связей между
переменными, в противовес ориентации на локальность, заложенной в детерми-
национном анализе. Действие этой причины подробно обсуждается в
следующем параграфе на примере методов изучения связей
между переменными X, 1ф» основанных на использовании расстояния
по Хеммингу между соответствуюпшми разбиениями множества
объектов.
133
§ 53. D -функции и расстояние по Хеммиигу
между разбиениями объектов
Коэффициенты Пирсона, Чупроьа, Крамера, рассмотренные в § 5.2,
измеряют связь как меру нарушения статистической независимости
между соответствующими переменными. В анализе качественных
данных, однако, используются и такие меры связи, в которых ситуация
статистической независимости специально не выделяется. Одной из
наиболее изученных мер такого рода является расстояние по Хем-
мингу между разбиениями множества объектов.
Пусть задан веер
X Y
Его компоненты «t, jb определяют два разбиения множества Е,
которые можно описать с помощью следующих характеристических
функций', определенных на Е х EL'.
г(е, в )ш\
»(*,«)'
Г t, в'е ^._1U(e)),
E.3.1)
О, е'ё jb_i(j>U)).
Первая из них описывает разбиение, определяемое компонентой
«с, вторая - разбиение, определяемое компонентой fl. Расстояние
между этими разбиениями по Хеммингу вводится следующим
образом [33, 34]:
<t=S ZL U(e,e')- s(e,e')]. E.3.2)
Зафиксируем некоторое значение Х€Х,Ему соответствует
множество E(x) = «t (x) респондентов,- эквивалентных по этому
значению. Если в € Е(х),то, очевидно, X «оС (е} и Е (х) я «С~ 0*(е)). Для
любого е'с Е,если € € Е(х) ,то согласно E.3.1) Х(е, е') - 1; в
противном случае x[tf%)^ О. Рассмотрим двойную сумму
J * 21 Yl i(e,e').
ееЕ е'еЕ
134
С учетом сказанного ее можно всегда представить в виде тройной
суммы
J = Z X Z г(е,е'),
Х€Х е€Б(*)е'бЕ(х)
в которой t(e,e)= 1. Производя суммирование, получим
• хеХ
где, как обычно, N(x)e |Е(х)| - число респондентов, попавших в
множество Е(х).
Учитывая эти замечания и справедливость соотношения % F,6')-
в х(в,? ),нетрудно убедиться в том, что выражение E.3.2) можно
представить в следующей форме;
A-N* ? аг+ Цьг-гТ: Z izl E.3.3)
LxcX ? ^cY хеХ ^Y J
где N , I , J i k определяются аналогично тому, как </го было
сделано в начале § 5.2.. В случае статистической независимости,
когда при любых значениях X , 1J справедливо-1 « qIv, расстояние d не
фиксировано и зависит от конкретного вида функций &, Я ; это
обстоятельство есть следствие того, что ситуация статистической
независимости здесь специально не выделяется.
Чтобы проанализировать отношение между детерминацнонным
анализом и способами исследования связей между переменными,
основанными на использовании расстояния А, прибегнем к приему,
использованному нами в предыдущем параграфе, а 1*менно: рассмотрим
двухпараметрическое семейство таблиц сопряженности, порождаемое
тестовой плотностью {, заданной выражением E.2.5), и посмотрим,
как классификация таблиц этого семейства по значениям d
соотносится с классификацией тех же таблиц по значениям параметра ?.
Подставляя функцию плотности f в E.3.3), получим
А-А
гц-tr-
гь'
tv
-1
tn
;n / tn \ I ( in f
E.3.4)
где, как и ранее, t - дефект (статистичность) детерминаций,
образующих D-функцию Ч e <p(X);tl- фиксированный размер стороны
квадратной таблицы сопряженности по переменным X, ц , A гАйЛИ цГ (-и^\ —
135
число значений переменной X, которым функция Cf ставит в соответ*-
ствие данное значение переменной Ч.
При постоянных П, Е максимум (минимум) выражения E.3.4)
в классе всевозможных отображений <р из X в Y достигается на функ««
или, которая обеспечивает максимум (минимум) суммы квадратов
Z_* А . Поскольку при А , А* |* О
и одновременно справедливо условие (следующее из определения Л)
С A =it,
то
Л < XI Л < **, E.3.5)
причем максимальное значение указанной суммы квадратов, равное
п у достигается на любой постоянной функции ср e COttst
(отображение X в одну точку множества Y), а минимальное значение, равное
П., реализуется на любой взаимно однозначной функции ф (в первом
случае имеется единственное ненулевое значение Лвл; во втором -
все значения Л равны единице и таких значений ровно п).
Используя E.3.4) и E.3.5), нетрудно устанввить, что величины
Дм (в, Ф ) подчиняются ограничениям
IV
CjU.^K *ftF,<0 < сгС*,10, E.3.6)
где функции С (?, >v), с (в, И» ) имеют вид
„ гь i ел \
cjt,*) - ct(ifn) + A*(i- ^~"У
E.3.7)
Фигурирующая здесь величина d определяется формулой
i*- Nz(l~ ~). E.3.8)
ft
Она представляет собой максимально возможное (при
фиксированном, как указывалось ранее, 1г ) значение d (& , if ), которое
достигается, если ^р e Corv&b, I «¦ О.
136
Предположим теперь, что нам известно значение d (&, ср ) я •?,
но неизвестны ни величина ?7 ни вид функции ср, характеризующие
распределение в таблице сопряженности, для которой получено это
значение. Чтобы изучать Ъ -функции с помощью расстояния d,
необходимо, как минимум, иметь возможность обнаруживать по
значениям d хотя бы факт их существования. В данном случае эта
возможность проверяется тем, можно ли по заданной величине А F , ср)=
= «6 определить, какое значение 6 характеризует таблицу
сопряженности, для которой она получена. Для ответа на этот вопрос нужно
знать, каков диапазон значений Ь в классе таблиц сопряженности,
эквивалентных по величине А ^?, if ) s оС.Если указанный
диапазон вырождается в точку, то, зная Л, можно точно указать ? и тем
самым установить интенсивность детерминаций, образующих Т)
-функцию <р. Если этот диапазон имеет ненулевую протяженность, то чем
он шире, тем более проблематичным становится определение
величины t по величине оС;тем меньше возможностей установить сущест*-
вование D -функций, образованных детерминациями, у которых
интенсивность лежит в заданных границах.
Диапазон изменений величины I при заданном значении с1л(б,«р)я
88 *, нетрудно рассчитать на основании E.3.6), E.3.7).
Аналитические формулы, определяющие границы этого диапазона, несложные,
но громоздкие, и мы их приводить не будем. Более удобно в данном
случае воспользоваться графиком на рис. 5.3.1, где наглядно
представлены диапазоны допустимых значений 6 при различных значениях
cL (It Ч )• Границы заштрихованной области задаются формулами
E.3.7).
Для таблиц сопряженности, характеризующихся значением d (?,ц>)«
е «с, величина t может лежать в пределах от О до ? (<?) (рис. 5.3.1).
При С A,дг)^вС^си»Ю°бласть допустимых значений I имеет разрью.
Как мы видим, по величине d (s ,ср ) «оС сделать определенные
суждения о значении Ь можно только либо при «с в О, либо при «С s
в d |ив том, и в другом случае I « О. Чем сильнее отличается
«С от этих двух крайних значений, тем шире становится диапазон
допустимых значений ?, Тем менее пригодно расстояние d по Хеммин-
гу между разбиениями множества объектов для обнаружения (и тем
более для анализа) D -функций, описывающих ситуации, в которых
условные суждения вида 'если а, то Б « (p(a)* справедливы с
достаточно малой ошибкой I.
Рассмотрим более подробно диапазон информативных и
неинформативных значений d при решении задачи нахождения некоторой неиз- '
вестной В-н^ункции ф, для которой i^y, где у - заранее заданный
порог.
Обратимся снова к рис. 5.3.1. Линия I я у пересекает границы
заштрихованной области в точках, которые по горизонтальной оси
137
«пМ
d = d„(g ,\p)
c,(%n) ?i! c2(%n)
Рис. 5.3.1. Область совместимых значений Ь и Л (&, Ц ) (за-
штрихована).Ее пересечение с прямой ({= <** дает диапазон
изменения 6 в классе таблиц сопряженности, характеризующихся
одинаковыми величинами dL (fc.cp) = оС.
TV 7
имеют координаты С (у,П ) и с (у, tv ) соответственно. Если dL ^
^СДу^) (как показано на рис. 5,3.1) либо если &>, СЛу,П%то
всегда t^ f. Точки горизонтальной оси, лежащие левее СДу,п) и правее
^г(Т*тО, образуют (вместе с самими этими точками) диапазон
информативных значений расстояния 1. Если же Ы* попадает в интервал
но неизвестно, вьшолняется ли t< J', поскольку, как мы видим, в этом
случае возможно и ?> у. Точки интервала E.3.9) образуют диапазон
неинформативных (в указанном смысле) значений расстояния d. Его
границы определяются выражениями E.3.7), где следует положить
? - f. Подсчитаем их, например, для случая, когда и - 5 (таблицы
сопряженности размером 5х5)иг = 0,2. Подставляя эти значения
в E.3.7), получим СД|,и) = 0,18d , С (f, Tt ) = 0,74 d .Как
мы видим, большая часть области изменений величины d покрывается
в этом случае диапазоном неинформативности (с ( г, 1г) -СДГ,пЛя
* * * х 1 t о /
s 0,74 d - 0,18d * 0,56d > т.е. диапазон неинформативности покрь!
вает 56% области изменений величины d).
Представляет интерес указать класс D-функций, которые
характеризуются статистичностью Ь $ у и при этом не могут быть
обнаружены по значениям расстояния d (сюда относятся все D -функции,
для которых величина d^v&.tp ) заведомо попадает в диапазон
неинформативности 'E.3.9)). Для выполнения такой задачи
необходимо сначала определить верхнюю и нижнюю границы изменения d (z, ц>)
при фиксированной функции ц>.
138
Продифференцируем E.3.4) по t \ имеем
-^-^r/v—h-^A (s-3-10'
В точке Е я 1 - 1/п производная обращается в нуль, т.е. в этой
точке А(г( 8, ц> ) принимает экстремальное значение, равное, как
следует из E.3.4) и E.3.8),
V1—^)-"^- E.3.11)
Отметим, что это экстремальное значение не зависит от функции
<р,т.е. является общим для всех отображений вида «f-.X^Yn всегда
лежит внутри диапазона неинформативности E.3.9) (см. рис. 5.3.1).
Из E.3.10) следует также, что экстремум E.3.11) представляет
собой максимум, если <р удовлетворяет условию
22 X < Зть-Ъ, E.3.12)
и минимум, если ср удовлетворяет противоположному неравенству
J^r Xt > ЗК " Z E.3.13).
(напомним, что A s A(U)e I<р" (и) |). Равенства в последних двух
соотношениях означают, очеввдно, что d (?, Cf ) не зависит от ц и
равно E.3.11).
Другое экстремальное значение (минимум в случае E.3.12) и
максимум, если имеет место E.3.13)) достигается в одной из двух
граничных точек: 8 = 0 либо & *• 1. Нетрудно убедиться в том, что
оно всегда достигается при & в О. Действительно, разность
^@,Ср)-<1иA,ср) = -^^[з,-г-1:^] E.3.14)
меньше или равна нулю в случае E.3.12) и больше или равна нулю
в случае E.3.13).
Итак, если выполнено условие E.3.12), то
2d*
А^СО^) < \{1^)< -?" E.3.15)
При выполнении условия E.3.13) имеем
d*
— < 0laU,q>)< АЛ@,<р). E.3.16)
139
2d*
Величина ^@, q> ) в последних двух соотношениях определяется
выражением E.3.4) при t я О:
d*
*^°»^"^>Т5
E.3.17)
Теперь можно непосредственно определить класс нераспознаваемых
функций. Сначала выделим такие функции среди тех, которые
удовлетворяют условию E.3.12). Согласно E.3.15) значения А (? , «f )
заведомо попадут в диапазон неинформативности E.3.9), если
Лп@,ч>) > С^у.п). E.3.18)
Подставляя сюда E.3.17) и пользуясь E.3.7), получим совместно
с E.3.12)
< E.3.19)
YL az< ъп-г.
г*
Эти два неравенства задают только часть нераспознаваемых
функций. Другая часть относится к функциям, удовлетворяющим условию
E.3.13). Для них согласно E.3.16) значения &n(t$ Ч> )
оказываются всегда в диапазоне неинформативности при
\@,ч>) < G^f,*), E.3.20)
Подставляя сюда E.3.17) и учитывая E.3.7), получим совместно
с E.3.13)
**Y E.3.21)
И Az>3n-2.
Объединяя E.3.19) и E.3.21), находим окончательно, что
искомый класс нераспознаваемых функций определяется системой
следующих неравенств:
( г* \ E.3.22)
L »«*
140
Для примера найдем нераспознаваемые функции в
рассматривавшемся выше случае П8» 5, у* 0,2, Условие E.3.22) при этих
значениях и, ^ превращается в двойное неравенство
8,5< 1EZ Кг < 19,75 E.3.23)
Ниже представлены все возможные наборы ненулевых значений Л,
соответствующие при Па5 функциям от X к Y с числом значений
|(р(Х)|от одного до пяти, а также величины сумм квадратов для
каждого набора.
Набор ненулевых Число элементов Величина
значений X в области значений у* г
1<р(ХI fftX
E} 1 25
П. 4) 2 17
B, 3? 2 13
{1, 1, 3} 3 11
[1, 2, 2} 3 9
Л, 1, 1, 2} 4 7
{1, 1, 1, 1,1) 5 5
Отсюда видно, что неравенству E.3.23) удовлетворяют функции,
имеющие либо два, либо три элемента в области значений |ф(ХI.
Сравнивай приведенный выше результат с полученным в
предыдущем параграфе для коэффициентов Пирсона, Чупрова, Крамера, мы
видим, что функция (f » COtvst, для которой |<р(Х))в 1, здесь не
входит в класс нераспознаваемых функций, тогда как там она входила
в него. Причина этого в том, что коэффициенты Пирсона, Чупрова,
Крамера измеряют связь как альтернативу статистической
независимости, в отличие от расстояния d, где используется иное
понимание связи. Вместе с тем и в том, и в другом случае.имеются
нетривиальные (отличные от постоянной) нераспознаваемые функции.
В этом проявляется действие интегральности подхода к описанию
связи между переменными, характерной для обоих случаев.
Представляется весьма правдоподобным, что любые интегральные
меры связи (несущие на себе отпечаток семантического казуса, как
коэффициенты Пирсона, Чупрова, Крамера, или нет, как расстояние
по Хеммингу между разбиениями объектов) не могут служить
адекватным инструментом обнаружения и описания ситуаций, в которых
условные утверждения типа *если а,то В =<р(а)г характеризуются
достаточно малой ошибкой (статистичностью). Разумеется,
интегральные меры связи могут давать полезную информацию в ограниченных
классах случаев (как, в частности, было продемонстрировано выше).
Однако инструментом систематического описания структуры отноше-
141
ний между социальными переменными они служить не • могут. Какой
бы ни была интегральная мера связи, всегда, по-видимому, можно
указать тестовые ситуации (возможно, отличные от использованных
нами выше), для которых анализ, подобный проведенному, покажет
существование значительных по размерам областей неинформативности
и нетривиальных классов зависимостей, не поддающихся
распознаванию с помощью этой меры связи. Иными словами, всякая
интегральная мера связи, по-видимому, не удовлетворяет принципам
конкретности и ограниченной статистичности. Если рассматривать это
как недостаток (а по отношению к приложениям в социальных и
социально-экономических исследованих это определенно недостаток), то
бесполезно пытаться его устранить, придумывая новые показатели
связи в виде тех или иных функций от частот или вероятностей,
сводящих распределения в таблицах сопряженности к одной или
нескольким интегральцым характеристикам. Общий порок всех таких
подходов в интегральности, т.е. в том, что объединяет подобные
показатели, а не в аналитических особенностях, отличающих их друг от
друга. По данным, приведенным в [34], в настоящее время
известно не менее сотни различных показателей связи. Вряд ли стоит
увеличивать их число, придумывая новые.
§. 5.4. Уравнение регрессии и метод главных компонент
как способы описания D-функций
Специфика детерминационного анализа, как должно быть ясно из
предыдущего, состоит не в том, что он предлагает другие способы
решения тех же задач, которые решаются другими методами анализа
данных. Так могло бы быть, если бы строгие постановки таких
задач существовали независимо от методов, если бы они были в
достаточно универсальной форме поставлены и сформулированы до того, как
возникнет вопрос о методах их решения. Но этого нет. Скажем,
всегда, когда идет речь об анализе социальных данных, ставится вопрос
об исследовании связей между социальными переменными. Может
показаться, что задача анализа связей и есть та задача, которая
возникает до формулировки методов, и ее решение позволяет
апробировать и сравнивать между собой разные методы. Дело, однако, в том,
что она не имеет строгой независимой постановки, а различные *ме-
тоды ее решения* всегда содержат такую постановку внутри себя.
Разнообразие методов объясняется здесь не множественностью
подходов к решению одной задачи, а множественностью постановок самой
задачи анализа связей, что не одно и то же. Если в первом случае
можно было бы говорить о наличии многих методов решения как о
свидетельстве гибкости ума авторов методов и о глубине самой
задачи, то во втором случае многоообразие методов свидетельствует
лишь об отсутствии ясности в. вопросе о том, что же, собственно,
следует понимать под анализом связей между социальными
переменными. Если в первом случае можно было бы сравнивать между собой
разные методы как разные способы решения одной задачи, то во вто-^
142
ром случае вопрос о том, какой метод лучше, следует
заменить вопросом о том. какая задача имеет более осмысленную
постановку.
Например, определяя связь через величины коэффициентов
Пирсона, Чупрова, Крамера, мы отнюдь не выбираем метод решения
задачи анализа связей, поскольку независимой постановки такой
задачи нет. Мы ставим эту задачу. Точно так же, выбирая в качестве
меры связи расстояние по Хеммингу между разбиениями множества
объектов, мы тем самым ставим совсем другую задачу. Выбор
энтропийных показателей приводит к третьей задаче и т.д.
Возвращаясь теперь к специфике детерминащюнного анализа в
сравнении с "другими методами анализа взаимосвязей" (мы поневоле
вынуждены пользоваться таким оборотом, создающим ложное ощущение,
будто имеется четкая постановка решаемой проблемы), отметим: она,
прежде всего, в том, что задача анализа взаимосвязей между
социальными переменными ставится как задача анализа D-функций.
Осмысленность такой задачи обосновывается особой ролью, которую
в характеристике условных суждений играют прямая и обратная
условные частоты, и принципами номинальности, конкретности и
ограниченной статистичности. Естественно, что вопрос о
взаимоотношении детерминационного анализа с "другими методами анализа
данных" решается нами как вопрос о том, насколько пригодны эти
"другие методы" для анализа D -функций. Под этим углом зрения мы уже
обсудили принципишхьные особенности взаимоотношения
детерминационного анализа с методами, предназначенными для обработки
качественных данных и удовлетворяющими принципу номинальности.
Здесь мы остановимся на методах, которые принципу номинальности
не удовлетворяют; иными словами, обязательное условие их
применения состоит в том, что значения социальных переменных должны
быть выражены в числовой форме. В качестве примера выбраны два
широко распространенных приема описания связей между
переменными: уравнение регрессии и метод главных компонент. Способ
проведения параллелей и разграничений между ними и детерминацион-
ным анализом остается таким же, как и ранее: выбираются
некоторые простые тестовые ситуации, в которых имеет место
D-функциональная зависимость, и ставится вопрос о том, как названные методы
"работают" в таких ситуациях.
На рис. 5.4.1 слева показана таблица сопряженности 3*3 по
переменным х, и , каждая из которых принимает целочисленные
значения 1, 2, 3. Из всех детерминаций от х к у, определяемых этой
таблицей, три (а именно, х •-* у , х -* ^ , х -*"$ ) имеют
довольно высокую интенсивность, I = 0,8. Вместе они образуют
D-функцию и = ср(х), график которой указан справа на том же рисунке в
виде точек, обведенных кружками.
Как известно, уравнение линейной регрессии ^ по х:
у«*х + jb (.5.4.1)
определяется коэффициентами ос , и , минимизирующими средний квадрат
143
У
у<3> «3
y<2>e2
УИ) -1|
10
10
80
xm«l|
! ю
80
10
х<2)=2
i
80
10
10
х,3>«3
X
Неглавная
компонента
Главная
компонента
Функция
[регрессии у по х
Рис. 5.4.1. Таблица сопряженности по переменным зс,и (слева) и
график линейнойЪ -функции u- (f (X) (точки, обведенные кружками),
график функции линейной регрессии и графическое представление
связи между X, Ц> в виде компонент (справа).
отклонения (по координате ц ) точек корреляционного поля от
точек прямой E.4.1):
Ot'Z-* 2_> f(xtu)[u -otx - л] —* mltv.
хеХ tjcY f *,,$>
E.4.2)
В нашем случае корреляционное поле состоит из 9 точек,
представленных клетками таблицы сопряженности, а функция распределения
i(x, ч ) задана числами заполнения N(xT^) ;
N(xy)
E.4.3)
Величины <**, J*, минимизирующие E.4.2), выражаются через
коэффициент парной корреляции
(x-x)(fr-fr)
в от
х ^
E.4.4)
(черта - усреднение по ? (х,^)) и среднеквадратичные отклонения
-Лх^хЛ, e^-Vky-Trf
E.4.5)
*>
Напомним, что обсуждаемые методы рассматриваются в режиме
описательной статистики. Учет статистического разброса величин ? (х,у)
обусловленного выборочным характером данных, представляет
автономную задачу, подходы к решению которой для широкого класса
случаев общеизвестны.
144
стандартным образом;
В случае,показанном на рис.. 5.4.1, уравнение E.4.1) имеет вид
у -0,7* +0,6. E#4#7)
График этой линейной функции регрессии изображен на рис. 5.4.1
справа. Он проходит довольно близко от точек графика Б -функции
у в ср сх), а при х » 2 совпадает с ним. Это отражает общее
положение: если х , ц - числовые переменные, а В -функция ^ = (р(х)
линейна по х и состоит из детерминаций, имеющих близкую к единице
интенсивность, то она мало отличается (в точках, где она
определена) от функции линейной регрессии ц пох.
Это можно проиллюстрировать более наглядно, если немного
обобщить ситуацию, зафиксированную в таблице сопряженности на рис.5.4.1.
Распределение чисел заполнения по ее клеткам соответствует
функции распределения E.2.5), в которой п= 3, I = 0,2, <f (х)« х.
Будем считать, что t может принимать любое значение на отрезке СО, 11
(в этом и состоит обобщение). Подставив указанное
распределение (при п= 3, ср(х)ях) в формулы E.4.4) - E.4.6), получим
вместо E.4.7) более общее'уравнение
4-Z^[l-~l)U-2), E.4.8)
которое переходит в предыдущее при 8=1-1 =0,2, где I -
интенсивность детерминаций, образующих D-функцию 4>(х). Отсюда
непосредственно видно, что при х = 1, 2, 3 абсолютные величины \ьу\
отклонения точек функции регрессии E.4.8) от точек D -функции ч>(х) суть
|ду|- -|-fc|x-2,l E.4.9)
и при стремлении Б к нулю стремятся к нулю. Средний квадрат
уклонений точек корреляционного поля от точек линии регрессии E.4.2),
равный
a-&u--f-o, E-4-10>
также, как и следовало ожидать, стремится к нулю при стремлении
к нулю Ь.
tj*Q Обратим внимание, что отклонения E.4.9) при любом сколь угод-
но малому отличны от нуля. Это обстоятельство, несущественное
(с определенной точки зрения) при малых Ь, имеет все же
принципиальное значение. Допустим, что кроме указанных трех значений
переменная и других значений* вообще не имеет и всякая гипотеза
об их существовании заведомо бессмысленна. Тогда из отличия от
нуля величин E.4.9) следует, что уравнение регрессий E.4.8) так-
145
У
у<3, = 3
у<2>.2
уИ)=1
10
10
80
хA) = 1
80
10
10
хB)=2
10
10
80
х(з)=3
X
Функция нелинейной
регрессии у по х
*и /
Неглавная
компонента
^Функция
линейной
регрессии
Рис. 5.4.2. Табшода сопряженности по переменным X , у (слева) и
график нелинейной D-функпии Ц~ ф(х) (точки, обведенные кружками),
графики функций регрессии (линейное и нелинейное приближения) и
графическое представление связи между X , U в виде компонент
(линейное приближение) (справа).
же не имеет смысла, поскольку оно дает значения переменной ^,
которых нет в природе. Для D -функций возможные недоразумения
такого рода исключены.
Рассмотрим теперь случай нелинейной Ъ -функции. Переставим
числа заполнения в таблице на рис. 5.4.1 так,, чтобы получилась
таблица сопряженности, показанная слева на рис. 5.4.2.
Три детерминации х(°^ ^\ хса,~^ л?*\ х{Ъ)*~* \?*\ имеющие
сравнительно высокую интенсивность, I - 0,8, образуют здесь нелинейную
D-функцию и=*</нх) (см# рИС# 5.4.2 справа). Коэффициент парной
корреляции в этом случае равен нулю, и линейное уравнение E.4.1)
дает плохое приближение ^ «= ctmst = 1,77. Оно характеризуется,
как нетрудно подсчитать, средним квадратом отклонений 0,== 0,85,
более чем в два раза превышающим аналогичную величину в ранее
рассмотренном линейном случае, которая при & - 0,2 равнялась Qt~
= 0,34 (см. E.4.10)).
Следуя рецептурной схеме построения .нелинейной регрессии,
выберем семейство нелинейных кривых, например полином второй степени,
и будем искать функцию регрессии в виде
оС X
оС^Х
E.4.11)
где коэффициенты &х, Л^»]Ь определяются условием минимальности
среднего квадрата отклонений
E.4.12)
Минимизация последнего выражения приводит к системе трех
линейных уравнений: ЭО/ЭЯ^ = О, Ъ&^/дЛ^ О, 30^/3^ = О, решая ко-
146
торую, получим в рассматриваемом случае
ц -5,6х ,4хг - 2,9 E.4.13)
График этой параболы представлен справа на рис. 5.4.2.
Средний квадрат отклонений E.4.12) при этом равен 0^= 0,41, т.е.
нелинейное приближение оказывается, как и следовало ожидать, го-"
раздо более точным, чем линейное.
Посмотрим теперь, как соотносятся точки графика функции E.4.13)
и точки графика Б-функции U ^tytel Как мы видим, расстояние по
координате и между ними при х = 1, 2, 3 невелико. Из соотношения
E.4.13) следует, что по абсолютной величине оно во всех трех
точках одинаково и равно 0,3. Перейди, аналогично тому, как было
сделано в линейном случае, к произвольным &, получим для функции
регрессии
у 8A-"f^* "^Ц- "t)**" 5* ~ЬЬ' E.4.14)
Модуль отклонения этой функции от D -функции ^ = (р (х) в точках
Iя 1, 2, 3 постоянен и равен
|ду1 - -уЬ. E.4.15)
Отсюда видно, что с увеличением интенсивности I детерминаций,
образующих Б-функцию Ц - </>(х),т.е. с уменьшением 6=1-1,
функция регрессии все более приближается к точкам графика D-функции,
а при I-lCS-О) проходит точно через них. При этом средний
квадрат отклонений
vtE-t-0 E-4Д6)
также стремится к нулю, когда &-*0.
Мы приходим, таким образом, к выводу: если семейство кривых,
в пределах которого ищется нелинейная функция регрессии, выбрано
удачно, то функция регрессии тем ближе к значениям Ъ -функции,
чем больше интенсивность (меньше статистичность) детерминаций,
образующих эту D -функцию.
Отметим, что при переходе к нелинейным зависимостям резко
возрастает сложность процедуры поиска удовлетворительной
функции регрессии. С ростом числа параметров и усложнением
аналитической формы представления выбранного семейства кривых, в
пределах которого ищется функция регрессии, возникают большие
расчетные трудности при нахождении значений этих параметров,
определяющих искомую функцию. Сам выбор семейства кривых также
превращается в серьезную проблему. Если в технических
приложениях характер этого семейства может быть подсказан теорией, то
в области социальных исследований такиа "подсказки", как правило,
либо исключены, либо носят весьма сомнительный характер. Так или
иначе, нелинейность порождает массу проблем даже в таком простей-
147
шем случае, какой рассмотрен выше. В детерминашюнном анализе
ничего подобного нет и быть не может. Действительно, отличие
линейной D -функции у = <р(х) (см. рис. 5.4.1) от нелинейной ^ « </>(х)
(см. рис. 5.4.2) только в том, что в первом случае рассматрива-
ваются детерминации х ^^A,хг^1} ,х *-* \?ъ, а во втором
последние две из них заменены на х »-*^(ь), хс* *-* ц^\ Никаких
изменений в технику анализа это не вносит. Причина этого - локальность
методов, развиваемых в детерминашюнном анализе, вытекающая в
свою очередь из принципов номинальности и конкретности.
Локальность сама по себе порождает свои трудности. Однако их природа
иная. Они вызваны необходимостью более детального поточечного
анализа функциональных зависимостей. Если в области технических
наук такой путь в случае переменных с непрерывными числовыми
множествами значений не ведет к осязаемому выигрышу ни в технике
расчетов, ни в форме их представления (скорее, напротив, сулит
новые трудности), то в социальных и социально-экономических
исследованиях, где подавляющее число переменных имеет качественную
природу и дискретные множества значений, он приводит к большей
простоте и ясности не только в технике расчетов и форме
представления результатов, но и в постановке самих задач анализа данных,
а возникающие расчетные трудности, обусловленные в основном
организацией вычислительного процесса, преодолеваются путем
использования специальной вычислительной техники, подобной описанной
выше в гл. Ш.
Вернемся к вопросу о взаимоотношении D- функций и функций
регрессии. Формулы E.4.9), E.4.15) могут создать впечатление, что
если D -функция имеет высокую, близкую к единице интенсивность
U « 1 - I * О), то при удачном (в смысле наименьших квадратов)
выборе функции регрессии разница между ней и В -функцией
становится всегда ничтожно малой. Такое впечатление ошибочно. Пусть,
например, х,и принимают любые целочисленные значения, ч>0<х>>
<Мх) - две произвольные, несовпадающие при любых значениях х
функции и плотность условного распределения i(^|x)« f Cxt^)/g(x)
определяется выражением
Г I" e, \j- cpo(x),
f(^lx)~j Ь, у-ч^х), E.4.17)
Наилучшая в смысле наименьших квадратов функция регрессии
(точная классическая регрессия) есть
Ф0(х)«Ц -yftylx). E.4.18)
148
Подставляя сюда E.4.17), получим
<Р0(х)=Ч>0(х) - е[сро(х) - 4>t(x)]. E.4.19)
Как мы видим, модуль разности между функцией регрессии %(х)
и D -функцией <ро (х).:
|Д^~1 Vx) ~Vx)l * &'Vx) ~ VX)' E.4.20)
можно выбором ср (х),ф (х) сделать сколь угодно большим при
любом сколь угодно малом 8^0.
При заданном х средний квадрат отклонений точек
корреляционного поля от линии точной регрессии равен
СЦх)«Х1 [Ц-ЧЛЮ] 1{ч\%). E.4.21)
us-»oo w о О
В случае плотности условного распределения E.4.17) он равен
ifOUxf- Vb(i-fc)]*0(x) ~ ^(x)|. E.4.22)
Как бы ни было мало Ь ? О, последнее выражение.приводит к сколь
угодно большим значениям ОЦх} при надлежащем выборе l^x), ^Д*)«
Перейдем к методу главных компонент. Его основная расчетно-фор-
мальная идея сводится к тому, что собственные числа матрицы кова-
риаций между исходными переменными суть дисперсии вдоль
направлений, которые можно найти путем ортогонального линейного
преобразования исходных переменных [1]. С каждым из этих
ортогональных направлений связываетсяг таким образом, определенная доля,
или компонента, суммарной дисперсии. Компоненты, сумма
дисперсий которых покрывает значительную долю суммарной дисперсии по
всем переменным, называются главными. Нахождение их и
составляет основу метода главных компонент.
В случае, показанном на рис. 5.4.1, ковариация по переменным
х, и есть
C0v(x,y> и^х^ *0,47;
2. х
.дисперсии по х , у одинаковы: 6Х» G « 0,667.
о
Матрица ковариаций
0,667 0,47 А E.4,23)
0,47 0,667 /
приводится к диагональной форме
( О 13 0,20 ) <SA24)
149
линейным преобразованием
E.4.25)
i i
V - -yrj? (ОС-2.) + ^у(^-г),
2,
Дисперсия вдоль направления и,,равная ^ s 1,13, покрывает
cost 2,
бой большую часть (85%) суммарной дисперсии #Л + <5 = 1,33. Ось
ина рис. 5.4.1 справа представляет собой главную компоненту, ось
tf,Ha которую падают оставшиеся 15% суммарной дисперсии (ь ^ =
= 0,20), изображает неглавную компоненту. Как мы видим, ось и
проходит через точки графика D -функции Ч - 4>(х). Если эту линей-
*)
ную D -функцию представить в виде обычной функции ^ = ?, то
главная компонента и есть не что иное, как параметр в параметрическом
представлении данной функции:
При переходе к произвольным & указанное соотношение между
линейной D-функцией ^= ср(эс) и главной компонентой сохраняется.
Матрица ковариаций, равная в этом случае
3 * ~\ E.4.26)
приводится к диагональной форме
E.4.27)
(*;• О
при помощи того же линейного преобразования E.4.25). Как
следует из E.4.26), E.4.27), при стремлении &к нулю (т.е. при
приближении интенсивностей детерминаций, образующих В -функцию ^ =
- <р(х), к единице) доля суммарной дисперсии, поглощаемая главной
компонентой и и равная
J^TJT ш i --**>, E.4.28)
х ?
стремится к единице.
Заметим, что равенство ^ = х понимать здесь как Ъ -функцию
нельзя. D -функция и - х нормальна, а Ъ -функция у = 4>(х) отлична
от нормальной, хотя их графики совпадают.
150
Если D-функциональная зависимость нелинейна, положение
усложняется. Рассмотрим, например, случай, когда таблица сопряженности
имеет вид, представленный на рис. 5.4.2. Здесь б' ** 0,67,- б =
- 0,85, ковариация по х, и равна нулю и матрица ковариаций имеет
с самого начала диагональный вид
°.67 О \ E.4.29)
О 0,85/
Главная компонента U в этом случае параллельна оси ^ (см.
2. 2.
рис, 5.4,2). Дисперсия вдоль нее 6\, - 6 =0,85 лишь немногим
г г *
отличается от дисперсии ^v ~ ^х в 0,67 .вдоль неглавной компоненты
\з и составляет всего 56% суммарной дисперсии.
Если пытаться интерпретировать E.4.29), не выходя за пределы
метода'главных компонент, то следует лишь констатировать, что ярко
выраженной главной компоненты в данном случае не существует.
Можно ли отсюда сделать какой-либо определенный вывод о характере
взаимосвязи между переменными х » 1^ , в частности о Ъ -функции
^« 0(х)? Очевидно, нет. Действительно, на рис. 5.4.3 показана
таблица сопряженности, для которой матрица ковариаций по переменным
х9у совпадает с E.4.29).
Если исходить из понимания связи как возможности делать
более или менее точные условные суждения, то ситуация,
изображенная здесь, резко отлична от показанной на рис. 5.4.2. Однако
материны ковариаций в обоих случаях одинаковы, т.е. с позиций метода
главных компонент, оперирующего с матрицей E.4.29), эти
ситуации неразличимы.
Таким образом, если Ъ -функциональная зависимость между
переменными линейна, то метод главных компонент позволяет ее
выявить. Чем точнее детерминации,© бразуюпще линейную D -функцию,
тем большая суммарная дисперсия падает на главные компоненты,
тем успешнее окажется результат применения метода главных
компонент. Справедливо и обратное: чем лучше результаты»
получаемые этим методом, чем больше доля суммарной дисперсии,
приходящаяся на главные компоненты, тем больше уверенность у
пользователя в том, что в обследуемой им ситуации существует
линейная D -функциональная зависимость, образованная достаточно
точными детерминациями. Сам метод главных компонент может при этом
рассматриваться как один из способов усредненного
параметрического представления такой зависимости.
Возможность обнаружения Б -функций методом главных компонент
нарушается при переходе к нелинейным 3)-функциональным
зависимостям. Чем больше выражена нелинейность, тем меньше, вообще
говоря, доля суммарной дисперсии, приходящаяся на главные
компоненты, тем худшие соответственно результаты дает метод
(причем, если отталкиваться от таких результатов, то никогда нельзя
сказать, почему они плохи: то ли потому, что имеется достаточно
151
У
уC)=3
уB)=2
ут = 1
42
15
43
хA) = 1
42
15
43
хB) = 2
42
15
43
х<3) = 3
>
Рис. 5.4.3. Таблица сопряженности, для которой матрица ковариа-
ций совпадает с матрицей ковариапий для таблицы на рис. 5.4.2.
точная D -функциональная зависимость, но она нелинейна, то ли
потому, что зависимость, состоящая из более или менее точных
детерминаций, на самом деле отсутствует и связь (в указанном смысле)
между переменными действительно слабая).
Переход к произвольным t ничего к этому выводу не добавляет.
Вместо E.4.29) появляется матрица ковариапий
(\ •
которая переходит в E.4.29) при ? = 0,2. С уменьшением Ь до
нуля доля суммарной дисперсии, поглощаемая главной компонентой,
увеличивается, но незначительно. При t = 0,2 она составляла 56%,
а в пределе при ?в О она составляет, как следует из E.4.30),
57%, т.е. повышается лишь на 1%.
Внешняя, наиболее заметная причина отмеченных особенностей
метода главных компонент состоит в том, что этот метод сам по
себе линеен, поскольку линейны преобразования координат, на
которых он построен. Поэтому многие авторы пытаются модифицировать
его, заменив линейные орто1юнальные преобразования координат
нелинейными (см. [1]). Такой путь модификации метода приводит к
массе трудностей. В частности, даже в простейших случаях, подобных
разобранному выше, резко возрастают объем и сложность расчетов,
не говоря уже о трудностях, обусловленных принципиальной
стороной дела и касающихся, прежде всего, проблемы оснований для
выбора того или иного класса нелинейных преобразований.
Заметим, однако, что объяснить недостаточную гибкость метода
главных компонент в случаях, когда зависимость между
переменными описывается достаточно жесткой нелинейной D -функцией, можно
не только его линейностью, но и интегральностью подхода к
описанию связей, которая лежит в его основе, причем последнее
объяснение, видимо, более основательно, чем первое. Действительно, во-
E.4.30)
152
первых, величины ковариапий и дисперсий, из которых состоит
ковариационная матрица, суть интегральные показатели. Во-вторых,
линейность как свойство метода главных компонент появляется лишь
потому, что исходными объектами анализа выбраны именно
названные интегральные характеристики, т.е. линейность в известном
смысле выступает как следствие интегральности. Путь создания
нелинейных модификаций (отказ от линейности) не является единственным
способом получения более гибких приемов описания связей между
переменными. Другой путь состоит в отказе от интегральности и
именно он позволяет перебросить мостик от рассматриваемых
методов к детерминационному анализу.
Когда переменные определены на непрерывных числовых
множествах, когда связи между ними заведомо линейны (как во многих
технических исследованиях и приложениях, где линейность чаще всего
обусловлена нормальностью функций распределения), отказываться
от интегральности нет оснований. Но когда переменные заведомо
дискретны, а их значения если и выражены числами, то последние
играют роль этикеток или кодирующих символов, когда никаких
ограничений на вид функций распределения нет и соответственно нет
никаких оснований предполагать линейность, то отказ от
интегральности является естественным шагом и ведет к схеме детерминацион-
ного анализа.
Разобранные выше, в качестве примеров простые модельные
ситуации, на которых "ототыкаются* обычные методы, для детерминацион-
ного анализа не представляют вообще никакой проблемы. Получаемое с
его помощью описание оказывается исчерпывающим и столь же
простым, сколь просты сами эти ситуации. Тем очевиднее, что, если
требуется систематически исследовать уточнения и дополнения в
различных контекстах, если необходимо строить объяснительные типологии
или анализировать игру существенностей, т.е. вести действительно
серьезней анализ D -функциональных зависимостей, обычные методы
не годятся хотя бы потому, что в их рамках многие из названных
задач нельзя соответствующим образом поставить.
Мы ограничились рассмотрением ситуаций, когда имеются всего
две переменные. В работе [56\ под тем же углом зрения разобран
пример, где фигурируют три переменные. Случай произвольного
числа переменных мы не рассматривали потому, что в этом нет
необходимости: ничего принципиально нового по сравнению со сказанным
выше многомерность не добавляет.
ПРИЛОЖЕНИЕ
СЖАТОЕ МАТЕМАТИЧЕСКОЕ ОПИСАНИЕ
ФОРМАЛЬНЫХ ЭЛЕМЕНТОВ
ДЕТЕРМИНАЦИОННОГО АНАЛИЗА
1. Исходный формальный объект
1.1. Веер отображений. Исходным формальным объектом детерминацион-
ного анализа является веер отображений
X Y Z...
Е
где Е, X, Y, Z, ... - дискретные конечные множества; точки означают,
что ряд отображений в A) неограничен, вообще говоря, указанными
тремя. Множество Е называется основанием веера A). Множества X ,Y ,
И, ... называются множествами значений переменных х, -и , % , ...
соответственно. Здесь и далее, если переменная обозначается строчной латинской
буквой, то множество ее значений автоматически обозначается той же буквой,
но прописной. Вариант интерпретации: основание Е- множество анкет;
переменные х, ^ , %, ... - вопросы анкеты с альтернативными наборами ответов;
веер - множество заполненных анкет.
1.2. Множество переменных (содержательная сфера). С веером A)
ассоциируется множество переменных F = I х, и , х , ...}, содержащее все
переменные, множества значений которых фигурируют в A). Всякая
переменная х обозначает по определению произвольный элемент соответствующего
множества значений X . Таким образом, как конкретный элемент множества
переменных F, переменная х принадлежит F (хеГ^но как символ,
обозначающий произвольный элемент множества значений, х принадлежит X (Х*Х).
В ряде случаев удобно говорить, что веер A) задает описание
множества Е, которое определено на содержательной сфере F.
1.3. Компоненты веера. С каждой переменной х из F веер A) ассоциирует
отображение ср:Е"*Х, которое называется компонентой веера по переменной ос.
Компонента <f ставит в соответствие переменной х отношение
эквивалентности на Е (называемое ядром отображения с?). Каждому значению X = Q/
соответствует в Е класс эквивалентности по этому отношению, обозначаемый
через Е ( а) = ср (а)( обозначение Е(«) используется далее как стандартное). Тем
самым каждой переменной X из F ставится в соответствие определенное
разбиение множества Е, а множеству F -множество разбиений (классификаций)
множества Е.
Анализировать веер A) можно, как часто делается [ЗЗ], пользуясь
терминологией, ориентированной на бинарные отношения, определенные на мно-
154
жестве Е. В таком случае усложняется язык описания отношений между
переменными, что не совсем удобно, поскольку практические прикладные
задачи чаше всего формулируются в терминах отношений между переменными.
Поэтому в детерминашюнном анализе принята терминология, в которой
отправными являются не бинарные отношения на множестве Е, а переменные
и отношения между ними.
2. Операции над переменными. Полный веер
2.1. Равенство переменных. Пусть с? , ф - компоненты веера A) по
переменным х , и соответственно и Е(х)= Ч>~ (х), Eltj)8» </> ~А(и).
Определение 2.1.1. Переменная х равна переменной^, по основанию
Е, если для любого ееЕ и ц=* <р{ е) существует значение х такое, что Е(х)=
= Е(у). Е
Равенство переменных х,и по основанию Е обозначается символом х-^>
однако, поскольку ниже везде (за исключением, быть может, специально
оговоренных случаев) мы пользуемся только понятием равенства по заданному
основанию Е, то символ Е над знаком равенства опускается.
Отношение равенства по заданному основанию является, очевидно,
симметричным, рефлексивным и транзитивным, т.е. оно представляет собой
отношение эквивалентности на множестве переменных F.
Определение 2.1.2. Значение а переменной х (элемент а множества
X) называется пустым относительно Е или просто пустым, если множество
Е(а) = ч>~ (а) пусто.
Согласно определению 2.1.1 расширение (сужение) множеств значений
переменных х, и путем добавления (отбрасывания) пустых относительно Е
элементов не может изменить наличия или отсутствия равенства переменных
х,и по основанию Е.
2.2. Произведение переменных. Пусть cf, ф , 8 - компоненты веера A)
по переменным х, у , х соответственно, и пусть Е(х) = ^ (х), Е(^)= <р (^),
Е(г) = 8-\*).
Определение 2.2.1. Переменная Ъ называется произведением (или
результатом умножения) переменных х, г^ по основанию Е и обозначается как
X «х\^,если для любых значений х= а, ^= 6 таких, что Е(й)ПЕ(&)
непусто, существует такое значение % = С, что Е(С) = Е(,оОПЕ(&).
Произведение (умножение) переменных, очевидно, коммутативно: xu = UX
и ассоциативно: x(ut) = [x\j)t.
Предложение 2.2.1. Для любой переменной х из F выполняется X = X
при любом tv > 1.
2.3. Полный веер. Пусть Я - множество всех разбиений множества Е. Как
отмечалось в пункте 1.3, каждой переменной из F однозначно соответствует
некоторое разбиение из %. Обозначим полученное таким образом отображение
через Ф'. F -* #.
Определение 2.3.1. Если 9(F) = Я., то множество переменных F
называется полным по основанию Е, а веер отображений с основанием Е, в
котором оно фигурирует, - полным веером.
Полное по заданному основанию множество переменных, очевидно,
замкнуто относительно операции умножения переменных по тому же основанию.
В дальнейшем (если обратное неочевидно или не оговорено особо)
множество переменных F предполагается полным по основанию Е.
Соответственно, полным предполагается также и веер A).
155
2.4. Индивидуальная (нулевая) и универсальная Iединичная; переменные.
Определение 2.4.1. Переменная в, которая при любой переменной х из
F удовлетворяет соотношению ех « е, называется индивидуальной или ну-
левой.
Предложение 2.4.1. Индивидуальная переменная е существует и
единственна в том смысле, что если е,е'- две индивидуальные переменные, то е * е'.
Доказательство. Переменная, компонента по которой - взаимно
однозначное отображение Е в себя, представляет собой индивидуальную переменную
(существование). Если е, е' - две индивидуальные переменные, то должно быть
ее = е = е (единственность).
Множество значений индивидуальной переменной е везде в дальнейшем
считается совпадающим с основанием веера и обозначается тем же символом Е.
Какова бы ни была переменная х из F, соотношение ex = e следует
понимать так: во-первых, для любого значения е *"€ Е существует такое един-
ственное значение х € А, что е х = е , во-вторых, для любого непус-
(ic) v г- ~(t)
того х €Л существует такое, вообще говоря, не единственное значение е .
что е х = в ,
Определение 2.4.2. Переменная со, которая при любой переменной х
из F удовлетворяет соотношению сох» х, называется универсальной или
единичной.
Предложение 2.4.2. Универсальная переменная со существует и единственна,
Доказательство. Переменная, компонента по которой является постоянным
отображением, представляет собой универсальную переменную (существование).
/ / /
Если со, со - две универсальные переменные, то должно быть о со я со ¦* со
(единственность).
3. Плотность меры на веере
3.1. Базисная плотность. Пусть на множестве Е, служащем основанием
веера A), задана ограниченная неотрицательная числовая функция Щб).
Определение 3.1.1. Функция N(e) называется базисной плотностью на
веере A).
Базисная плотность N (е) есть плотность меры jx на Е, определяемой для
любого ЬсЕкак
ju,(L)- ЦЖе).
e€L
В дальнейшем мы вместо "плотность меры* будем говорить просто
"плотность". Кроме того, везде ниже полагается NCe)» 1 для любого е€Е.
3.2. Перенос плотности компонентами веера. Рассмотрим компоненту
веера с^7сТ:*лТЕс7оГЩ^^ отображение <р определяет
для любого X s абХ плотность M(Ct) (переносит плотность с Е на X)
следующим образом:
N(a)«Zl N@,
в€Е(а)
где E(a)= Cfei(a).
Таким образом, если задана базисная плотность на множестве
Е,служащем основанием веера A), компоненты веера автоматически определяют
156
соответствующую плотность на каждом из множеств, фигурирующих в веере.
Базисная плотность как бы "перетекает" с основания Е на множества
значений переменных из веера A). Это обстоятельство играет важную роль в
детерминашюнном анализе.
Преддожение 3.2.1. Если значение оь переменной х пусто, то N(a)= О,
и, обратно, если N(a)= О, то а есть пустое значение переменной х.
Это предложение перефразирует определение 2.1.2 в терминах плотности.
Его можно использцвать как определение пустых значений переменных и
пустых элементов множеств.
3.3. Многомерная плотность. Эквивалентные преобразования. Пусть ос,^ -
переменные из F. Двумерная плотность определяется как
NU,y)-lE(x)nE(y)l.
Предложение 3.3.1. N fr,\fi~ N (xij).
Справедливость его очевидна. Оно показывает, что любую двумерную
плотность можно свести к одномерной путем перемножения входящих в нее
аргументов.
Пользуясь определением двумерной плотности и предложением 3.3.1,
можно по индукции определить плотность произвольной размерности.
Определение 3.3.1. Формы записи N(x,\p, N(x^) называются
эквивалентными представлениями плотности, а преобразование, осуществляющее
переход от одного эквивалентного представления к другому, называется
эквивалентным преобразованием.
Рассмотрим плотность N(x ,%, , ...»хн) размерности п. Пользуясь
эквивалентными преобразованиями, ее всегда можно представить в
эквивалентной форме как плотность любой размерности от единицы и выше (меньшей
или большей, чем п). Размерность плотности, таким образом, есть сугубо
относительное понятие, зависящее от выбора представления*
Таблица сопряженности есть одна из форм графической записи
соответствующей плотности.
3.4. Свертка плотности. Определение 3.4.1. Сверткой плотности по
некоторой переменной называется ее суммирование по значениям этой
переменной.
Пусть х, и - переменные из F.
Предложение 3.4.1.
N(x) -Ц N(x^),
N(y) -H Nlxij).
Х€.Э\
4. Детерминации и D -функции
4.1. Детерминации. Пусть х, «^ - переменные из Г, и пусть значению a
переменной х ставится в соответствие по какому-либо правилу значение Ь
переменной и, так что можно говорить о точечном (локальном)
соответствии a *"* 6.
Определение 4.1.1. Точечное соответствие a^fc называется
детерминацией, если определены величины
4 Ж*)
157
Величина I (a**&) называется интенсивностью (точностью) детерминации
а~6,величина С (а-* &)- емкостью (полнотой) детерминации &>-»(.
Предложение 4.1 Д. 0<1МК1, 0<С(а~>бК1.
Предложение 4.1.2. Для того чтобы точечное соответствие а~?было
детерминацией, необходимо и достаточно, чтобы значения a, & переменных х,
ц были непустыми, т.е. чтобы выполнялось N(a)^'0, Ы(ВM* О.
Предложение 4.1.3. Если детерминация а»-Ь существует, то существует и
обратная детерминация Ь** а, причем
ЦЬ^а) * С(а~Ь),
С(Ь~а,)- Ко,—6).
4.2. D -функции. Пусть х, ц - переменные из F. Рассмотрим некоторое
отображение ^:A^Yc областью определения А^Х.Оно состоит из точечных
соответствий вида х^о^х^ где хе А.
Определение 4.2,1. Если для любого Х€ А точечное соответствие х ** у {х,)
есть детерминация, то отображение ср называется детерминационной функцией
или D -функцией.
Исключим из рассмотрения при анализе веера A) все пустые значения
(и пустые сочетания-значений) всех переменных из F. В таком случае
любые отображения, в которых аргументами и функциями являются отдельные
переменные или произведения переменных из F, представляют собой
D-функции. Это обстоятельство оправдывает необходимость понятий детерминации
и D-функции для анализа веера A).
5. Основные утверждения о детерминациях
Везде ниже а, в, с, V. - значения переменных из F, называемые также
свойствами.
5.1. Уточнения. Существенность. Пусть D (a) - детерминация, в которой
свойство а входит сомножителем либо в аргумент, либо в функцию, либо и
в аргумент, и в функцию.
Обозначим через D(co) детерминацию D(a), в которой свойство а заменено
свойством со.
Определение 5.1.1. Свойство а называется уточнением детерминации
D(co) или уточнением в детерминации D(QQ.
Если а входит сомножителем только в аргумент, уточнение называется
*) ^
уточнением по аргументу . Если а входит сомножителем только в функцию,
то уточнение называется уточнением по функции. Если а входит
сомножителем и в аргумент, и в функцию, то уточнение называется уточнением по
контексту или контекстуальным уточнением.
Величина
S(D<a*fl-I(Dla))-I(D(«))
называется существенностью уточнения а.
В зависимости от знака существенности уточнение а называется:
позитивным, если S(D(a))>0, негативным, если S(D(a))<0, нулевым или
несущественным, если S(D(cn)« О.
Предложение 5.1.1. Если a = со, то S(D(w*))=o.
В основном тексте (см. § 2.6) мы, если не было особых оговорок,
называли уточнениями именно уточнения по аргументу.
158
Свойство а «со оказывается несущественным уточнением в любой
детерминации D(a).
Предложение 5.1.2. Любое уточнение детерминации, имеющей
интенсивность, равную единице, несущественно.
5.2. Уточнения по аргументу. Рассмотрим уточнение с в детерминации
ac~t.Ero существенность согласно определению 5.1.1. равна
S(ac*- Ь)- I(ac-&)-K<x~ 6);
здесь учтено, что асо25 си.
Предложение 5.2.1. Для того чтобы уточнение с в детерминации ас *-* &
было несущественным, достаточно, чтобы ICa^c)* 1,
Доказательство. Из I(a,«-*c)= 1 следует ас = а = а-аз,откуда
S(ac*-6) «S(aco*~b)-0.
Предложение 5.2.2. Для того чтобы уточнение с в детерминации ac—fc
было несущественным, достаточно, чтобы I (a*-*&)*= 1.
Доказательство. Из ICa-*^M5 1 следует, что al= a/, откуда Кае—в>=
- N(acfty^(ac)=N(ac)/N(ao)= 1, т.е. S(ac*~>b)« I(ac~ 6) -1(а~&)« 1-
-1=0.
Предложение 5.2.3. Уточнение по аргументу не увеличивает полноту
детерминаций.
C(ac~ b)<C(a~l).
Доказательство.
5.3. Уточнения по функции. Рассмотрим уточнение в детерминации
a >* 6с. Его существенность согласно определению 5.1.1 равна
S(a~&c*)- I(a~fec) - I(a~fc);
здесь учтено, что бсо = 6.
Предложение 5.3.1. S(a^&c*L0, т*е- уточнение по функции всегда
либо негативно, либо несущественно.
Доказательство. I(a*-*6c)= N(a6c)/N(aLN(ae)/N(a)eI(a»^ft),oTKyfla следует
названное предложение.
Предложение 5.3.2. Для того чтобы уточнение с в детерминации а~&с
было несущественным, достаточно, чтобы ICG^c)*» 1.
Доказательство. Из Ц&^с)» 1 следует Ьс я 8 = 8со, откуда ?(а~8с*) =
» S(a^6of)- О.
5.4. Уточнения по контексту. Рассмотрим уточнение к в детерминации
Предложение 5.4.1. S(ak ^&k)= S(ak ^6),т.е. уточнение -к по
контексту имеет ту же существенность, что и уточнение к по аргументу.
Доказательство. S(ak*^8k)- 3(ак^$) = [Ы(ак6к)- N(akfe)]/N(ak)« О.
Предложение 5.4.2. С (ак»» &к)> С(аУ»6),т.е. при переходе от
контекстуального уточнения к к уточнению к по аргументу емкость не возрастает.
Доказательство.C(ftk*>Ш =N(ak 6k)/Nifck)*N(akfeyKFk)>N(ak6v/M^) = C(ak-&).
5.5. Транзитивность. Предложение 5.5.1. Если I(ou>—%)>^, КЬ*-с)= 1, то
Ка^С)?^ (ослабленная транзитивность).
Доказательство. Из 1(&*-с)« 1 следует Ьс = Ь, По предложению 5.3.1
имеем I ( a »¦* С)> Ua^bc )= I(a~fc)>?, что и требовалось доказать.
В случае S" = 1 получаем сильную транзитивность: если 1(а*»в)ш it 1F*-*с)*
« 1, то I(a~c)= 1.
159
6. Основные утверждения о D-функплях
6.1. Нормальные функции. Рассмотрим D-функцию <f: А**Ч,где Ас- X.
Определение 6.1.1. Если для любого.хеА имеет место l(x»*<pix))« 1,
то D -функция <f называется нормальной функцией.
Предложение 6.1.1. Компоненты веера A) есть нормальные функции.
Доказательство. Пусть <р:Е»*Х- компонента веера A). Для любого есЕ
имеем е<р(«)ш е, откуда 1(е~цче))« 1.
В приложениях явно или неявно предполагается, что всевозможные
интегральные индексы, типологии, классификации представляют собой нормальные
функции от соответствующих переменных из F.
6.2. Композиция D-функций. Пусть х, у , % - переменные из F и заданы
D-функции у: Z-*Y^:X^Z. Рассмотрим композицию f в <р©ф функций ц>, 0 ,
. которая есть функция f :X"»Y такая, что ? (х) e <f (^>(х)).
Предложение 6.2.1. Если <р, ф - D -функции, то функция f « <f о^> есть
также Т^фушщия;
Доказательство. Необходимо показать, что множества X, i (X) состоят из
непустых относительно Е элементов. Элементы множества X непусты,
поскольку уб есть D -функция. Элементы множества <f (Ъ) непусты, поскольку tp есть
D-функция. Элементы множества ?(Х) непусты в силу того, что 1(Х) » <?(^(Х$С
C*(Z).
Определение 6.2,1, D-функция t^yotp называется композицией D-
функций ч> , р.
Таким образом, обычное понятие композиции функций полностью
переносится на D-функции.
6.3. Каноническое разложение. Рассмотрим некоторую функцию ^:X~*Y.
Обозначим через Rv отношение эквивалентности на множестве X, определяе-
мое соотношением <p(x) = cf(x) и называемое ядром отображения <f.
Обозначим, как принято, через X/R фактормножество множества X по отношению
эквивалентности R^.T.e. множество классов эквивалентности в
X,определяемое отношением R<-.
Всякая функция <f:X-*Yдопускает, как известно (см. [б], с. 130, 381),
единственное каноническое разложение в композицию трех функций vf « <j о Я° </>,
где a:<p(X)-»Y- каноническая инъекция (вложение) ф (X) bY, fv.X/R^<p(X.) ""
каноническая биекция, т.е. взаимно однозначное отображение
фактормножества X/R на множество <р(Х), ^:X-*X/R - каноническая сюръекция, т.е.
отображение множества X на фактормножество X/R ^. Каноническое разложение
можно представить следующей коммутативной диаграммой:
X ^У
¦1 4
X/FV~TP"*(X)
Пусть теперь х, ч - переменные из F, vp - D -функция из X в "Y. В
силу полноты F общие элементы множеств соответственно X/R^^QC) также
являются переменными из F. Рассмотрим каноническое разложение <f = goko^.
Предложение 6.3.1. Если tp естьЪ -функция, то компоненты $ , h , ф
канонического разложения q> BQ°ke^ также являются D-функциями.
Доказательство. Поскольку у есть D -функция, то по предложению 4.1.2
множества X, <f (X) состоят из- непустых относительно И элементов. Область
160
значений функции ^ состоит из непустых элементов, так мак ffcflX))- ср(Х).
Элементы множества Х/ТХ^также непусты, поскольку могут рассматриваться
как объединения непустых элементов из X. По предложению 4.1.2 отсюда
следует, что д, к, ф суть В -функции.
Таким образом, понятие канонического разложения обычной функции
полностью переносится на D -функции.
Предложение 6.3,2. Если ср e Q<>ii<>cJ>- каноническое разложение D -функции
Ф» то 1) ф , ф >ф - нормальные функции; 2) интенсивность и емкость
детерминаций р ft и, образующих D-функцию Ъь, связаны с интенсивностями и ем-
костями детерминаций х*-*р,х*-*и следующими соотношениями:
I(p~if)- Yl C(x^p) I(x~ij),
Х€^'4(р)
C(p~t,) = 21 C(x-u).
хе^'Чр)
Доказательство. 1) Для любого хеХ справедливо соотношение x 0(x)« x,
поскольку </>(х)- класс эквивалентности, которому принадлежит х; отсюда
следует 1(х^0(х))«1, т.е. нормальность ф. По определению канонической
инъекции Q(^)e ^, откуда следует 1(^^(^>» !($ <^)** *р s "Ц^*-*^)*8 1, т.е.
нормальность Q, ^ . 2) Справедливость приведенных соотношений между ин-
* * *
тенсивностями и емкостями детерминаций X*"*p,p*-ij, х~^ проверяется
непосредственно подстановкой соотношений для интенсивностей и емкостей,
выраженных через соответствующие плотности.
Детерминация р**Ч эквивалентна детерминации <р ty)***4t интенсивности
и емкости этих двух детерминаций совпадают. Детерминация р**и может,
таким образом, рассматриваться как образ пучка детерминаций 1х»^:хвср~ <Ч)},
а величины 1{р*+ц),С(р"ц) - как интегральные характеристики этого пучка.
Определение 6.3.1. Если <Р «cjok*^- каноническое разложение Т)-функ-
шш ср, то интенсивность 1(р»»у) и емкость С(р~ у) назьюаются
соответственно факторинтенсивностью (факторточностью) и факторемкостью (факторполно-
той) D-функции <р в точке ц.€ ср(Х).
Факторинтенсивность и факторемкость представляют собой примеры
интегральных характеристик, допустимых и систематически используемых в
детерминашюнном анализе.
6.4/ Стандартное разложение. Представим каноническое разложение Cf ¦
»goft*jp в форме ср «tp©y>, где ф = ^°Ti/:
X——У
Ф\/9
X/R
161
По предложению 6.3.2 в разложении <р s Ч 9%Р ^-функция ф нормальна.
Предложение 6.4.1.
Доказательство. Ч> (р) = frAtCp))a Мр), поскольку QD)s4.
Определение 6.4,1. Разложение <f *tf©^ называется стандартным
разложением D-функции <р на нормальную (^) и инъективную ($) компоненты.
Допуская известную условность» можно, когда это не приводит к недоразуме-
ниям, называть инъективную компоненту <f взаимно однозначной.
Предложение 6.4.1 говорит о том, что факторинтенсивности и фактор-
емкости D -функций можно изучать, пользуясь стандартным, а не
каноническим разложением. В детерминащюнном анализе часто удобнее пользоваться
именно стандартным разложением.
Необходимость рассматривать и изучать канонические и стандартные
разложения D -функций обусловлена ролью, которую эти разложения играют в
задачах типологии (классификации).
Пусть задана D -функция <f: X -»Y. Определим метрику j> в X следующим
образом:
J>(*,x )'
х'е ф~\<Мх)),
xV 4~4(<f l*'>).
Будем считать х, х близкими, если j> (x, x ) =0. Тогда классы
значений, близких между собой в этом смысле, образуют типологию
(классификацию) значений х9 которая описывается, как легко убедиться, нормальной
компонентой ф в стандартном разложении if = <f °</i. Нормальная функция р =
= ф (х) каждому значению хеХ ставит в точное соответствие название класса
(типа), которому принадлежит данное значение ». Ввиду этого функция vp
называется также стандартной типологией в X относительно Ф или стандартной
объяснительной типологией (типологией, объясняющей значения и ).Фактор-
интенсивность и факторемкость характеризуют точность и полноту
объяснений, которые можно получить с помощью этой типологии.
6.5. Ъ -функции с ограничениями на интенсивность и емкость образующих
их детерминаций. До сих пор речь шла о произвольных D -функциях. Рассмот-
рим теперь D'-функции, интенсивности и емкости которых подчиняются
следующим ограничениям:
1С(х-^)>ег.
Определение 6.5,1. Система ограничений B) называется основным
уравнением детерминациоиного анализа.
Предложение 6.5.1. Если существует решение уравнения B) при 8"? 0,5,
то оно единственно.
\ьг
Доказательство. Имеет место соотношение 5Z 1(х-*ч) = 1. Пусть 8/>0,5,
<р , ср - два решения уравнения B), не совпадающие при некотором X в Л/.
Тогда 1(а-<р(а.)) + I (а, м, <f'(a,)) >/ 25>1, что невозможно. , .
Зафиксируем lj.= $> и рассмотрим пучок всех детерминаций tx*-o:x€A(o,<3>)j,
удовлетворяющих уравнению B). Фактории те нсивность и факторемкость этого
пучка определяются выражениями
Цр~1)= X С(х-рI(х~Ь),
хеАAГ,б:)
С(р~8) = 21 С(х~6).
Х€А(&,<э)
Поскольку состав значений х, образующих множество А AГ, 6" ), зависит
согласно B) от порога точности 6* и порога полноты <Г, то факторинтенсив-
ность и факторемкость также являются функциями от $*, 6*. Обозначим их
через 1(&,<3> ),С ( ?\ 6*) соответственно. Зафиксируем б" и обозначим через
л
5F0максимальное из значений $*, при которых множество А (О, С ) непусто.
Предложение 6.5.2. При фиксированном от функции 1E*, С ), С(8>,@' ) опре-
¦*\
делены на полуинтервале (О, б'(в')]. На этом полуинтервале обе они
представляют' собой непрерывные слева, разрывные ступенчатые функции, причем
с ростом В" функция 1(А,в)не убывает, функция С(8,Ф)не возрастает.
Множество точек разрыва, общее для них обеих, индексируется элементами
множества А (У, & ) при У=0 к имеет вид
ГЧ*х = 1(х~Ь):хеА@,<зг)}.
Доказательство этого предложения мы опустим. Оно несложно и
основывается на уравнении B) и приведенных выше выражениях для факторинтен-
сивности I E,E ) = 1(р»"*8) и факторемкости С(8»,<3>) = С (р1-" 6).
7. Краткое резюме
7.1. В формальной структуре детерминациейного анализа четко
прослеживается схема: отображения (компоненты веера) порождают плотность
меры на множествах значений переменных, входящих в веер; плотность меры
порождает новые отображения, из которых могут быть образованы новые
веера, и т.д. Эта схема есть по существу схема локального подхода к
описанию классификаций и отношений между классификациями. Она не приводит (по
крайней мере на данном этапе своего развития) к каким-либо
нетривиальным математическим следствиям. Формальные положения в рамках данной
схемы, на которые опирается детерминационный анализ, сами по себе просты;
как заметил читатель, ни одно из приведенных выше формальных
предложений не требует для своего доказательства сколько-нибудь изощренной
техники и более или менее сложных в современном- понимании построений.
7.2. Рассмотрим два веера с основаниями Е,Ш; показанные на
следующей диаграмме:
х Z—^у U ^V
Р
V [ ~z
163
Здесь <р - некоторая D -функция. Зафиксируем X - <Ь, ^ - В *ф(а)и
положим
v-iv(*)-N(b) -l^'^nx^)!.
Вне зависимости от вида г определим базовую плотность М(х)на Х9
положив М(ж)в 1.
В таком случае мы приходим к определенному типу взаимодействия
между веерами, которое характеризуется следующим отношением между D -функ-
шей <р (точнее - детерминацией а н> Ь) и функцией регрессии V - ф (tv); если
<р
I, С - интенсивность и емкость детерминации &*+(>, то
[«-*(»)]* <t(I,С),
где черта - усреднение по плотности,
* M(utr)-|^1(u)ntb~V)lr
причем, когда точность I и полнота С детерминации а «-¦б стремятся к
единице, то функция i(I,С) стремится к нулю, а регрессия ф{ч>) становится
линейной (доказательство см. в § 4.4).
Это - лишь один из многочисленных вариантов взаимодействия между
веерами. Исследование подобных вариантов - важное направление в развитии
формальных структур, на которые опирается детерминаиионный анализ. Одна
из ключевых проблем здесь состоит в том, чтобы обнаружить и описать
такие типы взаимодействия между веерами, которые позволили бы установить
связь между В -функциями на дискретных множествах произвольной природы
и числовыми функциями на числовых множествах, обладающими свойством
непрерывности. Решение этой проблемы могло бы приблизить нас к более
глубокому пониманию того, как от данных нам в ощущение дискретных
образов перейти к математическим построениям, в которых столь важную роль
играет непрерывность.
ЛИТЕРАТУРА
1. Андрукович П.Ф. Некоторые свойства метода главных компонент.-
В кн.: Многомерный статистический анализ в
социально-экономических исследованиях. - М.: Наука, 1974.
2. Бестужев-Лада И.В., Варыгин В.Н., Малахов В.А.
Моделирование в социологических исследованиях. - М.: Наука, 1978.
3. Биркгоф Г., Барти Т. Современная прикладная алгебра: Пер. с англ.-
М.: Мир, 1976.
4. Бон гард М.М. Проблема узнавания. - М.: Наука, 1967.
5. Борель Э. Случай. - М. - Л.: 1923.
6. Бурбаки Н. Теория множеств. - М.: Мир, 1965.
7. Вапник В.Н. Восстановление зависимостей по эмпирическим данным.-
М.: Наука, 1979.
8. Веселов А,А., Деза В.Н., Подрабинович А.Я. Вычисление
характеристик детерминационных связей. - В кн.: Методология комплексного
исследования социально-экономических систем. Труды ВНИИСИ ГКНТ и
АН СССР. - М.: 1980, вып. 1.
9. Веселов А.А., Деза В.Н., Подрабинович А.Я. Система поиска
детерминационных зависимостей. - Препринт ВНИИСИ ГКНТ и АН СССР. -
М.: 1981.
10. Веселов А.А., Деза В.Н., Подрабинович А.Я. Диалоговая
система поиска детерминационных связей. - В кн.: Системное моделирование
социально-экономических процессов. - Воронеж: Изд-во Воронежского
Гос. ун-та, 1980, ч.1.
11. Дмитриев А.Н., Журавлев Ю.И., Кренделев Ф.П. - В кн.:
Дискретный анализ. Труды Ин-та математики СО АН СССР. - Новосибирск:
1966, вып. 7.
12. Докторов Б.З. О надежности измерения в социологическом
исследовании. - Л.: Наука, 1979.
13. Дородницын А. А. Математика и описательные науки. - В кн.: Число
и мысль. - М.: Знание, 1977.
14. Дорофеюк А.А. Алгоритмы автоматической классификации (обзор). -
Автом. и телемех., 1971, т. 33, № 12, с. 78-183.
15. Дридзе Т.М. Язык и социальная психология. - М.: Высшая школа,
1980.
16. Ежкова И.В., Поспелов Д.А. Принятие решения при нечетких
основаниях, ч. I. - Изв. АН СССР: Сер. Техн. киберн., 1978, М> 2, с. 5.
17. Жуковская В.М., Мучник И.Б. Факторный анализ в
социально-экономических исследованиях. - М.: Статистика, 1976.
18. Загоруйко Н.Г. Эмпирическое предсказание. - Новосибирск: Наука,
1979.
165
19. Заде Л.А. Основы нового подхода к анализу сложных систем и
процессов принятия решений. - В кн.: Математика сегодня: Пер. с англ. -
М.: Знание, 1974.
20. Здравомыслов А.Г. Методология и процедура социологических
исследований. - М.: Мысль, 1969.
21. К ад М. Статистическая независимость в теории вероятностей, анализе
и теории чисел. - М.: ИЛ, 1963.
22. К лиге р С. А., Косолапов М.С., Толстова Ю.Н. Шкалирование при
сборе и анализе социологической информации. - М.: Наука, 1978.
23. Колмогоров А.Н. Основные понятия теории вероятностей. - 2-е изд.-
М.: Наука, 1974.
24. Косолапов М.С. Классификация методов пространственного
представления структуры исходных данных. - Социолог, иссл., 1976, № 2, с. 98-
109.
25. Кравец А.С. Природа вероятности. Философские аспекты. - М.: Мысль,
1976.
26. Лаплас П.С. Опыт философии теории вероятностей. - М.: 1908.
27» Лбов Г.С, Котюков В.И., Машаров Ю.П. Метод обнаружения
логических закономерностей на эмпирических таблицах. - В кн.:
Вычислительные системы. Эмпирическое предсказание и распознавание образов.-
Новосибирск: 1976, вып. 67.
28. Лбов'Г.С. Логические функции в задачах эмпирического предсказания.-
В кн.: Вычислительные системы. Эмпирическое предсказание и
распознавание образов. - Новосибирск: 1978, вып. 76.
29. Лекции по методике конкретных социальных исследований: Поц рец. Г.М.
Андреевой. - М.: Изд-во МГУ, 1972.
30. Линдсей П., Норман Д. Переработка информации у человека: Пер. с
англ. - М.: Мир, 1976.
31. Марков А.А. Исчисление вероятностей.^- СПБ, 1913.
32. Меллер Ф„ Капекки В. Роль энтропии в номинальной
классификации. - В кн.: Математика в социологии (моделирование и обработка
информации): Пер. с англ. - М.: Мир, 1977.
33. Mhdkhh Б.Г. Анализ качественных признаков. - М.: Статистика, 1976.
34. Миркин Б.Г. Модели качественного анализа,- В кн.: Математика в
социологии (моделирование и обработка информации): Пер. с англ. - М.:
Мир, 1977.
35. Миркин Б.Г. Моделирование многомерной социально-экономической
информации, - В кн.: Математическое моделирование в социологии (методы
и задачи). - Новосибирск: Наука, 1977.
36. Миркин Б.Г. Анализ качественных признаков и структур. - М.:
Статистика, 1980.
37. Ноздрина Н.Н., Чесноков СВ. О соотношении микро- и
макроуровней описания миграционного процесса. - В кн.: Теоретические проблемы
оптимизации и функционирования социалистической экондмики. Труды
ВНИИСИ ГКНТ и АН СССР. - М.: 1979, вып. 10.
38. Ноэль Э, Массовые опросы (введение в методику демоскопии): Пер.
с нем. - М.: Прогресс, 1978.
39. Пфандагль И. Теория измерений: Пер. с англ. - М*: Мир, 1977.
40. Пэнто Р., Гравитц М. Методы социальных наук: Пер. с франц. - М.:
Прогресс, 1972,
41. Саганенко Г,И. Социологическая информация. - Л.: Наука, 1979.
42. Соколов К.Б. Об одном-методе моделирования и прогнозирования
социально-экономического поведения* - В кн.: Модели и методы
исследования социально-экономических процессов. Ротапринт 11 ЭМИ АН СССР. -
М.: 1975.
166
43. Соколов К.Б. Шаповалов А.С. Об одном подходе к проблеме
сокращения размерности описания социально-экономических объектов. - В
кн.: Модели и методы исследования социально-экономических процессов.
Ротапринт ЦЭМИ АН СССР. - М.: 1975.
44. Соколов К,Б. Об одном методе конструирования и оптимизации шкал
синтетических социальных признаков. - В кн.: Методы анализа, сбора
и обработки социально-экономической информации. Ротапринт ЦЭМИ АН
СССР. - М.: 1976.
45. Соколов К. Б. Детерминантный подход к исследованию и
прогшжированию социально-экономического поведения населения. - В кн.:
Модели и методы исследования социально-экономических процессов.
Ротапринт ЦЭМИ АН СССР. - М.: 197G.
46. Соколов К. Б. Методические вопросы прогнозирования
социально-экономического поведения населения (потребительского опроса, миграции,
повышения квалификации). - Автореферат дисс. на соискание уч. степ,
канд. экон, наук. - М.: 1976.
47. Суппсс П., Зин ее Дж. Основы теории измерений. - В кн.:
Психологические измерения: Пер. с англ. - М.: Мир, 1967.
48. Суханова Г. Б., Чес но ко в С. В. Детерминационный анализ
качественных социально-экономических данных в режиме диалога. - В кн.:
Методология комплексного исследования социально-экономических систем.
Труды ВИИИСИ ГКНТ и АН СССР.- М.: 1980, вып. 1.
49. Типология потребления: Под ред С. А. Айвазяна и И.М. Римашевской. -
М.: Наука, 1978.
50. Устинов В.Л., Феллингер А.Ф, Историко-социальныо исследования,
ЭВМ и математика. - М.: Мысль, 1973,
51. Филмор П., Филипсои М, и др. Новые направления в
социологической теории: Пер. с англ. — М.: Прогресс, 1978.
52. Чебышев П. Л. Опыт элементарного анализа теории вероятностей. -
(Сочинение, написанное для получения степени магистра кандидатом Че-
бышевым). - М.: 1845.
53. Чесноков Q.В. Способ ручной обработки небольших массивов
документов. - В кн.: Проблемы контент-анализа в социологии. Ротапринт ОУПЭС
СО АН СССР. - Новосибирск: 1970.
54. Чсснокоб СВ. Некоторые вопросы измерения связи между парой
дихотомических признаков. - В кн.: Математика и социология. Ротапринт ИЭ
и (>ПП СО All СССР. - Новосибирск: 1972.
55. Чесноков С.В. Об анализе квазифункциональных зависимостей. - В кн.:
Системное математическое обеспечение автоматизированных систем в
строительстве. Ротапринт ЦНИПИАСС Госстроя СССР. - М.: 1973.
56. Чесноков С.В. О локальном подходе к исследованию связей между
дискретными переменными (теория квазифункций). - В кн.: Модели и
метод исследования социально-экономических процессов. Ротапринт ЦЭМИ
АН СССР. - М.: 1976.
57. Чесноков СВ. О диалоговой системе поиска слабостатистических
(квазифункциональных) зависимостей. - В кн.: Теоретические и практические
вопросы создания АСУ строительством. Труды ЦНИПИАСС Госстроя «СССР,
вып. 13, М., 1977.
58. Чесноков СВ. Статистическая детерминация и статистическая связь. -
В кн.: Математические методы и модели в социологии. Ротапринт ИСИ АН
СССР. - М.: 1977.
59. Чесноков СВ. О представительности результатов социологических
исследований, проведенных по малым неслучайным выборкам. - В кн.:
Проектирование и организация выборочного социологического исследования.
Ротапринт ИСИ АН СССР. - М.: 1977.
167
60. Чесноков СВ., Соколов К.Б. Специфика прогнозирования
социально-экономического поведения и метод детерминаций. - В кн.: Модели
социально-экономических процессов и социальное планирование. - М.:
Наука, 1979.
61. Чесноков СВ. Взаимоотношение теоретического и эмпирического
уровней описания социально-экономической реальности. - Б кн.: Методология
комплексного исследования социально-экономических систем. Труды
ВНИИСИ ГКНТ и. АН СССР. - М.: 1980, вып. 1.
62. Чесноков СВ. Детерминационный анализ социально-экономических
данных в режиме диалога. Препринт ВНИИСИ ГКНТ и АН СССР. - М.: 1980.
63. Чесноков СВ. Детерминационный анализ социологических данных. -
Сошюл. иссл., 1980, № 3, с. 179.
64. Чесноков СВ. Парадокс номинальных измерений. - В кн.: Проблемы
надежности данных социологического исследования: теория и практика.-
Л.: Наука, 1982.
65. Чесноков СВ. Сравнительные особенности описания м1шросостаяний в
в социальной и механической системах. - В кн.: Методология
системного анализа регионального развития и управления. Труды ВНИИСИ ГКНТ
и АН СССР. - м.: 1980, вып. 8.
66. Ядов В.А. Социологическое исследование (методология, программа,
методы). - М.: Наука, 1972.