



























































































































































































































































































Автор: Кузнецов Б.А. Белоногов Г.Г.
Теги: вычислительная математика численный анализ программирование информационные технологии
Год: 1983




Текст
БИБЛИОТЕЧКА
П РОГ РАМ М ИСТА
Г. Г. БЕЛОНОГОВ
Б.А. КУЗНЕЦОВ
Языковые средства автоматизированных информационных систем
БИБЛИОТЕЧКА
ПРОГРАММИСТА
Г. Г. БЕЛОНОГОВ, Б. А. КУЗНЕЦОВ
ЯЗЫКОВЫЕ СРЕДСТВА
АВТОМАТИЗИРОВАННЫХ
ИНФОРМАЦИОННЫХ СИСТЕМ
МОСКВА «НАУКА» 4
ГЛАВНАЯ РЕДАКЦИЯ
ФИЗИКО-МАТЕМАТИЧЕСКОЙ ЛИТЕРАТУРЫ 1У8В
22.18
Б 43
УДК 519.6
Языковые средства автоматизированных информационных снесем. Белоногов Г. Г., Кузнецов Б. А,— М.: Наука. Главная редакция физико-математической литературы, 1983.—288 с.
В книге рассматриваются принципы построения языковых и программных средств, предназначенных для автоматизации процессов накопления, поиска и обработки информации. Описываются синтаксическая и семантическая структуры естественных языков и методы обработки ипформацип, представленной на этих языках. Особое внимание уделяется языковым и программным средствам общения человека с автоматизированными информационными системами, и в частности, диалоговым системам.
Библ. 102 назв.
1702070000- 111
Б 053(02)-83
©Издательство «Наука». Главная редакция физико-математической литературы, 1983
ОГЛАВЛЕНИЕ
Предисловие . > « , 5
Глава 1. Структуры данных............................♦ 7
1.1. Предикатно-актантная структура................... 7
1.2. Структуры данных в банках данных .... 18
1.3. Структура естественных языков ...... 25
Глава 2. Операции над массивами данных...................29
Глава 3 Входные языки автоматизированных информационных систем...................................... 39
3.1. Структура входных языков.........................39
3.2. Языковые средства для ввода и обновления информации ............................................, 41
3.3. Языковые средства для поиска информации . ♦ 46
3.4. Языковые средства для обобщения и выдачи инфор-мацип.............................................49
3.5. Языковые средства общения с базами данных реляционной, иерархической и сетевой структур . « 56
3.6. Языковые средства документальных ИПС . < , 61
Глава 4. Внутренние языки автоматизированных информационных систем 63
Глава 5. Программные средства автоматизированных информационных систем................................. 76
5.1. Структура программных средств АИС .... 76
5.2. Формирование и обновление массивов информации 85
5 3. Поиск и обобщение информации 91
Глава 6. Информационное и лингвистическое обеспечение АИС...................................................98
6.1. Состав и структура информационного и лингвистического обеспечения..................................98
6.2. Автоматизированное ведение информационного и лингвистического ' обеспечения......................101
6.3. Информационная и лингвистическая совместимость АИС............................................... 106
Глава 7. Синтаксическая и семантическая структура естественных языков ..................................110
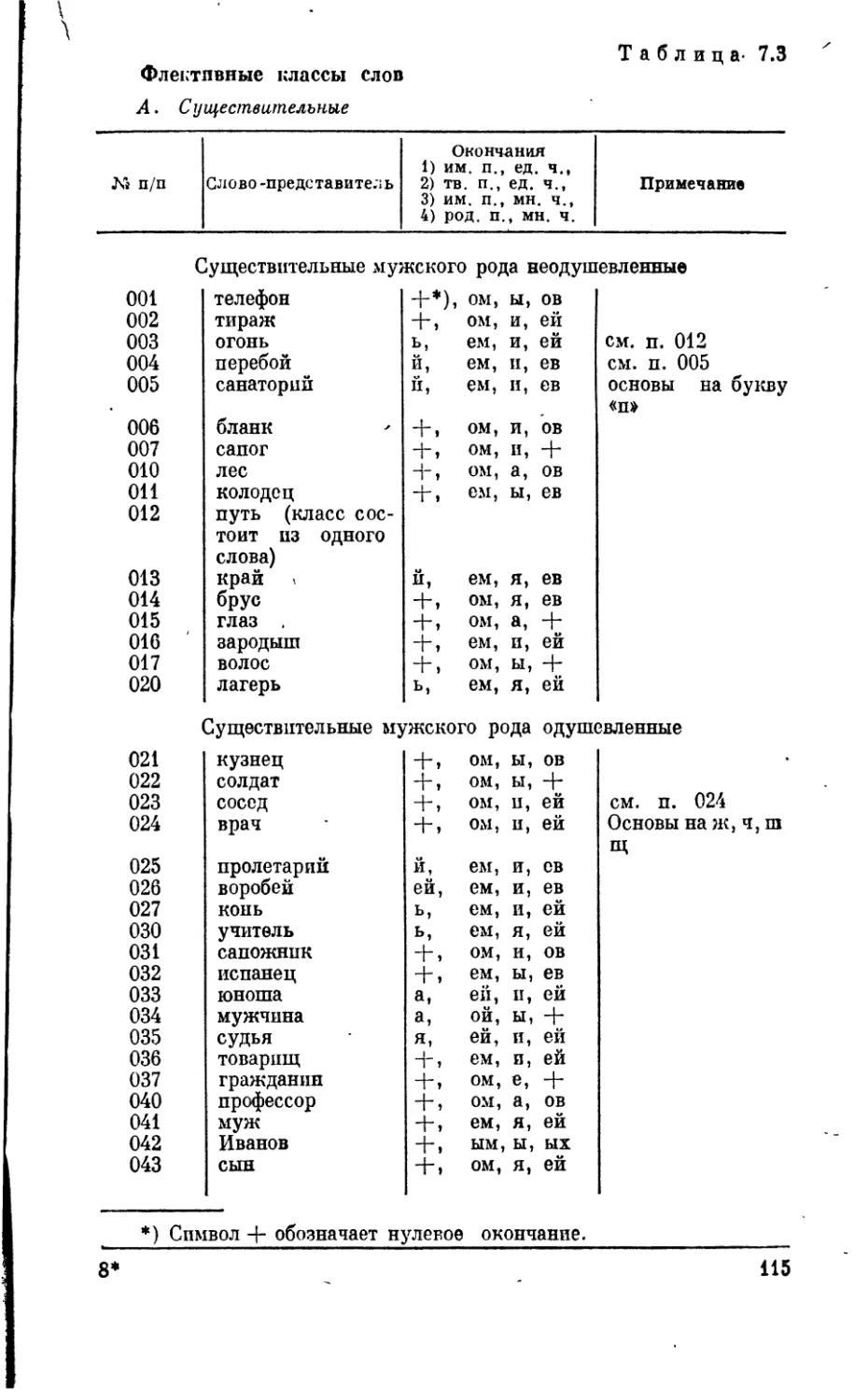
7 1. Структура слов . ......... 110
7.2. Структура именных словосочетаний ..... 128
7.3. Структура предложений и сверхфразовьтх единств 132
7.4. Семантико-синтаксическая структура текстов , 2 136
1*
3
Глава 8. СемантпКо-сйнтаксйческий анализ и синтез текстов на естественных языках..................... • ИЗ
8.1. Предварительные замечания...............................143
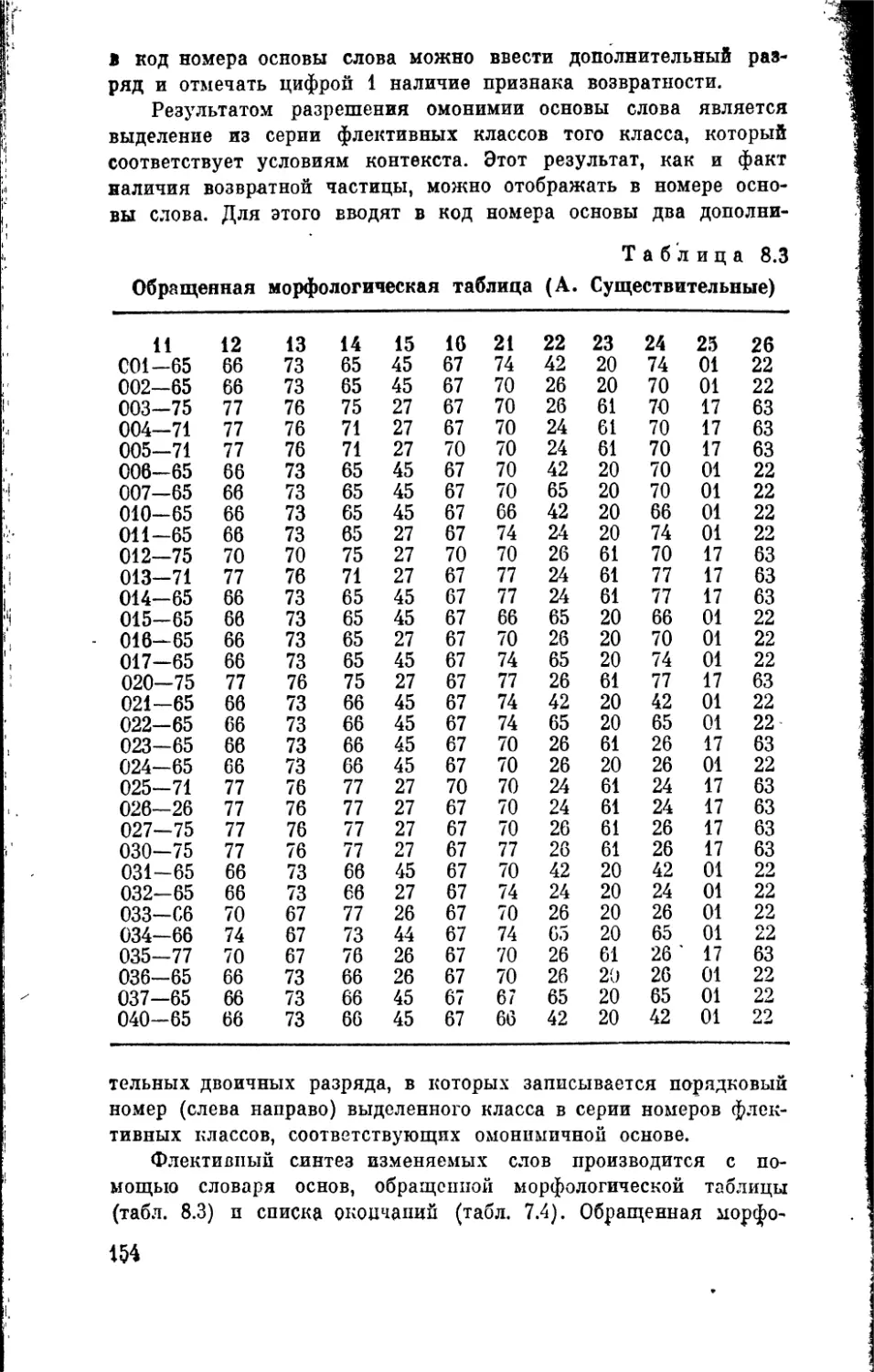
8 2. Морфологический анализ и синтез слов . . . 146
8 3. Анализ и синтез именных словосочетаний . . . 169
8.4. Синтаксический анализ текстов ...... 174
Глава 9. Автоматизированные информационные системы, «понимающие» естественный язык ...... 184
9.1. Общие положения.................................... . 184
9.2. Поиск документов по текстам их рефератов . . 189
Глава 10. Информационные сети..................♦ 200
10.1. Совокупность автоматизированных информационных систем как объединенная информационная система.......................................... 200
10.2 Формирование информационных массивов .
10 3. Функциональная специализация информационных центров и их взаимодействие........................204
10.4. Информационный фонд сети ....... 206
10.5. Полнота представления данных в информационном
фонде...................................................208
10 6 Влияние временных характеристик распределения документов в массивах текущих поступлений на полноту информационного фонда ..... 211
Глава И. Представление баз данных в информационной сети..........................................., . 217
11.1. Структура баз данных информационной сети , . 217
11.2. Тематическое разделение предметных областей 222 If 3. Оценка соответствия системы тематических баз данных интересам пользователей...............................225
11.4. Использование характеристик профильности тематики баз данных для оптимизации предоставления их в режим доступа пользователям ..... 232
Глава 12. Взаимодействие пользователя с информационной сетью . 237
12.1. Телекоммуникации в информационной сети . , . 237
12.2. Сети коммутации пакетов — перспективная ком-мунйкаЦиойная среда информационных сетей . . 242
12.3. Централизованная и распределенная информационная сеть............................... 248
12:4. Адресация запросов к базам данных .... 252
12.5. Совместимость языковых средств пользователей информационной сети 255
Приложение 1. Словообразовательные классы слов . , 258
Приложение 2. Словарь сочетаний суффиксов и псевдосуффиксов ’......................... . . . . f 262
Приложение 3. Фрагменты научно технического словаря 273
Литература ................................................. . 283
ПРЕДИСЛОВИЕ
Автоматизированные информационные системы (АИС) предназначены для накопления, поиска, обработки и выдачи информации о характеристиках различного рода объектов. Эти системы составляют основу автоматизированных систем управления (АСУ), систем научно-технической информации, автоматизированных систем проектирования и других систем, связанных с обработкой больших массивов информации. При создании АИС возникает широкий круг проблем, среди которых важное место занимают проблемы технического, математического, программного, информационного и лингвистического обеспечения. Перечисленные проблемы тесно связаны между собой. Так, информационное п лингвистическое обеспечение АЙС создается с учетом возможностей технических средств. То же самое можно сказать и о математическом и программном обеспечении. С другой стороны, вновь создаваемые технические средства должны быть ориентированы па перспективные методы автоматической обработки информации.
Среди проблем автоматической обработки информации ведущее место занимают проблемы, связанные с содержательной, смысловой стороной информационной технологии. Именно эта сторона является наиболее сложной и трудной. От уровня ее постижения в значительной степени зависят эффективность АИС в целом. Мы назвали проблемы, связанные со смысловой стороной процессов автоматической обработки информации, семантическими проблемами. Их рассмотрению прежде всего и посвящена настоящая книга.
К числу семантических проблем могут быть отнесены следующие проблемы автоматической обработки информации:
1. Проблема адэкватного представления логической структуры данных и вытекающая из нее проблема разработки эффективных формализованных информационных языков.
2. Проблема формализованного представления смысла текстов на естественных языках.
3. Проблема преобразования информации из одной формы представления в другую, например, ее перевод с естественного языка на информационный, с одного естественного языка на другой или с одного формализованного языка на другой.
4. Проблема отождествления информации, представленной в различной языковой форме, и установления смысловой связи между поисковыми запросами и высказываниями (сообщениями, документами), отвечающими на эти запросы.
5. Проблема обобщения информации и представления ее в виде, удобном для восприятия человеком,
&
г '
6. Проблема общения человека с АИС на формализованных языках и на естественном языке.
7. Проблема обеспечения информационной и лингвистической совместимости информационных систем.
В книге с единой точки зрения рассматриваются различные способы формализованного представления информации и различные информационные языки. При этом подчеркивается общность структуры всех известных формализованных информационных языков, более того, общность структуры этих языков и формализованных описаний элементов и структур естественных языков. Такая точка зрения позволяет создать единую концепцию автоматической обработки формализованной и неформализованной информации.
Книга состоит из двенадцати глав и 3 Приложений. По своему смысловому содержанию ее материалы могут быть объединены в • три крупных раздела. В первом разделе книги (главы 1 — 6) рассматривается логическая структура данных, структура формализованных информационных языков и принципы их функционирования. Во втором разделе (главы 7—9 и Приложения) — структура естественных языков и принципы обработки информации, представленной на этих языках. В третьем разделе (главы 10 — 12)—принципы построения информационных сетей и проблемы их информационного и лингвистического обеспечения. В написании глав 3, 4, 5 и 8 наряду с авторами принимал также участие к. т. н. А. П. Новоселов.
В заключение авторы выражают признательность проф. А. И. Михайлову и проф. И. А. Волошину, поддержавшим идею издания настоящей книги,
Г. Г. Белоногов; Б. А. Кузнецов
ГЛАВА 1
СТРУКТУРЫ ДАННЫХ
1.1. Предикатно-актантная структура
Логическая структура данных в автоматизированных информационных системах (АИС) определяется в значительной мере структурой современных ЭВМ, а последние, в свою очередь, ориентированы на предикатно-актантную структуру данных. К такому выводу, можно прийти, изучая структуру машинных операций и структуру алгоритмических языков высокого уровня (таких, как алгол, кобол, фортран, FL/1 и др.).
Предикатно-актантная структура данных строится на основе многоместных предикатов, которые имеют вид
F( , ..... ). (1.1)
Здесь имя предиката (многоместного отношения), а пустые места предназначены для актантов (значений предметных переменных). Конкретные высказывания (сообщения) формируются путем подстановки на пустые места значений предметных переменных, соответствующих описываемым ситуациям, процессам или объектам. Так, высказывание о ситуации, в которой выделено п элементов, будет иметь вид
F(A„ У2, ..., A,.). (1.2)
Здесь F, как и ранее,— имя понжия. обозначающего предикат, А’ь Х2, . •А‘„ —- имена понятий, обозначающих объекты, входящие в состав ситуации.
От структуры (1.2) высказывания легко перейти к структуре в виде конкатенации (связки, сочетания, пучка) двусоставных признаков (каждый признак состоит из его наименования и значения). Действительно, в записи (1.2) синтагматические (ситуационные, синтаксические) связи между понятиями, входящими в состав высказывания, выражаются позиционными средствами — пу-
7
тем совместною контактного расположения кодов этих понятии и закрепления* за их позициями определенной функциональной роли (скобки и запятые являются избыточными символами). Функциональная роль понятия может быть обозначена сочетанием кода (имени) отношения и номера позиции этого понятия в высказывании. Если обозначить ее каким-либо другим способом (например, путем присвоения имени, выраженного словом или словосочетанием), то необходимость в использовании для этой цели кода отношения и номера позиции отпадет,
Тогда характер отношения между понятиями Х2, • • ч %п в высказывании (1.2) будет определяться перечнем имен функциональных ролей, в которых эти понятия выступают, а само высказывание может быть представлено в виде конкатенации пар элементов: имя понятия — имя функциональной роли, в которой оно выступает. Имя функциональной роли может быть интерпретировано как наименование признака, а имя понятия — как 'его значение.
В автоматизированных информационных системах отображаются явления внешнего «мира» (внешнего по отношению к ЛИС), и в качестве элементов этого «мира» выступают его объекты (материальные или абстрактные). Членение внешнего «мира» на объекты может быть разным и зависит от целевой установки. Объекты могут быть простыми и сложными. Простой объект воспринимается как носитель совокупности характеризующих его свойств. Его сущность проявляется в этих свойствах, и они не отделимы от него. Внутренняя структура простого объекта не раскрывается.
Сложный объект состоит из простых объектов (как минимум двух), связанных между собой. Он также воспринимается как нечто целое и характеризуется определенными свойствами. Но, в отличие от простого объекта, в нем различается внутренняя структура — его расчлененность на простые объекты. Деление объектов на простые и сложные относительно: один и тот же объект внешнего мира может при решении одних задач рассматриваться как простой, а при решении других — как сложный.
Свойствам объектов в информационном отображении соответствуют их признаки, но в АИС отображаются не все свойства объектов, а лишь наиболее существенные, причем взгляд на существенность тех или иных свойств зависит от характера решаемых задач.
Простому объекту внешнего «мира» в информационном отображении соответствует конкатенация характеризующих его признаков^ а сложному — сетевая структура. В узлах этой структуры помещаются простые объекты, а узлы соединяются дугами, которые отражают связи (бинарные отношения) между объектами.
8
Понятия бинарное отношение и признак во многом сходны друг с другом. И то, и другое характеризует определенное свойство объекта: первое — находиться в определенном отношении к другому объекту, второе — соотноситься с определенной качественной или количественной категорией. Более того, бинарное отношение можно считать частным случаем признака, характеризующим связь объекта с некоторым другим объектом. Частным случаем признака является и математическое понятие переменной: наименование переменной может быть интерпретировано как наименование признака, а значение переменной — как значение признака.
При описаний объектов на формализованных информационных языках в качестве минимальной самостоятельной единицы смысла выступает элементарное высказывание, в котором утверждается принадлежность объекту одного его признака. Признак может выражаться одним понятием, но обычно он расчленяется на две части: на наименование признака и его значение. Таким образом, элементарное высказывание может быть представлено в виде триады, состоящей из идентификатора объекта, наименования признака и его значения. Все элементы этой триады присутствуют во всех формализованных языках, но кодируются они по-разному: часть элементов кодируется позиционными средствами, другая — комбинациями символов алфавита. В соответствии с этим, в АИС применяются три основных формата высказываний — позиционный, анкетный и триадный, которые могут использоваться самостоятельно и. в различных сочетаниях. В позиционном формате для каждого признака отводится определенное поле памяти, на котором записываются значения этого признака. .Связь между признаками обозначается контактным расположением полей, предназначенных для описания одпого объекта. В анкетном формате (его иногда называют ключевым) наименования и значения признаков обозначаются комбинациями символов алфавита, а связь между признаками — их контактным расположением. Порядок следования признаков в пределах одного высказывания не играет роли. В триодном формате все компоненты элементарных высказываний — идентификаторы объектов, наименования признаков и их значения — выражаются комбинациями символов алфавита.
Следует заметить, что в информационных отображениях внешнего «мира» имена объектов и ситуаций используются далеко по всегда (например, космический объект может быть охарактеризован его координатами, вектором скорости, линейными размерами и т. п., но собственного имени оп может и не иметь). В общем случае, «именем» объекта является совокупность характеризующих его признаков — высказывание об этом объекте, а идентификатором такого объекта может быть порядковый номер высказывания, или сочетание так называемых «ключевых» признаков, вы
деляющих его пз множества всех других объектов. Порядковый номер высказывания символизирует здесь конкатенацию всех признаков объекта ц он может рассматриваться в качестве указателя связи между ними.
Если обозначить через 5 указатель связи между признаками, через R — наименование признака (указатель роли), а через X — значение признака, то высказывание может быть представлено последовательностью триад вида
5»Я2Х2, 5,ЛПХЛ (1.3)
с одним и тем же указателем связи St. Запись вида SiRjXh читается следующим образом: понятие (актант) Xh выступает в высказывании Si в функциональной роли Яг. Это же высказывание может быть представлено и в анкетной форме;
№ RiX*........RnXnt (1.4)
если условиться, что его элементы будут располагаться рядом (контактно), а между записями различных высказываний будут стоять разделительные признаки (в различных высказываниях количество признаков может быть различным). Наконец, если описываемые объекты однородны и могут быть охарактеризованы одним и тем же набором наименований признаков 2?i, Я2, ..Rn, то, закрепив за этими наименованиями определенные позиции, можно представить высказывание (1.4) в виде записи
Хь Х2, ..., Хп. (1.5)
Как уже указывалось, такая структура называется позиционной, и она широко применяется на практике.
Популярной формой представления формализованной информации в позиционном формате являются двумерные таблицы. В таких таблицах в качестве наименований граф используются обобщенные наименования объектов учета и наименования их признаков. В графах записываются наименования конкретных объектов и соответствующие этим объектам значения характеристик (числовые или текстовые). Иногда наименования объектов и наименования характеристик группируются по их смысловой близости и для групп, связанных по смыслу элементов указываются наименования соответствующих обобщенных объектов и характеристик. Смысловые связи между конкретными и обобщенными объектами и характеристиками обычно представляют собой связи типа вид — род или часть — целое.
Образец двумерной информационной таблицы (без группировки объектов и характеристик по смысловой близости) показан в табл. 1.1. Здесь символом х обозначены объекты учета, символом у — характеристики, а символом z — значения характеристик. Каж
10
дая строка таблицы содержит сведения о характеристиках одного объекта. Характеристики представлены их значениями z. Смысловая функция этих значений уточняется в наименованиях граф. Таким образом, двумерную информационную таблицу можно рассматривать как множество высказываний, а форму этой таблицы—как высказывательную форму (многоместный предикат). Синтагматические связи между понятиями здесь, как и в высказываниях тппа (1.2), выражены позиционными средствами — путем
Таблица 1.1
X У1 Уз Уп
ZU Z12 •. • z In
*2 Z21 -22 ... z2n
• • • •
• • • • •
« • а •
хт zml zm2 • • • zmn
совместного контактного расположения (в одной строке таблицы) кодов понятий и закрепления за их позициями определенной функциональной роли. Функциональная роль позиций обозначена в наименованиях граф таблицы.
Более общий вид двумерной информационной таблицы показан в табл. 1.2. Ее строки обозначены символами указателей связи
Таблица 1.2
Я1 Яз Я„
^1 ^12 . . . Xln
52 21 X 22 X23 ... ^2n
♦ • • • •
• • • •
• • • •
5„_ ТП % m2 Xm3 ... V mn
5Ь 5:, ..., столбцы — символами указателей роли ••• Z?n, а на пересечении строк и столбцов записаны коды понятий
Л\;(/ — 1, 2, ..., т\ / = 1,2, .... n). t
Каждой строке таблицы соответствует одно высказывание.
И
В практике автоматической обработки информации используется представление сведений в виде массивов записей. Каждая запись состоит из нескольких участков (полей), па которых размещаются буквенные и числовые коды понятий. Количество полей в записях может быть постоянным или изменяться от записи к записи. Соответственно этому и форматы записей могут быть постоянными или переменными. В записях постоянного формата функциональная роль понятий выражается позиционными средствами (путем закрепления за каждым полем определенного смысла), в записях переменного формата — с помощью специальных кодовых комбинаций (ключевых слов, указателей роли и т. п.). Записи постоянного формата являются записями позиционной структуры, а записи переменного формата — записями анкетной структуры.
Массив записей позиционной структуры можно рассматривать в качестве линейной построчной развертки двумерной информационной таблицы. Применительно к условным обозначениям табл. 1.2 такая развертка будет иметь вид
*12.....
9 = Т X V
ml' Лт2’ mn*
Если записи имеют одинаковую длину, то границы между ними легко распознаются, и указатели связи 52, ..., Sm, становятся избыточными символами. Если они имеют переменную длину, то для распознавания границ необходимы разделительные признаки.
Массив записей анкетной структуры также может быть получен путем линейной развертки табл. 1.2. Для обозначения функциональной роли понятий здесь целесообразно применять указатели роли. После линейной развертки табл. 1.2 массив записей будет иметь вид
л2х12,
•••• (17)
^m^^i^mi' R ш2, ..., ЛпХтп,
Если часть клеток таблицы не заполнена кодами‘понятий, то для различения границ записей необходимы разделительные признаки.
Наконец, табл. 1.2 может быть представлена в линейной развертке в виде последовательности элементарных триад
8^Хп, ЗДЛЪ, ..., SJ^Xu, ..., SfliRnXmn, ’ (1.8)
12
Элементы S, R, X в линейных развертках (1.6), (1.7), (1.8) могут выражаться буквенными кодами их наименований или порядковыми номерами этих наименований по словарю. Для ускорения процессов формирования массивов информации, их обновления и поиска могут применяться ассоциативно-адресные структуры, т. е. такие структуры, в которых элементы сообщений связаны между собой адресными отсылками. Каждая из линейных разверток табл. 1.2 может быть представлена в виде ассоциативно-адресной структуры.
Структуры (1.6), (1.7), (1.8) легко преобразуются друг в друга. Для перехода от структуры (1.6) к структуре (1.7) необходимо записать в структуре (1.G) перед каждым кодом понятия Хц соответствующий указатель роли R} (указатели роли берутся из описания формата массива (1.6)); для перехода от структуры (1.6) к структуре (1.8) нужно записать перед каждым кодом понятия Xi} указатель роли Ri и указатель связи для перехода от структуры (1.7) к структуре (1.8) следует записать перед парами кодов вида RjXij соответствующие указатели связи Si.
Обратный переход от структуры (1.8) к структурам (1.7) и (1.6) осуществляется путем группировки триад в массиве (1.8) по признакам S *и R и вынесения этих признаков «за скобки». Причем при переходе от структуры (1.8) к структуре (1.7) «за скобки» выносятся только элементы 5, а при переходе от структуры (1.8) к структуре (1.6) — элементы S и R.
На входе ЭВМ, как и в ее памяти, массивы формализованных сообщений могут иметь одну из структур (1.6), (1.7) или (1.8) или представляться в виде сочетаний этих структур. Структура (1.6) применяется в тех случаях, когда входные документы имеют форму таблиц или анкет с фиксированными перечнями наименований характеристик. В память ЭВМ вводятся перечни наименований характеристик (перечни указателей роли), элементы X и разделительные знаки. Необходимость в разделительных знаках возникает в тех случаях, когда коды элементов X и строки из этих элементов имеют переменную длину.
Структуры (1.7) и (1.8) могут применяться для ввода в ЭВМ такой формализованной информации, для которой формы входных документов заранее не определяются. По их можно применять и для ввода информации по регламентированным формам входных документов, если переход от структуры (1.6) к структурам (1.7) (1.8) предусмотреть в правилах переноса этой информации на машинные носители (например, в правилах перфорации).
Сочетание позиционной и анкетной структур (структур типа (1.6) и (1.7)) может применяться для ввода в ЭВМ или храпения информации в ее памяти в тех случаях, когда объекты (ситуации) характеризуются одновременно постоянными и переменны
13
ми наборами признаков. Тогда наборы постоянных признаков целесообразно представлять в виде позиционной структуры, а переменных — в виде анкетной.
Выдача информации из ЭВМ может осуществляться также в виде структур (1.6), (1.7) или (1.8). При этом структура (1.6) применяется для выдачи информации в табличной форме, а структуры (1.7) и (1.8)—в анкетной форме и в форме элементарных
триад.
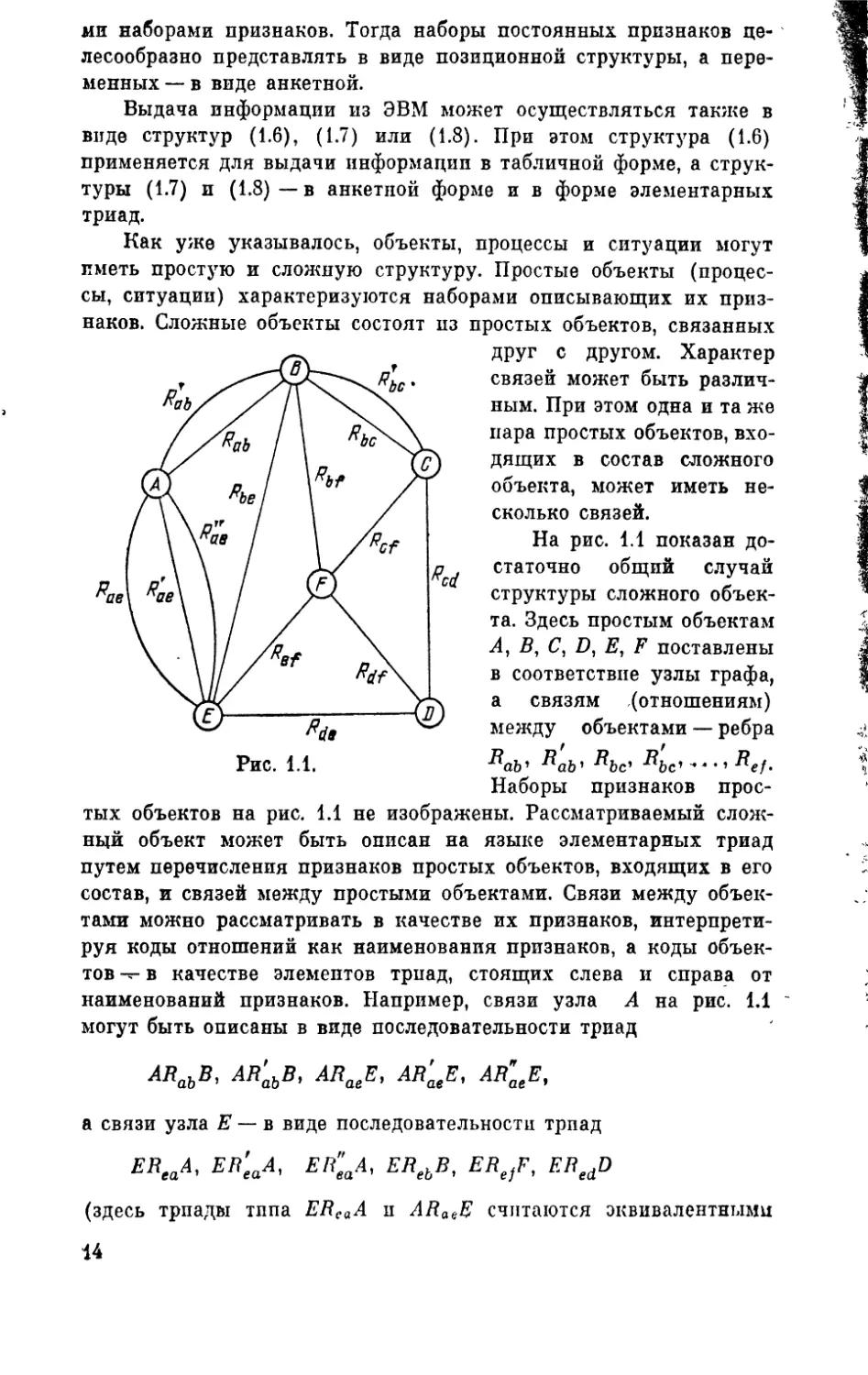
Рис. 1.1.
Как уже указывалось, объекты, процессы и ситуации могут иметь простую и сложную структуру. Простые объекты (процессы, ситуации) характеризуются наборами описывающих их признаков. Сложные объекты состоят из простых объектов, связанных
друг с другом. Характер связей может быть различным. При этом одна и та же пара простых объектов, входящих в состав сложного объекта, может иметь несколько связей.
На рис. 1.1 показан достаточно общий случай структуры сложного объекта. Здесь простым объектам А, В, С, D, В, F поставлены в соответствие узлы графа, а связям (отношениям) между объектами — ребра
R(ib' Rab' Rbc' ^bc'> - л •1 ^ef-Наборы признаков прос
тых объектов на рис. 1.1 не изображены. Рассматриваемый сложный объект может быть описан на языке элементарных триад путем перечисления признаков простых объектов, входящих в его состав, и связей между простыми объектами. Связи между объек
тами можно рассматривать в качестве их признаков, интерпретируя коды отношений как наименования признаков, а коды объек
тов — в качестве элементов триад, стоящих слева и справа от наименований признаков. Например, связи узла А на рис. 1.1 могут быть описаны в виде последовательности триад
ARabB, AR'abB, ARaeE, AR’aeE, AR^E,
а связи узла Е — в виде последовательности триад
ЕВеаА, ER’aA, ER"aA, ERebB, ERe)F, ERedD
(здесь триады типа EReaA п ARa6E считаются эквивалентными
по смыслу). В анкетной форме указанные связи могут быть описаны следующим образом:
V- R'abB, RaeE, R'aeE, RnaeE ReaA, R'eaA, R“aA, RebB, Re)F, RedD
(для узла A), (для узла
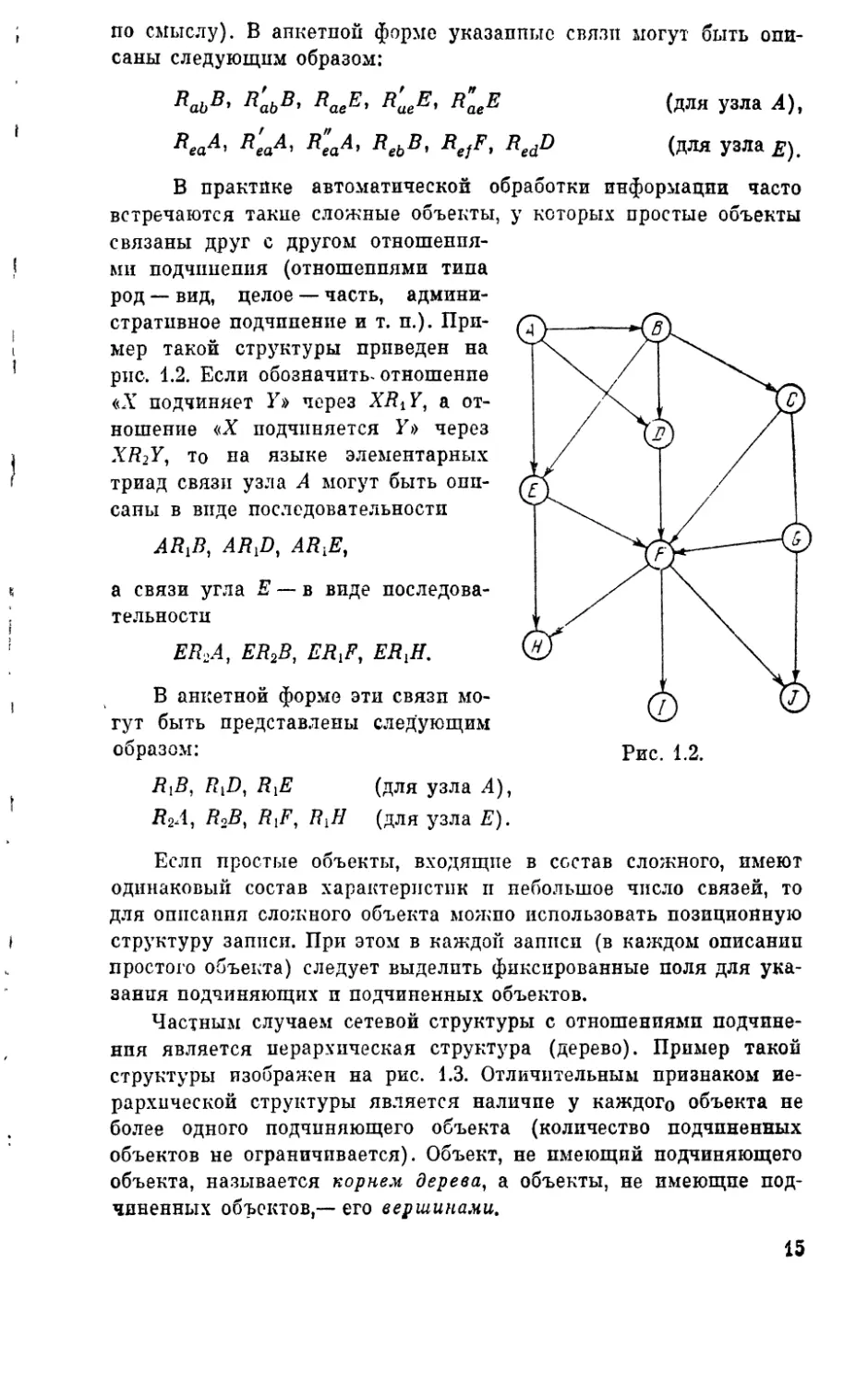
В практике автоматической обработки информации часто встречаются такие сложные объекты, у которых простые объекты
связаны друг с другом отношениями подчинения (отношениями типа
род — вид, целое — часть, административное подчинение и т. п.). Пример такой структуры приведен на рис. 1.2. Если обозначить-отношение «X подчиняет К» через XRiY, а отношение «X подчиняется У» через ХТ?2У, то на языке элементарных триад связи узла А могут быть описаны в виде последовательности
ARJ1, ARJ), ARLE,
а связи угла Е ~ в виде последовательности
er2a, er2b, er{f, erjl
В анкетной форме эти связи могут быть представлены следующим образом:
R,B, R{D, RXE
(для узла А),
Я2Л, R2B, RiF, RJ1 (для узла Е).
Еслп простые объекты, входящие в состав сложного, имеют одинаковый состав характеристик и небольшое число связей, то для описания сложного объекта можно использовать позиционную структуру записи. При этом в каждой записи (в каждом описании простого объекта) следует выделить фиксированные поля для указания подчиняющих и подчиненных объектов.
Частным случаем сетевой структуры с отношениями подчинения является иерархическая структура (дерево). Пример такой структуры изображен на рис. 1.3. Отличительным признаком иерархической структуры является наличие у каждого объекта не более одного подчиняющего объекта (количество подчиненных объектов не ограничивается). Объект, не имеющий подчиняющего объекта, называется корнем дерева, а объекты, не имеющие подчиненных объектов,— его вершинами.
15
Иногда иерархическими называют также структуры, в составе которых содержатся объекты с двумя и более подчиненными объектами. Это — структуры со слабой иерархией. Иерархическая структура может быть описана на языке элементарных триад, в анкетной или в позиционной форме по тем же правилам, что и сетевая структура, изображенная на рис. 1.2. При этом для каждого объекта (узла дерева) должны быть указаны все его признаки и все связи с другими объектами.
Способ описания сложных объектов по узлам (пообъектно) является универсальным, и он применим к структурам произвольной конфигурации. Но при этом каждая связь между объектами
Рис. 1.3.
отображается дважды. Этого можно избежать, если отмечать связи и исключать их из описаний тех узлов, у которых они встречаются повторно. В сетевых структурах с отношениями подчинения и в иерархических структурах нет необходимости отмечать связи. Здесь достаточно условиться, что при описании простых объектов фиксируются только их связи с подчиняющими объектами или только о подчиненными объектами, и требование однократного отображения связей будет выполнено.
При описании связей простых объектов в иерархических структурах можно обойтись одним или двумя элементарными сообщениями на каждый объект: одним — в случае отображения связей только с подчиняющими объектами, двумя — только с подчиненными. Последнее возможно несмотря на наличие у объектов переменного числа связей с подчиненными им объектами. Это достигается с помощью следующего приема. У каждого объекта фиксируется связь только с одним ив подчиненных ему объектов и с «соседом» — с одним из объектов, непосредственно подчиненных тому же «хозяину», что и описываемый объект. Далее у «соседа» аналогичным образом фиксируется связь с одним из подчиненных 16
ему объектов и с другим «соседом» и т. д., пока не будет исчерпана вся группа объектов, непосредственно подчиненных одному «хозяину». У последнего «соседа» в группе вместо связи к очередному «соседу» указывается признак конца группы. Признак конца указывается также в том случае, когда у описываемого объекта нет ни одного подчиненного ему объекта. Описание иерархических структур ведется по уровням подчинения сверху вниз, а в пределах каждого уровня — слева направо по группам объектов, подчиненных одному «хозяину».
Обозначим связь между объектами «сверху вниз» символом связь «от соседа к соседу» — символом Я2, признак отсутствия подчиненного объекта или «соседа» — символом 0 (нуль). Тогда, используя язык элементарных триад, связи между объектами на рис. 1.3 можно описать следующим образом:
AR\B, AR& BRiE, BR2C, CR{G, CRJ),
DR'H, DR20, ERxK, ER2F, FR2L, FR20,
GRfi, GR20, HRiN, HR2I, W, IR2J,
JRlP1 JR20, KRfi, M20, LR.R, LR2M, (1.9)
MRfi, MR20, NRfi, NR2O, OR.S, OR&
PRfl, PR2Q, QRfi, QR20, RRfi, RR£,
SR]Qt SR20.
Постоянство числа связей, отображаемых в описаниях простых объектов, имеет значение при использовании позиционных форматов представления данных. Если при этом наряду со связями «вниз» требуется отображать еще и связи «вверх», то в описания объектов следует добавить еще по одному элементарному сообщению.
В предыдущем изложении мы показали, какпц образом можно сократить число связей, отображаемых при описании иерархических структур. Однако сокращение числа связей приводит лпбо к усложнению процедур поиска информации, либо к ограничению их логических возможностей. Поэтому в ряде случаев не только не стремятся сократить число связей, а, наоборот, стараются отобразить их с максимальной полнотой. Например, на рис. 1.3, наряду со связями AR{B, BR{E, можно было бы указать также связи подчинения AR{E, AR{K, являющиеся следствием первоначально заданных. В целом, если учесть все производные связи между объектами рис. 1.3, то вместо 18 исходных связей окажется 44 (в среднем по 2—3 связи на объект).
Сведения об объектах, процессах или ситуациях (будем в дальнейшем называть эти предметы нашего рассмотрения обобщенным именем объекты) объединяются в автоматизированных информационных системах в массивы (другое название этих объедине-нпй — файлы). Каждый массив можно рассматрвать как пнформа-
2 Г. Г. Белоногов, Б А. Кузнецов
17
цпонное отображение одного сложного объекта, в состав которого входит множество составляющих его простых и сложных объектов. Массиву может быть присвоено уникальное имя (цифровое, буквенно-цифровое илп текстовое обозначение) илп/п набор характеризующих его признаков (в том числе индексов какого-либо классификатора). Эти признаки могут представлять собой обобщенное выражение признаков описываемых в массиве объектов, но они могут быть и независимы от них. Последнее обстоятельство является частным проявлением эмержентных свойств сложных систем, согласно которым характеристики таких систем не могут быть полностью определены на основе знаний только о характеристиках составляющих их объектов и связей между этими объектами — необходимы еще и сведения о сложных системах как о целостных объектах.
Связи между объектами, входящими в состав массива, могут носить различный характер. В общем случае они образуют сетевую структуру. Но если даже отношения между объектами отображаются в массиве слабо, то, как минимум, всегда фиксируется принадлежность этих объектов к массиву (самим фактом их включения в массив).
Массивы, как целостные объекты, характеризуются не только наборами собственных признаков, но и отношениями с другими массивами, хранящимися в автоматизированных информационных системах. Посредством этих отношений они могут объединяться в более сложные структуры — системы массивов, которые, в свою очередь, могут рассматриваться как сложные объекты. Системы массивов могут описываться в позиционной, анкетной или трпад-ной форме,
1.2. Структуры данных в банках данных
В последние годы большую популярность приобрела идея построения банков данных для систем автоматической обработки информации. Под банком данных понимают совокупность информационных массивов (базы данных) и средств общения с этими массивами (языковых и программных). Основное назначение банков данных — обеспечить безызбыточное хранение информации и доступ к ней различных категорий пользователей. Под безызбыточ-ным понимается такое хранение информации, когда исключается дублирование одних и тех же сведений в различных массивах и все сведения объединяются в единую систему под общим управлением. Поскольку для решения различных задач может потребоваться различный состав и структура исходной информации, то провозглашается принцип независимости структур данных в базе данных от пользовательских программ, а структуры, необходимые
18
пользователям, формируются автоматически программными средствами банка данных.
В системах обработки информации требуется обеспечить независимость программ как от изменении логической структуры данных, так и от изменений их физической структуры. Включение в массивы дополнительных признаков объектов, изъятие из них признаков и обновление информации об объектах не должно приводить к изменениям ранее составленных программ. Тем более не должны оказывать влияния на прикладные программы любые изменения в физической структуре данных (изменения, связанные с модификацией способов представления данных и их перезаписью с одних носителей на другие).
Важное значение придается также принципу независимости логической структуры данных от физической, реализация которого позволяет оградить пользователя (разработчика прикладной программы или человека, работающего на терминале) от необходимости знать физическую структуру данных. Более того, пользователь может не знать в полном объеме и логическую структуру данных (она известна лишь администратору баз данных). Тем не менее, основываясь на своих собственных представлениях о структуре данных, он может решать необходимые ему информационные и расчетные задачи. Переход от логической структуры базы данных к структуре, необходимой пользователю, выполняется автоматически с помощью системы управления базами данных.
В состав концепции банка данных входит также принцип разграничения доступа к информации. Этот принцип позволяет повысить ответственность должностных лиц за целостность баз данных и их поддержание в актуальном состоянии, обеспечивает соблюдение установленного порядка использования данных.
Концепция банка данных направлена прежде всего на централизацию процессов управления данными в сложных вычислительных системах, на уменьшение трудозатрат, связанных с их подготовкой и обновлением, и на обеспечение информационной и лингвистической совместимости прикладных программ.
Существуют различные подходы к построению банков данных. Зарубежные работы в этой области ведутся в трех основных направлениях: 1) в направлении, определенном рабочей группой по базам данных Комитета КОДАСИЛ; 2) в направлении, сформулированном авторами системы ИМС фирмы ИБМ; 3) в направлении, сформулированном американским ученым Е. Ф. Код дом и получившем название реляционная модель баз данных. Все три направления признают перечисленные выше принципы построения банков данных, но предлагают различные способы их реализации и различные языковые срества управления данными. Все они базируются на форматированном представлении информации [30, 50].
2*
19
Концепции рабочей группы по базам данным Комитета КОДАСИЛ и авторов системы ИМС во многом близки друг к дру< гу, но в системе ИМС последовательно проводится принцип иерархического построения структур данных, а система КОДАСИЛ ориентируется преимущественно на сетевые структуры данных.
Основной единицей хранения и выборки информации в иерархических системах является запись позиционной структуры (в системе ИМС она носит название сегмента). В записи указываются признаки одного простого объекта. Каждой записи может быть подчинено несколько других записей, которым, в свою очередь, могут быть также подчинены другие записи и т. д. Таким образом, может быть построено многоуровневое иерархическое дерево сегментов. При поиске информации корневой сегмент дерева идентифицируется значением своего ключевого признака, а остальные сегменты — перечнями значений своих ключевых признаков и ключевых признаков всех подчиняющих их сегментов. Поиск ведется, начиная от корневого сегмента «сверху вниз» и «слева направо», пока не будет найден и идентифицирован искомый сегмент.
В сетевых структурах основной единицей храпения и выборки информации также является запись позиционного типа, но здесь связи могут носить более сложный характер: каждая запись может иметь по несколько подчиненных и подчиняющих ее записей (в иерархических структурах каждая запись может иметь не более одной подчиняющей записи). В системах иерархической и сетевой структуры в одном массиве обычно хранятся описания сложных объектов одного типа. Тип сложного объекта определяется перечнями наименований признаков простых объектов, входящих в его состав, и указанием связей между простыми объектами. Конкретный экземпляр сложного объекта задается перечнями значений признаков всех его простых объектов.
Структуры данных, предлагаемые Комитетом КОДАСИЛ и авторами системы ПМС, обладают широкими логическими возможностями, но они недостаточно наглядны. По существу, в этих системах не удалось полностью отделить логическую структуру данных от физической, что побудило ряд исследователей и, прежде всего, Е. Ф. Кодда к поиску более простых и наглядных способов описания структур данных. В своей основополагающей работе «Реляционная модель данных для больших банков данных коллективного пользования» [79] Е. Ф. Кодд предлагает полностью отделить логическую структуру данных от физической и в максимальной степени ее упростить. Он справедливо указывает, что пользователь информации должен быть огражден от необходимости знать ее физическую структуру.
В качестве универсальной модели, ориентированной на пользователей-непрограммистов, Е. Ф. Кодд предлагает использовать ре-
20
яяцпонную модель, в которой массивы форматированной информа* ции интерпретируются как отношения. Каждое отношение может быть представлено в впде двумерной таблицы с поименованными графами. В графах указываются значения признаков, характеризующих объекты, учитываемые в информационной системе. Е. Ф. Кодд утверждает, что любая структура данных (линейная, иерархическая, сетевая) может быть представлена в впде совокупности таблиц — в нормальной форме. При этом связи между объектами фиксируются как значения соответствующих признаков.
В работах Е. Ф. Кодда и его последователей [30, 79 ,80, 81] вводятся четыре разновидности нормальной формы, отличающиеся друг от друга характером функциональных связей между признаками. Так, отношение (массив) считается находящимся в первой нормальной форме, если оно представлено в виде двумерной таблицы и содержит только атомарные (неделимые) значения. При этом никаких ограничений на характер функциональных связей между признаками не накладывается. Отношение считается находящимся во второй нормальной форме, если оно представлено в табличной форме и если епаченпя всех его неключевых признаков являются функциями ключевых признаков (а также сочетаний ключевых признаков, если объекты идентифицируются такими сочетаниями). Для отношений, находящихся в третьей нормальной форме, требуется дополнительно, чтобы у них отсутствовали транзитивные функциональные связи неключевых признаков от ключевых. На отношения в четвертой нормальной форме накладываются ограничения, связанные с так называемой многозначной зависимостью признаков, когда в роли зависимого от некоторого элемента может выступать не единственный строго детерминированный элемент, а один из элементов заданной группы. Отношение находится в четвертой нормальной форме тогда и только тогда, когда при существовании в этом отношении многозначной зависимости некоторого признака В от признака А все другие признаки этого отношения функционально зависят тоже от А [30].
Третья и четвертая нормальные формы рекомендуются для практического использования в реляционных базах данных, поскольку они по мысли их авторов позволяют избежать логически противоречивых ситуаций при вводе и обновлении информации. Первая и вторая нормальные формы являются промежуточными при переходе к третьей и четвертой формам. Переход осуществляется с помощью операции «проекция», описываемой во второй главе настоящей книги.
Реляционная модель Е. Ф. Кодда представляет собой первую серьезную попытку создания математической теории структур данных. На ее основе можно исследовать закономерности, имеющие место в этих структурах, и осуществлять оптимизацию структур.
21
Эта концепция является более перспективной, чем концепции Комитета КОДАСИЛ и авторов системы ИМС. Вместе с тем следует отметить, что рассмотренные выше три модели данных в большей мере отражают различные методы доступа к информации, чем ее логическую структуру. В логическом отношении они эквивалентны и могут быть преобразованы друг в друга. Неудовлетворительность этих моделей отмечает, в частности, Г. М. Нийсен [96]. Он пишет: «Анализ основных идейных направлений современных публикаций по вопросам управления базами данных показывает, что уровень зрелости в этой области еще невысок. Исследователи еще слишком заняты рассмотрением идеологии Комитета КОДАСИЛ, иерархических систем и нормализованных реляционных моделей... Общепринятая объединяющая концепция пока отсутствует.
С другой стороны, имеется ряд публикаций, вселяющих надежду на создание более зрелой и устойчивой теории управления базами данных. Поэтому разумно предполагать, что следующее поколение систем управления базами данных будет создано на более совершенной концептуальной основе, чем современные системы» (Перевод Белоногова Г. Г.)»
На наш взгляд этой более совершенной объединяющей концептуальной основой могла бы явиться концепция предикатно-актантной структуры, в рамках которой идеологию Комитета КОДАСИЛ, иерархических систем и нормализованных реляционных моделей можно интерпретировать как частные случаи.
Термин реляционная модель баз данных, применяемый для обозначения модели Е. Ф. Кодда, не вполне корректен, так как отношения (relation) между элементами данных имеют место во всех без исключения информационных системах. Речь может идти не о наличии или отсутствии таких отношений в тех или иных системах, а лишь о различных способах их представления. Поэтому модель Е. Ф. Кодда правильнее было бы назвать нормализованная реляционная модель баз данных, как предлагает Г. М. Нийсен [96], а не так, как это обычно принято. Да и понятие нормализации необязательно связывать с табличной формой представления информации. Ведь в эквивалентных ей анкетной и триадной формах также имеется возможность выражать связи между объектами через значения признаков. Кроме того, там есть еще и возможность хранить в одном массиве сведения об объектах различной структуры (что недопустимо в модели Е. Ф. Кодда) и оперативно изменять состав хранимой информации без изменения структуры массивов в целом.
Рассматривая логическую структуру данных и концепцию банка данных, мы, по существу, рассматривали и логическую структуру формализованных информационных языков. Формализованные языки создаются на базе естественных языков путем нало
22
жения ограничений па их лексику п грамматику, а также путем применения специальных обозначений для элементов этих языков. Формализованных информационных языков известно очень много. В конце 60-х годов их насчитывалось около сотни. В настоящее время их значительно больше. Назовем некоторые из них: Универсальная Десятичная Классификация (УДК), Библиотечно-библиографическая Классификация (ББК), Международная Классификация Изобретений (MKII), Рубрикатор Государственной Автоматизированной Системы Научно-технической Информации (ГАСНТИ), синтол (язык, разработанный французскими учеными Р. К. Кроссом, Ж. К. Гардэном и Ф. Леви [43]), язык ЯХ-кодов (разработан Э. Ф. Скороходько и возглавляемой им группой), язык объектно-характеристических таблиц (ОХТ) [40], языки анкетного типа, различные разновидности дескрипторных языков, языки стандартных фраз и т. д. и т. п. Некоторые пз этих языков мы более подробно будем рассматривать в гл. 3. Здесь же кратко охарактеризуем язык ЯХ-кодов, синтол, языки классификационного и дескрипторного типов.
Язык ЯХ-кодов первоначально предназначался для описания документов по электронике и вычислительной технике, но вскоре выяснилось, что его структура является достаточно общей и он может быть использован в любой другой предметной области. Основными элементами языка являются термины X, обозначающие объекты (конкретные или абстрактные), и релатемы R, обозначающие бинарные отношения между объектами. С помощью терминов и ре-латем строятся предложения, описывающие те или иные ситуации. Простейшие предложения имеют структуру типа
X, = ад, ад, .... RnXn.
Нетрудно видет, что это анкетная структура, в которой символы X обозначают коды понятий, а символы R — их функциональную роль в предложении (см. структуру 1.4). Подставляя вместо кодов понятий их определения, аналогичные определению понятия Хг. можно описывать сложные иерархические структуры объектов. Наряду с анкетной, в языке 7?Х-кодов используется и триадная форма представления высказываний (выражения типа Х^Х*).
Триадная форма используется также в языке синтол [43]. В этом языке высказывания представляются в виде цепочек элементарных синтагм типа Л»,а, Ь, где а и Ъ — дескрипторы, a Ri — название конкретного отношения между ними. В синтоле элементарные синтагмы применяются не только для отображения синтагматических (ситуационных) отношений между понятиями, но и парадигматических отношений между ними — устойчивых внекон-текстных отношений типа целое — часть, род — вид и т. п. В предисловии к книге авторы подчеркивают, что «...синтол — это не про
23
сто язык в собственном смысле слова, для определения которого достаточно указать некоторый словарь п/плп грамматику, но скорее логико-лингвистические рамки, в которые укладывается большинство информационных языков, независимо от их разработанности и области применения» (см. [43], с. 6).
Важным элементом информационного обеспечения АСУ являются классификаторы. Они играют двоякую роль: с одной стороны, служат для однозначного кодирования объектов (в отличие от имен на естественном языке), с другой стороны, несут информацию о наиболее существенных признаках объектов. В качестве объектов классификации могут выступать как конкретные объекты, так и абстрактные. Классификационные коды обычно оформляются в виде позиционных структур, а для кодирования значений признаков классификации используются цифры, буквы или буквенно-цифровые обозначения. Мы будем в дальнейшем рассматривать лишь цифровые классификационные коды, тем более, что в памяти ЭВМ различие между цифровыми и буквенными кодами весьма условно.
В автоматизированных информационных системах чаще всего применяются иерархическая и фасетная классификация объектов пли их сочетание. В случае иерархической классификации исходное множество объектов последовательно делится на классы, которым присваиваются порядковые номера. При этом на каждом этапе деления и для каждого классифицируемого множества могут применяться свои классификационные признаки и своя независимая нумерация классов. Классификационный код объекта представляет собой сочетание номеров классов, полученных па различных этапах деления. В качестве примера иерархической структуры кода может служить структура, используемая в универсальной десятичной классификации (УДК).
В случае фасетной классификации деление исходного множества объектов на классы осуществляется независимо по всем выбранным признакам (фасетам). Для каждого признака в структуре кода отводится строго фиксированный участок, а значения признаков кодируются их порядковыми номерами по соответствующим словарям (число словарей равно числу признаков классификации). Эта структура аналогична базовой структуре (1.5).
В документальных информационно-поисковых системах широко используются дескрипторные языки [53, 62, 69]. Они применяются в различных вариантах. Наиболее популярным из них является так называемый язык без грамматики. На этом языке каждый документ представляется своим формализованным описанием (поисковым образом), состоящим из его регистрационного номера и перечня номеров дескрипторов пли их наименований, характеризующих содержание документа. Наименования дескрипторов могут выражаться отдельными словами и словосочетаниями. Описания
24
документов отделяются друг от друга разделительными признаками. В этом простейшем дескрипторном языке присутствуют все компоненты элементарных триад — коды понятий, указатели роли и указатели связи. Коды понятий представлены здесь номерами документов и номерами дескрипторов; их функциональная роль в формализованных описаниях («быть номером документа», «быть номером дескриптора») — позиционными средствами (номер документа указывается в начале каждого поискового образа, а номера дескрипторов — на следующих позициях); связь между понятиями, описывающими один и тот же документ,— позиционными средствами (контактным расположением их кодов) и с помощью разделительных признаков, обозначающих границы поисковых образов.
Следует еще раз подчеркнуть, что в основе всех формализованных информационных языков лежит предикатно-актантная структура. Элементы этой структуры в разных языках кодируются по-разному: одни из них — позиционными средствами, другие — с помощью комбинаций символов алфавита. Если дано описание структуры языков, то в принципе возможен автоматический перевод информации с одних языков на другие (ее автоматическое конвертирование). При этом изобразительные средства языка, на который осуществляется перевод, не должны быть беднее, чем изобразительные средства входного языка (в противном случае возможна потеря части информации). Теоретической основой для конвертирования формализованной информации является наличие в ней такого инварианта, как предикатно-актантная структура.
1.3. Структура естественных языков
Как уже указывалось, в системах автоматической обработки информации широко используются естественные языки или их эле* менты. Единицами естественного языка являются морфемы, слова, словосочетания, фразы, сверхфразовые единства. Эти единицы могут вступать друг с другом в синтагматические (контекстуальные) и парадигматические (устойчивые внеконтекстные) отношения. Такие отношения всегда имеют место, и с их наличием необходимо считаться при поиске и обработке информации. Синтагматические и парадигматические отношения между единицами языка — такая же реальность, как и сами единицы. Более того, свойства этих единиц проявляются через их синтагматические и парадигматические отношения с другими единицами.
Единицы языка образуют иерархию (хотя и не в чистом виде): единицы более низкого уровня входят в состав единиц более высоких уровней (морфемы входят в состав слов, слова — в состав словосочетаний и т. д.). Свойства же единиц более высокого уровня не в полной мере определяются свойствамп единиц более низко
25
го уровня (хотя частично это и имеет место). В полной мере эти свойства определяются через всю систему синтагматических и парадигматических отношений в языке и речи — через систему этих отношений как между единицами одного и того же уровня, так и между единицами разных уровней.
При формализованном описании едпппц и структур естественных языков применяются различные методы, все они базируются на использовании предикатно-актантной структуры. Эта структура лежит, в частности, в основе так называемого компонентного анализа. Такие понятия, как семантические множители, семантические валентности, семантические падежи, семантические сети, концептуальные сети, по сути, являются вариациями понятия предикатноактантная структура. Разновидностью этого понятия можно считать и понятие фрейма, широко используемого в работах по искусственному интеллекту.
Существо компонентного анализа единиц языка в работе [35] определяется следующим образом: «Под компонентным анализом в широком смысле понимается такая последовательность процедур, которая, будучи применена к некоторым исходным речевым и/или языковым объектам, ставит в соответствие каждому такому объекту определенное множество (набор) семантических признаков, или иначе — компонентов. Такой набор будем называть компонентным представлением. Если мы пмеем дело не с представлением какой-то отдельной единицы, а сочетания единиц, то будем говорить о компонентном комплексе. Все множество простых компонентов, используемых при построении представлений, назовем алфавитом компонентов.
Конкретная методика всегда является разновидностью этого общего метода и определяется тем, к каким исходным объектам она применяется, каков логический статус соответствующих процедур, как много компонентов используется в описании и т. д.».
А несколько ранее, на с. 1 автор замечает: «Теория и практика компонентного анализа смысловой стороны языковых единиц являются одной из важнейших и в то же время дискуссионных областей современной лингвистической семантики. Между многочисленными подходами к этой проблеме наблюдаются порой весьма глубокие различия. Даже само название основного понятия данного метода меняется от автора к автору: семантический компонент, дифференциальный элемен^, семантический множитель, семантический признак, элементарное значение, атом смысла, сема, фигура плана содержания, основная единица значения, маркер, фактор, смысловая координата. Вот далеко не полный перечень бытующих в лингвистике имен центрального понятия компонентного анализа, не говоря уже о том, что ему может приписываться разный онтологический и гносеологический статус»,
26
Правда, на наш взгляд, между многочисленными подходами к проблеме компонентного анализа имеют место не такие уж глубокие различия, как это думает автор, но приведенный им перечень разных названий одного и того же явления весьма примечателен.
Чтобы раскрыть содержание понятия фрейма, нам представляется целесообразным процитировать его автора [54]: «Отправным моментом для данной теории служит тот факт, что человек, пытаясь познать новую для себя ситуацию или по-новому взглянуть на уже привычные вещи, выбирает из своей памяти некоторую структуру данных (образ), называемый нами фреймом, с таким расчетом, чтобы путем изменения в ней отдельных деталей сделать ее пригодной для понимания более широкого класса явлений или процессов.
Фрейм является структурой данных для представления стереотипной ситуации. С каждым фреймом ассоциирована информация разных видов. Одна ее часть указывает, каким образом следует использовать данный фрейм, другая — что предположительно может повлечь за собой его выполнение, третья — что следует предпринять, если эти ожидания не подтвердятся.
Фрейм можно представить себе в виде сети, состоящей из узлов и связей между ними. «Верхние уровни» фрейма четко определены, поскольку образованы такими понятиями, которые всегда справедливы по отношению к предполагаемой ситуации. На более низких уровнях имеется много особых вершин — терминалов пли «ячеек», которые должны быть заполнены характерными примерами или данными.
Каждым терминалом могут устанавливаться условия, которым должны удовлетворять его задания. Простые задания определяются маркерами, например, в виде требования, чтобы заданием терминала был какой-либо субъект или предмет подходящих размеров или указатель на субфрейм определенного типа. Более сложными условиями задаются отношения между понятиями, включенными в различные терминальные вершины.
Группы семантически близких друг к другу фреймов объединяются в систему фреймов».
Интересна конкретизация понятия фрейма в одной из работ по «интеллектуальным банкам данных» [27];
«Если аргументы предиката переменные, то, значит, имеется фрейм-образец, если аргументы — константы, следовательно, имеется подстановка фрейма, означающая высказывание, которое имеет истинностное значение в конкретной проблемной среде или в конкретной базе данных. Фрейм задается функцией, строящей замещения аргументов предиката константами из проблемной среды и означающей полученное высказывание. Истинное утверждение называется значением фрейма. Множество значений фрейма на-
27
вывается его расширением и хранится в банке данных в виде отношения».
И далее: «Связи между предикатами п его аргументами называются ролями, которые могут рассматриваться как понятийно простейшие отношения между участниками событий и действием, а также могут использоваться для ранжирования аргументов предиката. Роли указывают функцию каждого аргумента в предикате». Авторы далее осуществляют переход от конструкции семантической сети к реляционному банку данных и истолковывают понятие фрейма в терминах реляционной модели Е. Ф. Кодда.
Подводя итоги сказанному, можно утверждать, что наиболее общим видом формализованного описания сложных объектов является сетевая структура, в узлах которой помещены описания простых объектов, а узлы соединены друг с другом дугами, обозначающими отношения между простыми объектами. В составе сложных объектов могут быть выделены другие сложные объекты, которые, в свою очередь, также могут включать в свой состав сложные объекты. Таким образом, сложный объект может быть представлен в виде иерархии или сети входящих в его состав простых и сложных объектов. Такая иерархическая, или сетевая, структура может быть описана в виде линейной последовательности описаний всех ее узлов, где каждый узел представляется в виде конкатенации собственных признаков обозначаемого им объекта и признаков связи этого объекта с другими объектами. Конкатенация признаков может быть, в свою очередь, представлена в виде позиционной, анкетной или трпадной структуры или сочетания таких структур.
ГЛАВА 2
ОПЕРАЦИИ НАД МАССИВАМИ ДАННЫХ
В процессе функционирования автоматизированных информационных систем выполняются различные операции над массивами данных. Эти операции связаны с вводом информации в память ЭВМ, ее синтаксическим и семантическим контролем, пополнением, преобразованием формы представления, поиском, сортировкой, обобщением, документированием и др. Исходными данными для операций и результатом их выполнения являются формализовать ные описания объектов. Мы будем считать, что объекты любой сложности представляются в виде массивов описаний простых объектов в одной из трех эквивалентных форм — позиционной, анкетной и триадной. Тогда операции над массивами могут быть сведены к операциям над множествами формализованных описаний простых объектов.
Функционирование любой АИС начинается с ввода в нее информации, но нам удобно начать описание с операций поиска и сортировки, так как они используются в составе многих других операций (в том числе и операции ввода).
Поиск информации — это процесс отбора из массива множества описаний объектов, удовлетворяющих сформулированным в запросе условиям. При этом в качестве результатов поиска могут выдаваться не все признаки объектов, хранящиеся в массиве, а только часть их — в соответствии с условиями запроса. Объект может выбираться из массива по значению одного идентифицирующего его (ключевого) признака или по сочетанию значений нескольких ключевых признаков. Он может также выбираться по сочетанию значений любых других (неключевых) признаков, если это сочетание однозначно выделяет его из множества всех объектов массива.
Будем различать первичные и производные (в частности, обобщенные) признаки объектов. Первичные признаки назначаются при первоначальном описании объектов, а производные являются функциями первичных. Поиск может вестись как по первичным, так и по производным признакам.
29
Чаще всего в процессе поиска информации выбирается не один объект, а множество объектов. Оно может быть задано различными способами: 1) перечнем значений ключевых признаков или сочетаний ключевых признаков; 2) зпачеппем или интервалом (перечнем) значений одного неключевого признака; 3) булевой функцией значений или интервалов (перечней) значений любых признаков объекта (как ключевых, так и неключевых); 4) отношением между признаками, выраженным с помощью арифметических, логических операции (операций типа «и», «пли», «не») и отношений = , >, < и их отрицаний.
Условия выборки признаков у найденных объектов задаются в виде перечней наименований этих признаков.
Важной проблемой, возникающей при реализации процедур поиска информации, является проблема отождествления признаков объектов и установления парадигматических отношений между ними (отношений типа род —вид, целое —часть и др.). Общее решение этой проблемы связано с возможностью распознавания смыслового тождества и парадигматических отношений различных форм наименований понятий на основе их морфологического, синтаксического и семантического анализа. Но на практике широко применяются и более частные решения, основывающиеся на унификации формы представления наименований понятий и применении процедур маскирования, сканирования и усечения их кодов. Процедура маскирования заключается в выделении в составе кода его части, фиксированной по длине и по местоположению; сканирование — поиск в составе кода его заданной части независимо от ее местоположения; усечение — отделение от кода его начального или конечного участка (чаще всего применяется правое усечение слов, с целью отождествления их словоизменительных или словообразовательных вариантов).
Поиск информации может выполняться за один или за несколько шагов. В первом случае он ведется по одному запросу, во втором — по серии запросов. При многошаговом поиске возможны три основных способа организации процесса выполнения запросов:
Композиция запросов — запросы выполняются в строго определенной последовательности, а результаты поиска по предыдущему запросу попользуются в качестве исходных данных для следующего за ним запроса. При этом первый запрос в серии запросов определяется полностью, а остальные — не полностью и доопределяются в процессе поиска.
Объединение запросов — когда результаты поиска по нескольким запросам объединяются в одну общую выдачу.
Разветвление запросов — когда после выполнения очередного запроса есть возможность перехода к одному из нескольких запросов в зависимости от выполнения тех или иных условий. Перечне-
30
ленные способы выполнения запросов могут применяться в различных сочетаниях, что позволяет строить различные процедуры многошагового поиска.
Сортировка информации — это процесс размещения в памяти ЭВМ описаний объектов и входящих в их состав признаков в соответствии с заданным порядком следования. Описания объектов могут располагаться по возрастанию (убыванию) числовых значений или интервалов значений какого-либо признака, в алфавитном порядке его значений (если признак нечисловой) и в порядке, задаваемом списком значений признака. Описания объектов могут сортироваться также по сочетаниям значений двух, трех и т. д. признаков. При этом между признаками сортировки устанавливается отношение старшинства: сначала проводится сортировка по значениям первого (самого старшего) признака, затем — для фиксированных значений этого признака — по значениям второго признака, далее — для фиксированных сочетаний значений первого и второго признаков — по значениям третьего признака и т. д. Признаки в пределах каждого описания объекта также могут располагаться в заранее обусловленном порядке. Порядок следования признаков обычно задается перечнем их наименований.
Сортировка информации облегчает выполнение операций по ее поиску и обобщению. Она необходима также при форматировании информации перед ее выдачей на вход прикладной программы или на устройства отображения (видеотерминал, печатающее устройство и т. п.).
В практике использования автоматизированных информационных систем часто требуется выдавать по запросам не первичные сведения об объектах, а вторичные, обобщенные сведения, получаемые в результате решения информационных или расчетных задач.
Обобщение информации — это ее представление с помощью более широких понятий, чем при первоначальном вводе в ЭВМ. При этом создаются новые, обобщенные объекты, характеризуемые более общими признаками.
Различие между информационными и расчетными задачами весьма условное. II те, и другие можно считать информационными и расчетными: информационными — потому что речь идет о преобразовании и выдаче информации, а расчетными — потому что это преобразование проводится путем соответствующих вычислений. И все же такое различие целесообразно проводить, включив в состав информационных задач выдачу первичной информации по запросам потребителей и задачи, решаемые с помощью относительно простых вычислительных процедур (иапрпмер, учетно-ста-тпстических), а в состав расчетных задач — задачи, решаемые путем применения сложных математических методов.
3!
Учетно-статистические задачи — это задачи по обобщению информации. В процессе их решения на основе первичных сведений об объектах учета определяются обобщенные сведения (точнее, обобщенные признаки обобщенных объектов). Для этого из поисковых массивов по запросам выбираются сведения о первичных объектах, включаемых в состав обобщенных объектов, и вычисляются значения признаков обобщенных объектов. Наименования признаков этих объектов могут быть такими же, как и у первичных объектов, но могут быть и другими. Если наименования признаков сохраняются, то вычисление их значений сводится к суммированию значений признаков первичных объектов или к определению других простейших функций типа максимум, минимум, среднее значение и т. п. Если для обобщенных объектов необходимо получить обобщенные признаки, то сначала по заданным в запросе арифметическим выражениям вычисляются значения этих признаков для каждого первичного объекта, а затем над ними выполняются перечисленные выше операции.
Если необходимо выдать сведения не об одном, а о нескольких обобщенных объектах, то в общем случае для каждого из них следует сформулировать запрос на выборку первичных сведений и правила вычисления значений признаков. Но условие выдачи информации можно указать и в одном запросе, если отбор первичных сведений и вычисление характеристик для всех обобщенных объектов производится по одним и тем же правилам. Например, если для обобщенных объектов 0^ От можно выбрать первичные сведения по условию типа
(/71, П2..Z7r), (2.1)
где /Л, Z72, ..., Пг~ признаки, 9 — булева функция этих признаков, и сгруппировать эти сведения по значениям ai, а2,..ат одного и того же признака Л, и, кроме того, если для всех обобщенных объектов нужно выдавать значения одних и тех же признаков X, У, ..., РУ, то предписание на выдачу информация можно сформулировать следующим образом;
Найти Si (271, ZT2, ..., Пг)1
выдать для А == а{, a2l ..., ат СУМ X, У, ..., W,
Здесь оператор СУМ указывает на необходимость суммирования значений признаков X, У, ..., W первичных объектов для получения значений этпх же признаков обобщенных объектов. При этом сначала суммируются значения признаков X, У, ..W для Л затем для А = а2 и т. д.
Распределение первичных сведений по обобщенным объектам может производиться не по одному, а по нескольким признакам (например, по сочетаниям значений признаков Л, В, ..., L). Тогда
32
предписание на выдачу информации о группе обобщенных объектов будет иметь вид
Найти ©i(271, #2, Лг),
выдать для А == ah а2, ..аи1&, В = Ь2, ..bn&,
L = Zi, /2, ..ZA СУМ X, Y..W.
Признаки X, У, ..., W могут быть как первичными, так и производными. В последнем случае для вычисления каждого производного признака указывается соответствующее арифметическое выражение.
Если обработка информации ведется на основе применения сложных вычислительных процедур (решаются расчетные задачи), то порядок формирования для них массивов исходных данных может быть сохранен таким же, как и при решении учетностатистических задач, т. е. исходные данные могут выбираться по запросам типа (2.1). Но здесь обычно требуется дополнительное преобразование исходных данных к виду, удобному для расчетных задач. При этом регламентируется как порядок следования признаков первичных объектов, так и форма представления их значений. Необходимые преобразования выполняются с помощью специальных программ-интерфейсов. Программы-интерфейсы применяются также и для обратного преобразования результатов решения задач в базовое представление данных, принятое в автоматизированной информационной системе (если предполагается хранение этих результатов и их дальнейшее использование для решения других расчетных и информационных задач).
Важной функцией автоматизированной информационной системы является функция первоначального формирования и последующего пополнения и обновления массивов информации. При этом приходится выполнять поисковые операции, связанные с необходимостью идентификации сведений об объектах, поступающих на вход системы, и ранее введенных в нее сведений. Как уже указывалось, объекты можно идентифицировать по одному ключевому признаку (например, по их именам) или по нескольким признакам. В общем случае это может быть сложный признак типа (2.1).
Ввод информации в АИС можно рассматривать как процесс построения в памяти ЭВМ информационной модели некоторой совокупности объектов. Если объекты не изменяют своих свойств, то неизменной остается и их информационная модель. Если изменяют, то нужно отслеживать эти изменения и своевременно вносить необходимые коррективы (обновлять информацию).
Обновление информации может состоять в замене одних значений признаков объектов на другие, вводе новых признаков для ранее описанных объектов или новых описаний объектов, исключении признаков ранее описанных объектов или целых описаний
3 Г. Г. Белоногов, Б. А. Кузнецов
83
объектов. Операции по вводу, замене п исключению признаков могут выполняться как над единичными объектами, так и над группами объектов.
Процедуры ввода и обновления информации могут выполняться в сочетании с процедурами ее сортировки и обобщения. При этом первичные данные могут сохраняться или уничтожаться. Если, например, обновление носит характер частичных изменений числовых значений признаков, связанных с добавлением или вычитанием заданных величин, то постоянное хранение таких изменений обычно не требуется — достаточно хранить лишь конечный результат.
В числе операций над массивами важное место занимают теоретико-множественные операции объединения (U), пересечения (А) и разности массивов (\). Объединением массивов А и В называется массив Ci, содержащий в своем составе попарно-различные объект ты из массивов А и В (С\ — A U В). Пересечением массивов — массив С2, который включает в свой состав объекты, содержащиеся одновременно в массивах А и В (С2 = А А В). Разностью массивов— массив С3, который содержит объекты, входящие в состав массива А за вычетом объектов, входящих в состав массива В (С3 = А\В).
Перечисленные операции применяются при реорганизации массивов и при решении информационных и расчетных задач. По существу, они входят в состав процедур поиска, если условия поиска задаются в виде булевой функции признаков. Например, если поисковое предписание имеет вид
(A = ai \/В ==&;)&”! С > ck
— «найти объекты, у которых признак А имеет значение а{ или признак В имеет значение Ь, и у которых значение признака С не превосходит величину ср>, то сначала из массива выбираются и объединяются множества объектов со значениями признака А и bj признака В, затем из полученного множества вычитается множество объектов со значениями признака С, превосходящими величину ск. Но при поиске информации теоретико-множественные операции выполняются над подмассивами одного или нескольких массивов, тогда как выше речь шла об операциях над целыми массивами.
Родственными по отношению к теоретико-множественным операциям являются операции реляционной алгебры. Они позволяют осуществлять поиск информации в массивах и формирование описаний новых объектов на основе хранящихся в памяти ЭВМ описаний исходных объектов. Мы рассмотрим лишь две такие операции — операцию «проекция» (projection) и операцию «соединение» (join) [30, 79]. Первая операция применяется для выделения из
34
массивов попарно-различных кортежей значений признаков по заданным перечням наименований этих признаков, вторая — для объединения кортежей значений признаков в более длинные цепочки. При выполнении операции «проекция» указывается исходный массив и перечень признаков, на которые его необходимо спроектировать, при выполнении операции «соединение» —• два исходных массива и наименование признака, по значениям которого осуществляется их соединение.
Если, например, исходный массив для выполнения операции «проекция» задан табл. 2.1, где Л, В, С, В, Е — наименования признаков, а а, &, с, tZ, е — пх значения, и требуется спроектировать
Таблица 2.1 Таблица 2.2
А В С D Е в с Е
Ь{ С1 di *1 bi Cl Ч
«2 bl d2 е1 b-i С1 е2
Лз ^2 С1 ^2 *2 Ьз с2 с3
^4 Ьз с2 С3 bi с3 с4
«5 Ь% С1 *2 bl С1 е5
с3 С4
а7 Ъ1 С1 di С 5
этот массив на признаки В, С и В, то, выбирая из него попарно различные кортежи значений признаков В, С и В, мы получим табл. 2.2, которая и будет его проекцией на эти признаки.
Если требуется соединить массивы, заданные табл. 2.3 и 2.4 по значениям признака В, то после попарного объединения кортежей значений признаков из этих таблиц, содержащих одни и те же
Таблица 2.3 Таблица 2.4 Таблица 2.5
А BCD В E F А В C D E F
«1 bt Ci di bi ^1 bt C! di €1 fi
Ь2 ci d2 Ci /2 a2 b2 Ci d2 er /2
а3 bi c2 dt Ьз e2 /2 аз bi c2 di Ci fi
л2 b% C3 d3 . . - .. a2 b2 c3 d3 ei fi
а3 b3 Q d^ аз b3 c4 d4 e2 fi
“1 bi c5 d5 —
значения признака В, получим табл. 2.5, которая и будет соединением исходных массивов. При этом кортежи исходных массивов, у которых значение признака В не совпадает ни с одним значением этого признака в другом массиве, в результирующий массив не попадут (в таком положении оказался последний кортеж табл. 2.3). Операция соединения массивов может выполняться не только по значениям одного их общего признака, но и по сочетаниям значений признаков.
8*
35
Важной функцией автоматизированной информационной системы является контроль информации, вводимой в базы данных. Оп необходим в связи с ошибками, возникающими на этапах ее подготовки и ввода. Контроль может осуществляться путем повторного ввода. Но это связано с большими трудозатратами и не позволяет выявить ошибок в исходной информации. Более перспективным направленпем решения проблемы является синтаксический и семантический контроль информации. Спнтаксический контроль—это контроль формальной структуры информационных сообщений, семантический — контроль их содержания. Спнтаксический контроль может быть сделан независимым от содержания информации, а семантический, напротив, должен учитывать его специфику.
Специфика содержания пнформации может быть учтена путем разработки программ контроля отдельно для каждого ее вида. Но для АИС универсального назначения такой путь бесперспективен. Здесь нужны средства, которые могли бы легко настраиваться на различные виды информации. Такими средствами, на наш взгляд, могут служить входной язык АИС и ее интерпретирующая программная система.
Условия контроля могут быть сформулированы на входном языке как предписания (или серии предписаний) на поиск и обобщение информации. При этом подлежащие контролю сведения должны предварительно вводиться в буферный массив, там проверяться и затем передаваться в основные массивы АИС. Некорректная информация должна исключаться из буферного массива, выдаваться на регистрирующие устройства и после исправлений вводиться в ЭВМ повторно.
Простейшие условия контроля могут содержать ограничения, накладываемые на состав признаков объектов и характер их значений. Например, каждому классу объектов может быть поставлен в соответствие набор признаков с указанием допустимых интервалов их количественных значений и перечней допустимых качественных значений. В более сложных случаях могут указываться интервалы значений обобщенных признаков, количественные отношения между значениями первичных или обобщенных признаков, а также логические условия, которым должны удовлетворять значения признаков.
Типичными для АИС операциями над массивами являются перевод информации из одной формы представления в другую (ее конвертирование) или с одного языка на другой. Четкой грани между этими операциями нет, так как в обоих случаях можно считать, что имеет место перевод с одного информационного языка на другой. Различают входные языки (языки пользователей) и языки для внутреннего представления информации. И те, и дру-
86
гиб имеют предикатно-актантную структуру, но одни из них (входные) в большей мере учитывают интересы пользователей, другие (внутренние) ориентированы на рациональное использование памяти ЭВМ и эффективное выполнение процедур обработки информации. В процессе функционирования АИС приходится осуществлять перевод информации с входных языков на внутренние,
Рис. 2.1. Порядок работы АИС в режиме поиска и обобщения информации.
с внутренних на входные, с внутренних на внутренние (при изменении формы представления информации), с входных на входные (при совместной работе АИС с разными входными языками). Частными случаями перевода информации с одного языка на другой является ее оформление в виде выходных документов (документирование) или в виде исходных данных для решения расчетных задач.
37
Мы рассмотрели основные операции над массивами данных. Для всех них характерно то, что они имеют дело не с отдельными высказываниями (записями), а с множествами таких высказываний. Это позволяет очень экономно формулировать предписания на обработку информации п строить входные языки высокого уровня, доступные для пользователей-непрограммистов.
На рис. 2.1 схематично представлен порядок работы AITC в режиме поиска и обобщения информации. Запрос на выполнение этих операций формулируется на входном языке и вводится в ЭВМ (блок 7). Здесь он подвергается синтаксическому контролю (блок 2) и, еслп правила синтаксиса не нарушены, переводится на внутренний язык АИС (блок 3). Далее осуществляется поиск информации, удовлетворяющей условиям запроса (блок 4), и ее обобщение (блок 5), после чего она переводится с внутреннего языка на входной (блок 6), оформляется в виде документа (блок 7) п выдается на терминал (блок 8). В режиме ввода и обновления информации выполняются в основном те же операции, что и при ее поиске и обобщении, но вместо выборки и обобщения сведений об объектах производятся изменения в составе их описаний или вводятся новые описания объектов. Результаты проведенных операций отображаются на терминале. В действительности процессы обработки информации в АИС выглядят значительно сложнее. Но для их описания необходимы более детальные сведения о структуре ее языковых и программных средств. Такие сведения излагаются в последующих главах книги.
ГЛАВА 3
ВХОДНЫЕ ЯЗЫКИ АВТОМАТИЗИРОВАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
3.1. Структура входных языков
Как уже указывалось, входные языки информационных систем служат для составления предписаний на ввод, обновление, поиск, обобщение, редактирование и выдачу информации. Они должны иметь в своем составе средства, позволяющие обозначать следующие элементы предписаний:
—• идентификационные признаки пользователей (авторов предписаний) ;
— признаки массивов информации, к которым производится обращение;
— операции над массивами;
! — исходные данные для операций (вводимые или запрашива-
емые сведения);
— имена программ и комплексов программ, реализующих операции над массивами;
— адреса, по которым следует направлять результаты выполнения операций;
—• редакционные признаки выдаваемой информации;
—• разделительные признаки для обозначения границ предписаний и их структурных элементов.
Входные языки могут строиться различным образом. Мы проиллюстрируем принципы построения входных языков АИС на примере языка, разработанного авторами и реализованного в экспериментальной системе. В описываемом языке все предписания на обработку информации начинаются словом НАЧАЛО и заканчиваются словом КОНЕЦ. В промежутке между этими разделительными признаками могут записываться те компоненты, которые пользователь считает необходимым включить в состав предписания. Компоненты имеют следующие названия:
89
1) АБОНЕНТ, 8) ПРИСВОИТЬ,
2) ЗАДАЧА, 9) ВЫДАТЬ,
3) МАССИВ, 10) АДРЕС,
4) ВВЕСТИ, Н) ФОРМА.
5) ЗАТЕРЕТЬ,
6) НАЙТИ,
7) ВЫБРАТЬ,
Обязательными компонентами всех предписаний являются компоненты, обозначенные словами АБОНЕНТ, ЗАДАЧА, МАССИВ, остальные — факультативные (но по крайней мере одна из компонент пп. 4—6 должна в предписании присутствовать).
В компоненте АБОНЕНТ указывается идентификационный код абонента (фамилия, название организации и т. п.). Запись этой компоненты имеет вид
АБОНЕНТ - (ИВАНОВ)
Код абонента заключается в круглые скобки, а между левой скобкой и словом АБОНЕНТ проставляется тире. Слева и справа от тире оставляются пробелы.
В компоненте ЗАДАЧА указывается либо имя траектории решения задачи, либо (реже) ее описание, представляющее собой последовательность имен программ, участвующих в решении задачи. Каждая задача выполняет комплексную операцию по вводу, обновлению, поиску и обобщению информации. Имена траекторий решения задач и имена программ в их описаниях обозначаются русскими словами или аббревиатурами. В состав этих имен могут включаться также цифровые индексы.
Запись имени траектории решения задачи имеет вид
ЗАДАЧА - (ВВОД)
Слово в скобках обозначает имя комплексной операции ввода информации.
Запись полной траектории:
ЗАДАЧА — (ПГМ1 = СИНКОН, ПГМ2 = КОДСЛОВ,
РЕЖИМ = О,
ПГМЗ = СИПАИ, ПГМ4 = ФОРММОД, РЕЖИМ - Ф, ПГМ5 ==, «= АНКАЦПУ)
В описании траектории решения задачи справа от знаков равенства указываются имена программных модулей и режимы их работы, а слева — указатели функциональной роли элементов описания и порядковые номера программ. В приведенном примере указаны сокращенные имена программных модулей — синтаксический контроль (СИНКОН), кодирование слов (КОДСЛОВ), синтаксиче
40
ский анализ (СШ1АН), формирование модуля (ФОРММОД), выдача информации на АЦПУ в анкетной форме (АНКАЦПУ), а также обозначения режимов работы — обновление (О), формирование (Ф). Более подробно назначение этих модулей будет рассмотрено в гл. 5.
Обычно программные модули выполняются в порядке их следования. Для изменения последовательности выполнения программ в описание траекторий вводятся операторы безусловного и условного перехода. В операторе безусловного перехода, имеющем структуру типа
ПЕРЕХОД » ПГМ/ [имя модуля],
справа от знака равенства указывается аббревиатура ПГМ и порядковый номер программы, к которой следует перейти, а в скобках — имя этой программы. В операторе условного перехода
ЕСЛИ Р = 1 ТО ПГМ/ [имя модуля] ИНАЧЕ ПГМ/ [имя модуля]
указывается номер программы /, к которой следует перейти при Р = 1, и номер программы /, к которой следует перейти при Р = О (значение признака Р вырабатывается предшествующей программой) .
Имена траекторий указываются в компоненте ЗАДАЧА в тех случаях, когда для основных режимов работы информационной системы заблаговременно составляются описания траекторий (создается библиотека траекторий) и есть возможность выбирать эти траектории по их именам.
В компоненте МАССИВ указываются имена или признаки массивов информации, к которым производится обращение. При этом предполагается, что все сведения, хранящиеся в информационной системе, распределены по различным массивам в зависимости от их тематической принадлежности, а описания массивов сведены в каталог (в массив описаний массивов). Предполагается также, что формализованные описания массивов имеют такую же структуру, что и описания других объектов, учитываемых в системе, и поиск в каталоге массивов ведется по тем же правилам, что и в остальных массивах. Поэтому мы рассмотрим структуру компоненты МАССИВ несколько позднее, одновременно со структурой компоненты НАЙТИ.
3.2. Языковые средства для ввода и обновления информации
Сведения, подлежащие вводу в ЭВМ, указываются в компоненте ВВЕСТИ. Они представляют собой формализованные описания объектов в виде анкетной или позиционной структуры. Запись
41
сведений в виде анкетной структуры имеет вид
ВВЕСТИ: о—(Х(), II - (Ух = Z^/Y^ = Z2/.,.
n = zA), о-(х2), ^_(y1 = z;/y2 = z;/...
y, = z;), о-(хз), ff-(yi = z7y2 = z;7.../ym = z^)
Здесь X — коды объектов, У — коды наименований признаков, Z — коды значений признаков. Наименования объектов и перечни их признаков заключены в круглые скобки. Перед скобками проставляются функциональные указатели О (объекты) п П (признаки). Между скобками и функциональными указателями проставляется тире в пробелах. После слова ВВЕСТИ ставится двоеточие, а после каждой закрытой скобки — запятая. Между кодами наименований признаков и кодами их значений проставляется знак равенства. Признаки одного и того же объекта отделяются друг от друга косой чертой. В качестве наименований объектов и признаков могут использоваться любые слова, словосочетания и цифро-буквенные обозначения, а в качестве значений признаков — кроме того, еще и числа.
У объектов, указываемых в компоненте ВВЕСТИ, может быть различный состав и различное количество признаков, и признаки могут следовать в произвольном порядке. Ниже приводится описание одного объекта в анкетной форме:
ВВЕСТИ: О— (№ 123456), П — (фамилия » Иванов/имя =' « Иван/отчество = Иванович/социальное положение = служа-щий/год рождения = 1938/колпчество членов семьи » 3)
Коды объектов выполняют в описаниях объектов двоякую роль: с одной стороны, их можно рассматривать как значения признака с наименованием «объект», и в этом смысле они ничем не отличаются от значений любых других признаков; с другой стороны, коды объектов выступают в качестве идентификаторов описаний объектов, их «ключей». Поэтому иногда для удобства выполнения логических операций над описаниями объектов целесообразно продублировать коды объектов, указав их в скобках после символа О и одновременно в скобках после символа П (в качестве значения признака с наименованием «объект»). В качестве идентификаторов описаний объектов можно использовать и не коды объектов, а произвольные сочетания символов.
Если объекты, вводимые в одпн и тот же массив информации, имеют одинаковые наборы признаков, то можно зафиксировать порядок следования наименований признаков в описаниях объектов, ввести список наименований признаков в память ЭВМ и в дальнейшем, при вводе информации, указывать только одни значения признаков. Мы получим позиционный формат представле
42
ния данных на входе ЭВМ. В этом случае компонента ВВЕСТИ будет иметь вид
ВВЕСТИ О-(А\), П — (Ф ~ UZ^/Z^/.,./Z^, О - (А 2), л-(Ф=г/гХ/.../<), о-(^), л-(Ф=г/г;7 *;/•••/<)
(запись Ф = i указывает на номер списка наименований признаков). А приведенный выше пример после ввода в память ЭВМ списка наименований признаков «фамилия, имя, отчество, социальное положение, год рождения, количество членов семьи» и присвоения ему порядкового номера (например, номера 15) приобретет вид
ВВЕСТИ: О— (№ 123456), П — (Ф = 15/Иванов/Иван/Ивано-вич/служащий/1938/3)
Если необходимо вводить не все признаки объектов, а с пропусками, то вместо пропущенных признаков ставится косая черта. Например, если для объекта Хг нужно пропустить признаки, которые должны стоять на второй, пятой и шестой позициях, то описание этого объекта будет выглядеть следующим образом:
ВВЕСТИ: О — (Х¥), Z7 — (Ф = HZJIZ.IZJ //Z7/..JZn)
Если пропускаются признаки, стоящие в конце их упорядоченного списка, то соответствующие им разделительные признаки / (косая черта) проставлять не требуется. Например, описание объекта у которого пропускается второй по порядку признак и все признаки, начиная с пятого, будет иметь вид
ВВЕСТИ: О - (Х{), П - (Ф == HZJIZ^Z,)
Если в описаниях объектов пропуски признаков — частое явление, то позиционный формат оказывается неудобным для ввода информации, и лучше применять для этой цели анкетный формат с цифровым кодированием признаков. В этом случае вместо наименований признаков в анкетном формате проставляются их порядковые номера по общему списку, заблаговременно введенному в память ЭВМ.
Описание объектов приобретает вид
ВВЕСТИ: О- (Х^, П- (Ф=1/1^12==12/... /i=Zi), О-(Х2), П - (Ф = //3=73/5 = 25/ ... // =Zj)
Каждая из трех рассмотренных форм ввода информации (анкетная форма, позиционная форма, анкетная форма с цифровым кодированием наименований признаков) имеет свои достоинства и недостатки. Позиционная форма удобна для первоначального ввода информации об объектах, однородных по составу признаков. Анкетная форма с цифровым кодированием наименований призна
43
ков — при обновлении информации. Анкетная форма о полными наименованиями признаков позволяет вводить информацию о неоднородных объектах. Она удобна также при обновлении информации.
Иногда возникает необходимость вводить информацию в одни и те же массивы по различным формам. В этом случае приходится хранить в памяти ЭВМ перечни признаков для всех форм ввода, а в компоненте ВВЕСТИ указывать номера используемых форм. Если, например, требуется ввести информацию об объектах Х^ и Хг по формам ФЗ и Ф15, то соответствующая запись в позиционном формате будет иметь вид
ВВЕСТИ: 0-{Х^ П - (Ф - Ъ/ZJZJ.. .jZm), n-^~wz'Jzy...[z'n)
а в анкетном формате с цифровым кодированием наименований признаков — вид
ВВЕСТИ: О - (Хх), П - (Ф = 3/1 = Zx/2 = Z2/5 = Z5),
О - (Xs), П - (Ф - 15/2 = z;/5 = z;/9 = z;)
В предыдущих рассуждениях предполагалось, что в памяти ЭВМ связующим звеном между признаками объекта является имя этого объекта. Имя объекта указывалось при вводе п обновлении информации и выступало в роли его идентификатора. Но на практике часто встречаются случаи, когда в формализованном описании объекта нельзя указать один какой-либо признак, который мог бы служить в качестве его идентификатора. В подобных случаях целесообразно идентифицировать объекты не по одному признаку, а по сочетаниям нескольких ключевых признаков. В качестве ключевых могут выступать любые признаки объектов, которые в совокупности позволяют выделить эти объекты среди множества других.
Если имя объекта не может служить идентификатором или отсутствует, то при первоначальном вводе информации оно не указывается, а вместо него в компоненте ВВЕСТИ проставляется дефис. Например, если требуется ввести в анкетной форме описание некоторого объекта с признаками У1 = Zi, У2 = Z2, ..., Уп = Zzl, то компонента ВВЕСТИ предписания па ввод информации будет иметь вид
ВВЕСТИ: О - (-), n-iY^ZJY^Zz! n^Zn)
В процессе ввода информации объекту будет присвоен порядковый номер (по счетчику номеров объектов), который в дальнейшем будет выступать в роли указателя связи. При вводе инфор-
44
нации в позиционном формате компонента ВВЕСТИ будет иметь вид
ВВЕСТИ: О - (-), Z7 — .../2П)
При обновлении информации (ввод дополнительных признаков объектов, замена значений признаков, исключение признаков) в целях идентификации объектов вместо их наименований указываются их ключевые признаки или сочетания ключевых признаков. Ключевые признаки отделяются друг от друга знаком конъюнкции (И). Если, например, у некоторого ранее введенного в банк данных объекта признаки У,-, Yj и YK могут выступать в качестве ключевых и требуется дополнительно ввести в описание этого объекта признаки Уг —Zr, y,=Z„ Ytt=Zh то компонента ВВЕСТИ предписания па ввод информации будет иметь вид
ВВЕСТИ: О- (Yi^Zi И У} = Z; II yA = ZA),
П-(Yr~Zr/Yt = Zs/Yt = Zt)
В процессе выполнения предписания нужный объект будет найден по признакам У,-, У,, УА, и в его описание будут дополнительно включены признаки Уг, У3, Yt. Аналогичным образом составляются предписания на замену значений признаков. Признаки объектов, подлежащие вводу и замене, могут задаваться во всех формах представления, предусмотренных на входном языке.
В компоненте ЗАТЕРЕТЬ указываются перечни наименований признаков объектов, подлежащие исключению из состава массивов. Компонента имеет следующую структуру:
ЗАТЕРЕТЬ: О-(Хх)’ П ~ (У1/У2/- ’ -/М’
о-(т2), л-(у;/г'/.../у;)
Здесь X — объекты, у которых исключаются признаки с наименованиями У. Если необходимо исключить всю запись об объекте, то соответствующее предписание будет иметь вид
ЗАТЕРЕТЬ: О - (X), П - (ВСЕ)
Для исключения у всех объектов некоторого набора признаков предписание будет следующим:
ЗАТЕРЕТЬ: О — (ВСЕ), Л — (УЛ/У;/УА/...)
Весь массив информации стирается по предписанию
ЗАТЕРЕТЬ: О — (ВСЕ), Z7— (ВСЕ)
При затирании информации вместо наименований объектов могут указываться их ключевые признаки пли сочетания ключевых признаков (подобно тому, как это делается при вводе новых признаков и при замене значений признаков).
45
3.3. Языковые средства для поиска информации
Предписание на поиск объектов, удовлетворяющих заданным условиям, формулируется в компоненте НАЙТИ. При формулировке условий поиска используются отношения ==, >, < и их отрицания НЕ =, НЕ >, НЕ <. Логические связи между поисковыми признаками указываются с помощью операторов И и ИЛИ (операторов конъюнкции и дизъюнкции).
Поисковый признак может состоять из одного наименования признака, обозначающего класс всех возможных значений этого признака (например, У»); из наименования признака с предшествующим отрицанием, обозначающего класс любых признаков, кроме заданного (например, НЕ У,<); из наименования признака и его значения, соединенных отношениями =, >,t <, НЕ ==, НЕ >, НЕ <; из одного значения .признака с предшествующим знаком отношения. Таким образом, во входном языке допустимы следующие структуры признаков:
Yi, НЕ Yh Yi=Zh Yi HE—Zi, Yi>Zh Yi HE>Zi, Yi<Zil Yt HE<Zi,=Zit W=~Zi, >Zh Y№>Zi, < Zi? HE < Zb
В компоненте НАЙТИ предусматривается возможность указания двух групп поисковых признаков, заключаемых в круглые скобки,—имен объектов и любых других признаков объектов. Перед обеими группами может стоять знак отрицания НЕ. Группа имен объектов может иметь одну из следующих структур:
1) О—(Xi);
2) О -НЕ (Xi);
3) О — (Xi ИЛИ Х2 ИЛИ ... ИЛИ Хп);
4) О —НЕ (Xi ИЛИ Х2 ИЛИ... ИЛИ Хп);
5) О - (ВСЕ).,
Последняя структура используется в тех случаях, когда в поисковом предписании нет необходимости указывать имена объектов. Если нужно указывать несколько объектов, то их имена отделяются друг от друга знаком дизъюнкции.
Группа поисковых признаков объектов, не являющихся их именами, может быть представлена в дизъюнктивной или конъюнктивной нормальной форме. В первом случае это последовательность конъюнкций признаков, соединенных знаками дизъюнкции, во втором — последовательность дизъюнкций, соединенных знаками конъюнкции. Число признаков в конституентах (в конъюнкциях и дизъюнкциях) может быть различным. Перед первым признаком дизъюнктивной нормальной формы ставится связка ИЛИ, а перед первым признаком конъюнктивной нормальной формы — связка И. Эти связки необходимы для указания приоритетов логических
40
операций: в первом случае менее приоритетной операцией является операция ИЛИ, во втором случае — операция И. Если в компоненте НАЙТИ указываются имена искомых объектов и нет необходимости в указании дополнительных признаков этих объектов, то вместо них проставляется слово ВСЕ.
С учетом вышеизложенного, группа признаков объектов, не являющихся их именами, может представляться в виде одной из следующих структур:
1) 77- (ИЛИ Ai И А2 И ... И Ат ИЛИ И В2 И ... И Вп ИЛИ ... ИЛИ Lx И Ь2 И ... И Lk);
2) П - НЕ (ИЛИ At И А2 И ... И Ат ИЛИ В. И В2 И ... И Вп ИЛИ ... ИЛИ Lx И Ь2 И ... И £й);
3) П — (И Ai ИЛИ А2 ИЛИ ... ИЛИ Ат И Bt ИЛИ В2 ИЛИ ... ... ИЛИ Вп И ... И Ц ИЛИ L2 ИЛИ ... ИЛИ £а);
4) П — НЕ (И Ai ИЛИ А2 ИЛИ ... ИЛИ Ат И ИЛИ В2 ИЛИ ... ИЛИ Вп И ... И Li ИЛИ L2 ИЛИ ... ИЛИ Lh);
5) П— (ВСЕ).
В пп. 1—5 признаки А, В, ..., L могут иметь любую из описанных выше структур.
Обозначим перечень имен искомых объектов символом X, а логическую функцию поисковых признаков без учета знака отрицания перед скобкой — символом 53. Тогда компонента НАЙТИ может быть представлена в обобщенном виде как одна из следующих структур:
1) НАЙТИ: О - (ВСЕ), 77 — (53);
2) НАЙТИ: О - (ВСЕ), 77-НЕ (53);
3) НАЙТИ: О - (X), П- (ВСЕ);
4) НАЙТИ: О — НЕ (X), 77- (ВСЕ);
5) НАЙТИ: О -НЕ (X), 77- (S3);
6) НАЙТИ: О-НЕ (Х),77-НЕ (53);
7) НАЙТИ: О — (ВСЕ), 77— (ВСЕ).
Здесь первая запись означает: найти все объекты, удовлетворяющие условию 53; вторая — найти все объекты, не удовлетворяющие условию 53; третья — найти заданный перечень объектов; четвертая — найти объекты, не входящие в заданный перечень; пятая —найти среди объектов, не входящих в заданный перечень, объекты, удовлетворяющие условию 53; шестая — найти среди объектов, не входящих в заданный перечень, объекты, не удовлетворяющие условию 53. Последняя запись применяется в тех случаях, когда нужно выдать информацию о всех объектах массива.
При задании условий поиска объектов иногда возникает необходимость указывать для одного и того же наименования признака несколько его значений. Это можно сделать с помощью
47
дизъюнкции вида
r«=Zi ИЛИ y=z2 ИЛИ ... ИЛИ y=zn.
Но гораздо удобнее более компактная форма записи вида
Y^ZdZ,l.t,IZn.
предусмотренная во входном языке. Запись, представленная в такой форме, может включаться в компоненту НАЙТИ по тем же правилам, что и единичные признаки.
Другим специфичным случаем задания поисковых признаков является случай, когда в качестве их значений выступают классификационные коды и требуется искать информацию не по полным кодам, а по их фрагментам. Фрагменты кодов выделяются с помощью «масок». Маски задаются путем замены цифр или групп цифр классификационных кодов на символы X (буквы «икс») или группы таких символов. Символы X и группы этих символов могут проставляться на произвольных позициях кодов. Если, например, требуется вести поиск по классификационному признаку Y^-K.K.... Кп (где К^ Кг, ..., Кп— цифры), исключая позиции 1, 2, 5, 6, п — 1 его значения, то этот признак должен быть задан в виде записи
Y~XXKzKiXXK7 ... Кп-гХКп.
Вместо знака равенства здесь могут также использоваться любые другие отношения (НЕ =, >, НЕ >, <, НЕ <).
В компоненте ВЫБРАТЬ указываются перечни наименований признаков, которые следует выбирать из массивов для объектов, удовлетворяющих условиям поиска. Компонента может иметь одну из следующих структур:
1) ВЫБРАТЬ — (У1/У2/.../Уп);
2) ВЫБРАТЬ - (ВСЕ);
3) ВЫБРАТЬ - (ТО ЖЕ).
В первом случае задается перечень наименований выбираемых признаков объектов (в результатах попска они располагаются в той последовательности, которая указана в компоненте ВЫБРАТЬ). Во втором случае выбираются все признаки объектов и располагаются в результатах поиска в том порядке, в котором они вводились в АИС. В третьем случае из массивов информации выбираются признаки, упомянутые в условиях поиска.
В компоненте ПРИСВОИТЬ указываются перечни значений, которые следует присвоить признакам объектов, выбранных по заданным логическим условиям. Условия отбора объектов формулируются в компоненте НАЙТИ. Наименования признаков, у которых должны быть изменены значения, указываются в компонен-
та
те ВЫБРАТЬ, а новые значения признаков — в компоненте ПРИСВОИТЬ. Если, например, требуется присвоить признакам Yh Y2l •••» Yn значения Zh Z2, Zn во всех описаниях объектов, удовлетворяющих логическому условию §3, то необходимо в соответствующее предписание включить компоненты НАЙТИ, ВЫБРАТЬ, ПРИСВОИТЬ, оформив их следующим образом:
НАЙТИ: О — (ВСЕ), Z7- (8),
ВЫБРАТЬ - (У1/У2/.. JYn),
ПРИСВОИТЬ - (Ki = ZJY2 = Z2I.../Yn = Zn).
С помощью такого рода предписаний можно заменять значения признаков у больших групп объектов.
Иногда возникает необходимость исключения из массивов (затирания) сведений о группах объектов, определяемых логическими условиями поиска. Условия поиска формулируются в компоненте НАЙТИ, а признаки объектов, подлежащие исключению из массивов,— в компоненте ВЫБРАТЬ. Режим затирания сведений задается путем указания имени этого режима в компоненте ЗАДАЧА.
В начале главы уже указывалось, что поиск в каталоге массивов АИС ведется по таким же правилам, как и в самих массивах. Соответственно этому предписание на поиск массивов имеет структуру, аналогичную структуре предписания на поиск объектов в массивах. Отличие заключается лишь в том, что здесь вместо имени компоненты НАЙТИ пишется слово МАССИВ, а вместо ее функциональных указателей О и П проставляются функциональные указатели М (массивы) и ПМ (признаки массивов). В частности, предписание на поиск информации в каталоге может иметь вид
МАССИВ: ЛГ — (ВСЕ), ПМ - (8),
ВЫБРАТЬ — (ИМЯ МАССИВА),
где S — булева функция признаков массивов.
Допускается и сокращенная форма записи предписания:
МАССИВ - (ZI/Z2/.../Z„),
в котором символы Zi, Z2, .,Zn обозначают номера или имена массивов.
3.4. Языковые средства для обобщения и выдачи информации
Предписание на обработку информации, выбранной из массивов, формулируется в компоненте ВЫДАТЬ. В частности, здесь указываются процедуры сортировки и обобщения информации,
4 Г. Г. Белоногов, В А. Кузнецов 49
которые Следует выполнить, прежде чем выдавать ату информацию потребителю или записывать ее в один из массивов. Для описания процедур обобщения информации используются операторы ДЛЯ, СУМ, КОЛ, МИН, МАКС и арифметические операции 4-, —, *, :, ** (сложение, вычитание, умножение, деление, возведение в целую степень), для описания процедур сортировки информации-операторы ДЛЯ и СОРТ. В операторе ДЛЯ указываются значения признаков, по которым осуществляется группировка первичных объектов с целью вычисления характеристик обобщенных объектов. Группировка может производиться по значениям одного признака или по сочетаниям зпачений нескольких признаков. Оператор КОЛ применяется для определения количества объектов, удовлетворяющих заданным логическим условиям. Оператор СУМ — для суммирования значений указываемых в этом операторе признаков. Суммирование ведется для каждого признака отдельно. Арифметические операции применяются для вычисления производных признаков.
Операторы ЛМАКС и МИН используются для определения максимальных и минимальных зпачений заданных признаков у групп объектов. Например, если для выбранной в результате поиска группы объектов требуется определить максимальное значение признака А и минимальные значения признаков В и С, то компонента ВЫДАТЬ должна иметь вид
ВЫДАТЬ - (МАКС А/МИН В/МИН С).
В операторе ДЛЯ порядок группировки первичных объектов может задаваться шестью способами.
1. Путем перечисления через разделительный знак / (косая черта) количественных или качественных значений признаков в той последовательности, в которой должна выполняться группировка объектов;
ДЛЯ Х = Х1/Х2/.../Хп.
2. Путем перечисления интервалов значений количественных признаков;
ДЛЯ X = хгх2/х2-х3/... 1Хп-ГХп.
Интервалы задаются парами чисел через дефис, причем левая граница не входит в состав интервала.
3. Путем перечисления наряду с первичными значениями качественных признаков также и классов значений этих признаков. Классам значений присваиваются имена, а после них в квадратных скобках указываются перечни элементов этих классов:
ДЛЯ X = Х^/УЦХзШ... /Хт]/У2[Хт+1/Х7п+2/... /Хп/...
/У» [Хг+1/Хг+2/... /х,]/Х(/хи/х„.
50
Группировка объектов будет осуществляться по значениям Х2, Xtt Хи, Xv признака X и по классам значений Уь У2, ...» Ул этого признака. Такой способ задания порядка группировки первичных объектов позволяет переименовывать и обобщать значения. признаков. Для этого необходимо заключать исходные имена значений признаков в квадратные скобки, а их новые имена записать перед скобками.
4. Путем перечисления значений признаков, выраженных классификационными кодами с наложенными в них масками (структура маски такая же, что и в компоненте НАЙТИ). Например, если в описаниях объектов в качестве значений признака А указаны шестиразрядные классификационные коды и нужно сгруппировать объекты по этим кодам, игнорируя их второй слева и четвертый разряды, то соответствующая запись будет иметь вид
ДЛЯ А = КхХК3ХК5К6/К^ ...
Здесь К3, К5, К6 — цифры классификационного кода; X — элемент маски, указывающий на необходимость игнорирования при поиске соответствующего разряда классификационного кода.
5. Путем перечисления интервалов значений классификационных кодов с использованием масок. Например,
ДЛЯ А = KiXK'iXK^^
к"хк3хк,к^..
Классификационные коды, определяющие границы интервалов, соединяются дефисом.
6. Путем указания слова ВСЕ вместо перечня значений признака:
ДЛЯ А = ВСЕ.
В последнем случае группировка первичных объектов будет производиться по всем попарно-различным значениям признака, встречающимся в сортируемом массиве. При этом порядок следования групп объектов не регламентируется (он будет зависеть от структуры исходного массива).
Если группировка первичных объектов должна производиться по сочетаниям значений нескольких признаков, то в операторе ДЛЯ указываются перечни значений этих признаков. Перечни отделяются друг от друга знаком конъюнкции и могут иметь любую из описанных выше структур. Для структуры первого типа соответствующая запись будет иметь вид
ДЛЯ X = XJX2/... /хт И Y = Yi/Y2/ .,,/Yn
II ... II W = WilW2/..JWh.
Группировка объектов ведется сначала по значениям первого слева признака, затем, в пределах каждой полученной группы,—
4*
51
по значениям второго признака и т. д. Младшим группировочным признаком является последний признак оператора ДЛЯ.
Если в предписании на обобщение информации за оператором ДЛЯ следует оператор СУМ, то для всех групп объектов, получаемых в процессе сортировки информации, вычисляются суммарные значения признаков, указанных в операторе СУМ. Если за оператором ДЛЯ следует оператор КОЛ, то ведется пересчет объектов в группах.
Операторы СУМ и КОЛ могут применяться самостоятельно, в сочетании друг с другом и в сочетании с оператором ДЛЯ. В первом случае компонента ВЫДАТЬ может быть представлена в виде записи
ВЫДАТЬ - (СУМ AIB ... /£)
или записи
ВЫДАТЬ - (КОЛ)
(Л, В, ..., L — суммируемые признаки).
Во втором случае — в виде записи
ВЫДАТЬ - (СУМ А! В! ..JL КОЛ).
В третьем случае операторам СУМ и КОЛ может предшествовать оператор ДЛЯ в любом варианте его задания. При первом способе задания этого оператора возможны следующие варианты записи компоненты ВЫДАТЬ:
1) ВЫДАТЬ - (ДЛЯ X = Xi/Хг/ .../хп СУМ A/В/ .../L);
2) ВЫДАТЬ - (ДЛЯ X = Xt/X2/.../Xn КОЛ);
3) ВЫДАТЬ - (ДЛЯ X = XJX,/ .../Хп СУМ A/В/ .../L КОЛ);
4) ВЫДАТЬ - (ДЛЯ Х = Х1/Х2/.../Хт И У-У^Уг/.../ Yn И ... И W = WdWzI... /Wh СУМ A/В/ .../L);
5) ВЫДАТЬ - (ДЛЯ X = XJX2/ .../Хт И У = У,/У2/ ... / У„ И ... И W = WJWi! ... IWk КОЛ);
6) ВЫДАТЬ-(ДЛЯ Х = Х,/Х2/.../Хт II У=У1/У2/.../ У„ И ... II W = WJW,./ ...IWk СУМ A/В/ .../L КОЛ).
Аналогичным образом записывается компонента ВЫДАТЬ и при других способах задания группировочных признаков.
В операторе СУМ вместо имен первичных признаков могут указываться имена производных (в частности, обобщенных) признаков. Может также осуществляться переименование признаков. Порядок вычисления значений производных признаков задается алгебраическими выражениями без скобок с использованием операций +, —, #, **• Например, если Л2, ..А20 — наименова-
ния первичных признаков, Ви В2, ..., В^ — наименования вто-52
ричных признаков, то оператор СУМ может быть представлен в виде
СУМ Bi~Ai -f- А2 4- AzlAJA;JB2.—А4 4“ А81В8 — А&1В4 =А?—A8j
B$= A^-\~A\JB^-==- A n4“ A12—- AM = Л15: Л1б/Вв=Л1*Л2—A J
В^ = A17: Ai$/BiQ == Л20 * 11 4- 2
(наименование признака Лб здесь заменяется на B8l а в результате выполнения оператора СУМ будут выданы признаки Ви А41 А5, B2t В3, В41 В5, Be, B7, B8, B$, B10).
При бесскобочной записи алгебраических выражений наивысший приоритет имеет операция возведения в степень (#*), второй приоритет — операции умножения (*) и деления (:), третий приоритет — операции сложения (4-) и вычитания (—). Для изменения приоритетов операций могут использоваться круглые скобки.
При необходимости вычисления значений производных признаков по более сложным алгоритмам в состав оператора СУМ могут включаться операторы специальных функций. Операторы этих функций обозначаются на входном языке их именами и сопровождаются перечнями параметров. Параметры указываются после имен операторов в круглых скобках и отделяются друг от друга косой чертой. Программы специальных функций составляются заранее па одном из алгоритмических языков, записываются в библиотеку загрузочных модулей АИС и включаются в работу по мере необходимости.
Если требуется произвести сортировку информации без ее обобщения, то в компоненте ВЫДАТЬ указываются операторы ДЛЯ и СОРТ. Оператор ДЛЯ определяет порядок следования в выходном массиве сортируемых описаний объектов, а оператор СОРТ — порядок следования признаков в этих описаниях. Признаки отделяются друг от друга косой чертой. Например, если требуется рассортировать массив описаний объектов по значениям признаков А, В, С и расположить признаки XI, Х2, ХЗ, Х4, Х5, Х6, Х7 этих признаков в заданном порядке, то предписание на сортировку информации будет иметь вид
ВЫДАТЬ - (ДЛЯ А = ВСЕ И В = ВСЕ И С «= ВСЕ СОРТ Х1/Х2/ХЗ/Х4/Х5/Х6/Х7).
В компоненте ФОРМА указываются сведения о форме выдачи информации (номер формы или перечень параметров для программы редактирования). Указание о форме выдачи может содержаться также в траектории решения задачи, если в ее состав включена соответствующая программа редактирования. Таким образом, сведения о форме выдачи информации могут указываться на входном языке различными способами и с различной степенью детали-
53
вации. Более того, компонента ФОРМА может в запросе отсутствовать. Тогда выдаваемая информация оформляется стандартным образом в соответствии с возможностями программных средств, включенных в траекторию решения задачи.
В компоненте АДРЕС может быть указано устройство, на которое нужно выдавать информацию (например, дисплей, АЦПУ, канал связи), или имя (номер) массива, в который следует записать результаты поиска и обобщения информации.
Предписание па ввод, поиск, обобщение пли выдачу информации оформляется на входном языке в виде последовательности компонент описанной выше структуры. При этом некоторые компоненты могут не указываться (если необходимая информация содержится в траектории решения задачи пли в программных модулях). Ниже приводится перечень возможных структур предписаний с детализацией до имен их компонент.
1. Ввод информации:
НАЧАЛО: АБОНЕНТ — ..., ЗАДАЧА — ..МАССИВ — ..., ВВЕСТИ: О - ..., П — ..., ..., КОНЕЦ.
2. Затирание информации:
НАЧАЛО: АБОНЕНТ - ..., ЗАДАЧА -..., МАССИВ - ..., ЗАТЕРЕТЬ: О - ..., П - ..., ..., КОНЕЦ.
3. Поиск информации без ее обобщения с выдачей на заданное устройство или записью в заданный массив:
НАЧАЛО: АБОНЕНТ -..., ЗАДАЧА - ..МАССИВ - ...,
НАЙТИ: О —..., П — ..., ВЫБРАТЬ — ...,
АДРЕС — ..., КОНЕЦ.
4. Поиск и обобщение информации с выдачей ее на заданное устройство в заданной форме:
НАЧАЛО: АБОНЕНТ -..., ЗАДАЧА - ..., МАССИВ - ..., НАЙТИ: О — ..., П — ..., ВЫБРАТЬ — ..ВЫДАТЬ — ..., АДРЕС - ..., КОНЕЦ.
5. Поиск и обобщение информации с выдачей ее на заданное устройство в заданной форме:
НАЧАЛО: АБОНЕНТ - ..ЗАДАЧА - ..МАССИВ - ..., НАЙТИ: О — ..., П — ..., ВЫБРАТЬ-..., ВЫДАТЬ-..., АДРЕС — ..., ФОРМА - ..., КОНЕЦ.
6. Присвоение значений признакам объектов, выбранным по заданным логическим условиям:
НАЧАЛО: АБОНЕНТ-..., ЗАДАЧА-..., МАССИВ-...,
НА ЙТИ: О — ..., /7 — ..., ВЫБРАТЬ — ..., ПРИСВОИТЬ-..., КОНЕЦ.
54
Описанный входной язык АИС рассчитан на специалистов, знакомых с математической логикой и принципами формализации информации. Для мепее подготовленных пользователей целесообразно выделять из его состава более простые изобразительные средства (подмножества) и разрабатывать соответствующие инструкции. Другим путем упрощения входного языка является введение аппарата стандартных запросов и сообщений. Этот аппарат следует применять в тех случаях, когда информационные потребности пользователей достаточно стабильны и есть возможность описать их заранее. Соответствующие запросы и сообщения должны составляться с применением полного объема языковых средств и вводиться в память ЭВМ, а в последующем ввод информации и ее выдача могут осуществляться по номерам или именам этих запросов и сообщений.
Для ввода стандратных запросов, их обновления и инициирования их выполнения в рассматриваемом языке АИС предусмотрены специальные средства. Предписания на выполнение перечисленных манипуляций с запросами начинаются словами ВВЕСТИ, ИСКЛЮЧИТЬ, ЗАМЕНИТЬ, ВЫПОЛНИТЬ, ИЗМЕНИТЬ И ВЫПОЛНИТЬ. Приведем структуры этих предписаний:
1. ВВЕСТИ ЗАПРОС №... НАЧАЛО ... КОНЕЦ.
По этому предписанию запрос, указанный в полной форме между словами НАЧАЛО и КОНЕЦ, записывается в библиотеку запросов.
2. ЗАМЕНИТЬ ЗАПРОС №... НАЧАЛО ... КОНЕЦ.
По этому предписанию старый запрос, хранящийся в библиотеке под указанным номером, заменяется новым запросом с тем же порядковым номером.
“ 3. ИСКЛЮЧИТЬ ЗАПРОС №... КОНЕЦ.
По этому предписанию из библиотеки запросов исключается запрос с указанным порядковым номером.
4. ВЫПОЛНИТЬ ЗАПРОС №... КОНЕЦ.
По этому предписанию из библиотеки запросов исключается запрос с указанным порядковым номером п без изменения передается на вход программной системы АИС.
5. ИЗМЕНИТЬ И ВЫПОЛНИТЬ ЗАПРОС №... НАЧАЛО: КОМПОНЕНТА А, КОМПОНЕНТА В, ..., КОМПОНЕНТА С, КОНЕЦ.
55
По этому предписанию из библиотеки запросов выбирается запрос с заданным порядковым номером, в котором старые компоненты заменяются на компоненты, указанные в предписании. После этого измененный запрос передается на выполнение.
3.5. Языковые средства общения с базами данных реляционной, иерархической и сетевой структур
Мы рассмотрели подробно принципы построения одного из входных языков автоматизированных информационных систем, который, на наш взгляд, позволяет довольно полно проиллюстрировать функциональные возможности этих систем. Приведем еще несколько примеров входных языков, имеющих много общих черт с рассмотренным выше, но отличающихся от него либо составом операторов, либо способом их обозначения/
В начале 70-х годов Е. Ф. Коддом был предложен язык альфа (Alpha) для СУБД реляционного типа. Напомним, что согласно концепции Е. Ф. Кодда [79] результат выполнения любой операции поиска и выборки информации может рассматриваться как некоторое отношение (массив позиционной структуры), а реляционное исчисление — как набор правил для записи выражений, определяющих новые отношения на основе заданной совокупности исходных отношений.
Определение нового отношения содержит сведения о структуре ответа на запрос («целевой список») и формулировку условия, которому должны удовлетворять описания объектов в исходных отношениях. Например, для запроса «Для каждой поставляемой детали найти номер детали P# и названия городов, из которых она поставляется» определение результата поиска будет иметь вид [30]
{(SP. Р#, S. CITY): SP, S# « 5. «$#} (3.1)
Здесь фигурные скобки, окаймляющие все выражение, указывают, что оно является определением некоторого множества (отношения), а двоеточие «:» служит в качестве разделительного знака между перечнем наименований признаков нового отношения (выражение слева в круглых скобках) и условием, которому должны удовлетворять описания объектов исходных множеств (выражение справа); SP.— имя отношения «поставщики — детали», 5.— имя исходного отношения «поставщики», 5#—номер поставщика. Выражения SP. Р#, S. CITY, SP. 5#, S. 5# обозначают наименования признаков «номер детали P# из отношения 5Р.», «город (CITY) из отношения 5.», «помер поставщика (5#) из отношения 5Р.», «номер поставщика из отношения S.».
Ответом на запрос (3.1) будет множество всех пар (Р#, CITY) таких, что значение P# берется из кортежа (описания объекта) 56
отношения SP., значение CITY — из кортежа отношения S. и значения 5# в этих двух кортежах равны. В общем случае условия выборки значений признаков кортежей могут носить более сложный характер и включать в свой состав операции И, ИЛИ, НЕ, отношения =, >, < и их отрицания, кванторы общности и существования, а также скобки для определения нужного порядка вычислений.
В выражении (3.1) указаны наименования признаков нового отношения и условие выбора их значений, но не определено, какие операции следует выполнить над этим отношением. Для этой цели служат операторы типа GET (выбрать), HOLD (выбрать и записать в рабочую область) UPDATE (обновить), DELETE (удалить), PUT (включить) и др. Операторы сопровождаются выражениями типа (3.1) или именами отношений.
Язык альфа может быть расширен за счет включения в его состав библиотечных функций типа COUNT (пересчет числа объектов), TOTAL (суммирование значений признаков), МАХ (выделение максимального значения признака), MIN (выделение его минимального значения), AVERAGE (определение среднего арифме-’ тического списка значений признаков) и др. Этот язык не был ре-ализдван в чистом виде ни в одной из действующих систем, но он оказал значительное влияние на идеологию построения систем управления базами данных реляционного типа.
Другим языком манипулирования реляционными базами данных, предложенным Е. Ф. Коддом, является язык, основанный на реляционной алгебре. В отличие от языка альфа, на котором лишь определяется, каким должен быть ответ на запрос, но не указывается, как его получить (это возлагается на интерпретирующую программную систему), алгебраический язык позволяет формулировать алгоритмы получения ответов на запросы. Он представляет собой совокупность операций над отношениями — прежде всегр операций типа SELECT (выбрать), PROJECT (спроектировать) и JOIN (соединить), последовательное применение которых позволяет достичь необходимого эффекта. Эти операции описаны в гл. 2. Наряду с ними применяются также традиционные операции над множествами (объединение, пересечение, вычитание и декартово произведение множеств). Алгебраический язык по своим логическим возможностям эквивалентен языку альфа (языку реляционного исчисления).
Наряду с языком альфа и алгебраическим языком, для манипулирования реляционными базами данных был предложен ряд других языков. Мы кратко рассмотрим только два из них — язык SEQUEL и язык QUERY BY EXAMPLE (QBE). В языке SEQUEL (его название составлено из начальных букв английских слов в словосочетании Structured English Query Language) основной оде-
57
рацией является операция «отображение», описываемая синтаксической конструкцией, состоящей из трех частей, начинающихся словами SELECT (выбрать), FROM (из), WHERE (где). В первой части этой конструкции указывается перечень наименований признаков, который требуется включить в ответный (целевой) массив, во второй — имя массива или имена нескольких массивов, из которых осуществляется выборка информации, в третьей — логическое условие выборки. Например, запрос «Получить номера и статусы поставщиков, находящихся в Париже» на языке SEQUEL будет иметь вид [30]
SELECT 5#, STATUS
FROM 5
. WHERE CITY = „РЛР75”.
Здесь 5 —имя массива «поставщики» (SUPPLIER), 5* — номера поставщиков. Как и в случае языка альфа, логическое условие выборки информации может включать в свой состав операторы сравнения ( = , >, < и их отрицания), булевы операторы И, ИЛИ, НЕ, а также скобки, определяющие порядок вычислений.
В языке SEQUEL возможно рекурсивное построение запросов, когда за компонентой WHERE могут следовать один или несколько вложенных друг в друга запросов с компонентами SELECT FROM, WHERE и с указанием требуемых отношений между результатами поиска. Например, запрос «Получить имена поставщиков (SNAME), поставляющих по крайней мере одну красную (RED) деталь» на языке SEQUEL будет иметь вид
SELECT SNAME
FROM S
WHERE 5# IN
SELECT 5# FROM SP WHERE P# IN SELECT P# FROM P# WHERE COLOR = „RED”.
Наряду co средствами, предназначенными для выполнения поисковых процедур, язык SEQUEL включает в свой состав операторы обновления (UPDATE), включения (INSERTION) и удаления (DELETION) информации, а также библиотечные функции, аналогичные библиотечным функциям языка альфа.
Язык QUERY BY EXAMPLE («запросы по образцам»), как и язык SEQUEL, первоначально предназначался только для поиска информации. Позднее его функции были расширены, и он стал применяться также для выполпения операций ввода и обновления
58
информации. Запрос на языке QBE формулируется в табличной форме, причем пользователь заносит в таблицу не только условия поиска и обработки информации, но и образец возможного ответа (отсюда название языка «запросы по образцам»). Заполнение запроса-таблицы осуществляется в диалоговом режиме.
Пусть требуется выполнить запрос «Получить номера поставщиков, находящихся в Париже». В начале диалога на экран дисплея выдается пустая таблица. Затем, после указания имени S исходной таблицьр-отпошеппя, в которой предполагается вести поиск, производится автоматическое заполнснпе напменований столбцов этой таблицы. Далее пользователь формулирует запрос, занося в столбцы таблицы условие поиска информации и образец ответа (см. табл. 3.1).
Таблица 3.1
S S# SNAME STATUS CITY
P.S7 PARIS
Подчеркнутое буквосочетание 57 в табл. 3.1 является примером возможного ответа на запрос, буква Р перед этим буквосочетанием обозначает оператор «выдать на печать» (PRINT), а слово PARIS (не подчеркнутое) является элементом условия поиска. Вместо буквосочетания 57 могло бы быть любое другое буквосочетание (важен не столько конкретный пример ответа, сколько сам факт его указания).
Сформулированный в табл. 3.1 запрос интерпретируется следующим образом: «Напечатать все значения признака 5ф такие, как, скажем, 57, для которых признак SITY имеет значение PARIS». При этом элемент-пример 57 в результирующий массив может и не попасть.
Условия поиска и выборки информации в языке QBE могут быть значительно более сложными, чем это показано в табл. 3.1. При их формулировке могут использоваться булевы операторы и операторы сравнения. Поиск может производиться не в одном, а одновременно в нескольких исходных массивах, я результаты поиска могут обобщаться (например, с помощью операторов COUNT, SUM и др.). Для ввода и обновления информации в языке предусмотрены операторы UPDATE, INSERTION, DELETION.
Некоторые исследователи [7] подразделяют автоматизированные информационные системы на два типа: открытые — с включающим алгоритмическим языком — и закрытые — с входным языком
59
высокого уровня, позволяющим формулировать предписания на решение широкого класса задач. Это деление довольно условное, так как «закрытые» системы обычно бывают способны к наращиванию своих функциональных возможностей и по этой причине не являются закрытыми. Примером систем с включающим языком являются система ИМС фирмы ИВМ и система, предложенная комитетом КОДАСИЛ. В обеих этих системах входной информационный язык рассматривается как «подъязык данных», включаемый в состав алгоритмического языка. При этом он расчленяется на язык определения данных (ЯОД) и язык манипулирования данными (ЯМД). Язык определения данных имеет анкетную структуру и служит для описания форматов представления информации в памяти ЭВМ, язык манипулирования данными — для выполнения операций над масспвами.
В системе ИМС используется язык манипулирования данными DL/1 (Data Language one). Он включает в свой состав следующие основные операторы:
1. GET UNIQUE (GU) — выборка «уникального» (вернее первого в иерархической структуре) сегмента на основе заданного иерархического пути к нему.
2. GET NEXT (GN) — последовательная выборка сегментов в порядке, определяемом иерархической структурой данных (сверху вниз и слева направо).
3. GET NEXT WITHIN PARENT (GNP) — последовательная выборка сегментов, подчиненных заданному «родительскому» сегменту.
4. GET HOLD (GHU, GHN, GHNP) — те же действия, что и GU, GN и GNP, но допускается выполнение операций DELETE и REPLACE (см. пп. 6, 7).
5. INSERT (ISRT) — добавить в массив новый сегмент.
6. DELETE (DLET) — удалить из массива имеющийся в нем сегмент.
7. REPLACE (REPL) — заменить в массиве сегмент. В составе этих операторов при необходимости указываются иерархические пути доступа к сегментам и логические условия, которым они должны удовлетворять. При этом используются операторы сравнения и булевы логические операторы.
В языке манипулирования данными, предложенном комитетом КОДАСИЛ, основными операторами являются операторы FIND (найти), GET (выбрать), MODIFY (изменить), CONNECT (присоединить), DISCONNECT (отделить), ERASE (стереть) и STORE (запомнить). Оператор FIND служит для определения места экземпляра записи в базе данных с целью выполнения последующих операций. Он используется в нескольких формах (модификациях), позволяющих варьировать способы поиска информации. Оператор
60
GET служит для Перенесения экземпляра записи пз базы данных в рабочую область пользователя. Оператор MODIFY —для замещения экземпляра записи базы данных на запись из рабочей области пользователя. Оператор CONNECT — для включения экземпляра записи в требуемый экземпляр набора данных. Оператор DISCONNECT — для исключения экземпляра записи из определенных наборов, его содержащих (при этом исключаемый экземпляр записи продолжает оставаться в базе данных, но более не входит ни в один из указанных наборов). Оператор ERASE служит для удаления записей из базы данных. Оператор STORE — для занесения экземпляра записи из рабочей области пользователя в базу данных. Следует заметить, что, в отличие от рассмотренных нами ранее входных языков, языки DL/1 и комитета КОДАСИЛ оперируют отдельными записями (а не множествами) и являются, по существу, подъязыками языков программирования.
3.6. Языковые средства документальных ИПС
Документальные системы применяются для поиска документов по их обобщенным описаниям. В описания документов могут включаться их наименования, краткое изложение содержания, наименования организаций — издателей документов, время и место издания, учетные номера документов и т. п. Перед вводом в ЭВМ описания документов формализуются и представляются в виде последовательностей наименований признаков и их значений. Поиск документов ведется по их формализованным описаниям, а в качестве результатов поиска могут выдаваться любые фрагменты этих описаний.
Формализованные описания документов по своей структуре аналогичны формализованным описаниям любых других объектов, и для их ввода в ЭВМ, обновления и поиска можно использовать рассмотренные нами ранее входные языки АИС. Но в документальных системах часто возникает необходимость хранить в памяти ЭВМ наряду с формализованными также и неформализованные описания документов (рефераты, аннотации) и выдавать эти описания по запросам потребителей. Это может оказывать неко-которое влияние на структуру входных языков этих систем.
Входных языков, предназначенных специально для документального поиска, очень много. Часто они отличаются друг от друга больше внешней формой, чем логическими возможностями. В большинстве из них используются логические операторы типа И, ИЛИ, НЕ, отношения порядка типа =, <, > и их отрицания и различного рода синтагматические ограничения (например, требование, чтобы термины запроса входили в одно и то же предложение реферата). Применяются также средства маскирования эле
61
Ментов запросов, их усечения и средства поиска по весовым критериям.
При использовании весовых критериев каждому термину запроса или документа присваивается числовой индекс — его «вес». В процессе поиска веса терминов запроса, совпавшие с терминами документа, суммируются, а полученная сумма сравнивается с заданным порогом значимости. Если эта сумма превосходит пороговое значение или равна ему, то документ считается релевантным, если нет, то он отвергается. «Веса» найденных документов могут также пспользоваться для пх ранжирования по степени релевантности. Языковые средства документальных систем мы кратко рассмотрим на примере систем Асод и Поиск-1 [13, 28].
Система Асод предназначена для документального и фактографического поиска в пакетном режиме. Она позволяет вести поиск документов по ключевым словам, встречающимся в их описаниях, с применением логических операторов И, ИЛИ, НЕ и ограничителей, регламентирующих требуемое взаимное расположение ключевых слов в документе. В качестве ограничителей применяются средства для указания допустимых расстояний между словами, встречающимися в одном и том же документе, для указания принадлежности слов к одному и тому же предложению или параграфу и др. Запрос можно также формулировать в виде списка ключевых слов с приписанными им весами и с указанием порогового значения суммарного веса. Кроме того, к каждому ключевому слову может быть применена операция усечения и замены его списком синонимов.
При фактографическом поиске в системе Асод используются операторы сравнения, применяемые к форматированным полям описаний документов. В качестве операторов сравнения наряду с операторами =, <, > и их отрицаниями используется также оператор маскирования, оператор сканирования (проверка вхождения заданной последовательности символов в любое место анализируемого поля) и оператор проверки попадания численного значения поля в заданный интервал.
Языковые средства системы Поиск-1 во многом сходны с языковыми средствами системы Асод. Здесь, как и в системе Асод, применяются операторы И, ИЛИ, НЕ, позиционные ограничители, операторы сравнения, оператор усечения слов и оператор маскирования. Кроме того, система предоставляет пользователю возможность работы в диалоговом режиме. При этом он может с помощью специальной команды вызвать на экран дисплея любую информацию о системе и получить помощь в использовании средств общения с нею.
ГЛАВА 4
ВНУТРЕННИЕ ЯЗЫКИ АВТОМАТИЗИРОВАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
1 В памяти ЭВМ, как и на ее входе, информация может представляться в виде позиционной, анкетной или триадной структуры (см. гл. 1), а также в виде различных сочетаний указанных структур. Наибольшее распространение получила позиционная структура с посимвольным кодированием значений признаков и фиксированной длиной полей памяти, отводимых для их записи. Весь объем сведений, хранящихся в памяти ЭВМ, представляется в виде совокупности массивов, структура которых определяется и описывается заранее. В описаниях структур массивов указываются перечни наименований признаков объектов, длина полей памяти, выделяемых для записи значений этих признаков, а также дополнительная информация, характеризующая логические связи между признаками и структуру их значений. Длина полей памяти, выделяемых для записи значений различных признаков, может быть разной, но для одного и того же признака она сохраняется постоянной. Это позволяет относительно легко определять границы отдельных сообщений и значений признаков, входящих в их состав.
Наряду с описанной структурой применяются позиционные структуры с полями переменной длины. В этом случае указывается длина каждого сообщения или вводятся на границах этих элементов массивов специальные разделительные признаки. Разделительные признаки или указатели длины необходимы и в случае анкетной и триадной структур, если при этом используется посимвольное представление информации и поля переменной длины.
Поиск информации может осуществляться путем ее последовательного просмотра или путем применения различных методов ускоренного поиска, среди которых важное место занимают методы свертывания кодов (другое их название — методы хэширования (hashing)). Суть этих методов состоит в том, что места хра-
63
нения искомых информационных записей определяются путем преобразования значений их идентификационных признаков (ключей) в соответствующие адреса.
В идеальном случае каждому значению ключевого признака должен соответствовать свой адрес памяти. Но на практике этого не получается: в результате выполнения операции хэширования в один и тот же адрес могут отображаться по несколько значений ключевых признаков, а некоторые адреса могут оказаться незанятыми. Обычно стремятся к равномерному распределению значений ключевых признаков по адресам памяти.
Если в один и тот же адрес отображаются несколько значений ключевых признаков, то по этому адресу записывается только одно из конкурирующих значений (вместе с сопровождающим его информационным сообщением), а другие значения (и соответствующие им сообщения) переносятся в область переполнения и связываются с первым значением и между собой указателями (адресными отсылками). При поиске информации сначала происходит обращение к первому сообщению, а если оно не удовлетворяет заданным условиям, то с помощью указателей просматривают ассоциированную с ним цепочку других сообщений.
Известно много различных методов свертывания кодов. Во всех них исходное значение ключевого признака рассматривается как двоичное число, которое с помощью арифметических и логических операций преобразуется в адрес. Наиболее популярными методами являются [87]: 1) метод деления значения ключевого признака на заданное число и использование в качестве адреса остатка от деления; 2) метод расчленения числа, представляющего значение ключевого признака, на равные части и суммирование этих частей; 8) возведение значения ключевого признака в квадрат и выделение из середины полученной последовательности цифр заданного количества разрядов; 4) выборка из двоичного представления значений ключевых признаков цифр, стоящих на определенных позициях (этим позициям должно соответствовать наиболее равномерное распределение нулей и единиц). Теоретические и экспериментальные исследования показали [87], что перечисленные методы примерно равноценны и дают хорошие результаты.
Информация обычно хранится в ЭВМ на внешних устройствах и вызывается для обработки в ее оперативную память.
В ЕС ЭВМ информация на внешних устройствах размещается в поименованных наборах данных. Каждый набор имеет определенную организацию. Он делится на блоки (физические записи). Блок может содержать одну пли несколько логических записей (сообщений) или часть логической записи. Размер логической записи определяется программистом, исходя иэ характера инфор-
64
нации и условий ее обработки. Если блок содержит несколько логических записей, то они называются сблокированными. Обмен информацией между оперативной памятью и внешними устройствами ведется целыми блоками.
Логические записи могут иметь форматы фиксированной длины (формат Г), переменной длины (формат V) и неопределенной длины (формат U). Длина записи не может превышать 32 756 байт. В ОС ЕС допускаются также расширенные записи переменной длины. Одна расширенная запись может размещаться в нескольких блоках.
По своей организации наборы данных делятся на последовательные, индексно-последовательные, библиотечные и прямые. Все перечисленные типы организации наборов данных могут быть реализованы только на устройствах прямого доступа. На остальных устройствах возможна лишь последовательная организация данных. В наборах данных последовательной организации записи располагаются в том порядке, в каком они вводились на внешнее устройство. Выбор записей из наборов осуществляется также в последовательном порядке. В индексно-последовательных наборах записи упорядочиваются по возрастанию значения ключа, включаемого в состав каждой записи. Обращение к записям возможно как последовательное, так и в произвольном порядке. При библиотечной организации наборы данных делятся на разделы, которые располагаются внутри наборов последовательно. Каждый раздел имеет свое имя. В библиотечный набор данных входит оглавление, содержащее имена всех разделов набора, их адреса и размеры. Обращение к разделам производится по их именам.
В наборах данных прямой организации записи располагаются в порядке, определяемом программистом. Возможно установление соответствия ме?кду некоторой частью блока (идентификатором) и адресом блока на внешнем устройстве. Записи могут обрабатываться как в последовательном, так и в произвольном порядке.
В ОС ЕС реализованы два способа доступа к данным: способ доступа с очередями и базисный способ доступа. В способе доступа с очередями осуществляется последовательное обращение к записям и обеспечиваются наибольшие удобства и сервис при программировании. Здесь производится автоматическое выделение логических записей из блоков и автоматическое объединение записей в блоки (обмен данными ведется на уровне логических записей). Осуществляется также автоматическая синхронизация программы пользователя с процессом доступа к данным, совмещение процесса обработки данных с процессом ввода-вывода данных п автоматическое выделение участков оперативной памяти (буферов) для ввода-вывода информации (автоматическое управление буфе-
5 Г. Г. Белоногов, Б. А. Кузнецов
65
рамп). Способ доступа с очередями применим к наборам данных последовательной и индекс ио-последовательной организации.
В базисном способе доступа программист должен сам предусмотреть реализацию тех функций по обмену данными, которые в методе доступа с очередями выполняются автоматически, поэтому здесь могут быть созданы более гибкие и быстродействующие программы доступа к данным. Обмен данными ведется только на уровне блоков. Базисный метод доступа применим к наборам данных любой организации.
Сочетание типа организации наборов данных со способом доступа к ним называется методом доступа. Существуют следующие основные методы доступа: методы доступа с очередями — последовательный QSAM и индексно-последовательный QISAM —и базисные методы доступа — последовательный BSAM, индексно-последовательный BIS AM, библиотечный ВРАМ и прямой BDAM. Каждому методу доступа соответствует свой набор макрокоманд и набор параметров оператора dd-предложения (оператора описания данных на языке управления заданиями).
В системах управления базами данных пользователям (прикладным программистам) предоставляются дополнительные (по сравнению с методами доступа) удобства и возможности для работы с информационными массивами. При этом общение с базами данных происходит на языках более высокого уровня, чем язык управления заданиями (см. п. 3.5).
Структура хранения информации в базах данных может быть различной. Например, в системе ИМС, относящейся к классу иерархических систем, используются четыре структуры хранения, называемые HSAM (иерархический последовательный метод доступа), HISAM (иерархический индексно-последовательный метод доступа), HDAM (иерархический прямой метод доступа), HIDAM (иерархический индексный прямой метод доступа) [30]. Хранимая база данных может иметь одну из перечисленных четырех структур, которые, в свою очередь, могут базироваться на различных методах доступа более низкого уровня (QSAM, BSAM и др.).
База данных системы ИМС со структурой HSAM может размещаться на магнитной ленте. При этом иерархический порядок обеспечивается физическим следованием сегментов (дерево сегментов развертывается в линейную последовательность в порядке «сверху вниз» и «слева направо»). Структура HISAM обеспечивает индексный доступ к корневым сегментам и последовательный к подчиненным. Структура HDAM обеспечивает прямой доступ к корневым сегментам (по значению поля упорядочения) за счет техники хэширования и организации цепочек, а к подчиненным сегментам — при помощи указателей. Структура HIDAM представля-66
ет индексный доступ к корневым сегментам и доступ посредством указателей к подчиненным сегментам. Как и в случае HISAM, здесь индексирование производится по полю упорядочения корневых сегментов, но индекс управляется не методом доступа более низкого уровня, а системой ИМС. Для представления в памяти ЭВМ баз данных сетевой и реляционной структуры могут широко использоваться указатели и методы хэширования.
Обычно в базах данных применяется посимвольное представление информации. Посимвольное представление хорошо отражает структуру сообщений на входном языке, но при этом приходится иметь дело с кодами переменной длины, что осложняет процесс обновления сведений. Указанное затруднение можно частично преодолеть путем введения ограничений на длину элементов сообщений. Но такая мера не всегда приемлема: длина текстовых элементов может изменяться в широких пределах, и это приводит к дополнительному расходу памяти (приходится ориентироваться на максимальную длину элементов). Более радикальным решением является замена исходного представления элементов сообщений на равномерные коды (коды равной длины). Такой способ кодирования особенно эффективен применительно к текстовым элементам сообщений. Переход от буквенных кодов текстов к равномерным кодам и в обратном направлении (при выдаче информации человеку) должен выполняться с помощью словарей.
Рассмотрим одну из возможных систем представления информации в памяти ЭВМ с использованием перекодировочных словарей. Будем предполагать, что на вход АИС информация поступает на формализованном языке, описанном в начале гл. 3, а затем она перекодируется и распределяется по массивам. При этом текстовые наименования понятий и цифро-буквенные обозначения заменяются на их порядковые номера по словарю, а числа и цифровые коды значений характеристик записываются в массивы без перекодировки (изменяется лишь форма представления чисел). Кодирование и декодирование нечисловых наименований понятий выполняется автоматически.
Словарь наименований понятий может быть организован как словарь словоформ. Если наименование понятия выражается не отдельным словом, а сочетанием слов, то оно автоматически преобразуется в непрерывную цепочку символов и в дальнейшем интерпретируется как целостная словоформа. Преобразование словосочетания в псевдословоформу осуществляется путем замены пробелов между словами на знак подчеркивания. При кодировании информации знак подчеркивания снова заменяется на пробел. Таким образом, в памяти ЭВМ приходится оперировать с двумя основными типами массивов: словарь словоформ, массивы сообщений о признаках (характеристиках) объектов.
5*
67
В табл. 4.1 представлена структура одного модуля (участка) словаря словоформ. Модуль состоит из трех частей: массива буквенных кодов словоформ, первой и второй адресной части. В массиве буквенных кодов перед каждой словоформой указывается количество букв Li, входящих в ее состав. Во второй адресной части размещены двухэлементные записи, в которых на первой позиции указываются начальные адреса Ло словоформ в массиве буквенных кодов, на второй позиции — коды связи Кс». Количество записей во второй адресной части в точности равно количеству
Таблица 4.1
Структура модуля словаря словоформ
Первая адресная часть
-^вхО ^вх! ^вх2 ... Л Лвхт
Вторая адресная часть
^01 ^02 ^03 ...
«СВ1 ^св2 ^свЗ ... ^свп
Массив буквенных кодов словоформ
различных словоформ. Коды (адреса) связи объединяют в ассоциативные цепочки записи, соответствующие словоформам с одинаковыми двумя начальными буквами. При этом порядок перехода от одной записи к другой определяется алфавитным порядком следования словоформ. Номера позиций записей интерпретируются как номера словоформ и используются в АИС в качестве системных номеров понятий.
Вход во вторую адресную часть модуля осуществляется с помощью первой адресной части, в которой указаны начальные адреса Авх ассоциативных цепочек второй адресной части. Обращение к местам записи адресов Ап производится по кодам свертки словоформ. Коды сверток формируются по'кодам двух начальных букв словоформ. При этом исходная последовательность двоичных символов делится на участки, которые суммируются друг с дру-
68
гом. Могут применяться и другие способы получения кодов сверт-ки. Численные значения кодов сверток интерпретируются как адреса мест записи адресов Лвх.
Первая адресная часть модуля имеет фиксированный объем (количество позиций для записи адресов Лвх равно количеству различных кодов свертки). Вторая адресная часть и массив буквенных кодов словоформ имеют переменный объем. В процессе формирования модуля они заполняются постепенно, по мере поступления новых словоформ. При этом у второй адресной части фиксируется ее начало, а у массива буквенных кодов словоформ — его конец, так что у обоих массивов оказывается общий резерв свободной памяти.
Приведенная в табл. 4.1 структура модуля словаря позволяет при обращении к нему ограничить область поиска множеством словоформ с одинаковыми кодами свертки, а алфавитный порядок связи словоформ в ассоциативных цепочках делает излишним просмотр этих цепочек до конца. При исключении словоформ из словаря их буквенные коды затираются, а коды связи исключаются из ассоциативных цепочек. При этом адреса отсылки Ло во второй адресной части ц указатели Li в массиве буквенных кодов словоформ сохраняются, а освободившиеся позиции кодов связи используются для создания ассоциативной цепочки участков свободной памяти. В дальнейшем эти участки могут использоваться для записи новых словоформ (если последние имеют такую же длину, что и ранее исключенные).
Словарь словоформ может состоять из нескольких модулей. Максимальный объем одного модуля зависит от выделенной для него емкости оперативной памяти и от емкости позиций, отводимых в первой и второй адресной части для записи кодов связи и отсылочных адресов. Если емкость этих позиций равна двум байтам, то модуль может иметь объем порядка 102 килобайтов. На количество модулей в словаре ограничений не накладывается.
Для хранения основных массивов сведений о признаках объектов может быть использована ассоциативно-адресная структура, представляющая собой последовательность элементарных триад, в которой одинаковые коды понятий объединены в ассоциативные цепочки. Структура одного модуля массива сообщений приведена в табл. 4.2. Как и в случае словаря словоформ, эта структура имеет две адресные части. Они предназначены для перехода от системных кодов понятий к местным (с целью экономии памяти) и для ускорения процессов поиска информации в массиве сообщений.
Системные коды понятий представляют собой их номера по словарю словоформ или числа (числовые понятия), а местные коды — порядковые номера строк во второй адресной частп. Все элементы модуля, за исключением системных кодов понятий, имеют
69
длину два байта; системные коды понятий — как правило, четыре байта. Более четырех байтов могут занимать числовые понятия. Для их записи может дополнительно выделяться объем памяти, кратный восьми байтам. Перед кодами числовых понятий указывается их длина.
Во второй адресной части модуля каждому коду понятия поставлена в соответствие одна строка (для длинных кодов чисел
Таблица 4.2
Ассоциативно-адресная структура модуля массива сообщений Первая адресная часть
вкО ВХ1 вх2 ... вхй
Вторая адресная часть
^01 ^св!
02 %св2 Объекты
• • • •.. . • •
А от 1Z ЛСВ7П
1Z Л-свтп4-1
^от+2 ^свт+2 Характеристики и
• • • значения характерис-
тик
^ОП *свп -
Массив сообщений
^0 Vм Лоб № ^0 ДГМ 3
Vм Л об ^0 я и ^0 “ а
... ... . • • • W * • •е
^0 /Vм А об 0 Vм X Л 0 S
может отводиться по несколько строк). В строке записывается системный код понятия Лп, адрес Ао первого вхождения понятия в массив сообщений и код связи ХСв (см. табл. 4.2). С помощью кодов связи системные коды понятий, имеющие одинаковые коды свертки, объединяются в ассоциативные цепочки. Начальные ад
70
реса Лвх этих цепочек фиксируются в первой адресной части модуля.
Обращение к местам записи адресов Авх осуществляется по кодам свертки. Коды свертки формируются по системным кодам понятий путем пересчета в них количества значащих двоичных цифр и выделения их старших разрядов. Результат выполнения первой операции заносится в левую часть кода свертки, а результат выполнения второй — в правую.
Массив сообщений состоит из последовательности местных кодов объектов характеристик N™ и значений характеристик сопровождаемых адресами отсылки Ло (см. табл. 4.2). Адреса отсылки объединяют в ассоциативные цепочки одинаковые местные коды понятий (начала этих цепочек фиксируются во второй адресной части). Функциональная роль понятий в сообщениях выражается позиционными средствами: на первом месте в каждом элементарном сообщении стоит код объекта на втором — код характеристики N*, на третьем — код значения характеристики N* . Она частично отражена также и в структуре второй адресной части: здесь сначала идут системные коды объектов с сопровождающими их адресными отсылками и кодами связи, затем — системные коды характеристик и значения характеристик. Такое расположение кодов понятий во второй адресной части удобно для формирования логических шкал объектов при выполнении поисковых операций.
Поиск информации в модуле, показанном в табл. 4.2, можно осуществлять путем прослеживания вхождений в массив сообщений всех заданных в запросе признаков и выполнения операций с логическими шкалами объектов. Количество разрядов в логических шкалах равно количеству объектов в модуле, а местные коды объектов (номера строк второй адресной части) интерпретируются как номера двоичных разрядов шкалы. В процессе поиска каждое вхождение признака в элементарное высказывание отмечается символом 1 в разряде, соответствующем местному коду объекта в этом высказывании, а по окончании просмотра массива в логической шкале окажутся отмеченными все разряды, соответствующие объектам, обладающим заданным признаком.
Логические связи между поисковыми признаками типа конъюнкции, дизъюнкции и отрицания реализуются путем пересечения шкал, их объединения и инвертирования. В результате последовательного выполнения этих операций формируется шкала, в которой оказываются отмеченными разряды, соответствующие искомым объектам. Заменяя далее отмеченные разряды на их номера (на местные коды объектов), можно выбрать по ним нужную информацию. Местные коды объектов, характеристик и значений ха
71
рактеристик с помощью второй- адресной части заменяются на системные коды, а последние с помощью словаря словоформ могут быть заменены на буквенные коды. Если требуется выдавать не все сведения об объектах, а только часть их, то в запросе, наряду с поисковыми признаками, следует указывать еще и перечень признаков, подлежащих выдаче.
Структура массивов, показанная в табл. 4.2, удобна при выполнении операций поиска и обновления информации об объектах
Таблица 4.3
Позиционная структура модуля массива сообщений
Первая адресная часть
^вхО вх! ^вх2 ... ^вхт Характеристики
^вхО вх1 вх2 ^вхп Объекты
^вхО ^ВХ1 ^вх2 ^вхй Значения характеристик
Вторая адресная часть Массив сообщений
*СВ1 ^свтп *х1 Характеристики *01 *02 *ОП /Vм. Х1 Л пи №21 *ПП1 *Х2 *п12 *П22 *пп2 ... NM хт 1У nlm л п2ш 1У ппт
*св! ^СВП *01 *оп Объекты
г?5 . 4^ W, * W. *п *п ’ Значения характеристик
произвольной природы. Но на практике часто возникает необходимость хранения в памяти ЭВМ сведений об однородных объектах — объектах, имеющих одинаковые наборы наименовании характеристик. Тогда может быть применена более компактная структура, показанная в табл. 4.3 и получившая наименование позиционной. Эта структура может быть использована также в ка
72
честве промежуточной при выполнении процедур обобщения и редактирования информации.
Модуль в табл. 4.3 вклтрчает в свой состав две адресные части и массив сообщений. Первая и вторая адресные части этого модуля аналогичны соответствующим компонентам модуля в табл. 4.2. Отличие заключается в том, что в структуре модуля в табл. 4.3 вторая адресная часть не содержит адресных отсылок Ло к массиву сообщений и она разделена на три участка, в которых размещены системные коды характеристик NXl объектов NQ и значений характеристик Nn с сопровождающими их кодами связи. Вход в каждый участок осуществляется независимо, поэтому в первой адресной части предусмотрено три списка адресов Лвх.
Раздельное размещение во второй адресной части системных кодов объектов и характеристик необходимо для получения непрерывных рядов численных значений их местных кодов, что в свою очередь создает удобства при организации массива сообщений. Массив сообщений в табл. 4.3 представляет собой матрицу, строки которой обозначены местными кодами объектов Nq , столбцы — местными кодами характеристик N* , а на пересечении строк и столбцов указаны местные коды значений характеристик
Коды N™ и N™ упорядочены по возрастанию их численных значений и выступают в роли номеров строк и столбцов матрицы.
Выборка элементов матрицы по местным кодам объектов и характеристик выполняется без перебора (путем вычисления адресов их записи), а поиск объектов по произвольным логическим условиям сводится к просмотру столбцов матрицы, соответствующих указанным в запросе характеристикам, и выполнению операций над логическими шкалами. При этом номера строк матрицы интерпретируются как номера двоичных разрядов логической шкалы. Как и в случае ассоциативно-адресной структуры модуля, здесь отмеченные двоичные разряды результирующей логической шкалы заменяются их номерами, а последние используются для обращения к строкам матрицы. Из строк выбираются местные коды характеристик, указанных в поисковом предписании. Местные коды объектов, характеристик и значений характеристик заменяются далее на их системные коды с помощью второй адресной части модуля.
Первая адресная часть модуля, показанного на рис. 4.3, имеет постоянный объем. Объем первого и второго участка второй адресной части (списков характеристик и объектов) также фиксируется заранее. Граница же между списком системных кодов значений характеристик и массивом сообщений заранее не определяется, а возникает в процессе первоначального формирования модуля. При этом массив сообщений и массив системных кодов зна
73
чений характеристик заполняются навстречу друг другу (аналогичным образом определяется граница между второй адресной частью и массивом сообщений в модуле, показанном в табл. 4.2). Обновление информации в структуре (табл. 4.3) осуществляется путем изменения состава элементов матрицы. В случае необходимости вносятся также коррективы и во вторую адресную часть этой структуры.
Структура, показанная в табл. 4.3, является наиболее компактной из всех ранее рассмотренных нами структур. Однако она непригодна для представления сведений о разнородных объектах. Но если ее модифицировать, то с ее помощью можно описывать разнородные объекты с одинаковым или примерно одинаковым количеством признаков. При этом количество различных наборов наименований признаков, характеризующих объекты, должно быть ограниченным.
Существо модификации заключается в том, что вместо одного перечня наименований характеристик вводится столько перечней, сколько можно выделить групп однородных объектов. Перечням присваиваются порядковые номера, и они записываются в раздел «массив сообщений» модуля, а разделы «характеристики» из его первой и второй адресной части исключаются. Описания конкретных объектов представляются в массиве сообщений строками местных номеров значений характеристик с указанием в каждой строке соответствующего номера перечня наименований характеристик. Порядок следования значений характеристик и соответствующих им наименований характеристик должны совпадать. При составлении предписаний на поиск и обновление информации наряду с обычными их компонентами указываются также номера (или имена) используемых перечней наименований характеристик. Это позволяет правильно интерпретировать хранящуюся в массивах информацию.
Если описания объектов имеют различную длину, то можно ввести для перечней значений характеристик и соответствующих им перечней наименований характеристик знаки переноса (адресные отсылки), указывающие на их продолжение в других строках таблицы. При этом составные части перечней не обязательно должны располагаться в соседних строках.
В автоматизированной информационной системе массивы информации могут иметь различную структуру. Более того, в разных модулях массивов одни и те же понятия могут иметь различные кодовые обозначения (различные местные коды). Поэтому для передачи информации между массивами целесообразно применять специальный Обменный формат (см. табл. 4.4). Он представляет собой последовательность триад, каждая из которых содержит системный код объекта, системный код характеристики и систем-
74
ный код значения характеристики. Системные коды понятий занимают по четыре байта, а триады — по двенадцать байтов. Числовые значения характеристик представляются в упакованном десятичном формате (по две цифры в одном байте) и могут быть переменной длины. Если длина числа превосходит четыре байта, то для его записи отводится дополнительно двенадцать байтов или
Таблица 4.4
Обменный формат для массива сообщений
Об1 Л%1
^об2 х2 *з2
Лг 2 ’ обт хт *зт
число байтов, кратное двенадцати. Длина числа указывается перед его началом.
Кроме перечисленных основных форм представления информации в памяти ЭВМ в АИС приходится использовать и другие форматы данных: 1) побуквенно закодированные тексты (сообщения, запросы) на входном языке; 2) тексты на входном языке, представленные в системных кодах понятий; 3) побуквенно закодированные результаты поиска и обобщения информации в анкетной форме; 4) побуквенно закодированные результаты поиска и обобщения информации в табличной форме и др.
При переходе от буквенных кодов к системным формализованные тексты представляются в виде последовательностей номеров нечисловых понятий и чисел/При этом каждому элементу текста назначается один из следующих синтаксических признаков: признак начала, признак конца, признак разделительного знака, признак числа, признак нечислового понятия, признак отношения, признак логической операции. Структура входного текста, в которой системным кодам понятий поставлены в соответствие их синтаксические признаки, имеет следующий вид:
ВД
R 2% 2
RnXn
Здесь Xi, Х2, ..., Хп — системные коды понятий; Z?i, Т?2, ... ,.Rn — синтаксические признаки понятий. Далее, на основе этой структуры может формироваться массив элементарных триад (см. табл. 4.4).
75
ГЛАВА 5
ПРОГРАММНЫЕ СРЕДСТВА АВТОМАТИЗИРОВАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
5.1. Структура программных средств АИС
Автоматизированную информационную систему можно рассматривать как совокупность входного языка, интерпретирующей программной системы для выполнения предписаний на этом языке и массивов сведений о признаках объектов. При этом предполагается, что внутренние языки АИС являются принадлежностью интерпретирующей программной системы. Входной язык и интерпретирующая программная система составляют основу АИС, а массивы сведений отражают специфику ее конкретного применения.
Интерпретирующая программная система выполняет функции, связанные со вводом, обновлением, поиском, обобщением и редактированием информации. Эти функции могут быть реализованы в виде соответствующих самостоятельных программ или в виде наборов функциональных блоков — модулей, являющихся типовыми процедурами преобразования информации. Изменяя состав функциональных блоков и порядок их работы, можно строить различные технологические цепочки обработки информации. Эффективность такого подхода зависит от выбора функциональных блоков: если блоки представляют собой наиболее типичные, часто повторяющиеся процедуры обработки информации, то успех обеспечен; если же они выбраны недостаточно обоснованно, то возможности построения различных технологических цепочек будут ограниченными. Состав функциональных блоков целесообразно определять, исходя из структуры входного языка, языков представления информации в памяти ЭВМ и операций над массивами.
Как было показано в гл. 4, в автоматизированных информационных системах, ориентированных на представление информации равномерными кодами, приходится иметь дело с двумя основными типами массивов — с перекодировочными словарями и с массивами
76
сообщений о признаках объектов.. В отношении каждого из них требуется выполнять операции формирования, обновления и поиска. Соответственно этому необходимо иметь функциональные блоки для формирования массивов, их обновления и поиска в них. При наличии в АИС нескольких структур представления данных возникает также необходимость в операциях перехода от одних структур к другим. Кроме того, нужны программные средства для перехода от структуры входного языка к внутренним форматам представления информации, программные средства для обобщения информации и программные средства для перехода от внутренних форматов к форматам выходных документов. Управление последовательностью работы функциональных блоков должно осуществляться специальной программой-диспетчером.
Рассмотрим состав основных функциональных блоков экспериментальной АИС, построенной исходя из структуры входного языка и внутренних форматов представления информации, описанных в гл. 3 и гл. 4. При этом каждый блок будем характеризовать его назначением и форматами данных на входе и выходе. Перечень блоков приведен в табл. 5.1, а перечень форматов в табл. 5.2. Во второй графе табл. 5.1 указаны мнемонические обозначения (имена) блоков, в третьей графе — режимы работы этих блоков (в тех случаях, когда функциональные, блоки могут иметь несколько режимов работы),, в четвертой графе — назначение блоков. Имена функциональных блоков составлены из начальных букв и буквосочетаний ключевых слов текстов, характеризующих назначение этих блоков.
Первый блок табл. 5.1 (СИНКОП) выполняет функцию синтаксического контроля сообщений (запросов), представленных на входном языке. Он проверяет наличие в сообщениях обязательных компонент, баланс скобок (равенство числа открытых и закрытых скобок), наличие и количество пробелов между элементами сообщений. При обнаружении ошибок в синтаксической структуре входных сообщений они либо исправляются, либо некорректные сообщения выдаются на регистрирующее устройство (АЦПУ, дисплей) вместе с необходимыми пояснениями. Кроме того, блок СИНКОП заменяет в словосочетаниях пробелы между словами на знак подчеркивания. В результате такой замены вместо исходных словосочетаний получаются слитные последовательности букв, которые в дальнейшем рассматриваются как словоформы и в таком виде включаются в словарь. При декодировании информации и выдаче ее на печать знак подчеркивания снова заменяется пробелом (в блоках АНКАЦПУ и ТАБЛ АЦПУ).
Блок КОДСЛОВ (см. п. 2 табл. 5.1) предназначен для формирования словаря словоформ, его обновления и замены буквенных кодов слов на их номера по словарю. Он может работать > трех
77
Таблица 5.1
Перечень основных функциональных блоков
Аг п п Имя блока Режим работы Назначение
1 СИНКОП синтаксический контроль входных сообщений и запросов (проверка правильности п корректировка их синтаксической структуры); преобразование словосочетаний в псевдословоформы (в словосочетаниях вместо пробелов между словами вставляется знак подчеркивания)
2 кодслов П О 3 кодирование слов по словарю словоформ без его пополнения кодирование слов по словарю словоформ с пополнением словаря удаление из словаря словоформ заданно- го перечня его элементов
3 СИНАИ — синтаксический анализ входных сообщений и запросов и назначение их элементам синтаксических признаков
4 АНКТГИ преобразование массива сообщений, представленного на входном языке в анкетной форме с буквенными или цифробуквенными обозначениями признаков, в массив триад
5 АНКНРТРИ — преобразование массива сообщений, представленного на входном языке в анкетной форме с цифровыми обозначениями (номерами) признаков, в массив триад
6 ПОЗТРИ — преобразование массива сообщений, представленного на входном языке в позиционной форме, в массив триад
7 ФОРММОД ф 3 формирование (пополнение) модулей массивов сообщений ассоциативно-адресной структуры затирание информации в модулях массивов сообщений ассоциативно-адресной структуры
8 ПОИСКА — поиск в модулях массивов сообщений ассоциативно-адресной структуры
9 ТРИТАБЛ ф 3 формирование (пополнение) модулей массивов сообщений позиционной структуры (преобразование массива триад в табличную структуру) затирание информации в модулях массивов сообщений позиционной структуры
10 ПОИСКТ — поиск в модулях массивов сообщений по-1 зиционпон структуры
78
Таблица 5.1 (продолжение)
Лв п п Имя блока Режим работы Назначение
11 ТАБЛТРИ — перевод модуля массива сообщений из позиционной структуры в массив триад
12 ДЕКСЛОВ —• декодирование слов (замена системных номеров слов буквенными кодами этих слов)
13 АНКАЦПУ —• декодирование массива триад, представленного в системных кодах, и выдача его на АЦПУ в анкетной форме
14 ТАБЛАЦПУ — декодирование информации, представленной в табличной форме, ее редактирование и выдача на АЦПУ
15 СУМТАБЛ — процедура обобщения числовой информации (получение обобщенных характеристик обобщенных объектов) на основе ее табличного представления
16 СУММОД — процедура обобщения числовой информации, хранящейся в модулях массивов сообщений ассоциативно-адресной структуры
17 АИСПП — переход от обменного формата для массивов сообщений АИС к форматам исходных данных прикладных программ (расчетных задач)
18 ППАПС — переход от форматов исходных данных прикладных программ к обменному формату для массивов сообщений АИС
19 АНКВХ — переход от анкетной формы представления входной информации к структуре входного языка АИС
20 ТАБЛВХ — переход от табличной формы представления входной информации к структуре входного языка АИС
21 ЗАПРОС процедура, обеспечивающая формирование библиотеки запр< сов на входном языке, ее обновление, а также выборку запросов из библиотеки по их номерам с целью последующего выполнения
22 ДИСПАПС — диспетчер автоматизированной информационной системы
79
Таблица 5.2
Перечень форматов представления данных на входе и на выходе функциональных блоков
Кв п/п Наименование и краткая характеристика форматов
1 2 Сообщения и запросы на входном языке в побуквенном коде Сообщения и запросы на входном языке, скорректированные в результате выполнения процедуры синтаксического контроля
3 Сообщения и запросы на входном языке, у которых слова и словосочетания заменены их порядковыми номерами по словарю словоформ, а перед числами стоит признак побуквенного кодирования. Числа записаны в символьном формате
4 Результаты синтаксического анализа. Здесь нечисловые понятия представлены их порядковыми номерами по словарю, а числа — в символьном формате. Каждый код понятия сопровождается синтаксическим признаком (см. гл. 4). Порядок следования кодов понятий такой же, что и во входных сообщениях и запросах
5 Обменный формат для массивов сообщений. Этот формат представляет собой последовательность триад, каждая из которых содержит системный код объекта, системный код характеристики и системный код значения характеристики
6 7 Структура модуля словаря словоформ — гл. 4 Структура модуля массива сообщений (ассоциативно-адресная структура массива триад) — гл. 4
8 9 Позиционная структура модуля массива сообщений — гл. 4 Список буквенных кодов нечисловых понятий. Используется для входа в словарь словоформ
10 Анкетная форма представления входной и выходной информации с побуквенным кодированием понятий
И Табличная форма представления входной и выходной информации с побуквенным кодированием понятий
12 Форма представления исходных данных на входе расчетной задачи и результатов решения на ее выходе
13 Перечень буквенных кодов слов, получаемый в результате их декодирования. Перед каждым словом указывается его длина в байтах
режимах —в режиме П (поиск), в режиме О (обновление) и в режиме 3 (затирание). В режиме П происходит кодирование слов без пополнения словаря; в режиме О — кодирование с его попол*-ненпем или только пополнение словаря без использования результатов кодирования; в режиме 3 — исключение из словаря его эле-
80
ментов, указанных в виде, списка буквенных кодов слов. Обновление словаря осуществляется путем последовательного выполнения предписаний на ввод новых слов и затирание ненужных. При этом пополнение словаря может осуществляться одновременно с вводом в АИС сообщений о признаках объектов или на основе специальных сообщений, содержащих перечни вводимых слов.
Блок СИНАИ (п. 3 табл. 5.1) выполняет функцию синтаксического анализа сообщений (запросов) на входном языке после их кодирования по словарю словоформ. При этом каждому элементу сообщения присваивается соответствующий синтаксический признак (признак нечислового понятия, признак числа, разделительный признак и т. п.). В процессе анализа составляется таблица размещения компонент сообщений, в которой указывается место записи начала и конца каждой компоненты. Эта таблица в дальнейшем используется при обращении к компонентам сообщений.
Блоки 4, 5, 6 табл. 5.1 (блоки АНКТРИ, АНКНРТРИ, ПОЗТРИ) служат для преобразования массивов входных сообщений в последовательность триад, принятую в качестве внутреннего обменного формата АИС. Для всех этих блоков исходной структурой данных является формат 4 табл. 5.2 (результаты работы блока СИНАН). Блок АНКТРИ преобразует в последовательность триад массив сообщений, который на входном языке представляется в анкетной форме с буквенными или цифро-буквенными обозначениями наименований признаков (см. гл. 3). Блок АНКНРТРИ преобразует в последовательность триад массив сообщений, который на входном языке представляется в анкетной форме с цифровыми обозначениями (номерами) наименований признаков. При этом номера наименований признаков в точности совпадают с их порядковыми номерами в перечнях признаков, описывающих соответствующие формы ввода информации. Блок ПОЗТРИ преобразует в последовательность триад массив сообщений, который на входном языке представляется в позиционной форме. При этом порядок следования значений признаков во входном сообщении в точности соответствует порядку следования их наименований в описании формы ввода информации.
Блок ФОРММОД (п. 7 табл. 5.1) предназначен для формирования и обновления модулей массивов сообщений ассоциативно-адресной структуры. Формирование и обновление модулей осуществляется на основе исходных данных, представленных в виде последовательностей триад. Блок может работать в двух режимах—* в режиме Ф (формирование) п в режиме 3 (затирание). В режиме Ф производится первоначальное формирование массивов и их пополнение новыми элементами, в режиме 3 — исключение из массивов ненужных элементов.
6 Г. Г. Белоногов, Б А. Кузнецов
81
Блок ПОИСКА осуществляет поиск в массивах сообщений объектов, удовлетворяющих заданным в запросе логическим условиям, и выборку сведений об этих объектах. Логические условия поиска задаются в компоненте НАЙТИ запроса, а условия выборки сведений—в компоненте ВЫБРАТЬ (см. гл. 3). Блок предназначен для поиска в массивах ассоциативно-адресной структуры. В результате его работы формируется массив триад. Блок аналогичного назначения, осуществляющий поиск в массивах позиционной (табличной) структуры, имеет имя ПОИСКТ (п. 10 табл. 5.1).
Переход от обменного формата представления массивов сообщений (последовательности триад) к табличной (позиционной) форме представления этих массивов осуществляется с помощью блока ТРИТАБЛ (п. 9 табл. 5.1). В режиме Ф этот блок может формировать позиционную структуру представления данных, в режиме 3 — исключать из массивов ненужные сведения. Обратная операция — переход от табличной структуры к последовательности триад — выполняется блоком ТАБЛТРИ (п. И табл. 5.1).
Декодирование сообщений, выдаваемых на печать, и их оформление в виде выходных документов осуществляется блоками ДЕКСЛОВ, АНКАЦПУ, ТАБЛАЦПУ (пп. 12, 13, 14 табл. 5.1). Блок ДЕКСЛОВ декодирует наименования понятий (заменяет их системные номера на соответствующие буквенные коды), блок ТАБЛАЦПУ окончательно оформляет табличный документ. Если документ выдается в анкетной форме, то в качестве исходного массива используется массив триад, а его декодирование и редактирование выполняет блок АНКАЦПУ. Этот блок объединяет в себе функции, аналогичные функциям, выполняемым блоками ДЕКСЛОВ, ТАБЛАЦПУ при выдаче табличных документов.
Блоки СУМТАБЛ и СУММОД (пп. 15, 16 табл. 5.1) предназначены для обобщения информации. Их функции аналогичны, но один из них, СУМТАБЛ, работает с позиционной структурой представления исходных данных, другой, СУММОД,— с ассоциативноадресной. Результаты работы в обоих случаях представляются в виде последовательностей триад. Обобщение информации осуществляется на основе предписаний, содержащихся в компоненте ВЫДАТЬ (см. гл. 3).
При решении расчетных задач на основе сведений, хранящихся в массивах АИС (в ее базе данных), возникает необходимость перевода этих сведений в форму, удобную для выполнения вычислительных операций. По окончании решения результаты должны возвращаться в базу данных для их последующего документирования или использования в качестве исходных данных при решении других расчетных задач или для обобщения информации. Поэтому в АИС целесообразно предусмотреть блоки, обеспечивающие переход от обменного формата массивов сообщений к форматам исход
82
ных данных для расчетных задач (прикладных программ) и от форматов исходных данных расчетных задач к обменному формату (блоки АИСПП и ППАИС). Наличие в системе блоков АИСПП и ППАИС позволяет решать комплексы расчетных задач.
Описанный в гл. 3 входной язык предоставляет несколько возможностей для ввода информации: ввод в анкетной структуре, ввод в анкетной структуре с цифровыми обозначениями наименований признаков, ввод в позиционной структуре. Но на практике часто возникает необходимость вводить информацию в ЭВМ в том же виде, в каком она выдается потребителям (в анкетной или в табличной форме). Для этой цели служат блоки АНКВХ (анкетный вход) и ТАБЛВХ (табличный вход). Эти блоки преобразуют входные документы, представленные в виде заполненной анкеты или таблицы, в анкетную структуру входного языка с цифровыми обозначениями признаков. Далее преобразованная информация обрабатывается по тем же правилам, что и информация, представленная на входном языке.
Запросы на поиск информации и ее обработку, а также некоторые компоненты запросов на ввод и обновление информации могут подготавливаться пользователями заблаговременно. Формирование библиотеки запросов па входном языке, ее обновление, а также выборку запросов из библиотеки по их номерам с целью последующего выполнения осуществляет блок ЗАПРОС. Выполнение всех предписаний, формулируемых на входном языке, ведется под управлением диспетчера системы ДИСПАИС.
В начале главы указывалось, что различные режимы работы АИС могут быть реализованы путем формирования различных последовательностей функциональных блоков (различных траекторий решения задач). При включении блоков в траектории необходимо проверять, обеспечено ли поступление на их вход информации требуемой структуры. Помимо согласования форматов представления данных, требуется также осуществлять привязку про-грам1и функциональных блоков к адресам хранения информационных массивов (наборов данных). Операционные системы ЕС ЭВМ предоставляют такую возможность на уровне имен наборов данных, интерпретируемых как адреса записи соответствующих массивов. Поэтому в АИС всем массивам информации и всем программным модулям могут присваиваться имена. Эти имена (точнее, имена соответствующих DD-предложений) могут использоваться в дальнейшем для обращения к массивам и программам.
Каждый функциональный блок АИС, в зависимости от его сложности, может быть реализован в виде одного или нескольких программных модулей. Если блок реализован в виде нескольких модулей, то в его состав должен входить управляющий модуль, определяющий очередность работы остальных модулей этого блока.
G-:
83
Управляемые модули блоков должны выполняться в виде программ простой структуры, т. е. таких программ, которые возвращают управление вызвавшей их программе и никогда не вызывают другие программные модули. Управляющие модули блоков вызываются в память ЭВМ главной управляющей программой (главным диспетчером) системы.
Таким образом, в рассматриваемой структуре АИС применяется иерархический принцип управления. На первом (верхнем) уровне иерархии находится главная управляющая программа (главный диспетчер) системы, на втором уровне — управляющие программы функциональных блоков (местные диспетчеры), на третьем (нижнем) уровне — управляемые программные модули, входящие в состав функциональных модулей. В функции главного диспетчера системы входит обеспечение необходимой очередности работы функ? циональных блоков в процессе решения той или иной задачи. Местные диспетчеры блоков обеспечивают выполнение команд главного диспетчера путем организации работы управляемых ими программных модулей в определенной последовательности. Главный диспетчер может обращаться непосредственно как к местным диспетчерам функциональных блоков, так и к функциональным модулям (если блок состоит из одного модуля).
В АИС рассматриваемой структуры траектории решения задач описываются на входном языке в компоненте ЗАДАЧА (см. гл. 3). Описания траекторий представляют собой перечни имен функциональных блоков и операторов условного и безусловного перехода. В процессе работы системы главный диспетчер включает функциональные блоки в работу в порядке следования их имен в описаниях траекторий или в порядке, указанном в операторах условного и безусловного перехода. При выполнении оператора условного перехода главный диспетчер анализирует некоторый признак Р, выработанный функциональным блоком, предшествующим этому оператору, и, в зависимости от значения признака Р (0 или 1), включает в работу один из двух блоков, указанных в операторе.
Для типовых, часто используемых режимов работы системы описания траекторий решения задач могут составляться заблаговременно и включаться в библиотеку траекторий. При этом каждому описанию может присваиваться его мнемоническое обозначение — имя, которое будет являться одновременно и именем соответствующего режима работы. Если на входном языке в компоненте ЗАДАЧА указывается не полное описание траектории, а только его имя, то главный диспетчер должен выбрать из библиотеки полное описание траектории и затем реализовать необходимый режим работы.
Работа АИС должна начинаться с вызова в оперативную память ЭВМ главного диспетчера системы и передачи ему управле
84
ния. Вызов осуществляется операционной системой по информации, указанной в операторе EXEG на языке управления заданиями (во входном потоке). Одновременно с вызовом в оперативную память главного диспетчера АИС в нее вводятся описания необходимых для работы наборов данных (DD-предложения). С началом работы главного диспетчера из специального набора данных вводится очередной запрос и начинается анализ указанной в нем траектории решения задачи. По имени первой программы, записанной в траектории, вызывается соответствующий программный модуль, и передается ему управление. При этом, в случае необходимости, программе сообщается режим, в котором она должна работать.
По окончании работы программа возвращает управление главному диспетчеру и передает ему код возврата (код завершения работы). В случае нормального завершения работы диспетчер вызывает следующую программу, указанную в траектории, и передает ей управление. В случае ненормального — прекращает решение задачи и распечатывает диагностические сообщения (путем обращения к соответствующей программе). Решение прекращается также по окончании работы последней программы, указанной в траектории. Если на вход системы подается не один, а несколько запросов, то они выполняются последовательно друг за другом в автоматическом режиме вплоть до окончания обработки всей серии запросов.
5.2. Формирование и обновление массивов информации
Формирование и обновление массивов информации может осуществляться в различных режимах работы АИС. Эти режимы, в свою очередь, могут описываться в различных терминах и с различной степенью подробности. Чтобы сделать описание более наглядным, представляется целесообразным опереться на определенный класс языковых средств и фиксированный набор процедур преобразования информации. Поэтому в дальнейшем изложении будут использоваться ранее описанные нами языковые и процедурные средства. Рассмотрим основные режимы работы АИС по формированию и обновлению массивов информации.
1. Ввод информации на входном языке в анкетной форме с полными наименованиями признаков объектов. Имя траектории решения задачи —- ВВОДАНК. Описание траектории при вводе ее в библиотеку траекторий имеет вид
ЗАДАЧА— (ИМЯ = ВВОДАНК, ПГМ1 = СИНКОН,
ПГМ2 « КОДСЛОВ, РЕЖИМ «= О, ПГМЗ « СИНАН,
ПГМ4 « АНКТРИ, ПГМ5 » ФОРММОД,
РЕЖИМ = Ф, ПГМ6 = АНКАЦПУ).
85
Предписание на ввод информации имеет вид
НАЧАЛО: АБОНЕНТ—(ИВАНОВ), ЗАДАЧА — (ВВОД АНК), МАССИВ - (3), ВВЕСТИ: О — (01), П— (А = aJB = bJC = cj D = dJE = ed...]Z = Z1), О - (o2), П - (A = a2/B == 62/ C = c2/D = d*/E = e2/ ... /Z =? z2), ..., О — (о,), Я — (A == a,/ В = b{/C = a/D = di/E == ei/ ..JZ = Zi/t КОНЕЦ.
В процессе ввода информации сначала производится ее синтаксический контроль (блок СИНКОН). При этом в наименованиях признаков объектов и значений этих признаков пробелы между словами заменяются на знак подчеркивания. Затем словоформы и псевдословоформы исходного сообщения кодируются по словарю словоформ (блок КОДСЛОВ). При необходимости словарь словоформ дополняется новыми элементами (блок КОДСЛОВ работает в режиме О — обновление). Закодированное сообщение подвергается синтаксическому анализу (блок СИН АН), после чего его компонента ВВЕСТИ преобразуется в последовательность триад (блок АНКТРИ). Далее сведения, содержащиеся в компоненте ВВЕСТИ, вводятся в один из модулей массива № 3, указанного в компоненте МАССИВ. При этом блок ФОРММОД работает в режиме Ф (формирование и пополнение модулей массивов сообщений). Введенные сведения декодируются и выдаются на печать в анкетной форме (блок АНКАЦПУ). В качестве исходных данных для блока АНКАЦПУ служит последовательность триад, сформированная в результате работы блока АНКТРИ.
Если в процессе ввода информации выясняется, что часть вводимых сведений уже имеется в массиве, то эти сведения повторно не записываются; если у объектов изменились только значения признаков, а их наименования остались прежними, то в процессе ввода производится замена старых значений признаков на новые. Новые признаки объектов, ранее учтенных в системе, равно как и сведения о новых объектах, записываются в модули массивов сообщений на свободные поля памяти. При этом соблюдается условие, чтобы сведения о каждом объекте записывались в пределах одного модуля. Если в каком-либо модуле не хватает памяти для записи сведений о новом объекте, то эти сведения записываются в другой модуль, где имеется достаточная по объему свободная память; если в модуле не хватает памяти для записи дополнительных сведений о старом объекте, то ранее накопленные сведения об этом объекте изымаются из модуля и вместе с новыми сведениями переносятся в другой модуль.
Сведения, выдаваемые на печать в режиме ВВОДАНК, обычно имеют анкетную структуру. Если их нужно выдавать в табличной форме, то необходимо изменить траекторию решения задачи, заменив в ней блок АНКАЦПУ на последовательность из двух 86
блоков — ДЕКСЛОВ и ТАБЛАЦПУ. Тогда после формирования модуля массива сообщений (блок ФОРМ МОД) исходный массив триад декодируется (блок ДЕКСЛОВ) и оформляется в виде выходного документа табличной формы (блок ТАБЛАЦПУ).
2. Ввод информации на входном языке в анкетной форме с цифровыми обозначениями (номерами) признаков объектов. Имя траектории решения задачи — ВВОДНР. Описание траектории при вводе ее в библиотеку траекторий имеет вид
ЗАДАЧА - (ИМЯ = ВВОДНР, ПГМ1 == СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = О, ПГМЗ « СИНАН,
ПГМ4 = АНКНРТРИ, ПГМ5 == ФОРММОД, РЕЖИМ = Ф, ПГМ6 = АНКАЦПУ).
Предписание на ввод информации имеет вид
НАЧАЛО: АБОНЕНТ - (ИВАНОВ), ЗАДАЧА - (ВВОДНР), МАССИВ - (3), ВВЕСТИ: О — (01), 77 — (Ф = 1/1 = aJ2 = Ьх/ 3 = c{№ = dj5 = ej ... /n = zj), О-(о2), /7 - (Ф=1/1=а2/ 2 = Ьг/3 = с2/4 == d2/5 = е2/... /п = z2/, ..., О — (о/), П — (ф — 1/1 = at/2 = di/3 = Ci/4 = d4-/5 = ег/ ... /п = z,), КОНЕЦ.
Здесь имеется в виду, что информация вводится в массив № 3 по форме № 1 (в компонентах П предписания признак формы Ф равен единице). Формы ввода описываются таблицами, которые представляют собой перечни наименований признаков, и каждому наименованию (точнее, его системному коду) ставится в соответствие его порядковый номер в форме. Библиотека описаний форм ввода хранится в памяти ЭВМ.
Траектория решения задачи ВВОДНР аналогична траектории ВВОДАНК (см. п. 1). Она отличается лишь тем, что вместо блока АНКТРИ в нее включен блок АНКНРТРИ, позволяющий заменять в результатах синтаксического анализа (блок СИНАН) номера наименований признаков на системные коды этих признаков и формировать последовательность трпад.
Вводимая в ЭВМ информация может выдаваться на регистрирующие устройства в анкетной и в табличной форме (с целью контроля правильности ввода). В последнем случае траекторию решения задачи ВВОДНР следует модифицировать, заменив в ней блок АНКАЦПУ на последовательность блоков ДЕКСЛОВ и ТАБЛАЦПУ.
3. Ввод информации на входном языке в позиционном формате. Имя траектории задачи — ПОЗВВОД. Описание траектории при ее вводе в библиотеку траекторий имеет вид
ЗАДАЧА - (ИМЯ = ПОЗВВОД, ПГМ1 = СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = О, ПГМЗ = СИНАН,
87
. ПГМ4 = ПОЗТРИ, ПГМ5 =ФОРММОД, РЕЖИМ = Ф, ПГМ7 = АНКАЦПУ).
Предписание на ввод информации имеет вид
НАЧАЛО: АБОНЕНТ—(ИВАНОВ), ЗАДАЧА—(ПОЗВВОД), МАССИВ — (3), ВВЕСТИ: О - (01), П — (Ф = ilajbjcjdj «1/ ... Л1), О—(о2), П — (Ф == \la2lb2lc2ld2le2l ... /z2), ...» О — (о,), п-(ф = i/ai/bi/a/di/ei/ ..,/zi). КОНЕЦ.
Здесь, как и в п. 2, имеется в виду, что информация вводится в массив № 3 по форме № 1. Для ее ввода используется та же библиотека описаний форм, что и в случае применения анкетной формы с цифровыми обозначениями признаков. В компоненте Й предписания на ввод информации на определенных позициях указываются значения признаков (аи Ьь ..., а2, Ь2, ..., ait bi4 .,.). Наименования признаков в явном виде не записываются. В процессе преобразования позиционного формата в последовательность триад системные коды наименований признаков восстанавливаются по номерам соответствующих позиций.
4. Затирание (исключение) ненужной и ошибочной информации в массивах. Имя траектории решения задачи — ИСКИНФ. Описание траектории имеет вид
ЗАДАЧА - (ИМЯ = ИСКИНФ, ПГМ1 = СИНКОН, ПГМ2 == КОДСЛОВ, РЕЖИМ = О, ПГМЗ = СИНАН, ПГМ4 = АНКТРИ, ПГМ5 = ФОРММОД, РЕЖИМ = 3).
Предписание на затирание информации имеет вид
НАЧАЛО: АБОНЕНТ - (ИВАНОВ), ЗАДАЧА — (ИСКИНФ), МАССИВ-(3), ЗАТЕРЕТЬ: О-(щ), П - (AIBICID), О-(о2^ 'Л - (все), О- (оЦ, Л - [CIDIEIF), КОНЕЦ.
В предписании требуется, чтобы пз массива. № 3 была исключена следующая информация: а) признаки А, В, С, D объекта сч; б) все признаки объекта о2 (все сведения об этом объекте); в) признаки С, D, Е, F объекта о<.
В режиме ИСКИНФ все блоки траектории решения задачи, кроме блока ФОРММОД, выполняют те же функции, что и в режиме ВВОДАНК (см. п. 1). Блок ФОРММОД работает в режиме затирания информации (РЕЖИМ = 3). При этом на его вход поступает последовательность триад, в которой поля памяти, отводимые для значений признаков, остаются незаполненными.
Кроме режима ИСКИНФ для исключения информации из массивов может быть использован режим ИСКИНФ!. В этом режиме на входном языке могут задаваться условия, которым должна
88
удовлетворять исключаемая информация. Траектория решения задачи Пхмеет вид
ЗАДАЧА - (ИМЯ = ИСКИНФ1, ПГМ1 = СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = П, ПГМЗ = СИНАН,
ПГМ4 = ПОИСКА, ПГМ5 = ФОРММОД, РЕЖИМ == 3), а характер предписаний на затиранив информации зависит от характера упомянутых выше условий. Например, если требуется, чтобы из массива № 3 были исключены признаки С, D, £*, F объектов, удовлетворяющих логическому условию
(А > & В «= Ь,) V (В = bk & С « а),
!
то предписание на затирание информации будет иметь вид
НАЧАЛО: АБОНЕНТ-(ИВАНОВ), ЗАДАЧА—(ИСКИНФ1), МАССИВ-(3), НАЙТИ: О—(все), Л—(ИЛИ А > а< И В=*Ь, ИЛИ В=Ьк И С = с/), ВЫБРАТЬ-(C/D/E/F), КОНЕЦ.
Согласно этому предписанию блок ПОИСКА, входящий в состав траектории решения задачи ИСКИНФ1, выберет из массива Кз 3 информацию, указанную в компонентах НАЙТИ и ВЫБРАТЬ, и оформит -ее в виде последовательности триад, а работающий вслед за ним блок ФОРММОД исключит выбранную информацию из состава массива.
При формулировке логических условий отбора информации, подлежащей исключению из массивов, можно пользоваться всеми возможностями, предоставляемыми входным языком (см. описание компонент НАЙТИ и ВЫБРАТЬ в гл. 3).
Рассмотренные режимы работы АИС обеспечивают формирование основных ее массивов (массивов сообщений и словаря) и их обновление. Но эти режимы ориентированы на ассоциативно-адресную триадную структуру модулей массивов сообщений, а для хранения сведений об однородных объектах (об объектах, характеризующихся одинаковыми или почти одинаковыми наборами наименований признаков) более целесообразно применять позиционную структуру модулей. Поэтому следовало бы рассмотреть основные режимы работы АИС при ориентации на позиционную структуру модулей и при одновременном использовании в системе обеих структур. Мы опишем лишь часть этих режимов, полагая^ что принцип их описания уже достаточно ясен.
5. Ввод информации на входном языке в анкетной форме с полными наименованиями признаков объектов и запись ее в массивы позиционной структуры. Имя траектории решения задачи — ВВОДАНК1. Описание траектории;
89
ЗАДАЧА — (ИМЯ = ВВ0ДАНК1, ПГМ1 = СИНКОН, ПГМ2 = КОДСЛОВ, РЕЖИМ == О, ПГМЗ = СИНАН, ПГМ4 = АНКТРИ, ПГМ5 « ТРИТАБЛ, РЕЖИМ = Ф, ПГМ6 = АНКАЦПУ).
Введенная информация декодируется и выдается для контроля на печать в анкетной форме (блок АНКАЦПУ). Предписание на ввод информации имеет такую же структуру, что и в п. 1.
Информация может вводиться в массивы позиционной структуры не только в анкетной форме с полными наименованиями признаков, но и в анкетной форме с цифровыми обозначениями признаков и в позиционном формате. Соответствующие траектории решения задач и предписания на ввод информации строятся аналогично траекториям и предписаниям, описанным в пп. 2, 3, с той лишь разницей, что здесь вместо блока ФОРММОД работает блок ТРИТАБЛ.
6. Затирание (исключение) ненужной и ошибочной информации в массивах позиционной структуры. Имя траектории решения задачи — ИСКИНФ2. Описание траектории:
ЗАДАЧА - (ИМЯ = ИСКИНФ2, ПГМ1 = СИНКОН,
ПГМ2 « КОДСЛОВ, РЕЖИМ = О, ПГМЗ == СИНАН, ПГМ4 — АНКТРИ, ПГМ5 = ТРИТАБЛ, РЕЖИМ «= 3).
Здесь также возможен режим, когда на входном языке указываются не конкретные сведения, подлежащие исключению из массивов, а лишь условия, которым они должны удовлетворять. Предписания на затирание информации в массивах позиционной структуры строятся аналогично предписаниям, описанным в п. 4.
7. Преобразование массива информации из ассоциативно-адресной триадной структуры в позиционную. Имя траектории решения задачи — МСТРИПОЗ. Описание траектории:
ЗАДАЧА - (ИМЯ » МСТРИПОЗ, ПГМ1 = СИНКОН, ПГМ2 = КОДСЛОВ, РЕЖИМ «= П, ПГМЗ = СИНАН, ПГМ4 « ПОИСКА; ПГМ5 = ТРИТАБЛ, РЕЖИМ = Ф).
Предписание на преобразование информации имеет вид
НАЧАЛО: АБОНЕНТ-(ИВАНОВ), ЗАДАЧА — (МСТРИПОЗ), МАССИВ — (5), НАЙТИ: О — (все), П— (все), ВЫБРАТЬ - (все), АДРЕС - (6), КОНЕЦ.
(имеется в виду, что преобразуется массив № 5, а результаты преобразования записываются в массив № 6).
8. Преобразование массива информации из позиционной структуры в ассоциативно-адресную триадную структуру. Имя траектории решения задачи — МСПОЗТРИ. Описание траектории:
90
ЗАДАЧА — (ИМЯ = МСПОЗТРИ, ПГМ1 = СИНКОЙ, ПГМ2 = КОДСЛОВ, РЕЖИМ = 11, ПГМЗ = СИНАИ, \
ПГМ4 == ПОИСКТ, ПГМ5 = ФОРММОД, РЕЖИМ = Ф). ’
Предписание на преобразование информации имеет такую же структуру, что и в п. 7.
5.3. Поиск и обобщение информации
Рассмотрим основные режимы поиска и обобщения информации применительно к ранее описанным языковым средствам и функциональным возможностям АИС.
1. Поиск информации в массивах сообщений ассоциативно-адресной структуры. Этот режим может быть реализован в виде двух модификаций: 1) с выдачей результатов поиска в анкетной форме (режим ПОИСКАА); 2) с выдачей результатов в табличной форме (режим ПОИСКАТ). Траектория решения задачи в режиме ПОИСКАА имеет следующий вид:
ЗАДАЧА (ИМЯ = ПОИСКАА, ПГМ1 = СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = П, ПГМЗ = СИНАН,
ПГМ4 = ПОИСКА, ПГМ5 = АНКАЦПУ),
а в режиме ПОИСКАТ — вид ~
ЗАДАЧА - (ИМЯ «= ПОИСКАТ, ПГМ1 = СИНКОН, ПГМ2 « КОДСЛОВ, РЕЖИМ == П, ПГМЗ = СИНАН, ПГМ4 = ПОИСКА, ПГМ5 = ДЕКСЛОВ, ПГМ6 = ТАБЛАЦПУ).
В обоих случаях поисковое предписание (запрос) сначала подвергается синтаксическому контролю (блок СИНКОН). Затем слова и словосочетания кодируются по словарю словоформ без его пополнения новыми элементами (блок КОДСЛОВ работает в режиме. П). Наконец, осуществляется поиск, декодирование и редактирование информации (блок ПОИСКА и последующие блоки траектории решения задач ПОИСКАА и ПОИСКАТ). При этом в режиме ПОИСКАА функции декодирования и редактирования выполняются блоками АНКАЦПУ, а в режим ПОИСКАТ они распределяются между блоками ДЕКСЛОВ и ТАБЛАЦПУ.
Порядок составления предписаний на поиск информации описан в гл. 3. Здесь мы приведем лишь два частных примера таких предписаний для случая, когда в массивах № 3, № 4 и № 7 требуется найти и выдать в анкетной форме признаки А, В, С, D, Е объектов, удовлетворяющих логическому условию
(А = at & (В = bi V В = b2 V В == 63)) V
V (А а2 В Ъ2 &. С Cj),
91
и для случая, когда требуется найти в тех ясе массивах и выдать в табличной форме признаки Л, В, С, D, Е, F объектов, удовлетворяющих логическому условию
(Л = ах V В = &0 & (С = Cj V = di) & (Е = е^.
В первом случае предписание на поиск информации будет иметь вид
НАЧАЛО: АБОНЕНТ - (ИВАНОВ), ЗАДАЧА - (ПОИСКАА), МАССИВ — (3, 4, 7), НАЙТИ: О — (все), 77— (ИЛИ Л = а. И В = ЬМЬз ИЛИ Л НЕ <а2 И В НЕ <Ь2 И С НЕ = Ci), ВЫБРАТЬ - (ACCIDIE), ФОРМА - (АНКЕТА), КОНЕЦ.
Во втором случае — вид
НАЧАЛО: АБОНЕНТ - (ИВАНОВ), ЗАДАЧА — (ПОИСКАТ), МАССИВ — (3, 4, 7), НАЙТИ: О — (все), 77- (И Л = ИЛИ В == bi И С = Ci ИЛИ D = di И Е = еО, ВЫБРАТЬ - (Л/В/ CIDIEIF). ФОРМА - (ТАБЛИЦА), КОНЕЦ.
В обоих предписаниях форма выдачи информации определяется траекториями решения задач. Поэтому их компонента ФОРМА, по существу, является избыточной и может быть опущена. Эта компонента потребуется лишь в том случае, когда в состав АИС будет введен дополнительный блок редактирования информации с широкими возможностями по ее оформлению и потребуется управлять работой этого блока.
2. Поиск и обобщение информации с ее выдачей в табличной форме. Имя траектории решения задачи — СУМИНФПТ. Описание траектории имеет вид
ЗАДАЧА - (ИМЯ = СУМИНФПТ, ПГМ1 = СИНКОН,
ПГМ2 « КОДСЛОВ, РЕЖИМ = О, ПГМЗ = СИНАН,
ПГМ4 = ПОИСКА, ПГМ5 = ТРИТАБЛ, РЕЖИМ = Ф,
ИГМ6 «= СУМТАБЛ, ПГМ7 = ДЕКСЛОВ, ПГМ8 =» ТАБЛАЦПУ),
Структура предписания на поиск и обобщение информации аналогична структуре предписания на ее поиск без обобщения (см. п. 1), с тем лишь отличием, что здесь в компоненте ЗАДАЧА указывается режим СУМИНФПТ и добавляется компонента ВЫДАТЬ. В компоненте ВЫДАТЬ формулируются условия группировки первичных объектов, найденных в результате поиска, и определяется порядок вычисления значений характеристик обобщенных объектов.
Пусть требуется найти в массивах № 3, № 4 и № 7 объекты, удовлетворяющие логическому'условию Qt (оно может быть любого вида), выбрать их признаки А, В, С, D, Е. F, G, сгруппировать
92
объекты по значениям признака А и вычислить значения признаков В, С, ..., G обобщенных объектов (именами обобщенных объектов будут служить значения признака А). Тогда предписание на поиск и обобщение информации будет иметь вид
НАЧАЛО: АБОНЕНТ — (ИВАНОВ), ЗАДАЧА - (СУМИНФПТ), МАССИВ — (3, 4, 7), НАЙТИ: О — (все), Л —((?,), ВЫБРАТЬ — (A/B/C/D/E/F/G). ВЫДАТЬ-(ДЛЯ А = все СУМ В/В/С/В/Е) FIG}. КОНЕЦ.
Выходной результат будет иметь структуру, показанную в табл. 5.3 (знаки X X и X X X в этой таблице показывают числовые значения признаков).
Таблица 5.3
А в с D Е F G
XX XX XX XX XX XX
XX XX XX XX • XX XX
ап XX XX XX XX XX XX
Итого: XXX XXX XXX XXX XXX XXX
Если при обобщении информации группировка объектов ведется не по всем значениям одного признака Л, а по сочетаниям заданных значений трех признаков А, В и С. то компонента ВЫДАТЬ будет иметь вид
ВЫДАТЬ - (ДЛЯ А = ai/a2 И В = bxfb2 И С = Cl/c2/c3 СУМ
DIEIFIG).
Результат обобщения информации будет иметь структуру, показанную в табл. 5.4.
Здесь наряду со сведениями об объектах, соответствующих сочетаниям значений всех трех признаков, в таблицу включены также сведения об объектах, определяемых сочетаниями значений двух признаков (Л и В) и значениями одного признака (А). Эти сведения помещены в промежуточных итоговых строках. Последняя строка таблицы является общей итоговой строкой.
Если группировка объектов ведется не по первичным значениям признака А, а по классам этих значений zx {ah а2. as}. z2{a4, а5}, z3{«6, л?, 0в} и при этом вычисляются значения признаков Е —В + + C + D, L = E + F, М = G. то компонента ВЫДАТЬ будет иметь вид
93
ВЫДАТЬ— (ДЛЯ А = zi[al/a2la3]lz2[aja5]/z2[a6/a7las] СУМ К = ВС + D/L — ЕF/M = G);
а соответствующий выходной документ — вид табл. 5.5. Другие возможные варианты структуры компоненты ВЫДАТЬ описаны в гл. 3.
Таблица 5.4
А в с D Е F G
«1 Ь1 <л XX XX XX XX
с2 X X XX XX XX
—. — сз XX XX XX XX
— Итого: XXX XXX XXX XXX
— XX XX XX XX
— ?2 XX XX XX X X
— ?3 XX XX XX XX
— Итого: XXX XXX XXX XXX
Итого: — — хххх хххх хххх хххх
&2 bl XX XX XX XX
С2 XX XX XX XX
— —. с3 XX XX XX XX
Итого: XXX XXX XXX XXX
.— XX XX XX XX
—— С2 XX XX XX XX
— XX XX XX XX
— Итого: XXX XXX XXX XXX
Итого: —. —— хххх хххх хххх хххх
Всего: — — хххх хххх хххх хххх
3. Поиск и обобщение информации с выдачей в анкетной форме. Имя траектории решения задачи — СУМИНФПА. Описание траектории:
ЗАДАЧА - (ИМЯ = СУМИНФПА, ПГМ1 = СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = О, ПГМЗ = СИНАН, ПГМ4 == ПОИСКА, ПГМ5 = ТРИТАБЛ, РЕЖИМ = Ф, ПГМ6 = СУ МТ АБЛ, ПГМ7 = АНКАЦПУ).
Предписания на поиск и обобщение информации здесь формулируются по тем же правилам, что и в п. 2, но форма выдачи информации анкетная.
Таблица 5.5
А к L м
21 XX XX XX
22 XX XX XX
2.3 XX XX XX
Итого: XXX XXX XXX
94
4. Решение f-й расчетной задачи с выдачей результатов в табличной форме. Присвоим программному блоку, реализующему комплекс вычислительных операций i-й расчетной задачи, имя РАСНРг То же самое имя присвоим и траектории решения задачи. Описание траектории будет иметь вид
ЗАДАЧА- (ИМЯ = РАСНРЙ ПГМ1 = СИНКОП,
ПГМ2 = КОДСЛОВ, РЕЖИМ = П, ПГМЗ = СИНАН, ПГМ4 = ПОИСКА, ПГМ5 = АИСПП, ПГМ6 = РАСНР», ПГМ7 = ППАИС, ПГМ8 = ДЕКСЛОВ, ПГМ9 = ТАБЛАЦПУ).
Предположим, что исходные данные для расчетной задачи выбираются из массивов № 3, № 4, К® 5 по логическому условию Qi с выдачей характеристик А, В, С, D, Е, F для каждого объекта, удовлетворяющего этому условию. Тогда предписание на решение i-й расчетной задачи будет иметь вид
НАЧАЛО: АБОНЕНТ — (ИВАНОВ), ЗАДАЧА— (РАСНРг), МАССИВ - (3, 4, 5), НАЙТИ: О — (все), Л - ((?,), ВЫБРАТЬ- (AIBICIDIEIF), КОНЕЦ.
Согласно этому предписанию сначала из массивов № 3, № 4 и № 5 выбирается информация об объектах, удовлетворяющих логическому условию Qi (блоки 1 — 4 траектории). Затем выбранная информация преобразуется к виду, удобному для расчетной задачи (блок АИСПП), и используется при выполнении вычислительных операций (блок РАСНРг). Далее результаты решения представляются в виде последовательности триад (блок ППАИС), декодируются и оформляются в виде таблицы (см. блоки траектории решения задачи, следующие за блоком ППАИС). Варьируя условия поиска и выборки информации, можно подавать на вход расчетной задачи различные исходные данные.
Если результаты решения задачи необходимо выдавать не в табличной, а в анкетной форме, то следует заменить в ее траектории последние два блока на блок АНКАЦПУ. Если результаты решения не выдаются на печать, а направляются в один из массивов базы данных (например, в массив № 5), то траектория решения задачи и предписание на ее решение изменяется следующим образом.
Траектория:
ЗАДАЧА - (ИМЯ == РАСНРг, ПГМ1 = СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = П, ПГМЗ = СИНАН.
ПГМ4 = ПОИСКА, ПГМ5 = АИСПП, ПГМ6 = РАСНР», ПГМ7 = ППАИС, ПГМ8 = ФОРММОД, РЕЖИМ = Ф).
95
Предписание!
НАЧАЛО: АБОНЕНТ-(ИВАНОВ), ЗАДАЧА — (РАСНР<), МАССИВ-(3, 4, 5), НАЙТИ: О—(все), Z7—((?<), ВЫБРАТЬ- (A/B/C/D/E/F), АДРЕС - (5), КОНЕЦ.
Если требуется- выдать результаты решения на печать в табличной форме и одновременно сохранить их в памяти ЭВМ (например, записать их в массив № 5), то траектория решения задачи будет иметь вид
ЗАДАЧА - (ИМЯ = РАСНР/, ПГМ1 = СИНКОН,
ПГМ2 « КОДСЛОВ, РЕЖИМ =₽ П, ПГМЗ == СИНАН,
ПГМ4 « ПОИСКА, ПГМ5 = АИСПП, ПГМ6 = РАСНР<,
ПГМ7 = ППАИС, ПГМ8 = ФОРММОД, РЕЖИМ = Ф,
ПГМ9 » ДЕКСЛОВ, ПГМ10 = ТАБЛАЦПУ).
Форма запроса не изменится.
При решении расчетных задач в качестве исходных данных могут потребоваться не первичные сведения, хранящиеся в памяти ЭВМ, а обобщенные. В подобных случаях необходимо включать в предписания на решение задач компоненту ВЫДАТЬ, а в траектории — блоки ТРИТАБЛ и СУМТАБЛ. Например, если требуется решить расчетную задачу РАСНР< по обобщенным исходным данным с выдачей результатов решения в анкетной форме на АЦПУ, то соответствующая траектория будет иметь вид
ЗАДАЧА - (ИМЯ « РАСНР,-, ПГМ1 = СИНКОН,
ПГМ2 — КОДСЛОВ, РЕЖИМ = О, ПГМЗ « СИНАН,
ПГМ4 =» ПОИСКА, ПГМ5 = ТРИТАБЛ, РЕЖИМ — Ф,
ПГМ6 « СУМТАБЛ, ПГМ7 — АИСПП, ПГМ8 = РАСНР<, ПГМ9 =« ППАИС, ПГМ10 =» АНКАЦПУ).
Часто на практике требуется решать не отдельные расчетные задачи, а комплексы таких задач, причем результаты решения одних задач могут использоваться в качестве исходных данных для других. Предписание на решение комплекса задач может быть сформулировано в виде последовательности предписаний типа приведенных выше. Такая последовательность оформляется на языке операционной системы в виде одного задания.
5. Поиск информации в массивах позиционной структуры с выдачей результатов поиска в табличной форме. Имя траектории решения задачи — ПОИСКТТ. Описание траектории:
ЗАДАЧА - (ИМЯ = ПОИСКТТ, ПГМ1 = СИНКОН,
ПГМ2 = КОДСЛОВ, РЕЖИМ = П, ПГМЗ = СИНАН,
ПГМ4 « ПОИСКТ, ПГМ5 = ДЕКСЛОВ, ПГМ6 = ТАБЛАЦПУ).
Предписание на поиск информации имеет такую же структуру, что и в случае режима ПОПСКАТ в п. 1.
90
6. Поиск информации в массивах позиционной структуры, обобщение результатов поиска и выдача их на печать в табличной форме. Описание траектории решения. задачи аналогично приведенному в п. 5, с той лишь разницей, что здесь между блоками ПОИСКТ и ДЕКСЛОВ дополнительно включаются блоки ТРИТАБЛ и СУМТАБЛ. Структура предписания на обобщение информации такая же, что и в режиме СУМИНФПТ (п. 2).
Рассмотренный нами перечень основных режимов работы АИС при поиске и обобщении информации не является исчерпывающим, но он в достаточной мере иллюстрпрует принципы построения траекторий решения задач. Как было указано ранее, траектории решения задач обычно составляются заблаговременно, включаются в библиотеку траекторий и могут вызываться из нее центральным диспетчером. Запросы па выдачу обобщенных справок п на решение расчетных задач также могут составляться заранее, нумероваться и вводиться в систему. Каталогизация запросов осуществляется с помощью блока ЗАПРОС (см. п. 21 табл. 5.1). Этот блок позволяет заменять запросы и отдельные компоненты запросов в целом и по частям.
Каталогизировать можно не только запросы на поиск и обобщение информации, но и любые другие предписания, составленные на входном языке. Языковые средства, обеспечивающие эту возможность, описаны в гл. 3. Эти средства позволяют более экономно формулировать предписания на ввод, обновление, поиск и обобщение информации (вводить вновь только изменяющиеся компоненты этих предписаний).
Блок ЗАПРОС, совместно с блоками АНКВХ и ТАБЛВХ, позволяет осуществлять ввод информации в виде анкет и таблиц. При этом для каждой анкеты и формы таблицы составляется предписание на ввод информации и ее описание, которое используется при переводе анкет и таблиц в структуру компоненты ВВЕСТИ входного языка (точнее, в анкетную структуру этой компоненты с числовыми обозначениями наименований признаков). Перевод информации из анкетной или табличной формы в структуру входного языка выполняется блоками АНКВХ и ТАБЛВХ, после чего вновь сформированная компонента ВВЕСТИ включается в соответствующее предписание па ввод информации. В этом предписании содержится, в частности, и указание о режиме работы системы. Центральный диспетчер организует ввод информации в соответствии с заданным режимом.
В настоящей главе мы рассмотрели процедуры поиска и обобщения информации, инициируемые отдельными запросами. Но эти процедуры, как указайо в гл. 2, могут выполняться и путем задания серий запросов.
7 Г. Г. Белоногов. Б. А. Кузнецов
97
ГЛАВА6
ИНФОРМАЦИОННОЕ И ЛИНГВИСТИЧЕСКОЕ
ОБЕСПЕЧЕНИЕ АИС
6.1. Состав п структура информационного и лингвистического обеспечения
Под информационным обеспечением АИС мы будем понимать хранящиеся в ней сведения о признаках объектов. Под лингвистическим обеспечением — языковые средства системы. Целесообразно различать внешнее и внутреннее информационное и лингвистическое обеспечения АИС. Внешнее обеспечение ориентировано на человека, внутреннее —па программные средства АИС. В со-тав внешнего информационного и лингвистического обеспечения входит:
— входной язык АИС;
— формы входных и выходных документов;
— словари терминов, используемые для составления формализованных сообщений и запросов на входном языке, а также для заполнения форм документов;
— классификаторы понятий, представленные в виде, удобном для человека;
— массивы формализованной информации в виде заполненных форм документов илп сообщений (запросов) на входном языке.
В состав внутреннего информационного и лингвистического обеспечения АИС входят:
— языки представления информации в памяти ЭВМ;
— массивы информации, классификаторы и словари, записанные па этих языках.
Автоматизированные информационные системы создаются, как правило, для обработки формализованной информации. Формализовать информацию — это значит представить ее на формализованном языке. Поэтому разработка формализованных языков — 98
ключевая проблема информационного и лингвистического обеспет чения АИС. От ее решения зависит решение таких вопросов, как разработка форм входных и выходных документов, Классификаторов и словарей. Действительно, формы документов, как это было показано в гл. 1, можно рассматривать в логическом плане в качестве высказывательпых форм (многоместных предикатов), т. е. в качестве языковых средств, с помощью которых осуществляется формализация информации. Поэтому они должны создаваться с учетом структуры входного языка. Высказывательными формами являются и фасетные формулы классификаторов (упорядоченные перечни классификационных признаков). Наконец, структура словаря, как одной из составных частей формализованного информационного языка, непосредственным образом зависит от структуры этого языка.
Для АИС должна разрабатываться система словарей различного назначения. Целью создания словарей является унификация терминологии, используемой в формализованных документах и в классификаторах. В состав словарей следует включать, наряду с полными наименованиями понятий, также их сокращения (мнемонические обозначения). Словари, входящие в состав внешнего лингвистического обеспечения, должны сопровождаться необходимым справочным аппаратом, облегчающим поиск в них.
Для массового пользователя АИС основным средством формализации информации при ее вводе в ЭВМ являются формы входных документов. Формы документов позволяют четко определить информационные потребности, а классификаторы и словари служат для упорядочения процессов заполнения этих форм. В качестве форм входных документов обычно используются табличная и анкетная формы. Табличная форма определяется перечнем наименований ее граф и строгой регламентацией порядка их заполнения. В наименованиях граф, предназначенных для записи числовой информации, указываются единицы измерения, а графы, предназначенные для записи нечисловой информации, сопровождаются перечнями допустимых текстовых значений признаков или наименованиями (индексами) классификаторов, которыми можно пользоваться при заполнении этих граф. Анкетная форма входного документа описывается аналогичным образом, но здесь в роли граф выступают пункты анкеты.
Наряду с перечнями допустимых текстовых значений признаков (назовем эти перечни мпкрословарями), в составе внешнего лингвистического обеспечения АИС целесообразно иметь сводный словарь, содержащий полный перечень терминов и условных обозначений, используемых в информационных массивах системы. Этот словарь необходим для унификации формы представления одних и тех же понятий во всех массивах АИС. Следует, однако, за
7*
99
метить, что наличие сводного словаря еще не гарантирует единообразного представления понятий (из-за явлений омонимии, полисемии и синонимии). Оно достигается благодаря применению регламентированных форм ввода информации и микрословарей. При этом формы документов выступают в роли контекстного окружения, помогающего разрешить омонимию и полисемию терминов, а микрословари позволяют избежать использования синонимов для обозначения одних и тех же понятий.
Сводный словарь терминов целесообразно оформлять в двух видах: в виде алфавитного перечня и в виде систематического указателя. В алфавитном перечне термины расположены в лексикографическом порядке. В систематическом указателе они распределены по тематическим рубрикам, которые представляют собой иерархическую систему. Рубрики нижнего уровня заполняются терминами словаря, а остальные служат для поиска рубрик нижнего уровня. Допускается дублирование одних и тех же терминов в разных рубриках. В пределах рубрики нпжпего уровня термины располагаются по алфавиту.
Алфавитная форма представления словаря удобна для поиска терминов по их словесному выражению, а систематический указатель — по их смысловому содержанию. Последнее важно в тех случаях, когда точное наименование термина неизвестно или когда требуется для заданного термина найти в словаре эквивалентный или близкий ему по смыслу термин (синоним).
Поиск терминов с помощью систематического указателя проводится в следующем порядке. Сначала смысловое содержание искомого термина сопоставляется со смысловым содержанием рубрик верхнего уровня и определяется его принадлежность к одной из рубрик этого уровня. Затем по выбранной рубрике обращаются к подчиненным ей рубрикам второго уровня и определяют принадлежность термина к одной из этих рубрик. Далее по рубрике второго уровня переходят к подчиненным ей рубрикам третьего уровня и т. д. Процесс просмотра рубрик продолжается до тех пор, пока не будет выбрана одна из рубрик нижнего уровня. В заключение поиска просматриваются все термины выбранной рубрики и устанавливается эквивалентность или смысловая близость искомого термина и одного из терминов словаря.
Для общения с АИС необходимо знать ее функциональные возможности, уметь пользоваться входным языком и иметь представление о составе и структуре хранящихся в ней сведений. Последнее может быть достигнуто за счет включения в состав внешнего информационного и лингвистического обеспечения сведений о массивах информации, описаний форм входных документов и соответствующих этим формам микрословарей. Совокупность микрословарей АИС может быть оформлена в виде систематического указате-
лю
ля, в котором роль тематических рубрик нижнего уровня будут играть наименования граф табличных форм документов (или наименования пунктов анкет), а роль рубрик верхних уровней — груп-ппровочные признаки, объединяющие родственные по смыслу наименования граф и облегчающие их поиск. Рубрики нижнего уровня заполняются микрословарямп.
Обычно пользователям системы желательно располагать не только перечнями допустимых значений признаков, но и перечнями значений, фактически встречающихся в массивах информации. Такне перечни могут быть сформированы с помощью программных средств АИС.
Сведения о массивах информации, введенных в АИС, могут содержать наименования этих массивов, их регистрационные номера, признаки, по которым они могут объединяться в различные группы, и т. п. Эти сведения хранятся в памяти ЭВМ в каталоге массивов и, при необходимости, могут выдаваться па регистрирующие устройства в полном объеме или в любой их части. Для работы с массивами аналогичные сведения целесообразно иметь вне машины в виде, удобном для восприятия человеком (в составе внешнего информационного и лингвистического обеспечения АИС).
Таким образом, для обеспечения эффективной связи между человеком и массивами информации, хранящимися в памяти ЭВМ, необходимо иметь вне машины систему документации по информационному и лингвистическому обеспечению (описания массивов, описания форм входных п выходных документов, классификаторы, словари и т. п.). Эта документация должна адекватно отражать текущее состояние массивов и своевременно корректироваться (необходимо иметь постоянно действующую систему ведения документации). Процесс ведения документации может быть автоматизирован, и для этой цели можно использовать программные средства АИС.
6.2. Автоматизированное ведение компонент информационного и лингвистического обеспечения
Рассмотрим принципы автоматизированного ведения компонент внешнего информационного и лингвистического обеспечения АИС на примерах форм документов, классификаторов и словарей. Формы документов можно описывать как объекты, характеризующиеся упорядоченными наборами признаков П1, П2,..., IIN со значениями Xi, Х2, ..., Хп соответственно. Прп этом признаки Ш, П2, ..., IIN должны обозначать порядковые номера граф документов, а наименования граф должны выступать в качестве значений этих признаков. Ввод, обновление и поиск описаний форм документов может производиться по тем же правилам, что и аналогич-
101
йые операции с формализованными описаниями объектов любой другой природы.
Если, например, требуется ввести в ЭВМ описание формы ФИ, содержащей в своем составе графы: фамилия, имя, отчество, год рождения, место рождения, национальность, партийность, образование, место работы, занимаемая должность, должностной оклад, то компонента ВВЕСТИ предписания на ввод информации в анкетной форме будет иметь вид (см. гл. 3)
ВВЕСТИ: О — (ФИ), П — (771 = фамилия/772 = имя/773 — отчество/^ — год рожденпя/775 = место рождения/776 = нацпо-нальность/777 = партийпость/778 = образовапие/779 = место ра-боты/7710 = занимаемая должность/7711 = должностной оклад),
Описания форм документов можно представлять па входном языке АИС и в позиционном формате. Для этого необходимо предварительно ввести в ЭВМ форму ввода этих описаний. В нашвхМ примере первой графе формы ввода следует присвоить имя 77/, второй графе — имя П2 и т. д. Обозначив форму ввода через Ф/, мы можем сформулировать компоненту ВВЕСТИ следующим образом:
ВВЕСТИ: О — (ФИ), П — (Ф — 1/фамилпя/имя/отчест-во/год' рождештя/пациопальность/партийность/образовапие/место ра-боты/занимаемая должность/должностной оклад).
Наряду с наменоваппями граф, в состав описаний форм документов можно вводить и дополнительные признаки: назначение формы документа, ее тематическую принадлежность и т. п. Эти признаки позволят легче ориентироваться в больших массивах описаний форм и получать о них необходимые сведения. Описания форм могут выдаваться на регистрирующее устройство по запросам, сформулированным на входном языке АИС.
Автоматизированное ведение классификаторов имеет целью решение следующих задач:
— формироваппе массивов классификаторов в памяти ЭВМ;
— ввод в состав классификаторов сведений о новых объектах;
— исключение из классификаторов сведений, переставших быть актуальными;
— корректировка ошибок в массивах классификаторов;
— оповещение заинтересованных лиц и организаций об изменениях, вносимых в классификаторы;
— выдача классификаторов на печать в полном объеме с целью их переиздания;
— создание новых классификаторов на основе ранее созданных;
102
— выдача различного рода справок по классификаторам. Перечисленные задачи могут решаться путем выполнения операций ввода, обновления и поиска информации.
Объем сведений, включаемых в классификаторы, может изменяться в широких пределах. Как минимум в них должны быть представлены наименования объектов и их классификационные коды. Но объекты классификации могут сопровождаться и дополнительными признаками, позволяющими объединять их в различные группы. Ввод классификаторов в ЭВМ и их обновление могут осуществляться любыми способами, описанными в гл. 3 и 5.
Предписания на поиск информации в классификаторах строятся по тем же правилам, что п для любых других массивов формализованных сведений. Поиск может производиться по классификационным кодам, по их фрагментам и по дополнительным признакам, введенным в состав классификаторов. При поиске по фрагментам кодов применяется аппарат масок (см. гл. 3). Для хранения массивов классификаторов в памяти ЭВМ можно использовать любую структуру данных, но предпочтительнее позиционная структура, как более компактная.
Задача автоматизированного ведения словарей во многом аналогична задаче ведения классификаторов. Здесь в качестве объектов учета выступают термины, используемые в АИС. Они могут выражаться отдельными словами, словосочетаниями, аббревиатурами и буквенно-цифровыми обозначениями. Терминь! сопровождаются признаками. Если в число их признаков вводятся классификационные коды, то различие между словарями терминов и классификаторами практически исчезает. Тем не менее в рамках внешнего информационного и лингвистического обеспечения назначение классификаторов и словарей различное: классификаторы служат для присвоения объектам классификационных кодов, словари — для регламентации процессов выбора наименований признаков и выбора имен их значений.
Для автоматизированного’ ведения словарей, входящих в состав внешнего лингвистического обеспечения, можно воспользоваться языковыми и программными средствами, предназначенными для ввода, обновления и поиска произвольной информации (а не только словарной).
Проиллюстрируем это на примере языковых и программных средств, описанных в главах 3, 5.
Пусть требуется ввести в ЭВМ словарь терминов, оформленный в виде систематического указателя с тремя уровнями иерархии рубрик — У1, У2, УЗ, причем на первом уровне используются имена рубрик а2, ..., «т, на втором — bi, Ъ2, ..., Ьп, на третьем — ci, с2, ..., сг. Тогда компонента ВВЕСТИ предписания на ввод информации о терминах Ti, Т2, .. Т* в анкетной форме
103
будет иметь вид
ВВЕСТИ: О-(Л), Л-(У1==а1/У2==&1/УЗ==С1), О-(Г2), Л-(У1 = Л1/У2 = Ь^УЗ = с2), ..., О- (Tt), П—(У1 = а1/ У2 == &5/УЗ=сА), ..., О - (Т8), П — (У\=ат/У2—Ьп1УЗ=сг). При вводе информации в позиционном формате компонента
ВВЕСТИ будет иметь вид
ВВЕСТИ: О-ЧЛ), Л-(Ф = //а1/&1/с1), О-(Т2), П-(Ф = 1/ах] bjd) ..., О-(Т/), П —(Ф = 1МЬ;/ск)............. О-(Та),
П — (Ф = i/am/bn/Cr).
Здесь I — номер формы ввода информации, в которой на первом месте записываются наименования рубрик первого уровня (У1), на втором — второго уровня (У2), на третьем — третьего уровня (УЗ). Введенный словарь может в дальнейшем корректироваться и выдаваться на печать в полном объеме, в виде отдельных фрагментов или в виде сочетаний фрагментов.
При вводе в ЭВМ микрословарей форм документов в качестве объектов учета можно принять наименования граф этих форм, в качестве наименований признаков — цифро-буквенные обозначения Cl, С2, CN (слово № 1, слово № 2 и т. д.), а в качестве значений признаков — буквенные коды слов и словосочетаний, разрешенных к использованию при заполнении соответствующих граф. Кроме того, в качестве дополнительных признаков граф могут быть указаны номера включающих их документов и другие груп-пировочные признаки. Как и в случае систематического указателя, микрословари могут вводиться в ЭВМ в анкетном и в позиционном формате.
Микрословари целесообразно использовать не только для ввода информации по заданным формам и составления предписаний на поиск и обобщение информации, цо и при создании новых форм. В последнем случае необходимо предварительно убедиться, не было ли в ранее созданных формах аналогичных наименований граф п мпкрословарей. Если они были, то ими следует воспользоваться; если их не было, то необходимо дополнительно ввести их в ЭВМ. Поиск в микрословарях производится на основе предписаний, сформулированных на входном языке.
На основе описанных нами ранее языковых и программных средств АИС можно строить документальные информационно-поисковые системы. Такие системы применяются для поиска документов по их обобщенным описаниям. В описания'документов могут включаться их наименования, краткое изложение содержания, наименования организаций — издателей документов, время и место издания, учетные номера документов и т. п. Перед вводом в ЭВМ описания документов формализуются и представляются в виде последовательностей наименований признаков и их значений.
104
Поиск Документов ведется по их формализованным описаниям, а в качестве результатов поиска могут выдаваться любые фрагменты этих описаний.
Формализованные описания документов по своей структуре аналогичны формализованным описаниям любых других объектов, и для их ввода в ЭВМ, обновления и поиска можно использовать средства входного языка ЛИС. Но для поиска документов часто создаются и специализированные информационно-поисковые системы (ИПС), в которых наряду с формализованными описаниями документов хранятся их неформализованные описания (аннотации, рефераты), выдаваемые по запросам потребителей. В таких системах широко применяются тезаурусы. Тезаурусы представляют собой нормативные словарп-справочники, включающие в свой состав лексические единицы (слова, словосочетания) вместе со сведениями о парадигматических отношениях между ними (отношениях эквивалентности, родо-видовых и ассоциативных). Эти отношения пспользуются при поиске лексических единиц в процессе индексирования документов и запросов.
В последнее время внимание разработчиков ИПС привлекает возможность поиска документов по их неформализованным описаниям. В связи с этим возникает необходимость создания словарей лексических единиц с богатой синтаксической и семантической информацией и необходимость автоматизации процессов их составления и ведения. В общем случае система автоматического ведения словарей должна выполнять следующие функции:
1. Ввод (накопление) и идентификация словарной информации — слов, словосочетаний, их грамматических и семантических признаков. Сюда же следует отнести и автоматическое составление словарей по текстам.
2. Обновление словарей (их дополнение, исключение ненужных элементов, корректировка признаков).
3. Теоретико-множественные операции над словарной информацией: объединение словарей, пересечение словарей, вычитание словарей, выполнение над ними операций реляционной алгебры (проекция, объединение п др.).
4. Поиск словарной информации по запросам —как по именам лексических единиц (слов, словосочетаний), так и по любым их признакам (грамматическим и семантическим) и любым сочетаниям признаков с любыми условиями, выраженными, например, с помощью операций булевой алгебры. Выдача пользователям любых фрагментов и сочетаний фрагментов словарей.
5. Статистическая обработка словарей и выполнение над ними операций логического вывода (например, обогащение их парадигматическими связями на основе первоначально введенных связей).
105
В. Автоматическое редактирование (документирование) словарной информации, выдаваемой человеку и представление ее в виде, удобном для восприятия.
Как уже указывалось, для реализации функций автоматизированной словарной службы можно использовать системы управления базами данных, если они располагают соответствующим набором операций. Но более эффективными здесь могут оказаться программные системы, специально предназначенные для этой цели, тем более, что современные СУБД не имеют в своем составе процедур, необходимых для обработки русских текстов. Эти процедуры будут рассмотрены в гл. 7, 8.
6.3. Информационная и лингвистическая
совместимость АИС
Информационная совместимость АИС — это их способность к обмену релевантной информацией (релевантной по отношецию к каждой отдельной АИС); лингвистическая совместимость — способность воспринимать и интерпретировать языковую форму представления информации. Наиболее строгие требования по совместимости должны предъявляться к формализованной фактографической информации, используемой для научных расчетов и в интересах АСУ. Здесь необходимо четко регламентировать состав, содержание, степень обобщения и форму представления информации. Регламентация форм представления информации должна осуществляться как на этапе ее ввода в ЭВМ и обновления, так и при формулировке поисковых запросов.
Ввод фактографической информации в ЭВМ и ее поиск могут осуществляться в пакетном режиме на основе априорных знаний о структуре банка данных и его лингвистическом обеспечении и в диалоговом режиме. Более эффективен диалоговый режим, так как он создает комфортные условия для пользователей и позволяет управлять указанными процессами на основе сведений, получаемых от ЭВМ. Кроме того, здесь минимизируется объем клавиатурных операций, так как часто действия пользователя могут быть сведены к выбору предлагаемых ЭВМ альтернатив. Но такой режим эффективен, если система автоматической обработки информации располагает мощным банком признаков и банком форм ввода и выдачи с соответствующим программным обеспечением.
Выбор в процессе диалога предлагаемых ЭВМ альтернатив не всегда является наиболее удобным способом общения человека с банком признаков и банком форм ввода и выдачи информации, особенно если этих альтернатив очень много и процесс выбора носит многоступенчатый характер. Поэтому режим выбора альтернатив должен быть дополнен режимом поиска в банке признаков и
106
'форм документов по запросам на слабоформализованном пли неформализованном языке. Для этого необходимы процедуры морфологического, синтаксического и семантического анализа текстов. Тогда в результате выполнения поисковых процедур человеку сразу может быть предложен ограниченный выбор альтернатив, среди которых он должен будет сделать выбор.
. Языковые средства банков данных должны обладать достаточной функциональной полнотой, чтобы обеспечить выполнение вещего многообразия возлагаемых па них задач. С другой стороны, они должны быть простыми, чтобы быть доступными для неподготовленных пользователей. Удовлетворить этим противоречивым требованиям можно лишь на путях создания комплекса совместимых языков, ориентированных на различные категории пользователей — на пользователей, не знакомых с программированием; на пользователей, знакомых лишь с общими принципами программирования; на разработчиков прикладных программ; на системных программистов. Здесь нужны и алгоритмические языки высокого уровня, и входной язык, построенный на базе исчисления предикатов, и упрощенные средства этого языка, рассчитанные на менее подготовленных пользователей, и средства, предназначенные для неподготовленных пользователей.
Для неподготовленных пользователей довольно типичным случаем будет выдача из ЭВМ информации в виде документов заранее определенной формы. Для каждой формы документа должен быть указан алгоритм ее заполнения. Этот алгоритм может быть цписан на входном языке банка данных или, если это невозможно, на одном из алгоритмических языков и каталогизирован. Для получения информации из ЭВМ здесь достаточно указать номер или имя формы выдачи. Далее из библиотеки банка данных выбирается .соответствующая форма, запрос на поиск и обобщение информации и прикладная программа (если в пей есть необходимость), после чего осуществляется поиск, сортировка и обобщение информации, а также заполнение выбранной формы.
Должна быть также предусмотрена возможность варьирования некоторых параметров, определяющих состав выдаваемой информации, а также порядок ее поиска, сортировки и обобщения. В качестве языковых средств здесь могут выступать табличные или анкетные формы запросов, содержащие перечни варьируемых параметров, а в качестве программных средств — программные средства банка данных и специальные прикладные программы.
Следует подчеркнуть, что варьируемые параметры составляют лишь часть признаков, которые используются в процессе поиска, сортировки и обобщения информации. Остальные признаки, необходимые для обеспечения этого процесса, а также логические и алгебраические отношения между всеми (в том числе и варьируемы
107
ми) признаками указываются в заранее составленных запросах к/ банку данных, которые хранятся в памяти ЭВМ. Варьируемые при-( знаки служат для модификации заранее составленных запросов.
Важное место в системах автоматического поиска и обработку7 фактографической информации должен занять банк запросов. Банц запросов можно рассматривать, с одной стороны, как банк алгоритмов поиска и обобщения информации, с другой стороны — к^к банк парадигматическпх отношений между понятиями, бол^е сложных, чем обычно используемые отношения типа «род —вид», «часть — целое» и т. п. Заранее подготовленные и каталогизированные запросы могут использоваться как поодиночке, в свбем первоначальном виде, так и в различных комбинациях и модификациях. Для этого необходимо создавать соответствующие программные системы ведения запросов. С запросами, как и с тезаурусом, можно вести диалог. При этом их можно модифицировать.
Привлекательной является возможность диалогового общения с банком данных на естественном языке. Для этой цели пока можно использовать только письменную форму языка, так как проблема распознавания устной речи находится еще на начальной стадии решения. Более доступным и актуальным здесь является режим поиска и обобщения информации, чем режим ее ввода и обновления. При поиске и обобщении информации исходный запрос переводится с естественного языка на входной язык банка данных и далее интерпретируется его программной системой. Процесс пе* ревода заключается в распознавании понятий и отношений между ними применительно к концептуальной структуре и процедурным возможностям банка данных. Перевод запроса и его дальнейшая интерпретация могут осуществляться в диалоговом режиме. При этом первоначальное обращение к банку данных может быть на естественном языке, а продолжение — на формализованном, ограниченном языке, приближенным к содержанию, структуре и процедурным возможностям банка данных. Более подробно вопросы общения с банком данных на естественном языке будут рассмотрены в гл. 9.
Требования по информационной и лингвистической совместимости, предъявляемые к формализованной фактографической информации, в принципе можно было бы распространить и на документальные системы. Их соблюдение позволило бы существенным образом снизить уровень «потерь» и «шумов» при поиске информации или даже свести его к нулю. Но реализовать эти требования на практике оказывается весьма затруднительным из-за большого разнообразия содержания научно-технических документов и случайного характера процессов их порождения. Поэтому здесь приходятся ограничиваться менее строгими мерами. К числу таких мер можно отнести создание единого классификатора инфор-
108
нации, введение унифицированного коммуникативного формата утри передаче информации из одной АИС в другую, унификацию (синтаксических средств информационно-поисковых языков, контроль лексики по тезаурусу (сюда же следует отнести и методы автоматического индексирования). Все эти меры безусловно необходимы, но они недостаточны. Так, унифицированный коммуникативный формат оставляет большую свободу действий при выборе элементов его заполнения, а применение единого классификатора ii контроля лексики по тезаурусу еще не гарантирует единообразия описания документов (например, одни и те же документы могут описываться в терминах различной степени общности). В этой связи большую роль приобретает полнота отражения парадигматических связей между понятиями в тезаурусах и классификаторах и разработка программных средств, позволяющих использовать такие связи при поиске.
На наш взгляд, наряду с внедрением в систему автоматической обработки научно-технической информации унифицированного коммуникативного формата, единого классификатора и контроля лексики по тезаурусу, следует вести научные исследования в двух направлениях: 1) в направлении создания форм (фреймов) для описания смыслового содержания документов на основе использования регламентированных перечней наименований и значений признаков; 2) в направлении разработки более совершенных методов поиска документов по текстам их рефератов. Формы описания документов могут поначалу заполняться вручную, в дальнейшем этот процесс следует автоматизировать.
В предыдущем изложении мы рассматривали по преимуществу методы автоматической обработки формализованной информации. Эти методы лежат в основе большинства современных АИС. Но в последние годы проявляется тенденция использования для общения с АИС естественных языков пли языков, близких к естественным. Комплекс вопросов, связанных с обработкой информации на естественных языках, рассматривается в последующих трех главах.
ГЛАВА 7
СИНТАКСИЧЕСКАЯ И СЕМАНТИЧЕСКАЯ СТРУКТУРА ЕСТЕСТВЕННЫХ ЯЗЫКОВ
7.1. Структура слов
Человеческая речь — это прежде всего звуковая (устнак) речь. Письменная форма речи представляет собой лишь ее обедненное графическое отображение. Тем не менее письменная речь является весьма эффективным средством человеческого общения.
Существуют различные виды письменности. Чаще всего при их создании используется фонетический принцип — когда с помощью графических символов (букв) обозначаются минимальные смыслоразличительные отрезки звуковой речи (фонемы); а связная речь представляется в виде последовательности букв. На таком принципе построена и русская письменность, хотя здесь соответствие между фонемами и буквами не взаимооднозначное: некоторые фонемы могут обозначаться различными буквами, а одни и те же буквы в различных позициях слова могут обозначать различные фонемы. Положение осложняется еще и исторической традицией, сохраняющей графические образы отрезков речи, изменивших свой первоначальный звуковой состав. Мы будем в дальнейшем рассматривать только письменную форму речи.
В письменных текстах есть много условностей и элементов формализации. Довольно условно, например, устанавливаются границы между словами, предложениями и другими единицами речи, а для обозначения этих границ широко применяются различного рода разделители: пробелы — для обозначения границ между словами, прописные буквы и знаки препинания-— для обозначения границ между предложениями и составными частями предложений, абзацные отступы —для обозначения границ между связанными по смыслу группами предложений и т. п.
Минимальной формально выделяемой единицей связного текста является слово, но оно — не минимальная единица смысла и
110
может состоять из одной пли нескольких морфем. S составе слов различают корневые морфемы (корни), префиксы (приставки) и суффиксы. Основную смысловую нагрузку несет корень, а префиксы и суффиксы выступают в роли модификаторов смысла. ^Например, в слове выступающий можно выделить пять морфем:
- ступ - а - ющ - ий. Здесь морфема ступ — корень слова, горфема вы — префикс, морфемы а, ющ и ий — суффиксы (суффикс ий является грамматическим окончанием).
\ В табл. 7.1 приведено восемь групп одпокорепных слов, у которых с помощью дефисов п' пробелов обозначены границы меж-
Таблица 74
Группы одиокоренпых слов
I да — ется
/ за — да — ющпй । под — да — клея пере — да — ются раз — да — ться из — да — ние переиз — да — ние при — да — ются по — да — вать препо — да — ванне про — да — ваемый с — Да — ется от — да — ча
у — да — ться об — рез — анный в — рез — аются от — рез — аются вы — рез — ались пуск пуск — ать
о — пуск — ающийся до — пуск — аемый с — пуск — аться ис — пуск — ание
у — пуск — ают зна — ть
при — зна — ть по — зна — ние опо — зна — вательный распо — зна — ющий
со — зна — тельный осо — зна — ет
у — зна — ть на — бпр — аться под — бпр — ается раз — бпр — аются из — бир — ательность со — бир — ающий
от — бир — ались у — бир — ающийся вы — бир — аемый об — рыв про — рыв с — рыв под — рыв пере — рыв
пре — рыв — ает бсспре — рыв — но раз — рыв — ной вз — рыв — ной ход — овой за — ход — ить па — ход — ящийся об — ход
необ — ход — имый в — ход — пл под — ход — ить пере — ход — ят
При — ХОД/— ящий до — ход — ить по — ход — ный про — ход — ящий с — ход — имость ПС — ход — ный ВОС — ход — ящий от — ход — ящий у — ход — ил вы — ход — ной стро — ительство па — стро — ечный в — стро — енный под — стро — йка пере — стро — иться до — стро — йка по — стро — пли у — стро — йство
Ш
ду корнями и примыкающими к ним префиксами и суффиксами. В этой таблице есть слово пуск, состоящее только из одной корневой морфемы; есть слова, имеющие только корни и префиксы (обрыв, прорыв, обход и др.); есть слова, имеющие только корни и суффиксы (дается, пускать, строительство и др.); нако-у нец, есть слова, имеющие и корни, и префиксы, и суффиксы (задающий, поддается и др.). I
Членение слов на морфемы, равно как и члененпе текста па слова, словосочетания, предложения, сверхфразовые единства -4 дело непростое. Правда, определению границ слов носители язика обучаются с первых шагов овладения письменностью, а сами слова фиксируются в нормативных словарях. Что же касается остальных единиц речи, то здесь ситуация более неопределенная. В этой связи представляют интерес высказывания известного лингвиста К. Фосслера, содержащиеся в его работе «Позитивизм и идеализм в языкознании» [31, ч. 1, с. 328, 329]: «Как произошло подразделение на фонетику, морфологию и синтаксис ни для кого не является секретом. Посредством дробления и механического членения. Язык изучают не в процессе его становления, а в его состоянии. Его рассматривают как нечто данное и завершенное, т. е. позитивистски. Над ним производят анатомическую операцию. Живая речь разлагается на предложения, члены предложения, слова, слоги и звуки.
Этот метод вполне оправдан и может привести к ценным наблюдениям, но и одновременно может стать источником ошибок. Ошибки начинаются тогда, когда убеждают себя, что указанное членение находит основание в самом организме человеческой речи, что оно представляет собой нечто большее, чем абсолютно произвольное, механическое и насильственное рассечение. Чрезвычайно распространенным и почти неискоренимым предрассудком является убеждение, что предложение представляет естественную единицу речи, член предложения — естественную часть предложения, а слово или слог — дальнейшее естественное подразделение.
. В действительности дело обстоит приблизительно так, как в анатомии: если я отделю от туловища нижнюю конечность и при этом проведу разрез по естественным членениям или же перепилю берцовую кость посередине, — это всегда останется механическим разрушением организма, а не естественным расчленением. Единство организма заключается не в членах и суставах, а в его душе, его назначении, его энтелехии, или как это там не назови. Организм можно разрушить, но не разложить на его естественные части.
Анатом производит свои разрезы, конечно, не произвольно, но избирает такие места, которые представляются ему наиболее
112
5тдобными. Точно так же подразделение грамматиков на звуки, слова, основы, суффиксы п т. д. мы должны признать не наиболее естественным, а наиболее удобным и поучительным. Слоги, основы, суффиксы, слова и члены предложения являются, так сказать, суставами, по которым живая речь сгибается и движется.»
В процессе функционирования в речи в различных контекстных окружениях слова приобретают различные формы. Это могут быть формы словоизменения и словообразования. Граница между ними условная, и различные авторы проводят ее по-раз-пому. Можно, например, считать, что формы склонения существительных и прилагательных, формы спряжения глаголов настоящего и будущего времени, формы изменения глаголов прошедшего времени, кратких прилагательных и кратких причастий по родам и числам являются формами словоизменения, а все остальные трансформации слов — формами словообразования.
Изменения форм слов могут носить различный характер. Они могут быть связаны как с изменением основы слова, так и с изменением его окончания. Изменение буквенного состава основ имеет место, например, в следующих парах форм слов: сижу — сидишь, шел — шли, тренировка — тренировок, нес — несли, кто — кого, время — времени, судно — суда, человек — люди. Изменение окончаний является основным способом образования различных словоизменительных форм слов. В русском языке оно используется как самостоятельно, так и в сочетании с изменением основ слов.
В табл. 7.2 приведены примеры образования различных форм слов. При этом одна форма каждого слова указана полностью, а другие его формы представлены лишь своими окончаниями. Символ + обозначает «нулевое» окончание (отсутствие окончания).
По характеру изменения буквенного состава все основы слов могут быть отнесены к одному из следующих четырех типов: тип I — неизменяемые основы слов; тип II — основы слов, у которых имеет место чередование гласных; тип III — осповы слов, у которых имеет место чередование согласных; тип IV — изменяемые основы слов, не отнесенные к типам II п III. К основам типа IV относятся, в частности, супплетивные формы слов (например, следующие формы слов: кто, кого, кем, что, чего, он, ему и др.). По способу изменения грамматических окончаний (флексий) и своей синтаксической функции русские слова могут быть разбиты на ряд классов, которые получили название флективных. Флективные классы изменяемых слов выделяются на основе анализа их синтаксической функции и систем падежных, личных и родовых окончаний. Классы неизменяемых слов — толь-
8 Г. Г, Белоногов, Б. А. Кузнецов
ИЗ
Таблица 7.2
Примеры образования различных форм слов
Телефон — а, у, ом, е, ы, ов, ам, амп, ах Тираж — а, у, ом, е, и, ей, ам, амп, ах Огонь — я, ю, ем, е, и, ей, ям, ямп, ях Санаторий — я, ю, ем, п, ев, ям, ямп, як Путь — п, ем, ей, ям, ямп, ях Глаз — а, у, ом, е, ам, амп, ах Врач — а, у, ом, е, и, ей, ам, амп, ах Женщина — ы, е, у, ой, -f-, ам, амп, ах Переводчица — ы, е, у, ей, -f-, ам, ами, ах Место — а, у, ом, е, -Н, ам, амп, ах Поле — я, ю, ем, ей, ям, ями, ях Очко — а, у, ом, е, и, ов, ам, амп, ах Главный — ого, ому, ым, ом, ая, ой, ую, ое, ые, ых, ымп Передний — его, ему, им, ем, яя, ей, юю, ее, ие, их, ими Годовой — ого, ому, ым, ом, ая, ую, ое, ые, ых, ыми Наш — его, ему, им, ем, а, ей, у, е, и, их, ими Делаю — ешь, ет, ем, ете, ют Строю — ишь, пт, им, пте, ят Стучу — ишь, пт, им, пте, ат Ехал — а, о, и Сплен — а, о, ы Присущ—а, е, и Два — ух, ум, умя Двое — их, им, имп Пять — и, ью
Столько — о, их, им, имп
ко по синтаксическому принципу. Список флективных классов слов приведен в табл. 7.3.
По своей синтаксической функции изменяемые слова объединены в следующие группы: 1) существительные; 2) прилагательные; 3) глаголы в личной форме; 4) глаголы прошедшего времени, краткие прилагательные и причастия; 5) количественные числительные. Группа «существительные», в свою очередь, состоит из нескольких подгрупп, выделенных по признакам рода и одушевленности (для существительных мужского и женского рода). В каждой группе и подгруппе слова распределены по флективным классам.
Определение принадлежности изменяемого слова к синтаксической группе или подгруппе обычно не вызывает затруднений, так как в основу принятого здесь разделения на группы и подгруппы положена традиционная классификация слов. Следует лишь учитывать, что, наряду с полными прилагательными, к группе «прилагательные» отнесены также полные причастия, порядковые числительные, субстантивированные прилагательные, а также количественное числительное один. При выделении окон-114
Таблица- 7.3
Флектлвные классы слов
А. Существительные
Кг П/П Слово-представитель Окончания 1) им. п., ед. ч., 2) тв. п., ед. ч., 3) им. п., мн. ч.» 4) род. п.» мн. ч. Примечание
Существительные мужского рода неодушевленные
001 телефон +*), ом, ы, ов
002 тираж +, ом, и, ей
003 огонь ь, ем, и, ей см. п. 012
004 перебой Й, ем, и, ев см. п. 005
005 санаторий И, ем, и, ев основы на букву
«п»
006 бланк +, ом, и, ов
007 сапог -ь ом, и, +
010 лес -н ом, а, ов
ОН колодец -ь ем, ы, ев
012 013 путь (класс состоит из одного слова) край й, ем, я, ев
014 брус 4-, ом, я, ев
015 глаз . 4"» ом, а, +
016 зародыш ем, и, ей
017 волос +, ом, ы, 4-
020 лагерь ь, ем, я, ей
Существительные мужского рода одушевленные
021 кузнец +, ом, ы, ов
022 солдат +, ом, ы, 4-
023 сосед +, ом, и, ей см. п. 024
024 врач 4~, ом, и, ей Основы на ж, ч, ш
Щ
025 пролетарий й, ем, и, ев
026 воробей ей, ем, и, ев
027 конь ь, ем, и, ей
030 учитель ь, ем, я, ей
031 сапожник 4-, ом, и, ов
032 испанец 4-, ем, ы, ев
033 юноша а, ей, и, ей
034 мужчина а, ой, ы, 4"
035 судья я, ей, и, ей
036 товарищ 4-, ем, и, ей
037 гражданин 4-, ом, е, 4-
040 профессор 4-, ом, а, ов
041 муж 4"» ем, я, ей
042 Иванов 4-, ым, ы, ых
043 сын 4-, ом, я, ей
*) Символ -f- обозначает нулевое окончание.
8Ф
115
Таблица 7.3 (продолжение}
№ п/п Слово-представитель Окончания 1) им. п., ед. ч., 2) тв. п., ед. ч., 3) им. п., мн. ч., 4) род. п.» мн. ч. Примечание
Существительные женского рода одушевленные
044 женщина а, ой, ы, +
045 переводчица а, ей, ы, +
046 нутрия — я, ей, и, й основы на букву
«и»
047 швея я, ей, и, й см. п. 046
050 цапля я, ей, и, ь
051 санитарка а, ой, и, +
052 мышь ь, ю, и, ей
053 Иванова а, ой, ы, ых
Существительные женского рода неодушевленные
054 речь ь, ю, п, ей основы на ж, ч, ш, Щ
055 грань ь, ю, и, ей см. п. 054
056 колба а, ой, ы, +
057 задача а, ей, и, +
060 заготовка а, ой, и, +
061 линия я, ей, и, й основы на букву
«и»
062 галерея я, ей, п, й см. п. 061
063 земля я, ей, и, ь
064 эскадрилья я, ей, и, иц *
065 статья я, ей, и, ей
066 башня я, ей, и, +
067 улица а, ей, ы, +
Существительные среднего рода
070 место о, ом, а, +
071 облако О, ом, а, ов
072 поле е, ем, я, ей
073 сомнение е, ем, я, й
074 жилище ем, а, +
075 перо О, ом, я, ев
076 время я, ем, а, +
077 побережье е, ем, я, ий
100 колено О, ом, и, ей
101 очко о» ом, и, ов
102 ружье е, ем, я, ей
116
Таблица 7.3 (продолжение)
Б. Прилагательные
№ п/п Слово-представитель Окончания: 1) им. п., муж. р., ед. ч., 2) им. п., жен. р., ед. ч., 3) род. п., муж. р., ед. ч., 4) им. п., мн. ч. Примечание
103 главный ып, ая, ого, ые
104 передний ий, яя, его, не
105 хороший ий, ая, его, ие
106 легкий ий, ая, ого, не
107 годовой ой, ая, ого, ые
110 плохой ой, ая, ого, пе
111 третий ий, я, его, и
112 этот, сам + , а, ого, и
ИЗ мой, твой, свой й, я, его, и
114 наш, ваш +, а, его, и
115 весь ь, я, его, е
В. Глаголы в личной форме
Ks п/п Слово-представитель Окончания 1, 2 и 3-го лица ед. ч. и 3-го лица мн. ч. Примечание
116 делать ю, ешь, ет, ют
117 строить ю, ишь, пт, ят
120 писать у, ешь, ет, ут
121 стучать у, ишь, ит, ат
122 бежать у, ишь, ит, ут
123 хотеть у, ешь, ет, ят
124 зависеть у, ишь, ит, ят
Г. Глаголы прошедшего времени, краткие прилагательные и причастия
К» п/п Слово-представитель Окончания ед. и мн. ч. Примечание
125 ехал (глагол) +» о» а, и
126 силен (прилагательные) +» о, а, ы
127 присущ (прилагательное) + , е, а, и
130 краток (прилагательное) +, о, а, и
117
Таблица 7.3 (продолжение)
Д. Количественные числительные
Ла П/П Слово-представитель
131 132 133 134 135 136 Два, две три четыре двое, трое четверо, пятеро и т. д. прочие количественные числительные (пять, шесть, семь
137 140 и др., изменяющиеся, как слово мишень) столько, сколько оба, обе
Е. Неизменяемые слова
№ п'п Наименование класса слов
143 144 145 146 147 150 151 152 Модальные слова, неизменяемые глаголы Неопределенная форма глагола Неизменяемые существительные мужского рода Неизменяемые существительные женского рода Неизменяемые существительные среднего рода Неизменяемые существительные множ, числа Неизменяемые прилагательные Деепричастие, наречие, сравнительная степень прилагательного
153 154 155 156 157 160 161 162 163 164 Союзы Частицы, вводные слова, междометия Предлог (род. п.) Предлог (дат. п.) Предлог (вин. к.) Предлог (тв. и.) Предлог (предл. п.) Предлог (род., тв. и.) Предлог (вин., тв. и.) Предлог (вин., иредл. п.)
чания слова возвратные частицы ся, сь и внутренний мягкий знак (мягкий знак, стоящий между основой и ненулевым окончанием слова) опускаются. Список различных окончаний слов приведен в табл. 7.4.
Для характеристики системы окончаний слова пет необходимости перечислять окончания всех его форм. Обычно достаточно сделать это лишь для нескольких типичных форм. В качестве таких типичных форм для группы «существительные» приняты формы пменительного п творительного падежей едпнетвенпого
118
ЗйСла и именительного й родительного падежей множественного числа; для группы «прилагательные» — формы именительного падежа единственного числа мужского и женского рода, родительного падежа единственного числа мужского рода и именительного падежа множественного числа; для группы «глаголы в личной форме» — формы первого, второго и третьего лица единственного числа и третьего лица множественного числа.. В группе
Список окончаний слов Таблица 7.4
! 01 — ами 21 - ат 41 — 11я . 61 — ям
02 — его 22 - ах 42 — ов 62 — ят
03 — емп 23 - ая 43 — ое 63 — ях
04 — ему 24 - ев 44 — ой 64 — яя
05 — емя 25 - ее 45 — ом 65 Н
(нуль)
06 — ете 26 — ей 46 — ою 66— а
07 — ешь 27 - ем 47 — ум ' 67 — е
10 — ими 30- ет 50 — ут 70 — и
11 — ите 31 — сх 51 — ух 71 — й
12 — ишь 32 — ею 52 — ую 72 — о
13 — ого 33- ие 53 — ыо 73 — у
14 — ому 34 — ий 54 — ый 74 — ы
15 — умя 35 — им 55 — ым 75 — ь
16 — ыми 36 - ПТ j 56 — ых 76 — ю
17 — ями 37 — их 57 — ют 77 — я
20 — ам 40- ми 60 — юю
«глаголы прошедшего времени, краткие прилагательные и причастия» окончания указаны для всех форм единственного и множественного числа. Здесь флективный класс определяется с помощью системы окончаний и указания на принадлежность к одной из частей речи (глагол, причастие, прилагательное). Флективные классы группы «количественные числительные» характеризуются только словами-представителями.
Некоторые классы существительных мужского и женского рода имеют одинаковые окончания во всех формах, принятых в качестве типичных, хотя другие их формы не совпадают. Иллюстрацией этому могут служить пары слов: огонь — путь, пере^ бой — санаторий, сосед—врач, нутрия — швея, грань—речь, линия — галерея. Дополнительным признаком, необходимым для различения классов, здесь может служить информация о конечной букве основы слова, а для классов со словами-представителями огонь и путь — указание на то, что слово путь является единственным представителем класса (табл. 7.3).
Следует отметить, что в русском языке имеет место сильная корреляция между грамматической информацией к словам и бук-
JL19
Таблица 7.5
Фрагменты обратного словаря словоформ
масштаба — 001 хлеба — 001 служба — 056 дружба — 056 перегиба — 001 столба — 001 бомба — 056 оба — 140 желоба — 001 короба — 001 плавкие — 106 легкие — 106 редкие -—106 жидкие — 106 далекие — 106 резкие — 106 низкие — 106 узкие — 106 вязкие — 106 великие — 106
сперва — 152 бптва — 056 удобства — 070 рыболовства — 070 чувства — 070 средства — 070 радпосре детва — 070 производства — 070 делопроизводства — 070 шелководства — 070 устанавливали — 125 усиливали — 125 оценивали — 125 приваривали — 125 наращивали — 125 требовали — 125 потребовали — 125 участвовали — 125 способствовали — 125 чувствовали — 125
фабрика — 060 Америка — 060 метрика — 060 Африка — 060 Мексика — 060 тросика — 006 синтагматика — 060 парадигматика — 060 проблематика — 060 тематика — 060 па и лучшей — 105 вкладышей — 016 зародышей — 016 наибольшей — 105 меньшей — 105 лежащей — 105 служащей — 105 общей — 105 всеобщей — 105 бегущей — 105
перекосов — 001 откосов — 001 взносов — 001 запросов — 001 вопросов — 001 район — 001 закон — 001 балкон — 001 окон — 070 волокон — 070
измеренного — 103 расширенного — 103 растворенного — 103 подветренного — 103 рассмотренного — 103 предусмотренного — 103 занесенного — 103 перенесенного — 103 захваченного — 103 охваченного — 103 возникнуть — 144 проникнуть — 144 крикнуть — 144 подчеркнуть — 144 привыкнуть — 144 тронуть — 144 вернуть — 144 развернуть — 144 повернуть — 144 сунуть — 144
неожиданно — 152 безнаказанно — 152 расписанию — 073 возрастанию — 073
120
Таблица 7.5 (окончание)
странно —152
особенно — 152
мгновенно — 152
откровенно — 152
косвенно — 152
собственно — 154
явственно — 152
непосредственно — 152
исключает — 116
ухудшает — 116
мешает — 116
решает — 116
разрешает — 116
лишает — 116
завершает — 116
совершает — 116
улучшает — 116
превышает — 116
газеты — 056
макеты — 001
ракеты — 056
самолеты — 001
пистолеты — 001
отрицанию — 073
возникновению — 073
проникновению — 073
выпадению — 073
ведению — 073
введению — 073
возведению — 073
приведению — 073
степенью — 055
ступенью — 055
осенью — 055
болезнью — 055
жизнью — 055
цепью — 055
дверью — 055
смесью — 055
огнесмесыо — 055
статью — 065
острая — 103
быстрая — 103
косая — 107
начатая — 103
коробчатая — 103
венным оформлением их концов. Это легко обнаружить с помощью так называемых обратных словарей. Элементы таких словарей располагаются пе в обычном лексикографическом порядке, а в обратном — так что одинаковые концы различных слов оказываются стоящими рядом. Если теперь назначить всем словам индексы (номера) их флективных классов, то окажется, что, как правило, одинаковым рядом стоящим концам слов будут соответствовать и одинаковые флективные классы. Фрагменты обратного словаря словоформ с назначенными флективными классами приведены в табл. 7.5.
Следовательно, «новым» словам (словам, отсутствующим в словаре) флективные классы могут назначаться по аналогии со словами, имеющимися в словаре, если буквенный состав их концов совпадает с буквенным составом словарных слов. Для этой цели нужно выбирать такие слова из словаря, концы которых в максимальной степени совпадают с концами «новых» слов. Исследования показывают, что таким образом можно правильно назначать флективные классы слов с вероятностью 0,9. С высокой степенью вероятности можно назначать «новым»
121
Таблица 7.6
Наиболее часто встречающиеся префиксы
БЕЗ — беззащитный, безусловный;
БЕС — бесконечный, бесполезный;
В — введение, включить, внести;
ВЗ — взгляд, взлет, взлом;
ВНЕ — внеочередный, внеплановый;
ВО — вовлечение, вопрос;
ВОЗ — воздействовать, возложить, возрасти;
ВОС —воспроизводить, восстановление;
ВС —вскрыть, всплеск, всхолмленный;
ВЫ —выбрать, вывести, выдвинуть;
ДЕЗ —дезинформация, дезорганизация;
ДЕ —декодировать, дестабилизация;
ДО — доведение, допускать, достроить;
ЗА — завершение, заглушить, задолго, затраты;
ИЗ — изготовить, излагать, измерить;
ИС — использование, истечение, исход;
МЕЖ — межведомственный, межгосударственный;
МЕЖДУ — международный;
НА — наведение, нагревание, наземный;
НАД — надводный, надстройка, надклассовый;
НЕ — небольшой, невозможный, неподвижный;
НИ — никакой, ничего, ничем;
О — оказать, охарактеризовать, окончить;
ОБ — обгонять, обвал, обновить, обучение;
ОБЕЗ — обезвреживать;
ОБЕС — обескровить;
ОБО — обошли, обозначение, обозримый;
ОТ — отводить, отдать, открыть, отнести;
ОТО — отошел, чотомрет, отозван;
ПЕРЕ — перевод, перегрузка, передать;
ПО — повести, подать, показать;
ПОД — подвесить, подвести, подготовить;
ПОДО — подобрать, подогреть, подошел;
ПРЕ — превращать, превысить, прекрасный;
ПРЕД — предвидеть, предлагать, предсказание;
ПРИ — прибегать, прибыть, привести, пригодный;
ПРО — проанализировать, провести, проход;
ПРОТИВО — противодействовать, противоречие;
РАЗ — разбить, развить, разговор, разделить;
РАЗО — разобрать, разорвать, разослать;
РАС — раскрывать, расход;
РЕ — реконструкция, ремонтировать, реорганизация;
С — сбить, сбросить, сдавать;
СО — собирать, совершить, содержать, соединение;
У — увидеть, удаление, удержать, укладка, укрытый;
словам также и другую грамматическую информацию — прпнад-, лежпость к части речи, признаки рода, лица, числа, падежа и т. п.
122
Наряду с рассмотренными выше способами варьирования форм слов, которые мы назвали способами словоизменения, в практике речевого общения широко используются и способы словообразования. Словообразовательные трансформации слов связаны прежде всего с изменением состава их префиксов и суффиксов. При этом может иметь место также чередование гласных и
Таблица 7.7
Наиболее часто встречающиеся суффиксы и сочетания суффиксов
Буквенные коды Флективные классы Буквенные коды Флективные классы
А 116 ЛЕНИ 073
АЕМ 103 ЛЕНН 103
АЛ 125 ЛЯ 116
АНИ 073 Н 103
АНН 103 Н 107
АТЬ 144 НИ 073
АЦИ 061 ноет 055
АЮЩ 105 О 152
ВШ 105 ОВ 103
ЕН 126 ОВ 107
ЕНИ 073 ОВАЛ 125
ЕНН 103 ОВАН 126
И 073 ОВАНИ 073
ИВА 116 ОВАНН 103
ИВШ 105 ОВАТЬ 144
ИЛ 125 ОНН 103
ИМ 103 ОСТ 055
ИРОВАНП 073 СК 106
ИРУ 116 ть 144
ИРУЮЩ 105 У 116
ИТЕЛЬН 103 УЮТЦ 105
ИТЬ 144 ЫВА 116
ИЧЕСК 106 ьн 103
К 060 ющ 105
Л 125 я 116
ящ 105
яющ 105
согласных букв в корневых морфемах (например, у пар слов проводить — проведение, относиться — отношение, убедившийся — убежденный, проношу — пронесли). Перечень наиболее часто встречающихся префиксов и сочетапий префиксов приведен в табл. 7.6, а перечень наиболее часто встречающихся суффиксов и сочетаний суффиксов — в табл. 7.7. В табл. 7.7 каждому суффиксу и сочетанию суффиксов поставлен в соответствие номер флективного класса. При этом суффиксы (сочетания суффиксов),
123
имеющие одинаковый буквенный состав, но относящиеся к различным флективным классам (совместимые с различными наборами окончаний), считаются разными. Например, суффиксы н в словах главный и отрывной и суффиксы ов в словах портовый и годовой — разные суффиксы.
Замена у слов одних префиксов на другие приводит, как правило, к изменению их смысла, тогда как замена суффиксов в
Таблица 7.8
Примеры словообразовательных парадигм
Звучит — звуча, звучавший, звучавши, звучал, звучание, звучать, звучащий, звучен, звучный, звучно, звучность;
Отрыв — отрывает, отрывавший, отрывавши, отрываемый, отрывал, отрывание, отрывать, отрывающий, отрывая, отрывной;
Смешает — смешав, смешавший, смешавши, смешал, смешаны, смешанный, смешать, смешение, смешивает, смешивавший, смешиваемый, смешивал, смешивание, смешивать, смешивающий, смешивая;
Рассказ — рассказав, рассказавший, рассказавши, рассказаны, рассказанный, рассказал, рассказать, рассказывает, рассказывавший, рассказываемый, рассказывал, рассказывать, рассказывающий, рассказывая, рассказчик, рассказчица;
Издает — издав, издававший, издаваемый, издавал, издавать, издавая, издавший, издадут, издал, изданы, издание, изданный, издатель, издать, издающий;
Тип — типизация, типизировал, типизированы, типизированный, типизировать, типизирует, типизируемый, типизирующий, типизируя, типичен, типический, типичный, типичны, типичность, типовой;
Организует — организация, организационный, организовав, организовавший, организовавши, организовал, организован, организованный, организовать, организовывал, организовывать, организует, организуемый, организующий, организуя;
Плоский — плоско, плоскость, плоскостной;
Очаг — очаговый;
Завод — заводской;
Сила — силовой, сильный, сильны, сильнее, сильнейший;
Европа — европейский.
основном связана с изменением синтаксической функции. Поэтому закономерности суффиксального словообразования играют важную роль при автоматическом распознавании смыслового тождества слов и словосочетаний. В табл. 7.8 даны примеры близких по смыслу слов, отличающихся друг от друга составом суффиксов.
С целью изучения закономерностей суффиксального словообразования авторами совместно с Г. М. Губайдуллиной, Ю. П. Калининым, М. В. Поздняк, А. А. Хорошиловым и др. была предпринята попытка выявления словообразовательных классов слов. Классы выявлялись путем анализа словаря, составлен-
124
кого по научно-техническим текстам общей протяженностью более двух миллионов слов. Среди них тексты широкой тематики занимали объем около 500 000 слов, а более полутора миллиона слов —тексты реферативных журналов по информатике, вычислительной технике и радиоэлектронике (примерно в равной доле). Из текстов широкого профиля было отобрано около 19 000 наиболее часто встречающихся словоформ, а из текстов рефератов— около 9000 слов. При этом каждое слово было представлено своей наиболее частой формой. Словарь был также пополнен одной тысячей слов из частотного словаря Л. Н. Засориной, составленного по современным русским художественным, научнопублицистическим и деловым текстам. Таким образом, в конечном счете словарь был создан на основе статистического анализа текстов общей протяженностью более трех миллионов слов и включал в свой состав около 29 000 словоформ. При этом в словаре оказалось около 17 000 словоизменительных основ слов и около 10 000 словообразовательных основ. Фрагменты научно-технического словаря приведены в Приложении 3. Под словообразовательной основой слова понималась начальная часть его буквенного кода, остающаяся после отсечения максимального числа суффиксов и удовлетворяющая условию продуктивности. Условие продуктивности формулируется как способность выделенной основы образовывать осмысленные слова в сочетании с другими суффиксами.
Важной характеристикой словаря, определяющей его представительность, является полнота покрытия им текстов, по которым он не составлялся. Для оценки этой характеристики были взяты тексты рефератов по информатике, вычислительной технике, электронике и обществено-политический (газетный) текст. Отождествление слов текстов со словами словаря производилось тремя способами: 1) на основе полного совпадения буквенных кодов словоформ, 2) на основе совпадения буквенных кодов слов с точностью до словоизменения (отличие допускалось только в окончаниях), 3) на основе совпадения слов с точностью до словообразования (отличие допускалось только в суффиксах и окончаниях). Результаты эксперимента сведены в табл. 7.9.
Из таблицы видно, что в случае отождествления слов путем их словообразовательного анализа полнота покрытия текстов по информатике, вычислительной технике и электронике колеблется в пределах от 96% До 98%, а по геофизике и газетным текстам она равна примерно 91%.
Словообразовательный класс слова может быть охарактеризован перечнем суффиксов (сочетаний суффиксов), совместимых с его словообразовательной основой. При этом два слова относятся к различным классам, если перечни суффиксов (сочетаний
125
суффиксов), совместимых с их словообразовательными основами, отличаются друг от друга хотя бы одним элементом. Так, слова печатать и наблюдать со словообразовательными основами печат и наблюд относятся к различным классам, так как основа печат несовместима с суффиксом ени, который совместим с основой наблюд, а основа наблюд, в свою очередь, несовместима
Таблица 7.9
Полнота покрытия словарем текстов различной тематики
Характер текста Полнота покрытия в %
при совпадении словоформ при совпадении словоизменительных основ слов при совпадении словообразовательных основ слов
Информатика 77,9 95,7 96,7
Вычислительная техника 78,4 97,2 97,8
Электроника 71,6 94,3 95,8
Геофизика 68,1 86,3 90,7
Общественно-политический текст 69,0 85,0 91,4
с суффиксом ани, совместимым с основой печат. Всего в научно-техническом словаре было выявлено 1126 различных словообразовательных классов слов. Длина соответствующих им списков суффиксов и сочетаний суффиксов колебалась в пределах от 2-х до 38-ми и в среднем составляла 11,7.
Фрагмент словаря словообразовательных классов слов приведен в табл. 7.10. Здесь для каждого класса указан его порядковый номер, слово-представитель и перечень суффиксов и сочетаний суффиксов. Суффиксы и сочетания суффиксов сопровождаются номерами флективных классов. Знак + обозначает нулевой суффикс, а сопровождающий его номер флективного класса — перечень окончаний слов, совместимых со словообразовательной основой. Более полный список словообразовательных классов слов помещен в Приложении 1.
В процессе анализа научно-технического словаря в нем было обнаружено 669 различных суффиксов и сочетаний суффиксов. Распределены они весьма неравномерно. Так, 38 наиболее продуктивных из них встречаются у 60% слов, 72 —у 75%, 181—у 92%, а на остальные 488 суффиксов и сочетаний суффиксов приходится только 8% слов. При этом в расчет принимались только те слова из словаря, которые имели в своем составе ненулевые суффиксы. В процессе описания словообразовательных классов список суффиксов и сочетаний суффиксов постепенно по-
126
Нолвялся, и его объем возрос до величины 1033. Этот список приведен в Приложении 2.
Русские слова могут иметь в своем составе не одну, а две, три и более корневых морфем. Примерами двухкоренных слов являются слова пустотелый, газоразрядный, двухсекционный, дис-
Таблица 7.10
Структура словаря словообразовательных классов слов
001 — надлеж — агцпй
+ 003 — 121 — беж — енцы АЛ — 125 АЩ - 105
+ - 121 АВ - 152 АВШ - 105
лвши — 152 АЛ — 125 АТЬ - 144
лщ — 105 ЕНЕЦ - 032 ЕНЦ — 032
087 — указ — ав
+ — 001 АВ - 152 АВШ — 105
АВ ШИ - 152 АЛ — 125 АП — 126
АНИ — 073 АНН — 103 АТЕЛ — 003
АТЕЛЬН - 103 АТЬ — 144 И - 060
ЫВА -'116 ЫВАВШ — 105 ЫВАЕМ — 103
ЫВАЙ - 143 ЫВАЙТЕ — 143 ЫВАТЬ — 144
ЫВАЮЩ - 105 ЫВАЯ — 152
269 — доз — а
+ - 056 ATOP — 001 ИРОВАВП1 - 105
ПРОВАЛ — 125 ПРОВАН — 126 ИРОВАНИ — 073
ИРОВАНН — 103 ИРОВАТЬ - 144 ИРОВК -060
ИРОВОК — 060 ИРУ — 116 ИРУЕМ — 103
ИРУЙ — 143 ИРУЙТЕ - 143 ИРУЮЩ — 105
ИРУЯ 677 — 152 — алюмини — н
+ 679 — 005 — кварц ЕВ — 103
+ 685 -001 — реч — ь ЕВ - 103
+ — 054 ЕВ — 107
ковод, псевдокоманда; примерами трехкоренных слов — сверхбыстродействующий, самолетостроительный, фотополупроводнико-вый, светодальномер, электрофотография; примерами четырехкоренных слов — водородно-кислородный, хлорметилполистирол. В рассматриваемом нами научно-техническом словаре одпокорен-ных слов оказалось 80,6%, двухкоренных слов —18,7%, а трех- и четырехкоренных слов —0,7%.
Некоторые сложные (многокоренные) слова могут иметь внутренние флексии (как, например, слова завод-изготовитель, слесарь-инструментальщик), и в процессе их функционирования внутренние флексии изменяются по тем же правилам, что и
127 4
флексии, стоящие в конце слова (см. формы слов заводом-изгб* товителем, слесарем-инструментальщиком). Сложные слова занимают промежуточное положение между однокоренными словами и словосочетаниями.
7.2. Структура именных словосочетаний
В автоматизированных информационных системах, основанных на формализованной записи сведений, широко используются понятия, выраженные именными словосочетаниями. Эти понятия могут обозначать различного рода объекты, их признаки, значения признаков, рубрики классификационных схем и т. п. В именных словосочетаниях главным словом (основным носителем смысла) является, как правило, ж первое слева существительное, а остальные слова служат для уточнения значения главного слова.
Именные словосочетания могут включать в свой состав следующие классы слов*, существительные (С), прилагательные (П), предлоги (Р), сочинительные союзы (&) и наречия (И). Наряду с полными буквенными кодами слов в составе именных словосочетаний встречаются аббревиатуры, буквенно-цифровые обозначения п числа. Эти элементы словосочетаний обычно выступают в роли существительных и значительно реже в роли прилагательных (например, порядковые числительные в цифровом выражении).
Количество слов в наименованиях понятий колеблется в пределах от одного до десяти — пятнадцати и в среднем равно примерно трем. Слова могут находиться в различной связи друг с другом. Наиболее типичными видами связи являются связь согласования между существительными и определяющими их прилагательными, а также предложные и беспредложные связи между существительными.
Прилагательное, как правило, согласуется с существительным, к которому оно относится, в роде, числе и падеже. Существительное, выступающее в роли определения к другому существительному, располагается справа от последнего и может иметь форму родительного, творительного или, значительно реже, дательного падежа. В случае предложного управления форма существительного, стоящего справа от предлога, зависит от вида последнего.
Примеры различных структур именных словосочетаний приведены в табл. 7.11. Здесь каждому слову наименования понятия поставлен в соответствие символ синтаксического класса. Стрелками указано направление связей между существительными, существительными и предлогами, а также между существительными и определяющими их прилагательными, если последние расположены справа от существительных. Если прилагательные рас-
125
Структурные формулы словосочетаний
Таблица 7.11
Лв п/п Структурная формула Словосочетание-представитель
1 ПС индикаторное устройство
2 ппс цветное индикаторное устройство
3 пппс управляющая цифровая вычисли! ел ь-ная машина
4 с->ср испытания машин
5 С->ПСр испытания электронного оборудования '
6 С ППСр использование цифровых вычислительных машин
7 с пппср использование управляющих цифровых вычислительных машин
8 ПС-^Ср автоматический поиск информации
9 пс-> ср-> ср автоматизированная система поиска информации
10 ППС -> ПСр международная автоматическая система телефонной связи
И с->ср->ср автоматизация процессов управления
12 С -> Ср-> Ср-> Ср проектирование систем обработки информации
13 ПС -> Ср-> пст автоматизированная система управления воздушным движением
14 ПС -> Р -> пср информационная система для административного руководства
15 ПС-+Р->Ср-> Ср символические языки для поиска информации
1 1
16 С Ср&Ср-> Ср 1 t система хранения и поиска информации
17 С-> р-> Сп-»-Ср сопротивление в месте повреждения
18 t о. О t о t И t t о и f электрическая сеть с возвратом тока через землю
19 ПС -> Ср&Ср 1 1 комбинированный трансформатор тока и напряжения
20 С-> ПП медь листовая красная
9 Г. Г. Белоногов, Б. А, Кузнецов
129
полагаются слева от определяемых ими существительных, то стрелки не ставятся. В нижних индексах символов существительных, не являющихся главными словами, указаны падежи. Падежи обозначены начальными буквами их наименований.
Наименования одних и тех же понятий могут встречаться в АИС в различной форме. Их трансформации могут быть связаны с изменением порядка следования слов, с изменением форм слов, с переходом слов из одних синтаксических классов в другие. Например, словосочетания управляемые реактивные снаряды и реактивные управляемые снаряды отличаются друг от друга только порядком следования слов, словосочетания порождающие грамматики и порождающая грамматика — только формами слов, словосочетания заводской коллектив и коллектив завода — принадлежностью определителей слова коллектив к различным частям речи.
Чаще всего у именных словосочетаний в различных контекстных окружениях изменяется только форма главного слова и определяющих его прилагательных (см. информационно-поисковые языки дескрипторного типа — информационно-поисковых языков дескрипторного типа). Но в некоторых случаях имеет место зависимость форм несогласованных определений и относящихся к ним прилагательных от числа главного слова (например, в словосочетаниях директор автомобильного завода — директора автомобильных заводов, начальник цеха — начальники цехов и т. п.).
Опираясь на структуру именных словосочетаний, можно формальным образом устанавливать между ними различные смысловые отношения: отношения эквивалентности (синонимии), родовидовые и ассоциативные отношения. Так, словосочетания, у которых совпадают словоизменительные основы главных слов и словообразовательные основы их определителей, оказываются, как правило, синонимами. Более точно отношения синонимии устанавливаются, если кроме совпадения указанных элементов совпадают еще и схемы синтаксических связей между ними.
Родо-видовые отношения между словосочетаниями имеют место, когда совпадают словоизменительные основы их главных слов, а словообразовательные основы определителей главного слова одного из словосочетаний содержатся среди словообразовательных основ определителей главного слова другого словосочетания. При этом словосочетание с меньшим числом слов выражает родовое понятие, а с большим — видовое. Точность установления родовидовых отношений увеличивается, если схема синтаксических связей между словами в словосочетании с более широким смыслом совпадает со схемой связей между соответствующими словами в словосочетании с более узким смыслом. Родо-видовые от
130
ношения имеют место, например, между следующими словосочетаниями: учебные заведения — высшие учебные заведения, системы поиска документов — автоматизированные документальные поисковые системы, каналы связи — каналы телеграфной, связи.
Если словосочетания не являются синонимами и не находятся в родо-видовых отношениях, но тем йе менее имеют одинаковый или частично совпадающий состав словообразовательных основ слов, то они, как правило, связаны и по смыслу (находятся в ассоциативных отношениях). Ассоциативные отношения между словосочетаниями иногда бывают полезны при поиске информации.
Полнота установления родо-видовых связей между словосочетаниями может быть существенно увеличена, если при анализе их структуры учитывать родо-видовые отношения между составляющими их словами. Если, например, известно, что понятия сортировка и кодирование являются видовыми по отношению к родовому понятию обработка, а понятие сообщение — видовым по отношению к понятию информация, то, заменяя в словосочетании обработка информации исходные слова на слова, выражающие соответствующие видовые понятия, получим ряд новых, более узких по смыслу словосочетаний: сортировка информации, кодирование информации, обработка сообщений, сортировка сообщений, кодирование сообщений. При установлении родо-видовых связей между словосочетаниями на основе смысловых связей между составляющими их словами должны выполняться три условия: 1) главному слову родового словосочетания должно соответствовать эквивалентное или более узкое по смыслу главное слово видового словосочетания; 2) каждому определителю главного слова родового словосочетания должен соответствовать эквивалентный или более узкий по смыслу определитель главного слова в видовом словосочетании; 3) схемы синтаксических связей между словами в родовом словосочетании и соответствующими им словами в видовом словосочетайии должны совпадать. Третье условие не является строго обязательным.
Следует заметить, что далеко не всегда парадигматические отношения между словосочетаниями могут быть установлены на основе их синтаксической структуры и парадигматических отношений между словами. Исследования показывают [22], что для родо-видовых отношений и отношений эквивалентности это удается сделать лишь на 50%. Другая часть этих отношений должна устанавливаться независимо от структуры и словарного состава словосочетаний путем анализа их содержания как целостных смысловых единиц. Примерами парадигматических отношений, не сводимых к пословным связям, являются родо-видовые отношения между следующими словосочетаниями: дорожные машины —
9*
131
бульдозеры, строительные машины — подъемные краны, летательные аппараты — воздушные шары, программные средства ЭВМ — операционные системы, формальные грамматики — порождающие грамматики, режимы работы — холостой ход.
7.3. Структура предложений и сверхфразовых единств
Различают предложения простые и сложные. Обычно простое предложение состоит из группы подлежащего и группы сказуемого. Группа подлежащего обозначает предмет высказывания (то, о чем говорится), группа сказуемого — признак предмета (то, £то говорится). В общем случае группа подлежащего выражается именным словосочетанием, а группа сказуемого — глаголом, кратким прилагательным или кратким причастием с определяющими или дополняющими их словами и словосочетаниями. Она может также выражаться и другими частями речи. Приведем несколько примеров простых предложений, обозначив границу между группой подлежащего и группой сказуемого знаком - (дефис): 1) Изделия из порошков - позволяют регулировать пористость в сплавах. 2) Резервы экономии - не исчерпаны. 3) Коллектив Института химии Уральского центра Академии наук СССР - ведет работы по созданию твердых сплавов для режущего инструмента и технологической оснастки. 4) Он - сильный. 5) Эта работа - выполнена за очень короткий срок.
В составе группы сказуемого можно различать собственно сказуемое (глагол, краткое причастие, краткое прилагательное, п др.), дополнения (прямые и косвенные) и обстоятельства (места, времени, цели, причины, образа действия и др.). Таким образом, предложение представляется состоящим из ряда функциональных членов, называемых членами предложения. Члены предложения могут выражаться словами и словосочетаниями, принадлежащими к различным частям речи, но при этом наблюдается сильная корреляция между частями речи и той функциональной ролью, которую они выполняют в предложении.
Наряду с членением простого предложения на группу подлежащего и группу сказуемого, в теоретической и прикладной лингвистике часто применяется и другое его членение — на тему и рему. Это — так называемое актуальное членение. Обычно принято считать, что тема выражает известную информацию, а рема — новую. Актуальное членение предложения часто совпадает с его членением на группу подлежащего и группу сказуемого, но не всегда. Примером несовпадения актуального членения и членения на группу подлежащего и группу сказуемого может служить
132
предложение: особое место в ходе обсуждения заняли вопросы повышения производительности труда. Здесь темой предложения является словосочетание особое место в ходе обсуждения заняли — т. е. группа сказуемого, а ремой — словосочетание вопросы повышения производительности труда — т. е. группа подлежащего.
Сложное предложение может состоять из двух и более простых предложений, соединенных сочинительной или подчинительной связью. Прп сочинительной связи простые предложения относительно независимы друг от друга и равноправны, при подчинительной — одно из них является главным, а другие — зависимыми от него, придаточными. Придаточное предложение по сути своей является как бы развернутым членом главного предложения и выступает в той же функциональной роли, что и соответствующий член простого предложения. Так, оно может выступать в роли предложения-подлежащего, предложения-дополнения, предложения-обстоятельства и др.
В сложном предложенип может быть несколько главных предложений, соединенных сочинительной связью, а каждому из главных может быть подчинено несколько придаточных предложений. Придаточные предложения, в свою очередь, тоже могут иметь подчиненные им другие придаточные предложения и т. д.
В состав простых предложений могут входить причастные и деепричастные обороты, которые по своим функциям мало чем отличаются от придаточных предложений и могут быть в них преобразованы. Например, простое предложение повышенный шум заднего моста, возникающий при движении автомобиля, может свидетельствовать о неправильной установке ведущей шестерни главной передачи с причастным оборотом возникающий при движении автомобиля может быть преобразовано в сложное предложение с придаточным определительным: повышенный шум заднего моста, который возникает при движении автомобиля, может свидетельствовать о неправильной установке ведущей шестерни главной передачи.
Таким образом, граница между простым и сложным предложением оказывается довольно условной. Картина осложняется еще и тем, что часто несколько простых предложений, имеющих какую-либо общую часть (группу подлежащего, группу сказуемого, дополнение, обстоятельство и т. п.) объединяются в одно предложение, в котором дублирующиеся элементы оказываются представленными только один раз, а различающиеся элементы соединяются сочинительной связью. Например, два предложения предлагаемая схема предназначена для автомобильных автоматических коробок передач и предлагаемая схема определяет моменты переключения передач с низших скоростей на высшие и од-
133
ратно ё одной и той же. группой подлежащего, йо с разными группами сказуемого могут быть объединены в одно предложение: предлагаемая схема предназначена для автомобильных автоматических коробок передач и определяет моменты переключения передач с низших скоростей на высшие и обратно.
В связном тексте предложения выступают не изолированно друг от друга, а в тесной смысловой связи. В основе этой связи лежат мыслительные образы тех конкретных или абстрактных объектов (ситуации, явлений), которые человек имеет в виду, когда он порождает текст. Образы этих объектов могут иметь определенную структуру или они структурируются человеком при их описании на естественном языке. Соответственно этому структурируется и текст.* В структуре мыслительных образов могут быть элементы различного масштаба, находящиеся в различных отношениях друг к другу, и эти элементы и их отношения отображаются в тексте. Возникают различные структуры текста и структурные единицы текста, получившие общее пазвапие сверхфразовые единства. Границы сверхфразовых единств иногда выделяются формальными графическими средствами (абзацными отступами, обозначениями параграфов, глав и т. п.), но по большей части они распознаются только «по смыслу».
Итак, тексту соответствует некоторый мыслительный образ у его автора и порождаемый этим текстом мыслительный образ у читателя. Эти мыслительные образы могут и не совпадать, по в основе они должны быть сходными. Иначе акт коммуникации (передачи информации) с помощью текста можно считать несо-стоявшимся. Целью передачи информации с помощью текста является не исчерпывающее описание мыслительных образов его автора, а лишь возбуждение, создание соответствующих мыслительных образов в сознании читателя. Поэтому текст не столько «выражает», сколько «намекает», и большая часть его реального содержания оказывается «между строк». При этом автор текста обычно всегда имеет в виду определенную модель знаний своего будущего читателя.
Письменный текст, как и звуковая речь, развертывается последовательно во времени — имеет линейную структуру, тогда как мыслительные образы нелинейны. При их словесном описании может быть принят различный порядок линейной развертки, но цель описания должна быть в основном одна и та же — воссоздание в сознании читателя мыслительных образов, .подобных мыслительным образам автора текста. Такое воссоздание осуществляется постепенно — путем восприятия предложения за предложением и «монтажа» возникающих при этом частичных образов в целостный мыслительный образ, соответствующий содержанию текста. При этом в каждом предложении элемент его актуально
134
го членения «тема» выполняет роль «стыковочного узла», служащего для подключения нового частичного мыслительного образа, обозначаемого этим предложением, к ранее построенному мыслительному образу.
Описанная модель восприятия текста позволяет объяснить тот факт, что связи между предложениями в нем осуществляются по большей части с помощью лексических повторов: в «стыковочных узлах» предложений повторяются наименования понятий предшествующего текста либо* буквально, либо в виде синонимических и эллиптических конструкций, либо в виде наименований родовых понятий и местоимений. Для связи с предыдущим текстом применяются также средства, основанные на указании его координат (слов и выражений типа на основании вышеизложенного..., рассмотренный нами ранее..., описанный в главе..., в приведенном выражении..., здесь..., все это... и т. п.).
Приведем фрагмент связного текста, отметив в нем средства связи между предложениями (для удобства последующих ссылок предложения перенумерованы): «1) Одной из наиболее перспективных разработок для сферы телекоммуникаций являются волоконные световоды, представляющие собой пучки очень тонких нитей из специального стекла. 2) Они могут передавать лучи света на большие расстояния по изогнутым траекториям. 3) Модулированный луч света может быть использован в качестве носителя речевых, телевизионных или цифровых сигналов. 4) Для усиления затухающего светового сигнала в тракт световода через определенные расстояния включаются активные повторители. 5) Эти расстояния могут быть сделаны значительно большими, чем в случае медных коаксиальных кабелей той же пропускной способности. 6) Поэтому применение световодов потенциально является более дешевым методом доставки абонентам индивидуальных телевизионных программ, а также передачи телекоммуникационного графика высокой плотности на загруженных линиях. 7) Дополнительными достоинствами световодных кабелей являются отсутствие помех от соседних кабелей и значительная трудность несанкционированного подключения».
В приведенном фрагменте текста связь второго предложения с первым осуществляется с помощью местоимения они, соотносящегося со словосочетанием волокнистые световоды в цервом предложении. Связь третьего предложения со вторым — с помощью словосочетания луч света, входящего в состав обоих предложений. Связь четвертого предложения с третьим — с помощью словосочетания световой сигнал, которое в данном контексте является синонимом словосочетания луч света. С помощью слова световод четвертое предложение связано также с первым и вторым предложениями. Предложения пятое и четвертое связаны
139
между собой с помощью слова расстояния, а связь шестого и седьмого предложений с предыдущим текстом осуществляется через термины световод и световодный кабель.
Изучение структуры связного текста началось в лингвистической науке сравнительно недавно и здесь еще предстоит сделать очень многое.
7.4. Семантико-синтаксическая
структура текстов
При решении проблемы автоматической обработки текстов на естественных языках следует учитывать такие явления человеческого мышления, языка и речи, как возможность многоаспектного описания одних и тех же объектов и ситуаций, различный уровень обобщения информации, вариативность форм представления одного и того же содержания, пресуппозиции (информация, формально выраженная в сообщениях, всегда сопровождается еще и подразумеваемой информацией, в этих сообщениях формально не выраженной), инференции (информация, являющаяся логическим следствием информации, формально выраженной в сообщениях, и той, которой располагает человек). Проблема автоматического анализа текстов усложняется также из-за ситуационной обусловленности их содержания, анафорических (межфразовых) связей, явлений эллипсиса (сокращений, пропуска некоторых элементов словосочетаний и фраз), омонимии и др. Все это делает задачу автоматической обработки текстов па естественных языках чрезвычайно сложной.
С целью облегчения процесса решения этой задачи, а также в рамках теоретических исследований языковых значений был предложен ряд формализованных моделей смысловой структуры текста: семантические сети, концептуальные сети, фреймы и др. По существу, эти модели отражают не только смысловую, но и синтаксическую структуру текстов. Поэтому их правильнее было бы называть семантико-синтаксическими моделями. И вообще следует заметить, что граница между семантикой и синтаксисом весьма условна, так как смысловое содержание любого отрезка текста не может быть описано без опоры на его синтаксическую структуру, а синтаксическая структура немыслима без семантического наполнения. Синтаксис и семантика так же неразрывно связаны друг с другом, как категории формы и содержания.
Одна из первых семантических сетей для описания структуры текстов была предложена Квилианом (Quillian) в 1967 г. [101]. Квилиан определяет семантическую сеть как множество узлов, соединенных друг С другом дугами. Каждый узел сети представляет одно понятие, смысловое содержание которого определяется 130
совокупностью его связей с другими понятиями. Таким образом, определения понятии носят характер логического круга: содержание понятия А может определяться через его отношение к понятию В, а содержание понятия В — через его отношение к понятию А. Каждый узел сети выступает одновременно и в качестве определяемого, и в качестве определяющего.
Квилиан различает три основных типа связей между узлами: 1) родо-видовую связь (связь определяемого понятия с более широким по объему понятием); 2) определительную связь (содержание попятил конкретизируется с помощью прилагательного или наречия); 3) предикативную или любую другую синтагматическую связь, выражаемую с помощью глагола или предлога. Были введены также и другие виды связей.
Более дифференцированная система описания семантпко-спн-таксической структуры текста была предложена Филмором (Fillmore) в 1968 г. [101]. Согласно Филмору каждое предложение содержит в своем составе сведения о его модальности (время, залог, наличие или отсутствие отрицания и т. п.) и собственно высказывание. Высказывание состоит из глагола и его дополнений, называемых также актантами или аргументами. Актанты, в соответствии с их функциональной ролью в предложении, могут иметь следующие шесть глубинных (семантических) падежей:
1) агентивный падеж (Agentiv) — обозначает одушевленный субъект действия, выраженного глаголом;
2) инструментальный падеж (Instrumental) — неодушевленная сила или предмет, с помощью которых совершается действие, выраженное глаголом;
3) дательный падеж (Dativ) — выражает функциональную роль одушевленного существа, на которое оказывает влияние действие, выраженное глаголом;
4) фиктивный падеж (Faktiv) — обозначает одушевленное существо или предмет, которые возникают в результате действия или состояния, выраженного глаголом;
5) локативный падеж (Lokativ) — обозначает местоположение или пространственные размеры действия или состояния, выраженного глаголом;
6) объективный падеж (Objektiv) — семантически наиболее нейтральный падеж, функциональная роль которого непосредственно определяется семантикой глагола. Позднее Филмором и его последователями был введен еще ряд других семантических падежей (например, обозначение исходного пункта действия, конечного пункта действия и др.).
М. Веттлер [101] отмечает, что все системы семантических падежей страдают тем недостатком, что в них функциональная
137
роль падежей недостаточно определена. Поэтому, на его взгляд, они не могут быть эффективно использованы при автоматической обработке информации. Но идея семантических падежей оказала большое влияние на идеологию построения ряда других систем семантического представления текста и, в частности, на модель Симмонса (Simmons).
Семантическая сеть Симмонса является наиболее популярной в ряду ей подобных. Как и модель Квплиана, она представляет собой сеть связанных друге другом узлов. Но здесь связи более дифференцированы. Их можно разделить на три группы. Первую группу составляют связи, соединяющие глагол с его актантами. Эти связи подобны глубинным падежам Филмора и его последователей. Они имеют следующие обозначения:
СА1 — соответствует агентивному ,падежу Филмора;
СА2 — соответствует инструментальному падежу Филмора;
THEME — «тема действия», соответствует объективному падежу Филмора;
SOURS — «исток действия», обозначает исходный пункт действия или первоначального владельца некоторого объекта;
GOAL — целевой пункт действия (не только в пространственной интерпретации);
LOC — место действия.
С помощью второй группы связей соединяются актанты глагола с их атрибутами. Эти связи имеют следующие обозначения:
MOD — определительная связь;
HASP ART — связь типа «целое — часть»;
POSS — поссесивная связь (отношение владельца к его вещи);
ASSOC — ассоциативная связь (может обозначать различные недостаточно строго определенные связи);
SHAPE и SIZE — определители формы и размеров.
Третья группа связей включает парадигматические и другие отношения, не вошедшие в первую и вторую группы. Эю следующие связи: Q — нечисловые квантификаторы (например, некоторые) ; NBR — количество; DET — артикль; COUNT — псчисляемость; SUP — подчиняющее понятие; SU — подчиненное понятие; EQ — тождество; PART OF — часть целого; ТОК— имя узла.
Узел в сети Симмонса характеризуется его индексом и связями о другими узлами. Индекс узла обозначается сочетанием буквы С и порядкового номера. Каждая связь, исходящая от узла, состоит из двух компонент: из обозначения типа связи и индекса узла, к которому она идет. В табл. 7.12, заимствованной из работы [101], дан пример семантического представления фразы: мужчина, который поймал на удочку большую рыбу, пода* рил ее красивой женщине. Здесь первый узел с индексом CL опи
138
сывается четырьмя связями: связью TOR с именем узла поймать, агентивной связью СА1 с узлом С2 (мужчина), инструментальной связью СА2 с узлом СЗ (удочка) и объективной связью THEME с узлом С4 (рыба). Для каждой из этих связей имеется инверсная связь, обозначенная в таблице знаком минус. Например, узел С2 (мужчина) имеет две инверсных агентивных связи с глаголами поймать и подарить.
Таблица 7.12
Ci ТОК поймать С2 ТОК мужчина СЗ ТОК удочка
CAi С2 — CAi Ci СА2 СЗ — CAI С5 THEME Ci — CA2 Ci
Ci ТОК рыба С5 ТОК подарить SIZE Св С А1 С2 — THEME Ci GOAL Cl — THEME C5 THEME Ci Cl ТОК женщина СЗ ТОК красивый MOD C3 — MOD Cl — GOAL C5 СЗ ТОК большой — SIZE Ci
Дальнейшим шагом вперед в области формализованного описания семантико-синтаксической структуры текста является теория концептуальных зависимостей (conceptual dependency theory) Р. Шенга (Schank) [71, 101]. Здесь, как и в падежных грамматиках и семантических сетях, также считается, что смысл предложения текста может быть отражен в одной или нескольких семантических структурах, называемых концептуализациями, которые состоят из ряда понятий, связанных друг с другом конечным числом семантических отношений.
Шенк различает четыре типа понятий или концептуальных категорий:
1) действие (ACT) — понятие, о котором можно сказать, что здесь человек или животное оказывает влияние на некоторый объект;
2) источник представлений (РР — picture producer) — понятие, характеризующее физический объект как источник представления в сознании человека;
3) модификатор представлений (РА — picture aider) — специфицирует, уточняет понятие, являющееся источником представлений; в качестве модификаторов представлений в естественном языке выступают прилагательные;
4) модификатор действий (АА — action aider) — определяет, модифицирует понятия, обозначающие действия. В качестве модификаторов действий часто выступают наречия.
139
Перечисленные четыре типа понятий являются конституента-ми (составляющими элементами) двух видов концептуализаций — действий и состояний. Каждая концептуализация-действия имеет в своем составе ядро, состоящее из «деятеля» (РР — члена, который является инициатором действия) и действия (ACT). Эти элементы ядра связываются между собой «главной связью»:
РР -фф- ACT
Дополнительно к обязательному для него ядру, действие может быть модифицировано другими РР-членамп, которые могут находиться в следующих падежах:
О
1) объективный падеж 2) рецппиентный падеж АСТ< Я 1 АСТ< J — РР, РР — <рр
3) директивный падеж D л г т / - - - РР
А С1 < —<рр
Рециписнтный и директивный падежи имеют по два аргумента: «дающий — принимающий» — для реципиентного падежа и «исходный пункт — цель» — для директивного.
Основное отличие теории концептуальных зависимостей Шенка от ранее рассмотренных нами семантических представлений состоит в том, что здесь все действия сводятся к ограниченному числу так называемых примитивных действий. При этом предполагается, что примитивные действия отражают некоторые психические сущности, а сложные действия можно описывать в виде структур, состоящих пз примитивных действий. К числу примитивных действий относятся:
A TR A NS — передача владения (контроля над) некоторой вещью от одного лица к другому (давать, брать, покупать и др.);
PTRANS— движение объекта от одного места к другому;
PROPEL — приложение физического усилия к объекту (толкать, тянуть, давить и т. д.);
MOVE — движение части тела животного, инициированное им самим;
GRASP — захват «деятелем» некоторого объекта;
INGEST — поглощение (принятие внутрь) животным некоторого объекта (есть, пить, вдыхать и т. д.);
EXPEL — выделение из животного некоторого объекта (плевать, потеть и т. д.);
МТ RAN S — передача информации между людьми (животными) или между различными участками их памяти (видеть, слышать, вспоминать и др.);
140
MBUILD <- порождение новых знаний на основе имеющихся (решать, умозаЪпочать и др.);
SPEAK — похищение звуков одушевленными и неодушевленными объектами (говорить, музицировать, свистеть и др.);
ATTEND — направлять свое внимание на какой-либо объект (слушать, смотреть и др.).
Важную роль в модели Шенка играет так называемое инструментальное отношение. Оно применяется для соединения двух концептуализаций в одну. В отличие от падежных грамматик, где инструментальное отношение соединяет действие только с одним понятием, здесь оно может соединять концептуализации двух действий.
Наряду с действиями, в теории концептуальных зависимостей Шенка применяются еще два вида концептуализаций — состояние объекта и изменение его состояния. При описании состояний объектов применяются три двуместных отношения: POSS — владение (объект PPi владеет объектом РР2), LOC — пространственная локализация (объект PPi находится на месте РР2), CONT — пространственное включение (объект РР1 находится внутри объекта РР2). При этом элементы РР могут модифицироваться элементами РА. Изменение состояния объекта рассматривается у Шенка как изменение значения показателя этого состояния, оцениваемого по некоторой шкале значений. Шенком был введен также ряд других отношений между объектами, которые мы здесь не рассматриваем.
Важное место среди различных способов формализованного описания семантико-синтаксической структуры текстов занимают фреймы. Они получили широкое признание среди специалистов, работающих над проблемой искусственного интеллекта. В первой главе мы достаточно подробно охарактеризовали этот подход и здесь на нем останавливаться не будем. Более, подробные сведения о фреймах можно найти в работах [6, 27, 54, 101].
Мы рассмотрели ряд подходов к формализованному описанию семантико-синтаксической структуры текста, отличающихся друг от друга теми или иными чертами. Во всех случаях, по существу, используется предикатно-актантная структура. Текст представляется в виде сети, в узлах которой находятся единицы языка и речи, а эти единицы связываются друг с другом определенными отношениями. Различия в терминологии, которой пользуются авторы при изложении своих концепций, не меняют существа дела. Например, семантическая сеть Квилианд — это сеть, построенная на основе ограниченного числа бинарных отношений — предикатно-актантных структур. Семантические падежи Филмора — это элементы предикатно-актантной структуры. Здесь роль имени предиката выполняет глагол, а роль его актантов —
141
дополнения, стоящие в определенных семантически^ падежах. В семантической сети Симмонса в основном реализуются те же идеи, что и у Квилиана и Филмора, но применяемся более дифференцированная система бинарных отношений/ а пример сети Симмонса, приведенный в табл. 7.12,— это Типичная анкетная форма поузлового описания сетевой структуры, аналогичная описанию в анкетной форме узлов А и Е па рис. 1.1 гл. 1. Не являются исключением и модели Шенка и Минского: и концептуализации Шенка, и фреймы Минского — это тоже предикатно-актантные структуры.
Важно отметить следующее обстоятельство. Во всех моделях представления смысла исходят из того, что «значение» языковой единицы имеет сложную структуру. Оно описывается либо некоторым набором признаков (элементарных значений), либо совокупностью связей с другими единицами, либо сетевой структурой (например, концептуализацией у Шенка).
В основе значения языковой единицы лежит тот мыслительный образ, который ассоциируется с ней в сознании человека и свойства которого проявляются во всей системе парадигматических и синтагматических отношений этой единицы с другими единицами. Число таких отношений очень велико. Оно может измеряться сотнями, тысячами и > десятками тысяч. Поэтому все известные модели «смысла» языковых единиц являются довольно грубой аппроксимацией реальной картины, поскольку в них используется лишь ограниченное число отношений.
«Значения» языковых единиц нельзя исчерпывающим образом раскрыть в отрыве от процессов мышления человека, опираясь только на текст. Текст — это лишь внешнее проявление этих процессор Jia основе текста можно получить только часть необходимой информации. Для получения остальной информации нужно моделировать процессы мышления человека.
Г Л Л В A 8
СЕМАНТИКО-СИНТАКСИЧЕСКИЙ АНАЛИЗ
И СИНТЕЗ ТЕКСТОВ
НА ЕСТЕСТВЕННЫХ ЯЗЫКАХ
8.1. Предварительные замечания
В системах автоматической обработки информации семантико-синтаксический анализ текстов производится с целью формализованного представления их структуры — выделения в них смысловых единиц и установления связей между ними. При этом структура текстов может интерпретироваться по-разному и описываться на различных формализованных языках. Следовательно, и цели, и результаты анализа могут быть разными. По этому поводу М. Веттлер пишет [101, с. 131]: «словом „анализ предложений4* (Satzanalyse) обозначается множество различных процедур, которые имеют между собой лпшь то общее, что предложения каким-то образом расчленяются и трансформируются в другую структуру. При этом всегда необходимо уточнять, на какие составные части расчленяется предложение».
Если говорить о «естественных» составных частях текста, то ими, по-видимому, являются прежде всего речевые отрезки, обозначающие понятия: слова, словосочетанпя, фразы, сверхфразовые единства. Морфемы (корни, префиксы, суффиксы) тоже являются значащими отрезками текста, но они не обозначают понятий, если не становятся самостоятельными словами.
Мы уже говорили о том, что границы между словами и предложениями указываются в тексте с помощью пробелов, точек и прописных букв. Что же касается остальных единиц, то их границы не всегда можно обнаружить по формальным признакам. Они «отмечены» лишь в сознании человека — теми понятиями, которые ассоциируются с ними.
Содержание понятий значительно богаче содержания слов и выражений, которыми они обозначаются и которые отражают лишь те признаки (часто не самые важные), по которым эти понятия могут быть выбраны из совокупности всех других понятий. Наряду с признаками, выраженными в их наименованиях,
143
понятия могут иметь множество других признаков,, не получивших в этих наименованиях никакого отражения, ijo тем не менее оказывающих влияние на синтагматические и парадигматические отношения между ними. Многообразие признаков, характеризующих одни и те же понятия, являются объективной основой для существования различных способов их слрбесного описания.
Из предыдущих рассуждений следует, что для правильного анализа текстов необходимо располагать не только информацией о встречающихся в них словах и словесных выражениях, но и о понятиях, ими представляемых. И чем полнее будет эта информация, тем лучше. А еще лучше иметь модель мыслящего субъекта, в которой достаточно полно была бы представлена не только система понятий и их словесных обозначений, но и система знаний о соответствующей предметной области — «модель мира». Все известные способы автоматического анализа текстов еще не удовлетворяют этим требованиям и поэтому несовершенны. Но многие из них вносят существенный вклад в решение проблемы и могут быть уже в настоящее время использованы при решении ряда практических задач.
Среди различных способов автоматического анализа текстов видное место занимают способы, базирующиеся на концепции порождающей трансформационной грамматики Хомского [101]. Согласно этой концепции, каждое предложение можно рассматривать как результат некоторого порождающего процесса, связанного с последовательной заменой одних символов и сочетаний символов на другие. Порядок замены символов задается списком подстановок, в левой части которых стоят заменяемые символы или последовательности символов, а в правой части — заменяющие. При этом различают нетерминальные и терминальные символы: нетерминальные символы могут заменяться на другие символы и сочетания символов, а терминальные не могут.
Исходным пунктом процесса порождения предложения является начальный символ 5, обозначающий предложение в целом, а его конечным результатом — цепочка слов, являющихся терминальными символами. Вначале символ 5 заменяется на сочетание символов NP и VP (группа подлежащего и группа сказуемого). Далее каждый из этих символов заменяется на сочетание других нетерминальных символов, обозначающих более мелкие структурные элементы предложения, эти последние —на символы еще более мелких структурных элементов и т. д., пока в результате последовательных замен не появятся конкретные слова (терминальные символы). После замены всех нетерминальных символов на терминальные процесс порождения предложения заканчивается. Если в процессе порождения сохранить информацию о всех структурных элементах предложения, из которых оно составля-144
лось, то тем\амым будет получено описание его семантико-синтаксической структуры.
Наряду с подстановками, предназначенными для первоначального порождения предложений, в порождающей трансформационной грамматике ^огут применяться и другие подстановки, описывающие правила их трансформации. В левой части таких подстановок указывается последовательность символов, характеризующая исходную структуру, а в правой — структуру ее заменяющую.
Для анализа структуры предложений порождающая трансформационная грамматика может применяться двумя способами — «сверху — вниз» и «снизу — вверх». По первому способу порождающая процедура функционирует в обычном порядке, но подстановки применяются таким образом, чтобы терминальные символы раньше появлялись в начале предложения. Если они совпадают со словами анализируемого предложения, то переходят к порождению соседних справа терминальных символов, если не совпадают, то ищутся другие варианты подстановок, чтобы такое совпадение имело место. Так постепенно порождаются все слова анализируемого предложения, а заодно описывается и его семантико-синтаксическая структура. При анализе «снизу —- вверх», реализуется процесс, обратный процессу порождения предложения. При этом подстановки применяются в обратном порядке (справа налево), а исходная последовательность терминальных символов заменяется на символ 5. Когда это удается сделать, то оказывается описанной и семантпко-синтаксическая структура предложения.
Несмотря на кажущуюся простоту, в действительности процедуры анализа текстов на основе порождающей трансформационной грамматики сложны в реализации и не всегда достигают цели. Причиной последнего является то обстоятельство, что процесс анализа носит формальный характер и не опирается на содержание понятий, соответствующих структурным элементам предложений.
Более простыв в реализации является анализ, основанный на использовании сетей переходов [101]. Сеть переходов состоит пз ряда так называемых состояний, которые связаны друг с другом ориентированными, то есть проходимыми только в одном направлении, отношениями. При этом па отдельные отношения могут быть наложены условия, которыми определяется, когда каждое отношение (стрелка между узлами) может быть «пройдено» (когда переход может быть реализован). В процессе анализа проверяется, соответствует ли последовательность классов слов анализируемого предложения одной из последовательностей, которые могут быть «пройдены» в сети переходов. Этот процесс
Ю Г, Г, Белоногов, Б. А. Кузнецов ^5
существенным образом осложняется, если связаш#>те по смыслу слова оказываются на значительном расстояние друг от друга.
Идея применения сетей переходов для анализа структуры предложений весьма популярна и была реат^Дзовапа в различных модификациях. Одной из наиболее удачных из них является модификация, предложенная Вудсом [101]./В программе Вудса каждому состоянию (узлу) сети соответствует ZJSP-функцпя, с помощью которой определяется направление дальнейшего движения по сети. Симмонс модифицировал Программу Вудса таким образом, чтобы она могла строить семантическую сеть.
При попытках применения рассмотренных выше способов анализа к русским текстам наряду с общими нерешенными проблемами возникают еще и дополнительные трудности, связанные с богатой системой словоизменения и словообразования в русском языке и с более свободным (по сравнению, например, с германскими и романскими языками) порядком слов в предложении. Это делает необходимым создание специальных достаточно мощных процедур морфологического анализа и учета особенностей русского синтаксиса. Далее мы рассмотрим способы анализа и синтеза текстов, ориентированные прежде всего на специфику русского языка.
8.2. Морфологический анализ и синтез слов
8.2.1. Общий порядок морфологического анализа и синтеза. Морфологический анализ слов применяется с целью отождествления их различных форм и получения грамматической и семантической информации, необходимой на последующих этапах обработки текстов. Морфологический синтез —- с целью получения различных форм слов при декодировании текстовой информации и выдаче ее человеку. Морфологический анализ и синтез могут строиться как на базе словаря основ слов, так и на базе словаря словоформ. Обычно предпочитают первый путь, мотивируя это необходимостью экономии памяти ЭВМ. Но по мере развития вычислительной техники емкость оперативной памяти ЭВМ увеличивается и аргументы, приводимые в пользу такого выбора, становятся менее убедительными. Что же касается внешних запоминающих устройств, то экономичность их использования зависит главным образом от принятых способов кодирования основных массивов информации (массивов формализованных сообщений, текстов рефератов и т. п.), а не от объемов словарей. При достаточно больших объемах массивов (порядка нескольких миллионов слов) доля словарей в них не превосходит 5%.
Различные способы морфологического анализа и спптеза разрабатывались в связи с задачей автоматического перевода тексто-146
вых сообщенийчс русского языка на иностранные и с иностранных языков на русский, а также в связи с задачами построения автоматизированных информационных систем. Мы проиллюстрируем идеи морфологического анализа и синтеза слов на примерах алгоритмов, разработанных авторами и реализованных в ряде систем автоматической- обработки информации. В основу построения алгоритмов положено разбиение всех слов на классы, определяющие характер изменения буквенного состава форм слов. Эти классы рассмотрены в гл.-7.
Морфологический анализ и синтез слов производится с помощью словаря основ и ряда вспомогательных таблиц. В словарь включены основы простых и сложных слов без внутренней флексии. Для сложных слов с внутренней флексией типа слесарь-ин-струментальщик, завод-изготовитель и т. п. в словаре приведены лишь основы простых слов, входящих в состав этих сложных слов. Если слово имеет несколько форм основ, то в словарь, как правило, включены все формы основ слов. Исключение составляют лишь изменяемые основы типа II (основы с чередованием гласных), которые представлены в словаре только в одной из возможных форм, принятой за каноническую. Каждой основе словаря ставится в соответствие сочетание кода основоизменительно-го класса и кода флективного класса, а омонимичной основе — серия сочетаний таких кодов.
Морфологический анализ слова начинается с его флективного анализа. Флективный анализ слова производится с целью правильного выделения его основы, замены буквенного состава основы ее порядковым номером по словарю и определения грамматической информации к слову. После флективного анализа номера основ типа III (с чередованием согласных) заменяются на номера канонических форм основ (в частности, это может быть замена на тождественный номер, если анализируемое слово имело каноническую форму основы).
Понятия канонической (главной) и вариантной форм основы слова, а также процедуры замены вариантных форм основ на канонические потребовалось ввести в связи с необходимостью отождествлять различные формы слов на последующих этапах анализа текстов. Каноническая форма для основ типа II, III будет определена ниже.
В процессе флективного анализа основа слова может не найтись в словаре. Это возможно в тех случаях, когда анализируемое слово имеет основу типа II в вариантной форме, или является сложным словом с внутренней флексией, или когда основа анализируемого слова не представлена в словаре ни в канонической, ни в вариантной форме. До окончания флективного анализа слова обычно неизвестно, какой из трех перечисленных случа-10* 147
ев имеет место. Вначале анализируемое слово поверяется на возможность наличия вариантной формы основь^/ типа II. Если эта возможность вероятна, то вариантная .форь^а основы заменяется па каноническую и проверяется правильность этой замены с помощью словаря основ. При положительном результате проверки определяется номер основы и грамматической информации к слову.
Если анализируемое слово не содержит в своем составе вариантной формы основы типа II, то оно проверяется на сложность (по наличию дефиса между частями сложного слова). Сложное слово расчленяется на составляющие его простые слова, которые затем подвергаются флективному анализу.
Морфологический синтез слов в первом приближении можно рассматривать как процесс, обратный по отношению к их анализу. Однако при морфологическом синтезе не возникают трудности, аналогичные трудностям, связанным с отождествлением различных буквенных образов слов и разрешением омонимии основ слов. Кроме того, исходные данные для морфологического синтеза слов отличаются от результатов морфологического анализа тем, что здесь номер основы слова сопровождается однозначной морфологической информацией, поэтому синтез форм слов значительно проще их анализа.
Синтез форм неизменяемых слов сводится к простой выборке из словаря буквенного состава их основ. В некоторых случаях к последнему приформировывается возвратная частица. Формы изменяемых слов составляются из буквенных кодов их основ и окончаний. В случае необходимости к основе слова приформировывается «внутренний» мягкий знак, а к окончанию — возвратная частица с я или съ. Кроме того, канонические формы основ типов II, III заменяются на вариантные. Необходимость замены канонической формы основы на вариантную определяется по номеру основы и сопровождающей его грамматической информации.
8.2.2. Флективный анализ и синтез. Флективный анализ изменяемых слов производится с помощью морфологической таблицы с двумя входами. Строкам этой таблицы поставлены в соответствие порядковые номера окончаний, а столбцам — номера флективных классов слов (см. гл. 7). На пересечении строк и столбцов морфологической таблицы для каждого фактически возможного сочетания номера флективного класса и номера окончания изменяемого слова указывается номер соответствующей морфологической информации.
В качестве морфологической информации для синтаксического класса слов «существительные» указывается число и падеж, для класса «прилагательные» — род, число и падеж, для класса «глаголы в личной форме» — число и лицо, для класса «глаголы
148
прошедшего времени, краткие прилагательные и причастия»—* род и число, длй\класса «количественные числительные» — падеж.
Морфологическая информация отдельных форм слов, рассматриваемых вне контекста, обычно бывает многозначна. Поэтому им могут быть поставлены в соответствие наборы упомянутых выше морфологических характеристик. Возможные наборы морфологических характеристик для различных синтаксических классов слов сведены в табл. 8.1, где каждому набору присвоен определенный порядковый номер.
В табл. 8.1 грамматическая информация представлена в закодированном виде. Здесь используются следующие условные обозначения. Для синтаксического класса «существительные» первая цифра в каждой паре восьмеричных цифр указывает на грамматическую категорию числа, вторая —на падеж слова. При этом цифра 1 на первом месте означает единственное число, цифра 2 — множественное число. Цифры 1, 2, 3, 4, 5, 6, стоящие на втором месте, обозначают соответственно именительный, родительный, дательный, винительный, творительный и предложный падежи. Последовательность пар восьмеричных цифр' описывает случаи многозначности информации о формах слов.
Для синтаксического класса «прилагательные» первая цифра в каждой паре восьмеричных цифр обозначает род и число, а вторая — падеж слова. Цифра 1 на первом месте означает, что прилагательное имеет форму мужского рода единственного числа, цифра 2 является признаком среднего рода единственного числа, цифра 3 — признаком женского рода единственного числа, цифра 4 — признаком множественного числа. Падежи прилагательных обозначаются так же, как и падежи существительных.
Морфологическая информация слов, принадлежащих к синтаксическим классам «глаголы в личной форме», «глаголы прошедшего времени, краткие прилагательные и причастия», «количественные числительные», обозначается в табл. 8.1 одной цифрой, а в случае многозначности — последовательностью цифр. При этом для синтаксического класса «глаголы в личной форме» цифры 1, 2, 3 обозначают первое, второе и третье лицо единственного числа, а цифры 4, 5, 6 — первое, второе и третье лицо множественного числа. Для синтаксического класса «глаголы прошедшего времени, краткие прилагательные и причастия» цифры 1,2, 3 обозначают формы мужского, среднего и женского рода единственного чпсла, а цифра 4 — форму множественного числа. Формы слов синтаксического класса «количественные числительные» характеризуются только падежом, который кодируется так же, как и у существительных и прилагательных.
Двумерная морфологическая таблица содержит много пустых клеток. Поэтому при ее линейной записи следует принимать спе-
149
Таблица 8.1
Грамматическая информация к словоформа^ (для изменяемых слов)
№ п/п Информация
I. Существительные
01 11
02 11, 14
03 11, 14, 16
04 11, 14, 22
05 И, 22, 24
06 12
07 12, 13, 15, 16
10 12, 13, 16
11 12, 13, 16, 21
12 12, 13, 16, 21, 24
13 12, 14
14 12, 14, 21
15 12, 21
16 12, 21, 24
17 13
20 13, 16
21 14
22 15
23 15, 22
24 15, 22, 24
25 15, 23
26 16
27 16, 21
30 16, 21, 24
31 21
32 , 21, 24
33 22
34 22, 24
35 22, 24, 26
36 23
37 25
40 26
II. Прилагательные
41 И, 14
42 И, 14, 32, 33, 35,
36
43 12, 14, 22
44 13, 23
п/п Информация
45 15, 16, 25, 26, 43
46 15, 22
47 15, 25, 43
50 16, 26
51 21, 24
52 21, 24, 41, 44
53 31
54 32, 33, 35, 36
55 34
56 41, 44
57 42, 44, 46
60 45
III. Глаголы в личной форме
61 1
62 2
63 3
64 4
65 5
66 6
IV. Глаголы прошедшего
времени, краткие прпла-
гатсльные
67 1
70 2
71 3
72 4
V. Количественные числи-
тельные
73 1, 4
74 2, 3, 6
75 2, 4, 6
76 3
77 5
150
циальпые меры для экономии места в запоминающем устройстве ЭВМ. Один из возможных способов линейной записи морфологической таблицы иллюстрирует табл. 8.2 (приводится только начальный участок морфологической таблицы). Здесь каждому номеру класса (см. полужирные числа) поставлен в соответствие столбец пар чисел, разделенных тире. Чпсло, стоящее в каждой
Морфологическая таблица
Таблица 8.2
001 002 003 004 005 006 007 010
01-37 01-37 17-37 17-37 17-37 01-37 01-37 01—37
20-36 20—36 26-33 24-33 24-33 20-36 20-36 20-36
22-40 22-40 27-22 27-22 27-22 22-40 22-40 22—40
42-33 26-33 61-36 61-36 61-36 42-33 45-22 42-33
54-22 45-22 63-40 63-40 63-40 45-22 65-04 45-22
65-02 65-02 67-26 67-26 70-30 65-02 66-06 65-02
66-06 66-06 70-32 70-32 71-02 66-06 67-26 66-16
67-26 67—26 75-02 71-02 76-17 67-26 70-32 67-26
73-17 70-32 76-17 76-17 .77-06 70-32 73-17 73-17
74-32 73-17 . 77-06 77-06 — 73-17 — —
011 012 013 014 015 016 017 020
01-37 17-37 17-37 17-37 01-37 01-37 01-37 17-37
20-36 26-33 24-33 24-33 20-36 20-36 20-36 26-33
22-40 27-22 - 27—22 45-22 22-40 22-40 22-40 27-22
24-33 61-36 61-36 61-36 45-22 26-33 45-22 61-36
27-22 63-40 63-40 63-40 65-04 27—22 65-04 63-40
65-02 70-12 67—26 65-02 66-16 65—02 66-06 67-26
66-06 75-02 71-02 66-06 67-26 66-06 67-26 75-02
67-26 — 76-17 67—26 73-17 67-26 73-17 76—17
73-17 — 77-16 73-17 — 70-32 74-32 77-16
74-32 —- — 77-32 — 73-17 — —
021 022 023 024 025 026 027 030
01-37 01-37 17-37 01-37 17-37 17-37 17-37 17—37
20-56 20-36 26-34 20-36 24-34 24-34 26-34 26-34
22-40 22-40 45—22 22-40 27-22 26-01 27-22 27-22
42—34 45-22 61-36 26-34 61—36 27-22 61-36 61-36
45-22 65-05 63-40 45-22 63-40 61-36 63-40 63-40
65-01 66-13 65-01 65-01 70-27 63-40 67-26 67-26
63-13 67-26 66-13 66-13 71-01 67-26 70-31 75-01
67-26 73-17 67-26 67-26 76-17 70-31 75-01 76-17
73-17 74-31 70-31 70-31 77—13 76-17 76-17 77-14
74-31 — 73-17 73-17 — 77-13 77-13 —
паре чисел слева от тире, является номером окончания (по табл. 7.4), а число, стоящее справа от тире,— номером морфологической информации (по табл. 8.1), соответствующей сочетанию номера флективного класса и номера окончания слова. Общее ко
151
личество пар чисел в табл. 8.2 равно количеству непустых клеток двумерной морфологической таблицы.
При известном флективном классе и окончании слова его флективный анализ может быть сведен к выборке информации из табл. 7.4, 8.1, 8.2 в следующем порядке. Сначала по табл. 7.4 буквенный код окончания заменяется его номером Затем по номеру флективного класса и номеру окончания из табл. 8.2 выбирается номер морфологической информации о слове. Наконец, с помощью табл. 8.1 помер морфологической информации заменяется соответствующим набором морфологических характеристик.
Приведем пример флективного анализа слов. Пусть требуется проанализировать формы слов тираж и стола, которые принадлежат к флективным классам 002, 001 и имеют окончания + (нуль), а — соответственно.
Заменив по табл. 7.4 буквенные коды окончаний па их номера 65, 66, входим в табл. 8.2 и для сочетаний номеров классов и номеров окончаний (002, 65), (001, 66) определяем номера 02, 06 наборов морфологической информации. По табл. 8.1 находим, что морфологическая информация к слову тираж определяется набором И, 14 (именительный и винительный падежи единственного числа), а к слову стола — набором 12 (родительный падеж единственного числа).
Номер флективного класса основы определяется после ее выделения из состава анализируемого слова. Членение слова производится путем последовательного отделения его конечных букв и поиска сочетания отделенных букв в списке окончаний. Если оказывается, что сочетание отделенных букв содержится в списке окончаний, то начальная часть слова ищется в словаре основ.
При совпадении начальной части слова с одной из основ словаря определяется помер совпавшей основы и номер ее флективного класса пли, для омонимичных основ, сочетание номеров флективных классов. Это возможно благодаря тому, что, как указывалось выше, каждой основе словаря поставлен в соответствие номер флективного класса, а для омонимичных основ указывается сочетание номеров флективных классов (примером омонимичной основы является основа осмотр, входящая в состав форм двух различных слов — осмотр и осмотреть).
Совпадение начала слова с одной из основ словаря, а его конца с одним из окончаний возможно и при неправильном членения слова. Примером могут служить формы слов знаков и управляем с основами знак и управля. Эти формы слов могут совпасть с основами знаков и управляем слов знаковый и управляемый и неправильно расчлениться на основы знаков и управляем и нулевые окончания. Поэтому требуется проверка правильности членения слова.
152
Правильность членения слова определяется по морфологической таблице путем проверки найденных основы и окончания слова на совместимость. Основа и окончание слова считаются совместимыми, если клетка морфологической таблицы, соответствующая номеру флективного класса и номеру окончания слова, не пуста (или, применительно к структуре табл. 8.2, если номер окончания слова содержится в левой части столбца пар чисел, соответствующего номеру флективного класса). В противном случае основа и окончание несовместимы, и следует продолжать поиск правильного членения слова. При омонимии основ на совместимость проверяются все сочетания признаков «флективный класс» и «окончание», полученные в результате анализа слова.
Проверка основы и окончания слова на совместимость позволяет в основном преодолеть трудности морфологического анализа, связанные с омонимией основ слов. Однако при этом остается неразрешенной такая омонимия основ слов, которая может приводить к совпадению некоторых форм различных слов. Например, у слов техник и техника совпадают несколько форм единственного и множественного числа, и вне контекста по одной форме слова нельзя определить, о каком слове идет речь. Такого рода омонимия может быть разрешена только средствами синтаксического анализа, а в некоторых случаях потребуется и семантический анализ контекста, поэтому при морфологическом анализе необходимо сохранять все возможные классы и наборы морфологической информации омонимичных словоформ.
Описанный выше процесс членения на основу и окончание применим к словам, не имеющим в своем составе возвратной частицы и мягкого знака между основой и окончанием. Наличие одного из этих элементов несколько осложняет процесс членения слова из-за необходимости его обнаружения и выделения из состава основы или окончания. При этом обнаружение возвратной частицы ся или сь отмечается признаком возвратности, а внутренний мягкий знак исключается из состава слова.
Включение в состав чглова возвратной частицы влечет за собой изменение его синтаксической роли в предложении и обычно придает ему новый смысловой оттенок (сравни слова: оборонять— обороняться, управляющий — управляющийся, пытал — пытался). Естественно поэтому рассматривать возвратную частицу как составную часть основы слова с внутренней флексией (с внутренним окончанием). Чтобы отличить основу слова с возвратной частицей от основы слова без возвратной частицы, к порядковому номеру основы, полученному по словарю, прибавляется некоторое постоянное число. Величина этого постоянного числа должна быть выбрана такой, чтобы результирующее число не совпало ни с одним номерохМ словарной основы. С этой целью
153
в код номера основы слова можно ввести дополнительный разряд и отмечать цифрой 1 наличие признака возвратности.
Результатом разрешения омонимии основы слова является выделение из серии флективных классов того класса, который соответствует условиям контекста. Этот результат, как и факт наличия возвратной частицы, можно отображать в номере основы слова. Для этого вводят в код номера основы два дополни-
Таблица 8.3
Обращенная морфологическая таблица (А. Существительные)
И 12 13 14 15 16 21 22 23 24 25 26
СО1-65 66 73 65 45 67 74 42 20 74 01 22
002-65 66 73 65 45 67 70 26 20 70 01 22
003-75 77 76 75 27 67 70 26 61 70 17 63
004-71 77 76 71 27 67 70 24 61 70 17 63
005-71 77 76 71 27 70 70 24 61 70 17 63
006-65 66 73 65 45 67 70 42 20 70 01 22
007—65 66 73 65 45 67 70 65 20 70 01 22
010-65 66 73 65 45 67 66 42 20 66 01 22
011-65 66 73 65 27 67 74 24 20 74 01 22
012-75 70 70 75 27 70 70 26 61 70 17 63
013-71 77 76 71 27 67 77 24 61 77 17 63
014-65 66 73 65 45 67 77 24 61 77 17 63
015-65 66 73 65 45 67 66 65 20 66 01 22
016-65 66 73 65 27 67 70 26 20 70 01 22
017-65 66 73 65 45 67 74 65 20 74 01 22
020-75 77 76 75 27 67 77 26 61 77 17 63
021-65 66 73 66 45 67 74 42 20 42 01 22
022—65 66 73 66 45 67 74 65 20 65 01 22
023-65 66 73 66 45 67 70 26 61 26 17 63
024-65 66 73 66 45 67 70 26 20 26 01 22
025-71 77 76 77 27 70 70 24 61 24 17 63
026-26 77 76 77 27 67 70 24 61 24 17 63
027-75 77 76 77 27 67 70 26 61 26 17 63
030-75 77 76 77 27 67 77 26 61 26 17 63
031-65 66 73 66 45 67 70 42 20 42 01 22
032-65 66 73 66 27 67 74 24 20 24 01 22
033-06 70 67 77 26 67 70 26 20 26 01 22
034-66 74 67 73 44 67 74 65 20 65 01 22
035-77 70 67 76 26 67 70 26 61 26 ' 17 63
036-65 66 73 66 26 67 70 26 20 26 01 22
037-65 66 73 66 45 67 67 65 20 65 01 22
040-65 66 73 66 45 67 66 42 20 42 01 22
тельных двоичных разряда, в которых записывается порядковый номер (слева направо) выделенного класса в серии номеров флективных классов, соответствующих омонимичной основе.
Флективный синтез изменяемых слов производится с помощью словаря основ, обращенной морфологической таблицы (табл. 8.3) и списка окончаний (табл. 7.4). Обращенная морфо
154
логическая таблица состоит из нескольких частей, число которых определяется количеством синтаксических классов изменяемых слов (в табл. 8.3 приведен фрагмент таблицы для класса существительных). По одному входу таблицы (левому) перечислены коды морфологических классов, а по другому (верхнему) — морфологическая информация (коды морфологической информации выделены). На пересечении строк и столбцов указаны номера окончаний.
При формировании буквенного кода изменяемых слов сначала номер основы заменяется ее буквенным кодом, выбранным из словаря. Затем с помощью обращенной морфологической таблицы и табл. 7.4 отыскивается буквенный код окончания и приформи-ровывается к буквенному коду основы слова. В необходимых случаях к окончанию слова приформировывается также буквенный код возвратной частицы, а между основой и окончанием вставляется внутренний мягкий знак.
Поиск буквенного кода окончания проиллюстрируем на примере форм слов столами, тираж, перебоев, имеющих основы стол, тираж, перебо. Пусть для каждой формы слова указано сочетание кода флективного класса и кода однозначной морфологической информации, а последовательность этих сочетаний представлена в виде пар чисел (001, 25), (002, И), (004, 22). Тогда, используя пары чисел в качестве исходных данных, по табл. 8.3 можно найти соответствующие им номера окончаний 01, 65, 24, а по табл. 7.4 —получить искомые буквенные коды окончаний ами, +, ев.
Известно, что окончания прилагательных, имеющих формы винительного падежа единственного и множественного числа и согласующихся соответственно с существительными мужского и женского рода, бывают различными в зависимости от наличия или отсутствия признака одушевленности у существительных, к которым эти прилагательные относятся. При синтаксическом синтезе в подобных случаях винительный падеж заменяется родительным, что позволяет однозначно определить окончание по обращенной морфологической таблице (это правило не распространяется па винительный падеж единственного числа прилагательных, согласованных с существительными женского рода).
Буквенный код неизменяемых слов обычно совпадает с буквенным кодом их словарных основ. Исключение составляют только слова с признаком возвратности. В последнем случае присоединяется код возвратной частицы.
Для выяснения формальных признаков, по которым можно было бы определить необходимость введения мягкого знака между основой и окончанием, был проведен соответствующий анализ частотного словаря словоформ, составленного по научно-тех
155 •
ническим текстам. При этом проверялись две рабочие гипотезы. Первая из них заключалась в предположении, что свойство иметь внутренний мягкий знак присуще всем словам, входящим в флективные классы со словами-представителями: брус, воробей, судья, муж, сын, мышь, речь, грань, эскадрилья, статья, перо, побережье, третий, т. е. с такими словами-представителями, которые в определенных формах могут содержать внутренний мягкий знак. Согласно второй гипотезе предполагалось, что все слова с внутренним мягким знаком принадлежат только к одному из перечисленных выше флективных классов. В результате анализа частотного словаря не было обнаружено ни одного примера, противоречащего этим гипотезам. Поэтому обе гипотезы могут считаться практически достоверными и использоваться при разработке алгоритмов морфологического анализа и синтеза слов.
Таким образом, для введения внутреннего мягкого знака в состав синтезируемого слова требуется, чтобы его флективный класс совпадал с одним из классов слов, допускающих эту операцию, а морфологическая информация определяла именно ту форму слова, которая у данного класса должна содержать внутренний мягкий знак. Информация о формах слов, содержащих внутренний мягкий знак, выявляется заранее и используется при составлении алгоритма морфологического синтеза.
При синтезе слов с возвратными частицами ся или сь требуется в каждом случае выяснить, какая из двух частиц должна быть выбрана. Анализ форм слов показывает, что частица сь обычно встречается после букв а, е, и, о, у, ю, я и только у инфинитива, деепричастия и у личных форм глагола. В остальных случаях употребляется частица ся. Информация о тех или иных свойствах букв (например, о свойстве букв быть «согласными» и т. п.) оформляется в виде логических шкал. В виде логических шкал оформляются также и некоторые виды грамматической информации.
8.2.3. Морфологический анализ и синтез слов с изменяемой основой. Как уже было указано, изменяемые основы слов бывают трех типов — II, III и IV. У основ слов типа II имеет место явление чередования гласных. При этом в различных формах слов заменяется или пропадает буква, предшествующая последней букве основы слова. Возможные виды чередования гласных показаны в табл. 8.4 (см. рубрику «Вид подстановки»). Здесь же приведены и примеры форм слов с основами типа II.
Основы слов типа II представлены в словаре только в канонической форме. Эта форма основы встречается в словоформах с ненулевым окончанием, отличным от мягкого знака. Вариантная форма основы бывает у словоформ с нулевым окончанием или с мягким знаком‘в качестве окончания (см., например, слово
156
формы колодец и день). При морфологическом анализе вариантная форма основы приводится к канонической путем замены соответствующей буквы на «нуль» или на другую, букву (согласно табл. 8.4).
Проверка основы слова на наличие беглой гласной производится после того, как основа не нашлась в словаре в результате выполнения процедуры флективного анализа. Эта проверка осуще-
Таблица 8.4
Список подстановок для основ типа II при морфологическом анализе
Кв п/п Класс подстановки Вид подстановки Примеры
1 1 о + заготовок —- заготовка
2 1 и й достоин — достойна
3 2 е->4- сложен — сложна
4 2 е -> й паек — пайка
5 2 е -> ь колец — кольцо
ствляется только у слов, оканчивающихся на согласную или на мягкий знак. У слов, оканчивающихся на согласную, заменяется предпоследняя буква, если она является одной из букв левой части списка подстановок табл. 8.4. Прп обнаружении конечного мягкого знака он отделяется от слова (заносится вместо нулевого окончания), а затем производится замена гласной.
Подстановки табл. 8.4 разделяются на два класса:
а) класс с индексом 1 (подстановки 1 и 2),
б) класс с индексом 2 (подстановки 3, 4, 5).
Это разделение необходимо, чтобы обеспечить правильность морфологического анализа и синтеза слов. Индексы классов подстановок указываются в словаре для каждой канонической формы основы типа II.
Если в анализируемом слове заменяется гласная е, то приходится учитывать несколько возможных вариантов замены. Для этого последовательно применяют к анализируемому слову подстановки 3, 4 и 5 табл. 8.4 и проверяют их на совместимость с основами словаря. Проверка на совместимость производится после отождествления трансформированной основы с одной из основ словаря. Основа словаря и подстановка считаются совместимыми, если индекс класса используемой подстановки и индекс класса подстановки, указанный в словаре, совпадают. В противном случае основа словаря и используемая подстановка несовместимы, и необходимо проверить, можно ли применить другие подстанов
157
ки. Правильность применения подстановок 1 и 2 табл. 8.4 проверяется так же, как и в случае замены гласной е.
После проверки правильности замены беглой гласной следует обычная при флективном анализе проверка основы и окончания па совместимость и определяется номер основы и грамматической информации к слову.
Описанный порядок проверки правильности преобразования основы слова типа II в каноническую форму позволяет избежать
Таблица 8.5
Список подстановок для основ слов типа II при морфологическом синтезе
Ns п/п Класс подстановки Вид подстановки Примеры
1 1 + -* о кратка — краток
2 1 й -► п достойна — достоин
3 2 + -*е колодца — код о де ц
4 2 й -> е пайка — паек
5 2 ь е льда — лед
ложных отождествлений основ слов. Действительно, сочетания индексов подстановок и букв правой части таблицы подстановок однозначно определяют беглую гласную основы исходного слова (табл. 8.4), а полученная беглая гласная и неизменяемый буквенный состав словарных основ типа II полностью определяют вид основы анализируемого слова.
Для образования в процессе морфологического синтеза вариантных форм основ типа II используется табл. 8.5. При этом учитывается индекс класса подстановки, приписанный основе словаря, и сопровождающая номер основы грамматическая информация (вернее, буквенный код окончания). К табл. 8.5 обращаются только тогда, когда основа слова имеет индекс класса подстановки 1 или 2, а грамматической информации соответствует окончание + или ь.
После выборки по номеру основы ее буквенного кода последний анализируется для определения вида подстановки (табл. 8.5). Далее производится необходимое преобразование буквенного кода основы и приформирование окончания слова.
Вид подстановки определяется по следующим правилам. Выделяется вторая,от конца буква словарной основы и проверяется на совпадение с буквой й, если основа имеет индекс класса подстановки 1, и с буквами й и ь, если основа имеет индекс класса подстановки 2. При положительном результате проверки в первом случае применяется подстановка 2, при отрицательном — подстановка 1. Во втором случае при положительном результате при
158
меняется подстановка 4 (если выделенная буква совпала с буквой й) или подстановка 5 (если выделенная буква совпала с буквой ь). При отрицательном результате применяется подстановка 3.
К изменяемым основам слов типа III отнесены такие основы личных форм глаголов и глаголов прошедшего времени, у которых имеет место чередование согласных. Эти основы встречаются в двух формах, отличающихся друг от друга по буквенному составу. Обе формы основы включаются в словарь. Одна из них считается канонической, другая — вариантной. У личных форм глаголов в качестве канонической принята основа формы третьего лица единственного числа, у глаголов прошедшего времени — основа формы множественного числа.
При морфологическом анализе вариантная форма основы типа III заменяется на каноническую с помощью табл. 8.6 по специальным признакам, внесенным в словарь основ.
Таблица 8.6
Список подстановок для основ типа III при морфологическом анализе
п/п Конечные буквы ва-оиантных форм основ слов Конечные буквы канонических форм основ слов
вариант 0 вариант 1
1 ж Д 3
2 ш С —
3 Щ СТ т
4 ч т —
5 г Ж —
6 к ч —
7 л + —
8 т ч —
9 + л —
Примеры
сижу — сидит, вожу — возит ношу — носит х
очищу — очистит, сокращу — сок-кратит
лечу — летит
могу — может
отсеку — отсечет
ставлю — ставит
хостят — хочет вез — везли
Табл. 8.6 содержит список подстановок букв и примеры использования этих подстановок. Во втором столбце таблицы перечислены конечные буквы вариантных форм основ слов типа III, а в третьем и четвертом столбцах — конечные буквы соответствующих канонических форм. В последнем столбце приведены примеры для каждого варианта подстановок букв.
Словарными признаками, используемыми при морфологическом анализе слов с основами типа III, являются признак вида основы и признак варианта подстановки. При этом каноническая
159
форма основы сопровождается индексом 0, а вариантная — индексом 1. Различные варианты подстановок также обозначаются индексами 0 и 1 (табл. 8.6).
Анализ основ слов типа III производится следующим образом. Сначала основа словаря, найденная в результате флективного анализа, проверяется на наличие признака вариантной формы. Если у основы такой признак есть, то выделяется ее послед-
Таблица 8.7
Список подстановок для основ типа III при морфологическом синтезе
№ п/п Конечные буквы канонических форм основ слов Конечные буквы вариантных форм основ слов Примеры
вариант 0 вариант 1
1 ст Щ — очистит — очищу
2 т ч Щ летит — лечу, сократит — сокращу
3 ж г — может — могу
4 3 ж — возит — вожу
5 д ж —. сидит — сижу
6 с ш — носит — ношу .
7 ч. к — отсечет — отсеку
8 л -1- везли — вез
9 + л — ставит — ставлю
няя буква и сравнивается последовательно со всеми буквами второго столбца табл. 8.6 (исключая букву +). При совпадении выделенной буквы с одной из букв таблицы она заменяется на букву (или сочетание букв) третьего или четвертого столбца в зависимости от значения признака варианта подстановки. Далее полученная основа ищется в словаре. Если трансформированная основа отождествляется с одной из основ словаря, то последняя проверяется на совместимость с окончанием и на наличие у нее признака канонической формы основы типа III. При положительном результате проверки первоначальный номер вариантной формы основы заменяется на номер ее канонической формы.
В том случае, когда выделенная буква анализируемой основы не совпадает ни с одной из букв второго столбца табл. 8.6, к этой основе приформировывается буква л (см. девятую строку табл. 8.6) и далее выполняются операции, перечисленные в предыдущем абзаце. *
Формирование буквенного кода основ слов типа III прп морфологическом синтезе осуществляется с помощью табл. 8.7 и 8.8. Табл. 8.7 служит для преобразования канонических форм основ
160
в вариантные, а табл. 8.8 — для определения необходимости такого преобразования. Структура табл. 8.7 аналогична структуре табл. 8.6. В табл. 8.8 перечислены различные типы распределения канонических и вариантных форм основ в зависимости от грамматической информации слов. Строкам табл. 8.8 поставлены в соответствие коды типов распределения, а столбцам — коды грамматической информации (см. табл. 8.1). На пересечении строк и
z Таблица 8.8
Типы распределения канонических и вариантных форм основ слов
Тип распределения Грамматическая информация
1 2 3 4 б 6
0 0 0 0 0 0 0
1 1 0 0 0 0 0
2 0 0 0 1 1 1
3 1 0 0 0 0 1
столбцов указаны индексы канонических и вариантных форм основ.
Сочетание кода типа распределения и кода грамматической информации однозначно определяет необходимость введения в синтезируемое слово канонической или вариантной формы основы. Код типа распределения указывается в словаре для каждой канонической формы основы слова типа III наряду с индексом канонической формы и индексом варианта подстановки. Смысл индекса варианта подстановки для канонических форм основ определяется табл. 8.7, а для вариантных — табл. 8.6.
Формирование буквенного кода слова начинается с выборки из словаря буквенного кода его основы. Затем по табл. 8.8 определяется необходимость замены канонической формы основы на вариантную. Если такой необходимости нет, то к основе прифор-мировывается окончание. Если замена необходима, то она производится с помощью табл. 8.7<
Каноническая форма основы заменяется на вариантную в следующем порядке. Сначала две последние буквы основы проверяются на совпадение с сочетанием букв ст. Если совпадение имеет место, то эти буквы заменяются на букву щ (см. подстановку 1 табл. 8.7); если нет, то конечная буква основы отыскивается среди ненулевых букв второго столбца табл. 8.7. При отождествлении конечной буквы основы с одной из букв второго столбца она заменяется на соответствующую букву третьего или четвертого столбца (в зависимости от значения признака вариан-
11 Г. Г. Белоногов, Б. А. Кузнецов 161
та подстановки). В противном случае к словарной основе прп-формпровывается буква л (применяется подстановка 9).
Среди слов с изменяемой основой типа IV следует различать слова, способные иметь различные окончания, и слова, у которых выделять окончания трудно или практически нецелесообразно. Слова первого вида далее называются словами с супплетивными основами, слова второго вида — словами с супплетивными формами. Примерами слов первого вида являются слова: знамя, время, человек, судно; примерами слов второго вида — слова: кто, что, чей. Супплетивные формы основ и супплетивные формы слов заносятся в машинный словарь во всех своих вариантах и отмечаются специальным признаком, который используется при морфологическом анализе и синтезе.
Морфологический анализ слов с изменяемой основой типа IV начинается с их флективного анализа, причем слова с супплетивными формами сначала рассматриваются как неизменяемые. Далее с помощью специальных таблиц вариантные формы основ заменяются на канонические, а по супплетивным формам слов выбирается соответствующая им грамматическая информация.
Процесс морфологического синтеза слов с основами типа IV состоит из двух этапов: этапа замены канонической формы основы на вариантную, если такая замена необходима, и этапа флективного синтеза. Необходимость выбора канонической или вариантной формы может быть определена по грамматической информации. Если грамматической информации соответствует каноническая форма основы, то следует переходить к этапу флективного синтеза; если вариантная форма основы — то исходную основу необходимо заменить на вариантную.
При морфологическом анализе и синтезе супплетивные основы и супплетивные формы слов различаются по номерам флективных классов (супплетивные формы слов не имеют окончаний и относятся либо к неизменяемым существительным, либо к неизменяемым прилагательным).
8.2.4. Алгоритмы морфологического анализа и синтеза. Ниже приводятся обобщенные описания алгоритмов морфологического анализа и синтеза слов, построенные с учетом "соображений, изложенных в разделах 8.2.1—8.2.3 настоящей главы. Эти описания отражают все этапы работы алгоритмов в их взаимосвязи. Алгоритмы реализованы на ЭВМ.
А. Алгоритм морфологического анализа.
1. Проверка на конец текста. При положительном исходе проверки перейти к п. 2, при отрицательном — к п. 3.
2. Выход на алгоритм синтаксического анализа.
3. Занесение очередного слова в стандартное поле памяти.
162
4. Занесение в стандартное поле памяти номера нулевого окончания.
5. Поиск слова в словаре основ. При положительном исходе перейти к п. 6, при отрицательном — к п. 21.
6. Выборка из словаря номера основы и морфологического класса слова (или, в случае омонимии, сочетания морфологических классов).
7. Проверка выделенных основы и окончания слова на совместимость. При положительном исходе перейти к п. 8., при отрицательном — к п. 21.
8. Выборка из таблиц и запись в рабочее поле морфологической информации о слове.
9. Проверка на наличие у слова признака возвратности. При положительном исходе перейти к п. 10, при отрицательном — к п. 22.
10. Перенумерация основы слова (занесение в код номера слова признака возвратности). Перейти к п. 22.
И. Проверка условия: «Количество оставшихся букв в слове т = 1». При положительном исходе перейти к п. 24, при отрицательном —- к п. 12.
12. Отделение одной конечной буквы слова.
13. Проверка условия: «Количество отделенных букв в слове п — 2». При положительном лсходе перейти к п. 18, при отрицательном — к п. 14.
14. Поиск сочетания отделенных конечных букв слова в словаре окончаний. При положительном исходе перейти к п. 15, при отрицательном — к п. 21.
15. Определение номера окончания.
16. Проверка конца слова на наличие мягкого знака. При положительном результате проверки перейти к п. 17, при отрицательном —- к п. 5.
17. Отделение мягкого знака. Занесение числа 3 в счетчпк отделенных букв. Перейти к п. 5.
18. Проверка отделенных букв на совпадение с частицами ся или сь. При положительном исходе перейти к п. 19, при отрицательном — кп. 14.
19. Занесение в рабочее поле признака возвратности.
20. Гашение счетчика количества отделенных букв и чистка рабочего поля, содержащего отделенные буквы. Перейти к п. 4.
21. Проверка условия: «Количество отделенных букв п = 3». При положительном исходе перейти к п. 24, при отрицательном — к п. И.
22. Проверка на принадлежность основы слова к типу III. При положительном исходе перейти к п. 28, при отрицательном — к п. 23.
И*
163
23. Проверка на принадлежность основы слова к типу IV. При положительном исходе перейти к п. 30, при отрицательном — к п. 29.
24. Проверка на принадлежность основы слова к типу II. При положительном исходе перейти к п. 31, при отрицательном — к п. 25.
25. Проверка слова на сложность. Если слово сложное, то перейти к п. 27, в противном случае — к п. 26.
26. Занесение в ответный массив признака побуквенного кодирования и буквенного кода анализируемого слова. Перейти к п. 1.
27. Членение сложного слова на составные части. Перейти к п. 3.
28. Замена вариантной формы основы типа III на каноническую (с помощью табл. 8.6 и словаря основ).
29. Занесение в ответный массив результатов морфологического анализа слова. Перейти к п. 1.
30. Замена вариантной формы основы типа IV на каноническую. Выборка грамматической информации для супплетивных форм слов. Перейти к п. 29.
31. Замена вариантной формы основы типа II на каноническую (с помощью табл. 8.4).
32. Проверка с помощью словаря основ правильности замены формы основы типа II. При положительном исходе перейти к п. 6, при отрицательном —- к п. 25.
Б. Алгоритм морфологического синтеза.
1. Проверка на конец исходного массива. При положительном исходе проверки перейти к п. 2, при отрицательном — к п. 3.
2. Конец работы алгоритма.
3. Занесение в стандартное поле памяти исходной информации об очередном слове.
4. Проверка слова на принадлежность к группе слов с изменяющимися окончаниями. При положительном исходе перейти к п. 5, при отрицательном — к п. 16.
5. Проверка основы слова на принадлежность к типу IV. При положительном исходе перейти к п. 6, при отрицательном — к п. 7ц
6. Замена номера канонической формы основы типа IV на номер вариантной формы основы.
7. Выборка пз словаря буквенного кода основы слова.
8. Проверка морфологической информации к слову на наличие признака чередования согласных. При положительном исходе перейтп к п. 9, при отрицательном — к п. 10.
9. Замена канонической формы основы типа III на вариантную (с помощью табл. 8.7, 8.8).
164
10. Выявление необходимости приформирования мягкого знака к основе слова. Если такая необходимость есть, то перейти к п. 11, если нет — к п. 12.
И. Приформироваппе мягкого знака к основе слова.
12. Выборка с помощью табл. 7.4 и 8.3 буквенного кода окончания слова.
13. Проверка информации к слову на наличие признака чередования гласных. При положйтельпом исходе перейти к п. 14, при отрицательном — к п. 15.
14. Замена канонической формы основы типа II на вариантную.
15. Приформироваппе к основе слова буквенного кода окончания. Перейти к п. 19.
16. Проверка основы слова на принадлежность к типу IV. При положительном исходе перейти к п. 17, при отрицательном — к п. 18.
17. Замена номера канонической формы основы типа IV на цомер вариантной формы основы.
18. Выборка из словаря буквенного кода основы слова.
19. Проверка на наличие у слова признака возвратности. При положительном исходе перейти к п. 20, при отрицательном — к п. 1.
20. Приформирование к слову возвратной частицы. Перейти к п. 1.
Существенную часть алгоритмов морфологического анализа и синтеза слов составляют процедуры поиска в словаре. Словарь может быть оформлен различным образом и, в частности, в виде ассоциативно-адресной структуры, изображенной на рис. 3.1. При этом буквенные коды основ слов должны интерпретироваться как словоформы, а сопровождающая их грамматическая информация оформляться в виде отдельного массива. Выборка грамматической информации должна осуществляться по номерам основ (точнее, по той их части, которая отражает порядок следования адресных отсылок к буквенным кодам этих основ). При наличии в словаре семантической информации опа также должна выноситься в отдельный массив, который может имет^ структуру типа изображенной на рис. 3.2 или рис. 3.3.
8.2.5. Сравнение различных методов морфологического анализа и синтеза. В начале главы было указано, что морфологический анализ и синтез слов может производиться как на базе словаря основ слов, так и на базе словаря словоформ, поэтому представляет интерес сравнение основных количественных показателей, характеризующих эти подходы,— объема словаря и времени работы алгоритмов. Объем машинного словаря зависит от многих факторов. Однако при сравнении вариантов структуры словаря необ-
165
кодимо прежде всего учитывать соотношение количества словарных единиц при некоторых фиксированных условиях.
Известно, что в русском языке число различных словоформ значительно больше числа различных основ слов. Так, существительные могут иметь 7 — 10 различных форм, полные прилагательные — 10 — 12 форм, глаголы настоящего и будущего времени — 6 форм, глаголы прошедшего времени и краткие прилагательные — 4 формы и т. д. Если фиксировать объем словаря основ и потребовать, чтобы словарь словоформ включал все формы слов, которые могут быть образованы на базе словаря основ, то отношение числа словоформ к числу основ слов определяется выражением
А’= 2 MiPv
1=1
в котором п — количество флективных классов слов в русском языке, Mi — количество попарно-различных форм у слов f-го флективного класса, Pi — вероятность появления i-ro флективного класса в словаре. Проведенные авторами исследования словарей показывают, что К » 8.
Однако в речевой практике не все формы слов используются в равной степени. Это приводит к тому, что при фиксированном тексте достаточно большой протяженности объем словаря словоформ оказывается примерно в два раза больше объема словаря основ (мы наблюдали это явление на текстах протяженностью от 20 до 500 тыс. слов). Если в словарь включаются не все, а только наиболее часто встречающиеся словарные единицы, то при изменении коэффициента заполнения текстов в пределах 0,5 — 0,95 отношение объема словаря словоформ к объему словаря основ колеблется в пределах 3 — 3,8, причем максимум величины этого отношения соответствует коэффициенту заполнения, равному 0,8.
Время работы алгоритмов автоматического отождествления слов зависит от типа ЭВМ, которая используется для обработки текстовой информации, и от конкретной программной реализации этих алгоритмов. Имеет значение и объем словаря. Однако при прочих равных условиях программа морфологического анализа работает в несколько раз медленнее, чем программа отождествления слов с помощью словаря словоформ. Это обусловлено большей сложностью алгоритмов морфологического анализа и необходимостью многократного поиска по словарю при выделении основы из состава изменяемого слова.
Процедуры морфологического анализа и синтеза слов могут быть точными и приближенными. Точные процедуры основаны на использовании словарей, в которых для каждого слова указано правило изменения его формы. Эти процедуры могут приме-
166
пяться только к словам, которые включены в словарь. Между тем в реальных текстах всегда будут встречаться «новые» слова — слова, не содержащиеся в словаре.
«Новые» слова могут автоматически выявляться в процессе точного морфологического анализа и выдаваться на печать для ручной обработки и включения в словарь. Но такая организация работы не позволит полностью автоматизировать процессы обработки текстовой информации. Необходима процедура автоматического пополнения словарей. А это, в свою очередь, связано с необходимостью автоматического получения грамматической информации к словам.
Для анализа «новых» слов целесообразно использовать метод аналогии, основанный на связи между грамматическими признаками слов и их буквенным оформлением. Применительно к русской морфологии принцип аналогии можно было бы сформулировать следующим образом: слова, имеющие аналогичное буквенное оформление концов, аналогичны и по грамматической информации.
Для назначения грамматических признаков «новым» словоформам по методу аналогии необходимо иметь базовый словарь, в котором для каждой словоформы указана соответствующая ей грамматическая информация. Процедура назначения грамматических признаков выполняется в следующем порядке. «Новая» словоформа сравнивается со словоформами из словаря, и фиксируются все случаи совпадения концов словоформ. Из словаря выбираются словоформы, у которых длина конечных буквосочетаний, совпавших с конечным буквосочетанием «нового» слова, является максимальной. Если выбирается только одна словоформа, то набор ее грамматических признаков присваивается новой словоформе; если выбирается группа словоформ, то для этой группы строится распределение частот появления различных наборов грамматических признаков и «новой» словоформе назначается наиболее частый набор.
Назначение грамматических признаков «новым» словам по методу аналогии может осуществляться и с помощью словаря основ слов. В этом случае несколько изменяется способ выбора словарных элементов, по которым производится назначение признаков. У исходной словоформы отделяются все возможные варианты грамматических окончаний, а полученные таким образом варианты основ слова сравниваются с основами словаря. В процессе сравнения фиксируются все случаи совпадения концов основ «нового» слова с концами основ из словаря при условии, что соответствующие варианты окончаний нового слова совместимы со словарными основами (совместимость основ и окончаний проверяется по табл. 8.2). В каждом случае определяется сумма коли
167
чества совпавших букв в сравниваемых основах и количества букв в окончании «нового» слова. Из словаря выбираются основы с максимальным значением суммы. Выбранные основы используются для назначения грамматических признаков «новому» слову таким же порядком, что и словоформы из словаря словоформ. Далее у «нового» слова отделяется окончание и его основа включается в словарь вместе со своими грамматическими признаками.
8.2.6. Многоступенчатый морфологический анализ и синтез. Если строить морфологический анализ на базе словаря словоформ, то задача получения грамматических и семантических признаков для слов исходного текста сведется в основном к поиску в словаре, и только в тех случаях, когда это не удается, придется прибегать к морфологическому анализу. При этом, чем полнее словарь, тем меньше будет удельный вес операций по анализу структуры слов и тем больше скорость обработки текстов. Кроме того, применение словаря словоформ позволяет в значительной мере преодолеть трудности, связанные с такими явлениями словоизменения и словообразования, как чередование гласных, чередование согласных и наличие супплетивных форм слов. Эго достигается путем отображения в словаре парадигматических связей между словоформами независимо от их буквенного оформления.
Положительные свойства процедур морфологического анализа, построенных на базе словаря словоформ и словаря основ слов, можно сочетать в одном алгоритме. Такой алгоритм, получивший название алгоритма многоступенчатого морфологического анализа, был разработан авторами совместно с 10. П. Калининым, М. В. Поздняк, А. А. Хорошиловым и др. Алгоритм работает со словарем словоформ, в котором для каждой словоформы указывается длина ее словоизменительной и словообразовательной основы, а также номер ее флективного и словообразовательного класса (см. гл. 7 и Приложение 3).
В процессе работы алгоритма словоформы текста могут проходить три ступени анализа: 1) проверка на полное совпадение со словоформами словаря; 2) словоизменительный анализ; 3) словообразовательный анализ. Наиболее простой в реализации является первая ступень анализа, наиболее сложной — третья. Чаще всего анализ словоформ ограничивается только первой ступенью, значительно реже — первой и второй ступенью, а третья ступень анализа привлекается только тогда, когда словоформы текста не удается отождествить ни с одной из словоформ словаря ни в результате проверки на полное совпадение, ни в результате их словоизменительного анализа.
При словоизменительном анализе требуется совпадение словоизменительных основ сравниваемых слов и их принадлежность к одному и тому же флективному классу. При словообразователь
168
ном анализе — совпадение словообразовательных основ и расчленение несовпавших частей текстовых слов на суффиксы (сочетания суффиксов) и окончания. При этом суффиксы (сочетания суффиксов) должны быть совместимы с окончаниями и со словообразовательными основами.
Совместимость суффпксов (сочетаний суффиксов) с окончаниями проверяется с помощью приписанных им номеров флективных классов (см. Приложение 2), а их совместимость со словообразовательными основами — с помощью номеров словообразовательных классов. Последняя проверка осуществляется путем поиска суффикса (сочетания суффиксов) текстового слова в списке суффиксов (сочетаний суффиксов), соответствующем номеру словообразовательного класса, приписанному словарному слову. В результате морфологического анализа текстовым словам наряду с другой информацией приписываются также номера их словоизменительных и словообразовательных основ.
Алгоритм многоступенчатого морфологического анализа оказался довольно эффективным: на ЭВМ ЕС 1022 он обрабатывал тексты со скоростью 40 — 50 слов в секунду, причем словарь имел объем около 30 000 словоформ.
8.3. Анализ и синтез именных словосочетаний
8.3.1. Синтаксический анализ именных словосочетаний. В гл. 7 мы указывали, что именные словосочетания играют важную роль в системах автоматической обработки информации, так как они чаще используются для обозначения научно-технических понятий, чем однословные термины. Они могут применяться в АИС в различной форме, поэтому необходимы процедуры их морфологического, синтаксического и семантического анализа и синтеза.
В процессе синтаксического анализа наименований понятий выполняются следующие операции: 1) выявляется схема связей между словами; 2) каждому слову словосочетания назначается однозначная грамматическая информация, необходимая для формирования его буквенного кода при декодировании; 3) структура словосочетания приводится к каноническому виду.
Исходными данными для синтаксического анализа служат результаты работы алгоритма морфологического анализа слов. Ес-лЦ слова анализируются с помощью словаря словоформ, то для каждого слова наименования понятия указывается номер канонической формы слова (по словарю словоформ), набор переменной грамматической информации (по табл. 8.1), соответствующий данной форме слова, и постоянная грамматическая информация. В качестве постоянной грамматической информации для существительных, прила1ательыых, предлогов, сочинительных союзов
169
и наречий указывается признак принадлежности к соответствующему синтаксическому классу. Кроме того, для существительных указывается признак рода, а для предлогов — перечни падежей, которыми они могут управлять.
Если слова анализируются с помощью словаря основ, то для каждого слова наименованпя понятия указывается номер канонической формы основы, номер флективного класса и набор переменной грамматической информации. При этом постоянная информация к словам определяется по номерам их флективных классов. Это оказывается возможным благодаря тому, что система классификации слов отражена в нумерации флективных классов (см. табл. 7.3).
Первым этапом синтаксического анализа словосочетаний является выявление схемы связей между словами, входящими в их состав. Это можно сделать с помощью алгоритма типа описанного в разделе 8.4. Но такой способ анализа довольно сложен, и здесь уместно применить более простой способ, основанный на использовании принципа аналогии. Для синтаксиса принцип аналогии может быть сформулирован следующим образом: аналогичным последовательностям символов классов слов соответствуют аналогичные схемы синтагматических связей между словами*). Для применения этого принципа необходимо выявить все или наиболее часто встречающиеся в текстах последовательности симво- , лов классов слов и поставить им в соответствие схемы синтагматических связей. Тогда процесс синтаксического анализа сведется к распознаванию в текстах эталонных последовательностей символов классов и замене их на схемы синтагматических связей. Точность анализа будет зависеть от характера принятой классификации слов, от длины эталонных последовательностей символов классов слов и от полноты представления различных синтагматических ситуаций в словаре эталонов. Она будет тем большей, чем детальнее классификация слов, чем длиннее последовательности символов классов слов в эталонных описаниях синтагматических ситуаций и чем полнее словарь эталонов.
Метод аналогии целесообразно применять прежде всего для анализа текстов с ограниченными наборами синтагматических ситуаций, например для анализа именных словосочетаний. С целью оценки эффективности этого метода при синтаксическом анализе именных словосочетаний авторами был обследован словарь научно-технических терминов объемом около 12 000 единиц. При этом выяснилось, что словосочетания, описываемые оди-
*) Под классом слов мы здесь будем понимать множество слов, обладающих некоторой совокупностью признаков.
170
паковыми последовательностями символов обобщенных граммати* ческих классов слов, как правило, имели одинаковые схемы синтаксической связи между словами (одинаковые деревья зависимостей). Случаи отклонения от этого правила были редкими и составляли менее половины процента.
Вторым этапом синтаксического анализа наименований понятий является определение однозначной грамматической информации к каждому слову. Прежде всего, главному слову словосочетания (первому слева существительному) и определяющим его прилагательным назначается информация «именительный падеж, единственное число», а на прилагательные переносится признак рода главного слова. Далее выполняется операция выделения общей части наборов переменной грамматической информации в группах слов, состоящих из существительного и зависимых от него прилагательных. В результате выполнения этой операции получается либо однозначная грамматическая информация, либо наборы грамматической информации, которые в дальнейшем используются для назначения информации к существительным и прилагательным.
Информация к существительным уточняется в следующем порядке. Если существительное управляется предлогом, то ему назначается первый элемент из соответствующего набора, который содержит информацию о падеже, допустимую для данного типа предлогов (см. табл. 7.3). Если же существительное управляется другим существительным, то элемент набора выбирается с учетом возможных для такого существительного значений признака падежа. При этом сначала ищется элемент с признаком родительного падежа, затем с признаком творительного и, наконец, с признаком дательного падежа. Информация, выбранная для существительных, распространяется и на подчиненные им прилагательные. Неизменяемым словам словосочетания назначается «нулевая» информация.
Заключительным этапом синтаксического анализа является приведение структуры словосочетания к каноническому виду. При этом выполняются следующие операции: 1) прилагательные ставятся перед теми существительными, которые они определяют, и упорядочиваются по возрастанию их словарных номеров; 2) существительные, соединенные сочинительным союзом, располагаются по возрастанию их словарных номеров (при этом в случае необходимости изменяется расположение слов относительно союза); 3) группы слов, соединенные сочинительным союзом и управляемые существительными, располагаются таким образом, чтобы управляемые слова были упорядочены по возрастанию их номеров, 4) код главного слова словосочетания выносится на первое место.
171
8.3.2. Кодирование и декодирование наименований понятий. В автоматизированных информационных системах применяются различные способы кодирования понятий. Под кодированием понятий мы будем понимать процесс замены их наименований на естественном языке на некоторые формализованные смысловые коды, отражающие содержание этих понятий. Под декодированием — обратный процесс перехода от формализованных кодов к наименованиям понятий на естественном языке. Формализованный код понятия может представлять собой его порядковый номер по заранее составленному инвептарпому списку (словарю) или, в более общем случае,— описание его смыслового содержания на некотором формализованном языке. При этом понятие может описываться как объект простой или сложной структуры (см. гл. 1). Таким образом, и процесс кодирования понятий, и процесс их декодирования являются процессами перекодирования — перехода от одного способа представления понятий к другому.
Если понятия кодируются их номерами, то в памяти ЭВМ целесообразно иметь два словаря: словарь слов и словарь пословных кодов словосочетаний (словарь наименований понятий). Первый словарь может быть оформлен в виде словаря словоформ или словаря основ слов. Все его элементы нумеруются. Во втором словаре каждое наименование понятия представляется сочетанием номеров слов*), входящих в его состав, и номером грамматической структуры. Грамматическая структура словосочетания содержит информацию о связях между словами и информацию о формах слов, необходимую при декодировании. Различным сочетаниям номеров слов и номеров грамматических структур присваиваются порядковые номера, которые интерпретируются как номера соответствующих понятий.
Автоматическое кодирование понятий осуществляется в трп этапа. Сначала отождествляются слова, входящие в наименование понятия, с элементами словаря слов. Слова заменяются их номерами по словарю и сопровождаются грамматической информацией. На втором этапе кодирования выявляется грамматическая структура наименования понятия (синтаксический анализ). Наконец, полученный в результате первых двух этапов код отождествляется с одним из элементов словаря наименований понятий и заменяется на порядковый номер этого элемента (семантический анализ). Порядковый помер понятия далее используется в качестве его кода.
Отождествление исходных и словарных наименований понятий производится в следующем порядке. Сначала сочетание номе-
*) Под номером слова мы здесь будем понимать номер его канонической формы или номер канонической формы его основы.
172
'ров слов и грамматическая структура кодируемого наименование понятия ищутся по списку сочетаний номеров слов и по списку грамматических структур словаря понятий и заменяются порядковыми номерами по этим спискам. Далее по номеру понятия из словаря выбирается соответствующий ему номер грамматической структуры и сравнивается с номером, полученным в результате поиска по списку грамматических структур. Если эти номера совпадают, то понятия тождественны друг другу. В противном случае они не тождественны.
Подобно процессу кодирования наименований понятий, их декодирование также осуществляется в три этапа. Сначала по номеру понятия из словаря выбираются соответствующие ему сочетание номеров слов и номер грамматической структуры. Затем из списка грамматических структур извлекается информация о формах слов и о их связях, а также корректируется порядок слов в словосочетании (номер главного слова ставится после номеров определяющих его прилагательных). На заключительном этапе формируются буквенные коды словоформ.
Алгоритмы декодирования понятий значительно проще алгоритмов кодирования, в особенности если наименования понятий выдаются на печать в основной форме. Если же необходимо согласовать формы наименований понятий с их контекстным окружением, то главному слову и определяющим его прилагательным назначаются соответствующие число и падеж.
Наряду со способами декодирования понятий, основанными на морфологическом синтезе слов, в АИС могут применяться и другие способы. Можно, например, хранить в памяти машины таблицы соответствия между номерами понятий и их буквенными кодами. Можно также представить наименования понятий в виде сочетаний номеров словоформ, входящих в их состав, и хранить в памяти машины два словаря — словарь пословных кодов наименований понятий и словарь словоформ. В этом случае декодирование понятий будет производиться в два этапа: сначала, с помощью первого словаря, номера понятий заменяются на их пос-; ловные коды, затем, с помощью второго словаря, пословные коды наименований понятий заменяются па их буквенные коды. Последние два способа декодирования понятий очень просты, но их применение связано с необходимостью хранения в памяти машины дополнительных словарей. Кроме того, здесь можно получать только одну форму наименований понятий.
Рассмотренные методы кодирования понятий с автоматическим отождествлением трансформационных вариантов их наименований довольно сложны в реализации и не охватывают всех видов трансформаций. Например, здесь не учитывается возможность изменения основ слов (меры защиты — защитные меры) и воз-
173
мощность изменения схем связей между словами (автоматизированная документальная поисковая система — автоматизированная система поиска документов — система автоматизированного поиска документов). Между тем учет этих явлений весьма желателен, если в АИС не накладывается ограничений на словарь входного языка. Чаще всего это бывает необходимо в документальных системах. Здесь допустимо применение упрощенных способов кодирования, при которых хотя и возможны ошибки, но зато охватывается более широкий класс трансформаций словосочетаний.
Эффективным является такой способ кодирования понятий, когда слова, входящие в состав их наименований, заменяются на номера смысловых эквивалентов*), номер смыслового эквивалента главного слова выносится на первое место, а остальные номера смысловых эквивалентов располагаются по возрастанию их численных значений. Это дает возможность свести к одной унифицированной форме представления все трансформационные варианты словосочетаний, связанные с изменениями их синтаксической структуры, форм слов и основ слов.
8.4. Синтаксический анализ текстов
Мы проиллюстрируем принципы автоматического синтаксического анализа текстов на примере алгоритма, разработанного авторами**). Этот алгоритм выявляет только поверхностную структуру текстов и является приближенным, но в нем не накладывается никаких ограничений на их словарный состав. Анализ текстов здесь проводится по предложейиям. Для каждого предложения строится его граф-схема (дерево зависимостей), в которой отображаются буквенные коды слов, связи между словами и грам7 матическая информация к словам. В процессе анализа фиксируется лишь факт наличия смысловой связи между словами и направление этой связи (от подчиняющего слова к подчиненному). Более детальная дифференциация связей не производится. Сочинительная связь рассматривается как указание на отсутствие непосредственной связи между словами и словосочетаниями и их подчинение одному и тому же элементу текста.
В качестве материала для анализа использовались научно-технические тексты, на которые не накладывалось никаких огра-
*) Здесь эквивалентными по смыслу считаются слова, могущие заменять друг друга при трансформациях словосочетаний.
♦♦) В реализации алгоритма на ЭВМ и его исследовании принимали участие Г. П. Александрова, Е. А. Загика, А. К. Родионова, Е. И. Стогов.
174
хпиченнй по их словарному составу и синтаксической структуре. Некоторое представление о структуре исходных текстов могут дать следующие их характеристики. Длина предложений в текстах изменялась в пределах от 6 до 64 слов и составляла в среднем 25 слов. Более половины предложений были простыми, а сложные предложения включали в свой состав от двух до пяти простых предложений. Длина интервалов между связанными по смыслу словами (определяемая числом пробелов между ними) колебалась в пределах от единицы (для контактно расположенных слов) до 21. В среднем она была равна 2,4. Количество слов, подчиненных одному и тому же слову, изменялось в пределах от нуля до 6 и в среднем составляло 1,55. Длина цепочек связанных по смыслу слов (измеряемая количеством слов на пути от корня дерева зависимостей к его вершинам) колебалась в пределах от 1 до 10 и в среднем была равна 4.
В рассматриваемой системе синтаксический анализ выполняется за два этапа. На первом этапе устанавливаются связи между словами внутри небольших фрагментов предложений, границами которых, как правило, являются глаголы, знаки препинания и союзы (исключая знаки препинания и союзы, стоящие между прилагательными, определяющими одно и то же существительное). На втором этапе устанавливаются связи между упомянутыми выше фрагментами и ищутся «хозяева» для тех слов, для которых они не были найдены на первом этапе.
На первом этапе анализа предложение просматривается с конца с постепенным продвижением к началу. При этом последовательно анализируются пары слов с целью выяснения возможности установления связи между их элементами. Если такая возможность имеется, то связь устанавливается и переходят к следующей паре слов; если нет, то переход к следующей паре осуществляется без фиксации результатов анализа предыдущей пары.
Переход от одной анализируемой пары слов к другой производится по следующим правилам. Если в рассматриваемой паре слов левый элемент является управляющим, то в следующей паре он принимается за правый, а в качестве левого элемента новой пары берется соседнее слово, расположенное слева. Аналогичным образом поступают, когда слова не связаны друг с другом и расположены контактно. Если левый элемент анализируемой пары слов является управляемым, то в качестве левого элемента следующей пары берется слово, расположенное слева от левого элемента анализируемой пары, а правый элемент остается неизменным.
Если элементы анализируемой пары слов не связаны друг с другом и расположены неконтактно, то в качестве правого элемента новой пары слов берется слово, стоящее справа от левого элемента предыдущей пары, а в качестве левого элемента но
175
вой пары берется то же слово, которое было левым элементом в предыдущей паре.
Если в анализируемой паре управляющим словом является отрицательная частица не или ни, стоящая слева, то правым элементом в очередной анализируемой паре следует сделать слово, стоящее слева от отрицательной частицы, а левым — соседнее с ним слово.
Как уже указывалось, на первом этапе анализа глаголы, сочинительные союзы и знаки препинания служат признаком разрыва цепочки связей в предложении (за исключением сочинительных союзов и знаков препинания, разделяющих однородные прилагательные, определяющие одно и то же существительное). При разрыве связей анализ предложения продолжается слева от союза или знака препинания по тем же правилам, что и справа от них. Связь с прилагательным, отделенным от управляющего им существительного знаком препинания или союзом, устанавливается только в том случае, когда справа от этих элементов стоит хотя бы еще одно прилагательное, управляемое тем же существительным.
Решение о наличии или об отсутствии связи между элементами анализируемой пары слов принимается согласно правилам, приведенным в табл. 8.9. Эти правила были составлены на основе статистического анализа текстов. В первой графе таблицы пере- ' числены различные сочетания классов слов. Во второй —- правила установления синтакспческих связей между словами, принадлежащими к этим классам, и виды связей.
В табл. 8.9 и в последующем изложении приняты следующие условные обозначения:
Для классов слов
С — существительное;
Сн — неизменяемое существительное;
СГ — отглагольное существительное;
П — прилагательное;
ПМ — местоименное прилагательное;
Пн — неизменяемое прилагательное;
ПГ — отглагольное прилагательное;
Г — глагол;
ГЛ — глагол в личной форме;
ГП —глагол прошедшего времени, краткое прилагательное или краткое причастие;
ГИ — инфинитив;
Н — наречие;
НГ — отглагольное наречие;
Р — предлог;
&соч — сочинительный союз;
176
Таблица 8.9
Правила установления синтаксических связей между словами на первом этапе анализа
Сочетание классов слов Правила установления синтаксических связей и вид связи
CG 1. Проверка первого элемента сочетания на налпчпе признака местоименности: да — связь не устанавливать, нет — перейти к п. 2 2. Проверка второго элемента сочетания на налпчпе признака родительного падежа: да — связь вида нет — перейтп к п. 3 3. Проверка второго элемента сочетания на наличие признака творительного или дательного падежа: да — перейти к п. 4, нет — перейти к п. 5 4. Проверка первого элемента сочетания на налпчпе признака глагольности: да — связь вида нет — перейти к п. 5 5. Проверка второго элемента сочетанпя на налпчпе признака неизменяемого существительного: да — связь впда нет — связь не устанавливать'
СП 1. Проверка элементов сочетанпя на совпадение признака падежа: да — перейтп к п. 2, нет — связь не устанавливать 2. Проверка элементов сочетания на совпадение признаков рода и числа: да — связь вида нет — перейти к п. 3 3. Проверка элемента, стоящего слева от существительного, на принадлежность к синтаксическому классу «сочинительные союзы»: да — связь впда нет — связь не устанавливать
СР Проверка первого элемента сочетанпя на наличие признака глагольности: да — связь вида нет — связь не устанавливать
сч Проверка элементов сочетания на контактное расположение: да — связь впда нет — связь не устанавливать
12 г. Г. Белоногов, Б. А. Кузнецов
177
Таблица 8.9 (продолжение)
Сочетание классов слов Правила установления синтаксических связей и вид связи
ПС 1. Проверка элементов сочетания на совпадение признака падежа: да — перейти к п. 2, нет — перейти к п. 4 2. Проверка элементов сочетания на совпадение признаков рода и числа: да — связь вида нет — перейти к п. 3 3. Проверка элемента, стоящего справа от существительного, на принадлежность к синтаксическому классу «сочинительные союзы»: да — связь вида *-, нет — перейти к п. 4 4. Проверка второго элемента сочетания на наличие признака неизменяемого существительного:
да — связь вида нет — перейти к п. 5 5. Проверка первого элемента сочетания на наличие признака глагольности: да — связь вида нет — перейти к п. 6 6. Проверка первого ^элемента сочетания на наличие признака неизменяемого прилагательного: да — связь вида •*-, нет — связь не устанавливать В случае установления связи между словами выполнить операцию пересечения наборов переменной грамматической информации, поставленных в соответствие этим словам
пн Проверка первого элемента сочетания на наличие признака глагольности: да — связь вида нет — связь не устанавливать
ПР Проверка первого элемента сочетания на наличие признака глагольности: да — связь вида , * пет — связь не устанавливать
пч Проверка элементов сочетания на контактное расположение: да — связь вида нет — связь не устанавливать
178
Таблица 8.9 (продолжение}
Сочетание классов слов Правила установления синтаксических связей и вид связи
ГГ 1. Проверка второго элемента сочетания на наличие признака инфинитива: да — связь вида нет — перейти к п. 2 2. Проверка первого элемента сочетания на наличие признака инфинитива: да — связь вида нет — связь не устанавливать
ГН гч Проверка элементов сочетания на контактное расположение: да — связь вида нет — связь не устанавливать
НС 1. Проверка первого элемента сочетания на наличие признака глагольности: да — связь вида нет — перейти к п. 2 2. Проверка элементов сочетания на контактное расположение: да — связь вида нет — связь не устанавливать
нп нг НН Проверка элементов сочетания на контактное расположение: да — связь вида нет — связь не устанавливать
HP Проверка первого элемента сочетания на наличие признака глагольности: да — связь вида нет — связь не устанавливать
НЧ Проверка элементов сочетания на контактное расположение: да — связь вида нет — связь не устанавливать
PC 1. Проверка элементов сочетания на совпадение признака падежа: да — связь вида нет — перейти к п. 2 2. Проверка второго элемента сочетания на наличие признака неизменяемого существительного: да — связь вида нет — связь не устанавливать
12*
179
Таблица 8.9 (окончание)
Сочетание классов слов Правила установления синтаксических связей и вид связи
PG В случае установления связи между словами выполнить операцию пересечения наборов переменной грамматической информации, поставленных в соответствие этим словам
ЧП ЧГ Проверка первого элемента сочетания на наличие признака отрицательной частицы {не или ни): да — связь вида нет — связь вида-*-
ЧН 1. Проверка элементов сочетанпя на контактное расположение: да — перейти к п. 2, нет — связь не устанавливать 2. Проверка первого элемента сочетания на наличие признака отрицательной частицы {не или ни): да — связь вида нет — связь не устанавливать
&под — подчинительный союз;
Ч — частица.
Для видов связи
— левое слово анализируемой пары слов является управляющим, правое — управляемым;
-<—г правое слово анализируемой пары слов является управляющим, левое — управляемым.
Работа второго этапа алгоритма синтаксического анализа начинается с членения сложного предложения на простые. Границы между простыми предложениями проводятся по знакам препинания и сочинительным союзам, если слева и справа от них одновременно находятся либо глаголы в личной форме, либо слова, относящиеся к классу «глаголы прошедшего времени, краткие прилагательные и краткие причастия». Если между глаголами встречается несколько знаков препинания, то граница между предложениями проводится по последнему из них. При этом не допускается разрыва связей, установленных на первом этапе анализа. Если граница, проводимая по последнему знаку препинания, разрывает ранее установленные связи, то она переносится на предыдущий знак препинания. Выделенные предложения далее анализируются независимо друг от друга.
В процессе анализа для каждого слова без «хозяина» в пре
180
делах простого предложения ищется «хозяин» слева от него, а если «хозяин» не находится, то справа. «Хозяевами» слева от рассматриваемого слова могут быть глаголы или отглагольные формы типа СГ, ПГ, НГ. «Хозяевами» справа — глаголы в личной форме (ГЛ), глаголы прошедшего времени, краткие прилагательные и краткие причастия (ГП). Если при просмотре предложения слева направо встречается знак препинания или сочинительный союз, то проверяется возможность установления сочинительной связи между словом без «хозяина», стоящим справа от этих элементов, и словами, расположенными слева от них.
При поиске «хозяина» для существительного сначала проверяется возможность наличия сочинительной связи. Признаком, указывающим на возможность сочинительной связи, может служить запятая или сочинительный союз, стоящие перед существительным или словом, непосредственно ему подчиненным и расположенным слева от пего. Если этот признак имеется, то слева от запятой или сочинительного союза в пределах простого предложения производится поиск существительного, однородного по информации с существительным без «хозяина». Поиск прекращается, если в процессе его выполнения встречается глагол или запятая. Существительные считаются однородными по информации, если у них совпадают падежи. Если, кроме того, у них совпадают еще и значения признака глагольности, то управляющее слово левого существительного считается управляющим словом и правого существительного. Если эти признаки не совпадают, а управляющее слово левого существительного принадлежит к синтаксическому классу «предлоги», то оно также считается управляющим и для правого существительного.
Если гипотеза о наличии сочинительной связи не подтверждается, то для существительного ищется «хозяин» слева. При этом для существительных в именительном, - винительном или предложном падежах в качестве «хозяина» могут выступать только слова, принадлежащие к классам ГЛ, ГП и ГИ, а для существительных в родительном, дательном и творительном падежах в этой роли могут выступать также слова, принадлежащие к классам СГ, ПГ, НГ. Поиск «хозяина» осуществляется до границы предложения или до ближайшего знака препинания.
Если в результате поиска слева «хозяин» для существительного не находится, то производится его поиск справа. В качестве «хозяина» справа разрешается назначать только слова, принадлежащие к классам ГЛ и ГП. Если «хозяин» справа не находится, то повторяется его поиск слева, но при повторном поиске «хозяина» ищут среди слов, принадлежащих к классам ГЛ, ГИ, ГП. Попск ведется до левой границы предложения, не обращая внимания на знаки препинания.
181
Для отглагольного прилагательного и прилагательного в творительном падеже «хозяин» ищется сначала слева. Если прилагательное глагольное и перед ним стоит запятая, то производится поиск существительного, согласованного с прилагательным по падежу. Если такое существительное находится, то оно считается «хозяином» анализируемого прилагательного. Поиск ведется до ближайшего глагола.
Если прилагательное без «хозяина» имеет форму творительного падежа и слева от него расположен глагол, то глагол считается «хозяином» прилагательного. Если перечисленные условия не выполняются, то «хозяин» для прилагательного ищется справа от него. В качестве «хозяина» может выступать ближайшее существительное, согласованное по падежу с прилагательным. Поиск такого существительного ведется до 'границы предложения или до тех пор, пока не встретится глагол. Если и в этом случае «хозяин» для прилагательного не находится, то оно считается субстантивированным прилагательным. Информацию о прилагательном изменяют на соответствующую информацию о существительном, и синтаксический анализ предложения производится заново, начиная с первого этапа.
При поиске «хозяина» для инфинитива сначала проверяется возможность сочинительной связи этого инфинитива с другим инфинитивом анализируемого предложения. Признаком сочинительной связи служит знак препинания или сочинительный союз, стоящие непосредственно перед инфинитивом без «хозяина», а также наличие другого инфинитива слева от указанных элементов. Если имеет место сочинительная связь, то «хозяин» левого инфинитива считается также «хозяином» и правого. Если сочинительной связи не обнаружено, то «хозяин» для инфинитива (слово класса ГЛ или ГП) ищется в пределах простого предложения сначала слева, а затем справа.
Если в результате выполнения первого этапа синтаксического анализа без «хозяина» оказалось слово, принадлежащее к классу «наречия», то на втором этапе «хозяин» для него ищется сначала слева. Им могут быть слова, принадлежащие к классам ГЛ, ГП, ГИ, ПГ, НГ. «Хозяин» ищется до левой границы предложения. Если он не находится, поиск ведется справа до границы предложения, но здесь в роли «хозяина» могут выступать только слова, принадлежащие к классам ГЛ, ГП, ГИ.
Для предлога, точно так же как для существительного и инфинитива, при поиске «хозяина» сначала проверяется гипотеза о наличии сочинительной связи. Если перед предлогом стоит знак препинания или сочинительный союз, то слева от него ищется другой предлог с таким же управлением (однородный по информации). Поиск ведется либо до ближайшего глагола, либо до зпа-
182
ка препинания, либо до границы предложения (в зависимости от того, какой из этих трех элементов встретится первым). Если однородный по информации предлог находится, то его управляющее слово считается управляющим и для анализируемого предлога. В противном случае гипотеза о наличии сочинительной связи считается неподтвержденной и «хозяин» для предлога ищется в пределах простого предложения сначала слева, затем справа. Слева «хозяином» могут быть слова, принадлежащие к классам ГЛ, ГП, ГИ, СГ, ПГ, НГ, справа — слова из классов ГЛ, ГП, ГИ.
В рассматриваемой системе автоматического синтаксического анализа текстов применяются два алгоритма морфологического анализа: алгоритм точного анализа и алгоритм приближенного анализа. Алгоритм точного морфологического анализа работает со словарем, в котором человеком заранее определены все грамматические признаки слов. В алгоритме приближенного морфологического анализа грамматические характеристики слов определяются по их буквенному составу автоматически. Он позволяет анализировать слова, отсутствующие в словаре.
В процессе морфологического анализа основы слов заменяются их порядковыми номерами по словарю. При этом распознаются различные формы одного и того же слова, и им приписывается грамматическая информация, необходимая для последующего синтаксического анализа. Сопряжение алгоритмов морфологического и синтаксического анализов осуществляется с помощью алгоритма сопряжения. Алгоритм сопряжения готовит исходные данные для морфологического анализа и управляет совместной работой алгоритмов морфологического и синтаксического анализов.
В памяти ЭВМ синтаксические связи между словами оформляются в виде связей между их порядковыми номерами в предложении: каждому номеру слова ставится в соответствие перечень номеров непосредственно подчиненных ему слов. На основе этих исходных данных формируется граф-схема предложения.
Алгоритм синтаксического анализа был опробован на научно-технических текстах со сложной структурой с целью учета широкого класса явлений, имеющих место в естественном языке. В процессе экспериментов был обработан текст протяженностью более 20 000 слов (более 1000 предложений). При этом выяснилось, что алгоритм устанавливает связи между словами с коэффициентом полноты, равным 88,3%, и с коэффициентом «шума», равным 9,7%. На наш взгляд, этот алгоритм целесообразно использовать прежде всего для обработки текстов, имеющих более простую структуру. На такого рода текстах алгоритм дает лучшие результаты. Так, например, при анализе текстов рефератов научно-технических документов было получено значение коэффициента полноты около 93% и значение коэффициента «шума» около 7%.
ГЛАВА 9
АВТОМАТИЗИРОВАННЫЕ ИНФОРМАЦИОННЫЕ СИСТЕМЫ, «ПОНИМАЮЩИЕ» ЕСТЕСТВЕННЫЙ ЯЗЫК
9.1. Общие положения
Процессы понимания человеческой речи чрезвычайно сложны и мало исследованы. Поэтому при их рассмотрении мы по необходимости будем опираться в большей мере на догадки и предположения, чем на достоверные факты. Прежде всего, будем исходить из того, что в долговременной памяти человека (Langzeit-gedachtnis по М. Веттлеру [101]) хранится «модель мира»— мыслительные образы различных процессов, явлений, ситуаций, предметов и т. п. Число этих образов огромно и накапливаются они в течение всей жизни человека. В них отражается его индивидуальный опыт и опыт той общественной среды, в которой он живет. Это — так сказать, ретроспективная «картина мира». Но, кроме того, человек постоянно общается с окружающей его внешней средой, воспринимает, осмысливает и оценивает ее образы, реагирует на них, прогнозирует развитие событий, обобщает, порождает новые образы и т. д. —- одним словом, мыслит. Мышление, духовная деятельность человека происходят на фоне ранее накопленного им опыта и под воздействием «сиюминутной» ситуации.
Среди огромного числа мыслительных образов, хранящихся в памяти человека, имеются такие, которые являются социально значимыми и используются в коммуникативных целях как средство передачи информации от одних людей к другим. Это — понятия. В процессе коммуникации от человека к человеку передаются имена понятий, под воздействием которых в сознании реципиента (слушающего или читающего) возникают (вызываются из долговременной памяти) соответствующие им образы (с точностью до индивидуальных особенностей человека). При этом исходный (передаваемый) образ расчленяется на составляющие его образы-понятия, а на другом конце (у реципиента) он снова ре
184
конструируется в целостный образ. После этого «средства передачи информации» — частичные образы — могут быть и «забыты», тем более, что один и тот же исходный образ может быть описан с помощью различных комбинаций понятий. Количество образов-понятий существенно меньше, чем количество индивидуальных образов, но в развитых языковых сообществах оно измеряется по крайней мере десятками миллионов.
В качестве имен понятий могут выступать слова, словосочетания и более длинные отрезки речи. Обычно они выражают лишь незначительную часть содержания понятий. Большая часть этого содержания в наименованиях понятий никоим образом не отражается, но хранится в долговременной памяти носителей языка. В процессе коммуникации (при описании и реконструкции индивидуальных мыслительных образов) «работает» весь объем содержания понятий, как явно выраженный в их наименованиях, так и не выраженный.
Процесс понимания речи не сводится только к более или менее точному воспроизведению в сознании реципиента того мыслительного образа, который имел в виду говорящий или пишущий. Этот образ должен быть включен в систему мышления реципиента, сопоставлен с его «моделью мира» и соответствующим образом оценен. Результатом таких операций могут явиться определенные изменения в «модели мира» реципиента и, при необходимости, его ответные действия. В общем случае процесс понимания речи зависит от физического и эмоционального состояния человека, его интеллектуальных способностей,, образования и жизненного опыта.
При моделировании процессов понимания человеческой речи с помощью автоматических устройств необходимо, как минимум, иметь лингвистический процессор для перехода от единиц языка и речи к обозначаемым ими понятиям, модель системы понятий и средств манипулирования ими, «модель мира» (или, более узко,—предметной области) и процессов мышления. Если же общение человека с автоматом предполагается осуществлять в диалоговом режиме, то необходимо также иметь средства перехода от «модели мира» к представлению ее фрагментов в виде понятийных структур и от понятийных структур — к языковым средствам их обозначения.
Идея моделирования мыслительной деятельности человека с помощью ЭВМ возникла почти одновременно с появлением этих машин. Еще в конце 50-х и начале 60-х годов всерьез обсуждались такие вопросы как «Может ли машина мыслить?», «Может ли машина стать умнее своего создателя?» и т. п. В 70-х годах эта идея обрела форму проблемы «искусственного интеллекта» [3, 6, 8, 26, 58, 60, 71, 85, 99].
185
Вопрос о возможности создгния искусственного интеллекта есть вопрос гносеологический. Отрицать такую возможность по-видимому нельзя, если не становиться на позиции агностицизма. Создание искусственного интеллекта возможно в той мере, в какой возможно познание законов живой и неживой природы, законов человеческого мышления. По мере познания этих законов человек может моделировать свои мыслительные функции с помощью ЭВМ или подобных ей автоматических устройств. Но от принципиального признания такой возможности до ее практической реализации — дистанция огромного размера. А пока что успехи в области создания искусственного интеллекта более чем скромны. Например, системы, «понимающие естественный язык», имеют дело с весьма ограниченными «моделями мира» и оперируют запасом слов порядка нескольких сот единиц. Переход к более сложным предметным областям и более богатому набору языковых средств сразу выдвинет проблемы, которые еще не поддаются решению. Тем не менее, работы в области искусственного интеллекта заслуживают всяческой поддержки. Даже небольшие успехи в этой области позволяют глубже понять проблемы автоматической обработки информации и находить для них более эффективные решения.
Можно посмотреть на проблему искусственного интеллекта и с другой стороны. Разве созданные в настоящее время автоматизированные информационные системы не являются своего рода «моделями мира», более богатыми по охвату предметных областей, чем «модели мира» в специальных исследованиях по искусственному интеллекту? Разве актуальнейшая в настоящее время проблема диалогового общения человека с АИС не имеет непосредственного отношения к проблеме искусственного интеллекта? Так что можно с определенными оговорками считать, что системы «искусственного интеллекта» уже существуют, нашли широкое практическое применение и они будут «умнеть» по мере совершенствования наших знаний в области семантических проблем автоматической обработки информации.
К проблеме создания искусственного интеллекта непосредственно примыкает проблема автоматического (машинного) перевода текстов с одних естественных языков на другие. Идея машинного перевода возникла еще до создания ЭВМ, но первое ее экспериментальное воплощение было продемонстрировано только в 1954 г. в Джорджтаунском университете [47]. Этот эксперимент послужил толчком к развитию работ по машинному переводу в ряде стран мира (СССР, Англия, Франция и др.). Между тем проблема оказалась значительно более сложной, чем это думали пионеры машинного перевода в конце 50-х гг. Поэтому неоправданный энтузиазм в этой области быстро сменился пессимизмом,
186
что отрицательно сказалось на работе ряда исследовательских групп. С начала 70-х гг. снова наблюдается повышение интереса к машинному переводу.
Невысокое качество машинного перевода в системах, построенных до начала 70-х гг., объясняется многими причинами. Главная из них, на наш взгляд, состоит в том, что во всех этих системах применялся преимущественно пословный семантико-синтаксический перевод. Перевод осуществлялся примерно по следующей схеме. Сначала проводился поиск слов исходного текста по словарю с одновременным их морфологическим анализом (если в этом была необходимость). Далее осуществлялся семантикосинтаксический анализ и пословный перевод текста с одновременным разрешением многозначности слов (выбором для каждого многозначного слова одного из его возможных переводов). После этого производился синтаксический и морфологический синтез выходного текста с соответствующим грамматическим согласованием форм слов. Правда, наряду с пословным переводом текста одновременно применялся и его перевод по словосочетаниям (когда словосочетания исходного текста заменялись на эквивалентные им по смыслу словосочетания выходного текста без соблюдения пословного соответствия между ними), но удельный вес такого перевода был слишком мал и не соответствовал роли словосочетаний как основной языковой единицы, применяемой для обозначения понятий.
Человеческий перевод с одного языка на другой происходит путем восприятия и понимания исходного текста и последующей передачи его смысла средствами выходного языка. При этом переводятся не слова и словосочетания, а мыслительные образы, порождаемые в сознании переводчика под их воздействием. Однако если в настоящее время пока еще нет возможности моделировать работу человека-переводчика, то, по крайней мере, нужно стремиться оперировать теми единицами языка и речи, которые позволяют наиболее точно передать содержание текста, написанного на одном языке, средствами другого языка. Такими единицами, на наш взгляд, являются прежде всего фразеологические обороты и терминологические словосочетания и, во вторую очередь, отдельные слова.
Если в настоящее время полностью автоматизированный высококачественный научно-технический перевод практически невозможен, то человеко-машинный перевод вполне реален. В процессе человеко-машинного перевода ЭВМ должна выступать прежде всего в роли банка данных, содержащего переводные соответствия для наиболее часто встречающихся фраз, терминологических словосочетаний и отдельных слов, и располагать мощной программной системой для морфологического и синтаксического анализа
187
и синтеза текстов, а также их редактирования на основе указаний человека. ЭВМ должна осуществлять перевод текстов на основе их семантико-синтаксического анализа путем использования переводных соответствий в указанном выше приоритетном порядке: сначала делается попытка перевода всей фразы как целостной единицы, затем — перевода входящих в ее состав словосочетаний и, наконец, осуществляется пословный перевод тех фрагментов текста, которые не удается перевести первыми двумя способами. Фрагменты выходного текста, получаемые всеми тремя способами, должны быть в дальнейшем грамматически согласова-ваны друг с другом (с помощью процедур синтаксического и морфологического синтеза)-
Исходные иноязычные тексты должны вводиться в ЭВМ техническим персоналом, а их перевод выполняться с участием квалифицированных специалистов-переводчиков. Перевод должен осуществляться в диалоговом режиме. При этом машина будет выполнять рутинную часть работы, а человек — творческую. Это позволит в несколько раз увеличить производительность труда переводчиков.
На первый взгляд может показаться, что такие системы автоматического перевода трудно реализуемы из-за большого количества словосочетаний, встречающихся в текстах (количество вводимых в ЭВМ фразеологических оборотов можно сократить до минимума). Но это не так. Опыт автоматического индексирования по словосочетаниям показывает,'что словарь объемом в 20 000 словосочетаний покрывает информативные слова текстов примерно на 80%. Имея двуязычный словарь словосочетаний объемом в 25—30 тыс. словарных статей и двуязычный словарь слов такого же объема, можно получить удовлетворительное качество перевода для одной достаточно широкой предметной области (например, для текстов по информатике, электронике и вычислительной технике).
Важной практической областью применения методов автоматического анализа и синтеза текстов является общение человека с банком данных. Дело в том, что в больших политематиче-ских банках данных в качестве наименований признаков и их значений могут широко использоваться различные отрезки текста. Их число может измеряться десятками и сотнями тысяч. Это затрудняет формулировку запросов на поиск и обработку информации, так как пользователи могут не знать, какие термины используются в банке данных и как формулировать свои запросы, чтобы достичь нужного эффекта. Указанное затруднение может быть преодолено путем создания системы диалогового общения с банком данных. Такая система должна воспринимать запросы на естественном языке, анализировать пх и предъявлять человеку ре
188
зультаты анализа в формализованном виде. Если результаты анализа удовлетворяют человека, то запросы идут на исполнение, .если не удовлетворяют, то они уточняются. Уточнение запросов может производиться не только на этапе их формализации, но и на этапах поиска и обработки информации.
Процесс перевода запросов на формализованный язык должен включать в свой состав процедуры их морфологического и семантико-синтаксического анализа. При этом в исходных формулировках запросов должны опознаваться наименования понятий (термины), используемые в банке данных, и смысловые отношения между ними. Могут устанавливаться также и парадигматические отношения между исходными терминами запросов и другими терминами банка данных. В следующем разделе главы мы более подробно рассмотрим некоторые способы поиска документов по их неформализованным описаниям, где возникают аналогичные проблемы.
9.2. Поиск документов по текстам
их рефератов
В автоматизированных документальных системах поиск информации обычно производится по формализованным описаниям документов, которые составляются на основе их заголовков или текстов рефератов. В процессе формализации смысловое содержание документов переводится на формализованный язык. Процесс такого перевода принято называть индексированием. Индексирование связано, как правило, с потерей части информации, содержащейся в исходных текстах, и эта потеря бывает тем большей, чем беднее изобразительные средства информационного языка, на который осуществляется перевод. Получаемые в процессе индексирования формализованные описания документов (их поисковые образы) обычно бывают непригодны для восстановления исходных текстов. Поэтому для выдачи результатов поиска из ЭВМ приходится хранить в памяти машины наряду с формализованными описаниями документов также их заголовки или тексты рефератов*
Поиск документов может выполняться и по их неформализованным описаниям. При этом программы поиска строятся, исходя из определенной формализованной модели «понимания» текстов, и интерпретация содержания текстов осуществляется на уровне этой модели. Такой подход к построению документальных систем позволяет отказаться от хранения в них формализованных описаний документов и дает возможность совершенствовать модели «понимания» текстов без изменения массивов ранее накопленной информации.
189
Для индексирования документов чаще всего используются простейшие дескрипторные языки. В этих языках парадигматические отношения между понятиями (родо-видовые отношения, отношения эквивалентности, отношения типа «целое — часть» и др.) фиксируются в тезаурусах, а синтагматические отношения — путем контактного расположения кодов понятий, описывающих один и тот же документ, или с помощью других средств, позволяющих установить факт наличия связи между документами и характеризующими их понятиями. Формальных средств для различения типов синтагматических связей в простейших дескрипторных языках обычно не предусматривается.
Тезаурусы строятся таким образом, чтобы облегчить поиск в них информации. Тем не менее при массовом индексировании документов приходится затрачивать много усилий на поиск нужных дескрипторов. Поэтому актуальной является задача автоматизации процессов поиска информации в тезаурусах и процессов индексирования.
Автоматизация процессов индексирования может быть полной или частичной. При полной автоматизации в ЭВМ вводятся неформализованные тексты и на их основе с помощью программных средств формируются поисковые образы документов. При частичной автоматизации формирование поисковых образов выполняется с участием человека. Это участие может быть различным и чаще всего сводится к предварительной формализации описаний документов. Например, человек может на основе текстов рефератов или заголовков документов составлять перечни информативных слов и словосочетаний, входящих в их состав, а ЭВМ — с помощью автоматического тезауруса заменять выделенные элементы текстов на их машинные индексы.
Автоматические тезаурусы могут строиться на базе словарей однословных терминов или на базе словарей словосочетаний с включением в их состав однословных терминов. Второй способ построения тезаурусов предпочтительнее, так как научно-технические термины являются, по преимуществу, словосочетаниями и здесь легко можно учитывать парадигматические связи между понятиями, которые не могут быть сведены к парадигматическим связям между отдельными словами. Последнее достигается с помощью словаря парадигматических связей.
Автоматический тезаурус — это система машинных словарей и комплекс программ поиска в них, предназначенные для кодирования понятий, установления смысловых связей между ними и их декодирования. Автоматические тезаурусы могут иметь различный состав словарей и обслуживаться различными комплексами программ поиска в них. Состав тезауруса зависит от тех задач, для решения которых он создается. Мы рассмотрим струк
190
туру тезауруса, предназначенного для автоматического индексирования описаний документов и их поиска, имея в виду, что принципы функционирования его отдельных компонент были описаны в гл. 7, 8. Система автоматического индексирования была разработана под руководством Г. Г. Белоногова, А. П. Новоселова и Ю. И. Шемакина.
В состав тезауруса входят пять машинных словарей: три словаря для кодирования понятий и два — для их декодирования. Для кодирования понятий используются:
1) словарь основ слов (СО);
2) словарь наименований понятий, представленный в кодах номеров смысловых эквивалентов слов (СНП-1);
3) словарь парадигматических связей (СПС).
Для декодирования понятий используются:
1) словарь словоформ (ССФ);
2) словарь наименований понятий, представленных в кодах номеров словоформ (СНП-2).
Словарь основ слов представляет собой перечень буквенных кодов основ, сопровождаемых грамматической информацией и номерами смысловых эквивалентов. Номер смыслового эквивалента является кодовым обозначением слов, близких по смыслу и способных замещать друг друга при трансформации словосочетаний. В процессе работы алгоритма морфологического анализа для каждого слова, входящего в состав наименования понятия (или другого отрезка текста), определяется грамматический класс и происходит замена буквенного кода слова номером смыслового эквивалента его основы.
Словарь наименований понятий для кодирования (СНП-1) представляет собой перечень пословных кодов словосочетаний. В качестве кодов слов используются номера их смысловых эквивалентов. В наименованиях понятий, состоящих из двух и более слов, на первое место выносится код главного слова словосочетания (первого слева существительного или, при отсутствии существительного, первого слева слова), а номера смысловых эквивалентов остальных слов располагаются слева направо в порядке возрастания их величин. Все словосочетания сопровождаются их порядковыми номерами, которые при индексировании используются в качестве кодов понятий. Словарь наименований понятий СНП-1 применяется для кодирования терминов и для установления смысловых связей между ними.
Словарь парадигматических связей (СПС) — это перечень групп связанных по смыслу терминов. В СПС отражены наиболее устойчивые отношения между терминами: эквивалентности, родовидовые и некоторые отношения типа «целое — часть». Па первом месте группы стоит номер заглавного термина.
191
В «прямом» СПС заглавный термин является более широким по смыслу, чем остальные термины группы. В «обращенном» СПС заглавный термин является более узким по смыслу, чем остальные термины группы. Отношение эквивалентности учитывается в обоих словарях. В автоматических тезаурусах с ассоциативной структурой достаточно иметь один СПС (например, обращенный) и использовать его для поиска терминов, эквивалентных по смыслу исходным, а также более узких и более широких терминов.
Словарь словоформ (ССФ) представляет собой перечень буквенных кодов словоформ в виде ассоциативно-адресной структуры. Каждой словоформе словаря ставится в соответствие ее номер. Словарь словоформ пополняется по мере поступления новых словоформ с одновременным присвоением им номеров.
Словарь наименований понятий для декодирования (СНП-2) отличается от СНП-1 тем, что в качестве пословных кодов терминов в нем используются коды словоформ, полученные по словарю словоформ, и сохраняется естественный порядок слов словосочетания. Наименования понятий в СНП-2 сопровождаются теми же номерами, которые были присвоены им в СНП-1.
Все перечисленные словари представляются в памяти ЭВМ в виде ассоциативно-адресных структур. Использование ассоциативно-адресной структуры для представления словарей приводит к увеличению их объема. Однако этот недостаток компенсируют следующие преимущества:
1) увеличение скорости поиска в словарях;
2), простота процедур пополнения словарей и исключения из них отдельных элементов;
3) возможность использования одних и тех же процедур при поиске в словарях разного назначения;
4) удобства поиска элементов словарей, обладающих заданными признаками.
Описанная структура автоматического тезауруса и соответствующий комплекс программ были реализованы на различных системах словарей. В частности, был построен автоматический тезаурус на базе лексико-семантического указателя тезауруса научно-технических терминов, разработанного под руководством 10. И. Шемякина [18].
В различных режимах работы документальных АИС могут использоваться различные сочетания словарей тезауруса. Рассмотрим сначала порядок автоматического индексирования формализованных описаний документов. Формализованное описаие документа составляется в виде перечня информативных словосочетаний и слов, встречающихся в тексте реферата этого документа. Элементы перечня отделяются друг от друга запятыми, а описанию в целом присваивается порядковый номер документа. Далее
192
описание документа переносится на машиночитаемый носитель, вводится в ЭВМ и переводится на язык машинных индексов. Перевод выполняется с помощью автоматического тезауруса. В качестве машинных индексов используются номера наименований понятий по словарю.
Различают свободное индексирование формализованных описаний документов и индексирование с контролем по тезаурусу. В первом случае никаких ограничений на ввод в систему новых наименований понятий* не накладывается и тезаурус пополняется по мере необходимости. Во втором случае используется тезаурус, который в процессе индексирования не пополняется, а словосочетания и слова, встречающиеся в формализованных описаниях документов, заменяются па номера эквивалентных или близких им по смыслу понятий тезауруса.
Для автоматического индексирования необходимо иметь систему из двух словарей: словарь основ слов и словарь наименований понятий СНП-1. Процесс индексирования формализованных описаний документов с контролем по тезаурусу состоит в замене словосочетаний и слов, входящих в их состав, на номера понятий из тезауруса. Слова и словосочетания заменяются на эквивалентные им по смыслу понятия, более широкие по объему, и на понятия, ассоциированные с исходными. Допускается также разложение исходных словосочетаний на более короткие словосочетания и на отдельные слова.
Замена исходных терминов, на термины тезауруса может быть осуществлена путем поиска всех вхождений словарных наименований понятий в наименования понятий из формализованных описаний документов. При этом наименование понятия А считается входящим в состав наименования понятия В, если все смысловые эквиваленты слов, выражающих понятие Л, содержатся среди смысловых эквивалентов слов, выражающих понятие В, а схемы связей между соответствующими словами в обоих наименованиях понятий совпадают. В результате будут найдены понятия, эквивалентные по смыслу исходным, более широкие по объему и ассоциированные с исходными. В первом и втором случаях требуется совпадение смысловых эквивалентов главных слов сопоставляемых наименований понятий.
Включение в поисковые образы документов наряду с понятиями, эквивалентными исходным, также понятий, более широких по объему, не оказывает отрицательного влияния на результаты поиска информации, но и не является необходимым. Дело в том, что поиск сведений по более широким понятиям обеспечивается системой установления смысловых связей в тезаурусе. Поэтому такие понятия иногда целесообразно исключать из состава поисковых образов.
13 Г, Г. Белоногов, В. А. Кузнецов
193
Идеальным случаем замены исходных понятий на понятия тезауруса является эквивалентная замена. Если она невозможна, то необходимо стремиться к замене исходных понятий на наиболее узкие понятия пз числа родовых или ассоциированных. В случае замены исходных понятий на понятия, более широкие по объему, происходит обобщение информации. Это явление нежелательное, так как оно приводит к потерям документов при поиске.
Таким образом, процесс индексирования может быть расчленен на следующие основные этапы:
1) морфологический анализ формализованных описаний документов;
2) синтаксический анализ исходных словосочетаний;
3) поиск в тезаурусе наименований понятий, связанных по смыслу с исходными (эквивалентных исходным, родовых и ассоциированных) ;
4) отбор из числа найденных наименований понятий, наиболее узких по смыслу, и замена их словарными номерами.
Для выявления среди найденных понятий наиболее узких по смыслу может быть использован тезаурус. Но можно для этой цели применить и более простую процедуру. Можно, например, заменять каждое исходное наименование понятия только такими наименованиями понятий из тезауруса, которые содержат в своем составе максимальное количество слов (словосочетания, имеющие большую длину, выражают более узкие по объему понятия).
При формировании поисковых образов документов важно обеспечить полный охват смыслового содержания исходных словосочетаний. Это требование можно конкретизировать как требование отражения смыслового содержания всех или большей части слов, входящих в состав исходных словосочетаний. В процессе индексирования оно выполняется следующим образом:
1) для каждого слова исходного словосочетания строится перечень наименований понятий тезауруса, являющихся вхождениями в это словосочетание и включающих рассматриваемое слово;
2) в каждом перечне оставляются только словосочетания максимальной длины, остальные исключаются;
3) перечни словосочетаний объединяются в один общий перечень с исключением повторений одинаковых элементов.
Процесс автоматического индексирования можно существенно упростить, если отказаться от синтаксического анализа словосочетаний и производить поиск в тезаурусе без учета функциональной роли и порядка следования слов. Это приведет к некоторому увеличению «шума» при поиске, но одновременно увеличится и полнота установления смысловых связей между понятиями. Последнее обстоятельство объясняется тем, что при трансформациях
194
некоторых словосочетании происходит изменение схем синтаксических связей между словами (например, у таких словосочетаний, как документальные поисковые системы и системы поиска документов). В случае применения упрощенной процедуры индексирования подобные изменения не будут отрицательно влиять на полноту установления связей между понятиями.
Процедуру индексирования текстов рефератов можно свести к процедуре индексирования формализованных описаний документов. Для этого необходимо расчленить текст реферата на фрагменты и рассматривать эти фрагменты в качестве словосочетаний формализованного описания документа. Было опробовано два варианта индексирования текстов. Согласно первому из них термины тезауруса проверялись на вхождение в тексты в границах между двумя любыми соседними знаками препинания. Во втором варианте термины тезауруса проверялись на вхождение в тексты в пределах границ предложений (между двумя соседними точками). В обоих вариантах индексирования порядок следования и функциональная роль слов в терминах-словосочетаниях тезауруса и во фрагментах текстов рефератов не учитывались.
В процессе экспериментов выяснилось, что оба варианта индексирования примерно равноценны, но индексирование с поиском терминов тезауруса в границах предложений обеспечивает несколько большую полноту покрытия информативных слов текстов словосочетаниями. Это обстоятельство и определило выбор второго варианта индексирования в качестве основного.
В рассматриваемой экспериментальной системе запросы на поиск информации были формализованными. Существо формализации поисковых запросов заключалось в их представлении в виде последовательностей наименований понятий (именных словосочетаний или отдельных слов) с указанием логических связей между понятиями и между группами понятий (конъюнктивных и дизъюнктивных связей).
Автоматическое индексирование формализованных запросов выполняется путем замены исходных наименований понятий номерами терминов из тезауруса и дополнения полученных номеров номерами терминов, состоящих в родо-видовых *и ассоциативных отношениях с исходными. Первый этап процесса индексирования выполняется с помощью словаря основ и словаря наименований понятий СНП-1, второй — с помощью словаря наименований понятий СНП-1 и словаря парадигматических связей. Между этими этапами нет четкой границы; при обращении к словарю наименований понятий СНП-1 одновременно отыскиваются понятия тезауруса, эквивалентные по смыслу исходным, ассоциированные с ними и понятия, находящиеся с исходными в родо-видовых отношениях.
13*
195
В процессе индексирования словосочетания запроса сначала заменяются последовательностями номеров смысловых эквивалентов слов (с помощью процедуры морфологического анализа). Затем пословные коды исходных терминов проверяются на вхождение в пословные коды терминов тезауруса (поиск «вниз»), а термины тезауруса проверяются на вхождение в пословные коды исходных терминов (поиск «вверх»), В последнем случае требуется, чтобы перечни номеров смысловых эквивалентов слов терминов из тезауруса полностью входили в перечни номеров смысловых эквивалентов слов исходных терминов и при этом номера смысловых эквивалентов главных слов в исходных терминах и в терминах из тезауруса совпадали. При поиске «вниз» совпадения номеров смысловых эквивалентов главных слов не требуется. Такое правило поиска введено в связи с тем, что включение в поисковый образ запроса более узких по смыслу терминов, ассоциированных с исходными, приводит к увеличению полноты поиска при незначительном повышении уровня «шума».
Номера терминов, найденные в результате поиска по тезаурусу «вниз» и «вверх», объединяются в группы по числу исходных терминов или по числу групп исходных терминов, соединенных знаком дизъюнкции (в исходных формулировках запросов принято обозначать операцию дизъюнкции союзом «или», а операцию конъюнкции — запятой).
Группы номеров терминов, полученные в процессе поиска в словаре наименований понятий СНП-1, далее используются для поиска «вниз» и «вверх» в словаре парадигматических связей. При поиске «вниз» для исходных номеров терминов из тезауруса выбираются дополнительные номера терминов, эквивалентных исходным или более узких по объему. При поиске «вверх» выбираются номера терминов, эквивалентных исходным или более широких по объему. На заключительном этапе результаты поиска по словарю СНП-1 и по словарю парадигматических связей объединяются, и формируются такие же группы номеров терминов, что и при поиске по словарю СНП-1. Повторения одинаковых номеров в группах исключаются, а результаты индексирования используются для поиска документов.
В тех случаях, когда не предъявляется высоких требований к полноте выдачи информации по запросам, можно при обращении к словарю СНП-1 и к словарю парадигматических связей отказаться от выполнения процедур поиска «вверх». Это снизит уровень поискового «шума».
Описанный способ индексирования запросов рассчитан на следующую последовательность их подготовки:
1) формулирование запроса на русском языке;
2) формализация запроса;
196
3) автоматическое индексирование формализованного запроса.
В процессе формализации из первоначальной формулировки запроса вычленяются информативные наименования понятий (словосочетания или отдельные слова), и между ними устанавливаются логические связи.
Вычленение словосочетаний и слов из неформализованного текста запроса различными лицами может производиться по-разному, и это отрицательно влияет на качество индексирования. Поэтому целесообразно автоматизировать процесс вычленения словосочетаний из первоначальной формулировки запроса, применив процедуру индексирования текстов рефератов, что создает возможность использования при формализации запросов только таких терминов, которые содержатся в тезаурусе. После формализации запрос подвергается повторному индексированию с целью обогащения его смысловыми связями.
В процессе экспериментов было заиндексировано и введено в поисковую систему около 10 000 рефератов статей по электронной вычислительной технике и ее применениям. Индексирование проводилось с помощью тезауруса Ю. И. Шемакина, дополненного пятью тысячами однословных терминов. Такой тезаурус обеспечивал покрытие текстов на 95%. В процессе автоматического поиска документов среднее значение коэффициента полноты поиска составляло 90%, среднее значение коэффициента «шума» — 8%. Более подробное описание системы и результатов ее опытной эксплуатации можно найти в [22].
Как уже указывалось, автоматический поиск документов может осуществляться по текстам рефератов без их предварительного перевода на формализованный язык (индексирования). Это дает возможность отказаться от создания поисковых образов документов и хранить в памяти ЭВМ только тексты рефератов. Тексты рефератов целесообразно хранить не в буквенных, а в пословных кодах (например, в виде последовательностей номеров словоформ и знаков препинания), что позволяет сократить потребный объем памяти. При этом они могут иметь ассоциативноадресную структуру (одинаковые номера словоформ связываются друг с другом адресными отсылками). В процессе ввода рефератов в ЭВМ они кодируются по словарю словоформ, который по мере необходимости пополняется. При выдаче информации человеку номера словоформ и знаков препинания заменяются на их буквенные коды.
Запросы на поиск документов по текстам рефератов целесообразно формализовать (вручную или с помощью процедуры автоматической формализации). Смысловое содержание запросов может выражаться одним словом, одним именным словосочетанием или последовательностью слов и именных словосочетаний.
197
Смысловые связи между словами и словосочетаниями в запросе следует обозначать с помощью логических связок конъюнкции и дизъюнкции.
Простой (элементарный) запрос может состоять из одного слова или словосочетания. Сложный запрос включает в свой состав несколько элементарных запросов, соединенных логическими связками. Порядок выполнения операций, соответствующих логическим связкам, определяется путем соответствующей расстановки скобок и путем установления приоритета этих связок (например, можно условиться, что операция дизъюнкции выполняется раньше операции конъюнкции).
Рассмотрим более подробно поиск рефератов документов по одному элементарному запросу. В процессе поиска буквенные коды словоформ запроса заменяются на их номера по словарю. Затем прослеживаются все вхождения этих номеров в массив пословных кодов текстов рефератов и фиксируются соответствующие им адреса предложений и номера рефератов. В результате для каждой словоформы запроса формируется свое множество пар кодов, состоящих из адреса предложения и номера реферата. Полученные множества пересекаются, а из результирующего множества выделяются попарно-различные номера рефератов. По номерам рефератов выбираются их пословные коды и после декодирования выдаются на печать в качестве ответа на запрос. Таким образом, реферат документа считается удовлетворяющим запросу, если все словоформы запроса входят в состав одного из предложений реферата.
В рассмотренном способе поиска рефератов по элементарному запросу не учитывается возможность выражения одного и того же смысла различными языковыми средствами, когда одна и та же ситуация может быть описана в терминах различной степени общности, с использованием различных форм слов и различных синтаксических конструкций.
Смысловая эквивалентность форм одного и того же слова и трансформационных вариантов основ слов (например, в словосочетаниях типа заводской коллектив и коллектив завода) может быть установлена путем их морфологического анализа. Родо-видовые и ассоциативные связи между однословными терминами — с помощью специальных словарей смысловых связей слов. Родовидовые и ассоциативные связи между многословными терминами, если они не могут быть обнаружены на основе связей между составляющими их словами,— с помощью словаря парадигматических связей словосочетаний.
Если ввести в состав АИС процедуру установления смысловой эквивалентности слов, то поиск рефератов документов по элементарному запросу может быть модифицирован следующим образом.
198
После ввода запроса каждой его словоформе ставится в соответствие не один номер, а серия номеров словоформ из словаря, выражающих один и тот же смысл. Далее для каждой серии номеров словоформ прослеживаются вхождения этих номеров в массив пословных кодов текстов рефератов и формируется множество пар кодов, состоящих из адреса предложения и номера реферата. Полученные множества пересекаются, а из результирующего множества выделяются попарно-различные номера рефератов, которые используются для выдачи на печать текстов этих рефератов. В случае сложного запроса производится поиск по всем составляющим его элементарным запросам и над результатами поиска выполняются операции объединения и пересечения множеств, предписанные в исходной формулировке запроса.
В рассмотренном нами модифицированном способе поиска рефератов отсутствуют процедуры автоматического установления родо-видовых и ассоциативных связей между словами и словосочетаниями. Этот недостаток может быть частично компенсирован путем избыточной формулировки запроса, когда наряду с исходными словосочетаниями в нем указываются дополнительные перечни словосочетаний, связанных с исходными родо-видовыми или ассоциативными отношениями. Элементы перечней соединяются знаками дизъюнкции. Другая возможность устранения указанного недостатка состоит в использовании словарей смысловых связей слов и словосочетаний.
Системы поиска документов по текстам их рефератов в настоящее время нашли широкое практическое применение. Имеется ряд пакетов прикладных программ типа АСОД, ПОИСК-1 и др., которые обеспечивают такой режим поиска [13, 28]. Правда, в упомянутых пакетах слабо используются парадигматические связи между словами и словосочетаниями, но этот их недостаток может быть исправлен путем введения соответствующих лингвистических и программных средств.
До сих пор мы рассматривали процессы функционирования АИС без учета их взаимодействия друг с другом. Между тем при создании сетей АИС возникает ряд новых проблем, которых не было при их автономной работе. Эти проблемы далее рассматриваются на примере системы научно-технической информации.
ГЛАВА 10
ИНФОРМАЦИОННЫЕ СЕТИ
10.1. Совокупность автоматизированных информационных систем как объединенная информационная система
Широкое внедрение автоматизации обработки научно-технической информации в различных областях знаний ведет к созданию автоматизированных информационных систем (АИС) различного назначения. По мере роста числа АИС возникает необходимость организации их совместной работы.
Растет число потребителей, в той или иной степени связанных со многими АИС, тематика и виды документов начинают пересекаться, возппкает необходимость использования общих дорогостоящих ресурсов.
Применение автоматизированных информационных систем хотя и обеспечивает улучшение справочно-информационного обслуживания потребителей, однако требует решения многих проблем. К ним относятся: создание, ввод в ЭВМ и накопление на машиночитаемых носителях информационных массивов; разработка или адаптация пакетов прикладных программ для автоматизированной обработки информации, включая создание ИПС; выбор конфигурации вычислительного комплекса; разработка технологии ведения базы данных, организация режима доступа пользователей к ИПС. Кроме того, требуется провести анализ информационных потребностей пользователей, определить видовой и тематический состав документов базы данных, оценить требуемую глубину ретроспективного фонда, провести анализ экономической эффективности работы АИС, определить характеристики качества информационного обслуживания, а также решить много других проблем.
Ряд задач, с которыми приходится встречаться разработчикам при создании различных АИС, по существу, одинаковы. Так, технология ввода документов в ЭВМ слабо зависит от их вида. Прц
200
создания ИПС используется, как правило, ограниченный набор пакетов прикладных программ, которые годятся для информационных спстем различного назначения. Еще меньше разнообразия в используемых технических средствах. Средства передачи данных и каналы ^связи, применяемые для организации удаленного диалога пользователей с базой данных, вообще не связаны со спецификой ИПС.
Пользователи базы данных какой-либо конкретной предметной области редко бывают сосредоточены в организации, ее создавшей. Как правило они географически рассредоточены и работают в разных организациях. Создание множества локальных ППС с попыткой «охватить» основной контингент пользователей не всегда возможно с экономической точки зрения. Дело в том, что пользователи обращаются с запросами в ИПС с разной интенсивностью и поэтому некоторые локальные ИПС будут страдать от избытка нагрузки, в то время как другие будут работать малоэффективно из-за малого потока запросов.
По мере развития научно-технического прогресса становится очевидным, что решаемые наукой и производством проблемы все более становятся межотраслевыми. В связи с этим каждый конкретный пользователь (ученый, инженер или техник) совсем не обязательно должен ограничиваться лишь одной предметной областью. В зависимости от характера решаемой задачи он может обращаться к различным предметным областям. Отсюда возрастает необходимость обращения специалистов в информационные массивы с разной тематикой.
В условиях широкого внедрения автоматизированных методов обработки информации все более очевидными становятся недостатки независимого развития автоматизированных информационных систем и организации автономной технологии их функционирования. Дальнейшее развитие таких систем должно быть связано о объединением их в единую информационную сеть, которая позволит существенно улучшить как качество информационного обслуживания пользователей, так и условия эксплуатации отдельных систем.
В информационной сети важную роль играет функциональная специализация автоматизированных информационных центров. Она позволяет уменьшить дублирование одних и тех же работ, а их результаты становятся достоянием всех участников информационной сети. С другой стороны, центры, входящие в информационную сеть, должны кооперироваться при создании общей информационной базы, эксплуатации имеющихся баз данных, использовании общей оперативной коммуникационной среды (системы передачи данных) и абонентского оборудования удаленных пользователей.
201
10.2. Формирование информационных массивов
Как уже было указано, в информационной сети совсем не обязательно каждому центру самостоятельно создавать для своей ИПС базу данных. Необходима кооперация АИС и распределение усилий между ними по генерации информационных массивов на машиночитаемых носителях, что обеспечивает создание общей информационной базы сети.
Государственная система научно-технической информации СССР (ГСНТИ) имеет в своем составе информационные центры различного уровня (всесоюзные, центральные отраслевые, межотраслевые, территориальные). Причем основными создателями информационных массивов являются всесоюзные и центральные отраслевые органы информации. Всесоюзные центры научно-технической информации обрабатывают мировой поток документов различного вида: журнальные статьи, книги, патентные документы, ГОСТы, ОСТы и другую нормативно-техническую документацию, документы о научно-исследовательских и опытно-конструкторских работах, диссертации, каталоги промышленного оборудования и изделий и т. п. Центральные отраслевые информационные центры обрабатывают поток документов по соответствующей тематике отраслей. Это материалы о научно-технических достижениях, ценных исследованиях, передовом опыте. Важное место в этом потоке занимает фактографическая информация об изделиях, материалах, ресурсах и экономических показателях деятельности предприятий отраслей.
Каждый автоматизированный информационный центр, входящий в сеть, традиционно выпускает библиографические и реферативные информационные издания. При подготовке информационных изданий широко используется автоматизированная технология, когда поток документов переводится на машиночитаемые носители и обрабатывается на ЭВМ. Автоматизированная технология подготовки информационных изданий улучшает их качество, упрощает выполнение ряда сложных операций, облегчает контроль за ходом выпуска изданий. Важным для информационной сети здесь является то, что результаты аналитико-синтетической обработки документов, корректурных работ, операций формально-логического контроля элементов документов могут быть сохранены для дальнейшего использования, в том числе, для формирования информационных баз данных. Поэтому, в технологии автоматизированной обработки документов в АИС, входящей в сеть, должны быть предусмотрены средства для формирования информационных массивов на машиночитаемых носителях.
Уместно отметить, что вначале целью внедрения современных автоматизированных средств подготовки информационных изда
202
ний разработчики считали улучшение и ускорение собственно процесса подготовки этих изданий. Затем машиночитаемый аналог традиционного издания, получающегося по такой технологии, стал рассматриваться как побочная дополнительная услуга, которую можно предложить заинтересованным организациям. И лишь с началом серьезного внедрения в практику работы информационных служб больших библиографических и реферативных баз данных стало очевидно, что на самом деле все выглядит иначе: именно машиночитаемые информационные массивы на магнитных лептах являются главным продуктом, а возможность их использования для автоматизированного набора — всего лишь вторичный эффект. Следует иметь также в виду, что далеко не всегда автоматизированная технология подготовки информационных изданий имеет преимущества, если в качестве конечной цели рассматривать только подготовку этих изданий в традиционном виде. Так, некоторые небольшие реферативные и библиографические сборники можно издавать дешевле и быстрее и без широкого применения средств автоматизированной обработки информации.
Формирование информационных массивов для собственных нужд одной ЛИС и для информационной сети существенным образом отличаются друг от друга. При подготовке информационного массива для одной АИС характер аналитико-синтетической обработки документов, принципы их отбора в базу данных, полнота отражения первоисточников, набор элементов данных, способ их представления, точность введенных данных, выбор и способ записи поисковых признаков (дескрипторов, ключевых слов, классификационных кодов, указывающих тематику документа и др.) — все это определяется потребностями ограниченного круга пользователей, возможностями конкретного поискового пакета прикладных программ. Изменение внутренней информационной технологии АИС, смена математического обеспечения, модернизация технических средств иногда приводит к изменению как структуры, так и состава информационного массива. «Внешняя среда» почти не ограничивает возможности таких изменений. В выборе формата записи также допускается значительная свобода, так как имеется лишь одна забота — эффективное и удобное преобразование данных во внутренний формат собственной ИПС и стыковка. при необходимости, с собственным издательским процессом. И, наконец, в условиях создания автономных и независимых АИС допускается многократная аналитико-синтетическая обработка и перевод на машиночитаемые носители одних и тех же документов.
Информационная сеть предъявляет свои, особые требования к формированию информационных массивов.
203
Основными из них являются:
— полнота отбора документов для аналитико-синтетической обработки и ввода в информационный массив должна покрывать потребности всех пользователей сети;
— все виды источников, из которых вводятся документы в информационную сеть, должны обрабатываться однократно, в выделенных центрах;
.— набор элементов данных документов (набор поисковых признаков и элементов для выдачи пользователю в качестве результата поиска) должен быть достаточным для всех пользователей различных ИПС сети;
— структура элементов данных и их семантическое наполнение должны удовлетворять рациональным условиям функционирования различных поисковых пакетов прикладных программ, принятых в сети;
— преобразования массива для формирования поисковых файлов различных ИПС должны быть достаточно просты;
— тематическая идентификация массивов должна отвечать единым принципам построения информационной сети и обеспечивать простоту разделения предметных областей массивов, созданных в разных центрах;
— качество обработки поисковых признаков, глубина индексирования должны соответствовать требованиям множества ИПС, которые будут использовать информационный массив;
— источники, из которых формируется информационная база сети, должны в первую очередь и с наименьшими задержками поступать в те центры, которые ответственны за их аналитикосинтетическую обработку и ввод в состав информационного массива.
10.3. Функциональная специализация информационных центров и их взаимодействие
Каждый из центров, участвующих в информационной сети, может выполнять несколько функций. Главными из них являются генерация информационных массивов для сети и справочноинформационное обслуживание потребителей на основе сформированных баз данных. В том случае, когда автоматизированный информационный центр участвует в генерации информационных массивов, он называется ЛИЦ-генератором. Если же он функционирует в режиме информационно-справочного обслуживания пользователей, он называется обслуживающим центром.
В разветвленной информационной сети может оказаться необходимым выполнение еще одной функции — компоновки, интеграции и распределения множества информационных массивов,
204
полученных из АИЦ-генераторов, по многочисленным обслуживающим АИЦ. Центры, выполняющие такую функцию, называются распределительными. Распределительным АИЦ может быть, например, региональный центр, обеспечивающий поставку информационных массивов обслуживающим АИЦ региона. Наличие распределительных АИЦ в сети позволяет улучшить контроль за
Обозначения:
Автоматизиро -ванный ичфар-мацип.чнмц центр сети
0ИПС автоматизированного информационного центра
к Абонентский пункт
Л " пользователя
о,- Массивы на МЛ
Генерация информационных Базы данных, эксплуатируемые
массивов в АИЦ в обслуживающих АиЦ
□ —вида Af, v —вида А?. xj — вида > О — вида 4; о —вида /.$
вида Af, вида 4 г» вида Аъ, вида Л?, вида As
Рис. 10.1.
распределением информационных массивов, уменьшить информационные потоки в сети и упростить информационную технологию. Таким образом, в зависимости от возложенных на центр обязанностей, он может быть АИЦ-генератором, обслуживающим или распределительным АИЦ. Возможно также совмещение в одном центре функций генерации, распределения и обслуживания.
На рис. 10.1 схематически изображена информационная сеть. Для упрощения схемы на ней не показаны распределительные АИЦ. В информационной сети условно изображены 5 видов информационных массивов Ai—А5, составляющие основу информационного фонда сети. Центры 7, 2, 5, 5 являются АИЦ-генера-торами и обслуживающими центрами. Центр 4 является только АИЦ-генератором. Информационные массивы па магнитных лентах из АИЦ-генераторов посылаются в обслуживающие АИЦ б, 7, ..., п. На основе полученного набора информационных массивов в ИПС создаются соответствующие базы данных, с которыми пользователи взаимодействуют с абонентских пунктов сети.
Наиболее сложным режимом работы ИПС является удаленный поиск в ретроспективных базах данных в режиме теледоступа.
205
Для информационного обслуживания могут быть также использованы и более простые средства — ретроспективный поиск в автономном режиме по заранее подготовленному пакету запросов и избирательное распространение информации, когда поиск по пакету запросов ведется только в небольшом массиве текущих поступлений.
В территориально распределенных точках информационной сети может функционировать одна база данных или несколько копий баз данных (на рис. 10.1 база данных At эксплуатируется в 4 центрах, а база данных Л5 — только в одном центре). Количество эксплуатируемых копий баз данных и их территориальное размещение зависит от многих факторов и, в частности, от распределения вычислительных и других ресурсов по центрам сети, стоимостных и временных характеристик информационного обслуживания в центрах, интенсивности потоков информационных массивов в сети, распределения интенсивностей информационных потоков пользователей по центрам и базам данных, топологии сети, временных и стоимостных характеристик системы передачи данных. При изменении условий функционирования информационной сети, уровня оснащенности центров, структуры сети и т. д. может меняться распределение баз данных по центрам.
В изображенной на рис. 10.1 схеме формирование и функционирование базы данных Л5, строго говоря, не вполне соответствуют условиям работы в сети, так как все процессы, связанные с циклом жизни базы данных замыкаются в центре 5, а кооперативно используются лишь ресурсы системы передачи данных. Но такое явление может быть временным.
При изменении географического распределения пользователей или вводе в строй в ближайшем регионе эффективного вычислительного центра коллективного пользования (ВЦКП) может сказаться выгодной эксплуатация нескольких копий базы данных А5 или перевод ее в другой обслуживающий центр. Тогда сразу же потребуется перестройка технологического процесса в центре 5 в соответствии с принципами сетевой информационной технологии формирования и распространения информационных массивов.
10.4. Информационный фонд сети
Информационный фонд сети представляет собой совокупность информационных массивов, распределенных по центрам сети. Его пополпенпе и обновление происходит регулярно по мере обработки текущих поступлений документов в АТЩ-генераторах,
206
Технология формирования и ввода текущих поступлений документов в режим обслуживания включает следующие основные операции:
— аналитико-синтетическую обработку документов в АИЦ-ге-нераторах;
— ввод и машинную обработку документов в ЭВМ АИЦ-гене-раторов;
— создание информационных массивов текущих поступлений;
— формирование видо-тематических фрагментов информационных массивов для обслуживающих и распределительных АИЦ;
— рассылку информационных массивов на магнитных лентах заказчикам почтовыми средствами*);
— конвертирование информационных массивов из коммуникативного формата во внутрисистемный формат ИПС обслуживающих АИЦ;
— формирование необходимых поисковых и служебных файлов в соответствии со структурой ИПС обслуживающего АИЦ;
— обновление ретроспективной базы данных текущими поступлениями документов;
— предоставление обновленных баз данных в режим доступа пользователям сети.
Описанная технология формирования и распространения информационных массивов поддерживает устойчивое состояние информационной сети, когда все процедуры сводятся в основном к обновлению состава информационных массивов текущими поступлениями документов. Здесь, однако, не затронут пока ряд важных сторон функционирования информационной сети, когда условия ее работы изменяются. При этом информационная техно-нология должна обеспечивать сохранность информационного фонда, его адаптацию к новым условиям работы сети, снабжение новых центров сети не только текущими поступлениями, но и ретроспективными массивами.
Весь ретроспективный информационный фонд целесообразно разделить на два раздела: страховой и рабочий фонды. Страховой фонд распределяется между АИЦ-генераторами сети. Каждый АИЦ-генератор несет системные обязательства перед информационной сетью за хранение и поддержание в рабочем состоянии на магнитных лентах всего созданного фонда текущих поступлений соответствующих массивов на принятую для сети хронологическую глубину. Цель создания страхового фонда — сохранение сформированных различными центрами ретроспективных
*) Рассылка информационных массивов на магнитных лентах по почте в будущем уступит место их передаче через систему передачи данных. В настоящее время по экономическим соображениям такой режим пока не применяется.
207
информационных массивов для разнообразных нужд информационной сети. Рабочий фонд представляет собой совокупность информационных массивов, распределенных по обслуживающим АИЦ. Его основное назначение — это обеспечение непосредственного справочно-информационного обслуживания потребителей.
Создание страхового фонда в АИЦ-генераторах имеет серьезные основания, хотя на первый взгляд может показаться, что для этой цели можно привлечь в равной степени и обслуживающие центры, которые уже по характеру своей деятельности занимаются накоплением и поддержанием в рабочем состоянии полученных информационных массивов. Дело в том, что массивы в обслуживающих АИЦ претерпевают ряд преобразований, в результате которых часть элементов данных может быть удалена или модифицирована, а хронологическая глубина хранимого ретроспективного фонда определяется не столько общесистемными сетевыми требованиями, сколько практическими технико-экономическими соображениями. При этом бывает сложно определить ' конкретного «хранителя» информационного массива, так как в сети имеется несколько копий баз данных в разных местах.
Обращение к страховому фонду в сети может иметь место в следующих ситуациях:
— включение в состав информационной сети новых центров, для которых необходимо сформировать полные ретроспективные базы данных на требуемую хронологическую глубину;
— изменение тематического или видового состава баз данных некоторого обслуживающего АИЦ в соответствии с новыми потребностями пользователей;
— обеспечение процессов восстановления любых фрагментов рабочих фондов при потерях информации из-за нарушения условий эксплуатации и хранения или вследствие других причин;
— представление ретроспективных информационных массивов заинтересованным организациям, не входящим в информационную сеть.
10.5. Полнота представления данных в информационном фонде
В автономных ИПС потребители имеют дело, как правило, с ограниченными информационными массивамп. Их полнота, с одной стороны, зависит от характера информационных потребностей пользователей ИПС, а с другой — от технико-экономических ограничений, которые неизбежно принимаются во внимание при создании конкретных ИПС. В информационной сети представление о необходимой полноте доступных пользователю ин-208
формационных массивов существенно шире, так как здесь полнота представления данных характеризуется степенью охвата в базах данных различных ИПС всего накопленного множества документов (для библиографических и реферативных баз данных) и фактографических сведений (для фактографических баз данных). Пользователя сети в общем случае взаимодействуют со множеством баз данных, распределенных по обслуживающим центрам.
Полнота информационного фонда сети определяется следующими основными характеристиками:
1. Ширина охвата видового состава источников научно-технической информации (отечественные и зарубежные журналы, материалы симпозиумов, конференций, семинаров, нормативно-технические документы, отчеты о научно-исследовательских и опытно-конструкторских разработках, патентная документация, диссертации, каталоги, справочники и т. д.).
2. Ширина охвата предметных областей (степень включения в фонд различных тематических профилей).
3. Полнота отбора документов и данных из обрабатываемых источников.
4. Временной интервал накопления (хронологическая глубина фонда).
Многие характеристики полноты информационного фонда фактически задаются на этапе генерации информационных массивов еще до создания баз данных в обслуживающих центрах. Видовой и тематический состав информационных массивов определен функциональным распределением основных АИЦ-ге-нераторов по видам и тематическим разделам обрабатываемых документов.
Например, в Государственной системе научно-технической информации СССР Всесоюзный институт научной и технической информации (ВИНИТИ) обрабатывает опубликованную научно-техническую литературу, Всесоюзный научно-технический информационный центр (ВНТИЦентр) — отчеты о начатых, осуществляемых и завершенных научно-исследовательских и опытно-конструкторских работах, научно-производственное объединение «Поиск» — патентные документы, Всесоюзный научно-исследовательский институт технической информации классификации и кодирования (ВНИИКИ) — нормативно-техническую документацию-Республиканские центры научно-технической информации обрабатывают документы о передовом производственном опыте в соответствующих регионах.
Аналогично имеется распределение обязанностей между информационными органами по обработке документов и данных в различных предметных областях. Например, Институт научной
14 г, г. Белоногов, Б. А. Кузнецов
209
информации по общественным наукам (ИНИОН) обрабатывает документы и данные по общественным наукам, Всесоюзный научно-исследовательский институт медицинской и медико-технической информации (ВНИИМИ) обрабатывает документы и данные по медицине и т. д. По мере развития информационной сети должен расширяться видовой и тематический состав генерируемых информационных массивов.
Несколько слов еще об одной характеристике, влияющей на представительность информационного фонда,—полноте отбора документов и данных из обрабатываемых источников. Проблема такого отбора не проста. Стремление добиться тотальной обработки всех документов, включенных в определенный источник, может привести к снижению качества информационного массива в целом. Поэтому не каждый документ источника следует включать в информационный массив. В каждом АИЦ-генераторе принята определенная система критериев, обеспечивающая включение в информационный фонд важных и нужных документов и данных и исключение документов и данных, не представляющих большой ценности для потребителя.
Полнота представления данных в ретроспективном информационном фонде в значительной степени зависит от его хронологической глубины. В зависимости от информационных задач, решаемых пользователями сети, к глубине ретроспективного фонда могут предъявляться различные требования. Например, эксперты, ведущие поиск аналогов изобретений, предъявленных к экспертизе на новизну, в некоторых предметных областях нуждаются в информационном фонде патентной информации глубиной до 30 лет. С другой стороны, инженер, желающий получить информацию о патентах и изобретениях, в первую очередь интересуется последними достижениями, сосредоточенными главным образом в фонде за последние несколько лет.
Существенное влияние на определение разумной хронологической глубины оказывает видо-тематический профиль документов, отраженных в массиве, и фактор их старения. Известно, что научно-технические документы подвержены старению [52], которое отражает снижение на них спроса с течением времени в связи с появлением новых и более точных сведений в новых информационных источниках. При этом монографии, журнальные статьи, описания патентов, отчеты о научно-исследовательской работе имеют разные скорости старения, а работы по биологии, медицине, вычислительной технике имеют, например, более высокую скорость старения, чем документы по геологии, географии и математике.
210
10.6. Влияние временных характеристик распределения документов в массивах текущих поступлений на полноту информационного фонда
Анализ реальной технологии генерации информационных массивов показывает, что полнота представления данных в документальном ретроспективном фонде зависит не только от конкретных значений его хронологической глубины. Существенное влияние на полноту фонда имеют временные характеристики массивов текущих поступлений, из которых формируется ретроспективный фонд.
Чтобы продемонстрировать это, остановимся несколько подробнее на технологии формирования ретроспективного фонда. Для определенности рассмотрим, например, формирование массива записей, в которых отражены библиографические данные журнальных статей в какой-либо предметной области. Обычно генерация текущих поступлений и их поставка в ИПС обслуживающих центров происходит с равными, например, месячными интервалами. Между датой включения библиографической записи о документе в режим информационного поиска в некотором массиве и датой его публикации в первоисточнике имеется некоторый интервал времени т. В идеальной и наиболее благоприятной ситуации эта задержка т минимальна и постоянна для всех записей каждого массива текущих поступлений ретроспективного фонда. В этом случае в каждом массиве текущих поступлений (в каждом хронологическом слое) будут сгруппированы все записи с определенной датой публикации, полнота представления данных в каждом хронологическом слое будет максимальна и записи, относящиеся к разным массивам текущих поступлений, не будут иметь одинаковых дат публикации.
Идеализированная картина формирования ретроспективного фонда приведена на рис. 10.2. Здесь Тп и Тк — начальный и конечный моменты ввода в ретроспективный фонд соответствующих массивов текущих поступлений. Пти(0 и Птк(*) — временные распределения полноты представления данных в соответствующих хронологических слоях. Задержка отражения документов в массивах т постоянна для всех записей и составляет для рассматриваемого случая 9 месяцев. На рисунке можно видеть, что полугодовой фонд записей имеет полноту, равную единице по всем хоронологическим слоям. В данном случае под полнотой понимается отношение числа документов ретроспективного фонда, имеющих дату публикации в пределах заданного хронологического отрезка, к общему потенциально возможному числу документов, относящихся к этому хронологическому отрезку, из всего множества массивов текущих поступлений.
14*
211
Нетрудно видеть, что описанная идеализированная картина формирования ретроспективного фонда имеет мало общего с реальностью. На практике документы поступают-в ретроспективный фонд с различной задержкой. В общем случае задержку поступления конкретного документа i в ретроспективную базу данных
Рис. 10.2.
обслуживающего АИЦ относительно даты публикации можно выразить следующим образом:
Ti = Тзп + ТПг + Тасо + Тфм +Тдо + Тбд, (10.1)
где Тзп — задержка выпуска публикации относительно даты публикации; Тпг — время почтовой пересылки первоисточника, содержащего документ, в АИЦ-геператор; тасо —время аналитико-синтетической обработки документа в АИЦ-генераторе; ТфМ — время формирования массива текущих поступлений на магнитной ленте в АИЦ-генераторе; тПо — время почтовой пересылки информационных массивов в обслуживающие АИЦ; Тбд — время ввода массива текущих поступлений в ретроспективную базу данных обслуживающего АИЦ.
Первые четыре составляющих выражения (10.1) влияют на задержку и разброс времени поступления документов в массив текущих поступлений; два последних слагаемых определяют дополнительные, одинаковые для всех документов массива текущих поступлений задержки.
Приведенная зависимость отражает один из возможных вариантов сетевой информационной технологии формирования ретроспективных баз данных. В частности, здесь предполагается централизованная обработка документов в одном АИЦ-генераторе для создания массива текущих поступлений, хотя в общем случае функции обработки могут быть и распределены по различным центрам. Если рассматривается центр, совмещающий функции генерации информационных массивов и информационного обслужи-212
йания, то время на почтовую пересылку массивов текущих поступлений из АИЦ-генератора в обслуживающий АИЦ исключается.
Значения задержки тг- в выражении (10.1) зависят от множества факторов: вида обрабатываемых документов, их доступности, объемов документального потока, сложности и качества аналитико-синтетической обработки документов, степени совершенства сетевой технологии обработки, распространения и ввода информационных массивов в режим эксплуатации и др.
Чтобы представить себе характер реальной картины распределения временных задержек поступления документов, рассмотрим результаты исследований некоторых документальных массивов. Предлагаемые результаты не в полной мере охватывают все звенья сетевой информационной технологии, так как они базируются на анализе печатных вторичных изданий (реферативных журналов, реферативных сборников, библиографических указателей). Однако основные источники временных задержек здесь учитываются. Исключаются лишь процессы формирования массивов на магнитной ленте, их рассылка и ввод в ИПС. Вместо этого в технологию дополнительно включаются процессы подготовки и издания реферативных журналов и библиографических указателей.
Для оценки временных задержек отражения первоисточников в справочных информационных массивах исследовался ряд вторичных изданий: реферативные журналы ВИНИТИ («Автоматика и телемеханика», «Информатика»), реферативные сборники, выпускаемые ВНТИЦентром («Автоматика и вычислительная техника»), реферативные издания по патентной информации, выпускаемые НПО «Поиск», реферативные сборники по строительству и архитектуре, выпускаемые ВНИИИС, а также зарубежные реферативные журналы: «Sciences economiquos et problemes de gestion», «Informatique», «Information science abstract». Указанные издания исследовались с точки зрения оценки отражения в них документов с различной датой публикации. Распределения полноты отражения документов в различных хронологических слоях вычислялись по следующей формуле:
/ rj~^i + (Trnax“Tmin) \~ 1
пг (t) = JVr (t) 2 • <10-2)
Vj*ri~(4ndx~Tmin) /
где t — дата публикации документа; Т{ — дата выпуска реферативного журнала; NT^(t)-~число документов, имеющих дату публикации t в массиве с датой выпуска Z\; rm in — минимальное значение задержки для документов, включенных в выпуск реферативного журнала; ттах — максимальное значение задержки для документов, включенных в выпуск реферативного журнала.
213
Все множество документов, отраженных в i-м выпуске реферативного журнала, распределяется по хронологическим слоям между значениями Ti — тШах и Л - ттт. Наибольшее число документов попадает в некоторый хронологический слой, который соответствует модальному значению задержки т. Полноту представления документов хронологического слоя, соответствующего модальному
значению задержки будем называть максимальной или модальной полнотой.
Исследования показали, что диапазон колебания величины т довольно велик: от 2 до 30 месяцев. Значение модальной задержки сильно зависит от вида обрабатываемых документов и меняется от 3 до 14 месяцев. Модальная полнота для различных видов реферативных изданий и номеров выпусков меняется в пределах от 0,1 до 0,6. На рис. 10.3 приведено распределение полноты представления документов в зависимости от т для одного из выпусков реферативного журнала ВИНИТИ «Автоматика и телемеханика» за 1979 г.
Выясним теперь, какова будет полнота представления документов в ретроспективном фонде, составленном из реальных массивов текущих поступлений. Распределение полноты наполнения документами различных хронологических слоев ретроспективного фонда может быть получено из формулы
ПР(О= 2 птЛ0. (10.3)
Ti=T„
где Пг^ (/) — распределения полноты в массивах текущих поступлений, идентифицируемых датой выпуска; Тн, Тк — идентификаторы даты выпуска начального и конечного из текущих массивов, составляющих ретроспективный фонд.
На рис. 10.4 приведена зависимость Пр(0 для двух значений глубины ретроспективного фонда — полгода и год. При этом рас
214
пределения полноты представления данных в массивах текущих поступлений П(£) приняты одинаковыми для всех выпусков. Распределение П(£) получено на основе статистической обработки 6 выпусков реферативного журнала ВИНИТИ «Автоматика и телемеханика» и «Информатика» с последующей аппроксимацией
гладкой функцией. Оказалось, что модальная задержка распределения равна 9 месяцам, модальная полнота — 0,2, математическое ожидание задержки 9,9 месяцев, среднеквадратичное отклонение 2,6 месяца.
Распределения Птн(0> ПТп(0 и Птг(0 на рис. 10.4 соответствуют начальному, полугодовому и годовому массивам текущих поступлений. Величины Прп(0 и Прг(0 отражают распределение документов по хронологическим слоям соответственно в полугодовом и годовом ретроспективном фондах. Приведенные графики показывают, как меняется характер и распределения Пр(£) в зависимости от хронологической глубины фонда. Так фонд, состоящий из 6 месячных массивов текущих поступлений, имеет модальную полноту 0,8, годовой фонд —0,98. На границах хронологического диапазона, охватываемого ретроспективным фондом, полнота представления документов существенно падает.
Рассмотренная картина наглядно показывает, какие опасности таит порой для потребителя информационный попск в небольших по глубине ретроспективных фондах. Представление о том, что такие фонды достаточно эффективны для обеспечения полноты поиска «свежих» документов, как видим, справедливо далеко не всегда. Чтобы судить о возможностях обеспечения полноты поиска, нужно иметь четкое представление о распределении документов по хронологическим слоям в массивах текущих поступлений. Отме-
215
тпм, кстати, что снижение хронологической глубины реароспектив-ного фонда часто диктуется ограничениями объемов внешней дисковой памяти при создании относительно дорогих диалоговых ИПС, работающих в интерактивном режиме.
Необходимо сделать некоторые оговорки относительно условий построения зависимостей Пр(/). Графики построены па основе предположения о неизменности распределений П(г) для всех массивов текущих поступлений. На самом деле реальные распределения нестационарны. Другое принятое условие — это регулярность ввода массивов текущих поступлений. В реальных условиях функционирования информационной сети могут происходить колебания задержек поставки и ввода этих массивов в ретроспективный фонд. При исследовании характеристик конкретных ретроспективных фондов следует учитывать эти особенности.
Сложный характер распределения полноты представления документов в различных хронологических слоях ретроспективного фонда создает определенные трудности при формировании комплексных поливидовых или политсматическпх баз данных. Между тем это явление необходимо учитывать при построении рациональной системы информационного обслуживания в информационной сети. Очевидно, что простое объединение массивов на основе одинаковых дат их генерации не даст желаемого результата. Необходимо знать характеристики П(£) всех составляющих массивов комплексного информационного массива. Объединение должно происходить таким образом, чтобы средняя полнота по всем хронологическим слоям комплексного ретроспективного фонда была максимальной.
ГЛАВА И
ПРЕДСТАВЛЕНИЕ БАЗ ДАННЫХ В ИНФОРМАЦИОННОЙ СЕТИ
11.1. Структура баз данных информационной сети
Как уже отмечалось в предыдущей главе, базы данных в Государственной системе научно-технической информации формируются из различных фрагментов массивов, созданных в определенных центрах. С точки зрения общей концепции информационной сети ничто не мешает рассматривать все базы данных, как одну, «глобальную» базу данных, с которой взаимодействует множество пользователей. Однако, для практических целей информационного обслуживания целесообразно разделить эту «глобальную» базу данных на определенные фрагменты, так как реальные интересы пользователей, как правило, не связаны с необходимостью обращения с запросами в «глобальную» базу данных целиком. Здесь- мы оставляем пока без внимания характеристики, связанные'с размещением «глобальной» базы данных. В зависимости от степени концентрации информационных ресурсов, она может быть либо централизованной, когда все ресурсы сосредоточены в одном обслуживающем центре, либо распределенной, когда ресурсы размещены во многих рассредоточенных обслуживающих центрах.
Круг пользователей информационной сети чрезвычайно разнообразен. Ученые и научные сотрудники научно-исследовательских институтов в наибольшей степени заинтересованы в доступе к отечественным и зарубежным публикациям, где отражаются исследования их коллег в соответствующих предметных областях. Инженеры и специалисты проектных организаций заинтересованы в доступе к патентной информации, а также к нормативно-техническим документам (ГОСТам, ОСТам, нормалям и т. д.). Инженерно-технические работники производственных предприятий проявляют большой интерес к документам, в которых отражается передовой производственный опыт. Фактографические данные также избирательны в отношении круга пользователей. Каждая из баз данных, от
217
ражающая характеристики и свойства веществ и материалов, промышленных изделий, нацелена на определенное множество пользователей информационной сети.
Изложенные выше соображения дают основания считать, что необходимо разумное разбиение «глобальной» базы данных на разделы, каждый из которых должен представляться пользователям для доступа как самостоятельная часть. В этом смысле указанные разделы можно рассматривать как отдельные информационные базы данных. Обычно каждая такая база данных имеет самостоятельное имя, дается описание видов документов и данных, которые входят в ее состав, дается перечень элементов данных, характер их взаимосвязей, тип системы управления базой данных и пакетов поисковых прикладных программ, которые могут обеспечить накопление, обработку и поиск данных. Для базы данных определяется также порядок доступа пользователей различного приоритета как при формировании и обновлении базы данных, так и проведении информационного поиска. В случае эксплуатации нескольких копий базы данных указывается их размещение в сети и отмечается степень сходства копии с оригиналом (полная копия, тематический или видовой фрагмент, ограниченное число элементов данных и т. д.).
Основой для определения структуры баз данных в информационной сети служит структура информационных массивов, формируемых в АИЦ-генераторах (технология создания и распространения массивов в сети была кратко рассмотрена в гл. 10). Для обслуживающего АИЦ возникает естественная проблема: как формировать базы данных из полученных информационных массивов. Наиболее очевидное решение — оформить отдельные документальные и фактографические информационные массивы как самостоятельные базы данных. Тематический профиль базы данных задается классификационными признаками, которые определяются при формировании информационного массива в АИЦ-генераторе. Такой подход получил довольно большое распространение во многих известных информационных службах и информационных сетях. Пожалуй единственный вид дополнительной структуризации массивов, который часто присутствует при такой технологии — это разделение полных ретроспективных баз данных на хронологические разделы. Например, ретроспективная база 4, охватывающая записи за 1973—1980 гг. может быть разделена на две базы: 41 — с записями за 1973—1977 гг. и 42 —с записями за 1978—1980 гг. Подобное разделение облегчает учет эффекта старения записей при организации информационного обслуживания, так как к базе данных 42 поток запросов будет больше и опа будет чаще ставиться в сервисный режим.
Достоинства описанного принципа формирования баз данных
218
Кратко можно свести к следующему: технология формирования баз данных проста, так как их структура и состав практически повторяют исходные массивы; пользователю облегчается работа с базами данных, так как он часто знаком с содержанием исходных информационных массивов по реферативным и библиографическим изданиям, а также другим информационным материалам. Широкое использование описанного подхода в зарубежных сетях в какой-то степени объясняется еще и особенностями условий поставки информационных массивов в центры, которые ставят их в режим информационного обслуживания. Оформление полученного информационного массива в виде отдельной базы данных упрощает проведение финансовых операций между фирмами-поставщиками и фирмами-получателями, а иногда является и договорным условием поставки.
Вместе с тем приведенная выше «прямолинейная» стратегия формирования баз данных, повторяющих структуру поступивших в центр обслуживания информационных массивов, имеет и свои недостатки, так как структуризация массивов, создаваемых в информационной сети, бывает основана на разных принципах, а сами массивы предназначены для решения разных задач. Возможность представления массивов для автоматизированного' информационного поиска — лишь одна из них. Как правило, информация в АИС готовится в условиях многоцелевой интегральной технологии: один и тот же массив идет и для подготовки библиографического или справочного издания, и для создания документальной или фактографической ИПС. Однако условия использования массивов для подготовки традиционных бумажных справочных изданий и в ИПС— разные и невольная унификация требований к структурам массивов вряд ли обоснована. В реферативном издании, например, немалую роль при определении его объема играют удобство чтения, простота ручного отыскивания нужного раздела. Чрезмерный объем ненужных для конкретного пользователя разделов порой не имеет существенного значения, так как это компенсируется преимуществами тиражного размножения унифицированного выпуска.
Формирование тематических массивов даже в рамках одного генерирующего центра преследует подчас противоречивые цели. В силу многоаспектного характера ряда документов им присваиваются индексы различных рубрик и эти документы дублируются в разных изданиях. Для традиционных изданий реферативного или библиографического типа такая стратегия обоснована: подписчик реферативного журнала по определенной тематике вправе ожидать максимум документов в том издании, на которое он подписался с надеждой удовлетворить таким образом свои основные информационные потребности. С точки зрения традиционной реферативной
219
службы увеличение общего объема реферативных журналов из-за дублирования документов несущественно, но параллельную эксплуатацию сильно пересекающихся по составу баз данных вряд ли можно считать оправданной из-за чрезмерного расхода внешней памяти прямого доступа.
Структура информационных массивов, предназначенных для традиционных реферативных и библиографических изданий слишком консервативна, чтобы можно было надеяться, что она полностью будет соответствовать требованиям, предъявляемым к структуре баз данных информационной сети. Высокий или низкий уровень подписки на тот или иной раздел реферативного издания или библиографического указателя еще не свидетельствует о качестве группировки документов по интересам пользователей. Интересы многих пользователей часто распределены по ряду тематических изданий реферативного журнала, по чрезмерный информационный шум не позволяет им проводить утомительный ручной поиск по всем ассоциированным предметным областям.
Из сказанного можно заключить, что реальные пользователи совсем не обязательно сгруппированы так, как это заложено в структуре массивов некоторой реферативной, библиографической или справочной службы. Разработка оптимальной структуры баз данных должна опираться на анализ потребностей пользователей информационной сети и прежде всего на анализ поисковых средств, применяемых в реальной информационной среде АИС. Получение таких характеристик — процесс длительный. Они будут накапливаться постепенно, по мере роста потока обращений в информационную сеть.
Информационные ресурсы можно по-разному разделять, интегрировать и предоставлять пользователю в виде самостоятельных баз данных. Деление возможно по различным основаниям: по видам представленных документов, по предметным областям, хронологическим разделам, типам фактографических сведений и т. п. Точно так же можно ввести признаки, по которым можно интегрировать записи в рамках одной базы данных. В результате указанных операций можно сформировать в сети практически любое число баз данных. Поэтому приводимые в литературе сведения о числе доступных пользователям библиографических и фактографических баз данных в различных географических регионах и сетях дают лишь приблизительное представление об информационных ресурсах. На одном уровне упоминаются политематические и узкотематические, поливидовые и моновидовые, а также комплексные базы данных.
По объемам хранимых массивов записей базы данных также сильно различаются. В справочнике по сети EURONET DIANE приведены, например, сведения о 192 библиографических, реферат 220
тивных и фактографических базах данных (на 1980 г.) [86], но судить о полноте покрытия различных предметных областей л степени тематического пересечения баз данных крайне трудно.
Следует помнить, что число баз данных в информационной сети, степень их дробления и специализации существенно влияет на сложность взаимодействия пользователя с информационными ресурсами и эффективность их применения. С точки зрения удобства и простоты взаимодействия пользователей с информационными ресурсами базы данных должны представляться в максимально интегрированном виде. Чем меньше баз данных в информационной сети, тем проще адресация пользователей к нужным базам данных и тем меньше усилий требуется на управление потоками запросов.
Некоторые стандартные средства математического обеспечения ИПС имеют ограничения по числу представляемых одновременно пользователю баз данных. Например, пакет прикладных программ ПОИСК-1 [13] обеспечивает поддержку только 16 различных баз данных. Ограничения такого рода несущественны в том случае, когда число реальных баз данных невелико. Идеалом с точки зрения пользователя является представление информации в виде единственной базы данных, чтобы вообще не заниматься выбором баз данных для адресации запросов. С другой стороны, чрезмерная интеграция баз данных и минимизация их числа имеет свои отрицательные стороны: то, что удобно .пользователю, оказывается не очень выгодно с точки зрения рационального использования информационных и вычислительных ресурсов. Необходимость сосредоточения в небольшом числе баз данных объемных информационных массивов может войти в противоречие о объемами внешней памяти и мощностью процессора вычислительного комплекса конкретного АИЦ. Кроме того, чрезмерная интеграция в рамках одной базы данных разделов с разной информационной нагрузкой приводит к тому, что часть дисковых накопителей во время сеанса информационного обслуживания работает с недостаточной эффективностью из-за редких обращений.
Увеличение числа баз данных с детальным представлением информации по видам документов, данных и предметным областям существенно облегчает оптимизацию процесса справочно-информационного обслуживания, так как в сети выгоднее проводить поиск информации с адресацией только в те разделы, в которых вероятность получения ответа на запрос велика. Детальное описание информационных ресурсов с представлением их в виде отдельных баз данных упрощает процесс выявления интересов групп пользователей, так как сбор статистических данных системными программными средствами ИПС с ориентацией на базы данных как правило не вызывает трудностей.
221
Уже отмечалось, что при формировании баз данных следует ориентироваться на реальные интересы пользователей. Они имеют индивидуальный характер, а выявлять их чрезвычайно сложно. Кроме того, интересы пользователя нельзя считать устойчивыми. Обращение каждого нового пользователя к информационной системе имеет свои особенности, так как каждый пользователь представляет по своему модель базы данных, с которой он хочет взаимодействовать. В ней он интуитивно предполагает наличие некоторого уникального набора данных. Если говорить строже, то этот набор данных даже у одного и того же пользователя меняется от запроса к запросу. Поэтому так или иначе, но реальная база данных представляет собой некоторый компромиссный избыточный набор данных, который удовлетворяет требованиям некоторой ассоциации пользователей, ориентированных на эту базу данных. По экономическим соображениям невозможно формировать базы данных под интересы индивидуального пользователя, которые определяются множеством характеристик. Для библиографических баз данных это виды включаемых документов, предметные области, состав элементов данных, описывающих документ, языковые средства общения с базой данных, наличие машинного тезауруса, запаздывание отражения документов, хронологическая глубина фонда, скорость поиска, стоимость поиска п т. д.
11.2. Тематическое разделение предметных областей
Распределение баз данных по предметным областям представляет собой одну из наиболее сложных проблем. Их классификация по другим параметрам — по видам описываемых документов и данных, хронологическим слоям, составу элементов данных — легче поддается формализации. В процессе относительно независимого развития органов ГСНТИ всесоюзные, отраслевые и региональные информационные системы получили ориентацию на разные системы тематической классификации. При отсутствии информационного обмена между АИС создание независимых ИПС с несовместимыми принципами классификации баз данных было допустимо. Каждая ИПС имела свой круг пользователей, который привык к принятой тематической классификации и не страдал от того, что в других ИПС тематические массивы создаются по-другому. При внедрении сетевой технологии из-за неупорядоченности классификации возникает ряд трудностей при обмене информационными массивами на магнитных лентах и формировании баз данных.
Пусть, например, в некотором обслуживающем центре сети необходимо сформировать поливидовую базу данных, включающую журнальные публикации, нормативно-техническую документацию и отчеты по НИР и ОКР в определенной предметной области. Сра
222
зу же возникает вопрос: какая классификация должна быть взята за основу при формировании базы данных? Для этой цели каждый из центров-генераторов массивов на МЛ может предложить свой вариант: либо рубрикатор изданий ВИНИТИ, либо классификатор государственных стандартов, либо рубрикатор ВНТИЦентра. Выбор любого из предложенных вариантов классификации в общем случае повлечет за собой необходимость тематической реструктуризации массивов по двум из трех видов документов. Представление же трех информационных массивов в виде независимых баз данных с сохранением разных классификационных схем порождает сложности у пользователя. Ему необходимо будет самостоятельно определить, какие фрагменты предметных областей разных баз данных отвечают его собственному представлению о модели нужной предметной области.
Различие принципов деления предметных областей в АИЦ-ге-нераторах вызывает также трудности при организации информационного обмена на МЛ. С точки зрения генерирующего органа наилучший способ информационного обмена — это передача информационного массива на МЛ при определенной рубрике целиком. Однако при различии систем классификации информации обслуживающий АИЦ оказывается в невыгодном положении. Типичная ситуация при таком обмене изображена на рис. 11.1.
Пусть для формирования тематического массива обслуживающего АИЦ по некоторому профилю То требуется получение четырех массивов, идентифицируемых классификационными индексами рубрикатора АИЦ-генератора ТГь Тгг, Тгь ТТп (см. рис. 11.1). Необходимость выборки некоторого подмножества записей, соответствующих тематическому профилю То, потребует проведения в
223
АИЦ-генераторах информационно-поисковых операций в массивах указанных рубрик. Если этого не делать, то обслуживающий АИЦ, очевидно, получает много «шумовых» фрагментов информационных массивов, что приведет к лишним затратам на их приобретение и конвертирование, помимо собственно информационного поиска с целью их удаления. Для некоторых предметных областей удается найти удовлетворительное однозначное соответствие рубрик, используемых в АИЦ-генераторе и обслуживающем АИЦ. Тогда тематический попск сводится к отбору подмассивов, соответствующих определенному набору рубрик АИЦ-генератора. В общем же случае переформирование массивов при обмене придется вести с использованием поискового аппарата такого же уровня, как и при информационном обслуживании отдельного пользователя (ключевые слова, дескрипторы, элементы свободного текста). Приведенный пример показывает, что различие классификаторов и рубрикаторов, определяющих предметные области в центрах сети, вызывает значительные трудности в организации распространения массивов. Обмен между центрами происходит фактически не на уровне сформированных по тематике массивов, а на уровне отдельных документов, отбираемых из массивов по некоторым критериям преобразования предметных областей.
Наличие в разных центрах информационной сети различных систем классификации предметных областей усложняет слежение за территориальным распределением тематических массивов, сбор статистики по информационной нагрузке на тематические разделы, обнаружение неиспользуемых и дублируемых фрагментов тематических разделов и т. п. Для преодоления отмеченных недостатков целесообразно выбрать некоторый единый способ деления предметных областей, который послужил бы основой для решения различных задач ипформациопной сети. В Государственной системе научной и технической информации для этой цели разработан и принят рубрикатор ГАСНТИ, как основной классификационный язык в комплексе лингвистического обеспечения этой системы [16].
При разработке рубрикатора ГАСНТИ учитывалось, что общепринятой классификации наук и отраслей знаний пока еще не создано. Из всех ранее разработанных классификационных языков наиболее универсальным является УДК. Оставляя в стороне конкретные неудобства УДК для применения в информационных системах, отметпм только тот факт, что ВИНИТИ, ВНТИЦентр, НПО «Поиск», ВНИИКИ и другие всесоюзные центры НТИ для тематического разделения массивов использовали не УДК, а другие классификации. Отметим, что разработка специальных классификаций для больших информационных систем и сетей является общепринятой мировой и отечественной практикой [67].
224
Рубрикатор ГАСНТИ представляет собой классификационную схему с универсальным тематическим охватом, имеющую не более трех уровней иерархии и предполагающую полииерархические связи между рубриками. Для выполнения конкретных практических задач в процессе информационного обмена структура и наполнение рубрикатора ГАСНТИ должны быть предметом соглашения между органами НТИ. Функции рубрикатора ГАСНТИ описаны в [19]. Выделим среди них следующие:
— определение тематического охвата органов НТИ, соответствующего функциям этих органов в ГАСНТИ;
— систематизация информационных массивов в органах НТИ и информационных изданий органов НТИ;
— нормативная функция для рубрикаторов органов НТИ.
Рубрикатор ГАСНТИ построен таким образом, что каждый из трех иерархических уровней может содержать не более 100 рубрик. Часть рубрик являются резервными. Например, на первом уровне вне иерархии реальное число действующих рубрик 66. В рубрикаторе используется довольно простая система кодирования рубрик. Для кодирования рубрик каждого уровня используется двухразрядпое число. Таким образом, рубрики третьего уровня кодируются всегда шестиразрядным числом.
Проблема совместимости рубрикатора ГАСНТИ с рубрикаторами и классификаторами международных, отраслевых и региональных уровней решается по-разному. Так, на двух верхних уровнях иерархии рубрикатор ГАСНТИ рассматривается как национальная версия рубрикатора Международной системы научной и технической информации (МСНТИ), используемого в странах-членах СЭВ, а взаимодействие с международной классификацией изобретений (МКИ) обеспечивается двумя методами: совместным использованием МКП и рубрикатора ГАСНТИ в массивах патентной информации и разработкой таблиц соответствия. Совместимость рубрикатора ГАСНТИ с рубрикаторами и классификациями отраслевых и региональных органов НТИ обеспечивается привязкой рубрикаторов этих органов к рубрикатору ГАСНТИ. Дальнейшее иерархическое деление рубрик ниже третьего уровня может происходить на базе собственных рубрикаторов органов НТИ. Однако три верхних уровня этих рубрикаторов должны совпадать с соответствующими тематическими профилями рубрикатора ГАСНТИ.
11.3. Оценка соответствия системы тематических баз данных интересам пользователей
Какой бы совершенный рубрикатор не использовался для тематического разделения баз данных в информационной сети, принципиально невозможно удовлетворить все потребности каждого
15 Г. Г. Белоногов, В. А Кузнецов
225
пользователя единственной для нею базой данных. Можно лпшь говорить о таком разделении тематических профилей, чтобы пользователи возможно чаще удовлетворялись обращением в одну или по крайней мере ограниченное число баз данных. Этот тезис подтверждается, в частности, тем фактом, что в современных ИПС запросы к базам данных формируются, как правило, на уровне сочетаний терминов (булевых комбинаций дискрипторов, ключевых слов, элементов текста и т. п.), а словари терминов, соответствующих различным тематическим базам данных, пересекаются. Поэтому всегда есть определенная вероятность того, что пользователь обратится за поиском документов, содержащих термины или их сочетания, общие для нескольких баз данных.
При обращении в информационную сеть основную часть документов потребитель получает в профильной базе данных (по профильной тематической рубрике). По мере обращения в другие базы данных полнота ответа будет увеличиваться, пока не достигнет максимума. Запрос, поступивший в информационную сеть, в каждом конкрётпом случае потребует для обслуживания индивидуального подмножества баз данных. Очевидно, что степень соответствия некоторой тематической базы данных интересам пользователей определяется тем, с какой полнотой она может обслужить «профильные» запросы без обращения к другим базам данных. Сложность проблемы определения качества тематической базы данных заключается в том, что из всего множества запросов, поступивших в информационную сеть, нужно выбрать только те, которые в наибольшей степени ориентированы на нее.
Рассмотрим один из возможных путей оценки качества системы тематических баз данных на основе статистического анализа ответов на запросы в процессе сетевого обслуживания потребителей [45].
Пусть в информационную сеть поступает от пользователей поток запросов {(?,} ( t = 1, 2, ..., т) и пусть в информационной сети имеется множество баз данных, идентифицированных тематическими рубриками {Tj} (/— 1, 2, ..., п). Теоретически полнота ответа будет исчерпывающей, если каждый запрос направляется во все без исключения базы данных. Но практически целесообразно обращаться только в те базы данных, где вероятность получения хотя бы одного релевантного документа достаточно высока. В результате основную часть документов пользователь получит в профильной базе данных. Как уже указывалось, по мере обращений в другие необходимые базы данных полнота ответа будет увеличиваться, пока не достигнет максимума.
Пусть ац — число документов, выданных па запрос Qi по рубрике Л i —число документов, выданных на запрос Oi по всем п рубрикам. Нормализованная полнота ответа на запрос по 226
рубрике Ti будет равна
П| = Оу/Л{. (11.1)
Для запроса Qi профильной из всех тематических баз данных объявляется та, которая обеспечивает наибольшее количество документов в выдаче — шах (П?) .
Очевидно, что не все запросы, поступившие в некоторую базу данных, вызывают максимальную выдачу. Обозначим через Л/jmax множество запросов к рубрике Tj, для которых обеспечивается шах(Ш,). Тогда усредненная полнота обслуживания профильных запросов некоторой рубрики вычисляется следующим образом:
П;пр= 2 m4nDMrnaxb ^jmax
где — число элементов множества MJmax.
Теперь рассмотрим, как будет возрастать полнота выдачи ответа при обращении пользователя не только в профильную, но и ассоциированные с ней по тематике периферийные базы данных. Пусть имеются некоторые произвольные рубрики Тj и Ткоторые для некоторой группы запросов определены, соответственно, как профильная и периферийная рубрики. Обращепие профильных запросов только в базу данных с тематикой Tj обеспечит усредненную полноту обслуживания П;Пр. Если эта группа запросов будет отправлена еще в базу данных с тематикой то пользователь получит некоторое добавочное количество документов, определяемое усредненным значением дополнения по полноте обслуживания П;й. Дополнительная выдача связана со значениями на Множестве Jfjmax (/ =/= к)'-
Пй= 2 П1/1М;тах|- М
Меняя значения / и к, легко получить усредненное дополнение по полноте обслуживанпя для любого сочетания тематических баз данных.
Метод получения усредненных значений полноты обслуживания профильных запросов и дополнений по полноте иллюстрируется табл. 11.1 и 11.2. В табл. 11.1 каждый запрос Qi сопровождается двумя строками. Верхняя строка отражает распределение чпсла выданных документов ац в каждой из шести тематических баз данных (в конце нее справа приведено суммарное значение числа документов, выданных из всех баз данных). В нижней строке приведены значения нормализованной полноты ответа TIJ по всем базам данных. Выделенные значения соответствуют тах(П’). В самой нижней строке табл. 11.1 приведены значения П;пр.
15* 227
Таблица 11.1
Оценка профильности баз данных
Т, т» т» т4 т,
8 0 4 1 1 0 Аг-= 14
0,57 0 0,29 0.07 0,07 0 1
0 4 0 2 4 1 Д2= 11
Qi 0 0,36 0 0.19 0,36 0.09 1
1 1 1 4 0 0 А3= 7
Qi 0,15 0,14 0,14 0,57 0 0 1
Оа 1 1 0 0 1 5 8
¥4 0,13 0,12 0 0 0.12 0,63 1
Л. 0 2 0 2 3 0 Л- 7
х 6 0 0,29 0 0,28 0,43 0 1
5 1 7 0 0 0 13
Об 0,39 0,07 0,54 0 0 0 1
0 0 1 0 2 6 Л7= 9
с, 0 0 0,11 0 0,22 0,67 1
5 0 2 0 0 1 л8= 8
Q, 0,63 0 0,25 0 0 0,12 1
0 6 0 1 3 0 10
Qi 0 0,60 0 0,10 0,30 0 1
1 0 0 3 0 0 Ю~**
Ою 0,25 0 0 0,75. 0 0 1
0,60 0,48 0,54 0,66 0,43 0,65
В табл. 11.2 приведена матрица значений IIjA по шести базам данных рассмотренного примера. Значения П;пр — располагаются по диагонали матрицы. Из полученной матрицы следует, что базы данных, идентифицированные индексами и обеспечивают хорошее взаимное дополнение полноты обслуживания запросов. Обращение с профильными запросами в базы данных Тх и Ti обеспечивает соответственно полноту 0,60 и 0,54. Если пользо
223
ватель будет обращаться совместно в эти базы данных, то полнота обслуживания запросов, профильных для базы данных Т\ составит 0,87, а профильных для базы данных Т3 — 0,93. Аналогично просматривается выгодность совместного обращения пользователя в базы данных Т2 и Г5. Следует отметить, что чпсло обработанных запросов в приведенном примере явно недостаточно, чтобы гово-
Таблица 11.2
Матрица полноты информационного обслуживания
л Т, Тл Т4 т» Ti
л 0,60 0 0,27 0,04 0,03 0,06
Тг 0 0,48 0 0,15 0,33 0,04
Тз 0,39 0,07 0,54 0 0 0
0,20 0,07 0,07 0,66 0 0
Тз 0 0,29 0 0,28 0,43 0
Т, 0,07 0,06 0,05 0 0,17 0,65
рить о статистически устойчивых значениях. Поэтому к приведенным цифрам следует относиться только как к иллюстрации предлагаемых методов оценки характеристик тематических баз данных, функционирующих в условиях информационной сети. Значение П)пр для некоторой тематической базы данных определяет ее избирательность по отношению к поступающим запросам.
В процессе анализа полноты обслуживания запросов выявлялся и механизм определения степени профильности тематических баз данных и расслоения запросов на профильные группы. Обратим внимание, что в результате проведенного рассмотрения не возникло прямой необходимости делить пользователей на тематически ориентированные группы. Оказалось, что с точки зрения тематической избирательности баз данных не важно, принадлежат ли профильные запросы узкой ассоциации пользователей или ярко выраженная ориентация пользователей на базы данных отсутствует. В результате анализа можно сделать также вывод, что изменения интересов пользователей не так существенны, как изменения характера собственно запросов и применяемого для поиска информационно-поискового языка. Смена интересов пользователя или появление у него запросов, отклоняющихся от направления устойчивых интересов, не обязательно должны приводить к необходимости изменения структуры баз данных. При наличии в информационной сети политематического набора баз данных в такой ситу-
229
ации должно произойти просто изменение адресации Запросов нового профиля в другие тематические области.
Оппсаппый выше метод оценки баз данных дает возможность получить количественные характеристики полноты информационного обслуживания профильных запросов как средствами одной, так и нескольких баз данных. Такие характеристики позволяют судить о качестве разделения тематических областей. При этом принципы классификационного деления на тематические области не имеют значения. В набор баз данных могут быть включены также и комплексные базы данных, ориентированные на определенные проблемы. Значение полноты обслуживания профильных запросов для таких баз данных должно- быть выше, чем для тематических. Описанным выше способом можно оценивать любой набор баз данных, используемый в информационной сети, независимо от того, покрывается ли этим набором вся тематика полностью или только ее часть. Можно поэтому получать количественные оценки качества не только политематической системы баз данных, но и по отдельной предметной области, например, по отраслевой сети с узкотематическими базами данных.
Описанный нами метод вычисления характеристик полноты обслуживания профильных запросов связан с необходимостью обработки достаточно большого потока реальных запросов, поступающих в информационную сеть. Это непростая задача, так как каждый запрос должен быть адресован во все базы данных, где есть вероятность получения ненулевого ответа («релевантные» базы данных). Сам по себе выбор таких баз данных представляет серьезную проблему (некоторые пути ее решения будут обсуждены в следующей главе). Получение значений П! по каждому запросу потребует проведения серьезного специального эксперимента с прогоном тестового набора запросов по всем «релевантным» базам данных.
Заманчиво получить эти данные в процессе реального обслуживания пользователей в мультибазовом режиме поиска. Реальность такой перспективы сильно зависит от того, в какой степени запросы пользователя будут отсылаться во все «релевантные» базы данных. При этом исчерпывающая полнота их охвата — необязательное условие проведения всякого поиска. Длительное время поиска, высокая стоимость, большой объем выдачи, отсутствие со стороны пользователя требования полноты ответа — все это может быть причиной прекращения реального поиска до того, как будут получены ответы из всех «релевантных» баз данных.
Рассмотрим альтернативный подход к определению полноты обслуживания профильных запросов, который позволяет воспользоваться характеристиками баз данных, не прибегая к массивам запросов. Этот подход основан па допущении, что все запросы, по-230
ступающие в информационную сеть, состоят из одного термина. Такие запросы встречаются на практике, особенно, когда используются редко встречающиеся специфические для предметной области термины. Сделанное допущение позволяет значительно упростить процедуру вычисления средней полноты обслуживания профильных запросов. Дело в том, что, как показывает анализ работы диалоговых ИПС, имеется определенная связь между статистическими характеристиками встречаемости терминов в базе данных и выдачей документов на запрос, и статистика числа документов, включающих какой-либо термин в базах данных, полностью соответствует реальному распределению объемов выдач на запрос, состоящий из этого единственного термина. Если в качестве набора запросов {(?»} использовать словарь терминов, охватывающих все базы данных, то очевидно, никаких специальных запросов для анализа баз данных строить не нужно. Реальные запросы, конечно, состоят не только из отдельных терминов. Они, как правило, содержат их дизъюнктивные и конъюнктивные сочетания. Но принятое допущение вряд ли существенно повлияет на точность оценки полноты обслуживания профильных запросов, если такая оценка базируется на обработке большого числа запросов.
Дизъюнктивное сочетание терминов практически можно рассматривать как набор независимых подзапросов, состоящих из одного термина. Сумма распределений по базам данных выдач документов по каждому термину даст в первом приближении общий результат ответа на запрос в целом. Что же касается сочетаний терминов, связанных операторами «И», то здесь следует обратить внимание на общую тенденцию, обнаруженную во время эксплуатации диалоговых ИПС: чем больше в базе данных количество документов, содержащих отдельные термины запросов, тем больше выдача документов на запрос в целом. Это обстоятельство используется для управления стратегией диалогового поиска. Высказанное соображение относительно сопоставимости результатов, полученных на основании обработки реальных запросов и терминов словаря, подтверждаются выборочной проверкой выдач на реальные запросы и термины словаря, используемые в качестве запросов.
Проведенный выше анализ был бы неполным, если бы мы не остановились на ситуациях, требующих модификации полученных оценок полноты обслуживания запросов. Ведь до сих пор базы данных рассматривались нами только с точки зрения их принадлежности к некоторой тематике Т j. Объемы баз данных не нормализовались, так как на практике при совместном обслуживании потребителя могут участвовать базы данных с сильно отличающимися объемами, а нормализованная полпота ответа вычисляется для конкретного набора баз данных по формуле 11.1 независимо от распределения объемов. Однако, есть ситуации, когда
231
пересчет полученных значений П* необходим. Действительно, включение в информационную сеть новой тематической базы данных, скажем, Тh потребует пересчета значений Л, по крайней мере для тех запросов, которые входят в эту тематику. Соответственно пересчитываются значения П£ для тематического профиля Tk и значения nj для всех остальных п тематических профилей.
Иногда возникают ситуации, когда требуется дополнительная корректировка значений . Еслп, например, для получения соответствующих характеристик полноты обслуживания поток запросов {(?<} посылается в некоторый тестовый набор баз данных с ограниченной хронологической глубиной А^т, а результаты оценок предполагается использовать при работе с базами данных с другой, эксплуатационной хронологической глубиной то
требуется корректировка вычислений. При этом необходимо вначале привести значения к форме, нормализованной относительно хронологической глубины
а затем учесть изменение хронологической глубины для эксплуатационного режима
Af?
= (И.5)
Соответственно, для эксплуатационного режима
^ = 2 4 (и.б)
j=i
Дальнейшие вычисления выполняются на основе скорректированных значений по формулам (11.2) и (11.3).
11.4. Использование характеристик профильности тематики баз данных для оптимизации предоставления их в режим доступа пользователям
Приведенный в табл. 11.2 пример матрицы полноты информационного обслуживания дает некоторое представление о рациональных путях взаимодействия пользователей с системой тематических баз данныхгТак, рассмотрение одних только диагональных элементов этой матрицы позволяет судить о степени избирательности тех илй иных тематических профилей. Вместо интуитивных представлений об ожидаемой полноте ответа в базе данных пользователь здесь уже имеет некоторые количественные оценки, опирающиеся на опыт предыдущих поисков. Когда общее число рас
232
сМатриваемых баз данных Невелико, он может даже определит!» пути увеличения полноты, оценивая соответствующие значение П;А. К сожалению, обозримые матрицы ЦП, л II с небольшим числом элементов на практике не слишком ценны, так как в этом случае дпагональные элементы, как правило, имеют высокие значения и особого выигрыша от взаимодействия со многими тематическими разделами получить пе удается. В предельном случае, когда все тематические базы данных слиты в одну, матрица имеет всего один элемент, равный единице.
Распределение тематических разделов по первому уровню иерархии рубрикатора ГАСНТИ дает 66 элементов. Предварительная ориентировочная оценка показала, что диагональные элементы матрицы, построенной для таких крупных баз данных будут иметь довольно высокие значения: 0,8—0,95. Koi да значения диагональных элементов матрицы близки к единице, это означает/ что основная масса запросов практически может быть обслужена в единственной базе данных. Все остальные элементы матрицы ||ПЛ|| (/#= ^) имеют незначительный вес и их учет имеет смысл только в случае очень высоких требований к полноте (например, при экспертизе на патентную чистоту).
Переход к построению баз данных по рубрикам 2-го и 3-го иерархических уровней рубрикатора ГАСНТИ должен привести к снижению значений П;; и увеличению числа элементов матрицы, В целом рубрикатор ГАСНТИ содержит около 700 рубрик 2-го уровня и более 5000 рубрик 3-го уровня. В настоящее время еще нет четкого представления о том, какой стратегии следует придерживаться при организации обслуживания в политематическом множестве баз данных. Что лучше — иметь мною мелких или мало крупных баз данных?
Стремление к более дробному тематическому делению баз данных диктуется желанием ограничить объемы массивов, реально представляемых пользователю для информационного поиска по запросу. Это один из путей удешевления стоимости поиска и повышения эффективности использования баз данных. Но, очевидно, на каком-то иерархическом уровне тематического деления баз данных дальнейшее дробление становится малоэффективным для информационной сети, так как пользователь вынужден будет обращаться ко все большему числу баз данных, чтобы обеспечить определенную степень полноты ответа. Ситуация иллюстрируется рис. 11.2. Здесь зависимость Гг(А) отражает уменьшение среднего объема одной базы данных при увеличении числа тематических рубрик N. Если тематического разделения массива нет (N « 1), то его объем равен Тбдтах- Зависимость KQ (N) отражает рост среднего числа баз данных, в которые адресуется запрос Q при увеличении ?7. Когда N = 1, Kq(N)=1. Vq(N) отражает зависимость
233
среднего объема информационного массива, предоставляемого пользователю на один запрос. При некоторых значениях N дальнейшее дробление баз данных уже не имеет смысла, т. к. уменьшение Гг сопровождается существенным ростом числа совместно используемых баз данных. Возрастает сложность управления большим набором баз данных п затрудняется взаимодействие с ними пользователей, а реально предоставляемый на запрос объем массивов снижается мало.
При организации процесса эксплуатации баз данных необходимо учитывать еще один важный фактор, который существенно влияет на полноту предоставления данных пользователем. Речь идет об ограничениях внешней памяти прямого доступа. Обычно для хранения баз данных в ИПС используются накопители на магнитных дисках. Если общий объем памяти Va обслуживающих центров достаточен для одновременного размещения общего объема баз данных Рбд max,
имеющихся в распоряжении информационной сети, то проблема обеспечения полноты предоставления информации пользователю относительно проста. Здесь можно говорить о сложностях взаимодействия, неоптимальностп информационных потоков и т. п., но решающее значение имеет тот факт, что все информационные ресурсы доступны одновременно. На практике, однако, часто можно встретиться с ограничениями внешней памяти. В этом случае базы данных обычно предоставляются поочередно с соблюдением некоторого расписания их ввода в сервис. Очевидно, что если в одновременном доступе находится только часть общего фонда баз данных, то во время сеанса связи все пользователи уже принципиально не могут быть обеспечены на 100% всеми нужными им массивами. Возникает проблема выбора баз данных для одновременной нагрузки. На практике используются различные критерии такого выбора, зависящие от условий эксплуатации баз данных. Мы рассмотрим эту проблему с точки зрения повышения полноты предоставления информационных ресурсов пользователям.
Пусть в информационной сети имеется п баз данных с разными тематическими профилями, а объем внешней памяти с прямым доступом позволяет разместить одновременно только т баз данных. Без существенного ограничения общности задачи можно 234
считать, что т кратно н, т. е. п — к • т, где к — целое число. Информационные ресурсы могут предоставляться в режим обслуживания наборами по т баз данных, поэтому полный цикл предоставления всех п баз данных в режихМ обслуживания требует к наборов, причем предполагается, что каждый из них содержит подмножество баз данных, не повторяющихся в других наборах. Каждый набор по т баз данных вводится в режим обслуживания синхронно в течение определенного времени, отведенного для проведения информационного поиска.
Формально задача ставится следующим образом. Из множества индексов 1— {1, 2, ..., п} необходимо выделить к непересе-кающихся подмножеств 1Г — р’ц • • •, г’™} по т элементов в каждом так, чтобы средняя полнота
ncp=|2 2nij (11.7)
г-1
была максимальной. Здесь Пгj — значения полноты обслуживания матрицы Hllijll (г, j — 1, 2, ..., тг). Задача может быть сведена к задаче целочисленного программирования с числом переменных ~ /г2, а ограничений ~п3, которая даже при сравнительно небольшом числе баз данных в несколько десятков не может быть точно решена из-за чрезмерно большого объема вычислений. Реальное число баз данных, для которых требуется решать такую задачу, может колебаться от нескольких сотен до тысячи. Поэтому следует отказаться от методов целочисленного линейного программирования и искать другой путь решения.
Для решения задачи предлагается алгоритм, основанный на методах автоматической классификации [42] *). За меру близости между элементами Г,- и Т, (базами данных с тематическими рубриками Ti и Tj) принимается
Р(Л.^) = Пу + Пя. (11.8)
Очевидно, что такая мера близости вполне отвечает целям группирования рубрик. Для решения задачи необходимо также определять близость между классами из многих элементов. Мера близости между классом А и классом В, содержащими соответственно Nл и Nb элементов, определяется как
! Nb
Р<Л’В)= 2^’^ (Т^А,Т^В). (11.9)
г—1 1
Формирование классов происходит следующим образом. Из элементов выбираются два самых близких и объединяются в один
*) Разработка алгоритма и решение задачи выполнялись совместно с В. К. Кричевскпм,
235
класс. Число классов становится п — 1. Среди п — 1 классов опять ищутся два самых близких. Классы сравниваются на близость только в том случае, если сумма числа элементов в них не достигает т. Процесс продолжается до тех пор, пока никакие два класса нельзя будет объединить, не нарушив этого ограничения. В результате образуется некоторое число классов. Если ki > А*, то применяется процедура переформирования классов. При этом сначала выбираются к классов с наибольшими значениями суммарной полноты. Остальные — к классов расщепляются на единичные элементы, которые затем присоединяются к «ядерным» к классам по методу, аналогичному первой части алгоритма^ но с измененной -мерой близости между элементом и классом А
Р(Гр (И.Ю)
j=i
В этом случае в выражении для меры близости взвешивающий коэффициент 1/Na уже не требуется. В результате работы алгоритма получается к классов по т элементов.
Рассмотренный алгоритм, как и многие другие алгоритмы классификации, не дает возможности вычислить абсолютный максимум суммарной полноты, но обеспечивает удовлетворительное для практических целей решение. Алгоритм запрограммирован на языке PL/1 и проверялся на ЭВМ па ряде тестовых примеров с ограниченным числом элементов и заранее известным решением, полученным точными методами. При этом значение суммарной полноты оценивалось по всем образованным классам ио формуле (11.7). Решение, полученное по приведенному выше алгоритму было хуже абсолютного не более чем на 3—5%.
Следует отметить, что при нарушении условия кратности п = к • т работа алгоритма не усложняется. В этом случае строятся классы, которые частично отличаются друг от друга по числу элементов на единицу. На решение задачи не влияет также условие распределения баз данных по разным центрам. Необходимо только, чтобы базы данных, попавшие в один класс, одновременно вводились в синхронное расписание, но не имеет значения, в каких именно центрах.
ГЛАВА 12
ВЗАИМОДЕЙСТВИЕ ПОЛЬЗОВАТЕЛЯ С ИНФОРМАЦИОННОЙ СЕТЬЮ
12.1. Телекоммуникации в информационной сети
Генерация информационных массивов, их распространение и создание в обслуживающих АИЦ баз данных являются, по существу, подготовительными операциями для обеспечения доступа пользователей к информационным ресурсам. Основная цель этих операций — удовлетворение информационных потребностей ученых и специалистов. В современных информационных сетях все большее распространение получает непосредственное взаимодействие пользователей с базами данных в реяшме локального и удаленного доступа с терминальных абонентских пунктов. Такой режим создает комфортные условия работы пользователю, который, находясь на значительном удалении от ИПС, имеет возможность проводить поисковые операции с такой же оперативностью и эффективностью, как если бы оп находплся в непосредственной близости от вычислительной машины. Если в информационной сети базы данных территориально рассредоточены по нескольким обслуживающим АИЦ, то удаленный пользователь сети имеет даже преимущество перед локальными пользователями организации, где функционирует только одна информационно-поисковая система, так как при этом локальный пользователь имеет доступ к ограниченным ресурсам. Схема, отражающая в обобщенном виде взаимодействие пользователей с базами данных информационной сетп, показана на рис. 10.1.
Информационная сеть условпо может быть разделена на три самостоятельные функциональные группы:
1) информационные машины, поддерживающие базы данных и обеспечивающие решение информационных задач;
2) система передачи данных, обеспечивающая оперативную связь информационных машин с удаленными абонентами;
3) терминальная сеть абонентских пунктов пользователей.
Информационная машина представляет собой однопроцессор
237
ный или многопроцессорный вычислительный комплекс, включающий в свой состав ЭВМ универсального назначения с конфигурацией, ориентированной на выполнение информационно-поисковых операций в больших базах данных. Информационные машины располагаются в обслуживающих АИЦ. Отличительной особенностью информационной машины является развитая система аппаратных и программных средств телеобработки и наличие большого числа накопителей на магнитных дисках значительной емкости. Связь пользователя с базами данных, проведение поиска, обработка п выдача результатов выполняются в информационной машине с помощью диалоговой ИПС с развитыми языковыми средствами, программным обеспечением, поддерживающим одновременный интерактивный режим работы многих удаленных и местных пользователей (местным считается такой пользователь, который взаимодействует с ИПС с локально подключенного к ЭВМ терминала).
Информационные машины представляют собой ядро информационной сети, в котором сосредоточены информационные ресурсы. Система передачи данных и терминальная сеть абонентских пунктов обеспечивают пользователю оперативность получения информации. Следует отметить, что информационные машины могут также решать задачи, не требующие интерактивного взаимодействия: автономную пакетную обработку запросов к ретроспективным базам данных и поиск релевантных записей по постоянно действующим запросам к текущим поступлениям в базы данных (для системы избирательного распространения информации). Эти дополнительные задачи могут решаться в качестве «фоновых» для основного режима — удаленного диалога, пользующегося наивысшим приоритетом.
Система передачи данных представляет собой оперативную коммуникационную среду, через которую пользователь связывается с нужной информационной машиной и ведет с ней обмен сообщениями. Система передачи данных базируется на каналах связи, средствах коммутации и аппаратуре передачи данных. Для передачи данных могут быть использованы различные каналы связи. Прежде всего это традиционные сети связи, предназначенные для передачи телефонных и телеграфных сообщений между абонентами: сеть абонентского телеграфирования со скоростью 50 бод (сеть АТ-50) и телефонная сеть общего пользования (сеть ТФ-ОП). В системе передачи данных можно использовать также телеграфную сеть с коммутацией каналов, предназначенную для передачи данных со скоростью 200 бод (сеть ПД-200). Кроме того, могут быть использованы выделенные некоммутируемые каналы связи — обычные телефонные и широкополосные, а также неуплотненные физические линии.
238
Выбор тех или иных средств связи определяется па основе оценки следующих характеристик: территориальная разветвленность информационной сети, степень охвата предприятии и организаций — потенциальных пользователей НТИ, номерная емкость сети связи, диапазон скоростей передачи данных, допустимое время занятия линии, время установления соединения, надежность, помехозащищенность, простота сопряжения со стандартной телекоммуникационной аппаратурой, стоимость передачи данных.
Использование выделенных некоммутпруемых каналов связи обеспечивает малое время установления соединения, неограниченное время занятия линии, высокую надежность и помехоустойчивость. Пользователь находится в наиболее комфортном режиме взаимодействия с ИПС. Однако выделенные каналы связи — наиболее дорогостоящее средство, которое можно использовать только в ограниченных масштабах для небольших расстояний между пользователями и обслуживающими АИЦ.
Наиболее разветвленной сетью связи является ТФ-ОП. В любом ведомстве, научно-исследовательском или проектном институте, предприятии и т. п. имеется достаточное количество номеров телефонной сети, которые можно использовать для подсоединения терминала или вычислительной машины. Возможности коммутируемой телефонной сети общего пользования неоднократно проверялись при работе различных диалоговых ИПС. Каналы связи, образованные при каждом конкретном соединении, не всегда отвечают требованиям надежности и помехоустойчивости. При использовании помехозащищеппых процедур обмена (с защитой передаваемых блоков кодами циклического контроля, переспросами) можно устойчиво работать по ТФ-ОП со скоростями до 1200 бод. На низких скоростях (200 — 300 бод) обеспечивается работа с низким уровнем ошибок и использованием простых процедур обмена по каналам связи. Важной особенностью сети ТФ-ОП является то, что в настоящее время имеется достаточно широкий спектр терминальной аппаратуры, сопрягаемой с телефонными каналами.
Телеграфная сеть АТ-50 уступает телефонной сети ТФ-ОП по разветвленности и позволяет работать на существенно более низких скоростях, но многие учреждения уже имеют телеграфные аппараты, которые могут выполнять роль простых и дешевых терминальных средств.
Телеграфная сеть ПД-200 обладает более высокой помехоустойчивостью по сравнению с сетями АТ-50 и ТФ-ОП (в случае работы последних без помехозащищенных процедур обмена информацией), а по скорости передачи данных занимает среднее положение между ними. Телекоммуникационная аппаратура для ПД-200 более специфична и менее распространена.
239
Терминальная абонентская сеть представляет собой совокупность размещенных у пользователей абонентских пунктов (телетайпов, дисплеев с клавиатурами и других терминальных станций). Абонентские пункты сильно различаются по своим функциональным возможностям и стоимости. Наиболее сложная терминальная станция, по существу, представляет собой микро- или миниЭВМ с внешним накопителем на гибком диске и на магнитной ленте, печатающим устройством и набором дисплеев для одновременной работы многих пользователей. Наиболее простой абонентский пункт представляет собой одиночный низкоскоростной терминал телетайпного типа.
Разнообразие видов терминальной аппаратуры, способов ее соединения с каналами связи, процедур информационного обмена, методов поддержки удаленных абонентских пунктов телекоммуникационными средствами информационных машин — все это создает известные трудности обеспечения аппаратной и программной совместимости терминалов с информационными машинами. Стратегия построения абонентской терминальной сети должна быть такой, чтобы пользователь, имеющий один из допустимых в информационной сети типов абонентских пунктов мог иметь теледоступ по крайней мере в те информационные машины, которые поддерживают необходимые ему базы данных. Ситуации, когда для достижения аппаратно-программной совместимости с различными звеньями информационной сети пользователь вынужден использовать разные типы терминалов, крайне нежелательны. Чтобы избежать таких ситуаций телекоммуникационные аппаратные и программные средства информационных машин должны ориентироваться на обслуживание основных типов терминалов, функционирующих в абонентской сети пользователей.
Наличие в информационной сети телекоммуникационных средств дает возможность решать многие задачи в оперативном режиме. Сюда относятся ввод, корректировка и удаление записей в базах данных, сбор заказов на пакетную обработку предварительно заготовленных наборов запросов, передача найденных релевантных записей пользователям, отправление заданий на изготовление копий первоисточников, отраженных в базах данных, пересылка массивов выбранных записей для обработки специализированными программами (вывод из ЭВМ и оформление в виде полиграфического издания, преобразование записей в табличную форму, построение графиков и т. п.), транспортировка баз данных или их фрагментов из АИЦ-генератора в обслуживающие АИЦ (при повышении пропускной способности системы передачи данных и снижении стоимости пересылки информации).
Однако наиболее актуальной и важной задачей в информационной сети является удаленный поиск в базах данных в ре-
240
яшме диалога. Языковые и программные средства ведения диалога между пользователем и информационно-поисковой системой существенно повышают пе только оперативность проведения поиска, но и его качество. При равноценных информационно-поисковых языках возможность непрерывной корректировки формулировки запроса в зависимости от результатов поиска значительно повышает вероятность получения удовлетворительного ответа по сравнению с однократным автономным поиском без обратной связи с пользователем.
Выделенные телефонные и телеграфные каналы, а также сети коммутации каналов могут обеспечить различные виды передачи данных в информационной сети, в том числе и на значительные расстояния. Как уже указывалось, те или иные средства связи обеспечивают, как правило, достижение высоких значений одной или нескольких из многих характеристик: помехоустойчивости, быстроты соединения, территориальной разветвленности абонентских точек, допустимой длительности непрерывной связи, скорости передачи данных, экономической эффективности использования каналов связи и т. д. Однако высокие значения многих характеристик одновременно эти средства обеспечить не могут. Особенно большие трудности возникают при оценке наиболее важного для информационной сети режиме диалога. Дело в том, что диалог ведет к крайне неэффективному использованию канала связи, если он «жестко» закреплен за пользователем на время всего сеанса взаимодействия с информационно-поисковой системой, так как обычно информация по каналу связи в режиме диалогового поиска передается относительно короткими порциями со значительными временными интервалами между сообщениями. В наибольшей степени условиям диалогового интерактивного взаимодействия соответствуют сети коммутации пакетов.
По эффективности использования средства связи можно ранжировать следующим образом. Наиболее дороги выделенные каналы связи, так как оплачивается все время аренды канала (например, 24 часа в сутки), а реально используются только те отрезки времени, когда в сервисе находятся нужные для пользователя базы данных информационной машины, с которой связан абонент. Средства связи сетей с коммутацией каналов оплачиваются из расчета полного времени соединения абонента с информационной машиной во время сеанса связи, но в течение значительного времени по скоммутированному каналу никакого обмена информацией не происходит. В сетях коммутации пакетов связь между узлами системы передачи данных, терминалами и информационными машинами устанавливается на отрезки времени, когда необходим реальный обмен информацией. Канал связи сразу же освобождается после обмена информацией и может
16 Г. Г. Белоногов, Б А. Кузнецов
241
быть использован для передачи данных между другими элементами сети коммутации пакетов. В сетях коммутации пакетов созданы условия для построения стоимостной стратегии оплаты по реально переданному объему информации между абонентами.
12.2. Сети коммутации пакетов — перспективная коммуникационная среда информационных сетей
Современные наиболее развитые и разветвленные информационные сети создаются на базе аппаратных и программных средств коммуникационных сетей коммутации пакетов, к которым подсоединяются терминалы пользователей и информационные машины, где хранятся базы данных и проводится поиск релевантных записей. Средства коммуникационной сети коммутации пакетов достаточно универсальны, чтобы обеспечить любые виды взаимодействия (терминал — терминал, терминал — информационная машина, информационная • машина — информационная машина), однако в информационной сети преимущественный тип взаимодействия терминал — информационная машина.
Использование сети коммутации пакетов при построении информационной сети покажем на примере EURONET DIANE (информационной сети прямого доступа Европейского экономического сообщества) [86, 92]. Ее функционирование началось в феврале 1980 г. Схема этой сети показана на рис. 12.1. Основу информационной сети составляет сеть коммутации пакетов, которая включает 5 узлов пакетной коммутации и 5 концентраторов, свя-ганных между собой высокоскоростными магистральными каналами связи с пропускной способностью 48 кбод. Узлы пакетной коммутации служат для маршрутизации и управления транзитной передачей информационных пакетов между любыми узлами, а также концентраторами, входящими в коммуникационную сеть. Кроме того, узлы пакетной коммутации EURONET DIANE обеспечивают подсоединение информационных машин и терминалов и поддержку в них процедур информационного обмена с сетью. Концентраторы служат, главным образом, для подсоединения информационных машин и терминалов. Территориально концентраторы устанавливаются в местах сосредоточения пользователей и информационных ресурсов.
EURONET DIANE — развивающая сеть, в которой число информационных машин и терминалов постоянно растет. На 1980 г. было подключено к разным узлам и концентраторам 25 информационных машин, которые обслуживают 192 документальные и фактографические базы данных. Территориальное распределение информационных машин показано на схеме. Большинство пнфор-242
мацпонных машин располагается в городах, где размещены коммутационные узлы или концентраторы. Однако некоторые ЭВМ удалены от узлов коммуникационной сети/ Например, к франкфуртскому узлу подсоединены две информационные машины, рас-
@ Узлы пакетной коммутации
Q Концентраторы
# Центр управления коммуникационной сетью
0 Информационные машины (хост-машины)
Л Терминалы пользователей
— Каналы связи коммуникационной сети коммутации пакетов '— Каналы связи с информационными машинами и терминалами
Рис. 12.1.
положенные в Кельне и Карлсруэ, а к брюссельскому концентратору — информационная машина Льежа.
В сетях коммутации пакетов узлы бывают разных липов: специализированные — только для подсоединения хост-машин (т. е. ЭВМ, предоставляющих вычислительные ресурсы, программы и данные для решения различных задач в режиме сетевой телеобработки; в информационной сети в качестве хост-машин выступают информационные машины), или универсальные — для подсоединения хост-машин и терминалов пользователей [73]. В сети EURONET DIAXE все узлы — универсального типа и кроме ин
16*
243
формационных машин обеспечивают работу определенного числе терминалов абонентской сети пользователей. В 1980 г. к сети было подключено около. 500 терминалов, но их число с каждым годом быстро возрастает. Для подключения терминалов к узлам и концентраторам используются выделенные телефонные каналы связи, физические линии, а также средства обычных телефонных и телеграфных сетей общего пользования. Управление коммуникационной сетью осуществляется центром управления в Лондоне, где с помощью специальных программных средств и процедур' контролируется работа всей сети в целом.
Бурное развитие в мире сетей коммутации пакетов и создание средств их объединения позволяют все время расширять число доступных пользователяхМ информационных машин через дешевую и надежную коммуникационную среду. В частности, через парижский узел возможен выход пользователей в национальную сеть [ коммутации пакетов Франции (TRANSPAC), а через лондонский узел — в соответствующую сеть Великобритании.
Кроме сети коммутации пакетов EURONET в информационных сетях активно используются аналогичные американские коммуникационные сети TYMNET, TELENET и др. [25]. В них используются не только наземные, но и спутниковые каналы связи, существенно снижающие стоимость телекоммуникаций для пользователей, находящихся на значительном удалении от информационных машин. TYMNET функционирует с 1971 г., a TELENET — с 1975 г.
Работа сетей коммутации пакетов построена на основе стандартных сетевых программных средств, регламентирующих все виды взаимодействий, которые возникают при работе вычислительной сети. Стандартное сетевое программное обеспечение дает возможность не только надежно и экономно присоединить к коммуникационной сети информационные машины и терминалы, но строить также распределенные базы данных, работающие полностью илп частично под единым управлением.
Программная структура сети коммутации пакетов описана в работе [73]. В основе сетевого программного обеспечения лежит разделение всего информационно-вычислительного процесса на определенное число уровней, внутри которых достигается унификация средств программной реализации. Слоистость программной структуры обеспечивает относительную независимость программ друг от друга. Установлеппе четких правил стыковки соседних программ позволяет менять (совершенствовать) один из уровней программного обеспечения без изменения остальных.
Чем больше уровней в’ структуре программного обеспечения сети, Тем легче его совершенствовать, так как объемы и сложность каждого уровня снижаются. Однако с увеличением числа
244
уровней усложняется программное обеспечение в целом, так кай каждое выделение программ в один уровень требует решения вопросов стандартизации стыков с соседними уровнями. Поэтому необходимо выбирать оптимальное число уровней, обеспечивающее достаточную простоту программного обеспечения при значительном числе его независимых уровней.
Взаимосвязь одноименных уровней программной структуры сети определяется набором стандартных для всей сети правил, включающих обязательные характеристики элементов и процедуры их взаимодействия. Эти правила принято называть протоколами.
Взаимосвязь соседних уровней программной структуры (в одной машине) определяется стандартами, именуемыми интерфейсами. Интерфейсы имеют локальное значение, так как определяют стыковку соседних слоев программной структуры. Протоколы характеризуют функционирование всей вычислительной сети в целом.
В процессе разработки программного обеспечения вычислительных сетей наибольшее распространение получила семиуровневая структура, которая показана на рис. 12.2. Самый нижний —
Прикладной уровень (программы пользователей)
Представительский уровень (управление представлением)
Сеансовый уровень (управление сеансами)
Транспортный уровень (управление передачей)
Сетевой уровень (управление сетью)
Коммун и-, кационная сеть
Канальный уровень '
(управление информационным каналом)
Процессы
Порт
Транспортная сеть
Физический уровень (управление физическим каналом)
Рис. 12.2. Уровни программного обеспечения вычислительной сетп.
физический уровень определяет параметры сопряжения между оконечным оборудованием и аппаратурой передачи данных, свя-ванной с физическим каналом связи, процедуры установления, поддержания и расторжения соединения, а также передачу последовательности бит. Канальный уровень определяет целый ряд 245
функций управления передачи информации по информационному каналу. К иим в первую очередь относятся: упаковка передаваемой информации в кадры определенной длины (пакеты) перед передачей и распаковка после передачи по физическому каналу, формирование проверяющих символов и проверка содержимого кадров после их передачи, передача и прием подтверждении о приеме кадров, повторная передача неподтвержденных кадров. На сетевом уровне осуществляется маршрутизация пакетов, обрамление массивов информации служебными символами передачи по коммуникационной сети, управление потоками информации.
Транспортный уровень предназначен для транспортировки массивов из одного порта (портов) в другой (другие). Под портом понимается конец логического канала транспортной сети. В этой точке фактически завершаются все операции, связанные собственно с транспортировкой данных, и начинается выполнение операций между вычислительными процессами. Транспортный уровень обеспечивает установление и разъединение транспортных соединений, управление информационными потоками от порта до порта, обнаружение ошибок в массиве и восстановление передачи после их исправления, контроль последовательности передачи информационных пакетов на всей трассе от порта до порта. Транспортный уровень обеспечивает также разборку и сборку пакетов, принадлежащих передаваемому в сеансе связи массиву. На транспортном уровне могут быть использованы несколько различных коммуникационных ресурсов (например, передача массива частями одновременно по нескольким каналам).
Целью сеансового уровня является организация, поддержание и окончание сеансов между прикладными процессами. Сеансы устанавливаются через представительский уровень. Целью представительского уровня является выполнение преобразования данных в форму, удобную для прикладной программы. На представительском уровне происходят преобразования форматов данных и преобразования команд. Прикладной уровень обеспечивает выполнение собственно работы прикладной программы, как если бы она выполнялась не через коммуникационную сеть, а автономно в вычислительной машине. В информационной сети па прикладном уровне выполняются информационно-поисковые процессы.
Из всех рассмотренных уровней коммуникационная сеть охватывает первые три уровня протоколов. В узлах коммутации и концентраторах протоколы более высоких уровней не применяются. В хост-машинах (информационных машинах), кроме протоколов коммуникационной сети, реализуются и протоколы остальных четырех уровней.
В сетях пакетпоп коммутации интенсивно развивается процесс стандартизации протоколов, что упрощает сетевую телеобра
246
ботку в информационных сетях. Наиболее важные первьГе три уровня протоколов в большинстве сетей коммутации пакетов (TELENET, TYMNET, TRANSPAC, EURONET и др.) отвечают рекомендации Х-25 международного консультативного комитета по телеграфии и телефонии (МККТТ).
Рекомендация Х-25 охватывает протокол Х-21 или Х-21 бис для физического уровня, протокол управления информационным каналом 1IDLC (High-level Data Link Control) и протокол Х-25/3 (третий уровень Х-25) сетевого уровня [73]. Три уровня протоколов Х-25 применяются в основном при связи с хост-машинамп, однако в последнее время они стали использоваться и. для связи со специально созданными терминалами (терминал Х-25). Что касается подключения терминалов, работающих в режиме асинхронной побайтной передачи, то для них разработана своя гамма протоколов: Х-3, Х-28, Х-29 в соответствии с рекомендациями МККТТ. Протокол Х-3 определяет процедуру сборки пакетов из байтов, принятых от терминала (с добавлением служебной обрамляющей информации) и обратной разборки пакетов при подготовке передачи из коммуникационной сети на терминал. Протокол Х-28 определяет процедуры обмена информацией между асинхронным терминалом и модулем сборки-разборки пакетов, а протокол Х-29 — процедуры обмена между модулем сборки-разборки пакетов и коммуникационной сетью.
Краткий анализ работы сетей коммутации пакетов позволяет сделать следующие важные выводы с точки зрения их использования в информационных сетях:
1. Информационные машины постоянно связаны между собой выделенными каналами связи через узлы коммутации пакетов (концентраторы также можно считать транзитными узлами коммутации пакетов).
2. Выполнение физического соединения абонента с любым узлом через обычную общественную телефонную или телеграфную сеть означает установление физической связи со всеми информационными машинами, входящими в сеть.
3. Средства, определяющие оперативное взаимодействие пользователя с информационными ресурсами сети и решение задач (выбор информационных машин, баз данных, проведение поисковых операций, управление вводом запросов и выводом результатов, настройка реяшма выполнения задания и т. п.) укладываются в стандартную программную архитектуру сети и могут быть обеспечены многоуровневой системой протоколов и интерфейсов между ними.
Эти основные положения во многом определяют направления развития информационных сетей с оперативным доступом к данным.
247
12.3. Централизованная п распределенная информационная сеть
Характер выполнения информационно-поисковых задач допускает параллельное и относительно независимое их решение, а потребности взаимного обращения ЭВМ друг к другу могут быть сведены к минимуму или исключены совсем. Такие свободные условия работы представляют разработчикам информационных сетей возможность широкого выбора различных вариантов их построения. Информационные ресурсы могут размещаться в любой информационной машине, связанной с коммуникационной сетью. Если транспортная сеть имеет достаточную пропускную способность во всех звеньях, чтобы обеспечить малую задержку транспортировки, пакетов между любыми портами, пользователям информационной сетп с точки зрения оперативности доступа безразлично, где именно помещен нужный информационный ресурс. Вся совокупность баз данных информационной сети может быть сосредоточена в одном центре пли размещена в территориально распределенных информационных центрах. В первом случае образуется централизованная информационная сеть. Во втором случае пользова1ель имеет дело с распределенной информациопной сетью.
Примером централизованной информационной сети является система DIALOG фирмы Lockheed Missiles and Space Co. Многомашинный вычислительный комплекс, состоящий из нескольких ЭВМ обеспечивает одновременный доступ более чем к 130 библиографическим, реферативным и фактографическим базам данных, относящимся к различным областям знаний (состояние на 1980 г.). На внешних накопителях на магнитных дисках одновременно размещается более 40 млн. записей. Для создания и обновления баз данных, управления ими, а также для проведения диалогового поиска используется пакет прикладных программ, разработанный фирмой. Система DIALOG расположена в Пало-Альто (США) и связана с пользователями коммуникационными сетями коммутации пакетов TELENET и TYMNET. Система DIALOG на 1979 г. имеет более 4000 абонентов в 35 странах мира [70].
Сравнительный анализ показывает, что распределенные информационные системы перспективней и имеют больше преимуществ. Распределенная информационная сеть более надежна. Отказ одной из информационных машин нарушает работу пользователей только с тем подмножеством баз данных, которые она поддерживает. Остальные информационные машины продолжают обслуживание пользователей. В централизованной информационной сети выход из строя информационной машины парализует работу со всеми базами данных. Примером распределенной ин-243
формационной сети является рассмотренная выше EURONET DIANE.
Базы данных информационной сети неодинаковы по объему, разнородны по структуре и составу элементов данных. В условиях распределенной информационной сети значительно проще, чем в централизованной, подобрать под определенные типы баз дан- v ных специально ориентированные на работу с ними СУБД и поисковые пакеты прикладных программ, что повышает • эффективность использования программных средств и улучшает характеристики эксплуатации баз данных.
В распределенной информационной сети снижаются требования к производительности ЭВМ, так как общая нагрузка распределена между многими ЭВМ, процессоры которых могут вести независимые параллельные вычисления и взаимодействия с внешней памятью. Трафик (информационный поток) распределяется в узлах более равномерно,- а общая нагрузка ниже, так как точки размещения баз данных обычно приближены к местам основного потребления информационных ресурсов.
Из преимуществ централизованной информационной сети отметим упрощение управления всей совокупностью баз данных и унификацию языковых средств взаимодействия пользователей с ними, так как все базы данных поддерживаются единым программным обеспечением и имеют один и тот же входной язык.
Интенсивное развитие в мире коммуникационных сетей коммутации пакетов и их интеграция создает условия объединения разных информационных сетей. Коммуникационные сети TELENET, TYMNET, EURONET, TRANSPAC и другие имеют совместимые узлы, через которые пользователи одной информационной сети могут иметь доступ к информационным ресурсам другой. Например, через лондонский узел пользователи могут выходить в американские и европейские информационные центры, через парижский узел — в национальные информационные центры Франции и центры EURONET DIANE.
В информационных сетях обычно идет процесс подключения новых информационных машин и ввод новых баз данных. В этих условиях какой бы мощной по объему и числу баз данных не была централизованная информационная сеть, она не в состоянии будет полностью удовлетворять пользователя только своими ресурсами. Можно считать, что в перспективе рано или поздно все информационные сети станут распределенными.
Оптимизация географического размещения баз данных в распределенной информационной сети относится к категории задач распределения ресурсов. При ее решении учитываются: географическое расположение пользователей баз данных, объемы запрос-ответных потоков и потоков сообщений для обновления баз дан-
249
вых, топология коммуникационной сети, пропускная способность ее звеньев, ограничения на стоимость передачи данных, эксплуатацию баз данных, производительность процессоров информационных машин и объемы внешней памяти и т. д.
Рассмотрение методов распределения баз данных и оптимизации режимов доступа к ним с анализом указанных выше характеристик выходит за рамки настоящей книги. Мы будем анализировать только вопросы языковой и, частично, программной совместимости средств доступа пользователя во множество ИПС распределенной информационной сети.
Уже указывалось рапсе, что наиболее удобное решение проблемы доступа в информационную сеть с точки зрения пользователя — это отправление запроса в сеть без адресации к базам данных вообще. При этом функции синтаксического и семантического анализа запроса, выявления «релевантных» баз данных, трансляции формулировки запроса в подмножество запросов на языке локальных ИПС, транспортировки запросов в информационные машины, выполнения параллельного поиска в выбранных базах данных и сборки ответа пользователю необходимо возложить на мощные автоматизированные лингвистические и программные средства информационной сети.
Исследования по разработке архитектуры информационной сети, отвечающей изложенной концепции, уже реально ведутся коллективами специалистов. Одно из наиболее интересных исследовании в этой области — разработка проекта SIRIUS во Франции [77]. Работа над проектом начата в 1976 г. под руководством специалистов научно-исследовательского института вычислительной техники и автоматизации (Institut de Recherche d’lnformali-que et d’Automatique — IRIA). В целом проект рассчитан на исследование проблем организации распределенных баз данных различной структуры, систем управления распределенными базами данных, взаимодействия ЭВМ через коммуникационную сеть по решению общих задач и т. п. К работе над проектом было привлечено 15 научных коллективов в различных научно-исследовательских организациях Парижа, Нанси, Ренна, Тулузы, Гренобля и других городов.
На первом этапе работы над проектом в период с 1977 по 1979 гг. было создано несколько систем, ориентированных на исследование отдельных аспектов проблемы (IGOR, FRERES, POLYPHEME, SCORE). Система IGOR разработана исследовательским коллективом в Гренобле. В ней был проанализирован и экспериментально проверен механизм параллельной обработки данных в сетевом режиме. Система реализована на ЭВМ IRIS-80 и испытана на французской коммуникационной сети коммутации пакетов CYCLADES. Исследовательская группа в Ренне разработала
250
в системе FRERES механизм ввода запросов в распределенные разнородные базы данных, а также их исполнения в ЭВМ, расположенных в различных точках коммуникационной сети. Экспериментальные базы данных реализованы на трех ЭВМ тина IRIS-80, связанных между собой через CYCLADES. Система POLYPHEME реализована комплексным исследовательским коллективом в Гренобле. В этой системе создана разнородная экспериментальная распределенная база данных п отработан механизм перевода запросов с глобального уровня на локальный уровень с разнородными локальными СУБД. Система реализована на ЭВМ IRIS-80, взаимодействующих через CYCLADES. В системе SCORE (создана головным исследовательским коллективом IRIA) отрабатывался механизм управления разнородными распределенными базами данных. Базы данных реализованы на трех миниЭВМ REALITE-2000 в локальной коммуникационной сети.
На втором этапе исследований принципиальные решения, полученные в упомянутых выше системах, были интегрированы в рамках системы SIRIUS-DELTA. Поэтапная реализация этой экспериментальной системы осуществлена в период 1979 — 1980 гг. в экспериментальной вычислительной сети института IRIA.
На глобальном уровне распределенная база( данных SIRIUS-DELTA представляется как единая база данных. На этом уровне описывается концептуальная схема распределенной базы данных и связанные с ней глобальные внешние схемы. На локальном уровне описываются все внешние, концептуальные и внутренние схемы каждой локальной базы данных. Запрос пользователя, сформированный на специальном языке запросов, обращается к распределенной базе.данных на глобальном уровне. Проводится синтаксический и семантический анализ запроса, затем он декомпозируется в набор подзапросов к соответствующим базам данных на некотором промежуточном языке запросов. На локальном уровне запрос адаптируется применительно к конкретной структуре локальной базы данных. Поиск по подзапросам идет независимо, но в системе управления распределенной базой данных имеется система синхронизации выдачи общего результата. Ответы на каждый подзапрос приводятся к стандартной форме и транспортируются в определенной последовательности через коммуникационную сеть к месту расположения пользователя.
В ходе исследований по проекту SIRIUS проводятся эксперименты с базами данных разной структуры (иерархической и реляционной) и назначения (фактографические и библиографические документальные). После окончания исследований в 1981 г. предполагалось включение реальной распределенной базы данных в опытную эксплуатацию в коммуникационной сети TRANSPAG.
251
12.4. Адресация запросов к базам данных
Полная автоматизация процесса управления распределением запросов пользователя по реальным базам данных информационной сети с поиском в реальном масштабе времени требует серьезных теоретических и экспериментальных исследований. Необходима разработка и создание систем управления распределенными базами данных, которые могли бы охватить реальные действующие локальные СУБД и информационно-поисковые системы. Автоматизация анализа запросов, достижение совместимости поисковых языков в реальной информационной сети требует также проведения исследований в области лингвистического обеспечения и разработки соответствующих специальных программных средств. Наконец, важным условием внедрения систем управления распределенными базами данных является наличие развитой коммуникационной сети коммутации пакетов.
Исследования, аналогичные проведенным в проекте SIRIUS, позволяет ближе подойти к решению поставленных проблем, но переход к реализации режима «безадресного» ввода запросов в информационную сеть потребует, по-видимому, еще много усилий и времени. Оценка нынешней ситуации затруднена, так как в работе [77] и других, посвященных проекту SIRIUS, публикациях не дается детального описания лингвистических средств, используемых при выполнении поиска по запросу к распределенной базе данных; нет также сведений о том, какие конкретные типы баз данных при этом охватывались (фактографические пли документальные).
Следует отметить, что принципиальная возможность автоматического поиска в распределенной базе данных без указания точного адреса баз данных еще не означает, что такой режим всегда предпочтительнее поисковых операций полуавтоматического и «ручного» типа с явной адресацией, когда контроль и управление процедурами адресации запросов производится пользователем о терминального пульта. Как показал анализ (см. гл. 11), полнота выдачи информации на какой-либо запрос в разных базах данных неодинакова, а количество тематических разделов, куда пользователь пожелает адресовать запрос, зависит в общем случае от конкретных требований к полноте выдачи. Не всегда полнота охвата фонда записей является обязательной целью проведения поиска. Часто пользователю достаточно получить несколько релевантных запросу записей из одной профильной базы данных. Опыт работы удаленных пользователей, работающих в диалоговом режиме со многими базами данных, показывает, что при традиционной «ручной» адресации (самим оператором терминала) стратегия выбора их числа нередко зависит от количества записей, 252
полученных в качестве результата в первой из выбранных баз данных. При большом объеме выдачи релевантных документов пользователь может принять решение прекратить дальнейший поиск.
Есть еще один важный фактор, влияющий на полноту охвата фонда при поиске — стоимость. Стратегия оплаты диалогового поиска в современных информационных системах построена на учете времени взаимодействия пользователя с конкретной базой данных. Каждый информационный центр определяет тарифы повременной оплаты связи с базами данных, и пользователь в какой-то мере должен искать компромисс между стоимостью мультибазо-вого поиска и его полнотой.
Реально действующие в настоящее время информационные сети обеспечивают, как правило, ограниченную помощь пользователю в выборе баз данных нужного тематического профиля. Обычно пользователь имеет дело с кратким описанием предметной области, охватываемой базой данных, либо в виде традиционного печатного справочника, либо в прямом доступе на экране терминала [88]. Сфера поиска ограничивается некоторым набором баз данных, выбранных на основе практического опыта. Однако, как показывает отечественная и зарубежная практика, далеко не всегда пользователю удается правильно сориентироваться в информационных массивах. Нередко потребитель ведет поиск в массивах, которые не имеют релевантных документов. При этом впустую тратится время самого пользователя, ресурсы информационно-поисковых систем и каналов связи.
В информационной сети с полптематическим набором баз данных желательно предоставить пользователю средства оперативного выбора «релевантных» баз данных. Методы получения характеристик тематической связи между рубриками, рассмотренные в предыдущей главе, в данном случае недостаточны, так как связь между рубриками оценивается на основе усреднения потока запросов, а выбор «релевантных» баз данных различен для каждого индивидуального запроса.
Рассмотрим один из способов построения справочно-поискового аппарата для адресации к базам данных, описанный в [46]. По этому способу в выделенном центре информационной сети организуется специальная адресно-справочная база данных. Ее основу составляет массив основных терминов, охватывающих словари всех баз данных информационной сети. Каждому термину ставится в соответствие набор рубрикационных индексов, идентифицирующих тематический профиль базы данных и частотные характеристики числа документов, содержащих данный термин. Адресно-справочная база данных должна быть доступна удаленному пользователю сети так же, как и любая из информационных баз
253
данных. Если абонент сети не нуждаечся в подсказках, он обращается непосредственно в конкретные информационные базы данных. Пользователь, испытывающий затруднения с выбором конкретных баз данных, обращается сначала с запросом в адресносправочную базу данных. На запрос выдается ответ в виде цепочки индексов баз данных, содержащих термины запроса с частотными характеристиками встречаемости.
Допустим, пользователь обратился в адресно-справочную базу данных со следующим запросом:
Q = А • В V С • D,
где 4, В, С, D ключевые слова и дискрппторы, распределенные в базе данных следующим образом:
ТЛ"П’ ’’,«)• ’„МЛ
В^.М). ШИ.»- г,,
с - (О- «). (”«)
в-'Ж), Л,,К). г„к,).
Здесь Ti — индексы тематического профиля,^, nf, nf, частоты встречаемости терминов в соответствующих базах данных.
По запросу Q на терминал пользователя должен быть выдан результат:
М'4);
*=Л(4). ^04);
с = 7’31 (4);
Анализ частотного распределения терминов и булевого выражения, связывающего их в запросе, дает возможность оценить последовательность поиска в базах данных. Если, например,
4 =Г1 (20), Г25(80);
В = Л (ЮО), г25(2);
С = Т31 (120);
D = Тз1 (150),
то базы данных ранжируются в порядке уменьшения вероятной полноты выдачи следующим образом: Г31, Ть Т2з- Зная «релевантные» базы данных, пользователь может св/чзываться с центрами, где они эксплуатируются.
254
Ввод частотных характеристик встречаемости терминов в адресно-справочную базу данных требует опрсделенной технологии обработки словарных файлов информационных баз данных сети и передачи этих результатов в центр, поддерживающий адресносправочную базу данных. С течением времени следует обновлять статистические характеристики встречаемости терминов. Ведение адресно-справочной базы данных упрощается, если их не вводить совсем, но тогда качество адресации будет хуже, так как ранжирование информационных баз данных по степени «релевантности» запросу станет затруднительным.
12.5. Совместимость языковых средств пользователей информационной сети
Информационная сеть строится на основе множества ИПС, которые могут отличаться друг от друга программным обеспечением и языковыми средствами поиска. Средства взаимодействия с современной диалоговой ИПС достаточно сложны и их изучение и полное освоение требует определенного времени. Пользователи обращаются к информационным ресурсам с разной интенсивностью, причем некоторые из них прибегают к диалоговому поиску всего несколько раз в год.
Поддержание на необходимом уровне знаний пользователей о средствах общения даже с одной диалоговой ИПС сопряжено с известными трудностями. Эти трудности усугубляются, когда полы, зователь взаимодействует с разным набором баз данных. Поэтому он нередко ограничивает себя поиском только в тех базах данных, которые находятся в ИПС с известным ему поисковым языком. Взаимодействие с другими базами данных из-за языковых ограничений займет у него существенно больше времени И будет стоить дороже.
Одпн из путей решения проблемы — это унификация в информационной сети поисковых пакетов прикладных программ и систем управления базами данных. Как показывает опыт, полностью решить эту проблему таким образом не удается, так как различие в конфигурации информационных машин, структурах баз данных и характере запросов к ним требует применения разных программных средств. Кроме того, развитие информационных сетей может потребовать расширения числа информационных машин, что неизбежно увеличивает вероятность появления ИПС с новым поисковым языком.
В результате эксплуатации многих диалоговых ППС, особенно документальных, обнаружилось, что ряд отличий поисковых языков не является принципиальным и имеется возможность их
265
преодоления. В частности, документальные ИПС допускают значительную степень унификации языковых средств пользователей, так как структура и семантическое наполнение библиографических записей, а также способы ведения поиска во многих случаях одинаковы [2, 9, 10, 29].
Возможности, предоставляемые пользователю разными ИПС, неодинаковы. Ряд функций может выполняться в ограниченном числе ИПС. Например, в ПОИСК-1 [13] па определенных типах терминалов возможно инициирование отображения на экране дисплея ключевых слов запроса в тексте вызванного документа с двойной интенсивностью, ранжирование документов выдачи по степени релевантности по специальным алгоритмам. В ИПС CDS/ISIS [100] допускается применение булевых операторов, но отсутствуют средства указания взаимного расположения элементов текста. Однако даже те средства, которые есть во многих ИПС, обозначаются по-разному. Например, поисковые операторы И, ИЛИ, НЕ обозначаются в ИПС «ПОИСК-1» как AND, OR, NOT, во французской ИПС MISTRAL как ЕТ, OU, SAUF, в ИПС CDS/ISIS как +, *, "1.
Для упрощения задания набора различных словоформ при формулировке запроса во многих системах используется знак усечения. Например, в ИПС «ПОИСК-1» запись comput Q означает, что в запрос должны быть включены все слова, начинающиеся с сочетания comput — computer, computerizing, computation и т. д. Аналогичные записи в ИПС MISTRAL, DIALOG CDS/ISIS выглядят соответственно, как comput-)-, comput?, comput И. В системах ПОИСК-1 и DIALOG есть дополнительные средства ограничения числа знаков после усечения. Записи comput Ц 2 и comput?? выглядят по-разному, но означают одно и то же — в запрос включая ются слова, имеющие не более двух знаков после символа усечения: computer, computed, но не computerizing, computation. Приведенные примеры показывают, что одни и те же операции нередко выполняются в разных ИПС с помощью разных средств.
Очевидно имеет смысл определенным образом упорядочить языковые средства пользователя информационной сети. Один из вариантов решения этой проблемы предложен для информационной сети EURONET DIANE [95]. Речь идет о разработке единого командного языка пользователя (ЕКЯ). В основном он охватывает языковые средства, используемые в документальных ИПС, но в пего включены также некоторые средства для фактографического поиска. ЕКЯ включает следующие команды:
BASE — указать базы данных, в которых должен производиться поиск;
FIND — ввести запрос и выполнить поиск;
DISPLAY — отобразить список связанных поисковых терминов;
256
SAVE — запомнить поисковое предписание для использования в дальнейшем;
SHOW — вывести записи на терминал или терминальный принтер;
PRINT — заказать распечатку записей в режиме офлайн;
HISTORY — предоставить информацию о проведенных поисковых операциях в течение сеанса («историю поиска»);
STOP — закончить сеанс;
DEFINE — игнорировать параметры по умолчанию, создать макрокоманды пользователя;
DELETE — удалить поисковые предписания, распечатать заказы и т. д.;
MORE — вывести на терминал следующую порцию данных;
BACK — вывести на терминал предшествующую порцию данных, например, в алфавитном порядке;
HELP —• получить руководство по системе;
NEWS — получить последнюю информацию по системе;
INFO — предоставить общую информацию о системе.
Команда INFO включает подкоманды, конкретизирующие ее. Для получения различной информации рекомендуются следующие подкоманды:
COST — получить иформацию о стоимости поиска;
SCHEDULE — указать часы обслуживания;
USERS — указать число активных пользователей ИПС;
STATUS — дать информацию о текущем поиске, т. е. номер поискового предписания, имя пользователя, стартовое время поиска.
Конкретная ИПС может иметь в своем составе оригинальные команды, не укладывающиеся в ЕКЯ. В этом случае пользователь может перейти на локальный язык ИПС с помощью команды OWN. ЕКЯ содержит правила использования команд, ввода в нпх параметров и взапмодействия с ИПС.
Информационные центры, входящие в EURONET DIANE, уже начали включать средства ЕКЯ в программное обеспечение своих информационных систем. Предложения по ЕКЯ рассматриваются в международной организации по стандартизации. Введение ЕКЯ в практику работы информационных сетей позволит упростить общение с ними пользователей.
17 р. Г. Белоногов, Б. А. Кузнецов
Приложение 1
СЛОВООБРАЗОВАТЕЛЬНЫЕ КЛАССЫ СЛОВ
001 — надлеж — ащих
+ — 121 АЛ - 125 АЩ - 105
002 — гн — ать
АВ - 152 АВШ - 105 АВШИ — 152
АЛ - 125 АТЬ - 144 АТЬСЯ — 144
003 — беж — енцы
+ — 121 АВ - 152 АВШ - 105
АВШИ - 152 АЛ - 125 АТЬ - 144
АЩ - 105 ЕНЕЦ -032 ЕНЦ - 032
004 — клевет — нические
+ -056 АВ - 152 АВШ - 105
АВШИ — 152 АЛ - 125 АТЬ - 144
НИК - 031 НИЦ -045 НИЧЕСК - 106
005 — прпнадлеж — ащих
+ - 121 А - 152 АВ - 152
АВШ - 105 АВШИ - 152 АЛ - 125
АТЬ - 144 АЩ - 105 ноет -055
008 — попыт — аемся
А - 116 АВШ - 105 АВШИСЬ - 152
АИСЯ - 143 АПТЕСЬ - 143 АЛ - 125
АТЬСЯ — 144 К -060 ОК -060
009 — колеб — лющееся
АВШ — 105 АВШИСЬ - 152 АЛ - 125
АНИ — 073 АТЬ - 144 АТЬСЯ - 144
АЯСЬ — 152 Л - 117 ЛЮЩ - 105
ЛЕМ — 103 Л ЯСЬ - 152
:$3
Приложение 1 (продолжение}
065 — вмеш — ательства
А - 116 АВШ - 105 АВШИСЬ - 152
АЙСЯ — 143 АЙТЕСЬ - 143 АЛ — 125
АТЕЛЬСТВ - 070 АТЬСЯ - 144 ИВА — 116
ИВАВШ - 105 IIBAEM - 103 ИВАЛ - 125
ИВАТВСЯ - 144 ИВАЮЩ - 105 ИВАЯСЬ - 152
074 — насыщ — еяная
+ - 124 А - 116 АВ - 152
АВШ — 105 АВШИ - 152 АЕМ - 103
АЕМОСТ - 055 АЙ - 143 АЙТЕ - 143
АЛ - 125 АТЬ - 144 АТЬСЯ - 144
АЮЩ - 105 АЯ - 152 АЯСЬ - 152
ЕН - 126 ЕНИ - 073 ЕНН - 103
ЕННОСТ - 055
075 — замен — ательный
+ - 124 А - 116 АВ - 152
АВШ — 105 АВШИ - 152 АЕМ - 103
АЙ - 143 АЙТЕ -- 143 АЛ - 125
АНИ -073 АТЕЛЬН - 103 АТЕЛЬН - 126
АТЕЛЬНО - 152 АТЬ - 144 АЮЩ - 105
АЯ - 152 ЕНН - 103
082 — опас — ением
А - 116 АВШ - 105 АЙСЯ - 143
АЙТЕСЬ - 143 АЛ - 125 АТЬСЯ - 144
АЮЩ — 105 АЯСЬ - 152 ЕН — 126
ЕНИ - 073 К - 060 Н - 103
II - 126 НЕЕ - 152 НО - 152
ноет - 055
138 — оправд — ал
А - 116 АВ - 152 АВШ - 105
АВШИ - 152 АЙ - 143 АЙТЕ - 143
АЛ — 125 АН - 126 АНИ - 073
АНН - 103 АННОСТ - 055 АТЕЛЬН - 103
АТЬ - 144 АТЬСЯ - 144 ЫВА - 116
ЫВАВ1П — 105 ЫВАЕМ — 103 ЫВАЙ - 143
ЫВАЙТЕ - 143 ЫВАЛ - 125 ЫВАТЬ - 144
17* 259
ft р и л 6 Ж о н п е 1 (продолжение]
ЫВАТЬСЯ - 144 Е1ВАЮЩ — 105 Е1ВАЯ — 152
ЫВАЯСЬ — 152
149 — укры - - ТИТО
В - 152 ВА - 116 ВАВШ - 105
ВАЙ - 143 ВАЙСЯ - 143 ВАЙТЕ - 143
БАЙТЕСЬ - 143 ВАЕМ - 103 ВАЛ - 125
ВАНИ - 073 ВАТЕ - 144 ВАТЕСЯ - 144
ВАЮЩ - 105 ВАЯ - 152 ВАЯСБ - 152
ВШ - 105 ВШИ - 152 ВШИСЕ - 152
Л - 125 Т - 126 Т - 103
ТИ - 073 ТБ - 144 ТЕСЯ - 144
151 — еда — 1 ти
+ - 116 В - 152 ВАВШ - 105
БАЕМ - 103 ВАЙ - 143 ВАЙСЯ - 143
ВАЙТЕ - 143 ВАЙТЕСЕ - 143 ВАЛ - 125
BATE - 144 ВАЯ - 152 ВАЯСЕ - 152
ВШ - 105 В1ПИСБ - 152 Д - 116
Л - 125 Н — 126 НН -- 103
ТЕ - 144 ТЕСЯ - 144 Ч - 057
ЮЩ - 105
235 — реценз — ент
ЕНТ - 021 И - 061 ИРОВАВШ - 105
ПРОВАЛ - 125 ИРОВАНИ - 073 ИРОВАНН - 103
ИРОВАТЕ - 144 ИРОВАТЕСЯ - 144 ИРУ - 116
ИРУЕМ - 103 ИРУЙ - 143 ИРУЙТЕ - 143
ИРУЮЩ - 105 ИРУЯ - 152
236 — пилот - — ируемого
+ - 021 АЖ —002 ИРОВАВШ - 105
ИРОВАЛ — 125 ИРОВАНН - 103 ИРОВАН - 126
ИРОВАНИ - 073 ИРОВАТЕ - 144 ИРУ - 116
ИРУЕМ - 103 ИРУЮЩ - 105 ИРУЯ - 152
Н - 103
269 — доз — аторы
+ - 056 ATOP - 001 ИРОВАВШ - 105
ИРОВАЛ - 125 ИРОВАН - 126 ИРОВАНИ - 073
ИРОВАНН - 103 ИРОВАТЕ — 144 ИРОВК - 060
ИРОВОК - 060 ИРУ — 116 ИРУЕМ - 103
ИРУЙ - 143 ИРУЙТЕ — 143 ИРУЮЩ - 105
ИРУЯ — 152
270 — трансл — яции
ИРОВАВШ — 105 ИРОВАЛ - 125 ИРОВАН — 126
260
Приложение 1 (продолжение]
ИРОВАНИ — 073 ПРОВАНН - 103 КРОВАТЬ - 144
ПРОВАТЬСЯ - 144 ИРУ — 116 ИРУЕМ - 103
ИРУЙ - 143 ИРУЙТЕ — 143 ИРУЮЩ - 105
ИРУЯ — 152 ИРУЯСЬ — 152 ЯТОР -001
яци - 061 ЯЦИОНИ - 103
695 — внутр - - и
ЕНН - 104 ЕННЕ - 152 ЕННОСТ - 055
698 — особ — енностей
ЕНН — 103 ЕПЫО - 152 ЕННОСТ - 055
О - 152
702 — огн — евая
+ - 003 ЕВ - 107 ЕНН - 103
704 — прост - - ейшпе
+ - 126 + - 107 ЕЙШ - 105
О — 152 ОТ -056
710 — слов — есной
+ - 070 ЕСН - 103 ECHO - 152
714 — смерт - - ельные
•4“ - 055 ЕЛЕН - 103 ЕЛЬН — 126
ЕЛ ЬНО — 152 ЕН - 126 Н - 103
Н - 126 ноет - 055
732 — веры — истой
- 070 ИСТ - 103 ОВ - 107
738 - аналог — ичен
+ - 006 И - 061 ИЧЕН - 126
ичн - 126 ИЧН - 103 ИЧНО - 152
740 — селект — пвностп
ивн - 103 ИВНОСТ — 055 ОР -001
ОРН - 103
893 — доктор — а
+ - 040 СК - 106
894 — варшав — скип - 106
+ - 056 СК
895 — канцеляр — ия - 106
и - 061 СК
896 — жен — щины
СК - 106 ЩИН - 044
899 — автор - - ство
+ - 021 СК - 106 СТВ -070
906 — аспирант — уры - 106 УР — 056
+ - 021 СК
937 — тигел - - ь
+ -003 ЬН - 103
941 — сыр — ье
+ - 077 ЬЕВ - 107
949 — вертикал — ью — 126
- 055 ЬН - 103 ЬН
ьно - 152
958 — добровол — ьческпх — 152
ЕЦ — 032 ЬН - 103 ЬНО
ьц -032 ЬЧЕСК — 106
965 — дерев - - янный
+* — 075 ЯНН — 103
261
f 1 р п л о & е п п с 2
Словарь Сочетаний суффиксов и псевдосуффикеп» *)___________
Буквенные коды Флективные классы Буквенные коды Флективные классы
А 116 АНК 051
А 152 АНН 103
АВ 152 АННО 152
АВШ 105 АННОСТ 055
АВШИ 152 АНС 001
АВШИСЬ 152 АНОК 106
АД 056 ЛИОН 103
АЕМ 103 АНТ 021
АЕМОСТ 055 АР 003
АЖ 002 АР 027
АЖ 016 АРИ 005
АИЧЕСК 106 АРП 103
АИЧЕСКИ 152 АРП 126
АЙ 143 АРНО 152
АЙСЯ 143 АРНОСТ 055
АЙТЕ 143 АСЬ 152
АЙТЕСЬ 143 АТ 001
АЙШ 105 АТ 126
АЛ 001 АТЕЛ 003
АЛ 070 АТЕЛ 027
АЛ 125 АТЕЛЕН 126
АЛЕН 126 АТЕЛЬН 103
АЛИВ 103 АТЕЛЬН 126
АЛИВ 126 АТЕЛЬНО 152
АЛИВОСТ 055 АТЕЛЬСК 106
АЛИЗАЦИ 061 АТЕЛЬСТВ 070
АЛИЗИРОВАЛ 125 АТИВН 103
АЛИЗИРОВАН 126 АТИВНО 152
АЛИЗИРОВАНН 103 АТИВНОСТ 055
АЛИЗИРОВАТЬ 144 АТИЗАТОР 021
АЛИЗМ 001 АТИЗАЦИ 061
АЛИЗОВАН 126 АТИЗИРОВАВШ 105
АЛИЗОВНН 103 АТИЗИРОВАЛ 125
АЛИЗОВАННО 152 АТИЗИРОВАП 126
АЛИЗУ 116 АТИЗИРОВАНН 103
АЛИЗУЕМ 103 АТИЗИРОВАТЬ 144
АЛИЗУЮЩ 105 АТИЗИРОВАТЬСЯ 144
АЛИСТСК 106 АТИЗИРУ 116
АЛЬП 103 АТИЗИРУЕМ 103
АЛЬП 126 АТИЗИРУЙ 143
АЛЬНИК 031 АТИЗИРУЙТЕ 143
АЛЬНО 152 АТИЗИРУЮЩ 105
АЛЬПОСТ 055 АТИЗИРУЯ 152
АЛЬСТВУЮЩ 105 АТИК 060
АН 126 АТИЧЕСК 106
АНЕЦ 032 АТИЧЕСКИ 152
АНИ 073
♦) В составлении словаря принимали участие Н. Н. Абрамова, Г.М. Губайдулина, Ю.П. Калинин, М.В. Поздняк и А.А. Хорошилов.
262
Приложение 2 (продолжение)
Буквенные коды Флек тив-ные классы Буквенные коды Флективные классы
АТИЧН 103 влявш 105
АТИЧНО 152 ВЛЯЕМ 103
АТИЧНОСТ 055 ВЛЯЙ 143
ATOP 001 ВЛЯЙТЕ 143
ATOP 021 ВЛЯЛ 125
АТОРН 103 ВЛЯТЬ 144
АТОРСК 106 ВЛЯТЬСЯ 144
АТЬ 144 ВЛЯЯ 152
АТЬСЯ 144 вн 103
АЦИ 046 вн 107
АЦИ 061 ВОВАВШ 105
АЦИОНН 103 ВОВАЛ 125
АЦИОННПК- 031 ВОВАТЬ 144
АЦИОННО 152 вок 060
АЧ 105 ВУ 116
АШН 104 ВУЙ 143
АЩ 105 ВУЙТЕ 143
АЮЩ 105 ВУЮШ 105
АЯ 152 ВУЯ 152
АЯСЬ 152 ВЦ 021
Б 056 ВШ 105
В 001 ВШИ 152
В 055 ВШИСЬ 152
В 117 ВЬ 143
В 152 ВЬТЕ 143
ВА 116 ГИВА 116
ВАВШ 105 ГИВАВШ 105
ВАЕМ 103 ГИВАЕМ 103
ВАЙ 143 ГИВАЙ 143
БАЙСЯ 143 ГИВАЙТЕ 143
ВАЙТЕ 143 ГИВАЛ 125
БАЙТЕСЬ 143 ГИВАТЕЛ 003
ВАЛ 125 ГИВАТЬ 144
ВАНИ 073 ГИВАТЬСЯ 144
ВАТЕЛ 027 ГИВАЮЩ 105
ВАТЕЛЬН 103 ГИВАЯ 152
ВАТЬ 144 ГИВАЯСЬ 152
ВАТЬСЯ 144 д 056
ВАЮЩ 105 д 116
ВАЯ 152 д .. 120
ВАЯСЬ 152 ДЕБЕН 126
ВЕЦ 021 ДЕБН 103
ВИВ 152 ДЕБН 126
ВИЛ 125 ДЕБНО 152
ВИТЬ 144 ДЕН 126
ВК ВЛ ВЛЕН 060 117 126 ДЕНИ ДЕНН 073 103
ВЛЕНН 103 ДИ 143
ВЛЯ 116 ДИТЕ 143
263
Приложение 2 (продолжение)
Буквенные коды Флективные классы j Буквенные коды Флективные классы
ДОВАТЬ 144 ЕКО 152
ДУЩ 105 ЕЛ 001
ДУЯ 152 ЕЛ 125
дя 152 ЕЛЬН 103
Е 116 ЕЛЬН 126
Е 152 ЕЛ ЬНО 152
ЕВ 056 ЕМ 056
ЕБН 103 ЕМ 103
ЕБНИК 006 ЕМ 126
ЕВ 044 ЕМН 103
ЕВ 103 ЕМО 152
ЕВ 107 ЕМОСТ 055
ЕВ 152 ЕН 003
ЕВА 116 ЕН 066
ЕВАВ1П 105 ЕН 076
ЕВАЙ 143 ЕН 103
ЕВАЙТЕ 143 ЕН 126
ЕВАЛ 125 ЕНЕН 126
ЕВАНИ 073 ЕНЕЦ 032
ЕВАТЬ 144 ЕНИ 073
ЕВАЮЩ 105 ЕНИЗИРОВАН 126
ЕВАЯ 152 ЕНИЗИРОВАНН 103
ЕВН 103 ЕНИК 031
ЕВН 107 ЕНИЦ 045
ЕВНИК 006 ЕНН 103
ЕВНО 152 ЕНН 104
ЕВСК 106 ЕНН 107
ЕВСТВ 070 ЕНН 126
ЕВШ 105 ЕННЕ 152
ЕВШИ 152 ЕННЕЕ 152
ЕВШИСЬ 152 ЕННЕЙ 152
ЕЕ 152 ЕННИК 031
ЕЖ 002 ЕННО 152
ЕЖН 103 ЕННОСТ 055
ЕЖНИК 031 ЕНСТВ 070
ЕЖНИЦ 045 ЕНСТВОВАВШ 105
ЕЙ 143 ЕНСТВОВАЛ 125
ЕЙ 152 ЕНСТВОВАНИ 073
ЕЙК 060 ЕНСТВОВАТЬ 144
ЕЙН 103 ЕНСТВОВАТЬСЯ 144
ЕЙН 126 ЕНСТВУ 116
ЕЙНО 152 ЕНСТВУЕМ 103
ЕЙСК 106 ЕНСТВУЙ 143
ЕЙТЕ 143 ЕНСТВУЙТЕ 143
ЕЙЧАТ 103 ЕНСТВУЯ 152
ЕЙШ 105 ЕНСТВУЯСЬ 152
ЕК 006 ЕНТ 021
ЕК 060 ЕНТН 103
ЕК 106 ЕНЦ 032
264
Приложение 2 (продолжение)
Буквенные коды Флективные классы Буквенные коды Флективные классы
ЕНЦИ 061 ЗМ 001
ЕНЧЕСК 106 и 005
ЕНЬК 106 и 025
ЕР 001 и 061
ЕР 021 и 073
ЕРН 103 и 143
ЕРОВАТЬ 144 II 152
ЕРУ 116 ИАЛЕН 126
ЕРУ ЕМ 103 ИАЛЬН 103
ЕРУЮЩ 105 ИАЛЬН 126
ЕРУЯ 152 ИАЛЬНО 152
ЕСК 106 ПАТ 001
ECKII 152 ИВ 056
ЕСН 103 ИВ 103
ECHO 152 ИВ 126
ЕСТ 055 ИВ 152
ЕСТВ 070 ИВА 116
ЕСТВЕНН 103 ИВАВШ 105
ЕСТВЕННЕЕ 152 ИВАЕМ 103
ЕСТВЕННО 152 ИВАН 143
ЕТИК 031 ИВАПТЕ 143
ЕТИК 060 ИВАЛ 125
ЕТИЧЕСК 106 ИВАНН 073
ЕТИЧЕСКП 152 ИВАТЕЛ 003
ЕТЬ 144 ИВАТЬ 144
ЕТЬСЯ 144 ИВАТВСЯ 144
ЕЦ 001 ИВАЮЩ 105
ЕЦ 011 ИВАЯ 152
ЕЦ 021 ИВАЯСЬ 152
ЕЦ 032 ИВЕН 126
ЕЧЕК 060 ИВН 103
ЕЧК 060 ПВН 126
ЕЧН 103 ИВНЕЕ 152
ЕЮЧИ 152 ИВНЕЙШ 105
ЕЮЩ 105 ИВНО 152
ЕЯ 152 ИВНОСТ 055
Ж 057 ИВОСТ 055
жд 056 ИВШ 105
ЖЕК 060 ИВШИ 152
ЖЕНИ 073 ИВШИСЬ 152
ЖК 060 ИЕВ 103
ЖН 103 ИЗ 056
ЗАТОР 021 ИЗАТОР 001
ЗАТОРСК 106 ИЗАТОРСК 106
ЗАЧИ 061 ИЗАЦИ 061
ЗИРОВАВШ 105 ИЗАЦИОНН 103
ЗИРОВАЛ ЗИРОВАТЬ 125 144 ИЗИРОВАВ 152
ЗИРУ 116 ИЗИРОВАВШ 105
ЗИРУЕМ 103 ИЗИРОВАЛ 125
265
Приложение 2 (продолжение)
Буквенные коды Флективные классы Буквенные коды Флективные классы
ИЗИРОВАН 126 ИМО 152
ИЗИРОВАНИ 073 ИМОСТ 055
ИЗИРОВАНН 103 ИН 021
ИЗИРОВАТЬ 144 ИН 037
ИЗИРОВЛТЬСЯ 144 ИН 056
ИЗИРУ 116 ПН 103
ИЗИРУЕМ 103 ИНА 116
ИЗИРУЙ 143 ИНАВШ 105
ИЗИРУЙТЕ 143 ИНАЕМ 103
ИЗИРУЮЩ 105 ИН АЙ 143
ИЗИРУЯ 152 ИНАЙТЕ 443
ИЗИРУЯСЬ 152 ИНАЛ 125
изм 001 ИНАЛЬН 103
изн 056 ИНАНИ 073
ИЗОВАВШ 105 ИНАТЬ 144
ИЗОВАЛ 125 ИНАЮ1Ц 105
ИЗОВАН 126 ИНАЯ 152
ИЗОВАНН 103 ИНАЯСЬ 152
ИЗОВАТЬ 144 ИНЕЦ 032
ИЗОВАТЬСЯ 144 ИНК 051
ИЗУ 116 ПИСК 106
ИЗУЕМ 103 ПНСТВЕННО 152
ИЗУЙ 143 ИНСТВЕНН 103
ИЗУЙТЕ 143 ИНЦ 032
ИЗУЮЩ 105 ИОНН 103
ИЗУЯ 152 ИР 001
ИЗУЯСЬ 152 ИР 021
ИЙН 103 И PH 103
ИЙСК 106 КРОВАВ 152
ИК 006 ИРОВАВШ 105
ИК 031 ИРОВАВШИ 152
ИК 060 ИРОВАЛ 125
ИК 101 ИРОВАН 126
ИЛ 125 ИРОВАНИ 073
или 061 ИРОВАНН 103
илк 060 ИРОВАННО 152
ИЛЬИ 103 ИРОВАННОСТ 055
илвник 006 ИРОВАТЬ 144
им 103 ИРОВАТЬСЯ 144
им 126 ИРОВК 060
ИМА 116 ИРОВОК 060
ИМАВШ 105 ИРОВОЧН 103
ИМАЕМ 103 ИРОВЩИК 006
ИМАЙ 143 ИРУ 116
ИМАЙТЕ 143 ИРУЕМ 103
ИМАЛ ИМАТЬ 125 144 ИРУЙ 143
ИМАТЬСЯ 144 ИРУЙСЯ 143
ИМАЮЩ 105 ИРУЙТЕ 143
ИМАЯ 152 ИРУЙТЕСЬ 143
266
Приложение 2 (продолжение}
Буквенные коды Флектив- Флектив-
ныв Буквенные коды ные
классы j классы
ПРУЮЩ ИРУЯ ИРУЯСЬ ист ист ист истин ИСТИЧЕСК ИСТИЧЕСКИ истк исток 105 152 152 001 021 103 060 106 152 051 051 ИСК иск пся ПТЕ ЙТЕСЬ ЙЧИВ ЙЧИВ ЙЧИВОСТ к к к к к к ко КОВ КТОР KTOPCK кци 070 106 143 143 143 103 126 055 006 031 051 060 106 130 152 103 021 106 061 055 065 103 116 117 125 152 103 126 073
истск ись ит ит ИТЕ ИТЕЛ ИТЕЛ ИТЕЛ ИТЕЛЕН 106 143 103 126 143 003 027 030 126
ИТЕЛЬН 103 л л тт
ИТЕЛЬН 126
ИТЕЛЬНЕЕ 152 л тг
ИТЕЛЬНИЦ 045 л тт
ИТЕЛЫЮ 152 л
ИТЕЛЬНОСТ 055 л ЛЕ -ЛЕМ ЛЕН ЛЕНИ
ИТЕЛЬСК ИТЕЛЬСТВ ИТЕСЬ И ГЕТ 106 070 143 001
ИТО ИТЬ иться ИЦ ИЦ ИЧЕН ИЧЕСК ИЧЕСКИ ИЧЕСТВ 152 144 144 045 067 126 106 152 070 ЛЕНН ЛЕННОСТ ЛЕЦ ЛИВ лив ЛИВА ЛИВАЕМ ЛИВАН ЛИВАЙТЕ 103 055 032 103 126 116 103 143 143
ИЧН 103 126 ЛИВАНИ 073
ИЧН ЛИВАТЬ 144
ИЧНЕЕ 152 ЛИВАЮЩ 105
ИЧНО 152 ЛИВАН 152
И ч ноет 055 ЛИВОСТ 055
ищ и 074 143 060 ЛИВШ лил 105 125
ПК ЛИТЕЛ 003
пн 056 ЛИТЕЛЬН 103
пн 103 ЛИТЬ литься 144 144
пно 152 лк 060
267
Приложение 2 (продолжение)
Буквенные коды Флективные классы Буквенные коды Флективные ’классы
лок 060 нност 055
льн 065 но 143
льн льч 103 032 но 152
лющ 105 НОВЕНИ 073
ля 116 ноет 055
ля 117 ностн 103
ля 152 НУВ 152
лявш 105 НУВШ 105
ЛЯЕМ 103 НУВШИ 152
ЛЯЙ 143 НУВШИСЬ 152
ляйся 143 НУТ 103
ЛЯЙТЕ 143 НУТ 126
ЛЯЙТЕСЬ 143 ПУТЬ 144
лял 125 НУТЬСЯ 144
лясь 152 нь 143
лять 144 НЕСЯ 143
ляться 144 НЬТЕ 143
ляющ 105 ПЬТЕСЬ 143
ляя 152 О 116
ЛЯЯСЬ 152 О 143
н 103 О 145
н 104 О 147
н 107 О 152
н 120 О 154
н 126 ОБ 056
НЕВШ 105 ОБ1ЦИК 031
НЕЕ 152 ов 055
НЕЙ 152 ов 103
НЕЙШ 105 ов 107
НЕЛ 125 ов 126
НЕТЬ 144 OBAB 152
НЕЮШ 105 ОВАВПГ 105
НЕЯ 152 ОВАВШИ 152
НИ 073 ОВАВШИСЬ 152
НИ 143 ОВАЛ 125
НИК 006 ОВАЛ 126
НИК 031 ОВАЛЕН 103
НИТЕ 143 ОВАЛБНИК 006
НИЦ 045 О ВАН 126
НИЧА 116 ОВА1Ш 073
НИЧАВШ 105 ОВАНН 103
НИЧАЛ 125 ОВА1ШО 152
НИЧАТЬ 144 ОВАНПОСТ 055
НИЧАЯ 152 ОВАТ 103
НИЧЕСК 106 ОВАТ 126
НИЧЕСТВ 070 ОВАТЕЛ 027
НН 103 ОВАТЕЛЕН 126
НН 126 ОВАТЕЛБН 126
ННО 152 ОВАТЕЛЕНО 152
268
Приложение 2 (продолжение)
Буквенные коды Флективные классы Буквенные коды Флективные классы
ОВАТЕ ЛЬНОСТ 055 ОМ 152
ОВАТЕЛЬСК 106 ОНАЛ 001
ОВАТО 152 ОНАЛ ОНАЛЕН 021 126
ОВАТЬ 144 ОНАЛИЗМ 001
ОВАТЬСЯ 144 ОНАЛЬН 103
ОВЕНИ 073 ОНАЛЬН 126
ОВЕНН 103 ОНАЛЬНЕЕ 152
ОВЕННОСТ 055 ОПАЛЬНО 152
ОВИК 006 ОНАЛЬНОСТ 055
ОВИК 031 ОНЕР 001
овист 103 ОНЕРН 103
овк 051 ОНИЗМ 001
овк 060 ОНИРОВАВШ 105
овл 063 ОНИРОВАНИ 073
овн 103 ОНИРОВАНН 103
овник 031 ОПИРОВАТЬ 144
овниц 045 ОНИРУ 116
ОВОН 060 ОНИРУЮЩ 105
овочн 103 ОНИРУЯ 152
овочно 152 онист 021
овск 106 OHHCTCK 106
овш 105 онн 103
овщик 006 онн 126
ОБЩИ К 031 онно 152
овщин 056 онност 055
ОВЫВА 116 ОР 001
ОВЫВАВШ 105 ОР 021
СБЫВАЕМ 103 ОРН 103
ОВИВАЙ 143 ОРСК 106
ОВИВАЙТЕ 143 ост 055
ОВИВАЛ 125 остлив 103
ОВИВАТЬ 144 остливо 152
ОВИВАТЬСЯ 144 остн 103
ОВЫВАЮЩ 105 остн 107
ОВИВАЯ 152 от 056
ОВИВАЯСЬ 152 от 103
оид 056 отн 103
ОИДАЛЬН 103 отност 055
ОЙ 143 оть 144
ОЙ 152 оться 144
ОЙСЯ 143 ОЧЕК 006
ОЙТЕ 143 ОЧЕК 060
ОЙТЕСЬ 143 ОЧЕЧН - 103
ОК 006 очк 006
ОК 031 очк 060
ОК 051 очн 103
ок 060 очн 126
ОК 126 очно 152
ол 125
269
Приложение 2 (продолжение)
Буквенные коды Флективные классы Буквенные коды Флективные кл а < ы
РОВАН 126 ТЕЛ 003
РОВАНН 103 ТЕЛ 027
СК 106 ТЕЛЕН 126
СК 110 ТЕЛЬН 126
ст 021 ТЕЛЬН 103
ств 070 ТЕЛ ЬНО 152
СТВЕНЕН 126 ТЕЛЬНОСТ 055
СТВЕНН 103 ТЕЛЬСК 106
СТВЕНН 126 ТЕЛЬСТВ 070
CTBEHHEE 152 ТЕП 126
СТВЕННЕЙШ 105 ТЕНИ 073
СТВЕННО 152 ТЕНН 103
СТВЕННОСТ 055 ТИ 073
стви 073 ТИ 144
CTBOBAB 152 ТИВЕН 126
СТВОВАВШ 105 ТИВН 103
СТВОВАЛ 125 ТИВН 126
СТВОВАН 126 тивно 152
СТВОВАНИ 073 тись 144
СТВОВАНН 103 тк 006
СТВОВАПНО 152 тп 103
СТВОВАТЬ 144 TH 126
СТВОВАТЬСЯ 144 ток 006
СТВУ 116 ТОР 021
СТВУЕМ 103 ТОРСК 106
СТВУЙ 143 точн 103
СТВУЙСЯ 143 точн 126
СТВУЙТЕ 143 точно 152
СТВУЙТЕСЬ 143 ТЧИК 006
СТВУЮЩ 105 ТШ 105
СТВУЯ 152 ТЬ 144
СТВУЯСЬ 152 ться 144
сти 144 У 116
стись 144 У 152
сть 144 УАЛЕП 126
т 103 УАЛИЗАЦИ 061
т 120 УАЛЬН 103
т 126 УАЛЬН 126
ТА 116 УАЛЬНЕЕ 152
ТАВШ 105 УАЛЬНО 152
ТАЕМ 103 УАЛЫЮСТ 055
ТАЙ 143 УВ 152
ТАЙТЕ 143 УВШ 105
ТАЛ 125 УВШИ 152
ТАНИ 073 УВШПСЬ 152
ТАТЬ 144 УЕМ 103
ТАТЬСЯ 144 УЕМОСТ УЙ 055 143
ТАЮЩ 105 УЙСЯ 143
ТАЯ 152 УЙТЕ 143
270
Приложение 2 (продолжение)
Буквенные коды Флективные классы Буквенные коды Флективные классы
УЙТЕСЬ 143 ЧЕСКИ 152
УЛ 125 ЧЕСТВ 070
УР 056 чив 103
УРН 103 - ЧИВ 126
УРНО 152 ЧИВО 152
УТ 103 чивост 055
УТ 126 чик 006
УТЬ 144 чик 031
УТ вся 144 ЧИКОВ 103
УЧ 105 ЧИН 034
УЧЕСТ 055 чиц 045
УШК - 060 чн 103
УЩ 105 чн 126
УШЕСТВ 070 ЧНЕЕ 152
УШЕСТВЕН 126 чно 152
УШЕСТВЕНН 103 чност 055
УЮЩ 105 III 105
УЯ 152 ши 152
ФИКАТОР 001 шин 034
ФИКАТОР 021 шинств 070
ФИКАЦИ 061 шись 152
ФИКАЦИОНН 103 шн 104
ФИЦИРОВАВШ 105 шик 031
ФИЦИРОВАЛ 125 шин 044
ФПЗИРОВАП 126 шин 056
ФИЦИРОВАНИ 073 ыв 152
ФИЦИРОВАНН 103 ШВА 116
ФИЦИРОВАТЬ 144 ЫВАВШ 105
ФИЦИРОВАТЬСЯ 144 ЫВАЕМ 103
ФИЦИРУ 116 ЫВАЙ 143
ФИЦИРУЕМ 103 ЫВАЙСЯ 143
ФИЦИРУЙ 143 ЫВАЙТЕ 143
ФИЦИРУЙТЕ 143 ЫВАЙТЕСЬ 143
ФИЦПРУЮЩ 105 ЫВАЛ 125
ФИЦИРУЯ 152 ЫВАНИ 073
ц 001 ЫВАТЬ 144
ц 011 ЫВАТЬСЯ 144
ц 021 ЫВАЮЩ 105
Ц 032 ЫВАЯ 152
ЦП 061 ЫВАЯСЬ 152
цовск 106 ЫВШ 105
ч тт 002 ЫВШИ 152
ч ЧАН 057 037 ывшись 152
ЧАНИН 037 ЫЛ 125
ЧАНК 051 ыт 103
ЧАТ 126 ыт 126
ЧАТК ЧАТОСТ 060 055 ыти 073
ЧЕН 126 ыть 144
ЧЕНСК 106 ыться 144
271
Приложение 2 (окончание)
Буквенные коды Флективные классы
ыш 016
ЫШЕК 006
ЫШК 006
ышк 070
ышн 103
ь 143
ЬБ 056
ЬЕВ 107
ьк 006
ьк 060
ьков 103
ьм 070
ЬМЕНН 103
ЬМЕННО 152
ьн 066
ьн 103
ьн 104
ьн 107
ьн 126
ЬНЕЕ 152
ЬНЕЙ 152
ЬНЕЙШ 105
ЬНИК 031
ЬНИЦ 045
ЬНО 152
ьност 055
ьск 106
ьств 070
ьстви 073
ЬСТВОВАВШ 105
ЬСТВОВАЛ 125
ЬСТВОВАНИ 073
ЬСТВОВАТЬ 144
ЬСТВОВАТЬСЯ 144
ЬСТВУ 116
ЬСТВУЙ 143
ЬСТВУ ЙСЯ 143
ЬСТВУЙТЕ 143
ЬСТВУЙТЕСЬ 143
ЬСТВУЮЩ 105
ЬСТВУЙСЯ 152
ЬСТВУЯСЬ 152
ься 143
ЬТЕ 143
ЬТЕСЬ 143
ЬЦ 032
ьц 074
ЬЧАТ 103
ЬЧАТ 126
ЬЧАТОСТ 055
ЬЧЕСК 106
Буквенные коды Флективные классы
ып НО
ЫПЕ 152
ЫПИНСТВ 070
ыпик 006
ыцик 031
ЬЯНЕЦ 032
ЬЯНК 051
ьянск 106
ю 116
ЮЙ 143
ЮЙТЕ 143
юш 105
ююш 105
юя 152
я 116
я 152
яв 152
явш 105
явши 152
явшись 152
ЯЕМ 103
ЯЕМ 126
ЯЕМОСТ 055
ЯЙ 143
ЯЙСЯ 143
ЯЙТЕ 143
ЯЙТЕСЬ 143
як 031
ял 125
ян 103
ян 107
ян 126
яни 073
ЯНИН 037
ЯНК 060
ЯНН 103
ЯР 021
ЯСЬ 152
ЯТ 103
ят 126
ЯТОР 001
ЯТОРН 103
ЯТЬ 144
яться 144
яци 061
яционн 103
ЯШ 105
яющ 105
яя 152
272
Приложение 3
ФРАГМЕНТЫ НАУЧНО-ТЕХНИЧЕСКОГО СЛОВАРЯ
Настоящий научно-технический словарь составлен на основе анализа текстов общей протяженностью более трех миллионов слов. При его составлении использовались тексты широкой тематики и тексты реферативных журналов по информатике, автоматике и телемеханике, вычислительной технике и радиоэлектронике. В словарь вошли 29 000 наиболее часто встречающихся словоформ, которые содержат около 17 000 различных словоизменительных и около 10 000 словообразовательных основ слов (определения словоизменительных и словообразовательных основ см. в гл. 7). В создании научно-технического словаря наряду с авторами книги принимали участие Абрамова Н. Н., Гальперина Т. А., Калинин Ю. П., Матвеева Е. Г., Панова Н. С., Партыко 3. В., Позд-пяк М. В., Рыжова Е. Ю., Федорчук А. В., Хорошилов А. А., Штурман Я. П., Яфаева Г. М.
Словарная статья словаря состоит из следующих элементов: — буквенный код словоформы;
— длина словообразовательной основы (количество букв, составляющих словообразовательную основу);
— длина словоизменительной основы (количество букв, составляющих словоизменительную основу);
— номер флективного (словоизменительного) класса словоформы (см. табл. 7.3);
— номер словообразовательного класса словоформы (см. гл. 7 и приложение 1). Эти элементы являются минимально необходимыми при работе алгоритма многоступенчатого морфологического анализа (см. гл. 7).
Каждая словарная статья начинается с буквенного кода словоформы. Справа от нее указывается длина словообразовательной основы (две цифры), длина словоизменительной основы (две цифры), код флективного класса (три цифры) и код словообразовательного класса (четыре цифры). Цифровые характеристики словоформ отделяются друг от друга косой чертой. Словарь введен в ЭВМ и используется в различных системах автоматической обработки текстов.
а
аберраций абонентами абонентской абразива абразивные абсолютно абсолютного абсолютным
01/01/153/0000 08/08/061/0843 07/07/021/08'90 07/09/106/0892 07/07/001/0770 07/08/103/0770 08/09/152/0646 08/08/103/0646
08/08/103/0646
абсолютных абсорбера абстрагирования абстрагированных абстрактного абстрактной абстракции абсцисс
08/08/103/0646
08/08/001/0000
09/14/073/0452
09/14/103/0430
09/09/103/0638
09/09/103/0638
09/09/061/0870
07/07/056/0000
18 Г, Г, Белоногов, Б. А. Кузнецов
273
авангард 08/08/001/0770 австрийским 06/09/106/0765
авангарда 08/08/001/0770 австрийских 06/09/106/0765
авангардного 08/09/103/0770 австрийское 06/09/106/0765
авангардном 08/09/103/0770 австрийской 06/09/106/0765
авангардный 08/09/103/0770 Австрию 06/06/061/0765
авангарды 08/08/001/0770 Австрия 06/06/061/0765
аварии 05/05/061/0767 автобус 07/07/001/0770
аварий 05/05/061/0767 автобусов 07/07/001/0770
аварийного 05/07/103/0767 автогенератор 13/13/001/0000
аварийность 05/10/055/0767 автогрейдеры 11/11/001/0890
аварийные 05/07/103/0767 автодорожным 09/10/103/0000
аварийным 05/07/103/0767 автодорожных 09/10/103/0000
аварийных 05/07/103/0767 автоионном 08/08/103/0640
август 06/06/001/0837 автокода 07/07/001/0770
августа 06/06/001/0837 а втокорреля ционным 13/16/103/0864
августе 06/06/001/0837 автокранов 08/08/001/0837
авиабаз 07/07/056/0000 автокраны 08/08/001/0837
авиабаза 07/07/056/0000 автолегирования 14/14/073/0000
авиабазами 07/07/056/0000 автомагистралях 13/13/055/0939
авиабазах 07/07/056/0000 автомат 07/07/001/0206
авиабазе 07/07/056/0000 автомата 07/07/001/0206
авиабазой 07/07/056/0000 автоматами 07/07/001/0206
авиабазу 07/07/056/0000 автоматизации 07/12/061/0206
авиабазы 07/07/056/0000 автоматизированная 07/16/103/0206
авиабилетов 09/09/001/0770 автоматизированной 07/16/103/0206
авиабомб 08/08/056/0000 автоматизированы 07/15/126/0206
авиабомбами 08/08/056/0000 автоматизировать 07/16/144/0206
авиабомбы 08/08/056/0000 автоматизируется 07/12/116/0206
авиагруппа 09/09/056/0000 автоматизирующая 07/14/105/0206
авиалиний 08/08/061/0000 автоматики 007/09/060/0206
авианосец 07/09/011/0784 автоматическая 07/12/106/0206
авианосная 07/08/103/0793 автоматически 07/13/152/0206
авианосцы 07/08/011/0793 автоматические 07/12/106/0206
авиацией 06/06/061/0843 автоматических 07/12/106/0206
авиации 06/06/061/0843 автоматического 07/12/106/0206
авиационная 06/09/103/0843 автоматическое 07/12/106/0206
авиационного 06/09/103/0843 автоматической 07/12/106/0206
авиационное 06/09/103/0843 автоматическом 07/12/106/0206
авиационной 06/09/103/0843 автоматическую 07/12/106/0206
авиационном 06/09/103/0843 автоматного 07/08/103/0206
авиационному 06/09/103/0843 автоматов 07/07/001/0206
авиационную 06/09/103/0843 автоматом 07/07/001/0206
авиационные 06/09/103/0843 автоматчиками 07/10/031/0206
авиационный 06/09/103/0843 автоматчики 07/10/031/0206
авиационным 0*6/09/103/0843 автоматчиков 07/10/031/0206
авиационными 06/09/103/0843 автоматы 07/07/001/0206
авиационных 06/09/103/0843 автомашин 09/09/056/0777
авиацию 06/06/061/0843 автомашинами 09/09/056/0777
авиация 06/06/061/0843 автомашинах 09/09/056/0777
АВМ 03/03/146/0000 автомашине 09/09/056/0777
Австралии 08/08/061/0765 автомашины 09/09/056/0777
австралийскому 08/11/106/0765 автомобилей 09/09/003/0937
Австралию 08/08/061/0765 автомобилем 09/09/003/0937
Австралия 08/08/061/0765 автомобили 09/09/003/0937
Австрией 06/06/061/0765 автомобиль 09/09/003/0937
австриец 06/08/032/0767 автомобильного 09/11/103/0937
Австрии 06/06/061/0765 автомобильной 09/11/103/0937
274
автомобильную автомобильные автомобильный автомобильным автомобильных автомобилю автомобиля автомобилями автомобилях автономен автономно автономного автономности автономность автономных автопереключателя автоподстройки автоприцепов автор
автора автореферат авторитет авторитета авторов авторские авторских авторство автосброса автостраде автотранспорт автотранспорта автотранспорте автотранспортная автотранспортной автотранспортному автотранспортную автотранспортные автотранспортный автотранспортными автотранспортных автотранспортом автотранспорту автотрансформатора автофазной автоцистерн автоцистерна автоцистернам автоцистернах автоцистерне автоцистерну автоцистерны автошлагбаумов автоштурмана автоэлектронной автоэмиссионного автоэмиттера
агенсу
18*
09/11/103/0937 агент 05/05/021/0921
09/11/103/0937 агентов 05/05/021/0921
09/11/103/0937 агломерата 09/09/001/0770
09/11/103/0937 агломерационные 10/13/103/0843
09/11/103/0937 агрегат 07/07/001/0818
09/09/003/0937 агрегата 07/07/001/0818
09/09/003/0937 агрегатам 07/07/001/0818
09/09/003/0937 агрегатный 07/08/103/0770
09/09/003/0937 агрегатов 07/07/001/0818
09/09/126/0000 агрегаты 07/07/001/0818
08/09/152/0640 агрегированных 07/12/103/0430
08/08/103/0640 агрессивного 06/09/103/0751
08/11/055/0640 агрессией 06/07/061/0751
08/11/055/0640 агрессорам 06/08/021/0751
08/08/103/0640 агроном 07/07/021/0725
16/16/003/0937 адаптации 05/08/061/0256
13/13/060/0000 адаптацию 05/08/061/0256
10/10/001/0000 адаптер 07/07/001/0000
05/05/021/0899 адаптивного 05/08/103/0256
05/05/021/0899 адаптивность 05/11/055/0256
11/11/001/0757 адаптивных 05/08/103/0256
09/09/001/0808 адаптирован 05/11/126/0256
09/09/001/0808 адаптироваться 05/14/144/0256
05/05/021/0899 адаптируемого 05/10/103/0256
05/07/106/0899 адаптируется 05/08/116/0256
05/07/106/0899 адвербиальных 11/11/103/0000
05/08/070/0899 адгезию 06/06/061/0000
09/09/001/0000 аддитивной 08/08/103/0638
09/09/056/0777 адекватной 08/08/103/0629
13/13/001/0770 адекватности 08/11/055/0640
13/13/001/0770 адиабатического 07/12/106/0731
13/13/001/0770 административная 09/14/103/0663
13/14/103/0770 административного 09/14/103/0663
13/14/103/0770 административное 09/14/103/0663
13/14/103/0770 административной 09/14/103/0663
13/14/103/0770 административном 09/14/103/0663
13/14/103/0770 административную 09/14/103/0663
13/14/103/0770 административные 09/14/103/0663
13/14/103/0770 административный 09/14/103/0663
13/14/103/0770 административным 09/14/103/0663
13/13/001/0770 административными 09/14/103/0663
13/13/001/0770 административных 09/14/103/0663
17/17/001/0770 администратор 09/13/021/0215
08/08/103/0000 администратора 09/13/021/0215
11/11/056/0846 администрации 09/12/061/0215
11/11/056/0846 администрация 09/12/061/0215
11/11/056/0846 адмирал 07/07/021/0943
11/11/056/0846 адрес 05/05/010/0449
11/11/056/0846 адресатами 05/07/001/0449
11/11/056/0846 адресации 05/08/061/0450
11/11/056/0846 адресной 05/06/103/0770
12/12/001/0770 адресность 05/09/055/0808
11/11/001/0000 адресована 05/09/126/0449
13/13/103/0638 адресование 05/10/073/0449
13/13/103/0640 адресованного 05/10/103/0449
11/11/001/0770 адресовано 05/09/126/0449
05/05/001/0000 адресовать 05/10/144/0449
275
, 1 адресу 05/05/010/0440 активность 05/09/055/0808
адресуемой 05/08/103/0449 активностью 05/09/055/0808
адресуется 05/06/116/0449 активную 05/06/103/0808
адресуются 05/06/116/0449 активные 05/06/103/0808
адсорбата 08/08/001/0783 активный 05/06/103/0808
адсорбент 09/09/001/0770 активным 05/06/103/0808
i адсорбированного 08/13/103/0430 активными 05/06/103/0808
i> адсорбций 08/08/061/0843 активных 05/06/103/0808
адсорбционной 08/11/103/0843 актов 03/03/001/0837
адъютант 08/08/021/0892 актуализации 06/11/061/0963
азербайджанской 11/13/106/0890 актуализация 06/11/061/0963
Азии 03/03/061/0000 актуальной 03/08/103/0922
азимут 06/06/001/0770 актуальным 03/08/103/0922
азимута 06/06/001/0770 актуальных 03/08/103/0922
азимуту 06/06/001/0770 акустически 05/11/152/0929
азимуты 06/06/001/0770 акустических 06/10/106/0929
азорских 06/06/106/0000 акустической 05/10/106/0929
азота 04/04/001/0790 акустическую 06/10/106/0929
азотирования 06/11/073/0430 акустооптический 14/14/106/0000
азотная 04/05/103/0770 акустопроводимости 17/17/055/0000
i; азотной 04/05/103/0770 акцент 06/06/001/0277
Г АИПС 04/04/146/0000 акцентуация 10/10/061/0843
АИС 03/03/146/0000 акцепторных 08/09/103/0770
Г академии 07/07/061/0927 акцепторов 08/08/001/0770
академик 08/08/031/0000 алгебраических 06/12/106/0661
1 аккомодации 10/10/061/0843 алгебры 06/06/056/0661
I1 аккумулятора 07/11/001/0275 алгол 05/05/001/0000
аккумуляторная 07/12/103/0275 алголоподобный 12/12/103/0629
аккумуляторной 07/12/103/0275 алгоритм 08/08/001/0725
аккумуляторную 07/12/103/0275 алгоритмизация 08/13/061/0194
аккумуляторные 07/12/103/0275 алгоритмически 08/14/152/0758
аккумуляторных 07/12/103/0275 алгоритмический 08/13/106/0758
аксиального 08/08/103/0000 алеутские 05/07/106/0892
аксиом 06/06/056/0777 алеутских 05/07/106/0892
акт 03/03/001/0837 Алжир 05/05/001/0890
акта 03/03/001/0837 алжирская 05/07/106/0890
актами 03/03/001/0837 алжирцев 05/06/032/0910
актантами 06/06/001/0770 аллографов 08/08/001/0755
актантного 06/07/103/0770 алломорфы 08/08/001/0790 ;
актива 05/05/001/0808 алмаза 05/05/001/0770
активатор 09/09/001/0000 алмазной 05/06/103/0770 |
активатора 09/09/001/0000 алфавита 07/07/001/0770 j
активатором 05/09/001/0000
активации 05/08/061/0209 атомном 04/05/103/0770 '
активизации 07/10/061/0843 атомному 04/05/103/0770
активизировались 05/13/125/0843 атомную 04/05/103/0770
активированных 07/12/103/0430 атомные 04/05/103/0770
активируем 05/08/116/0209 атомный 04/05/103/0770
активная 05/06/103/0808 атомным 04/05/103/0770
активно 05/07/152/0808 атомными 04/05/103/0770
активно-индуктивную 17/17/103/0000 атомных 04/05/103/0770
активного 05/06/103/0808 атрибутивные 07/10/103/0747 ;
активное 05/06/103/0808 атрибутов 07/07/001/0818
активной 05/06/103/0808 аттенюатора 10/10/001/0000
активном 05/06/103/0808 аттестации 06/09/061/0466 J
активному 05/06/103/0808 аттестованных 06/11/103/0430 *
1 активности 05/09/055/0808 АУ 02/02/147/0000 '
276 -1
I
аудитории 07/08/081/0674 базу 03/03/056/0265
аудиторной 07/08/103/0674 базы 03/03/056/0265
афганец 05/07/032/0002 байт 04/04/001/0837
Афганистан 05/10/001/0909 байто-ориентированной 20/20/103/0000
афганская 05/07/106/0909 байтовой 04/06/103/0837
Африка 05/05/060/0665 бак 03/03/006/0000
африканские 05/09/106/0665 бака 03/03/006/0000
ацетата 06/06/001/0770 баками 03/03/006/0000
ацетилена 08/08/001/0837 баках 03/03/006/0000
ацетоне 06/06/001/0770 баке 03/03/006/0000
АЦПУ 04/04/147/0000 баки 03/03/006/0000
аэрации 06/06/061/0843 баков 03/03/006/0000
аэродинамических 14/14/106/0000 баком 03/03/006/0000
аэродром 08/08/001/0770 бактериальными . 07/11/103/0655
аэродромная 08/09/103/0770 бактериальных 07/11/103/0655
аэронавигационные 12/15/103/0843 бактериологическая 11/16/106/0733
аэронавтике 10/10/060/0000 баланса 06/06/001/0837
аэропортов 08/08/001/0837 балансирами 08/08/001/0430
аэроснимкам 09/09/006/0000 балансирования 08/13/073/0424
аэрофотоаппаратов 15/15/001/0826 балансировка 08/11/060/0456
аэрофоторазведка 14/15/060/0000 балансирующая 08/11/105/0453
аэрофотослужбы 12/13/056/0000 балансного 06/07/103/0770
аэрофотосъемка 12/13/060/0000 балатон 07/07/001/0890
аэрофотосъемочных 12/15/103/0863 балеарские 06/08/106/0000
баба 03/03/056/0000 балканском 06/08/106/0890
баз 03/03/056/0265 балки 04/04/060/0000
база 03/03/056/0265 балкон 06/06/001/0770
базам 03/03/056/0265
базами 03/03/056/0265 буксир 06/06/001/0770
Базанова 07/07/042/0000 буксировки 06/09/060/0770
базах 03/03/056/0265 буксировочные 06/11/103/0770
базе 03/03/056/0265 буксировщик 06/11/006/0770
базировавшаяся 03/10/105/0265 булевых 05/05/103/0677
базировалась 03/09/125/0265 бульдозеры 09/09/001/0770
базировались 03/09/125/0265 буля 03/03/027/0677
базировалось 03/09/125/0265 бумаге 05/05/056/0000
базирование 03/10/073/0265 бумагоделательного 15/15/103/0000
базировать 03/10/144/0265 бумагоопорного 11/11/103/0000
базироваться 03/12/144/0265 бумагопроводящей 14/14/105/0000
базируются 03/06/116/0265 бумажка 05/06/060/0705
базирующаяся 03/08/105/0265 бумажной 06/06/103/0000
базио 05/05/001/0770 бундесвера 09/09/001/0839
базиса 05/05/001/0770 бункеров 06/06/001/0770
базисной 05/06/103/0770 бур 03/03/001/0339
базисном 05/06/103/0770 буржуазией 07/08/061/0779
базо-эмиттерным 13/13/103/0000 буржуазии 07/08/061/0779
базовая 03/05/103/0265 буржуазная 07/08/103/0779
базового 03/05/103/0265 бурного 04/04/103/0629
базовое 03/05/103/0265 бурное 04/04/103/0629
базовой 03/05/103/0265 бурным 04/04/103/0629
базовому 03/05/103/0265 буровые 03/05/107/0339
базовые 03/05/103/0265 буровых 03/05/107/0339
базовый 03/05/103/0265 буртиком 06/06/006/0000
базовым 03/05/103/0265 бурю 03/03/117/0629
базовыми 03/05/103/0265 буря 03/03/063/0629
базовых 03/05/103/0265 буссолей 06/06/055/0939
базой 03/03/056/0265 бустера 06/06/001/0000
277
бутылками 06/06/060/0000 бытия
буфер 05/05/001/0815 бытового
буферизации 05/10/061/0815 быть
буферирование 05/12/073/0815 Бекуса
буферного 05/06/103/0815 БЭСМ
буферное 05/06/103/0815 бюджет
буфетов 05/05/001/0770 бюджетное
бухгалтерские 09/11/106/0895 бюллетень
бухты 04/04/056/0801 бюро
бую 02/02/004/0762 бюрократизация
бы 02/02/154/0000 бюрократические
бывать 02/06/144/0141 в
бывают 02/04/116/0141 в-третьих
бывшая 02/04/105/0141 вагон
бывшего 02/04/105/0141 вагонов
бывшее 02/04/105/0141 важен
бывшей 02/04/105/0141 важна
бывшие 02/04/105/0141 важная важнейшая важнейшего важнейшее важнейшей важнейшем
бывший бывшим бывших был была были 02/04/105/0141 02/04/105/0141 02/04/105/0141 02/03/125/0141 02/03/125/0141 02/03/125/0141
было 02/03/125/0141 важнейшие
быстрая 05/05/103/0653 важнейшим
быстрее 05/07/152/0653 важнейшими
быстрейшего 05/08/105/0653 важнейших
быстрейшее 05/08/105/0653 важнейшую
быстрейшей 05/08/105/0653 важно
быстро 05/06/152/0653 важного
быстрого 05/05/103/0653 важное
быстродействие 13/13/073/0000 важной
быстродействия 13/13/073/0000 важном
быстродействующей 12/15/105/0000 важности
быстродействующих 12/15/105/0000 важность
быстрое 05/05/103/0653 важностью
быстрой 05/05/103/0653 важную
быстром 05/05/103/0653 важные
быстрому 05/05/103/0653 важный
быстропечатающее 14/14/105/0000 важным
быстропротекающих 15/15/105/0000 важными
быстрота 05/07/056/0653 важных '
быстроте 05/07/056/0653 ваза
быстротой 05/07/056/0653 вакансий
быстроты 05/07/056/0653 вакансионный
быстроходные 09/10/103/0000 вакуум
быстроходный 09/10/103/0000 вакуумирование
быстроходными 09/10/103/0000 вакуумированный
быстроходных 09/10/103/0000 вакуумной
быструю 05/05/103/0653 вакуумноплотное
быстрые 05/05/103/0653 вакуумными
быстрый 05/05/103/0653 вакуумных
быстрым 05/05/103/0653 вакуумпровода
быстрых 05/05/103/0653 вакцин
быта 03/03/001/0861 вал
04/04/073/0.000
03/05/107/0861
02/04/144/0141
05/05/021/0839
04/04/146/0000
06/06/001/0770
06/07/103/0770
08/08/003/0000
04/04/147/0000
08/13/061/0194
08/13/106/0755
01/01/164/0000
09/09/154/0000
05/05/001/0770
05/05/001/0770
05/05/126/0000
04/04/126/0715
04/04/103/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/07/105/0715
04/04/126/1715
04/04/103/0715 •
04/04/103/0715
04/04/103/0715
04/04/103/0715
04/07/055/0-715
04/07/055/0715
04/07/055/0715
04/04/103/0715
04/04/103/0715
04/04/103/0715
04/04/103/0715
04/04/103/0715
04/04/103/0715
03/03/056/0000
07/07/061/0000
07/10/103/0843
06/06/001/0770
06/13/073/0267
06/13/103/0267
06/07/103/0770
13/13/103/0000
06/07/103/0770
06/07/103/0770
12/12/001/0813
06/06/056/0798
03/03/001/0336
278
ЁШ 03/03/001/0330 кожухом 05/05/006/0841
вале 03/03/001/0336 козел 05/05/021/0000
валентной 07/07/103/0638 койка 04/04/060/0000
валентностей 07/10/055/0645 колебалось 05/07/125/0035
валентные 07/07'103/063-8 колебания 05'08/073/0035
«••••• 1 $ i
книговыдачи 10/10/057/0000 отведенного 05/08/103/0596
книгообмена 10/10/001/0770 отведенной 65/08/103/0596
книготорговца 11/12/032/0644 отведенные 05/08/103/0596
книготорговых 11/11/103/0644 отведено 05/07/126/0596
книгохранилища 13/13/074/0000 отведены 05/07/126/0596
книжек 04/06/060/0705 отвергает 06/07/116/0094
книжка 05/05/060/0000 отвергают 06/07/116/0094
книжных 04/05/103/0000 отвергающее 06/09/105/0094
кнопки 05/05/060/0000 отвергающую 06/09/105/0094
кнопку 05/05/060/0000 отверстие 08/08/073/0000
кнопок 06/06/060/0000 отверстии 08/08/073/0000
кнопочного 07/07/103/0000 отверстий 08/08/073/0000
КНР 03/03/146/0000 отверстия 08/08/073/0000
ко 02/02/156/0000 отвесно 07/07/152/0000
коаксиальный 10/10/103/0000 отвести 07/07/144/0000
коалесценции 11/11/061/0000 ответ 05/05/001/0296
коалицией 07/07/061/0843 ответа 05/05/001/0296
коалиции 07/07/061/0843 ответвление 06/10/073/0000
коалиций 07/07/061/0843 ответвлений • 10/10/073/0000
коалиционной 07/10/103/0843 ответе 05/05/001/0296
Кобол 05/05/001/0000 ответил 05/07/125/0296
кобра 04/04/056/0846 ответили 05/07/125/0296
ковалентности 09/12/055/0640 ответить 05/08/144/0296
ковшом 04/04/002/0837 ответного 05/06/103/0296
когда 05/05/152/0000 ответную 05/06/103/0296
когда-то 08/08/152/0000 ответные 05/06/103/0296
когерентного 08/09/103/0770 ответный 05/06/103/0296
когерентной 08/09/103/0770 ответным 05/06/103/0296
когерентности 09/12/055/0770 ответными 05/06/103/0296
кого 04/04/145/0000 ответных 05/06/103/0296
код 03/03/001/0278 ответов 05/05/001/0296
кодированием 03/10/073/0278 ответом 05/05/001/0296
кодирования 03/10/073/0278 ответственная 05/11/103/0912
кодированное 03/10/103/0278 ответственность 05/14/055/0912
кодированных 03/10/103/0278 ответственны 08/11/126/0912
кодировать 03/10/144/0278 ответственных 08/11/103/0912
кодировки 03/08/060/0278 ответчики 05/08/031/0296
кодируемого 03/08/103/0278 ответы 05/05/001/0296
кодируется 03/06/116/0278 отвечает 05/06/116/0296
кодирующая 03/08/105/0278 отвечала 05/07/125/0032
кодов 03/03/001/0278 отвечали 05/07/125/0032
кодовой 03/05/103/0278 отвечало 05/07/125/0032
кодовые 03/05/103/0278 отвечать 05/08/144/0032
кодом 03/03/001/0278 отвечают 05/06/116/0032
коды 03/03/001/0278 отвечающая 05/08/105/0032
кое-что 07/07/147/0000 отвечающего 05/08/105/0032
коек 04/04/060/0000 отвечающий 06/08/105/0032
кожи 03/03/057/0821 отвечающим 05/08/105/0032
кожух 05/05/006/0841 отвечающими 05/08/105/0032
кожухе 05,'05.006/0841 отвечающих 05/08/105/0032
279
отвлечение 0в/06/й73/0000 отдельные 05/07/103/0559
отвлечению 06/09/073/0000 отдельный 05/07/103/0559
отвлечения 06/09/073/0000
отвлечь 07/07/144/0000 реакционные 06/09/103/0864
отвод 05/05/001/0319 реакционными 06/09/103/0864
отвода 05/05/001/0319 реализации 06/09/061/0458
отводилось 05/07/125/0319 реализацию 06/09/061/0458
отводимого 05/07/103/0319 реализация 06/09/061/0458
отводимых 05/07/103/0319 реализовался 06/10/125/0458
отводит 05/05/124/0319 реализована 08/10/126/0006
отводится 05/05/124/0319 реализованная 08/11/103/0458
отводить 05/08/144/0319 реализованных 06/11/103/0458
отводом 05/05/001/0319 реализованы 06/10/126/0458
отводят 05/05/124/0319 реализовать 06/11/144/0458
отводятся 05/05/124/0319 реализуемому 06/09/103/0458
отгибается 06/06/116/0493 реализуется 06/07/116/0442
отглагольного 10/10/103/0000 реализующая 06/09/105/0458
отгонки 05/06/060/0560 реалистический 04/12/106/0205
отдаваемое 04/08/103/0146 реальная 06/06/103/0640
отдавать 04/08/144/0514 реально 06/06/126/0640
отдаваться 04/10/144/0151 реального 06/06/103/0640
отдает 04/04/116/0151 реальной 06/06/103/0640
отдается 04/04/116/0151 реальность 06/09/055/0715
отдать 04/06/114/0494 реальную 06/06/103/0640
отдача 04/05/057/0151 реальны 06/06/126/0640
отдаче 04/05/057/0151 реальные 06/06/103/0640
отдачей 04/05/057/0151 реальным 06/06/103/0640
отдачи 04/05/057/0151 реальными 06/06/103/0640
отдачу 04/05/057/0151 реальных 06/06/103/0640
отдаются 04/04/116/0151 ребер 05/05/070/0000
отдел 05/05/001/0559 ребра 04/04/070/0720
отдела 05/05/001/0559 ребристого 04/07/103/0720
отделами 05/05/001/0559 реверсивного 06/09/103/0824
отделах 05/05/001/0559 реверсирования 06/13/073/0221
отделена 05/07/126/0559 реверсом 06/06/001/0770
отделение 05/08/073/0539 ревизии 06/06/061/0870
отделением 05/08/073/0539 ревизионизм 11/11/001/0000
отделении 05/08/073/0539 ревизионисты 11/11/021/0892
отделений 05/08/073/0539 ревизия 06/06/061/0870
отделению 05/08/073/0539 револьвер 09/09/001/0770
отделения 05/08/073/0539 революционного 08/11/103/0864
отделениям 05/08/073/0539 революция 08/08/061/0864
отделениями 05/08/073/0539 регенеративной 07/12/103/0215
отделенного 05/08/103/0947 регенератора 07/11/001/0215
отделены 05/07/126/0559 регенерации 10/10/061/0843
отделов 05/05/001/0559 регенерационное 10/13/103/0843
отделы 05/05/001/0559 регенерация 10/10/061/0843
отдельная 05/07/103/0559 регенерируемой 07/12/103/0221
отдельно 07/08/152/0947 региона 06/06/001/0667
отдельного 05/07/103/0559 региональная 06/10/103/0657
отдельное 05/07/103/0559 региональной 06/10/103/0657
отдельной 05/07/103/0559 региональные 06/10/103/0657
отдельном 05/07/103/0559 региональными 06/10/103/0657
отдельному 05/07/103/0559 регистра 07/07/001/0000
отдельности 05/10/055/0947 регистратор 07/11/001/0261
отдельную 05/07/103/0559 1 » • » S •
280
указал 04/06/125/0087 укомплектованность 09/17/055/0448
указан 04/06/126/0087 укомплектованных 09/14/103/0448
указана 04/06/126/0087 укомплектовано 09/13/126/0448
указание 04/07/073/0087 укомплектованы 09/13/126/0448
указанием 04/07/073/0087 укомплектовать . 09/14/144/0448
указаний 04/07/073/0087 укорачивается 09/09/116/0493
указанию 04/07/073/0087 укороченная 06/08/106/0894
указания 04/07/073/0087 » « » • 1 • 1 | |
указаниям 04/07/073/0087 ЯВЯТСЯ 02/02/117/0364
указаниями 04/07/073/0087 ядер 04/04/070/0797
указанная 04/07/103/0087 ядерного 05/05/103/0000
указанного 04/07/103/0087 ядерное 05/05/103/0000
указанное 04/07/103/0087 ядерной 05/05/103/0000
указанной 04/07/103/0087 ядерном 05/05/103/0000
указанном 04/07/103/0087 ядерному 05/05/103/0000
указанному 04/07/103/0087 ядерную 05/05/103/0000
указанную 04/07/103/0087 ядерные 05/05/103/0000
указанные 04/07/103/0087 ядерный 05/05/103/0000
указанный 04/07/103/0087 ядерным 05/05/103/0000
указанным 04/07/103/0087 ядерными 05/05/103/0000
указанными 04/07/103/0087 ядерных 05/05/103/0000
указанных 04/07/103/0087 ядра 03/03/070/0944
указано 04/06/126/0087 ядро 03/03/070/0944
указаны 04/06/126/0087 ядром 03/03/070/0944
указателей 04/08/003/0087 язык 04/04/006/0841
указатели 04/08/003/0087 языках 04/04/006/0841
указателями 04/08/003/0087 языковедения 08/11/073/0926
указать 04/07/144/0087 языковедов 08/08/021/0926
указывает 04/07/116/0087 языковедческих 08/12/106/0926
указывается 04/07/116/0087 языковые 04/06/103/0841
указывал 04/08/125/0087 языкознания 10/10/073/0000
указывали 04/08/125/0087 язычковые 05/07/103/0841
указывалось 04/08/125/0087 якобы 05/05/154/0000
указывался 04/08/125/0087 якорем 04/04/003/0772
указывать 04/09/144/0087 якорные 04/05/103/0772
указывают 04/07/116/0087 якобы 04/04/003/0772
указываются 04/07/116/0087 ямах 02/02/056/0987
указывающие 04/09/105/0087 яме 02/02/056/0987
указывающих 04/09/105/0087 ямки 02/03/060/0987
указывая 04/08/152/0087 ямок 02/04/060/0987
укладка 05/06/060/0532 ямы 02/02/056/0987
укладке 05/06/060/0532 январе 05/05/003/0936
укладки 05/06/060/0532 январский 05/07/106/0000
укладочного 05/08/103/0532 январь 05/05/003/0936
укладчику 05/08/031/0532 января 05/05/003/0936
укладываются 05/08/116/0532 японская 04/06/106/0910
уклон 05/05/001/0362 японцы 04/05/032/0910
уклонения 05/08/073/0362 ярдах 03/03/001/0837
уклониться 05/10/144/0390 ярдов 03/03/001/0837
укомплектована 09/13/126/0448 ярким 03/03/106/064!
укомплектование 09/14/073/0448 ярко 03/04/152/0636
укомплектования 09/14/073/0448 яркой 03/03/106/0641
укомплектованного 09/14/103/0448 яркость 03/06/055/0641
укомплектованное 09/14/103/0448 ярлыка 05/05/006/0000
укомплектованной 09/14/103/0448 ярма 03/03/070/0856
укомплектованности 09/17/055/0448 ярмарке 06/06/060/0000
281
ярус 04/04/001/0770
яруса 04/04/001/0770
ясная 03/03/103/0638
ясно 03/04/152/0638
ясного 03/03/103/0638
ясной 03/03/103/0638
ясности 03/06/055/0715
ясность 03/06/055/0715
ясные 03/03/103/0638
ясный 03/03/103/0638
ясным 03/03/103/0638
яхт 03/03/056/0801
яхты 03/03/056/0801
ячеек 03/05/060/0000
ячеечные 03/06/103/0769
ячейка 05/05/060/0000
ячейками 05/05/060/0000
ячейках 05/05/060/0000
ячейки 05/05/060/0000
ячейкой 05/05/060/0000
ячейку 05/05/060/0000
ящик 04/04/006/0000
ящика 04/04/006/0000
ящиках 04/04/006/0000
ящике 04/04/006/0000
ЯЩИКОМ 04/04/006/0000
ЛИТЕРАТУРА
1. Аспекты семантических исследований/Под ред. Н. Д. Арутюнова и А. А. Уфимцева.— М.: Наука, 1980.
2 Вопросы организации системы обмена научно-технической информацией на магнитных лентах (тезпсы докладов на всесоюзной конференции).—ВДНХ СССР. 26—30 ноября 1980.
3. Интеллектуальные банки данных. Вопросы кибернетики.— М.: Наука, 1979.
4. Информационная система для задач экономического управления ИНЭС-2 (краткое техническое описание).—ГВЦ Госплана СССР, М., 1976.
5 Информационно-поисковая система «БИТ».—Киев: Наукова думка, 1968.
6. Информационно-программное обеспечение систем искусственного интеллекта.— В кн.: Сб. трудов семинара МДНТП им. Ф. Э. Дзержинского, М., 1978.
7 Информационные системы общего назначения: Пер. с англ./ Под ред. Е. А. Ющенко.— М.: Статистика, 1975.
8. Искусственный интеллект. Итоги и перспективы.— В кп.: Сб. трудов семинара МДНТП им. Ф. Э. Дзержинского, М., 1974.
9. Коммуникативный формат библиографической записи и его семантическое наполнение.— М.: ГПНТБ, ВИНИТИ, 1979.
10. Коммуникативный формат. Структура библиографической записи и элементов данных на магнитной ленте. ГОСТ 7.14-78.
И. Лингвистическое обеспечение фактографического информационного поиска.— В кн.: Вопросы информационной теории и практики, Kg 42, М., ВИНИТИ, 1979.
12. Основы построения больших информационно-вычислительных сетей/Под ред. Д. Г. Жимерина и В. И. Максименко.— М.: Статистика, 1976.
13. Пакет прикладных программ «Поиск-1». Описание. НИИ «Интерпрограмма».— София, 1978.
14. Первая всесоюзная конференция «Банки данных». Тезисы докладов.— Тбилиси, 1980.
15. Проблемы интеграпип и взаимодействия автоматизированных информационных центров, входящих в САЦНТИ. Тезисы докладов XI научного семинара «Системные исследования ГАСНТИ».— Алма-Ата, 13—17 октября 1980.
16. Рубрикатор Государственной системы научно-технической информации.-М.: ВИНИТИ, 1980.
283
17. Система математического обеспечеппя ЁС ЭЁМ/Под рёД. А. М. Ларионова.-— М.: Статистика, 1974.
18. Тезаурус научно-технических термппов/Под род. Ю. И. Шемякина.— М.: Военпздат, 1972.
19 Антопольскпй А. Б., Казаков Е. Н., Клыков Л. В., Цукерман Э. М. Создание и применение рубрикатора ГАСНТИ.— В кн.: Вопросы информационной теории п практики, № 40, 1979.
20. Апресян Ю. Д. Идеи и методы современной структурной лингвистики (краткий очерк).—М.: Просвещение, 1966.
21 Апресян Ю. Д. Лексическая семантика и синонимические средства языка.— М.: Наука, 1974.
22 Белоногов Г. Г., Новоселов А. П. Автоматизация процессов накопления, поиска и обобщения информации.— М.: Наука, 1979.
23 Белоногов Г. Г., Новоселов А. П. О представлении пнформапии в памяти ЭВМ.— Автоматика и вычислительная техника, № 2, Рига: Зипатне, 1975.
24 Белоногов Г. Г., Новоселов А. П. О принципах построения автоматизированных информационных систем.— Семиотика и информатика, Кг 13, М.: ВИНИТИ, 1979.
25. Б у т р и м е н к о А. В. Разработка и эксплуатация сетей ЭВМ.— В кн.: Финансы и статистика, М.: 1981.
26 Виноград Т. Программа, понимающая естественный язык.— М.: Мир, 1976.
27. Вольфенгаген В. Э., Воскресенская О. В., Горбачев Ю. Г. Система представления знаний с использованием семантических сетей.— В кп.: Интеллектуальные банки данных. Вопросы киберпетики/Под ред. Л. Т. Кузина, М.: Наука, 1979.
28. Г о р н о с т а е в Ю. М. и др. Методические материалы по применению пакета прикладных программ «АСОД».— М.: МЦНТИ, 1978.
29. Г о р н о с т а е в Ю. М., С о с и н Е. В., Сумароков Л. Н. Информационно-поисковые системы и межмашинный обмен информацией.— М.: Информэлектро, 1976.
30 Дейт К. Введение в системы баз данных.— М.: Наука, 1980.
31. Звегинцев В. А. История языкознания XIX—XX веков в очерках и извлечениях. Ч. I, ч. II.— М.: Просвещение, 1964, 1965.
32 Звегинпев В. А. Предложение и его отношение к языку и речи.—МГУ, 19-76.
33 Звегинпев В. А. Теоретическая и прикладная лингвистика.— М.: Просвещение, 1968.
34. Звегинцев В. А. Язык и лингвистическая теория.— МГУ, 1973.
35 3 е в а х и н а Т. С. Компонентный анализ как метод выявления семантической структуры слова. Автореферат, канд. дисс.— МГУ, 1979.
36 Караулов Ю. Н. Частотный словарь семантических множителей русского языка.— М.: Наука, 1980.
37. К л ы к о в Ю. И., Горьков Л. Н. Банки данных для принятия решений.— М.: Сов. радио, 1980.
38. К л ы к о в Ю. И. Ситуационное управление болыпимп системами.— М.; Энергия, 1974.
284
50. Токарева JT. fi, M а л а ш й п й и 11 ft б реализаций диалога на естественном языке.— В кн.: Материалы второго всесоюзного совещания «Диалоговые вычислительные комплексы». Серпухов, 1979.
40. К р и н п ц к и ii Н. А. Таблицы объектно-характеристические.-— В кн.: Энциклопедия современной техники: Автоматизация производства и промышленная электроника, т. 3, М.: Энциклопедия, 1964.
41. Кристальный Б. В., Раскина А. А., Сидоров И. С. Язык объектно-признаковых фраз.— Вопросы информационной теории и практики, 1979, № 42, М.: ВИНИТИ, с. с. 19—48.
42. Кричевский В К., К у з не п о в Б. А. Задача группирования баз данпых для одновременного предоставления в режим теледоступа в САЦНТИ.— В кн.: Тезисы докладов XI научного семинара по системным исследованиям ГАСНТП. Ч. II, М., 1980.
43. Кросс P.-К., Г а р д э н Ж.-К., Леви Ф. Синтол — универсальная модель системы информационного поиска.— М.: ВИНИТИ, 1968.
44 Кузин Л. Т. Основы кибернетики.— М.: Энергия, 1979.
45. К у з н е ц о в Б. А. Оценка полноты ответа при поиске в системе баз данных в сетевом режиме.— В кн.: Тезисы докладов X научного семинара по системным исследованиям ГАСПТИ. Ч. II, М., 1979.
46. Кузнецов Б. А., А н т о п о л ь с к п й А. Б. Об организации сетевого режима работы РАБД САЦНТИ.— В кн.: Тезисы докладов X научного семинара по системным исследованиям ГАСПТИ. Ч. I, М.. 1979.
47. К у л а г и п а О. С. Исследования по машинному переводу.— М.: Наука, 1979.
48. Л а й о н з Джон. Введение в теоретическую лингвистику.— М.: Прогресс, 1978.
49. Л у к ь я н о в а Е. М. Информационная база автоматических словарей.— В кп.: Статистика речи и автоматический анализ текста, Л.: Наука, 1980.
50. М а р т и н Дж. Организация баз даппых в вычислительных системах.— М.: Мир, 1978.
51. Марчук Г. И. Некоторые проблемы развития Государственной системы научно-технической информации. Пресс-бюллетепь. Всесоюзная выставка-смотр НТИ-80.—М.: 1980.
52. М н х а й л о в А. И., Черный А. И., Гиляревский Р. С. Научные коммуникации и информатика.— М.: Наука, 1976.
53. Михайлов А. И., Черный А. И., Г и л я р е в с к и й Р. С Основы информатики.— М.: Наука, 1968.
54. Минский М. Фреймы для представления знаний.— М: Энергия, 1979.
55. Н а л и м о в В. В. Вероятностпая модель языка.— М.: Наука, 1979.
56. П и о т р о в с к и й Р. Г. и др. Формальное распознавание смысла текста.— В кн.: Статистика речи и автоматический анализ текста, Л.: Наука, 1980.
57. П и о т р о в с к и й Р. Г., Б е к т а е в К. Б., Пиотровская А. А. Математическая лингвистика.— М.: Высшая школа, 1977.
58. Р а ф а э л Б. Думающий компьютер.— М.: Мир, 1979.
285
I
Ml. Рыбаков Ф. If. Ёудлев Ё А.. Петухов В. А. Автй-магическое индексирование па естественном языке.—М.: Энергия, 1980.
60. Слейгл Дж. Искусственный интеллект.—М.: Мир. 1973.
61. Со л тон Дж. Динамические библиотечно-информационные системы.— М.: Мир, 1979.
62 Сэл тон Г. Автоматическая обработка, хранение и поиск информации.— М.: Сов. радио, 197'1
63. С к о р о х о д ь к о Э. Ф. Лингвистические проблемы обработки текстов в автоматизированных информационно-поисковых системах.—В кн.: Вопросы информационной теории и практики, № 25, М.: ВИНИТИ. 1974.
64. С к о р о х о д ь к о Э. Ф. Семантические связи в лексике и текстах.— В кн.: Вопросы информационной теории и практики, № 23. М.: ВИНИТИ. 1974.
65. Соколов А. В. Прогноз развития автоматизированного библиографического поиска,— В кн.: Библиотека и научно-технический прогресс, Киев: Вища школа, 1980.
66. С о с с ю р Ф. де. Курс общей лингвистики.— В кн.: Ф. де Соссюр. Труды по языкознанию. М.: Прогресс, 1977.
67. С ц и б о р Е. Универсальные классификации на рубеже 80-х гг.— Международный форум по информации и документации, 1981, т. 6, № 1.
68. Успенский В. А. К проблема построений машинного языка для информационной машины.— В кн.: Проблемы кибернетики, М.: Физматгпз, 1959.
69. Черный А. II. Введение в теорию информационного поиска.— М.: Паука, 1975.
70 Черный А. II., Горькова В. И. Зарубежные автоматизированные справочно-информационные системы интегрального типа. Итоги науки и техники. «Серия «Информатика», т. З.-М.: ВИНИТИ, 1980.
71. Шенк Р. Обработка концептуальной информации,—М.: Энергия, 1980.
72 Шрейдер Ю. А. Лингвистический подход в теории информационных систем.— ПТП, 1962, № 9.
73 Якубайтис Э. А. Архитектура вычислительных сетей.— М.: Статистика, 1980.
74. Якушин Б. В. Слово, понятие, информация.—М.: Молодая гвардия, 1975.
75. Ясин Е. Г. Проблемы развития систем информации.— В кн.: Экономика и математические методы, т. XIII, вып. 5, М.: Наука, 1977.
76. Astra han М. М., Biasgen М. W. а. о. System R: A Relational Data Base Management System.— Computer, May 1979.
77. Bihan J. Le, Esculier C., Le Lann C., Treille L. Sirius-Delta:^ In prototype de systeme de ge'stion de base de donnees reparties — Distributed Data Bases.— Amsterdam: INRIA, 1980.
78. C h a m p i n e G. A. Current Trends in Data Base Systems.— Computer, May 1979, pp. 42—48.
79. С о d d E. F. A Relational Model of Data for Large Shared Data Banks.—Comm, of ACM, 1970, v. 13, № 6.
80. С о d d E. F. Normalized Data Base Structure: A Brief Tutorial. Proc. 1971.— ACM-SIGFIDET Workshop on Data Description, Access and Control.
81. С о d d Е. F. Recent Investigations in Relational Data Base Systems. Information Processing 74.—North-Holland Publishing Company, 1974.
82. Data Base Task Group Report to the CODASIL Programming 'Commetee.— April 1971.
83. Date C. J. An Introduction to Database Systems.—Addison-Wesley Publishing Company, 1975.
84. Date C. J. Relational Data Base Systems: A Tutorial.—Proc. Fourth International Symposium on Computer and Information Sciences. Miami Beach Florida, December 14—16: Plenum Press, 1972.
85. D e 11 ’ о г с о P., Spadavecchio V. W. Using Knowledge of a Data Base World in Interpreting Natural Language Queries.— Information Processing 77. Proceeding of IFIP Congress 77, Toronto, August 8—12, 1977, pp. 139—144.
86. Euronet Diane directory.— Euronet Diane, 1980.
87. G h о s h S a к t i P. Data Base Organisation for Data Management.— New-York: Academic Press, 1977.
88. Henry W. M., Leigh J. A., T e d d L. A., Williams P. W. On line searching.— London — Boston: Butterworths Publ., 1980.
89. IFIP Congress 74, Information Processing 74.—North-Holland Publishing Company, 1974.
90. INIS: Thesaurus IAEA-INIS-13 (Rev. 19).—Vienna, 1980.
91. Jao S. B., Bernstein A., Goodman N., Schuster S. A. a. o. Data Base Systems.—Computer, September 1978, v. 11, № 9, pp. 46-60.
92. Kelly P. T. F. The EURONET telecommunication and information network.— The Radio and Electronic Engineer, v. 49, № 11, 1979.
93. Lieb II. H. Wortbedeutung: Argumente fur eine psycholo-gische Konzepzion.— Lingua, v. 52, № 1/2, September — Okto-ber, 1980.
91. Martin J. Principles of Data-Base Management.—N. Y.: Prentise-IIall, 1976.
95. Negus A. E. EURONET Guideline: Standard commands for retrieval systems. — Final report., London: Inspec., December 1977.
96. N i j s s e n G. M. On the Gross Architecture for the Next Generation Database Management System.— IF1P-77, pp. 327—335.
97. Nilson N. J. Artificial Intelligence.—Information Processing 74 — North — Holland Publishing Company, 1974.
98. Olle T. W. Current and Future Trends in Data Base Management Systems. Information Processing 74-North-Holland Publishing Company, 1974.
99. Schank R. C., Lebowitz M., Birnbaum L. An Integrated Understander.— American Journal of Computational Linguistics, v. 6, № 1, January — March 1980.
100. UNESCO Computerized documentation system CDS/ISIS.—Description, 1978.
101. Wet tier M. Semantisches Langzeit-gediichtnis und das Ver-stehen von Sprache.— Working Papers, Fondatione Dalle Moll, № 37, 1979.
102. Zamora A., Automatic Detection and Correction of Spelling Errors in Large Data Base.— J. Amer. Soc. Inform. Sci., 1980, y, 31, Xs 2, pp. 31—52.
287
Герольд Георгиевич Белоногов, Борис Антонович Кузнецов
ЯЗЫКОВЫЕ СРЕДСТВА
АВТОМАТИЗИРОВАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
Редактор Н. И. Васина
Техн, редактор С. Я. Шкляр
Корректоры Л. И. Назарова( Е, В. Сидоркина
ИВ № 12061
Сдано в набор 10 01.83. Подписано к печати 27.06.83. Т-12798. Формат 84Х1081/зг. Бумага тип. Кв 2. Обыкновенная гарнитура. Высокая печать. Условн. печ. л. 15,12. Уч.-изд. л. 19,98. Тираж 15 000 экз. Заказ Кв 481. Цена 1 р. 20 к.
Издательство «Наука»
Главная редакция физико-математической литературы
117071, Москва, В-71, Ленинский проспект, 15
4-я типография издательства «Наука» 630077, Новосибирск, 77, Станиславского, 25