












































































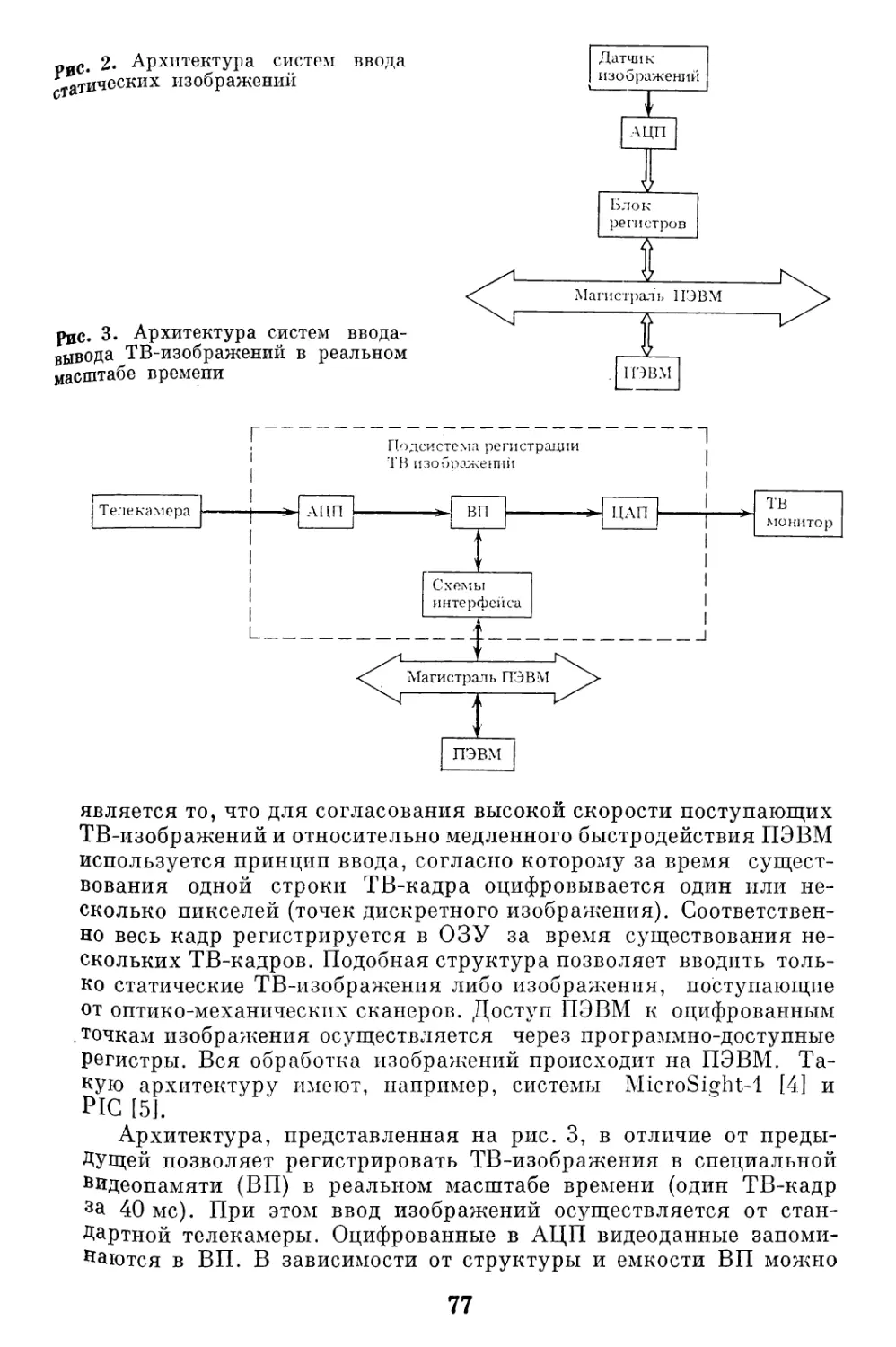

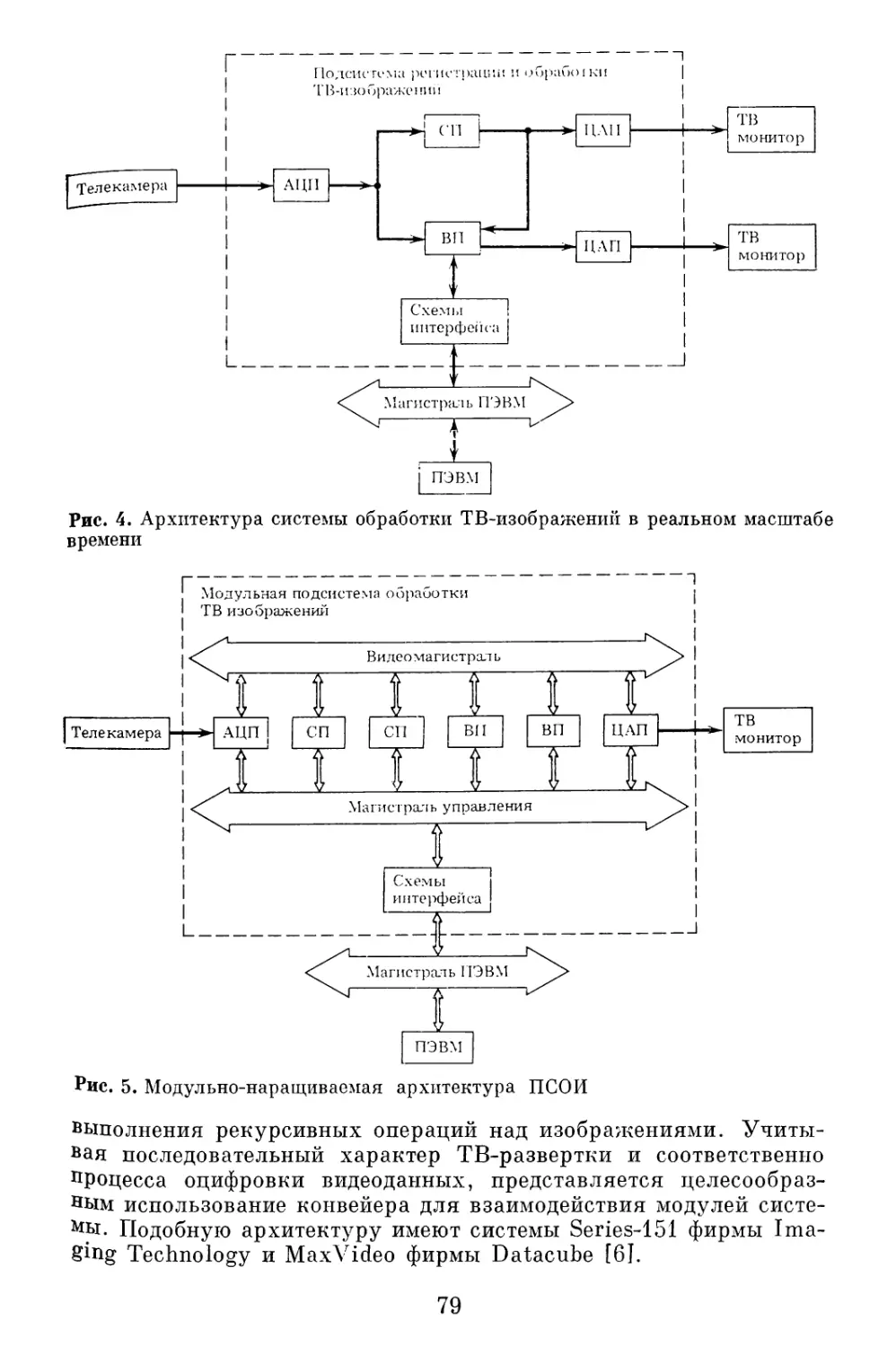
























































































































































































Автор: Наумов Б.Н.
Теги: компьютерные технологии информатика информационные технологии академия наук ссср издательство наука
ISBN: 5-02-006558-7
Год: 1989




Текст
АКАДЕМИЯ
НАУК
СССР
СРЕДСТВА
ИНФОРМАТИКИ
А
■> ■ ■
. .. ■■
■ £* . ■
F
■■■
«НАУКА»
АКАДЕМИЯ 1IAN K СССР
ИНСТИТУТ ПРОБЛЕМ ИНФОРМАТИКИ
СИСТЕМЫ
и
СРЕДСТВА
ИНФОРМАТИКИ
Ежегодник
В ы п . 1
Ежегодник основан в 1989 г.
Ответственный редактор
академик
Б. Н. НАУМОВ
МОСКВА
«II А У КА»
1989
УДК 681.3
С 1989 г. Институт проблем информатики Академии наук СССР
начинает выпускать ежегодник «Системы и средства информатики»,
в статьях которого, как правило, будут освещаться результаты иссле¬
дований, завершенных институтом в текущем году. Основная задача
института — фундаментальные исследования в области развития
новых поколений вычислительных систем, ориентированных на мас¬
совое применение.
В зависимости от конкретных результатов, полученных инсти¬
тутом, содержание ежегодников может в известных пределах видо¬
изменяться, однако в целом они должны охватывать следующие
направления: проблемы создания новых инструментальных систем;
технология программирования для ЭВМ массового применения; со¬
вершенствование человеко-машинного интерфейса на базе исполь¬
зования принципов искусственного интеллекта; проблемы разра¬
ботки аппаратных средств ЭВМ массового применения и, в частности,
ПЭВМ новых поколений; проблемы синтеза и применения приклад¬
ных систем информатики, базирующихся на ПЭВМ.
Для специалистов в области информатики, вычислительной
техники и автоматизации.
РЕДАКЦИОННАЯ КОЛЛЕГИЯ:
академик Б. И. НАУМОВ
(главный редактор)
кандидат технических наук Е. Н. ФИЛИНОВ (зам. главного редактора}
доктор технических наук Б. Г. ДОСТУПОВ
доктор технических наук Л. А. КАЛИНИЧЕНКО
доктор технических наук В. А. КОЗМИДИАДИ
кандидат технических наук И. Я. ЛАНДАУ
академик В. С. ПУГАЧЕВ
кандидат физико-математических наук В. Н. СЕМИК
доктор технических наук И. Н. СИНИЦЫН
кандидат технических наук А. В. ФИЛИН
И. А. РУБИЧЕВА
(ответственный секретарь)
Рецензент
В. С. ПУГАЧЕВ
2404000000-192
С 055(02)-89 698’89; кн- 2 © Издательство «Наука». 1989
ISBN 5-02-006558-7
УДК 681.3.06
РЕАЛИЗАЦИЯ ПРОГРАММ
МНОГОКРАТНОГО ПРИМЕНЕНИЯ
НАД БАЗАМИ ДАННЫХ,
НЕЗАВИСИМЫХ ОТ СУБД
Л. А. Калиниченко
В области систем управления базами данных (СУБД) в по¬
следнее десятилетие значительное внимание приковано к проб¬
леме создания эффективных систем интеграции неоднородных баз
данных [1 — 7]. При проектировании СУБД имеет место соревно¬
вание двух подходов — намерение разработки единой мобильной
СУБД с моделью данных, удовлетворяющей всеобщим потреб¬
ностям, и создание средств, обеспечивающих сосуществование
различных систем, поддерживающих разнообразные модели дан¬
ных, соответствующие требованиям прикладных систем.
Настоящая статья основана на опыте применения одной из
первых реализаций систем интеграции неоднородных баз данных
И, 7, 8], в которой удалось последовательно провести ряд важ¬
ных архитектурных принципов построения подобных систем.
Предпринята попытка проиллюстрировать, как тщательный
и систематический подход к проектированию архитектуры систем
интеграции приводит к созданию программных изделий с сущест¬
венно расширенным спектром возможных применений.
Внимание читателя в этой статье будет сконцентрировано на
вопросах сближения проблем применения систем интеграции
неоднородных баз данных с насущными проблемами программи¬
рования в области создания прикладных программ многократного
применения. Решение этой проблемы представляется немало¬
важным в условиях стремительного роста объема программного
продукта и уровня требований к его качеству, поскольку позво¬
ляет снизить стоимость, повысить надежность и упростить про¬
граммирование благодаря использованию однажды разработанных
программ для различных областей применения.
В языках программирования возможность повторного исполь¬
зования программных модулей достигается, как правило, на ос¬
нове метода параметризованного программирования [10]. Основ¬
ная идея этого метода заключается в написании и хранении про¬
грамм в максимально общей форме и последующей их конкрети¬
зации для применения в заданной ситуации посредством фиксации
3
необходимых параметров. Придание общего впда выражаемым
программой действиям достигается, когда программный модуль,
становится полиморфным, а его параметры имеют родовые типы
(параметризованные типы данных). Конкретизация родового типе
осуществляется заданием значений его параметров. Кроме того
посредством параметров необходимо обеспечить возможность за
дания окружения, в котором должен выполняться программный
модуль. «Настройка» модуля для его использования в определен
пом контексте достигается, таким образом, конкретизацией пара
метров и фиксацией среды, в которую «встраивается» модуль.
Специфика программирования в среде баз данных характери¬
зуется следующими особенностями:
1) языки манипулирования данными (ЯМД) включаются в язы¬
ки программирования. Для реализации родовых процедур над
базами данных требуется введение в такой совокупный язык ро¬
довых типов для объектов, определенных моделью данных СУБД,
и обеспечение техники конкретизации таких типов;
2) системы интеграции неоднородных баз данных, а также
развитые СУБД ориентированы на поддержку модульных мульти¬
баз данных, в которых каждому модулю базы данных соответст¬
вует модуль схемы мультибазы данных (далее — вид базы данных).
В таких условиях необходимы средства образования контекста
выполнения программы заданием совокупности видов баз данных
и передачи такого контекста в процедуру в качестве параметра:
3) родовые процедуры над базой данных не должны содержать
конкретных условий идентификации данных в базе данных либо
содержать их в параметризованном виде. Конкретные условия
идентификации образуются при выполнении программы. Тем
самым предопределяется необходимость частичной компиляции
программы, когда существенная часть действий по компиляции
реализуется динамически в процессе конкретизации программы.
Далее рассматриваются архитектурные решения, обеспечи¬
вающие реализацию родовых процедур над базами данных в кон¬
тексте системы интеграции неоднородных баз данных. Свойства
системы интеграции придают программам, используемым повтор¬
но, важное качество: они становятся независимыми от СУБД,
что еще больше расширяет сферу их применения.
1.
КОНЦЕПЦИИ ПОСТРОЕНИЯ
II СРЕДСТВА СИСТЕМЫ ИНТЕГРАЦИИ
НЕОДНОРОДНЫХ БАЗ ДАННЫХ
Методы и программные средства интеграции неоднородных
баз данных подробно рассмотрены в работе [7]. Система интегра¬
ции неоднородных баз данных, разработанная в соответствии
с изложенной в работе [71 идеологией, функционирует на машинах
серии ЕС ЭВМ и позволяет использовать совместно собственно
реляционные базы данных системы интеграции, базы .данных
4
СУБД ДПСОД или СПЕКТР, базы данных СУБД СЕТЬ, а также
Лайлы, организованные средствами ДРМ—процессора СУБД ВЕ-
ру [91. Охват системой интеграции других СУБД обеспечивается
включением в состав системы интеграции соответствующих пре¬
образователен моделей данных.
Здесь будет дай краткий обзор основных концепций построе¬
ния и средств системы интеграции.
1.1. Цели интеграции неоднородных баз данных
Интеграция неоднородных баз данных определяется как под¬
ход к проектированию, применению, управлению базами данных,
который обеспечивает достижение следующих целей:
1) совместное использование данных из нескольких неодно¬
родных баз данных как из логически единой базы данных:
2) управление мультибазами данных (однородное представле¬
ние для прикладных программ совокупности различных баз дан¬
ных, поддержание ее целостности, общий язык взаимодействия):
3) унификация представлений данных и языков определения
данных и манипулирования данными в различных моделях дан¬
ных;
4) поддержание независимого от СУБД концептуального уров¬
ня описания предметных областей;
5) независимость прикладных программ от СУБД;
6) охват быстрорасширяющегося спектра представлений дан¬
ных и операций над данными в ЭВМ.
1.2. Основные положения концепции
интеграции неоднородных баз данных
Основная идея интеграции неоднородных баз данных заклю¬
чается во введении независимого от СУБД концептуального уров¬
ня представления и манипулирования данными — уровня вир¬
туальной базы данных — и соответствующей этому уровню кон¬
цептуальной модели данных системы интеграции. Модели данных
(МД), поддерживаемые СУБД, по отношению к этой общей мо¬
дели являются внутренними.
Каждая модель данных полностью определяется. семантикой
некоторого языка определения данных (ЯОД) и языка манипу¬
лирования данными (НМД).
Построение многоуровневой архитектуры системы интеграции
возможно на основе специальных методов отображения одной МД
в другую (говоря об отображении, отображаемую МД будем на¬
зывать исходной, МД, в которую осуществляется отображение,—
целевой).
При переходе от внутренней МД к концептуальной необхо¬
димо обеспечить сохранение информации и операторов. Для этого
требуется, чтобы при отображении внутренняя МД была экви¬
5
валентно представлена в концептуальной. Понятие эквивалент
ности моделей данных вводится следующим образом.
Состояния базы данных в исходной и целевой МД эквивалент¬
ны, если они отображаются в одно и то же состояние в рамках
абстрактной метамодели данных. Схемы баз данных эквивалентны,
если они порождают равномощные множества состояний, на ко¬
торых задана биективная зависимость, связывающая эквивалент¬
ные состояния. Модели данных эквивалентны, если каждой схеме
базы данных в одной модели можно поставить во взаимнооднознач¬
ное соответствие эквивалентную схему в другой модели (и наобо¬
рот) при обеспечении полноты набора операторов НМД в каждой
модели данных.
Набор операторов ЯМД называется полным, если примени¬
тельно к каждому типу объектов ЯОД действия поиска, чтения,
помещения, удаления и изменения объектов в базе данных выра¬
зимы на ЯМД и для любого допустимого начального состояния
65дбазы данных со схемой можно задать последовательность
операторов : ЯМД, переводящую базу данных в произвольное
заданное состояние bs , удовлетворяющее схеме st.
Основу концепции интеграции неоднородных баз данных со¬
ставляют следующие положения.
Принцип аксиоматического расширения моделей данных. Кон¬
цептуальная модель данных в системе интеграции должна быть
расширяемой по мере охвата системой МД новых СУБД. Такое
расширение реализуется аксиоматически. Аксиоматическим на¬
зывается расширение целевой МД, осуществляемое введением в ЯОД
системы аксиом, определяющих в терминах целевой модели ло¬
гические зависимости данных исходной модели и измененную
семантику операторов ЯМД целевой модели. Результат расшире¬
ния должен быть эквивалентен исходной МД.
Построение аксиоматического расширения целевой МД рас¬
сматривается как конструирование новых языков (ЯОД и ЯМД)
на основе языков целевой МД.
Принцип коммутативного отображения моделей данных. При
отображении МД конкретных СУБД в концептуальную необ¬
ходимо обеспечить сохранение информации и операторов. Это
требование выполняется, если отображение моделей данных явля¬
ется коммутативным, т. е. выполняются следующие условия:
диаграмма отображения схем БД коммутативна; диаграмма ото¬
бражения операторов ЯМД коммутативна; отображение состояний
баз данных биективно [7, 8J.
При конструировании коммутативных отображений МД не¬
обходимы средства, позволяющие: формально определять пра¬
вила отображения схем баз данных исходной МД в схемы баз
данных целевой МД; определять семантику операторов ЯМД
расширенной целевой МД; обеспечивать согласованность опера¬
ционной семантики аксиом с семантикой операторов ЯМД рас¬
ширенной модели, задаваемой аксиоматически; определять и ве-
6
пИфицир°ватЬ алгоритмы интерпретации операторов ЯМД рас¬
ширенной МД средствами исходной модели данных.
При этом для получения практически полезных результатов
необходим учет всех существенных деталей семантики ЯОД и
ЯМД исходной и целевой МД.
Решение указанных проблем достигается на основе их пере¬
вода в абстрактную языковую среду с целью применения формаль¬
ного аппарата. В качестве такого средства абстрактного описания
разработана метамодель данных, базирующаяся на формализмах
денотационной семантики Скотта—Стрейчи и включающая на¬
бор правил эквивалентного преобразования функций, исполь¬
зуемых при верификации коммутативности диаграмм отображе¬
ния операторов.
Подробное описание метода конструирования коммутативных
отображений МД на этой основе содержится в работе [7].
Принцип синтеза унифицированной концептуальной модели
данных. Синтез концептуальной модели данных есть процесс
конструирования расширений ее ядра, эквивалентных МД охва¬
тываемых системой интеграции СУБД, и объединения таких рас¬
ширений в составе концептуальной МД. При этом образуется
унифицированная концептуальная МД, в которой МД различных
СУБД приведены к однородному, эквивалентному представ¬
лению.
Три названных взаимосвязанных принципа являются основой
для решения проблемы неоднородности баз данных.
Принцип многоуровневого построения систем интеграции.
Главной целью введения многоуровневой архитектуры является
превращение системы интеграции в открытую систему, позволяю¬
щую включать в нее произвольные СУБД на основе должным
образом выбранной системы интерфейсов. Распределенному ва¬
рианту системы интеграции соответствует «трехмерная» модель
архитектуры, учитывающая информационные, коммуникацион¬
ные и операционные аспекты функционирования системы. В ин¬
формационном «измерении» каждому уровню соответствует опре¬
деленная МД. Концептуальный уровень в системе интеграции
расслоен на два подуровня — локальный и глобальный. Локаль¬
ный подуровень составляет совокупность средств, позволяющих
образовать посредством унифицированной концептуальной МД
однородные представления разнотипных реальных баз данных
и манипулировать ими. Глобальный подуровень позволяет вво¬
дить абстракции данных, устанавливающие связи между типами
Данных локального уровня, выражающие, в частности, условия
Целостности интегрированной базы данных. Функцией трансфор¬
мационного уровня является преобразование внутренних МД
в концептуальную, осуществляемое в соответствии с методом ком¬
мутативного отображения МД. На центральном исполнительном
Уровне, занимающем положение между концептуальным и транс¬
формационным, организуется хранение данных системы интегра¬
ции и выполнение программ, в которые редуцируются условия
i
идентификации данных и операторы ЯМД концептуального
уровня.
Принцип модульности концептуальных схем. Принцип мо¬
дульности схем является ключевым при решении проблемы уп¬
равления мультибазами данных. Согласно этому принципу, каж¬
дой схеме реальной базы данных соответствует эквивалентный
модуль схемы локального концептуального уровня. Модули схем
глобального концептуального уровня используются для введения
абстракций данных, охватывающих объекты, принадлежащие раз¬
личным модулям базы данных локального концептуального уровня.
Согласно принципу модульности, произвольная совокупность
модулей схем локального и (или) глобального концептуальных
уровней одновременно может быть использована в прикладной
программе. Это обстоятельство позволяет рассматривать совокуп¬
ность интегрируемых баз как мультибазу данных.
Принцип совместимости систем интеграции с СУБД и их при¬
менениями. Согласно принципу совместимости, конструкция сис¬
темы интеграции должна обеспечивать ее совместную работу
с СУБД и их применениями в действующих автоматизированных
системах без каких-либо изменений существующих баз данных,
СУБД или прикладных программ.
1.3. Унифицированная концептуальная
модель данных (УКМД)
На основе систематического применения методов коммутатив¬
ного отображения и синтеза концептуальной модели данных по¬
лучены следующие результаты.
Сконструированы аксиоматические расширения реляционной
МД, эквивалентные МД различных классов — сетевых, иерар¬
хических, бинарных, дескрипторных. Пример такого расширения
для сетевой МД Кодасил дан на рис. 1.
На рис. 2 показан состав средств концептуальной МД, полу¬
ченных в результате применения метода синтеза. Там же показан
список рассмотренных исходных МД. Важным свойством процес¬
са синтеза является относительно быстрое насыщение концеп¬
туальной модели, когда рассмотрение новых моделей данных
уже не привносит новых аксиом. Полученная концептуальная
МД по отношению к известным МД является насыщенной. Это
обстоятельство позволяет считать ее унифицированной.
1.4. Язык определения данных
п язык манипулирования данными УКМД
Ядро концептуальной МД, выражаемое средствами ЯОД,
должно обеспечивать возможность ведения смешанных баз данных,
включающих как структурированные, так и неструктурирован¬
ные данные. К основным типам структурированных данных ядра
относятся типы нормализованных и иерархических отношений.
База данных является неструктурированной, если каждый новый
8
Простые аксиомы
(для отношения 7Л; А.— совокупность атрибутов /?,.)
1. Аксиома уникальности
UNIQUE А.
2. Аксиома постоянства
CONSTANT А.
3. Аксиома определенности
OBLIGATORY А^
4. Аксиома условной уникальности
I NIQLE NONNULL (А.1) & (А.2) &... & (А/1)
Аксиома порядка
/?. [RESTRICTED BY АД] IS ORDERED [(порядок)]
[BY (направленно АД {, (направление) АЛ}]
Составные аксиомы
(для отношений 7L, В.)
6. Аксиома полной функциональной зависимости (п.ф.з.)
Л>.(А.)->2?. (А.)
7. Аксиома частичной функциональной зависимости (ч.ф.з.)
8. Аксиома частичной сильной функциональной зависимости
(А.) = S = > Bi (Л4)
9. Аксиома частичной функциональной зависимости с перво¬
начальной связью
Я.(Л.) = £=>
Рис. 1. Аксиоматическое расширение реляционной МД, эквивалентное се¬
тевой МД КО ДАСИ Л
факт о предметной области обладает собственной структурой,
что не позволяет фиксировать схему базы данных. Неструкту¬
рированные данные представляются в базе данных посредством
семантических сетей.
Аксиомы, входящие в расширения ядра, показаны на рис. 2,
В состав УКМД введены специальные средства интеграции пред¬
ставлений данных локального уровня на глобальном. Таковыми
являются абстракции обобщения, соединения и разности отно¬
шений локального концептуального уровня и их суперпозиция.
В целом ЯОД унифицированной модели характеризуется
следующими особенностями, выделяющими его среди известных:
1) двухуровневое представление концептуальных схем на ло¬
кальном и глобальном концептуальных уровнях;
2) модульность концептуальной схемы базы данных;
9
Средства УКМД
Модель данных
1 2 3 4 5 6 7 8 9 10 И 12 13 14
Модель данных — ядро
Нормализованные отношения
Иерархические отношения
Позиционные агрегаты
Расширение ядра
Аксиома уникальности
Аксиома постоянства
Аксиома определенности
Аксиома условной уникальности
Аксиома условного постоянства
Аксиома синхронного нуля
Аксиома-функция
Аксиома — частичная функция
Аксиома порядка
Аксиома-предик ат
Аксиома п.ф.з.
Аксиома ч.ф.з.
Аксиома сильной ч.ф.з.
Аксиома ч.ф.з. с первоначаль¬
ной связью
Аксиома п.ф.з. с обратной связью
Аксиома ч.ф.з. с обратной связью
Аксиома устойчивой п.ф.з.
Аксиома у.п.ф.з. с обратной
связью
Аксиома дуплексной зависимо¬
сти
* * * *
* * * *
* * * *
*
*
*
* * * * *
* * *
*
*
♦
*
*
*
* ♦
ОБОЗНАЧЕНИЯ МОДЕЛЕЙ ДАННЫХ
1. Реляционная МД Кодда 1970 г.
2- Сетевая МД КОДАСИЛ
3. Иерархическая МД СУБД ОКА
. Сетевая МД СУБД БАНК
i МД СУБД ПАЛЬМА
МД СУБД ADABAS
7- Плоская МД СУБД ИРИС
8. МД СУБД HISS
9. Дескрипторная МД СУБД БАЗИС
10. МД СУБД ПОИСК-1
11. Сетевая МД СУБД СЕДАН
12. Иерархическая МД СУБД ИНЕС
13. Бинарная|реляционная МД
14. Реляционная МД Кодда 1979 г.
* * *
* *
* * *
*
*
*
*
*
*
*
*
*
*
*
*
*
Рис. 2. Подмножества УКМД, эквивалентные известным моделям данных
3) доступность модулей схем и объектов локального и глобаль¬
ного концептуальных уровнях для прикладных программ;
4) введение в язык средств обеспечения целостности интегри¬
рованной базы данных, включающих набор аксиом, полученных
в процессе синтеза УКМД;
5) возможность раздельного задания и компиляции специфи-
10
нации и тела модулей схем баз данных с целью разграничения
в определении модуля схемы наблюдаемой извне информации,
фиксирующей интерфейс прикладной программы с соответствую¬
щей частью базы данных, и внутренней, скрытой информации,
определяющей реализацию производных объектов и процедур¬
ных инвариантов базы данных;
6) введение производных категорий глобального концептуаль¬
ного уровня для обобщенного представления объектов локаль¬
ного уровня и установления их взаимосвязей в интегрированной
базе данных.
Уровень ЯМД в значительной мере определяется применяе¬
мыми в нем средствами идентификации компонентов базы данных.
Язык фильтров [7J в составе ЯМД У НМД основан на многосортном
исчислении предикатов. Для работы с неструктурированными дан¬
ными в язык фильтров введены специальные термы, которые
встраиваются в общую схему построения и интерпретации формул
и позволяют выразить условия идентификации неструктуриро¬
ванных данных в базе данных совместно с условиями идентифи¬
кации структурированных данных.
Отличительными особенностями ЯМД УКМД являются:
1) аксиоматическое задание семантики операторов ЯМД (се¬
мантика операторов определяется совокупностью аксиом, свя¬
занных с отношениями — объектами действия операторов);
2) определение контекста выполнения операторов ЯМД про¬
граммы посредством импорта необходимой совокупности модулей
схем баз данных;
3) использование в качестве основы языка идентификации
данных (языка фильтров) конструкций языка с переменными на
доменах, базирующегося на многосортной логике предикатов;
4) совместное использование в формулах фильтров условий
идентификации структурированных и неструктурированных дан¬
ных в базе данны ;
5) наличие в составе ЯМД инструментальных средств для
написания универсальных прикладных программ, независимых
от СУБД и просто адаптируемых к условиям конкретного приме¬
нения. Далее такие средства рассматриваются подробно.
1.5. Структура системы интеграции
В системе интеграции выделены три программных комплекса:
интерпретации, управления справочником данных, конструиро¬
вания программ и ведения диалога. В комплекс управления спра¬
вочником данных, обеспечивающий каталогизацию, хранение,
использование спецификаций схем и модулей схем (видов) баз
Данных, а также их трансляцию в объектное представление, вхо¬
дят: язык определения данных концептуального уровня; трансля¬
тор концептуальных схем баз данных; язык определения транс¬
формационных схем; транслятор трансформационных схем; мета¬
база данных, включающая справочники данных концептуального
11
п трансформационного уровней; генераторы интерфейсных моду¬
лей. обеспечивающих взаимодействие преобразователей моделей
данных с СУБД.
В состав комплекса конструирования программ и ведения
диалога входят: языки программирования, расширенные средст¬
вами ЯМД УКМД: прекомпиляторы расширенных языков про¬
граммирования; транслятор фильтров; языки ведения диалога и
диалоговые мониторы.
В состав интерпретирующего комплекса включены: процессор
данных центрального исполнительного уровня; преобразователи
моделей данных разнотипных СУБД, обеспечивающие интерпре¬
тацию ЯМД трансформационного уровня средствами конкретных
СУБД; блок сопряжения, реализующий связь прикладных про¬
грамм с процессором данных.
Накопленный опыт разработки преобразователей МД основан
па реализации преобразователей, поддерживающих СУБД UDS-2
и СЕТЬ с МД КОДАСИЛ, СУБД ОКА с иерархической МД,
СУБД СПЕКТР с «ДИСОД» с «плоской» МД, СУБД документаль¬
ного типа БАЗИС.
2.
ПРИНЦИПЫ МОДУЛЬНОЙ ОРГАНИЗАЦИИ
СПРАВОЧНИКОВ ДАННЫХ В СИСТЕМЕ ИНТЕГРАЦИИ
Основной особенностью схем баз данных в системе интеграции,
вытекающей из самой природы системы, является модульное
представление схем и их многоуровневое построение — от схем
баз данных внешнего и концептуального уровней через трансфор¬
мационную схему к схемам баз данных СУБД различных типов.
Объектное представление модуля схемы (вида) базы данных да¬
лее называется справочником данных схемы (вида). Существенно,
что каждому независимо транслированному программному мо¬
дулю также соответствует справочник данных, содержащий не¬
обходимую информацию об объектах действия операторов ЯМД.
Структура и формат справочника данных концептуального и внеш¬
него уровней определения данных, а также справочника данных
программного модуля идентичны. Местом хранения справочников
данных в системе интеграции служит метабаза данных.
Специфическими функциями, выполняемыми над справочни¬
ками данных в системе интеграции, являются:
— компоновка объединенного справочника данных из моду¬
лей при импорте видов базы данных из метабазы в процессе компи¬
ляции модулей схем баз данных и в процессе прекомпиляции
программных модулей: каждый независимо транслируемый про¬
граммный модуль может импортировать произвольную совокуп¬
ность концептуальных и внешних видов базы данных (функция
IMPORT & LINK);
— формирование динамического справочника данных в про¬
цессе выполнения программы по операторам динамического им¬
порта видов баз данных из метабазы (функция IMPORTD & LINK);
12
Рис. 3. Интерфейсы комплекса управления справочником данных
— включение в динамический справочник данных новых объек¬
тов пли исключение из него существующих (функция OBJECT
CAT/ERASE);
— динамическое формирование прикладной программой но¬
вого концептуального (внешнего) вида базы данных (функция
VIEWGEN);
— образование динамического контекста оператора ЯМД,
определяемого справочником данных модуля, включающего этот
оператор, динамическим справочником, соединенным со справоч¬
никами данных программных модулей, включающих процедуры,
динамически охватывающие данный оператор ЯМД (функция
COMPOSE).
Использование названных функций компонентами системы
и прикладной программой при взаимодействии компонентов сис¬
темы между собой и с метабазой данных показано на рис. 3.
3.
РОДОВЫЕ ТИПЫ ДАННЫХ И ИХ КОНКРЕТИЗАЦИЯ
В системе интеграции следует различать спецификацию и реа¬
лизацию типа данных. Спецификация типа задает информацию
об имени типа и операциях, связанных с типом, а реализация
содержит алгоритмы операций. Так, определение типа отношения
в концептуальном виде базы данных является спецификацией
типа. Операции над отношениями определяются посредством ак¬
сиом и процедур, задаваемых в схеме. Реализация типа отноше¬
ния задается трансформационной схемой и поддерживается пре¬
образователем модели данных и конкретной СУБД. В этом смысле
тип отношения базы данных является, по сути дела, абстрактным
типом.
При разработке программ многократного применения требуется
оперировать как объектами программы, имеющими в процессе
компиляции конкретные типы, так и объектами, имеющими ро¬
довые типы, конкретизируемые при выполнении. В программе
на включающих языках программирования допускается специ¬
фикация следующих родовых типов:
— RELATION — тип отношения с неспецифированным со¬
ставом атрибутов;
— TUPLE — тип кортежа с неспецифицированным составом
атрибутов;
— TUPLE OF (имя отношения) — тип кортежа, определяе¬
мый ссылкой на родовое отношение;
— DOM — тип родового домена;
— VAR — тип родовой переменной.
Параметрами родовых типов для отношений и кортежей явля¬
ются состав и типы доменов, на которых они определены. Типы
доменов, в свою очередь, могут быть родовыми. Кроме того, для
типа отношения параметрами служат также аксиомы и проце¬
дуры, связанные с конкретными типами. Спецификации родовых
типов имеют специальные представления в справочнике данных
программного модуля, допускающие их конкретизацию.
Переменные родовых типов — формальные параметры проце¬
дур. В качестве формальных параметров родовых процедур до¬
пускаются также фильтры и переменные, значениями которых
являются имена видов базы данных, определяющие необходимые
программе справочники данных, которые следует поместить в ди¬
намический справочник.
Конкретизация родовых типов производится при подстановке
параметров в процессе интерпретации операторов ЯМД. Эта функ¬
ция поддерживается вне включающего языка программирования
и его программных процессоров.
К основным средствам, обеспечивающим реализацию механиз¬
мов конкретизации, относятся:
— модульная, однородная организация справочников данных
схем баз данных и программных модулей;
— средства формирования динамического справочника дан¬
ных, устанавливающего динамический контекст выполнения про¬
граммы по отношению к базе данных;
— поддержание стека в каждом процессе прикладной програм¬
мы, позволяющего устанавливать динамически связь формальных
и фактических параметров в вызывающих процедурах.
Стек процесса организуется посредством специальных про¬
цедур, вызов которых обеспечивается прекомпилятором при входе
в каждую процедуру прикладной процедуры. При входе образу¬
ется новый элемент стека процессов, при выходе удаляется верх¬
ний элемент стека.
Каждый элемент стека процесса содержит:
14
имя справочника данных программного модуля, в который
входит процедура;
— идентификатор процедуры;
список параметров процедуры в виде последовательности
дар «(индекс формального параметра в статье справочника дан¬
ных модуля, индекс фактического параметра в справочнике дан¬
ных (или значение в случае параметра — фильтра));
— адрес операторного модуля, содержащего объектный код
операторов ЯМД модуля и образуемого в процессе компиляции
программного модуля транслятором фильтров или в процессе
динамической компиляции.
Процедура реализации подстановки параметров основана на
виртуальном представлении справочника данных, при котором
словари имен отдельных модулей справочника собраны в связ¬
ный массив. Для реализации подстановки параметров виртуаль¬
ное представление образуется функцией COMPOSE.
Конкретизация родовых типов сводится к замене в справоч¬
нике данных их параметров фактическими значениями.
В случае передачи фильтров в качестве параметров требуется
их динамическая компиляция, приводящая к генерации оператор¬
ного модуля, включающего операторы процессора данных, необ¬
ходимые для интерпретации операторов ЯМД, встречающихся
в вызываемой процедуре. Включение динамической компиляции
реализуется специальным оператором GENERATE, задаваемым
в прикладной программе. Областью действия GENERATE явля¬
ются все операторы ЯМД процедуры, в которой он встретился.
Оператор GENERATE необходимо выполнить до первого дина¬
мически выполнимого оператора ЯМД процессора. При выпол¬
нении GENERATE имеет место конкретизация всех родовых
параметров процедуры.
4.
ПРИМЕР УНИВЕРСАЛЬНОЙ ПРОГРАММЫ
КОНВЕРТИРОВАНИЯ БАЗ ДАННЫХ
Применение определенного выше подхода к разработке про"
грамм иллюстрируется на примере универсальной программы
конвертирования баз данных. Значительная сложность универ¬
сальных конверторов баз данных, разрабатываемых на основе
традиционных средств, выявлена еще в 70-е годы при разработке
продуктов подобного рода [И, 121.
При использовании предложенных средств требуется всего
Две процедуры, включающие несколько строк текста.
Первая процедура (ведущая) в качестве параметров принимает
имена локальных концептуальных видов баз данных L1 и L2
и имена отношений R1 из L1 и R2 из L2, а также фильтр, опре¬
деляющий подмножество R1, подлежащее конвертированию.
Программа осуществляет конвертирование заданного подмно¬
жества отношения R1 в отношение R2.
15
Ведущая процедура реализует динамический импорт L1 и L2
и формирование в динамическом справочнике новых объектов —
типов кортежей отношений R1 и R2. Затем осуществляется вызов
процедуры, реализующей собственно конвертирование отноше¬
ния базы данных из L1 в L2. Текст процедуры конвертирования
приводится полностью:
PROCEDURE RELOAD (Rl, R2: RELATION; Tl: TUPLE OF Rl;
T2: TUPLE OF R2; FLT: FILTRE);
BEGIN
GENERATE;
OPEN Rl, R2: UPD;
FOR T1:=TUPLE OF Rl IN FLT DO
BEGIN
CONV (T2, Tl);
PUT R2, T;
END;
CLOSE Rl, R2
END;
Действия по конвертированию реализуются операторохм цикла,;
вызывающим преобразование кортежей отношения R1 в кортежи
R2 и помещение кортежей отношения R1, релевантных фильтру,
в отношение R2. Построенный таким образом конвертор приме¬
няется для конвертирования баз данных СУБД «СЕТЬ» в базы
данных СУБД «ДИСОД».
Аналогично реализуются как родовые процедуры универсаль¬
ные программы загрузки, актуализации и реорганизации баз
данных, программы реализации диалога терминальных пользо¬
вателей с интегрированными базами данных.
Итак, применение систематического подхода к разработке
архитектуры системы интеграции позволило создать систему,
отличающуюся от других известных проектов подобного рода
следующим:
— достигнуто эквивалентное представление внутренних МД
в расширяемой концептуальной МД;
— синтезирована унифицированная концептуальная модель
данных;
— поддерживаются как структурированные, так п неструк¬
турированные внутренние МД;
— обеспечивается корректная поддержка операторов изме¬
нения базы данных на концептуальном уровне;
— реализована модульная мультибаза данных на основе мо¬
дульного справочника данных, поддерживающего разнообразные
функции.
Б работе, показано, что области применения систем интегра¬
ции неоднородных баз данных значительно шире, чем просто
обеспечение сосуществования неоднородных баз данных. Особо
можно выделить следующие виды возможных применений системы:
— интеграция неоднородных баз данных;
16
— управление мультибазами данных;
— установление соглашений по унифицированному описанию
данных, представлению схем и справочников данных и обмену
данными между разнородными базами данных в автоматизиро¬
ванных системах различного назначения;
— проектирование и разработка баз данных и прикладных
систем независимо от СУБД;
— разработка программ многократного применения над ба¬
зами данных, являющихся независимыми от СУБД.
Опыт реализации родовых процедур показывает, что в усло¬
виях модульного справочника базы данных аппарат поддержки
полиморфизма эффективен и прост. Вместе с тем благодаря гиб¬
кости архитектуры удается существенно расширить спектр при¬
менений систем интеграции неоднородных баз данных.
Важно отметить также, что накопленный опыт разработки
родовых процедур над базами данных заслуживает распростра¬
нения в среду обычных СУБД, включая их языковые стандарты.
ЛИТЕРАТУРА
1. Калиниченко Л. А., Рывкин В. II., Чабан И. А. Принципы организации
и архитектуры СИЗИФ-системы организации интегрированных баз
данных//Программирование. 1975. № 4. С. 28—35.
2. AdibaM. et al. Polypheme: an experience in distributed database system
design and implementation // Proc. Intern. Symp. Distributed Data Bases.
P.; Amsterdam: North-Holland, 1980. P. 67—84.
3. Cardenas A.F., Pirahesh M. II. Data base communication in a heterogeneous
DBMS network//Inform. Syst. 1980. N 5. P. 55—79.
4. Landers T., Rosenberg R. L. An overview of multibase// Proc. II Intern.
Symp. Distributed Data Bases. Amsterdam. North-Holland, 1982. P. 153—
184.
5. Litirin W. Logical model of a distributed data base//Proc. II Intern.
Seminar Distributed Data Sharing Syst. Amsterdam: North-Holland, 1982.
P. 173—208.
6. Gligor F. DLuckenbaugh G. L. Interconnecting heterogeneous database
management systems//Computer. J984. N 1. P. 33—43.
7. Калиниченко Л. А. Методы и средства интеграции неоднородных баз
данных. М.: Наука, 1983. 423 с.
8. КalinichenkoL. A. Data model transformation method based on axiomatic
data model extension/7 Proc. IV Intern. Conf. VLDB. B. (West); N. Y.:
IEEE, 1978. P. 123-134.
9. Системы управления базами данных для ЕС ЭВМ. М.: Финансы н стати¬
стика, 1984. 224 с.
Ю. Goguen J. A. Parameterized programming//IEEE Trans. Software Engi-
neering. 1984. Vol. 10, N 5. P. 528—543.
И. Shu N. C., Ilousel В. C., Lum V. Y. CONVERT: a high level translation
definition language for data conversion / CACM. 1975. Vol. 18, N 5.
P. 557-567.
12. Shu N. C. et al. EXPRESS: a data extraction, processing and restructuring
system//ACM TODS. 1977. N 2. P. 134—174.
17
УДК 681.3.06
АБСТРАКТНАЯ АРХИТЕКТУРА
ПРОЦЕССОРА ЛОГИЧЕСКОГО ВЫВОДА
Д. Буланже
Язык логического программирования Пролог [1] в последние
годы получил весьма широкое распространение как язык для
самых различных задач в области искусственного интеллекта
и даже для создания таких сложных программ, как интерпрета¬
торы и компиляторы. Но широкое использование Пролога в пол¬
номасштабных прикладных системах сдерживается относительно
невысокой эффективностью выполнения логических программ.
Использование компиляции логических программ [2, 3] дало
возможность существенно повысить эффективность выполнения
Пролог-программ (примерно в 15 раз по сравнению с непосредст¬
венной интерпретацией при программной реализации), но тем
не менее необходимость дальнейшего увеличения эффективности
выполнения Пролог-программ остается, так как компиляцией
можно достичь эффективного выполнения только относительно
простых программ. Для этого уже используется специальная
аппаратура [5—12].
В качестве спецификаций этой аппаратуры могут быть исполь¬
зованы наборы абстрактных команд, которые удается построить
при компиляции логических программ.
Для процессоров логического вывода [5 — 11] используются
системы команд, построенные на основе процедурной семантики
Пролог-программ. При этом используются два существенно
отличающихся друг от друга способа представления термов языка
Пролог. Способ представления термов является основой для са¬
мого сложного элемента процессора логического вывода — блока
унификации.
Поэтому сравнительный анализ архитектур процессоров на
абстрактном уровне представляет определенный интерес с точки
зрения определения моментов процесса логического вывода,
в которых способ представления термов играет существенную
роль. Этот анализ проводится в статье при помощи специальной
абстрактной машины логического вывода, которая позволяет
сравнить системы команд процессоров [5—11]. Это моделирование
дает возможность выявить те места, где использование способа
представления термов существенно влияет на время выполнения
той или иной операции либо на использование памяти.
В статье содержится краткое описание процедурной семантики
логических программ и описание системы команд абстрактной
машины логического вывода, которая способна функционировать
с использованием различных способов представления термов.
Для этих команд рассматривается зависимость алгоритмов их
выполнения от метода представления термов.
18
1.
ПРОЦЕДУРНАЯ СЕМАНТИКА ЛОГИЧЕСКИХ ПРОГРАММ
С точки зрения процедурной семантики логическая программа
на языке Пролог представляет собой множество предикатов
3 = {-Pl, Р2ч • • ?д}»
которые интерпретируются как множество процедур [4].
Каждый предикат Р е= 3й однозначно идентифицируется своим
именем и арностью. Это означает, что если Рj ЕЕ Зд и i ]\
то предикаты Pt и Pj различаются по крайней мере именами либо
числом аргументов.
Предикат Р GE 3> является упорядоченным множеством ут¬
верждений Р — <5\, 52, • • -ч 8-гУч каждое из которых имеет вид
h (...) gi gz (...), • • ., gt
где h (...) называетсяи головным литералом утверждения,,
a gi (...) — литералами тела утверждения. Если 0, то утверж¬
дение называется правилом, а если t = 0, утверждение называет¬
ся фактом.
Для всех утверждений S ЕЕ Р головной литерал имеет одно
и то же имя и число аргументов, однозначно идентифицирующих
предикат Р.
Логическая программа 3 называется замкнутой, если для
каждого предиката Р ЕЕ 3й тело его любого утверждения S со¬
держит только такие литералы, что для каждого из них существует
предикат программы 3 с тем же именем и числом аргументов.
Для реальных систем программирования на Прологе условие
замкнутости программы, как правило, не выполняется вследствие
необходимости использования встроенных предикатов для выпол¬
нения операций ввода/вывода, арифметических и металогических
операций. С точки зрения реализации механизма логического
вывода встроенные предикаты особого интереса не представляют
и могут быть опущены при анализе схемы выполнения логической
программы.
Литералы, входящие в утверждения логической программы
имеют вид
(^1? ^2ч • • •» t'rn) ч О,
гДе т — арность литерала; . . ., tm— термы; I — символ
литерала, определяющий его имя.
При реализации механизма логического вывода различаются
следующие типы термов нулевого уровня (это термы, которые мо¬
гут быть аргументами литералов).
В самом простом случае терм может являться константой.
В более сложном случае терм представляет собой первое или
Последующее вхождение логической переменной. Порядок вхож¬
дения логической переменной в утверждение определяется при
19
его просмотре слева направо. Утверждение, и только оно, яв¬
ляется областью определения логической переменной.
Если терм — первое вхождение логической переменной, то
он называется свободной переменной, а если терм является по¬
следующим вхождением логической переменной, то он называется
связанной переменной.
Последним и наиболее сложным случаем являются термы,
представляющие собой структуры вида
/ (*i, Ъ, . . к > 1,
где ix, £2, . . ., tk — термы ненулевого уровня; / называется глав¬
ным функтором терма. Для термов ненулевого уровня также может
использоваться приведенная выше классификация.
Основная операция, выполняющая вычисления в процессе
логического вывода над программой .J-*, называется унифика¬
цией термов. При унификации двух термов вычисляются значе¬
ния логических переменных этих термов, которые обеспечивают
графическое равенство унифицируемых термов. Если набор та¬
ких значений логических переменных существует, то алгоритм
унификации вычисляет их в наиболее общей форме. В противном
случае алгоритм унификации завершается неуспешно.
При процедурной интерпретации логической программы
механизм унификации используется как способ передачи пара¬
метров вызываемой процедуре, но фактически передача парамет¬
ров происходит в обоих направлениях, что существенно ослож¬
няет реализацию вызова процедуры предиката логической про¬
граммы.
Процедурная интерпретация логической программы Зк заклю¬
чается в следующем [4]. Процесс логического вывода над про¬
граммой ,9s выполняется как последовательность вложенных вызо¬
вов процедур, каждой из которых соответствует предикат Р ЕЕ 3<
Литералы тела утверждения интерпретируются как операторы
вызова соответствующих процедур, а головные литералы утверж¬
дений рассматриваются как исходные данные для выполнения
передачи параметров вызываемой процедуре при помощи ме¬
ханизма унификации.
Процедура, тело которой определяется предикатом Р ЕЕ
может иметь несколько точек входа, каждой из которых соответ¬
ствует утверждение этого предиката Р. Причем в момент вызова
процедуры точка входа, которая будет использована для выпол¬
нения процедуры, в общем случае неизвестна и. более того, воз¬
можен повторный вход в уже ранее вызванную процедуру. Это
обстоятельство существенно отличает способ реализации языков
типа Пролог от традиционных языков программирования, и
именно поэтому схема выполнения логической программы полу¬
чила название недетерминированных вычислений.
Реально недетерминизм используется в том случае, если вызов
определенной процедуры предиката завершается неуспешно.
В этом случае автоматически выполняется повторный вход в
20
одну и3 вызванных ранее процедур. Эта точка входа определяе¬
тся* стратегией вывода, вытекающей из процедурной семантики
югической программы 3>.
2.
СИСТЕМА КОМАНД АБСТРАКТНОЙ МАШИНЫ
ЛОГИЧЕСКОГО ВЫВОДА
Процедурная интерпретация логических программ, основные
элементы которой были рассмотрены, позволяет выполнить ком¬
пиляцию логической программы 3й в набор команд специальной
абстрактной машины логического вывода. Абстрактные команды,
описываемые ниже, представляют собой формальную специфика¬
цию вычислительной модели языка Пролог, которая может быть
использована либо для программной реализации, либо для раз¬
работки системы команд процессора логического вывода.
Схема компиляции логической программы основана па
замкнутости программы 3й и полной независимости определений
предикатов Р ЕЕ 3й друг от друга. Скомпилированный код пре¬
диката Р содержит только адреса точек входа в другие предикаты
программы и не использует никакой другой информации о
внутренней структуре предикатов, процедуры которых вызыва¬
ются в телах утверждений данного предиката Р. Поэтому относи¬
тельно несложно могут быть реализованы средства, позволяющие
добавлять или удалять предикаты вовремя выполнения логи¬
ческого вывода, если при этом гарантируется замкнутость про¬
граммы.
Код для предиката Р ЕЕ 3й в терминах команд абстрактной
машины логического вывода строится следующим образом. Аб¬
страктная машина логического вывода имеет специальный набор
регистров А2, . . .,Ат1. . . ., которые называются регистрами
аргументов вызова. Непосредственно до начала выполнения пер¬
вой команды кода предиката арности т первые т регистров Ах,
А2,. . . Ат должны быть загружены аргументами литерала
тела некоторого утверждения. Этот литерал определяет вызы¬
ваемую процедуру и значения, которые должны быть загружены
в регистры аргументов.
Структура кода вызова, т. е. последовательность команд аб¬
страктной машины логического вывода, выполняющих загрузку
регистров аргументов At, А2,. . . ., Ат и передачу управления
первой команде вызываемой процедуры предиката, во многом
°пределяет конкретный вариант вычислительной модели, исполь¬
зуемой для реализации Пролога.
Память абстрактной машины состоит из двух областей —
области кода программы 3> и динамической области, где разме¬
щается трасса логического вывода и некоторая информация,
Необходимая для выполнения повторных входов в уже вызван¬
ные ранее процедуры.
Трасса логического вывода есть последовательность элементов
21
Env, каждый из которых был создан сразу же после выполнения
входа в процедуру предиката.
Текущее состояние трассы логического вывода Т есть множе¬
ство
Т — <Envn Env2, . . ., EnVj,. . . ., Env/>.
Элемент EnvE T называется средой процедуры. Если Envf
Envy Т и i < /, то среда процедуры Env7- моложе среды про¬
цедуры Envf. Это означает, что среда Env^ была создана раньше
среды Env;. Самая молодая среда Env е? Т называется текущей
и образуется в момент выполнения первых команд кода вызывае¬
мой процедуры, т. е. после завершения операций вызова.
Повторный вход в процедуру может быть выполнен только
для процедуры, среда которой Env в данный момент уже содер¬
жится в трассе вывода Т. В этом случае она модифицируется.
В общем случае среда процедуры содержит управляющую
информацию Adm, копии значений регистров аргументов А1?
Л2,. . . ., Ат, которые они имели в момент вызова процедуры
(Args), вектор ячеек переменных Vars и структуры данных Strs
которые используются для представления термов, являющихся
структурами
Env = {Adm, Args, Vars, Strs}.
Управляющая информация Adm среды процедуры Env ЕЕ 7
содержит указатели на ближайшие вершины текущего и/или
дерева логического вывода, вершинами которого являются эле¬
менты Env ЕЕ Т. Управляющая информация Adm всегда опреде¬
ляет ближайшую «и»-вершину и может определять ближайшую
«или»-вершину, т. е. содержит указатели на соответствующие
элементы Env ЕЕ Т. Кроме того, Adm может содержать указатель
точки для повторного входа в процедуру, соответствующую!
ближайшей «или»-вершине. Управляющая ин ормация Adm все¬
гда содержит указатель точки входа, которая будет использована
для вызова следующей процедуры после завершения данной.
Для оперативного доступа к текущей трассе логического вы¬
вода Т абстрактная машина имеет специальный набор регистров
В, С и В. Регистр Е содержит указатель текущей среды вызова,
которую будем обозначать через Env (Е). Регистр С содержит
указатель вершины дерева вывода, связанной отношением «и»
с текущей. Эта вершина Env (С) является ближайшей «и»-вер-
шиной к текущей. Вершина дерева вывода Env (5) ее Т7, указа¬
тель которой содержится в регистре 5, называется ближайшей
точкой выбора и является ближайшей «или»-вершиной к текущей.
Вершина Env (В) связана отношением «или» с текущей верши¬
ной Env (В).
На рис. 1 изображены логическая программа и цель, ини¬
циировавшая логический вывод над Состояние дерева вы¬
вода на рис. 1 изображено в момент первого входа в процедуру
предиката b в предположении, что все предшествующие вызовы
22
рис. Ь Структуры
данных, создаваемые
и процессе логическо-
го вывода.
? Р.
р а, Ь, с.
а al.
д — логическая програм¬
а а2.
ма и цель вывода;
b <- Ь1? Ь2.
- дерево вывода в мо¬
<• cl. с2.
мент вызова про¬
цедуры предиката с
а).
а2.
bl.
Ъ2.
cl.
с2.
а
Е
процедур предикатов at завершены успешно. Пунктиром пока¬
зан возврат после завершения выполнения процедуры а±. Цифры
на рис. 1 показывают последовательность создания элементов
трассы логического вывода.
В момент входа в процедуру b выполняются соотношения
Env (Е) — Env (b), Env (С) = Env (р). Если при входе в про
цедуру а было использовано первое утверждение соответствую¬
щего предиката, то Env (В) = Env (а).
Для доступа в область кода абстрактная машина имеет ре¬
гистры Р, СР и ВР. Регистр Р всегда содержит указатель выпол¬
няемой команды. Регистр СР содержит указатель начала после¬
довательности команд вызова процедуры, которая должна быть
вызвана после завершения текущей процедуры, для выполнения
которой создана среда Env (Е). Регистр ВР содержит указатель
точки для повторного входа в процедуру, для которой была соз¬
дана среда Env (В).
Для ситуации, изображенной на рис. 1, в момент входа в про¬
цедуру b регистр СР содержит указатель на последовательность
команд вызова процедуры предиката с, а регистр ВР содержит
Указатель точки повторного входа в процедуру предиката, со¬
ответствующую второму утверждению предиката а.
Управляющая информация Adm содержит копии значений
регисторов С и СР в момент входа в процедуру. Сохранение ре¬
гистров В и ВР выполняется только в том случае, если используе¬
мая точка входа является не последней в процедуре предиката.
При этом условии в текущей среде сохраняется значение регистра
ав среде Env (В) сохраняется регистр ВР, после чего регистры
И и ВР получают новые значения, так как текущая среда стано¬
вится ближайшей точкой выбора.
Информация, содержащаяся в управляющей части Adm эле¬
ментов трассы Е, полностью определяет текущее дерево логиче¬
ского вывода.
23
Вектор переменных Vars содержит ячейки для каждой лонг
ческой переменной утверждения предиката, использованного
для входа в процедуру. Можно считать, что в момент создания
среды Env (Е) каждая ячейка вектора переменных Vars этой сре¬
ды содержит специальное пустое значение, соответствующее
пустой логической переменной.
В общем случае ячейки вектора переменных Vars могут иметь
наряду с пустым значением еще значение константы, структуры
и ссылки на другую переменную, принадлежащую любому век
тору переменных текущей трассы Т. Эти значения образуются
в результате унификации значений регистров Л1? Л2, .... Ап.
с аргументами головного литерала утверждения вызванной
процедуры. Поэтому унификация рассматривается как способ
передачи параметров при вызове процедуры.
Если ячейка вектора Vars имеет значение структуры, то она
содержит ссылку на структуру, расположенную в разделе Strs
одного из элементов трассы вывода Т.
Таким образом, регистры Е, С, В, Р, СР, ВР и трасса Т пол¬
ностью определяют текущее состояние логического вывода над
программой SP. Ио для выполнения возврата в ближайшую точку
выбора Env (В) и выполнения повторного входа в соответствую¬
щую процедуру этой информации недостаточно.
При возврате в ближайшую точку выбора необходимо вернуть
абстрактную машину в то состояние, которое она имела в момент
последней модификации среды Env (В). Это преобразование вы¬
полняется командой fail абстрактной машины логического вывода.
Для выполнения команды fail регистр Е получает значение
указателя на среду Env (В), т. е. Е = В. Регистры С, В и СР
восстанавливаются из раздела Adm среды Env (В), а регистр
Р : — ВР. Содержимое Args среды Env (В) не изменяется, а раз¬
делы Vars и Sirs уничтожаются и создаются заново во время
повторного выполнения процедуры. В разделе Adm сохраняется
только информация, связанная с точкой выбора. После чего уни¬
чтожаются элементы трассы, которые оказались моложе Env (Е),
и регистры Alf А2, . . ., Ат восстанавливаются из раздела Args
среды Env (£).
По этих операций недостаточно для полного приведения аб¬
страктной машины в требуемое состояние. Дело в том, что при
унификации регистров А1Т А21. . ., Ат с аргументами головного
литерала может происходить двунаправленная передача значе¬
ний, в результате которой некоторые ячейки векторов Vars,
которые до этого момента содержали пустые значения, могут
получить другие значения. При этом эти вектора могут принад¬
лежать элементам трассы Г, которые значительно старше теку¬
щей среды Env (А), в то время как указанные операции, выпол¬
няемые командой fail, не всегда ликвидируют эти значения.
Поэтому для завершения команды fail необходима специаль¬
ная информация. Эта информация сохраняется в динамической
области и называется следом логического вывода.
След логического вывода есть стек указателей ячеек перемен¬
ных векторов Vars трассы вывода Т. Специальный регистр вер¬
шины стека TR абстрактной машины содержит всегда указатель
следующего за последним элемента следа. Регистр BTR содержит
значение регистра TR в момент создания точки выбора Env (В),
редкий раз, когда пустая ячейка переменной и, среда которой
gnv старше среды последней точки выбора, получает некоторое
непустое значение во время унификации, ее адрес добавляется
в след, а регистр TR получае приращение.
При сохранении регистров В и ВР всегда сохраняется ре¬
гистр TR в разделе Aclm текущей среды Env (Е), a BTR: = TR.
Кроме того, регистры ВР и BTR получают новые значения,
когда последняя точка выбора оказывается полностью исчерпан¬
ной при возвратах. В результате этого ближайшей точкой выбора
становится предыдущая точка выбора, указатель которой хра¬
нится в разделе Adm текущей среды. В этом случае В восстанав¬
ливается из среды Env (5), а ВР и BTR из среды Env (/?*),
где 5* — восстановленное значение регистра В. Эта операция
называется восстановлением предыдущей точки выбора.
Эта дисциплина сохранения и восстановления регистров
возврата позволяет завершить операции команды fail следующими
образом.
Из стека следа выталкиваются все указатели в диапазоне
[BTR, TR), и каждый из них используется для ликвидации зна¬
чения указываемой ячейки переменной, т. е. эта ячейка получает
пустое значение. После чего TR: = BTR. Эта операция называ¬
ется распаковкой следа при возврате (undo trail).
Таким образом, команда fail полностью восстанавливает со¬
стояние абстрактной машины, которое она имела в момент послед¬
ней модификации последней точки выбора, но непосредственно
после выполнения этой команды необходима проверка, что
Env (В) остается точкой выбора, т. е., что она все еще содержит
более одной неиспользованной альтернативы. В противном слу¬
чае должна быть восстановлена предыдущая точка выбора.
На рис. 2 изображена структура кода для предиката Р логи¬
ческой программы. Код для каждого предиката Р Ez 3й строится
независимо от других предикатов с точностью до значений опе¬
рандов команд call и last_call, которые являются указателями
точек входа в другие процедуры предикатов программы 2К Точка
входа в процедуру предиката Р (Е Зъ отмечена меткой Pred:.
Точка входа в процедуру предиката Pred: используется то¬
лько после выполнения кода вызова этой процедуры, т. е. после
выполнения последовательности команд load args и команды
Са11 или last_call.
В момент начала выполнения команды proc_entry регистр Р
с°Держит указатель этой команды, регистры Аг, А2, . . ., Ат
Сгружены аргументами вызова (m-арность вызываемой проце¬
дуры предиката Р ЕЕ 3^. Среда Env (Е) является пустой,
а среды Env (С) и Env (В) полностью определены. Регистр СР
25
Рпч1:. procentry
search—block
Г choice-point
| try_stmt S’, |
I try.stmt S', |
точки | . I
повторного I - '
I ■ I
входа j : J
i : I
L_- I
Stmt: stmt—entry,,.
[ unify _ args |
allocate— env
| load _ args |
call P,
| load — args |
б.чоки
call P2
утверждений
load args
last _саГ1 Pk
St ml: stmt-entry ,,,
[unify args
return,..
trust _stmt S’
P
S, : код утверждении/
S;: код утверждении/
Sr; код утверждения^
| DATA
Рис. 2. Структура абстрактного
кода предиката
слева — код процедуры предиката^
в центре — код для правила,
справа — код для факта
содержит указатель блока команд load_args, которые должны быть
выполнены после возврата из данной процедуры. Регистр ВР
содержит указатель повторной точки входа в процедуру, среда
которой есть Env (В).
Команда proc entry имеет один операнд тп, равный числу ар¬
гументов предиката Р. Эта команда сохраняет значения регистров
А1? Л2,. . . Ат в текущей среде Env (£). После чего автомати¬
чески выполняется следующая команда.1
Последовательность команд search_block вычисляет одну из
точек входа Bj. Каждая точка входа Bj определяет блок команд,
который называется блоком утверждений. Операнды команд
блока утверждений содержат указатели точек входа в утвержде¬
ния предиката i = 1, 2,. . . ., г. Каждый блок утверждений
определяет некоторую подпоследовательность последовательно¬
сти утверждений предиката Р.
Блоки утверждений строятся компилятором и не имеют об¬
раза в исходном тексте определения предиката. Блок утверждений
определяет упорядоченное множество тех и только тех утвержде¬
ний предиката, аргументы головных литералов которых могут
унифицироваться со значениями регистров А1? Л2, . . ., Ат.
Условия, которые определяют блок, обычно требуют проверки,
что определенный регистр A t имеет значение некоторой структуры,
константы или переменной. Могут использоваться условия,
включающие проверку значений нескольких регистров в задан¬
ной последовательности. Порядок проверки значений регистров
и их число могут указываться в исходном тексте определения
предиката Р в виде дополнительного описания схемы индексации
утверждений. Если описатель индексации не задан, то использу¬
ется только регистр Аг.
26
Константы и структуры, используемые для генерации команд
проверки условий search_block, выбираются компилятором из
йСходного кода предиката. Например, если первый аргумент
головного литерала каждого утверждения предиката есть кон¬
станта и все эти константы различны, то компилятор может по¬
строить г + 1 блок утверждений (г — число утверждений пре¬
диката) при условии, что описатель индексации не задан. Условия
для этих блоков будут следующие. Если значение есть пустая
переменная, то необходимо использовать блок Вг+1, содержащий
точки входа во все утверждения предиката. Если значение ре¬
гистра есть константа, равная первому аргументу головного
литерала утверждения St предиката Р, то необходимо использо¬
вать блок содержащий точку входа только этого утверждения
Если эти условия не выполнены, то необходимо выполнить
команду fail абстрактной машины логического вывода.
Схемы индексации, реализуемые командами search_block,
могут быть весьма сложными, но в любом случае они гарантируют
только то, что утверждения, не включенные в блок, пе не могут быть
использованы для выполнения вызова процедуры, если выполнены
условия на значения регистров Аг, А2, . . ., Ат, определяющие
данный блок утверждений. Поэтому, если значения регистров
А1У А2, . . ., Ат не удовлетворяют ни одной группе условий,
определяющих блок, то выполняется команда fail, означающая
неуспешное завершение вызова.
Таким образом, группа команд search_block либо загружает
регистр Р указателем точки входа В] одного из блоков утвержде¬
ний, либо осуществляет запуск команды fail.
В общем случае блок утверждений начинается с команды
choice point, которая выполняет сохранение регистров В, TR
в разделе Adm среды Env (Е) и сохранение регистра ВР в разде¬
ле Adm среды Env (5). После чего В: = Е и BTR: = TR.
Команда del_choice_point выполняется, если ближайшая точка
выбора исчерпана, т. е. фактически проверка возникновения этой
ситуации не производится, а момент восстановления предыдущей
точки выбора определяется автоматически, т. е. если эта команда
выполняется, то необходимо восстановить предыдущую точку
выбора. Для этого регистр В восстанавливается из раздела Adm
среды Env (Е), так как всегда до начала выполнения этой команды
В = Е. Если 5*—новое значение регистра В, то регистры ВР и
BTR восстанавливаются из раздела Adm среды Env (В*). После
команды def_choice_point всегда выполняется следующая команда.
После выполнения команды choice_point- также выполняется
следующая команда try_stmt, которая имеет единственный опе¬
ранд, содержащий указатель точки входа в утверждение. Эта
команда загружает регистр ВР указателем следующей команды
к передает управление в точку входа утверждения, т. е. в ре¬
гистр Р загружается операнд команды. Таким образом, в ре¬
гистр ВР может быть загружен указатель команды try_stmt или
del choice_point. Из этого следует, что команды try_stmt
27
и del_clioice_point являются точками повторного входа в про¬
цедуру, так как команда fail всегда загружает регистр Р зна¬
чением регистра ВР, а повторный вход осуществляется только
в результате выполнения команды fail.
Группа команд, начинающаяся командой choice_point и
завершающаяся командой del_choice_point, имеется только
в блоках утверждений, которые содержат указатели более одного
утверждения. В противном случае блок утверждений состоит
только из одной команды trust_stmt, имеющей, так же как
и try_stmt, только один операнд, содержащий указатель точки
входа в утверждение. Команда trust_stmt осуществляет только
загрузку в регистр Р значения операнда, т. е. передает управле¬
ние в точку входа в утверждение. Эта команда всегда завершает
блок утверждений.
Команда slmt_entry, имеющая несколько операндов, необхо¬
дима для приведения разделов Vars и Sirs в исходное состояние
для выполнения последующей унификации регистров А 1? Л2, . . .,
Ат с аргументами головного литерала утверждения. Операнды
содержат размеры этих разделов. После этой команды всегда
выполняется следующая команда.
Команды унификации unify_args выполняют унификацию
значений регистров А19 А2, . . ., Ат с аргументами головного
литерала. Для каждого аргумента в общем случае имеется не ме¬
нее одной команды. Более одной команды имеют аргументы,
являющиеся структурами. Каждая унификационная команда
имеет два операнда. Первый операнд указывает номер регистра,
а второй — содержит либо сам аргумент литерала, либо ссылку
в раздел кода предиката DATA, где расположены структуры,
используемые для представления сложных термов. Если аргумент
литерала есть переменная, то второй операнд команды унифика¬
ции содержит указатель ячейки переменной, расположенной в
разделе Vars среды Env (Е).
В результате этих команд ячейки переменных вектора Vais
текущей среды Env (£) получают значения (может быть, и пу¬
стые). Кроме того, как это отмечалось выше, непустые значения
могут получить ячейки переменных и более старых элементов
трассы вывода Т. Таким образом, в результате выполнения ко¬
манд unify_args вектор Vars среды Env (Е) становится практи¬
чески определенным, если во время выполнения этих команд не
возникла ситуация, в которой была выполнена команда fail.
После успешного завершения уникации могут остаться недооп¬
ределенные ячейки в векторе Vars. Эти ячейки соответствуют
логическим переменным, имеющим первое вхождение в теле ут¬
верждения. Если была выполнена команда fail, то вектор Vars
текущей среды считается полностью неопределенным.
Если команда fail не была выполнена, то после окончания
unify.args выполняется следующая команда. Это означает, что
регистры Лх, А2, . . ., Ат успешно унифицированы с аргументами
головного литерала.
28
Если утверждение является правилом, то после успешной
унификации выполняется команда allocate_env, которая имеет
несколько операндов, позволяющих вычислить место для разме¬
щения в динамической области нового элемента трассы вывода Т.
Команда allocate_env выполняет сохранение регистров С
н СР в текущей среде Env (£), причем текущая среда фиксируется
как ближайшая «п»-вершина, т. е. С: = Е. После чего в трассу
вывода добавляется новый текущий пустой элемент, а в регистр £
загружается его указатель.
После команды allocate_env всегда выполняется следующая
команда. Эта команда может быть либо командой группы команд
]oad_args, либо командой call или last_call, если соответствующий
литерал тела не имеет аргументов. Команда last call исполь¬
зуется только для последнего литерала тела утверждения.
Команды load.args выполняют загрузку регистров Ап Л2, . • •
.. ., Ат аргументами соответствующего литерала тела утвержде¬
ния. Регистры Л1? А2, . . ., Ат загружаются значениями, которые
находятся в среде Env (С), если аргументы литерала тела со¬
держат логические переменные. Все ячейки для этих логических
переменных расположены в разделе Vars среды Env (С).
Для каждого аргумента имеется одна команда, выполняющая
загрузку соответствующего регистра A Первый операнд команды
определяет номер регистра, а второй операнд либо сам аргумент
литерала, либо есть ссылка в раздел Strs среды Env (С).
Команды unify_args и load_args существенно зависят от
способа представления термов. Поэтому эти команды и способы
представления термов рассматриваются более подробно в следую¬
щем разделе.
После завершения команд load_args всегда' выполняется сле¬
дующая команда, которая может быть либо командой call, либо
командой last_call.
Команда call загружает регистр СР указателем следующей
команды, а регистр Р — значением своего единственного опе¬
ранда, которое есть указатель точки входа в вызываемую про¬
цедуру предиката, т. е. эта команда передает управление вызы¬
ваемой процедуре предиката. Регистр СР при этом определяет
команду возврата из вызываемой процедуры.
Команда last_call является более сложной. Эта команда вы¬
полняет оптимизированный хвостовой вызов, соответствующий
последнему литералу утверждения. Основная задача этой ко¬
манды освободить память в динамической области, которая за¬
нята ставшими уже ненужными элементами трассы Т. Точнее,
команда last_call освобождает память, занимаемую только раз¬
делами Adm, Args и частично Vars некоторых элементов трассы Т.
Если в момент выполнения команды last_call среда Env (С)
Моложе, чем среда Env (5), то память, используемая разделами
Adm, Args и частью раздела Vars для всех элементов Strs, которые
Не старше элемента Env (С), может быть освобождена. Не могут
быть освобождены только части разделов Vars и разделы Strs
29
этих элементов. Если же среда Env (С) не моложе, чем сред^
Env (5), то эта оптимизация выполнена быть не может, поскольку
вся эта информация необходима для выполнения повторною
входа в процедуру, которой соответствует среда Env (В). Вгь
полнение команды оптимизированного хвостового вызова last
call приводит к частичному уничтожению среды вызывающей
процедуры Env (С).
Для выполнения команды last.call и return раздел Vars
организуется в виде двух векторов: локального Loc.Vars ц
глобального Glob_Vars. Локальные векторы Loc_Vars, удов¬
летворяющие указанным условиям, освобождаются во время
выполнения команды last_call и return. Глобальные векторы
Glob_Vars и раздел Strs могут уничтожаться только вместе с
соответствующей средой при выполнении команды fail. Необхо¬
димость введения двух типов ячеек в векторе Vars подробно рас¬
сматривается в следующем разделе.
Кроме указанной оптимизации используемой части динами¬
ческой области, команда last_call восстанавливает значения
регистров С и СР из среды Env (С) и загружает регистр Р зна¬
чением своего единственного операнда, которое есть указатель
точки входа в вызываемую процедуру, т. е. передает управление
этой процедуре.
Если утверждение есть факт, то после успешного окончания
команд унификации выполняется команда return, действие ко¬
торой эквивалентно выполнению команды allocate_env с пос¬
ледующей оптимизацией, выполняемой командой last_call, и за¬
грузкой регистра Р: = СР без предварительной модификации
регистра СР. Команда return выполняет возврат из процедуры
путем передачи управления в соответствии со значением ре¬
гистра. СР. Команда return имеет такие же операнды, что и команда
allocate_env, используемые аналогичным образом.
Оптимизация памяти, выполняемая в командах last_call и
return, чрезвычайно важна. Дело в том, что рекурсивные правила
являются единственным средством в языке Пролог, позволяющим
выполнять циклическую обработку. Если при выполнении такою
цикла оптимизацию не удается использовать, то в трассе Т появ¬
ляется столько новых элементов, содержащих полностью все
разделы, сколько итераций необходимо для выполнения этою
цикла. Если оптимизация используется (для этого необходимо,
чтобы рекурсивный вызов был хвостовым и выполнялись ука¬
занные условия), то на каждой итерации в трассу Т фактически
добавляются только разделы Grlob_Vars и Strs, а если рекур¬
сивное утверждение не содержит структур, то и эти разделы ока¬
зываются пустыми. В этом последнем случае цикл выполняется
с использованием фиксированного участка динамической области:
размер которого не зависит от числа итераций цикла.
Наличие регистров Л2, . . ., Лт, ... в структуре абстракт
ной машины связано только с выполнением оптимизированною
хвостового вызова, т. е. строго говоря, эти регистры необходимы
30
только для реализации команды last_call. Например, абстрак¬
тная машина [2] не использует команды типа last_call и не имеет
регистров Alf А2, • . Ат.
3
КОМАНДЫ ЗАГРУЗКИ АРГУМЕНТОВ И УНИФИКАЦИИ
Конкретный вид команд load args и unify args определя¬
ется способом представления термов. Это же обстоятельство вли¬
яет на использование и внутреннюю структуру разделов Vars
й Strs элементов Env ЕЕ Т.
Для представления термов известны два способа — метод
разделения структур и метод копирования структур (Structure
Sharing и Structure Coping соответственно) [2, 3].
Метод копирования структур (SC) впервые был использован
в работе [ЗГ и является наиболее простым. Метод разделения
структур (SS) был эффективно использован для выполнения
скомпилированных логических программ на ЭВМ DEC-10 [2].
Основные команды группы load_args могут быть четырех
типов в соответствии с четырьмя основными типами термов ну¬
левого уровня (см. разд. 2). Эти команды используются для ар¬
гументов литералов тела утверждения. Для каждого аргумента,
не являющегося структурой, используется только одна команда.
Если аргумент является константой, то используется команда
load_cons At с, которая загружает значение второго операнда
в регистр A i (1 <1 i тп). Значение второго операнда с есть код
константы.
Если аргумент является переменной, имеющей первое вхож¬
дение в теле, то используется команда load.var At и, которая
загружает в регистр At указатель ячейки вектора Vars среды
Env (С). Операнд v содержит смещение этой ячейки относительно
начала вектора и используется для вычисления указателя. Кроме
того, в эту ячейку записывается пустое значение, так как она
осталась неопределенной после унификации.
Если аргумент является связанной переменной, то использу¬
ется команда load_ref At v, которая только загружает в регистр
А} указатель ячейки этой переменной. Операнд v используется
так же, как и выше.
Все эти три команды практически не зависят от используемого
метода представления термов. Если же аргумент является струк¬
турой, то используется команда load_str s. Выполнение этой
команды и семантика второго операндам полностью определяются
используемым методом представления термов.
Если используется метод SC для представления термов, то
Для данного аргумента, являющегося структурой, генерируется
Несколько команд, выполняющих построение специальной струк-
тУры в разделе Strs среды Env (С). Для каждого терма ненуле¬
вого уровня данного аргумента генерируется своя команда,
создающая определенный элемент структуры в разделе Strs
среды Env (С).
31
Рис. 3. Размещение структур в памяти
с, — размещение структуры и ее загрузка в регистр при использовании метода копиро¬
вания структур; б — загрузка структуры в регистр при использовании метода раздел!-
нпя структур
Например, для терма
t = Л (X, Y, и (X, f3 (а, X), h (b, У)))
создается структура, изображенная на рис. 3, а. Сначала выпол¬
няются команды размещения подтермов /4 и /5, затем при исполь¬
зовании их указателей размещается подтерм /2 и только после
этого размещается сам терм t = Пунктиром показаны значе¬
ния ячеек переменных, которые имеют многократное вхождение
в терм. Ячейки, обозначенные через X и У, имеют некоторые
32
значения, зависящие от их остальных вхождений в тело утверж¬
дения. Таким образом, при использовании SG-метода все перемен¬
ные утверждения, имеющие вхождения в структурах, размеща¬
ются в разделе Strs, который совпадает с вектором Glob_Vars
среды Env (С), т. е. Glob_Vars не используется. Остальные логи¬
ческие переменные размещаются в векторе Loc_Vars среды Env (С).
Затем регистр At загружается указателем этой структуры, создан¬
ной в разделе Strs среды Env (С).
При использовании SS-метода загрузка структуры в регистр
при помощи команды load_str существенно упрощается. Для вы¬
полнения загрузки в регистр At любого терма достаточно одной
этой команды.
В этом случае операнд 5 есть указатель скелета загружаемого
терма. Скелет терма расположен в области кода в разделе DATA
(см. рис. 2) и является структурой, аналогичной той, которая
строится динамически при использовании SC-метода. Эта струк¬
тура изображена на рис. 3, б. Основное отличие заключается
в том, что скелет терма строится компилятором и никогда не ко¬
пируется в динамическую область, а ячейки скелета, соответст¬
вующие логическим переменным, содержат смещения относитель¬
но начала вектора Glob_Vars, который находится в среде Env (С).
Сами же ячейки логических переменных, входящих в структуру,
размещаются в векторе Glob_Vars, который содержит ячейки
для всех логических переменных утверждения, имеющих хотя
бы одно вхождение в структуру. Остальные логические перемен¬
ные размещаются в векторе Loc_Vars среды Env (С).
В разделе Strs среды Env (С) создается структура, называю¬
щаяся молекулой. Молекула mol (ptr 1, ptr 2) содержит два ука¬
зателя — указатель ptr 1 вектора Glob_Vars среды Env (С) и ука¬
затель ptr 2 скелета s, который содержится во втором операнде
команды load_str. В регистр At помещается указатель созданной
молекулы.
Молекула связывает в единую конструкцию вектор Glob_Vars
и скелет терма.
Если обозначить через
Loc_Env = {Adm J Args J Loc_Vars},
GlobJEnv = {Glob_Vars J Strs},
то как при использовании SC-метода, так и при использовании
ss-метода, Glob_Env содержит информацию, связанную с созда¬
нием структур. Поскольку ссылки на структуры в Glob_Env
загружаются в регистры аргументов и передаются в качестве
значений в вызываемую процедуру, то Glob_Env может быть
освобождена только при выполнении операции fail, так как при
заполнении команд last_call или return чрезвычайно сложно
определить, используются ли где-либо элементы данного раздела
Glob_Env в качестве элементов значений или нет. Для определе¬
ния этого необходимо выполнить сборку мусора на множестве
2 Закал -Ni 2514
33
L Glob_Env, где i пробегает номера всех элементов трасс:.;
вывода Т.
Из этой сравнительной схемы видно, что загрузка аргументов
при использовании SS-метода намного более эффективна как с точ¬
ки зрения быстродействия, так и с точки зрения использования
динамической области.
Кроме того, как для SS-метода, так и для SC-метода достаточно
иметь два стека для эффективной реализации доступа и мани¬
пулирования трассой вывода Т. Один стек необходим для сохра¬
нения Loc_Env, а второй стек — для сохранения Glob,Env.
Первый стек может освобождаться при выполнении команд last, call
и return, второй стек — только при выполнении команды fail.
Команды унификации unify_args во многом аналогичны ко¬
мандам load_args с точки зрения использования разделов Vars
и Strs элементов Erv ЕЕ Т для представления термов. Во время
унификации также могут создаваться новые структуры в разделе
Strs среды Env (£).
Основные типы команд унификации аналогичны соответст¬
вующим командам load,args и могут быть также четырех типов
в соответствии с типами термов нл левого уровня (см. разд. 2).
Для каждого аргумента головного литерала, не являющегося
термом, используется только одна команда.
Формат всех команд унификации следующий:
unify,... Af i,
где At — регистр аргумента, для которого используется команда,
t есть терм, являющийся соответствующим аргументом головного
литерала.
В качестве самой первой операции, выполняемой любой ко¬
мандой унификации, осуществляется дереференсирование регист¬
ра At.
Операция дереференсироваиия dereference А не меняет содер¬
жимого регистра А, если А содержит константу или указатель
структуры, расположенной в разделе Strs среды Env, либо ссыл¬
ку на пустую переменную. В последнем случае считается, что
регистр содержит пустое значение.
Если же регистр содержит ссылку на переменную, которая
содержит ссылку на другую переменную, то это значение загру¬
жается в регистр А и повторяется очередной шаг дереференсиро-
вания, в результате чего регистр А после дереференсироваиия
содержит либо константу, либо указатель структуры в разделе
Strs некоторого элемента Env ЕЕ Т, либо ссылку на пустую пере¬
менную, также расположенную в произвольном элементе Env ЕЕ I.
Если аргумент I головного литерала есть константа с, то ис¬
пользуется команда unify_const A t с. где с — код константы.
Эта команда после дереференсироваиия регистра А[ проверяет,
является ли его значение пустым, и если это так, то, используя
Ai как указатель ячейки, записывает в эту ячейку код константы
34
с после чего выполняется операция opt_trail которая фикси¬
рует указатель ячейки пустой переменной, получившей значение
константы, в стеке следа, если эта ячейка находится в среде
gnv G Т- которая старше Env (В).
Если регистр не пуст и его значение не равно с, то выпол¬
няется команда fail.
Если же регистр At содержит значение, равное с, то никаких
действий не выполняется.
Для аргумента i головного литерала, который является сво¬
бодной логической переменной, используется команда
unify.var At v,
которая после дереференсирования регистра А} записывает зна*
чение регистра At в ячейку, указатель которой определяется на
основе значения операнда v, содержащего смещение относительно
начала вектора Vars или Strs (для SC-метода — Loc_Vars и
Glob. Vars соответственно) среды Env (Е).
Для аргумента I головного литерала, который есть связанная
переменная, используется команда
unify.ref At v,
которая после дереференсирования регистра At п вычисления
указателя ячейки переменной addr (v, Е) запускает операцию
general.unify At addr,
которая выполняет общий алгоритм унификации двух термов,
первый из которых находится в регистре At, а второй — имеет
указатель addr. Этот алгоритм для SS-метода подробно описан
в работе [5].
Для аргумента i головного литерала, который есть структура,
генерируется последовательность унификационных команд, на¬
чинающихся с команды
uui£y_str At s,.
которая также в первую очередь дереференсирует регистр Лр
После чего его значение анализируется.
Если регистр At пуст, то при использовании SS-метода опе¬
ранд $ интерпретируется как указатель скелета терма в области
кода и создается в разделе Strs среды Env (Е) молекула
mol (addr, s), где addr — указатель вектора Glob_Vars среды
Env (Е). После чего, используя At как указатель ячейки, в эту
ячейку записывается ссылка на созданную молекулу и выпол¬
няется операция opt_trail At. Оставшиеся команды для данного
яргухмента не выполняются.
Если Лг- пуст, но используется SC-метод, то в разделе Strs
среды Env (Е) создается структура при помощи всей последова¬
тельности команд для данного аргумента I таким образом, как
при выполнении команды load_str.
35
2*
После того как терм создан в динамической области, его ука¬
затель загружается в ячейку, используя как ее указатель.
Затем выполняется операция opt.trail At.
Наиболее сложный случай возникает, если значение регистра
не пусто.
Если используется SS-метод, то выполняется команда fail,
если значение регистра не есть ссылка на молекулу. Если же
регистр содержит ссылку на молекулу, то эта молекула распако¬
вывается, т. е. в специальные регистры V и SKEL загружаются
указатель вектора глобальных переменных и указатель скелета
структуры, и SKEL сравнивается с операндом команды $. Если
SKEL и 5 указывают на полностью идентичные функторы, то
выполняются последующие команды для унификации вложенных
термов. Если же функторы не совпадают, то выполняется ко¬
манда fail.
При использовании SC-метода эта операция немного проще,
т. е. достаточно сравнить значение ячейки с указателем Л7- и не¬
посредственный операнд команды. Если они совпадают, то вы¬
полняются последующие команды глубокой унификации, а в про¬
тивном случае выполняется команда fail.
Для глубокой унификации необходим унификационный стек,
если в структуре имеются подструктуры. Для аргументов струк¬
туры нулевого уровня, которые не являются структурами, ис¬
пользуются команды, аналогичные unify_cons, unify_var и uni-
fy.ref, но только первый операнд в этих командах имеет несколько
другой смысл.
Для SS-метода первый операнд интерпретируется как смеще¬
ние относительно значения регистра SKEL, и тем самым вычис¬
ляется указатель скелета терма, представляющий соответствую¬
щий аргумент. Поэтому для выполнения унификации необходимо
вычислить еще указатель самой ячейки переменной V -4- offs,
где offs — содержимое элемента скелета, если аргумент есть ло¬
гическая переменная, и только после этого могут быть выполне¬
ны операции для unify_var или unify_ref.
Для SC-метода также существует регистр Я, аналогичный
SKEL, но содержащий уже указатель соответствующей ячейки..
Регистр Н загружается при выполнении команды unify_str.
Поэтому для SC-метода операции глубокой унификации также
намного проще. Так, опять достаточно сравнить значение ячейки
с указателем Я, и непосредственного второго операнда команды.
После выполнения этих команд регистр Я получает приращение
и указывает следующий аргумент структуры.
Если очередной аргумент терма нулевого уровня оказывается
структурой, то для него используется команда, аналогичная uni-
fv_str. Эта команда предварительно помещает в унификационный
стек значение пары SKEL> (для SS-метода) либо значение Я
(для SC-метода) и выполняет соответствующие операции, кото¬
рые были рассмотрены для команды unify_str, но, естественно,
с предварительным вычислением указателя для первого операнда.
36
Цосле завершения операций для вложенной структуры нослед-
вий элемент унификационного стека выталкивается, т. е. загру¬
жаются регистры V, SKEL (или Я).
4.
ЭФФЕКТИВНОСТЬ АРХИТЕКТУРЫ
ПРОЦЕССОРА ЛОГИЧЕСКОГО ВЫВОДА
Абстрактная машина логического вывода, рассмотренная вы¬
ше, позволяет провести сравнительный анализ процессоров ло¬
гического вывода, если принцип процедурной интерпретации
используется как основа для системы команд. В рамки рассмотрен¬
ной схемы выполнения логической программы укладываются
практически все существующие в настоящий момент как програм¬
мные, так и аппаратные реализации процессоров логического
вывода 16—11]. Система команд и структуры данных, необходимые
для выполнения Пролог-программ, были изложены в достаточно
абстрактной форме, что позволяет смоделировать любой из ука¬
занных процессоров логического вывода. Для этого достаточно
конкретизировать структуры данных, используемые для пред¬
ставления трассы логического вывода, и для некоторых команд,
рассмотренных в разд. 3 и 4, сформировать их более простые
частные случаи, которые можно использовать только в определен¬
ных ситуациях. Эти ситуации могут обнаруживаться компиля¬
тором, в результате чего код логической программы получается
более эффективным.
Команды абстрактной машины естественным образом делятся
на две группы: команды унификации и команды управления
выводом. Первая группа включает команды load_args и unify_args,
а вторая — остальные команды.
Поскольку команды управления выводом практически не за¬
висят от способа представления термов и определяются только
процедурной семантикой логических программ, то эффективность
этих команд зависит только от операций доступа к трассе вывода.
Все процессоры [6—И] используют одинаковый набор стеков:
стек для Loc_Env и стек для GlobJEnv — и примерно идентич¬
ный набор регистров для доступа к элементам стеков. Эти регист¬
ры образуются в результате «расщепления» каждого из регистров
С, Е, В на два регистра для локального и глобального стеков.
Существенного увеличения производительности можно до¬
стичь, если трасса вывода и след реализуются в виде нескольких
физических различных сегментов памяти [6, 7, 9]. В этом случае
Можно получить высокий уровень параллельности при выпол-
Невпи микроопераций, реализующих команды абстрактной ма¬
шины. Для процессора, реализованного в рамках проекта РЕК
'б, 7], в течение 70% времени выполняются параллельно три
микрооперации.
При одинаковых условиях реализации трассы вывода и следа
эффективность процессора логического вывода определяется бло¬
ком унификации.
37
Сравнительный анализ выполнения унификации при исполь¬
зовании методов копирования и разделения структур показы¬
вает. что эффективность выполнения логической программы су¬
щественно зависит от структуры программы в целом. Если струк¬
туры находятся в основном в телах утверждений, то использо¬
вание SS-метода будет намного эффективное, так как код будет
содержать относительно немного команд unify_str, которые мало¬
эффективны для SS-метода. Программы этого типа работают в ре¬
жиме конструирования новых объектов в виде сложных структур.
Эти программы могут описывать процессы проектирования.
Если же структуры сосредоточены в головных литералах,
и часто возникают операции унификации двух структур, то
SS-метод будет менее эффективным.
Поэтому для программной реализации SS-метод менее эффек¬
тивен, но если имеется специальная аппаратура, включающая
несколько комбинационных схем, обеспечивающих быстрое вы¬
полнение операций с молекулами, то эффективность команды
unify_str при использовании SS-метода может быть не намного
ниже, чем при использовании SC-метода. Эти комбинационные
схемы были использованы в процессоре РЕК [6, 7]. В результате
производительность этого процессора на стандартных тестах [2]
является одной из самых высоких — более 400 KLIPS при так¬
товой частоте 8—10 Мгц.
Но рассмотренная абстрактная машина не охватывает абсо¬
лютно все известные подходы к реализации процессоров логи¬
ческого вывода. Архитектура, рассмотренная в работе [12], пред¬
ставляет собой специализированную RISC-архитектуру, исполь¬
зующую некоторые идеи метода резолюций [4], на котором осно¬
ваны и алгоритмы классического логического вывода. Иммита-
ционные результаты показывают, что производительность этого
процессора может немного превышать производительность РЕК.
ЛИТЕРАТУРА
1. Clocsin W. F., Mellish С. S. Programming in prolog. Berlin: Springer,
1984. 297 p.
2. Warren D. II. D. Implementing prolog — compiling predicate logic pro¬
grams. Edinburgh, 1977. Vol. 1/2. 35 p. (DAI Univ. Res. Rep.; N 39/40).
3. И’штеп D. II. D. An abstract prolog instruction set. 1983. 45 p. (Tech.
Note Al Center SRI Intern.; N 309).
4. Lloyd J. W. Foundation of logic programing. Berlin: Springer, 1984,
5. IFoo Ar. S. The architecture of Hardware Unification Unit and implemen¬
tation//ACM SIG MICRO Newsletter. 1987. Vol. 17, N 4. P. 89—99.
G. Kaneda У., Tamur a N. Sequential prolog machine РЕК// New Generation
Comput. 1986. Vol. 4, N 2. P. 50-66.
7. Woda K., Miyamoto M. Intermidiate code rof the sequential prolog machine
РЕК / Euromicro J. 1987. Vol. 21, N 1/5. P. 275-282,
8. Dorbu T. P., Despain A. M. Performance studies of a prolog machine
architecture//SIGARCH Newslett. 1985. Vol. 13, N 3. P. 180-190.
9. Giuera P. L., Piccinini G. L. Design considerations on VLSI PROLOG
interpreter//Euromicro J. 1987. Vol. 21, N 1/5. P. 267—273.
10. Gee J., Mevlin S. W., Patt Y. N. The implementation of prolog via
38
VAX 8600 microcode// ACM SIG MICRO Newsletter. 1987. Vol. 17, N 4.
p. 68—74.
Nakazaki B., К on a gay a A. Design of high-speed prolog machine (HPM) //
1 SIGARCH Newslett, 1985. Vol. 13, N 3. P. 191—197.
4? Vlahavag J., Halatsts C. A RISC prolog machine architecture// Euromicro
1987. Vol. 21, N 1/5. P. 259-266.
ПОРОЖДЕНИЕ ПАКЕТОВ ПРОГРАММ
В. Д. Ильин
Программирование поведения символьных автоматов занимает
особое место среди всех видов деятельности, связанных с управ¬
лением. Оно делает потенциально короткой по времени и уникаль¬
ной по эффективности цепочку: замысел — его знаковое вопло¬
щение — реализация в виде задуманного поведения автомата.
К сожалению, пока только потенциально. Процесс знакового
воплощения замысла в виде сегодняшней разработки программ¬
ного обеспечения никак не назовешь коротким по времени. Из-за
этого остается лишь потенциальной и уникальная эффективность
всей цепочки. Ее среднее звено является критическим.
С тех пор как существует программирование, программисты
ищут способы повышения производительности своего труда.
Особенно актуальной проблема автоматизации программирова¬
ния стала теперь, когда недостаточный уровень продуктивности
разработки программного обеспечения сдерживает во многих
областях процесс их компьютеризации. Исследователи, работаю¬
щие в области автоматизации программирования, продолжают
поиск способов повышения продуктивности.
Интенсивно развиваются нетрадиционные методы создания
программ, исследуются систематические способы их конструиро¬
вания 11, 2]. Эта работа неразрывно связана с постоянным изу¬
чением существа самой проблемы синтеза программ. Какая часть
работы может быть поручена системе? Что необходимо оставить
человеку, определяющему задание на синтез искомой программы?
Велико стремление ряда исследователей [3—4] представить про¬
цесс конструирования программ как последовательность чисто
формальных шагов. Много усилий затрачивается на создание
систем автоматического синтеза программ по конечному множеству
образцов их поведения. Не оставляют надежд сторонники раз¬
работки программ в диалоге на естественном языке. Разрабаты¬
ваются языки и системы спецификации [5, 6]. Важным этапом
отала разработка пакетной проблематики как технологии решения
задач [7—10].
С нарастающей интенсивностью ведется разработка инстру¬
ментальных систем программирования как основного средства
Повышения продуктивности разработки прикладных программ
39
[11—14]. Исследуются методы построения генераторов программ,
пол ьз у ющихс я р астущим спр ос ом [15—17].
Статья посвящена проблеме создания системы порождения
пакетов программ, которая построена на регулярной методиче¬
ской основе и позволяет в диалоговом режиме разрабатывать
пакеты прикладных программ, имеющие статус систем, сдавае¬
мых под ключ. Вначале рассматривается состояние разработки
средств автоматизации программирования, ориентированных на
получение пакетов программ. Затем излагается основпая идея
метода порождения программных систем, приводится краткое
описание системы порождения пакетов программ для решения
задач учета и планирования, имеющих массовый характер.
1.
СОСТОЯНИЕ РАЗРАБОТКИ СРЕДСТВ АВТОМАТИЗАЦИИ
ПРОГРАММИРОВАНИЯ ПАКЕТОВ ПРОГРАММ
Все работы, целью которых можно считать решение задач авто¬
матизации процесса разработки программ, условно делятся на
четыре следующие группы:
— автоматизация синтеза программ;
— повышение уровня языков и мощи сред их реализации;
— создание генераторов прикладных программ;
— создание сред автоматизированной разработки программ¬
ного обеспечения.
Синтез программ — это дедуктивное вычисление утверждений
программы на основе утверждений о ее функциях. В задаче син¬
теза заданным является отношение вход-выход, а искомой —
программа, реализующая это отношение. Отношение вход-выход
представляет спецификацию задачи, решение которой должна
выполнять программа. Техника синтеза программ — это техника
доказательства теорем. Теорема существования программы реа¬
лизующей заданную спецификацию, доказывается на °снове
формальных методов математической логики. Доказательство
существования называется конструктивным, если в процессе
доказательства отыскивается способ построения того объекта,
существование которого доказывается.
В системах автоматического синтеза программа является тем
объектом, конструктивное доказательство существования которого
должно быть выполнено. Число работ по автоматическому син¬
тезу программ велико и продолжает расти [18—20].
Например, в системе ПРИЗ [19] схема синтеза программ пред¬
полагает задание входа X, выхода Y программы, предусловия
Р (X) и постусловия R (X, У). Теорема существования утверж¬
дает, что для любого входа, удовлетворяющего предусловию,
найдется выход, который удовлетворяет постусловию R (X, У).
Искомым является оператор А, представляющий отображение
множества X входов в множество У выходов. В системе ПРИЗ
оператор А представлен элементарным отношением, задающимся
40
идентификатором некоторого модуля. Система ПРИЗ позволяет
получить готовую к выполнению программу решения вычисли¬
тельных задач по их описанию на входном языке, представляю¬
щем собой расширение языка Утопист, который совмещает в себе
средства управления заданиями и средства языка программиро¬
вания.
Другим направлением в автоматическом синтезе программ
является синтез по образцам поведения программы [21]. Здесь
иначе выглядит спецификация. Она задается в виде конечного
множества образцов вход-выход: {(Хп Ух), . . ., (Хп, УГ1)}, где
(Xi, У/) — образец пары вход-выход.
Этот подход вызван к жизни тем, что некоторые программы,
определенные в абстрактных типах данных, легче описать, задав
конечное множество образцов, чем получить формальную специ¬
фикацию задачи.
Повышение уровня языков и мощи сред их реализации как
направление в автоматизации процесса разработки программ
является достаточно традиционным, с одной стооны, а с другой —
оно неразрывно связано с тремя остальными, что вполне естест¬
венно. Ведь именно в языке воплощается любой новый взгляд
на то, как должно выглядеть символьное описание задачи, рас¬
считанное на автомат.
Многие считают, что идеальным языком программирования
решений задач был бы такой язык, средствами которого можно
было бы запрограммировать любую задачу. Хотя известно, что
одни задачи удобнее программировать на одних языках, другие —
на других. Попытки объединить некоторое множество /языков
в языковую систему более продуктивны, чем попытки создать
единый «большой» язык. Стремление к повышению уровня язы¬
ков существует с тех пор, как существует программирование.
Сегодня в ходу словосочетание «язык очень высокого уровня».
Какие слова нам понадобятся завтра? Еще хуже то, что явно и
неявно уровень языка связывается со степенью его непроцедур-
ности. Мол, чем более непроцедурным является язык, тем выше
его уровень. Другими словами, при таком взгляде любой декла¬
ративный язык по уровню превосходит любой процедурный.
Это заблуждение иногда становится основой для рассуждений
0 том, что современная тенденция в развитии языков программи¬
рования связана с реализацией лозунга «ЧТО вместо КАК» (язы¬
ки, позволяющие описать ЧТО представляет собой задача, будто
°Ь1 должны постепенно потеснить языки, предназначенные для
описания алгоритма решения задачи, т. е. для ответа на вопрос
КАК?). Нетрудно представить несостоятельность такой точки зре¬
ния, если согласиться с тем, что языки описания постановок задач
(НТО-языки) так же необходимы, как и языки описания
Процессов решения задач (КАК-языки). Они не являются конку¬
рентами; более того, тот факт, что до недавнего времени ЧТО-
языки были представлены весьма немногочисленным семейством
110 сравнению с КАК-языками, говорит лишь о том, что програм¬
41
мирование как вид деятельности переживало период младенчества,
когда стремление к ДЕЙСТВИЮ превалирует над стремлением
осознать, ЗАЧЕМ оно совершается. Итак, нам всегда будут не¬
обходимы языки разных уровней как в классе ЧТО-языков, так
и в классе КАК-языков. Выбор языка и его уровня связан с ха¬
рактером задачи, намерением заниматься деталями, категорией
пользователя, стремлением к определенному уровню эффективно¬
сти создаваемой программы. Если теперь сказать, что во многих
случаях было бы удобно иметь в своем распоряжении выбранное
нами семейство языков, в которое входили бы и ЧТО-языки (для
описания постановок программируемых задач) и КАК-языки
(для описания процесса их решения), то вряд ли это вызовет чье-
то возражение.
В качестве примера можно привести следующее сопоставле¬
ние. В настоящее время среди КАК-языков, ориентированных
на пользователя-непрофессионала в программировании, нефор-
мальнььм лидером является АПЛ, если оценивать КАК-языки
по уровню в следующем смысле. Уровень языка тем выше, чем
более он ориентирован на описание потока данных, а не потока
управления; он также тем выше, чем более приспособлен к работе
с агрегатами данных как с простыми объектами (поскольку раз¬
мер и форма агрегатов могут меняться, процессор такого языка
должен иметь схему автоматического управления памятью). Хотя
АПЛ имеет хорошо определенную операционную семантику,, он
все-таки относится к языкам весьма высокого уровня в классе
КАК-языков. Ощущение свободы от деталей при работе с АПЛ
обеспечено такой важнейшей характеристикой, как УТАИВАНИЕ
ПОДРОБНОСТЕЙ. Можно уверенно говорить о том, что уровень
языка тем выше, чем совершеннее механизм УТАИВАНИЯ ПОД¬
РОБНОСТЕЙ. В частности, в АПЛ программист более свободен
от деталей, чем в Паскале или Фортране. Сегодняшний триумф
АПЛ во многом был, видимо, предопределен той ясной позицией,
которую имел Айверсон, начиная работу над созданием языка.
Поставив целью создать систему записи вычислительных алго¬
ритмов в сжатом виде, он не стал заботиться одновременно и о том.
насколько такой язык будет удобен в реализации. И хотя вначале
АПЛ использовался только как предъязык для записи формули¬
ровок алгоритмов, которые затем «вручную» транслировались
на выбранный язык программирования, уместно вспомнить, что
именно с помощью АПЛ было сделано точное и компактное опи¬
сание аппаратных средств IBM 360. И все ныне существующие
версии АПЛ так или иначе связаны с АПЛ/360. Интерактивность
и прямая ориентация на обработку структур данных определили
так называемый АПЛ-стиль программирования. Принцип «сна¬
чала вычислить, потом проверить», реализация которого обес¬
печена регулярным характером массивов для вычисления всех
возможных значений и возможностью* отфильтровать значения,
не представляющие интереса, определил парадигму АПЛ-про-
граммирования.
42
Однако многие программисты-профессионалы считают, что
такие языки, как С и Модула-2, более подходят для создания
больших программных систем, предназначенных для задач, ре¬
шение которых может быть представлено в виде алгоритмов»
Несложно представить, что их более интересует свобода в опре¬
делении деталей и эффективность, чем возможность компактной
записи алгоритма. Так что считать язык тем совершеннее, чем
выше его уровень, ровно столько же оснований, как, например,
для объявления о превосходстве языка принципиальных электри¬
ческих схем над языком монтажных схем (в электронике и электро¬
технике).
В классе ЧТО-языков воцарился Пролог. Его создание и по¬
явление многочисленных расширений ознаменовало завершение
периода младенчества в развитии программирования. Теперь
программисты получили язык для описания своего замысла при
создании программных систем. Важно и то, что программирование
сделало шаг навстречу своей сестре — математической логике.
Повышение уровня осознанности и доказательности при разра¬
ботке программ — вот краткая характеристика Пролог-стиля
программирования.
Исключительное значение имело создание языка SMALL-
TALK-80, появившегося на свет вместе с мощной интерактивной
средой и совершившего благотворный поворот ОТ ПРОЦЕДУРЫ
К ОБЪЕКТУ в сознании многих программистов. Идеи объектно-
ориентированного программирования продолжают свою работу
и в предлагаемом здесь подходе к порождению пакетов программ.
Если ныне существующий стиль мышления большинства про¬
граммистов определяется их привычкой к процедурным языкам,
где ведущая роль отведена процедуре, а данные выглядят чем-то
зависящим от нее, то рассуждения программиста, работающего
на языке объектно-ориентированного программирования, опре¬
деляются иной схемой. Здесь главная роль отведена созданию
информационного объекта, понимаемого как некоторая структура
данных с приписанными к ней процедурно-воплощенными мето¬
дами ее обработки, причем такой объект принадлежит некоторому
классу, полностью описывающему (для целей конструирования
и использования) входящие в него экземпляры. Класс — держа¬
тель всей информации о принадлежащих ему объектах. Класс
является также владельцем всех методов. Методы — это проце¬
дуры, которые вызываются посылками сообщений, адресованных
экземплярам класса. Все экземпляры одного класса имеют об¬
щий набор методов. Метод может на время своего выполнения
назначать переменные, необходимые ему при выполнении. Эти
ьремепные переменные похожи на локальные переменные в Пас¬
каль-процедурах в том смысле, что их значения не уничтожаются,
когда метод перестает быть работающим. Каждый экземпляр
имеет память, предназначенную для описания его состояния,
такое описание делается посредством переменных экземпляров.
Переменные экземпляра могут принадлежать простым типам
43
данных (например, иметь тип ЦЕЛЫЙ), они могут быть другими
объектами или и тем и другим одновременно (в зависимости от
языка). Каждый объект имеет свой собственный набор перемен¬
ных. для экземпляра. Как на временные переменные, так и на
переменные экземпляра можно свободно ссылаться во всем диапа¬
зоне действия объектного метода. Но в отличие от временных
переменных значения переменных экземпляра не уничтожаются,
когда работа с методом объекта прекращается. Вычисления ини¬
циируются посредством сообщений, посылаемых объектам. Объект,
получивший сообщение, вызывает определенный в сообщении
метод из числа методов, принадлежащих классу. Метод, если
необходимо, посылает сообщения другим объектам, которые,
в свою очередь, вызывают другие методы, и так, пока не будет
достигнута точка, где вызывается так называемый примитивный
метод. Здесь заканчивается цепочка посылок-сообщений. Каждая
посылка-сообщение приводит к тому, что отправитель сообщения
получает результат. В конечном итоге все эти посылки-сообщения
приводят обычно к изменению состояния одного или нескольких
объектов. Однако иногда сообщение посылается просто, чтобы
вызвать некоторый примитив, действие которого не распростра¬
няется на мир объектов (лежит вне его). Например, сообщение
может быть послано для того, чтобы обеспечить доступ к какому-
нибудь файлу системы или к аппаратным средствам. При этом
состояния объектов не изменяются.
Существуют разные точки зрения на множество признаков,
которыхми должен обладать язык, чтобы быть причисленным к язы¬
кам объектно-ориентированного программирования.
Например, говорят о трех необходимых признаках: имена
сообщений связываются с методами в процессе выполнения; су¬
ществует возможность задания подробной иерархии классов;
как структуры управления так и структуры данных единообразно
представлены объектами.
Другая точка зрения представлена четырьмя необходимыми
признаками: информационного утаивания, абстракции данных,
динамического связывания и наследования. Если сравнить эти
точки зрения, то выяснится, что в первом случае в отличие от
второго не сказано об информационном утаивании. Три других
признака близки: наследование обеспечивается возможностью
задания подробной иерархии классов; динамическое связывание
и связь с методами в процессе выполнения; абстракция данных
и единообразное представление объектами как структур данных,
так и структур управления. Заметим здесь же, что первое опре¬
деление сделано, как бы глядя изнутри (с использованием поня¬
тий объектно-ориентированного программирования), а второе
отражает внешний взгляд на языки объектно-ориентированного
программирования. В этом смысле второе определение более
совершенно, так как в первом первые два признака определены
в понятиях объектно-ориентированного программирования, а по¬
тому ничего не говорят тому, кто не знаком с ним.
44
На пути к образному программированию наметился серьезный
доворот в переоценке роли текстовых языков. Недостаток многих
работ по автоматизации программирования проистекает из стрем¬
ления дать логически завершенный образ предлагаемой системы
автоматизации программирования, используя монолог или диа¬
лог в традиционной последовательной текстовой среде. Эта при¬
вычка отображать результаты своей работы на последовательно¬
стях бумажных пли экранных страниц оказала решающее влияние
ga архитектуру большинства разработанных к настоящему вре¬
мени систем автоматизации программирования.
Успех таких программных продуктов, как dBaselll (Ashton¬
Tate), во многом определяется отказом от упомянутой привычки
в пользу табличных и графических форм. Расширяющиеся ис¬
следования по визуальному программированию как основному
средству программных систем искусственного интеллекта настоя¬
щего и ближайшего будущего подтверждают это. Языки визуаль¬
ного программирования и языки формоориентированного програм¬
мирования открывают новые возможности в разработке программ.
Образное представление структур данных, алгоритмов, процес¬
сов обработки — все это шаги в направлении к созданию языко¬
вых средств, лучше, чем текст, приспособленных для отображения
замысла создателя программы. Вполне вероятно, что текстовые
фрагменты скоро будут играть не главную, как теперь, а равную
(а в ряде случаев и второстепенную) роль по отношению к фраг¬
ментам, имеющим нетекстовое представление.
Графические и формоориентированные средства хорошо при¬
способлены для представления сути той или иной программы
или системы программирования. Графические методы многомер¬
ного отображения в статике и динамике различных точек зрения
на программное обеспечение послужат основой для исследования
его аспектов, определенных потребностями групп разработчиков.
Рост качества терминалов и их удешевление способствуют
тому, что в ближайшее время доминирующее положение займут
интерактивные языки. Программирование в диалоге с системой
станет таким же привычным, как сегодняшнее программирование
наедине с собой.
Специфика решения задач автоматизации разработки программ¬
ного обеспечения такова, что соответствующие языки нужда¬
ются в определенных, характерных для них реализациях. В про¬
тивном случае успешное решение задач автоматизации становится
затруднительным. Важной особенностью среды такого языка
Должна быть способность поддерживать построение больших
и сложных структур данных. Эти структуры должны содержать
символы без каких бы то ни было ограничении на размер или тип
атомов. Необходимо также освободить разработчика от управле¬
ния распределением и перераспределением памяти. Следует по¬
заботиться и о том, чтобы среда реализации языка адаптировала
и изменяющимся требованиям, которые предъ являют вновь воз¬
никающие программы.
45
Создание генератора прикладных программ можно рассматри¬
вать как задачу построения средств разработки программ, осп о
ванной на типовых проектных решениях. Если воспользоваться
определением А. II. Ершова [22], где введены понятия синтези¬
рующего, сборочного и конкретизирующего программирования,
то технология построения программ, применяемая в генераторах,
ближе всего к сборочному программированию.
Широкое распространение получают генераторы приложений
и генераторы кодов [15—17]. К первым относятся такие продукты,
как Nomad 2 (National CSS), FOCUS (Information Builders, Inc.),
RAMIS (Mathematica Products Group, Inc.), dBase III (Ashton —
Tate), каждый из которых состоит из СУБД, генератора отчетов,
языка запросов базы данных, графического пакета и программного
обеспечения специального назначения. Особую популярность
среди непрофессиональных программистов, занимающихся раз¬
работкой приложений, приобрел ADF(IBM). Он построен и ра¬
ботает на основе СУБД IMS. Все приложения, разработанные
посредством ADF, имеют общую структуру и представляют собой
множество программных модулей, так объединенных разработ¬
чиком, чтобы они наилучшим образом выполняли задачи кон¬
кретного приложения. Модули содержат средства для управле¬
ния диалогом, доступом к данным, реализацией прикладной
логики и средства управления взаимодействием с вышестоящими
модулями. ADF поддерживает также недиалоговый и пакетный
режимы работы. Объединение модулей реализуется с помощью
генератора правил, работа с которым выполняется посредством
простого англоподобного языка.
Генераторы приложений представляют собой специализиро¬
ванные программные системы, ориентированные на решение
задач заданной предметной области (рис. 1). Их общим призна¬
ком является то, что все они строятся на основе специально
выбранной или разработанной СУБД, имеют удобные для ноль
зователя средства взаимодействия, графические средства, гене¬
раторы отчетов и специальное программное обеспечение, опреде¬
ляющее предметную область их прикладной ориентации. Повы
шение продуктивности за счет применения генераторов приложений
различно. Оно зависит не только от подготовленности разработ¬
чиков, но и от характера приложений. Однако во всех случаях онс
оценивается как 5—10-кратное.
К генераторам приложений относится и система ДИЭКС [23],
предназначенная для обработки результатов эксперимента и их
графической интерпретации. Опыт разработки и эксплуата¬
ции этой системы использован при создании ИГЕН-генераторог
[24—25]. Обзор разработок, ведущихся в этом направлении в на¬
шей стране, приведен в работе [26].
Генераторы кодов предназначены для получения отторгаемого
программного кода, который затем может использоваться незави¬
симо от генератора. Генераторы кодов обычно представляю!
собой диалоговые системы, ориентированные на специфицирование
46
Программ. Часто такое специфицирование выглядит как постепенное
уточнение в диалоге с генератором некоторого прототипа, храня¬
щегося в базе генератора и представляющего собой начальное
приближение к искомой программе.
Итак, если генераторы приложений ориентированы на построе¬
ние средств решения задач без получения отторгаемого кода, то
генераторы кодов предназначены для получения отторгаемого
кода программы по ее спецификации. Обычно генераторы кодов
содержат и средства получения документации для разработанной
программы.
Растущий спрос на генераторы кодов и генераторы приложе¬
ний сделал актуальной проблему создания средств их автомати¬
зированной разработки. Возникает естественный вопрос: нельзя
ли построить систему автоматизированной разработки генерато¬
ров? Разработку каких генераторов имеет смысл автоматизи¬
ровать в первую очередь? Существует ли принципиальное отли¬
чие в решении задачи автоматизации разработки генератора
приложений, например, от решения задачи автоматизации разра¬
ботки пакета прикладных программ? Как построить систему авто¬
матизированной разработки программных систем, позволяющую
получать отторгаемый код? Ответы на эти вопросы нас будут
интересовать при обсуждении порождения программных систем.
Создание сред автоматизированной разработки программного
обеспечения по уровню сложности решения этой проблемы сегод¬
ня не имеет себе равных среди задач автоматизации программи¬
рования. Эта проблема как бы содержит внутри себя остальные
проблемы. И именно поэтому успех ее решения зависит от того,
насколько удачно будут решены другие задачи автоматизации
(рис. 2).
Среду разработки программного обеспечения можно рассмат¬
ривать как совокупность специализированных систем, объеди¬
ненных для решения задач конструирования программ. Воз¬
можность расширения — обязательный ее признак. Многие ис¬
следователи, работающие в области искусственного интеллекта,
считают процесс разработки сложных программных систем про¬
цессом решения так называемых слабоопределенных задач (по¬
становка которых меняется по мере получения результатов и
Для которых неизвестны алгоритмы решения). Традиция, по
которой автоматический синтез программ был отнесен к задачам
искусственного интеллекта, продолжается. Ведь предметом ис¬
следований в области искусственного интеллекта являются так
называемые творческие задачи, которые как раз и являются сла¬
боопределенными задачами.
Причина такой классификации в том, что пока нет той ясности
в представлении процесса разработки программного обеспечения
как некоторого процесса решения задач, которая бы позволила
алгоритмизировать его. Здесь более приемлема комбинация ис-
нислительного и алгоритмического подходов в сочетании с не¬
формализованным участием человека, выполняющего роль не
47
11 ро грамм ное обеспечение автоматизированной деятельности
Точка зрения пользователя
А в то м а т и з и ро в а в н ая
деятельность
[ Предметная
1 область
1 1
1 1
Множество Множество
понятий отношений
1 1 . Г"
—I
Множество
задач
Программное
обеспечение
автоматизиро¬
ванной деятель¬
ности в рамках
предметной
области
Совокупность
всех програм-
ных средств,
необходимых
для решения
задач предмет¬
ной о бласта
Рис. 1. К определению программного обеспечения автоматизированной дея¬
тельности
Среды генерации семейств сред
разработки программного обеспечения,
обладающих свойствами 1 и 2:
I
i
:1
;1
5
Система Gandalf:
автоматизированная
генерация проектно¬
ориентированных сред
разработки програм¬
много обеспечения
путем объединения
множеств связанных
сред ( процессы про¬
ектирования системы
программного обеспе¬
чения и собственно
программирования
объединены).
ИГЕН— среда:
автоматизированное
порождение
целевых программных
систем
Рис. 2. Направление исследований сред разработки программного обеспече¬
ния
I
48
Таблица 1
Характерные признаки среды порождения программ
функциональные требова¬
ния
Языковая среда
Инструментальные требо¬
вания
* Диалоговая поддержка
итерационного процесса
уточнения точки зрения
разработчика
* Мощные интерактив¬
ные средства
* Экспериментирование
с порождаемыми прог¬
раммами для определе¬
ния соответствия их
свойств замыслу разра¬
ботчика
* Накопление знаний,
необходимых для под¬
держки процесса порож¬
дения программ
* Гибкий интерфейс с
пользователем
* Многоязычная расши¬
ряющаяся среда
* Уменьшение инстру¬
ментальной озабоченно¬
сти разработчика
* Мощные средства Объ¬
яснения действий, вы¬
полняемых в среде
* Развитые средства
обучения на примерах
* Миогоязчная (вклю¬
чая языки объектно-ори¬
ентированного, формо¬
ориентированного, визу¬
ального программирова¬
ния)
* Расширяемость (по
составу языков и внутри
каждого языка)
* Разнообразные типы
данных
* Поддержка построе¬
ния сложных символь¬
ных структур данных
* Программный код в
структурах данных
* Структуры данных
для представления про¬
цедур
* Символьная обработка
* Обработка списков
* Соответствие образцу
* Представление проце¬
дур как данных
* Слияние процедура—
данные;
* Обработка процедур
как данных
* Конструирование но¬
вых процедур при вы¬
полнении
* Автоматическое рас¬
пределение п перерас¬
пределение памяти
* Позднее связывание
* Мощные системы упра¬
вления базами данных (в
том числе реляционного
типа)
* Интерактивные сред¬
ства образного предста¬
вление данных и процес¬
сов
* Построители гибкого
интерфейса пользовате¬
ля
* Поддержка отладки
(трассировка; пошаго¬
вое выполнение; анализ;
сбоев при выполнении;
доступ к экранному ре¬
дактору в любое время;
коррекция отдельных
процедур без рекомпи-
ляцпп правильной час¬
ти системы; автомати¬
ческий поиск и регист¬
рация процедур)
* Помощь в анализе
структуры программы
(какие вызовы подпро¬
грамм и т. п.)
только держателя замысла конструируемой программной систе-
,1Ы» но и принимающего решения в тех случаях, когда среда раз¬
работки не располагает средствами, позволяющими ей справиться
>ез участия человека.
Многие исследователи считают, что среда разработки программ¬
ного обеспечения должна иметь черты среды исследовательского
Рограммирования. Основные особенности, которые должны быть
в°иственны среде автоматизированной разработки программного
бесцечения, приведены в табл. 1.
49
Представляется целесообразным рассматривать такую среду
как совокупность взаимодействующих инструментальных систем,
каждая из которых специализируется на определенном подмно¬
жестве задач разработки программного обеспечения.
Состояние разработки инструментальных систем программи¬
рования в нашей стране отражено достаточно полно в работе [27].
Оценивая состояние работ в области автоматизации разработ¬
ки программного обеспечения в целом, можно заключить, что
происходит поворот от разработки одноязыковых систем про¬
граммирования к созданию многоязыковых сред разработки про¬
граммных систем, обладающих высоким уровнем интерактивности
и инструментальной мощи.
2.
РАЗРАБОТКА ПРОГРАММНОЙ СИСТЕМЫ
КАК ЗАДАЧА ЕЕ ПОРОЖДЕНИЯ
Изобретение программ, помогающих создавать другие про¬
граммы.— это и поиск средств повышения продуктивности,
и постижение сути программирования. Какими должны быть
программирующие программы? Как их строить? Попытки отве¬
тить на эти вопросы обычно бывают успешными в той мере, в ка¬
кой удалось понять, что такое программа как объект разработки
и программирование как деятельность. Когда говорим, что про¬
граммирование — это процесс передачи знаний автомату, то ха¬
рактеризуем программирование как средство символьного вопло¬
щения познанных закономерностей. Воплощения, рассчитанного
на восприятие автоматом.
Какие закономерности нам известны, когда мы беремся пере¬
давать автомату знания об умении разрабатывать программы?
Как организовать совместную работу программиста и его парт¬
нера-автомата, чтобы ее результат был больше суммы того, что
они смогли бы получить, работая раздельно? Одни вопросы по¬
рождают другие. И с какого из них не начинать, неизбежно вста¬
нет вопрос о задачах, из решения которых складывается процесс
разработки программ.
Представить деятельность, подлежащую автоматизации, в виде
совокупности задач — так же естественно, как вслед за этим раз¬
делить всю совокупность на два класса. В первом из них те за¬
дачи, которые изучены настолько, что методы их решения хорошо
известны и могут быть к тому же представлены алгоритмами*
С этими задачами по нашему поручению сможет справляться
автомат. Во второй класс поместим все другие задачи. Их решение
нельзя передать автомату. Участие человека здесь необходимо*
Предоставляя возможность программисту записывать про¬
граммируемое решение задачи в удобном для него виде, освободи
дая его от необходимости запоминать и выполнять многое из того»
что можно поручить автомату, разработчики средств автомат^
50
Зацпи программирования перекладывают эту работу на себя.
При этом им приходится взять на себя и тонкую задачу предви¬
дения того, что будет полезно и удобно программисту. Чем лучше
удастся им решить эту задачу, тем выше становится производи¬
тельность труда программистов, но одновременно сужаются воз¬
можности влиять на детали разработки программ.
Предел автоматизации (в смысле максимальной разгрузки
человека-разработчика программы от выполнения детализиро¬
ванных функций) можно представить следующим образом. Про¬
граммисту достаточно сформулировать начальный, пока нечеткий
замысел задачи, решение которой он хотел бы запрограммиро¬
вать. Далее, взаимодействуя с системой автоматизированной раз¬
работки программ, он окончательно оформил бы замысел и затем
с ее же помощью создал описание интересующей его задачи. Опи¬
сание, понятное ему и воспринимаемое системой. Остальное она
доделала бы сама, руководствуясь этим описанием. Выполняя
работу по детализации порученного ей задания на программи¬
рование, система предлагала бы программисту сотрудничество
в тех пунктах, где выбор из множества альтернативных решений
не формализован и потому требует участия человека.
Как приблизиться к такому уровню автоматизации? За счет
сокращения числа задач, на программную реализацию которых
рассчитана система. Тогда необходимо будет иметь много специа¬
лизированных систем. Сделаем еще шаг. Представим, что все
такие системы объединены в составе среды, где программирование
уступило место процессу изучения возможностей среды и поста¬
новки ей задач, которые должны быть запрограммированы.
Построение решения исходной задачи среда выполняла бы путем
представления ее в виде совокупности задач с известными реше¬
ниями. При этом разработчик выполняет работу постановщика
задач (его теперь неверно было бы называть программистом
в сегодняшнем значении этого слова), а среда — построителя ре¬
шения, в соответствие которому она затем поставит искомую
программу, посоветовавшись с разработчиком о деталях реали¬
зации. Идея создания такой среды явилась отправной для поиска
постановки и метода решения задачи порождения программных
систем (рис. 3).
В программировании и математике под порождением обычно
понимают процесс построения некоторого множества объектов на
основе заданного множества других объектов по заданным прави¬
лам. Каждый построенный таким способом объект считают пра-
пильным. Говорят о порождении цепочек из элементов алфавита.
Язык при этом рассматривают как множество всех порожденных
(правильно построенных) цепочек, каждая из которых является
пРсдложением и состоит только из терминальных символов. На-
сколько совпадает смысл слова «порождать», когда мы говорим
0 порождении программных систем, со смыслом этого слова, когда
речь идет о построении множества предложений формального
языка?
51
Три задачи разработки программного
обеспечения
| Анализ
| Синтез
Порождение
Найти отношение вход—выход дня
заданной программы
Найти программу, реализующую
заданное отношение вход—выход
Найти программу, реализующую
заданное отношение вход—выход,
при условии, что оно может быть
выражено через отношения из
заданного множества отношений,
каждому из элементов которого
со п о став л е на про гра м м а—заго то в -
ка
Рис« 3. Порождение в сравнении с анализом и синтезом
Пусть известно множество Т базовых задач, на котором задана
структура struc, определяющая связи между задачами по выхо¬
ду-входу и вместе с правилами 7?-способ построения для каждой
исходной задачи prob подструктуры solv, редуцирующей prob
к разрешающей структуре базовых задач, каждая из которых
имеет тщательно исследованную спецификацию и отображение
«вход-выход», представленное на формальном языке. Правила R
определяют поведение порождающей системы в процессе поиска
разрешающей структуры solv базовых задач. Каждая базовая
задача tasks Т задается входом task | р, выходом task | w и ото¬
бражением task | /. Исходная задача может быть представлена
следующими способами:
— найти Y по X, где Y — искомый выход (например, схема
интересующей нас программы); X — заданный вход (например,
описание постановки задачи, которую должна реализовать
искомая программа);
— найти У, когда состав X задается и уточняется в процессе
поиска разрешающей структуры базовых задач;
— по заданному X найти постепенно уточняющийся в процес¬
се поиска Y.
Во всех случаях неизвестное отображение «вход-выход» ис¬
ходной задачи prob, если она разрешима в данной системе, будет
представлено отображениями разрешающей структурой solv ба¬
зовых задач из множества Т.
Разберемся с тем. насколько совпадает смысл слова «порож¬
дать» в нашем случае с тем, как он понимается при определении
исчисления в математике или множества предложений формаль¬
ного языка в математике, логике и программировании. Истолко¬
вание аналогии с построением множества предложений формаль¬
ного языка можно представить следующим образом. Множество 'Т
базовых задач можно толковать как алфавит, если каждой базо-
52
рой задаче task сопоставить уникальное имя task|name;. рассмат¬
риваемое как элемент такого алфавита (/ = 1, лч; т — число
базовых задач в Т). Структура struc. заданная на Т, вместе с пра¬
вилами R построения разрешающей структуры solv базовых за¬
дач., сопоставляемой исходной задаче prob, могут быть истолко¬
ваны как правила порождения правильных подструктур струк¬
туры struc. Все множество правильных подструктур структуры
struc аналогично множеству предложений формального языка.
Процесс порождения решения исходной задачи prob на мно¬
жестве Т базовых задач со структурой struc с использованием
правил 7?, когда постановка исходной задачи prob задается на
языке L, аналогичен исчислению в том смысле, что struc вопло¬
щает аксиомы, правила R построения на основе struc разрешаю¬
щей структуры solv играют роль правил вывода. Множество всех
правильных подструктур, каждая из которых является разреша¬
ющей для некоторой исходной задачи, можно считать множеством
элементов, выводимых в исчислении.
Определим состав задач, решить которые необходимо, чтобы
получить продукт, обладающий заданными функциональными
характеристиками и теми потребительскими свойствами, которые
делают его применимым. Рассмотрим объект порождения (про¬
граммную систему) как результат решения следующих задач:
1) определение языка взаимодействия с системой;
2) создание модели предметной области, на которой интерпре¬
тируются предложения языка взаимодействия с системой;
3) разработка интерпретатора языка взаимодействия;
4) определение реализации интерфейса с пользователем;
5) разработка системы управления базами данных;
6) разработка формирователя отчетов, позволяющего пред¬
ставить результаты работы системы, хранящиеся в ее базе (или
базах) данных в форме, выбранной пользователем;
7) разработка функционального наполнения системы, опреде¬
ляющего ее целевое назначение;
8) разработка монитора системы;
9) разработка специальной системы программирования вы¬
числительных процессов, ориентированной на задачи данной
предметной области;
10) разработка системы информационного обслуживания поль¬
зователя, включающей обучающую систему и систему докумен¬
тации.
Еще раз заметим, что объектом порождения в нашем случае
является генератор прикладных задач, рассчитанный на пользо¬
вателя, не обязательно являющегося профессионалом в програм¬
мировании. Этим определяется необходимость решения задач,
отмеченных в п.п. 5, 6 и 9.
Решить десять перечисленных задач — значит решить задачу
Построения программной системы из класса генераторов приклад¬
ных задач (например, таких, как рассмотренный в работе [25]).
ели учесть то, что эти задачи связаны между собой (например,,
53
задача 3 может быть решена только после решения задач 1, 2),
возникает мысль представить их в виде некоторой структуры.
Теперь вообразим, что каждой из десяти задач удалось поставить
в соответствие свою порождающую систему, позволяющую решать
интересующие нас задачи на основе множества базовых задач.
Тогда порождающую систему, умеющую решать общую задачу
получения генератора приложений, можно представить как ассо¬
циативную систему, в составе которой работают связанные между
собой частные порождающие системы. Естественно, что и ассоциа¬
тивная и входящие в нее системы должны иметь отличающиеся
предметные области, а потому и множества базовых задач,
и структуры, заданные на них. Какие это множества и какие это
структуры? Даже неразвернутый ответ на эти вопросы требует
иного объема изложения и другой его направленности.
Итак, задача получения искомой программной системы состоит
в том, чтобы в диалоге с ассоциативной порождающей системой
найти решение десяти перечисленных задач, связанных между
собой (результат решения одной пли нескольких предыдущих
задач влияет на выбор возможных решений для последующих
задач). Заметим также, что входом при решении любой задачи
является описание функциональных (или качественных) характе¬
ристик порождаемого компонента, а выходом — разрешающая
структура базовых задач, для каждой из которых определены не
только вход и выход, но и отображение «вход-выход». Признаком
окончания процесса порождения является получение исходных
текстов всех компонент порожденной системы; причем выбор
языка реализации для каждого компонента делает системный
аналитик, выполняющий в диалоге с ассоциативной системой по¬
рождение искомого генератора прикладных задач. Он же выби¬
рает целесообразную операционную систему и конфигурацию
аппаратных средств из имеющихся в распоряжении заказчика.
3.
ОТЛИЧИЕ ПОРОЖДЕНИЯ ОТ ПРОГРАММИРОВАНИЯ
Язык программирования предназначен для создания беско¬
нечного множества программ. К программе предъявляются самые
общие требования, например не употреблять переменную, которая
не определена (в Паскале) и т. п. Как написать правильную про¬
грамму для решения некоторой задачи — это забота программис¬
та. Он свободен написать и совершенно бессмысленную, но син¬
таксически правильную программу. Бессмысленную из-за отсут¬
ствия задачи, имеющей содержательную интерпретацию, которую
можно было бы поставить в соответствие такой программе; други¬
ми словами, вполне допустимо появление программы, в соответ¬
ствие которой нельзя поставить какую-нибудь содержательно¬
цельную задачу.
При порождении отсутствует свобода составлять описаний
программных систем, не имеющих четко определенного целевое0
54
• факторы, спосооствующие неискажен-
: нОмУ В''ллощенпю замысла
i
многоязычие
>
I ПоДД€'Ржка по стадийною
воплощения замысла при
разработке программного
обеспечения
простые правила
перевода с одного
языка на другой
образность
стабильность
Рис. 4. К определению факторов, способствующих неискаженному вопло¬
щению замысла
назначения. Каждая порождающая система в отличие от системы
программирования позволяет получить конечное множество опи¬
саний программных систем. Эти порожденные системы могут от¬
личаться существенно или только деталями, но в одном они по¬
хожи все без исключения — это правильные системы (в том смыс¬
ле, что каждая из них предназначена для решения фиксирован¬
ного множества связанных задач и создана эта система по прави¬
лам, хранящимся в ее базе знаний).
Учитывая сказанное, языки описания порождаемых систем
не могут быть отнесены к языкам программирования. Языки по¬
рождения представляют собой интерактивные языки сообщений,
посредством которых реализуется взаимодействие системного
аналитика с порождающей системой. Язык порождения — это
сочетание языков запросов и спецификации по образцам. Праг¬
матика языка порождения определена стремлением его разра¬
ботчиков способствовать поддержке процесса пошагового пере¬
носа замысла разработчика системы в ее описание, доступное для
восприятия автоматом-партнером разработчика в процессе по¬
рождения (рис. 4).
С точки зрения изготовителя описания программной системы
полезной является помощь, связанная с решением следующих
задач:
1) конкретизация возникшего замысла путем постановки под¬
ходящих вопросов;
2) объяснение на каждом шаге в процессе описания, каким
множеством допустимых альтернатив располагает разработчик
и в чем суть каждой из них (естественно, при условии, что этим
заинтересовался разработчик; это эквивалентно истолкованию
Семантпки предстоящего описания);
3) выбор такой степени детализации па каждом шаге, чтобы,
с одной стороны, разработчик легко охватывал мысленпым взо¬
ром ^весь фрагмент, с которым он работает, с другой — чтобы
такой фрагмент был содержательно цельным;
55
4) предъявление синтаксических шаблонов и незамедлитель¬
ная интерпретация введенного описания (что освобождает разра¬
ботчика от необходимости запоминать синтаксические правила
и позволяет ему видеть реакцию системы на введенное описание').
4.
ПРИМЕНЕНИЕ МЕТОДА ПОРОЖДЕНИЯ:
СИСТЕМА ПОРОЖДЕНИЯ ПАКЕТОВ ПРОГРАММ
ДЛЯ МАССОВЫХ ВИДОВ УЧЕТА II ПЛАНИРОВАНИЯ
Создание методической основы порождения программных си¬
стем с заданными функциональными характеристиками и разра¬
ботка экспериментального образца порождающей системы
ИГЕН, подтвердившего продуктивность процесса порождения,
когда необходимо в короткие сроки создать архитектурноподоб¬
ные пакеты, обладающие свойствами программных продуктов,—
все это стало базой для разработки системы порождения пакетов
программ для массовых видов учета и планирования далее назы¬
ваемой ГЕНПАК-генератором.
ГЕНПАК-генератор относится к семейству ИГЕН-генераторов
[24, 25]; являясь средством повышения продуктивности приклад¬
ного программирования, он обеспечивает значительную эконо¬
мию трудозатрат при создании пакетов программ для массовых
видов прикладной деятельности. Экономия достигается прежде
всего в результате снижения трудоемкости специфицирования и
проектирования компонентов пакетов, кодирования п тестиро¬
вания.
Снижение трудоемкости специфицирования достигается за
счет того, что информация о возможном составе пакета, взаимо¬
связи компонентов, функциональном и качественном облике каж¬
дого из них, а также правила построения пакета — все это содер¬
жится в базе знаний генератора.
Этап программирования в его традиционном понимании от¬
сутствует. Системный аналитик выбирает язык реализации и
определяет интерфейс порождаемого пакета с пользователем.
Отладка и тестирование порожденного пакета нужны только для
того, чтобы пользователь мог убедиться в том, что полученный
пакет удовлетворяет его требованиям (в функциональном и ка¬
чественном отношениях). В этом смысле традиционная отладка
(как вылавливание ошибок) полностью исключается.
Порождение пакета складывается, таким образом, из специфи¬
цирования по образцам и проектирования по правилам, храня¬
щимся в базе знаний генератора.
Для своей реализации генератор требует достаточно мощного
инструментального комплекса. Порожденные пакеты могут экс¬
плуатироваться на целевых машинах, которые не обязательно
должны относиться к тому семейству, из представителей кото¬
рого составлен инструментальный комплекс.
56
Важной особенностью порожденных пакетов является то,, что
каждый из пих продуцируется на языке реализации, выбранном
системным аналитиком из некоторого множества возможных
языков. Выбирается также наиболее целесообразная операцион¬
ная система, которая обеспечит наибольшую прикладную эффек¬
тивность функционирования пакета в заданных условиях.
Надежность порожденных пакетов достигается за счет приме¬
нения доказательных методов конструирования пакета и приме¬
нения верифицированных заготовок программных модулей.
Генератор построен как интерактивная расширяющаяся си¬
стема. Расширение возможно как в части системных компонент,
так и в части компонент функционального наполнения. Расши¬
рение не сопровождается коррекцией существующих компонент,
что обеспечивается реализацией в его архитектуре принципов
объектно-ориентированного программирования.
Входным языком генератора для описания множества задач,
на решение которых он должен быть ориентирован, является
формоориентированный вариант естественного языка, термино¬
логически ограниченный словарем предметной области (из класса
ЧТО-языков).
Эксплуатация генератора осуществляется системным анали¬
тиком, специалистом в той области, применительно к которой
должен быть получен пакет. Перед началом эксплуатации систем¬
ный аналитик проходит обучение в режиме диалога с готовым
для применения генератором. После этого его подготовка доста¬
точна для получения с помощью генератора пакетов, функцио¬
нальный и качественный облики которых соответствуют требова¬
ниям заказчика.
Важно заметить, что ГЕНПАК-геиератор относится к порож¬
дающим системам, ориентированным на получение пакетов, по
своим функциональным характеристикам соответствующим гене¬
раторам приложений (см. разд. 1).
Таким образом, ГЕНПАК-генератор является генератором
генераторов приложений. Чтобы не вводить в затруднение чита¬
теля словосочетаниями типа предыдущего, условимся называть
продуцируемые ГЕНПАК-генератором генераторы приложений
просто ГЕНПАК-пакетами.
Эксплуатация каждого ГЕНПАК-пакета доступна пользова¬
телю-непрограммисту. Начиная работать, он также проходит
обучение в режиме диалога с использованием языковых средств,
соответствующих его подготовке (чем ниже уровень подготовки,
тем больше меню-оргаяизованпых фрагментов в обучающей си¬
стеме). При эксплуатации как ГЕНПАК-генератора, так и про¬
ецируемых ГЕНПАК-пакетов обеспечивается высокий уровень
защищенности от ошибок пользователя и адекватное текущей
С11тУациц информационное обслуживание. Удобство взаимодей-
ствия с генератором и пакетами обеспечивается настройкой ПК
с Учетом требований пользователя.
57
4.1. Функциональная характеристика ГЕН ПАК - генератора
и порожденных с его помощью пакетов
ГЕНПАК-генератор обеспечивает: обучение работе с генера¬
тором; настройку средств конструирования пакетов; описанье
требований к пакетам; порождение ИК пакетов; порождение
систем управления базами данных пакетов; порождение форми¬
рователя отчетов; порождение функционального наполнении:
порождение диалоговых мониторов пакетов; построение входных
языков; порождение обучающих систем пакетов; тестирование.
ГЕНПАК-пакет обеспечивает:
— возможность диалогового обучения работе с пакетом:
— решение задач предметной области с использованием си¬
стемы управления базами данных, средств экранного редактиро¬
вания и формирования отчетов в задаваемой пользователем форме:
— составление пользователем программ табс-вычислениц
(табс-многомерная табличная структура; подробнее — в следую ¬
щем разделе);
— проведение прикид очных расчетов в режиме калькулятора
(без занесения или с занесением результатов в базу данных);
— сохранение результатов промежуточных расчетов в спе¬
циальных контейнерах с возможностью их оперативного исполь¬
зования в текущем сеансе;
— использование в качестве исходных данных для расчетов
содержимого базы данных;
— создание табс-объектов, размеры которых ограничены
только разрядностью машины и располагаемой внешней памятью;
— занесение результатов расчетов в любой указанный табс
в табс-базе данных (ТБД);
— просмотр содержимого табс-объектов баз данных через
выбираемые пользователем (по локализации, размерам п атрибу¬
там) системы табличных окон с возможностью редактирования
содержимого табс-клеток и управления поведением окон в системе;
— возможность решения слабоопределенных задач в диало¬
говом режиме, когда постановка задачи, представленная на фор¬
моориентированном языке из класса ЧТО-языков, последов а*
тельно уточняется пользователем при содействии системы;
— планирование процесса решения задач путем составленья
так называемых Т-программ, которые могут храниться в соответ¬
ствующих табс-базах и вызываться пользователем; важно и то,
что Т-программы могут вызывать другие Т-программы;
— подсказки и помощь в затруднительных для пользователя
ситуациях.
4.2. Характеристика системы управления базами данных,”
применяемой в ГЕНПАК-генераторе и порожденных пакетах
Назначение. Система управления табс-базами даншА
(СУТБД) позволяет создавать, хранить табс-базы данных и мзх
нипулировать ими.
58
Основные понятия. Основным структурным эле¬
ментом является табс (многослойная таблица). Координаты клетки
задаются тройкой целых чисел, первое из которых соответствует
номеру строки, второе — номеру столбца, третье — номеру
слоя- Для любой непустой клетки должен быть определен тип
ее содержимого. В целом табс также может иметь тип. Сущест¬
вуют средства объединения табсов в табс-структуры, где каждый
табс может играть роль табс-объекта, пли табс-класса (в терми¬
нологии объектно-ориентированного программирования). Важным
понятием является канал, который служит для пользовательских
программ средством связи с табсом. В процессе работы пользо¬
ватель может применять несколько каналов.
Функциональные характеристики. Ос¬
новными функциями системы управления табс-базами данных
являются:
— читать (получать тип клетки и/или ее содержимое)
— писать (задавать тип клетки и/или заносить ее содержимое);
— перемещаться (устанавливать в канале координаты требуе¬
мой клетки).
Дополнительными функциями являются:
— перемещать данные (изменять координаты клеток и их
групп);
— устанавливать правило перебора клеток при поиске.
Вместо координат могут использоваться имена для определе¬
ния доступа к так называемым служебным клеткам табса, которые
хоть и принадлежат ему, но не имеют координат. Обычное назна¬
чение таких клеток— хранение служебной информации (напри¬
мер, даты, имени владельца, координат разрешенной для работы
области табса). Содержимым служебных клеток может быть так¬
же информация, определяющая список допустимых при работе
с данным табсом функций СУТБД. Это важно, в частности, для
ограничения доступа к содержимому клеток.
Типы и структуры данных. Содержимым клет¬
ки табса. имеющей координаты, могут быть данные одного из сле¬
дующих типов: СТРОКИ СИМВОЛОВ, ЧИСЛОВЫЕ ДАННЫЕf
ССЫЛКА. ВЛОЖЕННЫЙ ТАБС. Комментария заслуживают
типы ССЫЛКА и ВЛОЖЕННЫЙ ТАБС.
Клетка, имеющая тип ССЫЛКА, содержит символьную стро¬
ку,являющуюся указателем на табс или клетку табса. Существуют
Два режима работы со ссылками: режим интерпретации, когда
выполняется переход по ссылке, приводящий к переустановке
Канала, и режим запрета интерпретации, когда содержимое клет¬
ки рассматривается как обычные строки символов. При смене
табса в результате перехода по ссылке координаты клетки сменя¬
емого табса запоминаются как точка маршрута, возврат в кото¬
рую возможен с помощью функции ВОЗВРАТ В ПРЕДЫДУЩУЮ
ТОЧКУ.
Особую важность для реализации табс-структур, являющихся
°сновой для построения баз знании, имеет тип ВЛОЖЕННЫЙ
59
ТАБС. Вложенным называется табс, как бы размещающийся
в клетке другого табса. Попав в такую клетку, мы попадаем в не¬
который табс (условным именем которого является координата
соответствующей клетки). Число клеток табса, имеющих тип.
ВЛОЖЕННЫЙ ТАБС, не ограничено. Любой вложенный табс
может, в свою очередь, иметь клетки такого же типа.
Реализация отношений. Легко представить, что
все известные структуры могут быть реализованы посредством
табс-структуры. Важной является табс-графовая структура,
реализуемая посредством типов ВЛОЖЕННЫЙ ТАБС и ССЫЛ¬
КА. Отношения следования, принадлежности, задание соответ¬
ствий — все это без затруднений реализуемо с помощью табс-
структур.
Порождение С У Т Б Д п а к е т а. При порождении
определяются число каналов (задает число табсов, с которыми
можно одновременно работать), список функций и набор проце¬
дур, обеспечивающих различные варианты перебора клеток при
поиске. Порождение выглядит как процесс построения «по образ¬
цу». Системный аналитик выбирает подходящий образец и коррек¬
тирует его. Он располагает возможностью создавать табс-струк¬
туры для хранения образцов, чтобы облегчить свою работу по
мере накопления опыта работы с ГЕНПАК-генератором. Скор¬
ректированный образец описания СУТБД поступает на вход
порождающей компоненты, которая строит требуемую конфигу¬
рацию СУТБД.
4.3. Интерфейс с пользователем
Интерфейсные компоненты ГЕНПАК-генератора и порожден¬
ных пакетов должны обеспечить такую поддержку взаимодейст¬
вия пользователя с системой, чтобы на каждом шаге работы че¬
ловек мог убедиться в том, насколько адекватно его замысел
отображается в формализованную конструкцию. Неискаженное
отображение замысла в формализованную конструкцию можно
рассматривать в качестве идеальной цели. Судить о соответствии
может лишь сам пользователь, анализируя ответ системы. Учи¬
тывая то, что требования различных пользователей к интерфейсу
могут сильно отличаться, и то, что требования даже у одного и
того же пользователя меняются по мере накопления опыта работы
с программной системой, основным свойством интерфейса поль¬
зователя должна быть гибкость как возможность настройки [28’.
Требования к ГЕНПАК -интерфейс у. Не¬
обходимо обеспечить доступ к табс-структурам и визуализацию их
образного представления. Отобразить на экране необходимо не
только содержимое клеток, но и топологический образ всей струк¬
туры. Поскольку размеры табсов ограничены только разрядно¬
стью машин и располагаемой внешней памятью, на ограниченном
по площади экране невозможно в большинстве случаев отобра¬
зить целиком плоский табс-фрагмент (например, табс-слоил
60
Чтобы можно было просматривать такой табс-фрагмент по частям,
вводится система табличных окон, через каждое из которых мож¬
но показать прямоугольный фрагмент из клеток любого табса.
Планирование системы окон и ее возможного поведения
должен обеспечивать ИК.
Должна поддерживаться удобная навигация по табс-струк-
туре путем быстрого перемещения любого из окон системы в ин¬
тересующий нас фрагмент табс-структуры.
В каждой клетке окна должно быть возможным экранное ре¬
дактирование содержимого, если оно не запрещено из приклад¬
ных соображений. При этом содержимое клетки табса, когда оно
превосходит по размерам клетку табличного окна, должно быть
легкоперемещаемым в любом из направлений (по вертикали и
горизонтали). Состав функций, допустимых при редактировании
в ГЕНПАК-пакетах, выбирается системным аналитиком при по¬
рождении из полного состава функций.
Интерфейсная компонента должна обеспечить легкое вопло¬
щение процесса взаимодействия пользователя с любой из компо¬
нент ГЕНПАК-генератора (то же и для ГЕНПАК-пакетов).
Необходимо использовать систему графической нотации —
все виды пиктограмм с предоставлением возможности расширять
штатный набор пиктограмм индивидуальными наборами. Необ¬
ходимо также предусмотреть гибкую реализацию связей пикто¬
грамм с табличными окнами.
Принципы построения интерфейса. По¬
строение интерфейса в порождающих системах и продуцируемых
с их помощью программных продуктах определяется следующими
принципами.
Независимость интерфейса. Все, с помощью чего реализуется
интерфейс пользователя, полностью отделено от остального мира
компонент. Интерфейс конструируется независимо от приложе¬
ния, но в полном соответствии с его спецификой и требованиями
пользователя. Независимо в том смысле, что ни одна из компонент
системного пли функционального наполнения ГЕНПАК-генера¬
тора или ГЕНПАК-пакетов не имеет самостоятельных средств
взаимодействия с пользователем (минуя интерфейсную компо¬
ненту), а сама ИК при этом автономна.
Ориентация концептуальных моделей на разные типы пользо¬
вателей. Концептуальные модели интерфейса как объекта порож¬
дения и объекта использования должны быть разными, чтобы
обеспечить продуктивную работу, в первом случае —системного
аналитика, занимающегося порождением ПК посредством специ¬
ализирующейся на этом системы; во втором случае — пользова¬
теля порожденного пакета, изменяющего свой интерфейс с пакетом
в рамках возможностей, которыми была наделена ИК данного па-
Кета при порождении.
Изменяемость интерфейса по желанию пользователя. Пользо¬
ватель должен иметь возможность легкого перехода от одного ва¬
рианта интерфейса к другому. Для этого ему должно быть доста¬
61
точно скорректировать табс-оппсанпе интерфейса (на копии), пос¬
ле чего скорректированное описание должно быть объявлено дей¬
ствующим (в сеансе, например).
4.3.1. Интерфейсные компоненты ГЕНПАК-генератора
н порожденных пакетов
Назначение. Интерфейсная компонента (ИК) предна¬
значена для реализации взаимодействия пользователя, работаю¬
щего за терминалом, с любой из составляющих генератора (или
пакета). Другими словами, ни одна из составляющих не имеет вы¬
хода непосредственно на терминал, минуя ИК. Точно так же, как
никакой ввод с клавиатуры терминала не может быть направлен
прямо какой-нибудь составляющей, в обход ИК. С помощью ИК
пользователь создает виртуальный терминал, имеющий выбранные
им функциональные характеристики. Число виртуальных тер¬
миналов, которые может создать пользователь, не ограничено.
Табс-описание каждого из них, сделанное на формоориентированном
языке спецификации, может быть сохранено в табс-базе данных.
Начиная сеанс, пользователь может объявить действующим любое
из имеющихся описаний и таким способом определить свой вир¬
туальный терминал. Поведение клавиатуры, число окон в системе
окон, атрибуты окон — все это может отличаться для разных вир¬
туальных терминалов. ;
Учитывая то, что интерфейс пользователя с различными табс-
базами данных имеет особенное значение (метафора редактирования
табс-структур является определяющей во всех процессах взаимо¬
действия пользователя с генератором или пакетами), взаимодейст¬
вию с табс-объектамп уделено повышенное внимание. Их создание,
удаление, просмотр с помощью систем табличных окон, редак¬
тирование, визуализация — все это весьма важно, а потому долж¬
но выполняться с максимальным удобством для пользователя. Та¬
ким образом, СУТБД имеет настраиваемый интерфейс с пользо¬
вателем, как и любая другая составляющая генератора или пакета.
Состав. Интерфейсная компонента в качестве основных
составляющих содержит: табличный экранный редактор (ТЭР ,
диспетчер клавиатуры, диспетчер экрана/окон, процессор команд
к диспетчер буферов.
ТЭР организует работу всех остальных блоков ИК: запускает
инициацию, активизирует диспетчеры, осуществляет связь с табс-
объектами и файлами.
Диспетчер клавиатуры принимает кодовые последовательности
с клавиатуры, выдает номера клавишных команд и обеспечивает
ввод символьных строк. В момент инициации он начинает работу
с хранящимся описанием соответствия кодовых последовательнос¬
тей внутренним номерам команд. Замена описания позволяет из¬
менить поведение клавиатуры (любая клавиша может быть при¬
вязана к любому номеру команды пли вообще отключена, если я
соответствие ей в описании не поставлено никакого номера).
62
Диспетчер экрана/окон предназначен для обслуживания физи¬
ческого экрана конкретного терминала, принадлежащего конеч¬
ному множеству терминалов, на работу с которыми ориентирован
построитель ПК в ГЕНПАК-генераторе; создания-удаления си¬
стем окон, задания атрибутов визуализации самих окон, визуали¬
зации содержимого окон.
Процессор команд предназначен для интерпретации команд, не
имеющих клавишной реализации (текстовых, пиктографических).
Диспетчер буферов предназначен для создания-удаления бу¬
феров ПК, задания их атрибутов и редактирования содержимого
буферов.
Порождение II К. Работая с ГЕНПАК-генератором, си¬
стемный аналитик порождает ПК конкретного пакета, задавая при
этом определения каждой из составляющих (блоков) ПК.
ТЭР определяется составом функций из всего множества функ¬
ций, которые он может реализовать; числом экранов и клавиатур,
с которыми он должен работать; составом источников и приемни¬
ков данных; составом ПОМОЩЬ-табсов и ПОМОЩЬ-файлов.
Диспетчер клавиатуры определяется при порождении списком
имен описаний соответствия кодовых последовательностей внут¬
ренним номерам команд.
Диспетчер экрана/окон задается типом физического экрана,
максимально допустимым числом окон в системе окон, определе¬
нием возможности изменения параметров окон (положения, раз¬
меров, атрибутов визуализации); определением необходимости
задания так называемых постоянных окон (всегда находящихся в
рабочей области ПК и имеющих постоянные атрибуты, выбранные
при порождении).
Процессор команд задается подмножеством из всего множества
предусмотренных команд; списком умолчаний, принятых в пара¬
метрах команд, и описанием синонимических расширений команд.
Диспетчер буферов должен быть описан путем задания требуе¬
мых команд редактирования из множества предусмотренных ко¬
манд; определения, если необходимо, постоянных буферов и их
параметров; определения источников и приемников байтов для по¬
стоянных буферов, если необходимо ввести умолчание.
4.3.2. Обучение пользователя
Независимо от конкретного содержания процесса обучения он
складывается из показа на экране терминала графического и тек¬
стового материала и выполнения контрольных заданий под управ¬
лением обучающей системы. Взаимодействие человека с обучающей
системой реализуется с помощью специального языка запросов,
получившего в современной практике название языка «кнопок».
Кнопка — это выделенная яркостью, цветом или иным спо¬
собом часть изображения или текста. Нажатие на кнопку означа-
ет запрос на пояснение того, что она обозначает. Пояснение не
т°лько выводом поясняющего изображения пли текста (или их
63
сочетания), но и предложением выполнить в диалоге с системой
некоторое контрольное задание пли их совокупность по заранее
подготовленному сценарию. С одной и той же кнопкой можно свя¬
зать несколько типов обучающих действий: вывести обучающий
текст, вывести изображение, выполнить работу в диалоге или вы¬
полнить все три типа действий в заданной последовательности или
любую пару из них.
Чтобы нажать кнопку, нужно установить на нее курсор и на¬
брать клавишную (или текстовую, или меню-задаваемую) команду
выбора типа обучающего действия. Заметим, что в поясняющей
информации, которая выдается по нажатой кнопке, также могут
существовать кнопки. Глубина пояснения выбирается при порож¬
дении обучающей системы именно выбором уровней вложенности
кнопок. Число кнопок и их конкретизация выбираются в зависи¬
мости от категории пользователя, как и типы обучающих действий.
В любой точке процесса обучения пользователь может вернуться
в любую точку и продолжить обучение от выбранной точки.
В заключение приведем краткую характеристику подхода к
построению интерфейса пользователя путем порождения ИК.
Главной чертой интерфейса пользователя должна быть гибкость,
понимаемая как возможность быть измененным в соответствии с
пожеланиями пользователя. Гибкость обеспечивается реализа¬
цией принципов независимости, ориентации концептуальных мо¬
делей на типы пользователей, изменяемости интерфейса по же¬
ланию пользователя в процессе работы.
Важной чертой предложенного подхода к построению интерфей¬
са пользователя является также ориентация на широкий спектр
видеотерминалов (без логических ограничений на расширение
множества терминалов, применительно к которым можно поро¬
ждать ПК).
Порождение ПК основано на редактировании прототипов (за¬
готовок описаний компонент ПК), хранящихся в табс-базе данных
порождающей системы, специализирующейся на продуцировании
ИК. Поиск необходимого прототипа, получение его копии, кото¬
рая затем может быть отредактирована,— эти работы выполняют¬
ся автоматически по запросу системного аналитика, занимающего¬
ся порождением ПК.
Обучение пользователя перед началом его работы с генератором
или пакетом, а также в процессе работы реализуется под тем же
девизом ГИБКОСТЬ — ГИБКОСТЬ как возможность при порож¬
дении обучающей системы, предназначенной научить пользователя
работать с пакетом, учесть уровень его подготовленности и склон¬
ность к тому или иному типу обучающих действий; ГИБКОСТЬ
как возможность для обучающегося пользователя в любой момент
перейти в режим обучения, остановиться на любом уровне вложен¬
ности обучающих действий системы, вернуться в любую предыду¬
щую точку и на каждом шаге процесса самому выбрать тип обучаю¬
щего действия из числа типов, предусмотренных в этой точке при
порождении обучающей системы.
64
Л II Т Е Р А Т У Р А
1. Manna Z., Waldlnger R. Towards automatic program synthesis // Commun.
ACM. 1971. Vol. 14, N 3. P. 151 — 164.
2. Darlington J., Burstall R. M. A system which automatically improves
programs// Acta inform. 1976. Vol. 6. P. 41—60.
3. Broy M. Program construction by transformation: A family tree of sorting
programs// Proc. NATO Adv. Study Inst. C. 1981. Vol. 95. P. 1—49.
4. Manna Z., Waldlnger R. Deductive synthesis of the unification algorithm//
Proc, of the NATO Advances Study Institute Computer program synthesis
methodologies. 1981. Vol. 95. P. 251—307.
5. Агафонов В. И. Языки и средства спецификации программ // Требования
и спецификации в разработке программ: Сб. ст. / Пер. с англ, под ред.
B. Н. Агафонова. М.: Мир, 1984. С. 285-344.
6. Агафонов В. II. Спецификация программ: Понятийные средства и их
организация. Новосибирск: Наука, 1987.
7. Сергиенко И. В., Парасюк И. II., Гукалевская II. И. Автоматизированные
системы обработки данных. Киев: Наук, думка, 1976. 256 с.
8. Тамм Б. Г., Тыугу Э. X. Пакеты программ//Техн, кибернетика. 1977.
N 5. С. 121-124.
9. Ершов А. И., Ильин В. П. Пакеты программ — технология решения
прикладных задач: Препр. ВЦ СО АН СССР № 121. Новосибирск: Ин-т
теорет. и прикл. механики СО АН СССР, 1978.
10. Карпов В. Я., Корягин Д. А., Самарский А. А. Принципы разработки
пакетов прикладных программ для задач математической физики// Журн.
вычисл. математики и мат. физики. 1978. Т. 18, № 2. С. 458—467.
И. Гошев П. И. Об одном подходе к созданию инструментально-базовых
систем для построения 1ШП // ППП: Инструментальные системы. М.:
Наука, 1987. С. 112-116.
12. Кыпп М. Г. Система МИКРОПРИЗ // Там же. С. 29-40.
13. Маукин М. Б., Пеньям Я. Э., Тыугу Э. X., Шмундак А. Л. Персональ¬
ная система программирования//Там же. С. 54—65.
14. Мельников И. А., Прууден 10. И., Прууден Э. В. и др. Инструментальные
системы семейства МЕМО // Там же. С. 65—79.
15. Horowitz Е., Kemper А., Narasimhan В. A survey of application genera¬
tors// IEEE Software. 1985. Jan. P. 40—54.
16. Jenkins A. M. Surveying the software generator market//Datamation.
1985. Vol. 31, N 17. P. 105-120.
17. Luker P. A., Burns A. Program generators and generation software// Com-
put. J. 1986. Vol. 29, N 4. P. 315-321.
18. Darlington J. The synthesis of implementations for abstract data types.
A program transformation tactic// Proc. NATO Adv. Study Inst.: Compu¬
ter Program synthesis methodologies C. 1981. Vol. 95. P. 399—434.
19. Kaxpo M. И., Калья А. И., Тыугу Э. X. Инструментальная система про¬
граммирования ЕС ЭВМ (ПРИЗ). М.: Финансы и статистика, 1981.
20. Бабаев И. О., Лавров С. С. Развитие автоматизированной системы реше¬
ния задач СПОРА// ППП: Инструментальные системы. М.: Наука, 1987.
C. 5-17.
21. Jouannaud J.-Р., Kodratoff Y. Program synthesis from examples of beha¬
vior/ Proc. NATO Adv. Study Inst. C. 1981. Vol. 95. P. 309—334.
22. Ершов А. П. Опыт интегрального подхода к актуальной проблематике
программного обеспечения//Кибернетика. 1984. № 3. С. 11—21.
23. Барышников В. И., Ильин В. Д., Куров Б. И., Семик В. И. Обработка
результатов эксперимента в системе ДИЭКС // Управляющие системы и
машины. 1984. № 1. С. 62—64.
24. Ильин В. Д. Система ИГЕН: Концепция, архитектура, технология про¬
граммирования// Современные средства информатики. М.: Наука, 1986.
С. 117-125.
25. Ильин В. Д. Генератор прикладных задач в системе ИГЕН // ЭВМ мас¬
сового применения. М.: Наука, 1987. С. 28—37.
3 Заказ № 2514
65
26. Перевозчикова О. ЛЮщенко Е. Л. Системы диалогового решения зад;*ч
на ЭВМ. Киев: Наук, думка, 1986.
27. Пакеты прикладных программ: Инструментальные системы. М.: Наук;;,
1987.
28. Ильин В. Д., Мартьянов А. В. Взаимодействие с пользователем в ИГЕ1П
среде порождения программных систем// Программирование. 1988. № 3.
УДК 621.372.542
ЭЛЕМЕНТЫ КОНЦЕПЦИИ ПЕРСОНАЛЬНЫХ СИСТЕМ
ОБРАБОТКИ ИЗОБРАЖЕНИЙ
В. И. Дымков, И. Н. Синицын
В различных областях науки и техники возникают задачи обра¬
ботки видеоинформации, т. е. такой информации, которая может
восприниматься как изображение. Решение подавляющего боль¬
шинства этих задач становится возможным только благодаря ис¬
пользованию современных средств вычислительной техники. На¬
верное, поэтому обработка видеоинформации с помощью ЭВМ
стала одним из неотъемлемых разделов информатики. В настоящее
время в обработку видеоинформации с помощью ЭВМ вкладыва¬
ется более широкий смысл, чем в традиционный термин «цифровая
обработка изображений», который чаще всего означал преобразо¬
вание одного изображения в другое с использованием различных
математических методов, в принципе реализованных на ЭВМ.
Современное понимание обработки видеоинформации с помощью
ЭВМ (см. напр. [1—3]) предполагает взаимозависимое решение
комплекса методологических, алгоритмических и технических во¬
просов, обеспечивающее возможность практического использованп я
видеоинформации. Такое понимание обработки видеоинформации
с помощью ЭВМ позволяет выделить общие теоретические и тех¬
нические аспекты решения задач, связанных с обработкой видео¬
информации, и более четко сформулировать понятие вычислитель¬
ной системы для обработки изображений как средства решения
таких задач. Кроме того, это дает возможность создать единую тео¬
ретическую и техническую базу для таких направлений обработки
видеоинформации, как «машинная графика», «обработка изобра¬
жений» и «распознавание изображений», которые до сих пор раз¬
вивались самостоятельно и практически независимо.
В рамках такого понимания обработки видеоинформации с по¬
мощью ЭВМ в статье предлагается подход к созданию систем обра¬
ботки изображений для массового применения на базе персоналы
ных ЭВМ.
КЛАССИФИКАЦИЯ ЗАДАЧ
ОБРАБОТКИ видеоинформации
В обширной литературе по цифровой обработке изображений и
распознаванию образов существуют различные варианты классифи¬
кации задач, связанных с обработкой видеоинформации (см. напр.
66
[1, 2, 4]), которые преследуют
различные цели. Если стреми¬
ться к соответствию между спо-
собохИ классификации и воз¬
можностью эффективной реали¬
зации задач обработки видеоин¬
формации с помощью ЭВМ, то
представляется целесообразным
различать три основных клас¬
са задач: синтез изображений,
преобразование изображений и
анализ изображений.
Определим синтез изобра¬
жений как генерацию изобра¬
жений по некоторым правилам,
когда исходной информацией яв¬
ляется «не-изображение». При
Рис. 1. Связь между основными клас¬
сами задач обработки видеоинфор¬
мации
этом можно говорить о синтезе изображений по описанию (вклю¬
чая сюда и синтез по имеющимся атрибутам). Предполагается,
что в общем случае синтезируемое изображение может иметь раз¬
личную специфику: быть полутоновым или бинарным, черно-бе¬
лым или цветным, двумерным или трехмерным Е
Преобразование изображений (собственно обработку изобра¬
жений) определим как трансформацию исходного изображения,
когда в результате появляется тоже изображение, чем-то отличаю¬
щееся от исходного. Это отличие может потребоваться по различ¬
ным причинам: удаление шумов, восстановление изображения,
субъективное улучшение качества изображения, редактирование
изображения, устранение избыточности. Преобразование изобра¬
жения может затрагивать его различные параметры: яркость, цвет,
контраст, резкость, размерность, ориентацию в пространстве
и т. д.
К анализу изображений отнесем такую обработку исходного
изображения, когда в результате появляется некоторая оценка
(или описание) этого изображения, которая, вообще говоря, не
является изображением. Под оценкой можно понимать, например,
некоторые интегральные характеристики исходного изображения,
геометрические характеристики различных объектов на изображе¬
нии, отнесение исходного изображения к заданному классу * 2.
Отметим, что если приведенные определения синтеза и анализа
изображений лишь интегрируют различные толкования этих тер¬
минов, встречающихся в соответствующей литературе, то определе¬
ние анализа изображений значительно шире общепринятого [4]
и может показаться необоснованным. Прежде всего это касается
При таком определении синтеза изображений задачи машинной графики
являются частным случаем, когда генерируются бинарные изображения
2 в виде точек, линий, различных фигур и т. и.
Последний вариант трактовки оценки исходного изображения приводит
яас к задачам распознавания изображений.
67
з*
того, что в анализ изображений включен такой обширный и традв ■
цпонно самостоятельный раздел, как распознавание изображений,
который часто отождествляется с распознаванием образов (на наш
взгляд, неправомерно). Однако имеются достаточно убедительные
доводы [4], чтобы распознавание изображений (а не образов) рас¬
сматривать в контексте с задачами анализа изображений.
Между основными классами задач обработки видеоинформации
с помощью ЭВМ существует связь, представленная на рис. 1,
Будем понимать под системой обработки изображений средство.,
обеспечивающее практическое решение задач обработки видеоин¬
формации с помощью ЭВМ. Тогда такие системы должны пред¬
ставлять собой всю необходимую совокупность алгоритмического,
методологического и программно-аппаратного обеспечения, со¬
ответствующего конкретным целям создания и использования си¬
стемы. При этом в рамках упомянутых основных классов задач це¬
лесообразно выделить типовые, часто встречающиеся задачи об¬
работки изображений, ориентируясь на практическую реализацию
систем обработки изображений на базе вычислительной техники.
Большинство типовых задач обработки изображений можно от¬
нести к таким категориям, как «ввод изображений», «вывод изоб¬
ражений», «передача изображений» и «работа с изображением».
Такое деление типовых задач на категории преследует прежде всего
цель поставить в соответствие ряд задач обработки видеоинформа¬
ции вполне определенным и достаточно автономным режимам ра¬
боты вычислительных систем. Представим возможный состав типо¬
вых задач отдельно по категориям.
Категория «ввод изображений» может включать: преобразова¬
ние исходного изображения к виду, удобному для системы (дискре¬
тизация по уровню, времени и пространству; кодопреобразова-
ние и т. д.); ввод изображений со стандартных периферийных
устройств ЭВМ; ввод изображений с нестандартных по отношению
к ЭВМ устройств (например, ТВ-камеры, ПЗС-линейки, фотодиод¬
ные матрицы); поиск изображений в базе видеоданных.
«Ввод изображений», как правило, заканчивается появлением
в ОЗУ ЭВМ изображения в заданном формате видеоданных.
Вывод изображений может включать: вывод для оперативной
визуализации на видеомониторе, вывод с целью оперативного или
долговременного хранения (архивации), вывод с целью документи¬
рования и т. д.
Типизация задач обработки изображений в рамках категории
«работа с изображением» допускает множество подходов и способов.
Однако на практике можно и нужно выбрать какой-то вариант
типизации потому, что в современной литературе по рассматривае¬
мой области уже сложились некоторые устойчивые понятия типов
таких задач 3, а также потому, что типизация задач облегчает
процесс создания конкретных систем обработки изображений,
рассчитанных на тиражирование, и делает эти системы более
3 Например, улучшение качества, реставрация, редактирование и т. д.
68
эффективными в смысле возможности их развития, простоты ис¬
пользования и универсальности. Можно предложить следующий
состав типовых задач обработки изображений, относящихся к ка¬
тегории «работа с изображением»:
— реставрация (восстановление) изображений;
— улучшение качества изображений (удаление шумов, повы¬
шение резкости, изменение контраста и т. д.);
— редактирование изображений (изменение масштаба, выде¬
ление фрагментов, раскрашивание и т. д.);
— выделение и количественная оценка различных особенностей
исходных изображений (выделение контуров, сегментация, вы¬
числение размеров объектов и т. д.);
— интерактивное общение с изображением (нанесение меток,
аннотирование, фиксация курсором некоторых зон и т. д.);
— формирование признаков изображения;
— «ручная» или автоматическая генерация изображений (ри¬
сование, синтез по описанию, синтез из стандартных атрибутов,
формирование эталонов и т. д.);
— идентификация и классификация изображений;
— изменение способа представления изображений в ЭВМ (из¬
менение формата данных, битовые срезы, сегментирование с целью
согласования с архитектурой ЭВМ и т. д.);
— компрессия, декомпрессия изображений (устранение инфор¬
мационной избыточности, подготовка к хранению или передаче
и т. д.).
«Передача изображения» может включать:
— обмен изображениями между различными устройствами
ЭВМ (видеопамять — ОЗУ, ОЗУ — регистровая память спецпро¬
цессора и т. д.);
— обмен изображениями между различными компонентами
системы обработки изображений (например, обмен по линиям свя¬
зи в сетевых системах);
— обмен изображениями с устройствами, не входящими в сис¬
тему.
Следует сделать три замечания по поводу предложенного со¬
става типовых задач. Во-первых, приведенный здесь перечень ти¬
повых задач является укрупненным. Во-вторых, некоторые задачи,
отнесенные к одной категории, могут при желании или по необ¬
ходимости быть отнесены к другой категории. Например, задача
«компрессия изображений» из категории «работа с изображением»
Может быть отнесена к категории «передача изображений», если
Эта задача должна решаться техническими средствами передачи
Данных (изображений). В-третьих, типизация задач вообще и
предложенная здесь в частности, являясь, по-видимому, полез¬
ной при создании любых систем обработки изображений, стано¬
вится практически необходимой при создании массовых, персо¬
нальных систем обработки изображений.
69
ПЕРСОНАЛЬНЫЕ СИСТЕМЫ ОБРАБОТКИ ИЗОБРАЖЕНИЙ
Научно-технический прогресс на современном этапе развития
общества во многом определяется массовым характером автома¬
тизированной обработки информации с использованием таких
средств вычислительной техники и информатики, как персональ¬
ные ЭВМ (ПЭВМ) [5, 6, 7]. Гибкие вычислительные возможности
ПЭВМ, их ориентация на диалоговый режим общения с человеком-
оператором, высокие эксплуатационные и технико-экономические
показатели — все это делает ПЭВМ эффективным инструментом
для решения разнообразных задач практически во всех областях
человеческой деятельности. Не являются исключением и задачи
обработки видеоинформации. При этом использование ПЭВМ для
создания систем обработки изображений приобретает особое зна¬
чение по следующим причинам. Во-первых, процессы обработки
видеоинформации во всем своем многообразии не могут быть (по
крайней мере в настоящее время) полностью и однозначно форма¬
лизованы. Поэтому получение конечного результата при обработ¬
ке изображений в принципе связано с участием человека-операто¬
ра, т. е. процесс обработки является интерактивным. Это приводит
к тому, что ПЭВМ в составе систем обработки изображений часто
позволяет решить такие задачи, которые не удавалось ранее решать
даже с применением более мощных ЭВМ. Во-вторых, изображение
может быть не только объектом изучения, но и выступать в роли
универсального интеллектуального интерфейса между человеком и
ЭВМ. ПЭВМ в большей степени, чем другие ЭВМ, дает возможность
использовать изображение в этом качестве. В-третьих, задачи об¬
работки изображений очень разнообразны по составу, вычислитель¬
ной сложности, виду исходной и результирующей информации,
по необходимой скорости и точности вычислений, по объему хра¬
нимой информации ит. д. Даже уже существующие ПЭВМ позволя¬
ют технически и экономически рационально решать это многообра¬
зие задач. И наконец, надежность и доступность ПЭВМ для поль¬
зователя являются часто определяющими свойствами вычислитель¬
ных средств в составе систем обработки изображений, учитывая
большие объемы обрабатываемой информации и интерактивный ре¬
жим обработки.
По-видимому, перечисленные факторы определили наметившую¬
ся тенденцию создания систем обработки видеоинформации на базе
ПЭВМ [8]. Будем называть их персональные системы обработки
изображений (ПСОИ). К сожалению, дать краткое определение
ПСОИ не менее трудно, чем дать определение ПЭВМ. Поэтому
приведем несколько основных свойств таких систем обработки
изображений, которые и определяют наше понимание ПСОИ.
Факт использования ПЭВМ в составе системы обработки изоб¬
ражений определяет ПСОИ в том смысле, что система сохраняет
такие свойства ПЭВМ, как интерактивность, доступность для
непрофессионального в области вычислительной техники пользо¬
вателя, относительная универсальность, сбалансированные тех-
70
лико-экономические показатели. Кроме .этого. ПСОИ [должна об¬
ладать такими свойствами, как — диалоговая реактивность; ти-
оажируемость; готовность к использованию; приспособляемость
задаче; самотестируемость; унифицированность программных
л аппаратных средств; защищенность от некорректных действий
оператора.
Под диалоговой реактивностью понимается приемлемая с точки
зрения человека-оператора производительность выполнения ос¬
новных, часто повторяющихся функций системы. Например, если
система предназначена в основном для субъективного улучшения
качества изображений с использованием локальных операций,
то трудно назвать систему персональной, если оператору придется
ждать результата низкочастотной фильтрации исходного изображе¬
ния более одной-двух минут. Естественно, это требование не исклю¬
чает длительного времени выполнения принципиально сложных в
вычислительном отношении операций (например, БПФ над изоб¬
ражением большого формата).
Свойство тиражируемое™ вытекает из ориентации ПСОИ, так
же как ПЭВМ, на относительно массовое использование. Поэтому
ПСОИ должна быть доступна для повторения.
Готовность к использованию означает, что если ПСОИ уже соз¬
дана (или сгенерирована), то оператор должен иметь возможность
получать с ее помощью интересующий его результат без дополни¬
тельных работ, не относящихся к выполнению инициируемых им
функций системы.
Приспособляемостью к задаче условно названа возможность
расширения и сокращения функций системы. Это может означать
как возможность произвольного выбора одного из возможных ре¬
жимов работы системы, так и принципиальную модифицируемость
системы.
ПСОИ должна обладать элементами самодиагностики. В коли¬
чественном отношении самодиагностика может быть различна.
Но в любом случае система должна как-то информировать опера¬
тора о своей неработоспособности.
Так же как в случае ПЭВМ, технико-экономические показатели
ПСОИ, предполагающей тиражируемое™, зависят от степени уни¬
фикации и стандартизации программных и аппаратных средств,
входящих в нее. Поэтому ПСОИ должна создаваться с учетом этого
фактора, что не противоречит возможности создания ПСОИ для
решения конкретных прикладных задач. Практически в любой си¬
стеме обработки изображений можно и нужно выделить программ¬
ные и аппаратные средства, которые будут инвариантны относитель¬
но конкретного приложения и тем самым могут быть реализованы
более эффективным образом (например, операционная система,
программы ввода-вывода через стандартные периферийные устрой¬
ства, спецпроцессоры матричной обработки изображений и т. д.).
И наконец, понятие ПСОИ предполагает, что с системой рабо¬
тает оператор, который является частью человеко-машинного комп-
Ленса, предназначенного для решения задач обработки изображе-
71
нпй. Кроме того, что оператор может не быть специалистом в вь?-
числительной технике, он может допускать действия, не преду¬
смотренные правилами работы с ПСОИ. Поэтому существенным
свойством ПСОИ следует считать ее способность предупреждать
оператора о некорректных действиях.
Рассмотрим один из возможных способов классификации пер-
сональных систем обработки изображений, вытекающих из их
определения и учитывающий возможность выделения типовых за¬
дач обработки изображений, а также желание повысить эффектив¬
ность разработки, воспроизводства и применения ПСОИ.
Персональные системы обработки изображений можно разде¬
лить па четыре класса: базовые системы (БС), функционально¬
ориентированные системы (ФОС), проблемно-ориентированные
системы (ПОС), прикладные системы (ПС).
Базовые системы должны быть ориентированы на массовое
промышленное воспроизводство. Они реализуют только типовые
задачи обработки изображений в том или другом объеме и макси¬
мальным образом используют стандартные или унифицированные
аппаратные и программные средства. Они должны обладать наи¬
большей степенью универсальности по отношению к ПСОИ дру¬
гих классов. Отличия базовых систем друг от друга могут носить
как количественный, так и качественный характер. Они могут
отличаться мощностью входящих в их состав ПЭВМ, количеством
реализованных типовых функций обработки изображений, соот¬
ношением программно- и аппаратно-реализованных функций, ти¬
пом устройств ввода-вывода изображений и т. д. На рис. 2 при¬
веден пример образования некоторого ряда базовых систем.
На практике часто создается и используется система обра¬
ботки изображений с целью выполнения с ее помощью некоторой
основной функции, что связано с необходимостью решения не¬
скольких, вполне определенных типовых задач обработки изобра¬
жений. Такими функциями могут быть, например, регистрациям
контроль процессов и объектов; диагностика; синтез графических
объектов; архивация изображений; распознавание изображений;
текстообработка и редакторские функции и т. д.
Перечень основных функций довольно ограничен, а, с другой
стороны, выполнение этих функций может потребоваться в раз¬
личных приложениях. Это делает целесообразным выделение клас¬
са функционально-ориентированных ПСОИ, т. е. систем, ориенти¬
рованных на выполнение одной из основных функций. Таким об¬
разом, ФОС могут обладать довольно высокой степенью универ¬
сальности и быть доступны для разработки и воспроизводства
при минимальном участии будущего потребителя.
Прикладные системы обработки изображений — это системы,
предназначенные для решения конкретной специфической задави
в конкретной области. Они максимальным образом должны удов¬
летворять частным требованиям данного применения и могут об¬
ладать наименьшей степенью универсальности. Как правило, п*
появление невозможно без участия будущего пользователя по
72
Рис. 2. Пример образова¬
ния базовых систем
> медленный
Ввод
> быстрый в ТВ-норме
> черно-белый
> цветной
высокоточный
> на системный монитор
Вывод
> на ТВ-монитор
> в псевдоцветах
» на магнитный носитель
на бумажный носитель
улучшение качества'
Работа
редактирование
о идентификация
обработка ”в цвете”
4► генерация
- внутри системы
Передача
-о на расстояние
медленная
-о скоростная
Рис. 3. Типы персональных
систем обработки изобра¬
жений и их взаимосвязь
крайней мере в виде работ по созданию специального программного
обеспечения. Однако часто удается обобщить требования со сторо¬
ны конкретных приложений и выделить некоторые типовые при¬
кладные проблемы. Например, медицинская рентгенодиагности¬
ка, анализ биоструктур, визуальный контроль печатных плат и
т- Д. Отсюда возникает понятие проблемно-ориентированных сис¬
тем, которые занимают промежуточное положение между ФОС и
НС. Потенциальные пользователи ПОС могут принять участие в
разработке только на начальной стадии обобщения и типизации
Конкретных прикладных задач или на конечной стадии создания
ПОС — разработки некоторых специальных дополнений к про¬
граммному обеспечению, генерации ПОС. Это позволяет основную
^асть аппаратного и программного обеспечения ПОС создавать ав¬
тономно от пользователя и использовать унифицированные тох-
73
нические решения, что, в свою очередь, оолегчает тиражирование
ПОС.
Рассмотренные типы систем (БС, ФОС, ПОС и ПС) обработки
изображений находятся в определенной связи между собой. Так,
БС могут служить основой для создания ФОС, Г1ОС и ПС. При этом
создание ФОС может потребовать дополнительных аппаратных
и программных средств. Посредством разработки дополнительно¬
го программного обеспечения ФОС может служить основой для
создания ПОС и Г1С и т. д. Взаимосвязь между БС, ФОС, ПОС и
ПС условно показана на рис. 3.
Изложенный в настоящей статье подход к созданию персональ¬
ных систем обработки изображений, по мнению авторов, может
значительно сократить сроки разработки, производства и внедре¬
ния ПСОП, позволить реализовать рациональные технические ре¬
шения, повысить эффективность ПСОИ и в конечном счете получить
реальный эффект от широкого применения современных методов
и средств обработки видеоинформации в различных областях нау¬
ки и техники.
ЛИТЕРАТУРА
1. Павлидис Т. Алгоритмы машинной графики и обработки изображений.
М.: Радио и связь, 1986. 498 с.
2. Верхаген К., Дейл Р. и др. Распознавание образов: Состояние и перспек¬
тивы. М.: Радио и связь, 1985. 253 с.
3. Digital image processing systems / Ed. L. Bole, Z. Kulpa. Berlin; Heidel¬
berg: Springer, 1981. 360 c.
4. Image analysis: Principles and practice / Publ. J. Loebl. Short Run press.
London, 1985. 212 p.
5. Наумов Б. II. Микро- и мини-ЭВМ: Настоящее и будущее. М.: Знание,
1983. 63 с.
6. Персональные ЭВМ: Тематический выпуск// ТИИЭР. 1984. Т. 72, № 3.
С. 1-188.
7. ЭВМ массового применения. М.: Паука, 1987. 270 с.
8. Майерс X., Бернстайн Р. Обработка изображений на персональной ЭВМ
фирмы IBM//ТИИЭР. 1985. Т. 73, №6. С. 131-139.
УДК 621.372.542
АРХИТЕКТУРЫ ПЕРСОНАЛЬНЫХ СИСТЕМ
ОБРАБОТКИ ИЗОБРАЖЕНИЙ
А. В. Губищ Е.В, Шарыпин
Цифровая обработка изображений (ЦОИ) в настоящее время
является быстроразвивающейся областью пауки и техники. За
последнее десятилетие область применения ЦОИ значительно рас¬
ширилась за счет повышения производительности ЭВМ и новых
технических средств обработки, появления машин с более совер¬
шенными эксплуатационными характеристиками. Появление
74
Рис. 1. Основные функции ПСОИ
ПЭВМ [1, 2], которые наряду с существенно низкой стоимостью
и высокой надежностью обладают развитым периферийным обо¬
рудованием и более удобным человеко-машинным интерфейсом,
а также разработка на их основе видеосистем открывают широкие
возможности для практического решения задач ЦОИ. Основная
сложность решения задач ЦОИ прежде всего заключается в необ¬
ходимости обработки больших объемов видеоинформации при вы¬
сокой скорости ее поступления. Решение этой проблемы возможно
только путем комплексной автоматизации процессов обработки
изображений. В этой связи важным вопросом является разработка
архитектур персональных систем обработки изображений (ПСОИ),
максимальным образом удовлетворяющих тем или иным практи¬
ческим задачам ЦОИ. В данной статье рассматриваются типовые
архитектуры ПСОИ и даются рекомендации по их применению.
На рис. 1 представлены основные функции ПСОИ, реализую¬
щие типовые задачи обработки видеоинформации 13]. Для реали¬
зации этих функций в составе ПСОИ могут использоваться раз¬
личные устройства.
В качестве устройств ввода изображений в настоящее время
широкое распространение получили телевизионные датчики изоб¬
ражений с электронной разверткой (телекамеры). Для высокоточ¬
ного ввода изображений используются различные сканеры
с оптико-механическим типом развертки. В зависимости от требова¬
ний, предъявляемых к структуре и качеству исходных изображе¬
ний, в массовых ПСОП целесообразно использовать в основном
Указанные типы сканеров в качестве устройств ввода изображений.
Для преобразования аналогового видеосигнала в цифровую форму
эффективно использовать аналого-цифровые преобразователи
(АЦП) на базе стандартных БИС.
Раз личные виды обработки изображений могут быть реализова¬
ть! на ПЭВМ, если нет специальных требований к скорости обра¬
ботки. ПЭВМ имеют функционально-развитые центральные про¬
75
цессоры и сопроцессоры, и основная проолема в этом плане заклю-
чается в создании эффективного программного обеспечения. Одна¬
ко для обработки телевизионных (ТВ) изображений в реальном
времени требуется производительность, превышающая возмож¬
ности ПЭВМ (до 80 нс на одну точку дискретного изображения}.
В этом случае необходимо использовать функционально-ориенти¬
рованные спецпроцессоры. Для регистрации и оперативного хра¬
нения исходных ТВ-изображений и результатов обработки при
этом в ПСОИ должна присутствовать специальная видеопамять.
Для реализации функции долговременного хранения изобра¬
жений ПЭВМ имеют в своем составе развитые внешние запоминаю¬
щие устройства (ВЗУ) — накопители на гибких магнитных дис¬
ках, диски типа «винчестер», оптические диски.
Функцию вывода можно разделить на две составляющие функ¬
ции: оперативную визуализацию и документирование. Визуали¬
зация предполагает отображение текущей видеоинформации на
устройствах динамического вывода изображений, к которым от¬
носятся графические дисплеи ПЭВМ и ТВ-мониторы. Для полу¬
чения твердых копий изображений (документирование) можно ис¬
пользовать стандартные графические принтеры и плоттеры ПЭВМ,
Для реализации функции передачи изображений в ПСОИ це¬
лесообразно максимально использовать стандартные параллельные
и последовательные контроллеры связи, а также сетевые адаптеры,
входящие в состав ПЭВМ.
Следует отметить, что обработка изображений, как правило,
предполагает интерактивный режим, при котором пользователь
активно взаимодействует с системой. Для реализации диалога
с человеком ПЭВМ имеют развитые средства. К ним относятся
различные типы дисплеев, на которых отображается в виде меню
имеющийся набор процедур манипулирования и обработки изоб¬
ражений, устройства позиционирования курсора для воздействия
пользователя на работу системы.
Таким образом, архитектуры ПСОИ могут включать в себя как
стандартные средства вычислительной техники, так и специальные
устройства ввода-вывода, хранения и обработки изображений. Ор¬
ганизация эффективного их взаимодействия, рациональное рас¬
пределение функций обработки между аппаратными и програм¬
мными компонентами, управление потоками видеоинформации, раз¬
работка протоколов обмена видеоданными являются важными ас¬
пектами архитектур ПСОИ.
Быстрое развитие ПЭВМ и специальных средств обработки изоб¬
ражений сопровождается эволюцией архитектур ПСОИ, что позво¬
ляет наилучшим образом использовать новые технологические до¬
стижения и в максимальной степени удовлетворять потребности
пользователей. В настоящее время можно выделить несколько ти¬
повых архитектур ПСОИ.
На рис. 2 представлена архитектура системы, ориентированная
на ввод изображений от стандартных датчиков непосредственно в
ОЗУ ПЭВМ. Принципиальной особенностью такой архитектуры
76
р с. 2. Архитектура систем ввода
^•атических изображений
рис. 3. Архитектура систем ввода-
вывода ТВ-изображений в реальном
масштабе времени
является то, что для согласования высокой скорости поступающих
ТВ-изображений и относительно медленного быстродействия ПЭВМ
используется принцип ввода, согласно которому за время сущест¬
вования одной строки ТВ-кадра оцифровывается один или не¬
сколько пикселей (точек дискретного изображения). Соответствен¬
но весь кадр регистрируется в ОЗУ за время существования не¬
скольких ТВ-кадров. Подобная структура позволяет вводить толь¬
ко статические ТВ-изображения либо изображения, поступающие
от оптико-механических сканеров. Доступ ПЭВМ к оцифрованным
точкам изображения осуществляется через программно-доступные
регистры. Вся обработка изображений происходит на ПЭВМ. Та¬
кую архитектуру имеют, например, системы MicroSight-1 [4] и
РЮ [5].
Архитектура, представленная на рис. 3, в отличие от преды¬
дущей позволяет регистрировать ТВ-изображения в специальной
кидеопамяти (ВП) в реальном масштабе времени (один ТВ-кадр
за 40 мс). При этом ввод изображений осуществляется от стан¬
дартной телекамеры. Оцифрованные в АЦП видеоданные запоми¬
наются в ВП. В зависимости от структуры и емкости ВП можно
77
обеспечить регистрацию нескольких изображений. Доступ ПЭВМ
к ячейкам ВГ1 может осуществляться несколькими способами:
через адресные регистры, размещением в адресном пространстве
ПЭВМ, с помощью сегментирования блоков ВП, а также через ка¬
нал прямого доступа к памяти. Визуализация хранимого в ВЦ
изображения происходит через цифро-аналоговый преобразова¬
тель (ЦАП) на ТВ-мониторе. В блоке ЦАП могут быть размещены
просмотровые таблицы для преобразования черно-белых изобра¬
жений в псевдоцветные. Все функции по обработке изображений,
как и в предыдущей архитектуре (см. рис. 2), выполняются на.
ПЭВМ. Подобную архитектуру могут иметь, например, системы
визуализации изображений, контрольно-регистрирующие систе¬
мы ЦОИ. Примерами такой структуры являются системы IMAGE
III и MicroSight-2 [4].
Следующим этапом развития архитектур систем ЦОИ на базе
ПЭВМ является архитектура, позволяющая регистрировать и об¬
рабатывать ТВ-изображения в реальном масштабе времени
(рис. 4). Невысокая скорость обработки изображений на ПЭВМ
не позволяет достичь высокой производительности системы и яв
ляется недостаточной для обработки ТВ-изображений в темпе их
поступления. Одним из путей решения этой проблемы является
использование различных спецпроцессоров (СГ1) обработки изоб¬
ражений реального времени. Они могут иметь различную струк¬
туру- табличную, матричную, конвейерную и т. д. По характеру
выполняемых функций и взаимодействия с другими устройствами
системы они могут быть одно- и многовходовыми. Так, например,
в системе ВМ-901 фирмы В&М Spektronik на базе ПЭВМ IBM
PC/AT двухвходовой спецпроцессор выполняет следующие функ¬
ции в реальном масштабе времени ТВ-стандарта: вычитание двух
изображений; рекурсивную фильтрацию; масштабирование изоб¬
ражений.
Представляется возможным и целесообразным возложить на
подобные СП также функции коррекции яркостной шкалы, полу¬
чения статистических характеристик изображений, детектирова¬
ния движения, выделения признаков и др.
Использование в архитектуре двухмониторной конфигурации
(см. рис. 4) позволяет пользователю, например, оперативно срав¬
нивать обработанное на СП изображение с некоторым эталонным,
хранящимся в ВГ1.
Архитектура, представленная на рис. 5, является модульной
и позволяет функционально наращивать систему за счет подклю¬
чения дополнительных специальных устройств. Характерная ее
черта — наличие нескольких специальных магистралей, напри¬
мер магистрали управления функциональными модулями и видео¬
магистрали для обмена видеоданными со скоростью ТВ-стандарта-
Магистраль управления может быть реализована и на стандарт¬
ных интерфейсах, например VMEbus, Multibus, САМАС. Видео¬
магистраль может представлять собой совокупность нескольких
типов магистралей, что, в частности, является необходимым для
78
Рис. 4. Архитектура системы обработки ТВ-изображений в реальном масштабе
времени
Видео магистраль
Модульная подсистема обработки
I ТВ изображений
I
I
I
I
I I
J Телекамера
Магистраль управления
X
ПЭВМ
1
Схемы
интерфейса
ТВ
монитор
Магистраль ПЭВМ
Рис. 5. Модульно-наращиваемая архитектура ПСОИ
выполнения рекурсивных операций над изображениями. Учиты¬
вая последовательный характер ТВ-развертки и соответственно
процесса оцифровки видеоданных, представляется целесообраз¬
ным использование конвейера для взаимодействия модулей систе¬
мы. Подобную архитектуру имеют системы Series-151 фирмы Ima¬
ging Technology и MaxVideo фирмы Datacube [61.
79
Система Series-151 имеет в своем составе следующие модули:
ADI-150 — модуль ввода-вывода изображений:
FB-150 — видеопамять;
ALU-150 — арифметический спецпроцессор;
RTC-150 — спецпроцессор свертки;
HF-150 — спецпроцессор расчета статистических характерис¬
тик.
Для их взаимодействия в системе используется пять различ¬
ных видеомагистралей, а в качестве магистрали управления ис¬
пользуется стандартный интерфейс VMEbus.
Система MaxVideo представляет собой семейство спецпроцес¬
соров обработки изображений, которые можно разделить на груп¬
пы:
табличной обработки;
редактирования изображений;
выполнения фильтрации и свертки;
интерполяторы;
анализа изображений.
Их взаимодействие осуществляется через синхронную кон¬
вейерную впдеомагистраль MaxBus.
В настоящее время наметились две тенденции в реализации ар¬
хитектур ПСОИ. Первая из них связана с конструктивным оформ¬
лением подсистем регистрации и обработки изображений в виде
отдельного блока. Такие подсистемы часто являются машинно¬
независимыми и имеют разветвленную модульную структуру, что
придает им большую гибкость и позволяет пользователю органи¬
зовывать сложные конфигурации аппаратных средств для решения
разнообразных задач ЦОИ. К таким системам можно отнести Mic-
roSight-2, ВМ-901, Series-151, MaxVideo.
Вторая тенденция характеризуется тем, что для конкретно]'’
ПЭВМ разрабатывается набор модулей в виде плат, конструктив¬
но располагаемых в корпусе ПЭВМ. Эти модули обычно реализуют
элементарные типовые функции по обработке изображений и от¬
личаются низкой стоимостью. Примером такого подхода является
набор плат фирмы Data Translation [71 для ПЭВМ типа IBM PC/XT.
IBM PC/AT.
Таким образом, приведенные в статье типовые архитектуры
позволяют решать широкий круг задач ЦОИ и могут быть исполь
зовапы в качестве основы при разработке ПСОИ различного клас¬
са [31. Каждая из них имеет свои характерные особенности и об
ласти применения.
Первые две архитектуры (см. рис. 2, 3) ориентированы исклю¬
чительно на программную обработку изображений на стандартных
средствах ПЭВМ. Специальные устройства выполняют лишь функ¬
ции ввода-вывода изображений. Архитектура систем ввода стати¬
ческих изображений (см. рис. 2) отличается простотой исполне¬
ния и соответственно низкой стоимостью. Ее целесообразно ис¬
пользовать при разработке ПСОИ в тех случаях, когда ие предъ¬
являются высокие требования к качеству ввода и визуализации
80
изображений. Архитектура систем ввода-вывода ТВ-изображений
в реальном масштабе времени (см. рис. 3) имеет более широкий
диапазон применений, в частности она может быть использована
при построении ПСОИ для регистрации и накопления изображе¬
ний. Использование в ней самостоятельных узлов синхронизации
и управления процессами ввода-вывода изображений делает ее
работу автономной по отношению к ПЭВМ в отличие от предыду¬
щей архитектуры, в которой процесс ввода изображений пол¬
ностью контролируется и управляется процессором ПЭВМ.
Архитектура, представленная на рис. 4, имеет принципиаль¬
ную возможность осуществлять в реальном масштабе времени
не только ввод-вывод изображений, но и их обработку. Это может
быть полезным в функционально-ориентированных и прикладных
ПСОИ, в которых на спецпроцессор целесообразно возложить
наиболее часто встречающиеся функции ЦОИ либо требующие
большого времени выполнения при программной реализации.
Одним из недостатков этой архитектуры является наличие жест¬
ких связей спецпроцессора с другими компонентами системы, что
ограничивает возможности функционального расширения ПСОИ
за счет подключения других спецпроцессоров обработки изобра¬
жений.
Указанного недостатка лишена модульно-наращиваемая архи¬
тектура ПСОИ (см. рис. 5), которая позволяет эффективно орга¬
низовывать поддержку работы различных типов спецпроцессоров
обработки изображений, ориентированных на реализацию широ¬
кого круга функций ЦОИ. Универсальность их взаимодействия
достигается за счет унификации различных типов магистралей.
Подобная архитектура может быть использована в принципе при
разработке ПСОИ любого класса.
Таким образом, в статье были рассмотрены типовые архитек¬
туры ПСОИ, ориентированные в основном на работу с полутоно¬
выми изображениями. В перспективных разработках, по-видимо¬
му, будут широко использоваться архитектуры, ориентированные
на работу с цветными, многоракурсными, стереоизображениями
и т. д.
ЛИТЕРАТУРА
1- Персональные ЭВМ//ТИИЭР. 1984. Т. 72, № 3. С. 188-196.
2. Кондратьев В. К., Ландау И. Я., Ливеровский А. 10. Новые элементы
архитектуры процессоров профессиональных персональных ЭВМ // ЭВМ
Массового применения. М.: Наука, 1987. С. 111—119.
Дымков В. И., Синицын И. II. Элементы концепции персональных спс-
тем обработки изображений//Наст. сб.
*• SPEC Ltd. catalogue. L.: SPEC Ltd. College House, 1986. 48 p.
Ъ-ВанФ. А., Элъ-Шербини A. X. M., ФрайС. и др. Профессиональная
ЭВМ для обработки изображений фирмы Wang: Новые возможности в ис-
пользовании ЭВМ//ТИИЭР. 1984. Т. 72, № 3. С. 78-91.
Electron. Syst. Design Mag. 1987. Vol. 17, N 12. 1 p.
• Allan B. Video-processing board put IBM PC AT on brink of real time //
Electron. Design. 1986. Vol. 34, N 1. P. 41—42.
81
УДК 621.372.542
О ЗАДАЧАХ РЕДАКТИРОВАНИЯ
И ЯРКОСТНО-ЧАСТОТНОЙ КОРРЕКЦИИ
В ЦИФРОВОЙ ОБРАБОТКЕ ИЗОБРАЖЕНИЙ
Т. А. Пахомова, В. II. Перс/шлова, А. Г. Шур
Обрабатываемое изображение является искаженным образом
реального объекта. Это связано с различными причинами, в том
числе с техническими ограничениями физических источников изо¬
бражений. Поэтому в процессе обработки встают такие проблемы,
как компенсация искажений (получение изображения, максималь¬
но приближенного к идеальному); приведение изображения к ви¬
ду, удобному для дальнейшей обработки или дающему исследова¬
телю наиболее полную информацию о реальном объекте; а также
улучшение визуального восприятия изображения. Все эти пробле¬
мы связаны с геометрическими и яркостно-частотными преобра¬
зованиями изображений. Именно такие преобразования являются
предметом задач редактирования и яркостно-частотной коррек¬
ции, которые, дополняя друг друга, охватывают наиболее обще¬
употребительные и актуальные задачи обработки изображения.
Поэтому представляется целесообразным конкретизировать и оха¬
рактеризовать набор задач редактирования и яркостно-частотной
коррекции.
К основным задачам редактирования изображений можно от¬
нести восстановление и коррекцию структурных элементов на
изображении для облегчения визуальной интерпретации изобра¬
жений или с целью их подготовки к дальнейшей обработке, а так¬
же задачи формирования нового изображения из заранее подго¬
товленных составных частей. В основе редактирования лежат раз¬
нообразные методы, связанные с координатными преобразования¬
ми элементов изображения. Весь комплекс задач редактирования
можно разделить на две основные группы: геометрические пре¬
образования и компиляция изображений.
Геометрические преобразования включают задачи коррекции
пространственных искажений элементов на изображении при от¬
сутствии сведений об их источнике и оперируют с такими геомет¬
рическими характеристиками, как ориентация, масштаб, фор ян
изображения. Основными геометрическими преобразованиями яв¬
ляются аффинные, коллинеарные (проективные), ортогональные,
специальные ортонормальные, полиномиальные. Эти преобразо¬
вания охватывают линейные преобразования и преобразования
подобия, частными случаями которого являются такие стандарт
иые манипуляции над изображениями, как перенос изображения
или его фрагмента в заданном направлении, отражение относиы
тельно выбранной оси, поворот на произвольный угол, а также из¬
менение масштаба изображения [1, 21.
82
Изображения часто содержат такие участки, которые в кон¬
кретном приложении не нужны. Кроме того, желательно просто
иметь возможность создавать новые изображения и новые ви¬
зуальные эффекты, совмещая части нескольких изображений. Эти
задачи относятся к группе компиляции изображений. В сущест¬
венно интерактивном режиме решаются задачи выделения и изме¬
нения фрагментов изображения, компоновки нового изображения,
^сходной информацией для решения задач этой группы могут
служить как полноразмерные изображения, так и их фрагменты.
Компиляция изображений выполняется с помощью аппликации
фрагментов, композиции изображений, а также «рисования» на
изображении.
Аппликация фрагментов позволяет изменять фрагменты изо¬
бражения, перемещая фрагменты из одного изображения в дру¬
гое, либо из заранее подготовленных составных частей компоно¬
вать новые изображения. Для подготовки составных частей могут
использоваться, например, геометрические преобразования изо¬
бражений. В основе решения задач аппликации лежит координат¬
ная привязка (стыковка) фрагментов по выделенным элементам
(точкам, линиям, многоугольникам) и врезка этих фрагментов
в изображение [31.
Композиция применяется к полноразмерным изображениям.
В ее основе лежат логические операции, арифметические опера¬
ции над изображениями и их модификации [11.
С помощью «рисования» можно подправить мелкие детали, на¬
нести геометрические фигуры и другую графическую информа¬
цию на изображение.
Решение задач яркостно-частотной коррекции изображения
предполагает изменение определенных яркостно-частотных ха¬
рактеристик изображения (например, контраст, средняя яркость,
резкость, зашумленность и т. д.) без учета координатного распо¬
ложения элементов изображения (точек), смысла изображения,
понятий «объекта», «особых точек» и пр. Целью изменения таких
характеристик может быть: приведение изображения к виду, более
Удобному для анализа изображения, задач распознавания, субъ¬
ективного восприятия изображения человеческим глазом; получе¬
ние желаемых яркостно-частотных эффектов, а также получение
из предъявленного искаженного изображения его неискаженного
(идеального) варианта.
Как видно из данного определения, задачи, традиционно объе¬
диняемые понятием «улучшение качества изображения» [41, вхо¬
дят в круг задач яркостно-частотной коррекции. Однако новый
термин вводится не только потому, что термин «улучшение качест¬
ва» представляется не совсем точным (существует ряд задач улуч¬
шения качества, направленных, вообще говоря, не на улучшение,
в на ухудшение изображения в определенном смысле, например
Нанесение шума на изображение, уменьшение числа градаций яр¬
кости, бинаризация полутонового изображения и т. д.). На са-
м°м деле яркостно-частотная коррекция в данном определении ох¬
83
ватывает более широкий круг задач, чем улучшение качеству.
Дело в том, что известный из литературы термин «реставрация»
(«восстановление») понимается обычно [4, 5] как получение из
предъявленного искаженного изображения по известным харак¬
теристикам искажений максимально близкого к идеальному ва¬
рианта изображения, а также [61 как устранение «вручную» де¬
фектных областей на изображении и исправление искаженных
фрагментов при помощи информации, извлекаемой из неискажен¬
ных фрагментов. Представляется более целесообразным отнести
задачи реставрации, использующие яркостно-частотные преобра¬
зования, к определенной выше категории задач яркостно-частот¬
ной коррекции, так как характер и направленность этих задач
укладывается в данное определение.
При решении задач яркостно-частотной коррекции важную
роль играет получение таких яркостно-частотных характеристик
изображения, как гистограмма распределения яркостей, уровень
шума, распределение частот, контрастность и т. д. По этой инфор¬
мации может происходить выбор конкретной задачи, которую на¬
до решить для коррекции данного изображения, а также парамет¬
ров для решения этой задачи.
К задачам яркостно-частотной коррекции можно отнести: уда¬
ление шумов с изображения, «наведение на резкость», преобразо¬
вание шкалы яркостей с целью изменения контраста, представле¬
ние полутонового изображения в псевдоцвете, изменение частот¬
ных характеристик изображения.
Задача удаления шумов ставится следующим образом: необ¬
ходимо осуществить фильтрацию изображения от шумовых со¬
ставляющих, располагая либо только исходным (искаженным)
изображением, либо, кроме того, некоторыми оценками искаже¬
ния — в данном случае характеристиками шумов, а также, воз¬
можно, характеристиками идеального (неискаженного) изобра¬
жения. В случае, когда характеристики идеального изображения
и шумов не известны, можно рассчитывать только на приблизи¬
тельные оценки шумов, извлеченные из предъявленного зашум¬
ленного изображения. Соответственно и удаление шумов будет
не идеальным, т. е. шумы могут частично сохраняться, а кроме
того, может произойти частичная потеря полезной информации.
«Наведение на резкость» необходимо в случае, когда вследст¬
вие искажений при прохождении через физическое устройство
изображение оказывается размытым, четкие контуры и мелкие
детали на нем теряются. Аналогично предыдущему лишь при на¬
личии характеристик идеального изображения или оценок иска¬
жений можно произвести достаточно точное приближение изо¬
бражения к идеальному. В случае наличия лишь искаженного
изображения необходимо провести сначала автоматическую иди
визуальную оценку характера искажения, а затем — выбор по¬
правляющей операции.
Одним из распространенных видов искажений является де¬
фект контраста. Этот дефект определяют обычно [4, 5J как узость
84
диапазона яркостей изображения. Кроме того, даже при полном
(от черного до белого) диапазоне яркостей изображение может
иметь неровную гистограмму, что отражает неблагоприятное ло¬
кальное распределение яркостей на изображении. Задачи пре¬
образования шкалы яркостей направлены на исправление подоб¬
ных искажений, а также на получение заданных специальных
яркостных эффектов. Сюда можно отнести линейные изменения
яркости для просветления или затемнения изображения, растяже¬
ние и сжатие диапазона яркостей, выравнивание гистограммы,
бинаризацию по заданному порогу, яркостные срезы, получение
негатива, замену яркостей середины диапазона граничными яр¬
костями по определенному закону и т. д.
Эффекта визуального усиления контраста изображения для
улучшения его субъективного восприятия можно достичь путем
решения задачи представления изображения в псевдоцвете («рас¬
крашивания» изображения в псевдоцвета по уровням яркости).
Специфика результата такой обработки основана на особенностях
цветового восприятия изображения человеческим глазом.
Распределение низких, средних и высоких частот может быть
нарушено при прохождении изображения через физическое уст¬
ройство. Например, изображения естественного происхождения
при этом обычно приобретают большие низкочастотные и малые
высокочастотные составляющие. Перераспределение частот мо¬
жет дать, таким образом, объективное улучшение качества изоб¬
ражения. Кроме того, существуют различные способы субъектив¬
ного улучшения изображений. Так, усиление высокочастотных
и ослабление низкочастотных составляющих обеспечивает подчер¬
кивание границ на изображении, что дает улучшение визуально¬
го восприятия изображения.
Решение задач яркостно-частотной коррекции становится наи¬
более эффективным при интерактивном режиме обработки изоб¬
ражений, а для задач редактирования обработка в интерактивном
режиме является необходимым условием. Возможность выделе¬
ния фрагментов, точек изображения, ввода необходимых парамет¬
ров в процессе обработки, визуализация промежуточных и конеч¬
ных результатов обработки позволяют существенно повысить ка¬
чество обработки. Широкие возможности интерактивного режима
предоставляет использование персональных ЭВМ для решения
задач цифровой обработки изображений. Поэтому применение
персональной вычислительной техники расширяет круг приложе¬
ний, в которых возникает необходимость решать задачи яркостно¬
частотной коррекции и редактирования. Так, задачи яркостно¬
частотной коррекции возникают в оптических системах, реставра¬
ции фотоснимков, архивных документов и прочих твердых копий
Изображений, полиграфии, цифровом телевидении, медицине,
биологии, психологии, обучении, различных научных задачах для
заявления «скрытых» особенностей изображений и т. д. Наряду
с традиционными задачами компенсации геометрических искаже¬
ний в оптических и радарных системах для сбора данных, приве¬
85
дения к стандартным проекциям в космической и аэрофотосъе-.н
ке, картографии необходимость решать задачи редактировании
возникают при автоматизации полиграфии и издательского дела,
фотомозаике, цифровой мультипликации и т. д.
Таким образом, можно выделить следующие особенности за¬
дач редактирования и яркостно-частотной коррекции. Во-первых,
эти задачи являются наиболее общеупотребительными задачами
цифровой обработки изображений. Во-вторых, они могут иметь
как самостоятельный характер, так и характер предобработки
для дальнейшего исследования. В-третьих, наилучший эффект
при решении этих задач достигается в интерактивном режиме об¬
работки, что определяется субъективностью критериев качества
результата обработки. Все это позволяет отнести задачи редак¬
тирования и яркостно-частотной коррекции к типовым задачам
обработки изображений [7], актуальным при создании персональ¬
ных видеосистем.
ЛИТЕРАТУРА
1. ВанФ.А., Элъ-Шербини А. X. М., ФрайтС., СмутсекМ. Профессио¬
нальная ЭВМ для обработки изображений фирмы Wang: Новые возмож¬
ности в использовании ЭВМ // ТИИЭР. 1984. Т. 72, № 3. С. 78—91.
2. Бернстайн Р., Майерс X. Дж. Обработка изображений на персональной
ЭВМ фирмы IBM//Там же. 1985. Т. 73, № 6. С. 131-139.
3. КронродМ.А. Привязка и геометрическое совмещение изображений /7
Иконпка: Теория и методы обработки изображений. М.: Наука, 1983.
С. 99—104.
4. Прэтт У. Цифровая обработка изображений. М.: Мир, 1982. 792 с.
5. Розенфельд А. Распознавание и обработка изображений. М.: Мир, 1972.
253 с.
6. ЧочиаП.А. Применение методов цифровой обработки изображений для
реставрации архивных документов // Иконика: Теория и методы обра¬
ботки изображений. М.: Наука, 1983. С. 105—110.
7. Дымков В. И., Синицын И. Н. Элементы концепции персональных систем
обработки изображений // Наст. сб.
УДК 621.372.5i2
СОЗДАНИЕ СПЕЦИАЛИЗИРОВАННЫХ
ЯЗЫКОВЫХ СРЕДСТВ
ДЛЯ РАЗРАБОТКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
ПЕРСОНАЛЬНЫХ СИСТЕМ
ЦИФРОВОЙ ОБРАБОТКИ ИЗОБРАЖЕНИЙ
А. Л. Барабанов, А. Г. Шур
Появление персональной вычислительной техники определи*
ло новый подход к разработке систем цифровой обработки изобра¬
жений на ее основе. Сущность этого подхода заключается в толь
что персональная система обработки изображений (ПСОИ) дол ж’*
на быть, во-первых, массовой и, во-вторых, действительно «пер¬
сональной», т. е. должна обеспечивать пользователю быстрый’
86
удобный интерактивный режим работы с изображением. Как по¬
казал опыт практической разработки ПСОИ, в частности первой
в СССР системы «Микровидео-11», достижение этой цели невозмож¬
но без сознательного ограничения функциональных возможностей
системы набором «базовых» функций, которые должны сочетать
в себе общеупотребительность и необходимость с эффективностью
реализации в конкретной архитектуре ПЭВМ.
Таким образом, персональная система обработки изображений
должна представлять собой комплекс аппаратно-программных
средств, реализующих базовые функции обработки. Однако базо¬
вые средства по своему определению не могут и не должны предо¬
ставлять пользователю возможность для решения всех задач об¬
работки изображения, относящихся к конкретной предметной об¬
ласти, даже если они выполнены с учетом ее специфики. Отсюда
возникает задача предоставления пользователю средств расшире¬
ния функциональных возможностей системы за счет реализации
и включения в нее собственных программных модулей. В части
разработки программного обеспечения эта задача изначально оп¬
ределяется его организацией. Термин «организация» будем пони¬
мать в широком смысле слова, т. е. не только как архитектуру
программного пакета или системы, но и как структуру данных,
особенности межпрограммных интерфейсов, а следовательно, и ис¬
пользуемые языки программирования. Таким образом, большое
значение имеет набор языковых средств для реализации компо¬
нентов программного обеспечения ПСОИ. При этом у разработ¬
чика и у потенциального пользователя критерии такого выбора
достаточно противоречивы. С одной стороны, для пользователя-
специалиста в некоторой конкретной предметной области обра¬
ботка изображения является лишь средством получения содержа¬
тельного результата из этой области и программирование как та¬
ковое должно занимать как можно меньше усилий. Поэтому для
него более предпочтителен выбор языка высокого уровня, такого,
как Фортран, Паскаль, Ада и др.
Язык высокого уровня, как правило, прост в освоении (до оп¬
ределенного уровня), позволяет быстро создавать и отлаживать
программные модули, содержит развитую диагностику. Отрица¬
тельной стороной такого выбора для задач цифровой обработки
изображения является низкая эффективность программ, так как
трансляторы с языков высокого уровня общего назначения не
предназначены для создания машинного кода, учитывающего
и особенности архитектуры ПЭВМ, и особенности алгорит¬
мов ЦОИ, в частности того определяющего для эффективности про¬
граммного обеспечения факта, что любой алгоритм ЦОИ своим
объектом всегда имеет достаточно большой массив данных
(64 Кбайта и более). В результате элементарная программа, осу¬
ществляющая, например, высокочастотную фильтрацию изобра¬
жения формата 256 X 256 х 8 бит прямоугольным окном 3x3,
Записанная на языке Фортран, выполняется на ПЭВМ класса IBM
₽С хт в течение нескольких минут.
87
При выборе в качестве основного при разработке системы
работки изображения языка высокого уровня существует и дру^
гая отрицательная сторона — трудности компоновки системы
с программным обеспечением, написанным на другом алгоритму
ческом языке высокого или низкого уровня. Не вдаваясь в техни^
ческие подробности, связанные с особенностями конкретных
трансляторов с языков высокого уровня, можно утверждать, что
в этом случае наиболее простой способ компоновки — связь ,ц0
данным через магнитный носитель. При этом, естественно, возни¬
кают потери во времени при функционировании программного
обеспечения, а также налагаются определенные ограничения па
наличие свободного пространства на магнитном носителе во время
выполнения программы. Несмотря на это, за рубежом был пред¬
принят ряд достаточно успешных попыток разработки программ¬
ного обеспечения для видеосистем на базе языков высокого уров¬
ня. Например, фирма Joice Loebl разработала программное обес¬
печение для видеосистемы MAGISCAN на языке Паскаль. Видео¬
система, несмотря на высокую стоимость, пользуется спросом на
западном рынке. Советским Союзом закуплено несколько таких
видеосистем.
Общая идея создания программного обеспечения для MAGIS¬
CAN на языке Паскаль заключается в следующем: трансляция
исходного текста с этого языка происходит в несколько этапов,
из которых на предпоследнем генерируются так называемые Р-ко-
ды, содержащие различное число машинных команд, реализующих
наиболее часто встречающиеся обращения к операционной систе¬
ме, оптимальным образом организованные циклы по стандарт¬
ным массивам, поддержку элементарных функций и т. д. На пос¬
леднем проходе транслятор из P-кодов создает объектную про¬
грамму. При создании программного обеспечения для видеосисте¬
мы P-коды были переписаны разработчиками с учетом специфики
задач цифровой обработки изображения. Кроме того, была созда¬
на библиотека специализированных процедур, предоставляющих
пользователю широкий круг возможностей при работе с видео¬
данными. Таким образом, язык высокого уровня — Паскаль был
специализирован для решения задач цифровой обработки изобра¬
жений. Этот язык удобен для пользователя-непрограммиста, так
как он, предоставляя широкие возможности для работы с видео¬
данными, внешне мало чем отличается от обычного языка Паскаль.
Описанный метод можно считать удачным примером адаптации
языка высокого уровня общего назначения для задач цифровой
обработки изображения. Его слабой стороной является то, что
специфика задач ЦОИ учитывается только на одном — предпос¬
леднем — этапе трансляции исходного текста, поэтому програм¬
мы, написанные на этом языке, нельзя считать оптимальными —
общая структура объектного модуля формируется на ранних эыы
пах трансляции исходя из обычной для Паскаль-транслятора ло¬
гики, т. е. без учета специализации. Изменение же логики работы
транслятора на ранних этапах означает, по существу, разработку
88
нового языка высокого уровня, затраты на создание которого мо-
гут не оправдываться конечным результатом.
Существует и другой критерий выбора языка программирова¬
ния — критерий разработчика. Разработчик ПСОИ, как правило
программист-профессионал, стремится к выбору такого языка
программирования, который предоставляет ему наиболее i и иро¬
ний круг возможностей для использования конкретных архитек¬
турных особенностей ПЭВМ, работы со внешними устройствами,
распределения памяти и т. д. Естественным при этом является
выбор для программирования языка Ассемблер. Такой выбор
был сделан при разработке программного обеспечения персональ¬
ной видеосистемы «Микровидео-11». Существенной слабой сторо¬
ной такого выбора является проблема компоновка системы с «внеш¬
ним», т. е. разработанным дополнительно пользователем, про¬
граммным обеспечением. Программное обеспечение, написанное
на каком-либо языке выского уровня, может быть прикомпоиовано
к такой системе практически только путем обмена видеоданными
через^магнитный носитель. Отрицательные стороны такого обмена
уже были указаны.
Таким образом, выбор языка программирования по любому
из существующих критериев содержит свои существенно слабые
стороны, неустранимые в рамках описанных в начале концепции
персональных видеосистем.
Исходя из этого можно определить проблему создания спе¬
циализированных языковых средств для разработки программного
обеспечения персональных систем обработки изображений как
проблему создания языковых средств, удобных как для пользова¬
теля, так и для разработчика видеосистемы.
На пути решения этой проблемы, во всяком случае на первом
этапе, можно предложить разработку языковых средств «средне¬
го» уровня, сочетающих в себе черты высокого и низкого уровней
и удовлетворяющих, таким образом, полностью или частично как
первому, так и второму из описанных критериев. Такие средства
Должны, с одной стороны, предоставлять разработчику возмож¬
ность непосредственно работать с необходимыми устройствами
ПЭВМ, обращаться к функциям операционной системы, самостоя¬
тельно распределять память и т. д. С другой стороны, такие сред¬
ства должны быть удобны для пользователя, просты в освоении
и эксплуатации, должны предоставлять ему возможность непосред¬
ственно работать со структурными элементами изображения ка¬
кого либо стандартного формата, избавлять его от необходимости
самостоятельно программировать интерфейс с базовым программ¬
ным обеспечением видеосистемы, но в то же время в определенном
смысле должны «навязывать» ему наиболее эффективный для дан¬
ной архитектуры способ реализации алгоритма. Кроме того, та¬
кие средства должны быть относительно просты для разработки
110 сравнению с языковыми средствами высокого уровня, так как
°бладая многими чертами языка низкого уровня, они существен¬
ным образом ориентированы на конкретные архитектурные осо-
89
бенностй выбранного класса ПЭВМ и поэтому не могут быть непо¬
средственно использованы вне данного класса. Вместе с тем общие
принципы, примененные при разработке таких языковых средств,
будут обладать самостоятельной ценностью особенно в части ор¬
ганизации работы с основными структурными элементами видео¬
данных, такими, например, как строчка изображения, столбец,
отдельная точка, прямоугольная область и т. д.
Предлагаемые языковые средства «среднего» уровня сущест¬
венным образом зависят от конкретного класса персональной вы¬
числительной техники, для которого они будут разрабатываться.
В данной работе рассматриваются вопросы возможности разра¬
ботки специализированных языковых средств для ПЭВМ класса
IBM PC. ПЭВМ этого класса получили большое распространение
в мире. У нас в стране выпускается ряд ПЭВМ, совместимых
с IBM PC — ЕС 1841, «Искра 1030». Для машин этого класса
существует развитое общесистемное и прикладное программное
обеспечение, они удобны для пользователя и надежны в эксплуа¬
тации. Опыт разработки системы «Микровидео-11», которая ориен¬
тирована на ПЭВМ такого типа, в значительной мере определил
содержание предложений о конкретных путях реализации специа¬
лизированных языковых средств.
При разработке программного обеспечения системы «Микро¬
видео-11» были выявлены основные особенности, которые необ¬
ходимо учитывать при программировании алгоритмов цифровой
обработки изображения в архитектуре ПЭВМ данного класса.
Это прежде всего следующее:
— страничная организация памяти, обусловленная двухре¬
гистровым способом обращения к ОЗУ и 20-разрядной адресной
шиной микропроцессора типа INTEL 8086/8088, приводит к сег¬
ментации изображения любого формата на фрагменты по 64 Кбай¬
та (что соответствует максимальной величине смещения, задавае¬
мой 16-разрядным регистром), что, в свою очередь, соответствует
формату 256 X 256 X 8 бит. Именно для такого формата возмож¬
на реализация наиболее эффективных алгоритмов ЦОИ;
— архитектурные особенности микропроцессора позволяют
эффективно работать не более чем с двумя областями памяти одно¬
временно. Это связано со страничной организацией памяти и с на¬
личием двух регистров данных;
— наиболее эффективно реализуются алгоритмы, требующие
ограниченное число (не более 8) обращений к исходному массиву
на каждом шаге, что связано с наличием 4 основных регистров,
для которых возможен 8-разрядный доступ;
— для эффективной реализации алгоритмов необходима орга¬
низация количественного контроля за разрядностью результата;
— необходимо учитывать существующие ограничения при ис¬
пользовании некоторых классов системных команд, в частности
для группы команд условного перехода.
В процессе разработки был произведен анализ трудоемкосгй
программирования различных классов алгоритмов цифровой о<г
90
работки изображения, а также анализ некоторых конкретных ре¬
шений, реализующих как собственно алгоритмическую, так и си¬
стемную — сервисную — часть программного обеспечения видео¬
системы. Был произведен анализ некоторых зарубежных видео¬
систем (например, MicroSight-2).
На основе проведенного анализа предлагается следующий под¬
ход к реализации языковых средств «среднего» уровня для ПЭВМ
класса IBM PC:
— сохранить основной принцип построения программ, харак¬
терный для языка низкого уровня, т. е. исходный текст програм¬
мы должен состоять из набора элементарных команд вида:
МЕТКА - КОД КОМАНДЫ - ПЕРВЫЙ ОПЕРАНД -
ВТОРОЙ ОПЕРАНД;
МЕТКА - КОД КОМАНДЫ - ОПЕРАНД;
расположенных каждая на отдельной строке. Наличие метки при
этом не обязательно;
— взять за основу систему команд микропроцессора типа
INTEL 8086/8088, а также используемую систему их мнемониче¬
ских кодов;
— расширить число операндов для этой системы команд за
счет введения специализированных для задач цифровой обработки
изображения структур;
— автоматизировать непосредственный доступ к этим струк¬
турам за счет введения новых классов переменных (индексов,
псевдорегистров и т. д.);
— ввести автоматический контроль за разрядностью резуль¬
тата обработки посредством введения нового класса переменных
одностороннего доступа (флагов);
— автоматизировать формирование структуры программы
в части распределения памяти для кодового сегмента, сегментов
данных, стека и т. д.;
— ввести автоматический контроль за распределением памяти
во время выполнения программы;
— автоматизировать наиболее часто употребляемые обраще¬
ния к внешним устройствам (магнитным носителям, клавиатуре,
терминалу);
— снять определенные ограничения для некоторых классов
системы команд (в частности, для группы команд условных пере¬
ходов);
— организовать автоматическую связь по видеоданным для
Разных программных модулей, а также средства их непосредст¬
венного вызова друг из друга;
— автоматизировать организацию эффективных циклов по
большим массивам видеоданных за счет снятия ограничения с не-
к°торого класса системных команд;
организовать возможность выполнять часть текста про-
гРаммы непосредственно на языке Ассемблер;
Объем работ по созданию таких средств состоит из следующих
Разработок:
91
— сканирующей процедуры;
— процедур синтаксического анализа строки исходного текста-
— процедур семантического анализа строки исходного текста-
— процедур поиска по таблицам мнемонических кодов команд
и стандартных операндов, а также присвоенных им символьных
имен;
— процедур диагностики;
— управляющей процедуры;
— процедур ввода-вывода;
— процедур генерации результата.
Реализация предложенных компонент приведет к возникнове¬
нию нового алгоритмического языка «среднего» уровня, специа¬
лизированного для задач цифровой обработки изображения па
ПЭВМ класса IBM PC, пригодного как для задач системного
программирования, в частности создания базового программного
обеспечения видеосистем, так и для эффективной реализации при¬
кладных алгоритмов ЦОИ. Программы, написанные на этом
языке, составят как бы единую программную среду. Они не будут
нуждаться в специальной компоновке с системой, так как в каж¬
дой из них будет реализована автоматическая связь по видео¬
данным с вызывающей программой. Такие языковые средства
смогут служить как для непосредственного программирования,
так и в качестве основы для дальнейших разработок в этом на¬
правлении.
Наличие таких средств значительно сократит сроки разработ¬
ки программного обеспечения ПСОИ, обеспечит их расширяемость,
предоставит пользователям эффективное средство программиро¬
вания алгоритмов ЦОИ.
ЛИТЕРАТУРА
1. Барабанов А . Л., Губин А. В., Дымков В. И., СиницинИ.Н. Создание
систем обработки изображений на базе ПЭВМ // Тез. докл. II Всесоюз.
конф. «Информатика-87». Ереван, 1987.
2. Дымков В. И., Губин А. В., Перфилова В. Н., Пахомова Т. А., Шур А. Г,
Базовые программные средства в персональной видеосистеме «Мпкро-
видео-11» // Тез. докл. Всесоюз. конф, по распознаванию образов. Львов,
1987.
3. Грис Д. Конструирование компиляторов для цифровых вычислительных
машин. М.: Мир, 1975.
4. КнутД. Искусство программирования для ЭВМ. М.: Мир, 1977.
5. Зелковиц М., Шоу А., Геннон Дж. Принципы разработки программного
обеспечения. М.: Мир, 1982.
92
уДК 621-372.542
ПОДХОД К ОРГАНИЗАЦИИ СЖАТИЯ ИЗОБРАЖЕНИИ
В ПЕРСОНАЛЬНЫХ СИСТЕМАХ
ОБРАБОТКИ ИЗОБРАЖЕНИЙ
Е-В. Шарыпин
Одной из наиболее важных задач цифровой обработки изо¬
бражений (ЦОИ), позволяющей решить проблему эффективного
использования ресурсов персональных систем обработки изо¬
бражений (ПСОИ), является компактное представление видеоин¬
формации с помощью процедур сжатия изображений. Исполь¬
зование методов сжатия изображений позволяет снизить требо¬
вания к объему памяти, сократить время передачи и поиска
изображений, сократить время решения тематических задач обра¬
ботки изображений. Комплекс задач, решение которых позволит
создать эффективные ПСОИ с использованием процедур сжатия
изображений, включает в первую очередь выбор методов сжатия
и разработку аппаратно-программных средств для их реализации.
Это, в свою очередь, связано с логической, структурной и физи¬
ческой организацией системы.
В этой связи в статье предлагается подход, суть которого
заключается в том, что аппаратно-программные средства ПСОИ,
реализующие методы сжатия изображений, целесообразно объе¬
динить в некоторую распределенную подсистему сжатия. При
этом с целью эффективного взаимодействия средств сжатия
с другими средствами обработки изображений архитектуру ПСОИ
предлагается делить на функциональные уровни, отражающие
характер обработки.
К настоящему времени разработано большое количество раз¬
нообразных методов сжатия изображений [1 — 3], назначение ко¬
торых состоит в сокращении объема видеоинформации с учетом
ее полного восстановления или при заданном качестве воспроиз¬
ведения. В зависимости от вида устраняемой избыточности мето¬
ды сжатия можно разделить на структурные, статистические и
семантические. К структурным методам относятся интерполя¬
ционное кодирование, сжатие яркостной шкалы, кодирование
СеРий, кодирование разрядных плоскостей. Статистические мето¬
ды включают в себя блочное кодирование, неравномерное коди¬
рование кодами Хаффмена и Шеннона—Фано, кодирование
с предсказанием. Наконец, семантические методы, которые отно-
сят к методам сжатия изображений второго поколения [3], вклю¬
чают в себя кодирование контуров, текстур, метрических и яр¬
костных признаков и т. д., а также символическое описание изо¬
бражений.
в ПСОИ могут быть применены любые методы сжатия из пере¬
численных, поэтому важным моментом при проектировании или
Работе ПСОИ является выбор наиболее эффективного метода
93
сжатия изображения. Эффективность методов сжатия зависит ог
многих параметров, основными из которых являются характернее
тики используемой вычислительной техники и степень допусти¬
мых искажений восстанавливаемого изображения. Кроме этою
эффективность во многом определяется характеристиками самого
изображения. Следовательно, одним из принципов эффективной
организации сжатия изображений в ПСОИ должно быть исполь¬
зование в работе системы некоторого начального этапа «обучения»,
или, иначе говоря, некоторой экспертной подсистемы, непосред¬
ственно входящей в состав ПСОИ и реализующей обучающую
процедуру. При этом осуществляется анализ статистических и
структурных свойств изображения, на основе которого опреде¬
ляется группа методов, удовлетворяющих заданному диапазону
таких оцениваемых параметров, как коэффициент сжатия, время
выполнения алгоритма сжатия, степень искажения изображения
и др. Имея такую таблицу параметров, система автоматически
или пользователь в интерактивном режиме могут выбрать метод,
наиболее удовлетворяющий заданным требованиям.
Анализ современных ПСОИ [4—7] показал, что невысокая
скорость обработки изображений на ПЭВМ не позволяет достичь
высокой производительности. Одним из путей повышения произ¬
водительности ПСОИ может быть применение все более мощных
ПЭВМ, однако он не всегда бывает оправданным.
Другой путь, связанный с распараллеливанием вычислитель¬
ного процесса, является более перспективным и предполагает
параллельную работу всех вычислительных средств обработки
изображений, входящих в состав ПСОИ. Такой подход нашел
применение во многих последних разработках ПСОИ [8], в кото¬
рых средства обработки изображений, характеризующиеся еди¬
ными принципами взаимодействия друг с другом, выделяют в са¬
мостоятельные подсистемы.
Таким же образом можно выделить и средства сжатия изо¬
бражений в специальную подсистему сжатия. Рассмотрим основ¬
ные принципы ее организации. Для этого предлагается условно
разделить архитектуру ПСОИ на три функциональных уровня
(см. рисунок).
Первый уровень представляет собой подсистему регистрации
и обработки изображений в реальном масштабе времени телеви¬
зионного стандарта. Основой подсистемы является специализи¬
рованная быстрая конвейерная видеомагистраль, обеспечиваю¬
щая обмен видеоданными между различными специальными
устройствами (АЦП, спецпроцессор, видеопамять, ЦАП). В эту
подсистему могут быть включены различные спецпроцессоры сжа¬
тия изображений. В настоящее время, учитывая современны#
уровень развития элементной базы, могут быть разработаны тао-
личные спецпроцессоры сжатия яркостной шкалы, спецпронес-
соры кодирования длин серий, интерполяторы и т. д.
Второй уровень представляет собой совокупность сопроцес¬
соров, функционирующих под управлением непосредствен*10
94
Функциональные уровни ПСОИ
ПЭВМ и являющихся ее периферийными устройствами. Они
могут выполнять как функции управления специальными устрой¬
ствами первого уровня (например, инициализация спецпроцес¬
соров сжатия) и организации обмена видеоданными между уст¬
ройствами первого и третьего уровней, так и непосредственно
функции сжатия изображений. Причем в сопроцессорах целесо¬
образно реализовывать такие методы сжатия, которые в силу
сложности, неэффективности или принципиально не могут быть
реализованы в виде спецпроцессоров реального времени.
Следует отметить, что экспертная подсистема выбора опти¬
мального метода сжатия для конкретного изображения или для
некоторого класса типовых изображений может иметь свои ком¬
поненты как в первом, так и во втором уровне. Спецпроцессоры
реального времени могут, например, выполнять расчет характе¬
ристик изображения (получение гистограмм, расчет средней яр¬
кости и т. д.). Сопроцессоры могут производить анализ получен¬
ных характеристик и инициализацию соответствующих аппарат¬
ных средств. Важной функцией сопроцессоров может быть также
Формирование служебной информации о сжатых изображениях,
Чт° позволит при восстановлении исходного изображения одно¬
значно определить алгоритм декодирования.
Одним из принципов разработки сопроцессоров является
Достижение программной совместимости сопроцессоров с ПЭВМ.
15 маетности, это позволит не иметь в составе сопроцессора посто-
95
яийую память для храпения всех программ его работы, а затру,
жать их в оперативную память от ПЭВМ, что придаст системе
гибкость, возможность функционального расширения и опера,
тивного изменения функций обработки. Что касается реализации
сопроцессоров, то их основой могут быть стандартные микро,
процессорные комплекты, например серий 1801, 1804, 1810
1816, 1820.
Наконец, третьим уровнем является сама ПЭВМ. На ней осу¬
ществляется основная тематическая обработка изображений
организация долговременного хранения видеоинформации па
внешних запоминающих устройствах (ВЗУ), создание твердых
копий изображений на устройствах печати, организация диалога
с пользователем. На ПЭВМ целесообразно возложить функции
управления подсистемой сжатия, организации банка изображений
в сжатом виде. Учитывая дальнейшую обработку изображений,
хранящихся в сжатом виде на ВЗУ, ПЭВМ должна иметь про¬
граммы декодирования. Это же требование предъявляется к ПЭВМ
и при визуализации изображений на мониторе.
В аналитической форме подсистему сжатия можно определить
совокупностью алгоритмов сжатия Лож? структурой системы
5СЖ, устанавливающей состав подсистем и их взаимосвязь, и на¬
бором используемых аппаратно-программных средств 5С?К 19].
Конкретный вариант подсистемы сжатия изображений опреде¬
ляется и характеризуется вектором показателей качества:
^СЖ = (^СЖ1» • • •? ^СЖм) €=
где 7?м — m-мерное пространство качества подсистемы сжатия,
■определяемое множеством всех возможных значений вектора [/сж.
Взаимосвязь вектора С7сж с определяющими его факторами
Аст, 5СЖ, Веж описывается вектором-функцией фСж[-1-
ВСж — фсж [-4сж, Всж, Всж, X (£)],
где X (t) — изображение как функция от времени t.
Показатели качества подсистемы сжатия могут быть техни¬
ческие (эффективность сжатия, точность, адаптивность), кон¬
струкционные (масса, габариты, показатели унификации) и эко¬
номические (стоимость).
Таким образом, задачу проектирования подсистемы сжатия
в аналитической форме можно сформулировать в двух постанов¬
ках. Первая предполагает выбор при заданном изображении X (t)
таких алгоритмов Асж, структур Scw и аппаратно-программных
средств ВСж, которые обеспечивают выполнение ограничений на
показатели качества подсистемы, оговоренных техническим зада¬
нием и задаваемых областью D™ (DM CZ — приемлемые значе-
ния показателей качества). Вторая постановка предполагает
выбор при заданном изображении X (t) таких алгоритмов Ас#1
структур 5СЖ и аппаратно-программных средств Всж, который
обеспечивают экстремальное значение показателя эффективностЯ
подсистемы I определенного на области DM. Практическая
96
реализация приведенной схемы проектирования подсистем сжа-
изображений в аналитической форме сложна, поэтому на прак¬
тике целесообразно сочетать теоретические методы с методами
моделирования п эксперимента.
Предложенные принципы позволяют эффективно решить ряд
проблем, связанных с практической организацией сжатия изо¬
бражений в ПСОИ, учитывая современный уровень развития вы¬
числительной техники и элементной базы. Дальнейшее развитие
микроэлектроники сделает возможным реализацию средств сжатия
изображений и их компонент в компактном виде, используя идео¬
логию заказных БИС. Это определит существенный прогресс
в области практической реализации сжатия изображений. Кроме
этого, дальнейшее развитие ПСОИ с использованием сжатия изо¬
бражений связано с проработкой вопросов по следующим направ¬
лениям:
— исследование и разработка архитектур ПСОИ, ориенти¬
рованных на работу со сжатыми изображениями;
— разработка алгоритмов управления потоками сжатой ви¬
деоинформации;
— разработка протоколов взаимодействия устройств различ¬
ных функциональных уровней ПСОИ;
— разработка быстрых алгоритмов и программ анализа изо¬
бражений для выбора оптимального метода сжатия;
— разработка ряда высокопроизводительных спецпроцессоров
сжатия изображений в реальном времени;
— исследование и разработка алгоритмов сжатия цветных*
многоракурсных, трехмерных и стереоизображений.
ЛИТЕРАТУРА
1. Прэтт У. Цифровая обработка изображений. М.: Мир, 1982. 792 с.
2. Hemp авали А. И., Лимб Дж. О. Кодирование- изображений: Обзор//
ТИИЭР. 1980. Т. 68, №3. С. 76—124.
3. Кунш М., Икономопулос АКошер М. Методы кодирования изображений
второго поколения//Там же. 1985. Т. 73, № 4. С. 53—86.
4. ВанФ.А., Элъ-Шербини А. X. М., Фрай С. и др. Профессиональная
ЭВМ для обработки изображений фирмы Wang: Новые возможности в ис¬
пользовании ЭВМ // Там же. 1984. Т. 72, № 3. С. 78—91.
5. Майерс X. Дж., Бернстайн Р. Обработка изображений на персональной
ЭВМ фирмы IBM// Там же. 1985. Т. 73, № 6. С. 131—139.
6. SPEC Ltd. catalogue. L.: SPEC Ltd. College House, 1986. 48 p.
7. Allan R. Video-processing board put IBM PC AT on brink of real time//
Electron. Des. 1986. Vol. 34, N 1. P. 41—42.
8. Губин А. В., Шарыпин E. В. Архитектуры персональных систем обра¬
ботки изображений//Наст. сб.
9- Оращенко В. И., Санников В. Г., Свириденко В. А. Сжатие данных в сис¬
темах сбора и передачи информации. М.: Радио и связь, 1985. 184 с.
4 Заказ № 2514
97
дни’10.2.0^ КРИТЕРИИ ОПТИМАЛЬНОСТИ
В ЗАДАЧАХ ПРЕДСТАВЛЕНИЯ ВИДЕОДАННЫХ
С- О. Носиков
Одной из основных задач цифровой обработки изображеннй
(ЦОИ) является получение количественных характеристик л
анализ изображений [1, 2, 4], однако решение этой задачи пред¬
варяют этапы некоторой предобработки, наиболее важным из
которых является этап представления видеоданных. Иод этим
этапом в данной статье подразумевается как непосредственно
кодирование уровней градаций яркости, так и описание призна¬
ков, особенностей и текстур. О принципиальном единстве пере¬
численных понятий будет сказано ниже. В связи с различием
конкретных приложений в области представления видеоданных
возникает ряд проблем: во-первых, выбор оптимального из огром¬
ного количества имеющихся [3, 5, 6] методов кодирования изобра¬
жений, во-вторых, получение четких количественных показателей
качества признаков, выделенных тем или иным методом. Пока что
оценку качества получаемых признаков производят в основном
описательно.
Кроме того, опыт создания систем ЦОИ массового применения
показывает, что одна из основных трудностей работы с такими
системами заключается в необходимости введения пользователем
в интерактивном режиме некоторых параметров, определение ко¬
торых является своего рода искусством, поскольку существую¬
щие критерии качества результатов тех или иных функций обра¬
ботки дают желаемый эффект лишь для некоторых узких классов
изображений и использование их для более широких классов
может существенно ограничить возможности системы. В качестве
примеров задач, нуждающихся в формулировке критериев опти¬
мальности, можно привести задачи определения оптимальной би¬
наризации, оптимального выделения границ, улучшения связнос¬
ти и т. д. Разумеется, создать гибкую, самоадаптнрующуюся и
при этом содержащую функции обработки в реальном масштабе
времени систему по меньшей мере затруднительно, к тому же учет
всех возможных нюансов потребует больших объемов памяти и
сложных процедур обмена данными.
Ниже предлагается подход, использующий субъективизм лишь
на уровне выбора некоторой структуры более общего порядка,
названной системой представления, а уже в пределах данной
системы представления результат обработки изображения оце¬
нивается по степени эффективности его использования для обес¬
печения наименьшего объема памяти, резервируемой под описа¬
ние этого изображения в соответствии с принятым в данной си¬
стеме методом кодирования. При этом однозначно определяются
функции оценки качества результата работы того или иного
алгоритма обработки изображения.
98
Исследуются методы оптимизации кодирования с устранением
убыточности. Сделана попытка использования для этой цели
неоднородности изображения по пространству, не переходя при
эТом к описанию объектов на изображении и текстур, а исполь¬
зуя лишь установленный заранее класс разбиений матрицы изо¬
бражения. Для нескольких достаточно широких классов разбие¬
ний доказана большая вычислительная сложность реализации
методов, использующих такой подход. Излагаются понятия системы
представления и многоуровневой системы представления. В рам¬
пах предложенного формализма получены критерии оптималь¬
ности бинаризации и выделения границ.
ИЗОТРОПНЫЙ подход к оптимизации методов
КОДИРОВАНИЯ ИЗОБРАЖЕНИЙ
Большинство из существующих методов кодирования [3] об¬
ладают некоторыми параметрами, которые стремятся подобрать
так, чтобы получить использующее этот метод описание, опти¬
мальное в смысле наиболее полного устранения избыточности.
При этом обычно производится некоторый предварительный ана¬
лиз изображения с целью получения характеристик, под которые
должен адаптироваться рассматриваемый метод кодирования.
Характерным примером является статистически оптимальный
код Хаффмена [7], для построения которого требуется априорная
информация о гистограмме уровней яркости изображения. Здесь
уже следует оговориться, что само по себе определение гистограм¬
мы по одному изображению не корректно и, таким образом, полу¬
чение оптимального метода производится в рамках предположе¬
ния об изотропности, т. е. однородности по пространству, изо¬
бражения.
Для метода, традиционно не относящегося к классу статисти¬
чески оптимальных, а именно для пирамидально-рекурсивного
представления [5] в случае кодирования бинарных изображений
получение оптимальных параметров [61 основывается на марков¬
ской модели первого порядка с матрицей переходных вероят¬
ностей:
_ ;'P(w/w) p(b/w)\
~ \Р("7Ь) Р(Ь/Ь) / ’
гДе, например, р (b/w) — условная вероятность того, что элемент
является черным при предшествующем белом. Предполагается
Неизменность матрицы Т для горизонтального и вертикального
Направлений. Естественно, выбранная модель существенно ис¬
пользует изотропность. В рамках той же модели можно получить
°Птимальные параметры (количество бит, отводимых под описа¬
ние длины серии) для двух методов, принадлежащих еще одному
классу — классу методов кодирования длин серий.
Опишем более подробно суть этих методов. В первом из них
описание серии резервируется г 4- 1 бит: первый бит пока¬
99
4*
зывает значение первого элемента серии (ноль или единиц;;)
остальные выделены для записи длины серии. Тогда для билгр.
ного изображения размером Л7 х -V средняя длина кодового елою
вычисляется по формуле
L = (г + 1) (3 ((/ (2Г - 1)] + 1) (р (w) р (wpv)1-1 +
1=2
+ p(b)p (b/bp1) + p(w)p (b/w) + р (0 р (u'/b)), (1)
где квадратные скобки обозначают целую часть числа: р (iv) и
р (Ь) — вероятности появления соответственно белого и черною
элементов, получаемые по формуле
р (W) = р (Ь) = d-.bW
' P(w/b) + P(bpo) ' р(6/ш)+ plwjb)
Второй метод менее чувствителен к отсутствию серий. В рамках
этого метода под описание серии резервируют г + 1 бит, первый
из которых показывает наличие серии (т. е. совпадение текущего
и последующего элементов), второй — значение первого элемента
серии в случае ее наличия, тогда остальные г — 1 бит выделяются
для записи длины серии, если же обнаружено чередование значе¬
ний элементов, то под описание серии чередующихся элементов
выделяется уже г бит для записи длины такой серии. В этом сиу-
чае длина кодового слова вычисляется по формуле
L = (г 4- 1) 2 (П/(2Г 1 4- 1)] + 1) (/? (w) р (wjw)1 1 4-
1=2
+ p(b) Р (b/bp1) + s (Т + 1) (1^/2’ ] + I) X
Z=1
X (р (w) (р (b/w) р (w/bp'^p (b/wp'-2ll/21) +
+ Р (0 (Р (u’/b) Р (blw))v,iip (м>/6)('~2£'/2])). (2)
Заметим, что вычисление значения г, дающего минимум выра¬
жений в правых частях (1) и (2), даже при использовании прямого
перебора не требует больших затрат вычислительных ресурсов.
То же самое касается и нахождения оптимальных параметров для
статистического табличного кодирования и пирамидально-ре¬
курсивного представления.
Таким образом, предположение об однородности изображения
и вычисление соответствующих «глобальных», т. е. не учитываю¬
щих локальных особенностей и пространственной неоднородное
изображения, характеристик позволяют достаточно просто на¬
ходить оптимальный с точки зрения этих характеристик метэД
кодирования. Однако наличие структурных свойств, таких, кгК
непрерывность границ, резкие изменения характера текстуры
и т. д., делает модели, подобные указанным, недостаточно ад^
кватными. В настоящее время используются некоторые адаптив-
100
цые методы, учитывающие неоднородность [3]. Эти методы осно¬
ваны на равномерном разбиении матрицы изображения, в каждом
0з блоков которого вычисляются все те же «глобальные», но уже
р пределах блока характеристики. Возникает вопрос: нельзя ли
оптимальным образом учесть неоднородность, не переходя при
этом к сложным описаниям особенностей?
ВОЗМОЖНОСТИ ИСПОЛЬЗОВАНИЯ НЕОДНОРОДНОСТИ
ДЛЯ НЕКОТОРЫХ ФИКСИРОВАННЫХ
КЛАССОВ РАЗБИЕНИЙ
Итак, попытаемся для заданного метода кодирования найти
оптимальное в пределах некоторого класса разбиение. Жела¬
тельно, чтобы выбранный класс обладал достаточно большой мощ¬
ностью и разбиения из этого класса описывались достаточно
просто. Последнее условие необходимо для того, чтобы избежать
необходимости кодировать с устранением избыточности описание
самого разбиения, которое по объему может перекрыть выигрыш,
получаемый от оптимизации заданного метода кодирования изо¬
бражения за счет использования разбиения.
Сформулируем строгую постановку задачи. Под разбиением
матрицы в дальнейшем будем понимать совокупность подмножеств
ее элементов, каждое из которых однозначно определяется соот¬
ветствующим блоком разбиения (в комбинаторном смысле) мно¬
жества координат элементов матрицы. Определим следующие
классы разбиений матрицы изображения J: nsr — класс разбие¬
ний на 5 прямоугольников; л„’52— класс разбиений сеткой из
горизонтальных и s2 вертикальных прямых.
Функцию F (Е, J), определенную для всех разбиений класса л
назовем л-монотонной, если для любых двух разбиений и Е2
из класса л выполняется условие £2 CZ F (Е2, J) F (Ег, J).
Отметим, что л-монотонность определяет свойство функции умень¬
шаться при дальнейшем дроблении разбиения из класса л, и
в дальнейшем будут рассматриваться лишь такие способы описа¬
ния, для которых определяемая функция неопределенности по
способу описания заведомо не увеличивается при последователь¬
ных разбиениях J.
Функцию неопределенности разбиения t по способу описания /
с характеризующей его функцией /в (J), определенной для каж¬
дого блока В разбиения Е, определим как сумму:
Rfd, 7) = ^2 JAL(7), (3)
гДе N2 — количество элементов матрицы J.
Обозначим через ?гв количество элементов блока В, равных I.
Пусть I обозначает максимальное число уровней градаций яркости
Изображения /, а ргв = пв!\ В | — вероятность появления эле*
101
мента i в блоке В. Рассмотрим следующие функции:
(-1
hB(J) = — 3 /7в Л'
0. если все элементы В равны,
1 — в противном случае.
Нетрудно убедиться, что правая часть (3) для определенных
функций (4) удовлетворяет условию л-монотонностн для каждого
из описанных ранее двух классов разбиений. Функции Л, с и /
характеризуют соответственно способы описания статистически
оптимальными кодами, нумерационными методами [8], методом
описания блоков (первый уровень пирамидально-рекурсивною
представления). Отметим, что функции (1) и (2), характеризуя>
щие методы описания длин серий, в общем случае условию л-мо-
нотонности для приведенных классов разбиений не удовлетворяют.
Задача заключается в нахождении для данных матрицы J
и класса разбиений л разбиения £, при котором достигается ми¬
нимум правой части (3).
Теорема 1 Приложения демонстрирует NP-полноту [9] задави
нахождения оптимального разбиения из класса 4,,s\ Задача
нахождения оптимального разбиения из класса известна для
бинарного случая как задача об оптимальном покрытии прямо¬
угольниками 0,1-матрицы. Доказательство ее NP-полноты можно
найти, обратившись к работе 19].
Таким образом, для приведенных классов с достаточно простым
способом описания входящих в них разбиений нахождение опти¬
мального разбиения представляет собой труднорешаемую задачу.
Из этой ситуации имеется два выхода: либо находить субопти¬
мальные решения, либо не накладывать никаких ограничений на
класс разбиений. В последнем случае процесс кодирования раз¬
делится на несколько этапов (уровней): на первом из них исход¬
ной информацией будет само изображение, на втором — описание
разбиения изображения, на третьем — описание разбиения ис¬
ходной информации предыдущего уровня и т. д.
Опишем систему, охватывающую оба подхода.
СИСТЕМЫ ПРЕДСТАВЛЕНИИ.
ОТНОСИТЕЛЬНЫЕ ХАРАКТЕРИСТИКИ ПРИЗНАКОВ
Системой представления R изображения J назовем пару
В = </в (/), {L- (*0}, состоящую из функции /д (J), характерна\
ющей выбранный для данной системы способ описания, и мно¬
жества разбиений матрицы изображения (/)}, принадлежа¬
щего классу всех возможных разбиений л0. Каждое разбиений
однозначно определяется соответствующим ему признаком ил**
102
функцией обработки. Функция //■• (J) должна быть л0-монотонной.
По определению наибольшей структурностью относительно
данной системы представления будет обладать признак, дающий
минимум по множеству функции Яу (£ь J).
Приведем ряд примеров. Определим са как разбиение из клас¬
са полученное по координатам тех строк и столбцов, где,
например, для строк разность дисперсий, вычисленных по гисто¬
граммам уровней на данной и следующей за ней строках, превы¬
шает по абсолютной величине а. Нетрудно убедиться, что в этом
случае вычисление наиболее структурного признака (значения я)
относительно, например, системы представления R = (hy, (J),
{5а}(7(Що, хъ> достаточно несложно даже в случае прямого пере¬
бора. Аналогичным образом можно определить систему представ¬
ления с разбиениями из класса щ, получаемыми в результате
применения некоторого набора алгоритмов сегментации на пря¬
моугольные области однотонности.
Приведенные примеры иллюстрируют методы получения суб-
оптимальньтх в общем смысле разбиений, которые в рамках кон¬
кретных систем представлений являются оптимальными.
МНОГОУРОВНЕВЫЕ СИСТЕМЫ ПРЕДСТАВЛЕНИЯ
Для корректности изложенного определения системы пред¬
ставления необходимо, чтобы для данных признака или функции
обработки и способа описания существовало соответствующее
разбиение кроме того, следует учесть описание сложных раз¬
биений. Для этого введем понятие уровней описания.
Систему описания с п уровнями определим как объединение
= и ^,г,
где Rn = (Hf,"9, {Ь (Ен_1)}>. Здесь (£n_1) — функция,
характеризующая способ? описания разбиения (п — 1)-го уров¬
ня; (£zl_l) — способ р золения на 7г-м уровне описания раз¬
биения (п — 1)-го уровня, а Для изображения J формата Аг z А\
г бит на точку считаем: fn (J) = г, Н° (J) = {«/} — прямое опи¬
сание множества J.
В этом случае структурность определяется в пределах одного
Уровня и можно постулировать, что для любого признака сущест-
вУет уровень, на котором понятие структурности для этого при¬
знака имеет смысл.
Последовательность разбиений сц, . . ., назовем
траекторией разбиений и определим функцию неопределенности
траектории относительно системы представления Rn:
(5)
103
Примеры способов описания и разбиений в 3-уровневой системе
Уровень
Описание
Признаки
Разбиения
0
Прямое представ¬
ление
Элементы J
Тривиальное
1
Кодирование с
устр. избыточно¬
сти
Описание одно¬
родных областей
На области одш _
родности
Кодирование опи¬
саний сегментов
Особенности кон¬
туров, параметры
текстуры
На однородные
участки контура
о
•J
Кодирование
взаимосвязей
особенностей
Семантические
(логические)
соотношения
Кластеризация
особых точек
Таким образом, определена количественная оценка структур¬
ной зависимости признаков разных уровней относительно задан¬
ной системы представления. Пример способов описаний и раз¬
биений на различных уровнях приведен в таблице.
Для оценки оптимальных параметров функции обработки
изображения необходимо взять некоторую соответствующую этой
функции 7?п. В качестве примера рассмотрим задачу оптимальной
бинаризации.
Выберем двухуровневую систему Bin2, в которой Binx =
= <7*в (Т), где (3, — разбиение матрицы исходного изобра¬
жения на две части, определяемые бинаризацией по уровню г;
Bin2 = (pi), где F ([3,) — описание границ объектов на
получаемом бинарном изображении J (I) кодами Фримана [3].
Если обозначить через S (z) количество элементов исходною
изображения J, превосходящих г, через Р (I) — суммарный
периметр объектов на J (Z), через U (i) — количество узлов на
линиях границ этих объектов, а через Т (z) — количество связ¬
ных объектов на J (z), то по теореме 2 Приложения функция не¬
определенности по траектории, соответствующей уровню z, будет
иметь вид
(|Зг, g’, J) = А - h (i) + р (i) +u(i)+t (i), (О
где А — величина, не зависящая от i;
_ 3P(0 .
№ ’
и (0 =
2tZ(01og.V .
p(i)
В рамках выбранной системы представления критерий опти¬
мальности бинаризации заключается в нахождении z, дающего
минимум правой части (6).
104
Для оптимального выделения границ, если в качестве способа
описания на первом уровне взять кодирование с предсказанием,
а i считать параметром окрестности, например разностью между
значением в точке и средним, то вид функции неопределенности
будет аналогичен (6).
Приведенные критерии демонстрируют большие возможности
изложенных формальных конструкций для построения безынтер-
активных процедур ЦОИ и получения относительных оценок
признаков.
Приложение
Теорема 1. Если задача нахождения оптимального разбиения
из класса Лп’$2 для какой-либо из функций/г, с или х имеет поли*
номиальное решение, то полиномиальна по сложности и задача
нахождения наибольшего полного подграфа.
Доказательство. Пусть дан граф Г с к вершинами
и матрицей инцидентности А (Г): построим бинарное изображе¬
ние J размером (8 А’ 4- 4)(А 4- 1) х (8& 4- 4)(А — 1) следующим
образом.
Если в точке (i, j) элемент матрицы А (Г) равен единице, то
блок типа (рис. 1) помещается в J так, чтобы его левая нижняя
вершина находилась в точке ((8i — 4)(А* 4- 1), 8/ (к — 1)) матрицы
изображения. Расположив таким образом, все блоки типа Вх
в соответствии с инцидентностью, оставшиеся места матрицы изо¬
бражения J заполняются блоками типа BQ. Значение оптимизи¬
руемой функции неопределенности (3) по любому из способов
описания (4) для данной J при изменении разбиения изменяется
дискретно, и оптимальное разбиение имеет специфический вид
в окрестностях блоков Вх (рис. 2). Дополнив строки/столбцы
матрицы А (Г), соответствующие четверкам прямых оптимального
разбиения, до симметрии, получаем при некоторых sx, s.2 наи¬
больший полный подграф.
Теорема 2.
(Р1’ £°’ = ~ h т? (0 т и(0 + «(О-
Доказательство. Используя определение Bin?, а так¬
же (3) и (4), перепишем правую часть (5) в виде
йвь2 £0’ у) = (Рг -0 + Н? Р0-
Каждое слагаемое из правой части (7), используя (4), распи¬
шем в отдельности:
105
Рис. 1. Ji доказательству теоремы 1 Приложения:
— тип Вг>:: <' — тип
Рис. 2. К доказательству теоремы 2 Приложения'
Рас и о. Югкснис прямых оптимального f. избиения в окрестности блока тип’a й
-з. Ж М, /'2; С- М ~ прямые оптимального разбиения)
Следовательно:
/7Л (|-ц. ,/) ; 77Л (V .7) - h (/).
Л)
Описание кодами Фримана по
восьми соседям
можно од
1 о-
вначно определить, только если
предварительно
уста но в.п
. чо
положение некоторой точки границы каждой из Т (I) связиых
областей и координаты каждого из L (/) узлов на линиях гранки.
13 сумме на определение начальных точек при выбранном способе
описания потребуется (Т (z) — U (/)) log xV2 бит. Таким образам:
Ж (t°. РР = -уг(Р (0 log 8 -t- 27’ (?) logxV 2U (?) log Л'). ;'•>)
Из формул ((8) и (9) непосредственно следует главное утвер¬
ждение теоремы 2.
П II Т Е Р А Т У Р А
1. Мориа О. Практическая реализация цифровой обработки изображен'ii:
Современное состояние и перспективы // Донки гаккай дзасси. IMS.
Т. 98. Лз II. С. 1013 — 1018.
2. Майерс X. Дж., Бернстейн Р. Обработка изображений на персоналы: ы
ЭВМ фирмы IBM/7 ТИИЭР. 1985. Т. 73, Лаб. С. 131-139.
3. Крит М., IIкономопулос АКошер М. Методы кодирования изображен лй
второго поколения/7 Там же. Ла 4. С. 59—80.
4. Прэтт У. Цифровая обработка изображений. М.: Мир, 1982. Пи. 1. 31< с.;
Кн. 2. 480 с.
5. Александров В. В.. Горский II. Д. Представление и обработка изобра з‘-
ний: Рекурсивный подход. /1.: Наука. 1985. 188 с.
С. КунтМ.. Джонсен О. Блочное кодирование графических материн. лб
Обзор// ТП11ЭР. 1980. Т. 68, ..V 7. С. 21-39.
7. Яолонский С. В. Введение в дискретную математику. Af.: Паука, 1- 9.
2(55 с.
8. А .челькин В. А. Методы нумерационного кодирования. Новосибирск’
Паука. 1986. 156 с.
9. Г.,рн М.. Джонсон Д. Вычислительные мангипы и труднорешаемые задн ий
Мл Мир. 1982. 362 с.
106
УДН 621.372.542
ОБ ОДНОМ ПОДХОДЕ
К БЫСТРОМУ СЕГМЕНТИРОВАНИЮ ИЗОБРАЖЕНИЙ
О-1>. Калиничев, В. В. Кашматов
В последнее время в цифровой обработке изображений имеет
место явная тенденция проектирования эффективных алгоритмов
обработки с учетом архитектуры той вычислительной среды, в ко¬
торой данные алгоритмы будут реализованы [5, 61. Часто оказы¬
вается, что «быстрый» в традиционном смысле алгоритм, реали¬
зованный в неадекватной ему вычислительной среде, работает
медленнее, чем «медленный», но учитывающий ее архитектуру.
Весьма остро такая проблема встает в задачах сегментации
изображений, в которых требуется обработать некоторой доста¬
точно сложной последовательностью элементарных операций
двумерный массив информации объемом порядка 216—220 байт.
Применение сложных параллельных архитектур в данном случае
не всегда целесообразно ввиду их относительно высокой стоимости.
С другой стороны, наличие массовых дешевых универсальных вы¬
числительных средств, способных решать задачи цифровой обра¬
ботки изображений, делает актуальной задачу создания систем
обработки на базе ПЭВМ [3].
Задача сегментации изображений рассматривается в основном
как одна из подзадач распознавания образов. Согласно определе¬
нию. данному в работе [61, сегментация представляет собой про¬
цедуру, в которой каждому пикселу исходного изображения по
некоторому решающему правилу в зависимости от его локальных
признаков присваивается определенная метка принадлежности
к некоторому классу. В широком смысле слова к сегментации
можно отнести также и выделение локальных особенностей на
изображении, и ресегментацшо полученного массива меток.
Как правило, основное внимание в работах, посвященных
сегментации, уделяется определению наборов признаков и выбо¬
ру решающих правил [2, 71, вопросам же реализации данных про¬
цедур на ЭВМ — придается второстепенное значение. Однако
в системах анализа изображений на ПЭВМ возможность эффек¬
тивной реализации алгоритма является одним из наиболее зна¬
чимых критериев отбора.
Основные положения подхода. Решение задачи сегментации
На вычислительных средствах с классической архитектурой фон
Неймана имеет свою специфику. Она заключается в том, что не¬
обходимо разрабатывать алгоритмы, допускающие корректное
сведение двумерной пространственной задачи к одномерной
с одновременным сохранением эффективности алгоритма. Первой
Части критерия можно удовлетворить, используя последователь¬
ность «анализ точки — анализ ее непосредственного окружения».
Можно также использовать алгоритмы, инвариантные относи¬
тельно выбора последовательности просмотра изображения.
107
Второй части критерия мож-
но удовлетворить, если пр{*
разработке алгоритма
пользовать те операции, ко-
торые наиболее естественно
выполнять процессору ЭВМ.,
т. е. учитывать набор ко
манд процессора, их вой
числительную стоимость, а
также саму архитектур у
процессора. .Быстрота работы
алгоритма в таком случае до¬
стигается не только мпнимсы
зацией количества операций,
но и оптимизацией их типа,,
так как в вычислительном
плане операции различных
типов неэквивалентны. Например, операция сложения «стоит>
около 10 машинных циклов, а операция умножения — около
100 циклов. Кроме того, использование уже готовых и под¬
держанных аппаратно логических структур процессора и его
окружения, таких, например, как стек, позволяет добиться
высокой эффективности при реализации алгоритма. Приведет
несколько примеров.
Алгоритм разделения областей изображения. Пусть имеет
место следующая постановка задачи. На изображения
/ = {хц}, 1 I, / 7V, задана произвольная многосвязная
область D (см. рисунок). Точки, не принадлежащие £>, могут
лежать как внутри D (полости), так и вне ее (фон). Необходимо
разделить изображение I на точки, принадлежащие полостям и
фону. К этой постановке сводится широкий класс задач, таких,
например, как задача заполнения контуров, рассмотренная в ра¬
боте [6J.
Введем в рассмотрение три класса точек: активные Ка. пассив
ные Кр и нейтральные Кп. Будем говорить, что
V хи ЕЕ I ==? (х ЕЕ Кр <Н>
и наоборот:
е I (xtj xtj е D)
Таким образом, на исходном изображении присутствуют
лишь пассивные и нейтральные точки. Предлагается следующая
модель алгоритма разделения. Переведем произвольную нейтраль
ную точку xsr в класс Ка. Для каждой точки, попадающей в класс
Ка выполняется последовательность операций:
а) переводятся в класс Ка все нейтральные точки х^ 6= Кп-
для которых выполнено условие | s — г [ -j— ( /' — у | = 1;
б) сама точка xsv переводится затем в класс Кр.
108
Указанная процедура повторяется до тех пор, пока класс Ка
станет пуст, т. е. Ка = ф.
Очевидно, что если начальная нейтральная точка принад¬
лежала полости, то приведенный алгоритм отнесет к классу К у
все те и только те точки, которые также лежали внутри нее.
Рекурсивное применение данной процедуры позволит отделить
все полости миогосвязной области D. Таким образом, алгоритм
решает предложенную задачу. Однако при использовании после¬
довательной архитектуры необходимо перевести указанный алго¬
ритм с языка окрестностей на язык последовательностей. Для
этого введем список Л, в который будем заносить активизирован¬
ные на данном шаге точки, извлекая их далее по FIFO- или
LIFO-правилу. Определение правил FIFO (First In—First Out)
и LIFO (Last In—First Out) приводится в любом руководстве по
теоретическим основам программирования (см., например: [1, 41).
Нетрудно показать, что размер || L || не превышает размера ис¬
ходного изображения, т. е. || L || N-. Таким образом, на каждом
шаге анализируется вся окрестность точки и двумерная задача
корректно сведена к одномерной.
Если используется LIFO-правило выбора последовательности
просмотра точек в списке, то при реализации алгоритма на маши¬
нах, имеющих стековую архитектуру, целесообразно использо¬
вать в качестве списка L стек. Размер стека определим равным
размеру изображения I.
Данный алгоритм был реализован в составе программного
обеспечения персональной видеосистемы «Микровидео-11» на базе
персональной ЭВМ «Искра-1030» в подсистеме «Графика» [3].
В программной системе описан стек 8 Кбайт, что соответствует
размеру поля экрана. Использование операций PUSH и POP
(помещение в стек и изъятие из стека) позволяет избавиться от
сложных логических структур, связанных с организацией поряд¬
ка обращения к списку, что значительно ускоряет работу алго¬
ритма.
Алгоритм сегментации. Пусть задано изображение I =
где I N и определим некоторый набор признаков 5 =
= (Sy, . . ., Sk). Необходимо выделить на изображении / связные
области, точки которых обладают указанным набором. Введем
в рассмотрение четыре класса точек: нейтральные Кп, пассивные
Кр, активные Ка и терминальные Кт. На начальном этапе имеет
место
ее I =±xtj ЕЕ Кп.
Таким образом, на исходном изображении присутствуют лишь
Нейтральные точки. Аналогично предыдущему алгоритму можно
Предложить следующую модель алгоритма сегментации.
Просматривая последовательно изображение, проверяем ней¬
тральные точки на наличие набора признаков S. Точки, не обла¬
дающие 5, переводим в класс Ку, а обладающие — соответствен¬
109
но в класс Ка. Для каждой точки j'sr, переведенной в Ка, выпоек
няем следующую последовательность действий:
а) переводим все точки х^ GE Кп, такие, что | * - Ч +
+ I 7 — г | 1, в класс Ка, если Хц обладает набором 6'
и в класс А’р, если Хц не обладает 5;
б) затем переводим .zsr в класс K}J.
Повторяем указанную процедуру до тех пор, пока класс К
не станет пуст. Процесс сегментации изображения заканчивается,
когда на изображении не останется ни одной нейтральной точки.
Введение списка, аналогичного описанному в предыдущем
примере, также позволяет корректным образом свести двумерную
задачу к одномерной. Заметим^ что всякий раз, когда опустоша¬
ется класс Ка, заканчивается выделение очередного сегмента и на¬
чинается поиск новой «стартовой» точки для выделения следующе¬
го сегмента. Таким образом, присваивая каждому новому сегмен¬
ту соответствующую метку, в результате одного прохода алгорит¬
ма получаем совокупность разделенных пространственно и поме¬
ченных соответствующими им метками сегментов. Отметим также
и то, что алгоритм позволяет объединить такие стадии, как клас¬
сификация точек, анализ их связности и вычисление некоторых
признаков, таких, как площадь 5, периметр Р, компактность S Р~
и т. д. Это дает возможность использовать указанный алгоритм
при грубой, но быстрой классификации объектов на изображении
непосредственно в процессе их выделения.
Основные принципы реализации алгоритма сегментирования
те же, что и в предыдущем примере. Алгоритм был реализован на
ПЭВМ «Искра-1030» в виде отдельной программы выделения на
изображении форматом 256 X 256 (256 уровней яркости) связных
областей с яркостью выше пороговой и площадью больше задан¬
ной. Время работы алгоритма менее 2 с.
Таким образом, в статье изложен и проиллюстрирован подход
к проектированию эффективных алгоритмов сегментирования
изображений на стандартных вычислительных средствах с класси¬
ческой последовательной архитектурой. Подход базируется на
тезисе машинной ориентации, т. е. на максимальном использова¬
нии тех логических структур, которые реализованы в архитекто¬
ре данной ЭВМ. В данном конкретном случае использование сте¬
ка позволяет корректно свести двумерную задачу к одномерный
и эффективно организовать вычислительный процесс.
Л ПТЕРАТУРА
1. Ахо Л., Ульман Дж. Теория синтаксического анализа, перевода и компи¬
ляции. Синтаксический анализ. М.: Мир, 1978. Т. 1. 616 с.
2. Верхаген К., Дёйн Р. и др. Распознавание образов: Состояние и перспек¬
тивы. М.: Радио и связь, 1985. 104 с.
3. Дымков В. ИСиницын 11. II. Элементы концепции персональных сьс-
темообработки изображений // Наст. со.
4. В нут Д. Искусство программирования для ЭВМ. М.: Мир, 1976. Т. Р
Основные алгоритмы. 736 с.
110
к Майерс X. Дж., Бернстайн Р. Обработка изображений на персональной
' ЭВМ фирмы 1ВМ//ТИИЭР. 1985. Т. 73, № 6. С. 131 —139.
Павл ид нс Т. Алгоритмы машинной графики и обработки изображений.
М.: Радио и связь, 1986. 399 с.
7, Rosenfeld A. Computer vision tutorial // X Intern. Joint Conf. Artificial
Intelligence. Milano, 1987.
УДК 519.2,G.2:681.3.06
ПРИНЦИПЫ РАЗРАБОТКИ
ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
ДЛЯ ИССЛЕДОВАНИЯ СТОХАСТИЧЕСКИХ СИСТЕМ
В. С- Пугачев. И. II. Синицын, И.М. Зацман,
А. II. Карпенко, А. Л. Чередниченко, В. И. Шин
Задачи исследования стохастических систем возникают бук¬
вально во всех областях человеческой деятельности, так как сто¬
хастические системы служат адекватной математической моделью
различных процессов в природе, производстве, экономике и об¬
ществе. С помощью таких моделей описываются различные техни¬
ческие системы (в частности, процессы управления техническими
системами), экологические и экономические системы.
Современная теория стохастических систем располагает мощ¬
ными методами для исследования и фильтрации процессов в сто¬
хастических системах. Однако эти методы находят пока лишь не¬
значительное применение, так как требуют очень сложных и гро¬
моздких вычислений. А главное, составление необходимых для
применения этих методов уравнений представляет собой очень
сложную задачу, требующую больших затрат времени квалифи¬
цированных научных сотрудников.
Изложенное показывает, что для ускорения научно-техническо¬
го прогресса на базе современных средств вычислительной техни¬
ки необходимо создать программное обеспечение для исследова¬
ния стохастических систем. Создание такого программного обес¬
печения, включающего программы составления уравнений для
вероятностных характеристик систем, позволит широко внедрить
мощные методы теории стохастических систем в практику во всех
отраслях народного хозяйства.
Данная работа посвящена принципам разработки программно¬
го обеспечения для исследования стохастических систем, которые
подробно рассматриваются на примере проектирования интегри¬
рованного пакета прикладных программ для анализа стохастиче¬
ских систем. Решение задачи автоматизации процесса составле¬
ния и решения уравнений статистического анализа дает возмож¬
ность разработать программное обеспечение для исследования
Различных классов стохастических систем, ориентированное на
Пользователя-непрограммиста и обеспечивающее решение задач
анализа для следующих математических моделей.
111
1.
МАТЕМАТИЧЕСКИЕ МОДЕЛИ СТОХАСТИЧЕСКИХ СИСТЕМ
Подходящими математическими моделями для многих практи¬
ческих задач, возникающих в различных приложениях, служат
модели, описываемые дифференциальными, разностными, сме¬
шанными дифференциально-разностными уравнениями. Рассмот¬
рим последовательно математические модели систем, которые опи¬
сываются стохастическими уравнениями.
Стохастические дифференциальные системы
dX = а (X, t) dt+ b (X, t) dW. (1)
Уравнение (1) понимается в смысле Ито [1]. Здесь X = X (Z) -
вектор состояния системы, X ЕЕ Rp, t Ei R ~ = [0, оо); W -
= W (t) — случайный процесс с независимыми приращениями
(в частном случае W — винеровский процесс), W ЕЕ Rq; а: Rp
X R+ -+RP\ b: Rp X R+ -> Rpq.
Стохастические разностные системы
АТ^-+г) = ф|£(Х(Т.), • • •, Р%)) (& = 0, 1,. . .)• Й
Здесь X (fk) — значение р-мерного вектора состояния системы
в дискретный момент времени tk = kAt; At — интервал дискре¬
тизации; {V (tk)} — последовательность независимых s-мерньк
случайных величин с известным распределением; <р?: Rpl 7
XRS-+RP.
Стохастические дифференциально-разностные системы
dX' = а (X, t) dt+ b (X, t) dW, (3)
X" (W = (X (U . . ., X (W1), V o, (* = 0,1,.. Ф
В добавление к обозначениям, введенным в системы (1) и (2).
здесь ^-мерный вектор состояния X состоит из двух блоков X —
= [Х,ГХ"Т]Т, первый из которых X' ЕЕ Rn представляет собой
непрерывный вектор X' = X' (£), t ЕЕ R+, а второй X" ЕЕ Rp l
определен только в дискретные моменты времени tk = к At, X" -
= X" (ZR), к = 0, 1, . . . Значение вектора X" в произвольный мо¬
мент времени t ЕЕ R+ определяется следующим образом:
Х"(0= 5х'^)Ц> (4
к=о К
где lAj. (0 — индикатор интервала Ак = [ik, Zk+1), равный еди¬
нице при t ЕЕ Ак и 0 при t Е= Ак.
В работе [2] рассмотрены более общие математические модели,
описываемые стохастическими интегральными и интегродифферен-
циальными уравнениями Ито. В некоторых частных случаях
подынтегральных ядер такие модели сводятся к модели (1).
112
2
АНАЛИЗ СТОХАСТИЧЕСКИХ СИСТЕМ
Полный статистический анализ систем (1)—(3) состоит в опре¬
делении всех конечномерных распределений вектора состояния
[1, 3]. Однако в большинстве приложений оказывается достаточ¬
ном знание только одномерного распределения. В работе рассмат¬
ривается задача определения только одномерного распределения
вектора состояния X. Приводятся уравнения метода нормальной
аппроксимации [1 ] и модифицированного моментно-семиинвариант-
ного метода [4] применительно к моделям (1)—(2).
Уравнения метода нормальной аппроксимации для модели (1).
Метод нормальной аппроксимации основан на замене (аппроксима¬
ции) неизвестного одномерного распределения вектора состояния
X (t) нормальным:
g± (X; t) gi (X; t, т, К) = exp (iKTm — XTAX/2),
(х; t) х fi (х\ t, т, К) = [(2л)р det А]-1'2 ехр [(я — т)Т А'1 х
X (я - т)/2]. (5)
Здесь gi (X; t) и fT (.г; t) — одномерная характеристическая
функция и одномерная плотность вероятности вектора состояния
X (t); т = MX (t), К = М [(X (0 — т) (X (0 - т)Т] - неиз¬
вестные математическое ожидание и ковариационная матрица
вектора X (t), удовлетворяющие в случае, когдгч в (1) ИИ — вине-
ровский процесс с интенсивностью v (t), системе обыкновенных
дифференциальных уравнений
т = Ma (X, /), (6)
A = М [а (X, t) (X - mY + (X - т) а (X, Z)T + b (X, t)x
X v (t) b (X, t)TJ. (7)
Математические ожидания в правых частях уравнений (6), (7)
вычисляются приближенно по следующей формуле:
MF (X, t) = У F (х, t) fi (х; t, т, К) dx, (8)
гДе F : Rp х -> Rp для (6) или F: Rp X 7?+ -> Rp2 для (7).
Уравнения (6), (7) решаются при следующих начальных усло¬
виях :
mQ = МХ0, KQ = М [(Хо - /п0) (Хо - тоу ], Хо = X (0). (9)
В частном случае, когда b (X, t) = b (t), метод нормальной ап¬
проксимации дает те же уравнения относительно т и А, что и ме-
Т°Д статистической линеаризации [1].
Уравнения метода нормальной аппроксимации для модели (2).
^гласно (2), уравнения для вектора математического ожидания
(М и ковариационной матрицы A (tk) имеют вид
т fe+/) - Mqk (X (tk), . . .. X (^+z-:l), Т’ (tky
(Ю)
ИЗ
К = М [(c[R. (X (tk), . . X (^c+z-i), I (tk)) —
— w (^+/))фк.(Х(у, . . V ('O)l- (Hj
Математические ожидания MFk (X (tk) X (1К.+Ь1), V (tk)) в i]
вых частях уравнений (10), (11) вычисляются аналогично (8), при этом
в качестве плотности /f берется произведение /С (х1? . . Xf) ]\
где fi (<г1? . . гг/) — нормальное распределение случайного век¬
тора [X (0>)Т’ • • •, X (tk+l_1)TlT, а (и) — плотность вероятности
случайного вектора V (0J, который не зависит от X (tk), ,
Далее приведем уравнения модифицированного моментно-се-
миинвариантного метода. Этот метод разработан для моделей, опи¬
сываемых стохастическими уравнениями с полиномиальными ко¬
эффициентами. Идея его состоит в том, что для сокращения числа
параметров (моментов, семиинвариантов) в распределении, кото¬
рым аппроксимируется неизвестное распределение (gx (X; I) или
(х; t)) вектора состояния системы X, учитывается взаимная за¬
висимость компонент вектора X только в смысле ковариации
У равнения модифицированного моментио-семиинвариантиого
метода для модели (1). Уравнения модифицированного моментно-
семиинвариантного метода для моментов первого и второго поряд¬
ков т = MX, Г = М (ХХТ), а также для старших моментов от¬
дельных компонент М (X") (Z = 1, . . . , р\ п = 3, N) имеют
вид
m = Ma(X, t), (12)
Г =’Л/ |а (X, /) Хг + Ха (X, t)T + b (X. t) v (t) b (X, ?)т], (13)
dM (X-)dt = 72.1/ [Х'ГЧ (X. t)] +
Q
+ 4 n (n - 1) У M lX"~^ (X. t) V r':ir (X, t)] (14)
s=l r=l
(Z = 1, . . p- n =-- 3, . . ., A7).
Особенность системы (12) — (14) состоит в том, что в случае поли¬
номиальных нелинейностей at (х, t) и Ьц (х, t) (Z = 1, . . F
7=1, . . .,7) правые части уравнений (12)—(14) содержат момен¬
ты Mi (Х^1Хк . . . Х\ч), отличные от Гг;, М (X"). За¬
мыкание системы (12)—(14), согласно идее модифицированного
моментно-семиинвариаитного метода, проводится по следующий
рекуррентным формулам [4]:
+ ;|уг [м (Х^х^ -м (XZ1) м (х;,)] х
А\--1 к к -I к
xM(Xt Xi.—Xi -х*),
a - t q
(15)
114
= М (Xi,) - 'S СШ’-'Л/ (A’ts) (7 = 3,4,..., Л’),
8—1
где “0 (/ > X); — семиинвариант порядка ] случай¬
ной компоненты вектора состояния XС™' — сочетания.
В частном случае, если использовать формулы (15) для замы¬
кания системы уравнений для моментов первых двух порядков
(12), (13), то полученные уравнения совпадают с уравнениями ме¬
тода нормальной аппроксимации для полиномиальных коэффи¬
циентов at (я, t), bu (х, I) 15].
Уравнения модифицированного моментно-семипнвариаитного
метода для модели (2). Согласно (2), уравнения для т (^), Г (tk)
и М (X? (^.)) имеют вид
т (^) = (X (/,), • • - X V (Z0). (16)
Г(^) - М Ь (Х(М< • • - V (tk)) X
X<fl;(X(t,), ..„XU^). V (17)
Л/(Х?(М) = Л/ЦЬ(Х(7,),...,Хам_1), Г О). (18)
Модифицированный моментно-семииивариантиый метод для
модели (2) разработан для случая, когда функции фА. представляют
собой полиномы, т. е.
. . ., xt, V) = й|;(^1- • • ^l) + • ■ •, ^z)^ (i9)
где ак (z1? . . ^), Ьк (х±, . . ., jq) — полиномы от переменных
Я1, . . xt.
Замыкание системы уравнений (16)—(19) проводится по тем
же формулам (15) в предположении, что вектор V (tk) не зависит
от X (М, . . ., X (^_х).
3.
ПРОГРАММНАЯ РЕАЛИЗАЦИЯ ПРИБЛИЖЕННЫХ МЕТОДОВ
СТАТИСТИЧЕСКОГО АНАЛИЗА
Практическая реализация приближенных методов статистиче¬
ского анализа, основанных на аппроксимации неизвестного рас¬
пределения другим известным распределением, зависящим от па¬
раметров Oj (вероятностных характеристик вектора состояния си¬
стемы), связана с составлением большого количества уравнений
относительно 0^. Количество уравнений Q (р, N) для моментов,
определяющих модифицированный моментно-семпинвариаптный
К1етод (12)—(14) или (16)—(18), равно р (р + 3)'2 + р (N — 2),
где р — размерность вектора состояния X; N — максимальный
Порядок учитываемого семиинварианта. При N — 2 Q (р, 2) оп¬
ределяет количество уравнений для моментов первого и второго
Порядков метода нормальной аппроксимации (6), (7) или (10),
[11). Например, Q (10,2) = 65, Q (50,2) = 1325, £(100,2) = 5150.
Поэтому актуальной является задача автоматизации с помощью
115
ЭВМ процесса составления и решения уравнений, которые д;-;ет
тот или иной приближенный метод статистического анализа.
В работах [6.7] разработаны программы на языке Фортран ^
реализующие моментно-семиинвариантный метод, метод семицц,'
вариантов и метод статистической линеаризации. Однако эти про¬
граммы предназначены для анализа стохастических систем невы¬
сокой размерности (р 6) и с конкретными типовыми нелиней¬
ностями.
В Институте проблем информатики АН СССР (ИПИАН) соз¬
дается прикладное программное обеспечение (ПО) для анализа
различного класса многомерных стохастических систем [8]. К нас¬
тоящему времени разработаны программы на языке Фортран-4,
реализующие метод нормальной аппроксимации (6), (7) и (10),
(11) и модифицированный моментно-семиинвариантный метод (12)
и (14). Эти программы предназначены для анализа стохастических
систем, описываемых дифференциальными и разностными урав¬
нениями с полиномиальными коэффициентами, практически лю¬
бой размерности. Например, для модели (1) эти коэффициенты
имеют вид
а (х, t) = [aY (х, t) . . . ар (х, i)]T, b (х, t) = [Ьц (х. t)\,
к=1
Ьи(х, t)= У
Z=1
(t = 1. . . p; j = 1, . . 7),
где Aik (t), BijL (t) — известные функции времени; nik — чисто
множителей в к-м одночлене i-й компоненты (х, i); т^7 — число
множителей в i-м одночлене ij-й. компоненты Ьц (х, £); п1? . • •
.... — выборка различных чисел из 1, .... р; т1,
. . ., — выборка X}ji различных чисел из 1, . . ., р; $х, . . •
. . ., Sjxik, ?\, . . ., гТ — любые целые положительные числа.
Разработанные в ИПИАН программы предназначены для раз¬
личного класса современных ЭВМ. Для работы с программами
пользователю необходимо лишь задать следующие параметры*,
размерности р и q вектора состояния X и шумов W (£) (V (U)
соответственно; порядок метода Рунге — Кутта и шаг для числен¬
ного интегрирования дифференциальных уравнений (например’
в случае анализа стохастической дифференциальной системы (1))'»
начальные условия для моментов; коэффициенты полиноме5
(£), Biji (t) в (20); индексы и степени rj, определяю'
щие одночлены в (20).
Созданные программы могут быть без затруднений перенесен51
с одной ЭВМ на другую, где существует транслятор с языка Фор1'
ран. Мобильность этих программ определяется в основном сле'
дующими обстоятельствами:
116
а) программы не используют тех средств языка Фортран-4Л
которые определены как расширение или дополнение;
б) при переходе на другую ЭВМ достаточно изменить только
некоторые операторы;
в) каждая программа состоит из совокупности взаимосвязан¬
ных программных модулей, причем каждый модуль функциональ¬
но изолирован и независим от другого в том смысле, что изменение
в одном модуле не требует изменений в других модулях;
г) в программах практически нет связи с аппаратными средст¬
вами, что определяет их гибкость и возможность реализации на
различных классах ЭВМ.
Характерными особенностями этих программ являются: реа¬
лизация, как правило, на мощных дорогостоящих ЭВМ, предназ¬
наченных для коллективного использования в рамках вычисли¬
тельных центров (ВЦ); обеспечение работы только в пакетном ре¬
жиме; ориентация на специалистов, владеющих хотя бы одним
языком программирования (типа Фортрана) и языком управле¬
ния заданиями (типа ЯУЗ для ЕС ЭВМ); отсутствие сервисных
средств, призванных облегчить и ускорить процесс проведения
вычислительного эксперимента, а также повысить достоверность
результатов расчетов.
Конечно, появление этих программ ознаменовало собой важ¬
ный этап в практическом использовании мощного теоретического
аппарата исследования стохастических систем. Эти программные
средства сыграли существенную роль в развитии этого научного
направления.
4.
ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
ВЫЧИСЛИТЕЛЬНОГО ЭКСПЕРИМЕНТА
Характерные черты существовавшего ранее ПО наложили от¬
печаток на весь процесс проведения вычислительного эксперимен¬
та при исследовании стохастических систем. В первую очередь
это отразилось на технологии проведения расчетов. Кроме того,
они обусловили весьма высокие требования к квалификации поль¬
зователей в области программирования и вычислительной тех¬
ники.
Проведение вычислительного эксперимента на вц коллектив¬
ного пользования под наблюдением операторских служб ЭВМ
и необходимость соблюдения принятой на ВЦ технологии обра-
°отки данных, приводят к тому, что каждый «прогон» программы
^°Жет занимать до нескольких суток (при этом собственно время
Расчета лежит в пределах одного — трех часов). Существенные
Энологические проблемы могут возникать в случае рестарта
Мания с контрольной точки при сбоях в аппаратуре ЭВМ.
Работа с этими программами на тех ВЦ, где возможен непо-
Редственный доступ пользователей к ЭВМ, требует от исследова¬
на существенно более глубоких познаний в вычислительной
117
технике. Как минимум требуется знание языка взаимодействуя
с операционной системой ЭВМ (в том числе процедур загрузи
ЭВМ и т. д.) и определенный опыт работы в качестве оператора
ЭВМ. Это существенно ограничивает круг пользователей такщу
программ.
Пакетный режим обработки, заложенный в этих программны^
средствах, не позволяет пользователю вмешиваться в процесс
расчетов для принятия на ранней стадии вычислительного эксл^
римента решения о целесообразности его продолжения. Результат
ты могут быть оценены только после полного завершения расче¬
тов, что ведет к очень большим (и зачастую непроизводительгым)
затратам времени. Опыт проведения подобных расчетов показы¬
вает, что некорректность математической модели и необходимость
повторного проведения расчетов по измененной модели во многих
случаях могут быть определены задолго до окончания расчетов.
В существовавшем до последнего времени ПО структура и чис¬
ленные значения коэффициентов уравнений, описывающих сто¬
хастическую систему, жестко фиксировалось в текстах программ.
Поэтому даже незначительные изменения в этих уравнениях при¬
водили к тому, что пользователь был вынужден заново переписы¬
вать отдельные (пусть небольшие по объему) фрагменты программ,
заново их транслировать и формировать итоговые загрузочные мо¬
дули с помощью редактора связей. Поскольку при таких измене¬
ниях велика вероятность внесения ошибок, то ясна необходимость
проведения тестовых прогонов программ и их отладки. Это предъ¬
являет дополнительные требования к квалификации пользовате¬
лей и усложняет процесс проведения расчетов.
Процесс написания и отладки фрагментов программ требует от
пользователя изучения и умения использовать интерактивный ре¬
дактор текстов. При этом переход на другой ВЦ (с другой опера¬
ционной средой) требует освоение другого редактора текстов и м д.
Поэтому вновь создаваемые Г1ПП для анализа стохастических
систем должны:
1) быть, как правило, закрытыми программными продуктами,
не должны требовать от пользователя никаких дополнительных
знаний (кроме знаний в области исследования стохастических
систем);
2) полностью автоматизировать процесс подготовки уравнении
для вероятностных характеристик;
3) поддерживать отдельно от процедур алгоритмической о-Эра"
ботки данных описания структуры и численных значений к
фициентов исходных уравнений, выполненные в декларативной
текстовой форме, естественной для исследователя стохастических
систем;
4) включать в свой состав специализированный редактор еС"
тествениых описаний стохастических систем;
5) поддерживать графическое отображение результатов наь
во время эксперимента, так и после полного окончания расчетов»
6) быть реализованы на относительно недорогих универсс
118
jjjjx ЭВМ массового примененияt ориентированных на индиви¬
дуальное взаимодействие с пользователем;
7) быть рассчитаны на преимущественно интерактивный ре-
работы в процессе подготовки и проведения вычислительно-
го эксперимента.
Стоимостные и эксплуатационные характеристики персональ¬
ных ЭВМ наиболее полно удовлетворяют последним трем прин¬
ципам создания пакетов прикладных программ. Однако при оче¬
видных достоинствах современных персональных ЭВМ (низкая
стоимость, высокая надежность, простота эксплуатации, возмож¬
ность установки в рабочей комнате пользователя) производитель¬
ность микропроцессора оказывается недостаточной для исследова¬
ния стохастических систем большой размерности. В этом случае
целесообразно совместное использование больших ЭВМ и пер¬
сональных ЭВМ. Причем весь интерфейс с пользователем пред¬
почтительнее всего реализовать именно на персональных ЭВМ,
так как для этого, как правило, достаточно мощности микропро¬
цессора. Высокопроизводительные процессоры больших ЭВМ не¬
обходимы только для выполнения программных модулей, реали¬
зующих численные методы решения вычислительных задач боль¬
шой размерности.
5.
ИНТЕГРИРОВАННЫЙ ПАКЕТ ПРИКЛАДНЫХ ПРОГРАММ
ДЛЯ ПЕРСОНАЛЬНЫХ ЭВМ
Сформулированные в предыдущем разделе семь принципов
разработки были реализованы в первых двух версиях интегри¬
рованного пакета прикладных программ для анализа стохастиче¬
ских систем: 1) для 8-разрядных персональных ЭВМ семейства
MSX; 2) для 16-разрядных персональных ЭВМ с архитектурой
микропроцессора Intel 8086, поддерживающих операционную си¬
стему MS DOS. При этом 16-разрядиая версия реализована
на Ассемблере, предназначена в основном для исследователей-
профессионалов, а 8-разрядная версия реализована на Бейсике
и ориентирована на обучение в вузах [9]. Поскольку в обеих вер¬
сиях пакета реализованы одни и те же методы исследования сто¬
хастических систем, а интерфейс с пользователем обеих версий
базируется на одних и тех же принципах, то в дальнейшем не бу¬
дем подробно останавливаться на деталях реализации 8-разряд-
Пой версии.
Структура интегрированного пакета обусловлена сложившей¬
ся естественной последовательностью действий, выполняемых
цРи исследовании стохастических систем (СтС): формирование ма¬
гматической модели объекта; задание начальных условий и пара¬
метров модели; проведение вычислительного эксперимента; ви¬
зуализация и анализ результатов вычислений. Эта последователь¬
ность действий представлена в пакете в виде отдельных режимов
соответствующих этим режимам подсистем), каждый из кото¬
рых позволяет полностью или частично автоматизировать соот-
119
ветствующпй этап исследования стохастической системы. ]|г)а
этом состав автоматизируемых функций удовлетворяет требо!>(Ь
ниям. предъявляемым к программным продуктам для исследова¬
ния стохастических систем [10].
Интегрированный пакет для исследования стохастических
систем включает пять взаимосвязанных логических подсистем
предназначенных для: 1) управления меню; 2) решения задач а щь
лиза стохастических систем; 3) ввода и редактирования системы
уравнений для вектора состояния; 4) трансляции коэффициентов
уравнений для вектора состояния в объектный код; 5) отображе¬
ния результатов вычислений.
Первая подсистема поддерживает иерархию нескольких меню,
которые позволяют пользователю достаточно просто переходить
из одного режима работы в другой.
Вторая подсистема, включающая интерпретатор объектного
кода, управляет порядком выполнения функциональных моду-
лей и обеспечивает решение задач анализа стохастических систем
после определения пользователем начальных условий. Имеемся
возможность при задании начальных условий вводить литералы,
определяющие физическую размерность компонент вектора со-
стояния стохастической системы. Эта литерная информация ис¬
пользуется при отображении результатов расчетов. Согласование
физических единиц измерения в этом случае возлагается на поль¬
зователя. Отсутствие литерных данных при задании начальных
условий воспринимается пакетом как указание на безразмср-
ность системы уравнений.
Описание оставшихся трех подсистем пакета дано в отдельных
разделах статьи.
6.
ПОДСИСТЕМА ВВОДА
И РЕДАКТИРОВАНИЯ СИСТЕМЫ УРАВНЕНИЙ
Этап формирования математической модели объекта в пакете
поддерживается специализированным текстовым редактором, обес¬
печивающим традиционные функции ввода, модификации и ото¬
бражения на экране дисплея текстовых описаний математических
моделей. Отличительная особенность этого блока — набор симво¬
лов, обеспечивающий полностью естественную визуализацию тек¬
ста математической модели. При работе со стохастической систе¬
мой исследователь видит на экране дисплея привычную для нег°
нотацию системы дифференциальных уравнений, принятую в на¬
учной математической литературе.
Естественность записи достигается в результате использова¬
ния нестандартного программно-реализованного знакогенерато¬
ра с оригинальным набором математических знаков и символов'
Кроме того, при знакогенерации используются три уровня ви¬
зуализации математического выражения на экране дисплея: ос¬
новной, индексный и степенной. Индексные выражения в описа¬
нии системы дифференциальных уравнений располагаются пр а"
120
рее и несколько ниже индексируемого символа основной строки,
а степенные выражения — соответственно правее и выше.
размеры символов в индексных и степенных строках состав¬
ляют примерно 3 4 соответствующих размеров символов основной
строки, а их вертикальное смещение вверх и вниз относительно
основной строки составляет примерно 1/4 ее высоты. Таким обра¬
зом. основная строка частично перекрывается индексной и сте¬
пенной строками. Это в основном соответствует пропорциям ес¬
тественной записи математических выражений.
Для управления редактором текстов широко используется
функциональная и вспомогательная клавиатура. Так, например,
функциональные клавиши F1 и F2 обеспечивают перевод курсора
соответственно в степенную и индексную строки (повторное нажа¬
тие той же клавиши приводит к возврату в основную строку), кла¬
виша F3 удаляет строку с экрана. Клавиши Pgl’p и PgDn позволяют
перемещать экран дисплея вперед и назад по тексту модели, а кла¬
виши «-*», «[», «<—», «|», Ноте и End обеспечивают перемеще¬
ние курсора по экрану. Не останавливаясь более подробно на
функциях клавиш, отметим лишь, что их выбор соответствует
наиболее распространенным редакторам текстов. Кроме того,
при работе редактора на экране отображается назначение управ¬
ляющих клавиш, а с более подробным их описанием пользователь
может ознакомиться в подрежиме «Помощь».
7.
ТРАНСЛЯЦИЯ УРАВНЕНИЙ
После завершения редактирования уравнений математической
модели СтС строка внутреннего представления записывается на
дисковое внешнее запоминающее устройство в соответствующий
файл, а ее адрес в основной памяти передается лексическому
анализатору (сканеру). Сканер формирует таблицу символов, ста¬
вит в соответствие каждому символу его класс, формирует внут¬
реннее представление модели в форме специально организованных
списковых структур и передает управление блоку синтаксическо¬
го анализа. Синтаксический анализатор проверяет структурную
корректность введенного описания и, в свою очередь, обращается
к генератору программ вычисления коэффициентов правых час-
тей уравнений, описывающих стохастическую систему. Оконча¬
тельное внутреннее представление модели также помещается
в Дисковый файл.
Формально синтаксис языка описания стохастических диффе¬
ренциальных систем, реализованного в 16-разрядной версии ин¬
тегрированного пакета, может быть задан множеством G:
(GcCH, GCT, Сиид),
J-Де G()CH. Сиид и G(T — соответственно грамматики основной, ин-
Дексной и степенной строк. Каждая из этих грамматик, в свою
121
очередь может быть представлена четверкой
Gi = (Л, Nt, РЛ
где Тi — множество терминальных символов; Nt — множество
нетерминальных символов (нетерминалов); Si — начальный сим¬
вол грамматики I (St ЕЕ Nt)} Pi — множество продукций грамма¬
тики .
При описании грамматик используются следующие условные
обозначения: терминальные символы заключаются в апострофы
нетерминальные — в угловые скобки; альтернативные цепочки
символов — в фигурные скобки, а опционные — в прямоугольные
скобки. Знак «:: = » имеет смысл «может состоять из».
С отдельными терминальными символами из основной строки
могут быть связаны выражения (цепочки символов) из степенной
и индексной строк. Нетерминалы, к которым приводятся эти це¬
почки, изображаются соответственно выше и ниже символов ос¬
новной строки. Отметим, что эти нетерминалы не входят в множе¬
ство aV0(.jT нетерминалов грамматики G0Cn основной строки и ис¬
пользуются только для указания на возможность появления сте¬
пенного или индексного выражения определенной структуры.
Связь между символами основной строки и символами степей ной
и индексной строк изображается стрелками, направленными соот¬
ветственно вверх и вниз. Множества и Nt не описываются, гак
как их состав понятен из описаний множеств Pt. Нетерминалы,
являющиеся начальными символами грамматик, выделены жир¬
ным шрифтом.
Множество Рссн продукций грамматики GOCH основной строки
описания стохастического дифференциального уравнения:
(уравнение) : : (левая —' часть) ' = ' (правая— часть)
(левая — часть) : : = 'производная'
I ф (индекс)]
(правая — часть) : : = [[(правая — часть)] (знак)] (терм)
([(коэффициент)] (неизвестная)
(терм) : : = 4
^(коэффициент)
(неизвестная) : : = [(неизвестная)]
, >[(стелень-1>]
'пд-нензв'
1 *[ (индекс)]
'ид-шума'
I ,[ (индекс)]
(коэффициент) : : = [(коэффициент>’(знак>] (терм-1 >
(терм-1) : : = (терм-1) 1 Г (множитель)
(множитель) : :
рф(стенень-2)]
'(' [(знак)] (коэффициент)')'
(терм-2)
12?
I ф(степеиь-2>] [(степень-2)]
[(параметр) ]'t'
I >[<степеиь-2>]
(параметр)
<терм-2; • • = { |-*[(стеиень-2>]
'Sin'
'Cos (множитель)
<параметр) : : =
'лд-иараметра'
(вещественное-чпсло)
(целое-число)
(вещественное — число) :: = (целое-число) (целое-число)
(целое — число) : : = [(целое-число)] 'цифра'
(знак) : : = { }
Множество Рст продукций грамматики GCT выражений степен¬
ной строки:
(степень 1) : : = (целое число)
(степень 2) : : — (терм)
(терм) : : [[(терм)] (знак)] (терм 1)
<терм 1) = [(терм 1) (множитель)
( '(' (терм) ')' 1
(множитель) : : = < J-
I (терм 2) J
( [(параметр)] 'I' )
(терм 2) : : = 1 }
С (параметр) )
г 'ид-парам' а
(параметр) : : = (вещественное-чпсло) [
I (целое число) J
(вещественное число) : : = (целое число) (целое число)
(целое число) : : = [(целое число)] 'цифра'
(знак) : : = / / j-
И наконец, множество РШ1Д продукций грамматики винд для
выражений индексной строки:
(индекс) : : = [(индекс) ','] (целое число)
(целое число) : : = [(целое число)] 'цифра'
Синтаксис языка описания стохастических дифференциальных
систем в 8-разрядной версии пакета описывается грамматиками
с сУЩественно более простыми продукциями:
(уравнение) : : = (левая часть) (правая часть)
123
зевая часть/ : :
= 'производная*
1 >[ (индекс)]
(правая часть; : : = [[(правав часть;] (знак)] (терм)
[ [(коэффициент)] (неизвестная;
(терм) : : = <
V (коэффициент;
(неизвестная)
= '[(неизвестная;]
I >[(степень)] х
'ид непзв'
I ф(индекс)] ,
'ид шума'
| ф(индекс)] J
(коэффициент;
(вещественное число;
(целое число;
(вещественное число) : : = (целое число) (целое число)
(целое число) : : = [(целое число)] 'цифра'
(знак) :: = - , f
) : (степень) : : = (целое число)
ст (целое число) : : = [(целое число)] 'цифра'
( : (индекс) : : = (целое число)
инд (целое число) : : = [(целое число)] 'цифра'
8.
ГРАФИЧЕСКАЯ ПОДСИСТЕМА
Пакет поддерживает табличный и графический выводы инфор¬
мации. Табличный вывод организован традиционно и в работе' не
рассматривается. Концепция проектирования подсистемы графи¬
ческого вывода включает в себя следующие положения:
— на одном графике отображается динамика только одной ве¬
роятностной характеристики стохастической системы;
— ось ординат соответствует вероятностной характеристике
стохастической системы, которая рассматривается как функция
времени (ось абсцисс);
— выбор масштаба по оси ординат осуществляется в пакете
автоматически, однако при желании можно отменить автоматиче¬
ский выбор масштаба и задать его явно;
— масштаб по оси абсцисс определяется в пакете также авто¬
матически по заданному пользователем временному интервалу.
котором исследуется поведение стохастической системы; кроме
того, имеется возможность явного задания числа точек, отобра*
жаемых на заданном временном интервале;
— первоначально положение оси абсцисс выбирается автома¬
тически по знаку начального значения отображаемой вероятност¬
ной характеристики стохастической системы; во время построе¬
ния графика у пользователя имеется возможность изменения по¬
ложения оси абсцисс;
— предусмотрена возможность вывода на графике поясняю¬
щей информации: 1) текущее, минимальное и максимальное значе'
124
отображаемой вероятностной характеристики стохастической
с0стемы; 2) значение текущего, начального и конечного моментов
времени интервала исследования поведения системы; 3) цена од-
яого деления для каждой оси графика: 4) информация о физиче¬
ской размерности отображаемой характеристики;
— наряду с графиком отображается информация, позволяю¬
щая пользователю управлять процессом вычисления вероятностных
характеристик стохастической системы и процессом их графиче¬
ского отображения.
В настоящее время программно реализованы версии пакета
для анализа дифференциальных (1) и разностных (2) стохасти¬
ческих систем методом нормальной аппроксимации. Дальнейшее
направление работ по развитию пакетов состоит в разработке
функциональных модулей для реализации различных методов
статистического анализа стохастических систем (1) — (3), а также
методов условно оптимальной фильтрации и идентификации слу¬
чайных процессов и последовательностей в этих системах.
В разработке первых двух версий пакета для анализа стоха¬
стических систем принимали также участие сотрудники Инсти¬
тута проблем информатики АН СССР Е. В. Андреева, Ю. П. Анд¬
реянов, Т. Д. Конашенкова, II. В. Новикова, Е. Ю. Маишева,
Н. А. П отапова и А. II. Хатунцев.
ЛИТЕРАТУРА
1. Пугачев В. С., Синицын И. II. Стохастические дифференциальные сис¬
темы. М.: Наука, 1985. 560 с.
2. Синицын И. 11. Stochastic hereditory control systems/7 Пробл. управ¬
ления и теории информ. 1986. Т. 15, JV® 4. С. 30—42.
3. Пугачев В. С1., Синицын И. II., Шин В. И. Проблемы анализа и условно
оптимальной фильтрации в реальном масштабе времени процессов в не¬
линейных стохастических системах/7 АиТ. 1987. № 12. С. 3—24.
4. Кашкарова А. Г., Шин В. И. Модифицированные семиинвариантные ме¬
тоды анализа нелинейных стохастических систем// Там же. 1986. № 2.
С. 69-80.
5. Пугачев В. С., Синицын И. II., Шин В. И. Программная реализация
метода нормальной аппроксимации в задачах анализа нелинейных сто¬
хастических систем /7 Там же. 1987. № 2. С. 62—68.
6. Даше веки й М. Л. Техническая реализация моментно-семипивариантного
метода анализа случайных процессов/7 Там же. 1976. № 10. С. 23 — 26.
7. Каримов В. А. Расчет коэффициентов статистической линеаризации типо¬
вых многомерных нелинейностей//Тр. ЦАРИ. 1982. Т. 2153. С. 40—55.
8. Пугачев В. С., Синицын И. II. Направления развития математического
обеспечения для исследования стохастических систем /7 Современные
средства информатики. М.: Наука, 1986. С. 166 — 174.
9* Синицын И. II., Зацман И. Л/., Чередниченко А . A., Ill ин В. И. Исполь¬
зование ПЭВМ для обучения вероятностно-статистическим дисциплинам//
, Информатика и компьютерная грамотность. М.: Наука, 1988.
Пугачев В. С., Синицын И. И., Зацман И. М., Чередниченко А . А .,
Шин В. И. Перспективы применения ПЭВМ для исследования стохасти¬
ческих систем/7 Тез. докл. Всесоюз. конф. «Информатика-87». Ереван,
1987. С. 110-111.
125
УДК 621.3.049.77:681.3 - 181.48
ИНТЕРАКТИВНАЯ САПР МАГПСТР-П:
СТРУКТУРА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
И ОСНОВНЫЕ ХАРАКТЕРИСТИКИ
Е-Г- Ойхман. Ю.В. Повоженос, А. Б. Ришкус
ВВЕДЕНИЕ
В 1983 г. в работе [II были сформулированы принципы пост¬
роения интерактивной САПР печатных плат (ПП), предназначен
ной для организации индивидуального рабочего места конструк-
тора. Эти принципы положены в основу интерактивных графи¬
ческих систем (ПГС) проектирования узлов и блоков РЭА и ЭВА,
объединенных под общим именем МАГИСТР [1. 2]. Первые реа¬
лизации ПГС этой серии, выполненные на СМ ЭВМ, обладали
наряду с высокой реактивностью хорошими показателями в части
предельных значений основных параметров проектируемых lilt.
С появлением в нашей стране персональных ЭВМ (ПЭВМ)
ИГС индивидуального назначения получают дальнейшее разви¬
тие, что обусловливается их высокими технико-экономическими
показателями. Разработка ПГС на ПЭВМ в значительной мере
связана с необходимостью решения тех же проблем, что и при
создании ИГС на малых ЭВМ. К ним относятся задачи, опреде¬
ляемые ограниченностью вычислительных ресурсов, необходи¬
мостью использования режима окна при визуализации объекта
проектирования и т. д. Поэтому изложенные в работе [1] прин¬
ципы построения ИГС применены и при реализации на ПЭВМ.
Главными из них являются ориентация на индивидуального поль¬
зователя, специализация системы, размещение центральной базы
данных в оперативной памяти, проблемно-ориентированный диа¬
лог, визуализация в режиме «плавающего окна». Все эти прин¬
ципы положены в основу разработки ПГС на ПЭВМ, получившей
название МАГПСТР-П.
1.
ТЕХНИЧЕСКИЕ СРЕДСТВА
И ПАРАМЕТРЫ ИГС МАГИСТР-П
Интерактивная графическая система МАГПСТР-П предна¬
значается для автоматизированного проектирования узлов и бло¬
ков РЭА и ЭВА на основе односторонних, двусторонних и много¬
слойных ПП. Система функционирует на отечественных ПЭВМ
ЕС-1841, «Искра-1030», «Нейрон-1166», а также на ПЭВМ тип*
IBM PC, PC/XT (АТ) фирмы IBM (США) и на совместимых с ним*1
компьютерах. В состав комплекса технических средств входят'-
растровый дисплей (цветной или монохромный), клавиатура»
графопостроитель, печатающее устройство, дигитайзер. Систем3
реализована в двух вариантах, один из которых предусматривает
126
наличие в составе комплекса винчестерского доска (емкостью
оТ 5 до 40 Мбайт), другой ориентирован на использование только
гцбких дисков. ИГС реализована в операционной среде MS DOS.
МАГИСТР-11 обеспечивает сквозной цикл проектирования'уз-
лов и блоков и выполняет следующие функции: проектирование
Принципиальной электрической схемы (ЭЗ) в интерактивном ре-
,киме (включая разбиение 33 на листы, визуализацию ее графи¬
ческого представления, графическое редактирование); автома¬
тическое формирование задания на конструкторское проектиро¬
вание ПП; ввод и вывод описания ЭЗ па языке внешнего пред¬
ставления данных; ввод информации о конструкции fill (размеры
ПП, ее контур, расположение экранных областей, шин земли и
питания и т. д.) в текстовом виде или создание конструктива его
вычерчиванием на экране дисплея как на интеллектуальном чер¬
тежном столе; ввод технологических данных (размеров и форм
контактных площадок, допустимых толщин проводников, зазо¬
ров между элементами проводящего рисунка, правил расстановки
межслойных переходов, элементов пересечения (перемычек) для
односторонних ГП1 и т. д.); автоинтерактивное размещение раз¬
ногабаритных электрорадиоэлементов (ЭРЭ); автопнтерактивную
трассировку одно-, двусторонних и многослойных ПП, а также
плат поверхностного монтажа; внесение конструкторских изме¬
нений и доработок в режиме графического диалога; сверку ре¬
зультатов трассировки с ЭЗ, контроль и диагностику ошибок
пользователя; автоматическую проверку выполнения правил
проектирования после коррекции конструктором; вывод статис¬
тических данных о проектируемых узлах и блоках; ведение сис¬
темной библиотеки элементов во внешней памяти ПЭВМ, в которой
хранятся образы ЭРЭ для различных применений (представление
ЭРЭ на ЭЗ, сборочном чертеже, цокольное представление, типо-
номинал, данные для автоматизированной сборки и т. д.); полу¬
чение конструкторской документации путем вывода ЭЗ, эскизов
чертежей ПП на графопостроитель и печати текстовой докумен¬
тации на устройстве печати; связь с другими системами с целью
получения управляющих перфолент и магнитных лент для авто¬
мата зи р о в а н н о г о п р он з водств а.
Система позволяет проектировать печатные платы, имеющие
Следующие характеристики:
количество сигнальных слоев ПП — до 16
количество интегральных схем и других электрорадиоэлемен-
т°п, одновременно устанавливаемых на ПП — до 511
количество выводов у одного радиоэлемента — до 256
габариты проектируемых ПП — до 1000 хЮОО, дискрет. При
*Паге координатной сетки 0,625 — до 625 х625 мм
при шаге координатной сетки 1,25 — до 1250 x1250 мм
количество связей (парных соединений) — до 5000
премя реализации одной цепи — от 1,5 до 3 с
Количество автоматических программ размещения радиоэле-
127
количество автоматических программ трассировки (включая
быстрый волновой алгоритм, лучевой быстрый алгоритм, алго.
ритм трассировки ПС с планарными выводами) — 3
С целью получения носителей для программно-управляемого
оборудования (фотокоординатографов, сверлильных станков а
т. д.) осуществлена связь с СМ ЭВМ. МАГИСТР-П работает сов.
местно с системой МАГИСТР-2, реализованной на СМ-4 [2].
2.
СТРУКТУРА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Программный комплекс МАГИСТР-П имеет одноуровневую
оверлейную структуру. Корневой сегмент образует монитор си¬
стемы и системные программы, оверлеи — подсистемы.
Монитор системы содержит секции запуска и перезапуска.
В секции запуска выполняется начальная установка параметров
системы. В секции перезапуска распределяется память, устанав¬
ливается графический режим работы дисплея, выводится началь¬
ное меню, осуществляется вход в выбранную подсистему вызовом
соответствующего оверлея. С секции перезапуска возобновляется
работа монитора после выполнения программ работающих в
автоматическом режиме (авторазмещение, автотрассировка и
т. д.).
Системные программы обеспечивают ведение проблемно-ориен¬
тированного графического диалога. Они могут использоваться
во всех подсистемах. К числу выполняемых ими функций отно¬
сятся: вывод на экран системного и функционального меню; ввод
управляющих символов и текстов с клавиатуры; управление кур¬
сором; управление окном; вывод диагностических и системных
сообщений; вывод на экран вспомогательной информации: коор¬
динат положения курсора, положения окна в рабочей области,
имени проекта; установка графического статуса объектов на ЭЗ
или ПП при воспроизведении на дисплее (цвет, типы линий); выбор
цвета фона и активных цветов на экране дисплея; очистка экрана;
вывод и коррекция системных параметров (числа слоев МПП,
листов ЭЗ, величины дискрета, шага трассировочной решетки
и т. д.).
В состав корневого сегмента входят также библиотечные сра-
фи чес кие модули, которые обеспечивают интерфейс системы с кон¬
кретными графическими устройствами (дисплеем, графопострои¬
телем). К подпрограммам графического пакета обращаются как
монитор и системные программы, так и подсистемы с целью ви¬
зуализации соответствующих данных.
Аналогичным образом используются библиотечные моду*1*1
специализированной СУБД. В реализованном варианте С г БД
применяется для формирования системной библиотеки элементов
на винчестерском диске.
В состав системы МАГИСТР-П входят три подсистемы, Реа>
линованные в виде отдельных оверлеев.
1'28
Подсистема интерактивного проектирования ЭЗ выполняет
вВод; редактирование ЭЗ; выпуск документации об ЭЗ и подго¬
товку данных для конструкторского проектирования. В подсис-
теме можно выделить четыре основных режима.
Первый из них — формирование библиотеки схемы в опера¬
тивной памяти. В результате его работы из системной библиотеки
элементов вызываются в оперативную память образы ЭРЭ тех
типономиналов, которые используются в проектируемой ЭЗ. Каж¬
дый такой образ содержит геометрические характеристики ЭРЭ,
позволяющие визуализировать элемент на экране дисплея или
на чертеже ЭЗ. Вызываемые из системной библиотеки образы вос¬
производятся на экране дисплея. При желании ненужные образы
могут быть удалены из библиотеки схемы.
Режим редактирования предназначается для интерактивного
размещения компонент ЭЗ: ЭРЭ, узлов, выходов на разъем, раз¬
рывов цепей, текстов, линий. В этом режиме выполняется пере¬
движение объектов, вращение, удаление.
В режиме трассировки задаются попарные соединения (связи)
посредством указания соединяемых контактов курсором и с по¬
мощью задания наименований контактов. В наименование кон¬
такта входит схемное имя ЭРЭ и порядковый номер контакта в этом
ЭРЭ. Выполняется ручное проведение трасс, удаление ранее про¬
веденных трасс и их видоизменение. Имеется возможность под¬
ключения к системе программ автоматической трассировки ЭЗ
с возможностью произвольного чередования ручного и автома¬
тического режимов.
В режиме ввода-вывода предусмотрена возможность ввода
компонент ЭЗ с дигитайзера, ввода-вывода защитного дампа (дан¬
ных во внутреннем системном формате, которые сохраняются
в виде отдельных файлов на дисках, что позволяет создавать ва¬
рианты проекта, сохранять результаты проектирования в пере¬
рывах между сеансами работы). Для вывода результатов проек¬
тирования ЭЗ используются постпроцессоры формирования за¬
дания на проектирование и вывода на графопостроитель.
Все перечисленные модули подсистемы обращаются при своей
работе к программам управления данными об ЭЗ. Эти данные хра¬
нятся в оперативной памяти ПЭВМ, а программы управления
ими выполняют необходимые поиск и обновление данных. Визуа¬
лизация проектируемой ЭЗ на экране дисплея осуществляется
специальной программой формирования изображения.
Аналогичные режимы реализованы в подсистеме конструк¬
торского проектирования.
Режим ввода-вывода предназначен для ввода исходных дан¬
ных в подсистему конструкторского проектирования, вывода
Конструкторской документации и обеспечения связи системы
МАГИСТР-П с другими системами. Требуемое действие выбира¬
ется из меню. В этом режиме выполняется ввод задания на проек¬
тирование, сформированного в результате работы подсистемы
Проектирования ЭЗ; ввод-вывод данных в формате внешнего пред¬
5
Заказ № 2514
129
ставления; ввод-вывод дампа для сохранения и защиты данные
о ПП на внешних носителях; вывод статистики о проектируемой
ПП (количество ЭРЭ, связей, контактных площадок, трасс и т. д.)
Вывод результатов конструкторского проектирования на графой
построитель осуществляется программами-постпроцессорами.
В режиме размещения допускается произвольное чередование
ручных и автоматических процедур. В ручном режиме имеется
возможность движения ЭРЭ (произвольного или по выбранной
матрице размещения), вращения, задания матриц размещения
(до 8), фиксации ЭРЭ в заданном месте или, наоборот, расфикса-
цип с целью последующего перемещения ЭРЭ. Среди автомати¬
ческих программ размещения имеются программа конструктор¬
ского размещения по выбранной матрице и программы улучшения
размещения методом парных перестановок и методом силовых
функций. Предусмотрена также программа выбора минимальных
покрывающих деревьев. Оценка качества размещения осуществ¬
ляется как визуально с помогцыо вывода изображения ПГ1 со
связями в виде прямых линий, соединяющих контактные площадки
ЭРЭ и разъемов, так и с помощью интегральной оценки — сум¬
марной длины связей — н дифференциальных оценок на основе
выводимых на экран дисплея одновременно с изображением ПП
гистограмм распределения заторов [2].
В режиме трассировки осуществляется прокладка печатных
проводников. При этом также имеется возможность свободного
чередования ручной и автоматической трассировки. В системе
предусмотрено наличие нескольких альтернативных алгоритмов
трассировки. Каждая программа автотрассировки настраивается
на условия работы, определяемые как технологическими требо¬
ваниями (количество слоев, область трассировки, правила рас¬
становки межслойных переходов, размеры и форма контактных
площадок, специализация слоев и т. д.), так и требованиями кон¬
структора (завершение по первой нетрассируемой связи, по числу
рассмотренных связей, рассмотрение всех связей и т. д.). В ре¬
жиме диалога возможно проведение новых трасс, видоизменение
проведенных трасс (перепое отрезков трассы на другой слой, встав¬
ка новых звеньев трасс, изменение конфигурации трассы и т. д.)
и их удалеппе.|
Режим редактирования предназначен для построения пли
удаления объектов на ПП (ЭРЭ, шин земли и питания, экранных
областей, связей, текстов, неметаллизированных отверстий). При
построении новый объект сразу визуализируется в соответствии
с общими правилами. Предусмотрена возможность восстановления
удаленного или модифицированного объекта.
В подсистеме конструкторского проектирования также все
данные проекта хранятся в оперативной памяти, поэтому в ее соч¬
етав входит комплекс программ управления данными, который
выполняет поиск и обновление данных. Визуализацию изобра'
жени я ПП на экране выполняет специальная программа.
Третья подсистема представляет собой комплекс программ
130
пОддержки системной библиотеки элементов [1. 4|. Эта подсистема
реализована в двух вариантах. В первом из них библиотека соз¬
дается в виде совокупности файлов на сменных гибких дисках,
в0 втором, предназначенном для машин с наличием винчестер¬
ского диска,— с помощью модулей специальной СУБД. Тем не
к1енее в обоих вариантах используется общий набор программных
модулей, обеспечивающих пополнение библиотеки.
Для доступа к библиотечным элементам используется ключ —
набор символов, однозначно идентифицирующий элемент. Обычно
таким ключом служит типономинал элемента. Специальная про¬
грамма запрашивает, вводит и записывает в каталог библиотеки
новый ключ, проверяя при этом его допустимость, несовпадение
с другими библиотечными ключами.
Каждый библиотечный элемент хранится в библиотеке в виде
совокупности образов. Любой образ содержит, все данные, необ¬
ходимые для соответствующего применения. Так, например, для
проектирования ЭЗ необходимо, чтобы соответствующий образ
содержал все требуемые для визуализации на экране или чертеже
ЭЗ графические данные: начертание элемента; расположение его
выводов; тексты; помечающие контакты ЭЗ. Образ для конструк¬
торского проектирования должен включать расположение и типы
контактных площадок, образ для автоматизированной сборки —
установочные характеристики и т. д.
Все данные, требуемые для создания того или иного образа,
вводятся в режиме графического диалога и записываются в биб¬
лиотеку специальными программами. В состав подсистемы входят
также модули, выполняющие процедуры удаления образа и эле¬
мента целиком, и модуль, который записывает в библиотеку ин¬
формацию о том, что данный образ есть копия ранее созданного
элемента. Тем самым экономится память, занимаемая библиотекой
на дисках.
Итак, анализ современных ИГС проектирования ПП на ПЭВМ
показывает, что МАГИСТР-П не уступает лучшим зарубежным
системам такого класса, а по ряду характеристик (например, по
мощности алгоритмов автотрассировки, возможностям программ
автоинтерактивиого размещения) превосходит их.
В то же время опыт эксплуатации системы МАГИСТР-П по¬
казал необходимость совершенствования сервисных средств и
повышения реактивности и гибкости системы. В связи с этим даль¬
нейшее развитие системы МАГИСТР-П предполагает проведение
исследований в следующих направлениях: создание эффективных
структур данных в оперативной памяти; расширение функцио¬
нальных возможностей системы путем включения в ее состав новых
алгоритмов и программ; развитие сервисных средств, в том числе
средств организации эффективного графического диалога.
131
5*
ЛИТЕРАТУРА
1. ОйхманЕ.Г., Новоженов 10. ВЗюзин 10. В. Принципы построения
персональной САПР печатных плат//Приборы и системы упр. 1983
№ 11. С. 4—6.
2. Ойхман Е. Г. Графические системы для СМ ЭВМ. Интерактивные систему
для проектирования печатных плат на СМ ЭВМ. М.: Наука, 1986. 192 с.
3. ОйхманЕ.Г., Зюзин 10. В. Трассировка двусторонних и многослойных
печатных плат на персональных ЭВМ: Методы и средства борьбы с поме-
хами в цифровой технике// Тез. докл. Всесоюз. науч-техн. конф. Каунас
1986. С. 45—46.
4. Ойхман Е. Г. Модели системных библиотек элементов для интерактивных
САПР печатных плат // Автоматизация конструкторского проектирования
в радиоэлектронике и вычислительной технике: Межвуз. сб. науч. тр.
Вильнюс, 1985. Т. 2. С. 72 — 78.
УДК 621.3.0*9.77:681.3 - 181.48
АСИМПТОТИЧЕСКАЯ ОЦЕНКА ВРЕМЕНИ РАБОТЫ
ЦЕНТРАЛЬНОЙ БАЗЫ ДАННЫХ
В ИНТЕРАКТИВНЫХ САПР НА ПЭВМ
10. В. Зюзин, В. В. Петунии, К. Хорват
Наиболее важной частью интерактивной САПР печатных плат
(ПП) на персональных ЭВМ является центральная база данных
(ЦБД), размещаемая в ОЗУ, в которой хранится вся необходимая
информация о проекте. От качества разработки ЦБД зависят ос¬
новные параметры системы и в первую очередь реактивность сис¬
темы, размерности проектируемых ПП и т. д.
Различные способы проектирования и оценки ЦБД исследо¬
вались в целом ряде работ (см. напр.: [1, 2]). Данная статья про¬
должает эти исследования. В пей приведена методика разработки
структуры ЦБД, основанная на оценке общего времени выпол¬
нения запросов к ЦБД за полный цикл проектирования.
1.
ПОСТАНОВКА ЗАДАЧИ
Проектировщик, приступая к созданию повой структуры ЦБД,
должен точно определить для себя следующие характеристики
будущей САПР: ЭВМ, на которой реализуется САПР; предельно
допустимые параметры проектируемых плат; состав меню, реа¬
лизуемый набором пользовательских запросов к ЦБД. В выбор6
этих трех характеристик имеется определенный произвол проек¬
тировщика, однако на этапе создания структуры данных их не¬
обходимо зафиксировать, так как, не зная их, невозможно отве¬
тить на вопрос: какая структура данных удачна, а какая нет?
Рассмотрим эти характеристики САПР несколько подробнее-
ЭВМ, на которой реализуется САПР. При создании новой
структуры ЦБД стремятся как можно более компактно разместить
все необходимые данные в ОЗУ и обеспечить достаточную скорость
132
обработки этих данных. Ясно, что актуальность этих задач не¬
посредственно зависит от объема оперативной памяти ЭВМ, на
базе которой должна работать САПР, от ее быстродействия, реак¬
тивности оперативной системы, наличия сопроцессоров и т. д. Се¬
годня подавляющее большинство САПР ПП на персональных ЭВМ
рассчитаны на работу с ПЭВМ типа IBM РС/ХТ(АТ) под операцион¬
ной системой MS DOS. Также предполагается использование
этих машин с платами расширенной памяти и дальнейший переход
на 32-разрядные персональные компьютеры типа PS-2 фирмы IBM.
Предельно допустимые параметры проектируемой платы. Одной
из важнейших характеристик любой САПР ПН являются пре¬
дельные размеры проектов, которые можно обрабатывать с по¬
мощью этой САПР. Желательно, чтобы эти предельные размеры
не слишком ограничивали круг пользователей. Для лучших со¬
временных САПР ПП на ПЭВМ характерны следующие ограни¬
чения па размерность платы:
количество ЭРЭ — 500
количество трасс — 5000
количество сигнальных слоев — 16
количество выводов на ЭРЭ — 250
габариты платы — 1000x1000 мм
Эти параметры можно считать типичными предельными па¬
раметрами САПР ПП на ПЭВМ. Они вполне устраивают большин¬
ство пользователей. Разумеется, иногда встречаются платы и
большей размерности, но сегодня такие проекты редки и создавать
для них САПР на базе персональной ЭВМ вряд ли целесообразно.
Набор пользовательских запросов к ЦБД. Будем считать,
что на момент создания структуры данных нам известен прибли¬
зительный список пользовательских запросов к ЦБД. Пользо¬
вательские запросы к ЦБД могут быть двух типов. Во-первых,
это чисто интерактивные запросы: убрать связь, повернуть ЭРЭ,
провести печатную шину и т. д. Во-вторых, это запросы, связан¬
ные с вызовом прикладных программ. Дело в том, что включенные
в САПР прикладные программы (автотрассировка, авторазме-
Щение, пересоедииенпе и др.) могут работать на своей внутренней
структуре данных, отличной от структуры ЦБД. При этом воз¬
никает необходимость перехода от ЦБД к структуре данных при¬
кладной программы и обратно. Запросы типа «подготовить струк¬
туру данных для автоматического размещения» будем называть
Пользовательскими запросами к ЦБД и не будем их отличать от
Интерактивных запросов. Предположим, что нам известны струк¬
туры данных для всех прикладных программ, включенных в сис¬
тему.
Набор пользовательских запросов не зависит от конкретной
структуры ЦБД, но время их выполнения непосредственно за¬
висит от нее. Нашей целью будет по возможности уменьшить это
вРемя за счет выбора удачной структуры данных.
Будем рассматривать задачу улучшения структуры ЦБД как
^критериальную задачу с вектором оптимизации (Т, С), где Т —
133
время выполнения запросов к базе данных; С — максимально
допустимая размерность проекта при заданном объеме ОЗУ.
Для решения многокритериальной оптимизационной задниц
можно выделить главный критерий. При недостатке оперативной
памяти естественно выбрать в качестве главного критерия мак¬
симально допустимую размерность проекта, а время рассматри¬
вать как ограничение. Это приводит к следующей формулировке
задачи.
Найти структуру данных, удовлетворяющую набору неравенств
-С ■— 1,2, ..., тг), для которой значение С было бы макси¬
мальным. Здесь tK — это время выполнения Л-го'запроса к ЦБД,
a — заранее заданное ограничение на это время.
Практический смысл такой постановки задачи ясен — задав
априорные требования на реактивность САПР, проектировщик
старается найти структуру данных для размещения в ОЗУ объек¬
тов максимальной размерности. Для решения этой задачи были
разработаны специальные методы (см.: [1. Гл. 3]), опирающиеся
на понятие «модель данных».
Определение. Моделью данных (А, л) называется набор мно¬
жеств S = {5Х, . . ., 5П} и набор бинарных отношений л = {ли . . .
. . лш} между множествами из S.
Практический смысл этого определения состоит в следующем:
множества X; в реализации модели данных соответствуют наборам
данных, а отношения л у — информационным связям между на¬
борами данных, поддерживаемым СУБД. Точнее говоря, для каж¬
дой модели (S, л) СУБД поддерживает следующие запросы, в даль¬
нейшем называемые элементарными:
— определить, связаны ли элементы А и В отношением л,;
— найти все элементы, связанные отношением л;- с элементом Л;
— найти все пары элементов, связанных отношением лг
Конечно же, список всех запросов к ЦБД не исчерпывается
элементарными запросами. Комбинируя элементарные запросы,
можно создавать запросы более высокого уровня, из этих запросов
создавать запросы еще более высокого уровня и т. д. В целом
набор запросов к ЦБД образует сеть, на нижнем уровне которой
лежат элементарные запросы, а на верхнем уровне пользователь¬
ские запросы, о которых мы говорили раньше. Ясно, что набор
элементарных запросов зависит от модели данных, а набор поль¬
зовательских запросов от нее не зависит.
Методика улучшения модели данных по занимаемому объему
ОЗУ описана в работе [1] и сводится к следующим шагам.
1. Разработка исходной модели на основе анализа предметной
области.
2. Оценка модели с помощью реализационных лемм по объему
оперативной памяти и времени выполнения элементарных запросов-
3. При неудовлетворительной оценке по объему памяти сле¬
дует улучшение модели с помощью разработанных методов.
Применение этих методов позволило создать САПР МАГИСТР-П
134
базе ЕС 1841 с указанными типичными для САПР ПП па ПЭВМ
Предельными параметрами. Таким образом, с точки зрения раз-
1^ерн°стп проектируемых плат эта система сегодня удовлетворяет
Практически любого потенциального пользователя.
Для компьютера типа IBM PC с расширенной памятью или
типа PS-2 можно предложить несколько различных структур дан¬
ных для создания САПР ПП с типичными предельными парамет¬
рами. Пытаться сравнить эти структуры по тому, какая из них
допускает большую предельную размерность проекта, практи¬
чески бессмысленно, так как большинство пользователей не нуж¬
дается в дальнейшем росте предельной размерности. В этой си¬
туации естественно в качестве основного критерия оптимизации
структуры данных взять время работы ЦБД, а предельные па¬
раметры проекта рассматривать как ограничение. Прежде чем
дать точную постановку задачи, необходимо сделать несколько
замечаний.
Замечание 1. Обычно под временем работы ЦБД пони¬
мают время выполнения некоторых характерных запросов к ЦБД:
вписать связь, удалить ЭРЭ, провести трассу и т. д. При этом время
оказывается векторным критерием. Можно попытаться перевести
этот вектор в скаляр, взяв его свертку с некоторым весовым век¬
тором. Однако этот путь бесперспективен, так как заранее неиз¬
вестно, какой именно вес какому запросу надо приписать. Откло¬
нимся от традиционного пути и будем понимать под временем ра¬
боты ЦБД суммарное время, которое уходит на выполнение всех
запросов к ЦБД за один цикл проектирования.
Замечание 2. Время работы ЦБД будем рассматривать
не как константу, а как функцию Т(Х), где % — размерность проек¬
тируемой платы. Для различных структур данных будем получать
разные функции Т(Х) и сравнивать их по скорости роста при
X—>эс. Для этого будем разлагать Т(к) в асимптотический ряд по
степени X, выделять в полученном разложении главный член
2? и пытаться искать структуру данных, для которой сте¬
пень к в главном члене была бы минимальна.
Такой подход оправдан тем, что размерности современных пе¬
чатных плат очень высоки, поэтому структура данных с меньшей
асимптотической скоростью роста функции Т(%) обеспечивает
меньшее реальное время работы ЦБД.
Замечание 3. Понятие размерности платы нуждается
J* Уточнении. Всюду в дальнейшем будем считать, что количество
^РЭ на плате и количество парных соединений пропорциональны V;
Количество сигнальных слоев ПП постоянно, т. е. пропорциональ-
н° V; плотность размещения ЭРЭ па поверхности платы постоянна,
следовательно, площадь платы пропорциональна V, а линейные
Размеры всех объектов на плате пропорциональны X1'2.
Теперь мы готовы сформулировать точную постановку задачи
°Птимизации структуры ЦБД по суммарному времени выполне¬
ния запросов.
Найти структуру данных, удовлетворяющую набору неравенств
135
ск ск (к = 1, 2, . . ., zn), для которой функция Т (X) имела бЬ1
минимальную асимптотику роста при К ->оо.
Здесь ск — набор предельных параметров САПР, которые
допускает данная структура данных на данном объеме ОЗУ; ск
набор типичных предельных параметров.
2.
ОСНОВНЫЕ ХАРАКТЕРИСТИКИ ЗАПРОСОВ К ЦБД
Каждый из запросов к ЦБД может разлагаться на запросы
более низкого уровня, те, в свою очередь, могут разлагаться па
запросы еще более низкого уровня и т. д. Поэтому запросы к ЦБД
естественно описывать ориентированным графом Q = (У, £*), где
V = {рх, v2, . . ., vn} — набор запросов к ЦБД; Е — множество
таких пар vj) ЕЕ У2, что при выполнении запроса vt происхо¬
дит обращение к запросу Vj.
Запросом самого высокого уровня, очевидно, является запрос
«обеспечить информационную поддержку проектирования платы».
Этот запрос обозначим р0.
Вообще говоря, граф Q может иметь циклы, однако для нас
он будет деревом, так как всюду в дальнейшем будем рассматри¬
вать каждый запрос как несколько различных запросов в зави¬
симости от того, из какого запроса более высокого уровня он вы¬
зывается. Формально для этого надо перейти от графа Q к дереву
D = (М, N), где М — множество ориентированных путей на Q,
исходящих из vQ; N — множество таких пар (mz, тпД ЕЕ М2, что
путь inj получается из добавлением одной дуги из Е.
Дерево D будем называть деревом запросов. Все дерево за¬
просов можно разбить на две части: постоянную и переменную.
Постоянную часть составляют пользовательские запросы к ЦБД,
перечисленные в проектном задании на САПР. К переменным от¬
носятся все остальные запросы. Разрабатывая новые структуры
данных, можно произвольным образом менять переменную часть
дерева запросов, но при этом необходимо сохранять постоянную
его часть.
Множество вершин дерева запросов, в которых оканчиваются
ребра, выходящие из вершины будем называть разложением
запроса Для каждого из запросов к ЦБД определим четыре
величины: асимптотическую относительную частоту; асимптоти¬
ческую абсолютную частоту; асимптотическое время выполнения;
асимптотическое суммарное время.
Определение. Пусть запрос vt входит в разложение запроса
Vj. При каждом выполнении запроса Vj запрос vt должен выпол¬
няться в среднем Q(Z, X) раз, где X — размерность проекта.
Если при фиксированном i:
Q (f, X) ~
то величина со(Д называется асимптотической относительной часто¬
той запроса vt.
136
Определение. Пусть на каждый цикл проектирования запрос vt
выполняется в среднем й* (i, %) раз, где К — размерность проекта.
£Сли при фиксированном i:
й* (i, X) —
то величина (o*(Z) называется асимптотической абсолютной час¬
тотой запроса v^.
Определение. Пусть в среднем на одно выполнение запроса vt
затрачивается время T(f, X), где X — размерность проекта.
Если при фиксированном г.}
т G, X) ~
то величина t (Z) называется асимптотическим временем выпол¬
нения запроса
Определение. Пусть в среднем на один цикл проектирования
общее время, затраченное на выполнение запроса равно T*(i, %),•
где X — размерность проекта. Если при фиксированном I:
%) ~
то величина £*(/) называется асимптотическим суммарным време¬
нем запроса vt.
В дальнейшем слово «асимптотический», как правило, будем
опускать.
Для каждой конкретной структуры данных будем решать две
задачи:
а) найти суммарное время запроса «обеспечить информацион¬
ную поддержку проектирования платы», иначе говоря, найти
величину £*(0);
б) найти все запросы для которых £*(£) = 1*(0) (именно
эти запросы занимают основное время в ходе проектирования и
нуждаются в улучшении).
Лемма 1. Пусть запрос принадлежит разложению запроса Vj,
тогда
ш*(0 - со*(/) + со(0-
Доказательство. За цикл проектирования запрос Vj
вызывается й*(/, X) раз, и на каждый вызов запроса vj приходится
«О, X) вызовов запроса vt. Следовательно, на цикл проектиро¬
вания запрос вызывается й* (/, X) й (Z, X) раз. Имеем
й* (Z, X) - Й* (/, X) Й (/, %).
Зная относительные частоты всех запросов, пользуясь леммой 1,
Нетрудно вычислить абсолютные частоты. Для этого, учитывая,
Нто (о* (0) = 0, вычислим абсолютные частоты всех запросов, вхо¬
дящих в разложение запроса vQ, Потом для каждого из этих за¬
просов вычислим абсолютные частоты запросов из их разложений
И т. д. Двигаясь таким образом от корня дерева запросов к листьям,
Получим абсолютные частоты всех запросов к ЦБД.
137
Ясно, что листьями дерева запросов будут элементарные
просы к ЦБД. Для каждой конкретной структуры данных ;)Г11
запросы должны быть реализованы некоторыми программами
поэтому разработчик может оценить время выполнения каждого
элементарного запроса. Зная времена выполнения элементарных
запросов и относительные частоты всех запросов, нетрудно По\
считать время выполнения для любого запроса. Для этого над0
воспользоваться следующей леммой.
Лемма 2. Пусть множество {vtl, vi2, . . образует разло¬
жение запроса vz, тогда
i(i) = max
Доказательство. Выполнение запроса vt заключается
в вызове различных комбинаций запросов vti, viv ..., uim, поэтому
справедлива следующая формула:
T(i, Х)= 3 T(jz, X).
Главный член в последнем полиноме имеет степень
max (t (Zz) +co(iz)).
1<T
Лемма доказана.
Для любого запроса, зная его абсолютную частоту и время
выполнения,' можно посчитать его суммарное время. Для этого
надо воспользоваться следующей очевидной леммой.
Лемма 3. Для любого запроса справедливо соотношение
/*(Ц = о* (i) + t (i).
Видно, что для получения всех частотных и временных харак¬
теристик дерева запросов достаточно знать относительные частоты
всех запросов. Нам будет удобнее показать на конкретном при¬
мере, как устанавливаются относительные частоты.
3.
ПРИМЕР ОЦЕНКИ СТРУКТУРЫ ДАННЫХ
Чтобы продемонстрировать возможности предлагаемой ме¬
тодики оценки структуры ЦБД по времени и одновременно по¬
казать, каким способом можно установить относительные асимп¬
тотические частоты на дереве запросов, приведем небольшой
конкретный пример. Оценим эффективность описанной в работе 111
структуры данных при ее использовании в блоке трассировки
САПР ПП. Структура пользовательских запросов к ЦБД необ¬
ходимая для трассировки приведена на рисунке.
Считаем, что для автотрассировки используется волновоН
малоповоротный алгоритм, внутренняя структура данных которого
описана в работе ([1. Гл. 6]).
138
Дерев° пользовательских запросов
__ обеспечение информационной под¬
держки трассировки;
Гя — подготовка данных для автотрасси¬
ровки;
Vs — информационная поддержка ручной
трассировки;
Vi — поиск нереализованной связи;
— вывод части платы на экран графи¬
ческого дисплея;
Ve — занесение готовой трассы в ЦБД
Предполагается следующая стратегия работы пользователя:
— пользователь обращается к блоку трассировки только один
раз за цикл проектирования;
— сначала пользователь в автоматическом режиме реализует
90—95% парных соединений;
— оставшиеся соединения последовательно реализуются вруч¬
ную, для чего нереализованное соединение ищется; в режиме окна
проводится необходимая трасса; готовая трасса заносится в ЦБД.
Умышленно сильно упрощаем блок трассировки, так как наша
цель здесь — привести демонстрационный пример для пояснения
предложенной методики оценки структур данных, а не дать опи¬
сание какой-то реальной САПР.
Для начала расставим асимптотические относительные частоты
запросов щ, v2, z?3, i?4, р5, ц.. В цикле проектирования ГШ про¬
исходит только одно обращение к трассировке, поэтому со (1) ~
= со*(1) = 0. Во время трассировки автоматическая трассиров¬
ка вызывается один раз, поэтому со (2) = 0.
Ручная трассировка вызывается столько раз, сколько осталось
нереализованных связей после автоматической трассировки. Пред¬
положили, что автоматическая трассировка реализует постоянный
процент связей, поэтому со(3)= 1.
Во время ручной трассировки необходимо один раз выделить
нереализованную связь и один раз вписать готовую трассу, по¬
этому со (4) = со (6) = 0.
Чтобы реализовать парное соединение между точками (.т1? уг)
и (г2, У 2), обычно приходится просмотреть окном прямоугольник
{xi х С .т2; z/i у у2}. Длину всех линейных объектов на
плате (в том числе и среднее расстояние между точками (гщ, у4)
и Сг2, ^2)) мы приняли пропорциональной X1/-’, следовательно,
площадь прямоугольника, по которому будем двигать окно, про¬
порциональна V. Площадь участка платы, который имеет смысл
поводить на экран дисплея в режиме окна, зависит только от раз¬
решающей способности дисплея, т. е. для конкретного дисплея
°на постоянна. Из всего сказанного следует, что со (5) = 1.
На рисунке представлена только постоянная часть дерева за¬
просов — пользовательские запросы. Чтобы получить все дерево
Опросов необходимо достроить его вглубь вплоть до элементар¬
ных запросов в соответствии с изучаемой моделью данных.
Установить относительные частоты для всех запросов, кроме
139
пользовательских, сравнительно несложно. Дело в том, что вСе
оставшиеся запросы автоматические — их вызовом управляют
автоматические процедуры, не требующие вмешательства чело¬
века. Анализ работы этих автоматических процедур позволяет
непосредственно определить соответствующие относительные час¬
тоты.
Достроив дерево запросов до элементарных запросов и уста¬
новив относительные частоты, можно приступать к определению
асимптотических времен выполнения запросов. (Эта работа была
проделана, но здесь она не приводится в полном объеме, чтобы
не перегружать статью излишними подробностями). Пользуясь
леммами 1 и 2, можно получить, что для изучаемой модели данных
справедливы следующие соотношения:
/(4) = 1,
/(5)^1,
t (6) = О,
/(2) = 2,
Т(4, X)~V,
Г (5, %)~V,
Т(6, X) — V,
Т (2, А,)— А,2.
Запрос и3 разлагается на запросы и±, vb, vQ, поэтому согласно
лемме 2
t (3) = max (t (I) + co (i)) = t (5) (5) = 2.
Запрос разлагается на запросы v2l поэтому
t (1) = max (t (i) + co (i)) = t (3) Ц- co (3) = 3.
Мы получили, что время работы базы данных по информацион¬
ной поддержке трассировки пропорционально А3.
Теперь, используя лемму 1, вычислим абсолютные частоты
пользовательских запросов.
Имеем
со* (1) = О,
со* (2) = О,
со* (3) = 1,
со* (4) = 1,
со* (5) = 2,
(О* (6) = 1.
Согласно лемме 3, для любого запроса, зная его время выпол¬
нения и абсолютную частоту, можно вычислить суммарное время
выполнения.
Имеем
£* (1) = i*(3) = £* (5) = 3;
£* (2) - Z* (4) = 2;
£*(6) = 1.
Видно, что основное время в работе ЦБД занимает цепочка
ТРАССИРОВКА РУЧНАЯ ТРАССИРОВКА -> ОТКРЫТЬ
ОКНО.
140
Ключевым пользовательским запросом, тормозящим всю ра-
боту системы, оказывается запрос «открыть окно». Сократив время
выполнения этого запроса, тем самым существенно сократим об¬
щее время работы ЦБД. Сегодня уже разработана структура дан¬
ных, для которой время открытия окна пропорционально log2Z
И, следовательно, суммарное время работы ЦБД пропорционально
A* log2 k-
В заключение хотелось бы отметить, что при определении
асимптотических относительных частот пользовательских запросов
нам приходилось руководствоваться сценарием работы пользо¬
вателя. Обычно такие сценарии описываются в словесной форме
и не поддаются формализации. Однако при ближайшем рассмот¬
рении выясняется, что задание относительных частот на дереве
пользовательских запросов очень точно описывает деятельность
оператора. Поэтому представляется целесообразным ввести сле¬
дующее формальное определение.
Определение. Сценарием работы САПР называется пользо¬
вательская часть дерева запросов с заданными относительными
частотами этих запросов.
Таким образом, предлагается следующая методика разработки
новых структур данных для САПР ПП:
1) путем разработанных ранее [1] методов вырабатываются
структуры данных, на которых можно обрабатывать платы с за¬
данными предельными параметрами;
2) предполагаемый сценарий работы САПР (иначе говоря,
пользовательская часть дерева запросов) достраивается до пол¬
ного дерева запросов в соответствии с каждой из структур дан¬
ных;
3) непосредственным анализом процедур, реализующих эле¬
ментарные запросы, устанавливается их асимптотическое время
выполнения. Затем, используя приведенные леммы, вычисляются
времена выполнения всех запросов;
4) из всех предложенных структур данных выбирается та, у
которой минимальна асимптотика роста времени работы ЦБД
в зависимости от размерности платы;
5) при неудовлетворительном времени работы ЦБД выделяет¬
ся запрос с наибольшим асимптотическим суммарным временем
выполнения и происходит возврат на этап 1. При этом ищется
структура данных с минимальным временем выполнения выделен¬
ного запроса.
ЛИТЕРАТУР А1
Ойхман Е. Г. Графические системы для СМ ЭВМ. М.: Наука, 1986. 192 с.
Ойхман К. ГЗюзин Ю. ВНовоженов Ю. В, Модель представления дан¬
ных в БД интерактивной графической системы // Электрон, техника. Сер. 9.
1984. № 1. С. 42—45.
141
УДК 621.3.049.77:681.3 - 181.48
МЕТОДЫ РЕАЛИЗАЦИИ
КРЕМНИЕВОГО КОМПИЛЯТОРА
НА ОСНОВЕ БИНАРНЫХ МОДЕЛЕЙ ДАННЫХ
10. В. Зюзин, А. В. Рябинин
В этой работе изложены результаты исследования проблем
реализации кремниевого компилятора (КК) для проектирования
заказных СБИС с высоким уровнем интеграции. Разработка ори¬
ентирована на современные 32-разрядные малые ЭВМ типа СМ
1700, СМ 5212 и др.
Основной особенностью рассматриваемой задачи является
высокая размерность, которая приводит к необходимости учета
ограниченности вычислительных ресурсов указанных ЭВМ,
в том числе размера оперативной памяти и быстродействия. При
этом возникает целый ряд трудностей, преодоление которых
целиком зависит от качественной организации данных. Одним
из двух наиболее приемлемых решений является динамическое
распределение памяти, достигаемое при помощи спискового
устройства данных. При этом действительно память расходуется
экономно, в том смысле, что данные располагаются компактно
и практически весь объем памяти может быть занят полезной
информацией. Однако такой подход приводит к существенным
накладным расходам как по памяти (списки предполагают хра¬
нение большого числа ссылок), так и по быстродействию (дина¬
мическое распределение замедляет все манипуляции с памятью).
Поэтому предлагается использовать иной подход — бинарные
структуры данных. Смысл этой фразы раскрывается в статье.
1.
ПРЕДМЕТ ИССЛЕДОВАНИЯ
Следует отметить, что общепринятое определение КК в лите¬
ратуре отсутствует. Под КК понимаются самые различные САПР,
иногда мало отличающиеся от традиционных [1]. Не пытаясь
дать строгое формальное определение, определим КК косвенно —
по его признакам. Везде будем понимать под КК САПР СБИС,
обладающую следующими свойствами:
1) входное описание проекта СБИС выполняется на языке
достаточно высокого уровня;
2) получаемая топология кристалла находится в однозначном
структурном соответствии с исходным описанием, в частности
сохраняется иерархия ячеек, содержащаяся во входном описа¬
нии;
3) создание библиотечных ячеек (всех или части) производит¬
ся в процессе проектирования с помощью специальных парамет¬
ризованных программных функций — кремниевых ассемблеров.
142
Разработка КК вместо традиционных САПР обычно пресле¬
дует следующие цели: 1) привлечение к проектированию СБИС
разработчиков, не являющихся профессионалами в области то¬
пологии СБИС; 2) сокращение времени проектирования пол¬
ностью заказных СБИС; 3) увеличение степени интеграции до не¬
скольких миллионов транзисторов на кристалле.
2.
СОСТАВ И СТРУКТУРА САПР НА ОСНОВЕ КК
Предлагаемая структура системы приведена на рис. 1. Рас¬
смотрим отдельно каждую.
2.1. Подсистема ввода исходного описания
Как уже отмечалось входной язык КК должен иметь по воз¬
можности более высокий уровень, а процесс кремниевой компи¬
ляции — представлять собой трансляцию входного описания в
«язык кремния». В то же время известные сегодня методы крем¬
ниевой компиляции работают с исходным описанием логического
уровня [2], что явно недостаточно для описания сложных проек¬
тов СБИС. Для разрешения указанного противоречия представ¬
ляется целесообразной организация двухуровневого цикла про¬
ектирования. Первый цикл служит для понижения уровня ис¬
ходного описания до уровня, воспринимаемого КК, и осуществ¬
ляется с участием человека. Второй цикл представляет собой
собственно кремниевую компиляцию.
Рис. 1. Укрупненная
схема САПР на базе КК
Подсистема
ввода
исходного
описания
Подсистема
планирования
кристалла
‘ Задание н*
^оектирова^
Интерактивная
графическая
система ввода
библиотечных
элементов
библиотека
ячеек
И нтера ктив ный
графический
редактор
Ядро К К
Собственно
К К
Кремниевые
ассемблеры
FlpocK-i
143
Подсистема ввода исходного описания предназначена в ociioB,
иом для организации первого цикла проектирования. Работа с
подсистемой начинается с ввода укрупненной функциональной
схемы, описанной на языке высокого уровня.
После ввода и трансляции описания организуется интерак-
тивный процесс разбора исходного описания, результатом кото¬
рого является задание на проектирование уровня логических
уравнений (см. разд. 2.3). Разбор основан на двух интерактивны v
операциях: 1) детализация функционального описания сверху
вниз, когда отдельные составные части проекта могут быть под,
разделены на функциональные подъячейки; 2) замена функцио¬
нального представления ячеек на логическое снизу вверх, когда
для каждой ячейки вводятся логические уравнения, связывающие
ее внешние порты с портами подъячеек. На нижнем уровне иерар¬
хии — для ячеек, не имеющих подъячеек, операция 2) представ¬
ляет собой выбор готового библиотечного элемента либо наз¬
начение параметров кремниевого ассемблера для программной
генерации ячейки. В более развитых версиях системы разбора
входного описания целесообразно реализовать средствами экс¬
пертной системы. Кроме разбора входного описания, под¬
система ввода осуществляет логическую верификацию вводимого
описания проекта.
2.2. Планирование кристалла
Подсистема планирования кристалла предназначена для уп¬
равления последующими процедурами проектирования. Осо¬
бенно это касается процедуры слияния ячеек. С точки зрения
пользователя, план кристалла представляет собой черновой ва¬
риант размещения ячеек (подъячеек). При этом пользователь
может явно или неявно задавать каналы и порядок слияния яче¬
ек. С точки зрения внутренней архитектуры системы планирова¬
ние кристалла позволяет получить на основе анализа размеще¬
ние и полную или частичную информацию о приписке логических
портов к определенным сторонам ячеек, о потребности в сквозных
металлизированных проходах для облегчения соединений уда¬
ленных друг от друга ячеек, а также информацию о порядке
слияния подъячеек в виде бинарного дерева.
План кристалла формируется при просмотре иерархии яче¬
ек сверху вниз. Вообще говоря, по желанию пользователя мо¬
жет планироваться только несколько верхних уровней иерархии.
В частности, пользователь может вообще отказаться от планиро¬
вания. Отсутствие плана какой-либо ячейки при ее компиляции
означает, что слияние ее подъячеек производится в порядке,
неявно определенном входным описанием.
Черновой вариант размещения ячеек строится на основе оце¬
ночных данных о размерах и формах ячеек. Такой способ не
позволяет получить точные значения координат, но дает достаточ¬
но полную информацию о смежности ячеек. Эти данные, в свою
144
очередь, используются для анализа окружения каждой ячейки
с целью планирования сквозных металлизированных проходов
дЛя связи ячеек, не имеющих общих каналов.
Результаты планирования кристалла размещаются в централь¬
ной базе данных (ЦБД) проекта. При достаточной развитости
системы, когда в нее будут включены несколько КК, кремниевых
ассемблеров и т. д., в подсистему планирования кристалла це¬
лесообразно будет включить дополнительные средства для пла¬
нирования собственно процесса проектирования. В результате
для крупных ячеек могут быть намечены средства их проектиро¬
вания: конкретные КК, если их в системе несколько, ассемблеры
и т. Д.
2.3. Задание на проектирование (промежуточное)
Задание на проектирование представляет собой текстовое
описание исходных данных проекта, формируемое подсистемой
ввода. В качестве формата этого описания может быть принят
язык EDIF, специальным образом доработанный.
Задание на проектирование должно содержать:
1) явно определенную иерархию типа «ячейка—подъячейка»
(подробнее см. разд. 2.4);
2) явно заданные имена библиотечных элементов для готовых
ячеек, которые должны быть выбраны из системной библиотеки;
3) для ячеек нижнего уровня иерархии, генерируемых с по¬
мощью ассемблеров — явно указанные имена соответствующих
модулей и наборы необходимых параметров;
4) информацию о связности портов ячеек.
Последнее нуждается в пояснении. В традиционных САПР
связность задается списком соединений, записанном в той
или иной форме (список парных соединений, список сигналов и
т. д.). Одной из отличительных особенностей КК является воз¬
можность задания связности на более высоком уровне — в виде
логических уравнений, связывающих порты ячеек (подъячеек).
В дальнейшем уровень задания связности понижается путем
введения управляющих блоков (ПЛМ) по одной на каждую ячей¬
ку. Управляющие блоки реализуют требуемые логические урав¬
нения, поэтому информация о связности трансформируется в
обычный список соединений (сигналов).
2.4. Ядро КК
2.4.1. Центральная база данных.
Основным отличием предлагаемого подхода от концепции
развитой Айрисом [2], является наличие ЦБД, составляющей
Информационную основу ядра КК. Преимущества централизо¬
ванных (т. е. основанных на ЦБД) систем хорошо известны [3];
Недостатком их является затрудненная программная реализация.
145
Вопросы тщательной разработки структур данных имеют здеСь
первостепенное значение. Термин «центральная» означает сл^
дующее:^
а) ЦБД содержит данные о текущем состоянии проекта. д0^
статочно полные для работы со всеми программными компонентам^
ядра;
б) в случае, когда структура ЦБД неудобна для организации
какого-либо алгоритма, соответствующая программа может цс,
пользовать ЦБД в качестве исходных данных и подготовить с об,
ственную (периферийную) БД; однако по завершению счета та¬
кая программа обязана занести свои результаты в ЦБД.
Ввиду большого объема хранимых данных ЦБД располагает¬
ся на диске. Основу ЦБД составляет оглавление в виде описа¬
ния иерархии типа «ячейка—подъячейка». Иерархия не содержит
непосредственных описаний каждой ячейки; вместо этого в лей
задаются ссылки на описания ячеек. Это позволяет сэкономить
память за счет мультиплицируемых ячеек. (Следует обратить
внимание на упомянутую особенность разрабатываемой структуры
данных — мультипликации ячеек, т. е. использование одного
и того же библиотечного образа ячейки в разных контекстах.
Это приводит к невозможности задания каких-либо глобальных
параметров ячейки: все координаты обязательно отсчитываются
от привязочной точки самой ячейки, имена сигналов имеют смысл
только внутри одной ячейки и т. д.)
Описание каждой ячейки представляет собой объединение
описаний двух уровней:
а) внешний уровень описания (интерфейс) содержит информа¬
цию о границе ячейки (охватывающий бокс), а также описание
портов ячейки — их размеры, местоположение, электрические
параметры, инцидентные портам сигналы и т. д.;
б) внутренний уровень описания содержит информацию о
внутреннем строении ячейки. Распадается на ряд подуровней.
Рассмотрим некоторые подуровни внутреннего уровня опи¬
сания ячейки.
Подуровень Ы (иерархический) содержит полную информа¬
цию о составе подъячеек данной ячейки.
Подуровень Ь2 (логический верхний) содержит информацию
о логических связях в виде системы логических уравнений. Яв-
ляется исходным для формирования описания подуровня ЪЗ.
Подуровень ЬЗ (логический нижний) содержит информацию
о логических связях в виде явного списка соединений (сигналов)*
Вырабатывается из описания подуровня Ь2 посредством введения
дополнительной подъячейки (управляющего блока), реализуемо11
в виде ПЛМ с помощью Ассемблера.
Подуровень Ь4 (топологический) содержит описание лэйаутВ’
полученного из описания подуровня ЬЗ с помощью процедур1’1
слияния ячеек.
Отметим, что нами оговорен полный перечень информации 0
ячейках. Однако реально полная информация присутствует, толь
146
если ячейка уже спроектирована. Работу всех программных
процедур ядра КК можно рассматривать как процесс заполнения
соответствующих информационных нолей. Например, информа¬
ция о расположении портов ячейки может вначале отсутствовать
вОобще, частично появиться после планирования кристалла и
полностью сформироваться лишь после слияния подъячеек. В этом
смысле ЦБД является средством обмена информацией между
программами.
2.4.2. Процедура слияния ячеек. Процедура слияния ячеек
является основной программной процедурой КК. Запускается,
когда все подъячейки какой-либо ячейки спроектированы,
а уровень описания логических связен понижен (до подуровня
Ь 3). Результат этой процедуры — спроектированная ячейка. За¬
пуск этой процедуры производится при анализе иерархии ячеек
и повторяется до тех пор, пока не будет спроектирован весь кри¬
сталл (пли фрагмент, если проектируется фрагмент).
Рассмотрим формальную постановку задачи слияния подъ¬
ячеек.
Входная информация. Описание (неполное в части располо¬
жения портов и их электрических параметров) интерфейса про¬
ектируемой ячейки С. а также описания интерфейсов ее подъя¬
чеек (в том числе дополнительной подъячейки — управляющего
блока); описание связности подуровня ЬЗ.
Выходная информация. Полное описание интерфейса ячейки
С и ее внутреннее описание подуровня Ъ4. При реализации сое¬
динений запрещается прокладка линий внутри охватывающих
прямоугольников подъячеек.
Отметим, что с информационной точки зрения задача слияния
ячеек родственна задаче проектирования печатной платы.
Для поддержки этой процедуры предлагается следующая схема
управления данными: фрагмент ЦБД, соответствующий описа¬
нию одной (проектируемой в данный момент) ячейки, считы¬
вается в ОЗУ перед началом ее проектирования и находится там
на протяжении всего процесса построения ячейки. Следует,
впрочем, отметить, что некоторые части описания ячейки могут
храниться в ОЗУ в течение меньшего времени. Так, по-видимому,
нет необходимости в одновременном хранении в ОЗУ описаний
Подуровней Ь2 и ЬЗ. По мере формирования описания подуровня
ЬЗ описание подуровня Ь2 может быть удалено из ОЗУ. По окон¬
чании построения ячейки обновляются хранимые о ней данные в
ЦБД на диске и ОЗУ освобождается для построения следующей
ячейки. Что касается соответствия между форматами описания
ячейки в ЦБД и в ОЗУ при ее построении, то здесь, по-видимому,
Целесообразно полное соответствие, т. е. хранение в ЦБД файлов,
с°Держащих двоичные образы ОЗУ.
2.4.3. Кремниевые ассемблеры. Простые ячейки (листья иерар¬
хи) не могут строиться с помощью процедуры слияния ячеек,
как они не содержат подъячеек. Для получения полной инфор¬
мации таких ячеек существует две возможности: 1) взять готовую
147
ячейку пз системной библиотеки стандартных ячеек; 2) сгенер1ь
ровать полное описание требуемой ячейки с помощью специальна
программы — кремниевого ассемблера.
Кремниевые ассемблеры представляют собой програмную фуп^,
цию, которая строит ячейку заданного типа (например, ПЛМ) По
ее описанию (набору параметров). Необходимый набор параметров
должен содержаться в задании на проектирование. Кремниевые
ассемблеры являются связующим звеном между кремниевым ком,
пилятором и конкретным набором технологических требований.
Состав кремниевых ассемблеров может быть разнообразным:
различные реализации ПЛМ, ПЗУ, регистры, счетчики и т. д.
С точки зрения структуры программы кремниевый ассемблер апа~
логичен кремниевому компилятору, но имеет и существенные от¬
личия:
1) подъячейки (строительные блоки) кремниевого ассемблера
представляют собой «мини-ячейки» уровня отдельного транзистора
или даже его части (например, затвора);
2) при слиянии «мини-ячеек» не применяются процедуры типа
трассировки — порты соединяются простым наложением; при
несовпадении портов соответствующая «мини-ячейка» растягива¬
ется;
3) в отличие от процедур слияния ячеек кремниевый ассемблер
не выполняет автоматического контроля проектных норм;
соблюдение проектных норм учитывается программистом при
разработке программы.
Последняя особенность нуждается в пояснении. Как известно,
реальные технологические требования к топологии СБИС пред¬
ставляют собой сложный и трудноформализуемый набор правил.
При его формализации неизбежно принятие ряда упрощающих
соглашений, которые позволяют создавать проектирующие про¬
граммы, но в то же время приводят к потере эффективности в ис¬
пользовании площади кристалла. Типичным примером такого
соглашения в канальных процедурах слияния ячеек является
прокладка проводников с таким расчетом, чтобы в любом его ме¬
сте можно было установить контактное окно. Такие допущения
вряд ли целесообразны в кремниевом ассемблере, поскольку про¬
стые ячейки наиболее критичны к расходу площади.
Учет проектных норм программистом позволяет улучшить
качество генерируемых ассемблером ячеек. Следует отметить, что
система должна позволять развитие набора кремниевых ассембле-
ров как в плане расширения состава генерируемых ячеек, так п
в плане привязки кремниевого компилятора к новым техно логи¬
ческим требованиям. Поэтому с точки зрения программной реалп-
зации целесообразно оформлять кремниевые ассемблеры как ие"
зависимые процессы, запускаемые с помощью средств операцион¬
ной системы ядром кремниевого компилятора.
148
2.5. Библиотека стандартных ячеек
Системная библиотека стандартных ячеек содержит все виды
представления ячеек, необходимые для проектирования. Кроме
^Ого, в ней должна содержаться дополнительная информация,
облегчающая разбор входного описания в интерактивном режиме
/сМ- выше). При реализации экспертной системы разбора здесь
потребуется структурная связь библиотеки с базой знаний эк¬
спертной системы.
В системе должны быть предусмотрены средства ведения,
редактирования и пополнения библиотеки. При этом наряду с
традиционными средствами описания библиотечных ячеек на
языке следует предусмотреть средства графического ввода и ре¬
дактирования библиотечных элементов. Такая ИГС может быть
создана на базе ПЭВМ.
Оставим в стороне вопросы, связанные с аттестацией библио¬
течных элементов. Аттестация связана со сложными задачами
электрического моделирования и должна производиться 32-раз-
рядной ЭВМ средствами специальной системы.
2.6. Интерактивный иерархический редактор
Интерактивная работа в рассматриваемой САПР имеет сущест¬
венные отличия от традиционного подхода.
Во-первых, вмешательство оператора (если он вообще допус¬
кается) в собственно процесс компиляции возможно только в
жестких рамках иерархии ячеек, заданной в ЦБД. Это означает,
что оператору для ручного вмешательства в каждый момент вре¬
мени доступна топология только одной ячейки.
Во-вторых, даже если такое вмешательство допускается, оно
целесообразно лишь в отдельных исключительных случаях.
В противном случае неизбежны большие потери времени.
Главная точка приложения интеллекта оператора в процессе
проектирования методом кремниевой компиляции лежит в несколь¬
ко иной сфере, а именно в ситуациях, когда спроектированный
кристалл не удовлетворяет разработчика по каким-либо парамет¬
рам — быстродействию, площади и т. д.
В этом случае проектировщику предоставляется две возмож¬
ности: 1) попытаться применить другие схемотехнические решения,
Для чего следует переделать исходное описание проекта в необ¬
ходимом объеме; 2) попытаться улучшить качество топологии крис¬
талла, целенаправленно воздействуя на иерархию ячеек в исход¬
ном описании. В обоих случаях измененное описание проекта
Компилируется заново. Однако вторая из указанных возможностей
Наиболее удобно реализуется в интерактивном режиме. Именно
Для этой цели и предназначен иерархический редактор, позволяю¬
щий перестраивать иерархию ячеек. Конечно, элементы библио¬
теки стандартных ячеек иерархическому редактированию не под-
Лен^ат. Список операций, необходимых для иерархического ре¬
дактирования см. в работе [2].
149
3.
СТРУКТУРА ДАННЫХ САПР НА ОСНОВЕ КК
Как уже отмечалось, данные о проекте могут представлять^
в трех видах: в двоичном виде на диске (ЦБД), в ОЗУ (локалы[ая
база данных — ЛБД) и в текстовом виде на диске (задание Па
проектирование — ЗГ1).
Вводная система транслирует описание с ЯВУ в ЗП, написанное
на языке более низкого уровня — EDIF уровня 2. После этого
ЗП транслируется в ЦБД, что не составляет труда, поскольку
в ЗП проект описан в тех же терминах, что и в ЦБД (небольшое
исключение оговорено в пункте о ЗП). При вызове различных
программ в процессе проектирования в ОЗУ образуется ЛЕД,
содержащая нужную данной программе информацию. Содержание
ЛБД для различных программ может меняться, так, ЛБД прог¬
раммы кремниевого ассемблера для проектирования ПЛМ весьма
существенно отличается от ЛБД интерактивной процедуры пла¬
нирования компилируемой ячейки. Однако все ЛБД имеют одну
общую черту: они содержат данные об одной ячейке, обрабатывае¬
мой в данный момент, что и позволило назвать их локальными.
3.1. Модель данных в ЦБД
Как это принято в теории баз данных [4], под бинарной мо¬
делью данных (5, г) будем понимать набор множеств
5 = {Х15 . . ., Хп}
и набор бинарных отношений
г = {г15 . . г,п}
на этих множествах. С точки зрения практических приложений
множества Xj GE S соответствуют наборам данных, а отношения —
информационным связям между наборами, поддерживаемые СУБД-
В работе [3] описаны методы оценки модели (5, г) по расходу
памяти и времени выполнения элементарных запросов в случае,
когда все данные размещаются в ОЗУ. Эти методы оказались пло¬
дотворными для разработки систем проектирования менее насы¬
щенных объектов, таких, как печатная плата или матричная Б ПС
невысокого уровня интеграции.
В случае проектирования СБИС с высоким уровнем интегра¬
ции указанные методы неприменимы, так как объема ОЗУ явно
недостаточно для хранения всех данных. Тем не менее модель
данных в ЦБД, ориентированная на хранение данных на дне ко,
имеет смысл. В дальнейшем она позволит выбрать метод реализа¬
ции для каждого элемента модели и оценить объем памяти, IlC
прибегая к общим методам.
Модель данных в ЦБД изображена на рис. 2. Она содержа1
8 множеств (обозначены латинскими буквами) и 8 бинарных отно¬
шений (греческие буквы). Опишем компоненты модели подробно6*
150
ряс. 2. Бинарная модель
данных ЦБД ядра КК (иуп-
дТирнымн рамками обозпа-
чеЯа часть данных, считы¬
ваемая в ОЗУ при слиянии
дчеек)
Множество CELLS представляет собой библиотеку всех ячеек
проектируемой ИС. Множество MULT—CELLS формально может
быть определено следующим образом:
MULT—CELLS = {(с1? с2,
где с2 ЕЕ CELLS; с2 — подъячейкгт х — дополнительная
информация.
Везде в дальнейшем, когда будет идти речь об элементах мно¬
жества MULT CELLS, значение компоненты сг будет подра¬
зумеваться из контекста. Поэтому в реальном описании компонен¬
ты не хранятся. Таким образом, элементы множества MULT
CELLS представляют собой описание (с2, х) конкретных подъячеек
для каждой ячейки с1? где с2 — библиотечный образ подъячейки;
х — информация, придающая ей конкретное содержание (напри¬
мер, относительные координаты). Следует подчеркнуть, что раз¬
личные подъячейки одной ячейки могут иметь одинаковые библио¬
течные образы и различаться только значениями х.
Отношение со связывает ячейку с со всеми ее подъячейками
в MULT_CELLS:
со (q, с2, х) Фг с = с±.
Отображение ц ставит в соответствие т ЕЕ MULT CELLS
библиотечный образ:
И : (с17 с2, х) —> с2.
Таким образом, подмодель (CELLS, MULT CELLS, о, р.)
Полностью задает иерархию ячеек, рассматривавшуюся в преды¬
дущем разделе.
Множество INTERFACES представляет собой набор внешних
описаний ячеек с ЕЕ CELLS: минимальный охватывающий бокс,
Местоположение портов, электрические параметры портов. От¬
ношение р — естественное взаимно однозначное соответствие меж-
ДУ множествами CELLS и INTERFACES. Отношение % ставит в
соответствие ячейке с (Е CELLS ее описание на языке высокого
Уровня (HIGH LEVEL). Отношение % приведено здесь для ил¬
люстрации возможностей связи КК с другими подсистемами, ана¬
лизирующими входные и промежуточные описания проекта. От¬
151
ношений этого типа может быть много. Можно предусмотриТь
например, электрическое описание, поведенческое описание и т. д’
Множество PORTS представляет собой набор портов ячеек*
а отображение л ставит в соответствие порту конкретную подъ1
ячейку, которой он принадлежит. Отношение ср связывает порт
с инцидентным ему сигналом из множества SIGNALS, а отнощ^
ние е — сигнал с реализующей этот сигнал топологией в виде
бора отрезков, боксов или многоугольников пз множеству
LAYOUT.
Таким образов, модель данных нами определена полностью.
Ниже анализируются возможности ее реализации.
3.2. Очерк путей реализации модели
Как уже отмечалось методы реализации бинарных моделей
в виде структур, резидентных в ОЗУ в рассматриваемом случае
неприменимы ввиду большого объема памяти, необходимого для
хранения данных. В этих условиях естественно пытаться выделить
части модели, соответствующие данным, которые должны одно¬
временно находиться в ОЗУ, и применить указанные методы толь¬
ко для этих частей. Организуем данные с таким расчетом, чтобы
эти части хранились в отдельных файлах. Тогда реализация данных
внутри файлов может производиться по тем же правилам, что и в
ОЗУ, так как обработка их производится после считывания файла
в ОЗУ. Таким образом, получаем применение методов [3, 5, 6]
для кусочно-резидентных структур данных.
Сведение описанной модели к кусочно-резидентной структуре
несложно. Найдем образы отношений р и со:
Ie = р (с) е INTERFACES,
Мо = со (с) е MULT_CELLS
Затем вычислим Сс = ц (Afc), Nc = р (Сс\ Рс = л-1
So = ф (Pc), Lc = е (5С), Нс = X (с).
Подмодель, образованную множествами /с, Мс, Сс, Nc, Рс>
Sc, Lc, Hc и ограничениями на них соответствующих отношений
назовем полной спецификацией ячейки с. Другими словами, пол¬
ная спецификация ячейки есть набор данных, которые можно вы¬
числить по заданной ячейке с ЕЕ CELLS с помощью отношений мо¬
дели без спуска по иерархии ячеек (т. е. без многократных про¬
ходов по циклу, образованному отношениями со и ц).
Ясно, что вся модель разбивается на классы — полные спец#-
фикации ячеек. Условимся хранить данные с учетом этого разбие¬
ния. Всем файлам, описывающим одну полную спецификацию!
назначим одно общее имя (имя ячейки) и будем различать их только
по расширениям. В этом случае множество CELLS можно реали¬
зовать в виде каталога имен ячеек;
интерфейс ячейки с — файлом C.IFC,
описание высокого уровня — файлом C.HGH.
152
Можно поступить аналогичным образом с оставшимися компо¬
нентами полной спецификации: Мс, Рс, Sc, Lc, однако это пред¬
ъявляется нецелесообразным, поскольку все эти данные при слия-
Н0й ячеек считываются в ОЗУ одновременно. Поэтому их следует
реализовать в одном файле G.INT в виде структур, описанных в
работе [3].
3.3. Структуры данных в файлах
Дадим краткое описание файлов, описывающих компилируемую
ячейку с именем CELL.
1. CELL.IFC — содержит информацию об интерфейсе ячейки
CELL для тех процедур, которые воспринимают CELL в качестве
подъячейки рассматриваемой ими ячейки. В CELL.IFC входят:
а) минимальный охватывающий бокс — прямоугольник с
горизонтальными и вертикальными сторонами, принимаемый за
габариты CELL;
б) информация о портах CELL — их количество, для каждого
порта — расположение, тип порта, физические параметры, необ¬
ходимые для вычисления временных задержек с использованием
{R — С)-модели — емкость и сопротивление;
в) информация о временных задержках между зависимыми
парами вход-выход — количество пар, о каждой паре —
№ порта-входа, № порта-выхода, тактовая фаза, при которой
появляется зависимость, четыре величины временных задержек
при различных типах перехода.
2. CELL.HGH — файл сопутствующей (в основном текстовой)
информации о ячейке. Сюда, например, входит описание ячейки
во входном описании проекта, любые комментарии, которые поль¬
зователь захочет дать перед или в процессе проектирования, и т. д.
3. CELL.INT — файл, содержащий информацию о внутреннем
строении ячейки, используемую процедурой компиляции. Таковы
Данные, которые хранятся в ЦБД о каждой компилируемой ячейке.
Следует отметить, что записанная в ЦБД информация о ячей¬
ках пополняется (или частично уничтожается) по мере работы
Различных программ. Таким образом, многие поля могут не содер¬
жать информации. Программы должны отличать поля, в которых
записан «мусор», от тех, в которых находится существенная ин¬
формация. Этого можно добиться, отводя под каждое поле на 1 бит
больше, чем требуется для записи информации, и занося в этот
бит 0 или 1 в зависимости от того, существенна ли записанная в
Данном поле информация.
3.4. Задание на проектирование
Задание на проектирование (ЗП) есть текстовое изображение
^формации, находящейся в ЦБД. Единственное отличие - то,
т° в описании ячейки присутствуют логические уравнения, свя-
^вающие сигналы различных портов ячейки и ее подъячеек.
153
При трансляции ЗГ1 в ЦБД в файле. INT при необходимости 3<г
водится еще одна подъячейка, которую собирает кремниевый ас¬
семблер, проектирующий ПЛМ, реализующую эти логические ураю
нения. После этого в ячейке остаются только соединения между
портами ее самой и ее подъячеек (в том числе и добавленной ПЛ
Все данные, находящиеся в ЦБД, могут быть записаны на E.l)Jp
уровня 2.
3.5. Локальные базы данных
ЛБД создаются в ОЗУ при работе различных программ, входя¬
щих в состав САПР. Основной программой является ядро К К
занимающееся слиянием подъячеек в ячейку. При этом в ОЗУ
должна находиться полная спецификация ячейки.
В зависимости от свойств программы в ЛБД включаются не¬
которые данные, используемые именно этой программой. Так,
программа трассировки, использующая предварительную гло¬
бальную трассировку, должна иметь место для записи результатов
глобальной трассировки — распределения трасс по каналам. Таким
образом, в ОЗУ естественно ввести секцию с описанием всех ка¬
налов как исходных данных для канальной трассировки. Про¬
грамма физического и временного моделирования, запускаемая при
каждом слиянии, также создает в ОЗУ какие-то необходимые ей
данные.
Естественно, формат записи в ЦБД данных, черпаемых в ОЗУ
непосредственно из ЦБД, должен быть максимально приближен
к формату записи этих же данных в ОЗУ, чтобы уменьшились за¬
траты времени на формирование ЛБД.
ЛИТЕРАТУРА
1. Превращение персонального компьютера в компилятор микросхем//
Электроника. 1986. Т. 59, № 12. С. 49—54.
2. Ayres В.. F. VLSI: Silicon compilation and the art of automatic microchip
design. N. Y.: Prentice-Hall, 1983, 482 p.
3. Ойхман E. Г. Графические системы для СМ ЭВМ. М.: Наука, 1986. 192 с.
4. Дейт К. Введение в системы баз данных. М.: Наука, 1980. 463 с.
5. Зюзин Ю. В., Новоженов Ю. ВОйхман Е. Г. Структурная модель дан¬
ных графических систем проектирования печатных плат//АиТ. 1984.
№ 12. С. 138-144.
6. Ойхман Е. Г., Зюзин Ю. В. Методы оптимизации прикладных структур¬
ных данных в интерактивных графических системах на персональны^
ЭВМ//Информатика-87: Тез. докл. II Всесоюз. конф. Ереван. 1987-
С. 242.
154
УДК 681-3.001
ПРИМЕНЕНИЕ СИСТЕМ ИНФОРМАТИКИ
ДЛЯ АВТОМАТИЗАЦИИ
УЧРЕЖДЕНЧЕСКОЙ ДЕЯТЕЛЬНОСТИ
Б. И. Ростокин
Современные системы организационного управления (или уч¬
реждения) можно рассматривать как высокопараллельные и вы-
^окоинтерактивные системы, характеризующиеся большим объ¬
емом и разнообразием типов информации. Доля этих систем в ин¬
фраструктуре общества постоянно возрастает, поскольку предме¬
том их деятельности является преобразование информации и по¬
лучение на этой основе «качественно новой» информации, влияющей
на эффективность процесса выработки и принятия решений. Темпы
роста объема перерабатываемой информации постоянно увеличива¬
ются, что неизбежно ведет к значительному увеличению издер¬
жек, связанных с функционированием подобных систем [1].
Опыт применения в системах организационного управления
средств вычислительной техники, информатики и оргтехники поз¬
воляет выделить несколько основных стадий автоматизации тех¬
нологии обработки информации. На первой стадии основные уси¬
лия, как правило, направлялись на автоматизацию отдельных
конторских или рутинных операций и поиск методов повышения
производительности тех категорий служащих, которые были свя¬
заны с выполнением технической работы, например накоплением
и извлечением информации, подготовкой документов, контролем
за прохождением документов, планированием различных меро¬
приятий и т. п. Временные затраты на подобного рода операции
достаточно велики, чем и объясняется стремление руководителей
учреждений в максимальной степени рационализировать труд
Данной категории служащих [2]. Характерной особенностью данной
стадии являлось то обстоятельство, что автоматизация учрежден¬
ческой деятельности носила фрагментарный характер, при этом
технологические средства не объединялись в единый «техноло¬
гический процесс».
На второй стадии автоматизация организационного управления
Развивалась в направлении создания систем, ориентированных
®а выполнение конечного множества регулярных задач на основе
Централизованной обработки данных с использованием ЭВМ сред¬
ней и большой производительности. В этом случае первичные дан-
Нь*е поступали в центральную ЭВМ с локальных мест возникнове¬
ния запросов на их хранение и обработку.
^Третья стадия характеризуется переходом от централизован¬
ней обработки информации к распределенной обработке данных с
Применением персональных ЭВМ (ПЭВМ), объединенных в ло¬
кальной вычислительной сети и имеющих доступ к большой ЭВМ
113 Данной сети. На последующих стадиях все большее значение
155
будут приобретать проблемы автоматизации аналитических видОм
деятельности в учреждениях, решение которых в значительно^
степени базируются на системах информатики, в основу которые
положены идеи и разработки в области искусственного пптел„
лекта: базы знаний, экспертные системы, естественные языкц
взаимодействия с системой и т. п. Эта тенденция сохранит^
в течение длительного периода времени, поскольку лишь 27 % всех
видов деятельности учреждения связаны с выполнением достаточно
хорошо формализованных задач, остальная доля приходится на
трудноформализуемьте задачи или задачи, не имеющие алгоритми¬
ческого решения, т. е. задачи, которые выполняют эксперты
и руководители, принимающие участие в процессе выработки
и принятия решений [3].
Если основными целями автоматизации организационного
управления является совершенствование организационной струк¬
туры (и как следствие уменьшение непроизводственных издержек
в работе служащих), то успешное продвижение в этом направле¬
нии требует значительных усилий, связанных с глубоким и все¬
сторонним пониманием структуры учреждения и существующих
в нем информационных и организационных связей.
В данной работе анализируются особенности систем органи¬
зационного управления с позиций применения средств информа¬
тики и вычислительной техники, а также рассматриваются основ¬
ные проблемы построения технологии обработки информации
в учреждении.
Концептуальная модель учреждения. Система организацион¬
ного управления (или учреждение) — это сложная многоуровне¬
вая система, предназначенная для решения задач на основе при¬
нятого разделения труда с целью повышения эффективности про¬
цесса подготовки и принятия решений. Эту систему можно опи¬
сать в виде множества объектов (которые, в свою очередь, также
могут быть множествами составляющих их элементов) и отноше¬
ний, определяющих связи между ними. Используя теоретико¬
множественный подход, концептуальная модель учреждения фор¬
мулируется следующим образом:
и = (G, W, Т, R, ф, <
где определены четыре «спецификации» и два преобразования,
выполняемые над элементами множеств и формирующие новые
множества, состоящие из упорядоченных пар элементов исходны*
множеств:
G — множество всех возможных целей управления, выраженны*
в терминах требуемых задач;
W — множество всех возможных задач, которые отвечают цел#*1
управления; w GE W — конкретная задача, связанная с той нЛ#
иной целью управления;
Т — множество всех возможных методов организации решен^
задач (или технологических средств), обеспечивающих получен#6
некоторого решения, отвечающего цели управления;
156
R — множество всех возможных конкретных решений, которые
отвечают сформулированной цели управления; г ЕЕ В — кон¬
кретное решение, удовлетворяющее цели g ЕЕ G-,
ср — преобразование, описывающее декартово произведение мно¬
жеств G и формирующее множество Л, элементы которого удов¬
летворяют заданным целям управления. Во множестве А содер¬
жатся такие упорядоченные пары (g, ш), в которых элементы w
реализуют цель g;
ф — преобразование, описывающее декартово произведение мно¬
жеств А и Т и формирующее множество R, элементы которого
определяют отдельные решения, обеспечивающие достижение
цели g ЕЕ G.
Таким образом, основные этапы процесса решения в учрежде¬
нии описываются следующим: образом:
ф: (ср: (G х И7)) х Т -> R.
В общем случае в концептуальной модели учреждения можно
выделить такие составные части, как собственно учреждение
(цели, функции, задачи, структура, информационная модель),
персонал (служащие учреждения) и технологические средства,
определяющие технологию решения задач. При возникновении
«события» (например, получение информации из какой-либо точки
учреждения или подготовка документа) деятельность учреждения
(в конечном итоге человека) направлена на создание «новой»
информации. Между любыми парами выделенных частей учреж¬
дения существуют связи. Если человек (субъект) обнаруживает
некоторое событие, которое входит в сферу деятельности учреж¬
дения, то для достижения поставленной цели он вызывает опре¬
деленный набор задач, для решения которых используются необ¬
ходимые технологические средства. Такая концептуальная модель
означает, что нельзя отдельно исследовать только учреждение,
только персонал или только технологию. Эти аспекты должны
изучаться во взаимосвязи. Ниже кратко рассмотрим особенности
составных частей концептуальной модели.
Учреждение. Вопросы построения информационной модели
и Достижения глобальной эффективности функционирования обус¬
ловливает необходимость выделения в учреждении функциональ¬
ной и организационной структур. Такое разделение обосновано
Различием в характере знаний, которые влияют на решение задач
в рамках учреждения. Организационная структура описывает
Формальные и неформальные отношения между подразделениями
11Ли служащими и определяет служебную иерархию. Знания, со-
°тветствующие этой структуре, непосредственно влияют на пове¬
дения учреждения в целом и на способы выполнения учрежденче-
сКих задач. Функциональная структура описывает функциональ¬
но услуги и включает объекты и операции (правила, процедуры),
°торыми пользуются служащие, чтобы достичь поставленной
win. функциональная структура должна определять сферу
Ятельности учреждения и представлять информационную мо¬
157
дель, характеризующую учреждение в целом. Системы органи3а
ционного управления характеризуются следующими свойствам^.
— неполнота и противоречивость знаний о предметной об.|а*
сти и решаемых задач не позволяет определить полный набор ОГ1С<
раций, соответствующий выполняемым задачам. Множество вОз^
ножных состояний при решении задач не ограничено, так цак
имеется неограниченное множество вариантов достижения постав,
ленной цели;
— организационная и операционная среды, в которых выра.
батываются решения, постоянно изменяются;
— значительная часть деятельности учреждения связана
с решением неформализованных задач, т. е. задач, характеризую¬
щихся неполнотой исходных данных и не имеющих точного он ре.
деления целевой функции.
Отмеченные особенности систем организационного управления
стимулируют интенсивные исследования в области разработки
и внедрения экспертных систем, ориентированных на решение
широкого круга задач в неформализованных областях [4].
Персонал. Опыт автоматизации систем организационного типа
показывает, что для привлечения как можно большего числа
служащих, состоящего в основном из неискушенных в информа¬
тике людей, к активному использованию средств вычислительной
техники на первых этапах автоматизации учрежденческой дея¬
тельности целесообразно придерживаться подходов, обеспечива¬
ющих эволюционное внедрение технологических средств, ориен¬
тированных в первую очередь на повышение производительности
труда при выполнении рутинных операций, отвлекающих служа¬
щих от непосредственной аналитической работы и занимающих
большое количество времени. Последовательность и целенаправ¬
ленность в реализации этого принципа позволяет прежде всего
выявить интерес к средствам информатики и вычислительной тех¬
ники со стороны этой категории лиц и постепенно развить у них
вкус к работе с этой техникой и выработать потребность в постоян¬
ном использовании современных технологий обработки информа¬
ции. При этом не следует значительно изменять существующие
формы связи человека с информацией (т. е. формализация доку¬
ментов должна проводиться с учетом психологических факторов
служащих, работающих с этими документами). В то же время
система должна эффективно поддерживать работу служащий
аналитиков, обладающих большими знаниями в области обра¬
ботки данных и способных во многих случаях сформулировать
нетривиальные задачи.
Эти особенности позволяют определить требования к совре'
менным индивидуальным рабочим станциям, используемым в Ух?
реждениях. К числу таких требований следует отнести дешевизн)
и эффективность рабочих станций, чтобы учреждение было заин¬
тересовано в оснащении ими всех (или почти всех) служащий’
а также их привлекательность с точки зрения удобства и просТ°
ты работы, чтобы внедряемая система не была отвергнув
158
большинством потенциальных пользователей. «Дружественный»
интерфейс с пользователями предполагает наличие многооконной
-технологии, ввода-вывода аудиоинформации, функциональной
клавиатуры, ввода-вывода графической информации и изображе¬
ний, Команды, обеспечивающие связь с рабочей станцией, должны
быть легкими для изучения и запоминания, мнемоника их в явном
вйде должна нести смысловое содержание предпринимаемых дей¬
ствий, т. е. инерфейс служащего с системой должен быть доста¬
точно прозрачным, надежным, гибким и т. п. [5].
Технологические средства. Постоянно возрастающие требова¬
ния к обработке информации и увеличение издержек администра¬
тивного управления обусловливают необходимость целенаправ¬
ленного внедрения средств информатики и вычислительной тех¬
ники в практику деятельности учреждений. Эта.проблема может
быть решена на основе интегрированных систем, обеспечивающих
поддержку технологии распределенного управления, хранения,
обработки, передачи и контроля информации. Современные ин¬
формационные технологии, интегрируемые в рамках распреде¬
ленных систем, предоставляют развитые средства, ориентиро¬
ванные на [6]:
информацпи (графичес-
и т. п.).
обработки информации
для автономной работы
рабочих мест), объеди-
— создание первичных данных;
— создание и ведение баз данных и баз знаний;
— организацию и передачу данных;
— организацию интерфейсов пользователей с информацион¬
ными и вычислительными ресурсами системы;
— обработку нетрадиционных видов
кой, документальной, конструкторской
В рамках распределенной системы
имеется широкий спектр возможностей
индивидуальных рабочих станций (или
ненных в локальные вычислительные сети. Основная цель рас¬
пределенных систем — поддерживать высокую степень автоном¬
ности, гибкости функционирования индивидуальных рабочих
станций, одновременно обеспечивая рациональный объем глобаль¬
ного управления информацией и ее целостности. Снижение стои¬
мости электронного оборудования предоставляет возможности для
введения новых или расширения уже известных технологий хра¬
нения, обработки и передачи данных. Это создает предпосылки
Для построения интегрированных систем обработки информации,
°сновными (или первичными) элементами которых являются ин¬
дивидуальные станции обработки данных, базирующиеся на
ПЭВМ, которые оснащаются развитыми функциональными про¬
граммными средствами [7]. На рисунке показана конфигурация
сИстемы, являющаяся обобщенной моделью автоматизированной
системы обработки данных в учреждении. Основными элементами
Г??й системы являются индивидуальные рабочие станции на базе
(ИРС) и специализированные разделяемые станции (СРС):
ииции печати, станции управления файлами, машины баз дан-
коммуникационные станции и т. п. Эти специальные стан-
159
ции предоставляют служащим такие функции, как электрону
почта, быстрая и высококачественная печать документов, храН(?
ние больших массивов данных и документов, выход в другие к0А
муникационные среды.
Одно из преимуществ такой системы — это высокая степець
доступности (т. е. высокая вероятность доступа к физическим j
логическим ресурсам), которая достигается за счет распределения
между узлами наборов необходимых процедур. Однако такая кож
фигурация требует больших капитальных вложений. Поэтому
при проектировании подобных систем критерий доступности
Конфигурация автоматизирован гтоц
системы
ИРС — индивидуальная рабочая став]п1я
ЛБД — локальная база данных;
КС — коммуникационная станция-
СП — станция печати;
С PC — специализированная разделяемая
станция: машина управления фай¬
лами, машина баз данных, маши¬
на баз знаний и т. п.
играет ключевую роль. Это определяет подходы, основанные на
распределении функций таким образом, что часто используемые
функции размещаются в ИРС, а более трудоемкие и времяемкпе
функции (например, обработка больших массивов данных) рас¬
полагаются в СРС. Это, безусловно, предполагает, что ИРС об¬
ладают значительными функциональными возможностями, в том
числе и физическими ресурсами. При этом допускается дубли¬
рование данных, которое обеспечивает снижение интенсивности
обращений к данным, размещенным в локальной вычислительной
сети. В каждой ИРС (или большинстве) находится локальная
(или личная) база данных, а в СРС размещаются данные, разде¬
ляемые служащими одного или нескольких подразделений.
Достижения в области разработки технических и программных
средств ПЭВМ позволяют разработчикам автоматизированных
систем концентрировать свои усилия на решении проблем, свя¬
занных с построением интегрированных технологических систем,
отвечающих целям и задачам конкретного учреждения. В процес¬
се разработки проекта автоматизации учрежденческой деятель¬
ности необходимо стремиться получить достаточно объективную
информацию об объекте управления, его сфере деятельности й
требования к информационному обслуживанию. В решении этой
задачи следует выделить пять основных фаз:
— определение границ проекта и участников проекта, пссле-
дование методов и средств анализа организационной и функций
нальной структуры учреждения, планирование работ по обсле¬
дованию учреждения;
— анализ существующих в учреждении уровней информ3'
ционного обслуживания, определение целей, задач и проблем
в подразделениях. Эта информация позволит определить пр110'
ритетные направления при разработке проекта;
— идентификация, описание и моделирование функций п 1111
160
д рационных требований учреждения. Эта информация являет-
основой для разработки детальной информационной модели
упреждения и определения границ проекта;
У анализ существующей информационной технологии в уч¬
реждении с целью определения возможных путей ее совершен-
сТрования или введения новых информационных технологий,
обеспечивающих эффективное выполнение функций, определен¬
ных сферой деятельности учреждения;
— определение границ предлагаемых организационных и
технических решений с учетом областей интересов и потребностей
каждого структурного подразделения учреждения.
Создание на основе современных технологий эффективных
автоматизированных систем обработки информации обусловливает
проведение широких исследований в таких областях теории и
практики информатики и вычислительной техники, как:
— исследование и разработка методов и средств представле¬
ния информации; информационных моделей учрежденческих сис¬
тем и их подсистем; архитектуры интегрированных учрежденче¬
ских систем;
— разработка инструментальных программных средств для
организации и управления данными; текстовой обработки; под¬
готовки, хранения, поиска и обработки документов произвольной
формы; передачи информации между рабочими станциями, участ¬
вующими в кооперативной обработке данных, и т. п.;
— разработка перспективных технических средств для хра¬
нения, обработки и передачи информации.
Комплексное решение этих проблем позволит перейти к целе¬
направленному применению интегрированных систем обработки
данных, базирующихся на принципах разделения информации и
распределенной обработки. Это обеспечит повышение эффектив¬
ности работы как отдельных служащих, так и всего учреждения
в целом, приведет к улучшению внутренних и внешних коммуни¬
каций, а также создаст предпосылки для продвижения к рацио¬
нальной организационной структуре учреждения.
ЛИТЕРАТУРА
Кочетков Г. Б. Автоматизация конторского труда в США: Теория и прак¬
тика «офиса будущего». М.: Наука, 1985. 223 с.
г Ершов А. П. Автоматизация работы служащих. М.: МЦНТИ, 1985. 52 с.
a. Bergerud М., Gouzalez J. Word/Information processing: concepts of office
automation. N. Y.: Wiley, 1984. 493 p.
Попов Э. В. Экспертные системы: Решение неформализованных задач в
t Диалоге с ЭВМ. М.: Наука, 1987. 288 с.
• Картофлицкий В. П. Об одном подходе к разработке пользовательских
прикладных программ//ЭВМ массового применения. М.: Наука, 1987.
6 с. 69-74.
* Гриценко В. И., Паньшин Б. Н. Новая информационная технология в ор¬
ганизационных системах // Управляющие системы и машины. 1988. № 1.
7 С. 20-27.
КигдайЛ. К., Филинов Е. Н. Основные направления развития приклад¬
ного программного обеспечения персональных компьютеров // Там же.
8—19.
Заказ к» 2514
161
УДК 681.3.06:519
ОБ ОДНОМ ВАРИАНТЕ
ПРОБЛЕМНО-ОРИЕНТИРОВАННОЙ
СИСТЕМЫ ПРОГРАММИРОВАНИЯ
ДЛЯ РЕШЕНИЯ МАТЕМАТИЧЕСКИХ УРАВНЕНИЙ
/>./’. Доступов. В. Г. Колобов. М.Н. Черныш
Важнейшим условием массового и эффективного применения
персональных ЭВМ (ПЭВМ) является разработка систем програм¬
мирования, обеспечивающих создание надежных прикладных
программ (ПП) пользователем-непрограммистом. Разработка по¬
добных систем может осуществляться по нескольким направле¬
ниям.
Во-первых, создание систем генерации прикладных программ
на основе организации вызова и композиции заранее разработан¬
ных прикладных программных модулей, размещаемых в соответ¬
ствующей базе.
Во-вторых, переход при разработке прикладных программ
к проблемно-ориентированным языкам программирования сверх¬
высоких уровней.
В-третьих, использование языков предметных областей в ка¬
честве входных языков для разработки программ решения при¬
кладных задач.
С точки зрения повышения надежности получаемых приклад¬
ных программ последнее направление представляет особый инте¬
рес, поскольку пользователь, как правило, владеет в совершенстве
языком своей предметной области и в связи с этим вероятность
возникновения ошибок в программах в случае применения систе¬
мы, базирующейся на языке предметной области, должна резко
снижаться.
Среди; пользователей ПЭВМ выделяется обширная группа
специалистов, заинтересованных в реализации методов математи¬
ческого моделирования для выполнения научно-исследователь-
ских работ и проектирования новых объектов и технологических
процессов. Характерная особенность условий применения
ПЭВМ специалистами этой группы заключается в большом раз¬
нообразии реализуемых ими математических моделей. В связи
с этим разработка типового прикладного программного обеспе¬
чения оказывается затруднительной. Большинство прикладных
программ, реализующих математические модели, используется
узким кругом специалистов либо носит уникальный характер*
В этих условиях особое значение приобретают исследования’
направленные на максимальное упрощение человеко-машинно^
интерфейса для обеспечения возможности применения ПЭЬ1
пользователем-непрограммистом. Разработка систем программ11
рования, ориентированных на использование языков предметны5
областей, идет именно в этом направлении.
162
Одной из первых работ, относящихся к данному направлению,
^откно считать генератор Бейсик-программ для компьютера VAX
(1J, разработанный Марти Халворсоном (фирма DEC, США).
дтОт генератор обеспечивает создание программ, реализующих
решение алгебраических и трансцендентных уравнений методом
ртерации. Однако непременным условием применения программы
является то, что пользователь должен уметь приводить уравнения
к виду, приемлемому для последующего применения языка
Бейсик.
Более совершенными являются программы решения алгебраи¬
ческих и трансцендентных уравнений, созданные в 1985—1986 гг.
Б. Райтом (США). Последняя из них т. н. Formula/One [2] обес¬
печивает решение уравнений на основании ввода в ЭВМ их ана¬
литического выражения и задания констант. Система ориенти¬
рована на ПЭВМ.
Разработка программных систем, указанных выше, свидетель¬
ствует о том, что в США идет поиск технологии программирования
вычислительных задач, позволяющих пользователю взаимодей¬
ствовать с ПЭВМ на языке, близком к языку математики. Однако
в этом направлении пока что получены лишь первые результаты.
Важным достоинством подобных программных систем является
автоматизация процедуры генерирования прикладной программы.
Благодаря этому значительно сокращается как время разработ¬
ки ПП, так и вероятность появления ошибок. Однако организа¬
ция самого диалога ввода уравнений в этих системах не избавляет
пользователя от необходимости изучения синтаксиса языков
общения с ЭВМ. Любое отступление от синтаксиса этих языков
при вводе уравнений, допущенное пользователем, может привести
к отказу функционирования программных систем. Таким обра¬
зом, подобная организация диалога ввода не только требует
от пользователя дополнительное время на усвоение языка обще¬
ния, но, что значительно важнее, не позволяет достичь высокой
степени надежности ПП.
Авторами разработана программная система, позволяющая
пользователю-непрограммисту генерировать Бейсик-программы
численного решения обыкновенных дифференциальных уравнений
На ПЭВМ. Принципиальное отличие этой системы от упомянутых
аналогов заключается в оригинальном способе организации диа¬
лога пользователя с ЭВМ при вводе уравнений. Суть этого спо¬
соба состоит в том, что пользователь вводит правые части своих
Уравнений, используя предлагаемое ему ЭВМ «меню» из наиболее
Ласто встречающихся фрагментов математических зависимостей,
включающих элементарные арифметические операции, наиболее
Употребимые математические функции, а также более сложные
Зависимости. Если ни один из предлагаемых ЭВМ фрагментов не
Позволяет полностью идентифицировать его с правой частью
какого-либо из уравнений, у пользователя имеется возможность
с Помощью промежуточных буквенных обозначений ввести это
Уравнение поэтапно, используя несколько фрагментов последо¬
163
6*
вательно. Таким образом, на пользователя лишь возлагается
элементарная задача идентификации подходящих фрагментов
а также последующий ввод выбранных буквенных обозначений
и известных числовых значений. Все остальное, включая опреде,
ление последовательности вычисления введенных промежуточны^
обозначений и дальнейшую генерацию подпрограммы вычисления
правых частей уравнений, согласно этой последовательности
выполняет ЭВМ.
Функционально, в разработанной программной системе можНо
выделить три основных блока. Во-первых, диалоговый блок ввода
правых частей уравнений «Ввод», во-вторых,- блок генерация
Бейсик-подпрограммы вычисления правых частей уравнений
«Связь» и, в-третьих, блок численного решения «Счет».
Большую часть системы составляет блок ввода уравнений
реализующий упомянутую выше идею организации диалога’
Прежде всего пользователь вводит размерность системы уравне¬
ний N, что позволяет в дальнейшем контролировать корректность
введенных им значений индексов I при неизвестных и правых
частях уравнений Ft (0 i N). После этого пользователю
предлагается ввести первое из уравнений, а именно представить
его правую часть Fr в виде последовательности наиболее упо-
требимых математических операций. Каждая из этих операций
г г
(например: Y = A, Y = 2 А’’ = П А/> = АВ\ У =
j=i
= Лйш у и т. д.) имеет свой номер L, так что для инициализации
выбранной операции пользователю достаточно ввести этот номер.
Затем пользователь определяет результат операции У, присваи¬
вая ему некоторое обозначение из одного-двух символов. Это
может быть либо «Fp>, являющееся обозначением всей правой
части уравнения, либо промежуточное обозначение, которое ис¬
пользуется в качестве операнда в других (другой) операциях.
Определив результат У, пользователь переходит к диалогу ввода
операндов. Операнды могут быть следующих типов: десятичные
константы в форме с плавающей или фиксированной точкой;
имена неизвестных Хх, Х2, . . ., XN\ а также введенные пользова¬
телем обозначения результатов других операций. Прежде чем
вводить каждый операнд, пользователь определяет его тип, что
позволяет осуществлять дополнительный контроль за правиль¬
ностью ввода. Так, например, если пользователь вводит число,
блокируется любая возможность ввода последовательности сим¬
волов, которая не является десятичной записью числа. При этом
блокируется также ввод лишних знаков мантиссы и порядка, что
позволяет избежать ситуации «overflow». Кроме того, если по
смыслу вводимое число должно быть целым положительным (на¬
пример, количество членов суммы ряда г), то блокируется воз¬
можность ввода десятичной точки«.», признака порядка «Е»
знака «—».
После того как пользователь определил все операнды, входя*
164
в выбранную им операцию, в программе формируется строка
^мволов, соответствующая записи введенной операции в виде
рдератора присваивания на языке Бейсик. При этом правиль¬
ность всех языковых конструкций соблюдается автоматически,
Н для использования этого оператора в подпрограмме вычисления
правых частей уравнений необходимо только присвоить ему нуж¬
ный номер.
Дело в том, что пользователю не обязательно использовать
в качестве операндов во вводимой им операции лишь те обозна¬
чения, которые были определены им предварительно как резуль-
таты предшествующих операций. Это было бы, по-видимому,
слишком обременительно. Поэтому задачу упорядочивания опе¬
раторов генерируемой подпрограммы вычисления правых частей
уравнений выполняет специальный блок «Связь», который функ¬
ционирует в автономном режиме после окончания диалогового
режима работы блока «Ввод». Процесс упорядочивания сопровож¬
дается контролем за корректностью ввода, а именно: каждое из
введенных пользователем обозначений операндов должно быть
результатом одной и только одной операции, все правые части
должны быть определены и т. д. В случае обнаружения ошибки
на мониторе появляется сообщение о ее характере, управление
передается блоку «Ввод» и пользователь имеет возможность ее
исправить. Если ошибок не обнаружено, блок «Связь» генерирует
подпрограмму вычисления правых частей уравнений и управле¬
ние передается третьему блоку системы — «Счет».
Блок «Счет» осуществляет решение введенных уравнений с вы¬
водом на монитор численных значений всех неизвестных Xt и
графика любой из них по выбору пользователя. Кроме того,
пользователь может менять размеры «окна» графика, начальные
условия, шаг и интервал интегрирования дифференциальных
уравнений и повторять расчеты.
В описываемой системе реализован простейший численный
метод решения системы обыкновенных дифференциальных урав¬
нений (метод Эйлера). Однако в дальнейшем предполагается рас¬
ширить набор численных методов, а выбор метода и шага инте¬
грирования автоматизировать на основе анализа правых частей
Уравнений и требуемой точности, вводимых пользователем. Это
Позволит повысить надежность программной системы за счет
обеспечения устойчивости вычислительного процесса [31.
В заключение следует указать, что предлагаемая программная
система носит промежуточный характер с точки зрения возмож¬
ностей автоматизации ввода уравнений на языке математики.
Вднако удачное распределение функций между ЭВМ и пользова¬
телем допускает реализацию данной системы на ПЭВМ с малыми
Ресурсами. На ЭВМ с высоким быстродействием и значительным
0&ьемом оперативной памяти достигается более высокий уровень
^птоматизации интерфейса с пользователем [4, 5].
Заказ № 2514
165
ЛИТЕРАТУРА
1. Халворсон М. Генерация Бейсик-программ на компьютере// Электропил
1983. № 3. С. 68-71. F
2. Wright V. Е. Equation solving by FORMULA/ONE// PC Techn. J
Vol. 4, N 6. P. 110-125. ’ й6-
3. Веревкин Г. Ф., Доступов Б. Г., КолобовВ.Г., КомаровМ.А., Тарасу
ва Н. А., Черныш М. Н. Пути повышения надежности прикладных ппл.
грамм для ЭВМ массового применения//Тез. докл. II Всесоюз. ковй
«Информатика-87», Ереван, 1987. С. 82—83.
4. Ильин В. Д. Генератор прикладных задач в системе ИГЕН // ЭВМ массо.
вого применения. М.: Наука, 1987. С. 28—37.
5. Кыпп М. Г. Система Микроприз // ППП: Инструментальные системы М .
Наука, 1987. С. 29-40. ’ ”
УДК 681.31
ВОЗМОЖНЫЕ НАПРАВЛЕНИЯ
РАЗВИТИЯ АРХИТЕКТУРЫ ЭВМ
МАССОВОГО ПРИМЕНЕНИЯ
JLM. Козлова, В. А. Козмидиади,
А.Н. Макаров, С-А. Шац
Несмотря на огромное разнообразие применений средств вы¬
числительной техники, большое количество очень различных по
архитектуре и характеристикам моделей ЭВМ, можно выделить
три больших класса машин: персональные ЭВМ (ПЭВМ), ЭВМ
общего назначения и супер-ЭВМ. Использование этих ЭВМ со¬
вершенно различно, однако именно оно определяет масштабы их
применения.
ПЭВМ рассчитана в основном на индивидуальное использо¬
вание вне зависимости от того, где они применяются —
в учреждениях, учебных заведениях или дома. Обычно при этом
предполагается, что на них обрабатываются индивидуальные
данные, принадлежащие владельцу или пользователю ПЭВМ.
Не меняет дела то обстоятельство, что одной машиной может
пользоваться группа людей. Так может быть везде — ив учреж¬
дении и в школе. Каждый из пользователей обрабатывает свои
данные, имеет свои личные ресурсы (скажем, дискеты). ПЭВМ
может быть ориентирована на то или иное профессиональное при¬
менение; в основном это делается за счет периферийных устройств,
хотя, возможно, различные применения требуют разной произ¬
водительности микропроцессора и связанной с этим разной Ра3"
рядности. В этом случае ПЭВМ превращается в рабочую стаН'
цию — рабочее место профессионала — будь то конструктор'
машиностроитель, медицинский работник или программист-
Однако по-прежнему такая рабочая станция предназначается
индивидуальной работы, обработки своих данных. Поэтому целе'
сообразно считать, что основная характеристика ПЭВМ — эТ°
166
^дивидуэльнэя обработка индивидуальных данных. С этим свя¬
зан и критерий, который определяется огромной массовостью
дЭВМ и ее основной характеристикой. Этот критерий является
руководящим при разработке и заключается в обеспечении мак¬
симума функций при заданной стоимости.
Конечно, сказанное не означает, что все ПЭВМ должны быть
одинаковы по своим характеристикам, в частности по архитек¬
туре. В различных применениях возможна вариация стоимости
ДЭВМ в широких диапазонах. Например, ПЭВМ для использо¬
вания в быту (игры, ведение домашнего хозяйства) может быть
в 10 и более раз дешевле рабочего места разработчика микро¬
электронных схем. Это делает класс ПЭВМ (как и другие классы)
очень неоднородным как по архитектуре, так и по многим другим
параметрам.
Индивидуальный характер данных и их обработки в ПЭВМ
дают возможность ослабить или вообще отказаться от аппарат¬
ных и программных средств защиты данных, в частности от не¬
санкционированного доступа. Можно также в меньшей степени
заботиться об изоляции пользователя от операционной системы.
Нарушение целостности системы приведет лишь к тому, что по¬
страдает сам нарушитель, других пользователей нет. Именно
отказ от многих привычных по машинам других классов средств
защиты характерен для архитектуры и программного обеспече¬
ния (ПО) большинства существующих ПЭВМ. Это позволяет при
той же стоимости реализовать другие более полезные функции.
Однако во многих случаях не удается ограничиться только
индивидуальным использованием ПЭВМ. Это касается в первую
очередь не бытовых или учебных, а профессиональных приме¬
нений. Во многих случаях — в учреждениях, на промышленных
предприятиях, существен взаимосвязанный характер деятельнссти
людей. Эти взаимосвязи находят свое техническое отражение
в том, что пользователи вычислительной системы должны обме¬
ниваться своей информацией и иметь доступ к общей информа¬
ционной базе. Поэтому пользователей уже не могут удовлетво¬
рить возможности ПЭВМ из-за изолированности, несвязанности
последних. Сведение АСУ к сумме информационно несвязанных
Между собой подсистем было одной из многих причин провала
программы «асунизации». Широкое внедрение ПЭВМ провоци¬
рует повторение этой ошибки. ПЭВМ как бы технически закреп¬
ляют разобщенность, изолированность отдельных подсистем,
вероятно, в следующем десятилетии будут широко распростра¬
няться интегрированные промышленные системы, которые дол¬
жны обеспечить комплексную автоматизацию информационных
Процессов, сопровождающих материальные процессы на всем
Чикле функционирования предприятия. Техническая база таких
сИстем характеризуется, с одной стороны, территориальной рас¬
пределенностью средств, объединенных в вычислительную сеть,
J* Другой — наличием единой информационной базы. Средства
°льзователей — это их рабочие места; технически они могут
167
6**
представлять собой ПЭВМ или даже обычные (неинтеллектуаль-
ные) терминалы в простейших случаях; возможны также сложны^
рабочие станции, построенные на базе ПЭВМ или более мощц14х
ЭВМ и оснащенные специфическими периферийными устройствами
Важно, что эти рабочие места (будем называть их абонентами)
объединены в сеть, причем для многих производственных систем
это локальная сеть, которая удовлетворяет требованиям по нр0.
пускной способности, накладывает приемлемые ограничения По
расстояниям и имеет умеренную стоимость.
Объединение ПЭВМ в вычислительную сеть необходимо и
когда ПЭВМ применяются для обучения. Нужно, чтобы рабочие
места учеников имели связь с рабочим местом преподавателя,
это дает возможность раздавать общие задания, позволяет препо¬
давателю вести диалог с каждым из учащихся и многое другое.
Конечно, школьная сеть ПЭВМ чрезвычайно проста по сравне¬
нию с той вычислительной сетью, которая требуется для реализа¬
ции интегрированных промышленных систем, однако у них име¬
ются общие черты — возможность обмена информацией и доступа
к общим ресурсам всех абонентов.
Теоретически сетевые средства дают возможность обобщест¬
вить все ресурсы перечисленных абонентов, но к этому имеются
серьезные практические препятствия.
Основная сложность состоит в том, что принципиально трудна
организация управления распределенными ресурсами, а в случае
сети мы имеем дело именно с распределенным вычислительным
комплексом, включающим много отдельных ЭВМ. Каждая ЭВМ
представляет собой сосредоточенный комплекс, состоящим из
одного или нескольких процессоров, имеющих доступ к общей
основной памяти (пока предполагаем, что такие комплексы имеют
достаточно традиционную архитектуру; это несущественно для
следующих ниже рассуждений). Для сосредоточенного комплекса
целесообразно ввести понятие состояния, которое описывает со¬
стояния всех процессоров и содержимое общей основной памяти.
Такое состояние может быть доступно программе в любом из
процессоров комплекса. Это означает, что можно, не разрешая
другим процессорам комплекса менять свое состояние, опериро¬
вать в одном из процессоров этим состоянием; такая работа не
приводит к значительным накладным расходам. В свою очередь,
это означает возможность централизованного управления всеми
ресурсами комплекса; для однородных комплексов такое управ¬
ление можно осуществить, располагая одной единственной ко¬
пией операционной системы.
Комплексы, в которых можно ввести понятие состояния, на¬
зывают согласованными в пространстве и времени. Именно такая
согласованность является отличительной чертой многопроцес¬
сорных комплексов, которые в связи с этим целесообразно назы¬
вать сосредоточенными. В распределенных комплексах свойство
согласованности утрачивается, поскольку в них никакой про>
цессор не может оперировать состоянием всего комплекса. ЧтсшЫ
168
такая обработка была возможна, необходимо, чтобы состояния
вСех компонентов комплекса (их памятей и процессоров), за ис¬
ключением одного, во время обработки не изменились и были
доступны этому единственному процессору. Однако имеющиеся
средства взаимодействуют слишком медленно для того, чтобы
такую обработку можно было осуществить. Поэтому реально
можно, не останавливая работы процессора, лишь информировать
другой процессор о своем состоянии. К моменту, когда эта ин¬
формация окажется доступной, она не будет соответствовать дей¬
ствительности, устареет, поскольку состояние процессора про¬
должает меняться. При таких условиях построение вычисли¬
тельной системы с централизованным управлением ресурсами.
оказывается невозможным; в системах реализуется децентрали¬
зованное управление, причем отдельные сосредоточенные ком¬
плексы, входящие в состав распределенного комплекса, коорди¬
нируют между собой свою работу, обмениваясь сообщениями.
Таким образом, в распределенной системе объединить рассре¬
доточенные ресурсы отдельных абонентов не удается, да это и
противоречило бы индивидуальному характеру работ, ведущихся
с использованием ПЭВМ. Этот индивидуальный характер сказы¬
вается на том, что пользователь ПЭВМ фактически является ее
владельцем, т. е. владельцем всех ее ресурсов. Объединение ре¬
сурсов этому противоречит; в этом случае пользователь, напри¬
мер, не может свободно включать и выключать ПЭВМ, менять
дискеты, использовать место на жестких дисках и т. д.
Итак, мы приходим к необходимости выделить в распределен¬
ной системе одну (или несколько) ЭВМ, которая, не должна при¬
надлежать никакому конкретному пользователю. Эта ЭВМ должна
включать (как сосредоточенный комплекс) общие ресурсы, дос¬
тупные всем пользователям системы (абонентам). К таким ресур¬
сам мы относим как информационные и программные средства
(например, общесистемную базу данных), так и технические сред¬
ства (скажем, дорогостоящие внешние устройства). Описываемые
сосредоточенные комплексы мы называем центрами обработки
Данных.
Можно ли такие центры строить на базе ПЭВМ? (Конечно,
в этом случае их некорректно называть ПЭВМ, поскольку они
Утрачивают основное свое свойство — работать в интересах одного
Пользователя; мы применяем все же термин ПЭВМ в этом контексте
За неимением лучшего.) Оказывается, что применять ПЭВМ для
Этих целей можно лишь в самых простых случаях (например, в
Школьных системах). Причин, из-за которых это невозможно, не¬
вольно. Во-первых, общие ресурсы таковы, что возможности ПЭВМ
позволяют их обслужить. Например, одним из основных общих
курсов обычно выступает база данных. Для нее нужно иметь
возможность использовать внешнюю память с емкостью до десят-
в перспективе сотен и тысяч) гигабайт. И для нынешних
, и для ПЭВМ ближайшего десятилетия это непосильная
3аДача. Подключение и тем более эффективное управление памятью
£>в (а
ПЭВМ
169
такой емкости достаточно дорого и в то же время не нужно масс.(х
вому пользователю. Поэтому такие возможности не будут закла'
дываться ни в архитектуру ПЭВМ, ни тем более в конкретные
модели. Фактически те же самые соображения касаются вОз.
можностей подключения и обслуживания дорогостоящих уник ал ы
ных периферийных устройств, например высокопроизводительны^
лазерных печатающих устройств, прецизионных графопостр0.
ителей и т. д.
Избыточны для ПЭВМ также средства, которые нужны дПн
управления общими ресурсами, однако зачастую такие средства
затрагивают не только программное обеспечение, но и архитек»
туру. При управлении общими ресурсами приходится считаться
с тем, что, во-первых, поток заявок на их использование может
оказаться весьма значителен (потому ресурсы и общие), а во-вто-
рых, ресурсы достаточно дороги. Высока как их собственная
стоимость, так и их ценность для всех абонентов. Во многих слу¬
чаях неработоспособность базы данных может просто помешать
работе всех пользователей, а ее разрушение привести к катастро¬
фическим последствиям. Поэтому при управлении общими ресур¬
сами на первый план выходят вопросы эффективности использо¬
вания ресурсов, защиты их от несанкционированного доступа,
надежности функционирования, в частности обеспечение целостнос¬
ти информации в большинстве возможных ошибочных ситуаций.
В ПЭВМ отсутствует эффективная, гибкая система ввода-вывода,
допускающая подключение произвольного набора и количества
устройств ввода-вывода в достаточно широких пределах. Отсут¬
ствуют развитые аппаратные средства защиты, обеспечивающие
изоляцию процессов пользователей. Перечисленные функции
в ПЭВМ просто не нужны из-за индивидуального характера ее
использования. Ожидать, что они будут все-таки реализованы
в нужном объеме, также не приходится, потому что это приведет
к удорожанию ПЭВМ, что, конечно, недопустимо. Поэтому при¬
ходим к выводу, что центры обработки данных должны быть
построены на ЭВМ, которые отличаются архитектурно от ПЭВМ.
Их принято, хотя это и весьма неудачный термин, называть ЭВМ
общего назначения (в западной литературе их называют MAIN
FRAME). Назначение этих машин в распределенных вычислитель¬
ных системах — управление общими ресурсами. Для них не столь
важна, как для ПЭВМ, их стоимость, скорее, важны те функции,
которые должны быть реализованы. Поэтому критерий, поло¬
женный в основу их разработки, можно сформулировать так:
обеспечение минимума стоимости при заданном объеме функции.
Описываемый класс машин достаточно массовый. Сейчас даи<е
в нашей стране количество ПЭВМ и ЭВМ общего назначения
имеет один и тот же порядок, хотя представляется естественный
положение, когда число ПЭВМ на 1—2 десятичных порядна
больше, чем число ЭВМ общего назначения.
Подобно ПЭВМ, класс ЭВМ общего назначения очень неоди0'
роден, что обусловливается широким диапазоном сложности,
170
которым обладают конкретные распределенные системы, а это,
р свою очередь, связано с разной сложностью самих объектов
автоматизации. Ведь и школьный класс, и крупное промышленное
Предприятие (например, автомобильный завод) должны обслужи¬
ваться распределенными системами.
Наконец, имеется еще один класс ЭВМ — супер-ЭВМ. Одно
0з определений этих машин дал Н. Линкольн из фирмы СДС:
«Супер-ЭВМ — это ЭВМ, которая отстает только на одно поколе¬
ние от задач, над проблемами решения которых работают в насто¬
ящее время ученые». Основное свойство этих ЭВМ — это предель¬
но возможные на данный момент характеристики. Обычно такой
характеристикой является производительность. При разработке
на второй план отступают экономические вопросы (хотя, конечно,
и для супер-ЭВМ стоимость — немаловажный параметр). Поэто¬
му несколько утрированно критерий разработки можно сформули¬
ровать так: предельные характеристики — любой ценой.
Супер-ЭВМ, конечно, нельзя отнести к массовым машинам,
хотя в ближайшие годы их количество будет измеряться тысячами.
Они применяются для решения задач, которые не удается решить
на других ЭВМ, и не предоставляются массовым пользователям.
В связи с этим не будем далее рассматривать супер-ЭВМ, хотя и
существует мнение, что решения, применяемые в супер-ЭВМ
сегодня, завтра начинают применяться в массовых машинах,
это все же в большей степени относится не собственно к супер-ЭВМ,
а к подклассу «больших» машин из класса ЭВМ общего назначения.
В следующее десятилетие, по всей вероятности, по-прежнему
применение средств вычислительной техники будет базироваться
на трех классах ЭВМ: ПЭВМ, ЭВМ общего назначения и супер¬
ЭВМ, причем назначение этих классов сохранится. Массовыми
прежде всего будут ПЭВМ, они будут объединяться в сети; центры
обработки данных в этих сетях будут строиться на базе ЭВМ обще¬
го назначения.
Рассмотрим теперь более детально, каким представляется раз¬
витие архитектуры ЭВМ общего назначения. Будет ли здесь отход,
от традиционной неймановской архитектуры или нет?
Сначала поясним, что понимать под традиционной архитек¬
турой. По мнению авторов, она характеризуется двумя основными
свойствами. Во-первых, это последовательность в вычислениях,;
Иными словами, управление потоком команд. При этом операнды
Команд могут быть достаточно сложными, например векторами t
Матрицами. Это не меняет сути дела. Во-вторых, это детермини¬
рованность вычислений. Предыдущее состояние системы, с точки
зрения программиста, полностью определяет следующее состояние.
Нарушение первого свойства можно усмотреть в многопроцессор¬
ных комплексах и далее в распределенных системах, которые
&Ыли рассмотрены. Однако если в таких системах мало процес¬
сов, а взаимодействуют они достаточно редко (а это именно тот
СлУчай, с которым мы в основном имеем дело), проще предста¬
вить себе, что это не отказ от традиционной архитектуры, а незна¬
171
чительное ее расширение, которое позволяет рассматривать слабо-
взаимодействующие между собой последовательные процессор^
(уже вполне традиционной архитектуры). Совсем другое деЛо
когда процессоров в системе много — сотни, тысячи, десятку
тысяч,— причем взаимодействуют они почти все время, по крайней
мере столь часто, что без понимания как работы каждого процес,
сора в отдельности, так и их взаимодействий нельзя понять, как
же совокупность процессоров выполняет порученную ей работу.
Технически такие машины не только возможны, но даже уже
реализованы. Станут ли они массовыми? В следующем десятиле¬
тии этого не случится. Пока не видно общих подходов, которые
позволили бы утверждать, что подобные ЭВМ (назовем их сверх,
многопроцессорными) можно будет использовать столь же эффек¬
тивно, как и традиционные, т. е. последовательностные машины.
Обычно на сверхмногопроцессорных ЭВМ удачно решаются
задачи, для которых из их физической интерпретации следуют
алгоритмы их решения на таких ЭВМ. Например, это некоторые
классы уравнений в частных производных, некоторые задачи рас¬
познавания образов. Но во многих случаях приходится решать
задачи обычными последовательностными методами. Можно до¬
казать, что существуют задачи, решение которых нельзя ускорить,
применяя сверхмногопроцессорные ЭВМ, однако с какого же сорта
задачами сталкивается в основном человек? Отсутствие параллель¬
ных алгоритмов для многих задач — это закон природы • или
особенности мышления человека? Так или иначе, пока сверхмно¬
гопроцессорные ЭВМ находят применение для решения весьма
ограниченного круга задач (хотя для этих задач они вне всякой
конкуренции); вероятно, это положение сохранится, поскольку
ни математика, ни программистская практика не сулят в скором
будущем эффективного использования таких ЭВМ для широкого
круга задач, интересных массовому пользователю. Таким обра¬
зом, сверхмногопроцессорность может найти свое применение
либо в супер-ЭВМ (это уже сделано), либо в специализированных
процессорах, входящих в состав ЭВМ общего назначения и пред¬
назначенных для выполнения ограниченного набора функции
(например, вычислительных).
Напротив, многопроцессорные комплексы с небольшим коли¬
чеством процессоров найдут широкое применение в центрах обра¬
ботки данных. Работа их, как уже говорилось, почти традиционна^
Уже сейчас видно, что технические трудности, которые еще 10—10
лет назад мешали реализации таких комплексов, решены успешно.
Развиты также методы программирования для таких комплексов,
поэтому нет препятствий к их широкому распространению-
Целесообразность же применения таких архитектурных решении
будет рассмотрена ниже.
Поговорим немного о нарушении второго свойства традицион¬
ных архитектур — их детерминированности. Фактически это
свойство нарушено существенно (т. е. предложена новая концеп¬
ция всех вычислений на ЭВМ, а не только специализированных)
172
д0ШЬ в машинах, управляемых потоком данных. По поводу этих
^ашин можно высказать почти те же соображения, что и по
поводу сверхмногопроцессорных ЭВМ: либо мы не готовы (или
jje приспособлены) к их использованию, либо они позволяют
решать эффективно и удобно только узкий класс задач. Пока,
однако, мы еще не можем их применять широко, хотя, возможно,
что этого не будет и в значительно более отдаленном будущем.
Итак, мы считаем, что в ближайшее десятилетие машины об¬
щего назначения сохранят традиционную архитектуру, причем
весьма вероятно применение многопроцессорных комплексов с
0еболыпим количеством процессоров (скорее всего, не более 10).
Очень трудно предугадать сейчас, в каком направлении пой¬
дет развитие традиционной архитектуры. Имеется 3 различные
тенденции, которые иногда называют RISC, CISC и HLL. Направ¬
ление RISC предполагает, что в процессоре должна быть обеспе¬
чена высокоэффективная реализация минимального набора про¬
стых команд. Далее этот набор либо предоставляется пользовате¬
лю (т. е. возлагается на компилятор задача оптимального преоб¬
разования программы с языка высокого уровня в машинную
программу), либо используется для реализации более сложного
набора команд следующего уровня архитектуры. Направление
HLL прямо противоположно направлению RISC: предлагается
повысить уровень машинного языка до уровня языков программи¬
рования. Промежуточное положение занимает направление CISC
и в известном смысле беспринципно. Это направление предпола¬
гает реализацию на уровне машинного языка набора команд,
значительно более сложного, чем RISC, но в то же время не ориен¬
тированного на эффективный объектный код для какого-либо
языка программирования высокого уровня. Поэтому набор команд
в CISC-машинах обычно выглядит довольно случайным, в его
выборе отсутствуют какие-либо серьезные принципы. Но на сторо¬
не CISC-машин традиция и огромный консерватизм программного
обеспечения и самих программистов — ведь подавляющее боль¬
шинство используемых ныне ЭВМ — это CISC-машины. Стрем¬
ление сохранить старое ПО, накопленное пользователями, воз¬
можность использовать его на вновь разрабатываемых ЭВМ —■
серьезный практический довод в пользу направления CISC. Сле¬
дует отметить еще одно соображение, говорящее не в пользу на¬
правления RISC. Непрерывное и идущее очень быстрыми темпами
совершенствование элементной базы заставляет архитекторов —
Разработчиков ЭВМ находить все новые способы использовать все
более сложные элементы (заметим, что новые элементы довольно
быстро становятся даже дешевле старых менее сложных). Так
в°т, в RISC-архитектуре находить такие способы весьма
Сложно, поскольку она тогда превращается в CISC-архитектуру
Далее в HLL. Тенденция фактического превращения RISC в
^ISC видна уже сейчас хотя бы на примере ПЭВМ IBM PC/RT.
Возможно, что ближайшая перспектива очень похожа на сегод-
**пц1ний день: RISC-машины массового применения достаточно
173
редки, превалируют CISC-машины, причем происходит их посте¬
пенное усложнение. Это усложнение идет не только в сторону
сближения машинного языка с языком высокого уровня, но и в
сторону более совершенного управления машинными ресурсами
Именно на последнем направлении остановимся более подробно
Это направление развития можно охарактеризовать как функ¬
циональную ориентацию ресурсов вычислительной системы и
развитие аппаратных средств управления ими. Это направление
обусловлено, в частности, изменением роли машин общего назна¬
чения, которое происходит из-за широкого распространения
ПЭВМ. ПЭВМ дали возможность решать большинство задач
пользователя непосредственно на его рабочем месте, в то время
как раньше (еще 5—10 лет назад) пользователь имел в своем
распоряжении лишь неинтеллектуальный терминал; для любой
самой мелкой работы необходимо было привлекать центральную
ЭВМ сети. Поэтому сейчас в центре обработки данных в основном
должны обслуживаться заявки пользователей не к собственно
вычислительным ресурсам, а к общей базе данных или к файлам,
уникальным периферийным устройствам и т. д. Поэтому прежде
всего требуются средства подключения аппаратуры, необходимой
для реализации этих ресурсов, управления этой аппаратурой.
На второй план отступает выполнение программ пользователей,
не требующих большой производительности процессора, боль¬
шого объема памяти, т. е. тех программ, которые ранее выполня¬
лись в диалоговом режиме.
Остановимся более подробно на организации машин общего
назначения, используемых в распределенных информационно-вы¬
числительных системах, включающих ПЭВМ, т. е. центров обра¬
ботки данных (ЦОД). Основными задачами ЦОД является:
— обеспечение интенсивного доступа к общим данным весьма
большого объема со стороны значительного числа абонентов;
— предоставление абонентам (ПЭВМ) вычислительных мощ¬
ностей ЦОД (основной памяти, центрального процессора, спец¬
процессоров и пр.).
Совершенно естественно, что эффективная реализация перечис¬
ленных функций возможна только на пути использования специа¬
лизированных процессоров: процессоров баз данных, процессоров
ввода-вывода, матричных процессоров и пр. Сам же ЦОД становит¬
ся, таким образом, неоднородной мультипроцессорной системой.
Для организации вычислительного процесса в ЦОД весьма
перспективной представляется техника виртуальных машин, как
способ выделения ресурсов пользователям и их управления [1, 2L
В указанных работах предполагаются расширения традиционной
архитектуры ЕС ЭВМ, которые минимизируют системные затраты
по управлению системой виртуальных машин. Аналогичны?
средства планируется использовать в центральном процессор?
ЦОД.
Имеет смысл рассматривать два типа виртуальных машин-
— «чистые» виртуальные машины. Это машины, содержащие
174
7раДИЦионные ресурсы: процессор, основную память, каналы
вВода-вывода, устройства управления и внешние устройства —
в обеспечивающие работу в режиме совместимости с традиционны¬
ми архитектурами ЭВМ (например, ЕС ЭВМ, IBM 370/ХА);
виртуальные машины «высокого уровня». Это виртуальные
машины, предоставляемые пользователям операционными система¬
ми. В этом смысле можно рассматривать ОС/ЕС-машины, ПДО-
машины и т. д. В данном случае, т. е. применительно к ЦОД, это
средства операционных систем, расширенные дополнительными
возможностями, реализуемыми на спецпроцессорах. С точки зре¬
ния управления виртуальными машинами спецпроцессор представ¬
ляет собой ресурс, придаваемый по мере необходимости той или
иной виртуальной машине.
Обращение к функциям, реализуемым спецпроцессорами, пред¬
ставляет собой с точки зрения пользователя обычный системный
вызов. В результате его выполнения формируется и при необходи¬
мости очередизируется запрос к соответствующему спецпроцессору.
Выполнение этих функций, т. е., по сути дела, интерпретацию
команд виртуальной машины, берет на себя центральный про¬
цессор.
Итак, принципиальной особенностью организации ЦОД явля¬
ется их неоднородность, т. е. наличие в их составе, кроме централь¬
ного процессора (ЦП), определенного числа спецпроцессоров
(СП). Цоэтому первый вопрос, требующий решения,— вопрос
взаимодействия центрального и специализированных процессо¬
ров, а также связь СП—СП.
Отметим, что взаимодействие с СП организуется с учетом двух
факторов — возможности параллельной обработки в СП несколь¬
ких запросов и времени выполнения отдельного запроса.
Ряд СП построены так, что они допускают выполнение только
одного запроса. Примерами могут служить векторный и матрич¬
ный процессоры, а также Фурье-процессор в предположении, что
входные данные и результат работы располагаются в основной
памяти. На все время выполнения одного запроса оборудование
в таких СП фактически монополизируется. Время выполнения
запроса в упомянутых СП колеблется в широких пределах: оно
Может быть сравнимо с временем выполнения команды в ЦП либо
превышать его на несколько порядков.
Имеются 2 способа взаимодействия с такими СП: синхронный
й асинхронный. При первом способе работа ЦП приостанавливается
время выполнения запроса в СП. В этом случае запрос к СП
представляет собой команду, для выполнения которой ЦП обра¬
щается к соответствующему СП. Таким образом, синхронное
взаимодействие с СП является «интимным» делом ЦП, т. е. за-
Яачей чисто инженерной.
При втопом. асинхоонном. способе ПП продолжает работу.
175
существенно больше не только времени выполнения команд в I щ
но и времени, которое будет потрачено на обработку прерывания
в ЦП.
Однако многие СП целесообразно реализовывать так, чтобы
они допускали параллельное выполнение нескольких запросов
Как правило, работа таких СП связана с внешними носителями*
Примерами таких СП являются процессоры ввода-вывода (в част¬
ности, телекоммуникационные процессоры), файловые процессоры
процессоры баз данных. Время выполнения запроса в них обычно
значительно превышает время выполнения одной команды в Ц|[
Таким образом, можно выделить три основных типа СП:
— с малым временем выполнения запроса. Обычно они не
допускают параллельное выполнение нескольких запросов (тип 1);
— с большим временем выполнения запроса, не допускающие
параллельного выполнения (тип 2);
— с большим временем выполнения запроса, допускающие
параллельное выполнение (тип 3).
СП типа 1 фактически являются частями ЦП. Например,
в ряде случаев обработка операндов различных видов (с фикси¬
рованной точкой, с плавающей точкой, десятичных, строковых
ит. д.) выполняется в различных процессорах. Такая организация
характерна как для машин средней и высокой производительности
(ЕС-1066, IBM 3033, IBM 3081), так и для некоторых персональных
машин, в которых широко распространены сопроцессоры.
Если СП типа 1 достаточно сложен (например, это векторный
процессор), организуется его совместное использование несколь¬
кими ЦП. При этом требуется, чтобы эти процессоры работали с
общей (разделяемой) основной памятью. Очередь к СП организу¬
ется аппаратно. Программа, выполняемая в ЦП, останавливается
до тех пор, пока команда, требующая для своего выполнения СП,
не будет завершена. Так построена, например, IBM 3090, в которой
несколько центральных процессоров, работающих на общей
памяти, могут использовать до четырех векторных процессоров.
Особенности применения СП типа 1 рассматриваться не будут.
В СП типа 2 запросы обрабатываются параллельно с работой
ЦП, т. е. образуется сопроцесс. Очереди запросов к СП организу¬
ются программно средствами ЦП. О завершении процесса обра¬
ботки запроса основной процесс информируется с помощью механиз¬
ма прерываний. На таком принципе построено применение ряДа
векторных и матричных процессоров в ЕС ЭВМ, Фурье-процес¬
сора в СМ ЭВМ. В ЕС ЭВМ для подключения СП используются
каналы ввода-вывода, т. е. СП рассматриваются как внешние усг
ройства (фактически то же самое имеет место в СМ ЭВМ). Поэтому
они имеют свои тракты доступа к основной памяти (через капал)*
Недостатки такой организации связаны с двумя обстоятельств^
ми. Во-первых, программное управление СП как ресурсом (noZV
держка очередей запросов и обработка прерываний) приводит я
системным затратам. Во-вторых, взаимодействие с СП как с впе^
ним устройством является искусственным и приводит к ряДУ
176
0Граничений. Например, в ЕС ЭВМ спецпроцессор может обра¬
щаться к основной памяти только по последовательным адресам.
»ГаКИМ образом, затруднена возможность параллельной работы
СЛ с двумя массивами.
Итак, для СП типа 2 характерны:
— асинхронная организация работы;
— организация очередей запросов;
— наличие собственного тракта доступа к основной памяти.
Спецпроцессоры типа 3, как правило, являются логически
наиболее сложными как по своей внутренней организации,
так и по работе с ними. Для них необходима организация много¬
процессной работы — по процессу на каждый принятый к обработ¬
ке запрос. В остальном их работа в ЦОД сходна с работой СП
типа 2.
Перечислим некоторые спецпроцессоры, наличие которых
целесообразно в различных ЦОД: процессор ввода-вывода,
процессор баз данных, логического вывода, векторный и матрич¬
ный, а также Фурье-процессор.
Взаимодействие ЦП с любым из СП осуществляется стандарт¬
ным образом. При этом очереди запросов к СП обслуживаются
программно или аппаратно. Как указывалось, использование
системы ввода-вывода для взаимодействия процессоров представ¬
ляется неоправданным.
Необходимо также рассчитывать на то, что работы, выполняе¬
мые одним СП, могут потребовать обращения к другим СП. Нап¬
ример, процессор базы данных может опираться в своей работе
на функции, выполняемые процессором ввода-вывода. Такое тре¬
бование вполне естественно, иначе в процессоре баз данных
пришлось бы дублировать многие функции процессора ввода-вы¬
вода. Взаимодействие между двумя СП должно осуществляться
без участия ЦП.
Удовлетворительное решение вопроса взаимодействия централь¬
ного и специализированных процессоров возможно, если объеди¬
нить их в неоднородный многопроцессорный комплекс с общей
памятью и развитыми межпроцессорными связями.
Тут, однако, возникают большие трудности в управлении
основной памятью, доступной различным по своей природе
абонентам. Здесь целесообразно введение нескольких видов памя¬
ти:
1) память центрального процессора (для хранения программ
и данных ЦП, включая буфера ввода-вывода);
2) общая память (для обеспечения совместных действий про¬
цессоров комплекса); функционально общая память разделяется
На 2 части:
память данных (для хранения входных и выходных данных
спецпроцессоров);
служебная память для реализации механизмов межпроцессор¬
ной связи, очередей к процессорам, общих семафоров и т. д.;
Также может использоваться процессорами как вспомогательная
177
память для хранения локальных и общих управляющих структур).
3) локальная память СИ (используется спецпроцессорами дл^
реализации требуемых функций).
Память ЦП и общая память общедоступны. Локальная память
СП доступна только спецпроцессору-владельцу.
Для доступа к памяти ЦП со стороны центрального процессор^
(но, вероятно, не спецпроцессоров) применяется буферная память
(КЭШ). При этом должна быть обеспечена прозрачность буфер frog
памяти для работы ЦП.
Общая память доступна всем процессорам комплекса, однако
не предназначена для массового программного обращения. Она
должна иметь специальные примитивы для реализации семафо¬
ров и может быть обеспечена промежуточной буферной памятью.
По этой причине общая память имеет худшие характеристики по
среднему времени доступа. Кроме того, эти характеристики допол¬
нительно снижаются из-за обеспечения доступа многих абонен¬
тов (спецпроцессоров).
Сложной проблемой является нормальная работа при ограни¬
ченном объеме общей памяти данных. Для этого могут употреб¬
ляться следующие методы:
передачи входных и выходных данных запросов отдельными
блоками;
динамического распределения памяти;
обработки аварийных ситуаций при переполнении общей па¬
мяти.
Наконец, следует отметить, общая память может быть реали¬
зована как часть основной памяти; в таком случае деление основ¬
ной памяти на память ЦП и общую память является логическим.
При этом, естественно, должны быть предусмотрены средства
защиты от несанкционированного доступа к общей памяти.
Рассмотрим теперь другую, весьма важную проблему органи¬
зации распределенной информационно-вычислительной системы —
проблему совместных вычислительных процессов с ПЭВМ. Взаи¬
модействие это, как отмечалось, необходимо для следующих
целей: — информационный обмен и — разделение функций при
решении одной задачи.
В первом случае (информационный обмен) с точки зрения ЦОД
персональная ЭВМ выступает как обычный абонент сети и мало
чем отличается от привычного терминала. Для обеспечения такого
взаимодействия можно использовать обычные методы телекомму¬
никационного доступа, применяемые для работы с сетевыми
абонентами. Со стороны ПЭВМ нужны средства эмуляции термина¬
лов или других оконечных устройств. Однако обеспечиваемые
таким образом возможности не дают ничего нового по сравнению
с терминалами качества, так как взаимодействуя с терминалом,
ЦОД исходит из того, что данное устройство предназначено лишь
для ввода и отображения информации.
Более сложные задачи, которые может решать ПЭВМ, обычно
маскируются под функции ввода и отображения, что приводит
178
сложностям в использовании вычислительных возможностей
цЭВМ.
Во втором случае (разделение функций) ЦОД и ПЭВМ решают
общую задачу. Например, в центре осуществляется работа с ба¬
зой данных, а дальнейшая работа с полученными данными выпол¬
няется в ПЭВМ. Для реализации такого взаимодействия требуется
значительно более сложный механизм связи, чем применяемый для
обмена информацией с терминалом. Причем эта сложность ка¬
сается в основном не непосредственно протокола взаимодействия,
а возможностей программного обеспечения центра обработки.
В общих словах, совместный вычислительный процесс в ЦОД
0 ПЭВМ; можно рассматривать следующим образом: в ПЭВМ
должны присутствовать средства, с помощью которых пользова¬
тель мог бы описать виртуальную машину с ресурсами, разме¬
щенными как в самой ПЭВМ, так и в ЦОД. Основной процесс
всегда выполняется на процессоре ПЭВМ. Центр обработки в
данном случае реализует параллельный процесс, в нем могут быть,
например, реализованы функции ввода-вывода (эмуляция гиб¬
ких дисков).
Вообще говоря, можно рассматривать и симметричный только
что описанному способ работы, при котором основной процесс
выполняется в ЦОД, а параллельные процессы — в ПЭВМ.
Однако такой режим работы представляется нецелесообразным,
поскольку пользователь ПЭВМ может бесконтрольно менять
носители, отключаться от сети и т. д. Отметим здесь, что ресурсы
ПЭВМ могут использоваться неявно, например для удаленного
ввода заданий.
Остановимся более подробно на организации работы программы
в ПЭВМ. При этом предполагается, что на начальном этапе связь
основного процессора (ПЭВМ) с сопроцессором (ЦОД) будет реа¬
лизована с помощью программных средств ПЭВМ и ЦОД и уни¬
версальных сетевых средств (сначала путем расширения имею¬
щихся операционных систем, а затем их специализации). В даль¬
нейшем, после уточнения набора функций и алгоритмов взаимо¬
действия возможна их аппаратно-программная реализация как
в целом, так и отдельных процедур, а также соответствующая
специализация сетевых средств.
Выполнение программы (пользовательской или системной)
Иожно представить как последовательность запросов, которые
врабатываются аппаратно или аппаратно-программно. Все зап¬
росы с точки зрения их выполнения можно разделить на 2 группы:
— синхронно выполняемые запросы. К ним относятся соб-
Ственно команды ПЭВМ и большинство макрокоманд обращения
к системе. В этих случаях обработка последующих команд и макро-
к°манд производится после их выполнения;
— асинхронно выполняемые запросы. К ним, как правило,
^Носятся операции ввода-вывода, а также автономные действия,
ь^Полняемые спецпроцессорами (например, арифметическим про¬
бором INTEL 8087).
179
В соответствии с двумя этими типами запросов целесообразно
реализовать логический сопроцессор с наборами псевдокоманд
логических каналов ввода-вывода.
Псевдокоманды расширяют основной набор команд ПЭ13-\|
и характеризуются следующими свойствами:
— выборка и выполнение псевдокоманд «приостанавливают»
выполнение программ пользователя, т. е. выполняются син¬
хронно;
— все результаты выполнения псевдокоманд становятся до¬
ступными только после их завершения.
Естественно, все это не ограничивает параллельное выпо/iпе¬
ние нескольких псевдокоманд в различных компонентах ЦОД.
Действия, вызванные выполнением псевдокоманды, могут про¬
должаться и после ее завершения, однако они не должны быть
заметными или оказывать какое-либо влияние на работу ПЭВМ.
Логические каналы реализуют функции, сходные с функциями
системы ввода-вывода. При этом может, например, выполняться
эмуляция внешних устройств в ПЭВМ с использованием перифе¬
рии ЦОД и ряд других работ. Обращение из ПЭВМ лишь иниции¬
рует выполнение соответствующей функции, собственно же ее
выполнение производится параллельно с дальнейшей работой.
С помощью логических каналов могут, например, быть реали¬
зованы обращения к базам данных, операции над матрицами и пр.
Макрокоманды обращения к средствам операционной системы
ПЭВМ и локальным устройствам ввода-вывода выполняются
традиционным образом; при обнаружении запроса к логическому
внешнему устройству, входящему в состав системы ввода-вывода
сопроцессора, управление посредством логического канала пере¬
дается соответствующему компоненту сопроцессора на выполне¬
ние.
Отметим, что псевдокоманды и типы логических внешних
устройств могут быть как общими для всех ПЭВМ, так и инди¬
видуальными, зависящими от применяемой на ПЭВМ операцион¬
ной системы (например, организация логического метода доступа
к файлам на дисках в UNIX отличается от принятого в других
операционных системах, используемых в ПЭВМ).
Таким образом, пользователь ПЭВМ имеет дело с виртуальной
машиной, включающей как традиционные средства ПЭВМ, так
и дополнительные средства, предоставляемые ЦОД (псевдоко¬
манды и логические каналы). Явно определяя виртуальную
шину, пользователь ПЭВМ передает в ЦОД запрос на выделение
в нем конкретных ресурсов. Эти ресурсы могут представлять
собой:
— наборы входных и выходных данных;
— средства управления виртуальной машиной в ЦОД — преД'
ставителя ПЭВМ.
Входные и выходные данные располагаются на реальны*
устройствах ЦОД и представляют собой с точки зрения ЦОД
обычные файлы пользователя. Средства управления виртуально^
180
машиной в ЦОД интерпретируют эти файлы как виртуальные
диски ПЭВМ (гибкие или жесткие) с эмуляцией физического мето¬
да доступа или как отдельные файлы, доступные ПЭВМ с методом
доступа, принятым в ПЭВМ или в ЦОД. В последнем случае
наличие ЦОД становится непрозрачным для программ в ПЭВМ.
В ЦОД имитируются также функции виртуального АЦПУ
и ввода с перфокарт.
В свою очередь, в ПЭВМ должны быть предусмотрены средства
эмуляции для работы ПЭВМ как стандартного удаленного пакет¬
ного терминала.
Отметим также, что управление виртуальной машиной может
осуществляться оперативно с терминала ПЭВМ, либо программно
в процессе работы, либо одноразово при создании виртуальной
машины в ЦОД.
В заключение коротко остановимся на функциях и совместной
работе двух взаимосвязанных спецпроцессоров: процессора ввода-
вывода и файлового процессора. Рассмотрение их не случайно.
Во-первых, их работа взаимосвязана, так как к процессору ввода-
вывода обращается файловый процессор. Во-вторых, от эффектив¬
ности их работы во многом зависит эффективность ЦОД в целом
и, наконец, па их примере можно проследить путь развития средств
ввода-вывода.
Прежде всего следует сказать, что традиционная организация
системы ввода-вывода по схеме «канал — устройство управления —
внешнее устройство», принятая ЕС ЭВМ, в условиях ЦОД являет¬
ся совершенно неудовлетворительной из-за малой пропускной
способности и больших системных затрат. Уже в архитектуре
IBM 370/ХА такая система ввода-вывода была заменена более
эффективной, а именно позволяющей:
— организовать средствами системы очереди запросов на ввод-
вывод и прерываний по вводу-выводу;
— автоматически выбирать путь доступа к внешнему устрой¬
ству.
Однако и этого оказывается недостаточно для эффективной
организации системы ввода-вывода системы виртуальных машин
[3, 4]. Помимо анализа недостатков, в указанных работах имеются
конкретные предложения по их устранению.
Основные требования, предъявляемые к процессору ввода-вы¬
вода ЦОД, следующие:
1) обеспечение эффективного управления ресурсами; сюда
входит: разделение внешних устройств между виртуальными ма¬
шинами, т. е. обслуживание логической системы ввода-вывода;
°рганизация очередей к устройствам; автоматический выбор фи¬
зических путей доступа к устройствам; взаимодействие с операто¬
ром для выполнения административных функций; коррекция оши¬
бок ввода-вывода; буферизация данных (например, обслуживание
Дискового КЭШа);
2) возможность включения в состав спецпроцессора интегриро¬
ванных адаптеров с функциями управления и канала, обслуживаю¬
181
щих устройства, подключенные по малому интерфейсу (накопите,
ли на магнитных дисках и лентах);
3) удовлетворение запросов непосредственно со стороны других
спецпроцессоров.
Функции файлового процессора стандартны — это обеспечение
логического уровня ввода-вывода при обращении к файлам на
дисках. При этом собственно доступ к накопителям производится
с помощью процессора ввода-вывода, не затрагивая дискового
КЭШа.
Имеется ряд трудностей в организации такого спецпроцессора.
В основном они связаны с тем, что в различных операционных сис¬
темах, работа которых планируется в виртуальных машинах ЦОД,
структура файлов и обслуживание, предоставляемые логическим
уровнем ввода-вывода (последовательный, прямой и индексно-по¬
следовательный методы доступа) отличаются. Таким образом, фай¬
ловый процессор обязан учитывать эти отличия.
Наконец, следующим шагом пути увеличения эффективности
системы ввода-вывода является использование процессоров баз
данных. Однако их работа является предметом рассмотрения от¬
дельной статьи.
ЛИТЕРАТУРА
1. Средства повышения эффективности виртуальных машин / А. Е. Задан,
Л. М. Козлова, В. А. Козмидиади, М. Е. Неменман, С. А. Шан//
ЭВМ массового применения. М.: Наука, 1987. С. 125—142.
2. Концепция виртуальной машины в архитектуре ЭВМ / И. В. Богуслав¬
ский, А. Е. Задан, Л. М. Козлова, В. А. Козмидиади, И. Я. Ландау,
М. Е. Неменман, С. А. Шац // Современные средства информатики. М.:
Наука, 1986. С. 5-21.
3. Система ввода-вывода в ЭВМ с расширенной архитектурой / И. В. Богус¬
лавский, Л. Ф. Глухова, Л. М. Козлова, Н. П. Козмидиади, В. А. Коз¬
мидиади, С. А. Шац//ЭВМ массового применения. М.: Наука, 1987.
С. 142-148.
4. Виртуальная система ввода-вывода в архитектуре ЭВМ / И. В. Богуслав¬
ский, Л. Ф. Глухова, Л. М. Козлова, В. А. Козмидиади, Н. П. Козми¬
диади// Современные средства информатики. М.: Наука, 1986. С. 21—31.
УДК £81.3.062
ПОСЛЕДОВАТЕЛЬНЫЕ
И ПАРАЛЛЕЛЬНЫЕ ПРОЦЕССЫ
В ЗАДАЧАХ ОПИСАНИЯ И МОДЕЛИРОВАНИЯ
АРХИТЕКТУРЫ ВЫЧИСЛИТЕЛЬНЫХ УСТРОЙСТВ
Г. М. Погосянц
В последнее время большое внимание уделяется задаче формаль¬
ного описания архитектуры вычислительных устройств (В У)-
Это обстоятельство объясняется возросшей сложностью проектов
ВУ, в особенности их элементной базы. Различия в элементной ба¬
зе, применение заказных СБИС и программируемых логически*
182
матриц приводят к тому, что для формального описания разных
Проектов архитектуры ВУ требуются, вообще говоря, разные язы¬
ковые средства, базирующиеся, однако, на общей семантической
основе. Такую основу составляют базовые типы данных и оборудо¬
вания, как, например, сигнал, вентиль, регистр и т. п.
Перспективной является разработка открытого семейства язы¬
ков, [1, 5, 6], объединенных преемственной семантикой так, чтобы
в каждом языке были отражены конкретные особенности данного
проекта аппаратуры.
Существенно, что вне зависимости от особенностей языковой
нотации поведение аппаратуры удобно представляется в виде со¬
вокупности взаимодействующих между собой процессов. Такое
описание может быть использовано для построения модели вы¬
числений языка, верификации поведения ВУ, отработки интер¬
фейсных взаимодействий. Формальному описанию процессов и их
взаимодействий применительно к задачам описания архитектуры
ВУ и посвящена основная часть данной работы.
В качестве примера реализации концепции процессов рас¬
сматривается международный проект Конлан [1]. Это один из
наиболее развитых проектов семейства объектно-ориентированных
языков описания структуры и поведения ВУ.
В заключительных разделах статьи ставится задача реализа¬
ции основных идей проекта Конлан в виде прототипной программ¬
ной системы, поддерживающей как тестирование, так и верифи¬
кацию моделей.
1.
МАТЕМАТИЧЕСКАЯ МОДЕЛЬ ПРОЦЕССА
В этом разделе будет описан математический аппарат, позво¬
ляющий формально определять поведение процесса и его взаимо¬
связь с другими процессами. Из многих возможных способов опи¬
сания процессов за основу была взята нотация и математическая
теория Хоара [3], расширенная с учетом специфики процессов, воз¬
никающих при описании работы ВУ. Эти расширения касаются
в основном таких понятий, как сорт события и свертка процессов,
позволяющих установить в модели определенную иерархию про¬
цессов. Выбор в качестве базовой нотации Хоара объясняется сле¬
дующими обстоятельствами:
— современной концепцией понятия процесса, учитывающей
особенности синхронизации и параллельного выполнения процес¬
сов, включая модель обмена данными по каналам связи;
развитой техникой работы с трассами (последовательностью
событий) процессов, позволяющей легко выделять и анализировать
₽езультаты работы модели;
— приспособленностью теории для алгоритмической реализа-
на ЭВМ: как известно, на базе этой теории создан алгоритми-
®ский язык Оккам [4]. Возможны и иные эквивалентные отобра¬
жения теории с помощью других алгоритмических языков парал-
еИьного программирования, как, например, Поляр [2].
183
1.1. Под процессом будем понимать модель поведения объекта
выраженную в терминах предварительно определенных событий’
События образуют некоторое конечное множество, называемое
алфавитом процесса. В алфавит процесса могут входить как собьь
тия, возникающие в определенном контексте поведения объекта
так и события, не реализующиеся ни в каком контексте. В каждый
момент в модели может произойти только одно событие. Выявле¬
ние нереализуемых событий может рассматриваться как одна ц3
задач исследования объекта.
Всюду в тексте идентификаторы, состоящие из малых букв,
будут обозначать события, а идентификаторы из заглавных букв
процессы. В виде исключения идентификаторы А, В, С зарезор,
вированы для обозначения множеств событий. Так, например;
Р, Q, ALL1 — процессы,
х, clock, in — события,
А = {у, out, ell} — множество событий.
Будем также обозначать через аР алфавит процесса Р.
Заметим, что с идентификатором можно связывать целый класс
реальных событий, несущественно различающихся с точки зрения
поведения объекта. Так, событие opl может означать для процесса
SUM (1) появление любого числа, допустимого в качестве первого
операнда процесса сложения двух чисел.
Символом х -> Р будем изображать тот факт, что событие х
является первым в описании поведения объекта, дальнейшее по¬
ведение которого задается процессом Р. Неформально эту запись
можно понимать, например, как «активизацию» процесса Р или
как переход объекта в другое «состояние» под воздействием со¬
бытия х. По определению, х-+- Р также представляет собой процесс?
что дает возможность конструктивного определения процессов.
Так, например:
SUM = (opl (ор2 -> (add -> (out STOP))))
описывает процесс суммирования, реконструируя его от момента
окончания (процесс STOP) через цепочку процессов выдачи ре¬
зультата (out -> STOP), суммирования с выдачей результата
(add (out -> STOP)) и т. д. (такие частичные процессы будем
называть субпроцессами.). Скобки в записи можно отбросить,
считая знак -> правоассоциативной операцией. Полученную по¬
следовательность событий
opl, ор2, add, out,-
описывающую поведение объекта, будем в дальнейшем называть
трассой процесса.
В теории постулируется, что а (х -> Р) = аР. Поскольку а л*
фавит процесса конечен, то трассы бесконечной длины могут преД'
ставлять собой периодические последовательности — это основан^
для рекурсивного определения процессов, работа которых мо/КеТ
не завершаться остановом (т. е. процессом STOP). Например, ,<>еС'
184
конечный процесс суммирования может быть описан как
SUMI = opl ор2 add ->• out SUMI,
иди в несколько иной записи
SUM1 = цХ (opl -> ор2 -> add -> out -> X).
Во второй нотации подчеркивается, что с формальной точки зре¬
ния процесс задается решением уравнения рекурсии относительно
переменной X.
1.2. Линейную схему конструирования процессов, в которой
в каждый момент может произойти только одно определенное собы¬
тие, можно расширить на случай альтернативного возникновения
одного из нескольких возможных событий. В основе этого описа¬
ния лежит конструкция выбора процесса:
х -> Р \ y^Q,
выражающая тот факт, что при возникновении события х дальней¬
шее поведение объекта описывается процессом Р, тогда как про¬
цесс Q определяет поведение объекта при появлении события у.
Эта конструкция описывает новый процесс, реагирующий на поя¬
вления х или у в качестве первого события. Существенно, что со¬
бытия х и у должны быть обязательно различны. Конструкция вы¬
бора легко обобщается на случай многих альтернативных событий.
Например, процесс
add ADD | sub SUB | mul -> MUL | div DIV
описывает выбор функции АЛУ в зависимости от заданной команды
(события add, sub, mul, div).
Приведем примеры более сложных конструкций процессов:
INVBIT = цХ (inO outl -> X | ini -> outO -> X).
Процесс INVBIT преобразует значение входного бита (inO,
ini) в инвертированное значение (outl, outO), вслед за чем анали¬
зируется новое значение входного бита.
TRIG = цХ (setd (inO -> outO -> X | ini —> outl ->
-> X) | reset -> outO -> X).
Процесс TRIG описывает работу триггера, запоминающего при
Появлении управляющего сигнала setd значение информационно¬
го сигнала (inO, ini) и устанавливающегося в нуль при появле¬
нии сигнала reset.
На данных примерах легко видеть, что в теории не делается
Различий между событиями, возникающими по инициативе про-
Досса или являющимися результатом внешнего воздействия на мо-
Дель. Заметим также, что с появлением событий и реакцией на них
Процесса не связывается временная длительность, предполагает¬
ся» что они мгновенны. Однако существует некоторая последова¬
тельность «регистрации» событий процессом. Для придания модели
внутренних атрибутов, необходимых при описании ВУ, таких, как
185
интервал времени, тактовый импульс и т. п., нужно ввести в
дель события с соответствующей «временной» семантикой. Так
например, можно стробировать работу триггера последовательны,’
ми тактовыми импульсами сП и с12:
TRIG1 — цХ (сП —>- setd -> (inO -> с12 -> outO X | ini
-> с12 outl -> X) | reset —(с12 outO -> X)).
Некоторые другие детали временной синхронизации моденец
будут рассмотрены в следующих частях раздела.
1.3. Перейдем к описанию конструкций совместного выполне¬
ния процессов. Рассмотрим процессы Р и Q, для которых, вообще
говоря, аР У= aQ. Нотация
Р|| Q
обозначает новый процесс, поведение которого при появлении оче¬
редного события описывается каким-либо субпроцессом процесса
Р или процесса Q. Операция || ассоциативна и симметрична.
Далее, если R = Р || Q, то
aR = а (Р) U а (<?). (1)
Кроме того, для операции || выполняются следующие свойства:
P)W(c^Q) = с->(Р||0, СЕа(Р)П«(0, (2)
(я->Р)||(2 = X^(P\\Q), геа(Р)\а(0, (3)
{x^p)\\{y^Q) = (X-^p\\(y_+Q)) | y^{{x^P)\\Q),
у e a (0 \ a (P), (4)
(c P) || (a -> 0) - DEADLOCK, c, d e a (P) П a (0, _
c d. (5)
С помощью заданных правил можно, зная определения про¬
цессов Р и 0 построить конструктивное описание процесса R-
Пусть, например, процессы суммирования и подготовки операндов
разделены:
SUM = ИХ (ell -> add с12 -> out -> X),
ОР1 = цХ (clO opl -> ell -> X),
ОР2 = цХ (clO -> ор2 ell -> X).
Тогда
SUM || ОР1 || ОР2 = цХ (clO -> (opl ор2 -> ell -> add
с12 out -> X | ор2 —opl -> сП add —с12 ->
out —X).
В примере видно, что порядок вычисления операндов (opL
ор2) на самом деле несуществен. Это означает, что действия по
вычислению операндов могут быть проведены параллельно. Onpej
деление таких параллельных фрагментов обычно является одной
из задач исследования архитектуры ВУ, описанной в виде сово¬
купности взаимодействующих процессов.
186
Другой существенной задачей, решаемой при описании архи¬
тектуры ВУ, является определение тупиков (DEADLOCK). Как
рядно из свойства (5), тупиковые ситуации возникают в случае
появления нескольких конкурирующих событий, реакция на ко¬
торые У взаимодействующих процессов, вообще говоря, различна.
Существенно, что выявление тупиковых ситуаций может быть про¬
ведено формальными методами, на основании описания совместно
выполняемых процессов.
1.4. При описании процессов функционирования ВУ часто встре¬
чаются ситуации, которые, если исходить из предыдущего рас¬
смотрения, должны быть признаны тупиковыми, однако исполь¬
зуются на практике как рабочие.
Действительно, в вычислительной аппаратуре часто встреча¬
ются совместно работающие процессы, производящие разгар, но
согласованные действия после получения какого либо управляю¬
щего сигнала. Типичным примером такого рода являются устрой¬
ства с микропрограммным управлением, где в дешифрации и вы¬
полнении микрокоманды участвуют, как правило, несколько
процессов. Каждый из процессов выполняет самостоятельные функ¬
ции, как то управление сумматором, подготовка операндов, обра¬
ботка прерываний, причем некоторые из рассматриваемых про¬
цессов могут быть функционально эквивалентными. Разумеется,
на более высоком уровне абстракции все эти разнородные дей¬
ствия могут быть охарактеризованы как событие «выполнение
микрокоманды», и задача состоит в том, чтобы обеспечить переход
с одного уровня абстракции на другой по мере наращивания слож¬
ности во взаимодействии процессов. Для этого введем понятие
сорта события.
Назовем сортом некоторую совокупность событий. Каждому
сорту присвоим имя-идентификатор, начинающееся с символа @.
Например:
{add, opl, interupt, out} : @ sortl
обозначает, что описанное в фигурных скобках множество событий
принадлежит сорту @ sortl. Для определенности считаем, что
каждое событие не может принадлежать более чем к одному сорту.
Принадлежность событий определенному сорту, естественно,
означает, что их можно отождествить на более высоком уровне
абстракции, а имя сорта в этом случае будет служить в качестве
Имени обобщенного события. Итак, если
R - Р || Q и Р - si -> Pl, Q = s2 -> Q2, {si, s2} : @ sortl,
To
R1 = ©sortl (Pl II QI).
Заметим, что указанное соотношение имеет смысл как в случае
si, s2 ЕЕ а (Р) П а ((?),
о. в случае тупиковой ситуации, так и в случае
si (= а (Р) \ а (0, s2 Е а (« \ а (Р),
187
т. е. в случае совмещаемых за счет параллелизма событий si и §2
Процесс R1, полученный в результате введения обобщенного Со*
бытия, условимся далее называть сверткой процессов Р и Q. Так
в примере из разд. 1.3 композиция процессов SUM || ОР1 || ()р2
может быть свернута к процессу
SHMOP = цХ (сЮ (@ор -> ell -> acid -> с12 -> out -> А))
Разумеется, имя сорта, трактуемое как обобщенное событие
может, в свою очередь, вместе с другими событиями также прц!
надлежать какому-либо другому сорту. Тем самым возможна мц0,
гоуровневая иерархическая свертка процессов.
1.5. Как говорилось, поведение процессов может быть проана¬
лизировано с помощью упорядоченной последовательности собы¬
тий, произошедших при его функционировании — трассы процес¬
са. При этом возможны как теоретические, так и эксперименталь¬
ные методики исследования трасс.
Теоретическое исследование трассы процесса обычно возника¬
ет при решении задач верификационного плана.
Спецификация процесса в виде набора предикатов — условий,
определяющих допустимые значения элементов трассы процесса,
позволяет оценить корректность построения процесса или системы
процессов.
Экспериментальное исследование трасс возникает при модели¬
ровании поведения процессов. Сбор трасс процессов — одна, из
основных задач любой системы моделирования. При оценке ре¬
зультатов эксперимента, а возможно, уже и при сборе трасс, как
правило, используются результаты теоретических исследований
поведения данной системы процессов.
Для работы с трассами применяется широкий спектр операций
обработки списковых данных.
2.
ПРОЦЕССЫ В ЯЗЫКАХ КОНЛАН-СЕМЕЙСТВА
Как отмечалось, языки Конлан-семейства имеют общую мо¬
дель выполнения. Это означает, что во всех Конлан-языках имеется
общий взгляд на интерпретацию текстов, представляющих описа¬
ние вычислительной аппаратуры и терминах данного языка.
2.1. Модель устройства или его фрагмента представляется в
Конлан-язьтке в виде одного или нескольких связанных между
собой описаний (DESCRIPTIONS), в каждом из которых находит¬
ся список выполняемых операторов. Все операторы описания вы¬
полняются одновременно.
Основным элементом определения поведения модели служи1,
функциональное описание (FUNCTION). Каждое функционально6
описание также состоит из последовательности параллельно вы¬
полняемых операторов.
Большинство операторов представляет собой запись функцио^
нальных выражений. Каждое выражение выполняется в некоторой
188
последовательности, определяемой уровнем вложенности функ¬
ций и старшинством операций. Функциональное выражение —
единственная конструкция Конлан, при интерпретации которой
учитывается последовательность выполняемых действий.
Существуют также условные операторы и операторы выбора
варианта, представляющие собой наборы конструкций, выпол¬
няющихся альтернативно в зависимости от выполнения условий.
Итак, в Конлан-язьтках используются все три базовых способа
композиции процессов: последовательный, параллельный и аль¬
тернативный. Событиями в Конлан-моделях служат изменения
значений объектов данных и связанных с ними условий,определяю¬
щих выбор вариантов работы модели. Кроме того, существуют так¬
же элементарные временные события, такие, как смена интервала
времени или его более мелкой единицы — шага моделирования.
2.2. Проверка корректности поведения модели во времени мо¬
жет проводиться как в режиме тестирования модели, так и путем
верификации описания модели.
При тестировании система моделирования интерпретирует по¬
ведение модели на заданных тестовых наборах и строит трассы
специального вида — временные диаграммы изменения сигналов
и других объектов модели. Правила Конлан позволяют также сфор¬
мулировать утверждения (ASSERTIONS) относительно изменения
сигналов во времени или по отношению к другим данным. Эти ус¬
ловия будут проверяться при выполнении модели, и нарушение
их будет фиксироваться как ошибка. Полнота тестирования опре¬
деляется полнотой и корректностью входного текста.
При верификации задаваемые в модели условия рассматрива¬
ются как временные спецификации процессов. Кроме того, форми¬
руется одна или несколько целей — условий, выполнение которых
необходимо проверить. В процессе верификации каждая цель долж¬
на быть логически выведена из заданных спецификаций и некото¬
рых общих аксиом.
Языковые средства для описания поведения устройства во
времени должны включать в себя два ряда понятий, связанных со¬
ответственно с событиями и интервалами времени, а также пре¬
дикаты, связывающие эти понятия, как, например, «событие на¬
ходится в интервале заданной длины», «интервал между заданными
событиями не превосходит определенной длины» и т. п. Эти язы¬
ковые средства проектируются в так называемую временную ло¬
гику, представляющую собой одну из разновидностей нечеткой
логики.
2.3. Верификационные методы могут применяться не только для
Доказательства истинности временных или логических соотноше¬
ний в модели, но и во многих других случаях, в частности для
Установления эквивалентности описаний одного и того же фраг¬
мента оборудования на различных уровнях детальности или в
Разных аспектах.
Особый интерес представляют так называемые межаспектные
т₽ансформации описаний, дающие, например, доказательство эк-
189
Бивалентности модели поведения некоторого устройства и еГо
структурной схемы.
Как видно из сказанного, языки Конлан-семейства поддержи¬
вают с некоторыми ограничениями математическую модель, опи¬
санную в предыдущем разделе. Некоторые особенности реализа¬
ции прототипа системы, поддерживающей идеологию Конлан, бу¬
дут приведены в следующем разделе статьи.
3.
ИНСТРУМЕНТАЛЬНЫЕ СРЕДСТВА РЕАЛИЗАЦИИ
ПРОТОТИПА КОНЛАН-СИСТЕМЫ
Ранее в работах [5, 6, 7] обсуждался вопрос о функциональных
возможностях и структуре Конлан-системы. Поэтому в данном
разделе коснемся только вопроса об инструментальных средствах
для реализации прототипной версии системы, выбор которых был
обоснован в предыдущих разделах статьи.
Как было сказано, при работе исполнительной части Конлан-
системы могут использоваться два режима: верификационный и
режим тестирования.
В режиме тестирования система должна воспроизводить работу
многих совместно выполняемых (параллельных) процессов. Поэто¬
му при программировании режима тестирования можно восполь¬
зоваться языком параллельного программирования. При реали¬
зации прототипа в качестве такого языка будет использоваться
язык Оккам, а также язык Си — для программирования алгорит¬
мических фрагментов, не связанных с диспетчеризацией процессов.
В верификационном режиме необходимым элементом системы
является логический вывод и развитая работа со списковыми
структурами данных. Поэтому для этого режима будет использо¬
ваться техника программирования в языках Пролог и Лисп.
Еще одна особенность Конлан-системы состоит в том, что на¬
стройка системы на грамматику входного текста может происхо¬
дить динамически, т. е. в процессе его интерпрерации. Это обстоя¬
тельство затрудняет применение обычных «компиляторов-компи¬
ляторов» для построения процедуры грамматического разбора
текста. Возможным выходом из данной ситуации является исполь¬
зование Пролога для грамматического разбора текстов.
ЛИТЕРАТУРА
1. Pilloty В., Barbacct М., Borrione D. et al. Conlanjreport. N. Y.: Springer’
1983. 235 p. (Leet. Not. Comput. Sci.; N 151).
2. Марчук A. Г., Лельчук T. И. ПОЛЯР-язык параллельного синхронного
программирования. 1984. № 4. С. 59—68. р,
3. Hoare С. Communicating sequentional processes. L.: Prentice-Hall, I™0-
256 p.
4. OCCAM. Programming Manual. L.: Prentice-Hall, 1984. 100 p.
5. Ландау И. Я., Погосянц Г. М. К вопросу о конструировании языков
делирования вычислительных систем // ЭВМ массового применения. №•'
Наука, 1987. С. 165—169.
190
g, Landau I., Pogosjantz G. Object-oriented approach toward microprocessor
unit modelling//Proc. I Intern. Symp. Microprocessor. Syst. «MA1PS-85».
Bautzen, 1985. Vol. 1. P. 101—111.
7, Ландау И. ЯПогосянц Г. М. Некоторые вопросы языкового обеспечения
систем моделирования вычислительных устройств // Современные средст¬
ва информатики. М.: Наука, 1986. С. 150—157.
УДК 681.325.001.57
АРХИТЕКТУРА ОТКРЫТОЙ,
МОБИЛЬНОЙ ПРОГРАММНОЙ СИСТЕМЫ
ЛОГИКО-ВРЕМЕННОГО МОДЕЛИРОВАНИЯ (ЛВМ)
ДИСКРЕТНЫХ ПРОЦЕССОВ
В ЛОГИЧЕСКИХ СХЕМАХ
М. И. Иоффе
Современные тенденции развития вычислительной техники, в
первую очередь повышение интеграции микросхем, необходи¬
мость сокращения сроков новых разработок обусловливают все
более широкое использование моделирования при создании тех¬
нических средств ВТ. На различных этапах создания средств ВТ
применяются соответствующие системы моделирования [1].
В данной работе пойдет речь о системе моделирования для этапа
логического проектирования средств ВТ. На этом этапе моделиро¬
вание позволяет выполнить без изготовления экспериментального
образца проверку правильности разрабатываемой логической схе¬
мы с точки зрения выполнения ею функции переработки и хране¬
ния информации, а также исследовать временные характеристики
и детерминированность работы схемы с учетом допустимого раз¬
броса задержек компонентов схемы. Необходимо отметить, что по¬
следняя задача принципиально не может быть решена с помощью
экспериментального образца.
Возможности систем моделирования неизменно отстают от
требований практики. Ограничения, из-за которых происходит
Невозможность применения существующих систем для новых про¬
ектов, обычно следующие: а) объем схемы, подлежащей моделиро¬
ванию, не может быть эффективно или вообще обработан системой;
®) адекватность моделирования не достаточна для требуемого
анализа создаваемого проекта; в) существующая система не мо-
Шет быть использована на новой, более мощной ЭВМ из-за не¬
совместимости или наличия внутренних ограничений в системе.
В то же время достижения и тенденции развития ВТ создают
Предпосылки для создания долгоживущей за счет заложенных в
Нее возможностей к развитию системы моделирования. Важней¬
шими для создания такой системы достижениями являются: а)
снижение стоимости вычислительных ресурсов; б) наличие мо-
191
бильных систем программирования; в) наличие виртуальной
мяти.
Далее в работе описывается архитектура системы моделир0,
вания логических схем, при создании которой была предпринята
попытка исключить внутренние ограничения на объем обрабатьь
ваемой схемы и открыть возможность использования программи
моделей, имеющих практически неограниченную точность моде~
лирования, а также совместить в одной системе возможность \t0,
делирования схем на различных уровнях детализации — от
тильного до уровня целых устройств. На выбор архитектуры ока.
зало влияние стремление создать систему, которая могла бы быть
использована для программно-аппаратного моделирования, когда
часть схемы представлена в виде аппаратной модели, а другая —
в виде программной модели.
СОСТАВ ПОДСИСТЕМ
Описываемая система состоит из следующих подсистем:
1) ввод описания логической схемы;
2) информационная база данных компонент;
3) формирование внутрисистемного описания схемы и компонов¬
ка программы моделирования схемы;
4) ввод теста и вывод результатов моделирования;
5) управление процессом моделирования, взаимодействие с
пользователем.
ОПИСАНИЕ ЛОГИЧЕСКОЙ СХЕМЫ
Логическая схема определяется используемыми в ней компо¬
нентами, внешними выводами, соединениями между компонентами,
соединениями между внешними выводами и компонентами.
В качестве компонента логической схемы в данной системе
может выступать произвольная логическая схема, которую для
пользователя имеет смысл рассматривать как единое целое. Обыч¬
но разработчики технических средств оперируют в своей работе
компонентами, которые представляют собой серийно выпускаемые
цифровые интегральные микросхемы (ИМС). Степень интеграппй
ИМС в современных разработках колеблется в больших предела \ —
от малой (10 вентилей на кристалле ИМС) до сверхбольших (де¬
сятки тысяч вентилей на кристалле).
Базовым понятием при описании логической схемы является
существенная точка схемы. Существенной точкой (далее ДЛЯ
краткости просто точкой) в схеме является место, состояние сиг¬
нала в котором представляет интерес для пользователя, а так#6
влияет на функцию, реализуемую компонентой, отображает функ¬
ционирование компоненты или всей схемы.
По умолчанию в системе в качестве точек рассматриваются»
если пользователем не оговорено иначе, входные/выходные
такты разъемов и входные/выходные выводы компонент.
192
Компоненты и разъемы имеют собственное имя. Имя точки об¬
разуется путем конкатенации имени компоненты или разъема и
номера контакта или вывода.
Базовым языком описания логической схемы в системе принят
перечень эквипотенциальных цепей соединений и перечень ком¬
понент. Эквипотенциальная цепь задается списком точек, соеди¬
ненных данной цепыо. В перечне компонент каждому собственному
имени компоненты ставится в соответствие ее тип. В тех случаях,
когда в качестве компонента используется ИМС, тиц совпадает
с ее обозначением по принятому стандарту. При необходимости
стандартное обозначение может содержать расширение.
К базовому языку могут быть приведены любые другие спосо¬
бы описания схемы, к примеру использующие графическое пред¬
ставление схемы.
БАЗА ДАННЫХ КОМПОНЕНТ
Для каждого компонента логической схемы в системной базе
данных должна быть таблица, в которой для всех выводов указа¬
но, является ли он входным, выходным или двунаправленным, до¬
пускается ли групповая обработка сигналов на данном выводе, и
если да, то совместно с какими другими выводами образуется эта
группа. В этой таблице для компонента указываются также вре¬
менные параметры и формат структуры для хранения промежуточ¬
ных данных и значений сигналов, которая должна быть сформиро¬
вана во внутрисистемном описании схемы.
Кроме указанной обязательной таблицы, в базе данных для
каждого компонента целесообразно иметь справочные таблицы и
текстовые описания, позволяющие разработчикам получить ин¬
формацию, достаточную для применения компонента.
Для каждого типа компонента в базе данных должна быть под¬
программа моделирования (ПМК) его работы. ПМК удобно пред¬
ставить состоящей из трех частей: операционной, области стати¬
ческих данных и области динамических данных. Операционная
часть выполняет вычисление функции, реализуемой компонентом.
В области статических данных задаются значения переменных,
которые в процессе одного сеанса моделирования схемы остаются
Неизменными. Такими переменными, к примеру, являются вре¬
менные параметры. В области динамических данных хранятся пе¬
ременные, изменяющие значения в процессе сеанса моделирования
схемы. Подробнее вопросы, связанные с написанием ПМ компонен-
Та, рассматриваются ниже.
ВНУТРИСИСТЕМНОЕ ОПИСАНИЕ СХЕМЫ
В основе внутрисистемного описания схемы лежит понятие
^кгнала. Возможны два типа сигналов: одиночные и регистровые,
каждый из этих типов сигналов может быть однонаправленным и
^направленным.
193
Одиночный сигнал соответствует одной точке схемы, регисгр0^
вый — упорядоченной группе точек, для которых допускается
групповая обработка при вычислении функции компонента. Оди¬
ночный сигнал может включаться в регистровый и, наоборот, м0„
жет быть выделен из регистрового.
Базовый алфавит значений сигналов четырехзначный: — {д
1, X, Z}, где 0 и 1 — логические значения низкого и высокого
уровней; X — неизвестное или неопределенное значение; Z — сос¬
тояние высокого импеданса. Для регистровых сигналов, которые
обычно соответствуют точкам в шинах данных и адреса, этого
алфавита, как правило, достаточно. Алфавит одиночных сигналов
при необходимости может быть расширен. К примеру, полезно
использовать символы f | , соответствующие изменениям сиг¬
нала из 0 в 1 и из 1 в 0.
Сигналы схемы могут выступать в качестве источника события,
состоящего в изменении значения сигнала, и приемника этого со¬
бытия. Сигналом-источником события могут быть только те сигна¬
лы, которые соответствуют следующим точкам: входным контак¬
там разъема, выходным выводам компонентов, двунаправленным
выводам, когда они функционируют в качестве выходных.
Во внутрисистемном описании схемы сигнал-источник и сиг¬
нал-приемник должны быть одного типа: либо оба одиночные,
либо оба регистровые. При рассогласовании во внутрисистемное
описание должен быть включен согласователь-разбиратель, если-
регистровый сигнал-источник взаимодействует с одиночным сиг¬
налом-приемником, и включается согласователь-собиратель, ес¬
ли одиночный сигнал-источник взаимодействует с регистровым
сигналом-приемником.
Для каждого сигнала во внутрисистемном описании схемы
имеется описатель, в котором указывается идентификатор сигна¬
ла, значение сигнала и момент времени, в который произошла
установка данного значения сигнала.
Внутрисистемное описание схемы включает три структуры:
1) область промежуточных, статических и динамических данных
программ моделирования компонент S; 2) справочную информацию
о всех точках схемы Р; 3) справочную информацию об именах точек
и их размещении в структуре Р (название этой структуры V).
Структура S состоит из множества областей компонент, а также
областей разъемов схемы. В области каждой компоненты имеются
поля для хранения описателей всех сигналов этой компоненты
(область динамических данных ПМК), поля для хранения кон¬
стант (область статических данных ПМК) и рабочее поле для ра"
боты ПМК.
Структура Р состоит из областей описания всех точек схемы.
В области описания каждой точки имеются поля, в которых хра'
нится следующая информация: 1) адрес поля в структуре 5, где
хранится значение сигнала, соответствующего данной точке: Д
тип точки, а для регистровых сигналов, кроме того, и адрес сос.еД"
ней регистровой точки в Р; 3) если данной точке соответствуй
194
сигнал, который может служить источником события, то для этого
сигнала указывается описание всех сигналов-приемников. В опи¬
сании каждого сигнала-приемника задается: 1) адрес в структуре
где хранится значение этого сигнала-приемника; 2) адрес
начала области в структуре S, соответствующей компоненте, ак¬
тивизированной сигналом-приемником; 3) адрес ПМК, соответ¬
ствующей активизируемой компоненте.
Структура N содержит для каждой точки ее имя и адрес на¬
чала описания точки в структуре Р.
Формирование внутрисистемного описания схемы осуществля¬
ется на основе описания схемы с помощью заготовок форматов
структур, находящихся в базе данных для каждой компоненте.
Для выполнения моделирования схемы внутрисистемное опи¬
сание компонуется с подпрограммами моделирования компонен¬
тов и управляющими программами в один загрузочный модуль.
МОДЕЛИРОВАНИЕ ТЕЧЕНИЯ ВРЕМЕНИ
Для моделирования течения времени в системе используется
техника, обычно называемая «колесом времени» [2]. Оригиналь¬
ным является прием, позволяющий выполнять моделирование на
практически бесконечном интервале времени.
В данной системе «колесо времени» содержит два циферблата:
СО и С1. Цена деления СО соответствует дискрету модельного
времени, а дискрет моделирования — наибольшему общему де¬
лителю учитываемых задержек компонентов и временному сме¬
щению между моментами изменения сигналов на входах компо¬
нентов или входах всей схемы. Весь интервал времени, отобра¬
жаемый на циферблате СО, соответствует интервалу, отображае¬
мому в одном делении циферблата С1.
Каждый циферблат имеет указатель текущего момента вре¬
мени для данного циферблата.
С делениями циферблатов, другими словами, с моментами вре¬
мени, соответствующими делениям циферблатов, связываются
события в моделируемой схеме. Описатель события по формату
совпадает с описателем сигнала: в нем указаны идентификатор
изменяющегося сигнала, новое значение сигнала и момент вре¬
мени, когда новое значение сигнала станет действительным.
Для хранения будущих событий используется структура С,
в которой описатели событий располагаются в произвольном
Порядке. В делении циферблата указывается ссылка на адрес
соответствующего описателя события в структуре С. Если в мо¬
мент времени, соответствующий делению циферблата СО, или
в интервал времени, соответствующий делению циферблата С1,
происходит несколько событий, то из описателей событий в струк¬
туре С связывается цепочка с помощью соответствующих ссылок.
Течение модельного времени отслеживается по циферблату СО.
Указатель перемещается от одного деления к другому, и для каж-
^°го момента времени отрабатываются события, происходящие
195
Рис. 1. Структура циферблатов и массива описателей событии (а), тикала
модельного времени (б)
в текущий момент. После отработки описатель события исклю¬
чается из структуры С. После отработки всех событий, происходя¬
щих в текущий момент, указатель циферблата перемещается на
следующее деление. После завершения одного оборота указателя
по СО указатель циферблата С1 перемещается на одно деление н
ссылки на события, происходящие в этот интервал времени, пере¬
писываются в соответствии с моментами времени, когда они пр°'
исходят, в деления циферблата СО. Далее описанный процесс дня
СО аналогично повторяется. Структура циферблатов и массив3
описателей событий представлена на рис. 1, а).
Теперь рассмотрим прием, который позволяет обеспечит17
моделирование логической схемы практически на неограничен¬
ном интервале времени. Заметим, что ограничение возникав
в связи с конечной длиной поля для хранения момента изменения
196
олгнала. Увеличение длины этого поля ведет к значительному
росту объема памяти, расходуемого для хранения описателей
сигналов.
Предлагаемый прием состоит в использовании плавающего
интервала моделирования. При его использовании ограничивается
удаленность прошедших и будущих событий от текущего момента
времени. Все эти события при моделировании должны уклады¬
ваться в один интервал моделирования. К примеру, при исполь¬
зовании инструментальной ЭВМ с 16-битным словом плавающий
интервал моделирования целесообразно принять равным 64К
дискретов. Максимальную удаленность прошедшего события имеет
смысл принять равным 16К дискретов, а будущих событий — 32К
дискретов. Тогда интервал изменения текущего момента времени
будет 16К дискретов. При достижении границы интервала изме¬
нения текущего момента для продолжения моделирования необ¬
ходимо выполнить сдвиг: вычесть из моментов изменения сигна¬
лов 16К. Операция сдвига позволяет продолжить моделирование
еще в течение интервала, равного 16К дискретов.
При выполнении сдвига интервала моделирования для момента
изменения сигнала может образоваться отрицательный результат.
Будем заменять этот результат значением 0. Для современной
схемотехники такое округление несущественно. Справедливость
этого утверждения для рассмотренного приема вытекает из сле¬
дующего рассуждения. Для правильного моделирования работы
компонента не важно, произошло ли событие на его входе за 16К
дискретов до текущего момента времени или еще раньше. Суще¬
ственным является учет моментов наступления событий, пред¬
шествовавших текущему моменту не ранее чем за 16К дискретов.
Первый сдвиг следует выполнять, когда текущий момент станет
равным 32К дискретов и в дальнейшем через каждые 16К дис¬
кретов .
Для определения момента изменения значения сигнала в аб¬
солютной временной шкале необходимо просуммировать момент
в текущем интервале с моментом, соответствующим началу теку¬
щего интервала.
На рис. 1, б представлена схема размещения интервалов мо¬
делирования на временной оси и моментов выполнения сдвигов
Для рассмотренного примера.
ПОДПРОГРАММА МОДЕЛИРОВАНИЯ КОМПОНЕНТЫ
К подпрограмме моделирования компоненты (ПМК) проис¬
ходит обращение при возникновении события на входе этой ком¬
поненты. ПМК вычисляет значение внутренних сигналов и сиг-
*алов на выходе компоненты в соответствии с реализуемой им
Логико-временной функцией.
Вычисленное значение сигнала на выходе элемента, если оно
^Личается от существующего в текущий момент, рассматривается
событие. Если момент наступления события отличается от
197
текущего, то событие рассматривается как гипотетическое (r0w
потеза). Действительным оно станет, когда момент наступления
события станет равным текущему моменту в моделируемом
тервале времени и выполнится отработка этого события.
Гипотеза отображает переходной процесс переключения зца^
чения сигнала в компоненте. До того момента, когда она станет
действительной, ее могут аннулировать события, которые проис¬
ходят на входах элемента после рождения гипотезы.
При работе ПМК в ответ на одно событие на входе компоненты
может быть порождено несколько гипотез о событиях. ПМК со¬
стоит из операционной части и области для хранения статических
и динамических данных. Такое разделение позволяет иметь для
каждого типа компонент, использованного в моделируемой схеме
в процессе моделирования, одну операционную часть и столько
областей для хранения данных, сколько компонент данного типа
используется в схеме.
При обращении к ПМК ей передаются следующие параметры:
1) описатель события; 2) адрес начала области для хранения дан¬
ных. Далее ПМК вычисляет значение внутренних и выходных
сигналов, а также порождает и/или аннулирует гипотезы о собы¬
тиях в схеме как функцию от события на входе компоненты и те¬
кущего состояния, которое включает значение входных, выход¬
ных и внутренних сигналов и, кроме того, гипотезы. Заметим, что
гипотезы следует учитывать при вычислении нового состояния
компоненты в период времени от момента порождения гипотезы
до момента, когда гипотеза станет действительным событием.
Порожденные гипотезы запоминаются, а аннулируемые исклю¬
чаются из области динамических данных моделируемой компо¬
ненты и из области хранения описателей событий — структуре С.
Ссылка на адрес описателя события в структуре С записывается
в деление циферблата «колеса времени», соответствующего момен¬
ту наступления этого события.
Написание ПМК — трудоемкий и неформализованный про¬
цесс. Снижение трудоемкости может быть достигнуто за счет
средств автоматизации программирования — структурного про¬
граммирования, применения языков программирования высокого
уровня. К примеру, структуризацию ПМК удобно выполнять по
возможным событиям на входе моделируемой компоненты. Задача
моделирования компоненты в таком случае будет сведена к под¬
задачам отработки каждого из возможных событий на входе ком¬
поненты. Для формализации описания работы компонент#
удобно использовать дерево решений. При программирования
целесообразно разработать набор специализированных подпр0'
грамм-функций или макрокоманд, реализующих типовые проИе-
дуры в процессе работы ПМК.
Требования к адекватности, которые должны обеспечить
ПМК, можно сформулировать следующим образом. Модель коМ*
поненты должна обеспечить вычисление логико-временных фУй1^
ций компоненты, которые явным образом заданы в ^руководят6
198
техническом материале (РТМ) по применению. Временные пара¬
метры при этом учитываются в виде фиксированных значений,
а не интервалов. Необходимо подчеркнуть, что явное задание
функций компоненты в РТМ является неполным, поэтому при
написании ПМК требуется доопределение. В основном это каса¬
ется условий формирования неопределенных значений сигналов.
Для разработки этих условии целесообразно привлечь экспертов
в области схемотехники, а в дальнейшем создать экспертную
систему.
Для иллюстрации сказанного рассмотрим случай, когда на
одном из входов компоненты произошло два изменения сигнала
в моменты tY и t2, каждое из которых ведет к изменению сигнала
да выходе этой компоненты, но второе изменение произошло до
того, как на выходе установилось новое значение вследствие из¬
менения сигнала в момент tv Отработка события в момент t2
включает аннулирование гипотезы, порожденной в момент
При этом возможны различные варианты моделирования пове¬
дения компоненты. Одним из вариантов является сохранение не¬
изменным выхода компоненты, т. е. подавление импульса. Другим
вариантом отработки этих событий является установка в момент
t2 на выходе компоненты значения X, а в момент (t2 + ^за.р) —
значения сигнала, соответствующего изменению сигнала на входе
в момент t2. Возможно совместное использование обоих вариантов.
Скажем, когда (Л2 — ^i) <С выполняется подавление помехи,
а в случае (t2 — £х) £ — формирование значения X. Здесь
| — константа, значение которой выбирается с учетом особеннос¬
тей моделируемой компоненты
Возможность при отработке события на входе формировать
несколько гипотез позволяет моделировать неопределенность,
возникающую при изменении значения сигнала. В этом случае
формируется две гипотезы. На период неопределенности устанав¬
ливается X, а затем определенное значение.
Идеальной представляется возможность вариации правил вы¬
числения значений сигналов по желанию пользователя. Такую
возможность нетрудно предусмотреть в ПМК.
Описанный принцип построения ПМК позволяет достичь прак¬
тически любого уровня адекватности моделирования, которая
Достижима при учете фиксированных значений временных пара¬
метров. К примеру, могут контролироваться значение предуста¬
новки и удержания сигналов на выводах данных относительно
синхросигнала или длительность интервала неопределенности
цри изменении значения сигнала»
ЗАДАНИЕ ТЕСТА
II ВЫВОД РЕЗУЛЬТАТОВ МОДЕЛИРОВАНИЯ
Задание теста состоит в указании последовательности вход¬
ных воздействий, на которых необходимо промоделировать схему.
Удобным представляется матричный формат с произвольным
199
числом строк и столбцов. Строки соответствуют точкам схемы
а столбцы — моментам изменения сигналов и специальным
рективам. В качестве директив могут быть указания о режиме
подачи воздействий, повторение ранее определенных воздействий
и другие указания.
Ввод теста осуществляется в интерактивном режиме. При этом
экран дисплея представляет собой перемещаемое окно в матрицу
описывающей входные воздействия. Для определенных входных
воздействий на экране слева указываются имена точек, а сверху
моменты времени. В процессе моделирования происходит накахь
ливание информации о событиях в схеме; можно запоминать все
события или только события, которые происходят в заданных
точках. Запоминаемые события группируются по моментам вре¬
мени.
Вывод результатов моделирования выполняется в том же фор¬
мате, что и ввод теста. Точно также экран дисплея представляет
собой перемещаемое окно в матрице, в которой отображены собы¬
тия в схеме на временной оси.
АЛГОРИТМ МОДЕЛИРОВАНИЯ СХЕМЫ
На рис. 2 представлена упрощенная блок-схема алгоритма
моделирования схемы на заданном множестве наборов воздейст¬
вий, который реализуется подсистемой управления. В блок-схеме
не отображены этапы ввода наборов воздействий и вывода резуль¬
татов.
ОТКРЫТОСТЬ II МОБИЛЬНОСТЬ СИСТЕМЫ.
РЕАЛИЗАЦИЯ
Описанная архитектура позволяет в широких пределах варьи¬
ровать значность алфавита моделирования и учет временных за¬
держек. В качестве компоненты в системе может быть логическая
схема произвольной величины от простейшей — вентиля до,
к примеру, микропроцессора или процессора ЭВМ.
В качестве языка программирования выбран Си. На всех сов¬
ременных ЭВМ имеются компиляторы для языка Си, и, что осо¬
бенно важно, версии языка мало чем отличаются для различных
машин. Таким образом, пакет программ, реализующий данную
систему, является мобильным.
В настоящее время создан работающий макет описанной
системы для ПЭВМ, совместимых с ЕС 1841. Структура базы
данных в этом макете представляет собой файлы, величины кото¬
рых определяются ресурсом внешнего запоминающего устрой'
ства инструментальной ЭВМ. Необходимая часть файла считы¬
вается в оперативную память в соответствии с принципами органи¬
зации виртуальной памяти.
При организации структур данных наименьшим элементов
структуры выбрано слово инструментальной ЭВМ. Таким обра"
зом, при переносе пакета программ с микро- на мини- или боДъ"
200
Рис. 2. Блок-схема алгоритма временного моделирования
СО, G1 — циферблаты «колеса времени»; ТТ — момент времени, соответствующий нача¬
лу текущего интервала моделирования;
ТСО, ТС1 — указатели делений на циферблатах СО и С1; А — величина сдвига интер¬
вала моделирования
Шую ЭВМ с ростом ресурсов ЭВМ увеличиваются такие возмож¬
ности обработки логической схемы, как ее величина и количество
битов в регистровых сигналах.
Система позволяет при использовании соответствующей аппа¬
ратуры организовать программно-аппаратное моделирование,
7 Заказ № 2514 201
когда часть модели представляет собой физическую модель, а др
гая часть — программную. В таком случае подпрограмма моде'
лирования компонента, представленная физической моделью'
является драйвером, который подает на физическую модель Воз’
действия и считывает реакции. Воздействия считываются из Со^
ответствующих полей структуры, считанные реакции сравнпВ£ь
ются с реакциями до подачи воздействий, изменения выходцы^
сигналов рассматриваются как события и запоминаются, а в даль,
нейшем обрабатываются так же, как это было описано для чисто
программной модели.
Простой входной язык системы позволяет легко включить ее
в интегрированную систему автоматизированного проектироВа,
ния логических схем.
ЛИТЕРАТУРА
1. Goering R. Simulation challanges Breadboarding for design verification.
Computer Design. June 15, 1986. P. 63—82.
2. Теория и методы автоматизации проектирования вычислительных систем/
Под ред. М. Брейера. М.: Мир, 1977. 256 с.
УДК 681.327.8
ОЦЕНКА ЭФФЕКТИВНОСТИ
ФУНКЦИОНИРОВАНИЯ КОМПЛЕКСА
ПРОЦЕССОР—ПАМЯТЬ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
II. А. Фандюшина
Широкое внедрение средств вычислительной техники сразу
дало огромные преимущества благодаря сокращению времени
обработки и повышению точности решения задач. Поэтому дол¬
гое время внимание специалистов было сосредоточено лишь на
вопросах построения и надежности вычислительных средств.
Вопросы сравнительной оценки эффективности функциониро¬
вания различных вычислительных комплексов отодвигались на
задний план, а в ряде случаев и не рассматривались вообще.
В настоящее время проблема количественной оценки функцио¬
нирования вычислительных систем интересует практически всех
специалистов, имеющих дело с современной вычислительной тех¬
никой. Для потребителей вычислительных комплексов это свя¬
зано с выбором варианта, удовлетворяющего их по функциональ¬
ным и временным возможностям и достаточно недорогого. У иссле¬
дователей, занятых развитием систем, возникает задача плани¬
рования усовершенствований для увеличения производительности
при минимуме изменений. Разработчики вычислительных
плексов сталкиваются с необходимостью оценки при попытке
202
априорного определения того, как должна быть сконструирована
вычислительная система, способная удовлетворительно для за¬
данного класса задач справляться с переработкой информации.
Что выгоднее и насколько увеличивать объем памяти или раз¬
рядность» машины, каково оптимальное количество регистров?
Эти и подобные им вопросы все чаще встают перед разработчиками
вычислительной техники.
Способы расчета производительности вычислительных систем
освещены в литературе пока мало. В большинстве источников
оценка производительности основана, или на суммировании ха¬
рактеристик быстродействия отдельных устройств, или на осно¬
вании прогонки некоторых тестовых программ на рассматривае¬
мых системах. Исключением, пожалуй, являются работы [1—3],
в которых рассматриваются некоторые методы аналитического и
имитационного моделирования.
В данной статье предлагается способ количественной оценки
эффективности функционирования вычислительной системы. В ка¬
честве критерия выбрано значение функционала, являющегося
отношением математического ожидания работы, выполненной
системой в единицу времени, к стоимости системы. Приводятся
приближенные формулы для расчета времени исполнения машин¬
ной инструкции в зависимости от таких параметров системы, как
объем и длительность циклов основной памяти, КЭШ-памяти,
а также количества регистров и машинных инструкций. Работа,
выполняемая системой, измеряется суммарным уменьшением
неопределенностей из-за всех информационно-теоретических ис¬
точников процесса исполнения машинной команды. Для получе¬
ния значений математического ожидания работы и времени вы¬
полнения инструкции используется рабочая нагрузка в виде «сме¬
си команд». Хотя представленный здесь материал относится
к комплексу процессор—память (основная, КЭШ, регистры),
существует возможность оценки в дальнейшем многопроцессор¬
ной системы, а также системы с учетом параметров диска. В ра¬
боте дается пример расчета.
Самый очевидный путь сравнения систем — измерение харак¬
теристик реально существующих систем на реально решаемых
задачах. Он является и самым трудоемким, а при проектировании
и недоступным. В ряде случаев для получения ориентировочных
Результатов удобен аналитический метод, основанный на изуче¬
нии динамических характеристик системы, описанных статисти¬
чески с необходимой степенью подробности. Однако из-за раз¬
личия в технологии, архитектуре, стратегии управления и про¬
граммах обслуживания пользователей сравнение друг с другом
Даже существующих систем вызывает немалые трудности. Про¬
блема становится почти неразрешимой, если такое сравнение
Проводится с целью определения наилучшей системы независимо
°т применения. Тем не менее некоторые индексы, ориентирован¬
ные только на оборудование, предлагались и предлагаются.
Самые ранние работы по оценке производительности системы
203
7*
основывались на таких характеристиках оборудования,
тактовая частота центрального процессора, или скорость сло;Ке
ния чисел с фиксированной точкой, или длительность цикла Ос.
новной памяти. Затем предлагались более сложные критсрИ11
[1]. Например, критерии Шиейдевиида Р = и Грюц01ь
бергера Р = — М (1/7сл + 1^умп), где М — размер памяти
в словах или символах; ^ЦИкл — время ее цикла; £сл и £ух11[
соответственно времена сложения и умножения с фиксированной
точкой.
Возможно, с некоторой натяжкой, эти индексы могут прц^е,
няться для сопоставления эффективности работы вычислитель
ных систем одного класса, предназначенных, кроме того, для ре¬
шения одной и той же группы задач. Однако такие оценки мало¬
пригодны при решении задач оптимизации параметров, характе¬
ризующих оборудование системы, и при выборе эффективной
системы команд.
В последнее время при проектировании вычислительных ма¬
шин проявляется тенденция максимального согласования струк¬
туры вычислительных устройств и реализуемых на них алгорит¬
мов. Одно из ее проявлений — появление архитектуры компью¬
тера с сокращенным набором команд (RISC) в результате изуче¬
ния статистики повторяемости машинных инструкций.
1.
ПОСТАНОВКА ЗАДАЧИ
Вычислительные системы имеют характерные черты сложных
систем. При их анализе критерии качества выбираются из усло¬
вия достаточно полного отражения основного целевого назначе¬
ния системы и являются показателями, определяющими предпоч¬
тительность решений при оценке вариантов систем.
Задача проектирования системы практически всегда может
рассматриваться как экстремальная задача принятия решений,
обращающих в максимум некоторый функционал — критерий
эффективности. В качестве последнего часто используется матема¬
тическое ожидание некоторой целевой функции, определяю щей
степень выгодности допустимых состояний.
Пусть А и В — два варианта систем, эффективность функцио¬
нирования которых необходимо сравнить. Целью сравнения
является выбор лучшего варианта и придание этому выбору ко¬
личественного вида.
Предположим, что выбрано множество {Д}-индексов эффек-
тивности, адекватно отражающих наше представление об эффек¬
тивности функционирования для А и В. Тогда целью работы
является вывод из индексов {D} удобного критерия F, такого,
что сравнение по критерию F наборов индексов для А и В пока¬
зывает, какой из них лучше и насколько.
Заметим, что если в {/)} только один индекс или индекс нре'
204
обладающей важности, то он и должен быть взят в качестве кри¬
терия. Для сложных систем трудно, а во многих случаях не воз¬
можно выделить наиболее существенный критерий качества,
^следствие чего приходится создавать иерархическую совокуп¬
ность критериев, каждый из которых позволяет оценивать сте¬
пень достижения некоторой частной цепи при функционировании
системы. Поэтому предлагаемый ниже вариант не претендует,
па универсальность и абсолютность.
Эффективность является как бы техническим эквивалентом
экономического понятия ценности (потребительской стоимости).
Подобно ценности, одной стороной эффективности является про¬
изводительность, другой — затраты пользователя (цена). И при
выборе, и при усовершенствовании, и при разработке системы
приходится сталкиваться как с величиной производительности,
так и с величиной затрат.
Под индексом «производительности» здесь будет пониматься
описатель, который используется для представления всей произ¬
водительности или какого-то из ее аспектов. Различные индексы
производительности описывают разные аспекты поведения систе¬
мы в рамках одной установки. Причем эти индексы не независимы
друг от друга. Улучшение одного не всегда улучшает или ухуд¬
шает показатели других индексов. Ряду важных индексов произ¬
водительности очень трудно или даже невозможно придать коли¬
чественный вид, например легкость пользования системой, струк¬
турность языка, удобство набора команд. Хотя иногда именно эти
индексы, относящиеся к человеческому фактору, а также надеж¬
ность системы и наличие в ней большого набора программных
средств и определяют выбор системы пользователем.
Не будем останавливаться на анализе таких индексов. Рас¬
смотрим зависимость производительности от индексов, легко при¬
нимающих количественный вид. Хотя эффективность исполь¬
зования системы зависит не только от производительностей от¬
дельных компонент оборудования, но и от координации взаимо¬
действия пользователя с системой, трансляторов, программных
средств и т. д., пока воздержимся от учета влияния этих пара¬
метров.
Пусть процесс S состоит в выполнении z-й машинной инструк¬
ции; h (z) — некоторая мера работы процесса (способ ее расчета
будет приведен ниже). Пусть, кроме того, инструкция i выпол¬
няется за время t (z). Тогда величина h (i)/t (г) определяет работу
процесса S в единицу времени. Если инструкция I встречает-
?гэф 71 эф
ся с частотой / (z) I X / (0 = 1, т0 S / (О Л (z) определяет матема-
V i=l 7 i=l
тическое ожидание величины работы инструкции системы,
пэф
a3/(z)^(z)— математическое ожидание времени исполнения
Инструкции, где — количество различных инструкций
205
системы,
(1)
/(код) — длина операционного кода; 7Щад) — количество типов
адресации; п(иуЛ) — количество неиспользованных комбинаций.
Предлагается производить оценку эффективности функциони¬
рования системы (комплекса центральный процессор — память)
руководствуясь значением F, бит/(с-руб.):
(2)
где S — стоимость системы; к2, к3 — весовые коэффициенты,
выражающие компромисс ценности для потребителя характери¬
стик объема обрабатываемой информации, скорости и стоимостп.
Суммирование проводится по инструкциям системы.
Таким образом, в качестве основных индексов, входящих
в {D}, выбираются: математическое ожидание объема выполнен¬
ной работы; математическое ожидание времени ее выполнении и
стоимость комплекса. Заметим, что при отсутствии подробных
данных о рабочей нагрузке и использовании «стандартной смеси»
(см. ниже) величины / (Z), h (г), t (Z) должны представлять собой
соответственно среднюю частоту появления, среднюю работу п
среднее время исполнения команд в i-м классе. Суммирование
тогда будет проведено по классам операций. Будем говорить, что.
эффективность системы А составляет а (%) от эффективности
системы В, если (FA/FB) = а, где Рл и FB — значения функцио¬
нала F для систем А. и В соответственно, вычисленные для одной
и той же рабочей нагрузки и одних весовых коэффициентов.
Итак, для расчета значения F по (2) для систем А и В необ¬
ходимо располагать величинами или уметь рассчитывать рабочую
нагрузку, проявляющуюся в частоте повторяемости / (Z) данной
инструкции, меру работы h (Z) и время ее выполнения t (Z) в зави¬
симости от параметров системы и класса решаемых задач.
2.
МЕТОД ОЦЕНКИ ПРОИЗВОДИТЕЛЬНОСТИ СИСТЕМЫ
2.1. Учет влияния рабочей нагрузки
При любом оценочном исследовании приходится решать во¬
прос, при какой рабочей нагрузке должна исследоваться произ¬
водительность системы? Под рабочей нагрузкой вычислительной
системы понимается совокупность всей входной информаций
поступающей извне в систему. Рабочие нагрузки для сравнивае¬
мых систем должны быть идентичны. Какую рабочую нагрузку
выбрать для определения и оценки индексов производительности.
Если установка уже существует, то выбранная рабочая нагрузка
должна совпадать с обычной производственной нагрузкой этой
установки или быть близка к ней. Если стоит проблема покупки
206
системы обработки данных и нужно выбрать ее среди нескольких,
то можно воспользоваться набором эталонов. Однако такой метод,
мало или совсем не поможет при проектировании систем.
Система команд — одна из важнейших характеристик ЭВМ.
С точки зрения получения на ЭВМ решения задачи интересно
знать, посредством какого набора операций машины оно дости¬
гается, и какова частотная функция распределения этих операций.
Одной из первых искусственных моделей рабочей нагрузки,
предложенных для оценки производительности, была модель
«смеси команд» [1], представляющая собой набор частот / (Q-
распределения команд, выполняемых во время обработки рабо¬
чей нагрузки, характеризующий относительную используемость
отдельных команд, или, другими словами, относительные запросы
на процессорные ресурсы.
Обычно в момент проектирования системы рабочая нагрузка,
которую предстоит обрабатывать системе, известна настолько
приблизительно, что не может быть указана точнее, чем в кате¬
гориях широкой области применения (например, научные вычис¬
ления, обучение, обработка статистических данных и т. д.). В этом
случае необходима некоторая фиктивная рабочая нагрузка, до¬
статочно полная для того, чтобы представлять возможное при¬
менение системы. Поэтому эффективность работы системы на за¬
дачах данного типа находится в прямой зависимости от качества
модели рабочей нагрузки при проектировании системы.
Одним из примеров «стандартной смеси» является смесь Гиб¬
сона. Частоты в этой смеси получены из усреднения данных боль¬
шого числа программ для научных и технических приложений,
собранных на установках IBM 7090. Однако те же потребности
в обработке информации, выраженные на языке другой машины,
дадут другую смесь команд, причем отличие будет не только
в частотах, но и в типах команд, присутствующих в смеси. Можно
уменьшить зависимость частотных характеристик смеси от систе¬
мы, выбирая параметры, которые представляют, скорее, логичес¬
кие, чем физические ресурсы, группируя инструкции в более
широкие классы, имеющиеся в большинстве центральных про¬
цессоров.
Исследования, проведенные многими авторами [1] и нами, по¬
казывают, что такая смесь существенно зависит лишь от класса
задач и, видимо, позволяет сравнивать несколько архитектур.
В дальнейшем под / (Z) и t (/) будем понимать либо частоту и
Длительность исполнения конкретной инструкции г, либо соот¬
ветственно среднюю частоту и среднюю длительность для класса
Команд, тогда суммирование проводится по классам.
2.2. Объем обрабатываемой информации
Для расчета производительности компьютеров необходимо
Прежде всего определить меру их работы. К решению этого во¬
проса существует несколько подходов [1]. Один из вариантов —
207
набор «заданий». Производительность тогда характеризуется ко¬
личеством заданий в единицу времени. Предпринимались попытки
сравнения систем по соотношению суммарного объема тестовых
програМлМ и данных в битах к скорости их исполнения. Иногда
мощность системы оценивалась количеством операций в единицу
времени, однако проводить такую оценку при сравнении разных
архитектур бессмысленно.
Ряд исследователей [4—6] предлагает оценивать объем обра¬
батываемой информации «трудоемкостью», используя аппарат
теории информации. Так, Хеллерман [5] определяет работу [р
процесса /, отображающего множество X в множество Y (X ~> Y)
чья область определения X конечна и может быть разбита на п
подобластей X (Z), таких, что все данные из X (Z) дают одну и ту
же точку множества У, т. е. / (X (Z)) = Y (Z) тогда и только тогда,
когда х принадлежит X (Z); вероятность появления Y (Z) равна
| X (Z) |/| X |. Общее изменение информации
ш (/) = S IX (О I log2 (I X |/| X (i) I) = IX IH (pv..pn).
2=1
где pt = | X (Z) |/| X |; | X (Z) | — число элементов множества
X (Z); | X | — число элементов множества X\ H — функция эн¬
тропии в теории информации. Байю [6] определяет работу W
процесса /, как
№(/) = (1/|Х|) 5 |X(i)| iog2|x(0|,
2=1
что соответствует потере информации при вводе, если / необратим,
и потере упорядоченности, если / обратим. Однако здесь не учи¬
тывается, например, пересылка данных. Источники информации
и их энтропии рассматриваются также Розвадовски [7], определя¬
ющим количество вычислений как суммарное уменьшение неопре¬
деленностей из-за всех (информационно-теоретических) источ¬
ников, составляющих процесс. Представленные упомянутыми
исследователями определения объема работы процесса близки
друг другу и обоснованы математически.
В этой работе, следуя Розвадовски, в качестве меры объема
обработанной информации (работы) также принимается суммар¬
ное уменьшение неопределенностей из-за источников, составляю¬
щих процесс.
2.3. Расчет времени исполнения команды
с учетом КЭШ-памятп и регистров
Время t (Z) выполнения команды Z складывается из не совме¬
щенного с предыдущей операцией времени подготовки команд1*1
и операндов и времени выполнения операции в устройстве
208
обработки
t (0 — %(0 4~ (А (0 4~ (0 4~ (0 4- z3 (0.1 ’
(3)
где tQ (Z) — время выполнения операции; ZH (Z) — время выборки
й распаковки команды; ZM (Z) — время модификации адресов опе¬
рандов; tB (0 — время выборки операндов; t3(i)— время записи
результата.
В первом приближении предлагается в выражении (2) рас¬
сматривать в качестве времени t (Z) = t0 (Z) + (Z) — время
выборки операндов и выполнения операции как параметр, наи¬
более полно характеризующий иерархию памяти и АЛУ. Кроме
того, в ряде вычислительных систем распаковка следующей ко¬
манды совмещена с записью результата предыдущей, вследствии
чего учет остальных частей времени исполнения команды должен
производиться дифференцированно для разных ЭВМ.
Итак, в дальнейшем под Z (Z) понимается его часть, а именно
to (Z) 4- tB (Z). При определении времени выборки операндов
необходимо учитывать наличие регистровой или буферной па¬
мяти.
В данной работе предполагается возможность наличия в си¬
стеме, кроме основной памяти, высокоскоростного буфера —
КЭШ-памяти и быстрых регистров. Маленькие вычислительные
системы обычно не имеют КЭШа, но зато обладают быстрыми
регистрами. В больших системах бывает и то и другое.
Пусть £(М0) — время цикла основной памяти; £(кэш) — время
цикла КЭШ-памяти; 71/(кэ1П) — объем информации в КЭШ-
памяти в словах; 7lfocn — объем информации в основной памяти
в словах; Р(кэш) — коэффициент использования КЭШ-памятит
равный частоте удовлетворения запросов к КЭШ; Р(М0) — час¬
тота обращения к основной памяти не через КЭШ (т. е. операнд
находится в основной памяти). Тогда Р(кэш) = 1 — Амо)-
Поскольку обращение к КЭШ-памяти занимает обычно 10 —
25 % от времени обращения к основной памяти, вопрос о частоте
попадания в КЭШ и выборе стратегии организации КЭШ является
весьма существенным для оценки производительности системы.
Без учета организации КЭШ, т. е. если считать равновероят¬
ным попадание операнда в любое слово памяти:
(4)
Заметим, что приведенный ниже расчет не использует это пред¬
положение.
Найти аналитическую зависимость частоты удовлетворения
Запросов при обращении к КЭШ от размеров КЭШ с учетом алго¬
ритма кэширования, видимо, пока сложно, так как частота удов¬
летворения запросов при обращении к КЭШ зависит от решаемой
Задачи, системы команд машины, объемов кэш и основной памяти.
Например, частота удовлетворения запросов к кэш на PDP—
11/70 —98%, на тех же программах на IBM(VMS) — 90% или
Лиже [9].
209
операнда из памяти
обращается к пей,
(5)
(G)
гп
выборку операнда;
В работе [4] приводятся статистические данные о вероятности
нахождения информации в буферной памяти при наличии буфер,
ной памяти большой емкости. Получение такой статистики
в ближайшем будущем для малых и микроЭВМ, безусловно
представляет интерес. На сегодняшний день мы располагав
лишь отдельными статистическими исследованиями кэш.
От значения используемого операционного кода и типа адре,
сации существенно зависит длительность исполнения инструкции.
Кроме того, скорость исполнения команды зависит, как уже упо¬
миналось от того, расположен операнд в КЭШ-памяти или в ре,
гистрах.
Величина tn есть среднее время выборки
(КЭШ + основная), если команда вообще
а не к регистрам:
для одноместной операции:
= £(мо) + £(кэш) ^(мо)Т^(кэш) »
для двухместной:
in2 “ 2 (£(М0) “h ^(КЭШ) (кэш))»
для трехместной операции:
^пз = (^(мо) Ч~ £(КЭШ) ^(МО)^(КЭШ))’
Среднее время £Сб (Z), расходуемое на
складывается из выборки операнда в регистре (регистрах) и обра¬
щений к памяти:
МО — ^рег (0 -^рег (0 + Сг -^рег (0)’ ($)
где £рег (Z) — время выборки операнда для j-й команды из регист¬
ра; Лрег (0 — частота обращений к регистру в z-й команде. Вооб¬
ще говоря, прсг (Z) — количество регистров, из которых разреше¬
но выбирать при работе Z-й команде, а следовательно 7?рег (0-^
различны. Поэтому при проведении исследований эффективности
работы системы для повышения точности расчетов и при наличии
статистики лучше оценивать эти величины конкретно по каждой
команде, при необходимости усредняя затем по классам команд.
Пусть ?грсг — количество регистров общего назначения дли¬
ной ИИэф, равной длине слова; Дрег — средняя частота обращения
к регистру; £рег — квант времени выборки из регистра одного опе¬
ранда.
Тогда математическое ожидание времени выборки операндов
с учетом регистров определяется
для одноместной операции:
*1об — ^рег-^рсг 4“ (1 -Sper)(^(iMo) Ч~ ^(кэш) ^(мо)-Р(кэш))»
для двухместной:
^2об = 2^Рег-^рег 4“ (1 -йрсг)(^(мо) “4 ^(кэш) Z(M0)P(кэш))» (ВО
210
для трехместной:
^"зоб — 3^рег/?рег 9 (1 Лрег)(^(мо) 4~ ^(кэш) (кош))* (^)
Если предположить, как для кэш, что регистры — лишь более
быстрая часть общей памяти, то можно получить формулу, анало¬
гичную (4):
•^рег — 1О£э2 ^per/log2 (^(осн) 4“ ^(кэш))* (^)
Однако если имеется статистика для 7?рег, то ее использование
предпочтительней. В соответствии с работой [4] при наличии ре¬
гистровой памяти вероятность нахождения операнда в регистрах
должна соответствовать табл. 1.
Таблица 1
Количество регистров
Вероятность
обращений
Количество регистров
Вероятность
обращений
2
0,3
16
0,6
4
0,4
32
0,7
8
0,5
Если вероятность использования одноадресного, двухадресно¬
го, трехадресного форматов команды соответственно ср2, ср3^
то время выборки операндов
— Ф1 [-^рсг^рег 4“ (1 -^рег)(^(мо) 4“ ^(кэш) 1(мо)Р(кэш))] 4“
4" 2(р2 [7?рег^ per 4“ 2 (1 ^?рег)(^(мо) 4~ ^(кэш) t(Mo)P(кэш))] 4“
+ З(р3 [Лрег^рег 4~ 3 (1 — Дрег)(£(мо) 4“ t (кэш) ^(мо)-Р (кэш ))]• (13)
Подставляя статистические данные для /?рег, Фр Фг/ Фз 11
Р(кэп)> находим величину t — среднего времени выборки операн¬
да. В случае предположений (4) и (12) подстановка их в формулы
(9), (10), (И) даст возможность выразить £1об, £20б, ?30б только
через следующие параметры системы: ^рсг, £(М0), ^кэш), М(0Сн),
^(КЭЛ) , 72рег«
3.
ПРИМЕРЫ РАСЧЕТА
Рассмотрим способ вычисления производительности для ко¬
манды, осуществляющей сложение регистра общего назначения
и памяти (с учетом работы и времени, необходимых для выборки
операндов).
При оценке количества вычислений Н (5) как суммарного
Уменьшения неопределенностей для процесса 5-выполнения одной
Команды, ссылающейся на память, можно выделить три источни¬
ка: источник 51, выбирающий команду для выполнения, произ¬
водимую операцию и используемые регистры (если они есть), а
также определяющий адрес операнда в основной памяти (если
К ней есть обращение); источник 52, выбирающий значения опе¬
211
рандов; источник S3, выбирающий значение результата операнда
Для машины с памятью Л/(Осп) слов, размером слова Wi)(p, коли¬
чеством разных инструкций п,ф уменьшение неопределенностей
из-за SI, S2, S3 при выполнении команды, осуществляющей сло¬
жение содержимого слова памяти с содержимым центрального ре¬
гистра, будет:
h (51) = log2.V/( сен) "Т~ log2raper + log2ra;,0 -b log2/)/(OCH),
/г (52) = log/'* + log22Wa* = 2ЖРф,
/г(53) = 1о^22Ж:ф = Ж,ф,
h (S) = h (SI) + h (S2) + h (S3).
Пусть tadd — время выборки и исполнения регистровой опе¬
рации сложения. Тогда для команды add, согласно приведенным
выше расчетам:
^об = 2^абм7?рег + 2 [2 (^(кэ'Л) ^(мо)) “г iadd, 2^(-VI0)Z)pojn](l 7?уСГ).
В табл. 2 приведены для сравнения вычисленные величины /г,
^Об и /г/^об Для команды, осуществляющей сложение регистра об¬
щего назначения и памяти для ЭВМ DEG VAX 11/780 и IBM
PC/XT. Здесь оценивается производительность одной команды,
однако расчеты аналогично могут проводиться и по всем инструк¬
циям системы.
Таблица 2
Параметр
Единицы измерения
VAX 11/780
IBM PC XT
ЖОФ)
бит
32
16
^(осн)
Кбайт
8192
640
(2048 32р кслов)
(320 16 р кслов)
т(ад)
число
16
12
п(нул)
»
1218
630
^add (per)
нс
515
1677
число
14
8
per
Z(MO)
нс
400
420
*(КЭШ)
»
150
—
^(КЭШ)
Кбайт
8
0
h
бит
150,5
94,9
t
нс
1334
4194
hit
байт/нс
0,113
0,022
-
При расчетах частота обращения к регистрам 7?рег выбиралась
согласно табл. 1; частота удовлетворения запросов при обращений
к кэш принималась, по данным [9], равной 90% для VAX 11/780;
212
Предположения (4) и (12) ие использовались. Данные для расчета,
относительно размеров памяти M(0Cji) и ЛДкэш), времени цикла
памяти ^(^ю) и £(кэп]ц и также 72рсГ, ^(код)? ^(пул) получены из опи~
сания упомянутых систем и приведены в табл. 2.
Для IBM PC XT, у которой нет кэш-памяти:
t об — 2Z;1dd-^pcr “Т" 2 (2/(мо) Cridd)(l -йрег)«
Согласно расчетам, h!t для VAX 11/780 составляет
0,113 байт/нс, для IBM PC XT — 0,022 байт/нс, т. е. операция
add системы VAX 11/780 в 5,2 раза производительнее аналогич¬
ной операции системы IBM PC XT.
При использовании сокращенного варианта «стандартной сме¬
си команд» Гибсона [8] производительность
пэф ,п?ф
?=1 i=l
рассчитанная предложенным методом, для IBM PC XT в 12,4 ра¬
за меньше производительности VAX 11/780.
Приведенный метод позволяет сопоставить эффективность
функционирования двух вычислительных систем А и В, основы-
ваясьна «трудоемкости», «смеси команд», стоимости системы. В слу¬
чае отсутствия реальной «смеси команд» используется информа¬
ция о частотах повторения классов команд, которая мало зависит
от архитектуры системы. Временной член в знаменателе (2) до¬
пускает среднюю априорную оценку и может быть вычислен по
величинам КЭШ-памяти, общей памяти, количества регистров,
длины слова и времен циклов КЭШ-памяти и основной памяти,
а также времени выборки из регистра.
Заметим, что в числителе (2) стоит выражение вида
71 Эф w
zLj f (0 [^1 (i} log2^(Mo) + (Z) log2723q) + K3 (Z) log22 +
-i=l
+ (Z) log272per].
где (Z), K2 (Z), A3 (Z), /<4 (Z) — некоторые константы, которые
можно получить, вычисляя суммарное уменьшение неопределен¬
ностей для процесса выполнения Z-й машинной инструкции.
Тогда числитель (2) приводится к виду
Ci log2 М(мо) + С2 Iog2 тгЭф + С3 log2 тгрег + С41УэфЛ
где
С} = X/ = 1,2,3, 4.
i=l
Отсюда можно сделать вывод, что если работа команды вычис¬
лительной системы определена как уменьшение неопределеннос¬
ти, то ее величина является линейной комбинацией длины слова
И только двоичных логарифмов объема памяти (в словах), величи¬
ны набора инструкций, числа регистров. Таким образом, объем
213
произведенной работы наиболее чувствителен к изменению пмещ
но длины машинного слова, а не объема памяти, числа регистров
и т. д., т. е. 16-разрядная система, имеющая вдвое большую, чем
32-разрядная система, память, будет существенно уступать ед
в производительности, даже если времени циклов памяти и кэць
памяти у нее не хуже.
ЛИТЕРАТУРА
1. Феррари Д. Оценка производительности вычислительных систем. М.:
Мир, 1981. 576 с.
2. Мищенко В. А ., Лазаревич Э. Г., Аксенов А. И. Расчет производитель¬
ности многопроцессорных вычислительных систем. Минск: Вышэйш. шк
1985. 208 с.
3 ЗеленкоГ.В., Кукин М. А., Панов С. И., Попов С. И. Оценка произво¬
дительности микропроцессоров в однокристальной микромульти-ЭВМ //
Микроэлектроника. 1985. Т. 14, вып. 1. С. 10—15.
4. ГОСТ 16325 — 76: Машины вычислительные электронные цифровые об¬
щего назначения: Общие технические требования. М.: Изд-во стандартов,
1976. 32с.
5. Heller man L. A measure of computational work П IEEE Trans. Comput.
1972. Vol. 21. N 5. P. 13-25.
6. Bailliu G. B. A definition, measure and measurement of the activity of an
information processing system: Ph. D. Thesis. Berkley, 1972.
7. Bozwadovsky В. T. A measure for the quantity of computation//Proc.
I ASM—SIGME Symp. Measurement and Evaluation. 1973. P. 100 — 111.
8. Flinn M. J. Trends and problems in computer organization//Proc. Il'LP
Congr. Amsterdam: North-Holland, 1974. P. 3—10.
9. Smite A. J. Cache memories ACM//Comput. Surv. 1982. Vol. 14. N 3.
P. 473—530.
УДК 621.391
НЕКОТОРЫЕ ВОПРОС 4 РАСПОЗНАВАНИЯ ДИСКРЕТНОЕ
КЛИППИРОВАННОЕ РЕЧИ
В. А. Макуха, Е.Н. Пилимое, Г. !. G ролов
Реализация речевого диалога человека и технических средств
является актуальной задачей современной кибернетики. Речевой
диалог в человеко-машинной системе предполагает наличие трех
модулей: анализа и распознавания речи, семантической интер¬
претации речевого сообщения, ответа системы. Практическая реа¬
лизация любого из этих модулей является самостоятельной зада¬
чей. Рассмотрим задачу анализа и распознавания речи.
К настоящему времени наметился определенный прогресс
в создании как экспериментальных, так и промышленных разра¬
боток систем распознавания речи. В работах [1—4] описываются
действующие системы распознавания речи. Обзор более рантиг*
отечественных разработок можно найти в работе [5], а зарубеж¬
ных — в работах [5, 6]. Действующие системы распознавали0
различают по методу первичной обработки исходного акустически"
214
го сигнала. Традиционно выделяется три группы методов первич¬
ной обработки: спектральный анализ, линейное предсказание
И анализ клиппированного сигнала. Первые два подхода предпо¬
лагают наличие значительной аппаратно-технической поддержки
интерфейса ввода аналогового сигнала в ЭВМ. Причем, как пра¬
вило, отечественные системы распознавания речи па основе спект¬
рального анализа и линейного предсказания работают на неболь¬
ших — порядка 250 слов — специально подобранных словарях.
Диализ клиппированного сигнала, аппаратный интерфейс кото¬
рого дешев и довольно тривиален, и разработка программных
средств его обработки предполагают решать более сложные задачи
распознавания. Следует отметить, что разборчивость клиппиро¬
ванной речи высока и, следовательно, амплитудные характеристики
акустического сигнала являются избыточными [1]. Определенный
интерес представляет возможность использования клиппирован¬
ного сигнала для получения его спектральных характеристик [7].
Несмотря на существенное продвижение вперед в области рас¬
познавания, все проблемы, связанные с созданием реальных си¬
стем, еще не решены. Некоторые из них будут рассмотрены ниже.
В зависимости от выбранного метода первичной обработки речево¬
го сигнала формируются различные описания и пространства при¬
знаков, т. е. возникает проблема выбора того или иного простран¬
ства признаков. Выбор метода статистического анализа данных
в пространстве признаков является следующим этапом. Возмож¬
ные пути реализации этой задачи рассмотрены в работах [8, 9].
Затем возникает вопрос выбора метода распознавания. Как пра¬
вило, классические приемы теории распознавания образов (см.:
[10, И]) в реальных приложениях трудиоосуществимы. Поэтому
приходится либо разрабатывать специфические для вводимого
пространства признаков методы распознавания, либо адаптиро¬
вать уже известные в рамках этой теории подходы. Довольно час¬
то в реальных системах распознавания используется метод дина¬
мического программирования (ДП) [4] либо гибридные методы ре¬
шения экстремальных задач совместно с ДП-методом [3]. Метод
Динамического программирования предполагает наличие эталонов
фонетических единиц словаря. Эти эталоны формируются, как
правило, на основе приемов, описанных в работе [8], что требует,
по мнению авторов, дополнительного исследования структуры
классов.
В предлагаемой вниманию читателей статье излагается один
из возможных подходов к формированию признакового простран¬
ства, выделению информативных с точки зрения распознавания
признаков и организации решающего правила при программной
обработке клиппированного речевого сигнала.
Пространство признаков и гипотеза компактности. Перед каж¬
дым разработчиком системы распознавания (речевых) образов
истает задача создания адекватной математической модели изу¬
чаемого процесса, объекта или явления. Предпримем попытку
осуществления такой задачи.
215
Пусть А =-- {а} — множество изучаемых объектов; S = {$}
множество описаний объекта; X = {%} — пространство призП£ь
ков; U = {и} — множество решений. Тогда задачу распознавания
сформулируем следующим образом: найти преобразование /?.
А -> U, имеющее минимальный процент ошибок распознавания
если R = R2 ° ° Rq, где под ошибкой распознавания пощД
мается отнесение объекта а из класса i к классу 7, / у= Z, Ro: А
-+• S, Rr: S -> X, R2: X -> U. Оператор 7?0 обычно интерпрети¬
руется как первичная обработка исходного сигнала: R± — выделе¬
ние из параметров основных с точки зрения их информативности
причем R± таково, что dim X < dim S; R2 — оператор решающе¬
го правила — отнесения к тому или иному классу и либо отказ
от распознавания.
Опишем преобразование 7?0: А -> S акустического сигнала
а = a (t), а ЕЕ А в последовательность s = {sj е S, s ЕЕ т, где
тп — пространство ограниченных последовательностей действи¬
тельных чисел, причем st ЕЕ Z, st /> О, Z — множество целых чи¬
сел. Рассмотрим двоичную последовательность {у J, определяемую
на временной сетке tt = Z-6:
yt =- О [a (£jl, i = 1 -4- п, п = int (776), (1)
где 0 — функция Хевисайда; Т — время наблюдения акустиче¬
ского сообщения а = a (t), 6 — период опроса. По последователь¬
ности {yt} составляется последовательность {sj}, каждый элемент
которой есть количество нулей (единиц) между соседними едини¬
цами (нулями). Преобразование (1) называют клиппированием,
а последовательность {sj} — математической моделью клиппиро¬
ванного сигнала. Поскольку акустический сигнал, как правило,
зашумлен, а на преобразование (1) влияют помехи электрического
тракта, то будем говорить о последовательности {s7} как о квази-
случайной реализации речевого сообщения.
Пусть 5 = {st}iLx отвечает некоторому речевому сообщению
а = a (t). Построим конечное покрытие положительной полуоси
вещественной прямой 7?1 системой полуинтервалов [схг, рД, ai+1 ■■=
= Pi, I ЕЕ 7, такое, что R+ = (J [af, pf [, card I = М. Статпс-
"itE-T
тическим портретом {sJiLi назовем M-мерный вектор z, z •■=
= (zn . . .,zm), компоненты которого удовлетворяют соотноше¬
нию
Zj = nj/N, j = M, (2)
N
где nj = 3 Х[а., ₽.[(50>
2=1 L J 1
ция множества [а7, р7 [:
Х[«р р;.[ (•) — характеристическая фупк-
1,
О,
Si [ар Ру [’
si ф [ар РД-
Зафиксируем выбранное покрытие [cq, РД, I ЕЕ 7.
216
Меру различия (несходства) двух портретов z, z', отвечающих
соответственно речевым сообщениям а, а СЕ А, определим стан¬
дартно:
dv(z, z') = (3 \zi — 2{[Р]1/Р, РЕ {1,2}. (3)
7=1
В терминах теории вероятности вектор z является плотностью
распределения дискретной квазислучайпой величины t = 1 ч-
-4- N. Заметим, что можно создать статистический портрет любой
подпоследовательности последовательности {st}£=1. Это позволяет
изучать структуры оболочек фонем данного языка.
Признаки, определяемые по правилу (2), и мера различия (3)
позволяют говорить о множестве векторов {z} как о пространстве.
В зависимости от выбора покрытия [о^, |3/ [, i Её I можпо сформи¬
ровать пространство признаков произвольной размерности.
Теория распознавания образов для применения ее приемов
в статистическом анализе данных и распознавании предполагает
выполнение гипотезы компактности (см. напр. [11]). Опишем один
из подходов, позволяющих установить ее невыполнимость в про¬
извольном, в том числе и во введенном выше, пространстве призна¬
ков.
Пусть имеется классифицированная выборка S = {(s1, и1), . . .
. . ., (?, и1)} объема Z, где s3 = Ы}^1 ““ код Речевого сообщения,
отнесенного к классу с номером и3, и3 ЕЕ {1, . . К}, j =
— 1 -н Z; К — количество классов выборки S. Выполняя преоб¬
разование (2), строим классифицированную выборку
Z = {(z1, ^), . . (z\ и1)}. (4)
Здесь и далее без ограничения общности будем считать, что выбор¬
ка Z упорядочена по принадлежности к классу и его номеру, т. е.
иг = 1, i = н- т2; иг = 2, i = т2 + 1 т3; . . .;
ъА = К; Z = w Е- 1 Z, (5)
где /гц = 1. Очевидно, что если классы не обладают свойством ком¬
пактности, то выпуклые линейные оболочки классов имеют непус¬
тое пересечение.
Введем обозначение
Ij - {к\ ик j, к = 1 н- Z}, у = 1 н- К.
Методом Гаусса решается система линейных неоднородных
Уравнений
м
у (6)
1=1
Яля фиксированных у (у СЕ {1, . . К}), к (к её Ij)- Как правило,
определитель матрицы системы (6) относительно Xj, i = 1 -н М,
отличен от нуля. Если решение системы (6) удовлетворяет
217
i=l
условиям
4 > о,
то в выпуклую оболочку класса с номером j попадает предстать
гель zk «чужого» класса и делается вывод о некомпактности клас¬
сов в пространстве признаков. В противном случае свойство (7)
не выполняется, система решается для следующего представите¬
ля к' ЕЕ Ij \ {к}, и т. д. пока не будет исчерпано все множе¬
ство индексов Ij. Затем (при необходимости) выбирается новое
значение /.
В случае, если вывода о некомпактности при всех к ЕЕ Ij при
фиксированном / (7 ЕЕ {1, . . ., К}) не делается, то существует (см.:
[10]) кусочно-линейное решающее правило выделения класса
с номером /. Аналогично если для всех 7,7 = 14- К, такого вы¬
вода. сделать нельзя, то существует общее кусочно-линейное ре¬
шающее правило. Заметим, что никаких ограничений на простран¬
ство признаков процедура (6), (7) не накладывает.
В случае пересекаемости выпуклых линейных оболочек клас¬
сов выборки (4), (5) прогнозируется возрастание вероятности оши¬
бочных классификаций па пересекающихся классах при исполь¬
зовании методов распознавания на основе центров тяжести [8]
и их модификаций.
Опорные множества и «комитет». Рассмотрим процедуру выде-'
ления различительных признаков классов, основывающуюся па
понятиях опорного множества при формировании эталонов клас¬
сов и «комитета» характеристических функций, и построение ре¬
шающего правила. Введем определение опорного множества.
Пусть дана выборка Z объемом I, Содержимое выборки зане¬
сем в матрицу В ЕЕ Mixm (В), так что
btj = ^ i = j = м. (8)
Иначе говоря, сформируем таблицу «объект—свойство» Не¬
определим
ci = i = i = (9)
как часть транспонированного вектор-столбца матрицы В призна¬
ка 7, отвечающую классу с номером Z (Z ЕЕ {1, . . ., A}), — 1,
тпм = Фиксируем 7 и i. Упорядочивая по возрастанию компо¬
ненты вектора с$, получим
Ci = (с1У, . . cnjj), nt = — + 1, СИ <’"< спу»
где Yti — очевидно, количество представителей класса с номером
i в выборке Z.
Для cl введем вектор расстояний)
d = (d1;. . = ск+и — c):j, k = l-i-ni — 1. (И)
218
<- )—ше—(—
Рис. 2. «Траектория»
признаков через опор¬
ные множества
Рис. 1.1 Расположе¬
ние двух опорных
множеств иа 7?1 п их
центров тяжести
Компоненты d есть не что иное как вариационный ряд. По ря¬
ду (11) строится гистограмма его распределения и осуществляется
поиск статистически значимых локальных минимумов . . ., уп.
Окрестности ]g\, /гД минимумов ук, к = 1 -- п, объявляются
опорным множеством О{ признака / в классе с номером i. Если
п 1, то О{ = J jg\, h1:\. Если п = 0, то в качестве опорного
множества выбирается = [cXJ-, сп.Д, где cXj-, cn.j определяются
в (10). Несложно построить все семейство опорных множеств
(СУJi, 7=^1 для выборки Z.
Описанная процедура нахождения семейства является
трудоемкой. Однако множества О\, I = 1 К, j н- М, предпо¬
лагается использовать в качестве эталонов, поскольку методы
статистического усреднения нивелируют особенности распреде¬
ления вероятности признака / в классе с номером i в выборке Z.
Причем если это распределение не унимодально, то усреднение
приводит к ошибкам. Например, иа рис. 1 схематично иллюстри¬
руется возможный случай взаимного расположения иа R' двух
опорных множеств О{ и О32 (последнее заштриховано), где тпх,
^2 — центры тяжести (либо средние значения), элементов, мно¬
жеств, Ox, О2 соответственно. На этом рисунке центр множест¬
ва О[ оказался в одном из подмножеств, составляющих О2.
Опишем процедуру распознавания на базисе семейства опор¬
ных множеств. Для этого введем определение характеристической
Функции.
Будем называть характеристической функцией признака /$
7 ЕЕ {1, . . ., М}, отображение ц7-, такое, что
Vj:Rl-+CK, = (%0Лу), ■ ■ ■, %oiK(y)), (12)
гДе С = {0, 1}, СК — декартова К степень множества С, т. е<
219
p,, (zj), i = 1 ч- К, у = 1 ч- М, — индикатор принадлежности £
опорным множествам О/-, к =-- 1 К. Классификаторпую фун^
цию р: RM Ск'м определим как вектор-функцию, компоненты
которой — характеристические функции р7-, т. е.
И (У) = CLli (у)У- (13)
Очевидно, р (z/), у ЕЕ RM, является бинарной матрицей р
ММхк (С).
Решающее правило построим по принципу большинства «к0-
митета» характеристических функций гц-, т. е.
к* = arg шах || АГ ||, (14)
где || AI2 || — норма (длина) вектор-столбца Мг с номером Z, I =
= 1 -4- К, в матрице М. В случае, если соотношение (14) дает не
единственное решение, необходимо привлечь дополнительные
свойства обучающей выборки Z. Рассмотрим геометрическую ин¬
терпретацию семейства {01}%’4л, при К = 2, М = 4 на рис. 2.
Для изображенной на рисунке «траектории» признаков у, у = 1 ч-
4, через опорные множества решающее правило (14) даст два
равнозначных ответа /с* = 1, к* = 2. Этот факт указывает на не¬
обходимость введения «отношения порядка» признаков в каждом
классе на обучающей выборке Z.
Пусть = Ми (z2), АГ (z2) и z2 ЕЕ Z при некотором Z, I Е
ЕЕ {1, . . О’ таково, что
II АГ || = || М2С || = цтах,
где цтах — максимальная длина вектор-столбца в бинарной мат¬
рице ц (z2) (см.: (13)); v, w — номера столбцов. Для определеннос¬
ти будем считать, что вектор
q = АГ Э АГ Ф 0, (15)
где О — покомпонентное сложение по модулю 2.
Будем говорить, что признак у (у ЕЕ {1, . . ., М}) предпочти¬
тельнее в классе и = и\ если
Al- = 1, А1-у - 0. (16)
Для каждого класса Z, i = 1 ч- К, сформируем множества
предпочтительности Ph индексов у, удовлетворяющих (16). Тогда
«отношение порядка» признаков можно описать, например, функ-
JC
цией предпочтения f\C2M X Ц Р[ —определяющейся
г=1
у: (АГ, АГ, Л, . . ,,РК) = V.
если существуют у\, у2, . . ., уп, такие, что 1, у\- Е: Pv, 1
= 1 Ч~ 72, {у\, у2, . . ., yn} \ Pw 7^ ф-
220
В случае, если для вектора q условие (15) не выполняется,
принимается решение об отказе от распознавания.
Нечеткие множества. Описанная процедура выделения в ка¬
честве эталонов опорных множеств и классификация «комитетом»
характеристических функций j = 1~М, станет более гибкой,
если привлечь теорию нечетких множеств [12].
В выборке Z зафиксируем z (z GE {1, . . ., /<}), j (/ ЕЕ {1, . . .
. . ., М}) и сформируем cl — (9), с] — (10), d — (И). На множе¬
стве Q\ = {ё17, . . ., с,Ч7} определим функцию принадлежности
•Vi*:Qi->[0, 1] со следующим законом соответствия:
Vi (Ci;) = 1 — d-Jp,
Vi (cmj) = 1 — + dm)/2p), m = 2
— 1,
v'l (cn) = 1 — d yjp, p = max dK.
1 I'
Пара (Qi, vj) полностью определяет нечеткое опорное множе¬
ство Т\ = (Q], v^), z = 1 -н 7Г, / = 1 4- M. В «комитете» характе¬
ристических функций изменится вид ц7 в (12), т. е. рассматривают¬
ся характеристические функции v7 вида
= (^(i/)? • • м ^ (?/)).
Матрица «комитета» характеристических функций
V (*/) = (Vj. (г/), . . vM (z/))T
будет вещественнозначной. Решающее правило также строится
по большинству (см.: (14)).
Следует отметить, что подход с позиции нечетких множеств
требует существенно большего объема памяти ЭВМ для хранения
табулированных значений Vi, i — 1 ч- /<, / = 1 -н М, по срав¬
нению с подходом на основе обычных множеств.
ЛИТЕРАТУРА
1. Деев В. В., Фролов Г. Д. Использование свойств речевого сигнала при
автоматическом опознавании речевых образов слов // Программный
контроль ЭЦВМ: Сб. тр. М.: Министерство обороны СССР, 1973. С. 94—
111.
2. ВащенкоВ. Ф., Пажитное А. Л., Трунин-Донской В. И. Речевой за¬
прос при автоматическом поиске рефератов по биохимии // Анализ рече¬
вых сигналов / Под ред. В. Н. Трунина-Донского. М.: ВЦ АН СССР,
1984. С. 86 — 99.
3. Туркин В. II. Распознавание речевых образов методом динамического
программирования с использованием ассоциативного кодирования при¬
знаков // Там же. С. 58—66.
4. Винцюк Т. К. КДП — методы распознавания и смысловой интерпрета¬
ции речи// Акустический диалог человека с машиной: Материалы сов.-
фр. симпоз. Пущино-на-Оке, 1984. С. 88 — 93.
3. Обжелян II. К., Трунин-Донской В. II. Речевое общение в системах «че¬
ловек—ЭВМ». Кишинев: Штииица, 1985. 175 с.
221
6. Методы автоматического распознавания речи / Под ред. У. Ли. М.: Mun
1983.720 с. Р>
7. К едем Б. Спектральный анализ и различение сигналов по пересечениям
нуля // ТИИЭР. 1986. Т. 74, № 11. С. 6-24.
8. Методы анализа данных: Подход, основанный на методе динамических
сгущений: Пер. с фр. / Под ред. Э. Дидэ. М.: Мир, 1985. 357 с.
9. Загоруйко 11. ГЕлкина В. 11., Лбов Г. С. Алгоритмы обнаружения
закономерностей. Новосибирск: Наука, 1985. 230 с.
10. ВапникВ.П., Червоненкис А. Я. Теория распознавания образов. М.-
Наука, 1974. 415 с.
11. Левин Л. Л. Введение в теорию распознавания образов: Учеб, пособие.
Томск: Изд-во Том. ун-та, 1982. 183 с.
12. Орловский С. А. Проблемы принятия решений при нечеткой исходной ин¬
формации. М.: Наука, 1981. 206 с.
УДК 621.391
АВТОМАТИЧЕСКИЙ СИНТЕЗ
РУССКОЙ РЕЧИ НА ЭВМ
А. В. Лаптев, В.Ю. Олюнин, С-Н. Полещук,
Е- Н- Филинов, Г-Д- Фролов
Стремительное развитие вычислительной техники, появление
все более мощных компьютеров и внедрение их во многие сферы
деятельности человека расширяют круг пользователей ЭВМ, не
являющихся профессиональными программистами. Кроме того,
все чаще традиционные каналы обмена информацией с микропро¬
цессорной системой оказываются недостаточными или неподходя¬
щими. Поэтому возникает проблема сделать общение человека
с вычислительной системой более естественным, привычным по
форме. Одним из решений этой проблемы может стать реализация
речевого диалога с ЭВМ. Создание системы речевого диалога обес¬
печит существенное расширение сферы применения ЭВМ нового
поколения, в особенности персональных компьютеров, и повыше¬
ние эффективности их использования. Для решения этой задачи
необходимо обеспечить надежное распознавание и качественный
синтез речевого сигнала. Предметом данной работы является вто¬
рая часть задачи, а именно проблема синтеза устной речи с по¬
мощью ЭВМ, т. е. преобразование текста на русском языке в ре¬
чевой сигнал.
Исследования в этой области ведутся во многих странах, и в
последние 10—15 лет наметились определенные успехи. Все чаШе
появляются сообщения о создании систем синтеза, которые, как
правило, реализуются на базе специализированных микропроцес¬
соров или на базе микроЭВМ и рассчитаны на воспроизведение
словаря с запасом от 200 до 1000 слов. Именно ограниченность
словарного запаса не позволяет считать проблему синтеза решен¬
ной.
В настоящей статье приводятся способы преобразования рУс'
ской письменной речи в устную с помощью ЭВМ. В основу эти*
222
методов положено дискретное представление информации о рече¬
вом сигнале ср (t) некоторого отрезка устной речи, которое может
.быть получено с помощью специального устройства II]. Это уст¬
ройство по программе, которую будем называть оператором Ф,
клиппированный сигнал ф (£), соответствующий речевому сигна¬
лу <р (t), преобразует в двоичный код
= {Ко,^},
где
( 1, если ср(/)Х>0,
^°, 5 ~ I Q, есдц (р < Q
вычислены с некоторым шагом = tj+1 — tj. Под клиппирован¬
ным понимается сигнал с двумя значениями амплитуды.
Величина определяется структурой оператора Ф. Точки tj
в дальнейшем будем называть отсчетами дискретной числовой
оси t.
Под пиком клиппированного сигнала будем понимать его вы¬
сокий уровень, а под длиной пика — отрезок времени, в течение
которого сигнал имеет высокий уровень. Это же устройство по
другой программе, которую назовем оператором Ф1, может вы¬
полнять и обратное преобразование двоичного кода в клиппиро¬
ванный сигнал с последующей задачей этого сигнала на электро¬
акустические приборы.
Будем рассматривать кортеж К = двоичных кодов
к<?\ каждый из которых представляет собой дискретное описа¬
ние некоторых речевых единиц. В качестве таких единиц можно
выбрать слова, слоги или фонемы. Остановимся на фонемном син¬
тезе. В этом случае код описывает некоторый отдельный звук
или фонему русского языка.
Исходный текст письменной речи представлен в виде слова
Q = {per} в алфавите A [J С, где р — слово в алфавите А русских
букв; o' — слово в алфавите разделителей С, состоящее из раз¬
делителей трех типов: а) оу — пробел; б) оу — запятая и пробел,
точка с запятой и пробел, двоеточие и пробел, тире и пробел;
в) оу — точка и пробел, следующий непосредственно за ней.
В естественной речи «не все слышится так, как пишется», т. е.
нет взаимио-однозначиого соответствия между набором знаков
алфавита А и множеством звуков, воспроизводимых в устной речи.
Поэтому возникает задача преобразования слова р в алфавите А
в слово z в алфавите V транскрипционных букв.
Кроме этого, для качественного синтеза необходимо в каждом
слове определить ударную гласную и весь исходный текст раз¬
бить па синтагмы, т. е. наименьшие смыслоразличительные еди¬
ницы речи. При этом исходим из предположения, что из всего
Множества информационных средств используются лишь ударе¬
ние в словах и паузы. Паузы могут быть трех типов:
1) при произнесении слов, разделенных в исходном письменном
тексте пробелами, т. е. разделителями первого типа;
223
2) при произнесении слов исходного текста, разделенных
ним из синтаксических знаков (запятая и пробел, точка с запятой
и пробел, двоеточие и пробел, тире и пробел), т. е. разделителям^
второго типа;
3) при произнесении слов, разделенных точкой с иепосредст_
веино за пей следующим пробелом, т. е. разделителями третьего
типа.
Даже при таком минимальном наборе информационных средств
можно синтезировать речь достаточно высокого качества.
Первым этапом синтеза речевого сигнала является автоматиче¬
ское определение ударной гласной в слове. Алгоритм F определе¬
ния ударной гласной подробно описан в работах [2, 3]. В даль¬
нейшем будем обозначать номер ударной гласной в слове, опре¬
деленный с помощью алгоритма F, через ц = F (J).
Большое значение для получения качественной и разборчивой
синтезированной речи имеет так называемое синтагматическое уда¬
рение, которое определяется паузой после произнесения синтагмы.
Таким образом, необходимо научиться выделять синтагмы в ис¬
ходном тексте. Один из подходов к решению этой задачи для прос¬
того предложения описан в работе [4].
Кроме того что разбиение на синтагмы дает информацию о син¬
тагматическом ударении, оно позволяет построить функцию изме¬
нения частоты основного тона для синтезируемой фразы, так как
каждая синтагма в зависимости от эмоциональной насыщенности
и места в предложении имеет различный характер изменения ос¬
новного тона. Использование этого параметра позволяет сделать
синтезированную речь более разборчивой и придать ей некоторую
эмоциональную окраску [5].
Автоматическое транскрибирование осуществляется с помощью
алгоритма фонетической транскрипции. Таких алгоритмов су¬
ществует несколько. Рассмотрим один из них.
Исходными данными являются:
1) алфавит А русских букв, С — алфавит разделителей;
2) алфавит V транскрипционных букв;
3) совокупность {х —у} подстановок вида х у, где х — сло¬
во в алфавите А; у — в алфавите V;
4) ц — номер ударной гласной в слове.
Транскрипционный алфавит состоит из следующих букв:
1) [а], [а], [Л], [о], [б], [е], [э], [э], [и], [и], [и], [ы], [ы], 1у1»
[у], lyL [у], 1ь], [ъ], [ыэ], [ъы], [ие], [о] — буквы, соответствующие
гласным звукам русского языка;
2) [б], [в], [г], [д], [ж], [з], [к], [л], [м], [п], [р], [с], [т], 1ф]»
[х], [ц], [ч], [ш] — буквы, соответствующие твердым согласный
русского языка;
3) [б’], [в’], [г’], [д’], [з’], [к’], [л’], [м’], [п’1, [р’], [с’], [т’Ь
[ф’], [х’], [ц’], [ч’], [ш’] — буквы, соответствующие мягким со¬
гласным русского языка;
4) буква [j] соответствует фарингальному звуку «йот», а б у К"
ва [i] — звуку, получаемому в результате произнесения буквы «и)Л
224
В русском языке произношение букв определяется ударением
И окружением. Именно поэтому транскрипционный алфавит имеет
значительно больше букв, чем алфавит А. Укажем коротко значе¬
ние той или иной буквы алфавита V:
— буква [Л] обозначает гласный звук первого предударного
слога, близкий к звуку [а] ударного слога;
— буквы [ъ] и [ь] обозначают соответственно звук, средний
между [а] и [ы], который произносится после твердых согласных,
и средний между [и] и [е], который произносится после мягких
согласных;
— буквы [нА и [ьг‘1 обозначают несколько ослабленные на¬
пряженные гласные первого предударного слога;
— буквы [а], |о], [у] обозначают соответственно звуки, образо¬
вание которых определяется передвижкой артикуляции соответ¬
ствующих гласных fa], [о], [у] вперед на протяжении всей дли¬
тельности каждого из них.
Для рассмотрения подстановок вида х у, где х — слово в А;
у — слово в V, введем некоторые обозначения.
В алфавите А выделим подмножества:
Ах = {б, в, г, д, ж, й, к, л, м, н, п, р, с, т, ф, х, ш, щ};
А2 = {а, е, ё, и, о, у, э, ы, ю, я};
А3 = {и, е, ё, ю, я};
А4 = {б, в, г, д, ж, з};
А5 = {п, ф, к, т, ш, с};
Аб = {п, б, в, ф, з, т, д, с, н, м, р};
А7 = {ж, ш, ц};
А8 - {ч, щ};
А9 = {к, п, с, т, ф, ш, х, ц, ч, щ];
А10 = {р, л, м, н, г, д, б, в, з, ж}.
Кроме того, совокупность грамматических окончаний обозна¬
чим через Ап.
Пусть ц — номер ударной гласной в слове р = £4g2 • • •
. . . . . . £п, где ЕЕ А. Будем называть такие ударными
Или силовыми.
Мягкой согласной будем называть такую S р (р — слово
в А), для которой выполняется
Е= ^41? (£г+1 ЕЕ А3) V (£j+i = b).
Совокупность мягких согласных обозначим V2p-
Твердой согласной будем называть такую ЕЕ р, для которой
ЕЕ ^4р (£1+1 ЕЕ А2\ А3)\/(Si+i =- Ъ).
Совокупность твердых согласных обозначим Vip- В этих обо¬
значениях в таблице приведены подстановки вида х-+у, применяе¬
мые в алгоритме фонетической транскрипции, а также условия при¬
менения этих подстановок.
225
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
£ i = а — [а]
1; = а-[а]
= я — [а]
= я -»[ja]
= о ->[о]
= е — [б]
= е ->• [jo]
= э -> [э]
= е -* [е]
= е — [je]
= е ->• [е]
?Ч = е-[э]
= и -»[и]
= и [и]
= и [ы]
= Ы [ы]
= У —»[у]
i = F(/)A(i = i Vi=t=iABi_1S
Е Vlp и Ф V1 = nV I Ф п Л s
EV1PU(A\4)
' = F СО Л 1 Ф 1 Л е Ф /\ i ф
ф п A ?i+1 *= ^2Р U Лз
i = /’(/)A(i = iV^iA(li_i=bV
V е Аг)) Л i Ф п л li+1 е Vlp
i = F (7) Л t Ф 1 Л е V2p A i Ф
ф«А^+1е v2), ОФ
i = F (7) А (1 = 1 V i Ф 1 Л В;.! s
е Vlp U Ф) Л (' = re V * Ф « Л
Л £i+1 е Vlp U >12)
i = F (7) A i Ф 1 Л е V2p Л I ф
ф ГС Л £j+1 е 2р
i = F(I)/\i = 'i V^lA^s
е Ф Л = ь(ъ) A i Ф гс Л £i+1 s
еА
i = F (7) А (1 Ф гс Л li+ie VlpV i =гс)
i = 7?(7) А 1ф 1 Л ^_х е V2P Л (»Ф
Ф« A&j+1 е Vlp V * = ге)
i = F (7) A (i = 1 V i Ф 1 A £i_i е
е ф) A i Ф гс Л ^+1 s Vjp
i = F (7) A i Ф 1 A I,.! e V2P A i Ф
-F ГС A ^i+i e '■/ 2P
i = Г(7) A i Ф1 Л^_1 e а 1фгсЛ
А (£;+1e Vlp V 5|+ie v 2p)
i = F (7) A (1 = 1 V i Ф 1 A U1 ®
<= Л-) A (i = П V i Ф rc A *,+1e ^lp)
i_=F(7)A(i = iVi*i AUiS
Еф)Л1фгс/\^+1Е V2P)
.^(ЦДгф^еА
i = /■ (7)
i = F (7) A (i = 1 V i Ф 1 A &
e Ф \ -4.0 A (1Ф rc A £j+1 e V1P V
V I = rc)
226
18
19
20
21
22
23
24
25
26
27
28
29
30
= ю [у]
= ю -»[jy]
= а - [Л]
^ = о-[Л]
^ = а-[Л]
^=а-»[ис]
= Я -» [IIе]
= Я -» [jA]
= Я - [Ь]
£ г = Я — [Э]
Ч = е - [ыэ]
= е —»[ъы]
^ = е-[ъ]
Ъ = е - [IIе]
i = ГУ)Л Ф ь (ъ) Д (г ф га Д
A^i+1eVlpU A2Vi = «)
i = F GO A i Ф 1 A ii_! = ь (ъ)
i = P (J) A i = 1
Если существует такое zvz ф> 0, что
i 4. m = F (7) Д i ф 1 Д 1 л2 V
V <= Л) для всех 0 < к < т
Если существует такое т^>0, что
i + т = F (7) Д I ф 1Д (^_х е ф Д
Д 5-+ft е= А2) для всех 0 < к < т
Если существует такое ттгДО, что
П_7п = ^(7)Л(>.+1 ее А2 V
е А2) для всех 0 < к < т
Если существует такое т?г^>0, что
i ф in = F (7) Д i ф! Д \-_х = ь (ъ) Д
Д £i+k (= А2 для всех 0 < к < т
i==FU) Л = ь (ъ) Д (i = п V
V^+1^u)
Если существует такое т^>0, что
* - т = 7?(7)Д(/ф7п д Л„),
или, если существует хотя бы одна
буква такая, что для 0 <7с< т
i ф m = F (7) Д <= Аг f\i Ф 1
Если существует такое т^>0, что
i ф т = F (7) Д i ф 1 Д ^7 Л
А *4+1 е Vlp Д ^А3(0<к<т)
Если существует такое т >> 0 и хотя
бы одна буква ^i+k (0 <ф < ?п), та¬
кая, что i ф т = F (7) Д i ф 1 Д
Если существует такое т > 0 и хотя
бы одна буква такая, что
i ф т -_= F (7) Д i ф 1 Д е Л7 Д
Л^еА2Д^+1ёф2р(0<й<т)
Если существует такое т>0, что
i + т = F (7) Д « . 7= А2 (О<fc О)
227
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
ч =е м
? . = и [и]
? . = и _ [ы]
= ы —> [ы]
li = У - [у]
ф = ю-фу]
^+1 = бь-Чб’],
VW = Bb-*[B’]’
Wi+1 = ГЬ^[Г’]>
£Л+1 = «ь - [Д’Ь
^+1 = зЬ-.[з’],
^г+1 = кь^[к’]’
Mi+i = ЛЬ-ЧЛ’]>
^+1 = иь -* [н’Ь
&Лг+1 = 11Ь — tn’b
&Л1+1 = Рь tP’b
= СЬ — СС’Ь
SKi = Tb^[T’]’
Цч+1 = фь-Чф’],
~гЩ+1 ~ ХЬ -4х’]
ф = б-фб’],
- В - [В’],
= Г — [Г’],
ё; = д —> La’]»
Si = зЩз’],
£{ = К-»[к’],
Если существует такое т > 0 п Хотя
бы одна буква ^ик, такая, что /л,
-1- т = F (/) Д i ф 1 Д е А- Д
A ti+k е л2 V i - т = F (/) (0 <
< к < т)
Если существует такое т > 0 и ХоТя
бы одна буква такая, что
i ф т = F (Z) Д i = 1 Д е J2
(О < к < т)
г = ^(ОД
гф/’(7)А Щ = Л7
гфГ(/)
*ф/Щ)
гф/’(/)Д(«фпАЩ1е V1(,V
V i = п)
i Ф F (/) Л i ф 1 л V2P и л
i —1~ 1 —
i + 1 Ф п Л £i+1 s Аз
228
60
Вг = Л-[л’],
' — 1 = « Л В;+1 es Л
61
В; = M-> [M’J,
62
5; = н^[н’],
63
ё; = и-[л’],
64
В; = P - [P’l>
65
Bj = c->[c’],
66
Bi = T —» [t’],
67
Bi = Ф-ЧФ’1,
68
Bi = x-[x’]
69
Si.Bi+1 = 6b-[n’l,
i -к 1 = п
70
£Дг+1 ~ Bb “* 1Ф ] ’
71
Vsi+i = rb- [«’]’
72
&Лг+1 = ЛЬ— [T’J,
73
= зь [c’l
74
Bj = 6 -* [n] >
i=--n\J i^n f\ ^i+1 t= Л9
75
Bi = в -► [ф],
76
Bi = r-M,
77
В{ = Д-»[т],
78
Bi = ж— [ш]>
79
Bi=3-[C]
80
Bi = к — [г] >
Ч-i-l e Ao Д ^j+9 ~ \ ^3
81
^ = с^[з],
82
= Т — [д],
83
Bi = n-[6]
84
Bi = K-[r’L
(r4+i e= л10 д a.+2 e А) V ь д
85
Bi =с — [з>],
A ^i + 2
86
Bi=T-[fl’],
87
Bi = n^[6’]
88
Bi =--4— [ч’Ь
Всегда. Исключения:
89
В{ = щ-»[щ:]
[ш]то, [ш]тобы, нп[ш]то
90
Bi = ж-* [ж],
Всегда
91
В; = ц— [ц],
92
В; = ш—» [ш]
93
ёДг+1 = 61. — [б],
Всегда
94
95
Mi+i = ДЪ —> [д],
229
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
ИЗ
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
Ui+i = :rb^[3J’
ёЛг+1 = съ ЕСЬ
^г+1 = тъ^[т1
^ = В-.[В’]
1г = к-»[к’]
^ = л-[л’]
= м-[м’1
^ = Г-[Х’1
^г+1 = ЗШ-[Ш:]
ёЛг+1 = СЧ^[Ш’:1-
&;5г+1 = 34 [Ш’:Ь
5ААж,1Чш-1.
&Лг+1 = ТС ^ТЦЬ
£&+i = да - [да]
S&+&+2 = ТЬС -* [ТЦ]
5Лг+1 = ТС-’М’
Vw=да [ц]
Mi+i = да [да]-
^г+1 = да^[да]’
ёЛ;+1 =тш^ [ч’шь
ёЛг+1 = да* [Ч’Ш]
?. Д. „ = стн —> [си]
~’г’эг+1ъ^+2 L J
£.£. Д • п = стл -+ [сл]
^г^г+1^1+2 L J
VSi+A+2 = СТС [С°]
Ц,Д+! = стцЧсц]
и;+А+2 = зда-*[зц]
^^г+1^+2=Ида->[НЦ]
SiWi+a = ида [да]
&Ai+iWi+3 =ндск - [нск]
&Лг+К2 = НДК^[НТК]
Лг+1^+2 = Рда [РЧ]
5Лг+1^+2 = РДЧ [РЧ]
5Дг+Лг+2 = ЛИЦ [ИЦ]
Всегда
V2р
‘’Щ = К *= V2Р
^+1 ~ л е V2P
= V2P
^1+1 = М е ^72Р
Всегда. Исключение:
сумасшедший, масштаб
Всегда
^•+2 = я Л i + 2 = п
Ч+з = я Д i + 3 = ге
^i+2 = к V =;+2^= г+3 = ТВ
Всегда
Всегда
В словах: счастливый, завистли¬
вый, совестливый и т. д.
^г+З
= К
Всегда
Всегда
Всегда
В словах: солнце, сердце, сердИе'
вина, «сердчишко»
230
130
= б - [б],
Во всех случаях, не отмеченных
131
~ в —* [в],
выше
132
= г - [Г],
133
= Д— [д].
134
£
= 3 [з],
135
= к—» [к],
136
= Л -» [л],
137
= М -> [м] ,
138
= н-»[и],
139
= П-* [п],
140
= р-ЧрЬ
141
= с — [с],
142
— т [т],
143
= ф-,[ф],
144
= х-*[х]
145
it
= й-*П]
Всегда
Множество всех подстановок х —у в таблице позволяет лю¬
бое слово р = в алфавите 4, где 1 i q,
преобразовать в слово z в алфавите V. Такое преобразование на¬
зывается фонетической транскрипцией и выполняется в три этапа:
1) для данного I (первоначально i = 1) запоминаем букву GE
€= 4, если z’^> 1 в слове р, и в таблице выбираем все подстановки
х-^у, где в качестве первой буквы х содержится
2) для каждой из выбранных подстановок последовательно
(вначале для трехбуквенных х, если такие имеются, затем для
двухбуквеиных и, наконец, для одиобуквеииых) проверяем усло¬
вие ее выполнения, и если подстановка выполнима, то производим
замену вхождения х в данном слове на у;
3) если после двух этапов слово р еще содержит хотя бы одну
букву алфавита А, то в этом слове выполняется перенумерация
букв и соответственно изменяется номер анализируемой буквы
и номер ударной буквы. Затем все этапы повторяются. В против¬
ном случае процесс преобразования заканчивается.
Итак, с помощью процедуры автоматической транскрипции
слово р в алфавите А преобразовали в слово z в алфавите V.
В зависимости от интонации, расположения по отношению к
Ударной гласной, соседних фонем слова р звучание фонемы Wi
Может несколько варьироваться. Поэтому можно говорить о том¬
-то фонема Wt представляет собой класс фонемных оболочек:
Wi = {Wif jX
231
и в каждом конкретном случае бывает представлена элементом
Wit^ этого класса.
Пусть принятый нами транскрипционный алфавит V состоит
из п букв. Каждой букве из V соответствует класс оболочек фоне¬
мы Wi. Таким образом, имеем множество
w= =
классов фонемных оболочек, причем существует взаимно-одчо-
значпое соответствие между множествами W и V. Элемент Ж,,
можно разбить на стационарный участок Ж,л, который в основ-
ном и определяет звучание фонемы Wt и его окружение,— началь¬
ный участок Ж, к и конечный Ж,л (А, = 1, . . Участки Ж;,
и Wif^ могут быть и пустыми, т. е. фонема может начинаться со
стационарного участка, или заканчиваться им, либо и то и другое
одновременно. Различные Ж,л (X = 1, . . ., имеют одинаковые
стационарные участки с точностью до длительности звучания и от¬
личаются друг от друга окружением. Обозначим общий стацио¬
нарный участок оболочек класса Wt через W
Итак, произнесенное слово представляет собой последователь¬
ность фонемных оболочек Ж^цЖо,/., . . Ж.рхг
Рассмотрим в транскрибированном слое две соседние оболочки
и Ж,-* Фонем Ж и И7;, выделенные из реального сигнала,
имеющие стационарные участки Wt и И7;, начальные Wi,r и Ж,5
и конечные и Wj,s- Тогда пару Ж,гЖ*»« можно записать сле¬
дующим образом:
Ж,7’ЖЖ,
Теперь, естественно, возникает желание объединить W;,r
и Ж,в_^ единый переходный участок между стационарными участ¬
ками Wi и Wj и вместо
жж.МзЖ
записать
WtWiWjYVj.
где ЖЖ — переходный участок от Wt к Wj.
Заметим, что теперь получено взаимно-однозначное соответст¬
вие между множеством V букв транскрипционного алфавита
и множеством {Ж}?=1 стационарных участков фонем.
Максимальное количество переходов ЖЖ (* = 1» • • •’
j — 1, . . ., п) равно Ап, где А — число размещений. На самом
деле, так как Ж,х и Ж,?, могут быть пустыми, а также некоторое
Ж Ж могут совпадать, количество таких переходов значите л
но меньше. Обозначим минимальное количество переходов через /•
232
Каждому стационарному и переходному участку соответствует
двоичный код Kf* из множества К (1 ~ 1, . . ., т), где т — п 4-
4- I. Следующим этапом преобразования письменной речи в уст¬
ную должно быть формирование двоичного кода К, соответствую¬
щего слову z в алфавите V. Этот этап заключается в замене каж¬
дой буквы слова z двоичным кодом стационарного участка
а также в соединении кодов стационарных участков
и Wj двоичным кодом переходного участка
Рассмотрим процесс формирования кодов (I = 1, . . т).
Одним из способов является «вырезание» участков кода Aj0) из
кода А”(0), полученного с помощью клиппирующего устройства
при произнесении слов конкретным диктором. Затем полученные
коды обрабатываются и заносятся в словарь К. Хранение
в памяти всего множества К в этом случае неэкономично, поэтому
рассмотрим другой способ, позволяющий компактно хранить ин¬
формацию о каждом коде а в нужный момент восстановить по
этой информации весь код.
Будем рассматривать числовую модель стационарного или пе¬
реходного участка реального сигнала, полученную с помощью
клиппирующего устройства и представляющую собой последова¬
тельность
X =
где X] — расстояние в количестве отсчетов между двумя последо¬
вательными нулями функции речевого сигнала ср (t). Очевидно,
последовательность X однозначно определяет соответствующий
ей код
Теперь задача состоит в построении последовательности X
для всех стационарных и переходных участков. Для различных
фонем эта задача решается по-разному.
Для построения моделей шипящих звуков используется спе¬
циально настроенный генератор случайных чисел с распределе¬
нием, полученным экспериментально [6]. В качестве информации
о последовательности X для этих фонем, хранящейся в ЭВМ,
берутся четыре числа которыми определяются
границы изменения четных и нечетных элементов Xj последователь¬
ности X, выдаваемых генератором случайных чисел.
Взрывные и фрикативные согласные моделируются паузами,
г. е. введением в последовательность X элементов, в несколько
раз больших по сравнению с соседними. Обычно последователь¬
ность X для взрывных согласных содержит только два числа
и Хо0, причем величина паузы определяется вторым из них.
Для моделирования стационарных участков гласных и сонор¬
ных разобьем модель X оболочки фонемы, вырезанную из реаль¬
ного сигнала, на сегменты, соответствующие одному полному
Колебанию голосовых связок. Под сегментом здесь понимается
8 Заказ № 2514
233
последовательность
2б?,
Лг =
где 1 аг < Ъг п, г 1, . . ., 6*. Каждая из выделенных JJ0,
следовательностей Хг имеет четное количество членов. Будеч
называть сегменты Хг отрезками основного тона. На стационар,
пых участках все Хг (г = 1, . . имеют одинаковое количество
членов Xj.
Пусть dr — сумма элементов последовательности Хг, т. о.
(Уг = Xj
j=2ar-l
— длина (в количестве отсчетов) отрезка основного тона X .
Обозначим qK = (к = 1, . . Z), где I = Ьг — аг +
+ 1 — количество нечетных элементов на отрезке основного тона
Хг. Практически qk — это длина /с-го пика клиппированного
сигнала на отрезке Хг.
Введем параметр
Ук = X (^2(ar+k-l)-l + ^2(ar+fc-l)) (к = 1, . . ., I)
г=1
— расстояние в количестве отсчетов от начала отрезка основного
тона Хг до А:-го пика клиппированного сигнала или сумма 2 (к — 1)
первых элементов последовательности Хг.
Пусть d± и ds — суммы элементов последовательностей А\
и Xs соответственно. Введем функцию /, такую, что
1) / (1) =
2) / (s) - ds.
С помощью функции / (г) можно восстановить dr для г — 2, . . .
. . S — 1.
Покажем, что зная параметры qk, ук и dr (к = 1, . . .,5;
г = 1, . . ., Z) можно восстановить всю числовую модель X для
стационарного участка.
Действительно, восстановим любой отрезок основного тона
= {^j}j=2ar-l = 1? • • •, s)j
*^2(аг+1С-1)-1 — Ун (к = 1, . . ., Z);
^2(ar+k-i) = Уи+1 — Ун — Чн (к = 1, .... I — 1);
^2(аг+/-1) = / (И — У1 — У1-
Таким образом, можно найти элементы всех отрезков основ*
ного тона Хг (г = 1, . . .,$), а значит, восстановить последова¬
тельность X.
234
Эталонная информация о соответствующем стационарном участ¬
ке Wi должна включать в себя числа qk\ у к\к = 1, ... Z),
и d,.
Рассмотрим числовую модель X, соответствующую переход¬
ному участку. Ее тоже разобьем на s сегментов, соответствующих
полному колебанию голосовых связок, т. е. на отрезки основного
тона Хг 0 = 1,..., s).
Па переходных участках различные Хг уже не содержат оди¬
наковое количество элементов, но это количество всегда остается
четным числом.
Пусть Хг имеет параметры dj, qk\ у\Р (к = 1, . . ., ZJ; Xs —
параметры ds, d{k\ z/!/51 (к = 1, . . ., ls). Введем понятие фиктив¬
ного элемента q\r\ которому не соответствует никакой элемент
j’y последовательности Хг. Для фиктивных элементов будем
допускать неположительное значение. Теперь имеем возможность
выбрать Z = max {Zx, Zs} и дополнить параметры одного из отрез¬
ков Хг или Xs фиктивными q^ или ^s) и параметрами у^ —
= yf> или yi^ = у^. Получим наборы параметров для Х± —
- dr, у^ (к = 1, . . Г) и Xs- ds, у? (fc = 1, . . I).
Введем функции (г) и hk (г), такие, что
g* (1) = g* («) = g4s);
Ы1)^^ («) = Ук\
где к — 1, . . ., Z. Тогда получим для любого г = 2, . . ., s — 1:
qV = gi; ('•),
Ук} = hK (г) =
dr = Цг),
где функция / (г) — та же, что и в случае стационарных участков.
Покажем, как в этом случае можно восстановить последова¬
тельность X, если известны параметры d±, q{k\ у\}\ ds, qk\ у^
(к = 1, . . Z). Восстановим сегмент^
Xr = (Z =ЪГ — ar -|- 1):
^2(ar+k-i)-i-2c = gk (Г), если qk > 0 (к = 1, . . ., Z),
^2(ar+k-l)-2c = hk+1 (г) — Z?/-_v (г) — (г), если qk > О
(& = 1, .. Z — 1),
^2(ar-i-Z-l) = / (г) — Л/_г (г) — gl-v (г),
где с — количество фиктивных элементов, встретившихся среди
Параметров сегмента Хг к моменту нахождения xt; v — количество
подряд идущих фиктивных параметров перед qk\ иначе говоря,
v показывает, сколько фиктивных параметров q\P стоит слева до
235
8*
ближайшего уД 0. Таким же образом восстанавливаются Ос„
тальные Хг.
Итак, имеем возможность восстанавливать числовую мод ел г
X переходных участков, имея эталонную информацию в виде
параметров dx, d„, Дп, Д1\ ijf, (к = 1, . . Z).
Для хранения эталонной информации для каждого кода
в вычислительной машине отводится от 4 до 36—40 байт.
Описанный алгоритм реализован авторами на персональной
ЭВМ. Для подготовки эталонной информации используется спе,
циальный редактор числовой модели, который позволяет в i ра,
фическом режиме выделять отрезки основного тона -и кодировать
их для занесения в словарь эталонов.
Сборка слова средней длины (7—8 букв) в зависимости от бую
венного состава происходит за 4—8 с (программа написана на
языке Паскаль).
ЛИТЕРАТУРА
1. ЛисайН.Ю. Контроллер обмена речевой информацией с ЭВМ/7 Тез.
док л. и сообщ. Всесоюз. семинара АРСО-12. Киев: ИК АН УССР, 1982
С. 181 — 182.
2. Криницкий II. А., Миронов Г. А., Фролов Г. Д. Автоматизированные ин¬
формационные системы. М.: Наука, 1982. 381 с.
3. Иващенко II. И., Фролов Г. Д. К автоматическому анализу русских слов
с помощью ЭВМ // Программирование. 1975. № 1. С. 60—65.
4. Чудина А. Ф. Правила определения синтагмы в письменном тексте// Тр.
ЦНИПИАСС. 1978. № 2. С. 38-42.
5. Кучеров В. Я., Лобанов Б. М. Синтезированная речь в системах массо¬
вого обслуживания. М.: Радио и связь, 1983. 131 с.
6. Олюнин В. 10., Фролов Г. Д. Распознавание и синтез речи //Современ¬
ные средства информатики. М.: Наука, 1986. С. 180—185.
7. Фролов Г. Д. Автоматическое преобразование с помощью ЭВМ русской
письменной речи в устную// Проблемы кибернетики. М.: Наука, 1974.
№ 28. С. 245-268.
8. Кейтер Дж. Компьютеры — синтезаторы речи. М.: Мир, 1985. 237 с.
9. Чистович Л. А. Речь, артикуляция и восприятие. М.: Наука, 1965.
241 с.
10. Ожегов С. И. Словарь русского языка. М.: Рус. яз., 1987. 748 с.
УДК 621.391
ОБ ОДНОМ ПОДХОДЕ К ВЫДЕЛЕНИЮ
РАЗЛИЧИТЕЛЬНЫХ ПРИЗНАКОВ ФОНЕМ
О. В. Давыдов, Г.Д. Фролов
Проблема распознавания речи в настоящее время приобретает
все большее значение. Это связано с развитием вычислительно0
техники и автоматизацией производства — возрастает число си¬
туаций, когда речевой ввод наиболее приемлем (например, из-за
его высокой скорости). Важной причиной является также высо¬
кая производительность речи как средства общения.
236
Существует несколько подходов к распознаванию речи: по"
словный, послоговый, пофонемный. Из них пофонемный способ
распознавания представляется наиболее перспективным, так как,
во-первых, распознавание изолированных слов можно будет вести
для словаря любого объема и, во-вторых, возможен более простой
переход к распознаванию непрерывной речи.
Пофонемный способ распознавания речи предполагает иссле¬
дование речевого сигнала в двух направлениях:
сегментирование речевого сигнала, т. е. разделение сигнала
на участки, соответствующие оболочкам фонем произнесенного
слова; выделение различительных признаков оболочек фонем.
Под оболочкой фонемы понимается отрезок речевого сигнала,
соответствующий определенному звуку данного языка, такой, что:
— он находится в окружении либо двух оболочек фонем,
либо начальной пустой оболочки и оболочки фонемы, либо обо¬
лочки фонемы и конечной пустой оболочки;
— учитывается его положение относительно ударения в сло¬
ве — ударный, предударный, заударный.
При выделении различительных признаков оболочек фонем
ставится две задачи:
1) выделение различительных признаков оболочек фонем для
нескольких дикторов D
2) выделение различительных признаков оболочек фонем для
одного диктора D.
В первой задаче желательно наличие дикторов как мужчин,
так и женщин. В настоящей статье изложен один из подходов
к решению второй задачи на базе клиппированного речевого сиг¬
нала (сигнал с постоянной амплитудой). Разработанное в 1985 г.
в ИПИ АН устройство ввода-вывода клиппированного речевого
сигнала для ЭВМ СМ-4 осуществляет преобразование функции
/ (со, t) речевого сигнала в числовую модель.
Моделью является последовательность целых положительных
чисел где — расстояние между двумя соседними нулями
функции клиппированного сигнала. Практически • Az (где Az =
— 50 мкс) есть временной интервал между Z-м и (Z — 1)-м нулями,
т. е.
/((О,
Из X выделим подпоследовательности
х+ = {z2i+J}^,
Х+ — назовем верхними элементами модели, X — нижними.
Пусть г — некоторая фонема, г* — оболочка фонемы г.
Отрезок последовательности X, , Z г 2лг <; 2/?г, соот¬
ветствующий г*, обозначим X (г*).
Верхним индексом I будем обозначать последовательности и их
элементы, относящиеся к Z-му произнесению данного слова.
237
Создай комплекс программных средств для обработки и иссле¬
дования речевого сигнала. Программы написаны на языке Форт¬
ран и реализованы в виде независимых модулей. В частности,
это подпрограмма формирования модели речевого сигнала
и записи ее в память ЭВМ, подпрограмма обработки речевого
сигнала, выделения любых отрезков сигнала и прослушивания
их, вывода на дисплей или АЦПУ числовой модели X1 или ее
графика и т. д., а также подпрограмма сбора статистики.
Исследовались гласные фонемы а, о, у, и, ы, э. Для каждой
фонемы был составлен словарь из нескольких десятков слов —
одно-, двух-, и трехсложных. Слова подбирались так, чтобы ис¬
следуемая фонема имела различные оболочки, т. е. находилась
в окружении оболочек шипящих, взрывных и сонорных согласных,
а также была ударной и неударной. Примеры слов: крокус, окно,
ананас, крыжовник.
Диктором являлся мужчина, исследуемое слово произно¬
силось К раз. В каждом произнесении I К из модели X1 вруч¬
ную с контролем на слух выделялась модель оболочки X1 (/*)
исследуемой фонемы г. При этом в Xе (г*) сохранялось отношение
верх-низ для элементов модели, т. е. Xl+ (г*) CZ Х1+, Х1~ (г*)
С; Х1~'. Далее X1 (г*) обрабатывалась подпрограммой статисти¬
ческой обработки.
Для анализа были выбраны следующие характеристики X (г*):
— наиболее часто встречающиеся элементы
{П М(г*)},
/=1
т. е. элементы, встретившиеся в модели оболочки фонемы К — 1
или К произнесений;
— частоты элементов модели {тг-}?.°?|, т. е. числа, показываю¬
щие, сколько раз данный элемент i встретился в X (г*);
— длительность звучания X (г*).
Статистика собиралась отдельно для верхних и нижних эле¬
ментов. Назовем ф (г*) {tJI00] функцией распределения обо¬
лочки фонемы. Для каждой оболочки можно рассматривать функ¬
ции распределения для верхних и нижних элементов. Эти функции
обозначим соответственно ф+ (г*), ф" (г*).
Элементы = xi2 ~ xiz . . . = i назовем соответствую¬
щими элементу функций распределения ф+ (?’*) или ф~ (? *)•
Определим основные составляющие элементы оболочки. Пусть
Т 1 — некоторый порог, определяемый экспериментально для
каждой фонемы и каждого диктора Di- Составим последователи-
ность {тг1, тг2, . . Tip} с: {т;}, так, что тг1 > т/2 > . . . > т;р
> Т. Элементы х/2, . . ., xip ЕЕ X (г*) назовем основными
составляющими X (г*). Можно рассматривать основные состав¬
ляющие для Х+ (?’*) и X (г*).
Получены следующие результаты.
238
Фонема а. Наиболее часто встречающиеся верхние элементы
расположены в отрезке [5, 12]. Как правило, для оболочек фонем
разных слов все элементы этого отрезка — наиболее часто встре¬
чающиеся.
Наиболее часто встречающиеся нижние элементы лежат в oi
резке [9, 16J. Чаще всего это элементы 10—14.
В оболочках фонемы для некоторых слов как для верхних,
так и для нижних элементов наиболее часто встречающимися
являются элементы 1—3.
Основными составляющими для верхних элементов являются
от 3 до 6 элементов из отрезка [5, 15], идущих подряд. Чаще
всего это элементы 7—12. Один из основных составляющих соот¬
ветствует глобальному максимуму функции распределения.
Для нижних элементов основными составляющими являются
3—6 элементов из отрезка [7, 16], идущие подряд. Как правило:
шах ф4’ max ф".
i i
В безударных оболочках количество основных составляющих
для верхних и нижних элементов уменьшается до 2—3.
Фонема о. По виду функции распределения напоминает а.
Наиболее часто встречающиеся верхние элементы расположены
в отрезке [6, 20]. Как правило, это элементы 7—15 или 10—18.
Для нижних элементов наиболее часто встречающиеся располо¬
жены в отрезке [9, 25]. Почти всегда это элементы 11—20.
Основные составляющие для верхних элементов — это 4—5
подряд идущих чисел из отрезка [8, 13].
Для нижних элементов основные составляющие — это, как
правило, 1—2 группы, содержащие от 1 до 3 элементов из отрезка
[10, 18]. Положение этих групп и их количество меняются даже
для оболочек фонемы одного и того же слова.
В безударном варианте фонемы группы основных составляющих
нижних элементов состоят из 1—2 элементов.
Как для о, так и для а элементы 1—3 почти пи в одном слове
не являются основными составляющими ни для верхних, ни для
нижних элементов.
В моделях оболочек а для 98% всех произнесений нет эле¬
ментов, больших 30, а в моделях оболочек о также почти нет
элементов, больших 40.
Фонема э. Наиболее часто встречающиеся верхние и нижние
элементы — это 3—5 подряд идущих чисел из отрезка 110, 18],
а также элементы 1—3.
Как для верхних, так и для нижних элементов основные со¬
ставляющие расположены в отрезке [10, 18] и образуют группу
из 2—5 подряд идущих чисел. Также основными составляющими
являются элементы 1—3.
Расположение основных составляющих в отрезке 110, 18]
очень не стабильно и меняется от оболочки к оболочке.
Фонема и. Характерная особенность функции распределения —
элемепты 1—3 являются основными составляющими.
239
Для верхних и нижних элементов также основными состав¬
ляющими являются элементы из отрезкгт 16, 20], причем онц
образуют 1—2 группы по 1—2 элемента.
Наиболее часто встречающиеся верхние и нижние элементы __
это 1—3, а также 2—3 элемента из отрезка [8, 20], не обязательно
идущих подряд.
Фонема ы. Наиболее часто встречающиеся: для верхних эле¬
ментов — 4—5 подряд идущих чисел из отрезка [16, 23], д,;1я
нижних элементов — группа из 4—5 чисел, лежащих в отрезке
(14, 19].
Так же, как для и, основными составляющими являются для
верхних и нижних элементы 1—3. Однако в некоторых оболочках
порог 71 для этих элементов значительно меньше порога Т для
таких же элементов в оболочках и.
В отрезке 1.8, 25] расположены 1—3 группы по 2—3 числа,
являющихся основными составляющими для верхних и нижних
элементов. Однако их положение на этом отрезке нестабильно.
Фонема у. Наиболее часто встречающиеся для верхних и шгж-
ни элементов — это, как правило, 4—5 элементов из отрезка
110. 20]. идущих подряд.
Основными составляющими для верхних и нижних элементов
являются 1—3 группы из 1—3 чисел, лежащих в отрезке [10, 2л|.
В большинстве оболочек у верхних элементов две такие группы.
Как для верхних, так и для нижних элементов 1—3 не явля¬
ются основными составляющими.
Таким образом, можно сделать следующие выводы.
1. Фонемы а, о, у, и, ы, э можно разделить на три класса:
в первый класс войдут фонемы а, о; во второй класс — фонемы
и, ы, э; в третий класс — фонема у.
Первый класс характеризуется во-первых, тем, что элементы
1—3 не являются основными составляющими ни для верхних,
ни для нижних элементов, а во-вторых, основными составляю¬
щими являются 3—4 последовательных числа из отрезка [6, 15]
для верхних элементов и из отрезка [7, 20] для нижних.
Второй класс определяется тем, что элементы 1—3 являются
основными составляющими для верхних и нижних элементов,
а также тем, что основными составляющими являются 1—3 груп¬
пы по 2—3 элемента из отрезка 110, 25] для нижних и верхних
элементов. Порог Т 5.
Третий класс определяется тем, что числа 1—3 пе являются
основными составляющими для верхних и нижних элементов;
основные составляющие — 2—3 группы из 1—3 чисел, располо¬
женных в отрезках [10, 16] или [16, 22] для верхних элементов
и в отрезках [11, 20] или [25, 30] для нижних.
2. Внутри каждого класса фонемы могут различаться по наи¬
более часто встречающимся элементам.
3. Заметное влияние на частотные характеристики оболочек
фонем оказывают оболочки, окружающие их. Особенно сильно
влияют оболочки м, н, л.
240
Результаты .эксперимента
по преобразованию модели одной фонемы
в модель другой фонемы
-+204-4-^0 у
у х 'И
о X и
4-5-: -i-9
и— :—а
а X и
и
'Кроме исследования частотных характеристик фонем для на¬
хождения различительных признаков фонем проводился следую¬
щий эксперимент. Из произнесенного слова выделялась оболочка
X (г*) фонемы г, где г — один из звуков а, о, у, э, и, ы. Все эле¬
менты оболочки программно увеличивались или уменьшались па
заданное число. Если преобразованный элемент имел отрицатель¬
ный знак, то он заменялся на 1, 2 или 3.
Выяснилось, что при прослушивании полученной модели
в ряде случаев слышится не исходный звук, а другой гласный
звук. В таблице сведены результаты эксперимента. В этой табли¬
це также указаны обозначения ц—> v, где ц — фонема, оболочка
которой преобразуется по указанному правилу в числовую мо¬
дель, которая звучит как фонема v при увеличении или уменьше¬
нии элементов числовой модели оболочки фонемы ц на целое
число из отрезка 1н, &], где а и b могут быть положительными
и отрицательн ыми.
Например, обозначение и — 5■ ■' > а показывает, что при увели*
чении всех элементов модели оболочки фонемы и звучание ее пре
образуется в звучание фонемы а.
Значок —х—> показывает, что указанного перехода в эксперименте
достичь не удалось.
Приведенная классификация гласных фонем позволяет объяс¬
нить результаты этого эксперимента.
Переходы а -> о и о —> а объясняются гем, что а и о находятся
в одном классе, т. е. имеют одинаковую структуру основных
составляющих элементов. Звучание же а или о объясняется поло¬
жением основных составляющих для верхних и нижних элемен¬
тов. У а они расположены несколько выше, что подтверждается
и видом преобразования, соответствующего этим переходам.
Переходы а, о в у можно объяснить тем, что при указанном
преобразовании основные составляющие фонем а и о смещаются
241
па места, которые характерны для основных составляющих фо¬
немы у. Обратный переход не возможен, так как основные состав¬
ляющие для у имеют меньший порог, чем основные составляю¬
щие для а или о.
Переходы и в а, о, у происходят также за счет смещении
основных составляющих. Обратный переход невозможен из-за
различия в структурах основных составляющих фонем а, о, у
и фонемы и, а именно разные пороги у и и у, а также одна группа
основных составляющих для а, о и две группы для и.
Переходы э в а, о, у происходят аналогично переходам для и,
разница в том, что у э переходы происходят за счет двух групп
составляющих, а не одной, как у и.
Следует заметить, что качество звучания, полученное в экс¬
перименте, не очень хорошее. Это позволяет предположить, что
существенную роль в образовании оболочек гласных фонем иг¬
рают другие характеристики модели X (г*), например, перио¬
дичность.
В дальнейшем предполагается уточнить приведенную клас¬
сификацию, найдя различительные признаки фонем в классах,
и исследовать периодичность модели как различительный признак.
ЛИТЕРАТУРА
1. Криницкий И. Л., Миронов Г. А., Фролов Г. Д. Автоматизированные ин¬
формационные системы. М.: Наука, 1982. 480 с.
2. Олюнин В. 10., Фролов Г. Д. Распознавание и синтез речи// Современные
средства информатики. М.: Наука, 1986. С. 180—185.
УДК 621.391
СИНТАКСИЧЕСКИЙ АНАЛИЗ
ПРОСТОГО ПРЕДЛОЖЕНИЯ РУССКОГО ЯЗЫКА
НА ПЕРСОНАЛЬНЫХ ЭВМ
Г. А. Немова, Г. Д. ролов, А.Ф. Чудина
Развитие вычислительной техники определило одно из цент¬
ральных направлений исследований — искусственный интеллект,
в состав которого входит решение проблемы автоматическою
анализа письменного текста естественного языка, что должно
обеспечить создание диалога «человек — ЭВМ» на естественном
языке. Решение этой проблемы основано на создании автомати¬
ческих систем морфологического, синтаксического и семанти¬
ческого анализов.
В настоящее время разработана система морфологического
анализа слов русского письменного текста [11 и ведется активная
работа в области создания системы синтаксического анализа пред¬
ложений письменного текста русского языка, поскольку разра-
242
ботаппая система 14] дает приближенные результаты (около 88%)
при анализе весьма простой структуры предложения.
При разработке системы анализировались тексты достаточно
большой протяженности, в которых рассматривались практи¬
чески все конструкции простых предложений русского языка.
Синтаксический анализ предложения письменного текста со¬
стоит из четырех разделов: 1) синтаксический анализ простого
предложения; 2) выделение простых предложений в сложносо¬
чиненном предложении; 3) выделение простых предложений в
сложноподчиненном предложении; 4) выделение простых предло¬
жений в сложном предложении с сочинением и подчинением.
В настоящей статье приводится система формальных правил
синтаксического анализа простого предложения, не содержащего
однородиых членов, вводных слов и конструкций, обращений.
Синтаксический анализ простого предложения выполняется
поэтапно. Каждый этап характеризуется формальными правилами
установления синтаксической связи пары слов, из которых одго
является грамматически главенствующим (главным), другое —
грамматически зависимым (зависимым), причем главное слово
синтаксически подчиняет себе зависимое. Например, в словосо¬
четании «синтаксический анализ» главным словом является ана¬
лиз, зависимым — синтаксический.
Этапы синтаксического анализа выполняются в определенном
порядке, причем на каждом последующем этапе возможность
наличия синтаксической связи проверяется только для слов,
которые не вошли в пары на предыдущих этапах или вошли как
главные.
Исходной информацией для синтаксического анализа является
грамматическая информация (грамматические параметры) каж¬
дого слова анализируемого предложения. Эти параметры опре¬
деляются в результате выполнения системы морфологического
анализа. Так, например, для слова «стол» будут указаны пара¬
метры: существительное, неодушевленное, мужской род, единст¬
венное число, именительный (винительный) падеж. Далее выпол¬
няется анализ с целью исключения многозначности грамматиче¬
ской информации.
Существо синтаксического анализа простого предложения сво¬
дится к определению главных членов предложения и связей:
— полного согласования;
— существительного (или прилагательного, или причастия)
с инфинитивом;
— существительного с существительным;
— наречия с другими частями речи;
— существительного родительного падежа с другими частями
речи;
— слов в синтаксических конструкциях.
Ниже приводятся правила определения указанных связей.
1. Правила определения связи полного согласования. Полное
согласование — это вид синтаксической связи, при котором грам-
243
магические параметры зависимого слова совпадают с граммати¬
ческими параметрами главного слова. Такими грамматическими
параметрами является род, число и падеж.
Главное слово при полном согласовании представляется:
1) существительн ьгм;
2) местоименными существительными, к числу которых отгкь
сятся личные (я, ты, он, она, оно, мы, вы, они); возвратные (себя);
неопределенные (кто-то, что-то, кто-нибудь, что-нибудь, кто-либо,
что-либо, кое-что, кое-кто, некто, нечто); отрицательные (никто
ничто).
Зависимое слово при полном согласовании представляется;
1) местоименными прилагательными, к числу которых отно¬
сятся притяжательные (мой, твой, наш, ваш, его, ее, их); возврат¬
ные (свой); указательные (тот, этот, такой, этакий, таков, таковой),
определительные (всякий, всяческий, каждый, весь, следующий,
иной, другой, самый); вопросительные (какой, который, какое,,
чей, сколько); неопределенные (какой-то, какой-нибудь, чей-то,
чей-нибудь, чей-либо, кое-какой, некоторый, некий, какой-либо,
который-либо, который-нибудь); отрицательные (никакой, ничей,
никоторый);
2) прилагательным положительной степени, сложной сравни¬
тельной степени, образованной с помощью слова «более», простой
превосходной степени, если за ним не следует предлог «из»;
3) полным причастием;
4) порядковым числительным.
Связь полного согласования выполняется следующим обра¬
зом. Просматривая слова предложения слева направо, определя¬
ется слово путем сопоставления грамматических параметров этого
слова с указанными грамматическими параметрами зависимого
слова. Как только просматриваемое слово будет отнесено к за¬
висимому, начинается поиск для пего главного слова. Первона¬
чально поиск главного слова осуществляется справа от зависи¬
мого. Если результат поиска положительный, то проверяется,
не находится ли между зависимым и выделенным словами спря¬
гаемый глагол. Если да, то проверяется возможность вхождения
главного слова в составное именное сказуемое. При наличии та¬
кого вхождения выделенное слово не есть главное и его поиск
справа продолжается. В противном случае выделенное слово
является главным словом.
В случае, если главное слово справа не найдено, поиск его
ведется слева от зависимого слова до начала предложения. Если
выделенное слово удовлетворяет требованиями главного слова,
то устанавливается связь между этими словами, и процедура
установления связи полного согласования для других слов про
должаете я.
Если же для рассматриваемого зависимого слова главное Ш‘
определено, то это слово проверяется на субстантивированное
прилагательное, играющее роль существительного. Список суб¬
стантивированных прилагательных, составлен пый по словарю
244
Ожегова, приведен в Приложении 1. В случае отсутствия такого
прилагательного зависимое слово проверяется тта возможность
вхождения его в составное именное сказуемое. В случае принад¬
лежности к составному именному сказуемому это слово является
именной частью сказуемого. В обоих случаях поиск главного
слова прекращается.
2. Правила определения связи существительного (или при¬
лагательного, или причастия) с инфинитивом. Первоначально
в предложении осуществляется поиск слова с грамматическим
параметром «инфинитив». Это слово принимается зависимым
словом. Тогда контактно расположенное слово с инфинитивом
или отделенное от инфинитива одним или несколькими наречия¬
ми, непосредственно следующими друг за другом, является глав¬
ным словом, если оно входит в словарь Р2 (Приложение 2),
составленный на базе словаря Ожегова, или причастием, обра¬
зованным от слова, входящего в словарь Р3 (Приложение 3).
3. Правила определения связи существительного с сущест¬
вительным с предлогом и без предлога \ Выделяются два кон¬
тактно расположенных существительных и проверяется их рас¬
положение относительно сказуемого. Если они расположены слева
относительно сказуемого, то устанавливается связь между этими
существительными, если второе существительное имеет форму
дательного, винительного или творительного падежа и не имеет
предлога. Причем первое существительное является главным,
второе — зависимым. Если второе существительное имеет форму
родительного падежа, то осуществляется поиск третьего сущест¬
вительного, контактно расположенного со вторым, и устанавли¬
вается связь между первым и третьим существительным, если
третье существительное не имеет предлога и представлено в форме
дательного, винительного или творительного падежа. Причем
первое существительное является главным, третье — зависимым.
Связь существительного с существительным с предлогом можно
установить только по смыслу. С этой целью проводится работа
по определению такого рода связи среди слов словаря Ожегова.
4. Правила определения связи наречия с другими частями
речи. При контактном расположении двух и более наречий пред¬
шествующее наречие считается зависимым, последующее— главным.
Если слева от наречия контактно расположено прилагатель¬
ное (или причастие), то наречие рассматривается как главное
слово, а прилагательное (или причастие) — как зависимое.
Если справа от наречия контактно расположено прилагатель¬
ное (или причастие), то наречие рассматривается как зависимое
слово, прилагательное (или причастие) — как главное.
Если слева от наречия контактно расположено существитель¬
ное, неодушевленное, то существительное рассматривается как
главное слово, а наречие — зависимое. Причем такая связь уста-
1 Это правило выполняется после определения главных членов предложения,
которые определяются по правилам разд. 7.
245
навливается только в том случае, если наречие входит в сосг;1Г$
словаря Р5 (Приложение 5).
Если слева от существительного именительного или родитель-
ного падежа контактно расположено наречие со значением коли¬
чества (наполовину, несколько, много и др.), то наречие рассмат¬
ривается как зависимое слово, существительное — как главно^
5. Правила определения связи существительного родительного
падежа с другими частями речи. Существительное родительного
падежа (с предлогом или без предлога), контактно расположенное
справа от слова любой части речи, рассматривается как зависимое
слово, а контактно расположенное слева — как главное слово.
6. Правила определения связей в синтаксических конструк¬
циях. Под синтаксической конструкцией здесь понимаются при¬
частный оборот, деепричастный оборот и последовательность
слов, расположенных между синтаксически связанными словами
(эта связь установлена по правилам разд. I).
В синтаксической конструкции первоначально устанавлива¬
ется связь по правилам, приведенным в разд. 1—5. Затем слога
этой конструкции, не находящиеся ни в какой связи, а также
главные слова во всех установленных связях являются зависи¬
мыми от определяющего слова данной конструкции.
7. Определение главных членов предложения — подлежащего
и сказуемого. Правила определения главных членов простого
предложения разработаны на основе статистического анализа
предложений русского языка и на базе изучения структурных,
схем предложений, приведенных в работах [2, 3], причем сказуе¬
мые разбиты на четыре класса:
— спрягаемоглагольный класс, в котором в роли сказуемого
выступает либо сама форма глагола, либо в сочетании с инфини¬
тивным рядом. Для переходных глаголов характерно следование
за ними существительного винительного падежа;
— инфинитивный класс, где в роли сказуемого выступаем
либо собственно инфинитив (инфинитивный ряд); либо переход¬
ный инфинитив в сочетании с существительным винительного
падежа; либо инфинитив в сочетании со сравнительной степенью
прилагательного; либо инфинитив в сочетании с кратким при
лагательным (или кратким причастием);
— предикативный класс, в котором в роли сказуемого вы¬
ступают краткие прилагательные, краткие причастия, сравнитель¬
ная степень прилагательного как самостоятельно, так и в соче¬
тании с частицей «нет». Сюда же относится и наречие;
— именной класс, в котором для двусоставных предложений
сказуемое выражено именительным падежом существительного
или субстантивированного прилагательного, а для односоставны4
предложений сказуемое выражено или существительным имени¬
тельного падежа; или существительным именительного падеж г
(или наречием количественным) в сочетании с существительными
родительного падежа; или существительным родительного нс
дежа, не выступающим в роли зависимого слова.
246
Грамматические формы главных членов предложения
Р-
Ф
гС
д
s
Д
ф
3
ЕС
Д
ю
X
д
г*
ф
Рч
ф
X
н
Л
И
ф
3
ЕС
о
гС
Е-
X
F-1
X
д
о
Рч
>>
О
>>
ГС
>>
ЕС
ЕС
О
ф
Ф
V©
3
Д
Д
К
О
ч
о
о
pi
ф
33
а
>>
и
о
о
о
и
д
ф
н
X
со
\о
О
3
Н
о
ч
ф
н
н
о
I
S
аЗ
Д
о
Ч
о
К
т
о
д
Ен
О
X
и
Рч
ч
\о
о
>»
я
д
д
со
О
д
(У
о
И
EJ
О
Ен
X
Ен •
О
о
к
Й
VO
Ен
X
Ф
д
Л
Ен
Ен
О
. и
Ф
Ф
ЕС
ЕС
X
Ф
Ф
а
W
И
X
о
о
С
ЕС
О
Рч
О
о
S
247
я£
Я
ПЭ
Ен
ф
О
tQ
Ф
Ен
И
О
Я
Он
К
ф
Р
я
ф
О-
О
Ен
ь
д
Ф
Q
с
й
О
О
к
н
о
Ен
05
яс
>»
ч
ф
ф
Он
к
ф
Н
5
V
05
S
Он
05
о
И
и
~
И
Ф
о
ч
ф
О
д
С
я
g
И
ф
ч
яс
в
Я
а
« •
о
1
И
£
1
с=С
>>
я
о
о
ф
Он
д
я
яс
о
Ен
05
ф
о
«
О
Ч
3
ф
Он
и
д
£ч
СС
>>
о
к
а
a
Таблица (продолжение)
и
©
а.
О
2
S
О
я
о
О
с
с
2
©
rt
X
rt
2
О
о
*6*
Л
а
Сч
+
я
к
се
5
(3
со
S
я
я
П
и
я
s
5
a
+
CL
E
05
c
05
+
Cl"
я
О
c°
E-
s
к
E~
EL
О
\C
CU
S
Рн
+
Е
я
+
S S
+
s
и
rt
a
о
_l_
i
E
2
4
E
К
a a
a
E
a
и
E tf
248
н
ф
р -
>>
о
ч
и
н
о
ф
о
н
>>
\о
2
Рч
о
ч
со
н
S
ф
о
О
и
ю
ь
ф
>»
д
н
о
н
>>
о
н
о
сб
о
W
о
(-1
ф
к
О
'.-1ч
и
d*
о
о
а
+
+
+
...!_
О
Ен
Н
Н
Я S
+
Ф
К
Ф
д
Ф
W
о” о"
Щ
о
а
249
Грамматические формы главных членов предложения приве¬
дены в таблице, где приняты условные обозначения: ГЛ — глагол
в личной форме; Г И — инфинитив; II — прилагательное; Г.ГР
причастие; СМ — местоименное существительное; И — имя су¬
ществительное именительного падежа; или субстантивированное
прилагательное именительного падежа; или местоименное сущест¬
вительное именительного падежа; или порядковое числительное
именительного падежа; или собирательное (количественное) чис¬
лительное именительного падежа, одиночное либо в сочетании
с существительным родительного падежа); И — наречие; Ч --
числительное; 1, 2, 3 — соответственно первое, второе и третье
лицо: ед., мн.— соответственно единственное и множественное
число; проги., буд., наст.— соответственно прошедшее, будущее,
настоящее время; изъяв., повел.— изъявительное и повелительное
наклонения глагола; перех., неперех.— переходный и непереход¬
ный глаголы; одунг.— одушевленное; им., род., вин., тв.— име¬
нительный, родительный, винительный, творительный падежи;
к — краткое; сравнит.— сравнительная степень; кол.— количе¬
ственное.
Определение главных членов предложения выполняется сле¬
дующим образом. Главные члены предложения определяются
среди слов, которые на предыдущих этапах вообще не были свя¬
заны синтаксической связью, а также среди слов, которые в лю¬
бых синтаксических связях с другими словами выполняли роль
главных. По грамматическим формам слов определяется наличие'
в предложении спрягаемой формы глагола. Если таковая имеется,
то глагол считается сказуемым и для него определяется соответст¬
вующее подлежащее из таблицы с учетом форм уподобления глав¬
ных членов. В случае, если ни одна из указанных в таблице грам¬
матических форм для подлежащего в предложении не присутст¬
вует, считается, что в данном предложении главный член — под¬
лежащее отсутствует, и его поиск прекращается.
Если в предложении не найдена спрягаемая форма глаголя,
происходит просмотр слов предложения на предмет идентификации
их с неопределенной формой глагола. При наличии неопределен¬
ной формы глагола контактные слова справа (в случае пекоптакт-
ности они могут разделяться наречиями) проверяются на неоп¬
ределенную форму глагола, сравнительную степень прилагатель¬
ного или краткую форму прилагательного (или причастия), и если
они являются таковыми, то сочетание неопределенной формы
глагола с указанным контактным словом объявляется сказуемым
Если контактное слово справа выражено другими частями речи,
то проверяется, нет ли в предложении еще слова, выраженного
неопределенной формой глагола и неконтактно расположенного
с первым словом, выраженным неопределенной формой глагола.
При наличии такового проводится граница перед вторым словом
и все слова, что слева от нее, считаются группой подлежащего,
в которой слово, выраженное неопределенной формой глагола,-
подлежащее, последовательность слов, находящаяся справа от
250
границы, считается группой сказуемого, а слово, выраженное
в ней неопределенной формой глагола,— сказуемым. Если же
второго слова, выраженного неопределенной формой глагола,
не встретилось, то слова просматриваются на предмет идентифи¬
кации с существительным именительного падежа, которое при
положительном результате играет роль подлежащего, а слово,
выраженное неопределенной формой глагола,— роль сказуемого.
В случае отсутствия существительного в именительном падеже
поиск подлежащего прекращается. В этом случае предложение
считается односоставным, в котором сказуемое выражено неопре¬
деленной формой глагола.
Если в предложении не найдена ни одна глагольная форма,
проверяется наличие в нем слов, выраженных краткой формой
прилагательного или краткой формой причастия, которые в пред¬
ложении всегда выполняют роль сказуемого. При наличии таких
форм сказуемого подлежащее может быть выражено существитель¬
ным именительного падежа, неопределенной формой глагола или
количественным числительным в сочетании с существительным
родительного падежа.
Отдельно рассматривается случай, когда при наличии пере¬
численных грамматических форм подлежащего и при отсутствии
в предложении перечисленных форм сказуемого определяется
сказуемое, выраженное наречием, которое ранее ни в одной син¬
таксической связи не выступало как зависимое слово.
Если сказуемое не было идентифицировано ни с одной из опи¬
санных форм, проверяется наличие в предложении сравнительной
формы прилагательного, и при нахождении такого оно само либо
в сочетании с частицей «нет» объявляется сказуемым. Подлежащее
для него определяется по грамматическим формам, описанным
в соответствующей графе таблицы. Именной класс сказуемых
определяется в последнюю очередь. В нем сказуемое может быть
выражено существительным именительного падежа. Причем если
в предложении имеется еще существительное именительного
падежа или существительное любого косвенного падежа, разде¬
ленное тире с первым существительным именительного падежа,
то существительное именительного падежа, стоящее за тире, или
последнее в предложении существительное косвенного падежа
считается подлежащим и каждое слово, расположенное слева
от тире и не вошедшее ни в одну синтаксическую связь пли во¬
шедшее как главное, будет рассматриваться как зависимое в син¬
таксической связи с главным словом — подлежащим. Опальные
случаи выражения сказуемого именного класса относятся к одно¬
составным предложениям, в которых подлежащие отсутствуют.
Грамматические формы выражения таких сказуемых приведены
в таблице.
После определения в предложении главных членов предложе¬
ния каждый член предложения, оставшийся без синтаксической
связи или выступающий только как главный в определенных па
предыдущих этапах синтаксических связях, образует синтакси¬
251
ческую связь со сказуемым, причем сказуемое выступает как
главное слово.
Синтаксическая омонимия специально в данной работе не рас
сматривается, однако она разрешается всей системой правил
предлагаемого подхода.
Л II Т Е Р А Т У Р А
1. Криницкий Н. А... Миронов Г. А Фролов Г. Д. Автоматизированные си¬
стемы. М.: Наука, 1978.
2. Грамматика современного русского литературного языка. М.: Наука,
1970. 767 с.
3. Лека нт И. А . Синтаксис простого предложегптя в современном русском
языке. М.: Высш, шк., 1986. 173 с.
4. Белоногов Г. ГНовоселов А. II. Автоматизация процессов накопления,
поиска и обобщения информации. М.: Наука, 1979. 256 с.
ПРИЛОЖЕНИЕ 1
Словарь Рх субстантивированных прилагательных
Белый
беглый
безработный
благоверный
благоверная
блаженный
ближний
блинная
богатый
бедный
бойлерная
больной
борзая
былое
ведомый
ведущий
виноватый
виновный
влюбленный
водяной
военный
вожатый
возлюбленный
вольный
всевышний
вселенная
всякий
выходной
гардеробная
гл ухой
глухонемой
горнорабочий
городничий
городовой
данные
дворецкий
дворницкая
дворовый
дежурный
доверенный
доезжачий
должное
домашние
дорогой
другой
душевая
душевнобольной
животное
заведующий
загребной
заключенный
знакомый
золотой
исходящий
комарииская
кладовая
коверный
коренной
коридорный
кормчий
косой
красный
крестный
крепостной
крещеный
кривая
кухмистерская
ламповая
легавый
лежачий
лесничий
леший
лишний
ловчий
любой
любопытный
людская
маленький
малый
мастеровой
мастерская
мертвецкая
местный
миленький
252
мил ый
подхорунжий
седьмой
младший
подчиненный
секущая
многое
подъячий
слагаемое
мп о г о у в а ж а е мый
пожарный
следующий
множимое
позывной
слепой
молодые
покойницкая
слепорожденный
мороженое
покойный
служащий
мостовая
понятой
смешной
набережная
пивная
сосисочная
накладная
портерная
сотский
нарочный
портной
сохатый
насекомое
последнее
ссыльный
начинающий
постовой
старый
ire возможный
посыльный
стряпчий
неизвестный
прачечная
суженая
нелегкая
престарелый
сумасшедший
нервнобольной
приближенный
существительное
неуспевающий
придворный
трудящийся
новобрачный
приезжий
тысяцкий
новобрачная
присяжный
уборная
новорожденный
прилагательное
уборочная
обвиняемый
провожатый
угнетенный
одинаковый
проезжий
умалишенный
окаянный
прозекторская
управляющий
отверженный
прокаженный
участковый
отс у т ст в у ющий
проходная
ученый
отъезжающий
пьяный
хорунжий
падучая
рабочий
цитрусовые
парикмахерская
равный
чаевые
пельменная
разводящий
чайная
перепончатокрылые
разнорабочий
часовой
пионервожатый
раненый
чебуречная
пленный
родной
челобитная
поверенный
рукопашная
чернорабочий
подданный
русский
четвертной
подлежащее
рядовой
числительное
поднадзорный
саврасый
шампанское
поднаготная
связной
шашлычная
подручный
святейший
швейцарская
подследственный
святой
юродивый
подсудимый
ПРИЛОЖЕНИЕ 2
Словарь Р2 существительных
Воля
готовность
дозволение
возможность
грех
допуск
время
дар
жажда
выгода
директива
желание
253
замысел
опасность
слово
задание
основание
случай
задача
особенность
смелость
задумка
охота
соблазн
идея
охотник
согласие
инициатива
перспектива
соображение
искусство
пижонство
сообщение
искушение
повадка
способность
искусник
повинность
средство
клятва
повод
страстишка
команда
поползновение
страсть
кощунство
попытка
специалист
логика
пора
способ
легкость
потребность
стремление
манера
право
стыд
мания
предлог
срам
мастер
предложение
судьба
мастак
предписание
суждение
мысль
предположение
счастье
намерение
привычка
талант
настрой
приглашение
традиция
наука
призвание
требование
нежелание
приказ
тяга
необходимость
причина
трудность
надобность
просьба
угроза
неохота
радость
удача
неприличие
разрешение
указание
несогласие
распоряжение
умелец
нужда
решение
умение
обещание
риск
устремление
обыкновение
ручательство
устремленность
обычай
свобода
участь
обязательство
склонность
хобби
обязанность
слабость
шанс
опасение
ПРИЛОЖЕНИЕ 3
Слсварь Р3 прилагательных
Бессильный
склонный
недостойный
готовый
свободный
горазд
одержимый
согласный
должен
полномочный
способный
рад
привычный
убежденный
здоров
прирожденный
УМОЛИ Ю1ЦИЙ
намерен
обязанный
алчущий
обязан
расположенный
254
ПРИЛОЖЕНИЕ 4
Словарь Р4 глаголов
Агитировать
бежать
беспокоиться
б л а г о п р и я т ст в о в а т ь
благословить
божиться
бояться
брать
бредить
брезгать
бросить(ся)
валиться
ввести
вдохновить(ся)
везти
велеть
вернуть(ся)
вести
взалкать
вздумать
взойти
взять(ся)
внушить
водить
возвратить(ся)
воздержаться
возмечтать
вознамериться
воодушевить(ся)
ворваться
воротиться
воспротивиться
востребовать
впустить
вразуметь
врываться
вскакивать
встать
втолковать
втянуться
выбежать
выбраться
вывезти
вывесить
вывешивать
вывести
выводить
вываживать
выглянуть
выгнать
выгнуться
выгонять
выдумать
выехать
вызвать(ся)
вьгискать(ся)
выйти
вылезтп(ь)
вылететь
выманить
вынести
вынудить
вынырнуть
выплыть
выползти
выпорхнуть
выпрыгнуть
выпрямиться
выпустить
вырасти
вырваться
вырезать
высадиться
высвободить(ся)
выскользнуть
выскочить
выслать
выставиться
высунуться
вытащить
вытолкать
вытолкнуть
вытяиуть(ся)
выучиваться
выучить(ся)
гарантировать
гнать
гнушаться
говорить
годиться
гонять
готовиться
грозить(ся)
давать(ся)
дать(ся)
дерзнуть
двинуть (ся)
дерзать
добиться
доверить
довестись
доводиться
догадаться
договориться
додуматься
дозволить
должен (должно)
домогаться
допустить
думать
езжай (ть)
ехать
желать
забежать
забыть(ся)
завалиться
заверить
завернуть
завещать
загадать
загореться
задумать (ся)
заехать
зазвать
зайти
заказать
закончить
заладить
залезть
замедлить
замучиться
замыслить
запоздать
запретить
запрещать(ся)
заречься
заслать
заспешить
255
заставить
обещать
пойти
затрудниться
обучить
поклясться
захотеть (ся)
обязать(ся)
положить
звать
окончить
помечтать
избегать
опасаться
помочь
изволить
опоздать
пообещать
изготовиться
оробеть
попытаться
измучиться
осмелиться
поручить
класть
оставить
порываться
кликать
остаться
постановить
командировать
отвадить
постараться
кончить
отвыкнуть
посчастли виться
лениться
отговорить
потрудиться
лечь
отдать
предложить
ложиться
отказать(ся)
предоставить
любить
отнести
предписать
мешать
отослать
предполагать
мочь
отправить
собраться
надлежит
отсоветовать
совеститься
надо
отучить (ся)
советовать
надоумить
отчаяться
согласиться
надумать
оформиться
сообразить
назваться
передумать
спешить
наказать
переехать
стараться
намекать
перейти
стать
намереваться
планировать
стесняться
наметить
побаиваться
стремиться
нанимать(ся)
побеждать
стыдиться
иапять(ся)
побояться
сулить
наобещать
побудить
убедить
напомнить
повадиться
угораздии»
напрашиваться
повалиться
удосужиться
напроситься
повести
уложить
наскучить
повезти
уметь
научить(ся)
погрозиться
ум удриться
начать
подбить
умолять
начинать
подгадать
усадить
неволить
подождать
успеть
неймется
подумать
устать
необходимо
подумывать
устроиться
нести
подучиться
ухитриться
носить
позаботиться
учить(ся)
нравиться
позабыть
хватит
нужно
позволить
хотеть(ся)
256
ПРИЛОЖЕНИЕ 5
Словарь Р5 наречий
Босиком
исподлобья
наружу
вволю
исподнизу
наспех
верхом
исподтишка
наугад
взаймы
кряду
начистоту
взатяжку
летом
наяву
вкрутую
зимой
невпопад
внакидку
весной
ненароком
внизу
молчком
почыо
вничью
набекрень
осенью
вообще
набок
отроду
вперевалку
навзрыд
ощупью
впотьмах
навыворот
пешочком
вприглядку
навыкате
пешком
вприкуску
навылет
плашмя
впроголодь
навынос
подряд
впрок
навыпуск
подчистую
вразвалку
навытяжку
ползком
вразрядку
нагишом
понаслышке
враскачку
начало
поневоле
врозь
назавтра
пополам
врукопашную
назад
попусту
всерьез
назади
порожняком
вслепую
наизнанку
прописью
вслух
наизусть
сбоку
всмятку
наискосок
сообща
всухомятку
наискось
сплеча
втемную
накоротке
справа
вчерне
налегке
слева
голышом
наперевес
спросонок
гольем
наперегонки
стоймя
голяком
напоказ
стремглав
гуськом
напрокат
тайком
гуртом
напролет
торчком
дыбом
напротив
украдкой
изнутри
напрямик
урывками
искоса
нараспашку
целиком
исподволь
нараспев
шагом
СОДЕРЖАНИЕ
Реализация программ многократного применения над базами дан¬
ных, независимых от СУБД 3
Калиниченко Л. А.
Абстрактная архитектура процессора логического вывода 18
Буланже Д. Ю.
Порождение пакетов программ .19
Ильин В. Д.
Элементы концепции персональных систем обработки изображений 66
Дымков В. ИСиницын И. II .
Архитектуры персональных систем обработки изображений .... 74
Губин А. В., Шарыпин Е. В.
О задачах редактирования и яркостно-частотной коррекции в цифро¬
вой обработке изображений S2
Пахомова Т. А., Перфилова В. II., Шур А. Г.
Создание специализированных языковых средств для разработки
программного обеспечения персональных систем цифровой обработки
изображений 86
Барабанов А . Л., Шур А. Г.
Подход к организации сжатия изображений в персональных систе¬
мах обработки изображений 93
Шарыпин Е. В.
Критерии оптимальности в задачах представления видеоданных . . 98
Новиков С. О.
Об одном подходе к быстрому сегментированию изображений . . . 107
Калиничев О. Б., Каиьмапгов В. В.
Принципы разработки программного обеспечения для исследования
стохастических систем И I
Пугачев В. С., Синицын И. II., ЗацманИ. М., Карпенко А. Н., Че¬
редниченко А. А., Шин В. И.
Интерактивная САПР МАГИСТР-П: структура программного обес¬
печения и основные характеристики . . . 186
Оихман Е. Г., II овоженов 10. В., Р иш кус А . Б.
Асимптотическая оценка времени работы центральной базы данных
в интерактивных САПР на ПЭВМ 1’3
Зюзин 10. В., Петунии В. В., Хорват К.
Методы реализации кремниевого компилятора на основе бинарных
моделей данных 142
Зюзин Ю. В., Рябнин А. В.
Применение систем информатики для автоматизации учрежденчес¬
кой деятельности 155
Ростокин Б. И.
258
Об одном варианте проблемно-ориентированной системы програм¬
мировании для решения математических уравнений 162
Доступов Б. r.t Колобов В. Г., Черныш М. Н.
Возможные направления развития архитектуры ЭВМ массового при¬
менения 166
Козлова Л. МКозмидиади В. А Макаров А . IIШацС.А.
Последовательные и параллельные процессы в задачах описания и
моделирования архитектуры вычислительных устройств 182
Погосянц Г. М.
Архитектура открытой, мобильной программной системы логико¬
временного моделирования (ЛВМ) дискретных процессов в логичес¬
ких схемах 191
Иоффе М. И.
Оценка эффективности функционирования комплекса процессор —
память вычислительных систем 202
Фандюшина Н. А,
Некоторые вопросы распознавания дискретной клиппированной ре¬
чи ...... 214
Макуха В. АФилинов Е. IIФролов Г. Д.
Автоматический синтез русской речи на ЭВМ 222
Лаптев А. В., Олюнин В. Ю., П о лещу к С. IIФилинов Е. Н., Фро¬
лов Г. Д.
Об одном подходе к выделению различительных признаков фонем 236
Давыдов О. В., Фролов Г. Д.
Синтаксический анализ простого предложения русского языка на
персональных ЭВМ 242
Немова Г. А,, Фролов Г. Д., Чудина А. Ф.
Since 1989 the Institute of Informatics Problems of the Academy
of Sciences of the USSR will publish an annual edition «Informatics
and Computer Systems» which will highlihgt the scientific results of the
researches that were completed by the Institute in the current year. The
main goal of the Institute is fundamental researches and development
of new generation computer systems for various applications.
Depending upon the final achievements the contents of the book
may vary hut it should include the following main problems: design
of new hardware and software tools: software engineering; development
of man-machine intelligent interfaces hardware design for new generati¬
on personal computer systems; synthesis and use of personal computer-
based application systems.
For professionals in informatics, computer science and automation.
Научное издание
СИСТЕМЫ
И СРЕДСТВА
ИНФОРМАТИКИ
Утверждено к печати
Институтом проблем информатики
АН СССР
Редактор В. К. Черкасов
Редактор издательства Н. А. Ермолаева
Художественный редактор Н. Н. Власик
Технический редактор Н. Н. Кокина
Корректоры А. Б. Васильев, Т. И. Чернышова
ИБ № 39994
Сдано в набор 18.01.89
Подписано к печати 17.04.89
Т-00138
Формат 60x90716
Бумага книжно-журнальная
Гарнитура обыкновенная новая
Печать высокая
Усл. печ. л. 16,5. Усл. кр. отт. 16,75
Уч.-изд. л. 18,1
Тираж 6800 экз. Тип. зак. 2514
Цена 1 р. 90 к.
Ордена Трудового Красного Знамени
издательство «Наука»
117864, ГСП-7, Москва, В-185,
Профсоюзная ул., 90
2-я типография издательства «Наука»
121099, Москва, Г-99, Шубинский пер., 6
Издательство
«НАУКА»
Готовятся к печати
книги:
Гринченко С. И., Загускпн С. П.
МЕХАНИЗМ ЖИВОЙ КЛЕТКИ:
Алгоритмическая модель
12 л.
Монография посвящена вопросам разработки оригинальной
модели живой клетки и реализации ее на персональной профес¬
сиональной ЭВМ. Концептуальной особенностью такой модели
является рассмотрение клетки как адаптивной системы, оптими¬
зирующей свое состояние в соответствии с энергетическим кри¬
терием по алгоритму случайного поиска. Приводится краткое
описание структуры и особенностей применения программной
системы «Живая клетка».
Для специалистов в области информатики, а также биоло¬
гов, биофизиков.
Соколов Е. Н., Вайткявичюс Д. Г.
НЕЙРОИНТЕЛЛЕКТ
13 л.
В книге рассматриваются структура и свойства «нейроком¬
пьютера», излагаются современные представления о работе на¬
шего мозга. Представлены механизмы обработки информации
в различных анализаторах: зрения, слуха и др. На примере зри¬
тельного анализатора показывается, что гипотеза общности
механизмов обработки информации во всех анализаторах, не¬
видимому, верна,/г. е. можно говорить о некоем общем абстракт¬
ном анализаторе. Обсуждаются простейшие механизмы обработ¬
ки информации, которые служат сигналом для систем более глу¬
бокого специализированного анализа. Рассматривается актив¬
ный процесс восстановления внутреннего^образа внешнего сти¬
мула. Предлагается современное представление о будущем ней¬
рокомпьютера.
Для читателей, интересующихся проблемами искусствен¬
ного интеллекта.
Ильин В. Д.
ИНТЕЛЛЕКТУАЛЬНАЯ
СИСТЕМА ПРОГРАММИРОВАНИЯ
15 л.
Книга посвящена проблеме автоматизации синтеза программ.
Рассматривается интеллектуальная система программирования
И ГЕН, ориентированная па получение пакетов прикладных про¬
грамм (ППП) для обучения, обработки и образного представле¬
ния результатов эксперимента, учета и планирования. Приве¬
дены примеры синтеза ППП для ЭВМ, совместимых с УВК/СМ-4.
Для специалистов в области информатики и вычислитель¬
ной техники.
Айламазян А. К., Стась Е. В.
ИНФОРМАТИКА
И ТЕОРИЯ РАЗВИТИЯ
18 л.
Монография посвящена изложению информационной кон¬
цепции процессов развития открытых систем различной приро¬
ды: вопросам самоорганизации систем, математическому модели¬
рованию процессов развития, управлению этими процессами.
Книга содержит определения категорий информатики: информа¬
ции, информационных процессов, информационных моделей,
информационной деятельности. Даны примеры использования
предлагаемых в книге методов исследования открытых систем
для прогнозирования их развития.
Для специалистов, занимающихся исследованием систем,
а также в области информатики.
Для получения книг почтой
заказы просим направлять по адресу:
117192 Москва, Мичуринский проспект, 12, магазин «Книга — почтой»
Центральной конторы «Академкнига»; 19734а Ленинград, Петрозавод¬
ская ул., 7, магазин «Книга — почтой» Северо-Западной конторы «Ака¬
демкнига» или в ближайший магазин «Академкнига», имеющий отдел
«Книга — почтой».
Адреса магазинов «Академкнига»:
480091 Алма-Ата.
ва, 91/97
той»);
ул. Фурмано-
(«Книга — поч-
370001 Баку, ул.
ская, 51
той»);
232600 Вильнюс,
тето, 4;
Коммунистиче-
(«Книга — поч-
ул. У ни вер си-
690088 Владивосток,
проспект, 140
почтой»);
Океанский
(«Книга —
320093 Днепропетровск, проспект
Гагарина, 24 («Книга —
почтой»);
734001 Душанбе, проспект Лени¬
на, 95 («Книга — почтой»);
375002 Ереван, ул. Туманяна, 31;
-664033 Иркутск, ул. Лермонто¬
ва, 289 ( «Книга — почтой*):
420043 Казань, ул. Достоевско¬
го, 53 («Книга — почтой»);
252030 Киев, ул. Ленина, 42;
252142 Киев, проспект Вернадско¬
го 79;
252030 Киев, ул. Пирогова, 2;
252030 Киев, ул. Пирогова, 4
( «Книга — почтой»);
277012 Кишинев, проспект Лени¬
на, 148 («Книга — почтой»);
343900 Краматорск Донецкой обл.,
ул. Марата, 1 («Книга —
почтой»);
660049 Красноярск, проспект Ми¬
ра, 84;
443002 Куйбышев, проспект Лени¬
на, 2 («Книга — почтой»);
191104 Ленинград, Литейный прос¬
пект, 57;
199164 Ленинград Таможенный
пер. 2;
196034 Ленинград, В/О, 9 линия,
16;
197345 Ленинград, Петрозаводская
ул., 7 («Книга •— почтой»)!
194064 Ленинград, Тихорецкий
проспект, 4;
220012 Минск, Ленинский прос¬
пект, 72 («Книга —поч¬
той» );
103009 Москва, ул. Горького, 19а;
117312 Москва, ул. Вавилова, 55/7;
117192 Москва, Мичуринский прос¬
пект, 12 («Книга —поч¬
той» );
630076 Новосибирск, Красный про¬
спект, 51;
630090 Новосибирск, Морской про¬
спект, 22 (Книга — поч¬
той» );
142284 Протвино Московской обл.,
ул. Победы, 8;
142292 Пущино Московской обл.,
МР, «В», 1 («Книга — поч¬
той» );
620151 Свердловск, ул. Мамина-
Сибиряка, 137 («Книга —
почтой»);
700000 Ташкент, ул. 10. Фучика, lj
700029 Ташкент, ул. Ленина, 73;
700070 Ташкент, ул. Шота Руста¬
вели, 43;
700185 Ташкент, ул. Дружбы на¬
родов, 6 («Книга — поч¬
той» );
634050 Томск, наб. реки Ушай-
ки, 18;
634050 Томск, Академический про¬
спект, 5;
450059 Уфа, ул. Р. Зорге, 10 («Кни*
га — почтой»);
450025 Уфа, ул. Коммунистиче¬
ская, 49;
720000 Фрунзе, бульвар Дзержин¬
ского, 42 («Книга — поч¬
той» );
310078 Харьков, ул. Чернышевско¬
го, 87 («Книга — почтой»).
1 р. 90 к.
СИСТЕМЫ
и
СРЕДСТВА
ИНФОРМАТИКИ
Распределенные базы данных, цифровая
обработка изображений и речи, новые ар¬
хитектуры ЭВМ, технология программиро¬
вания, САПР’ы вычислительных систем —
актуальные направления исследований и
разработок в современной информатике.
С некоторыми результатами своих иссле¬
дований по этим направлениям Вас знако¬
мит в данном сборнике Институт проблем
информатики АН СССР.
• НАУКА•