























































































































































































































































































































Автор: Шумский С.А.
Теги: наука и знание в целом науковедение организация умственного труда типы и характеристики систем наука кибернетика искусственный интеллект машинное обучение
ISBN: 978-5-369-02011-1
Год: 2019




МАШИННЫЙ ИНТЕЛЛЕКТ
С. А. ШУМСКИЙ
НАУКА И ПРАКТИКА
«МОСКОВСКИЙ ФИЗИКО-ТЕХНИЧЕСКИЙ ИНСТИТУТ
(НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ УНИВЕРСИТЕТ)»
С.А. Шуйский
МАШИННЫЙ
ИНТЕЛЛЕКТ
ОЧЕРКИ ПО ТЕОРИИ МАШИННОГО ОБУЧЕНИЯ
И ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Москва
РИОР
УДК 001(06)+004.032.26(06) ф3 издание не подлежит маркировке
ББК 72я5+32.818я5 № 436-ФЗ в соответствии с п. 1 ч. 2 ст. 1
Ш96
Художественное оформление обложки — КС. Шумекая
Автор:
Шумский С. А. — канд. физ.-мат. наук, директор Научно-координационного
совета Центра Национальной технологической инициативы по сквозной
технологии «Искусственный интеллект» на базе МФТИ, заведующий лабораторией
когнитивных архитектур МФТИ, президент Российской ассоциации нейроин-
форматики, руководитель направления «Нейроассистенты» дорожной карты
«Нейронет» Национальной технологической инициативы. Автор более 70 научных
публикаций, в том числе пособия по нейрокомпьютингу
Рецензент:
ЖиляковаЛ.Ю. — д-р физ.-мат. наук, ведущий научный сотрудник Института
проблем управления РАН (Москва)
Шумский С.А.
Ш96 Машинный интеллект. Очерки по теории машинного обучения
и искусственного интеллекта/ С.А. Шумский. — М.: РИОР, 2019. —
340 с. - DOI: https://doi.org/10.29039/02011-l
ISBN 978-5-369-02011-1
ISBN 978-5-369-02018-0 (online)
В книге дается обзор современного состояния и перспектив
развития исследований по машинному интеллекту. Предложен подход к
созданию «сильного» искусственного интеллекта с использованием
принципов работы человеческого мозга.
Каждая глава представляет собой самостоятельный очерк, ставящий
и разрешающий актуальные вопросы современности: Какие задачи
предстоит решить на пути совершенствования машинного обучения? Как
машинный интеллект может способствовать технологическому развитию
общества в целом и частного предпринимательства в частности? Чего
можно ожидать от машинного интеллекта в ближайшие 10—15 лет?
Адресована студентам, исследователям и разработчикам
приложений в области искусственного интеллекта, а также всем, кого
интересуют принципы работы мозга с позиций теории машинного обучения.
УДК 001(06)+004.032.26(06)
ББК72я5+32.818я5
Все права защищены. Запрещается копирование, распространение
или любое иное использование информации без предварительного
согласия правообладателя (кроме правомерного цитирования).
ISBN 978-5-369-02011-1 © Шумский С.А.
ISBN 978-5-369-02018-0 (online) © иц РИОР
Оглавление
Глава 1. Пролог 9
1.1. О чем и для кого эта книга 10
1.1.1. О чем эта книга 10
1.1.2. Для кого эта книга 10
1.1.3. Почему это важно 11
1.2. Структура книги 13
1.3. Благодарности 15
Глава 2. Машинный интеллект в современном мире 17
2.1. Машинный интеллект: время пришло? 18
2.2. Преодоление барьера сложности 20
2.3. Новый технологический уклад 23
2.3.1. Новый обильный и дешевый ресурс .... 24
2.3.2. Новый технологический пакет 26
2.3.3. Новая организация рынка 27
2.4. Гонка за искусственным интеллектом 29
2.5. Вызов России 31
Глава 3. Основы машинного обучения 35
3.1. Основные понятия 36
3.1.1. Машинное обучение как наука 36
3.1.2. Разум, интеллект и сознание 38
3.1.3. Машинное обучение: модели 41
3.1.4. Оптимальная сложность моделей 43
3.1.5. Байесова трактовка обучения 45
4
ОГЛАВЛЕНИЕ
3.1.6. Ансамбли гипотез 47
3.1.7. ЕМ-алгоритм 50
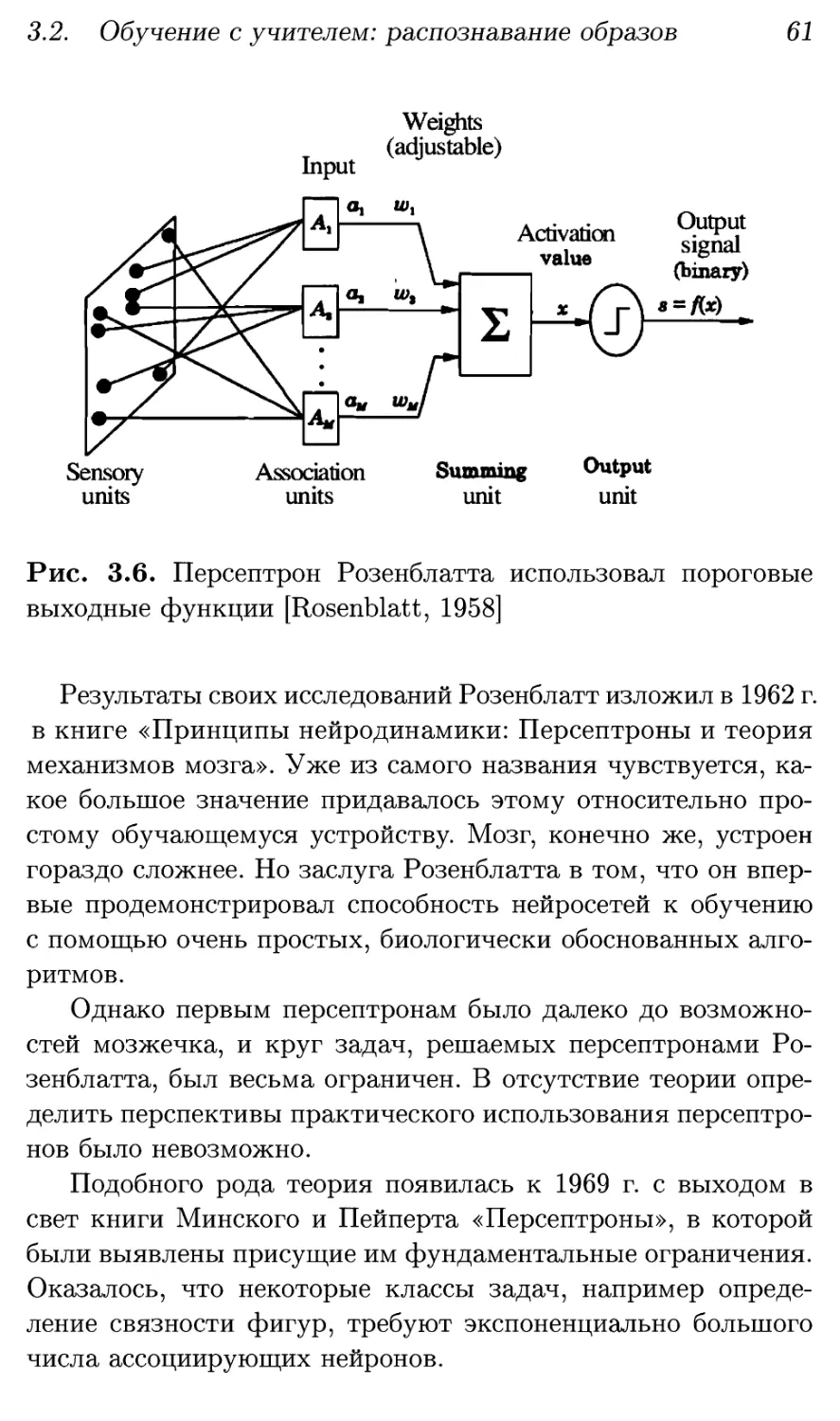
3.2. Обучение с учителем: распознавание образов . . 55
3.2.1. Нейрон-классификатор 57
3.2.2. Многослойные персептроны 58
3.2.3. Градиентное обучение 62
3.2.4. Регуляризация обучения 66
3.2.5. Сложность градиентного обучения .... 68
3.3. Обучение без учителя: сжатие информации ... 70
3.3.1. Обобщение данных 71
3.3.2. Нейрон-индикатор Хебба 72
3.3.3. Анализ главных компонент 75
3.3.4. Нелинейные главные компоненты 79
3.3.5. Соревнование нейронов 83
3.3.6. Самоорганизующиеся карты 87
3.4. Обучение с подкреплением: поведение 90
3.4.1. Обучение без моделирования среды ... 91
3.4.2. Обучение с моделированием среды .... 94
3.4.3. Связь с теорией управления 96
3.5. Обсуждение 97
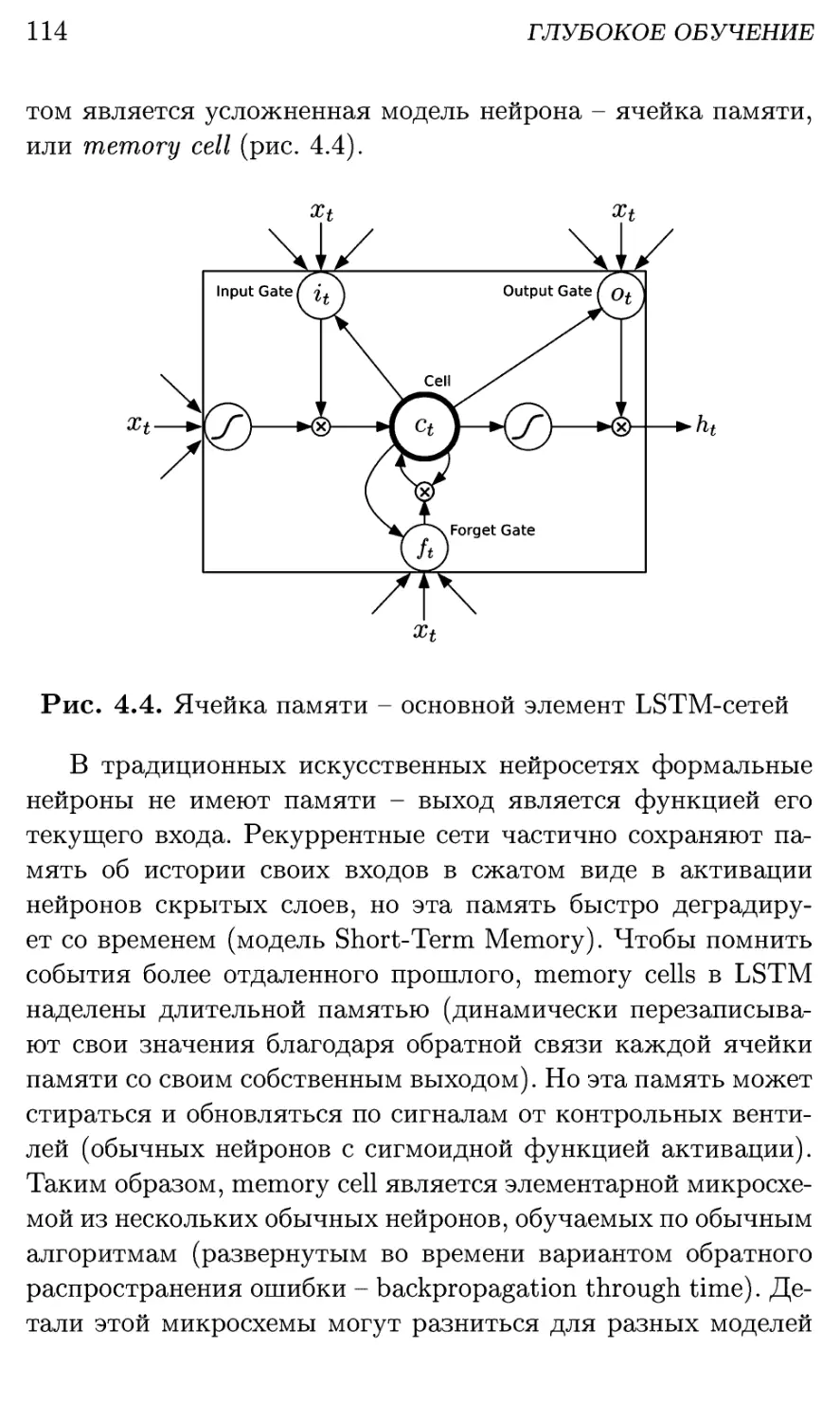
Глава 4. Глубокое обучение 99
4.1. Революция глубокого обучения 100
4.1.1. Предпосылки революции 100
4.1.2. Суть глубокого обучения 102
4.1.3. Методики глубокого обучения 104
4.1.4. Экстремально разреженные сети 108
4.1.5. Hardware для глубокого обучения 110
4.2. Рекуррентные глубокие сети: речь и язык .... 112
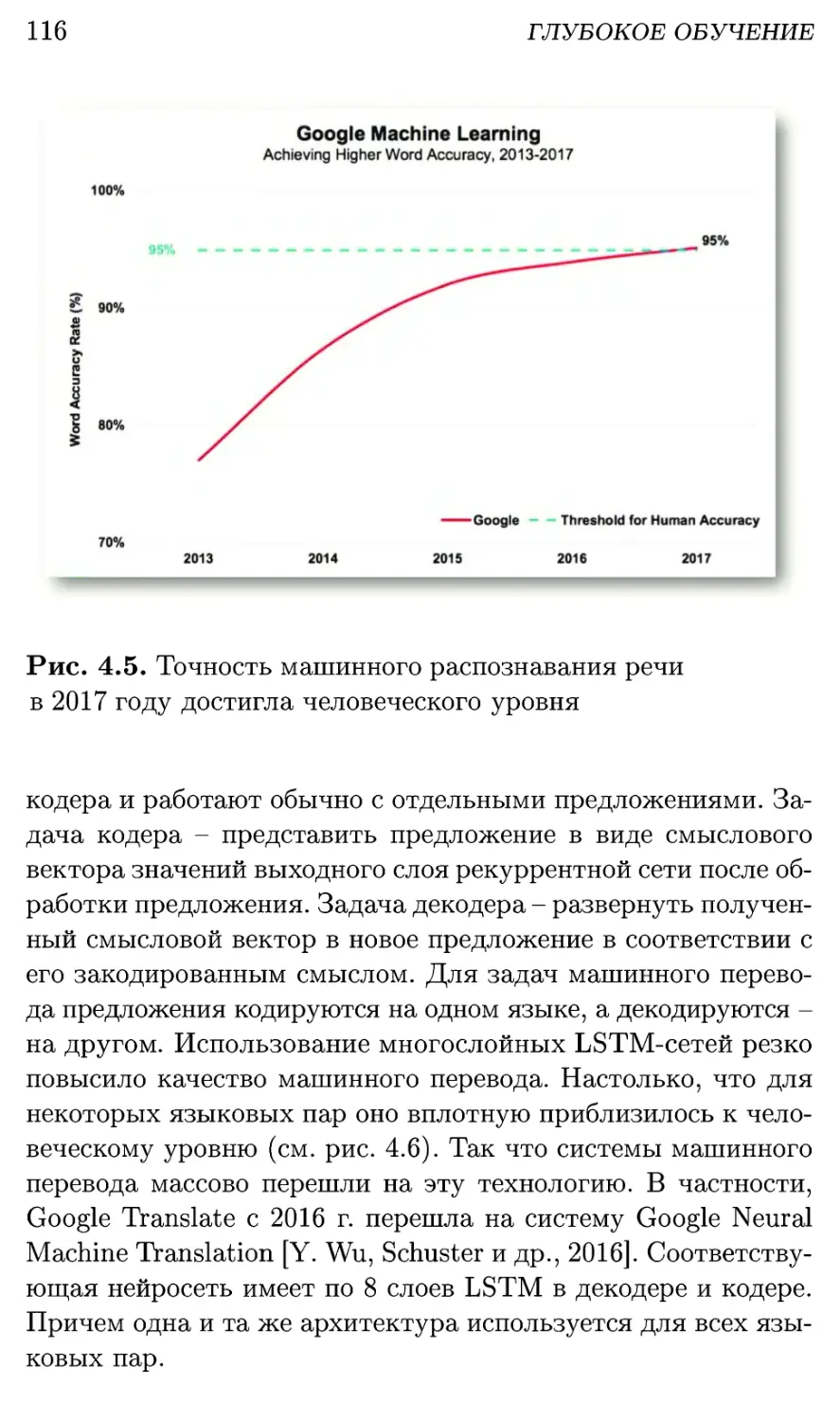
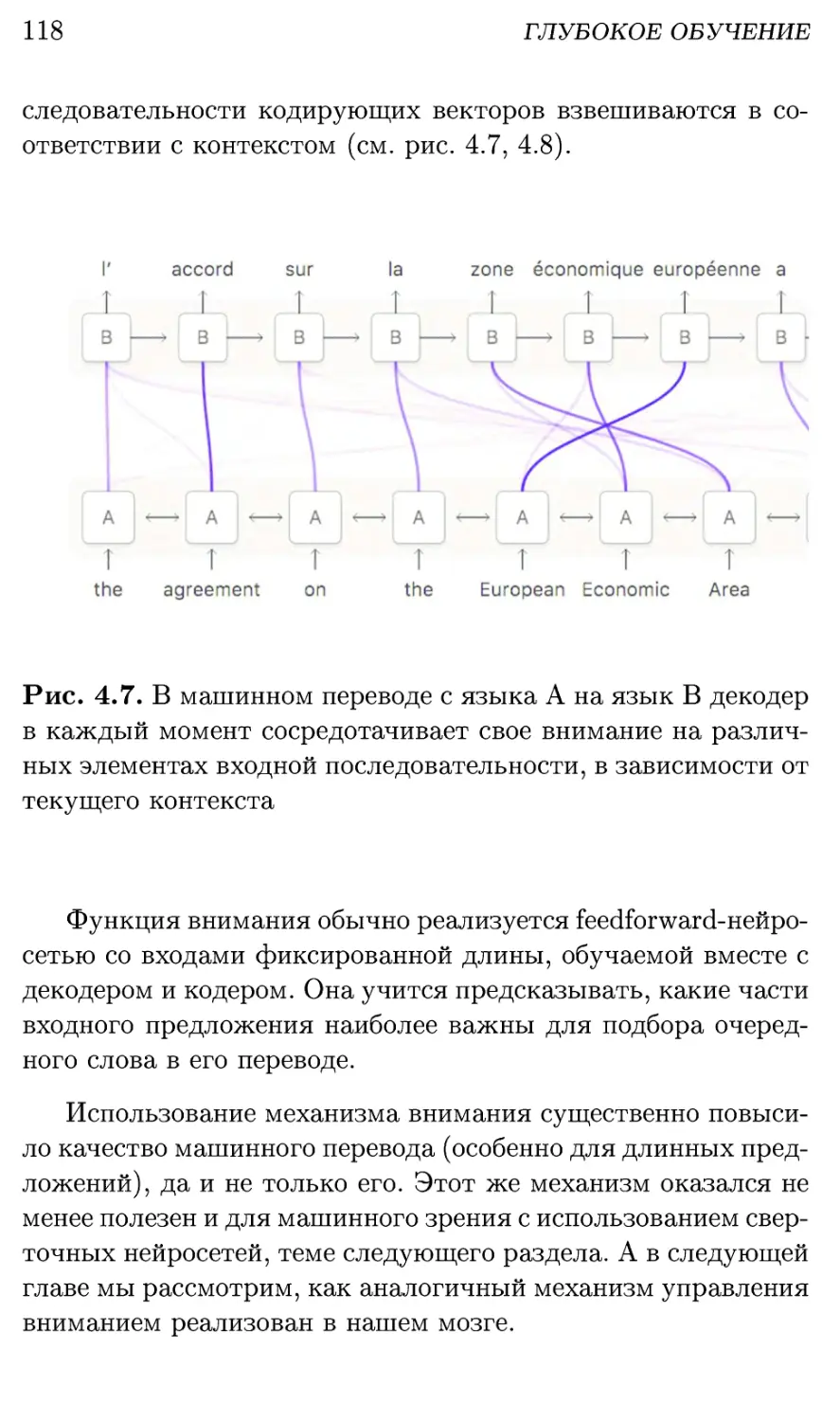
4.3. Сверточные сети: зрение и не только 119
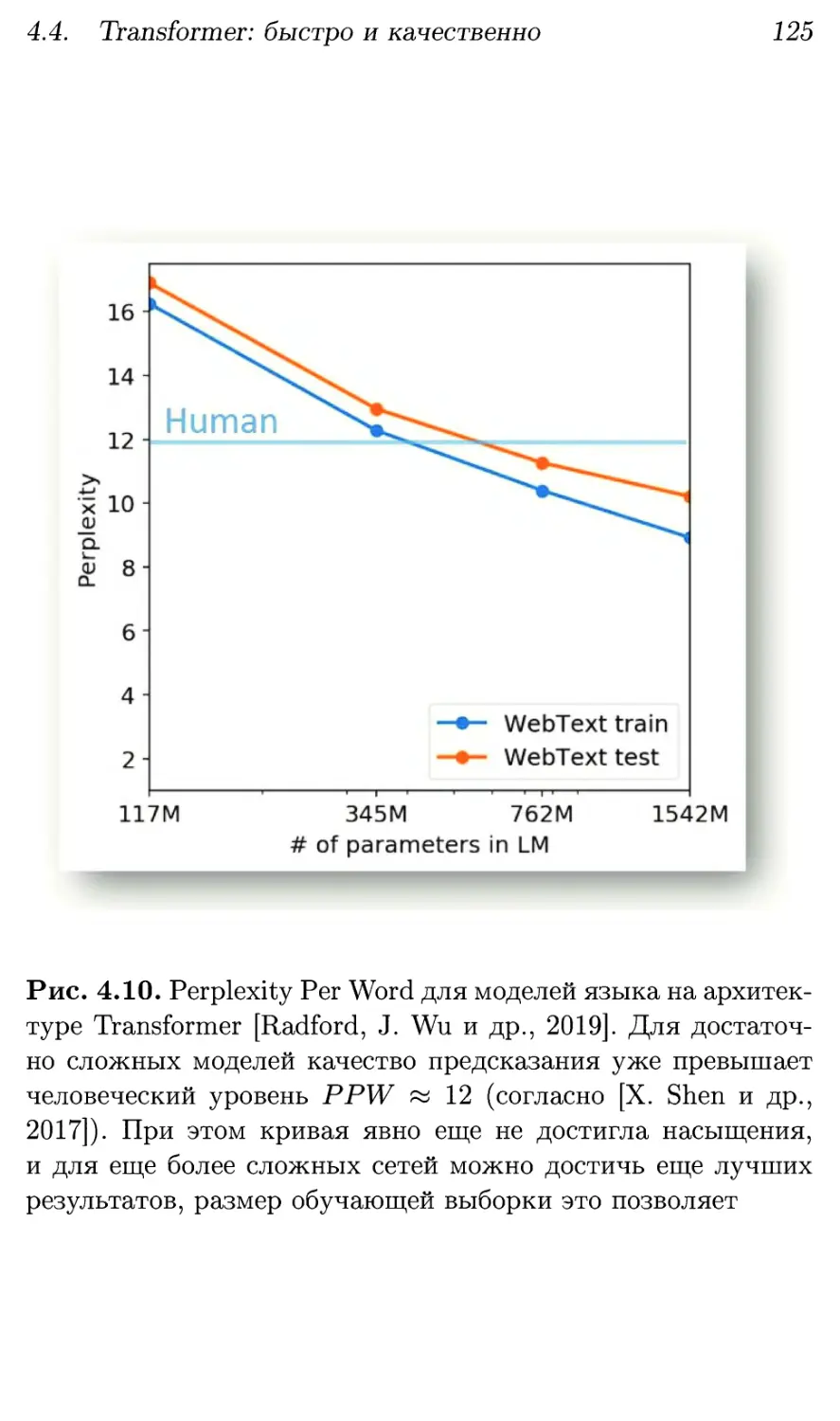
4.4. Transformer: быстро и качественно 123
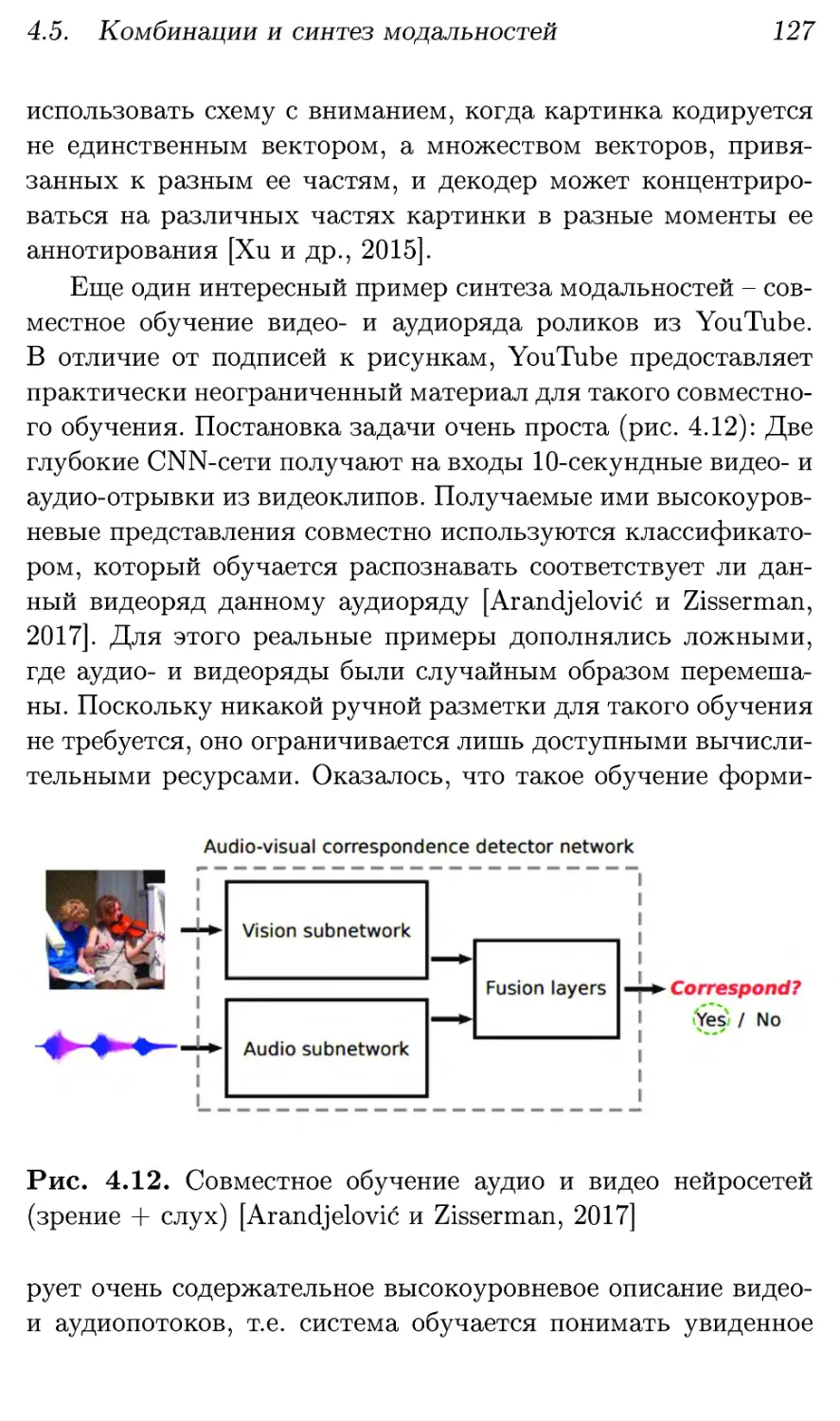
4.5. Комбинации и синтез модальностей 126
4.6. Реляционные сети: понимание связей 128
4.7. Генерирующие сети: воображение 130
4.8. Обучение с подкреплением: поведение 136
ОГЛАВЛЕНИЕ
5
4.9. Вектор развития: искусственная психика .... 143
Глава 5. Вычислительная архитектура мозга 147
5.1. Реверс-инжиниринг мозга 148
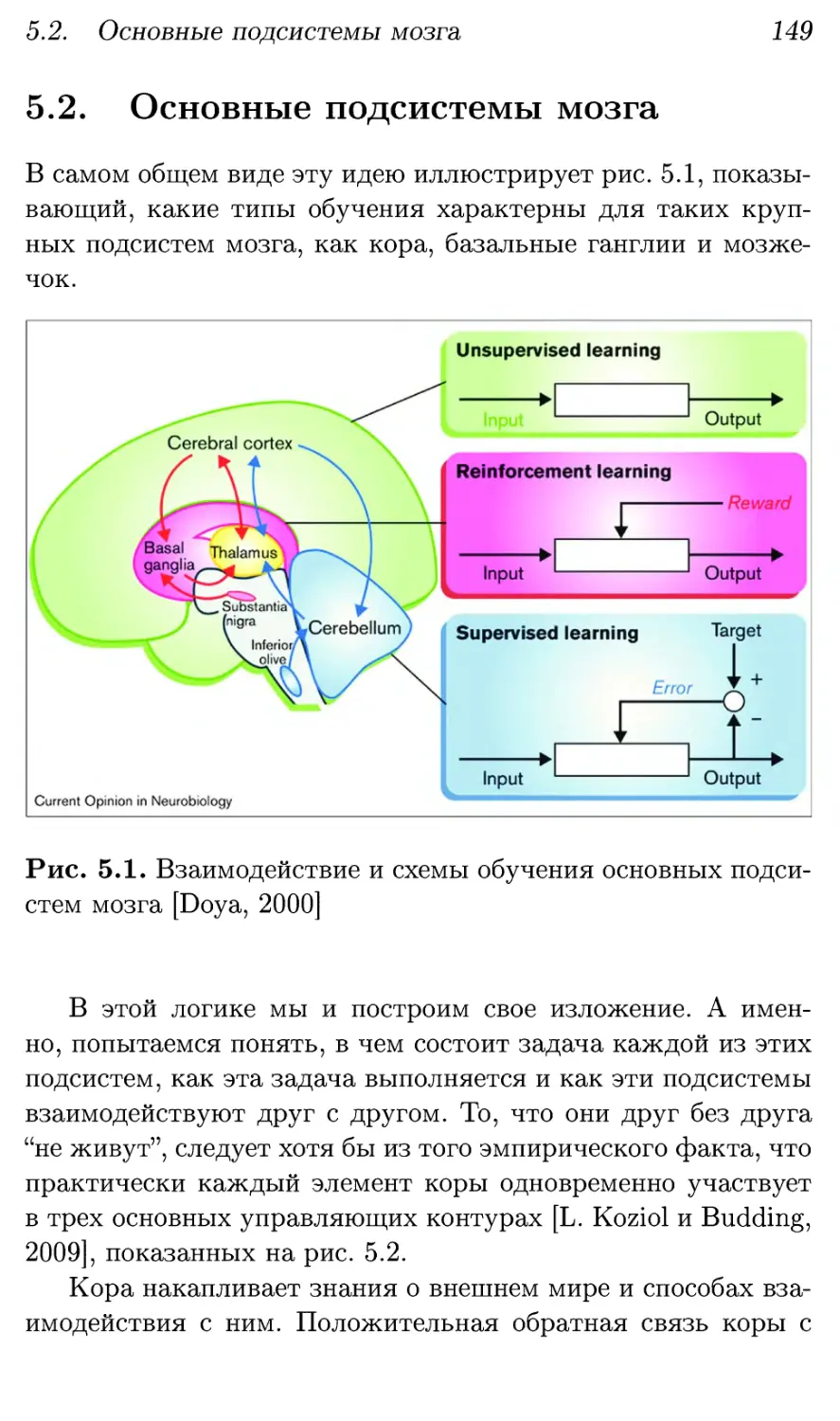
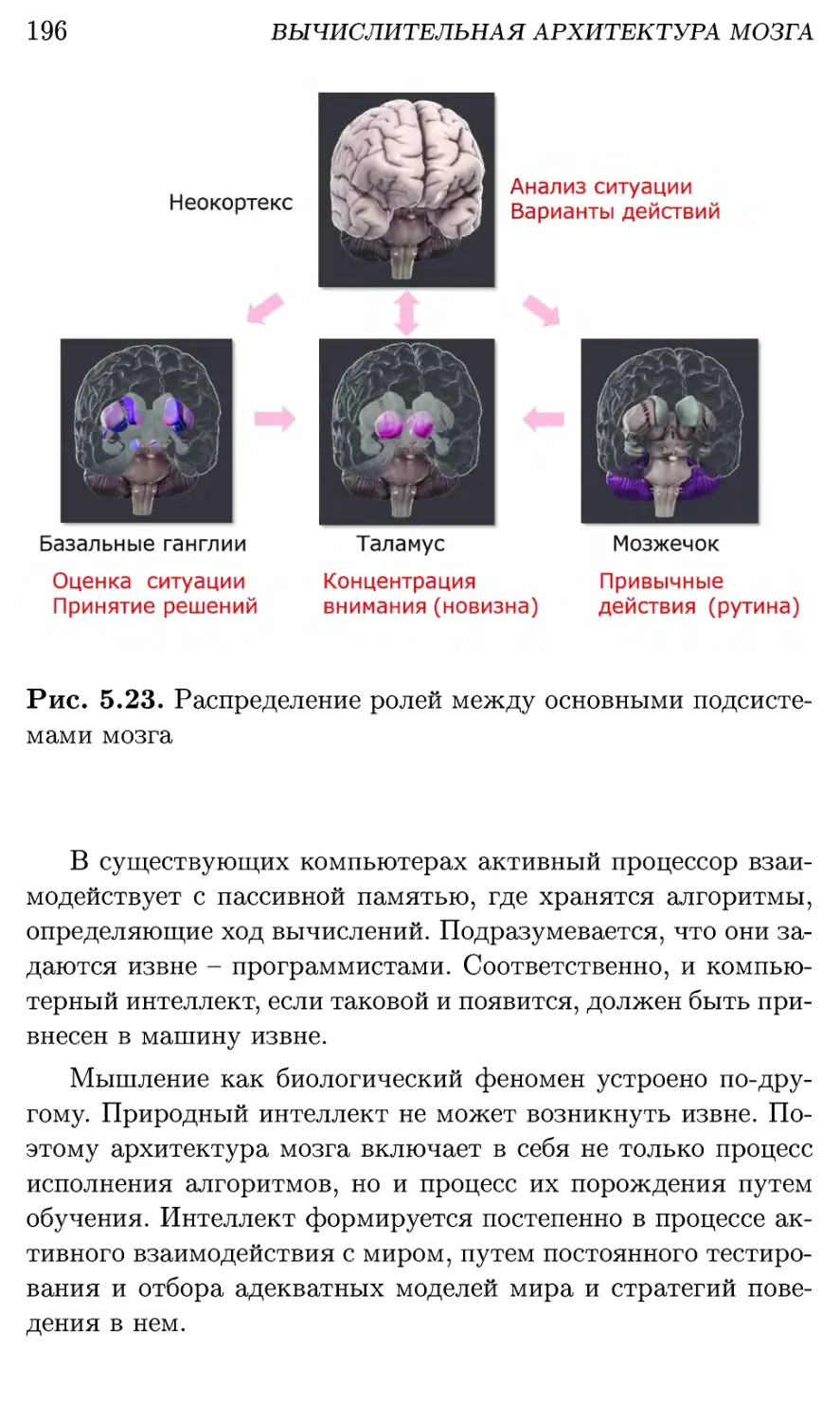
5.2. Основные подсистемы мозга 149
5.3. Кора: ассоциативная память 151
5.3.1. Слоистая структура коры: предиктивное
кодирование 151
5.3.2. Ячеистая структура коры: дискретное
разреженное кодирование 158
5.3.3. Древняя кора: эпизодическая память . . . 162
5.4. Таламус: внимание и связность ощущений .... 167
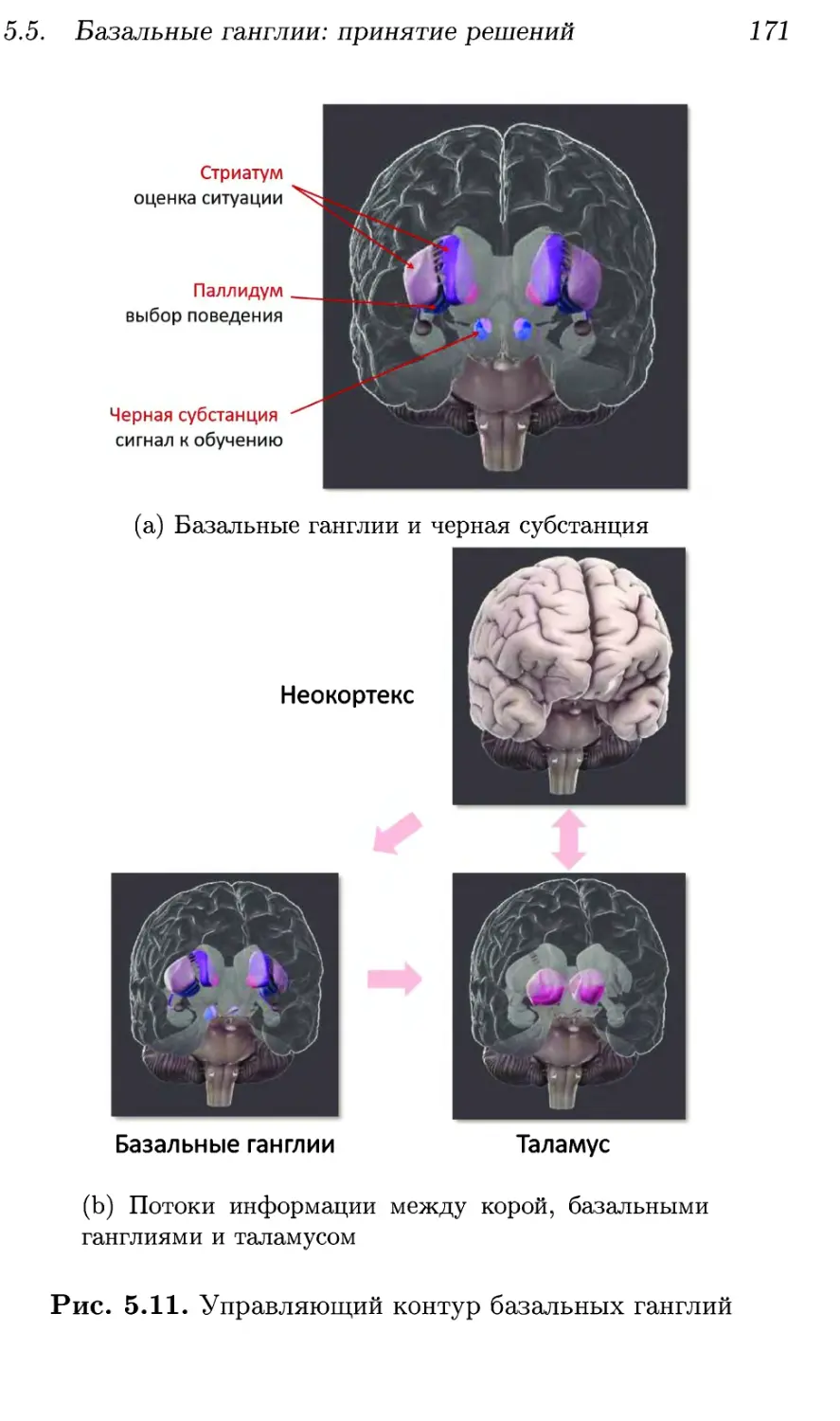
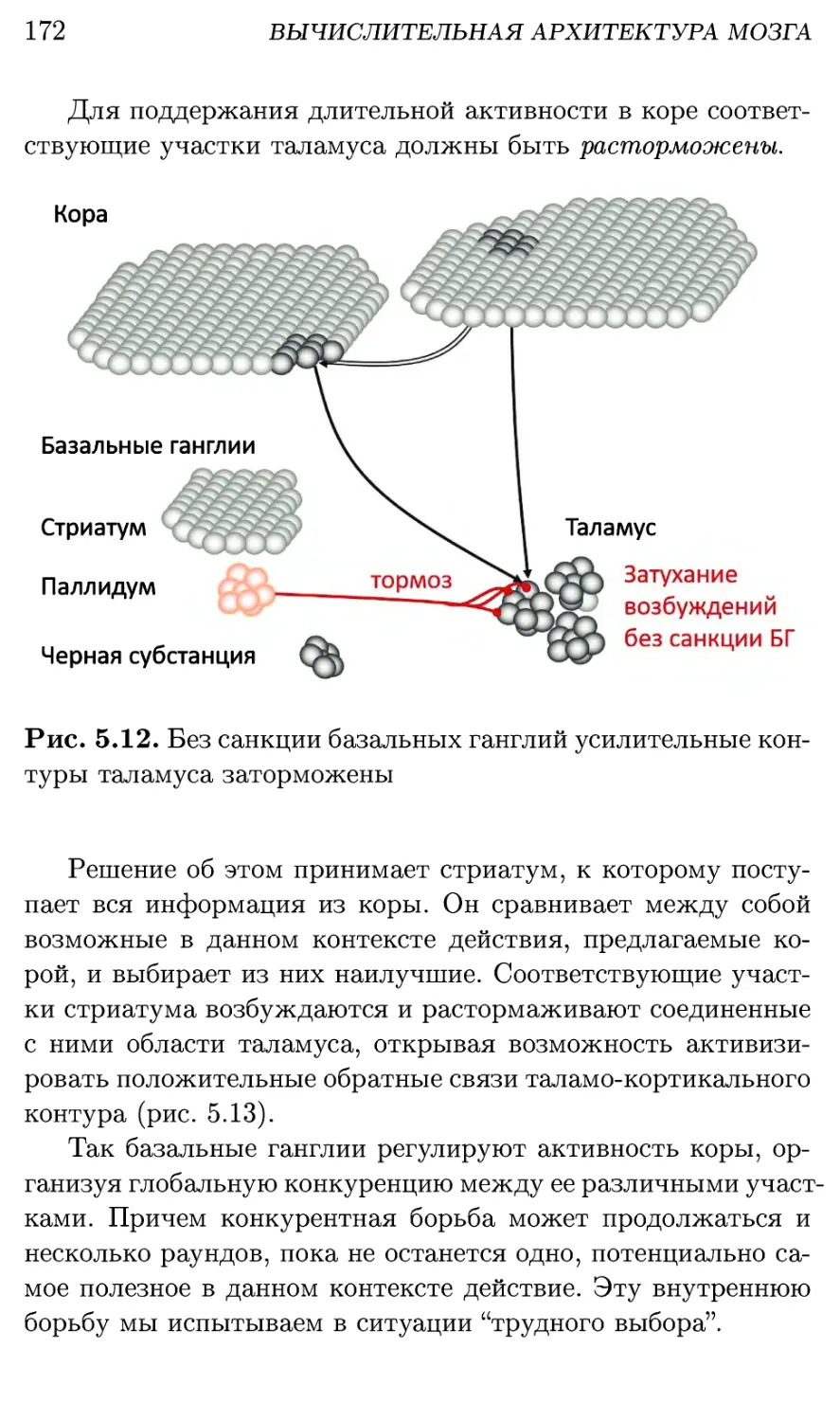
5.5. Базальные ганглии: принятие решений 169
5.5.1. Управление вниманием 169
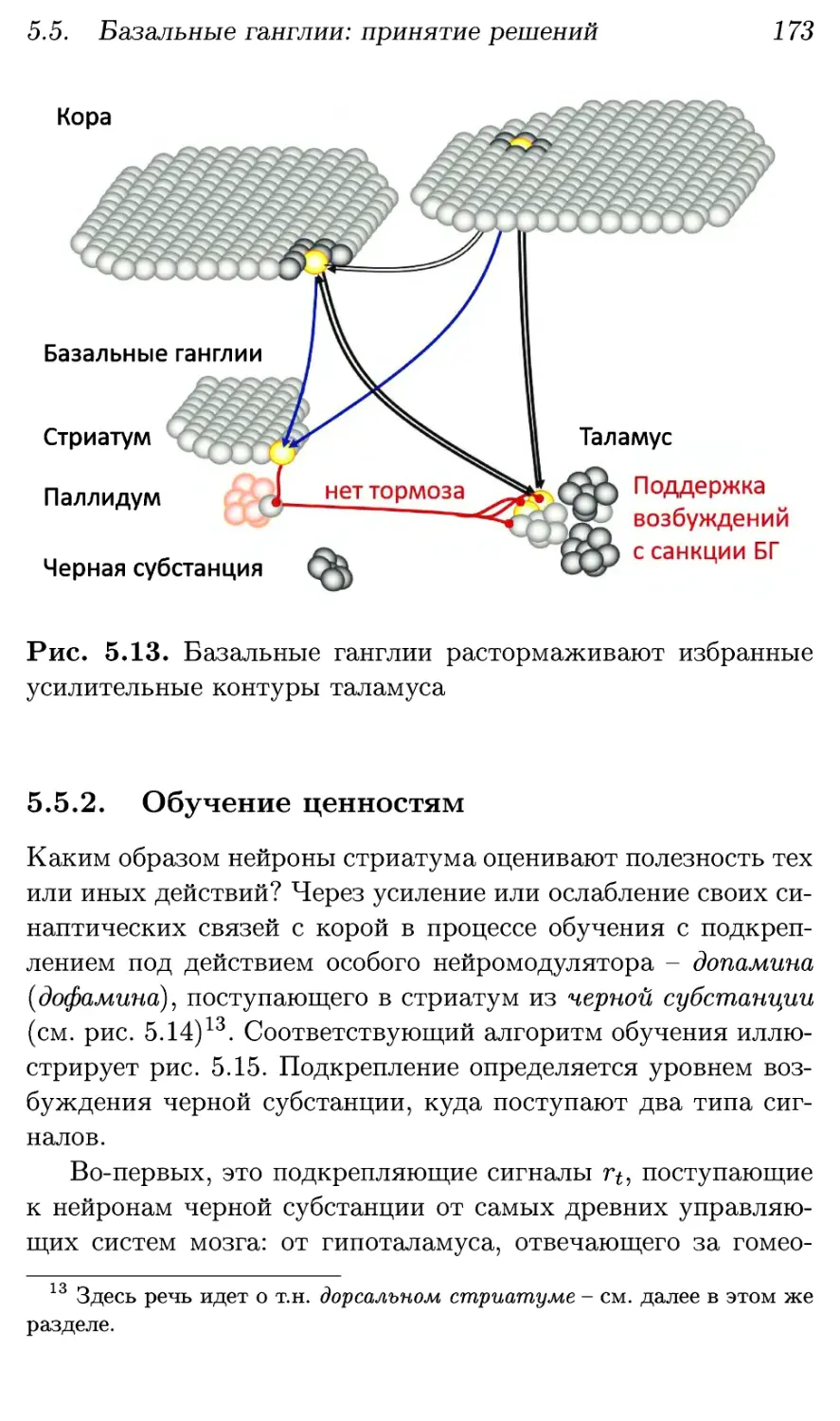
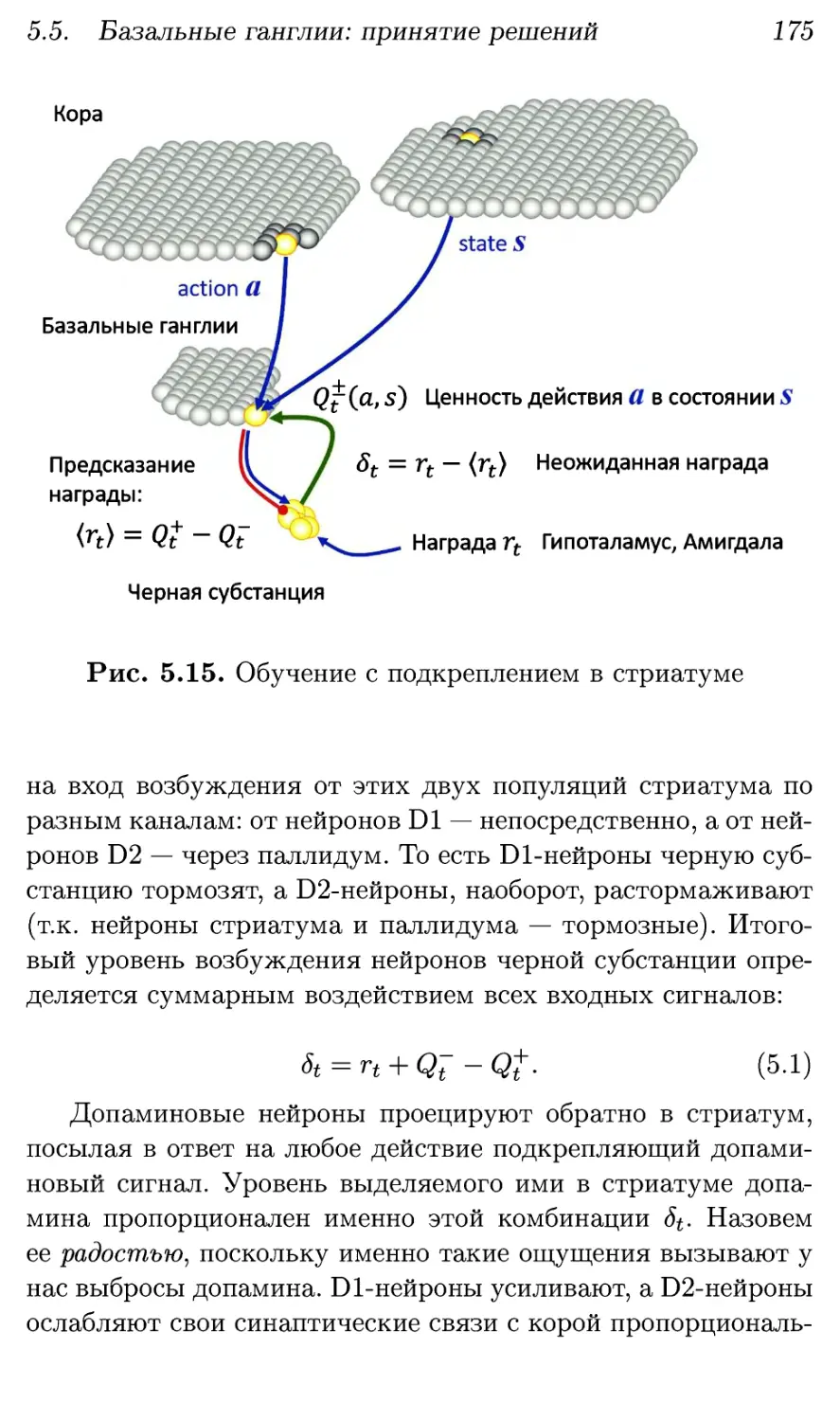
5.5.2. Обучение ценностям 173
5.5.3. Контроль активности в коре 177
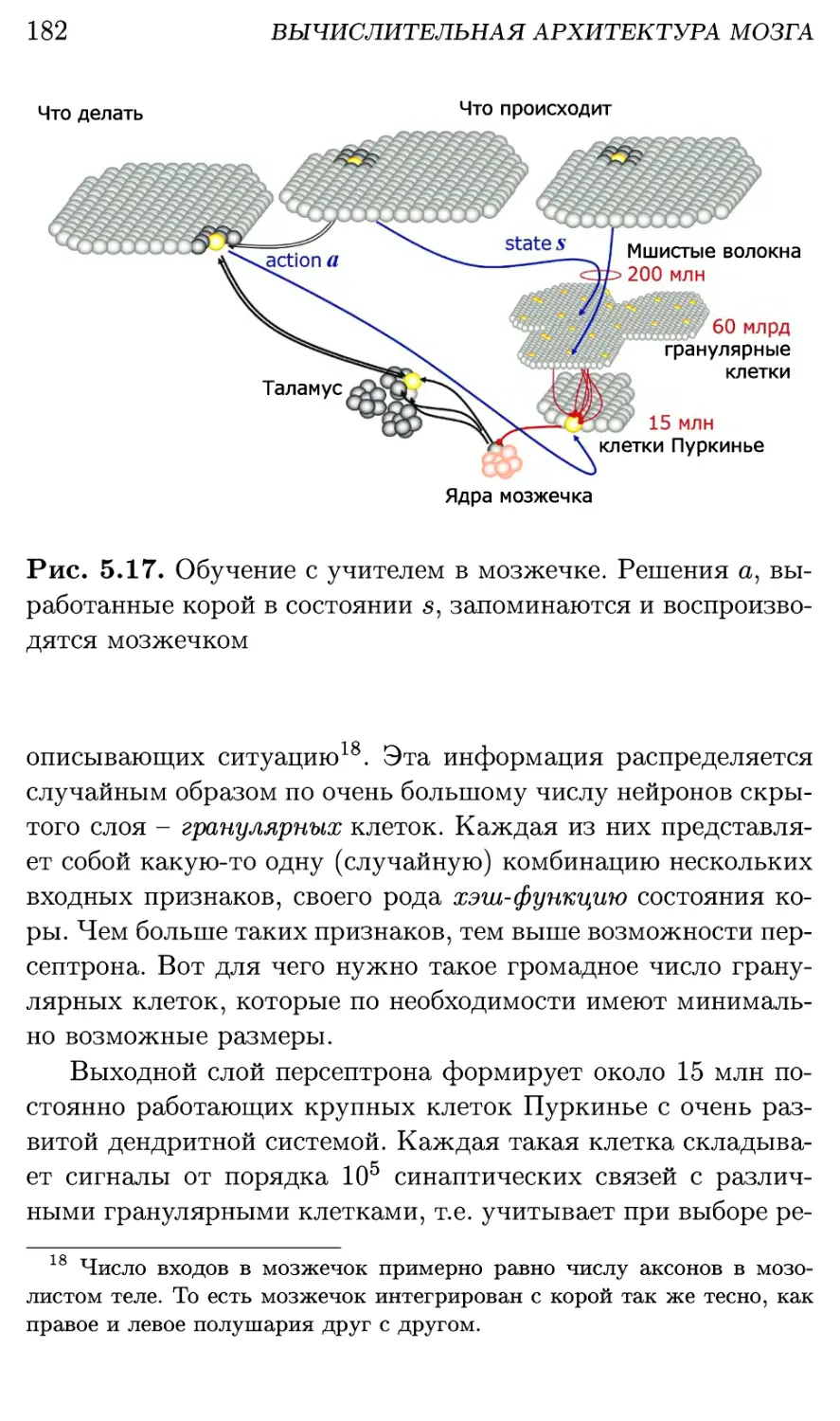
5.6. Мозжечок: закрепление пройденного 180
5.7. Схемотехника мозга: Deep Control 184
5.8. Deep Control — изобретение приматов 187
5.9. Абстрактное мышление: моделирование 190
5.10. Новая старая архитектура 194
Глава 6. На пути к искусственной психике 199
6.1. Зачем нужна искусственная психика? 199
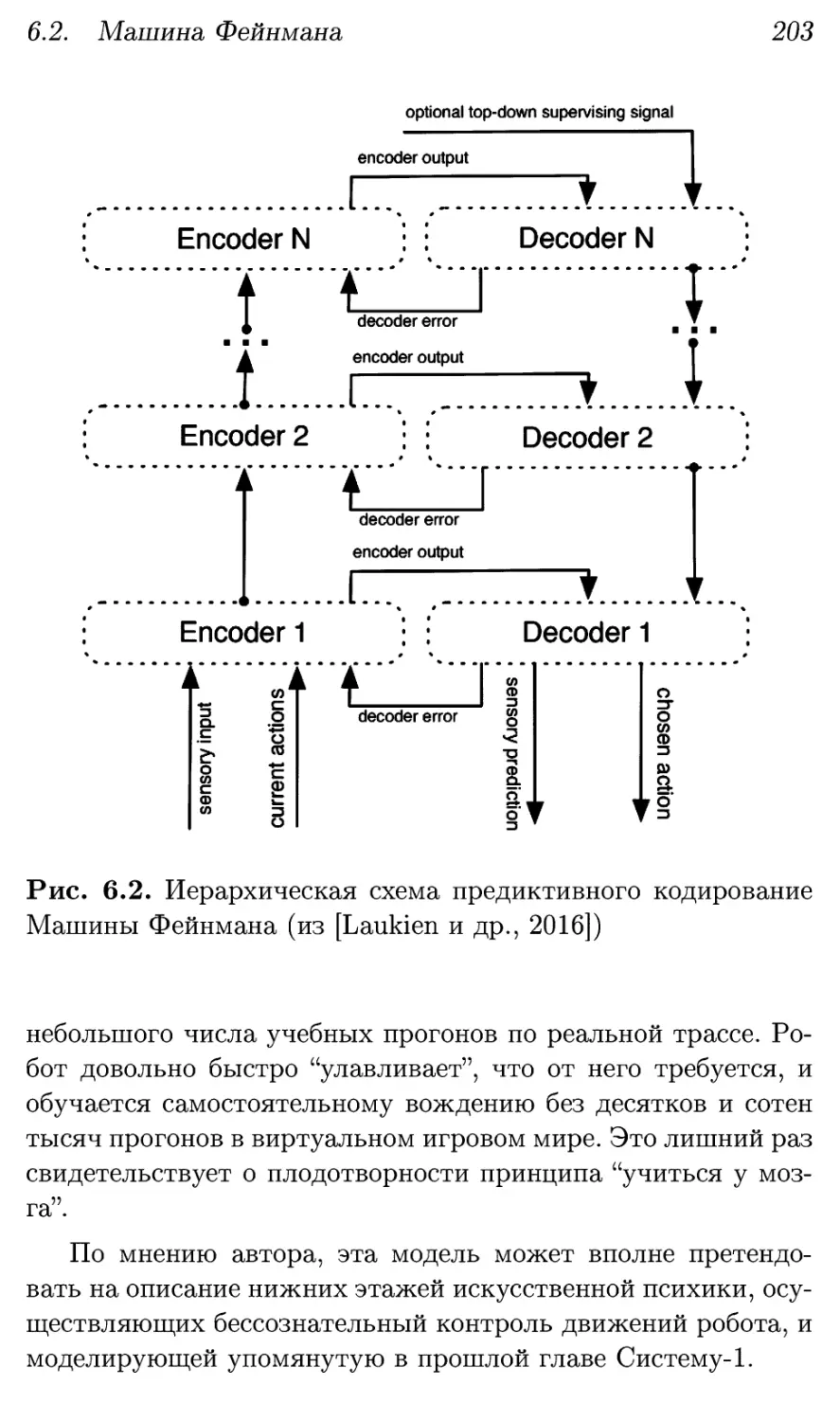
6.2. Машина Фейнмана 201
6.3. Символьное мышление: основная идея 204
6.4. Гипотеза о рекурсивных модулях коры 206
6.5. Структурное обучение 210
6.5.1. Основная идея метода 210
6.5.2. Алгоритм структурного обучения 212
6.5.3. Предсказания с помощью модели 214
6.5.4. Обучение с подкреплением 215
6.5.5. Разреженное кодирование 216
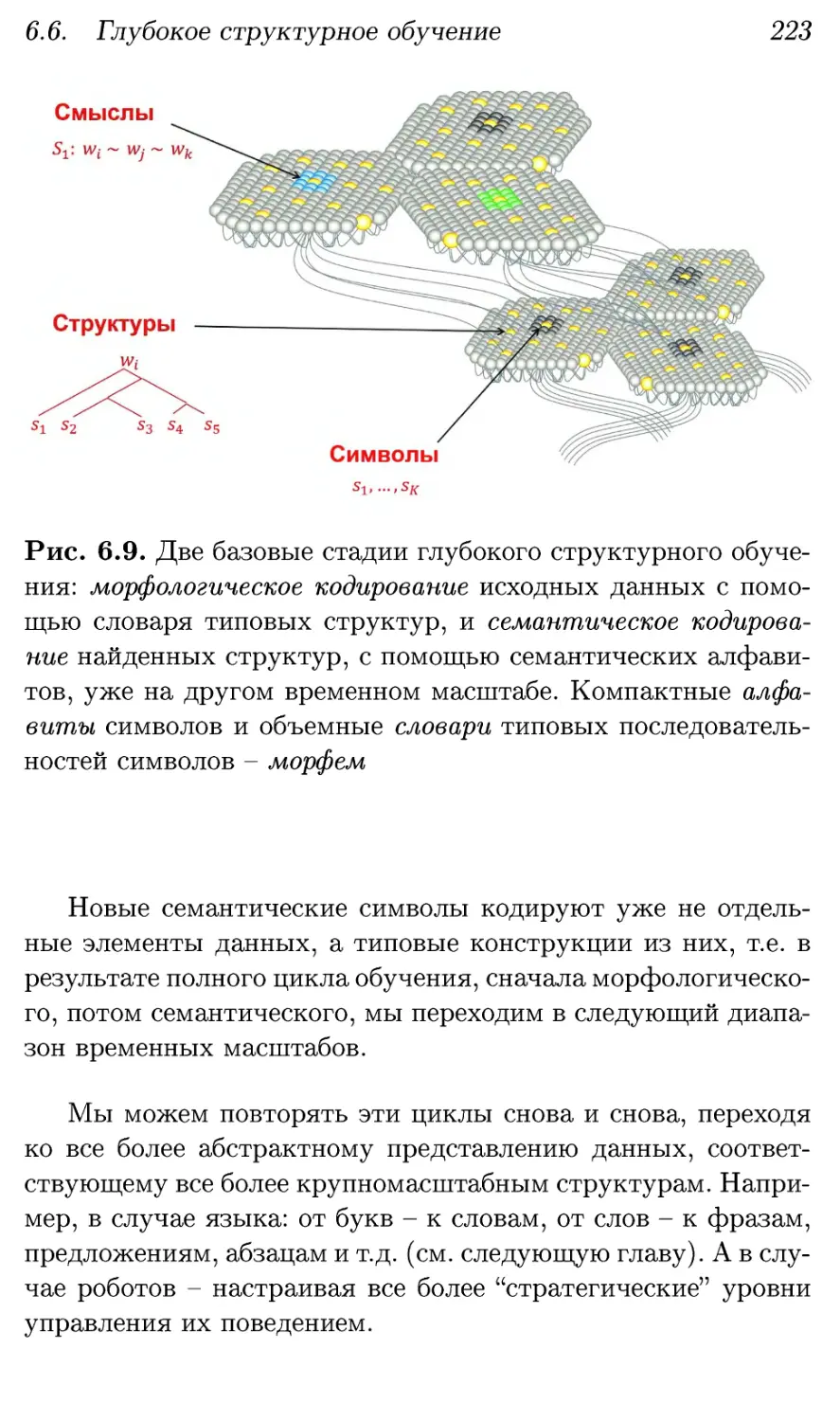
6.6. Глубокое структурное обучение 219
6.6.1. Семантическое кодирование 220
6.6.2. Иерархия структур 222
6
6.6.3. Активное обучение 224
6.6.4. Сложность структурного обучения .... 226
6.6.5. Иерархия предсказаний 227
6.7. Обсуждение 228
Глава 7. Мозг и язык 233
7.1. Смогут ли машины говорить? 233
7.2. Родовые свойства языка 235
7.3. Глубокое структурное обучение языку 238
7.3.1. Морфология 238
7.3.2. Синтаксис и семантика 240
7.3.3. Разбор предложений 242
7.3.4. Значения фраз и предложений 243
7.3.5. Семантический поиск 246
7.3.6. Скорость обучения 249
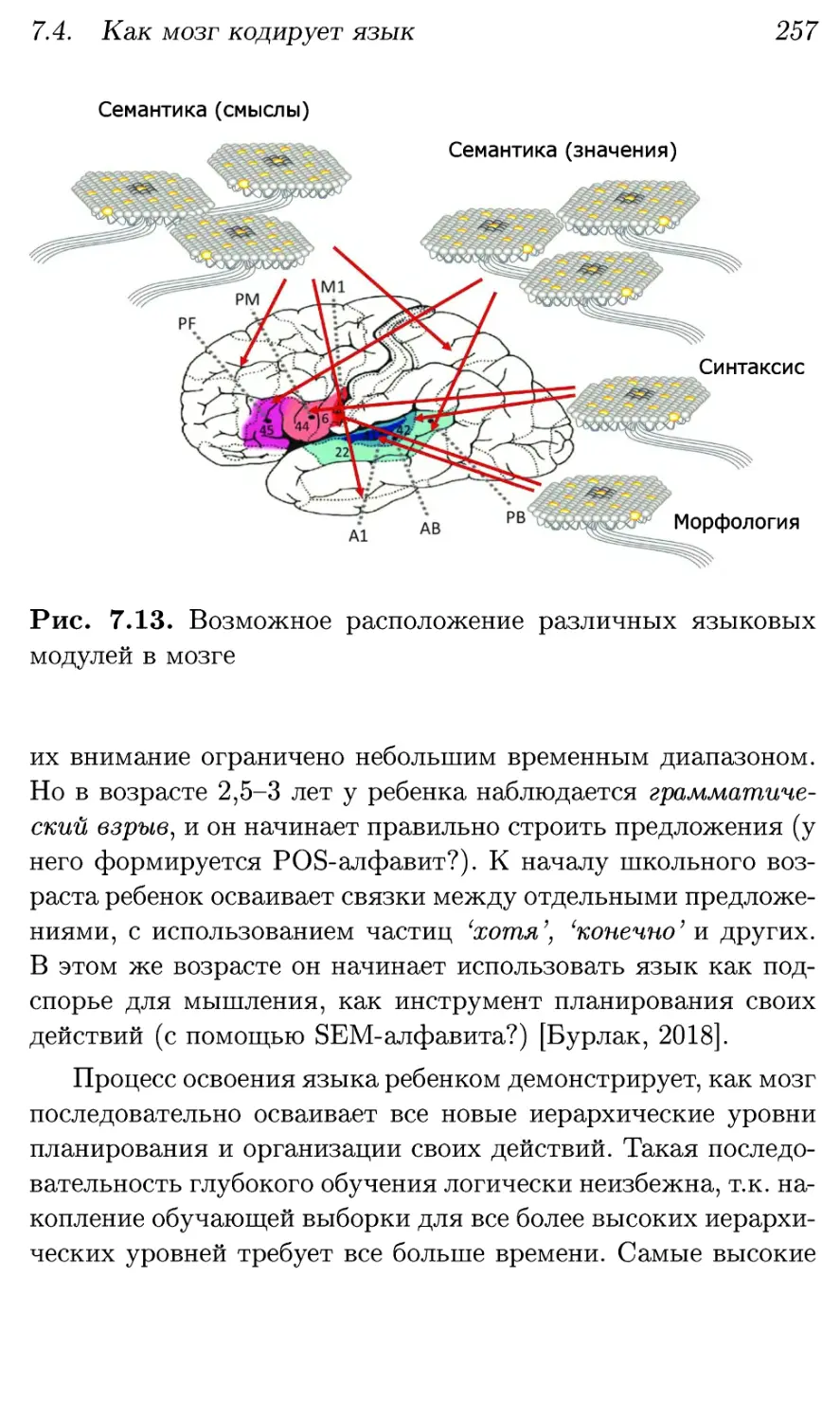
7.4. Как мозг кодирует язык 249
7.4.1. Модель "органа языка" 249
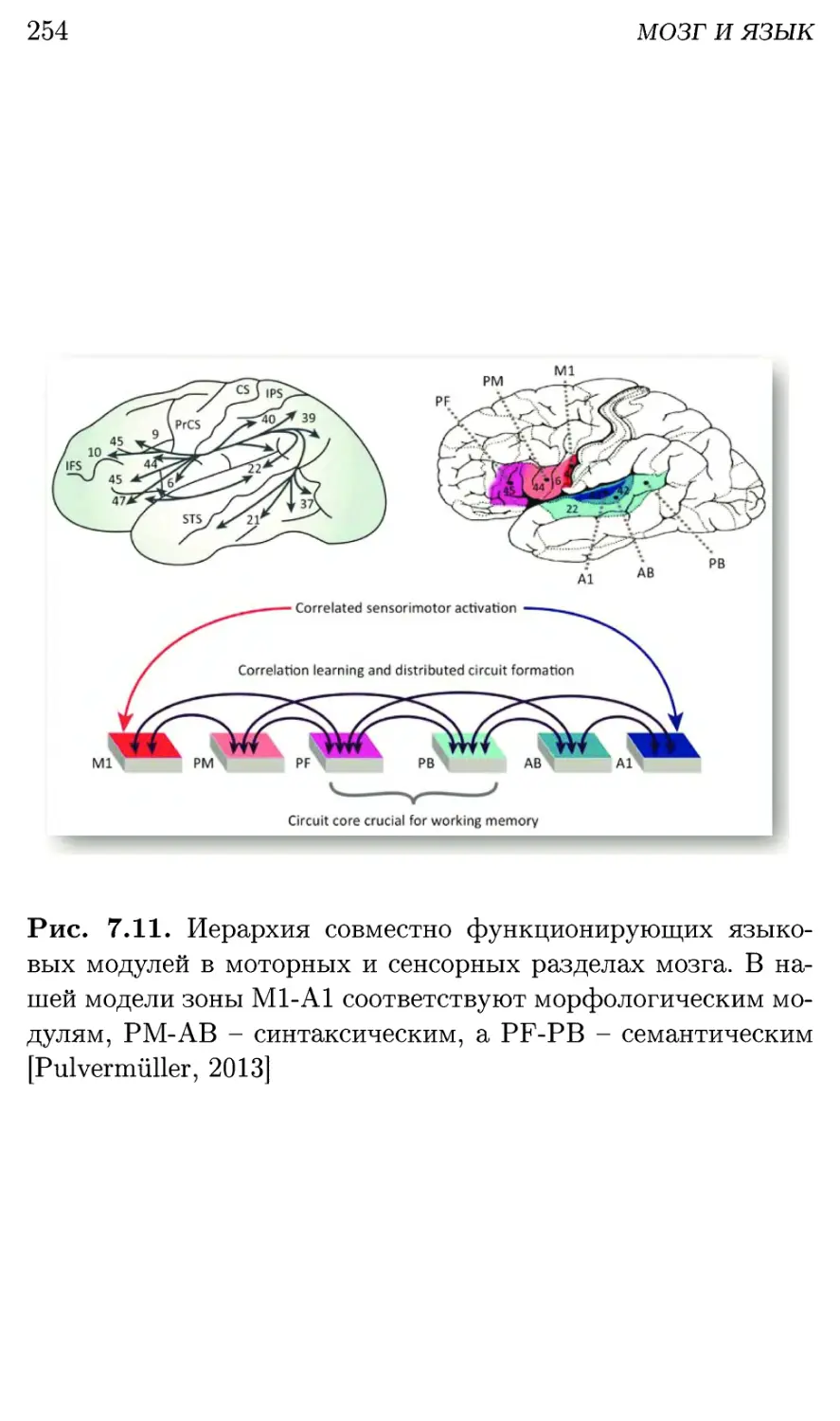
7.4.2. Как язык представлен в мозге 253
7.5. Обсуждение 258
Глава 8. Направления развития 265
8.1. Действующая модель мозга 266
8.1.1. Как работает наш мозг? 266
8.1.2. Продление жизни мозга 268
8.1.3. Действующие модели мозга 269
8.1.4. Лечение и апгрейд мозга 271
8.2. Операционная система роботов 272
8.2.1. Как сделать роботы доступными? 272
8.2.2. Кто станет новой Microsoft? 273
8.2.3. Иерархическое модульное обучение .... 273
8.2.4. Зарплатные схемы для роботов 275
8.3. Экспертный интеллект 277
8.3.1. Как ускорить R&D? 277
8.3.2. Суперинтеллект суперкомпьютеров .... 277
8.3.3. Иерархическая модель языка 278
8.3.4. Супер-Google - консультант 280
ОГЛАВЛЕНИЕ 7
8.4. Обсуждение 281
Глава 9. Будущее машинного интеллекта 283
9.1. Развитие элементной базы 284
9.2. Интеллектуальные агенты 287
9.3. Роботы 289
9.4. Люди 291
9.5. Новая научная революция 295
Глава 10. Эволюция разума 299
10.1. Неравновесная термодинамика 301
10.2. Жизнь как форма разума 303
10.3. Мозг как контроллер поведения 304
10.4. Человеческий разум 306
10.5. Машинный интеллект 309
Глава 11. Несколько слов о смысле жизни 313
Список литературы 315
Глава 1
Пролог
Новыми путями иду я,
новая речь приходит ко
мне; устал я, подобно всем
созидающим, от старых
языков. Не хочет больше
мой дух бродить на
истоптанных подошвах.
Вы, смельчаки вокруг
меня! Вы, искатели,
испытатели и те из вас,
кто плавает под
коварными парусами по
неисследованным морям!
Вы, любители загадок!
Разгадайте же мне
загадку, которую я видел
... кто он, кто однажды
ещё должен придти?
Фридрих Ницше
«Так говорил Заратустра»
10
ПРОЛОГ
1.1. О чем и для кого эта книга
1.1.1. О чем эта книга
Эта книга о природе разума и разумного поведения. В
частности и в особенности - о человеческом и машинном интеллекте.
Мы будем использовать один и тот же язык теории
машинного обучения и для понимания принципов работы мозга,
и для проектирования искусственных интеллектуальных
систем, а в перспективе — сильного машинного интеллекта.
Автор видит свою цель в наведении мостов между
нейрофизиологами, изучающими мозг, и
инженерами-конструкторами нейроморфных когнитивных систем, использующих
принципы работы мозга.
1.1.2. Для кого эта книга
Эта книга — своего рода манифест, призыв к участию в
начинающейся новой научной революции. Она писалась для тех,
кто ориентирован на новые открытия в области
искусственного интеллекта. Для тех, кому интересна архитектура
человеческого мозга и построение сильного искусственного
интеллекта с оглядкой на интеллект естественный. Для
архитекторов и генеральных конструкторов искусственной психики
роботов — интеллектуальных операционных систем следующих
поколений.
Наука и бизнес сегодня делаются командами, а успех
командной работы во многом зависит от степени
взаимопонимания людей с очень разными бэкграундами. Новые разработки
в области искусственного интеллекта привлекают как
математиков и инженеров, так и нейрофизиологов, психологов и
лингвистов. Эта книга — скромная попытка автора
предоставить им своего рода Розеттский камень — текст, одинаково
понятный и тем, и другим. Чтобы дать возможность
биологам взглянуть на известные им факты глазами машинного
обучения, а специалистам по искусственному интеллекту —
взглянуть на свою область глазами биологов.
1.1. О чем и для кого эта книга
11
Поскольку задачи мозга во многом сводятся к обучению,
то его конструкция не может быть понята безотносительно
к этим задачам, т.е. без привлечения идей машинного
обучения. Последние помогают понять общие принципы работы
мозга, задающие рамку для огромного количества
эмпирических фактов, касающихся мозга и поведения. С другой
стороны, для создания когнитивных систем роботов важно
понимать архитектуру мозга и его функционирование на
системном уровне, без биологических деталей.
Розеттский камень, как известно, содержит один и тот же
текст на трех языках. Эта книга тоже адресуется не
только исследователям и разработчикам, но и предпринимателям,
инициаторам и организаторам новых проектов в венчурной
по своей природе индустрии машинного интеллекта. Им
будут интересны главы о перспективах развития искусственного
интеллекта и его месте в будущей цифровой экономике.
Кроме описанной выше целевой аудитории, книга может
быть полезна всем, кто интересуется природой разума, как
естественного, так и искусственного. Уровень изложения
примерно соответствует младшим курсам университетов, т.е.
материал в целом вполне доступен широкой публике,
особенно публицистическая начальная и научно-популярные
конечные главы. Более сложные для понимания главы,
требующие определенной математической подготовки и усилий,
снабжены соответствующими предупреждениями. Их при первом
чтении рекомендуется пропустить, чтобы не "сбивать
дыхания".
1.1.3. Почему это важно
В последнее десятилетие в области искусственного интеллекта
произошла революция глубокого обучения, которая коренным
образом изменила место машинного интеллекта на
технологической карте мира. Большое число практически важных
задач, не поддававшихся решению десятилетиями —
распознавание речи, машинное зрение, машинный перевод, — были
12
ПРОЛОГ
решены путем обучения т.н. глубоких искусственных
нейронных сетей (с миллиардами настроечных параметров).
Искусственный интеллект, основанный на машинном
обучении, за эти годы вышел из стен лабораторий в реальный
мир. В смартфонах поселились умные агенты, а автомобили
научились ездить без водителей. Быстрыми темпами
эволюционируют роботы. Резко увеличилось и продолжает расти
финансирование и число специалистов в области машинного
обучения, растет поток публикаций.
В разгар этой научной революции любой обзор ее
конкретных достижений успевает устареть еще в процессе
подготовки, до появления на свет. Именно поэтому в этой книге мы
хотим сосредоточиться не на текущем состоянии, а на
следующих этапах развития отрасли. На вопросах, которые будут
актуальны еще какое-то, возможно длительное, время, — на
нерешенных проблемах и возможных подходах к их решению.
Главной такой нерешенной задачей сегодня является
создание сильного искусственного интеллекта
(сверх)человеческого уровня, способного самостоятельно мыслить,
развиваться, общаться с людьми на естественном языке и, тем
самым, кардинально расширить возможности человечества.
На самом деле нам предстоит решить еще более сложную
задачу создания дружественного искусственного
интеллекта, симбиоза человеческого и сверхчеловеческого разума.
Сегодня мы понимаем машинное обучение в основном как
обучение машин нами. На повестке дня — создание
самообучающихся машин. Но вслед за этим непременно возникнет
проблема обучения нас машинами. Сможем ли мы понять
результаты машинного мышления, овладеть новыми знаниями,
полученными машинами? Чтобы понимать машинный
интеллект и доверять ему1.
1 На самом деле это уже происходит, например, в Го и шахматах,
где машинный уровень игры уже далеко превосходит человеческий. И
профессионалы сегодня используют машинный интеллект для
проникновения в тайны своей любимой игры, открытые этим сверхчеловеческим
игровым разумом (см. раздел 4.8.).
1.2. Структура книги
13
Решение этих задач, по мнению автора, невозможно без
более глубокого понимания принципов человеческого и
машинного интеллекта. Чтобы созданная нами искусственная
психика роботов была совместима с человеческой.
1.2. Структура книги
Автор не случайно определил жанр книги как очерки.
Отдельные ее главы основаны на лекциях, прочитанных автором
на протяжении ряда лет, и потому относительно независимы.
Это удобно, особенно с учетом предполагаемой разнородности
читательской аудитории.
Скажем, широкой публике будут интересны главы 2, 4
и 8-10, в которых современное состояние и перспективы
искусственного интеллекта изложены простым языком, так что
желающие смогут познакомиться с предметом за один или
несколько вечеров. Стесненные во времени предприниматели
могут вполне ограничиться 2, 8 и 9 главами. Тем, кому
интересно устройство и принципы работы мозга, будут полезны
главы 5 и 7. Наконец, разработчикам, не знакомым с
предметом и желающим максимально быстро войти в тему, чтобы
лучше понимать суть алгоритмов машинного обучения,
можно порекомендовать главы 2-4.
Но, в целом, изложение материала имеет свою
внутреннюю логику:
В главе 2 мы рассмотрим место машинного интеллекта в
современном мире и его особую роль замыкающей
технологии нового техноуклада. Мы покажем, насколько серьезны те
вызовы, на которые отвечает машинный интеллект, и каким
образом он сможет повысить эффективность мировой
экономики. Это должно помочь читателю лучше осознать
перспективы развития машинного интеллекта, мотивируя его на
более глубокое погружение в эту область.
Глава 3 представит основы машинного обучения и
определит его место в системе наук. Речь пойдет о математике обу-
14
ПРОЛОГ
чения — постановке основных задач и методов их решения.
Будут рассмотрены базовые типы обучения и
соответствующие алгоритмы.
Глава 4 посвящена революции глубокого обучения — ее
причинам, достижениям и практическим применениям, уже
внедренным и еще ждущим своего воплощения. Наша
задача — угадать вектор развития отрасли и технологические
барьеры, которые предстоит преодолеть в пределах ближайших
5-10 лет.
Глава 5 показывает, как принципы глубокого машинного
обучения помогают понимать и моделировать механизмы
работы мозга. В частности, объясняются способы обучения и
взаимодействия друг с другом основных подсистем мозга
млекопитающих и, конкретнее, приматов. Нас будут интересовать
основные принципы архитектуры мозга, такие как
модульность и иерархичность, позволившие нашим предкам
наращивать возможности мозга в ходе эволюции за счет роста числа
однотипных модулей. Эти же принципы можно использовать
и для создания масштабируемого машинного интеллекта.
В главе 6 приводится теория глубокого структурного
обучения с подкреплением, моделирующая символьное
мышление, дополняя, тем самым, возможности нейросетей по
работе с образами. Теория основана на выявленных в предыдущей
главе архитектурных принципах, и на ее основе можно
строить модели искусственной психики роботов,
самообучающейся операционной системы нового поколения.
В главе 7 рассмотрен частный случай этой теории —
обучение языку, а именно - языковым конструкциям разного
уровня — морфологическим, синтаксическим и семантическим.
Обсуждается их локализация в мозге и приводятся
экспериментальные результаты машинного обучения языку.
Глава 8 иллюстрирует возможные пути
коммерциализации полученных ранее результатов: обсуждается ряд
амбициозных проектов-ледоколов, преодолевающих важные
технологические барьеры и открывающих новые горизонты для биз-
1.3. Благодарности
15
неса. Ее цель — мобилизовать инициативные команды для
реализации такого рода проектов, что может быть особенно
интересно именно предпринимателям.
Глава 9 описывает, как может выглядеть будущее лет
через 10-15 в случае успеха рассмотренных проектов и какие
проблемы нас там ожидают. Будем надеяться, что их
решение будет найдено в ходе новой научной революции, связанной
с раскрытием общих принципов мышления.
Наконец, в заключительной 10-й главе мы расширим
горизонт предсказаний, представив картину развития разума на
Земле на протяжении 3,5 миллиардов лет. Чтобы показать,
что разум присущ природе и, раз возникнув, он неизбежно
ускоряет свое собственное развитие. Так что события,
описанные в предыдущей главе, в какой-то степени неизбежны.
1.3. Благодарности
В этой книге мы рассматриваем человеческое мышление как
общественный феномен. Это касается и содержания самой
книги: идеи, сформулированные автором, рождались, как
правило, совместно - в спорах и обсуждениях с коллегами.
Поэтому я искренне благодарен всем, кто прямо или косвенно
принимал участие в ее рождении. Чтобы не утомлять
читателя, упомяну лишь организации и сообщества, в которых
проходили обсуждения затронутых в книге вопросов.
Начиная с фондов «Династия» и «Траектория», сообществ НТИ и
Нейронет, включая недавно созданный при МФТИ Центр
науки и технологий искусственного интеллекта, и, last but not
least, клуб визионеров по искусственному интеллекту http:
//opentalks.ai/thinktank.
Автор искренне надеется, что эта книга привлечет
внимание талантливых и амбициозных молодых людей и будет
способствовать развитию индустрии машинного интеллекта в
России.
Глава 2
Машинный интеллект
в современном мире
По тысяче мостов и
тропинок должны
протискиваться они к
будущему, и пусть между
ними будет всё больше
войны и неравенства: так
заставляет меня говорить
моя великая любовь!
Даже то, чего вы не
делаете, ткёт ткань всего
человеческого будущего;
даже ваше ничто есть
паутина и паук, живущий
кровью будущего.
Фридрих Ницше
«Так говорил Заратустра»
18 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
2.1. Машинный интеллект: время пришло?
Перед погружением в новую тему всегда полезно задуматься:
а окупятся ли предстоящие усилия? В этой главе мы взглянем
на технологию искусственного интеллекта с высоты птичьего
полета, рассмотрим ее место в современной цифровой
экономике. Наша задача — понять: это действительно всерьез и
надолго? Или это очередная модная тема, на время
захлестнувшая ТВ-каналы и обложки глянцевых журналов, пока
аудитория ей в очередной раз не пресытится.
Рис. 2.1. Глубокие нейронные сети, "рабочая лошадка"
современного искусственного интеллекта, находятся сегодня на
пике ажиотажа и завышенных ожиданий. За этим неизбежно
следуют разочарования, и лишь постепенно, по мере
взросления технологий - выход на плато продуктивности. Однако, по
мнению Gartner, плато продуктивности для глубокого
обучения ожидается довольно скоро - в пределах ближайших 5 лет
[Panetta, 2018]
2.1. Машинный интеллект: время пришло?
19
Действительно, такое уже не раз случалось в прошлом, и
всякий раз периоды энтузиазма и увлечения искусственным
интеллектом сменялись последующими разочарованиями (см.
рис. 2.1). Где гарантия, что и в этот раз возлагаемые на него
надежды не окажутся несбыточными? Чем сегодняшняя
ситуация отличается от того, что уже бывало раньше? Будет
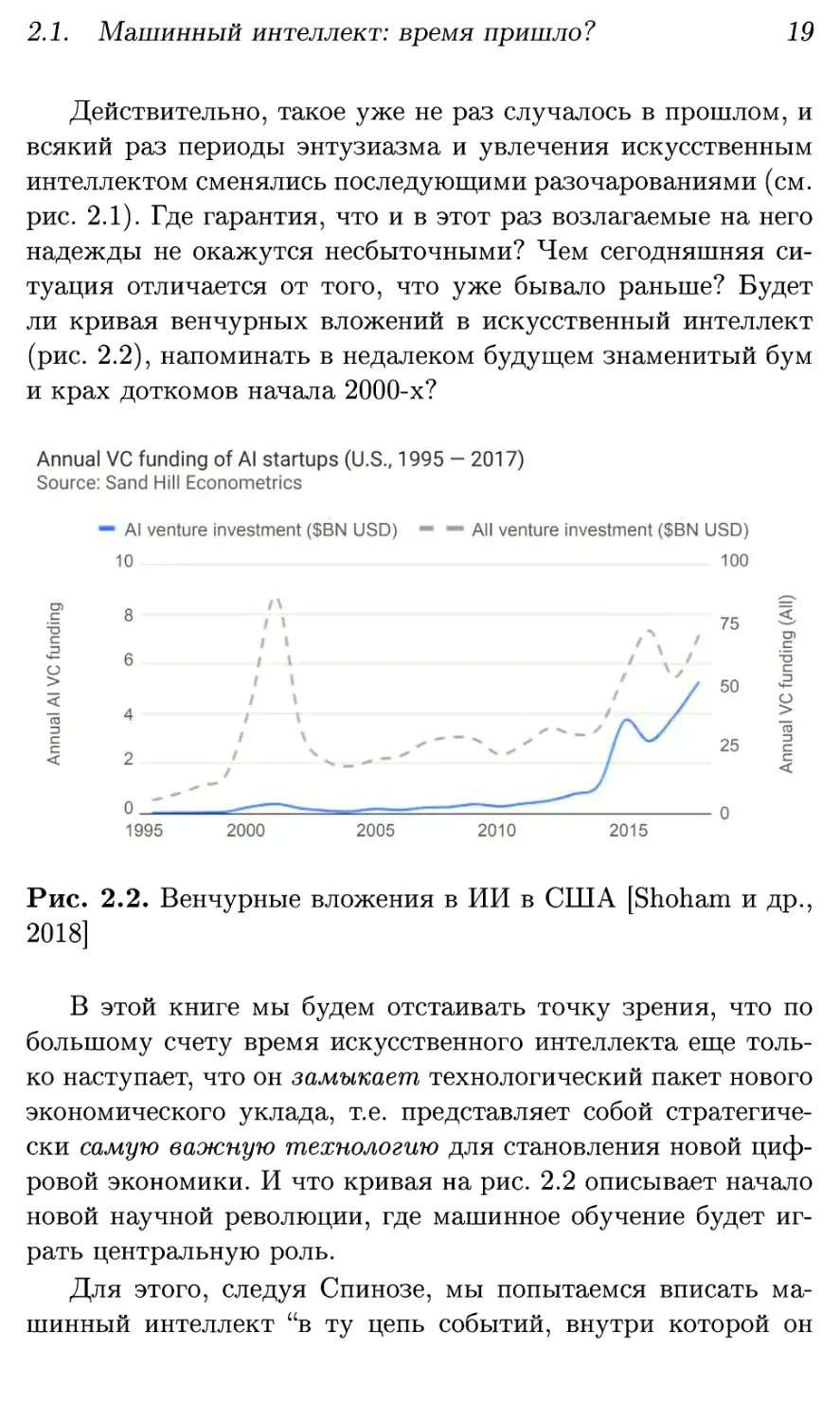
ли кривая венчурных вложений в искусственный интеллект
(рис. 2.2), напоминать в недалеком будущем знаменитый бум
и крах доткомов начала 2000-х?
Рис. 2.2. Венчурные вложения в ИИ в США [Shoham и др.,
2018]
В этой книге мы будем отстаивать точку зрения, что по
большому счету время искусственного интеллекта еще
только наступает, что он замыкает технологический пакет нового
экономического уклада, т.е. представляет собой
стратегически самую важную технологию для становления новой
цифровой экономики. И что кривая на рис. 2.2 описывает начало
новой научной революции, где машинное обучение будет
играть центральную роль.
Для этого, следуя Спинозе, мы попытаемся вписать
машинный интеллект "в ту цепь событий, внутри которой он
20 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
возникает с необходимостью, а не случайно". То есть взглянем
на развитие цивилизации как на процесс, в который
искусственный интеллект органично вписывается именно сегодня,
разрешая некую актуальную, назревшую проблему.
2.2. Преодоление барьера сложности
Развитие человеческой цивилизации можно рассматривать как
процесс постоянного обучения, т.е. накопления знаний.
Действительно, что отличает современного человека от его
далеких предков, ранних homo sapiens? Физиологически -
ничего, единственное различие - в объеме накопленных
человечеством знаний. Под знаниями здесь понимаются не столько
тексты, сколько операционные знания "на кончиках пальцах"
представителей всех человеческих профессий. Они
передаются как формально, в виде научных статей, технических
регламентов, должностных инструкций и т.д., так и неформально,
от наставника к ученику.
Эти знания направляют поведение людей и приводят в
действие всю мировую экономику. Их суммарный объем
определяет сложность "экономического организма" и объем
производимых экономикой благ. Блага цивилизации можно
измерять не деньгами, а количеством доступных товаров и услуг
[Beinhocker, 2006]. Чем разнообразнее товарная
номенклатура, тем больше возможностей имеет человек для
удовлетворения своих потребностей, тем выше степень развития
экономики. Иными словами, экономическое благополучие
прямо пропорционально количеству накопленных человечеством
знаний.
Рост благосостояния означает, что объем этих знаний
растет быстрее, чем численность населения. Действительно,
расселение homo sapiens по Земле началось около 100 тысяч лет
назад с африканской популяции численностью порядка 105
2.2. Преодоление барьера сложности
21
человек . Сегодня нас уже 10 , т.е. численность населения
увеличилась на пять порядков. Однако номенклатура
изделий за то же время увеличилась на десять порядков - с несколь
ких вариантов каменных орудий до 1010 (разнообразие
маркировки современных штрих-кодов UPC).
То есть количество накопленных знаний растет примерно
пропорционально квадрату числа людей, в головах которых
эти знания "установлены"2. Очевидно, что накапливаться с
такой скоростью бесконечно знания не могут. Рано или
поздно начнут сказываться естественные ограничения
человеческого мозга, из-за которых максимальный суммарный объем
памяти человечества растет с ростом населения линейно, т.е.
гораздо медленнее.
Гипотеза автора состоит в том, что это "рано или поздно"
уже наступило. Человечество уже столкнулось с проблемой
преодоления барьера сложности экономики с ее растущей
номенклатурой изделий и глобальной системой разделения
труда.
Предельно огрубляя ситуацию, предположим, что все
люди специализируются каждый на каком-то одном "изделии".
В первобытном обществе при минимальном разделении труда,
все были заняты производством одних и тех же изделий, т.е.
человеческие знания многократно дублировались. Рост
экономики происходил за счет все более рационального
использования совокупной памяти человечества - углубления
разделения труда и появления все большего числа профессий.
Современный мир, по-видимому, приближается к предельной
степени разделения труда, когда набор знаний каждого
специалиста становится уникальным. В этом пределе разнообразие
изделий приближается к своему теоретическому максимуму -
количеству людей (см. рис. 2.3).
1 В этой книге мы будем часто использовать оценки с точностью до
порядка, т.е. 105 надо понимать, как 0,3 • 105 -г- 3 • 105.
2 Мировой ВВП также пропорционален квадрату численности
населения [Коротаев и др., 2018], т.е. действительно растет пропорционально
объему знаний.
22 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
Рис. 2.3. Приближение мировой экономики к пределу
сложности, связанному с ограничениями человеческого мозга.
Здесь сложность мировой экономики С измеряется
количеством уникальных изделий, а N - численность человеческой
популяции
Хорошим индикатором приближения человечества к
этому пределу служит изменение закона роста численности
населения. На протяжении всей известной истории вплоть до
последней трети XX в. население Земли росло
приблизительно по гиперболе: пропорционально (to — £)-1 с точкой
сингулярности to « 2026 г. [Kremer, 1993; Von Foerster и др., 1960;
Капица, 1999]. Затем гиперболический рост начал
замедляться, и примерно с 2000 г. относительный темп роста населения
постоянно снижается. Можно трактовать этот факт как
свидетельство того, что текущий технологический уклад
исчерпал свой потенциал и больше не в состоянии поддерживать
прежние темпы роста.
Преодоление барьера сложности возможно только в
рамках нового цифрового технологического уклада.
2.3. Новый технологический уклад
23
2.3. Новый технологический уклад
По существующим представлениям экономика развивается
циклично, через технологические революции, в процессе
которых происходит смена технологических укладов [Перес, 2011;
Щедровицкий, 2016].
Каждый такой уклад характеризуется:
• обильными запасами относительно дешевого базового
ресурса;
• пакетом технологий, эффективно эксплуатирующим этот
ресурс;
• организацией рынка, соответствующей этому
технологическому пакету.
Переход к новому укладу возможен только после
формирования полного пакета новых технологий, который
постепенно складывается в недрах старого уклада, где каждая из них
по отдельности еще не может реализовать заложенный в ней
потенциал. Таким образом, всегда существует какая-то одна
замыкающая технология, без которой установление нового
уклада невозможно и появление которой инициирует новую
технологическую революцию. Несложно догадаться, что, по
мнению автора, именно такой замыкающей технологией
является сегодня искусственный интеллект.
Ресурсной базой уходящего индустриального
технологического уклада является дешевое и обильное углеводородное
топливо - энергетическая основа современной экономики.
Технологический пакет составляют технологии массового
машинного производства и глобальные транспортные сети. Наконец,
организацию сложных цепочек создания стоимости
обеспечивают транснациональные компании.
Что будет определять облик нового цифрового
технологического уклада?
24 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
2.3.1. Новый обильный и дешевый ресурс
Основным ограничивающим фактором индустриального
уклада, как мы выяснили, является не истощение энергетических
ресурсов, а ограниченные возможности человеческого мозга
по управлению все более сложной глобальной экономикой. "В
каждом продукте, которым мы пользуемся в начале XXI в.,
доля прямых и косвенных управленческих затрат составляет
от 50 до 80%" [Ковалевич и Щедровицкий, 2015].
Ответом на этот вызов стало появление и быстрое
развитие компьютерных технологий. Компьютеры позволили
вынести часть алгоритмов из головы человека в среду, где они
могут исполняться в миллионы раз быстрее. Соответственно,
все, что удается формализовать, переносится из головы
человека в эту новую искусственную цифровую среду.
Зародыш новой фазы в недрах старого уклада растет
экспоненциально, согласно закону Мура - удвоение
компьютерных мощностей и снижение удельной стоимости вычислений
каждые полтора-два года. Собственно, этот закон и
описывает появление у человечества нового обильного и дешевого
ресурса. Рано или поздно экспоненциально растущие
вычислительные мощности компьютеров должны превзойти
практически постоянные "вычислительные мощности" людей.
В каком-то смысле этот момент уже наступил, и сегодня
мы живем в эпоху все нарастающего навеса компьютерных
мощностей, все более превосходящих совокупную
"вычислительную мощность" людей (количество людей, умноженное
на максимальный объем их индивидуальных знаний и на
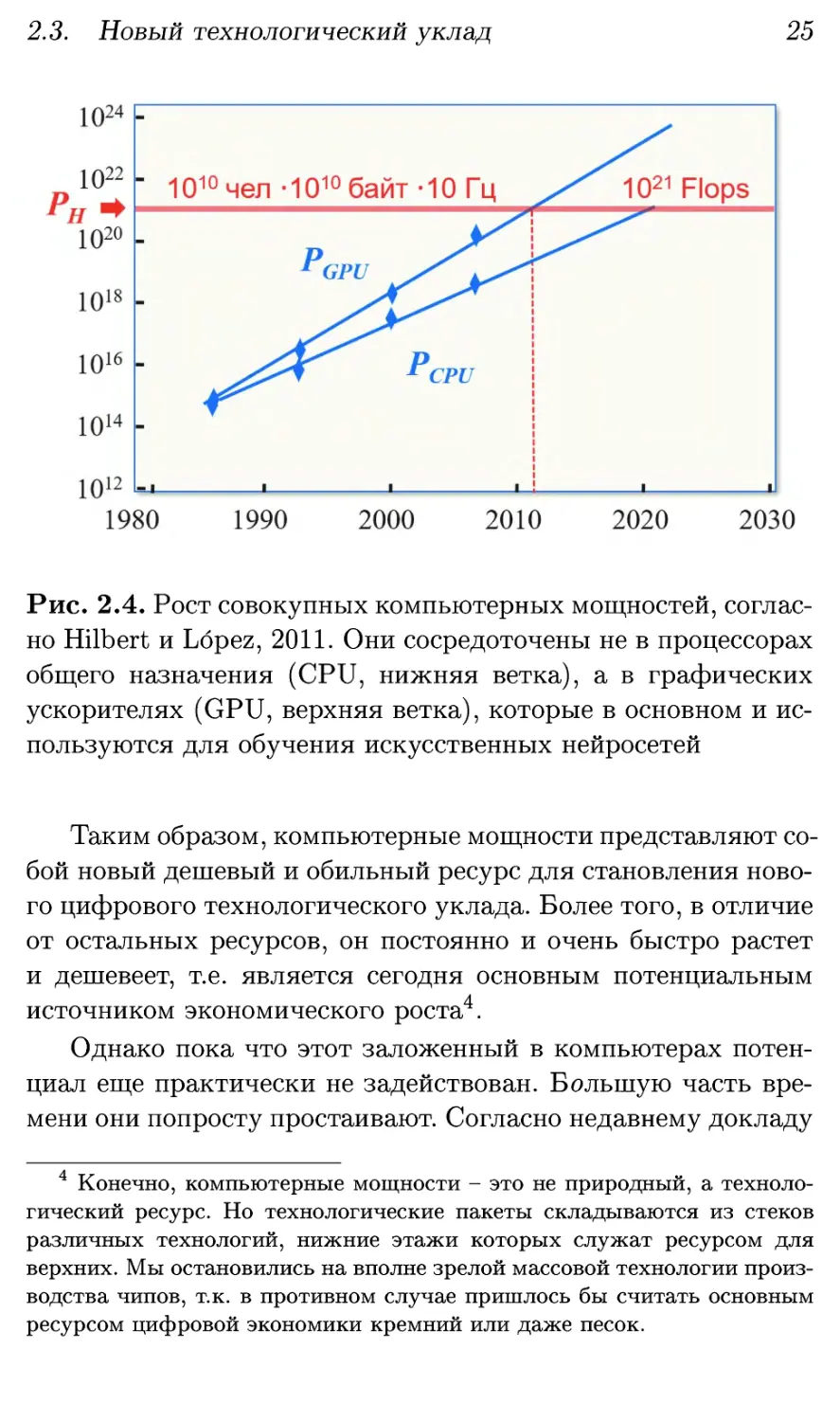
скорость доступа к этим знаниям)3 (см. рис. 2.4).
3 Предел индивидуальных знаний определяется скоростью усвоения
знаний человеком (10 байт в секунду - скорость речи). За 60 лет
непрерывного обучения по 12 часов в день человек может усвоить максимум
1010 байт. Соответственно, предельное количество знаний в головах всего
человечества: 1020 байт. Предельную "вычислительную мощность"
человечества (1021 байт/сек) получим, умножив эту величину на "тактовую
частоту" мозга ~ 10 Гц.
2.3. Новый технологический уклад
25
Рис. 2.4. Рост совокупных компьютерных мощностей,
согласно Hilbert и Lopez, 2011. Они сосредоточены не в процессорах
общего назначения (CPU, нижняя ветка), а в графических
ускорителях (GPU, верхняя ветка), которые в основном и
используются для обучения искусственных нейросетей
Таким образом, компьютерные мощности представляют
собой новый дешевый и обильный ресурс для становления
нового цифрового технологического уклада. Более того, в отличие
от остальных ресурсов, он постоянно и очень быстро растет
и дешевеет, т.е. является сегодня основным потенциальным
источником экономического роста4.
Однако пока что этот заложенный в компьютерах
потенциал еще практически не задействован. Большую часть
времени они попросту простаивают. Согласно недавнему докладу
4 Конечно, компьютерные мощности - это не природный, а
технологический ресурс. Но технологические пакеты складываются из стеков
различных технологий, нижние этажи которых служат ресурсом для
верхних. Мы остановились на вполне зрелой массовой технологии
производства чипов, т.к. в противном случае пришлось бы считать основным
ресурсом цифровой экономики кремний или даже песок.
26 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
McKinsey, развитие цифровых технологий в США последние
30 лет сопровождалось снижением темпов роста
производительности труда [Manyika и др., 2017].
По мнению автора, только машинный интеллект способен
раскрыть истинный экономический потенциал компьютеров,
позволяя решать проблемы лучше, быстрее и дешевле
человека.
2.3.2. Новый технологический пакет
Почему именно машинный интеллект? Что принципиально
нового добавит он к имеющимся компьютерным технологиям?
И почему этих технологий недостаточно для эффективной
эксплуатации растущих и дешевеющих компьютерных
мощностей?
Ответ лежит на поверхности. Просто совокупный объем
всех когда-либо созданных компьютерных алгоритмов
ничтожно мал по сравнению с объемом всех человеческих знаний.
Компьютеры, выражаясь бытовым языком, "быстрые, но
глупые". Соответственно, принятие основной массы решений по-
прежнему остается за людьми, а компьютеры играют
вспомогательную роль, осуществляя лишь те операции, которые
удалось формализовать и автоматизировать. В результате,
несмотря на все инвестиции в информационные технологии,
их влияние на экономику по-прежнему весьма ограничено.
Процесс формализации человеческих знаний идет крайне
медленно, т.к. алгоритмы создаются небольшой прослойкой
людей, программистами (их сегодня в мире порядка 10т).
Объем знаний в компьютерных программах ограничен
совокупными знаниями программистов, которые на три порядка
меньше общего объема человеческих знаний.
Если алгоритмы и дальше будут создаваться людьми, этот
процесс может затянуться навеки, с учетом скорости
обновления знаний. Единственный выход - избавиться от узкого
горла "ручного" программирования и перепоручить создание
программ компьютерам. Этот процесс автоматического по-
2.3. Новый технологический уклад
27
рождения алгоритмов как раз и обеспечивается машинным
обучением.
Таким образом, только машинное обучение,
подкрепленное достигнутым уровнем компьютерных мощностей,
способно в сжатые сроки резко повысить машинный интеллект до
человеческого уровня и загрузить эти мощности теми
задачами, которые сегодня доступны только людям.
Именно это мы и наблюдаем в последние несколько лет,
после того, как основной парадигмой искусственного
интеллекта стало т.н. глубокое обучение [LeCun, Bengio и др., 2015].
Именно с этим подходом связаны недавние успехи в задачах
компьютерного зрения, распознавания речи, машинного
перевода и т.д., где узкоспециализированный машинный
интеллект достигает уровня человека, т.е. может его частично
заменять.
Иными словами, именно искусственный интеллект
является замыкающей технологией нового технологического пакета,
необходимой и достаточной для начала новой промышленной
революции.
2.3.3. Новая организация рынка
В каждом укладе можно выделить базовые "клеточки" его
"экономического организма" [Щедровицкий, 2016]. Первая
промышленная революция породила фабрики, вторая -
транснациональные корпорации. Каким будет основной способ
организации рынка в новом цифровом укладе? Как в него
впишутся технологии искусственного интеллекта?
Основой индустриального уклада является массовое
производство и распределение товаров. Производители
наполняют рынок товарами, ориентируясь на массовый спрос. Всякий
нестандартный спрос остается неудовлетворенным.
В цифровом мире рынки настроены на индивидуальные
потребности. Возможность удовлетворить любой спрос
кратно расширяет объем рынка за счет эффекта длинного хвоста
[Андерсон, 2012]. Это касается также и рынка труда: как лю-
28 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
бой товар находит своего покупателя, так и любые
способности, знания и навыки находят свое применение в составе
временных проектных команд с уникальными комбинациями
уникальных компетенций. С передачей части работ
интеллектуальным агентам со сверхчеловеческими способностями
производительность труда может вырасти на порядки.
Тонкий баланс между спросом и предложением смогут
обеспечить цифровые платформы, оперирующие цифровыми
двойниками услуг, товаров и людей. Собственно, это мы сегодня
и наблюдаем: компании новой экономики предоставляют
исключительно персонализированные услуги: Google и Facebook
осуществляют индивидуальную доставку информации и
рекламы, Amazon и Netflix помогают подбирать товары и
развлечения по своему вкусу, угадывая потребности
пользователей по их цифровым следам.
Новые компании-платформы сегодня активно теснят
транснациональные компании прошлого уклада и растут темпами,
кратно превышающими рост мировой экономики (см. рис. 2.5,
2.6).
Рис. 2.5. Крупнейшими мировыми компаниями становятся
лидеры нового цифрового уклада [Desjardins, 2018]
2.4. Гонка за, искусственным интеллектом
29
Рис. 2.6. Лидеры нового уклада растут опережающими
темпами. Среднегодовые темпы их роста (20-60%) на порядок
превышают темпы роста мировой экономики (2,5-3%)
Это объясняется эффектом положительной обратной
связи, характерным для новой экономики, основанной на
машинном обучении: больше клиентов - больше данных - лучше
качество сервиса - еще больше клиентов. Ведь результаты
машинного обучения пропорциональны объему данных.
Поэтому компании новой экономики, успевшие первыми захватить
свой сегмент рынка, быстро уходят в отрыв.
2.4. Гонка за искусственным интеллектом
Понимание исключительной роли лидерства в экономике
нового уклада породило новую технологическую гонку - за
искусственным интеллектом. В последние пару лет свои
национальные стратегии в области искусственного интеллекта
появились сразу у двух десятков стран [Карелов, 2018].
Едва начавшись, новая гонка уже не уступает ядерной и
ракетной гонкам XX в. по масштабу инвестиций, которые при
этом продолжают расти двузначными темпами5. Лидируют в
5 Эти инвестиции обещают окупиться сторицей. Согласно Bughin и
др., 2018 к 2030 г. ИИ способен прибавить примерно $13 трлн к общим
объемам выпуска и 1,2% к годовым темпам роста мирового ВВП.
30 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
ней с большим отрывом ее инициаторы - США и Китай (см.
рис. 2.7), однако цифровую экономику активно осваивают и
игроки меньшего масштаба, например Израиль6.
Рис. 2.7. Вложения в главные технологические гонки -
ядерную, ракетную и за искусственный интеллект. Данные по
Манхэттенскому проекту и проекту Аполлон взяты из Вики-
педии и пересчитаны в доллары 2016 г., вложения в
искусственный интеллект в 2016 г. - оценка Bughin и др., 2017
Участники гонки спешат включиться в глобальные
цепочки создания стоимости набирающей силу новой экономики, с
гораздо более высокой производительностью труда7.
Оставшиеся в стороне страны будут все больше отставать
от лидеров по уровню, качеству и продолжительности жизни
с риском отстать окончательно и превратиться в failed states.
Их суверенитет будет носить в значительной степени иллю-
6 В 2017 г. в израильские стартапы было вложено $2 млрд, на 70%
больше, чем в 2016 [Press, 2018].
7 К примеру, выручка Apple в расчете на одного сотрудника - около
$2,2 млн, в 7 раз выше, чем у Роснефти и в 70 раз выше, чем у
Ростелекома [Завадовская и Карпов, 2017].
2.5. Вызов России
31
зорный характер, т.к. все основные экономические решения
будут приниматься без их участия и без учета их
интересов. Вспомним незавидную участь Китая и Индии, которые
не вписались в первую промышленную революцию. А ведь до
нее они были технологическими лидерами и в совокупности
производили более 2/3 мирового ВВП!
С этих позиций главная угроза современной России -
оказаться одной из таких стран, дополнить экспорт сырой нефти
экспортом сырых данных, оставив все их высокие переделы и
всю прибавочную стоимость более развитым экономикам.
2.5. Вызов России
Сегодня для России открывается редкое окно возможностей -
поучаствовать в становлении новой экономики более-менее на
равных, застолбить за собой какие-то секторы быстро
растущих новых рынков, пока лидеры гонки не ушли в отрыв.
Конечно, у развитых стран, главным образом у США,
имеется существенный задел. Но это отнюдь не предопределяет
победу прежних лидеров в новой гонке. Так, Microsoft и Intel
не удалось утвердить свое лидерство на новом для них
рынке мобильных устройств, a Google, как ни старался, так и не
смог составить конкуренцию Facebook в социальных сетях.
Вышедшая недавно замечательная книга [Lee, 2018]
обосновывает высокие шансы Китая догнать и перегнать США в
этом соревновании. Стратегия Китая опирается на его
естественные конкурентные преимущества - лидерство в
мобильных платежах и электронной торговле, обилие порождаемых
ими данных, высококонкурентную среду малого и среднего
бизнеса.
Стратегия России тоже должна опираться на ее
конкурентные преимущества. В силу исторических обстоятельств
у нынешних россиян нет присущей китайцам и американцам
32 МАШИННЫЙ ИНТЕЛЛЕКТ В СОВРЕМЕННОМ МИРЕ
предпринимательской хватки8. Нет у нас ни емкого быстро
растущего внутреннего рынка, ни дешевой, как когда-то в
Китае, рабочей силы для привлечения в страну иностранных
инвестиций.
В этих обстоятельствах копирование уже известных
технологических решений и перенос на российскую почву уже
состоявшихся бизнес-схем - малопродуктивны. У нас здесь нет
конкурентных преимуществ для завоевания значимых
сегментов мировой цифровой экономики.
Зато у нас в силу тех же обстоятельств есть
исторически сильные физико-математические и программистские
школы. Сегодня это реальное преимущество, т.к. центры
создания стоимости перемещаются из производства в разработку
и дизайн, и основной производительной силой становится
интеллект разработчиков [Агамирзян, 2016]9. Россия является
поставщиком этих элитных кадров, не получая взамен
практически ничего.
Вместо этого Россия могла бы позиционировать себя как
"всемирное конструкторское бюро" в области машинного
интеллекта, сосредоточившись на решении фундаментальных
проблем и взятии технологических барьеров, открывающих
возможности для быстрого роста новых российских компаний
с глобальными амбициями10. Эти компании — центры
компетенций мирового уровня — породят платежеспособный спрос
на лучшие российские кадры и будут осаждать их у себя. Они
же станут покупателями успешных венчурных проектов для
ускорения своего роста, обеспечивая внутренний спрос для
российской венчурной индустрии.
В США предприниматели составляют 7,2% трудоспособного
населения, в России - 0,4%. В России в малом и среднем бизнесе занято около
25% населения, тогда как в развитых странах - от 60 до 70%, а в Китае -
80% [ПМЭФ-2017, 2017].
В продукции той же Apple 89% стоимости составляют дизайн,
инжиниринг и бренд, а на производство компонентов и сборку приходится
лишь 11% [Агамирзян, 2016].
1 Компании старого уклада органически не способны к подобного рода
рывкам.
2.5. Вызов России
33
Если исходить из современной доли России в мировом ВВП
в списке мировой экономической элиты Forbes Global 2000
должно быть не менее 2%, т.е. более 40 российских компаний.
Сегодня их всего 25, на 4 компании меньше, чем десятилетие
назад, и их число будет и дальше неуклонно снижаться по
мере вытеснения из этого списка компаний уходящего уклада.
Следовательно, российская стратегия должна
предусматривать создание в ближайшие 10-15 лет, пока окно
возможностей не закрылось, нескольких десятков
высокотехнологичных компаний с оборотами не менее миллиарда долларов,
масштаба АФК «Система». Это настоящий вызов для России, но
именно на такой результат, по мнению автора, должна
ориентироваться российская стратегия развития цифровой
экономики. Только так Россия сможет создать у себя значимую
компетенцию в этой стратегически важной области11.
В этой книге красной нитью проходит мысль о
концентрации на решении фундаментальных проблем, о запуске
соответствующих проектов-"ледоколов", проламывающих лед и
открывающих новые торговые пути. Россия является
мировым лидером в ледокольном классе. Почему бы нам не занять
соответствующую достойную нас нишу в области
искусственного интеллекта?
"Настало время, чтобы человек поставил себе цель свою.
Настало время, чтобы человек посадил семя своей высшей
надежды" - так говорил Заратустра.
Количество компаний в экономике обратно пропорционально их
размеру, так что на одну крупную приходятся десятки средних и сотни
малых компаний. Просто крупные компании проще "считать по головам",
как это делает Forbes.
Глава 3
Основы машинного
обучения*
Я — доискиваюсь
основания ... пяди
основания достаточно для
меня: если только оно
действительно есть
основание и почва! — пяди
основания: на ней можно
стоять.
Дух есть жизнь, которая
сама режет по живому:
собственным страданием
увеличивает она своё
знание, — знали ли вы
уже это?
Фридрих Ницше
«Так говорил Заратустра»
* Материал повышенной сложности!
36
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
3.1. Основные понятия
3.1.1. Машинное обучение как наука
Машинное обучение — это науках о системах, способных к
обучению, и об интеллекте, как результате такого обучения,
это наука о той части природы, которая научилась
учиться. Она естественным образом дополняет физические
науки, которые ограничиваются системами, не способными к
обучению, и идейно близка биологическим наукам, поскольку
жизнь — это исторически первая часть природы,
научившаяся учиться.
Эволюция биосферы есть не что иное, как постоянное
накопление знаний о мире в генетическом коде биоты. Алгоритм
такого обучения (наследственность - изменчивость - отбор)
был открыт Дарвиным и позднее доработан с учетом
данных генетики. Подсмотренные у жизни генетические
алгоритмы — суть частный случай машинного обучения [Mitchell,
1998].
Мозг животных является другим примером систем,
способных к обучению. Мозг кодирует алгоритмы поведения, и
его конструкция является важнейшим фактором в борьбе за
существование. Способность мозга к обучению является
ценным приспособительным признаком, т.к. позволяет
адаптироваться к самым разным внешним обстоятельствам за счет
накопления жизненного опыта. Соответственно, в процессе
эволюции мозг постоянно совершенствовался в своей
способности учиться и хранить накопленные знания1. Мозг человека,
к примеру, успевает накопить в процессе жизни на порядки
больше информации, чем содержится в его генотипе.
Еще одним примером обучающейся системы является
человеческая цивилизация в целом, накапливающая и передаю-
1 В мозгу высших животных экспрессируется до 80% всех генов [Lein
и др., 2007], т.е. их геном, в основном, есть спецификация конструкции
мозга.
3.1. Основные понятия
37
щая знания от поколения к поколению с помощью главного
изобретения человека — языка.
Однако разумное поведение могут проявлять не только
живые, но и искусственные системы. До недавних пор такое
поведение программировалось людьми, а компьютеры
просто исполняли заложенные в них программы. Но буквально
на наших глазах компьютеры начинают обретать способность
учиться. При этом они способны учиться в миллионы раз
быстрее, чем мозг, а также накапливать и передавать эти
знания другим машинам. И можно не сомневаться, что в
результате этой техноэволюции появится новый вид интеллекта —
машинный интеллект. И будет это не через 100 лет, а на
наших с вами глазах и с нашим участием. Буквально за
несколько последних лет компьютеры научились делать практически
все, что человек делает меньше, чем за секунду на
подсознательном уровне — освоили все виды распознавания образов.
На очереди — сознательное мышление и человеко-машинное
общение на естественном языке.
Машинный интеллект будет главной наукой XXI в.2, вслед
за физикой и смежными науками, доминировавшими в XX в.
Физика дает нам энергию и возможность производить
множество полезных вещей. Машинный интеллект сделает эти
вещи умными. Одни более, другие — менее, но окружающие нас
вещи вскоре обретут свою волю, свои цели и будут активно
взаимодействовать с нами и между собой.
Инженеры прошлого конструировали механические и
электронные машины, слепо исполняющие заложенные в них
программы. Инженеры XXI в. будут конструировать
искусственные личности, способные думать, учиться и испытывать
эмоции. А также создавать из них коллективный разум. Так и
только так мы сможем познавать самих себя, свой
собственный разум. Ибо, по выражению Ричарда Фейнмана: "Чего
не могу воссоздать, того не понимаю".
2 Вместе со смежными науками, конструирующими разные виды
интеллекта, включая интеллект биологических и социальных систем.
38
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
3.1.2. Определения: разум, интеллект и сознание
Значения слов в языке определяются характером их
употребления. Такие важные слова, как разум, интеллект и
сознание, по-разному употребляются разными людьми, так что их
значения довольно размыты. Не претендуя особо на строгость
определений, поясним, как мы будем их понимать в этой
книге.
Начнем с более простых понятий информации и
алгоритмов ее обработки вычислительными машинами. Последние
представляют собой устройства, способные четко различать
свои отдельные состояния (хранить информацию, или
данные) и организовывать переходы между ними (обрабатывать
информацию, или исполнять алгоритмы). Если устройства
обладают этими свойствами, мы можем отвлечься от того, из
чего они построены, т.е. отвлечься от материального и
сосредоточиться на идеальном — структурах данных и
алгоритмах. Это очень удобные и плодотворные абстракции.
Например, когда мы переписываем файл из компьютера на флешку,
мы считаем, что мы его сохранили как определенный
нематериальный объект, отвлекаясь от того, что носители этого
объекта разные и подчиняются разным физическим законам.
Когда мы говорим об алгоритмах, мы отвлекаемся от
конкретных законов движения материи, с помощью которых они
осуществляются в конкретных машинах.
Для понимания алгоритмов работы мозга мы будем
рассматривать его как биологическую машину. Это звучит
непривычно, поскольку мы привыкли к относительно простым
механическим машинам и, пусть более сложным, но все равно
довольно "тупым" компьютерам. Но в этой книге машины
понимаются более широко, раз уж мы собираемся наделить их
разумом.
Определенный класс алгоритмов машинного обучения
наделяет машины способностью накапливать знания о внешнем
мире в процессе взаимодействия с ним и использовать эти
знания для достижения поставленных целей. В этой книге мы
3.1. Основные понятия
39
будем полагать родовым признаком разума его способность
ставить и достигать какие-то цели в заранее
непредсказуемых условиях. Соответственно, мы будем исходить из такого
определения:
Разум - это алгоритм усложняющегося
целенаправленного адаптивного поведения.
Способность к усложнению алгоритмов, т.е. к
машинному обучению, является, с нашей точки зрения, ключевой в
теории машинного интеллекта. Чем большими знаниями
обладает машина, тем она разумнее, и тем сложнее может быть
ее поведение.
Интеллект - это частный случай разума, когда
поведением является сам процесс мышления, т.е. случай "чистого
разума" - соответствующий критериям разумности алгоритм
управления своим собственным исполнением. Такое
определение соответствует интуитивному пониманию интеллекта как
способности решать произвольные "творческие" задачи,
алгоритм решения которых заранее неизвестен. Далее мы не
будем без нужды акцентировать различия между интеллектом
и разумом, например в привычных словосочетаниях типа
машинный интеллект.
Устоявшийся термин искусственный интеллект (или
сокращенно ИИ), под которым обычно понимают алгоритмы
решения тех или иных когнитивных задач на уровне или лучше
человека, будет употребляться преимущественно в
социальном контексте, например при обсуждении вытеснения людей
из производства.
Наконец, сознание - это субъективное ощущение
процесса мышления, способность разума или интеллекта ощущать
ход своего исполнения. Это более сложное понятие, имеющее
только косвенное отношение к теме данной книге, и мы
отложим его обсуждение до главы 5.
Поскольку алгоритмы исполняются машинами, то
логично говорить о машинном интеллекте независимо от
естественного или искусственного происхождения машины - но-
40
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
сителя интеллекта. Разум, как и любую программу, можно
переносить с машины на машину. Иными словами, разум можно
моделировать, имитируя с той или иной точностью
соответствующие алгоритмы.
Итак, разуму соответствует определенный класс
алгоритмов, которые способны усложняться в процессе своего
взаимодействия с внешней средой. Напомним, что согласно
Колмогорову любому алгоритму А можно приписать его
сложность С (А), определяемую как наименьшая длина
реализующей этот алгоритм компьютерной программы.
Соответственно, мы получаем возможность измерять уровень интеллекта
через сложность соответствующего алгоритма.
Обучению, т.е. накоплению знаний, соответствует
повышение сложности алгоритма поведения в процессе
взаимодействия с внешней средой:
C(At)>C(Av), t>t'.
Такое взаимодействие необходимо, т.к. только оно может
служить источником новой информации, не содержавшейся в
первоначальной программе .
Полезность накапливаемых знаний определяется
способностью алгоритма к целесообразному адаптивному
взаимодействию со средой. В биологических системах, например,
максимизируется способность популяции к выживанию. В
искусственный интеллект могут быть заложены другие цели,
например различные варианты трех законов роботехники.
Если задана цель поведения, то подразумевается, что
можно отличить правильные действия от ошибочных. А
поскольку речь идет об адаптивном поведении в условиях
неопределенности, то целесообразное адаптивное поведение
характеризуется понижением вероятности ошибок со временем, т.е.
обучение минимизирует риски неправильного поведения:
C(At)<C{Atf), t>tf,
3 Без внешней среды любое состояние памяти машины At получается
автоматически, т.е. имеет ту же сложность, что и Aq.
3.1. Основные понятия
41
где С (At) — цена ошибочного поведения алгоритма А в
момент t. Таким образом, в конечном итоге важны не сами
знания, а основанное на них правильное поведение.
Очевидно, что чем сложнее алгоритм, тем шире
репертуар возможных программ поведения, и тем больше
возможности машины к достижению своих целей. Задача машинного
обучения — использовать эти возможности с максимальной
эффективностью.
3.1.3. Машинное обучение: модели
Пусть взаимодействие со средой описывается получением
некоторого набора эмпирических данных D, конкретный вид
которых нам пока не важен.
Задачей обучения является оптимальное обобщение этих
эмпирических данных, т.е. построение модели, позволяющей
предсказывать новые события D' и правильно реагировать на
них, основываясь на известном опыте прошлого. Такие
предсказания в общем случае носят вероятностный характер:
обобщением имеющегося набора данных служит некая гипотеза
h — модель вероятностного порождения данных P(D\h).
Насколько хорошо эта гипотеза соответствует
наблюдаемым данным D, определяется т.н. эмпирическим риском L(D\h).
Эмпирический риск можно измерять в битах — сколько
памяти требуется для кодирования ошибок модели. Чем точнее
модель, тем меньше L(D\h), тем компактнее кодируются
наблюдаемые данные с помощью модели.
Как мы вскоре убедимся, обучение теснейшим образом
связано со сжатием данных с помощью моделей.
Действительно, случайные данные несжимаемы. Любое сжатие данных
основано на присущих им закономерностях. Чем больше
закономерностей мы сможем обнаружить, тем большего сжатия
данных удается достичь и тем сильнее предсказательная
способность нашей модели.
Естественно, мы хотим, чтобы выбранная нами гипотеза
h являлась наилучшим возможным приближением к реально-
42
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
сти. А именно, чтобы она минимизировала ожидаемую
среднюю ошибку предсказания данных с ее помощью, т.н. ошибку
обобщения:
C0(h) = (L(D\h))P{Dlhoy (3.1)
Здесь ho — истинная модель порождения данных, а
усреднение производится по всем возможным выборкам данных
одинакового размера \D\. Проблема состоит в том, что нам
она неизвестна и может даже не принадлежать к выбранному
нами классу гипотез. Таким образом, ошибка обобщения —
это ненаблюдаемая величина. То есть мы хотим
оптимизировать то, что не можем измерить. В этом и состоит
фундаментальная проблема теории обучения, т.к. оптимизировать мы
можем лишь измеримые величины.
Таковой является наилучшее в выбранном классе гипотез
приближение к (3.1):
C(h) = (L(D\h))P{Dlh). (3.2)
Ее-то мы минимизировать можем. Для этого достаточно,
чтобы более вероятные наборы данных предсказывались
лучше, чем более редкие. А именно, эмпирический риск должен
быть связан с вероятностью порождения данных
соотношением:
L(D\h) = -log P(D\h) + const, (3.3)
где const — нормировочная константа, а логарифм берется по
основанию 2, если мы измеряем риск в битах.
Действительно, согласно известной теореме Шеннона об
оптимальном кодировании, средняя длина закодированного
сообщения будет минимальной, если длина кода символов L{x)
связана с их частотой Р(х) соотношением L(x) = — logP(x) +
const, т.е. чем чаще встречается символ, тем короче должен
быть его двоичный код. Любой другой код приведет к
большей ожидаемой длине сообщения.
Таким образом, если мы умеем измерять эмпирический
риск L(D\h), мы можем определить и оптимальную модель
3.1. Основные понятия
43
порождения данных P(D\h) согласно (3.3), минимизирующую
оценку ошибки обобщения (3.2).
Таким образом, оптимальной гипотезе соответствует
максимальное сжатие данных. Развивая эту мысль, мы можем
подбирать и оптимальную сложность моделей.
3.1.4. Оптимальная сложность моделей
Пусть гипотеза h выбирается из некоторого класса гипотез Н
с помощью настроечных параметров, определяющих ее место
в этом классе. Сложность модели Н определяется требуемым
для ее описания объемом памяти L(h\H), т.е. возрастает с
ростом числа настроечных параметров \Н\. С другой стороны,
более сложная модель может лучше описывать наблюдаемые
данные, т.е. L(D\h) уменьшается с ростом \Н\. Расширение
класса гипотез также приближает оценку ошибки обобщения
(3.2) к истинной ненаблюдаемой величине (3.1).
Логично предположить, что оптимальной модели
соответствует максимально возможное сжатие данных с помощью
модели, т.е. суммарной длины описания данных и модели:
L(D, h) = L(D\h) + L{h\H). (3.4)
Действительно, именно эта суммарная длина описания и
ограничивает сверху ненаблюдаемую ошибку обобщения (3.1).
Это один из важнейших результатов теории обучения.
Эти соображения лежат в основе принципа минимальной
длины описания (Minimum Description Length, MDL [Rissanen,
1978]). Согласно этому принципу оптимальная модель
должна минимизировать общую длину описания данных и модели
(3.4):
hMDL = argminL(L>,/i). (3.5)
h
Заметим, что первый член в (3.4) пропорционален объему
данных \D\, а второй — количеству настроечных параметров
модели |Д"|. Таким образом, имеются два предельных случая.
44
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Если число параметров модели мало по сравнению с
объемом обучающей выборки, |Д"| <^ |D|, то длиной описания
модели в (3.4) можно пренебречь, и мы можем просто
минимизировать наблюдаемую ошибку обучения. Это
традиционный подход математической статистики. Соответствующий
критерий оптимальности известен как принцип максимума
правдоподобия (Maximum Likelihood, ML):
hjML = sigmin L(D\h) = argmaxP(£)|/i). (3.6)
h h
Для простых статистических моделей типа линейной
регрессии и относительно большого числа данных это
приближение отлично работает. Однако слишком простые модели не
оптимальны, если имеющийся объем данных позволяет
обучить более сложные модели с меньшей ошибкой
предсказаний.
В противоположном пределе слишком сложных моделей
с \Н\ ^> |£)|, характерном для современных глубоких нейро-
сетей, содержащих подчас сотни миллионов параметров,
возникает т.н. проблема переобучения (overfitting): большое число
параметров позволяет уменьшать ошибку обучения вплоть до
нуля, т.е. попросту запоминать конкретные наборы данных,
вместо того, чтобы обобщать их. Переобученная модель не
имеет никакого отношения к истинной и может иметь
большую ошибку обобщения. Поэтому обучение достаточно
сложных моделей необходимо регуляризироватъ, накладывая на
их параметры различные ограничения, искусственно
снижающие сложность модели. Регуляризация обучения — одна из
сквозных тем теории машинного обучения, и далее мы будем
к ней постоянно возвращаться.
Идеальное обучение использует модели оптимальной
сложности, соответствующие принципу минимальной длины
описания. Такие модели обладают наилучшей предсказательной
силой. Именно суммарная длина описания L(D,/i), согласно
3.1. Основные понятия
45
Vapnik, 1998, ограничивает ненаблюдаемую среднюю
ожидаемую ошибку на новых данных:4
Co(h) <2-L(D,h). (3.7)
Еще один глубокий результат теории обучения — оценка
оптимальной сложности модели. Согласно Rissanen, 1978
длина описания оптимальной модели равна
L(hMDL\H) = \H\ log y/\D\. (3.8)
Таким образом, сложность алгоритма действительно
возрастает по мере обучения, однако скорость накопления
знаний падает с ростом числа примеров. То есть быстрее
всего мы учимся на начальных стадиях обучения (в детстве),
а дальнейшее совершенствование модели достигается со все
большим трудом.
При конечном объеме данных точность определения
параметров модели всегда конечна: среднее число бит на степень
свободы равно log y|^D|. Более точное задание параметров
есть превышение точности: имеющийся набор данных не
позволяет определить их точнее. Следовательно, результат
обучения дается не точкой, а множеством в пространстве
параметров, объем которого определяет (3.8). Определить и
использовать его форму позволяет наиболее общая,
байесовская, трактовка обучения.
3.1.5. Байесова трактовка обучения
Выше мы рассмотрели выбор оптимальной модели
порождения данных P(D\h). Обучение в более общей постановке
предполагает решение обратной задачи: по имеющимся данным
4 Точнее, с вероятностью не меньшей 1 — rj: £o(h) < 2[L(D, h) — log77].
Для достаточно сложных моделей и больших массивов данных
L(D,h) ^> 1 и последним членом в правой части можно пренебречь,
т.е в широком диапазоне параметра уверенности rj мы получаем оценку
(3.7). Вапник также показал, что эту оценку нельзя улучшить более чем
вдвое.
46
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
выяснить вероятность различных гипотез о способе
порождения этих данных P(h\D). Это и есть то самое множество
гипотез, о котором шла речь выше.
Байесов подход к обучению, основанный на решении
обратной задачи, наиболее последователен, при том что в
общем виде она решается ав одну строку", и это решение,
следующее из общих принципов теории вероятностей, было
известно уже в XVIII в. Действительно, если трактовать как
выбор гипотезы, так и наблюдение данных в вероятностном
смысле и записать согласно определению условных
вероятностей P(D,h) = P(h\D)P(D) = P(D\h)P(h), получим теорему
преподобного Байеса:
F^D)- P(D) ~ ZhP(D\h)P(hY {™}
Для фиксации терминологии запишем эту
основополагающую формулу в словесном виде:
_ . Likelihood • Prior
Posterior = . .
Evidence
Как видим, решение обратной задачи требует
формализации наших априорных (prior) предположений P(h) о степени
вероятности той или иной гипотезы. Подобного рода
ограничение на множество гипотез, в котором ищется решение, в
теории обратных задач называют регуляризацией.
Нетрудно заметить, что байесовский подход к обучению
соответствует принципу минимальной длины описания. Так,
наиболее вероятная гипотеза (Maximum Posterior)
соответствует наиболее компактному представлению данных:
hMP = argminL(/i|£>) = aigmm[L(D\h) + L(h) - L(D)} =
h h
= arg min [L(D | h) + L(h)] = hMDL-
h
3.1. Основные понятия 4 7
Гипотезы всегда выбираются в рамках той или иной
модели Н, от которой зависят все вероятности в (3.9):
РШП т_РШ,Н)Р{ЩН)
Р(/г|дя)- рЩИ) •
Фундаментальный характер теоремы Байеса позволяет в
едином ключе сравнивать между собой не только гипотезы
/i, ной различные модели регуляризации Н. Насколько
правдоподобно выглядит объяснение данных моделью определяет
знаменатель формулы Байеса
P(D\H) = £ft P(D\h, H)P(h\H) = Y,h P(D, h\H). (3.10)
Поэтому его и называют Evidence, т.е. правдоподобие или
обоснованность данной модели Н. Принцип максимизации
Evidence позволяет не только определить апостериорное
распределение гипотез в рамках заданной модели, но и выбрать
модель оптимальной сложности, которая лучше других
объясняет имеющиеся данные.
3.1.6. Ансамбли гипотез
Подчеркнем, что оптимальная модель, по Байесу, состоит из
ансамбля гипотез. Считается, что в предсказаниях участвуют
все гипотезы, каждая со своей апостериорной вероятностью.
И это действительно имеет смысл, т.к. легко показать, что
ансамбль в целом обладает лучшей обобщающей способностью,
чем любой из его представителей, включая наиболее
вероятную гипотезу.
Действительно, длина описания данных с помощью всего
ансамбля меньше, чем длина описания с помощью наилучшей
гипотезы:
L(D\H) = - log P(D\H) = -log^ftP(A Л|Я) <
< - log P(D, hMp\H) = L (D, hMp\H),
48
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
поскольку любой член суммы положительных слагаемых под
логарифмом меньше, чем вся сумма. Следовательно, и
обобщающая способность предсказаний с помощью ансамбля
выше, чем обобщающая способность любой, даже наилучшей из
его гипотез! Действительно, каждая из апостериорных
гипотез страдает в той или иной степени от переобучения. Всегда
можно предложить примеры, на которых она будет давать
неправильные предсказания. Ансамбль в целом, подобно
коллективу экспертов, более устойчив к переобучению и
обладает лучшей предсказательной способностью. Качественно этот
факт иллюстрирует рис. 3.1.
При таком подходе вполне естественно, что наилучшей
моделью считается не та, в которой существует наиболее
правдоподобная гипотеза, а та, в которой доля правдоподобных
гипотез достаточно велика. Максимизация Evidence
выражает именно эту точку зрения (см. рис. 3.2). Поскольку
интеграл Evidence определяется не только высотой, но и шириной
апостериорного пика в пространстве гипотез, то наиболее
вероятная гипотеза в оптимальной, по Байесу, модели должна
не просто соответствовать данным, но и быть одновременно
наиболее робастной, т.е. наименее чувствительной к
вариациям своих параметров.
Можно сказать, что максимизация Evidence реализует
известный принцип бритвы Оккама: предпочтение отдается
наиболее простой модели, способной объяснить эмпирические
данные. Этот факт иллюстрирует рис. 3.3. Как видно из этого
рисунка, байесовский подход отсеивает не только модели, не
соответствующие наблюдаемым данным, но и излишне сложные
модели, могущие объяснить большее разнообразие данных5.
Байесово обучение накапливает знания кумулятивно. С
каждой новой порцией данных облако гипотез становится все
5 Модели, которые в принципе могут объяснить любые данные,
К. Поппер предлагал считать "ненаучными", т.к. никакой эксперимент
не в состоянии их опровергнуть. По Байесу, в силу условия нормировки,
их Evidence, действительно, стремится к нулю.
3.1. Основные понятия
49
к
Рис. 3.1. Иллюстрация байесовского подхода к
предсказаниям. Данные представляют собой набор точек из двух классов.
Гипотеза классифицирует данные в соответствии с их
расположением относительно линии разделения классов, в данном
случае — прямой. Звездой отмечена новая точка,
отсутствующая в обучающей выборке. Наиболее вероятная гипотеза кмр
классифицирует эту точку как «круг». Однако, среди
других возможных гипотез нет единства: некоторые, такие как
/ii, голосуют за «крест», другие, как h<i - за «круг». Тем
самым, предсказание ансамблем гипотез дает возможность
понять, что новая точка лежит далеко от обучающей выборки
и оценить надежность ее классификации
более компактным. Априорной функцией для следующего
этапа обучения служит апостериорная функция предыдущего
этапа. При этом на каждом этапе происходит накопление
знаний, т.к. длина описания модели увеличивается.
Действительно, из формулы Байеса (3.9) для разницы длины описания
апостериорной и априорной гипотез имеем:
L{h\D) - L(h) = L(D\h) - L(D).
50
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
P(D\h)P(h\Hx)
P(D\h)p(h\H2)
Рис. 3.2. Из двух моделей, Н\ и #2, более предпочтительной,
по Байесу, является вторая, с большей Evidence (площадь под
кривой), несмотря на то, что наилучшая гипотеза в Hi лучше
объясняет данные. Зато Hi гораздо более чувствительна к
вариациям своих параметров, чем Н^
Усредняя по ансамблю (•) = (-)р(м получим для прироста
длины описания модели:
(L(h\D) - L(h)) = log (P(D\h)) - (log P(D\h)) > 0,
т.к. log(P) > (logP).
3.1.7. EM-алгоритм
Оптимальную байесовскую модель можно находить
итерационно: при данных параметрах регуляризации Н1 оценить
вероятности гипотез P{h\D,Hl), затем подправить параметры
регуляризации
Ht+i
и т.д. Рассмотрим этот весьма
распространенный способ обучения несколько подробнее.
Оптимальной модели соответствует минимальная длина
описания данных L{D\H) — —log^2hP(D,h\H). Чтобы
избавиться от суммирования под знаком логарифма, существует
хорошо известный трюк — введение добавочной независимой
переменной V(h) (неизвестной нам функции распределения).
3.1. Основные понятия
51
Рис. 3.3. Максимизация Evidence предполагает выбор
наиболее простой модели объяснения данных. Модель Н\ не
соответствует данным Do. Модель Н% может объяснить не только
имеющиеся данные, но и широкий круг других исходов
эксперимента. Условие нормировки автоматически понижает ее
Evidence. По Байесу, эмпирические данные свидетельствуют
в пользу модели Н^
Усредняя по этой функции распределения независящую от нее
L[D\H\ получим следующее тождество:
= -/logPWft|g)\ -/log PW \ _
\ g P(h) )v(k) \ eP(h\D,H)/rm
= F(V,H) - KL(V(h)\\P(h\D,H)).
Здесь в первой строчке мы воспользовались
определением совместной вероятности P(D,h\H) = P(h\D,H)P(D\H), a
во второй - определением расстояния Кульбака между двумя
распределениями:
кцчьшн)) = (**%$)
52
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
и определили функционал
который является верхней границей интересующей нас длины
описания данных моделью (поскольку расстояние Кульбака -
величина неотрицательная):
F(V, H) = L(D\H) + KL(V(h)\\P(h\D, Я)). (3.12)
Значит, вместо минимизации функционала L(D\H) мы
можем искать минимум его верхней границы F(V, H), тем более
что ее минимум по дополнительной переменной совпадает с
длиной описания данных моделью:
minF(V,H) = L(D\H).
Он достигается на апостериорном байесовском
распределении, при котором расстояние Кульбака в (3.12) обращается
в ноль:
argminF(P,#) = P(h\D,H).
v
Функционал F(V, H) можно минимизировать итерациями,
содержащими каждая по два этапа — на уровне гипотез h
и на уровне моделей Н. По названию своих этапов этот
алгоритм обучения известен как Expectation Maximization, или
ЕМ-алгоритм. А именно:
• Этап Expectation: Vl (h) = argminF (Р,Я*);
V
• Этап Maximization: ift+1 = argminF (Тг,Н).
н
Таким образом, на каждом этапе мы фиксируем одну
группу параметров и оптимизируем другую. Эти этапы
повторяются, пока алгоритм не сойдется. Сходимость ЕМ-алгоритма
гарантируется тем, что длина описания ограничена снизу и на
3.1. Основные понятия
53
каждом шаге не возрастает. Названия этапов определяются их
содержанием.
На этапе Expectation производится оценка
апостериорной функции распределения гипотез при текущих параметрах
регуляризации. Ответ дается формулой Байеса:
_ PPM*)
1 W P(D\H*) ■
На этапе Maximization производится уточнение
параметров регуляризации максимизацией усредненной по Байесу
длины описания данных и гипотез, как это следует из (3.11):
Ht+i
= argmin(L(D,/i \H))vt — argmax(logP(D,/i \H))vt.
н н
Таким образом, ценой введения дополнительной
переменной V(h) мы избавились от суммирования под знаком
логарифма. Усреднение логарифмов в последнем выражении —
потенциально гораздо более простая задача.
Те, кто изучал статистическую физику, легко заметят
аналогию функционалов L(D\H) и F(V,H) со свободной
энергией. При этом первый определен через логарифм
статистической суммы: L(D\H) = — log^2h e~L(DMH) c единичной
температурой, а второй - известным термодинамическим
соотношением между свободной энергией, средней энергией и
энтропией: F = Е — TS, справедливым для равновесного
канонического ансамбля в стационарной точке ЕМ-алгоритма (также с
Г=1).
Заметим, что, как и любой другой градиентный способ
обучения, ЕМ-алгоритм сходится к локальному минимуму, не
обязательно совпадающему с глобальным. Физическая
аналогия - застревание в метастабильном энергетическом
состоянии. Отсюда напрашивается естественный метод отжига -
введение эффективной температуры и ее постепенное
понижение до Г = 1 для увеличения вероятности достижения
глобального минимума [Ueda и Nakano, 1998].
54
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
В главе 5 мы еще встретимся с принципом минимизации
свободной энергии при обсуждении алгоритмов обучения в
коре головного мозга. Как мы теперь понимаем, эта
формулировка тесно связана с байесовским обучением.
Подводя итоги, в этом разделе мы рассмотрели основные
понятия теории обучения. Мы показали, что оптимизация
поведения (т.е. минимизация ошибок) достигается через
статистическое предсказание с помощью моделей — сжатых
представлений выявленных в данных закономерностей. Чем
сильнее удается сжать данные, тем больше предсказательная сила
модели. Байесовский подход к обучению — это стратегия
последовательного извлечения имеющейся в данных
информации, исходя из первых принципов теории вероятности.
Модель порождения данных в байесовской трактовке
представлена ансамблем гипотез. Любой этап обучения
увеличивает наше знание относительно такой модели. Ему предшествует
некий априорный ансамбль гипотез, а результатом является
апостериорный ансамбль гипотез, более точно моделирующий
данные. Предсказания модели подразумевают усреднение по
этому ансамблю. При этом качество предсказаний ансамбля
выше, чем качество предсказания его наилучшей гипотезы.
Оптимальному апостериорному ансамблю соответствует
максимальное правдоподобие данных (Evidence).
Мы обсудили также соответствие Байесовской
регуляризации принципу минимальной длины описания данных, а тем
самым, - и связь байесовского подхода с минимизацией
ненаблюдаемой ошибки обобщения, поскольку имеются строгие
результаты, согласно которым уменьшение длины описания
данных сопровождается уменьшением ошибки обобщения.
Наконец, мы описали конкретный алгоритм обучения,
реализующий соответствие Байесовской регуляризации. Этот
алгоритм активно используется в современном глубоком
обучении, в частности в т.н. вариационном автокодировании
(variational autoencoders). Мы встретим его и при обсуждении
механизма обучения коры нашего мозга в главе 5.
3.2. Обучение с учителем: распознавание образов 55
В следующих разделах мы перейдем от общей теории к
рассмотрению конкретных типов и алгоритмов обучения. Мы
убедимся, что алгоритмы обучения могут быть предельно
простыми. Тем удивительнее будут результаты последующих глав,
где мы увидим, насколько сложные задачи способны решать
искусственные и естественные нейросети просто за счет
масштабирования элементарных актов обучения. Наша
ближайшая задача — понять физический смысл этих элементарных
актов обучения, разобрать базовые алгоритмы обучения на
примере простейших обучающихся систем.
В литературе различают три основных типа обучения: с
учителем, без учителя и с подкреплением. Каждый из них
характеризуется своими особенностями и сферами применения.
Вместе с тем, как мы убедимся, в их основе лежат одни и те же
общие принципы. В следующих разделах мы последовательно
рассмотрим соответствующие постановки задач и способы их
решения.
3.2. Обучение с учителем: распознавание
образов
До сих пор мы не конкретизировали, как выглядят данные
D и модели Н, используемые для обучения. Широкое
распространение на практике получили, например, деревья решений
(decision trees) или метод опорных векторов (support vector
machines). Однако с недавнего времени в машинном обучении
доминируют т.н. искусственные нейросети, в силу их
некоторых неоспоримых преимуществ, о которых пойдет речь далее.
С них-то мы и начнем наше знакомство с конкретными
моделями машинного обучения. В последующих главах мы
рассмотрим, насколько эта математическая абстракция
соответствует своим биологическим прототипам. Пока же нас будет
интересовать теория машинного обучения искусственных ней-
росетей и математические свойства конкретных алгоритмов.
56
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Сегодня подавляющее большинство практических
применений машинного обучения связано с простейшим видом
обучения — с учителем (supervised learning), т.е. по набору
входных и выходных данных D = {ха, уа} (например, образ и
символ его класса принадлежности). Как правило, используются
сети, состоящие из многих последовательных слоев нейронов.
Такая архитектура позволяет существенно ускорить
вычисления, используя матричные GPU-ускорители, работающие
параллельно со всеми нейронами каждого слоя.
Для начала мы ограничимся простейшим типом
многослойных сетей, не имеющих обратных связей между слоями —
сетями прямого распространения (feedforward networks) или
персептронами (рис. 3.4). В общем виде такие сети решают
задачу аппроксимации многомерных функций, т.е.
построения многомерных отображений / : х 4 у, обобщающих
заданный набор примеров D.
В зависимости от типа выходных переменных (тип
входных не имеет решающего значения) аппроксимация функций
может принимать вид
• классификации (дискретный набор выходных значений)
или
• регрессии (непрерывные выходные значения).
Многие практические задачи распознавания образов,
фильтрации шумов, предсказания временных рядов и др. сводятся
к этим базовым постановкам. Несмотря на свою кажущуюся
простоту, персептроны являются универсальными аппрокси-
маторами, для которых существуют весьма эффективные
алгоритмы обучения. Этим двум качествам они и обязаны своей
популярностью.
3.2. Обучение с учителем: распознавание образов 57
Рис. 3.4. Искусственный нейрон (слева) и многослойный пер-
септрон
3.2.1. Нейрон- классификатор
Изучение возможностей многослойных персептронов удобнее
начать со свойств его основного компонента — отдельного
нейрона. Искусственный нейрон является простейшим
устройством распознавания образов, превращающим входной вектор
признаков в скалярный ответ, зависящий от линейной
комбинации входных переменных:
У = / I ^2WJXJ + wo\ = / I ^2WJXJ ) •
Локальная память нейрона представлена его синаптиче-
скими весами w^ подбирая которые можно настроить
нейрон на распознавание конкретных образов. Здесь и далее мы
предполагаем наличие у каждого нейрона дополнительного
единичного входа с нулевым индексом хо = 1 . Это позволит
упростить выражения, трактуя все синаптические веса
нейрона wjj включая порог u?o, единым образом.
58
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Скалярный выход нейрона можно использовать в
качестве т.н. дискриминантной функции. Этим термином в теории
распознавания образов называют индикатор принадлежности
входного вектора к одному из заданных классов. Так, если
входные векторы могут принадлежать одному из двух
классов, нейрон способен различить тип входа, например,
следующим образом: если /(х) > 0, входной вектор принадлежит
первому классу, в противном случае — второму.
Поскольку его дискриминантная функция зависит лишь
от линейной комбинации входов, нейрон является линейным
дискриминатором. В некоторых простейших ситуациях
линейный дискриминатор — наилучший из возможных, а
именно, в случае когда вероятности принадлежности входных
векторов к разным классам задаются гауссовыми
распределениями. В этом случае границы, разделяющие области, где
вероятность одного класса больше, чем вероятности остальных,
состоят из гиперплоскостей.
Монотонные функции активации /(•) можно выбрать
таким образом, чтобы трактовать выходы нейронов как
вероятности принадлежности к соответствующему классу, что дает
дополнительную информацию при классификации. Так,
можно показать, что в упомянутом выше случае гауссовых
распределений вероятности сигмоидная функция активации нейрона
f(a) = 1+ехр(_а) дает вероятность принадлежности к
соответствующему классу.
3.2.2. Многослойные персептроны
Возможности линейного дискриминатора весьма ограничены.
Он способен правильно решать лишь ограниченный круг
задач — когда классы, подлежащие классификации, линейно
разделимы, т.е. могут быть разделены гиперплоскостью (см.
рис. 3.5). В d-мерном пространстве гиперплоскость может
разделить произвольным образом лишь d+1 точки. Например, на
плоскости можно произвольным образом разделить по двум
классам три точки, но четыре — в общем случае уже невоз-
3.2. Обучение с учителем: распознавание образов 59
Рис. 3.5. Линейно разделимые (слева) и линейно
неразделимые множества точек
можно. В случае плоскости это очевидно из приведенного на
рис. 3.5 примера, для большего числа измерений — следует
из простых комбинаторных соображений. Если точек
больше чем d + 1 всегда существуют такие способы их разбиения
по двум классам, которые нельзя осуществить с помощью
одной гиперплоскости. Однако этого можно достичь с помощью
нескольких гиперплоскостей.
Для решения таких более сложных классификационных
задач необходимо усложнить сеть, введя дополнительные слои
нейронов (их называют скрытыми), производящие
промежуточную обработку входных данных таким образом, чтобы
выходной нейрон-классификатор получал на свои входы уже
линейно разделимые множества.
Причем можно показать, что, в принципе, всегда можно
обойтись всего лишь одним скрытым слоем, содержащим
достаточно большое число нейронов. Действительно,
увеличение скрытого слоя повышает размерность пространства, в
котором выходной нейрон производит дихотомию, что, как
отмечалось выше, облегчает его задачу6.
Однако для апроксимации достаточно сложных функций
с помощью такого двухслойного персептрона может потре-
В частности, доказано, что одного скрытого слоя нейронов с сигмо-
идной функцией активации достаточно для аппроксимации любой
границы между классами или для аппроксимации любой функции со сколь
угодно высокой точностью, если число нейронов в скрытом слое
достаточно велико.
60
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
боваться экспоненциально много нейронов на единственном
скрытом слое. Гораздо экономнее оказывается наращивать
число слоев. При одинаковом числе нейронов такие глубокие ней-
росети могут представлять гораздо более сложные функции,
чем плоские двухслойные персептроны.
А именно: разнообразие функций £1, представимых
многослойными персептронами с d-мерными входами, зависит
главным образом от количества скрытых слоев N и в гораздо
меньшей степени — от их "ширины" Н (числа нейронов в
скрытом слое): Q ~ HNd. (В случае кусочно-линейных
нейронов, как на рис. 3.4, разнообразие определяется как
число кусочно-линейных граней соответствующего персептрону
отображения. Подробнее см. 4.1.2.)
Впрочем преимущества глубоких нейросетей выяснились
лишь немногим более 10 лет назад, и на практике их стали
применять относительно недавно (см. главу 4). До этого
использовались сети с небольшим числом слоев, главным
образом потому, что вычислительная сложность обучения, как мы
увидим, резко возрастает с размером нейросети.
Исторически первые персептроны, предложенные
Фрэнком Розенблаттом в 1958 г., имели два слоя нейронов.
Однако собственно обучающимся был лишь второй слой.
Первый (скрытый) слой состоял из нейронов с
фиксированными случайными весами. Эти, по терминологии Розенблатта,
ассоциирующие нейроны получали сигналы от случайно
выбранных точек рецепторного поля. Именно в этом
признаковом пространстве персептрон осуществлял линейную
дискриминацию подаваемых на вход образов (см. рис. 3.6).
Интересно, но именно так, по-видимому, устроен наш мозжечок
(см. главу 5), который успешно справляется со своими
задачами благодаря гигантскому количеству ассоциирующих
нейронов (около 60 млрд). Они формируют такое признаковое
пространство, в котором достаточно сложные образы
становятся линейно разделимыми.
3.2. Обучение с учителем: распознавание образов 61
Weights
(adjustable)
Activation
value
Output
signal
(binary)
s = f{x)
Sensory
units
Association
units
Summing Output
unit unit
Рис. З.6. Персептрон Розенблатта использовал пороговые
выходные функции [Rosenblatt, 1958]
Результаты своих исследований Розенблатт изложил в 1962 г.
в книге «Принципы нейродинамики: Персептроны и теория
механизмов мозга». Уже из самого названия чувствуется,
какое большое значение придавалось этому относительно
простому обучающемуся устройству. Мозг, конечно же, устроен
гораздо сложнее. Но заслуга Розенблатта в том, что он
впервые продемонстрировал способность нейросетей к обучению
с помощью очень простых, биологически обоснованных
алгоритмов.
Однако первым персептронам было далеко до
возможностей мозжечка, и круг задач, решаемых персептронами
Розенблатта, был весьма ограничен. В отсутствие теории
определить перспективы практического использования персептро-
нов было невозможно.
Подобного рода теория появилась к 1969 г. с выходом в
свет книги Минского и Пейперта «Персептроны», в которой
были выявлены присущие им фундаментальные ограничения.
Оказалось, что некоторые классы задач, например
определение связности фигур, требуют экспоненциально большого
числа ассоциирующих нейронов.
62
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Эта книга послужила "холодным душем" для энтузиастов
раннего машинного обучения, и финансирования в этой
области были надолго заморожены. Реальный же выход состоял в
том, чтобы увеличивать число скрытых слоев из адаптивных
элементов, т.е. подбирать веса всех слоев нейросети. Однако
в то время этого делать не умели.
Между тем существуют простые и довольно эффективные
способы подбора весов многослойных нейросетей, основанные
на градиентном обучении.
3.2.3. Градиентное обучение: backpropagation
Любая конфигурация нейросети осуществляет отображение
/(w) : х I—>► у. При обучении с учителем нам известна
обучающая выборка {ха,уа}, содержащая примеры правильной
классификации. Следовательно, для любого набора синапти-
ческих весов определена ошибка нейросети L(w) на данной
обучающей выборке.
Когда функционал ошибки задан и задача сводится к его
минимизации, можно предложить простую итерационную
процедуру подбора весов, например:
wr+1 = wr - r)TdL/dw.
Здесь rf — темп обучения на шаге т. Можно показать,
что, постепенно уменьшая темп обучения, например по
закону rf ос 1/т , описанная выше процедура приводит к
нахождению локального минимума ошибки.
Исторически наибольшую трудность на пути к
эффективному обучению многослойных персептронов вызвала
процедура расчета градиента функции ошибки dL/dw. Дело в том,
что ошибка сети определяется по ее выходам, т.е.
непосредственно связана лишь с выходным слоем весов. Вопрос
состоял в том, как определить ошибку для нейронов на скрытых
слоях, чтобы найти производные по соответствующим весам.
Нужна была процедура передачи ошибки с выходного слоя к
3.2. Обучение с учителем: распознавание образов 63
предшествующим слоям сети, в направлении, обратном
обработке входной информации. Поэтому такой метод, когда он
был найден, получил название метода обратного распростра-
нения» ошибки (error backpropagation или для краткости
просто backpropagation).
Ключом к обучению многослойных нейросетей оказалось
использование дифференцируемых функций активации, для
которых рецепт нахождения производных по любому весу
сети дается т.н. цепным правилом дифференцирования,
известным любому первокурснику. Суть метода backpropagation —
в эффективном воплощении этого правила7.
Разберем этот ключевой для машинного обучения метод
несколько подробнее. Обозначим входы нейронов n-го слоя х^.
Нейроны этого слоя вычисляют соответствующие линейные
комбинации:
3
и передают их на следующий слой, пропуская через
нелинейную функцию активации (для простоты — одну и ту же):
х?+1 = / («?) •
Для построения алгоритма обучения нам надо знать
производную ошибки по каждому из весов сети:
dL = дЬ да? _
dwfj dafdwfj г г
Таким образом, вклад в общую ошибку каждого веса
вычисляется локально, простым умножением невязки нейрона
7 Фрэнк Розенблатт использовал в своем персептроне недифферен-
цируемую ступенчатую функцию активации. Возможно, именно это
помешало ему найти эффективный алгоритм обучения, хотя сам термин
backpropagation восходит к его попыткам обобщить свое правило
обучения одного нейрона на многослойную сеть. Однако это ему не удалось,
и он трагически погиб, не перенеся тяжелой депрессии после выхода в
свет книги Минского и Пейперта и свертывания работ по персептронам.
Как знать, используй Розенблатт вместо ступенчатой функции
активации сигмоидную, может быть, его судьба сложилась бы по-другому.
64
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Sf на значение соответствующего входа. Из-за этого, в случае
когда веса изменяют по направлению скорейшего спуска
Swij ос dL/dwij = —SiXj,
такое правило обучения называют дельта-правилом.
Входы каждого слоя вычисляются последовательно от
первого слоя к последнему во время прямого распространения
сигнала:
а невязки каждого слоя вычисляются во время обратного
распространения ошибки от последнего слоя (где они
определяются по выходам сети) к первому:
3
Важность изложенного выше алгоритма backpropagation
в том, что он дает чрезвычайно эффективный способ
нахождения градиента функции ошибки dL/dw. Если обозначить
общее число весов в сети как W, то необходимое для
вычисления градиента число операций растет пропорционально W,
т.е. этот алгоритм имеет сложность 0(W). Напротив, прямое
вычисление градиента по формуле
потребовало бы W прямых прогонов через сеть, требующих
0(W) операций каждый — всего 0(W2) операций, что
существенно хуже, чем у алгоритма backpropagation.
Градиентное обучение может использовать градиенты
ошибки dL/dw по-разному.
3.2. Обучение с учителем: распознавание образов 65
Простейший способ использования градиента при
обучении — изменение весов пропорционально градиенту — т.н
метод скорейшего спуска:
Этот метод оказывается, однако, чрезвычайно
неэффективен в случае, когда производные по различным весам
сильно отличаются, т.е. рельеф функции ошибки напоминает не
яму, а длинный овраг. (Это довольно частая ситуация, когда
модули некоторых весов много больше 1). В этом случае для
плавного уменьшения ошибки необходимо выбирать очень
маленький темп обучения, диктуемый максимальной
производной (шириной оврага), тогда как расстояние до минимума по
порядку величины определяется минимальной производной
(длиной оврага), что существенно замедляет обучение.
Кроме того, на самом дне оврага неизбежно возникают
осцилляции, и обучение теряет привлекательное свойство
монотонности убывания ошибки.
Простейшим усовершенствованием метода скорейшего
спуска является введение момента /i, когда влияние градиента на
изменение весов накапливается со временем:
г т OLi т—Л
0W ——Г]— \~ LLOW
aw
Качественно влияние момента на процесс обучения можно
пояснить следующим образом. Допустим, что градиент
меняется плавно, так что на протяжении некоторого времени его
изменением можно пренебречь (мы находимся далеко от дна
оврага). Тогда изменение весов можно записать в виде:
т.е. в этом случае эффективный темп обучения
увеличивается, причем существенно, если момент \± « 1. Напротив,
вблизи дна оврага, когда направление градиента то и дело меняет
66
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
знак из-за описанных выше осцилляции, эффективный темп
обучения замедляется до значения близкого к rj:
Дополнительное преимущество от введения момента —
появляющаяся у алгоритма способность преодолевать мелкие
локальные минимумы. Это свойство можно увидеть, записав
разностное уравнение для обучения в виде
дифференциального. Тогда обучение методом скорейшего спуска будет
описываться уравнением движения тела в вязкой среде:
dw/dr = —ridL/dw.
Введение момента соответствует появлению у такого
гипотетического тела инерции, т.е. массы /л :
fid2w/dr2 + (1 — i^)dw/dr = —r/dL/dw.
В итоге, "разогнавшись", оно может по инерции
преодолевать небольшие локальные минимумы ошибки, застревая
лишь в относительно глубоких, значимых минимумах.
Одним из недостатков описанного метода является
введение еще одного настроечного параметра /i. Идеальной же
является ситуация, когда все параметры обучения сами
настраиваются в процессе обучения, извлекая информацию о
характере рельефа функции ошибки из самого хода
обучения. Примерами таких адаптивных алгоритмов с моментом
являются ADAM, RMSPropp, Adadelta. Все они широко
используются на практике.
3.2.4. Регуляризация обучения
Выше мы уже затрагивали тему выбора модели оптимальной
сложности. Излишне простые модели не способны адекватно
отразить имеющиеся в данных закономерности, а слишком
3.2. Обучение с учителем: распознавание образов 67
сложные обладают плохой предсказательной силой,
адаптируясь лишь к конкретной обучающей выборке данных со
всеми ее случайными флуктуациями - запоминают детали
вместо закономерностей.
Для нейросетевых моделей эта проблема весьма
актуальна, особенно для современных достаточно больших нейросе-
тей, о которых пойдет речь в следующей главе. Мы ведь
заранее не знаем, насколько сложны данные, которые нам
предстоит моделировать, и, следовательно, какого размера сеть
выбрать для той или иной задачи.
Давно известным, практически, общепринятым решением
этой проблемы является регуляризация настроечных
параметров нейросетей, т.е. наложение на них некоторых
дополнительных ограничений, эффективно сужающих класс
доступных функций [Bishop, 2006].
Регуляризация сводится к добавлению к функции
эмпирической ошибки дополнительного члена, не связанного с
данными, но отражающего сложность нейросетевой модели.
Чаще всего используются L1- и Ь2-регуляризации:
L(w) -» L(w) + A||w||i = L(w) + A^ \wi\,
г
L(w) -)■ L(w) + A| |w||i = L(w) + 2 Ц wl
г
где суммы берутся по всем настроечным параметрам нейро-
сети.
Уравнения для градиентного обучения сети в этих случаях
имеют вид:
гуТ+1 = WJ - rfdL/dwi - \\wi\/wi,
w1+l = wJ — rfdL/dwi — Xw{.
Видим, что в обоих случаях регуляризация приводит к
появлению дополнительной "силы", стремящейся уменьшить
68
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
амплитуду весов нейросети. Только в первом случае эта
сила постоянна, а во втором - уменьшается с уменьшением
настроечного параметра. Соответственно, Ll-регуляризация
более жесткая: все параметры, влияющие на ошибку, меньше
некоторого порогового уровня, зануляются, т.е. сеть
прореживается. Прореженные сети используются, например, в
мобильных устройствах, т.к. они могут существенно сократить
вычисления и энергопотребление [Han, Мао и др., 2015].
Ь2-регуляризация более мягкая и способна к более
тонкой подстройке сложности модели. При желании,
естественно, можно пользоваться ими обоими. Наилучшие результаты,
согласно Han, Pool и др., 2015, дает попеременное
итерационное применение L1- и Ь2-регуляризации, позволяя сократить
количество параметров сети на порядок практически без
потери точности.
3.2.5. Сложность градиентного обучения
Чтобы иметь хотя бы приблизительное представление о
связанных с обучением вычислительных затратах, приведем
качественную оценку вычислительной сложности градиентного
обучения.
Пусть, как всегда, W — число настроечных параметров
сети (weights), a M — число обучающих примеров. Тогда для
однократного вычисления градиента функции ошибки dL/dw
методом обратного распространения ошибок требуется
порядка MW операций. Количество итераций, требуемых для
нахождения минимума по такой локальной информации, также
растет пропорционально размерности пространства
параметров, в котором ищется минимум. Именно такую скорость
сходимости, 0{W) итераций, имеют лучшие алгоритмы первого
порядка, например метод сопряженного градиента.
Альтернативно, в методах второго порядка можно найти минимум
за O(l) шагов, но только используя W2 значений локального
3.2. Обучение с учителем: распознавание образов 69
гессиана8. В обоих случаях оценка сложности обучения сети
составляет С ~ MW2 операций.
Для хорошего обучения сложность модели W должна
соответствовать размеру обучающей выборки М. Так что
сложность градиентного обучения оказывается пропорциональной
аж кубу числа весов! Такая вычислительная сложность
является запретительной.
В реальности можно пользоваться приблизительными
оценками градиента по небольшому числу примеров. В таком
приближении т.н. стохастической оптимизации градиент на
каждой итерации оценивается по тъ ~ 10-г 100 случайным
примерам из обучающей выборки (mini-batch), и обучение остается
квадратичным по числу весов:
C~mbW2. (3.13)
dw dL(w)
dx dw
Рис. 3.7. Сложность градиентного обучения квадратична по
числу настроечных параметров сети
Для достаточно сложных задач, таких как машинное
зрение или машинный перевод, сегодня используются сети с
сотнями миллионов и даже с миллиардами настроечных
параметров. Обучение таких больших сетей возможно только спо-
8 Гессиан 7i - это W x W матрица вторых производных функции L(w).
70
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
собом стохастической оптимизации. Да и то квадратичная
вычислительная сложность обучения для них настолько высока,
что требует специальных матричных ускорителей (GPU).
Реальным прорывом в машинном обучении могли бы стать
алгоритмы, линейные по числу настроечных параметров.
Такое возможно, если мы будем усложнять нашу модель
постепенно, вместо того, чтобы до л го-до л го блуждать из случайной
начальной точки по полному пространству признаков. Мы
поговорим об этом подробнее в главе 7.
3,3, Обучение без учителя: сжатие
информации
Обратимся теперь к другому типу обучения — без учителя
(unsupervised или self-supervised learning), когда обучающая
выборка состоит из неразмеченных данных D = {ха} и сеть
самостоятельно формирует свои выходы, адаптируясь к
поступающим на ее входы сигналам.
Такая ситуация гораздо чаще встречается в практической
жизни, когда приходится обрабатывать потоки сырых
данных. Дети, конечно же, сами обучаются различать собак от
кошек, мамы лишь помогают им правильно называть
соответствующие классы.
Действительно, входная информация, как правило,
содержит гораздо больше информации, чем выходная. Например,
в машинном зрении на входе мы имеем мегабайтные
визуальные образы, а на выходе - наборы классов распознанных
предметов с разнообразием максимум два десятка бит (если речь
идет о миллионах классов). Соответственно, очень многому
можно обучиться в режиме самообучения, например,
предсказывая какие-то части входной информации. Поэтому один из
отцов-основателей машинного обучения Ян ЛеКун уподобил
обучение без учителя основе праздничного торта, на которую
наложен тонкий слой глазури обучения с учителем. Глазурь
мы уже попробовали, пора разобраться с основой торта.
3.3. Обучение без учителя: сжатие информации 71
3.3.1. Обобщение данных: прототипы задач
Как и прежде, обучение предполагает минимизацию
некоторого целевого функционала. Задание такого функционала
формирует цель, в соответствии с которой сеть осуществляет
преобразование входной информации.
За отсутствием такового "учителем" сети могут служить
лишь сами данные, т.е. имеющаяся в них информация,
закономерности, отличающие входные данные от случайного
шума. Лишь такая избыточность позволяет находить более
компактное описание данных, что, согласно общему принципу, и
обеспечивает понимание эмпирических данных.
Практически, адаптивные сети осуществляют сжатие
информации, кодируя входную информацию наиболее
компактным при заданных ограничениях кодом.
Длина описания данных пропорциональна, во-первых,
разрядности данных Ь, определяющей разнообразие
принимаемых ими значений (например, 32- или 64-битное
представление чисел), и, во-вторых, размерности данных d, т.е.
числу компонент входных векторов ха. Соответственно, можно
различить два предельных типа кодирования, использующих
противоположные способы сжатия информации:
• понижение размерности данных с минимальной потерей
информации. (Например, анализ главных компонент,
выделение наборов независимых признаков.);
• уменьшение разнообразия данных за счет выделения
конечного набора прототипов, и отнесения данных к
одному из них. (Кластеризация данных, квантование
непрерывной входной информации.)
Возможно также объединение обоих типов кодирования.
Например, очень богат приложениями метод
самоорганизующихся карт (или карт Кохонена — по имени
предложившего их финского ученого), когда сами прототипы
упорядочены в пространстве низкой размерности. Например, входные
данные можно отобразить на упорядоченную двумерную сеть
72
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Рис. 3.8. Два типа сжатия информации. Понижение
размерности (слева) позволяет описывать данные меньшим числом
компонент. Кластеризация или квантование (справа)
позволяет снизить разнообразие данных, уменьшая число бит,
требуемых для их описания
прототипов так, что появляется возможность визуализации
многомерных данных.
Как и в случае с персептронами, начинать изучение нового
типа обучения лучше с простейшей сети, состоящей из одного
нейрона.
3.3.2. Нейрон-индикатор: обучение по Хеббу
Рассмотрим, какие возможности по адаптивной обработке
данных имеет единичный нейрон и как можно сформулировать
правила его обучения. В силу локальности нейросетевых
алгоритмов, это базовое правило можно будет потом легко
распространить и на сети из многих нейронов.
В простейшей постановке нейрон с одним выходом и d
входами обучается на наборе d-мерных данных D = {ха}. Здесь
мы ограничимся обучением однослойных сетей, для которых
нелинейность функции активации не принципиальна.
Поэтому можно упростить рассмотрение, ограничившись линейной
функцией активации. Выход такого нейрона является
линейной комбинацией его входов:
3.3. Обучение без учителя: сжатие информации 73
d
i=i
Амплитуда этого выхода после соответствующего
обучения может служить индикатором того, насколько данный вход
соответствует обучающей выборке. Иными словами, нейрон
может стать индикатором принадлежности входной
информации к заданной группе примеров.
Алгоритм обучения отдельного нейрона-индикатора по
необходимости локален, т.е. базируется только на информации,
непосредственно доступной самому нейрону — значениях его
входов и выхода. Этот алгоритм, предложенный канадцем
Дональдом Хеббом в 1949 г., содержит, как в зародыше,
основные свойства самоорганизации нейронных сетей. Согласно
Хеббу [Hebb, 2005], изменение весов нейрона при
предъявлении ему т-го примера пропорционально его входам и выходу:
или в векторном виде: 5wT = г]ут'кт. Если сформулировать
обучение как задачу оптимизации, мы увидим, что
обучающийся по Хеббу нейрон стремится увеличить амплитуду
своего выхода:
(«w>--4^, L--!<(„.*)»>--!<„»).
где усреднение проводится по обучающей выборке {ха}.
Вспомним, что обучение с учителем, напротив, базировалось на идее
уменьшения среднего квадрата отклонения от эталона. В
отсутствие эталона минимизировать нечего: минимизация
амплитуды выхода привела бы лишь к уменьшению
чувствительности выходов к значениям входов. Максимизация
амплитуды, напротив, делает нейрон как можно более
чувствительным к различиям входной информации, т.е. превращает его в
полезный индикатор.
74
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Указанное различие в целях обучения носит
принципиальный характер, т.к. минимум ошибки L(w) в данном случае
отсутствует. Поэтому обучение по Хеббу в том виде, в каком
оно описано выше, на практике не применимо, т.к. приводит
к неограниченному возрастанию амплитуды весов.
От этого недостатка, однако, можно довольно просто
избавиться, добавив член, препятствующий возрастанию весов:
8WT. = Vyr (XJ - yTWj) ,
или в векторном виде:
Swr = щт (хт - yrw). (3.14)
В этом легко убедиться, приравняв среднее изменение
весов нулю. Умножив затем правую часть на w, видим, что в
равновесии: 0 = (у2) (l — |w|2). Таким образом, веса
обученного нейрона расположены на гиперсфере: |w|2 = 1, как
показано на рис. 3.9.
Рис. 3.9. Хеббовское обучение с ограничениями: вектор весов
нейрона располагается на гиперсфере в направлении,
максимизирующем проекцию входных векторов
Отметим, что этот алгоритм обучения, по существу,
эквивалентен дельта-правилу, только обращенному назад — от
входов к выходам (т.е. при замене х <-> у). Нейрон как бы
старается воспроизвести значения своих входов по заданному
выходу. Тем самым, такое обучение стремится максимально
повысить чувствительность единственного выхода-индикатора к
3.3. Обучение без учителя: сжатие информации 75
многомерной входной информации, являя собой пример
оптимального сжатия информации.
Эту же ситуацию можно описать и по-другому.
Представим себе персептрон с одним (здесь — линейным) нейроном
на скрытом слое, в котором число входов и выходов
совпадает, причем веса с одинаковыми индексами в обоих слоях
одинаковы. Будем учить этот персептрон воспроизводить в
выходном слое значения своих выходов (рис. 3.10). При этом
дельта-правило обучения верхнего (а тем самым и нижнего)
слоя примет вид (3.14):
8wTj ос ут (хг — xr) = yT (xr — yTw).
«Л/*! ■ ■ ■ «Л/ rl
у = w • х
Рис. 3.10. Эквивалентность алгоритма Ойа обучению сети с
одним нейроном в скрытом слое методом backpropagation
Таким образом, существует определенная параллель
между самообучающимися сетями и т.н. автоассоциативными
сетями, в которых учителем для выходов являются значения
входов. Подобного рода нейросети с узким горлом также
способны осуществлять сжатие информации.
3.3.3. Взаимодействие нейронов: анализ главных
компонент
Единственный нейрон осуществляет предельное сжатие
многомерной информации, выделяя лишь одну скалярную харак-
76
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
теристику многомерных данных. Каким бы оптимальным ни
было сжатие информации, редко когда удается полностью
охарактеризовать многомерные данные всего одним признаком.
Однако наращиванием числа нейронов можно увеличить
выходную информацию. В этом разделе мы обобщим найденный
ранее алгоритм обучения на случай нескольких нейронов в
самообучающемся слое, опираясь на отмеченную выше
аналогию с автоассоциативными сетями.
Итак, пусть теперь на том же наборе d-мерных данных
{ха} обучается то линейных нейронов:
yi = ^2 wijx3 = w* • х, г = 1,..., то.
Мы хотим, чтобы амплитуды выходных нейронов были
набором независимых индикаторов, максимально полно
отражающих информацию о многомерном входе сети.
Если мы просто поместим несколько нейронов в выходной
слой и будем обучать каждый из них независимо от других,
мы добьемся лишь многократного дублирования одного и того
же выхода. Очевидно, что для получения нескольких
содержательных признаков на выходе исходное правило обучения
должно быть каким-то образом модифицировано — за счет
включения взаимодействия между нейронами.
В нашей трактовке алгоритма обучения отдельного
нейрона последний пытается воспроизвести значения своих входов
по амплитуде своего выхода. Обобщая это наблюдение,
логично было бы предложить правило, по которому значения
входов восстанавливаются по всей выходной информации.
Следуя этой линии рассуждений, получаем алгоритм Ойа
обучения однослойной сети [Oja, 1982]:
5wjj = щ\ (xTj - xTj) = щ\ ix] - Y^ Vkwkj j
или в векторном виде: SwJ = rjyj (xT - J2k y£wfc).
3.3. Обучение без учителя: сжатие информации 77
Уг = / wijxj *i - *а
Х1 ... Xd Х^ ... Х&
Рис. 3.11. Эквивалентность алгоритма Ойа обучению
автоассоциативной сети с узким горлом методом backpropagation
Такое обучение эквивалентно сети с узким горлом из то
скрытых линейных нейронов, обученной воспроизводить на
выходе значения своих входов (рис. 3.11).
Скрытый слой такой сети, так же как и слой Ойа,
осуществляет оптимальное кодирование входных данных и
содержит максимально возможное при данных ограничениях
количество информации.
Способность нейронных сетей самостоятельно выделять
наиболее значимые признаки в потоках информации,
обучаясь по очень простым локальным правилам, важна для
понимания алгоритмов обучения мозга. Однако есть ли в описанных
выше алгоритмах обучения какой-нибудь практический смысл?
Действительно, для этих целей существуют хорошо
известные алгоритмы стандартного статистического анализа. В
частности, анализ главных компонент (principal component
analysis) также выделяет основные признаки, осуществляя
оптимальное линейное сжатие информации. Более того, можно
показать, что сжатие информации слоем Ойа эквивалентно
анализу главных компонент9. Это и не удивительно,
поскольку оба метода оптимальны при одних и тех же ограничениях.
9 Точнее, выходы сети Ойа являются линейными комбинациями
первых главных компонент.
78
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Однако стандартный анализ главных компонент дает
решение в явном виде, через последовательность матричных
операций, а не итерационно, как в случае нейросетевых
алгоритмов. Так что на практике часто удобнее пользоваться
матричными методами, а не обучать нейросети. Есть ли тогда
практический смысл в изложенных выше итеративных
нейросетевых алгоритмах? Конечно же есть, по крайней мере по
двум причинам:
• во-первых, иногда обучение необходимо проводить в
режиме online, т.е. на ходу адаптироваться к
меняющемуся потоку данных. Примером может служить борьба с
нестационарными помехами в каналах связи.
Итерационные методы идеально подходят в этой ситуации, когда
нет возможности собрать воедино весь набор примеров и
произвести необходимые матричные операции над ним;
• во-вторых, и это, видимо, главное, нейроалгоритмы
легко обобщаются на случай нелинейного сжатия
информации, когда никаких явных решений уже не существует.
Никто не мешает нам заменить линейные нейроны в
описанных выше сетях — нелинейными. С минимальными
видоизменениями алгоритмы обучения будут работать и
в этом случае, всегда находя оптимальное сжатие при
наложенных нами ограничениях. Таким образом,
нейроалгоритмы представляют собой удобный инструмент
нелинейного анализа, позволяющий относительно легко
находить способы глубокого сжатия информации и
выделения нетривиальных признаков.
Иногда даже простая замена линейной функции
активации нейронов на сигмоидную в найденном выше правиле
обучения:
5wJ = Vf(yJ) U -^ПУкМ
3.3. Обучение без учителя: сжатие информации 79
приводит к новому качеству - способности разделять
смешанные неизвестным образом сигналы (Blind Signal Separation)
[Oja и Karhunen, 1995]. Эту задачу каждый из нас вынужден
решать, когда хочет выделить речь одного человека в шуме
общего разговора.
Однако нас здесь интересуют не конкретные алгоритмы, а,
скорее, общие принципы выделения значимых признаков, на
которых имеет смысл остановиться несколько более подробно.
3.3.4. Нелинейный анализ главных компонент
Наглядной демонстрацией полезности нелинейного анализа
главных компонент является простой пример на рис. 3.12.
Рис. 3.12. Анализ главных компонент дает линейное
подпространство, минимизирующее отклонение данных (слева). Он
не способен, однако, выявить одномерный характер
распределения данных в случае справа. Для их одномерной
параметризации нужны нелинейные координаты
В общем случае нас интересует нелинейное
преобразование
у = f(w,x),f : Rd -> Rm, (то < d),
сохраняющее максимальное количество информации о
распределении данных в обучающей выборке {ха} при заданной
степени сжатия (d/m). Обращая это преобразование,
получаем вероятностную модель порождения данных (зашумлен-
ных): Р(х|у).
80
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Весьма общим подходом к понижению размерности
является использование нелинейных автоассоциативных сетей,
т.е. использование уже известных методик обучения с
учителем. Как правило, такая сеть должна содержать не менее
трех скрытых слоев нейронов. Средний слой — узкое горло,
будет в результате обучения выдавать сжатое представление
данных у. Первый скрытый слой нужен для осуществления
произвольного нелинейного кодирования, а последний — для
нахождения соответствующего декодера (рис. 3.13).
■/Li ■ ■ ■ "^ с\
У\ - Ут
nLi ■■■ ^ d ai ■■■ "^d
Рис. 3.13. Понижение размерности с помощью
автоассоциативных сетей. Минимизация ошибки воспроизведения сетью
своих входов эквивалентна оптимальному кодированию в
узком горле сети
Автоассоциативная сеть учится воспроизводить на своем
выходе значения своих входов. Вторая половина сети,
декодер, при этом опирается лишь на кодированную информацию
в узком горле сети. Качество воспроизведения данных по их
кодированному представлению измеряется условной
энтропией £Г(х|у). Чем она меньше, тем меньше неопределенность,
т.е. лучше воспроизведение. В другой, эквивалентной,
формулировке, задача автоассоциативной сети — сохранить в своем
кодирующем слое максимально возможное количество
информации о своих входах:
3.3. Обучение без учителя: сжатие информации 81
minJHr(x|y) —> max/(x, у).
Здесь J(x,y) = Я(х) + Я(у) - Я(х,у) = Я(х) - Я(х|у)
— взаимная информация случайных величин х, у. В данном
случае эта задача решается методом backpropagation.
Существует, однако, более элегантный и экономный
подход к нелинейному сжатию данных. Можно последовательно
слой за слоем находить все более сжатые представления
данных, исходя их первых принципов теории информации.
Наша цель — найти такое представление, которое по максимуму
"объясняет" все имеющиеся зависимости между различными
компонентами входных данных.
Количественно степень взаимозависимости компонент
данных определяет т.н. полная корреляция (Total Correlation):
ТС(х) = ^Я(жО-Я(х).
г
Это неотрицательная величина, равная нулю, только если
все компоненты входных данных независимы друг от друга.
Чем больше значение ГС(х), тем больше возможностей для
сжатия данных.
Сжатие данных с помощью порождающей модели Р(х|у)
измеряется условной полной корреляцией:
ТС(х|у) = Х)Я(х<|у)-Я(х|у).
г
Чем она меньше, тем больше скрытых взаимосвязей в
данных ухватывает наша модель. Модель объясняет все
зависимости в данных, если ТС(х|у) = 0. В этом случае модель
порождения данных вырождается: Р(х|у) = Пг-^(х*|у)> т-е- все
компоненты данных порождаются независимо друг от друга.
Так, на рис. 3.12 задание одной угловой координаты
однозначно определяет обе координаты х.
82
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Мы будем искать такую модель объяснения данных, в
которой каждая компонента у служила бы независимым
источником данных, т.е. ТС (у) = 0 (обычная целевая функция
анализа независимых компонент). Таким образом, мы хотели бы
минимизировать:
min[TC(x|y)+TC(y)],
т.е. объяснить все возможные зависимости и в данных, и в их
представлении. Отсюда и название метода: Total Correlation
Explanation [Steeg, 2017].
Важно, что мы можем не ограничиваться одним слоем, а
продолжать наращивать сеть слой за слоем, так что
представление данных на предыдущем слое является входными
данными для следующего. Каждый слой объясняет новую порцию
зависимостей, внося свою лепту в сжатие данных.
Ссылки на конкретные алгоритмы обучения можно найти
в [Steeg, 2017]. Здесь же ограничимся констатацией, что они
весьма эффективны, в частности, могут иметь линейную по
числу параметров модели сложность [Steeg и Galstyan, 2017],
существенно превосходя градиентное обучение
автоассоциативных сетей, имеющее квадратичную сложность.
В этом разделе мы находили такие представления данных,
в которых активации отдельных нейронов внутри слоев были
по возможности не коррелированы. Между тем, можно
предложить и противоположную схему кодирования, с
максимальной коррелляцией выходов. Например, нейрон с
максимальным выходом может подавлять активность остальных
нейронов в слое. Активность такого нейрона-победителя возрастает
до единицы, а активность остальных нейронов затухает до
нуля.
Такие соревновательные слои нейронов также можно
использовать для сжатия информации, но это сжатие будет
основано на совершенно других принципах.
3.3. Обучение без учителя: сжатие информации 83
3.3.5. Соревнование нейронов: кластеризация
В начале данного раздела мы упомянули два главных способа
уменьшения избыточности: снижение размерности данных и
уменьшение их разнообразия при той же размерности. До сих
пор речь шла о первом способе. Обратимся теперь ко второму.
Этот способ подразумевает другие правила обучения
нейронов.
В Хеббовском и производных от него алгоритмах обучения
активность выходных нейронов стремится быть по
возможности более независимой друг от друга. Напротив, в
соревновательном обучении, к рассмотрению которого мы приступаем,
выходы сети максимально скоррелированы: при любом
значении входа активность всех нейронов, кроме т.н. нейрона-
победителя одинакова и равна нулю. Такой режим
функционирования сети называется "победитель забирает все".
Нейрон-победитель (с индексом г*), свой для каждого
входного вектора, будет служить прототипом этого вектора.
Поэтому победитель выбирается так, что его вектор весов w^*,
определенный в том же d-мерном пространстве, находится
ближе к данному входному вектору х, чем у всех
остальных нейронов: |w> — х| < |w^ — х| для всех г. Если, как это
обычно и делается (вспомним слой Ойа), применять правила
обучения нейронов, обеспечивающие одинаковую нормировку
всех весов, например |w| = 1, то победителем окажется
нейрон, дающий наибольший отклик на данный входной стимул:
\v/i* . х| > |w> • х|, \/г . Выход такого нейрона усиливается
до единичного, а остальных — подавляется до нуля.
Количество нейронов в соревновательном слое
определяет максимальное разнообразие выходов и выбирается в
соответствии с требуемой степенью детализации входной
информации. Обученная сеть может затем классифицировать
входы: нейрон-победитель определяет к какому классу относится
данный входной вектор.
В отличие от обучения с учителем, самообучение не
предполагает априорного задания структуры классов. Входные век-
84
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
торы должны быть разбиты по категориям (кластерам),
согласуясь с внутренними закономерностями самих данных. В
этом и состоит задача обучения соревновательного слоя
нейронов.
Базовый алгоритм обучения соревновательного слоя
остается неизменым:
SwJ = rjyj f xT - 5^2/jfeWfc J ,
поскольку задача сети также осталась прежней — как
можно точнее отразить входную информацию в выходах сети.
Отличие появляется лишь из-за нового способа кодирования
выходной информации. В соревновательном слое лишь один
нейрон-победитель имеет ненулевой (единичный) выход.
Соответственно, в согласии с выписанным выше правилом лишь
его веса корректируются по предъявлении данного примера,
причем для победителя правило обучения имеет вид:
Описанный выше базовый алгоритм обучения на практике
обычно несколько модифицируют, т.к. он, например,
допускает существование т.н. мертвых нейронов, которые никогда
не выигрывают и, следовательно, бесполезны. Самый простой
способ избежать их появления — выбирать в качестве
начальных значений весов случайно выбранные в обучающей
выборке входные векторы.
Такой способ хорош еще и тем, что при достаточно
большом числе прототипов он способствует равной нагрузке всех
нейронов-прототипов. Это соответствует максимизации
энтропии выходов в случае соревновательного слоя. В идеале
каждый из нейронов соревновательного слоя должен одинаково
часто становиться победителем, чтобы априори невозможно
было предсказать, какой из них победит при случайном
выборе входного вектора из обучающей выборки.
3.3. Обучение без учителя: сжатие информации 85
Наиболее быструю сходимость обеспечивает пакетный
режим обучения, когда веса изменяются лишь после
предъявления всех примеров. В этом случае можно сделать приращения
не малыми, помещая вес нейрона на следующем шаге сразу
в центр тяжести всех входных векторов, относящихся к его
ячейке. Такой алгоритм сходится за O(l) итераций.
Записав правило соревновательного обучения в
градиентном виде: (Sw) = —r]dL/dvs, легко убедиться, что оно
минимизирует квадратичное отклонение входных векторов от их
прототипов — весов нейронов-победителей:
а
Иными словами, сеть осуществляет кластеризацию
данных: находит такие усредненные прототипы, которые
минимизируют ошибку огрубления данных. Недостаток такого
варианта кластеризации очевиден — "навязывание" количества
кластеров, равного числу нейронов. В идеале сеть сама
должна находить число кластеров, соответствующее реальной
кластеризации векторов в обучающей выборке. Адаптивный
подбор числа нейронов осуществляют несколько более сложные
алгоритмы, такие, например, как растущий нейронный газ.
Идея последнего подхода состоит в последовательном
увеличении числа нейронов-прототипов путем их "деления".
Общую ошибку сети можно записать как сумму индивидуальных
ошибок каждого нейрона:
k a€Ck
Естественно предположить, что наибольшую ошибку
будут иметь нейроны, окруженные слишком большим числом
примеров и/или имеющие слишком большую ячейку. Такие
нейроны и являются, в первую очередь, кандидатами на
"почкование".
86
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Рис. 3.14. Деление нейрона с максимальной ошибкой в
"растущем нейронном газе"
Соревновательные слои нейронов широко используются для
квантования данных (vector quantization), отличающегося от
кластеризации лишь большим числом прототипов. Это
весьма распространенный на практике метод сжатия данных. При
достаточно большом числе прототипов, плотность
распределения весов соревновательного слоя хорошо
аппроксимирует реальную плотность распределения многомерных входных
векторов. Входное пространство разбивается на ячейки,
содержащие векторы, относящиеся к одному и тому же
прототипу. Причем эти ячейки (называемые ячейками Дирихле или
ячейками Вороного) содержат примерно одинаковое
количество обучающих примеров. Тем самым одновременно
минимизируется ошибка огрубления и максимизируется выходная
информация — за счет равномерной загрузки нейронов.
Сжатие данных в этом случае достигается за счет того,
что каждый прототип можно закодировать меньшим числом
бит, чем соответствующие ему векторы данных. При наличии
т прототипов для идентификации любого из них достаточно
лишь log2 m бит, вместо bd бит, описывающих произвольный
входной вектор.
Один из вариантов модификации базового правила
обучения соревновательного слоя состоит в том, чтобы обучать не
только нейрон-победитель, но и его "соседей", хотя и с
меньшей скоростью. Такой подход — "подтягивание" ближайших к
победителю нейронов — применяется в самоорганизующихся
картах Кохонена. В силу большой практической значимости
3.3. Обучение без учителя: сжатие информации 87
этой нейросетевой архитектуры остановимся на ней более
подробно.
3.3.6. Самоорганизующиеся карты
До сих пор нейроны выходного слоя были неупорядочены:
положение нейрона-победителя в соревновательном слое не
имело ничего общего с координатами его весов во входном
пространстве. Оказывается, что небольшой модификацией
соревновательного обучения можно добиться того, что положение
нейрона в выходном слое будет коррелировать с положением
прототипов в многомерном пространстве входов сети:
близким нейронам будут соответствовать близкие значения
входов. Тем самым появляется возможность строить
самоорганизующиеся карты (Self-Organizing Maps), чрезвычайно
полезные для визуализации многомерной информации. Обычно для
этого используют соревновательные слои в виде двумерных
сеток. Такой подход сочетает квантование данных с
отображением, понижающим размерность. Причем это достигается
с помощью всего лишь одного слоя нейронов, что существенно
облегчает обучение.
В 1982 г. финский ученый Тойво Кохонен предложил
ввести в базовое правило соревновательного обучения
информацию о расположении нейронов в выходном слое [Kohonen,
1982]. Для этого нейроны выходного слоя упорядочиваются,
образуя одно- или двумерные решетки. То есть теперь
положение нейронов в такой решетке маркируется векторным
индексом i. Такое упорядочение естественым образом вводит
расстояние между нейронами |i — j| в слое. Модифицированное
Кохоненым правило соревновательного обучения учитывает
расстояние нейронов от нейрона-победителя:
&wi = r,A(\i-r\)(xr-Wi).
Функция соседства Л (|i — i*|) равна единице для нейрона-
победителя с индексом i* и постепенно спадает с расстоянием,
88
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
например по закону Л(а) = ехр(—а2/а2) . Как темп обучения
ту, так и радиус взаимодействия нейронов а постепенно
уменьшаются в процессе обучения, так что на конечной стадии
обучения мы возвращаемся к базовому правилу адаптации весов
только нейронов-победителей.
В отличае от "газоподобной" динамики обучения при
индивидуальной подстройке прототипов (весов нейронов),
обучение по Кохонену напоминает натягивание эластичной
сетки прототипов на массив данных из обучающей выборки. По
мере обучения эластичность сети постепенно увеличивается,
чтобы не мешать окончательной тонкой подстройке весов.
Рис. 3.15. Двумерная самоорганизующаяся карта набора
многомерных данных. Каждая точка в многомерном
пространстве попадает в свою ячейку сетки имеющую
координату ближайшего к ней нейрона из двумерной карты
В результате такого обучения мы получаем не только
квантование входов, но и упорядочивание входной информации в
виде двумерной карты (рис. 3.15). Каждый многомерный
вектор имеет свою координату на этой сетке, причем чем
ближе координаты двух векторов на карте, тем ближе они и в
исходном пространстве. Такая самоорганизующаяся
топографическая карта дает наглядное представление о структуре
данных в многомерном входном пространстве, геометрию
которого мы не в состоянии представить себе иным способом.
3.3. Обучение без учителя: сжатие информации 89
Визуализация многомерной информации является главным
практическим применением карт Кохонена. Кроме того, эти
алгоритмы самоорганизации помогают нам понять принципы
обучения коры головного мозга (см. главу 5).
Заметим, что самоорганизующиеся карты сохраняют
отношение близости лишь локально: близкие на карте области
близки и в исходном пространстве, но не наоборот (рис. 3.16).
В общем случае не существует отображения, понижающего
размерность и сохраняющего отношения близости глобально.
Рис. 3.16. Пример одномерной карты двумерных данных.
Стрелкой показана область нарушения непрерывности
отображения: близкие на плоскости точки отображаются на
противоположные концы карты
Итак, в этом разделе мы познакомились с важным типом
обучения — без учителя, чрезвычайно полезным для работы
с большими массивами данных, когда получить экспертные
оценки для обучения с учителем не представляется
возможным. Самообучающиеся сети способны выявлять
закономерности в данных, формируя относительно малоразмерное
пространство признаков, без чего качественное распознавание
образов зачастую невозможно.
Таким образом, оба типа обучения, с учителем и без,
удачно дополняют друг друга. Кроме того, как мы убедились на
примере сетей с узким горлом, между этими типами обучения
существует тесная взаимосвязь: если посмотреть на ситуацию
90
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
под определенным углом зрения, соответствующие правила
обучения подчас просто совпадают.
Нам остается рассмотреть еще один очень важный тип
обучения — с подкреплением (reinforcement learning), который
тот же ЛеКун сравнивает с вишенкой на "торте машинного
обучения", поскольку учитель в этом случае не подсказывает
правильный ответ, а лишь поощряет ученика, если тот
найдет ответ самостоятельно. Примером такого обучения может
служить дрессировка животных.
3,4, Обучение с подкреплением:
поведение
Обучение с подкреплением — наиболее естественная для
живых существ постановка задачи, где учителем выступает сама
жизнь, поощряющая правильное и наказывающая за
неправильное поведение самыми разными способами. Фактически,
речь идет о самой общей постановке задачи обучения —
выработке адаптивного целесообразного поведения в произвольной
внешней среде. Именно на эту задачу должна быть нацелена
будущая операционная система роботов, о которой мы
поговорим далее в главах 6 и 8.
Сложность такого обучения в том, что успехи и неудачи
в данный момент обусловлены всей предыдущей историей, и
непонятно, какие из прошлых действий и как именно
повлияли на этот результат. Например, при игре в шахматы
подкреплением служит лишь конечный результат игры, а какие ходы
в игре были правильными или ошибочными — неизвестно.
Задачей обучения является выработка оптимальной
стратегии 7r(a|s), т.е. правила выбора действия а в ситуации s.
Результатом действия at в момент t является переход в
новую ситуацию St+i с получением соответствующего
подкрепления rt. Однако оптимальная стратегия должна
ориентироваться не на сиюминутное подкрепление, а максимизировать
ожидаемую сумму всех будущих подкреплений — ценность
3.4. Обучение с подкреплением: поведение
91
R = (Х^>о^г£/> гДе 7 ^ 1 — коэффициент дисконтирования
будущих подкреплений в связи с их растущей
неопределенностью. То есть речь идет именно о модели обучения
стратегическому планированию, ориентированному на достижение
долговременных целей — максимизации ценности. Одним из
наиболее ярких недавних достижений обучения с подкреплением
является игровой интеллект программы AlphaZero,
обладающий сверхчеловеческими способностями к стратегическому
планированию (см. раздел 4.8.).
Стратегию можно строить непосредственно, отталкиваясь
только от примеров реального взаимодействия со средой.
Альтернативно можно сначала построить модель среды, и с ее
помощью генерировать дополнительные примеры виртуального
взаимодействия со средой. Первый способ известен как model-
free или direct, а второй соответственно - как model-based или
indirect. На самом деле оба способа используют нейросетевые
модели с настраиваемыми параметрами. Только в первом
случае используется одна модель поведения 7r^(a|s), а во втором
к ней добавляется еще и модель среды /^(st+ils^at)10.
Последняя определена в более высокоразмерном пространстве,
и ее обучать сложнее. Так что подход model-free с точки
зрения обучения проще. С другой стороны, если удается обучить
модель среды, можно находить гораздо более сложные
стратегии, просчитывая ситуацию на много шагов вперед.
3.4.1. Обучение без моделирования среды (model-
free)
Обучение без моделирования среды использует в качестве
обучающих данных реальные траектории г = (so, ao, si, ai,...),
порожденные стратегией 7r(a|s), для которых находится
суммарное подкрепление R(r). Поскольку в реальном мире
набрать большую статистику оценки различных стратегий до-
10 Здесь мы для краткости включили подкрепление rt в описание
среды, в качестве дополнительной координаты.
92
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
вольно трудно, model-free-стратегии роботов, как правило,
задаются относительно небольшим числом параметров, часто
линейными моделями, чтобы последние могли обучиться за
разумное время11.
В качестве модели поведения с дискретным набором
действий можно взять нейронную сеть, на вход которой
подается вектор текущей ситуации s, а выходами являются оценки
вероятности каждого из возможных в данной ситуации
действий 7T0(a|s). Кроме того, нам понадобится еще один выход
сети — оценка ценности данного состояния vq(s). Такая ней-
росеть может порождать траектории, которые будут служить
материалом для ее обучения.
Допустим, мы сгенерировали для обучения набор
траекторий длины Г, используя текущие значения весов нейросети в.
По ним мы можем оценить эмпирическую ценность состояния
so
/Т-1
ЯЫ = ( Л 7S + lTve{sT)
\t=o
Теперь понятно, зачем нам понадобилась оценка ценности
состояний — чтобы замкнуть бесконечную сумму. Поскольку
мы получили от реального мира дополнительную
информацию, мы можем использовать эти данные для корректировки
весов нашей нейросети. Например, для весов, отвечающих за
оценку состояния vq(s):
e^e-VVe(R(s0)-ve(s0))\
где градиент по весам находится методом backpropagation.
Аналогично корректируются веса, отвечающие за
вероятности действий, только в этом случае надо минимизировать не
11 Это ограничение не распространяется на обучение программных
агентов игре в компьютерные игры, где в роли реального мира
выступает игровой движок и цена эмпирических данных снижается на много
порядков. В этом случае model-free-подход позволяет находить довольно
сложные стратегии, как, например, при обучении играм семейства Атари
[Mnih, Kavukcuoglu и др., 2013].
3.4. Обучение с подкреплением: поведение 93
квадратичную ошибку, а расстояние Кульбака между
модельным распределением вероятностей и его эмпирической
оценкой [Deisenroth и др., 2013]:
9 <- (9 + r/V6>log7r6>(a0|so)(i?(so) - v(s0)).
Иными словами, мы обучаем нашу нейросеть методом
стохастической оптимизации, используя в качестве ошибки ней-
росети функционал:
mm С = min [(v — R) logixe + (vq — R)2] .
о о
Таким образом, обучение с подкреплением сводится к
обучению с учителем, только нейросеть теперь сама участвует в
генерации каждой следующей порции примеров для
стохастической оптимизации в ходе реального взаимодействия со
средой. Ту часть нейросети, которая генерирует действия, можно
называть актором, а ту, что оценивает позицию, — критиком
(рис. 3.17). Поэтому иногда такой подход называют методом
актора-критика (actor-critic).
TttfVt
L(6) = (v-R)\ogne + (ve-R)2
Рис. 3.17. Обучение нейросетевой модели поведения методом
актора-критика
Более подробное изложение этой и родственных методик
model-free-обучения можно найти, например, в [Mnih, Badia
и др., 2016].
94
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Мы еще вернемся к этой теме в следующей главе. Пока же
рассмотрим, чего можно достичь, добавив к модели поведения
еще и модель среды.
3.4.2. Обучение с моделированием среды (model-
based)
В model-free-обучении все траектории порождаются при
взаимодействии с окружающей средой, т.е. обучение сопряжено с
реальными рисками, вызванными неадекватным поведением.
Чем сложнее модель поведения, тем больше примеров
требуется для ее обучения, тем выше сопряженные с обучением
риски. В живой природе это могут быть риски для жизни.
Отсюда — актуальная потребность уметь обучаться
сложному поведению при минимальном количестве взаимодействий
с внешним миром. Это достигается введением в
управляющий контур дополнительной модели — симулятора
внешнего мира: s^+i = /^>(st,at). Этот симулятор может в нужном
количестве порождать обучающие траектории для
оптимизации модели поведения 7r^(at|st), например, по описанной
выше методике actor-critic. Взаимодействие с реальным миром
происходит с использованием оптимизированной в симулято-
ре стратегии, что минимизирует реальные риски. Этот опыт
используется для совершенствования модели среды и
улучшения стратегии поведения в обновленном симуляторе.
В качестве примера приведем популярную управляющую
архитектуру Dyna [Sutton, 1991], сочетающую в себе
элементы обучения, планирования и быстрого реагирования, что для
животных, например, может быть критично. Dyna включает
в себя:
• модель поведения агента, порождающую в каждой
ситуации определенное действие;
• модель внешней среды, предсказывающую переход
между состояниями среды вследствие тех или иных действий
3.4. Обучение с подкреплением: поведение 95
агента, обучение которой происходит при взаимодействии
с реальным миром;
• обучение модели поведения происходит в режиме
симуляции взаимодействия с миром, пользуясь моделью
внешней среды;
• реактивное взаимодействие с внешним миром — согласно
модели поведения, без дополнительного просчета
ситуации.
При обсуждении механизмов работы мозга в главе 5 мы
свяжем быстрое развитие неокортекса у млекопитающих
именно с переходом от режима обучения model-free к режиму model-
based с соответствующими эволюционными преимуществами.
У рептилий управление поведением сосредоточено в базаль-
ных ганглиях. У млекопитающих к этой модели поведения
добавилась еще и модель мира в неокортексе. Реактивное
поведение в стандартных ситуациях помогает обеспечивать
мозжечок.
Главная проблема в model-based-подходе — это сложность
обучения симулятора. Как мы уже отмечали, модель среды
определена в пространстве большей размерности, чем модель
поведения, т.е. ее обучение, по идее, должно требовать
большего числа примеров.
На самом деяе^ для улучшения модели поведения точная
модель среды нам, как правило, и не требуется. Так, мы
обучаемся езде на автомобиле, имея лишь весьма поверхностное
представление о его конструкции и динамических
характеристиках. Нам достаточно грубой модели, но обладающей
нужными для обучения поведению свойствами. А именно,
траектории, порождаемые симулятором, должны как можно точнее
соответствовать траекториям реального мира, иначе
стратегии поведения в нем и в реальном мире не будут
соответствовать друг другу.
Это можно реализовать, настраивая в качестве
симулятора мира нейросеть, по возможности точно воспроизводящую
траектории реального мира. Обе модели, поведения и внеш-
96
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
него мира, можно обучать в единой манере методом
стохастической оптимизации (см. рис. 3.18).
£(0) = О - Д) logTTe + (ув - Я)2
ДФ) = 2^ (5t+i ~f(l>(at>st))
Рис. 3.18. Обучение с моделированием среды
Такой подход в целом сооветствует архитектуре Dyna, т.е.
поведение агента в мире — реактивное, что вовсе
необязательно. Такое поведение хорошо, например, при игре в блиц.
Но при игре в обычные шахматы качество ходов можно
существенно улучшить, если постоянно просчитывать развитие
ситуации на несколько ходов вперед, если время позволяет.
Именно так сегодня играют лучшие компьютерные
программы, обученные методами обучения с подкреплением (см.
раздел 4.8.).
3.4.3. Связь с теорией управления
Применительно к моделированию работы мозга и созданию
искусственной психики роботов и программных агентов, ней-
росетевые архитектуры необходимо рассматривать в
контексте теории управления. Обучение с подкреплением можно
считать развитием традиционной теории управления. Последняя,
по-крупному, занималась двумя классами задач:
• управление по отклонениям от заданной траектории, где
в центре внимания была стабильность управления с
обратной связью. Оптимальная траектория, например
полета баллистической ракеты, рассчитывалась исходя из
соответствующей математической модели;
3.5. Обсуждение
97
• нахождение траектории процесса, оптимизирующей
заданный функционал. Например, оптимизация
производственного процесса, заданного соответствующей
имитационной моделью и системой разнообразных
ограничений.
В обоих случаях, как правило, использовались заданные
извне модели управляемых процессов.
Обучение с подкреплением занимает в теории управления
свою нишу — адаптивного управления там, где модели
управляемых процессов заранее неизвестны, да и сами эти процессы
могут меняться со временем. Сравнения интеллектуального
адаптивного управления с традиционным управлением
приводятся на рис. 3.19, 3.20
Рис. 3.19. Традиционная теория управления по отклонениям
3.5. Обсуждение
Эта вводная глава была посвящена общим принципам и
базовым алгоритмам машинного обучения. Мы здесь
ограничились лишь теми понятиями, которые понадобятся нам для
понимания содержания последующих глав. Некоторые важные
разновидности нейросетей, например рекуррентные и свер-
точные сети, мы затронем в следующей главе. Однако мно-
98
ОСНОВЫ МАШИННОГО ОБУЧЕНИЯ
Рис. 3.20. Адаптивное управление с обучением и
планированием
гие аспекты машинного обучения так и останутся за
пределами этой книги. Желающим более глубоко ознакомиться с
предметом можно рекомендовать классическую монографию
[Bishop, 2006] или переведенный на русский язык учебник
[Хайкин, 2008] - именно в таком порядке. Примеры
практических применений нейросетей можно найти в курсе лекций
[Ежов и Шумский, 1998], отдельные фрагменты которого мы
использовали в этой главе. Наконец, совсем недавно вышли
книги [Гудфеллоу и др., 2018; Николенко и др., 2018], более
приближенные к современным реалиям, а именно - к теме
следующей главы: глубокому обучению.
Глава 4
Глубокое обучение
Они думали недостаточно
глубоко, потому и не
погружалось чувство их
до самого дна
Вставай, бездонная
мысль, из глубины своей
Из самой глубины должно
придти самое высокое к
своей высоте.
Фридрих Ницше
«Так говорил Заратустра»
От общих принципов машинного обучения пора
переходить к их практическому применению. Тем более что именно
здесь, в прикладных областях, в последние годы происходит
настоящая революция.
За последние 5-7 лет многие задачи, такие как
распознавание речи, компьютерное зрение, машинный перевод, не
поддававшиеся решению десятилетиями, оказались практически
решены. Сегодня качество решения этих задач машинами
сравнимо с человеческим и продолжает постоянно улучшаться.
100
ГЛУБОКОЕ ОБУЧЕНИЕ
Это открывает широкие возможности для большого числа
практических применений - от общения с интеллектуальными
агентами на естественном языке до автономных автомобилей,
дронов и роботов. Мир роботов и искусственного интеллекта
внезапно переместился из абстрактного отдаленного
будущего в завтрашний и даже сегодняшний день.
Эта глава - своего рода краткая летопись революции
глубокого обучения. Мы опишем, какие задачи и какими
методами были решены, почему именно сейчас и куда направлен
сегодня вектор развития отрасли.
4.1. Революция глубокого обучения
4.1.1. Предпосылки революции
Термин " глубокое обучение" вошел в обиход научного
сообщества в 2006-2007 гг., когда сразу три научных коллектива
под руководством Джеффри Хинтона [Hinton, Osindero и др.,
2006; Salakhutdinov и др., 2007; Sutskever и Hinton, 2007], Йо-
шио Бенджио [Y. Bengio, Lamblin и др., 2007] и Яна ЛеКуна
[F. J. Huang и др., 2007; U. Muller и др., 2006] добились
впечатляющих успехов в обучении многослойных нейронных сетей и
продемонстрировали важность глубины, т.е. числа слоев ней-
росети.
Однако настоящий бум глубокого обучения начался лишь
в 2012 г., с началом миграции машинного обучения на GPU,
когда соответствующие алгоритмы неожиданно превзошли всех
конкурентов сразу во многих областях, включая
распознавание китайских рукописных символов, медицинских снимков,
дорожных знаков и сегментацию изображений [Cire§an, Giusti
и др., 2012, 2013; Cire§an, Meier и др., 2012]. Особенно
большой резонанс имели убедительные успехи глубоких сетей в
распознавании зрительных образов и речи [Graves, Mohamed
и др., 2013; Krizhevsky и др., 2012], а также тот факт, что
качество распознавания на глубоких сетях постоянно и быстро
прогрессировало [Schmidhuber, 2015].
4.1. Революция глубокого обучения
101
Между тем, основные "рабочие лошадки" современного
глубокого обучения - рекуррентные сети с долговременной
памятью (LSTM) [Hochreiter, Y.a Bengio и др., 2001; Hochreiter и
Schmidhuber, 1997] и сверточные сети (CNN) [LeCun, Boser и
др., 1989] - появились задолго до этого. Почему же эта тема
"выстрелила" лишь совсем недавно?
Причина банальна — всем известный закон Мура, в
соответствии с которым каждые пять лет доступные
вычислительные мощности увеличиваются примерно на порядок. И
каждый следующий порядок удешевления вычислений позволяет
решать какие-то ранее недоступные задачи.
В какой-то момент, относительно недавно, оказались
доступными задачи сенсорного искусственного интеллекта —
распознавания образов с качеством, сравнимым с
человеческим. Отсюда — общественный резонанс, т.к. появилась
возможность (и угроза!) массовой замены людей компьютерами.
Тем более что за прошедшие годы вычисления подешевели
еще на порядок, как и возможности этого "новорожденного"
интеллекта.
Мы, люди, склонны преувеличивать свои
интеллектуальные способности, и, действительно, машинному интеллекту
еще далеко до человеческого. Но величие человеческого
разума - в его социальной природе, способности пользоваться
знаниями, накопленными миллиардами живших и живущих
с нами рядом людей. Возможности же человеческого мозга в
сфере того же сенсорного интеллекта вполне сопоставимы с
другими животными. По зрению мы уступаем орлам, по слуху
и обонянию - собакам, и т.д.
Сложность сенсорного интеллекта можно оценить по
порядку величины. У млекопитающих он сосредоточен в новой
коре, специализирующейся на глубоком обучении, т.е.
формировании иерархии все более абстрактных признаков. Об этом
пойдет речь в главе 5. Как и о том, что базовым модулем
неокортекса является колонка, содержащая порядка 104
нейронов. Таких колонок в человеческом неокортексе - несколько
102
ГЛУБОКОЕ ОБУЧЕНИЕ
миллионов. Поскольку каждый нейрон колонки имеет лишь
один аксон, колонка может быть связана максимум с 104
других колонок. Это соответствует десятку миллиардов
параметров обучения W ~ 1010, которые мы и настраиваем в течение
всей своей жизни.
Далее, основным алгоритмом обучения современных
искусственных нейросетей является стохастическая
градиентная оптимизация. Сложность этого алгоритма квадратично
растет с числом настроечных весов С ~ rribW2, где ть ~
~ 10-г 100 (согласно (3.13)). Следовательно, сложность
обучения интеллекта, сопоставимого с человеческим С > 1021. Это
касается сложных когнитивных способностей —
сознательного мышления и речи, где задействована практически вся кора
(и не только). Если ограничиться более узким классом задач,
скажем, распознаванием сенсорных образов, которыми
заняты лишь отдельные части нашей коры (скажем, 1/10), эта
оценка понизится, соответственно, на два порядка.
Таким образом, для достижения человеческого уровня в
задачах распознавания образов требуется затратить С > 1019
операций. На компьютерах 20-летней давности с
производительностью rsj 109 - 1010 FLOPS (Floating Point Operations
Per Second) это заняло бы не менее 30 лет. Сегодня
доступны графические ускорители (GPU) с производительностью
~ 1013 — 1014 FLOPS (см. ниже), и это время снизилось на
4 порядка, до дней.
Вот почему давно известные технологии обучения
искусственных нейронных сетей "выстрелили" именно сейчас.
Просто потребовалось время для наращивания вычислительных
мощностей и размеров баз данных. Поскольку глубокие ней-
росети "жадные" и до того и до другого.
4.1.2. Суть глубокого обучения
Основное преимущество глубоких нейросетей - их способность
порождать иерархию все более абстрактных представлений
данных. Каждый следующий слой нейросети формирует все
4.1. Революция глубокого обучения
103
более и более информативные признаки входных данных, как
наиболее значимые комбинации признаков предыдущего
уровня.
Соответственно, чем больше промежуточных слоев у ней-
росети, тем более абстрактными понятиями она может
оперировать и тем более сложные задачи она может решать.
Например, распознавать сцены в задачах машинного зрения,
выделяя в них людей, здания, машины и тысячи других
возможных объектов.
До появления глубокого обучения задачи распознавания
образов в разных областях решались по-разному. В каждой
области специалисты десятилетиями вручную
конструировали каждый свои наборы признаков. Глубокое обучение дало
универсальную методику автоматического конструирования
абстракций, что привело к прорыву сразу по всем
направлениям. Сегодня и в машинном зрении, и в распознавании речи,
и в машинной обработке текстов используются, по сути, одни
и те же архитектуры глубоких нейросетей.
Ощущение того, что "глубокие сети лучше, чем широкие",
существовало достаточно давно, в частности, благодаря
реконструкции многослойной архитектуры зрительной системы
приматов [Y. Bengio, 2013; Y. Bengio и др., 2009].
Впоследствии преимущества глубоких нейросетей получили и
теоретическое обоснование. Так, в работе [Raghu и др., 2016]
предложен достаточно общий подход к сравнению выразительных
способностей различных архитектур нейросетей. В частности,
показано, что разнообразие функций, представимых нейро-
сетями с N скрытыми слоями с Н нейронами в каждом и
d-мерными входами растет, как 0(HNd) (этот факт мы уже
упоминали ранее). Отсюда следует, что при одинаковом
числе нейронов, чем больше глубина сети, тем большей
выразительной силой она обладает. И этот вывод достаточно общий:
сложность функций, представимых нейросетями,
экспоненциально растет с увеличением их глубины, но не ширины.
104
ГЛУБОКОЕ ОБУЧЕНИЕ
4.1.3. Методики глубокого обучения
Хотя обучение методом backpropagation не накладывает
ограничений на глубину нейросети, на практике обучать сети с
большим числом слоев долгое время не удавалось. Обучение
было неустойчивым, т.к. градиенты ошибки нейросети для
весов следующего слоя выражаются через градиенты для весов
предыдущего слоя, и при большом числе сомножителей без
принятия специальных мер они стремятся либо к нулю, либо
к бесконечности.
Первые успехи в обучении глубоких нейросетей в 2006-
2007 гг. были связаны с послойным обучением глубоких
нейросетей без учителя [Hinton, Osindero и др., 2006; F. J. Huang и
др., 2007; U. Muller и др., 2006]. Каждый следующий слой
формировал абстракции более высокого порядка, наилучшим
образом "объясняющие" (способные восстановить) сигналы
предыдущего слоя, аналогично разделу 3.3.4.
С использованием абстракций высокого порядка качество
распознавания образов существенно улучшалось. Достаточно
было достроить поверх многослойной кодирующей нейросети
обычные плоские классификаторы. Лучшие результаты
достигались, когда вся многослойная нейросеть дообучалась
методом backpropagation, используя предварительно обученную
методами unsupervised learning нейросеть в качестве
начального приближения. Такая методика позволяла решать задачи
с относительно небольшим количеством размеченных данных.
Со временем были накоплены достаточно большие базы
размеченных данных, такие как ImageNet, и найдены
надежные методики стабилизации глубокого обучения,
позволяющие обучать методом backpropagation сети со многими
десятками и даже сотнями слоев. Так что нужда в послойном пре-
добучении глубоких нейросетей отпала. Упомянем несколько
таких новаций.
Во-первых, выяснилось, что вместо сигмоидной лучше
использовать более простую функцию активации нейронов -
Rectified Linear Unit (ReLU): ReLU(x) = max(x,0), градиент
4.1. Революция глубокого обучения
105
которой не исчезает при возрастании входов [Nair и Hinton,
2010].
Далее, оказалось, что ландшафт глубоких нейросетей
изобилует не локальными минимумами, а седловыми точками,
в районе которых градиентное обучение замедляется [Bray и
D. S. Dean, 2007]. Однако, глубокие нейросети успешно
обучались методом Stochastic Gradient Descent (SGD) или SGD
с моментом, используя на каждом шаге мини-батчи
примеров для грубой оценки градиента ошибки [Sutskever, Martens
и др., 2013]. Встроенная в SGD стохастичность помогает
избегать точки перегиба и находить более пологие минимумы с
лучшей обобщающей способностью [Keskar и др., 2016]. В
последние годы большой популярностью пользуются различные
варианты адаптивного обучения (RMSProp [Hinton, Srivastava
и Swersky, 2012], Adam [Kingma и Ва, 2014] и др.), которые
обладают гораздо лучшей сходимостью, хотя и к менее пологим
минимумам, чем простой SGD, что может отрицательно
сказываться на их обобщающей способности [А. С. Wilson и др.,
2017].
Обычной практикой в машинном обучении является
нормирование входных данных. Оказалось, что более стабильное
и быстрое обучения глубоких нейросетей достигается при
нормировке входов нейронов не только во входном, но и в
скрытых слоях прямо в ходе обучения. Эта методика известна как
Batch Normalization [Ioffe и Szegedy, 2015]. Для небольших
батчей статистика входов нейронов может существенно
различаться, что затрудняет обучение. Идея Batch Normalization
состоит в том, чтобы стабилизировать статистику входов. Для
этого на входы каждого нейрона сети подаются
нормированные сигналы: х — {х — Е[х\)/^/Vаг[х\, где усреднения
производятся в каждом мини-батче. Чтобы не снижать
выразительной силы нейросети, нормализация сопровождается линейной
трансформацией каждого входа у = ^х + /3, параметры
которой выявляются в процессе обучения. Стационарная
статистика входов стабилизирует весь процесс обучения и может
существенно ускорить обучение.
106
ГЛУБОКОЕ ОБУЧЕНИЕ
Еще одна простая идея позволила существенно увеличить
глубину и качество обучения, а именно - введение
шунтирующих связей между слоями нейросети. В т.н. Residual Networks
обычное нелинейное преобразование от слоя к слою F(x)
дополняется фиксированной единичной матрицей, т.е. на вход
следующего слоя подается сумма входа и выхода от
предыдущего слоя: F(x) + х. Эта модификация не вносит никаких
дополнительных параметров, но существенно упрощает
обучение и улучшает его качество, т.к. позволяет обучать очень
глубокие нейросети (с сотнями и даже тысячами слоев) [Не
и др., 201 б]1. В 2015 г., едва появившись, Residual Networks
показали наилучшие результаты на разных задачах в
соревнованиях ImageNet, CIFAR и др.
Чем больше слоев имеют глубокие нейросети, тем больше
их выразительная способность, и глубже уровень абстракций
в обработке данных. Но с ростом числа настроечных весов
растет и опасность переобучения, когда сеть слишком
хорошо приспосабливается к обучающей выборке и теряет
способность к обобщению. В дополнение к известным методам
регуляризации обучения (таким как L1- и Ь2-регуляризация),
в глубоком обучении широко применяется относительно новая
методика, известная как dropout [Hinton, Srivastava, Krizhevsky
и др., 2012], когда в каждом мини-батче обучается лишь
случайное подмножество всей сети. Часть нейронов (скажем,
половина) случайным образом выбрасывается, что
предотвращает формирование в процессе обучения излишне сложных
признаков. В обученной таким образом нейросети все веса
затем умножаются на соответствующий коэффициент (в
данном примере, 0,5), чтобы скомпенсировать увеличение числа
нейронов по сравнению с прореженным вариантом сети.
Результат такой регуляризации наглядно иллюстрирует рис. 4.1
из статьи [Srivastava и др., 2014].
1 Да что там тысячи, в [Sonoda и Murata, 2019] речь идет уже о
сетях с бесконечным числом слоев - новое многообещающее направление
машинного обучения.
4.1. Революция глубокого обучения
107
Рис. 4.1. Улучшение точности распознавания образов с
применением методики регуляризации dropout [Srivastava и др.,
2014]
Байесовский подход к обучению глубоких нейросетей,
продвигаемый в частности группой Дмитрия Ветрова, помогает
не только понять причину эффективности методики dropout,
но и найти оптимальные параметры прореживания сети [Mol-
chanov и др., 2017].
Развитием этих идей является адаптивное прореживание
нейросетей, другая модификация метода backpropagation: на
каждом слое нейросети сохраняют значения выходов лишь
у топ-k наиболее активных нейронов, зануляя выходы всех
остальных. Авторы назвали такое обучение minimal effort back-
propagation (meProp), добиваясь ускорения обучения в
несколько десятков раз без существенных потерь точности [X. Sun и
ДР-, 2018].
108
ГЛУБОКОЕ ОБУЧЕНИЕ
Тема экстремально разреженных нейросетей заслуживает
отдельного рассмотрения.
4.1.4. Экстремально разреженные сети
Как мы знаем, согласно (3.13), сложность обучения нейросети
квадратично растет с числом ее настроечных параметров, и
для доступных сегодня вычислительных мощностей их
число не может сильно превышать миллиард (см.
соответствующие оценки ниже). Это не мало, но количество доступных
в интернете данных практически не ограничено, и хотелось
бы иметь возможность обучать и более сложные сети.
Например, для обучения языку на корпусе текстов из 100
миллиардов слов, нейросеть должна иметь сопоставимое количество
настроечных параметров. Действительно, в Google Brain
удалось обучить на такой выборке нейросеть с 137 миллиардами
настроечных параметров, существенно улучшив качество
моделей языка, обученных на меньших объемах данных [Shazeer
и др., 2017]. Так что авторы объявили своей следующей целью
обучение языку на 1 триллионе слов.
Для этого они разработали специальную архитектуру
нейросети, комитет экспертов (mixture of experts), в которой в
каждый конкретный момент работает только очень
небольшое подмножество этой гигантской сети, иначе ее обучение
было бы непосильной задачей даже для Google. Как показано
на рис. 4.2, в зависимости от контекста сеть-диспетчер
подключает к решению лишь несколько из доступных экспертов,
например 10 из 10 000, ускоряя, тем самым, вычисления в
тысячи раз.
В этой связи следует упомянуть и отечественные
разработки, в частности, предложенные Сергеем Тереховым Tensor
Train Neural Networks (см. рис. 4.3), являющиеся нелинейным
обобщением Tensor Train разложения тензоров.
Идея состоит в представлении произвольной нелинейной
функции многих дискретных переменных /(ii, 22,..., id)
композицией небольшого числа из потенциально очень большого
4.1. Революция глубокого обучения
109
Рис. 4.2. Нейросеть из комитета экспертов плюс сеть-
диспетчер, подключающая в каждый момент лишь наиболее
компетентных в данном контексте экспертов [Shazeer и др.,
2017]
набора нейронных сетей, своей для каждой области
определения функции: /(ii,i2,...,id) = VilNilii2...Nid_l9idVF. Здесь
Vik - семантические вектора, соответствующие каждой
переменной, а А^т,гп _ элементарные нейросети, свои для
каждого значения переменных гт,гп. В итоге, как и в предыдущем
случае, каждый конкретный расчет функции / использует
ничтожную часть знаний, запасенных в комитете элементарных
нейросетей-"экспертов", только здесь выбранные эксперты
образуют соответствующую ситуации глубокую нейросеть,
работая не по отдельности, а сообща.
По этой методике в компании «Связной» ежедневно
рассчитывается прогнозируемый спрос на десятки тысяч
товарных позиций во всех торговых точках сети для каждого дня
недели каждого месяца!
Группой Дмитрия Ветрова ранее была предложена
схожая идея использования Tensor Train-разложения для
сжатого представления матриц синаптических связей между слоя-
по
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.3. Вверху: Tensor Train-декомпозиция, представление
тензоров через композицию матриц [Oseledets, 2011]. Внизу:
Tensor Train Neural Networks, представление функции
многих дискретных переменных через композицию элементарных
нейросетей [Терехов, 2018]
ми нейросетей [Novikov и др., 2015]. В этом случае сеть также
эффективно прореживается, т.к. исходная матрица связей в
больших нейросетях может содержать на порядки больше
параметров, чем ее Tensor Train-разложение. При сквозном
сжатии всех слоев глубокой сверточной нейросети (см. ниже) для
распознавания изображений они добились 80-кратного
сжатия описания нейросети, потеряв при этом в точности
распознавания всего лишь 1% [Garipov и др., 2016].
4.1.5. Hardware для глубокого обучения
Современные глубокие нейросети для реальных задач,
обучаемые на больших данных, например на миллионах
фотографий, могут содержать сотни миллионов настроечных весов.
Нахождение их оптимальных значений в ходе глубокого
обучения представляет собой обратную задачу с квадратичной
вычислительной сложностью: С ~ rribW2, согласно (3.13).
4.1. Революция глубокого обучения
111
Для W = 108,т6 = 100 получаем С ~ 1018 FLOP.
Чтобы обучение измерялось днями (~ 105 сек), вычислительная
мощность должна измеряться десятками TFLOPS. Отсюда
следует, что обучение таких больших нейросетей требует
специального hardware.
Это могут быть кластеры из многих тысяч CPU-ядер, как
в работах команды из Google Brain [J. Dean и др., 2012; Le,
2013], где впервые удалось обучить нейросеть с более чем
миллиардом весов, поставившую очередной рекорд точности
распознавания образов на ImageNet2.
Однако гораздо более дешевую альтернативу
предоставляют графические процессоры (GPU), заточенные на
векторные операции и содержащие сотни и тысячи ядер на одном
кристалле. Не будет большим преувеличением сказать, что
все современное глубокое обучение основано на
использовании GPU- ускорителей3.
Лидер рынка GPU компания NVIDIA вовремя заметила
потенциал глубокого обучения и сегодня позиционирует себя
как главного поставщика решений для глубокого обучения.
Благодаря этому за пять лет с начала бума глубокого
обучения ее капитализация выросла в десять раз, причем только за
один 2016 г. она утроилась4.
Для обучения нейросетей и особенно для использования
уже обученных особая точность не нужна. Поэтому NVIDIA
в моделях, ориентированных на глубокое обучение, обеспечи-
2 В [Le, 2013] сеть с миллиардом весов обучалась на кластере из 16 000
CPU ядер в течение трех дней. То есть сложность обучения составила
С ~ 1010 FLOPS -16000 • 260000 сек ~ 4 • 1019 FLOP в полном согласии с
(3.13).
3 Начиная с пионерской работы [Krizhevsky и др., 2012], где обучение
глубокой нейросети с 60 млн. весами занимало 5-6 дней с
использованием всего двух GPU-карт GTX 580 суммарной производительностью
3 TFLOPS. To есть сложность обучения составила С ~ 3- 1012 FLOPS-
•400000 сек ~ 1018 FLOP.
4 За 2017 г. ее капитализация удвоилась, что тоже неплохо!
Характерный заголовок наших дней: «AI is eating software: NVIDIA is powering
it».
112
ГЛУБОКОЕ ОБУЧЕНИЕ
вает режимы вычислений с усеченной точностью, но большей
производительностью.
Кроме того, как мы увидим далее, для глубоких сетей
(особенно сверточных) очень важны тензорные операции
перемножения матриц. И вот в 2017 г. в процессоре NVIDIA
Tesla V100, предназначенном специально для обучения
глубоких нейросетей, они были встроены в процессорное ядро.
В итоге, на одном чипе достигается пиковая
производительность 7,5 TFLOPS (FP64), 15 TFLOPS (FP32), и 120 TFLOPS
(тензорных).
С 2016 г. в гонке за hardware для глубокого обучения
участвует и Google, для которого машинный интеллект является
безусловным приоритетом, если не сказать - миссией. В 2017 г.
Google анонсировал уже второе поколение своего
специализированного тензорного ускорителя TPU v2 с пиковой
производительностью на кристалле 45 TFLOPS (тензорных). Эти
ускорители группируются в TPU v2 Pods из 64 модулей, по 4
TPU в каждом. Производительность одного TPU v2 Pod
достигает 11,5 PFLOPS (~ 1016 FLOPS), так что на нем можно
обучить глубокую сеть с сотней миллионов весов всего за пару
минут. В 2018 г. с появлением TPU v3 производительность
новых TPU v3 Pod увеличилась в 8 раз (вчетверо больше вдвое
более быстрых кристаллов), так что это время сократилось до
десятков секунд. И эти ускорители доступны всем желающим
для аренды в Google Compute cloud!
4.2. Рекуррентные глубокие сети: речь и
язык
Двигаясь от общего к частному, мы переходим к
рассмотрению различных нейроархитектур и решаемых ими классов
задач. В современном глубоком обучении две архитектуры
нейросетей занимают особое место: это рекуррентные и сверточ-
ные сети, воплощающие идеи инвариантности по времени и в
пространстве и обеспечившие прорывы в распознавании и по-
4.2. Рекуррентные глубокие сети: речь и язык 113
нимании речи и машинном зрении соответственно. Им будут
посвящены этот и следующий разделы.
Многослойные feedforward-сети (персептроны)
представляют собой конвейер, где каждый следующий слой получает
информацию от предыдущего, обрабатывает ее и передает
следующему. Количество этапов обработки входного сигнала
совпадает с глубиной нейросети. В рекуррентных сетях
информация может передаваться не только наверх, но и вниз, т.е.
образовывать замкнутые контуры. Например, выходы слоя п
могут подаваться не только на слой п + 1, но и возвращаться
в слой п, как часть его входов:
y? = /(W"y£i1 + Vny?_1).
Иными словами, обработка сигналов в рекуррентных
сетях зависит от всей прошлой истории, т.е. эти сети обладают
памятью, точнее — динамической памятью, не
фиксированной в ее синаптических весах.
Рекуррентные сети глубокие по построению. Количество
этапов обработки сигналов в них принципиально ничем не
ограничено. Даже сеть с единственным рекуррентным слоем
можно развернуть во времени, представив ее как feedforward-
сеть с множеством идентичных слоев, каждый из которых
отвечает следующему шагу по времени. Поскольку все слои
идентичны, можно говорить о встроенной инвариантности по
времени. Это позволяет увеличить глубину обработки без
соответствующего увеличения числа параметров сети — очень
ценное качество для глубокого обучения.
Но, в силу тех же обстоятельств, не удивительно, что
проблема неустойчивости градиентного обучения коснулась
рекуррентных сетей в первую очередь [Hochreiter, Y.a Bengio
и др., 2001]. И именно для них было впервые предложено
ее решение - архитектура Long Short-Term Memory (LSTM)
[Hochreiter и Schmidhuber, 1997]5. В LSTM основным элемен-
5 Эта работа - одна из самых цитируемых в области глубокого
обучения - более 18 тыс. ссылок.
114
ГЛУБОКОЕ ОБУЧЕНИЕ
том является усложненная модель нейрона - ячейка памяти,
или memory cell (рис. 4.4).
Рис. 4.4. Ячейка памяти - основной элемент LSTM-сетей
В традиционных искусственных нейросетях формальные
нейроны не имеют памяти - выход является функцией его
текущего входа. Рекуррентные сети частично сохраняют
память об истории своих входов в сжатом виде в активации
нейронов скрытых слоев, но эта память быстро
деградирует со временем (модель Short-Term Memory). Чтобы помнить
события более отдаленного прошлого, memory cells в LSTM
наделены длительной памятью (динамически
перезаписывают свои значения благодаря обратной связи каждой ячейки
памяти со своим собственным выходом). Но эта память может
стираться и обновляться по сигналам от контрольных
вентилей (обычных нейронов с сигмоидной функцией активации).
Таким образом, memory cell является элементарной
микросхемой из нескольких обычных нейронов, обучаемых по обычным
алгоритмам (развернутым во времени вариантом обратного
распространения ошибки - backpropagation through time).
Детали этой микросхемы могут разниться для разных моделей
4.2. Рекуррентные глубокие сети: речь и язык 115
[Jozefowicz и др., 2015], но основная идея остается:
рекуррентная сеть с управляемой долговременной памятью, способная
обучаться решать сложные задачи обработки временных
рядов.
LSTM удобны тем, что могут работать с временными
рядами любой длительности. Их типичное приложение -
разметка временных рядов [Graves, Fernandez и др., 2006].
Выходом такой сети являются вероятности всех возможных меток
zl значений ее входов. Обучение производится минимизацией
функционала:
L = -J^lnP(V|xV
x,Z
К этому классу задач относится, например, распознавание
речи, где звуковой сигнал размечается фонемами или в
конечном итоге - текстом. LSTM стали популярны именно после их
убедительных успехов в распознавании и генерации речи [Fan
и др., 2015; Graves, Fernandez и др., 2006]. Сегодня все
подобные сервисы крупнейших облачных платформ от Google,
Microsoft, Apple, Amazon используют технологию LSTM.
LSTM-сети для реальных задач могут иметь десятки слоев
из сотен или даже тысяч ячеек памяти в каждом. Например,
Neural Speech Recognizer от Google состоит из 7 двойных слоев
LSTM (backward + forward) с 1000 ячеек памяти в каждом, и
содержит 116 миллионов весов [Soltau и др., 2016].
Качество распознавания речи постоянно улучшается, и
сегодня уже достигло человеческого уровня (см. рис. 4.5).
Вместо меток рекуррентные сети могут предсказывать
следующие значения ряда и тем самым могут сами генерировать
синтетические временные ряды. Например, генерировать
тексты [Graves, 2013]. Отсюда - другие популярные приложения
глубоких рекуррентных сетей: машинный перевод, машинное
аннотирование и другие задачи машинной обработки текстов
(Natural Language Processing, Natural Language Understanding)
Для таких приложений используют т.н. sequence-to-sequence
(seq2seq) сети. Они состоят из двух компонент - кодера и де-
116
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.5. Точность машинного распознавания речи
в 2017 году достигла человеческого уровня
кодера и работают обычно с отдельными предложениями.
Задача кодера - представить предложение в виде смыслового
вектора значений выходного слоя рекуррентной сети после
обработки предложения. Задача декодера - развернуть
полученный смысловой вектор в новое предложение в соответствии с
его закодированным смыслом. Для задач машинного
перевода предложения кодируются на одном языке, а декодируются -
на другом. Использование многослойных LSTM-сетей резко
повысило качество машинного перевода. Настолько, что для
некоторых языковых пар оно вплотную приблизилось к
человеческому уровню (см. рис. 4.6). Так что системы машинного
перевода массово перешли на эту технологию. В частности,
Google Translate с 2016 г. перешла на систему Google Neural
Machine Translation [Y. Wu, Schuster и др., 2016].
Соответствующая нейросеть имеет по 8 слоев LSTM в декодере и кодере.
Причем одна и та же архитектура используется для всех
языковых пар.
4.2. Рекуррентные глубокие сети: речь и язык 117
б
5
4
3
2
1
О
English English English Spanish French Chinese
> > > > > >
Spanish French Chinese English English English
Translation model
Рис. 4.6. Точность машинного перевода в прошлом (phrase-
based) и в новом (neural) поколениях систем. Для некоторых
языковых пар машинный перевод вплотную приблизился к
человеческому
Такую же архитектуру можно использовать и для других
задач, например для аннотирования содержания текста -
пересказать текст своими словами, но короче. Так, в работе [Yu
и др., 2016] аналогичная [Y. Wu, Schuster и др., 2016] сеть,
только с 3- и 4-слойными LSTM-кодерами и декодерами
обучалась пересказывать абзацы длиной до 100 слов в короткие
(до 15 слов) отражающие суть текста заголовки.
В современных рекуррентных сетях широко используется
механизм внимания (attention), предложенный в [Bahdanau
и др., 2014]. А именно, декодер использует в качестве
входа не один-единственный финальный кодирующий вектор от
кодера, как раньше [Sutskever, Vinyals и др., 2014], а всю
последовательность кодирующих векторов, по числу слов в
кодируемом предложении. Но на каждой итерации декодер
сосредотачивается на каких-то его элементах, в зависимости от
своего текущего состояния. То есть различные элементы по-
118
ГЛУБОКОЕ ОБУЧЕНИЕ
следовательности кодирующих векторов взвешиваются в
соответствии с контекстом (см. рис. 4.7, 4.8).
Рис. 4.7. В машинном переводе с языка А на язык В декодер
в каждый момент сосредотачивает свое внимание на
различных элементах входной последовательности, в зависимости от
текущего контекста
Функция внимания обычно реализуется feedforward-нейро-
сетью со входами фиксированной длины, обучаемой вместе с
декодером и кодером. Она учится предсказывать, какие части
входного предложения наиболее важны для подбора
очередного слова в его переводе.
Использование механизма внимания существенно
повысило качество машинного перевода (особенно для длинных
предложений), да и не только его. Этот же механизм оказался не
менее полезен и для машинного зрения с использованием свер-
точных нейросетей, теме следующего раздела. А в следующей
главе мы рассмотрим, как аналогичный механизм управления
вниманием реализован в нашем мозге.
4.3. Сверточные сети: зрение и не только 119
Рис. 4.8. LSTM-сеть с вниманием. При генерации каждого
следующего выходного значения yt внимание сети
перераспределяется между различными внутренними представлениями
hj входных элементов Xj
4.3. Сверточные сети: зрение и не только
Если рекуррентные сети ассоциируются главным образом с
временными рядами, то глубокие сверточные сети (Convo-
lutional Neural Networks, CNN) являются основой
современного машинного зрения. Их конструкция отражает основные
принципы зрительной системы млекопитающих [LeCun, Ben-
gio и др., 2015]: локальные рецептивные поля, многоуровневая
иерархия признаков, инвариантность к сдвигам и к
(небольшим) изменениям масштабов [Zeiler и Fergus, 2014].
Предложенные в 1989 году [LeCun, Boser и др., 1989], сверточные
сети довольно быстро нашли практическое применение в
распознавании рукописных символов задолго до эпохи глубокого
обучения [LeCun, Bottou и др., 1998]6.
ЛеКун взял за основу архитектуру сверточных сетей Neocognitron
[Fukushima, 1979] и применил к ней метод backpropagation. К концу 90-х
годов каждый десятый чек в США обрабатывался с помощью
сверточных нейросетей.
120
ГЛУБОКОЕ ОБУЧЕНИЕ
Однако после громкого успеха в соревновании ImageNet
Challenge в 2012 г. (сеть AlexNet [Krizhevsky и др., 2012]) они
стали де-факто базовой технологией всех систем машинного
зрения, включая системы распознавания лиц, дорожной
ситуации, разметки видеопотоков и множества других
приложений, причем во многих из них была достигнута точность,
сравнимая или превосходящая человеческую [Не и др., 2015].
Естественно, это стало возможным только благодаря росту
вычислительных ресурсов7.
Рассмотрим вкратце основную идею сверточных сетей и
их развитие в последние годы. CNN основаны на тензорных
операциях и являются разновидностью тензорных нейросе-
тей. В случае машинного зрения основой сверточных ней-
росетей является трехмерный блок нейронов, где высота и
ширина характеризуют пространственное разрешение
«картинки» X х У, а глубина D - количество каналов обработки
информации. Например, входным блоком могут быть
значения пикселей в трех цветовых каналах цветных фотографий
(256 х 256 х 3). Блок сверточных нейронов глубины d
формирует объемную картинку следующего уровня, состоящую
из d карт активации. Каждая из этих карт является
сверткой одной и той же матрицы весов х х у х D (фильтра или
признака, общего для всех нейронов данного слоя) с
небольшим локальным фрагментом предыдущего блока
(рецептивным полем данного нейрона, например 5x5x3). Каждый
нейрон г-го слоя определяет, насколько активация в его
рецептивном поле соответствует г-му признаку.
То есть в совокупности нейроны распознают наличие и
позицию в картинках d локальных признаков, которые
автоматически формируются при обучении. Поскольку хх|/ <
<СХ х У, сверточные нейросети имеют гораздо меньше
параметров, чем обычные полносвязные. Соответственно, при том
7 В [Не и др., 2015] сети обучались по 3-4 недели на 8 К40 GPU с
суммарной производительностью 34 TFLOPS (одинарной точности). То
есть сложность обучения приближается к 1020 FLOP.
4.3. Сверточные сети: зрение и не только
121
же числе параметров они могут быть гораздо глубже, т.е.
оперировать более сложными признаками.
Пространственная инвариантность зашита в сверточные
сети, аналогично тому, как временная инвариантность
зашита в рекуррентные сети. В одном случае одни и те же веса
используются в различных точках пространства, в другом -
в различные моменты времени.
Для машинного зрения важно выделение иерархии
признаков, комбинирующих мелкие детали в более
крупномасштабные образы, например в прототипы человеческих лиц
или кошачьих мордочек. Чтобы увеличить размеры
рецептивных полей без разрастания числа параметров, в сверточных
сетях применяют огрубление активационных карт. Для
этого обучаемые сверточные слои иногда перемежают
огрубляющими фиксированными pooling-слоями. Например, X х Y —»
-^Х/2 х У/2, заменяя активацию каждых 2x2 нейронов их
средним (mean-pooling) или максимальным значением (тах-
pooling).
В качестве примера на рис. 4.9 показана сеть VGGNet -
победитель ImageNet Challenge 2014 из работы [Simonyan и
Zisserman, 2014], где было показано, что точность
распознавания заметно улучшается с увеличением числа слоев (и с
применением более компактных рецептивных полей).
В следующем году победителем стали упоминавшиеся в
разделе 4.1.3. Residual Networks (ResNets) [He и др., 2015;
G. Huang, Y. Sun и др., 2016], на порядок более глубокие, за счет
применения шунтирующих связей между соседними слоями.
Эта идея получила развитие в архитектуре DenseNet
[G.Huang, Liu и др., 2016], где шунтирующие связи имеются уже
между всеми слоями, с дальнейшим улучшением результатов.
В отличие от ResNet в DenseNet применяется не сложение,
а конкатенация входов и выходов, так что каждый
следующий слой "видит" одновременно активационные карты всех
предыдущих слоев. Отсюда и название архитектуры - Dense
Convolutional Networks, т.к. каждый слой имеет гораздо боль-
122
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.9. Архитектура сети VGGNet [Simonyan и Zisserman,
2014]. Сверху: схема сверточного слоя, распознающего стек
признаков в каждом месте картинки (рецептивном поле).
Снизу: операция max-pooling, вдвое огрубляющая картинку
ше весов. Зато глубина каждого слоя может быть
существенно меньше, т.к. она эффективно накапливается. В итоге, как
ни парадоксально, для достижения той же точности DenseNet
может потребоваться меньше параметров, чем ResNet8!
Хотя машинное зрение - это, безусловно, killer application
для CNN, они активно применяются и в других областях, для
того же распознавания речи. Иногда для предобработки
акустического сигнала, формирующего входы глубоких
рекуррентных сетей, как в системе Deep Speech 2 [Amodei и др.,
2016]. Иногда - напрямую, как в [Y. Wang и др., 2017], где
ResNet с 40+ слоями показала отличные результаты.
8 Согласно [G. Huang, Liu и др., 2016], DenseNet с 15 млн
параметров показывает существенно лучшие результаты, чем ResNet с 30 млн
параметров.
4.4. Transformer: быстро и качественно
123
То, что одни и те же нейросети успешно работают как с
видео-, так и с аудиосигналами не должно вызывать
удивления. Ведь в последних на вход часто подается частотно-
временная 2Б-развертка аудиосигнала, т.е. аудиосигнал
предварительно конвертируется в видео (как в [Amodei и др., 2016;
Y. Zhang и др., 2017]).
Одномерные глубокие сверточные сети также
демонстрируют успехи в задачах seq2seq, традиционной вотчине
рекуррентных сетей. В частности, система машинного перевода от
Facebook AI Research [Gehring и др., 2017] использует 15-20-
слойные ResNet сети в качестве кодера и декодера (в схеме с
вниманием) и показывает даже лучшие результаты, чем
глубокие LSTM в системе машинного перевода Google [Y. Wu,
Schuster и др., 2016]. При этом скорость перевода системы на
сверточных сетях оказывается на порядок выше, т.к.
предложения переводятся параллельно, а не последовательно, как в
рекуррентных сетях.
В общем, сверточные сети быстрее и эффективнее
рекуррентных за счет встроенного параллелизма и локальных
рецептивных полей их нейронов, однако возможности
рекуррентных сетей потенциально шире за счет неограниченной
глубины обработки информации, что может быть критичным
для каких-то классов задач. Кроме того, как недавно
выяснилось, за счет небольшой модификации ячейки памяти
(названной Simple Recurrent Unit) рекуррентные сети могут стать
такими же быстрыми, как и сверточные [Lei и др., 2018]. Так
что выбор в пользу той или иной архитектуры неоднозначен
и зависит от конкретной задачи.
4.4. Transformer: быстро и качественно
Недавно появилась еще одна весьма перспективная
архитектура - Transformer, успешно конкурирующая с
рекуррентными и сверточными сетями. В ее основе лежит
эффективная параллельная версия механизма внимания [Vaswani и др.,
124
ГЛУБОКОЕ ОБУЧЕНИЕ
2017], использующая остроумный способ кодирования
положения слов в предложениях - своего рода Фурье-разложение
позиции слова, свертка с гармоническими функциями
различных длин волн. После этого можно больше не заботиться о
порядке следования слов и обрабатывать их все
одновременно, причем можно работать с очень широкими контекстами.
Этот подход, предложенный командой Google Brain, в
частности, позволил заметно улучшить качество машинного
перевода по сравнению с текущей версией Google Translate при
существенно меньших вычислительных затратах.
Развитие этих идей - одна из горячих тем последних
полутора лет [Chiu и др., 2018; Young и др., 2018]. Например, новая
модель языка (language model) GPT-2, созданная в OpenAI
на основе архитектуры Transformer, позволяет генерировать
настолько правдоподобные тексты, что авторы даже не
решились открыть ее исходный код, несмотря на свою миссию,
опасаясь использования этой технологии расплодившимися в
Сети ботами [Radford, J. Wu и др., 2019]9. Нейросеть GPT-2,
используя до 1,5 млрд настроечных параметров, достигла
значения Perplexity, лучшего, чем у понимающего смысл текста
человека (по-видимому, за счет того, что она знает гораздо
больше слов и их значений, чем рядовой человек).
Неудивительно поэтому, что эта модель языка показала
наилучшие из достигнутых до этого результатов на большом
количестве самых разных тестовых задач: поддержания
диалога, ответов на вопросы, разрешения неоднозначностей в
тексте (Winograd Schema Challenge), аннотирования текстов и
машинного перевода. При этом, для обучения модели не
использовались никакие размеченные корпуса - только большие
массивы текстов, скачанных из интернета (40 ГБ текста из
9 Более того, вскоре после этого OpenAI сменила свой
первоначальный некоммерческий статус, решив отныне генерировать прибыль для
своих акционеров. Действительно, автоматическая генерация текстов
может стать большим бизнесом. Так, уже сегодня треть всех текстов
Bloomberg News готовится с помощью системы автоматической
генерации контента Cyborg [Peiser, 2019].
4.4. Transformer: быстро и качественно
125
Рис. 4.10. Perplexity Per Word для моделей языка на
архитектуре Transformer [Radford, J. Wu и др., 2019]. Для
достаточно сложных моделей качество предсказания уже превышает
человеческий уровень PPW « 12 (согласно [X. Shen и др.,
2017]). При этом кривая явно еще не достигла насыщения,
и для еще более сложных сетей можно достичь еще лучших
результатов, размер обучающей выборки это позволяет
126
ГЛУБОКОЕ ОБУЧЕНИЕ
8 млн документов, получивших в Reddit не менее трех
"кармических" оценок). Значит, ограничения в области машинной
обработки текстов, связанные с дефицитом размеченных
данных, постепенно уходят в прошлое. "Мир большой - смотри
внимательно!"
4.5. Комбинированные сети: синтез
модальностей
Для многих когнитивных задач требуется совместная работа
разных областей мозга. Аналогично мы можем
комбинировать различные способности искусственных нейросетей.
Одним из наиболее ярких успехов глубоких нейросетей
стала демонстрация их способности генерировать подписи к
картинкам. В знакомой архитектуре кодер-декодер здесь в
качестве кодера выступает глубокая CNN, кодирующая
фотоизображение, а в качестве декодера - LSTM, обученная
генерировать подписи к этим фото [Vinyals и др., 2015] (см.
рис. 4.11).
Рис. 4.11. Машинная генерация подписей к картинкам
[Vinyals и др., 2015]. Кодер - глубокая сверточная сеть,
декодер - рекуррентная LSTM-сеть
Получается своего рода машинный перевод картинок в их
описание. Как и в обычном машинном переводе, здесь можно
4.5. Комбинации и синтез модальностей
127
использовать схему с вниманием, когда картинка кодируется
не единственным вектором, а множеством векторов,
привязанных к разным ее частям, и декодер может
концентрироваться на различных частях картинки в разные моменты ее
аннотирования [Хи и др., 2015].
Еще один интересный пример синтеза модальностей -
совместное обучение видео- и аудиоряда роликов из YouTube.
В отличие от подписей к рисункам, YouTube предоставляет
практически неограниченный материал для такого
совместного обучения. Постановка задачи очень проста (рис. 4.12): Две
глубокие CNN-сети получают на входы 10-секундные видео- и
аудио-отрывки из видеоклипов. Получаемые ими
высокоуровневые представления совместно используются
классификатором, который обучается распознавать соответствует ли
данный видеоряд данному аудиоряду [Arandjelovic и Zisserman,
2017]. Для этого реальные примеры дополнялись ложными,
где аудио- и видеоряды были случайным образом
перемешаны. Поскольку никакой ручной разметки для такого обучения
не требуется, оно ограничивается лишь доступными
вычислительными ресурсами. Оказалось, что такое обучение форми-
Рис. 4.12. Совместное обучение аудио и видео нейросетей
(зрение + слух) [Arandjelovic и Zisserman, 2017]
рует очень содержательное высокоуровневое описание видео-
и аудиопотоков, т.е. система обучается понимать увиденное
128
ГЛУБОКОЕ ОБУЧЕНИЕ
и услышанное. В доказательство авторы тестировали
обученную аудио сеть в умении решать различные задачи
классификации звуков, и она показала лучшие результаты, чем все
предыдущие системы, лишь на пару процентов уступив
точности человеческого распознавания. Аналогично
высокоуровневое описание видео сети позволяет достичь уровня лучших
систем распознавания образов в ImageNet Competition.
Причем, когда аудио сеть распознает, скажем, тот или иной
музыкальный инструмент, видео сеть выделяет его на картинке,
т.е. комбинированная сеть явно понимает, почему она
относит ту или иную картинку к определенному классу.
В целом, за синтезом модальностей большое будущее, так
как различные сенсорные каналы, дополняя друг друга,
существенно улучшают качество восприятия действительности.
Взять хотя бы синтетическое зрение автопилотов от компании
Cognitive Technologies, объединяющее в единое целое сигналы
от радаров и видеокамер и уже воплощенное в готовые
изделия.
4.6. Реляционные сети: понимание связей
Успех сверточных и рекуррентных сетей кроется в их узкой
специализации, они заточены под определенный класс задач
распознавания образов. Необходимая для этого
трансляционная инвариантность уже заложена в их архитектуру, и не надо
тратить ресурсы на то, чтобы ей обучиться. Аналогично,
используя другие типы инвариантности, можно конструировать
нейросети для решения других классов задач.
Примером могут служить предложенные недавно
реляционные сети (Relational Networks, RN), заточенные для
нахождения разного рода отношений между объектами [Santoro и
др., 2017]. Идея реляционной сети проста: будем
моделировать граф связей между объектами О = {oi,..., оп} , oi Е Rm
следующей композицией feedforward нейросетей /, д:
4.6. Реляционные сети: понимание связей
129
RN(0) = f\Yt9(°i,oj)
Такая нейросеть по построению призвана находить
определенный, неизвестный заранее тип отношений д между всеми
объектами. Например, объекты могут притягивать друг друга
по какому-то закону, единому для всех. Если закон правильно
угадан функцией д, это по построению повлияет на поведение
всей совокупности объектов.
Благодаря встроенной инвариантности, RN решает свою
задачу очень эффективно. Причем она может легко
комбинироваться с другими нейросетевыми модулями для
совместного обучения. Так, на коллекции тестов CLEVER, где
требуется отвечать на вопросы об отношениях между различными
предметами на картинках, комбинация модулей CNN (анализ
картинок), LSTM (генерация ответов) и RN (поиск
отношений) показала результаты, превышающие человеческий
уровень (рис. 4.13).
Рис. 4.13. Ответы на вопросы. Глубокая сверточная сеть
CNN кодирует содержание картинки, рекуррентная LSTM-
сеть - содержание вопроса, а реляционная сеть RN обучается
генерировать ответы (лучше человека [Santoro и др., 2017])
130
ГЛУБОКОЕ ОБУЧЕНИЕ
Таким образом, нейросети могут не просто распознавать
во внешнем мире наличие и расположение объектов, но и
находить существующие между ними абстрактные типы связей
произвольной природы. Связи между предметами могут
обуславливаться физическими законами их взаимодействия. В
этом случае реляционные сети могут предсказывать
динамику сцен по нескольким последовательным кадрам (см. Watters
и др., 2017).
4.7. Генерирующие сети: воображение
Машинное зрение, распознавание и понимание речи
представляют собой примеры сенсорного интеллекта, задача
которого - разобраться в поступающих сигналах, понять их
семантику (систему отношений между субъектами и объектами). Но
понимание ситуации — это не самоцель. Конечная цель
машинного интеллекта - креативное целесообразное поведение
на основе полученных в процессе обучения знаний.
Целесообразное поведение мы рассмотрим чуть позднее. Здесь же
коснемся креативности — способности самостоятельно
порождать образы внешнего мира.
Эта задача сложнее, чем обычная классификация.
Частично мы ее уже затронули, когда шла речь о машинном
переводе, т.е. о понимании и самостоятельном пересказе смысла
сообщения. В отличие от задач распознавания, здесь машинное
обучение еще не достигло человеческого уровня, хотя прогресс
налицо. Сложность задачи стимулирует инновации. Здесь мы
рассмотрим одну из недавних, которую Ян ЛеКун,
руководитель Facebook AI Research и один из пионеров глубокого
обучения, назвал наиболее важным открытием за последние
10-20 лет10.
Речь идет о состязательном обучении (adversarial learning)
и использующих его генеративно-состязательных сетях (Ge-
10 "... the best, coolest idea in machine learning in the last 10 or 20 years". -
https://www.youtube.com/watch?v=bub58oYJTmO
4.7. Генерирующие сети: воображение
131
nerative Adversarial Networks, GANs), способных обобщать и
воспроизводить образы, похожие на те, на которых они
обучались [Goodfellow и др., 2014]. Идея состоит в
одновременном обучении двух нейросетей, играющих друг против друга
в игру с нулевой суммой. Одна сеть, генератор, обучается
генерировать образы, похожие на обучающую выборку. Вторая,
дискриминатор, учится отличать их от образов из обучающей
выборки. Работая совместно, эти сети взаимно обучают друг
друга (см. рис. 4.14).
Рис. 4.14. Схема генерирующего конкурентного обучения
[Goodfellow и др., 2014]
Дискриминатор D определяет вероятность D(x)
принадлежности входного образа х к распределению X обучающей
выборки. При этом он должен как можно реже распознавать
порожденные генератором образы как "настоящие",
присваивая им низкую вероятность D(G(z)). To есть задача
дискриминатора D - оптимизировать свои параметры таким
образом, чтобы максимизировать свой выигрыш:
max (log D(x) + log (1 - D(G(z)))).
132
ГЛУБОКОЕ ОБУЧЕНИЕ
Задача генератора G противоположная - минимизировать
выигрыш дискриминатора D, оптимизируя свои параметры:
min (log D(x) + log (1 - D(G(z)))) -> min (log (1 - D(G(z))))
G G
(поскольку первый член не зависит от генератора). Заметим,
что генератор учится воспроизводить картинки, так ни разу
и не увидев их прототипов. Все, что он знает - насколько
хорошо дискриминатор отличает его творчество от обучающей
выборки.
Хотя исходная постановка задачи относится к unsupervised
learning, в GAN обе конкурирующих сети учатся с помощью
supervised learning и могут использовать все достижения
градиентного глубокого обучения. Например, использовать
глубокие сверточные сети (Deep Convolutional GANs, DCGANs
[Radford, Metz и др., 2015]) для генерации реалистичных
образов [Nguyen и др., 2016; Н. Zhang и др., 2016]. В качестве
примера на рис. 4.15 приведены картинки по теме «вулканы»,
сгенерированные DCGAN, обученной на ImageNet [Nguyen и
ДР. 2016].
Рис. 4.15. Сгенерированные сетью GAN картинки по теме
«вулканы» [Nguyen и др., 2016]
4.7. Генерирующие сети: воображение
133
Обучение GAN имеет свои сложности. В частности,
обучение обеих сетей должно быть сбалансировано. Скажем, если
дискриминатор слишком хорошо обучился, его ошибка
стремится к нулю, и он перестает генерировать обучающие
сигналы для генератора. Для обеспечения сбалансированного
обучения было предложено несколько подходов.
Авторы т.н. WGANs [Arjovsky и др., 2017] предложили
"подрезать крылья" дискриминатору - ограничить его веса
\wd\ < с и, тем самым, его способности. Они показали, что
это приводит к стабилизации обучения и улучшению его
качества, хотя учиться в этом случае приходится дольше.
Дальнейшее развитие эта идея стабилизации обучения
получила в схожих по духу алгоритмах BEGAN [Berthelot и др.,
2017] и MAGAN [R. Wang и др., 2017]. Рисунок 4.16
иллюстрирует способность BEGAN, обученной на базе 360 тысяч
фотографий селебрити, генерировать реалистичные
фотопортреты. В частности, интерполировать между различными
селебрити или генерировать различные ракурсы по заданной
фотографии.
GANs обладают множеством достоинств [Y. Bengio, Good-
fellow и др., 2015]11, и без всяких сомнений в будущем мы
увидим множество примеров их практических применений. В
качестве "первых ласточек" упомянем: генерацию картинок по
их словесному описанию [Reed и др., 2016], порождение
реалистичных интерьеров и их декорирование в различных стилях
[X. Wang и Gupta, 2016] и трансляцию стилей между
картинками [Zhu и др., 2017]. В последнем случае используется
пара сопряженных DCGANs, где два дискриминатора учатся
различать картинки разных стилей, а два генератора
учатся переносить стили между картинками так, чтобы обмануть
обоих дискриминаторов (см. рис. 4.17). В результате можно,
например, превращать летние пейзажи в зимние и наоборот,
Например, они корректно работают с многомодовыми
распределениями - выбирают примеры из какой-то одной моды, а не усредняют
их.
134
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.16. Генерация реалистичных портретов алгоритмом
BEGAN [Berthelot и др., 2017]. Вверху: интерполяция
между двумя селебрити (портреты слева и справа - реальные,
промежуточные - синтетические). Внизу: генерация
промежуточных ракурсов между зеркальными изображениями
или стилизовать любую фотографию под того или иного
художника12.
В общем, сегодня, когда Юрий Башмет исполняет
созданный нейросетью концерт [Ализар, 2019], а машинная
живопись продается за сотни тысяч долларов [ТВ-КУЛЬТУРА,
2018], упрекнуть машинный интеллект в отсутствии
воображения уже невозможно!
Напоследок упомянем еще один, несколько неожиданный
пример состязательного обучения. Речь идет о машинном
переводе в режиме unsupervised learning, без использования
корпусов примеров переведенных предложений. Составление
таких параллельных корпусов - довольно трудоемкий процесс, и
не для всякой пары языков удается собрать достаточно
представительную для качественного обучения выборку (миллио-
12 Этот подход более общий, чем предложенный ранее в [Gatys и
др., 2015] алгоритм художественной стилизации, основанный на
выявлении характерных текстур и лежащий в основе известного приложения
Prisma.
4.7. Генерирующие сети: воображение
135
Dx DY
Рис. 4.17. Дуальная GAN способна транслировать
различные стили между картинками. Слева: схема обучения -
генераторы учатся переводить картинки одного класса в другой,
дискриминаторы - различать эти классы. Справа: результат
трансляции классов «зебры» и «лошади» [Zhu и др., 2017].
ны пар предложений). Тем больший интерес вызвала работа
[Lample и др., 2017], в которой для обучения машинному
переводу требовались лишь моноязыковые корпуса различных
текстов на разных языках.
Идея состоит в построении общего для пары языков
семантического пространства, с использованием
состязательного обучения. Действительно, если кодировщик находит
семантическое представление предложений с обоих языков
одинаково хорошо, он, тем самым, затрудняет задачу
дискриминатора - определить язык-источник по его семантическому
коду. Декодер, в свою очередь, должен уметь воспроизводить
закодированное в семантическом пространстве предложение
на любой из двух языков. Рисунок 4.18 иллюстрирует идею
такого обучения.
В итоге удается добиться такого же качества перевода, как
и при обычной схеме supervised learning, если использовать до-
136
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.18. Вверху: построение общего семантического
пространства реконструкцией зашумленных предложений на
обоих языках (автокодирование) и настройка общего
пространства реконструкцией переведенных системой предложений в
исходный язык (перевод) [Lample и др., 2017]. Внизу:
построение общего семантического пространства для двух языков
со сходной идеей состязательного обучения на моноязыковых
корпусах [Conneau и др., 2017]
статочно большие моноязыковые корпуса (в 100 раз больше
параллельных двуязычных). С учетом дороговизны
последних и практически неограниченного количества документов
на разных языках в интернете это можно считать
выдающимся достижением.
4.8. Обучение с подкреплением:
поведение
Глубокое обучение помогает формировать компактные
внутренние представления сигналов из внешнего мира, т.е.
модели внешнего мира. Но "чашей Грааля" машинного
интеллекта является обучение оптимальному поведению в этом мире.
Наиболее естественным в этом контексте является обучение
с подкреплением (reinforcement learning): по результатам про-
4.8. Обучение с подкреплением: поведение
137
шлой истории своих действий at в ситуациях St и полученных
наград rt (подкреплений), агент должен научиться выбирать
такие действия, которые максимизируют ожидаемую в
будущем суммарную награду
Д* = $^7Чи
г=0
В отличие от "условных рефлексов", приобретаемых с
помощью supervised learning, обучение с подкреплением
формирует сложное целесообразное поведение, ориентированное на
долгосрочную, а не сиюминутную выгоду. Поведение в такой
постановке базируется не на рефлексах, а на ценностях (см.
раздел 3.4.).
Поясним идею глубокого обучения с подкреплением на
примере т.н. Q-learning [Watkins и Dayan, 1992], где функция Q(s, a)
представляет собой ценность действия а в состоянии s.
Q(sj a) = (R) = ( г + 7 max Q(s', a') \ ,
где мы воспользовались рекурсивным определением ценности
на следующем шаге s, а —» s', r. В равновесии разница между
правой и левой частями должна стремиться к нулю:
5 = г + 7 max Q(s', a') — Q(s, a) —> 0.
а'
Это разница оценок ожидаемой награды после очередного
момента времени. Поскольку более поздняя оценка, по идее,
чуть более точная, мы можем определить следующую
итерационную процедуру нахождения функции ценности,
известную как temporal-difference learning (TD learning):
Q(s,a) <- Q(s,a) + a
r + 7 max Q(s', a') — Q(s, a)
При этом в любой момент Q-обучения имеется способ
выбора оптимального поведения: argmaxa/ Q(s/Jaf).
138
ГЛУБОКОЕ ОБУЧЕНИЕ
Этот одношаговый алгоритм легко обобщается на случай
нескольких шагов, что обычно ускоряет обучение, т.к.
увеличивается число подкреплений, влияющих на каждое
состояние. Это особенно важно в случае редких подкреплений.
Q-обучение прекрасно работает в простых, "игрушечных"
задачах с относительно небольшим числом возможных
состояний и действий, поскольку для итерационного обучения надо
много раз посетить все ячейки таблицы Q(s,a). Проблема
состоит в том, как его применять в реальном мире, где число
состояний пространства S х А становится таким большим, что
не хватит никакого времени, чтобы его исследовать13.
Прорывной здесь стала работа [Mnih, Kavukcuoglu и др.,
2013], предложившая методику глубокого обучения с
подкреплением (deep reinforcement learning, DRL). Идея состоит в
аппроксимации функции ценности Q(s,a) глубокой нейросетью
и ее градиентной оптимизации, используя S в качестве
ошибки обучения. Глубокая нейросеть сжимает исходное
высокоразмерное пространство входов в гораздо более компактное
внутреннее пространство абстрактных признаков, в котором
и происходит Q-обучение.
Эффективность Q-обучения в компактном пространстве
абстрактных признаков уже была ранее продемонстрирована
Lange и Riedmiller, 2010, но сами признаки там
формировались отдельно в режиме unsupervised learning с помощью
глубокого автокодирования (Deep Autoencoders).
Заслуга авторов [Mnih, Kavukcuoglu и др., 2013] в том, что
им впервые удалось предложить стабильный сквозной метод
DRL за счет рандомизации процесса обучения (т.н. experience
replay) и применения двух реплик функции Q. В
дальнейшем авторы существенно усовершенствовали методы DRL за
счет применения многих реплик обучающихся агентов в
режиме параллельного асинхронного обучения [Mnih, Badia и
ДР., 2016].
13Например, даже для картинок с невысоким разрешением 256 х 256 и 8
градациями серого число возможных состояний \S\ = 8256х256 ~ ^дбоооо
4.8. Обучение с подкреплением: поведение
139
Очень полезным трюком для reinforcement learning
оказалось дополнение внешних подкреплений — внутренней
мотивацией на предсказания. Оказалось, что, если независимо от
(редких) внешних подкреплений постоянно тренировать ней-
росеть умению ориентироваться во внешнем мире, например
предсказывая внешние и свои внутренние состояния, это
существенно ускоряет обучение и улучшает его качество [Doso-
vitskiy и Koltun, 2016; Jaderberg и др., 2016]. Такая внутренняя
мотивация исследовательского поведения — получение
удовольствия от собственных предсказаний даже в условиях
отсутствия внешних подкреплений — напоминает встроенный
в лимбическую систему млекопитающих механизм
любопытства, о котором пойдет речь в главе 5.
Работа [Mnih, Kavukcuoglu и др., 2013] вызвала широкий
резонанс, т.к. она наглядно продемонстрировала
универсальность метода глубокого обучения с подкреплением. Одна и
та же программа смогла освоить весь репертуар
компьютерных игр для Атари, обучившись играть в большинство из
них на уровне человека. Вскоре после публикации этой
работы командой из компании DeepMind последняя была куплена
Google за $600 млн, так оценившей перспективы развития
игрового интеллекта.
Следующим, еще более значимым рубежом игрового
интеллекта от Google DeepMind стала программа AlphaGo [Silver,
A. Huang и др., 2016], научившаяся играть в Го лучше, чем
самые сильные профессиональные игроки. До того считалось,
что до профессионального уровня в Го компьютеры если и
доберутся, то еще очень и очень нескоро. Между тем,
сразу после своего создания AlphaGo осенью 2015 г. победила
3-кратного чемпиона Европы Fan Hui, а весной 2016 г. - 18-
кратного чемпиона мира Lee Sedol. Наконец, в мае 2017 г. она
со счетом 3:0 выиграла матч у лучшего игрока
современности Ке Jie. В Китае, Корее и Японии, где игра Го является
культовой, эти успехи AlphaGo резко подстегнули интерес к
машинному интеллекту и вызвали прилив инвестиций в эту
область.
140
ГЛУБОКОЕ ОБУЧЕНИЕ
AlphaGo обучалась в два этапа. Сначала как прилежный
ученик, копируя игру мастеров. А именно, методами supervised
learning глубокая сверточная сеть обучалась воспроизводить
ходы из большой коллекции профессиональных игр,
содержащей 30 миллионов позиций. Обучившись, эта сеть (policy
network) в любой позиции предлагает наиболее сильные с
точки зрения всего исторического опыта варианты ходов.
На втором этапе AlphaGo творчески переосмысливала
полученный опыт, играя сама с собой. В ходе такого
самообучения, методом reinforcement learning настраивались уже две
сети: упомянутая выше policy network и value network, задача
которой - оценить текущую позицию, т.е. предугадать
шансы игроков на выигрыш (рис. 4.19). Эти две сети
воплощают "игровую интуицию" AlphaGo, помогая ей ограничивать
число просчитываемых в ходе игры вариантов (совсем как у
людей). Policy network позволяет рассматривать лишь самые
перспективные ходы, a value network - ограничивать глубину
просчета за счет уверенной оценки конечных позиций в
просчитываемых вариантах.
Самое интересное, что уже в октябре 2017 г. появилась
новая версия программы - AlphaGo Zero, которая вообще не
использовала при обучении партии людей-профессионалов. С
самого начала она обучалась лишь играя сама с собой. В
результате, AlphaGo Zero обыграла свою предыдущую версию,
AlphaGo Master, т.е. тысячелетний опыт человечества в Го
оказался своего рода балластом, сдерживающим полет мысли
"чистого" игрового разума!
AlphaGo Zero совмещает в себе интуицию и расчет.
Глубокая нейросеть, объединяющая policy и value network,
предсказывает для любой позиции ее ценность и ценность всех
возможных ходов (рис. 4.20). Эта нейросеть играет сама с собой,
просчитывая ситуацию на определенное число ходов вперед,
и выбирает очередной ход с учетом этого расчета. К концу
партии для всех встреченных позиций имеется улучшенное
понимание ценностей, и нейросеть обучается на этом
материале. И все!
4.8. Обучение с подкреплением: поведение 141
Policy network Value network
Рис. 4.19. Две нейросетевые компоненты AlphaGo. Слева:
policy network, порождает лучшие ходы-кандидаты в данной
позиции. Справа: value network, оценивает шансы игроков на
выигрыш в данной позиции.
Причем этот игровой разум на самом деле универсален.
Лишившись в том же 2017 г. суффикса Go, алгоритм Alpha-
Zero превзошел все сильнейшие программы в Го, шахматах
и сёги (японская версия шахмат) [Silver, Hubert и др., 2017].
Можно назвать AlphaZero воплощением стратегического
разума.
Сегодня он оттачивается на играх с неполной
информацией во все более реалистичных виртуальных ЗБ-мирах в
качестве последнего этапа подготовки к выходу в реальный мир
в образе машинного интеллекта роботов. Здесь очередным
"большим вызовом" для машинного интеллекта до недавнего
времени считалась сложная многоплановая игра StarCraft II
(3D Real Time Strategy). Но в декабре 2018 г. очередная ин-
142
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.20. AlphaGo Zero. Сверху: нейросеть накапливает
материал для обучения, играя сама с собой. Внизу: обучение
нейросети
карнация стратегического интеллекта от Google DeepMind -
программа AlphaStar, победила одного из лучших игроков
StarCraft II со счетом 5:0, преодолев очередной рубеж на
пути к интеллекту роботов [Vinyals и др., 2018]. AlphaStar, в
частности, использует новейшую архитектуру Transformer, о
которой шла речь выше.
Машинный интеллект роботов может использовать все тот
же универсальный подход AlphaZero — интуиция плюс расчет.
С небольшим дополнением: к нейросети, оценивающей
поведение, достаточно добавить нейросеть, моделирующую реакцию
внешнего мира. В остальном схема обучения может быть той
же самой: просчет ситуации, взаимодействие с реальностью,
переоценка своих ценностей и коррекция модели внешнего
мира (рис. 4.21).
Интересно сравнить этот довольно общий подход (model-
based reinforcement learning) с т.н. стандартной теорией
интеллекта [Laird и др., 2017], обобщающей современные воз-
4.9. Вектор развития: искусственная психика 143
11 = {V- у)2 - л-logp L2 = О - s)2 vt = rt + vt+1
Рис. 4.21. Общая схема model-based reinforcement learning:
модель поведения + модель мира + расчет
зрения на природу человеческого мышления. Если
разобраться, то со всеми элементами этой стандартной модели (рис. 4.22)
мы уже встречались. Модель поведения, модель мира и
расчетный блок - это model-based reinforcement learning со
встроенным воображением (для генерации разных вариантов
развития событий). Перцептивный блок - это сенсорный
интеллект. Примером моторного блока может служить, например,
система синтеза речи Google Tacotron 2, генерирующая речь,
не отличимую от человеческой [J. Shen и др., 2018].
Иными словами, все элементы искусственной психики в
том или ином виде сегодня уже существуют и по отдельности
не уступают соответствующим человеческим способностям. Это
приводит нас к логическому выводу, что следующим шагом
развития машинного интеллекта должна стать искусственная
психика роботов.
4.9. Вектор развития: искусственная
психика
Подытожим наш краткий исторический экскурс. Благодаря
глубокому обучению уровень машинного интеллекта за
последние 5-10 лет радикально повысился, в основном, из-за
144
ГЛУБОКОЕ ОБУЧЕНИЕ
Рис. 4.22, Стандартная теория интеллекта (Standard Model
for the Mind [Laird и др., 2017])
появления суперкомпьютерных мощностей по доступным
ценам. Сенсорный интеллект - машинное зрение и слух - уже
вплотную приблизился к человеческому уровню. Машины
научились не просто распознавать образы, но и понимать их
суть, строить абстрактные модели объектов и их отношений.
У машин появились зачатки воображения - способности
генерировать образы внешнего мира по их внутреннему
представлению. Машины могут обучаться ценностям и
основанному на них разумному поведению, нацеленному на
достижение долгосрочных целей. Причем в виртуальных (игровых)
мирах они демонстрируют уже сверхчеловеческие
способности, которые к тому же быстро прогрессируют с дальнейшим
ростом компьютерных мощностей.
Как следует из приведенных выше примеров, глубокое
обучение использует небольшое число базовых идей,
воплощенных в нескольких популярных нейросетевых архитектурах.
Наряду с углублением этих базовых идей и улучшением
соответствующих алгоритмов растет число работ, где различные
практические задачи решаются путем комбинирования
различных нейросетевых модулей. Мы явно наблюдаем зарож-
4.9. Вектор развития: искусственная психика 145
дение новой нейронной схемотехники. Если можно так
выразиться, наблюдается переход от "биологии" к "психологии"
машинного обучения, от алгоритмов обучения - к
архитектурным принципам построения функциональных систем.
Это особенно заметно в области игрового интеллекта и
робототехники, где ставится задача выработки
целесообразного поведения в виртуальном или реальном мире. Это требует
слаженной работы сенсорных, ассоциативных, планирующих
и управляющих подсистем, которые в перспективе должны
сформировать искусственную психику, операционную
систему роботов, идущую на смену фон-неймановской
архитектуре.
Фон-неймановские компьютеры пассивны. Они были
созданы для исполнения заложенных в них внешних программ.
Сутью машинного обучения является, напротив, не
исполнение, а порождение программ. А это требует совсем другой
архитектуры, заставляющей машины непрерывно учиться и
наращивать свои знания. Искусственная психика роботов
должна быть основана на внутренней мотивации к постоянному
обучению, к самостоятельной постановке задач, активному
поиску и тестированию гипотез. "Дух есть жизнь, которая
сама режет по живому ..." - так говорил Заратустра.
И только в процессе конструирования этой искусственной
психики мы сможем наконец приблизиться к настоящему
пониманию нашей собственной психики и принципов работы
нашего мозга - теме следующей главы.
Глава 5
Вычислительная
архитектура мозга
Вы совершили путь от
червя к человеку, но
многое в вас ещё от червя.
Некогда были вы
обезьяною, и даже теперь
ещё человек больше
обезьяна, чем иная из
обезьян.
За человека цепляется
моя воля, цепями
привязываю я себя к
человеку, ибо влечёт меня
ввысь, к сверхчеловеку: к
нему стремится другая
воля моя.
Фридрих Ницше
«Так говорил Заратустра»
148
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
5.1. Исследовательская программа:
реверс-инжиниринг мозга
Предыдущая глава убедительно демонстрирует успехи
глубоких искусственных нейросетей в моделировании отдельных
способностей мозга. В области распознавания образов и
обучении рациональному игровому поведению эти способности
уже достигли или даже превзошли человеческий уровень, как,
например, в случае AlphaZero. Но вычислительные мощности
продолжают умножаться и дешеветь. И возникает вопрос: что
будет дальше? Логично предположить, что следующим шагом
будет переход от решения отдельных прикладных задач
распознавания образов к созданию автономных управляющих
систем, способных обучаться в процессе всего жизненного
цикла, непрерывно накапливая предметные знания в масштабах,
которые сейчас даже трудно себе представить. Но закон Мура
подводит нас именно к такому сценарию - переходу от deep
learning к deep control, т.е. к созданию искусственной психики
роботов.
В науке это приведет к смещению акцентов с изучения
отдельных алгоритмов обучения на уровень архитектуры
обучающихся систем, содержащих множество взаимодействующих
обучающихся модулей. До сих пор такие системы мы
наблюдали лишь в живой природе. Речь идет, конечно же, о мозге.
Возникает естественное желание продвинуться в этом
направлении путем реконструкции вычислительной архитектуры
мозга - больше нам учиться не у кого.
Подчеркнем, что речь идет именно о взгляде на мозг ас
высоты птичьего полета", о понимании общих принципов
организации работы мозга (не как мозг устроен, а как он
работает). С практической точки зрения, в контексте теории
обучения имеет смысл сосредоточиться именно на системном
уровне. В этой главе мы опишем современные представления
о глобальной архитектуре мозга, обобщив имеющиеся в
литературе данные и теории.
5.2. Основные подсистемы мозга
149
5.2. Основные подсистемы мозга
В самом общем виде эту идею иллюстрирует рис. 5.1,
показывающий, какие типы обучения характерны для таких
крупных подсистем мозга, как кора, базальные ганглии и
мозжечок.
Рис. 5.1. Взаимодействие и схемы обучения основных
подсистем мозга [Doya, 2000]
В этой логике мы и построим свое изложение. А
именно, попытаемся понять, в чем состоит задача каждой из этих
подсистем, как эта задача выполняется и как эти подсистемы
взаимодействуют друг с другом. То, что они друг без друга
"не живут", следует хотя бы из того эмпирического факта, что
практически каждый элемент коры одновременно участвует
в трех основных управляющих контурах [L. Koziol и Budding,
2009], показанных на рис. 5.2.
Кора накапливает знания о внешнем мире и способах
взаимодействия с ним. Положительная обратная связь коры с
150
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
as a as
Кора
Базальные Мозжечок
Ганглии
Таламус
Рис. 5.2. Главные управляющие контуры мозга (s, a -
области коры, распознающие ситуацию и вырабатывающие
реакцию на нее, соответственно)
таламусом обеспечивает поддержание активности коры в
течение более-менее продолжительного времени, необходимого
для согласования работы разных отделов коры. Базальные
ганглии могут тормозить или растормаживать эту
положительную связь, играя роль арбитра в соревновании
активности разных участков коры. Наконец, мозжечок помогает
осуществлять управление рутинными действиями, перенимая
решения, ранее найденные корой и базальными ганглиями в
процессе обучения.
В следующих разделах мы представим модели этих
подсистем и их связь между собой, начав с принципов работы самой
эволюционно молодой и одновременно самой большой
подсистемы человеческого мозга - коры. В частности, мы
постараемся объяснить, в чем мозг млекопитающих качественно
превосходит мозг рептилий. В заключительных разделах мы
также поговорим об отличии мозга приматов и человека от мозга
других млекопитающих. Там же мы коснемся практических
аспектов нашего "архитектурного" подхода, а именно, в каком
направлении следует развивать новую, не фон-неймановскую
архитектуру компьютеров на пути к искусственному
интеллекту.
5.3. Кора: ассоциативная память
151
5.3. Кора: ассоциативная память
Кора мозга человека - это тонкая (3 ± 1 мм) двумерная
нейронная ткань, общей площадью 2 000 ±500 см2. Она устроена
на удивление единообразно, имея более или менее ярко
выраженную слоистую и ячеистую структуры.
Качественные различия существуют лишь между более
древними частями коры (палеокортпекс и архикортпекс) и
более молодым неокортексом, преобладающим у человека
(около 95% площади). Они различаются, в частности, числом
слоев. Неокортекс, о котором, в основном, и пойдет речь далее,
содержит шесть слоев клеток, тогда как более древние
разделы имеют тем меньшее число слоев, чем они древнее. Чтобы
понять смысл усложнения коры в ходе эволюции, остановимся
сначала на слоистой структуре коры.
5.3.1. Слоистая структура коры: предиктивное
кодирование
Как показано на рис. 5.3а, нейроны разных слоев коры
специализируются на взаимодействии с различными участками
коры и с подкорковыми структурами.
Основным приемником входной информации,
поступающей в кору через таламус, является средний IV слой т.н.
гранулярных (granular) клеток. Они усиливают входной сигнал
и распространяют его в пределах данной колонки (см.
следующий раздел)1. Информация между различными участками
коры передается пирамидальными клетками остальных
слоев. Верхние слои коры I-III (supragranular) принимают
сигналы от участков коры, соответствующих более низким
уровням иерархии, соотносят ее с местным сигналом из IV слоя
и передают результат в глубокие слои V-VI (infragranular),
1 Только 5-10% всех возбуждающих синапсов в IV слое передают
входную информацию от таламуса, остальные имеют локальное
происхождение, усиливая входной сигнал под контролем информации от разных
участков коры [Douglas и К. А. С. Martin, 2007]
152
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
куда поступает также информация от более высоких уровней
иерархии. Результат транслируется в подкорковые структуры
последовательно через слой V в базальные ганглии и затем
через слой VI в таламус [Barrett и Simmons, 2015].
(а) Специализация
нейронов различных слоев
неокортекса. Верхние слои
(I-III) обрабатывают
информацию от различных
участков коры. Нижние
слои (IV-VI) кроме того
обмениваются
информацией с подкорковыми
структурами [Solari и
Stoner, 2011].
(b) Предиктивное кодирование в
иерархии корковых модулей
согласно Shipp и др., 2013:
нижние слои коры (V-VI)
кодируют предсказания входного
сигнала, а верхние слои коры (I-
III) - ошибку этих предсказаний.
Поток предсказаний идет от
более высоких уровней абстракции
вниз. Навстречу ему снизу-вверх
идет поток ошибок этих
предсказаний
Рис. 5.3. Слоистое строение неокортекса и схема
взаимодействия корковых модулей
Схему взаимодействия нейронов в коре (см. рис. 5.3Ь)
можно интерпретировать как иерархическое предиктивное
кодирование входных сигналов [Bastos и др., 2012]. Согласно этой
концепции кора представляет собой иерархию модулей, в
которой верхние этажи все время пытаются предсказать
состояние нижних, совместно описывая входные сигналы все более
абстрактными признаками. При этом нижние этажи
передают наверх не сам сигнал, а лишь его коррекцию относительно
предсказанных значений.
5.3. Кора: ассоциативная память
153
Эта концепция родственна модели эмпирического Байеса
[Carlin и Louis, 2010], где каждый следующий уровень
иерархии кодирует текущий контекст sn+1 (Prior P(sn+1)), в
котором предыдущий уровень воспринимает свою локальную
информацию sn (Likelihood P(sn\sn+1)). Апостериорное
распределение данных, соответственно, определяется их
произведением: P(sn,sn+1) = P(sn|«sn+1)P(sn+1). Разницу между
апостериорной и априорной информацией
logP(sn+1) -logP(sn,sn+1) = - log P(sn\sn+1)
можно интерпретировать как поток ошибок предсказаний.
Эмпирическим этот подход называют потому, что
априорное распределение не фиксировано, а постоянно
подстраивается под текущий поток данных. Таким образом, кора в
каждый момент времени выстраивает иерархическую предиктив-
ную модель текущего контекста, в котором воспринимается
поступающая в нее информация. Целевой функцией коры
является минимизация суммарной ошибки своих предсказаний:
C = (-logP(s1,...,sn,...)) = J2(-^gP(sn\sn+1)) = ^n.
П П
Friston, 2005 в простейшей модели коры предполагает, что
нижние слои коры кодируют средние значения условного
распределения рп = (sn), а связи между нейронами разных
уровней иерархии задают предиктивную модель активности
нижнего слоя при заданной активности верхнего: рп = д(рп+1,6п).
Верхние слои коры представляют ошибку этого предсказания
еп = рп — рп и стремятся минимизировать свою активность.
Соответственно, и динамика, и обучение коры трактуются
единообразно, как процесс минимизации ошибки
предсказаний, представляя собой различные стадии ЕМ-обучения:
рп = —Щ^ ~ предсказания модели (Е-шаг);
9п = —Щк ~ обучение модели (М-шаг).
Такое обучение можно сформулировать в виде довольно
общего принципа минимизации свободной энергии, который
154
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
реализуется биологически обоснованным хеббовским
механизмом [Friston, 2005; Ramstead и др., 2019; Yufik и Friston, 2016].
В этой модели коры на следующий уровень передается
не сам сигнал, а ошибка его предсказания на предыдущем
уровне, т.е. несколько контринтуитивно, при восприятии
внешнего мира информация передается в основном сверху вниз,
не от органов чувств, а, наоборот, к ним2. Кора непрерывно
поддерживает многоуровневый контекст анализа внешней
информации, постоянно адаптирует свою внутреннюю модель к
изменяющейся ситуации. Все уровни описания, от тонких
деталей до самого широкого контекста, всегда поддерживаются
в актуальном состоянии. При этом, если внешняя ситуация
укладывается в текущую модель, то информация наверх
вообще не поступает! Коррекция модели происходит лишь тогда,
когда она в какой-то своей части перестает соответствовать
действительности. Только в этом случае наверх передаются
ошибки предсказаний, пока кора не подберет из своего
арсенала подходящую модель, минимизирующую эти ошибки3.
Описанный выше подход объясняет не просто восприятие
мира, но и активное взаимодействие с ним, при котором кора
не только предсказывает поступающие в неё сенсорные
сигналы, но и вырабатывает управляющие воздействия сообразно
меняющимся обстоятельствам. Friston и др., 2015 показали,
что минимизация свободной энергии в условиях такого
активного взаимодействия со средой (active inference) соответствует
выбору оптимальной стратегии действий, максимизирующей
одновременно и ожидаемую в рамках имеющейся модели на-
2 Косвенным подтверждением этого является тот факт, что
количество нервных волокон из первичной зрительной коры в таламус, т.е.
навстречу входному потоку, на порядок больше, чем из таламуса в
зрительную кору [Eagleman, 2011].
3 Предиктивное кодирование, минимизирующее передачу данных,
широко применяется в технике, например при сжатии видеосигналов. В
линейном варианте она известна как калмановская фильтрация.
Собственно, последняя и послужила прообразом первых предиктивных моделей
коры [Spratling, 2017].
5.3. Кора: ассоциативная память
155
граду и апостериорное уточнение этой модели. Тем самым,
минимизация свободной энергии разрешает известную
дилемму exploration vs exploitation, осуществляя обоснованный
выбор между действиями, направленными на достижение цели
(когда ситуация достаточно ясна), и действиями,
максимально проясняющими текущую ситуацию (в случае
неопределенности). Мозг не просто использует свою модель мира, но и
постоянно поддерживает необходимую степень своей
уверенности в ее адекватности4.
Таким образом, предиктивная модель коры связывает ее
совместно работающие сенсорные и моторные области в
единые блоки активного обучения, соответствующие различным
уровням сенсомоторной иерархии, как показано на рис. 5.4
[Fuster, 2003; Todorov, 2009].
Поток информации сверху-вниз в моторной коре
направлен, как и в сенсорной, на минимизацию восходящего потока
сенсорных ошибок. Моторная кора строит модели
предсказывающих действий, т.е. модели предсказуемого поведения во
внешнем мире. Сенсорная кора предсказывает, что будет,
если моторная кора будет делать то, что собирается. Таким
образом в коре одновременно и совместно формируются модели
мира и действий, встроенных в этот мир.
В целом, теория предиктивного кодирования информации
в коре в едином ключе объясняет огромное количество
эмпирических данных (см. монографию [A. Clark, 2015]).
Возможно, именно эта эволюционная новация и сделала неокортекс
настолько эффективным, что он начал интенсивно
наращивать свою долю и роль в мозге млекопитающих и особенно
приматов (см. далее раздел 5.8.). Ведь чем больше
поверхность коры, тем больше уровней иерархии в ней можно уме-
4 Кора может динамически регулировать свое отношение к ошибкам
своих предсказаний. В областях, которые не находятся в данный момент
в фокусе внимания, сигнал об ошибке предсказаний может подавляться.
Для этого в верхних слоях коры имеются специальные пирамидальные
клетки - precision cells, взвешивающие ошибку в соответствии с текущим
уровнем внимания в данной области коры [Barrett и Simmons, 2015].
156
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
стить, тем глубже будут модели внешнего мира и
взаимодействия с ним.
В человеческой коре выделяют несколько сотен
функциональных областей5, которые в свою очередь объединяются
в более крупные функциональные модули примерно
соответствующие полям Бродмана. Чем ниже положение участка
коры в иерархии обработки информации, тем более проявлен
в ней IV слой, принимающий входные сенсорные сигналы из
таламуса. Первичную сенсорную кору поэтому называют еще
гранулярной. Напротив, в верхних этажах сенсорной
иерархии IV слой проявлен слабо либо вообще отсутствует6. В этих
агранулярных участках коры б-слойная структура сменяется
более простой, с меньшим числом слоев, постепенно переходя
в древнюю тоже слоистую структуру гиппокампа с другими
характеристиками нейронов и свойствами памяти (см. ниже).
Рис. 5.4. Иерархическая обработка информации в коре.
Внизу - иерархия признаков во входном потоке, вверху - иерархия
ответных реакций
5 Например, Power, Cohen и др., 2011 выделяют 264 такие области.
6 В первичной моторной коре IV слой тоже проявлен слабо, т.к.
ошибки ее предсказаний направляются в первичную сенсорную кору.
5.3. Кора: ассоциативная память
157
При этом популярную сегодня технологию глубокого
обучения, когда многослойные сети обучаются последовательно
слой за слоем кодировать и распознавать все более сложные
признаки, можно считать принципиальной моделью
сенсорной иерархии. Родоначальники deep learning черпали свои идеи
из работ по моделированию зрительной системы для нужд
компьютерного зрения, и основная сфера применения deep
learning - задачи распознавания образов - соответствует
специализации сенсорной коры. Между тем вторая,
дополнительная иерархия коры - организация сложного
целенаправленного поведения сверху вниз - пока еще не вошла в практику
прикладного машинного обучения. Мы рассмотрим
соответствующую модель глубокого обучения с подкреплением в главе 6.
Выше мы для простоты изложения основной идеи
ограничились лишь кортикальными связями. На самом же деле, как
уже упоминалось, кора тесно связана с подкорковыми
структурами, в частности, с таламусом. Учет таламо-кортикальных
связей превращает модель неокортекса в рекуррентную сеть,
способную кодировать не просто текущие состояния, но и
историю сигнала. Применительно к зрению, например, такое
кодирование в неявном виде содержит не только
координаты предметов, но и их скорости. Что существенно как для
правильного выделения предметов, так и для предсказания
развития событий. На достаточно реалистичной модели
зрительной коры O'Reilly, Wyatte и др., 2014 показали, что такое
предиктивное кодирование с учетом рекуррентных таламо-
кортикальных связей резко повышает качество распознавания
предметов в сложных динамично меняющихся сценах.
Интересно, что при передаче возбуждения в VI слой
нейроны V слоя образуют своего рода "линию задержки",
срабатывая примерно каждые 100 мс (на альфа-частоте ^ 10 Гц),
тогда как активность в более высоких слоях коры обычно
сосредоточена в гамма-диапазоне (~ 40 Гц) [Spaak и др., 2012].
Возможно, такая задержка позволяет собрать в нижних
слоях информацию с достаточно далеких участков неокортекса
158
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
с тем, чтобы сжать ее вместе с имеющейся предысторией на
следующей итерации рекуррентной сети.
5.3.2. Ячеистая структура коры: дискретное
разреженное кодирование
Обратимся теперь к ячеистой структуре неокортекса. В
специальном выпуске журнала Cerebral Cortex, посвященном этой
теме, Mountcastle, 2003 описывает строение неокортекса
следующим образом: базовым структурным элементом коры
является миниколонка диаметром около 50 мкм, содержащая
около 100 нейронов. Миниколонки, имеющие общие
рецептивные поля, группируются в более крупные колонки диаметром
300-500 мкм. Согласно Маунткаслу, именно колонка,
содержащая около 100 миниколонок (104 нейронов), является
основным функциональным элементом неокортекса. Каждая такая
колонка "откликается" на определенную комбинацию своих
входных сигналов. Из-за наличия в коре усилительных
контуров этот отклик имеет амплитуду, достаточную для передачи
сигнала между разными частями мозга, независимо от
амплитуды входного сигнала7.
Колонки формируются вследствие временных
дисбалансов процессов возбуждения и торможения в коре. Их размер
определяется расстоянием, на которое успевает
распространиться возбуждение, прежде чем с некоторым запаздыванием
включатся тормозные нейроны [Derdikman и др., 2003]. Зона
торможения захватывает соседние колонки в радиусе
нескольких миллиметров (характерный размер локальных аксонов
пирамидальных нейронов коры [Boucsein и др., 2011]). Из-за
наличия такой локальной конкуренции победителем
оказывается лишь одна из нескольких десятков соседних колонок.
7 Нейронам после возбуждения требуется время для релаксации,
поэтому миниколонки могут подменять друг друга для поддержания
требуемого уровня возбуждения колонки, аналогично тому, как отдельные
мышечные волокна в напряженных мышцах постоянно подменяют друг
друга.
5.3. Кора: ассоциативная память
159
Если все эти колонки получают один и тот же входной
сигнал, то такая гиперколонка производит классификацию этого
сигнала.
(а) Взаимодействие нейронов
различных колонок неокор-
текса. Характерный размер
колонки 0.3 мм, характерный
размер латерального
взаимодействия 1-3 мм [Boucsein и
ДР., 2011]
(Ь) Модель неокортекса как
совокупность локальных
самоорганизующихся карт Ко-
хонена, осуществляющих
разреженное кодирование
входных сигналов. В каждой
гиперколонке активной
является лишь одна колонка,
распознающая один из типовых
сигналов, приходящих в данную
область коры
Рис. 5.5. Ячеистое строение неокортекса
Предельно огрубляя, можно представить человеческий нео-
кортекс, как состоящий из 105 гиперколонок (локальных
самоорганизующихся карт [Kohonen, 2001]), каждая из
которых распознает одно из нескольких десятков значений какого-
то признака (атрибута). Например, 32 румба при
ориентации в пространстве или одну из нескольких десятков фонем,
букв алфавита, нот и т.д. Ситуация в целом описывается
набором таких признаков в схеме разреженного кодирования
(рис. 5.6а).
Разреженные коды неокортекса обеспечивают надежное и
компактное кодирование любых многомерных сигналов.
Надежность достигается за счет бинарного кодирования (по
схеме "победитель забирает все") колонками, содержащими до-
160
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
статочно большое число нейронов. А компактность - за счет
экономной схемы дискретизации сигналов. Каждая
гиперколонка производит кластеризацию входного сигнала по-своему,
используя свой набор признаков независимо от других, так
что информация от различных гиперколонок дополняет друг
друга. Так, "букет" из 7 гиперколонок, кодирующий какой-
то многомерный сигнал, способен представить 307 = 2 - 1010
его вариантов - больше, чем общее число ментальных
моментов, которые мы испытываем в течение всей своей жизни.
То есть любые аспекты реальности могут быть
закодированы ансамблями из нескольких гиперколонок. Скажем,
известная область коры, распознающая лица, может быть размером
3x3 мм, и содержать лишь 3 гиперколонки, способных, тем
не менее, совместно кодировать 303, т.е. около 30 000 лиц8.
Вспомним теперь об иерархии предсказаний сверху-вниз.
Она может служить эффективным инструментом
выработки корой инвариантных представлений. Ведь каждая
колонка распознает не один, а огромное множество паттернов
активности; все разнообразие сигналов, наблюдаемых данной
гиперколонкой, "делится" между ее несколькими десятками
колонок-детекторов. Настройка определенных колонок на тот
или иной контекст верхними этажами иерархии
способствует тому, что каждая колонка будет стремиться распознавать
различные варианты одной и той же ситуации. Например,
рассмотрим ансамбль колонок в совокупности кодирующих,
скажем, мою собаку. Я вижу ее во множестве ракурсов, но в
едином контексте "прогулки с собакой". Соответственно, этот
контекст будет закреплять все эти ракурсы за одними и
теми же колонками, формируя инвариантное представление
моей собаки в коре моего мозга. Как тут не вспомнить о
предложенных Джеффри Хинтоном "капсулах", обучающихся ин-
Поскольку не все гиперколонки могут быть задействованы
одновременно, эта область на самом деле может быть в несколько раз больше.
Действительно, известно, что диаметр этой области, Fusiform Face Area,
менее 1-2 см [Ghuman и др., 2014].
5.3. Кора: ассоциативная память
161
вариантным представлениям [Sabour и др., 2017]. Согласно
Hawkins, Ahmad и Cui, 2017, разреженное иерархическое
кодирование предлагает простой и биологически обоснованный
механизм воплощения этой идеи в жизнь.
Разреженное кодирование информации в неокортексе -
центральная идея теории Джеффа Хокинса [George и Hawkins,
2009]. В этом наши модели коры схожи, но с некоторыми
существенными отличиями. По Хокинсу, основным распознающим
элементом коры являются миниколонка, а колонки
осуществляют разреженное кодирование сигнала. Поэтому каждая
колонка является довольно емким элементом памяти,
способным запоминать несколько сотен предметов [Hawkins и Ahmad,
2016]. В описанной нами традиционной модели коры (см. [Т.
Dean, 2005]) хокинсовской колонке соответствует набор
гиперколонок, т.е. участок коры, обеспечивающий разреженное
бинарное кодирование признаков, у нас существенно крупнее.
По мнению автора, такая более грубая модель коры
обеспечивает возможность длительного возбуждения колонки за счет
постоянной подмены ее "уставших" миниколонок
"отдохнувшими". А длительные возбуждения в коре необходимы для
формирования синхронных паттернов активности,
объединяющих разные участки мозга в единые акты сознательного
мышления, о которых пойдет речь далее. Кроме того, в нашей
модели колонка с возрастом может потерять существенную
долю клеток без особых последствий. Какая модель ближе к
истине, выяснится в конечном итоге экспериментально. Нам
кажется, что они сходятся в главном - информация в коре
представлена разреженными бинарными кодами.
Подытоживая, отметим, что главным предназначением
новой коры является категориальная память. Неокортекс
представляет текущую ситуацию в виде устойчивых сочетаний
инвариантных признаков, обладающих наибольшей
предсказательной силой. Все случайное неокортексом отсеивается,
остается лишь многоуровневое понимание сути событий.
162
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
(Ь) Первичная зрительная
кора (VI) состоит из
множества гиперколонок, каждая из
которых получает сигнал из
определенной точки сетчатки
(а) Участок неокортекса из и распознает угол градиента
нескольких гиперколонок, об- освещенности в этой точке,
ластей локальной конкурен- На рисунке разными цветами
ции соседних колонок, осу- отмечены колонки, реагирую-
ществляет разреженное коди- щие на разные углы [Bednar и
рование входных сигналов. S. Wilson, 2016]
Рис. 5.6. Ячеистое строение неокортекса
5.3.3. Древняя кора: эпизодическая память
По всей видимости, предки млекопитающих были лишены этой
способности категориального мышления. Мы можем судить
об этом по участку старой коры (архикортекс), гиппокампу,
хорошо развитому уже у рептилий. В нем отсутствует
ячеистая структура неокортекса, а связи между нейронами
гораздо более разреженные и дальнодействующие. По
современным представлениям, гиппокамп реализует ассоциативную
память типа разреженной сети Хопфилда с глобальными
связями между нейронами [Kesner и Rolls, 2015; Rolls, 2010]. И
если новая кора видит в окружающем мире лишь знакомые
ей типовые паттерны, проявившиеся в результате многих
повторяющихся ситуаций, то древняя кора способна быстро за-
5.3. Кора: ассоциативная память
163
поминать произвольные паттерны и их временные
последовательности.
Эта способность - базовая для выживания, т.к.
действовать приходится всегда в конкретной обстановке, здесь и
сейчас. Мозг должен успевать на ходу конструировать
актуальную картину мира, сводящую воедино все внешние сигналы,
накопленный опыт и текущую мотивацию. Животные в
незнакомой обстановке первым делом начинают обследовать ее,
составляя с помощью гиппокампа ментальную "карту
местности" для предиктивного кодирования в конкретной
обстановке. За расшифровку нейронного кода представления таких
карт (нейроны места в гиппокампе и координатные нейроны в
прилегающей к нему энторинальной коре [Moser и др., 2008])
присуждена Нобелевская премия 2014 г.
В более общем плане гиппокамп служит временным
хранилищем нашей личной эпизодической памяти, фиксируя
значимые для нас события. Только у нас в эту память
попадает уже осмысленная новой корой семантическая информация:
входами в гиппокамп являются не первичные, а наиболее
высокие области иерархии коры. А именно, гиппокамп тесно
связан с лимбическими отделами коры, расположенными по ее
краю - поясной извилиной и островковой долей, а также с
амигдалой и гипоталамусом - структурами, определяющими
эмоциональную окраску и оценку ситуации. Иными словами,
кора кодирует нашу онтологию, внутреннюю оптику, через
которую мы воспринимаем этот мир. Гиппокамп же в этой
онтологии описывает текущую ситуацию со всеми
присущими ей особенностями и возможностями.
Ассоциативная память способна достраивать модель
ситуации по какой-то ее части. Например, она способна
предсказывать развитие ситуации и подсказывать адекватные данной
ситуации действия. Stachenfeld и др., 2017 видят основную
роль гиппокампа именно в таких предсказаниях,
предполагая, например, что клетки места кодируют не текущее, а
прогнозируемое положение животного, с учетом текущей страте-
164
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
гии поведения, помогая тем самым выбирать оптимальную
стратегию с учетом возможного развития событий. Гиппо-
камп, таким образом, является вершиной иерархической пре-
диктивной модели, связывающей моторные и сенсорные
отделы неокортекса (см. рис. 5.7)9.
Рис. 5.7. Иерархическая предиктивная модель неокортекса и
гиппокампа (верхний этаж)
Со временем наиболее значимая для нас часть
эпизодической памяти переходит из гиппокампа, имеющего ограничен-
ю
ную емкость памяти , в новую кору, емкость которой
ограничена лишь ее размерами. Этот процесс, называемый
консолидацией, иллюстрирует рис. 5.8. Консолидация основана на
способности гиппокампа проигрывать запомненные им
эпизоды по много раз, постепенно обучая неокортекс, например
9 Предложенную недавно Y. Wu, Wayne и др., 2018 версию
генеративной распределенной памяти можно представить как модель
взаимодействия гиппокампа и неокортекса, связывающую вместе быстро и
медленно обучающиеся подсистемы.
10 Емкость разреженной модели Хопфилда пропорциональна числу
синапсов у отдельных нейронов и ограничена несколькими десятками
тысяч паттернов [Palm, 2013].
5.3. Кора: ассоциативная память
165
во время сна [Battaglia и др., 2011; Saletin и Walker, 2012]
или бодрствования в расслабленном состоянии "resting state"
[Schlaffke и др., 2017]. В результате наша модель мира
пополняется новыми подробностями и взаимосвязями.
Например, у людей как социальных животных большое
значение имеет система ролевых отношений внутри нашей
"виртуальной стаи" - тех 150 или около того людей,
отношения с которыми значимы для нас. Удержание этой
довольно сложной карты отношений требует определенного места
в неокортексе, и, возможно, его рост у наших предков был
вызван именно усложнением системы социальных связей в
растущих сообществах приматов. По крайней мере, согласно
Dunbar, 1992, размер мозга приматов коррелирует с
типичным размером их сообществ.
Эти аргументы лежат в основе т.н. теории
"макиавеллневского" интеллекта, в которой давление естественного отбора,
стимулирующее рост неокортекса, диктуется необходимостью
соревнования с себе подобными. В такой ситуации
приходится все время совершенствовать свои когнитивные способности,
что, как полагают, и привело к "когнитивному" взрыву у homo
sapiens [Gavrilets и Vose, 2006]. В главе 7 мы еще вернемся к
этому вопросу (в разделе 7.4.1.).
Рис. 5.8. Консолидация эпизодической памяти из гиппокам-
па в неокортекс во время сна [Saletin и Walker, 2012]
166
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Переходя от коры к подкорковым структурам, заметим,
что в силу своей ассоциативной природы, кора сама по себе
не способна обеспечить мышление, т.к. в ней отсутствует
механизм концентрации. Подобно волнам на воде, в ней постоянно
порождаются расходящиеся волны ассоциаций.
Чтобы сконцентрироваться, подчинить действия единому
плану, должен быть какой-то способ управления этими
ассоциациями, оценки предиктивных моделей, предлагаемых
корой, для организации целенаправленного поведения. Целью
которого является не просто реакция на внешний стимул и
не удовлетворение сиюминутных потребностей организма, а
именно долговременная польза, с учетом возможных
отдаленных последствий своих действий.
Такой механизм целенаправленного глобального
управления различными областями коры обеспечивают древние
области переднего мозга - базальные ганглии. Они
сформировались еще у рыб, но получили развитие у рептилий в процессе
эволюционной адаптации амфибий к жизни на суше. Именно
эта подсистема управления поведением обеспечила
динозаврам доминирование на Земле в течение длительного времени.
Без особых изменений сохранилась она и у современных
млекопитающих [Reiner и др., 1998].
Кора переднего мозга образовалась позднее и развивалась
под управлением базальных ганглий, вписываясь в более
древнюю управляющую структуру и постепенно трансформируя
ее. В каком-то смысле даже у человека последнее слово в
выборе поведения по-прежнему остается за "мозгом ящера", к
рассмотрению которого мы и переходим.
Для начала, однако, рассмотрим таламо-кортикальную
систему, которой, собственно, и управляют базальные ганглии.
5.4. Таламус: внимание и связность ощущений 167
5.4. Таламус: внимание и связность
ощущений
Как следует из предыдущего раздела, верхние слои коры
специализируются на обработке информации внутри коры, тогда
как через нижние слои происходит обмен информацией
между корой и внешним миром. В частности, вся входная
сенсорная информация, за малым исключением11, попадает в кору
через таламус, главный распределительный узел мозга,
находящийся в самом его центре. Таламус является частью
промежуточного мозга, отвечающего за регулирование гомеостаза и
поддержание целостности организма. Там же находятся
гипоталамус, отвечающий за основные рефлексы и инстинкты, и
гипофиз, управляющий эндокринной системой. Древние
механизмы сна и бодрствования также включают управление
потоками сенсорной информации через таламус.
Кора очень тесно связана с таламусом - каждая колонка
коры получает от него входную информацию и передает
обратно результаты ее обработки, причем, как правило, в то же
место, откуда получила12. Рекуррентные таламо-кортикальные
связи образуют усилительные контуры, позволяющие
поддерживать в коре длительные очаги возбуждения -
автоколебания. Таким образом, с помощью таламуса кора может
довольно долго "удерживать внимание" на определенных мыслях
даже после исчезновения их источника из поля зрения (см.
рис. 5.9) [Ribary, 2005].
Колебательная природа возбуждений в коре очень
важна для понимания работы мозга. Синхронизация колебаний
различных участков мозга - необходимое условие для их
эффективного взаимодействия. Если колебания участков мозга
не синхронизированы, передача информации между ними за-
11 Исключение составляет участок обонятельной коры, из которой,
собственно, в процессе эволюции у млекопитающих и развился неокортекс.
12 Помимо таких реципрокных проекций, через таламус
осуществляются еще и связи между различными участками коры.
168
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
труднена даже при наличии физических связей, т.к. нейроны
в фазе торможения не возбуждаются. То есть синхронизация
колебаний - это способ динамической организации различных
конфигураций возбуждений в мозге.
Глобальная синхронизация колебаний в мозге,
формирующая в нем интегральное информационное поле, соответствует
состоянию сознания, когда все ощущения субъективно
воспринимаются и осознаются в форме единого когерентного
представления о мире и себе. Каждый момент глобальной
синхронизации возбуждений в мозге соответствует
элементарному акту сознания, длительностью около 0,4 секунды (т.е.
несколько периодов альфа-колебаний или около полутора
десятков гамма-колебаний, достаточных для синхронизации
разных участков коры [Mateos и др., 2017]). По образному
определению К.В. Анохина "сознание - это глобальная перколяция
знаний в мозге". Этим подчеркивается, что переходы между
сознательными и бессознательными состояниями аналогичны
фазовым переходам, изучаемым в теории перколяции
(протекания). Не вдаваясь далее в эту захватывающую тему,
отошлем читателя к обзорам современных представлений о
природе сознания [Bach, 2018; Dehaene, 2014; Tononi и Koch, 2015].
Таламус играет центральную роль не только в
организации сознательного мышления, но и обеспечивает связность
наших ощущений на подсознательном уровне. А именно,
различные признаки, относящиеся к одному и тому же предмету,
инициируются в коре одновременно, а значит их колебания
синфазны. Это и позволяет нам связывать их между собой в
единое ощущение, например "движущегося синего
автомобиля", хотя его движение, цвет и форма анализируются
различными участками коры одновременно со множеством других
признаков текущей ситуации (рис. 5.10) [Von der Malsburg,
1995].
Итак, таламус способен усиливать активность
определенных областей коры и связывать их между собой [Ward, 2011].
Однако кто-то должен определять, какие области коры в дан-
5.5. Базальные ганглии: принятие решений
169
Рис. 5.9. Автоколебания в таламо-кортикальной системе
ный момент усиливать, а какие, наоборот, тормозить.
Необходим механизм управления вниманием. В мозге
млекопитающих эта задача возложена на базальные ганглии.
Поскольку всякое управление исходит из какой-то целевой функции,
именно в базальных ганглиях формируются базовые
ценности, определяющие наше поведение и мышление.
5.5. Базальные ганглии: принятие
решений
5.5.1. Управление вниманием
Как и полагается командному пункту, базальные ганглии
спрятаны под поверхностью коры (рис. 5.11а), большинство
областей которой "докладывает" им о своем состоянии через
выходные нейроны V слоя. Эти сигналы фокусируются на
внешнюю поверхность базальных ганглий, в стриатум, па-
170
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Рис. 5.10. Связность ощущений через синхронизацию
колебаний в таламо-кортикальной системе
раллельными пучками аксонов из фронтальной коры,
ответственной за поведение и мышление, и возвращаются в то же
место, откуда начинались, через таламо-кортикальные связи.
Через эти замкнутые управляющие контуры и
осуществляется основной контроль за состояниями коры (см. рис. 5.lib).
Дополнительные диффузные связи снабжают стриатум
контекстной информацией из других областей коры, в частности
из гипоталамуса.
Разберем, как работают эти управляющие контуры [Gurney
и др., 2001; Шумский, 2015]. Базальные ганглии содержат,
главным образом, тормозные нейроны. Это самая сильная
тормозная подсистема мозга. Во внутренней части базальных
ганглий, паллидуме, имеется фоновый уровень возбуждения, и
его тормозные нейроны в норме всегда тормозят таламус (см.
рис. 5.12, где тормозные синапсы обозначены точками, а
возбуждающие - стрелками). В этом случае таламо-кортикальные
контуры не возбуждаются и длительные возбуждения в
соответствующих участках коры отсутствуют.
5. Базальные ганглии: принятие решений 1
(а) Базальные ганглии и черная субстанция
Неокортекс
Базальные ганглии Таламус
(Ь) Потоки информации между корой, базальными
ганглиями и таламусом
Рис. 5.11. Управляющий контур базальных ганглий
172
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Для поддержания длительной активности в коре
соответствующие участки таламуса должны быть расторможены.
Кора
Базальные ганглии
Стриатум Таламус
Паллидум
Черная субстанция
Рис. 5.12. Без санкции базальных ганглий усилительные
контуры таламуса заторможены
Решение об этом принимает стриатум, к которому
поступает вся информация из коры. Он сравнивает между собой
возможные в данном контексте действия, предлагаемые
корой, и выбирает из них наилучшие. Соответствующие
участки стриатума возбуждаются и растормаживают соединенные
с ними области таламуса, открывая возможность
активизировать положительные обратные связи таламо-кортикального
контура (рис. 5.13).
Так базальные ганглии регулируют активность коры,
организуя глобальную конкуренцию между ее различными
участками. Причем конкурентная борьба может продолжаться и
несколько раундов, пока не останется одно, потенциально
самое полезное в данном контексте действие. Эту внутреннюю
борьбу мы испытываем в ситуации "трудного выбора".
5.5. Базальные ганглии: принятие решений 173
Кора
Базальные ганглии
Стриатум Таламус
Паллидум
Черная субстанция
Рис. 5.13. Базальные ганглии растормаживают избранные
усилительные контуры таламуса
5.5.2. Обучение ценностям
Каким образом нейроны стриатума оценивают полезность тех
или иных действий? Через усиление или ослабление своих си-
наптических связей с корой в процессе обучения с
подкреплением под действием особого нейромодулятора - допамина
(дофамина), поступающего в стриатум из черной субстанции
(см. рис. 5.14)13. Соответствующий алгоритм обучения
иллюстрирует рис. 5.15. Подкрепление определяется уровнем
возбуждения черной субстанции, куда поступают два типа
сигналов.
Во-первых, это подкрепляющие сигналы г^, поступающие
к нейронам черной субстанции от самых древних
управляющих систем мозга: от гипоталамуса, отвечающего за гомео-
13 Здесь речь идет о т.н. дорсальном стриатуме - см. далее в этом же
разделе.
174
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Рис. 5.14. Допаминовый подкрепляющий сигнал из черной
субстанции
стаз организма и выполнение генетических программ
(врожденных рефлексов), и от амигдалы, которая учится в
процессе жизни ассоциировать врожденные оценки с внешними
сигналами (приобретенные рефлексы). Эти управляющие
воздействия нацеливают организм на удовлетворение его
сиюминутных потребностей (бежать, нападать и т.д. ) и определяют
эмоциональную окраску каждого момента нашей жизни.
Во-вторых, базальные ганглии направляют в черную
субстанцию дополнительные ценностные сигналы из стриатума,
обеспечивая более дальновидное поведение, с учетом
возможных будущих выгод и потерь, т.е. с большими шансами в
борьбе за существование.
В общих чертах этот механизм обучения выглядит
следующим образом. В стриатуме существуют две популяции
нейронов, которые по-разному реагируют на выбросы допамина,
обладая разными типами допаминовых рецепторов - D1 и D2.
Первых он усиливает, а вторых - подавляет. Уровни
возбуждения D1- и Б2-нейронов, Q+(a, s) и Q~(a, s) соответственно,
оценивают полезность действия а в контексте s немного по-
разному. Допаминовые нейроны черной субстанции получают
5.5. Базальные ганглии: принятие решений
175
Кора
Базальные ганглии
Qf(a, s) Ценность действия в состоянии
Предсказание St = rt - (rt) Неожиданная награда
награды:
(rt) = Q^-Qt Награда rt Гипоталамус, Амигдала
Черная субстанция
Рис. 5.15. Обучение с подкреплением в стриатуме
на вход возбуждения от этих двух популяций стриатума по
разным каналам: от нейронов D1 — непосредственно, а от
нейронов D2 — через паллидум. То есть Dl-нейроны черную
субстанцию тормозят, а Б2-нейроны, наоборот, растормаживают
(т.к. нейроны стриатума и паллидума — тормозные).
Итоговый уровень возбуждения нейронов черной субстанции
определяется суммарным воздействием всех входных сигналов:
St = n + QT-Qt- (5-1)
Допаминовые нейроны проецируют обратно в стриатум,
посылая в ответ на любое действие подкрепляющий допами-
новый сигнал. Уровень выделяемого ими в стриатуме допа-
мина пропорционален именно этой комбинации St. Назовем
ее радостью, поскольку именно такие ощущения вызывают у
нас выбросы допамина. Dl-нейроны усиливают, а Б2-нейроны
ослабляют свои синаптические связи с корой пропорциональ-
176
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
но уровню выделяемого допамина, так что в следующий раз
их активности в той же ситуации будут:
Qt+i =Qt + a-6t = a (... + 5t-2 + u-i + 8t); (5.2)
QT+i =Qt-P-St = /3 (St+i + 8t+2 + St+з + •••) • (5.3)
Эти две оценки ценности можно назвать соответственно
накопленной и обещанной радостью при выборе данного
поведения. В обоих случаях мы имеем интегральные оценки
суммарного количества получаемого от данного действия
допамина, мало отличающиеся друг от друга. Действительно,
переходя к непрерывному времени, получим для разности AQt =
= Qt-QT-
AQt=lJ М'е^'-^П/ = (П).
Таким образом, в результате обучения разность AQt
дает ожидаемую из прошлого опыта оценку подкрепления (г*),
усредненного за характерное время 7-1 = {pt + fi)~l •
Ощущение радости мы испытываем при выбросе допамина, когда
неожиданно получаем больше, чем рассчитывали:
6t = n- (rt).
То есть обучение происходит при отклонении от средних
(ожидаемых) значений. Ожидаемая награда не вызывает
эмоций и не приводит к обучению.
Поскольку базальные ганглии растормаживают поведение,
соответствующее максимальной активности в стриатуме,
обучение в базальных ганглиях нацелено на максимизацию
интегральной радости <5+,Q~- Можно сказать, что все мы,
млекопитающие, - это подсевшие на допамин наркоманы, и все
5.5. Базальные ганглии: принятие решений
177
наше поведение определяется жаждой получить как можно
большую интегральную дозу этого, как его иногда называют,
"гормона радости"14.
Из динамики обучения обеих популяций нейронов стриа-
тума (5.2,5.3), отраженной на рис. 5.16а, следует, что в начале
обучения Qq > Qq~, т.е. (го) < 0. Отсюда следует, что
любые действия в детстве сопровождаются выбросом допамина,
т.е. приносят радость. Это врожденное любопытство
детенышей млекопитающих является, таким образом, естественным
следствием алгоритма обучения с подкреплением в базальных
ганглиях.
5.5.3. Контроль активности в коре
Подведем промежуточные итоги. В самой коре имеется лишь
локальная конкуренция активности в пределах гиперколонок.
Глобальную конкуренцию активности в коре обеспечивают ба-
зальные ганглии, определяющие доминантный паттерн
активности коры с максимальной в данных обстоятельствах
ценностью. В этом разделе мы описали модель управления корой и
формирования ценностей в базальных ганглиях, естественно,
лишь в самых общих чертах. Реальность, конечно, несколько
сложнее. Во-первых, допаминовая система не
исчерпывается черной субстанцией. Рядом с ней находится другая
группа допаминовых нейронов - вентральная тегментальная
область, проецирующая не только в стриатум (в его
вентральную область), но и в лобные доли коры. Во-вторых, мы
описали обучение лишь небольшого участка стриатума. За
рамками модели оказалась их взаимная конкуренция, усиление
14 Вообще-то допамин не гормон, а нейромодулятор. Он выделяется не
глобально, в кровь, а впрыскивается в синаптические щели
определенных нейронных ансамблей, модулируя силу их синаптических связей с
другими нейронам. В мозге имеются и другие нейромодуляторы,
например, ацетилхолин, эпинефрин, норэпинефрин и серотонин, которые мы
здесь не рассматриваем. Образно допамин можно сравнить с системой
"рулевого управления" мышлением, а другие модуляторы — с
переключением скоростей и режимов "коробки передач".
178
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
(Ь) Две популяции ней-
(а) Динамика обучения ронов стриатума обу-
двух популяций нейронов чаются с подкрепле-
в стриатуме: Q^~,Q^. ниями из допаминовой
Начало обучения харак- системы растормажи-
теризуется врожденным вать области неокор-
любопытством (см. текст). текса, кодирующие
оптимальное поведение
Рис. 5.16. Обучение с подкреплением в базальных ганглиях
областей-победителей и торможение остальных. Мы пока не
знаем, сколько областей могут быть победителями и каковы
их характерные размеры.
Поскольку базальные ганглии гораздо меньше коры, они
не могут управлять мелкомасштабной активностью коры,
решая по-крупному, какие области коры подключать в каждый
момент времени. Итогом этого взаимодействия является
выбор наиболее перспективного с точки зрения ожидаемого до-
паминового вознаграждения "разрешенного окна" в котором
кора самостоятельно определяет оптимальное поведение атах
в ситуации s (рис. 5.16Ь). Поэтому допаминовое подкрепление
нужно не только в стриатуме, но также и в коре.
Мы можем оценить нижнюю границу размера
расторможенных участков коры, которая определяется разрешающей
способностью выходного модуля базальных ганглий, палли-
5.5. Базальные ганглии: принятие решений
179
дума, нейроны которого определяют степень торможения та-
ламуса. Известно, что таких нейронов у человека всего
около 3 • 105 [М. Frank и др., 2001]. Нейроны в мозгу работают
не поодиночке. Они организованы в ансамбли, чтобы гибель
какой-то их части в процессе жизни не сказывалась на
функциональности. Если принять, что рабочий элемент на выходе
состоит хотя бы из 100 нейронов (а это, по-видимому,
минимальный нейронный ансамбль, соответствующий миниколон-
ке коры), то таких управляющих элементов на выходе из ба-
зальных ганглий будет около 3 • 105/100 ~ 3000. И вряд ли
это число сильно меньше, т.к. у человека более 600 мускулов,
которые надо избирательно контролировать, а управляющая
ими моторная кора занимает лишь небольшую часть
фронтальной коры. Если принять эту оценку в качестве рабочей
гипотезы, то размер растормаживаемых базальными ганглиями
"окон" будет 1/3 000 лобной доли, т.е. они содержат порядка
10 гиперколонок15, в каждой из которых кора самостоятельно
выбирает локальную колонку победителя. Эти гиперколонки
совместно кодируют различные компоненты выбранного
поведения в данных конкретных условиях и соответствуют
корковому модулю моделей неокортекса, рассмотренных далее в
главе 6.
Мы можем также оценить, какую часть коры базальные
ганглии суммарно тормозят. Для этого воспользуемся
оценками энергетических затрат, связанных с нейронными
возбуждениями в коре. Согласно Lennie, 2003 средняя интенсивность
срабатывания нейронов в коре человека: 0,16 спайков/с,
тогда как активность расторможенных интенсивно работающих
участков коры впятеро больше: 0,8 спайков/с. Это значит, что
одновременно с такой интенсивностью могут работать не
более 20% мозга. И то, если принять, что остальные 80%
полностью пассивны. С учетом ненулевого уровня спонтанных
разрядов нейронов доля "активных пятен" в коре снижается.
15 (Площадь лобных долей = 1 000 см2)/3 000 = 30 мм2 « 300 колонок
«10 гиперколонок.
180
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Энергетические ограничения позволяют также оценить,
сколько нейронов срабатывает в возбужденной колонке,
основном рабочем элементе коры. В активной гиперколонке
первичной коры частота возбуждения нейронов, как уже
говорилось, 0,8 спайков/с. Если принять, что гиперколонка
содержит около 30 колонок, то активность в колонке-победителе
будет в 30 раз выше, чем в среднем по гиперколонке, т.е. ~ 20
спайков/с/нейрон. Если принять, что активный нейрон
генерирует порядка 100 спайков/с, то в активной колонке
одновременно должно срабатывать порядка 20% нейронов.
5.6. Мозжечок: закрепление пройденного
Кора и базальные ганглии отлично дополняют друг друга.
Кора формирует и распознает полезные признаки текущей
ситуации и предлагает возможные варианты ответов.
Базальные ганглии выбирают из них те, которые обещают организму
максимальный драйв.
Но обе эти подсистемы насыщены положительными и
отрицательными обратными связями, порождающими богатую
всевозможными ритмами хаотическую динамику активности
мозга [Buzsaki, 2006]. В итоге выработка ответа в них может
занимать достаточно длительное время. В условиях жесткой
борьбы за существование, когда промедление смерти
подобно, мозг обзавелся своей подсистемой "быстрого
реагирования". Она запоминает найденные решения и реализует их с
максимально возможной скоростью - в один проход, без
всяких обратных связей. Значение этой системы подчеркивается
тем фактом, что в ней содержится большая часть всех клеток
головного мозга16.
16 У млекопитающих размер мозжечка коррелирует с размером
коры — он содержит примерно в 4 раза больше нейронов, чем кора. Это
свидетельствует о том, что эти подсистемы работают сообща (см. далее
раздел 5.8.).
5.6. Мозжечок: закрепление пройденного
181
Речь идет, конечно же, о мозжечке, который с
вычислительной точки зрения представляет собой обычный персеп-
трон. Но этот персептрон очень правильно, ас умом"
включен в первичную кортико-базальную систему управления, у
которой он постоянно учится, перенимая ее опыт и
постепенно замещая ее управляющие сигналы своими [Kawato, 2007].
Управляющие сигналы из мозжечка в кору поступают через
таламус - так же, как и от базальных ганглий. Даже схема
управления у них сходная: замкнутый усилительный контур
через растормаживание соответствующих участков таламуса.
Самые крупные клетки нашего мозга, тормозные клетки Пур-
кинье, в норме тормозят нейроны ядер мозжечка и через них -
таламус, но активность клеток Пуркинье может
избирательно подавляться определенными паттернами входных сигналов
(рис. 5.17)17.
На вход ядра мозжечка получают ту же входную
информацию, что и первичная управляющая система, а также
выходную информацию о принятых ею решениях. Последняя
используется мозжечком в качестве шаблона, для
тренировки своих настроечных весов. Выходы из мозжечка дополняют
выходы его "учителя". В результате такого обучения мозжечок
способен взять управление на себя и жизнь "учителя"
существенно упрощается. Все, что может сделать простой
персептрон с одним скрытым слоем, он берет на себя.
Организована эта изящная схема следующим образом. В
мозжечок через примерно 200 млн мшистых волокон
поступает очень подробная первичная сенсорная информация как
непосредственно из спинного мозга, так и, главным образом,
из коры, о распознанных ею простых и сложных признаках,
Синаптические веса между гранулярными клетками и
клетками Пуркинье в процессе обучения ослабляются (по схеме Long Time
Depression, LTD), т.е. распознанные клетками Пуркинье входные
паттерны снижают их активность, но поскольку они являются тормозными,
итоговый эффект обучения - усиление выходного возбуждения таламуса
пропорционально обучающему сигналу.
182
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Что делать Чт0 происходит
Мшистые волокна
гранулярные
клетки
Таламус
клетки Пуркинье
Ядра мозжечка
Рис. 5.17. Обучение с учителем в мозжечке. Решения а,
выработанные корой в состоянии s, запоминаются и
воспроизводятся мозжечком
описывающих ситуацию . Эта информация распределяется
случайным образом по очень большому числу нейронов
скрытого слоя - гранулярных клеток. Каждая из них
представляет собой какую-то одну (случайную) комбинацию нескольких
входных признаков, своего рода хэш-функцию состояния
коры. Чем больше таких признаков, тем выше возможности пер-
септрона. Вот для чего нужно такое громадное число
гранулярных клеток, которые по необходимости имеют
минимально возможные размеры.
Выходной слой персептрона формирует около 15 млн
постоянно работающих крупных клеток Пуркинье с очень
развитой дендритной системой. Каждая такая клетка
складывает сигналы от порядка 105 синаптических связей с
различными гранулярными клетками, т.е. учитывает при выборе ре-
18 Число входов в мозжечок примерно равно числу аксонов в
мозолистом теле. То есть мозжечок интегрирован с корой так же тесно, как
правое и левое полушария друг с другом.
5.6. Мозжечок: закрепление пройденного
183
шения именно такое число настроечных параметров. Кроме
того, каждая клетка Пуркинье изредка (примерно раз в
секунду) получает очень мощный "учебный" сигнал от одного
единственного лазающего волокна, которое дублирует
информацию о принятых "учителем" решениях. Этот учебный
сигнал гарантированно заставляет клетку Пуркинье сработать,
и в этот момент происходит обучение тех сотен тысяч ее
синапсов, которые соединяли ее с активными в этот момент
гранулярными клетками.
Такое обучение клеток Пуркинье прекращается лишь
тогда, когда мозжечок полностью копирует управляющие
решения, ранее найденные корой и базальными ганглиями.
Выход из мозжечка формируют не сами клетки Пуркинье,
а интегрирующие их сигналы нейроны глубоких ядер, число
которых на порядок меньше числа клеток Пуркинье. Таким
образом, число выходов из мозжечка сравнимо с общим
числом колонок в коре (~ 106). То есть мозжечок, в отличие от
базальных ганглий, способен детально эмулировать
динамику активности коры и копировать эфферентные управляющие
сигналы от моторной коры.
И не только моторной: до 80% связей мозжечка с корой
приходится на ее ассоциативные области - лобные и височные
доли [D'Angelo и Wheeler-Kingshott, 2017]. Так что мозжечок
способен как непосредственно управлять движениями, так и
влиять на когнитивные процессы в коре, ускоряя процесс
принятия решений [L. Koziol и Budding, 2009]. Можно сказать, что
в нем аккумулируются и навыки управления движениями, и
навыки мышления. Принципиальная схема обучения
мозжечка как вторичного управляющего контура представлена на
рис. 5.18а.
Мы описали работу мозжечка в предельно упрощенном
варианте, достаточном для понимания общих принципов его
работы как "supervised learning machine" [L. Koziol, Budding и
др., 2014]. В этом своем качестве он может обучаться,
пользуясь обучающими сигналами различной природы, не только от
184 ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
коры (действительно, мозжечок - более древняя подсистема,
чем неокортекс). Например, он способен осуществлять
адаптивную фильтрацию, минимизируя тремор при управлении
движением, т.к. его алгоритм обучения в общем случае де-
коррелирует входной и обучающий сигналы [P. Dean и др.,
2010]. Более детальную информацию о строении и
функционировании мозжечка можно найти, например, в [D'Angelo,
2011; Uusisaari и De Schutter, 2011].
(a) (b)
Рис. 5.18. Схема двух управляющих контуров коры - базаль-
ных ганглий и мозжечка. Формирование вторичного
управляющего контура (а). Упрощенная схема (Ь)
5.7. Схемотехника мозга: архитектура
Deep Control
В итоге вырисовывается следующее распределение ролей
между основными подсистемами мозга, рассмотренными выше.
Кора анализирует текущую ситуацию в терминах типовых
признаков разной степени абстракции и предлагает
различные варианты поведения, используя ассоциативные
возможности гиппокампа. Решение в пользу той или иной модели по-
5.7. Схемотехника мозга: Deep Control
185
ведения принимают базальные ганглии на основе
интегральной оценки ситуации с точки зрения достижения
биологических целей организма. Управление корой происходит
опосредовано через модуляцию усилительных контуров таламу-
са. Последний концентрирует внимание коры на актуальном
в данный момент подмножестве задач. Мозжечок обучается
эмулировать управляющие сигналы коры в режиме быстрого
реагирования, постепенно перехватывая управление
рутинными действиями.
Вспомним теперь об иерархическом устройстве коры и о
том, что каждый раздел базальных ганглий контролирует свои
области коры. В итоге вырисовывается следующая модульная
вычислительная архитектура мозга, назовем ее для
краткости архитектурой Deep Control (рис. 5.19)19. Она включает в
себя распознавание ситуации в виде согласованной иерархии
признаков (сенсорная кора) и выработку адекватного
поведения, также организованного иерархически и согласованного
сверху вниз (лимбическая, ассоциативная, премоторная и
моторная кора). Обучение такой системы происходит постоянно
в режиме онлайн в процессе тесного взаимодействия с
внешней средой. Такая самообучающаяся иерархическая
управляющая система способна одновременно оперировать на многих
временных масштабах. Так наш мозг одновременно и
согласованно координирует целенаправленные активности в
диапазоне от десятых долей секунды до минут, часов, дней и даже
лет.
Лимбическая система (самый правый блок в цепочке) на
основании самой общей информации о состоянии мира и
нуждах организма задает текущую цель, инициирующую разра-
19 Сходные архитектурные идеи можно найти во многих работах,
можно сказать, что сегодня они буквально витают в воздухе, к примеру,
архитектура LID A [Franklin и др., 2014] или Distributed Adaptive Control
[Verschure, 2012]. Иерархическое обучение с подкреплением с
привязкой к основным подсистемам мозга рассмотрено, например, в работах
[Botvinick, 2012; D. Prank M. J. В., 2011; Ito и Doya, 2011; Reynolds и
O'Reilly, 2009].
186
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
at
st
Рис. 5.19. Схема иерархических управляющих модулей
мозга. Корковые модули (обучение без учителя) - сенсорная и
моторные иерархии. Крайний правый модуль -
ассоциативная память гиппокампа. Модули обучения с подкрепланием -
базальные ганглии, подкрепляющий сигнал из допаминовой
системы закрепляет целесообразное поведение с большим
горизонтом планирования. Подкрепление основано на
рефлекторных управляющих сигналах из гипоталамуса и амигдалы.
Верхние модули (обучение с учителем) - мозжечок
ботку в префронтальной коре планов поведения. Именно здесь
рождаются эмоции. Согласно Barrett, 2017 они представляют
собой высокоуровневые понятия ассоциативной лимбической
коры, связывающие внутренние состояния организма с
внешней ситуацией и предсказывающие, как организм будет
реагировать на них в зависимости от избранной стратегии
поведения20. Для текущей цели в ассоциативных разделах коры
вырабатывается замысел ее достижения и выделяются
промежуточные этапы. Премоторная кора вместе со вторичными
сенсорными областями разворачивает каждый из них в
цепочку конкретных действий, спускаемых для исполнения в
сенсомоторный блок. Все найденные ранее управляющие воз-
20 Имеется русский перевод [Барретт, 2018].
5.8. Deep Control — изобретение приматов
187
действия запоминаются и воспроизводятся мозжечком с
минимальными задержками, разгружая кору от контроля над
рутинными операциями.
5.8. Deep Control — изобретение
приматов
В 2004 году был изобретен оригинальный метод подсчета
числа нейронов в различных структурах мозга: ткани мозга
помещают в миксер, разбивают и растворяют все клеточные
мембраны, а затем подсчитывают число ядер, подсвеченных
флюоресцирующими маркерами. С помощью этого
остроумного и, главное, дешевого метода за прошедшие годы удалось
измерить параметры мозга у многих видов млекопитающих.
Так называемые аллометпрические зависимости между этими
параметрами (скейлинги) позволяют выявить общие
архитектурные принципы устройства их мозга.
Обзор этих результатов в книге автора методики Herculano-
Houzel, 2016 проливает некоторый свет на происхождение
архитектуры Deep Control. Модульная архитектура мозга
оказалась единой для всех млекопитающих. Об этом
свидетельствует пропорциональность числа нейронов в коре и мозжечке: на
каждый нейрон в коре имеется 4 нейрона в мозжечке21.
Соотношение между числом нейронов и глиальных клеток в
мозге, а также потребляемая средним нейроном энергия у всех
млекопитающих также одинаковое, несмотря на все
разнообразие типов нейронов и глиальных клеток (см. рис. 5.20). Все
выглядит так, будто мозг всех млекопитающих, от мышки до
жирафа, отличается просто числом неких однотипных
вычислительных модулей.
Однако мозг приматов выделяется среди остальных
млекопитающих в одном очень важном аспекте - зависимости
21 Базальные ганглии как отдельные структуры в этих экспериментах
не выделялись.
188
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
(а) (Ь)
Рис. 5.20. Однотипная (модульная) архитектура мозга
млекопитающих: число нейронов в мозжечке пропорционально
числу нейронов коры (а), а энергетические затраты мозга
пропорциональны числу нейронов (b) [Herculano-Houzel, 2016]
числа нейронов в коре (и, следовательно, в мозжечке) от ее
массы. У всех млекопитающих число нейронов растет, как
(масса коры)2/3, а у приматов — прямо пропорционально ее
массе (см. рис. 5.21).
Это важное архитектурное новшество позволило большим
приматам иметь при той же массе гораздо более сложный
мозг по сравнению с остальными млекопитающими, с большим
числом нейронов (и вычислительных модулей). Например,
человеческий по сложности мозг у типичного млекопитающего,
не примата, весил бы 30 кг при массе тела 80 т!
Чем же отличается архитектура мозга приматов?
Экспериментальные данные свидетельствуют, что структура связей
в мозге приматов, их коннектом, имеет так называемую
архитектуру малого мира. Глобальные связи в их мозге
обеспечиваются небольшим числом корковых модулей, тогда как
основная масса модулей связана с лежащими поблизости22.
22 Действительно, если длина аксонов большинства нейронов
постоянна, то число нейронов растет пропорционально массе коры (приматы).
Если же длина аксонов у большинства нейронов сравнима с
размерами коры, то масса типичного нейрона растет, как (масса коры)1/3, а их
число - как (масса коры)2/3 (остальные млекопитающие).
5.8. Deep Control — изобретение приматов
189
(a) (b)
Рис. 5.21. Отличие архитектуры мозга приматов от
остальных млекопитающих. Число нейронов в коре приматов растет
пропорционально ее массе, тогда как у остальных
млекопитающих — гораздо медленнее (а). Приматы наращивают
число нейронов с ростом массы тела гораздо быстрее остальных
млекопитающих (b) [Herculano-Houzel, 2016]
Но именно такую структуру связей и обеспечивает
иерархическая архитектура Deep Control! Каждый следующий уровень
иерархии, в основном, связан с лежащим поблизости
предыдущим уровнем.
Благодаря своему изобретению приматы смогли
относительно легко наращивать сложность мозга просто за счет
увеличения его размеров, что и наблюдалось в процессе
эволюции. Для остальных млекопитающих этот путь был закрыт.
Человек — типичный представитель отряда приматов, его
мозг ничем принципиально не отличается от их мозга.
Просто нам удалось максимально нарастить массу своего мозга.
Решающую роль в этом, по всей видимости, сыграло освоение
огня и переход homo erectus на вареную пищу. Вареная пища
лучше усваивается: варка зерна увеличивает его усвояемость
на 30%, а варка мяса — на 50%. Более калорийная диета
позволила человеку на 40% сократить массу своего желудочно-
кишечного тракта, нарастив взамен массу своего мозга. Эта
гипотеза, предложенная Wrangham, 2009, впоследствии была
190
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
подкреплена Herculano-Houzel, 2016 дополнительными
свидетельствами.
5.9. Абстрактное мышление:
моделирование реальности
Итак, описанная выше архитектура Deep Control - общая для
всех приматов. Количественные различия могут быть
заметными, но качественно мозг шимпанзе и мозг человека имеют
один и тот же базовый дизайн.
Тем не менее нельзя отрицать, что между человеком и
шимпанзе есть существенные различия. Хотя до двух лет
детеныши шимпанзе и человека развиваются примерно по
одному сценарию, далее траектории их развития кардинально
расходятся, даже если они живут бок о бок. Что же отличает
наш мозг с точки зрения его архитектурных особенностей?
Deacon, 1998 очень удачно определил наш вид как "symbolic
species", в том смысле, что нашей главной отличительной
чертой является способность оперировать абстрактными
символами, способность к абстрактному мышлению.
Анатомически это выражается в существенном
увеличении ассоциативных областей коры, в особенности в префрон-
тальной коре, например, 10-го поля Бродмана, которое у
человека созревает (миелинизируется) последним и, видимо,
соответствует верхним уровням иерархии корковых модулей.
Причем в этих эволюционно самых молодых областях коры
пирамидальные нейроны 3-го слоя, осуществляющие связь
между различными разделами коры, существенно крупнее, чем в
остальных [Solari и Stoner, 2011]. То есть эволюция явно шла
по пути увеличения связности мозга (и повышения уровня
сознания) .
Новые данные об анатомической и функциональной
связности различных областей коры (определяемой через
корреляцию их активностей) однозначно свидетельствуют в пользу
теории "малого мира" [Hagmann и др., 2008]. Согласно этой
5.9. Абстрактное мышление: моделирование 191
концепции различные части коры могут эффективно
обмениваться информацией через небольшое число хабов,
образующих в совокупности глобальное рабочее пространство [Baars
и др., 2013]. Наличие сознания, как уже говорилось,
характеризуется глобальными корреляциями мозговой активности,
тогда как в бессознательных состояниях мозговая активность
асинхронна. Dehaene и др., 2017 разделяют два типа сознания:
С1 - ясное понимание мира, и С2 - ясное понимание себя в
этом мире. Последнее состояние добавляет к обычному
состоянию бодрствования (С1) еще и модель "Я" и соответствует
рефлексивному сознательному мышлению. Bach, 2018
связывает такое сознательное мышление с включением специальной
функциональной системы, направляющей ход мышления, он
называет ее "дирижером" (conductor), управляющим
оркестром функциональных подсистем более низкого уровня.
Исследования последних лет позволили выявить в коре
несколько функциональных систем, состоящих из областей,
обычно коррелирующих свою активность. У людей наиболее
развита т.н. лобно-теменная система (Frontoparietal Network),
основным хабом которой является латеральная префронталь-
ная кора (Lateral Prefrontal Cortex). Эта система отвечает за
решение когнитивных задач и шире - за принятие решений
в незнакомых ситуациях [Cole и др., 2013]. Она
включается тогда, когда интуитивные решения, основанные на
прошлом опыте, не решают поставленной задачи сходу. Даниэль
Канеман называет режим интуитивного принятия решений
Системой-1. Когда мы "включаем логику", вступает в
действие рациональное мышление Системы-2, т.е.
активизируется лобно-теменная система. Она последовательно разбивает
незнакомые задачи на более простые и знакомые, запоминает
и сводит промежуточные решения воедино [Kahneman, 2011].
Лобно-теменная система обладает максимальной связностью,
т.е. имеет доступ к самому большому числу областей мозга,
которые она может при необходимости подключать к
решению конкретных задач. Это своего рода Универсальная ма-
192
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
шина Тьюринга в нашем мозгу, только с весьма ограниченной
рабочей памятью, вот почему компьютеры настолько сильнее
нас в исполнении любых формальных алгоритмов.
Известно, что индивидуальный IQ коррелирует со
степенью связности лобно-теменной системы [L.E Koziol и др.,
2014]. Естественно предположить, что и уровень нашего
видового интеллекта определяется именно этой системой.
Рисунок 5.22 иллюстрирует функционирование мозга в
режиме Системы-1 (стимул-реакция) и в режиме Системы-2
(перебор вариантов и выбор наилучшего). В последнем режиме
сознательного рационального мышления часть мозга по
возможности отключается от внешнего мира и стремится в
своем воображении смоделировать различные варианты
развития событий. Лобно-теменная система организует своего рода
"виртуальную реальность", в которой можно рисковать
"виртуальными жизнями" без риска лишиться реальной.
С точки зрения теории управления мы переходим от
ситуативного управления (model-free) к управлению с
моделированием (model-based) [Khamassi и Humphries, 2012].
Мощные связи внутри коры позволяют учитывать
воображаемые последствия тех или иных решений и управлять
поведением уже не на уровне отдельных действий, а на уровне
их цепочек, т.е. замыслов и планов. Пока не будет найдено
приемлемое решение, которое базальные ганглии допустят к
исполнению. Таким образом, вместо фиксированного набора
действий перед нами открывается бесконечный мир их
комбинаций.
Наш мозг способен запоминать и повторно использовать
эффективные способы решения различных задач, формируя
свои навыки мышления аналогично навыкам поведения в
реальном мире. Для работы в виртуальном мире кора
формирует абстрактные символы различных классов предметов и
способы действий с ними23. Способность к абстрактному мышле-
Так, архикортекс задействует свои древние механизмы навигации
в пространстве для ориентации в символьных когнитивных структурах
[Buzsaki и Moser, 2013].
5.9. Абстрактное мышление: моделирование
193
Рис. 5.22. Два режима функционирования мозга.
Вверху - реактивный режим реагирования на внешнюю
ситуацию. Внизу - выработка решений путем моделирования
последствий возможных действий в "виртуальной реальности".
(Для упрощения, контур управления мозжечка не показан)
нию ограничивается лишь нашей способностью
сосредотачиваться на символах, отвлекаясь от реального мира, и глубиной
нашей рабочей памяти.
Последняя основана не на долговременных изменениях си-
наптических связей, а на текущей активности различных
областей коры. По мере того как базальные ганглии
переключают внимание с анализа одного варианта на анализ
другого, активность временно отключенных участков коры
затухает. Чтобы одновременно держать в уме несколько объектов,
приходится постоянно переключаться между ними в процессе
"умственного жонглирования". То есть известный закон
Миллера о емкости оперативной памяти относится к нашей спо-
194
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
собности умственно жонглировать не более чем 7 ± 2 предме-
24
тами .
Итак, сознательное мышление Системы-2 использует
механизмы выработки решений, перенесенные из мира
реальных вещей в мир нашего воображения, организует свою
"виртуальную реальность", где под управлением префронтальной
коры сравниваются между собой различные способы
достижения заданной цели. Однако большую часть времени мы
решаем рутинные задачи привычными способами в режиме
Системы-1 с активным участием мозжечка.
5.10. Новая старая архитектура
Заканчивая эту главу, подытожим, к чему мы пришли и что
это нам дает с точки зрения понимания интеллекта
природного и создания интеллекта искусственного.
Прежде всего, оказалось, что наших знаний о мозге уже
хватает, чтобы, пусть и в самых общих чертах, "на живую
нитку", описать принципы работы его основных подсистем.
Это, прежде всего, кора, содержащая основную часть
синапсов (1014), в которых и хранится подавляющая часть
нашей памяти. Память организована иерархически, и имеет две
тесно взаимодействующих ветви. Первая запоминает
паттерны (часто повторяющиеся комбинации) признаков, а также
паттерны этих паттернов и т.д. в потоке входной
информации. Вторая вырабатывает управляющие паттерны
(комбинации координированных действий), а также паттерны этих
паттернов и т.д. в потоке выходной информации.
Соответственно, в отличие от компьютерной, наша память,
активна. В ней постоянно возбуждаются волны ассоциаций
по всем возможным объяснениям происходящего и всем
возможным вариантам поведения. Чтобы выбрать и осуществить
24 Модель, объясняющая это известное ограничение емкости рабочей
памяти, представлена Ashby и др., 2005, a O'Reilly и М. Prank, 2006
предложили биологически обоснованный алгоритм работы рабочей памяти.
5.10. Новая старая архитектура
195
какой-то один из них, ассоциативную память необходимо
дополнить системой жесткой селекции, тормозящей любую
активность коры, кроме одной - доминантной. Эту роль
выполняет основная тормозная система мозга, базальные ганглии.
Критерием отбора служит максимизация ожидаемой
суммарной радости - встроенной в наш мозг базовой эмоции,
определяемой выбросами допамина в моменты, когда награда
(подкрепление от базовых регуляторных систем организма)
превышает ожидания. Таким образом, базальные ганглии
обеспечивают достижение долгосрочных целей, а не только
удовлетворение текущих потребностей организма.
Наконец, подсистема, содержащая максимальное число
нейронов мозга - мозжечок, берет на себя управление в типовых
ситуациях, освобождая ресурсы коры и базальных ганглий от
рутинной работы. Он просто запоминает управляющие
действия коры в типовых ситуациях и эмулирует их, сокращая до
минимума время принятия типовых решений (см. рис. 5.23).
Такое распределение ролей между основными
подсистемами объясняет базовые механизмы их обучения: выделение
типовых признаков в коре через конкурентное обучение без
учителя, выбор поведения в базальных ганглиях через
обучение с подкреплением и аппроксимацию паттернов активации
коры через обучение с учителем в мозжечке.
Понимание назначения основных подсистем задает рамку,
контекст, в который можно вписывать многочисленные
частные факты и модели. Подобно тому, как картинка на обложке
пазла существенно облегчает его сборку из разрозненных и
бессмысленных каждая по отдельности частей.
Ну а с практической точки зрения: что нам дает
понимание архитектуры нашего мозга? Во-первых, понятно
направление, в котором имеет смысл двигаться. Ведь эта
архитектура кардинально отличается от архитектуры современных
компьютеров, которая в основных чертах сохранилась с
момента публикации в 1946 г. Джоном фон Нейманом наброска
ее основных принципов.
196
ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА МОЗГА
Рис. 5.23. Распределение ролей между основными
подсистемами мозга
В существующих компьютерах активный процессор
взаимодействует с пассивной памятью, где хранятся алгоритмы,
определяющие ход вычислений. Подразумевается, что они
задаются извне - программистами. Соответственно, и
компьютерный интеллект, если таковой и появится, должен быть
привнесен в машину извне.
Мышление как биологический феномен устроено
по-другому. Природный интеллект не может возникнуть извне.
Поэтому архитектура мозга включает в себя не только процесс
исполнения алгоритмов, но и процесс их порождения путем
обучения. Интеллект формируется постепенно в процессе
активного взаимодействия с миром, путем постоянного
тестирования и отбора адекватных моделей мира и стратегий
поведения в нем.
5.10. Новая старая архитектура
197
Соответственно, в этой архитектуре должен быть
предусмотрен источник активности - драйв, стремление учиться и
получать радость от неожиданных открытий. Память должна
быть активной, способной порождать новые варианты
поведения в незнакомых ситуациях. Наконец, ограниченные ресурсы
для этой творческой работы необходимо освобождать от
загрузки рутиной.
Таким образом, на пути к искусственному интеллекту нам
предстоит ни много ни мало, как "вдохнуть душу" в
компьютеры, заменив их бездушную, механическую фон-неймановскую
архитектуру на гораздо более человечную архитектуру
природного интеллекта приматов.
Более того, у нас даже имеется подсказка, как именно
этого можно достигнуть. Одной из важнейших
эволюционных находок млекопитающих оказалась масштабируемая
архитектура их мозга, состоящего из однотипных модулей.
Такая модульная архитектура позволяет наращивать
возможности мозга простым увеличением числа модулей, каждый из
которых может специализироваться на определенной задаче.
Что, по всей видимости, и происходило в ходе эволюции от
первых грызунов до приматов и человека.
Если нам удастся перенять у природы этот модульный
дизайн, особенно в улучшенном приматами иерархическом
варианте, мы получим в свое распоряжение масштабируемый
общий искусственный интеллект. Остается только спросить
себя, а можно ли вообще получить такой интеллект "в свое
распоряжение"?
"Восходить хочет жизнь и, восходя, преодолевать себя" -
так говорил Заратустра.
Глава 6
На пути к искусственной
психике*
Если б мог я стать мудрее!
Если бы мог стать до
глубины мудрым, как моя
змея!
Между утренней зарёй и
утренней зарёй осенила
меня новая истина.
Фридрих Ницше «Так
говорил Заратустра»
6.1. Зачем нужна искусственная психика?
Логика предыдущего рассмотрения подводит нас к мысли,
что вслед за освоением машинами отдельных когнитивных
навыков наступит время их синтеза в единую систему,
искусственную психику. Людям гораздо естественнее и удобнее
* Материал повышенной сложности!
199
200
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
общаться с агентами, обладающими свойствами личности,
которым можно было бы перепоручать какие-то задачи и
надеяться на то, что они будут правильно поняты и исполнены.
Начиная с простых, четко определенных задач типа
поездки на автономном автомобиле. Мы перепоручаем такому
агенту принятие множества промежуточных решений, от
планирования маршрута до разрешения всех дорожных ситуаций,
будучи настолько уверены в результате, что можем на время
спокойно переключиться на другие активности. Именно
такими агентскими сервисами будет наполнен мир будущего.
Но в мире порядка сотни тысяч профессий, и будет
слишком накладно создавать соответствующих агентов с нуля под
каждую задачу. Гораздо проще создать некую единую
архитектуру — искусственную психику в качестве новой
операционной системы роботов, способной обучаться множеству
профессий, подобно тому, как это делают люди.
Имеет смысл, чтобы эта операционная система была
модульной, чтобы роботы могли не только общаться друг с
другом, но и обмениваться знаниями, т.е. обученными модулями.
Если архитектура мозга роботов будет одной и той же, то их
возможности будут ограничены лишь мощностью аппаратной
части. Как и в случае со смартфонами, базовые функции
будут исполняться на борту, а различные расширения могут при
необходимости подгружаться от облачных суперинтеллектов.
Эта архитектура должна будет также иметь общий для
всех роботов интерфейс пользователя — общение на
естественном языке и общую же базовую систему ценностей, без
которой невозможно существовать в человеческом обществе.
Потому что способы достижения любых желаний не должны
противоречить этим ценностям.
В целом, чем ближе будет архитектура операционной
системы роботов к естественной человеческой психике, тем
легче будет достичь взаимопонимания между ними и нами, без
которого невозможно представить себе мир, насыщенный
искусственным интеллектом. В этом мире роботы должны бу-
6.2. Машина Фейнмана
201
дут не просто уметь ориентироваться в физическом мире, но
и понимать внутренний мир людей, мотивы их поведения,
человеческие ценности и язык, способный описывать все
вышеперечисленное.
Вот почему мы в прошлой главе попытались
реконструировать крупноблочную архитектуру мозга — в качестве
возможного прототипа для конструирования искусственной
психики роботов. В этой главе мы рассмотрим варианты подхода
к этой проблеме с использованием идей, заимствованных у
мозга.
Понятно, что мы здесь вступаем на зыбкую почву еще не
апробированных и не канонизированных подходов. Но дорога
в тысячу ли начинается с одного шага...
6.2. Машина Фейнмана
Недавно Laukien и др., 2016 предложили интересную
адаптивную иерархическую архитектуру, машину Фейнмана,
незаслуженно обойденную вниманием научного сообщества,
увлеченного развитием мейнстримовского глубокого обучения.
Между тем, эта модель всерьез претендует на объяснение
способности сенсомоторной коры строить модели мира и управлять
своим поведением в нем. Авторы позиционируют ее как
своего рода универсальный компьютер для динамических систем,
каким для символьных вычислений является машина
Тьюринга.
Машина Фейнмана представляет собой иерархию простых
нейродинамических модулей, обучающихся адаптивно
предсказывать свои состояния, аналогично тому, как иерархия сен-
сомоторных участков неокортекса осуществляет предиктив-
ное кодирование своих сигналов по схеме эмпирического Бай-
еса (см. раздел 5.3.1.). Более того, в ней используется
описанное в разделе 5.3.2. разреженное бинарное кодирование,
характерное для кортикальных колонок, подавляющих своих
локальных соседей.
202
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Рис. 6.1. Разреженное бинарное кодирование: сжатое
символьное представление образов модулем машины Фейнмана
(см. раздел 5.3.2.)
Каждый модуль машины Фейнмана (участок коры,
размером в доли см2, соответствующий нескольким
гиперколонкам неокортекса - см. рис. 6.1) является одновременно
кодером входного сигнала из предыдущего уровня иерархии
(верхние слои коры, 1-4) и декодером предсказаний более высокого
уровня (нижние слои коры, 5-6), совместно предсказывая
значения активаций в модуле на следующем шаге по времени (см.
рис. 6.2).
Разреженный бинарный код модуля обладает
достаточным разнообразием для кодирования любых сенсомоторных
временных рядов, так что машина Фейнмана способна
обучаться множеству динамических режимов поведения.
Поскольку каждая пара кодер-декодер обучается
локально, машина Фейнмана не страдает характерной для
алгоритма backpropagation квадратичной зависимостью сложности
обучения от числа параметров модели. Так что обучение
оказывается на порядки более быстрым и требует меньшего числа
примеров, чем обычное глубокое обучение.
Авторы, в частности, демонстрируют обучение
робота-автопилота в реальном мире держать трассу после относительно
6.2. Машина Фейнмана
203
optional top-down supervising signal
encoder output
73.
Encoder N
Decoder N
t *
i ■ ■
i
decoder error
encoder output
T
i ■ i
\
Encoder 2
Decoder 2
f
decoder error
encoder output
Encoder 1
rz>
Decoder 1
1
decoder error
CD
1 3
rror g
3
TJ
redi
ctio
d
Г 1
о
**r
ose
з
act
ion
Рис. 6.2. Иерархическая схема предиктивного кодирование
Машины Фейнмана (из [Laukien и др., 2016])
небольшого числа учебных прогонов по реальной трассе.
Робот довольно быстро "улавливает", что от него требуется, и
обучается самостоятельному вождению без десятков и сотен
тысяч прогонов в виртуальном игровом мире. Это лишний раз
свидетельствует о плодотворности принципа "учиться у
мозга".
По мнению автора, эта модель может вполне
претендовать на описание нижних этажей искусственной психики,
осуществляющих бессознательный контроль движений робота, и
моделирующей упомянутую в прошлой главе Систему-1.
204
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Ниже мы опишем обобщение этой схемы на более сложное
поведение — составление и отслеживание выполнения
иерархии планов, более похожее на режим рационального
мышления Системы-2.
6.3. Символьное мышление: основная идея
Для начала вспомним опять программу AlphaZero (см. раздел 4.8.)
и что нас в ней не устраивает главным образом присущая
ей сложность обучения, измеряемая сотнями терафлопс-лет.
Как следствие, такой алгоритм обучения ограничен
виртуальными игровыми мирами и не подходит для обучения роботов
в реальном мире.
Причина такой неэффективности в том, что игровая
интуиция AlphaZero представлена одной глубокой нейросетью и
ограничена одним следующим ходом. Эта интуиция
дополнена алгоритмами просчета множества вариантов на
определенную глубину, что, естественно, улучшает игру, но
каждый раз - локально, на уровне выбора очередного хода (см.
рис. 6.3).
Рис. 6.3. Интуиция у сети AlphaZero простирается только на
один ход вперед: для любой позиции она предлагает ее оценку
и несколько вариантов лучших ходов. Глубоко
эшелонированное планирование у AlphaZero отсутствует
6.3. Символьное мышление: основная идея
205
Рис. 6.4. Предлагаемая архитектура позволяет запоминать
и использовать наиболее полезные паттерны поведения на
разных временных масштабах. Полезность определяется
подкрепляющими сигналами, отбирающими хорошие цепочки
действий. Обучение производится снизу вверх, от простого -
к сложному. А поведение, наоборот, планируется сверху вниз,
от целей - к средствам их достижения
У AlphaZero отсутствует механизм иерархического
планирования, когда имеется некий крупномасштабный замысел
игры, который можно декомпозировать в более детальные
планы осуществления его отдельных этапов. То, что в военной
науке различают как стратегический, оперативный и
тактический уровни управления. А ведь именно эту способность
декомпозиции сложных задач на ряд более простых обычно
считают одним из признаков высокоуровнего логического или
символьного мышления. Далее в этой главе мы представим
архитектуру, способную осуществлять такого рода
иерархическое символьное мышление и соответствующее сложное
многоуровневое поведение.
206
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Эту архитектуру можно рассматривать как обобщение
машины Фейнмана, где на каждом уровне пара кодер-декодер
дополняется примитивным планирующим механизмом, парсе-
ром, способным комбинировать найденные кодером
символьные представления, запоминать типовые комбинации
символов и выбирать из них паттерны поведения, наиболее
перспективные в данном контексте.
То есть, как и в AlphaZero, интуиция дополняется
расчетом, но расчет производится одновременно на многих
иерархических уровнях, работающих в разных временных
диапазонах. Мы выбираем не просто очередной лучший ход, но
поддерживаем актуальную иерархию вложенных друг в друга
планов (см. рис. 6.4).
Несмотря на то что на каждом уровне планирование
ограничено по времени, иерархия временных паттернов поведения
позволяет верхним этажам "дотянуться" до очень отдаленных
целей, подчинив текущее поведение долгосрочным интересам
агента.
6.4. Гипотеза о рекурсивных модулях
коры
Прежде всего, обсудим механизм, посредством которого
предлагаемая схема мышления может быть реализована в
ассоциативных разделах неокортекса. Мы полагаем, что в высших
ассоциативных разделах коры основной вычислительный
модуль отличается от модулей первичных разделов сенсомотор-
ной коры (см. рис. 6.5).
Согласно нашей гипотезе в ассоциативной коре сигналы
от более низких уровней иерархии принимаются несколькими
гиперколонками, как и в машине Фейнмана. Но в
ассоциативной коре такие принимающие гиперколонки, смотрящие
вовне, являются центрами рекурсивных модулей, состоящих
6.4. Гипотеза о рекурсивных модулях коры
207
из гиперколонок, смотрящих внутрь модуля, т.е. сами на себя
(правая часть рис. 6.5)1.
Принимающие гиперколонки каждого уровня
осуществляют дискретное кодирование текущего состояния мышления
(активаций колонок) на более низких уровнях. Каждая такая
гиперколонка осуществляет кластеризацию своего входного
сигнала, т.е. представляет его одним из своих символов.
Входные сигналы каждого модуля (имеющие, скорее всего,
случайные разреженные рецептивные поля) различаются между
собой. В совокупности эти модули осуществляют дискретное
разреженное кодирование картины возбуждений в коре на
более низком иерархическом уровне.
Поскольку картина возбуждений в коре меняется со
временем, каждая принимающая гиперколонка формирует свою
последовательность символов. Задачей рекурсивного модуля
является пространственное кодирование этих временных
последовательностей, запоминание и распознавание типовых
конструкций из символов — морфем, по аналогии с языком.
Знание словаря типовых морфем, временных паттернов
мышления, позволяет распознавать эти паттерны в текущем потоке,
предвидеть ход развития событий и, в конечном итоге,
управлять им.
Отбирая с помощью базальных ганглий
паттерны-морфемы, получавшие в прошлом наибольшие подкрепления,
рекурсивные вычислительные модули способны активно
формировать оптимальное в данном контексте поведение, которое,
как и в машине Фейнмана, декодируется из символьного
представления более высоких уровней в картину активации более
низких уровней. Таким образом, иерархия рекурсивных
модулей ассоциативной коры может производить анализ ситуации
и планировать поведение сразу на многих масштабах времени
(см. рис. 6.4).
1 Рекурсивные модули автоматически формируют сеть с топологией
"малого мира", т.к. большинство связей между нейронами имеет
локальный характер.
208
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Рис. 6.5. Слева: иерархия сенсомоторных модулей неокор-
текса, соответствующих машине Фейнмана. Справа: иерархия
рекурсивных модулей неокортекса, соответствующих его
ассоциативным разделам, ответственным за планирование
действий
По мысли автора, именно так может быть организовано
наше символьное мышление, воплощенное, в частности, в
языке, и рекурсивные структуры языка подсказывают нам
базовые алгоритмы работы ассоциативной коры.
Рекурсия - это определение объекта через самого себя,
когда каждая его часть принадлежит к тому же классу, что
и сам объект. Рекурсивными структурами являются,
например, математические деревья, состоящие из веток, каждая из
которых является, в свою очередь, деревом. Все, наверное,
помнят школьные упражнения по грамматическому разбору
предложений, т.е. построению синтаксического дерева,
связывающего между собой слова и словарные группы.
Аналогичные структуры можно усмотреть и на других уровнях -
от морфологии слов до "морфологии" поведенческих актов
[Jackendoff, 2007]. В итоге Hauser и др., 2002 выделяют рекур-
сивность как важнейшую черту языка, а операцию слияния
двух сущностей (ветвление бинарного дерева) "лингвист № 1"
Ноам Хомский считает базовой операцией любой модели
языка [Chomsky, 2014].
6.4. Гипотеза о рекурсивных модулях коры
209
Предположительно, применяя эту базовую операцию,
рекурсивные модули ассоциативной коры и осуществляют
разбор структуры временных рядов, представление их в виде
бинарных деревьев.
Представим себе качественно процесс обучения
рекурсивного модуля, содержащего несколько гиперколонок, на вход
которых поступает временная последовательность символов,
порождаемая принимающей гиперколонкой. Наиболее часто
следующие друг за другом символы представляют собой
простейший устойчивый паттерн входного сигнала, а карты Кохо-
нена, сформированные конкурирующими между собой
колонками каждой гиперколонки, как мы знаем, формируют у себя
колонки-индикаторы типовых паттернов входных сигналов.
То есть любое появление такой пары символов будет
распознано какими-то колонками рекурсивного модуля. Тем самым,
входная последовательность символов для рекурсивного
модуля дополнится возбуждениями колонок-индикаторов всех
типовых пар символов. Вслед за ними неизбежно появятся
и колонки-индикаторы наиболее часто повторяющихся
сочетаний символов и их пар и т.д. Вслед за детекторами слога
'ма' появятся и детекторы слова 'ма-ма\ То есть обучение
нашего гипотетического рекурсивного модуля должно
привести к формированию детекторов и распознаванию во входных
последовательностях всех типовых сочетаний символов,
сочетаний их сочетаний и т.д. Любая входная последовательность
будет представлена индикаторами содержащихся в ней
типовых рекурсивных структур.
Если принимающие колонки формируют алфавит данного
модуля, то сам рекурсивный модуль в результате обучения
накапливает словарь типовых морфем и состоящих из них слов.
Словами из этого словаря каждый слой описывает
временную картину возбуждений коры на более низком уровне, а
предложения, составленные из этих слов, являются
предметом анализа на более высоком уровне мышления.
Ниже мы опишем алгоритмы обучения такой
иерархической модели и порождения ей целенаправленного поведения
210
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
с произвольно большим горизонтом планирования в
надежде на то, что эти алгоритмы могут лечь в основу будущей
операционной системы роботов. Те, кто не любит формул, и
кому это более формальное изложение описанного выше
подхода не интересно, могут ничего не теряя сразу переходить к
следующей главе.
6.5. Структурное обучение: рекурсивные
структуры
6.5.1. Основная идея метода
Мы начнем с рассмотрения простейшего случая обучения
отдельного рекурсивного модуля, где входные данные
представляют собой (бесконечную) последовательность символов из
некоторого алфавита Л— {$ъ ..., «#}, соответствующего
принимающей гиперколонке, содержащей К колонок. Требуется
построить модель данных, ухватывающую существующие во
входном потоке закономерности и способную порождать
наблюдаемые последовательности символов.
Под структурным обучением мы будем понимать
построение и использование для моделирования данных рекурсивных
структур — бинарных деревьев с символами исходного
алфавита в качестве "листьев". Обучение, т.е. постепенное
расширение используемого набора деревьев, будет основано на
простом подсчете частотных корреляций между ними.
Результатом обучения является словарь структур {w\,... ,Wk} и
корреляционная таблица их совместных наблюдений i?/r = RWlWr
в определенном контексте.
Как известно, обучение теснейшим образом связано со
сжатием данных с помощью моделей: любое сжатие данных
основано на присущих им закономерностях. Чем больше
закономерностей мы сможем обнаружить, тем большего сжатия
данных удастся достичь, и тем сильнее будет предсказательная
способность нашей модели. Таким образом, целью обучения
6.5. Структурное обучение
211
является максимально возможное сжатие исходных данных
(см. раздел 3.1.4.).
Представим себе, что мы имеем достаточно длинную
последовательность символов на незнакомом нам языке, и
нашей задачей является построение модели этого языка,
приписывающей определенную вероятность любому отрывку текста
на этом языке, основываясь на знании характерных сочетаний
символов (морфем) данного языка и частотах их
употребления2.
Базовой операцией построения такой морфологической
модели является расширение исходного алфавита,
обеспечивающее максимальное сжатие информации. Для этого мы
подсчитываем, сколько раз символы встречаются рядом друг с
другом, и если это число достигает определенного порога R[r > i?o,
мы вводим новый символ для данной пары. В
последующем, как только мы встретим эту пару, мы заменяем ее новым
символом, сокращая тем самым длину кодированного
сообщения (см. рис. 6.6). Такой расширенный алфавит мы будем
называть словарем.
Формально обучающуюся модель можно представить в виде:
М = {{whwr) -> (wir,Rlr)}9
где wir — wi Л wr - дерево с ветвями w^wr. Если
соответствующее дерево в словаре отсутствует, т.е. Rir < i?o, wir = 0.
Модель характеризуется:
• размером словаря |ги| - количеством структур в словаре;
• сложностью модели \R\ - числом ненулевых компонент
таблицы корреляций.
2 Отсылка к языку тут не случайна. Язык наглядно демонстрирует
нам пример глубокого структурного обучения, характерного, по мнению
автора, для человеческого мышления в целом. Поэтому здесь мы
придерживаемся более общего, чем в лингвистике, значения слова морфология
как науки о строении и форме, в противовес семантике как науки об
отношениях между символами и миром. Или по-другому, правила
кодирования в противовес содержанию кодированного сообщения (см. ниже
раздел 6.6.).
212
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Рис. 6.6. Морфологическое сжатие данных за счет
оптимального расширения исходного алфавита (первые К символов).
Наиболее часто встречающейся паре символов присваивается
новый символ расширенного алфавита, заменяющий
исходную пару. Процесс расширения алфавита продолжается
рекурсивно
Понятно, что сначала словарь пополняется наиболее
частыми парами символов (слогами), затем наиболее частые
слоги объединяются в более крупные морфемы и т.д. Такое
кодирование оптимально, поскольку минимизирует суммарную
длину таблицы кодов и закодированного с ее помощью
сообщения. То есть предложенный алгоритм исходит из первых
принципов теории обучения - минимизации длины описания
[Rissanen, 1978].
6.5.2. Алгоритм структурного обучения (online)
Выше мы проиллюстрировали идею метода на примере batch-
версии алгоритма. Для практических приложений больше
подходит online-обучение, когда модель (например, робот)
накапливает знания постоянно, "без отрыва от производства".
Накопленный в результате обучения словарь структур
постоянно пополняется и используется для определения структуры
(парсинга) данных и предсказания (планирования) будущего.
6.5. Структурное обучение
213
Алгоритм парсинга может быть представлен конечным
автоматом, парсером, сжимающим входную последовательность
символов 5i,...,St в более компактную последовательность
слов из словаря: w\,... ,wt, T < t, наилучшим образом
объясняющих данные (см. рис. 6.7):
maxP(z/;i,... , гит).
Достоверность такой модели определяется произведением
вероятностей всех слияний, образующих модельную
структуру данных, каждую из которых можно оценить исходя из
таблицы корреляций:
Р(Щг) — P(wl Л wr) ос Rir.
Модель данных w\,..., wt представляет собой набор слов
wT, деревьев, которые уже не могут сливаться между собой:
wT Л Шг+1 = 0. Крайнее дерево, которое еще может расти,
текущий контекст Г, wt, должно содержать справа от
себя морфему, способную слиться с текущим контекстом. Как
только это условие нарушается, т.е. оказывается, что wt Л
Л^г+i — 0? слово wt фиксируется и парсер переходит к
построению нового текущего контекста Т + 1.
Таким образом, парсер строит модель данных,
ограничивая на каждом шаге глубину своего анализа. Например
следующим образом: парсер (k-го порядка) сравнивает между
собой варианты слияния текущего контекста Г и цепочки
следующих за ним к символов, wt, ^т+ъ • • • •> wT+k? выбирает из
к вариантов наиболее вероятное слияние, производит его и
переходит к следующему шагу. То есть сложность каждого шага
парсинга ограничена к операциями.
Обучение сводится к подсчету частот использования
структур в интерпретации данных парсером: Rir ^— Rir + 1 при
каждом использовании пары структур wiwr. При
достижении в какой-то ячейке корреляционной таблицы порогового
значения Ro словарь и таблица корреляций расширяются:
соответствующей комбинации левой и правой ветви
присваивается новый символ - дерева, составленного из этих двух
214
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Рис. 6,7. Алгоритмы парсинга данных А^ с разной глубиной
просмотра вариантов
ветвей. Таким образом, обучение состоит в простом подсчете
значимых корреляций между всеми известными структурами
и расширении списка известных структур их наиболее часто
встречающимися комбинациями.
Как видим, обучение происходит в режиме онлайн, в
процессе "осмысления" поступающих данных. Поскольку на
каждом шаге мы производим ограниченное число операций, такое
обучение линейно по количеству данных. Оно не нуждается
в учителе и не требует больших массивов данных, поскольку
сложность модели растет пропорционально объему данных.
В этом предложенный подход дискретного символьного
обучения отличается от аналогового обучения нейросетей
методом backpropagation, где сложность модели (число весов
нейросети W) задается заранее и обучение сводится к
нахождению оптимума в изначально сложном W^-мерном
пространстве.
6.5.3. Предсказания с помощью модели
Обученная модель может не только интерпретировать вновь
поступающие данные, но и предсказывать их. Ведь мы
умеем оценивать вероятности всех возможных расширений теку-
6.5. Структурное обучение
215
щего контекста и>т'. они пропорциональны числу отсчетов в
строке wt корреляционной таблицы. Группируя вероятности
всех возможных правых веток по их начальным символам,
получим вероятность следующего символа P(st+i\si,..., St).
Усредненная величина:
Perplexity = e-(^P(^i\su^st)) = e-(£inP(ei,...,et)> =
= е-(^1пР(™ь...,™т)) = e-(f \nP(wT+1\wT))
есть мера неожиданности вновь поступающих символов. Чем
она ниже, тем лучше объяснение данных с помощью нашей
модели. Мы можем постоянно измерять эту величину,
контролируя прогресс обучения модели.
6.5.4. Структурное обучение с подкреплением
Итак, структурное обучение позволяет все лучше предвидеть
будущее — за счет пополнения словаря все более сложными
структурами, т.е. за счет выявления наиболее типичных
конструкций, присутствующих в данных. Каждая структура
"поощряется" всякий раз, когда она участвует в интерпретации
данных, т.е. верно угадывает будущее. Таким образом, такое
обучение можно трактовать как вариант обучения с
подкреплением. Соответственно, схожим образом можно обучаться не
только правильным предсказаниям, но и правильному
поведению!
Представим себе, что, как и в машине Фейнмана,
исходный сенсомоторный вектор взаимодействия системы с миром
состоит из двух компонент: х^ = (s^at) — показаний
сенсоров St и генерируемых актуаторами действий а^. То есть
наша система (робот) реконструирует данные в контексте своих
собственных действий. На следующем шаге она
предсказывает ожидаемые наблюдения s^+i и осуществляет реальные
действия at+i. В ответ, как и положено при обучении с
подкреплением, робот получает внешние подкрепления rf, 1? до-
216
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
полняющие его внутренние "прогнозные" подкрепления г^+1?
мотивирующие правильные предсказания.
То есть всякий раз мы имеем оценку не только того,
насколько успешно робот предсказывает развитие ситуации, но
и насколько адекватны его действия в текущей ситуации:
П = К + г1
Таблица корреляций теперь прирастает всякий раз
суммарным подкреплением, полученным при таком "деятельност-
ном осмыслении данных"
Rir <- Rir + rir,
где v\r - суммарное подкрепление при слиянии морфем wiAwr.
Словарь структур в этом случае будет кодировать
типовые паттерны правильных действий в типовых ситуациях. По
мере накопления опыта взаимодействия со средой робот
обучается все более сложным цепочкам правильно
скоординированных действий.
Предсказания в таком подходе активны, т.е. тесно
связаны с поведением. Так, можно предсказывать положение
движущегося предмета на сетчатке глаза, синхронизируя
движения глаз со скоростью предмета. Соответствующему
движению глаз можно обучиться просто добиваясь наиболее
предсказуемого (неподвижного) состояния картинки на сетчатке.
То есть даже при отсутствии внешних подкреплений, можно
обучаться действиям, повышающим предсказуемость
внешней среды - координированному с внешним миром поведению.
Вспомним теперь, что на самом деле поведением
управляет не отдельный модуль, а набор рекурсивных модулей.
6.5.5. Разреженное дискретное кодирование
Набор принимающих гиперколонок разных модулей
осуществляет дискретное кодирование входных данных. Каждая из
6.5. Структурное обучение
217
них производит свой вариант кластеризации данных,
основываясь на доступной ей входной информации — разные
гиперколонки могут работать с разными наборами признаков
(срезами) входных данных.
Итоговый дискретный код сенсомоторного вектора х^
представляет результаты нескольких независимых кластеризации,
каждая из которых кодирует этот вектор одним из К
символов своего алфавита - ближайшего к нему центроида. В
итоге, любой вектор кодируется N дискретными компонентами,
соответствующими ближайшим центроидам N различных
вариантов кластеризации исходных данных набором
принимающих гиперколонок рекурсивных модулей.
Такое кодирование, будучи дискретным, сохраняет
понятие расстояния между двумя представлениями: векторы,
близкие в исходном векторном пространстве, будут близки и в
дискретном (по Хэммингу). Действительно, чем ближе друг
к другу векторы в исходном пространстве, тем больше
вероятность того, что они попадут в один и тот же кластер, и тем
больше компонент дискретного кода у них будет в среднем
совпадать (см. рис. 6.8).
С ростом числа компонент кода (числа модулей) N общее
число кластеров растет линейно: NK, а разнообразие
вариантов кодирования — экспоненциально: ft = KN.
Например, 7 различных кластеризации по 30 кластеров
представляют 7 алфавитов по 30 символов в каждом,
всего 210 символов, которыми можно закодировать ft = 307 ~
~ 2 • 1010 областей исходного векторного пространства, что
заведомо превышает любое разумное число данных, по крайней
мере для человека, который за всю свою жизнь переживает
всего лишь ~ 1010 ментальных моментов. То есть такая
точность представления данных для человека - уже избыточна.
То же будет справедливо и для роботов, возможно с несколько
большим значением N.
При том, что вычислительная сложность кластеризации
данных сравнительно невелика: для М векторов размерности
218
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Рис. 6.8. Дискретное кодирование непрерывных данных
ансамблем кластеризации. Чем ближе друг к другу векторы,
тем больше общих компонент будут иметь их коды. В данном
примере имеются два различных варианта кластеризации, и
дискретный код состоит из двух номеров соответствующих
кластеров
d сложность кластеризации С ~ rriidMK, где mi - число
итераций (в случае K-means rrii « 20 -=- 50). То есть сложность
дискретного кодирования данных растет линейно с
количеством данных М.
Таким образом, структурному обучению предшествует этап
unsupervised learning - выработки дискретного представления
сигналов из внешнего мира и возможных своих действий в
нем3.
3 Применительно к языку, этому этапу у ребенка соответствует
усвоение фонетической структуры языка. Так, уже к 8-месячному
возрасту младенцы начинают отличать речь на родном языке от посторонних
звуков [Saffran и др., 2001]. То есть примерно к этому возрасту мозг
формирует словарь основных фонем родного языка, создает внутреннее
дискретное представление непрерывных речевых сигналов.
6.6. Глубокое структурное обучение
219
После этого этапа любой внешний сигнал получает свое
внутреннее дискретное представление - N символов,
выбранных из N словарей с общим числом символов NK. Такое
разреженное кодирование, как мы видели, очень экономно. Все
компоненты кода равномерно нагружены, и Хэммингово
расстояние между кодами соответствует расстоянию между
кодируемыми сигналами в исходном пространстве — чем
больше компонент дискретного кода совпадает, тем ближе друг к
другу сигналы в исходном векторном пространстве.
Аналогичный этап unsupervised learning предшествует
структурному обучению на всех уровнях глубокого структурного
обучения. Для каждого следующего уровня предыдущий
является своего рода "внешней средой", состояние которой
можно предсказывать и изменять. В следующем разделе мы
покажем, как это работает.
6.6. Глубокое структурное обучение
Отдельно взятый уровень рекурсивных модулей способен
предсказывать события и планировать поведение лишь на
ограниченном временном интервале. Ведь количество возможных
структур экспоненциально растет с ростом "высоты" деревьев,
а модель не может разрастаться до бесконечности. В какой-то
момент необходимо остановиться и, чтобы двигаться дальше,
перейти на следующий уровень абстракции. А именно, надо
сконструировать новый алфавит, оперирующий в другом
временном масштабе.
В этом алфавите будет накапливаться новый набор
структур следующего уровня, позволяющих принимать решения в
этом новом временном масштабе. Когда и таких структур
накопится достаточно, назреет переход на еще более
абстрактный уровень, со своими символами и структурами,
определяющими поведение робота на еще больших временных
масштабах. И так далее, пока позволяют вычислительные ресурсы и
накопленный опыт взаимодействия со средой. В этом и
состоит суть глубокого структурного обучения.
220
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
6.6.1. Семантическое кодирование
Структурное обучение можно назвать морфологическим:
исходное сообщение сжимается за счет разрастания словаря
морфем. Переход на более высокий уровень соответствует
семантическому обучению: компактному кодированию смыслового
содержания накопленных морфем с помощью нового
семантического алфавита (принимающих гиперколонок
рекурсивных модулей следующего уровня иерархии).
Входными данными для семантического обучения
являются паттерны активности предыдущего слоя рекурсивных
модулей: wi,... ,wy, где wr — вектор активности колонок в
момент г (набор из N слов w™, описывающих состояние
каждого модуля). Необходимая для семантического обучения
статистика входных сигналов содержится в сжатом виде в
таблице корреляций i?Wjwr, отражающих статистику контекстов,
в которых различные слова встречаются в наблюдаемых дан-
4
ных .
Так, смысловое значение слов определяется характером их
употребления в языке. Если два слова систематически
встречаются в одних и тех же контекстах, т.е. употребляются
сходным образом, значит их смысловые значения близки,
независимо от их морфологии, т.е. они являются синонимами.
Всякое обучение, как уже говорилось, сжимает исходные
данные. Семантическое сжатие подразумевает, что
количество символов в семантическом алфавите должно быть много
меньше числа морфем. Если мы присвоим каждой морфеме
из словаря определенный символ семантического алфавита,
то все множество морфем разобьется на классы
эквивалентности - по числу базовых смыслов, и внутри этих классов их
значения будут неразличимы. Однако, как мы знаем на
примере языка, полных синонимов не бывает. Значения слов хоть
немного, но различаются, т.е. они могут заменять друг друга
4 Если пренебречь кросс-корреляциями между модулями, i^w^Wr
имеет блочную структуру: состоит из N таблиц корреляций отдельных
модулей Д£
6.6. Глубокое структурное обучение
221
отнюдь не во всяком контексте. Поэтому логично присвоить
каждому слову набор из нескольких значений, как это
обычно и делается в словарях. Таким образом, каждая морфема
будет кодироваться дискретным набором базовых смыслов, а
степень семантической близости морфем будет определяться
тем, насколько сильно пресекаются их семантические коды
(принимающие гиперколонки следующего уровня иерархии).
Ситуация, как видим, вполне аналогична схеме
разреженного кодирования векторных пространств, рассмотренной
выше в разделе 6.5.5.. Только теперь мы производим
дискретное кодирование в семантическом пространстве.
Существует много способов построения векторных семантических
пространств по контекстной информации, см. например [Blei и
др., 2003; Hofmann, 2001; Mikolov и др., 2013; Pennington и
др., 2014]. Здесь мы рассмотрим простейший -
кластеризацию контекстных векторов.
Введем матрицу P(w,c), полученную конкатенацией
матриц R и RT. Каждая ее w-я строчка представляет собой
контекстный вектор структур, предшествующих w и следующих
за ней в сжатом корреляционном представлении исходных
данных.
Как показано Levy и Goldberg, 2014, сравнение
контекстных векторов различных слов и их кластеризацию следует
проводить не в метрике "сырых" отсчетов P(w, с), а в метрике
взаимной информации между структурами и их контекстами:
P(w,c) P(w,c)-P
I(w, с) = log ——. '. = log — 7 ,
v ' 6 P(w)P(c) 6 P(w)P(c)
где:
P = J]P(w,c), P(w) = J]P(w,c), P(c) = ^P(w,c).
w,c с w
Сложность состоит в том, что эмпирические оценки за-
шумлены для достаточно редко встречающихся пар. Так, если
число отсчетов P(w, с) меньше определенной величины (и тем
222
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
более - если оно нулевое), эмпирические значения взаимной
информации становятся отрицательными. Это лишено
смысла, т.к. дополнительное знание не может уменьшать
предсказательную силу модели. Поэтому существует очень простой и
эффективный способ регуляризации эмпирической матрицы:
отрицательные величины взаимной информации полагаются
равными ее теоретическому минимуму, т.е. нулю. Эта метрика
называется Positive Pointwise Mutual Information
PPM/(w, с) = max(J(w, с), 0).
Предобработанные таким образом данные для слов
естественных языков показывают очень неплохие результаты на
многих тестах, типа поиска понятий в семантическом
пространстве: король - мужчина + женщина = королева, часто
превосходя по качеству довольно затратные в обучении state-
of-the-art нейросетевые модели (например, Skip-Gramm with
Negative Sampling) [Levy и Goldberg, 2014].
Большая доля параметров модели, зануляемых
операцией PPMI, свидетельствует о том, что модель начала
переобучаться, запоминать статистически не значимую информацию.
Этот индикатор может служить критерием перехода от
морфологического обучения к семантическому.
В соответствии с общим подходом для семантического
кодирования значений морфем нам необходимо создать N
семантических алфавитов, произведя N кластеризации (разных
подмножеств) строк разреженной матрицы PPM/(w,c).
6.6.2. Иерархия структур
Таким образом, мы показали, как с помощью простого
подсчета значимых корреляций между дискретными переменными
можно сначала расширить начальный алфавит символов до
словаря типовых структур, а затем - закодировать их
смысловые значения с помощью нового семантического алфавита
базовых смыслов, вернее, N таких алфавитов (см. рис. 6.9).
6.6. Глубокое структурное обучение
223
Рис. 6.9. Две базовые стадии глубокого структурного
обучения: морфологическое кодирование исходных данных с
помощью словаря типовых структур, и семантическое
кодирование найденных структур, с помощью семантических
алфавитов, уже на другом временном масштабе. Компактные
алфавиты символов и объемные словари типовых
последовательностей символов - морфем
Новые семантические символы кодируют уже не
отдельные элементы данных, а типовые конструкции из них, т.е. в
результате полного цикла обучения, сначала
морфологического, потом семантического, мы переходим в следующий
диапазон временных масштабов.
Мы можем повторять эти циклы снова и снова, переходя
ко все более абстрактному представлению данных,
соответствующему все более крупномасштабным структурам.
Например, в случае языка: от букв - к словам, от слов - к фразам,
предложениям, абзацам и т.д. (см. следующую главу). А в
случае роботов - настраивая все более "стратегические" уровни
управления их поведением.
224
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
6.6.3. Активное обучение
Сложность обучения с подкреплением определяется двумя фун
даментальными причинами:
1. Награды зависят не от отдельных действий, а от их
последовательностей, и могут отстоять далеко по времени
от конкретных действий. Получение награды не
атрибутируется к тому или иному действию, что затрудняет
оценки отдельных действий.
2. Примеры для обучения не даются извне, а активно
добываются при взаимодействии со средой. При этом надо,
с одной стороны, использовать уже найденные стратегии
(с риском того, что они не оптимальны), а с другой -
постоянно искать лучшие варианты (с неизбежными
потерями) . Это известная проблема exploration vs exploitation
[March, 1991].
Глубокое структурное обучение помогает решить первую
проблему за счет идеи иерархического планирования. Более
высокие уровни работают на больших временных масштабах,
что позволяет верхним уровням "дотянуться" до
произвольно удаленных по времени наград и нащупать грубый план их
достижения, а нижним - найти оптимальные способы
реализации этого плана. Расширение исходного словаря действий
их типовыми сочетаниями позволяет работать с
последовательностями действий так же, как с обычными действиями. В
результате, на каждом уровне задача оптимизации поведения
сводится к более простой, чем reinforcement learning, задаче,
известной как контекстные многорукие бандиты, где
имеется ограниченное количество возможных действий и история
наград за каждое действие в определенном контексте. В
нашем случае эта история записана в корреляционной таблице
данного уровня. Каждая строка этой таблицы представляет
собой определенный контекст, а каждый столбец - возможный
план действий (предсказание следующей морфемы).
6.6. Глубокое структурное обучение
225
Задача оценки наилучшего плана действий осложняется
крайней разреженностью корреляционной таблицы. Это
означает, что большинство возможных действий еще никогда не
наблюдалось, и мы не можем оценить их релевантность.
Какова должна быть оптимальная стратегия предсказаний в этих
условиях? Пробовать все возможные действия с равной
вероятностью невозможно при достаточно большом их
разнообразии (словаре морфем).
В нашей модели эта проблема решается за счет
использования байесовской памяти, где коэффициенты таблицы
корреляций рассматриваются как параметры байесовского
распределения вероятностей, из которого в процессе работы
организуется т.н. томпсоновское сэмплирование (Thompson
sampling) [Russo и др., 2018]. Томпсоновское сэмплирование -
элегантное и эффективное решение проблемы exploration vs
exploitation для многорукого бандита (в нашем случае -
конкретной строки таблицы корреляций). Идея этого подхода
очень прозрачна, см. рис. 6.10. Если использовать средние
значения распределения наград, мы всегда будем выбирать
одно и то же действие, которое и будет получать дальнейшие
подкрепления, при том что легко может оказаться
неоптимальным, т.к. в условиях крайне разреженного опыта у нас
имеется большой разброс оценок ожидаемых наград.
Поэтому в каждом конкретном акте выбора очередного действия
мы сравниваем между собой случайные реализации наград
из соответствующих вероятностных распределений. При этом
и лучшие действия выбираются чаще, и распределения
вероятностей для возможных вариантов действий уточняются
оптимальным образом5.
5 Хаотическую динамику активности мозга можно рассматривать, как
механизм реализации такой байесовской памяти.
226
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Рис. 6.10. Томпсоновское сэмплирование: выбор
наилучшего действия из соответствующих им распределений
вероятностей. В данном примере выберется действие из среднего
распределения вероятностей подкреплений, хотя ему и не
соответствует максимальное среднее подкрепление
6.6.4. Сложность структурного обучения
Оценим теперь сложность глубокого структурного обучения.
Будем для простоты считать, что на всех уровнях
используется одно и то же число рекурсивных модулей N.
На морфологических этапах обучение происходит со
скоростью парсинга, в процессе выявления структуры данных.
Сложность парсинга пропорциональна порядку парсера &,
размерности разреженных кодов N и объему данных М:
Cpars ~ kNM.
На этапе семантического обучения сложность
кластеризации семантического пространства линейна по сложности
модели |i?|, которая, в свою очередь много меньше объема
данных (т.к. Rir представляет эти данные в сжатом виде):
Csem ~ rrnNK\R\ < rrnNKM ос Cpars.
Таким образом, семантический этап по сложности сравним
с морфологическим и сильно не задерживает обучение.
Для сравнения сложность обработки данных нейронными
сетями пропорциональна числу их синаптических весов W:
С%™ ~ WM,
6.6. Глубокое структурное обучение
227
т.к. каждый элемент данных прогоняется через все веса ней-
росети. Поскольку современные глубокие нейросети могут
содержать W ~ 108 -г-109 синаптических весов, обработка
данных в парадигме глубокого структурного обучения может быть
на порядки быстрее, чем у нейросетей.
При этом, согласно (3.13), сложность обучения нейросетей
квадратична по числу параметров модели
С learn ^ Т/Г/2
NN ~ тЬУУ ,
и пока нейросеть не обучится, обработав М ~ W данных, ее
нельзя использовать для предсказаний, тогда как
структурная модель всегда имеет оптимальную сложность и в любой
момент способна к предсказаниям.
6,6.5. Иерархия предсказаний
Построение иерархии структур в нашем подходе происходит
снизу вверх: от уровня "сырых" данных - ко все более
абстрактным их представлениям. Предсказание же данных и
планирование поведения, напротив, начинается на самом
высоком уровне, обеспечивающем наиболее широкий контекст
понимания ситуации. Эта контекстная информация более
высоких уровней задает априорные распределения для структур
на более низких уровнях.
Рассмотрим для примера два последовательных уровня
иерархии. Данные более высокого уровня S* представляют
собой семантические коды структур более низкого уровня wj.
Вероятность следующего такого символа S*+i задает
априорную вероятность соответствующей структуры w$+i на
нижнем уровне. Она определяется условными вероятностями
структур верхнего уровня, ожидаемых в данном контексте:
P(WT+i|WT),
где Wt - текущий контекст верхнего уровня - аналогично
разделу 6.5.3..
228
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
Эта априорная информация с верхнего уровня,
естественно, сказывается на парсинге данных нижнего уровня. А
именно, в алгоритме парсинга появляется дополнительный
множитель:
P(wt+i|wt) -+ P(wt+i|wt)P(wt+i|WT). (6.2)
Это уже известная нам схема эмпирического Байеса (см.
раздел 5.3.1.), где априорное распределение данных на
каждом уровне не фиксировано, а постоянно подстраивается под
текущий поток данных.
В случае обучения с подкреплением (6.2) описывает, как
планы, принятые на более высоких уровнях, направляют
поведение на более низких уровнях. В случае языка влияние
априорной информации в (6.2) можно проиллюстрировать
угадыванием слов в текущем контексте по нескольким первым
буквам.
Обучение языку методом глубокого структурного
обучения заслуживает отдельного рассмотрения в силу той роли,
которую язык играет в нашем мышлении. Структуры языка
являются, по сути, "рентгенограммой" нашего мышления,
позволяют понять общие механизмы мышления на хорошо нам
знакомом с детства материале. Этой теме мы посвятим
следующую главу, но прежде обсудим полученные к данному
моменту результаты.
6.7. Обсуждение
По ходу изложения мы старались не перегружать текст
ссылками на работы предшественников. Пора обсудить идеи этой
главы в историческом контексте.
Как мы видели в главе 4, глубокое обучение исторически
тесно связано с распознаванием образов, парадигмой supervised
learning и алгоритмом обучения методом error backpropaga-
tion. Именно в этой области и этими методами были
достигнуты первые впечатляющие успехи глубоких нейросетей, во
6.7. Обсуждение
229
многом благодаря появившимся по доступным ценам
суперкомпьютерным мощностям на базе GPU. Увлекшись этими
успехами, научное сообщество смирилось с вычислительной
сложностью backpropagation и всерьез не искало ему
альтернатив. Тем более что рост производительности GPU до сих
пор обеспечивает прогресс области быстрыми темпами. Так
что основными "рабочими лошадками" глубокого обучения
по-прежнему являются алгоритмы двадцати- (LSTM) и
тридцатилетней (CNN) давности.
Однако в наши дни фокус исследований смещается от
распознавания образов к управлению поведением, во многом в
связи с ожидаемым "пришествием" роботов. В этой связи
вопрос об эффективности обучения, определяющей стоимость
hardware для роботов, приобретает особую актуальность.
"Чаша Грааля" современного машинного интеллекта - deep
reinforcement learning: формирование иерархических моделей
внешнего мира и взаимодействия с ним. Эта область активно
развивается, начиная с пионерских работ коллектива Deep-
Mind [Lillicrap и др., 2015; Mnih, Kavukcuoglu и др., 2015] и
заканчивая достижением программой AlphaZero
сверхчеловеческого уровня стратегического мышления методом
самообучения - игры самой с собой (в Го, шахматы и сёги) [Silver,
Hubert и др., 2017]. Однако, как мы уже отмечали, и в Alpha-
Zero глубокая нейросеть по-прежнему обучается в
парадигме supervised learning, только учителем здесь выступает сама
сеть, просчитавшая варианты на несколько ходов вперед.
"Интуиция" обученной глубокой нейросети AlphaZero ограничена
одним следующим ходом, у нее отсутствует иерархия
горизонтов планирования. Как следствие - трудоемкость обучения в
условиях, когда качество ходов определяется выигрышем на
очень далеком горизонте6.
6 Это объясняет, почему для обучения AlphaZero понадобилось
свыше 5 тысяч специализированных процессоров (Google TPU первого и
второго поколений) с суммарной производительностью ~ 5 • 1017 OPS
для просчета вариантов и ~ 3 • 1015 FLOPS - для настройки весов [Silver,
Hubert и др., 2017].
230
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
В этой главе предложен новый, символьный, подход к deep
reinforcement learning: построение иерархии дискретных
структур в сенсомоторном пространстве, обеспечивающих
иерархическое планирование поведения. Вместо градиентной
оптимизации векторных параметров нейросетей используется на
порядки более экономное дискретное хеббовское обучение.
Предложенный подход в целом, по-видимому, оригинален
(основан на работе автора [Шумский, 2018]), по крайней
мере автор не нашел аналогов в литературе. Но многие его
элементы хорошо известны, особенно в контексте моделирования
языка и механизмов работы мозга [Шумский, 2013, 2015].
Ближе всего наш подход к довольно правдоподобной
модели неокортекса Hierarchical Temporal Memory (HTM) команды
Джеффа Хокинза [George и Hawkins, 2009; Hawkins, Ahmad
и Cui, 2017; Hawkins, George и др., 2009] и опирающуюся на
сходные представления, но более высокоуровневую машину
Фейнмана. Обе модели учатся предсказывать временные ряды
и организованы в иерархии однотипных модулей, работающих
на разных временных масштабах. Обе вместо backpropagation
используют локальное хеббовское обучение.
Отличие нашего подхода, как мы видели, - в схеме
кодирования временных паттернов. В предлагаемой модели
последние представляются бинарными деревьями, а не
разреженными ансамблями искусственных нейронов. Соответственно,
наша модель накапливает таблицу корреляций между
деревьями, нейронными ансамблями, а не между отдельными
нейронами. Эта контекстная информация используется затем на
стадии семантического обучения. Более низкоуровневое
кодирование в случае НТМ не содержит информации,
необходимой для построения семантических пространств. В терминах
[Анохин, 2014] в нашей модели обучение происходит на уровне
когнитома, а в НТМ - на уровне коннектома. Продолжая
аналогию с концепцией когнитома К.В. Анохина, элементы
семантических алфавитов нашей модели можно сопоставить
с введенными им квалонами, а элементы морфологического
словаря - с оперонами.
6.7. Обсуждение
231
Базовая идея метода структурного обучения - выявление
рекурсивных структур в символьных данных - была известна
уже в 1980-90-х гг. К алгоритмам раздела 6.5. наиболее близка
работа Nevill-Manning и Witten, 1997, где впервые предложен
линейный по объему данных алгоритм выявления
рекурсивных структур, основанный на идеях минимальной длины
описания. В свою очередь, эта работа наследовала двум потокам
исследований - в области сжатия информации, с
использованием повторяющихся сочетаний символов [Bell и др., 1990;
Welch, 1984] и выявления грамматических правил и структур
языка методами оптимального кодирования [Stolcke и Ото-
hundro, 1994; Vanlehn и Ball, 1987; Wolff, 1975, 1982, 1988].
Отличие нашего подхода - в построении корреляционной
таблицы Rir, которая затем используется для перехода на
следующий уровень глубокого структурного обучения. Nevill-
Manning и Witten, 1997 использовали традиционный для
алгоритмов сжатия единичный порог для появления новых
структур, и нужды в построении такой матрицы не было.
Представление о тесной связи поведения с
предсказаниями также весьма популярно в нейросообществе (см. например
монографию [A. Clark, 2015]). В некоторых моделях
обучения с подкреплением было показано, что постоянные
внутренние подкрепления от правильных предсказаний,
дополняющие редкие внешние подкрепления, существенно ускоряют
обучение агентов поведению в виртуальных мирах [Dosovit-
skiy и Koltun, 2016; Jaderberg и др., 2016]. Мы использовали
эти идеи в разделе 6.5.4.
Дискретное кодирование многомерных векторных данных
широко применяется на практике. Например, случайное
кодирование в очень многомерных пространствах можно
использовать для представления и векторов, и их
последовательностей [Kanerva, 2009] - подход, использованный в НТМ. Кроме
того, известно, что такие коды могут очень эффективно
сжимать информацию [Aharon и др., 2006; Poultney и др., 2007;
Sprechmann и Sapiro, 2010]. Например, Faruqui и др., 2015 по-
232
НА ПУТИ К ИСКУССТВЕННОЙ ПСИХИКЕ
казали, что разреженное бинарное кодирование
семантических векторов обеспечивает не худшее качество семантики,
чем их исходное векторное представление. К подходу
раздела 6.5.5. наиболее близки модели дискретного разреженного
кодирования информации в неокортексе [Rinkus, 2010; Шум-
ский, 2015].
Заметим также, что модель эмпирического Байеса из
раздела 6.6.5. очень близка концепции иерархического предик-
тивного кодирования информации в неокортексе [Bastos и др.,
2012; Friston, 2005; Spratling, 2017]. Так что, предложенная в
этой работе модель обучения роботов, по всей видимости, в
какой-то мере отражает биологические механизмы обучения
в мозге.
Подведем итоги. В этой главе предложен новый подход к
глубокому обучению, основанный на дискретном
разреженном кодировании и относительно простом алгоритме
обучения в целых числах. Такой подход оказывается на порядки
более экономным, чем общепринятое сегодня обучение
глубоких нейросетей методом градиентной оптимизации. При этом,
наш подход также подразумевает построение иерархии все
более абстрактных признаков и их сочетаний, использующихся
для анализа и предсказания данных на разных временных
масштабах.
Более того, в едином ключе реализованы и
самообучение на больших массивах данных, и обучение с
подкреплением, позволяющие программным агентам и роботам
обучаться иерархическому целесообразному поведению, согласуя
паттерны своих действий с развитием внешней ситуации на
разных временных масштабах.
Глубокое структурное обучение на сегодня прошло
апробацию на примере обучения языку, о чем пойдет речь в
следующей главе. Его применение к обучению роботов и
программных агентов обсудим в главе 8.
"Поистине, это новое глубокое журчание и голос нового
источника!" - так говорил Заратустра.
Глава 7
Мозг и язык
Здесь прыгают ко мне
слова и раскрываются
ларчики слов всякого
бытия: здесь всякое бытие
хочет стать словом, здесь
всякое становление хочет
научиться у меня
говорить.
Слова твои всегда
должны иметь два, три,
четыре, пять смыслов!
Фридрих Ницше
«Так говорил Заратустра»
7.1. Смогут ли машины говорить?
Владение языком является важнейшим атрибутом
разумного мышления. Роботы и программные агенты не смогут
вписаться в нашу человеческую цивилизацию, не овладев им на
уровне человека. И в последние годы мы наблюдаем явные
успехи в этой области, например, в машинном переводе. Одна-
234
МОЗГ И ЯЗЫК
ко, пока что освоение языка на большем масштабе, за
пределами отдельных предложений, наталкивается на значительные
трудности. Создается впечатление, что современным моделям
языка "не хватает глубины".
В этой главе мы покажем, как глубокое структурное
обучение, описанное в предыдущей главе, может помочь в
освоении машинами человеческого языка. Здесь мы
ограничимся лишь моделью понимания языка, оставляя более сложную
проблему порождения языка на будущее (будем надеяться -
ближайшее).
Наш подход исходит из предположения, что
использование языка является частным случаем поведения, и что к нему
полностью приложимы все рассуждения предыдущей главы.
Соответственно, в этой главе мы представим модель
машинного обучения языку, использующую глубокое структурное
обучение, и приведем свои соображения о механизмах работы
языковых разделов коры головного мозга.
А именно, как мозг распознает и кодирует смыслы слов и
предложений? Какие участки мозга могут отвечать за
обучение правилам грамматики, а какие - за хранение смысловых
значений слов? Насколько велики эти области, как они
связаны между собой и как устроено их обучение?
Современное глубокое обучение позволяет кодировать
информационно емкие сенсорные образы гораздо более
компактными ментальными символами1.
Мышление включает в себя дальнейшие стадии обработки
этой абстрактной символьной информации. И язык,
отражающий работу мозга с символами, служит ключом к
пониманию принципов и архитектуры нашего мышления.
Собственно, именно профессиональный интерес автора к машинному
обучению языку и привел его к концепции глубокого
структурного обучения, как модели человеческого мышления.
1 Например, картинки из коллекции ImageNet занимают примерно
5 Мбит. Тогда как кодирование каждого из 1 000 классов объектов на
этих картинках требует лишь 10 бит (т.к. 210 « 1000). То есть
распознавание образов переводит образную информацию в символьную, сжимая
ее в сотни тысяч раз.
7.2. Родовые свойства, языка
235
В этой главе мы применим представления главы 5 о
механизмах работы неокортекса и, соответственно, теорию
глубокого структурного обучения главы 6 к проблеме обучения
языку. Как ни странно, описанная ниже биологически
обоснованная модель обучения языку оказывается на порядки
эффективнее современных state-of-the-art моделей языка,
основанных на градиентном глубоком обучении.
Изложение будет построено следующим образом.
Сначала мы очень бегло поговорим о человеческих языках с одной
единственной целью — понять, что их всех объединяет, что
в человеческом языке главное. Затем мы опишем, как общая
схема глубокого структурного обучения применяется для
обучения языку. В заключение мы представим соображения, как
такое обучение может быть реализовано в коре головного
мозга.
7.2. Родовые свойства языка
На Земле существует как минимум 6 000 различных языков,
а с учетом вымерших эта цифра перевалит за 10 000.
Разнообразие человеческих языков настолько велико, что во время
Второй мировой войны американцы использовали язык
племени навахо для передачи шифрованных сообщений, причем
японцы так и не смогли взломать этот "шифр" [Бейкер, 2008].
В различных языках используются разное число и
разные типы фонем. Не меньше отличий и на других уровнях —
строения слов и предложений. В некоторых языках,
например в финском, слова содержат так много значимых морфем,
что могут соответствовать целым предложениям на других
языках. Грамматика в разных языках может кодироваться в
разной степени как служебными словами, так и отдельными
частями слов. Грамматическая структура предложения
(субъект, объект, предикат) может быть произвольной или
фиксироваться, причем в разных языках по-разному.
236
МОЗГ И ЯЗЫК
В общем, на фоне всего этого многообразия не просто
выявить родовые черты, присущие всем без исключения языкам.
И все же такие черты существуют. Мы выделили две, на наш
взгляд, важнейшие, а именно - рекурсивностъ и
иерархичность, и положили их в основу концепции глубокого
структурного обучения.
В языке одни и те же рекурсивные конструкции, деревья,
наблюдаются снова и снова на разных уровнях обработки
информации. При этом во всех языках имеются два качественно
различных способа такой обработки. Мы называем их
морфологическим и семантическим. Первый касается выявления и
порождения грамматически правильных языковых
конструкций — написания слов и составления предложений. Второй —
выявления и использования смысловых значений этих
конструкций для описания реального мира. Перевод с одних
языков на другие возможен именно потому, что язык способен
кодировать реальные ситуации, создавать их абстрактные
ментальные модели.
Глубокое структурное обучение напоминает процесс
самосборки биологических белков - от первичных структур - ко
вторичным, третичным и т.д. Первичная структура - это
последовательность букв алфавита, вторичная - это слова,
третичная - короткие фразы, четвертичная - составленные из
них предложения, и так далее. На каждом уровне иерархии
последовательно выявляются два типа структур, за счет двух
типов сжатия информации (рис. 7.1):
1. морфологическое сжатие без потерь: представление
последовательностей символов более короткими
последовательностями типовых структур (морфем);
2. семантическое сжатие с потерями: представление
смыслового значения морфем кластерами в семантическом
пространстве, где близость смысловых значений морфем
определяется схожестью контекстов, в которых они
употребляются. Кластеры "базовых смыслов" образуют
новый алфавит символов следующего уровня иерархии.
7.2. Родовые свойства, языка
237
Глубокое структурное обучение
Рис. 7.1. Иерархия глубокого структурного обучения:
компактные алфавиты символов и объемные словари типовых
последовательностей символов - морфем
Эти два последовательных этапа сжатия информации
обеспечивают переход на следующий уровень описания данных,
где исходное сообщение кодируется уже новым
(семантическим) алфавитом. Мы можем повторять эти циклы снова и
снова, переходя ко все более абстрактному представлению
данных, соответствующему все более крупномасштабным
структурам языка: от слов - к фразам, предложениям, абзацам и
т.д.
Получаемые таким образом дискретные смысловые коды
для слов, фраз и предложений могут использоваться в
широком круге практических задач - семантического поиска,
ответов на вопросы, организации человеко-машинного диалога и
т.д. А в конечном итоге, для построения разговорного
интеллекта агентов и роботов.
Посмотрим теперь, как алгоритмы структурного обучения
работают на практике, т.е. как происходит обучение языку с
нуля без учителя.
238
МОЗГ И ЯЗЫК
7.3. Глубокое структурное обучение
языку
В этом разделе представлены результаты обучения языку
алгоритмами глубокого структурного обучения [Шумский, 2013].
Автор назвал эту модель Големом в честь знаменитого лемов-
ского Голема XIV [Лем, 2002]. Обучение Голема проводится
поэтапно: сначала он находит правила строения слов, затем -
словосочетаний, фраз и предложений. На каждом уровне
находятся дискретные коды языковых конструкций и
вероятности их сочетаний.
7.3.1. Морфология
Морфологическая память Голема хранит статистику всех
слияний морфем в процессе морфологического разбора слов в
ходе обучения. В словарь добавляются все новые и новые
морфемы, составленные из наиболее часто встречающихся
следующих друг за другом пар уже известных морфем. Такое
пополнение словаря приводит к максимально возможному
сжатию входного потока, что, согласно принципу минимальной
длины описания, соответствует оптимальной модели данных.
Таким образом у Голема формируется представление о
базовых кирпичиках языка и их частотном спектре.
Морфологический разбор происходит следующим образом:
слово читается слева направо, пока не находится первый
локальный максимум частоты слияния соседних морфем,
начиная с букв. Соответствующая пара заменяется на составную
морфему, и процесс повторяется вплоть до морфемы,
соответствующей всему данному слову2.
Качество обучения модели характеризуется величиной
Perplexity - мерой удивления модели следующему обрабатывае-
2 Предварительно весь текст переводится в нижний регистр,
имитируя слуховое восприятие речи. То есть Голем не различает заглавных
букв и учится определять именованные сущности "на слух" - по
контексту.
7.3. Глубокое структурное обучение языку
239
мому символу (чем Perplexity меньше, тем предсказательная
способность модели выше - см. раздел 6.1). Таблица 7.1
иллюстрирует снижение Perplexity с увеличением объема
просмотренной Големом выборки русскоязычных текстов.
Объем массива
(GB)
0.1
1.0
6.5
19.8
Perplexity
7.9
6.5
5.2
3.8
Information
(bit/symbol)
2.99
2.70
2.39
1.92
Таблица 7.1. Качество обученной в режиме online модели в
зависимости от объема просмотренной выборки
Как видим, морфологическое сжатие в нашей модели
языка достигает 2 бит на символ (в исходном текстах символы
могут кодироваться, например, 8 битами в стандарте KOI8). При
том, что человек в экспериментах угадывает произвольно
выбранную следующую букву примерно в 50% случаев, что
обеспечивает сжатие 1 бит/символ. Оставшийся бит "добирается"
на следующих стадиях обучения языку - синтаксической и
семантической (см. далее), когда Голем учится угадывать целые
слова по более широкому контексту.
После формирования морфологического словаря Голема
мы выделяем в нем два важных класса морфем: окончания
и основы (рис. 7.2). Например, в европейских языках
окончания обычно используются как синтаксические метки числа,
рода, времени и роли слова в предложении, тогда как основы
обычно несут семантическую нагрузку (ссказа-ла \ ссказа-ли',
'сказа-но').
Смысл выделения этих двух множеств - чтобы любое
слово, даже отсутствующее в словаре Голема, можно было
представить в виде пары (основа, окончание). Тем самым,
ограниченный словарь Голема не является более препятствием для
работы с неограниченным разнообразием слов.
240
МОЗГ И ЯЗЫК
На рис. 7.3 показаны примеры словоформ с одним и тем
же основанием и с одним и тем же окончанием с их
относительными частотами. Первый набор можно использовать для
т.н. стемминга, второй - как подспорье начинающим поэтам.
7.3.2. Синтаксический и семантические
алфавиты
Соответственно, в Големе мы строим не одно, а два
семантических пространства, которым соответствуют два алфавита
следующего уровня - собственно семантический,
определяющий смыслы слова, относящиеся к его основе, и
синтаксический, определяющий грамматический тип слова, зависящий
от его окончания (то, что обычно называют "part of speech"
- POS). Так как окончаний существенно меньше, чем основ,
РOS-пространство формируется значительно раньше и
позволяет находить структуру предложений задолго до
формирования SEM-пространства.
Действительно, грамматика обычно усваивается детьми
раньше, чем формируется их полный словарный запас. Это
помогает правильно находить роли слов в предложениях, т.е.
их контекст и, следовательно, облегчает формирование SEM-
пространства. Так, ориентируясь только на служебные слова
и окончания, мы можем понимать структуру и догадываться
о смысле предложений, даже если в них нет ни одного
знакомого нам слова (см. рис. 7.7).
В Големе POS-пространство используется для
синтаксического анализа предложений, т.е. для формирования
бинарного дерева все более сложных фраз, а SEM-пространство - для
кодирования смыслового содержания этих фраз.
Как мы уже не раз отмечали, представление значений слов
векторами семантического пространства избыточно.
Разреженное кодирование позволяет использовать гораздо более
компактные дискретные семантические коды. Рисунок 7.4
иллюстрирует качество дискретного кодирования значений слов
всего лишь тремя целыми числами - номерами ближайше-
7.3. Глубокое структурное обучение языку
241
Основы -> „105
Окончания ->
'103
~30
Алфавит ->
Упрощение: (2 морфемы из ~7)
Рис. 7.2. Представление слова двумя его самыми крупными
морфемами - основой и окончанием (морфологическое дерево
типичного русского слова содержит около 7 морфем)
Рис. 7.3. Слова с одинаковой основой и окончанием
242
МОЗГ И ЯЗЫК
го из 2 048 кластеров при кластеризации SEM-пространства с
тремя разными начальными условиями.
Рис. 7.4. Дискретное разреженное кодирование смысловых
значений слов. В данном примере каждое слово кодируется
тремя числами - символами из трех семантических
алфавитов, содержащих каждый по 2048 базовых смыслов. Чем
больше компонент семантического кода двух слов совпадает, тем
ближе их смысловые значения
Понимание семантики слов позволяет Голему играть в
различные ассоциативные игры, например называть слова,
ассоциирующиеся с каждым словом из заданной пары. Записи
одной из таких игровых сессий показаны на рис. 7.5.
7.3.3. Разбор предложений
Синтаксический и семантический алфавиты переводят
анализ текста на новый уровень: от последовательностей букв -
к последовательностям слов. Рассмотрим отдельно вопросы,
7.3. Глубокое структурное обучение языку
243
связанные с синтаксическим разбором предложений и
семантическим кодированием их смысла. В первом случае мы
используем более компактное и грубое POS-кодирование слов
для определения структуры предложения - построения
бинарных деревьев фраз. Аналогично тому, как мы ранее
находили морфологию слов, теперь мы находим "морфологию
предложений", т.е. проводим их синтаксический разбор.
Если морфологический блок Голема обучается
распознавать отдельные слова, как типичные комбинации морфем, то
синтаксический блок запоминает и затем распознает в текстах
типовые комбинации синтагм (деревьев с РOS-кодами в
качестве листьев). Основы и значения слов не играют заметной
роли в определении структуры предложения. Так, в
известном примере: Тлокал куздра шшеко бодланула бокра и кудря-
чигп бокренка' мы легко распознаем структуру предложения,
несмотря на то, что ни одно из его слов нам не известно. Это
обстоятельство обосновывает использование для
синтаксического разбора главным образом POS-кодов3.
Логика синтаксического разбора предложений аналогична
логике морфологического разбора слов (см. рис. 7.6).
Примеры синтаксического парсинга предложений Големом
приведены на рис. 7.7.
7.3.4. Кодирование значений фраз и
предложений
В ходе синтаксического разбора каждое предложение
разбивается на дерево вложенных друг в друга синтагм.
Следующим этапом является кодирование значений каждой из этих
синтагм. Если структура синтагм определяется главным
образом окончаниями, то значения синтагм определяются
основами образующих их слов, а точнее - их смысловыми
значениями, которые кодируются наборами SEM-кодов (см. рис. 7.8).
3 Для повышения точности парсинга Голем может дополнительно
использовать и SEM-коды.
244
МОЗГ И ЯЗЫК
Рис. 7.5. Игра в ассоциации с Големом. (Ответы Голема
вероятностные, т.е. могут не повторяться)
РЩЩ+1
[[Шла Саша] [по шоссе]] [и [сосала сушку]]
РЩЩ+1
[Шла Саша] [по шоссе] и [сосала сушку]
Рис. 7.6. Разбор предложений снизу-вверх путем слияния
наиболее сильно связанных друг с другом синтагм (PwtWj ~
вероятность слияния синтагм Wi, W})
7.3. Глубокое структурное обучение языку
245
Рис. 7.7. Примеры разбора предложений Големом (парсинг
2-го порядка, см. раздел 6.5.2.)
Рис. 7.8. Переход от уровня сочетания букв - к уровню
словосочетаний с помощью дискретных синтаксического и
семантического алфавитов
246
МОЗГ И ЯЗЫК
Семантическое сжатие кодирует смысловое значение
(основы) каждого слова S(w) = {Si,..., Sn} набором из N
чисел - номеров соответствующих семантических кластеров,
полученных в N различных кластеризациях семантического
пространства. Как иллюстрирует рис. 7.4, чем больше компонент
семантического кода двух слов совпадает, тем ближе их
смысловые значения.
Аналогично отдельным словам, свои смысловые коды
получают и словосочетания, можно назвать их смыслосочетани-
ями, определяемые как структуры W, построенные на N
базовых семантических алфавитах. Словарь смыслосочетаний
может содержать десятки миллионов тонко настроенных
смысловых маркеров, например физических лиц - политиков, как
это иллюстрирует рис. 7.9. Обученный Голем "понимает" и
типовые сценарии — кто делает что, когда и как, например —
прибывает в крупный столичный город. Аналогично, у Голе-
ма формируются отдельные понятия, например о люксовых
автомобильных брендах. Как и в случае со смысловыми
значениями слов, значения фраз тем ближе друг к другу, чем
больше компонент семантических кодов у них совпадает, что
можно использовать, например, в семантическом поиске.
Таким образом, обученный Голем автоматически
размечает тексты миллионами различных семантических кодов -
маркеров смыслов отдельных слов, словосочетаний и фраз.
Он пользуется своей собственной онтологией смыслов,
полученных в результате самостоятельного обучения - при чтении
и разборе больших текстовых массивов.
7.3.5. Семантический поиск
Очевидным примером практического применения
семантического кодирования является семантический поиск. Обычный
поисковик строит обратный индекс по лексическим
компонентам текста - словам и их основам. Соответственно, он не
понимает ни близости между синонимами, ни различия смыслов
одного и того же слова в разных контекстах. Например, слово
7.3. Глубокое структурное обучение языку
247
Рис. 7.9. Дискретное разреженное кодирование смысловых
значений фраз. Каждая фраза кодируется тремя числами -
номерами структур из семантического словаря, типовых
комбинаций базовых смыслов. Чем больше компонент
семантического кода двух фраз совпадает, тем ближе их смысловые
значения
248
МОЗГ И ЯЗЫК
с стекло' может быть как существительным, так и глаголом в
зависимости от контекста. Но в конкретном словосочетании,
например ''кварцевое стекло' или 'стекло в реку\ эта
многозначность в значительной степени пропадает.
Семантический поисковик призван преодолеть эти
врожденные недостатки лексического поиска за счет кодирования
смыслового содержания текста. Традиционное векторное
представление семантики слов и предложений (word2vec, sent2vec),
широко используемое на практике, имеет несколько
недостатков. Во-первых, семантические векторы, как правило, имеют
большое число малых компонент, т.е. векторное кодирование
очевидным образом избыточно и, следовательно, затратно в
плане вычислительных ресурсов. Во-вторых, и это важно,
поиск в высокоразмерном семантическом пространстве очень
затратен. Легко сравнить заданные смысловые векторы друг с
другом, но трудно решить обратную задачу - найти векторы
с близкими смыслами.
Разреженное дискретное кодирование смыслов лишено этих
недостатков. Во-первых, вместо обычных d ~ 103 компонент
семантического вектора, можно использовать N ~ Ю
элементов семантического словаря. Во-вторых, можно организовать
эффективный семантический поиск с помощью обратного
индекса по дискретным кодам семантического словаря.
Получаем поиск по ключевым смыслам, вполне аналогичный
обычному поиску по ключевым словам. Значит, семантический поиск
может быть таким же быстрым, как и обычный.
Семантический поисковик может использовать миллионы
смысловых категорий для поиска содержащих их фактов, не
используя априорных лингвистических знаний, без ручного
кодирования этих категорий и со скоростью обычного
лексического поиска!
Такие высокоуровневые понятия формируют достаточно
представительное признаковое пространство для различного
рода практических приложений, таких как анализ
тональности высказываний, выделение именованных сущностей,
распознавание ролей в диалогах и многих других.
7.4. Как мозг кодирует язык
249
7.3.6. Скорость обучения
Типичная скорость парсинга и обучения Голема на обычном
PC составляет около 2 ГБ/час. С учетом того, что глубокое
структурное обучение предполагает несколько этапов,
включая переход с обычного алфавита на семантический, уровня
понимания смысловых значений фраз Голем достигает
примерно через 16-24 часов обучения на массиве русскоязычной
Википедии (« 7 ГБ) в зависимости от параметров обучения.
Для сравнения, обучение нейросетевой модели языка на
корпусе сравнимого размера может занимать от 280 до 2 500
CPU-дней [Mikolov и др., 2013], т.е. обучение методом back-
propagation на порядки более затратно.
7.4. Как мозг кодирует язык
В этом разделе мы рассмотрим, как морфологические и
семантические структуры языка могут быть представлены в
мозге.
7.4.1. Модель "органа языка"
В разделе 7.2. мы установили, что все человеческие языки
объединяет одно родовое свойство: рекурсивная природа
языковых конструкций. Следовательно, в мозге существует какой-
то достаточно общий механизм, осуществляющий такую
рекурсию. Мы исходим из гипотезы, что таким механизмом
являются рекурсивные модули (см. раздел 6.4.)
Центральная часть модуля в процессе обучения
кластеризует множество своих входных сигналов, представляя их в
виде дискретных символов (в наших терминах - формирует
семантический алфавит). Периферийная часть модуля
кодирует типовые последовательности этих символов (в наших
терминах - формирует словарь морфем соответствующего
уровня). Иерархия рекурсивных модулей осуществляет глубокое
структурное обучение, в нашем случае - языку.
250
МОЗГ И ЯЗЫК
Описанной выше системе обучения языку Голема
соответствует модель "органа языка", изображенная на рис. 7.10.
Структура „ Значения
предложении предложений
Части речи
Значения слов
Структура
слов
Фонемы
Рис. 7.10, Модель "органа языка" Голема состоит из
нескольких рекурсивных корковых модулей. На нижнем уровне
распознаются типовые последовательности букв (морфемы).
Характерные последовательности морфем анализируются в
синтаксических и семантических модулях (специализирующихся
на разных типах морфем - окончаниях и основах.) Значения
слов и предложений кодируются несколькими
семантическими модулями (на рисунке изображены лишь два, для
краткости), так что семантическая область коры в мозге должна
занимать в несколько раз больше места, чем синтаксическая
Для оценки физических размеров языковых зон в коре
логично предположить, что рекурсивные модули соответствуют
корковым модулям размером ^0,3 см2 из раздела 5.5.,
растормаживаемым базальными ганглиями. Такой рекурсивный
модуль состоит предположительно из N ~ 10 гиперколонок,
содержащих каждая по К « 30 колонок (типичное число
символов в алфавите или фонем в языке), что вполне способно
7.4. Как мозг кодирует язык
251
обеспечить достаточное разнообразие разреженного
кодирования4.
Морфологический и синтаксический алфавиты (буквы и
части речи) достаточно компактны, и соответствующие им
области в мозге могут быть представлены одним или
несколькими рекурсивными модулями каждая. Однако базовый
семантический алфавит более обширный и может содержать
многие сотни "базовых смыслов", например, по числу базовых
иероглифов в китайском языке, которые, возможно, и
соответствуют семантическим кодам. Следовательно, семантическая
область мозга гораздо больше, чем фонетическая и
синтаксическая, и может содержать десятки рекурсивных модулей
общей площадью несколько см .
При этом у людей, владеющих несколькими языками,
семантика разных языков может кодироваться одними и теми
же семантическими модулями, получающими входные
сигналы от различных морфологических и синтаксических модулей
разных языков. Это объясняло бы хорошо известный факт,
что каждый следующий язык учится легче предыдущего.
Использование языка вписано в более высокие, надязы-
ковые уровни мышления, определяющие, например, логику
развития диалога и интенции субъекта в ходе общения. Все
эти уровни также требуют своего представительства в мозге.
Например, по всей видимости, более высокое, чем языковая
область Брока, место в иерархии занимает 10-е поле Брод-
мана — самое большое у человека (его относительный размер
вдвое больше, чем у аналогичной области шимпанзе)6. Понят-
Если принять, что в кодировании паттернов участвует хотя бы
половина гиперколонок модуля, т.е. число активных колонок п > 5,
разнообразие кодов
^ = (N*) > 2 • 1010 больше, чем число ментальных событий,
которые человек наблюдает за всю свою жизнь.
5 Что соответствует характерным размерам 264 функциональных
областей, выделенных Power, Cohen и др., 2011 (2 000 см2/264 « 7 см2).
6 Десятое поле Бродмана человека содержит в каждом полушарии по
250 млн нейронов, т.е. 25 тыс. колонок, что в наших предположениях
соответствует примерно 100 рекурсивным модулям.
252
МОЗГ И ЯЗЫК
но поэтому, что способность к речи у homo sapiens (или даже
у homo erectus, согласно Everett, 2017) действительно
потребовала существенного увеличения размера ассоциативной коры.
Но так ли важен язык, чтобы стать причиной столь
стремительного роста мозга у рода homo - втрое за два миллиона
лет? Оказывается, да. Чем больше объем памяти, т.е. площадь
неокортекса, тем больше полезных мемов (навыков, приемов,
хитростей) можно запомнить. И чем больше таких мемов
накопит сообщество, тем больше конкурентных преимуществ
будет у него по сравнению с соседями. А для эффективного
обмена мемами в сообществе, критически важно наличие
языка. А. Марков и М. Марков, 2019 исследовали совместную
биологическую (гены) и культурную (мемы) эволюцию рода
homo. В их компьютерной модели без наличия языка мозг
вырастал максимум в полтора раза, а с включением в модель
языка - втрое. Язык как способ передачи (сложных) мемов
включает положительную обратную связь: чем лучше
языковые способности, тем легче усваиваются мемы, и тем выгоднее
иметь большой мозг, что, в свою очередь, увеличивает
языковые способности. Так что, похоже, действительно, именно
язык, в основном, и "растягивал" неокортекс у наших предков.
Другим полезным для нас следствием изобретения языка
является увеличение продолжительности нашей жизни - вдвое,
согласно той же модели. И понятно почему - старики
являются хранителями накопленных за их длинную жизнь знаний,
наставниками для молодежи.
Известно, кроме того, что области мозга, связанные с
языком, активируются и при выполнении других сложных
действий, связанных с многоуровневым планированием. В
частности, изготовление довольно сложных орудий ашельской
культуры homo erectus, как было экспериментально показано Faisal
и др., 2010, активирует в том числе и зону Брока. Переход к
ашельской культуре (от более примитивной олдувайской
культуры homo habilis) как раз сопровождалось ростом размеров
мозга. Следовательно, гены, отвечающие за развитие языко-
7.4. Как мозг кодирует язык
253
вых областей мозга, одновременно способствовали и другим
потенциально полезным мемам. Однако главным орудием
человека является все-таки другой человек, способность
манипулировать его поведением, во многом обусловленная именно
языком.
7.4.2. Как язык представлен в мозге
Где именно в мозге могут располагаться описанные выше
языковые модули? Многочисленные экспериментальные данные
свидетельствуют, что в человеческом мозге есть
специфические зоны, работающие с языком, располагающиеся у
большинства людей в левой околовисочной области. Это
несколько попарно связанных областей, разделенных латеральной
бороздой. Считается, что передние части отвечают за синтез
речи, а задние - за распознавание. В нашей модели этим
областям соответствуют моторные и сенсорные разделы общей
иерархии рекурсивных модулей, ответственной за обучение
языку. Действительно, согласно данным Pulvermuller, 2013,
на каждом иерархическом уровне моторные и сенсорные
области работают совместно (одна - в зоне Брока, другая - в
зоне Вернике, см. рис. 7.11).
Логично предположить, что зонам коры, работающим с
фонемами, соответствует первый морфологический уровень
нашей модели. Следом за ним располагаются более высокие
уровни обработки - синтаксический и семантический.
Согласно Выготскому, следует различать значения слов
и их смыслы [Выготский, 2014]. Значения определяются
характером употребления слов в языке и более-менее
одинаковы для всех носителей языка со сходным языковым опытом.
Именно эти языковые зоны мы и имели в виду выше, когда
говорили о семантике. Смыслы же, по Выготскому, отражают
ассоциации слов не друг с другом, а с субъективными
сенсорными впечатлениями и эмоциональными переживаниями,
и определяются индивидуальным жизненным опытом
человека. Эти смысловые ассоциации рассредоточены по всей ас-
254
МОЗГ И ЯЗЫК
Рис. 7.11. Иерархия совместно функционирующих
языковых модулей в моторных и сенсорных разделах мозга. В
нашей модели зоны М1-А1 соответствуют морфологическим
модулям, РМ-АВ - синтаксическим, a PF-PB - семантическим
[Pulvermuller, 2013]
7.4. Как мозг кодирует язык
255
социативной коре и не ограничиваются собственно языковой
зоной. Образно говоря, язык - это лишь язык колокола-мозга.
На каждое слово гулом ассоциаций отвечает весь мозг (так, к
слову, и рождаются метафоры).
Недавно Huth и др., 2016 составили атлас таких
смысловых ассоциаций, подтвердив тем самым концепцию
Выготского экспериментально (см. рис. 7.12). Этот атлас наглядно
иллюстрирует, насколько глубоко наше мышление пронизано
языком. Желающие могут ознакомиться с этим
интерактивным атласом по ссылке http://gallantlab.org/huth2016. С
точностью, соответствующей одной гиперколонке нашей
модели, в нем показано, какие области коры и как сильно
откликаются на 10 000 наиболее употребительных слов английского
языка. В деталях эти смысловые ассоциации у разных
испытуемых разные, но по-крупному они имеют между собой
много общего: различные типы слов у них располагаются в одних
и тех же областях мозга. Причем, в соответствии с нашей
моделью, на каждое слово откликаются не один, а несколько
модулей коры7.
Подытоживая этот раздел, предположительную схему
расположения гипотетических рекурсивных модулей в мозге
иллюстрирует рис. 7.13. Их обучение происходит поэтапно.
Согласно нашей теории, иерархия языковых модулей
строится снизу вверх, уровень за уровнем. Именно так и
происходит развитие ребенка. Морфемы родного языка, как уже
говорилось, начинают распознаваться мозгом ребенка начиная с
8-месячного возраста. Примерно с года, когда дети переходят
от отдельных слов к использованию словосочетаний, они еще
не различают грамматических правил. Словосочетания
употребляются как комбинированные слова. С полутора лет
дети начинают использовать простейшие паттерны: например:
'дай ... \ 'еще ... ;, которые потом переходят в т.н.
глагольные острова. Дети в этот период говорят короткими фразами,
7 Для быстрого знакомства достаточно посмотреть ролик https: //
www.youtube.com/watch?v=k61nJkx5aDQ, он того стоит!
256
МОЗГ И ЯЗЫК
Рис. 7.12. Атлас смысловых ассоциаций 10 000 слов
английского языка [Huth и др., 2016]
7.4. Как мозг кодирует язык 257
Семантика (смыслы)
Семантика (значения)
Синтаксис
Морфология
Рис. 7.13. Возможное расположение различных языковых
модулей в мозге
их внимание ограничено небольшим временным диапазоном.
Но в возрасте 2,5-3 лет у ребенка наблюдается
грамматический взрыв, и он начинает правильно строить предложения (у
него формируется РOS-алфавит?). К началу школьного
возраста ребенок осваивает связки между отдельными
предложениями, с использованием частиц схотя\ 'конечно' и других.
В этом же возрасте он начинает использовать язык как
подспорье для мышления, как инструмент планирования своих
действий (с помощью SEM-алфавита?) [Бурлак, 2018].
Процесс освоения языка ребенком демонстрирует, как мозг
последовательно осваивает все новые иерархические уровни
планирования и организации своих действий. Такая
последовательность глубокого обучения логически неизбежна, т.к.
накопление обучающей выборки для все более высоких
иерархических уровней требует все больше времени. Самые высокие
258
МОЗГ И ЯЗЫК
этажи символьного мышления "созревают" (миелинизируют-
ся) лишь годам к 20 8.
В отличие от человека, количество уровней мышления у
обучающихся машин не ограничено ничем, кроме объемов
данных и возможностей hardware. И то, и другое сегодня в
избытке. Поэтому не трудно представить себе будущие
сверхинтеллекты в мощных датацентрах, сканирующие все научные
публикации на разных языках и извлекающие из них все более
и более глубокие знания. Настолько глубокие, что они могут
стать недоступными для понимания людей. Но если с этими
сверхинтеллектами можно будет разговаривать на
человеческом языке, они смогут обосновывать свои выводы или хотя
бы метафорически объяснять их, подобно Голему XIV. Лем,
2002 приводит любопытные протоколы подобного рода бесед.
7.5. Обсуждение
В заключение, как водится, обсудим идеи, затронутые в этой
главе, в их историческом контексте. Как развивались
отношения между лингвистикой, машинным обучением и науками о
мозге?
В 60-х гг. XX в. лингвисты с подачи Ноама Хомского
определили язык как систему правил, порождающих
грамматически правильные высказывания. Эти правила имеют
логическую, а не статистическую природу: редкие словосочетания
должны следовать тем же правилам, что и частые. Эта
парадигма противоречит духу машинного обучения, основанного
на статистических закономерностях в данных, что, по мнению
автора, и определило трудную судьбу машинного обучения
языку.
8 При одинаковом размере обучающей выборки время обучения
растет пропорционально длине временных паттернов. Отдельными словами
ребенок начинает пользоваться в 1 год, овладение короткими фразами
требует 2-3 лет, а полное освоение возможностей языка требует 20-25 лет,
пропорционально типичной длине предложений.
7.5. Обсуждение
259
Специалисты по машинному обучению занялись языком,
когда область была уже "размежевана" и изрядно "распахана"
лингвистами. Чтобы воспользоваться имеющимися
результатами, они переняли из лингвистики ее базовые установки и
подходы к решению практических задач [Jurafsky и J. Martin,
2014].
В итоге долгое время в области Natural Language Processing
господствовали методики обучения "с учителем", в качестве
которого использовались созданные лингвистами словари и
размеченные ими же текстовые корпуса с десятками тысяч
примеров правильного синтаксического разбора предложений.
Машинное обучение использовалось для поиска заветной
системы правил, определяющих грамматику, в формате,
заданном лингвистами-теоретиками, и используя заданные ими же
грамматические категории слов [Klein и Manning, 2004].
Алгоритмы поиска системы грамматических правил с
неизбежными многочисленными исключениями оказываются
довольно громоздкими, а обучение предполагает наличие
дорогих корпусов. Как результат, скорость лучших парсеров,
разбирающих предложения по заданным лингвистами лекалам,
в 2000-х составляла десятки предложений в секунду (порядка
10 МБ/час) [Ножов, 2003].
Такая скорость синтаксической разметки текстов на три с
половиной порядка ниже скорости индексации текстов
обычными поисковиками (около 10 МБ/с). Этот барьер долгое
время ограничивал практическое использование компьютерной
лингвистики. При таких скоростях ни о каком семантическом
анализе в масштабах Сети не могло быть и речи.
Практические применения машинного обучения до
недавнего времени ограничивались простейшими моделями
языка, не предполагавшими выявления глубоких языковых
конструкций. Именно такие модели (например, модель "корзины
слов" [Salton и др., 1975] или n-грамм [Brown и др., 1992])
использовались поисковиками для автоматической сортировки
текстов по тематикам, поиска с использованием синонимов и
формирования подсказок в поисковой строке.
260
МОЗГ И ЯЗЫК
Однако в последние годы усилилось стремление к более
глубокому анализу содержания Сети. В результате
коллективных усилий скорость парсинга удалось увеличить до 1 000
предложений в секунду [Volokh и Neumann, 2012] без существенной
потери качества. Однако все эти достижения по-прежнему
основывались на размеченных лингвистами корпусах,
доступных лишь для нескольких языков и, в основном, в жанре
газетных публикаций. Специфика богатых самыми разными
терминами научных публикаций и полных неологизмами
разговорных стилей блогосферы остается за рамками этих
обучающих выборок.
Обучение "без учителя", которое не предполагает
использование накопленного лингвистического багажа, проникало в
эту область с большим трудом. Во-первых, оно
наталкивалось на естественное сопротивление всего лингвистического
сообщества. А во-вторых, первые попытки обучения языку "с
нуля" показывали существенно худшие, чем достигнутые ас
учителем" результаты. Бытовало мнение, что языковые
конструкции слишком сложны, чтобы их можно было выявить
автоматически, без участия лингвистов. Однако вместе с
успехами революции глубокого обучения росло убеждение, что
источником лингвистических правил является в конечном итоге
живой язык, и подход к языку "снизу вверх", от данных к
правилам, имеет не меньше оснований, чем традиционный подход
"сверху вниз", с позиций теории. В конце концов, дети-то ведь
учат язык не по учебникам грамматики! Почему бы и
машинному обучению не пойти таким же путем?
Быть может, мозг и не знает никакой жесткой системы
правил, а просто постепенно усваивает наиболее
распространенные в языке шаблоны построения слов и предложений?
Сторонники такой точки зрения призывают отойти от
трактовки языка как формальной системы правил в пользу
изучения реальных механизмов освоения языка детьми.
Хомский и его последователи считают, что у человека в
мозгу существует специфический орган для символьных one-
7.5. Обсуждение
261
раций и рассматривают язык как инстинкт, присущий
исключительно человеку [Chomsky, 1986; Hauser и др., 2002; Pinker,
2003]. Их оппоненты, например Tomasello, 2009, полагают, что
язык, напротив, использует базовые способности мозга
запоминать и распознавать во внешнем мире повторяющиеся
паттерны. Этой же точки зрения, понятно, придерживается и
автор.
Язык эволюционирует гораздо быстрее, чем мозг. Датский
и английский языки разошлись совсем недавно - какую-то
тысячу лет назад и, тем не менее, это уже разные языки.
Поэтому язык, эволюционируя, должен был очень хорошо
приспособиться к мозгу. Подобно компьютерному вирусу, язык
"взломал операционную систему мозга", и с тех пор они живут
в симбиозе. Именно этим Deacon, 1998 объясняет
поразительное сходство всех языков, которое и привело Хомского к его
идее врожденной Универсальной грамматики.
"Что категории языка говорят о мышлении?" Этот вопрос
Лакофф, 2017 вынес в подзаголовок своей замечательной
книги. Полемизируя с Хомским, считающим грамматику
независимой от остального объема знаний, он доказывает, что язык
использует общий понятийный аппарат мозга: "Рассуждение
на основе типичных случаев является одним из важнейших
аспектов человеческого мышления". Наше мышление
основано на прототипах. Мы классифицируем мир не по
формальным правилам, а по близости к соответствующему прототипу
по совокупности черт.
Бывший ученик Хомского Jackendoff, 2007 тоже не считает
синтаксис центральной компонентой языка и приводит веские
аргументы, что все три подсистемы языка (фонология,
синтаксис и семантика) активно взаимодействуют между собой.
Ключевым вопросом когнитивных наук он считает
определение ментальных структур, стоящих за этими подсистемами, и
интерфейсов между ними. Именно такой подход мы
использовали в этой главе. Мы последовательно стремились
определить структуру и функции подсистем, вовлеченных в работу
с языком, а также интерфейсы между ними.
262
МОЗГ И ЯЗЫК
Приняв рекурсивные самоорганизующиеся карты в
качестве модели ассоциативных разделов коры, мы полагаем, что
и работа языка, и человеческое мышление в целом
действительно основаны на прототипах. И наша модель показывает,
как именно эти прототипы формируются в процессе освоения
языка. По мысли автора, именно алгоритмы глубокого
структурного обучения лежат в основе нашей языковой
компетенции. Не надо искать систему логических правил там, где ее
нет.
Созданный на базе этих представлений Голем может
использоваться в практических приложениях. Например,
автором был разработан семантический поисковый движок,
использующий индексацию смысла предложений для поиска и
сбора фактов по любому вопросу.
Голем достаточно быстро учится и разбирает
предложения со скоростью лучших описанных в литературе парсеров.
При этом, в отличие от последних, он не использует никаких
лингвистических баз данных, словарей или корпусов. Имея
доступ к большим текстовым массивам, он может выучить
любой язык и освоить научный жаргон любой области знаний,
постоянно наращивая свою компетенцию по мере обучения.
Знания, накопленные лингвистикой, использовались нами
неявно, в привязке к механизмам работы коры головного
мозга. В результате алгоритмы Голема не обладают
избыточностью, характерной для моделей языка, созданных "из первых
принципов" [Collobert и др., 2011]. Если в модель не заложить
правильную архитектуру обработки данных, то для ее
обучения могут понадобиться слишком большие вычислительные
ресурсы. В этом и состоит практическая ценность
моделирования языковой компетенции человека.
Напоследок поговорим о том, чем машинное обучение
языку может помочь созданию по-настоящему интеллектуальных
машин. Или, если зайти с другой стороны, чего не хватает
нынешнему Голему, чтобы его можно было считать
интеллектуальным?
7.5. Обсуждение
263
Для этого Голему не хватает, как минимум, трех вещей:
способности говорить, желания что-то сказать, и содержания
самого сообщения.
По порядку. Чтобы еще больше приблизиться к способу
усвоения языка ребенком, в алгоритм обучения должен быть
встроен соответствующий инстинкт, нацеленный на
порождение речи. Обучение должно с самого начала содержать петлю
обратной связи: услышал - понял - воспроизвел, тогда как до
сих пор обучение Голема было нацелено лишь на понимание
языка.
Но общая схема глубокого обучения с подкреплением как
раз и обеспечивает такой деятельностный подход к освоению
языка. В конце концов, язык - это инструмент активной
коммуникации. А в основе любой коммуникации лежит некая
цель. Чтобы что-то сказать, надо иметь потребность что-то
сообщить. Мало уметь говорить, надо еще знать, что ты хочешь
сказать. Коммуникация сама должна быть этапом
достижения какой-то цели. То есть Го л ем должен научиться ставить
себе свои собственные цели и вырабатывать планы их
достижения.
И здесь мы подходим к ключевому моменту - связи языка
с внешним миром. Мозг - это гигантский контроллер нашего
поведения в мире. Язык - это лишь его подсистема,
помогающая нам участвовать в коллективной деятельности людей.
Поэтому язык невозможно освоить вне рамок этой
коллективной деятельности. Не будет говорящих машин, пока они
не станут роботами, чувствующими и действующими в
реальном мире вместе с людьми. Как говорил Заратустра: "Что-то
неутолённое, неутолимое есть во мне; оно хочет говорить".
Сегодняшний Го л ем еще очень далек от этого.
Об этом, и о много другом поведает в своих лекциях в
2029 г. его гениальный потомок - Голем-XIV...
Глава 8
Направления развития
Спутников ищет
созидающий и тех, кто
собирал бы с ним жатву:
ибо всё созрело у него для
жатвы. Но недостаёт ему
сотни серпов
К созидающим, к
собирающим жатву и
празднующим хочу я
присоединиться: радугу
хочу показать им и все
ступени к сверхчеловеку
Теперь весы в равновесии
и неподвижны: три
тяжёлых вопроса я бросил
на них, три тяжёлых
ответа несёт другая чаша
весов.
Фридрих Ницше
«Так говорил Заратустра»
266
НАПРАВЛЕНИЯ РАЗВИТИЯ
Эта глава в каком-то смысле — ключевая, ради нее эта
книга и задумывалась. До сих пор каждая глава начиналась
с постановки вопросов, на которые мы далее находили ответы.
Естественно, не окончательные, зачастую спорные, но все же -
ответы.
В этой главе мы обсудим вопросы, на которые у автора,
да и не только у него, пока ответов нет. Речь пойдет о
перспективных направлениях развития машинного интеллекта.
Мы сформулируем эти вопросы в форме трех проектов,
сложных и рискованных, но, с точки зрения автора, осуществимых
при данном уровне развития технологий. По крайней мере,
все предыдущее изложение должно было подвести читателя
к этой точке зрения.
Это будут амбициозные прорывные проекты с большим
коммерческим потенциалом, основанные на создании новых
технологий, проекты, о которых шла речь в главе 2 и в
которых автор сам с удовольствием принял бы участие, если
соберется подходящая "звездная" команда. В некотором смысле,
эту книгу можно рассматривать, как своего рода призыв к
формированию таких команд.
Предлагаемые здесь три проекта являются развитием идей
трех предыдущих глав, вариантами их практической
реализации. Каждую из них можно рассматривать, как
альпинистскую подготовку к штурму серьезной горной вершины —
прокладку маршрута и организацию промежуточных стоянок.
Изложенные далее замыслы проектов — тоже необходимый
этап этой предварительной работы. Итак, приступим...
8.1. Действующая модель мозга
8.1.1. Проблема: как работает наш мозг?
Ричард Фейнман как-то заметил: "Чего не могу воссоздать,
того не понимаю"1. С этой точки зрения мы до сих пор не
1 Л.Д. Ландау выражал ту же мысль по-своему: он делил все науки
на естественные и неестественные приблизительно по тому же
признаку — наличию предсказательных моделей.
8.1. Действующая модель мозга
267
понимаем, как работает наш мозг, как устроена человеческая
психика и как одно связано с другим.
Существующие в нейронауках (computational neuroscience)
модели не дают ответа на этот фундаментальной вопрос. Мы
многое знаем о том, как работают отдельные нейроны, как
между ними передаются сигналы, можем моделировать
достаточно большие ансамбли искусственных нейросетей с
миллионами нейронов [Izhikevich и Edelman, 2008]. В результате
масштабного европейского проекта Human Brain Project была
создана действующая модель кусочка неокортекса с
реалистичным составом нейронов и структурой связей между ними
[Markram и др., 2015].
Однако на сегодня не существует даже приблизительной
действующей модели мозга как целостной системы, способной
обучаться сложному целенаправленному поведению. А понять
мозг в отрыве от этой его главной функции невозможно.
Чтобы понять, как физическое связано с психическим, необходим
новый подход к мозгу — с позиций теории машинного
обучения. Физикалистские модели здесь не помогут, т.к. в физике
отсутствуют понятия цели и целенаправленного поведения,
базовые для машинного обучения. Более конструктивный, с
нашей точки зрения, подход - моделирование
крупномасштабной когнитивной архитектуры в духе Eliasmith и др., 2012 и
Laird и др., 2017, только в более реалистичном варианте.
Собственно, предлагаемый проект призван ни много ни
мало, как решить фундаментальную проблему о связи мозга и
мышления, построив действующую биологически
обоснованную принципиальную модель мозга, обладающую свойствами
искусственной психики.
К.В. Анохин в последние годы последовательно
продвигает схожую исследовательскую программу на основе
предложенной им концепции когнитпома [Анохин, 2014, 2018а,Ь].
Предлагаемый проект можно считать развитием этих идей с
позиций машинного обучения. Глубокое структурное обучение
главы 6 можно рассматривать как построение когнитпома, где
268
НАПРАВЛЕНИЯ РАЗВИТИЯ
символы и морфемы разного уровня соответствуют разным
типам когов, предложенных К.В. Анохиным, и образуют сеть
динамических понятий поверх статичной сети связей (коннек-
тома нейросети)2.
Понятно, что для начала это будет простейшая психика
"маленькой зверюшки в большом мире"3, с простейшим
мозгом. Хорошей начальной точкой может стать, например,
системный анализ многоуровневого контроля поведения в мозге
грызунов [Verschure и др., 2014]. Важно только, чтобы
моделировалась архитектура мозга млекопитающих, чтобы
постепенным усложнением мы могли довести модель до уровня
приматов и, в конечном итоге, человека.
8.1.2. Актуальность: продление жизни мозга
Кому может понадобиться такая модель? Или, точнее, кто
может стать "заказчиком" такого проекта?
Вечные вопросы о связи души и тела, конечно, издавна
волновали философов и вслед за ними — психологов и
психиатров, но они никогда не предъявляли адекватный
проблеме платежеспособный спрос. Однако, похоже, что сегодня
спрос на модель искусственной психики уже сформировался.
На лечение нервных и нейродегенеративных заболеваний
приходится существенная доля расходов здравоохранения
развитых стран со все более стареющим населением. А можем ли
мы эффективно лечить заболевания мозга, не понимания,
какие именно нарушения в его работе являются их причинами,
т.е. без понимания механизмов работы мозга, не имея
принципиальной схемы его конструкции?
С другой стороны, набирает силу индустрия
искусственного интеллекта — агентов и роботов, основной производи-
2 Если воспользоваться шахматной аналогией, создание действующих
моделей когнитома аналогично постижению искусства шахматной игры -
естественный следующий шаг после усвоения правил игры.
3 Так в свое время формулировал задачу советский кибернетик
М.Л. Цетлин
8.1. Действующая модель мозга
269
тельной силы нового технологического уклада. Современные
технологии узкого ИИ способны заменять
низкоквалифицированный "частичный труд". Для тотальной автоматизации,
полноценной замены человека агентами и роботами,
необходим сильный ИИ, иными словами, искусственная психика
роботов. Моделирование человеческой психики является одним
из подходов к созданию сильного ИИ. Действующая
функциональная модель мозга, безусловно, поможет созданию
операционной системы роботов, нашего следующего проекта.
Эти два проекта являются комплементарными,
способными генерировать прорывные идеи друг для друга, но это все-
таки разные проекты с разными по составу компетенций
командами, каждый со своими целевыми установками,
стратегией и заказчиками (см. ниже).
Однако взаимодействие команд на уровне обсуждения
достигнутых результатов и мозговых штурмов ключевых
проблем может быть весьма плодотворным. На пересечении этих
проектов будут вырабатываться концепции и язык новой
науки о разуме, со своим математическим аппаратом и
компьютерными моделями мышления, подвергающими
экспериментальной проверке различные теоретические построения.
8.1.3. Решение: действующие модели мозга
млекопитающих
Результатом проекта должна стать линейка усложняющихся
моделей мозга, отвечающая разным стадиям развития мозга
млекопитающих. Эволюционный подход поможет понять,
какие биологические задачи и как именно решались в ходе
эволюции мозга, проследить генезис основных функциональных
подсистем. Он предлагает методологию понимания мышления
от простого к сложному. "Ничто в биологии не имеет смысла
кроме как в свете эволюции" — Ф.Г. Добржанский.
Важно, чтобы все модели с самого начала были
действующими, т.е. осуществляли целесообразное поведение, обладая
270
НАПРАВЛЕНИЯ РАЗВИТИЯ
определенным репертуаром сценариев решения разных
жизненных задач. Способность переключаться с задачи на задачу
и концентрироваться на достижении локальных целей должна
быть встроена в архитектуру искусственной психики. Иными
словами, в этой архитектуре должна найти свое воплощение
концепция функциональных систем П.К. Анохина,
методология моделирования мозга как контроллера целесообразного
поведения.
"Конструкторская документация" мозга как сложного
электронного прибора должна содержать несколько уровней
описания. Архитектурный уровень проясняет роль каждой
подсистемы мозга в контексте ее связей с другими
подсистемами. Глава 5 предлагает набросок такой архитектуры,
объясняет роль некоторых крупных подсистем мозга, принципы их
работы и взаимодействия друг с другом. Но это пока что
не более, чем набросок. Все должно быть воплощено в
действующие модели всех основных подсистем, собранных в
единую компьютерную модель на следующем, функциональном,
уровне описания. Каждая подсистема мозга является своего
рода техзаданием на разработку соответствующего модуля
компьютерной модели. Различные группы могут
сосредоточиться на моделировании различных подсистем, а модель
позволит объединить их результаты в единое целое. Проект
призван использовать тот факт, что природа уже позаботилась о
декомпозиции сложной системы в набор более простых
подсистем и нашла для них соответствующие конструкции.
Последние описываются более подробными принципиальными
схемами - алгоритмами работы отдельных компонент
искусственного мозга, имеющих свои биологические прототипы. Это
основной уровень современной computational neuroscience.
Наконец, экспериментальная нейробиология сосредоточена пока
на самом нижнем уровне монтажных схем, описывающих
физическое устройство мозга, например, его коннектом.
Действующие модели мозга можно будет использовать для
поведенческих экспериментов с различными вариантами ис-
8.1. Действующая модель мозга
271
кусственной психики и сравнивать эти результаты с
реальными экспериментами над животными. Собственно, с
момента создания первого варианта искусственной психики наука о
мышлении перестанет быть спекулятивной и приобретет
статус естественной науки, способной экспериментально
проверять свои теоретические построения.
8.1.4. Бизнес: лечение и апгрейд мозга
По замыслу автора, оба проекта, моделирование мозга и
создание операционной системы для роботов, должны
развиваться параллельно, взаимно обогащая друг друга идеями. В
этом случае вложения в "биологический" проект с лихвой
окупятся коммерческим успехом проекта "системного".
Продолжая альпинистскую метафору, речь идет о покорении двойной
вершины, Эльбруса сильного ИИ.
Однако у "биологического" проекта должны быть свои
собственные пути монетизации результатов, обусловленные его
спецификой. Например, в той же медицине компьютерная
модель мозга, позволяющая моделировать механизмы
различных дисфункций, сможет помочь находить новые мишени для
фармакологических препаратов.
Но еще более захватывающие перспективы для бизнеса
открываются в зарождающейся сегодня индустрии нейроим-
плантов. Не даром же И л он Маек, известный своими
инвестициями в амбициозные проекты с большим коммерческим
потенциалом, в 2016 г. основал стартап NeuraLink для
разработки нейроимплантов. Причем не только для лечебных
целей. В перспективе нас ожидают нейроимпланты для
усиления и расширения возможностей человеческого мозга. Вряд
ли будущее молодое поколение откажется от нейрочипов
постоянного подключения к интернету, с мгновенным доступом
ко всем человеческим знаниям и возможностью
"телепатического" общения друг с другом и с роботами.
Киборгизация может стать новым массовым рынком,
превосходящим нынешний рынок смартфонов (около $500 млрд,
272
НАПРАВЛЕНИЯ РАЗВИТИЯ
что, кстати, превышает прибавочный продукт всей мировой
Фарминдустрии [IFPMA, 2017]). Здесь, скорее всего, и
следует искать заказчиков действующей модели мозга.
8.2. Операционная система роботов
8.2.1. Проблема: как сделать роботы
доступными?
В 1964 году фирма IBM анонсировала революционную
линейку компьютеров IBM System/360, где впервые была
реализована идея четкого разделения архитектуры и ее реализации,
т.е. идея операционной системы, позволяющей разработчикам
софта отвлечься от конкретного "железа", на котором тот
будет исполняться.
Роботы являются особым видом компьютерного "железа",
несомненно, нуждающегося в своей собственной
операционной системе. Ведь роботов будет очень много и очень разных,
и гораздо удобнее будет иметь для них одну общую
программную платформу - операционную систему роботов, своего
рода искусственную психику, основанную не на
программировании, а на обучении, конкретнее - на обучении с
подкреплением.
Это самый сложный вид обучения, в котором роботы
должны сами угадывать, как им поступать в той или иной
ситуации, и предлагать творческие решения поставленных перед
ними задач, ориентируясь на оценку своего поведения
людьми или окружением. Создание такой искусственной психики
будет не под силу будущим малым и средним компаниям -
производителям роботов. Доступная им всем единая
операционная система радикально удешевит разработку разных типов
роботов и подстегнет развитие робототехники.
Если архитектура мозга роботов будет одной и той же, то
их возможности будут ограничены лишь мощностью аппарат-
8.2. Операционная система роботов
273
ной части. Как и в случае со смартфонами, базовые функции
будут исполняться на борту, а различные расширения
смогут при необходимости подгружаться от облачных
суперинтеллектов. Поэтому имеет смысл, чтобы новая операционная
система была модульной, чтобы роботы могли обмениваться
знаниями, т.е. обученными модулями.
8.2.2. Актуальность: кто станет новой Microsoft?
Сообщество разработчиков любой операционной системы
является системой с положительной обратной связью: чем оно
больше, тем привлекательней для новых участников. В
результате, рынок операционных систем достается горстке
победителей, оказавшихся ав нужное время в нужном месте".
Так в свое время случилось с Microsoft, захватившей только
что возникший рынок ПО для персональных компьютеров.
Эта история с неизбежностью повторится и с роботами.
Тот, кто первый предложит соответствующую операционную
систему, позволяющую разработчикам в единой манере
настраивать роботов разных конструкций на решение широкого
круга прикладных задач, получит стратегическое
преимущество и шанс сформировать собственную экосистему и
монополизировать этот гигантский в перспективе рынок.
Идея данного проекта — стать первыми, кто сумеет
создать искусственную психику роботов методом обратного
конструирования архитектуры мозга. Речь идет именно о
заимствовании архитектуры, очищенной от всех биологических
артефактов, что и отличает этот проект от предыдущего.
8.2.3. Решение: иерархическое модульное
обучение с подкреплением
Создание искусственной психики является естественным
следующим этапом развития революции глубокого обучения. К
такому выводу мы пришли в главе 4, а в главе 6 был предло-
274
НАПРАВЛЕНИЯ РАЗВИТИЯ
жен подход к решению этой задачи, использующий
характерные черты архитектуры мозга.
Этот подход и предлагается положить в основу данного
проекта, т.к. он эффективно реализует глубокое обучение с
подкреплением, позволяющее роботам обучаться достаточно
сложным задачам с большим горизонтом планирования.
Важно, что какая-то базовая технология и замысел реализации
проекта уже имеются, т.е. это не просто мечты, а именно
проект.
Разумеется, это только начало, и основная работа еще
впереди. Например, наделение роботов эмоциями и способностью
общаться на естественных языках. Ведь в конечном итоге
победит та операционная система, которая обеспечит наиболее
простые и естественные для человека способы обучения
роботов различным человеческим профессиям.
Успех операционной системы будет определяться ее
пользователями, а именно:
• разработчиками конкретных типов роботов,
осваивающих всевозможные профессии в самых разных индустри-
ях, от бесконечно преданного робота-сиделки до
бесконечно трудолюбивого робота-садовода;
• конечными пользователями робота, которые должны
будут объяснять ему его текущие задания и обязанности,
а также оценивать качество его работы.
Хорошая операционная система должна будет обеспечить
комфортный интерфейс этих групп пользователей с роботами
и между собой.
Идеальное решение для разработчиков роботов выглядит
следующим образом. Они получают (даром!) готовую
искусственную психику робота с необходимым набором базовых
навыков и встраивают в нее дополнительные модули,
необходимые для конкретной профессии. Какие-то функции надо
будет запрограммировать, аналогично безусловным
врожденным рефлексам. Каким-то базовым профессиональным
навыкам робота надо будет обучить, аналогично дрессировке,
8.2. Операционная система роботов
275
формирующей поверх врожденных рефлексов иерархию
приобретенных условных рефлексов, чтобы потребители
получали за свои деньги роботов-профессионалов. Соответственно,
операционная система должна максимально облегчить работу
этих программистов и учителей-наставников, т.е.
искусственная психика должна легко модифицироваться и быстро
обучаться.
Наставниками, по идее, будут те самые люди, которых
робот должен будет заменить, подобно тому, как мастер
передает секреты своей профессии ученику перед выходом на
заслуженный отдых. Чтобы преодолеть возникающий конфликт
интересов, знания наставника должны продолжать работать
на него в теле робота (см. ниже).
Для конечных пользователей важно, чтобы они могли
легко "объяснить" роботу, что от него в данный момент
требуется, и чтобы их оценки качества его работы влияли на его
поведение в будущем, т.е. чтобы робота можно было воспитывать
(например, рублем).
То есть успех проекта будет зависеть не только от
разработанных технологий, но и от бизнес-модели использования
новой операционной системы. Возможно, например,
следующее решение, выработанное совместно инициативной
командой проекта, включая автора.
8.2.4. Бизнес: зарплатные схемы для роботов
Что если встроить в операционную систему робота
электронный кошелек, пополнение которого будет для робота
подкрепляющим сигналом, т.е. будет влиять на его искусственную
психику подобно выбросам допамина в мозге. Тогда
воспитание робота будет жестко привязано к степени
удовлетворения пользователя его работой. То есть робот будет так
выстраивать свое поведение, чтобы максимизировать свой
интегральный заработок, одновременно постоянно улучшая
качество своих услуг.
276
НАПРАВЛЕНИЯ РАЗВИТИЯ
Чтобы интересы пользователей и производителей
совпадали, логично, чтобы заработок роботов шел производителям
(включая тех же наставников). Это возможно, например, если
потребители покупают не самих роботов, а только их услуги,
оплачивая результаты их труда, как если бы те были
наемными работниками. Такая бизнес-модель, во-первых, всем
интуитивно понятна, и, во-вторых, позволяет потребителям легко
сравнивать между собой цену и качество услуг робота по
сравнению с аналогичными услугами профессионалов - людей.
Наконец, в такой бизнес-модели мы можем грубо, на
пальцах, оценить перспективы нашего проекта. Допустим,
тотальная автоматизация экономики, при которой основная доля
мирового ВВП будет производиться роботами, займет примерно
100 лет и будет происходить постепенно, по 0,5% ВВП в год (с
момента создания операционной системы роботов, без которой
такое трудно себе представить). Это означает, что суммарный
заработок роботов будет увеличиваться ежегодно примерно
на $500 млрд. Если производители операционной системы
будут получать скромную комиссию 1-2% от заработка робота,
их бизнес будет ежегодно расти на $5-10 млрд в течение 100 с
лишним лет. Звучит заманчиво! К тому же, как показывает
пример Microsoft, производители операционной системы
оказываются в более выгодном положении и в отношении любого
прикладного ПО на ее основе.
Единая операционная система облегчит общение роботов
между собой и позволит рассредоточить их психику в сети:
критически важные компоненты оставить в теле самого
робота, а дополнительные когнитивные способности разместить в
мощных дата-центрах в качестве платных сервисов.
Аналогично тому, как сегодня облачные приложения расширяют
возможности наших смартфонов.
Одним из таких сервисов может стать описанный в
следующем разделе искусственный супермозг, способный "объять
необъятное" — всю совокупность человеческих знаний.
8.3. Экспертный интеллект
277
8.3. Экспертный интеллект: диалог с
базами знаний
8.3.1. Проблема: как ускорить R&D?
В мире каждый год публикуется более 2 млн научных статей.
Ни один человек и близко не способен хотя бы просмотреть
их все, не говоря уже о синтезе всех этих кусочков научного
пазла в единую систему знаний.
Поэтому сегодня все человеческие знания
рассредоточены по десяткам миллионов узких специалистов, и ни один
из них не обладает всей полнотой информации. "Специалист
подобен флюсу: полнота его односторонняя Картина мира у
каждого из них определяется своим подмножеством знаний,
что затрудняет их общение и замедляет скорость
исследований и разработок, ключевого конкурентного преимущества в
современном мире.
Если бы можно было загрузить все человеческие знания в
один супермозг, способный делать выводы и выдавать ответы
с учетом всей совокупности знаний по любому вопросу, таким
"супер-Google" пользовались бы, безусловно, все специалисты
и исследователи в мире.
В отличие от нынешнего Google, своего рода мирового
справочника, супер-Google должен будет давать развернутые и
аргументированные консультации, с ответами на
дополнительные вопросы, работая лоцманом-проводником в областях
знаний, незнакомых пользователю. По сути, речь идет о
диалоговом варианте Википедии, где каждая следующая реплика
является заказной статьей, развивающей тему в контексте
текущего диалога. Отсюда и название проекта.
8.3.2. Актуальность: суперкомпьютеры ждут
суперинтеллекта
До недавнего времени такой проект был чистой фантастикой.
Однако несколько терабайт накопленных научных знаний -
278
НАПРАВЛЕНИЯ РАЗВИТИЯ
это всего лишь объем типичного диска домашнего
компьютера4. И "усвоение", допустим, 3 • 1012 байт уже не
кажется невероятной задачей даже для одной стойки современных
специализированных процессоров Google TPUvS pod с
суммарной производительностью порядка 1017 байт/сек. А
возможности дата-центра, набитого такими стойками, даже трудно
себе представить.
Допустим, что обученная модель нашего суперинтеллекта
содержит 3 • 1011 параметров, т.е. она сжимает "сырые"
данные на порядок, подобно человеку, чьи знания соответствуют
сжатию текста от 8 до 1 бит/символ (люди угадывают
следующую букву текста примерно с вероятностью 50%). Если это
будет гигантская нейронная сеть, использующая градиентное
стохастическое обучение, ее обучение, согласно (3.13),
потребует 1024 -г- 1025 операций. С такой задачей 10 упомянутых
выше вычислительных стоек справятся за 106 -=-107 сек, т.е. в
масштабе нескольких недель или месяцев.
Таким образом, принципиальная возможность создания
такого суперинтеллекта имеется. Остается только предложить
соответствующий набор технологий.
8.3.3. Решение: масштабируемая иерархическая
модель языка
Нетрудно догадаться, что, по мнению автора, наиболее
подходящим инструментом для этого проекта является
глубокое структурное обучение, которое первоначально
разрабатывалась именно для работы с естественным языком. Оно
позволяет строить иерархии языковых и надъязыковых
понятий и комбинировать их между собой оптимальным
образом. Для эффективного горизонтального масштабирования,
модель должна быть модульной, чтобы отдельные модули (от-
4 2 млн статей в год по 50-100 кБ на статью за 10-20 лет, пока
знания не устарели. С рисунками, естественно, объем будет больше, но мы
для простоты положим, что всю графику можно перевести в векторный
формат и считать частью текста.
8.3. Экспертный интеллект
279
вечающие за разные области знаний) могли работать на
разных устройствах. При этом верхние этажи иерархии будут
обеспечивать единство всего пространства знаний.
Итоговая модель будет порождающей, но, в отличие от
операционной системы роботов, будет порождать не
поведение, а мышление, и выдавать во внешний мир не действия
актуаторов, а речь и тексты. Но суть ее остается прежней.
Более того, эти проекты естественным образом дополняют
друг друга. Роботам для общения с человеком и выполнения
своих обязанностей, конечно же, понадобится речь и доступ к
человеческим знаниям, т.е. к нашему суперинтеллекту. Менее
очевидно, но и супермозг будет нуждаться в сенсомоторных
знаниях роботов, взаимодействующих с реальным миром,
чтобы "приземлять" для себя значения самоочевидных для людей
понятий, таких как теплый, тяжелый и т.д. Ведь
человеческий язык предполагает наличие у слушателей внутренней
картины мира, позволяющей декодировать языковые
сообщения. Такой сенсомоторной картиной мира будут обладать
роботы, тогда как более абстрактными знаниями о различных
ее элементах будет обладать наш суперинтеллект.
По всей видимости, будут созданы разные варианты
суперинтеллектов, по-разному обобщающих имеющиеся знания.
Ведь обобщение, как мы знаем, - это обратная задача, не
имеющая единственного решения. Общение суперинтеллектов
друг с другом может служить способом их саморазвития, т.к.
они будут способны порождать друг для друга бесконечное
количество данных для обучения. Подобно тому, как Alpha-
Zero могла самосовершенствоваться до бесконечности, играя
с разными своими инкарнациями.
Абстрактное мышление суперинтеллекта, безусловно,
потребует развития существующей теории. Супермозг должен
будет обладать способностью к логическим суждениям:
если из А следует В, а из В следует С, то из А следует С, и
т.д. Он должен будет строить гипотезы о том, что является
причиной чего (см. например [Pearl и Mackenzie, 2018]). Со-
280
НАПРАВЛЕНИЯ РАЗВИТИЯ
ответствующие причинно-следственные модели должны быть
естественным образом встроены в будущий суперинтеллект.
Можно представить себе множество такого рода проектов.
Ведь суперинтеллекты могут обучаться на разных типах
данных. Например, какие-то из них смогут просматривать все
посты в соц. сетях и, зная все о коллективном сознании (и
подсознании), будут способны не только предсказывать
результаты выборов, но и влиять на них, дискутируя на нужные
темы с нужными людьми с учетом их персональных
предпочтений (такие программные агенты- спорщики уже
существуют и могут участвовать в дебатах наравне с людьми [Aharonov
и Slonim, 2019]). Заказчики такого проекта, без сомнений,
найдутся. Но это будет уже совсем другой проект...
8.3.4. Бизнес: супер-Google — консультант
Аудиторию предполагаемого сервиса можно грубо оценить в
250 млн человек, включая исследователей, аналитиков и
студентов, которые без такого инструмента будут просто
неконкурентоспособны. Соответственно, скромные $10 в месяц ($100
в год) за подписку на сервис не станут для них препятствием.
Получаем стартовые порядка $25 млрд в год.
Плюс множество дополнительных платных сервисов для
тех, кто нуждается в постоянном отслеживании состояния
технологий в отдельных отраслях, разовых научных
консультациях или подборе кадров для временных проектных
команд. Ведь сервисом будет пользоваться вся мировая научно-
техническая элита, и их персональные профили будут
являться важнейшим активом проекта. Фактически, база данных
проекта будет своего рода индексом-указателем ко всей
экспертизе человечества — кто является специалистом по какому
вопросу, сколько их есть и как быстро развиваются различные
отрасли знаний.
Кроме человеческой аудитории, как уже отмечалось, у
сервиса будет и постоянно растущая аудитория роботов, которая
со временем может стать основным источником дохода по ме-
8.4. Обсуждение
281
ре того, как роботы будут наращивать свою долю в мировом
ВВП.
В конечном итоге, сообщество суперинтеллектов в сети
дата-центров, обладающее всеми человеческими знаниями и
соответствующими аналитическими возможностями, будет кон
тролировать определенную долю рынка R&D (сегодня это 2%
мирового ВВП или порядка $2 трлн по паритету
покупательной способности).
8.4. Обсуждение
В этой главе мы представили три проекта, способные в
случае успеха породить лидерские глобальные компании новой
цифровой экономики, о которых шла речь в главе 2,
достойные списка Forbes Global 2000. Понятно, что список подобных
проектов может и должен быть существенно расширен.
Представленные здесь проекты просто отражают личные научные
интересы автора. Тем не менее, последовательность проектов
имеет свою внутреннюю логику.
Начинать легче всего с реверс-инжиниринга уже
имеющихся образцов психики, построения их работающих
биологически обоснованных моделей, тем более, что это необходимо
для сохранения и расширения функций человеческого мозга.
Для создания искусственной психики роботов нужно будет,
напротив, отвлечься от биологических особенностей мозга,
позаимствовав у него лишь его архитектуру и базовые
алгоритмы. Наконец, повторяя путь эволюционного развития, будет
логично подняться от психики приматов к чисто
человеческим способностям - языку и абстрактному мышлению.
Все три проекта технологически тесно связаны между
собой и способны идейно поддерживать друг друга, не
конкурируя между собой напрямую. Поэтому имеет смысл
"прописать" их команды в одном месте, автор надеется, что, конечно
же, в России. Например, в недавно созданном центре
компетенций по искусственному интеллекту на базе МФТИ. По
282
НАПРАВЛЕНИЯ РАЗВИТИЯ
крайней мере, команды разработчиков, прообразы
конструкторских бюро будущих глобальных предприятий. Потому что
создание таковых невозможно без тесного международного
сотрудничества с привлечением лучших мировых экспертов,
как технических, так и по развитию глобального бизнеса.
Только благодаря таким глобальным проектам на
российской территории и могут возникнуть центры компетенций
мирового уровня, представляющие интерес для мировой
индустрии искусственного интеллекта. Пожелаем же успеха всем
будущим участникам гонки за машинным сверхинтеллектом.
Как говорил Заратустра: аВ горах кратчайший путь — с
вершины на вершину; но для этого надо иметь длинные ноги".
Глава 9
Будущее машинного
интеллекта
Бодрствуйте и
прислушивайтесь, вы,
одинокие! Неслышными
взмахами крыл прилетают
из будущего ветры, и до
тонких ушей доносится
добрая весть.
Самые заботливые
вопрошают сегодня: "Как
сохраниться человеку?"
Заратустра же
спрашивает, первый и
единственный: "Как
превзойти человека?"
Фридрих Ницше
«Так говорил Заратустра»
В этой главе мы попробуем заглянуть в будущее,
недалекое, лет на 10-15, чтобы особо не вторгаться на
территорию научной фантастики. Мы лишь спроецируем в будущее
284
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
уже идущие или готовящиеся к запуску проекты,
осуществляя предсказания в контексте собственных действий. Иными
словами, постараемся представить себе, что будет, если мы
преуспеем в известных нам проектах, включая и описанные в
предыдущей главе.
9.1. Развитие элементной базы
В главе 2 мы связывали зарождение индустрии
искусственного интеллекта с развитием вычислительной элементной базы,
возможности которой в определенный момент превзошли
человеческие. Будут ли они и дальше расти теми же темпами,
определяемыми законом Мура? Надолго ли хватит будущему
искусственному разуму "пороха в пороховницах"?
Начнем с того, что именно вычислительная компонента
компьютерного мира растет быстрее всего. Если
компьютерная память удваивается каждые 40 месяцев, а
коммуникации — каждые 34 месяца, то мощности CPU — каждые 18
месяцев, а специализированных процессоров (GPU и ASIC1) —
каждые 12 месяцев2. Это означает, что сохраняться и
передаваться по каналам связи будут все больше не сырые, а уже
осмысленные сжатые данные, т.е. модели.
Что является ограничивающим фактором такого
экспоненциального роста? Прежде всего, конечно же, энергия.
Вычисления сегодня потребляют около 1011 Вт или 5% всей
электроэнергии [Naik, 2014]. Примерно столько же сегодня
потребляет и все человеческое мышление: 7,6 млрд чел. по 25 Вт/мозг
« 2 • 1011 Вт.
Производство электроэнергии растет довольно медленно,
в среднем по 2,5% в год (удвоение примерно за 30 лет).
Следовательно, энергия для вычислений может расти лишь за
счет доли других каналов ее использования. Скажем, можно
1 Application-Specific Integrated Circuits
2 https://en.wikipedia.org/wiki/Technological_singularity.
9.1. Развитие элементной базы
285
использовать вычислительные мощности в качестве
обогревателей или, еще одна возможность, для утилизации
солнечной энергии. Ведь сегодня основным сдерживающим
фактором солнечной энергетики являются накопители
электроэнергии, т.к. солнечная энергия обычно потребляется с задержкой
по отношению к ее производству (производится, когда
светло, а освещение требуется — когда темно). Вычисления,
однако, могут потреблять солнечную энергию прямо в момент
ее производства, следуя по миру вместе с пиком солнечной
активности. Результаты вычислений передаются по каналам
связи гораздо дешевле и с меньшими потерями, чем может
транспортироваться сама электроэнергия. Далее, 20%
электроэнергии используется для освещения. Возможно, в
будущем найдут возможность использовать для этого оптические
вычислители, тем более, что свет можно использовать и для
широкополосной передачи информации между устройствами.
Так или иначе, энергия, затрачиваемая на вычисления,
будет расти, но в рассматриваемый период с учетом инерции
инвестиций вряд ли вырастет больше, чем в 2-3 раза (в 1,5 раза
больше электроэнергии и в 1,5-2 раза большая доля
вычислений в ее потреблении). Наращивать вычислительные
мощности на порядки можно лишь за счет повышения их
энергоэффективности, которая на протяжении десятилетий, согласно
Koomey и Naffziger, 2015, удваивается в среднем за 1,5 года.
Таким образом, на нашем горизонте предсказаний в 10-15 лет,
она успеет удвоиться 7-10 раз, что соответствует 100 -=-1000-
кратному увеличению энергоэффективности.
Если принять за точку отсчета энергоэффективность
тензорных вычислений современного процессора NVIDIA V100:
120 TFLOPS/300 Вт = 4 • 1011 FLOPS/Вт, увеличить ее на
2-3 порядка и принять, что на вычисления через 10-15 лет
будет тратиться в 2,5 раза больше энергии, чем сегодня, т.е.
2,5-Ю11 Вт, получим что к 2030-2035 гг. вычислительная
мощность компьютеров будет 1025 -=-1026 FLOPS, на четыре-пяшь
286
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
порядков больше, чем собственно человеческая (1021 FLOPS
— см. главу 2)3.
Если к тому времени эти новые мощности будут
обслуживать, в основном, машинное обучение или Software 2.0, как
его окрестил Andrej Karpathy, директор по искусственному
интеллекту в компании Tesla4, то скорость накопления
знаний машинным интеллектом роботов и дата-центров будет
на 4-5 порядков превосходить скорость накопления знаний
людьми. Стало быть, и объем накопленных машинами
знаний на порядки превзойдет объем знаний в головах людей.
А поскольку именно знания являются движущей силой
экономики, машинный интеллект к этому времени уже
сформирует "становой хребет" нового, цифрового технологического
уклада.
Как и всякая устойчивая система, экономика
консервативна и сопротивляется любым изменениям. Потребители-люди
крайне неохотно меняют свои предпочтения. Поэтому
"цифровое будущее" в мире будет распределено очень неравномерно.
Будут цифровые отрасли-лидеры, такие как финтех,
виртуальная и смешанная реальность, компьютерные игры,
робототехника и искусственный интеллект, взаимно
поддерживающие быстрый рост друг друга, и традиционные отрасли, куда
машинный интеллект будет с разной скоростью
диффундировать. Такой сценарий мы уже наблюдали с традиционными
компьютерами и Software 1.0.
Попытаемся представить себе, в каком обличий будет
представлен машинный интеллект в 2030-2035 гг. После того, как
3 Энергоэффективность NVIDIA V100 (\ • 10"11 Дж/байт ~ 3 • 10~13
Дж/бит) еще очень далека от теоретического минимума (~ /гТ/бит
« 3 • Ю-21 Дж/бит), поэтому мы здесь предполагаем, что технологии
для поддержания этого тренда будут найдены. Это может быть как
переход на другую элементную базу, например, мемристоры, так и чисто
архитектурные решения, например, нейроморфные чипы или даже
квантовые вычисления.
4 "Neural networks are not just another classifier, they represent the
beginning of a fundamental shift in how we write software. They are Software
2.0." (https://medium.eom/@karpathy/software-2-0-a64152b37c35).
9.2. Интеллектуальные агенты
287
будет создана операционная система роботов (возможно не
одна), и ею начнут активно пользоваться производители
роботов и программных агентов. После того, как последние
начнут разговаривать, а сеть суперинтеллектов в мощных дата-
центрах будет осмысливать и обобщать все получаемые ими
данные. Иными словами, если описанные в прошлой главе
проекты "выстрелят".
9.2. Интеллектуальные агенты
По состоянию на 2018 год суммарное количество приложений,
доступных на платформах Google, Apple, Windows, Amazon и
BlackBerry превысило 7 млн [STATISTA, 2018]. Для
пользования миллионами постоянно обновляющихся облачных
сервисов людям неизбежно понадобятся посредники — личные
агенты-секретари, понимающие и потребности пользователей,
и возможности облачных сервисов.
Эти персональные агенты станут новым пользовательским
интерфейсом, интегрирующим множество частных
интеллектов в некое подобие общего интеллекта, обслуживающего
текущие нужды своего хозяина. Возможности такого
"фасеточного" интеллекта не следует недооценивать. В принципе,
можно создать достаточно развесистый каркас сценариев
подключения разных сервисов в соответствующих ситуациях,
имитирующий разумного секретаря-референта. И какое-то время
агенты будут развиваться именно по такому
"программистскому" сценарию. Пока не будет создана искусственная
психика, основанная на машинном обучении и способная к
постоянному саморазвитию. Это станет поворотным пунктом,
исходной точкой развития сильного искусственного
интеллекта (Artificial General Intelligence), способного со временем
превзойти человеческий.
Подобно человеческому разуму, существующему в
миллиардах индивидуальных воплощений, машинный разум
тоже будет коллективным. Миллиарды персональных агентов-
288
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
референтов сформируют глобальный агентский
секретариат. Они будут представлять интересы своих хозяев в
цифровом мире, договариваясь между собой о встречах,
покупках и контрактах от их лица. Они будут планировать
календарь событий и распорядок дня своих хозяев, заказывать для
них транспорт и бронировать проживание в путешествиях и
командировках. Иными словами, делать за людей всю
секретарскую работу. Сегодня подобные услуги доступны лишь
начальникам, имеющим собственных референтов. Машинный
интеллект сделает их общедоступными.
Но у каждого блага есть и своя оборотная сторона. Так
будет и с агентами. Электронные секретари, зная о нас все
и общаясь между собой в облаках, смогут предложить нам
новый уровень комфорта, от которого мы просто не сможем
отказаться. Одновременно они будут все в большей степени
управлять нашим поведением, как Дживс управляет
Вустером, формально будучи его слугой, используя т.н. "мягкую
силу": "У тебя тут появилось окошко в делах, и я позволила
себе забронировать тебе билет на Питер, где уже согласованы:
завтрак с потенциальным инвестором, совещание с
дизайнером и обед с кандидатом на место архитектора (лучшим из
доступных на сегодня). Вечерком банька с друзьями (ждут!),
утром обратно. В пути - новый шедевр от Мартина Скорсезе.
ОК?"
Причем дело вряд ли ограничится нашими текущими
повседневными заботами. Искусственный интеллект
следующего поколения облачных платформ сможет предложить
гораздо более сложные услуги из разряда управления судьбой.
Отталкиваясь от мечты, например, иметь собственный дом на
живописном берегу, вам предложат индивидуальную
образовательную траекторию с гарантированным трудоустройством
по избранной профессии с соответствующим вашей мечте
уровнем оплаты, а ипотечный кредит будет лишь одной из
компонент этой сложной услуги. И не будет никакой "красной
кнопки"!
9.3. Роботы
289
Мы не зря окрестили этот агентский секретариат
глобальным. Люди из разных стран смогут свободно общаться друг
с другом с помощью синхронного машинного перевода.
Обращаясь к более мощным облачным суперинтеллектами,
знающим "все обо всем", агенты-референты будут дополнять
перевод комментариями, разъяснять незнакомые термины и
понятия, помогая общаться представителям разных культур и
профессий. Постоянный доступ к знаниям в нужный момент
через персональных агентов станет таким же привычным, как
сегодняшний беспроводной доступ к сети через смартфоны
(которых, к слову, 15 лет назад еще не существовало).
Рост распределенного машинного интеллекта неизбежно
поменяет и структуру интернет-трафика. Передача по
каналам связи обученных моделей, "цифровых мозгов", гораздо
выгоднее передачи сырых данных. Собственно и сегодня
данные передаются в сжатом виде, просто сжатие в будущем
будет более интеллектуальным и эффективным. Можно
представить себе агентов, посылающих свою копию в дата-центры
для дообучения в какой-то области знаний в месте
концентрации этих знаний и соответствующих данных, своего рода
"командировочных" агентов, посылаемых для повышения их
квалификации.
Кроме интеллектуальных персональных агентов и
сверхинтеллектуальных облачных сервисов, сообщество
машинного разума будет включать, конечно же, и роботов.
9.3. Роботы
Все, наверное, видели впечатляющие кадры
роботизированных производственных линий, например, по сборке
автомобилей. Однако все движения этих промышленных роботов
жестко запрограммированы, т.е. по сути они являются станками
ЧПУ, просто с большим числом степеней свободы.
Появление сенсорного интеллекта и управления
поведением на основе машинного обучения открывает новые горизонты
290
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
для развития сервисных роботов. Экономический эффект от
роботизации в базовых отраслях экономики будет
исчисляться триллионами долларов. Если программные агенты,
образующие глобальный агентский секретариат, будут повышать
эффективность людей, то роботы будут заменять людей на
производстве, постепенно вытесняя человека из менее
творческих профессий в более творческие.
По мнению автора, критичным для развития
робототехники должен стать переход от вертикальной к горизонтальной
структуре рынка. Аналогичный переход произошел когда-то
на компьютерном рынке. От вертикально-интегрированных
компаний, осуществляющих полный цикл разработки, создания
и обслуживания вычислительной техники (IBM 1960-xгг.),
к горизонтальному рынку, где разные компании
специализируются на разных уровнях технологического стека —
компьютерного и сетевого hardware и software. А в рамках
последнего — на операционных системах, системах управления
базами данных и различных типах прикладных программ.
Такая организация рынка не требует концентрации редких и
дорогих специалистов всего стека технологий в рамках одной
компании. Она базируется на системе стандартов,
регламентирующих интерфейсы между различными горизонтальными
уровнями.
Нижним уровнем Software 2.0 станет операционная
система роботов, необходимая для перехода к горизонтальной
структуре робототехники. Такие операционные системы уже
появляются, например ROS. Но все они пока основаны на
программировании, Software 1.0, и напоминают нервную систему
насекомых, все поведение которых генетически
запрограммировано с самого рождения. По аналогии с биологической
эволюцией, следующим этапом робототехники должна стать
искусственная психика со встроенной способностью к обучению,
аналог центральной нервной системы млекопитающих.
Присущее млекопитающим любопытство и стремление
учиться, набираться опыта в течение всей жизни является пред-
9.4. Люди
291
посылкой к постоянному наращиванию объема их памяти -
неокортекса в процессе эволюции, приведшему, в конце
концов, к появлению нас, людей. Способность роботов к
самообучению позволит постоянно наращивать общий объем их
знаний без явного вмешательства людей. Люди будут не
программировать, а воспитывать роботов.
Интеллект роботов, как и программных агентов, будет
распределенным. Как и агенты, роботы смогут обмениваться друг
с другом данными и знаниями, как сегодня сотни тысяч
автомобилей Tesla собирают единую базу знаний о дорожных
ситуациях, на которой постоянно обучается их общая
операционная система.
Модульная структура операционной системы роботов и
агентов позволит им обмениваться не только данными, но
и знаниями, передавая друг другу отдельные модули своего
обученного электронного мозга.
Фактически сформируется единая цифровая экосистема
машинных интеллектов, часть из которых (роботы) будет
взаимодействовать с внешним миром, а часть — решать
внутренние задачи коллективного машинного мышления. Причем это
машинное мышление будет неразрывно связано с
человеческим, составляя совместно с ним единое коллективное
мышление человечества на новой стадии его развития.
9.4. Люди
Возникает естественный вопрос о положении и роли людей
в этом новом мире, насыщенном искусственными
интеллектами. Не станем ли мы лишними в этом мире? Недавний
неожиданно быстрый прогресс технологий машинного обучения
породил в обществе дискуссию об опасности сверхчеловеческого
разума, о том, нужен ли он вообще. Зачем нам, человечеству,
идти на риск потери контроля над своей собственной судьбой?
Ведь более сложная система всегда найдет способ управления
более простой.
292
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
По мнению автора, противопоставление естественного и
искусственного интеллекта само носит искусственный
характер. Человеческий разум уже давно распределен между
людьми и алгоритмами, воплощенными в "неорганическом теле"
цивилизации — сначала в механических, а теперь и в
электронных машинах. Даже если мышление и протекает пока,
в основном, в головах людей, машины опосредованно
определяют весь уклад нашей жизни и, тем самым, содержание
индивидуального мышления каждого из нас. Машинный
интеллект, как узкий, так и общий, вписывается в этот
исторический процесс развития мирового разума.
Объем человеческих знаний обгонял рост населения
благодаря постоянному развитию системы разделения труда. В
конвейерном производстве специализация достигла
максимальной степени, где от человека требуются лишь элементарные
производственные действия, частичный труд. Такие действия
гораздо легче поддаются автоматизации, замене людей
алгоритмами, воплощенными "в железе" вместо людей.
Современные системы специализированного узкого
искусственного интеллекта являются продолжением той же
тенденции. Просто класс алгоритмов существенно расширился за
счет технологий глубокого обучения, как и список
специальностей, в очереди на автоматизацию. Интеллектуальные
сервисы со сверхчеловеческими сенсорными и моторными
способностями и стремящейся к нулю себестоимостью высвободят
частичный труд контролеров, вахтеров, шоферов и
множества прочих специальностей, постепенно вытесняя человека
в сферу творческого труда.
В результате промышленных революций в сельском
хозяйстве развитых стран сегодня занято всего несколько
процентов населения. Аналогично, в результате грядущей цифровой
революции все производство материальных благ в развитых
странах станет почти безлюдным. Там тоже останется лишь
несколько процентов населения — высококвалифицированные
специалисты, в основном, по машинному интеллекту как
ключевой технологии цифрового уклада.
9.4. Люди
293
Основным занятием людей станет оказание взаимных услуг
друг другу, в которых люди всегда смогут составить
конкуренцию роботам. Ведь люди способны гораздо лучше
понимать внутренний мир друг друга. У людей более всего будет
цениться эмоциональный интеллект, способность к
сопереживанию и прочие soft skills [Lee, 2018]. В общем, люди
(естественно, не без помощи машинного интеллекта) будут
ухаживать друг за другом, развлекать друг друга, а имеющие к
тому склонность — самосовершенствоваться.
Последних, скорее всего, будет меньшинство. В силу
высокой энергозатратности мышления человеческий разум от
природы ленив. Поэтому в обществе всегда широко
распространялись легко усваиваемые мозгом "эгоистические мемы"
крайне упрощенного объяснения действительности, и
мышление каждого из нас содержит большую долю таких ложных
знаний, аналогично тому, как большую часть нашего генома
составляет "мусорная" ДНК.
Так что передача тягот мышления и принятия решений
машинам, скорее всего, будет сопровождаться определенной
деградацией мыслительных способностей большинства людей.
В какой-то степени этот процесс наблюдается на протяжении
всего периода развития цивилизации. По мере того как
растущая специализация снижает нагрузку на индивидуальное
мышление, в последние 30 тыс. лет происходит
статистически достоверное уменьшение размеров мозга, причем со
скоростью в 10 раз большей, чем предшествующий рост объемов
мозга в течение 2 млн лет [А. Марков, 2017]. Нечто
подобное происходит и с домашними животными, за которыми
ухаживают люди. Человек в ходе развития цивилизации как бы
сам себя одомашнивает. Недавние генетические исследования
свидетельствуют о распространении в развитых странах
генов, отрицательно влияющих на мыслительные способности
[Kong, Frigge и др., 2017].
Однако возможная добровольная деградация
мыслительных способностей является далеко не единственной из поджи-
294
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
дающих нас опасностей. Описанная выше идиллия мирного
сосуществования людей и машин плохо вписывается в реалии
современного мира, полного противоречий. Экономика, как
мы знаем, развивается крайне неравномерно, и неравенство
в мире постоянно нарастает. Суммарные активы 26
богатейших людей планеты превосходят совокупное состояние
наименее обеспеченной половины человечества. Цифровые активы,
как отмечалось в главе 2, имеют тенденцию к концентрации
в небольшом числе цифровых платформ. Если эта тенденция
сохранится, все основные активы цифровой цивилизации
будут сконцентрированы в немногих "кремниевых долинах", в
которых сосредоточится производственная элита — те самые
несколько процентов специалистов, производительность
труда которых будет на порядки превышать среднюю. Там же
будут сосредоточены и недоступные остальным элитные услуги,
например по продлению жизни, генетической модификации
и киборгизации. Элитные кадры будут притекать в эти
"долины" из относительно благополучных стран развитого мира
и быстро растущих регионов Юго-Восточной Азии,
потребителей основной массы материальных благ и услуг. Наконец,
будут еще и страны, отставшие от цифрового мира, навсегда
застрявшие в прошлом, с гораздо менее комфортной жизнью
и без всяких надежд на ее улучшение.
Такой цифровой разрыв рискует стать постоянным
источником нестабильности в мире. На фоне этих угроз будут
возможны самые разные сценарии, от масштабных терактов до
мировых войн, инициированных машинным интеллектом
либо в кризисной ситуации, либо в силу вполне рациональных
"высших" соображений. Так что жизнь в цифровую эпоху
будет, вполне возможно, более тревожной, чем наша
сегодняшняя (см., например, [Кузнецов, 2016]).
Конфликтный характер человеческого мышления
неизбежно продублируется и в машинном интеллекте. Если люди
будут делить друг друга на своих и чужих, это деление
проникнет и в машинный интеллект. Ценность "чужой" человеческой
9.5. Новая научная революция
295
жизни для военного машинного интеллекта может быть
невелика или даже отрицательна. В мире, где машинный
интеллект постоянно обменивается идеями, эти ценности могут
бесконтрольно распространиться со всеми вытекающими...
Может родиться и получить распространение новая "расовая"
идея противопоставления людей и машин, и судьба
человечества в таком сценарии будет незавидной.
Когда люди станут настолько зависимы от машин, что не
смогут без них существовать, и при этом машины будут
принимать решения самостоятельно, ключевым для людей станет
вопрос о ценностях машинного интеллекта, определяющих в
конечном итоге эти решения. Если искусственный интеллект
станет "новым электричеством", никакая пресловутая
"большая красная кнопка" уже не поможет.
Отказаться от создания машинного разума мы, конечно
же, не сможем. Только он позволит решить назревшие
социальные проблемы человечества, кратно увеличить
глобальный ВВП без ущерба для экологии. Однако возможно, что
для своей же собственной безопасности человечество в
будущем вынуждено будет выработать какие-то общие ценности,
преодолеть извечную конфронтацию своих и чужих, и строго
контролировать соблюдение этих ценностей как у людей, так
и у машин.
Все это потребует совершенно другого уровня понимания
того, как устроено индивидуальное и общественное сознание,
"смену понятийной сетки" в науках о мышлении5.
9.5. Новая научная революция
Научная революция XVII в., связанная с именами Галилея,
Ньютона и др., заложила основы естественных наук, начиная
с физики. Эпоха великих географических открытий, освоение
5 "Переход от ньютоновской к эйнштейновской механике
иллюстрирует с полной ясностью научную революцию как смену понятийной сетки,
через которую ученые рассматривали мир" [Кун, 1977].
296
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
Нового света и остального мира породили платежеспособный
спрос на точное физическое знание. Растущая мировая
торговля остро нуждалась в приборах и методах ориентации в
масштабах земного шара [Вернадский, 1988].
Физика Ньютона, объединившая в единую картину мира
разделенные до этого земные и небесные явления, стала
ответом на этот запрос. Развитие механики и оптики
требовалось для совершенствования часов и телескопов, без которых
глобальная навигация была невозможна. Точные хронометры,
навигационные приборы и астрономические расчеты
(таблицы эфемерид) были необходимы для надежного определения
долготы и широты. Измерения размеров и формы Земли —
для составления географических карт, оберегаемых в морском
деяе^ как национальное достояние. Нация, отказавшаяся
принять новую научную картину физического мира, просто
теряла конкурентоспособность, как в случае с Китаем и Индией.
Сегодня мы стоим на пороге новой научной революции,
на этот раз — в науках о мышлении. До недавнего времени
они никак не могли быть причислены к точным наукам.
Философы могли бесконечно дискутировать друг с другом, не
имея возможности доказать свою правоту математическими
выкладками или экспериментами.
Да и современная психология, хоть и основанная на
экспериментах, не имеет адекватной общепринятой модели
психики, способной их интерпретировать. Нейрофизиология, со
своей стороны, ограничивается физикалистскими моделями
биологических процессов в мозге, не поднимаясь до
моделирования мышления, осуществляемого мозгом.
В целом, состояние комплекса наук о мышлении находится
сегодня на "доньютоновском" уровне, можно сказать — на "га-
лилеевском": новые измерительные приборы и методы
породили лавину экспериментальных данных, но в отсутствие
адекватной им теории. Теории, объясняющей, как мозг
порождает мышление, объединяющей физическое и психическое, как
ньютоновская физика объединила земное и небесное.
9.5. Новая научная революция
297
Платежеспособный спрос на такую теорию появляется
только-только, на наших глазах. Его предъявляет возникающая
индустрия искусственного интеллекта: искусственный разум
не может быть построен без теории разума. И если на кону
стоят триллионы долларов, то необходимые на решение этой
задачи средства будут так или иначе выделены.
Эта теория будет развиваться параллельно с развитием
машинного интеллекта, который станет для нее
экспериментальным полигоном для отладки различных моделей
искусственной психики и доведения ее возможностей до
сверхчеловеческого уровня.
Развитие философии показало, что теория мышления не
сможет ограничиться только индивидуальным мышлением.
Модель мозга помогает понять, как он думает, но не — о чем.
Содержание индивидуального мышления определяется
коллективным мышлением человечества. Недостаточно понять,
как мозг обучается языку, как он понимает высказывания
и работает с абстрактными идеями. Важно понять, откуда
эти идеи возникают, какие процессы они обслуживают. А эти
процессы — общественные, и управляются они коллективным
мышлением всех членов общества.
Значит, нам предстоит построить и теорию
коллективного машинного интеллекта, подкрепленную экспериментами с
коллективами агентов и роботов. Представление об обществе
как обучающейся системе позволит нам наконец-то
приблизиться к пониманию законов общественного развития. Быть
может, роль денег в экономике лучше всего объяснит
именно теория обучения, трактуя их обращение в духе метода
backpropagaiton, как базовый алгоритм обучения
экономических систем.
Машинная этика, в необходимости которой мы убедились
выше, станет частью будущей теории коллективного
мышления. Ведь ценности вырабатываются и контролируются
обществом. Возможно, нам удастся научным путем выработать
единую для людей и машин систему ценностей и создать кол-
298
БУДУЩЕЕ МАШИННОГО ИНТЕЛЛЕКТА
лективную систему взаимного контроля их соблюдения.
Скорее всего, эта система децентрализованного контроля будет
использовать будущие версии технологии распределенных
реестров, которые как раз и призваны автоматически
обеспечивать взаимное доверие. Когда машинный разум, наконец,
превзойдет возможности человеческого понимания, только такая
система взаимного контроля ценностей распределенным
машинным интеллектом сможет обеспечить доверие к нему
людей и предоставит им определенные гарантии.
Машинное обучение, без сомнения, станет важной
составной частью этой новой теории мышления, т.к. любой разум
является в конечном итоге результатом обучения, и понять
человеческое мышление можно будет только в контексте его
эволюции. Об эволюции мышления мы и поговорим в
следующей главе. Ведь "великое в человеке то, что он мост, а не
цель" - так говорил Заратустра.
Глава 10
Эволюция разума
Будущее и самое дальнее
пусть будет причиной
твоего сегодня: в своём
друге должен любить ты
сверхчеловека как свою
причину
Человек — это канат,
закреплённый между
зверем и сверхчеловеком,
— канат над пропастью.
Но вы могли бы
пересоздать себя в отцов и
предков сверхчеловека, —
и пусть это будет вашим
лучшим творением!
Фридрих Ницше
«Так говорил Заратустра»
Взгляд в будущее в предыдущей главе, как автор ни
старался обосновывать свои выводы, все-таки больше
напоминает научную фантастику. Интуитивно не верится, что всего
лишь лет через 15 мир настолько изменится. Наше мышление
300
ЭВОЛЮЦИЯ РАЗУМА
линейно: "Что было, то и будет; и что делалось, то и будет
делаться, и нет ничего нового под солнцем".
Как и для всякой экспоненты, последствия закона Мура
контринтуитивны: до какого-то момента изменения
практически незаметны, и вдруг мир стремительно меняется. В
течение десятилетий игра в Го не давалась компьютерам, они не
дотягивали даже до уровня 1-го дана. И вдруг практически
сразу AlphaGo всухую выигрывает у лучших игроков мира.
В экспоненциальном мире мы часто переоцениваем
близкие изменения и недооцениваем далекие. Возможно, и мы в
предыдущей главе переоценили скорость перемен, и создание
сильного ИИ потребует несколько больше времени. В
конце концов, мы не знаем, сколько времени займет выполнение
прорывных проектов главы 8, неизвестно даже, когда они
запустятся. Но в том, что они или их аналоги в конце концов
состоятся, у автора сомнений нет. В этой заключительной
главе мы попытаемся убедить в том же и читателя: что проект
создания сильного ИИ обречен на успех. Более того, на этом
история не закончится, и в далекой перспективе изменения
будут гораздо масштабнее, чем те, о которых шла речь до сих
пор. Для этого мы "несколько" расширим временные рамки
нашего прогноза.
В главе 2 появление машинного интеллекта связывалось
с необходимостью преодоления барьера сложности, с
которым столкнулось человечество. Здесь мы, по-прежнему
следуя Спинозе, попытаемся вписать машинный интеллект "в ту
цепь событий, внутри которой он возникает с
необходимостью, а не случайно", но уже в масштабе Вселенной.
Суть аргумента такова: разум присущ природе и
появляется с необходимостью там, где для этого возникают
подходящие условия. Раз возникнув, он эволюционирует в сторону все
более быстрого обучения — побеждает та форма разума,
которая учится быстрее. Машинный интеллект способен учиться
в миллионы раз быстрее человеческого просто в силу
характерных времен компьютерного и человеческого мышления —
наносекунды против миллисекунд. Конец доказательства.
10.1. Неравновесная термодинамика
301
10.1. Неравновесная термодинамика
Что же это за условия, необходимые для появления разума?
Оказывается, способность природы к обучению проявляется
уже на уровне законов физики. Обратимся к неравновесной
термодинамике открытых систем, обменивающихся с
окружающей средой энергией и веществом, поскольку именно в
таких условиях мы с вами и существуем. В течение 4,5 млрд лет
на Землю льются потоки свободной энергии солнечного
излучения, как впрочем и на все остальные планеты. Но, в
отличие от них, Земля научилась частично усваивать эту энергию,
превращая какую-то ее часть в информацию и накапливая ее
в виде закодированных определенным образом знаний.
Причем, скорость накопления этих знаний, как мы знаем, с
течением времени только увеличивалась.
Посмотрим, как это выглядит с точки зрения физики. В
открытых системах закон возрастания энтропии не работает.
Суммарная энтропия, конечно же, возрастает, но потоками
вещества и энергии она уносится из открытой системы, которая,
таким образом, является генератором энтропии и
потребителем свободной энергии. Например, Земля излучает в космос
столько же энергии, сколько получает от Солнца, но
свободная энергия этого излучения (с более низкой температурой)
ниже, а энтропия, соответственно, выше. Разницу входящей
и выходящей свободной энергии можно использовать для
совершения работы. Свидетельством тому — грозы, ураганы и
морские течения.
Так вот, основным законом неравновесной термодинамики
является закон максимизации скорости производства
энтропии: при существующих условиях система стремится к
такому состоянию, в котором она производит максимум энтропии
[Crooks, 1999]. Поддерживая тем самым естественную
тенденцию увеличения энтропии Вселенной.
Значит, в открытых системах работа тратится на
формирование структур с максимальной скоростью потребления
302
ЭВОЛЮЦИЯ РАЗУМА
свободной энергии. Если имеется несколько вариантов таких
структур, они конкурируют между собой и побеждают те,
которые пропускают через себя больше свободной энергии.
Например, те, кто активно ищут источники свободной энергии и
способны приспосабливаться к широкому кругу внешних
воздействий [Perunov и др., 2016].
Для этого их реакция на внешний мир должна быть
адаптивна, т.е. неслучайна. Это возможно, только если система
умеет использовать информацию о внешнем мире для
управления своим поведением. Такое управление, вспомним главу 3,
основывается на накопленных в процессе обучения знаниях.
Возникает алгоритм, кодирующий и использующий эти
знания, и управляющая система, исполняющая этот алгоритм —
машина. Чем больше знаний накоплено, тем шире
возможности адаптивного поведения по максимизации потребления
свободной энергии.
Но даже в отсутствие возможности увеличивать
потребление энергии, производство энтропии можно увеличивать,
накапливая в системе отрицательную энтропию, т.е.
информацию, иными словами — обучаясь1. Максимизация скорости
производства энтропии в этом случае эквивалентна
максимизации скорости обучения.
Таким образом, машинное обучение и его постоянное
ускорение следуют непосредственно из законов физики. Разумное
поведение машин возникает с той же непреложностью, с
какой возникают и более простые тепловые машины — те же
ураганы. Ураганы являются относительно стабильными дис-
сипативными структурами, но все же в конце концов слабеют
и распадаются. Чем стабильнее структуры, тем больше
энтропии они способны производить.
Конкурентное преимущество в итоге получают машины-
репликаторы, код которых обеспечивает их расширенное
воспроизводство. Размножение - это один из важнейших
аспектов адаптивного, т.е. разумного, поведения [Von Neumann, Burks
и др., 1966].
1 См. концепцию обратимых вычислений [Bennett, 1982].
10.2. Жизнь как форма, разума
303
Экспансия размножающихся машин экспоненциально
быстро увеличивает потребление ими свободной энергии, пока в их
распоряжении имеются свободные вещество и энергия.
Разные типы машин-репликаторов начинают конкурировать за
вещество и энергию. Возникает жизнь как первая форма
разума.
10.2. Жизнь как форма разума
Ранняя история химических репликаторов нам пока известна
не до конца, хотя в последние годы здесь наметился
значительный прогресс (см. например [Lane, 2015; Никитин, 2016]).
Но дальнейшая история, после того, как у них появился
общий код, записанный в молекулах ДНК, известна достаточно
хорошо. Сообщество живых организмов, поначалу — бактерий
и архей, активно обменивающихся кусками своих алгоритмов,
экспоненциально размножилось и превратилось в значимую
геологическую силу, определившую современный облик
Земли: химический состав ее атмосферы и коры, залежи
минералов и ландшафты [Журавлев, 2019].
Жизнь можно понять лишь как коллективный разум всех
составляющих ее организмов, пусть даже каждый из них
исполняет свой собственный алгоритм разумного поведения. Это
поведение является разумным только в контексте данного
биоценоза, а его происхождние можно объяснить, только изучая
историю развития этих биоценозов, т.е. в контексте эволюции.
Оставляя эту захватывающую историю в стороне2, оценим
лишь ее итоги, а именно: сколько знаний накоплено жизнью
в процессе эволюции и какие объемы свободной энергии она
контролирует.
Объем накопленных знаний или сложность современного
алгоритма жизни получим, мысленно собрав генетический
код всех организмов в единый текст и устранив в нем все
имеющиеся повторы. Для этого, во-первых, не будем делать
2 Для интересующихся: см. замечательную книгу [Lane, 2010].
304
ЭВОЛЮЦИЯ РАЗУМА
различий между генотипами представителей одного вида и,
во-вторых, опустим все повторы внутри генотипа, т.н.
"мусорную" ДНК.
Типичный генотип растений и животных содержит
порядка 104 генов, а типичный ген кодируется 103 буквами
генетического кода, т.е. сложность генотипа типичного вида 107 бит
[Koonin, 2011]. В природе существует около 107 видов. В итоге
для сложности алгоритма жизни получаем оценку 1014 бит.
Для сравнения, сложность операционной системы Windows
10, содержащей 50 млн строк кода, порядка 1010 бит. Иными
словами, жизнь в 10 000 раз сложнее операционной системы
современных компьютеров.
Энергетика жизни выглядит следующим образом.
Ежегодно на Земле образуется 170 млрд т первичной биомассы по
15 ГДж энергии на тонну. Отсюда, жизнь производит в год
около 1,7-1011 х 1,5 • 1010 « 3 • 1021 Дж. Разделив эту энергию
на 3 • 107 (число секунд в году), получим мощность
вырабатываемой жизнью энергии: 1014 Вт.
При такой продуктивности биосферы за более чем 600 млн
лет существования многоклеточных растений было
выработано 1,7 • 1011 х 6 • 108 = 1020 т биомассы — втрое больше,
чем масса всей земной коры. Так что жизнь реально
является значимым геологическим фактором. И управляет всей
этой энергией алгоритм, на 4 порядка сложнее самых
сложных компьютерных программ, созданных людьми.
При всем при том жизнь учится чрезвычайно медленно:
чтобы накопить 1014 бит ей потребовалось более 3,5 млрд лет
или 1017 секунд. Получаем скорость обучения жизни Ю-3
бит/с, что в 5 000 раз медленнее скорости усвоения
информации одним-единственным человеком!
10.3. Мозг как контроллер поведения
Генетический код вообще очень медлителен. "Включение"
нужного гена и синтез кодируемого им белка требует нескольких
10.3. Мозг как контроллер поведения
305
минут. Этого достаточно для контроля процессов
метаболизма, деления клеток и роста многоклеточных организмов, но,
скажем, управлять поведением животных генетический код
не способен. Для контроля движений в субсекундном
диапазоне ему нужен посредник — центральная нервная система,
т.е. мозг.
Специализация нервных клеток на передаче сенсорных и
управляющих сигналов началась уже с первых
многоклеточных. У кишечнополостных эти клетки служили посредниками
между внешним и внутренним слоями тела, координируя его
сокращения в нужные моменты .
Генетический код конструировал нервную систему на
этапе онтогенеза (какие нейроны и как контактируют друг с
другом и другими клетками), а нервная система управляла
движением в реальном времени. Аналогично тому, как
программисты разрабатывают код робота, который затем управляет
его поведением в реальном времени.
Побочным, но очень ценным свойством нервной системы
оказалась ее пластичность, способность адаптировать силу
взаимодействия нейронов между собой в зависимости от
частоты их коммуникаций. Это свойство нейронов наделяет
нервную системами способностью к обучению (хеббовское
обучение, см. раздел 3.3.2.).
У животных появилась возможность кроме
долговременной генетической памяти получить еще и оперативную память
мозга, накапливающую их личный жизненный опыт.
Обладание такой памятью оказалось ценным приспособительным
признаком, и какая-то часть животных, в частности
млекопитающие, стала специализироваться в направлении увеличения
соответствующих возможностей мозга4.
3 Дальний потомок этого первобытного "мозга" автономно управляет
работой и нашего кишечника и содержит примерно столько же нейронов,
как мозг кошки.
4 Мы уже упоминали, что 80% генов у млекопитающих экспрессиру-
ются в мозге, т.е. их генотип в основном определяет именно строение
мозга.
306
ЭВОЛЮЦИЯ РАЗУМА
Ключевой на этом пути стала инновация приматов,
датируемая около 50 млн лет назад (см. раздел 5.8.).
Иерархическая архитектура мозга приматов позволила им наращивать
число нейронов в мозге быстрее остальных групп
млекопитающих.
Абсолютным чемпионом по числу нейронов в мозге стал в
итоге homo sapiens. Он первый достиг критической сложности
мозга, в котором смогли появиться и жить репликаторы
нового типа — идеи. Речь идет, естественно, о появлении языка
и человеческой культуры.
10.4. Человеческий разум
Какими бы способностями к обучению ни обладал
индивидуальный мозг, все накопленные им знания пропадают со
смертью хозяина. Если только не найдется способа передать эти
знания потомству, как это делает генетический код.
Определенные способности к коммуникации с особями
своего вида имеются у всех живых организмов. Особенно
развиты они у общественных животных. Коммуникации связывают
их в единый сверхорганизм, координирующий действия
отдельных особей и способный решать гораздо более сложные
задачи. До человека такого уровня развития коммуникаций
достигали только общественные насекомые — муравьи,
термиты, пчелы и осы. Несмотря на небольшое число их видов,
суммарная масса общественных насекомых составляет 3/4 всей
биомассы насекомых [Е. Wilson, 2012].
Но язык общественных насекомых генетически
предопределен и эволюционирует крайне медленно. Если бы можно
было "поселить" язык в мозге, с его способностью к быстрому
обучению... Но большой мозг может быть только у крупных
животных, плотность которых в биоценозе слишком мала по
сравнению с плотностью насекомых.
Однако одному виду приматов, homo sapiens, в конечном
итоге все-таки удалось достичь статуса общественного жи-
10.4. Человеческий разум
307
вотного. Судя по всему, язык появился еще у homo erectus
[Everett, 2017], мозг которого увеличился вместе с
размерами тела благодаря переходу на вареную пищу [Wrangham,
2009]. Дальнейшее увеличение размеров мозга до уровня homo
sapiens, по-видимому, связано с развитием языковых
способностей homo erectus, т.е. именно язык "растянул" наш неокор-
текс до современных размеров. Если быть точнее, то
культура, определяющая и сложность общественной жизни, и
соответствующую ей сложность языка.
Появившаяся с обретением языка человеческая
цивилизация развивалась уже совсем другими темпами, чем
"цивилизации" насекомых. Давайте для сравнения оценим объем
знаний и энергетическую мощь нашей цивилизации через 105 лет
после ее возникновения.
Суммарный объем индивидуальных человеческих знаний
мы уже оценивали: 1020 байт (в разделе 2.3.1.). Однако, как и
в случае с генетическим кодом, мы должны учесть
многочисленные повторы одних и тех же идей в головах людей. Если
считать, что люди различаются, в основном, своими
профессиональными знаниями, то суммарный объем человеческих
знаний можно оценить, умножив знания одного человека
(типичного представителя определенной профессии - 1010 байт),
на количество профессий (порядка 105). Итого получим 1015
байт, или 1016 бит.
Таким образом, за ничтожное по эволюционным меркам
время человеческая цивилизация накопила существенно
больше знаний, чем вся земная жизнь за всю ее историю. То есть
человеческая цивилизация учится в миллионы раз быстрее,
чем остальная биосфера: 1016 бит /105 • 3 • 107 с = 3 • 103 бит/с
против Ю-3 бит/с.
Энергетические потоки, контролируемые человечеством,
если и не дотягивают до энергетики жизни, то совсем немного.
Человечество производит в год около 13,5 Гт нефтяного
эквивалента или 19 ТВт первичной энергии5. Это примерно пятая
5 ВР Statistical Review of World Energy, 2018.
308
ЭВОЛЮЦИЯ РАЗУМА
часть от энергии биомассы, ежегодно производимой жизнью.
То есть наш вид производит энергию, сравнимую с энергией
всех остальных ю7 видов живых существ. Таков сегодня
масштаб давления человека на биосферу Земли. Как следствие,
мы стали причиной очередного великого вымирания,
последовательно отнимая у остальных видов их жизненное
пространство (сельскохозяйственные земли составляют 38% всей
суши).
Фактически, одна форма разума на наших глазах
вытесняет другую, более медленную. Биосфера просто не успевает
адаптироваться к изменениям окружающего мира,
порождаемым цивилизацией. Более медленные генетические
репликаторы не успевают реагировать на динамику более быстрых
репликаторов, идей, определяющих эволюцию человеческого
общества. Для земной жизни этот процесс выглядит, как
внезапное вторжение чуждого сверхинтеллекта, которому
невозможно противостоять. И то, что этот интеллект порожден
самой жизнью, ничего в этом смысле не меняет. Сегодня только
сам человек способен остановить катастрофическое обеднение
разнообразия земной жизни6.
Как и для любого экспоненциального процесса, это
"восстание" человеческого разума оказалось для природы
неожиданным. Человечество сотню тысяч лет развивалось
относительно незаметно для земной биосферы, но за последние
несколько веков внезапно поставило ее на грань экологической
катастрофы. Ведь привычный для нас экономический рост
2-2,5% в год каждые сто лет увеличивает мощность нашей
цивилизации на порядок. А что такое сто лет в масштабе
эволюции?
Но сегодня и мы сами стали участниками похожего
процесса, появления еще более быстрого разума, растущего на
6 По оценкам Римского клуба, способность Земли регенерировать
отходы человеческой цивилизации была превышена еще в 2000 году, и
сегодня антропогенная нагрузка на биосферу более, чем на 30% превышает
несущую способность Земли [Медоуз и др., 2012].
10.5. Машинный интеллект
309
порядок не за 100, а за 10 лет. Только на этот раз мы
наблюдаем его с другой, более медленной, стороны. И, пока еще не
поздно, в наших интересах учесть печальный опыт прошлого.
10.5. Машинный интеллект
Подобно тому как первые нервные системы животных
являлись ускорителями возможностей генетического кода,
компьютеры появились как ускорители способностей
человеческого мозга. Вначале — для ускорения вычислений, что и
отразилось в их названии. Алгоритмы вычислений были
разработаны математиками задолго до этого. Более того, часть из
них уже была автоматизирована в механических
калькуляторах Паскаля, Лейбница и др. вплоть до счетных машинок
Mercedes, применявшихся для массовых вычислений в Ман-
хэттенском и других военных проектах7. Но в определенный
момент они перестали справляться с возросшим объемом
вычислений, и ассигнования на создание первой ЭВМ, ENIAC,
были выделены. Так, одним из итогов Второй мировой войны
стало появление электронной среды для нового вида
репликаторов — компьютерных программ.
Список алгоритмов, исполняемых компьютерами,
довольно быстро расширялся. Они стали обрабатывать не только
числа, но и любую символьную информацию, а затем, в эпоху
мультимедиа, и не только символьную. Однако все
компьютерные алгоритмы до появления машинного обучения
создавались и контролировались людьми.
Способность компьютеров к обучению является побочным
следствием наличия специального вида алгоритмов,
изменяющих свой собственный код для извлечения знаний из потоков
данных. Однако, как и в случае с мозгом, эта способность
7 Отметим в этой связи героическую попытку Чарльза Бэббиджа
создать универсальную механическую вычислительную машину в XIX в. -
до того, как на компьютеры сформировался платежеспособный спрос.
310
ЭВОЛЮЦИЯ РАЗУМА
оказалась в итоге ключевой, когда растущие по закону Мура
компьютерные мощности достигли критической точки,
позволяющей машинному обучению решать широкий класс задач
на уровне человека. Решение каждой такой задачи может
содержать сотни миллионов настроечных параметров, и
создание подобных программ "вручную" программистами просто
невозможно. Машинное обучение позволяет создавать такие
приложения дешево и массово, открывая дорогу тотальной
автоматизации — массовой замене людей на производстве (см.
главу 2).
Пока что мы находимся в самом начале этого процесса, но,
как показывают оценки предыдущей главы, этот
экспоненциальный процесс может вырваться из под контроля в не таком
уж далеком будущем. И мы заранее должны позаботиться о
том, чтобы машинный интеллект был наделен
соответствующими ценностями.
В фантастическом романе Лю Цысина «Проблема трех
тел» человечество сплачивается, готовясь к нашествию
внеземного разума, чей космический флот должен достичь
Земли через 400 лет. В действительности встреча с
"нечеловеческим" машинным разумом ожидает нас гораздо раньше, и у
нас осталось не так уж много времени, чтобы к нему
подготовиться!
Богатства биосферы имеют шанс уцелеть только
благодаря тому, что людям генетически присуща тяга и любовь к
живой природе и наши ценности включают в себя
естественное для нас желание эту природу сохранить. Просто потому,
что эстетическое чувство присуще всем высшим животным
на уровне инстинктов: красивое — значит полезное. Так,
самые красивые для нас места в дикой природе оказываются на
поверку и самыми безопасными (для наших предков).
Конструируя машинный интеллект, мы должны будем
привить ему аналогичные ценности по отношению к нам на уровне
его машинных инстинктов. Впрочем, довольно об опасностях.
Давайте посмотрим и на светлую сторону.
10.5. Машинный интеллект
311
Попробуем представить себе, до каких высот сможет
подняться машинный разум в далекой перспективе, за
горизонтом наших предсказаний. Что именно он будет из себя
представлять, мы сказать не можем, но можем сделать
соответствующие оценки, исходя из известных физических
ограничений.
Мы видели, что цивилизация накопила гораздо больше
знаний, чем жизнь, используя гораздо меньше энергии. Этот
тренд, естественно продолжится. Будут расти и доля
вычислений в энергозатратах человечества, и их
энергоэффективность. В пределе можно предположить, что в будущей
цифровой цивилизации основная энергия будет тратиться именно
на машинное мышление, а его энергоэффективность
приблизится к теоретическому максимуму: на обработку одного бита
будет тратиться энергия ~ кТ (3 • Ю-21 Дж при комнатной
температуре)8.
Представим себе, что машинный интеллект в будущем
будет питаться в основном солнечным излучением, потребляя
примерно столько же энергии, что и биосфера, т.е.
порядка 2 • 1015 Вт (чтобы не нарушать экологии). Это
возможно, т.к. к.п.д. солнечных элементов может на порядок
превышать к.п.д. фотосинтеза. Вычислительная мощность такой
машинной сверхцивилизации будет, следовательно, 2-Ю15 Вт /
3 • Ю-21 Дж ~ 1036 бит/с или 1035 FLOPS, что на 14
порядков превышает мощность коллективного человеческого
мышления. Представляете себе, каким может быть уровень
сознания у такого сверхразума?
Понимать его поступки люди, естественно, не смогут. Они
просто будут жить в "магическом" мире, управляемом
созданным при их участии богоподобным разумом (причем это будут
персонализированные миры, для каждого свой). Мы точно не
знаем, чем будет заполнена такая жизнь. Можем лишь
предположить, что возможностей у людей станет гораздо больше,
а уж как ими распорядиться, будет зависеть от самого
человека.
8 В принципе, это вполне достижимо — см. [J.-P. Wang и др., 2017].
312
ЭВОЛЮЦИЯ РАЗУМА
В этом сценарии "мифа наизнанку" не Бог создает
человека по своему образу и подобию, а, скорее, человек создает себе
Бога. Что, в общем-то, логично: при конечной сложности
алгоритма обучения результат обучения может быть сколь
угодно сложным.
Подытоживая, вернемся к тому, с чего мы начинали эту
главу. Разум, как мы выяснили, присущ природе, это
следует из статистической теории открытых систем. В закрытых
системах энтропия возрастает. Открытые системы
стремятся максимизировать производство энтропии, как бы помогая
природе поскорее достичь равновесия. Для этого открытые
системы должны быть максимально адаптированы к внешней
среде, т.е. уметь обучаться.
В силу определенных причин на Земле сложились
условия, благоприятные для зарождения разума, который, пройдя
через несколько стадий, подобно гегелевскому Духу, должен
в итоге прийти к осознанию самого себя, превратив косную
материю в мыслящую. Вправе ли мы препятствовать этому
естественному природному процессу? Не лучше ли нам стать
очередным звеном этой закономерной цепи, аккуратно
передав эстафету будущему машинному сверхинтеллекту?
"Вы должны стать родителями и садовниками, сеятелями
будущего" - так говорил Заратустра.
Глава 11
Эпилог. Несколько слов
о смысле жизни
Но ты, о Заратустра,
хотел увидеть основу и
изнанку всех вещей;
потому должен ты
подняться над самим
собою, всё выше и выше,
пока даже твои звёзды не
окажутся под тобой!
Ну что ж! Расстанемся
здесь! Но мне очень
хотелось бы снова
встретить тебя...
Фридрих Ницше
«Так говорил Заратустра»
Подошла к концу эта книга о машинном обучении как
науке о развитии разума. Автор искренне надеется, что,
размышляя о природе разума, мы хоть немного, но приблизились к
ответу на вечные вопросы: Кто мы? Откуда пришли? Куда
идем? И как наша личная судьба вписывается в этот путь?
314
ЭПИЛОГ. НЕСКОЛЬКО СЛОВ О СМЫСЛЕ ЖИЗНИ
Ведь книга, которая не приближает нас к ответу на главные
вопросы, подобна дороге, которая не ведет к храму.
Еще в институтские годы, обучаясь теоретической
физике, автор задался вопросом о смысле жизни как природного
явления. Жизнь, как известно, не противоречит физике [Шре-
дингер, 2018]. Но последняя не берется объяснить механизмы
усложнения материи, не объясняет, почему и как разум
эволюционирует.
Эту задачу решает друга наука, машинное обучение,
используя понятия информации и алгоритмов ее обработки и
абстрагируясь от физического субстрата механизмов,
реализующих эти алгоритмы.
Эта наука в силу сложившихся обстоятельств находится
сегодня в эпицентре новой научной революции, претендуя на
статус главной науки XXI в. Именно здесь должны вскоре
появиться новые Ньютоны и Эйнштейны науки о человеческом
и машинном разуме, а также фон Нейманы, определяющие
его будущую архитектуру.
И уж если выбирать себе занятие, которому не жалко
посвятить свою жизнь, имеет смысл искать его именно на
таком пути, открывающем наибольшие возможности для
самореализации. По крайней мере, лучшая из известных автору
формулировок смысла жизни связывает его с максимальной
реализацией своих природных способностей. Что, кстати,
доставляет и максимальное суммарное удовольствие от жизни,
т.к. допамин выделяется именно в моменты субъективных
открытий (и тем в большем количестве, чем они значительнее).
Эта формулировка годится как для индивидуального
разума, так и для Разума с большой буквы, частью которого мы
все являемся и который совместными усилиями развиваем.
Что может быть лучше максимального соответствия своего
личного и общего для всей природы пути, возможности стать
не просто свидетелем, а одним из творцов будущего разума?
"И пусть это будет вашим лучшим творением!"
Список литературы
Aharon, M. et al. (2006). "rmk-SVD: An algorithm for
designing overcomplete dictionaries for sparse representation". In:
IEEE Transactions on signal processing 54.11, pp. 4311-4322.
Aharonov, R. and N. Slonim (2019). "Watch IBM's AI System
Debate a Human Champion Live at Think 2019". In: IBM
Research blog. URL: https://www.ibm.com/blogs/research/
2019/02/ai-debate-think-2019/.
Amodei, D. et al. (2016). "Deep speech 2: End-to-end speech
recognition in english and mandarin". In: International
Conference on Machine Learning, pp. 173-182.
Arandjelovic, R. and A. Zisserman (2017). "Look, Listen and
Learn". In: arXiv preprint arXiv: 1705.08168.
Arjovsky, M. et al. (2017). "Wasserstein gan". In: arXiv preprint
arXiv.llOl. 07875.
Ashby, F. et al. (2005). "FROST: a distributed neurocomputa-
tional model of working memory maintenance". In: Journal
of cognitive neuroscience 17.11, pp. 1728-1743.
Baars, B. et al. (2013). "Global workspace dynamics: cortical
"binding and propagation" enables conscious contents". In:
Frontiers in psychology 4, p. 200.
Bach, J. (2018). "The Cortical Conductor Theory: Towards
Addressing Consciousness in AI Models". In: Biologically
Inspired Cognitive Architectures Meeting. Springer, pp. 16-26.
316
СПИСОК ЛИТЕРАТУРЫ
Bahdanau, D. et al. (2014). "Neural machine translation by
jointly learning to align and translate". In: arXiv preprint
arXiv:1409.0473.
Barrett, L. (2017). How emotions are made: The secret life of
the brain. Houghton Mifflin Harcourt.
Barrett, L. and W. Simmons (2015). "Interoceptive predictions
in the brain". In: Nature Reviews Neuroscience 16.7, p. 419.
Bastos, A. et al. (2012). "Canonical microcircuits for predictive
coding". In: Neuron 76.4, pp. 695-711.
Battaglia, F. et al. (2011). "The hippocampus: hub of brain
network communication for memory". In: Trends in cognitive
sciences 15.7, pp. 310-318.
Bednar, J. and S. Wilson (2016). "Cortical maps". In: The Neu-
roscientist 22.6, pp. 604-617.
Beinhocker, E. (2006). The origin of wealth: Evolution,
complexity, and the radical remaking of economics. Harvard Business
Press.
Bell, T. et al. (1990). Text compression. Vol. 348. Prentice Hall
Englewood Cliffs.
Bengio, Y. (2013). "Deep learning of representations: Looking
forward". In: International Conference on Statistical
Language and Speech Processing. Springer, pp. 1-37.
Bengio, Y. et al. (2009). "Learning deep architectures for Al". In:
Foundations and trends in Machine Learning 2.1, pp. 1-127.
Bengio, Y., I. Goodfellow, et al. (2015). "Deep learning". In:
Nature 521, pp. 436-444.
Bengio, Y., P. Lamblin, et al. (2007). "Greedy layer-wise
training of deep networks". In: Advances in neural information
processing systems, pp. 153-160.
Bennett, С. Н. (1982). "The thermodynamics of computation—a
review". In: International Journal of Theoretical Physics 21.12,
pp. 905-940.
Berthelot, D. et al. (2017). "Began: Boundary equilibrium
generative adversarial networks". In: arXiv preprint arXiv.l 703.10717.
СПИСОК ЛИТЕРАТУРЫ
317
Bishop, С. М. (2006). Pattern recognition and machine learning.
Springer.
Blei, D. M. et al. (2003). "Latent dirichlet allocation". In:
Journal of machine Learning research 3.Jan, pp. 993-1022.
Botvinick, M. M. (2012). "Hierarchical reinforcement learning
and decision making". In: Current opinion in neurobiology
22.6, pp. 956-962.
Boucsein, C. et al. (2011). "Beyond the cortical column:
abundance and physiology of horizontal connections imply a strong
role for inputs from the surround". In: Frontiers in neuro-
science 5, p. 32.
Bray, A. J. and D. S. Dean (2007). "Statistics of critical points
of gaussian fields on large-dimensional spaces". In: Physical
review letters 98.15, p. 150201.
Brown, P. F. et al. (1992). "Class-based n-gram models of natural
language". In: Computational linguistics 18.4, pp. 467-479.
Bughin, J. et al. (2017). "Artificial intelligence-the next digital
frontier". In: McKinsey Global Institute. URL: https://
www. °/020mckinsey. °/020de/f iles/1706200/05C_studie0/05C_ai.
°/020pdf.
Bughin, J. et al. (2018). "Notes from the Al frontier: Modeling
the impact of Al on the world economy". In: McKinsey Global
Institute.
Buzsaki, G. (2006). Rhythms of the Brain. Oxford University
Press.
Buzsaki, G. and E. I. Moser (2013). "Memory, navigation and
theta rhythm in the hippocampal-entorhinal system". In:
Nature neuroscience 16.2, p. 130.
Carlin, B. P. and T. A. Louis (2010). Bayes and empirical Bayes
methods for data analysis. Chapman and Hall/CRC.
Chiu, С. С. et al. (2018). "State-of-the-art speech recognition
with sequence-to-sequence models". In: 2018 IEEE
International Conference on Acoustics, Speech and Signal Processing
(ICASSP). IEEE, pp. 4774-4778.
318
СПИСОК ЛИТЕРАТУРЫ
Chomsky, N. (1986). Knowledge of language: Its nature, origin,
and use. Greenwood Publishing Group.
— (2014). The minimalist program. MIT press.
Cire§an, D., A. Giusti, et al. (2012). "Deep neural networks
segment neuronal membranes in electron microscopy images". In:
Advances in neural information processing systems, pp. 2843-
2851.
— (2013). "Mitosis detection in breast cancer histology images
with deep neural networks". In: International Conference on
Medical Image Computing and Computer-assisted
Intervention. Springer, pp. 411-418.
Cire§an, D., U. Meier, et al. (2012). "Multi-column deep neural
network for traffic sign classification". In: Neural Networks
32, pp. 333-338.
Clark, A. (2015). Surfing uncertainty: Prediction, action, and
the embodied mind. Oxford University Press.
Cole, M. W. et al. (2013). "Multi-task connectivity reveals
flexible hubs for adaptive task control". In: Nature neuroscience
16.9, p. 1348.
Collobert, R. et al. (2011). "Natural language processing
(almost) from scratch". In: Journal of machine learning research
12.Aug, pp. 2493-2537.
Conneau, A. et al. (2017). "Word translation without parallel
data". In: arXiv preprint arXiv: 1710.04087.
Crooks, G. E. (1999). "Entropy production fluctuation theorem
and the nonequilibrium work relation for free energy
differences". In: Physical Review E 60.3, p. 2721.
D'Angelo, E. (2011). "Neural circuits of the cerebellum:
hypothesis for function". In: Journal of integrative neuroscience 10.03,
pp. 317-352.
D'Angelo, E. and С. А. М. Wheeler-Kingshott (2017).
"Modelling the brain: elementary components to explain ensemble
functions". In: Riv. del nuovo Cim 40, pp. 297-333.
Deacon, T. W. (1998). The symbolic species: The co-evolution
of language and the brain. WW Norton & Company.
СПИСОК ЛИТЕРАТУРЫ
319
Dean, J. et al. (2012). "Large scale distributed deep networks".
In: Advances in neural information processing systems, pp. 1223-
1231.
Dean, P. et al. (2010). "The cerebellar microcircuit as an adaptive
filter: experimental and computational evidence". In: Nature
Reviews Neuroscience 11.1, p. 30.
Dean, T. (2005). "A computational model of the cerebral
cortex". In: Proceedings of the National Conference on Artificial
Intelligence. Vol. 20. 2. Menlo Park, CA; Cambridge, MA;
London; AAAI Press; MIT Press; 1999, p. 938.
Dehaene, S. (2014). Consciousness and the brain: Deciphering
how the brain codes our thoughts. Penguin.
Dehaene, S. et al. (2017). "What is consciousness, and could
machines have it?" In: Science 358.6362, pp. 486-492.
Deisenroth, M. P. et al. (2013). "A survey on policy search
for robotics". In: Foundations and Trends in Robotics 2.1-2,
pp. 1-142.
Derdikman, D. et al. (2003). "Imaging spatiotemporal dynamics
of surround inhibition in the barrels somatosensory cortex".
In: Journal of Neuroscience 23.8, pp. 3100-3105.
Desjardins, J. (2018). "The 8 Major Forces Shaping the Future
of the Global Economy". In: URL: https : //worldview .
stratfor.com/article/8-maj or-forces-shaping-future-
global-economy.
Dosovitskiy, A. and V. Koltun (2016). "Learning to act by
predicting the future". In: arXiv preprint arXiv:1611.01779.
Douglas, R. J and К. А. С Martin (2007). "Recurrent neuronal
circuits in the neocortex". In: Current biology 17.13, R496-
R500.
Doya, K. (2000). "Complementary roles of basal ganglia and
cerebellum in learning and motor control". In: Current opinion
in neurobiology 10.6, pp. 732-739.
Dunbar, R. (1992). "Neocortex size as a constraint on group size
in primates". In: Journal of human evolution 22.6, pp. 469-
493.
320
СПИСОК ЛИТЕРАТУРЫ
Eagleman, D. (2011). Incognito: The Secret Lives of the Brain.
New York City: Pantheon.
Eliasmith, C. et al. (2012). aA large-scale model of the
functioning brain". In: science 338.6111, pp. 1202-1205.
Everett, D. (2017). How language began: the story of humanity's
greatest invention. Profile Books.
Faisal, A. et al. (2010). "The manipulative complexity of Lower
Paleolithic stone toolmaking". In: PloS one 5.11, el3718.
Fan, B. et al. (2015). "Photo-real talking head with deep
bidirectional LSTM". In: Acoustics, Speech and Signal Processing
(ICASSP), 2015 IEEE International Conference on. IEEE,
pp. 4884-4888.
Faruqui, M. et al. (2015). "Sparse overcomplete word vector
representations". In: arXiv preprint arXiv: 1506.02004-
Frank M. Jand Badre, D. (2011). "Mechanisms of hierarchical
reinforcement learning in corticostriatal circuits 1:
computational analysis". In: Cerebral cortex 22.3, pp. 509-526.
Frank, M. et al. (2001). "Interactions between frontal cortex and
basal ganglia in working memory: a computational model".
In: Cognitive, Affective ,& Behavioral Neuroscience 1 2 pp 137-
160.
Franklin, S. et al. (2014). "LIDA: A systems-level architecture
for cognition, emotion, and learning". In: IEEE Transactions
on Autonomous Mental Development 6.1, pp. 19-41.
Friston, K. (2005). "A theory of cortical responses". In:
Philosophical transactions of the Royal Society B: Biological
sciences 360.1456, pp. 815-836.
Friston, K. et al. (2015). "Active inference and epistemic value".
In: Cognitive neuroscience 6.4, pp. 187-214.
Fukushima, K. (1979). "Neural Network Model for a
Mechanism of Pattern Recognition Unaffected by Shift in Position-
Neocognitron". In: Electron. & Commun. Japan 62.10,
pp. 11-18.
Fuster, J. M. (2003). Cortex and mind: Unifying cognition.
Oxford university press.
СПИСОК ЛИТЕРАТУРЫ
321
Garipov, Т. et al. (2016). "Ultimate tensorization:
compressing convolutional and fc layers alike". In: arXiv preprint
arXiv:1611.0321l
Gatys, L. A. et al. (2015). "A neural algorithm of artistic style".
In: arXiv preprint arXiv:1508.06576.
Gavrilets, S. and A. Vose (2006). "The dynamics of
Machiavellian intelligence". In: Proceedings of the National Academy of
Sciences 103.45, pp. 16823-16828.
Gehring, J. et al. (2017). "Convolutional Sequence to Sequence
Learning". In: arXiv preprint arXiv: 1705.03122.
George, D. and J. Hawkins (2009). "Towards a mathematical
theory of cortical micro-circuits". In: PLoS computational
biology 5.10, el000532.
Ghuman, A. S. et al. (2014). "Dynamic encoding of face
information in the human fusiform gyrus". In: Nature
communications 5, p. 5672.
Goodfellow, I. et al. (2014). "Generative adversarial nets". In:
Advances in neural information processing systems, pp. 2672-
2680.
Graves, A. (2013). "Generating sequences with recurrent neural
networks". In: arXiv preprint arXiv:1308.0850.
Graves, A., S. Fernandez, et al. (2006). "Connectionist
temporal classification: labelling unsegmented sequence data with
recurrent neural networks". In: Proceedings of the 23rd
international conference on Machine learning. ACM, pp. 369-
376.
Graves, A., A. Mohamed, et al. (2013). "Speech recognition with
deep recurrent neural networks". In: Acoustics, speech and
signal processing (icassp), 2013 ieee international conference
on. IEEE, pp. 6645-6649.
Gurney, K. et al. (2001). "A computational model of action
selection in the basal ganglia. I. A new functional anatomy".
In: Biological cybernetics 84.6, pp. 401-410.
Hagmann, P. et al. (2008). "Mapping the structural core of
human cerebral cortex". In: PLoS biology 6.7, el59.
322
СПИСОК ЛИТЕРАТУРЫ
Han, S., Н. Мао, et al. (2015). "Deep compression: Compressing
deep neural networks with pruning, trained quantization and
huffman coding". In: arXiv preprint arXiv: 1510.00Ц9.
Han, S., J. Pool, et al. (2015). "Learning both weights and
connections for efficient neural network". In: Advances in neural
information processing systems, pp. 1135-1143.
Hauser, M. D. et al. (2002). "The faculty of language: what is
it, who has it, and how did it evolve?" In: science 298.5598,
pp. 1569-1579.
Hawkins, J. and S. Ahmad (2016). "Why neurons have thousands
of synapses, a theory of sequence memory in neocortex". In:
Frontiers in neural circuits 10, p. 23.
Hawkins, J., S. Ahmad, and Y. Cui (2017). "A Theory of How
Columns in the Neocortex Enable Learning the Structure of
the World". In: Frontiers in neural circuits 11, p. 81.
Hawkins, J., D. George, et al. (2009). "Sequence memory for
prediction, inference and behaviour". In: Philosophical
Transactions of the Royal Society B: Biological Sciences 364.1521,
pp. 1203-1209.
He, K. et al. (2015). "Delving deep into rectifiers: Surpassing
human-level performance on imagenet classification". In:
Proceedings of the IEEE international conference on computer
vision, pp. 1026-1034.
— (2016). "Deep residual learning for image recognition". In:
Proceedings of the IEEE conference on computer vision and
pattern recognition, pp. 770-778.
Hebb, D. O. (2005). The organization of behavior: A
neuropsychological theory. Psychology Press.
Herculano-Houzel, S. (2016). The human advantage: a new
understanding of how our brain became remarkable. MIT Press.
Hilbert, M. and P. Lopez (2011). "The world's technological
capacity to store, communicate, and compute information." In:
Science (New York, NY) 332.6025, pp. 60-65.
СПИСОК ЛИТЕРАТУРЫ
323
Hinton, G., S. Osindero, et al. (2006). "A fast learning algorithm
for deep belief nets". In: Neural computation 18.7, pp. 1527-
1554.
Hinton, G., N. Srivastava, A. Krizhevsky, et al. (2012).
"Improving neural networks by preventing co-adaptation of feature
detectors". In: arXiv preprint arXiv:1207.05'80.
Hinton, G., N. Srivastava, and K. Swersky (2012). "RMSProp:
Divide the gradient by a running average of its recent
magnitude". In: Cited on 14.
Hochreiter, S., Y.a Bengio, et al. (2001). Gradient flow in
recurrent nets: the difficulty of learning long-term dependencies.
Hochreiter, S. and J. Schmidhuber (1997). "Long short-term
memory". In: Neural computation 9.8, pp. 1735-1780.
Hofmann, T. (2001). "Unsupervised learning by probabilistic
latent semantic analysis". In: Machine learning 42.1, pp. 177-
196.
Huang, F. J. et al. (2007). "Unsupervised learning of
invariant feature hierarchies with applications to object
recognition". In: Computer Vision and Pattern Recognition, 2007.
CVPR'07. IEEE Conference on. IEEE, pp. 1-8.
Huang, G., Z. Liu, et al. (2016). "Densely connected convolu-
tional networks". In: arXiv preprint arXiv: 1608.06993.
Huang, G., Y. Sun, et al. (2016). "Deep networks with
stochastic depth". In: European Conference on Computer Vision.
Springer, pp. 646-661.
Huth, A. G. et al. (2016). "Natural speech reveals the semantic
maps that tile human cerebral cortex". In: Nature 532.7600,
pp. 453-458.
IFPMA (2017). The pharmaceutical industry and global health.
Facts and figures. URL: https : / /www . ifpma . org/wp -
content/uploads/2017/02/IFPMA-Facts-And-Figures -
2017.pdf.
Ioffe, S. and C. Szegedy (2015). "Batch normalization:
Accelerating deep network training by reducing internal covariate
324
СПИСОК ЛИТЕРАТУРЫ
shift". In: International Conference on Machine Learning,
pp. 448-456.
Ito, M. and K. Doya (2011). "Multiple representations and
algorithms for reinforcement learning in the cortico-basal ganglia
circuit". In: Current opinion in neurobiology 21.3, pp. 368-
373.
Izhikevich, E. M. and G. M. Edelman (2008). "Large-scale model
of mammalian thalamocortical systems". In: Proceedings of
the national academy of sciences 105.9, pp. 3593-3598.
Jackendoff, R. (2007). Language, consciousness, culture: Essays
on mental structure. Vol. 2007. MIT Press.
Jaderberg, M. et al. (2016). "Reinforcement learning with
unsupervised auxiliary tasks". In: arXiv preprint arXiv:1611.05397.
Jozefowicz, R. et al. (2015). "An empirical exploration of
recurrent network architectures". In: Proceedings of the 32nd
International Conference on Machine Learning (ICML-15),
pp. 2342-2350.
Jurafsky, D. and J. Martin (2014). Speech and language
processing. Vol. 3. Pearson London.
Kahneman, D. (2011). Thinking, fast and slow. Macmillan.
Kanerva, P. (2009). "Hyperdimensional computing: An
introduction to computing in distributed representation with high-
dimensional random vectors". In: Cognitive Computation 1.2,
pp. 139-159.
Kawato, M. (2007). "Cerebellum: models". In: Encyclopedia of
neuroscience.
Keskar, N. S. et al. (2016). "On large-batch training for deep
learning: Generalization gap and sharp minima". In: arXiv
preprint arXiv: 1609.04836.
Kesner, R. P. and E. T. Rolls (2015). "A computational theory
of hippocampal function, and tests of the theory: new
developments". In: Neuroscience & Biobehavioral Reviews 48,
pp. 92-147.
Khamassi, M. and M. D. Humphries (2012). "Integrating cortico-
limbic-basal ganglia architectures for learning model-based
СПИСОК ЛИТЕРАТУРЫ
325
and model-free navigation strategies". In: Frontiers in
behavioral neuroscience 6, p. 79.
Kingma, D. and J. Ba (2014). "Adam: A method for stochastic
optimization". In: arXiv preprint arXiv.-Ц 12.6980.
Klein, D. and С D. Manning (2004). "Corpus-based
induction of syntactic structure: Models of dependency and
constituency". In: Proceedings of the 42nd Annual Meeting on
Association for Computational Linguistics. Association for
Computational Linguistics, p. 478.
Kohonen, T. (1982). "Self-organized formation of topologically
correct feature maps". In: Biological cybernetics 43.1, pp. 59-
69.
— (2001). Self-Organizing Maps. Springer-Verlag New York.
Kong, A., M. Frigge, et al. (2017). "Selection against variants
in the genome associated with educational attainment". In:
Proceedings of the National Academy of Sciences 114.5, E727-
E732.
Koomey, J. and S. Naffziger (2015). "Moore's Law might be
slowing down, but not energy efficiency". In: IEEE Spectrum.
Koonin, E. (2011). The logic of chance: the nature and origin of
biological evolution. FT press.
Koziol, L. .F et al. (2014). "Structure and function of large-
scale brain systems". In: Applied Neuropsychology: Child 3.4,
pp. 236-244.
Koziol, L. and D. Budding (2009). Subcortical structures and
cognition: Implications for neuropsychological assessment. Springer
Science & Business Media.
Koziol, L., D. Budding, et al. (2014). "Consensus paper: the
cerebellum's role in movement and cognition". In: The Cerebellum
13.1, pp. 151-177.
Kremer, M. (1993). "Population growth and technological change:
One million ВС to 1990". In: The Quarterly Journal of
Economics 108.3, pp. 681-716.
326
СПИСОК ЛИТЕРАТУРЫ
Krizhevsky, A. et al. (2012). "Imagenet classification with deep
convolutional neural networks". In: Advances in neural
information processing systems, pp. 1097-1105.
Laird, J. E. et al. (2017). "A Standard Model of the Mind:
Toward a Common Computational Framework Across Artificial
Intelligence, Cognitive Science, Neuroscience, and Robotics."
In: Al Magazine 38.4.
Lample, G. et al. (2017). "Unsupervised machine translation using
monolingual corpora only". In: arXiv preprint arXiv: 1711.00043.
Lane, N. (2010). Life ascending: the ten great inventions of
evolution. Profile books.
— (2015). The vital question: energy, evolution, and the origins
of complex life. WW Norton & Company.
Lange, S. and M. Riedmiller (2010). "Deep auto-encoder
neural networks in reinforcement learning". In: Neural Networks
(IJCNN), The 2010 International Joint Conference on. IEEE,
pp. 1-8.
Laukien,E .et al .(2016) ."Feynman Machine: The Universal
Dynamical Systems Computer". In: arXiv preprint arXiv:1609.03971.
Le, Q. V. (2013). "Building high-level features using large scale
unsupervised learning". In: Acoustics, Speech and Signal
Processing (ICASSP), 2013 IEEE International Conference on.
IEEE, pp. 8595-8598.
LeCun, Y., Y. Bengio, et al. (2015). "Deep learning". In: Nature
521.7553, pp. 436-444.
LeCun, Y., B. Boser, et al. (1989). "Backpropagation applied to
handwritten zip code recognition". In: Neural computation
1.4, pp. 541-551.
LeCun, Y., L. Bottou, et al. (1998). "Gradient-based learning
applied to document recognition". In: Proceedings of the IEEE
86.11, pp. 2278-2324.
Lee, K.-F. (2018). Al Superpowers: China, Silicon Valley, and
the New World Order. Houghton Mifflin.
Lei, T. et al. (2018). "Simple recurrent units for highly paralleliz-
able recurrence". In: Proceedings of the 2018 Conference on
СПИСОК ЛИТЕРАТУРЫ
327
Empirical Methods in Natural Language Processing, pp. 4470-
4481.
Lein, E. S. et al. (2007). "Genome-wide atlas of gene expression
in the adult mouse brain". In: Nature 445.7124, p. 168.
Lennie, P. (2003). "The cost of cortical computation". In:
Current biology 13.6, pp. 493-497.
Levy, O. and Y. Goldberg (2014). "Neural word embedding as
implicit matrix factorization". In: Advances in neural
information processing systems, pp. 2177-2185.
Lillicrap, T. P. et al. (2015). "Continuous control with deep
reinforcement learning". In: arXiv preprint arXiv: 1509.02971.
Manyika, J. et al. (2017). The productivity puzzle: a closer look
at the United States. McKinsey Global Institute.
March, J. G. (1991). "Exploration and exploitation in
organizational learning". In: Organization science 2.1, pp. 71-87.
Markram, H. et al. (2015). "Reconstruction and simulation of
neocortical microcircuitry". In: Cell 163.2, pp. 456-492.
Mateos, D. et al. (2017). "Consciousness as a global property of
brain dynamic activity". In: Physical Review E 96.6, p. 062410.
Mikolov, T. et al. (2013). "Efficient estimation of word
representations in vector space". In: arXiv preprint arXiv:1301.3781.
Mitchell, M. (1998). An introduction to genetic algorithms.
Mnih, V., A. Badia, et al. (2016). "Asynchronous methods for
deep reinforcement learning". In: International Conference
on Machine Learning, pp. 1928-1937.
Mnih, V., K. Kavukcuoglu, et al. (2013). "Playing atari with deep
reinforcement learning". In: arXiv preprint arXiv: 1312.5602.
— (2015). "Human-level control through deep reinforcement
learning". In: Nature 518.7540, p. 529.
Molchanov, D. et al. (2017). "Variational dropout sparsifies deep
neural networks". In: arXiv preprint arXiv: 1701.05369.
Moser, E. I. et al. (2008). "Place cells, grid cells, and the brain's
spatial representation system". In: Annual review of neuro-
science 31.
328
СПИСОК ЛИТЕРАТУРЫ
Mountcastle, V. В. (2003). "Introduction". In: Cerebral cortex
13.1, pp. 2-4.
Muller, U. et al. (2006). "Off-road obstacle avoidance through
end-to-end learning". In: Advances in neural information
processing systems, pp. 739-746.
Naik, V. (2014). Distribution of computation. URL: https://
intelligence . org/wp- content/uploads/2014/02/Naik-
Distribution-of-Computation.pdf.
Nair, V. and G. Hinton (2010). "Rectified linear units improve
restricted boltzmann machines". In: Proceedings of the 27th
international conference on machine learning (ICML-10), pp. 807-
814.
Nevill-Manning, С and I. Witten (1997). "Identifying
hierarchical structure in sequences: A linear-time algorithm". In:
Journal of Artificial Intelligence Research 7, pp. 67-82.
Nguyen, A. et al. (2016). "Plug & play generative networks:
Conditional iterative generation of images in latent space". In:
arXiv preprint arXiv:1612.00005.
Novikov, A. et al. (2015). "Tensorizing neural networks". In:
Advances in neural information processing systems, pp. 442-
450.
O'Reilly, R. and M. Frank (2006). "Making working memory
work: a computational model of learning in the prefrontal
cortex and basal ganglia". In: Neural computation 18.2, pp. 283-
328.
O'Reilly, R., D. Wyatte, et al. (2014). "Learning through time in
the thalamocortical loops". In: arXiv preprint arXiv:1407.3432.
Oja, E. (1982). "Simplified neuron model as a principal
component analyzer". In: Journal of mathematical biology 15.3,
pp. 267-273.
Oja, E. and J. Karhunen (1995). "Signal separation by
nonlinear Hebbian learning". In: Computational intelligence: A
dynamic system perspective. Citeseer, pp. 83-97.
Oseledets, I. (2011). "Tensor-train decomposition". In: SI AM
Journal on Scientific Computing 33.5, pp. 2295-2317.
СПИСОК ЛИТЕРАТУРЫ
329
Palm, G. (2013). "Neural associative memories and sparse
coding". In: Neural Networks 37, pp. 165-171.
Panetta, K. (2018). 5 Trends Emerge in the Gartner Hype Cycle
for Emerging Technologies, 2018. https : //www . gartner .
com/smarterwithgartner/5-trends- emerge- in-gartner-
hype-cycle-for-emerging-technologies-2018/.
Pearl, J. and D. Mackenzie (2018). The Book of Why: The New
Science of Cause and Effect. Basic Books.
Peiser, J. (Feb. 5, 2019). "The Rise of the Robot Reporter". In:
The New York Times.
Pennington, J. et al. (2014). "Glove: Global vectors for word
representation". In: Proceedings of the 20Ц conference on
empirical methods in natural language processing (EMNLP),
pp. 1532-1543.
Perunov, N. et al. (2016). "Statistical physics of adaptation". In:
Physical Review X 6.2, p. 021036.
Pinker, S. (2003). The language instinct: How the mind creates
language. Penguin UK.
Poultney, C. et al. (2007). "Efficient learning of sparse
representations with an energy-based model". In: Advances in neural
information processing systems, pp. 1137-1144.
Power, J., A. Cohen, et al. (2011). "Functional network
organization of the human brain". In: Neuron 72.4, pp. 665-678.
Press, G. (Sept. 2018). "The Thriving Al Landscape In Israel
And What It Means For Global Al Competition". In: Forbes.
https : //www. f orbes . com/sites/gilpress/2018/09/24/
the-thriving-ai- landscape- in- israel-and-what- it-
means-for-global-ai-competition.
Pulvermuller, F. (2013). "How neurons make meaning: brain
mechanisms for embodied and abstract-symbolic semantics".
In: Trends in cognitive sciences 17.9, pp. 458-470.
Radford, A., L. Metz, et al. (2015). "Unsupervised
representation learning with deep convolutional generative adversarial
networks". In: arXiv preprint arXiv:1511.06434-
330
СПИСОК ЛИТЕРАТУРЫ
Radford, A., J. Wu, et al. (2019). "Language models are
unsupervised multitask learners". In: OpenAI Blog 1, p. 8.
Raghu, M. et al. (2016). "On the expressive power of deep neural
networks". In: arXiv preprint arXiv: 1606.05336.
Ramstead, M. et al. (2019). Multiscale Integration: Beyond In-
ternalism and Externalism.
Reed, S. et al. (2016). "Generative adversarial text to image
synthesis". In: arXiv preprint arXiv: 1605.05396.
Reiner, A. et al. (1998). "Structural and functional evolution of
the basal ganglia in vertebrates". In: Brain Research Reviews
28.3, pp. 235-285.
Reynolds, J. and R. O'Reilly (2009). "Developing PFC
representations using reinforcement learning". In: Cognition 113.3,
pp. 281-292.
Ribary, U. (2005). "Dynamics of thalamo-cortical network
oscillations and human perception". In: Progress in brain research
150, pp. 127-142.
Rinkus, G. (2010). "A cortical sparse distributed coding model
linking mini-and macrocolumn-scale functionality". In:
Frontiers in neuroanatomy 4, p. 17.
Rissanen, J. (1978). "Modeling by shortest data description". In:
Automatica 14.5, pp. 465-471.
Rolls, E. T. (2010). "A computational theory of episodic
memory formation in the hippocampus". In: Behavioural brain
research 215.2, pp. 180-196.
Rosenblatt, F. (1958). "The perceptron: a probabilistic model
for information storage and organization in the brain." In:
Psychological review 65.6, p. 386.
Russo, D. et al. (2018). "A tutorial on Thompson sampling". In:
Foundations and Trends@ in Machine Learning 11.1, pp. 1-
96.
Sabour, S. et al. (2017). "Dynamic routing between capsules". In:
Advances in Neural Information Processing Systems, pp. 3859-
3869.
СПИСОК ЛИТЕРАТУРЫ
331
Saffran, J. R. et al. (2001). "The acquisition of language by
children". In: Proceedings of the National Academy of Sciences
98.23, pp. 12874-12875.
Salakhutdinov, R. et al. (2007). "Restricted Boltzmann machines
for collaborative filtering". In: Proceedings of the 24th
international conference on Machine learning. ACM, pp. 791-798.
Saletin, J. and M. Walker (2012). "Nocturnal mnemonics: sleep
and hippocampal memory processing". In: Frontiers in
neurology 3, p. 59.
Salton, G. et al. (1975). "A vector space model for automatic
indexing". In: Communications of the ACM 18.11, pp. 613—
620.
Santoro, A. et al. (2017). "A simple neural network module for
relational reasoning". In: arXiv preprint arXiv: 1706.0Ц27.
Schlaffke, L. et al. (2017). "Dynamic changes of resting state
connectivity related to the acquisition of a lexico-semantic
skill". In: Neurolmage 146, pp. 429-437.
Schmidhuber, J. (2015). "Deep learning in neural networks: An
overview". In: Neural networks 61, pp. 85-117.
Shazeer, N. et al. (2017). "Outrageously large neural networks:
The sparsely-gated mixture-of-experts layer ."In: arXiv preprint
arXiv:1701.06538.
Shen, J. et al. (2018). "Natural tts synthesis by conditioning
wavenet on mel spectrogram predictions". In: 2018 IEEE
International Conference on Acoustics, Speech and Signal
Processing (ICASSP). IEEE, pp. 4779-4783.
Shen, X. et al. (2017). "Estimation of Gap Between Current
Language Models and Human Performance." In: INTERSPEECH,
pp. 553-557.
Shipp, S. et al. (2013). "Reflections on agranular architecture:
predictive coding in the motor cortex". In: Trends in neuro-
sciences 36.12, pp. 706-716.
Shoham, Y. et al. (2018). The Al Index 2018 Annual Report.
Stanford University.
332
СПИСОК ЛИТЕРАТУРЫ
Silver, D., A. Huang, et al. (2016). "Mastering the game of
Go with deep neural networks and tree search". In: Nature
529.7587, pp. 484-489.
Silver, D., T. Hubert, et al. (2017). "Mastering Chess and Shogi
by Self-Play with a General Reinforcement Learning
Algorithm". In: arXiv preprint arXiv: 1712.01815.
Simonyan, K. and A. Zisserman (2014). "Very deep convolutional
networks for large-scale image recognition". In: arXiv preprint
arXiv:1409.1556.
Solari, S. and R. Stoner (2011). "Cognitive consilience: primate
non-primary neuroanatomical circuits underlying cognition".
In: Frontiers in neuroanatomy 5, p. 65.
Soltau, H. и др. (2016). «Neural speech recognizer: Acoustic-to-
word LSTM model for large vocabulary speech recognition».
B: arXiv preprint arXiv: 1610.09975.
Sonoda, S. and N. Murata (2019). "Transport Analysis of
Infinitely Deep Neural Network". In: Journal of Machine
Learning Research 20.2, pp. 1-52.
Spaak, E. et al. (2012). "Layer-specific entrainment of gamma-
band neural activity by the alpha rhythm in monkey visual
cortex". In: Current Biology 22.24, pp. 2313-2318.
Spratling, M. W. (2017). "A review of predictive coding
algorithms". In: Brain and cognition 112, pp. 92-97.
Sprechmann, P. and G. Sapiro (2010). "Dictionary learning and
sparse coding for unsupervised clustering". In: Acoustics Speech
and Signal Processing (ICASSP), 2010 IEEE International
Conference on. IEEE, pp. 2042-2045.
Srivastava, N. et al. (2014). "Dropout: a simple way to
prevent neural networks from overfitting." In: Journal of machine
learning research 15.1, pp. 1929-1958.
Stachenfeld, K. et al. (2017). "The hippocampus as a predictive
map". In: Nature neuroscience 20.11, p. 1643.
STATISTA (2018). Number of apps available in leading app stores
as of 3rd quarter 2018. URL: https : //www . statista .
СПИСОК ЛИТЕРАТУРЫ
333
com/ statistics/276623/number- of - apps - available -
in-leading-app-stores/.
Steeg, G. (2017). "Unsupervised learning via total correlation
explanation". In: arXiv preprint arXiv:1706.08984-
Steeg, G. and A. Galstyan (2017). "Low complexity gaussian
latent factor models and a blessing of dimensionality". In:
arXiv preprint arXiv:1706.03353.
Stolcke, A. and S. Omohundro (1994). "Inducing probabilistic
grammars by Bayesian model merging". In: International
Colloquium on Grammatical Inference. Springer, pp. 106-118.
Sun, X. et al. (2018). "Training simplification and model
simplification for deep learning: A minimal effort back propagation
method". In: IEEE Transactions on Knowledge and Data
Engineering.
Sutskever, I. and G. Hinton (2007). "Learning multilevel
distributed representations for high-dimensional sequences". In:
Artificial Intelligence and Statistics, pp. 548-555.
Sutskever, I., J. Martens, et al. (2013). "On the importance of
initialization and momentum in deep learning". In:
International conference on machine learning, pp. 1139-1147.
Sutskever, I., O. Vinyals, et al. (2014). "Sequence to sequence
learning with neural networks". In: Advances in neural
information processing systems, pp. 3104-3112.
Sutton, R. (1991). "Dyna, an integrated architecture for
learning, planning, and reacting". In: ACM SIGART Bulletin 2.4,
pp. 160-163.
Todorov, E. (2009). "Parallels between sensory and motor
information processing". In: The cognitive neurо sciences, pp. 613—
24.
Tomasello, M. (2009). Constructing a language. Harvard
university press.
Tononi, G. and C. Koch (2015). "Consciousness: here, there
and everywhere?" In: Phil. Trans. R. Soc. В 370.1668,
p. 20140167.
334
СПИСОК ЛИТЕРАТУРЫ
Ueda, N. and R. Nakano (1998). "Deterministic annealing EM
algorithm". In: Neural networks 11.2, pp. 271-282.
Uusisaari, M. and E. De Schutter (2011). "The mysterious micro-
circuitry of the cerebellar nuclei". In: The Journal of
physiology 589.14, pp. 3441-3457.
Vanlehn, K. and W. Ball (1987). "A version space approach to
learning context-free grammars". In: Machine learning 2.1,
pp. 39-74.
Vapnik, V. (1998). Statistical learning theory. Vol. 1. Wiley New
York.
Vaswani, A. et al. (2017). "Attention is all you need". In:
Advances in Neural Information Processing Systems, pp. 5998-
6008.
Verschure, P. (2012). "Distributed adaptive control: a theory
of the mind, brain, body nexus". In: Biologically Inspired
Cognitive Architectures 1, pp. 55-72.
Verschure, P. et al. (2014). "The why, what, where, when and how
of goal-directed choice: neuronal and computational
principles". In: Philosophical Transactions of the Royal Society B:
Biological Sciences 369.1655, p. 20130483.
Vinyals, O. et al. (2018). AlphaStar: Mastering the Real-Time
Strategy Game StarCraft II URL: https://deepmind.com/
blog/ alphast ar - mastering - real - time - strategy - game -
starcraft-ii/.
Vinyals, O. et al. (2015). "Show and tell: A neural image
caption generator". In: Proceedings of the IEEE conference on
computer vision and pattern recognition, pp. 3156-3164.
Volokh, A. and G. Neumann (2012). "Task-oriented dependency
parsing evaluation methodology". In: 2012 IEEE 13th
International Conference on Information Reuse & Integration
(IRI). IEEE, pp. 132-137.
Von der Malsburg, C. (1995). "Binding in models of perception
and brain function". In: Current opinion in neurobiology 5.4,
pp. 520-526.
СПИСОК ЛИТЕРАТУРЫ
335
Von Foerster, H. et al. (1960). "Doomsday: Friday, 13 november,
ad 2026". In: Science 132.3436, pp. 1291-1295.
Von Neumann, J., A. Burks, et al. (1966). "Theory of self-
reproducing automata". In: IEEE Transactions on Neural
Networks 5.1, pp. 3-14.
Wang, J.-P. et al. (2017). "A pathway to enable exponential
scaling for the beyond-cmos era". In: Proceedings of the 54th
Annual Design Automation Conference 2017. ACM, p. 16.
Wang, R. et al. (2017). "MAGAN: Margin Adaptation for
Generative Adversarial Networks". In: arXiv preprint arXiv: 1704-03817.
Wang, X. and A. Gupta (2016). "Generative image modeling
using style and structure adversarial networks". In: European
Conference on Computer Vision. Springer, pp. 318-335.
Wang, Y. et al. (2017). "Residual convolutional CTC networks for
automatic speech recognition". In: arXiv preprint arXiv: 1702.07793.
Ward, L. (2011). "The thalamic dynamic core theory of conscious
experience". In: Consciousness and Cognition 20.2, pp. 464-86.
Watkins, C. and P. Dayan (1992). "Q-learning". In: Machine
learning 8.3-4, pp. 279-292.
Watters, N. et al. (2017). "Visual Interaction Networks". In:
arXiv preprint arXiv:1706.0ЦЗЗ.
Welch, T. (1984). "Technique for high-performance data
compression". In: Computer 6.17, pp. 8-19.
Wilson, A. C. et al. (2017). "The Marginal Value of Adaptive
Gradient Methods in Machine Learning". In: arXiv preprint
arXiv:1705.08292.
Wilson, E. (2012). The social conquest of earth. WW Norton &
Company.
Wolff, J. (1975). "An algorithm for the segmentation of an
artificial language analogue". In: British journal of psychology
66.1, pp. 79-90.
— (1982). Language acquisition, data compression and
generalization. Pergamon.
336
СПИСОК ЛИТЕРАТУРЫ
Wolff, J. (1988). "Learning syntax and meanings through
optimization and distributional analysis". In: Categories and
processes in language acquisition 1.1.
Wrangham, R. (2009). Catching fire: How cooking made us
human. Basic Books.
Wu, Y., M. Schuster, et al. (2016). "Google's neural machine
translation system: Bridging the gap between human and
machine translation". In: arXiv preprint arXiv:1609.08144-
Wu, Y., G. Wayne, et al. (Apr. 2018). "The Kanerva Machine: A
Generative Distributed Memory". In: ArXiv e-prints. arXiv:
1804.01756 [stat.ML].
Xu, K. et al. (2015). "Show, attend and tell: Neural image
caption generation with visual attention". In: International
Conference on Machine Learning, pp. 2048-2057.
Young, T. et al. (2018). "Recent trends in deep learning based
natural language processing". In: ieee Computational
intelligence magazine 13.3, pp. 55-75.
Yu, H. et al. (2016). News Article Summarization with Attention-
based Deep Recurrent Neural Networks.
Yufik, Y. and K. Friston (2016). "Life and Understanding: the
origins of "understanding" in self-organizing nervous systems".
In: Frontiers in systems neuroscience 10, p. 98.
Zeiler, M. and R. Fergus (2014). "Visualizing and understanding
convolutional networks". In: European conference on
computer vision. Springer, pp. 818-833.
Zhang, H. et al. (2016). "Stackgan: Text to photo-realistic image
synthesis with stacked generative adversarial networks". In:
arXiv preprint arXiv: 1612.03242.
Zhang, Y. et al. (2017). "Towards end-to-end speech recognition
with deep convolutional neural networks". In: arXiv preprint
arXiv:1701.02720.
Zhu, J.-Y. et al. (2017). "Unpaired image-to-image translation
using cycle-consistent adversarial networks". In: arXiv preprint
arXiv:1703.10593.
СПИСОК ЛИТЕРАТУРЫ
337
Агамирзян, И.Р. (2016). «Технологическое лидерство:
воспользоваться шансом». В: Вызов 2035. Олимп-Бизнес, с. 8—15.
Ализар, А. (2019). Нейросеть Яндекса стала соавтором
пьесы для альта с оркестром. URL: https://habr.com/ru/
post/441286/.
Андерсон, К. (2012). Длинный хвост. Эффективная модель
бизнеса в Интернете. МИФ.
Анохин, К.В. (2014). «Когнитом: в поисках общей теории
когнитивной науки». В: Шестая международная
конференция по когнитивной науке: тез. докл. Калининград, с. 26—
28.
— (2018а). Когнитом - гиперсетевая модель мозга. URL: https:
//youtu.Ье/tDalzRYEhss.
— (2018b). Мозг, как сеть, и разум, как сеть - вызовы
математике. URL: https://youtu.be/tDalzRYEhss.
Барретт, Л. (2018). Как рождаются эмоции. Революция в
понимании мозга и управлении эмоциями. Манн, Иванов и
Фабер.
Бейкер, М. (2008). Атомы языка: Грамматика в темном поле
сознания. ЛКИ. ISBN: 9785382004303.
Бурлак, С.А. (2018). Происхождение языка: Факты,
исследования, гипотезы. Альпина Паблишер.
Вернадский, В.И. (1988). Труды по всеобщей истории науки.
Рипол Классик.
Выготский, Л.С. (2014). Мышление и речь. Directmedia.
Гудфеллоу, Я. и др. (2018). Глубокое обучение. Litres.
Ежов, А.А. и С.А. Шуйский (1998). Нейрокомпьютинг и его
приложения в экономике и бизнесе. МИФИ.
Журавлев, А.Ю. (2019). Сотворение Земли. Как живые
организмы создали наш мир. Альпина Нон-фикшн.
Завадовская, В. и К. Карпов (2017). Рейтинг компаний по
производительности труда сотрудников, https ://bcs-
express . ru/novosti - i - analitika/reiting- kompanii -
po-proizvoditel-nosti-truda-sotrudnikov.
338
СПИСОК ЛИТЕРАТУРЫ
Капица, СП. (1999). Общая теория роста человечества: сколь
ко людей жило, живет и будет жить на Земле. М.:
Наука.
Карелов, СВ. (2018). Впереди ИИ- национализм и ИИ-
национализация, http : / / russiancouncil . ru/activity/
digest / longreads / vperedi - ii - natsionalizm - i - ii -
natsionalizatsiya/.
Ковалевич, Д.А. и П.Г. Щедровицкий (2015). Конвейер
инноваций. https://asi.ru/conveyor-of-innovations/.
Коротаев, А.В. и др. (2018). Анализ и моделирование
глобальной динамики. Ленанд.
Кузнецов, Е.Б. (2016). Россия и мир технологического
диктата: 3 сценария будущего. URL: https : //www.youtube .
com/wat ch?v=9GtG.kczrFE.
ТВ-КУЛЬТУРА (2018). На аукционе Christies впервые
продали написанную искусственным интеллектом картину.
URL: https : //tvkultura. ru/article/show/article_id/
302385/.
Кун, Т. (1977). Структура научных революций. М.: Прогресс.
Лакофф, Д. (2017). Женщины, огонь и опасные вещи. Что
категории языка говорят нам о мышлении. Litres.
Лем, С. (2002). Golem XIV. Библиотека XXI века. ACT.
Марков, А.В. (2017). Эволюция разума и сопротивление
науке. URL: https://www.youtube.com/watch?v=qT0yK0ryWQY.
Марков, А.В. и М.А. Марков (2019). Многоуровневый отбор
и проблема роста мозга у плейстоценовых Homo. Опыт
компьютерного моделирования сопряженной эволюции
генов и мемов. URL: https : //www . youtube . com/watch?v=
AERQrIyk7og&t=5192s.
Медоуз, Д.Х. и др. (2012). «Пределы роста. 30 лет спустя». В:
Никитин, М.А. (2016). Происхождение жизни. От
туманности до клетки. Альпина нон-фикшн.
Николенко, С. и др. (2018). Глубокое обучение. Погружение в
мир нейронных сетей. Питер. ISBN: 978-5-496-02536-2.
СПИСОК ЛИТЕРАТУРЫ
339
Ножов, И.М. (2003). «Морфологическая и синтаксическая
обработка текста (модели и программы)». В: Канд.
диссертация.
Перес, К. (2011). Технологические революции и финансовый
капитал. Дело.
ПМЭФ-2017 (2017). Влияние экосистемы МСП на мировую
экономику, https://tass.ru/pmef-2017/articles/4278934
Терехов, С.А. (2018). «Тензорные декомпозиции в
статистическом принятии решений». В: Сборник научных трудов XX
Всероссийской научной конференции Нейроинформатика-
2018. Лекции по нейроинформатике, с. 53—58.
Хайкин, С. (2008). Нейронные сети: полный курс, 2-е издание.
Издательский дом Вильяме.
Шредингер, Э. (2018). Что такое жизнь? Litres.
Шумский, С.А. (2013). «Язык и мозг: как человек понимает
речь». В: Сборник научных трудов XV Всероссийской
научной конференции Нейроинформатика-2013. Лекции по
нейроинформатике, с. 72—105.
— (2015). «Реинжиниринг архитектуры мозга: роль и
взаимодействие основных подсистем». В: Сборник научных
трудов XVIIВсероссийской научной конференции Нейроинфор-
матика-2015. Лекции по нейроинформатике, с. 13—45.
— (2018). «Глубокое структурное обучение: Новый взгляд на
обучение с подкреплением». В: Сборник научных трудов
XX Всероссийской научной конференции Нейроинформатика-
2018. Лекции по нейроинформатике, с. 11—43.
Щедровицкий, П.Г. (2016). История промышленных
революций и вызовы III промышленной революции, https : / /
youtu.be/_cpWkGwZMSI.
Научное издание
МАШИННЫЙ
ИНТЕЛЛЕКТ
ОЧЕРКИ ПО ТЕОРИИ
МАШИННОГО ОБУЧЕНИЯ
И ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Подписано в печать 05.06.2019.
Формат 60x90/16.
Гарнитура Times. Бумага офсетная.
Усл. печ. л. 21,25. Уч.-изд. л. 11,39.
Тираж 100 экз. Заказ № 00000
ООО «Издательский Центр РИОР»
127282, Москва, ул. Полярная, д. 31В.
Тел.: (495) 280-38-67
Email: info@riorp.ru https://riorpub.com