/


















































































































































































































































































































































































































































































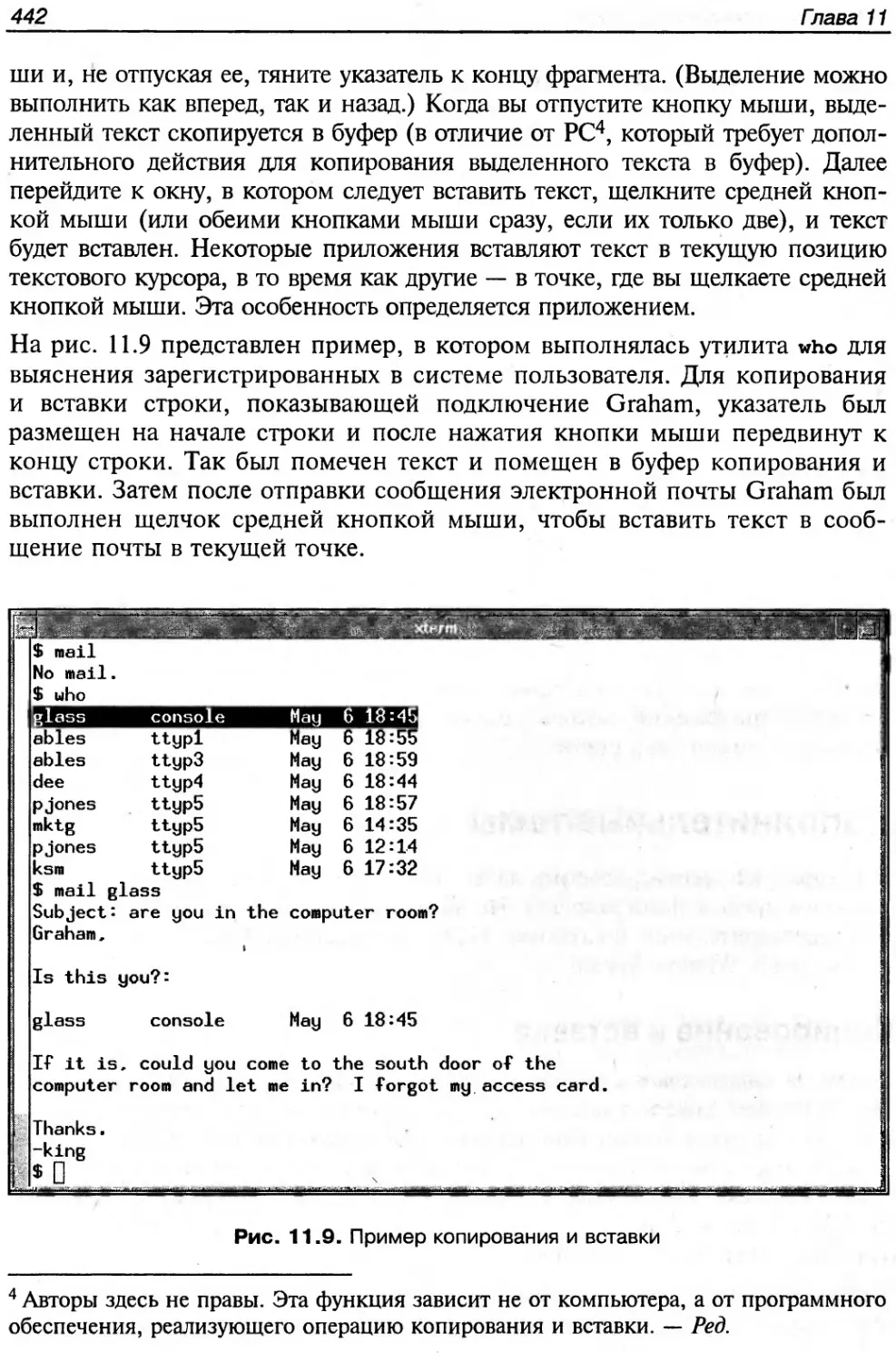
































































































































































































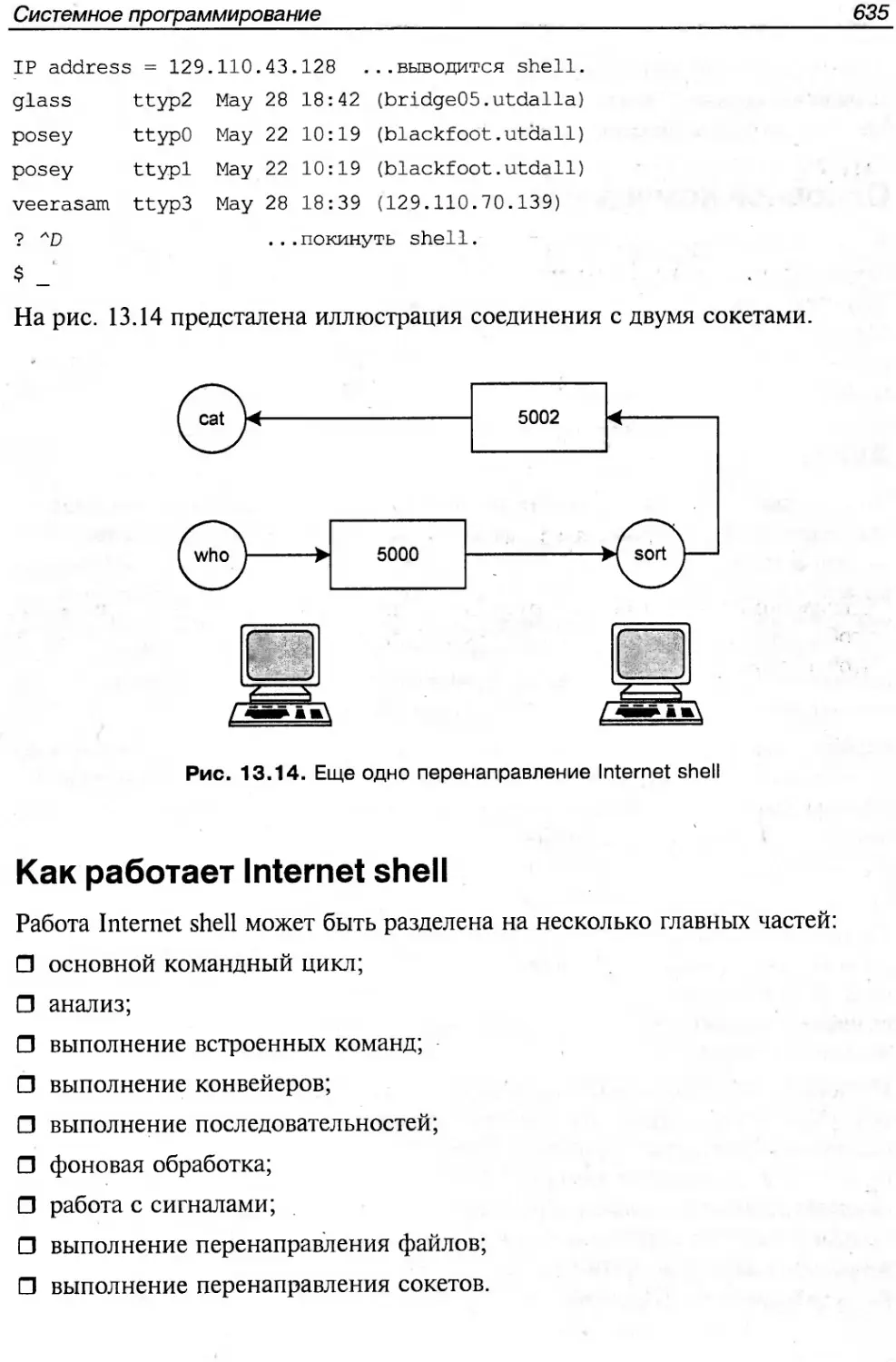









































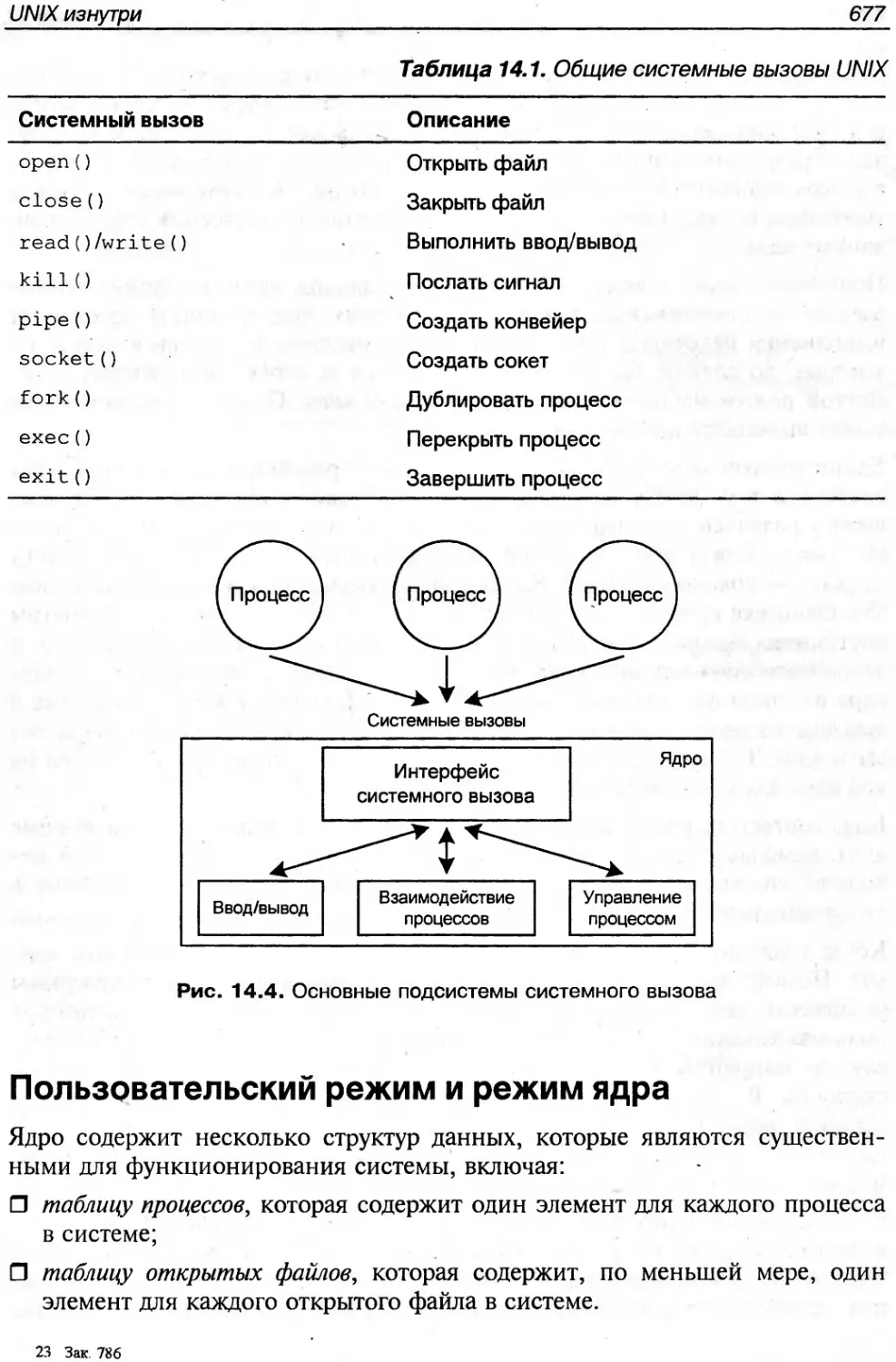










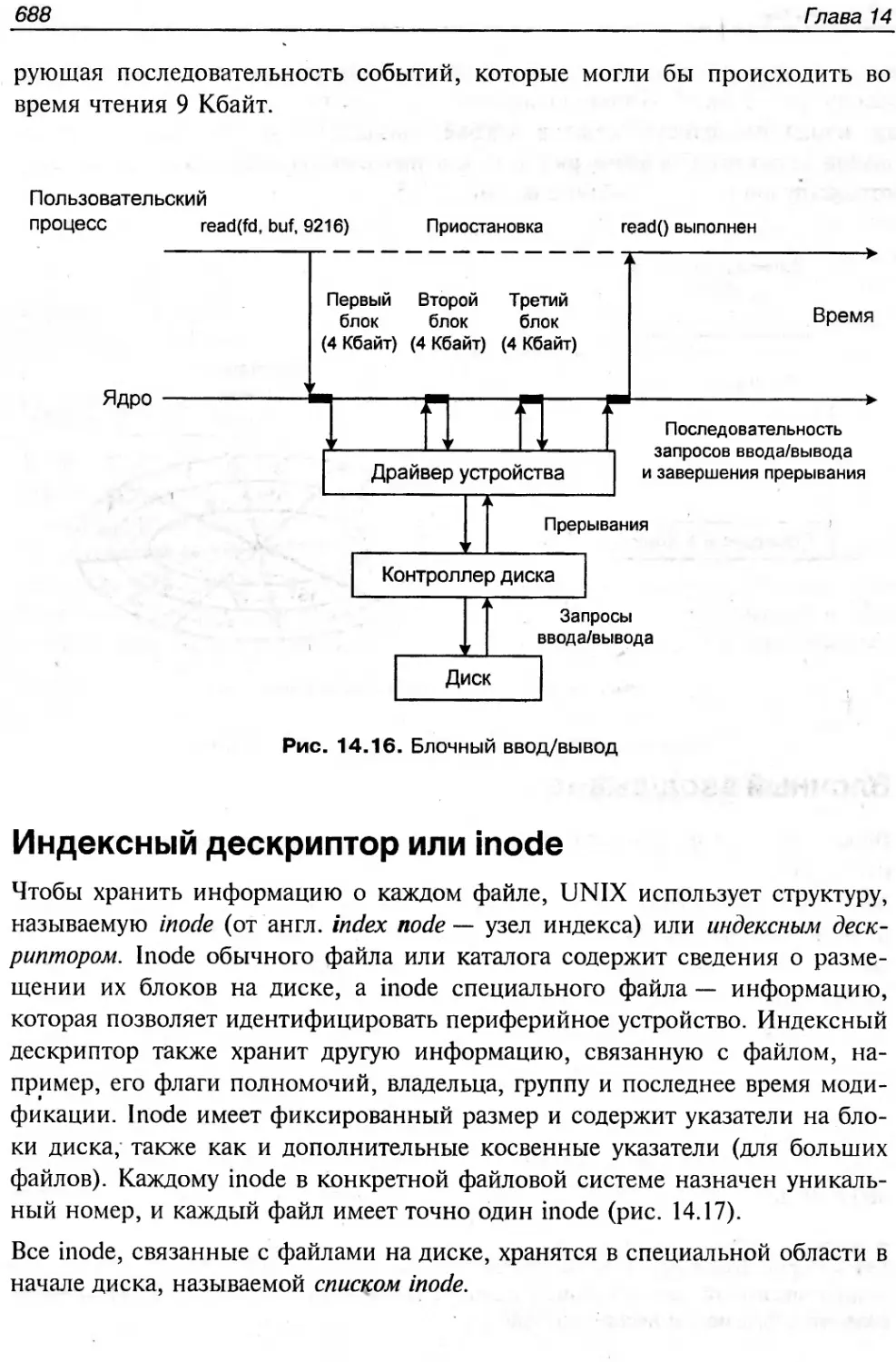
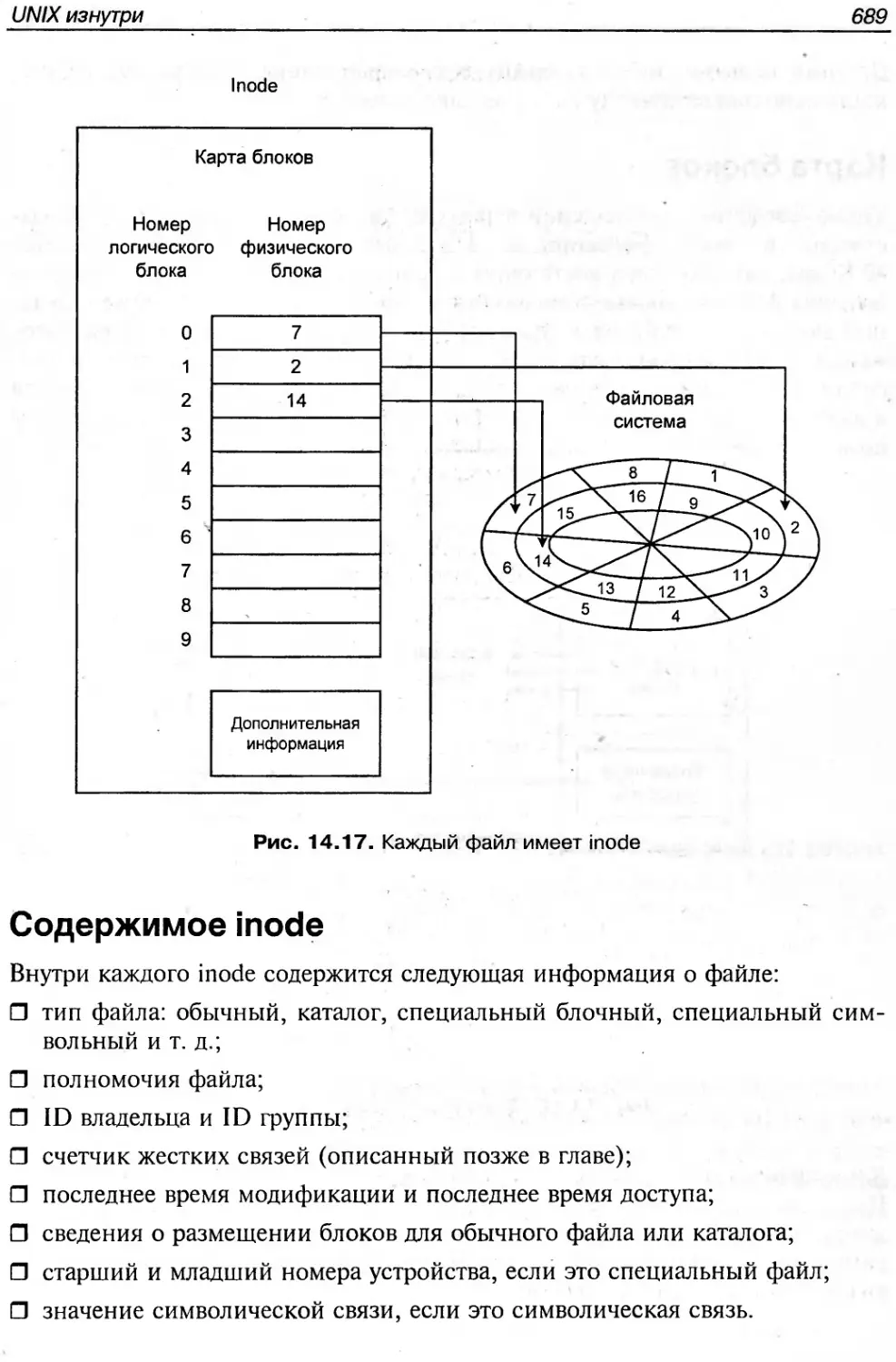

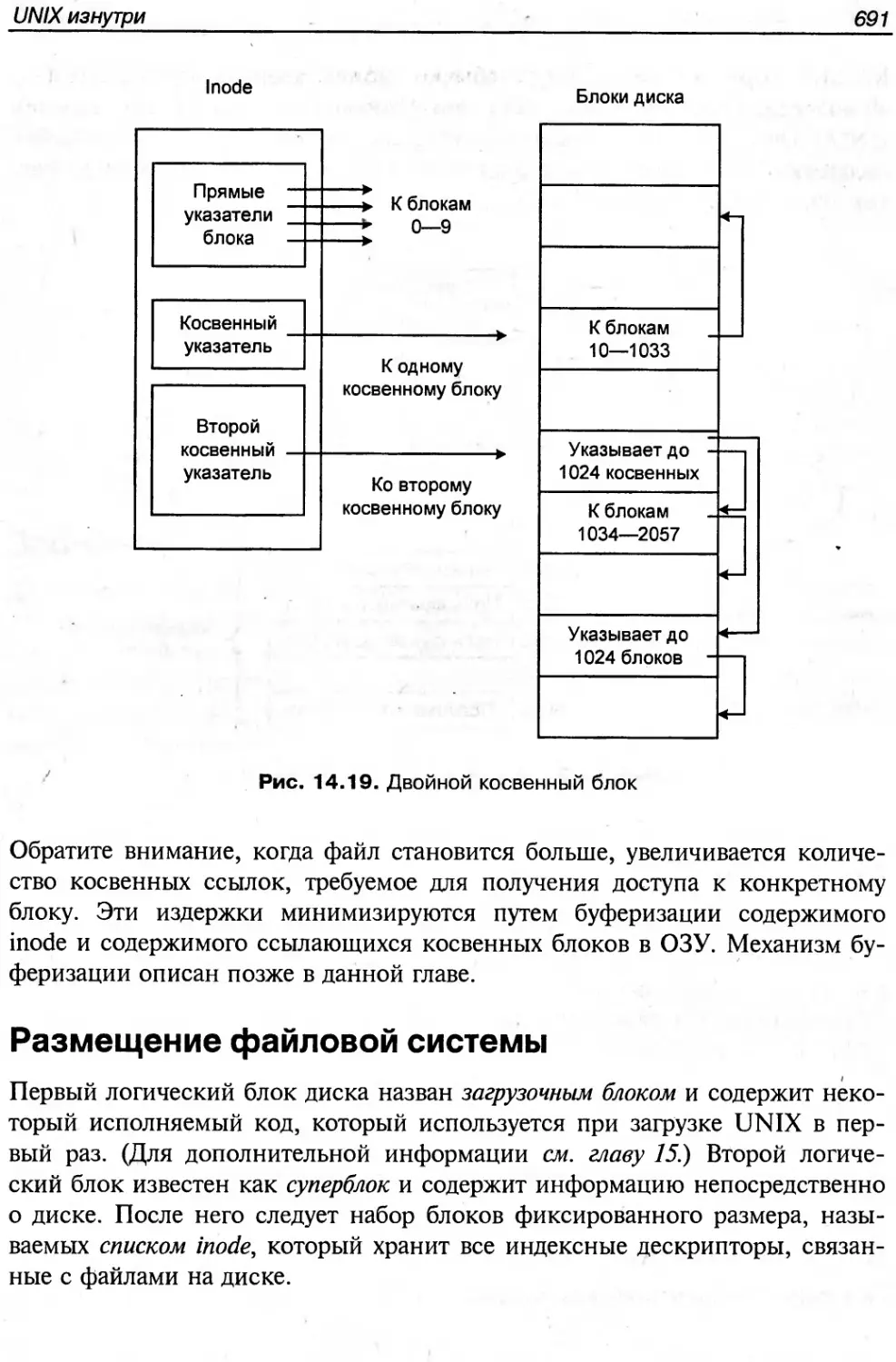








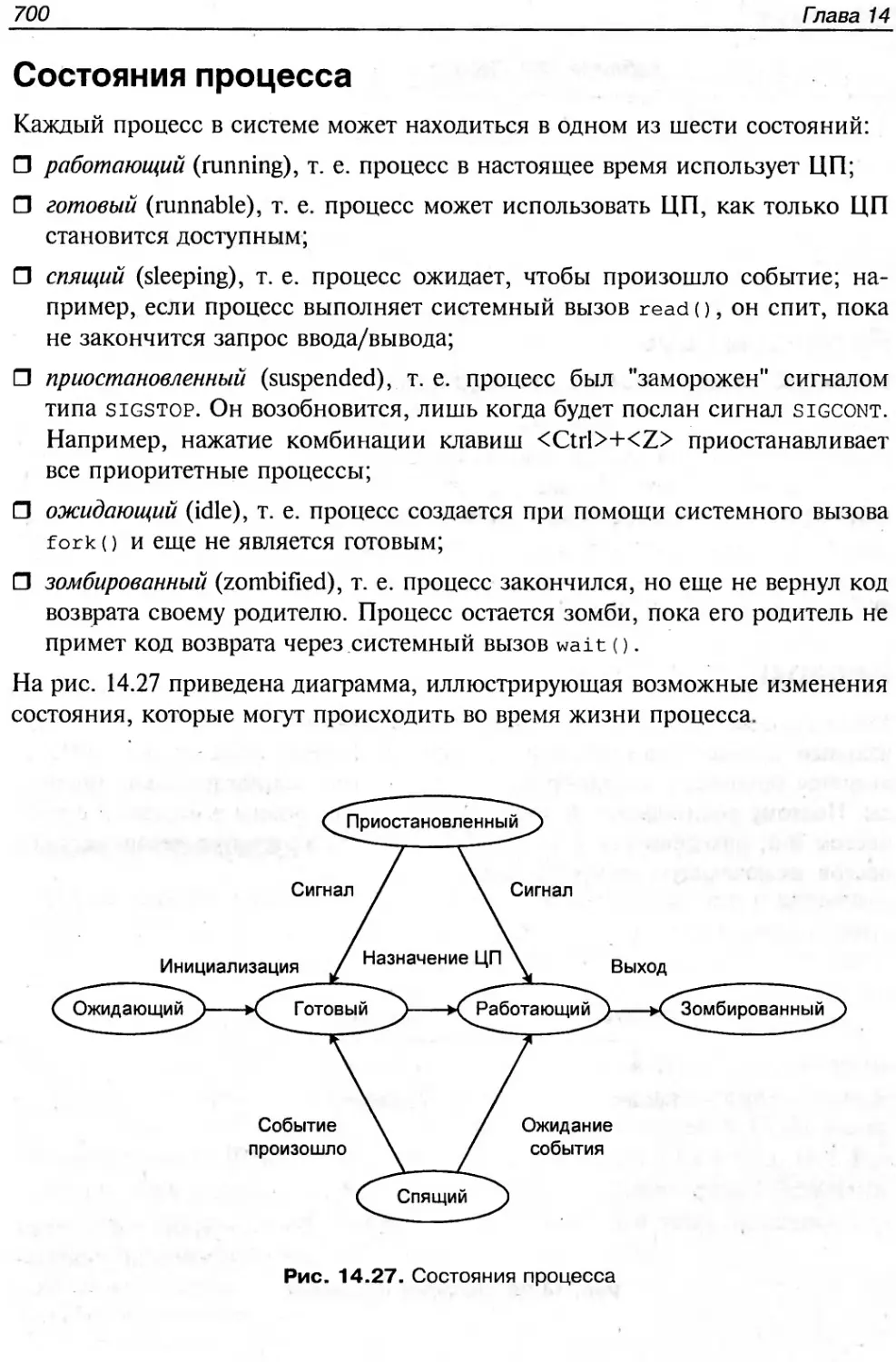






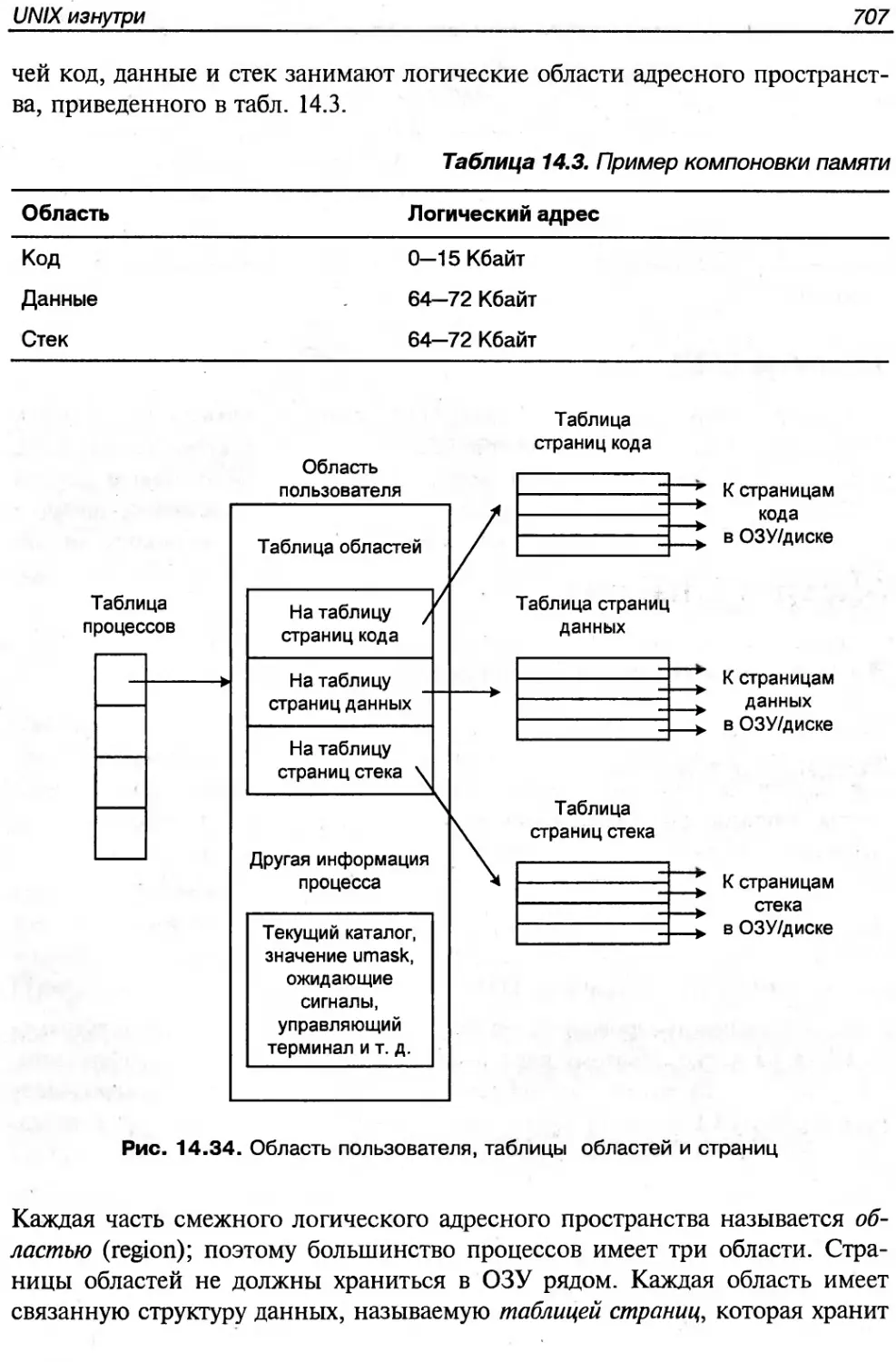


















































































































Текст
ii пользователей
У ЛЯ 3-е издание
программистов о пользователей
Unix® for Programmers and Users
Third Edition
Unix® for Programmers and Users
Third Edition
Graham Glass and King Ables
PEARSON
Education
Pearson Education, Inc.
Upper Saddle River, New Jersey 07458
Г. Гласс
К. Эйблс
УЛЯ З-е издание программистов и пользователей
Санкт-Петербург «БХВ-Петербург» 2004
УДК 681.3.066
ББК 32.973.26-018.2
Г52
Гласс Г., Эйблс К.
Г52 UNIX для программистов и пользователей. — 3-е изд., перераб. и доп.— СПб.: БХВ-Петербург, 2004. — 848 с.: ил.
ISBN 5-94157-404-5
Приводятся общие сведения о развитии UNIX. Рассматриваются утилиты, команды, системные вызовы и библиотечные функции для различных категорий пользователей. Описываются командные интерпретаторы Bourne shell, Korn shell, C shell и Bourne Again shell. Обсуждаются проблемы организации сети и использования Интернета. Подробно рассматриваются организация файловой системы, управление вызовами, ввод/вывод и взаимодействие процессов. Обсуждаются вопросы системного администрирования. Особое внимание уделено средствам программирования на языке С и системному программированию.
Для преподавателей и студентов, а также широкого круга пользователей,
программистов и системных администраторов
УДК 681.3.066
ББК 32.973.26-018.2
Группа подготовки издания:
Главный редактор
Зав. редакцией
Перевод с английского Редактор
Компьютерная верстка Корректор
Дизайн обложки Зав. производством
Екатерина Кондукова Григорий Добин Андрей Питько Анна Кузьмина Натальи Смирновой Наталия Першакова Игоря Цырульникова Николай Тверских
Authorized translation from the english language edition, entitled UNIX FOR PROGRAMMERS AND USERS, 3rd Edition, ISBN 0130465534, by ABLES, KING and GLASS, GRAHAM, published by Pearson Education, Inc, publishing as Prentice Hall Copyright © 2003. All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording or by any information storage retrieval system, without permission from Pearson Education, Inc. RUSSIAN language edition published by BHV St. Peteisbuig, Copyright © 2004.
Авторизованный перевод английской редакции, выпущенной Prentice Hall, Pearson Education, Inc, © 2003. Bee права защищены. Никакая часть настоящей книги не может быть воспроизведена или передана в какой бы то ни было с}юрме и какими бы то ни было средствами, будь то электронные или механические, включая фотокопирование и запись на магнитный носитель, если на то нет разрешения Pearson Education, Inc. Перевод на русский язык "БХВ-Петербург", © 2004.
Лицензия ИД № 02429 от 24.07.00. Подписано в печать 21.06.04.
Формат 70х1001/16. Печать офсетная. Усл. печ. л. 68,37.
Тираж 4000 экз. Заказ № 786 "БХВ-Петербург", 190005, Санкт-Петербург, Измайловский пр., 29.
Гигиеническое заключение на продукцию, товар № 77.99.02.953.Д.001537.03.02 от 13.03.2002 г. выдано Департаментом ГСЭН Минздрава России.
Отпечатано с готовых диапозитивов в ОАО "Техническая книга"
190005, Санкт-Петербург, Измайловский пр., 29.
ISBN 0-13-046553-4 (англ.)
ISBN 5-94157-404-5 (русск.)
© 2003 Pearson Education, Inc., Pearson Prentice Hall
© Перевод на русский язык "БХВ-Петербург", 2004
Содержание
Информация о торговых марках.......................................2
Об авторах.........................................................3
Введение......................................................... 4
О чем эта книга..................................................4
Структура книги..................................................5
Структура глав................................................. 6
Мотивация.....................................................6.
Предпосылки....................................................6
Задачи.........................................................6
Изложение......................................................6
Утилиты........................................................6
Системные вызовы...............................................6
Команды shell..................................................6
Перечень тем...................................................6
Контрольные вопросы............................................6
Упражнения.....................................................7
Проекты........................................................7
Руководство для преподавателей...................................7
Условные обозначения.............................................7
Ссылки на другие книги...........................................8
Доступность исходного кода в режиме on-line......................9
Благодарности.....................................................10
Глава 1. Что такое UNIX?...........................................И
Мотивация.........:............................................. 11
Предпосылки.....................................................11
Задачи..........................................................11
Изложение....................................................... 11
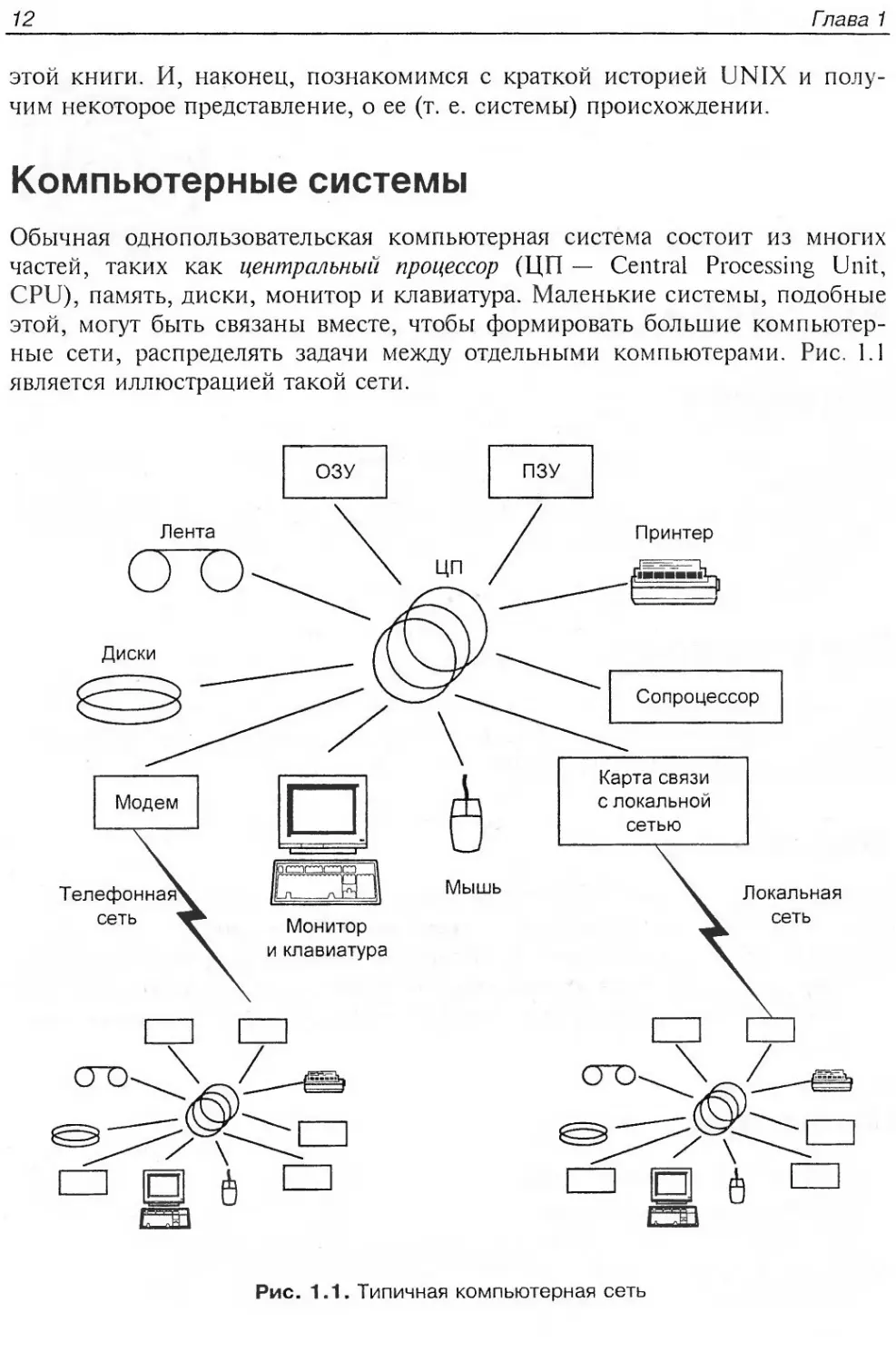
Компьютерные системы............................................12
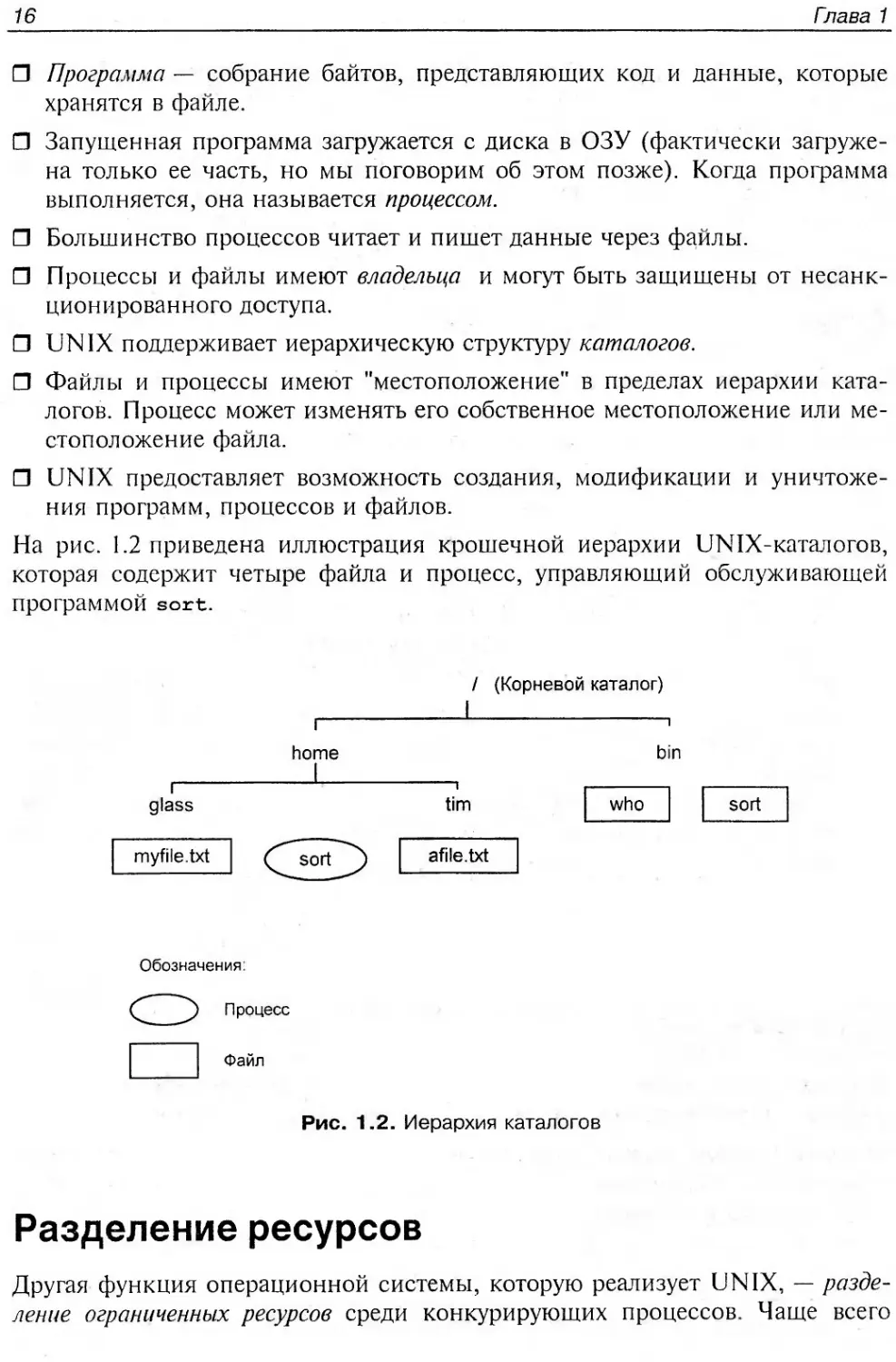
Операционные системы............................................15
Программное обеспечение.........................................15
Разделение ресурсов.............................................16
Коммуникация................................................... 17
Утилиты.........................................................18
Поддержка программиста..........................................................19
Стандарты.......................................................................19
Особенности UNIX................................................................20
Принципы UNIX...................................................................20
Прошлое UNIX....................................................................22
Настоящее UNIX..................................................................23
Будущее UNIX.................................................................. 24
Остальная часть этой книги......................................................24
Обзор главы.....................................................................25
Перечень тем.................................................................25
Контрольные вопросы..........................................................25
Упражнение...................................................................26
Проект.......................................................................26
Глава 2. Утилиты UNIX для непрограммистов.........................................27
Мотивация.......................................................................27
Предпосылки.....................................................................27
Цели............................................................................27
Представление................................................................. 27
Утилиты.........................................................................28
Команда shell...................................................................28
Получение учетной записи........................................................28
Вход в систему..................................................................29
Командные интерпретаторы — shell................................................30
Выполнение программ.............................................................30
Входной, выходной каналы и канал сообщения об ошибках...........................31
Получение оперативной помощи: man...............................................32
Специальные символы.............................................................34
Завершение процесса: <Ctrl>+<C>..............................................35
Приостановка вывода: <Ctrl>+<S>/<Ctrl>+<Q>...................................35
Завершение ввода: <Ctrl>+<D>.................................................36
Установка пароля: passwd........................................................................................ 36
Выход из системы.............................................................. 37
Поэзия в движении: изучение файловой системы................................38
Определение текущего каталога: pwd..............................................39
• Абсолютные и относительные имена путей..........................................40
Создание файла..................................................................41
Просмотр содержимого каталога: Is...............................................42
Распечатка файла: cat/ тоге/page/ head/ tail............................................................. 44
Переименование файла: mv........................................................46
Создание каталога: mkdir........................................................46
Перемещение по каталогам: cd....................................................47
Копирование файла: ср........................................................................................... 49
Редактирование файла: vi........................................................49
Удаление каталога: rmdir........................................................50
Удаление файла: гт..............................................................51
Печать файла: lp/lpstat/cancel.................................................................52
Печать файла: Ipr/lpq/lprm ....................................................................54
Подсчет слов в файле: wc.......................................................................56
Атрибуты файла............................................................................... 56
Размер файла................................................................................57
Имя файла...................................................................................57
Время модификации...........................................................................58
Владелец файла..............................................................................58
Группа владельцев файла.....................................................................58
Типы файла..................................................................................59
Параметры полномочий файла..................................................................60
Счетчик жесткой связи.......................................................................62
Группы.........................................................................................62
Вывод групп: groups............................................................................63
Изменение группы: chgrp........................................................................................ 63
Изменения прав доступа файла: chmod............................................................64
Изменение владельца файла: chown ...................................................................... 66
Изменение групп: newgrp........................................................................................ 67
Поэзия в движении: эпилог......................................................................68
Определение типа вашего терминала: tset........................................................68
Изменение характеристик терминала: stty............................................................ 71
Редактирование файла: vi....................................................................................... 73
Запуск vi............................................................................................................... 73
Режим ввода текста..........................................................................74
Режим ввода команд..........................................................................75
Буфер памяти и временные файлы..............................................................76
Общие функции редактирования................................................................76
Перемещение курсора.........................................................................77
Удаление текста.............................................................................77
Замена текста...............................................................................78
Вставка текста..............................................................................79
Поиск.......................................................................................80
Поиск и замена..............................................................................80
Сохранение или загрузка файлов..............................................................81
Разное......................................................................................82
Настройка vi................................................................................83
Сохранение пользовательских настроек........................................................84
Для дополнительной информации...............................................................84
Редактирование файла: emacs....................................................................84
Запуск emacs................................................................................84
Команды emacs...............................................................................85
Как избежать проблем...................................................................... 86
Получение помощи............................................................................86
Выход из emacs..............................................................................86
Режимы emacs................................................................................86
Ввод текста.................................................................................87
Общие функции редактирования..................................................87
Перемещение курсора...........................................................87
Удаление, вставка и отмена....................................................88
Поиск....................’....................................................89
Поиск и замена................................................................90
Сохранение и загрузка файлов..................................................90
Дополнительные команды........................................................90
Для дополнительной информации.................................................90
Электронная почта: mail/mailx....................................................91
Отправка почты................................................................93
Чтение почты..................................................................94
Связь с системным администратором.............................................96
Обзор главы......................................................................96
Перечень тем..................................................................96
Контрольные вопросы...........................................................96
Упражнения....................................................................97
Проект........................................................................97
Глава 3. Утилиты UNIX для опытных пользователей....................................99
Мотивация........................................................................99
Предпосылки......................................................................99
Задачи...........................................................................99
Изложение........................................................................99
Утилиты.........................................................................100
Фильтрация файлов...............................................................101
Шаблоны фильтрации: egrep/fgrep/grep.........................................101
Шаблоны соответствия....................................................... 104
Удаление одинаковых строк: uniq.....................................................................105
Сортировка файлов: sort.........................................................106
Сравнение файлов................................................................109
Тестирование на сходство: стр.........................................................................109
Различие файлов: diff........................................................111
Поиск файлов: find..............................................................113
Архивы..........................................................................115
Копирование файлов: cpio.....................................................116
Архивация на ленту: tar......................................................119
Инкрементальные резервные копирования: dump и restore...........................122
Планирование выполнения команд..................................................123
Периодическое выполнение: cron/crontab.......................................124
Однократное выполнение: at............................................................................126
Программируемая обработка текста: awk...:.......................................128
яи;А:-программы..............................................................129
Доступ к отдельным полям.....................................................130
BEGIN и END..................................................................130
Операторы....................................................................131
Переменные...................................................................131
Структуры управления....................................................................132
Расширенные регулярные выражения........................................................132
Цепочки условий.........................................................................133
Разделители полей.......................................................................133
Встроенные функции......................................................................134
Жесткие и символические связи: In..........................................................134
Идентификация shell: whoami................................................................137
Замена пользователя: su.........................................................................................137
Проверка почты: biff...............................................................................................138
Преобразование файлов......................................................................139
Сжатие файлов: compress/uncompress и gzip/gunzip........................................139
Шифрование файла: crypt.................................................................141
Потоковое редактирование: sed......................................................... 142
Команды sed........................................143
Замена текста.........................................................................143
Удаление текста.......................................................................144
Вставка текста........................................................................145
Замена текста.........................................................................145
Вставка файлов........................................................................146
Составные команды sed.................................................................................146
Преобразование символов: tr.............................................................147
Преобразование подчеркнутых последовательностей: id...............................148
Просмотр необработанного содержимого файла: od..........................................149
Монтирование файловых систем: mount/ amount.............................................151
Идентификация терминалов: tty.......................................................................152
Форматирование текста: nroff/troff/style/spell....................................................153
Измерение времени выполнения: time......................................................153
Создание собственных программ: Perl........................................................154
Получение Perl..........................................................................154
Печать текста...........................................................................155
Переменные, строки и целые..............................................................155
Массивы.................................................................................156
Математические и логические операторы...................................................158
Строковые операторы.....................................................................159
Операторы сравнения.....................................................................160
Конструкции if, while, for и foreach ................................................................... 160
Ввод/вывод файла........................................................................161
Функции.................................................................................162
Библиотека функций......................................................................163
Аргументы командной строки..............................................................164
Пример из реального мира............................................................... 165
Обзор главы................................................................................168
Перечень тем............................................................................168
Контрольные вопросы.....................................................................168
Упражнения..............................................................................169
Проекты............................................................................... 169
Глава 4. Командные интерпретаторы shell.........................................171
Мотивация.....................................................................171
Предпосылки...................................................................171
Задачи........................................................................171
Утилиты.......................................................................172
Команды shell.................................................................172
Общие сведения о shell...................................................... 172
Функциональные возможности shell..............................................173
Выбор shell...................................................................173
Функционирование shell........................................................175
Исполняемые файлы и встроенные команды....................................... 175
Вывод информации на экран: echo............................................176
Смена каталогов: cd............................................................................................176
Метасимволы...................................................................176
Перенаправление ввода/вывода..................................................178
Перенаправление вывода.....................................................178
Переназначение ввода.......................................................179
Групповые символы поиска файлов...............................................180
Конвейеры.....................................................................181
Замещение команды.............................................................183
Последовательности............................................................184
Условные последовательности................................................184
Группирование команд..........................................................185
Фоновое выполнение........................................................ 186
Перенаправление фоновых процессов.............................................187
Перенаправление вывода.....................................................187
Перенаправление ввода......................................................188
Программы shell: скрипты......................................................188
Дочерние shell................................................................190
Переменные....................................................................191
Использование кавычек.........................................................193
Перенаправление ввода в буфер shell...........................................194
Управление работой............................................................195
Статус процесса: ps........................................................196
Процессы передачи сигналов: kill...........................................199
Ожидание дочернего процесса: wait.................................................................201
Поиск команды: $РАТН........................................................................................202
Подмена стандартных утилит....................................................203
Завершение и коды выхода.................................................... 203
Основные встроенные команды...................................................205
eval.......................................................................205
exec.......................................................................205
shift......................................................................206
umask......................................................................207
Обзор главы...................................................................208
Перечень тем...............................................................208
Контрольные вопросы..............................................................209
Упражнения.......................................................................209
Проект...........................................................................210
Глава 5. Bourne shell................................................................211
Мотивация..........................................................................211
Предпосылки........................................................................211
Задачи.............................................................................211
Изложение..........................................................................211
Утилиты............................................................................211
Команды shell......................................................................212
Общие сведения о Bourne shell......................................................212
Запуск.............................................................................212
Переменные.........................................................................213
Создание и назначение переменной.................................................213
Доступ к переменной..............................................................214
Чтение переменной со стандартного ввода..........................................216
Экспорт переменных...............................................................217
Переменные только для чтения.....................................................218
Предопределенные локальные переменные.......................................... 219
Предопределенные переменные окружения............................................220
Арифметические действия............................................................222
Условные выражения.................................................................224
Структуры управления...............................................................226
case ... in ... esac..................................................................................................226 for ... do ... done....................................................................................................228 if... then ...ft........................................................................................................229 trap.............................................................................230
until... do ... done.................:...........................................231
while ... done.........................................................................................................232
Пример проекта: track..............................................................233
track.sed........................................................................235
track, cleanup...................................................................236
track............................................................................236
Дополнительные встроенные.команды..................................................237
Команда чтения: точка (.)........................................................237
Команда null........................................................................................................238
Установка опций shell: set.......................................................238
Усовершенствования.................................................................239
Перенаправление................................................................ 239
Последовательности команд........................................................240
Опции командной строки........................................................... 241
Обзор главы........................................................................241
Перечень тем.....................................................................241
Контрольные вопросы..............................................................242
Упражнения.......................................................................242
Проекты..........................................................................243
Глава 6. Korn shell......................................................245
Мотивация..............................................................245
Предпосылки............................................................245
Задачи.................................................................245
Изложение..............................................................245
Команды shell..........................................................245
Общие сведения о Korn shell............................................246
Запуск.................................................................246
Псевдонимы.............................................................248
Создание псевдонимов встроенных команд...............................249
Удаление псевдонимов.................................................249
Предопределенные псевдонимы..........................................250
Некоторые полезные псевдонимы........................................250
Псевдонимы путей.....................................................251
Экспортируемые псевдонимы............................................251
История................................................................252
Пронумерованные команды............................................ 252
Сохранение команд....................................................253
Повторное выполнение команд..........................................253
Редактирование команд................................................254
Редактирование команд..................................................255
Встроенный редактор и................................................256
Дополнительные перемещения.........................................256
Дополнительный поиск...............................................257
Использование маски для имени файла................................257
Замещение псевдонима...............................................258
Встроенный редактор emacs/gmacs......................................258
Арифметические действия................................................259
Предотвращение интерпретации метасимволов............................260
Возвращаемые значения................................................261
Замена тильды..........................................................261
Меню: select.............................................................................................................262
Функции................................................................263
Использование параметров в функциях..................................265
Возврат из функции...................................................265
Контекст.............................................................266
Локальные переменные.................................................266
Рекурсия.............................................................267
Рекурсивный факториал: использование кода возврата.................267
Рекурсивный факториал: использование стандартного вывода...........268
Использование кода функций в нескольких скриптах.....................268
Расширенное управление заданиями.......................................269
Задания..............................................................269
Спецификация задания.................................................270
bg...................................................................270
fg................................................................. 271
kill.................................................................272
Усовершенствования...........................................................................273
Перенаправление............................................................................273
Конвейеры..................................................................................274
Замещение команды..........................................................................274
Переменные.................................................................................275
Гибкие методы доступа...................................................................275
Предопределенные локальные переменные...................................................276
Одномерные массивы......................................................................278
typeset.................................................................................278
Форматирование.............................................................................279
Регистр....................................................................................279
Тип........................................................................................280
Разное................................................................................... 281
typeset о не именованными переменными...................................................282
Встроенные команды.........................................................................283
cd.......................................................................................................................283
set.....................................................................................284
print................................................................................. 286
read...................................................................................................................287
test.....................................................................................................................287
trap....................................................................................................................288
Пример проекта: junk.......................................................................289
junk...................................................................................................................290
Ограниченный shell...........................................................................293
Опции командной строки.......................................................................293
Обзор главы..................................................................................294
Перечень тем...............................................................................294
Контрольные вопросы........................................................................294
Упражнения.................................................................................294
Проекты....................................................................................295
Глава 7. С shell................................................................................297
Мотивация....................................................................................297
Предпосылки..................................................................................297
Задачи..................................................................................... 297
Изложение.................................................................................. 297
Команды shell................................................................................297
Общие сведения о С shell.....................................................................298
Запуск.......................................................................................299
Переменные...................................................................................300
Создание и присвоение значений простым переменным..........................................300
Доступ к простой переменной.............................................................. 301
Создание списочных переменных..............................................................302
Доступ к списочной переменной..............................................................303
Построение списков.........................................................................304
Предопределенные локальные переменные...............................................304
Создание и присвоение переменных окружения..........................................306
Предопределенные переменные окружения...............................................306
Выражения............................................................................ 307
Строковые выражения............................................................... 307
Арифметические выражения............................................................307
Выражения, ориентированные на файл..................................................310
Автоматическое дописывание имени файла................................................311
Псевдонимы............................................................................311
Удаление псевдонима.................................................................313
Полезные псевдонимы.................................................................313
Разделение псевдонимов..............................................................314
Параметризованные псевдонимы...................................................... 314
История...............................................................................314
Пронумерованные команды.............................................................314
Сохранение команд...................................................................315
Чтение истории......................................................................315
Повторное выполнение команды...................................................... 316
Доступ к частям команд истории................................................317
Доступ к частям имен файлов....................................................318
Замена истории......................................................................318
Структуры управления..................................................................319
foreach ... end.....................................................................319
goto................................................................................320
if... then ... else ... endif.......................................................321
onintr............................................................................ 322
repeat..............................................................................323
switch ... case ... endsw...........................................................323
while ... end...........................................................................................................326
Пример проекта: junk.............................................................................................327
junk.............................................................................. 327
Усовершенствования....................................................................329
Повторное выполнение команды: клавиатурная комбинация быстрого вызова.....................................................................330
Метасимволы: {}................................................................................................330
Замещение имен файлов...............................................................330
Запрещение замещения имени файла.................................................331
Ситуации несовпадения............................................................331
П еренаправление....................................................................331
Перенаправление стандартного канала ошибки.......................................331
Защита файлов от случайного переписывания........................................332
Конвейеризация......................................................................332
Управление заданием.................................................................333
stop.............................................................................333
suspend..............................................................................................................334
nice.............................................................................334
nohup.................................................................................................................334
notify..................................................................................................................335
Завершение входного shell................................................................335
Встроенные команды.........................................................................336
chdir......................................................................................................................336
glob........................................................................................................................336
source....................................................................................................................336
Стек каталогов.............................................................................337
Хеш-таблица..............................................................................339
Опции командной строки.....................................................................340
Обзор главы................................................................................341
Перечень тем.............................................................................341
Контрольные вопросы......................................................................341
Упражнения...............................................................................342
Проект...................................................................................342
Глава 8. Bourne Again shell................................................................. 343
Мотивация..................................................................................343
Предпосылки................................................................................343
Задачи.....................................................................................343
Изложение..................................................................................344
Команды shell..............................................................................344
Общие сведения о Bourne Again shell........................................................344
Получение Bash...........................................................................345
Запуск.....................................................................................345
Переменные.................................................................................346
Создание и назначение простой переменной.................................................346
Доступ к простой переменной..............................................................347
Создание списочных переменных............................................................347
Доступ к списочным переменным............................................................348
Построение списков.......................................................................349
Удаление списков.........................................................................350
Экспорт переменных.......................................................................350
Предопределенные переменные..............................................................351
Клавиатурные комбинации быстрого вызова команд.............................................352
Псевдонимы...............................................................................352
История команд...........................................................................353
Хранение команд.......................................................................353
Чтение истории команд.................................................................353
Повторное выполнение команд...........................................................353
Замена истории........................................................................354
Редактирование команды................................................................355
Автозаполнение...........................................................................356
Арифметические действия....................................................................356
Условные выражения.........................................................................357
Арифметические выражения.................................................................357
Сравнение строк..............................................................358
Выражения, ориентированные на файл...........................................358
Структуры управления...........................................................360
case ... in ... esac...................................................................................................360
if... then ... elif... then ... else ...ft........................................................................361 for ... do ... done....................................................................................................362
while/until... do ... done...................................................362
Стек каталогов............................................................... 363
Управление заданием............................................................364
Функции........................................................................365
Разные встроенные команды......................................................366
Опции командной строки....................................................... 367
Обзор главы....................................................................368
Перечень тем.................................................................368
Контрольные вопросы..........................................................368
Упражнение...................................................................369
Проект.......................................................................369
Глава 9. Организация сети........................................................371
Мотивация......................................................................371
Предпосылки....................................................................371
Задачи.........................................................................371
Изложение......................................................................371
Утилиты........................................................................372
Общие сведения о сетях.........................................................372
Построение сети................................................................372
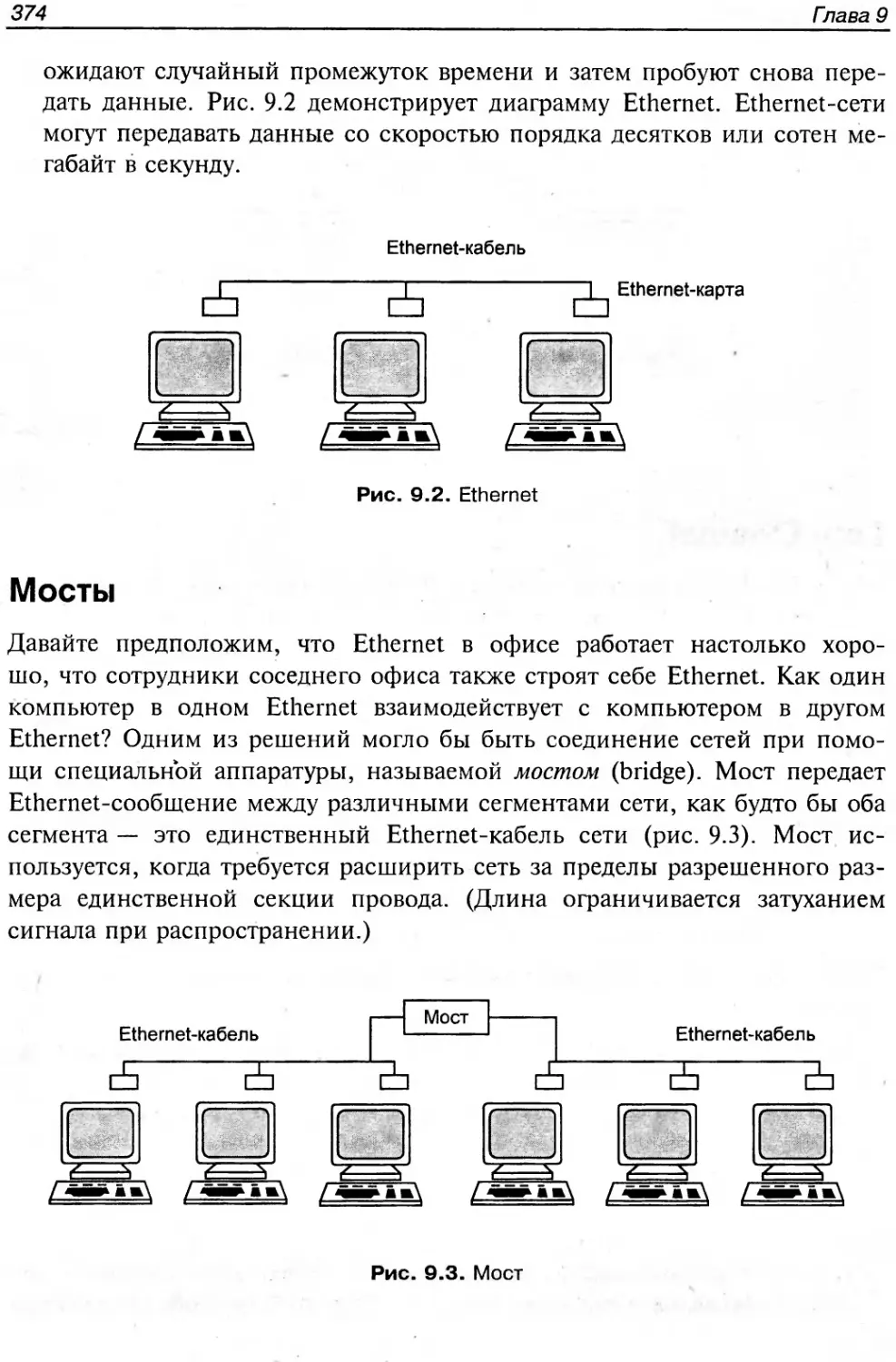
Сети Ethernet................................................................373
Мосты........................................................................374
Маршрутизаторы............................................................. 375
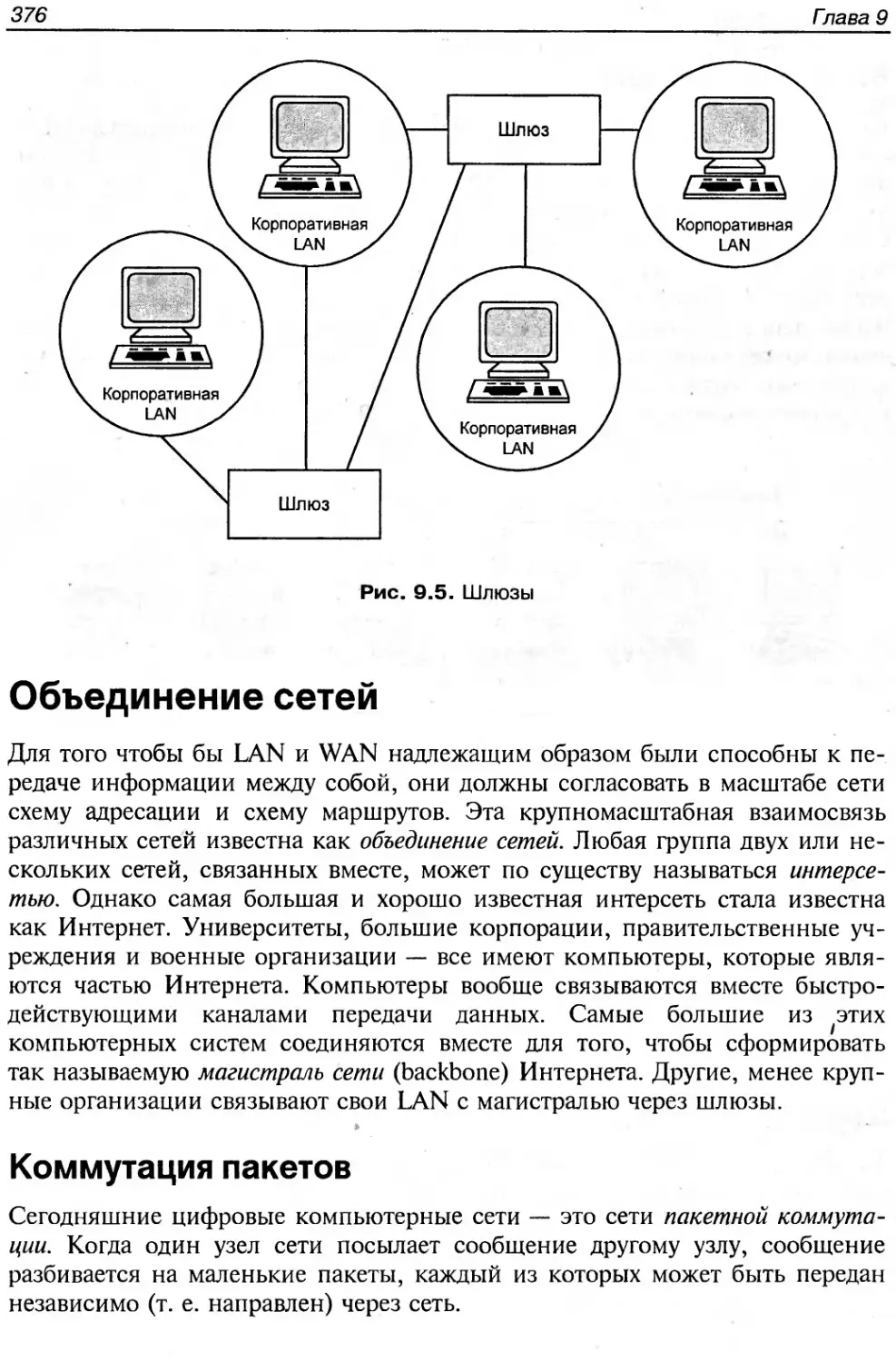
Шлюзы........................................................................375
Объединение сетей..............................................................376
Коммутация пакетов...........................................................376
Адреса Интернета.............................................................377
Именование...................................................................378
Маршрутизация................................................................378
Безопасность.................................................................378
Порты и общие сервисы...................................................... 379
Сетевое программирование.....................................................380
Пользователи...................................................................380
Распечатка списка пользователей: users/rusers................................381
Расширенные сведения о пользователях: who/rwho/w....................................382
Собственное имя хоста: hostname..............................................383
Персональные данные: finger..................................................384
Взаимодействие с пользователями................................................386
Защита от общения: mesg......................................................386
Передача строки за один раз: write...........................................387
Интерактивные диалоги: talk............................................................................388
Сообщения всем пользователям: wall..............................................................388
Распределенные данные..............................................................389
Копирование файлов между двумя UNIX-хостами: гср................................390
Копирование файлов между He-UNIX-хостами: ftp.......................................390
Распределенная обработка...........................................................393
Удаленный вход в систему: rlogin .....................................................................394
Выполнение удаленных команд: rsh.................................................................395
Удаленные соединения: telnet....................................................396
Сетевая файловая система: NFS......................................................399
Для дополнительной информации......................................................400
Обзор главы........................................................................400
Перечень тем....................................................................400
Контрольные вопросы.............................................................400
Упражнения......................................................................400
Проект..........................................................................401
Глава 10. Интернет...................................................................403
Мотивация..........................................................................403
Предпосылки........................................................................403
Задачи.............................................................................403
Изложение..........................................................................403
Эволюция Интернета.................................................................404
В начале: 1960-е................................................................404
Сетевая связь.................................................................405
ARPANET.......................................................................405
Стандартизация Интернета: 1970-е................................................405
Семейство протокола IP........................................................406
TCP/IP........................................................................406
UDP/IP........................................................................407
Интернет-адресация............................................................407
Интернет-приложения...........................................................408
Изменение архитектуры и переименование Интернета: 1980-е........................408
Служба доменных имен........................................................ 409
Дальнейшее развитие...........................................................412
Web: 1990-е.....................................................................413
"Убийственное приложение"................................................... 413
Web против Интернета..........................................................415
Достижимость..................................................................415
Изменения в Интернете.........................................................416
Безопасность..................................................................417
Авторское право...............................................................418
Цензура.......................................................................418
Дезинформация.................................................................418
Приемлемое использование......................................................419
Современный Интернет...........................................419
URL..........................................................420
Web-поиск..................................................421
Поиск пользователей и доменов............................ 422
Факторы, влияющие на будущее использование.................422
Обзор главы....................................................422
Перечень тем............................................... 422
Контрольные вопросы..........................................423
Упражнения...................................................423
Проект.......................................................423
Глава 11. Пользовательские интерфейсы............................425
Мотивация......................................................425
Предпосылки....................................................425
Задачи.........................................................425
Изложение......................................................425
Утилиты........................................................426
Общие сведения.................................................426
Графические пользовательские интерфейсы......................426
X Window System..............................................427
Х-серверы......................................................428
Геометрия экрана.............................................428
Безопасность и авторизация...................................429
Диспетчеры окон................................................430
Фокус........................................................430
Запуск программы.............................................431
Открытие и закрытие окон.....................................431
Выбор диспетчера окна........................................432
Виджеты........................................................433
Меню....................................................... 434
Командные кнопки.............................................434
Флажки и переключатели.......................................435
Полосы прокрутки.............................................435
Функции диспетчера окна Motif..................................436
Вызов корневого меню.........................................436
Открытие окна................................................437
Закрытие окна................................................437
Перемещение окна.............................................437
Изменение размера окна.......................................437
Размещение поверх других окон.........;......................437
Вызов меню окна............................................. 437
Приложение-клиент..............................................438
xclock.......................................................438
xbiff........................................................438
xterm...................................................... 440
Стандартные аргументы X-клиента................................440
Геометрия....................................................440
Цвет переднего и заднего плана...............................441
Заголовок....................................................441
Значок.......................................................441
Дополнительные темы............................................441
Копирование и вставка........................................441
Сетевые возможности..........................................443
Ресурсы приложения...........................................443
Как работают ресурсы.......................................444
Определение ресурсов.......................................445
Конфигурация и запуск........................................447
xinit и .xinitrc...........................................447
mwm и .mwmrc...............................................448
Обзор других Х-совместимых рабочих столов......................448
CDE..........................................................449
Gnome........................................................449
KDE..........................................................449
Open Windows.................................................449
VUE..........................................................450
Обзор главы....................................................450
Перечень тем.................................................450
Контрольные вопросы..........................................450
Упражнения...................................................451
Проект.......................................................451
Глава 12. Инструментальные средства программирования на С........453
Мотивация......................................................453
Предпосылки....................................................453
Задачи.........................................................453
Изложение......................................................453
Утилиты........................................................454
Язык С.........................................................454
Компиляторы С..................................................455
Одномодульные программы........................................455
Компиляция С-программы.......................................456
Листинг скорректированной программы reverse..................457
Выполнение С-программы.......................................458
Переопределение имени исполняемого файла.....................459
Многомодульные программы.......................................459
Многократно используемые функции.......................459
Подготовка многократно используемой функции..................460
reverse.h..................................................460
reverse, с.................................................460
mainl.c....................................................461
Отдельное компилирование и компоновка модулей......................................461
Автономный загрузчик: Id.................................................................................462
Повторное использование функции reverse.....................................................463
palindrome.h....................................................................463
palindrome.с....................................................................463
main2.c.........................................................................464
Поддержка многомодульных программ..................................................464
Система зависимости файлов UNIX: make................................................465
Make-файлы.........................................................................466
Порядок make-правил................................................................467
Выполнение таке...............................................................................................468
Маке-правила.......................................................................469
Написание собственных пользовательских правил......................................470
touch..............................................................................470
Макросы............................................................................471
Другие возможности таке............................................................472
Система поддержки архивов UNIX: аг...................................................472
Создание архива....................................................................473
Добавление файла...................................................................473
Присоединение файла................................................................473
Получение оглавления...............................................................474
Удаление файла.....................................................................474
Извлечение файла...................................................................474
Обработка архива из командной строки...............................................474
Обработка архива при помощи утилиты таке...........................................475
Упорядочение архивов...............................................................476
Создание оглавления: ranlib........................................................477
Разделяемые библиотеки.............................................................478
Система управления исходным кодом UNIX: SCCS.........................................479
Создание SCCS-файла................................................................480
Выборка файла......................................................................481
Наблюдение SCCS-активности.........................................................482
Отмена выборки и возврат файла.....................................................483
Создание новой дельты..............................................................483
Получение истории файла............................................................485
Идентифицирующие ключевые слова SCCS...............................................485
Создание нового релиза.............................................................486
Выборка копий только для чтения предыдущих версий..................................487
Выборка редактируемых копий предыдущих версий......................................487
Редактирование различных версии....................................................488
Удаление версии....................................................................489
Сжатие SCCS-фаилов.................................................................490
Ограничение доступа к SCCS-фаилам..................................................491
Блокировка релизов.................................................................492
Профайлер UNIX: prof...........................................................................................492
Перепроверка программ : lint................................................................................493
Отладчик UNIX: dbx............................................................................494
Подготовка программы для отладки............................................................496
Вход в режим отладки........................................................................496
Выполнение программы........................................................................497
Трассировка программы.......................................................................497
Трассировка переменных и вызовов функции....................................................498
Ошибки......................................................................................500
Точки останова..............................................................................500
Пошаговое выполнение........................................................................501
Организация доступа к переменным............................................................501
Листинг программы...........................................................................502
Выход из отладчика..........................................................................503
Резюме......................................................................................503
Удаление лишнего кода: strip..................................................................503
Обзор главы...................................................................................504
Перечень тем................................................................................504
Контрольные воросы..........................................................................504
Упражнения..................................................................................505
Проекты.....................................................................................505
Глава 13. Системное программирование.............................................................507
Мотивация.....................................................................................507
Предпосылки...................................................................................507
Задачи........................................................................................507
Изложение.....................................................................................507
Системные вызовы и библиотечные процедуры.....................................................508
Общие сведения................................................................................508
Обработка ошибки: реггог()...................................................................................510
Управление обычными файлами...................................................................513
Общие сведения об управлении файлами........................................................513
Первый пример: reverse......................................................................................515
Как работает reverse............................................................................................517
Листинг: reverse.с..........................................................................518
Открытие файла: ореп()......................................................................524
Создание файла...........................................................................526
Открытие существующего файла.............................................................526
Другие флаги открытия....................................................................526
Чтение из файла: read().....................................................................526
Запись в файл: \vrite().........................................................................................527
Перемещение в файле: lseek()................................................................528
Закрытие файла: close()......................................................................................530
Удаление файла: unlink()....................................................................531
Второй пример: monitor.................................................................... 532
Как работает monitor...................................................................................... . ..533
Листинг: monitor.c..........................................................................534
Получение информации о файле: stat()...........................................................543
Чтение информации каталога: getdentsQ...................................................545
Смешанные вызовы системы управления файлами.............................................546
Замена владельца файла или группы: chown() и fchovm()...................................547
Изменение прав доступа файла: chmod() и fchmod()........................................548
Дублирование дескриптора файла: dup() и dup2() ..........................................549
Действия с дескриптором файла: fcntl()..................................................550
Управление устройствами: ioctl()......................................................................552
Создание жестких связей: Нпк()........................................................................552
Создание специальных файлов: mknod()..........................................................554
Сбрасывание на диск буферов файловой системы: sync()....................................554
Усечение файла: truncate() и ftruncateQ.................................................555
STREAMS.................................................................................556
Усовершенствования по сравнению с традиционным вводом/выводом UNIX..................................................................556
Анатомия STREAMS.....................................................................557
Системные вызовы STREAMS.............................................................557
Управление процессами.....................................................................558
Создание нового процесса: fork() .....................................................................560
Осиротевшие процессы....................................................................562
Завершение процесса: exit().............................................................564
Зомби-процессы..........................................................................565
Ожидание дочернего процесса: wait().....................................................566
Замена кода процесса: ехес()............................................................568
Смена каталогов: chdir()................................................................569
Смена приоритетов: nice().................................................................................570
Доступ к ID пользователя и ID группы....................................................572
Пример программы: фоновая обработка.....................................................573
Пример программы: использование диска...................................................573
Подпроцессы-нити........................................................................576
Управление нитями....................................................................577
Синхронизация нитей..................................................................577
Безопасность нитей...................'...............................................577
Перенаправление.........................................................................578
Сигналы...................................................................................580
Определенные сигналы....................................................................581
Список сигналов.........................................................................581
Сигналы терминала.......................................................................582
Запрос аварийного сигнала: alarm()......................................................583
Обработка сигналов: signal()..............................................................................584
Защита критического кода и формирование цепочки обработчиков прерываний..............................................................................586
Посылка сигналов: кШ()..................................................................587
’’Смерть" дочерних процессов............................................................587
Приостановка и возобновление процессов..................................................589
Группы процесса и терминалы управления..................................................591
IPC..................................................................596
Конвейеры..........................................................596
Безымянные конвейеры: pipe()......................................................................597
Именованные конвейеры............................................601
Программа-читатель...............................................603
Программа-писатель...............................................604
Примерный вывод..................................................605
Сокеты.............................................................605
Виды сокетов.....................................................607
Написание сокетных программ......................................608
Листинг примера “Chef-Cook"......................................609
Анализ исходного кода............................................613
Разделяемая память.................................................628
Семафоры...........................................................629
Internet shell.......................................................630
Ограничения........................................................630
Синтаксис команды..................................................631
Запуск Internet shell..............................................631
Встроенные команды.................................................631
Примеры обычных команд.............................................632
И нтернет-примеры..................................................633
Как работает Internet shell........................................635
Основной командный цикл............................................636
Анализ........................................................... 636
Выполнение командной последовательности............................637
Выполнение конвейеров..............................................637
Выполнение простой команды.........................................638
Переключение.......................................................638
Расширение возможностей............................................639
Листинг исходного кода Internet shell............................639
Обзор главы..........................................................666
Перечень тем.......................................................666
Контрольные вопросы................................................666
Упражнения.........................................................667
Проекты............................................................669
Глава 14. UNIX изнутри.................................................673
Мотивация............................................................673
Предпосылки..........................................................673
Задачи...............................................................673
Изложение............................................................673
Общие сведения...................................................... 674
Основы ядра..........................................................674
Подсистемы ядра....................................................674
Процессы и файлы...................................................675
Взаимодействие с ядром.............................................675
Системные вызовы..............................................676
Пользовательский режим и режим ядра...........................677
Синхронная обработка против асинхронной.......................679
Прерывания....................................................680
Прерывание прерывании.........................................681
Файловая система................................................683
Архитектура диска.............................................684
Чередование...................................................686
Хранение файла................................................686
Блочный ввод/вывод............................................687
Индексный дескриптор или inode................................688
Содержимое inode..............................................689
Карта блоков..................................................690
Размещение файловой системы...................................691
Суперблок.....................................................692
Bad-блоки.....................................................693
Каталоги......................................................693
Преобразование путевых имен в номера inode....................694
Пример преобразования путевого имени в inode..................695
Монтирование файловых систем..................................696
Система ввода/вывода файлов...................................697
Управление процессами...........................................697
Исполняемые файлы.............................................697
Первые процессы...............................................698
Процессы ядра и пользовательские процессы.....................699
Иерархия процессов............................................699
Состояния процесса............................................700
Состав процесса...............................................701
Область пользователя..........................................701
Таблица процессов.............................................702
Планировщик...................................................703
Правила планирования..........................................704
Управление памятью............................................706
Страницы памяти............................................. 706
Таблицы страниц и области.................................... 706
Таблица ОЗУ...................................................708
Загрузка исполняемого файла: ехес()...........................708
Преобразование адреса.........................................709
Иллюстрация алгоритма MMU.....................................710
ММU и таблица страниц.........................................710
Схема памяти после первой команды.............................711
Схема памяти после нескольких команд..........................712
Демон страниц.................................................714
Пространство обмена...........................................714
Алгоритм демона страниц.......................................714
Схема памяти после удаления нескольких страниц................715
Доступ к странице, которая хранится в пространстве обмена.................716
Дублирование процесса: fork()............................................................717
Обработка ссылок на разделяемые страницы ОЗУ
и пространства обмена....................................................................719
Пробуксовка и свопинг....................................................................720
Прекращение процесса: exit() ...............................................................720
Сигналы..................................................................................721
setpgrp()..............................................................................721
signal()...............................................................................................................722
Сигналы после системных вызовов fork() или ехес() ................................722
Обработка сигнала......................................................................723
exit()..................................................................................................................723
wait ()................................................................................723
кШ()...................................................................................724
Ввод/вывод..................................................................................724
Объекты ввода/вывода.....................................................................724
Системные вызовы ввода/вывода............................................................725
Буферизация ввода/вывода.................................................................725
sync().................................................................................727
Ввод/вывод обычных файлов................................................................728
ореп()................................................................................................................728
read().................................................................................................................729
yvrite()...............................................................................730
IseekQ.................................................................................730
close()................................................................................731
dup()................................................................................ 733
unlink()........................................................................................ ....................733
Ввод/вывод каталогов.....................................................................734
mknod()................................................................................734
link().................................................................................735
Монтирование файловых систем.............................................................735
mount().............................................................................. 735
Перевод имен файлов......................................................................736
amount()...............................................................................737
Ввод/вывод специальных файлов............................................................737
Интерфейс устройства...................................................................738
Старшие и младшие номера...............................................................739
Таблицы переключения...................................................................739
ореп().................................................................................741
read().................................................................................742
write()................................................................................742
close()742
ioctl()................................................................................742
Ввод/вывод терминала.....................................................................743
Структуры данных терминала.............................................................744
Чтение с терминала.........................................744
Запись на терминал.........................................745
Потоки.......................................................745
Взаимодействие процессов.......................................746
Конвейеры....................................................746
Конвейеры System V Release 3...............................746
Структуры данных конвейера.................................747
Запись в конвейер..........................................747
Чтение из конвейера........................................747
Закрытие конвейера....................................... 747
Конвейеры System V Release 4............................. 748
Конвейеры BSD..............................................748
Сокеты.......................................................748
Управление памятью.........................................748
Сокеты и таблица открытых файлов......................... 749
Запись в сокет.............................................749
Чтение из сокета...........................................750
Обзор главы....................................................750
Перечень тем.................................................750
Контрольные вопросы..........................................750
Упражнения...................................................751
Проекты......................................................752
Глава 15. Системное администрирование............................753
Мотивация......................................................753
Предпосылки....................................................753
Задачи.........................................................753
Изложение......................................................753
Утилиты........................................................754
Общие сведения о системном администрировании...................754
Как стать привилегированным пользователем......................755
Запуск UNIX....................................................755
Остановка системы..............................................757
Поддержка файловой системы.....................................759
Целостность файловой системы.................................759
Использование диска........................................ 760
Назначение квот..............................................763
Создание новых файловых систем...............................763
Создание резервных копий файловых систем.....................764
Поддержка пользовательских учетных записей.....................764
Файл паролей.................................................765
Файл групп...................................................766
Установка программного обеспечения.............................767
Периферийные устройства........................................769
Установка драйвера устройства................................769
Терминальные файлы.......................................-...770
Сетевой интерфейс...............................................771
Автоматизация задач.............................................772
Учет системных ресурсов.........................................773
Конфигурирование ядра...........................................773
Проблемы безопасности...........................................774
Обзор главы.....................................................776
Перечень тем..................................................776
Контрольные вопросы...........................................776
Упражнения....................................................777
Проект........................................................777
Глава 16. Будущее.................................................779
Мотивация.......................................................779
Предпосылки.....................................................779
Задачи..........................................................779
Изложение.......................................................779
Общие сведения..................................................780
Влияние настоящего и будущего на UNIX...........................780
Объектно-ориентированное программирование.....................780
Что такое объект?...........................................781
Как объект используется.....................................781
Так чем же хорошо все это?..................................782
Наследование................................................782
Открытые программные средства.................................783
Free Software Foundation....................................783
Linux.......................................................784
Параллельные, распределенные и многопроцессорные системы......784
Параллельная обработка......................................785
Распределенные системы......................................785
Многопроцессорные системы...................................786
"Ошибка" 2000 года............................................786
Что же это в действительности?..............................787
Год в две цифры.............................................787
Годы, начиная с 1900........................................788
UNIX и XXI столетие.........................................789
64-разрядные системы..........................................789
Интернет-адресация: IPv6......................................790
Сети с высокой пропускной способностью........................791
Отказоустойчивые системы......................................792
Обзор современных популярных версий UNIX........................792
AIX...........................................................794
Caldera SCO/Unixware..........................................794
FreeBSD.......................................................794
HP-UX.........................................................795
IRIX..........................................................795
Linux.........................................................796
NetBSD......................................................796
OpenBSD.....................................................797
Tru64 UNIX..................................................797
Solaris.....................................................797
Обзор главы...................................................798
Перечень тем................................................798
Контрольные вопросы.........................................798
Упражнение..................................................799
Проект......................................................799
Приложение......................................................801
Регулярные выражения..........................................801
Шаблоны.....................................................802
Расширенные регулярные выражения............................802
Модифицированная для UNIX нотация Бэкуса—Наура................803
Библиография....................................................805
Предметный указатель............................................808
Правде и Красоте, где бы их ни находили, и Свободе, и всем, кто жертвовал ради них
Информация о торговых марках
AIX — торговая марка корпорации IBM.
Ethernet — зарегистрированная торговая марка корпорации Xerox.
FreeBSD — торговая марка Berkeley Software Design, Inc.
GNU — торговая марка Free Software Foundation.
HP-UX — зарегистрированная торговая марка компании Hewlett-Packard.
Itanium — зарегистрированная торговая марка корпорации Intel.
IRIX — зарегистрированная торговая марка Silicon Graphics, Inc.
Java — торговая марка Sun Microsystems, Inc.
KDE и К Desktop Environment — торговые марки KDE e. V.
Linux — торговая марка Linus Torvalds.
MacOS — зарегистрированная торговая марка Apple Computer.
Microsoft Windows, Windows NT и Windows 2000 — зарегистрированные торговые марки корпорации Microsoft.
Netscape — зарегистрированная торговая марка корпорации Netscape Communications.
SCO и UNIXWare — торговые марки Caldera.
Solaris, Spare и Open Windows — торговые марки Sun Microsystems, Inc.
Tru64 — торговая марка компании Hewlett-Packard.
UNIX — зарегистрированная торговая марка The Open Group.
VMS и Open VMS — зарегистрированные торговые марки компании Hewlett-Packard.
X Window System — торговая марка The Open Group.
Об авторах
Грэхэм Гласс (Graham Glass) окончил Университет Саутгемптона (Англия) со степенью бакалавра по информатике и математике в 1983 г. Эмигрировав в Соединенные Штаты, он получил степень мастера по информатике Техасского университета в Далласе (University of Texas at Dallas) в 1985 г. В то время он работал как системный аналитик UNIX/С и активно принимал участие в исследованиях нейронных сетей и параллельной распределенной обработки данных. Позже он преподавал в Техасском университете в Далласе разнообразные курсы, включая UNIX, С, ассемблер, языки программирования C++ и Smalltalk. Он был соучредителем корпорации ObjectSpace и в настоящее время обучает и консультирует такие компании, как DSC Corporation, Texas Instruments, Northern Telecom, J.C. Penney и Bell Northern Research, используя свои знания объектно-ориентированного программирования (ООП) и параллельных систем, чтобы проектировать и строить параллельную объектно-ориентированную компьютерную систему и язык, основанные на транспьютерном чипе Inmos Т9000. В свободное время он пишет музыку, ныряет с аквалангом, ходит на лыжах и иногда спит.
Кинг Эйблс (King Ables) получил степень бакалавра по информатике в Техасском университете в Остине (University of Texas at Austin) в 1982 г. Он был пользователем, разработчиком, системным администратором UNIX и консультантом с 1979 г., работая как в маленьких начинающих компаниях, так и в больших корпорациях. Обеспечивал поддержку и обучение, разрабатывал программное обеспечение UNIX и системные инструментальные средства, писал документацию на продукты и материалы для обучения. В 1990-х гг. он был единоличным владельцем консультационной фирмы по UNIX в Остине до момента, когда решил перебраться в горы Колорадо. До этого проекта он издал книгу по администрированию системы UNIX. Он также написал много журнальных статей на различные темы, относящиеся к UNIX, и имеет патент на механизм секретности для электронной коммерции. Его профессиональные интересы включают организацию безопасности сети и конфиденциальности в Интернете, но он любит путешествовать пешком и кататься на лыжах немного больше.
Введение
О чем эта книга
Одной из моих работ1 перед написанием этой книги было преподавание UNIX множеству разных людей, включая университетских студентов, промышленных С-хакеров и иногда друзей и коллег. За это время я приобрел обширные знания, в том числе и в форме существенной библиотеки примеров. Поэтому я часто думал, что будет хорошо систематизировать их и написать книгу. Когда я начал готовить мою университетскую серию лекций о UNIX, то нашел, что ни один из доступных учебников UNIX не удовлетворяет моей цели — они были или слишком неструктурированными, слишком специализированными или страдали недостатком неподходящих упражнений и проектов для моих студентов. В ответ на сложившуюся ситуацию я написал самую первую версию этой книги. После прошествия пары лет я полностью ее переписал, допуская осторожную мысль о включении нового материала. Я решил сгруппировать информацию, основываясь на типичных категориях пользователей UNIX, позволяя использовать книгу большому количеству людей без превышения (или принижения) умственных способностей каждого. Одно хитрое решение касалось уровня деталей, чтобы включить темы, подобные системным вызовам и утилитам. Большинство их имеет множество специализированных опций и особенностей, которые редко используются, и описание их всех при охвате всего диапазона желаемых тем завершится книгой толщиной приблизительно в два фута1 2. Из-за этого я включил в книгу информацию только о наиболее общих и полезных особенностях утилит, командных интерпретаторов (shells) и системных вызовов. Я включаю ссылки на другие коммерчески доступные книги для большего количества деталей. Этот гибридный подход оказался хорошим компромиссом; я надеюсь, что вы согласны.
В это издание добавлена глава о командном интерпретаторе Bourne Again shell (также называемом Bash), который стал важным из-за его всеобъемлющей позиции в Linux. Также обновлена информация о версиях UNIX/Linux, рабочих столах X Window System и нюансах работы менеджера окон, расширено описание' редактора vi, языка Perl и стандарта IPv6, добавлено и улучшено описание некоторых команд, контрольных вопросов и упражнений.
1 Здесь, по видимому, повествование идет от имени Грэхэма Гласса. — Ред.
2 Около 60 см. — Ред.
Структура книги
UNIX — большая система. Чтобы описать ее полностью, требуется объяснение многих различных вопросов с нескольких различных точек зрения. Что я как раз и попытался сделать. Книга разбита на следующие секции, каждая предназначена для конкретной категории пользователей:
П Глава 1. Что такое UNIX?
П Глава 2. Утилиты UNIX для непрограммистов.
□ Глава 3. Утилиты UNIX для опытных пользователей.
□ Глава 4. Командные интерпретаторы shell.
П Глава 5. Bourne shell.
□ Глава 6. Korn shell.
П Глава 7. С shell.
П Глава 8. Bourne Again shell.
□ Глава 9. Организация сети.
□ Глава 10. Интернет.
□ Глава 11. Пользовательские интерфейсы.
□ Глава 12. Инструментальные средства программирования на С.
□ Глава 13. Системное программирование.
□ Глава 14. UNIX изнутри.
□ Глава 15. Системное администрирование.
П Глава 16. Будущее.
□ Приложение.
□ Библиография.
Я рекомендую, чтобы различные категории пользователей читали главы так, как представлено в табл. В1.
Таблица В1
Категория пользователя Главы
Повседневные нерегулярные пользователи 1,2
Опытные пользователи 1-4, 9-11
Программисты 1-13, 16
Системные аналитики 1-14, 16
Мастера Все главы
2 Зак. 786
Структура глав
Каждая глава в этой книге имеет перечисленные ниже стандартные вводные разделы.
Мотивация
Объясняется, почему полезно изучить материал, который представлен в главе.
Предпосылки
Описано, что читатель должен знать, чтобы успешно усвоить материал главы.
Задачи
Приводится список представленных тем.
Изложение
Описывается метод, которым представлены темы.
Утилиты
Дается список утилит, описываемых в главе (когда уместно).
Системные вызовы
Приводится список системных вызовов, рассматриваемых в главе (когда уместно).
Команды shell
Представлен список команд shell, охваченных в главе (когда уместно).
Кроме того, каждая глава заканчивается разделом обзора, содержащим перечисленные ниже разделы.
Перечень тем
Резюме тем.
Контрольные вопросы
Быстрая самопроверка.
Упражнения
Список упражнений, расположенных по рангу: легкий, средний или высокий.
Проекты
Один или более имеющих отношение к теме главы проектов, расположенных по рангу: легкий, средний или высокий.
Руководство для преподавателей
Как было упомянуто ранее, эта книга была первоначально написана для студентов старших курсов и аспирантов. Я советую разрабатывать лекционный цикл, основанный на книге, следующим образом.
П Если студенты не знают язык С, то среднескоростной курс может начинаться с глав 1, 2, 4 и 12. Лектор может тогда представить студентам С и использовать содержание главы 13 для упражнений в аудитории и проектов.
□ Если студенты уже знают язык С, то среднескоростнои курс может включать главы 1, 2, 4, 7, 12—14. Проекты, ориентированные на параллельную обработку и взаимодействие процессов, будут гарантировать, что студенты окончат курс с хорошим знанием основных принципов UNIX.
□ Если студенты знают язык С и полны энтузиазма, предлагаю охватить все главы за исключением глав 3, 5 и 6 в одном семестре. Знаю, что это возможно, поскольку я преподавал курс лекций этим способом!
Условные обозначения
В книге имеются ссылки на утилиты UNIX, команды shell (т. е. команды, которые являются непосредственно частью командного интерпретатора) и системные вызовы (функции библиотеки UNIX). Весьма легко перепутать эти три вещи, так что я принял непротиворечивый способ для их различия: □ утилиты UNIX всегда написаны полужирным моноширинным шрифтом, вот так: "утилита mkdir создает каталог";
П команды shell всегда написаны моноширинным шрифтом, вот так: "команда history выводит ваши предыдущие команды";
□ системные вызовы всегда сопровождаются круглыми скобками, вот так: "системный вызов fork() дублирует процесс".
Формальные описания утилит, команд shell и системных вызовов предваряются выделенной серым цветом строкой, за которой следует синтаксис и разъяснение. Для примера ниже приведено описание утилиты UNIX man.
Синтаксис
man [глава] слово
man -к ключевоеСлово
Первое использование man выводит содержимое секций справочника, связанных с параметром слово. Значение параметра глава необязательно. Если номер главы не указан, будет показана первая глава, которую найдет man. Второе использование man выводит список всех статей справочника, которые содержат ключевоеСлово.
Примеры UNIX-сессий представлены шрифтом Courier. Пользовательский ввод с клавиатуры всегда показывается курсивом, а примечаниям всегда предшествуют пропуски слов (...). Вот пример:
$ 1s ...генерирует листинг каталога.
myfile.txt yourfile.txt $ whoami
glass
$ ... выводится новое приглашение.
Ссылки на другие книги
Насколько удобно повторно использовать существующий код, настолько хорошо иметь другой справочный материал, когда он не пересекается с естественным потоком изложения. Информация, которая, как мы считаем, слишком специализирована для данной книги, отмечается ссылкой на публикацию в библиографии, приведенной в конце книги. Например, "Для получения информации относительно порта UNIX на процессоре 68030, см. с. 426 из [Wait 1987]". В квадратных скобках обычно указаны имя автора и год публикации, когда книге дано право "относиться к литературе по UNIX".
Доступность исходного кода в режиме on-line
Примеры исходного кода, используемого в этом издании, доступны в режиме on-line. Короткие примеры не включены, но примеры любой "существенной” длины могут быть найдены в сети по адресу ftp://ftp.prenhall.com/pub/esm/the_apt__series.s-042/glass_ables_unix-3e/.
(Вы можете напечатать эту строку в браузере или см. главу 9 для получения дополнительной информации об FTP.)
Благодарности
Следующие люди способствовали выпуску предыдущих изданий этой книги: Джеймс Ф. Петерс (James F. Peters), Фади Диик (Fadi Deek), доктор Уильям Бурне (Dr. William Burns), Ричард Невман-Волф (Richard Newman-Wolfe), Дэвид Карвер (David Carver), Билл Тепфенхарт (Bill Tepfenhart), Стивен Раго (Stephen Rago) и Марк Эллис (Mark Ellis).
Этому изданию способствовал ценный технический вклад от Лори Мурфи (Lori Murphy), Лоренса Б. Веллса (Lowrence В. Wells) и Майкла Д. Брека (Michael D. Breck). Как всегда, сотрудники Prentice Hall — особенно Петра Ректер (Petra Recter), Камилла Трентакост (Camille Trentacoste) и Лакшми Баласубраманиан (Lakshmi Balasubramanian) — всегда были благосклонны и ободряли нас.
Глава 1
Что такое UNIX?
Мотивация
UNIX — хорошо известная в техническом мире операционная система, популярность которой в последнее время растет и в деловых кругах. Знание ее возможностей и особенностей поможет понять, почему все больше и больше людей предпочитает использовать UNIX, и сделает вашу работу более эффективной.
Предпосылки
Для понимания данной главы необходим небольшой опыт работы с компьютером и знакомство с такими компьютерными терминами, как программа, файл и центральный процессор (ЦП).
Задачи
В этой главе будет дано определение термину "операционная система" н описаны ее основные компоненты, а также рассказано, почему UNIX очень перспективна. Мы рассмотрим эту систему с нескольких различных ракурсов, поэтому информация будет интересна и полезна достаточно широкой аудитории, от начинающего пользователя до продвинутого системного программиста.
Изложение
Сначала будет рассказано о главных частях и элементах, которые формируют обычную компьютерную систему. Затем мы убедимся, насколько необходима специальная программа, называемая операционной системой, чтобы эффективно управлять этими частями, и рассмотрим некоторые ее возможности. Далее обратимся к философии UNIX, которая лежит в основе всей
этой книги. И, наконец, познакомимся с краткой историей UNIX и получим некоторое представление, о ее (т. е. системы) происхождении.
Компьютерные системы
Обычная однопользовательская компьютерная система состоит из многих частей, таких как центральный процессор (ЦП- Central Processing Unit, CPU), память, диски, монитор и клавиатура. Маленькие системы, подобные этой, могут быть связаны вместе, чтобы формировать большие компьютерные сети, распределять задачи между отдельными компьютерами. Рис. 1.1 является иллюстрацией такой сети.
ОЗУ
ПЗУ
Рис. 1.1. Типичная компьютерная сеть
Аппаратные средства ЭВМ, которые составляют компьютерную сеть — только половина истории; программное обеспечение, которое работает на компьютерах, не менее важно. Давайте рассмотрим детальнее различные аппаратные средства ЭВМ и компоненты программного обеспечения компьютерной системы.
□ Аппаратные средства (hardware).
Компьютерные системы, большие или маленькие, одно- или многопользовательские, дорогие или дешевые, состоят из множества компонентов.
П Центральный процессор (ЦП).
ЦП (Central Processing Unit, CPU) читает машинные коды (инструкции в форме, которую компьютер может понимать) из памяти и выполняет их. Как часто считают, ЦП является "мозгом" компьютера.
П Оперативное запоминающее устройство (ОЗУ).
ОЗУ (Random Access Memory, RAM) хранит машинные коды и данные, к которым обращается ЦП. ОЗУ обычно "забывает" все, что хранит, когда питание выключено.
□ Постоянное запоминающее устройство (ПЗУ).
ЗУ (Read Only Memory, ROM) хранит машинные коды и данные. Его содержимое не изменяется и хранится, даже когда питание выключено.
□ Диск (disk).
Диски хранят большое количество данных и кода в магнитной или оптической среде и "помнят” все это, даже когда питание выключено. Дискеты, как правило, сменные, тогда как жесткие диски — нет. Объем жестких дисков позволяет хранить на нем гораздо больше информации, чем на дискете.
□ Накопитель CD-ROM (CD-ROM Drive).
Накопители CD-ROM позволяют компьютеру читать информацию, записанную в цифровой форме, с компактного диска. Информация может представлять собой поток данных или файловую систему, которую ОС (операционная система) может читать так, как если бы она была расположена на жестком диске.
□ Монитор (monitor).
Мониторы отображают информацию и поставляются в двух разновидностях: монохромные и цветные. Монохромные мониторы редки в более новых (современных) компьютерных системах.
□ Видеокарта (Graphics card).
Видеокарты позволяют ЦП показывать информацию на мониторе. Некоторые графические карты могут показывать только знаки, тогда как другие поддерживают графику.
□ Клавиатура (keyboard).
Клавиатура позволяет пользователю вводить алфавитно-цифровую информацию. Доступны несколько различных видов раскладок клавиатуры, что частично-зависит от языка пользователя. Например, японская раскладка клавиатура больше, чем западная, поскольку алфавит первой намного больше. Западная раскладка клавиатуры часто называется QWERTY-клавиатура — по первым шести символам левой верхней строки.
□ Мышь (mouse).
Мышь обеспечивает легкое позиционирование курсора на экране короткими движениями руки. Большинство мышей имеет ’’хвосты”, которые соединяют их с компьютером, но некоторые имеют радио- или инфракрасные связи, которые делают ’’хвост" ненужным. Беспроводная форма будет весьма удобна для того, кто имеет кота, т. к. эти животные очень часто запутываются в этом проводе.
□ Принтер (printer).
Принтер позволяет пользователю получить твердую копию информации. Некоторые принтеры печатают только знаки, тогда как другие печатают графику.
□ Лента (tape).
Магнитные ленты используются для создания резервных копий информации, хранящейся на дисках. Они медленнее, чем диски, но хранят большие количества данных и довольно дешевы.
□ Модем (modem).
Модем позволяет связываться с другими компьютерами по телефонной линии. Различные модемы допускают разные скорости связи. Большинство модемов даже исправляет ошибки, которые происходят из-за плохой телефонной связи.
□ Ethernet-интерфейс (Ethernet interface).
Ethernet — это среда (обычно провода), которая делает доступной связь на высоких скоростях. Компьютеры подсоединяются к Ethernet через специальное устройство аппаратных средств, называемое интерфейсом Ethernet.
□ Другие периферийные устройства (peripherals).
Существует множество периферийных устройств, которые могут поддерживать компьютерные системы, включая графические планшеты, оптические сканеры, матричные процессоры, звуковые карты, карты распознавания голоса и синтезаторы (это далеко не полный список).
Вы не можете просто соединить эти части аппаратных средств ЭВМ вместе и иметь рабочую систему: необходимо установить программное обеспече
ние, управляющее и координирующее все части. Способность разделять периферийные устройства, распределять память, связываться с другими компьютерами, выполнять более, чем одну программу одновременно обеспечивается специальным видом программы, называемой операционной системой (ОС). Можно представить себе ее как "суперпрограмму", которая обеспечивает работу остальных программ. Давайте поближе познакомимся с операционными системами.
Операционные системы
Как вы могли заметить, компьютер не может функционировать без операционной системы. Существует множество различных операционных систем, доступных для персональных компьютеров (ПК — Personal Computer, PC), мини-компьютеров и универсальных ЭВМ; наиболее распространенными являются Windows NT и Windows 20001, VMS, MacOS и разновидности UNIX. Операционная система UNIX доступна для различных платформ, тогда как большинство других ОС привязано к определенному семейству аппаратных средств. Одно из главных достоинств в UNIX — доступность практически для любого компьютера. Из перечисленных операционных систем только UNIX и VMS позволяют использовать ресурсы компьютера более, чем одному пользователю одновременно, что является очевидным преимуществом для коммерческих систем. Многие фирмы покупают мощный мини-компьютер с двадцатью или более терминалами и устанавливают операционную систему UNIX, позволяющую распределять ЦП, память и дисковое пространство между пользователями. Что же мы получаем, когда выбираем UNIX, как операционную систему? Давайте рассмотрим ее с точки зрения программного обеспечения.
Программное обеспечение
Один из способов описать аппаратные средства системы состоит в том, чтобы рассказать, какие они обеспечивают условия для выполнения программ и хранения файлов. Виды программ, работающих на UNIX-платформах, различаются по размеру и сложности, но имеют некоторые общие характеристики. Далее приведен список характеристик UNIX-программ и файлов.
□ Файл — набор данных, который обычно хранится на диске или другом носителе. UNIX обращается с периферийными устройствами как со специальными файлами, поэтому терминалы, принтеры и другие устройства были доступны таким же образом, как файлы на обычном диске. *
В настоящий момент есть и другие версии Windows. — Ред.
□ Программа — собрание байтов, представляющих код и данные, которые хранятся в файле.
П Запущенная программа загружается с диска в ОЗУ (фактически загружена только ее часть, но мы поговорим об этом позже). Когда программа выполняется, она называется процессом.
□ Большинство процессов читает и пишет данные через файлы.
□ Процессы и файлы имеют владельца и могут быть защищены от несанкционированного доступа.
□ UNIX поддерживает иерархическую структуру каталогов.
□ Файлы и процессы имеют "местоположение" в пределах иерархии каталогов. Процесс может изменять его собственное местоположение или местоположение файла.
□ UNIX предоставляет возможность создания, модификации и уничтожения программ, процессов и файлов.
На рис. 1.2 приведена иллюстрация крошечной иерархии UNIX-каталогов, которая содержит четыре файла и процесс, управляющий обслуживающей программой sort.
/ (Корневой каталог)
I---------------1---------------------.
home bin
•---------------1--------------• —
glass tim who
sort
myfile.txt
afile.txt
Обозначения:
Процесс
Файл
Рис. 1.2. Иерархия каталогов
Разделение ресурсов
Другая функция операционной системы, которую реализует UNIX, — разделение ограниченных ресурсов среди конкурирующих процессов. Чаще всего
ограниченные ресурсы в компьютерной системе включают ЦП, память, место на диске и периферийные устройства типа принтеров. Вот краткая схема того, как эти ресурсы разделяются.
□ UNIX разделяет ЦП среди процессов путем деления каждой секунды процессорного времени на "кванты" равного размера (обычно 1/10 секунды) и затем выдает их процессам на основе системы приоритетов. Важным процессам выделяется большее количество квантов, чем другим.
□ UNIX разделяет память среди процессов путем деления ОЗУ на тысячи "страниц" памяти равного размера и затем выделяет их процессам на основе системы приоритетов. Только те части процесса, которые фактически должны быть в ОЗУ, всегда загружаются с диска. Страницы ОЗУ, к которым не обращаются некоторое время, вновь сохраняются на диск так, чтобы память могла быть перераспределена другим процессам.
□ UNIX разделяет дисковое пространство среди пользователей путем деления дисков на тысячи "блоков" равного размера и затем выделяет их пользователям согласно системе квот. Отдельный файл построен из одного или более блоков.
Глава 14 содержит подробное описание, как реализуется механизм разделения ресурсов. Итак, мы рассмотрели все функции, которые выполняет UNIX как операционная система, кроме одной — среды коммуникации.
Коммуникация
Компоненты системы малоэффективны без взаимодействия друг с другом. Это хорошо иллюстрируют следующие примеры:
□ процесс может нуждаться во взаимодействии с видеокартой, чтобы вывести результаты на экран;
□ процессу требуется взаимодействие с клавиатурой, чтобы получить входные данные;
□ почтовой системе необходимо взаимодействие с другими компьютерами, чтобы посылать и получать почту;
□ два процесса должны взаимодействовать друг с другом для совместного решения отдельной проблемы.
В зависимости от типа и скорости связи UNIX предусматривает несколько различных способов взаимодействия процессов и периферийных устройств. Например, один из путей, посредством которого процесс может взаимодействовать с другим процессом, —- это механизм межпроцессной связи, называемый pipe (конвейер). Конвейер — это односторонний канал данных средней скорости, который позволяет взаимодействовать двум процессам на той
же самой машине. Если процессы находятся на различных машинах, связанных сетью, то вместо него используется механизм, называемый сокетом (socket — гнездо, двунаправленный канал). Сокет — двусторонний быстродействующий канал данных.
Разделение задачи между различными процессами — распространенная в настоящее время технология. Например, есть графическая система X Window, которая работает, используя так называемую клиент-серверную модель. Один компьютер (Х-сервер) используется для управления графическим терминалом и рисования различных линий, кругов и окон, в то время как другой (X-клиент) воспроизводит данные, которые должны быть показаны. Системы, подобные этой, являются примерами распределенной обработки, в которой вычислительная нагрузка разделена среди нескольких компьютеров. Фактически единственный Х-сервер может обслуживать множество Х-клиентов. На рис. 1.3 представлена иллюстрация X Window System.
Х-сервер
Ethernet
Рис. 1.3. Х-сервер и Х-клиенты
Мы обсудим X Window System в главе 11.
Утилиты
Даже очень мощная операционная система не представляет большой ценности для пользователя, если не содержит достаточного количества полезных программ. Успех на рынке и достаточно ’’солидный” возраст UNIX делают очень разнообразным состав входящего в эту операционную систему программного обеспечения. Стандартная UNIX-система дополняется, как минимум, парой редакторов, С-компилятором, утилитами сортировки, графическим пользовательским интерфейсом, различными оболочками, программами обработки текста. Коммерчески доступны популярные пакеты, включающие в
себя электронные таблицы, компиляторы, издательские системы и т. д. Кроме того, большое количество бесплатного программного обеспечения распространяется через Интернет, которому посвящена глава 10.
Поддержка программиста
Система UNIX очень удобна для программистов. Это открытая система, внутренняя программная архитектура которой хорошо документирована и доступна либо в форме исходного текста, либо за небольшую плату. Особенности этой операционной системы, такие как параллельная обработка, взаимодействие процессов и работа с файлами, — все является легко доступным из языка программирования С и набора библиотечных подпрограмм, называемых системными вызовами. Многие функции, использование которых было затруднено в старых операционных системах, теперь легкодоступны для любого системного программиста.
Стандарты
Эта операционная система придерживается определенных стандартов, разработанных двумя основными группами. UNIX была создана в AT&T Bell Laboratories и впоследствии развилась в систему, известную как System И Калифорнийский Университет (Беркли) получил копию UNIX в самом начале его разработки и создал другую версию, впоследствии ставшую доминирующей, — Berkeley Standard Distribution (BSD) UNIX. System V и BSD UNIX имеют свои сильные и слабые стороны, но в них и много общего. Два консорциума ведущих компьютерных изготовителей развивают каждый свою систему и полагают, что их версия будет лучшей. Консорциум UNIX International, возглавляемый AT&T и Sun, поддержал самую последнюю версию System V UNIX — System V Release 4. Группа Open Software Foundation (OSF), возглавляемая IBM, Digital Equipment Corporation и Hewlett-Packard, попыталась создать преемника BSD UNIX, названного OSF/1. Обе группы следовали набору стандартов, установленных комитетом Portable Operating System Interface (POSIX) и подобными организациями. Проект OSF не так давно провалился, сделав System V "победителем UNIX-войны”, хотя лучшие черты BSD UNIX были включены в большинство версий операционных систем, базирующихся на System V. В разной степени черты BSD UNIX свойственны таким дистрибутивам, как Solaris (от Sun Microsystems), HP-UX (от Hewlett-Packard), AIX (от IBM) и IRIX (от Silicon Graphics, Inc).
Система UNIX написана главным образом на языке С, который делает относительно несложным ее перенос на различные аппаратные платформы. Такая мобильность — одно из основных свойств, способствующих быстрому распространению и успеху UNIX.
Особенности UNIX
Краткий перечень основных особенностей UNIX таков:
□ позволяет нескольким пользователям одновременно взаимодействовать с системой;
□ поддерживает создание, модификацию и уничтожение программ, процессов и файлов;
□ реализует иерархическую систему каталогов;
□ эффективно разделяет ресурсы системы: ЦП, память и дисковое пространство между процессами;
□ позволяет процессам и внешним устройствам, взаимодействовать друг с другом, даже если они находятся на различных компьютерах;
□ включает в себя большое количество различных утилит;
□ для большинства версий UNIX имеется множество коммерческих программных пакетов;
□ позволяет программистам взаимодействовать с операционной системой через набор системных вызовов, аналогичных библиотеке подпрограмм.
UNIX — мобильная операционная система, доступная практически на всех аппаратных платформах.
Теперь, после того как мы рассмотрели основные особенности UNIX, пришло время исследовать принципы ее организации и заглянуть в прошлое и будущее.
Принципы UNIX
Исходная реализация UNIX-системы была весьма и весьма ограничена. Она содержала небольшое число утилит, не имела практически никаких сетевых возможностей и средств администрирования. Первые разработчики UNIX выработали основной принцип, положенный в основу создания утилит: программа должна хорошо справляться с конкретной проблемой, а сложные задачи выполняются путем использования этих утилит вместе. Так возник специальный механизм, называемый конвейером (pipe). Конвейер предоставляет возможность использовать выходные данные одного процесса как входные данные для другого процесса. Два или более процесса могут быть связаны этим способом, создающим конвейер данных, текущих от первого процесса до последнего, как показано на рис. 1.4 и 1.5.
Рис. 1.4. Конвейер
устройство
Рис. 1.5. Сортирующий конвейер
Компоновка процессов в виде конвейера оказалась исключительно эффективной. Каждый процесс в этом случае выполняет набор операций над данными и затем передает результаты следующему процессу для дальнейшей обработки. Например, вообразите, что вы желаете получить отсортированный список всех пользователей UNIX-системы. Есть утилита who, которая выводит несортированный список пользователей, и другая утилита sort, которая выводит отсортированную версию ее входных данных. Обе утилиты могут быть связаны вместе каналом так, чтобы выходные данные от who передавались непосредственно в sort, что дает в результате отсортированный список пользователей. Это более эффективный подход к решению проблем, чем написание новой программы с нуля или использование двух программ, одна из которых должна будет сохранять промежуточные данные во временном файле, который в последствии будет использоваться второй программой. Основной алгоритм UNIX, подходящий для решения любой задачи, можно выразить следующим образом:
□ если можно решить проблему, используя каналы для объединения существующих утилит, делайте это;
□ иначе обратитесь к другим пользователям в Интернете. Если они знают, как решить эту проблему, воспользуйтесь их советом;
□ иначе если вы можете написать собственную утилиту для решения этой проблемы — напишите ее и добавьте в коллекцию UNIX. Проектируйте каждую утилиту так, чтобы она хорошо справлялась с поставленной задачей и могла использоваться другими для решения аналогичных проблем. Если дописанные утилиты не могут решить проблему, напишите программу для ее решения (например, на С, C++ или Java).
ОС UNIX реализует еще одну концепцию, от которой постепенно приходится отказываться. Изначально система была разработана программистами, которые хотели иметь доступ к данным или коду вне зависимости от уста
новленных прав доступа. Для реализации этой идеи они разработали концепцию суперпользователя (привилегированного пользователя, root), которая подразумевала получение неограниченных прав некоторыми пользователями. Например, администратор UNIX-системы всегда имеет возможность стать привилегированным пользователем для выполнения таких задач, как завершение нестандартных процессов или удаление нежелательных пользователей из системы. Очевидно, что концепция суперпользователя подрывает систему безопасности: любой пользователь с правильным паролем может получить доступ к защищенным данным или уничтожить всю систему. Поэтому в некоторых, находящихся в разработке, версиях UNIX полностью отказываются от концепции привилегированного пользователя, подразделяя задачи между несколькими "менее привилегированными".
Прошлое UNIX
Кен Томпсон (Ken Thompson) из Bell Laboratories разработал самую первую версию UNIX. Кен работал над проблемой создания видеоигры под названием "Космические войны" ("Space Wars"), которая требовала быстрой реакции системы. Используемая им операционная система MULTICS не давала ему той производительности, в которой тот нуждался. Он назвал свою систему UNIX: часть названия "UNI" подразумевала, что она будет делать нечто единственное хорошо, в противоположность "MULTI" — части имени "MULTICS" — которая пыталась делать многое, но без особого успеха. Кен написал систему на ассемблере, и первая версия оказалась очень простой: это была однопользовательская система без каких-либо сетевых возможностей с примитивной системой управления разделением памяти. Однако она была компактной и быстродействующей, как и хотел Кен Томпсон.
Несколькими годами позже коллега Кена, Деннис Ритчи (Dennis Ritchie), предложил переписать UNIX, используя язык С, который Деннис недавно разработал на основе языка В. Идея написания операционной системы на языке высокого уровня в те времена была необычной. Большинство программистов полагали, что скомпилированный код не будет работать достаточно быстро2 и что для операционной системы обоснованно только прямое использование машинного языка. К счастью, выбор С оказался удачным, и система UNIX внезапно получила огромное преимущество над другими операционными системами: ее исходный код был понятен. На ассемблере осталась лишь небольшая часть, а это означало возможность переноса операционной системы на другую платформу. Если платформа имеет С-компилятор, большая часть кода будет работать без изменений; должны быть переписаны только секции ассемблера.
2 С тех пор технология компиляторов также претерпела изменения, поэтому большинство компиляторов создает более эффективный код.
Bell Laboratories начала использовать этот прототип версии UNIX в ее патентном отделе, прежде всего, для обработки текста, и множество UNIX-утилит, которые присутствуют в современных UNIX-системах — например, nroff и troff — были разработаны в этот период. Но в то время в соответствии с антимонопольными инструкциями AT&T были запрещены продажи программного обеспечения, поэтому Bell Laboratories бесплатно передала лицензию на исходный код UNIX университетам, надеясь, что инициативные студенты расширят систему и поспособствуют ее продвижению на рынок. Действительно, аспиранты Университета Калифорнии в Беркли отнеслись к задаче серьезно и внесли немало усовершенствований, включая создание хорошей системы управления памятью и реальной возможности организации сети. Университет начал продавать всем желающим свою собственную версию UNIX, названную Berkeley Standard Distribution (BSD) UNIX. Различия между версиями UNIX сохраняются и по сей день.
Настоящее UNIX
Многие компании производят и продают собственные версии UNIX, обычно предназначенные для работы на собственных аппаратных платформах. Не так давно появилась еще одна UNIX-подобная операционная система — Linux. В разработке Linux участвовали многие программисты со всего мира, и теперь она продается и поддерживается несколькими различными компаниями.
UNIX
Рис. 1.6. Сокращенная UNIX-генеалогия
Предыдущие версии UNIX базировались либо на System V, либо на BSD, тогда как современные включают в себя особенности обеих систем. На рйс. 1.6 представлена сокращенная генеалогия UNIX.
Так как ОС Linux полностью написана заново и не использует общих кодов UNIX, она не входит в состав "генеалогического дерева". Тем не менее, ощущается значительное влияние всех версий UNIX на создание и развитие этой операционной системы. В главе 16 мы увидим, какие версии UNIX являются доступными для различных аппаратных платформ.
Будущее UNIX
Вероятно, последующие версии UNIX будут поддерживать ее философию подобно современным версиям UNIX — например, сохраняя идею построения приложения из конвейера связанных утилит. Кроме того, UNIX должна реализовать некоторые актуальные тенденции, такие как параллельная обработка и объектно-ориентированное программирование. Мы рассмотрим ряд вопросов, связанных с перспективами развития UNIX, в главе 16.
Остальная часть этой книги
Теперь вы, скорее всего, осознали, что описание UNIX — довольно обширная тема, которая может быть должным образом усвоена лишь небольшими порциями. Для удобства пользователей и предоставления возможности сосредоточиться на наиболее интересных для них темах главы книги ориентированы на различные категории пользователей. Эти пользователи могут быть объединены в следующие группы:
□ непрограммисты, или простые пользователи, которым время от времени необходимо выполнять простые задачи, такие как отправление и получение электронной почты, использование электронных таблиц или обработка текстов;
□ пользователи shell (shell — командный интерпретатор), использующие фоновую обработку и пишущие небольшие программы на макроязыке shell в рамках пользовательского интерфейса;
□ опытные пользователи, применяющие шифрование файлов, потоковые редакторы и файловую обработку данных;
□ опытные пользователи shell, пишущие программы на языке высокого уровня shell (он немного похож на язык управления задачами, или JCL) для того, чтобы автоматизировать такие задачи, как создание резервных
копий файлов, мониторинг использования диска, установка программного обеспечения;
□ программисты, создающие программы на языке типа С;
□ системные программисты, которым необходимо хорошее знание операционной системы для создания программ взаимодействия с сетью или доступа к файлам;
□ системные архитекторы, совершенствующие компьютерные системы;
□ системные администраторы, поддерживающие работу системы и пользователей.
Читайте наиболее заинтересовавшие вас главы. Затем, если располагаете временем, вернитесь назад и заполните пробелы в своих знаниях. Если вы не можете определить, где содержится необходимая информация, ознакомьтесь с Введением.
Обзор главы
Перечень тем
В этой главе мы познакомились с:
□ главными компонентами аппаратных средств системы;
П назначением операционной системы;
□ значением терминов программа, процесс и файл',
□ схемой иерархической структуры каталогов;
П разделением процессорного времени, памяти, дискового пространства между процессами;
П взаимодействием между процессами и внешними устройствами;
□ набором стандартных утилит UNIX;
П главными пакетами программ, доступными для UNIX-систем;
П концепцией "открытой" системы;
□ перспективами развития UNIX.
Контрольные вопросы
1. Как называются основные версии UNIX, как они развивались?
2. Назовите пять главных функций операционной системы.
3. Укажите различие между процессом и программой.
4. Расскажите об основных концепциях, легших в основу UNIX.
5. Назовите создателей UNIX.
6. Почему UNIX называется "открытой" системой?
Упражнение
Составьте список популярных в настоящее время операционных систем, отличных от UNIX, выделите их достоинства и недостатки. [Уровень: средний.]
Проект
Рассмотрите систему MULTICS и найдите сходство и различия с UNIX-системой. [Уровень: средний.]
Глава 2
Утилиты UNIX для непрограммистов
Мотивация
Эта глава содержит основы, необходимые вам для работы с UNIX.
Предпосылки
Для понимания изложенной ниже информации вам необходимо ознакомиться с главой 7. Кроме того, более глубокому усвоению будет способствовать наличие UNIX на вашем компьютере для того, чтобы вы могли познакомиться на практике с теми особенностями, которые мы рассмотрим в теории.
Цели
В этой главе мы познакомимся с процедурой входа/выхода из системы, научимся изменять пароль, пользоваться встроенным справочником, работать с файловой системой. Кроме того, мы узнаем, как пользоваться почтовой системой, что станет первым шагом на нашем пути в Интернет.
Представление
Информация в этой главе представлена в форме нескольких примеров UNIX-сессий. Если сейчас на вашем компьютере не установлена ОС UNIX, попробуйте повторить описанные процедуры, как только появится такая возможность.
Утилиты
Ниже в алфавитном порядке приведен список стандартных утилит UNIX:
cancel head mv wc
cat Ip newgrp
chgrp Ipr page
chmod Iprm passwd
chown Ipq pwd
clear Ipstat rm
cp Is rmdir
date mail stty
emacs man tail
file mkdir tset
groups more vi
Команда shell
Этот раздел посвящен следующей команде shell: cd
Получение учетной записи
Для того чтобы установить UNIX-систему на своем компьютере, вы можете купить один цз представленных дистрибутивов Linux в любом компьютерном магазине либо скачать ее из Интернета. Если вы располагаете необходимыми средствами, то можете приобрести коммерческий дистрибутив UNIX. В настоящее время существуют как коммерческие, так и бесплатные версии UNIX (см. главу 16). Преимущество в наличии собственной UNIX-системы состоит в том, что вы можете быть привилегированным пользователем, полноправно распоряжающимся всеми ресурсами. Если у вас нет возможности установить UNIX, то для того, чтобы поработать с этой операционной системой, вам придется получить учетную запись у обладателя этой установленной системы. Естественно, ваши права в этом случае будут сильно ограничены.
Вход в систему
Первое, что необходимо сделать для работы с UNIX-системой — войти в нее, бведя учетное имя пользователя (suitable username) — уникальную комбинацию символов, отличающую вас от других пользователей. Как правило, учетное имя пользователя и пароль назначаются администратором системы, либо в случае, если вы установили UNIX на свой компьютер, эти параметры установлены в процессе конфигурации или заложены по умолчанию. Бывает, необходимо нажать клавишу <Enter> (также известна как клавиша <Return>) несколько раз, прежде чем появится приглашение ввести имя пользователя (login) и пароль (password). Из соображений безопасности символы, которые вы вводите при наборе пароля, не отображаются. UNIX чувствительна к регистру клавиатуры, поэтому удостоверьтесь, что вводите имя пользователя и пароль в том регистре, в котором оно было выдано вам администратором. В зависимости от настроек системы вы должны увидеть приглашение $ или %. Эти символы означают, что регистрация в системе прошла успешно, и она ожидает ваших дальнейших команд.
Так выглядит процедура регистрации пользователя в UNIX:
UNIX(г) System V Release 4.0 login: glass
Password: ...то, что я напечатал здесь — секрет и не показано
Last login: Sun Feb 15 18:33:26 from dialin $ _
В процессе регистрации система спросит вас, какой вид терминала вы используете для того, чтобы адекватно реагировать на вводимые вами символы. Если вам неизвестна эта информация, просто нажмите клавишу <Enter>, тем самым соглашаясь использовать установленный по умолчанию терминал. Позже будет рассказано, как в случае необходимости изменить тип терминала. В зависимости от настроек системы в процессе регистрации может происходить следующее:
□ если вы входите в систему в первый раз, вам может быть предложено пройти ознакомительный тур по UNIX;
□ на вашем экране могут появляться новости дня и другая полезная информация.
Ниже приведен еще один пример входа в систему, где предлагается выбрать тип терминала. Нажав клавишу <Enter>, мы подтверждаем выбор терминала по умолчанию — vtioo:
UNIX(г) System V Release 4.0 login: glass
Password: ...секрет
Last login: Sun Feb 15 21:26:13 from dialin
You have mail. ...система сообщает о наличии почты.
TERM = (vtlOO) ...я нажал клавишу <Enter>.
Командные интерпретаторы — shell
Приглашения $ или %, которые пользователь видит, когда в первый раз регистрируется в UNIX, выводятся специальным видом программы, называемой командным интерпретатором или shell, являющейся посредником между пользователем и операционной системой. Shell позволяет выполнять программы, строить конвейеры из процессов, сохранять результаты в файлы и управлять несколькими программами одновременно. Shell выполняет все команды, которые вы вводите. Существуют четыре наиболее популярных программных оболочки:
□ Bourne shell;
□ Korn shell;
П C shell;
□ Bourne Again shell (или Bash).
Все эти оболочки похожи друг на друга, хотя и имеют некоторый ряд отличий. Большинство пользователей предпочитают Korn shell, потому что эта оболочка имеет лучший интерфейс командной строки и в ней легко программировать. Каждой оболочке посвящена одна из глав этой книги. Но до этого, в главе 4, мы рассмотрим, общие принципы работы с shell. Каждый shell имеет свой собственный язык программирования. Вы можете спросить, зачем писать программу на языке shell, а не языке С или Java? Ответ — языки shell разработаны специально для управления файлами и процессами в UNIX, поэтому во многих ситуациях они более удобны. В этой главе мы научимся пользоваться разнообразными утилитами UNIX и сохранять результаты работы в файл. Рассмотрим выполнение нескольких простых UNIX-команд.
Выполнение программ
Для того чтобы запустить программу, просто вводят ее название и нажимают клавишу <Enter>. Давайте договоримся, что в тех случаях, когда в книге говорится, что вы должны ввести какой-нибудь текст, имеется в виду также, что вы должны нажать клавишу <Enter> после того, как закончите набор. Этим вы сообщаете операционной системе, что закончили ввод команды и желаете, чтобы она была выполнена.
Все системы обладают разным набором утилит, так что, возможно, некоторые примеры не будут работать в вашей версии UNIX. Рассматривая специфические утилиты, мы будем указывать, в каких версиях они будут работать. А сейчас рассмотрим утилиту date, имеющуюся в каждой системе и показывающую текущую дату и время.
$ date ... запуск утилиты date.
Thu Mar 12 10:41:50 MST 1998
$ _
Для описания синтаксиса используется интуитивно понятная система обозначений в форме Бэкуса—Наура (Backus—Naur FORM, BNF), расшифровка которой описана в Приложении. Книга не ставит своей целью описать все параметры какой-либо утилиты. При необходимости вы можете узнать их, пользуясь встроенным в систему справочником или специализированной литературой.
Синтаксис
date [yymmddhhmm [.ss]]
Утилита date по умолчанию показывает текущие дату и время. В остальных случаях date возвращает заданные в параметрах значения, где уу — последние две цифры года, первые mm — месяц (числовая нумерация), dd — день, hh — час (используется 24-часовая система) и следующие mm — минуты. Дополнительный параметр — ss — секунды. Устанавливать дату может только привилегированный пользователь (root).
Ниже описана команда, очищающая экран.
Синтаксис
clear
Эта утилита очищает экран.
Входной, выходной каналы и канал сообщения об ошибках
Результаты выполнения команды date, рассмотренной в предыдущем разделе, выводились на терминал. Кроме того, что UNIX может записывать полу
ченные результаты в файл, для любой команды или программы существуют три стандартных канала ввода/вывода:
□ стандартный вход, известный как stdin, при помощи которого программа получает входные данные;
П стандартный выход, называемый stdout, в который по умолчанию программа пишет выходные данные;
□ стандартный канал вывода сообщений об ошибках — stder.
По умолчанию все три канала ввода/вывода взаимодействуют с терминалом, выполняющим команду или программу, что позволяет одним программам использовать результаты выполнения других как входные данные. Вывод результатов работы одной команды может быть легко передан на вход другой с помощью переназначения. Чуть позже мы поподробнее остановимся на переназначении ввода/вывода. А более подробно разберемся с механизмом в работы каналов в главе 13.
Получение оперативной помощи: man
При работе часто случается, что вы не знаете, что делает или как называется та или иная утилита, или, возможно, не помните ее синтаксиса.
Для выхода из такой ситуации во всех версиях UNIX предусмотрен встроенный справочник, вызываемый по команде man (сокращение от англ, manual — справочник).
Синтаксис
man [ [—s] раздел] слово
man -к ключевое слово
На страницах этого справочника собрана вся документация по UNIX, предназначенная для работы в диалоговом режиме и разделенная на восемь секций. В справочнике содержится информация об утилитах, системных вызовах, форматах файлов и командных интерпретаторах (shell). При выводе справки о некоторой конкретной утилите указывается также, к какой секции она принадлежит. При первом обращении man выводит содержимое раздела справочника, связанного с интересующей вас командой. Некоторые версии UNIX используют аргумент -s, чтобы указать номер секции. Если номер секцищ не указан, будет показана первая секция, которую найдет man. Второе использование man выводит список всех статей справочника, которые содержат ключевое_слово (keyword).
Справочник содержит следующие разделы.
1. Команды и прикладные программы.
2. Системные вызовы.
3. Библиотечные функции.
4. Специальные файлы.
5. Файловые форматы.
6. Игры.
7. Разное.
8. Утилиты системного администрирования.
Иногда ключевое слово входит в несколько различных секций справочника. Например, есть утилита chmod, описание которой находится в секции 1, и системный вызов chmod (), информация о котором находится в секции 2. По умолчанию man выдает первую статью, в которой встречается искомое слово. В случае повторного поиска программа выдаст список всех статей, в которых искомое слово встречается. Ниже приведен пример работы утилиты man.
$ man -к mode chmod (IV)
chmod, fchmod (2V) getty (8) ieeeflags (3M) umask (2V) $ man chmod
...поиск ключевого слова "mode".
- change the permissions mode of a file
- change mode of file
- set terminal mode
- mode and status function
- set file creation mode mask
...выбор первой статьи справочника.
CHMOD(IV) USER COMMANDSCHMOD (IV)
NAME
chmod — change the permissions mode of a file SYNOPSIS
chmod C -fR V mode filename ...
...the description of chmod goes here.
SEE ALSO
csh(l), Is(IV), sh(l), chmod (2V), chown(8)
$ man 2 chmod ...выбор статьи справочника из секции 2.
CHMOD(2V) SYSTEM CALLS CHMOD(2V)
NAME
chmod, fchmod — change mode of file
SYNOPSIS
#include <sys/stat.h> int chmod (path, mode)
char *path;
mode_t mode;
...the description of chmod () goes here. SEE ALSO
chown(2V), open(2V), stat(2V), sticky(8) $
Специальные символы
Некоторые символы интерпретируются специальным образом, вводятся с UNIX-терминала. Такие знаки называются метасимволами и могут быть выведены утилитой stty с опцией -а (от англ. all). Утилита stty более подробно рассматривается в конце этой главы. Пример:
$ stty -а ...получение списка метасимволов терминала
speed 38400 baud; -parity hupcl
rows = 24; columns = 80; ypixels = 0; xpixels = 0;
-inpck -istrip ixoff imaxbel crt tostop iexten
erase kill werase rprnt flush Inext susp intr quit stop eof
Лн Ли Aw ло AV Лг/Лу Лс Л\ Лз/Ло
$ _
Знак Л перед каждым символом означает, что клавиша <Ctrl> должна быть нажата одновременно с символом. В табл. 2.1 перечислены значения по умолчанию.
Описание символов этого списка ожидает вас в других главах данной книги, однако о некоторых из них мы поговорим прямо сейчас.
Таблица 2.1. Опции утилиты stty
Опция Описание
erase Сдвиг назад на один символ
kill Стирание всей текущей строки
werase Стирание последнего слова
rprnt Повторение строки
flush Игнорирование любого незаконченного ввода и повторный вывод строки Inext Отказаться от рассмотрения следующего символа, как специального
susp Приостановка процесса для будущего пробуждения
Таблица 2.1 (окончание)
Опция Описание
Intr Завершение (прерывание) фоновой работы без дампа ядра операционной системы
quit Завершение фоновой работы и генерация дампа ядра операционной системы
stop Остановка/возобновление вывода на терминал
Eof Конец ввода
Завершение процесса: <Ctrl>+<C>
Иногда возникает необходимость завершить программу до того, как она выполнится. Сделать это можно, нажав комбинацию клавиш <Ctrl>+<C>. Большинство программ сразу же реагируют, выводя приглашение shell. Но есть программы, которые невозможно завершить таким способом. Давайте посмотрим на примере, что происходит при нажатии этих клавиш: $ man chmod CHMOD(IV) USER COMMANDS CHMOD(IV)
NAME chmod — change the permissions mode of a file SYNOPSIS ЛС ...прерывание работы и возвращение в shell.
$_
Приостановка вывода: <Ctrl>+<S>/<Ctrl>+<Q>
Иногда, в результате выполнения команды выводится слишком много данных, которые не помещаются на экране, в таких случаях можно приостановить вывод, нажав комбинацию клавиш <Ctrl>+<S>. Для возобновления вывода необходимо вновь воспользоваться этой комбинацией (<Ctrl>+<S>) или нажать комбинацию клавиш <Ctrl>+<Q>. Такая последовательность управляющих символов известна также, как протокол XON/XOFF.
Пример: $ man chmod CHMOD(IV) USER COMMANDS CHMOD(IV) NAME chmod — change the permissions mode of a file AS ...приостанавливает вывод на терминал.
...возобновляет вывод.
SYNOPSIS
chmod С -fR V mode filename ...
...the rest of the manual page is displayed here.
SEE ALSO
csh(l), Is(IV), sh(l), chmod (2V) , chown(8) $ _
Завершение ввода: <Ctrl>+<D>
Многие утилиты UNIX получают входную информацию из файла или с клавиатуры. Если данные вводятся с клавиатуры, вам необходимо сообщить системе о завершении ввода. Для этого нажмите комбинацию клавиш <Ctrl>+<D> после того, как наберете последнюю строчку. Система воспринимает эту комбинацию как завершение ввода информации. Рассмотрим это на примере утилиты mail, позволяющей посылать почту конкретному пользователю:
$ mail tim . . .посылка почты моему другу Тиму.
Hi Tim, ...ввод информации с клавиатуры.
I hope you get this piece of mail. How about building a country one of these days?
- with best wishes from Graham
...говорит системе, что ввод окончен.
$_
Более подробно утилита mail будет рассмотрена в конце этой главы.
Установка пароля: passwd
После того как вы зарегистрировались в системе, целесообразно будет сменить свой первоначальный пароль, т. к. по крайней мере, он известен человеку, который выдал вам его. Отнеситесь к выбору пароля серьезно. Он должен состоять не менее, чем из шести символов, и не являться правильным существительным или каким-либо другим словом из словаря. Это необходимо для того, чтобы злоумышленник, решивший воспользоваться вашим паролем, не смог получить его, установив специальную программу, которая попробует подобрать пароль, перебирая слова стандартного словаря. В качестве примера хорошего пароля можно привести: "GWK145W".
Для изменения существующего пароля воспользуйтесь утилитой passwd.
Синтаксис
passwd
Утилита passwd позволяет изменять пароль. Для этого вам потребуется ввести старый пароль, после чего дважды ввести новый. Это необходимо потому, что вводимый пароль не отображается на экране, и проверить, не допустили ли вы опечатку, можно только подтверждением ввода и проверкой их на совпадение. После того как вы поменяли пароль, он в зашифрованном виде сохраняется в зависимости от версии UNIX в файле пароля /etc/passwd или в shadow-файле (для большей безопасности). В некоторых версиях UNIX пароль может сохраняться в базе данных на удаленном компьютере.
Для большей наглядности в приведенном далее примере отображаются пароли, но обычно при работе с UNIX символы, которые вы вводите, на экране не отображаются.
$ passwd
Current password: penguin
New password (? For help): GWK145W
New password (again): GWK145W
Password changed for glass
$_
Если вы забыли пароль, единственное, что можно сделать, — связаться с системным администратором и попросить его выдать вам новый.
Выход из системы
Для выхода из системы воспользуйтесь комбинацией клавиш <Ctrl>+<D>. Подавляющее большинство систем после этого выводит приглашение login:, после чего к работе может приступить другой пользователь.
Пример:
$ ... я все сделал!
UNIX(г) System V Release 4.0
login: ...ожидает другого пользователя для регистрации.
Теперь вы знаете, как зарегистрироваться в системе, изменить пароль и выйти из системы. В следующих разделах мы рассмотрим утилиты, которые позволят вам перемещаться по каталогам и управлять файлами.
3 Зак. 786
Поэзия в движении: изучение файловой системы
Вероятно, лучший способ познакомиться с общими утилитами UNIX — это рассмотреть их на примере. Представим себе поэта, которому необходимо написать заключительную версию стихотворения. В табл. 2.2 приведена последовательность действий, которую ему для этого необходимо совершить.
Таблица 2.2. Пример последовательности действий для написания стихотворения
Действие Утилита
Определение текущего местонахождения pwd
Сохранение наброска в файле heart cat
Вывод содержимого каталога для определения размера файла Is
Просмотр файла с использованием нескольких утилит cat, more, page,
head, tail
Переименование файла heart в файл heart.verl mv
Создание каталога lyrics для сохранения в нем вариантов mkdir стихотворений
Перемещение файла heart.verl в каталог lyrics mv
Создание копии файла heart.verl с именем heart.ver2 ср
Редактирование файла heart.ver2 vi
Возвращение в домашний каталог cd
Создание каталога lyrics.final mkdir
Переименование каталога lyrics в lyrics.draft mv
Копирование файла heart.ver5 из каталога lyrics.draft ср
в каталог lyrics.final, переименование файла в heart, final
Удаление файлов из каталога lyrics.draft rm
Удаление каталога lyrics.draft rmdir
Перемещение в каталог lyrics.final cd
Распечатка файла heart.final 1рг
Подсчет слов в файле heart.final wc
Определение атрибутов файла heart.final Is
Определение типа файла heart.final file
Таблица 2.2 (окончание)
Действие Утилита
Определение группы владельцев groups
Изменение группы владельцев файла heart.final chgrp
Изменение прав на файл heart.final chmod
Определение текущего каталога: pwd
Работа в UNIX начинается с определенного места в системе, называемого текущим рабочим каталогом. Когда происходит регистрация пользователя в системе UNIX, shell начинает работать в индивидуальном каталоге — домашнем каталоге. Вообще, каждый пользователь имеет свой домашний каталог, который обычно начинается с префикса /home. Например, каталог пользователя glass может располагаться в каталоге /home/glass. Системный администратор указывает местонахождение каждого пользователя. Для определения местонахождения пользователя применяется утилита pwd.
Синтаксис
pwd
Печатает имя текущего рабочего каталога.
Для иллюстрации утилиты рассмотрим, что произошло при регистрации в UNIX пользователя, который хочет начать работу над лирическими стихами: UNIX(г) System V Release 4.0 login: glass
Password: ...секрет.
$ pwd /home/glass $ _
На рис. 2.1 изображена схема нахождения пользователя glass во время регистрации в системе.
home
glass
Положение Korn shell во время входа в систему
Рис.
, 2.1. Запуск командного интерпретатора из домашнего каталога пользователя
Абсолютные и относительные имена путей
Перед тем как мы продолжим знакомство с системой каталогов, нам необходимо обратить внимание на уникальность названий файлов и каталогов.
Два файла, расположенные в одном и том же каталоге, не могут называться одинаково. Однако никто не запрещает вам давать одни и те же имена файлам, находящимся в разных каталогах. На рис. 2.2 представлена иерархия каталога, содержащего процесс ksh и три файла с одинаковым именем my File.
home
myFile
myFile
, Г" glass
myFile
Рис. 2.2. Различные файлы с одинаковыми именами
Несмотря на то, что файлы имеют одинаковые имена, они идентифицируются по месту расположения относительно каталога / — корня всей иерархии каталогов. Путь — последовательность имен каталогов, от стартового каталога до необходимого файла. Путь, определяемый относительно корневого каталога, часто называют абсолютным или полным. В табл. 2.3 представлено местоположение трех файлов с одинаковыми именами.
Таблица 2.3. Абсолютные пути
Файл Абсолютное путевое имя
А /home/glass/myFile
В /home/myFile
С /bin/myFile
Не менее успешно можно определить файл, указывая его расположение относительно текущего рабочего каталога. При задании относительного пути в UNIX принято использовать символы, представленные в табл. 2.4. Табл. 2.5 иллюстрирует расположение файлов myFile относительно домашнего каталога пользователя glass.
Внимание
Указание пути myFile эквивалентно ./myFile, однако эта форма является избыточной и поэтому используется редко.
Таблица 2.4. Условные обозначения текущего и родительского каталога
Поле Описание
Текущий каталог
• • Родительский каталог
Таблица 2.5. Относительные пути
Файл Относительный путь
А myFile
В ../myFile
С ../../bin/myFile
Создание файла
Для того чтобы создать файл в UNIX, как правило, пользуются специальными редакторами, например, vi или emacs, но в этой главе мы рассмотрим более простой, но не менее эффективный способ — утилиту cat.
Синтаксис
cat -п {имяФайла} *
Название утилиты — cat (от сокращения англ, concatenate — связывать) — переводится, как соединять в последовательность связей. Она читает входные данные из файла или стандартного входа и передает их на стандартный выход. Опция -п позволяет указать номера необходимых строк.
По умолчанию стандартный вход процесса — это ввод данных с клавиатуры, стандартный выход — вывод данных на экран. Мы можем перенаправить стандартный выход в файл, используя переназначение вывода. Если после команды вы укажете символ > и имя файла, результат работы этой программы будет сохранен в файле с указанным именем. Если такого файла не существует, он создается, в противном случае, вся информация, содержащаяся в нем до этого, перезаписывается. В главе 4 мы рассмотрим этот вопрос более подробно. Ниже приведен пример работы утилиты cat:
$ cat > heart , ...сохраняет ввод с клавиатуры в файл heart.
I hear her breathing,
I’m surrounded by the sound.
Floating in this secret place,
I never shall be found.
...говорит cat, что конец ввода был достигнут.
$
Просмотр содержимого каталога: Is
После создания файла вам, вероятно, захочется убедиться, что он действительно существует, и узнать его размер. Для получения этой информации служит утилита is.
Синтаксис
Is -adglsFR {имяФайла}* {имяКаталога}★
По умолчанию утилита is выводит в алфавитном порядке список всех файлов текущего каталога за исключением скрытых файлов, имена которых начинаются с точки. Опция -а включает в листинг скрытые файлы.
Для вывода содержимого каталогов необходимо указать их имена после параметров команды. Опция -d включает в листинг описание каталогов, а не их содержание.
Опция -д вносит в список группу файла. Опция -1 выводит список файлов с такими параметрами, как время последней модификации, имя владельца файла и флаги доступа. Опция -s выводит размер файла. Опция f указывает тип файла:
• * — исполняемый файл;
• / — каталог;
• @ — связанный файл;
• = — сокет.
Опция -r рекурсивно выводит содержимое каталога и его подкаталогов.
Большинство описанных выше опций утилиты is вам пока не потребуются. Пример выполнения утилиты is:
$ Is ...распечатывает все файлы в текущем каталоге,
heart
$ Is -1 heart ...большая распечатка файла heart.
-rw-r—г— 1 glass 106 Jan 30 19:46 heart $_
Немного позже мы рассмотрим значение каждого поля, выводимого утилитой is, а пока в табл. 2.6 представлен их краткий обзор.
Таблица 2.6. Описание вывода утилиты 1s
Номер поля Символы Значение
1 -rw -г —г-- Тип и режим полномочий файла, которые указывают, кто может читать, писать и выполнять файл
2 1 Счетчик жестких связей (обсуждаемый намного позже в этой книге)
3 glass Имя пользователя — владельца файла
4 106 Размер файла в байтах
5 Jan 30 19:46 Время последней модификации файла
6 heart Имя файла
$ Is -algFs total 3
...полный листинг текущего каталога.
...общее число блоков памяти.
1 drwxr-xr-x 3 glass cs 512 Jan 30 22:52 , /
1 drwxr-xr-x 12 root cs 1024 Jan 30 19:45 • . /
1 —rw-r—r— 1 glass cs 106 Jan 30 19:46 heart
$
Опция -s выводит размер каждого файла. Если размер блока диска равен 1024 байта, то файл размером в 106 байт займет его целиком. Это следствие физического устройства файловой системы, которое мы рассмотрим в главе 14. Опция -а выводит полный листинг каталога, включая скрытые файлы, имена которых начинаются с точки. Например, "." и — скрытые файлы, которые представляют собой текущий и родительский каталоги соответственно. Опция -F добавляет в конец символ / ко всем именам, которые являются каталогами, а опция -д выводит группу, владеющую файлом.
Распечатка файла: cat/тоге/раде/head/tail
Чтобы просмотреть содержимое файла, можно воспользоваться утилитой cat. Для этого после команды необходимо указать имя файла:
$ cat heart ...выводит содержимое файла heart.
I hear her breathing,
I’m surrounded by the sound.
Floating in this secret place, I never shall be found.
$ _
Утилита cat принимает в качестве аргументов любое количество файлов, имена которых указываются друг за другом. Она отлично подходит для вывода небольших файлов. Для вывода информации большого объема следует пользоваться утилитами more и раде, которые позволяют приостановить вывод и прокручивать файл. Ниже представлено описание этих утилит.
Синтаксис
more -f [+номерС троки] {имяФайла}*
Утилита more организует постраничный вывод на экран. Вывод начинается с первой строки каждого файла, но с помощью опции + можно указать стартовую строку. Опция -f предписывает не переносить длинные строки. После заполнения страницы появляется сообщение "—More—". Для распечатки следующей страницы вам нужно всего лишь нажать клавишу <Пробел>. Для
выхода используйте клавишу <q>. Для получения более подробной информации нажмите клавишу <h>.
Синтаксис
page -f [ +номерСтроки] {имяФайла}*
Утилита раде работает подобно утилите more, за исключением того, что первая очищает экран перед выводом каждой страницы. В некоторых случаях это помогает ускорить вывод.
Следует упомянуть еще о двух полезных утилитах: head и tail, с помощью которых можно просмотреть начало и конец файла соответственно.
Синтаксис
head -п {имяФайла}*
Утилита head показывает первые п строк файла. Если п не определено, по умолчанию выводятся 10 строк. Если необходимо вывести начальные строки нескольких файлов, перед каждым из них будет указано его имя.
Синтаксис
tail -п {имяФайла}*
Утилита tail показывает последние п строк файла. Если п не определено, по умолчанию выводятся последние 10 строк. Выводу содержимого нескольких файлов предшествуют их имена.
Пример:
S head -2 heart
...вывод первых двух строк
I hear her breathing
I’m surrounded by the sound.
$ tail -2 heart
...вывод последних двух строк
Floating in this secret place
I never shall be found.
Переименование файла: mv
Очень часто в процессе работы возникает необходимость переименовать файл. Для этого используется утилита mv.
Синтаксис
mv -i староеИмяФайла новоеИмяФайла
mv -i {имяФайла}* имяКаталога
mv -i староеИмяКаталога новоеИмяКаталога
Утилита mv перемещает или переименовывает файлы и каталоги. Для того чтобы переименовать файл или каталог, необходимо указать в качестве параметров старое и новое имя файла/каталога. Для перемещения файлов в каталог потребуется указать имена файлов и каталога после команды. Вследствие того, что физического перемещения не происходит, а меняются только метки, утилита mv работает очень быстро. Опция -i выводит предупреждение, что файл с указанным именем уже существует.
Пример:
$ mv heart heart.ver1 ...переименование в heart.verl
$ Is heart.verl $ _
Пример перемещения каталогов и файлов в каталоги будет приведен чуть позже.
Создание каталога: mkdir
Для создания каталогов пользуются утилитой mkdir.
Синтаксис
mkdir [~р] новоеИмяКаталога
Утилита mkdir создает каталог. Опция -р создает любые родительские каталоги в каталоге новоеИмяКаталога, который еще не существует. Если новоеИмяКаталога уже существует, выводится сообщение об ошибке, и существующий файл никаким образом не изменяется.
Пример:
$ mkdir lyrics ...создает каталог lyrics.
$ Is -IF ...подтвердить.
-rw-r—г— 1 glass 106 Jan 30 23:28 heart.verl
drwxr-xr-x 2 glass 512 Jan 30 19:49 lyrics/
$ _
Символ d в начале поля полномочий говорит о том, что это каталог.
Для облегчения поиска необходимо, чтобы имя каталога отвечало его содержанию. Чтобы убедиться, удалось ли переместить файл в нужное место, также воспользуемся утилитой is:
$ mv heart.verl lyrics ...переместить в lyrics.
$ Is ...вывод текущего каталога,
lyrics/ ...heart.verl ушел.
$ Is lyrics ...вывод каталога lyrics,
heart.verl ...heart.verl перемещен.
$
Перемещение по каталогам: cd
Можно оставаться в своем рабочем каталоге, создавая по мере необходимости подкаталоги внутри него. Но это неудобно, по крайней мере, по нескольким причинам: во-первых, это затруднит поиск, а во-вторых, придется указывать очень длинные пути, содержащие имена всех каталогов, предшествующих каталогу, в котором находится необходимый файл. Чтобы сделать работу более удобной, лучше заранее переместиться в каталог, с содержимым которого вы собираетесь работать. Например, если вы собираетесь редактировать файл heart.verl, то целесообразно переместиться из своего стартового каталога в каталог lyrics, в котором этот файл находится.
$ vi lyrics/heart.verl ...запуск'редактора vi.
Для перемещения по каталогам служит команда cd, которая фактически представляет собой встроенную команду shell.
Внимание
Название всех команд shell дается светлым моноширинным шрифтом, согласно системе обозначений, описанных во Введении.
Синтаксис
cd [имяКаталога]
Команда cd (от англ, change directory — изменить каталог) изменяет текущий рабочий каталог на указанный в имяКаталога. Если аргумент имяКаталога опущен, shell перемещается в домашний каталог его владельца
Проверить, произошло ли перемещение в необходимый каталог можно, используя утилиту pwd:
$ pwd ...определение текущего каталога.
/home/glass
$ cd lyrics ...переместить в .каталог lyrics.
$ pwd ...вывести, где я теперь.
/home/glass/lyrics
На рис. 2.3 проиллюстрировано перемещение shell, инициированное командой cd:
home
lyrics
glass
shell перемещается в каталог /home/glass/lyrics
Рис. 2.3. Перемещение shell
Возможно перемещение на уровень выше или в рабочий каталог с помощью указания ".и соответственно. Пример:
/home/glass/lyrics $ cd . .
...переместиться вверх на один уровень.
$ pwd /home/glass $
...вывести новое текущее положение.
Копирование файла: ср
Часто возникает необходимость скопировать файл, например, для того, чтобы отредактировать его, не испортив оригинал. Чуть ниже описана утилита ср, предназначенная для копирования файлов.
Синтаксис
ср -i староеИмяФайла новоеИмяФайла ср -ir {имяФайла}* имяКаталога
Утилита ср копирует файлы, при этом необходимо указать староеИмяФайла и новоеИмяФайла. Если файл с таким именем уже существует, его содержимое перезаписывается. Опция -i выводит предупреждение о том, что файл с таким именем уже существует. Опция -г рекурсивно копирует файлы и дочерние каталоги в указанный каталог.
Утилита ср создает физическую копию содержимого каталога и новую метку, указывающую на скопированные файлы. Поэтому любая работа с копией документа никак не затронет оригинал.
Ниже приведен пример работы этой утилиты:
$ ср heart.verl heart.ver2
...копировать в файл heart.ver2.
$ Is -1 heart.verl heart.ver2
...подтверждение.
-rw-r—r— 1 glass
-rw-r—r— 1 glass
106 Jan 30 23:28 heart.verl
106 Jan 31 00:12 heart.ver2
$
Редактирование файла: vi
В этой главе мы познакомимся с двумя программами обработки текстов: редакторами vi и emacs. Представим себе, что нам необходимо отредактировать файл в vi. Ниже показано, какие действия необходимо совершить для этого:
$ vi heart.ver2 ...редактировать файл.
...сессия редактирования приводится здесь.
$ cat heart.ver2 ...вывести файл.
I hear her breathing,
I’m surrounded by the sound.
Floating in this secret place,
I never shall be found.
She pushed me into the daylight, I had to leave my home.
But I am a survivor, And I’ll make it on my own. $
После создания пяти версий лирических стихов песни моя работа была завершена. Я вернулся к своему домашнему каталогу и создал подкаталог lyrics.final, чтобы хранить заключительную версию лирических стихов. Я также переименовал первоначальный каталог lyrics в lyrics.draft. Команды, реализующие описанный алгоритм, таковы:
$ cd
$ mkdir lyrics.final
$ mv lyrics lyrics.draft
...вернуться в свой домашний каталог.
...создать финальный каталог lyrics.
...переименовать старый каталог lyrics.
$
Заключительная версия лирических стихов была сохранена в файле heart.ver5 каталога lyrics.draft, который я затем скопировал в файл heart.final в каталоге lyrics.final:
$ ср lyrics.draft/heart.ver5 lyrics.final/heart.final
$
Удаление каталога: rmdir
Сохранение информации для потомков — цель весьма и весьма достойная, однако не реализуемая в условиях ограниченного дискового пространства. Поэтому время от времени необходимо удалять ненужные файлы и каталоги. Однако перед тем как подписать смертный приговор какому-либо файлу, подумайте, не потребуется ли он (т. е. файл) вам в будущем. Если возникают сомнения по этому поводу, то перед удалением лучше заархивировать файл при помощи утилиты cpio, о которой мы подробнее поговорим в главе 3. Теперь, когда информация сохранена, можно удалить каталог, пользуясь утилитой rmdir.
Синтаксис
rmdir {имяКаталога}+
Утилита rmdir удаляет указанный каталог и все его подкаталоги. Удалить можно только пустые каталоги. Для того чтобы рекурсивно удалить ката
логи и подкаталоги вместе со всем их содержимым, следует воспользоваться утилитой rm с опцией -г.
При попытке удалить каталог, содержащий файлы, система выдаст сообщение об ошибке:
$ rmdi г lyri cs. dr a f t nadir: lyrics.draft:
$
Directory not empty1
Удаление файла: rm
Утилита rm удаляет метки, ссылающиеся на файл. Как правило, этого достаточно, чтобы удалить и сам файл. Однако, если файл имеет более чем одну метку — такие случаи мы рассмотрим в главе 3 — данная утилита удаляет лишь ссылку на файл.
Синтаксис
rm -fir {имяФайла} *
Утилита rm удаляет ссылку на файл из иерархии каталогов. Если файла не существует, выводится сообщение об ошибке. Опция -i выводит предупреждение перед удалением файла; требуется нажать клавишу <у> для подтверждения операции или клавишу <п> для отмены. Использование этой утилиты с опцией -г для удаления каталога вызывает удаление всего его содержимого, включая подкаталоги. Опция -f подавляет вывод сообщений об ошибках и предупреждений.
Удаление файлов из каталога:
$ cd lyrics.draft ...переместиться в каталог lyrics.draft.
$ rm heart.verl heart.ver2 heart.ver3 heart.verA heart.ver5
$ Is ... ничего не осталось.
$ _
Удаление пустого каталога:
$ cd ... возвращаемся в домашний каталог.
$ rmdir lyrics.draft ...каталог пуст, и теперь мы можем его удалить. $
1 Каталог не пуст. — Пер.
В главе 4 мы обсудим более простой способ удаления файлов:
$ cd lyrics.draft ...переместиться в каталог lyrics.draft.
$ rm * ...удалить все файлы из текущего каталога.
$
Можно воспользоваться лучшим способом: указать более "продвинутую" опцию -г утилиты rm, чтобы удалить каталог lyrics.draft и все его содержимое одной командой:
$ cd
$ rm -г lyrics.draft
$
...переместиться в домашний каталог.
...рекурсивно удалить каталог.
Печать файла: 1р/Ipstat/cancel
Мы выяснили, как создавать, редактировать и удалять файлы. Теперь было бы неплохо научиться их распечатывать. Для вывода документа на печать используется утилита 1р.
Синтаксис
ip [-d пунктНазначения] [-п копий] {имяФайла}*
Утилита 1р отправляет выбранные файлы на принтер, который необходимо указать с помощью опции -d. Если не заданы имена файлов, на печать выводятся данные, поступающие со стандартного входа. По умолчанию печатается одна копия. Однако количество необходимых экземпляров можно изменить, пользуясь опцией -п.
Говоря о печати файлов, нельзя обойти вниманием еще одну полезную утилиту — ipstat — отображающую состояние печати и загрузку принтера.
Синтаксис
Ipstat [пунктНазначения]
Утилита ipstat выводит информацию о статусе принтера, объеме выполненной работы, пользователе, отправившем задание на печать с помощью команды 1р. Если принтер определен, ipstat сообщает информацию об очереди только для этого принтера.
Если по каким-либо причинам вам нужно отменить печать документа, вы можете сделать это, воспользовавшись утилитой cancel.
Синтаксис
cancel {ID—запроса} +
Утилита cancel удаляет все указанные задания из очереди принтера. В качестве параметра команды необходимо указать ID задания, который можно узнать, воспользовавшись утилитой ipstat. Привилегированный пользователь (root) может отменить печать любого документа.
Представим, что нам поручили распечатать два экземпляра файла heart.final на принтере Iwcs. После отправки задания на печать оказалось, что вполне достаточно будет одного экземпляра. Ниже приведена последовательность действий, которые необходимо совершить, чтобы реализовать задуманное:
$ Ip -d Iwcs heart.final ...отправили на печать, request id is lwcs-37 (1 file)
$ Ipstat Iwcs ...узнали статус принтера,
printer queue for Iwcs
lwcs-36 ables priority 0 Mar 18 17:02 on Iwcs
inventory.txt 457 bytes
lwcs-37 glass priority 0 Mar 18 17:04 on Iwcs
heart.final 213 bytes
$ Ip -n 2 -d Iwcs heart.final ...заказали еще две копии, request id is lwcs-38 (1 file)
$ Ipstat Iwcs
...еще раз посмотрели статус принтера.
printer queue for Iwcs
lwcs-37 glass priority 0 Mar 18 17:04 on Iwcs
heart.final 213 bytes
lwcs-38 glass priority 0 Mar 18 17:05 on Iwcs
heart.final 2 copies 213 bytes
$ cancel lwcs-38 ...удалили последнее задание.
request "lwcs-38" cancelled $
В приведенном ниже примере проиллюстрирован вывод на печать данных, введенных с клавиатуры:
$ Ip -d Iwcs ...печать со стандартного входа. Hi there,
This is a test of the print facility. - Graham
... конец ввода. request id is lwcs-42 (standard input) $
Печать файла: Ipr/lpq/lprm
Утилиты печати, с которыми мы уже познакомились, уходят корнями к System V и поддерживаются практически во всех версиях UNIX. Однако в некоторых версиях и Linux используются другие команды, берущие свое начало в BSD UNIX. Эти команды выполняют те же самые функции, но имеют другие названия и аргументы. Так, например, для печати файла применяется утилита ipr. Для определения статуса принтера и мониторинга выполнения задания служит утилита ipq. Остановимся на них более подробно.
Синтаксис
1рг -ш [-Рпринтер] [-#копий] {имяФайла} *
Утилита ipr выводит на печать указанные файлы, принтер задается опцией -р. Если принтер не определен, используется значение переменной окружения $ printer (об этих переменных мы поговорим в главе 4). Если не указано имя файла, печатаются данные со стандартного входа. По умолчанию печатается одна копия каждого файла, хотя необходимое количество экземпляров задается опцией -#. С помощью опции -т можно настроить отправление уведомления о завершении печати.
Синтаксис
Ipq -1 [-Рпринтер] {номерЗа Дания}* {Ю_пользователя}*
Утилита ipq показывает информацию о текущих заданиях и пользователях, отправивших их на печать. Если не определено конкретное задание, будут показаны все задания на указанном с помощью опции -р принтере. В противном случае выводятся данные работы принтера, прописанного в переменной окружения $ printer. Опция -1 позволяет получить более подробную информацию.
Отменить печать можно с помощью утилиты iprm.
Синтаксис
Iprm [-Рпринтер] [-] [номерЗа дания] * {Ю_пользователя} *
Утилита iprm отменяет задания на принтере, указанном опцией -р, либо (если принтер не определен) прописанном в переменной окружения $ printer. Опция - отменяет все назначенные вами задания. Привилегированный пользователь root может прекратить печать заданий конкретного пользователя, идентифицируя его по ю_пользователя.
Пример:
$ Ipr -Plwcs heart.final ...вывод на печать.
$ Ipq -Plwcs glass ...просмотр статуса принтера.
Iwcs is ready and printing
Rank Owner Job Files Total Size
active glass 731 heart.final 213 bytes
$ Ipr -#2 -Plwcs heart. final ...еще две 2 копии.
$ Ipq -Iwcs is Plwcs glass ready and printing ...статус принтера снова.
Rank Owner Job Files Total Size
active glass 731 heart.final 213 bytes
active glass 732 heart.final 426 bytes
$ Iprm -Plwcs 732 ...удаление последнего задания.
centaur: dfA732vanguard dequeued
centaur: cfA732vanguard.utdallas.edu dequeued $ _
Пример вывода на печать данных, введенных непосредственно с клавиатуры.
$ Ipr -m -Plwcs ...печать со стандартного входа.
Hi there, This is a test of the print facility.
- Graham
...конец ввода.
$ . подождал немного.
$ mail ...читать почту.
Mail version SMI 4.0 Sat Oct 13 20:32:29 PDT 1990 Type ? for help.
>N 1 daemon@utdallas.edu Fri Jan 31 16:59 15/502 printer job
& 1 ...читать первое почтовое сообщение.
From: daemon@utdallas.edu
То: glass@utdallas.edu
Subject: printer job
Date: Wed, 18 Mar 1998 18:04:32 -0600
Your printer job (stdin)
Completed successfully
& q ...завершил почтовый сеанс.
$
Подсчет слов в файле: wc
Иногда бывает весьма полезно узнать, сколько слов содержит тот или иной файл. Сделать это гораздо проще, чем можно предположить: достаточно воспользоваться утилитой wc.
Синтаксис
wc -Iwc {имяФайла}*
Утилита wc считает строки, слова или символы в одном или нескольких файлах, либо в данных, введенных с клавиатуры Опция -1 осуществляет подсчет строк, опция -w — слов, опция -с — символов. Если никакие опции не определены, то выполняются все три подсчета. Слово определено как последовательность символов, окруженная символами табуляции, пробелами или новыми строками.
Рассмотрим пример:
$ wc heart.final ...выполнить подсчет слов.
9 43 213 heart.final
Атрибуты файла
Теперь, когда рассмотрены основные утилиты работы с файлом, пришло время обратить внимание на его атрибуты.
Для получения подробной информации о файле используется рассмотренная уже утилита is:
$ Is -IgsF heart. final
1 -rw-r—r— 1 glass cs 213 Jan 31 00:12 heart.final
$ _
В табл. 2.7 расшифровано значение каждого поля.
Таблица 2.7. Атрибуты файла
Номер поля Символы Описание
1 1 Число блоков физической памяти, занятой файлом
' 2 -rw-r—г— Тип и режим полномочий файла, который указывает, кто может читать, записывать и выполнять файл
3 1 Счетчик жестких связей (обсуждаемый в главе 3)
4 glass Имя владельца файла
5 cs Группа, владеющая файлом
6 213 Размер файла в байтах
7 Jan 31 00:12 Время последней модификации
8 heart.final Имя файла
В следующих разделах мы поподробнее остановимся на значениях каждого поля.
Размер файла
Первое поле атрибутов файла указывает количество занимаемых файлом блоков. Фрагментированные файлы, имеющие большой объем в байтах, могут занимать совсем немного физической памяти. Фрагментированные файлы обсуждаются подробно в главе 13.
Имя файла
Имя файла отображается в восьмом поле. Имена файлов в UNIX могут содержать до 255 символов. При этом можно использовать любые печатные символы, кроме косой черты (/). Однако не рекомендуется также использовать знаки, являющиеся специальными для shell, например, <,>,*, ?, табуляции, т. к. они могут неправильно трактоваться как пользователем, так и системой. Нельзя также называть файлы и поскольку эти имена
зарезервированы для обозначения родительского и текущего каталогов. В отличие от некоторых операционных систем, не требуется, чтобы файл заканчивался расширением типа .с и .h, хотя многие утилиты UNIX (например, С-компилятор) работают с файлами, которые заканчиваются определенным суффиксом. Поэтому, heart и heart.fmal вполне допустимые имена.
Время модификации
Седьмое поле показывает время последней модификации файла. Например, утилита make, описанная в главе 12, использует время последней модификации файлов, чтобы управлять средством контроля зависимости. Утилита find, представленная в главе 3, использует это поле для поиска наиболее поздних версий файлов.
Владелец файла
Четвертое поле сообщает нам имя владельца файла. Каждый процесс UNIX имеет владельца, имя которого совпадает с именем пользователя, его запустившего. Например, мой shell запущен от имени пользователя glass, поэтому каждый создаваемый файл принадлежит данному пользователю, владельцу shell. В главе 13 мы более подробно рассмотрим процессы и их владельцев.
Имя пользователя ассоциируется с тем или иным набором символов, хотя сама система использует для идентификации число, называемое пользовательским ID. Однако человеку проще запомнить какое-либо имя, нежели число, поэтому, когда мы будем говорить об имени пользователя, то станем иметь в виду какую-либо буквенную комбинацию и применять термин "пользовательский ID" для указания числового значения.
Группа владельцев файла
Пятое поле информирует нас о группе, владеющей файлом. Каждый пользователь UNIX является членом какой-либо группы. Принадлежность к группе назначается системным администратором и является инструментом, позволяющим повысить безопасность системы. Каждый процесс UNIX также принадлежит определенной группе, обычно эквивалентной группе пользователя, запустившего процесс. Если пользователь входит в группу cs, то все создаваемые им файлы также принадлежат этой группе. В главе 13 этот вопрос будет рассмотрен подробнее. Использование групп относится к механизму безопасности UNIX, которому посвящены следующие разделы.
Как и в ситуации с именем пользователя, имя группы задается набором буквенных символов. Однако системой используется числовой идентификатор — ID группы.
Типы файла
Во втором поле указывается тип файла и полномочия. Для удобства еще раз приведем еже знакомую нам строчку листинга:
1 -rw-r—г— 1 glass cs 213 Jan 31 00:12 heart.final
Первый символ второго поля указывает на тип файла. В табл. 2.8 даны описание и обозначение различных типов. Мы с вами познакомились только с обычными файлами. В главе 3 будут рассмотрены файлы с символическими связями, в главе 13 — каналы и сокеты, а в главе 14 — буферированные и небуферированные файлы.
Таблица 2.8. Типы файла
Символ Тип файла
Обычный файл
d Каталог
Ь Буферированный специальный файл (например, драйвер диска)
с Небуферированный специальный файл (например, терминал)
1 Символическая связь
р Канал
s Сокет
Тип файла определяется утилитой file, которую мы сейчас и рассмотрим. Чаще всего эта утилита будет выдавать такой результат:
$ file heart.final ...определить тип файла.
heart.final: ascii text
$
Синтаксис
file {имяФайла} +
Утилита file определяет тип файла по его содержимому2. При использовании для файла символической связи утилита выдает характеристики того файла, на который эта связь указывает.
2 Эта программа весьма полезна, однако ее использование не гарантирует 100% верного результата.
Параметры полномочий файла
Следующие 9 символов второго поля указывают назначения параметров полномочии файла. В текущем примере назначения параметров полномочий — это rw-r--г--:
1 -rw-r—г— 1 glass cs 213 Jan 31 00:12 heart.final
Итак, мы разобрались со значением первого символа, теперь пришло время рассмотреть следующие девять, представляющие собой три группы по три символа (табл. 2.9 и 2.10). Прочерк на месте какого-либо символа говорит о юм, что этот вид работы с файлом запрещен. Разрешение на чтение, запись и выполнение файла очень часто зависят от типа файла (табл. 2.11).
Таблица 2.9. Гоуппы параметров полномочий файла
Группа параметров Описание
rw- Пользователь (владелец)
г-- Группа
г-- Другие
Таблица 2.10. Значения параметров полномочий файла
Значение Описание
г Разрешение на чтение
W Разрешение на запись
X Разрешение на выполнение
Таблица 2.11. Описание значений полномочий для файлов различных типов
Операция Обычный файл Каталог Специальный файл
Чтение Процесс может читать содержимое Процесс может читать каталог (выводить имена входящих в него файлов) Процесс может читать из файла, используя системный вызов read()
Запись Процесс может изменять содержимое Процесс может добавлять и удалять файлы из каталога Процесс может писать в файл, используя системный вызов write()
Выполнение Процесс может выполнять файл (при условии что файл — программа) Процессу разрешен доступ к файлам каталога и его подкаталогов —
Запущенный процесс обладает следующими характеристиками:
□ реальный пользовательский ID;
П эффективный пользовательский ID;
□ реальный ID группы;
□ эффективный ID группы.
Эти значения определяются во время регистрации в системе и являются характеристиками любого запушенного вами процесса. Параметры полномочий применяются следующим образом:
П если эффективный пользовательский ID процесса такой же, как у владельца файла, применяются пользовательские параметры полномочий;
а если эффективный пользовательский ID процесса отличается от ID владельца файла, но его эффективный ID группы равен ID группы, владеющей файлом, то применяются групповые параметры полномочий;
□ если ни эффективный пользовательский ID процесса, ни эффективный ID группы не совпадают, применяются другие параметры полномочий.
Следовательно, система полномочий является средством, с одной стороны, позволяющим повысить безопасность, защитив ваши файлы от несанкционированного доступа, а с другой — разрешает работать с ними пользователям, принадлежащим к определенной группе. Мы рассмотрим оптимальные для работы и безопасности установки доступа к файлам и научимся пользоваться утилитами, их изменяющими. Обратите внимание, что разрешение на доступ к файлу устанавливается на основе эффективного пользовательского и группового ID; его реальный пользовательский и групповой ID используются только для учетных целей. Кроме того, права на доступ к файлу обычно зависят от имени инициатора процесса, а не от владельца исполняемого файла. Тем не менее, иногда эта особенность мешает. Например, существует игра rogue, которая поставляется с некоторыми системами UNIX, записывает в отдельный файл лучшие результаты предыдущих игроков. Очевидно, во время выполнения rogue-процесс должен иметь право изменить этот файл, но игрок, от имени которого тот запущен, таких возможностей иметь не должен. Это кажется невозможным на основе той системы полномочий, которая была описана выше. Для того чтобы обойти эту проблему, разработчики UNIX добавили еще две характеристики файла: когда выполняется файл с полномочием "присваиваемый пользовательский ID", эффективный пользовательский и групповой ID устанавливаются равными ID исполняемого файла. Реальный пользовательский или групповой ID не затрагиваются. В нашем примере исполняемый файл и файл результатов принадлежат пользователю rogue, а т. к. в файл результатов может записывать результаты только его владелец (в данном случае rogue), то он (т. е. файл) защищен от изменений обычными пользователями. Так что, когда игрок запускает игру,
она выполняется с эффективным пользовательским ID rogue и таким образом способна изменить файл результатов.
Полномочия ’’присваиваемый пользовательский ID” и "присваиваемый групповой ID" обозначаются как s вместо х в пользовательском и групповом наборе полномочий. Они могут быть установлены с использованием утилиты chmod и системного вызова chmod (), описанного в главе 13.
Вот еще несколько примечаний, касающихся параметров полномочий файла:
П когда процесс создает файл, полномочия по умолчанию, данные этому файлу, заменяются специальным значением, называемым umask. Об этом значении мы поговорим позже, в главе 4;
□ привилегированный пользователь автоматически имеет все права доступа независимо от того, предоставлены они или нет;
П владелец файла может иметь меньшие права доступа, чем группа или кто-то еще.
Счетчик жесткой связи
Третье поле указывает на счетчик жесткой связи файла, т. е. сколько ссылок на один физический файл существует в иерархии. Жесткие связи являются отдельной темой и обсуждаются в главе 3 вместе с утилитой in.
Г руппы
Теперь, когда мы описали параметры полномочий файла, пришло время выяснить, как они работают. Рассмотрим уже известный нам пример, в котором имя пользователя установлено равным glass, а группа равной cs:
$ Is -lg heart.final
-rw-r—r— 1 glass cs 213 Jan 31 00:12 heart.final
$ _
По умолчанию установки доступа разрешают любому пользователю читать файл, однако правами на запись в него обладает только его владелец. Представим себе, что нам необходимо запретить доступ к файлу всех пользователей, кроме входящих в группу music, которым бы разрешалось чтение файла, и его владельца, у которого были бы права на чтение и запись в него.
Если такой группы не существует, то единственный способ ее создать — попросить об этом системного администратора. Сам же процесс создания будет рассмотрен в главе 15.
Вывод групп: groups
Утилита groups позволяет вывести названия всех групп, членом которых вы являетесь.
Синтаксис
groups [ID—Пользова теля]
По умолчанию утилита groups показывает список всех групп, членом которых вы являетесь. Если имя пользователя определено, выводится список групп, в которые он входит.
Пример:
$ groups cs music
$
. . .вывести мои группы.
Изменение группы: chgrp
Первый шаг к защите моих лирических стихов должен был состоять в изменении имени группы heart.final с cs на music. Сделано это с помощью утилиты chgrp:
$ Is -lg heart.final
-rw-r—r— 1 glass cs $ chgrp music heart.final $ Is -lg heart.final
213 Jan 31 00:12 heart.final
...изменить группу.
...подтвердить, что изменилось.
-rw-r—г— 1 glass music 213 Jan 31 00:12 heart.final
$
Синтаксис
chgrp -R имяГруппы {имяФайла}*
Утилита chgrp предоставляет возможность пользователю изменять групповую принадлежность файлов, которыми он владеет. Привилегированный пользователь (root) может изменять групповую принадлежность любого файла. За аргументом имяГруппы следуют имена файлов, групповую
принадлежность которых необходимо изменить. Опция -R рекурсивно изменяет групповую принадлежность файлов в каталоге.
Вы можете также использовать утилиту chgrp для изменения группы каталога.
Изменения прав доступа файла: chmod
Теперь, когда групповая принадлежность файла была изменена, нам может потребоваться изменить уровень доступа. Для этого используется утилита chmod:
$ Is -lg heart.final -rw-r—r— 1 glass
$ chmod o-r heart.final $ Is -lg heart.final -rw-r----- 1 glass
$
...прежде.
music 213 Jan 31 00:12 heart.final
...запрещение чтения для других.
...после.
music 213 Jan 31 00:12 heart.final
Синтаксис
chmod -R замена {, замена} * {имяФайла} +
Утилита chmod изменяет атрибуты указанных файлов согласно параметрам замена, которые могут принимать любую из форм:
• ВыборГруппы + новыеПрава (добавить права)’
• ВыборГруппы - новыеПрава (убрать права);
• ВыборГруппы = новыеПрава (назначить права абсолютно).
Здесь ВыборГруппы — это любая комбинация:
• и (пользователь/владелец);
• g (группа);
• о (другие);
• а (все).
новыеПрава — это любая комбинация:
• г (читать);
• w (писать);
• х (выполнять);
• s (присваиваемый пользовательский ID или присваиваемый групповой ID).
Опция -R рекурсивно изменяет атрибуты файлов в каталогах. (Для примера см. фрагмент кода, который следует далее.) Изменение прав доступа каталога не меняет права доступа файлов, содержащихся в каталоге.
В табл. 2.12 представлены дополнительные параметры утилиты chmod.
Таблица 2.12. Параметры утилиты chmod
Требование Параметры изменения
Добавить группе право записи g+w
Удалить право чтения и записи для пользователя u-rw
Добавить право выполнения для пользователя, группы и других а+х
Предоставить группе только право чтения g=r
Добавить право записи для пользователя и удалить право чтения u+w, g-r для группы
Желательно защитить свой домашний каталог от несанкционированного доступа, запретив всем пользователям записывать в него, оставив лишь права чтения и, возможно, выполнения:
$ cd
$ Is -Id . drwxr-xr-x 45 $ chmod o-rx
$ Is -Id drwxr-x--- 45
$
...перейти в домашний каталог.
...вывести атрибуты домашнего каталога, glass 4096 Apr 29 14:35
...изменить права доступа.
...получить подтверждение.
glass 4096 Apr 29 14:35
Обратите внимание, что для просмотра атрибутов каталога, а не содержащихся в нем файлов, была использована опция -d утилиты 1s.
Вы можете определять права доступа, используя восьмеричное число — триплет значений, разрешающих запуск, чтение и изменение файлов. Например, необходимо, чтобы файл имел следующие разрешения:
rwxr-x--
Восьмеричный эквивалент этой записи выражается числом 750. В табл. 2.13 представлены различные форматы записи прав доступа.
Ниже приведен пример задания флагов доступа с использованием восьмеричных значений:
$ chmod 750 ...обновить права.
$ Is -Id ...подтвердить.
drwxr-x--- 45 glass 4096 Apr 29 14:35
$
Таблица 2.13. Восьмеричный эквивалент прав доступа
Пользователь Группа Другие
Установка rwx r-x —
Двоичная 111 101 ООО
Восьмеричная 7 5 0
Изменение владельца файла: chown
Если, по каким-либо причинам, вы захотите передать права собственности на файл, вы сможете это сделать, используя утилиту chown. Некоторые версии UNIX позволяют только привилегированному пользователю (root) изменять права собственности файла, особенно в случае квотирования дискового пространства, доступного каждому пользователю, другие — передавать права может и владелец файла. Случаи, когда системному администратору приходится изменять права собственности на файлы и каталоги, рассмотрены в главе 15.
Синтаксис
chown -R новыиПользовательскийЮ {имяФайла} +
Утилита chown позволяет привилегированному пользователю изменять права собственности на файлы. Смена принадлежности производится для всех файлов, следующих за аргументом новыйпользовательскийю. Опция -R рекурсивно изменяет владельца файлов в каталогах и подкаталогах.
Пример передачи прав собственности на файл от владельца glass пользователю tim и возращение их glass:
$ Is -lg heart.final ...определить владельца.
-rw-r---- 1 glass music 213 Jan 31 00:12 heart.final
$ chown tim heart, final ... изменить - владельца на tim.
$ Is -lg heart.final ...проверить владельца.
-rw-r---- 1 tim music 213 Jan 31 00:12 heart, final
$ chown glass heart.final ...изменить владельца на glass.
$
Изменение групп: newgrp
Если вы член нескольких групп, то какой из них будет принадлежать создаваемый вами файл? Ответ на вопрос прост — вы можете быть членом нескольких групп, но текущая эффективная группа у вас одна, и процесс, создающий файл, использует эффективный ID именно этой группы. Это означает, что после создания файла из shell групповой ID файла устанавливается на эффективный групповой ID вашего shell. В рассматриваемых примерах членство принадлежит группам cs и music, а эффективное имя группы рабочего shell — cs.
Системный администратор выбирает, какая группа является для вас основной. Поэтому при необходимости изменить текущую группу можно воспользоваться УТИЛИТОЙ newgrep.
Синтаксис
newgrp [-] [имяГруппы\
Утилита newgrp изменят текущую группу пользователя. Если вы указываете символ - вместо имени группы, то ваша группа остается той же, что и при регистрации в системе.
В представленном ниже примере созданы файл test 1 с группой владельцев cs и файл test2, которым владеет music:
$ date > testl ...создать из shell группу cs.
$ newgrp music ...создать группу music.
$ date > test2 ...создать из shell группу music.
...прекратить работу нового shell.
$ Is -lg testl test2 ...посмотреть атрибуты каждого файла.
-rw-r—г— 1 glass cs 29 Jan 31 22:57 testl
-rw-r—r— 1 glass music 29 Jan 31 22:57 test2
Поэзия в движении: эпилог
Мы познакомились с основными утилитами UNIX, и, желательно, перед дальнейшим чтением попробовать проделать действия, описанные в примерах. Оставшаяся часть главы посвящена настройке терминала и двум наиболее популярным редакторам UNIX.
Определение типа вашего терминала: tset
Отдельные утилиты UNIX, включая два стандартных редактора vi и emacs, должны ’’знать", какой терминал вы используете, чтобы правильно управлять выводом. Тип вашего терминала сохраняется в глобальной переменной, называемой переменной окружения (см. главу 4). По умолчанию эта переменная чаще всего равна vtioo или vt52. Есть несколько способов задать необходимый тип.
П Тип term может устанавливаться непосредственно, через строку вида
setenv, TERM vtlOO (ДЛЯ С shell)
ИЛИ
TERM=vti00; export term (для Bourne, Korn и Bash)
вашего терминала. Этот метод установки эффективен, если вы знаете его тип заранее и всегда регистрируетесь с одного и того же терминала.
□ Стартовый файл запуска shell может вызвать утилиту tset, определяющую порт коммуникаций, с которым вы связаны, и затем производящую поиск соответствия порт/терминал в специальном файле /etc/ttytab. Если утилита tset не может найти тип терминала, она запрашивает информацию о нем при регистрации в системе.
П Вы можете вручную установить term из shell.
Далее мы познакомимся с двумя утилитами, позволяющими определить и установить тип терминала: tset и stty.
Самый простой способ установить тип терминала состоит в использовании утилиты tset.
Синтаксис
tset -s [-ес] [~ic] {-m портЮ: [?] типТерминала] *
Утилита tset определяет тип терминала.
Если опция -s не используется, то предполагается, что ваш тип терминала уже сохранен в переменной term окружающей среды, и утилита tset
определяет тип, используя информацию в зависимости от вашей версии UNIX, хранящуюся в файле /etc/termcap или базе данных terminfo.
Если вы используете опцию -s, утилита tset исследует файл /etc/ttytab и пробует соотнести порт вашего терминала с его типом. Если тип найден, утилита указанным в файле /etc/termcap образом его инициирует. Опция -s также выводит команды shell на стандартный выход. Переменные окружающей среды term и termcap устанавливаются в необходимое значение, и запускается нужный тип терминала. В имени файла не должно содержаться символов, которые могут быть неправильно интерпретированы shell. Эти символы будут указаны чуть ниже.
Опция -е задает стирающий символ терминала в аргументе с вместо установленной по умолчанию комбинации клавиш <Ctrl>+<H>. Символы управления могут быть обозначены или просто введенным символом, или вместе с предшествующим ему символом л (чтобы указать на комбинацию клавиш <Ctrl>+<H>).
Опция -i определяет прерывающий символ терминала в аргументе с вместо установленной по умолчанию комбинации клавиш <Ctrl>+<C>. Обозначение символов управления рассматривается в разд. "Режим ввода текста " далее в этой главе.
Записи файла /etc/ttytab могут быть удалены или добавлены с помощью опции -т. Последовательность -mpp:tt сообщает утилите tset следующее: если тип порта терминала является рр, то он должен быть заменен на тип терминала tt. Помещенный после двоеточия (:) знак вопроса (?) показывает tt и просит пользователя либо нажать клавишу <Enter> для подтверждения, либо ввести другой тип терминала.
Пример:
ttyOf ”usr/etc getty std.9600” vtlOO off local
ttypO none network off secure
ttypl none network off secure
Первое поле содержит имена портов, а третье — типы терминалов. Например, если пользователь зарегистрировался через порт ttyOf, то его тип терминала, в соответствии с записями этого файла, определялся бы как vtioo. В конфигурациях, где терминалы являются жестко замонтированными (т. е. непосредственно связаны с определенным портом), этот алгоритм работает прекрасно, поскольку терминал всегда связан с тем же самым портом. Но, как мы увидим вскоре, это не работает в сетевых конфигурациях. В следующем примере определим фактическое имя порта, используя утилиту tty (описанную в главе 3)\
$ tty ...вывести ID порта моего терминала.
/dev/ttypO
4 Зак 786
$ tset -s ...вызов tset.
set noglob; ...команды shell, генерируемые tset. TERM=network;
export TERM;
TERMCAP='sa;cent;network:li#24:co#80:am:do=AJ: ’;
export TERMCAP;
unset noglob;
Erase is Ctrl-H
$
Предыдущий пример дан только для иллюстрации работы утилиты tset. Чтобы действительно изменить переменные term и termcap, вы должны выполнить команду eval, которая подробно описана в главе 4. Вот более реалистический пример использования утилиты tset:
$ set noglob
$ eval 'tset -s' Erase is Backspace $ unset noglob
$ echo $TERM network $
...временно запрещает расширение имени файла.
...оценить вывод tset.
...сообщение tset.
...разрешение расширения имени файла.
...посмотреть новое значение TERM.
...тип терминала, который нашел tset.
К сожалению, тип терминала network (сеть) — не очень удобен, поскольку он не имеет практически никаких возможностей. Утилита tset определяется правилом: если обнаружен тип терминала network, следует предполагать, что данный терминал — vtlOO — и запросить у пользователя подтверждение этого. Пример:
$ set noglob ...запрещает расширение имени файла.
$ eval 'tset -s -т 'network:vtlOO'' ...предоставить правило.
TERM = (vtlOO) <Enter> ...нажата клавиша <Enter>.
Erase is Backspace
$ unset noglob ...разрешение расширения имени файла.
$ echo $TERM ...вывести новую установку TERM.
vtlOO ...это тип терминала, который использует tset.
$ _
Обобщая, можно сказать, что достаточно удобно записать запуск утилиты tset в стартовый файл вашего терминала. Файлы запуска shell описаны в главе 4. Самый простой синтаксис утилиты tset представлен ниже.
□ С shell
setenv TERM vtlOO tset
□ Bourne/Korn/Bash shell
TERM=vt100; export TERM tset
Более сложная форма tset определяет местонахождение файла /etc/ttytab и чаще всего выглядит, как это показано в примере.
□ С shell
set noglob
eval ’tset -s -m ’network:?vtl00’' unset noglob
□ Bourne/Korn/Bash shell
eval ’tset -s -m ’network:?vtl00’’
Изменение характеристик терминала: stty
Каждый терминал определенным образом обрабатывает некоторые символы. Эти знаки называются метасимволами. Например, метасимволом является символ возврата на шаг назад и завершающая программу последовательность, генерируемая комбинацией клавиш <Ctrl>+<C>. Переопределить значения метасимволов можно, используя утилиту stty.
Синтаксис
stty -а {опция}★ {строкаМета символа <значение>} *
Утилита stty позволяет проверить и установить характеристики терминала. С ее помощью можно изменить около 100 различных параметров, здесь будут рассмотрены наиболее используемые..
Для получения листинга текущих установок терминала служит опция -а. Чтобы изменить конкретный параметр, используйте одну или несколько следующих опций:
Опция Значение
-echo He отображать печатаемые символы
echo Отображать печатаемые символы
-raw Разрешить специальное значение метасимволов
raw Запретить специальное значение метасимволов
(окончание)
Опция Значение
-tostop Позволить фоновым процессам посылать информацию на терминал
tostop Остановить фоновые процессы, которые пытаются послать информацию на терминал
sane Установить характеристики терминала по умолчанию
Также имени или \ 1 новны> вы можете переопределить значение метасимвола, присваивая его новое значение. Символ управления может быть обозначен как Л 1епосредственно перед этим символом. Ниже приведен список ос-с метасимволов и их значений.
Опция Значение
erase Удалить предыдущий символ
kill Стереть всю текущую строку
Inext Не обращаться со следующим символом, как со специальным
susp Приостановить текущий процесс
intr Прервать фоновую работу без распечатки памяти
quit Завершить фоновую работу с распечаткой памяти
stop Остановить/возобновить вывод на терминал
eof Задать конец ввода
Вот пример работы утилиты stty:
$ stty -а . ..вывести текущие установки терминала.
speed 38400 baud, 24 rows, 80 columns
parenb -parodd cs7 -cstopb -hupcl cread -clocal -crtscts
-ignbrk brkint ignpar -parmrk -inpck istrip -inlcr -igncr icrnl -iuclc ixon -ixany -ixoff imaxbel
isig rexten icanon -xcase echo echoe echok -echonl -noflsh -tostop echoctl -echoprt echoke
opost -olcuc onlcr -ocrnl —onocr -onlret -ofill -ofdel
erase kill werase rprnt flush Inext susp intr quit stop eof
$ stty erase
$ stty erase ^h
...задать удаление символа
...через комбинацию клавиш <Ctrl>+<B>.
...задать удаление символа
...через комбинацию клавиш <Ctrl>+<H>.
$ _
Используйте утилиту stty для установки более удобных для вас значений метасимволов. Настройте свой терминал "под себя" путем создания сценариев, один из вариантов которого мы рассмотрим в главе 7. Вот пример кода, в котором используется утилита stty, чтобы отключить вывод символов:
$ stty -echo
$ stty echo
$
...отключить вывод.
...включить его снова.
Обратите внимание, что последнюю строку ввода (stty echo) вы не увидите из-за ранее установленного запрета вывода. Теперь, когда мы узнали, как определить тип терминала и его установки, пришло время рассмотреть два наиболее популярных редактора UNIX: vi и emacs.
Редактирование файла: vi
Как мы уже упомянули, наиболее популярными редакторами в UNIX являются vi и emacs. Неплохо иметь опыт работы с vi, т. к. он поставляется практически с каждой версией UNIX. Второй редактор, emacs, встречается не во всех версиях, однако достаточно традиционен для этой системы. В этом и последующих разделах мы поподробнее познакомимся с каждым из них. Также будут даны ссылки на другие источники, из которых вы можете получить более подробную информацию.
Запуск vi
Немного истории. Изначально Билл Джой (Bill Joy) из Sun Microsystems, Inc., работая в Калифорнийском университете в Беркли создал этот редактор для BSD UNIX. Однако популярность vi выросла настолько, что он стал стандартной утилитой большинства версий UNIX. Название vi (от англ, visual editor) расшифровывается, как визуальный редактор. Для запуска этого редактора необходимо просто ввести команду vi без параметров. В случае, если вам необходимо редактировать существующий файл, то в качестве параметра следует передать его имя. После запуска чистые (пустые) строки указываются тильдами (~), после чего vi ожидает от вас ввода команд. Для экономии места мы будем рассматривать примеры длиной не более шести строк.
Например, при запуске vi без параметров на вашем экране отобразится следующее:
Режим ввода команды — один из двух режимов, которые предоставляет редактор vi. Другой режим называется режимом ввода текста. Так как легче проиллюстрировать работу командного режима на примере каких-нибудь фраз, мы начнем знакомство с режима ввода текста.
Режим ввода текста
В табл. 2.14 дано описание клавиш ввода текста. Любой текст, который вы вводите, отображается на экране. Для перехода на следующую строку служит клавиша <Enter>. Для удаления последнего символа пользуйтесь клавишей < Backspaced
Внимание
Вы не можете двигаться по экрану с помощью клавиш перемещения курсора, когда находитесь в режиме ввода текста. В режиме ввода текста эти клавиши интерпретируются, как обычные символы ASCII, и коды управления вводятся, как нормальный текст.
Таблица 2.14. Клавиши ввода текста в редакторе vi
Клавиша Действие
<i> Текст вставляется перед курсором Текст вставляется в начало текущей строки
<а> Текст добавляется после курсора
<А> Текст добавляется к концу текущей строки
<0> Текст добавляется после текущей строки
<О> Текст вставляется перед текущей строкой
<R> Текст заменяется (переписывается)
Для перехода к вводу текста из режима команд нажмите клавишу <Esc>.
Так, чтобы ввести короткую поэму, необходимо нажать клавишу <а> для перехода в текстовый режим, и клавишу <Esc> для возврата к режиму команд.
I always remember standing in the rains,
On a cold and damp September,
Brown Autumn leaves were falling softly to the ground,
Like the dreams of a life as they slide away.
В следующем разделе мы узнаем, как сделать из представленного текста нечто более интересное.
Режим ввода команд
Для редактирования текста следует войти в командный режим. Для этого нажмите клавишу <Esc>. Если вы нажмете ее в командном режиме, ничего не произойдет. Система лишь звуковым сигналом напомнит вам, что вы уже работаете с ним. Редактирование документа происходит путем нажатия последовательности специальных клавиш. Например, для того чтобы стереть отдельное слово, поместите курсор к его началу и нажмите клавишу <d> и затем клавишу <w> (от англ, delete word — удалить слово).
Некоторым функциям редактирования необходимы параметры, которые передаются после двоеточия (:). Если эта клавиша нажата, остальная часть команды выводится внизу экрана. Например, чтобы удалить строки с 1 по 3, необходимо ввести следующую командную последовательность:
:1,3d<Enter>
Некоторые функции редактирования типа команды удаления блока, которую мы только что рассмотрели, действуют в каком-либо диапазоне строк. Редактор понимает два формата указания диапазона:
□ чтобы выбрать единственную строку, укажите ее номер;
□ чтобы выбрать блок строк, укажите номер первой и последней строк включительно, разделенных запятой.
Символ $ используется для указания номера последней строки в файле; символ . — для строки, содержащей курсор. Кроме того, для определения строк можно пользоваться различными арифметическими выражениями. Например, такой последовательностью, которая удалила бщ текущую строку и две следующие за ней строки:
:.,.+2d<Enter>
В табл. 2.15 представлены другие способы задания диапазона.
Таблица 2.15. Выбор диапазона строк в редакторе vi
Диапазон Выбирает
Все строки в файле
1,. Все строки от начала файла до текущей строки включительно
Все строки от текущей строки до конца файла включительно
.-2 Отдельную строку, которая находится на две строки выше текущей строки
Буфер памяти и временные файлы
Во время редактирования файла vi хранит его копию в памяти и вносит туда изменения. Файл на диске не изменяется, пока вы не сохраните его или не выйдете из vi с помощью одной из команд, которая автоматически сохраняет файл (эти команды мы рассмотрим чуть позже). По этой причине рекомендуется почаще сохранять изменения во время работы. В противном случае, при сбое системы будут потеряны все внесенные вами изменения. Однако, если вы сохраняете промежуточные версии, в случае сбоя системы будут потеряны не все изменения, и вы сможете восстановить файл, используя опцию -г (vi -г имяФайла) из временного файла. Некоторые версии UNIX пошлют вам электронное письмо со сведениями, как восстановить утерянный файл. Но, несмотря на существующую возможность восстановления, безопаснее все-таки почаще сохранять изменения.
Общие функции редактирования
Основные функции редактирования в vi^ могут быть сгруппированы в следующие категории:
□ перемещение курсора;
□ удаление текста;
□ замена текста;
□ вставка текста;
□ поиск по тексту;
□ поиск и замена текста;
□ сохранение или загрузка файлов;
□ разное (включая, выход из vi).
Данные категории описаны и проиллюстрированы чуть ниже, на примере поэмы, о которой мы говорили в разд. "Режим ввода текста" ранее в этой главе.
Перемещение курсора
В табл. 2.16 представлены общие команды перемещения курсора. Например, чтобы вставить слово Just перед словом Like в четвертой строке, необходимо переместить курсор на четвертую строку, нажав клавишу <i>, чтобы войти в режим ввода текста, а затем нажать клавишу <Esc> для возвращения в режим команд. Для перемещения курсора на четвертую строку используется последовательность: 4<Enter> (либо 4G).
Таблица 2.16. Команды перемещения курсора в редакторе vi
Перемещение Ключевая последовательность
Вверх на строку <?> или <к>
Вниз на строку <Х> или <j>
Вправо на один символ <-»> или <1>
Влево на один символ «-> или <h>
К началу строки В конец строки Назад на одно слово <~> <$> <Ь>
Вперед на одно слово Вперед к концу текущего слова К началу экрана В середину экрана В конец экрана Вниз на половину экрана Вперед на один экран Вверх на половину экрана Назад на экран К строке пп <w> <е> <Н> <м> <Ctrl>+<D> <Ctrl>+<F> <Ctrl>+<U> <Ctrl>+<B> : nn<Enter> (nnG также работает)
К концу файла <G>
Удаление текста
В табл. 2.17 приведены общие команды удаления текста. Например, для удаления слова always следует воспользоваться последовательностью:
□ i<Enter> для перемещения на начало первой строки;
□ нажать клавишу <w> для перемещения на одно слово вперед;
□ ввести dw для удаления.
Для удаления буквы s в конце слова rains, находящегося в первой строке, нам необходимо переместить курсор на символ s и затем нажать клавишу <х>.
Таблица 2.17. Команды, удаляющие текст
Элемент для удаления Ключевая последовательность
Символ Поместите курсор на символ и затем нажмите клавишу <х>
Слово Поместите курсор на начало слова и затем введите dw
Строка Поместите курсор куда-нибудь в строку, а затем введите dd. (Ввод числа перед dd заставит vi удалить указанное число строк, начиная с текущей строки.)
С текущей позиции до конца текущей строки Г руппа строк Нажмите клавишу <D> : <диапазон>&<ЕпЪег>
Вот как выглядит текст после описанных выше манипуляций:
I remember standing in the rain,
On a cold and damp September, Brown Autumn leaves were falling softly to the ground, Just Like the dreams of a life as they slide away.
Замена текста
Основные команды замены текста рассмотрены в табл. 2.18. Так, например, для замены слова standing на walking необходимо переместиться в его начало и набрать cw, а затем напечатать walking и нажать клавишу <Esc>. Для замены строчной s в слове September на прописную S следует поместить курсор на s и нажать клавишу <г>, а затем набрать s.
Таблица 2.18. Замена текста в редакторе vi
Элемент для замены
Символ
Ключевая последовательность
Поместите курсор на символ, нажмите клавишу <г>, а затем напечатайте символ замены
Таблица 2.18 (окончание)
Элемент для замены Ключевая последовательность
Слово Поместите курсор в начало слова, наберите cw и затем
напечатайте текст замены, в конце нажмите клавишу <Esc>
Строка Разместите курсор где-нибудь в строке, наберите с с, а
затем напечатайте текст замены, в конце нажмите клавишу <Esc>
Теперь наша поэма выглядит так:
I remember walking in the rain,
On a cold and dark September,
Brown Autumn leaves were falling softly to the ground, Just like the dreams of a life as they slip away.
Вставка текста
Для копирования и вставки текста редактор vi пользуется специальным буфером. Например, для копирования первых двух строк в буфер и вставки их после третьей нам необходимо совершить следующее:
:1,2у
: Зри
В табл. 2.19 описаны основные команды работы с буфером.
Таблица 2.19. Команды работы с буфером
Действие Ключевая последовательность
Скопировать строки в буфер вставки :<диапазон>у<Enter>
Скопировать текущую строку в буфер вставки <Y>
Вставить содержимое буфера вставки после текущей строки р или :pu<Enter> (содержимое буфера вставки не изменяется)
Вставить содержимое буфера вставки после строки ПП : nnpu<Enter> (содержимое буфера вставки не изменяется)
Сейчас наша поэма выглядит так: I remember walking in the rain, On a cold and dark September,
Brown Autumn leaves were falling softly to the ground,
I remember walking in the rain,
On a cold and dark September,
Just like the dreams of a life as they slip away.
Поиск
Если необходимо найти то или иное слово или выражение в тексте, вы можете воспользоваться поиском, который осуществляется выше и ниже от текущей строки. В табл. 2.20 рассмотрены наиболее общие команды поиска. Замыкающие символы / и ? необязательны для первых двух команд (т. к. редактор понимает, что вы имели в виду; однако использование / и ? является полезной привычкой, позволяющей добавить другие команды после этих символов).
Таблица 2.20. Команды поиска в vi
Действие Ключевая последовательность
Поиск вперед от текущей позиции строки sss /sss/<Enter>
Поиск назад от текущей позиции строки sss ?sss?<Enter>
Повторить последний поиск <n>
Повторить последний поиск в обратном направлении <N>
Например, для поиска слова ark, начиная с первой строки, необходимо ввести следующие команды:
:l<Enter>
/ark/<Enter>
В результате выполнения этой последовательности курсор будет установлен на часть слова dark, содержащего эту последовательность:
I remember walking in the rain,
On a cold and dark September,
Brown Autumn leaves were falling softly to the ground,
Just like the dreams of a life as they slip away.
Поиск и замена
Очень часто возникает необходимость замены определенных выражений в тексте. Для этого следует сначала найти указанные выражения, а потом
произвести замену. Эта задача выполняется с помощью команд, описанных в табл. 2.21.
Таблица 2.21. Поиск и замена в редакторе vi
Действие Ключевая последовательность
Заменяет первое вхождение sss на ttt :<.диапазонуз/ sss/ ttt/<Enter>
в каждой строке
Заменяет каждое вхождение sss на ttt :<диапазонУг/ sss/ ttt/g<Enter> в каждой строке
После замены всех символов ге на XXX получим следующее:
I XXXmember walking in the rain, On a cold and dark September, Brown Autumn leaves weXXX falling softly to the ground, Just like the dXXXams of a life as they slip away.
:1,$s/re/XXX/g
Сохранение или загрузка файлов
Для сохранения и загрузки файла используются команды, описанные в табл. 2.22.
Таблица 2.22. Команды сохранения и загрузки файлов в редакторе vi
Действие Ключевая последовательность
Сохранить файл как <имя> : w<MMtf><Enter>
Сохранить файл с текущим именем :w<Enter>
Сохранить файл с текущим именем и выйти :wq<Enter> (zz также работает)
Сохранить только определенные строки в другой файл : <диапазон>ы<имя><Еп^гУ
Прочитать содержимое другого файла в текущую позицию :г <имяХЕп!ег>
Редактировать файл <имя> вместо текущего файла : e<wMHXEnter>
Редактировать следующий файл из первоначальной командной строки :n<Enter>
Пример записи содержимого буфера в файл с именем rain.doc:
I remember walking in the rain,
On a cold and dark September,
Brown Autumn leaves were falling softly to the ground,
Just like the dreams of a life as they slip away.
:w rain, doc
При сохранении файла редактор vi сообщает его размер.
Случайно выйти из vi, не сохранив изменения, невозможно.
Если вы задаете больше, чем один файл в командной строке во время первоначального вызова vi, редактор стартует, загружая первый файл. Перейти к редактированию следующего файла можно, используя ключевую последовательность :п.
Разное
В табл. 2.23 приведены наиболее общие команды работы с редактором vi, включая выход из него. Комбинация клавиш <Ctrl>+<L> особенно полезна для обновления экрана в случае вывода сообщений о сбоях в работы системы во время работы с vi.
Таблица 2.23. Основные команды работы с редактором vi
Действие Ключевая последовательность
Перерисовать экран Отменить последнюю операцию Отменить многочисленные изменения в текущей строке Соединить следующую строку с текущей Повторить последнюю операцию Выполнить команду в новом shell и затем вернутся В vi <Ctrl>+<L> <u> <U> :!<команда><Еп1ег>
Выполнить команду в новом shell и прочитать ее вывод в буфер редактирования в текущую позицию Выйти из vi, если работа сохранена :г!<команда><Еп1ег> :q<Enter>
Выйти из vi без сохранения :q!<Enter>
Выход из редактора:
I remember walking in the rain,
On a cold and dark September,
Brown Autumn leaves were falling softly to the ground, Just like the dreams of a life as they slip away.
Настройка vi
Путем установки определенных опций вы можете настроить поведение вашего редактора в тех или иных ситуациях. Полный список доступных опций изменяется в зависимости от версии и платформы, но мы обсудим наиболее часто используемые.
Команда :set служит для вывода опций, поддерживаемых редактором vi. После ввода .-set all будут выведены текущие и поддерживаемые редактором установки. Они задаются либо числовыми и строковыми величинами, либо переключателями "Вкл" и "Выкл". Наиболее используемые опции показаны в табл. 2.24.
Таблица 2.24. Настройки редактора vi
Опция Описание Установка по умолчанию
autoindent Во включенном состоянии говорит о том, что следующая строка, которую вы печатаете, имеет такой же отступ, как и предыдущая строка Выкл
ignorecase В процессе поиска и замены строчные и прописные символы удовлетворяют критерию, требуемому для совпадения Выкл
number Нумерация строк выводится по левой стороне экрана Выкл
showmode Показывает текущий режим (текстовый или командный) Выкл
showmatch Подсвечивает открывающую скобку при печати закрывающей Выкл
Например, для того чтобы включить опцию autoindent, напечатайте :set autoindent<Enter>
А для того чтобы выключить, напечатайте
:set noautoindent<Enter>
Сохранение пользовательских настроек
Для того чтобы не настраивать каждый раз заново редактор, вы можете создать файл, в котором укажите необходимые установки. Файл конфигурации должен называться .ехгс.
Внимание
Обратите внимание, что имя файла начинается с точки: это специальное соглашение, о котором мы узнаем позже, когда будем рассматривать команды shell.
set autoindent set ignorecase set nonumber
В действительности нет необходимости устанавливать опцию nonumber, т. к. ее начальное значение "Выкл", но в данном случае имеется в виду, что вы как бы выключили ее. Потому-то она и была установлена.
Для дополнительной информации
Для более глубокого знакомства с редактором vi рекомендуется обратиться к книге [Christian 1988].
Редактирование файла: emacs
emacs (от англ. Editor MACroS) — не менее популярный редактор, который можно обнаружить на многих UNIX-системах (либо загрузить из Интернета). История emacs начиналась в Lisp-based artificial intelligence community. В 1975 г. Ричард Сталлман (Richard Stallman) и Гай Стил (Guy Steele) написали первоначальную версию, которая была в последствии доработана и сейчас свободно распространяется в форме исходных кодов через Free Software Foundation (FSF). О группах Open Sourse и Free Software Foundation мы поговорим в главе 16.
Запуск emacs
Для запуска этого редактора, как и для запуска vi, необходимо просто ввести команду emacs без параметров. Чтобы начать редактирование существующего файла, задайте его имя в качестве параметра. При запуске emacs без параметров на вашем экране отобразится следующее:
GNU Emacs 19.34.1
Copyright (С) 1996 Free Software Foundation, Inc.
Type С-х С-с to exit Emacs.
Type C-h for help; C-x u to undo changes.
Type C-h t for a tutorial on using Emacs.
Emacs: ^scratch*
(Fundamental)-----All
Для экономии места будем рассматривать небольшие примеры. Вторая снизу строка называется строкой режима и содержит следующую информацию:
□ если первые три черты содержат **, то текущий файл был изменен;
□ название, которое следует за Emacs: — имя текущего файла; если ни один файл не загружен, вместо него используется имя *scratch*;
□ текущий режим редактирования показывается в круглых скобках. В данном случае это Fundamental, который является стандартным режимом редактирования;
□ следующий элемент указывает текущую рабочую позицию в файле, как процент относительно размера всего документа. Если файл очень маленький и полностью помещается на экране, то это значение равно ан. Если вы находитесь в начале или конце файла, то соответственно отображается Тор И Bot.
Команды emacs
В отличие от vi, в редакторе emacs не различаются режим ввода текста и режим команд. Для того чтобы ввести текст, просто начинают печатать. Начальный приветствующий заголовок emacs автоматически исчезает, когда вы вводите первый символ. Длинные строки не разрываются автоматически, так что необходимо нажать клавишу <Enter> для перехода на новую строку. Строки, превышающие ширину экрана, заканчиваются символом \ и переносятся на следующую строку, как это показано в следующем примере:
Это очень длинная строка, иллюстрирует способ, каким выв \
одятся неразрывные строки
Это более короткая строка
--- Emacs: ^scratch* (Fundamental) -- All ---------
Редактирование в emacs происходит через набор определенных команд. В данной книге одновременное нажатие клавиш будет обозначаться следующим образом:
<Ctrl>+<H> <t> ’
Это означает, что нажимают и удерживают клавишу <Ctrl> и затем нажимают клавишу <Н>. Затем отпускают обе клавиши и нажимают клавишу <t>. Точно так же используется клавиша <Esc>. Например, последовательность
<Esc> <х>
означает, что нажимают клавишу <Esc> (но не держат ее) и затем нажимают клавишу <х>. Если же когда-нибудь вы нажмете <Esc> два раза подряд, то emacs предложит вам нажать клавишу <п> для отмены операции. В следующих разделах мы познакомимся подробнее с приемами редактирования В emacs.
Как избежать проблем
Всякий раз, когда вы изучаете новую программу, весьма легко растеряться и запутаться. Вот пара полезных команд для возврата к нормальному состоянию:
□ комбинация клавиш <Ctrl>+<G> заканчивает любую команду редактора emacs, даже если она (т. е. команда) только частично введена, и возвращает emacs к ожиданию новых команд;
□ комбинация клавиш <Ctrl>+<X> <1> закрывает все окна emacs кроме главного окна редактирования файла. Это полезно, поскольку часто редактор выводит какую-либо информацию в новом окне, и следует знать, как его закрыть после ознакомления с его содержимым.
Получение помощи
Существует немало способов получить помощь о работе emacs. Однако лучше всего воспользоваться встроенным в редактор справочником, вызов которого осуществляется комбинацией клавиш <Ctrl>+<H> <t>.
Выход из emacs
Для того чтобы закрыть emacs и сохранить файл, используют комбинацию клавиш <Ctrl>+<X> <Ctrl>+<C>. Если файл не сохранен со времени его последнего изменения, появится запрос на подтверждение сохранения.
Режимы emacs
Редактор поддерживает несколько различных режимов для ввода текста, включая Fundamental, Lisp Interaction И С. Каждый режим имеет специальные функции для работы с конкретным видом текста. По умолчанию emacs запускается в режиме Fundamental. Рассмотрим именно этот режим. За информацией о других режимах обращайтесь ко встроенному справочнику.
Ввод текста
Чтобы ввести текст, просто начинают печатать. Пример:
There is no need for fear in the night,
You know that your Mommy is there,
To watch over her babies and hold them tight,
When you are in her arms you can feel her sigh all night.
--- Emacs: *scratch*
(Fundamental)-----All------------
Общие функции редактирования
Наиболее общие функции редактора emacs могут быть сгруппированы в следующие категории:
□ перемещение курсора;
□ удаление, вставка и отмена текста;
□ поиск в тексте;
□ поиск и замена текста;
□ сохранение и загрузка файлов;
□ разное.
Далее мы рассмотрим эти функции на уже знакомом нам примере поэмы.
Перемещение курсора
Общие комбинации клавиш перемещения курсора описаны в табл. 2.25. Например, для того чтобы вставить слова worry or перед словом fear в первой строке, необходимо переместить курсор в первую строку файла, нажимая клавиши <Esc> «> и затем, передвинуться вперед на несколько слов, нажимая клавиши <Esc> <f>. После этого необходимо напечатать слова, которые будут автоматически вставлены в текущую позицию курсора.
Таблица 2.25. Перемещение курсора в редакторе emacs
Действие Ключевая последовательность
Вверх на одну строку Вниз на одну строку <Ctrl>+<P> (предыдущий) <Ctrl>+<N> (следующий)
Вправо на один символ <Ctrl>+<F> (вперед, переход на новую строку)
Влево на один символ <Ctrl>+<E> (назад, переход на новую строку)
К началу строки <Ctrl>+ <А> (а — это первая буква)
Таблица 2.25 (окончание)
Действие Ключевая последовательность
К концу строки Назад на одно слово <Ctrl>+<E> (end — конец) <Esc> <b> (back — назад)
Вперед на одно слово Вниз на один экран Вверх на один экран В начало файла В конец файла <Esc> <f> (forward — вперед) <Ctrl>+<V> <Esc> <v> <Esc> «> <Esc> <»
Удаление, вставка и отмена
Всякий раз, когда удаляется элемент текста, emacs запоминает его в индивидуальном буфере уничтожения. Список буферов уничтожения поддерживается для того, чтобы удаленные элементы могли быть восстановлены после удаления с экрана. Чтобы восстановить последний стертый элемент, используйте комбинацию клавиш <Ctrl>+<Y>. После ее нажатия вы можете применить последовательность клавиш <Esc> <у>, чтобы заменить восстанавливаемый элемент предварительно удаленным. Каждый раз, когда вы нажимаете клавиши <Esc> <у>, восстанавливаемый элемент продвигается на одну позицию назад в списке буфера уничтожения.
Вы можете добавить очередной удаляемый элемент в конец последнего буфера уничтожения, не создавая новый буфер, используя последовательность клавиш <Esc> <Ctrl>+<W> до того, как воспользуетесь командой удаления. Это может быть полезно, если необходимо сначала вырезать различные части файла, а потом вставить в одно место.
В табл. 2.26 приведены комбинации клавиш, позволяющие удалять символы.
Таблица 2.26. Удаление, вставка и отмена в редакторе emacs
Элемент для удаления Ключевая последовательность
Символ перед курсором <Delete>
Символ после курсора <Ctrl>+<D>
Слово пред курсором <Esc> <Delete>
Слово после курсора <Esc> <d>
До конца текущей строки <Ctrl>+<K>
Предложение <Esc> <k>
Вы можете отменить сделанные изменения, нажимая клавиши <Ctrl>+<X> <u> для каждого отменяемого действия.
В табл. 2.27 описаны комбинации клавиш работы с буфером.
Таблица 2.27. Буфер уничтожения в редакторе emacs t
Действие Ключевая последовательность
Вставить последний буфер уничтожения <Ctrl>+<Y>
Извлечь предыдущий удаленный фрагмент <Esc> <у>
Добавить следующий удаляемый фрагмент <Esc> <Ctrl>+<W>
Отменить последнее действие <Ctrl>+<X> <u>
Поиск
Работая в emacs, вы можете пользоваться инструментом, называемым инкрементным поиском. Для того чтобы найти конкретную последовательность символов вперед от текущего местонахождения курсора, нажмите комбинацию клавиш <Ctrl>+<S>. Внизу экрана появится подсказка "I-search:", после которой вы должны ввести искомую строку. По мере того, как вы будете вводить последовательность символов, редактор emacs станет искать ближайшую к текущему положению строку, совпадающую с введенной. То есть во время ввода поискового выражения подыскиваются подстроки, содержащие уже введенную последовательность. Для завершения поиска и остановки на текущей позиции следует нажать клавишу <Esc>. Стирая символы в поисковом выражении до нажатия клавиши <Esc>, вы передвигаете курсор к ближайшему совпадению с оставшимся набором символов поиска. Для повторения поиска не нажимайте клавишу <Esc>, а воспользуйтесь комбинацией клавиш <Ctrl>+<S> для поиска вперед от текущего положения курсора или <Ctrl>+<R> для поиска назад. В табл. 2.28 рассмотрены основные комбинации клавиш поиска.
Таблица 2.28. Поиск в редакторе emacs
Действие Ключевая последовательность
Поиск вперед строки str <Ctrl>+<S> str
Поиск назад строки str <Ctrl>+<R> str
Повторить последний поиск вперед <Ctrl>+<S>
Повторить последний поиск назад <Ctrl>+<R>
Завершить режим поиска <Esc>
Поиск и замена
Для того чтобы найти и заменить какие-либо выражения, нажмите клавиши <Esc> <х> и введите г epi s, а затем нажмите клавишу <Enter>. Далее emacs попросит ввести искомую строку, а затем заменяющую строку. После нажатия клавиши <Enter> будет выполнена замена по всему тексту.
Сохранение и загрузка файлов
Чтобы сохранить файл, нажмите комбинации клавиш <Ctrl>+<X> <Ctrl>+<S>. Если файл не имеет имени, вам будет предложено назвать его.
Для редактирования файла нажмите комбинации клавиш <Ctrl>+<X> <Ctrl>+<F>. Появится запрос на ввод имени файла. Если файл уже существует, его содержимое загрузится в emacs; иначе файл будет создан.
Для сохранения файла и выхода из emacs служат комбинации клавиш <Ctrl>+<X> <Ctrl>+<C>.
В табл. 2.29 описаны основные комбинации клавиш для работы с emacs.
Таблица 2.29. Основные команды работы с редактором emacs
Действие Ключевая последовательность
Сохранить текущую работу <Ctrl>+<X> <Ctrl>+<S>
Редактировать другой файл <Ctrl>+<X> <Ctrl>+<F>
Сохранить работу и затем выйти из редактора <Ctrl>+<X> <Ctrl>+<C>
Дополнительные команды
Для того чтобы обновить экран, нажмите комбинацию клавиш <Ctrl>+<L>. Для перехода в режим autowrap, который автоматически производит перенос слов на новую строку, когда достигается ее конец, нажмите последовательно клавиши <Esc> <х>, а затем клавишу <Enter>. Для выхода из этого режима повторите действие.
Для дополнительной информации
Для получения дополнительных сведений о emacs рекомендуется обратиться к книге [Roberts 1991].
Электронная почта: mail/mailx
Последний раздел этой главы посвящен использованию электронной почты UNIX. Будет полезным как можно быстрее научиться работать с электронной почтой, потому что это весьма эффективный способ задать вопрос о работе UNIX системному администратору или другим, более опытным пользователям. Существуют, как минимум, две наиболее популярные почтовые программы. Одна из них называется mail, а другая maiix. Для упоминания обеих будем пользоваться термином "почта". Программа mail имеет большое количество функций, но мы с вами остановимся только на основных, тех — которые будут вам наиболее полезны. За дополнительной информацией обращайтесь к встроенному справочнику.
Синтаксис
mail -Н [-f имяФайла] [1р_пользователя]*
Утилита mail позволяет посылать и получать почту. Если указан список пользователей, то программа отправляет им данные, полученные со стандартного входа, после чего завершается. Имя пользователя может быть задано следующим образом:
• локальное имя пользователя (т. е. login name — имя входа в систему);
• интернет-адрес в форме name@hostname.domain;
• имя файла;
• почтовая группа.
Об использовании интернет-адресов мы поговорим в главе 9. Почтовые группы очень коротко мы рассмотрим сейчас.
Если имя пользователя не определено, утилита mail предполагает, что вы собираетесь читать почту из каталога. Каталог /var/mail/ <имяПолъзователя>, где <имяПользователя> — собственное имя пользователя, читается по умолчанию, хотя это действие можно отменить через опцию -f. Тогда mail выдает приглашение & и ждет команды. Опция -н выводит заголовки содержимого вашего почтового каталога, но не входит в режим команды. Список наиболее полезных параметров командного режима представлен ниже.
При запуске утилита mail читает конфигурационный файл .mailrc из вашего домашнего каталога, в котором содержатся параметры настройки почтовой программы. Имя файла конфигурации может быть изменено
путем установки соответствующего значения переменной окружения mailrc. Переменные окружения обсуждаются в главе 4.
У программы существует большое количество разнообразных настроек. Наиболее важная — способность определить почтовые группы (также иногда называемые псевдоименами). Это переменные, обозначающие группу пользователей. Для задания почтовой группы разместите строку вида group имя {Ю_пользователя}+
в файле запуска почты. Вы сможете использовать это имя в качестве псевдонима заданной группы пользователей.
В табл. 2.30 дано описание основных команд работы с утилитой mail.
Таблица 2.30. Команды работы с утилитой mail
Команда Описание
7 Выводит справку
сору [списокСообщений] [имяФайла] Копирует сообщения в имяФайла, не помечая их как сохраненные
delete [списокСообщений] Удаляет списокСообщений из системного почтового каталога
file [имяФайла] Читает почту из почтового ящика имяФайла. Если никакое имяФайла не определено, показывает имя текущего почтового ящика вместе с размером и числом сообщений, в нем находящихся
headers [сообщение] Выводит на экран заголовки сообщений, которые содержать в себе сообщение
mail {10_пользователя}+ Посылает почту перечисленным пользователям
print [списокСообщений] Выводит перечисленные сообщения с использованием утилиты more
quit Осуществляет выход из утилиты mail
reply [списокСообщений] Передает ответ отправителям списокСообщений
save [списокСообщений] [имяФайла] Сохраняет указанные сообщения в имяФайла. Если никакое имяФайла не задано, сохраняет их в файле mbox пользовательского домашнего каталога
В табл. 2.31 дано описание команд, используемых для работы с сообщениями.
Таблица 2.31. Работа с сообщениями в mail
Синтаксис Описание
Текущее сообщение
nn Сообщение по номеру пп ' Первое неудаленное сообщение
$ Последнее сообщение
* Все сообщения
nn-mm Сообщения, пронумерованные от пп до mm включительно
user Все сообщения от пользователя
Для вызова большинства команд в mail можно использовать первый символ их названия (например, р вместо print).
Отправка почты
Самый простой способ отправить почту состоит в том, чтобы ввести сообщение непосредственно с клавиатуры и закончить ввод, нажав комбинацию клавиш <Ctrl>+<D>:
$ mail tim ...послать почту локальному пользователю tim.
Subject: Mail Test ...ввести тему почты.
Hi Tim,, How is Amanda doing?
with best regards from Graham
AD ...закончить ввод; стандартный вход посылается как почта.
$ _
Мы уже немного обсудили создание почтовых групп, позволяющих посылать почту входящим в них людям. Теперь рассмотрим это на примере: group music jeff richard kelly bev $ mail music ...послать почту каждому члену группы.
Subject: Music
Hi guys How about a jam sometime? with best regards from Graham. AD $
...конец ввода.
Для набора больших сообщений целесообразно будет воспользоваться каким-нибудь текстовым редактором и сохранить письмо в файл, который потом переадресовать на вход программы mail:
$ mail music < jam.txt $
...послать jam.txt по почте.
Чтобы послать почту пользователям Интернета, используйте стандартную адресную схему Интернета, описанную в главе 9.
$ mail glass@utdallas.edu < mesg.txt ...послать файл.
Чтение почты
Присланная вам почта сохраняется в файле /var/mai\/< ИмяПользователя>, где <ИмяПолъзователя> — это имя, с которым пользователь регистрируется в системе. Для чтения почтового каталога введите mail с необязательным именем каталога. Если в настоящее время почты нет, система уведомит вас об этом:
$ mail ...попытаться прочитать мою почту из каталога по умолчанию.
No mail for glass
$ _
Если почта присутствует, утилита mail покажет список почтовых заголовков и выведет приглашение &. Следует нажать клавишу <Enter>, чтобы прочитать по порядку все сообщения, а затем — клавишу <q> (от англ, quit) для выхода из утилиты mail. Адресованная пользователю почта автоматически сохраняется в каталоге mbox его домашнего каталога, и ее можно прочитать позднее, введя следующую команду:
$ mail -f mbox . . .читать почту, сохраненную в каталоге mbox.
При чтении писем на экране будет отображено примерно следующее:
$ Is -1 /var/mail/glass ...посмотреть, есть ли почта.
-rw------- 1 glass 7 58 May 2 14:32 /var/mail/glass
$ mail ...читать почту из каталога по умолчанию.
Mail version SMI 4.0 Thu Oct 11 12:59:09 PDT 1990
Type ? for help.
"/var/mail/glass": 2 messages 2 unread
>U 1 tim@utdallas.edu Sat May 2 14:32 11/382 Mail test
U 2 tim@utdallas.edu Sat May 2 14:32 11/376 Another
& <Enter> ...нажал клавишу <Enter> для чтения сообщения 1.
From tim@utdallas.edu Sat Mar 14 14:32:33 1998
То: glass@utdallas.edu
Subject: Mail test hi there
& <Enter> ...нажал <Enter> клавишу для чтения сообщения 2.
From tim@utdallas.edu Sat Mar 14 14:32:33 1998
To: glass@utdallas.edu
Subject: Another hi there again
& <Enter> ...нажал клавишу <Enter> для чтения следующего сообщения.
At EOF ...нет ни одного!
& q ...покинуть mail.
Saved 2 messages in /home/glass/mbox $ _
Для просмотра заголовков сообщений пользуйтесь опцией -н:
$ mail -Н ...взглянуть на мой почтовый каталог.
>U 1 tim@utdallas.edu Sat Мау 2 14:32 11/382 Mail test
U 2 tim@utdallas.edu Sat May 2 14:32 11/376 Another
$ _
Чтобы ответить на сообщение после его прочтения, используйте опцию г (от англ, reply). Для сохранения его в файл служит опция s (от англ. save). Если список сообщений не определен, выводится первое сообщение. Например:
& 15 ...читать сообщение 15.
From ssmith@utdallas.edu Tue Mar 17 23:27:11 1998
То: glass@utdallas.edu
Subject: Re: come to a party
The SIGGRAPH party begins Thursday NIGHT at 10:00 PM!!
Hope you don’t have to teach Thursday night.
& г ...ответить ssmith.
To: ssmith@utdallas.edu
Subject: Re: come to a party
Thanks for the invitation.
- see you there
... конец ввода.
& s ssmith.party ...сохранить сообщение от ssmith.
"ssmith.party" [New file] 27/1097
& q ...выйти из mail.
$
В некоторых почтовых программах опция г применяется для ответа отправителю, а опция r — для ответа всем, в других — наоборот. Поэтому будьте внимательны и обратитесь за более подробной информацией к справочной системе.
Вероятно, вам потребуется удалять некоторые сообщения, для этого используйте опцию d (от англ, delete)'.
& dl-15 ...удалить сообщения с 1 по 15 включительно.
& d* ...удалить все оставшиеся сообщения.
Связь с системным администратором
Как правило, почтовый адрес системного администратора — root или, возможно, sysadmin. Проблемы, связанные с работой электронной почты, чаще всего решает человек с псевдонимом postmaster.
Обзор главы
Перечень тем
В этой главе мы научились:
□ регистрироваться в системе UNIX;
□ выходить из системы;
П изменять пароль;
□ работать с командами shell;
□ запускать утилиты;
□ работать со встроенной справочной системой;
□ пользоваться специальными метасимволами терминала;
□ работать с файлами;
□ пользоваться двумя текстовыми редакторами;
□ правильно конфигурировать терминал;
П посылать электронную почту.
Контрольные вопросы
1. Как можно нарушить безопасность UNIX?
2. Каков лучший вид пароля?
3. Какую команду UNIX надо использовать, чтобы изменить имя или местоположение файла?
4. Является ли ОС UNIX чувствительной к регистру клавиатуры?
5. Назовите четыре общих команды shell.
6. Почему командный интерпретатор shell лучше приспособлен для решения некоторых задач, чем С-программы?
7. Какая последовательность клавиш завершает процесс?
8. Какую комбинацию клавиш необходимо нажать для указания на конец ввода текста с клавиатуры?
9. Как вы заканчиваете работу с shell?
10. Как называется текущее расположение shell?
11. Какие атрибуты имеет файл?
12. Каково назначение групп?
13. Какие флаги права доступа существуют у каталогов?
14. Кто может изменять принадлежность файла?
Упражнения
2.1. Отправьте письмо знакомому, проживающему в другой стране. Как вы думаете, за какое время оно дойдет до адресата? [Уровень: легкий.]
2.2. Почему процесс принадлежит только одной группе, в то время как запустивший его человек может быть членом нескольких? [Уровень: средний.]
2.3. Спроектируйте механизм файловой безопасности, который сможет исключить потребность в необходимости идентификации через команду set 10_пользователя. [Уровень: высокий.]
2.4. Многие даже весьма тривиальные изобретения защищены патентами. Как вы считаете, насколько необходим этот механизм защиты интеллектуальной собственности? [Уровень: высокий.]
Проект
Отправьте почту системному администратору и создайте две новых группы непосредственно для себя. Поэкспериментируйте с утилитами, используемыми для работы с системой полномочий файла. [Уровень: легкий.]
Глава 3
Утилиты UNIX
для опытных пользователей
Мотивация
В дополнение к общим утилитам работы с файлами в UNIX-системах имеется немало программ, обрабатывающих текст, архивирующих и сортирующих файлы, выполняющих мониторинг системы. В этой главе дано описание утилит, помогающих сделать работу пользователя с операционной системой удобной и эффективной.
Предпосылки
Для понимания данной главы необходимо предварительно ознакомиться с предыдущими двумя. Желательно также, чтобы на вашем компьютере была установлена ОС UNIX, и вы могли закрепить на практике изученный материал.
Задачи
В этой главе мы научимся использовать более 30 утилит, способных облегчить работу в UNIX любому пользователю.
Изложение
Для лучшего понимания информация в данной главе представлена в виде нескольких UNIX-сессий.
Утилиты
Ниже приведен список утилит, которые будут рассмотрены в данной главе.
at crypt gzip tar
awk diff In time
biff dump mount tr
cmp egrep od ul
compress fgrep perl umount
cpio find sed uncompress
cron grep sort uniq
crontab gunzip su whoami
Кроме того, мы познакомимся с основами языка программирования Perl, ставшего неотъемлемой частью большинства UNIX-систем.
Утилиты, которые мы будем обсуждать, могут быть логически сгруппированы, как показано в табл. 3.1. Далее мы рассмотрим каждую из групп поподробнее.
Таблица 3.1. Утилиты UNIX
Категория Утилиты
Фильтрация файлов egrep, fgrep, grep, uniq
Сортировка файлов sort
Сравнение файлов cmp, diff
Архивирование файлов tar, cpio, dump
Поиск файлов find
Команды планирования at, cron, crontab
Программируемая обработка текста awk, perl
Жесткие и символические связи In
Переключение пользователей su
Проверка почты biff
Трансформация файлов compress, crypt, gunzip, gzip, sed, tr, ul, uncompress
Поиск необработанного содержимого файла od
Монтирование файловых систем mount, umount
Таблица 3.1 (окончание)
Категория Утилиты
Идентификация командных интерпретаторов whoami
Подготовка документов nroff, spell, style, troff
Выбор времени выполнения команды time
Фильтрация файлов
Часто бывает необходимо выбрать из файла только строки, отвечающие определенным критериям. Перечисленные ниже утилиты осуществляют такую обработку:
□ утилиты egrep, fgrep и grep отфильтровывают все строки, которые не содержат установленный шаблон;
□ утилита uniq выбирает одинаковые смежные строки.
Шаблоны фильтрации: egrep/fgrep/grep
Утилиты egrep, fgrep И grep Сканируют файл И отфильтровывают Все СТрО-ки, которые не соответствуют установленному шаблону. Перечисленные утилиты очень похожи, разница состоит в виде шаблонов, с помощью которых осуществляется поиск.
Синтаксис
grep -hilnvw шаблон {имяФайла}* fgrep -hilnvwx строка {имяФайла}* egrep -hilnvw шаблон {имяФайла}*
Утилита grep (от англ. Global или Get Regular Expression or Print) позволяет находить соответствия заданному шаблону в списке файлов.
Если файлы не определены, то поиск совпадения с искомой строкой проводится в стандартном входном потоке. Шаблоном может быть набор символов либо регулярное выражение. Все строки, соответствующие шаблону, отображаются как стандартный вывод. Если определено больше одного файла, то каждой строке предшествует имя файла, в котором она найдена, если определена опция -h. Опция -п нумерует найденные строки. Опция -i заставляет игнорировать регистр шаблонов. Опция -1 ото-
5 Зак. 786
Сражает список файлов, которые содержат определенный шаблон. Опция -v выводит все строки, не соответствующие заданной модели. Опция -w ограничивает соответствие только целыми словами.
Утилита fgrep (от англ, fixed grep) осуществляет быстрый поиск, который производится только в указанных строках. Опция -х производит поиск по строкам.
Утилита egrep (от англ, extended grep) использует в качестве шаблона регулярные выражения.
В Приложении содержится информация о регулярных выражениях.
Для получения всех строк, совпадающих с шаблоном, необходимо указать строку и имя файла, в котором следует производить поиск, непосредственно за командой grep:
$ cat grepfile ...вывести файл, который следует отфильтровать.
Well you know it’s your bedtime,
So turn off the light,
Say all your prayers and then,
Oh you sleepy young heads dream of wonderful things,
Beautiful mermaids will swim through the sea,
And you will be swimming there too.
$ grep the grepfile ...искать слово "the".
So turn off the light,
Say all your prayers and then,
Beautiful mermaids will swim through the sea,
And you will be swimming there too.
$ _
Обратите внимание, что слова, которые содержат строку "the", также удовлетворяют соответствующему условию. Поэтому для вывода целых слов, совпадающих с моделью поиска, следует воспользоваться опцией -w. Опция -п нумерует строки:
$ grep -wn the grepfile ...более частный случай!
2:So turn off the light,
5:Beautiful mermaids will swim through the sea, $ _
Для отображения слов, не совпавших с шаблоном, воспользуйтесь опцией -v:
$ grep -wnv the grep file ...противоположный фильтр.
l:Well you know it’s your bedtime,
3:Say all your prayers and then,
4:Oh you sleepy young heads dream of wonderful things,
6:And you will be swimming there too.
$ _
При одновременном поиске в нескольких файлах найденные строки предваряются именем документа. В приведенном ниже примере был осуществлен поиск символа х в нескольких файлах одновременно:
$ grep -w х *.с ...искать во всех файлах, заканчивающихся на .с.
а.с:test (int х)
fact2.с:long'factorial (х)
fact2.c:int х;
fact2.c: if ((x == 1) ,, (x == 0))
fact2.c: result = x * factorial (x-1);
$ grep -wl x *.c ...перечислить имена соответствующих файлов.
а. с fact2. с
$
Утилиты fgrep, grep И egrep ПОДДерЖИВаюТ ОПЦИИ, КОТОрые МЫ ТОЛЬКО ЧТО описали. Отличие состоит в модели поиска, которую можно использовать в каждой из них. В табл. 3.2 приведены шаблоны, поддерживаемые конкретной утилитой.
Таблица 3.2. Шаблоны различных утилит сортировки
Утилита Вид шаблона, который может разыскиваться
fgrep Только установленная строка
grep Регулярное выражение
egrep Расширенное регулярное выражение
Регулярные выражения, используемые С утилитами grep И egrep, должны быть заключены в одиночные кавычки для отделения от других команд shell. Для лучшего понимания использования регулярных выражений с grep, egrep рассмотрим их на примере приведенного ниже текста: Well you know it’s your bedtime, So turn off the light, Say all your prayers and then, Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea, And you will be swimming there too.
Шаблоны соответствия
В табл. 3.3 и 3.4 строки, соответствующие регулярному выражению, выделены курсивом.
Таблица 3.3. Шаблоны в grep
grep-шаблон Строки, которые соответствуют
. nd Say all your prayers and then,
Oh you sleepy young heads dream of wonderful things, And you will be swimming there too.
А. nd And you will be swimming there too.
sw.*ng And you will be swimming there too.
[А-D] Beautiful mermaids will swim through the sea, And you will be swimming there too.
\ , And you will be swimming there too.
а. Say all your prayers and then,
Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea,
а. $ Beautiful mermaids will swim through the sea,
[a-m]nd Say all your prayers and then,
[Аа-т]nd • Oh you sleepy young heads dream of wonderful things,
And you will be swimming there too.
Таблица 3.4. Шаблоны в едгер
едгер-шаблон Строки, которые соответствуют
s. *w Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea, And you will be swimming there too.
s. +w Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea,
off I will So turn off the light, Beautiful mermaids will swim through the sea, And you will be swimming there too.
Таблица 3.4 (окончание)
egrep-шаблон Строки, которые соответствуют
im*ing And you will be swimming there too
im?ing Нет совпадений
Удаление одинаковых строк: uniq
Утилита uniq сообщает о наличии в файле одинаковых строк.
Синтаксис
uniq -с -число [входнойФайл [ выходнойФайл] ]
Утилита uniq выводит входной файл со всеми смежными одинаковыми строками, сокращенными до единственного вхождения повторенной строки. Если входной файл не определен, то производится чтение из стандартного ввода. Опция -с добавляет перед каждой строкой число вхождений, которые были найдены. Если определено число, то заданное число полей каждой строки игнорируется.
Пример:
$ cat animals ...рассмотрим тестовый файл, cat snake monkey snake dolphin elephant dolphin elephant goat elephant pig pig pig pig monkey pig
$ uniq animals ...отфильтровать двойные смежные строки, cat snake monkey snake dolphin elephant goat elephant pig pig monkey pig
$ uniq -с animals ...отобразить строки с нумерацией.
1 cat snake
1 monkey snake
2 dolphin elephant
1 goat elephant
2 pig pig
1 monkey pig
$ uniq -1 animals ...проигнорировать первое поле каждой строки, cat snake
dolphin elephant pig pig $
Сортировка файлов: sort
Утилита sort сортирует файл в лексикографическом или обратном порядке строк на основе одного или нескольких полей сортировки.
Синтаксис
sort -tc -г {полеСортировки-bfМп} * {имяФайла}*
Утилита sort сортирует строки, отвечающие некоторому критерию, в одном или нескольких файлах. По умолчанию строки сортируются в порядке возрастания1. Опция -г устанавливает сортировку по убыванию. Строки разбиты на поля, отделенные пробелами или позициями табуляции. Для определения иного разделителя используйте опцию -t. По умолчанию сортировка производится по всем полям строки. Однако ее можно ограничить одним или несколькими полями путем задания одной или нескольких опций после команды. Опция -f заставляет утилиту sort игнорировать регистр поля. Опция -м обеспечивает сортировку поля по месяцам. Опция -п сортирует поле в числовом порядке. Опция -ь игнорирует предшествующие пробелы.
Некоторые поля упорядочиваются лексикографически, это означает, что соответствующие символы сравниваются на основе их ASCII-кодов. (См. man ascii для получения списка всех символов и их соответствующих кодов.) Например, заглавная буква "меньше", чем ее строчный эквивалент, а
1 То есть в лексикографическом порядке символов этих строк. — Ред.
пробел имеет более низкий приоритет, чем какой-либо символ. Ниже приведен пример сортировки по возрастанию и убыванию:
$ cat sortfile ...вывести файл, который нужно отсортировать.
jan Start chapter 3 10th
Jan Start chapter 1 30th
Jan Start chapter 5 23rd
Jan End chapter 3 23rd
Mar Start chapter 7 27
may End chapter 7 17th
Apr End Chapter 5 1
Feb End chapter 1 14
$ sort sortfile ...сортировать его.
Feb End chapter 1 14
Jan End chapter 3 23rd
Jan Start chapter 5 23rd
may End chapter 7 17th
Apr End Chapter 5 1
Jan Start chapter 1 30th
Mar Start chapter 7 27
jan Start chapter 3 10th
$ sort -r sortfile ...сортировать в обратном порядке.
jan Start chapter 3 10th
Mar Start chapter 7 27
Jan Start chapter 1 30th
Apr End Chapter 5 1
may End chapter 7 17th
Jan Start chapter 5 23rd
Jan End chapter 3 23rd
Feb End chapter 1 14
$ _
Для сортировки по конкретному полю необходимо задать диапазон, определив после префикса + номер стартового поля и после - номер конечного поля. Нумерация полей начинается с 0. Если не задано конечное поле, то сортируются все поля, следующие за стартовым. Сортировка по первому полю:
$ sort +0 -1 sortfile ...сортировать только по первому полю.
Feb End chapter 1 14
Jan End chapter 3 23rd
Jan Start chapter 5 23rd may End chapter 7 17th
Apr End Chapter 5 1
Jan Start chapter 1 30th
Mar Start chapter 7 27
jan Start chapter 3 10th
$
Обратите внимание, что предшествующие пробелы были интерпретированы как часть первого поля, что привело к странным результатам. Логично, чтобы месяцы были отсортированы в правильном порядке — январь перед февралем и т. д. Для этого воспользуемся опцией -м, которая такую сортировку выполняет, и опцией -ь, игнорирующей лишние пробелы.
$ sort +0 -1 —ЬМ sortfile ...сортировать по полю месяц.
*
Jan End chapter 3 23rd
Jan Start chapter 5 23rd
Jan Start chapter 1 30th
jan Start chapter 3 10th
Feb End chapter 1 14
Mar Start chapter 7 27
Apr End Chapter 5 1
may End chapter 7 17th
$ _
Теперь наш файл правильно отсортирован по месяцам, однако даты все еще не в порядке. Для решения этой проблемы нужно определить несколько полей сортировки, т. к. утилита выбирает строки, отвечающие первому из заданных условий, а потом применяет к этой выборке следующие условия. Поэтому чтобы отсортировать текст по месяцу и дате, он сначала должен быть отсортирован по первому полю, а затем по пятому. Кроме того, к пятому полю должна быть применена числовая сортировка (опция -п).
$ sort +0 -1 -ЬМ +4 -п sortfile
jan Start chapter 3 10th
Jan End chapter 3 23rd
Jan Start chapter 5 23th
Jan Start chapter 1 30th
Feb End chapter 1 14
Mar Start chapter 7 27
Apr End Chapter 5 1
may End chapter 7 17th
$
Очень часто поля отделяются друг от друга с помощью символов, отличных от пробела. Например, в файле /etc/passwd поля, содержащие информацию о пользователе, отделяются двоеточием. Для определения альтернативного разделителя воспользуйтесь опцией -t. Ниже приведен пример, разделителем полей в котором был символ двоеточие (:):
$ cat sortfile2 ...посмотреть на тестовый файл.
jan:Start chapter 3:10th
Jan:Start chapter 1:30th
Jan .-Start chapter 5:23 rd
Jan:End chapter 3:23rd
Mar:Start chapter 7:27
may:End chapter 7:17th
Apr:End Chapter 5:1
Feb:End chapter 1:14
$ sort -t; +0 -1 -bM +2 —n sortfile2 ...двоеточие, как разделитель.
jan:Start chapter 3:10th
Jan:End chapter 3:23rd
Jan:Start chapter 5:23rd
Jan:Start chapter 1:30th
Feb:End chapter 1:14
Mar:Start chapter 7:27
Apr:End Chapter 5:1
may:End chapter 7:17th
$ _
Рассмотренная утилита имеет немало других опций, обсуждать которые мы не будем. Для получения информации о них пользуйтесь утилитой man.
Сравнение файлов
Следующие две утилиты позволяют сравнивать содержимое двух файлов:
□ утилита стр ищет до нахождения первого отличающегося байта двух файлов;
□ утилита diff отображает все различные и сходные элементы файлов.
Тестирование на сходство: стр
Утилита стр сравнивает файлы. В приведенном ниже примере сравниваются файлы ladyl, lady2, lady3:
$ cat ladyl
Lady of the night,
...посмотреть на первый тестовый файл.
I hold you close to me,
And all those loving words you say are right.
$ cat lady2 ...посмотреть на второй тестовый файл.
Lady of the night,
I hold you close to me,
And everything you say to me is right.
$ cat lady3 ...посмотреть на третий тестовый файл.
Lady of the night,
I hold you close to me,
And everything you say to me is right.
It makes me feel,
I’m so in love with you.
Even in the dark I see your light.
$ cmp ladyl lady2 ...файлы различаются.
ladyl lady 2 differ: char 48, line 3
$ cmp lady2 lady3 ...файл 2 — префикс файла 3.
cmp: EOF on lady 2
$ cmp lady3 lady3 ...файлы одинаковые.
$
Синтаксис
cmp -Is имяФайла! имяФайла2 [смещение!] [смещение2]
Утилита стр проверяет два файла на соответствие. Если имяФайла! и имяФайла2 равны, то утилита стр возвращает 0 и ничего не выводит; иначе возвращает 1 и показывает номер строки, начиная с первого несовпадающего байта. Если один файл является префиксом другого, то выводится сообщение EOF для файла, который короче. Опция -1 отображает смещение и значения всех несовпадающих байтов. Опция -s блокирует любой вывод. Дополнительные значения смещение! и смещение2 определяют стартовые значения В имяФайла! И имяФайла2, С КОТОРЫХ ДОЛЖНО начаться сравнение.
Пример выполнения команды стр с опцией -1:
$ стр -1 ladyl lady2
48 141 145
49 154 166
...показывает байты, которые не совпадают.
81 145 56
82 40 12
cmp: EOF on lady2 $
...lady2 меньше, чем ladyl.
Различие файлов: diff
Утилита diff сравнивает два файла и выводит на экран различия между ними. Существует три вида изменений: добавление, изменение и удаление строки.
Синтаксис
diff -i -Офлаг имяФайла! имя Файл а 2
Утилита diff сравнивает два файла и выводит описание их различий. Опция -i заставляет утилиту diff игнорировать регистр строк. Опция -D генерирует вывод, предназначенный для С-препроцессора (см. ниже).
Результат работы утилиты выводится в зависимости от различий файлов в следующем виде.
• Для добавления строки
начало1 а начало2,конец2
> строки из второго файла, которые необходимо добавить к первому. Здесь начало1 — стартовая строка первого файла, начало2 — стартовая строка второго файла, конец2 — последняя строка второго файла.
• Для удаления строки
начало!,конец! d номерСтроки
< строки первого файла, которые требуется удалить.
Здесь начало 1 —- начало первого файла, конец1 — конец первого файла, номерСтроки — номер строки, начиная с которой, происходит сравнение.
• Для изменения строки
начало1,конец! с начало,конец2
< строки первого файла, которые должны быть заменены.
> строки из второго файла, которые нужно использовать для замены Здесь начало! — стартовая строка первого файла, конец1 — конечная строка первого файла, начало2 — стартовая строка второго файла, конец2 — конечная строка второго файла.
Рассмотрим пример:
$ cat ladyl ...посмотреть первый тестовый файл.
Lady of the night,
I hold you close to me, And all those loving words you say are right. $ cat lady2 ...посмотреть второй тестовый файл.
Lady of the night, I hold you close to me, And everything you say to me is right.
$ cat lady3 ...посмотреть третий тестовый файл.
Lady of the night,
I hold you close to me, And everything you say to me is right. It makes me feel, I’m so in love with you.
Even in the dark I see your light.
$ cat lady4 ...посмотреть четвертый тестовый файл.
Lady of the night, I’m so in love with you.
Even in the dark I see your light.
$ diff ladyl lady2 ...сравнить ladyl и lady2. 3c3
< And all those loving words you say are right.
> And everything you say to me is right.
$ diff lady2 lady3 ...сравнись lady2 и lady3. 3a4,6
> It makes me feel, > I’m so in love with you.
> Even in the dark I see your light.
$ diff lady3 lady4 ...сравнить lady3 и lady4.
2,4dl
< I hold you close to me, < And everything you say to me is right. < It makes me feel, $ _
Опция -d утилиты diff полезна для соединения двух файлов и записи их в отдельный файл, содержащий директивы препроцессора С. Каждая версия
файла может быть восстановлена с помощью компилятора сс с подходящими опциями и макроопределениями. Например:
$ diff -Dflag lady3 lady4 ...посмотреть вывод.
Lady of the night, ttifndef flag ...директива препроцессора.
I hold you close to me, And everything you say to me is right. It makes me feel, ttendif flag ...директива препроцессора.
I’m so in love with you. Even in the dark I see your light.
$ diff -Dflag lady2 lady4 > lady.diff ...сохранить вывод. $ cc ~P lady.diff ...вызвать препроцессор.
$ cat lady.i ...посмотреть вывод.
Lady of the night, I hold you close to me, And everything you say to me is right.
$ cc -Dflag -P lady.diff ...посмотреть другую версию. $ cat lady.i ...посмотреть вывод.
Lady of the night, I’m so in love with you.
Even in the dark I see your light. $
Поиск файлов: find
Утилита find имеет гораздо больше возможностей, чем простой поиск заданного файла. Она выполняет действия над группой файлов, удовлетворяющих определенным условиям. Например, вы можете использовать утилиту find, чтобы удалить все файлы, принадлежащие пользователю tim, которые не изменялись в течение трех дней. Работа и синтаксис этой команды подробно описана в табл. 3.5.
Синтаксис
find списокПути выражение
Утилита find рекурсивно проходит через списокПути И применяет выражение к каждому файлу.
Таблица 3.5. Синтаксис утилиты find
Выражение Описание
-name образец Возвращаемое значение равно 1, если имя файла соответствует образцу, который может включать метасимволы shell *, [,] и ?
-perm oct Истинно, если восьмеричное описание флагов полномочий файла точно равно oct
-тип ch Истинно, если тип файла — ch (b — блок, с — символ, и т. д.)
-user Ю_пользователя Истинно, если владелец файла — Ю_пользователя
-group 10_группы Истинно, если группа файла — 10_труппы
-atime количествоДней Истинно, если к файлу обращались в течение количествоДней
-mtime количествоДней Истинно, если содержимое файла изменялось в течение количествоДней
-ctime количествоДней Истинно, если содержимое файла было изменено в течение количествоДней или если любой из атрибутов файла был изменен
-exec команда Истинно, если код возврата от выполнения команда — 0. Команда должна заканчиваться \;. Если вы определяете {}, как аргумент строки команды, он заменяется именем текущего файла
-print Распечатывает имя текущего файла и возвращает истину
-Is Показывает атрибуты текущего файла и возвращает 1
-cpio устройство Пишет текущий файл в формате cpio на устройство и возвращает 1
!выражение Возвращает логическое отрицание выражение
выражение1 [ - а ] выражение2 Если выражение! ложно, возвращает 0, и величину выражение2 не выполняется. Если выражение! истинно, возвращает величину выражение2
выражение 1 [-о] выражение2 Если выражение! истинно, возвращает истину. Если выражение! ложно, возвращает величину выражение2
Рассмотрим примеры работы утилиты find:
$ find . -name r*.c' -print ...распечатать исходные С-файлы
...из текущего каталога или любого
...из его подкаталогов.
./proj/fall.89/play.с
./proj/fall.89/referee.c
./proj/fall.89/player.c
./госк/guess.c
./госк/play.c
./rock/player.c
./rock/referee.c
$ find. . -mtime 14 -Is ...вывести файлы, модифицированные
...в течение последних 14 дней.
-rw-r—г— 1 glass cs 14151 May 1 16:58 ./stty.txt
-rw-r—г— 1 glass cs 48 May 1 14:02 ./myFile.doc
-rw-r—г— 1 glass cs 10 May 1 14:02 ./rain.doc
-rw-r—г— 1 glass cs 14855 May 1 16:58 ./tset.txt
-rw-r—г— 1 glass cs 47794 May 2 10:56 . /mail.txt
$ find . -name '*.bak' -Is -exec rm {} \;
...вывести и затем удалить все файлы, ...которые заканчиваются на .bak.
-rw-r—г— 1 glass cs 9 May 16 12:01 ./a.bak
-rw-r—r— 1 glass cs 9 May 16 12:01 ./b.bak
-rw-r—r— 1 glass cs 15630 Jan 26 00:14 ./s6/gosh.bak
-rw-r—r— 1 glass cs 18481 Jan 26 12:59 .7s6/gosh2.bak
$ find . \f -name '*.c' -o -name txt' \) -print
...напечатать имена всех файлов, которые ...заканчиваются на .с или .txt.
./proj/fall.89/play.с
./proj/fall.89/referee.c
./proj/fall.89/player.c
./rock/guess.c ./rock/play.c
./rock/player.c ./rock/referee.c ./stty.txt ./tset.txt ./mail.txt $
Архивы
Существует, как минимум, несколько причин, по которым необходимо сохранять файлы на дискеты или ленты:
□ для ежедневного, еженедельного или ежемесячного резервирования (backup):
□ для переноса между несоединенными сетью UNIX-системами;
П для будущих поколений.
В UNIX существуют три утилиты, позволяющие архивировать файлы, каждая из которых имеет собственные сильные и слабые стороны.
П Утилита cpio позволяет сохранять структуру каталога в одинарный резервный том. Удобна для сохранения небольших объемов данных, т. к. создание единственного тома делает его бесполезным для архивации больших массивов данных.
□ Утилита tar предоставляет возможность сохранять структуры каталогов в одинарный резервный том. Специально разработана для сохранения файлов на ленту, поскольку она всегда архивирует файлы в конец носителя данных. Недостатком этой утилиты также является ограничение на создание одного тома.
П Утилита dump обеспечивает сохранение файловой системы во множественные резервные тома. Специально разработана для выполнения полных и инкрементных резервных копирований, но восстановление отдельных файлов из архива с ее помощью достаточно трудоемко.
Примечание
Во многих системах, основанных на версии System V UNIX, существует программа uf sdump, эквивалентная утилите dump.
Копирование файлов: cpio
Утилита cpio позволяет создавать и восстанавливать из архивов файлы специального cpio-формата. Она очень эффективна для создания небольших архивов. К сожалению, утилита cpio не может разбивать файлы на несколько томов, поэтому весь архив должен помещаться на носитель данных. Если ЭТО НевОЗМОЖНО, ВОСПОЛЬЗуЙТеСЬ УТИЛИТОЙ dump.
Синтаксис
cpio -ov
cpio -idtu шаблоны
cpio -pl каталог
Утилита cpio позволяет архивировать файлы. Опция -о берет список имен файлов со стандартного входа и создает файл формата cpio, который содержит резервную копию файлов с этими именами. Опция -v предписывает выводить имя каждого файла после копирования. Опция -i
читает файл cpio-формата из стандартного входа и воссоздает все файлы из входного канала, имена которых соответствуют указанному образцу. По умолчанию старые файлы не переписываются вместо более новых. Опция -и вызывает безоговорочное копирование. Опция -d создает каталоги, если они необходимы в течение процесса копирования. Опция -t показывает оглавление вместо выполнения копирования. Опция -р берет список имен файлов со стандартного входа и копирует содержимое файлов в указанный каталог. Данная опция полезна для копирования подкаталогов в другое место, хотя в большинстве случаев проще это сделать воспользовавшись утилитой ср с опцией -г. Опция -1 создает связи вместо создания физических копий.
Чтобы продемонстрировать опции -о и -i, была создана резервная версия всех исходных С-файлов в рабочем каталоге и удалены исходные файлы, а затем восстановлены из архива. Действия, необходимые для выполнения этой задачи:
$ Is -1 *.с ...вывести файлы, которые должны быть сохранены.
-rw-r—r— 1 glass 172 Jan 5 19:44 mainl.c
-rw-r—r— 1 glass 198 Jan 5 19:44 main2.c
-rw-r—r— 1 glass 224 Jan 5 19:44 paliridrome.c
-rw-r—r— 1 glass 266 Jan 5 23:46 reverse.c
$ Is * .C / cpio -ov > backup ...сохранить в backup.
'ma ini.с
main2.с palindrome.с reverse.с 3 blocks
$ Is -1 backup ...просмотреть backup.
-rw-r—г— 1 glass 1536 Jan 9 18:34 backup $ rm * .c ...удалить исходные файлы.
$ cpio -it < backup ...восстановить файлы, mainl.c main2.c palindrome.c reverse.c 3 blocks
$ Is -1 *.c ...подтвердить их восстановление, -rw-r—г— 1 glass 172 Jan 5 19:44 mainl.c
-rw-r—r— 1 glass 198 Jan 5 19:44 main2.c
-rw-r—г— 1 glass 224 Jan 5 19:44 palindrome.с
-rw-r—г— 1 glass 266 Jan 5 23:46 reverse.c
$ _
Чтобы создать резервную копию всех файлов, включая подкаталоги, которые соответствуют образцу *.с, используют выход утилиты find как вход для утилиты cpio. Опция -depth утилиты find рекурсивно ищет соответствие шаблонам. В представленном ниже примере обратите внимание на символ обратной косой черты перед * в аргументе опции name. Это сделано для того, чтобы он не был воспринят shell как символ расширения:
$ find. . -name \*.с -depth -print / cpio -ov > backup2 ma ini. c
main2. c
palindrome.c
reverse.c
tmp/b.c
tmp/a. c
3 blocks
$ rm -г *.c ...удалить исходные файлы.
$ rm tmp/*.c ...удалить файлы нижнего уровня.
$ cpio -it < backup2 . . .восстановить файлы.
maini.с
main2.с
palindrome.с
reverse.с
tmp/b.с
tmp/a. с 3 blocks
$ _
Чтобы ПОНЯТЬ работу ОПЦИИ -р, воспользуемся УТИЛИТОЙ find для получения списка всех файлов текущего каталога, которые были изменены в последние два дня, и затем скопируем эти файлы в родительский каталог. Без использования опции -1 файлы будут физически скопированы, что увеличит объем занятого дискового пространства на 153 блока. Однако использование опции -1 создало ссылки на файлы и никак не отразилось на размере свободного пространства. Рассмотрим пример:
$ find . -mtime -2 -print / cpio -p.........скопировать 153 блоков.
$ Is -1 ../reverse.с ...посмотреть скопированные файлы.
-rw-r—г— 1 glass 266 Jan 9 18:42 ../reverse.с
$ find . -mtime -2 -print / cpio -pl........связать 0 блоков.
$ Is -1 ../reverse.с ...посмотреть связанные файлы.
-rw-r—г— 2 glass 266 Jan 7 15:26 ../reverse.с $ _
Архивация на ленту: tar
Утилита tar была специально разработана для создания архивов файлов на магнитной ленте. При добавлении файла к файлу архива с использованием утилиты tar файл всегда помещается в конце файла архива, поскольку нет возможности изменять середину файла, сохраненного на ленте. Если вы не архивируете файлы на ленту, лучше вместо утилиты tar использовать утилиту cpio.
Синтаксис
tar -cfrtuvx [Ёаг_имяФайла] списокФашюв
Утилита tar позволяет создавать и получать доступ к специальным файлам архива в формате tar. Опция -с создает файл tar-формата. По умолчанию имя файла tar-формата — /dev/rmtO. (Оно может измениться в различных версиях UNIX.) Однако значение по умолчанию разрешено переопределить путем установки переменной окружающей среды $таре или с помощью опции -f, сопровождаемой необходимым именем файла. Опция -v вызывает многословный вывод. Опция -х позволяет извлекать указанные файлы, а опция -t генерирует оглавление. Опция -г безусловно добавляет перечисленные файлы к файлу архива. Опция —и добавляет последние версии имеющихся в архиве файлов. Если в аргументе списокФайлов указаны имена каталогов, содержимое каталогов добавляется или извлекается рекурсивно.
В следующем примере показано, что все файлы из текущего каталога сохраняются в файле архива tarfile:
$ Is ...просмотреть текущий каталог.
mainl* main2 palindrome.с reverse.h
mainl. c main2.c palindrome.h tarfile
mainl.make main2.make reverse.c tmp/
$ Is tmp ...посмотреть каталог tmp.
a.c b.c
$ tar -cvf tarfile . ...архивировать текущий каталог.
a ./mainl.с 1 blocks
а ./main2.с 1 blocks
а ./main2 48 blocks
a ./tmp/b.c 1 blocks
а ./tmp/а.с 1 blocks
$ Is -1 tarfile ...посмотреть архивный файл tarfile.
-rw-r—г— 1 glass 65536 Jan 10 12:44 tarfile
$ _
Чтобы получить оглавление tar-архива, используйте опцию -t, как показано в следующем примере:
$ tar -tvf tarfile ...посмотреть оглавление.
rwxr-xr-x 496/62 0 Jan 10 12:44 1998 , /
rw-r—r— 496/62 172 Jan 10 12:41 1998 ./mainl.c
rw-r—r— 496/62 198 Jan 9 18:36 1998 ./main2.c
rw-r—r— 496/62 24576 Jan 7 15:26 1998 . /main2
rwxr-xr-x 496/62 0 Jan 10 12:42 1998 ./tmp/
rw-r—r— 496/62 9 Jan 10 12:42 1998 ./tmp/b.c
rw-r—r— 496/62 9 Jan 10 12:42 1998 ./tmp/а.c
$ _
Для безусловного добавления файла в конец tar-архива используйте опцию -г, сопровождаемую списком файлов или каталогов. Заметьте, что в следующем примере tar-архив содержит в конце две копии reverse.c:
$ tar -rvf tarfile reverse.c a reverse.c 1 blocks ...безусловное добавление.
$ tar -tvf tarfile ...посмотреть оглавление.
rwxr-xr-x 496/62 0 Jan 10 12:44 1998 , /
rw-r—r— 496/62 172 Jan 10 12:41 1998 ./mainl.с
rw-r—r— 496/62 266 Jan 9 18:36 1998 ./reverse.c
rw-r—r— 496/62 266 Jan 10 12:46 1998 reverse.с
$ _
Чтобы добавить файл только тогда, когда он отсутствует в архиве или был изменен со времени последнего архивирования, используйте опцию -и вместо -г. В следующем примере обратите внимание, что файл reverse.c не был заархивирован, потому что не изменялся:
$ tar -rvf tarfile reverse.c ...безусловное добавление.
a reverse.c 1 bloc.ks
$ tar -uvf tarfile reverse.c ...условное добавление.
$
Чтобы извлечь файл из файла архива, используйте опцию -х, сопровождаемую списком файлов или каталогов. Если имя каталога определено, он рекурсивно извлекается, как показано в следующем примере:
$ rm tmp/* ...удалить все файлы из tmp.
$ tar -vxf tarfile ./tmp ...извлечь архивированные tmp-файлы.
x ./tmp/b.с, 9 bytes, 1 tape blocks
x ./tmp/а.c, 9 bytes, 1 tape blocks
$ Is tmp ...подтвердить восстановление.
a. c b. с
$ _
К сожалению, утилита tar не поддерживает соответствие шаблону списка имен. Таким образом, чтобы извлечь файлы, которые соответствуют конкретному шаблону, используют утилиту grep, как часть командной последовательности:
$ tar -xvf tarfile 'tar -tf tarfile / grep x ./mainl.c, 172 bytes, 1 tape blocks
x ./main2.c, 198 bytes, 1 tape blocks
x ./palindrome.c, 224 bytes, 1 tape blocks
x ./reverse.c, 266 bytes, 1 tape blocks
x ./tmp/b.c, 9 bytes, 1 tape blocks
x ./tmp/а.c, 9 bytes, 1 tape blocks $
Если вы перемещаетесь в другой каталог, а затем извлекаете файлы, которые были сохранены, используя относительные имена пути, имена интерпретируются относительно текущего каталога. В следующем примере восстанавливается файл reverse.c из предварительно созданного tar-файла в новый каталог tmp2:
$ mkdir tmp2 ...создать новый каталог.
$ cd tmp2 ...переместиться туда.
$ tar -vxf ../tarfile reverse.c ...восстановить один файл.
х reverse.c, 266 bytes, 1 tape blocks
x reverse.c, 266 bytes, 1 tape blocks
$ is -1 . ..подтвердить восстановление,
total 1
-rw-r—r— 1 glass 266 Jan 10 12:48 reverse.c $
Обратите внимание, что каждая копия файла reverse.c записалась, поверх предыдущей, поэтому самая последняя версия была оставлена неповрежденной.
Инкрементальные резервные копирования: dump и restore
Утилиты dump и restore пришли из версии Berkeley UNIX, но были добавлены в большинство других версий. (Во многих системах, базирующихся на версии System V UNIX, они называются ufsdump и ufsrestore.) Вот типичная стратегия системного администратора для резервного копирования:
□ выполнять еженедельное резервное копирование всей файловой системы;
□ выполнять ежедневное инкрементное резервное копирование, сохраняя только те файлы, которые были изменены со времени последнего резервного копирования.
Этот вид резервной стратегии точно поддержан утилитами dump и restore.
Синтаксис
dump [уровень] [f дампФайл] [v] [w] файловаяСистема dump [уровень] [f дампФайл] [v] [w] {имяФайла} +
Утилита dump имеет две формы. Первая форма копирует файлы из указанной файловой системы в дампФаил, которым по умолчанию является /dev/rmtO. (Имя может изменяться в различных версиях UNIX.) Если параметр уровень определен как п, то копируются все файлы с более низким уровнем, чем л, при условии, что они были изменены после последнего дампа. Например, уровень дампа 0 всегда обеспечивает выполнение дампа всех файлов, тогда как уровень дампа 2 выполнит дамп всех измененных файлов, начиная с последнего дампа уровня 0 или уровня 1. Если никакой уровень дампа не определен, уровень дампа равен 9. Опция v предписывает утилите dump проверять каждый том носителя после того, как он записан. Опция w обеспечивает демонстрацию списка всех файловых систем, над которыми должен быть выполнен дамп вместо выполнения резервного копирования.
Вторая форма утилиты dump позволяет задать имена файлов, которые нужно сохранить.
Обе формы напоминают пользователю, когда необходимо вставить или удалить носитель дампа. Например, большой дамп системы на ленточное устройство часто требует, чтобы оператор удалил заполненную ленту и заменил ее пустой.
Когда дамп выполнен, информация о нем записывается в файл /etc/dumpdates для использования в будущем при вызове утилиты dump.
Приведем пример, который выполняет дамп с проверкой уровня 0 файловой системы /dev/daO на ленточный накопитель /dev/rmtO:
$ dump 0 fv /dev/rmtO /dev/daO
Утилита restore позволяет восстанавливать файлы из резервной копии, выполненной утилитой dump.
Синтаксис
restore -irtx [f дампФайл] {имяФайла}*
Утилита restore позволяет восстанавливать набор файлов из предыдущего дампФайла. Если дампФайл не определен, по умолчанию используется /dev/rtmO. (Имя может быть иным в других версиях UNIX.) Опция -г заставляет каждый файл из дампФайла восстанавливаться в текущий каталог, поэтому используйте эту опцию осмотрительно. Опция -t вместо восстановления файлов осуществляет ВЫВОД оглавления дампФайла. Опции -х служит для восстановления только файлов с указанными имена-миФайлов ИЗ дампФайла. ЕСЛИ имяФайла — ЭТО ИМЯ Каталога, еГО СОДерЖИ-мое восстанавливается рекурсивно.
Опция -i предписывает утилите restore читать оглавление дампФайла и затем входить в диалоговый режим, который позволяет пользователю выбирать файлы для восстановления. Для получения дополнительной информации об этом диалоговом режиме обращайтесь за справкой — man restore.
В следующем примере используется утилита restore, чтобы извлечь пару предварительно сохраненных файлов с дампа устройства /dev/rmtO:
$ restore -х f /dev/rmtO wine.с hacking.с
Планирование выполнения команд
Представленные ниже две утилиты позволяют планировать команды, которые будут выполнены в более позднее время.
□ Утилита crontab позволяет создать расписание, описывающее ряд работ, которые будут выполняться периодически.
□ Утилита at предоставляет возможность планировать работы, которые будут выполнены однократно.
Периодическое выполнение: cron/crontab
Утилита crontab позволяет запланировать ряд работ, которые будут выполняться периодически.
Синтаксис
crontab сгопЬаЬИмя
crontab -ler [имяПользователя]
Утилита crontab обеспечивает пользовательский интерфейс в системе UNIX. Когда она указывается без опций, crontab-файл cront-аьимя регистрируется, и его команды выполняются согласно указанным правилам выбора времени. Опция -1 выводит содержимое зарегистрированного crontab-файла. Опция -е редактирует и затем регистрирует crontab-файл. Опция -г отменяет регистрацию зарегистрированного crontab-файла. Опции -1, -е и -г может использовать привилегированный пользователь (root), чтобы получить доступ к crontab-файлу другого пользователя, добавляя имя пользователя как дополнительный аргумент. Содержимое crontab-файла описан ниже.
Итак, ЧТОбы ИСПОЛЬЗОВаТЬ УТИЛИТУ crontab, вы должны подготовить входной crontab-файл, который содержит строки в формате:
Минута Час День Месяц День_недели Команда
Таблица 3.6. Значения полей для входного файла утилиты cron tab
Поле Допустимое значение
Минута 0-59
Час 0-23
День 1-31
Месяц 1-12
День_недели 1—7 (1 — понедельник, 2 — вторник, 3 — среда, 4 — четверг, 5 — пятница, 6 — суббота, 7 — воскресенье)
Команда Любая команда UNIX
Всякий раз, когда текущее время совпадает с описанным в строке, shell, указанный в переменной окружающей среды shell, выполняет ассоциированную команду. Если эта переменная не установлена, то используется
Bourne shell. Если любое из первых пяти полей содержит звездочку (*) вместо числа, то значение этих полей считается произвольным. Стандартный вывод команды автоматически посылается пользователю через утилиту mail. Любые символы после символа % копируются во временный файл и используются как стандартный вход команды. Ниже представлен образец crontab-файла с именем crontab.cron, который создан в пользовательском домашнем каталоге:
$ cat cron tab. cron
0 8**1
Jr ★ Jr ★ Jr
30 14 1 * 1
$
...вывод crontab-файла.
echo Радостного утра понедельника echo Одна минута прошла > /dev/ttyl mail users % Jan Meeting At 3pm
Первая строка отправляет сообщение "Радостного утра понедельника" в 8:00 каждый понедельник. Следующая строка выводит каждую минуту строку "Одна минута прошла" на устройство /dev/ttyl, которое играет роль терминала. Последняя строка посылает почту всем пользователям 1 января в 14:30, чтобы напомнить им о предстоящей встрече.
Отдельный процесс, называемый cron, ответствен за своевременное выполнение команд в зарегистрированных crontab-файлах. Процесс запускается, когда UNIX-система загружается, и не останавливается, пока с ОС UNIX не будет завершена работа. Копии всех зарегистрированных crontab-файлов сохраняются в каталоге /var/spool/cron/crontabs.
Чтобы зарегистрировать crontab-файл, используйте утилиту cron tab с именем crontab-файла в качестве единственного аргумента:
$ crontab cron tab.cron ...зарегистрировать crontab файл.
$ _
Если у вас уже есть зарегистрированный crontab-файл, новый регистрируется вместо старого. Чтобы просмотреть содержимое вашего зарегистрированного crontab-файла, используйте опцию -1. Чтобы посмотреть чей-нибудь еще зарегистрированный crontab-файл, добавьте имя пользователя в качестве аргумента. Эту опцию может использовать только привилегированный пользователь (root).
В представленном ниже примере один из предварительно зарегистрированных crontab-файлов был вызван по совпадению времени после запуска ути-
ЛИТЫ crontab:
$ crontab -1 ...вывод содержимого текущего crontab-файла.
08**1 echo Радостного утра понедельника
* * * * * echo Одна минута прошла > /dev/ttyl
30 14 1 * 1 mail users % Jan Meeting At 3pm
$ Одна минута прошла ...вывод одной из crontab-команд.
$ _
Для редактирования crontab-файла и его сохранения используют опцию -е. Чтобы отменить регистрацию crontab-файла, используйте опцию -г:
$ crontab -г ... отменить регистрацию crontab-файла.
$ _
Привилегированный пользователь (root) может создавать файлы cron.allow и cron.deny в каталоге /var/spool/cron, чтобы разрешить и запретить индивидуальным пользователям применять crontab-средства. Каждый файл состоит из списка пользовательских имен: один пользователь на одной строке. Если этих файлов нет, то только привилегированный пользователь может запускать утилиту crontab. Если файл cron.deny пуст, а файл cron.allow не существует, все пользователи могут работать с утилитой crontab.
Однократное выполнение: at
Утилита at позволяет запланировать однократные команды или скрипты.
Синтаксис
at -csm время [дата [, под]][+ приращение] [скрипт] at -г {ID_задания} +
at -1 {ID—задания} ★
Утилита at позволяет запланировать однократные команды или скрипты. Она поддерживает гибкий формат для задания времени. Опции -с и -s указывают, что команды будут выполняться соответственно С shell или Bourne shell. Опция -m предписывает утилите at послать вам почту, когда задание будет закончено. Если имя скрипта не определено, утилита at воспринимает список команд со стандартного входа. Опция -г удаляет указанные задания из очереди, а опция -1 выводит список заданий, находящихся в списке. Задание удаляется из очереди после ее выполнения.
Аргумет время имеет формат нн или ннмм с необязательным спецификатором до полудня — дм, после полудня — рм, а дата записывается с указанием первых трех символов дня или месяца. Ключевое слово now (сейчас) может применяться вместо задания времени. Ключевые слова today (сегодня) и tomorrow (завтра) могут использоваться вместо даты. Если дата не определена, то вступают в силу следующие правила:
• если время больше текущего времени, то предполагается дата today;
• если время установлено меньше текущего времени, то предполагается дата — tomorrow.
Заявленное время может быть увеличено приращением — числом, следующим за аргументами время, дата, год. Скрипт выполняется командным интерпретатором shell, указанным в переменной окружающей среды shell, или Bourne shell, если эта переменная не установлена. Весь стандартный вывод от скрипта отправляется по почте пользователю.
В следующем примере предусмотрено выполнение скрипта для передачи сообщения на терминал /dev/ttyl: $ cat at.csh ...посмотреть скрипт, который будет выполняться. #! /bin/csh echo at done > /dev/ttyl ...echo-вывод на терминал.
$ date ...посмотреть текущее время.
Sat Jan 10 17:27:42 CST 1998
$ at now + 2 minutes at.csh ...включить в расписание скрипт ...для выполнения через 2 минуты
job 2519 at Sat Jan 10 17:30:00 1998 $ at -1 ...посмотреть расписание.
2519 a Sat Jan 10 17:30:00 1998 $ _ at done ...вывод выполненного скрипта.
$ at 17:35 at.csh ...снова внести скрипт в расписание,
job 2520 at Sat Jan 10 17:35:00 1998 $ at -г 2520 ...исключить из расписания.
$ at -1 ...посмотреть расписание.
$ _
Приведем несколько примеров правильных форматов времени для утилиты at:
0934am Sep 18 at.csh 9:34 Sep 18 , 1994 at.csh 11:00pm tomorrow at.csh now + 1 day at.csh 9pm Jan 13 at.csh 10pm Wed at.csh
Если имя команды пропускается, утилита at выводит подсказку и ждет список команд, которые должны быть введены со стандартного входа. Для того чтобы закончить список команд, нажмите комбинацию клавиш <Ctrl>+<D>. Пример: $ at 8pm ...ввод команд для внесения в расписание с клавиатуры.
at> echo at done > /dev/ttypl
at> ... конец ввода.
job 2530 at Sat Jan 10 17:35:00 1998
$ _
Вы можете запрограммировать скрипт, чтобы он сам себя перепланировал путем вызова утилиты at внутри скрипта:
$ cat at.csh ...скрипт, который перепланирует сам себя.
#! /bin/csh
date > /dev/ttyl
# Reschedule script
at now + 2 minutes at.csh
$ _
Привилегированный пользователь (root) может создавать файлы at.allo и at.deny в каталоге /var/spool/cron, чтобы разрешить и запретить индивидуальным пользователем применять at-средства. Каждый файл состоит из списка пользовательских имен: один пользователь на одной строке. Если этих файлов нет, то только привилегированный пользователь может запускать утилиту at. Если файл at.den пуст, а файл at.allow не существует, все пользователи могут работать с утилитой at.
Программируемая обработка текста: awk
Утилита awk просматривает один или несколько файлов и исполняет действие на всех строках, которые соответствуют конкретному условию. Действия и условия описаны в программе awk и расположены от простого к сложному.
Утилита awk получила свое имя от объединения первых символов фамилий его авторов: Ахо (Aho), Венбергер (Weinberger) и Керниган (Kernighan). Она заимствует свои структуры управления и синтаксис выражений из языка С. Если вы уже знаете С, то изучение awk не вызовет затруднений.
awk — это комплексная утилита, настолько всеобъемлющая, что фактически существует книга, посвященная ей! Поэтому в данной главе описаны лишь главные особенности и опции awk. Однако хочется надеяться, что приведенный в этом разделе материал позволит вам писать большое количество полезных awk-приложений.
Синтаксис
awk -Fc [-f имяФайла] программа {переменная=значение} * {имяФайла}*
awk — программируемая утилита обработки текста, которая просматривает строки своего входа и исполняет действия на каждой строке, соответст
вующей определенному критерию. Программа awk может быть включена в командную строку. В этом случае она должна быть окружена апострофами. Альтернативно она может быть задана с использованием опции -f, а ее вызов сохранен в файле. Начальные значения переменных могут быть заданы в командной строке. По умолчанию разделители полей — это символы табуляции и пробел. Чтобы переопределить значения по умолчанию, используйте опцию -г, сопровождаемую новым разделителем полей. Если имяФайла не определено, утилита awk читает со стандартного входа.
awk-программы
awk-программа может быть задана в командной строке. Но более общий способ состоит в том, чтобы поместить ее вызов в текстовый файл и специфицировать файл, используя опцию -г. Если вы решили разместить awk-программу в командной строке, окружите ее апострофами.
Когда утилита awk читает строку, она разбивает ее на поля, которые разделены символами табуляции или пробелами. Разделитель полей может быть переопределен путем использования опции -f, как вы увидите позже в этом разделе, awk-программа — это список из одной или нескольких команд в формате
[ условие ] [ \ {действие\} ]
где условие — это:
□ либо специальная лексема begin или end;
П либо выражение, включающее любую комбинацию логических операторов, операторов отношений и регулярных выражений,
а действие — это список из одного или большего количества С-подобных операторов, заканчивающихся точкой с запятой и имеющих следующий вид: П if (условие) оператор [else оператор]
□ while (условие) оператор
Л for (выражение; условие; выражение) оператор
П break
О continue
П переменная=выражение
О print [список выражений] [> выражение]
П printf формат [,список выражений] [> выражение]
□ next (перескакивает оставшиеся шаблоны на текущей строке ввода)
П exit (перескакивает остаток текущей строки)
П {список операторов}
Действие выполняется для строк, которые соответствует условию. Если условие отсутствует, действие выполняется на каждой строке. Если действие отсутствует, то все строки, соответствующие условию, просто посылаются на стандартный вывод. Операторы в awk-программе могут иметь отступ и быть отформатированы с использованием пробелов, символов табуляции и перевода строки.
Доступ к отдельным полям
К первому полю текущей строки можно обращаться, указав $1, второй $2, и т. д. $о обозначает строку целиком. Встроенная переменная nf равна числу полей в текущей строке. В следующем примере выполняется простая awk-программа на текстовом файле float, чтобы вставить число полей в каждую строку: $ cat float ...посмотреть оригинальный файл.
Wish I was floating in blue across the sky, My imagination is strong, And I often visit the days When everything seemed so clear.
Now I wonder what I’m doing here at all... $ awk '{print NF, $0}' float ...выполнить команду. 9 Wish I was floating in blue across the sky, 4 My imagination is strong, 6 And I often visit the days 5 When everything seemed so clear.
9 Now I wonder what I’m doing here at all... $
В EG IN и END
Специальная конструкция begin вызывается прежде, чем читается первая строка, а специальная конструкция end — после того, как последняя строка была прочитана. Когда выражения перечисляются в операторе печати, между ними не выводятся пробелы, а по умолчанию печатается символ перевода строки. Встроенная переменная filename равна имени входного файла. В следующем примере представлено управление программой, которая выводила первое, третье и последнее поля каждой строки:
$ cat awk2 ...посмотреть скрипт awk.
BEGIN { print "Start of file:’’, FILENAME }
{ print $1 $3 $NF } ...печатать 1-е, 3-е и последнее поля.
END { print "End of file" }
$ awk -f awk float ...выполнить скрипт. Start of file: float
Wishwassky,
Myisstrong,
Andof tendays Whenseemedclear.
Nowwonderall...
End of file
$
Операторы
Когда в операторе печати между выражениями помещаются запятые, пробел печатается. Все обычные операторы С доступны в awk. Встроенная переменная nr содержит номер текущей строки. В следующем примере должна выполняться программа, которая выводит первые, третьи и последние поля строк 2 и 3 из файла float:
$ cat awk3 ...посмотреть скрипт awk.
NR > 1 && NR < 4 { print NR, $1, $3, $NF } $ awk -f awk3 float ...выполнить скрипт.
My is strong, And often days $
Переменные
Утилита awk поддерживает определенные пользователем переменные. Нет необходимости объявлять переменную. Ее начальное значение — это пустая строка или ноль, в зависимости от того, как вы используете переменную. В представленном ниже примере программа должна подсчитывать число строк и слов в файле по мере того, как она будет выводить строки на стандартный вывод: $ cat awk4 ...посмотреть скрипт awk.
BEGIN { print "Scanning file" }
printf "line %d: %s\n", NR, $0;
lineCount++;
wordCount += NF;
END { printf "lines = %d, words = %d\n", lineCount, wordCount }
$ awk -f awk4 float ...выполнить скрипт. Scanning file
line 1: Wish I was floating in blue across the sky,
line 2: My imagination is strong, line 3: And I often visit the days line 4: When everything seemed so clear.
line 5: Now I wonder what I’m doing here at all...
lines = 5, words = 33 $
Структуры управления
Утилита awk поддерживает большинство стандартных структур управления С. В следующем примере печатаются поля каждой строки в обратном порядке:
$ cat awk5 ...посмотреть скрипт awk.
{
for (i = NF; i >= 1; i—) printf "%s ", $i;
printf "\n"; }
$ awk -f awk5 float ...выполнить скрипт,
sky, the across blue in floating was I Wish strong, is imagination My days the visit often I And clear, so seemed everything When all... at here doing I’m what wonder I Now $
Расширенные регулярные выражения
Условия для соответствия строкам могут быть расширенными регулярными выражениями, которые определяются в Приложении. Допустимые выражения должны быть помещены между косыми чертами (/). В следующем примере происходит вывод всех строк, которые содержат строки, начинающиеся с буквы t и заканчивающиеся буквой е, с любым числом символов между ними (для ясности последовательность символов выходных строк, которые удовлетворили условию, выделена курсивом):
$ cat awk6
/t.*e/ { print $0 }
...посмотреть скрипт.
$ awk -f awk6 float ...выполнить скрипт.
Wish I was floating in blue across the sky,
And I often visit the days
When everything seemed so clear.
Now I wonder what I'm doing here at all...
$ _
Цепочки условий
Условием могут быть два выражения, разделенные запятой. В этом случае awk исполняет действие на каждой строке от первой строки, которая соответствует первому условию, до строки, удовлетворяющей второму условию, как показано в следующем примере:
$ cat awk7 ...посмотреть скрипт.
/strong/ , /clear/ { print $0 }
$ awk -f awk7 float ...выполнить скрипт.
My imagination is strong,
And I often visit the days
When everything seemed so clear.
$ _
Разделители полей
Если разделители полей — не пробелы, используют опцию -F, чтобы задать символ-разделитель. В следующем примере обрабатывается файл, поля которого разделялись двоеточиями:
$ cat awk3 ...посмотреть скрипт awk.
NR > 1 && NR < 4 {print $1, $3, $NF}
$ cat float2 ...посмотреть входной файл.
Wish:I:was:floating:in:blue:across:the:sky,
My: imagination:is:strong,
And:I:often:visit:the:days
When:everything:seemed:so:clear.
Now:I:wonder:what:I’m:doing:here:at:all...
$ awk -F: -f awk3 float2 ...выполнить скрипт.
My is strong,
And often days $
6 Зак. 786
Встроенные функции
Утилита awk поддерживает несколько встроенных функций, включая expo, logo, sqrt о, into и substr о. Первые четыре функции работают точно так же как их стандартные двойники С. Функция substr (str, х, у) возвращает подстроку строки str, начиная от символа в позиции от х, длиной у символов. Ниже приведен пример работы и вывод этих функций:
$ cat test ...посмотреть входной файл.
1.1 а
2.2 at
3.3 eat
4.4 beat
$ cat awk8 ... посмотреть скрипт awk.
printf "$1 = %g ", $1;
printf "exp = %.2g ", exp ($1);
printf "log = %.2g ", log ($1);
printf "sqrt = %.2g ", sqrt ($1);
printf "int = %d ", int ($1);
printf "substr (%s, 1, 2) = %s\n", $2, substr($2, 1, 2);
$ awk -f awk8 test ...выполнить скрипт.
$1 = 1.1 exp = 3 log = = 0.095 sqrt = 1 int = 1 substr (a, 1, 2) = a
$1 = 2.2 exp - 9 log = = 0.79 sqrt = 1.5 int = 2 substr (at, 1, 2} I = at
$1 = 3.3 exp = 27 log =1.2 sqrt = 1.8 int = 3 substr (eat, It 2) = ea
$1 = 4.4 exp =81 log =1.5 sqrt =2.1 int = 4 substr (beat, 1, 2) = be
$
Жесткие и символические связи: In
Утилита in позволяет создавать как жесткие связи, так и символические связи между файлами.
Синтаксис
In -sf оригинал [новаяСвязь] In -sf {оригинал} + каталог
Утилита in позволяет создавать жесткие или символические связи к существующим файлам.
Чтобы создать жесткую связь между двумя нормальными файлами, определите существующую метку файла, как оригинал имени файла, и новую метку файла как новаяСвязь. Обе метки будут ссылаться на один физический файл, и эта структура отразится в счетчике жестких связей, показываемых утилитой is. Тогда к файлу можно обращаться через любую метку, а он удаляется из файловой системы, лишь когда все его ассоциированные метки будут удалены. Если аргумент новаяСвязь опущен, то предполагается последний компонент оригинала. Если последний аргумент — имя каталога, то жесткие связи создаются от этого каталога к указанным оригинальным именам файлов. Жесткие связи не могут охватывать файловые системы.
Опция -s предписывает утилите in формировать символические связи, приводящие к созданию нового файла, который содержит указатель (по имени) на другой файл. Символическая связь может охватывать файловые системы, поскольку нет никакой явной связи с адресуемым файлом кроме имени. Обратите внимание, если указанный символической связью файл удален, а символический файл связи все еще существует, то обращение через него приведет к ошибке.
Опция -f позволяет привилегированному пользователю (root) создавать жесткую связь к каталогу.
Для дополнительной информации о том, как жесткие связи представлены в файловой системе, обсуждение файловой системы UNIX см. в главе 14.
В представленном ниже примере добавляется новая метка hold к файлу, имеющему метку hold.3 (обратите внимание, что поле счетчика жестких связей было увеличено с 1 до 2, когда жесткая связь была добавлена, а затем значение снова вернулось к 1, когда жесткая связь была удалена):
$ Is -1 ...посмотреть содержимое текущего каталога.
total 3
-rw-r—г— 1 glass 124 Jan 12 17:32 hold.l
-rw-r—г— 1 glass 89 Jan 12 17:34 hold.2
-rw-r—r— 1 glass 91 Jan 12 17:34 hold.3
$ In hold.3 hold ...создать новую жесткую связь.
3 Is -1 ...посмотреть новое содержимое каталога.
total 4
-rw-r—r— 2 glass 91 Jan 12 17:34 hold
-rw-r—r— 1 glass 124 Jan 12 17:32 hold.l
-rw-r—r— 1 glass 89 Jan 12 17:34 hold.2
-rw-r—r— 2 glass 91 Jan 12 17:34 hold.3
3 rm hold ...удалить одну из связей.
$ Is -1 ...посмотреть обновленное содержимое каталога.
total 3
-rw-r—r— 1 glass 124 Jan 12 17:32 hold.l
-rw-r—r— 1 glass 89 Jan 12 17:34 hold.2
-rw-r—r— 1 glass 91 Jan 12 17:34 hold.3
Серия жестких связей может быть добавлена к существующему каталогу, если имя каталога определено в качестве второго аргумента утилиты in. В следующем примере создаются связи в каталоге tmp ко всем файлам, удовлетворяющим шаблону hold. *:
$ mkdir tmp ...создать новый каталог.
$ In hold.* tmp ...создать серию связей в tmp.
$ Is -1 tmp ...посмотреть содержимое tmp.
total 3
-rw-r—г— 2 glass 124 Jan 12 17:32 hold.l
-rw-r—r— 2 glass 89 Jan 12 17:34 hold.2
-rw-r—r— 2 glass 91 Jan 12 17:34 hold.3
$
Жесткая связь не может быть создана от файла в одной файловой системе к файлу в другой файловой системе. Чтобы обойти эту проблему, создайте символическую связь, которая может охватывать файловые системы. Для этого используйте опцию -s утилиты in. В приведенном ниже примере осуществляется попытка создать жесткую связь из пользовательского домашнего каталога к файлу /usr/include/stdio.h. Но файл находится в другой файловой системе, по этой причине утилита in не создала связи. Однако запуск утилиты in с опцией -s достиг цели. Когда утилита is используется с опцией -F, символическим связям предшествует символ @. По умолчанию утилита is показывает содержимое символической связи. Для того чтобы получить информацию о файле, на который ссылается связь, используйте опцию -L.
$ In /usr/include/stdio.h stdio.h ...жесткая связь.
In: stdio.h: Cross-device link
$ In -s /usr/include/stdio.h stdio.h ...символическая связь.
$ Is -1 stdio.h ...проверить файл.
Irwxrwxrwx 1 glass 20 Jan 12 17:58 stdio.h -> /usr/include/stdio.h
$ Is -F ' ...@ указывает символическую связь.
stdio.h@
$ Is -IL stdio.h ...посмотреть связь.
-г—г—г— 1 root 1732 Oct 13 1998 stdio.h
$ cat stdio.h
...посмотреть файл.
# ifndef FILE
#define BUFSIZ ttdefine SBFSIZ 8 extern struct
1024
iobuf {
$
Идентификация shell: whoami
Предположим, что вы случайно натолкнулись на свободный терминал и на экране находится приглашение shell. Очевидно, что кто-то работал в системе UNIX и забыл выйти из нее. Вы задаетесь вопросом: любопытно, кто это был? Чтобы раскрыть тайну, можете использовать утилиту whoami, которая показывает имя владельца shell. Например, запустив whoami на терминале пользователя glass, можно увидеть:
$ whoami
glass
$
Синтаксис
whoami
Показывает имя владельца shell.
Замена пользователя: su
Многие думают, что su — это сокращение от англ, superuser (привилегированный пользователь). Но это не так. Данная аббревиатура означает substitute user (заменить пользователя) и позволяет создать новый shell, принадлежащий другому пользователю.
Синтаксис
su [-] [имяПолъзователя] [аргументы]
Утилита su создает временный shell с реальным и эффективным пользовательским и групповым идентификаторами. Если имя пользователя не определено, предполагается root, и новая подсказка shell как напомина
ние устанавливается на знак #. Работая в новом shell, вы воспринимаетесь как новый пользователь. Завершая сеанс shell нажатием комбинации клавиш <Ctrl>+<D>, вы возвращаетесь в свой первоначальный shell. Конечно, чтобы использовать эту утилиту, следует знать пароль другого пользователя. Переменные окружения shell и номе задаются из файла пароля имяПользователя. Если имяПользователя — не root, устанавливаются пользовательские переменные окружающей среды. Новый shell не проходит через последовательность регистрации, если не задана опция Все другие параметры передаются, как аргументы командной строки новому shell.
Пример использования su:
$ whoami ...выяснить текущий ID пользователя.
glass
$ SU ...заменить пользователя.
Password: <ввел пароль привилегированного пользователя>
$ whoami ...подтвердить, что мой текущий ID пользователя изменился.
root
$ ...выполнить задачи привилегированного пользователя здесь.
$ ...прекратить дочерний shell.
$ whoami ...подтвердить восстановление текущего ID пользователя.
glass $
Проверка почты: biff
Командные интерпретаторы UNIX периодически осуществляют проверку наличия поступающей почты. Это означает, что может пройти несколько минут между поступлением почты в ваш почтовый ящик и уведомлением shell на вашем терминале. Чтобы избежать подобной задержки, вы можете разрешить мгновенное уведомление о почте, используя утилиту biff.
Синтаксис
biff [у|п]
Утилита biff разрешает или запрещает мгновенное уведомление о получении почты. Чтобы увидеть текущую установку biff, используйте утилиту без параметров. Укажите у, чтобы позволить вывод мгновенного уведомления, и п, чтобы запретить его. Почему эта утилита называется
biff? Разработчица из Калифорнийского университета в Беркли, которая написал утилиту для BSD UNIX, назвала ее в честь своей собаки Biff, которая всегда лаяла, когда почтальон приносил почту.
Пример: $ biff biff is n $ biff у $ biff biff is у $
...вывести текущую установку biff.
...разрешить моментальное уведомление о почте.
...подтвердить новую установку biff.
Преобразование файлов
Перечисленные ниже утилиты, в числе других, осуществляют преобразование над содержимым файлов.
□ Утилиты compress/uncompress и gzip/gunzip конвертируют файл в пространственно-эффективный промежуточный формат и обратно. Полезны для экономии дискового пространства.
□ Утилита crypt кодирует файл.
□ Утилита sed — программируемый потоковый редактор общего назначения, который редактирует файл согласно предварительно подготовленному набору инструкций.
□ Утилита tr связывает символы из одного набора с другим. Полезна для выполнения простого связывания типа преобразования файла из прописных букв в строчные.
□ Утилита ul конвертирует встроенные подчеркнутые последовательности символов в файл подходящей для конкретного терминала формы.
Сжатие файлов: compress/uncompress и gzip/gunzip
Утилита compress кодирует файл в более компактный формат, который может быть декодирован позже с использованием утилиты uncompress.
Синтаксис
compress -cv {имяФайла}+ uncompress -cv {имяФайл}+
Утилита compress заменяет файл его сжатой версией, добавляя в конец суффикс ".Z". Опция -с посылает сжатую версию на стандартный вывод, а не перезаписывает первоначальный файл. Опция -v показывает величину сжатия, которое имеет место. Утилита uncompress инвертирует файл, созданный compress, воссоздавая первоначальный вид из его сжатой версии.
Утилита compress полезна для уменьшения места на диске, занимаемого файлами,'и упаковки большего количества файлов в архивированный файл. Пример:
$ Is -1 palindrome.с reverse.с ...проверить оригиналы.
-rw-r—г— 1 glass 224 Jan 10 13:05 palindrome.с
-rw-r—г— 1 glass 266 Jan 10 13:05 reverse.с
$ compress -v palindrome.c reverse.с ...сжать их.
palindrome.c: Compression: 20.08% — replaced with palindrome.c.Z reverse, c: Compression: 22.93% — replaced with reverse.c.Z
$ Is -1 palindrome, c. Z reverse.c.Z
-rw-r—r— 1 glass 179 Jan 10 13:05 palindrome.c.Z
-rw-r—r— 1 glass 205 Jan 10 13:05 reverse.c.Z
$ uncompress -v *.Z ...восстановить оригиналы.
palindrome.c.Z: — replaced with palindrome.c
reverse.c.Z: — replaced with reverse.c
$ Is -1 palindrome.c reverse.с ...подтвердить.
-rw-r—r— 1 glass 224 Jan 10 13:05 palindrome.c
-rw-r—r— 1 glass 266 Jan 10 13:05 reverse.c
$ _
Алгоритм, который реализуют утилиты compress и uncompress, был запатентован уже после их написания (хотя многие не знали этот факт). Когда их владелец начал процедуру получения патента, выяснилось, что либо должны были быть оплачены лицензионные отчисления за использование обеих утилит, либо они должны быть удалены из системы. Поэтому многие продавцы UNIX выбрали утилиту GNU, известную как gzip, которая работает почти таким же образом, как compress, но использует другой, не имеющий лицензионных ограничений алгоритм. Следующий пример их применения фактически Идентичен Показанному ранее ДЛЯ compress И uncompress:
$ Is -1 palindrome.с reverse.с
-rw-r—г— 1 ables 224 Jul 1 14:14 palindrome, с
-rw-r—r— 1 ables 266 Jul 1 14:14 reverse, c
$ gzip -v palindrome, c reverse, c
palindrome.с: 34.3% — replaced with palindrome.с.gz
reverse.c: 39.4% — replaced with reverse.c.gz
$ Is -1 palindrome.c.gz reverse.c.gz
-rw-r—r— 1 ables 178 Jul 1 14:14 palindrome.c.gz
-rw-r—r— 1 ables 189 Jul 1 14:14 reverse.c.gz
$ gunzip -v ★ .gz
palindrome.c.gz: 34.3% — replaced with palindrome.c
reverse.c.gz: 39.4% — replaced with reverse.c
$ Is -1 palindrome.c reverse.c
-rw-r—r— 1 ables 224 Jul 1 14:14 palindrome, c
-rw-r—r— 1 ables 266 Jul 1 14:14 reverse.c
$
Синтаксис
gzip -cv {имяФайла}+ gun z ip - cv {имяФайла} +
Утилита gzip заменяет файл его сжатой версией, добавляя в конец суффикс ".gz". Опция -с посылает сжатую версию на стандартный вывод, а не перезаписывает первоначальный файл. Опция -v показывает величину сжатия, которое имеет место. Утилита gunzip может восстановить файл, созданный как gzip, так и compress. Утилиты gzip и gunzip доступны с Web-сайта GNU по адресу http://www.gnu.org/software/gzip/gzip.html.
Вы можете загрузить их, если они отсутствуют в вашей системе.
Шифрование файла: crypt
Утилита crypt создает кодируемую ключом версию текстового файла. Единственный способ восстановить первоначальный текст из закодированного файла — выполнить crypt с тем же самым ключом.
Синтаксис
crypt [ ключ]
Утилита crypt выполняет одно из действий:
• если на стандартном входе текст допустимого вида, кодируемая версия текста посылается на стандартный вывод, используя параметр ключ как ключ шифрования;
• если на стандартном входе закодированный текст, декодированная версия текста посылается на стандартный вывод, используя параметр ключ как ключ для расшифровки.
Если ключ не определен, утилита crypt напоминает, что вы должны ввести его со своего терминала. Вводимый ключ не отображается. Если ключ указан в командной строке, имейте в виду, что вывод листинга при помощи утилиты ps покажет значение ключа. Утилита crypt использует алгоритм кодирования, подобный тому, который использовался в немецкой шифровальной машине Enigma.
Пример использования утилиты crypt:
$ cat sample.txt
Here’s a file that will be encrypted.
$ crypt agatha < sample., txt > sample.crypt
$ rm sample.txt
$ crypt agatha < sample.crypt > sample.txt
$ cat sample, txt
Here’s a file that will be encrypted.
$
...вывести оригинал.
...agatha — это ключ.
...удалить оригинал.
...декодировать.
...вывести оригинал.
Потоковое редактирование: sed
Утилита потокового редактирования sed просматривает один или несколько файлов и осуществляет редактирование всех строк, которые соответствуют конкретному условию. Действия и условия могут быть заблаговременно сохранены в sed-скрипте. Утилита полезна для выполнения простых повторяющихся задач редактирования.
Утилита sed имеет много параметров и опций. Из-за этого здесь описаны только ее главные особенности и опции. Однако хочется надеяться, что представленный в этом разделе материал позволит вам писать большое количество полезных sed-скриптов.
Синтаксис
sed [-е скрипт] [-f скриптФайл] {имяФайла}^
Утилита sed редактирует входной поток согласно скрипту, который содержит команды редактирования. Каждая команда редактирования отделяется символом перевода строки и содержит действие, строку или диапазон строк для выполнения действия, sed-скрипт может быть сохранен
в файле и выполнен с помощью указания опции -f. Если текст срипта помещается непосредственно в командную строку, он должен быть окружен апострофами. Если файлы не определены, утилита sed читает из стандартного входа.
Команды sed
sed-скрипт — это список из одной или более команд, разделенных символом перевода строки. Существуют правила применения команд утилиты sed (табл. 3.7).
□ Адрес должен быть или номером строки или регулярным выражением. Регулярное выражение выбирает все строки, которые соответствуют выражению. Вы можете использовать символ $, чтобы выбрать последнюю строку.
П диапазонАдреса может быть единственным адресом или парой адресов, отделенных запятыми. Если определены два адреса, то выбираются все строки между первой строкой, которая соответствует первому адресу, и первой строкой, которая соответствует второму адресу.
□ Если адрес не определен, то команда применяется ко всем строкам.
Таблица 3.7. Команды редактирования в sed
Синтаксис команды Описание
адрес а\ текст Добавляет текст после строки, указанной адресом
диапазонАдреса с\ текст Заменяет текст, указанный диапазономАдреса текстом
диапазонАдреса d Удаляет текст, указанный диапазономАдреса
адрес i\ текст Вставляет текст после строки, укзанной адресом
адрес г имя Добавляет содержимое файла имя после строки, указанной адресом
диапазонАдреса s/выражение/строка/ Заменяет первое появление регулярного выражения выражение строкой строка
диапазонАдреса а/выражение/строка/д Заменяет каждое появление регулярного выражения выражение строкой строка
Замена текста
В приведенном ниже примере sed-скрипт вводится в командной строке. Скрипт вставляет пару пробелов в начало каждой строки.
$ cat arms .•.посмотреть оригинальный файл.
People just like me,
Are all around the world, Waiting for the loved ones that they need. And with my heart,
I make a simple wish, Plain enough for anyone to see.
$ sed. 's/^/ /' arms > arms, indent ...отступ в файле.
$ cat arms.indent ...посмотреть результат.
People just like me,
Are all around the world, Waiting for the loved ones that they need.
And with my heart,
I make a simple wish, Plain enough for anyone to see. $ _
Чтобы удалить все ведущие пробелы из файла, используйте оператор замены обратным способом, как показано в следующем примере:
$ sed ’s/" *//' arms.indent ...удалить ведущие пробелы.
People just like me, Are all around the world, Waiting for the loved ones that they need.
And with my heart,
I make a simple wish, Plain enough for anyone to see. $ _
Удаление текста
Следующий пример иллюстрирует скрипт, который удаляет все строки, содержащие регулярное выражение ' а' в качестве отдельного символа:
$ sed '/а/d' arms ...удалить все строки, содержащие ’а'
People just like me, $ _
Чтобы удалить только те строки, которые содержат слово 'а1, пришлось окружить регулярное выражение скобками (\< и \>): $ sed '/\<a\>/d' arms
People just like me,
Are all around the world, Waiting for the loved ones that they need.
And with my heart, Plain enough for anyone to see. $
Вставка текста
Рассмотрим пример, в котором вставлено предупреждение об авторском праве в начале файла с помощью команды вставки. Заметьте, sed-скрипт сохранен в файле и выполнялся с использованием опции -f: $ cat sed5 ...посмотреть sed-скрипт.
Copyright 1992, 1998, & 2002 by Graham GlassX All rights reservedX $ sed. -f sed5 arms ...вставить предупреждение об авторском праве. Copyright 1992, 1998, & 2002 by Graham Glass All rights reserved People just like me, Are all around the world, Waiting for the loved ones that they need.
And with my heart, I make a simple wish, Plain enough for anyone to see. $
Замена текста
В приведенном ниже примере группа строк 1—3 заменяется сообщением о том, что они были подвергнуты цензуре:
$ cat sed6 ...посмотреть sed-скрипт.
1,3с\
Lines 1-3 are censored.
$ sed -f sed6 arms ...выполнить скрипт.
Lines 1-3 are censored.
And with my heart,
I make a simple wish,
Plain enough for anyone to see.
$ _
Чтобы заменить сообщением отдельные строки, а не группу, создайте команды для каждой строки:
$ cat sed7 ...посмотреть sed-скрипт.
1с\
Line 1 is censored.
2c\
Line 2 is censored.
3c\
Line 3 is censored.
$ sed -f sed7 arms ...выполнить скрипт.
Line 1 is censored.
Line 2 is censored.
Line 3 is censored.
And with my heart,
I make a simple wish, Plain enough for anyone to see. $ _
Вставка файлов
В следующем примере вставлено сообщение за последней строкой файла:
$ cat insert ...посмотреть файл, который будет вставлен.
The End
$ sed '$r insert' arms ...выполнить скрипт.
People just like me,
Are all around the world,
Waiting for the loved ones that they need.
And with my heart,
I make a simple wish, Plain enough for anyone to see. The End $
Составные команды sed
Приведенный ниже пример иллюстрирует использование составных команд sed. В начало каждой строки вставлена последовательность «, а вконец строк — последовательность >>:
$ sed — 'з/л/« /' -е 's/$/ »/' arms
« People just like me, »
« Are all around the world, »
« Waiting for the loved ones that they need. »
« And with my heart, »
« I make a simple wish, »
« Plain enough for anyone to see. » $
Преобразование символов: tr
Утилита tr ставит в соответствие символы в файле из одного набора символам из другого набора.2
Синтаксис
tr -cds строка! строка2
Утилита tr связывает все символы набора строка! на своем стандартном входе с набором символов строка2. Если длина строки2 меньше, чем длина строки!, строка2 дополняется, повторяя свой последний символ; другими словами, команда tr abc de является эквивалентной команде tr abc dee.
Набор символов может быть определен с помощью системы обозначений shell:
• чтобы определить набор из символов a, d, и f, просто пишут их, как отдельную строку: adf;
• чтобы определить набор символов от а до z, отделяют начальный и конечный символ дефисом: a-z.
По умолчанию утилита tr заменяет каждый символ стандартного входа строки! соответствующим ему СИМВОЛОМ строки2.
Опция -с предписывает дополнить строку! прежде, чем будет выполнено связывание. Дополнение строки означает, что она заменяется строкой, которая содержит все символы ASCII кроме тех, которые имеются в первоначальной строке. В результате такого действия заменяется каждый символ стандартного входа, которого нет в строке!.
Опция -d удаляет каждый символ, имеющийся в строке!, из стандартного входа.
Опция -s заменяет последовательность повторяющихся символов единственным экземпляром символа.
2 Фактически создается таблица символов. — Ред.
Вот некоторые примеры утилиты tr в действии:
$ cat до.cart go cart racing
...посмотреть пример входного файла.
$ tr a-z A-Z < до.cart ...преобразовать прописные буквы в строчные. GO CART
RACING
$ tr a-c D-E < go.cart ...заменить abc на DEE.
go EDrt
rDEing
$ tr -с a X < go. cart ...заменить все символы, кроме а, на X.
ХХХХаХХХХХаХХХХХ$ ...даже последний перевод строки заменен.
$ tr -с a-z *\012* < до.cart ...заменить не буквы
go ...ASCII 12 (перевод строки).
cart
racing
$ tr -cs a-z '\012* < go. cart ...повторить, но сжать
go ...повторяющиеся переводы строк.
cart
racing
$ tr -d a-c < go.cart
...удалить все символы a-c.
go rt ring $
Преобразование подчеркнутых последовательностей: ul
Утилита ul преобразует файл, который содержит подчеркнутые символы так, чтобы он правильно выводился на конкретном типе терминала. Она полезна с командами, подобными man, которая генерирует подчеркнутый текст.
Синтаксис
ul -t терминал {имяФайла}*
Утилита ul преобразовывает подчеркнутые символы на своем входе так, чтобы они корректно отображались на указанном терминале. Если терминал не определен, то предполагается, что он определяется переменной
окружающей среды term. Файл /etc/termcap используется утилитой ui для определения правильной последовательности.
Рассмотрим пример совместного использования утилит ui и man. Предположим, что вы хотите использовать утилиту man для создания документа, который желаете печатать на простом ASCII-принтере (принтер при этом не выводит подчеркнутых символов). Утилита man генерирует подчеркнутые символы для текущего терминала, поэтому нужно отфильтровать выходные данные, чтобы сделать их подходящими для "немого” принтера. Создадим конвейер с выхода-утилиты man через утилиту ui с установкой терминала dumb.
$ man who | ul -tdumb > man.txt
$ head man.txt ...посмотреть первые десять строк.
WHO(l) USER COMMANDS WHO(l)
NAME
who — who is logged in on the system
SYNOPSIS
who [who-file] [am i]
$
Просмотр необработанного содержимого файла: od
Утилита восьмеричного дампа od позволяет увидеть содержимое нетекстового файла в различных форматах.
Синтаксис
od -acbcdfhilosx имяФайла [смещение[.][Ь]]
Утилита od показывает содержимое имяФайла в форме, указанной одной из следующих опций.
Опция Описание
-а Интерпретирует байты, как символы, и печатает как имена ASCII (т. е. 0 соответствует NULL)
-Ь Интерпретирует байты, как восьмеричное значение без знака
-с Интерпретирует байты, как символы, и печатает в нотации С (т. е. 0 соответствует \0)
(окончание)
Опция Описание
-d Интерпретирует пары байтов, как десятичные без знака
-f Интерпретирует пары байтов, как значения с плавающей запятой
-h Интерпретирует пары байтов, как шестнадцатеричное без знака
—i Интерпретирует пары байтов, как десятичные со знаком
-1 Интерпретирует четыре байта, как десятичные со знаком
-о Интерпретирует пары байтов, как восьмеричное без знака
-s [n] Ищет строки минимальной длины п (по умолчанию 3), завершающиеся символом NULL
-x Интерпретирует пары байтов, как шестнадцатеричное значение
По умолчанию содержимое отображается как ряд восьмеричных чисел. Параметр смещение определяет, где должен начаться вывод. Если смещение заканчивается на ь, то это интерпретируется как число блоков. Иначе — как восьмеричное число. Чтобы определить шестнадцатеричное число, укажите перед ним х. Для определения десятичного числа поставьте в конце его точку.
В следующем примере содержимое исполняемого файла /bin/od отображается в виде восьмеричных чисел, а затем в виде символов, начиная с позиции 1000 (восьмеричный):
$ od /bin/od ...восьмеричный дамп । файла /bin/od.
0000000 100002 000410 000000 017250 000000 003630 000000 006320
0000020 000000 000000 000000 020000 000000 000000 000000 000000
0000040 046770 000000 022027 043757 000004 021002 162601 044763
0000060 014004 021714 000002 000410 045271 000000 020746 063400
0000100 000006 060400 000052 044124 044123 027402 047271 000000
0000120 021170 047271 000000 021200 157374 000014 027400 047271
0000140 000002 000150 054217 027400 047271 000002 000160 047126
$ od -с /bin/od 1000 ...символьный дамп файла /bin/od.
0001000 Н х \0 । 001 N @ \0 002 \0 \0 / u s г / 1
0001020 i b / 1 d s о \0 / d е v / z е
0001040 г о \0 ' \0 \0 \0 \0 030 с г t 0 : п о
0001060 / и S г / 1 i ь / 1 d . s о \п
0001100 \0 \0 \0 % c r t 0 • / u s r / 1
0001120 i b / 1 d • s о m a p P i n g
0001140 f a i 1 u r e \n \0 \0 \0 \o 023 c r
0001160 t 0 • n о / d e v / z e г о
0001200 \n \0 200 \0 \0 002 200 \0 \0 022 \0 \0 \0 007 \0 \0
$ _
Вы можете производить поиск строки минимальной длины, используя опцию -s. Любой ряд символов, сопровождаемых ASCII-символом NULL, рассматривается в качестве строки. Пример:
$ od -s7 /bin/od ...поиск строк длиной от 7 символов.
0000665 \fNANu о
0001012 /usr/lib/ld. so
0001031 /dev/zero
0001050 crtO: no /usr/lib/ld.so\n
0001103 %crt0: /usr/lj.b/ld. so mapping failure\n
Монтирование файловых систем: mount/umount
Привилегированный пользователь (root) может расширять файловую систему, используя утилиту mount.
Синтаксис
mount -оопции [имяУстройства каталог] umount имяУстройства
Утилита mount позволяет соединять файловую систему устройства с корневой иерархией. При использовании без аргументов утилита mount показывает список смонтированных в настоящее время устройств. Чтобы определить специальные опции, за опцией -о указывают список адекватных кодов, среди которых rw монтирует файловую систему для чте-ния/записи, а го монтирует файловую систему только для чтения.
Утилита umount размонтирует предварительно смонтированную файловую систему.
В следующем примере объединяются файловая система, содержащаяся на устройстве /dev/dsk2, с каталогом /usr. Обратите внимание, что перед вы
полнением монтирования каталог /usr был пуст. После монтирования файлы, хранящиеся на устройстве /dev/dsk2, появились внутри этого каталога.
$ mount ‘...посмотреть текущие смонтированные устройства,
/dev/dskl on / (rw)
$ Is /usr .../usr is currently empty.
$ mount /dev/dsk2 /usr ...монтировать устройство /dev/dsk2.
$ mount ...посмотреть текущие смонтированные устройства,
/dev/dskl on / (rw) /dev/dsk2 on /usr (rw)
$ Is /usr ...посмотреть содержимое смонтированного устройства.
bin/ etc/ .include/ lost+found/ sre/ ueb/
demo/ game lib/ pub/ sys/ ueblib/
diet/ hosts/ local/ spool/ tmp/
$ _
Чтобы размонтировать устройство, используйте утилиту umount. В следующем примере размонтируется устройство /dev/dsk2, а* затем происходит просмотр каталога /usr:
$ umount /dev/dsk2 ...размонтировать устройство.
$ mount ...посмотреть текущие смонтированные устройства,
/dev/dskl on / (rw)
$ Is /usr ...заметьте, что каталог /usr снова пустой.
$ _
Файлы больше не доступны.
Идентификация терминалов: tty
Утилита tty идентифицирует имя рабочего терминала.
Синтаксис
tty
Утилита tty показывает путевое имя вашего терминала. Возвращает О, если ее стандартный вход — терминал; иначе возвращает 1.
В следующем примере входным терминалом является специальный файл /dev/ttypO:
$ tty ...вывести путевое имя терминала.
/dev/ttypO
$
Форматирование текста: nroff/troff/style/spell
Одной из первых применяемых функций UNIX должна была стать поддержка обработки текста в Bell Laboratories. Несколько утилит, включая nroff, troff, style и spell, были созданы специально для форматирования текста. В настоящее время они фактически устарели из-за использования более сложных инструментов, поддерживающих принцип "What You See Is What You Get" (WYSIWYG, "Что видите, то и получаете"). Например, утилита nroff требует ручного размещения специальных команд типа ,ра внутри текстового документа, чтобы отформатировать его правильно, тогда как современные инструменты позволяют вам делать это с помощью графического интерфейса.
Для получения дополнительной информации об утилитах обработки текста в "старинном стиле" см. [Sobell 1994].
Измерение времени выполнения: time
Иногда полезно знать, сколько потребуется времени для выполнения определенной команды или программы (или как долго они выполняются относительно времени выполнения чего-то еще). Утилита time может использоваться, чтобы получить отчет о времени выполнения любой указанной команды UNIX.
Синтаксис
time команднаяСтрока
Утилита time служит для получения сведений о времени выполнения любой команды UNIX, указанной параметром команднаяСтрока. Время сообщается и в виде общего затраченного времени и времени ЦП. (Время ЦП выражается в виде двух значений: пользовательское время и системное время.)
Пример:
$ time sort allnames.txt >sortednames. txt real Om 4.18s
user Om 1.85s
sys Om 0.14s $
Эта команда сообщает нам, что требуется почти 4,2 секунды астрономического времени, чтобы отсортировать наш файл, тогда как общее время использования ЦП было 1,99 секунды.
Утилита time особенно полезна в определении времени работы программ или скриптов, обрабатывающих маленькие порции данных, когда невозможно "почувствовать" разницу в требуемом времени из-за слишком быстрого их выполнения.
Создание собственных программ: Perl
Мы выяснили, что при возникновении сложных задач обработки данных, когда требовалось объединение двух или нескольких утилит UNIX, необходимо было писать скрипты shell на одном из языков shell. Скрипты shell медленнее, чем С-программы, т. к. они интерпретируются вместо компиляции. С другой стороны, они намного более легки для написания и отладки. С-программы предоставляют возможность использования большего количества функций UNIX, но, как правило, требуют большего времени для написания и изменения.
В 1986 г. Ларри Уолл (Larry Wall) выяснил, что shell-скриптов недостаточно, а С-программы оказались ’’убийственны” для многих намерений. Он собирался написать скриптовый язык, который должен был стать лучше shell-скриптов и С-программ. Результатом стал Perl (Practical Extraction Report Language, Практический Язык Извлечения Сообщений). Perl разрешил многие проблемы, с которыми Ларри Уолл сталкивался при генерации отчетов и применении других ориентируемых на текст функций, хотя язык также обеспечил свободный доступ к функциям UNIX, чего не делали shell-скрипты.
Синтаксис языка Perl покажется знакомым для shell- и С-программистов, т. к. многое было заимствовано от элементов обоих языков. Хочется надеяться, что в этой книге нам удалось дать высокоуровневое представление о Perl. Подобно программе awk, о Perl написаны целые книги (см., например, [Medinets 1996] и [Wall 1996].) Детализация такого уровня находится за пределами возможностей этой книги, но, несмотря на первое знакомство, мы уверены, что вы захотите выяснить больше о Perl.
Получение Perl
Хотя Perl используется в большинстве сред UNIX, система программирования на языке часто не поставляется вместе с этой ОС, поскольку не является частью UNIX. Если ваш продавец UNIX не поставляет Perl, вы должны будете загрузить и установить его самостоятельно. Лучший источник — http://www.perl.com. Этот узел сети содержит рассылки Perl для различных платформ в секции downloads (загрузка), а также документацию и ссылки на многие другие полезные ресурсы.
Огромное преимущество реализации инструментов на Perl — это наличие языка на основных платформах, включая большинство версий UNIX, Windows и MacOS. Следует остерегаться несовместимости в системных запросах и системном расположении файлов данных. Однако ваш код потребует очень мало изменений для того, чтобы работать должным образом на различных платформах.
Не менее важное преимущество Perl состоит в том, что он бесплатный. Perl лицензирован разновидностью GNU Public License (Общедоступной лицензией GNU), известной как Artistic License (Художественная лицензия). Она не затрагивает никакого кода, который вы пишете на Perl. Вы можете использовать и распространять собственный код любым пригодным для вас способом.
Печать текста
Без возможности печатать большинство программ не могли бы выполнить многого. Итак, согласно традиции UNIX, начнем наши примеры скриптов Perl с демонстрации печати единственной строки: print "hello world.\n”;
Именно из этого простого примера вы можете сделать вывод, что каждая строка в Perl должна заканчиваться точкой с запятой (;). Также обратите внимание, что \п используется (так же как в языке программирования С) для печати символа перевода строки.
Переменные, строки и целые
Для программирования, конечно, необходимо иметь возможность присваивать и изменять значения. Perl поддерживает немало переменных, как, например, это делают интерпретаторы командной строки. Переменные могут иметь любой тип. Perl позволяет визуально определить тип переменных по специальным символам. Главное различие между Perl-переменными и переменными shell заключается в том, что в Perl символ $ сам по себе не используется. Он указывается в имени переменной: $i = 3;
Это различие следует уяснить закаленным программистам shell.
В дополнение ко всем "типичным" математическим операторам (сложение, вычитание и т. д.), целые числа также поддерживают оператор диапазона "..который служит для указания диапазона целых чисел. Он полезен для создания цикла на диапазоне значений.
Как и в большинстве языков программирования, строки в Perl определяются текстом в кавычках. Строки также поддерживают оператор конкатенации, который соединяет строки вместе. Пример:
print 1, 2, 3..15, "\п"; # оператор диапазона
print "А”, "В", "С”, "\п"; # строки
$i = "А" . "В"; # оператор конкатенации
print "$i", "\n";
Эти строки генерируют следующие выходные данные:
123456789101112131415
АВС
АВ
Вы можете видеть, что печатается каждое значение, предоставляя контроль над всеми промежутками.
Массивы
Большинство языков программирования поддерживает работу с массивами, которые являются списками значений данных. Массивы в Perl весьма просты в использовании, поскольку они распределяются динамически. (Программист не должен определять, насколько большими они будут. И если применяется больший по размеру массив, чем определен, Perl выделит больше памяти и увеличит массив.) Массив обозначается знаком @ следующим образом:
@агг = (1, 2,3, 4,5) ;
Эта строка объявляет массив агг и помещает в него пять значений. Можно определить тот же самый массив строкой кода @arr = (1..5);
которая использует оператор диапазона с целыми.
Доступ к отдельному индексированному элементу осуществляется так: print @arr[0],”\n";
Как в большинстве реализаций массивов, первый элемент нумеруется нулем. Таким образом, указанная строка печатала бы 1, т. к. это первое значение массива.
Если указать массив без индексов, выведутся все определенные значения. Если используется имя массива без индекса в месте, где ожидается скалярное значение3, оно будет интерпретировано, как количество элементов этого массива.
/
3 То есть имя переменной. — Ред.
Пример:
@al = (1); # массив из 1 элемента
@а2 - (1,2,3,4,5); # массив из 5 элементов
@аЗ = (1..10); # массив из 10 элементов
print @al, " ", @а2, " ", @аЗ, "\п";
print @al[0], " ", @а2[1], " ", @аЗ[2], "\п";
# Используется, как скаляр, выдаст число элементов
print @а2 + @аЗ, "\п";
Когда код выполнится, пользователь увидит следующее:
1 12345 12345678910
123
15
В Perl предусмотрен специальный тип массива — ассоциативный массив. В обычном массиве индекс элемента определяется целым числом между 0 и максимальным размером массива. Ассоциативный массив может иметь индексы в произвольном порядке и любых значений. Рассмотрим, например, массив названий месяцев. Определим массив $month с 12 значениями "Январь", "Февраль" и т. д. (Так как массивы начинаются с индекса 0, вы или должны помнить о вычитании 1 из индекса, или определить множество из 13 значений и игнорировать $month[0], начиная вместо этого с $month[l] = "Январь").
Но что делать, если происходит чтение названия месяца со входа, и нужно посмотреть числовое значение. Можно использовать цикл для поиска в массиве, но это требует дополнительного кода. Было бы лучше, если бы можно было просто индексировать массив названием? В ассоциативном массиве вы можете это сделать следующим образом:
@month{’January’} = 1;
@month{’February'} = 2;
Тогда можно читать название месяца и получать доступ к его числовому значению через код $monthnum = $month {$monthname) ;
без применения цикла.
Вместо того чтобы вводить в массив элементы по одному, как мы делали в предыдущем примере, можно определить массив в начале Perl-программы:
%month = ("January", 1, "February", 2, "March", 3,
"April", 4, "May", 5, "June", 6,
"July", 7, "August", 8, "September", 9, "October", 10, "November", 11, "December", 12);
Набор значений, которые могут использоваться в ассоциативном массиве (также называемый ключами к массиву), возвращается, как и в нормальном массиве, вызовом функции Perl keys ():
Omonthnames = keys (%month) ;
Если вы попытаетесь использовать недопустимое значение как ключ, будет возвращен пустой указатель или ноль (в зависимости от того, как вы используете значение).
Математические и логические операторы
Следующий шаг после объявления переменной — изменение ее значения. Большинство действий над величинами знакомо из С-программирования. Типичные операторы для целых и вещественных чисел — это сложение (+), вычитание (-), умножение (*) и деление (/). Целые числа также поддерживают С-конструкции пре- и постинкремента и пре- и постдекремента. Кроме того, к ним применимы логические операторы and и or.
В приведенном ниже примере указана обратная косая черта перед знаком $, используемым в качестве текста в операторе печати, поскольку в этом месте выводится не значение переменной, а ее имя с добавленным к нему символом $ как приставки:
$п = 2;
print ( "\$П=", $n, "\n");
$п = 2; print ("increment after \$n=", $n++, "\n");
$п = 2; print ("increment before \$n=", ++$n, "\n")
$п = 2; print ("decrement after \$n=", $n—, "\n");
$п = 2; print ("decrement before \$n=", —$n, "\n")
$п = 2; # сброс
print ( "\$n+2=" , $n + 2, "\n");
print ( "\$n-2=" , $n - 2, "\n");
print ( "\$n*2=" , $n * 2, "\n");
print ( "\$n/2=" , $n / 2, "\n");
$г = 3.14;
# вещественное число
print ("\$r=", $r, "\n");
print ("\$r*2=", $r * 2, "\n"); # удвоить
print ("\$r/2=", $r / 2, "\n"); # поделить пополам
print ("1 && 1 -> ”, 1 && 1, "\n");
print ("1 && 0 -> ", 1 && 0, "\n");
print ("1 || 1 -> ", 1 |I 1, "\n");
print ("1 j | 0 -> ", 1 | | 0, "\n");
Этот скрипт генерирует следующие выходные данные:
$п=2
increment after $n=2 increment before $n=3 decrement after $n=2 decrement before $n=l $n+2=4 $n-2=0
$n*2=4
$n/2=l $r=3.14 $r*2=6.28 $r/2=1.57 1 && 1 -> 1
1 && 0 -> 0
1 II 1 -> 1
1 || 0 -> 1
Строковые операторы
Действия над строковыми типами более сложны, чем над целыми числами, и обычно требуют использования строковых функций. Единственная простая операция, которая имеет смысл для строк, — это конкатенация. Строки конкатенируются оператором "Л Пример: $firstname = "Graham"; $lastname = "Glass"; $fullname = $firstname . " " . $lastname; print "$ fullname\n";
Результат работы кода:
Graham Glass
Однако несколько простых операторов сопоставления доступны для строк: if ($value =~ /abc/) {print "contains 'abc'\n"};
$value =~ s/abc/def/; # изменить 'abc1 на 'def'
$value =~ tr/a-z/A-Z/; # перевести в прописные
Опытный пользователь UNIX признает синтаксис замены от редактора vi и утилиты sed, а также синтаксис перевода, основанный на UNIX-утилите tr.
Операторы сравнения
Наверняка вам потребуется выполнить сравнение значений. Операторы сравнения, как показано в табл. 3.8, являются обычными. В случае сравнения строк на "больше, чем" или "меньше, чем" эти операторы выясняют порядок сортировки строк.
Таблица 3.8. Операторы сравнения в Perl
Операция Числовые величины Строковые величины
Равно eq
Не равно ! = пе
Больше, чем > gt
Больше, чем или равно >= де
Меньше, чем < It
Меньше, чем или равно <= 1е
Конструкции if, while, for и foreach
Существенная часть любого языка программирования — это способность выполнять различные операторы в зависимости от значения переменной и организовывать циклы для повторяющихся задач или индексирования значений массива. Оператор if и цикл while в Perl подобны операторам в языке С.
В конструкции if оператор сравнения используется для сопоставления двух значений, а различные наборы операторов исполняются в зависимости от результата сравнения (истина или ложь):
$i = 0;
if ( $i = 0 ) {
print "it's true\n";
} else { print "it’s false\n”;
}
Этот скрипт выводит на печать строку it’s true
Можно организовать цикл с помощью оператора while, например, для печати текста до тех пор, пока оператор сравнения возвращает истину: while ( $i = 0 ) { print "it’s true\n";
Конечно, сравнение возвратит ложь на следующем же цикле, т. к. $i был увеличен.
Perl также работает, как с циклами for из С, так и с циклами foreach из С shell. Пример:
for ($i = 0 ; $i < 10 ; $i++ ) { print $i, " ’’;
print "\n";
Этот скрипт считает от 0 до 9, печатает значение (без символа перевода строки) и генерирует следующие выходные данные: 0123456789
Пример цикла foreach:
foreach $n (1..15) { print $n, " ";
}
print ”\n";
Этот скрипт производит то, что вы могли ожидать:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Ввод/вывод файла
Одно весомое усовершенствование Perl перед shell-скриптами — это способность направлять ввод и вывод к определенным файлам и использовать не только стандартный ввод, вывод или каналы ошибки. Вы можете получить доступ к стандартному вводу и выводу следующим образом: while (@line=<stdin>) { foreach $i (@line) {
print $i; # также читает символ EOL (конец строки)
} }
Этот скрипт будет читать каждую строку из стандартного входа и печатать ее. Но вы можете определить файл данных, из которого захотите выполнить чтение. Вот как это сделать:
$FILE= "info.dat";
open (FILE); # имя переменной, не вычисляется
@array = <FILE>;
close (FILE);
foreach $line (@array) { print "$line";
}
Этот Perl-скрипт открывает файл info.dat и читает все его строки в массив array. (Остроумное имя, что вы скажете?) Затем он делает то же самое, что и предыдущий скрипт — распечатывает каждую строку.
Функции
Для реализации одних и тех же алгоритмов в разных программах язык должен предусмотреть возможности использования функций или подпрограмм. Korn shell обеспечивает слабый тип функций, реализованных через командный интерфейс, и это единственный основной shell, который предусматривает функции вообще. Конечно, язык С обеспечивает функции, но авторы скриптов имели много проблем с ним прежде, чем появился Perl.
Функции Perl использовать достаточно просто, хотя синтаксис может показаться замысловатым. Следующий простой пример функции Perl даст вам интересную идею: sub pounds2dollars {
$EXCHANGE_RATE =1.54; # изменить в случае необходимости
$pounds = $_[0] ;
return ($EXCHANGE_RATE * $pounds);
)
Данная функция заменяет значение, указанное для фунта стерлингов на американские доллары (заданный обменный курс $1.54 к фунту, который может быть изменен по мере необходимости). Специальная переменная $_ [ о ] ссылается на первый аргумент функции.
Чтобы вызвать функцию, в Perl-скрипт надо добавить строки:
$book =3.0; # цена в британских фунтах
$value = pounds2dollars($book);
print "Value in dollars = $value\n";
Когда мы запустим этот скрипт (который включает функцию Perl в конец), то получим
Value in dollars = 4.62
Библиотека функций
В противовес shell-скриптам Perl обладает способностью выполнять системные вызовы UNIX. Кроме того, Perl обеспечивает интерфейс ко многим системным вызовам UNIX. Интерфейс осуществляется через функции библиотеки Perl, а не прямо через библиотеку системных вызовов. Поэтому использование языка зависит от его реализации и версии, и вы должны обратиться к документации имеющейся у вас версии для получения конкретной информации. Когда интерфейс доступен, он обычно очень похож на библиотеку С.
Мы уже рассмотрели несколько функций Perl в предыдущих разделах, когда видели применение системных вызовов open (), close () и print (). Другой простой пример полезной системной функции
exit(1);
использующейся для выхода из Perl-программы и передачи заданного кода возврата shell. Perl также имеет специальную функцию выхода для печати сообщения на стандартный выход stdout и выхода с текущим кодом ошибки:
open(FILE) or die("Cannot open file.");
Таким образом, если вызов функции open () завершается ошибкой, функция die о будет выполнена, генерирует вывод сообщения об ошибке на stdout, и Perl-программа завершается с кодом ошибки.
Существуют некоторые строковые функции, позволяющие манипулировать значениями строк: length о, index о и split о . Команда
$len = length($fullname);
присваивает переменной $1еп длину текста, хранящегося в строковой переменной $fullname.
Для того чтобы расположить одну строку внутри другой, используйте конструкцию
$i = index($fullname, "Glass");
Значение $i будет равно 0, если строка начинается с текста, указанного в строке поиска во втором аргументе.
Для того чтобы разбить строку на основе разделительного символа (например, если нужно разбить признаки из файла пароля UNIX на части), используйте ($username, $password, $uid, $gid, $name, $home, $shell) = split(/:/, $line)
В этом случае функция split о возвращает массив значений, найденных в строке, обозначенной $iine и отделенной двоеточием. В данной строке кода определены отдельные переменные для сохранения каждого элемента в массиве так, чтобы можно было использовать их значения более простым способом, чем индексация в массиве.
Следующая общая функция позволяет манипулировать в Perl-программе временем и датой: ($s, $m, $h, $dy, $mo, $yr, $wd, $yd, $dst) = gmtime(); $mo++; # отсчет месяцев начинается с нуля.
$уг+= 1900; # Perl возвращает значение года, начиная с 1900.
print "The date is $mo/$dy/$yr.\n";
print "The time is $h:$m:$s.\n";
Предыдущий код выдает результат:
The date is 4/25/2002.
The time is 13:40:27.
Обратите внимание, что функция gmtimeO возвращает 9 значений. Синтаксис языка Perl обязывает определить эти величины в круглых скобках (как если бы вы присваивали многочисленные значения массиву).
Аргументы командной строки
Еще одна полезная возможность состоит в том, что можно передавать аргументы командной строки Perl-скрипту. Скрипты shell предусматривают очень простой интерфейс к аргументам командной строки, в то время как программы С обеспечивают более сложный (но и более гибкий) интерфейс. Perl-интерфейс находится где-то между ними, как показано в следующем примере:
$n = $#ARGV+1; # количество аргументов (начиная с нуля).
print $n, " args: \п" ;
for ( $i = 0 ; $i < $n ; $i++ ) {
print " @ARGV[$i]\n";
}
Этот Perl-скрипт выводит число аргументов, которые были переданы программе peri (после имени Perl-скрипта) и затем распечатывает каждый аргумент на отдельной строке.
Мы можем изменить рассмотренный ранее скрипт "фунты в доллары", чтобы позволить значению британских фунтов быть определенным в командной строке следующим образом:
if ( $#ARGV < 0 ) { # если аргументы не заданы.
print "Specify value in to convert to dollars\n";
exit
$poundvalue = @ARGV[0];
# получить значения из командной строки.
$dollarvalue = pounds2doliars($poundvalue); print "Value in dollars = $dollarvalue\n";
sub pounds2doliars { $EXCHANGE_RATE =1.54; # из
$pounds = $_[0];
return ($EXCHANGE_RATE * $pounds);
# изменить, когда необходимо.
Пример из реального мира
Все краткие предыдущие примеры должны были дать вам представление о том, как работает Perl. Но пока мы не сделали ничего действительно очень полезного. Поэтому давайте, воспользовавшись уже имеющимися у нас сведениями, напишем Perl-скрипт для печати таблицы о ссуде. Определим еще одну команду.
Синтаксис
loan -а величина -р платеж -г норма
Программа loan печатает таблицу, заданный размер ссуды, норму процента и платеж, который должен быть сделан ежемесячно. Таблица показывает необходимое количество месяцев для выплаты ссуды, а также сколько процентов и какая основная сумма будут оплачены каждый месяц. Все аргументы необходимы.
7 Зак. 786
Perl-скрипт loan.pl доступен в сети (см. Введение) и похож на код: # show loan interest $i=0;
while ( $i < $#ARGV) { # аргументы процесса
if ( @ARGV[$i] eq ”-r" ) {
$RATE=@ARGV[++$i]; # норма процента
} else { if ( @ARGV[$i] eq "-a” ) {
$AMOUNT=@ARGV[++$i]; # размер ссуда
} else { if ( @ARGV[$i] eq "-p" ) {
$PAYMEOT=@ARGV[++$i]; # размер платежа
} else { print "Unknown argument (@ARGV[$i])\n"; exit } }
}
if ($AMOUNT == 0 || $RATE == 0 || $PAYMENT ==0) { print "Specify -r rate -a amount -p payment\n"; exit
}
print "Original balance: \$$AMOUNT\n";
print "Interest rate: ${RATE}%\n";
print "Monthly payment : \$$PAYMENT\n";
print "\n";
print "Month\tPayment\tInterest\tPrincipal\tBalance\n\n";
$month=l;
$rate=$RATE/12/100; # получить фактическую ежемесячную норму процента
$balance=$AMOUNT;
$payment=$ PAYMENT;
while ($balance > 0) { # цикл для нормы процента
$interest=roundUpAmount($rate * $balance);
$principal=roundUpAmount($payment — $interest);
if ( $balance < $principal ) { # последний платеж
$principdl=$balance; # не платить слишком много!
$payment=$principal + $interest;
}
$balance = roundUpAmount($balance — $principal);
print
"$month\t\$$payment\t\$$interest\t\t\$$principal\t\t\$$balance\n"; $month++;
}
sub roundUpAmount {
#
# in: floating point monetary value
# out: value rounded (and truncated) to the nearest cent
#
$value=$_[0] ;
$newvalue = ( int ( ( $value * 100 ) + .5 ) ) / 100;
return ($newvalue);
Если предполагается платить по $30 в месяц при балансе кредитной карточки в $300 и учитывать норму процента, как 12.9% годовой процентной ставки, то график оплаты напоминает следующее:
Original balance: $300
Interest rate: 12.5%
Monthly payment: $30 9
Month Payment Interest Principal Balance
1 $30 $3.13 $26.87 $273.13
2 $30 $2.85 $27.15 $245.98
3 $30 $2.56 $27.44 $218.54
4 $30 $2.28 $27.72 $190.82
5 $30 $1.99 $28.01 $162.81
6 $30 $1.7 $28.3 $134.51
7 $30 $1.4 $28.6 $105.91
8 $30 $1.1 $28.9 $77.01
9 $30 $0.8 $29.2 $47.81
10 $30 $0.5 $29.5 $18.31
11 $18.5 $0.19 $18.31 $0
Таким образом, потребуется 11 месяцев, чтобы оплатить баланс при платеже по $30 в месяц, но последний платеж будет только $18.31. Если есть желание погасить ссуду быстрее, чем за 11 месяцев, нужно поднять ежемесячную оплату!
Обзор главы
Перечень тем
В этой главе вы познакомились с утилитами, которые:
□ фильтруют файлы;
П сортируют файлы;
□ сравнивают файлы;
□ архивируют файлы;
□ производят поиск файлов;
□ планируют команды;
□ поддерживают программируемую обработку текста;
П создают жесткие и символические связи;
□ заменяют пользователей;
П проверяют наличие почты;
□ изменяют файлы;
□ просматривают необработанное содержимое файла;
П монтируют файловые системы;
П подготавливают документы.
Также было рассмотрено написание скриптов Perl.
Контрольные вопросы
1. При каких условиях вы архивировали бы файлы, используя утилиту tar?
2. Как вы преобразовали бы содержание файла к прописным буквам?
3. В чем разница между утилитами стр и diff?
4. Опишите что, означает "монтирование” файловой системы.
5. Какой процесс обслуживает утилита crontab?
6. Какие дополнительные функциональные возможности имеет расширенное регулярное выражение?
7. В чем состоят главные отличия между утилитами sed и awk?
8. Как утилита awk получила свое имя?
9. При каких условиях вы использовали бы символическую связь вместо жесткой связи?
10. В чем заключаются недостатки использования символической связи?
11. Для чего предназначено инкрементное резервное копирование, и как бы вы выполнили его?
12. Какими способами Perl делает программирование скриптов более легким по сравнению с обычными скриптами shell?
Упражнения
3.1. Выполните тесты измерения времени для утилит grep и fgrep, чтобы определить преимущество использования быстродействия fgrep. [Уровень: легкий.]
3.2. Попросите системного администратора продемонстрировать использование утилиты tar для выполнения резервного копирования ваших файлов на ленту. [Уровень: легкий.]
3.3. Используйте утилиту crontab, чтобы включить в расписание скрипт, который в начале каждого дня удаляет ваши старые базовые файлы. [Уровень: средний.]
Проекты
1. Напишите командный конвейер, который сжимает содержание файла и затем шифрует его, используя известный ключ, а результат записывает в новый файл. Какой соответствующий командный конвейер должен принимать этот зашифрованный файл для дешифрования и разархивирования его, чтобы получить первоначальный файл? [Уровень: легкий.]
2. Напишите командный конвейер, который находит и сжимает файлы в иерархии каталогов (например, в вашем домашнем каталоге), к которым не было обращений в течение 30 дней. [Уровень: средний.]
3. Измените Perl-скрипт loan так, чтобы вы могли передавать ему список платежей, а не использовать каждый месяц один и тот же размер платежа. [Уровень: средний.]
Глава 4
Командные интерпретаторы shell
Мотивация
Shell — это программа-посредник между пользователем и ядром операционной системы. Существуют четыре shell, которые, как правило, входят в стандартную поставку UNIX: Bourne shell (sh), Korn shell (ksh), C shell (csh) и Bourne Again shell (bash). Все перечисленные оболочки поддерживают базовый набор возможностей, позволяющих управлять UNIX. Так, например, все командные интерпретаторы позволяют сохранять вывод процесса в файл или перенаправлять его на вход другого. В этой главе мы рассмотрим базовые функции командной оболочки, а в главах 5—8 обсудим особенности каждой из них.
Предпосылки
Для понимания этой главы вам необходимо усвоить материал первых двух глав. Кроме того, некоторые из упоминаемых утилит были рассмотрены в главе 3. Поэтому, в случае необходимости, прочитайте ее еще раз. Большим преимуществом для изучения материала будет наличие UNIX на вашем компьютере.
Задачи
В данной главе мы научимся использовать базовые возможности shell, такие как перенаправление ввода/вывода, конвейеризацию, управление заданиями. Изложение по сложившейся уже традиции в этой главе проиллюстрировано примерами UNIX-сессий, которые вы можете повторить на своем компьютере для более глубокого усвоения материала.
Утилиты
Нам предстоит познакомиться со следующими утилитами:
chsh nohup tee
echo ps
kill sleep
Команды shell
Вы научитесь пользоваться следующими командами:
echo kill umask
eval login wait
exec shift
exit
Общие сведения о shell
Shell — это программа-интерфейс между пользователем и операционной системой. Она позволяет работать с файлами, осуществлять перенаправление данных и выполняет немало других полезных функций. Существуют четыре основных командных интерпретатора:
П Bourne shell (sh);
П Korn shell (ksh);
□ C shell (csh);
□ Bourne Again shell (bash).
Выбор командной оболочки — это, прежде всего, вопрос вкуса. Хотя у каждой оболочки есть свои особенности, например, С shell лучше приспособлен для диалоговой работы, чем Bourne shell, но в некотором отношении хуже для написания скриптов. Korn shell совмещает в себе положительные черты Bourne shell и С shell, а также поддерживает дополнительные полезные функции. Bash впитал в себя лучшие черты остальных программных оболочек. Bourne shell имеется в каждой версии UNIX. Другие командные интерпретаторы не обязательно будут присутствовать в вашей ОС. В главе 8 содержится немало информации о том, что делать, если ваша любимая оболочка не входит в стандартную поставку системы.
Функциональные возможности shell
Рассмотрим более подробно, какие функциональные возможности присущи всем командным оболочкам. На рис. 4.1 изображена взаимосвязь различных командных интерпретаторов, а на рис. 4.2 представлена иерархия базовых функциональных возможностей shell.
Рис. 4.1. Взаимосвязь функциональных возможностей различных shell
Локальные Окружения
Условные Безусловные
Рис. 4.2. Базовые функциональные возможности shell
Выбор shell
Когда вам предоставляют имя для регистрации в UNIX, системный администратор определяет программную оболочку, которой вы будете пользоваться. Для того чтобы узнать, какая оболочка вам досталась, просмотрите на приглашение shell. Если вы видите приглашение %, то, скорее всего, вы пользуетесь С shell. Другие оболочки используют символ $ в качестве приглашения по умолчанию. Для изменения установленного по умолча
нию shell воспользуйтесь утилитой chsh. При этом необходимо знать месторасположение всех оболочек. В табл. 4.1 указано стандартное местоположение различных оболочек.
Таблица 4.1. Местоположение shell
Командный интерпретатор Полное имя
Bourne shell /bin/sh
Korn shell /bln/ksh
C shell /bin/csh
Bash /bin/bash
Синтаксис
chsh
Утилита chsh позволяет изменить установленный по умолчанию входной shell. Необходимо указать местоположение командного интерпретатора, который будет использоваться во время ваших последующих входов в систему.
Рассмотрим пример замены установленного по умолчанию Bourne shell на Korn shell:
% chsh ...изменить входной shell c sh на ksh.
Changing login shell for glass ...замена входного shell для glass
Old shell: /bin/sh ...вывод путевого имени старого shell.
New shell: /bin/ksh ...ввод полного путевого имени нового shell.
% "D ...завершить входной shell.
login: glass Password: ...войти в систему снова. ...секрет
$ . ...в этот раз я в Korn shell.
Для того чтобы определить месторасположение shell, воспользуйтесь следующим способом:
$ echo $SHELL /bin/ksh $
...выводит имя моего входного shell.
...полное путевое имя Korn shell.
Эти строки с помощью команды echo выводят место расположения оболочки, указанное в переменной окружения shell. Вывод данных с помощью echo и использование переменных окружения будет рассматриваться чуть позже.
Функционирование shell
При вызове shell, который либо инициируется автоматически во время входа в систему, либо запускается вручную из скрипта или с клавиатуры, выполняется следующая последовательность действий:
1. Оболочка читает специальный файл запуска, обычно расположенный в домашнем каталоге пользователя. Этот файл содержит некоторую инициализирующую информацию. Последовательность запуска каждого shell различна, поэтому пока не будем останавливаться на конкретных деталях.
2. Выводится приглашение и ожидается пользовательская команда.
3. Если пользователь нажал комбинацию клавиш <Ctrl>+<D>, это интерпретируется shell, как "конец ввода", после чего командный интерпретатор завершает работу. Иначе shell выполняет команду пользователя и возвращается к шагу 2.
Команды могут представлять собой как простой вызов отдельной утилиты, например:
$ 1S
так и сложный конвейер последовательно выполняющихся команд:
$ ps -ef I sort ul -tdumb I Ip
При необходимости ввести команду, которая превышает размер строки, воспользуйтесь символом обратной косой черты (\), а затем продолжите набор на следующей строке:
$ echo это - очень длинная команда shell, и поэтому необходимо \ пользоваться специальным символом для продолжения набора \ на другой строке. \
Обратите внимание, что команда может занимать несколько строк. \
это - очень длинная команда shell, и поэтому необходимо пользоваться специальным символом для продолжения набора на другой строке. Обратите внимание, что команда может занимать несколько строк.
$ _
Исполняемые файлы и встроенные команды
Большинство команд UNIX вызывает утилиты, которые хранятся в каталогах. Код утилит находится в исполняемых файлах. Например, когда вы печатаете
$ 1S
командная оболочка определяет местоположение исполняемой программы, по имени is, которая обычно находится в каталоге /bin, и выполняет ее. (Алгоритм поиска нужной утилиты будет рассмотрен чуть позже.) Кроме способности определять месторасположение утилиты shell имеет несколько встроенных команд, которые выполняются непосредственно оболочкой. Сейчас мы рассмотрим наиболее полезные из них — echo и cd.
Вывод информации на экран: echo
Встроенная команда echo выводит свои данные, указанные в качестве аргументов, на стандартный вывод. Все командные интерпретаторы имеют эту встроенную функцию, но кроме нее может быть использована и утилита echo (которая по умолчанию находится в каталоге /bin). Если вы пишете скрипты для различных shell, использование утилиты оправданно, т. к. в разных командных оболочках встроенные команды могут вести себя по-разному и требовать различных аргументов.
Синтаксис
echo {аргументы} ★
Встроенная команда shell echo (эхо) выводит следующие за ней аргументы на стандартный выход. По умолчанию форматирует данные, используя символ перевода строки.
Смена каталогов: cd
Со встроенной командой cd, изменяющей текущий рабочий каталог, мы познакомились в главе 2.
Метасимволы
Некоторые знаки обрабатываются shell специальным образом и называются метасимволами. Все командные интерпретаторы поддерживают основной набор метасимволов, представленных в табл. 4.2. После ввода команды shell анализирует ее на наличие метасимволов и обрабатывает их специальным образом.
Таблица 4.2. Метасимволы shell
Символ
Описание
Перенаправление вывода; записывает стандартный вывод в файл
Перенаправление вывода; добавляет стандартный вывод в файл
Таблица 4.2 (окончание)
Символ Описание
< Перенаправление ввода; читает стандартный ввод из файла
★ Групповой символ замены файла; соответствует нулю или большему количеству символов
9 Групповой символ замены файла; соответствует любому единственному символу
[. .] Групповой символ замены файла; соответствует любому символу между скобками
'команда' Замещение команды; заменяется выводом команды
I Символ конвейера; посылает вывод одного процесса на ввод другого
г Используется в последовательности команд
I Условное выполнение; выполняет команду, если предыдущая завершилась с ошибкой
&& Условное выполнение; выполняет команду, если предыдущая команда была успешной
( • • ) Группирует команды
& Выполняет команду в фоновом режиме
# Все символы, которые следуют за #, до символа перевода строки, игнорируются shell и программами (т. е. символизирует комментарий)
$ Раскрывает значение переменной
\ Предотвращает специальную интерпретацию следующего символа
<< tok Переназначение ввода; читает стандартный ввод из скрипта до tok
После обработки метасимволов выполняется сама команда. Для того чтобы отменить интерпретацию символа, как специального, используйте перед ним косую черту (\). Например:
$ echo hi > file
$ cat file
hi
$ echo hi \> file
hi > file
$
...сохранить вывод echo в file.
...посмотреть содержимое file.
...запретить метасимвол >.
...> интерпретируется подобно другим символам.
...и вывод идет на терминал вместо файла.
Перенаправление ввода/вывода
Средство перенаправления позволяет:
□ сохранить вывод процесса в файл (перенаправление вывода)}
П использовать содержимое файла как входные данные процесса (переназначение ввода).
Рассмотрим эти задачи подробнее.
Перенаправление вывода
Перенаправление вывода удобно, т. к. дает возможность сохранить вывод процесса в файл, который может быть просмотрен, напечатан, отредактирован или использован как вход для другого процесса. Чтобы перенаправить вывод, используйте метасимволы > или ». Последовательность
$ команда > имяФайла
посылает стандартный вывод команды в файл с именем имяФайла. Командный интерпретатор создает файл с именем имяФайла, если тот еще не существует, или перезаписывает его предыдущее содержимое. Если файл существует и не имеет разрешения на запись, выводится сообщение об ошибке.
Создадим файл alice.txt, в который перенаправим вывод утилиты cat. Вызываемая без параметров утилита cat просто записывает данные, полученные со стандартного входа (в данном случае с клавиатуры) на свой стандартный вывод:
$ cat > alice.txt ...создать текстовый файл.
In ту dreams that fill the night,
I see your eyes,
... конец ввода.
$ cat alice.txt ...посмотреть его содержимое.
In my dreams that fill the night, I see your eyes,
$ _
Последовательность
$ команда » имяФайла
добавляет стандартный ВЫВОД команды В файл С именем имяФайла. Командный интерпретатор создает файл с именем имяФайла, если тот еще не существует. Добавим какой-нибудь текст к созданному ранее файлу alice.txt:
$ cat » alice.txt ...добавить к файлу.
And I fall into them, Like Alice fell into Wonderland.
..конец ввода.
$ cat alice.txt ...посмотреть новое содержимое. In my dreams that fill the night, I see your eyes, And I fall into them, Like Alice fell into Wonderland. $ _
По умолчанию обе формы перенаправления выводят на терминал сообщение об ошибке в случае сбоя. В С shell, Korn shell и Bash также предусмотрена защита против случайного переписывания файла из-за переназначения вывода. (Эти возможности подробно описаны в следующих главах.)
Переназначение ввода
Переназначение ввода полезно, поскольку исходные данные для выполнения команды можно взять из файла, созданного ранее. Чтобы переназначить ввод, используйте метасимволы < или «. Последовательность
$ команда < имяФайла
выполняет команду, используя содержимое файла имяФайла, как стандартный ввод. Если файл не существует или не имеет разрешения на чтение, выводится сообщение об ошибке.
Для примера перешлем содержимое созданного нами файла alice.txt, используя УТИЛИТУ mail: $ mail glass < alice.txt ...послать почту самому себе. $ mail ...посмотреть свою почту.
Mail version SMI 4.0 Sat Oct 13 20:32:29 PDT 1990 Type ? for help.
>N 1 glass@utdallas.edu Mon Feb 2 13:29 17/550
& 1 ...прочитать сообщение #1.
From: Graham Glass <glass@utdallas.edu> To: glass@utdallas.edu
In my dreams that fill the night, I see your eyes, And I fall into them, Like Alice fell into Wonderland & q ... завершить работу c mail.
$ _
Последовательность $ команда « слово
позволяет скопировать в буфер входные данные до слова, а затем выполняет команду, используя буфер. Чуть позже мы рассмотрим эту возможность, которая используется в основном для передачи потока данных другим командам.
Групповые символы поиска файлов
Все командные оболочки поддерживают возможность поиска по шаблону. Любое слово в командной строке, которое содержит, по крайней мере, один метасимвол, рассматривается как шаблон и заменяется отсортированным в алфавитном порядке списком всех соответствующих ему имен файлов. Эта процедура называется globbing (универсализация файловых имен). В табл. 4.3 приведены такие символы и их значения.
Таблица 4.3. Символы поиска в shell
Групповой символ Описание
* Соответствует любой строке, включая пустую строку
? Соответствует любому единственному символу
[ • - ] Соответствует любому из символов в скобках. Диапазон символов может быть определен, разделением пары символов чертой
Вы можете запретить командному интерпретатору обрабатывать шаблоны в строке, заключив их в апострофы или двойные кавычки. Вот несколько примеров использования шаблонов:
$ Is -FR ...рекурсивно выводит мой текущий каталог,
а.с Ь.с сс.с dirl/ dir2/
dirl: d.c e.e
dir2:
f.d g. c
$ 1s *. с ...любой текст с последующим .с.
а. с Ь.с сс.с
$ 1s ?.с . ...один символ с последующим .с.
а. с Ь >. с
$ Is /ас] * ...любая строка, начинающаяся с "а" или "с"
а. с сс.с
$ Is [A-Za-z]* ...любая строка, начинающаяся с буквы.
а. с Ь. с сс. с
$ Is dir*/*.с ...все .с-файлы в каталоге dir*.
dirl/d.c dir2/g.c
$ Is */*.c ...все .с-файлы в любом подкаталоге.
dirl/d.c dir2/g.c
$ Is *2/?. ? ?.?
а.с Ь.с dir2/f.d dir2/g.c
$ _
Программные оболочки по-разному обрабатывают случаи, когда не найдено ни одного соответствия шаблону.
Конвейеры
Командный интерпретатор позволяет использовать стандартный вывод одного процесса как стандартный ввод другого путем их соединения через конвейер с помощью метасимвола |. Последовательность $ команда! | команда2
направляет стандартный вывод команды! на стандартный ввод команды2. Конвейером (pipeline) может быть связано любое количество команд. Конвейеры реализуют основную философию UNIX, исходя из которой большие задачи должны состоять из цепочки более мелких, решаемых предназначенными для этого утилитами. Стандартный канал вывода ошибок передается через стандартный конвейер, хотя некоторые shell поддерживают эту возможность.
В приведенном ниже примере перенаправим вывод утилиты 1s на вход утилиты wc (рис. 4.3), чтобы посчитать количество файлов в текущем каталоге (сл/. главу 2 для получения информации о wc):
$ Is . ..посмотреть текущий каталог.
а.с Ь.с сс.с dirl dir2
$ Is I wc -w ... считать элементы
5
$
Рис. 4.3. Пример конвейера
В следующем примере перенаправим содержимое файла etc/passwd в утилиту awk для того, чтобы извлечь первое поле каждой строки. Вывод awk после этого перенаправим утилите sort, которая отсортирует строки в алфавитном порядке (рис. 4.4). В результате получим отсортированный список всех пользователей системы.
$ head -4 /etc/passwd ...просмотреть файл password. root:eJ2S10rVe8mCg:0:1:Operator:/:/bin/csh nobody:*:65534:65534::/: daemon:*:1:1::/: sys:*:2:2::/:/bin/csh
$ cat /etc/passwd | awk -F: '{print $1}' I sort audit bin daemon glass ingres news nobody root sync sys tim uucp $
Терминал
Рис. 4.4. Сортирующий конвейер
Есть очень удобная утилита tee, позволяющая копировать вывод конвейера в файл и в то же время передавать эти данные дальше по конвейеру. Название этой утилиты навеяно Т-соединением.
Синтаксис
tee -ia {имяФайла} +
Утилита tee записывает данные, которые получает на стандартный вход, в файл и одновременно передает их по конвейеру другим утили
там. Опция -а дописывает данные в конец файла. Опция -i игнорирует прерывания.
Скопируем вывод утилиты who в файл who.capture и одновременно передадим информацию дальше к утилите sort:
$ who I tee who.capture I sort
ables ttyp6 May 3 17:54 (gw.Waterloo.com)
glass ttypO May 3 18:49 (bridgeOS.utdalla)
posey ttyp2 Apr 23 17:44 (blackfoot.utdall)
posey ttyp4 Apr 23 17:44 (blackfoot.utdall)
$ cat who.capture ...посмотреть захваченные данные.
glass ttypO May 3 18:49 (bridgeOS.utdalla)
posey ttyp2 Apr 23 17:44 (blackfoot.utdall)
posey ttyp4 Apr 23 17:44 (blackfoot.utdall)
ables ttyp6 May 3 17:54 (gw.Waterloo.com)
$ .
Замещение команды
Команда, окруженная обратными штрихами ('), выполняется, после чего замещается результатом своей работы. Любой перевод строки в выводе данных заменяется пробелами, как в следующих примерах:
$ echo the date today is 'date'
the date today is Mon Feb 2 00:41:55 CST 1998 $ _
Это дает возможность применять хитрости, передавая, таким образом, результат выполнения команды в конвейер. Например, утилита who (о которой рассказывается в главе 9) выводит список всех пользователей в системе, а утилита wc (описанная в главе 2) подсчитывает число слов или строк в данных со стандартного входа. Объединяя конвейером вывод утилиты who с утилитой wc, можно сосчитать количество пользователей на системе: $ who
posey ttypO Jan 22 15:31 (blackfoot:0.0)
glass ttyp3 Feb 3 00:41 (bridge05.utdalla)
huynh ttyp5 Jan 10 10:39 (atlas.utdallas.e)
$ echo there are who I wc -1' users on the system
there are 3 users on the system $
Вывод результатов выполнения одной команды может использоваться, как часть другой. Например, утилита vi позволяет указать в командной строке список файлов, которые будут отредактированы. В этом случае они открываются редактором один за другим. Утилита grep, вызываемая с опцией -1, описанная в главе 3, выводит в командной строке список всех файлов, соответствующих указанному шаблону. С помощью замещения команды (вывод результатов ее работы) можно одной строкой заставить редактор vi отобразить список всех файлов, заканчивающихся на .с и соответствующих шаблону debug:
$ vi 'grep -1 debug *.c'
Последовательности
Если пользователь вводит серию простых команд или конвейеров, отделенных точкой с запятой (;), shell будет выполнять их последовательно, слева направо. Эту возможность можно применять для ’’опережающего ввода с клавиатуры" тем пользователям, которые любят определять всю последовательность действий сразу. Например:
$ date; pwd; Is ...выполнить три команды в последовательности.
Mon Feb 2 00:11:10 CST 1998
/home/glass/wild
а. с Ь.с сс.с dirl dir2
$ _
Каждая команда в представленной последовательности может иметь индивидуально переадресованный ввод/вывод, как показано в следующем примере:
$ date > date.txt; Is; pwd > pwd. txt
a.c b.c cc.c date.txt dirl dir2
$ cat date.txt ...посмотреть вывод date.
Mon Feb 2 00:12:16 CST 1998
$ cat pwd. txt ...посмотреть вывод pwd.
/home/glass
$ _
Условные последовательности
Каждый UNIX-процесс возвращает определенное значение при завершении. Если процесс возвращает 0, это значит, что ошибок не было, и процесс завершился успешно. В противном случае возвращается 1. Все встроенные
команды shell возвращают 1, если в процессе выполнения произошел сбой. Можно использовать эту информацию следующим образом:
□ если вы задаете последовательность команд, отделенных символами &&, следующая команда выполняется только в случае, если предыдущая команда возвращает 0;
П если вы задаете последовательность команд, отделенных символами | |, следующая команда выполняется в случае, если предыдущая команда возвращает 1.
Метасимволы && и | | эквивалентны соответствующим операторам С и обозначают логическое and и or.
Например, если в процессе компиляции программы в сс (С-компилятор) не обнаружено фатальных ошибок, создается выполняемая программа a.out и возвращается 0. В противном случае возвращается значение, отличное от 0. Приведенная ниже строка компилирует программу с именем myprog.c и выполняет файл a.out в случае, если компиляция прошла успешно:
$ cc myprog.c && a.out
Следующий пример в случае неудачи выводит сообщение об ошибке:
$ cc myprog.c || echo compilation failed.
Группирование команд
Команды могут быть сгруппированы путем заключения их в круглые скобки, что заставляет дочерний shell (subshell) выполнить их. Этим командам доступны те же возможности, что и обычным: перенаправление и конвейеризация, использование стандартного ввода и вывода, канала сообщения об ошибках:
$ date; Is; pwd > out. txt Mon Feb 2 00:33:12 CSTxl998 a. c b. c $ cat out.txt /home/glass
$ (date; Is; pwd) > out. txt Background Processing 159 $ cat out.txt
Mon Feb 2 00:33:28 CST 1998.
...выполнить последовательность
...вывод утилиты date.
...вывод утилиты Is.
...только pwd была перенаправлена.
...сгруппировать и затем перенаправить.
...все выводы были перенаправлены.
а. с
Ь. с /home/glass $
Фоновое выполнение
Если вы завершаете простую команду, конвейер, последовательность конвейеров или группу команд метасимволом &, создается дочерний shell для выполнения команды в фоновом режиме, который работает одновременно с родительским shell и не взаимодействует с клавиатурой. Режим очень полезен для выполнения нескольких задач одновременно, если они не требуют ввода с клавиатуры. В системах с графическим интерфейсом принято выполнять каждую команду в отдельном окне, а не использовать для этого возможность фоновой обработки. Когда создается фоновый процесс, shell выводит информацию, которая может применяться в дальнейшем для управления этим процессом. Формат такой информации различен для каждого shell.
Для того чтобы найти файл с именем а.с, вызовем утилиту find в приоритетном режиме. Она выполняется достаточно долго, поэтому запустим еще раз find в фоновом режиме. В этом случае shell выведет ID (уникальный номер) фонового процесса и приглашение, предлагая тем самым продолжить работу. Вывод результатов работы фонового процесса будет появляться на основном терминале, что, согласитесь, неудобно. Мы научимся использовать ID для управления процессом и подавления вывода результатов на основной терминал в следующих разделах этой главы. Приведенный ниже пример иллюстрирует поиск файла а.с:
$ find . -пате а.с -print /wild/а.с /reverse/tmp/а.с
$ find . -name Ь.с -print & 27174
$ date /wild/Ь.с Mon Feb 2 18:10:42 CST 1998 $ ./reverse/tmp/b.c
...появился после
...поиск а.с.
...поиск в фоновом режиме.
...ID процесса.
...запуск date в приоритетном режиме. вывод произведен фоновой утилитой find, вывод утилиты date.
еще от фоновой утилиты find.
того, как мы получили приглашение shell,
...поэтому мы не увидели нового приглашения.
Вы можете задать несколько фоновых вызовов в одной строке, отделяя их друг от друга амперсантом, как показано в следующем примере:
$ date & pwd & 27310 27311
Mon Feb 2 18:37:22 CST 1998 /home/glass $
...создать два фоновых процесса.
...ID процесса для date.
...ID процесса для pwd.
...вывод утилиты date.
. . . вывод утилиты pwd.
Перенаправление фоновых процессов
Перенаправление вывода
Чтобы воспрепятствовать отображению фонового процесса на терминале, перенаправьте его вывод в файл. В следующем примере показана переадресация стандартного вывода утилиты find в файл find.txt. По мере выполнения команды можно наблюдать увеличение занимаемого им объема, исполь
зуя утилиту is:
$ find. . -name а. с 27188
$ Is -1 find.txt -rw-r—r— 1 glass $ Is -1 find.txt -rw-r—r— 1 glass $ cat find.txt ./wild/а.c
-print > find-, txt &
...ID процесса для find.
...посмотреть find.txt.
0 Feb 3 18:11 find.txt
...наблюдать его увеличение.
29 Feb 3 18:11 find.txt
...просмотреть find.txt.
./reverse/tmp/а.c
$
Другой альтернативой является отправка вывода по почте самому себе, как показано в приведенном ниже примере:
$ find . -name а. с -print I mail glass & 27193
$ сс program.с ...выполнять другую полезную работу. $ mail ...читать свою почту.
Mail version SMI 4.0 Sat Oct 13 20:32:29 PDT 1990 Type ? for help.
>N 1 glass@utdallas.edu Mon Feb 3 18:12 10/346 & 1 From: Graham Glass <glass@utdallas.edu> To: glass@utdallas.edu ./wild/a.c ...вывод утилиты find.
./reverse/tmp/а.c & g $ _
Некоторые утилиты также осуществляют вывод в стандартный канал ошибок, который должен быть перенаправлен в дополнение к стандартному выводу. В следующей главе подробно описано, как это делается, а сейчас просто приведем пример реализации этой возможности в Bourne Korn shell: $ man ps > ps.txt & ...сохранить документацию в фоновом режиме.
27203
$ Reformatting page. Wait done
man ps > ps.txt 2>&1 & 27212
$
...приглашение shell появилось здесь.
...стандартное сообщение об ошибке.
...перенаправление канала ошибок.
...все выводы перенаправлены.
Перенаправление ввода
Когда фоновый процесс пытается читать данные с терминала, последний автоматически посылает ему сигнал ошибки, который приводит к завершению процесса. Представленный ниже пример иллюстрирует запуск утилиты chsh в фоновом режиме. Сразу после запуска появляется сообщение, что терминал не был изменен. Если же мы запустим фоновое выполнение утилиты mail, на нашем экране отобразится строка "No message !?!" ("Нет сообщения!?!"):
$ chsh & ...запуск chsh, как фонового процесса.
27201
$ Changing NTS login shell for glass on csservrl.
Old shell: /bin/sh
New shell: Login shell unchanged. ...не ожидает ввода.
mail glass & ...запуск mail, как фонового процесса.
27202
$ No message !?! ...не ожидает ввода с клавиатуры.
Программы shell: скрипты
Любая последовательность команд shell может быть сохранена в обычном текстовом файле и выполнена позднее. Файл, который содержит команды shell, называется скриптом. Прежде чем выполнить скрипт, необходимо установить разрешение на его выполнение с помощью утилиты chmod. Далее для запуска скрипта потребуется лишь указать его имя. Скрипты полезны для хранения часто используемых последовательностей команд. Могут состоять как из одной, так и из нескольких сотен строк. Структуры управления, встроенные в shell, достаточно мощны, чтобы решать широкий диапазон задач. Скрипты значительно облегчают работу системного администратора, автоматизируя такие задачи, как предупреждение пользователей о превышении объема дискового пространства, мониторинг системы и т. д. При запуске скрипта система определяет, для какого командного интерпретатора он был написан, и затем запускает оболочку, используя содержимое файла скрипта как стандартный ввод. Чтобы определить оболочку, для ко
торой написан скрипт, программа анализирует его первую строку, используя следующие правила:
П если первая строка содержит только символ #, то скрипт интерпретируется тем shell, из которого он был вызван;
П если первая строка имеет формат ?#.' путевоеИмя, тогда для интерпретации используется программа, месторасположение которой указано в параметре путевоеИмя',
□ если ни одно из двух первых правил не применимо, то скрипт интерпретируется Bourne shell.
Если символ # появляется на любой строке кроме первой, все символы до конца этой строки рассматриваются как комментарий. Комментирование скриптов является хорошим тоном программирования, облегчающим работу с кодом. Для указания оболочки, интерпретирующей скрипт, лучше всего использовать формат #!, т. к. он понятен всем командным интерпретаторам. Приведенный ниже пример иллюстрирует содержимое и выполнение скриптов для С shell и Korn shell:
$ cat > script.csh
#l/bin/csh
...создать скрипт для C shell.
# Это пример скрипта для С shell.
echo -n the date today is
date
# в csh,, -n опускает перевод строки # вывести сегодняшнюю дату.
... конец ввода.
$ cat > script.ksh ...создать скрипт для Korn shell.
#/ /bin/ksh
# Это пример скрипта для Korn shell.
echo "the date today is \c" Ив ksh, \c опускает перевод строки date # вывести сегодняшнюю дату.
... конец ввода.
$ chmod +х script.csh script.ksh ...сделать их исполняемыми.
$ Is -IF script.csh script.ksh ...посмотреть атрибуты.
-rwxr-xr-x 1 glass 138 Feb 1 19:46 script.csh*
-rwxr-xr-x 1 glass 142 Feb 1 19:47 script.ksh*
$ script.csh ...выполнить скрипт C shell.
the date today is Sun Feb 1 19:50:00 CST 1998
$ script.ksh ... выполнить. скрипт Korn shell.
the date today is Sun Feb 1 19:50:05 CST 1998
Расширения csh и ksh в данном примере используются только для ясности; скрипты могут называться как угодно и даже не нуждаются в расширении. Обратите внимание на использование \с и -п в качестве аргументов утилиты echo. Вид символа запрещения перевода строки способен варьироваться в зависимости от версии утилиты. Это может зависеть также от используемого shell: если оболочка имеет встроенную функцию echo, то специфические особенности утилиты не имеют значения.
Дочерние shell
Когда вы регистрируетесь в системе UNIX, запускается командный интерпретатор. Этот shell выполняет любые вводимые вами команды. Однако в некоторых случаях ваш текущий (родительский) shell создает новый (дочерний) для выполнения некоторых задач:
□ родительский shell создает дочерний shell, чтобы выполнить сгруппированные утилиты, такие как is, pwd, date. Если команда выполняется не в фоновом режиме, то родительский shell бездействует до тех пор, пока дочерний не завершит работу;
П при выполнении скрипта родительский shell создает дочерний, чтобы его выполнить;
П если задание выполняется в фоновом режиме, родительский shell также создает дочерний shell и продолжает работать одновременно с ним.
Дочерний shell называется subshell. Точно так же как любой другой процесс UNIX, subshell имеет свой собственный текущий рабочий каталог, так что перемещение при помощи команды cd, выполненное в subshell, не затрагивает родительской оболочки.
Рассмотрим пример:
$ pwd ...вывести текущий каталог моего входного shell.
/home/glass
$ (cd /; pwd) ...subshell перемещает и выполняет pwd.
/ ...вывод исходит от subshell.
$ pwd ...мой входной shell никогда не перемещался,
/home/glass
$ _
Каждый shell содержит две области данных: пространство переменных окружающей среды и пространство локальных переменных. Дочерний shell наследует копию пространства переменных окружающей среды своего родителя и получает чистое пространство локальных переменных, как показано на рис. 4.5. '
Дочерний shell
Рис. 4.5. Области данных subshell
Переменные
Командный интерпретатор поддерживает два вида переменных: переменные окружения и локальные. Оба типа являются строковыми. Основное различие между ними в том, что переменные окружения наследуются при запуске дочернего shell, в то время как локальные переменные не передаются. В переменных окружения хранится информация, передаваемая между родительским и дочерним shell.
Каждый shell имеет набор предопределенных переменных окружения, которые обычно инициализируются файлами запуска, описанными в следующих главах. Аналогично, каждый shell имеет набор предустановленных локальных переменных. Однако и те, и другие могут быть созданы в случае необходимости, что очень удобно для написания скриптов. В табл. 4.4 перечислены предопределенные переменные окружения, общие для всех shell.
Таблица 4.4. Предопределенные переменные окружения
Имя Описание
$НОМЕ Полное путевое имя пользовательского домашнего каталога
$РАТН Список каталогов для поиска команд
$MAIL Полное путевое имя пользовательского почтового ящика
$USER Ваше имя пользователя
$SHELL Полное путевое имя пользовательского входного shell
$TERM Тип пользовательского терминала
Синтаксис назначения переменных отличается в разных shell, но способ, которым вы получаете доступ к переменным, один и тот же: при добавлении приставки $ к имени переменной эта символическая последовательность заменяется значением указанной переменной.
Чтобы создать переменную, просто присваивают ей значение:
variableName=value ...не ставьте пробелы вокруг =.
В следующем примере выводятся значения некоторых общих переменных окружающей среды shell:
$ echo HOME = $НСМЕ, PATH = $РАТН . . .вывести две переменных.
НОМЕ = /home/glass, PATH = /bin:/usr/bin:/usr/sbin
$ echo MAIL = $MAIL ...вывести другую.
MAIL = /var/mail/glass
$ echo USER = $USER, SHELL = $SHELL, TERM=$TERM
USER = glass, SHELL = /bin/sh, TERM=vtlOO
$ _
Приведенный ниже пример иллюстрирует различие между локальными переменными и переменными окружающей среды. Присвоим значение двум локальным переменным и затем сделаем одну из них переменной окружающей среды, используя команду export Bourne shell (подробно описанную главе 5). Затем создадим дочерний Bourne shell и выведем значения переменных, для которых было выполнено присвоение в родительском shell. Обратите внимание, что значение переменной окружающей среды было скопировано в дочерний shell, а значение локальной переменной нет. В конце нажмем комбинацию клавиш <Ctrl>+<D>, чтобы завершить работу дочернего shell и возобновить выполнение родительского, а потом выведем первоначальные переменные:
$ firstname=Graham ...присвоить значение локальной переменной.
$ lastname=Glass ...присвоить значение другой локальной переменной.
$ echo $firstname $lastname ...вывести их значения.
Graham Glass
$ export lastname ...сделать lastname переменной окружающей среды.
$ sh ...запустить дочерний shell; родительский приостановлен.
$ echo $firstname $lastname ...вывести значения снова.
Glass ...заметьте, что firstname не было скопировано.
$ ...завершить дочерний; родительский возобновлен.
$ echo $firstname $lastname ...они остались неизменными.
Graham Glass
$
В табл. 4.5 приведено несколько общих встроенных переменных, имеющих специальное значение. Первая специальная переменная особенно полезна для создания временных имен файлов, а остальные — для доступа к аргументам командной строки в скриптах shell. Ниже в примере были использованы все специальные переменные:
$ cat script.sh ...вывести скрипт.
echo the name of this script is $0
echo the first argument is $1
echo a list of all the arguments is $*
echo this script places the date into a temporary file
ecAo called $1.$$
date >$1.$$ # перенаправить вывод date.
Is $1.$$ # посмотреть файл.
rm $1.$$ # удалить файл.
$ script.sh paul ringo george john ...выполнить его.
the name of this script is script.sh
the first argument is paul
a list of all the arguments is paul ringo george john
this script places the date into a temporary file
called paul.24321
paul.24321 $
Таблица 4.5. Специальные встроенные переменные shell
Имя Описание
$$ ID процесса shell
Имя скрипта shell (если применимо)
$1. . $ 9 ссылается на n-й аргумент командной строки (если применимо)
$ * Список всех аргументов командной строки
Использование кавычек
Часто бывает необходимо заместить групповой символ переменной или использовать механизмы замещения команд. Система расстановки кавычек shell позволяет сделать именно это.
Существуют правила их расстановки:
□ одинарные кавычки1 (’) подавляют замещение группового символа, переменной и команды;
П двойные кавычки (") подавляют замещение только группового символа;
□ если кавычки вложены, то внешние кавычки не вызывают замещение.
Следующий пример иллюстрирует различие между двумя видами кавычек:
$ echo 3*4 =12 ...помните, * — это групповой символ.
3 а.с Ь.с с.с 4 = 12
$ echo "3 * 4 = 12" ...двойные кавычки подавляют групповые символы.
3 * 4 = 12
$ echo '3 * 4 = 12' ...одинарные кавычки подавляют групповые символы.
3 * 4 = 12
$ name=Graham
Заключая текст в одинарные кавычки, мы подавляем подстановку группового символа, переменной и команды:
$ echo 'ту name is $пате - date is 'date''
my name is $name - date is 'date'
Заключая текст в двойные кавычки, мы подавляем подстановку группового символа, но разрешаем замещение переменной и команды:
$ echo "ту name is $пате - date is 'date'"
my name is Graham - date is Mon Feb 2 23:14:56 CST 1998
$ _
Перенаправление ввода в буфер shell
Ранее в этой главе мы уже упомянули метасимвол «, и теперь пришло время поговорить о нем подробнее. Когда shell сталкивается с последовательностью вида
$ команда « слово
он копирует собственный стандартный ввод до строки, начинающейся со слова, в буфер shell и затем выполняет команду, используя содержимое буфера в качестве своего стандартного ввода. Если слово не встречается в тексте, Bourne shell и Korn shell прекращают копировать ввод, когда они достигают конца скрипта, а С shell выводит сообщение об ошибке. Все ссылки на переменные shell в скопированном тексте заменяются их значениями.
1 В книге также встречается название "апострофы". — Ред.
Чаще всего метасимвол « используется при передаче данных из скрипта на стандартный ввод других команд без применения вспомогательных файлов. Пример:
$ cat here.sh ...посмотреть пример.
mail $1 « ENDOFTEXT
Dear $1,
Please see me regarding some exciting news!
- $USER
ENDOFTEXT
echo mail sent to $1
$ here.sh glass ...послать почту самому себе, используя скрипт. • I
mail sent to glass
$ mail ...посмотреть свою почту.
Mail version SMI 4.0 Sat Oct 13 20:32:29 PDT 1990 Type ? for help.
>N 1 glass@utdallas.edu Mon Feb 2 13:34 12/384
& 1 ...прочитать сообщение #1.
From: Graham Glass <glass@utdallas.edu>
To: glass@utdallas.edu
Dear glass, Please see me regarding some exciting news! glass
& q ...завершить работу утилиты mail.
$
Управление работой
Поддержка многозадачности — одна из привлекательнейших особенностей UNIX, и чтобы использовать ее в полной мере, важно иметь возможность управлять процессами. Помогут в этом деле две утилиты и одна встроенная команда:
□ утилита ps генерирует список процессов и их атрибуты, такие как имена, ID процессов, управляющие терминалы и имена входа владельцев;
□ утилита/команда kill завершает процесс, используя его ID;
□ команда wait указывает shell на необходимость подождать завершения одного из дочерних процессов.
Статус процесса: ps
Утилита ps позволяет осуществлять контроль статуса текущих процессов. Используем утилиту sleep, чтобы задержать работу команды echo и выполнить ее в фоновом режиме. Далее запустим утилиту ps, чтобы получить список текущих процессов. Все процессы принадлежат sh — Bourne shell:
$ (sleep 10; echo done) & 27387
$ ps
PID TTY TIME CMD
27355 pts/3 0:00 -sh
27387 pts/3 0:00 -sh
27388 pts/3 0:00 sleep 10
27389 pts/3 0:00 PS
$ done
...задержать echo в фоновом режиме.
...ID процесса.
...получить список статуса процессов.
...входной shell.
...subshell.
...утилита sleep.
...сама команда ps!
...вывод из фонового процесса.
Синтаксис
ps -efl
Утилита ps выводит информацию о статусе процесса. По умолчанию вывод ограничен процессами, созданными текущим пользовательским shell. Опция -е указывает ps на необходимость включить в список все процессы, которые в настоящее время выполняются. Опция -f выводит полный список. Опция -1 генерирует расширенный список.
Синтаксис
sleep секунды
Утилита sleep выставляет таймер на указанное количество секунд, после чего завершается.
В табл. 4.6 описаны значения полей утилиты ps.
Таблица 4.6. Значения полей вывода утилиты ps
Поле Описание
S Состояние процесса
UID Эффективный пользовательский ID процесса
Таблица 4.6 (окончание)
Поле Описание
PID ID процесса
PPID ID родительского процесса
С Процент времени ЦП, что использовал процесс в последнюю минуту
PRI Приоритет процесса
SZ Размер данных и стека процесса в килобайтах
STIME Время создания процесса или дата, если процесс был создан не сегодня
TTY Управляющий терминал
TIME Время ЦП, использованное до настоящего момента (в формате ММ: ss)
CMD Имя команды
Табл. 4.7 иллюстрирует значения данных в поле s, описывающем состояние процесса.
Таблица 4.7. Коды состояния процесса, сообщаемые утилитой ps
Значение Описание
0 Работает на процессоре
R Работоспособный
S Спящий
т Приостановленный
Z "Убитый" процесс
Значения большинства этих параметров будут описаны позже. Однако сейчас необходимо остановиться на значении двух полей - r и s:
$ (sleep 10; echo done) &
27462
$ ps -f ...запрос ориентированного на пользователя вывода.
UID PID PPID C STIME TTY TIME CMD
glass 731 728 0 21:48:46 pts/5 0:01 -ksh
glass 831 830 1 22:27:06 pts/5 0:00 sleep 10
glass 830 731 0 22:27:06 pts/5 0:00 -ksh
$ done ...вывод предыдущей команды
8 Зак. 786
Если вас интересует работа других пользователей, воспользуйтесь опциями
-е и -f утилиты ps:
$ ps -ef ...вывести все пользовательские процессы.
UID PID PPID С STIME TTY TIME CMD
root 0 0 0 18:58:16 ? 0:01 sched
root 1 0 0 18:58:19 9 0:01 /etc/init -
root 2 0 0 18:58:19 9 0:00 pageout
root 3 0 1 18:58:19 9 0:53 fsflush
root 198 1 0 18:59:38 ? 0:00 /usr/sbin/nscd
root 178 1 0 18:59:35 ? 0:00 /usr/sbin/syslogd
root 302 1 0 18:59:58 9 0:00 /usr/lib/saf/sac
root 125 1 0 18:59:14 9 0:00 /us r/sbin/rpcbind
root 152 1 0 18:59:29 9 0:01 /usr/sbin/inetd -s
root 115 1 0 18:59:13 9 0:00 /usr/sbin/in.routed -q
root 127 1 0 18:59:15 9 0:00 /usr/sbin/keyserv
root 174 1 0 18:59:34 9 0:00 /etc/automountd
glass 731 728 0 21:48:46 p5 0:01 -ksh
$ _
В главе 5 мы рассмотрим программу track, которая использует эти опции для осуществления текущего контроля за другими пользователями. Bourne shell и Korn shell автоматически заканчивают фоновые процессы, когда пользователь выходит из системы, в то время как С shell и Bash продолжают их выполнение. Если вы работаете с Bourne shell или Korn shell и хотите завершить фоновые процессы после выхода из системы, используйте утилиту nohup.
Синтаксис
nohup команда
Утилита nohup выполняет команду и делает ее устойчивой к сигналу отбоя (hup) и завершения (term). Стандартный вывод и канал сообщений об ошибках автоматически переадресовываются в файл nohup.out, а значение приоритета процесса увеличивается на 5, таким образом снижая его приоритет2.
Если команда выполняется с вызовом утилиты nohup, а затем происходит выход из системы, после чего пользователь вновь регистрируется, использо
2 Чем больше значение, тем ниже приоритет. — Ред.
ванная команда не появится в листинге утилиты ps. Это происходит потому, что при выходе из системы процесс теряет свой управляющий терминал и выполняется без него. Для включения в листинг всех процессов без управляющих терминалов следует запустить утилиту ps с опцией -х:
$ nohup sleep 10000 & ...фоновый nohup-процесс
27406
Sending output to ’nohup.out ’ ... сообщение от nohup.
$ ps ...посмотреть процессы.
PID TT STAT TIME COMMAND
27399 p3 S 0:00 -sh (sh)
27406 p3 S N 0:00 sleep 10000
27407 p3 R 0:00 PS
$ • • .выйти из системы.
UNIX(r) System l V Release 4.0
login: < jlass • • .войти в систему.
Password: • • .секрет.
$ ps • • . фоновый процесс не виден.
PID TT STAT TIME COMMAND
27409 p3 S 0:00 -sh (sh)
27411 p3 R 0:00 PS
$ ps -x . . . фоновый процесс может быть виден.
PID TT STAT TIME COMMAND
27406 IN 0:00 sleep 10000
27409 p3 S 0:00 -sh (sh)
27412 p3 R 0:00 ps -x
$ _
Для дополнительной информации об управляющих терминалах см. главу 13.
Процессы передачи сигналов: kill
Если возникла необходимость завершить процесс прежде, чем он закончится, используйте команду kill. Korn shell и С shell содержат встроенную -команду kill, тогда как Bourne shell вместо этого вызывает стандартную утилиту kill. Представленный ниже пример иллюстрирует создание фонового процесса и завершение его командой kill:
$ (sleep 10; echo done) && ...создать фоновый процесс.
27390 ...ID процесса.
$ kill 27390 ..."убить" процесс.
$ ps ... он ушел
PID тт STAT TIME COMMAND
27355 рЗ S 0:00 -sh (sh)
27394 рЗ R 0:00 PS
$
Синтаксис
kill [ -сигналЮ ] {Ю_процесса} + kill -1
Утилита/команда kill посылает сигнал с параметром сигнал_ю списку пронумерованных процессов, сигналю может быть номером или названием сигнала. По умолчанию kill посылает сигнал term (номер 15), получая который, процесс завершается. Чтобы вывести список допустимых названий сигналов, используйте опцию -1. Для передачи сигнала процессу пользователю необходимо быть его владельцем или привилегированным пользователем (для получения более подробной информации о сигналах см. главу 13). Процессы могут игнорировать все сигналы, кроме kill (номер которого 9). Поэтому, чтобы гарантированно завершить процесс, пошлите сигнал номер 9. (Обратите внимание, что отправка сигнала kill не позволяет процессу произвести очистку и закончиться обычным образом, как это делают многие программы при получении сигнала term.) Утилита kill (в противоположность встроенной команде в Korn shell и С shell) имеет параметр pid, равный 0. В главе 6 подробно описано использование команды kill.
Представленный ниже пример иллюстрирует использование опции -1 и идентификаторов сигналов, которые выведены в порядке возрастания:
$ kill -1 ...вывести имен^ сигналов.
HUP INT QUIT ILL TRAP ABRT EMT FPE KILL BUS SEGV SYS PIPE ALRM TERM URG
STOP TSTP CONT CHLD TTIN TTOU IO XCPU XFSZ VTALRM PROF WINCH LOST USR1
USR2
$ (sleep 10; echo done) &
27490 ...ID процесса.
$ kill -KILL 27490 ..."убить" процесс с сигналом номер 9.
$
Данный пример иллюстрирует завершение всех процессов, связанных с текущим терминалом:
$ sleep 30 & sleep 30 & sleep 30 & ...создать три.
27429
27430
27431
$ kill 0 ..."убить" их все.
27431 Terminated
27430 Terminated
27429 Terminated $
Ожидание дочернего процесса: wait
Командный интерпретатор shell может ожидать завершение дочерних процессов, выполняя встроенную команду wait.
Синтаксис
wait [ Ю_процесса ]
Команда wait предписывает командному интерпретатору приостановить работу, пока дочерний процесс с указанным ID в качестве аргумента не завершится. Если аргумент не указан, shell ждет завершения всех дочерних процессов.
В следующем примере shell перед продолжением своей работы ожидает завершения двух дочерних процессов, работающих в фоновом режиме:
$ (sleep 30; echo done 1) & ...создать дочерний процесс.
24193
$ (sleep 30; echo done 2) & ...создать дочерний процесс.
24195
$ echo done 3; wait; echo done 4 ...ждать дочерние процессы.
done 3
done 1 ... вывод первого дочернего процесса.
done 2 ... вывод второго дочернего процесса.
done 4
Поиск команды: $РАТН
При обработке команды shell в первую очередь проверяет, не является ли она встроенной. Если это так, команда выполняется непосредственно shell:
$ echo Некоторые команды выполняются shell непосредственно
Некоторые команды выполняются shell непосредственно $ _
Если команда не встроенная, shell проверяет, начинается ли она с символа /. Если это так, shell интерпретирует его, как первый символ абсолютного пути, и пытается запустить соответствующий файл. Если система не находит данный файл по указанному адресу, возникает ошибка:
$ /bin/Is ...полное путевое имя утилиты 1s. < script.csh script.ksh
$ /bin/nsx ...несуществующее имя файла.
/bin/nsx: not found
$ /etc/passwd ...имя файла password.
/etc/passwd: Permission denied ...он не исполняемый.
$ _
Если введенная последовательность не является ни встроенной командой, ни путем к файлу, shell ищет каталоги, указанные в переменной path. После чего каждый каталог просматривается на предмет наличия в нем заданного файла, и если таковой находится, он выполняется. Если файл не является исполняемым или просто не найден, выводится сообщение об ошибке. Если переменная path не установлена или равна пустой строке, то просматривается только текущий каталог. Значение переменной path может быть изменено, но это будет обсуждаться в следующих главах. Первоначально путь поиска инициализируется файлом запуска shell и обычно включает все стандартные каталоги UNIX, содержащие выполняемые утилиты. Вот некоторые примеры:
$ echo $РАТН
/bin:/usr/bin:/usr/sbin ...просматриваемые каталоги.
$ Is ...расположена в /bin.
script.csh script.ksh $ nsx
...отсутствует.
nsx: not found
Подмена стандартных утилит
Пользователи часто создают каталог bin в своем домашнем каталоге и размещают его перед основным каталогом bin в переменной path. Такой способ позволяет им опередить загрузку установленных по умолчанию утилит UNIX собственными версиями, т. к. поиск в персональных каталогах будет производиться прежде, чем в стандартных. Однако необходимо использовать данную возможность с осторожностью, потому как shell может неправильно интерпретировать нестандартные утилиты.
Рассмотрим пример. Создадим собственный каталог bin, пропишем его в переменной path, после чего поместим в него скрипт is:
$ mkdir bin
$ cd bin
$ cat > Is echo my Is
$ chmod +x Is
$ echo $PATH
. ..создать персональный каталог bin.
...перейти в новый каталог.
...создать скрипт 1s.
...конец ввода.
...сделать его исполняемым.
...посмотреть текущую установку PATH.
/bin:/usr/bin:/usr/sbin
$ echo $HOME ...получить путевое имя моего домашнего каталога, /home/glass
$ РАТН= /home/glass/bin:$РАТН ...обновить.
$ 1s ... вызов 1s.
my Is ... версия подменяет /bin/Is.
$
Внимание
Только этот shell и его дочерние shell находятся под влиянием изменения path.
Все другие shell при этом не затрагиваются.
Завершение и коды выхода
Завершаясь, каждый процесс возвращает числовое значение — код выхода. В соответствии с соглашением, значение кода выхода 0 означает, что процесс завершился успешно, в то время как любое значение, отличное от нуля, — выполнение закончилось неудачей. Все встроенные команды возвращают 1 в случае неудачи. В Bourne shell, Korn shell и Bash специальная переменная $? всегда содержит значение кода выхода предыдущей команды. В С shell это значение содержится в переменной $ status. В представленном
ниже примере утилита date завершилась успешно, тогда как утилиты сс и awk — С ошибкой:
$ date ...date завершилась успешно.
Sat Feb 2 22:13:38 CST 2002
$ echo $? ...вывести ее выходное значение.
0 ...указывает на успех.
$ cc prog, с ...компилировать несуществующую программу.
cpp: Unable to open source file ’prog.с’.
$ echo $? ...вывести ее выходное значение.
1 ...указывает на неудачу.
$ awk ...использовать awk неправильно.
awk: Usage: awk . [-Fc] [-f source ’cmds’] [files]
$ echo $? ...вывести ее выходное значение.
2 ...указывает на неудачу.
$ _
Любой создаваемый пользователем скрипт должен возвращать код выхода. Чтобы завершить скрипт, используйте встроенную команду exit. Если оператор exit не указан в скрипте, по умолчанию возвращается значение выхода последней команды. Скрипт в представленном ниже примере возвратил значение 3:
$ cat script, sh ...просмотреть скрипт.
echo this script returns an exit code of 3 exit 3
$ script.sh ...выполнить скрипт.
this script returns an exit code of 3
$ echo $? . ...посмотреть выходное значение.
3
$
Синтаксис
exit номер
Команда exit заканчивает выполнение и возвращает значение выхода родительскому процессу. Если аргумент номер опущен, то используется значение выхода предыдущей команды.
В следующей главе представлено несколько примеров скриптов, использующих значения выхода.
Основные встроенные команды
Большое число встроенных команд поддерживается четырьмя командными интерпретаторами, но только несколько команд являются общими для всех. Этот раздел описывает наиболее полезные общие команды.
eval
Команда eval выполняет вывод команды, как обычной команды shell.
Синтаксис
eval команда
Команда eval выполняет вывод команды, как обычную команду shell. Она полезна при обработке вывода утилит, которые генерируют команды shell (например, tset).
В представленном примере переменная х была установлена в результате выполнения команды echo:
$ echo х=5 ...первое выполнение echo напрямую.
х=5
$ eval 'echo х=5' ...выполнить результат echo.
$ echo $х ...подтвердить, что х было присвоено 5.
5
$
ехес
Команда ехес замещает заданной командой образ shell.
Синтаксис
ехес команда
Команда ехес предписывать заместить образ shell командой в пространстве памяти процесса. Если команда выполнена успешно, выполняющий команду ехес shell завершается. Если этот shell был входным, то сессия работы с системой заканчивается после завершения выполнения команды.
В следующем примере командой ехес была запущена утилита date:
$ exec date ...заместить процесс shell процессом date.
Sun Feb 1 18:55:01 CDT 1998 ...вывод от date.
login: _ ...входной shell завершился.
shift
Синтаксис встроенной команды указан ниже.
Синтаксис
shift
Команда shift изменяет порядковые номера 2, 3, ..., п аргументов, указанных в командной строке на номера 1, 2, п — 1. При этом первый аргумент (с номером 1) теряется. Это особенно удобно в shell-скриптах, когда они циклически обрабатывают ряд параметров командной строки. Если нет никаких позиционных аргументов, оставленных для сдвига, выводится сообщение об ошибке.
Следующий пример содержит скрипт С shell, в котором демонстрируются аргументы команды перед и после сдвига.
$ cat shift.csh ...посмотреть скрипт.
#!/bin/csh
echo first argument is $1, all args* are $* shift
echo first argument is $1, all args are $*
$ shift, csh abed ...выполнить с четырьмя аргументами.
first argument is a, all args are abed
first argument is b, all args are bed
$ shift, csh а ...выполнить с одним аргументом. .
first argument is a, all args are a
first argument is , all args are .
$ shift.csh ' ...выполнить без аргументов.
first argument is f all args are
shift: No more words ...сообщение об ошибке.
umask
Когда С-программа создает файл, первоначальная установка параметров полномочий задается как восьмеричное значение, передаваемое системному вызову open (). Например, чтобы создать файл с разрешением на чтение и запись для владельца, группы и остальных пользователей, программа выполнила бы следующий системный вызов:
fd = open ("myFile", OCREAT | ORDWR, 0666);
Для получения информации относительно шифрования параметров полномочий в виде восьмеричного числа см. главу 2. Системный вызов open () более подробно описан в главе 13. Когда shell выполняет перенаправление (с помощью символа >), он использует последовательность системного вызова, подобную показанной в предыдущем примере, чтобы создать файл с восьмеричным разрешением 666. Однако, если вы попробуете создать файл, указывая символ переназначения >, то скорее всего получите файл с установкой параметров полномочий 644 (восьмеричное), как показано в следующем примере:
$ date > date.txt
$ Is -1 date.txt
-rw-r—r— 1 glass 29 May 3 18:56 date.txt
$ _
Причина различия в установке параметров полномочий состоит в том, что каждый процесс UNIX содержит специальную величину umask, используемую для ограничения назначения параметров полномочий и запрашиваемую системой во время создания файла. По умолчанию величина umask равна восьмеричному значению 022. Набор битов значения umask маскирует набор битов требуемой установки параметров полномочий. В предыдущем примере требуемые параметры полномочий 666 были замаскированы значением 022, что в результате дало 644. В табл. 4.8 приведена расшифровка параметров umask и получаемых в результате наложения значений.
Таблица 4.8. Побитовый пример эффекта установки umask
rwx rwx rwx
Начальный 110110110
Маска 000010010
Финальный 110100100
Если файл уже существует до перенаправления в него вывода, значения первоначальных параметров полномочий файла сохраняются, а значение umask игнорируется.
Синтаксис
umask [восьмеричнаяВеличина]
Команда shell umask присваивает umask указанное восьмеричное число или, если аргумент опущен, показывает текущее значение umask. Значение umask сохраняется до следующего изменения. Дочерние процессы наследуют свое значение umask от родителей.
В следующем примере значение umask изменено на 0, после чего был создан новый файл:
$ umask ...вывести текущее значение umask.
22 ...маскирует разрешение записи для группы/других.
$ umask 0 ...установить значение umask на 0.
$ date > date2.txt ...создать новый файл.
$ Is -1 date2.txt
— rw—rw—rw— 1 glass 29 May 3 18:56 date2.txt
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
□ общую функциональность четырех основных командных интерпретаторов;
□ общие метасимволы shell;
□ перенаправление ввода и вывода;
□ подстановку имени файла;
□ конвейеры;
□ подстановку команды;
□ командные последовательности;
□ сгруппированные команды;
□ создание скриптов;
□ различие между локальными переменными и переменными окружения;
□ два различных типа кавычек;
□ основы управления работой;
□ механизм поиска команды;
□ несколько основных встроенных команд.
Контрольные вопросы
1. Можете ли вы изменить shell, установленный по умолчанию?
2. Какая команда UNIX используется для того, чтобы изменить текущий пользовательский каталог?
3. Как вы можете ввести команды, которые длиннее одной строки терминала?
4. В чем заключается различие между встроенной командой и утилитой?
5. Как сделать скрипт исполняемым?
6. Как иногда называется замещение имени файла?
7. Объясните использование замещения команды.
8. Объясните значения терминов "родительский shell", "дочерний shell" и "subshell".
9. Как вы думаете, почему команда kin получила свое имя?
10. Опишите способ подмены стандартной утилиты.
11. Чем удобна величина umask и почему?
Упражнения
4.1. Напишите скрипт, который печатает текущую дату, ваше пользовательское имя и название вашего входного shell. [Уровень: легкий.]
4.2. Поэкспериментируйте с командой ехес путем создания серии из трех shell-скриптов a.sh, b.sh и c.sh, каждый из которых выводит свое имя, выполняет утилиту ps и затем вызывает при помощи ехес следующий скрипт этой последовательности. Пронаблюдайте, что происходит, когда вы запускаете первый скрипт, выполняя ехес а. sh. [Уровень: средний.]
4.3. Объясните, почему файл, который создан в следующей сессии, не затрагивается значением umask? [Уровень: средний.]
$ Is -1 date.txt
-rw-rw-rw- 1 glass 29 Aug 20 21:04 date.txt
$ umask 0077
$ date > date.txt
$ Is -1 date.txt
-rw-rw-rw- 1 glass 29 Aug 20 21:04 date.txt
4.4. Напишите скрипт, который создает три фоновых процесса, ждет их завершения, после чего выводит простое сообщение. [Уровень: средний.]
Проект
Сравните и противопоставьте особенности командного интерпретатора
UNIX с графическими shell, доступными в Windows. [Уровень: средний.]
Глава 5
Bourne shell
Мотивация
Командный интерпретатор Bourne shell, написанный Стивеном Боурном (Stephen Bourne), был первым популярным UNIX shell и сейчас присутствует во всех UNIX-системах. Он поддерживает довольно универсальный язык программирования и похож на более мощный Кот shell, который описан в главе 6. Знание Bourne shell поможет вам понять работу многих скриптов, уже написанных для UNIX, а также подготовит к знакомству с Кот shell.
Предпосылки
Перед чтением данной главы вам необходимо ознакомиться с главой 4 и поэкспериментировать с основными функциями shell.
Задачи
В этой главе мы познакомимся со специфическими для Bourne shell функциями, включая использование локальных переменных и переменных окружения, встроенного языка программирования и средств перенаправления ввода/вывода.
Изложение
Как обычно, материал главы представлен в виде нескольких UNIX-сессий, что позволяет увидеть в работе обсуждаемое в теории.
Утилиты
В этой главе мы познакомимся с утилитами: expr test
Команды shell
Ниже перечислены команды shell, которые будут рассмотрены в данной главе.
break for...in...do...done set
case...in...esac if...then...elif...fi trap
continue read while...do...done
export readonly
Общие сведения о Bourne shell
Bourne shell поддерживает все основные функции программной оболочки, описанные в главе 4, а также следующие специфические возможности (рис. 5.1):
□ несколько способов задания значений и доступа к переменным;
П встроенный язык программирования, который обеспечивает условные переходы, организацию циклов и обработку прерываний;
□ усовершенствованные средства перенаправления и работы с последовательностью команд;
П несколько новых встроенных команд.
Рис. 5.1. Функции Bourne shell
Запуск
Bourne shell — это обычная С-программа, исполняемый файл которой хранится в каталоге /bin/sh. Если оболочка является установленной по умолчанию, то она запускается автоматически в процессе регистрации в системе. Можно также вызвать Bourne shell вручную из скрипта или с терминала, используя команду sh.
Когда Bourne shell стартует в диалоговом режиме, он ищет файл .profile в домашнем каталоге пользователя. Если файл найден, то выполняются все команды shell, содержащиеся в файле. Затем, независимо от того, был ли .profile найден, диалоговый режим Bourne shell выводит свое приглашение и ждет пользовательских команд. Стандартное приглашение Bourne shell — это символ $, хотя он может быть изменен путем установки локальной переменной psi, о которой мы поговорим чуть позже.
Внимание
Если Bourne shell запущен не в диалоговом режиме, файл не читается.
Одно из обычных применений .profile — это инициализация переменных окружения типа term (содержит тип пользовательского терминала) и path (сообщает shell, где искать исполняемые файлы). Вот пример файла запуска .profile для Bourne shell:
TERM=vtlOO # установка типа терминала.
export TERM # скопировать в окружение.
# Установить путь и метасимволы
stty erase ,1Л?" kill "Ли" intr ”ЛС” eof
РАТН='.:$HOME/bin:/bin:/usr/sbin:/usr/bin:/usr/local/Ып’
Переменные
Bourne shell поддерживает следующие действия с переменными:
П простое назначение и доступ;
□ проверка переменной на существование;
□ чтение переменной со стандартного ввода;
□ создание неизменяемой переменной;
□ экспорт локальной переменной в переменные окружения.
Командный интерпретатор Bourne shell также определяет несколько локальных переменных и переменных окружения в дополнение к тем, которые были рассмотрены в главе 4.
Создание и назначение переменной
Bourne shell имеет следующий синтаксис для присвоения значения переменной:
{имя=значение}+
Если переменная не существует, она неявно создается; иначе ее предыдущее значение переписывается. Недавно созданная переменная всегда локальна,
хотя может быть превращена в переменную окружения способом, о котором мы поговорим позднее. Чтобы присвоить значение, которое содержит пробелы, обрамите его кавычками. Например:
$ firstName=Graham lastName-Glass аде=29 ...назначение переменных.
$ echo $firstName $lastName is $age
Graham Glass is 29 ...простой доступ.
$ name=Graham Glass ...синтаксическая ошибка.
Glass: not found
$ name="Graham Glass" ...используйте кавычки для задания строк.
$ echo $name ...теперь это работает.
Graham Glass
$
Доступ к переменной
Bourne shell поддерживает методы доступа к переменным, перечисленные в табл. 5.1. Если доступ к переменной осуществляется прежде, чем ей присвоено значение, то возвращается пустая строка.
Таблица 5.1. Специальные переменные Bourne shell
Синтаксис Описание
$имя Заменяется значением имя
${имя} Заменяется значением имя. Эта форма полезна, если выражение следует сразу за алфавитно-цифровым символом, который иначе интерпретировался бы как часть имени переменной
${имя-слово} Заменяется значением имя, если оно установлено, в противном случае — слово
${имя+слово} Заменяется слово, если имя установлено, в противном случае ничего не делает
${name=word} Присваивает слово переменной имя, если имя еще не установлено, и затем заменяется значением имя
${имя?слово} Заменяется имя, если имя установлено. Если имя не установлено, слово выводится в стандартный канал ошибки, и происходит выход из shell. Если слово опущено, то вместо этого выводится стандартное сообщение об ошибке
Возможно, указанные методы несколько сложны, однако, даже если вы никогда не будете их использовать, то сможете понимать код, в котором они применяются. Представленные ниже примеры иллюстрируют каждый из
методов доступа. В первом примере мы будем использовать фигурные скобки, чтобы добавить строку к значению переменной:
$ verb=sing ...определить переменную.
$ echo I like $verbing ...нет переменной verbing.
I like
$ echo 1 like ${verb}ing ...теперь это работает.
I like singing
$ _
В следующем примере используется замещение команды для присвоения переменной startDate текущей даты, если переменная еще не установлена:
$ startDate=${startDate-'date'} ...если не установлена, выполнить date.
$ echo $startDate ...посмотреть ее значение.
Tue Wed 4 06:56:51 GST 1998
$ _
Далее переменной х присваивается значение по умолчанию, после чего оно выводится на терминал:
$ echo х - ${х=10) ...присвоить значение по умолчанию.
х = 10
$ echo $х ...подтвердить, что значение переменной было установлено.
10
$ _
В данном примере в зависимости от того, установлены переменные или нет, выводятся те или иные сообщения:
$ flag=l ...определить переменную.
$ echo ${flag+'flag is set'} ...первое условное сообщение.
flag is set
$ echo ${flag2+'flag2 is set'} ...второе условное сообщение.
...результат нулевой.
$ _
Следующий пример иллюстрирует доступ к неопределенной переменной grandTotal и вывод сообщения об ошибке:
$ total=10 ...определить переменную.
$ value=${total?'total not set'} ...доступ осуществлен.
$ echo $value ...посмотреть ее значение.
10
$ value=${grandTotal?'grand total not set'} ...не установлена.
grandTotal: grand total not set $ _
В завершающем примере используется скрипт с тем же методом доступа, что и в предыдущем, в результате чего произошла ошибка:
$ cat script.sh ...посмотреть скрипт.
value=${grandTotal?’grand total is not set’}
echo done # эта строка никогда не выполнится. -
$ script.sh 4 ...выполнить скрипт.
script.sh: grandTotal: grand total is not set $ _
Чтение переменной co стандартного ввода
Команда read позволяет читать переменные со стандартного ввода. Если пользователь определяет только одну переменную, то вся строка сохраняется в переменной. Вот стандартный скрипт, напоминающий пользователю о необходимости ввести его полное имя:
$ cat script.sh ...посмотреть скрипт.
echo ’’Please enter your name: \c”
read name # читать только одну переменную.
echo your name is $name # вывести переменную.
$ script.sh ...выполнить скрипт.
Please enter your name: Graham Walker Glass
your name is Graham Walker Glass ...была прочитана вся строка.
$
Синтаксис
read {переменная}+
Команда read читает одну строку со стандартного ввода и затем последовательно присваивает слова из строки указанным переменным. Оставшиеся слова присваиваются последней переменной.
В представленном ниже примере была определена более чем одна переменная:
$ cat.script.sh ...посмотреть скрипт.
echo ’’Please enter your name: \c"
read firstName lastName # читать две переменных.
echo your first name is $firstName echo your last name is $lastName
$ script.sh ...выполнить скрипт.
Please enter your name: Graham Walker Glass
your first name is Graham ...первое слово.
your last name is Walker Glass ...остаток.
$ script.sh ...выполнить его снова.
Please enter your name: Graham
your first name is Graham ...первое слово.
your last name is ...только одно.
$
Экспорт переменных
Команда export позволяет отмечать локальные переменные для экспорта в переменные окружения.
Синтаксис
export {переменная} +
Команда export отмечает указанные переменные для экспорта в переменные окружения. Если переменные не определены, то выводится список всех переменных, отмеченных для экспорта в течение сессии shell.
Как правило, для именования переменных окружения используются большие1 буквы. Однако вы можете использовать и строчные, если это вам удобно. Утилита env позволяет изменять и выводить такие переменные.
Синтаксис
env {переменная = значение} * [команда]
Утилита env присваивает значения определенным переменным окружения и затем выполняет дополнительную команду, используя переопределенные таким образом переменные. Если переменные или команда не определены, выводится список текущих переменных окружения.
1 Прописные. — Ред.
Для примера создадим локальную переменную с именем database, которую затем пометим для экспорта. После этого создадим дочерний shell, который унаследует копию переменных окружения родителя:
$ export ...вывести мой текущий экспорт.
export TERM ...установлена в моем стартовом файле .profile.
$ DATABASE=/dbase/db ...создать локальную переменную.
$ export DATABASE ...отметить ее для экспорта.
$ export export DATABASE ...заметьте, что она была добавлена.
export TERM
$ env DATABASE=/dbase/db . . .вывести переменные окружения.
НОМЕ=/home/glass LOGNAME=glass
PATH=:/usr/ucb:/bin:/usr/bin SHELL=/bin/sh
TERM=vtlOO
USER=glass
$ sh ...создать дочерний shell.
$ echo $DATABASE /dbase/db ...копия была унаследована.
$ ...завершить subshell.
$ _
Переменные только для чтения
Команда readonly позволяет защищать переменные от модификации.
Синтаксис
readonly {переменная} *
Команда readonly устанавливает статус "только для чтения" для указанных в качестве аргументов программы переменных, тем самым защищая их от изменений. Если переменные не определены, выводится список текущих переменных с таким статусом чтения. Копии экспортируемых переменных не наследуют статус "только для чтения".
В следующем примере переменная устанавливается в режим, доступный только для чтения, после чего экспортируется, а мы посмотрим на статус копии — она не унаследует разрешения только на чтение:
$ password=Shazam. ...определить локальную переменную.
$ echo $password Shazam ...вывести ее значение.
$ readonly password ...защитить ее.
$ readonly readonly password ...вывести все переменные со статусом readonly.
$ password=Phoombah password: is read only ...попытаться модифицировать ее.
$ export password ...экспортировать переменную.
$ password=Phoombah ...попытаться модифицировать ее.
password: is read only
$ sh ...создать subshell.
$ readonly $ echo $password Shazam ...экспортированная переменная не readonly. ... ее значение было скопировано корректно.
$ password=Alacazar $ echo $password Alacazar . . .но ее величина может быть изменена. ...вывести ее значение.
$ AD ...завершить subshell.
$ echo $password Shazam ...вывести оригинальное значение.
$ _
Предопределенные локальные переменные
В дополнение к предопределенным локальным переменным ядра, Bourne shell определяет собственные локальные переменные, перечисленные в табл. 5.2.
Таблица 5.2. Предопределенные локальные переменные Bourne shell
Имя Описание
$0 Индивидуально указанный список всех позиционных параметров
$# Число позиционных параметров
$ ? Код возврата последней команды
Таблица 5.2 (окончание)
Имя Описание
$ 1 ID процесса последней фоновой команды
$- Текущие опции shell, назначенные в командной строке или встроенным набором команд
$$ ID процесса, выполняемого shell
Ниже приведен небольшой скрипт, в котором компилятор С (сс) вызывается с переданным в качестве параметра несуществующим файлом, вследствие чего операция терпит неудачи и возвращает код ошибки:
$ cat script.sh ...посмотреть скрипт.
echo there are $# command line arguments: $@
cc $1 # компилировать первый аргумент.
echo the last exit value was $? # вывести код возврата.
$ script.sh nofile tmpfile ...выполнить скрипт.
there are 2 command line arguments: nofile tmpfile
cc: Warning: File with unknown suffix (nofile) passed to Id
Id: nofile: No such file or directory i the last exit value was 4 ...сообщение об ошибке от cc.
$ _
Следующий пример иллюстрирует использование имени $! для принудительного завершения последнего фонового процесса:
$ sleep 1 000 & ... создает фоновый процесс.
29455 ...ID фонового процесса.
$ kill $! ..."убить” его!
29455 Terminated
$ echo $! ...ID процесса все еще помнится.
29455
$
Предопределенные переменные окружения
Базовые переменные окружения, о которых мы говорили в главе 4, дополняются перечисленными в табл. 5.3 переменными.
Таблица 5.3. Предопределенные переменные окружения Bourne shell
Имя Описание
$IFS Когда shell разбирает командную строку перед ее выполнением, он использует символы из этой переменной в качестве разделителей, ips обычно содержит пробел, символ табуляции и символ перевода строки
$PS1 Переменная содержит значение приглашения командной строки (по умолчанию используется $). Чтобы заменить приглашение, просто присвойте PS1 новое значение
$PS2 Переменная содержит значение вторичного приглашения командной строки (по умолчанию >), которое отображается, когда shell требует ввода дополнительной информации. Чтобы изменить приглашение, присвойте PS2 новое значение
$SHENV Если эта переменная не установлена, shell ищет файл запуска .profile в домашнем каталоге пользователя, когда создается новый shell. Если переменная определена, то командный интерпретатор ищет каталог, указанный в shenv
Ниже приведен небольшой пример, иллюстрирующий использование первых трех переменных. Здесь приглашение shell, сохраненное в переменной psi, устанавливается в отличное от заданного по умолчанию. Кроме того, разделитель полей задается равным двоеточию (:), а предыдущее значение сохраняется в локальной переменной. Далее производится проверка вывода приглашения:
$ PSI = "sh?" sh? old.IFS=$IFS sh? IFS-":" sh? ls:*.c badguy.c number.c fact2.c number2.c sh? IFS=$oldIFS sh? string="a long\ > string" sh? echo $s tring a long string sh? PS2 = "??? " sh? string="a long\ ??? string" sh? echo $string a long string sh? ...установить новое первичное приглашение. ...запомнить старое значение IFS. ...заменить разделитель слов на двоеточие. ...это выполняется хорошо! open.с trunc.c writer.с reader.с who.с ...восстановить старое значение IFS. ...определить строку через две строки терминала ...> — это вторичное приглашение. ...посмотреть значение string. ...изменить вторичное приглашение. ...задать длинную строку. ...??? — это новое вторичное приглашение. ...посмотреть значение string. \
Арифметические действия
Сам Bourne shell не поддерживает арифметических операций, однако утилита ехрг помогает устранить этот недостаток.
Синтаксис
ехрг выражение
Утилита ехрг вычисляет выражение и посылает результат на стандартный вывод. Все компоненты выражения должны быть разделены пробелами, а все метасимволы shell должны завершаться символом \ (экранироваться). Выражение может давать результат в числовом или строчном виде в зависимости от операторов, которые оно содержит. Результат выражения может быть присвоен переменной shell соответствующим использованием команды замещения.
Допустимо построение выражения с помощью перечисленных ниже бинарных операторов к целочисленным операндам, сгруппированным в порядке увеличения приоритета:
Оператор Описание
*, /, % Умножение, деление, остаток
+> ~ Сложение, вычитание
:=j i= Операторы сравнения
& 1 Логическое И Логическое ИЛИ
Круглые скобки могут использоваться для явного управления порядком вычисления (однако их также нужно экранировать).
Утилита также поддерживает следующие строчные операторы:
Оператор Описание
строка: регулярноеВыражение Обе формы возвращают длину строки
match строка регулярноеВыражение строка, если выражения совпадают, иначе возвращают ноль
substr строка начало длина Возвращает подстроку строки, начинающейся с индекса на чало и состоящей из длина символов
(окончание)
Оператор Описание
index строка списокСимволов Возвращает индекс первого символа в строке. который появляется В спискеСимволов
length строка Возвращает длину строки
Формат регулярного выражения определен в Приложении.
Следующий пример иллюстрирует некоторые функции ехрг и использует
замещение команд:
$ Х=1
$ х=' ехрг $х + 1'
$ echo $х
2
$ х= 'ехрг 2 + 3 \* 5'
$ echo $х
17
$ echo 'ехрг \(2 + 3\) \* 5'
25
$ echo 'ехрг length "cat”'
3
$ echo 'ехрг substr "donkey” 4 3' key
$ echo 'expr index "donkey" "ke"' 4
$ echo 'expr match "Smalltalk" *.
9
$ echo 'expr match "transputer" 1
0
$ echo 'expr "transputer" : ’★.Ik
0
$ echo 'expr \ ( 4\ > 5 \ ) '
...начальное значение x.
...увеличить x на единицу.
... * перед +.
...перегруппировать.
...найти длину cat.
...выделить подстроку.
...определить позицию подстроки.
★1k’' ...проверить
...на совпадение.
★.!&'' ...проверить
... на совпадение.
г' ... проверить
...на совпадение.
...больше ли 4 > 5?
О
$ echo 'ехрг \ ( 4 \ > 5\) \/ \ (6 \ < 7 \ ) ' .. .больше ли 4 > 5 или 6 < 7?
1
$
Условные выражения
Структуры управления, подробно описанные в следующем разделе, часто используются для перехода в зависимости от значения логического выражения, возвращающего истину или ложь. Утилита test поддерживает достаточно большой набор UNIX-ориентированных выражений, которые являются подходящими для большинства случаев. Выражение test может иметь формы, показанные в табл. 5.4.
Внимание
Утилита очень требовательна к синтаксису выражений; пробелы, указанные в этой таблице, нельзя опускать.
Синтаксис
test выражение [выражение]
Эквивалентной формой, используемой в некоторых UNIX-системах, является заключение выражения в круглые скобки.
Утилита test возвращает 0, если выражение вычисляет истину; иначе возвращает код выхода, отличный от 0. Код возврата обычно используется структурами управления shell, выполняющими переходы по условию.
Некоторые Bourne shell выполняют утилиту test, как встроенную команду. В таком случае они также поддерживают вторую форму вычисления. Однако чтобы эта форма работала, скобки должны быть отделены пробелами.
Таблица 5.4. Выражения, используемые утилитой test
Форма
-Ь имяФайла
-с имяФайла
Описание
Возвращает истину, если имяФайла существует в качестве специального блочного файла
Возвращает истину, если имяФайла существует в качестве специального символьного файла
Таблица 5.4 (продолжение)
Форма Описание
-d имяФайла Возвращает истину, если имяФайла существует в качестве каталога
-f имяФайла Возвращает истину, если имяФайла существует, как не каталог
-g имяФайла Возвращает истину, если имяФайла существует в качестве файла "установки ID группы"
-h имяФайла Возвращает истину, если имяФайла существует в качестве символической связи
-к имяФайла Возвращает истину, если имяФайла существует и имеет установленный "промежуточный бит округления"
-1 строка Длина строки
-п строка Возвращает истину, если строка содержит, по крайней мере, один символ
-р имяФайла Возвращает истину, если имяФайла существует в качестве именованного конвейера
-г имяФайла Возвращает истину, если имяФайла существует в качестве читаемого файла
-s имяФайла Возвращает истину, если имяФайла содержит, по крайней мере, один символ
-t fd Возвращает истину, если дескриптор файла fd связан с терминалом *
-и имяФайла Возвращает истину, если имяФайла существует в качестве файла "установки ID пользователя"
-w имяФайла Возвращает истину, если имяФайла существует в качестве файла для записи
-х имяФайла Возвращает истину, если имяФайла существует как исполняемый файл
— z строка Возвращает истину, если строка не содержит никаких символов
strl - str2 Возвращает истину, если strl равна str2
strll - str2 Возвращает истину, если strl не равна str2
строка Возвращает истину, если строка не нулевая
intl-eq int2 Возвращает истину, если целое inti равно целому int2
inti -ne int2 Возвращает истину, если целое inti не равно целому int2
inti -gt int2 Возвращает истину, если целое inti больше целого int2
inti -ge int2 Возвращает истину, если целое inti больше или равно целому in t2
Таблица 5.4 (окончание)
Форма Описание
inti -It int2 Возвращает истину, если целое inti меньше целого int2
inti -le int2 Возвращает истину, если целое inti меньше или равно целому in t2
! выражение Возвращает истину, если выражение ложно
exprl -a expr2 Возвращает истину, если выражения exprl и ехрг2 оба истинны
exprl —о expr2 Возвращает истину, если exprl или ехрг2 истинно
\ (выражение \) Экранированные круглые скобки используются для группирования выражений
Структуры управления
Bourne shell поддерживает широкий диапазон структур управления, которые делают командный интерпретатор удобным инструментом программирования высокого уровня. Программы shell обычно хранятся в скриптах и, как правило, используются для автоматизации задачи инсталлирования и обслуживания. В следующих разделах в алфавитном порядке будут описаны структуры управления. Однако для их понимания желательно быть знакомым хотя бы с одним языком программирования высокого уровня.
case... in... esac
Команда case поддерживает многопозиционный переход, базирующийся на значении отдельной строки.
Синтаксис
case выражение in шаблон { | шаблон} *) списокКоманл
esac
выражение определяет строку, возможно, содержащую групповые символы, сравниваемую с шаблоном. списокКоманл включает одну или нескольких команд shell. Командный интерпретатор вычисляет выражение, а затем сравнивает его по порядку с каждым шаблоном. Когда первое соот
ветствие шаблону найдено, выполняется связанный с ним списокКоманд. Далее shell переходит на строку esac. Шаблоны в последовательности отделяются символом | ("или") и связаны с одним и тем же набором действий. Если shell не находит совпадения, выполняется esae.
echo ’your choice? \c*
read reply
echo
case $reply in
"I")
date
r r
"2”|”3") pwd
r r
”4”)
stop=l
r r
*)
echo illegal choice
Ниже приведен пример скрипта menu.sh, который использует структуру управления case (скрипт также доступен в сети; см. Введение для получения дополнительной информации): #! /bin/sh echo menu test program stop=0 # переустановить флаг прекращения цикла,
while test $stop -eq 0 # цикл до выполнения,
do cat « ENDOFMENU # вывести меню.
1 : print the date.
2 , 3: print the current working directory. 4 : exit
ENDOFMENU echo # приглашение. # читать ответ. # отклик процесса. # вывести дату. # вывести рабочий каталог. # установить флаг прекращения цикла. # по умолчанию. # ошибка. esac
done
Пример работы скрипта menu.sh: $ menu.sh menu test program
1 : print the date.
2r 3: print the current working directory. 4 : exit
your choice? 1
Thu Feb 5 07:09:13 CST 1998 1 : print the'date.
2r 3: print the current working directory. 4 : exit
your choice? 2 /home/glass
1 : print the date.
2 , 3: print the current working directory.
4 : exit
your choice? 5 illegal choice
1 : print the date.
2 , 3: print the current working directory.
4 : exit
your choice? 4 $
for... do... done
Структура for позволяет выполнить несколько раз список команд, используя различные значения переменной цикла во время каждой итерации.
Синтаксис
for имяПеременной [ in {списокСлов} * ] do
списокКоманл
done
Команда for циклически присваивает значению имяПеременной каждое из слов параметра списокСлов, выполняя команды из аргумента список-команд после каждой итерации. Если списокСлов не представлен, вместо
него используется $@. Команда break заставляет цикл завершиться, а команда continue переводит его к следующей итерации.
Ниже приведен пример скрипта со структурой управления for:
$ cat for.sh ...посмотреть скрипт.
for color in red yellow green blue do
echo one color is $color
done
$ for.sh ...выполнить скрипт.
one color is red
one color is yellow
one color is green one color is blue $ _
if... then... fi
Команда if поддерживает вложенные условные ветвления.
Синтаксис
if условие!
then
списокКоманд!
elif условие2 ...необязательнаяг
...elif может повторяться несколько раз.
then
списокКома нд2
else ...необязательная, else может появляться один раз.
списокКома ндЗ
fi
Выполняются команды из условие!. Если они завершаются удачно, выполняются команды ИЗ списокКоманд!. ЕСЛИ ПОСЛеДНЯЯ команда условие! завершается неудачно, и если указан один или более el if-компонентов (возвращающих истину), выполняются команды, указанные после then. Если команда возвращает сигнал об ошибке, и в скрипте задано условие else, выполняются команды, указанные после него.
9 Зак. 786
Вот пример скрипта, который использует структуру управления if: $ cat if.sh ...посмотреть скрипт, echo ’enter a number: \с’ read number if [ $number -It 0 ] then
echo negative
elif [ $number -eq 0 ] then echo zero
else
echo positive fi
$ if.sh ...выполнение скрипта, enter a number: 1 positive
$’ if.sh ...выполнить скрипт снова, enter a number: -1 negative $
trap
trap позволяет задать команду, которая должна быть выполнена, когда командный интерпретатор получает сигнал конкретного значения.
Синтаксис
trap.[[команда ] {сигнал} + ]
Команда trap предписывает shell выполнять команду всякий раз, когда получен любой из пронумерованных сигналов. Если поступило несколько сигналов, они перехватываются в числовом порядке. Если значение сигнала 0 определено, тогда команда выполняется при завершении shell. Если команда опущена, то значения пронумерованных сигналов сбрасываются в их первоначальное значение. Если команда — пустая строка, то пронумерованные сигналы игнорируются. Выполнение trap без аргументов приводит к выводу списка всех сигналов и их trap-установок. (Для получения дополнительной информации о сигналах и их действиях по умолчанию см. главу 13.)
Вот пример скрипта, который использует структуру управления trap:
$ cat trap.sh ...посмотреть скрипт.
trap ’echo Control-C; exit 1’ 2 # выполнить <Ctl>+<C> (сигнал 2)
while 1 do
echo infinite loop
sleep 2 # приостановиться на две секунды,
done
$ trap.sh ...выполнить скрипт.
infinite loop
infinite loop
... я нажал <Ctrl>+<C>.
Control-C ...выведено командой echo.
$ _
Обратите внимание, что после нажатия комбинации клавиш <Ctrl>+<C> shell выполнил команду echo, сопровождаемую командой exit.
until... do... done
Команда until выполняет некоторую серию команд до тех пор, пока другая серия команд2 не станет истинной.
Синтаксис
until условие do
списокКоманл done
Команда until выполняет команды из списка условие и прекращается, если условие истинно. Иначе, выполняются команды из аргумента списокКоманл, и процесс повторяется. Если списокКоманл пуст, ключевое слово do должно быть опущено. Команда break вызывает немедленное завершение цикла, а команда continue переводит его к следующей итерации.
Вот пример скрипта, который использует структуру управления until:
$ cat until.sh
...вывести скрипт.
2 Иными словами, условие. — Ред.
until [ $х -gt 3 ]
do
echo x = $x
x='expr $x + 1'
done
$ until.sh ...выполнить скрипт.
x = 1
x = 2
x = 3
$
while... done
Команда while выполняет серию команд до тех пор, пока другая серия3 выполняется успешно.
Синтаксис
while условие
do
списокКома нд done
Команда while выполняет условие и прекращается, если последняя команда из него заканчивается неудачно. Иначе выполняется списокКо-манд, и процесс повторяется. Если списокКоманд пуст, ключевое СЛОВО do должно быть опущено. Команда break вызывает прерывание цикла, а команда continue переводит его к следующей итерации.
Ниже приведен пример скрипта, который содержит структуру управления while и демонстрирует генерацию небольшой таблицы умножения:
$ саt multi.sh ... вывести скрипт.
if [ "$1" -eq "" ]; then
echo "Usage: multi number"
exit
fi
x=l # установка значения для внешнего цикла
3 Условие. — Ред.
while [ $x -le $1 ] # внешний цикл
do
y=l # установка значения для внутреннего цикла
while [ $у -1е $1 ]
do # генерирует один вход таблицы
echo 'ехрг $х \* $у' " \с"
у = 'ехрг $у + 1' # обновить счетчик внутреннего цикла
done echo # пустая строка
x='expr $х + 1' # обновить счетчик внешнего цикла
done
$ multi.sh 7 ...выполнить скрипт.
1 2 3 4 5 6 7
2 4 6 8 10 12 14
3 6 9 12 15 18 21
4 8 12 16 20 24 28
5 10 15 20 25 30 35
6 12 18 24 30 36 42
7 14 21 28 35 42 49
$
Пример проекта: track
Для иллюстрации основной части возможностей Bourne shell воспользуемся небольшим скриптом track. Этот скрипт отслеживает регистрацию и выход из системы пользователей, генерируя простой отчет о пользовательских сессиях. Скрипт использует следующие утилиты:
□ утилита who выводит список текущих пользователей системы;
□ утилита grep фильтрует текстовые строки, которые соответствуют указанному шаблону;
П утилита diff показывает различия между двумя файлами;
□ утилита sort сортирует текстовый файл;
□ утилита sed выполняет предварительно запрограммированное редактирование файла;
□ утилита ехрг вычисляет значение выражения;
П утилита cat выводит содержимое файла;
□ утилита date отображает текущее время;
П утилита rm удаляет файл;
П утилита mv перемещает файл;
□ утилита sleep устанавливает паузу на несколько секунд.
Утилиты grep, diff, sort и sed описаны в главе 3\ о другой утилите (who) рассказано в главе 9. Рассмотрим пример работы этого скрипта:
$ track -пЗ Ivor -t200 ...отследить сессию Ивора.
track report for ivor: ...первоначальный вывод.
Login ivor ttyp3 Feb 5 06:53
track report for ivor: ...Ивор вышел из системы.
Logout ivor ttyp3 Feb 5 06:55
...завершить программу, используя комбинацию клавиш <Ctrl>+<C>.
stop tracking ...сообщение прекращения программы.
$
Синтаксис
track [-псчетчик] [-tnaysa] Ю_пользователя
Скрипт track отслеживает сессии входа и выхода указанного пользователя. С периодичностью в указанное паузой число секунд track просматривает систему и фиксирует зарегистрированных в системе. Если указанный пользователь зарегистрировался или вышел из системы за время последнего просмотра, эта информация передается на стандартный вывод. Скрипт работает, пока не сбросится счетчик количества просмотров. По умолчанию пауза равна 20 секундам, а счетчик 10 000 просмотров. Обычно этот скрипт выполняется в фоновом режиме с переадресацией стандартного вывода в файл.
Программа track состоит из трех файлов:
□ track — главный скрипт Bourne shell;
□ Track.sed — sed-скрипт для редактирования вывода утилиты diff;
П track.cleanup — маленький скрипт, который очищает временные файлы.
Алгоритм работы описанного скрипта может быть разделен на три части.
1. Разбор командной строки и установка значений трех локальных переменных: user, pause и loopcount. Если произошли какие-нибудь ошибки, скрипт завершается выводом сообщения о них.
2. Затем устанавливается перехват двух событий: завершение скрипта и int-(<Ctrl>+<C>) или QUiT-сигналы (<Ctrl>+<\>). Если был получен сигнал выхода quit, инициализируется событие завершения скрипта. Скрипт очистки получает ID процесса главного скрипта в качестве единственного аргумента и удаляет временные файлы.
3. Далее цикл выполняется заданное количество раз, сохраняя отфильтрованный список текущих пользователей во временном файле .track.new.55, где 55 — ID процесса скрипта. Затем файл сравнивается с последней версией вывода, сохраненного в файле .track.old.55. Если строка находится в новом файле, а не в старом, это означает, что пользователь, скорее всего, зарегистрировался в системе. Если строка размещена в старом файле, пользователь покинул систему. Если после работы diff-файл вывода имеет длину, отличную от нуля, то информация передается утилите sed и выводится. После чего скрипт делает паузу на указанное количество секунд и продолжает выполнять цикл.
Листинг двух пропущенных через утилиту diff наборов данных, переданных ей утилитой who, иллюстрируется следующей сессией:
$ cat track.new.1112 ...новый вывод от who.
glass ttypO Feb 4 23:04 glass ttyp2 Feb 4 23:04 $ cat track.old.1112 glass ttypO Feb 4 23:04 glass ttypl Feb 4 23:06 ...старый вывод от who.
$ diff track.new.1112 track.old.1112 2c2 < glass ttyp2 Feb 4 23:04 > glass ttypl Feb 4 23:06 $ . ...изменения.
track.sed
Скрипт track.sed удаляет все строки, которые начинаются с цифры или ", а затем подставляет символ < вместо login и символ > вместо logout.
/А[0-9].*/d /А---/d
s/A</login/
s/A>/logout/
track.cleanup
echo stop tracking rm -f .track.old.$1 .track.new.$1 .track.report.$1
track
pause=20 # пауза по умолчанию между сканированиями
loopCount=10000 # счетчик числа сканирований, по умолчанию
error=0 # флаг ошибки
for arg in $* # разбор аргументов командной строки
do case $arg in \
-t*) # время
pause='expr substr $arg 3 10' # извлечение числа
-n*) # счетчик сканирований
loopCount='ехрг substr $arg 3 10' # извлечение числа
f г
*) user=$arg # имя пользователя
esac done if [ ! "$user" ] # проверка, был ли найден ID пользователя
then error=l fi if [ $error -eq 1 ] # вывести ошибку, если ошибка найдена
then
cat « ENDOFERROR # вывести сообщение использования usage: track [-n#] [-t#] userid ENDOFERROR exit 1 # завершить shell
fi
trap ’track.cleanup $$; exit $exitCode’ 0 # trap в режиме выхода
trap ’exitCode=l; exit’ 23 # trap в режиме INT/QUIT
> .track.old.$$ # обнулить старый track-файл.
count=0 # число сканирований так же
while [ $count -It $loopCount ]
do
who grep $user | sort > .track.new.$$ # сканировать систему
diff .track.new.$$ .track.old.$$ | \
sed -f track.sed > .track.report.$$
if [ —s .track.report.$$ ]
then
echo track report for ${user): cat .track.report.$$
fi
mv .track.new.$$ .track.old.$$
sleep $pause
count='expr $count +1'
done
exitCode=0
# изменяется только отчет
# вывести отчет
# запомнить текущее состояние
# подождать немного
# обновить счетчик сканирования
# установить код возврата
Дополнительные встроенные команды
Bourne shell поддерживает несколько специализированных встроенных команд. Некоторые, имеющие отношение к структурам управления, мы уже обсудили ранее. В следующих разделах в алфавитном порядке будут описаны остальные встроенные команды.
Команда чтения: точка (.)
Чтобы выполнить содержимое текстового файла, не запуская subshell, как это происходит при выполнении скрипта, командный интерпретатор использует точку (.), за которой следует имя файла. Файл не должен быть исполняемым. Команда удобна, если пользователь изменяет файл .profile и желает выполнить его повторно. Пример:
$ cat .profile ...предположим, что .profile только что редактировался. TERM=vtlOO
export TERM
$ . .profile ...выполнить его повторно.
Обратите внимание, что subshell не создан, любые локальные переменные являются локальными переменными текущего shell.
Команда null
Команда null обычно используется в соединении со структурами управления, о которых мы уже поговорили ранее, и не выполняет никакого действия. Она часто указывается в структурах case, чтобы обозначить пустой набор операторов, связанных с конкретной веткой.
Синтаксис
null
Команда null не выполняет никакого действия.
Установка опций shell: set
Команда зе1позволяет управлять некоторыми опциями shell (табл. 5.5).
Таблица 5.5. Опции команды set
Опция Описание
е Если shell не выполняет команды с терминала или файла запуска, и команда терпит неудачу, тогда происходят системное прерывание err и выход
п Принимает, но не выполняет команды. Опция не затрагивает диалоговые shell
t Выполняет следующую команду и затем выходит
и Генерирует ошибку, когда сталкивается с неустановленной переменной
v Выводит команды shell, когда они читаются
х Выводит команды shell, когда они выполняются
Выключает опции х и v и интерпретирует дальнейшие символы, как аргументы
Опции -х и -v полезны в отладке shell-скрипта, т. к. они выводят строки до и после обработки переменной, группового символа и метасимволов замещения команды.
Синтаксис
set -ekntuvx {аргументы}*
Команда set позволяет пользователю выбирать опции shell. Любые указанные аргументы назначаются позиционным параметрам $1, $2 и т. д., переписывая их текущие значения.
В приведенном ниже примере проиллюстрировано использование различных опций команды set:
$ cat script.sh ...посмотреть скрипт.
set -vx а.с # установить режим отладки и перезаписать $1.
Is $1 # получить доступ к первому позиционному параметру.
set - # выключить трассировку.
echo goodbye $USER
echo $notset
set -u # неустановленные переменные будут теперь генерировать ошибку.
echo $notset # генерировать ошибку.
$ script.sh Ь.с ...выполнить скрипт.
Is $1 ...вывод от опции -v.
+ Is а.с ...ВЫВОД ОТ ОПЦИИ -X.
а.с ...обычный вывод.
set - . ...ВЫВОД ОТ ОПЦИИ -V.
+ set - ...ВЫВОД ОТ ОПЦИИ -X.
goodbye glass ...обычный вывод.
script.sh: notset: parameter not set ...доступ к неустановленной ...переменой.
$
Усовершенствования
В дополнение к новым функциями, которые уже были описаны ранее, в Bourne shell усовершенствованы следующие общие для всех командных интерпретаторов возможности:
□ перенаправление ввода/вывода;
П использование последовательностей команд.
Перенаправление
Помимо использования обычных возможностей перенаправления, Bourne shell позволяет дублировать, закрывать и переадресовывать произвольные каналы ввода/вывода. Вы можете связывать стандартный дескриптор ввода файла (0) с файловым дескриптором п, используя следующий синтаксис:
$ команда <& п
...связать стандартный ввод.
Точно так же можно связывать стандартный дескриптор вывода файла (1) с дескриптором файла п при помощи последовательности:
$ команда >& п
...связать стандартный вывод.
Для закрытия каналов стандартного ввода и вывода служит синтаксис:
$ команда <&-
$ команда >&-
...закрывает стандартный ввод и выполняет команду.
...закрывает стандартный вывод и выполняет команду.
Вы можете использовать файловый указатель перед любым метасимволом, который должен применяться вместо 0 (для переназначения ввода) или 1 (для переназначения вывода). Очень часто дескриптор файла 2 соответствует стандартному каналу ошибки.
Приведенный ниже пример иллюстрирует использование описанных выше возможностей переназначения. Утилита man всегда пишет "Reformatting page. Wait" ("Переформатирование страницы. Ждите") в стандартный канал ошибки, когда начинает работать, и "done" ("завершено") — после завершения. Если вы переадресовываете только стандартный вывод, эти сообщения появляются на терминале. Для переадресации стандартного канала ошибки в отдельный файл используйте последовательность переназначения 2>. Для записи ошибок в файл стандартного входа указывайте последовательность: 2>*1. Пример:
$ man Is > Is.txt Reformatting page. $ man Is > Is.txt $ cat err. txt Reformatting page. $ man Is > Is.txt
$ head -1 Is.txt Reformatting page.
...направить стандартный вывод в Is.txt.
Wait... done ...из стандартного канала ошибки.
2> err.txt ...направить канал ошибки в err.txt.
...посмотреть файл.
Wait... done
2>&1 ...связать канал ошибки со стандартным
. . .каналом вывода.
...посмотреть первую строку ls.txt.
$
Последовательности команд
Если группа команд помещена между круглыми скобками, они выполняются дочерним shell. Bourne shell также позволяет группировать команды, обрамляя их фигурными скобками, в которых разрешено указывать перенаправление ввода/вывода и конвейеризацию внутри группы, при этом команды выполняются непосредственно родительским shell. После открывающей фигурной скобки должен следовать пробел, а после закрывающей — точка с запятой.
В представленном ниже примере первая команда cd не затрагивает текущий рабочий каталог shell, т. к. она работает внутри subshell, а вызванная второй раз выполняется shell:
$ pwd ...вывести текущий рабочий каталог.
/home/glass
$ (cd /; pwd; Is | wc -1)
22
$ pwd
/home/glass
$ { cd /;>pwd; Is I wc -1; }
22
$ pwd
$
...подсчитать файлы при помощи subshell.
...мой shell не перемещался.
...подсчитать файлы при помощи shell.
...мой shell переместился.
Опции командной строки
В табл. 5.6 описаны параметры командной строки, поддерживаемые Bourne
shell. Таблица 5.6. Параметры командной строки Bourne shell
Опция Описание
-с строка Создает shell для выполнения командной строки строка
-s Создает shell, который читает команды со стандартного ввода и посылает сообщения shell в стандартный канал ошибки
-i Создает диалоговый shell; подобна опции -s, за исключением того, что все сигналы sigterm, sigint и sigquit игнорируются (для информации о сигналах см. главу 13)
Обзор главы
Перечень тем
В данной главе мы рассмотрели:
□ создание стартового файла Bourne shell;
□ создание и доступ к переменным командного интерпретатора;
□ арифметические операции;
□ условные выражения;
□ шесть структур управления;
□ пример проекта для отслеживания сессий пользователя с системой;
□ несколько встроенных команд;
□ усовершенствования базовых функций.
Контрольные вопросы
1. Кто автор Bourne shell?
2. Опишите обычное использование встроенной переменной $$.
3. Как легче всего повторно выполнить пользовательский файл .profile?
4. Какой метод применяется для передачи значения переменной shell в subshell?
5. Какие возможности отладки предоставляет Bourne shell?
Упражнения
5.1. Напишите утилиту shheip, которая работает так, как описано ниже.
Синтаксис
shheip [-к] {команда}*
Утилита shheip выводит справку об указанной команде Bourne shell. Опция -к ВЫВОДИТ каждую команду, КОТОрая известна shheip.
Вот пример shheip в действии:
$ shheip null ...запрос помощи о null.
The null command performs no operation.
$ _
Удостоверьтесь, что ваша утилита показывает соответствующее сообщение об ошибке, если указана недопустимая команда. Желательно, чтобы текст сообщения справки о каждой команде хранился в отдельном файле, а не внутри скрипта shheip. Если вы решите справку внутри скрипта, пробуйте использовать функцию перенаправления документа в буфер.4 [Уровень: легкий.]
4 См. главу 4. — Ред.
5.2. Напишите утилиту junk.
Синтаксис
junk [-1] [-p] {имяФайла}*
Утилита junk является аналогом утилиты rm. Вместо удаления файлов, она перемещает их в каталог junk, находящийся в домашнем каталоге пользователя. Если .junk не существует, он автоматически создается. Опция -1 выводит текущее содержимое каталога .junk, а опция -р производит очистку этого каталога.
Вот пример работы скрипта:
$ Is -1 reader.с ...вывести существующие файлы.
-rw-r—г— 1 glass 2580 May 4 19:17 reader.с
$ junk reader.с ...выполнить j unk!
$ Is -1 reader.с reader.c not found ...подтвердить, что он был перемещен.
$ junk badguy.c, $ junk -1 ...выполнить junk с другим файлом. ...вывести содержимое каталога .junk.
-rw-r—r— 1 glass 57 Мау 4 19:17 badguy.c
-rw-r—r— 1 glass 2580 Мау 4 19:17 reader.с
$ junk -p ...очистить .junk.
$ junk -1 $ ...вывести .junk.
Не забывайте подробно комментировать ваш скрипт. [Уровень: средний.]
5.3. Измените скрипт junk так, чтобы он управлялся с помощью меню. [Уровень: легкий.]
Проекты.
1. Напишите скрипт ghoul, который трудно "убить". Когда скрипт получает сигнал sigint (от нажатия комбинации клавиш <Ctrl>+<C>), он должен создать перед "смертью" свою копию. Таким образом, каждый раз, когда пользователь пытается ликвидировать ghoul, запускается его копия. Однако он может быть "убит" сигналом sigkill (—9). [Уровень: средний.]
2. Спроектируйте утилиту телефонной книги, которая позволяет просматривать и изменять алфавитный список имен, адресов и телефонных номеров. Используйте утилиты, описанные в главе 3, такие как awk и sed, для поддержки и редактирования информации в файле телефонной книги. [Уровень: высокий.]
3. Постройте утилиту управления процессом, которая позволяет ликвидировать его на основе информации об использовании процессора, ID пользователя, общего количества истекшего времени и т. д. Этот вид утилиты был бы особенно полезен для системных администраторов (см. главу 15). [Уровень: высокий.]
Глава 6
Korn shell
Мотивация
Korn shell, написанный Дэвидом Корном (David Korn), является более мощной версией Bourne shell и имеет усовершенствования в области управления заданиями, редактирования командной строки и программных возможностей. Это позволило командному интерпретатору Korn shell завоевать большую популярность в мире UNIX-систем.
Предпосылки
Для понимания этой главы вам необходимо прочитать предыдущую и поэкспериментировать с Bourne shell.
Задачи
В данной главе рассмотрим специфичные для Korn shell возможности.
Изложение
По сложившейся уже традиции материал главы представлен в виде нескольких примеров UNIX-сессий.
Команды shell
Мы рассмотрим следующие команды shell:
alias jobs select
bg kill typeset
fc let unalias
fg print
function return
Общие сведения о Korn shell
Korn shell поддерживает все функции Bourne shell, описанные в главе 5, и содержит следующие дополнительные функции (рис. 6.1):
□ настройка команд с использованием псевдонимов;
□ доступ к выполненным командам через механизм истории (vi- и emacs-подобные редактирующие возможности командной строки);
□ функции;
□ расширенное управление заданиями;
□ несколько новых встроенных команд и усовершенствованные существующие.
jobs bg fg <Ctrl>+<Z>
Рис. 6.1. Функциональные возможности Korn shell
Запуск
Korn shell — это обычная С-программа, выполняемый файл которой хранится как /bin/ksh. Если вашим shell является /bin/ksh, его диалоговый режим активизируется автоматически, в процессе регистрации в UNIX. Можно также вызвать Korn shell вручную из скрипта или с терминала, используя команду ksh, которая имеет несколько опций командной строки.
Последовательность запуска Korn shell различна для диалогового и недиалогового shell (табл. 6.1). Значение $env обычно устанавливается в скриптах $HOME/.kshrc и $HOME/.profile. После чтения файлов запуска диалоговый режим Korn shell отображает свое приглашение и ожидает ввода команды. Стандартное приглашение Korn shell — $, хотя оно может быть изменено путем установки локальной переменной psi, описанной в главе 5. Ниже
приведен пример Korn shell скрипта .profile, который выполняется один раз в начале каждой сессии:
TERM=vtlOO; export TERM # тип моего терминала.
ENV=-/.kshrc; export ENV # имя файла окружения.
HISTSIZE=100; export HISTSIZE # помнить 100 команд.
MAILCHECK=60; export MAILCHECK # секунды между проверками,
set -о ignoreeof # не позволяет <Ctrl>+<D> завершить сессию,
set -о trackall # ускорить поиск файла,
stty erase ,ЛН* # установить символ возврата,
tset # установить терминал.
Таблица 6.1. Последовательность запуска Korn shell
Шаг Тип командного интерпретатора Действие
1 Только диалоговый Выполняет команды из /etc/profile, если он существует
2 Только диалоговый Выполняет команды из $номе/. profile, если он существует
1 3 Оба Выполняет команды из $env, если он существует
Некоторые из этих команд могут быть вам непонятны, но их значение станет ясным по мере чтения главы.
Ниже показан пример Korn shell скрипта .kshrc, содержащего, как правило, полезную специфичную для этой оболочки информацию, используемую всеми shell, включая те, которые были созданы исключительно для выполнения скриптов:
РАТН='.:-/bin:/bin:/usг/bin:/usг/local/bin:/gnuemacs’
PS1=’! $ export PSI # поместить номер команды в подсказку.
alias h="fc -1” # установить полезные псевдонимы,
alias ll="ls -1” alias rm=,,m -i" alias ccb^'ccLx" alias up="cdx .." alias dir="/bin/ls” alias ls="ls -aF" alias env="printenv|sort"
# Функция, чтобы показывать путь и каталог при перемещении function cdx
{
if ’cd’ ’^G"
then
echo $PWD
Is -aF
fi
}
Каждый Korn shell, включая все subshell, выполняет этот скрипт при запуске.
Псевдонимы
Korn shell позволяет создавать собственные команды, используя псевдонимы (alias). Ниже проиллюстрирована работа команды alias:
$ alias dir='ls -aF1 ...регистрировать псевдоним.
$ dir ...то же самое, как напечатать Is -aF.
./ main2.c р.reverse.c reverse.h
../ main2.o palindrome.c reverse.old
$ dir *.c ...то же самое, как напечатать Is -aF *.c.
main2.c p.reverse.c palindrome.c
$ alias dir ...определение dir.
dir=ls -aF $
Синтаксис
•alias [-tx] [слово [=строка]]
Команда alias поддерживает простую форму настройки командной строки. Если слово псевдонима равно строке, а вы вводите команду, начинающуюся с этого словз^ первое появление словз заменяется строкой^ и команда обрабатывается повторно. Если слово или строка не определены, то выводится список всех текущих псевдонимов shell. Если пользователь указывает только слово, то выводится строка, в настоящее время связанная со словом псевдонима. Если слово и строка указаны, shell добавляет данный псевдоним в свою коллекцию. В случае, если псевдоним для слова уже существует, он заменяется. Если строка замены начинается со слова, оно не обрабатывается повторно для псевдонимов, предотвращая, таким образом, бесконечные циклы. Если строка замены заканчивается пробелом, то следующее слово обрабатывается, как псевдоним.
Пример:
$ alias ls='ls -aFr ...нет проблем.
$ Is *.c ...аналогично Is -aF *.c.
main2.c p.reverse.c palindrome.c
$ alias dir='ls' ...определить dir через Is.
$ dir ...аналогично Is -aF.
, / main2.c p.reverse.c reverse.h
• • / main2.о palindrome.c reverse.old
$
Создание псевдонимов встроенных команд
Все встроенные команды за исключением
case esac select {
do fi then }
done for time
elif function until
else if while
могут иметь псевдонимы.
Удаление псевдонимов
Чтобы удалить псевдоним, используйте команду unalias.
Синтаксис
unalias {слово}+
Команда unalias удаляет все указанные псевдонимы.
Пример:
$ alias dir . . .посмотреть существующий псевдоним. dir=ls
$ unalias dir ...удалить псевдоним.
$ alias dir ...попытка посмотреть псевдоним снова, dir alias not found
$
Предопределенные псевдонимы
В табл. 6.2 представлены предопределенные псевдонимы Korn shell. Их использование станет понятным по мере изучения главы. Например, псевдоним г очень удобен для повторного вызова предыдущих команд вместо длинной последовательности fc -е
*
Таблица 6.2. Предопределенные псевдонимы Korn shell
Псевдоним Значение
false let 0
functions typeset -f
history fc -1
integer typeset -i
nohup nohup
r fc -e -
true
type whence -v
hash alias -t
Некоторые полезные псевдонимы
В табл. 6.3 перечислены полезные псевдонимы. Другие интересные псевдонимы рассмотрены в главе 7.
Таблица 6.3. Некоторые полезные псевдонимы
Псевдоним Значение Описание
rm rm -i Указывает rm о необходимости запрашивать подтверждение
mv mv -i Указывает mv о необходимости запрашивать подтверждение
Is Is -aF Указывает 1s о необходимости выводить подробную информацию
env printenv | sort Демонстрирует отсортированный список переменных окружающей среды
11 Is -1 Позволяет получить более удобный расширенный листинг каталога
Псевдонимы путей
Обычное использование псевдонимов — это сокращение полного путевого имени. Чтобы ускорить процесс поиска, воспользуйтесь псевдонимами путей. Все псевдонимы с опцией -t интерпретируются, как псевдонимы путей, и для того чтобы установить их первоначальное значение служит механизм поиска. В этом случае псевдоним пути заменяется его значением, таким образом сводя время поиска к минимуму. Если за опцией -t не указано ни одного псевдонима, выводится весь список текущих псевдонимов путей. Например:
$ alias -t page ...определить псевдоним пути для раде.
$ alias -t ...посмотреть все псевдонимы путей.
page=/usr/ucb/page ...сохранено его полное путевое имя. $
Опция -о trackaii команды set (которая будет описана чуть позже в этой главе) предписывает shell отслеживать все команды автоматически, как показано в следующем примере:
$ set -о trackaii ...все команды теперь заносятся в список псевдонимов.
$ date ...выполнить date.
Fri Feb 6 00:54:44 CST 1998
$ alias -t ...посмотреть все псевдонимы путей.
date=/bin/date ...date теперь в списке псевдонимов. page=/usr/ucb/page
$ _ -
Так как значение псевдонима пути зависит от переменной $ратн, все псевдонимы путей вычисляются повторно всякий раз, когда она изменяется. Если переменная path не определена, значения всех псевдонимов путей оказываются установленными на пустой указатель, но при этом остаются в списке псевдонимов.
Экспортируемые псевдонимы
Чтобы сделать псевдоним доступным дочернему shell, необходимо пометить его как экспортируемый псевдоним, указывая в команде alias после опции -х. Если псевдонимы опущены, выводится список всех текущих экспортируемых псевдонимов.
Внимание
Если значение псевдонима изменено в дочернем shell, это не затрагивает значение первоначального псевдонима в родительском.
Пример использования экспортированного псевдонима:
$ alias -х mroe='morer ...добавить экспортируемый псевдоним.
$ alias -х ...посмотреть экспортируемые псевдонимы.
autoload=typeset -fu ...стандартный псевдоним.
... ...другие псевдонимы выводятся здесь.
ls=ls -F
mroe=more ...псевдоним, который я только что добавил.
. . . ...другие псевдонимы выводятся здесь.
type=whence -v vi=/usr/ucb/vi $ cat test.ksh mroe main2. c ...скрипт, использующий новый псевдоним.
$ test.ksh /★ MAIN2.C */ #include #stdio.h, #include "palindrome.h" main () ...выполнить скрипт, mroe работает!
printf ("palindrome (\"cat\") = %d\n", palindrome ("cat"));
printf ("palindrome (\"noon\") = %d\n", palindrome ("noon"));
}
$
История
Korn shell хранит список команд, введенных с клавиатуры для того, чтобы их можно было отредактировать и выполнить повторно позднее. Эта функция известна как механизм истории. Встроенная команда fc (от англ, fix command) дает к ней доступ. Есть две формы f с. Первая, более простая, разрешает выполнить повторно указанный набор команд; вторая, более сложная, позволяет редактировать их перед повторным выполнением.
Пронумерованные команды
При использовании истории очень удобно знать номер команды, которую вы собираетесь ввести. Для этого укажите в переменной приглашения psi символ
$ PS1=’! $ '
103 $
...установка, чтобы PS1 содержала символ !. ...приглашение для команды с номером 103.
Сохранение команд
Korn shell записывает выполненные команды в количестве $histsize в файл $histfile. Если переменная окружения histsize специально не задана, ее значение по умолчанию равно 128. Если имя файла histfile не установлено или указанный файл не имеет прав записи, то по умолчанию используется файл $HOME/.sh_history, единый для всех Korn shell. Поэтому пока пользователь не изменит значение $histfile во время сессии, введенные команды доступны, как история для применения в следующей сессии.
Ниже приведен файл, в котором сохранена история выполнения команд:
$ echo $HISTSIZE ...установлена в .profile.
100
$ echo $HISTFILE ...не установлена предварительно.
$ tail -3 $НСМЕ/.sh_history ...вывести последние 3 строки.
echo $HISTSIZE
echo $HISTFILE
tail -3 $НОМЕ/.sh_history $
Повторное выполнение команд
Команда fc позволяет повторно выполнять отработанные команды.
Синтаксис
fc -е - [стараяСтрока=новаяСтрока] префикс
Вариант команды fc, которая повторно выполняет предыдущую команду, начинающуюся с префикса после необязательной замены первого появления старойСтроки новойСтрокой. префикс МОЖеТ быть ЧИСЛОМ, В ЭТОМ случае повторно выполняется пронумерованное событие.
Пример:
360 $ fc -е - ech ...последняя команда, начинающаяся с ech.
echo $HISTFILE
361 $ fc -e - FILE=SIZE ech ...заменить FILE на SIZE, echo $HISTSIZE 100
362 $ fc -e - 360 echo $HISTFILE 363 $
...выполнить команду с номером 360.
Символ г — предопределенный псевдоним для команды fc -е позволяющий более удобным способом повторно выполнить команды:
364 $ alias г ...посмотреть на псевдоним г. r=fc -е 365
365 $ г 364 ...выполнить команду с номером 364. alias г r=fc -е -
366 $
Редактирование команд
Korn shell позволяет выполнить предварительное редактирование команд до их повторного выполнения.
Пример:
371 $ whence vi ...найти расположение vi.
/usr/ucb/vi
372 $ FCEDIT=/usr/ucb/vi ...присвоить FCEDIT значение полного пути.
373 $ fc 371 ...редактировать команду с номером 371.
...войти в vi, редактировать команду для замены ...на whence Is, сохранить, выйти из vi.
whence Is ...вывести отредактированную команду.
/bin/Is ...вывод от отредактированной команды.
374 $ fc 371 373 ...редактировать команды с номерами 371-373.
...войти в vi и редактировать список последних трех команд. ...предположим, что я удалил первую строку, ...изменил оставшиеся строки ...на echo -n hi и echo there, и затем вышел.
echo —n "hi " ...вывести редактированные команды,
echo there
hi there ...вывод от отредактированных команд.
375 $
Синтаксис
fc [-е редактор] [-nlr] [начало] [конец]
Данный вариант синтаксиса команды fc позволяет вызвать редактор с указанным диапазоном команд. После выхода из него выполняется отре
дактированный набор команд. Если редактор не указан, то используется редактор, путь к которому указан в переменной окружения fcedit. По умолчанию значение $fcedit равно /bin/ed, но желательно не использовать это значение. Неплохим вариантом будет /usr/ucb/vi (либо другой полный путь до редактора vi в вашей системе), или путь до иного редактора, с которым вы хорошо знакомы. Если другие опции не определены, редактор вызывается для предыдущей команды. После выхода из редактора Кот shell автоматически повторяет и выполняет ее сохраненную версию.
Чтобы определить конкретную команду по ее индексу или префиксу, укажите номер или префикс как значение начала, но не задавайте значение конца. Задание диапазона команд осуществляется так: установите значение начала, чтобы выбрать первую команду в серии, и значение конца, чтобы выбрать последнюю. Отрицательный номер интерпретируется, как смещение по отношению к текущей команде.
Опция -1 показывает выбранные команды, но не выполняет их. Если команды не определены, выводятся 16 последних. Опция -г инвертирует порядок отобранных команд, а опция -п запрещает генерацию их номеров при выводе.
Пример использования опции -1:
376 $ fc -1 371 373 ...вывести команды с номерами.
371 $ whence vi
372 $ FCEDIT= /usr/ucb/vi
373 $ fc 371
377 $ fc -6 ...редактировать команду с номером 371.
. . . редактировать команду для замены на whence Is и затем выйти, whence Is ...вывод отредактированной команды.
/bin/Is ...вывод в результате выполнения команды.
378 $
Редактирование команд
Korn shell содержит упрощенные встроенные версии редакторов vi, gmacs и emacs для редактирования текущей или предыдущей команд. Чтобы выбрать один из встроенных редакторов, задайте в переменных visual или editor строку, которая заканчивается именем одного из них. Следующий пример иллюстрирует выбор редактора vi:
380 $ VISUAL=vi ...выбрать встроенный редактор vi.
381 $
Встроенный редактор vi
Дальнейшее описание предполагает, что вы немного знакомы с редактором vi, который был описан в главе 2. Начните редактирование текущей строки нажатием клавиши <Esc> для входа в командный режим vi, а затем сделайте необходимые изменения. Для перехода из командного режима в режим добавления или вставки нажмите соответственно клавишу <а> или <i>. Возврат в командный режим осуществляется нажатием клавиши <Esc>. Для повторного выполнения команды служит клавиша <Enter>.
Внимание
Будьте внимательны: если вы нажмете комбинацию клавиш <Ctrl>+<D>, находясь в редакторе, то завершите работу shell, а не редактора.
В командном режиме ключевые последовательности попадают в одну из следующих категорий:
□ стандартные ключевые последовательности vi (см. главу 2)\
□ дополнительные перемещения;
□ дополнительный поиск;
□ маскирование имени файла;
□ замещение псевдонима.
Дополнительные перемещения
Клавиши <Т> (<к> или <->) и <J^> (<j> или <+>) позволяют выбрать соответственно предыдущие и следующие команды в списке истории. Это облегчает доступ к ним из встроенного редактора. Чтобы загрузить команду с конкретным номером, перейдите в командный режим, а затем введите номер команды, сопровождаемый нажатием клавиши <G>. Пример: 125 $ echo line 1 line 1 126 $ echo line 2 line 2 127 $ . . . в этом месте я нажал клавишу <Esc> с последующим двойным ....нажатием клавиши <к>. Это действие загрузило команду . . .с номером 125 в командную строку, которую я затем выполнил ...путем нажатия клавиши <Enter>. line 1 128 $ ...здесь я нажал клавишу <Esc> с последующим 125 <G>.
...Это действие загрузило команду с номером 125 в командную строку, ...которую я затем выполнил путем нажатия клавиши <Enter>.
line 1
129 $ _
Дополнительный поиск
Стандартные конструкции /строка и ?строка производят поиск команды соответственно назад и вперед по списку истории. Например:
127 $ echo line 1
line 1
138 $ echo line 2
line 2
139 $ ...в этом месте я нажал клавишу <Esc> с последующим вводом /ech,
...что загрузило последнюю команду, содержащую строку ech, ... в командную строку.
...Затем я нажал клавишу <п> для продолжения поиска
...очередной команды, которая совпала с искомой. В завершение
...я нажал клавишу <Enter> для выполнения команды.
line 1
$ _
Использование маски для имени файла
Использование звездочке (*) в командном режиме добавляет ее к слову, на котором расположен курсор, вследствие чего слово будет обработано, как маска для замены имен файлов. Если совпадения не произойдет, пользователь услышит звуковой сигнал. В противном случае слово будет заменено списком в алфавитном порядке всех соответствующих имен файлов, и редактор автоматически перейдет в режим ввода. Пример:
114 $ Is m*
m m3 main.c mbox
ml madness . c main, о mon.out
m2 main makefile myFile
115 $ Is ma ... в этом месте я нажал клавишу <Esc>
. . . и клавишу <*>, а затем клавишу <Enter>.
115 $ Is madness.c main main.с main.о makefile
madness.c main.с makefile
main main.о
116 $
Если вы используете символ равно (=) в командном режиме, редактор выводит пронумерованный список всех файлов, которые содержат текущее слово как префикс, а затем повторно выводит командную строку:
116 $ 1s та ...в этом месте я нажал клавишу <Esc>, ...а затем клавишу <=>.
1) madness.с
2) main
3) main.с
4) main.о
5) makefile
116 $ Is та_ ...возврат к первоначальной командной строке.
При использовании символа косой черты (/) в командном режиме редактор пытается интерпретировать имя текущего файла. Если оно соответствует каталогу, добавляется /; иначе добавляется пробел. Пример:
116 $ 1s та ...в этом месте я нажал клавишу <Esc>, а затем клавишу <\>.
...завершения не было выполнено, поскольку "та" — ...это префикс больше, чем одного файла.
116 $ 1s так ...в этом месте я нажал клавишу <Езс>, а затем клавишу <\>.
... Редактор дописал имя, и получилось "makefile".
116 $ Is makefile _
Замещение псевдонима
Если, работая в редакторе, вы часто указываете один и тот же шаблон, можно воспользоваться механизмом замены псевдонимов. Если вы задаете _символ, как псевдоним слова, последовательность @ символ заменяется словом в командном режиме.
В представленном ниже примере символ i в начале псевдонима переводит встроенный редактор в режим вставки, а нажатие клавиши <Esc> в конце строки заставляет его завершить сеанс vi:
123 $ alias _с= ' icommon text^[' . ..Л[ — это символ от комбинации
...клавиш <Ctrl>+<V>, который будет ...сгенерирован после <Esc>
124 $ echo ...в этом месте я нажал клавишу <Esc> за @с
124 $ echo common text
Встроенный редактор emacs/gmacs
Дальнейшее описание предполагает, что вы знакомы с редактором emacs, который был представлен в главе 2. Во встроенном редакторе поддерживается
большинство ключевых последовательностей emacs. Вы можете перемещать курсор и управлять текстом, используя стандартные ключевые последовательности редактора emacs. Для повторного выполнения команды следует нажать клавишу <Enter>.
Главное различие между встроенным редактором и стандартным emacs в том, что ключевые последовательности перемещения курсора или вниз, поиск вперед и обратный поиск работают в списке истории. Например, последовательность <Т> <Ctrl>+<P> показывает предыдущую команду в командной строке. Точно так же ключевая последовательность обратного поиска <Ctrl>+<R> строка демонстрирует самую последнюю команду, содержащую строку.
Арифметические действия
Команда let позволяет выполнять арифметические вычисления.
Синтаксис
let выражение
Команда let выполняет арифметические вычисления над целыми числами двойной точности и поддерживает все основные математические операторы, используя стандартные правила предшествования. Они приведены ниже в порядке уменьшения приоритета операций:
Оператор Описание
। Унарный минус Логическое отрицание
* / 9- > /> ° Умножение, деление, остаток
Сложение, вычитание
< j > > о Операторы отношения
== 1 = » • Равенство, неравенство
= Присвоение
Все операторы объединяются слева направо за исключением оператора присвоения. Выражения могут быть помещены между круглыми скобками для изменения порядка вычисления. Shell не проверяет переполнение, учитывайте это! Операнды могут быть целочисленными кон-
стантами или переменными. Когда встречается переменная, она заменяется значением, которое в свою очередь может содержать другие переменные. Вы можете явно заменить основание по умолчанию (10), используя формат основание#значение, Где основание — ЭТО ЧИСЛО между.2 и 36. Нельзя помещать пробелы или знаки табуляции между операндами или операторами. Недопустимо размещать $ перед переменными, которые являются частью выражения.
Вот несколько примеров работы команды let:
$ let х = 2 + 2
ksh: =: syntax error
$ let x=2+2
$ echo $x
4
$ let y=x*4
$ echo' $y
16
$ let x=2#100+2#100
$ echo $x
4
$
...выражение содержит пробелы.
...пробелы или табуляция недопустимы!
...хорошо.
...не помещайте $ перед переменными.
...сложить два двоичных числа.
...число выводится в десятичной системе.
Предотвращение интерпретации метасимволов
К сожалению, shell интерпретирует некоторые из стандартных операторов типа <, > и * как метасимволы. Поэтому они должны быть заключены в кавычки или им должна предшествовать обратная косая черта (\) для запрещения интерпретации их как специальных. Чтобы избежать этого неудобства, существует эквивалентная форма команды let, которая автоматически оперирует всеми символами, как будто они были окружены двойными кавычками, и позволяет использовать пробелы вокруг символов. Например, последовательность (( list ))
эквивалентна
let " list "
Я лично всегда использую синтаксис ( о ) вместо let. Вот пример: $ (( х = 4 )) ... пробелы — это нормально.
$ (( у = х * 4 ))
$ echo $y
16
$ _
Возвращаемые значения
Если результат вычисления выражения равен 0, возвращается код 1; иначе — 0. Код возврата может использоваться структурами управления, например, оператором if, как в этом примере:
$(( х = 4 )) ...4 присвоить х.
$ if (( х > 0 )) ...использовать в структуре управления.
> then
> echo х is positive
> fi
x is positive ...вывод структуры управления.
$
Для простых арифметических проверок стоит использовать ((..)) вместо test-выражений.
Замена тильды
Любое обозначение в формате -имя является объектом замены тильды. Командный интерпретатор проверяет файл пароля, чтобы определить, является ли имя именем пользователя и, если это так, заменяет последовательность -имя полным именем пути до домашнего каталога пользователя. В противном случае последовательность —имя остается неизменной. Замена тильды происходит после обработки псевдонимов. В табл. 6.4 приведен список замен тильды, включая специальные случаи -+ и —.
Таблица 6.4. Замена тильды в Korn shell
Последовательность тильды Заменяется на
$НОМЕ
-user домашний каталог пользователя — user
-/путь $ НОМЕ/путь
-+ $PWD (текущий рабочий каталог)
.— $OLDPWD (предыдущий рабочий каталог)
Ю Зак. 786
Предопределенные локальные переменные pwd и oldpwd будут описаны позже в этой главе. Ниже приведены некоторые примеры замены тильды:
$ pwd /home/glass $ echo ~ /home/glass $ cd / $ echo
$ echo — /home/glass $ echo ~dcox /home/de ox $
...текущий рабочий каталог.
...мой домашний каталог.
...изменить на корневой каталог.
...текущий рабочий каталог.
...предыдущий рабочий каталог.
...домашний каталог другого пользователя.
Меню: select
Команда select позволяет создавать простые меню. Она выводит пронумерованный список слов, указанных в in-выражении в стандартном канале ошибок, после чего отображает приглашение, хранящееся в специальной переменной PS3, а затем ждет входную строку от пользователя. Когда пользователь вводит строку, та сохраняется в предопределенной переменной reply. Далее происходит одно из следующих действий:
□ если пользователь ввел одно из предложенных чисел, имя устанавливается равным этому числу, команды из списка выполняются, посде чего вновь выводится приглашение, и система ожидает выбор очередной команды;
П если пользователь ввел пустую строку, варианты выбора выводятся снова;
П если пользователь указал отсутствующий вариант, имя устанавливается на пустой указатель, команды из списка выполняются, и выводится приглашение сделать другой выбор.
Синтаксис
select имя [in {слово}+] do
списокКома нд
done
Приведенный ниже пример заменяет цикл while более простой командой
select!
$ cat menu.ksh ...вывести скрипт, к
echo menu test program
select reply in "date" "pwd" "pwd" "exit" do
case $reply in "date")
date
11
"pwd") pwd
"exit") break
r r
*)
echo illegal choice z / esac done $ menu.ksh ...выполнить скрипт, menu test program 1) date 2) pwd 3) pwd 4) exit #? 1 Fri Feb 6 21:49:33 CST 1998 #? 5 illegal choice #? 4 $ _
Функции
Korn shell позволяет определять функции, которые могут быть вызваны, как команды shell. Параметры, передаваемые функциям, доступны через стан
дартный механизм передачи параметров. Функции должны быть определены перед их использованием. Существуют два способа определить функцию (см. синтаксис). Рекомендуется использовать вторую форму, т. к. она похожа на конструкцию в языке С. Для вызова функции следует ввести ее имя, сопровождаемое соответствующими параметрами. По очевидным причинам shell не проверяет количество или тип параметров.
Синтаксис
function имя
{
списокКоманд
Ключевое слово function может быть опущено: имя{)
списокКоманд
Ниже представлен пример скрипта, который определяет и использует функцию, которая не имеет параметров:
$ cat fund. ksh
...вывести скрипт.
message () # нет параметров функции.
{
echo hi
echo there
}
i=l
while (( i <= 3 ))
do
message ' # вызов функции.
let i=i+l # увеличить на единицу счетчик цикла,
done
$ fund. ksh . . . выполнить скрипт.
hi
there
hi /
there
hi there $
Использование параметров в функциях
Как уже было отмечено, параметры передаются функции стандартным способом. Пример:
$ cat func2.ksh f О {
echo parameter 1 = $1 echo parameter list = $*
}
# main program.
f 1
f cat dog goat $ func2.ksh parameter parameter parameter parameter $
. . .вывести скрипт.
# вывести первый параметр.
# вывести входной список.
# вызвать с одним параметром.
# вызвать с тремя параметрами ...выполнить скрипт.
1 = 1
list = 1
1 = cat
list = cat dog goat
Возврат из функции
Команда return возвращает значение.
Синтаксис
return [ значение ]
Когда return используется без аргументов, передается код возврата последней выполненной в функции команды. Иначе, возвращается код, равный значению. Если команда return выполняется из главного скрипта, она эквивалентна команде exit. Код возврата доступен вызывающему процессу через переменную $?.
Ниже в качестве примера приведена функция, которая перемножает аргументы и возвращает результат: $ cat func3.ksh ...вывести скрипт, f () # функция с двумя параметрами.
(( returnValue = $1 * $2 )) return $returnValue
}
# main program.
f 3 4 # вызов функции.
result=$? # сохранить код возврата,
echo return value from function was $result $ func3.ksh ...выполнить скрипт,
return value from function was 12 $
Контекст
Функция выполняется в том же самом контексте, что и процесс, который вызывает ее. Это означает, что функция и процесс разделяют одни и те же переменные, текущий рабочий каталог и перехватчики событий. Единственное исключение — событие выхода, которое наступает, когда функция выполняет возврат.
Локальные переменные
Команда typeset (которая далее будет описана более подробно) имеет специальные ориентированные на функцию возможности. Созданная с использованием typeset переменная ограничивается областью действия функции, в которой она создана, и всех вызываемых функций. Если переменная с указанным именем уже существует, ее значение заменяется, когда функция выполняет возврат. Эта особенность напоминает понятие "область действия переменной" в языках программирования высокого уровня.
В следующем примере используется команда typeset для объявления локальной переменной:
$ cat func4.ksh f О
typeset х
(( х = $1 * $2 ))
...вывести скрипт.
# функция с двумя параметрами.
# объявить локальную переменную.
# установить локальную переменную.
echo local x = $x return $x
}
# main program.
x=l # установить глобальную переменную.
echo global x = $x # вывести значение перед функциональным вызовом.
f 3 4 # вызвать функцию.
result=$? # сохранить код возврата.
echo return value from function was $result echo global x = $x # значение после функции.
$ func4.ksh ...выполнить скрипт.
global х = 1
local x = 12
return value from function was 12
global x = 1
$
Рекурсия
Как показывает практика, во многих случаях целесообразно использовать рекурсивные функции. Ниже приведены два скрипта, которые выполняют рекурсивное вычисление факториала — factorial о. Первый использует код возврата, чтобы вернуть результат, а второй — стандартный вывод для отображения результата.
Внимание
Эти скрипты доступны в сети (см. Введение для получения дополнительной информации).
Рекурсивный факториал: использование кода возврата 4
factorial () # функция с одним параметром.
if (( $1 <= 1 )) then
return 1 # вернуть результат в коде возврата,
else
typeset tmp # объявить две локальных переменных,
typeset result
( ( tmp = $1 - 1 ) ) factorial $tmp # вызвать рекурсивно.
( ( result = $?*$!)) return $result # передать результат в коде возврата,
fi
}
# main program, factorial 5 # вызвать функцию
echo factorial 5 = $? # вывести код возврата.
Рекурсивный факториал:
использование стандартного вывода
factorial () # функция с одним параметром
{
if (( $1 <= 1 )) then
echo 1 # вывести результат на стандартный вывод,
else
typeset tmp # объявить две локальных переменных,
typeset result (( tmp = $1 - 1 )) (( result = 'factorial $tmp' * $1 ) ) echo $result # вывести результат на стандартный вывод,
fi } # echo factorial 5 = 'factorial 5' # вывод результата.
Использование кода функций в нескольких скриптах
Для использования исходного кода функции в нескольких скриптах следует сохранить его в отдельном файле, а прочитать его можно с помощью встроенной команды в начале скрипта, содержащего функцию.
Предположим, что исходный код одного из предыдущих скриптов вычисления факториала был сохранен в файле fact.ksh: $ cat.ksh ...вывести скрипт. . fact.ksh # читать исходный код функции, echo factorial 5 = 'factorial 5' # вызов функции.
$ func6.ksh ...выполнить скрипт, factorial 5 = 120
$
Расширенное управление заданиями
Korn shell дополняет возможности управления заданиями Bourne shell и поддерживает команды, перечисленные в табл. 6.5. Они доступны только в UNIX-системах, которые поддерживают управление заданиями. Следующие несколько разделов содержат описание управления заданиями и примеры их использования. Особенности управления заданиями Korn shell идентичны средствам командного интерпретатора С shell, о котором речь пойдет в следующей главе.
Таблица 6.5. Команды управления заданием Korn shell
Команда Описание
jobs Выводит задания пользователя
bg • Помещает специфицированное задание в фоновый режим
fg Помещает специфицированное задание в приоритетный режим
kill Посылает произвольный сигнал процессу или заданию
Задания
Команда shell jobs выводит список всех заданий данного командного интерпретатора.
Синтаксис
jobs [-1]
Команда jobs выводит список всех работ shell. В случае использования с опцией -1 к листингу добавляется ID процесса. Синтаксис каждой выводимой строки выглядит следующим образом:
номерЗадания [+|~] PID Статус Команда
Здесь + и - соответственно означают, что задание было последним или предпоследним, помещенным в фоновое выполнение. Статус может быть таким:
• Running (Выполняется);
• stopped (Остановлено (отложено));
• Terminated (Прекращено ("убито" сигналом));
• Done (Выполнено (нулевой код возврата));
• Exit (Выход (ненулевой код возврата)).
Основное назначение символов + и - состоит в том, что они могут использоваться при определении задания в следующей команде (см. разд. "Спецификация задания " далее в этой главе).
Пример:
$ jobs ...нет заданий.
$ sleep 1000 & ...запустить фоновое задание.
[1] 27128
$ man Is | ul -tdumb > Is.txt & ...другое фоновое задание.
[2] 27129
$ jobs -1 ...вывести текущие задания.
[2] +27129 Running man Is 1 ul -tdumb > Is.txt &
[1] - 27128 Running sleep 1000 &
$ _
Спецификация задания
Команды bg, fg, и kill позволяют специфицировать работу с помощью одного из форматов, перечисленных в табл. 6.6.
Таблица 6.6. Спецификация заданий в Korn shell
Форма Специфицирует
%целоеЗначение Задание с номером целоеЗначение
% префикс Задание, чье имя начинается с префикса
9- 4-Ъ Т Задание, которое было указано последним
о. 9-о о То же самое, что и % +
С о Задание, которое было указано предпоследним
bg
Команда shell bg возобновляет указанное задание как фоновый процесс. В следующем примере задание выполнялось в приоритетном режиме, а потом было приостановлено нажатием комбинации клавиш <Ctrl>+<Z> и переведено в фоновый.
Ниже приведены используемые для этого команды:
$ man ksh | ul -tdumb > ksh.txt ...запустить в приоритетном режиме.
AZ ...приостановить его.
[1] + Stopped man ksh | ul -tdumb > ksh.txt
$ bg %1 ... возобновить в фоновом режиме.
[1] man ksh | ul -tdumb > ksh.txt &
$ jobs ...вывести текущие задания.
[1] + Running man ksh | ul -tdumb > ksh.txt
$
Синтаксис
bg [%задание]
Команда shell bg возобновляет указанное задание, как фоновый процесс. Если никакое задание не определено, возобновляется последнее.
fg
Команда shell fg возобновляет указанное задание, как приоритетный процесс.
Синтаксис
fg [%задание]
Команда shell fg возобновляет указанное задание, как приоритетный процесс. Если никакое задание не специфицировано, возобновляется последнее упомянутое задание.
В представленном ниже примере фоновое задание было переведено в приоритетный режим:
$ sleep 1000 &
[1] 27143
$ man ksh | ul
[2] 27144
$ jobs
[2] + Running
[ 1] - Running
-tdumb > ksh.txt &
...запустить фоновое задание.
...запустить другое.
...вывести текущие задания. man ksh | ul -tdumb > ksh.txt & sleep 1000 &
$ fg %та . . .перевести задание в приоритетный режим,
man ksh I ul -tdumb > ksh.txt ...команда выводится повторно.
$
kill
Команда shell kill посылает сигнал указанному заданию или процессам.
Синтаксис
kill [-1] [-сигнал] {процесс | %задание}+
Команда shell kill посылает сигнал указанному заданию или процессам. Процесс задается его номером PID. Сигнал может быть определен или его номером, или символически, путем удаления приставки "SIG" из символической константы в файле /usr/include/sys/signal.h. Чтобы получить список сигналов, используйте опцию -1. Если сигнал не определен, посылается сигнал term. Если сигнал term или hup был отправлен приостановленному процессу, посылается сигнал cont, который возобновляет его.
Пример:
$ kill -1 ...вывести все сигналы kill.
1) HUP 12) SYS 23) STOP
2) INT 13) PIPE 24) TSTP
3) QUIT 14) ALRM 25) CONT
4) ILL 15) TERM 26) TTIN
5) TRAP 16) USR1 27) TTOU
6) ABRT 17) USR2 28) VTALRM
7) EMT 18) CHLD 29) PROF
8) FPE 19) PWR 30) XCPU
9) KILL 20) WINCH 31) XFSZ
Ю) BUS 21) URG
11) SEGV 22) POLL
$ man ksh | ul -tdumb > ksh. txt & ...запустить фоновое задание. [1] 27160
$ kill -9 %1 ..."убить" его через спецификацию задания.
[1] + Killed man ksh | ul -tdumb > ksh.txt &
$ man ksh | ul -tdumb > ksh.txt & ...запустить другое. [1] 27164
$ kill -KILL 27164
[1] + Killed
$
..."убить” его через ID процесса, man ksh ul -tdumb > ksh.txt &
Усовершенствования
В дополнение к новым возможностям, которое уже были описаны, Кот shell содержит усовершенствования следующих возможностей:
□ перенаправление;
□ конвейеры;
□ замещение команд;
П доступ к переменной;
□ дополнительные встроенные команды.
Перенаправление
Korn shell имеет некоторые усовершенствования перенаправления, а именно, способность удалять ведущие символы табуляции в документах, находящихся в буфере1. Если слову предшествует знак -, то ведущие символы табуляции удаляются из строки, введенной со стандартного входа.
Синтаксис
команда « [-] слово
Пример:
$ cat «- ENDOFTEXT
this input contains
> some leading tabs
> '"D z
this input contains
some leading tabs
$ _
Данный пример команды позволяет тексту, находящемуся в буфере, в скрипте размещаться с отступом, чтобы соответствовать близлежащим командам shell.
1 См. разд. "Перенаправление ввода в буфер shell" главы 4. — Ред.
Конвейеры
Оператор | & поддерживает простую форму параллельной обработки. Когда команда сопровождается |&, она выполняется как фоновый процесс, стандартный ввод и вывод которого связаны с первоначальным родительским shell двусторонним конвейером. Когда первоначальный shell генерирует вывод, используя команду print -р, он посылается на стандартный канал ввода дочернего shell. Когда первоначальный shell читает ввод, используя команду read -р, он принимается со стандартного вывода дочернего shell. Вот пример:
$ date |& ...начать дочерний процесс.
[1] 8311
$ read -р theDate ...читать со стандартного вывода дочернего процесса.
[1] + Done * date |& ... дочерний процесс прекратился.
$ echo $theDate ...вывести результат.
Sun Мау 10 21:36:57 CDT 1998 $
Замещение команды
В дополнение к уже описанному методу замещения команды (окружения ее тупыми штрихами (')) Korn shell позволяет выполнять замену команды, используя следующий синтаксис:
$ (команда)
Обратите внимание, что символ $, который непосредственно предшествует открывающей круглой скобке, является частью синтаксиса, а не приглашением shell.
Пример:
$ echo there are $(who | wc -1) users on the system
there are 6 users on the system
$ _
Чтобы подставить содержимое файла в команду shell, используйте конструкцию
$ (<имяФайла)
вместо более длинной формы
$(cat имяФайла}
Переменные
Korn shell поддерживает следующие дополнительные средства работы с переменными:
□ более гибкие методы доступа;
□ предопределенные локальные переменные;
□ предопределенные переменные окружения;
□ простые массивы;
□ команду typeset для форматирования вывода переменных.
Гибкие методы доступа
В дополнение к методам доступа к переменной, поддерживаемым Bourne shell, Korn shell реализует возможности работы с ними, перечисленные в табл. 6.7.
Таблица 6.7. Методы доступа к переменной в Korn shell
Синтаксис Действие
${#имя} Заменяется длиной значения имя
${#ИМЯ[* ] } Заменяется числом элементов в массиве имя
${имя:+слово} Работают подобно аналогам, которые не содержат :, за исклю-
${имя:=слово} чением того, что имя должно быть установлено и не равно нулю, а не просто определено
${имя:2 слово}
${имя:+слово}
$ {имяЪша блон] Удаляет ведущий шаблон из имени. Выражение заменяется зна-
$ {имя# #ша блон} чением имя, если оно не начинается с шаблона, и оставшимся суффиксом, если оно начинается с шаблона. Первая форма синтаксиса удаляет самый маленький шаблон соответствия, а вторая — большой
$ {имя%та блон} Удаляет замыкающий шаблон из имени. Выражение заменяется
$ {имя% % та блон} значением имя, если оно не заканчивается шаблоном, и оставшимся суффиксом, если оно завершается шаблоном. Первая форма синтаксиса удаляет самый маленький шаблон соответствия, вторая — самый большой
Вот некоторые „примеры:
$ fish='smoked salmon' ...установить переменную.
$ echo ${#fish} ...вывести длину значения переменной.
13
$ cd dirl ...переместиться в каталог.
$ echo $PWD ...вывести текущий рабочий каталог,
/home/glass/dirl
$ echo $HOME /home/glass
$ echo ${PWD#$HOME/} ...удалить ведущее $НОМЕ/ dirl
$ fileName=menu.ksh ...установить переменную.
$ echo $ {fileName%. ksh} .bak ...удалить замыкающее .ksh
menu.bak - ...и добавить .bak.
$
Предопределенные локальные переменные
В дополнение к стандартному набору предопределенных локальных переменных, Korn shell поддерживает переменные, перечисленные в табл. 6.8.
Таблица 6.8. Предопределенные локальные переменные Korn shell
Имя Описание
$_ Последний параметр предыдущей команды
$PPID ID процесса родительского shell
$PWD Текущий рабочий каталог shell
$OLDPWD Предыдущий рабочий каталог shell
$RANDOM Случайное целое число
$REPLY Устанавливается командой select
$SECONDS Число секунд, прошедших с начала вызова shell
$CDPATH Используется командой cd
$COLUMNS Устанавливает ширину окна редактирования для встроенных редакторов
$EDITOR Указывает тип встроенного редактора
$ENV Содержит имя стартового файла Korn shell
$FCEDIT Определяет редактор, который вызывается командой f с
$HISTFILE Имя файла истории
$HISTSIZE Количество строк истории для запоминания
Имя Таблица 6.8 (окончание) Описание
$LINES Используется командой select для определения отображения вариантов выбора
$MAILCHECK Указывает shell, сколько секунд ожидать перед проверкой почты. Значение по умолчанию 600
$MAILPATH Содержит список имен файлов, разделенных двоеточием. Shell проверяет эти файлы на изменение каждые $ MAILCHECK секунд
$PS3 Приглашение, используемое командой select, по умолчанию #?
$TMOUT Если переменная равна значению, большему, чем 0, и истекает больше, чем $тмоит секунд между командами, происходит завершение работы shell
$VISUAL Содержит тип встроенного редактора
Пример:
$ echo hi there hi there ...вывести сообщение для демонстрации
$ echo $_ ...вывести последний аргумент последней команды.
there
$ echo $PWD /home/glass ...вывести текущий рабочий каталог.
$ echo $PPID 27709 ...вывести PID родительского shell.
$ cd / ...переместиться в корневой каталог.
$ echo $OLDPWD /home/glass ...вывести последний рабочий каталог.
$ echo $PWD ...вывести текущий рабочий каталог.
$ echo $RANDOM $ RANDOM . . . вывести два случайных числа.
32561 8323
$ echo $SECONDS 918 ...вывести секунды с начала работы shell.
$ echo $TMOUT ...вывести значение тайм-аут
0 $ ...нет выбранного тайм-аута.
Одномерные массивы
Korn shell поддерживает простые одномерные массивы.
Синтаксис
Для присвоения значения элементу массива используйте конструкцию: имяМассива[индекс]=значение
Для доступа к значению элемента массива используйте конструкцию:
${имяМассива[индекс]}
Для того чтобы сформировать массив, просто присвойте значение переменной, указывая в скобках список индексов между 0 и 511. Элементы массива создаются по мере необходимости. Если вы опускаете индекс, используется 0 в качестве значения по умолчанию.
Вот пример, который использует скрипт для вывода квадратов чисел от 0 до 9: $ cat squares.ksh ...посмотреть скрипт.
i=0 while ( ( i < 10 ) ) do
(( squares[$i] = i * i )) ...присвоить отдельные элементы.
(( i = i + 1 }) ...увеличить счетчик цикла.
done
echo 5 squared is ${squares[5]} ...вывести один элемент,
echo list of all squares is ${squares[*]} ...вывести все.
$ squares.ksh ...выполнить скрипт.
5 squared is 25
list of all squares is 0 1 4 9 16 25 36 49 64 81 $
typeset
Команда typeset позволяет создавать и манипулировать переменными.
В табл. 6.9 перечислены ее опции.
Синтаксис
typeset {-HLRZfilrtux [значение] [имя [=слово]]}*
Команда typeset позволяет создавать и манипулировать переменными: форматировать, конвертировать их во внутреннее представление целых
чисел для более быстрого выполнения арифметических операций, присваивать им статус "только для чтения", переключаться между строчными и прописными буквами, экспортировать переменные.
Каждая переменная имеет связанный с ней набор флагов, которые определяют ее свойства. Например, если переменной поставлен в соответствие флаг "заглавный", она будет всегда выводить свое содержимое прописными буквами, даже когда они строчные. Опции typeset используются путем установки и переустановки различных флагов, связанных с переменными. Предшествующий опции знак - активизирует заданный флаг. Для выключения флага и отмены действия опции поставьте перед ней + вместо -. %
Таблица 6.9. Опции команды typeset
Опция Описание
L Включает флаг L и выключает флаг R. Выравнивает слово влево и удаляет ведущие пробелы. Если ширина слова меньше, чем ширина поля имени, то дополняет слово заключительными пробелами. Если ширина слова больше ширины, то усекает конец слова до размера поля. Если флаг Z установлен, ведущие нули также удаляются
R Включает флаг R и выключает флаг L. Выравнивает слово вправо и удаляет завершающие пробелы. Если ширина слова меньше чем ширина поля имени, то дополняет слово ведущими пробелами. Если ширина слова больше, то усекает конец слова до размера поля
z Выравнивает слово вправо и заполняет нулями, если первый непробельный символ — это цифра, и флаг L выключен
Форматирование
Во всех опциях форматирования ширина поля имени равна ширине значения, если оно установлено. В противном случае она установлена на ширину
слова.
Регистр
С помощью опций изменения регистра значение может быть конвертировано в строчные и прописные буквы, как показано в табл. 6.10. Ниже приведен пример, который выравнивает влево все элементы в массиве, а затем отображает их прописными буквами:
$ cat justify. ksh wordList[0] = ’j eff’
...вывести скрипт.
# установить три элемента.
wordList[1]=’John’ wordList[2]= ’ellen' typeset -uL7 wordList # форматировать все элементы массива.
echo ${wordList [*]} # осторожно! shell удаляет пробелы без кавычек,
echo "${wordList[*]}" # работает хорошо.
$ justify.ksh ...выполнить скрипт.
JEFF JOHN ELLEN JEFF JOHN ELLEN $ _
Таблица 6.10. Изменение регистра символов при помощи команды typeset
Опция Описание
1 Включает флаг 1 и выключает флаг и. Конвертирует слово в регистр строчных букв
и Включает флаг и и выключает флаг 1. Конвертирует слово в регистр прописных букв
Тип
Тип хранящегося значения может быть установлен с помощью опций, перечисленных в табл. 6.11.
Изменим рассмотренный выше фрагмент кода, объявив массив квадратов, как массив целых чисел. Это ускорит его работу:
$ cat squares.ksh ...посмотреть скрипт.
typeset -i squares # объявить массив целых (для скорости).
i=0
while (( i < 10 )) do
(( squares[$i] = i * i ))
(( i = i + 1 ))
done
echo 5 squared is ${squares[5]}
echo list of all squares is ${squares[*]}
$ squares.ksh ...выполнить скрипт.
5 squared is 25
list of all squares is 0 1 4 9 16 25 36 49 64 81
$
Таблица 6.11. Установка типа значениям при помощи команды typeset
Опция Описание
i Сохраняет имя, как целое число для ускорения арифметических вычислений. Задает основание вывода, равное значению, если оно установлено; иначе использует основание слова
r Устанавливает атрибуты доступа к переменной равными "только для чтения"
X Помечает переменную, как экспортируемую
Разное
В табл. 6.12 показаны две дополнительные опции команды typeset.
Таблица 6.12. Дополнительные опции команды typeset
Опция Описание
f Единственные флаги, которые можно использовать с этой опцией, — t, устанавливающий трассировку функции, и х, выводящий все функции с установленным атрибутом х
t Связывает имя с меткой слова
Приведенный ниже пример демонстрирует трассировку функции factorial с применением опций -ft, после чего скрипт выполняется: $ cat func5.ksh ...посмотреть скрипт
factorial () # функция одного параметра
{ if (( $1 <= 1 )) then return 1 else
typeset tmp typeset result ( ( tmp = $1 - 1 )) factorial $tmp
(( result =$?*$1)) return $result
#
typeset -ft factorial ...выбрать трассировку функции, factorial 3
echo factorial 3 = $?
$ func5.ksh ...выполнить скрипт.
+ let 3 <= 1 ...информация отладки.
+ typeset tmp
+ typeset result
+ let tmp =3-1
4- factorial 2
4- let 2 <= 1
4- typeset tmp
4- typeset result
4- let tmp =2-1
4- factorial 1
4- let 1 <= 1
4- return 1
4- let result =1*2
4- return 2
4- let result =2*3
4- return 6 factorial 3=6 $
typeset с не именованными переменными
Если переменные не определены, выводятся имена всех переменных, имеющих указанный набор флагов. Если никакие флаги не указаны, то отображается список всех переменных и их параметров. Пример:
$ typeset export NODEID export PATH
...вывести список всех переменных typeset.
leftjust 7 t
export integer MAILCHECK
$ typeset -i ...вывести список целых переменных typeset. LINENO=1
MAILCHECK=60
$
Встроенные команды
Korn shell использует усовершенствованные версии следующих встроенных команд:
□ I cd;
□ set;
□ print (улучшенная версия команды echo из Bourne shell);
□ read;
□ test;
О trap.
cd
Версия команды Korn shell cd содержит несколько новых возможностей.
Синтаксис
cd { имя }
cd староеИмя новоеИмя
Первая форма команды cd обрабатывается следующим образом:
• если имя опущено, shell перемещается в домашний каталог, указанный в переменной $номе;
• если имя равно -, shell перемещается в предыдущий рабочий каталог, который сохраняется в переменной $oldpwd;
• если имя начинается с /, shell перемещается в каталог, полный путь которого — имя',
• если имя начинается с других символов, командный интерпретатор производит поиск совпадений в каталогах, указанных в переменной $cdpath, после чего перемещает shell в соответствующий каталог. Значение $cdpath по умолчанию равно пустой строке, поэтому поиск производится только в текущем каталоге.
Если используется вторая форма синтаксиса команды cd, shell заменяет первое найденное совпадение, указанное в параметре староеИмя, значением новоеИмя. Затем shell использует новое имя пути. Новое имя текущего каталога сохраняется в переменной pwd. Текущее значение $pwd может быть просмотрено с помощью встроенной команды pwd.
Ниже приведен пример cd в действии:
$ CDPATH=.:/usr ...установить мой CDPATH.
$ cd dirl $ pwd /home/glass/dirl ...переместиться в dirl, размещенный в
$ cd include ...переместить ся в include, размещенный в /usr.
$ pwd /usr/include ...вывести текущий рабочий каталог.
$ cd - ...переместиться в мой предыдущий каталог.
$ pwd /home/glass /dirl $ . ...вывести текущий рабочий каталог. *
set
Команда set позволяет устанавливать и снимать флаги, управляющие широким набором характеристик shell. В табл. 6.13 перечислены опции, доступные этой команде.
Синтаксис
set [ +-aefhkmnostuvx ] [ +-о опция] {аргумент} ★
Команда Korn shell set поддерживает все возможности аналогичной команды Bourne shell и несколько дополнительных усовершенствований. Опция, которой предшествует + вместо изменяет свое значение на противоположное.
Таблица 6.13. Опции команды set
Опция Описание
а Все переменные автоматически получают флаг для экспорта
f Запрещает замещение имени файла
h Все невстроенные команды автоматически интерпретируются, как прослеженные псевдонимы
ш Помещает все фоновые задания в уникальную процессную группу и выводит уведомление о завершении. Эта опция автоматически устанавливается для диалоговых shell
п Принимает, но не выполняет команды. Опция не влияет на диалоговые shell
Таблица 6.13 (окончание)
Опция Описание
о Описание опции см. далее
Р Присваивает $РАТН значение по умолчанию, заставляя последовательность запуска игнорировать файл $ номе/, profile, и читает /etc/suid_profile вместо файла $env. Этот флаг устанавливается автоматически, когда shell выполняется процессом в режиме "set user ID" или "set group ID". Для получения дополнительной информации о процессах "set user ID" см. главу 13
s Сортирует параметры
Не изменяет никакие флаги. Если аргументов нет, все параметры возвращаются в исходное состояние
Опция о
Опция о команды set принимает аргумент, часто имеющий тот же самый эффект, что и один из флагов, используемых с set. Если аргумент не указан, выводятся текущие установки. В табл. 6.14 приведен список допустимых аргументов и их значения: Обратите внимание, что, установив опцию ignoreeof в .profile, можно защитить себя от случайного выхода из системы по нажатию комбинации клавиш <Ctrl>+<D>: set -о ignoreeof
Таблица 6.14. Аргументы set -о
Опция Описание
allexport Эквивалентна флагу a
errexit Эквивалентна флагу е
bgnice Фоновые процессы выполняются с низшим приоритетом
emacs Вызывает встроенный редактор emacs
gmacs Вызывает встроенный редактор gmacs
ignoreeof Не выходит по нажатию комбинации клавиш <Ctrl>+<D>. Вместо этого используется exit
keyword Эквивалентна флагу к
markdirs Добавляет окончание / к каталогам, сгенерированным путем замены имени файла
monitor Эквивалентна флагу m
Таблица 6.14 (окончание)
Опция Описание
noclobber Предотвращает перенаправление усечения существующих файлов поехес Эквивалентна флагу п
noglob Эквивалентна флагу f
no log Не сохраняет определения функции в файле истории
nounset Эквивалентна флагу и
privileged То же самое, как -р
verbose Эквивалентна флагу v
trackall Эквивалентна флагу h
vi Вызывает встроенный редактор vi
viraw Символы обрабатываются во время печати в режиме vi xtrace Эквивалентна флагу х
print
Команда print — усовершенствованная версия встроенной команды Bourne shell echo, позволяющая посылать вывод в произвольный описатель файла.
Синтаксис
print -npsuR [п] {аргумент}*
По умолчанию команда print выводит значения, указанные в качестве аргументов, на стандартный вывод, и сопровождает это переводом строки. Опция -п запрещает перевод строки, а опция -и позволяет определить описатель файла л из одной цифры для канала вывода. Опция -s добавляет вывод к файлу истории вместо направления его на стандартный выход. Опция -р посылает вывод в двунаправленный конвейерный канал shell. Опция -R интерпретирует все остающиеся слова как аргументы.
Пример:
121 $ print -u2 hi there ...послать вывод в стандартный канал ошибок, hi there
122 $ print -s echo hi there
124 $ r 123
echo hi there
hi there
125 $ print -R -s hi there
-s hi there
$
...добавить в историю.
...вызвать снова команду с номером 123.
...рассматривает -s, как аргумент.
read
Команда Korn shell read — это расширенная версия одноименной команды Bourne shell.
Синтаксис
read -prsu [п] [имя?приглашение] {имя}*
Команда Korn shell read работает точно так же, как одноименная команда Bourne shell, и имеет следующие дополнительные возможности:
• опция -р читает входную строку с двунаправленного конвейера shell;
• опция -и использует описатель файла п для ввода;
• если первый аргумент содержит ?, остаток аргумента используется, как приглашение.
Пример:
$ read. 'name?Enter your name ' Enter your name Graham $ echo $name Graham $ _
test
Команда Korn shell test поддерживает несколько новых операторов, описанных в табл. 6.15. Кроме того, она предлагает удобный синтаксис, позволяющий сделать программу более читаемой.
Таблица 6.15. Операторы проверки, уникальные для команды test Korn shell
Оператор Описание
-L имяФайла Возвращает истину, если имяФайла — символическая связь
файл! -nt файл2 Возвращает истину, если файл1 новее, чем файл2
файл1 -ot файл2 Возвращает истину, если файл1 старше, чем файл 2
файл! -ef файл2 Возвращает истину, если файл! такой же, как файл2
Синтаксис
[ [ testBbipaxeHHe] ]
эквивалентно
test textBMpaxceHne
Ниже приведен пример использования нового синтаксиса команды test:
$ cat test.ksh ...посмотреть скрипт.
i=i '
while [[ i -le 4 ]]
do
echo $i
(( i = i + 1 ))
done
$ test.ksh ... выполнить скрипт.
1
2
3
4
$
trap
Команда Korn shell trap— это доработанная версия аналогичной команды Bourne shell.
Синтаксис
trap [команда] [сигнал]
Команда Korn shell trap работает аналогично одноименной команде из Bourne shell, но имеет некоторые особенности:
• если аргумент то все указанные сигналы повторно устанавливаются в их начальные значения;
• если сигнал exit или 0 устанавливается trap внутри функции, тогда команда выполняется после выхода из нее.
В следующем примере установлен перехват события exit внутри функции: $ cat trap.ksh ...вывести скрипт.
f О { echo ’enter f () ’ trap ’echo leaving f...’ EXIT # установить локальную ловушку, echo ’exit f ()’
}
# main program.
trap ’echo exit shell’ EXIT # установить глобальную ловушку.
f # вызов функции f().
$ trap.ksh ...выполнить скрипт,
enter f () exit f ()
leaving f... ...локальный EXIT перехвачен.
exit shell ...глобальный EXIT перехвачен. $
Пример проекта: junk
Чтобы проиллюстрировать некоторые возможности Korn shell, рассмотрим проект junk, упомянутый в главе 5. Скрипт Korn shell использует функцию, чтобы обработать сообщения об ошибке, и массив с именами файлов. Остальные действия будут понятны читателю из комментариев. (Этот скрипт доступен в сети. Для дополнительной информации см. Введение.)
Синтаксис
junk -1р {имяФайла}*
Утилита junk — это аналог утилиты rm. Вместо удаления файлов она перемещает их в каталог junk домашнего каталога пользователя. Если .junk не существует, он автоматически создается. Опция -1 выводит текущее содержимое каталога .junk, а опция -р производит его очистку.
junk
#! /bin/ksh
# junk script
# Korn shell version
# author: Graham Glass
# 9/25/91
#
# Initialize variables
fileCount=0
listFlag=O purgeFlag=O fileFlag=O
# количество специфицированных файлов.
# 1, если используется опция list (-).
# 1, если используется опция очистки -р.
# 1, если специфицирован хотя бы один фа
если используется опция list (-).
если специфицирован хотя бы один файл.
junk=~/.junk # имя каталога junk.
#
error () ’
{
#
# Вывести сообщение об ошибке и выйти
#
cat « ENDOFTEXT
Dear $USER, the usage of junk is as follows:
junk -p means "purge all files"
junk -1 means "list junked files" junk clist of files, to junk them
ENDOFTEXT exit 1
#
# Разбор командной строки.
#
for arg in $* do
case $arg in
"-P")
purgeFlag=l r r "-I") listFlag=l r r -*) t r echo $arg is an illegal option • • r r *) fileFlag=l fileList[$fileCount]=$arg # добавить в список, let fileCount=fileCount+l r r esac done # # Проверка: не слишком ли много опций. # let total=$listFlag+$purgeFlag+$fileFlag if (( total != 1 )) then error fi # # Если каталог junk не существует, создать его. # if [[ ! (-d $junk) ]] then
’mkdir’ $junk # взято в кавычки на случай, если есть псевдоним.
#
# Обработка опций. #
if (( listFlag = 1 )) then
’Is1 -IgF $junk # вывод каталога junk, exit 0 fi # if (( purgeFlag == 1 ) ) then
’rm’ $junk/* # удалить файлы из каталога junk,
exit О fi #
if (( fileFlag == 1 )) then
’mv’ ${fileList [*] } $junk # поместить файлы в каталог junk, exit О fi # exit 0
Вот пример вывода результатов работы junk:
$ Is *.ksh ...вывести некоторые для junk.
fact.ksh* func5.ksh* test.ksh* trap.ksh*
f unc4.ksh* squares.ksh* track.ksh*
$ junk func5.ksh func4.ksh ...выполнить junk для пары файлов.
$ junk -1 ...вывести мой junk-каталог,
total 2 -rwxr-xr-x 1 gglass apollocl 205 Feb 6 22:44 func4.ksh* -rwxr-xr-x 1 gglass apollocl 274 Feb 7 21:02 func5.ksh* $ junk -p ...очистить мой junk-каталог.
$ junk -z ...испытать глупую опцию.
—z is an illegal option
Dear glass, the usage of junk is as follows:
junk -p means "purge all files"
junk -1 means "list junked files"
junk <list of files> to junk them
$ _
Ограниченный shell
Существует разновидность Korn shell, называемая ограниченным Korn shell, который поддерживает все возможности командного интерпретатора за исключением того, что пользователь не может:
П менять каталог;
□ осуществлять перенаправление вывода, используя > или »;
□ устанавливать переменные окружения shell, env или path;
□ использовать абсолютные пути.
Эти ограничения накладываются только после выполнения файлов .profile и $env. Любые скрипты, выполненные ограниченным Korn shell, интерпретируются их ассоциированными shell и не ограничены никаким образом.
Ограниченный Korn shell — это обычная С-программа, исполняемый файл которой хранится в /bin/rksh. Если выбранный shell — /bin/rksh, при регистрации в системе автоматически вызывается ограниченный диалоговый Korn shell . Его также можно запустить вручную, из скрипта или с терминала, с ПОМОЩЬЮ КОМанДЫ rksh.
Системные администраторы, как правило, используют такой shell, чтобы предоставить пользователям ограниченный доступ к системе следующим образом:
1. Пишут серии обычных скриптов Korn shell, позволяющих пользователям получить доступ к возможностям, которые они (пользователи) желают применять.
2. После чего размещают эти скрипты в каталоге с атрибутом "только для чтения", обычно находящемся в /usr/local/rbin.
3. Далее присваивают переменной $ратн пользовательского .profile значение /usr/local/rbin и несколько других каталогов на выбор.
4. Изменяют вход пользователя в файле пароля (см. главу 15), устанавливая shell равным /bin/rksh.
Опции командной строки
Если первый аргумент командной строки -, Korn shell стартует, как входной shell. Korn shell поддерживает опции командной строки Bourne shell, флаги
11 Зак. 786
встроенной команды set (включая -х и -v) и опции, перечисленные в табл. 6.16.
Таблица 6.16. Опции командной строки Korn shell
Опция Описание
-г Делает Korn shell ограниченным Korn shell
имяФайла Выполняет команды shell в имяФайла, если опция -s не используется.
имяФайла — это $0 внутри имяФайла-скрипта
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
П создание стартового файла Korn shell;
П псевдонимы и механизм истории;
□ встроенные строчные редакторы vi и emacs;
П арифметические операции;
П функции;
П усовершенствованное управление заданиями;
П несколько дополнительных возможностей команд.
Контрольные вопросы
1. Кем был написан Korn shell?
2. Почему полезен механизм псевдонимов?
3. Каким образом вы можете повторно отредактировать и выполнить предыдущую команду?
4. Поддерживает ли Korn shell рекурсивные функции?
5. Опишите современный синтаксис команды test.
Упражнения
6.1. Перепишите скрипт junk, представленный в данной главе, так, чтобы он управлялся с помощью меню. Используйте команду select. [Уровень: легкий.]
6.2. Напишите функцию dateToDays, которая принимает три параметра: название месяца, например, Sep; день, например, 18; год, например, 1962 — и возвращает количество дней, прошедших с 1 января 1900 г. до указанной даты. [Уровень: средний.]
6.3. Напишите набор функций, которые эмулируют каталожные стековые возможности С shell (будут описаны в главе 7). Используйте переменные окружающей среды, чтобы определить стек и его размер. [Уровень: средний\
6.4. Напишите скрипт pulse, который принимает два параметра: имя скрипта и целое число. Скрипт должен выполняться указанное число секунд, потом приостановиться на то же самое время, а затем продолжить выполнение, пока условие будет истинно. [Уровень: высокий.]
Проекты
1. Напишите скелетный скрипт, который автоматизирует администрирование системы, используя интерфейс меню. Скрипт должен выполнять следующие задачи:
• автоматическое удаление файлов ядра;
• автоматические предупреждения пользователям, захватывающим много процессорного времени или дискового пространства;
• автоматическая архивация.
[Уровень: легкий.]
2. Напишите скрипт-менеджер псевдонимов, который позволяет выбрать эмуляцию DOS, эмуляцию VMS или ее отсутствие. [Уровень: средний.]
Глава 7
С shell
Мотивация
С shell был написан после Bourne shell и придерживается синтаксиса и структур управления языка С. Первый С shell стал фаворитом разработчиков UNIX, поскольку был призван поддерживать расширенное управление заданиями. Многие пользователи С shell переходят к Korn shell и Bash shell из-за их дополнительных возможностей и эффективности, но С shell все еще остается популярным.
Предпосылки
Вам необходимо прочитать главу 4 и поэкспериментировать с некоторыми из основных возможностей командного интерпретатора.
Задачи
В данной главе объясняются и демонстрируются специфические для С shell возможности.
Изложение
Информация представлена в форме нескольких примеров UNIX-сессий и небольшого проекта.
Команды shell
В главе рассматриваются следующие команды shell:
alias nice chdir nohup dirs notify source stop suspend
foreach...end onintr switch...case...endsw
glob popd unalias
goto pushd unhash
hashstat rehash unset
history repeat unsetenv
if...then...else...endif set while...end
logout setenv
Общие сведения о С shell
С shell поддерживает все основные возможности shell, описанные в главе 4. а также новые:
П несколько способов установки и доступа к переменным;
П встроенный язык программирования, который поддерживает условные переходы, циклы и обработку прерываний;
□ настройку команд с помощью псевдонимов;
□ доступ к предыдущим командам через механизм истории;
П расширенное управление заданиями;
□ несколько новых встроенных и усовершенствованные существующие команды.
Эти новые возможности проиллюстрированы в иерархической диаграмме на рис. 7.1.
программирования заданиями команды
alias unalias J°^s S,OP repeat while notify nohup set /setenv \ .cshrc unsetenv unset
Рис. 7.1. Функциональность С shell
Запуск
С shell — это обычная С-программа, исполняемый файл которой хранится как /bin/csh. Если ваш выбранный shell — это /bin/csh, диалоговый режим С shell активизируется автоматически при регистрации пользователя в UNIX. Вы можете также вызвать С shell вручную из скрипта или с терминала, используя команду csh, которая имеет несколько опций командной строки, описанных в конце главы.
Когда С shell стартует, как входной shell, существующий глобальный файл инициализации входа в систему, который применим ко всем пользователям, может также’быть выполнен. Этот файл полезен для установки переменных окружения (типа path) так, чтобы они содержали информацию о локальном окружении. Имя файла изменяется от одной версии UNIX к другой, но похоже на /.login или /etc/login.
При вызове С shell последовательность запуска различна для входа в систему с регистрацией и входе без регистрации shell, как показано в табл. 7.1. Обратите внимание, что файл .cshrc выполняется при входе в систему перед любым типом файла инициализации. Это может показаться нелогичным и, в конце концов, стало причиной непредвиденного поведения пользователей, когда обрабатывались их файлы инициализации. Следует помнить, что С shell всегда выполняет собственный файл инициализации немедленно при старте, а затем определяет, является ли shell входным shell, который требует выполнения других файлов инициализации.
Таблица 7.1. Последовательность запуска С shell
Шаг Тип shell Описание
1 Оба Выполняет команды из $HOME/.cshrc, если он существует
2 Только при входе Выполняет команды из глобального файла инициализации входа в систему, если он существует
3 Только при входе Выполняет команды из $номе/.login, если он существует
Как только диалоговый shell стартует и завершает выполнять все соответствующие файлы инициализации, он выводит приглашение и ждет команды пользователя. Стандартным приглашением С shell является символ %, хотя он может быть изменен путем установки локальной переменной $prompt, которая описывается далее.
Файл .login обычно содержит команды, которые устанавливают переменные окружения, например, term, содержащую тип вашего терминала, и path, сообщающую shell, где искать исполняемые файлы. Помещайте в пользовательский .login-файл определения, которые должны быть установлены толь
ко однажды (переменные окружения, чьи значения наследуются другими shell), или то, что имеет смысл лишь для диалоговой сессии (такие, как определенные установки терминала). Вот пример .login-файла:
echo -n "Enter your terminal type (default is vtlOO):" set termtype = $< set term - vtlOO if ("$termtype" != "") set term = "$termtype" unset termtype set path=(. /bin /usr/bin /usr/local/bin )
stty erase "/ч?" kill ,,/4U" intr "ЛС" eof , ,,/чр" crt crterase set cdpath = (~) set history = 40 set notify set prompt = "! % " set savehist = 32
Файл .cshrc в основном содержит команды, которые устанавливают общие псевдонимы, или что-нибудь еще, что применимо только к текущему shell. Суффикс "гс" является аббревиатурой от англ, run commands — выполняемые команды. Вот пример файла .cshrc: alias emacs /usr/local/emacs alias h history alias 11 Is -1 alias print prf -pr pbl-2236-lp3 alias Is Is -F alias rm rm -i alicts m more
Переменные
C shell поддерживает локальные переменные и переменные окружения. Локальная переменная может содержать одно значение, тогда она называется простой переменной, или больше, чем одно значение, тогда она называется списком.
Создание и присвоение значений простым переменным
Чтобы присвоить значение простой переменной, используйте встроенную команду set.
Синтаксис
set {имя [-значение]}*
Если аргументы не представлены, команда set выводит список всех локальных переменных. Если значение не указано, параметру имя присваивается пустая строка. Если переменная имя не существует, она создается неявно.
Вот некоторые примеры:
% set flag ...присвоить переменной flag пустую строку.
% echo $flag ...ничего не печатается, т. к. она пустая.
% set color = rec? ...присвоить color строку red.
% echo $color red
% set name = Graham Glass ...осторожно! должны использоваться кавычки.
% echo $пате ...только первая строка была присвоена.
Graham
% set name = "Graham Glass" ...теперь это работает, как ожидалось. % echo $пате
Graham Glass
% set ...вывести список всех локальных переменных,
argv ()
cdpath /home/glass
color red
cwd /home/glass
flag
name Graham Glass
term vtlOO
user glass
%
Доступ к простой переменной
В дополнение к простому синтаксису доступа к переменной ($имя), С shell поддерживает сложные методы доступа, показанные в табл. 7.2.
Представленные ниже примеры иллюстрируют эти методы доступа. В первом примере использовались фигурные скобки, чтобы добавить строку к значению переменной: % set verb = sing % echo I like $verbing verbing: Undefined variable.
% echo I like ${verb}ing
I like singing
Таблица 7.2. Доступ к переменным С shell
Синтаксис Описание
${имя}
${2 имя}
Заменяется значением имя. Этот формат полезен, если за выражением немедленно следует алфавитно-цифровой символ, который иначе интерпретировался бы, как часть имени переменной
Заменяется 1, если имя существует, и 0 в противном случае
В следующем примере переменная использовалась как простой флаг в условном выражении:
% cat flag.csh ...посмотреть скрипт.
#
set flag ...присвоить переменной flag пустую строку.
if (${?flag}) then ...перейти, если flag установлен.
echo flag is set
endif
% flag.csh ...выполнить скрипт.
flag is set
Q,
Q
Создание списочных переменных
Чтобы присвоить переменной список значений, используйте встроенную команду set.
Синтаксис
set {имя = ({слово}* )}*
Если указанная переменная не существует, она создается неявно. Переменной присваивается копия списка слов.
Пример:
% set colors = ( red yellow green ) ...задать строку.
% echo $colors ...вывести введенный список,
red yellow green %
Доступ к списочной переменной
С shell поддерживает пару способов для доступа к списочной переменной. Оба эти метода имеют две формы, вторая окружена фигурными скобками (табл. 7.3).
Вторая форма полезна, если за выражением немедленно следует алфавитно-цифровой символ, который иначе интерпретировался бы как часть имени переменной.
Таблица 7.3. Доступ к списочным переменным С shell
Синтаксис Описание
$имя[селектор] Обе формы заменяются элементом имя, чей индекс опреде-
${имя[селектор]} лен значением селектора, который может быть числом, диапазоном чисел в формате “начало-конец" или звездочкой (*). Если начало опущено, предполагается 1. Если конец опущен, предполагается индекс последнего элемента. Если представлена *, то выбираются все элементы. Первый элемент списка имеет индекс 1
$#имя $ {#имя} Обе формы заменяются числом элементов в имени
Вот некоторые примеры:
% set colors = ( red yellow green )
% echo $colors[1]
red
% echo $colors[2-3]
yellow green
% echo $colors[4]
Subscript out of range.
% echo $#colors
3
%
...задать список.
...вывести первый элемент.
...вывести второй и третий элементы.
...недопустимый доступ.
...вывести размер списка.
Построение списков
Чтобы добавить элемент в конец списка, присвойте первоначальному списку собственное значение, следом через пробел укажите новый элемент и окружите эту конструкцию круглыми скобками. Если вы пробуете присвоить новому несуществующему элементу значение, то получите сообщение об ошибке. Следующий пример иллюстрирует некоторые манипуляции со списком:
% set colors = ( red yellow green ) % set colors[4] = pink Subscript out of range.
% set colors = ( $colors blue )
% echo $colors red yellow green blue •*
% set colors[4] = pink % echo $colors
red yellow green pink
% set colors = $colors black
% echo $colors red
$ set girls - ( sally georgia )
$ set boys = ( harry blair )
$ set both = ( $girls $boys )
$ echo $both
sally georgia harry blair g. о
...задать список.
...попытка установить четвертый. *
...добавить к списку.
...это работает!
.хорошо, т. к. четвертый существует.
.ч - I ,
.не забудьте использовать (). .только первый был установлен.
• 9'
.построить один список.
.построить другой.
.объединить списки.
.вывести результат.
Предопределенные локальные переменные
В дополнение к обычным предопределенным локальным переменным С shell определяет переменные, перечисленные в табл. 7.4. Вот маленький скрипт, который использует переменную $<, чтобы получить ответ пользователя:
% cat var5.csh ...вывести скрипт.
#
echo -n "please enter your name: "
set name = $< # получить входную строку,
echo hi $name, your current directory is $cwd
% var5.csh ...выполнить скрипт.
please enter your name: Graham
hi Graham, your current directory is /home/glass g о
Таблица 7.4. Предопределенные локальные переменные С shell
Имя Описание
$?0 Равно 1, если shell выполняет команды из указанного файла; 0 — иначе
$< Следующая строка стандартного входа приводится полностью
$argv Список, содержащий все позиционные параметры: $argv[l], эквивалентен $1
$cdpath Список альтернативных каталогов, которые использует chdi г для целей поиска
$cwd Текущий рабочий каталог
$echo Установлена, если опция командной строки -х активна
$histchars Может применяться, чтобы переопределить метасимволы истории по умолчанию. Первый символ используется вместо ! для замен истории, а второй — вместо 74 для быстрого повторного выполнения команды
$history Размер списка истории
$home Домашний каталог shell
$ignoreeof Защищает shell от завершения, когда тот получает сигнал от нажатия комбинации клавиш <Ctrl>+<D>
$mail Список файлов для проверки почты. По умолчанию shell проверяет почту каждые 600 секунд (10 минут). Если первое слово $mail — это число, shell использует его значение вместо значения по умолчанию
$noclobber Защищает существующие файлы от подмены по символу > и не-
$noglob существующие файлы от добавления по символу » Предотвращает расширение групповых символов
$nonomatch Предотвращает появление ошибки, если нет файлов, соответствующих имени файла при расширении группового символа
$notify По умолчанию shell уведомляет пользователя об изменениях в статусе работы как раз перед выводом нового приглашения. Если переменная $ not if у установлена, изменения в статусе отображаются немедленно, когда они происходят
$path Используется shell для определения местоположения выполняемых файлов
$prompt Приглашение shell
$savehist Количество команд, сохраняемых в файле истории
$shell Полное путевое имя входного shell
Таблица 7.4 (окончание)
Имя Описание
$status Код возврата последней команды
$time Если переменная установлена, любой процесс, который берет больше указанного количества секунд, приводит к выводу сообщения, указывающего статистику процесса
$verbose Установлена, если используется опция командной строки -v
Создание и присвоение переменных окружения
Чтобы назначать значение переменной окружения, используйте встроенную команду setenv.
Синтаксис
setenv имя значение
Если указанная переменная не существует, она неявно создается; в противном случае переписывается. Обратите внимание, что переменные окружения всегда хранят одно значение. Для них нет такого понятия, как список окружения.
Пример:
% setenv TERM vt52 ...установить тип моего терминала.
% echo $TERM ...подтвердить.
vt52
о о
Предопределенные переменные окружения
В дополнение к общим предопределенным переменным окружения, С shell поддерживает переменную, показанную в табл. 7.5.
Таблица 7.5. Предопределенная переменная окружения С shell
Имя Описание
$LOGNAME ID владельца shell
Выражения
С shell поддерживает строковые, арифметические и ориентированные на файл выражения.
Строковые выражения
С shell поддерживает строковые операторы, показанные в табл. 7.6. Если операнд — это список, то первый элемент списка служит для сравнения.
Скрипт в следующем примере использовал технику соответствия строки, чтобы сделать вывод об ответе пользователя:
% cat exprl.csh #
echo -n "do you like the C shell?" set reply = $< if ($reply == "yes") then
echo you entered yes
else if ($reply =~ y*) then
echo I assume you mean yes endif % exprl.csh
do you like the C shell? yeah
I assume you mean yes %
...посмотреть скрипт.
# приглашение.
# получить строку со входа.
# проверить на точное совпадение.
# проверить на неточное совпадение.
...выполнить скрипт.
Таблица 7.6. Строковые операторы С shell
Оператор Описание
== Возвращает истину, если строковые операнды абсолютно равны
! = Возвращает истину, если строковые операнды не равны
=~ Подобен ==, за исключением того, что правый операнд может содержать групповые символы
! ~ Подобен ! =, за исключением того, что правый операнд может содержать групповые символы
Арифметические выражения
I
С shell поддерживает арифметические операторы, перечисленные в табл. 7.7 в порядке убывания приоритета. Они работают точно так же, как их стандартные С-копии за исключением того, что обрабатывают только целые
числа. Выражения могут быть окружены круглыми скобками для управления порядком вычислений.
Таблица 7.7. Арифметические операторы С shell
Операторы Описание
। Унарный минус Логическое отрицание
* / 9- > / > ° Умножение, деление, остаток
+ > “ Сложение, вычитание Побитовый сдвиг влево, побитовый сдвиг вправо
< , > , о Операторы отношения
== I = ! • Равенство, неравенство
А> 1 Битовое И, битовое исключающее ИЛИ, битовое ИЛИ
1 1 , & & Логическое ИЛИ, логическое И
Когда вычисляется арифметическое выражение, пустая строка эквивалентна 0. Любое выражение, содержащее операторы &, &&, |, I I, <, >, « или >>, должно быть заключено в круглые скобки, чтобы помешать shell интерпретировать эти символы специальным образом. Вот типичный скрипт, который использует пару операторов:
% cat ехргЗ.csh ...вывести скрипт.
#
set а = 3
set Ь = 5
if ($а >2 && $Ь > 4) then
echo expression evaluation seems to work endif
% ехргЗ.csh ...выполнить скрипт.
expression evaluation seems to work о о
Вы не можете применять команду set, чтобы назначить результат выражения переменной. Вместо этого используйте встроенную команду @, которая имеет форматы, показанные ниже.
Синтаксис
Формат
Описание
Выводит все переменные shell
@ переменная ор выражение
Присваивает переменной выражение
@ переменная [ индекс] ор выражение
Присваивает выражение переменной с индексом
Здесь ор — это =, +=
*= или /=.
Вот некоторые примеры:
% set <а=2*2
...вы не можете использовать set для присвоения.
set: Syntax error.
о, о
...использование @ вместо.
о, о
echo $а
0 а = 2 * 2
% @ а = $а + $а
...сложить две переменные.
% echo $а
8
% set flag = 1
% @ b = ($а && $flag) ...нужны скобки, потому что &&.
% echo $b
1
% @ b = ($а && $flag)
% echo $b
О
Вы можете также увеличить или уменьшить значение переменной на 1, используя ++ или —, как в следующих командах: % set value = 1 % @ value ++ % echo $value 2
Выражения, ориентированные на файл
Чтобы сделать решение задач с использованием файлов немного легче для программирования, С shell поддерживает несколько файловых выражений. Описание каждой опции показано в табл. 7.8.
Синтаксис
-опция имяФайла
Возвращается 1 (истина), если выбранная опция истинна, и 0 (ложь) в противном случае. Если имяФайла не существует или недоступно, все опции возвращаются 0.
Таблица 7.8. Опции, используемые в файловых выражениях
Опция Описание
г Shell имеет разрешение чтения для имяФайла
w Shell имеет разрешение записи для имяФайла
X Shell имеет разрешение выполнения для имяФайла
е имяФайла существует
о имяФайла принадлежит тому же самому пользователю, что и процесс shell
z имяФайла существует и имеет размер 0 байт
f имяФайла — это обычный файл (не каталог или специальный файл)
d имяФайла — это файл каталога (не обычный каталог или специальный
файл)
Вот пример скрипта, который использует опцию -w, чтобы определить, является ли файл перезаписываемым:
% cat ехрг4.csh ...вывести скрипт.
#
echo -n "enter the name of the file you wish to erase:"
set filename = $< # получить строку ввода.
if (! (-w "$filename")) then # проверить, имею ли доступ.
echo you do not have permission to erase that file.
else
rm $ filename
echo file erased endif
% expr4.csh ...выполнить скрипт.
enter the name of the file you wish to erase: / you do not have permission to erase that file.
%
Автоматическое дописывание имени файла
Подобно Korn shell, С shell предусматривает способ избежать ввода длинных имен файлов в командной строке. (Эта функциональная возможность была введена в течение эволюции С shell, поэтому старые версии не могут обеспечивать ее.)
Чтобы включать функцию дописывания имени файла, вы должны установить переменную fiiec:
% set fiiec
Теперь всякий раз, когда вы напечатаете часть имени файла, можете нажать клавишу <Esc>, и если часть имени файла, которую вы напечатали только что, уникально идентифицирует файл, остальная часть имени будет добавлена автоматически. Если текст уникально не идентифицирует файл, ничего изменено не будет, и вы услышите звуковой сигнал. Вы можете также ввести *, чтобы увидеть список имен файлов, которые в настоящее время соответствуют части напечатанного имени. Пример:
% Is -al . log* .login .logout % Is -al .login
...нажал клавишу <Esc> — ничего, тогда напечатал *
...shell повторно вывел, я добавил i и нажал клавишу ...<Esc>, а затем была добавлена буква "п".
Псевдонимы
С shell позволяет создавать и настраивать собственные пользовательские команды с помощью встроенной команды alias. Пример:
% alias dir 'Is -aF' ...регистрация псевдонима.
% dir ...так же как печатание Is -aF.
. / main2.c р.reverse.с reverse.h
../ main2.o palindrome.c reverse.old
% dir *.c ...так же как печатание Is -aF *.с.
main2.с р.reverse.с palindrome.с
% alias dir ...посмотреть значение, ассоциированное с dir.
Is -aF
$
Синтаксис
alias [слово [строка]]
Команда alias поддерживает простую форму настройки командной строки. Если ваше слово псевдонима равно строке и позже вы вводите команду, начинающуюся со слова, первое его появление зал^еняется строкой, и затем команда обрабатывается повторно. Если вы не вводите слово или строку, то отображается список всех текущих псевдонимов shell. Если вводится только слово, то выводится строка, в настоящее время связанная со словом псевдонима. Если вы снабжаете слово и строку, shell добавляет указанный псевдоним к его собранию псевдонимов. Если для слова псевдоним уже существует, он заменяется. Если строка замены начинается со слова, оно не обрабатывается повторно для псевдонимов, чтобы предотвратить бесконечные циклы. Если строка замены содержит слово где-нибудь в другом месте, появляется сообщение об ошибке во время выполнения псевдонима.
В следующем примере создается псевдоним слова в терминах его самого:
% alias Is 'Is -aF'
% Is *.c
main2.c p.reverse.c
% alias dir 'Is'
% dir
./ main2.c p.reverse.c ../ main2.o palindrome.c % alias who 'date; who' % who
...определить Is в терминах его самого.
...так же как печатание Is -aF *.с.
palindrome.с
...определить dir в терминах 1s.
...так же как печатание Is -aF.
reverse.h reverse.old
...идентифицирует проблему цикла.
Alias loop.
% alias who 'date; /bin/who' ...полный путь предотвращает ошибку.
% who ...теперь работает прекрасно.
Fri Feb 13 23:33:37 CST 1998 glass ttypO Feb 13 23:30 (xyplex2)
Удаление псевдонима
Чтобы удалить псевдоним, используйте встроенную команду unalias.
Синтаксис
unalias шаблон
Команда unalias удаляет все псевдонимы, которые соответствуют шаблону. Если в качестве шаблона указан символ *, то удаляются все псевдонимы.
Полезные псевдонимы
В табл. 7.9 предоставлен список полезных псевдонимов вместе с кратким описанием каждого. Я храню эти псевдонимы в моем файле .cshrc.1
Таблица 7.9. Полезные псевдонимы С shell
Псевдоним Команда Описание
cd cd \!*; set prompt = "$cwd \!>"; Is V Приглашение пользователя изменяется так, чтобы оно содержало и текущий рабочий каталог, и самый последний номер команды (см. разд. “История" далее в этой главе)
Is Is -F Предписывает утилите 1s включить дополнительную информацию о файле
rm rm -i Предписывает утилите rm запрашивать подтверждение
rm mv\!* -/tomb Заставляет утилиту rm перемещать файл в специальный каталог tomb вместо удаления файла
h history Отображает список предварительно используемых команд, печатая только один символ
vi (mesg n; /bin/vi \!*; mesg y) Защищает от получения сообщений от других пользователей, в то время как вы находитесь в редакторе vi
mroe more Исправляет обычную ошибку орфографии при использовании утилиты more
1 Очень часто повествование в книге ведется от имени одного автора, по видимому, Грехама Гласса. — Ред.
Таблица 7.9 (окончание)
Псевдоним Команда Описание
ls-11 1s -1 * Исправляет обычную ошибку орфографии при использовании утилиты 1s
11 1s -1 Позволяет получать расширенный листинг каталога
Разделение псевдонимов
Чтобы делать псевдоним доступным дочернему shell, разместите его определение в shell-файле .cshrc.
Параметризованные псевдонимы
Псевдоним может ссылаться на аргументы в оригинальной команде, используя механизм истории, описанный в следующем разделе. К первоначальной команде обращаются, как будто это была предыдущая команда. Полезный псевдоним для cd, который я упомянул, демонстрирует удачное использование этой возможности: часть псевдонима \! * заменяется всеми аргументами первоначальной команды. Символ \ предшествует !, чтобы запретить его специальное значение во время назначения псевдонима:
alias cd ’cd \!*; set prompt = "$cwd \l > ”; Is’
История
C shell хранит запись команд, введенных с клавиатуры так, чтобы их можно было отредактировать и позднее повторно выполнить. Эта функция известна как механизм историй. Метасимвол ! дает доступ к истории.
Пронумерованные команды
При использовании истории удобно принять меры, чтобы приглашение содержало номер команды, которую пользователь собирается ввести. Для этого добавьте последовательность \! в значение переменной приглашения:
% set prompt = '\! % 1 ...включить номер события в приглашение.
1 % echo Genesis . . . эта команда — событие с номером 1.
Genesis
2 % ... следующая команда будет событием с номером 2.
Сохранение команд
С shell делает запись последних $history команд во время конкретной сессии. Если значение переменной $history не установлено принудительно, по умолчанию используется 1. Если вы хотите, чтобы следующая сессия могла иметь доступ к этим командам, установите переменную $savehist. Тогда последние $savehist команды поддерживаются в файле, указанном переменной histfile (который обычно определен по умолчанию в $HOME/.history, но может изменяться с версиями UNIX). Файл истории разделяется всеми диалоговыми С shell, созданными одним пользователем, если переменной histfile преднамеренно не присвоено никакое уникальное значение в каждом из shell.
В представленном ниже примере я проинструктировал мой shell помнить последние 40 команд в списке истории и сохранять последние 32 команды между сессиями:
2 % set history = 40 . . .помнить последние 40 команд.
40
3 % set savehist = 32 ...хранить 32 команды между сессиями.
32
4 %
Чтение истории
Чтобы получить листинг истории shell, используйте встроенную команду history.
Синтаксис
history [-rh] [номер]
Команда history позволяет получать доступ к списку истории shell. Если никакие параметры не указаны, команда выводит последние $history команд. Опция -г обеспечивает вывод списка истории в обратном порядке, а опция -h запрещает показ номеров событий. Команде history обычно назначается псевдоним h для скорости ее ввода.
Вот пример:
4 % alias h history ...создать полезный псевдоним.
5 % h ' ...вывести текущую историю.
1 set prompt = ’\! % ’
2 set history = 40
3 set savehist =32
4 alias h history
5 h
6 % h -r 3 ... вывести последние 3 команды в обратном порядке.
6 h 3
5 h
4 alias h history
%
Повторное выполнение команды
Чтобы повторно выполнить предыдущую команду, используйте метасимвол ! в одном из форматов, указанных в табл. 7.10. Эти последовательности могут появляться где угодно в командной строке, хотя обычно используются самостоятельно.
Таблица 7.10. Повторное выполнение команд в С shell
Формат Описание
। । Заменяется текстом самой последней команды
! номер Заменяется текстом команды с указанным номером
!префикс Заменяется текстом самой последней команды, которая начиналась с префикса
!?подстрока? Заменяется текстом самой последней команды, которая содержит подстроку
Вновь вызванная команда выводится на терминал до своего выполнения. Значение префикса или подстроки не может содержать пробел. Специальное значение ! не запрещается никаким видом кавычек, но может быть заблокировано предшествующим ему пробелом, символом табуляции, =, ( или \.
Вот некоторые примеры:
41 % echo event 41
event 41
42 % echo event 42
event 42
43 % !! . ’
echo event 42
event 4 2
44 % !41
...простое echo.
...другое простое echo.
...повторно выполнить последнюю команду.
. . .вывод команды перед повторным выполнением.
...повторно выполнить команду с номером 41.
echo event 41
event 41
45 % /ec
echo event 41
event 41
46 %
. . .вывод команды перед повторным выполнением.
...повторно выполнить команду, начинающуюся с ес.
. . .вывод команды перед повторным выполнением.
Доступ к частям команд истории
Вы можете получить доступ к части предыдущей команды с помощью модификаторов истории, которые являются набором опций. Эти опции могут немедленно следовать за спецификатором события. Каждый модификатор возвращает отдельную лексему или ряд лексем от указанного события. Табл. 7.11 предоставляет список модификаторов. Двоеточие перед опциями $ и * является необязательным.
Таблица 7.11. Модификаторы истории С shell
Модификатор Возвращаемые лексемы
:0 Первая
: номер (номер + 1)
:начало-конец (начало + 1) до (конец + 1)
. Первая
:$ Последняя
. * Предпоследняя
Для использования одного из модификаторов на самой последней команде вы можете указать перед ним модификатор !! или только !.
Вот некоторые примеры:
48 % echo I'like horseback riding ...оригинальная строка.
I like horseback riding
49 % !!:0 !!:1 !!:2 !!:4 ...доступ к указанным аргументам.
echo I like riding
I like riding
50 % echo !48:l-$ ...доступ к ряду аргументов.
echo I like horseback riding
I like horseback riding
51 %
Доступ к частям имен файлов
Если модификатор истории ссылается на имя файла, оно может быть далее изменено для получения доступа к конкретной части имени. Существующие модификаторы могут сопровождаться модификаторами имени файла, показанными в табл. 7.12.
Таблица 7.12. Модификаторы имен файлов С shell
Модификатор Часть файла Часть указанного имени файла, которая возвращается
:h Заголовок Путь к файлу
: г Корень Полное имя файла без расширения файла
: е Расширение Расширение файла
: t Остаток Имя и расширение файла
Следующий пример демонстрирует обращение к различным частям оригинального имени файла с помощью вышеупомянутых средств доступа к имени файла:
53 % Is /usr/include/stdio.h ...оригинал.
/usr/include/stdio.h
54 % echo 153:l:h ...доступ к заголовку.
echo /usr/include /usr/include
55 % echo !53:l:r echo /usr/include/stdio /usr/include/stdio ...доступ к корню.
56 % echo !53:l:e echo h h ...доступ к расширению.
57 % echo !53:l:t echo stdio.h ...доступ к остатку.
stdio.h
Q. О
Замена истории
Модификатор замены замещает указанную часть команды в предыдущем событии.
Синтаксис
!событие:s/часть1/часть2/
Эта последовательность заменяется указанным событием после замены первого Появления части1 частью2.
Пример:
58 % Is /usr/include/stdio.h /usr/include/stdio.h
58 % echo 158:1:s/stdio/signal/ echo /usr/include/signal.h /usr/include/signal.h
59 %
...оригинал.
...выполнить замену.
Структуры управления
С shell поддерживает широкий диапазон структур управления, которые делают язык похожим на инструмент программирования высокого уровня. Программы shell обычно сохраняются в скриптах и, как правило, используются для автоматизации задачи установки и сопровождения.
Некоторые структуры управления требуют, чтобы вводились несколько строк. Если такая структура управления вводится с клавиатуры, shell выводит приглашение символом ? для ввода каждой дополнительной строки, пока структура управления не закончится в точке, в которой она выполняется.
Далее приводится описание каждой структуры управления в алфавитном порядке. Демонстрационные примеры С shell похожи на примеры Bourne shell, чтобы вы могли сравнить и противопоставить два командных интерпретатора.
foreach... end
Команда foreach позволяет списку команд выполняться многократно, каждый раз используя различное значение для указанной переменной.
Синтаксис
foreach имяПеременной (списокСлов)
списокКоманл
end
Команда foreach выполняет итерацию значения имяПеременной через каждое значение В спискеСлов, ВЫПОЛНЯЯ списокКоманд ПОСЛе КаЖДОГО присвоения. Команда break заставляет цикл немедленно завершиться, а команда continue — перейти к следующей итерации.
Вот пример скрипта, который содержит команду foreach:
% cat foreach.csh ...вывести скрипт.
#
foreach color (red yellow green blue)
# четыре цвета
echo one color is $color end
% foreach. csh one color is red one color is yellow one color is green one color is blue
...выполнить скрипт.
о, о
goto
Команда goto осуществляет безусловный переход к указанной метке. Для того чтобы объявить метку, просто начините строку с ее имени, а за именем поставьте двоеточие.
Синтаксис
goto метка
Метка в виде
метка:
должна существовать далее в скрипте.
Появляется утверждение goto, управление передается строке, следующей за меткой. Обратите внимание, что метка может как предшествовать, так и следовать за утверждением goto, даже если команда вводится с клавиатуры.
Используйте goto осторожно, избегайте кода "похожего на спагетти"2 (даже если вы любите спагетти). Вот пример простой конструкции с командой goto:
% cat goto.csh ...вывести скрипт.
#
echo gotta jump
2 To есть длинного кода. — Ped.
goto endOfScript # переход
echo I will never echo this endOfScript: # метка
echo the end % goto.csh ...выполнить скрипт,
gotta jump the end о Ъ
if... then... else... endif
Есть два формата команды if. Первый поддерживает простой односторонний переход.
Синтаксис
i f (условие) команда \
Эта форма команды if вычисляет условие и, если оно истинно (не НОЛЬ), ВЫПОЛНЯет команду.
Вот пример этого формата if:
% if (5 > 3) echo five is greater than 3
five is greater than three о "6
Второй формат команды if поддерживает альтернативный переход.
Синтаксис
if {условие!) then списокКоманд!
else if {условие2) then списокКоманд2
else
списокКомандЗ
endif
Части команды else и else if не обязательны, но завершающий endif должен обязательно присутствовать. Если условие1 истинно, выполняются команды из спискаКоманд1 и команда if завершается. Если условие! ложно и есть одно или больше составляющих else if, то истинное выражение, следующее после else if, вызывает выполнение команд после связанного then, и команда if заканчивается. Если не найдено ни одного истинного выражения и есть составляющая else, выполняются команды После else.
Пример второй формы if:
% cat if.csh ...вывести скрипт.
#
echo -n ’enter a number: ’ set number = $<
if ($number < 0) then
# приглашение пользователю.
# читать строку ввода.
echo negative
else if ($number == 0) then
echo zero
else
echo positive endif
% if. csh
...выполнить скрипт.
enter a number: -1
negative
g. о
onintr
Команда onintr позволяет определить метку, на которую должен быть осуществлен переход, когда shell получает сигнал sigint. Этот сигнал обычно производится нажатием комбинации клавиш <Ctrl>+<C> и описан более подробно в главе 13.
Синтаксис
onintr [- | метка]
Команда onintr инструктирует shell перейти на метку, когда получен сигнал sigint. Если используется опция сигнал sigint игнорируется. Если опции не указаны, восстанавливается оригинальная shell-программа обработки SIGINT.
Пример:
% cat onintr.csh
...вывести скрипт.
onintr controlC
# установить ловушку на <Ctrl>+<C>.
while (1) echo infinite loop
sleep 2
end
controlC:
echo control C detected
% onintr.csh ...выполнить скрипт,
infinite loop infinite loop
ЛС ...нажал <Ctrl>+<C>.
control C detected
repeat
Команда repeat позволяет выполнять отдельную команду указанное количество раз.
Синтаксис
repeat выражение команда
Команда repeat вычисляет выражение И ВЫПОЛНЯет команду необходимое количество раз.
Пример использования repeat:
% repeat 2 echo hi there ...вывести две строки. hi there
hi there
switch... case... endsw
Команда switch поддерживает многопозиционный переход, основанный на значении единственного выражения.
Синтаксис
switch (выражение)
case шаблон1: списокКоманд! breaksw
case шаблон2: списокКомандЗ breaksw
case шаблонЗ: списокКомандЗ breaksw
default:
списокКоманД—defa ul t endsw
В выражении определяется строка., шаблон1, шаблон2, шаблонЗ могут включать Групповые СИМВОЛЫ, а списокКоманд 1, списокКоманд2, списокКомандЗ, списокКоманд_(1еfault — списки из одной или более команд shell. Командный интерретатор вычисляет выражение и сравнивает его с каждым шаблоном сверху вниз. Как только шаблон соответствия найден, выполняется его ассоциированный список команд, и затем shell переходит на строку endsw. Если никакого совпадения не найдено и условие по умолчанию присутствует, то выполняется списокКоманд-default. Если ника-кого совпадения не найдено, а условие по умолчанию отсутствует, то выполнение продолжается с команды после endsw.
Ниже приведен пример скрипта menu.csh, который использует структуру управления switch: # echo menu test program set stop =0 # переустановить флаг завершения цикла
while ($stop ==0) # пока не выполнится цикл
cat « ENDOFMENU # вывести меню
1 : print the date
2r 3: print the current working directory 4 : exit ENDOFMENU
echo
echo -n ’your choice? ' set reply = $< echo "" switch ($reply)
case "1":
date
breaksw
case ”2H:
case ”3”:
pwd breaksw
case "4":
set stop = 1 breaksw
default:
echo illegal choice breaksw
endsw
end
# приглашение
# читать ответ
# процесс ответа
# вывести дату
# вывести рабочий каталог
# установить флаг завершения цикла
# по умолчанию
# ошибка
\
Вот вывод скрипта menu.csh: % menu.csh menu test program
1 : print the date
2f 3: print the current working directory 4 : exit
your choice? 1
Sat Feb 14 00:50:26 CST 1998
1 : print the date.
2 , 3: print 'the current working directory 4 : exit
your choice? 2 /home/glass
1 : print the date.
2 , 3: print the current working directory 4 : exit
your choice? 5 illegal choice
12 Зак. 786
1 : print the date.
2 , 3: print the current working directory
4 : exit
your choice? 4
while... end
Встроенная команда while позволяет многократно выполнять список команд, пока указанное выражение истинно (не ноль).
Синтаксис
while (выражение)
списокКоманл end
Команда while вычисляет выражение и, если оно истинно, выполняет каждую команду в спискеКоманд, а затем повторяет процесс. Если выражение ложно, цикл while заканчивается и скрипт продолжает выполнять команды, следующие за end. Команда break немедленно завершает цикл, команда continue предписывает перейти к следующей итерации.
Вот пример скрипта, который содержит структуру управления while, чтобы вывести маленькую таблицу умножения:
% cat multi.csh ...вывести скрипт.
#
set x = 1 # установить значение внешнего цикла
while ($x <= $1) # внешний цикл
set у = 1 # установить значение внутреннего цикла
while ($y <= $1) # внутренний цикл
@ v = $x * $y # вычисление входа
echo -n $v " " # вывести вход
@ у ++ # обновить счетчик внутреннего цикла
end
echo "" # новая строка
@ x ++ # обновить счетчик внешнего цикла
end
% multi. csh 7
...выполнить скрипт.
т 2 3 4 5 6 7
2 4 6 8 10 12 14
3 6 9 12 15 18 21
4 8 12 16 20 24 28
5 10 15 20 25 30 35
6 12 18 24 30 36 42
7 14 21 28 35 42 49
% _
Пример проекта: junk
Для иллюстрации некоторых возможностей С shell, которые мы обсудили, ниже представлена версия скрипта С shell junk, который был предложен в конце главы 6.
Синтаксис
junk -1р {имяФайла}★
junk заменяет утилиту rm. Вместо удаления файлов она перемещает их в каталог .junk домашнего каталога пользователя. Если каталог .junk не существует, он автоматически создается. Опция -1 выводит текущее содержимое каталога .junk, а опция -р производит его очистку.
Скрипт С shell, который представлен ниже, использует списочную переменную для хранения имен файлов. Остальная часть функциональных возможностей очевидна из представленных комментариев. (Скрипт shell доступен в сети. Для дополнительной информации см. Введение.)
junk
#! /bin/csh
#junk script
#author: Graham Glass
#9/25/91
#
#Initialize variables
#
set fileList = () # список всех специфицированных файлов.
set listFlag =0 # установлена в 1, если Опция -1 указана.
set purgeFlag =0 # 1, если опция -р указана.
set fileFlag =0 # 1, если хотя бы один файл специфицирован,
set junk = ~/.junk # каталог .junk.
#
# Разбор командной строки.
#
foreach arg ($*)
switch ($arg) case "-p":
set purgeFlag = 1 breaksw
case "-1":
set listFlag = 1 breaksw
case
echo $arg is an illegal option goto error breaksw
default:
set fileFlag = 1
set fileList = ($fileList $arg) # добавить в список, breaksw
endsw
end
#
# Проверка: не слишком ли много опций. #
0 total = $listFlag + $purgeFlag + $fileFlag
if ($total != 1) goto error
#
# Если каталог .junk не существует, создать его.
#
if (!(-е $junk)) then 'mkdir' $junk
endif
#
# Обработка опций.
#
if ($listFlag) then
'Is’ -IgF $junk # вывести каталог .junk, exit 0 endif # if ($purgeFlag) then
'rm' $junk/* # удалить содержимое каталога .junk,
exit 0 endif # if ($fileFlag) then
’mv' $fileList $junk # переместить файлы в каталог .junk, exit О endif # exit 0 #
# Вывести сообщение, об ошибке и выйти. # error: cat « ENDOFTEXT
Dear $USER, the usage of junk is as follows:
junk -p means "purge all files"
junk -1 means "list junked files"
junk <list of files> to junk them ENDOFTEXT exit 1
Усовершенствования
В дополнение к новым возможностям, которые уже были описаны, С shell имеет усовершенствования в следующих областях:
□ клавиатурные комбинации быстрого вызова для повторного выполнения команды;
□ метасимволы {, };
□ замещение имени файла;
□ перенаправление;
□ конвейеризация;
П управление заданием.
Повторное выполнение команды: клавиатурная комбинация быстрого вызова
Обычно возникает желание повторно выполнить предыдущую команду с небольшой модификацией. Например, скажем, вы напечатали с ошибкой имя файла. Вместо fil.txt вы хотели ввести file.txt. Есть удобный стенографический способ исправить такую ошибку. Если вы напечатаете команду
Л часть1^часть2
то предыдущая команда повторно выполнится после того, как первое вхождение части! заменится частыо2. Эта сокращенная процедура применима только к предыдущей команде. Вот пример:
% Is -1 fil.txt ...on!
Is: File or directory "fil.txt" is not found.
% ^fil^file ...быстрая коррекция.
Is -1 file.txt ...хорошо.
-rw-r-xr-x 1 ables 410 Jun 6 23:58 file.txt % _
Метасимволы: {}
Вы можете использовать фигурные скобки вокруг имен файлов, чтобы сэкономить ввод обычных приставок и суффиксов.
Нотация
a{b, c}d
заменяется abd acd
В следующем примере я скопировал С-файлы заголовков /usr/include/stdio.h и /usr/include/signal.h (которые имеют обычную приставку и суффикс) в мой домашний каталог:
% ср /usr/include/(stdio,signal).h . ...копировать два файла.
О
Замещение имен файлов
В дополнение к обычным возможностям замещения имени файла С shell поддерживает две новых особенности: способность запретить замещение имени файла и способность определить, какое действие должно быть предпринято, если шаблон ни с чем не совпадает.
Запрещение замещения имени файла
Чтобы запретить замещение имени файла, установите переменную $nogiob. Тогда групповые символы теряют их специальное значение. Переменная $nogiob по умолчанию не установлена. Вот пример:
% echo а* р* ...один групповой символ совпадает: р* progl.с • prog2.с ргодЗ.с ргод4.с
% set noglob ...скрыть обработку группового символа. % echo а* р*
а* р* о О
Ситуации несовпадения
Если несколько шаблонов присутствуют в команде и, по крайней мере, один из них имеет совпадение, то ошибка не возникает. Однако, если ни один из шаблонов не имеет совпадения, по умолчанию shell выводит сообщение об ошибке. Если переменная $nonomatch установлена, и совпадения не происходит, то первоначальные образцы используются без изменения. Переменная по умолчанию $nonomatch не установлена. Пример:
% echo а* р* ...один групповой символ совпадает: р*
progl.с prog2.с ргодЗ.с ргод4.с
% echo а* b* ...ни один групповой символ не совпадает.
echo: No match. ...по умолчанию произошла ошибка.
% set nonomatch ...установить специальную переменную nonomatch.
% echo a* b* ...групповые символы теряют их специальные значения.
a* b* ...нет ошибок.
Перенаправление
В дополнение к обычным возможностям перенаправления С shell поддерживает пару усовершенствований: способность переадресовывать стандартный канал ошибки и способность защитить файлы против случайного переписывания.
Перенаправление стандартного канала ошибки
Для того чтобы переадресовать стандартный канал ошибки в дополнение к стандартному каналу вывода, просто добавляют амперсант (&) к оператору переназначения > или », как показано в следующем примере:
% Is -1 a.txt b.txt >list.out
...Is посылает ошибки
...в стандартный канал ошибок.
Is: File or directory "b.txt" is not found.
% Is -1 a.txt b.txt >& list.out ...так же переадресовывает . . .и стандартный канал ошибок, о. о
Хотя не существует простого способа переадресовать только канал ошибки, это может быть сделано с помощью следующей хитрости: (процесс! > файл!) >& файл2
Это работает путем переадресации стандартного вывода процесс! в файл! (который может быть /dev/null, если вы не хотите сохранять вывод), позволяя только стандартным ошибкам покидать командную группу. Вывод командной группы и каналы ошибки тогда переадресованы в файл2.
Защита файлов от случайного переписывания
Вы можете защитить существующие файлы от случайного переписывания и несуществующие файлы от случайного добавления путем установки переменной $nociobber. Если команда shell пробует выполнить то или другое действие, она терпит неудачу и выводит сообщение об ошибке.
Внимание
Обычные системные вызовы типа write () не затрагиваются.
По умолчанию $nociobber не установлена. Вот пример:
% Is -1 errors ...посмотреть существующие файлы,
-rw-r-хг-х 1 glass 225 Feb 14 10:59 errors
% set noclobber ...защитить файлы.
% Is a.txt >& errors ...не может быть переписан, errors: File exists, о о
Чтобы временно заблокировать эффект от $nociobber, добавьте символ « к оператору переназначения:
% Is a.txt >&! errors ...существующий файл переписан.
о, о
Конвейеризация
В дополнение к поддержке обычных возможностей конвейеризации С shell позволяет направлять стандартный вывод и стандартный канал ошибки от процесса! К процессу2.
Синтаксис
процесс! |& процесс2
В приведенном ниже примере организован конвейер стандартного вывода и канала ошибки от утилиты is к утилите more:
% Is -1 a.txt b.txt |& тоге ...конвейеризация стандартных каналов ...вывода и ошибки.
Is: File or directory "b.txt" is not found, -rw-r-xr-x 1 ables 988 Dec 7 06:27 a.txt
о о
Хотя нет никакого прямого пути конвейеризации только канала ошибки, это может быть сделано, если прибегнуть к хитрости, подобной описанной ранее, для того чтобы конвейеризировать в файл только канал ошибки: (процесс! > файл) |& процесс2
Эта хитрость работает путем переадресации стандартного вывода процесс! в файл! (который может быть /dev/null, если вы не хотите сохранять вывод), позволяя только стандартным ошибкам покидать командную группу. Вывод командной группы и канал ошибки тогда конвейеризированы в процесс2. Но поскольку стандартный вывод теперь пуст, результатом является только стандартный вывод ошибки.
Управление заданием
Возможности управления заданиями С shell те же самые, как и в Korn shell, с дополнительными встроенными командами:
О stop; О nice;
О suspend; О nohup;
О notify.
stop
Чтобы приостановить указанную работу, используйте команду stop.
Синтаксис
stop {%задание}*
Команда stop приостанавливает указанное задание, используя стандартный формат спецификатора задания, описанный в главе 6. Если аргументы отсутствуют, приостанавливается последнее упомянутое задание.
suspend
Чтобы приостановить командный интерпретатор, вызовите команду suspend.
Синтаксис
suspend
Команда suspend приостанавливает shell, который ее вызвал. Имеет смысл применять данную команду тогда, когда shell является дочерним по отношению к входному shell, и это обычно делается, чтобы приостановить shell, вызванный утилитами su или script.
nice
Чтобы установить уровень приоритета shell или команды, используйте команду nice. Для дополнительной информации о приоритетах процесса см. главу 13.
Синтаксис
nice [+|- число] [команда]
Команда nice запускает команду с уровнем приоритета число. Вообще, чем выше приоритет, тем медленнее будет выполняться процесс. Только привилегированный пользователь (root) может определить отрицательный уровень приоритета. Если уровень приоритета опущен, уровень приоритета предполагается равным 4. Если аргументы не специфицированы, устанавливается уровень приоритета shell.
nohup
Чтобы защищать команду от зависания, используйте встроенную команду nohup.
Синтаксис
nohup [команда ]
Команда nohup выполняет команду и защищает ее от зависания. Если аргументы не специфицированы, то все дальнейшие команды работают под уровнем защиты shell. Обратите внимание, что все фоновые команды в С shell автоматически защищены от зависания.
notify
Обычно shell уведомляет пользователя относительно изменения в состоянии задания прямо перед выводом нового приглашения. Если пользователь желает получить немедленное (асинхронное) уведомление об изменении состояния задания, используется встроенная команда notify.
Синтаксис
notify {%задание}*
Команда notify инструктирует shell немедленно сообщать пользователю, когда указанные задания изменяют состояние. Задания должны быть определены в соответствии со стандартным форматом спецификатора задания, описанным в главе 6. Если никакое задание не определено, используется самое позднее упомянутое задание. Для разрешения передачи немедленного уведомления обо всех заданиях установите переменную $notify.
Завершение входного shell
Команда logout заканчивает работу входного shell. В отличие от команды exit рассматриваемая команда не может использоваться, чтобы завершить работу диалогового дочернего shell. Поэтому можно закончить работу входного С shell одним из следующих трех способов:
□ на отдельной строке нажать комбинацию клавиш <Ctrl>+<D> (пока не установлена переменная $ignoreeof);
□ использовать встроенную команду exit;
□ использовать встроенную команду logout.
Вот пример:
% set ignoreeof ...установить для предотвращения выхода по <Ctrl>+<D>.
% ... теперь не хочет работать.
Use "logout" to logout.
% logout ...лучший способ выхода из системы.
login:
Когда входной С shell заканчивает работу, он ищет "завершающие" файлы. Если команды в каждом таком файле найдены, то они последовательно выполняются. Завершающий файл пользователя — это $HOME/.logout. После данного файла выполняется любой глобальный завершающий файл. Имя этого файла может быть /etc/logout или /.logout, в зависимости от вашей версии UNIX.
Обычно файл завершения содержит команды для очистки временных каталогов, выполнение других подобных действий по очистке и вывода прощального сообщения.
Если заканчивает работу невходной С shell с помощью команды exit или комбинации клавиш <Ctrl>+<D>, завершающие файлы не выполняются.
Встроенные команды
С shell поддерживает следующие дополнительные встроенные команды:
О chdir;
П glob; П source.
chdir
Команда shell chdir описана ниже.
Синтаксис
chdir [путь]
Команда chdir работает таким же образом, как и команда cd, изменяя текущий рабочий каталог пользователя на указанный в параметре путь.
glob
Синтаксис и описание команды shell glob представлены ниже.
Синтаксис
glob {аргументы}
Команда glob работает таким же образом, как и команда echo, печатая список аргументов после обработки механизмом метасимволов shell. Различие состоит в том, что аргументы в списке отделены друг от друга нулями (ASCII 0) вместо пробелов в заключительном выводе. Это делает вывод идеально пригодным для использования С-программами, которые принимают строки, завершающиеся пустыми символами.
source
Когда скрипт выполняется, он интерпретируется subshell. Поэтому любые назначения псевдонимов или локальных переменных, выполненные скрип
том, не имеют никакого эффекта для родительского shell. Если вы хотите, чтобы скрипт интерпретировался текущим shell и, таким образом, оказал влияние на этот shell, следует использовать встроенную команду source.
Синтаксис
source [-h] имяФайла
Команда source заставляет shell выполнять каждую команду в скрипте имяФайла без вызова subshell. Команды в скрипте помещаются в список истории, только если используется опция -h. Это в полной мере применимо для файла имяФайла, чтобы содержать дальнейшие source-команды. Если происходит ошибка во время выполнения файла имяФайла, управление возвращается к первоначальному shell.
В представленном ниже примере применяется команда source для повторного выполнения отредактированного .login-файла:
% vi .login ...редактировать мой файл .login.
% source .login ...повторно выполнить его.
Enter your terminal type (default is vtlOO): vt52 о о
Иной способ повторно выполнить файл заключался бы в выходе из системы и затем входе в систему снова.
Стек каталогов
С shell позволяет создавать и управлять стеком каталогов, который облегчает жизнь, когда пользователь переключается между рабочими каталогами. Для помещения каталога в стек каталогов используйте команду pushd.
Синтаксис
pushd [+число | имя]
Команда pushd проталкивает указанный каталог в стек каталогов и работает следующим образом:
• когда имя указано, текущий рабочий каталог проталкивается в стек и shell перемещается в указанный каталог;
• когда нет аргументов, два верхних элемента стека каталогов переставляются;
• когда задано число, указанный по номеру элемент стека каталогов циклически сдвигается к вершине стека и становится текущим рабочим каталогом. Элементы стека нумеруются в возрастающем порядке, номер вершины стека — 0.
Чтобы вытолкнуть каталог из стека каталогов, следует вызвать команду popd.
Синтаксис
popd [+число]
Команда popd выталкивает каталог из стека каталогов и работает так:
• когда нет аргументов, shell перемещается в каталог, находящийся на вершине стека каталогов, и затем выталкивает его;
• когда задано число, shell перемещается в пронумерованный каталог стека и сбрасывает стек.
Команда dirs позволяет видеть содержимое стека каталогов.
Синтаксис
dirs
Команда dirs выводит текущий стек каталогов.
Вот некоторые примеры манипуляций со стеком каталогов:
% pwd /home/glass % pushd /
% pushd /usr/include /usr/include / ~
. . .я в моем домашнем каталоге.
...переход в корневой каталог, протолкнуть ...домашний каталог.
...автоматически вывести стек каталогов.
...протолкнуть другой каталог.
% pushd
/ /usr/include ~
% pushd
/usr/include / ~
% popd
% popd
...переставить два элемента стека,
...перейти обратно в корневой каталог.
...переставить их опять,
...перейти обратно в /usr/include.
...вытолкнуть каталог,
...перейти обратно в корневой каталог.
...вытолкнуть каталог,
...перейти обратно в домашний каталог.
Хеш-таблица
Как описано в главе 4, переменная path используется, когда ищется исполняемый файл. Чтобы ускорять этот процесс, С shell хранит внутреннюю структуру данных, называемую хеш-таблицей, которая позволяет быстрее осуществлять поиск в иерархии каталогов. Хеш-таблица автоматически строится всякий раз, когда читается файл .cshrc. Однако для того, чтобы хеш-таблица работала правильно, она должна восстанавливаться всякий раз, когда изменяется $ратн, или всякий раз, когда новый исполняемый файл добавляется к любому каталогу в последовательности $ратн. С shell автоматически обслуживает первый случай, но вы должны заботиться о втором.
Если вы добавляете или переименовываете исполняемый файл в любом из справочников в последовательности $ратн, исключая ваш текущий каталог, то должны использовать команду rehash, чтобы заставить С shell восстановить хеш-таблицу. Если желаете, вы можете использовать команду unhash для запрета функционирования хеш-таблицы, таким образом замедляя процесс поиска.
Команда hashstat может применяться для исследования эффективности системы хеширования. Однако вывод этой команды ничего для вас не означает, если вы не знакомы с алгоритмами хеширования.
В приведенном ниже примере добавлен новый исполняемый файл в каталог ~/bin, который был в пользовательском пути поиска. Командный интерпретатор не мог найти файл до тех пор, пока пользователь не выполнил команду rehash.
% pwd ... я в моем домашнем каталоге.
/home/glass
% echo $РАТН . . .вывести мою переменную PATH.
.:/home/glass/bin:/usr/bin:/usr/local/bin:/bin:
% cat > bin/script.csh ...создать новый скрипт. #
/ echo found the script
''D ... конец ввода.
% chmod +x bin/script. csh ...сделать исполняемым.
% script.csh ...попытаться выполнить его.
script.csh: Command not found.
% rehash ...выполнить rehash.
% script.csh ...попытаться выполнить его снова,
found the script ...успех!
% hashstat ...вывести хеш-статистику.
5 hits, 6 misses, 45%
Опции командной строки
Если первый аргумент командной строки — это символ С shell запускается как входной shell. В дополнение к этой особенности, С shell поддерживает опции командной строки, перечисленные в табл. 7.13.
Таблица 7.13. Опции командной строки С shell
Опция Описание
-с строка Создает shell для выполнения командной строки
-е Завершает shell, если любая команда возвращает ненулевой код возврата
-f Запускает shell, но не ищет или читает команды из .cshrc
-i Создает диалоговый shell, как опция -s, за исключением того, что игнорируются все сообщения SIGTERM, SIGINT И SIGQUIT
—n Разбирает команды, но не выполняет их; применяется только для отладки
-s Создает shell, который читает команды со стандартного ввода и посылает сообщения shell в стандартный канал ошибки
-t Читает и выполняет отдельную строку со стандартного ввода
-v Вызывает установку $ verbose
Таблица 7.13 (окончание)
Опция Описание
-V Подобно -v за исключением того, что перед установкой $ verbose выполняется .cshrc
-х Вызывает установку переменой $echo
-X Подобно -х за исключением того, что перед установкой $echo читается .cshrc
имяФайла Выполняет команды shell в файле имяФайла, если не используются ОПЦИИ с, -i, -s, ИЛИ -t. имяФайла — ЭТО $0 В скрипте имяФайла
Обзор главы
Перечень тем
В этой главе было описано:
□ создание стартового файла С shell;
□ простые и списочные переменные;
□ выражения, включая целочисленную арифметику;
□ псевдонимы и механизм истории;
□ несколько структур управления;
□ усовершенствованное управление заданием;
□ несколько новых встроенных команд.
Контрольные вопросы
1. Почему целочисленные выражения нужно предварять знаком @?
2. В чем состоит удобный способ исправления простой ошибки в предыдущей команде?
3. В чем заключается функция метасимволов {}?
4. Опишите разницу между встроенными командами set и setenv.
5. Как вы защищаете файлы от случайной перезаписи?
6. Как вы защищаете скрипты от прерываний от комбинации клавиш <Ctrl>+<C>?
Упражнения
7.1. Напишите С shell версию скрипта track, который был описан в главе 5. [Уровень: легкий.]
7.2. Напишите утилиту hunt, которая действует, как препроцессор для утилиты find, hunt берет имя файла, как свой единственный параметр, и показывает полное путевое имя каждого соответствия имени файла. Поиск производится вниз от текущего каталога. [Уровень: средний.]
Проект
Изучите текущие тенденции в объектно-ориентированном программировании и затем спроектируйте объектно-ориентированный shell (C++ shell?). [Уровень: высокий.]
Глава 8
Bourne Again shell
Мотивация
Bash, известный под именем Bourne Again Shell, изначально написанный Брайеном Фоксом (Brian Fox) из Free Software Foundation (Фонд открытых программных средств), является самым новым из командных интерпретаторов и быстро становится популярным UNIX shell. Bash возник в результате Стремления создать ’’наилучший изо всех shell”, который не только бы обеспечивал обратную совместимость с Bourne shell, но и включал наиболее полезные возможности как С shell, так и Korne shell. Другое преимущество состоит в том, что Bash как продукт Открытых программных систем (Open Software product) является свободно распространяемым, может быть найден на всех Linux-узлах сети, загружен и установлен почти в любой версии UNIX, если он там еще не существует. (Для получения дополнительной информации об открытом программном обеспечении см. главу 16.)
Предпосылки
Советуем вам прочитать главу 4 и поэкспериментировать с частью основных возможностей UNIX shell. Рекомендуется также изучить главу 5, потому что вся информация из нее также применима к Bash.
Задачи
В данной главе объясняются и демонстрируются возможности Bash, которые являются уникальными или отличают этот командный интерпретатор от ранее обсужденных shell. Все, изложенное в главе 5, работает в Bash, и многое из материала глав би 7также применимо к Bash.
Изложение
Информация в главе представлена в форме нескольких примеров UNIX-сессий.
Команды shell
Описываются следующие команды shell:
alias if...then...elif...then...else...fi set
builtin jobs source
case...in...esac kill unalias
declare local unset '
dirs popd until...do...done
export pushd while...do...done
for...do...done readonly
history select
Общие сведения о Bourne Again shell
Bourne Again shell (или Bash) — это shell, выбранный для системы Linux. (Для получения дополнительной информации о Linux см. главу 16.) Bash поддерживает все основные возможности, описанные в главе 4, и совместим с Bourne shell, рассмотренным в главе 5 (таким образом, скрипты Bourne shell выполняются в Bash). Bash соответствует стандарту команд POSIX1 для shell (IEEE 1003.2). Хотя Bash пытается соответствовать функциональным возможностям и синтаксису sh и csh, в случае конфликта будет преобладать sh. Следующие особенности Bash являются новыми или немного отличаются от тех, что обсуждались в предыдущих главах:
П манипуляция переменной;
□ обработка командной строки, псевдонимы и история;
□ арифметические действия, условные выражения, структуры управления;
□ стек каталогов; /
□ управление заданием;
□ функции shell.
1 Portable Operating System Interface for Computing Environment, переносимый интерфейс операционной системы для вычислительной среды. — Ред.
Получение Bash
Bash доступен почти для каждой версии UNIX и даже для Windows-платформ. Узел сети GNU Bash имеет адрес http://www.gnu.org/ software/bash/bash.html. Исходный код Bash можно найти на сайте ftp://ftp.gnu.org/pub/gnu/bash. Bash для Windows может быть найден на2 http://www.cygwin.com. Справочное руководство по Bash также доступно в сети: http://www.gnu.org/manual/bash.
Если ваша UNIX-система еще не имеет Bash, вы должны скачать надлежащий пакет для конкретной UNIX-платформы, скомпоновать его и установить в каталог /bin.
Внимание
Вы должны иметь права привилегированного пользователя (root), чтобы установить программу в каталог системы. Однако вы можете инсталлировать ее в свой собственный каталог и запускать вручную. (Тем не менее, если вы сделаете это, могут возникнуть проблемы, связанные с безопасностью, которые воспрепятствуют в создании программы вашего входного shell.)
Запуск
Подобно другим shell, Bash — это UNIX-программа. Когда новый Bash-интерпретатор стартует, он выполняет команды из файла .bashrc в домашнем каталоге пользователя, выполняющего shell. Существует одна особенность: когда Bash запускается, как входной shell, вместо файла .bashrc он выполняет команды из файла .bash_profile в домашнем каталоге пользователя. Поэтому если необходимо, чтобы .bashrc-файл также был выполнен в вашем входном shell, вы должны добавить следующий код в свой файл .bashprofile:
if [ -f -/.bashrc ]; then . -/.bashrc
fi
Позже в данной главе мы увидим, как и почему работает этот код. По умолчанию код часто находится в системе в файлах .bash_profile.
В дополнение к файлам .bashrc и .bash-profile системный администратор может поместить команды инициализации, подходящие всем пользователям,
2 Чтобы установить любой или все компоненты инструментальной системы Cygwin, щелкните на значке install, который загрузит и выполнит файл setup.exe. Установка проведет вас через процесс, где вы сможете выбрать Bash и другие части системы Cygwin, которые захотите установить.
в файле /etc/profile, который Bash также будет читать и выполнять. Обратите внимание, что Bash будет читать файл /etc/profile перед выполнением любых файлов инициализации, принадлежащих пользователю.
Переменные
Bash поддерживает создание и использование переменных shell для следующих целей:
□ присвоение и доступ к значению;
□ определение и использование списков значений;
□ проверка значения или проверка на существование переменной;
□ чтение или запись значения переменной.
Создание и назначение простой переменной
Синтаксис Bash для присвоения значения простой переменной подобен синтаксису других shell.
Синтаксис
{имя=значение}+
Вот некоторые примеры:
$ teamnате= "Denver Broncos"
$ gameswon=12
$ gameslost=3
Встроенная команда set может использоваться для задания и отображения установок shell и вывода значений переменных shell. Встроенная команда set имеет много аргументов и применений; мы обсудим их по мере необходимости. Ее самое простое использование — это демонстрация переменных shell и их значений.
Синтаксис
set
Встроенная команда set показывает весь набор переменных в shell.
Пример:
$ set
gameslost=3
gameswon=12
teamname-" Denver Broncos"
$ _
Другие действия, которые может осуществлять команда set, сейчас не рассматриваются. Позже мы увидим другие способы вызова set для выяснения поведение shell.
Доступ к простой переменной
Доступ к значению простых переменных такой же, как и в других shell (табл. 8.1).
Таблица 8.1. Доступ к значению простой переменной
Синтаксис Описание
$имя Используется значение переменной имя
$ {имя} Значение переменной имя указывается рядом с другими символами в тех случаях, когда имя переменной может быть неверно истолковано
С переменными, установленными так, как показано в разд. "Создание и назначение простой переменной" ранее в этой главе, можно использовать следующую команду, чтобы резюмировать командные сезонные факты:
$ echo "The $teamname went ${gameswon}-$(gameslost) last year”.
The Denver Broncos went 12-3 last year.
Создание списочных переменных
Списочные переменные или массивы подобны аналогичным структурам данных в С shell. Bash, однако, предусматривает более явный метод для определения массива при помощи встроенной команды declare, хотя использование переменной в форме массива также будет работать.
Синтаксис
declare [-ах] [имя]
Если переменная имя еще не существует, она создается. Если имя массива опущено, когда используется опция -а, команда declare отобразит все
определенные в настоящее время массивы и их значения. Если указывается опция -х, переменная экспортируется в дочерний shell. Команда пишет свой вывод в формате, пригодном для повторного использования в качестве команд ввода. Это полезно, когда пользователь хочет создать задающий переменные скрипт, т. к. они уже установлены в пользовательском текущем окружении.
Вот пример создания списка команд:
$ declare -a teamnames
$ teamnames[0]="Dallas Cowboys"
$ teamnames[1] = "Nashington Redskins"
$ teamnames [2] = "New York Giants"
На практике, если команду declare опущена, другие строки все же будут работать, как и ожидается.
Доступ к списочным переменным
После формирования списка значений логично использовать его для каких-либо манипуляций. При доступе к значениям массива допустимо добавлять фигурные скобки вокруг имени переменной, чтобы явно отличить ее от другого текста, который может располагаться вокруг нее (чтобы воспрепятствовать shell использовать иной текст, как часть имени переменной). Это соглашение показано в табл. 8.2. Если применяют массивы, то для распознавания их среди других операторов shell требуются фигурные скобки.
Таблица 8.2. Доступ к значениям списочной переменной
Синтаксис Описание
$ {имя [индекс] } Доступ к индексированному (индекс) элементу
массива $имя
$ {имя [ * ] } или $ {имя [ @ ] } Доступ ко всем элементам массива $имя
$ {#имя [ * ] } или $ {% имя [ 0 ] } Доступ к количеству элементов в массиве $имя
Предположим, что существует список из 32 команд NFL (Национальной футбольной лиги), сохраненный как $teamname [0], ..., $ teamname [31]. Можно было бы использовать эту информацию следующим образом:
$ echo "There are ${tfteamnames[*]} teams in the NFL"
There are 32 teams in the NFL
$ echo "They are: ${teamnames[*]}"
Построение списков
Легко построить массив или список переменных одним из двух способов. Если известно необходимое количество элементов, то можно использовать встроенную команду declare, чтобы определить пространство и присвоить значения определенным элементам в списке. Если заранее неизвестно или нет необходимости заботиться о количестве элементов в списке, то можно просто перечислить их, и они будут добавлены в определенном вами порядке. Например, чтобы задать наш список команд NFL, количество которых (по крайней мере, сегодня) равно 32, можно определить его: $ declare -a teamnames
$ teamnames[0]^"Dallas Cowboys"
$ teamnames[1]^"Washington Redskins"
$ teamnames[2]="New York Giants"
$ teamnames[31] = "Houston Texans"
Или в следующей единственной (хотя и длинной) команде: $ declare -a teamnames
$ teamnames=([0] = "Dalias Cowboys" \ [l]="Washington Redskins" \
[31] = "Houston Texans")
Обратная косая черта (\) применяется для сообщения shell, что команда продолжается на следующей строке. Даже притом, что мы знаем количество команд заранее, в действительности в этом нет необходимости для определения массива. Мы могли бы сделать так:
$ teamnames — ("Dallas Cowboys" "Washington Redskins" \
"New York Giants" "New York Jets" \
...
"Houston Texans")
Обратите внимание, что, если массив заполнен не подряд (т. е. если некоторым элементам не присвоены значения, а просто пропущены), то при запросе количества значений в массиве оно будет фактическим числом внесенных элементов, а не самым большим определенным индексом. Пример: $ туlist[0]=27 $ mylist[5]=30 $ echo ${#mylist [★]} ...количество элементов в mylist[]
2
$ declare -а
declare -a mylist='{[0]="27" [5]=”30”)1
$ _
Удаление списков
Списочные переменные могут быть освобождены или удалены с помощью встроенной команды unset. После окончания работы с массивом можно освободить используемое им пространство, уничтожив его полностью. Однако более вероятно, что вы захотите удалить конкретный элемент из массива.
Синтаксис
unset имя
unset имя[индекс]
Команда unset освобождает конкретную переменную или элемент списочной переменной (массива).
Например:
$ unset teainn ames [17]
Теперь массив содержит 31 элемент вместо 32.
Экспорт переменных
Во всех shell переменные являются локальными к определенному командному интерпретатору и, если иначе не определено, не передаются дочернему shell. Вы должны экспортировать переменную shell в соответствующий Bourne shell или Korn shell. Встроенная команда export поддерживается в Bash, так же как и в Bourne shell, а опция -х во встроенной команде declare, как мы видели ранее, экспортирует переменную в subshell. В С shell переменная должна быть создана, как переменная окружения, чтобы быть доступной в subshell.
Bash поддерживает опцию shell, которая позволяет определить выполнение по умолчанию экспорта переменных shell в любые созданные дочерние shell. Опции shell задаются во встроенной командой set.
Синтаксис
set -o allexport
Команда set сообщает shell об экспорте всех переменных subshell.
Предопределенные переменные
Подобно большинству shell, Bash определяет некоторые переменные во время запуска. В дополнение к обычным предопределенным переменным Bash поддерживает переменные, перечисленные в табл. 8.3.
Таблица 8.3. Предопределенные переменные Bash
Имя Описание
BASH Полное путевое имя исполняемого файла Bash
BASH_ENV Расположение стартового файла Bash (по умолчанию это ~/. bashrc)
BASH_VERSION Строка версии
BASH_VERSINFO Массив "только для чтения" информации о версии
DIRSTACK Массив, определяющий стек каталогов
EUID Значение "только для чтения" эффективного ID пользователя, выполняющего Bash (только для UNIX)
HISTFILE Расположение файла, содержащего историю shell (по умолчанию ~/. bash_history)
HISTSIZE Максимальное количество команд в истории (по умолчанию 500)
HISTFILESIZE Максимальное количество строк, разрешенное в истории (по умолчанию 500)
HOSTNAME Имя главной машины, на которой работает Bash
HOSTTYPE Тип главной машины, на которой выполняется Bash
MAILCHECK Период (секунды) проверки новой почты
OSTYPE Операционная система машины, на которой выполняется Bash
PPID Только для чтения ID родительского процесса Bash
SHLVL Уровень shell (увеличивается на единицу каждый раз, когда процесс Bash стартует; показывает, как глубоко shell вложен)
DID Только для чтения. ID пользователя, выполняющего Bash (только для UNIX)
Клавиатурные комбинации быстрого вызова команд
Bash предусматривает несколько способов сокращения команд и аргументов, которые пользователь вводит с клавиатуры.
Псевдонимы
Как С shell и Korn shell, Bash позволяет определять собственные пользовательские команды при помощи встроенной команды alias. Псевдонимы Bash работают подобно псевдонимам Korn shell, как показано в следующем примере:
$ alias dir="ls -aF"
$ dir
./ main2.c
../ main2.o
$ dir *.c
main2.c p.reverse.c
p.reverse.c palindrome.c
palindrome.c
reverse.h
reverse.old
$
Синтаксис
alias [-p] [cuzobo[=строка] ]
Если пользователь ставит в соответствие новое слово команды строке, то при вводе слова команды с клавиатуры строка будет подставлена на его место (и любые последующие аргументы будут добавлены к строке. Если указать alias слово, то будет напечатан любой псевдоним, определенный для слова. Самое простое использование команды alias (без аргументов) будет печатать все определенные псевдонимы. Если указана опция -р, псевдонимы печатаются в формате, подходящем для ввода shell. (Так, если вы вручную установили свои любимые псевдонимы, то можете записать их в файл, чтобы включить в свой файл .bashrc.)
Для отказа от специального определения псевдонима служит встроенная команда unalias. Можно отменить определение псевдонима, если вы хотите возвратиться к нормальному поведению команды, когда ваш обычный псевдоним приводит к иному поведению. (Скажем, может случиться, что вы
больше не захотите, чтобы псевдоним dir использовал утилиту is в предыдущем примере, потому чт. е. другая команда dir в системе.)
Синтаксис
unalias [-а] {слово}+
Команда unalias удаляет конкретный псевдоним. Если используется опция -а, удаляются все псевдонимы.
История команд
Подобно С shell и Korn shell, Bash поддерживает историческую запись команд, которые вы вводите с клавиатуры. Команды, поддерживаемые в истории, можно выборочно повторно выполнять или изменить, а затем выполнить их с внесенными изменениями.
Хранение команд
Вводимые с клавиатуры команды сохраняются в файле истории, определенном переменной shell $histfile. По умолчанию значение задает файл .bash history в домашнем каталоге пользователя. Этот файл может содержать максимум $histfilesize элементов; значение по умолчанию равно 500.
Чтение истории команд
Чтобы увидеть историю shell, используйте встроенную команду history.
Синтаксис
history [-с] [п]
Встроенная команда history распечатывает текущую историю команд shell. Если числовое значение п определено, показывает только последние п элементов списка истории. Если используется опция -с, очищает список истории.
Повторное выполнение команд
Bash принимает метасимвол !, чтобы повторно выполнять команды из списка истории таким же образом, как это делает С shell. Метасимволы повторного выполнения Bash показаны в табл. 8.4.
Таблица 8.4. Метасимволы повторного выполнения команды в Bash
Формат Описание
। । Заменяется текстом самой последней команды
’ номер Заменяется командой с номером из списка истории
! -номер Заменяется текстом команды с номером команды, определяемым от конца списка.(! -1 эквивалентно ! ’)
!префикс Заменяется текстом самой последней команды, которая начиналась с префикса
!?подстрока? Заменяется текстом самой последней команды, которая содержит подстроку
Замена истории
Иногда возникает желание сделать больше, чем просто повторно выполнить уже отработанную команду. Например, вы можете немного изменить команду (чтобы заменить имя файла или отдельный аргумент длинной команды). Самая простая форма замены истории такая же, как в С shell.
Синтаксис
строка 1А строка2*
Заменяет строку1 на строку2 в предыдущей команде и выполняет ее.
Эта форма полезна, когда пользователь делает незначительную ошибку в команде и не хочет повторно печатать команду целиком. Пример:
$ 1р financial_report_july_2001.txt Ip: File not found.
$ ^2001^2002^
Ip f inancial_report_july_2002.txt request id is lwcs-37 (1 file) $ _
Или, возможно, пользователь хочет заменить кое-что в более ранней команде. Вот пример:
$ 1р financial_report_july_2001.txt Ip: file not found.
$ Is
financial- report_july_2002. txt financial_report_may_2002. txt
financial_report_june_2002. txt $ ! Ip:s/2002/2001/
request id is lwcs-37 (1 file) $
Синтаксис
!команда:s/строка 1/строка2/
Строка2 заменяется строкой1 в недавно выполненной команде, начинающейся с текста, специфицированного командой.
Редактирование команды
Bash обеспечивает возможность редактирования команды, во многом подобную таковой в Korn shell. Поддерживаются emacs- и vi-стили редактирования; emacs — по умолчанию. Так как в emacs пользователь всегда находится в режиме ввода текста, то можно перемещать курсор ввода в любое время, когда происходит ввод команды. Так, например, если вы пропустили слово, то можете вернуться назад при помощи комбинации клавиш <Ctrl>+<B> и вставить его. Чтобы получить доступ к своему списку истории предыдущих команд, можете нажать комбинацию клавиш <Ctrl>+<P> для перемещения "вверх”, как будто бы ваш список истории — это файл. Большинство других команд перемещения в редакторе emacs поддерживается в Bash. (См. разд. "Редактирование файла: emacs" в главе 2.)
Bash также позволяет vi-пользователям применять подобные действия, но этот редактор должен быть установлен с помощью встроенной команды set, описанной ниже. Поскольку редактор vi имеет два режима (командный и режим ввода текста), в то время как вы печатаете обычную команду, Bash обращается с вами, будто вы находитесь в режиме входа текста. Поэтому, чтобы получить доступ к vi-возможностям редактирования команды, вы должны нажать клавишу <Esc> так, как если бы вы работали с этим редактором, чтобы вернуться в командный режим. Затем можно передвигаться тем же самым способом, как если бы вы были в vi (используя клавишу <h> для возврата к команде и клавишу <к> для перемещения к предыдущим командам в списке истории). (См. разд. "Редактирование файла: vi" в главе 2.)
Синтаксис
set -о vi
Команда set предписывает shell использовать vi-стиль редактирования команды. Если вы когда-либо захотите вернуться к стилю по умолчанию редактора emacs, замените vi на emacs в команде.
Автозаполнение
Bash может закончить имя файла, название команды, имя пользователя или имя переменной shell, которое вводится с клавиатуры, если уже введено достаточно текста для уникальной идентификации.. Чтобы попытаться закончить текущий аргумент команды, нажмите клавишу <ТаЬ>. Если соответствующие имена файлов доступны, но введенный текст не идентифицирует полностью ни одного из них, общий текст, который имеют возможные имена, будет дописан до символа, начиная с которого, они больше не имеют совпадений. Это предоставляет пользователю возможность заполнять длинные имена файлов, у которых лишь несколько символов в конце различны (подобно числовой последовательности или дате). Тогда вы можете печатать только уникальную часть имени файла, к которому желаете получить доступ.
Арифметические действия
Арифметические действия более просты в Bash, чем в Bourne shell. Все, что можно выполнить с помощью утилиты ехрг, доступно через встроенные команды в Bash. Это не только требует меньше набора текста, но и быстрее выполняет скрипты shell в Bash.
Чтобы выполнить арифметическое действие в B^sh, следует поместить оператор внутри двойных круглых скобок.
Синтаксис
( ( оператор ))
Обычные числовые действия включают действия, перечисленные в табл. 8.5.
Таблица 8.5. Арифметические операторы
Оператор Описание
+> - Сложение, вычитание
++, — Инкремент, декремент
*, /, % Умножение, деление, остаток
★ * Возведение в степень
Арифметические действия над целыми числами выполняются быстрее, чем над числами с плавающей запятой. Если известно, что переменная будет всегда целочисленной (например, счетчик или индекс массива), то можно использовать встроенную команду declare для объявления ее целой.
Синтаксис
declare -i имя
Этот формат команды declare определяет переменную с именем, как целое.
После того как будут рассмотрены некоторые простые условные выражения, мы объединим их в простой математический скрипт.
Условные выражения
Вы можете сравнивать значения (обычно хранящиеся в переменных shell) друг с другом и переходить на различные команды в зависимости от результата сравнения. (В разд. "Структуры управления" далее в этой главе будет показано, как управлять и что делать после сравнения.)
Подобно арифметическим действиям, арифметические выражения заключаются в двойные круглые скобки. Типы сравнений, которые можно осуществлять, показаны в табл. 8.6.
Таблица 8.6. Арифметические условные операторы
Оператор Описание
Л JI V JI A V Сравнения: меньше, чем или равно; больше, чем или равно; меньше, чем; больше, чем
— — 1 — > • I Равно, не равно Логическое НЕ
& & Логическое И
1 1 Логическое ИЛИ
Арифметические выражения
Сравнения с использованием арифметических выражений позволяют просто выполнять математические вычисления в скрипте Bash.
Мы досчитаем до 20 и проверим, какие числа делят 20 нацело (не волнуйтесь слишком много о конструкции while; мы рассмотрим ее позже):
$ cat divisors.bash
#!/bin/bash
declare -i testval=20
declare -i count=2 # начать c 2, 1 всегда работает
while (( $count <= $testval )); do
(( result = $testval % $count ))
if (( $result == 0 )); then # делится нацело echo " $testval is evenly divisible by $count" .
fi
( ( count++ ) )
done
$ bash divisors .bash
20 is evenly divisible by 2
20 is evenly divisible by 4
20 is evenly divisible by 5
20 is evenly divisible by 10
20 is evenly divisible by 20
$ _
Сравнение строк
Строковые условные операторы Bash показаны в табл. 8.7.
Таблица 8.7. Строковые условные операторы
Оператор Описание
-п строка Истина, если длина строки не ноль
-z строка Истина, если длина строки ноль
строка 1 == строка2 Истина, если строки равны
строка! ’= строка2 Истина, если строки не равны
Выражения, ориентированные на файл
В табл. 8.8 перечислены ориентируемые на файл условные операторы Bash.
Таблица 8.8. Ориентированные на файл условные операторы
Оператор Возвращает
-а файл истину, если файл существует
—b файл истину, если файл существует и является специальным блочным файлом
Таблица 8.8 (окончание)
Оператор Возвращает
-с файл истину, если файл существует и является специальным символьным файлом
-d файл истину, если файл существует и является каталогом
-е файл истину, если файл существует
-f файл истину, если файл существует и является обычным файлом
-g файл истину, если файл существует и его бит установки группового ID установлен
-k файл истину, если файл существует и его атрибут sticky bit установлен
"P файл истину, если файл существует и является поименованным конвейером
— r файл истину, если файл существует и читаемый
-s файл истину, если файл существует и имеет размер больше нуля
-t дескрипторФайла истину, если дескрипторФайла открыт и ссылается на терминал
-u файл истину, если файл существует и его бит SUID3 установлен
-w файл истину, если файл записываемый
-x файл истину, если файл существует и исполняемый
-0 файл истину, если файл существует и принадлежит эффективному ID пользователя
-G файл истину, если файл существует и принадлежит эффективному групповому ID пользователя
-L файл истину, если файл существует и является символической связью
-N файл 4 истину, если файл существует и модифицировался со времени последнего чтения
-s файл истину, если файл существует и является сокетом
файл1 -nt файл 2 истину, если файл1 более новый, чем файл2
файл1-ot файл 2 истину, если файл1 более старый, чем файл2
файл! -ef файл2 истину, если файл1 и файл2 имеют то же самое устройство и номера индексных дескрипторов (inode)
3 Set User ID, бит установки пользовательского ID. — Ped.
Простым примером применения операций над файлами может быть следующий код: $ cat owner.bash #!/bin/bash #
if [ -О /etc/passwd ]; then
echo "you are the owner of /etc/passwd." else
echo "you are NOT the owner of /etc/passwd." fi
$ bash owner.bash you are NOT the owner of /etc/passwd. $_
Структуры управления
Вы можете применять различные управляющие структуры, чтобы указывать shell, какая команда должна выполниться следующей. Эти структуры управления подобны структурам, поддерживаемым Bourne shell, Korn shell и С shell. Хотя они могут использоваться в диалоговом режиме Bash, но чаще всего используются при написании скриптов Bash.
case... in... esac
Оператор case позволяет специфицировать многократные действия, которые будут приняты, когда значение переменной соответствует одному или большему числу значений. Фрагмент скрипта для Bash shell, который использует оператор case, чтобы распечатать местожительство команд NFL, перечисленных в нашем более раннем примере, мог бы напоминать следующее: case ${teamname[$index]} in
"Dallas Cowboys") echo "Dallas, TX";;
"Denver Broncos") echo "Denver, CO";;
"New York Giants"|"New York Jets") echo "New York, NY";;
*) echo "Unknown location";;
esac
Синтаксис
case слово in шаблон {| шаблон }*) команды ;; esac
Оператор case выполняет команды, когда значение слова соответствует шаблону. Символ ) означает конец списка шаблонов для совпадения. Символ ;; требуется, чтобы указать конец команд, которые будут выполняться.
Обратите внимание на специальное использование шаблона * в качестве последнего. Если скрипт проходит через все шаблоны и не находит совпадения, шаблон * отловит эту ситуацию. Если нет соответствия никаким шаблонам, то ни одна из команд не будет выполнена.
if... then... elif... then... else... fi
Команда if покажется знакомой пользователям Korn shell и Bourne shell. Данная конструкция позволяет сравнить два или большее количество значений и перейти к блоку команд в зависимости от результата сравнения.
Синтаксис
if условие!; then команды!;
[elif условие2; then команды2; ]
[else командыЗ; ]
fi
Если условное выражение условие! ИСТИННО, ТО ВЫПОЛНЯЮТСЯ команды!. Если проверки условия! ложные, то, если структура elif присутствует, выполняются следующее проверки в условии2 (else if). Если условие2 истинно, то выполняются команды2. Конструкция else используется, когда нужно выполнять команды после того, как условие в результате дало ложь.
В качестве примера рассмотрим случай для пары наших команд NFL, когда мы печатаем информацию о них.
# $index был установлен на некоторую произвольную команду в списке #
if [ "${teamname[$index]}" == "Minnesota Vikings" ]; then cat "vikings.txt" # печатать "специальную" информацию
elif [ "${teamname[$index]}" == "Chicago Bears" ]; then
cat "bears.txt" # повторить
else
cat "nfl.txt" # для кого-нибудь еще, печатать стандартный файл
fi
for... do... done
Конструкцию for лучше использовать, если существует известный набор значений, по которым нужно выполнить цикл (например, список машин, имен файлов или чего-то похожего).
Синтаксис
for имя in слово {слово}★ ; do команды ; done
Команда for выполняет команды для каждого слова в списке с параметром $имя, содержащим значение текущего слова.
Можно использовать сравнение, чтобы выйти из такого цикла, или просто последовательно обработать каждый пункт списка. Самый простой пример — печать всех файлов текста в текущем каталоге: $ for file in *.txt do
Ip $file done request id is lwcs-37 (1 file) request id is lwcs-37 (1 file) request id is lwcs-37 (1 file) $
while/until ...do... done
Конструкции while и until работают похожим образом, выполняя цикл, "пока" или "пока не" проверочное условие встречено (while в случае, если условие первоначально истинно, и нужно организовать цикл, пока оно не станет ложным; until в случае, если условие первоначально ложно, и необходимо создать цикл, пока оно не станет истинным).
Синтаксис
while условие; do команды; done
until условие; do команды; done
В конструкции while исполняются команды, пока выражение проверки условие вычисляет ИСТИНУ. В конструкции until ВЫПОЛНЯЮТСЯ команды, пока выражение проверки условие вычисляет ложь.
Обе конструкции полезны, если заранее неизвестно, когда изменится условие проверки.
Стек каталогов
Bash поддерживает стек каталогов подобно предлагаемому в С shell, с несколькими усовершенствованиями. Одно из них заключается в том, что полный стек сохраняется в массиве строк $ dirstack, обеспечивая простой доступ к любому элементу стека из скрипта Bash.
Для того чтобы протолкнуть текущий каталог в стеке каталогов и заменить его на новый каталог, применяется встроенная команда pushd. Когда приходит время возвратиться к предыдущему каталогу, используется встроенная команда popd для восстановления предыдущего местоположения каталога и переключения на него. В дополнение к доступу к содержимому стека при помощи переменной shell $dirstack встроенная команда dirs позволяет выводить (или очищать) содержимое стека каталогов.
Синтаксис
pushd [-п] [каталог] t
Команда pushd сохраняет текущий каталог как самое последнее дополнение (т. е. в вершине) к стеку каталогов. Последующая команда popd восстановит этот каталог. К тому же pushd заменяет каталог на специфицированный. Если никакой новый каталог не определен, текущий каталог и каталог на вершине стека переставляются (т. е. вы проталкиваете текущую вершину стека и меняете каталоги, а затем проталкиваете текущий каталог в стек). Если присутствует опция -п, переключение на новый каталог не происходит, а просто текущий каталог проталкивается в стек.
Синтаксис
popd [—п]
Команда popd восстанавливает последний каталог, который был помещен в стек, и переходит в этот каталог. Запись удаляется из стека. Если присутствует опция —п, переход в новый каталог не осуществляется, он просто удаляется из вершины стека.
Синтаксис
dirs [-ср]
Если аргументов нет, команда dirs просто распечатывает содержимое стека каталогов. Опция -р выводит каталоги по одному на строке. Опция -с очищает стек каталогов.
Управление заданием
Bash добавляет несколько возможностей к управлению заданием, кроме описанных в главе 6. Если вы пропустили изучение Korn shell, предлагаем вернуться и прочитать разд. "Расширенное управление заданиями ".
Управление заданием позволяет пользователю приостанавливать и возобновлять выполнение процесса, начатого при помощи командной строки Bash. Как и в Korn shell или С shell, нажатие комбинации клавиш <Ctrl>+<Z> во время выполнения процесса приостановит его. Затем вы можете использовать команды shell fg или bg, чтобы возобновить процесс соответственно как фоновый или приоритетный. Спецификация задания та же самая, как и в Korn shell, с двумя дополнительными опциями, показанными в табл. 8.9. Спецификатор должен уникально идентифицировать работу. Если больше, чем одно задание соответствует спецификатору, Bash сообщает об ошибке. Иначе команды fg, bg и wait работают так же, как в Korn shell. Встроенные команды shell jobs и kill в Bash работают немного по-другому.
Таблица 8.9. Дополнительные спецификаторы задания в Bash
Формат Описание
% имя Ссылается на Процесс, чье имя начинается с имя
% ?имя Ссылается на процесс, в котором имя возникает где-нибудь в командной строке
Синтаксис
jobs [-Irs]
Команда jobs отображает список всех заданий shell. Когда jobs используется с опцией -1, ID процессов включаются в листинг. Если указана опция -г, выводятся только задания, работающие в настоящее время. Опция -s позволяет напечатать только остановленные в настоящее время задания.
Синтаксис
kill [-s signame ] [-n signum] специфика цияЗадания или 1с1_процесса
Команда kill посылает специфицированный сигнал конкретному процессу. Требуется указать или спецификациюзадания (например, %1), или ID процесса. Если используется опция -s, signame — это допустимое имя сигнала (например, sigint). Если приводится опция -n, signum — это номер сигнала. Если ни одна из опций не указана, процессу посылается сигнал SIGTERM.
Функции
Функции Bash синтаксически похожи на функции в Korn shell. Если вы пропустили изучение Korn shell, возвратитесь и прочитайте разд. "Функции" главы 6. Bash имеет пару ценных дополнений к существующим в Korn shell функциям, которые мы и рассмотрим в данной главе.
Функции в Bash могут экспортироваться в subshell с помощью встроенной команды export. Командный интерпретатор также поддерживает встроенную команду local, которая ограничивает переменную, делая ее локальной только в текущей функции (значение переменной нельзя передать в дочерний shell).
Синтаксис
export -f имяФункции
Встроенная команда export, используемая с опцией -f, экспортирует функцию в subshell подобно экспорту значения переменной.
Синтаксис
local имя[=значение]
Встроенная команда local определяет переменную так, чтобы она была локальной только в текущей функции, имя переменной может быть выведено, или ей может быть присвоено значение в той же самой конструкции.
Существует еще одна полезная команда для написания функций — builtin.
Синтаксис
builtin [команда [ аргументы] ]
Встроенная команда shell builtin выполняет указанную встроенную команду shell и передает ее аргументы, если они представлены. Команда полезна, когда пользователь пишет функцию для shell, которая имеет аналогичное имя, что и существующая встроенная команда, но в функции нужно выполнять встроенную команду, а не вызывать рекурсивно функцию.
Разные встроенные команды
Bash включает много других встроенных команд, некоторые из них он заимствует из других shell для совместимости.
Синтаксис
readonly
Команда readonly применяется, чтобы не допустить изменения значения переменной shell. В Bash подобное действие может быть выполнено при помощи команды declare -г. Использование readonly то же самое, что и в Bourne shell и Korn shell (см. главу 5).
Синтаксис
select
Команда select служит для создания приглашения меню. Данная встроенная команда аналогична одноименной команде в Korn shell (см. главу 6).
Синтаксис
source file
. file
Команды source и могут применяться для выполнения скрипта shell в текущем командном интерпретаторе. Это полезно для повторного выполнения файлов .profile или .bashrc после их модификации. Встроенная команда source аналогична одноименной команде С shell. Использование то же самое, что и в Bourne shell и Korn shell.
Встроенная команда set имеет несколько опций, которые мы прежде не обсуждали. В табл. 8.10 перечислены наиболее полезные опции.
Таблица 8.10. Некоторые опции встроенной команды set
Опция Описание
-о allexport | -а Экспортирует все созданные или модифицированные переменные и функции
-о emacs Устанавливает стиль редактирования команд для того, чтобы поведение было подобно редактору emacs
-о ignoreeof Диалоговый shell не будет выходить на EOF — конец файла (например, если вы случайно нажали комбинацию клавиш <Ctrl>+<D>)
-о noclobber | -С Предохраняет перенаправление вывода от переписывания существующих файлов
-о noglob | -f Запрещает замещение имени файла (известна под именем globbing)
-о posix Предписывает Bash четко придерживаться стандарта POSIX 1003.2
-о verbose | -v Отображает строки ввода shell по мере их чтения (полезна для отладки скриптов)
-о vi Устанавливает стиль редактирования команд для того, чтобы поведение было подобно редактору vi
Опции командной строки
Bash поддерживает много опций командной строки. Некоторые из наиболее полезных показаны в табл. 8.11.
Таблица 8.11. Некоторые опции командной строки Bash
Опция Описание
-с строка Выполняет строку, как команду shell
—s Читает команды со стандартного ввода
—login Делает Bash входным shell. Полезна, если нельзя заставить Bash быть входным shell из команды chsh
--noprofile Игнорирует Bash-файлы профиля (в масштабе всей системы и пользовательских версий)
--norc Игнорирует rc-файлы Bash (~/.bashrc)
— posix Выполняется в соответствии со стандартом POSIX (тр же самое, что и set -о posix)
--verbose | -v Отображает строки ввода shell, когда они читаются (то же самое, как set -о verbose)
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
□ стартовые файлы Bash;
П использование переменных shell;
□ применение псевдонимов, механизма истории и редактирование командной строки;
□ арифметические действия в Bash, условные операторы и структуры управления;
□ использование стека каталогов;
□ реализацию в Bash управления заданием;
□ функции Bash.
Контрольные вопросы
1. Почему обеспечение собственных арифметических действий в Bash существенно улучшает время выполнения скриптов shell?
2. Почему требуются фигурные скобки ({}) вокруг списочных переменных?
3. Все ли скрипты Bourne shell работают в Bash?
4. Все ли Bash-скрипты работают в Korn shell?
5. Какая переменная shell содержит стек каталогов?
Упражнение
Скрипт track, представленный в главе 5, выполняется и в Bash. Однако он использует утилиту UNIX ехрг, чтобы выполнить свои арифметические вычисления. Измените track так, чтобы он использовал арифметику Bash, и сравните его скорость выполнения со скоростью в первоначальной версии. Можете использовать утилиту UNIX time (описанную в главе 5), чтобы измерить различия, если совсем не "почувствуете" значительных различий. [Уровень: легкий.]
Проект
Напишите скрипт Bash mv (заменяющий утилиту UNIX mv), который пробует переименовать указанный файл (используя утилиту UNIX mv). Но если файл назначения уже существует, вместо него создается файл с индексом — своего рода номер версии. Так, если ввести $ mv а.txt b.txt
но файл b.txt уже существует, mv переместит файл в b.txt.I. Обратите внимание, если b.txt. 1 уже существует, вы должны переименовать файл в b.txt.2 и т. д., пока не возникнет возможность успешно переименовать файл и получить имя, которого не существует. [Уровень: средний.]
Глава 9
Организация сети
Мотивация
Одно из наиболее существенных преимуществ UNIX перед другими конкурирующими операционными системами во время ее возникновения заключалось в том, что она была одной из первых ОС, которые обеспечивали доступ к широко распространенным локальным сетям, а также к Интернету. Сегодня миллионы пользователей и программ разделяют информацию в этих сетях по разным причинам, от распределения больших вычислительных задач до обмена рецептами для приготовления лазаньи. Для того чтобы наилучшим образом использовать ресурсы сети, вы должны понимать работу утилит, управляющих обменом информацией. Данная глава описывает наиболее полезные сетевые утилиты. Несмотря на то, что они применимы и к локальным сетям, и к Интернету, акцент будет сделан на утилитах, связанных с Интернетом.
Предпосылки
Для понимания материала данной главы необходимо изучить главы 7 и 2 Не будет лишним иметь доступ к системе UNIX, чтобы вы могли испытать различные обсуждаемые утилиты.
Задачи
В настоящей главе я покажу вам, как определить, что находится на сети, общаться с другими пользователями, копировать файлы при помощи сети и выполнять процессы на других компьютерах в сети.
Изложение
Глава начинается с краткого обзора концепций сети и терминологии, а затем описываются сетевые утилиты UNIX.
Утилиты
Будут рассмотрены следующие утилиты:
finger rsh w
ftp rusers wall
hostname rwho who
mesg talk whois
rep telnet write
rlogin users
Общие сведения о сетях
Сеть — связанная система взаимодействующих компьютеров. С помощью сети вы можете разделять ресурсы с другими пользователями через постоянно увеличивающееся количество сетевых приложений, типа Web-браузеров и систем сообщений электронной почты.
В 1990-х годах был огромный взрыв использования сети UNIX. Например, парадигма, "клиент-сервер" описанная в главе 7, была принята многими из ведущих компьютерных корпораций и в большой степени основывается на способности сетевых операционных систем распределять рабочую нагрузку между сервером и его клиентами.
Чтобы иметь представления о сети, важно знать:
□ общую сетевую технологию;
□ как строятся сети;
□ как общаться с людьми через сеть;
□ как использовать другие компьютеры сети.
Эта глава охватывает перечисленные темы и даже больше.
Построение сети
Один из лучших способов понять, как выглядит работа современной сети, — это выяснить эволюцию ее развития. Вообразите, что два человека в офисе хотят соединить свои компьютеры вместе так, чтобы они могли разделять данные. Самый легкий способ — соединить их через последовательные порты. Получится самая простая форма локальной сети (local area network, LAN), и она не требует фактически никаких специальных программ или аппаратуры. Когда один компьютер хочет передать информацию другому, он
просто посылает данные со своего последовательного порта.. Эта организация показана на рис. 9.1.
Последовательное соединение
Рис. 9.1. Простейшая LAN
Сети Ethernet
Теперь давайте предположим, что другой человек хочет подключиться к существующей сети этих двух парней. При трех компьютерах в сети мы нуждаемся в схеме адресации для того, чтобы можно было различить компьютеры. Мы также хотели бы иметь минимальное число связей. Самое обычное выполнение этого вида LAN называется Ethernet. Ethernet — это стандарт аппаратного подключения, определяющий кабельную сеть, передачу сигналов и поведение, которые позволяют данным распространяться по проводам. Формат данных назначается в соответствии с протоколами сети, которые мы рассмотрим немного позже. Ethernet-стандарт был первоначально разработан корпорацией Xerox и работает следующим образом.
П Каждый компьютер содержит Ethernet-карту, которая является специальной частью аппаратуры ЭВМ и имеет уникальный адрес Ethernet.
□ Ethernet-карта каждого компьютера соединена с ним единственным проводом.
П Когда компьютер хочет послать сообщение другому компьютеру с конкретным адресом Ethernet, он передает в широковещательном режиме сообщение в Ethernet вместе с Ethernet-заголовком и последующей информацией, которая содержит Ethernet-адрес назначения. Принимает сообщение только Ethernet-карта, чей адрес соответствует адресу назначения.
□ Если два компьютера одновременно пробуют передавать данные в Ethernet в широковещательном режиме, то в результате возникает ситуация, называемая коллизией (collision). При коллизии оба компьютера
ожидают случайный промежуток времени и затем пробуют снова передать данные. Рис. 9.2 демонстрирует диаграмму Ethernet. Ethernet-сети могут передавать данные со скоростью порядка десятков или сотен мегабайт в секунду.
Ethernet-кабель
Ethernet-карта
Рис. 9.2. Ethernet
Мосты
Давайте предположим, что Ethernet в офисе работает настолько хорошо, что сотрудники соседнего офиса также строят себе Ethernet. Как один компьютер в одном Ethernet взаимодействует с компьютером в другом Ethernet? Одним из решений могло бы быть соединение сетей при помощи специальной аппаратуры, называемой мостом (bridge). Мост передает Ethernet-сообщение между различными сегментами сети, как будто бы оба сегмента — это единственный Ethernet-кабель сети (рис. 9.3). Мост используется, когда требуется расширить сеть за пределы разрешенного размера единственной секции провода. (Длина ограничивается затуханием сигнала при распространении.)
Рис. 9.3. Мост
Маршрутизаторы
Использование мостов облегчает построение маленьких последовательно связанных секций Ethernet. Но это довольно неэффективный способ связать вместе большое количество сетей. Например, предположим, что корпорация имеет четыре LAN, которые желательно связать эффективным способом. Соединение их вместе при помощи мостов заставило бы данные проходить через "средние" секции, чтобы достигнуть концов, в то время как владельцы этих средних секций не заинтересованы в получении передаваемых данных. Чтобы передать данные непосредственно от исходящей сети до сети назначения, может использоваться маршрутизатор (router). Маршрутизатор.— это устройство, которое соединяет вместе две или более сетей и автоматически направляет входные сообщения в соответствующую сеть (рис. 9.4).
Ethernet-кабель
Ethernet-кабель
Шлюзы
Заключительная стадия в развитии сети происходит, когда много корпораций хотят соединить свои локальные сети в единую, глобальную сеть (wide area network, WAN). Чтобы сделать это, несколько высокопроизводительных маршрутизаторовь называемых шлюзами (gateway), помещаются по всей стране, и каждая корпорация связывает свою LAN с самым близким шлюзом (рис. 9.5).
Рис. 9.5. Шлюзы
Объединение сетей
Для того чтобы бы LAN и WAN надлежащим образом были способны к передаче информации между собой, они должны согласовать в масштабе сети схему адресации и схему маршрутов. Эта крупномасштабная взаимосвязь различных сетей известна как объединение сетей. Любая группа двух или нескольких сетей, связанных вместе, может по существу называться интерсе-тъю. Однако самая большая и хорошо известная интерсеть стала известна как Интернет. Университеты, большие корпорации, правительственные учреждения и военные организации — все имеют компьютеры, которые являются частью Интернета. Компьютеры вообще связываются вместе быстродействующими каналами передачи данных. Самые большие из ,этих компьютерных систем соединяются вместе для того, чтобы сформировать так называемую магистраль сети (backbone) Интернета. Другие, менее крупные организации связывают свои LAN с магистралью через шлюзы.
»
Коммутация пакетов
Сегодняшние цифровые компьютерные сети — это сети пакетной коммутации. Когда один узел сети посылает сообщение другому узлу, сообщение разбивается на маленькие пакеты, каждый из которых может быть передан независимо (т. е. направлен) через сеть.
Пакеты содержат специальную информацию, которая позволяет им объединиться в пункте назначения. Они также содержат информацию для целей маршрутизации, включая адрес узла назначения и узла источника. Объединенный набор протоколов называется комплектом протокола управления передачей (Transmission Control Protocol, TCP) и протокола Интернета (Internet Protocol, IP). Связь между процессами UNIX (interprocess communication, IPC) использует протокол TCP/IP, чтобы позволить им на различных машинах ’’взаимодействовать" друг с другом.
Адреса Интернета
Узлы Интернета, так же как многие частные интерсети, используют протокол TCP/IP для передачи данных. Несмотря на то, что данный протокол обычно реализуется в сетях Ethernet, он может также использоваться в сетях других типов. Это делает его полезным для соединения различных сетей, поскольку не все компьютеры связаны Ethernet. Например, некоторые LAN могут использовать систему маркерного кольца IBM (Token Ring). Поэтому система адресации IP применяет независимую от аппаратуры схему маркирования: мосты, маршрутизаторы и шлюзы передают сообщения, основанные исключительно на их IP-адресе назначения, который связывается с физическим адресом аппаратуры только, когда сообщение достигает узла LAN-назначения. Таким образом, компьютер, посылающий сообщение, не должен знать конкретную информацию об аппаратуре компьютера, которому передается сообщение.
Механизм IP-адресации работает одинаково независимо от того, подключили ли вы фактически ваши компьютеры к Интернету или нет. Когда организация устанавливает LAN, которая должна быть частью глобальной сети, она должна получить уникальный диапазон адресов, предназначенных для ее компьютеров (см. главу 10). Пока будем предполагать, что мы используем локальную 1Р-сеть.
Адрес IP — это 32-битовое значение, которое записывается, как четыре отделенных точкой числа. Каждое число представлено 8 битами из 32 битов адреса. Поскольку каждая часть является 8-битовой, максимальное значение, которое она может иметь, равно 255.
Из-за стремительного роста Интернета, по-видимому, кажущиеся бесконечными ресурсы 32-битовых адресов могут быстро исчерпаться. Текущий IP-стандарт протокола (IPv4) модифицируется, чтобы позволить большие адреса. IPv6 определит 128-битовый IP-адрес так, чтобы можно было назначить существенно больше адресов. (Для получения дополнительной информации о IPv6 см. главу 76.)
Именование
Числовые IP-адреса не очень удобны для людей, чтобы использовать их для доступа к отдаленным компьютерам. Пользователи гораздо больше применяют именование объектов (например, людей, домашних животных и автомобилей). Поэтому мы взялись также и за именование наших компьютеров.
Когда имя ведущего узла назначено конкретному компьютеру, может быть установлено взаимоотношение между именем и числовым IP-адресом компьютера. Тогда' пользователь способен указать имя, чтобы сослаться на компьютер, а программное обеспечение автоматически переведет имя в адрес IP.
Связь IP-адресов и локальных имен хост-машин хранится администратором системы LAN в файле /etc/hosts. Продемонстрируем маленький фрагмент файла Техасского университета в Далласе (University of Texas at Dallas):
129.110.41.1
129.110.42.1
129.110.43.2
129.110.43.128
129.110.43.129
129.110.66.8
129.110.102.10
ташпахОЗ csservr2 ncubeOl vanguard jupiter neocortex corvette
Маршрутизация
Протокол IP выполняет два вида маршрутизации: статическую и динамическую. Статическая информация маршрутизации хранится в файле /etc/route и имеет вид "You may get to the destination DEST via the gateway GATE with X hops" ("Вы можете получить назначение DEST через шлюз GATE с X-ретрансляциями"). Когда маршрутизатор должен переслать сообщение, он может использовать информацию из этого файла, чтобы определить лучший маршрут. Динамическая информация маршрутизации разделяется между хост-машинами через демоны1 (daemons) /etc/routed или /etc/gated. Эти программы постоянно модернизируют свои локальные маршрутные таблицы на основе информации, собираемой из сетевого трафика, и периодически делятся своей информацией с другими соседними демонами.
Безопасность
Несколько сетевых утилит UNIX дают возможность пользователю с учетными записями на нескольких компьютерах выполнять команду на одном из
1 Демон — это причудливый термин для постоянно работающего фонового процесса, который обычно начинается, когда система загружается.
них, запуская ее с другого компьютера. Например, я зарегистрирован на машинах csservr2 и vanguard в Техасском университете в Далласе (University of Texas at Dallas). Для того чтобы выполнить утилиту date на машине vanguard с машины csservr2, я могу использовать утилиту rsh (обсуждаемую позже в этой главе2) следующим образом:
$ rsh vanguard date ...выполнить date на vanguard.
Любопытно, что rsh и несколько других утилит способны запустить shell на отдаленной хост-машине без необходимого пароля. Они могут делать это из-за возможности UNIX, называемой эквивалентностью машин. Если в своем домашнем каталоге вы создаете файл .rhosts, который содержит список имен хост-машин, то любой пользователь с тем же самым пользовательским ID, как ваш собственный, может зарегистрироваться с этих хост-машин без предоставления пароля. В моих домашних каталогах на csservr2 и vanguard есть файл .rhosts, который содержит следующие строки: csservr2.utdallas.edu vanguard.utdallas.edu
Мы должны использовать "официальное" имя хост-машины, которое включает интернет-домен, в .rhosts-файле (см. главу 10).
Эта способность получения shell без необходимости указывать пароль обеспечивает выполнение удаленных команд с любого компьютера без всяких препятствий. UNIX также позволяет системному администратору регистрировать глобально эквивалентные машины в файле /etc/hosts.equiv. Глобальная эквивалентность означает, что любой пользователь, зарегистрировавшийся на одной из перечисленных машин, может получить доступ к локальной хост-машине без пароля. Например, если файл vanguard /etc/hosts.equiv содержит строки csservr2.utdallas.edu vanguard.utdallas.edu
то любой пользователь на csservr2 может войти в vanguard или выполнить удаленную команду на нем без упоминания пароля. Глобальная эквивалентность должна использоваться с большой осторожностью (как всегда).
Порты и общие сервисы
Один хост-компьютер3 сети взаимодействует с другим через набор пронумерованных портов. Каждый хост поддерживает некоторое количество стандартных портов для обычного использования и позволяет прикладным программам создавать другие порты для транзитных коммуникаций. Файл
2 См. разд. "Выполнение удаленных команд: rsh " далее в этой главе. — Ред.
3 Далее может использоваться термин ’’хост". — Ред.
/etc/services содержит список стандартных портов. Вот отрывок из файла Техасского университета в Далласе (University of Texas at Dallas):
echo 7/tcp
discard 9/top sink null
systat 11/tcp users
daytime 13 /tcp
ftp-data 20/tcp
ftp 21/tcp
telnet 23/tcp
smtp 25/tcp mail
time 37/tcp timeserver
rip 39/udp resource
whois 43/tcp
finger 79/tcp
sunrpc 111/tcp
exec 512/tcp
login 513/tcp
Описание утилиты telnet, представленное далее в этой главе4, содержит примеры соединений с некоторыми из этих стандартных портов.
Сетевое программирование
Коммуникации между процессами UNIX позволяют вам связываться с другими программами с известным IP-адресом и портом. Данная возможность описана в конце главы 13, вместе с полным исходным кодом для проекта Internet shell, который может конвейеризировать и переадресовывать данные к другим интернет-shell на различных хост-машинах.
Пользователи
Работая в сети UNIX, следует знать все о перемещении по сети и взаимодействии с другими пользователями. Поэтому один из наиболее важных аспектов заключается в том, чтобы уметь выяснять, кто работает на конкретном хосте. Существует несколько утилит, которые это делают:
□ утилита users перечисляет всех пользователей на вашем локальном хосте;
□ утилита rusers выводит список всех пользователей в вашей локальной сети;
4 См. разд. "Удаленные соединения: telnet" далее в этой главе. — Ред.
□ утилита who подобна утилите users, за исключением того, что предоставляет больше информации;
□ утилита rwho похожа на утилиту rusers, но выводит больше информации;
□ утилита w подобна утилите who, за исключением того, что предоставляет еще больше сведений;
□ утилита whois позволяет получить информацию о главных интернет-узлах;
□ утилита hostname выводит локальное имя вашего хоста.
Распечатка списка пользователей:
users/rusers
Утилиты users и rusers выводят список текущих пользователей вашего локального хоста и локальной сети соответственно.
Синтаксис
users
Утилита users выводит простой, краткий список пользователей на вашем локальном хосте.
Синтаксис
rusers -а {хост}*
Утилита rusers отображает список пользователей вашей локальной сети. По умолчанию опрашиваются все машины сети, хотя можно отменить это умолчание, предоставив список имен хостов, rusers работает, передавая широковещательный запрос об информации всем хостам, а затем показывает поступившие ответы. Для того чтобы хост ответил, должен работать rusersd-демон. (Дополнительную информацию о демонах см. в главе 15.)
Например:
$ users ...вывести пользователей на локальном хосте,
glass posey
$ rusers -al ...вывести пользователей в локальной сети.
csservr4.utd posey
vanguard.utd huynh posey datta venky csservr2.utd posey glass $
Расширенные сведения о пользователях:
who/rwho/w
Утилиты who и rwho предоставляют немного больше информации, чем это делают утилиты users И rusers.
Синтаксис
who ^ЬоФайл] [am 1]
По умолчанию утилита who показывает список всех пользователей на вашем локальном хосте. Если вы представите аргументы "ат 1", утилита опишет только вас. Всякий раз, когда пользователь регистрируется в системе или выходит из нее, файл /var/adm/wtmp обновляется информацией о сессии пользователя. Вы можете указать имя этого файла (или файла в том же самом формате), как аргумент who Файл. В этом случае утилита расшифрует информацию в файле и представит ее в типичном формате who.
Вот пример использования утилиты who:
$ who ...вывести всех текущих пользователей на локальном хосте,
posey ttypO May 15 16:31 (blackfoot.utdall) glass ttyp2 May 17 17:00 (bridge05.utdalla) $ who am i ... вывести себя.
csservr2!glass ttyp2 May 17 17:00 (bridgeOS.utdalla)
$ who /var/adm/wtmp ...проверить файл who.
leui ttyp2 May 17 12:48 (bridgeOS.utdalla)
juang ttyp3 May 17 12:49 (annex.utdallas.e)
ttyp3 May 17 12:52
ttyp2 May 17 12:57
weidman ttyp2 May 17 16:25 (annex.utdallas.e)
ttyp2 May 17 16:33
glass $ ttyp2 May 17 17:00 (bridgeOS.utdalla)
Синтаксис
rwho
Утилита rwho аналогична утилите who, за исключением того, что она выводит список пользователей, зарегистрированных на всех отдаленных хостах вашей локальной сети.
Синтаксис
w {ID—Пользователя} *
Утилита w отображает список, в котором зафиксировано, что делает каждый указанный пользователь. Другими словами, w похожа на утилиту who.
Утилита w столь же удобна, как и утилита who. Вот пример:
$ w ...получить более детальную информацию, чем who.
5:27pm up 11 days, 11 ruins, 3 users , load average: 0.08, 0.03, 0.01
User tty login® idle JCPU PCPU what
posey ttypO Fri 4pm 2 days 1 -csh
glass ttyp2 5:00pm 1 13 1 w
$ w glass ...проверить только самого себя.
5:27pm up 11 days, 11 mins, 3 users, load average: 0.08, 0.03, 0.01
User tty login® idle JCPU PCPU what
glass ttyp2 5:00pm 13 1 w glass
Собственное имя хоста: hostname
Чтобы выяснить имя вашей локальной хост-машины, используйте утилиту hostname.
Синтаксис
hostname [имяХоста]
Если утилита hostname используется без параметров, то показывает имя вашей локальной хост-машины. Привилегированный пользователь может изменить его, предоставляя новое имя хоста, как аргумент, что обычно
делается автоматически в файле /etc/rc.local. (Дополнительную информацию об этом файле см. в главе 15.)
Пример:
$ hostname csservr2 $
. . .вывести имя моей хост-машины.
Персональные данные: finger
Как только вы получили список пользователей вашей системы, удобно получить о них расширенную информацию. Утилита finger позволяет сделать это. Рекомендуется создавать собственные файлы .plan и .project в своем домашнем каталоге так, чтобы другие пользователи тоже могли вас "вычислить". Веселитесь!
Синтаксис
f inger { Ю_пользова теля} *
Утилита finger выводит информацию о пользователях, которая собирается из следующих источников:
• домашний каталог пользователя, shell запуска и полное имя читаются из файла пароля /etc/passwd;
• если пользователь имеет файл .plan в своем домашнем каталоге, содержимое файла показывается, как plan пользователя;
• если пользователь имеет файл .project в своем домашнем каталоге, содержимое файла показывается, как project пользователя.
Если пользовательский ID не указан, утилита finger отображает сведения о каждом пользователе, который в настоящее время зарегистрирован в системе. Вы можете указать пользователя на отдаленном хосте с ромо-щью @. В этом случае запускается finger-демон удаленного хоста для ответа на локальный finger-запрос.
В представленном ниже примере сначала выводится информация обо всех пользователях системы, а затем собственные сведения:
$ finger ...указать на каждого в системе.
Login Name TTY Idle When Where
posey John Posey pO 2d Fri 16:31 blackfoot.utdall
glass Graham Glass p2 Sun 17:00 bridgeOS.utdalla
$ finger glass ...указать самого себя.
Login name: glass In real life: Graham Glass
Directory: /home/glass Shell: /bin/ksh
On since May 17 17:00:47 on ttyp2 from bridgeOS.utdalla No unread mail
Project: To earn an enjoyable, honest living.
Plan: To work hard and have fun and not notice the difference. $ _
В следующем примере выводятся три источника информации finger о себе:
$ cat .plan ...вывести файл .plan.
То work hard and have fun and not notice any difference.
$ cat .project ...вывести файл .project.
To earn an enjoyable, honest living.
$ grep glass /etc/passwd ...посмотреть файл password, glass:##glass:496:62:Graham Glass:/home/glass:/bin/ksh $ _
В заключительном примере используется утилита rusers для получения листинга удаленных пользователей, а затем запускается удаленная утилита finger, чтобы выяснить все о Сьюзен:
$ rusers ...посмотреть на удаленных пользователей.
csservr4.utd posey vanguard.utd huynh posey datta venky centaur.utda susan
csservr2.utd posey posey leui glass
$ finger susanOcentaur ...выполнить удаленную утилиту finger, [centaur.utdallas.edu]
Login name: susan In real life: Susan Marsh
Directory: /home/susan Shell: /bin/csh
On since May 11 11:00:55 on console 1 day Idle Time
New mail received Fri May 15 19:24:01 1998;
unread since Fri May 15 16:40:28 1998
No Plan. $
Взаимодействие с пользователями
Перечисленные далее утилиты позволяют вам взаимодействовать с пользователем:
□ утилита write предоставляет возможность посылать пользователю отдельную строку за один раз;
□ утилита talk позволяет иметь диалоговый полиэкран для двустороннего разговора;
□ утилита wall помогает посылать сообщение всем пользователям на локальном хосте;
□ утилита mail обеспечивает отправку почтовых сообщений.
Утилита mail была описана в главе 2. Она поддерживает полную стандартную адресную схему Интернета. Другие утилиты описаны далее вместе с простой утилитой mesg, которая позволяет защитить себя от сообщений других пользователей.
Защита от общения: mesg
Утилиты write, talk и wall связываются с другими пользователями путем передачи данных непосредственно на их терминалы. Вы можете блокировать способность других пользователей писать на ваш терминал с помощью УТИЛИТЫ mesg.
Синтаксис
mesg [n | у]
Утилита mesg запрещает другим пользователям писать на ваш терминал. Она работает, изменяя разрешение записи вашего устройства tty. Аргументы п и у соответственно запрещают и разрешают запись. Если аргументы не указаны, выводится ваш текущий статус.
В следующем примере утилита mesg предохраняет от получения сообщения ОТ утилиты write:
$ mesg n ... защитить терминал.
$ write glass ...попытаться использовать write для себя самого.
write: You have write permission turned off
$
Передача строки за один раз: write
write является простой утилитой, которая позволяет посылать одну строку за один раз указанному пользователю.
Синтаксис
write Ю_пользователя [ tty]
Утилита write копирует свой стандартный ввод, одну строку за один раз, на терминал, связанный с ю_пользователя. Если пользователь зарегистрирован на нескольких терминалах, можно определить конкретное устройство tty при помощи дополнительного аргумента tty.
Первая строка ввода, которую вы посылаете пользователю при помощи утилиты write, предваряется сообщением
Message from yourHost!yourld on yourTty
таким образом, чтобы получатель мог инициировать write для взаимодействия с вами. Для выхода из утилиты следует нажать в отдельной строке комбинацию клавиш <Ctrl>+<D>. Можно запретить вывод от write на ваш терминал С ПОМОЩЬЮ утилиты mesg.
В представленном ниже примере получено write-сообщение от другого пользователя, Тима, а затем инициировалась собственная утилита write для передачи ему ответа. Для синхронизации работы использовалось соглашение: -о- (перейти на прием) и -оо- (перейти на прием и отключится):
$
Message from tim@csservr2 on ttyp2 at 18:04
hi Graham -о-$ wri te tim ... от Тима. ...инициировать ответ.
hi Tim —o— ...от меня.
don't forget the movie later -oo- ... от Тима.
OK -oo- ... от меня.
...конец моего ввода.
$ _
Хотя можно вести беседу с помощью утилиты write, это ужасно неудобно. Лучше использовать утилиту talk.
Интерактивные диалоги: talk
Утилита talk позволяет вести беседу через сеть. Это забавная утилита, которая заслуживает проведения исследований с другом.
Синтаксис
talk 10_полъзователя [tty]
Утилита talk позволяет общаться с другим пользователем в сети через многоэкранный интерфейс. Если пользователь зарегистрирован на нескольких терминалах, можно выбрать конкретный терминал, указывая конкретное имя устройства tty.
Чтобы говорить с кем-нибудь, введите с вашего терминала:
$ talk theirUserId@theirHost
Это вызовет появление на экране получателя сообщения:
Message from TalkDaemon@ their Host ...
talk: connection requested by yourUserId@yourHost
talk: respond with: talk yourUserId@yourHost
Если получатель соглашается на ваше приглашение, он напечатает следующее в ответ на приглашение shell:
$ talk yourUserldGyourHost
Далее ваш экран разделится на две части: одна будет отображать вводимый с клавиатуры текст, другая — сообщения собеседника. Все, что вы печатаете, будет отображаться на терминале другой персоны, и наоборот. Для того чтобы повторно вывести экран, если возникнет неполадка, следует нажать комбинацию клавиш <Ctrl>+<L>. Для завершения работы утилиты talk существует комбинация клавиш <Ctrl>+<C>. Чтобы запретить другим пользователям вести с вами диалог, используйте УТИЛИТУ mesg.
Сообщения всем пользователям: wall
Если у вас есть нечто важное сообщить миру (или, по крайней мере, каждому на вашем локальном хосте), утилита wail может вам помочь. Название утилиты wail составлено из слов "write all" — "пишут все". Она позволяет передавать широковещательное сообщение. •
Синтаксис
wall [имяФайла]
Утилита wall копирует СВОЙ стандартный ВВОД (или содержимое имяФайла. если он представлен) на терминал каждого пользователя локального хоста, предваряя ввод сообщением "Broadcast Message..." ("Широковещательное сообщение..."). Если пользователь запретил связь с терминалом утилитой mesg, сообщение не будет получено, исключая привилегированного пользователя wall.
В следующем примере показано, как каждому пользователю на локальном хосте (в том числе, автору сообщения) посылается шутка:
$ wall ...написать всем.
this is a test of the broadcast system
... конец ввода.
Broadcast Message from glass@csservr2 (ttyp2) at 18:04 ...
this is a test of the broadcast system
$ _
Утилита wall чаще всего используется системными администраторами, чтобы послать пользователям важную, своевременную информацию (например, "Система будет выключена через пять минут!").
Распределенные данные
Основополагающий вид дистанционных операций —• это передача файлов, и UNIX имеет для этого несколько утилит:
П утилита гср (удаленное копирование) позволяет копировать файлы между локальным и удаленным UNIX-хостами;
□ утилита ftp (протокол передачи файлов или программа) обеспечивает копирование файлов между локальным UNIX-хостом и любым другим хостом (включая не-UNIX-хост), который поддерживает протокол FTP; таким образом, утилита ftp мощнее утилиты гср;
□ утилита uucp (копирование с UNIX на UNIX) подобна утилите гср и позволяет копировать файлы между любыми двумя UNIX-хостами.
14 Зак. 786
Копирование файлов между двумя UNIX-хостами: гср
Утилита гср позволяет копировать файлы между UNIX-хостами.
Синтаксис
гср -р оригинальныиФайл новыиФайл гср -рг {имяФайла}+каталог
Утилита гср позволяет копировать файлы между UNIX-хостами. И локальный хост, и удаленный хост должны быть зарегистрированы как эквивалентные машины (см. разд. "Безопасность"ранее в этой главе). Чтобы определить удаленный файл на хосте, используйте синтаксис
хост:путь
Если указан относительный путь, он интерпретируется, как путь относительно домашнего каталога пользователя на удаленном хосте.
Опция -р пробует сохранить последнее время модификации, последнее время доступа и флаги разрешения во время копирования. Опция -г заставляет рекурсивно копироваться любой файл каталога.
В приведенном ниже примере файл original.txt скопирован с удаленного хоста vanguard в файл new.txt локального хоста csservr2, а затем скопирован файл original2.txt с локального хоста в файл new2.txt на удаленном хосте:
$ гср vanguard:original.txt new.txt ...удаленный в локальный.
$ гср original2.txt vanguard:new2.txt ...локальный в удаленный.
$ _
Копирование файлов
между He-UNIX-хостами: ftp
Протокол FTP (Протокол передачи файлов) — это общий протокол для передачи файлов, который поддерживается многими машинами. Вы можете использовать для передачи файлов со своего локального UNIX-хоста на удаленный хост любого другого вида, если вы знаете интернет-адрес удаленного FTP-сервера. Пользователи He-UNIX-компьютеров часто запускают утилиту ftp для передачи файлов между UNIX и их собственной системой. В табл. 91.1 представлен список наиболее полезных ftp-команд, которые являются доступными из режима команд этой утилиты.
Синтаксис
ftp -п [имяХоста]
Утилита ftp позволяет управлять файлами и каталогами, как на локальном, так и удаленном хосте. Если указано имя удаленного хоста, утилита ищет файл .netrc, чтобы определить, имеет ли удаленный хост анонимный вход ftp (т. е. вход без пароля). Если имеет, то этот вход используется для регистрации пользователя на удаленном хосте. В противном случае предполагается, что пользователь имеет свою учетную запись на удаленном хосте, и выводится приглашение для ввода пользовательского ID и пароля. Если регистрация в удаленной системе прошла успешно, утилита ftp входит в свой режим команд и показывает приглашение ftp >.
Если имя удаленного хоста не указано, утилита входит в свой командный режим немедленно, и следует использовать команду открытия, чтобы соединиться с удаленным хостом. Опция -п не допускает осуществление начальной автоматической последовательности входа в систему.
Вы можете прервать передачу файла без выхода из утилиты ftp, нажимая комбинацию клавиш <Ctrl>+<C>.
Таблица 9.1. Команды утилиты ftp
Команда Описание
! команда Выполняет команду на локальном хосте
append локальныйФайл удаленныйФа йл Добавляет локальныйФайл к удаленномуФайлу >
bell Вызывает звуковой сигнал после каждой передачи файла
bye Закрывает сеанс текущей удаленной связи с хостом и выходит из ftp
cd удаленныйКаталог Изменяет ваш текущий удаленный рабочий каталог на уда ленныйКа талог
close Закрывает текущую удаленную хост-связь
delete удаленныйФайл Удаляет удаленныйФайл на удаленном хосте
get удаленныйФайл [локальныйФайл] Копирует удаленныйФайл в локальныйФайл. Если локальныйФайл опущен, ему присваивается то же самое имя, что и у удаленного файла
Таблица 9.1 (окончание)
Команда Описание
help [команда] Выводит справку о команде. Если команда опущена, отображается список всех команд утилиты ftp
led локальныйКатало Изменяет ваш текущий локальный рабочий каталог на локальныйКатало
1s удаленныйКаталог Выводит содержимое вашего текущего удаленного рабочего каталога удаленныйКа талог
mkdir удаленныйКаталог Создает удаленныйКа талог на удаленном хосте
open имяХоста [порт] Делает попытку связи с хостом с именем имяХоста. Если пользователь определяет дополнительный номер порта, ftp предполагает, что это порт FTP-сервера
put локальныйФайл [удаленныйФайл] Копирует локальныйФайл в удаленныйФайл. Если удаленныйФайл опущен, ему присваивается то же самое имя, что и у локального файла
pwd Показывает текущий удаленный рабочий каталог пользователя
quit Аналогично bye
rename удаленныйФайл1 удаленныйФайл2 Переименовывает удаленный файл с удаленныйФайл 1 на удаленныйФайл2
rmdi г удаленныйКаталог Удаляет удаленныйКа та лог
В следующем примере копируется файл writer.c с удаленного хоста vanguard на локальный хост, а затем копируется файл who.c с локального хоста на удаленный хост:
$ ftp vanguard ...открыть FTP-соединение с vanguard.
Connected to vanguard.utdallas.edu.
vanguard FTP server (SunOS 5.4) ready.
Name (vanguard:glass): glass ...вход в ситстему
Password required for glass.
«Password: ...секрет!
User glass logged in.
ftp> Is ...получить каталог удаленного хоста.
PORT command successful.
ASCII data connection for /bin/ls (129.110.42.1,4919) (0 bytes).
... ...много файлов было выведено здесь.
uniq upgrade who. с writer.с ASCII Transfer complete.
1469 bytes received in 0.53 seconds (2.7 Kbytes/s)
ftp> get writer.с ...скопировать с удаленного хоста.
PORT command successful.
ASCII data connection for writer.c (129.110.42.1,4920) (1276 bytes).
ASCII Transfer complete.
local: writer.c remote: writer.c
1300 bytes received in 0.012 seconds (le+02 Kbytes/s)
ftp> !ls ...получить каталог локального хоста.
reader.с who.с writer.с
ftp> put who.с ...копировать файл на удаленный хост.
PORT command successful.
ASCII data connection for who.c (129.110.42.1,4922).
ASCII Transfer complete.
ftp> quit ...отключиться.
Goodbye.
$ _
Распределенная обработка
Мощность распределенных систем становится поразительной, когда вы начинаете перемещаться по сети и регистрироваться на различных хостах. Некоторые хосты обеспечивают ограниченные беспарольные учетные записи с пользовательским ID, подобно имени guest. Так что исследователи могут бродить по сети без причинения вреда, хотя эта практика исчезает, поскольку все больше пользователей злоупотребляют данной привилегией. В наши дни пользователь почти всегда должен иметь учетную запись на удаленном компьютере, чтобы войти в сеть.
Существуют три утилиты для распределенного доступа:
□ утилита г login позволяет войти на удаленный хост;
□ утилита rsh предоставляет возможность выполнения команды на удаленном UNIX-хосте;
□ утилита telnet поддерживает выполнение команд на любом удаленном хосте, который имеет Telnet-сервер.
Из перечисленных утилит telnet наиболее гибкая, т. к. есть другие системы в дополнение к UNIX, которые поддерживают Telnet-серверы.
Удаленный вход в систему: rlogin
Чтобы зарегистрироваться на удаленном хосте, используйте утилиту rlogin.
Синтаксис
rlogin -ес [-1 Ю_пользователя] имяХоста
Утилита rlogin пытается зарегистрировать пользователя на удаленном хосте имяХоста. Если не указан 10_пользователя с помощью опции -1, во время входа в систему берется ваш локальный пользовательский ID.
Если удаленный хост не установлен как эквивалент локального хоста в пользовательском файле $HOME/.rhost, появится запрос о пароле на удаленном хосте.
Как только пользователь соединится, его локальный shell приостанавливается, а удаленный shell начинает выполняться. После окончания работы с удаленным входным shell, завершая его нормальным способом (обычно нажатием комбинации клавиш <Ctrl>+<D>), возобновляется локальный shell.
Существует несколько специальных ’’команд перехода", вводимых с клавиатуры и имеющих специальное значение. Каждой предшествует символ перехода, которым по умолчанию является тильда (-). Вы можете заменить этот символ путем указания в опции -е привилегированного символа перехода. Вот список команд перехода:
Последовательность Описание
Отключается немедленно от удаленного хоста
-susp Приостанавливает удаленную входную сессию. Для повторного старта удаленной входной сессии используется команда f g
~dsusp t Приостанавливает ввод половины удаленной входной сессии, но все еще выводит информацию локальной входной сессии на локальный терминал пользователя. Для повторного старта удаленной входной сессии используется команда fg
В представленном ниже примере пользователь регистрируется на удаленном хосте vanguard с собственного локального хоста csservr2, выполняет утилиту date, а затем разъединяется:
$ гlogin vanguard ...удаленный вход.
Last login: Tue May 19 17:23:51 from csservr2.utdallas
vanguards date ...выполнить команду на vanguard.
Wed May 20 18:50:47 CDT 1998
vanguard% AD ...завершить удаленный входной shell.
Connection closed.
$ _ ...вернуться домой на csservr2!
Выполнение удаленных команд: rsh
Если вы хотите выполнить только единственную команду на удаленном хосте, утилита rsh намного удобнее, чем riogin.
Синтаксис
rsh [-1 1р_пользователя] имяХоста [команда]
Утилита rsh пытается создать удаленный shell на хосте имяхста, чтобы выполнить команду. Утилита копирует свой стандартный ввод команде и копирует стандартный вывод и канал ошибок от команды в свои аналогичные каналы. Сигналы прерывания, выхода и завершения отправляются команде, так что пользователь может нажимать комбинацию клавиш <Ctrl>+<C> для удаленной команды, rsh заканчивается сразу же по завершении работы команды. Если Не указан 19_пользователя с помощью опции -1, для связи берется локальный пользовательский ID. Если никакая команда не определена, rsh предоставляет удаленный shell, вызывая утилиту riogin. Метасимволы в кавычках обрабатываются удаленным хостом; все другие — локальным shell.
В следующем примере выполняется утилита hostname как на локальном хосте csservr2, так и на удаленном хосте vanguard:
$ hostname ...выполнить на локальном хосте.
csservr2
$ rsh vanguard hostname ...выполнить на удаленном хосте, vanguard
$
Удаленные соединения: telnet
Утилита telnet позволяет связываться с любым удаленным хостом в Интернете, который имеет Telnet-сервер.
Синтаксис
telnet [хост [порт]]
Утилита .telnet устанавливает двустороннюю связь с отдаленным портом. Если указано имя хоста, но не специфицируется порт, пользователь автоматически связывается с Telnet-сервером на указанном хосте, который обычно позволяет зарегистрироваться на удаленной машине. Даже если не задано имя хоста, telnet переходит непосредственно в командный режим (таким же образом, как и утилита ftp). Что происходит далее и как устанавливается связь, зависит от функциональных возможностей порта, с которым произошла связь. Например, порт 13 из любой интер-нет-машины отправит время дня и затем отключится, тогда как порт 7 вернет (ping) назад введенный с клавиатуры текст. Для того чтобы войти в командный режим после установки связи, следует нажать комбинацию клавиш <Ctrl>+<]>, которая является последовательностью перехода telnet. Это вызывает вывод приглашения командного режима. Допускаются также следующие команды:
Команда Описание
close Закрывает текущее соединение
open хост [порт] Соединяет с хостом с необязательным спецификатором порта
quit Выходит из telnet
z Приостанавливает telnet
? Печатает сводку команд telnet
Чтобы закончить telnet-связь, следует нажать комбинацию клавиш <Ctrl>+<]>, сопровождая ее командой quit.
В представленном ниже примере telnet используется, чтобы эмулировать функциональные возможности утилиты riogin, опуская явный номер порта в команде open:
$ telnet ...стартовать telnet.
telnet> ? ...получить help.
Commands may be abbreviated. Commands are:
close close current connection
display display operating parameters
mode try to enter line-by-line or character-at-a-time mode
open connect to a site
quit exit telnet
send transmit special characters (’send ?’ for more)
set set operating parameters (’set ?’ for more)
status print status information
toggle toggle operating parameters (’toggle ?’ for more)
z suspend telnet
? print help information
telnet> open vanguard ...получить входной shell на vanguard.
Trying 129.110.43.128...
Connected to vanguard.utdallas.edu.
Escape character is ,Л]’.
SunOS 5.4 (vanguard)
login: glass ...ввод пользовательского ID.
Password: ...секрет!
Last login: Tue May 19 17:22:45 from csservr2.utdalla
*** For assistance, send mail to UNIXINFO.
Tue May 19 17:23:21 CDT 1998
Erase is Backspace
vanguard% date ...выполнить команду.
Tue May 19 17:23:24 CDT 1998
vanguard% ...отключиться от удаленного хоста.
Connection closed by foreign host.
$ _ ...утилита telnet завершилась.
Если хотите, можете определить имя хоста непосредственно в командной строке, следующим образом:
$ telnet vanguard ...спецификация имени хоста в командной строке.
Trying 129.110.43.128...
Connected to vanguard.utdallas.edu.
Escape character is ,Л]’.
SunOS 5.4 (vanguard)
login: glass ...ввод пользовательского ID и т. д.
Вы можете использовать утилиту telnet, чтобы испытать некоторые из стандартных услуг портов, которые описаны ранее в этой главе. Например, порт 13 печатает день и время на удаленном хосте, а затем немедленно отключается:
$ telnet vanguard 13 ...какое время и день на удаленном хосте?
Trying 129.110.43.128 ...
Connected to vanguard.utdallas.edu.'
Escape character is ,A]’.
Tue May 19 17:26:32 1998
Connection closed by foreign host ...telnet-связь завершилась.
$ _
Аналогично, порт 79 позволяет ввести имя удаленного пользователя и получать информацию ОТ утилиты finger:
$ telnet vanguard 79 ...вручную выполнить удаленную утилиту finger.
Trying 129.110.43.128 ...
Connected to vanguard.utdallas.edu.
Escape character is ,Л]’.
glass ...ввод пользовательского ID.
Login name: glass In real life: Graham Glass
Directory: /home/glass Shell: /bin/csh
Last login Tue May 19 17:23 on from csservr2.utdalla
No unread mail
No Plan.
Connection closed by foreign host. ... telnet-связь завершилась.
$ _
Когда системные администраторы проверяют сеть, они часто используют порт 7 для проверки связи хоста. Порт 7 возвращает назад на пользовательский терминал все, что пользователь напечатает, и иногда известен как ping-порт. Вот пример:
$ telnet vanguard 7 ...проверить ping.
Trying 129.110.43.128 ...
Connected to vanguard.utdallas.edu.
Escape character is ’Л]’.
hi ...моя строка.
hi ... эхо.
there
there
л] . . .переключиться в командный режим.
telnet> quit ...завершить соединение.
Connection closed.
$ _
Утилита telnet принимает числовые интернет-адреса так же, как символические имена. Например: $ telnet 129.110.43,128 7 ...числовой адрес vanguard.
Trying 129.110.43.128...
Connected to 129.110.43.128.
Escape character is ,Л]’.
hi ...моя строка.
hi ... эхо.
*] ...переключиться в командный режим.
telnet> quit ...отключиться. Connection closed. $
Сетевая файловая система: NFS
В порядке выработки хорошего использования сетевых возможностей UNIX, Sun Microsystems представила свободно копируемую спецификацию для сетевой файловой системы (Network File System, NFS). NFS поддерживает перечисленные ниже полезные возможности.
□ Позволяет нескольким локальным файловым системам быть смонтированными в отдельную сетевую файловую иерархию, к которой можно открыто обращаться с любого хоста. Чтобы поддержать эту способность, NFS включает удаленную возможность монтировки.
П Удаленный вызов процедуры (Remote Procedure Call, RPC) используется NFS, чтобы позволить одной машине делать вызов процедуры на другой машине, таким образом обеспечивая распределенные вычисления.
□ NFS поддерживает нейтральную по отношению к хосту схему внешнего представления данных (external data representation, XDR), которая позволяет программистам создавать структуры данных, которые могут быть разделены хостами с различным порядком байтов и длиной слова.
NFS очень популярна и используется на большинстве компьютеров, где работает UNIX. (См. [Nemeth 2000] для дополнительной информации о NFS.)
Для дополнительной информации
Если вы насладились представленным кратким обзором организации сети UNIX и желаете узнать больше, то [Stevens 1998], [Anderson 1995] и раздел о сети в [Nemeth 2000] являются превосходными источниками.
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
□ основные сетевые концепции и терминологию UNIX;
□ утилиты просмотра пользователей и взаимодействия с ними;
□ утилиты для манипулирования удаленными файлами;
□ утилиты для получения удаленного входного shell и выполнения удаленных команд.
Контрольные вопросы
1. В чем заключается различие между мостом, маршрутизатором и шлюзом?
2. В чем заключается способ для системного администратора сообщать пользователям о важных событиях?
3. Почему утилита ftp более мощная, чем утилита гср?
4. Опишите некоторые варианты использования общих портов.
5. Что означает эквивалентность машин и как вы можете ее использовать?
Упражнения
9.1. Испытайте утилиты гср и rsh следующим образом:
• скопируйте отдельный файл с вашего локального хоста на удаленный хост, используя гср;
• запустив rsh, получите shell на удаленном хосте и отредактируйте файл, который вы только что скопировали;
• покиньте удаленный shell с помощью команды exit;
• используя гср, скопируйте файл с удаленного хоста обратно на локальный хост.
[Уровень: легкий.]
9.2. Используйте утилиту telnet, чтобы получить время дня на нескольких удаленных хост-узлах. Действительно ли их время точное относительно друг друга? [Уровень: средний.]
Проект
Напишите shell-скрипт, который работает в фоновом режиме на двух машинах и гарантирует, что содержимое указанного каталога на одной машине всегда является зеркальным отображением каталога на другой машине. [Уровень: высокий.]
Глава 10
Интернет
Мотивация
Пожалуй, Интернет — наиболее популярное применение вычислительной техники. Возникнув как сетевой инструмент для соединения пользователей в университетских и правительственных учреждениях, он превратился в огромное самостоятельное образование, используемое миллионами людей во всем мире. Даже самый компьютерно-неграмотный человек в Соединенных Штатах, по крайней мере, слышал об Интернете. В большой степени привлекательность наличия домашнего компьютера в настоящее время определяется возможностью иметь доступ к информации в Интернете. В данной главе вы узнаете, что собой представляет Интернет, и что пользователь может с ним делать.
Предпосылки
Можно не разбираться в тонкостях механизма работы протокола IP (см. главу 9), чтобы с пользой прочитать данную главу. Но чем лучше вы знакомы с организацией сети UNIX, тем полезнее окажется для вас эта глава.
Задачи
Познакомившись с главой, вы лучше станете понимать сущность Интернета, историю его возникновения, принцип работы -и назначение.
Изложение
Для настоящего изучения любой темы необходимо знать исторические факты. Сначала мы опишем возникновение Интернета и сегодняшнее его состояние, учитывая его неблагоприятное начало. После обзора инструментов, используемых для доступа к информации в Интернете, рассмотрим перспективы, которые могут ожидать пользователей глобальной сети.
Эволюция Интернета
Эволюция началась с увеличением локальных сетей, которые мы рассмотрели в главе 9. Сначала некоторые компании связали свои собственные LAN через индивидуальные соединения. Другие передавали данные через сеть, реализованную на базе общедоступной телефонной сети. В конечном счете, сетевые исследования, финансируемые американским правительством, объединили все вместе.
Пусть кажется невероятным, но можно сделать вывод, что Интернет был почти неизбежен. Хоть прототип Интернета и возник в "компьютерной лаборатории", и в то время большинство думало, что лишь активные компьютерные ученые будут когда-нибудь использовать его, способ хранения и применения информации почти продиктовал, что будет найден лучший способ передачи информации из одного места в другое.
Сейчас, когда я смотрю телевизор и вижу адреса страниц сети в конце видеорекламы для широко распространенных продуктов, знаю, что Интернет действительно достиг широкого применения. Мало того, что высокотехнологичные корпорации поддерживают страницы сети, но даже зерновые компании имеют узлы во всемирной сети. Можно спорить о полноценности некоторых из этих узлов, но факт их существования свидетельствует, что общество восприняло новую технологию.
Наверняка у вас возник вопрос: как мы добились этого и куда можно двигаться дальше?
В начале:1960-е
В 1960-х люди побывали на Луне, общество прошло через потрясения на нескольких фронтах, а технология изменялась быстрее, чем когда-либо прежде. Агентство Исследований Министерства обороны США Advanced Research Projects Agency (ARPA) пыталось разработать компьютерную сеть, чтобы соединить вместе правительственные компьютеры (и компьютеры некоторых правительственных подрядчиков). Как и во многих достижениях в нашем обществе, инициатива (и часть финансирования) поступила от правительства, которое надеялось усилить поступательное движение в военных или оборонных целях. Быстродействующая связь данных могла бы потребоваться, чтобы помочь в некоторый момент выиграть войну.. Кстати, причины возникновения существующей американской системы дорог между штатами (другой вид сети) почти аналогичны.
В 1960-х ЭВМ в основном использовались для вычислений, и будут еще доминировать в течение некоторого времени. Сменные диски, маленькие ленты и технология компактных дискет были еще в будущем. Перемещение данных с одного большого компьютера на другой обычно требовало записи
данных на относительно большое ленточное устройство или на некоторый большой диск, физического переноса этого носителя на другой большой компьютер и загрузки данных на этот компьютер. Хотя такая процедура была обычной, конечно, все-таки оказывалась чрезвычайно неудобной.
Сетевая связь
В то время организация компьютерной сети была все еще в младенчестве, локальные сети также существовали, но были прообразом Интернета. В течение 1968 и 1969 годов ARPA экспериментировало с соединениями между несколькими правительственными компьютерами. Основной архитектурой был 50-килбайтный выделенный телефонный канал, связанный с каждой стороны с машиной, называемой Interface Message Processor (IMP). Концептуально это мало чем отличается от вашей личной интернет-связи сегодня, если предположить, что модем пользователя выполняет работу IMP (Конечно, IMP была по сравнению с модемом гораздо более сложным устройством.) На каждой стороне IMP затем соединялась с компьютером или компьютерами, которые нуждались в доступе к сети.
ARPANET
Сеть ARPANET появилась в сентябре 1969 года, когда первые четыре IMP были установлены в Южно-калифорнийском университете (University of Southern California), Стэнфордском исследовательском институте (Stanford Research Institute), Калифорнийском университете в Санта-Барбаре (University of California at Santa Barbara) и Университете Юты (University of Utah). Перечисленные узлы имели существенное число ARPA-контрагентов. Успех первых экспериментов на этих четырех узлах вызвал большой интерес со стороны ARPA, так же как и в академическом сообществе. Вычисления никогда больше не станут такими, какими были тогда.
Стандартизация Интернета: 1970-е
Проблема с первыми соединениями в ARPANET состояла в том, что каждая IMP была до некоторой степени сделанной на заказ для каждого узла в зависимости от операционных систем и сетевой конфигурации других компьютеров. Много времени и усилий было израсходовано, чтобы получить сеть из четырех узлов. Сотни узлов требовали бы в сотню раз больше времени и очень много заказной работы, если бы это пришлось делать тем же самым способом.
Стало ясно, что если все компьютеры связать в сеть таким же образом и использовать одинаковые протоколы, они могли бы соединиться друг с другом более эффективно и с гораздо меньшими усилиями в каждом узле. Но в то время различные компьютерные продавцы снабжали собственные операци
онные системы собственной аппаратурой и были лишь в начале пути стандартизации, которая облегчает взаимодействие. Требовался набор стандартов, которые могли быть реализованы в программном обеспечении на различных системах, чтобы существовала возможность разделения данных в форме, понятной различным компьютерам.
Несмотря на то, что возникновение стандартных сетевых протоколов началось в 1970-х, реализоваться они смогли не раньше 1983 года, когда все члены ARPANET стали использовать исключительно их.
Семейство протокола IP
В начале 1970-х исследователи начали проектировать протокол IP. Слово "интернет" использовалось в более общем смысле, чем ARPANET, которое означало конкретную сеть. Слово "интернет" указывало на общую организацию сети компьютеров, чтобы позволить им взаимодействовать.
Протокол IP (Internet Protocol, Протокол Интернета) — фундаментальный программный механизм, который перемещает данные из одного места в другое через сеть. Данные, которые должны быть переданы, разделяются на пакеты, которые являются основными элементами данных, используемыми в цифровой компьютерной сети. IP не гарантирует, что любой отдельный пакет достигнет другого конца или порядок прибытия пакетов окажется последовательным. Но он гарантирует неизменность прибывшего пакета по сравнению с исходным пакетом в источнике. Эта особенность может показаться сначала не очень полезной, но подождите немного.
TCP/IP
Раз можно передать пакет на другой компьютер и известно, что прибывший пакет будет верным, то другие протоколы могут быть добавлены "сверху" основного протокола IP для обеспечения большего количества функциональных возможностей. Протокол TCP (Transmission Control Protocol, Протокол управления передачей) чаще всего используется с IP. (Вместе они упоминаются, как TCP/IP.) Как подразумевает имя, TCP управляет фактической передачей потока пакетов данных. Протокол добавляет информацию последовательности и подтверждения к каждому пакету, и стороны ТСР-"беседы" сотрудничают для выяснения, что полученный поток данных восстановлен в том же самом порядке, как в оригинале. Когда отдельный пакет будет не в состоянии достичь другого конца из-за некоторых неполадок в сети, получающая TCP-программа узнает это, поскольку порядковый номер пакета отсутствует. Программа может контактировать с отправителем и сделать так, чтобы он снова послал пакет. С другой стороны, отправитель, не имея квитанции подтверждения о получении рассматриваемого пакета, будет в конечном счете повторно передавать пакет, предполагая, что тот не
был получен. Если пакет был получен, а потерялось только подтверждение, TCP-программа при получении второй копии пропустит ее, т. к. первая уже достигла цели. Приемник будет все же посылать подтверждение, которое ожидает посылающая ТСР-программа.
TCP — это протокол, ориентированный на связь. Прикладная программа открывает TCP-связь с другой программой на другом компьютере, и оба компьютера пересылают данные друг другу. Когда они заканчивают свою работу, то закрывают сеанс связи. Если один конец (или поломка сети) неожиданно закрывает сеанс, это на другом конце рассматривается, как ошибка.
UDP/IP
Другой полезный протокол, который сотрудничает с IP, — это UDP (User Datagram Protocol, Пользовательский дейтаграммный протокол), иногда полунежно называемый Ненадежным (Unreliable) дейтаграммным протоколом. UDP реализует низкоуровневый сигнальный метод для поставки коротких сообщений по IP, но не гарантирует их прибытие. В некоторых случаях приложение должно послать информацию о статусе другому приложению (например, агент управления, посылающий информацию о статусе в сеть или приложению управления системами), но информация не является критически важной. Если она не прибывает, или будет послана снова позже, или в ней нет необходимости, то данные должны быть получены приложением. Конечно, такой подход предполагает, что любой отказ происходит из-за некоторого переходного состояния и метод "следующий раз" будет работать. Если он терпит неудачу все время, подразумевается, что существует проблема сети, которая не может стать явной.
В подобном случае служебные протокольные сигналы требуют открыть и поддержать TCP-связь. Это, правда, больше, чем действительно необходимо. Ведь вы хотите всего лишь послать короткое сообщение о статусе. В действительности вас не заботит, получит ли его компьютер на другом конце (т. к. если он это не сделает, то, вероятно, получит следующее сообщение), и вы, конечно, не хотите ждать подтверждение о получении. Так что "ненадежный протокол" точно соответствует названию.
Интернет-адресация
Когда организация монтирует LAN, которая должна быть частью Интернета, она запрашивает уникальный интернет-адрес в Центре Информации Сети (Network Information Center, NIC). Число, которое назначается, зависит от размера организации.
□ Огромной организации или стране назначается адрес класса А — число, которое является первыми 8 битами из 32-битового IP-адреса. Организация свободна использовать остающиеся 24 бита, чтобы обозначать свои
локальные хосты. NIC редко выдает адреса класса А, т. к. каждое число расходует полное 32-битовое пространство.
□ Организации среднего размера назначается адрес класса В — число, которое является первыми 16 битами 32-битового IP-адреса. Организация может тогда использовать оставшиеся 16 битов, чтобы обозначать свои локальные хосты.
□ Маленьким организациям назначается адрес класса С, который является первыми 24 битами 32-битового IP-адреса.
Например, Техасский университет в Далласе (University of Texas at Dallas) классифицируется, как организация среднего размера, и ее LAN был назначен 16-битовый номер 33 134. IP-адреса записываются как серия четырех 8-битовых чисел. Старший байт указывается в начале этой серии. Все компьютеры LAN Техасского университета в Далласе поэтому имеют IP-адрес вида 129.110. XXX.YYY1, где XXX и YYY - числа между 0 и 255.
Интернет-приложения
Раз существовало семейство протоколов, которое позволяло легкую передачу данных удаленному хосту сети, следующий шаг должен был обеспечить поддержку прикладных программ, которые воспользовались бы преимуществом этих протоколов. Первыми приложениями, работающими с TCP/IP, были две программы, которые раньше TCP/IP возникли для ARPANET: telnet и ftp (см. главу 9).
Программа telnet служила (до сих пор) для соединения с другим компьютером в сети, чтобы пользователь мог войти и работать с удаленным компьютером со своего локального компьютера или терминала. Эта особенность была весьма полезной во времена дорогостоящих вычислительных ресурсов. Организация могла и не иметь собственный суперкомпьютер, но пользователи получали к нему доступ с другого узла, telnet позволяет входить в систему удаленно без необходимости физически приближаться к другому узлу.
Программа ftp использовалась для передачи файлов между узлами. Несмотря на то, что ftp все еще доступен сегодня, большинство пользователей для этой цели применяют сетевые браузеры или сетевые файловые системы.
Изменение архитектуры
и переименование Интернета: 1980-е
Пока университеты и правительственные агентства использовали ARPANET, распространилось известие о пользе сети. Вскоре к ней подклю
1 129 х 256 + ПО = 33 134.
чились и корпорации. Сначала из-за правительственного финансирования корпорация обязана была заключать некоторый правительственный контракт, чтобы получить право доступа к сети. Через некоторое время это требование стало выполняться все реже и реже.
С ростом сети появились проблемы. Как и с локальной сетью, чем меньше любая сеть и количество связанных узлов, тем легче ее администрировать. С ростом сети увеличивается сложность управления ею. Стало ясно, что рост ARPANET скоро опередит способность Отдела защиты (Defense Department) управлять сетью.
Степень прибавления новых хостов теперь требовала ежедневных модификации в таблице хостов сети. Кроме того, каждый узел ARPANET должен был загружать новые таблицы хостов каждый день, если он хотел иметь современные таблицы. С другой стороны, число доступных имен хостов истощалось, т. к. каждое имя должно было быть уникальным во всей сети.
Служба доменных имен
Появилась служба доменных имен (Domain Name Service, DNS). Вместе с Berkeley Internet Name Daemon (BIND), служба DNS предложила иерархию обозначения доменов хостов сети и метод для поддержки требуемой адресной информацией любого пользователя в сети.
В новой системе были установлены имена домена верхнего уровня, под которым каждый участок сети мог устанавливать подчиненные домены. Министерство обороны (Department of Defense, DOD) управляло бы доменами верхнего уровня и делегировало управление каждым подчиненным доменом подразделению или организации, которая зарегистрировала домен. Программы DNS/BIND обеспечили метод поиска сетевой адресной информации конкретного хоста для любого участка сети.
Давайте посмотрим на реальном примере, как имя хоста превращается в адрес. Один из наиболее популярных доменов верхнего уровня — это сот, так что мы будем использовать его в нашем примере, поскольку большинство знакомо с ним. DOD поддерживает сервер для домена сот. Все подобласти, зарегистрированные в com-домене, были "известны" серверу DOD. Когда некоторый хост сети нуждался в адресе для имени хоста под сот-доменом, он запрашивал сервер имен сот.
Если бы вы попытались связаться с snoopy.hp.com, ваш компьютер не знал бы IP-адрес, потому что нет никакой информации в вашей локальной таблице хоста для snoopy.hp.com. Ваш компьютер вошел бы в контакт с сервером доменных имен для сот-домена, чтобы выяснить адрес у него. Этот сервер, однако, "знает" только адрес сервера имен hp.com; нет необходимости знать все в домене. Так как hp.com зарегистрирован в сервере имен сот,
он (сервер сот) может запросить hp.com-сервер имен для получения адреса2. Как только входят в контакт с сервером имен, который имеет полномочия для домена hp.com, адрес для snoopy.hp.com (или сообщение, что хоста не существует) возвращается инициатору запроса.
До того момента каждое имя хоста в ARPANET было только именем, подобно utexas для хоста ARPANET в Техасском университете. При новой системе эта машина была бы переименована, чтобы стать членом домена utexas.edu. Однако такое изменение не могло быть сделано всюду и быстро. Поэтому какое-то время был установлен домен по умолчанию .агра. По умолчанию все хосты стали известны под этим доменом (следовательно, utexas изменил свое имя на utexas.arpa). Как только был сделан этот шаг, узлу стало проще войти в сообщество своего "реального” домена, поскольку большинство вовлеченных программ 'понимали" систему доменных имен.
Как только сообщество ARPANET приняло эту систему, все виды проблем были решены. Имя хоста должно было быть уникально только в пределах подчиненного домена. Таким образом, если HP имел машину snoopy, то это еще не означало, что никто в Техасском университете уже не мог использовать данное имя, поскольку snoopy.hp.com и snoopy.utexas.edu были различными именами. Еще не было проблемы, пока с сетью были связаны только большие компьютеры, но быстро приближалась эра взрывного роста рабочих станций. Другое преимущество состояло в том, что больше не было нужды поддерживать и обновлять каждый день отдельную охватывающую всю сеть таблицу хоста. Каждый узел хранил его собственные актуальные локальные таблицы хостов и просто запрашивал сервер имен, когда был необходим адрес хоста на другом участке. Путем запроса сервера имен гарантировалось получение наиболее актуальной информации.
Домены верхнего уровня, с которыми чаше всего приходится сталкиваться пользователям, перечислены в табл. 10.1.
Таблица 10.1. Общие имена областей верхнего уровня
Имя Категория
biz Деловая
сот Коммерческая
2 В протоколах доступны две опции. Первая, когда запрашивающая машина переад-ресуется к ’’наиболее осведомленному" хосту и может делать последующие запросы, пока не получит информацию, которая ей необходима. Другая состоит в том, что исходная машина может сделать единственный запрос, и каждая следующая машина, не имеющая адреса, может делать очередной запрос к наиболее осведомленному хосту от имени первоначального хоста. Это опция конфигурации решающего программного обеспечения домена, и не имеет значения, сколько запросов сделано или какова эффективность запросов.
Таблица 10.1 (окончание)
Имя Категория
edu Образовательная
gov mil Правительственная Военная
net Поставщик сетевых услуг
org Некоммерческая организация
XX Две буквы кода страны
Например, LAN в Техасском университете в Далласе было назначено имя utdallas.edu. Поскольку организация получила свой уникальный IP-адрес и имя домена, она может использовать остальную часть IP-номера, чтобы назначать адреса другим хостам в LAN.
Вы можете увидеть, какие адреса ваш локальный DNS-сервер возвращает для конкретных имен хостов по вызову утилиты nsiookup, имеющейся в большинстве UNIX-систем. Утилита наиболее полезна для получения адресов компьютеров в вашей собственной сети. Компьютеры в Интернете часто защищены программами межсетевой защиты (брандмауэрами, firewalls), так что полученный адрес не может использоваться непосредственно.
Синтаксис
nsiookup [имяХоста или адрес]
Утилита nsiookup контактирует с локальной службой имен (Name Serv-icce) и запрашивает IP-адрес для данного имени хоста. Некоторые версии также позволяют осуществлять обратный поиск, в котором задается IP-адрес, а пользователь получает имя хоста для него. Если nsiookup запускается без аргументов, происходит вход в диалоговую сессию, в которой можно посылать многократные команды. (Для выхода применяется комбинация клавиш <Ctrl>+<D>.)
Однако nsiookup хороша для выяснения, допустимы ли в пределах домена имена доменов или Web-серверы (компьютеры, которые могли бы находиться вне брандмауэров для общего доступа). Вы могли бы увидеть следующий тип вывода от nsiookup:
$ nsiookup www.hp.com
Server: localhost
Address: 127.0.0.1
Non-authoritative answer:
Name: www.hp.com
Addresses: 192.151.52.217,. 192.151.52.187, 192.151.53.86, 192.6.118.97, 192.6.118.128, 192.6.234.8
$ nslookup www.linux.org
Server: localhost
Address: 127.0.0.1
Non-authoritative answer:
Name: www.linux.org
Address: 198.182.196.56 $_
Сначала nsiookup сообщает имя и IP-адрес DNS-сервера, используемого для запроса. В этом случае компьютер, на котором выполняется утилита, также запускает bind. После этого нам предоставляется текущий IP-адрес для имени хоста, который и запрашивался. Если имя хоста не существует или DNS-сервер не может (или не хочет) предоставить адрес, появится что-то вроде этого: $ nsiookup
Server: localhost
Address: 127.0.0.1
> xyzzy
Server: localhost
Address: 127.0.0.1
*** localhost can’t find xyzzy: Non-existent host/domain
> AD $ _
Дальнейшее развитие
Подобно родителю, чей ребенок вырос и нуждается в независимости, Министерство обороны (Department of Defense, DOD) США "уяснило, что его ребенок, ARPANET, должен уйти из дома и быть предоставлен самому себе". Министерство обороны инициировало сеть, как научно-исследовательскую работу для доказательства своей концепции. Сеть стала полезной, так что Министерство продолжило работать над ней и управлять ею. Но по
скольку количество членов сети росло, управление ею забирало все большие ресурсы и приносило меньше и меньше дохода, поскольку к сети подключалось все большее число клиентов, не связанных с DOD. Для Министерства обороны настало время покинуть бизнес управления сетью.
В конце 1980-х годов Национальный научный фонд (National Science Foundation, NSF) начал создавать сеть NSFNET. Взяв за основу принцип крупномасштабной организации сети, в то время уникальной и конструируемой, как "магистральная” сеть, к которой могли подключаться другие региональные сети. NSFNET была первоначально предназначена для связи суперкомпьютерных центров.
Используя те же самые типы оборудования и протоколы, которые формировали ARPANET, NSFNET обеспечила альтернативную среду с более свободным и легким доступом, чем управляемая государством ARPANET. Большинству людей, кроме вовлеченных программистов и менеджеров, кажется, что ARPANET сегодня мутировала в Интернет. В действительности были созданы подключения к NSFNET (и его региональной сети), а связи ARPANET разорваны. Но из-за разделения соглашений о наименовании и внешнего вида изменение было гораздо менее очевидно для случайного пользователя.
Результатом оказалась сеть, которая работала (с точки зрения пользователя) так же, как ARPANET, но она была собрана из намного большего количества корпораций и неправительственных агентств. Очень важно, что эта новая сеть не снабжалась правительственными деньгами, а скорее выживала на частном финансировании от своего использования.
Web: 1990-е
В 1990-х Интернет вошел во всеобщий обиход. Хотя, соответственно, он вырос, но это был все еще мир, преимущественно принадлежащий компьютерным пользователям и программистам. Нужно было произойти двум событиям, чтобы Интернет появился для ничего не подозревающей публики: продолжающееся быстрое увеличение количества домашних персональных компьютеров (ПК) и одна удивительно хорошая идея.
“Убийственное приложение"
Опять выбор времени сыграл роль в истории Интернета. Сама сеть росла и использовалась миллионами людей, но все еще не воспринималась широко распространенной. Более искушенные пользователи домашних ПК соединялись с Интернетом через подключение к сети их работодателя или присоединялись к компании, которая обеспечивала доступ в Интернет. Эти компании стали называться поставщиками услуг Интернета (Internet Service Provider, ISP). В начале 1990-х годов существовала только горстка этих по
ставщиков, т. к. лишь немногие признавали, что предоставление доступа к Интернету любому желающему было коммерческим предприятием.
Затем появился Mosaic. Это был первый браузер, задуманный проектировщиками программного обеспечения в Национальном центре разработки приложений для супер-ЭВМ (National Center for Supercomputing Applications, NCSA) в Иллинойском университете в Урбана-Чэмпинг (University of Illinois at Urbana-Champaing). C Mosaic пользователь мог получить доступ к информации на других участках Интернета без необходимости использования сложных и неинтуитивных инструментов, которые были популярны в то время (например, telnet, ftp).
Браузер Mosaic был (как и вообще все браузеры) приложением, показывающим страницу данных как в текстовом, так и в графическом виде. Он демонстрировал информацию, описанную языком гипертекстовой разметки документа (HyperText Markup Language, HTML). Наиболее революционным аспектом HTML стала гиперсвязь. Это способ связать информацию в одном месте документа с информацией в другой части документа (или вообще в другом документе).
Разрабатывая страницу в HTML, можно было показывать информацию и добавлять ссылки на другие части страницы или страницы на других участках, которые содержали родственную информацию. Этот подход создавал документ, по которому можно было "осуществить навигацию", чтобы позволить пользователям получать конкретную информацию без необходимости читать или искать документ последовательно, как это было принято в то время.
Почти сразу серверы осуществляли "прыжки" по Интернету и предоставляли информацию, которая могла быть представлена в Mosaic. Теперь вместо поддержки анонимного FTP-узла узел мог выдавать свою общедоступную информацию в гораздо более презентабельном формате. Анонимные FTP-участки обычно требовали, чтобы обращающиеся к ним пользователи знали, что хотят найти или, в лучшем случае, получали README-файл, который помогал им отыскать желаемое. Взаимодействуя с сервером, который предоставлял HTML, пользователи могли просто наводить указатель, щелкать мышью и выбирать страницу, содержащую искомую информацию.
Конечно, описанное "волшебство" произошло не автоматически: на каждом узле, который поддерживал произвольную информацию для внешних пользователей, необходимо было установить сервер и форматировать информацию. Но это не требовало значительно большей работы, чем предоставление информации через анонимный FTP. Вначале, поскольку люди переключались с предоставления информации через FTP-инструменты на использование Web-инструментов, обе альтернативы были сопоставимы в терминах требующихся усилий, для того чтобы сделать доступными данные. Ввиду
того, что узлы стали более сложными, выполняемой работы прибавилось, но выигрыш от представления также увеличился.
Некоторые разработчики, вовлеченные в создание ранних версий Mosaic, позже сформировали компанию Netscape Communications, Inc., где они использовали опыт, накопленный во время предыдущей разработки браузера, и создали Netscape — следующее поколение браузеров. С тех пор браузеры во главе с Netscape и Microsoft Internet Explorer стали изощренными приложениями, которые каждый год открывают новые возможности как просматривающему, так и публикующему.
Web против Интернета
Смысл слова "Web" различен для людей в разных контекстах и вызывает так много путаницы. Перед Mosaic и другими браузерами был только Интернет — просто всемирная сеть компьютеров. Она сама по себе может быть изображена схематически как паутина (web) связей сети.
Когда Mosaic, используя HTML, обеспечивал возможность перепрыгивать из одного места Интернета в другое, возникла иная концептуальная "сеть" — "Web". Мало того, что мой компьютер связан с несколькими другими, формирующими сеть (Web), но теперь мой HTML-документ также связан с несколькими другими (через гиперсвязи), создавая виртуальную паутинную сеть информации. Эта паутина (web) подарила термины "Web-страница" и "Web-просмотр" (Web browsing).
Когда кто-то говорит сегодня о Web, они обычно подразумевают непосредственно Интернет. С другой стороны (особенно, когда термин представлен строчными буквами), они могут подразумевать сеть информации, доступной в Интернете. Хотя первоначально этот способ не имелся в виду, термины "Web" и "Интернет" в настоящее время часто используются как взаимозаменяемые. Однако изначально написание "web" строчными буквами относится к информации, которая доступа в инфраструктуре Интернета.
Достижимость
Несколько ISP возникли в то время, когда Web лишь появлялся. Как только концепция Web получила ясное представление, оказалось, что, возможно, каждый захочет войти в Интернет. В то время, как электронная почта была и остается одной из наиболее известных услуг, предоставляемых доступом к Интернету, Web-просмотр стал более "визуальным", что привлекло к нему широкую публику.
Неожиданно обычный пользователь обнаружил пользу (или, по крайней мере, забаву) от подключения к Интернету; в основном это не были компьютерные идиоты. Что бы там ни было, Интернет изменялся быстро. Больше людей, больше информации и больший спрос заставили Интернет расцве
тать в применении и доступности. Конечно, с увеличением количества пользователей появляются более неопытные люди, и чаще возникает перегрузка сети; популярность — это всегда палка о двух концах.
Другим фактором, позволяющим обычной публике иметь доступ к Интернету, было геометрическое увеличение скоростей модема. В то время как крупные компании имеют прямое подключение к Интернету, большинство индивидуальных соединений — это коммутируемые связи по домашним телефонным линиям, требующим модемов. Когда высшая скорость модема стала 2400 байт/с (bps), которая была еще совсем недавно предельной, загрузка Web-страницы выполнялась невыносимо медленно. Поскольку скорости модема увеличились до 100 Кбайт/с, и быстродействующие цифровые линии стали экономичными для домашнего использования, оказалось гораздо рациональнее иметь больше одного терминала, используя коммутируемую связь.
В среднем плата за индивидуальные соединения составляет от $10 до $60 в месяц, в зависимости от скорости передачи данных и использования служб. Счет за интернет-обслуживание, которое является сопоставимым со счетом кабельного телевидения или телефонным счетом, является приемлемым; обычная публика, вероятно, не принимала бы счет, который был бы на порядок выше других счетов.
Изменения в Интернете
По мере того как общественность играла все большую и большую роль в развитии Интернета, часть первоначального духа сети изменилась. Интернет изначально был разработан “только чтобы доказать, что это могло быть сделано", а не как объект создания прибыли. Предполагалось, особенно в дни ARPANET, что информация и программное обеспечение должны быть свободно доступными. Многое из раннего кода, который управлял Интернетом (комплект IP-протокола и инструментарий типа ftp и telnet), было отдано его авторами, изменено сторонними разработчиками и возвращено назад для "большей пользы". Это было необходимо для роста и процветания Интернета. Однако сегодня бизнес присутствует и в Интернете, и немало информации доступно за дополнительную плату. Нельзя сказать, что все зарабатывают деньги или это плохо. Но такой поворот принес существенное изменение в культуру Интернета.
Интернет нуждался "в свободном духе" истоков, которые он когда-то имел. Но теперь общество в основном использует ресурсы сети, и естественно, что Интернет изменяется в соответствии с увеличивающимся влиянием на него экономики. Размещение рекламы в сети стало обычным делом. К тому же некоторые узлы предлагают пользователям подписаться на конкретные ресурсы (за дополнительную плату), чтобы иметь возможность подключения и
получения информации. Торговля через Интернет3 (например, заказ товаров и услуг, включая диалоговую информацию), как ожидается, продолжит бурно развиваться и в будущем.
Безопасность
Существует масса книг по безопасности Интернета (например, [Cheswick 1994]). Поскольку в Интернете существует коммерческая деятельность, в будущем потребность в безопасности и опасения по поводу безопасности действий станут только увеличиваться.
Вообще, отдельная передача данных предусматривает обеспечение собственной безопасности. Другими словами, если вы делаете закупку, продавец, вероятно, будет использовать безопасные протоколы, чтобы получить подходящую информацию от вас (например, номер кредитной карточки).
Существуют четыре главных рискованных действия при использовании Web-сервера: копирование информации, модификация информации, заимствование прав и отказ от обслуживания. Услуги шифрования могут предотвращать копирование или изменение информации. Пользовательская осведомленность может помочь минимизировать заимствование прав.
Наиболее "страшное" для пользователей рискованное действие (и, кстати, реже всего с ним возникают проблемы) — это копирование информации, которая путешествует через сеть. Интернет — общественная сеть, и поэтому информация, которая послана "в явном" (не зашифрованном) виде, в теории, может быть скопирована кем-то между отправителем и получателем. Но поскольку данные разделяются на пакеты, которые могут прийти по одному или разным маршрутам к месту назначения, зачастую нецелесообразно пытаться захватить (подслушать) полезную информацию.
Модификация информации, которая находится в процессе доставки, имеет ту же самую проблему, как подслушивание, с дополнительной опасностью фактического осуществления модификации. Хотя это можно сделать, но данная задача очень сложна и обычно не стоит усилий.
Заимствование прав пользователя через интерфейс входа в систему или сообщение электронной почты является, вероятно, самым обычным типом нарушения безопасности. Пользователи часто не защищают свои пароли. Как только некто узнает чье-нибудь имя пользователя и пароль, он может войти в систему и иметь те же права и привилегии, как и законный владелец. К сожалению, тривиально послать сообщение электронной почты с подделанными заголовками, чтобы казалось, что сообщение пришло от другого пользователя. Обычно внимательное изучение способно подтвердить подлинность заголовка, но может и привести к неразберихе, особенно если сообщение получает неопытный пользователь. Можно также играть роль
3 Так называемая электронная коммерция. — Ред.
другого хоста сети, требуя использовать тот же самый сетевой адрес. Ситуация известна, как spoofing (имитация соединения)’, это не тривиальное упражнение, но опытный сетевой программист или администратор могут это осуществить.
Нападение для отказа обслуживания происходит, когда внешний источник посылает огромное количество информации серверу с целью его перегрузки и подрыва способности выполнять свою работу. Столкнувшись с такими трудностями, сервер становится непригодным для использования так, что никто не может его использовать.
Авторское право
Одна из самых больших проблем в развитии .информационного обмена в Интернете — сохранение авторского права (copyright). В традиционных печатных средствах информации требуется время, чтобы воспроизвести информацию, и доказательство этого воспроизводства будет существовать. Другими словами, если бы я переиздал чей-то текст без разрешения автора, созданная копия доказала бы противозаконное действие. В Интернете информация может быть воспроизведена буквально со скоростью света. За время, требуемое для копирования файла, авторское право может быть нарушено совершенно незаметно.
Цензура
В любой среде, где может быть распределена информация, будут существовать люди, желающие ограничить доступ к данным. Если информация принадлежит мне, и я хочу ограничить доступ к ней посторонних, это называется моим правом на секретность. Если информация принадлежит кому-то другому, а я хочу ограничить доступ к ней, это называется цензурой.
Нельзя сказать, что цензура плоха. Как и во многом, проблема заключается не в идее, а в ее интерпретации. Цензура в Интернете, мягко говоря, — сложная проблема. Правительства и организации могут пробовать ограничить отдельные виды доступа к некоторым видам материалов (часто из лучших намерений). Но поскольку Интернет является всемирным ресурсом, такие действия не всегда правомерны. Как, например, закон в Нэшвилле (Nashville) может применяться к Web-серверу в Сиднее (Sydney)? Кроме того, даже если Web-сервер делает что-нибудь противозаконное, кто будет преследовать по суду корпус (сервера)?
Дезинформация
Безусловно, неприятна ситуация с нарушением авторских прав или публикацией оскорбительного материала, но гораздо больше раздражения вызывает заведомо ложная информация. Так как никто не имеет полномочий на одобрение пли подтверждение правильности информации, размещаемой в
сети, любой может опубликовать все, что угодно. Это прекрасно для свободы слова, но люди имеют тенденцию верить информации, которую они видят в печати. Не могу сказать, сколько я слышал историй о людях, действующих на основе информации, найденной в сети, которая вводила в заблуждение или была неправильной. Смогли бы вы доверять слухам? Это равносильно доверию информации, которую вы находите в сети, по крайней мере, когда вы не уверены в источнике.
Приемлемое использование
Многие ISP проводят политику приемлемого использования, которой вы должны придерживаться, чтобы получать их услуги. В будущем эта политика поможет решить многие из интернет-проблем, начиная с момента его создания. Большинство политик приемлемого использования требуют, чтобы пользователи вели себя достойно и не делали ничего противозаконного или оскорбительного в отношении других пользователей, в том числе отправку "бесконечной" электронной почты, копирование чужих файлов и т. д.
Существует осознанная анонимность4 пользователей Интернета. Если вы посылаете мне электронную почту, с которой я не согласен, возможно, для меня окажется затруднительным выяснять с вами отношения лично. Я мог бы успокоиться, ВОПЯ НА ВАС ПО ЭЛЕКТРОННОЙ ПОЧТЕ5. Благодаря этому люди склонны вести себя так, как никогда бы не вели при личном общении. Поскольку Интернет и его пользователи растут, эта проблема должна уменьшиться.
Современный Интернет
В прошлом сеанс связи в Интернете предполагал хранение выполненных команд и обращений к FTP-узлам. Нужно было хранить сведения о ресурсах и методы организации доступа к ним. Сегодня почти все, к чему вы получаете доступ в Интернете, базируется на Web, т. е. доступно через Web-браузер. Существует много Web-браузеров, но самый обычный для UNIX-компьютеров — это Netscape, написанный компанией Netscape Communications. Подобно любой другой программе с оконным интерфейсом, Web-браузер имеет кнопки, меню, область управления и область вывода. Пользо-
4 Я пишу здесь "осознанная", потому что фактически можно найти нужного человека, если вы приложите для поиска достаточно усилий. Даже люди, посылавшие сообщения с угрозами через услуги "анонимной электронной почты", были найдены с помощью правоохранительных органов. ISP сотрудничают с властями, когда выписываются ордера на арест!
5 Текст прописными буквами обычно интерпретируется, как крик. Это не относится к тем немногим пользователям, которые все еще используют компьютеры или терминалы, способные генерировать лишь прописные символы.
ватель печатает или выбирает Web-адрес, а браузер посылает запрос на указанный компьютер сети (локальной сети или Интернета) и отображает информацию в окне. Не будем подробно останавливаться на том, как использовать Netscape или любой другой браузер, поскольку самостоятельное испытание его возможностей — лучший способ научиться работать с Web-обозревателем. Вообще, все браузеры имеют место для ввода Web-адреса, способ посмотреть историю обозревателя, Web-адреса, которые вы посетили раньше, и кнопки, чтобы помочь вам перемещаться назад или вперед по этому списку. Большинство браузеров позволяет запоминать или печатать информацию и сохранять Web-адреса в списке закладок так, чтобы пользователь смог возвратиться к узлу в будущем, без необходимости помнить и повторно печатать его адрес.
URL
Web-страница отображается в окне браузера после того, как пользователь напечатает определенный Web-адрес. Адрес называется универсальным локатором ресурсов (Uniform Resource Locator, URL). Например, URL для узла сети Prentice Hall это
http://www.prenhall.com
Компонентами URL являются протокол, использующийся для получения Web-страницы, интернет-адрес или имя компьютера, на котором находится страница, необязательный номер порта и необязательное имя файла. В случае URL для Prentice Hall номер порта и имя файла были опущены, и браузер предположил порт 80 и затребовал корневой (/) файл в рамках дерева документов Web-сервера (не то же самое, что корень файловой системы UNIX).
Чаще всего указывается протокол HTTP (HyperText Transport Protocol, Протокол транспортировки гипертекста), который является протоколом для организации доступа к HTML-информации. Зашифрованный канал (защищенный HTTP, HTTPS) используется для страниц или деловых операций, вовлекающих конфиденциальную информацию (например, номера кредитных карточек). Большинство Web-браузеров также поддерживает FTP-протокол, который дает базирующийся на GUI способ доступа к анонимным FTP-узлам через браузер пользователя (см. главу И).
Если протокол не определен, большинство браузеров предположат, что перед URL идет http://, так что вы можете опустить это при ручном наборе адреса.
Как правило, при загрузке определенной Web-страницы в браузер появляется приятно отформатированная страница, содержащая информацию и некоторый выделенный текст или значки (гиперсвязи), по которым можно щелкать для перехода на другие связанные Web-страницы, возможно, принад
лежащие иной части данного узла или другой организации. Гиперсвязь — фундаментальная концепция в сердце Всемирной паутины. Она "плетет" сеть информации, где каждая страница содержит ссылки на другие страницы. Так как много содержащих связанную информацию Web-страниц имеют связи друг с другом, результат — "сеть" связей через весь Интернет.
Web-поиск
Итак, имея браузер, можно получить доступ к Web-узлам. Но как обнаружить необходимую информацию? Я мог бы назвать некоторые из тысяч известных мне узлов, содержащих интересные сведения, но к моменту издания этой книги многие из перечисленных узлов могут быть больше недоступны. Вместо того чтобы дать вам рыбу, я лучше покажу, как эту рыбу ловить, чтобы вы могли найти самостоятельно то, в чем, возможно, нуждаетесь.
В Интернете существует достаточное количество поисковых Web-машин. Это узлы, которые строят и непрерывно обновляют свою базу данных Web-страниц и ключевых слов, относящихся к этим страницам. Обычно их услуги бесплатны; страницы, которые. показывают результаты поиска, как правило, содержат рекламу, являющуюся источником финансирования для поддержки работы узла.
Вот некоторые поисковые машины:
□ www.altavista.com;
□ www.excite.com;
□ www.google.com;
□ www.infoseek.com;
□ www.lycos.com;
□ www.webcrawler.com;
□ www.yahoo.com.
У каждого есть собственные предпочтения. Ваш фаворит может зависеть от скорости ответа, расположения информации, качества результата поиска, легкости, с которой вы можете строить запрос, или некоторых других услуг, которые может предлагать узел.
Сегодня в Интернете существует так много узлов, что самая большая проблема использования поисковой машины состоит в построении достаточно конкретного запроса таким образом, чтобы пользователь не получил тысячи ссылок, большинство из которых будут не нужны.
Если вы пытаетесь найти "обыкновенную компанию", можно попытаться угадать адрес ее узла. URL-форма вроде http://wwxompanynamexxm работает чаще, чем не работает.
15 Зак. 786
Поиск пользователей и доменов
NIC обеспечивает доступ к базе данных зарегистрированных интернет-пользователей и интернет-доменов. Пользовательская база данных не содержит список всех интернет-пользователей; точнее сказать, она перечисляет только пользователей, которые зарегистрировались в NIC. Обычно это системные администраторы и администраторы сети, которые управляют информацией домена для узла. Web-узел NIC — это http://www.internic.net, а его Web-страница направит вас на ресурсы, которые можно использовать, чтобы выполнить все виды поиска для домена и интернет-информации.
Факторы, влияющие на будущее использование
Продолжит ли Интернет расти, как это происходило до настоящего времени? Раньше единственный фактор, ограничивающий его использование, состоял в его недоступности. Эта проблема была решена ISP и быстродействующими коммутируемыми и широкополосными линиями. Сегодня миллионы людей получают доступ к Интернету каждый день. Одни используют его, чтобы посылать и получать электронную почту и читать информационные бюллетени. Другие обращаются к нему для поиска информации всех видов на корпоративных и образовательных Web-серверах. Многим нужен Интернет для заказа товаров. Ввиду того, что удобство становится приоритетом в беспокойной жизни людей, доступ в глобальной сети может оказаться наиболее эффективным путем обнаружения информации даже на локальном уровне.
Благодаря наличию миллионной аудитории рекламодатели стремятся разместить свои сообщения на новом рынке. Поскольку Web-серверы и приложения стали "серьезнее”, рекламодатели будут направлять свои сообщения только заинтересованным пользователям. Это является преимуществом и для торговца, и для клиента, т. к. помогает уменьшить информационную перегрузку, от которой мы уже страдаем в наши дни.
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
□ историю Интернета;
□ протоколы, используемые в Интернете;
□ приложения, которые предоставляют доступ к Интернету;
□ службу DNS, используемую в Интернете;
□ Всемирную Паутину, Web-просмотр и Web-поиск.
Контрольные вопросы
1. Почему NIC выделяет очень мало адресов класса А?
2. В чем заключается различие между HTTP- и HTTPS-протоколами?
3. Если бы вы искали Web-страницу Sun Microsystems, какой адрес вы ввели бы сначала?
4. Каковы два наиболее существенных различия между TCP- и UDP-протоколами?
Упражнения
10.1. Выберите некоторые известные вам компании и попробуйте получить доступ к их Web-страницам с URL, которые вы составляете в формате www.company.com. [Уровень: легкий.]
10.2. Соединитесь с Web-узлом www.intemic.net и исследуйте его, чтобы выяснить, какие виды услуг обеспечивает NIC. Посмотрите информацию об имени вашего домена (или имени домена вашего ISP). [Уровень: средний.]
Проект
Сделайте вид, что вы хотите купить самый последний компакт-диск вашей любимой группы, но не знаете об интернет-узле, который продает их. (Есть несколько.) Проведите Web-поиск с несколькими ключевыми словами (например, музыка, компакт-диск, закупка и цмя группы). Посмотрите, сможете ли вы найти способ приобрести компакт-^иск, и исследуйте другие узлы, которые попали в результаты поиска, чтобы выяснить, почему они удовлетворили ваш запрос. Полезно знать, как в следующий раз сделать лучший поиск. [Уровень: средний.]
Глава 11
Пользовательские интерфейсы
Мотивация
Фактически все UNIX-компьютеры используют графические оболочки, поддерживающие оконный интерфейс. Большинство этих систем основано на X Window System, разработанной в Массачусетском технологическом институте (Massachusetts Institute of Technology, MIT). Дружественный интерфейс X Window System облегчает работу в любой оконной системе UNIX.
Предпосылки
Так как X Window System пользуется преимуществами некоторых возможностей сетевой организации UNIX, до чтения данной главы изучите главу 9.
Задачи
В настоящей главе будут представлены краткий обзор X Window System и методы использования некоторых ее наиболее общих функций. Вы узнаете, как система может улучшить вашу производительность. В других книгах (например, [Quercia 1993]; [OSF 1992] и [Fountain 2000]) тщательнее рассматриваются детали этой системы. Наша цель состоит в предоставлении информации в достаточном количестве, чтобы пользователь мог начать работать с X Window System.
Изложение
Сначала будет представлена краткая история систем с оконным интерфейсом. Затем мы исследуем X Window System и выясним, что она напоминает, как работает, рассмотрим команды UNIX, применяемые в ней.
Утилиты
В данной главе рассматриваются следующие утилиты: xbiff xhost xterm
xclock xrdb
Общие сведения
На заре развития UNIX-систем символьный терминал был единственным интерфейсом к системе. Пользователь регистрировался в системе и выполнял всю работу в отдельной, основанной на обмене символами, сессии. В лучшем случае пользователь имел терминал с "разумными” способностями курсора, обеспечивающего полноэкранные манипуляции (т. е. курсор позволял экранное редактирование текста или отладку). Но чаще всего в его распоряжении был просто строковый терминал, с которого можно было вводить строку текста (команду) и получать обратно несколько строк текста в ответ. И пользователь был счастлив иметь его вместо перфокарт, которые применялись ранее!
Графические пользовательские интерфейсы
По мере того как компьютерные системы становились более сложными, растровые дисплеи (где каждая частица на экране может быть засвечена или затемнена, а не просто отображается символ в определенном месте) позволили пользовательским интерфейсам стать более изощренными. Появился графический пользовательский интерфейс (Graphical User Interface, GUI), часто произносимый как "gooey". Первым компьютером с полуизвестным'GUI был Xerox STAR. Он был исключительно системой обработки текста и впервые позволил использовать напоминающие страницу с завернутым уголком пиктограммы (значки), представляющие документы. Xerox STAR имел пиктограммы для папок, документов и принтеров на рабочем столе (экране), а не интерфейс командной строки, который был нормой в то время.
Возможность щелкнуть на значке документа для его редактирования и перетащить его на значок принтера для распечатывания вместо необходимости помнить, какие команды соответствуют этим действиям, была в то время революционной. Некоторые из инженеров Xerox перешли в Apple Computer и работали над компьютером Apple Lisa, что привело к разработке Macintosh.
UNIX также "вошел в игру" GUI. Сотрудники Sun Microsystems внедрили Suntools в ранней версии SunOS (предшественника Solaris, текущей версии Sun UNIX). Suntools предоставляла многотерминальные окна на одном эк
ране с функциями вырезания (копирования) и вставки. Сначала было несколько приложений, которые предоставляли реальные функциональные возможности GUI. Измеритель производительности мог графически демонстрировать статистику производительности системы вместо того, чтобы показывать ее в виде чисел в таблице. Программа mailtool предоставляла возможность читать электронную почту при помощи иной программы, нежели традиционная программа /bin/maii.
Но в традиционных системах с оконным интерфейсом приложение могло показывать информацию только на экране того компьютера, на котором приложение работало. Очередной шаг в развитии был еще впереди.
X Window System
В 1984 году Массачусетский технологический институт (Massachusetts Institute of Technology, MIT) выпустил X Window System. Понимая пользу систем с оконным интерфейсом, но будучи неудовлетворенными тем, что предоставляли UNIX-продавцы, студенты в MIT с активностью, сопоставимой с движением компании BSD1 из Беркли (Berkeley), намеревались написать собственную систему с оконным интерфейсом. Первоначально компания Digital Equipment Corporation помогла финансировать проект Athena, откуда X начала свое шествие.
Революционная идея, стоящая за X Window System, которая и по сей день является конкурентоспособной, — это различие между функциями клиента и сервера в процессе рисования изображения на компьютерном экране. В отличие от большинства систем с оконным интерфейсом, X определяется в соответствии с протоколом сети, заменяющим традиционный интерфейс вызова процедуры. Таким образом, вместо простого наличия приложения, рисующего изображение непосредственно на экране, как делали предыдущие системы, X Window System разделяет две функции на части. Х-сервер заботится о рисовании и управлении содержимым компьютерного растрового дисплея, а также связью со всеми клиентами, которые желают рисовать на экране. Х-клиент не рисует непосредственно на экране, но связывается с Х-сервером, работающим на компьютере, где находится экран для графического вывода. Позволяя этому взаимодействию между двумя процессами существовать на одном компьютере или через сетевое соединение между двумя процессами на различных машинах, неожиданно пользователь получает возможность вывода графики на другом экране. Это открывает дверь к новым возможностям (также как решение проблемы безопасности).
X Window System часто упоминается просто как ”Х" или "XI Г, что относится к ее самой современной версии. Пока авторы писали эту книгу, XII находилась в своей шестой версии; следовательно, полное название — это
1 Berkeley Software Distribution. — Ред.
ходилась в своей шестой версии; следовательно, полное название — это X11R62. Для самой последней информации о X Window System см. Web-узел Open Group's X.Org Consortium http://www-x.org.
Х-серверы
X-cepeep стартует и "занимает" растровый дисплей на компьютерной системе. Это может случиться автоматически, когда пользователь входит в систему или выполняет команду запуска Х-сервера, в зависимости от реализации.
Обычно во время старта Х-сервера один или два Х-клиента также запускаются. Х-клиенты — это программы, которые взаимодействуют с пользователем через один или несколько Х-серверов. Должна стартовать некоторая программа, что обеспечит пользовательский доступ к системе. (Экран, управляемый Х-сервером, но не выполняющий ни какое приложение, ничего не позволит делать на нем.) Терминальное окно и диспетчер окон — типовые программы, которые можно запустить.
В системах, которые не запускают Х-сервер во время входа, обычно существует команда, подобная xinit или xstart, которую пользователь может либо ввести вручную, либо добавить в свой входной скрипт или скрипт профиля так, чтобы он запускался автоматически при входе в систему.
Г еометрия экрана
Разметка экрана называется геометрией. Растровый дисплей имеет определенный размер, измеряемый в пикселах — точках, которые могут быть установлены в состояние "включено" или "выключено" (белый или черный) или в некоторое цветовое значение. Маленький экран может быть 600x480 пикселов (типичный PC-монитор с низкой разрешающей способностью). Больший экран может быть 1280x1000 пикселов или даже больше для графических экранов с очень высоким разрешением.
Геометрия экрана определяется либо путем ссылки на определенную позицию на экране (например, 500x200 пикселов), либо путем ссылки на позицию относительно угла экрана. Позиция +0+0 — это верхний левый угол экрана, а —0—0 — это нижний правый угол (—0+0 — это верхний правый, +0—0 — нижний левый). Поэтому, +500+500 означает 500 пикселов от верхнего левого угла экрана в обоих направлениях по осям X и Y. Мы рассмотрим примеры, когда будем обсуждать Х-клиентов.
2 XII Release 6. — Ред.
Безопасность и авторизация
Возможно, вы думаете, что ввод текста и отображение его на экране компьютера, подключенного к вашей сети, вряд ли могут привести к возникновению проблем безопасности. Ведь ввод/вывод на Х-сервер — это всего лишь ввод и вывод. Разрешение на запись на Х-сервере также предоставляет возможность запросить у системы текущую копию экрана или даже от входа с клавиатуры.
X Window System имеет систему безопасности, встроенную в Х-сервер. Это не высококлассная система, но она достаточна, чтобы воспрепятствовать случайному сыщику в получении неправомочного доступа. По умолчанию Х-сервер, работающий на любой компьютерной системе, позволяет только Х-клиентам на этой же самой системе общаться с ним. Х-сервер не принимает подключений от ’’иностранных” Х-клиентов без осведомления, кто они. Это заставляет конфигурацию по умолчанию Х-сервера быть очень похожей на обычную систему с графическим оконным интерфейсом, в которой лишь приложения, выполняющиеся на данном компьютере, могут писать на его экран.
Чтобы воспользоваться преимуществом сетевых функций X Window System, вы должны разрешить внешний доступ. Для этого служит утилита xhost (X-клиент).
• Синтаксис
xhost [+|-][имяХоста]
Утилита xhost разрешает или запрещает доступ к Х-серверу в системе. Без аргументов утилита печатает свои текущие установки и список хостов (если есть), которые имеют доступ. Специфицируя только +, можно разрешить доступ всем хостам; определяя только -, можно запретить доступ всем хостам. Когда имя хоста определено после + или -, соответственно предоставляется или запрещается доступ этому хосту.
Например, xhost +bluenote
позволит Х-клиентам, работающим на компьютере bluenote, писать на дисплей системы, в которой работала утилита xhost. Позже после выполнения работы можно запретить доступ с командой
xhost -bluenote
В безопасной среде, где нет опасений по поводу записи с другой системы на пользовательский дисплей, можно позволить любому Х-клиенту в сети писать на ваш дисплей командой xhost +
А закрыть доступ от всех Х-клиентов при помощи xhost
Диспетчеры окон
Возможность выводить на экран в действительности не очень полезна, если пользователь лишь наблюдает появление и пропадание окон, но не может с ними ничего делать. Как раз в такой ситуации нужны диспетчеры окон. Диспетчер окна — программа (Х-клиент), которая взаимодействует с X-сервером, клавиатурой и мышью в системе. Он обеспечивает интерфейс для пользователя, чтобы давать инструкции Х-серверу об операциях с окнами.
Хотя диспетчеры окон обычно работают на том же самом компьютере, где существует дисплей, которым они управляют, но это необязательно. Если вы имеете специальный диспетчер окна X, который работает только на одном определенном типе компьютера, допустимо установить его для управления вашей рабочей станцией с удаленного компьютера. Конечно, есть внутренние проблемы. Например, что произойдет, если удаленный компьютер, выполняющий диспетчер окна, или сеть испортились? Вашим X-сервером нельзя было бы управлять, потому что он не мог бы взаимодействовать с диспетчером окна, и ваши клавиатура и мышь, вероятно, не будут отвечать (по крайней мере, должным образом) на ваш ввод. Но факт, что система могла бы все еще работать, является гарантией гибкости архитектуры X Window System.
Одна из важных особенностей, предоставляемых диспетчером окна, —- это "облик и ощущение" рабочего стола. Облик и ощущение интерфейса окна зависят от приложения, создающего окно. В то время как все диспетчеры окон предоставляют похожую функциональность, вид каждого может сильно варьировать.
Фокус
Самая важная работа диспетчера окна — это поддержка фокуса окна. Термин используется, чтобы характеризовать, какое окно в настоящее время выбрано или активно. Если пользователь осуществляет ввод с клавиатуры, окно с фокусом — это место, куда данные будут посланы. Фокус позволяет перемещаться из одного окна в другое и выполнять разнообразные действия в различных окнах. Вообще, окно с фокусом имеет отличную от других окон границу, хотя его интерфейс может быть сконфигурирован так, чтобы не отличаться в этом отношении.
Фокус окна настраивается в зависимости от предпочтения пользователя: выбрана граница окна или строка заголовка или указатель мыши перемещен на окно.
Запуск программы
Большинство диспетчеров окон предусматривает наличие выпадающего меню, которое может быть настроено для разного запуска часто применяемых приложений. Например, если указатель мыши находится на корневом окне (рабочий стол непосредственно, а не прикладное окно) и пользователь щелкает и удерживает кнопку мыши, то большинство диспетчеров окон выведет меню. Список команд меню обычно включает функции, подобные старту нового терминального окна или выходу из диспетчера окна. Набор команд изменяется от одного диспетчера окна к другому и может быть в большой степени настроен. Кнопки мыши могут быть настроены на выводы различных списков. На рис. 11.1 приведен пример окна.
Рис. 11.1. Окно и выпадающее меню корневого окна
Открытие и закрытие окон
Диспетчер окна также заботится об отображении активных окон и расположении значков. Если вы открываете новое терминальное окно и заканчиваете с ним работать, но не хотите удалять его, потому что, возможно, оно понадобится позже, то можете закрыть3 терминальное окно. Диспетчер окна создаст значок на рабочем столе, ассоциированный с программой
3 Это соответствует сворачиванию окна в Windows. — Ред.
терминального окна, который не займет много места. Вы будете видеть его и можете щелкнуть (или щелкнуть дважды, в зависимости от используемого диспетчера окна) по нему позже, чтобы восстановить окно (повторно открыть). Сама программа будет работать, в то время как ее окно представлено значком. Можно убедиться, что сам Х-сервер ничего не знает об этой функции, если в какой-либо ситуации вы удалите диспетчер окна. (Если вы сделаете это, все ваши значки снова откроют окна на всем пространстве вашего экрана!). На рис. 11.2 представлен рабочий стол с открытым окном и значками.
Рис, 11,2. Рабочий стол с открытым окном и значками
Выбор диспетчера окна
Для Х-серверов доступно много различных диспетчеров окон. Большинство основано на стандарте графической оболочки Motif, разработанной Open Software Foundation (OSF). Некоторые диспетчеры окон имеют общее происхождение от первоначального диспетчера окна Motif. Многие реализуют виртуальный рабочий стол, который расширяет область рабочего стола за пределы области реального участка на экране. Диспетчер окна в этом случае помогает управлять отображением определенной области большого виртуального рабочего стола.
К часто встречающимся диспетчерам окон относятся:
О dtwm
диспетчер окон рабочего стола, часть общего окружения рабочего стола (Common Desktop Environment, CDE), подобен vuewm, но поддерживает виртуальный рабочий стол;
О fvwm
бесплатный виртуальный диспетчер окна, написанный Робертом Нэйше-ном (Robert Nation), который стал очень популярным в сообществе Linux;
О kwm
диспетчер К Window, используемый с KDE (К Desktop Environment);
□ mwm
диспетчер окна Motif, исходный диспетчер окна;
□ olwm/olvwm
диспетчер окна OpenLook фирмы Sun Microsystems и диспетчер виртуального окна OpenLook;
Л twin/tvtwm
диспетчер" окна Тома и диспетчер виртуального окна Тома, написанные Томом ла Стрэнджем (Tom LaStrange), чтобы исправить некоторые из функций, которые он не любил в Motif;
□ vuewm
диспетчер окна VUE фирмы Hewlett-Packard.
Ради простоты будем рассматривать диспетчер окон Motif в качестве образца с общими характеристиками для всех этих диспетчеров. Motif предусматривает дополнительные компоненты окна, о котором приложение (X-клиент) не должно волноваться. Например, Motif рисует границу вокруг окна, которая может быть указана мышью, чтобы изменить фокус окна, перемещает (тянет) окно или изменяет его размер. Граница окна содержит заголовок и кнопки, позволяющие перемещать окно, устанавливать размеры, минимизировать (заменять значком), разворачивать окно на полный экран или удалять.
Виджеты
Виджет (widget) — термин, используемый для того, чтобы описать каждый отдельный компонент Х-окна. Кнопки, границы и полосы прокрутки — все это виджеты. Каждый Х-инструментарий может определять свой собственный набор виджетов. Так как мы фокусируемся на окружении Motif, то бу
дем интересоваться лишь его набором виджетов, который предоставляется прикладной программе через программный интерфейс приложения (Application Programming Interface, API) Motif.
Меню
Команды меню обеспечивают GUI доступ к функциям, предоставляемым приложением. Часто эти функции не связаны непосредственно с содержимым конкретного окна. (Скорее, они выполняют действия, подобные открытию файлов, установке опций и выходу из программы). Команды меню находятся наверху окна, как показано на рис. 11.3.
Рис, 11,3, Выпадающее меню
Командные кнопки
Командные кнопки могут быть размещены любым способом, удобным для приложения. Типичный пример — кнопки ОК и Cancel диалогового окна (дополнительное окно, которое появляется с новой информацией или запросом к пользователю). На рис. 11.4 представлено типичное диалоговое окно.
Рис, 11,4, Диалоговое окно с командными кнопками
Флажки и переключатели
Флажки и переключатели — это генерирующие ввод виджеты. Флажки служат для установки или сброса выбора. Если флажок отмечен, он указывает "истина", "да" или "присутствует" в зависимости от контекста приложения. Переключатели —- это набор взаимно исключающих альтернатив. Когда одна выбрана, любые другие, выбранные ранее, сбрасывают отметки (подобно кнопкам в автомобильном радио). Оба типа виджетов показаны на рис. 11.5.
Рис, 11,5, Флажки и переключатели
Полосы прокрутки
Полосы прокрутки позволяют пролистывать назад и вперед содержимое окна или его части. Прокрутка полезна, когда отображается много текста, но до
ступна маленькая область экрана так, что будет помещаться не весь текст. Полосы прокрутки могут быть или горизонтальными, или вертикальными. Вертикальные полосы обычно расположены справа в окне (рис. 11.6). Горизонтальные полосы обычно — внизу окна.
Рис. 11.6. Терминальное окно с вертикальной полосой прокрутки
Функции диспетчера окна Motif
Операции, выполняемые с окнами и значками на рабочем столе под управлением диспетчера окон Motif, подобны функциям других диспетчеров X Window,System, хотя некоторые детали могут слегка изменяться.
Вызов корневого меню
Корневое меню (root menu) содержит основные операции, необходимые для управления Х-сессией. По умолчанию список включает команды запуска терминального окна, перемещения фокуса на другое окно и выход из диспетчера окон. Корневое меню можно настроить, чтобы добавить в него часто используемые Х-приложения, чтобы их легко было запускать. Допустимо вызвать различные меню для разных кнопок мыши.
Открытие окна
Чтобы открыть (или максимизировать) окно, дважды щелкните на значке, представляющем закрытое окно.
Закрытие окна
Чтобы закрыть (или минимизировать) окно, щелкните на кнопке закрытия в заголовке окна. Можно также вызвать меню с командой Close (Закрыть), выбирая границу окна. Кроме того, большинство диспетчеров окон предусматривают возможность задания комбинации клавиш, которая может использоваться, когда фокус находится на окне.
Перемещение окна
Чтобы переместить окно, наведите указатель мыши на его границу, нажмите среднюю кнопку мыши и, удерживая ее нажатой, перетаскивайте окно. Выпадающее меню границы окна также обычно имеет команду Move (Переместить).
Изменение размера окна
Чтобы изменить размер окна, наведите указатель мыши на его границу, нажмите и удерживайте левую кнопку мыши и тяните границу в нужном направлении. Когда тянут угол, изменяются размеры и X, и Y. При выборе верхней, нижней или боковой границы и перемещении ее размер окна изменяется только в одном направлении.
Размещение поверх других окон
Окно может быть размещено поверх остальных окон (над другими окнами) путем выбора его границы. Это действие также устанавливает фокус на данном окне.
Вызов меню окна
Диспетчер окна может снабдить меню каждое окно. Меню вообще содержит одну или несколько функций, описанных ранее, и может быть настроено. Чтобы вызвать меню окна, щелкните на кнопке меню в верхнем левом углу окна или нажмите правую кнопку мыши где-нибудь на границе окна или в области заголовка.
Приложение-клиент
Каждая программа, которая осуществляет вывод на экран Х-сервера, называется Х-клиентом. X Window System содержит много полезных Х-клиентов.
Далее мы рассмотрим несколько самых простых Х-клиентов, которые используют новички, изучая X Window System. Чтобы узнать о дополнительных аргументах, которые могут использоваться для настройки программы клиента, обратитесь к утилите man.
xclock
Утилита xclock, являющаяся Х-клиентом (рис. 11.7), может быть запущена вручную или через пользовательский файл инициализации.
Синтаксис
xclock [-digital]
Утилита xclock отображает часы на рабочем столе пользователя. По умолчанию появляется циферблат с широкими стрелками. Если определен аргумент -digital, демонстрируются цифровые часы.
Рис, 11.7, xclock-клиент
xbiff
Утилита xbiff, Х-клиент, является в основном версией для X Window System biff-программы от Berkeley UNIX, которая сообщает пользователю о поступлении новой почты.
Синтаксис
xbiff
Утилита xbiff показывает изображение почтового ящика на рабочем столе. Если пользователь, запустивший xbiff, не получал новой почты, в окне клиента будет изображен стеллаж с пустыми полками (рис. 11.8, а). Когда почта доставлена, появляются изображения конвертов, и значок может изменить цвет (рис. 11.8, б).
Как упоминалось ранее, по легенде один из разработчиков Калифорнийского университета в Беркли (University of California at Berkeley) имел собаку по имени Biff, которая всегда лаяла, когда почтальон доставлял почту. Много более сложных программ было написано, но xbiff — это оригинал.
а
Рис, 11,8, Два вида xbiff-клиента: а — почты нет; б — почта пришла
xterm
Утилита xterm — вероятно, самый популярный Х-клиент у пользователей UNIX. Она обеспечивает оконный интерфейс терминала в системе. Самые первые пользователи системы с оконным интерфейсом использовали свои Х-терминалы главным образом, чтобы организовать многотерминальный интерфейс и объединить мониторы на рабочем столе. По мере того как X-клиенты становились более сложными, xterm применялась все реже и реже. Но до сих пор все еще весьма полезна, если вы используете в UNIX shell-интерфейс.
Утилита имеет несметное количество аргументов, позволяющих определять в командной строке размер окна, цвет и шрифт. (Для дополнительной информации СМ. страницу man ДЛЯ xterm.)
Синтаксис
xterm [-С]
Утилита xterm запускает терминальное окно на рабочем столе. Если указана опция -с, терминальное окно получит сообщения консоли. Эта особенность полезна для предотвращения получения сообщений консоли, чтобы производить вывод поперек экрана системы, в которой растровый монитор является также консольным устройством.
Стандартные аргументы Х-клиента
Большинство Х-клиентов принимают стандартные аргументы, которые позволяют настраивать размер Х-клиента и положение при запуске.
Г еометрия
Х-геометрия клиента определяется аргументом -geometry. Можно задать не только размер клиента, но и позицию смещения для отображения его на экране. Общий формат для указания размера — xxy, для смещения — +х+/. Например, чтобы запустить утилиту xciock, окно которой сдвинуто на 10 пикселов в каждом направлений от верхнего правого угла экрана и размер составляет по 100 пикселов в ширину и высоту, следует использовать команду
$ xciock -geometry 100x100-10+10
Обратите внимание на значение аргумента -geometry: отсутствуют пробелы.
Цвет переднего и заднего плана
Цвета переднего плана и заднего плана могут быть установлены аргументами -foreground и -background. Следующая команда xterm создаст терми-нальное окно с символами цвета циан (легкий оттенок синего) на черном фоне:
$ xterm -foreground cyan -background black
Эта комбинация цветов очень удобна для работы, но каждый имеет собственные предпочтения.
Заголовок
Аргумент -title выводит строку в заголовке окна. Данная функция полезна для пометки одного из многих терминальных окон, используемых во время сессии на удаленном компьютере. Например:
$ xterm -title "Remote access to mail server"
Значок
Аргумент -iconic применяется, чтобы запустить Х-клиента в минимизированном окне так, чтобы на рабочем столе появился лишь значок. Это полезно для приложений, которые будут использоваться, но не обязательно в настоящий момент при старте.
Дополнительные темы
Некоторые из рассматриваемых далее тем можно отнести к одному или нескольким предыдущим разделам. Но авторы считают, что читатель нуждается в предварительной подготовке перед обсуждением более сложных возможностей X Window System.
Копирование и вставка
Операция копирования и вставки — одна из наиболее полезных особенностей X Window System. Способность выделять текст в одном окне и копировать его в другое окно без необходимости повторно печатать — это большая экономия времени. Обсудим тему вне возможностей диспетчера окон, т. к. она фактически обеспечивается непосредственно Х-сервером. Вы можете удостовериться в этом, используя копирование и вставку, даже когда ни один диспетчер окон не работает.
Чтобы скопировать текст в буфер копирования и вставки, установите указатель мыши на начало выделяемого фрагмента, щелкните левой кнопкой мы
ши и, не отпуская ее, тяните указатель к концу фрагмента. (Выделение можно выполнить как вперед, так и назад.) Когда вы отпустите кнопку мыши, выделенный текст скопируется в буфер (в отличие от PC4, который требует дополнительного действия для копирования выделенного текста в буфер). Далее перейдите к окну, в котором следует вставить текст, щелкните средней кнопкой мыши (или обеими кнопками мыши сразу, если их только две), и текст будет вставлен. Некоторые приложения вставляют текст в текущую позицию текстового курсора, в то время как другие — в точке, где вы щелкаете средней кнопкой мыши. Эта особенность определяется приложением.
На рис. 11.9 представлен пример, в котором выполнялась утилита who для выяснения зарегистрированных в системе пользователя. Для копирования и вставки строки, показывающей подключение Graham, указатель был размещен на начале строки и после нажатия кнопки мыши передвинут к концу строки. Так был помечен текст и помещен в буфер копирования и вставки. Затем после отправки сообщения электронной почты Graham был выполнен щелчок средней кнопкой мыши, чтобы вставить текст в сообщение почты в текущей точке.
$ mail No mail. $ who
glass console May 6 18:45И
ables ttypl May 6 18:55
ables ttyp3 May 6 18:59
dee ttyp4 May 6 18:44
pJones ttyp5 May 6 18:57
mktg ttyp5 May 6 14:35
pjones ttyp5 May 6 12:14
ksm ttyp5 $ mail glass May 6 17:32
Subject: are you in Graham, Is this you?: the computer room?
glass console May 6 18:45
IT it is. could you come to the south
Thanks.
-king
door of the computer room and let me in? I forgot my.access card.
Рис. 11.9. Пример копирования и вставки
4 Авторы здесь не правы. Эта функция зависит не от компьютера, а от программного обеспечения, реализующего операцию копирования и вставки. — Ред.
Сетевые возможности
Ранее упоминалось, что X Window System является сетевой системой с оконным интерфейсом, и существует возможность передать информацию от Х-клиента, работающего на одном компьютере, Х-серверу, работающему на другом. Эта способность фундаментальна для Х-конструкции, и ее весьма просто использовать с любого Х-клиента, определяя аргумент -display. Аргумент сообщает Х-клиенту, с каким Х-сервером войти в контакт, чтобы показать его виджеты. По умолчанию дисплей относится к локальной машине, на которой работает клиент. Чтобы запустить утилиту xterm на сервере savoy, укажите конструкцию типа
$ xterm -display savoy: 0. О
Спецификация : о. о — это способ уникально идентифицировать дисплей и Х-сервер, работающий на компьютере. Несмотря на то, что можно управлять множественными Х-серверами, также как иметь множественные мониторы, связанные с отдельным компьютером, при обычном использовании каждый компьютер будет иметь только один монитор и управлять лишь одним Х-сервером. Так что значение : о. о будет почти всегда обозначать эту конфигурацию. По умолчанию имя дисплея для локальной системы должно быть unix:о.о или, возможно, :0.0 без имени сервера. Имя unix имеет специальное значение "локальный компьютер" и поэтому не будет работать удаленно, если фактически существует локальный сервер unix.
Если вводится команда
$ xterm -display bluenote, utexas. edu: 0. 0
и пользователь на bluenote запустил утилиту xhost, чтобы разрешить доступ машине, на которой вводилась указанная команда, тогда создаваемое терминальное Х-окно будет показано на bluenote.utexas.edu.
Ресурсы приложения
Прикладные ресурсы являются и ящиком Пандоры, и одним из наиболее революционных аспектов X Window System. Х-ресурсы позволяют пользователям настраивать "облик и ощущение" их рабочих столов и приложений, которыми они управляют в той мере, в которой не обеспечивает никакая другая система. Мы кратко рассмотрим самые основные части использования Х-ресурсов. Я настоятельно рекомендую прочитать главу "Setting Resources" ("Установка ресурсов") в [Quercia 1993] для получения дополнительной информации.
Как работают ресурсы
Каждое приложение, включая диспетчера окон, непосредственно может воспользоваться преимуществом Х-ресурсов. Х-ресурс — это строка текста, подобно имени переменной и значению, которое устанавливается как часть Х-сервера. Значение ресурса привязано к определенному виджету. Когда X-сервер рисует конкретный виджет, он ищет значение, связанное с ним в своем списке ресурсов и соответственно устанавливает описанный признак.
Например, рассмотрим гипотетическое приложение xask. Это приложение представляет диалоговое окно, содержащее текстовое сообщение (вопрос) и две кнопки: Yes и No. Окно можно определить (по крайней мере) следующими ресурсами:
xask.Button.yes.text
xask.Button.no.text
Приложение может иметь значения по умолчанию в случае, если эти ресурсы не установлены. При отсутствии набора ресурсов во время выполнения xask пользователь увидел бы окно, подобное показанному на рис. 11.10.
Рис. 11.10. Вымышленное приложение Xask
Но что, если пользователь предпочтет иметь более интересные надписи на кнопках, чем Yes и No? Возможно, следует изменить язык, используемый приложением, но вряд ли пользователь пожелает иметь отдельную версию программы для каждого языка. Существует другой выход — настроить значения Х-ресурсов. В нашем примере мы установим следующие ресурсы для Xask:
xask.Button.yes.text: Sure
xask.Button.no.text: No way
Конечно, это тривиальный пример, но зато видна мощь Х-ресурсов. Путем присвоения вышеупомянутых значений этим ресурсам на Х-сервере в следующий раз выполняется xask и отображает окно, показанное на рис. 11.11. Если один пользователь установит значения ресурсов и выполнит xask, а
другой не установит и тоже запустит эту программу, то они увидят разные результаты!
Х-ресурсы используются, чтобы настроить характеристики окна, например, размер, цвет, шрифт и значения строк текста. Хотя они типичны, в действительности нет никаких ограничений в том, что пользователь может настроить в приложении. Каждое Х-приложение использует некоторое количество Х-ресурсов, и они должны быть описаны в документации для приложения. Чем больше (сложнее) приложение, тем больше ресурсов оно будет требовать. Например, Motif имеет почти бесконечное количество ресурсов, которые позволяют настраивать в нем почти все.
Рис. 11.11. Приложение Xask с настроенными Х-ресурсами
Определение ресурсов
Как настроить необходимые ресурсы? Х-ресурсы — это ресурсы Х-сервера, поэтому они устанавливаются на машине, на которой Х-сервер работает. Есть много способов загрузить ресурсы в Х-сервер. Ручной способ доступа к ресурсной базе данных Х-сервера — это утилита xrdb.
Синтаксис
xrdb [-query|-load|-merge|-remove] [имяФайла]
Утилита xrdb обеспечивает доступ к базе данных Х-ресурса для X-сервера. Использованная с аргументом -query, xrdb печатает ресурсы, определенные в Х-сервере. Аргумент -load заставляет загружать новую ресурсную информацию в базу данных ресурса, при этом заменяя предыдущую информацию. Если имяФайла определено, информация ресурса загружается из этого файла, иначе читается стандартный канал ввода. Аргумент -merge загружает- новый информационный ресурс, действует^ подобно аргументу -load, за исключением того, что существующая ин-
формация не удаляется. (Информация дублирующихся ресурсов перепи-* сывается.) Наконец, аргумент -remove очищает базу данных ресурса X-сервера.
Вы можете добавлять или удалять индивидуальный ресурс или группу ресурсов в любое время. Однако ручное добавление и удаление Х-ресурсов очень быстро становится утомительным. Хотелось бы иметь способ спецификации ресурса, который будет применяться каждый раз, когда выполняется некоторое приложение. Делается путем создания файл ресурса по умолчанию .Xdefaults. Это файл инициализации, распознающийся Х-программой сервера, когда та выполняется пользователем. После запуска Х-сервер загружает все ресурсы, перечисленные в файле. Например, если мы хотим, чтобы наша программа xask всегда использовала более легкомысленный текст на кнопках, мы можем ввести соответствующие ресурсы в наш .Xdefaults-файл, и следующий раз при запуске Х-сервера эти ресурсы будут установлены.
Внимание
Мы могли бы также непосредственно запустить утилиту xrdb с нашим .Xdefaults-файлом, чтобы загрузить или перезагрузить вышеупомянутые ресурсы в любое время.
Если пользователь настраивает большое количество ресурсов во многих приложениях, помещая все эти строки настройки ресурса в свой .Xdefaults-файл, через какое-то время обнаружится, что файл стал чрезвычайно большим. Файл неудобно читать. Также некоторые приложения приходят с набором ресурсов по умолчанию, которые определяют признаки виджетов используемого приложения вместо задания значений по умолчанию непосредственно в коде. В этом случае возникает необходимость в способе загрузки ресурсов в Х-сервер при выполнении приложения.
Определение каталога, где сохраняются Х-ресурсы, позволяет Х-серверу загружать множественные файлы ресурса. Списки ресурсов для приложения сохраняются в файле, названном так, чтобы приложение нашло его. (Это обычно имя приложения, но оно определяется непосредственно приложением.) Таким образом, ресурсами легче управлять, т. к. каждый файл будет содержать ресурсы для одного приложения. Можно обнаружить десятки или даже сотни файлов в этом каталоге, но каждый файл будет иметь разумный размер.
В предыдущем примере Xask мы могли бы помещать наши ресурсы в файл Xask, который, как известно, используется приложением. Тогда единственное, в чем мы нуждаемся, — это в способе сообщить приложению, где искать данный файл. Определим shell-переменную xapplresdir (Х-каталог ресурса приложения). В С shell она должна быть переменной окружения
так, чтобы дочерние shell унаследовали ее значение. В Bourne-подобых shell эта переменная должна экспортироваться, когда будет установлена.
Конфигурация и запуск
Может показаться странным, что данный раздел до сих пор оставался без внимания. Но попытка выполнять X Window System без понимания, как она работает, иногда создает препятствие. Читатель уже знаком с отношениями между Х-сервером и Х-клиентом, а также как используется диспетчер окон, и поэтому представленные ниже разделы окажутся для него простыми. Следует учесть, что особенности запуска X Window System изменяются от платформы к платформе и от реализации к реализации.
xinit и .xinitre
При выполнении исходной X Window System, распространяемой от Массачусетского технологического института, пользователь регистрируется на UNIX-компьютере, как обычно. Можно затем ввести команду xinit, чтобы запустить Х-сервер, или указать ее в своем файле инициализации shell.
xinit запускает Х-сервер и выполняет команды, найденные в файле shell-скрипта .xinitre. В этом файле можно определить любое приложение, которое пользователь хочет запустить при старте Х-сервера. Типичные команды, находящиеся в .xinitrc-файле, — это вызовы утилиты xterms и почтовых программ или, возможно, любимого Web-браузера пользователя. Здесь же разрешено запускать предпочтительный диспетчер окон.
Следует обратить внимание на то, что Х-сервер выполняет команды из .xinitrc-файла подобно скрипту shell, и когда скрипт завершается (т. е. все команды выполнены), Х-сервер прекращает работу. Это ключевой момент. Часто пользователи помещают команды в свои .xinitrc-файлы и используют символ &, чтобы распараллелить процессы (выполнять их в фоновом режиме). Но они делают это в последней команде списка. В данном случае .xinitre выходит из скрипта и Х-сервер прекращает работу. Проявляется это так: Х-сервер стартует, запускается приложение, а затем резко прекращается. Причина в том, что последнее приложение, начатое в .xinitrc-файле, не должно быть запущено в фоне с символом & на конце команды! Когда это конкретное приложение завершает работу, сам Х-сервер тоже останавливается.
Некоторые пользователи предпочитают делать "последним приложением" диспетчер окон (mwm). Продвинутые пользователи иногда ставят последней командой специальное "console" терминальное окно, потому что хотят останавливать и запускать свой диспетчер окон без прекращения работы X-сервера. В этом случае, чтобы заставить Х-сервер выйти, следует просто за
вершить работу (печатать exit или нажать комбинацию клавиш <Ctrl>+ +<D>) в консольном окне.
В приведенном ниже примере .xinitrc-файла диспетчер окон mwm стартовал последним и не был помещен в фоновый режим, так что выполнение скрипта приостановлено до тех пор, пока выполняется mwm. После выхода из вашего диспетчера окон выполнение .xiiiitrc-скрипта продолжается до конца, и когда скрипт заканчивается, Х-сервер также завершает работу: $ cat .xinitrc xbiff & mailtool & xterm -C & mwm $ _
Приведенное обсуждение может выглядеть простым, но отказ от этой идеи может вызвать огорчение у пользователя-новичка X Window System!
mwm и .mwmrc
Так же как .xinitrc — файл запуска для xinit, .mwmrc — файл инициализации для mwm. При старте Motif диспетчер окон должен быть проинструктирован, какие действия назначить кнопкам мыши, что делать, когда пользователь щелкает на различных виджетах, и, вообще, как вести себя. Обычно регистрационная запись пользователя будет обеспечиваться по умолчанию копией .mwmrc-файла, который разрешено редактировать.
В .mwmrc-файле определяются все выпадающие меню, которые будут доступны пользователю. Это один путь, с помощью которого можно осуществлять некоторые действия, когда Х-сервер выполняется без запуска других приложений (в пользовательском .xinitrc-файле). Через какое-то время некоторые приложения могут оказаться настолько полезными, что пользователь добавит команду для их запуска в выпадающие меню. (Подробности см. в [OSF 1992].)
Обзор других
Х-совместимых рабочих столов
В настоящее время применяются три основных рабочих стола UNIX: CDE, KDE и Gnome. Старые рабочие столы типа VUE и OpenWindows фигурируют в истории рабочего стола UNIX, но мы лишь упоминаем их, поскольку они больше не используются во многих окружениях UNIX.
CDE
С развитием компаниями своих реализаций Х-серверов и добавлением собственных "звонков и свистков" к ним стало ясно, что Х-окружения усложнятся и разнообразятся. Hewlett-Packard, IBM, SunSoft и Novell объединились, чтобы определить новую Х-реализацию, которая могла быть разделена и использоваться всеми UNIX-платформами. Результатом стал Common Desktop Environment (CDE).
Интерфейс CDE похож на VUE, хотя есть также повсюду очевидные влияния и OpenWindows. CDE также базируется на Motif и имеет диспетчера регистрации и сессии. CDE не представляет никакого большого технологического прыжка по отношению к OpenWindows, VUE или даже непосредственно к X Window System. Он обеспечивает общее окружение, разделяемое главными UNIX-продавцами, и доступность UNIX-пользователям на различных UNIX-платформах. CDE стал первым рабочим столом UNIX, который был принят несколькими UNIX-продавцами.
Gnome
GNU Network Object Model Environment (Gnome) — это вклад GNU-проектов в рабочий стол UNIX. Как с другим программным обеспечением GNU, он бесплатно доступен и работает на большинстве платформ UNIX. Несмотря на то, что рабочий стол поставляется теперь со многими коммерческими дистрибутивами UNIX и Linux, он может быть также найден на сайте http://www.gnome.org. Предназначение Gnome состоит в том, чтобы обеспечить удобный в работе рабочий стол для начинающих пользователей и не связать руки опытным.
KDE
Во многом подобный Gnome, KDE — К Desktop Environment, является бесплатным рабочим столом UNIX, разработанным свободной группой программистов со всего мира. KDE также доступен почти для каждой версии UNIX и Linux и может быть найден по адресу http://www.kde.org. KDE пытается обеспечивать интерфейс, подобный рабочим столам MacOS и Windows, чтобы содействовать установке UNIX или Linux на домашние компьютеры и в офисе (где MacOS и Windows традиционно доминируют).
OpenWindows
Сознавая, что его оригинальная система управление окнами, Suntools, не была правильным решением, корпорация Sun отказалась от нее и разработала собственный, базирующийся на X Window System, рабочий стол OpenWindows. Хотя OpenWindows способен к выполнению Х-клиентов, он
обеспечил новый "облик и ощущение" и новый набор виджетов (и, конечно, новый набор приложений). Новый стиль называли OpenLook. Несмотря на то, что пользователи Sun и Open Software Foundation воспользовались Open-Look и OpenWindows, он никогда в действительности не копировался в остальной части Х-сообщества.
VUE
Hewlett-Packard также хотела улучшить оригинальную Х-концепцию наряду с тем, чтобы сохранилась совместимость с общими Х-клиентами. Visual User Environment (VUE) реализовало Х-сервер, новый дизайн рабочего стола и новую парадигму запуска.
VUE обеспечил экран регистрации так, чтобы пользователь никогда не видел общий диалог регистрации UNIX или приглашение shell на терминале. VUE выполнялся, когда включался компьютер, и это переместило контроль над файлами инициализации пользователя на момент, когда тот регистрировался в системе. VUE также предоставил полезный набор таких файлов по умолчанию, чтобы окружение изначально хорошо работало, но мог все еще настраиваться опытным Х-пользователем. В тех случаях, когда в обычной X Window System пользователь должен был редактировать файлы инициализации, чтобы изменить поведение системы, VUE предложил много методов для изменения поведения через GUI, что было гораздо проще для среднего пользователя.
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
□ что делает графический пользовательский интерфейс;
□ X Window System Массачусетского технологического института;
□ Х-серверы, Х-клиенты и виджеты;
□ диспетчер окон Motif;
□ ресурсы X-приложения. i
Контрольные вопросы
1. Какая команда используется для изменения прав доступа к Х-серверу?
2. Какой Motif-виджет вы использовали бы в окне, в котором хотите предоставить пользователям выбор одной из нескольких опций?
3. Какой Х-аргумент приложения используется, чтобы отобразить окно приложения на экране другого компьютера?
4. Какой признак Х-сервера позволяет изменить вид Х-приложения без необходимости изменять программу?
Упражнения
11.1. Объясните, почему диспетчер окон является Х-клиентом. [Уровень: легкий.]
11.2. Предположим, что ваш диспетчер окон завершился, и вы не можете получить фокус в окне и напечатать команду для вызова нового диспетчера окна. (Предположим также, что у вас нет команды в корневом меню, которая запускает новый диспетчер окон.) Объясните, как вы могли бы использовать копирование и вставку в своих существующих окнах для выполнения команды. [Уровень: высокий.]
Проект
Используйте утилиту xrdb для печати базы данных ресурсов работающего X-сервера. Изучите вывод, чтобы узнать, какие типы ресурсов какими типами приложений используются. [Уровень: средний.]
Глава 12
Инструментальные средства программирования на С
Мотивация
Чаще всего в системах UNIX применяются языки программирования С и C++. Это не удивительно, т. к. ОС UNIX была написана на С, и многие версии поставляются со стандартным С-компилятором. Большинство утилит UNIX и масса коммерческих продуктов написаны на С или C++. Поэтому надеемся, знакомство с написанием, компилированием и выполнением С-программ окажется для читателя очень полезным. Конечно, UNIX поддерживает много других популярных языков программирования, но данная глава предлагает описание прежде всего на языке С и инструментов его поддержки, поскольку они фундаментальны для окружения UNIX.
Предпосылки
Глава предполагает, что вы уже знаете С и компилировали программы, по крайней мере, на одной платформе. Например, много читателей, возможно, использовали С-компиляторы от Borland или Microsoft.
Задачи
В этой главе описываются инструментальные средства, которые поддерживают некоторые стадии разработки программы: компиляция, отладка, поддержка библиотек, профилирование и управление исходным кодом.
Изложение
Программное окружение С представлено естественным способом, со множеством примеров и маленьких программ.
16 Зак. 786
Утилиты
В данной главе будут рассмотрены следующие утилиты:
admin Id sact
аг lint strip
сс lorder touch
comb make tsort
dbx prof unget
get prs
help ranlib
Язык С
Язык С может быть обнаружен в двух главных формах: K&R С и ANSI С. K&R, названый в честь авторов первого популярного программного С-текста Брайана Кернигана (Brian Kernighan) и Денниса Ритчи (Dennis Ritchie), определяет С, как это было в дни юности UNIX. Некоторые ссылаются на него, как на "классический С". Американский национальный институт стандартов (American National Standards Institute, ANSI) разработал собственный стандарт С, добавив некоторые полезные особенности и конкретизировав синтаксис для существующих, но плохо определенных, возможностей. Большинство компиляторов поддерживают оба стандарта.
Прежде чем мы перейдем к исходным кодам, следует уточнить важный момент: исходный код в этой книге не соответствует стандарту ANSI С. Приходится лишь сожалеть, потому что ANSI С содержит несколько хороших синтаксических возможностей и проверку типа, которые позволяют создавать сопровождаемые и удобочитаемые программы. Причина, по которой я не использовал1 указанные особенности, заключается в том, что несколько ведущих корпораций и университетов, которые я знаю, непосредственно поддерживают только K&R С. Чтобы сделать мой исходный код как переносимым, так и полезным насколько возможно, я подогнал его к наиболее разумному наименьшему общему знаменателю. Я делал это без удовольствия, поскольку я профессиональный разработчик программного обеспечения, так же как и автор, и это действительно идет против моей воли. Фактически яч предпочел бы написать весь код на C++, но это другая история.
1 Здесь опять ведется повествование от имени Грэхэма Гласса. — Ред.
Компиляторы С
До недавнего времени С-компилятор был стандартным компонентом в UNIX, особенно в версиях, которые поставлялись с исходным кодом. (Как еще вы могли бы изменить код и создать новое ядро?) К сожалению, некоторые продавцы захотели "оторвать" компиляторы С от своих дистрибутивов UNIX и продают их отдельно. В зависимости от потребностей, пользователь должен проверить его для каждой версии UNIX, которую собирется использовать. Однако даже если некоторая версия UNIX больше не поставляет компилятор С, существует альтернатива. Спасибо проекту GNU: GNU С (gcc) и GNU C++ (g++). Эти компиляторы С и C++, соответственно, свободно доступны для большинства UNIX-платформ на Web-узле GNU по адресу http://www.gnu.org/software/gcc/gcc.html.
Одномодульные программы
Исследуем С-программу2, которая выполняет простую задачу: перестановки в обратном порядке символов строки (будем называть это короче: реверсирование строки). Для начала посмотрим, как писать, компилировать, компоновать модули и выполнять программу, используя единственный исходный файл. Затем выясним, почему лучше разделить программу на несколько независимых модулей, и рассмотрим, как это сделать. Вот исходный листинг КОДа первой ВерСИИ Программы reverse:
1 /* REVERSE.C */
2
3 #include <stdio.h>
4
5 /* Function Prototype */
6 reverse ();
7
g I ★ ★ ★ к * к k-k kkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkk /
9
10 main ()
11
12 {
char str [100]; /* Буфер для хранения реверсированной строки */
14
15 reverse ("cat", str); /* Реверсировать строку "cat" */
2 Большинство примеров, используемых в этой главе, доступно в сети. (Для дополнительной информации см. Введение.)
16 printf ("reverse ("cat") = %s\n", str); /* Вывести результат */
17 reverse ("noon", str); /* Реверсировать строку "noon" */
18 printf ("reverse ("noon") = %s\n", str); /* Вывести результат */
19 } 20
2 у****************************************************************J
22
23 reverse (before, after)
24 '
25 char *before; /* Указатель на исходную строку */
26 char *after; /* Указатель на реверсированную строку */
27
28 {
2 9 int i;
30 int j;
31 int len;
32
33 len = strlen (before);
34
35 for (j = len — 1; i = 0; j >= 0; j—; i++) /* Цикл реверсирования */
36 after[I] =before[j];
37
38 after[len] = NULL; /* NULL прекращает реверсирование строки */ 39 }
Компиляция С-программы
Чтобы написать и выполнить программу reverse, я сначала создал каталог называемый reverse, внутри своего домашнего каталога, а затем — файл reverse.c, используя UNIX-редактор emacs. Далее я компилировал Сопрограмму при помощи утилиты сс.
Чтобы подготовить выполняемую версию единственной, самодостаточной программы, следует ввести за сс имя файла с исходным кодом, который должен закончиться суффиксом ”.с”. Компилятор сс ничего не выводит, когда компиляция проходит без ошибок. По умолчанию сс создает исполняемый файл a.out в текущем каталоге. Чтобы выполнить программу, необходимо ввести: a.out. Любые встречающиеся ошибки передаются в стандартный канал ошибки, который связан по умолчанию с экраном пользовательского терминала.
Вот что получилось при компиляции программы:
$ mkdir reverse ...создать подкаталог для исходного кода.
$ cd reverse
$ ...я создал файл reverse.c, используя emacs.
$ сс reverse.с ... компилировать источник.
"reverse.c", line 16: syntax error at or near variable name "cat"
"reverse.c", line 18: syntax error at or near variable name "noon"
"reverse.с", line 35: syntax error at or near symbol ;
"reverse.c”, line 35: syntax error at or near symbol )
$ _
Как вы видите, компилятор сс нашел ошибки и вывел их список:
□ ошибки на строках 16 и 18 были из-за несоответствующего использования двойных кавычек внутри двойных кавычек;
□ ошибки на строке 35 возникли из-за неправильного использования точки с запятой (;).
Так как эти ошибки было легко исправить, я скопировал отягощенный ошибками файл reverse.c в файл reverse.oldl.c, а затем удалил ошибки времени компиляции при помощи редактора emacs. Я оставил исходный файл в каталоге для того, чтобы можно было видеть эволюцию моего программирования.
Листинг скорректированной программы reverse
Ниже представлена вторая, исправленная, версия программы reverse. Строки, ранее содержащие ошибки, которые я исправил, выделены курсивом:
1 /* REVERSE.C */
2
3 #include <stdio.h>
4
5 /* Function Prototype */
6 reverse ();
7
g у****************************************************************/
9
10 main ()
11
12 {
13 char str [100]; /* Буфер для хранения реверсированной строки */
14
15 reverse ("cat", str); /* Реверсировать строку "cat" */
16 printf ("reverse (\"cat\") = %s\n", str); /* -Вывести */
17 reverse ("noon", str); /* Реверсировать строку "noon" */
18 printf ("reverse (\"noon\") = %s\n", str); /* Вывести ★/
19 } 20
у****************************************************************/
22
23 reverse (before, after)
24
25 char *before; /* Указатель на исходную строку */
26 char *after; /* Указатель на реверсированную строку */
27
28 {
2 9 int i;
30 int j;
31 int len;
32
33 len = strlen (before);
34
35 for (j = len — 1, i = 0; j >= 0; j —, i ++) /* Цикл реверсирования ★/ 3 6 after[I] =before[j];
37
38 after[len] = NULL; /* NULL прекращает реверсирование строки */
39 }
Выполнение С-программы
После компиляции второй версии reverse.c я запустил программу, введя имя исполняемого файла a.out. Как видно, ошибок нет:
$ сс reverse.с ... скомпилировать источник.
$ Is -1 reverse.c a.out ...вывести информацию о файлах.
-rwxr-xr-x 1 glass 24576 Jan 5 16:16 a.out*
-rw-r—r— 1 glass 439 Jan 5 16:15 reverse.c
$ a.out ...выполнить программу.
reverse ("cat") = tac
reverse ("noon") = noon
$
Переопределение имени исполняемого файла
По умолчанию имя исполняемого файла a.out является довольно загадочным, и очередной файл a.out, созданный следующей компиляцией, переписал бы старый файл. Чтобы избежать таких проблем, лучше использовать опцию -о с сс, которая позволяет задать имя исполняемого файла:
$ сс reverse.с -о reverse ...назвать исполняемый файл reverse.
$ Is -1 reverse
-rwxr-xr-x 1 glass 24576 Jan 5 16:19 reverse*
$ reverse ...запустить исполняемый файл reverse.
reverse ("cat") = tac reverse ("noon") = noon $ _
Многомодульные программы
Неудобство способа, которым я строил программу reverse, состоит в том, что функция reverse не может легко использоваться в других программах. Например, необходимо написать функцию, которая возвращает 1, если строка является палиндромом, и 0 в противном случае. (Палиндром — это строка, которая читается одинаково справа налево и слева направо. Например, "noon” — это палиндром, но "попо" — нет.) Можно использовать функцию reverse, чтобы реализовать функцию палиндрома. Один способ: вырезать и вставить reverse о в программу палиндрома, но это убогий метод, по крайней мере, по трем причинам:
□ вырезание и вставка выполняются медленно;
□ если будет создан улучшенный код функции reverse о, необходимо заменить каждую копию старой версии новой версией, что является кошмаром сопровождения;
П каждая копия reverse о поглощает дисковое пространство.
Уверен, вы понимаете, что есть лучший способ’ разделить использование функции.
Многократно используемые функции
Лучшая стратегия для разделения reverse о состоит в том, чтобы удалить ее из программы reverse, скомпилировать отдельно, а затем скомпоновать результирующий объектный модуль с какой угодно программой. Данный способ позволяет обойти перечисленные в предыдущем разделе проблемы и дает возможность использовать функцию в различных программах. Такие функции назваются многократно используемыми.
Подготовка многократно используемой функции
Чтобы подготовить функцию многократного использования, следует создать модуль с исходным кодом функции вместе с файлом заголовка, который содержит прототип функции. Затем необходимо скомпилировать исходный модуль с кодом в объектный модуль, используя опцию -с компилятора сс. Объектный модуль содержит машинный код вместе с информацией в форме таблицы символов, которая позволяет объединить модуль с другими объектными модулями, когда создается исполняемый файл. Ниже представлены листинги новых файлов reverse.c и reverse.h.
reverse.h
1 /* REVERSE.H
2
3 reverse (); /* Объявляет, но не определяет эту функцию */
reverse.c
1 /* REVERSE.C */
2
3 #include <stdio.h>
4 ftinclude "reverse.h"
5
g /************************************************************/
7
8 reverse (before, after)
9
10 char *before; /* Указатель на исходную строку */
11 char *after; /* Указатель на реверсированную строку */
12
13 {
14 int i;
15 int j;
16 int len;
17
18 len = strlen (before);
19
20 for (j = len — 1, i = 0; j >= 0; j—, i++) /* Цикл реверсирования */
21 after[i] = beforefj];
22
23 after[len] = NULL; /* NULL прекращает реверсирование строки */
24 }
mainl.c
Вот листинг основной программы, которая использует reverse ():
1 /* MAIN1.C */
2
3 #include <stdio.h>
4 #include "reverse.h" /* Содержит прототип reverse() */
5
/**w*w*****w*+*w*M*iirw******:w*w*****:w**:w**w*'k******
7
8 main ()
9
10 {
11 char str [100];
12
13 reverse ("cat", str); /* Вызвать внешнюю функцию */
14 printf ("reverse (\"cat\") = %s\n", str);
15 reverse ("noon", str); \ /* Вызвать внешнюю функцию */
16 printf ("reverse (\"noon\") = %s\n", str);
17 }
Отдельное компилирование и компоновка модулей
Для компиляции каждого исходного файла кода отдельно используйте опцию -с компилятора сс. При этом создается отдельный объектный модуль для каждого исходного файла кода с суффиксами ".о”. Например:
$ сс -с reverse.c ...скомпилировать reverse.c в reverse.о.
$ сс -с mainl.c ...скомпилировать mainl.c в mainl.o.
$ Is -1 reverse.c mainl.o
-rw-r—r— 1 glass 311 Jan 5 18:24 mainl.o
1 glass 181 Jan 5 18:08 reverse.о
-rw-r—r—
В качестве альтернативы можно перечислить все исходные файлы кодов в одной строке: $ сс -с reverse.с mainl.с ...скомпилировать каждый .с-файл в .о-файл. $ _
Чтобы скомпоновать их все вместе в исполняемый файл mainl, следует перечислить имена всех объектных модулей после команды компилятора сс: $ сс reverse.о mainl.о -о mainl ...скомпоновать объектные модули.
$ Is -1 mainl ...проверить исполняемый.
-rwxr-xr-x 1 glass 24576 Jan 5 18:25 mainl*
$ mainl ...запустить исполняемый.
reverse (’’cat") = tac reverse ("noon") = noon $
Автономный загрузчик: Id
Когда используется компилятор сс для компоновки нескольких объектных модулей, он, очевидно, вызывает автономный загрузчик UNIX id. Загрузчик известен как linker (компоновщик). Хотя большинство С-программистов непосредственно никогда не вызывают утилиту id, все-таки разумно кое-что знать о ней.
Синтаксис
Id —п {-Ьлуть}* {объектныйМодуль}* {библиотека}★ {-1х}* [-о имяФайла]
Утилита id компонует вместе указанный объектный (объектныйМодуль) и библиотечный (библиотека) модули, чтобы создать исполняемый файл. Можно отменить имя выполняемого файла по умолчанию a.out, используя опцию -о. Если пользователь хочет создать автономный исполняемый файл (в противоположность динамически подключаемому модулю, который находится вне сферы описания этой книги), то следует задать опцию -п. Когда утилита id сталкивается с опцией в виде -1х, она ищет стандартные каталоги /lib, /usr/lib и /usr/local/lib для библиотеки libx.a. Чтобы добавить путь каталога в этот путь поиска, необходимо применить опцию -ъпуть. Утилита id (в большей степени, чем другие утилиты UNIX) меняется от версии к версии. Следует обратиться за дополнительной информацией к документации конкретной версии UNIX при использовании Id.
Если пользователь компонует С-программу вручную, важно определить объектный С-модуль времени выполнения, /lib/crtO.o как первый объектный модуль, и стандартную С-библиотеку, /lib/libc.a как библиотечный модуль. Пример:
$ Id -n /lib/crtO.o mainl.о reverse.c -1с -о mainl ...ручная компоновка.
$ mainl ...выполнить программу.
reverse ("cat") - tac
reverse ("noon") = noon $ _
Повторное использование функции reverse
Теперь, когда вы узнали, что исходная программа reverse может содержать пару модулей, используем модуль reverse снова для построения программы палиндрома. Приведем листинги заголовка и исходного кода функции палиндрома.
palindrome.h
1 /* PALINDROME.H */
2
3 int palindrome О; /* Объявляет, но не определяет */
palindrome.с
1 /* PALINDROME.С */
2
3 #include "palindrome.h"
4 #include "reverse.h"
5 #include <string.h>
6
*7 /★★★★*★★★*★**★*★★★★★★★*★★**★★*****★★*★**★★★*******★★★*•*••*•★*★★•*•★•*••*•★ /
8
9 int palindrome (str)
10
11 char *str;
12
13 {
14 char reversedStr [100];
15 reverse (str, reversedStr); /* Реверсировать оригинал */
16 return (strcmp (str, reversedStr) == 0); /* Сравнить оба */
17 }
main2.c
Вот исходный код программы main2.c, которая проверяет функцию
palindrome () ’.
1 /* MAIN2.C */
2
3 #include <stdio.h>
4 ttinclude "palindrome.h"
5
g /***-**'11г*****'<г*^'А'****^^т1гЛ'*Л***Л'*'** + ^*'<г***********Лт>гЛ,>1г*******'1<'**'<г** /
7
8 main ()
9
10 {
11 printf ("palindrome (\'cat\) = %d\n", palindrome ("cat"));
12 printf ("palindrome (\'noon\) = %d\n", palindrome (."noon"));
13 }
Способ объединить модули reverse, palindrome И main2 ТДКОЙ Же, как И ранее использованный: скомпилируйте объектные модули, а затем скомпонуйте их. Не нужно повторно компилировать reverse.c, поскольку он не изменился с момента создания объектного файла reverse.о.
$ сс -с palindrome.с ...скомпилировать palindrome.с в palindrome.о.
$ сс -с main2.c ...скомпилировать main2.c в main2.o.
$ сс reverse.о palindrome.о main2.o -о main2 ...скомпоновать все.
$ Is -1 reverse.о palindrome.о main2.o main2
-rwxr-xr-x 1 glass 24576 Jan 5 19:09 main2*
-rw-r—г— 1 glass 306 Jan 5 19:00 main2.о
-rw-r—г— 1 glass 189 Jan 5 18:59 palindrome.о
-rw-r—г— 1 glass 181 Jan 5 18:08 reverse.о
$ main2 ...выполнить программу,
palindrome ("cat") = О palindrome ("noon") = 1 $ _
Поддержка многомодульных программ
При поддержке многомодульных систем нужно рассмотреть несколько различных вопросов:
1. Что гарантирует сохранение последних версий объектных модулей и исполняемых файлов?
2. Что содержат объектные модули?
3. Кто отслеживает каждую версию исходных файлов и файлов заголовков?
К счастью, есть утилиты UNIX, которые решают каждую проблему. Вот ответ на каждый вопрос:
1. Утилита make, система зависимости файлов UNIX.
2. Утилита аг, архивная система UNIX.
3. Система управления исходным кодом SCCS.
Система зависимости файлов UNIX: make
Теперь понятно, как несколько независимых объектных модулей могут быть скомпонованы в единственный исполняемый файл. Вдобавок, один и тот же объектный модуль может быть связан с несколькими различными исполняемыми файлами. Хотя многомодульные программы эффективны в терминах возможности многократного использования и дискового пространства, они должны тщательно поддерживаться. Например, предположим, что мы изменяем исходный код reverse.c так, чтобы он использовал указатели вместо массива. Это привело бы к более быстрой обратной функции. Чтобы модернизировать исполняемые файлы двух главных программ, mainl и main2, вручную, мы должны проделать следующие шаги:
1. Повторно скомпилировать reverse.c.
2. Связать reverse.o и mainl.о для того, чтобы создать новую версию mainl.
3. Связать reverse.o и main2.o для того, чтобы создать новую версию main2.
Вообразите также ситуацию, что предложение #define в файле заголовка изменено. Все исходные файлы кодов, которые непосредственно или косвенно включают файл заголовка, должны повторно компилироваться, а затем все исполняемые модули, которые обращаются к измененным объектным модулям, должны быть повторно скомпонованы.
Представьте систему с 1000 объектными модулями и 50 выполняемыми программами. Помнить все отношения среди заголовков, файлов исходных кодов, объектных модулей и исполняемых файлов было бы кошмаром. Один из способов избежать этой проблемы состоит в том, чтобы использовать утилиту UNIX make, которая позволяет создавать make-файл, который содержит список всех взаимозависимостей для каждого исполняемого файла. Как только такой файл создан, повторно создать исполняемый файл легко: просто запускается утилита make: $ make -f makefile
Синтаксис
make [-f такеФайл]
Утилита make модернизирует файл на основе ряда правил зависимостей, сохраняемых в специальном формате, make-файл. Опция -f позволяет определить собственное имя make-файла. Если оно не указано, принимается имя makefile.
Маке-файлы
Чтобы использовать утилиту таке для поддержки исполняемого файла, следует сначала создать make-файл. Этот файл содержит список всех взаимоза-висимостей, которые существуют между файлами и используются для создания исполняемого файла. Make-файл может иметь любое имя. Рекомендуется называть его, добавляя к имени исполняемого файла суффикс ".make". Таким образом, имя make-файла для mainl могло бы быть mainl.make. В своей самой простой форме make-файл имеет формат, представленный ниже.
Синтаксис
списокЦелей: списокЗависимости
списокКоманд
Здесь списокЦелей — СПИСОК целевых файлов, списокЗависимости — список файлов, ОТ которых зависят файлы В спискеЦелей. списокКоманд — список команд (команды вообще могут отсутствовать), разделенных символом перевода строки, которые реконструируют целевые файлы из файлов зависимостей. Каждая строка в спискекоманд должна начинаться с символа табуляции. Правила следует разделить, по крайней мере, одной пустой строкой.
Например, давайте подумаем о взаимозависимостях файла, связанных с исполняемым файлом mainl. Этот файл построен из двух объектных модулей: main 1.о и reverse.©. Если любой файлов изменен, mainl может быть восстановлен путем компоновки файлов через утилиту сс. Поэтому одно правило в mainl.make было бы
mainl: mainl.о reverse.о
сс mainl.о reverse.о -о mainl
Эта строка должна теперь приводить к двум объектным файлам. Файл mainl.o построен из двух файлов: mainl.c и reverse.h. (Помните, что любой файл, который является непосредственно или косвенно включенным через директиву #included в исходный файл, является эффективной частью этого файла.) Если один из файлов изменен, то mainl.o может быть восстановлен компиляцией mainl.c. Здесь, следовательно, появляются дополнительные правила в mainl.make:
mainl.o: mainl.c reverse.h
сс -c mainl.c
reverse.©: reverse.c reverse.h
cc -c reverse.c
Порядок make-правил
Порядок make-правил важен. Утилита make создает "дерево” взаимозависи-мостей, первоначально исследуя первое правило. Каждый целевой файл в первом правиле — корневой узел дерева зависимости, и каждый файл в его списке зависимости добавляется, как лист корневого узла. В нашем примере начальное дерево может иметь такой вид, как представлено на рис. 12.1.
mainl
mainl.o
reverse, о
Рис. 12.1. Начальное дерево зависимости make
Далее утилита make просматривает каждое правило, связанное с файлами в списке зависимости, и выполняет те же самые действия. В нашем примере заключительное дерево выглядит так, как показано на рис. 12.2.
mainl
mainl.o
reverse, о
mainl.c
reverse.h
reverse.c
reverse.h
Рис. 12.2. Заключительное дерево зависимости make
Наконец, утилита make обрабатывает дерево от нижних узлов (листьев) до коревого узла, определяя, является ли последнее время модификации каждого дочернего узла более поздним, чем последнее время модификации его непосредственного родительского узла. Для каждого случая, где это условие соблюдается, выполняется правило, связанное с родителем. Если файл не существует, его правило выполняется без учета времени последних модификаций его дочерних узлов. Чтобы проиллюстрировать порядок, в котором узлы могли быть исследованы, на рис. 12.3 представлена пронумерованная диаграмма.
main17
mainl.о
reverse, о
reverse, h
reverse. с3
Рис. 12.3. Упорядочение make
mainl. с1
reverse. h4
Выполнение make
Поскольку make-файл создан, можно выполнить утилиту make для создания исполняемого файла, чьи информационные зависимости определены make-файлом. Для демонстрации ее работы были удалены все объектные модули и исполняемый файл, чтобы выполнился каждый список команд. Когда затем была запущена утилита make, на экране появилось:
$ таке -f mainl.make ...сделать новейший исполнимый файл.
сс -с mainl.с
сс -с reverse.с
сс mainl.о reverse.о -о mainl
$ _
Заметьте, что каждое make-правило было выполнено в точном порядке, показанном на рис. 12.3. Так как был создан второй исполняемый файл после программы palindrome, также был сформован второй make-файл main2.make. Вот он:
main2: main2.o reverse.о palindrome.о
сс main2.o reverse.о palindrome.о -о main2
main2.o: main2.c palindrome.h
сс -с main2.с reverse.o: reverse.c reverse.h
сс -c reverse.c
palindrome.о: palindrome.c palindrome.h reverse.h cc -c palindrome.c
После запуска make с использованием этого файла получен вывод: $ make -f main2.make ...создать более поздний исполняемый файл, сс -с main2.с сс -с palindrome.с сс main2.o reverse.o palindrome.о -о main2 $ _
Заметьте, что файл reverse.c повторно не компилировался, потому что предыдущий запуск make уже СОЗДВЛ обновленный объектный модуль, a make повторно компилирует файлы, только когда это необходимо.
Маке-правила
Маке-файлы, продемонстрированные ранее, на самом деле гораздо больше, чем должны быть. Это потому, что некоторые добавленные шаке-правила уже известны утилите таке в более общем виде. Например, обратите внимание, что некоторые из правил имеют форму
ххх.о: reverse.c reverse.h
сс -с ххх.с
где ххх изменяется среди правил. Утилита таке содержит предопределенное правило, подобное
. с. о:
/bin/сс -с -0 $<
Это выглядящее загадочно правило сообщает утилите таке, как создать объектный модуль из исходного файла кода С. Существование такого общего правила позволяет отбросить правило перекомпиляции С. Поэтому представим улучшенную версию main2.make:
main2: main2.o reverse.o palindrome.о
cc main2.o reverse.o palindrome.о -о main2
main2.o: main2.c palindrome.h
reverse.o: reverse.c reverse.h
palindrome.о: palindrome.c palindrome.h reverse.h
Утилита make также включает другие правила вывода. Например, она "знает", что имена объектного модуля и его соответствующего исходного файла кода обычно связаны. Утилита использует эту информацию, чтобы вывести стандартные зависимости. Например, она выводит, что main2.o зависит от main2.c и, таким образом, можно убрать эту информацию из списка зависимости. Приведем еще раз переработанную версию main2.make:
main2: main2.0 reverse.0 palindrome.0 cc main2.o reverse.0 palindrome.0 -0 main2
main2.0: palindrome.h
reverse.0: reverse.h
palindrome.о: palindrome.h reverse.h
Написание собственных пользовательских правил
К сожалению, метод для написания собственных пользовательских правил или даже описание тех, что уже существуют, находится вне рамок данной книги. Для получения дополнительной информации консультируйтесь с одним из источников, указанных в разд. "Другие возможности таке" далее в этой главе.
touch
Чтобы удостовериться, что новая версия make-файла работала, была запущена утилита make и получен следующий вывод:
$ make -f main2.make
'main2' is up to date.
$ _
Поскольку make успешно выполнлась ранее, другой запуск этой утилиты не собирался вызывать никакие правила! Чтобы заставить make работать с целью проверки, следует воспользоваться удобной утилитой touch, которая делает последнее время модификации всех указанных файлов равным текущему времени системы.
Синтаксис
touch -с {имяФайла}+
Утилита touch обновляет время последней модификации и доступа указанных файлов, чтобы сделать его равным текущему времени. По умолчанию, если указанный файл не существует, он создается с нулевым размером. Чтобы предотвратить это, используйте опцию -с.
В представленном ниже примере утилита touch использоваась для файла reverse.h, который впоследствии вызвал перекомпиляцию нескольких исходных файлов:
$ touch reverse.h ...полная сборка.
$ make -f main2.make
/bin/сс -с —о reverse.c
/bin/сс —с —о palindrome.c
cc main2.o reverse.© palindrome.© -o main2 $
Макросы
Утилита make поддерживает примитивные макросы. Если вы определяете строку в формате, представленном ниже, в начале make-файла, каждое появление $ (символ) в make-файле заменяется такстомЗамены.
Синтаксис
символ = текстЗамены
В дополнение к существующим правилам стандартный файл правил содержит определения макросов по умолчанию, типа cflags, которые используются некоторыми из встроенных правил. Например, правило, которое сообщает утилите make, как модернизировать объектный файл из исходного С-файла, напоминает это:
.с.о:
/bin/сс -с $(CFLAGS) $< ,
Стандартный файл правил содержит строку в формате
CFLAGS = -О 4
Если пользователь желает повторно откомпилировать набор программ, используя опцию -р компилятора сс, следует отменить значение по умолчанию cflags в начале make-файла и указать опцию -р в заключительном запросе к сс в правиле main2, подобно этому:
CFLAGS = -Р
main-2: main2.o reverse.© palindrome.0 cc -p main2,.o reverse.0 palindrome.0 -0 main2
main2.о: palindrome.h
reverse.о: reverse.h
palindrome.0: palindrome.h reverse.h
Чтобы повторно скомпилировать набор программ, запускается утилита touch:
$ touch *.с ...заставить make повторно компилировать все.
$ таке -f main2.make
/bin/сс -с -р main2.с
/bin/сс -с -р palindrome.с
/bin/сс -с -р reverse.c
сс -р main2.o reverse.o palindrome.о -о main2 $
Другие возможности таке
make — довольно сложная утилита, которая обеспечивает обработку правил вывода и библиотек. Сведения почти обо всех возможностях, кроме возможностей поддержки библиотек, включены в эту книгу, в других книгах содержится меньше данных о make. Поэтому обратитесь к страницам man UNIX для получения дополнительной информации.
Система поддержки архивов UNIX: аг
С-проект среднего размера обычно содержит несколько сотен объектных модулей. Описание такого большого числа объектных модулей в правилах make-файла может оказаться довольно утомительным. Поэтому рекомендуется изучить применение утилиты поддержки архивов аг, чтобы организовывать и группировать объектные модули. Данная утилита, иногда известная как библиотекарь, позволяет выполнять следующие задачи:
□ создание специального файла формата архива, заканчивающегося суффиксом ’’.а”;
□ добавление, удаление, замену и присоединение любого вида файлов к архиву;
□ получение оглавления архива.
Синтаксис
аг ключ имяАрхива {имяФайла} ★
Утилита аг позволяет создавать и управлять архивом. имяАрхива — имя файла архива, к которому пользователь желает получить доступ, должно заканчиваться суффиксом ".а". Аргумент ключ может принимать одно из значений:
• d — удаляет файл из архива;
• q — добавляет файл в конец архива, даже если он уже существует;
• г — добавляет файл к архиву, если его там нет, или заменяет текущую версию, если он есть;
• t — посылает оглавление архива на стандартный вывод;
• х — копирует список файлов из архива в текущий каталог;
• v — производит многословный вывод.
Когда набор объектных модулей сохраняется в файле архива, к нему можно просто обращаться из компилятора сс и загрузчика id, указывая имя файла архива в качестве аргумента. Любые объектные модули, которые необходимо взять из файла архива, автоматически компонуются. Это сильно уменьшает количество параметров, которые требуют данные утилиты при объединении большого числа объектных модулей.
Создание архива
Архив автоматически создается, когда добавляется первый файл. Поэтому, чтобы узнать, как создается архив, см. разд. "Добавление файла" далее.
Добавление файла
Чтобы добавить (или заменить) файл к указанному архиву, используйте утилиту аг с опцией г. Эта опция добавляет все указанные файлы к файлу архива имяАрхива, заменяя уже существующие файлы. Если файлАрхива не существует, он автоматически создается. Имя архива должно иметь суффикс ".а".
Синтаксис
аг г имяАрхива {имяФайла}+
Присоединение файла
Чтобы присоединить файл к указанному архиву, используйте утилиту аг с опцией q. Эта опция добавляет все указанные файлы к файлу архива имяАрхива независимо от того, существуют они или нет. Если файл архива не существует, то автоматически создается. Опция q удобна, если известно, что файл уже существует, поскольку она позволяет утилите избежать поиска в архиве.
Синтаксис
ar q имяАрхива {имяФайла}+
Получение оглавления
Чтобы получить оглавление архива, используйте утилиту аг с опцией t.
Синтаксис
ar t имя Арх ив а
Удаление файла
Для удаления списка файлов из архива используйте утилиту аг с опцией а.
Синтаксис
ar d имяАрхива {имяФайла} +
Извлечение файла
Для копирования списка файлов из архива в текущий каталог применяйте утилиту аг с опцией х. Если список файлов не определен, то копируются все файлы из архива.
Синтаксис
аг х имяАрхива {имяФайла}+
Обработка архива из командной строки
Приведенный ниже пример иллюстрирует, как можно создать архив и управлять им из командной строки с помощью объектных модулей, описанных ранее в главе. Позже будет показано, как библиотека способна поддерживаться автоматически из make-файла.
Сначала был создан файл архива string.a, чтобы хранить все связанные со строкой объектные модули. Затем по очереди добавлялся каждый модуль с помощью опции г. И, наконец, продемонстрированы различные опции аг.
$ сс -с reverse.c palindrome.с main2.c ...создать объектный файл.
$ 1s ★.о ...подтвердить.
main2.o palindrome.о reverse.o
$ ar г string.a reverse.o palindrome.о ...добавить в архив.
ar: creating string.a
$ ar t string.a ...получить оглавление.
reverse.© palindrome.о $ сс main2.o string.а -о main2 $ main2 palindrome ("cat") = О palindrome ("noon") = 1 $ ar d string.a $ ar t string.a palindrome.о $ ar r string.a $ ar t string.a palindrome.о reverse.© $ rm palindrome.о reverse.о $ Is *.o main2.о $ ar x string.a reverse.о $ Is *.o main2.©reverse.о $
reverse.о
reverse.о
...скомпоновать объектные модули.
...выполнить программу.
...удалить модуль.
...подтвердить удаление.
...поместить обратно.
...подтвердить добавление
...удалить оригиналы.
...подтвердить.
...скопировать их обратно.
...подтвердить.
Обработка архива при помощи утилиты таке
Хотя архив может быть создан и обработан из командной строки, намного лучше применять утилиту make. Чтобы обратиться к объектному файлу в архиве, поместите после имени архива имя объектного файла внутри круглых скобок. Утилита make имеет встроенные правила, которые автоматически заботятся об операциях над архивом. Ниже приведен обновленный файл main2.make, который использует архив вместо простых объектных файлов:
main2: main2.o string.a(reverse.©) string.a(palindrome.о)
cc main2.o string.a -o main2
main2.o: palindrome.h
string.a(reverse.o): reverse.h
string.a(palindrome.o): palindrome.h reverse.h
Вот вывод утилиты make, запущенной с предыдущим файлом:
$ гт *.о ...удалить все объектные модули.
$ make -f main2.make ...выполнить make.
сс -с main2.с
ar rv string.a reverse.© ...объектный модуль сохранен.
a — reverse.©
ar: creating string.a
rm -f reverse.c ...оригинал удален.
сс -c palindrome.с
ar rv string.a palindrome.о a — palindrome.о
rm -f palindrome.©
cc main2.o string.a -o main2 ...доступ к архивированным
. . .объектным модулям.
$ _
Заметьте, что встроенные make-правила автоматически удалили первоначальный объектный файл, как только он был скопирован в архив.
Упорядочение архивов
Встроенные make-правила не поддерживают никакого специфического порядка в файле архива. В большинстве систем это нормально, т. к. утилиты сс и id способны извлечь объектные модули и разрешить внешние ссылки независимо от порядка. Однако в некоторых старых системах такая ситуация невозможна. Вместо этого, если объектный модуль А содержит функцию, которая вызывает функцию в объектном модуле В, то В должен быть перед А в последовательности компоновки. Если А и В находятся в одной и той же библиотеке, то В должен появиться перед А в библиотеке. Если пользовательская система является одной из старых, то, вероятно, появится следующая ошибка в конце make, показанного в предыдущем примере:
Id: Undefined symbol
_reverse
*** Error code 2
make: Fatal error: Command failed for target 'main2'
Данная загадочная ошибка происходит, потому что reverse.o содержит запрос к функции palindrome о в palindrome.o. Это означает, что reverse.o должен быть, после palindrome.o в архиве. Чтобы устранить ошибку, следует либо реорганизовать модули в архиве с помощью утилит lorder и tsort, либо использовать утилиту raniib, как описано в следующем разделе. В приведенном ниже примере создана новая упорядоченная версия старого архива, а затем переименована, чтобы заменить оригинал:
$ ar cr string2.a lorder string, а | tsort' $ ar t string, а
...упорядочить архив.
...старый порядок.
reverse.о
palindrome.о
$ ar t string2.а palindrome.о
...новый порядок.
reverse.о
$ mv string2.a string.a
$ make -f main2d.make
...заменить старый архив.
...попытка выполнить make снова.
сс main2.o string.a -о main2
$ _
Make-файл тогда отработает правильно.
ДЛЯ ПОЛучеНИЯ ДОПОЛНИТеЛЬНОЙ информации Об уТИЛИТах lorder И tsort используйте ВОЗМОЖНОСТЬ man.
Создание оглавления: ranlib
В старых системах, в которых упорядочение является проблемой, можно помочь компоновщику обработать неупорядоченные объектные модули путем добавления оглавления к каждому архиву через утилиту ranlib. (Если ranlib не существует в системе, то не стоит волноваться о порядке.)
Синтаксис
ranlib {имяАрхива} +
Утилита ranlib добавляет оглавление к каждому указанному архиву. (Она делает это, вставляя вход .SYMDEF в архив.)
В приведенном далее примере ошибка ссылки возникла из-за неправильного порядка следования объектных модулей в архиве string.a. Компилятор сс напомнил, что следует добавить оглавление. Как вы можете видеть, компоновка прошла успешно:
$ ar г string.a reverse.o palindrome.о ...этот порядок вызывает
.. . проблемы.
ar: creating string.a
$ сс main2.o string.a -о main2 ...компилировать файлы.
Id: string.a: warning: archive has no table of contents; add one using ranlib(1)
Id: Undefined symbol
reverse
$ ranlib string.а
$ cc main2.o string.a -o main2
$ main2
...добавить оглавление.
...нет проблемы.
...программа работает прекрасно.
palindrome (’’cat’’) = 0 palindrome ("noon") = 1 $ _
Разделяемые библиотеки
Статические библиотеки работают, безусловно, прекрасно для многих приложений. Однако поскольку скорость процессоров увеличилась и стоимость микросхем памяти снизилась, код стал более сложным. Таким образом, программы, связанные с большими архивами библиотек, теперь производят очень большие выполняемые файлы. (Маленькая программа, которая создает единственное Х-окно, может иметь мегабайтный размер, когда связана с требуемыми Х-библиотеками.)
Для того чтобы уменьшить размер созданного объектного кода, разумно связать программу с разделяемой библиотекой (shared library). Разделяемая (или динамическая) библиотека связана с компилируемой программой, но ее функции загружаются динамически, по мере необходимости, а не все сразу во время загрузки. Результирующий объектный код меньше, потому что он не включает текст библиотеки, как это делается, когда осуществляется компоновка со статической библиотекой.
Одно неудобство использования разделяемой библиотеки состоит в том, что объектный код будет написан для определенной версии библиотеки. Если код изменен, но интерфейсы не менялись, то пользовательской программе полезнее взаимодействовать с новой библиотекой, которая работает лучше. Однако если изменения сделаны в интерфейсе библиотеки, то при компоновке программы с обновленной версией библиотеки во время выполнения могут возникнуть проблемы (и, вероятно, они появятся). Поэтому важно быть осведомленным об изменениях в поддерживаемых библиотеках при написании приложения.
Утилита id содержит аргументы, предписывающие ей построить разделяемую библиотеку (в системах, которые поддерживают такие библиотеки) вместо статической библиотеки. Эти аргументы изменяются в разных версиях UNIX, и необходимо свериться с документацией к ОС. Наиболее общая форма — это -shared. Можно также проинструктировать утилиту id связываться либо со статическими, либо с динамическими библиотеками, используя аргумент -В (-Bstatic ИЛИ -Bdynamic). В заВИСИМОСТИ ОТ пользовательского С-компилятора утилита сс может иметь один из указанных (или других) аргументов, чтобы создать разделяемую библиотеку во время компиляции.
Система управления
исходным кодом UNIX: SCCS
Чтобы должным образом поддерживать большой проект, важно уметь хранить, получать доступ и защищать все версии файлов исходных кодов. Например, предположим, что я решил изменить функцию reverse о для использования указателей ради эффективности. Было бы хорошо, если бы я мог легко вернуться и посмотреть, как исходный файл выглядел прежде, чем были сделаны изменения. Точно так же важно запретить другим пользователям вносить изменения в файл, в то время как вы активно его редактируете.
Ниже представлены принципы работы системы управления исходным кодом UNIX (Source code control system, SCCS).
□ Когда программист создает первоначальную версию функции, то преобразует ее в файл формата SCCS, используя утилиту admin. Файл формата SCCS сохраняется специальным способом и не может быть отредактирован или скомпилирован, как обычно. Он содержит информацию о времени и пользователе, создавшем его. Новые модификации будут содержать информацию об изменениях, которые были сделаны по сравнению с предыдущей версией.
□ Всякий раз, когда необходимо отредактировать файл формата SCCS, следует сначала "оформить выдачу" (check out) самой последней версии файла, применяя утилиту get. Она создает текстовый файл стандартного формата, который можно редактировать и компилировать. Утилита get также позволяет получать предыдущую версию файла.
□ Когда работа над новой версией файла завершена, следует возвратить ее в SCCS-файл посредством утилиты delta. Она оптимизирует хранение SCCS-файла, запоминая лишь различия между старой и новой версиями. Утилита get не позволяет кому-либо еще выбрать файл, пока пользователь не вернет его.
□ Утилита sact предоставляет возможность наблюдать за процессом редактирования конкретного SCCS-файла.
SCCS также содержит утилиты help, prs, comb, what и unget. Прежде чем мы исследуем более продвинутые опции SCCS, давайте рассмотрим типовую сессию. Учтите, что некоторые системы имеют отличный от SCCS способ работы. Поэтому следует проконсультироваться с man, чтобы определить, соответствуют ли SCCS-примеры, приведенные в данной книге, вашей версии системы SCCS. Обратите внимание, что SCCS обсуждается потому, что она поставляется с большинством версий UNIX. Другое программное обеспечение управления исходным кодом, которое может лучше удовлетворять вашим потребностям, доступно через Интернет (например, Система управ
ления модификациями GNU (Revision Control System, RCS)) и за определенную плату.
Создание SCCS-файла
Чтобы создать SCCS-файл, используйте утилиту admin.
Синтаксис
admin -1имя -flсписок -dlсписок -еимя -аимя зссз_Файл
Утилита SCCS admin позволяет создавать и управлять файлом формата SCCS. Опция -i создает файл зссз^Файл из файла имя. Имя sccs-Файла должно иметь приставку ”.s". Опции -fi и -di позволяют закрывать и открывать набор перечисленных версий соответственно. Опции -а и -е предоставляют возможность добавлять и удалять указанных пользователей из списка пользователей, которым разрешается получать редактируемую версию SCCS-файла. Как только SCCS-файл будет создан, можно удалить оригинал. Если появляется ошибка от любой утилиты SCCS, необходимо вызвать SCCS-утилиту help с кодом сообщения в качестве ее аргумента.
В представленном ниже примере создается SCCS-версия исходного файла reverse.c.
$ Is -1 reverse.c ...посмотреть оригинал.
-rw-r—г— 1 gglass 266 Jan 7 16:37 reverse.c
$ admin -ireverse.c s.reverse.c ...создать SCCS-файл.
No id keywords (cm7)
$ help cm7 ...получить помощь о cm7.
cm7: "No id keywords"
No SCCS identification keywords were substituted for. You may not have any keywords in the file, in which case you can ignore this warning. If this message came from delta then you just made a delta without any keywords. If this message came from get then the last time you made a delta you changed the lines on which they appeared. It’s a little late to be telling you that you messed up the last time you made a delta, but this is the best we can do for now, and it’s better than nothing.
This isn’t an error, only a warning.
$ Is -1 s.reverse.c ...посмотреть SCCS-файл.
-г—г—г— 1 gglass 411
$ rm reverse.с $
Jan 7 17:39 s.reverse.с
...удалить оригинал.
Синтаксис
help {сообщение}+
Утилита SCCS help выводит объяснение указанных ключевых сообщений, которые, в свою очередь, генерируются другими SCCS-утилитами в случаях предупреждений или фатальных ошибок.
Выборка файла
Чтобы вызвать копию SCCS-файла только для чтения, используйте утилиту get.
Синтаксис
get -е -р -гредакция sccS—Файл
SCCS-утилита get проверяет редакцию файла из его SCCS-дубликата. Если номер версии не задан, проверяется самая последняя версия. Если указана опция -е, файл подвергся изменениям и должен быть возвращен в SCCS-файл с помощью утилиты delta. Иначе он только читается и не должен возвращатся. Опция -р отправляет копию файла только для чтения на стандартный вывод; никакой файл не создается.
В следующем примере проверяется копия только для чтения самой последней версии файла reverse.c:
$ get s.reverse.с 1.1 29 lines
No id keywords (cm7) $ Is -1 reverse.c -r—r—r— 1 gglass
...проверить копию только для чтения.
...номер версии.
...количество строк в файле.
...посмотреть копию.
266 Jan 7 18:04 reverse.c
$
Утилита get показывает номер версии файла, который проверяется. В данном случае это номер версии по умолчанию — 1.1. Номер версии имеет
формат релиз.дельта. Обратите внимание, что каждый раз, когда сохраняется изменение в SCCS-файл, номер дельты увеличивается автоматически. Номер релиза изменяется явно лишь с использованием утилиты get. Пример создания нового релиза будет приведен немного позже.
Когда пользователь получает версию SCCS-файла только для чтения, она не может быть отредактирована, и ничего не делается для установки запрета на доступ к файлу. Чтобы получить редактируемую версию SCCS-файла, используйте опцию -е. Она создает перезаписываемый файл и предотвращает многократные "вызовы". Следующие команды иллюстрируют использование -е:
$ get -е s.reverse.с 1.1
new delta 1.2
29 lines
$ Is -1 reverse.c -rw-r-xr-x 1 gglass $ get -e s.reverse.c
...получить записываемую версию.
...редактируемая версия это 1.2.
...посмотреть ее.
266 Jan 7 18:05 reverse.с,
...версия закрыта.
ERROR [s.reverse.с]: writable ereverse.с* exists (ge4)
$
Наблюдение SCCS-активности
Утилита sact демонстрирует список процессов редактирования, связанных с указанным файлом.
Синтаксис
sact {sccS—Файл} +
Утилита SCCS sact показывает текущий процесс редактирования по указанным SCCS-файлам. Вывод содержит версию существующей дельты, версию новой дельты, имя пользователя, который проверил файл с помощью get -е, дату и время, когда была выполнена команда get -е.
Вот вывод sact от предыдущего примера:
$ sact s.reverse.с ...наблюдать активность на reverse.c.
1.1 1.2 gglass 98/01/07 18:05:11
$
Отмена выборки и возврат файла
Если пользователь выполняет утилиту get, а затем хочет отменить результат ее работы, следует воспользоваться утилитой unget.
Синтаксис
unget -гредакция -п {зссз_Файл} +
Утилита SCCS unget полностью отменяет результат предыдущей работы утилиты get. Данная утилита восстанавливает SCCS-файл в его прежнее состояние, удаляет He-SCCS-версию файла и открывает файл для использования другими людьми. Если в настоящее время редактируются несколько редакций, следует использовать опцию -г для определения номера редакции, кторая подлежит отмене. По умолчанию unget поместит обратно файл в SCCS-файл. Опция -п предписывает unget копировать файл, оставляя выбранную версию на месте.
В следующем примере предположим, что сначала была запущена утилита get с файлом reverse.c, а потом было решено отменить результат ее работы:
$ Is -1 reverse.с -rw-r-xr-x 1 gglass $ unget s.reverse.c 1.2
$ Is -1 reverse.c reverse.c not found $ sact s.reverse.c No outstanding deltas for: $
...посмотреть выбранный файл.
266 Jan 7 18:05 reverse.c
...вернуть его.
...версия возвращенного файла.
...оригинал ушел.
...активность над оригиналом ушла.
s.reverse.с
Создание новой дельты
Предположим, что пользователь выбирает редактируемую версию файла reverse.c и изменяете ее так, чтобы она использовала указатели вместо индексов массива. Далее приведен листинг новой версии:
1 /* REVERSE.C */
2
3 #include <stdio.h>
4 #include "reverse.h"
5
6
7 reverse (before, after)
8
9 char *before;
10 ch^r *after;
11
12 {
13 char* p;
14
15 p = before + strlen (before);
16
17 while (p— != before)
18 *after++ = *p;
19
20 *after = NULL;
21 }
Когда новая версия файла сохранена, пользователь должен возвратить ее в SCCS-файл, используя утилиту delta.
Синтаксис
delta -гредакция -п {зссз_Файл} +
Утилита SCCS delta возвращает проверенный файл назад в указанный SCCS-файл. Номер новой версии дельты равен старому номеру дельты плюс один. Вдобавок, delta описывает изменения, которые пользователь сделал в файле. Утилита напоминает о комментарии перед возвращением файла. Если тот же самый пользователь имеет две невыполненные версии и желает возвратить одну из них, должна использоваться опция -г, чтобы определить номер редакции. По умолчанию файл удаляется после возвращения. Опция -п предотвращает это.
Пример:
$ delta s.reverse.с ... возврат модифицированной версии.
comments? converted the function to use pointers ...комментарий. No id keywords (cm7) 1.2 ...номер новой версии.
5 inserted ...описание модификаций.
7 deleted
16 unchanged
$ Is -1 reverse.c ...оригинал был удален,
reverse.c not found
$ _
Получение истории файла
Чтобы получить листинг истории модификации SCCS-файла, используйте утил иту prs.
Синтаксис
prs -гper акция {зссз_Файл} +
SCCS утилита prs выводит историю, связанную с указанными SCCS-файлами. По умолчанию демонстрируется история всего файла. Можно ограничить вывод конкретной версией, используя опцию -г. Числа в правой колонке вывода относятся к номеру строк, вставленных, удаленных и сохраненных неизменными соответственно.
Пример:
$ prs s.reverse.с ...вывести историю,
s.reverse.c:
D 1.2 98/01/07 18:45:47 gglass 2 1 00005/00007/00016
MRs:
COMMENTS:
converted the function to use pointers
D 1.1 98/01/07 18:28:53 gglass 1 0 00023/00000/00000
MRs:
COMMENTS:
date and time created 98/01/07 18:28:53 by gglass $
Идентифицирующие ключевые слова SCCS
В исходный файл могут быть помещены и обработаны утилитой get несколько специальных последовательностей символов, когда получаются версии копий только для чтения. В табл. 12.1 перечислены наиболее общие прел едовательности. Удобно помещать эти последовательности в комментарий
17 Зак. 786
в начале исходного файла. Комментарий не затронет исходный код программы и будет виден при чтении файла.
Таблица 12.1. Идентифицирующие ключевые последовательности SCCS
Последовательность Заменяется на
%м% имя файла исходного кода
%i% номер релиз. дельта. ветвь, последовательность
%D% текущую дату
%Н% текущий час
о гр о. ъ 1 ъ текущее время
Создание нового релиза
Чтобы создать новый релиз SCCS-файла, следует определить его номер через опцию -г утилиты get. Новый номер релиза основан на самой современной версии предыдущего релиза. В представленном ниже примере создается релиз 2 из файла reverse.c и добавляются идентификационные ключевые слова SCCS, описанные в предыдущем разделе: $ get -е ~r2 s. reverse.c ...выбрать версию 2. 1.2 ...номер предыдущей версии.
new delta 2.1 ...номер новой версии.
21 lines $ vi reverse.c ...редактировать перезаписываемую копию.
. . .Я добавил следующие строки в начале программы: /* Module: %М% SCCS Id: %I% Time: %D% %T% * / ...и затем сохранил файл. $ delta s.reverse.с ...вернуть новую версию,
comments? added SCCS identification keywords 2.-1 6 inserted 0 deleted 21 unchanged $ get -p s.reverse.c ...вывести файл на стандартный вывод.
2.1 /* REVERSE.Н */
/*
Module: reverse.с
SCCS Id: 2.1
Time: 98/01/07 22:32:38
*/
...остаток файла
$ _
Обратите внимание, что ключевые слова были замещены, когда была получена копия версии 2 только для чтения.
Выборка копий только для чтения предыдущих версий
Чтобы выбрать другую, а не самую последнюю версию, используйте опцию -г утилиты get для задания номера версии. Например, следует получить копию только для чтения версии 1.1 файла reverse.c. Вот как это сделано:
$ get -г 1.1 s.reverse.с ...выборка версии 1.1.
1.1
23 lines $
Выборка редактируемых копий предыдущих версий
Если пользователь желает получить редактируемую копию предыдущей версии, следует использовать опции -е или -г утилиты get. Предположим, что необходимо получить редактируемую копию версии 1.1 файла reverse.c. Номер версии редактируемой копии не может быть 1.2, т. к. эта версия уже существует. Вместо этого утилита get создает новую "ветку" из версии 1.1, пронумерованную 1.1.1.1 (рис. 12.4). Дельты, добавленные к этой ветке, нумеруются 1.1.1.2, 1.1.1.3 и т. д.
1.1 ------------► 1.2
Ветка
1.1.1.1 -----------► 1.1.1.2
Рис, 12,4, "Ветвление" дельты
Пример:
$ get -е -г1.1 s.reverse.с ...создать ветку версии 1.1.
1.1 .
new delta 1.1.1.1 23 lines $ _
Редактирование различных версий
Допустимо одновременное редактирование различных редакций файла. Однако следует определить номер редакции файла, который возвращается, когда выполняется утилита delta. Необходимо также переименовать копию, когда пользователь получает другую копию, т. к. всем копиям присваивается одно и то же имя. В приведенном ниже примере возвращаются копии версий 1.1 и 2.1 для редактирования, а затем обе сохраняются:
$ get -е -г1.1 s.reverse.с ...редактировать новую версию на основе 1.1. 1.1 new delta 1.1.1.1 23 lines
$ mv reverse.c reverse2.c ... переименовать версию 1.1.1.1.
$ get -e -r2.1 s. reverse.c ...редактировать новую версию на основе 2.1.
2.1 new delta 2.2 27 lines
$ sact s.reverse.c ...показать SCCS-активность.
1.1 1.1.1.1 gglass 98/01/07 22:42:26
2.1 2.2 gglass 98/01/07 22:42:49
$ delta s.reverse .c ... неясный возврат.
comments? try it ERROR [s.reverse.c]: missing -r argument (del) $ delta -r2.1 s.reverse.c ...возврат модифицированной версии 2.1. comments? try again 2.2 0 inserted 0 deleted 27 unchanged $ mv reverse2.c reverse.c
...переименовать другую версию.
$ delta s.reverse.с
...однозначный возврат.
comments? save it
No id keywords (cm7)
1.1.1.1
0 inserted
0 deleted
23 unchanged
$ sact s.reverse.c
No outstanding deltas for: s.reverse.c $
Удаление версий
Можно удалять дельту из SCCS-файла, когда она является листом в дереве SCCS-версий, с помощью утилиты rmdei. В примере, изображенном на рис. 12.5, не было разрешено удалить версию 1.1, поскольку она не является листом, а версия 1.1.1.1 удалилась успешно. Команды таковы:
$ rmdei ~rl.1 s.reverse.с
...попытка удалить 1.1.
ERROR [s.reverse.с]: not a ’leaf delta(rc5)
$ rmdei -rl.1.1.1 s.reverse.c ...удалить 1.1.1.1. $
Синтаксис
rmdei -гредакция зссз_Файл
Утилита rmdei удаляет указанную версию из SCCS-файла, когда она является листом.
Не может быть удалена
Л.1
> 1.2
Ветка
1.1.1.1
Рис. 12.5. Только листья могут быть удалены
Сжатие SCCS-файлов
Существует возможность сжатия SCCS-файла и удаления любых ненужных дельт с помощью утилиты comb.
Синтаксис
comb {s ссз_Файл} +
Утилита comb сжимает SCCS-файл так, чтобы он содержал лишь самую последнюю исходную версию. Остаются самая последняя дельта и дельты, которые имеют ветви. Утилита работает, генерируя скрипт Bourne shell, который должен быть впоследствии запущен, чтобы выполнить фактическое сжатие. Скрипт посылается в стандартный вывод. Поэтому его следует сохранить и затем выполнить.
Рассмотрим пример. Предположим, что файл s.reverse.c содержал несколько различных версий. Ниже осуществляется его сжатие в меньший файл, содержащий только самую последнюю версию: $ comb s.reverse.c > comb.out ...создать скрипт.
$ cat comb.out ...посмотреть скрипт.
trap "rm -f COMB$$ comb$$ s.COMB$$; exit 2" 1 2 3 15
get —s -k -r2.3 -p s.reverse.c > COMB$$ ...другие строки идут здесь. rm comb$$ rm -f s.reverse.c mv s.COMB$$ s.reverse.c admin -dv s.reverse.c $ chmod +x comb.out ...сделать скрипт исполняемым.
$ comb.out ...выполнить скрипт.
$ prs s.reverse.c ...посмотреть историю,
s.reverse.c:
D 2.3 98/01/08 15:35:53 gglass 1 0 00028/00000/00000
MRs:
COMMENTS: This was COMBined
Ограничение доступа к SCCS-файлам
По умолчанию файл из SCCS-файла способен выбрать любой пользователь. Однако можно ограничить доступ одному или нескольким пользователям (включая ГРУППЫ Пользователей) С ПОМОЩЬЮ ОПЦИЙ -а И -е УТИЛИТЫ admin.
Опция -а может сопровождаться:
П пользовательским именем; в этом случае пользователь добавляется к списку пользователей, которые могут выбирать файл;
□ номером группы; в этом случае любой пользователь в группе может выбирать файл.
Если значению предшествует символ 1, тогда указанный пользователь лишается права выбора. Если применяется С shell, следует убедиться, что введен символ ! для предотвращения случайной ссылки на список истории.
Для удаления пользователя из списка применяется опция -е. Повторяющиеся Ьпции -а и -е могут появляться в отдельной командной строке.
В приведенном далее примере устанавливается запрет на собственные права доступа пользователя, а затем они восстанавливаются.
$ admin -а\!glass s.reverse.с ...удалить права от пользователя glass.
$ get -е s.reverse.с ...попытка доступа.
2.3
ERROR Гs.reverse.c]: not authorized to make deltas (col4)
$ admin -aglass s.reverse.c
$ get -e s.reverse.c
2.3
new delta 2.4
28 lines
$ unget s.reverse.c
2.4
$ admin -atim s.reverse.c
$ admin -eglass s.reverse.c
$ get -e s.reverse.c
2.3
...восстановить доступ.
...нет проблемы.
...вернуть файл.
...добавить tim в список пользователей.
...лишить glass прав доступа.
...попытка доступа.
ERROR [s.reverse.с]: not authorized to make deltas (col4)
$ admin -aglass s.reverse.c
$ admin -al82 s.reverse.c
$
...восстановить права glass.
...дать права группе 182.
Блокировка релизов
Можно защищать отдельный релиз или все релизы от редактирования с помощью опций -fl и-dl утилиты admin. Для блокировки конкретного релиза следует указать за опцией -fl номер релиза. Для блокировки всех релизов — за опцией -fl символ а. Чтобы разблокировать, необходимо использовать те же самые правила, но с опцией -di.
Пример:
$ admin -fla s.reverse.c ...блокировать все релизы.
$ get -е -r2.1.s.reverse.с ...попытка доступа.
2.1
ERROR [s.reverse.с]: SCCS file locked against editing (co23)
$ admin -dla s.reverse.c ...разблокировать все.
$ get -e -rl.l s.reverse.c ...нет проблемы.
1.1
new delta 1.1.1.1
21 lines
$ _
Профайлер UNIX: prof
Часто необходимо знать, как программа тратит время на свое выполнение. Например, если на работу конкретной функции тратится времени больше, чем ожидается, тогда, вероятно, стоит оптимизировать функцию вручную для улучшения производительности. Утилита prof позволяет получать профиль программы.
Синтаксис
prof -In [ исполняемыйФайл [ профайл ] ]
prof — стандартный UNIX-профайлер. Он генерирует таблицу, которая указывает время, потраченное каждой функцией на обработку, и число вызовов функции в исполняемом файле исполняе^шйФайл, основываясь на трассеровке эффективности, сохраняемой в файле профайл. Если аргумент профайл опущен, предполагается файл mon.out. Если аргумент исполняемыйФайл отсутствует, используется файл a.out. Исполняемый файл должен быть скомпилирован с помощью опции -р утилиты сс. Опция позволяет генерировать специальный код, который пишет файл mon.out во время работы программы. Далее утилита prof разбирает выходной файл после окончания работы программы и отображает содержа
щуюся в нем информацию. По умолчанию информация профиля выводится в убывающем порядке времени. Опция -1 определяет вывод информации по имени, опция -п — по совокупному времени.
Пример prof в действии:
$ main2 ...выполнить программу.
palindrome ("cat") = 0 palindrome ("noon") = 1 • ..вывод программы.
$ Is -1 mon.out -rw-r-xr-x 1 gglass • • .посмотреть 1472 Jan вывод монитора. 8 17:19 mon.out
$ prof main2 mon.out • ..получить профиль программы.
%Time Seconds Cumsecs 42.9 0.05 0.05 #Calls msec/call Name rdpcs -
42.9 0.05 0.10 2002 0.025 reverse
14.3 0.02 0.12 2002 0.008 palindrome
0.0 0.00 0.12 1 0. main
$ prof -1 main2 ..порядок по именам.
%Time Seconds Cumsecs #Calls msec/call Name
0.0 0.00 0.05 1 0. main
14.3 0.02 0.07 42.9 0.05 0.05 2002 0.008 palindrome rdpcs
42.9 0.05 0.12 $ . 2002 0.025 reverse
После того как профиль будет просмотрен, можно выполнить некоторую ручную настройку, а затем получить другой профиль.
Перепроверка программ: lint
Язык С имеет удобную утилиту lint, которая проверяет пользовательскую программу более тщательно, чем это делает компилятор сс. Если программа состоит из нескольких исходных модулей, лучше всего специфицировать их в одной командной строке так, чтобы lint могла проверить взаимодействие между модулями.
Синтаксис
lint {имяФайла}*
Утилита lint просматривает указанные исходные файлы и выводит любые найденные потенциальные ошибки.
Пример, который демонстрирует различие между проверкой единственного модуля и проверкой множества модулей, приведен ниже: $ lint reverse.c ...проверить reverse.c.
reverse defined( reverse.с(12) ), but never used $ lint palindrome.с ...проверить palindrome.c.
palindrome defined( palindrome.c(12) ), but never used reverse used( palindrome.c(14) ), but not defined $ lint main2.c ...проверить main2.c.
main2.c(ll): warning: main() returns random value to invocation environment
printf returns value which is always ignored palindrome used( main2.c(9) ), but not defined $ lint main2.c reverse.c palindrome.с ...проверить все модули вместе. main2.c:
main2.c(ll): warning: main() returns random value to invocation environment
reverse.c:
palindrome.c:
Lint pass2:
printf returns value which is always ignored $ _
Отладчик UNIX: dbx
UNIX-отладчик dbx позволяет отлаживать программы символически. Несмотря на то, что этот отладчик не может конкурировать с большинством профессиональных отладчиков, dbx поставляется как удобная стандартная утилита в большинстве версий UNIX. Она обладает следующими возможностями:
□ выполнение в пошаговом режиме;
□ точки останова;
□ редактирование из отладчика;
□ доступ и изменение переменных;
□ поиск функций;
□ трассировка.
Синтаксис
dbx исполняемыйФайл
Утилита dbx — ЭТО стандартный отладчик UNIX. Указанный исполняемыйФайл загружается в отладчик, и появляется приглашение для пользователя. Чтобы получить информацию о различных командах dbx, введите help в ответ на приглашение.
Чтобы продемонстрировать работу утилиты dbx, рассмотрим пример, в котором выполняется отладка следующей рекурсивной версии palindrome о:
1 /* PALINDROME.С */
2
3 tfinclude "palindrome.h"
4 #include <string.h>
5
6
7 enum { FALSE, TRUE };
8
9
10 int palindrome (str)
11
12 char *str;
13
14 {
15 return (palinAux (str, 1, strlen (str)));
16 }
17
18 /★★*★★***★********★**★**★*********************************/
19
20 int palinAux (str, start, stop)
21
22 char *str;
23 int start;
24 int stop;
25
26 }
27 if (start >= stop)
28 return (TRUE);
29 else if (str[start] != strfstop])
30 return (FALSE);
31 else
32 return (palinAux (str, start + 1, stop — 1));
33 }
Подготовка программы для отладки
Для отладки программу необходимо скомпилировать с пОмощью опции -д компилятора сс, которая помещает отладочную информацию в объектный модуль.
Вход в режим отладки
Если программа скомпилировалась правильно, можно вызвать dbx с именем исполняемого файла в качестве первого аргумента, dbx покажет приглашение. Рекомендуется в ответ на приглашение ввести help, чтобы увидеть список всех команд dbx3:
$ dbx main2 ...вызвать отладчик.
dbx version srl0.3(4) of 7/6/90 17:52
reading symbolic information
Туре 'help' for help.
(dbx) help ...получить помощь.
run [args] - начинает выполнение программы
stop at <line> - приостанавливает выполнение на строке
stop in <func> - приостанавливает выполнение, когда вызывается <func>
stop i f <cond> - приостанавливает выполнение, когда <cond> истинно
trace <line#> - трассировка выполнения строки
trace <func> - трассировка вызовов функции
trace <var> - трассировка изменений переменных
trace <exp> at <line#> - печатает <ехр>, когда <line> достигнута
status - печатает пронумерованный список трассировок
и останавливается
delete <#> [<#> ...] - отменяет трассировку или остановку
каждого указанного номера
3 Ниже приводится перевод. — Ред.
cont
step
next
return
call <func>(<params>) print <exp> [, <exp> ...] where
whatis <name>
assign <var> = <exp>
dump <func>
list [<line#>], <line#>> use <directory-list>
sh <connmand-line> quit
(dbx)
- продолжает выполнение с места остановки
- выполняет одну исходную строку, входит
в функции
- выполняет одну исходную строку, игнорирует вызовы
- продолжает до возврата из текущей функции
- выполняет данный вызов функции
- печатает значения выражений
- печатает текущие активные процедуры
- выводит описание имени
- присваивает переменной программы значение <ехр>
- печатает все переменные активной функции
— выводит исходные строки
- устанавливает путь поиска для исходных файлов
- передает командную строку shell
- выходит из dbx
Выполнение программы
Для выполнения программы следует ввести команду run, которая выполняет программу до завершения:
(dbx) run . . .выполнить программу.
palindrome ("cat") = О
palindrome ("noon") = О program exited (dbx) _
On! Строка "noon" — это палиндром, но функция palindrome () выдает иной результат. Пришло время тщательно исследовать dbx.
Трассировка программы
Чтобы получить трассировочный список, строка за строкой, необходимо ввести команду trace. Когда требуется любой вид трассировки, dbx возвращает числовой указатель, который может использоваться командой delete, чтобы выключить трассировку.
Продолжим рассмотрение примера: программа запускается повторно с помощью команды rerun:
(dbx) trace ...запрос трассы.
[1] trace ...запрос 1.
(dbx) rerun ...выполнить программу с начала.
trace: 9 printf ("palindrome (\"cat\") = %d\n", palindrome
("cat"));
trace: 10 int palindrome (str)
trace: 15 return (palinAux (str, 1, strlen (str)));
trace: 20 int palinAux (str, start, stop)
trace: 27 if (start >= stop)
trace: 29 else if (str[start] != str[stop])
trace: 30 return (FALSE);
trace: 33 }
trace: 33 }
trace: 16 }
palindrome ("cat") = 0
trace: 10 printf ("palindrome (\"noon\") = %d\n", palindrome
("noon")
trace: 10 int palindrome (str)
trace: 15 return (palinAux (str, 1, strlen (str)));
trace: 20 int palinAux (str, start, stop)
trace: 27 if (start >= stop)
trace: 29 else if (str[start] != str[stop])
trace: 30 return (FALSE);
trace: 33 }
trace: 33 }
trace: 16 } palindrome ("noon") = 0
trace: 11 }
trace: 11 }
program exited
(dbx) _
Трассировка переменных и вызовов функции
Трассировка может быть выполнена для значения переменной или вызова конкретной функции путем добавления параметров к команде trace.
Синтаксис
trace переменная in функция
Для отслеживания вызовов указанной функции используйте синтаксис:
trace функция
Ниже представлен вывод dbx после того, как были выполнены три новых трассировки, а затем программа была повторно запущена:
(dbx) trace start in palinAux ...трассировка переменной start.
[2] trace start in palinAux
(dbx) trace stop in palinAux ...трассировка переменной stop.
[3] trace stop in palinAux
(dbx) trace palinAux ...трассировка функции palinAux.
[4] trace palinAux
(dbx) rerun ...запуск программы с начала.
trace: 9 printf ("palindrome (\"cat\") = %d\n", palindrome
("cat"));
trace: 10 int palindrome (str)
trace: 15 return (palinAux (str, 1, strlen (str)));
trace: 20 int palinAux (str, start, stop)
calling palinAux (str = "cat", start = 1, stop = 3) from function
palindrome.palindrome
trace: 27 if (start >= stop)
initially (at line 27 in "/home/glass/reverse/palindrome.c"): start = 1 initially (at line 27 in "/home/glass/reverse/palindrome.c"): stop = 3 trace: 29 else if (str[start] != str[stop])
trace: 30 return (FALSE);
trace: 33 )
trace: 33 }
trace: 16 }
palindrome ("cat") = 0
trace: 10 printf ("palindrome (\"noon\") = %d\n", palindrome
("noon"));
trace: 10 int palindrome (str)
trace: 15 return (palinAux (str, 1, strlen (str)));
trace: 20 int palinAux (str, start, stop)
after line 20 in "/home/glass/reverse/palindrome.c": stop = 4
calling palinAux(str = "noon", start = 1, stop = 4) from function
palindrome, palindrome
trace: 27 if (start , = stop)
trace: 29 else if (strfstart] != str[stop])
trace: ' 30 return (FALSE);
trace: 33 }
trace: 33 }
trace: 16 }
palindrome ("noon") = 0
trace: 11 }
trace: 11 }
program exited
(dbx)
Ошибки
Теперь природа ошибок достаточно ясна: значения start и stop неправильны, каждое больше чем оно должно быть. Это весьма обычная ошибка, когда программист забывает, что индексирование элементов массива в языке С начинается с нуля, а не с единицы. Можно вызвать редактор, указанный переменной окружения $editor, используя команду edit. Это удобно для исправления ошибок налету, хотя следует помнить, что нужно повторно скомпилировать программу перед ее повторной отладкой. Вот правильная версия функции palindrome () : int palindrome (str) char *str;
4 return (palinAux (str, 0, strlen (str) — 1));
}
Далее рассматриваются некоторые полезные команды dbx для задания точек останова, пошагового выполнения, организации доступа к переменным и вывода частей программы.
Точки останова
Для остановки отладчика dbx при обнаружении вызова конкретной функции служит команда stop. Она позволяет выполнять программу с полной скоростью до той функции, которую необходимо проверить более тщательно. Например:
(dbx) stop in palinAux ...добавить точку останова.
[7] stop in palinAux
(dbx) rerun ...запустить программу сначала.
trace: 9 printf (’’palindrome (\’’cat\") = %d\n", palindrome
(’’cat”)) ;
trace: 10 int palindrome (str)
trace: 15 return (palinAux (str, 1, strlen (str)));
trace: 20 int palinAux (str, start, stop)
calling palinAux(str = "cat", start = 1, stop = 3) from function palindrome.palindrome
[7] stopped in palinAux at line 27 in file
’’/home/glass/reverse/pal indrome. c"
27 if (start >= stop)
(dbx)
Пошаговое выполнение
Чтобы выполнить программу по одной строке за один шаг, используется команда step. Она предписывает отладчику dbx повторно показывать свое приглашение сразу после того, как очередная строка программы будет выполнена.
В следующем примере выполняется команда step после того, как программа остановилась на строке 27:
(dbx) step ...выполнить строку после 27-й и остановиться.
trace: 29 else if (str[start] != str[stop])
initially (at line 29 in ’’/home/glass/reverse/palindrome.c"):
start = 1
initially (at line 29 in ’’/home/glass/reverse/palindrome.c"):
stop = 3
stopped in palinAux at line 29 in file
"/home/glass/reverse/palindrome.c"
29 else if (str[start] != strfstop]) (dbx)
Организация доступа к переменным
Для вывода значения конкретной переменной применяется команда print. Команда whatis показывает объявление переменной, а команда which сообщает, где переменная объявлена. Команда where показывает полную трассу стека, а команда whereis сообщает, где расположена конкретная функция. Перечисленные команды демонстрируются в следующем примере: (dbx) print start ...вывести текущее значение start.
1
(dbx) whatis start
...получить информацию о типё.
int start;
(dbx) which start . ..найти ее расположение,
palindrome.palinAux.start
(dbx) where ...получить трассу стека.
palinAux(str = "cat", start = 1, stop = 3), line 29 in "/home/glass/reverse/palindrome.c" palindrome.palindrome(str = "cat"), line 15 in "/home/glass/reverse/palindrome.c" main(), line 9 in "/home/glass/reverse/main2.c" unix_$main() at 0x3b4e7al4
_start(), line 137 in ”//garcon/unix_src/lang/sgs/src/crtO/crtO.c" (dbx) whereis palinAux ...определить место функции,
palindrome.palinAux
(dbx) whereis start ...определить место переменной,
palindrome.palinAux.start (dbx) _
Листинг программы
Команда list позволяет вывести первые несколько строк функции, а команды / и ? предоставляют возможность осуществить поиск, соответственно, вперед и назад по тексту, как показано в следующем примере: (dbx) list palindrome ...вывести десять строк.
5
6
7 enum { FALSE, TRUE }; х
8
9
10 int palindrome (str) 11
12 char* str; 13
14 {
15 return (palinAux (str, 1, strlen (str))); (dbx) list 10,20 ...вывести строки с 10 по 20.
10 int palindrome (str)
11
12 char* str;
13
14 }
15 return (palinAux (str, 1, strlen (str)));
16 {
17
18 /**************************^***i**************************
19
20 int palinAux (str, start, stop)
21
(dbx) ?palinAux ...поиск назад строки "palinAux".
20 int palinAux (str, start, stop)
(dbx) /palinAux ...поиск вперед строки "palinAux".
32 return (palinAux (str, start + 1, stop — 1)); (dbx) _ r
Выход из отладчика
Для выхода из отладчика dbx служит команда quit: (dbx) quit ...покинуть отладчик.
$ _
Возврат осуществляется в командный интерпретатор shell.
Резюме
В разд. "Отладчик UNIX: dbx"я представил краткое изложение часто используемых команд dbx. Они могут дать полезные подсказки об ошибках в разработанной программе. По моему собственному мнению, dbx— довольно бедный отладчик по сравнению с некоторыми популярными РС-отладчиками, типа Turbo Debugger от Borland, и развитых системных отладчиков UNIX, типа ObjectWorks\C ++. С другой стороны, dbx доступен на большинстве UNIX-машин, что делает элементарное понимание его действий полезным.
Удаление лишнего кода: strip
Утилиты отладчика и профайлера требуют, чтобы компиляция программы выполнялась с помощью специальных опций, каждая из которых добавляет код к исполняемому файлу. Для того чтобы удалить этот дополнительный код после завершения отладки и профилирования, можно применять утилиту strip.
Синтаксис
strip {имяФайла} +
Утилита strip удаляет все: таблицу символов, информацию перераспределения, отладки и профилирования из указанных файлов.
Пример экономии места:
$ Is -1 main2 ...посмотреть оригинальный файл,
-rwxr-xr-x 1 gglass 5904 Jan 8 22:18 main2*
$ strip main2 ...убрать побочную информацию.
$ Is -1 main2 ...помотреть очищенную версию.
-rwxr-xr-x 1 gglass 3^73 Jan 8 23:17 main2*
$
Обзор главы
Перечень тем
В этой главе вы познакомились с утилитами, которые:
□ компилируют С-программы;
П управляют компиляцией программ, состоящих из многих модулей;
□ поддерживают архивы;
□ поддерживают множественные версии исходного кода;
П профилируют исполняемые файлы;
□ отлаживают исполняемые файлы.
Контрольные воросы
1. Почему полезно иметь историю своего исходного кода?
2. Каково определение концевой вершины на SCCS-дереве дельты?
3. Каково преимущество опции -q утилиты аг?
4. Может ли утилита make использовать объектные модули, сохраненные в файле архива?
5. Что означает термин "функция многократного использования"?
6. Назовите причины профилирования исполняемого файла.
7. Опишите кратко, что делает утилита strip.
Упражнения
12.1. Создайте разделяемую библиотеку с простой функцией, которая возвращает значение целого числа. Затем напишите программу, чтобы вызвать функцию и напечатать ее возвращаемое значение. После скомпилируйте и выполните программу, внесите изменение в библиотечную функцию, перестройте библиотеку и выполните программу снова (без повторной компиляции главной программы). Что происходит, если вы переименовываете функцию в разделяемой библиотеке? [Уровень: легкий.]
12.2. Скомпилируйте файлы reverse.c и palindrome.c и поместите их в архив string.a. Напишите главную программу в файле prompt.c, которая выводит приглашение пользователю для ввода строки, а затем выводит 1, если строка является палиндромом, и 0 — в противном случае. Создайте make-файл, который связывает prompt.о с функциями reverse о и palindrome о, сохраненными в файле string.a. Если необходимо, используйте утилиту dbx для отладки кода. [Уровень: средний.]
12.3. Попробуйте поработать с современным отладчиком типа отладчика исходного кода Borland C++. Каков он по сравнению с dbx? [Уровень: средний.].
Проекты
1. Напишите документ, в котором укажите, как бы вы использовали утилиты, представленные в этой главе, чтобы помочь управлять командой из 10 человек, работающей с вычислительной техникой. [Уровень: средний.]
2. Замените первоначальную версию palindrome о, сохраненную в программе palindrome, версией на основе указателя. Используйте SCCS для управления изменениями исходного кода и утилиту аг для замены старой версии в файле string.a. [Уровень: средний.]
Глава 13
Системное программирование
Мотивация
Если вы С-программист, и хотите воспользоваться преимуществом возможностей многозадачности и взаимодействия процессов UNIX, весьма важно, чтобы вы хорошо знали системные вызовы UNIX.
Предпосылки
Чтобы понять материал данной главы, необходимо иметь хороший опыт программирования на С. Для получения дополнительных сведений об Интернете обратитесь к главам 9 и 10.
Задачи
В этой главе объясняется и демонстрируется большинство системных вызовов UNIX, в том числе поддерживающих ввод/вывод, управление процессами и взаимодействие процессов.
Изложение
Информация представлена в форме нескольких примеров программ, включая пример командного интерпретатора shell, разработанного для Интернета. Большинство кодов доступно в сети (для дополнительной информации см. Введение).
Системные вызовы и библиотечные процедуры
i
В главе представлены следующие системные вызовы и библиотечные процедуры:
accept fchown inet__addr perror
alarm fcntl inet_ntoa pipe
bind fork ioctl read
bzero f stat kill- setegid
chdir ftruncate 1chown seteuid
chmod getdents link setgid
chown getegid listen setpgid
close geteuid Iseek setuid
connect getgid Istat signal
dup gethostbyname memset socket
dup2 gethostname mknod stat
execl getpgid nice sync
execlp getpid ntohl truncate
execv getppid ntohs unlink
execvp getuid open wait
exit htonl pause write
f chmod htons
Общие сведения
Чтобы использовать такие возможности, как создание файла, дублирование процесса и взаимодействие между процессами, прикладные программы должны "взаимодействовать" с операционной системой. Они могут делать это через совокупность процедур, называемых системными вызовами, которые являются функциональным интерфейсом программиста к ядру UNIX. Системные вызовы аналогичны библиотечным процедурам, за исключением того, что первые выполняют вызов подпрограммы непосредственно в сердце UNIX.
Системные вызовы UNIX могут быть объединены в следующие условные главные категории:
□ управление файлами;
□ управление процессами;
□ обработка ошибок.
Взаимодействие процессов (Interprocess communication, IPC) фактически является подмножеством управления файлами, поскольку UNIX обрабатывает механизмы IPC, как специальные файлы. На рис. 13.1 представлена диаграмма, которая иллюстрирует иерархию системных вызовов управления файлами.
Рис. 13.1. Иерархия системных вызовов управления файлами
Иерархия системных вызовов управления процессами включает процедуры для дублирования, отделения и завершения процессов, как показано на рис. 13.2. Единственный системный вызов, поддерживающий обработку ошибки, реггого, я поместил в иерархию только, чтобы быть последовательным (рис. 13.3).
Рис. 13.2. Иерархия системных вызовов управления процессами
Обработка ошибки
реггог
Рис. 13.3. Иерархия обработки ошибки
Далее системные вызовы, представленные на этих диаграммах иерархии, будут обсуждаться в следующем порядке.
□ Обработка ошибки. Я начинаю главу с описания реггог ().
П Обычное управление файлами. Оно включает сведения о создании, открытии, закрытии, чтении и записи обычных файлов. Мы также увидим краткий обзор STREAMS.
П Управление процессами. Здесь существенны дублирование, отделение, приостановка и прекращение процессов. Кратко обсуждаются многопр-точные процессы.
□ Сигналы. Хотя возможности сигналов можно рассматривать, как часть либо управления процессами, либо взаимодействия между процессами, это достаточно серьезная тема, чтобы выделить ее в специальный раздел.
□ IPC. Взаимодействие процессов осуществляется через конвейеры (как именованные, так и не имеющие имени) и сокеты (включая информацию об интернет-сокетах). Представлен краткий обзор двух механизмов IPC, встречающихся в некоторых версиях UNIX: разделяемая память и семафоры.
Глава заканчивается листингом исходного кода и обсуждением проекта Internet shell, который является командным интерпретатором, поддерживающим конвейеризацию и перенаправление на другие Internet shell на удаленных хостах. Программа Internet shell использует большинство возможностей, описанных в этой главе.
Обработка ошибки: реггогО
Большинство системных вызовов способно определенным образом завершиться с ошибкой. Например, системный вызов open о будет неудачным, если вы пробуете открыть для чтения несуществующий файл. В соответствии с соглашением, все системные вызовы возвращают ~ 1, если происходит ошибка. Однако трудно понять, почему произошла ошибка; системный вызов open () может потерпеть неудачу по нескольким различным причи
нам. Если вы хотите детализировать ошибки системных вызовов, то должны знать две вещи:
□ существует глобальная переменная errno, которая хранит числовой код * последней ошибки системного вызова;
□ подпрограмма реггог о описывает ошибки системного вызова.
Каждый процесс содержит глобальную переменную errno, которая первоначально равна нулю при создании процесса. Когда происходит ошибка системного вызова, в errno устанавливается числовой код, связанный с причиной ошибки. Например, если пользователь пробует открыть для чтения файл, который не существует, errno будет равна 2. Файл /usr/include/sys/errno.h содержит список предопределенных кодов ошибки. Вот отрывок этого файла:
#define #define EPERM ENOENT 1 2 /* Нет владельца */ /* Нет такого файла или каталога */
#define ESRCH 3 /* Нет такого процесса */
#define EINTR 4 /* Прерванный системный вызов */
#define EIO 5 /* Ошибка ввода/вывода */
Успешный системный вызов никогда не затрагивает текущее
значение
errno, а неудачный системный вызов всегда переписывает ее значение. Для того чтобы из программы получить доступ к переменной errno, включите заголовок <errno.h>. Подпрограмма реггого разъясяет по-английски те
кущее значение errno.
Синтаксис
void реггог (char* str)
Библиотечная процедура реггог о показывает строку str, снабженную двоеточием и сопровождаемую описанием последней ошибки системного вызова. Если ошибки нет, реггог о выводит строку "Error 0". Фактически реггог () — это не системный вызов, а стандартная процедура библиотеки С.
Ваша программа должна проверять системные вызовы на возвращаемое значение —1, а затем немедленно обработать ситуацию. Для начала необходимо вызвать реггог о для описания ошибки, особенно во время отладки.
В представленном ниже примере намеренно создана пара ошибок системного вызова, чтобы продемонстрировать работу реггого, а затем показано, что переменная errno сохранила последний код ошибки системного вызова
даже после того, как был сделан успешный вызов: единственный способ повторно установить errno — это вручную назначить ей 0.
$ cat showErrno.c #include < stdio.h> ttinclude <sys/file.h> #include <errno.h> main () {
int fd;
/* Открыть несуществующий файл, чтобы вызвать ошибку */ fd - open ("nonexist.txt", O_RDONLY); v
if (fd — -1) /* Ошибка произошла */
{
printf ("errno = %d\n", errno); perror '("main");
}
fd = open ("/", O—WRONLY); /* Вызвать другую ошибку */
if (fd = -1)
printf ("errno = %d\n", errno); perror ("main");
}
/* Выполнить успешный системный вызов */
fd = open ("nonexist.txt", O_RDONLY | O_CREAT, 0644);
printf ("errno = %d\n", errno);/* Вывести после успешного вызова */ perror ("main");
errno =0; /* Вручную установить переменную ошибки */
perror ("main"); }
Не волнуйтесь о том, как работает системный вызов open (). Он будет описан позже в данной главе *. Вот вывод программы:
$ showErrno ...выполнить программу,
errno = 2 main: No such file or directory errno = 21 ...даже после успешного вызова
main: Is a directory
1 См. разд. "Открытие файла: open() " далее в этой главе. — Ред.
errno = 21
main: Is a directory
main: Error 0
$ _
Управление обычными файлами
Мое описание системных вызовов управления файлами разбивается на четыре главных части:
П вводная часть, которая представляет главные концепции файлов UNIX и дескрипторов файлов;
□ описание основных системных вызовов управления файлами с применением демонстрационной программы reverse, которая переставляет символы в строках и сами строки файла;
□ объяснение нескольких расширенных системных вызовов с использованием демонстрационной программы monitor, которая периодически просматривает каталоги и выводит имена файлов, которые изменились со времени последнего просмотра;
□ описание оставшихся системных вызовов управления файлами с помощью различных отрывков исходного кода.
Общие сведения об управлении файлами
Системные вызовы управления файлами позволяют манипулировать полной совокупностью обычных файлов, каталогами и специальными файлами, включая:
□ файлы на дисках;
□ терминалы;
П принтеры;
□ файлы взаимодействия между процессами, такими как конвейеры и сокеты.
В большинстве случаев системный вызов open () служит для первоначального доступа или создания файла. Если open о выполняется успешно, он возвращает маленькое целое число, называемое дескриптором файла, которое используется в последующих операциях ввода/вывода с этим файлом. Если open о завершается с ошибкой, возвращается —1. Ниже представлен отрывок кода, который иллюстрирует типичную последовательность событий:
int fd;
/* Дескриптор файла */
fd = open (fileName, Открыть файл, возвращает дескриптор файла */
if (fd == -1) { /* Обработать условия ошибки */ }
fcntl (fd, ...); /* Установить некоторые флаги ввода/вывода, */
/* если необходимо */
read (fd, /* Читать из файла */
write (fd, ...); /* Писать в файл */
Iseek (fd, ...); /* Поиск в файле */
close (fd); /* Закрыть файл, освобождает дескриптор файла */
Когда процесс больше не нуждается в доступе к открытому файлу, он должен закрыть его, используя системный вызов close о. Все открытые файлы процесса автоматически закрываются, когда процесс заканчивается. Хотя это означает, что можно опустить явный вызов close о, лучшая практика программирования состоит в том, чтобы закрыть файлы явно.
Дескрипторы файла нумеруются последовательно, начиная с 0. В соответствии с соглашением, первые три значения дескриптора файла имеют специальное значение (табл. 13.1).
Таблица 13.1. Значения дескрипторов файлов для стандартных каналов ввода/вывода
Значение Описание
0 Стандартный ввод (stdin)
1 Стандартный вывод (stdout)
2 Стандартный канал ошибки (stderr)
Например, библиотечная функция printf о всегда посылает свой вывод с помощью дескриптора файла 1, a scanf () всегда читает свой ввод через дескриптор файла 0. Когда ссылка на файл закрыта, его дескриптор освобождается и может быть повторно назначен последующим вызовом open (). Большинство системных вызовов ввода/вывода требуют дескриптор файла в качестве своего первого параметра, чтобы знать, с каким файлом работать.
Отдельный файл может быть открыт несколько раз и, таким образом, иметь несколько дескрипторов, связанных с ним (рис. 13.4).
Рис. 13.4. Много дескрипторов файла — один файл
Каждый дескриптор файла имеет собственный частный набор свойств, которые не имеют никакого отношения к файлу.
П Указатель файла, который записывает смещение в файле, когда тот читается или пишется. Когда дескриптор файла создан, его указатель файла помещается по умолчанию на смещение 0 в файле (первый символ). По мере того как процесс читает или пишет, указатель файла соответственно обновляется. Например, если бы процесс открыл файл и затем прочитал 10 байтов из него, указатель файла достиг бы позиции на смещении Ю. Если бы процесс затем написал 20 байтов, байты со смещением 10—29 в файле были бы переписаны, и указатель файла достиг бы смещения 30.
□ Флаг, который указывает, должен ли дескриптор автоматически быть закрыт, если процесс выполняет ехес ().
□ Флаг, который указывает, должен ли весь вывод файла быть добавлен к концу файла.
В дополнение к перечисленным свойствам, следующие свойства являются значащими, если только это специальный файл типа конвейера или сокета.
О Флаг, который указывает, должен ли процесс блокировать ввод из файла, если файл в настоящее время не содержит никакого входа.
□ Число, которое указывает ID процесса или группу процесса, которой должен быть послан сигнал sigio, если вход становится доступным на файле. (Сигналы и группы процесса обсуждаются далее.)
Системные вызовы ореп() и fcntio позволяют управлять этими флагами.
Первый пример: reverse
В качестве первого примера опишем основные системные вызовы ввода/вывода. В табл. 13.2 представлен их список вместе с кратким описанием.
Таблица 13.2. Системные вызовы для базовых операций ввода/вывода
Имя системного вызова Описание
open Открывает/создает файл
read Читает байты из файла в буфер
write Пишет байты из буфера в файл
Iseek Перемещает указатель на конкретное смещение в файле
close Закрывает файл
unlink Удаляет файл
Для иллюстрации применения этих системных вызовов будет использована маленькая сервисная программа reverse.c. Она может служить хорошим примером того, как писать утилиты UNIX.
Синтаксис
reverse -с [имяФайла]
Утилита reverse переставляет символы строки из ввода в обратном порядке и посылает их на стандартный вывод. Если имя Фа ил а не определено, reverse переворачивает свой стандартный ввод. Когда используется опция —с, reverse также переворачивает символы в каждой строке.
Пример:
$ сс reverse.с -о reverse $ cat test
Christmas is coming,
The days that grow shorter, Remind me of seasons I knew $ reverse test
Remind me of seasons I knew The days that grow shorter, Christmas is coming, $ reverse -c test
.tsap eht ni wenk I snosaes
...компилировать программу.
...вывести тестовый файл.
in the past.
...переставить строки, in the past.
i
...переставить символы в строках. fo em dnimeR
,retrohs worg taht syad ehT , gnimoc si samtsirhC
$ cat test I reverse ...направить вывод в reverse.
Remind me of seasons I knew in the past.
The days that grow shorter, Christmas is coming, $_
Как работает reverse
Утилита reverse работает, выполняя два прохода над своим вводом. Во время первого прохода она обращает внимание на стартовое смещение каждой строки в файле и сохраняет эту информацию в массиве. Во время второго прохода она переходит к началу каждой строки в обратном порядке, копируя ее из первоначального файла ввода на свой стандартный вывод.
Если имя файла не определено в командной строке, reverse читает со сво-‘его стандартного ввода во время первого прохода и копирует это во временный файл для второго прохода. Когда программа заканчивается, временный файл удаляется.
В табл. 13.3 представлен краткий обзор потока программы вместе с переч-. нем функций, которые связаны с каждым действием, и списком системных вызовов, используемых каждым шагом. Затем следует полный листинг reverse.c, исходный код reverse. Смотрите код и читайте описание системных вызовов. Код также доступен в сети (см. Введение для дополнительной информации).
Таблица 13.3. Описание алгоритма, используемого в reverse.c
Шаг Действие Функции Системные вызовы
1 Разбирает командную строку parseCommandLine, processoptions open
2 Если читает со стандартного ввода, создает временный файл для хранения ввода, в противном случае открывает входной файл для чтения passl open
3 Читает из файла по кускам, сохраняя смещение начала каждой строки в массиве. При чтении со стандартного ввода копирует каждый кусок во временный файл passl, trackLines read, write
18 Зак. 786
Таблица 13.3 (окончание)
Шаг Действие Функции Системные вызовы
4 Читает входной файл снова, на сей раз назад, копируя каждую строку в стандартный вывод. Полностью переворачивает строку, если была указана опция -с \ pass2, processLine, reverseLine Iseek
5 Закрывает файл. Удаляет его, если это временный файл pass2 close
Листинг: reverse.c
1 #include <fcntl.h> /* Для определения режима файла */
2 #include <stdio.h>
5 #include <stdlib.h>
4
5
6 /* Энумератор */
7 enum { FALSE, TRUE }; /* Стандартные значения: истина и ложь */
8 enum { STDIN, STDOUT, STDERR}; /* Стандартные индексы каналов */
9 /* ввода/вывода */
10
11 /* Операторы #define */
12 #define BUFFER_SIZE 4096 /* Размер буфера копирования */
13 ttdefine NAME_SIZE 12
14 #define MAX_LINES 100000 /* Максимальное число строк в файле */
15
16
17 /* Глобальные */
18 19 char *fileName = NULL; /* Указывает на имя файла */ char tmpName [NAME_SIZE];
20 int charOption = FALSE; /* Установить true, если есть опция -с */
21 int standardinput = FALSE; /* Установить true, если читается stdin *
22 int lineCount =0; /* Общее число строк во вводе */
23 int lineStart [MAX_LINES]; /* Хранит смещение каждой строки */ /
24 int fileOffset =0; /* Текущая позиция во вводе */
25 int fd; /* Дескриптор файла ввода */
26
27 /*****************★******★*★***★****★*******★**********★*****/
28
29 main (argc, argv)
30
31 int argc;
32 char* argv [];
33
34 {
35 parseCommandLine (argc,argv); /* Разбирает командную строку */
36 passl(); /* Выполняет первый проход по вводу */
37 pass2(); /* Выполняет второй проход по вводу */
38 return (/* выход успешный */ 0); /* Выполнено */
39 }
40
/********★★★**★★***★**************★★**★**★★***★*★★***★***★*★****★/
‘42
43 parseCommandLine (argc, argv)
44
45 int argc;
46 char* argv [ ];
47
48 /* Разбор аргументов командной строки */
49
50 {
51 int i; 52
53 for (i= 1; i < argc; i++)
54 {
55 if(argv[i] [0] = ’-')
56 processoptions (argv[i]);
57 else if (fileName == NULL)
58 fileName= argv[i];
59 else
60 usageError(); /* Произошла ошибка */
61 }
62
63 standardinput = (fileName == NULL);
64 }
65
520
Глава 13
66
67
68
processoptions (str)
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
char* str;
/* Разбор опций */
{
int j;
for (j= 1; str[j] != NULL; j++)
{
switch(str[j]) /* Переключиться по флагу командной строки */ {
case' с':
charOption = TRUE;
break;
default:
usageError();
break;
}
}
}
usageError()
{
fprrntf (stderr, "Usage: reverse -c [filename]\n");
exit (/* Выход при ошибке */ 1);
^•к-к-к'к^^'к’к-к-к'к-к-к'к-к-к'к-к'к'к-к'к-к'к'к-к-к-к'к-к-к-к-к-к-к^-к'к-к-к-к-к-'к-к'к'к-к-^-к-к-к'-к'к^'к'к-к'к'к'/с'к'к'к I
passl ()
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
/* Выполнить первый просмотр файла */
{
int tmpfd, charsRead, charsWritten; char buffer [BUFFERJSIZE];
if (standardinput) /* Читать co стандартного ввода */
{
fd = STDIN;
sprintf (tmpName, ’’.rev.%d",getpid()); /* Случайное имя */ /* Создать временный файл для хранения копии ввода */ tmpfd = open (tmpName, O_CREAT | O_RDWR, 0600);
if (tmpfd == -1) fatalError();
}
else /* Открыть именованный файл для чтения */
{
fd = open (fileName, O_RDONLY);
if (fd == -1) fatalError();
}
lineStart[0] =0; /* Смещение первой строки */
while (TRUE) /* Читать весь ввод */
{
/* Заполнить буфер */
charsRead = read (fd, buffer, BUFFER_SIZE);
if (charsRead == 0) break; /* EOF */
if (charsRead == -1) fatalError(); /* Ошибка */
trackLines (buffer, charsRead); /* Обработать строку */
/* Копировать строку во временный файл, если чтение из stdin ★/ if (standardinput)
{ charsWritten = write (tmpfd, buffer, charsRead); if(charsWritten ’= charsRead) fatalError();
}
} 1
/* Сохранить смещение замыкающей строки, если существует */ lineStart[lineCount +1] = fileOffset;
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
/★ Если читается стандартный ввод, подготовить fd для прохода 2 */ if (standardinput) fd = tmpfd;
}
trackLines (buffer, charsRead)
char* buffer; int charsRead;
/* Сохранить смещение каждой строки в буфере */ { int i;
for (i = 0; i < charsRead; i++)
{
++fileOffset; /* Обновить текущую позицию файла */ ;if (buffer[i] == ’\n’) lineStart[++lineCount] = fileoffset; } }
/**★*★★★*****★★★*★★★******★**★***★★*★★★*****★*****★★★★*★★**★★★★★*/ int pass2()
/* Просмотр входного файла снова, вывод строк в обратном порядке */ { int i;
for (i = lineCount — 1; i >= 0; i—) processLine (i);
close (fd); /* Закрыть входной файл */
if (standardinput) unlink (tmpName); /* Удалить временный файл */ }
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
processLine (i)
int i;
/* Читать строку и вывести ее */
{
int charsRead;
char buffer [BUFFER_SIZE];
Iseek (fd, lineStart[i], SEEK_SET); /* Найти строку и читать ее */ charsRead = read (fd, buffer, lineStart[i+1] — lineStart[i]);
/* Перевернуть строку, если была выбрана опция -с */
if (charOption) reverseLine (buffer, charsRead);
write (1, buffer, charsRead); /* Писать ее на стандартный вывод */ }
у***************************************************************/
reverseLine (buffer, size)
char* buffer;
int size;
/* Перевернуть все символы в буфере */
{
int start = 0, end — size — 1;
W char tmp;
if (buffer[end] == ’\n') —end;
/* Переставить символы попарно */
while (start < end)
{
tmp = buffer[start];
222 buffer[start] = buffer[end];
223 buffer[end] = tmp;
224 ++start; /* Увеличить на единицу индекс start */
225 —end; /* Уменьшить на единицу индекс end */
226 }
227 }
228
229 /***************************************************************
230
231 fatalError()
232
233 {
234 perror ("reverse: "); /* Описать ошибку */
235 exit (1);
236 }
Открытие файла: ореп()
Утилита reverse начинается С выполнения функции parseCommandLine () (строка 43), которая устанавливает различные флаги в зависимости от выбранных опций. Если имя файла определено, задается переменная fileName, чтобы указать на имя, и standardinput сбрасывается в false; иначе fileName получает значение null, a standardinput присваивается true. Затем выполняется функция passio (строка 103), которая исполняет одно из описанных ниже действий.
□ Если reverse читает со стандартного ввода, создается временный файл с разрешением чтения и записи для владельца и без разрешений для кого-либо еще (восьмеричный код 600). Файл открывается в режиме чтения/ записи и используется для сохранения копии стандартного ввода, которая нужна во время прохода 2. Во время прохода 1 вход принимается со стандартного ввода, так что дескриптор файла fd установлен на stdin, определен 0 вверху программы. Вспомните, что стандартный ввод всегда имеет нулевой дескриптор файла.
П Если reverse читает из указанного файла, файл открывается в режиме только для чтения так, чтобы его содержимое могло читаться во время прохода 1, используя дескриптор файла fd.
Каждое действие нуждается в системном вызове open (). Первое действие использует его, чтобы создать файл, второе — чтобы получить доступ к существующему файлу.
Синтаксис
int open (char* fileName, int mode [, int permissions])
Системный вызов open () позволяет открыть или создать файл для чтения или записи. fileName — абсолютное или относительное имя пути, mode — поразрядное or флага чтения/записи, с учетом или без учета некоторых смешанных флагов, permissions — число, которое кодирует значение флагов доступа к файлу, необходимо только, когда файл создается. Оно обычно записывается с помощью восьмеричной схемы шифрования, описанной в главе 2. На значение доступа влияет значение процесса umask, описанного в главе 4. Значения предопределенного флага чтения/записи и смешанных флагов заданы в файле /usr/include/fcntl.h.
Флаги чтения/записи:
Флаг Описание
o_rdonly Открывает только для чтения
O_wronly Открывает только для записи
O_RDWR z Открывает для чтения и записи
Смешанные флаги:
Флаг Описание
O_APPEND Позиция указателя в конце файла перед каждым write ()
O_CREAT Если файл не существует, создает его и устанавливает ID владельца на эффективный UID процесса. Значение umask используется при определении начальных значений флага доступа
O_EXCL Если O_CREAT установлен и файл существует, тогда open () завершается с ошибкой
O_NONBLOCK (Называется O_NDELAY на некоторых системах). Флаг работает только для указанных конвейеров. Если флаг установлен, open () для файла в режиме "только для чтения" немедленно вернет управление, независимо от того, является ли конец записи открытым. open () для файла в режиме "только для записи" завершится с ошибкой, если конец для чтения не открыт, open () для файла в режиме "только для чтения" или "только для записи" блокируется, пока другой конец не будет открыт
O_TRUNC Если файл существует, он усекается до нулевой длины, open () возвращает неотрицательный дескриптор файла, если завершится успешно; иначе возвращается -1
Создание файла
Чтобы создать файл, используйте флаг o_creat в параметре mode и добавьте восьмеричное значение для начальной установки флага. Например, строки 114—117 создают временный файл с доступом на чтение и запись для владельца и затем открывают файл для чтения и записи:
114 sprintf (tmpName, ”.rev.%d", getpidO); /* Случайное имя */
115 /* Создать временный файл для хранения копии ввода */
116 tmpfd = open (timpName, O_CREAT | O_RDWR, 0600) ;
117 'if (tmpfd == -1) fatalError();
Функция getpidO является системным вызовом, который возвращает ID процесса (PID) — номер, который будет уникальным. Это удобный способ сформировать уникальное временное имя файла. (Для дополнительной информации о getpidO см. разд. "Управление процессами" далее в этой главе.) Обратите внимание, что имя временного файла начинается с точки так, чтобы оно не появлялось в листинге утилиты is. Файлы, которые начинаются с точки, иногда называют скрытыми файлами.
Открытие существующего файла
Чтобы открыть существующий файл, задайте только флаги параметра mode. Строки 121—122 демонстрируют открытие файла в режиме "только для чтения":
121 fd = open (fileNamer O_RDONLY);
122 if (fd — -1) fatalError();
Другие флаги открытия
Другие более сложные установки флага системного вызова open (), типа o_nonblock, используются с конвейерами, сокетами и STREAMS. Вероятно, флаг o_creat — пока единственный смешанный флаг, в котором читатель будет нуждаться.
Чтение из файла: read()
Поскольку утилита reverse имеет инициализированный дескриптор файла fd для ввода, она читает фрагменты входа и обрабатывает их, пока не будет достигнут конец файла. Чтобы читать байты из файла, reverse использует системный вызов read (). Он выполняет ввод низкого уровня и не имеет ни одной из способностей форматирования scanf (). Преимущество read о состоит в том, что он обходит дополнительный этап буферирования, обеспечиваемый библиотечными функциями С, и поэтому является очень быстрым. Можно читать один символ входа за раз, что закончилось бы большим количеством системных вызовов и привело к значительному замедлению
выполнения программы. Вместо этого был использован системный вызов read о для чтения по buffer_size символов одновременно. BUFFER_SIZE был выбран кратным размеру блока диска для эффективного копирования.
Внимание
Здесь приведено краткое описание работы системного вызова read () при чтении обычного файла. Сведения о чтении специальных файлов см. далее в данной главе.
Синтаксис
ssize_t read (int fd, void* buf, size_t count)
Систмный вызов read о копирует count байтов из файла, заданного дескриптором файла fd в буфер buf. Байты читаются, начиная с текущей позиции файлового указателя, которая затем обновляется.
read () копирует столько байтов из файла, сколько может, до значения count и возвращает количество фактически скопированных байтов. Если read о предпринимается после того, как последний байт уже считался, он возвращает 0, который указывает на конец файла. Если системный вызов завершился успешно, read о возвращает количество прочитанных байтов; иначе возвращает —1.
Строки 130—132, выполняют чтение и проверяют возвращаемый результат:
130
charsRead = read (fd, buffer, BUFFER_SIZE);
131 if (charsRead == 0) break;
/* EOF */
132
if (charsRead == -1) fatalError(); /* Ошибка */
По мере чтения каждый фрагмент входа передается функции trackLines о. Эта функция просматривает буфер входа до символа перевода строки и сохраняет смещение первого символа в каждой строке в массиве linestart. Переменная fileoffset служит для хранения текущего смещения файла. Содержание linestart используется во время второго прохода.
Запись в файл: write()
Когда утилита reverse читает со стандартного входа, она создает копию входа для использования во время второго прохода. Чтобы сделать это, она заставляет дескриптор файла tmpfd ссылаться на временный файл и затем пишет каждый фрагмент входа в файл во время цикла чтения. Для записи байтов в файл она использует системный вызов write о, который выполни-
ет вывод низкого уровня и не имеет ни одной из способностей форматирования библиотечной функции printf о. Преимущество write о состоит в том, что он обходит дополнительный этап буферирования, обеспечиваемый библиотечными функциями С, и поэтому является очень быстрым.
Внимание
Здесь приведено краткое описание работы системного вызова write () при записи в обычный файл. Сведения о записи в специальные файлы см. далее в данной главе.
Синтаксис
ssize_t write (int fdr void* buf, size_t count)
Системный вызов write о копирует count байтов из буфера buf в файл, заданный дескриптором файла fd. Байты записываются, начиная с текущей позиции файлового указателя, которая затем обновляется. Если флаг o_append был установлен для fd, позиция файлового указателя перемещается на конец файла перед каждой записью.
write () копирует столько байтов из буфера, сколько может, до значения count и возвращает количество фактически скопированных байтов. Пользовательский процесс должен всегда проверять возвращаемое значение. Если возвращаемое значение не равно count, то диск, вероятно, заполнен, и пространства не осталось. Если системный вызов завершается без ошибки, write () возвращает количество записанных байтов; иначе возвращает —1.
Строки 134—139 демонстрируют выполнение записи:
134 /* Копировать строку во временный файл, если чтение из stdin */
135 if (standardinput)
136 {
137 charsWritten = write (tmpfd, buffer, charsRead);
138 if(charsWritten != charsRead) fatalError();
139 }
Перемещение в файле: IseekO
После первого прохода массив linestart содержит смещение первого символа каждой строки входного файла. Во время второго прохода строки читаются в обратном порядке и выводятся на стандартный вывод. Чтобы чи
тать строки из последовательности, программа использует системный вызов iseek о, который позволяет изменять файловый указатель.
Синтаксис
off_t Iseek (int fd, off_t offset, int mode)
Системный вызов iseek о позволяет изменять текущую позицию дескриптора файла, fd — дескриптор файла, offset — смещение, длинное целое число. Параметр mode описывает, как смещение должно интерпретироваться. Три возможных значения режима * определены в файле /usr/include/stdio.h и имеют следующие значения:
Величина Описание
SEEKJSET Смещение offset относительно начала файла
SEEK__CUR Смещение offset относительно текущей позиции файла
SEEK_END Смещение offset относительно конца файла
Системный вызов iseek о завершается с ошибкой, если будет осуществлена попытка перемещения за начало файла.
При нормальном завершении iseek о возвращает текущую позицию файла; иначе возвращает —1.
В некоторых системах режимы определены в файле /usr/include/unistd.h.
Строки 196—197 демонстрируют выполнение поиска до начала строки и чтения всех символов в строке. Обратите внимание, что количество символов для чтения рассчитывается путем вычитания смещения начала следующей строки от смещения начала текущей строки:
196 Iseek (fd, lineStart[i], SEEK_SET); /* Найти строку и читать ее */ 197 charsRead = read (fd, buffer, lineStart[i+1] — lineStart[i]);
Если необходимо выяснить текущее местоположение без перемещения, следует указать значение смещения 0 относительно текущей позиции: currentOffset = Iseek (fd, 0, SEEK__CUR) ;
Если произошло перемещение за конец файла, а затем выполняется системный вызов write о , ядро автоматически расширяет размер файла и обращается с промежуточной областью файла, как будто она была заполнена сим
волами null (ASCII 0). Интересно, что оно не выделяет пространство диска для промежуточной области. Это подтверждает следующий пример:
$ cat sparse.с ...посмотреть тестовый файл.
# include <fcntl.h>
# include <stdio.h>
# include <stdlib.h>
/***************************************************************/
main ()
{
int i, fd;
/* Создать разбросанный файл */
fd = open ("sparse.txt", O_CREAT | O_RDWR, 0600);
write (fd, "sparse", 6);
Iseek (fd, 60006, SEEKJSET);
write (fd, "file", 4);
close (fd);
/* Создать нормальный файл */
fd = open ("normal.txt", O_CREAT I O_RDWR, 0600);
write (fd, "normal", 6);
for (i = .1; i <= 60000; i++) write (fd, "/О", 1);
write (fd, "file", 4);
close (fd);
}
$ sparse ...выполнить файл.
$ Is -1 ★.txt ...посмотреть файлы.
-rw-r—r— 1 glass 60010 Feb 14 15:06 normal.txt
-rw-r—r— 1 glass 60010 Feb 14 15:06 sparse.txt
$ Is -s ★.txt ...вывести их использованные блоки.
60 normal.txt* ...использует 60 блоков целиком.
8 sparse.txt* ...использует только 8 блоков.
$
Файлы, которые содержат промежутки, называются разбросанными файлами (sparse file). (Для дополнительной информации см. главу 14).
Закрытие файла: closeO
После второго прохода утилита reverse использует системный вызов close (), чтобы освободить дескриптор входного файла.
Синтаксис
int close (int fd)
Системный вызов close о освобождает дескриптор файла fd. Если fd — последний дескриптор файла, связанный с конкретным открытым файлом, ресурсы ядра, отведенные для файла, освобождаются. Когда процесс заканчивается, все его дескрипторы автоматически закрываются, но лучший стиль программирования состоит в том, чтобы закрыть файл явно. Если осуществляется попытка закрытия дескриптора файла, который уже закрыт, происходит ошибка. При нормальном завершении системный вызов close о возвращает 0; иначе возвращает —1.
Строка 180 содержит вызов close ():
180 close (fd); /* Закрыть входной файл */
Закрытие файла не гарантирует, что буфер файла немедленно сбрасывается на диск. Для получения дополнительной информации о буферизации файлов см. главу 14.
Удаление файла: unlinkf)
Если утилита reverse читает со стандартного ввода, она сохраняет копию входа во временном файле. В конце второго прохода она удаляет этот файл, ИСПОЛЬЗУЯ СИСТемНЫЙ ВЫЗОВ unlink ().
Синтаксис
int unlink (const char* fileName)
Системный ВЫЗОВ unlink о удаляет жесткую СВЯЗЬ между fileName и его файлом. Если fileName — последняя связь к файлу, ресурсы файла освобождаются. В этом случае, если дескрипторы файла любого процесса в настоящее время связаны с файлом, вход каталога удаляется немедленно, но файл освобождается только тогда, когда все дескрипторы файла будут закрыты. Это означает, что исполняемый файл может откреплять себя во время выполнения и все еще продолжать работать до завершения. При нормальном завершении unlink о возвращает 0; иначе возвращает —1.
Строка 181 содержит вызов unlink о:
181 if (standardinput) unlink (tmpName); /* Удалить временный файл */ Дополнительные сведения о жестких связях см. в главе 14.
Второй пример: monitor
Данный раздел содержит описание несколько дополнительных системных вызовов, перечисленных в табл. 13.4. Их* использование демонстрируется в контексте программы monitor, которая позволяет контролировать ряд указанных файлов и получать информацию всякий раз, когда любой из них изменяется.
Таблица 13.4. Углубленные системные вызовы ввода/вывода UNIX
Имя Функция
stat Получает статусную информацию о файле
f stat Работает точно так же, как stat
getdents Получает вхождения каталога
Синтаксис
monitor [-t delay] [-1 count] {имяФайла}+
Утилита monitor просматривает все указанные файлы каждые delay секунд и показывает информацию о любом из указанных файлов, которые были изменены с последнего просмотра. Если имяФайла является каталогом, просматриваются все файлы внутри этого каталога. Модификация файла обозначается одним из трех способов:
Обозначение Описание
ADDED Указывает, что файл был создан после последнего просмотра. Каждому файлу в списке файлов дают эту метку во время первого просмотра
CHANGED Указывает, что файл был изменен после последнего просмотра
DELETED Указывает, что файл был удален после последнего просмотра
По умолчанию monitor будет осуществлять просмотр в любом случае, хотя вы можете определить общее количество просмотров с помощью опции -1. По умолчанию время задержки между просмотрами составляет 10 секунд, хотя оно может быть переопределено через опцию -t.
В приведенном ниже примере проводится мониторинг индивидуального файла и каталога с сохранением вывод monitor во временном файле:
% 1s ...посмотреть домашний каталог.
monitor.с monitor tmp/
% Is tmp ...посмотреть каталог tmp.
ь
% monitor trap myFile.txt >& monitor.out &
[1] 12841
...запустить.
% cat > tmp/a ...создать файл в ~/tmp.
hi there "D
% cat > myFile.txt ...создать myFile.txt.
hi there
% cat > myFile.txt hi again ...изменить myFile.txt.
% rm tmp/a ...удалить tmp/a.
% jobs ...посмотреть задания.
[ 1] + Running monitor tmp myFile.txt , & monitor.out
% kill %1 ..."убить" задание monitor.
[1] Terminated monitor tmp myFile.txt , & monitor.out
% cat monitor.out ...посмотреть вывод.
ADDED tmp/b size 9 bytes, mod. time = Sun Jan 18 00:38:55 1998
ADDED tmp/a size 9 bytes, mod. time = Fri Feb 13 18:51:09 1998
ADDED myFile.txt size 9 bytes, mod. time = Fri Feb 13 18:51:21 1998 CHANGED myFile.txt size 18 bytes, mod. time = Fri Feb 13 18:51:49 1998 DELETED tmp/a Q. О
Заметьте, как содержимое файла monitor.out отразило дополнение, модификацию и удаление проверяемого файла и каталога.
Как работает monitor
Утилита monitor непрерывно просматривает указанные файлы и каталоги на модификацию. Она использует системный вызов stat () для получения информации о статусе заданных файлов, включая их тип и самое последнее время модификации, и системный вызов getdentsO, чтобы просмотреть
каталоги, monitor поддерживает таблицу статуса, называемую stats, которая хранит следующую информацию о каждом найденном файле:
□ имя файла;
□ информацию статуса, полученную stat о;
□ запись о том, существовал ли файл во время текущего и предыдущего просмотра.
Во время просмотра monitor обрабатывает каждый файл таким образом:
□ если файл в настоящее время не находится в таблице просмотра, он добавляется, и выводится сообщение "ADDED";
□ если файл уже размещен в таблице просмотра и был изменен после последнего просмотра, выводится сообщение "CHANGED".
В конце просмотра все вхождения, которые существовали во время предыдущего, но не во время текущего просмотра, удаляются из таблицы, и выводится сообщение "DELETED".
Ниже представлен полный листинг файла monitor.c, исходный код программы monitor. Просмотрите его, а затем прочитайте описание системных вызовов.
Листинг: monitor.c
1 #include <stdio.h> /* Для printf, fprintf */
2 #include <string.h> /* Для strcmp */
3 #include <ctype.h> /* Для isdigit */
4 #include <fcntl.h> /* Для O_RDONLY */
5 ttinclude <sys/dirent.h> /* Для getdents */
6 #include <sys/stat.h> /* Для IS macros */
7 #include <sys/types.h> /* Для modet */
8 #include <time.h> /* Для локального и актуального времени */
9
10
11 /* # define-операторы */
12 #define MAX_FILES 100
13 #define MAX_FILENAME 50
14 #define NOT^FOUND -1
15 #define FOREVER -1
16 #define DEFAULT_DELAY_TIME 10
17 #define DEFAULT_LOOP_COUNT FOREVER
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
/★ Логические */
enum { FALSE, TRUE }
/* Структура Status, одна на файл */ struct statStruct
{
char fileName [MAX_FILENAME]; /* Имя файла */
int lastCycle, thisCycle; /* Для определения изменений */ struct stat status; /* Информация от stat() */
};
/* Глобальные */
char* fileNames [MAX_FILES]; /* Один на файл в командной строке */
int fileCount; /* Счетчик файлов в командной строке */
struct statStruct stats [MAX_FILES]; /* Один на совпадающий файл */ int loopCount = DEFAULT_LOOP_COUNT; /* Количество циклов */ int delayTime = DEFAULT_DELAY_TIME; /* Секунд между циклами */
Jr***************************************************************/
main (argc, argv)
int argc; char* argv [];
parseCommandLine (argc, argv); /* Разобрать командную строку */ monitorLoop(); /* Выполнить главный цикл monitor */
return (/* ВЫХОД_УСПЕХ */ 0) ;
****************************************************************/
parseCommandLine (argc, argv)
int argc;
char* argv [];
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
/★ Разобрать аргументы командной строки */
{
int i;
for (i = 1; ( (i < argc) && (i < MAKEFILES) ); i++) {
if (argv[i] [0] == )
processoptions (argv[i]);
else fileNames[fileCount++] = argv[i];
}
if (fileCount == 0) usageError();
}
у****************************************************************/
processoptions (str)
char* str;
/* Разобрать опции */
{
int j;
for (j = 1; str[j] != NULL; j++)
X {
switch(str[j]) /* Переключатель по символу опции */
{
case ’t’: delayTime — getNumber (str, &j);
break;
case 111: loopCount = getNumber (str, &j);
break;
98 }
99 }
100 }
101
]_ Q2 /★**★**★**★*★**★★★**★***★**★*★★★★★★★*****★*****★+★★★★★*****★****+ /
103
104 getNumber (str, i)
105
106 char* str;
107 int* i;
108
109 /* Преобразовать числовую ASCII-опцию в число */
110
111 { '
112 int number = 0;
113 int digits =0; /* Счетчик цифр в числе */
114
115 while (isdigit (str[(*i) + 1]))/Преобразовать символы в целое*/
116 {
117 number = number *10+ str[++(*i)] — ’O’;
118 ++digits;
119 }
120
121 if (digits == 0) usageError(); /* Здесь должно быть число */
122 return (number);
123 }
124
2 5 ^•к'к'к'к-к~к--к-к'к’-к-к-к-к-к^'к-к-к^к-к-к-)с'к'к'к'к'к'к'к-к-к-к'к-к-к^к-к-к-)с-к-к--к'к'к'к'к-к-к-к-к-)г--к-к-)г-^-к-'к'к--к-к-к-к-к'к- I
126
127 usageError()
128
129 {
130 fprintf (stderr, "Usage: monitor -t<seconds> -l<loops> (filename}+\n");
131 exit (/* ВЫХОД_НЕУСПЕХ */ 1);
132 }
133
1 4 /****************************************************************/
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
163
164
165
166
167
168
169
170
171
172
173
174
175
monitorLoop()
/* Главный цикл monitor */
{
do
{
monitorFiles(); /* Просмотреть все файлы */
fflush (stdout); /* Вывести стандартный вывод */
fflush (stderr); /* Вывести стандартный канал ошибки */
sleep (delayTime); /* ЭКдать следующего цикла */
}
while (loopCount == FOREVER || —loopCount > 0);
/★★★★★**^*****************************************т1гт1г*****'/г*т1гт1г***
monitorFiles()
/* Обработать все файлы */
int i;
for (i = 0; i < fileCount; i++) monitorFile (fileNames[i]); 162
for (i = 0; i< MAX_FILES; i++) /* Обновить массив stat */ {
if (stats[i].lastCycle && !stats[i].thisCycle) printf ("DELETED %s\n", stats[i].fileName);
stats[i].lastCycle = stats[i].thisCycle;
stats[i].thisCycle = FALSE;
}
}
★★*★★★★★*******★★**★★★★★★★*★★★★★★★★★★***★**********************
monitorFile (fileName)
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
char* fileName;
/* Обработать одиночный файл/каталог */
{
struct stat statBuf;
mode_t mode;
int result;
result = stat (fileName, &statBuf); /* Получить статус файла */
if (result == -1) /* Статус был недоступен */
{
fprintf (stderr, "Cannot stat %s\n", fileName); return;
}
mode = statBuf.st_mode; /* Вид файла */
if(S__ISDIR (mode)) /* Каталог *•/ processDirectory (fileName);
else if (S-ISREG (mode) || S_ISCHR (mode) || S_ISBLK (mode)) updateStat (fileName, &statBuf); /* Обычный файл */
}
********************★*****************************************/
/*
processDirectory (dirName)
char* dirName;
/* Обработать все файлы в указанном каталоге */
int fd, charsRead;
struct dirent dirEntry;
char fileName [MAX_FILENAME];
215 fd = open (dirName, O_RDONLY); /* Открыть для чтения */
216 if (fd == -1) fatalError();
217
218 while (TRUE) . /* Читать все элементы каталога */
219 {
220 charsRead = getdents(fd, &dirEntry, sizeof (struct dirent));
221 if (charsRead == -1) fatalError();
222 if (charsRead == 0) break; /* EOF */
223 if (strcmp (dirEntry.d_name, ”.") != 0&&
224 strcmp (dirEntry.d_name, != 0) /* Пропустить . и .. */
225 {
226 sprintf (fileName, "%s/%s", dirName, dirEntry.d_name);
227 monitorFile (fileName); /* Рекурсивный вызов */
228 }
229
230 Iseek (fd, dirEntry.d_off, SEEK_SET); /* Искать следующий
элемент */
231 }
232
233 close (fd); /* Закрыть каталог */
234 }
235
у****************************************************************/
237
238 updateStat (fileName, statBuf)
239
240 char* fileName;
241 struct stat* statBuf; 242
243 /* Добавить элемент status, если необходимо */
244
245 {
246 int entryindex;
247
248 entryindex = findEntry (fileName);/* Найти существующий элемент */
249
250 if (entгуIndex == NOT_FOUND)
251 entryindex = addEntry (fileName, statBuf); /* Добавить новый элемент */ /
252
else
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
284
285
286
287
288
289
290
291
updateEntry (entгуIndex, statBuf); /* Обновить существующий элемент */
if (entryIndex != NOT_FOUND)
stats[entryindex].thisCycle = TRUE; /* Обновить массив status */ }
★ ***★****★**★★★*★*******★*****★***★*★★** + **★*** + ***★************ I
findEntry (fileName)
char* fileName;
/* Определить индекс указанного файла в массиве status */
{
int i;
for (i = 0; i < MAX_FILES; i++)
if (stats[i].lastCycle &&
strcmp (stats[i].fileName, fileName) == 0) return (i);
return (NOT_FOUND) ; }
/**************************************************************** j
addEntry (fileName, statBuf)
char* fileName;
struct stat* statBuf; 283
/* Добавить новый элемент в массив status */
{
int index;
index = nextFreeO; /* Найти следующий свободный элемент */
if (index == NOT_FOUND) return (NOT_FOUND); /* He осталось */
strcpy (stats[index].fileName, fileName); /* Добавить имя файла */ stats[index].status = *statBuf; /* Добавить информацию статуса */
292
293
294
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
printf ("ADDED "); printEntry (index); return (index);
/* Известить стандартный вывод */
/* Вывести информацию статуса */
***•*•**•*•********★****★★*•*******★★*•★★★★★★*★*★*•*•*★★★*★****•★*•**•*•*★**
nextFree()
/* Вернуть следующий свободный индекс в массив status */
int i;
for (i = 0; i < MAX_FILES; i++)
if (!stats[i].lastCycle && !stats[i].thisCycle) return (i);
return (NOT_FOUND);
updateEntry (index, statBuf)
int index;
struct stat* statBuf;
/* Вывести информацию, если файл был модифицирован */
if (stats[index].status.st_intime != statBuf->st_mtime)
stats[index].status = *statBuf;/* Сохранить информацию статуса */
printf ("CHANGED "); printEntry (index);
/* Известить стандартный вывод */
if***************************************************************/
332
333 printEntry (index)
334
335 int index;
336
337 /* Вывести элемент массива status */
338
339 {
340 printf ("%s ", stats[index].fileName) ;
341 printstat (&stats[index].status);
342 }
343
244 у**********************************************'****'*’*************/
345 '
346 printStat (statBuf)
347
348 struct stat* statBuf;
349
350 /* Вывести буфер status */
351
352 {
353 printf ("size %lu bytes, mod. time = %s", statBuf->st_size,
354 asctime (localtime (&statBuf->st_mtime)));
355 }
356
357 y**************************************************************y
358
359 fatalError()
360
361 {
362 perror ("monitor: ") ;
363 exit (/* ВЫХОД_СБОЙ */ 1);
364 }
Получение информации о файле: stat()
Утилита monitor получает свою информацию о файле через системный вызов stat о из monitorFile о (строка 175) на строке 186:
186 result = stat (fileName, &statBuf); /* Получить статус файла */
Синтаксис
int stat ( const char* name, struct stat* buf) int Istat (const char* name, struct stat* buf) int fstat (int fdr struct stat* buf)
Системный вызов stat о заполняет буфер buf информацией о файле пате. Структура stat определена в файле /usr/include/sys/stat.h. istat о возвращает информацию непосредственно о символической связи, а не о файле, на который она ссылается, fstat о исполняет ту же самую функцию, что и stat (), но требуется дескриптор файла, который должен быть задан в качестве его первого параметра.
Структура stat содержит следующие поля;
Имя Описание
st_dev st_ino Номер устройства Номер узла
st_mode st_nlink st_uid Флаги разрешения доступа Счетчик жестких связей ID пользователя
st_gid ID группы
st_size st_atime st_mtime st_ctime Размер файла Последнее время доступа Последнее время модификации Последнее время изменения статуса
Есть некоторые предопределенные макросы, заданные в файле /usr/include/sys/stat.h, которые берут поле st_mode в качестве аргумента и возвращают истину (1) для следующих типов файла:
Макрос Возвращает истину для файла типа
S_IFDIR Каталог
S_IFCHR Специальное символьное устройство
S_IFBLK Специальное блочное устройство
S_IFREG Обычный файл
S_IFFIFO Конвейер
Поля времени могут быть декодированы стандартными подпрограммами библиотеки С asctime () И localtime ().
stat о и f stat о возвращают 0, если завершились без ошибок, и —1 — в противном случае.
Утилита monitor проверяет режим файла с помощью макросов s isdir, s_isreg, s ischr и s_isblk, обрабатывая каталоги и другие файлы следующим образом.
□ Если файл — ЭТО каталог, monitor вызывает процедуру processDirectory () (строка 204), которая применяет monitorFile о рекурсивно к каждому из элементов каталога.
О Если файл — это обычный файл, символьный файл или блочный файл, monitor вызывает процедуру updatestat () (строка 238), которая либо добавляет, либо модернизирует элемент статуса файла. Если статус изменяется любым способом, вызывается процедура updateEntry() (строка 315), чтобы показать новый статус файла. Расшифровка полей времени выполняется подпрограммами localtime о И asctime о В printstat о (строка 346).
Чтение информации каталога: getdentsO
Подпрограмма processDirectory о (строка 204) открывает файл каталога для чтения и использует системный вызов getdents о, чтобы получить каждый элемент в каталоге. processDirectory о осторожничает, чтобы не пропустить каталоги и и применяет lseek(), чтобы перескочить с одного элемента каталога на следующий. Когда каталог полностью просмотрен, он закрывается.
Синтаксис
int getdents (int fd, struct dirent* buf, int structSize)
Системный вызов getdents () читает файл каталога с дескриптором fd с его текущей позиции и заполняет структуру, указанную buf, следующим элементом. Структура dirent определена в файле /usr/include/sys/dirent.h и содержит поля:
Имя Описание
d_ino Номер узла
d_of f Смещение следующего элемента каталога
(окончание)
Имя Описание
d_reclen Длина структуры элемента каталога
d_nam Длина имени файла
Системный вызов getdents () возвращает длину элемента каталога при нормальном завершении; 0, когда последний элемент каталога уже читался; —1 — в случае ошибки.
Некоторые старые системы используют системный вызов getdirentriesо вместо getdents(). getdirentries () несколько отличается от getdents(). (См. соответствующую страницу руководства используемой системы.)
Смешанные вызовы системы управления файлами
В табл. 13.5 приведено краткое описание некоторых смешанных вызовов системы управления файлами UNIX.
Таблица 13.5. Вызовы системы управления файлами UNIX
Имя Описание
chown Заменяет владельца файла или группы
chmod Изменяет установки прав доступа файла
dup dup2 Дублирует дескриптор файла Подобен dup
fchown Работает точно так же, как chown
fchmod Работает точно так же, как chmod
fcntl Дает доступ к разным характеристикам файла
ftruncate Работает точно так же, как truncate
ioctl Управляет устройством
link Создает жесткую связь
mknod Создает специальный файл
sync Планирует выгрузку всех буферов файла, которые должны быть сброшены на диск
truncate Укорачивает файл
Замена владельца файла или группы: chownQ и fchownQ
Системные вызовы chown о и fchown о изменяют владельца или группу файла.
Синтаксис
int chown (const char* fileName, uid_t ownerId, gid_t groupld) int Ichown (const char* fileName, uid__t owner Id, gid__t groupld) int fchown (int fd, uid_t ownerld, gid_t groupld)
Системный вызов chown о заставляет ID владельца и группы fileName измениться соответственно на owner id и groupld. Значение —1 в специфическом поле означает, что ассоциированное с ним значение должно остаться неизменным.
Системный вызов ichown о изменяет непосредственно собственность символической связи, а не файла, на который связь ссылается.
Только привилегированный пользователь (root) может изменять собственность файла, а обычный пользователь способен изменять только одну группу на другую группу, членом которой он является. Если fileName — символическая связь, изменяется владелец и группа связи вместо файла, на который связь ссылается.
Системный вызов fchownо точно такой же, как chownо, но требует открытый дескриптор в качестве аргумента вместо filename.
Все функции возвращают —1, если завершились с ошибкой, и 0 — в противном случае.
В приведенном далее примере происходит замена группы файла test.txt с music на cs, который имеет ID группы, равный 62 (для дополнительной информации о ID группы и его локализации см. главу 15^:
$ саt mychown.с ... посмотреть файл.
main()
int flag;
flag = chown ("test.txt", -1, 62); /* Оставить ID пользователя неизменным */
if (flag == -1) perror("mychown.c");
$ Is -lg test.txt ...проверить файл перед..
-rw-r—г— 1 glass music 3 May 25 11:42 test.txt
$ mychown ...выполнить программу.
$ Is -lg test.txt ...проверить файл после.
-rw-r—г— 1 glass cs 3 May 25 11:42 test.txt
$
Изменение прав доступа файла: chmod() и fchmodO
Системные вызовы chmod () и f chmod () изменяют флаги прав доступа файла.
Синтаксис
int chmod (const char* fileName, int mode)
int fchmod (int fd, mode_t mode)
Системный ВЫЗОВ chmodj) изменяет режим fileName на mode, обычно восьмеричное число, как описано в главе 2. Флаги "установка ID пользователя" и "установка ID группы" имеют, соответственно, восьмеричные значения 4000 и 2000. Чтобы изменить режим файла, вы должны быть либо его владельцем, либо привилегированным пользователем.
Системный вызов fchmod () работает аналогично chmod (), но требует открытый дескриптор файла в качестве аргумент вместо filename.
Оба вызова возвращают —1, если завершились с ошибкой, и 0 — в противном случае.
В следующем примере изменяются флаги прав доступа файла test.txt на восьмеричное 600, которое соответствует разрешению чтения и записи только для владельца:
$ cat ту chmod. с ...посмотреть файл,
main()
{
int flag;
flag = chmod ("test.txt", 0600);/*Использовать восьмеричную кодировку*/ if (flag == -1) perror ("mychmod.c");
}
$ Is -1 test.txt ...проверить файл перед.
-rw-r—г— 1 glass 3 May 25 11:42 test.txt
$ mychmod ...выполнить программу.
$ Is -1 test.txt ...проверить файл после.
-rw------- 1 glass 3 May 25 11:42 test.txt
$
Дублирование дескриптора файла:
dup() и dup2()
Системные вызовы dup () и dup2 () позволяют дублировать дескрипторы файла. Shell использует dup2(), чтобы выполнить перенаправление и конвейеризацию. Примеры см. в разд. "Управление процессами" далее в этой главе и изучите Internet shell в конце главы.
Синтаксис
int dup (int oldFd}
int dup2 (int oldFdf int newFd)
Системный вызов dup о находит самый маленький свободный элемент дескриптора файла и направляет его на тот файл, с которым связан дескриптор oldFd.
Системный вызов dup2 () закрывает дескриптор newFd, если он в настоящее время активен, и затем направляет его на файл, с которым связан Дескриптор oldFd.
В обоих случаях первоначальные и скопированные дескрипторы файла разделяют один и тот же указатель файла и режим доступа. Оба вызова возвращают индекс нового дескриптора файла, если завершились без ошибки, и —1 — в противном случае.
В представленном ниже примере создается файл st.txt и производится запись в него через четыре различных дескриптора файла:
П первый дескриптор файла — первоначальный дескриптор;
П второй дескриптор — копия первого, размещенная в области 4;
П третий дескриптор — копия первого, размещенная в области 0, которая была освобождена оператором close (0) (стандартный канал ввода);
П четвертый дескриптор — копия дескриптора 3, продублированная на место существующего дескриптора в области 2 (стандартный канал ошибки).
$ cat mydup.c ...посмотреть файл.
ftinclude < stdio.h>
19 Зак. 786
ttinclude <fcntl.h> main ()
{
int fdl, fd2, fd3;
fdl = open ("test.txt", O_RDWR | O_TRUNC);
printf ("fdl — %d\n", fdl);
write (fdl, "what’s", 6);
fd2 = dup (fdl) ; /* Сделать копию fdl */
printf ("fd2 = %d\n", fd2);
write (fd2, " up", 3);
close (0); /* Закрыть стандартный ввод */
fd3 = dup (fdl); /* Сделать другую копию fdl */
printf ("fd3 - %d\n", fd3);
write (0, " doc", 4);
dup2 (3, 2); /* Дублировать канал 3 в канал 2 */
write (2, "?\n", 2);
$ mydup ...выполнить программу.
fdl = 3 fd2 = 4 fd3 = 0
$ cat test.txt .посмотреть выходной файл,
what’s up doc?
$ _
Действия с дескриптором файла; fcnttf)
Системный вызов fcnti () непосредственно управляет установкой флагов, связанных с дескриптором файла.
Синтаксис
int fcntl (int fd, int cmdf int arg)
Системный вызов fcntl () исполняет действие, заданное командой cmd, на файле, связанном с дескриптором файла fd. arg — дополнительный аргумент для cmd.
Обычные значения cmd:
Значение Описание
F_SETFD Устанавливает флаг "закрыть при выходе" в младшем бите агд (0 или 1)
F_GETFD Возвращает число, чей младший бит — 1, если флаг "закрыть при выходе" установлен, и 0 — в противном случае
F-GETFL Возвращает число, соответствующее текущим флагам статуса файла и режимам доступа
F_SETFL Устанавливает текущие флаги статуса файла в агд
F_GETOWN Возвращает ID процесса или группу процесса, которая в настоящее время установлена, чтобы получить сигналы SIGIO/SIGURG. Если возвращенное значение положительно, оно относится к ID процесса. Если оно отрицательно, его абсолютное значение относится к группе процесса
F-SETOWN Устанавливает ID процесса или группу процесса, которая должна получить сигналы SIGIO/SIGURG в агд. Схема кодирования аналогична F_GETOWN
Системный вызов fcnti() возвращает -1, если завершается с ошибкой.
В следующем примере открывается существующий файл для записи, и начальные символы заменяются фразой "hi there". Затем используется fcnti (), чтобы установить флаг append в дескрипторе файла, который предписывает добавление всех дальнейших записей. Это стало причиной размещения слова "guys" в конце файла, даже притом, что файловый указатель был перемещен обратно на начало при помощи iseeko. Код следующий:
$ cat myfcnti.с ...посмотреть программу.
#include <stdio.h>
#include <fcntl.h>
main()
{ int fd;
fd = open ("test.txt", O_WRONLY); /* Открыть файл для записи */
write (fd, "hi there\n", 9);
Iseek (fd, 0, SEEK_SET); • /* Поиск начала файла */
fcnti (fd, FJSETFL, O_WRONLY | O_APPEND); /* Установить^флаг APPEND */ write (fd, " guys\n", 6);
close (fd);
$ cat test.txt
...посмотреть оригинальный файл.
here are the contents
of the original file.
$ my fcntl
$ cat test.txt
...выполнить программу.
...посмотреть новое содержимое.
hi there
the contents
of the original file.
guys $
...обратите внимание, что "guys” — в конце.
Управление устройствами: ioctlO
Ниже приведено описание системного вызова ioctl О.
Синтаксис
int ioctl (int fdf int cmdr int arg)
Системный вызов ioctl() исполняет действие, заданное командой cmd, на файле, связанном с дескриптором файла fd. arg — дополнительный аргумент для cmd. Имеющие силу значения cmd зависят от устройства, на которое ссылается fd, и обычно документируются в инструкциях производителя. Поэтому здесь примеры не приводятся для данного системного вызова, ioctl () возвращает ~1, если завершается с ошибкой.
Создание жестких связей: Ппк()
Системный вызов link о создает жесткую связь к существующему файлу.
Синтаксис
int link (const char* oldPath, const char* newPath)
Системный вызов link о создает новую метку newPath и связывает ее с тем же самым файлом, что и метка oldPath. Счетчик жестких связей связанного файла увеличивается на единицу. Если oldPath и newPath находятся на различных физических устройствах, жесткая связь не может
быть создана, и link о завершается с ошибкой. Для дополнительной информации о жестких связях см. описание enbkbns in в главе 3. Системный вызов link о возвращает -1, если завершается с ошибкой, и 0 — в противном случае.
В приведенном далее примере создается файл another.txt, который связывается с файлом original.txt. Затем демонстрируется, что обе метки были связаны с одним и тем же файлом. Код следующий:
$ cat mylink.с ...посмотреть программу.
main ()
link ("original.txt", "another.txt");
}
$ cat original.txt ...посмотреть оригинальный файл,
this is a file.
$ Is -1 original.txt another.txt ...проверить файлы перед.
another.txt not found
-rw-r—r— 1 glass 16 May 25 12:18 original.txt
$ my link ...выполнить программу.
$ Is -1 original.txt another.txt ...проверить файлы после.
-rw-r—г— 2 glass 16 May 25 12:18 another.txt
-rw-r—r— 2 glass 16 May 25 12:18 original.txt
$ cat » another.txt ...изменить another.txt.
hi
"D
$ Is -1 original.txt another.txt ...обе метки отражают изменение.
-rw-r—г— 2 glass 20 May 25 12:19 another.txt
-rw-r—r— 2 glass 20 May 25 12:19 original.txt
$ rm original.txt ...удалить оригинальную метку.
$ Is -1 original.txt another.txt ...проверить метки.
original.txt not found
-rw-r—r—‘ 1 glass 20 May 25 12:19 another.txt
$ cat another.txt ...посмотреть содержимое через другую метку,
this is a file.
hi
$
Создание специальных файлов: mknod()
Системный вызов mknod () позволяет создавать специальный файл. В качестве примера работы mknod () рассмотрите разд. "Конвейеры" далее в этой главе.
Синтаксис
int mknod (const char* fileName, mode_t type, dev_t device]
Системный вызов mknod о создает новый обычный файл, каталог или специальный файл с именем fileName, чей тип может быть одним из следующих:
Значение Описание
S_IFDIR Каталог
S_IFCHR Символьный файл устройства
S_IFBLK Блочный файл устройства
S_IFREG Обычный файл
S_IFIFO Именованный конвейер
Если файл является символьным или блочным, то байт младшего разряда device должен определять младший номер устройства, а старший байт — старший номер устройства. (Это может изменяться в различных версиях UNIX.) В других случаях значение device игнорируется. (Для получения дополнительной информации о специальных файлах см. главу 14.)
Только привилегированный пользователь (root) может вызывать mknodj), чтобы создавать каталоги, ориентируемые на специальные символьные или блочные файлы.
mknod () возвращает —1, если завершается с ошибкой, и 0 — в противном случае.
Сбрасывание на диск буферов файловой системы: sync()
Системный вызов sync () сбрасывает на диск буферы файловой системы.
Синтаксис
void sync()
Системный вызов sync () планирует запись на диск всех буферов файловой системы. (Для получения дополнительной информации о буферной
системе см. главу 14.) sync() должен выполняться любыми программами, которые обходят буферы файловой системы и исследуют файловую систему. sync о всегда завершается нормально.
Усечение файла: truncateO и ftruncateO
Системные вызовы truncate () и ftruncate () устанавливают длину файла.
Синтаксис
int truncate (const char* fileName, off_t length) int ftruncate (int fd, off_t length)
Системный вызов truncateO устанавливает длину файла filename, равную length байтов. Если файл длиннее, чем length, он обрезается. Если короче, чем length, то дополняется ASCII-нулями.
Системный ВЫЗОВ ftruncateO работает аналогично truncateO, за ИС-. ключением того, что требует открытый дескриптор файла в качестве своего аргумента вместо filename.
Обе функции возвращают —1, если завершаются с ошибкой, и 0 — в противном случае.
В приведенном ниже примере устанавливается длина двух файлов, равная 10 байтам; один из файлов был первоначально короче, а другой длиннее. Вот код:
$ cat truncate, с ...посмотреть программу.
main()
{
truncate ("filel.txt", 10);
truncate ("file2.txt", 10);
$ cat filel.txt ...посмотреть filel.txt.
short
$ cat file2.txt ...посмотреть file2.txt.
long file with lots of letters
$ Is -1 file*.txt ...проверить оба файла.
-rw-r—г— 1 glass 6 May 25 12:16 filel.txt
-rw-r—r— 1 glass 32 May 25 12:17 file2.txt
$ truncate ...выполнить программу.
$ Is -1 file*.txt ...проверить оба файла снова.
-rw-r—г— 1 glass 10 May 25 12:16 filel.txt
-rw-r—r— 1 glass 10 May 25 12:17 file2.txt
$ cat filel.txt ...filel.txt длиннее, short
$ cat file2.txt ...file2.txt короче, long file $
STREAMS
STREAMS2 — более новая и обобщенная возможность ввода/вывода, которая была представлена в System V UNIX. Потоки чаще всего используются для добавления драйвера устройства к ядру и обеспечения интерфейса к драйверам сети.
Первоначально разработанная Деннисом Ритчи (Dennis Ritchie), одним из создателей UNIX, подсистема ввода/вывода STREAMS обеспечивает двусторонний путь между пространством ядра и пользовательским процессным пространством. Реализация STREAMS более обобщена, чем предыдущие механизмы ввода/вывода, делая их, таким образом, более легкими для реализации новых драйверов устройств. Одной из первоначальных мотиваций для создания STREAMS была очистка и улучшение традиционного символьного ввода/вывода UNIX, посылаемого терминальным устройствам.
Базирующиеся на System V версии UNIX также включают Transport Layer Interface (TLI) — сетевой интерфейс к драйверам STREAMS, подобный интерфейсу сокетов, позволяющий драйверам сети на основе STREAMS связаться с другими программами на основе сокетов.
Усовершенствования по сравнению с традиционным вводом/выводом UNIX
Традиционный символьный ввод/вывод UNIX развивался с момента возникновения этой ОС. Как и в любой сложной программной подсистеме, через какое-то время незапланированные и плохо спроектированные изменения привели к большим сложностям. Часть преимуществ STREAMS исходит из факта, что посистема является более новой и может реализовать знания, полученные за прошдшие годы. Это приводит к более прозрачному интерфейсу, чем раньше.
STREAMS также позволяет легче добавлять протоколы сети, чем создание целого драйвера и всех его необходимых частей на пустом месте. Зависимый от устройства код был выделен в модули так, чтобы только значимая часть
2 Потоки. — Ред.
переписывалась для каждого нового устройства. Общий код действий по обслуживанию ввода/вывода (например, распределение буферов и управление) был стандартизирован, и каждый модуль смог усилить услуги, предоставляемые потоком.
Работа STREAMS производит посылку и получение потоковых сообщений, а не просто выполнение грубого ввода/вывода символа за символом. STREAMS также добавила управление потоком и приоритетную обработку.
Анатомия STREAMS
Каждый поток имеет три части:
□ заголовок потока — точка доступа для пользовательского приложения, функций и структур данных, представляющих поток;
□ модули — код для обработки читаемых или записываемых данных;
□ драйвер потока — прикладная часть кода, который связывается с определенным устройством.
Все три работают в пространстве ядра, хотя модули могут быть добавлены из пользовательского пространства.
Заголовок потока обеспечивает интерфейс системного вызова для пользовательского приложения. Заголовок потока создается с помощью системного вызова open () .
Ядро заведует любым требуемым распределением памяти, восходящим и нисходящим потоком данных, планированием очереди, управлением потока и регистрацией ошибок.
Данные, записанные в заголовок потока из прикладной программы, находятся в форме сообщения, которое передается к первому модулю для обработки. Этот модуль обрабатывает сообщение и передает результат второму модулю. Обработка и передача продолжаются, пока последний модуль не передаст сообщение драйверу потока, который пишет данные на соответствующее устройство. Данные, поступающие от устройства, проходят тот же самый путь в обратном направлении.
Системные вызовы STREAMS
В дополнение к системным вызовам ввода/вывода, которые были описаны ранее в этой главе— ioctl О, open о, close о, read () и write (),— следующие системные вызовы работают с потоком:
□ getmsg () — получает сообщение из потока;
□ putmsgo — помещает сообщение в поток;
П poll о — опрашивает один или более потоков для деятельности;
□ isastreamo — выясняет, является ли данный дескриптор файла потоком.
Управление процессами
Процесс UNIX — это уникальный экземпляр работающей или работоспособной программы. Каждый процесс в системе UNIX имеет следующие атрибуты:
□ некоторый код (известный также как текст);
□ некоторые данные;
□ стек;
□ уникальный ID процесса (Process ID, PID).
Когда UNIX стартует, в системе существует только один видимый процесс. Этот процесс называется init и имеет PID 1. Единственный способ создать новый процесс в UNIX состоит в том, чтобы продублировать существующий процесс, так что init — предок всех последующих процессов. Когда процесс дублируется, родительский и дочерний3 процессы фактически идентичны (если бы не вещи, подобные PID, PPID (Parent PID), и времена выполнения); код порожденного процесса, данные и стек — это копия родителя, и он даже продолжает выполнять тот же самый код.
Дочерний процесс может, однако, заменить свой код кодом другого выполняемого файла, таким образом, отделяя себя от родителя. Например, когда процесс init начинает выполняться, он быстро дублируется несколько раз. Каждый из дубликатов дочерних процессов затем заменяет свой код из исполняемого файла getty, который является ответственным за обработку пользовательского входа в систему. Поэтому иерархия процессов напоминает схему, представленную на рис. 13.5.
Дочерний getty (PID 4) управляет входом в систему
Дочерний getty (PID 5) управляет входом в систему
Дочерний getty (PID 6) управляет входом в систему
Рис. 13.5. Начальная иерархия процесса
3 Дочерний процесс также называется порожденным. — Ред.
Когда дочерний процесс заканчивается, этот факт сообщается его .родителю, чтобы родитель мог предпринять некоторое соответствующее действие. Обычное действие для родительского процесса — приостановка, пока один из порожденных процессов не закончится. Например, когда shell выполняет утилиту в приоритетном режиме, он дублируется в два процесса shell; дочерний процесс shell заменяет свой код кодом утилиты, тогда как родительский shell ждет завершения дочернего процесса. Когда порожденный процесс заканчивается, первоначальный родительский процесс ’’пробуждается" и представляет пользователю следующее приглашение shell.
Рис. 13.6 иллюстрирует способ, которым shell выполняет утилиту. Указаны запросы системы, которые являются ответственными за каждую стадию выполнения. Internet shell, представленный позже в данной главе, имеет базовые возможности управления процессами классических UNIX shell и является хорошим проектом, чтобы рассмотреть некоторые удачные примеры кодирования, которые используют ориентируемые на процесс системные вызовы. А пока давайте рассмотрим некоторые простые программы, которые представляют эти системные вызовы один за другим. Следующие немногие подразделы описывают системные вызовы перечисленные в табл. 13.6.
Родительский процесс PID 34
выполняет shell -----------------^Дублируется: fork()
Родительский процесс PID 34 Дочерний процесс PID 35
выполняет shell, выполняет shell
ждет дочерний
Ждет дочерний: wait()
- Заменяет код: ехес()
Дочерний процесс PID 35 запускает утилиту
Сигнал
Родительский процесс PID 34 выполняет shell, пробуждается
Завершить: ехес()
Дочерний процесс PID 35 завершается
Таблица 13.6. Ориентированные на процесс системные вызовы UNIX
Имя Описание
fork Дублирует процесс
getpid Получает ID процесса
getppid Получает ID родительского процесса
exit Прекращает процесс
wait Ожидает дочерний процесс
exec Замещает код, данные и стек процесса
Создание нового процесса: fork()
Процесс может дублировать себя, используя fork о. fork о — это странный системный вызов, потому что один процесс (оригинал) вызывает его, а два процесса (оригинал и его порожденный процесс) возвращаются из него. Оба процесса продолжают выполнять один и тот же код одновременно, но имеют полностью отдельные стеки и пространство данных.
Синтаксис
pid_t fork (void)
Системный вызов fork() заставляет процесс дублироваться. Дочерний процесс — почти точная копия первоначального родительского процесса; он наследует копию кода своего родителя, данные, стек, открытые дескрипторы файла и таблицу сигналов. Однако родитель и порожденный процесс имеют различные ID порожденного процесса и ID родительского процесса. Если fork о завершается нормально, он возвращает PID порожденного процесса родительскому и 0 дочернему процессу. Если fork о завершается с ошибкой, он возвращает —1 родительскому процессу, а дочерний процесс не создается.
Теперь это напоминает мне о великолепном научно-фантастическом рассказе, который я однажды читал, о человеке, который проходил через очаровательную кабину в цирке. Продавец кабины сообщает человеку, что кабина является, в сущности, репликатором: любой, кто проходит через кабину, дублируется. Но это не все: "исходный" человек выходит из кабины невредимым, а его дубль оказывается на Марсе в качестве раба Марсианских строительных команд. Продавец затем сообщает человеку, что ему дадут
миллион долларов, если он позволит себя скопировать, и человек соглашается. Он счастливо идет через машину, ожидая получения миллиона долларов... и выходит на поверхность Марса. Тем временем на Земле его дубликат уходит с запасом наличных денег. Вопрос такой: если бы вы прошли через кабину, что делали бы вы?
Процесс может получить его собственный ID процесса и номер ID родительского процесса, используя, соответственно, системные вызовы getpido И getppid().
Синтаксис
pid_t getpid (void) pid_t getppid (void)
Систмные вызовы getpido и getppidо возвращают, соответственно, ID процесса и ID родительского процесса. Они всегда завершаются нормально. ID родительского процесса с PID 1 равен 1.
Для иллюстрации действия fork.o ниже приведена небольшая программа, которая дублируется и затем ветвится, базируясь на значении, возвращаемом fork():
$ cat myfork.с ...посмотреть программу.
#include <stdio.h>
main()
{
int pid;
printf ("I’m the original process with PID %d and PPID %d.\n", getpid(), getppid());
pid = fork(); /* Дублироваться. Порожденный и родительский процессы */ /* продолжаются отсюда */
if (pid != 0) /* PID не ноль, тогда я должен быть родителем */
printf ("I’m the parent process with PID %d and PPID %d.\n", getpid(), getppid());
printf ("My child's PID is %d\n", pid); }
else /* PID ноль, тогда я должен быть порожденным */
printf ("I'm the child process with PID %d and PPID %d.\n", getpid ()., getppid () );
printf ("PID %d terminates.\n”, getpid() ); /* Оба процесса */ /* выполняются здесь */ }
$ ту fork . . .выполнить программу.
I’m the original process with PID 13292 and PPID 13273.
I’m the parent process with PID 13292 and PPID 13273.
My child’s PID is 13293.
I’m the child process with PID 13293 and PPID 13292.
PID 13293 terminates. ...порожденный процесс завершился.
PID 13292 terminates. ...родительский процесс завершился. $
PID родителя ссылается на PID shell, который выполнял программу myfork.
Внимание
Для родительского процесса опасно заканчиваться без ожидания "смерти” своего порожденного процесса. Единственная причина, по которой в приведенном выше примере родитель не ждет, чтобы его дочерний процесс "умер", — отсутствие описания системного вызова wait ().
Осиротевшие процессы
Если родитель умирает прежде своего дочернего процесса, порожденный процесс автоматически усыновляется первоначальным процессом init с PID 1. Чтобы проиллюстрировать эту особенность, предыдущая программа была изменена, в коде порожденного процесса остался оператор sleep. Это гарантирует, что родительский процесс закончится прежде, чем ребенок. Вот программа й результирующий вывод:
$ cat orphan.с ...посмотреть программу.
#include- <stdio.h> main()
{
int pid; printf ("I’m the original process with PID %d and PPID %d.\n", getpid(), getppid());
pid = fork(); /* Дублироваться. Порожденный и родительский процессы */ /* продолжаются отсюда */
if (pid != 0) /* Ветвление, базирующееся */
/* на возвращаемом значении fork() */
{
/* PID не ноль, тогда я должен быть родителем */
printf ("I’m the parent process with PID %d and PPID %d.\n",
getpid(), getppid() );
printf ("My child’s PID is %d\n", pid);
} else
{
/* PID ноль, тогда я должен быть ребенком */
sleep (5); /★ Для уверенности, что родитель заканчивается первым */ printf ("I’m the child process with PID %d and PPID %d.\n", • getpid(), getppid());
}
printf ("PID %d terminates.\n", getpidO); /* Оба процесса */ /* выполняются здесь */ }
$ orphan ...выполнить программу.
I’m the original process with PID 13364 and PPID 13346.
I’m the parent process with PID 13364 and PPID 13346.
PID 13364 terminates.
I’m the child process with PID 13365 and PPID 1 ...осиротел!
PID 13365 terminates.
$ _
X
Рис. 13.7 иллюстрирует эффект усыновления.
init
Родительский "умирает" первым "Усыновление дочернего Дочерний переживает родительский
Завершение процесса: exit()
Процесс может закончиться в любое время, выполняя системный вызов exit (). Код завершения дочернего процесса может использоваться родительским процессом для различных целей.
Синтаксис
void exit (int status)
Системный вызов exit о закрывает все дескрипторы файла процесса, освобождает его код, данные и стек, а затем заканчивает процесс. Когда дочерний процесс завершается, он посылает своему родителю сигнал sigchld и ждет его код статуса — status завершения для того, чтобы принять его. Используются только младшие восемь битов статуса, так что значения ограничены диапазоном 0—255. Процесс, который ожидает своего родителя, чтобы принять от него код возврата, называется зомби-процессом. Родитель принимает код завершения дочернего процесса, выполняя wait ().
Ядро гарантирует, что все осиротевшие дети завершающегося процесса усыновляются процессом init путем установки их PPID в 1. Процесс init всегда принимает коды завершения своих порожденных процессов.
exit () не возвращает никакого результата.
Командные интерпретаторы могут получить доступ к коду завершения их последнего дочернего процесса через одну из их специальных переменных. Например, в представленном ниже коде С shell сохраняет код завершения последней команды в переменной $ status:
% cat myexit.c ...посмотреть программу.
#include <stdio.h>
main ()
{
printf ("I’m going to exit with return code 42\n");
exit(42);
% myexit ... выполнить программу.
I’m going to exit with return code 42
% echo $status
42
...вывести код завершения.
Во всех других shell значение возвращается в специальной переменной shell $?.
Зомби-процессы
Процесс, который заканчивается, не может оставить систему, пока его родитель не примет его код возврата. Если родительский процесс к этому моменту мертв, код возврата будет принят уже процессом init, который всегда принимает коды возврата своих порожденных процессов. Однако если родитель процесса функционирует, но никогда не выполняет системный вызов wait о, код возврата дочернего процесса никогда не будет принят, и процесс останется в состоянии "зомби". Зомби-процесс не имеет кода, данных или стека, так что он не расходует много системных ресурсов, но он продолжает существовать в системной таблице процессов, которая имеет фиксированный размер. Слишком большое количество зомби-процессов может потребовать вмешательства системного администратора. (Для дополнительной информации см. главу 15.)
Представленная далее программа создает зомби-процесс, который был показан в выводе утилиты ps. Когда был "убит" родительский процесс, порожденный процесс был усыновлен процессом init, и ему было позволено "успокоиться". Вот код:
$ cat zombie.с ...посмотреть программу, ^include <stdio.h> main () {
int pid;
pid = fork(); /* Дублироваться */
if (pid != 0) /* Ветвление, базирующееся на возвращаемом */
/* значении fork() */
while (1) /* Никогда не заканчивается */
/* и никогда не выполняет wait() */ sleep (1000);
else
exit (42); /* Выход с небольшим номером */
$ zombie & ... выполнить программу в фоновом режиме.
[1] 13545
$ ps PID ТТ STAT 13535 р2 S 13545 р2 S ...получить статус TIME COMMAND 0:00 -ksh (ksh) 0:00 zombie
13546 р2 Z 0:00 <defunct>
13547 р2 R 0:00 ps
$ kill 13545
[1] Terminated zombie
$ ps
PID TT STAT TIME COMMAND
13535 p2 S 0:00 -ksh (ksh)
13548 p2 R 0:00 ps
$
процессов.
...shell.
...родительский процесс.
...порожденный зомби-процесс.
..."убить" родительский процесс.
...заметьте, что теперь зомби пропал.
Ожидание дочернего процесса: wait()
Родительский процесс может ждать завершения одного из своих дочерних процессов, и затем принять его код завершения, выполняя системных вызов wait().
Синтаксис
pid_t wait (int* status}
Системный вызов wait () заставляет процесс приостановиться, пока один из его дочерних процессов не закончит выполнение. Успешный вызов wait () возвращает PID завершившегося порожденного процесса и помещает код статуса в status, который кодируется следующим образом:
• если правый байт status — 0, левый байт содержит восемь битов значения, возвращенного exit () или return ();
• если правый байт отличен от 0, самые правые семь битов равны номеру сигнала, который заставил дочерний процесс завершить работу, и оставшийся бит самого правого байта установлен в 1, если порожденный процесс произвел дамп памяти
Если процесс выполняет системный вызов wait о и не имеет дочерних процессов, wait о возвращается немедленно с —1. Если процесс выполняет wait о и один или большее его порожденных процессов уже зомби, wait о возвращается немедленно со статусом одного из зомби.
В приведенном ниже примере дочерний процесс заканчивается прежде завершения программы, выполняя exit () с кодом возврата 42. Между тем, родительский процесс выполнил wait о и приостановился, пока не получил код завершения своего порожденного процесса. В этой точке родитель вывел информацию о кончине порожденного процесса и выполнил остальную часть программы.
$ cat mywait.с ...посмотреть программу.
#include <stdio.h>
main ()
int pid, status, childPid;
printf ("I’m the parent process and my PID is %d\n", getpidO);
pid = fork(); /* Дублироваться */
if (pid != 0) /* Ветвление, базирующееся */
/* на возвращаемом значении fork() */
{
printf ("I’m the parent process with PID %d and PPID %d\n", getpid (), getppid ());
childPid = wait (^status); /* Ждать завершения дочернего процесса */ printf ("A child with PID %d terminated with exit code %d\n", childPid, status » 8) ;
}
else
{
printf ("I’m the child process with PID %d and PPID %d\n", getpid (), getppid ());
exit (42); /* Выход с небольшим числом */
}
printf ("PID %d terminates \n ", getpidO);
}
$ my wait ...выполнить программу.
I’m the parent process and my PID is 13464
I’m the child process with PID 13465 and PPID 13464
I’m the parent process with PID 13464 and PPID 13409
A child with PID 13465 terminated with exit code 42 PID 13-465 terminates $
Замена кода процесса: exec()
Процесс может заменить свой текущий код, данные и стек с таковыми другого исполняемого файла, используя один из системных вызовов семейства ехес(). Когда процесс выполняет ехес(), его номера PID и PPID остаются теми же самыми — заменяется лишь код, выполняемый процессом. Члены семейства ехес(), перечисленные ниже, не являются действительными системными вызовами: скорее, они функции библиотеки С, которые вызывают системный вызов execve(). execve () непосредственно почти не применяется, поскольку содержит некоторые редко используемые опции.
Синтаксис
int excecl (const const char* char* pa th, argl, const char* ..., const argOr char* argn, NULL)
int execv (const char* pa th, const char* argv[]}
int execlp (const const char* char* pa th, argl, const char* argO, ..., const char* argn, NULL)
int execvp (const char* pa th, const char* argv[])
Библиотечные процедуры семейства ехес() заменяют код вызывающего процесса, данные и стек из исполняемого файла, чье путевое имя хранится В path.
execl() идентична execipO, a execv() идентична execvpO, за исключением того, что execio и execvо требуют абсолютного или относительного путевого имени исполняемого файла, который должен быть предоставлен. execlpo и execvpO для поиска пути используют переменную окружения $ратн.
Если исполняемый файл не найден, системный вызов возвращает — 1; иначе вызывающий процесс заменяет свой код, данные и стек из исполняемого файла и начинает выполнять новый код. Нормально завершенный системный вызов ехес () никогда не возвращается.
ехесК) и execipO вызывают исполняемый файл со строковыми аргументами, указанными в argi, argn. Аргумент агдО должен содержать имя исполняемого файла, а список аргументов обязан заканчиваться NULL.
execv() и execvp () вызывают исполняемый файл со строковыми аргументами, указанными В argv[l], argv[n], где argv[n+l] — ЭТО NULL. Аргумент argv[0] должен содержать имя исполняемого файла.
В приведенном ниже примере программа выводит сообщение, а затем заменяет свой код кодом исполняемого файла is:
$ cat myexec.c ...посмотреть программу.
#include <stdio.h>
main()
printf ("I’m process %d and I’m about to exec an Is -l\n", getpidO); execl (’’/bin/ls’’,. "Is", "-I", NULL); /* Выполнить Is */
printf ("This line should never be executed\n"};
}
$ myexec ...выполнить программу.
I’m process 13623 and I’m about to exec an Is -1
total 125
-rw-r—r— 1 glass 277 Feb 15 00:47 myexec.c
-rwxr-xr-x 1 glass 24576 Feb 15 00:48 myexec
$ _
Обратите внимание, что execl () завершился нормально и поэтому ничего не вернул.
Смена каталогов: chdir()
Каждый процесс имеет текущий рабочий каталог, который используется при обработке относительного путевого имени. Дочерний процесс наследует текущий рабочий каталог от своего родителя. Например, когда утилита выполняется из shell, ее процесс наследует текущий рабочий каталог shell. Для изменения текущего рабочего каталога процесса служит системный вызов chdir ().
Синтаксис
int chdir (const char* pathname)
Системный вызов chdir () изменяет текущий рабочий каталог процесса на каталог pathname. Процесс должен иметь, разрешение выполнения каталога, чтобы завершиться без ошибки, chdir () возвращает 0, если закончился нормально, иначе возвращает —1.
В следующем примере процесс вводит название текущего рабочего каталога перед и после выполнения системного вызова chdir о'путем выполнения команды pwd, используя библиотечную процедуру system о:
$ cat туchdir.с ...посмотреть исходный код.
#include <stdio.h>
main ()
{
system ("pwd"); /* Вывести текущий рабочий каталог */
chdir ("/"); /* Изменить рабочий каталог на корневой каталог */
system ("pwd"); /* Вывести новый рабочий каталог */
chdir ("/home/glass"); /* Изменить */
system ("pwd"); /* Вывести */
}
$ туchdir ...выполнить программу.
/home/glass /
/home/glass
$
Смена приоритетов: nice()
Каждый процесс имеет значение приоритета между —20 и +19, влияющее на количество времени ЦП, которое выделяется процессу. Вообще, чем меньше значение приоритета, тем быстрее будет выполняться процесс. Только процессы привилегированного пользователя (root) и ядра (описанные в главе 14) могут иметь отрицательное значение приоритета, а приоритеты shell, выполняющих вход в систему, начинаются с 0.
Дочерний процесс наследует значение приоритета от родителя и может изменять его с помощью библиотечной процедуры nice о.
Синтаксис
int nice (int delta)
Библиотечная процедура nice о добавляет delta к текущему значению приоритета процесса. Только привилегированный пользователь (root) может определить значение delta, которое приводит к отрицательному значению приоритета. Допустимые значения приоритета находятся между —20 и +19. Если значение delta определено таким образом, что выводит значение приоритета вне предела, значение усекается до предела. Ес
ли библиотечная процедура nice () завершается нормально, она возвра-щает новое значение, иначе возвращает —1. Обратите внимание, что это может вызвать проблемы, т. к. значение —1 является допустимым.
В приведенном ниже примере процесс выполняет утилиты ps перед и после пары вызовов nice ().
$ cat mynice.c ...посмотреть исходный код.
#include <stdio.h>
main ()
{
printf ("original priority\n");
system ("ps"); /* Выполнить ps */
nice (0); /* Добавит 0 к моему приоритету */
printf ("running at priority 0\n");
system ("ps"); /★ Выполнить другой ps */
nice (10); /* Добавит 10 к моему приоритету */
printf ("running at priority 10\n");
system ("ps"); /* Выполнить последний ps */
$ mynice
original priority
...выполнить программу.
PID TT STAT
TIME COMMAND
15099 p2 S
15206 p2 S
15207 p2 S
15208 p2 R
0:00 -sh (sh)
0:00 a.out
0:00 sh —c ps
0:00 ps
running at priority 0
PID TT STAT TIME COMMAND
...добавление 0 не меняет его.
15099 р2 S
15206 р2 S
15209 р2 S
15210 р2 R
0:00 -sh (sh)
0:00 a.out
0:00 sh -c ps
0:00 ps
running at priority 10
добавление 10 заставляет их работать медленнее.
PID TT STAT TIME COMMAND
15099 p2 S 0:00 -sh (sh)
15206 p2 S N 0:00 a.out
15211 р2 S N 0:00 sh -с ps
15212 p2 RN 0:00 ps
$
Обратите внимание, что при значении приоритета процесса, отличного от нуля, оно отмечается утилитой ps, как N, вместе с командами sh и ps, которые были созданы благодаря библиотечному вызову system о .
Доступ к ID пользователя и ID группы
Ниже приводится описание системных вызовов и библиотечных процедур, которые позволяют читать и устанавливать реальный и эффективный ID процесса.
Синтаксис
uid__t getuidQ uid_t geteuidO gid_t getgid() gid_t getegidO
Системные вызовы getuido и geteuidO возвращают, соответственно, реальный и эффективный пользовательский ID запрашивающего процесса. Системные вызовы getgido и getegidO возвращают, соответствен-но, реальный и эффективный ID группы запрашивающего процесса. Номера ID, соответствующие пользовательскому ID и ID группы, перечислены в файлах /etc/passwd и /etc/group. Эти вызовы всегда завершаются без ошибок.
Синтаксис
int setuid (uid_t id) int seteuid (uid_t id) int setgid (gid_t icfj int setegid (gid_t id)
Библиотечные процедуры seteuido и setegid о устанавливают эффективный пользовательский (групповой) ID запрашивающего процесса. Библиотечные процедуры setuid о и setgid о устанавливают на указанное значение эффективный и реальный пользовательский (групповой) ID запрашивающего процесса.
Эти вызовы завершаются нормально, если выполняются привилегированным пользователем или если id — это реальный или эффективный пользовательский (групповой) ID запрашивающего процесса. Они возвращают 0, если заканчиваются без ошибок; иначе возвращают —1.
Пример программы: фоновая обработка
Далее мы исследуем код, который использует системные вызовы fork о и ехесо, чтобы запустить программу в фоновом режиме. Первоначальный процесс создает дочерний процесс для выполнения указанного файла, а затем заканчивается. Осиротевший порожденный процесс автоматически усыновляется процессом init.
$ cat background, с ...посмотреть программу.
#include <stdio.h>
main (argc, argv)
int argc;
char* argv [];
{
if (fork() == 0) /* Дочерний процесс */
execvp (argv[l], &argv[l]); /* Выполнить другую программу */ fprintf (stderr, "Could not execute %s\n", argv[l]);
}
}
$ background cc mywait.c ...выполнить программу.
$ ps ...подтвредить, что cc работает в фоне.
PID ТТ STAT TIME COMMAND
13664 рО S 0:00 -csh (csh)
13716 рО R 0:00 ps
13717 рО D 0:00 сс mywait. с
$ .
Обратите внимание, как необчно передан список аргументов от main о к execvp(), указывая &argv[i] в качестве второго аргумента execvp(). Заметьте также, что использован вызов execvp () вместо execv (), чтобы программа для поиска исполняемого файла могла использовать $ратн.
Пример программы: использование диска
Следующий пример программирования применяет новую технику для подсчета файлов, котоые не являются каталогами, в иерархии. Когда программа
стартует, ее первый аргумент должен быть именем каталога для поиска. Программа исследует элемент за элементом в каталоге, порождая новый процесс для каждого. Любой дочерний процесс либо выходит с результатом 1, если его связанный файл — не каталог, либо повторяет процесс, суммируя коды выхода своих потомков и выходя с общим счетом. Этот алгоритм интересен, но бессмыслен: мало того, что он создает большое количество процессов, что не особенно эффективно, но еще и используется код завершения, чтобы возвратить количество файлов, а он ограничен восьмибитовым значением. Код следующий:
$ cat count.с ...посмотреть программу.
#include <stdio.h>
#include <fcntl.h>
#include <sys/dirent.h>
#include <sys/stat.h>
long processFile();
long processDirectory();
main (argc, argv)
int argc;
char* argv [];
{
long count;
count = processFile (argv[l]);
printf ("Total number of non-directory files is %ld\n"/ count);
return (/* ВЫХОД-УСПЕШНО */ 0) ;
}
long processFile (name)
char* name;
{
struct stat statBuf; /* Чтобы хранить возвращаемые данные от stat() */ mode_t mode;
int result;
result = stat (name, &statBuf); /* Считать указанный файл */
if (result == -1) return (0); /* Ошибка */
mode = statBuf.st_mode; /* Посмотреть вид файла */
if (S_ISDIR (mode)) /* Каталог */
return (processDirectory (name));
else
return (1); /* Был обработан не каталог */
long processDirectory (dirName) char * dirName;
{
int fd, children, i, charsRead, childPid, status;
long count, totalCount;
char fileName [100];
struct dirent dirEntry;
fd = open (dirName, O_RDONLY); /* Открыть каталог для чтения */
children =0; /* Инициализировать счетчик дочерних процессов */
while (1) /* Просмотреть каталог */
{ charsRead = getdents (fd, &dirEntry, sizeof (struct dirent)); if (charsRead == 0) break; /* Конец каталога */ if (strcmp (dirEntry.d_name, ”.”) != 0 && strcmp (dirEntry.d_name, "..") != 0)
{ if (fork() == 0) /* Создать дочерний процесс */ /* для обработки каталога */ {
sprintf (fileName, "%s/%s’’, dirName, dirEntry.d_name) ; count = processFile (fileName);
exit (count);
} else ++children; /* Увеличить счетчик дочерних процессов */ }
Iseek (fd, dirEntry.d_off, SEEK_SET);/* Перейти на следующий.каталог */ } close (fd); /* Закрыть каталог */
totalCount =0; /* Инициализировать счетчик файлов */ for (i=l; i <= children; i++) /* Ждать завершения дочерних процессов */ {
childPid = wait (&status); /* Принять код завершения дочернего */
totalCount += (status » 8); /* Обновить счетчик файлов */
}
return (totalCount); /* Вернуть количество файлов в каталоге */
}
$ Is -F ...посмотреть текущий каталог.
a.out* disk.с fork tmp/ zombie*
background myexec.c myfork.c mywait.c
background.с myexit.c orphan.c mywait*
count* myexit* orphan* zombie.c
$ Is tmp ...вывести только подкаталоги.
a. out* disk.c myexit.c orphan.с
background.c zombie.c myexec.c myfork.c mywait.c
$ count . ...считать обычные файлы с ".".
Total number of non-directory files is 25
$
Подпроцессы-нити
Множественные процессы дороги для того, чтобы их создавать либо заново, либо путем копирования существующего процесса системным вызовом fork о. Часто целиком новое пространство процесса не является необходимостью для маленькой, но все же независимой, задачи в программе. Фактически можно пожелать, чтобы отдельные задачи были способны разделить некоторые ресурсы в процессе, такие как пространство памяти или открытое устройство.
Когда стали доступны мультипроцессорные системы, выяснилось, что UNIX нуждался в лучшем способе воспользоваться преимуществом многочисленных процессоров без того, чтобы запускать новый процесс на отдельном процессоре. Нить (thread) — абстракция, которая делает возможным множественные "нити управления" в единственном пространстве процесса. О ней можно думать почти как о процессе в пределах процесса (почти). Во многих отношениях модель нити подобна модели процесса UNIX.
Терминология некоторых из реализаций нитей бывает путанной. Вы можете найти термин "легкие процессы" (lightweight processes), используемый поочередно с "нитью", или найти места, где применяются оба термина, чтобы характеризовать тонкие различия. В большинстве случаев идея относительно более легкого веса (т. е. менее дорогие издержки) — это то, что планировалось. Мы будем попросту ссылаться на нити.
Так как реализация функциональных возможностей нити варьируется в различных версиях UNIX, исследование любой незаконно игнорировало бы другие, а полное изучение всех текущих реализаций — вне возможностей данного обзора. Поэтому будут представлены функциональные возможности нити UNIX на высоком уровне, который является общим для всех реализаций. Рекомендуется обратиться за справкой к документации используемой версии UNIX для получения информации относительно конкретных системных вызовов.
Управление нитями
Четыре главных функции поддерживают общие возможности управления нитями в большинстве реализаций:
□ create — создать нить;
П join — приостановиться и ждать завершения созданной нити (подобно системному вызову wait о между родительскими и дочерними процессами);
□ detach — позволить нити передать ее ресурсы системе, когда она заканчивается, и не требовать объединения (в этом случае значение выхода недоступно);
□ terminate — вернуть ресурсы процессу.
Синхронизация нитей
В многопоточном окружении одна или несколько нитей могут быть созданы, чтобы справиться с определенными задачами. Если задачи не связаны, нити могут быть запущены и выполняться до завершения. Если какая-нибудь часть задачи требует информации от другой задачи, взаимодействие между нитями должно быть синхронизировано. Синхронизация способна часто осуществляться через стандартные IPC-механизмы UNIX, но большинство библиотек нитей также предусматривают синхронизирующие примитивы, характерные для использования нитями.
Объект mutex может использоваться, чтобы управлять взаимным исключением между нитями. Mutex-объекты могут быть созданы, разрушены, блокированы и разблокированы. Признаки mutex-объекта разделяются между нитями и применяются, чтобы позволить другим нитям знать состояние нити, которую mutex-объект описывает. Mutex-объекты могут также использоваться в соединении с условными переменными, которые поддерживают значение (такое как порог), чтобы обеспечить более точное управление синхронизацией нитей.
Безопасность нитей
Итак, теперь вы синхронизировали различные нити управления в вашей собственной программе. Но как быть с библиотечными функциями, которые они вызывают? Должен ли ваш код синхронизировать (например) использование графической библиотеки, чтобы гарантировать запрет одновременного вывода нитями в одну и ту же часть экрана? Как насчет двух нитей, которые используют математическую библиотеку, чтобы модернизировать разделяемые данные? Вы синхронизировали применение ваших переменных, но используют ли математические функции какие-нибудь разделяемые
переменные? Являются ли функции повторно входимыми (т. е. может ли одновременно больше, чем одна точка управления использоваться в пространстве памяти функции)?
Задавая эти вопросы, вы спрашиваете, является ли библиотека нитей безопасной? Безопасно ли вызывать функции этих библиотек из многопоточной программы? Вероятно, не трудно вообразить разновидности непредвиденных проблем, которые могут возникнуть при таких обстоятельствах. Если продавец или автор библиотеки заявляет, что она является нитебезопасной, вы должны предположить, что это не так, и писать ваш код соответственно (управляя взаимным исключительным доступом к библиотеке между различными нитями в своей программе).
Другие связанные с процессом системные вызовы, которые описаны ранее, могут быть затронуты реализацией нитей. Например, каждая нить поддерживает свой собственный стек, маску сигнала и локальную область хранения. Поэтому, не всегда очевидно, в какой момент системный вызов применяется только к нити или к полному процессу, управляющему нитью. Для вас будет важно определить, как ваша реализация нитей может оказывать влияние на другие системные вызовы UNIX.
Перенаправление
Когда процесс разветвляется, дочерний процесс наследует копию дескрипторов файла своего родителя. Когда процесс выполняет системный вызов ехес (), все незакрытые после выполнения дескрипторы файла остаются незатронутыми, включая стандартный ввод, вывод и каналы ошибки. UNIX shell использует эту информацию, чтобы осуществить перенаправление. Например, предположим, что вы напечатаете на терминале команду:
$ 1s > Is.out
чтобы выполнить перенаправление. Shell производит следующий ряд действий:
1. Родительский shell ветвится и ждет завершения дочернего shell.
2. Дочерний shell открывает файл Is.out, создавая или усекая его по мере необходимости.
3. Дочерний shell дублирует дескриптор файла Is.out в стандартный дескриптор файла вывода с номером 1 и закрывает первоначальный дескриптор Is.out. Поэтому весь стандартный вывод перенаправляется в Is.out.
4. Дочерний shell выполняет системный вызов ехес() с утилитой 1s. Так как дескрипторы файла унаследованы во время выполнения ехес (), весь стандартный вывод 1s идет в Is.out.
5. Когда дочерний shell завершается, родительский возобновляется. Дескрипторы файла-родителя не затронуты действиями дочернего процесса, поскольку каждый процесс поддерживает собственную персональную таблицу дескрипторов.
Чтобы перенаправить стандартный канал ошибки в дополнение к стандартному выводу, shell мог бы просто дублировать дескриптор файла Is.out дважды — один раз в дескриптор 1 и другой раз в дескриптор 2.
Представленная ниже программа делает приблизительно тот же самый вид перенаправления, как и UNIX shell. При вызове с именем файла в качестве первого параметра и последовательностью команд в качестве остальных параметров программа redirect осуществляет перенаправление стандартного вывода команды в указанный файл.
$ cat redirect, с
#include <stdio.h>
...посмотреть программу.
#include <fcntl.h>
main (argc, argv) int argc;
char* argv [];
{
int fd;
/* Открыть файл для переназначения */
fd = open (argv[l], O_CREAT | O_TRUNC | O_WRONLY, 0600);
dup2 (fd, 1); /* Дублировать дескриптор на стандартный вывод */
close (fd); /* Закрыть оригинальный дескриптор */
/* для сохранения пространства дескрипторов */ execvp (argv[2], &argv[2]); /* Вызвать программу; унаследует stdout */ реггог ("main"); /* Не должна выполняться никогда */
}
$ redirect Is.out Is -1 ...переназначить Is -1 на Is.out.
$ cat Is.out ...посмотреть выходной файл,
total 5
-rw-r-xr-x 1 gglass 0 Feb 15 10:35 Is.out
-rw-r-xr-x 1 gglass 449 Feb 15 10:35 redirect.c
-rwxr-xr-x 1 gglass 3697 Feb 15 10:33 redirect
$ _
Internet shell, описанный в конце этой главы, имеет лучшие возможности переназначения, чем стандартный shell UNIX; он может даже переадресовывать вывод на другой Internet shell на удаленном хосте.
Сигналы
Программы должны иногда иметь дело с неожиданными или непредсказуемыми событиями, например, такими:
□ ошибка плавающей запятой;
□ отказ питания;
□ ’’звонок” будильника;
□ ’’смерть" дочернего процесса;
□ завершение, запрашиваемое от пользователя (т. е. нажатие комбинации клавиш <Ctrl>+<C>);
□ запрос приостановки от пользователя (т. е. нажатие комбинации клавиш <Ctrl>+<Z>).
Эти виды событий иногда называются прерываниями, т. к. они должны прервать обычный поток программы, чтобы быть обработанным. Когда UNIX распознает, что сложилась такая ситуация, ОС посылает соответствующему процессу сигнал. Существует уникальный пронумерованный сигнал для каждого возможного случая. Например, если процесс становится причиной ошибки плавающей запятой, ядро посылает сигнал номер 8 процессу, нарушающему нормальную работу (рис. 13.8). Ядро — это не единственный источник, который может посылать сигнал; любой процесс способен отправить сигнал произвольному процессу, когда он имеет права на это. (Правила, касающиеся прав, обсуждаются далее.)
Сигнал № 8
Процесс
Рис. 13.8. Сигнал ошибки плавающей запятой
Через специальную часть кода, называемую обработчиком сигнала, программист может принять меры, чтобы конкретный сигнал был проигнорирован или обработан. В последнем случае получающий сигнал процесс приостанавливает свой текущий поток управления, выполняет обработчик сигнала и возобновляет первоначальный поток управления, когда обработчик сигнала заканчивает свою работу.
Путем изучения сигналов вы можете "защитить" свои программы от нажатия комбинации клавиш <Ctrl>+<C>, организовывать завершение программы
по сигналу будильника, если она слишком долго выполняет задачу, и узнать, как UNIX использует сигналы во время ежедневных операций.
Определенные сигналы
Сигналы определены в файле /usr/include/sys/signal.h. Программист может выбрать для конкретного сигнала либо обработчик сигнала, определенный пользователем, либо вызывать обработчик сигнала, по умолчанию предоставляемый ядром, либо проигнорировать его. По умолчанию обработчик обычно выполняет одно из следующих действий:
□ завершает процесс и генерирует файл-дубликат содержимого оперативной памяти (dump);
□ завершает процесс без генерации файла дубликата содержимого оперативной памяти (quit);
□ игнорирует и отказывается от сигнала (ignore);
□ приостанавливает процесс (suspend);
□ возобновляет процесс.
Список сигналов
В табл. 13.7 перечислены предопределенные сигналы System V наряду с их макроопределениями, числовыми значениями, действиями по умолчанию и кратким описанием каждого.
Таблица 13.7. Сигналы
Макро Номер По умолчанию Описание
SIGHUP 1 quit Зависание
SIGINT 2 quit Сигнал прерывания
SIGQUIT 3 dump Завершить
SIGILL 4 dump Неправильная команда
SIGTRAP 5 dump Системное прерывание трассировки (используется отладчиком)
SIGABRT 6 dump Аварийное прекращение
SIGEMT 7 dump Команда эмуляции системного прерывания
SIGFPE 8 dump Арифметическое исключение
SIGKILL 9 quit "Убить” (не может быть пойман, блокирован или игнорирован)
20 Зак. 786
Таблица 13.7 (окончание)
Макро Номер По умолчанию Описание
SIGBUS 10 dump Ошибка шины — bus error (плохой формат , адреса)
SIGSEGV 11 dump Нарушение сегментации (выход за диапазон адреса)
SIGSYS 12 dump Плохой аргумент системного вызова
SIGPIPE 13 quit Запись в конвейер или сокет, который никто не читает
SIGALRM 14 quit Будильник
SIGTERM 15 quit Сигнал завершения программы (сигнал по умолчанию, посылается kill)
SIGUSR1 16 quit Пользовательский сигнал 1
SIGUSR2 17 quit Пользовательский сигнал 2
SIGCHLD 18 ignore Статус дочернего процесса изменился
SIGPWR 19 ignore Отказ питания или повторный старт
SIGWINCH 20 ignore Изменение размера окна
SIGURG 21 ignore Срочная ситуация сокета
SIGPOLL 22 exit Опрашиваемое событие
SIGSTOP 23 quit Остановленный (сигнал)
SIGSTP 24 quit Остановленный (пользователь)
SIGCONT 25 ignore Продолженный
SIGTTIN 26 quit Остановленный (tty-ввод)
SIGTTOU 27 quit Остановленный (tty-вывод)
SIGVTALRM 28 quit Действительное время истекло
SIGPROF 29 quit Время профилирования истекло
SIGXCPU 30 dump Превышен лимит времени ЦП
SIGXFSZ 31 dump Превышен лимит размера файла
Сигналы терминала
Самый легкий способ послать сигнал приоритетному процессу — это нажать комбинацию клавиш <Ctrl>+<C> или <Ctrl>+<Z>. Когда драйвер терминала (часть программного обеспечения, которое поддерживает терминал) рас
познает комбинацию клавиш <Ctrl>+<C>, он посылает сигнал sigint всем текущим приоритетным процессам. Точно так же комбинация клавиш <Ctrl>+<Z> заставляет драйвер посылать сигнал sigtstp всем текущим приоритетным процессам. По умолчанию sigint заканчивает, a sigtstp приостанавливает процесс. Далее будет продемонстрировано, как выполнить подобные действия из С-программы.
Запрос аварийного сигнала: alarmf)
Один из самых простых способов увидеть сигнал в действии состоит в том, чтобы организовать процесс для получения сигнала будильника, sigalrm, с помощью библиотечной процедуры alarm(). Обработчик по умолчанию для этого сигнала выводит сообщение "Alarm clock" и заканчивает процесс.
Синтаксис
unsigned int alarm (unsigned int count)
Библиотечная процедура alarm о предписывает ядру послать сигнал sigalrm запрашивающему процессу после count секунд. Если сигнал был уже намечен, он переопределяется. Если count равно 0, Любые незаконченные запросы отменяются, alarm о возвращает количество секунд, которые остаются до передачи сигнала.
Ниже приведена программа, которая использует alarm (), вместе с ее выводом:
$ cat alarm.с ...посмотреть программу.
#include <stdio.h>
main ()
{
alarm (3); /* Запланировать аварийный сигнал через 3 секунды */ printf ("Looping forever.\п");
while (1);
printf ("This line should never be executed\n");
}
$ alarm ...выполнить программу.
Looping forever...
Alam clock . . .происходит через 3 секунды.
$
Обработка сигналов: signalO
Последний пример программы реагировал на сигнал sigalrm в манере, заданной по умолчанию. Библиотечная процедура signal о может использоваться для подмены действия по умолчанию.
Синтаксис
void (*signal (int sigCode, void (★func) (int))) (int)
Библиотечная процедура signal о позволяет процессу определять выполняемое действие, когда конкретный сигнал будет получен. Параметр sigCode задает номер сигнала, который должен быть перепрограммирован, a fund может быть одним из значений:
• siG-iGN указывает, что сигнал должен быть проигнорирован и отвергнут;
• sig dfl означает, что должен использоваться подразумеваемый обработчик ядра;
• адрес определенной пользователем функции, который указывает, что функция должна быть выполнена, когда поступает сигнал.
Имеющие силу номера сигналов хранятся в файле /usr/include/signal.h. Сигналы sigkill и sigstp не могут быть перепрограммированы. Дочерний процесс наследует назначения сигнала от своего родителя во время выполнения системного вызова fork о. Когда процесс выполняет системный вызов ехес (), предварительно игнорируемые сигналы остаются игнорируемыми, но обработчики заменяются на обработчики по умолчанию. За исключением sigchld, сигналы не помещаются в стек. Это означает, что, если процесс спит, и ему посланы три идентичных сигнала, фактически обрабатывается только один из сигналов, signal о возвращает предыдущее значение func, связанное с sigCode, если завершается нормально; иначе возвращает —1.
В представленный выше пример были внесены изменения так, чтобы был пойман и эффективно обработан сигнал sigalrm:
□ установлен обработчик сигнала aiarmHandier(), использующий signal();
□ организован цикл while, эксплуатирующий в меньшей степени ресурсы системы разделения времени, с помощью библиотечной процедуры pause о. Старая версия цикла while имела пустое тело, которое заставляло его выполнять цикл очень быстро и поглощать ресурсы ЦП. Новая версия цикла while каждый раз приостанавливается до получения сигнала.
Вот обновленная версия программы:
$ cat handler.с ...посмотреть программу.
#include <stdio.h> К ’ • -
#include <signal.h>
int alarmFlag =0; /* Глобальный флаг alarm */
void alarmHandler(); /* Опережающее описание обработчика alarm */ /*i*^i***^**Jr*****i***Jr*************i^****JrJr**********Jr***Jr**** / main() {
signal (SIGALRM, alarmHandler); /* Установка обработчика сигнала */ alarm (3); /* Назначить сигнал alarm через 3 секунды */
printf ("Looping...\n");
while (! alarmFlag) /* Цикл, пока флаг установлен */ {
pause(); /* Ждать сигнала */
}
printf ("Loop ends due to alarm signal\n"); }
у**************************************************************/ void alarmHandler()
printf ("An alarm clock signal was received\n");
alarmFlag = 1;
}
$ handler ...выполнить программу.
Looping...
An alarm clock signal was received ...происходит через 3 секунды. Loop ends due to alarm signal $
Синтаксис
int pause (void)
Библиотечная процедура pause о приостанавливает запрашивающий процесс и возвращается, когда вызывающий процесс получает сигнал, pause () чаще всего применяется для эффективного ожидания сигнала alarm. Она не возвращает ничего полезного.
Защита критического кода и формирование цепочки обработчиков прерываний
Описанные выше методы могут применяться для защиты критических участков кода против нажатия комбинации клавиш <Ctrl>+<C> и других сигналов. В этих случаях обычно сохраняют предыдущее значение обработчика, чтобы оно могло быть восстановлено после выполнения критического участка кода.
Ниже приведен исходный код программы, которая защищает себя против сигналов sigint:
$ cat critical.с ...посмотреть программу, ftinclude <stdio.h> ftinclude <signal.h>
main()
void (*oldHandler)(); /* Для хранения старого значения обработчика */ printf ("I can be <Ctrl>+<C>\n");
sleep (3);
oldHandler = signal (SIGINT, SIG_IGN); /* Игнорировать <Ctrl>+<C> */
printf ("I’m protected from <Ctrl>+<C> now\n");
sleep (3);
signal (SIGINT, oldHandler); /* Восстановить старый обработчик */
printf ("I can be <Ctrl>+<C> again\n”);
sleep (3);
printf ("Bye!\n");
}
$ critical ...выполнить программу.
I can be <Ctrl>+<C>
ЛС ...<Ctrl>+<C> работает здесь.
$ critical ...выполнить программу снова.
I can be <Ctrl>+<C>
I’m protected from <Ctrl>+<C> now
AC ...<Ctrl>+<C> игнорируется.
I can be <Ctrl>+<C> again
Bye!
$
Посылка сигналов: kill()
Процесс может посылать сигнал другому процессу, используя системный вызов kill о. Для системного вызова kill о его название не характеризует выполняемые им действия, поскольку многие из сигналов, которые он способен посылать, не заканчивают ("убивают") процесс. Вызов получил свое название вследствие исторических причин: когда UNIX была разработана, основным использованием сигналов оказалось завершение процессов.
Синтаксис
int kill (pid_t pidr int sigCode)
Системный вызов kill о посылает сигнал со значением sigCode процессу с PID pid. kill о завершается нормально, а сигнал посылается до тех пор, пока, по крайней мере, одно из следующих условий удовлетворяется:
• посылающий и получающий процессы имеют одного и того же владельца;
• посылающий процесс принадлежит привилегированному пользователю (root).
Есть несколько вариантов работы kill о:
• если pid равен 0, сигнал посылается всем процессам в группе процесса-отправителя;
• если pid равен —1 и отправитель принадлежит привилегированному пользователю (root), сигнал посылается всем процессам, включая отправителя;
• если pid равен —1 и отправитель непривилегированный пользователь, сигнал посылается всем процессам, принадлежащим тому же самому владельцу, что и отправитель, исключая процесс посылки;
• если pid отрицателен и не равен — 1, сигнал посылается всем процессам в группе процесса. (Группы процесса обсуждаются позже в данной главе.)
Если kill о ухитрится послать сигнал без ошибки, по крайней мере, один сигнал, он возвращает 0; иначе возвращает —1.
"Смерть" дочерних процессов
Когда дочерний процесс заканчивается, он посылает своему родителю сигнал siGCHLD. Родительский процесс часто устанавливает обработчик, чтобы взаимодействовать с этим сигналом, и обычно выполняет системный вызов
wait о для принятия кода завершения дочернего процесса и не позволить ему перейти в состояние "зомби”.4
Альтернативно родитель может выбрать игнорирование сигналов sigchld, тогда порожденный процесс автоматически перестает быть зомби. Одна из программ сокета, .которая представлена позже в данной главе, использует эту особенность.
Приведенный ниже пример иллюстрирует обработчик сигнала sigchld и позволяет пользователю ограничить время для выполнения команды. Первый параметр limit — это максимальное количество секунд, которое отводится для работы, а остальные параметры — это сама команда. Программа работает, выполняя следующие шаги:
1. Родительский процесс устанавливает обработчик сигнала sigchld, который выполняется, когда его дочерний процесс заканчивается.
2. Родительский процесс разветвляется и, чтобы выполнить команду, порождает дочерний процесс.
3. Родительский процесс "спит" указанное количество секунд. Когда он пробуждается, то посылает своему дочернему процессу сигнал sigint, чтобы "убить" его.
4. Если порожденный процесс заканчивается прежде, чем его родитель выйдет из состояния сна, выполняется обработчик сигнала sigchld родителя, заставляя родителя немедленно завершиться.
Вот исходный код и пример вывода программы:
$ cat limit.с ...посмотреть программу.
ttinclude <stdio.h>
#include <sigrial.h> int delay;
void childHandler();
/******•*•★********•************•*•*********************•*•***************/
main (argc, argv)
int argc;
char* argv[];
{
int pid;
signal (SIGCHLD, childHandler); /* Установить обработчик "смерти” */ /* ребенка */
pid = fork().; /* Дублироваться */
4 Это означает, что дочерний процесс полностью прекратил работу, чтобы не оставаться больше зомби.
if (pid == 0) /* Дочерний процесс */
{ execvp (argv[2], &argv[2]); /* Выполнить команду */
реггог ("limit"); /* Не должно выполняться никогда */ } else /* Родитель */
{
sscanf (argv[l], "%d", &delay); /* Прочитать задержку */ /* из командной строки */
sleep (delay); /* Заснуть на указанное количество секунд */
printf ("Child %d exceeded limit and is being killed\n", pid);
kill (pid, SIGINT); /* "Убить" дочерний процесс */ } } /jr****'Jt***i**********^**'^*******^*****^*4r**Jr^*****'^-Jr*^4-*****Jr**Jr****** / void childHandler() /* Выполняется, если дочерний процесс "умирает" */ /* раньше родителя */ { int childPid, childstatus;
childPid = wait (&childStatus); /* Принять код завершения дочернего */ printf ("Child %d terminated within %d seconds\n", childPid, delay);
exit (/* ВЫВОД_УСПЕШНО */ 0); } $ limit 5 Is ...выполнить программу; команда завершилась хорошо,
a.out alarm critical handler limit
alarm.c critical.c handler.c limit.c
Child 4030 terminated within 5 seconds $ limit 4 sleep 100 ...выполнить ее снова;
...команда выполняется слишком долго. Child 4032 exceeded limit and is being killed $
Приостановка и возобновление процессов
Сигналы sigstop и sigcont, соответственно, приостанавливают и возобновляют процесс. Они используются UNIX shell (большинством shell, кроме Bourne shell), поддерживающими управление заданиями, чтобы реализовать встроенные команды типа stop, fg и bg.
В приведенном далее примере главная программа создает два дочерних про-цеса, которые входят в бесконечный цикл и выводят сообщение каждую секунду. Главная программа ждет в течение трех секунд, а затем приостанавливает первый порожденный процесс. Второй процесс продолжает выполняться, как обычно. После следующих трех секунд родитель возобновляет первый дочерний процесс, ожидает некоторое, более продолжительное, время и завершает оба порожденных процесса. Вот код:
$ cat pulse.с ...вывести программу.
#include <signal.h>
ftinclude <stdio.h>
main()
{
int pidl; int pid2;
pidl = fork();
if (pidl == 0) /* Первый дочерний процесс */
{
while (1) /* Бесконечный цикл */
{
printf ("pidl is alive\n");
sleep (1);
}
}
pid2 = fork(); /* Второй дочерний процесс ★/
if (pid2 == 0)
while (1) /★ Бесконечный цикл */
{
printf (”pid2 is alive\n”);
sleep (1);
}
}
sleep (3);
kill (pidl, SIGSTOP); /★ Приостановить первый дочерний процесс */
sleep (3);
kill (pidl, SIGCONT); /* Возобновить первый дочерний процесс ★/ sleep (3);
kill (pidl, SIGINT); /* ’’Убить” первый дочерний процесс ★/
kill (pid2, SIGINT); /* ’’Убить" второй дочерний процесс */
$ pulse ...выполнить программу.
pidl is alive ...оба работают в первые три секунды. •
pid2 is alive
pidl is alive
pid2 is alive
pidl is alive
pid2 is alive
pid2 is alive ...только второй дочерний процесс сейчас работает.
pid2 is alive
pid2 is alive
pidl is alive ...первый дочерний процесс возобновился.
pid2 is alive
pidl is alive
pid2 is alive
pidl is alive
pid2 $ . is alive
Группы процесса и терминалы управления
Когда пользователь находится в shell и выполняет программу, которая создает несколько дочерних процессов, единственное нажатие комбинации клавиш <Ctrl>+<C> обычно заканчивает программу и ее порожденные процессы, а затем возвращает пользователя в shell. Чтобы поддержать этот вид поведения, в UNIX введено несколько новых концепций.
□ В дополнение к уникальному номеру ID процесса каждый процесс является членом группы процесса. Несколько процессов могут быть членами одной и той же группы процесса. Когда процесс осуществляет ветвление, дочерний процесс наследует свою группу от родителя. Процесс может заменить свою группу на новое значение с помощью системного вызова setpgidO. Когда процесс выполняется, его группа процесса остается неизменной.
□ Каждый процесс может иметь связанный с ним терминал управления — обычный терминал, с которого стартовал процесс. Когда процесс осуществляет ветвление, дочерний процесс наследует свой терминал управления от родителя. Когда процесс выполняется, его терминал управления остается тем же самым. х
□ Каждый терминал может быть связан с единственным процессом управления. Когда обнаруживается метасимвол, подобный генерируемому комбинацией клавиш <Ctrl>+<C>, терминал посылает соответствующий сигнал всем процессам в группе своего процесса управления.
□ Если процесс пытается читать со своего терминала управления и не является членом той же группы, что и процесс управления терминалом, процессу посылается сигнал sigttin, который обычно приостанавливает его.
Shell использует эти особенности описанным ниже образом.
□ Когда начинается диалоговый shell, он является процессом управления терминала и воспринимает этот терминал в качестве своего терминала управления. Описание, как это происходит, лежит за рамками данной книги.
□ Когда shell выполняет приоритетный процесс, дочерний shell занимает место в другой группе процесса перед выполнением команды и берет под свой контроль терминал. Любые сигналы, генерируемые терминалом, таким образом, идут в приоритетную команду, а не в первоначальный родительский shell. Когда приоритетная команда заканчивается, первоначальный родительский shell забирает назад управление терминалом.
□ Когда shell выполняет фоновый процесс, дочерний shell занимает место в другой группе процесса пред выполнением, но не берет под свой контроль терминал. Любые сигналы, генерируемые терминалом, продолжают идти в shell. Если фоновый процесс пробует читать со своего терминала управления, он приостанавливается сигналом sigttin.
Диаграмма на рис. 13.9 иллюстрирует типичную схему. Предположим, что процессы 145 и 230 — лидеры фоновых работ, а процесс 171 является лидером приоритетных работ.
Системный вызов setpgido заменяет группу процесса. Процесс может определить свой текущий ID группы процесса через системный вызов getpgidO .
Синтаксис
pid_t setpgid (pid_t pidf pid_t pgrpid)
Системный вызов setpgido устанавливает групповой ID процесса для процесса с pid на pgrpid. Если pid равен 0, групповой ID вызывающего процесса устанавливается на pgrpid. Для того чтобы setpgido завершился нормально и установил групповой ID процесса, по крайней мере, должно быть выполнено одно из условий:
• вызывающий и указанный процессы должны иметь одного и того же владельца;
• вызывающий процесс должен принадлежать привилегированному пользователю (root).
Когда процесс хочет запустить собственную уникальную группу процесса,* он обычно передает свой ID процесса в качестве второго параметра в системный вызов setpgido. Если setpgido завершается с ошибкой, то возвращает — 1.
Процесс, управляющий терминалом —171
Рис. 13.9. Управляющие терминалы и группы процесса
Синтаксис
pid_t getpgid (pid_t pid)
Системный вызов getpgid о возвращает групповой ID процесса с pid. Если pid равен 0, возвращается групповой ID вызывающего процесса.
Очередной пример иллюстрирует случай, когда терминал распределяет сигналы всем процессам процессной группы своего процесса управления. Поскольку дочерний процесс унаследовал группу процесса от родителя, то и родитель, и порожденный процесс ловят сигнал sigint. Код следующий:
$ cat pgrpl.c ...посмотреть программу,
ftinclude <signal.h>
#include<stdio.h> void sigintHandler(); main() {
signal (SIGINT, sigintHandler); /* Обработчик <Ctrl>+<C> */ if (fork() == 0)
printf ("Child PID %d PGRP %d waits\n", getpidO, getpgid (0)); else
printf ("Parent PID %d PGRP %dwaits\n", getpid(), getpgid (0)); pause(); /* Ждать сигнал */
} void sigintHandler() { printf ("Process %d got a SIGINT\n", getpidO); } $ pgrpl . . . выполнить программу.
Parent PID 24583 PGRP 24583 waits Child PID 24584 PGRP 24583 waits ЛС ... нажать комбинацию клавиш <Ctrl>+<C>.
Process 24584 got a SIGINT Process 24583 got a SIGINT $ _
Если процесс помещает себя в разные группы, он больше не связан с процессом управления терминалом и не получает сигналы с терминала. В приведенном ниже примере на дочерний процесс не воздействует нажатие комбинации клавиш <Ctrl>+<C>: $ cat pgrp2 .с ... посмотреть программу.
ttinclude <signal.h> #include <stdio.h> void sigintHandler(); main() { int i;
signal (SIGINT, sigintHandler); /* Установить обработчик сигнала */ if (fork() == 0)
setpgid (0, getpidO); /* Поместить дочерний процесс */ /* в его собственную группу процесса ★/ printf ("Process PID %d PGRP %dwaits\n", getpidO, getpgid (0));
for (i = 1; i <= 3; i++) /* Цикл три раза */
printf ("Process %d is alive\n", getpidO); sleep(1);
void sigintHandler()
printf ("Process %d got a SIGINT\n", getpidO); exit (1);
$ pgrp2 . . . выполнить программу.
Process PID 24591 PGRP 24591 waits
Process PID 24592 PGRP 24592 waits
. <Ctrl>+<C>
Process 24591 got a SIGINT
Process 24592 is alive
...родитель получает сигнал.
...дочерний процесс продолжается.
Process 24592 is alive
Process 24592 is alive
$ _
Если процесс пытается читать со своего терминала управления после того, как он непосредственно отключается от процесса управления терминалом, ему посылается сигнал sigttin, который по умолчанию приостанавливает приемник. Далее в примере отлавливается сигнал sigttin собственным обработчиком:
$ cat рдгрЗ.с ...посмотреть программу.
'#include <signal.h>
#include <stdio.h>
#include <sys/terraio. h>
#include <fcntl.h>
void sigttinHandler();
main ()
{
int status;
char str [100];
if (fork() ==0} /* Дочерний процесс */
signal (SIGTTIN, sigttinHandler);
/★ Установить обработчик */
setpgid (0, getpidO); /* Поместить себя в новую группу процесса */ printf ("Enter a string: ");
scant ("%s", str); /* Пытаться читать с управляющего терминала */
printf ("You entered %s\n", str);
else /* Родитель */
{
wait (&status); /* Ждать завершения дочернего процесса */
}
}
void sigttinHandler()
{
printf ("Attempted inappropriate read fpom control terminal\n");
exit (1);
}
$ рдгрЗ ...выполнить программу.
Enter a string: Attempted inappropriate read from control terminal
$
IPC
Взаимодействие процессов (Interprocess communication, IPC) — это общий термин, описывающий, как два процесса могут обмениваться информацией друг с другом. Вообще, два процесса могут работать как на одной и той же машине, так и на разных, хотя некоторые механизмы IPC могут поддерживать только локальное использование (например, сигналы и конвейеры). IPC может быть обменом данными, где два или больше процессов совместно обрабатывают данные или другую синхронизированную информацию с целью помочь двум независимым, но связанным процессам запланировать работу так, чтобы они не перекрывались.
Конвейеры
Конвейеры (pipes) — механизм межпроцессного взаимодействия, который позволяет двум или более процессам посылать информацию друг другу. Они обычно используются внутри shell, чтобы соединить стандартный вывод одной утилиты со стандартным вводом другой. Например, ниже приведена простая команда shell, которая определяет, сколько пользователей находится в системе:
$ who | wc -1
Утилита who генерирует одну строку вывода для одного пользователя. Этот вывод затем "конвейеризируется” в утилиту wc, которая при вызове с опцией -1 выводит общее количество строк на своем входе. Итак, конвейеризированная команда особым образом вычисляет общее количество пользователей, считая число строк, которые генерирует утилита who. На рис. 13.10 представлена схема конвейера.
Байты от who следуют через конвейер к wc
Рис. 13.10. Простой конвейер
Важно понять, что и пишушии, и читающий процессы конвейера выполняются одновременно; конвейер автоматически буферирует вывод "писателя" и приостанавливает его, если конвейер становится слишком заполненным. Аналогично, если конвейер освобождается, "читатель" временно приостанавливается до тех пор, пока некоторый вывод не станет доступным.
Все версии UNIX поддерживают безымянные конвейеры, которые являются видом конвейеров, применяемых shell. System V также поддерживает более мощный вид конвейера, называемый именованным конвейером. В следующих разделах будет показано, как построить конвейер каждого вида.
Безымянные конвейеры: pipe()
Безымянный конвейер (unnamed pipe) — это однонаправленная коммуникационная связь, которая автоматически буферирует свой вход (максимальный размер изменяется в различных версиях UNIX, но приблизительно равен 5 Кбайт) и может быть создан с помощью системного вызова pipe (). Каждый конец конвейера имеет ассоциированный дескриптор файла. "Пишущий" конец конвейера может быть записан через системный вызов write о , а "читаемый" конец может читаться с помощью системного вызова read о. Когда процесс завершает работу с конвейерным дескриптором файла, он должен закрыть его, используя системный вызов close ().
Синтаксис
int pipe (int fd[2])
Системный вызов pipe() создает безымянный конвейер и возвращает два дескриптора файла; дескриптор, связанный с "читаемым" концом
конвейера сохраняется в fd[0], а дескриптор, связанный с "пишущим" концом конвейера, сохраняется в fd[l].
Перечисленные далее правила применимы к процессам, которые читают из конвейера:
• если процесс читает из конвейера, чей пишущий конец был закрыт, системный вызов read () возвращает 0, указывая конец ввода;
• если процесс читает из пустого конвейера, чей пишущий конец все еще открыт, он засыпает до тех пор, пока некоторый ввод не становится доступным;
• если процесс пробует читать большее количество байтов из конвейера, чем там присутствует, возвращается текущее содержимое всего конвейера, и системный вызов read () возвращает количество фактически прочитанных байтов.
Следующие правила применимы к процессам, которые пишут в конвейер:
• если процесс пишет в конвейер, чей читаемый конец был закрыт, пишущий завершается с ошибкой, а писателю посылается сигнал sigpipe. По умолчанию действие этого сигнала должен завершить приемник;
• если процесс пишет в конвейер меньшее количество байтов, чем тот может держать, системный вызов write о, как гарантируется, будет атомарным; т. е. процесс-писатель закончит свой системный вызов без прерывания другим процессом. Если процесс пишет в конвейер большее количество байтов, чем тот может держать, гарантия атомарности отсутствует.
Так как доступ к безымянному конвейеру происходит через механизм дескриптора файла, обычно только процесс, который создает конвейер, и его потомки могут использовать конвейер5. Системный вызов -iseek () не имеет никакого значения, когда применяется к конвейеру. Если ядро не может выделить достаточно пространства для нового конвейера, pipe () возвращает — 1; иначе возвращается 0.
Если код выполняется, то будут созданы структуры данных, показанные на рис. 13.11. Безымянные конвейеры обычно используются для связи между родительским и дочерним процессами с одним процессом записи и другим процессом чтения, int fd[2];
pipe (fd);
5 В продвинутых ситуациях фактически возможно передать дескрипторы файла несвязанным процессам через конвейер.
Типичная последовательность событий следующая:
1. Родительский процесс создает безымянный конвейер с помощью системного ВЫЗОВа pipe ().
2. Родительский процесс ветвится.
3. Писатель закрывает свой читаемый конец конвейера и указывает читателю закрыть его пишущий конец конвейера.
4. Процессы связываются через системные вызовы write () и read ().
5. Каждый процесс закрывает свой активный дескриптор конвейера, когда работа с конвейером завершается.
Рис. 13.11. Безымянный конвейер
Двунаправленная связь возможна только при использовании двух конвейеров. Вот маленькая программа, которая применяет конвейер, чтобы позволить родителю читать сообщение от своего дочернего процесса:
$ cat talk.с ...вывести программу.
#include <stdio.h>
#define READ 0 /* Индекс читающего конца конвейера ★/
#define WRITE 1 /* Индекс пишущего конца конвейера */
char* phrase = ’’Stuff this in your pipe and smoke it";
main()
int fd[2], bytesRead;
char message [100]; /* Буфер сообщений родительского процесса */
pipe (fd); /* Создать безымянный конвейер */
if (fork() == 0) /* Дочерний, пишущий */
{
close(fd[READ]); /* Закрыть неиспользуемый конец */
write (fd[WRITE], phrase, strlen (phrase) + 1); /* Включая NULL*/ close (fd[WRITE]); /* Закрыть используемый конец */
else /* Родитель, читающий */
{ close (fd[WRITE]); /* Закрыть неиспользуемый конец */ bytesRead = read (fd[READ], message, 100);
printf ("Read %d bytes: %s\n", bytesRead, message); /* Послать */ close (fd[READ]); /* Закрыть используемый конец */
}
}
$ talk ...выполнить программу.
Read 37 bytes: Stuff this in your pipe and smoke it $
Заметьте, что дочерний процесс добавил null — признак конца фразы, как части сообщения, чтобы родитель мог легко показать сообщение. Когда процесс писателя посылает больше, чем одно сообщение переменной длины в конвейер, он должен использовать протокол для индикации конца сообщения читателю. Методы для выполнения этого включают:
□ посылку длины сообщения (в байтах) перед посылкой непосредственно сообщения;
□ завершение сообщения специальным символом, например, символом НОВОЙ строки ИЛИ NULL.
UNIX shell использует безымянные конвейеры, чтобы строить конвейерные связи. Для этого он использует ухищрение, подобное механизму переназначения, описанному ранее, чтобы соединить стандартный вывод одного процесса со стандартным вводом другого. Для иллюстрации такого подхода рассмотрим программу, которая выполняет две указанных программы, соединяя стандартный вывод первой со стандартным вводом второй. Программа, осуществляющая соединение, предполагает, что никакая программа не вызывается с опциями и что имена программ перечислены в командной строке.
$ cat connect.с ...посмотреть программу. #include <stdio.h> #define READ 0
#define WRITE 1 main (argc, argv) int argc; char* argv[]; {
int fd [2]; pipe (fd); if (fork() != 0)
/* Создать безымянный конвейер */
/* Родитель, пишущий */
{
close (fd[READ]); /* Закрыть неиспользуемый конец */
dup2 (fd[WRITE], 1); /* Дублировать используемый конец на stdout */
close (fd[WRITE]); /* Закрыть оригинальный используемый конец */ execlp (argv[l], argv[l], NULL); /* Выполнить программу-писатель */ perror ("connect’'); /* He должен никогда выполняться ★/
} ,
else /* Дочерний, читающий */
close (fd[WRITE]); /* Закрыть неиспользуемый конец */
dup2 (fd[READ], 0); /* Дублировать используемый конец на stdin */ close (fd[READ]); /* Закрыть оригинальный используемый конец */
execlp (argv[2], argv[2], NULL); /* Выполнить программу-читатель */ perror ("connect"); /* He должен никогда выполняться */
}
}
$ who ...выполнить who сам по себе.
gglass ttypO Feb 15 18:45 (xyplex_3)
$ connect who wc ...конвейеризировать who на wc.
1 6 57 ...1 строка, 6 слов, 57 символов.
$
Позже в данной главе будет рассмотрен более сложный пример использования безымянных конвейеров. Также в конце главы представлено интересное упражнение, которое затрагивает создание кольца конвейеров.
Именованные конвейеры
Именованные конвейеры (named pipes), часто упоминаемые как очереди FIFO (First Input First Output, первым пришел, первым вышел), меньше ограничены, чем безымянные конвейеры, и обладают следующими преимуществами:
□ имеют имя, которое существует в файловой системе;
□ могут использоваться несвязанными процессами;
□ существуют, пока не удалены явно.
К сожалению, именованные конвейеры поддерживаются только System V. Все правила, упомянутые в предыдущем разделе относительно безымянных конвейеров, применимы к именованным конвейерам за исключением того, что именованные конвейеры обладают большей вместимостью буфера — обычно, приблизительно 40 Кбайт.
Именованные конвейеры в файловой системе существуют как специальные файлы и могут быть созданы одним из двух способов:
□ путем запуска утилиты UNIX mknod;
□ путем использования системного вызова mknod ().
Чтобы создать именованный конвейер с помощью цтилиты mknod, следует указать опцию р. (Дополнительную информацию о mknod см. в главе 15.) Режим именованного конвейера может быть установлен через утилиту chmod для того, чтобы позволить другим получить доступ к создаваемому конвейеру.
Ниже представлен пример этой процедуры, выполненной в Korn shell:
$ mknod туPipe р ... создать конвейер.
$ chmod ug+rw туPipe ...обновить права.
$ Is -1д ту Pipe ...посмотреть атрибуты.
prw-rw--- 1 glass cs 0 Feb 27 12:38 myPipe
$ _
Обратите внимание, что тип именованного конвейера — это символ р в первой позиции листинга утилиты is.
Чтобы создать именованный конвейер через системный вызов mknod (), следует определить s_ififo в качестве режима файла. Режим конвейера затем может быть изменен путем использования системного вызова chmod ().
Вот отрывок С-кода, который создает именованный конвейер с разрешением чтения и записи для владельца и группы:
mknod ("myPipe", S_IFIFO, 0); /* Создать именованный конвейер */ chmod ("myPipe", 0660); /* Изменить его флаги разрешения */
Независимо от того, как создается именованный конвейер, результат один и тот же: специальный файл добавляется в файловую систему. Как только именованный конвейер открыт через системный вызов open (), другой системный вызов — write о — добавляет данные в начало очереди FIFO, и read () удаляет данные с конца FIFO-очереди. Когда процесс закончил использовать именованный конвейер, он должен закрыть его с помощью системного вызова close о, а когда именованный конвейер перестает быть нужным, его необходимо удалить из файловой системы через системный ВЫЗОВ unlink о .
Подобно безымянному конвейеру, именованный конвейер предназначен только для использования в качестве однонаправленной связи. Процесс-писатель должен открыть именованный конвейер только для записи, а процесс-читатель — только для чтения. Хотя процесс мог бы открыть именованный конвейер и для записи, и для чтения, это не имеет большого практического смысла. Прежде чем будет представлен пример программы,
которая использует именованные конвейеры, приведем специальные правила их применения:
□ если процесс пробует открыть именованный конвейер только для чтения, и нет процесса, который в настоящее время открыл этот файл для записи, читатель будет ждать, пока процесс не откроет файл для записи; но если установлен флаг o_nonblock/o_ndelay, тогда системный вызов open () сразу завершится нормально;
□ если процесс пробует открыть именованный конвейер только для записи, и нет процесса, который в настоящее время открыл этот файл для чтения, писатель будет ждать, пока процесс не откроет файл для чтения; но если установлен флаг o_nonblock/o_ndelay, тогда системный вызов open () сразу звершится с ошибкой;
□ именованные конвейеры не работают через сеть.
Очередной пример использует две программы — "читатель" и "писатель" — и работает так, как описано ниже.
□ Единственный читающий процесс выполняется, создавая именованный конвейер aPipe. Затем процесс читает и выводит заканчивающиеся символом null строки из конвейера, пока конвейер не закрывается всеми пишущими процессами.
□ Один или несколько пишущих процессов выполняются, каждый из них открывает именованный конвейер aPipe и посылает ему три сообщения. Если конвейер не существует, когда писатель пытается открыть его, писатель повторяет попытку каждую секунду, пока не завершится нормально. Когда все сообщения писателя посланы, он закрывает конвейер и выходит.
Далее следует исходный код для каждого файла и некоторый примерный вывод.
Программа-читатель
ftinclude <stdio.h>
ftinclude <sys/types.h>
#include <sys/stat.h> /* Для S_IFIFO */
#include <fcntl.h>
main()
{
int fd; »
char str[100];
unlink("aPipe"); /★ Удалить именованный конвейер, если он существует */
mknod ("aPipe", S_IFIFO, 0); /* Создать именованный конвейер */
chmod ("aPipe", 0660); /* Изменить его права */
fd = open ("aPipe”, O_RDONLY); /* Открыть его для чтения */
while (readLine (fd, str)) /* Вывести получаемые сообщения */
printf ("%s\n", str);
close (fd); /* Закрыть конвейер */
readLine (fd, str)
int fd;
char* str;
/* Читает отдельную, заканчивающуюся NULL, строку в str из fd */
/* Возвращает 0, когда достигнут конец ввода, и 1 — иначе */
{
int п;
do /* Читать символы до NULL или конца ввода */
{
n = read (fd, str, 1); /* Читать один символ */
while (п > 0 && *str++ != NULL);
return (n > 0); /* Возвращает ложь, если конец ввода */
Программа-писатель
ttinclude <stdio.h>
#include <fcntl.h>
main()
{
int fd, messageLen, i;
char message [100];
/* Подготовить сообщение */
sprintf (message, "Hello from PID %d", getpidO);
messageLen = strlen (message) + 1;
do /* Пытаться открыть файл до успеха */
{ >
fd = open ("aPipe", O_WRONLY); /* Открыть именованный конвейер */ /* для записи */
if (fd == -1) sleep (1); /* Пытаться снова через 1 секунду */
while (fd == -1); for (i = 1; i <= 3; i++) /* Послать три сообщения */
write (fd, message, message-Len); /* Записать сообщение */ /* в конвейер */
sleep (3); /* Подождать немного */
} close (fd); /* Закрыть дескриптор конвейера */
Примерный вывод
$ reader & writer & writer & ...старт одного читателя, двух писателей.
[1] 4698 ...читающий процесс.
[2] 4699 ...первый пишущий процесс.
[3] 4700 ...второй пишущий процесс.
Hello from PID 4699
Hello from PID 4700
Hello from PID 4699
Hello from PID 4700
Hello from PID 4699
Hello from PID 4700
[2] Done writer ...первый писатель вышел.
[3] Done writer ...второй писатель вышел.
[1] Done reader ...читатель вышел. $
Сокеты
Сокеты являются традиционным механизмом связи между процессами в UNIX, который позволяет процессам взаимодействовать друг с другом, даже если они находятся на различных машинах. Такая сетевая возможность делает сокеты очень полезными. Например, утилита riogin, которая позволяет пользователю, работающему на одной машине, регистрироваться на удаленном хосте, реализована через сокеты.
Другие общие применения сокетов включают:
П печать файла на одной машине с другой машины;
П передача файлов с одной машины на другую.
Связь процессов через сокеты основана на клиент-серверной модели. Один процесс, называемый серверным процессом, создает сокет, чье имя известно другим клиентским процессам. Эти процессы клиентов могут взаимодействовать с серверным процессом через подключение к его именованному сокету. Чтобы это сделать, процесс клиента сначала создает безымянный сокет и требует, чтобы он был связан с именованным сокетом сервера. Успешное соединение возвращает один дескриптор файла клиенту и один — серверу, которые могут использоваться для чтения и записи. Обратите внимание, что, в отличие от конвейеров, связи через сокеты двунаправлены. Рис. 13.12 иллюстрирует процесс.
1. Сервер создает именованный сокет
2. Клиент создает безымянный сокет и требует соединения
3. Клиент создает соединение. Сервер поддерживает начальный именованный сокет
Завершенное соединение
Рис. 13.12. Соединение через сокет
Как только подключение через сокет организовано, обычно серверный процесс осуществляет ответвление дочернего процесса, чтобы общаться с клиентом в то время, как первоначальный родительский процесс продолжает принимать другие подключения клиентов. Типичный пример — удаленный сервер печати: серверный процесс сначала принимает клиента, который хочет послать файл на печать, а затем ответвляет дочерний процесс, чтобы выполнить передачу файла. Родительский процесс тем временем ждет другие запросы клиентов на печать.
Рассмотрим следующие темы:
□ виды сокетов;
□ как сервер создает именованный сокет и ждет подключений;
□ как клиент создает безымянный сокет и запрашивает подключения к серверу;
□ как сервер и клиент взаимодействуют после выполнения подключения через сокет;
□ как закрывается сокетное соединение;
□ как сервер может создать дочерний процесс, чтобы общаться с клиентом.
Виды сокетов
Различные виды сокетов могут классифицироваться по трем признакам:
□ домен;
□ тип;
□ протокол.
Домены
Домен сокета указывает, где могут находиться сокеты сервера и клиента. В настоящее время поддерживаются следующие домены:
□ AFJJNIX (клиенты и сервер должны быть на одной машине);
□ AF_INET (клиенты и сервер могут быть где угодно в Интернете);
□ AF_NS (клиенты и сервер могут быть в сети XEROX).
"AF” является аббревиатурой "Address Family" (семейство адреса). Есть подобный набор констант, которые начинаются с буквы "Р" (например, PFJJNIX и PF_INET), которая означает "Protocol Family" (семейство протокола). Может использоваться любой набор, т. к. они эквивалентны. Эта книга содержит сведения об AF_UNIX и AF_INET-coKeTax, но не об AF_NS-coKeTax.
Типы
Тип гнезда определяет тип связи, которая может существовать между клиентом и сервером. В настоящее время поддерживаются два главных типа:
□ SOCK_STREAM — последовательный, надежный, с двусторонней связью, переменной длины поток байтов;
□ SOCK_DGRAM — подобно телеграммам: без соединения, ненадежный, сообщения фиксированной длины.
Другие типы, которые находятся либо в стадии планирования, либо реализованы только в некоторых доменах, таковы:
П SOCK_SEQPACKET — последовательный, надежный, с двусторонней связью, фиксированной длины пакеты байтов;
□ SOCK_RAW — обеспечивает доступ к внутренним сетевым протоколам и интерфейсам.
Данная книга содержит информацию только об использовании SOCK STREAM-сокетов, которые являются наиболее общими. Эти сокеты интуитивно понятны и удобны.
Протоколы
Значение протокола определяет средства низкого уровня, которыми реализован тип сокета. Системные вызовы, ожидающие параметр протокола, воспринимают 0, как "правильный протокол". Другими словами, значение протокола вообще не должно волновать пользователя. Большинство систем в качестве дополнительных услуг поддерживают только протоколы, отличные от тех, что имеют нулевые параметры. Поэтому во всех примерах будем применять протокол по умолчанию.
Написание сокетных программ
Любая программа, использующая сокеты, должна включать файлы /usr/include/sys/types.h и /usr/include/sys/socket.h. Дополнительные файлы заголовков должны быть добавлены в базовый компонент необходимого со-кетного домена. Наиболее общие домены показаны в табл. 13.8. Другие со-кетные домены определены в файле socket.h.
Таблица 13.8. Общие сокетные домены и соответствующие файлы заголовков
Домен Дополнительные файлы заголовка
AF_UNIX /usr/include/sys/un.h
AFJNET /usr/include/netinet/in.h /usr/include/arpa/inet. h /urs/include/netdb.h
Для иллюстрации способа, которым написана программа, использующая сокеты, построим описание ориентируемых на сокеты системных вызовов вокруг маленького клиент-серверного примера, который содержит AF-UNIX-сокеты. Затем будет приведен другой пример, который использует AF INET-сокеты.
AF-UNIX-пример состоит из следующих двух программ:
П chef — сервер, который создает именованный сокет recipe и пишет рецепт любым клиентам, которые его запрашивают; рецепт — набор строк переменной длины, заканчивающихся символом null;
П cook — клиент, который соединяется с именованным сокетом recipe и читает рецепт с сервера, cook выводит рецепт на стандартный вывод по мере того, как читает его, а затем завершает работу.
Серверный процесс программы chef работает в фоновом режиме. Любые клиентские процессы, которые соединяются с сервером, заставляют его разветвиться, дублируя сервер для передачи рецепта и позволяя первоначальному серверу принимать другие поступающие подключения. Вот образец вывода из примера "Chef-Cook":
$ chef & ... запустить сервер в фоновом режиме.
[1] 5684
$ cook ...запустить клиента для вывода рецепта.
spam, spam, spam, spam, spam, and spam.
$ cook ...запустить другого клиента для вывода рецепта.
spam, spam, spam, spam, spam, and spam.
$ kill %1 ..."Убить" сервер.
[1] Terminated chef
$
Листинг примера "Chef-Cook"
В данном разделе представлены полные листинги программ chef и cook. Предлагается сначала просмотреть код, а затем прочитать следующие разделы для выяснения деталей работы обеих программ. В целях экономии места преднамеренно пропущена большая часть проверки ошибок.
Сервер chef
1 ftinclude <stdio.h>
2 #include <signal.h>
3 #include <sys/types.h>
4 #include <sys/socket.h>
5 #include <sys/un.h> /* Для AF_UNIX-сокетов */
6
7 ttdefine DEFAULT-PROTOCOL 0
8
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
main()
int serverFd, clientFd, serverLen, clientLen;
struct sockaddr_un serverUNIXAddress; /* Адрес сервера */
struct sockaddr_un clientUNIXAddress; /* Адрес клиента */
struct sockaddr* serverSockAddrPtr; /* Указатель на адрес сервера */ struct sockaddr* clientSockAddrPtr; /* Указатель на адрес клиента */
/* Игнорировать сигнал "смерти” дочернего для предотвращения зомби */ signal (SIGCHLD, SIG_IGN);
serverSockAddrPtr = (struct sockaddr*) ^serverUNIXAddress;
serverLen = sizeof (serverUNIXAddress);
clientSockAddrPtr = (struct sockaddr*) &clientUNIXAddress;
clientLen = sizeof (clientUNIXAddress);
/* Создать UNIX-сокет, двунаправленный, подразумеваемый протокол */ serverFd = socket (AF_UNIX, SOCK_STREAM, DEFAULT-PROTOCOL);
serverUNIXAddress.sun_family = AF_UNIX; /* Установка типа домена */ strcpy (serverUNIXAddress.sun_path, "recipe”); /* Установить имя */ unlink ("recipe"); /* Удалить файл, если он уже существует */
bind (serverFd, serverSockAddrPtr, serverLen); /* Создать файл */
listen (serverFd, 5);/*Максимальное число незаконченных соединений*/
while (1) /* Бесконечный цикл */
/* Принять клиентское соединение */ clientFd = accept (serverFd, clientSockAddrPtr, &clientLen);
if (fork() == 0) /* Создать дочерний, чтобы послать рецепт */
writeRecipe (clientFd); /* Послать рецепт */
close (clientFd); /* Закрыть сокет */
exit (/* ВЫХОД_УСПЕХ */ 0); /* Завершиться */
48 else
49 close (clientFd); /* Закрыть дескриптор клиента */
50 }
51 }
52
^2 /**^*******************************************************^*****/
54
55 writeRecipe (fd)
56
57 int fd;
58
59 ‘ {
60 static char* linel = "spam, spam, spam, spam,";
61 static char* line2 = "spam, and spam.";
62 write (fd, linel, strlen (linel) + 1); /* Писать первую строку */
63 write (fd, line2, strlen (line2) + 1); /* Писать вторую строку */
64 }
Клиент cook
1 #include <stdio.h>
2 #include <signal.h>
3 #include <sys/types.h>
4 #include <sys/socket.h>
5 #include <sys/un.h> /* Для AF—UNIX-сокетов */
6 1
7 #define DEFAULT_PROTOCOL. 0
8
Q /**★★**★★★★******★*★*★★*★******★**★****★*•*****★*★*********★ /
10
11 main()
12
13 {
14 int clientFd, serverLen, result;
15 struct sockaddr_un serverUNIXAddress;
16 struct sockaddr* serverSockAddrPtr;
17
18 serverSockAddrPtr = (struct sockaddr*) &serverUNIXAddress;
19 serverLen = sizeof (serverUNIXAddress);
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
58
59
60
61
/* Создать UNIX-сокет, двунаправленный, подразумеваемый протокол */ clientFd = socket (AF_UNIX, SOCK_STREAM, DEFAULT_PROTOCOL); , serverUNIXAddress.sun_f ami1у = AF_UNIX; /* Домен сервера */
strcpy (serverUNIXAddress.sun_path, "recipe"); /* Имя сервера */
do /* Цикл до создания соединения с сервером */
{
result = connect (clientFd, serverSockAddrPtr, serverLen);
if (result == -1) sleep (1); /* Ждать и пробовать снова */
} while (result = -1); readRecipe (clientFd); /* Читать рецепт */
close (clientFd); '/* Закрыть сокет */
exit (/* ВЫХОД_УСПЕХ */ 0); /* Сделано */
readRecipe (fd)
int fd;
{
char str[200];
while (readLine (fd, str)) /* Читать строку до конца ввода */ printf ("%s\n", str); /* Вывести строку через сокет */ }
I к'к-к'к-к'к-к'к'к-к-к'к'к'к'к-к-к-к'к'к'к'к-к'к'к'к-к'к'к'к'к'к'к'к'к'к'к'к-к'к'к-к-к-к-к-к-к'к'к'к'к'к'к'к'к'к'к-к'к /
readLine (fd, str)
int fd;
char* str; 57
/* Читать одиночную строку, завершающуюся символом NULL */
{
int n;
62
63 do /* Читать символы до NULL или конца ввода */
64 (
65 n = read (fd, str, 1); /* Читать один символ */
66 }
67 while (п > 0 && *str++ != NULL);
68 return (n > 0); /* Вернуть ложь, если конец ввода */
69 }
Анализ исходного кода
Теперь, когда вы просмотрели программы, пришло время вернуться и проанализировать их. Начинаем с сервера.
Сервер
Сервер — это процесс, который является ответственным за создание именованного сокета и установку связи с ним. Для того чтобы выполнить это, сервер должен использовать системные вызовы, перечисленные в табл. 13.9.
Таблица 13.9. Системные вызовы, используемые типичным процессом-демоном UNIX
Системный вызов Описание
socket Создает именованный сокет
bind Дает сокету имя
listen Специфицирует максимальное количество отложенных соединений
accept Принимает сокетное соединение от клиента
Создание сокета: socketf)
Процесс может создавать сокет через системный вызов socket о. Сервер chef создает свой безымянный сокет на строке 30 программы:
30 serverFd = socket (AF_UNIX, SOCK_STREAM,; DEFAULT_PROTOCOL);
Синтаксис
int socket (int domain, int type, int protocol)
Системный вызов socket о создает безымянный сокет указанного домена (dmain), типа (type) и протокола (protocol). Допустимые значения этих параметров были описаны ранее.
21 Зак. 786
Если socket о завершается нормально, то возвращает дескриптор файла, связанный с недавно созданным сокетом; иначе возвращает —1. t ♦
Именование сокета: bind()
Как только сервер создал безымянный сокет, он должен связать его с именем через системный вызов bind (). Сервер chef назначает поля sockaddr_un и исполняет bind () в строках 31—34:
31 serverUNIXAddress. sun_family = AF__UNIX; /* Установка типа домена */
32 strcpy (serverUNIXAddress.sunjpath, "recipe"); /* Установить имя */
33 unlink ("recipe"); /* Удалить файл, если он уже существует */
34 bind (serverFd, serverSockAddrPtr, serverLen); /* Создать файл */
Синтаксис
int bind (int fd, const struct sockaddr* address, size_t addressLen)
Системный вызов bind () связывает безымянный сокет, представленный дескриптором файла fd, с адресом сокета, сохраненным в address. addressLen должен содержать длину структуры адреса. Тип и значение поступающего адреса зависят от домена сокета. Если сокет находится в AF-UNIX-домене, указатель на структуру sockaddr un должен быть направлен к sockaddr* и передан, как address. Эта структура имеет два поля, которые должны быть установлены следующим образом:
Поле Назначить значение
sun_family AFUNIX
sun_path Полное путевое UNIX-имя сокета (абсолютное или относительное), до 108 символов длиной
Если именованный AF-UNIX-сокет уже существует, возникает ошибка, поэтому лучше вызвать unlink о перед попыткой связать его. Если сокет находится в АЕ_1\ЕТ-домене, указатель на структуру sockaddr_in должен быть направлен к sockaddr* и передан, как address. Эта структура имеет четыре поля, которые должны быть установлены следующим образом:
Поле Назначить значение
s i n_ f ami 1 у AF_I N ЕТ
sin port Номер порта интер нет-co кета
(окончание)
Поле Назначить значение
sin_addr Структура типа in_addr, которая держит интернет-адрес ।
sin_zero Оставить пустым
Ддя дополнительной информации об интернет-портах и адресах см. далее разделы, посвященные Интернету.
Если bind о завершается нормально, он возвращает 0; иначе возвращает — 1.
Создание очереди сокета: listenO
В то время как серверный процесс обслуживает связь клиента, возможно, что другой клиент также будет пытаться осуществить связь. Системный вызов listenO позволяет процессу определить количество возможных связей, которые могут быть с очередями. Сервер chef слушает свой именованный сокет в строке 35:
35 listen (serverFd, 5);/*Максимальное число незаконченных соединений*/
Синтаксис
int listen (int fd, int queueLength)
Системный вызов listenO позволяет определить максимальное число ожидаемых связей на сокете. Максимальная длина очереди равна 5. Если клиент пытается соединиться с сокетом, чья очередь полна, ему отказывается в доступе.
Прием клиента: acceptf)
Раз сокет создан и имеет имя, а также размер его очереди определен, заключительным шагом является прием запросов связи клиентов. Чтобы это сделать, сервер должен использовать системный вызов accept (). Сервер chef принимает связь в строке 40:
40 clientFd = accept (serverFd, clientSockAddrPtr, &clientLen);
Синтаксис
int accept (int fd, struct sockaddr* address, int* addressLen)
Системный вызов accept о слушает именованный сокет сервера, указанный дескриптором файла fd, и ждет, пока запрос связи клиента не
будет получен. Когда это происходит, accept о создает безымянный сокет с теми же самыми признаками, как у оригинального именованного сокета сервера, соединяет безымянный сокет с сокетом клиента и возвращает новый дескриптор файла, который может использоваться для связи с клиентом. Оригинальный именованный сокет сервера может применяться для принятия добавочных связей.
Структура address заполняется адресом клиента и обычно выступает только в соединении с интернет-связями. Поле addressLen должно быть первоначально установлено, чтобы указывать на целое число, содержащее размер структуры, указанной address. Когда связь создана, целое число, на которое оно указывает, изменяется на реальный размер в байтах результирующего address.
Если accept () завершается нормально, он возвращает новый дескриптор файла, который может использоваться для взаимодействия с клиентом; иначе возвращает — 1.
Обслуживание клиента
Когда связь с клиентом завершается без ошибк, самая обычная последовательность событий такова:
1. Серверный процесс разветвляется.
2. Родительский процесс закрывает недавно сформированный дескриптор файла клиента и возвращается к системному вызову accept (), готовый обслужить новые требования о связи.
3. Используя системные вызовы read () и write (), дочерний процесс взаимодействует с клиентом. Когда "беседа" закончена, дочерний процесс закрывает дескриптор файла клиента и завершается.
Процесс сервера chef определяет этот ряд действий в строках 37—50:
37 while (1) /* Бесконечный цикл */
38 {
39 /* Принять клиентское соединение */
40 clientFd = accept (serverFd, clientSockAddrPtr, SclientLen);
41
42 if (fork() == 0) /* Создать дочерний, чтобы послать рецепт */
43 {
44 writeRecipe (clientFd); /* Послать рецепт */
45 close (clientFd); /* Закрыть сокет */
46 exit (/* ВЫХОД УСПЕХ */ 0); /* Завершиться */
47 }
48 else
49 close (clientFd); /★ Закрыть дескриптор клиента */
50 }
Обратите внимание, что сервер выбирает игнорирование сигналов sigchld в строке 21 так, чтобы его потомки могли "умирать” немедленно без требования у родителя приема своих кодов возврата. Если бы сервер не сделал это, потребовалось бы установить обработчик сигнала sigchld, что было бы более утомительно.
Клиент
Теперь, когда стало понятно, как написана программа сервера, рассмотрим структуру программы клиента. Клиент — это процесс, который является ответственным за создание безымянного сокета и подключение его к именованному сокету сервера. Для этого он должен использовать системные вызовы, перечисленные в табл. 13.10.
Таблица 13.10. Системные вызовы, используемые типичным клиентским процессом UNIX
Системный вызов Описание
socket Создает безымянный сокет
connect Присоединяет безымянный сокет клиента к именованному
сокету сервера
Способ, которым клиент применяет системный вызов socket о для создания безымянного сокета, аналогичен способу, которым пользуется его сервер. Домен, тип и протокол клиентского сокета должны соответствовать таковым в целевом сокете сервера. Клиентский процесс cook создает свое безымянное гнездо в строке 22:
22 clientFd = socket (AF_UNIX, SOCK_STREAM, DEFAULT_PROTOCOL);
Создание соединения: connect()
Чтобы соединяться с сокетом сервера, процесс клиента должен заполнить структуру адресом сокета и затем воспользоваться системным вызовом connect (). В строках 26—31 процесс клиента cook вызывает connect о до тех пор, пока не будет организована успешная связь:
26 do /* Цикл до создания соединения с сервером */
27 {
28 result = connect (clientFd, serverSockAddrPtr, serverLen);
29 if (result === -1) sleep (1); /* Ждать и пробовать снова */
30
31 while (result == -1);
Синтаксис
int connect (int fd, struct sockaddr* address, int addressLen)
Системный вызов connect () пытается соединяться с сокетом сервера, чей адрес содержится в структуре, указанной address. Если все проходит успешно, дескриптор файла fd может служить для связи с сокетом сервера. Тип структуры, которая указывает address, должен следовать тем же самым правилам, какие указаны в описании bind ():
• если сокет находится в AF-UNIX-домене, указатель на структуру sockaddr un должен быть помещен в sockaddr* и передан, как address’,
• если сокет находится в АР_1НЕТ-домене, указатель на структуру sockaddr_in должен быть помещен в sockaddr* и передан, как address.
addressLen должен быть равен размеру адресной структуры. (Образцы интернет-клиентов см. в примере connect () сокета и программы Internet shell в конце главы.) Если связь произведена, connect () возвращает 0. Если сокет сервера не существует или его очередь в настоящее время заполнена, connect о возвращает —1.
Взаимодействие через сокеты
Как только сокет сервера и сокет клиента соединились, их дескрипторы файлов могут использоваться системными вызовами write () и read (). В программе примера сервер использует write () в строках 55—64:
55 writeRecipe (fd)
56
57 int fd;
58
59 {
60 static char* linel = "spam, spam, spam, spam,";
61 static char* line2 = "spam, and spam.";
62 write (fd, linel, strlen (linel) + 1); /* Писать первую строку */
63 write (fd, line2, strlen (line2) + 1); /* Писать вторую строку */
64 }
Клиент использует системный вызов read () в строках 53—69:
53 readLine (fd, str)
54
55 int fd;
56 char* str; 57
58 /* Читать одиночную строку, завершающуюся символом NULL */
59
60 {
61 int n;
62
63 do /* Читать символы до NULL или конца ввода */
64 {
65 n = read (fd,str, 1); /* Читать один символ */
66 }
67 while (п > 0 && *str++ != NULL);
68 return (n > 0); /* Вернуть ложь, если конец ввода */
69 }
Сервер и клиент должны быть внимательны, чтобы закрыть свои дескрипторы файлов сокетов, когда в них больше нет необходимости.
Интернет-сокеты
AF_UNIX-coKeTbi, которые были представлены выше, прекрасны для изучения сокетов, но они не являются центром активности. Большинство полезного материала вовлечено во взаимодействие между машинами в Интернете, так что остальная часть данной главы посвящена AF-INET-сокетам. Если вы еще не читали об организации сети в главе 9, теперь подходящее время, чтобы это сделать.
Интернет-сокет определяется двумя значениями: 32-битовым IP-адресом, который определяет отдельный уникальный интернет-хост, и 16-битовым номером порта, задающим конкретный порт на хосте. Это означает, что интернет-клиент должен знать не только IP-адрес сервера, но и номера порта сервера.
Как было упомянуто в главе 9, несколько стандартных номеров портов зарезервированы для системного использования. Например, порт 13 всегда обслуживается процессом, который передает время дня хоста любому клиенту, который в этом заинтересован.
Первый интернет-пример сокета позволяет соединяться с портом 13 с любого интернет-хоста в мире и выяснять ’’удаленное’’ время дня.
Это осуществляют три вида интернет-адресов:
□ если пользователь вводит "s", это автоматически означает локальный хост;
□ если вводится значение, начинающееся с цифры, предполагается А.В.С.D-формат IP-адреса, который преобразуется программным обеспечением в 32-битовый 1Р-адрес;
□ если пользователь вводит строку, предполагается, что это символическое имя хоста, и оно преобразуется программным обеспечением в 32-битовый 1Р-адрес.
Далее приведен пример вывода программы internet time. Третий адрес, который я ввел, — это IP-адрес ddn.nic.mil национального интернет-сервера базы данных. Заметьте разницу в один час между временем моего локального хоста и временем хоста сервера базы данных.
Пример вывода
$ inettime ...выполнить программу.
Host name (q = quit, s = self): s ...какое мое время?
Self host name is csservr2
Internet Address = 129.110.42.1
The time on the target port is Fri Mar 27 17:03:50 1998 Host name (q = quit, s = self): wotan .-..какое время на wotan? Internet Address = 129.110.2.1
The time on the target port is Fri Mar 27 17:0*3:55 1998
Host name (q = quit, s = self): 192.112.36.5 ...пробовать ddn.nic.mil. The time on the target port is Fri Mar 27 18:02:02 1998
Host name (q = quit, s = self): q ...покинуть программу.
$
Листинг программы Internet time
Этот раздел содержит полный листинг клиентской программы internet time. Предполагается, что читатель просмотрит код, а затем изучит следующие за ним разделы, чтобы выяснить детали ее работы.
1 #include <stdio.h>
2 #include <signal.h>
3 #include <ctype.h>
4 #include <sys/types,h>
5 #include <sys/socket.h>
6 #includ’e <netinet/in.h>
7 #include <arpa/inet.h>
/* Для AF_INET-сокетов */
8
9
10
11
12
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
#include <netdb.h>
#define DAYTIME PORT
#define DAYTIME_PORT 13 /* Стандартный порт о */
#define DEFAULT PROTOCOL 0
unsigned long promptForINETAddress(); unsigned long nameToAddr () ;
у***********************************************************
main()
int clientFd; /* Дескриптор файла клиентского сокета */
int serverLen; /* Длина структуры адреса сервера */
int result; /* От вызова connect() */
struct sockaddr_in serverINETAddress; /* Адрес сервера */ struct sockaddr* serverSockAddrPtr; /* Указатель на адрес */
unsigned long inetAddress; /* 32-битовый IP-адрес */
/* Установить две переменные сервера */
serverSockAddrPtr = (struct sockaddr*) &serverINETAddress; serverLen = sizeof (serverINETAddress); /* Длина адреса */
while (1) /* Цикл, пока не будет прерван */
inetAddress = promptForINETAddress(); /* Получить 32-бита IP */
if (inetAddress == 0) break;
/* Сделано */
/* Начать обнуление входной адресной структуры */
bzero ((char*)&serverINETAddress, sizeof(serverINETAddress)); serverINETAddress.sin_family = AF_INET; /* Интернет */ serverINETAddress.sin_addr.s_addr = inetAddress; /* IP */ serverINETAddress.sin_port = htons (DAYTIME_PORT);
/* Теперь создать сокет клиента */
clientFd = socket (AF_INET, SOCK_STREAM, DEFAULT-PROTOCOL);
do /* Цикл до соединения с сервером */
result = connect (clientFd, serverSockAddrPtr, serverLen);
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
if (result == -1) sleep (1);/* Пытаться снова через 1 сек*/
while (result == -1); и
readTime (clientFd); /* Читать время с сервера */ close (clientFd); /* Закрыть сокет */
}
exit (/* ВЫХОД-УСПЕШЕН */ 0); }
unsigned long promptForINETAddress ()
{
char hostName [100]; /* Имя от пользователя: числовое или символьное */
unsigned long inetAddress; /* 32-бита IP-формат */
/* Цикл до выхода или ввода правильного имени */
/* Если выход, вернуть 0; иначе вернуть IP-адрес хоста */ do
{
printf ("Host name (q = quit, s = self): ");
scanf ("%s", hostName); /* Получить имя с клавиатуры */
if (strcmp (hostName, "q") == 0) return (0); /* Выход */
inetAddress = nameToAddr (hostName); /* Преобразовать в IP */ if (inetAddress == 0) printf ("Host name not found\n");
while (inetAddress == 0);
return (inetAddress);
}
/***★★•*•★*★•*•*★★★★★★★★*★*★★★****★**★★**★***★★*★★*★★**★★★★****★/ unsigned long nameToAddr (name)
char* name;
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
{
char hostName [100];
struct hostent* hostStruct;
struct in_addr* hostNode;
/* Преобразовать имя в 32-битовый IP-адрес */
/* Если имя начинается с цифры, допустить, что это числовой */
/* интернет-адрес в формате A.B.C.D, и преобразовать его */ if (isdigit (name[0])) return (inet_addr (name));
if (strcmp (name, "s") == 0)/* Получить имя хоста из базы данных */ {
gethostname (hostName, 100);
printf ("Self host name is %s\n", hostName);
else /* Принять, что это имя — правильное символьное имя хоста */ strcpy (hostName, name);
/* Теперь получить адресную информацию из базы данных */ hostStruct = gethostbyname (hostName);
if (hostStruct == NULL) return (0); /* He найден */
/* Выделить IP-адрес из структуры */
hostNode = (struct in_addr*) hoststruet->h_addr;
/* Вывести читаемую версию ради шутки */
printf ("Internet Address = %s\n", inet_ntoa (*hostNode));
return (hostNode->s_addr); /* Вернуть IP-адрес */ }
readTime (fd)
int fd;
{
char str [200]; /* Строковый буфер */
printf ("The time on the target port is ");
123 while (readLine (fd, str)) /* Читать строку до конца ввода */
124 printf ("%s\n", str); /* Вывести строку с сервера пользователю */
125 }
126
2 7 /***>H****O****ilri************i*ilt*i**fc**:llriii**:lr****i*JH*:IH*y
128
129 readLine (fd, str)
130
131 int fd;
132 char* str;
133
134 /* Читать отдельную NEWLINE - заключительную строку */
135
136 {
137 int n;
138
139 do /* Читать символы до NULL или конца ввода */
140 {
141 n = read (fd, str, 1); /* Читать один символ */
142 }
143* while (п > 0 && *str++ != '\п');
144 return (п > 0); /* Вернуть ложь, если конец ввода */
145 }
Анализ исходного кода
Теперь, когда вы просмотрели исходный код интернет-сокета, пришло время исследовать его интересные части. Программа фокусируется главным образом на клиентскую сторону интернет-связи, поэтому сначала приведено описание этой части.
Интернет-клиенты
Процедура для создания интернет-клиента та же самая, как и для создания AF-UNIX-клиента, за исключением адреса инициализации сокета. Ранее было упомянуто, что структура интернет-адреса сокета имеет тип struct sockaddr_in и содержит четыре поля:
□ sin_famiiy — домен сокета, который должен быть установлен на AFJNET;
□ sin_port — номер порта, который в данном случае равен 13;
□ sin addr — 32-битовый IP-номер клиента-сервера;
□ sin_zero — поле, дополненное пробелами и не установленное.
В создании сокета клиента единственная хитрость — это определение 32-битового IP-адреса сервера. promptForiNETAddressо (строка 59) получает ИМЯ хоста ОТ пользователя И затем вызывает nameToAddr о (строка 80), чтобы преобразовать это в адрес IP. Если пользователь вводит строку, начинающуюся с цифры, для выполнения преобразования вызывается библиотечная процедура inet_addr (). Обратите внимание, что порядок "байтов сети" — это хост-нейтральный порядок байтов в адресе IP. Этот порядок необходим потому, что обычный порядок байтов может отличаться от машины к машине, что сделало бы адреса IP непереносимыми.
Синтаксис
in_addr_t inet_addr (const char* string)
Библиотечная процедура %inet_addr() возвращает 32-битовый IP-адрес, который соответствует string формата A.B.C.D. Адрес IP имеет сетевой порядок байтов.
Если string не начинается с цифры, следующий шаг заключается в том, чтобы определить, является ли первый символ "s", означающий локальный хост. Имя локального хоста получается при помощи системного вызова gethostname() (строка 97). Как только символическое имя хоста определено, программа может искать его в файле хостов сети /etc/hosts. Это выполняется при ПОМОЩИ библиотечнй Процедуры gethostbyname () (строка 104).
Синтаксис
int gethostname (char* name, int nameLen)
Системный вызов gethostname () устанавливает символьный массив, указанный name ДЛИНОЙ nameLen, На Строку, заканчивающуюся NULL, рав-ным имени локального хоста.
Синтаксис
struct hostent* gethostbyname (const char* name)
Библиотечная процедура gethostbyname о ищет файл /etc/hosts и возвращает указатель на структуру host ent, которая описывает элемент файла, связанный со строкой name. Если name не найдено в файле /etc/hosts, возвращается null.
Структура hostent имеет несколько полей, но единственное интересующее нас поле — это поле типа struct in_addr*, называемое h addr. Оно содержит связанный с хостом IP-номер в подобласти s addr. Перед возвращением IP-номера программа выводит строковое описание адреса IP, вызывая библиотечную процедуру inet_ntoa () (строка 109).
Синтаксис
char* inet_ntoa (struct in_addr address)
Библиотечная процедура inet_ntoa () берет структуру типа in_addr в качестве своего аргумента и возвращает указатель на строку, которая описывает адрес в формате A.B.C.D.
Заключительный 32-битовый адрес возвращается в строке ПО. Как только IP-адрес inetAddress определен, поля адреса сокета клиента заполняются в строках 37—40:
37
38
39
40
bzero ((char*)&serverINETAddress, sizeof(serverINETAddress)); serverINETAddress.sin_family = AF_INET; /* Интернет */ serverlNETAddress.sin_addr.s_addr = inetAddress; /* IP */ serverlNETAddress.sin_port = htons (DAYTIME_PORT);
Библиотечная процедура bzero о очищает содержимое адресной структуры сокета прежде, чем назначаются его поля, bzero () вызов происходит от Беркли-версии UNIX. Эквивалент в System V — это библиотечная процедура memset (). Подобно адресу IP, номер порта имеет сетевой порядок байтов, который создается при помощи библиотечной процедуры htons ().
Синтаксис
void bzero (void* buffer, size_t length)
Библиотечная процедура bzero о заполняет массив buffer размером length НУЛЯМИ (ASCII-СИМВОЛ NULL).
Синтаксис
void memset (void* buffer, int value, size_t length)
Библиотечная процедура memset () заполняет массив buffer размером length значением value.
Синтаксис
in_addr_t htonl
in_port_t htons
in_addr_t ntohl
in_port_t ntohs
(in_addr_t (in_port_t (in_addr_t (in_port_t
host Long) hostShort) network Long) networkshort)
Каждая из этих библиотечных процедур осуществяет преобразование из числового формата хоста в числовой формат сети. Например, htonio возвращает эквивалент формата сети формату хоста в длинном целом без знака hostLong, a ntohsO — эквивалент хост-формата сети в коротком целом без знака networkshort.
Заключительным шагом следует создать сокет клиента и сделать попытку связи. Код для этого почти аналогичен AF_UNIX-coKeTy:
42 clientFd = socket (AF_INET, SOCK_STREAM, DEFAULTJPROTOCOL);
43 do /* Цикл до соединения с сервером */
44 {
45 result = connect (clientFd, serverSockAddrPtr, serverLen);
46 if (result == -1) sleep (1);/* Пытаться снова через 1 сек*/
47 }
48 while (result == -1);
Остальная часть программы не содержит ничего нового.
Интернет-серверы
Создание интернет-сервера — фактически довольно простое дело. Должны быть заполнены поля структуры адреса сокета sin family, sin port и sin zero, как это было сделано в примере клиента. Единственное различие заключается в том, что поле s addr должно иметь сетевой порядок байтов, который устанавливается константой inaddr_any, означающей "принимать любые поступающие запросы клиента".
Приведенный ниже пример процедуры, использованной для создания адреса сокета сервера, — слегка измененная версия некоторого кода, взятого из программы Internet shell:
int serverFd; /* Сокет сервера */
struct sockaddr_in serverINETAddress; /* Интернет-адрес сервера */ struct sockaddr* serverSockAddrPtr; /* Указатель на адрес сервера */ struct sockaddr_in clientINETAddress; /* Интернет-адрес клиента */ struct sockaddr* clientSockAddrPtr; /* Указатель на адрес клиента */
int port =13; /* Установить на порт, который вы хотите обслуживать */ int serverLen; /* Длина адресной структуры ★/
serverFd = socket (AFJENET, SOCK_STREAMZ DEFAULT-PROTOCOL); /* Создать */ serverLen = sizeof (serverINETAddress); /* Длина структуры */
bzero ((char*) &serverINETAddress, serverLen); /* Очистить структуру */
serverINETAddress . sin_family = AF_INET; /* Интернет-домен */
serverINETAddress.sin_addr.s_addr = htonl (INADDR_ANY); /* Принять все */ serverINETAddress.sin_port = htons (port); /* Номер порта сервера */ Когда адрес создан, сокет связывается с ним, и размер очереди сокета определяется обычным способом.
serverSockAddrPtr = (struct sockaddr*) &serverINETAddress;
bind (serverFd, serverSockAddrPtr, serverLen);
listen (serverFd, 5);
Заключительный шаг — это прием связей клиентов. Когда организуется успешная связь, адрес сокета клиента заполняется IP-адресом клиента, и возвращается новый дескриптор файла.
clientLen = sizeof (clientINETAddress);
clientSockAddrPtr = (struct sockaddr*) clientINETAddress; clientFd = accept (serverFd, clientSockAddrPtr, &clientLen); Как видно, код интернет-сервера подобен коду AFUNIX-сервера.
Разделяемая память
Разделение сегмента памяти — это прямой и интуитивный метод, который позволяет двум процессам на одной и той же машине разделять данные. Процесс, который размещает разделяемый сегмент памяти, при вызове получает назад ID, предполагая, что создание разделяемого сегмента памяти прошло успешно. Другие процессы могут использовать этот ID, чтобы получить доступ к разделяемому сегменту памяти.
Доступ к разделяемому сегменту памяти — самая быстрая форма IPC, т. к. никакие данные не должны копироваться или посылаться куда-нибудь еще. Однако поскольку существует только одна копия данных, если несколько процессов обновляют данные, они должны синхронизировать свои действия для предотвращения искажения данных.
Нужны некоторые общие системные вызовы, необходимые для размещения и использования разделяемых сегментов памяти в системах, базирующихся на System V:
□ shmgeto — размещает разделяемый сегмент памяти и возвращает ID сегмента;
□ shmato — присоединяет разделяемый сегмент памяти к виртуальному адресному пространству вызывающего процесса;
□ shmdt () — отсоединяет присоединенный сегмент от адресного пространства;
□ shmctio — позволяет изменить атрибуты (например, разрешение на доступ), связанные с разделяемым сегментом памяти.
После успешного вызова shmgeto разделяемый сегмент памяти существует и может быть доступен через ID, возвращенный в вызове. Обратите внимание, что любой другой процесс для использования того же самого сегмента должен также знать этот ID. ID можно сделать доступным другим процессам через другой механизм IPC, или конкретный ID можно передать shmgeto, чтобы иициировать применение конкретного известного ID (с пониманием, что вызов может быть неудачным, если этот ID уже использовался с другим разделяемым сегментом памяти).
Как только пользователь получит эффективный ID для разделяемого сегмента памяти, вызов shmat () возвратит указатель на адрес в виртуальном пространстве памяти локального процесса, куда был присоединен разделяемый сегмент памяти. Затем можно изменять этот указатель на индекс блока памяти аналогично использованию любого другого блока памяти. (Это предполагает, что пользователю известен формат данных, содержащихся в разделяемом сегменте памяти.) Если разделяемая память больше не нужна, можно освободить (отсоединить) ее вызовом shmdt () (в который передается указатель на ID неразделяемого сегмента памяти). Когда последний процесс, имеющий присоединенный разделяемый сегмент памяти (не обязательно процесс, который создавал его), отсоединяет его, освобождается пространство, выделенное сегменту.
Семафоры
Семафор — это не механизм связи, который мы видели в конвейерах, сокетах и разделяемой памяти. Фактические данные не пересылаются при помощи семафора. Скорее, семафор — это счетчик, который описывает доступность ресурса (который может быть разделяемым сегментом памяти).
Семафор создается и получает значение, обозначающее разрешенное количество параллельного использования ресурса. Каждый раз, когда процесс готовится использовать некоторый ресурс, он проверяет семафор, чтобы узнать, является ли ресурс доступным. Если значение семафора большее 0, то ресурс доступен. Процесс выделяет "единицу ресурса", и семафор уменьшается на единицу. Если значение семафора 0, процесс засыпает, пока значение не станет большее 0 (т. е. другой процесс не "вернет" ресурс).
Семафоры могут применяться для блокировки ресурса путем создания семафора со значением 1 (как только один процесс использует его, значение
семафора будет 0). Он известен как бинарный семафор. Семафоры могут помочь в установке максимального числа параллельного использования специфического ресурса.
Семафор System V немного более сложен, чем только что описанный. Семафоры управляются, как список или набор семафоров, а не индивидуально. Это обеспечивает метод определения составных семафоров для сложного блокирующего механизма, но требует ненужных издержек, когда пользователю нужен только один семафор. Связанные с семафором системные вызовы таковы:
□ semget о — создает набор (массив) семафоров;
□ semopO — манипулирует с набором семафоров;
□ semcti о — изменяет атрибуты набора семафоров.
Internet shell
Вы когда-нибудь задавались вопросом, что собой представляет внутренняя часть shell? Хорошо, вот замечательная возможность узнать, как он работает, и получить некоторый исходный код, который поможет создать ваш собственный shell. Я разработал Internet shell, во многом похожий на стандартный UNIX shell в том смысле, что он обеспечивает конвейеризацию и работу в фоновом режиме. Но я также добавил некоторые специфичные для Интернета возможности, в которых другие shell испытывают недостаток.
Ограничения
Чтобы уместить функциональные возможности Internet shell в разумных пределах, имеются ограничения.
□ Все символы должны быть отделены явным пробелом (символ табуляции или пробелы). Это означает, что вместо записи
Is; date
вы должна писать
Is ; date
В результате этого лексический анализатор стал очень простым.
□ Замена имени файла (универсализация файловых имен) не поддерживается. Это означает что стандартные символы *, ? и метасимволы о не истолковываются.
Эти ограничения хороши для реализации их в повседневном shell.
Синтаксис команды
Синтаксис команды Internet shell подобен синтаксису команд стандартного UNIX shell. Здесь комады описываются формально на основе нотации BNF (обратите внимание, что символы перенаправления < и > отделяются \, чтобы предотвратить двусмысленность; см. Приложение):
<internetShellcommand> = <sequence> [ & ]
<sequence> = <pipeline> {; <pipeline> }*
<pipeline> = <simple> { I <simple> }
<simple> = { <token> }* { <redirection>)*
<redirection> = <fileRedireqtion> | <socketRedirection>
<fileRedirection> = \> <file> > <file> I \< <file>
<socketRedirection> = <clientRedirection> | <serverRedirection>
<clientRedirection> = @\>c <socket> | @\<c <socket>
<serverDirection> = @\>s <socket> | @\<s <socket>
<token> = строка_ символов
<file> = допустимый—путь
<socket> = либо путь (сокет UNIX-домена) , либо имя интернет-сокета в формате именя_хоста. номер_порта
Запуск Internet shell
Исполнимым файлом Internet shell назван ish. Приглашение Internet shell — знак вопроса (?).
Когда ish стартует, он наследует переменную окружающей среды $ратн от shell, который вызывает его. Значение $ратн может быть изменено путем использования встроенной команды setenv.
Чтобы выйти из Internet shell, следует нажать комбинацию клавиш <Ctrl>+ +<D> в отдельной строке.
Встроенные команды
Internet shell выполняет большинство команд, создавая дочерний shell, который запускает указанную утилиту, в то время как родительский shell ждет порожденный shell. Однако некоторые команды включены в shell и выполняются непосредственно. В табл. 13.11 перечислены встроенные команды. Они могут быть перенаправлены.
Таблица 13.11. Встроенные команды Internet shell
Встроенная Функция
echo {<token>}* Выводит символы на терминал
cd path Изменяет рабочий каталог shell на path
getenv name Выводит значение переменной окружения пате
setenv name value Устанавливает значение переменной окружения name на value
Перед описанием Internet shell рассмотрим несколько примеров обычных команд и команд, специфичных для Интернета.
Примеры обычных команд
Ниже приведены примеры, которые иллюстрируют последовательности, перенаправление и возможности конвейера Internet shell:
$ ish ...старт shell.
Internet Shell.
? Is ..простая команда.
ish.с ish.cs ish.van who. socket who.sort
? Is | wc • ..конвейер.
5 5 41
? who I sort > who.sort & ..конвейер, перенаправление, фон.
[4356] ..PID фонового процесса.
? cat who.sort • ..показать работу перенаправления
glass ttyp2 May 28 18:33 (bridge05.utdalla)
posey ttypO May 22 10:19 (blackfoot.utdall)
posey ttypl May 22 10:19 (blackfoot.utdall)
? date ; whoami ..последовательность команд.
Thu Mar 26 18:36:24 CDT 1998 glass
? echo hi there ...выполнить встроенную команду.
hi there
? getenv PATH ...посмотреть путь переменной окружения.
:.:/usr/local/bin:/usr/ucb:/usr/bin:/bin:/usr/etc
? mail glass < who.sort ...перенаправление входа также работает.
? ...выйти из shell.
$
Интернет-примеры
Internet shell становится довольно интересным, если исследовать особенности его сокета. Вот пример, который использует сокет домена UNIX для передачи информации:
$ ish ...старт Internet shell.
Internet Shell. ? who @>s who.sck & ...сервер посылает вывод в сокет who.sck. [2678]
? Is ...выполнить команду для смеха,
ish.с ish.van who.sock who.sort
ish.cs who.sck who.socket
? sort @<c who.sck ...клиент читает ввод с сокета who.sck. glass ttyp2 May 28 18:33 (bridgeOS.utdalla)
posey ttypO May 22 10:19 (blackfoot.utdall)
posey ttypl May 22 10:19 (blackfoot.utdall)
veerasam ttyp3 May 28 18:39 (129.110.70.139)
? ...покинуть shell.
$
Действительно, забавные вещи происходят, когда выполняется внедрение интернет-сокетов. Первый shell в следующем примере работает на хосте csservr2, а второй shell — на хосте vanguard:
$ ish Internet Shell. ? who @>s 5000 & [7221] ? "D
$ rlogin vanguard % ish Internet Shell.
...запустить Internet shell на csservr2.
...фоновый сервер посылает вывод в порт 5000.
...покинуть shell.
...войти на хост vanguard.
...выполнить Internet shell на vanguard.
? sort @<с csservr2.5000
...клиент читает ввод с csservr2.
...порт 5000.
IP address = 129.110.42.1 ...выведен Internet shell.
glass ttyp2 May 28 18:42 (bridgeOS.utdalla) ...вывод c
posey ttypO May 22 10:19 (blackfoot.utdall) ...c who
posey ttypl May 22 10:19 (blackfoot.utdall) ...на csservr2
veerasam ttyp3 May 28 18:39 (129.110.70.139)
? ...покинуть shell.
% logout $
...выйти c vanguard.
...вернуться на csservr2
На рис. 13.13 приведена иллюстрация сокетного соединения.
Рис. 13.13. Перенаправление Internet shell
Следующий пример более интересен: первый shell использует один сокет, чтобы взаимодействовать со вторым shell, а второй shell — другой сокет, чтобы "говорить" с третьим:
$ ish Internet Shell. ? who @>s 5001 & [2001] ?
$ rlogin vanguard % ish Internet Shell.
...запустить shell на csservr2.
...фоновый сервер посылает вывод в порт 5001.
...покинуть shell.
...войти на vanguard.
...запустить shell на vanguard.
? sort @<с csservr2.5001 @>s 5002 & ...фоновый процесс читает [3756] ...ввод с порта 5001
...на csservr2 и посылает его ...в локальный порт 5002.
IP address = 129.110.42.1 - ...выводится shell.
? ...покинуть shell.
% ...выйти из vanguard,
logout
$ ish ...стартовать другой shell на csservr2.
Internet Shell.
? cat @<c vanguard.5002 ...читать ввод с порта 5002 на vanguard.
IP address = 129.110.43.128 ...выводится shell.
glass ttyp2 May 28 18:42 (bridge05.utdalla)
posey ttypO May 22 10:19 (blackfoot.utdall)
posey ttypl May 22 10:19 (blackfoot.utdall)
veerasam ttyp3 May 28 18:39 (129.110.70.139)
? ...покинуть shell.
$
На рис. 13.14 предсталена иллюстрация соединения с двумя сокетами.
Рис. 13.14. Еще одно перенаправление Internet shell
Как работает Internet shell
Работа Internet shell может быть разделена на несколько главных частей: □ основной командный цикл;
□ анализ;
□ выполнение встроенных команд;
□ выполнение конвейеров;
□ выполнение последовательностей;
□ фоновая обработка;
□ работа с сигналами;
□ выполнение перенаправления файлов;
□ выполнение перенаправления сокетов.
Далее приводится описание каждого действия вместе с фрагментами кода и указанием номера строки, когда необходимо. Перед чтением объснений следует просмотреть листинг исходного кода.
Основной командный цикл
Когда shell стартует, он инициализирует обработчик сигнала для перехвата прерывания от клавиатуры и сбрасывает флаг ошибки. Затем он входит в функцию commandLoop () (строка 167), которая выводит приглашение пользователю для ввода строки, разбирает ввод и выполняет команду. commandLoop() осуществляет цикл до нажатия пользователем комбинации клавиш <Ctrl>+<D>, после чего shell заканчивается.
Анализ
Чтобы проверить командную строку на ошибки, она сначала разбивается на отдельные символы процедурой tokenizeO (строка 321), которая расположена в секции лексического анализатора исходного кода. tokenizeO вызывается процедурой commandLoop () И заполняет ГЛОбалЬНЫЙ массив tokens указателями на каждый индивидуальный символ. Например, если строка ввода была is -1, tokens [0] указал бы на строку is, a tokens [1] — на строку -1. После разбора строки глобальный указатель на символы tindex устанавливается на 0 (строка 350) в подготовке к разбору.
Разбор выполняется нисходящим способом. Главный анализатор parseSequence () (строка 194) вызывается ИЗ функции commandLoop () . parsesequence () разбирает каждый конвейер в последовательности, вызывая parsepipeline (), и записывает информацию, которую возвращает parsepipeline о. Наконец, он проверяет, должна ли последовательность быть выполнена в фоновом режиме.
Точно так же функция parsepipeline о (строка 222) разбирает каждую простую команду в конвейере, вызывая parseSimpleO, и записывает информацию, возвращаемую parseSimpleO. parseSimpleO (строка 242) записывает символы простой команды и обрабатывает любые замыкающие метасимволы типа >, » и @>s.
Информация, которую каждая из этих разбирающих функций собирает, сохраняется в структурах для дальнейшего использования процедурами выполнения. Структура sequence (строка 75) может хранить детали до пяти (max_pipes) конвейеров вместе с флагом, указывающим, действительно ли последовательность должна быть выполнена в фоновом режиме. Каждый конвейер зарегистрирован в структуре pipeline (строка 67), которая может записывать детали до пяти (max_simple) простых команд. Наконец, структура simple (строка 52), может содержать до 100 (max_tokens) символов вме
сте с несколькими полями, которые записывают информацию, связанную с перенаправлением ввода/вывода.
Если команда разобрана без ошибок, локальной переменной sequence (строка 182) присваивается значение структуры sequence, которая содержит проанализированную версию команды.
Обратите внимание, что можно было использовать указатели для более эффективного возвращения структуры, но был выбран простой способ программирования, чтобы фокусироваться на специфичных для UNIX аспектах.
Выполнение командной последовательности
Основной командный цикл выполняет успешно разобранную команду, вызывая процедуру executesequence () (строка 444), которая делает следующее.
□ Если команда должна быть запущена в фоновом режиме, она создает дочерний процесс, чтобы выполнить конвейеры в последовательности; первоначальный родительский shell не ждет порожденный. Перед выполнением конвейера дочерний процесс восстанавливает его оригинальный обработчик прерываний и помещает себя в новую группу процесса, чтобы освободиться от зависаний и других сйгналов. Это гарантирует, что фоновый процесс продолжит выполняться, даже когда shell закончится, и пользователь выйдет из системы.
□ Если команда должна быть выполнена в приоритетном режиме, родительский shell выполняет конвейеры в последовательности.
В обоих случаях вызывается executepipeline () (строка 472), чтобы выполнить каждый компонент конвейера последовательности команды.
Выполнение конвейеров
Процедура executepipeline () выполняет одно из двух действий.
□ Если конвейер — ЭТО простая встроенная команда, executepipeline () выполняет простую команду непосредственно, без создания дочернего процесса. Это очень важно. Например, встроенная команда cd выполняет chdirо, чтобы изменить текущий рабочий каталог shell. Если бы создавался дочерний shell, чтобы выполнить эту встроенную команду, рабочий каталог первоначального родительского shell был бы не затронут, что будет неправильно.
□ Если конвейер — это больше, чем простая встроенная команда, executepipeline о создает дочерний shell, чтобы выполнить конвейер; первоначальный родительский shell ждет порожденный процесс, чтобы закончить свою обработку. Заметьте, что родитель ждет определенный PID, вызывая процедуру waitForPidO (строка 503), потому что роди
тельский shell мог создать некоторых предыдущих "потомков", чтобы выполнить фоновые процессы, и будет неправильным для родителя возобновиться, когда один из этих фоновых процессов закончится. Если конвейер содержит только одну простую команду, то никакие конвейеры создаваться не должны, и вызывается процедура executesimple о (строка 569). Иначе, вызывается процедура executepipes о (строка 516), которая соединяет каждую команду с ее собственным конвейером.
executepipes () — довольно сложная процедура. Если конвейер содержит п простых команд, то executepipes о создает п дочерних процессов, один на команду, и п — 1 конвейер, чтобы соединить порожденные процессы. Каждый дочерний процесс повторно присоединяет свой стандартный ввод или каналы вывода к соответствующему конвейеру и затем закрывает все первоначальные дескрипторы конвейерных файлов. Далее каждый "потомок" выполняет свою ассоциированную простую команду. Тем временем первоначальный процесс, который вызвал процедуру executepipes о , ждет все свои порожденные процессы, чтобы получить возможность завершиться.
Выполнение простой команды
Процедура executesimple о переадресовывает стандартный ввод или каналы вывода по мере необходимости, а затем выполняет либо процедуру executeBuiltinO (строка 635), либо процедуру executeprimitive о (строка 596). В зависимости от категории команды builtin о (строка 624) возвращает истину, если лексема — имя встроенной команды. Если команда встроенная, возможно, что она выполняется непосредственно shell. Чтобы не допустить изменение переадресации каналов ввода/вывода shell, первоначальный стандартный ввод и каналы вывода записываются для более позднего восстановления.
Процедура executeprimitive о (строка 596) работает, вызывая execvpO. К счастью (но не по совпадению), p->token уже находится в форме, необходимой ДЛЯ execvpO. Встроенные функции ВЫПОЛНЯЮТСЯ executeBuiltinO, используя простой switch-оператор.
Переключение
redirect о (строка 761) выполняет всю предварительную обработку, необходимую для переключения как сокета, так и файла. Основная техника заключается в том, чтобы переадресовывать стандартные каналы ввода/вывода, и аналогична той, которая была описана ранее в главе. Если требуется переназначение файла, вызывается функция dupFdO (строка 806) для создания файла с соответствующим режимом и дублирования стандартного дескриптора файла. Если требуется переназначение сокета, вызывается либо функция server о (строка 950), либо функция client о (строка 879),
чтобы создать соответствующий тип связи сокета. Эти функции манипулируют и UNIX-доменом и доменом интернет-сокетов тем же самый способом, как это происходило в более ранних примерах сокетов.
Расширение возможностей
Я думаю, что можно добавить некоторые новые возможности к Internet shell. Если вы заинтересованы в этом, см. разд. "Проекты" в конце главы для получения некоторых советов.
Листинг исходного кода Internet shell
1 #include <stdio.h> 2 '# include <stdlib.h> 3 #include <string.h>
4 #include <signal.h>
5 #include <ctype.h>
6 #include <sys/types.h>
7 #include <fcntl.h>
8 #include <sys/ioctl.h>
9 #include <sys/socket.h>
10 #include <sys/un.h>
11 #include <netinet/in.h>
12 ttinclude <arpa/inet. h>
13 #include <netdb.h> 14
14
15
16 /* Макросы */
17 ttdefine MAX_STRING_LENGTH 200
18 ttdefine MAX_TOKENS 100
19 tfdefine MAX_TOKEN_LENGTH 30
20 ttdefine MAX_SIMPLE 5
21 ttdefine MAX_PIPES 5
22 ttdefine NOT_FOUND -1
23 tfdefine REGULAR -1
24 ttdefine DEFAULT-PERMISSION 0660
25 tfdefine DEFAULT-PROTOCOL 0
26 ttdefine DEFAULT-QUEUE_LENGTH 5
27 tfdefine SOCKET_SLEEP 1
28
29
30 /* Энумераторы */
31 enum { FALSE, TRUE };
32 enum metacharacterEnum
33 {
34 SEMICOLON, BACKGROUND, END_OF_LINE, REDIRECT_QUTPUT,
35 REDIRECT_INPUT, APPEND_OUTPUT, PIPE,
36 REDIRECT_OUTPUT_SERVER, REDIRECT_OUTPUT__CLIENT,
37 REDIRECT_INPUT_SERVER, REDIRECT_INPUT_CLIENT
38 };
39 enum builtInEnum { ECHO_BUILTIN, SETENV, GETENV, CD };
40 enum descriptorEnum { STDIN, STDOUT, STDERR };
41 enum pipeEnum {. READ, WRITE };
42 enum lOEnum
43 {
44 NO-REDIRECT, FILE_REDIRECT,
45 SERVER_REDIRECT, CLIENT_REDIRECT
46 };
47 enum socketEnum { CLIENT, SERVER };
48 enum { INPUTJSOCKET, OUTPUT_SOCKET };
49
50
51 /* Каждая простая команда имеет одну из структур */
52 struct simple *
53 54 char* token [MAXJTOKENSJ; / '* Лексемы команды */
55 int count; / Число лексем */
56 int outputRedirect; / z* Установить на lOEnum */
57 int inputRedirect; / z* Установить на lOEnum */
58 int append; /* Присвоить истину для режима добавления */
59 char *outputFile; /* Имя выходного файла или NULL, если нет */
60 char *inputFile; /* Имя входного файла или NULL, если нет */
61 char *outputSocket; /* Имя выходного сокета или NULL, если нет */
62 char *inputSocket; /* Имя входного сокета или NULL, если нет */
63 };
64
65
66 /* Каждый конвейер имеет одну из структур, ассоциированную с ним */
67 struct pipeline
68 {
69 struct simple simple [MAX_SIMPLE]; /* Команд в конвейере */
70 int count; /* Число простых команд */
71 };
72
73
74 /* Каждая последовательность команд имеет одну из структур */
75 struct sequence
76 {
77 struct pipeline pipeline [MAX_PIPES]; /* Конвейеров в последовательности */
78 int count; /* Число конвейеров */
79 int background; /* Истина, если это фоновая последовательность *
80 * };
81
82
83 /* Прототипы */
84 struct sequence parseSequence();
85 struct pipeline parsePipeline();
86 struct simple parseSimple();
87 char *nextToken();
88 char *peekToken();
89 char *lastToken();
90 char* getTokenO;
91
92
93 /* Глобальные */
94 char* metacharacters [] =
95
&
"@>s", "@>c", "@<s", "@<c"/ ’”’
96 char* builtlns [] = { ’’echo”, ’’setenv", "getenv", "cd", ’”’ };
97 char line [MAX_STRING_LENGTH]; /* Текущая строка */
98 char tokens [MAX_TOKENS][MAX_TOKEN_LENGTH]; /* Лексем в строке */
99 int tokenCount; /* Число лексем в текущей строке */ \
100 int tIndex; /* Индекс в строке для лексического анализатора */
101 int errorFlag; /* Имеет значение "истина", когда происходит ошибка */
102
103
104 /* Несколько предварительных объявлений */
105 void (*originalQuitHandler) О;
106 void quitHandler() ;
107
108
109 /* Внешние */
110 char **environ; /* Указатель на окружение */
111
/*************************************************************** /
113
114 main (argc, argv)
115
116 int argc;
117 char* argv [];
118
119 {
120 initialize(); /* Инициализировать некоторые глобальные */
121 commandLoop(); /* Принять и обработать команды */
122 return (/* ВЫХОД_УСПЕШНО */ 0) ;
123 }
124
126
127 initialize()
128
129 {
130 printf ("Internet Shell.\n"); /* Введение */
131 /* Установить обработчик <Ctrl>+<C>, чтобы ловить прерывания от
клавиатуры */
132 originalQuitHandler = signal (SIGINT, quitHandler);
133 }
134
j_35 у****************************************************************j
136
137 void quitHandler()
138
139 {
140 /* Обработчик <Ctrl>+<C> */
141 printf ("\n");
142 displayPrompt();
143 }
144
145
146
•147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
error (str)
char* str;
{
/* Вывести строку, когда ошибка будет в стандартный канал ошибки */ fprintf (stderr, ”%s", str);
errorFlag = TRUE; /* Установить флаг ошибки */
/****************************************************************j
displayPrompt()
printf (”? ”); }
commandLoop ()
{
struct sequence sequence;
/* Принимать и обрабатывать команды до появления <Ctrl>+<D> */ while (TRUE)
{
displayPrompt();
if (gets (line) = NULL) break; /* Получить входную строку */ tokenizeO; /* Разбить входную строку на лексемы */
errorFlag = FALSE; /* Сбросить флаг ошибки */
if (tokenCount >1) /* Обработать любую непустую строку */
sequence = parseSequence();
/* Разобрать строку */
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
/* Если нет ошибок во время разбора, */
/* выполнить команду */
if (’errorFlag) executesequence (&sequence);
ПРОЦЕДУРА РАЗБОРА
**********★*****************************************************/
struct sequence parseSequence()
{
struct sequence q;
/★ Разобрать командную последовательность и вернуть указатель на структуру */
q.count =0; /* Число конвейеров в последовательности */
q.background = FALSE; /* По умолчанию не в фоне */
while (TRUE) /* Цикл до найденной точки с запятой */
q.pipeline[q.count++] = parsePipeline(); /* Разобрать */
if (peekCode() != SEMICOLON) break;
nextToken(); /* Выключить разделитель "точка с запятой" */
if (peekCode() == BACKGROUND) /* Последовательность в фоне */
q.background = TRUE;
nextToken(); /* Выключить амперсанд */
getToken (END_OF_LINE); /* Проверить достижение конца строки */ return (q);
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
22
struct pipeline parsePipeline()
{
struct pipeline p;
/* Разобрать конвейер и вернуть дескриптор структуры на него */
р.count =0; /* Число простых команд в конвейере */
while (TRUE) /* Цикл до появления разделителя конвейера */ {
р.simple[р.count++] = parseSimple(); /* Разобрать команду */
if (peekCode() != PIPE) break;
nextTokenO; /* Выключить разделитель конвейера */
}
return (р);
}
struct simple parseSimple()
{
struct simple s;
int code;
int done;
/* Разобрать простую команду и вернуть дескриптор структуры */
s.count =0; /* Число лексем в простой команде */
s.outputFile = s.inputFile = NULL;
s.inputsocket = s.outputsocket = NULL;
s.outputRedirect = s.inputRedirect = NO_REDIRECT;/*По умолчанию*/ s.append = FALSE;
while (peekCode() == REGULAR) /* Сохранить все обычные лексемы */ s.token[s.count++] = nextToken();
s.token[s.count] = NULL; /* Заканчивающийся NULL список лексем */
Зак. 786
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
done = FALSE;
/* Разобрать специальные метасимволы, подобные > и » ★/ do
{
code = peekCode(); /* Считать следующую лексему */
switch (code)
{
case REDIRECT_INPUT: /* < */
nextToken();
s.inputFile = getToken (REGULAR);
s.inputRedirect = FILE_REDIRECT;
break;
case REDIRECT—OUTPUT: /* > */
case APPEND_OUTPUT: /* > */
nextToken();
s.outputFile = getToken (REGULAR);
s.outputRedirect = FILE_REDIRECT;
s.append = (code = APPEND_OUTPUT);
break;
case REDIRECT—OUTPUT—SERVER: /* @>s */ nextToken();
s.outputsocket = getToken (REGULAR);
s.outputRedirect = SERVER_REDIRECT;
break;
case REDIRECT—OUTPUT—CLIENT: /* @>c */ nextToken();
s.outputsocket = getToken (REGULAR);
s.outputRedirect = CLIENT—REDIRECT;
break;
I
I a
case REDIRECT—INPUT—SERVER: /* @<s */ nextToken();
s.inputsocket = getToken (REGULAR);
s.inputRedirect = SERVER_REDIRECT;
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
break;
case REDIRECT_INPUT_CLIENT: /* @<c */ nextToken();
s.inputsocket = getToken (REGULAR);
s.inputRedirect = CLIENT_REDIRECT; break;
default:
done = TRUE;
break;
}
while (’done);
return (s);
}
/* ПРОЦЕДУРА ЛЕКСИЧЕСКОГО АНАЛИЗАТОРА */
^•к-к'к-к-к^-к-к-к-к-к-к-к-к-к-к^’к'к-к-к-к-к-к-к-к-к’к-к-к-к’к'к-к-к-к-к-к-к-к-к-к-к-к-к'к-к-к-к-к'к-к-к-к-к-к-к-к-к-^-^-^-к-^ /
tokenize()
char* ptг = line; /* Указывает на входной буфер */ char token [MAX_TOKEN_LENGTH]; /* Держит текущую лексему */ char* tptr; /* Указатель на текущий символ */
tIndex =0; /* Глобальный: указывает на текущую лексему */
/* Разбить текущую входную строку на лексемы */ while (TRUE)
{
tptr = token;
while (*ptr == ’) ++ptr; /* Пропустить ведущие пробелы */
if (*ptr =- NULL) break; /* Конец строки */
do
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
{
*tptr++ = *ptr++; }
while (*ptr != ’ ’ && *ptr != NULL);
*tptr = NULL;
strcpy (tokens[tlndex++], token); /* Хранит символ */ }
/* Поместить лексему "конец-строки" в конец списка лексем */ strcpy (tokens[tlndex++], "\n");
tokenCount = tlndex; /* Запомнить общее число лексем */
tIndex =0; /* Установить индекс лексем на начало списка лексем */ }
^•к-к-кк-кк-к'к-к'к'к'к'к-к'к'к'к'к-к'кк-'к-к-к'к'к'к-к-к-к'к'к'к-к'ккк-к'к'к'к-к-кк-к-кккк-к-к-кк-к-к-к-к-к-ккк /
char* nextToken()
return (tokens[tlndex++]); /*Вернуть следующую лексему из списка*/
кк'к-кк’к-кк-к'к-к-к'к-кк-к-к-к'к-к'к'к'к'к'к'к'к'к'кк-кк-к * -к к-ккк-к-к-к-к-к-к-к-к-к-к-к-к-кк-к-кккк-к
char *lastToken()
{
return (tokens[tIndex — 1]); /* Вернуть предыдущую лексему из списка */
к’кк’к'к-к-к'к-к-кк'к-кк'кк-к-к-к-к-к'к-кк-кк-кк-кк-к-кк-ккккк-к-кк-к-к'кк-к-к-кк-к-кккккк-к-к-к-к-кккк
peekCode()
{
/* Вернуть указатель кода следующей лексемы в списке */ return (tokenCode (peekToken()));
Системное программирование
649
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
char* реекТокепО
{
/* Вернуть указатель следующей лексемы в списке */ return (tokens[tlndex]);
}
^•k'k-k-k-ir-k-k-ir-k'k-ie-k-k-k'k-k-k-k-k'k-k-ic-k'k-k'k'k-k'kic-k'k'ic'ie'k-k’k'k-k’k'k'k-ic-k-k-k'k-ir-k-k-k'k'k-k-k-k-ic-k-k-k-k-k-k'k-k I char *getToken (code) int code;
{
char str [MAXJSTRING_LENGTH];
/* Генерировать ошибку, если код следующей лексемы — не code, */
/* иначе вернуть лексему */ if (peekCode() != code)
{
sprintf (str, "Expected %s\n", metacharacters[code]);
error (str); return (NULL);
}
else
return (nextToken());
/Jt****Jr*f********Jrir*i*ilr****5lr*i**ilr*************^Jri*****************/ tokenCode (token) char* token;
{
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
421
443
444
445
446
447
448
449
450
451
452
453
/★ Вернуть индекс лексемы в массиве метасимволов */ return (findString (metacharacters, token));
findString (strs, str)
char* strs []; char* str;
int i = 0;
/* Вернуть индекс строки в строковом массиве strs */
/* или NOT_FOUND, если строки там нет */
while (strcmp (strs[i], "") !=0)
if (strcmp (strs[i], str) == 0) return (i);
else
return (NOT_FOUND) ; /* He найдена */
ПРОЦЕДУРА ВЫПОЛНЕНИЯ КОМАНДЫ
executeSecqence (р)
struct sequence* p;
int i, result;
/* Выполнить последовательность операторов (возможно, один) */ if (p->background) /* Выполнить в фоне */
454
455
456
457
458
459
4 60
461
462
463
464
4 65
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
if (fork() == 0)
{
printf (”[%d]\n"/ getpidO); /* Вывести дочерний PID */
/* Дочерний процесс */
signal (SIGQUIT, originalQuitHandler);/* Старый обработчик */ setpgid (0, getpidO); /★ Изменить группу процесса */
for (i = 0; i < p->count; i++) /* Выполнить конвейеры */
executepipeline (&p->pipeline[i]);
exit (/* ВЫХОД-УСПЕШНО */ 0) ;
}
}
else /* Выполнить в фоне */
for (i = 0; i < p->count; i++) /* Выполнить каждый конвейер */
executepipeline (&p->pipeline[i]);
}
*****★*********★*****★+*^**^**************,111*****^*********^*^** /
executepipeline (p)
struct pipeline *p;
{
int pid, processGroup, result;
/* Выполнить каждую простую команду в конвейере (возможно, одну) */ if (p->count == 1 && builtin (p->simple[0].token[0]))
executeSimple (&p->simple[0]); /* Выполнить ее непосредственно */ else
{
if ((pid = fork()) == 0)
{
/* Дочерний shell выполняет простую команду */
if (p->count == 1)
executeSimple (&p->simple[0]); /* Выполнить команду */
else
executePipes (p) ; /* Выполнить больше, чем одну команду */ exit ( /* ВЫХОД—УСПЕШНО */ 0) ;
}
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528-
529
530
531
else
{
/* Родительский shell ждет завершения "потомка" */ waitForPID (pid);
}
}
}
★ ★fr^O*********************************************************
waitForPID (pid)
int pid;
{
int status;
/* Возврат, когда дочерний процесс с PID завершится */ while (wait (&status) ! = pid);
}
***i**************i*******Jr******Jr****Jr*****Jr**** + *****Jf****
executePipes (p)
struct pipeline *p;
{
int pipes, status, i;
int pipefd [MAX_PIPES][2];
/* Выполнить две или больше простых команды в конвейере */ pipes = p->count — 1; /* Число строящихся конвейеров */
for (i = 0; i < pipes; i++) /* Построить конвейеры */
» pipe (pipefdfi]);
for (i =0; i < p->count; i++)/* Создать 1 процесс на конвейер */
{ t if (fork() != 0) continue;
/★ Дочерний процесс */
532
*/
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
/^Первое: соединить stdin с конвейером, если нет первой команды
if (i != 0) dup2 (pipefd[i-1][READ], STDIN);
/^Второе: соединить с конвейером, если нет последней команды */ if (i != p->count — 1) dup2 (pipefd[i][WRITE], STDOUT);
/★ Третье: закрыть все файловые дескрипторы каналов ★/ closeAllPipes (pipefd, pipes);
/★ Последнее: выполнить простую команду */
executesimple (&p->simple[i]);
exit (/* ВНХОД_УСПЕШНО */0);
}
/* Родительский shell приходит сюда после отделения "потомка" ★/ closeAllPipes (pipefd, pipes);
for (i = 0; i < p->count; i++) /* Ждать завершения "потомков" */
wait (^status);
/****************** + ************* + *********-*••********★*****★**★*** /
closeAllPipes (pipefd, pipes)
int pipefd [] [2];
int pipes;
int i ;
/* Закрыть каждый дескриптор файла конвейера */
for (i = 0; i < pipes; i++)
{
close (pipefd[i][READ]);
close (pipefd[i][WRITE]);
}
}
****************************************************************
executeSimple (p)
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
struct simple* p;
{
int copyStdin, copyStdout;
/* Выполнить простую команду */
if (builtin (p->token[0])) /* Встроенная */
/* Родительский shell выполняет это, так что помните */
/* stdin и stdout в случае встроенной переадресации */ copyStdin = dup (STDIN);
copyStdout = dup (STDOUT);
if (redirect (p)) executeBuiltln (p); /* Выполнить встроенный */ /* Восстановить stdin и stdout */
dup2 (copyStdin, STDIN);
dup2 (copyStdout, STDOUT);
close (copyStdin);
close (copyStdout);
}
else if (redirect (p)) /* Переадресовать, если необходимо */
executePrimitive (p); /* Выполнить простую команду */
}
у*^***********************^*^********^************************^**/
executePrimitive (р)
struct simple* р;
/* Выполнить команду путем вызова ехес */
if (execvp (p->token[0], p->token) == -1) {
perror (”ish”);
exit (/* ВЫХОД_НЕУДАЧА */ 1);
}
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
ВСТРОЕННЫЕ КОМАНДЫ
**********************************************************************
builtlnCode (token)
char* token;
, {
/* Вернуть индекс лексемы в массиве встроенных */ return (findString (builtlns, token));
}
^'к'к’к'к'к'к'к'к'к’к'к'к'к’к'к'к'к’к-к’к'к'к-к’к'к’к-к-к-к'к'к'к'к-к-к^ск'к-к'к-к-к'к-к’к'к'к-ктк-к'к-к'к-к^-к-к^^'к'к’к-к'к^
builtln (token) »
char* token;
{
/* Вернуть истину, если лексема встроенная */ return (builtlnCode (token) != NOT_FOUND);
}
**★★****★*★★****★***★★********★****★*★**★*****★★*★**★***********/
executeBuiltln (p)
struct simple* p;
{
/* Выполнить отдельную встроенную команду */ switch (builtlnCode (p->token[0]))
{
case CD: executeCd (p); break;
case ECHO BUILTIN:
648 executeEcho (р);
649 break;
650
651 case GETENV:
652 executeGetenv (p);
653 break;
654
655 case SETENV:
656 executeSetenv (p);
657 break;
658 }
659 }
660
g /******Jr********* + **^**** + ^ik****** + ****************** + + ***** + **i*/
662
663 executeEcho (p)
664
665 struct simple* p;
666
667 {
668 int i;
669
670 /* Вывести лексемы в этой команде */
671 for (i = 1; i < p->count; i++)
672 printf ("%s "> p->token[i]);
673
674 printf ("\n");
675 }
676
677 у****************************************************************/
678
679 executeGetenv (p)
680
681 struct simple* p;
682
683 {
684 char* valuel-
ess
686 /* Вывести значение переменной окружения */
657
if (p->count != 2)
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
error ("Usage: getenv variable\n"); return;
value = getenv (p->token[1]);
if (value == NULL)
printf ("Environment variable is not currently set\n"); else
printf ("%s\n", value);
executeSetenv (p)
struct simple* p;
/* Установить значение переменной окружения */ if (p->count != 3)
error ("Usage: setenv variable value\n");
else
setenv (p->token[1], p->token[2]);
setenv (envName, newValue)
char* envName;
char* newValue;
int i = 0;
char newStr [MAX_STRING_LENGTH]; int len;
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
/* Установить переменную окружения envName на newValue */ sprintf (newStr, "%s=%s", envName, newValue);
len = strlen (envName) + 1;
while (environ[i] != NULL)
if (strncmp (environ[i], newStr, len) == 0) break; }
if (environ[i] == NULL) environ[i+1] = NULL;
environ[i] = (char*) malloc (strlen (newStr) + 1);
strcpy (environ[i], newStr);
}
executeCd (p)
struct simple* p;
{
/* Изменить каталог */
if (p->count != 2)
error ("Usage: cd path\n");
else if (chdir (p->token[1]) == -1) perror ("ish");
}
***★★★*★**★★★★*★*★★******★★*****★★★*★*★*★******★★★★★**★+**★*•*•*★* /
ПЕРЕАДРЕСАЦИЯ
********************************************★*******************/
redirect (p)
struct simple *p;
765
766
767
768
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
{
int mask; 767
/* Выполнить переадресацию ввода */
switch (p->inputRedirect)
{
case FILE_REDIRECT: /* Переадресовать от файла */
if (IdupFd (p->inputFile, O_RDONLY, STDIN)) return(FALSE); break;
case SERVER_REDIRECT: /* Переадресовать от сокета сервера */ if (!server (p->inputSocket, INPUT_SOCKET) ) return(FALSE); break;
case CLIENT_REDIRECT: /* Переадресовать от сокета клиента */
if (!client (p->inputSocket, INPUT_SOCKET)) return(FALSE); break;
}
/* Выполнить переадресацию вывода */ switch (p->outputRedirect)
{
case FILE—REDIRECT: /* Переадресовать в файл */
mask = O_CREAT | O_WRONLY | (p->append?O_AP.PEND:O_TRUNC) ; if (IdupFd (p->outputFile, mask, STDOUT)) return (FALSE); break;
case SERVER—REDIRECT: /* Переадресовать в сокет сервера^ */
if (1 server(p->outputSocket, OUTPUT_SOCKET)) return(FALSE); break;
case CLIENT—REDIRECT: /* Переадресовать в сокет клиента */
if (1 client(p->outputSocket, OUTPUT_SOCKET)) return(FALSE); break;
}
return (TRUE); /* Если я попал сюда, тогда все прошло хорошо */ }
**★★*★★*★★★*★★★★*****★****★******★ ***★***★★★*******•*★****!
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
dupFd (name, mask, stdFd)
char* name;
int mask, stdFd;
int fd;
/* Дублировать новый дескриптор файла поверх stdin/stdout */ fd = open (name, mask, DEFAULT_PERMISSION);
if (fd == -1)
{ .
error ("Cannot redirect\n");
return (FALSE);
dup2 (fd, stdFd);^Копировать по стандартному дескриптору файла */
close (fd);
/* Закрыть другой дескриптор */
return (TRUE);
УПРАВЛЕНИЕ СОКЕТОМ
internetAddress (name)
char* name;
/* Если имя содержит цифры, предположить, что это интернет-адрес */ return (strpbrk (name, "01234567890") != NULL);
****************************************************************/
socketRedirect (type)
844
845 int type;
846
847 {
848 return (type == SERVER_REDIRECT || type == CLIENT_REDIRECT);
849 }
850
/************************************************************/
852
853 getHostAndPort (str, name, port)
854
855 char *str, *name;
856 int* port;
857
858 {
859 char *tokl, *tok2;
860
861 /* Декодировать имя и номер порта из входной строки */
862 ’ /* формы ИМЯ.ПОРТ */
863 tokl = strtok (str, ".");
864 tok2 = strtok (NULL, ".");
865 if (tok2 == NULL) /* Имя отсутствует, тогда предположить локальный
хост */
866 {
867 strcpy (name, "") ;
868 sscanf (tokl, "%d", port);
869 }
870 else
871 {
872 strcpy (name, tokl);
873 sscanf (tok2, "%d", port);
874 }
875 }
876
g'y'y у************************************************************/
878
879 client (name, type)
880
881 char* name;
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902 ,
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
int type;
int clientFd, result, internet, domain, serverLen, port;
char hostName [100];
struct sockaddr_un serverUNIXAddress;
struct sockaddr_in serverINETAddress;
struct sockaddr* serverSockAddrPtr;
struct hostent* hostStruct;
struct in_addr* hostNode;
/* Открыть сокет клиента с указанным именем и типом */ internet = internetAddress (name); /* Интернет-сокет? */
domain = internet ? AF_INET : AF_UNIX; /* Выбрать домен */ /* Создать сокет клиента */ clientFd = socket (domain, SOCK_STREAM, DEFAULT_PROTOCOL);
if (clientFd == -1)
{
perror ("ish"); return (FALSE);
}
if (internet) /* Интернет-сокет */
getHostAndPort (name, hostName, &port); /* Получить имя, порт */ if (hostName [0] == NULL) gethostname (hostName, 100);
serverINETAddress. sin_family = AF_INET; /* Интернет */
hostStruct = gethostbyname (hostName); /* Найти хост */
if (hostStruct == NULL)
perror ("ish");
return (FALSE);
}
hostNode = (struct in_addr*) hostStruct->h_addr;
printf ("IP address = %s\n", inet_ntoa (*hostNode));
serverINETAddress.sin_addr = *hostNode; /*Установить IP-адрес */
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
serverINETAddress.sin_port = port; /* Установить порт */ serverSockAddrPtr = (struct sockaddr*) &serverINETAddress;
serverLen = sizeof (serverINETAddress);
else /* Домен сокет UNIX */
serverUNIXAddress.sun_family — AF_UNIX; /* Домен */ strcpy (serverUNIXAddress.sun_path, name); /* Имя файла */ ♦
serverSockAddrPtr = (struct sockaddr*) &serverUNIXAddress; serverLen = sizeof (serverUNIXAddress);
do /* Соединится с сервером */ (
result = connect (clientFd, serverSockAddrPtr, serverLen);
if (result == -1) sleep (SOCKET_SLEEP);/*Попробовать снова*/
while (result == -1);
/* Выполнить переадресацию */
if (type == OUTPUT_SOCKET) dup2 (clientFd, STDOUT);
if (/type == INPUT_SOCKET) dup2 (clientFd, STDIN);
close (clientFd);/*3акрыть оригинальный дискриптор файла клиента*/
return (TRUE);
}
у****************************************************************/
server (name, type)
char* name;
int type;
int serverFd, clientFd, serverLen, clientLen;
int domain, internet, port;
struct sockaddr un serverUNIXAddress;
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
struct sockaddr_un clientUNIXAddress;
struct sockaddr_in serverlNETAddress;
struct sockaddr_in clientINETAddress;
struct sockaddr* serverSockAddrPtr;
struct sockaddr* clientSockAddrPtr;
/★ Подготовить сокет сервера */
internet = internetAddress (name); /* Интернет? */
domain = internet ? AF_INe£ : AF_UNIX; /* Выбрать домен */
/* Создать сокет сервера */
serverFd = socket (domain, SOCK_STREAM, DEFAULT-PROTOCOL);
if (serverFd == -1)
{
perror ("ish");
return (FALSE);
}
if (internet) /* Интернет-сокет */
sscanf (name, "%d", &port); /* Получить номер порта */ /*'Заполнить поля адреса сокета сервера */ serverLen = sizeof (serverlNETAddress);
bzero ((char*) &serverlNETAddress, serverLen);
serverlNETAddress. sin_family = AF_INET; /* Домен */
serverlNETAddress.sin_addr.s_addr = htonl (INADDR_ANY); serverlNETAddress.sin_port = htons (port); /* Порт */ serverSockAddrPtr = (struct sockaddr*) &serverINETAddress;
}
else /* домен сокета UNIX */
serverUNIXAddress.sun_family = AF_UNIX; /* Домен */ strcpy (serverUNIXAddress.sun_path, name); /* Имя файла */ serverSockAddrPtr — (struct sockaddr*) &serverUNIXAddress; serverLen = sizeof (serverUNIXAddress);
unlink (name); /* Удалить сокет, если все готово */ }
/* Связаться с адресом сокета */
998 if (bind (serverFd, serverSockAddrPtr, serverLen) == -1)
999 {
1000 perror ("ish");
1001 return (FALSE);
1002 }
1003
1004 /* Установить максимальную длину очереди ожидающих соединений */
1005 if (listen (serverFd, DEFAULT_QUEUE_LENGTH) == -1)
1006 {
1007 perror ("ish");
1008 return (FALSE);
1009 }
1010
1011 if (internet) /* Интернет-сокет */
1012 {
1013 clientLen = sizeof (clientINETAddress);
1014 clientSockAddrPtr = (struct sockaddr*) &clientINETAddress;
1015 }
1016 else /* Домен сокета UNIX */
1017 {
1018 clientLen = sizeof (clientUNIXAddress);
1019 clientSockAddrPtr = (struct sockaddr*) &clientUNIXAddress;
1020 }
1021
1022 /* Принять соединение */
1023 clientFd = accept (serverFd, clientSockAddrPtr, sclientLen);
1024
1025 close (serverFd); /* Закрыть оригинальный сокет сервера */
1026
1027 if (clientFd == -1)
1028 {
1029 perror ("ish");
1030 return (FALSE);
1031 }
1032
1033 /* Выполнить переадресацию */
1034 if (type == OUTPUT_SOCKET) dup2 (clientFd, STDOUT);
1035 if (type == INPUT_SOCKET) dup2 (clientFd, STDIN);
1036 close (clientFd); /* Закрыть оригинальный сокет клиента */
1037
1038 return (TRUE);
1039 }
1040
Обзор главы
Перечень тем
В этой главе были описаны:
О общие запросы системы управления файлами;
□ системные вызовы для дублирования, завершения и отделения процессов;
□ ожидание родительским процессом своих "потомков";
□ термины "сирота” и "зомби";
□ процессы-нити;
□ перехват и игнорирование сигналов;
□ способ "убивать” процессы;
□ приостановка и возобновление процесса;
□ механизмы IPC: безымянные конвейеры, именованные конвейеры, разделяемая память и семафоры;
□ клиент-серверная парадигма;
□ сокеты домена UNIX и сокеты домена Интернета;
□ разработка и функционирование Internet shell.
Контрольные вопросы
1. Как можно выяснить, что достигнут конец файла?
2 цто такое "дискриптор файла"?
3. Каков самый быстрый способ перемещения на конец файла?
4. Опишите путь, которым shell осуществляет перенаправление ввода/вывода.
5. Что такое "осиротевший процесс"?
6. Чем задание, работающее в двух процессах, отличается от задания, работающего в двух нитях?
7. При каких обстоятельствах накапливаются зомби?
8. Как родитель может выяснять, каким образом "умерли" его "потомки"?
9. В чем различие между библиотечными процедурами execv () и execvp () ?
10. Почему имя системного вызова kill о не отражает его назначения?
11. Как можно защищать критический код?
12. Какова цель групп процесса?
13. Что происходит, когда писатель пробует переполнить конвейер?
14. Как можно создать именованный конвейер?
15. Опишите парадигму клиент-сервера.
16. Опишите стадии, которые клиент и сервер проходят, чтобы установить связь.
Упражнения
13.1. Напишите программу, которая ловит все посланные' ей сигналы и распечатывает сведения об этих сигналах. Затем пошлите команду kill -9 процессу. Как сигнал sigkill отличается от других сигналов? [Уровень: легкий.]
13.2. Напишите программу, которая берет единственный целочисленный аргумент п из командной строки и создает двоичное дерево процессов глубины п. Когда дерево создано, каждый процесс должен вывести фразу "I am process х" ("Я процесс х") и завершиться. Узлы дерева процесса должны перечисляться согласно обходу в ширину. Например, если пользователь вводит
$ tree 4 ... построить дерево глубиной 4.
то дерево процессов могло бы выглядеть подобно представленному на рис. 13.15.
Рис. 13.15. Дерево глубиной 4
Вывод был бы таким:
I am process 1
I am process 2
I am process 15
Удостоверьтесь, чтобы первоначальный родительский процесс не закончился, пока все его дочерние процессы не "умрут". Сделайте так, чтобы вы могли завершить родителя и его "потомков" со своего терминала нажатием комбинации клавиш <Ctrl>+<C>. [Уровень: средний.]
13.3. Напишите программу, которая создает кольцо из трех процессов, связанных конвейерами. Первый процесс должен предложить (prompt) пользователю ввести строку, а затем послать ее второму процессу. Второй процесс должен реверсировать (reverse) строку и передать ее третьему процессу. Третий процесс обязан конвертировать строку в прописные буквы (uppercase) и послать ее назад первому процессу. Когда первый процесс получит обработанную строку, он должен вывести (display) ее на терминал. Когда это сделано, все три процесса должны закончиться. Иллюстрация кольца процессов приведена на рис. 13.16.
Рис. 13.16. Кольцо процессов
Вот пример программы в действии: $ ring ...выполнить программу. Please enter a string: ole Processed string is: ELO $ _
[Уровень: средний.]
13.4. Перепишите упражнение 5.1, используя язык С. [Уровень: средний.]
13.5. Напишите программу, которая использует библиотечную процедуру setuido, чтобы разрешить пользователю получать доступ к файлу, к которому он обычно доступа не имел. [Уровень: средний.]
Проекты
1. Напишите набор программ для игры "Камень, ножницы, бумага", которые взаимодействуют и работают параллельно. В этой игре каждый из двух игроков тайно выбирает бумагу, ножницы или камень. Затем они показывают свой выбор. Арбитр решает, кто победил следующим образом:
• бумага побеждает камень (покрывая его);
• камень побеждает ножницы (затупляя их);
• ножницы побеждают бумагу (разрезая ее);
• совпадение выборов — ничья.
Победивший игрок получает очко. При ничьей очки не присуждаются. Ваша программа должна смоделировать такую игру, разрешая пользователю выбрать количество повторений, предоставляя возможность наблюдать за игрой и видеть заключительный счет. Вот пример игры:
$ play 3 ...играть три раза.
Paper, Scissors, Rock: 3 iterations
Player 1: ready
Player 2: ready
Go Players [1]
Player 1: Scissors
Player 2: Rock
Player 2 wins
Go Players [2]
Player 1: Paper
Player 2: Rock
Player 1 wins
Go Players [3]
Player 1: Paper
Player 2: Paper
Players draw.
Final score:
Player 1: 1
Player 2: 1
Players Draw
$
Вы должны написать три программы, которые работают следующим образом.
• Одна программа — главная, разветвляется и выполняет один процесс арбитра и два процесса игрока. Затем она ждет, когда все три закончатся. Главная программа должна проверять, что параметр командной строки, который определяет число повторений, — правильный, и должна передать число процессу арбитра в качестве параметра к библиотечной процедуре ехес ().
• Одна программа — программа-арбитр, играет роль сервера. Она должна подготовить сокет и ждать от обоих игроков для вывода строки "READY", означающей, что они готовы сделать выбор. Арбитр должен приказать каждому игроку сделать выбор, посылая им строку "GO". Их ответы читаются, а счет вычисляется и обновляется. Описанный процесс должен повторяться до тех пор, пока все партии не будут завершены. Тогда арбитр должен послать обоим игрокам строку "STOP", которая заставляет партии закончиться.
• Одна программа — программа-игрок, выполняет роль клиента. Она запускается дважды главной программой и должна стартовать, соединяясь с сокетом арбитра. Затем она должна послать сообщение "READY". Когда программа получает сообщение от арбитра "GO", игрок должен сделать выбор и передать его арбитру в качестве строки. Когда игрок получает строку "STOP", он должен "убить" себя.
Эти три программы будут, конечно, разделять некоторые функции. Создайте make-файл, который собирает отдельные общие функции и компонует с использующими их выполняемыми файлами. Не пренебрегайте посылать строки, зашифровывая их, как однобайтовые числа — это только часть проблемы. [Уровень: средний.]
2. Перепишите упражнение 1, используя безымянные конвейеры вместо сокетов. Какая программа проще для написания? Какая программа легче для понимания? [Уровень: средний.]
3. Перепишите упражнение 1, чтобы позволить игрокам находиться на различных интернет-машинах. Организуйте возможность запуска каждого компонента игры отдельно. [Уровень: высокий.]
...выполните эту команду на vanguard.
$ referee 5000 ...использовать локальный порт 5000.
...выполните эту команду на csservr2.
$ player vanguard.5000 ...игрок на удаленном порту.
...выполните эту команду на wotan.
$ player vanguard.5000 ...игрок на удаленном порту.
4. Internet shell готов для улучшений. Ниже приведен список особенностей, которые были бы перспективны для добавления.
• Возможность указывать интернет-адрес в формате A.B.C.D. Это фактически легко добавить, т. к. мой первый интернет-пример уже имеет эту способность. [Уровень: легкий.]
• Возможности управления заданиями, подобные командам shell fg, bg и jobs. [Уровень: средний.]
• Замещение имени файла, использующее *, ? и (). [Уровень: высокий.]
• Поддержка двунаправленных сокетов, которая соединяет каналы стандартного ввода и вывода, клавиатуры или указанного процесса с интер-нет-сокетом. Эта особенность позволила бы вам соединяться со стандартными услугами без помощи утилиты telnet. [Уровень: высокий.]
• Простой встроенный язык программирования. [Уровень: средний.]
• Способность обращаться к любому интернет-адресу символически. Например, было бы хорошо иметь возможность переадресации на vanguard.utdalIas.edu.3000. [Уровень: средний.]
Глава 14
UNIX изнутри
Мотивация
Операционная система UNIX — одна из лучших разработанных операционных систем своего времени. Многие из основных базовых концепций ОС, заложенных в UNIX, продолжают в некоторой форме использоваться и в настоящее время. Например, способ, которым UNIX разделяет ЦП среди конкурирующих процессов, применяется во многих операционных системах типа Microsoft Windows. Знание принципов работы системы может помочь в проектировании быстродействующих приложений UNIX. Например, сведения о структуре системы виртуальной памяти позволяют организовать структуры данных так, чтобы количество информации, передаваемой между главной и вторичной памятью, было минимизировано. В результате знание UNIX важно как источник полезной информации, которая поможет при проектировании других подобных систем, и как помощь при программировании быстродействующих приложений UNIX.
Предпосылки
Для изучения материала данной главы следует прочитать главу 13. Также поможет хорошее знание структур данных, указателей и связанных списков.
Задачи
В этой главе описываются используемые UNIX механизмы, предназначенные для поддержки процессов, управления памятью, ввода/вывода и файловой системы. Также объясняются главные структуры данных ядра и алгоритмы.
Изложение
Различные части UNIX системы описаны по очереди.
Общие сведения
Система UNIX — довольно сложная ОС, которая все больше и больше "обрастает" новыми возможностями. Чтобы хорошо в ней разбираться, необходимо разделить систему на поддающиеся управлению части и заняться изучением каждой части, используя многоуровневый подход. Следовательно, мы обсудим следующие темы:
□ основы ядра', системные вызовы и прерывания;
□ файловая система*, управление иерархией каталогов, обычными файлами, периферийными устройствами и сложной файловой системой;
□ управление процессами*, разделение ЦП и памяти процессами и реализация сигналов;
□ ввод/вывод*. организация доступа к файлам, специальное внимание уделено терминальному вводу/выводу.
□ взаимодействие процессов (IPC)*. механизмы, которые позволяют процессам связываться друг с другом, даже если они находятся на различных машинах.
Есть некоторые различия в способах, которыми проектировщики BSD и System V реализовали части перечисленных подсистем. Всякие существенные различия в подходе будет указаны.
Основы ядра
Ядро UNIX — это часть операционной системы UNIX, которая содержит код для:
□ разделения ЦП и ОЗУ между конкурирующими процессами;
□ обработки всех системных вызовов;
□ управления периферийными устройствами.
Ядро — программа, которая загружается с диска в ОЗУ, когда компьютер впервые включается. Оно всегда остается в ОЗУ и работает, пока система не выключена или не случится аварийный отказ. Хотя ядро написано главным образом на языке С, некоторые части, по причинам эффективности, запрограммированы на ассемблере. Пользовательские программы взаимодействуют с ядром через интерфейс системных вызовов.
Подсистемы ядра
Возможности ядра могут быть разделены на следующие подсистемы:
□ управления памятью;
□ управления процессами;
□ взаимодействия процессов (IPC);
□ ввода/вывода;
□ управления файлами.
Эти подсистемы взаимодействуют по четким иерархическим правилам.
Рис. 14.1 иллюстрирует иерархическое представление.
Рис. 14.1. Подсистемы UNIX
Процессы и файлы
Ядро (kernel) UNIX поддерживает концепции процессов и файлов. Процессы — это "живые формы", которые существуют в компьютере и принимают решения. Файлы — это контейнеры информации, которые подвержены чтению и записи. Кроме того, процессы могут взаимодействовать друг с другом, используя несколько различных типов механизмов межпроцессной связи, включая сигналы, конвейеры и сокеты (рис. 14.2).
Взаимодействие с ядром
Обрабатывающие возможности ядра доступны через интерфейс системных вызовов, а периферия (специальные файлы) связывается с ядром через аппаратные прерывания. Системные вызовы и аппаратные прерывания — это единственные способы, которыми внешний мир может взаимодействовать с ядром, как показано на рис. 14.3.
Рис. 14.2. Поддержка процессов и файлов в UNIX
I
Системные вызовы
Ядро
Прерывания аппаратуры
Внешнее устройство
Внешнее устройство
Внешнее устройство
Рис. 14.3. Взаимодействие с ядром
Так как системные вызовы и прерывания, очевидно, очень важны, начнем обсуждение структуры UNIX с описания каждого из этих механизмов.
Системные вызовы
Системные вызовы — это функциональный интерфейс программиста к ядру. Они представляют собой процедуры, которые находятся внутри ядра UNIX и поддерживают основные функции системы, подобно перечисленным в табл. 14.1. Системные вызовы могут быть сгруппированы в три главных категории, как показано на рис. 14.4.
Таблица 14.1. Общие системные вызовы UNIX
Системный вызов Описание
open() Открыть файл
close() Закрыть файл
read () /write () Выполнить ввод/вывод
kill О Послать сигнал
pipe() Создать конвейер
socket() Создать сокет
fork() Дублировать процесс
exec() Перекрыть процесс
exit() Завершить процесс
Рис. 14.4. Основные подсистемы системного вызова
Пользовательский режим и режим ядра
Ядро содержит несколько структур данных, которые являются существенными для функционирования системы, включая:
□ таблицу процессов, которая содержит один элемент для каждого процесса в системе;
□ таблицу открытых файлов, которая содержит, по меньшей мере, один элемент для каждого открытого файла в системе.
23 Зак. 786
Указанные структуры данных находятся в пространстве памяти ядра, защищенном от пользовательских процессов системой управления памяти, которая будет описана позже. Поэтому пользовательские процессы не могут случайно разрушить эти важные структуры данных ядра. Процедуры системных вызовов отличаются от обычных функций, потому что они могут, хотя и в тщательно контролируемой манере, непосредственно управлять структурами данных ядра.
Пользовательский процесс работает в специальном режиме машины, называемом пользовательским режимом. Этот режим предотвращает процесс от выполнения некоторых привилегированных машинных команд, включая те, которые позволили бы ему получать доступ к структурам данных ядра. Другой режим машины называется режимом ядра. Процесс в режиме ядра может выполнять любую машинную команду.
Единственный способ для пользовательского процесса войти в режим ядра состоит в том, чтобы выполнить системный вызов. Каждому системному вызову назначен кодовый номер, начиная с 1. Например, системному вызову open о может быть назначен кодовый номер 1, а системному вызову close о — кодовый номер 2. Когда процесс осуществляет системный вызов, С-библиотека времени выполнения системного вызова помещает параметры системного вызова и его кодовый номер в некоторые регистры машины, а затем выполняет команду trap. Команда trap переключает машину в режим ядра и использует кодовый номер системного вызова а в качестве индекса в таблице векторов системных вызовов, расположенной в младших адресах памяти ядра. Таблица векторов системных вызовов — это массив указателей на код ядра для каждого системного вызова.
Код, соответствующий индексированной функции, выполняется в режиме ядра, изменяя по мере необходимости структуры данных ядра, а затем исполняет специальную команду return, которая переключает машину назад в пользовательский режим и возвращается к коду пользовательского процесса. Когда я впервые изучал UNIX, то не понимал, почему был принят этот подход. Почему просто не используют клиент-серверную модель с серверным процессом ядра, который обслуживает системные вызовы от клиентских пользовательских процессов? Это позволило бы пользовательским процессам не выполнять непосредственно код ядра. Причина ясная и простая: скорость. В текущей архитектуре издержки обмена между процессами слишком велики, чтобы на практике сделать клиент-серверный подход приемлемым. Однако интересно обратить внимание, что некоторые из современных микроядерных систем принимают этот подход.
С точки зрения программиста, использование системного вызова удобно: вы вызываете С-функцию с допустимыми параметрами, и функция возвращает управление, когда заканчивает обработку. Если происходит ошибка, функция возвращает — 1, и устанавливается глобальная переменная errno, чтобы
указать причину ошибки. Рис. 14.5 содержит диаграмму, которая иллюстрирует поток управления во время системного вызова.
Пользовательский процесс
Пользовательский
result = open (7home/glass/file.txt", O_RDONLY)rn ► ... код
— ►open (char* name, int mode) { «Поместить параметры в регистры» «Выполнить команду trap, переключиться на код ядра и режим ►ядра» «Вернуть результаты системного вызова» } Библиотека С времени выполнени
Адрес в ядре closeQ
►Адрес в ядре ореп() —
Адрес в ядре write()
Таблица векторов системных вызовов
►Код ядра для ореп() { 1 «Манипулировать структурами данных ядра» «Вернуться к пользовательскому коду и режиму»
Рис. 14.5. Пользовательский режим и режим ядра
Код ядра системного вызова
Синхронная обработка против асинхронной
Когда процесс выполняет системный вызов, обычно он не может быть выгружен. Это означает, что планировщик не будет назначать ЦП другому процессу во время действия системного вызова. Однако некоторые системные вызовы требуют действий ввода/вывода от устройства, и эти действия могут потребовать определенное время для выполнения. Чтобы избежать простоя ЦП во время ожидания завершения операции ввода/вывода, ядро переводит ожидающий процесс в состояние сна и будит его снова только тогда, когда получит аппаратный сигнал прерывания о завершении вво-
да/вывода. Планировщик назначает ЦП не спящему процессу, а другим процессам, в то время как аппаратура обслуживает запрос ввода/вывода.
Интересный результат применения способа, каким UNIX обрабатывает системные вызовы read о и write о, заключается в том, что пользовательские процессы чувствуют синхронное выполнение системного вызова, несмотря на то, что ядро демонстрирует асинхронное поведение. Это рассогласование проиллюстрировано на рис. 14.6.
read ()
Процесс А
Процесс А спит
Возврат из read()
read ()
Процесс В
Процесс В спит Возврат из read()
Время >
Ядро
Аппаратные прерывания
Рис, 14.6, Синхронные и асинхронные события
Прерывания
Прерывание — это способ, которым аппаратные устройства уведомляют ядро, что им нужно выполнить определенную работу. Таким же образом, каким процессы конкурируют за время ЦП, аппаратные устройства конкурируют за обработку прерываний. Устройствам назначены приоритеты прерывания, базирующиеся на их относительной важности, как показано на рис. 14.7. Например, прерывание от системных часов, имеют более высокий приоритет, чем прерывания от клавиатуры.
Высший приоритет
Низший приоритет
Таблица векторов прерываний
О
1
2
3
4
Указатели на обработчики прерываний ядра
Рис. 14.7. Прерывания имеют приоритеты
Когда происходит прерывание, текущий процесс приостанавливается, а ядро выясняет источник прерывания. Далее ядро проверяет свою таблицу векторов прерываний, расположенную в младших адресах памяти ядра, и находит код, который обрабатывает прерывания. Затем выполняется код обработчика прерывания. Когда обработчик прерывания завершается, возобновляется текущий процесс. Обработка прерывания проиллюстрирована на рис. 14.8.
Текущим Приостановка ' Возобнавление
процесс ----------------------------------------------------------------------> Время
Обработчик |
• прерывания |
I клавиатуры
| Обработка прерывания .
« Выполнено
Прерывание клавиатуры
Рис. 14.8. Обработка прерывания
Прерывание прерываний
Обработка прерывания может быть также прервана! Если поступает прерывание более высокого приоритета, чем текущее, происходит последовательность событий, подобных нормальному процессу обработки прерываний, и
обработчик прерывания более низкого приоритета приостанавливается, пока обработчик прерывания более высокого приоритета не закончит обработку. Этот процесс показан на рис. 14.9.
Текущий процесс
Приостановка
Возобнавление
> Время
Обработчик 1
прерывания I
клавиатуры I
Приостановка Возобнавление ।
------------------------------—>1
I Обработчик * Выполнено
I прерывания '
| таймера I
I------------------
Выполнено
Прерывание клавиатуры
Прерывание таймера
Рис. 14.9. Прерывания могут прерываться
Если обрабатывается некоторое прерывание и происходит другое прерывание равного или более низкого приоритета, пришедшее прерывание игнорируется и отвергается, как показано на рис. 14.10. Обработчики прерываний поэтому созданы так, чтобы быть очень быстрыми, поскольку, чем быстрее они выполняются, тем меньше вероятность, что другое прерывание будет потеряно.
Рис. 14.10. Прерывания могут игнорироваться
Большинство машин имеют команды, которые позволяют программе игнорировать все прерывания ниже некоторого уровня приоритета.
Критические секции кода ядра защищают себя от прерываний, временно вызывая такие команды. Ниже приведен псевдокод, который делает только это:
Оапретить почти все прерывания самого высокого приоритета> <Войти в критическую секцию кода>
<Покинуть критическую секцию кода> восстановить все прерывания>
Позже в данной главе будет приведен способ, которым периферийные устройства обрабатывают прерывания ядра, чтобы осуществлять эффективный ввод/вывод.
Файловая система
UNIX использует файлы для долговременного хранения и ОЗУ для кратковременного хранения. Программы, данные и текст — все хранится в файлах, которые в свою очередь обычно находятся на жестких дисках, но могут также размещаться и в других средах, например, на магнитных лентах и дискетах. Файлы UNIX организованы в виде иерархии обозначений, известных как структура каталогов. Файлы, отмеченные этими обозначениями, могут иметь три вида:
□ обычные файлы, которые содержат последовательность байтов, которая соответствует коду или данным; к обычным файлам можно обратиться через стандартные системные вызовы ввода/вывода;
□ каталоги, которые хранятся на диске в специальном формате и формируют основу файловой системы; к каталогам можно обратиться только через системные вызовы, ориентированные на каталог;
□ специальные файлы, которые соответствуют периферийным устройствам, например, принтерам и дискам, и механизмам межпроцессной связи, ти
па конвейеров и сокетов; к специальным файлам можно обратиться через стандартные системные вызовы ввода/вывода.
Концептуально UNIX-файл — это линейная последовательность байтов. Ядро UNIX не поддерживает более высокие порядки структуры файла, типа записей или полей. Это будет очевидно, если вы рассмотрите системный вызов iseeko, который позволяет помещать указатель файла только в терминах смещения байтов. Старые операционные системы имели тенденцию поддерживать структуры записей, так что UNIX в этом отношении довольно необычна.
Давайте начнем наше изучение файловой системы UNIX с рассмотрения архитектуры наиболее общего аппаратного носителя файла — диска.
Архитектура диска
На рис. 14.11 представлена схема типичной архитектуры диска. Диск разбивается двумя способами: он ’разрезан" подобно пицце на области, называемые секторами, а они, в свою очередь, делятся на концентрические1 кольца, называемые дорожками. Индивидуальные области, ограниченные пересечением секторов и дорожек, называются блоками и формируют основную единицу хранения данных на диске. Типичный блок диска может хранить 4 Кбайт. Отдельная головка чтения/записи перемещается по неподвижной консоли, обращаясь к информации, т. к. диск вращается и его поверхность проходит под головкой. Специальный чип, называемый контроллером диска, перемещает головку чтения/записи в ответ на команды от драйвера дискового устройства, который является частью специального программного обеспечения, расположенного в ядре UNIX.
Рис. 14.11. Архитектура диска
1 Имеющие общий центр. — Ред.
Имеется несколько разновидностей этой простой архитектуры диска. Многие драйверы диска фактически предназначены для нескольких жестких дисков, скомпонованных один над другим, как показано на рис. 14.12. В этих системах совокупность дорожек с одним и тем же индексом называется цилиндром. В большинстве мультидисковых систем консоли диска связаны друг с другом так, что все головки чтения/записи ходят синхронно, подобно расческе, перемещающейся по волосам. Поэтому головки чтения/записи таких дисковых систем перемещаются через цилиндры устройства. Некоторые сложные дисковые драйверы имеют отдельно управляемые головки чтения/записи.
Одна головка на диск
Рис. 14.12. Мупьтидисковая архитектура
Замедление диска при Увеличение скорости
доступе передачи на внешних
к внешним дорожкам добавочные блоки Дорожках
на внешних дорожках
Уменьшение скорости передачи на внутренних дорожках
Ускорение диска при доступе к внутренним дорожкам
Рис. 14.13. Техника хранения данных на диске
Заметьте, что блоки на внешней дорожке больше, чем блоки на внутренней дорожке из-за способа, которым разделен диск. Если диск всегда вращается с одной и той же скоростью, то плотность данных относительно внешних блоков диска меньше, чем она могла быть. Таким образом, теряется потенциальная возможность для хранения данных. Некоторые из самых последних разработок драйверов диска пытаются поддержать плотность данных постоянной на всей поверхности диска путем увеличения числа блоков на внешних дорожках и замедления вращения диска или увеличения скорости передачи данных, когда головка перемещается к внешней стороне диска. Техника хранения данных на диске представлена на рис. 14.13.
Чередование
Когда читается последовательность пронумерованных подряд блоков, существует задержка чтения между блоками из-за накладных расходов на связь между диспетчером диска и драйвером устройства2. Поэтому смежные3 блоки логически размещаются на поверхности диска так, чтобы ликвидировать задержку. В этом случае головка находится над необходимой областью. Расстояние между блоками из-за этой задержки называется коэффициентом чередования. Рис. 14.14 демонстрирует два различных коэффициента чередования.
Чередование 1:1
Рис. 14.14. Чередование диска
Чередование 3:1
Хранение файла
Допустим, размер блока равен 4 Кбайт, отдельный UNIX-файл размером 9 Кбайт требует трех блоков хранения: один, чтобы хранить первые 4 Кбайт,
2 Иными словами, пока осуществляется попытка чтения очередного блока, диск поворачивается и под головкой оказывается совсем не тот блок, что нужен. — Ред.
3 То есть, пронумерованные подряд. — Ред.
один, чтобы хранить следующие 4 Кбайт, и последний, чтобы хранить оставшийся 1 Кбайт4. Потеря дискового пространства из-за использования не до конца последнего блока в 4 Кбайт называется фрагментацией. Блоки файла редко расположены рядом и, как правило, разбросаны по всему пространству диска, как показано на рис. 14.15.
Логический файл (9 Кбайт)
Рис. 14.15. Блоки файла разбросаны
Блочный ввод/вывод
Ввод/вывод всегда делается в терминах блоков. Если производится системный вызов read () для чтения первого байта данных из файла, драйвер устройства делает запрос ввода/вывода к диспетчеру диска, чтобы прочитать первый блок из 4 Кбайт в буфер ядра, а затем копирует первый байт из буфера в ваш процесс. (Дополнительная информации о буферизации ввода/вывода представлена позже в данной главе.)
Большинство контроллеров диска обслуживают запрос на один блок ввода/вывода за один раз. Когда контроллер диска заканчивает текущий запрос на ввод/вывод блока, он порождает аппаратное прерывание к драйверу устройства, чтобы сигнализировать, что текущий ввод/вывод завершен. В этом месте драйвер устройства обычно делает следующий запрос ввода/вывода блока. На рис. 14.16 представлена диаграмма, иллюстри
4 Некоторые файловые системы исправляют эту ситуацию, имея блок диска, содержащий последний элемент данных в файле. Таким образом, один блок диска может содержать фрагменты нескольких файлов.
рующая последовательность событий, которые могли бы происходить во время чтения 9 Кбайт.
П ол ьзовател ьски й
процесс read(fd, buf, 9216) Приостановка read() выполнен
Рис, 14.16. Блочный ввод/вывод
Индексный дескриптор или inode
Чтобы хранить информацию о каждом файле, UNIX использует структуру, называемую inode (от англ, index node — узел индекса) или индексным дескриптором. Inode обычного файла или каталога содержит сведения о размещении их блоков на диске, a inode специального файла — информацию, которая позволяет идентифицировать периферийное устройство. Индексный дескриптор также хранит другую информацию, связанную с файлом, например, его флаги полномочий, владельца, группу и последнее время модификации. Inode имеет фиксированный размер и содержит указатели на блоки диска; также как и дополнительные косвенные указатели (для больших файлов). Каждому inode в конкретной файловой системе назначен уникальный номер, и каждый файл имеет точно один inode (рис. 14.17).
Все inode, связанные с файлами на диске, хранятся в специальной области в начале диска, называемой списком inode.
Inode
Рис. 14.17. Каждый файл имеет inode
Содержимое inode
Внутри каждого inode содержится следующая информация о файле:
□ тип файла: обычный, каталог, специальный блочный, специальный символьный и т. д.;
□ полномочия файла;
П ID владельца и ID группы;
□ счетчик жестких связей (описанный позже в главе);
□ последнее время модификации и последнее время доступа;
□ сведения о размещении блоков для обычного файла или каталога;
□ старший и младший номера устройства, если это специальный файл;
□ значение символической связи, если это символическая связь.
Другими словами, inode содержит всю информацию, которую вы видите, когда исполняете команду 1s -1, исключая имя файла.
Карта блоков
Только сведения о размещении первых 10 блоков файла хранятся непосредственно в inode. Большинство UNIX-файлов имеют размер меньше 40 Кбайт, так что этого достаточно в большинстве случаев. Для адресации больших файлов используется косвенная схема доступа. В этой схеме отдельный пользовательский блок предназначен для хранения данных о расположении до 1024 пользовательских блоков. Когда блок используется этим способом, он называется косвенным (рис. 14.18). Его местоположение хранится в inode и применяется для адресации следующих 1024 блоков. Такой подход позволяет адресовать файлы до 4 Мбайт.
Inode
Блоки диска
Рис. 14.18. Отдельный косвенный блок
Для файлов больше 4 Мбайт используется двойная косвенная схема доступа. При этом пользовательский блок служит для хранения сведений о расположении до 1024 других косвенных блоков, каждый из которых указывает максимум на 1024 пользовательских блока (рис. 14.19). Inode хранит местоположение двойного косвенного блока.
Inode
Блоки диска
Рис. 14.19. Двойной косвенный блок
Обратите внимание, когда файл становится больше, увеличивается количество косвенных ссылок, требуемое для получения доступа к конкретному блоку. Эти издержки минимизируются путем буферизации содержимого inode и содержимого ссылающихся косвенных блоков в ОЗУ. Механизм буферизации описан позже в данной главе.
Размещение файловой системы
Первый логический блок диска назван загрузочным блоком и содержит неко-торый исполняемый код, который используется при загрузке UNIX в первый раз. (Для дополнительной информации см. главу 15.) Второй логический блок известен как суперблок и содержит информацию непосредственно о диске. После него следует набор блоков фиксированного размера, называемых списком inode, который хранит все индексные дескрипторы, связанные с файлами на диске.
Каждый блок в списке inode обычно может хранить приблизительно 40 индексных дескрипторов (хотя это изменяется в различных версиях UNIX). Оставшиеся блоки на диске доступны для размещения блоков файла и содержат как каталоги, так и пользовательские файлы. Расположение блоков диска показано на рис. 14.20.
Физическая
компоновка диска
О
1
2
3
4
200
202
Загрузочный блок Суперблок Inodes 1—40 Inodes 41—80 Inodes 81—120
Пользовательский блок
Пользовательский блок
Пользовательский блок
Пользовательские блоки
Блоки содержат inodes, которые описывают файлы
20000
Ползовательский блок
Рис. 14.20. Использование блоков диска
Суперблок
Суперблок содержит информацию, имеющую отношение ко всей файловой системе. Он включает битовый массив свободных блоков, как показано на рис. 14.21. Битовый массив — это линейная последовательность битов, один на блок диска. Значение 1 указывает, что соответствующий блок свободен, а значение 0 — используется.
Суперблок содержит следующую информацию:
□ общее число блоков в файловой системе;
П количество индексных дескрипторов в списке свободных inode;
□ размер блока в байтах;
П количество свободных блоков;
□ количество используемых блоков.
Битовый массив
Рис. 14.21. Битовый массив свободных и занятых блоков
Bad-блоки
Диск всегда содержит несколько блоков, которые по той или другой причине непригодны для использования. Утилита, которая создает новую файловую систему, описанная в главе 15, также создает отдельный файл "наихудшего кошмара", составленный из всех плохих блоков на диске; и записывает местоположение всех этих блоков в inode с номером 1. Что предотвращает выделение этих блоков другим файлам.
Каталоги
Inode с номером 2 содержит сведения о размещении блоков, хранящих корневой каталог. Каталог UNIX содержит список связей между именем файла и номером inode. Когда создается каталог, в нем автоматически назначаются элементы для ".." (его родительского каталога) и "." (самого каталога). Поскольку пара <имя файла, номер inode> эффективно связывает имя с файлом, эти связи названы жесткими связями. Поскольку имена файлов хранятся в блоке каталога, они не хранятся в inode файла. Фактически не имело никакого смысла хранить имя в inode, поскольку файл может иметь больше, чем одно имя. Соответственно, правильнее рассматривать иерархию каталогов как иерархию обозначений файлов, а не иерархию файлов.
Все версии UNIX позволяют имени файла иметь, по крайней мере, длину 14 символов, а большинство поддерживает имя длиной до 255 символов. На рис. 14.22 приведена иллюстрация корневого inode, соответствующего обычному корневому каталогу. Номера inode, связанные с каждым именем файла, обозначены нижними индексами.
Inode для корневого каталога (номер 2)
Жесткая связь
Рис. 14.22. Корневой каталог связан с inode 2
Преобразование путевых имен в номера inode
Системные вызовы типа open () должны получить inode файла из его путевого имени. Они выполняют преобразование следующим образом:
1. Определяется inode, с которого следует начинать поиск путевого имени. Если путевое имя является абсолютным, поиск начинается с inode 2. Если путевое имя относительное, поиск начинается с inode, соответствующего текущему рабочему каталогу процесса. (Для дополнительной информации см. разд. "Управление процессами" далее в этой главе.)
2. Компоненты путевого имени обрабатываются слева направо. Каждый компонент кроме последнего должен соответствовать либо каталогу, либо символической связи. Будем называть inode, с которого начинается поиск путевого имени, текущим inode.
3. Если текущий inode соответствует каталогу, производится поиск текущего компонента путевого имени в каталоге, соответствующем текущему inode. Если он не найден, возникает ошибка; иначе значение текущего номера inode становится номером inode, связанным с компонентом путевого имени, который был обнаружен.
4. Если текущий inode соответствует символической связи, то путевое имя до текущего компонента пути и сам компонент заменяются содержимым символической связи, и путевое имя повторно обрабатывается.
5. Inode, соответствующий заключительному компоненту путевого имени, является индексным дескриптором файла, упомянутого полным путевым именем.
Пример преобразования путевого имени в inode
Чтобы проиллюстрировать алгоритм, представленный в предыдущем разделе, опишем шаги, необходимые для перевода путевого имени /usr/test.c в номер inode.
Номер inode
1
Номер блока
Номер блока Полномочия
200 dr-xr-xr-x
201 dr-xr-xr-x
202 dr-xr-xr-x
203 -r-xr-xr-x
204, 206 -rwxr-xr-x
205 -r-xr-xr-x
2
usr
201
Is
ср
202
test.c
> 203
2
3
4
3
2
4
5
2
Дескриптор Bad-блоков Корневой дескриптор
Is выполняемый
Определенный номер inode
Иерархия
> 204
> 205
> 206
teste, первый блок
ср выполняемый
teste, второй блок
usr4
bin3
ср7
test.c6
2
3
4
5
6
8
> 200
. bin
Рис. 14.23 содержит схему, которая иллюстрирует процесс перевода. На ней путь перевода обозначен жирными линиями, а цель обведена кружком.
Вот логика, которую использует ядро:
1. Путевое имя абсолютно, таким образом, текущий номер inode равен 2.
2. В каталоге, соответствующем inode 2, происходит поиск компонента путевого имени usr. Соответствующий элемент найден, и текущий номер inode устанавливается на 4.
3. В каталоге, соответствующем inode 4, выполняется поиск компонента путевого имени test.c. Соответствующий элемент найден, и текущий номер inode устанавливается на 6.
4. test.c — заключительный компонент путевого имени, так что алгоритм возвращает номер inode 6.
Как вы можете видеть, происходят перемещения при переводе между inode и блоками каталога, пока путевое имя не будет полностью обработано.
Монтирование файловых систем
Когда UNIX стартует, иерархия каталогов соответствует файловой системе,, расположенной на единственном диске, называемом корневым устройством. UNIX позволяет создать файловые системы на других устройствах и подключить их к первоначальной иерархии каталогов с помощью механизма, называемого монтированием. Утилита mount позволяет привилегированному пользователю (root) встроить корневой каталог файловой системы в существующую иерархию каталогов. Как правило, иерархия большой UNIX-системы распределена по многим устройствам, каждое содержит поддерево полной иерархии. Например, поддерево /usr обычно хранится на устройстве, отличном от корневого устройства. Некорневые файловые системы обычно автоматически монтируются во время загрузки. (Для дополнительной информации см. главу 15.) Например, предположим, что файловая система хранится на устройстве /dev/flp дискеты. Для подключения ее к каталогу /mnt главной иерархии можно выполнить команду $ mount /dev/flp /mnt
На рис. 14.24 проиллюстрирован эффект работы этой команды.
Файловые системы могут быть отделены от главной иерархии при помощи утилиты umount. Команды
$ umount /dev/flp
ИЛИ
$ umount /mnt
отключили бы файловую систему, хранящуюся на /dev/flp.
После монтирования
/
Перед монтированием
Сращивание
Рис. 14.24. Монтирование каталогов
bin usr mnt
tmp1 tmp2
Система ввода/вывода файлов
Чтобы узнать подробности о реализации в ядре системы ввода/вывода файлов, см. разд. "Ввод/Вывод" далее в этой главе.
Управление процессами
В этом разделе описывается способ, которым ядро разделяет ЦП и ОЗУ между конкурирующими процессами. Область ядра, которая разделяет ЦП, называется планировщиком, а область ядра, разделяющая ОЗУ, называется менеджером памяти. Раздел также содержит информацию об ориентированных на процесс системных вызовах, включая ехес о, fork о и exit о. Ради простоты не будем интересоваться нитями ядра (нити, которые работают в режиме ядра), т. к. большинство программистов, создающих приложения, не имеют никакой возможности их использовать. Однако следует знать, что так же как пользовательское приложение может выполнять многопоточные задачи, некоторые модули ядра (подобно драйверам устройств) могут выполняться многопоточно.
Исполняемые файлы
Когда исходный код программы компилируется, он сохраняется в специальном формате на диске. Первые несколько байтов файла известны как волшебное число (magic number) и используются ядром, чтобы идентифицировать тип исполняемого файла. Например, если первые два байта файла — символы ядро идентифицирует исполняемый файл, как содержащий текст shell, и вызывает shell, чтобы выполнить этот текст. Другая последова
тельность идентифицирует файл, как правильный загружаемый образ, содержащий машинный код и данные. Этот вид файла разделяется на несколько секций, содержащих код или данные, с отдельной секцией заголовка для каждой секции. Заголовки используются ядром для подготовки системы управления памятью. На рис. 14.25 приведена иллюстрация типичного исполняемого файла.
Главный заголовок, включая волшебное число
Заголовок первой секции
Заголовок второй секции
Секция 1
Секция 2
Рис. 14.25. Компоновка выполняемого файла
Первые процессы
UNIX выполняет программу, создавая процесс и связывая его с исполняемым файлом. Достаточно неожиданно, но нет никакого системного вызова, который предписывает "создать новый процесс, чтобы выполнить программу X". Вместо этого следует продублировать существующий процесс, а затем связать недавно созданный дочерний процесс с исполняемым файлом X.
Первый процесс с ID процесса (PID), равным 0, создается UNIX во время загрузки. Этот процесс немедленно дважды выполняет системные вызовы fork () и ехес (), создавая два процесса с PID 1 и 2. В System V UNIX имена этих нескольких первых процессов подобны показанным на в табл. 14.2. Назначение этих процессов будет описано позже в данной главе. Остальные процессы в системе — это потомки процесса init. (Для дополнительной информации о последовательности загрузки см. главу 15.)
Таблица 14.2. Первые процессы, стартующие в системе UNIX
PID Имя
0 sched
1 init
2 pageout
Процессы ядра
и пользовательские процессы
Большинство процессов работают в пользовательском режиме, за исключением осуществления ими системных вызовов, когда они временно переключаются в режим ядра. Однако процессы-демоны sched (PID 0) и pageout (PID 2) из-за их важности выполняются постоянно в режиме ядра и называются процессами ядра. В отличие от пользовательских процессов их код связан непосредственно с ядром и не находится в отдельном исполняемом файле. Кроме того, процессы ядра никогда не выгружаются.
Иерархия процессов
Когда процесс дублируется, используя системный вызов fork(), первоначальный процесс известен, как родитель дочернего процесса, init (PID 1) является процессом, от которого происходят все пользовательские процессы. Поэтому родительские и дочерние процессы связаны в иерархии с процессом init, находящимся в корне. Рис. 14.26 иллюстрирует иерархию процессов, включающую четыре процесса.
Процесс 1
fork()/exec() fork()/exec()
I I
Процесс 48
Процесс 12
fork()/exec()
Процесс 34
Рис. 14.26. Иерархия процессов
Состояния процесса
Каждый процесс в системе может находиться в одном из шести состояний:
□ работающий (running), т. е. процесс в настоящее время использует ЦП;
□ готовый (runnable), т. е. процесс может использовать ЦП, как только ЦП становится доступным;
□ спящий (sleeping), т. е. процесс ожидает, чтобы произошло событие; например, если процесс выполняет системный вызов read (), он спит, пока не закончится запрос ввода/вывода;
□ приостановленный (suspended), т. е. процесс был "заморожен" сигналом типа sigstop. Он возобновится, лишь когда будет послан сигнал sigcont. Например, нажатие комбинации клавиш <Ctrl>+<Z> приостанавливает все приоритетные процессы;
□ ожидающий (idle), т. е. процесс создается при помощи системного вызова fork () и еще не является готовым;
□ зомбированный (zonibified), т. е. процесс закончился, но еще не вернул код возврата своему родителю. Процесс остается зомби, пока его родитель не примет код возврата через системный вызов wait о .
На рис. 14.27 приведена диаграмма, иллюстрирующая возможные изменения состояния, которые могут происходить во время жизни процесса.
Рис. 14.27. Состояния процесса
Состав процесса
Каждый процесс составлен из нескольких различных частей:
□ область кода (code area) содержит исполняемую (текстовую) порцию процесса;
□ область данных (data area) используется, чтобы хранить статические данные;
□ область стека (stack area) служит для хранения временных данных;
□ область пользователя (user area) хранит вспомогательную информацию о процессе;
□ таблицы страниц (page tables) предназначены для системы управления памятью.
Использование первых трех областей должно быть знакомо читателю. Таблицы страниц будут обсуждаться позже. Следующий раздел содержит описание пользовательской области. Состав процесса показан на рис. 14.28.
Рис. 14.28. Состав процесса
Область пользователя
Каждый процесс в системе имеет некоторую ассоциированную с ним "вспомогательную" информацию, которая используется ядром для управления процессом. Эта информация хранится в структуре данных, называемой областью пользователя. Каждый процесс имеет свою собственную область
пользователя, которая создана в области данных ядра и доступна только ядру. Пользовательские процессы не могут получить доступ к их пользовательским областям. Поля в области пользователя процесса хранят запись:
□ о том, как процесс должен реагировать на каждый вид сигнала;
□ об открытых дескрипторах файла процесса;
□ о том, сколько времени ЦП процесс недавно использовал.
Содержание области пользователя более подробно описано позже в данной главе.
Таблица процессов
Существует отдельная структура данных ядра фиксированного размера, называемая таблицей процессов, которая содержит один элемент для каждого процесса в системе.
Таблица процессов
Рис. 14.29. Таблица процессов
Таблица процессов создается в области данных ядра и доступна только ядру. Ее элемент содержит следующую информацию о каждом процессе:
□ ID процесса (PID) и ID родительского процесса (PPID);
□ реальный и эффективный пользовательский ID (UID) и ID группы (GID);
□ состояние процесса (работающий, готовый, спящий, приостановленный, ожидающий или зомби);
□ местоположение кода, данных, стека и областей пользователя;
□ список всех ожидаемых сигналов.
На рис. 14.29 приведена таблица процессов, которая возникла бы из маленькой иерархии процессов, представленных на рис. 14.26. Она предполагает, что процесс с PID 48 в настоящее время ожидает завершения ввода/ вывода.
Планировщик
Ядро ответственно за разделение времени ЦП среди конкурирующих процессов. Секция кода ядра, называемая планировщиком, выполняет эту обязанность и поддерживает специальную структуру данных, называемую очередью многоуровневых приоритетов, которая позволяет ему эффективно планировать процессы. Очередь приоритетов — это связанный список готовых процессов, которые имеют одинаковые приоритеты. Способ, которым ядро вычисляет приоритет процесса, обсуждается позже.
Время ЦП выделяется процессам пропорционально их важности и измеряется в единицах фиксированного размера, называемых квантом времени (time quanta). В большинстве систем каждый временной квант равен 1/10 секунды. Рис. 14.30 иллюстрирует очереди совместно с таблицей процессов, основанной на маленькой иерархии процессов, которая приведена на рис. 14.26.
Таблица процессов
Рис. 14.30. Таблица процессов и очереди приоритетов
Правила планирования
Ниже приведены правила, которые описывают способ работы планировщика.
□ Каждую секунду планировщик вычисляет приоритеты всех готовых процессов в системе и объединяет их в несколько очередей приоритета. Очереди формируются на основе значения приоритета процесса.
□ Каждую 1/10 секунды планировщик выбирает процесс самого высокого приоритета в очередях приоритета и выделяет ему ЦП (если в настоящее время работающий процесс не находится в режиме ядра).
□ Если процесс все еще готов и находится в конце своего кванта времени, он помещается в конце своей очереди приоритета.
□ Если процесс засыпает в течение своего кванта времени, планировщик немедленно выбирает другой процесс для выполнения и выделяет ему ЦП.
□ Если процесс возвращается из системного вызова во время его кванта и процесс более высокого приоритета готов работать, процесс более низкого приоритета выталкивается процессом более высокого приоритета.
□ При каждом аппаратном прерывании таймера (которое обычно происходит 100 раз в секунду) увеличивается счетчик импульсов времени процесса. Каждый четвертый импульс планировщик повторно вычисляет значение приоритета процесса. Он стремится уменьшить приоритет процесса во время его кванта.
Формула для вычисления приоритета процесса может быть приблизительно сформирована следующим образом:
Приоритет = (Последнее_исполъзование_ЦП) / константа + + (Базовый-Приоритет) + (Точная_установка),
где Базовый-Приоритет — это пороговый приоритет, а Точная_установка — это значение, устанавливаемое системным вызовом nice (). Данная формула обеспечивает уменьшение приоритета процесса, если он использует много времени ЦП в конкретном "окне" времени. Это также гарантирует, что процессы, имеющие высокую Точную-установку, будут иметь более низкий приоритет. Последствие формулы заключаются в том, что диалоговые процессы будут иметь хорошее время ответа: Так как диалоговый процесс ждет нажатия клавиши пользователем, он не использует время ЦП, и поэтому его уровень приоритета быстро повышается.
Акт переключения с одного процесса на другой назван переключением контекста (context switch). Чтобы "заморозить" процесс, ядро сохраняет счетчик программы, указатель стека и другие важные детали процесса в области пользователя процесса. Чтобы "разморозить" процесс, ядро восстанавливает информацию из указанной области.
В результате соблюдения перечисленных выше правил каждую секунду ЦП выделяется циклическим методом процессам из непустой очереди с самым высоким приоритетом. В конце каждой секунды процессы повторно помещаются в очереди в зависимости от их новых приоритетов, й циклическое назначение повторяется. На рис. 14.31—14.33 представлены некоторые иллюстрации правил планирования.
Работает кажую секунду
——|
Пересчитывает приоритеты всех процессов
Рис. 14.31. Каждую секунду
Работает каждую 1/10 секунды
I
Выделяет процесс с наивысшим приоритетом в рабочей очереди
1
Выполняет его, пока что-нибудь не станет истинным:
1. Конец временного кванта.
2. Он засыпает.
3. Он возвращается из системного вызова и процесс высшего приоритета готов выполняться.
I
Если процесс остается готовым, поместить в конец его рабочей очереди
Работает каждый импульс таймера
I
Добавить единицу к счетчику импульсов таймера процесса
Пересчитать приоритет текущего процесса, если накопилось четыре импульса таймера
Рис. 14.33. Каждый импульс таймера
Управление памятью
В дополнение к управлению планированием ядро отвечает за разделение ОЗУ между процессами безопасным и эффективным способом. Следующие немногие разделы описывают систему управления памятью UNIX.5
Страницы памяти
Система управления памятью UNIX позволяет выполняться процессам, которые больше полной емкости ОЗУ системы. Чтобы достичь этого, она делит области ОЗУ, кода, данных и стека на куски памяти фиксированного размера, называемые страницами (pages), аналогично способу, каким диск разделен на блоки фиксированного размера. Размер страницы памяти обычно устанавливается равным размеру блока диска. Причина этого соотношения скоро станет очевидной. Только страницы процесса, к которым в настоящее время обращаются или обращались недавно, хранятся в страницах ОЗУ; остальное размещается на диске.
Таблицы страниц и области
Области кода, данных и стека процесса не должны находиться в логически смежной памяти. Например, компилятор мог бы сгенерировать программу,
5 Реализация управления памятью UNIX изменяется от версии к версии. Алгоритм, описанный здесь, ориентирован на BSD.
чей код, данные и стек занимают логические области адресного пространст-
ва, приведенного в табл. 14.3.
Таблица 14.3. Пример компоновки памяти
Область Логический адрес
Код 0—15 Кбайт
Данные 64—72 Кбайт
Стек 64—72 Кбайт
Таблица страниц кода
Таблица процессов
Область
пользователя
Таблица областей
На таблицу / страниц кода
На таблицу страниц данных
На таблицу страниц стека \
Другая информация процесса
Текущий каталог, значение umask, ожидающие сигналы, управляющий терминал и т. д.
Таблица страниц стека
К страницам кода в ОЗУ/диске
Таблица страниц данных
К страницам данных в ОЗУ/диске
* К страницам стека
в ОЗУ/диске
Рис. 14.34. Область пользователя, таблицы областей и страниц
Каждая часть смежного логического адресного пространства называется областью (region); поэтому большинство процессов имеет три области. Страницы областей не должны храниться в ОЗУ рядом. Каждая область имеет связанную структуру данных, называемую таблицей страниц, которая хранит
сведения о размещении каждой из ее страниц. Таблицы страниц процесса объединяются в области данных ядра и доступны только ядру. Местоположения таблиц страниц процесса хранятся в области пользователя процесса. Таблица страниц в системе управления памятью аналогична inode в файловой системе, т. к. каждый из них отслеживает местоположение индивидуальных единиц хранения.
Рис. 14.34 иллюстрирует таблицу процессов, область пользователя и таблицы страниц.
Таблица ОЗУ
Менеджер памяти выделяет страницы ОЗУ процессу, только когда они ему необходимы. Единственная фиксированного размера структура данных ядра, называемая таблицей ОЗУ (RAM table), записывает информацию о каждой странице ОЗУ, например, используется ли страница в настоящее время и заблокирована ли она в памяти. Заблокированные страницы никогда не перемещаются на диск; например, все страницы, которые содержат ядро UNIX, заблокированы.
Загрузка исполняемого файла: ехес()
Когда процесс выполняет ехес (), ядро выделяет таблицы страниц для областей кода, данных и стека процесса. В этот момент весь код и инициализированные данные находятся на диске в исполняемом файле, поэтому элементы таблицы страниц данных и кода установлены так, что содержат сведения о расположении их соответствующих блоков диска.
Эти сведения извлекаются из inode и заголовка исполняемого файла. Когда процесс впервые получает доступ к одной из страниц, его соответствующий блок копируется с диска в ОЗУ, и элемент таблицы страниц обновляется физическим номером страницы ОЗУ.
Стек и неинициализированные области данных не имеют соответствующего места на диске. Поэтому ядро помечает их элементы таблицы страниц, как zeroed (пусто). Когда к zeroed-странице обращаются впервые, ядро выделяет страницу ОЗУ и заполняет ее нулями без загрузки чего-нибудь с диска. Оно затем обновляет элемент таблицы страниц физическим номером страницы ОЗУ.
Предположим, что первые восемь страниц ОЗУ были первоначально свободны. На рис. 14.35 приведена иллюстрация расположения памяти процесса Сразу ПОСЛе ВЫПОЛНеНИЯ ехес ().
Номер Диск
Таблица блока
Рис. 14.35. Схема памяти сразу после выполнения ехес ()
Список свободных блоков
Преобразование адреса
Все логические адреса, которые перемещаются по аппаратной шине адреса из процесса, должны быть отображены в физический адрес на основе информации, содержащейся в таблице страниц и областей процесса.
Этому переводу (трансляции) помогает специальная часть аппаратуры, называемая устройством управления памятью (memory management unit, MMU). Предположим, что каждая страница ОЗУ имеет размер 4 Кбайт, и все адреса являются 32-битовыми значениями. MMU работает следующим образом:
I. Когда процесс запланирован, в MMU устанавливаются несколько определенных аппаратных регистров, чтобы указать на область процесса и
24 Зак. 786
таблицы страниц. MMU использует эти регистры для доступа к структурам данных во время процесса перевода адреса.
2. Когда адрес появляется на аппаратной шине адреса, MMU активизируется и начинает процесс перевода. Будем называть поступающий адрес ADDR.
3. Затем MMU определяет, какой области принадлежит поступающий адрес ADDR — коду, данным или стеку.
4. Тогда MMU вычитает стартовый виртуальный адрес (SVA) области от поступающего адреса ADDR. В результате получается смещение поступающего адреса от начала области (OSR).
5. OSR разбивается на две части. Старшие 20 битов соответствуют номеру страницы региона (RPN) поступающего адреса, а младшие 12 битов равны смещению внутри страницы области (ORP).
6. Затем MMU обращается за справкой к таблице страниц области, чтобы определить текущее местоположение логической страницы RPN. Если в настоящее время страница находится в ОЗУ, поступающий логический адрес переводится в физический адрес, заменяя логический номер страницы физическим номером ОЗУ. Если страница не в ОЗУ, MMU не пытается переводить логический адрес, генерирует прерывание допустимости страницы и обрабатывает другие поступающие логические адреса.
7. Когда UNIX получает прерывание допустимости страницы, она генерирует запрос ввода/вывода, чтобы загрузить страницу с диска в свободную страницу ОЗУ. После загрузки соответствующий элемент таблицы страниц обновляется номером страницы ОЗУ, и перевод адреса начинается снова.
Иллюстрация алгоритма MMU
На рис. 14.36 приведена иллюстрация алгоритма отображения MMU.
MMU и таблица страниц
Каждый элемент таблицы страниц содержит множество полей, которые используются различными составляющими системы управления памятью. Некоторые из этих полей устанавливаются автоматически MMU при определенных обстоятельствах:
□ бит модификации (modified bit) устанавливается, когда процесс пишет страницу;
□ бит обращения (referenced bit) устанавливается, когда процесс читает из страница или пишет в нее.
Рис. 14.36. Упрощенный алгоритм управления памятью
Следующие дополнительные поля автоматически используются MMU при переводе поступающего логического адреса:
□ если бит применимости (valid bit) установлен, MMU заменяет логический номер страницы поступающего адреса полем физического номера страницы}
□ если бит применимости не установлен, MMU генерирует ошибку страницы;
□ если бит копирования при записи (сору-оп-write bit) установлен, и процесс пытается изменить страницу, MMU генерирует ошибку страницы независимо от состояния бита применимости.
Схема памяти после первой команды
Выполнение ехес о заставляет первую команду исполняемого файла быть выбранной из памяти, а команда, в свою очередь, предписывает MMU генерировать ошибку на первой странице. Адрес первой команды хранится в
заголовке исполняемого файла и, как правило, является младшим адресом памяти. В диаграмме, показанной на рис. 14.37, сделано предположение, что первая команда была расположена по логическому адресу 0, и страница О области кода переводится в физическую страницу О ОЗУ.
Таблица
Номер Диск блока
страниц кода
о
О
Область пользователя
Смещение
Таблица областей
Таблица процессов
О Кбайт
16 Кбайт
64 Кбайт
Код
Данные
Стек
MMU-доступ к информации области
Номер
_ страницы
Таблица
страниц стека
пусто
пусто
пусто
пусто
Аппаратная шина
О х 00000000
Рис. 14.37. Схема памяти после выполнения первой команды
Страница ОЗУ О
Блок диска 6
Блок диска 4
Блок диска 9
Блок диска 7 z
Блок диска 8
Таблица страниц данных
1
2
3
5
6
8
9
3
4
5
6
7
1
2
Таблица ОЗУ
Список свободных блоков
1
2
3
О
1
2
з
о
О
1
Схема памяти после нескольких команд
Когда процесс продолжает выполняться после ехесо, он возвращает ошибки доступа к большинству его страниц кода, данных и стека. Диаграмма,
показанная на рис. 14.38, иллюстрирует ситуацию, в которой все физические страницы ОЗУ были заполнены единственным процессом. Это никогда не может случиться в реальной системе UNIX, т. к. ядро занимает младшие адреса ОЗУ, и несколько других процессов-демонов будут всегда размещаться в старших адресах ОЗУ. Но диаграмма показывает, как таблицы страниц процесса постепенно заполняются адресами ОЗУ.
Таблица
Номер блока
страниц кода
Область пользователя
Таблица процессов
Смещение Таблица у областей /
0 Кбайт Код 1
16 Кбайт Данные -
64 Кбайт Стек ।
О
1
2
3
Таблица страниц данных
1
2
3
Страница ОЗУ О
Страница ОЗУ 2 J г ►
Блок диска 4 +
Страница ОЗУ 1 J
Диск
Номер страницы
ОЗУ
Страница ОЗУ 3
MMU-доступ к информации области
Блок диска 8
Страница ОЗУ 5
Страница ОЗУ 4
Страница ОЗУ 7
Страница ОЗУ 6
Таблица страниц стека
о
1
2
3
4
5
6
7
Таблица
ОЗУ
Список свободных блоков
Аппаратная шина
О X 00005064
О
О
1
Демон страниц
Диаграмма на рис. 14.38 иллюстрирует ситуацию, в которой все физические страницы ОЗУ заполнены.
Если возникает ошибка еще на одной из страниц процесса, система могла бы сохранить одну или несколько страниц ОЗУ на диске, чтобы создать место для поступающей страницы. Практически разработки получаются намного лучше, когда система управления памятью всегда имеет некоторое количество страниц ОЗУ свободными для последующих ошибок. Минимальное число страниц, которые она пробует держать свободными, называется низшей точкой (low-water mark). Когда число свободных страниц ниже этого уровня, система управления памятью побуждает процесс, называемый демоном страниц (page daemon) или ретранслятором страниц (page stealer), освободить некоторые страницы ОЗУ. Демон страниц использует особый алгоритм, чтобы сохранить страницы в специальной области диска, называемой пространством обмена (swap space), пока число свободных страниц не превысит высшую точку (high-water mark). Тогда демон страниц засыпает, пока снова не понадобится.
Пространство обмена
Пространство обмена (swap space) — это специальная непрерывная область диска, расположенная отдельно и предназначенная для эффективной передачи страниц в ОЗУ и из ОЗУ. Хотя пространство обмена может находиться на корневом устройстве, оно часто размещается на отдельном диске так, чтобы обычный доступ к файлу и страничная подкачка могли происходить одновременно. Пространство обмена поддерживается специальной структурой ядра данных, называемой картой обмена (swap map), которая служит для отслеживания использования ее блоков. Карта обмена ищет свободные смежные блоки в пространстве обмена и обновляет их всякий раз, когда пространство обмена выделяется или освобождается. Когда два соседних участка памяти пространства обмена становятся свободными, карта обмена автоматически объединяет их в отдельный, больший участок памяти свободного пространства.
Алгоритм демона страниц
Каждый элемент таблицы страниц включает три поля, называемые битом модификации (modified bit), битом обращения (Referenced bit) и возрастом (age). Всякий раз, когда процесс получает доступ к конкретной странице, ее бит обращения устанавливается, а поле возраста сбрасывается в ноль. Демон
страниц (page daemon) использует эти два поля, чтобы освобождать наиболее давние по применению страницы. Он проходит циклически через каждую таблицу страниц в системе, выполняя следующие действия: если бит обращения страницы установлен, он повторно устанавливает его и сбрасывает поле возраста в ноль; иначе, увеличивает поле возраста.
Поля возраста страниц, к которым в настоящее время обращаются, едва ли увеличатся вообще, т. к. они непрерывно повторно обнуляются. Однако поля возраста страниц, которые являются бездействующими, продолжают расти. Когда поле возраста достигает некоторого, зависящего от системы, значения, демон страниц пытается освободить страницу, используя следующие правила:
□ если страница никогда не перемещалась на устройство обмена, она помещается в список страниц, которые нужно переместить, и ее элемент таблицы ОЗУ отмечается как "готов к перемещению";
□ если страница ранее перемещалась и не изменялась с тех пор, ее бит применимости (valid bit) повторно устанавливается, а соответствующий элемент таблицы ОЗУ немедленно отмечается как "свободный" и помещается в список свободных страниц;
□ если страница прежде перемещалась и с тех пор была изменена, она помещается в список страниц, которые нужно переместить, а соответствующий элемент таблицы ОЗУ отмечается как "готов к перемещению", и ее предыдущая область пространства обмена освобождается.
Когда список страниц для перемещения достигает некоторого размера, ядро выделяет подходящий участок памяти пространства обмена, консультируясь с картой обмена, и затем намечает страницы, которые будут записаны в пространство обмена. Когда страница записана, ее бит применимости повторно устанавливается, а элемент таблицы ОЗУ отмечается как "свободный" и помещается в список свободных.
В результате этого алгоритма наиболее "старые" страницы постепенно перемещаются в пространство обмена, пока количество свободных страниц не превысит высшую точку.
Схема памяти
после удаления нескольких страниц
Диаграмма, приведенная на рис. 14.39, иллюстрирует состояние карты памяти процесса после того, как страница кода 1, страница данных 0 и страница стека 1 были перемещены в пространство обмена.
Диск
Таблица
Номер блока
Номер блока
Пространство обмена
Список свободных блоков
Рис. 14.39. Схема памяти после удаления нескольких страниц
Доступ к странице, которая хранится в пространстве обмена
Когда MMU пытается получать доступ к странице, чей бит применимости не установлен, оно генерирует ошибку страницы. Перед запросом этой страницы для чтения с диска ядро проверяет, чтобы удостовериться, находится ли страница, освобожденная демоном страниц, но еще не перекрыта другой страницей, все еще в ОЗУ. Оно может сделать это быстро, потому что поддерживает таблицу мусора (hash table), которая связывает адреса блоков диска с номерами страниц ОЗУ. Если ядро выясняет, что страница все еще присутствует в ОЗУ, оно просто модернизирует элемент таблицы страниц и
устанавливает бит применимости. Если страница не найдена в ОЗУ, возможен один из двух.исходов:
□ если страница никогда не была загружена в ОЗУ, ядро выполняет запрос, чтобы страница была загружена из исполняемого файла;
□ если страница хранится в пространстве обмена, ядро осуществляет запрос, чтобы страница была загружена с устройства обмена.
Одно последствие этого алгоритма заключается в том, что страница загружается только однажды из исполняемого файла; затем она проводит остальную часть своей "жизни”, путешествуя между пространством обмена и ОЗУ. Диаграмма, приведенная на рис. 14.40, иллюстрирует это поведение.
/
Исполняемый --► ОЗУ
Страница входящая
Пространство обмена
Страница выходящая
Рис. 14.40. Жизненный цикл страницы
Дублирование процесса: fork()
Когда процесс ветвится, дочернему процессу должна быть выделена родительская копия областей кода, данных и стека. К сожалению, процесс часто немедленно за системным вызовом fork о выполняет ехес о, таким образом, освобождая его предыдущие области памяти. Чтобы избежать любого ненужного и дорогостоящего копирования, подсказываемого этими наблюдениями, ядро обрабатывает fork о особым способом, описанным ниже.
□ Ядро устанавливает элемент области кода дочернего процесса, чтобы тот указывал на таблицу страниц кода родителя, и увеличивает счетчик ссылок, связанный с таблицей страниц для того, чтобы показать, что она разделяется.
□ Ядро создает таблицу страниц данных и таблицу страниц стека для дочернего процесса, которые являются дубликатами таблиц родителя, и устанавливает бит копирования при записи (сору-оп-write bit) для каждого элемента таблицы страниц данных и таблицы стека обоих процессов. Если элементы таблицы страниц родителя указывают на ОЗУ, элемент таблицы страниц потомка устанавливается, чтобы указывать на то же самое местоположение, а счетчик ссылок, связанный со страницей ОЗУ, увеличивается для того, чтобы показать, что она разделяется.
Счетчик ссылок
Таблица
Диск
Номер блока
2
страниц кода
Страница ОЗУ 0 \
Блок обмена 0 ।
Блок диска 4 4
Страница ОЗУ 1 у
Таблица страниц данных
Блок обмена 1
Блок диска 8
Страница ОЗУ 5
Страница ОЗУ 4
Таблица страниц стека
Страница ОЗУ 7
Блок обмена 2
Таблица страниц данных
Блок обмена 1
Блок диска 8
Страница ОЗУ 5
Страница ОЗУ 4
Таблица страниц стека
Страница ОЗУ 7
Блок обмена 2
Таблица
ОЗУ
Пространство обмена
Номер блока
Список свободных блоков
Аналогично, если элемент таблицы страниц родителя указывает на пространство обмена, элемент таблицы страниц дочернего процесса устанавливается, чтобы указывать на то же самое местоположение, и счетчик ссылок, связанный с местоположением пространства обмена, увеличивается для того, чтобы показать, что оно разделяется.
Бит копирования при записи используется UNIX для обработки специальным образом разделяемого ОЗУ и страницы обмена. На рис. 14.41 приведена иллюстрация карт памяти родителя и дочернего процесса сразу после выполнения системного вызова fork (). Маленькие числа рядом с таблицами областей, таблицей ОЗУ и таблицей пространства обмена — это счетчики ссылок, обслуживаемые ядром.
Обработка ссылок
на разделяемые страницы ОЗУ и пространства обмена
UNIX обрабатывает разделяемые страницы следующим образом.
□ Если процесс читает разделяемую страницу ОЗУ, вообще ничего особенного не происходит.
□ Если демон страниц решает переместить разделяемую страницу ОЗУ, счетчик ссылок страницы уменьшается, и копия страницы перемещается в пространство обмена. У процесса, чья страница была перемещена, обновляется элемент таблицы страниц перемещенной страницы, чтобы отразить передачу, но другие процессы, которые разделяют ту же самую страницу, все еще ссылаются на страницу ОЗУ. Если счетчик ссылок страницы ОЗУ все еще отличен от нуля после того, как он уменьшился на единицу, страница ОЗУ не добавляется к списку свободных.
□ Если процесс осуществляет доступ к разделяемой странице пространства обмена, она перемещается из пространства обмена, и у процесса, чья страница была перемещена, обновляется элемент таблицы страниц перемещенной страницы, чтобы отразить передачу в ОЗУ. Другие процессы, разделяющие ту же самую страницу обмена, ссылаются на пространство обмена.
□ Если процесс пытается изменять страницу, у которой установлен бит копирования при записи, MMU автоматически генерирует ошибку страницы. Обработчик ошибки страницы проверяет, является ли счетчик ссылок страницы ОЗУ больше 1. Если это так, то означает, что процесс записывает в разделяемую страницу. В данной ситуации обработчик ошибки копирует страницу в другую страницу ОЗУ и модернизирует элемент таблицы страниц дочернего процесса, чтобы он указывал на новую копию. Повторно устанавливается бит копирования при записи элемента табли
цы страниц потомка. Затем обработчик ошибки уменьшает на 1 первоначальный счетчик ссылок страницы ОЗУ и повторно устанавливает ее бит копирования при записи, если счетчик уменьшился до 1. Если процесс пытается изменить страницу, чей бит копирования при записи установлен, а счетчик ссылок равен 1, обработчик ошибки позволяет процессу использовать физическую страницу и повторно устанавливает бит копирования при записи, но также и отсоединяет страницу от ее текущей копии обмена. Это потому, что другой процесс, созданный разветвлением, также может разделять ту же самую копию обмена.
Пробуксовка и свопинг
Если одновременно работает много процессов, возможно, что интенсивность недостатка страниц заставляет ЦП большую часть времени тратить на перемещение страниц в/из пространства обмена. Эта ситуация, называемая пробуксовкой (thrashing), заканчивается плохой производительностью системы. Когда система управления памятью обнаруживает пробуксовку, она пробуждает процесс sched, который выбирает процессы для дезактивирования и перемещения на диск, sched находит процессы на основе их приоритета и использования памяти, помечает их "на перемещение" (swapped) и перемещает все их страницы ОЗУ в пространство обмена. Процесс sched продолжает откачку процессов в пространство обмена до прекращения пробуксовки, а затем снова засыпает. Как только истекает предопределенный период, откачанный процесс отмечается, как "готовый работать" (ready to run), и его страницы нормальным образом перемещаются назад в ОЗУ.
Прекращение процесса: exit()
Когда процесс завершается, происходят следующие события:
□ его код возврата помещается в элемент таблицы процесса;
□ его дескрипторы файлов закрываются;
□ счетчик ссылок каждой из его областей уменьшается на 1;
П если счетчик ссылок области уменьшается до 0, сметчики ссылок страниц ОЗУ и страниц обмена процесса (если уместно) уменьшаются на 1;
П любые страницы ОЗУ или страницы обмена, которые имеют нулевой счетчик ссылок, освобождаются.
Элемент таблицы процесса освобождается только тогда, когда родительский процесс принимает его код завершения при помощи системного вызова wait ().
Сигналы
Сигналы (signals) информируют процессы об асинхронных событиях. Структуры данных, которые поддерживают сигналы, хранятся в таблице процесса и пользовательских областях. Каждый процесс имеет три элемента данных, связанных с обработкой сигнала:
а массив элементов пользовательской области, называемый массивом обработчиков сигнала (signal handler array), который описывает, что процесс должен сделать, когда он получает конкретный тип сигнала;
а массив битов в элементе таблицы процесса, называемый битовой картой ожидающих сигналов (pending signal bitmap), по одному на каждый тип сигнала, которая записывает, поступил ли для обработки конкретный тип сигнала;
□ ID группы процесса, который применяется при распространении сигналов.
На рис. 14.42 представлена диаграмма связанных с сигналом структур данных ядра.
Таблица процесса
Область пользователя
Битовая карта отложенных сигналов
Массив обработчиков сигналов
Рис. 14.42. Относящиеся к сигналу структуры ядра
\
setpgrpO
Системный вызов setpgrpO присваивает номеру группы вызывающего процесса его собственный PID, таким образом, помещая его в свою уни
кальную группу процесса. Разветвленный процесс наследует группу процесса своего родителя, setpgrpo работает, изменяя элемент номера группы процесса в системной таблице процессов. Номер группы процесса используется системным вызовом kill о , как вы увидите позже.
signatf)
Системный вызов signal о устанавливает способ, которым процесс отвечает на конкретный тип сигнала. Есть три опции: игнорировать сигнал, исполнить действие ядра по умолчанию, выполнить установленный пользователем обработчик сигнала. Элементы в массиве обработчиков сигналов задаются следующим образом:
П если сигнал должен игнорироваться, элементу присваивается значение 1;
П если сигнал должен вызывать действие по умолчанию, элемент сбрасывается в 0;
П если сигнал должен быть обработан с помощью инсталлированного пользователем обработчика, элемент устанавливается на адрес обработчика.
Когда сигнал посылается процессу, ядро устанавливает соответствующий бит в битовой карте сигналов процесса получателя. Если процесс-получатель спит в прерываемом приоритете, он пробуждается, чтобы обработать сигнал. Ядро проверяет битовую карту ожидаемых сигналов процесса всякий раз, когда процесс возвращается из режима ядра в пользовательский режим (т. е. когда он возвращается из системного вызова) или когда процесс входит или покидает состояние сна. Поэтому обратите внимание, что сигнал едва ли когда-либо немедленно обрабатывается. Вместо этого процесс-получатель имеет дело с ожидаемыми сигналами только, когда это запланировано. Данная ситуация делает сигналы относительно слабым механизмом для приложений реального времени. Обратите внимание также, что битовая карта ожидаемых сигналов не хранит счетчик конкретных типов сигналов, находящихся в ожидании. Это означает, что, если три сигнала sigint поступают почти одновременно, возможно, что только один из них будет замечен.
Сигналы после системных вызовов fork() или ехес()
Разветвленный процесс наследует содержимое массива обработчиков сигналов от своего родителя. Когда процесс выполняется, первоначально игнорируемые сигналы продолжают игнорироваться, а остальные настроены на действия по умолчанию. Иными словами, все элементы, равные 1, не изменяются, а другие сброшены в 0.
Обработка сигнала
Когда ядро обнаруживает, что процесс имеет ожидаемый сигнал, оно либо игнорирует его, выполняя действие по умолчанию, либо вызывает установленный пользователем обработчик. Чтобы вызвать обработчик, ядро добавляет новую структуру к стеку процесса и изменяет счетчик команд процесса так, чтобы заставить процесс-получатель действовать, будто тот вызвал обработчик сигнала из своей текущей программы. Когда ядро возвращает процесс в пользовательский режим, процесс выполняет обработчик и затем возвращается из функции назад в предыдущую программу. Сигнал sigchld ("смерть" дочернего процесса) обрабатывается чуть иначе (см. описание системного вызова wait ()).
exit()
Когда процесс заканчивается, он оставляет код возврата в поле своего элемента таблицы процессов и отмечается, как процесс-зомби. Код возврата доступен родительскому процессу при помощи системного вызова wait(). Ядро всегда информирует родительский процесс, что один из его потомков "умер", посылая ему сигнал sigchld.
wait()
Системный вызов wait () возвращается только при одном из двух условии, или запрашивающий процесс не имеет дочерних процессов, тогда он возвращает код ошибки, или один из "потомков" процесса закончился, тогда возвращаются PID дочернего процесса и код возврата. Алгоритм, которым ядро обрабатывает системный вызов wait о, таков:
П если процесс вызвал wait о и не имеет "потомков” , wait () возвращает код ошибки;
□ если процесс вызвал wait о и один или несколько его дочерних процессов уже зомби, ядро наугад выбирает "потомка", удаляет его из таблицы процессов и возвращает его PID и код возврата;
□ если процесс вызвал wait о и ни один из его порожденных процессов не зомби, вызов wait о засыпает. Он пробуждается ядром, когда получает любые сигналы, тогда проверка возобновляется?
Хотя данный алгоритм будет работать и в таком виде, есть одна маленькая проблема: если бы процесс выбрал игнорирование сигналов sigchld, все его "потомки" остались бы зомби, что привело бы к засорению таблицы процессов. Во избежание этого ядро обращается с игнорированием сигнала sigchld как со специальным случаем. Если поступает сигнал sigchld и иг
норируется, ядро немедленно удаляет всех "потомков"-зомби данного родителя из таблицы процессов, а затем позволяет системному вызову wait () работать нормально. Когда вызов wait о возобновляется, он не находит никаких зомби, поэтому опять засыпает. В конце концов, когда "смертельный" сигнал последнего порожденного процесса игнорируется, системный вызов wait о возвращается с кодом ошибки, чтобы показать, что запрашивающий процесс не имеет никаких дочерних процессов.
кто
Системный вызов kill о использует поля реального пользовательского ID и ID группы процесса в таблице процессов. Например, когда выполняется следующая строка кода
kill (О, SIGINT);
ядро устанавливает бит в битовой карте ожидающих сигналов, соответствующий sigint в каждом элементе таблицы процессов, чей групповой ID процесса равен ID запрашивающего процесса. UNIX использует эту возможность, чтобы распространять сигналы, вызванные нажатием комбинаций клавиш <CtrI>+<C> и <Ctrl>+<Z>, всем процессам в группе процесса управляющего терминала.
Ввод/вывод
В этом разделе описываются структуры данных и алгоритмы, которые использует ядро UNIX, чтобы поддержать системные вызовы, относящиеся к вводу/выводу. В частности, будет рассмотрена UNIX-реализация этих запросов в связи с тремя главными категориями файлов:
□ обычные файлы;
□ файлы каталогов;
□ специальные файлы (т. е. периферийные устройства, конвейеры и сокеты).
5 /
Объекты ввода/вывода
Я представляю файлы как объекты специального вида, которые обладают возможностями ввода/вывода. UNIX-объекты ввода/вывода могут быть классифицированы согласно иерархии, приведенной на рис. 14.43.
Каталог
Обычный файл
Специальный файл
Сокет
Конвейер
Внешнее устройство
Именованный конвейер
Безымянный Буферизированный Не буферизированный конвейер
Диск Терминал
Лента
Рис. 14.43. Иерархия объектов ввода/вывода
Системные вызовы ввода/вывода
Как описано в главе 13. системные вызовы ввода/вывода UNIX могут применяться унифицированным способом ко всем объектам ввода/вывода с некоторыми исключениями. Например, вы не можете использовать системный вызов iseek о для конвейера или сокета. Ниже представлен список системных вызовов, которые описаны в следующих разделах:
close () dup ()
ioctl () link ()
Iseek()
mknod() /mkdir() mount()
open() read()
sync()
umount() unlink()
write()
Буферизация ввода/вывода
Ядро избегает ненужного ввода/вывода устройств путем буферизации большинства операций ввода/вывода в фиксированного размера структуре данных в масштабе всей системы, называемой буферным пулом (buffer pool). Это набор буферов, которые используются для кэширования блоков файла в ОЗУ. Когда процесс читает из блока в первый раз, блок копируется из файла в буферный пул, а затем копируется оттуда в пространство данных процесса. Следующее чтение из того же самого блока обслуживается непосредственно из ОЗУ. Аналогично, если процесс пишет в блок, которого нет в
буферном пуле, блок копируется из файла в пул, а затем буферированная копия изменяется. Если блок уже находится в пуле, буферированная версия изменяется без всякой потребности в физическом вводе/выводе. Несколько смешанных списков, основанных на блочных устройствах и количестве блоков, поддерживаются для буферов в пуле так, чтобы ядро могло быстро расположить буферируемый блок.
Когда процесс получает доступ к буферу во время системного вызова вво-да/вывода, буфер выделяется или блокируется, чтобы препятствовать его использованию другими процессами. Если другой процесс пытается получать доступ к выделенному буферу, ядро погружает его в сон до тех пор, пока буфер не освободится. Когда UNIX загружается, все буферы в пуле отмечаются как свободные и помещаются в список свободных буферов.
Когда ядро обслуживает системный вызов ввода/вывода процесса и нуждается в копировании блока из объекта ввода/вывода в буферный пул, для этого требуется несколько шагов.
1. Сначала ядро выбирает первый буфер в списке свободных буферов и отмечает его как выделенный.
2. Затем оно удаляет буфер из списка свободных буферов и делает асинхронный запрос чтения соответствующему драйверу устройства.
3. Наконец, ядро погружает процесс в сон. Когда запрос чтения будет обслужен, процесс пробуждается и ядро продолжает выполнять системный вызов. Если список свободных буферов пуст, процесс погружается в сон, пока свободный буфер не становится доступным. Если блок уже буфери-рован, ядро просто выделяет существующий буфер.
4. Когда системный вызов завершает работу с буфером, буфер освобождается и помещается в конец списка свободных буферов.
Эта схема гарантирует, что каждый раз, когда требуется новый буфер, выбирается наиболее давний по использованию буфер.
Заманчиво предполагать, что, когда файл закрывается, ядро копирует измененные буферированные блоки всего файла обратно на диск. Этого не происходит; взамен ядро устанавливает флаг отложенной записи (delayed-write flag) в заголовке буфера всякий раз, когда он изменяется системным вызовом write (). Буферированный блок физически записывается на диск только, когда другой процесс пытается удалить его из списка свободных буферов. Эта схема задерживает физический ввод/вывод до последнего возможного момента.
На рис. 14.44 представлена иллюстрация буферизации в действии.
1. Процесс читает из блока 217 первый раз
2. Процесс записывает в блок 217
3. Процесс закрывает файл
4. Буфер сбрасывается на диск
5. Буферы сшиваются несколькими списками
Рис. 14.44. Буферизация в действии
sync()
Системный вызов sync о заставляет ядро сбрасывать на диск все буферы с флагом отложенной записи. В системах, где демон System V fsflush не существует, администраторы системы создают утилиту sync, которая заставляет системный вызов sync() регулярно выполняться. Это гарантирует, что со
держимое диска всегда современно. Если процесс fsflush работает в системе, ОН управляется функцией flushing.
Ввод/вывод обычных файлов
ореп()
Рассмотрим, что' происходит, когда процесс открывает существующий обычный файл только для чтения. Позже будет представлен способ, которым ядро создает новый файл. Предположим, что некоторый процесс первым открывает файл после последней перезагрузки системы, и предполагается также, что он выполняет следующий код:
fd = open (’’/home/glass/sample.txt", O_RDONLY) ;
Ядро начинает, переводя имя файла в номер inode, выполнять описанный ранее в главе алгоритм6. Если inode файла не найден, возвращается код ошибки. Иначе, ядро выделяет компонент фиксированного размера структуры данных, называемой таблицей активных inode (active inode table), и копирует inode с диска в этот компонент. Ядро также сохраняет в компоненте несколько других значений, которые описаны позже. Ядро кэширует активные и недавно используемые inode в таблице активных inode, чтобы избежать излишнего доступа к диску.
Затем ядро выделяет компонент в другой фиксированного размера структуре данных, называемой таблицей открытых файлов (open file table). Оно заполняет этот компонент несколькими полезными значениями, включая:
□ указатель на новый элемент в таблице активных inode;
□ флаги разрешения чтения/записи, указанные в системном вызове open о ;
□ текущую позицию файла процесса, установленную на 0 по умолчанию.
Наконец, ядро выделяет компонент в массиве дескрипторов файла процесса, направляет этот элемент в новый элемент в открытой таблице файлов и передает индекс дескриптора файла в качестве возвращаемого значения системного вызова open о. На рис. 14.45 приведена иллюстрация процесса и структур данных ядра.
Если процесс открывает несуществующий файл и определяет флаг o creat, ядро создает указанный файл. Чтобы сделать это, оно выделяет свободный inode из списка inode файловой системы, устанавливает поля внутри него для демонстрации, что файл пуст, а затем добавляет жесткую связь к соответствующему файлу каталога. Вспомните, что жесткая связь — это элемент, состоящий из имени файла и его номера inode.
6 См. разд. "Преобразование путевых имен в номера inode"ранее в этой главе. — Ред.
Диск
Массив дескрипторов файла (в области пользователя)
Таблица открытых файлов
Таблица активных inode
о
1
2
(fd)3
Рис. 14.45. Файловые структуры ядра
ф TJ о с
Теперь, когда представлен способ, которым ядро справляется с системным вызовом open о, опишем системные ВЫЗОВЫ read(), write о, lseek() И close о. Для простоты предположим, что к типовому файлу обращается только один процесс; позже в главе будет описана поддержка ядра для многочисленных пользователей того же самого файла.
read()
Рассмотрим, что происходит, когда типовой процесс выполняет следующую последовательность системных вызовов read ():
read (fd, bufl, 100); /* Читать read (fd, buf2, 200); /* Читать read (fd, buf3, 5000); /* Читать
100 байтов в буфер bufl */ 200 байтов в буфер buf2 */
5000 байтов в буфер buf3 *
Вот последовательность событий, которые произошли бы во время выполнения этих запросов:
1. Данные, требуемые первым read о, находятся в первом блоке файла. Ядро решает, что блок не в буферном пуле, и поэтому копирует его с диска в свободный буфер. Затем оно копирует первую сотню байтов из буфера в bufl. Наконец, позиция файла, хранящаяся в таблице открытых файлов, обновляется новым значением 100.
2. Данные, требуемые вторым read (), также находятся в первом блоке файла. Ядро выясняет, что блок уже присутствует в буферном пуле, и поэто
му копирует следующие 200 байтов из буфера в buf 2. Затем оно модернизирует позицию файла на 300.
3. Данные, требуемые третьим read о, находятся частично в первом и частично во втором блоках файла. Ядро перемещает остаток первого блока (3796 байтов) из буферного пула в buf3. Затем оно копирует второй блок с диска в свободный буфер в пуле и оставшиеся данные (1204 байта) из буферного пула в buf3. Наконец, ядро модернизирует позицию файла на 5300.
Обратите внимание, что единственный read о может вызвать копирование больше одного блока с диска в буферный пул. Если процесс читает из блока, который не имеет выделенного пользовательского блока (см. главу 13 для обсуждения разбросанных файлов (sparse file))7, то read о не буферирует ничего, а вместо этого обращается с блоком, как будто он был заполнен символами ASCII null (0).
write()
Предположим, теперь типовой процесс выполняет следующую серию системных вызовов write о:
write (fd, buf4, 100); /* Записать 100 байтов из буфера buf4 */
write (fd, buf5, 4000); /* Записать 4000 байтов из буфера buf5 ★/
Вспомните, что текущее значение позиции файла — 5300, и эта позиция расположена около начала второго блока файла. Вспомните также, что данный блок в настоящее время буферирован благодаря последнему системному вызову read(). Последовательность событий, которые произошли бы во время выполнения нашего типового процесса, такова:
1. Данные, которые должны быть переписаны первым write(), находятся полностью во втором блоке. Этот блок уже присутствует в буферном пуле, так что 100 байтов buf 4 копируются в соответствующие байты буферированного второго блока.
2. Данные, которые будут переписаны вторым write (), находятся частично во втором и частично в третьем блоках. Ядро копирует первые 3792 байта buf5 в оставшиеся 3792 байта буферированного второго блока. Затем оно копирует третий блок из файла в свободный буфер. Наконец, ядро копирует оставшиеся 208 байтов buf 5 в первые 208 байтов буферированного третьего блока.
IseekO
Реализация системного вызова 1s ее к () тривиальна: ядро просто изменяет значение дескриптора, связанного с позицией файла, расположенного в таб
7 См. разд. "Перемещение в файле: lseek()" в главе 13. — Ред.
лице открытых файлов. Обратите внимание, что нет необходимости в физическом вводе/выводе. Рис. 14.46 иллюстрирует результат следующего кода:
Iseek (fd, 3000, SEEK_SET);
Область пользователя
Таблица открытых файлов
Таблица активных inode
Диск
Рис. 14.46. Системный вызов Iseek () изменяет смещение файла
closeO
Когда дескриптор файла закрывается, и только он связан с конкретным файлом, ядро копирует inode файла обратно на диск, а затем помечает соответствующую таблицу открытых файлов и таблицу активных inode как свободные. Когда процесс заканчивается, ядро автоматически закрывает дескрипторы файла всего процесса.
Как было упомянуто ранее, ядро имеет специальные механизмы, чтобы поддерживать множественные дескрипторы файла, связанные с тем же самым файлом. Чтобы осуществлять эти механизмы, ядро имеет.поле счетчика ссылок для каждого элемента таблицы открытых файлов и каждого элемента таблицы активных inode. Когда файл открывается впервые, оба счетчика устанавливаются в 1. Есть три способа, которыми файл может быть разделен между несколькими описателями файла:
□ файл явно открывается несколько раз либо одним и тем же процессом, либо различными процессами;
□ дескриптор файла дублируется при помощи системных вызовов dup (), dup2 () ИЛИ fcntl ();
□ процесс разветвляется, что заставляет все вхождения его дескриптора файла дублироватся.
Когда дескриптор файла формируется первым методом, ядро создает новый элемент таблицы открытых файлов, который указывает на тот же самый активный inode. Затем ядро увеличивает поле счетчика ссылок в таблице активных inode файла, как показано на рис. 14.47.
Область пользователя
Таблица открытых файлов
Таблица активных inode
Диск
о 1 2 (fd) 3 (fd2)4
Рис. 14.47. Системный вызов ореп() создает новый элемент в таблице открытых файлов
Когда дескриптор файла создается любым из следующих двух методов, ядро устанавливает новый дескриптор файла, чтобы он указывал на тот же самый элемент таблицы открытых файлов, как и первоначальный дескриптор файла, и увеличивает поле счетчика ссылок в элементе дескриптора таблицы открытых файлов, как показано на рис. 14.48.
Системный вызов close о обращается с полями счетчиков ссылок следующим образом:
1. Когда дескриптор файла закрывается, ядро уменьшает на 1 поле счетчика ссылок в связанной с ним таблице открытых файлов.
2. Если счетчик ссылок таблицы открытых файлов остается больше 0, ничего не происходит. Если счетчик ссылок уменьшается до нуля, элемент таблицы открытых файлов отмечается как свободный, и поле счетчика ссылок в таблице активных inode файла уменьшается на 1.
3. Если счетчик ссылок в таблице активных inode остается больше 0, ничего не происходит. Если счетчик ссылок уменьшается до нуля, inode копируется обратно на диск, и элемент таблицы активных inode отмечается как свободный.
Область пользователя
Таблица открытых файлов
Таблица активных inode
Диск
о 1 2
(fd) 3 (fd2)4
Рис. 14.48. Дублирование дескриптора файла
dup()
Реализация системного вызова dup () проста: он копирует указанный дескриптор файла в следующий свободный элемент массива дескрипторов файла и увеличивает соответствующий счетчик ссылок таблицы открытых файлов.
unlinkO
Системный вызов unlink о удаляет жесткую связь из каталога и уменьшает на 1 счетчик жесткой связи соответствующего ему inode. Если счетчик жесткой связи уменьшается до 0, освобождаются inode файла и пользовательские блоки, когда последний процесс, который использует файл, завершается. Это означает, что процесс может отключить файл и продолжать получать доступ к нему до завершения процесса. Процесс удаления связи показан на рис. 14.49.
Исходная
пользователя
Удаление одной связи
Метка 1
inode 27
Счетчик ссылок 1
Удаление последней связи: блоки пользователя и inode свободны
inode 27 свободен
К блокам пользователя
Блоки пользователя свободны
Рис. 14.49. Удаление связи
Ввод/вывод каталогов
Каталоги отличаются от обычных файлов тем, что они могут:
□ создаваться ТОЛЬКО С ПОМОЩЬЮ системных ВЫЗОВОВ mknod () ИЛИ mkdir () ;
□ читаться только через системный вызов getdents о ;
□ изменяться только с использованием системного вызова link ().
Эти различия гарантируют целостность иерархии каталогов. Каталоги могут быть открыты тем же самым способом, как и обычные файлы. Рассмотрим
реализацию системных вызовов mknod () и. link ().
mknod()
Системный вызов mknod () создает каталог, именованный конвейер или специальный файл. В каждом случае системный вызов начинается с выделения нового inode на диске и установки, соответственно, его поля типа и добавлением его в иерархию каталогов через жесткую связь. Если создается8 ката
8 Во многих версиях UNIX при создании каталога предпочтителен системный вызов mkdir().
лог, пользовательский блок связывается с inode и заполняется элементами и по умолчанию. Если формируется специальный файл, соответствующие старшие и младшие номера устройства сохраняются в inode.
Нпк()
Системный вызов link о добавляет жесткую связь к каталогу. Вот пример: link ("/home/glass/filel.с", "/home/glass/file2.с");
В этом примере ядро нашло бы номер inode имени файла источника /home/glass/filel.c, а затем связало его с меткой file2.c в каталоге назначения /home/glass. Далее увеличился бы счетчик жестких связей. Только привилегированный пользователь (root) может связывать каталоги, чтобы предохранить неосторожных пользователей от создания циклических структур каталогов.
Монтирование файловых систем
Ядро поддерживает единственную в масштабе всей системы фиксированного размера структуру данных, называемую таблицей монтирования (mount table), которая позволяет множественным файловым системам обращаться через единственную иерархию каталогов. Системные вызовы mount () и umount () изменяют эту таблицу и могут выполняться только привилегированным пользователем (root).
mountO
Когда файловая система монтируется, используя системный вызов mounto, компонент, содержащий перечисленные ниже поля, добавляется к таблице монтирования:
□ номер устройства, которое содержит недавно смонтированную файловую систему;
□ указатель на корневой inode недавно установленной файловой системы;
□ указатель на inode точки монтирования;
□ указатель на структуру данных монтирования, специфическую для недавно смонтированной файловой системы.
Каталог, связанный с точкой монтирования (mount point), становится синонимичным с корневым узлом недавно смонтированной файловой системы, и ее предыдущее содержимое оказывается недоступным для процессов, пока файловая система не будет размонтирована. Чтобы разрешить корректный перевод путевых имен, которые пересекают точки монтирования, активный inode каталога монтирования отмечен как точка монтирования, и установ
лен, чтобы указывать на связанный элемент таблицы монтирования. Например, рис. 14.50 демонстрирует эффект следующего системного вызова, который устанавливает файловую систему, содержащуюся на устройстве /dev/daO в каталоге /mnt:
mount ("/dev/daO", "/mnt", 0);
Перед монтированием
После монтирования
bin
Сращивание
I -----/
Н--------! \
usr mnt tmp1 tmp2
bin usr mnt
tmp1 tmp2
Рис. 14.50. Прямое монтирование
Перевод имен файлов
Алгоритм трансляции имени использует содержимое таблицы монтирования при переводе путевых имен, которые пересекают точки монтирования. Это может происходить при движении вверх или вниз по иерархии каталогов. Рассмотрим следующий пример: $ cd /mnt/tmp 1 $ cd ../../bin
Первая команда cd пересекается с корневым устройством на устройстве /dev/daO, а вторая команда cd пересекается на корневом устройстве. Вот как алгоритм включает смонтированные файловые системы в процесс перевода: □ когда во время процесса перевода обнаруживается inode, который является точкой монтирования, вместо него возвращается указатель на корневой inode смонтированной файловой системы. Например, когда путь /mnt, являющийся частью /mnt/dirl, переведен, возвращается указатель на корневой узел смонтированной файловой системы. Этот указатель используется в качестве отправной точки для перевода остальной части путевого имени;
□ когда возникает компонент ".." путевого имени, ядро проверяет, окажется ли точка монтирования пересеченной. Если текущий указатель inode процесса перевода и компонент ".." указывают на корневой узел, то точка пересечения возникнет. Тогда ядро заменяет текущий указатель inode процесса перевода указателем inode точки монтирования в родительской файловой системе, который оно находит, просматривая таблицу монтирования для элемента, соответствующего номеру устройства текущего inode.
Точка пересечения показана на рис. 14.51.
Корневое устройство
/ ч---------- Точка пересечения
Устройство /dev/daO
mnt
tmp1 tmp2
Рис. 14.51. Точка пересечения
umountO
При размонтировании файловой системы ядро выполняет несколько действий.
1. Проверяет, что нет никаких открытых файлов в файловой системе, которая собирается быть размонтированной. Ядро может делать это, просматривая таблицу активных inode для элементов, которые содержат номер устройства файловой системы. Если найден любой активный inode, то системный вызов терпит неудачу.
2. Сбрасывает обратно в файловую систему суперблок, блоки отложенной записи и буферированные inode.
3. Удаляет элемент таблицы монтирования и метку "точка монтирования" из каталога точки монтирования.
Ввод/вывод специальных файлов
Почти все специальные файлы соответствуют периферийным устройствам типа принтеров, терминалов и драйверов диска, так что в остальной части
этого раздела будут использоваться термины "специальный файл'м "периферия" как синонимы. Каждое периферийное устройство в системе имеет связанный с ним драйвер устройства, являющийся заказной частью программного обеспечения, которое содержит весь специфический для периферийного устройства код. Например, драйвер ленточного устройства содержит код для перемотки и удержания ленты. Единственный драйвер устройства может управлять всеми экземплярами конкретного вида периферийных устройств. Другими словами, три драйвера ленты одного типа могут разделять единственный драйвер устройства. Драйверы устройства для каждого типа периферийных устройств в системе должны быть связаны с ядром, когда системный администратор конфигурирует ее. (Для дополнительной информации см. главу 15).
Интерфейс устройства
Драйвер периферийного устройства обеспечивает интерфейс к периферийному устройству, который может появляться в двух следующих разновидностях:
□ блочный (block oriented interface) означает, что ввод/вывод буферируется и физический ввод/вывод выполняется на базе поблочной передачи. Драйверы диска и драйверы ленты имеют блочный интерфейс;
□ символьный (character oriented interface) означает, что ввод/вывод не буферируется и физический ввод/вывод происходит на базе передачи символа за символом. Символьный интерфейс иногда известен, как интерфейс доступа низкого уровня (raw interface). Все периферийные устройства, включая драйверы диска и драйверы ленты, обычно имеют символьный интерфейс.
Драйвер периферийного устройства иногда содержит оба вида интерфейса. Вид выбираемого интерфейса зависит от того, как будет организован доступ к устройству. При выполнении случайного и повторяющегося доступа к общему набору блоков будет правильным осуществление доступа к периферии через ее блочный интерфейс. Однако если вы собираетесь получать доступ к блокам в- единственной линейной последовательности, как при создании резервной ленты, тогда больше смысла в доступе к периферийному устройству через его символьный интерфейс. Это позволяет избежать издержек механизма внутренней буферизации ядра и иногда позволяет ядру использовать аппаратные возможности прямого доступа к памяти.
Возможно, хотя не желательно, обеспечивать доступ к отдельному устройству одновременно через оба интерфейса. Неприятность состоит в том, что символьный интерфейс обходит систему буферизации, приводя к сбивающим с толку результатам ввода/вывода.
Вот пример:
□ Процесс А открывает дискету, используя блочный интерфейс, /dev/flp.
А затем пишет 1000 байтов на диск. Этот вывод сохраняется в буферном пуле и отмечается для отсроченной записи.
□ Затем процесс В открывает ту же самую дискету, /dev/rflp, используя символьный интерфейс. Когда он читает 1000 байтов с диска, записанные процессом А данные игнорируются, т. к. они все еще находятся в буферном пуле.
Решение этой проблемы простое: не открывайте устройство одновременно через различные интерфейсы!
Старшие и младшие номера
Старшие и младшие номера устройства используются, чтобы классифицировать драйвер, связанный с конкретным устройством. Старший номер устройства определяет тот драйвер устройства, который конфигурируется в ядре и используется для доступа к устройству. Младший номер устройства выясняет, какое (возможно, несколько) устройство будет использоваться. Например, предположим, что в системе существует три драйвера ленты, и драйвер устройства для драйвера ленты соответствуют старшему номеру 15. Если запустить утилиту is, чтобы просмотреть блочные устройства ленты, можно увидеть следующий вывод:
brw—w—w- 1 root 15, 0 Feb 13 14:27 /dev/mtO
brw—w—w- 1 root 15, 1 Feb 13 14:29 /dev/mt1
brw—w—w- 1 root 15, 2 Feb 13 14:27 /dev/mt2
Из этого мы видим, что ко всем драйверам ленты обращается один и тот же драйвер устройства (помеченный индексом 15), и каждый младший номер уникально идентифицирует определенный драйвер ленты. Старшие и младшие номера используются для индексации в таблицах переключения, чтобы определить местонахождение соответствующего драйвера устройства.
Таблицы переключения
Все драйверы устройств UNIX должны удовлетворять предопределенному формату, включающему набор стандартных точек входа для функций, которые открывают, закрывают и обеспечивают доступ к периферийному устройству. Драйверы блочных устройств также содержат точку входа, называемую стратегией (strategy), которая используется ядром для выполнения блочного ввода/вывода на физическое устройство. Точки входа каждого блочного и символьного интерфейсов находятся в системных таблицах, называемых таблицей переключения блочных устройств (block device switch table) и таблицей переключения символьных устройств (character, device switch table).
Эти таблицы хранятся в виде массивов указателей на функции и создаются автоматически, когда конфигурируется UNIX. Одна размерность массива индексируется старшим номером периферийного устройства, другая — кодом функции. На рис. 14.52 приведен пример таблицы переключения.
Рис. 14.52. Пример таблицы переключения
Рис. 14.53 иллюстрирует структуры данных ядра, которые могли бы быть сформированы для выполнения следующего фрагмента кода:
fd = open ("/dev/tty2", O_RDWR);
Системные вызовы iseek(), chmodо и stat () работают тем же самым способом для специальных файлов, как и для обычных файлов. Системные вызовы read(), write о и close () работают несколько иначе и используют таблицу переключения блочных устройств и таблицу переключения символьных устройств. В каждом случае их действие может быть разбито на периферийно независимую и периферийно зависимую части.
Область пользователя
Таблица Таблица открытых активных inode файлов
Рис. 14.53. Доступ к специальному файлу
ореп()
Когда процесс открывает файл, ядро может сообщить, что он является периферийным устройством, рассматривая поле типа inode файла. Если поле указывает на блочное или символьное устройство, оно читает старший и младший номера, чтобы определить класс и экземпляр устройства, которое открывается.
При обработке системного вызова open о ядро исполняет периферийнонезависимые действия. Периферийно-независимая часть open о работает точно так же, как и open () для обычного файла; inode файла помещается в таблицу активных inode, и создается элемент таблицы открытых файлов. Периферийно-зависимая часть open () вызывает процедуру open () драйвера устройства. Например, процедура open () драйвера ленты обычно повторно натягивает и перематывает ленту, тогда как процедура ореп() терминального драйвера устанавливает скорость двоичной передачи устройства и задает терминальные установки по умолчанию.
25 Зак. 786
read()
При чтении С СИМВОЛЬНОГО устройства read о вызывает функцию read в драйвере устройства, чтобы выполнить физический ввод/вывод. При чтении с блочного устройства системный вызов read () использует стандартный буферированный механизм ввода/вывода. Если блок должен быть скопирован с устройства в буферный пул, вызывается функция стратегии драйвера устройства, которая объединяет как возможность чтения, так и возможность записи.
write()
При записи на символьное устройство write о выполняет функцию write в драйвере устройства, чтобы осуществить физический ввод/вывод. При записи на блочное устройство системный вызов write () использует буферированную систему ввода/вывода. Когда, в конечном счете, имеет место отложенная запись, чтобы произвести физический ввод/вывод, используется функция стратегии устройства.
close()
Ядро закрывает периферийное устройство таким же образом,-как оно закрывает обычный файл кроме ситуации, когда выполняющий системный вызов close о процесс является последним обратившимся к устройству процессом. В этом специальном случае выполняется процедура close о драйвера устройства, сопровождаемая рядом действий для закрытия обычного файла.
Ядро не может определить, что специальный файл был закрыт его последним пользователем, просто исследуя счетчик ссылок активного режима, т. к. к единственному устройству можно обращаться через несколько inode. Такая ситуация возникает, если один процесс получает доступ к устройству через его блочный интерфейс, а другой получает доступ к тому же самому файлу через его символьный интерфейс. В этом случае должен просматриваться список активных inode для поиска других inode, связанных с тем же самым физическим устройством.
ioctl()
Системный вызов ioctio управляет определенными особенностями устройства через дескриптор файла. Он просто передает свои аргументы элементу ioctl драйвера устройства. Специфичные для устройства действия включают установку скорости двоичной передачи терминала, выбор шрифта принтера и управление перемоткой ленты.
Ввод/вывод терминала
Хотя терминалы являются своего рода периферийными устройствами, терминальные драйверы устройств интересны и достаточно разнообразны, что служит основанием для их отдельного обсуждения. Главное различие между терминальными и другими драйверами устройств заключается в том, что терминальные драйверы устройств должны поддерживать несколько различных видов как предварительной обработки, так и постобработки на входе и выходе. Каждый вариант обработки назван дисциплиной линии (line discipline). Дисциплина линии терминала может быть установлена с помощью системного вызова ioctl(). Большинство терминальных драйверов поддерживают три общие дисциплины линии.
□ Низкоуровневый режим (raw mode), который вообще не выполняет никакой специальной обработки. Символы, введенные с клавиатуры, становятся доступными процессу чтения, основанному на параметрах системного вызова ioctl(). Ключевые последовательности вроде <Ctrl>+<C> не генерируют никаких специальных действий и передаются, как обычные ASCII-символы. Например, нажатие комбинации клавиш <Ctrl>+ +<С> воспринимается, как ASCII-символ со значением 3. Низкоуровневый режим используется приложениями типа редакторов текста, которые предпочитают делать всю обработку символов самостоятельно.
□ Режим cbreak (cbreak mode), который специально обрабатывает только некоторые ключевые последовательности. Например, поток управления после нажатия комбинаций клавиш <Ctrl>+<S> и <Ctrl>+<Q> остается активным. Точно так же комбинация клавиш <Ctrl>+<C> генерирует сигнал прерывания для каждого процесса, работающего в привилегированном режиме. Как и в низкоуровневом режиме, все символы доступны процессу чтения, основанному на параметрах системного вызова iocti ().
□ Режим с обработкой (cooked mode), иногда известный как канонический режим, который исполняет полную предварительную обработку и постобработку. В этом режиме клавиши удаления и возврата на один символ сохраняют свои специальные значения вместе с менее обычными комбинациями клавиш для удаления слова или строки. Ввод делается доступным процессу чтения только, когда нажата клавиша <Enter>. Точно так же символы табуляции имеют специальное значение при выводе, и они расширены для дисциплины линии, чтобы корректировать число пробелов. Символ перевода строки расширен до пары "перевод карет-ки/перевод строки".
Структуры данных терминала
Основные структуры данных, которые необходимы ядру для реализации дисциплины линии, таковы:
□ С -списки, которые связывают списки массивов символов фиксированного размера. Ядро использует эти структуры для буферизации препро-цессорного ввода, постобработки ввода и вывода, ассоциированные с каждым терминалом;
□ tty-структуры, которые содержат состояние терминала, включая указатели на его С-списки, текущую выбранную дисциплину линии, список символов, которые должны быть обработаны специальным образом, и опции, установленные ioctl (). Существует одна структура tty на терминал.
На рис. 14.54 приведена иллюстрация структуры tty и связанных с ней С-списков.
Рис. 14.54. Структура tty и С-списки
Чтение с терминала
При нажатии клавиши обработчик прерывании клавиатуры, в зависимости от режима терминала, выполняет следующие действия.
□ Низкоуровневый режим. Символ копируется в конец необработанного С-списка, и процесс, ожидающий чтения, пробуждается для чтения из необработанного С-списка. В этот момент все символы из необработанного С-списка перемещаются в адресное пространство процесса.
□ Cbreak-режим. Если символ — это символ управления потоком или символ прерывания, он обрабатывается специальным образом; иначе, символ копируется в конец необработанного С-списка, и ожидающий чтения процесс пробуждается. Когда процесс пробуждается, все символы из необработанного С-списка перемещаются в адресное пространство процесса.
□ Режим с обработкой. Если символ — это символ управления потоком или символ прерывания, он обрабатывается специальным образом; иначе, символ копируется в конец необработанного С-списка. Если символ — это перевод каретки, содержимое необработанного С-списка перемещается в конец входного С-списка обработки, и ожидающий чтения процесс пробуждается. В этот момент специальные символы, типа backspace и delete, во входном С-списке обрабатываются, а затем содержимое копируется в адресное пространство процесса.
Системный вызов iocti () позволяет определять условия, которые должны быть удовлетворены прежде, чем процесс чтения пробудится. Среди этих условий — количество символов в необработанном С-списке и время, прошедшее с последнего системного вызова read (). Если несколько процессов пробуют читать с одного и того же терминала, для синхронизации их действий необходимо обеспечить выполнение условий. Иначе, вход будет разделен без разбора между конкурирующими процессами. Сигналы, генерируемые специальными символами в режиме cbreak и режиме с обработкой, идут в процессы, связанные с терминалом управления (control terminal). (Для дополнительной информации о терминалах управления см. главу 13.)
Запись на терминал
Когда процесс пишет на терминал, любые используемые специальные символы обрабатываются согласно текущей выбранной дисциплине линии, а затем помещаются в конец выходного С-списка терминала. Терминальный драйвер вызывает аппаратные прерывания, чтобы вывести содержимое этого списка на экран. Если выходной С-список полон, процесс записи помещается в сон до тех пор, пока некоторый вывод не попадет на экран.
Потоки
Когда поток создается системным вызовом open (), формируется заголовок потока. Он обеспечивает интерфейс системных вызовов к пользовательскому приложению и содержит структуры данных, которые представляют поток. Заголовок потока управляет последующими вызовами read о, write о, getmsgO или putmsgO, посылая или получая данные от первого модуля в потоке.
Заголовок потока, все модули и драйвер потока работают в режиме ядра. Драйверы потока могут быть вставлены в поток из пользовательского режима. Это делается путем "проталкивания" драйвера в поток. Новый модуль, выдвинутый в поток, попадает на вершину любых существующих модулей (т. е. он связывается с заголовком потока). Список модулей — это LIFO (Last In First Out, последний пришел, первый вышел), т. е. стек. Модули выдвигаются в потоки, когда драйвер установлен в ядре. Подобно традицион
ным драйверам устройств, модули выполняются в режиме ядра и связываются с ядром, когда ядро строится.
Некоторые более новые терминальные драйверы реализуются при помощи архитектуры STREAMS, а не через только что описанный механизм С-списков.
Взаимодействие процессов
Ядро UNIX использует ряд структур данных и алгоритмов, чтобы поддержать конвейеры и сокеты.
Конвейеры
Реализации конвейеров значительно отличаются в System V и BSD, поэтому начнем с описания конвейеров System V.
Конвейеры System V Release 3
В System V есть два вида конвейеров: именованные конвейеры (named pipes) и безымянные конвейеры (unnamed pipes). Именованные конвейеры создаются при помощи системного вызова pipe (), а безымянные конвейеры — при помощи системного вызова mknod (). Данные, записанные в конвейер, хранятся в файловой системе, как показано на рис. 14.55. Когда создается любой вид конвейера, ядро выделяет inode, два элемента открытых файлов и два дескриптора файла.
Область пользователя
Таблица открытых файлов
Таблица активных inode
Диск
Рис. 14.55. Конвейеры системы V.3 хранятся в файловой системе
Первоначально inode описывает пустой файл. Если конвейер именованный, то создается жесткая связь от указанного каталога до inode конвейера; иначе, никакая жесткая связь не создается, и конвейер остается анонимным.
Структуры данных конвейера
Ядро поддерживает текущую позицию записи и текущую позицию чтения для каждого конвейера в его inode, а не в элементе таблицы открытых файлов. Это гарантирует, что каждый байт в конвейере читается точно одним процессом. Ядро также хранит след количества процессов, читающих из конвейера и записывающих в него. Ядру требуются оба счетчика, чтобы должным образом обработать системный вызов close о .
Запись в конвейер
Когда данные пишутся в конвейер, ядро выделяет блок диска и увеличивает по мере необходимости текущую позицию записи до тех пор, пока не будет выделен последний прямой блок. По причинам простоты и эффективности конвейер никогда не выделяет косвенные блоки; это запрещение ограничивает размер конвейера приблизительно до 40 Кбайт в зависимости от размера блока файловой системы. Если бы запись в конвейер вышла за пределы его возможностей хранения, процесс запишет в конвейер, сколько сможет, и затем заснет до тех пор, пока некоторые из данных не будут откачены процессами-читателями. Если процесс-писатель пробует записывать мимо конца последнего прямого блока, позиция записи "заворачивается" к началу файла, начиная со смещения 0. Таким образом, с прямыми блоками обращаются подобно круговому буферу. Хотя может показаться, что использование файловой системы для реализации конвейера будет медленным, следует вспомнить, что блоки диска помещаются в буферный пул, поэтому большинство конвейерного ввода/вывода буферируется в ОЗУ.
Чтение из конвейера
По мере того как данные читаются из конвейера, текущая позиция чтения обновляется. Ядро гарантирует, что позиция чтения никогда не настигает позицию записи. Если процесс пытается читать из пустого конвейера, он переводится в состояние сна до тех пор, пока вывод не станет доступным.
Закрытие конвейера
Когда дескриптор файла конвейера закрывается, ядро осуществляет следующую специальную обработку:
□ модернизирует счетчик конвейерных процессов читателей и писателей;
□ если счетчик процессов-писателей уменьшается до 0, и есть процессы, пробующие читать из конвейера, они возвращаются из системного вызова read () с состоянием ошибки;
□ если счетчик процессов-читателей уменьшается до 0, и есть процессы, пробующие писать в конвейер, им посылается сигнал;
□ если счетчики процессов-читателей и процессов-писателей уменьшаются до 0, блоки всего конвейера освобождаются, и текущие позиции записи и чтения в inode устанавливаются повторно. Если конвейер безымянный, inode также освобождается.
Конвейеры System V Release 4
Начиная с System V Release 4, конвейеры в UNIX были реализованы с использованием архитектуры STREAMS.
Конвейеры BSD
Конвейеры BSD реализованы в терминах сокетов. Дескрипторы файла записи и чтения связаны с анонимной конечной точкой сокета внутри домена системы UNIX.
Сокеты
Полное описание реализации сокетов было бы довольно длинным, требуя объяснения работы адресации в Интернете, маршрутизации и взаимодействия. По этой причине представлен только краткий обзор системы сокетов в терминах управления ее памятью и интерфейса с интернет-протоколами. Для более глубокого обсуждения сокетов, см. главу 13, а также [Stevens 1998].
Управление памятью
Данные, передаваемые между конечными точками сокета, буферируются посредством динамической системы распределения памяти, которая использует пакеты данных фиксированного размера, называемые mbuf. Каждый mbuf имеет длину 128 байтов и разбит следующим образом:
□ буфер размером 112 байтов;
□ область, которая записывает размер данных в буфере;
□ поле, которое записывает смещение данных в буфере.
Процедуры, читающие буферы, могут просто разбирать заголовки протокола, подгоняя размер данных и поля смещения, а не перемещать данные в памяти. Менеджер памяти mbuf достаточно эффективен, и некоторые другие процедуры ядра используют его для целей, не связанных с сокетом.
Сокеты и таблица открытых файлов
Когда создается сокет с помощью системного вызова socket о, система в свою очередь создает структуру сокета, которая записывает всю информацию, имеющую отношение к сокету, включая следующие поля:
□ домен сокета;
□ протокол сокета;
□ указатель на список mbuf сокета.
Чтобы связывать систему дескрипторов файла с системой сокета, ядро хранит указатель от сокетного элемента таблицы открытых файлов к связанной с ним структуре сокета. К этой структуре происходит обращение, когда выполняется сокетный ввод/вывод. Рис. 14.56 показывает диаграмму этого взаимодействия.
Область пользователя
Таблица открытых файлов
Таблица активных inode
Рис. 14.56. Сокеты
Запись в сокет
Данные, записанные в сокет через системный вызов write (), помещаются в выходной список mbuf для передачи модулем протокола.
Чтение из сокета
Данные, которые поступают в модуль протокола, помещаются на входной список mbuf для процесса. Когда процесс выполняет системный вызов read (), данные передаются от входного списка mbuf в адресное пространство процесса.
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
П иерархическое представление подсистем ядра;
П различие между пользовательским режимом и режимом ядра;
П реализацию системных вызовов и обработчиков прерывания;
П физическую и логическую компоновку файловой системы;
□ inode;
П алгоритм, который использует ядро для перевода путевого имени в номер inode;
П иерархию процессов;
П шесть состояний процесса;
П выделение центрального процессора планировщиком;
П управление памятью и MMU;
П подсистему ввода/вывода, включая буферизацию;
П взаимодействие процессов через конвейеры и сокеты.
Контрольные вопросы
1. Почему ядро поддерживает множественные очереди приоритета?
2. Почему системные вызовы используют режим ядра?
3. Что происходит, когда прерывание прерывает другое прерывание?
4. Как конструкция современных дисков пытается увеличить полную емкость хранения?
5. Где хранится имя файла?
6. Какую информацию содержит суперблок?
7. Как UNIX избегает использования Bad-блоков?
8. Почему inode 2 является специальным?
9. Каково значение термина "магический номер"?
10. Каково значение термина "контекстное переключение"?
11. Какая информация хранится в пользовательской области процесса?
12. Если сигнал посылается процессу, который приостановлен, где сигнал хранится?
13. Кратко опишите отображение памяти, которое выполняет MMU.
14. Что делает демон страницы?
15. Как UNIX копирует данные родителя своему дочернему процессу?
16. Каково значение термина "отложенная запись"?
17. В чем назначение таблицы открытых файлов?
18. Каково использование таблицы переключения ввода/вывода?
19. Почему терминальный драйвер UNIX использует С-списки?
20. Каково основное различие реализации конвейера в BSD и System V?
Упражнения
14.1. Используя утилиту ps, найдите процесс в системе с самым низким ID процесса (PID). Что это за процесс и почему он имеет данный PID? [Уровень: легкий.]
14.2. Суперблок содержит много важной информации. Предложите некоторые способы минимизировать разрушение в файловой системе в случае, когда суперблок искажен. [Уровень: средний.]
14.3. Когда создаются очень маленькие файлы, теряется некоторое пространство диска из-за минимального размера выделяемой единицы. Это потраченное впустую пространство называется внутренней фрагментацией. Предложите некоторые способы минимизировать внутреннюю фрагментацию. [Уровень: средний.]
14.4. Отложенная запись обычно заставляет измененный буфер сбрасываться на диск, когда это необходимо ОЗУ, а не в момент закрытия файла. Альтернативный метод состоит в том, чтобы сбрасывать на диск измененные буферы, когда трафик диска низкий, таким образом, улучшая использование времени простоя. Критически проанализируйте эту стратегию. [Уровень: средний.]
14.5. Низкоприоритетное прерывание может быть потеряно, если оно происходит во время обслуживания прерывания с более высоким приоритетом. Как вы думаете, каким образом системное программное обеспечение взаимодействует с потерянным прерыванием? [Уровень: высокий.]
Проекты
1. Исследуйте некоторые операционные системы, например, Mach, Plan 9 и Windows NT. Как они соотносятся с UNIX? [Уровень: средний.]
2. Если вы знаете объектно-ориентированную технику программирования, спроектируйте основное объектно-ориентированное ядро, которое обеспечивает системные услуги через набор системных объектов. Чем конструкция вашего ядра отличается от ядра UNIX? [Уровень: высокий.]
Глава 15
Системное администрирование
Мотивация
Необходимо выполнять администрирование системы UNIX, чтобы позволить ей работать без сбоев. При отсутствии этих действий файлы могут быть потеряны навсегда, утилиты устареть, а система работать медленнее своей потенциальной скорости. Многие инсталляции UNIX достаточно велики и не рассчитаны на один полный рабочий день системного администратора. Независимо от того, собираетесь ли вы выполнять обязанности системного администратора, эта глава содержит ценную информацию о том, как проследить за установкой UNIX.
Предпосылки
Чтобы понимать материал данной главы, следует прочитать главы 1 и 2.
Также поможет изучение глав 4 и 9.
Задачи
В этой главе описываются главные задачи, которые должен выполнять системный администратор, чтобы поддерживать беспрепятственную работу ОС UNIX.
Изложение
Информация представлена в форме нескольких небольших разделов.
Утилиты
Рассматриваются следующие утилиты:
ас getty newfs
accton halt рас
config ifconfig reboot
cron last route
df mkfs shutdown
du mknod su
fsck netstat
Общие сведения о системном администрировании
Задачи, которые системный администратор должен выполнять, чтобы поддерживать правильную работу системы UNIX, включают:
□ запуск и остановку системы;
□ поддержку и восстановление предыдущего состояния файловой системы;
П поддержку учетных записей пользователей;
□ установку операционной системы и прикладного программного обеспечения;
□ установку и конфигурирование периферийных устройств;
□ управление интерфейсом сети;
□ автоматизацию повторяющихся задач;
□ выполнение учетных записей системы;
□ конфигурирование ядра;
□ проверку системы безопасности.
Почти все эти задачи требуют, чтобы администратор находился в режиме привилегированного пользователя (root), т. к. он получает доступ и изменяет важную информацию. Если вы не имеете доступа к паролю привилегированного пользователя, то должны просто использовать ваше воображение. Однако даже в этом случае будьте уверены, что описываемые функции позволят вам лучше понять работу UNIX.
Чтобы глубоко рассмотреть каждую из перечисленных тем, потребовалась бы целая книга, так что эта глава просто представляет краткий обзор администрирования системы. (Для более детальной информации см. [Nemeth 2000]).
Как стать
привилегированным пользователем
Привилегированный пользователь (root) имеет специальный пользовательский ID (0) с разрешением делать фактически все, что угодно в системе UNIX. Поэтому очень важно, что не каждый пользователь имеет доступ к системе, особенно со злонамеренными наклонностями. Большинство задач администрирования требует, чтобы вы имели полномочия привилегированного пользователя, и есть два способа получить их:
□ войти в систему как root (это имя привилегированного пользователя);
□ использовать утилиту su, описанную в главе 3, чтобы создать дочерний shell, принадлежащий root.
Хотя первый метод является прямым, есть некоторые опасности, связанные с ним. Если вы регистрируетесь в системе как root, каждая отдельная команда, которую вы будете выполнять даже с ошибками, получит права привилегированного пользователя. Вообразите печать rm -г*.bak вместо rm-r*.bak в то время, когда текущим является каталог /! Из-за этой проблемы настоятельно рекомендуется всегда использовать второй метод: регистрироваться в UNIX, как обычный пользователь, и становиться привилегированным пользователем только, когда есть необходимость.
Другое преимущество второго метода состоит в том, что утилита su регистрирует в системе использующего ее и лишь в то время, когда она работает. В коллективе, где может быть несколько системных администраторов, иногда трудно удостовериться, что пароль привилегированного пользователя дается только тем, кто действительно нуждается в нем. Наличие регистрации для проверки помогает увидеть, кто использует root-привилегии.
Запуск UNIX
В зависимости от происхождения вашей версии UNIX есть два режима, в которых ОС может работать. Системы UNIX, базирующиеся на BSD, обычно работают в одном из двух режимов.
□ Однопользовательский режим (single-user mode) означает, что единственный пользователь может регистрироваться в системе с системной консоли и выполнять команды shell. В этом режиме система управляет очень немногими системными демонами и вообще используется только для обслуживания системы, резервного копирования и изменения конфигурации ядра.
□ Многопользовательский режим (multiuser mode) означает, что много пользователей могут зарегистрироваться в системе с различных терминалов.
Данный режим имеет активную систему демонов и является эксплуатационным режимом по умолчанию для большинства систем.
Версии UNIX, основанные на System V, работают на различных уровнях управления (run levels). Уровни управления описывают, как работает система (подобно однопользовательскому и многопользовательскому режимам в BSD), но предусматривают большую степень детализации в опциях. Как правило, системы имеют восемь уровней управления: 0—6 и s для однопользовательского режима. Каждый рабочий уровень может иметь свои собственные специфические скрипты загрузки и быть сконфигурирован, чтобы удовлетворить локальные потребности пользователя. Например, можно сконфигурировать рабочий уровень 3, чтобы он обладал всем, что ваша система обычно выполняет в эксплуатационном режиме, кроме приложения базы данных об изделиях вашей компании. Это помогло бы обслуживать базу данных, позволяя другим пользователям использовать остальную часть системы.
Некоторые машины предоставляют возможность выбирать режим путем переключения выключателей на передней панели; другие машины по умолчанию входят в многопользовательский режим, если последовательность загрузки не прерывается нажатием комбинации клавиш <Ctrl>+<C>. Единственный способ узнать, что делает ваша собственная система, это прочитать руководство.
Когда вы включаете компьютер, происходит следующая последовательность событий:
1. Аппаратура производит диагностическое самотестирование. f
2. Ядро UNIX загружается с корневого устройства.
3. Ядро начинает работать и инициализируется.
4. Ядро запускает init, первый процесс в пользовательском режиме.
Процесс init запускается, проверяя непротиворечивость файловой системы, используя утилиту fsck. Если был выбран однопользовательский режим, init создает Bourne shell, связанный с системной консолью. Если был выбран многопользовательский режим, init осуществляет следующие действия:
□ запускает скрипты загрузки системы, которые выполняют задачи инициализации, например, старт почтового демона и очистка каталога /tmp;
□ создает процесс getty для каждого терминала в файле /etc/ttytab, который содержит одну строку информации на терминал в системе, включая его скорость двоичной передачи и путевое имя.
Названия скриптов загрузки изменяются с различными версиями UNIX. Системы, базирующиеся на BSD, обычно выполняют /etc/rc, чтобы запустить стандартные демоны UNIX, и /etc/rc.local, чтобы начать поддержку услуг в местном масштабе. System V объединяет файлы загрузки в более слож
ный набор файлов, группируя их по подсистемам (типа организации сети, диска и т. д.). Эти файлы хранятся в каталоге /etc/rc.d. Процесс getty прослушивает активность на связанном с ним терминале и заменяет себя процессом login, если он обнаруживает чью-то попытку зарегистрироваться в системе. Программа login выводит приглашение для имени пользователя и пароля, сверяет их с элементами в файле /etc/passwd и заменяет себя программой запуска пользователя, если пароль указан верно. Обычно программа запуска — это shell.
Когда пользователь выходит из системы, init получает сигнал sigchld от '’умирающего" shell, удаляет пользователя из файла /etc/utmp (который содержит список всех текущих пользователей) и затем добавляет элемент в файл /var/adm/wtmp (который содержит список всех недавних регистраций в системе и выходов из нее). Наконец, init создает новый процесс getty для освобожденного терминала.
Поведение процесса init может быть изменено путем посылки ему одного из перечисленных ниже сигналов.
□ Сигнал sighup заставляет init повторно просматривать файл /etc/ttytab и создавать процессы getty для всех терминалов в файле, который им необходим. Сигнал также "убивает" getty-процессы, которые не имеют связанного с ними терминала. Таким образом, sighup позволяет добавлять и удалять терминалы без повторной загрузки системы.
□ Сигнал sigterm заставляет init перевести UNIX в однопользовательский режим.
□ Сигнал sigtstp предписывает init не создавать новый процесс getty, когда пользователь выходит из системы. Это позволяет системе постепенно сокращать терминалы.
Для функционирования UNIX процесс init жизненно важен, поскольку он ответственен за создание и поддержку входных shell. Если, по любой причине, процесс init "умирает", происходит автоматическая повторная загрузка системы.
Остановка системы
Современный компьютер хорошо служит своему пользователю, если все время работает; его включение и выключение вызывает проблемы. Однако есть некоторые обстоятельства, при которых лучше всего выключить компьютер. Например, если наступает шторм, вы должны отключить ваш компьютер от источника питания, чтобы избежать скачков высокого напряжения. Систему UNIX нельзя выключить непосредственно. Вместо этого необходимо запустить одну ИЗ утилит: shutdown, halt ИЛИ reboot.
26 Зак. 786
Утилита shutdown может использоваться, чтобы или остановить UNIX, перевести ОС в однопользовательский или многопользовательский режим. Утилита выводит предупреждающее сообщение перед закрытием так, чтобы пользователи могли выйти из системы перед изменением состояния системы. Утилита halt вызывает немедленное закрытие системы без предупреждающих сообщений. Утилита reboot служит для выполнения повторной загрузки системы.
Синтаксис
shutdown -hkrn время [сообщение]
Утилита shutdown закрывает систему постепенно. Время закрытия может быть определено одним из трех способов (в аргументе время):
• now: система закрывается немедленно;
• +minutes: система закрывается через указанное число минут;
I
• hours minutes: система закрывается в указанное время (24-часовой формат).
Заданное сообщение предупреждения (или сообщение по умолчанию, если ничего другого не определено) показывается периодически, когда подходит время закрытия. Регистрационные имена выводятся за пять минут до закрытия.
Когда наступает время закрытия, shutdown выполняет системный вызов sync и затем посылает сигнал sigterm в процесс init. Это заставляет init перевести UNIX в однопользовательский режим. Опция -ь заставляет shutdown выполнить halt вместо посылки сигнала. Опция -г приводит к выполнению reboot вместо посылки сигнала. Опция -п мешает shutdown выполнить по умолчанию его sync. Интересна опция -к: она заставляет shutdown вести себя так, как будто собираются закрывать систему, но когда наступает время закрытия, она ничего не делает. (Опция к происходит от англ, just kidding — просто шучу.)
Синтаксис
halt
Утилита halt исполняет системный вызов sync и затем останавливает ЦП. Она добавляет запись закрытия к файлу /var/adm/wtmp.
Синтаксис
reboot -q
Утилита reboot заканчивает все пользовательские процессы, исполняет системный вызов sync, загружает ядро UNIX с диска, инициализирует систему и затем переводит UNIX в многопользовательский режим. Запись reboot добавляется в конец файла /var/adm/wtmp. Чтобы осуществить быструю повторную загрузку, следует использовать опцию -q. Она указывает reboot не "убивать" текущие процессы перед повторной загрузкой.
г
Поддержка файловой системы
Данный раздел описывает связанные с файловой системой задачи администрирования:
□ обеспечение целостности файловой системы;
□ проверка использования диска;
□ назначение квот;
□ создание новых файловых систем.
Целостность файловой системы
Одно из первых действий, которые выполняет процесс init, — это запуск утилиты fsck, предназначенной для проверки целостности файловой системы. К счастью, утилита fsck очень хороша при исправлении ошибок. Это означает, что пользователь, вероятно, никогда не станет исправлять ошибки диска вручную, как это делалось в "старые добрые времена".
Синтаксис
fsck -р [файловаяСистема]*
Утилита fsck (от англ, file system check — проверка файловой системы) просматривает указанные файловые системы и проверяет их на целостность. Виды ошибок целостности, которые могут существовать, включают следующее:
• блок отмечен, как свободный в битовой карте, но также упомянут в inode;
• блок отмечен, как используемый в битовой карте, но никогда не упоминается в inode;
• больше, чем один inode ссылается на один и тот же блок;
• номер блока недействителен;
• счетчик связей inode неверен;
• используемый inode не упоминается ни в каком каталоге.
Для получения дополнительной информации об inode см. главу 14. Если используется опция -р, утилита fsck автоматически исправляет любые ошибки, которые находит. Без опции -р она выводит приглашение пользователю для подтверждения любых исправлений, которые предлагает. Если fsck находит блок, который используется, но не связан с указанным файлом, она соединяет блок с файлом, чье имя равно номеру inode блока в каталогах /lost и /found. Если файловая система не определена, fsck проверяет стандартную файловую систему, указанную в /etc/fstab.
Использование диска
Ошибки диска редко встречаются и вообще исправляются автоматически. С другой стороны, проблемы использования диска являются общими. Многие пользователи обращаются с файловой системой, как будто она бесконечно большая, и создают огромное число файлов необдуманно. Когда я преподавал UNIX в Техасском университете в Далласе (University of Texas at Dallas), диски неизменно заполнялись в последний день семестра, т. к. все студенты пытались завершить свои проекты. Студенты пробовали сохранить свою работу в редакторе vi, а тот отвечал сообщением "Диск полон" ("disk full"). Когда же студенты выходили из vi, они обнаруживали, что их файлы удалены.
Чтобы избежать истощения пространства диска, благоразумно запускать скрипт shell из утилиты cron, которая периодически выполняет утилиту df, чтобы проверить доступное пространство диска.
Синтаксис
df [-к] [ - Р ] [файловаяСистема]*
Утилита df показывает таблицу используемого и доступного пространства диска для указанных смонтированных файловых систем. Если никакая файловая система не задана, описываются все смонтированные файловые системы. Формат вывода df слегка отличается в разных версиях UNIX. Традиционная df, основанная на версии System V, показывает количество 512-байтовых блоков, в то время как базирующиеся на BSD и более поздние версии df обычно выводят количество блоков в терминах 1024-байтового (1 Кбайт) блока. Расположение информации также изменяется от версии к версии, но почти все версии имеют аргу
менты, которые позволяют задать формат и информацию, которую пользователь желает увидеть. Опция -к позволяет показать счетчик блоков размером 1024 байта. Опция -р служит для вывода сведений в формате POSIX (близко к формату BSD). В некоторых системах, когда используется -к, предполагается -р.
Вот пример df в действии:
$ df ...выводит информацию обо всей файловой системе.
Filesystem kbytes used avail capacity Mounted on
/dev/sd3a 16415 10767 4006 73% /
/dev/sd3g 201631 125513 55954 69% /usr
/dev/sd3d 60015 34773 19240 64% /export
$
Та же самая утилита df произвела бы другой вывод в системе UNIX, бази-
рующейся на System V:
$ df
/ (/dev/sd3a ) : 21£?34 blocks 14922 files
/usr (/dev/sd3g ): 251026 blocks 108277 files
/export (/dev/sd3d ): 69546 blocks 20844 files
$
Обратите внимание на отсутствие заголовка во втором формате. Это может быть полезно, когда производится конвейеризация вывода в другую команду. (Иначе следует удалить заголовок, если обращаться с каждой строкой, как с информацией файловой системы.) Заметьте также, что количество используемых блоков различно в разных версиях, потому что не одинаков размер блока, используемого для подсчета. Во второй системе использование команды df -Pk сгенерировало бы вывод, подобный первому примеру.
Пользователь может получать информацию об определенной файловой системе, явно определяя ее имя или точку монтирования, как в следующих командах:
$ df /dev/sd3a ...вывести конкретную файловую систему.
Filesystem kbytes used avail capacity Mounted on
/dev/sd3a 16415 10767 4006 73% /
$ df / ..точка монтирования также работает •
Filesystem kbytes used avail capacity Mounted on
/dev/sd3a 16415 10767 4006 73% /
$ _
Также легко определить, сколько осталось дискового пространства на устройстве, на котором находится домашний каталог пользователя: $ df . Filesystem kbytes used avail capacity Mounted on
/dev/sd3d 4194304 4194304 . 0 100% /home
Если утилита df сообщает, что диск полон больше, чем на 95%, пользовательский скрипт мог бы обнаружить это и посылать некоторое предупреждающее сообщение. Даже лучше, если скрипт запустит утилиту du, чтобы определять, какие пользователи занимают большинство дискового пространства, и автоматически посылать этим пользователям почтовое сообщение, предлагающее удалить некоторые файлы.
Синтаксис
du [—s] [-к] [имяФайла]*
Утилита du показывает количество килобайт (BSD) или 512-байтовых блоков (System V), которые выделены каждому из указанных файлов. Если имя файла ссылается на каталог, его файлы рекурсивно характеризуются. Утилита du с опцией -s показывает только общее количество для каждого файла. Когда добавляется опция -к, пространство всегда сообщается в килобайтах. Если никакое имя файла не определено, то просматривается текущий каталог.
В представленном ниже примере утилита du применяется для выяснения, сколько килобайт занимают текущий каталог и все его файлы, после чего появляется пофайловое разбиение диска:
$ du -s ...получить общую сумму текущего каталога.
9291 .
$ du ... получить пофайловый листинг.
91 ./proj/fall.89
158 ./proj/summer.89/proj4
159 ./proj/summer.89
181 ./proj/spring.90/proj2
21 ./proj/spring.90/proj1
204 ./proj/spring.90
455 ./proj
...другие файлы выводились здесь.
38 ./sys5 859 ./sys6 9291 .
$
Назначение квот
Некоторые системы позволяют системному администратору устанавливать квоты диска для индивидуальных пользователей. Можно определить максимальное количество файлов и блоков, которые позволено создать конкретному пользователю. Довольно сложно добавлять квоты, ведь выполнение этого может повлечь за собой переконфигурирование ядра, обновление файла /etc/ге, изменение файла /etc/fstab и создание файла управления квотами. Квоты реализованы по-разному в различных версиях UNIX, так что лучше всего обратиться за справкой к документации своей системы.
Создание новых файловых систем
Если вы покупаете новый диск, то должны выполнить следующие работы прежде, чем ваша файловая система сможет использовать его:
1. Отформатировать носитель информации.
2. Создать новую файловую систему на носителе информации.
3. Смонтировать диск в корневую иерархию.
Изготовитель устройства может снабдить вас утилитой форматирования. В этом случае используйте ее, чтобы выполнить шаг 1. Если ваша версия UNIX имеет команду format, это также может работать. Конкретные средства являются индивидуальными для системы, так что вновь обратитесь за справкой к документации своей системы о форматировании носителя информации.
Далее создайте файловую систему на носителе информации, используя утилиты mkfs ИЛИ newfs.
Синтаксис
mkfs специальныйФайл [размерСектора]
Утилита mkfs создает новую файловую систему на указанном специальном файле. Новая файловая система состоит из суперблока, списка inode, корневого каталога и объединенного каталога lost и found. Файловая система строится с секторами размером размерСектора. Эту утилиту может использовать только привилегированный пользователь (root).
Поскольку маловероятно, что вы знаете правильное значение для параметра размерСектора без осведомления в руководстве изготовителя, была разработана утилита newfs (доступная в большинстве (но не во всех версий) UNIX), как дружественный внешний интерфейс утилиты mkfs. Обратите внимание, что newfs может работать, если геометрические сведения о носителе информации указаны в файле /etc/disktab.
Синтаксис
newfs special File deviceType
i • '
Утилита newfs вызывает mkfs После просмотра sectorCount deviceType в файле /etc/disktab, который содержит информацию о стандартных характеристиках устройства.
Как только файловая система будет создана, ее можно связать с файловой системой корня через утилиту mount, описанную в главе 3.
Создание резервных копий файловых систем
Создание резервной копии информации файловой системы наиболее важно и чаще всего игнорируется системным администратором. Обидно тратить время на эту работу, т. к. предполагается, что никогда не возникнет нужда в резервной копии информации. Но точно так же, как покупка страховки для автомобиля: вы должны делать это, потому что, если она когда-либо вам понадобится, будет масса проблем при ее отсутствии. Процедура и утилиты для поддержки файловой системы описаны в главе 3.
Поддержка пользовательских учетных записей
Одна из самых обычных задач системного администрирования — это добавление нового пользователя в систему. Чтобы сделать это, нужно:
□ добавить новый элемент в файл паролей;
□ добавить новый элемент в файл групп;
□ создать домашний каталог для пользователя;
□ предоставить пользователю некоторые соответствующие файлы запуска.
Файл паролей
Каждый пользователь системы имеет элемент в файле паролей (обычно /etc/passwd), в формате
username:password:userid:groupld:personal:homedir:startup
где каждое поле имеет значение, описанное в табл. 15.1.
Таблица 15.1. Поля файла паролей UNIX
Поле Описание
username Регистрационное имя пользователя
password Зашифрованная версия пароля пользователя
userid Уникальное целое, выделенное пользователю
groupld Уникальное целое, относящееся к группе пользователя
personal Описание пользователя, которое выводится утилитой finger
homedir Домашний каталог пользователя
startup Программа, которая выполняется для пользователя во время регистрации в системе
Так как поле пароля — это зашифрованное значение, помещение любого единственного символа в это поле эквивалентно отмене регистрационной записи в рассматриваемом элементе. Нет такой строки, которую вы могли бы напечатать и которая не будет зашифрована. Например, звездочка (*) в тексте (означает любой вводимый символ) будет соответствовать какому-нибудь символу (или строке) в поле пароля после шифрования. Вот фрагмент файла паролей из реальной жизни:
$ head -5 /etc/passwd ...посмотреть первые пять строк.
root:refsmtio:0:0:Operator:/:/bin/csh
daemon:*:1:1::/:
sync:*:1:1::/:/bin/sync
sys:*:2:2::/:/bin/csh
bin:*:3:3::/bin:
$ _
Я использовал утилиту grep, чтобы найти собственный элемент:
$ grep glass /etc/passwd ...найти мою строку.
glass:dorbnla:496:62:Graham Glass:/home/glass:/bin/ksh
Файл групп
Чтобы добавить нового пользователя, следует решить, в какой группе будет находиться пользователь, а затем найти файл групп, чтобы выяснить связанный с пользователем ID группы. Приведем пример добавления нового пользователя по имени Саймон в группу cs4395.
Каждая группа в системе имеет элемент в файле групп (обычно /etc/group) в формате
groupname:groupPassword:groupld:users
где каждое поле определено в табл. 15.2.
Таблица 15.2. Поля файла групп UNIX
Поле Описание
groupname Имя группы
groupPassword Зашифрованный пароль для группы (не используется и часто заполняется звездочкой (*))
groupld Уникальное целое, относящееся к группе
users Список пользователей в группе, отделенных запятыми
Вот отрывок из реального файла /etc/group:
$ head -5 /etc/group ...посмотреть начальный файл групп.
cs4395:*:91:glass
cs5381:*:92:glass
wheel:*:0:posey,aicklen,shrid,dth,moore,lippke,rsd,garner
daemon:*:1:daemon
sys:*:3:
$ _
Как видно, группа cs4395 имеет связанный ID группы с номером 91. Чтобы добавить Саймона в качестве нового пользователя, ему выделен уникальный пользовательский ID-номер 10 и ID группы 91, а поле пароля оставлено пустым. Вот как его элемент выглядел:
simon::101:91:Simon Pritchard:/home/simon:/bin/ksh
Поскольку элемент был добавлен к файлу паролей, сведения о Саймоне добавлены в конец списка cs4395 в файле /etc/group, создан его домашний каталог и переданы некоторые файлы запуска по умолчанию, такие как .kshrc и .profile. Эти файлы скопированы из каталога /usr/template, который я создал для хранения версий по умолчанию пользовательских файлов запуска.
Команды таковы:
$ mkdir /home/simon
$ ср /usr/template/- /home/simon
$ chown simon /home/simon /home/simon/.*
$ chgrp cs4395 /home/simon /home/simon/.* $
...создать домашний каталог.
...копировать файлы запуска.
...установить владельца.
...установить группу.
Наконец, была выполнена регистрация пользователя Саймона и запущена утилита passwd для изменения его пароля на разумное значение по умолчанию.
Чтобы удалить пользователя, выполните описанные действия в обратном порядке: удалите элемент пароля пользователя, элемент файла групп и домашний каталог.
Установка программного обеспечения
Установка нового программного обеспечения или модернизация существующего является важной задачей системного администратора. Однако детали могут сильно изменяться от узла к узлу. Если некто поддерживает большой узел со множеством серверов на базе сетевой файловой системы (Network File System, NFS), он может установить приложение на сервере так, чтобы рабочие станции могли получить доступ к нему из одной точки. На меньшем узле или при наличии более дорогого программного обеспечения его можно установить только на тех машинах, где это необходимо.
Давняя традиция для UNIX была такой, что локальное программное обеспечение (ПО) должно было устанавливаться в каталоге /usr/local. Это делало очевидным отсутствие ПО в дистрибутиве UNIX. Через какое-то время продавцы изменили имя "стандартного” каталога, который предназначен для прикладного программного обеспечения (например, Sun использует /opt для дополнительного программного обеспечения, a AIX — /usr/lpp для лицензированных программных продуктов). Можно определить один или несколько каталогов, но важно поддержать некоторую логику в структуре так, чтобы легко можно было найти необходимые программы. С философской точки зрения, есть два способа установить программное обеспечение. Один подход — это создать каталог для программного обеспечения и поместить все. что требуется (кроме, возможно, системных файлов), в этот каталог. Например, если создается приложение pianoman, можно записать инструментальные средства установки для него в предположении, что оно будет установлено в каталог /opt/pianoman. Если пользователь хочет установить его в каталог /usr/local/pianoman, он должен иметь возможность сделать это. Другой подход состоит в том, чтобы поместить программное обеспечение
только в основной каталог, а любые необходимые конфигурационные, заголовочные или библиотечные файлы записать в более централизованное место для этих типов файлов. Пример здесь может быть такой, требуемое программное обеспечение для построения приложения может находиться в каталоге /usr/local/pianoman, но когда оно установлено в системе, исполняемый файл копируется в каталог /usr/local/bin/pianoman, а используемая им библиотека помещается в файл /usr/local/lib/pianolib.a. Этот метод имеет преимущества и недостатки. Главное преимущество состоит в том, что пользовательское сообщество не должно добавлять другой каталог к определению $ратн, т. к. двоичный код находится в "известном" месте (/usr/local/bin), которое уже присутствует в списке путей. Главное неудобств^ в том, что пользователь имеет файлы, распределенные по многим другим каталогам помимо /usr/local/pianoman.
Предпочтение пользователя в установке программного обеспечения может зависеть от подразумеваемого метода, который выбрал разработчик программного обеспечения. Любой хороший инструментарий установки (скрипт или программа) должен позволить изменять предлагаемое по умолчанию место установки. Несмотря на то, что легче согласиться с предлагаемыми установками, если они разумным образом вписываются в общее окружение, пользователь свободен в их конфигурировании. Любое программное обеспечение, которое твердо кодирует место установки, является плохо разработанным.
Утилиты tar и cpio — это два наиболее популярных метода создания образа установки для системы UNIX. Преимущество здесь в том, что обе утилиты уже существуют в большинстве версий UNIX. Скрипт shell, который использует tar и- другие стандартные команды UNIX для установки программного обеспечения, может работать в большинстве систем UNIX без требования другого программного обеспечения. Некоторые продавцы UNIX обеспечивают собственные улучшенные средства установки ПО (например, HP-UX имеет утилиту swinstaii, a AIX — утилиту instaiip). Конечно, эти средства лучше, чем общие команды UNIX, но неудобство состоит в том, что при их применении пользователь "запирает" себя в одной архитектуре. Конечно, можно писать инструкции установки для каждого средства, но это влечет больше работы, чем написание всего одного метода установки для всех UNIX-платформ, которые ваше приложение поддерживает. Лучший выбор метода установки сильно зависит от целевых клиентов, их платформ и опыта работы с инструментами UNIX.
Как администратор системы UNIX, вы столкнетесь почти со всеми возможностями и должны знать, как лучше всего интегрировать приложение в локальное окружение.
Периферийные устройства
Предположим, вы только что купили новое устройство и хотите присоединить его к своей системе. Как вы его установите? Кроме того, если это — терминал, какие специфические для терминала файлы должны быть обновлены? Следующие разделы представляют краткий ‘обзор установки устройства и список связанных с терминалом файлов.
Установка драйвера устройства
Чтобы система была способна "говорить" с новым устройством, аппаратура должна быть подключена, а программное обеспечение установлено или активизировано. Некоторые системы требуют, чтобы новые драйверы устройства были загружены в ядро, и ядро должно быть переконфигурировано. Другие могут использовать динамически загружаемые драйверы устройств, которые загружаются в ядро при обращении к устройству. Основные шаги установки устройства таковы:
1. Установить драйвер устройства, если он в настоящее время не в ядре и если загружаемый драйвер устройства не используется.
2. Определить старший и младший номера устройства.
3. Использовать утилиту mknod, чтобы связать имя файла в каталоге /dev с новым устройством.
Как только драйвер устройства установлен, и старший и младший номера известны, следует запустить утилиту mknod, чтобы создать специальный файл.
Синтаксис
mknod имяФайла [с] [Ь] старшийНомер младшийНомер mknod имяФайла р
Утилита mknod СОЗДаеТ специальный файл имяФайла в файловой системе.
Первая форма mknod позволяет привилегированному пользователю (root) создавать либо специальный символьный файл (с), либо специальный блочный файл (ь) с указанными старшим и младшим номерами. старшийНомер идентифицирует класс устройства, а младшийНомер — экземпляр устройства.
Вторая форма mknod создает именованный конвейер и может использоваться любым пользователем.
В представленном ниже примере установлен 13-й экземпляр терминала, чей старший номер был равен 1:
$ mknod /dev/tty!2 с 1 12 ...заметьте: 13-й экземпляр, а индекс 12.
$ _
Буква с указывает, что терминал — это символьное устройство.
В следующем примере задается первый экземпляр дискового устройства, чей старший номер был равен 2:
$ mknod /dev/dkl b 2 0 ...заметьте: 1-й экземпляр, а индекс 0.
$ _
Буква ь указывает, что диск — это блочное устройство.
Старший и младший номера — это, соответственно, четвертое и пятое поле в листинге команды is -1. В следующем примере выводится длинный листинг каталога /dev:
$ Is -1 /dev ...получить длинный листинг каталога устройств
crw—w—w— 1 root 1, 0 Feb 13 14:21 /dev/ttyO
Crw—w—w— 1 root 1, 1 Feb 13 14:27 /dev/ttyl
brw—w—w— 1 root 2, 0 Feb 13 14:29 /dev/dkO
crw—w—w— 1 root 3, 0 Feb 13 14:27 /dev/rmtO
$ _
Терминальные файлы
Несколько файлов содержат информацию, специфическую для терминала. В табл. 15.3 перечислены эти файлы и представлено краткое описание их функций.
Таблица 15.3. Системные файлы UNIX, содержащие информацию о терминалах
Имя Описание
/etc/termcap или /etc/terminfo Кодированный список возможностей каждого стандартного терминала и кодов управления. Редакторы UNIX используют значение переменной окружения $term, как индекс в этот файл, и получают характеристики терминала пользователя
/etc/ttys Список, содержащий сведения о каждом терминале в системе, вместе с программой, которая должна быть связана с ним, когда система инициализируется (обычно процесс getty). Если тип терминала постоянен и известен, эта информация также включается
Zetc/gettytab Список информации о скорости двоичной передачи, которая используется процессом getty при определении, как слушать терминал регистрации в системе
Сетевой интерфейс
Важный этап администрирования системы — так настроить UNIX-машину, подключенную к локальной сети, чтобы другие машины и все пользователи могли связываться с ней. Некоторые необходимые для этого основные концепции и инструментарий обсуждались в главе 9. Поскольку детали сильно изменяются в различных версиях UNIX, в данной главе будут затронуты только главные моменты. Для подробного изучения сетевого администрирования настоятельно рекомендуется прочитать [Nemeth 2000].
Если ваша сеть не является беспроводной, некоторый сетевой кабель должен быть связан с вашим UNIX-компьютером для взаимодействия с сетью. Компьютер должен иметь назначенные ему IP-адрес и имя хоста, а остальная часть сети должна знать их (путем обновления локальной таблицы хостов или базы данных DNS).
Большинство систем использует утилиту ifconfig, чтобы сконфигурировать интерфейс сети. Типичный способ активизировать его таков:
$ ifconfig НО 194.27.1.14 up
Это вызывает назначение IP-адреса 194.27.1.14 интерфейсу ПО (это имена устройств где-нибудь в иерархии каталогов /dev) и конфигурирует его, чтобы он появился. Другие признаки IP могут также быть сконфигурированы с помощью утилиты ifconfig. Запуск утилиты можно осуществить вручную с терминала. Кроме того, она обычно находится в загрузочных скриптах, которые инициализируют все сетевые интерфейсы. Когда пользователь добавляет сетевой интерфейс, он должен указать команду конфигурации в соответствующем файле загрузки.
Чтобы UNIX-машина взаимодействовала с любым другим компьютером, который непосредственно не связан с тем же самым сетевым кабелем (сегмент), должна быть определена информация маршрутизации на этой машине. Утилита route служит для определения маршрутизаторов, которые обеспечивают путь к другим сетям. Вообще, достаточно удостовериться в том, что установлен маршрут по умолчанию. Этому маршрутизатору будет послан пакет, когда пункт назначения находится не в локальной сети. Пакет посылается подразумеваемому маршрутизатору с предположением, что другие маршрутизаторы будут знать, как добраться к пункту назначения.
Можно посмотреть свою текущую таблицу маршрутов при помощи утилиты netstat, указав опцию -г:
$ netstat -г
Routing tables
Destination Gateway Flags Refs Use If
194.27.1.0 194.27.1.1 U 1 16611 ill
default 194.21.1.1 UG 0 231142 ilO
$ _
Эта машина "знает” о двух маршрутизаторах, 194.21.1.1 является путем по умолчанию. Любой адрес вне локальной сети и вне сети 194.27.1 будет послан 194.21.1.1 для направления к пункту назначения.
Автоматизация задач
Некоторые задачи системы довольно просты, но утомительны для исполнения:
□ добавление учетной записи пользователя;
□ удаление учетной записи пользователя;
□ проверка заполнения дисков;
□ генерация отчетов о входе в систему и выходе из нее;
□ выполнение инкрементного резервного копирования;
□ учет системных ресурсов;
□ удаление старых файлов ядра;
□ устранение процессов-зомби.
Одна из способностей UNIX — это его возможность облегчить программисту написание простых скриптов shell или С-программ для автоматизации задач, которые выполняются вручную. Рекомендуется автоматизировать столько задач, сколько возможно. Периодически выполняемые задачи могут быть запланированы при помощи утилиты cron. Она работает по-разному в различных версиях UNIX, но вообще, позволяет запланировать программу, чтобы она выполнялась с периодичностью от одного раза в минуту до одного раза каждый год. Любые сообщения, генерируемые программой, посылаются через электронную почту пользователю, зарегистрировавшему программу.
Например, ниже приведен простой скрипт, позволяющий выяснить, является ли любая из файловых систем заполненной на 95% или больше:
# !/bin/sh #
df | egrep "9 [56789]%1100%"
Если этот скрипт регистрируется привилегированным пользователем (root) утилитой cron, которая должна работать каждый час, пока файловая система не будет заполнена на 95% или больше, ничего (во всяком случае, видимого) не происходит. Скрипт запускается каждый час, но никакой вывод не производится. Когда файловая система доходит до 95%, образец поиска,
указанный к утилите egrep, будет соответствовать строке для утилиты df и сообщать о нарушении в файловой системе, так что скрипт сгенерирует строку вывода. Строка будет послана по электронной почте привилегированному пользователю, так что в течение одного часа можно узнать о заполнении файловой системой 95% дискового пространства.
Учет системных ресурсов
Возможности UNIX по учету системных ресурсов позволяют отслеживать деятельность подсистем этой ОС. Каждая подсистема хранит запись своей истории в специальном файле, как описано ниже.
□ Управление процессами. Запись пользовательского ID, использования памяти и ЦП каждым процессом добавляется к файлу /usr/adm/acct. Для получения отчета о содержимом данного файла можно запустить утилиту sa. Учет системных ресурсов включается утилитой accton.
□ Связи. Запись времени регистрации в системе, пользовательский ID и время выхода из системы каждого соединения добавляются к файлу /usr/adm/wtmp. Утилиты ас и last могут применяться для просмотра информации в этом файле. Учет системных ресурсов связи становится возможным за счет присутствия файла /usr/adm/wtmp.
□ Использование принтера. Каждый принтер записывает сведения о своих заданиях в каталоге /usr/adm. Утилита рас может генерировать отчеты из этой информации. Учет ресурсов принтеров включается записью в файле /etc/printcap.
□ Другие подсистемы, вызывающие такие утилиты, как uucp и quota, также генерируют регистрационные файлы.
Различные подсистемы создают файлы, которые конвертируются в отчеты скриптами shell и утилитами. Администратор системы ответственен за поддержку отчетов учета ресурсов целевых подсистем и за периодическую чистку и архивирование файлов учета системных ресурсов.
Конфигурирование ядра
Ядро UNIX — это программа, написанная главным образом на С, с несколькими секциями на ассемблере. Производитель UNIX включает несколько частей программного обеспечения, связанных с ядром:
□ общее выполняемое ядро;
□ библиотеку объектных модулей, соответствующих частям ядра, которые никогда не изменяются;
□ библиотеку модулей С, соответствующих частям ядра, которые могут быть изменены;
□ файл конфигурации, описывающий текущую установку ядра;
□ утилиту config, которая позволяет повторно собрать ядро, когда изменен файл конфигурации.
Файлы конфигурации ядра сохраняются в каталогах /usr/conf (BSD) или /usr/src/uts/cf (System V). Части ядра, которые могут быть изменены, включают:
□ драйверы устройств;
□ максимальное количество открытых файлов, С-списков, квот и процессов;
□ размер буферного пула ввода/вывода и таблицы системных страниц;
П некоторую важную сетевую информацию;
□ физические адреса устройств;
□ имя машины;
□ временную зону машины.
Чтобы повторно скомпилировать новое ядро, необходимо следовать многошаговому процессу:
1. Отредактируйте файл конфигурации и замените значения параметров новыми.
2. Запустите утилиту config, которая создает некоторые заголовочные файлы, некоторый исходный код С и make-файл.
3. Выполните утилиту make, передавая ей имя make-файла, созданного config. Сделайте повторную компиляцию недавно созданного исходного кода и скомпонуйте его с неизменяющейся частью ядра, чтобы создать новый исполняемый код.
4. Переименуйте старое ядро UNIX.
5. Переименуйте новое ядро UNIX, чтобы поместить его на место старого.
6. Повторно загрузите систему.
Проблемы безопасности
Безопасность — это тема, которой можно посвятить целую книгу для досконального обсуждения. За дополнительной информацией рекомендуется обратиться к [Garfinkel 1996] и [Curry 1992], а также прочитать главу о безопасности в [Nemeth 2000].
Как вы, без сомнения, знаете, UNIX-системы не являются безопасными на 100%. Ни один компьютер, подключенный к сети, не может быть безопас
ным. Со взрывом интернет-взаимодействий количество проблем только увеличилось.
Система UNIX первоначально не была разработана в расчете на безопасность. Изначально пользователи UNIX доверяли друг другу, и не было потребности в безопасности. Большинство UNIX-систем в настоящее время весьма безопасны, но это произошло только после многих лет выявления слабостей и их устранения.
Среди аспектов безопасности UNIX есть такие, с которыми каждый пользователь имеет дело. Это права доступа к файлу и пароли. Данные механизмы противостоят обычным пользователям при попытках взлома, но не составляют проблемы для опытных хакеров.
Лучшее, что может сделать системный администратор, — это постоянно читать об известных лазейках в системе безопасности и адаптировать известные стратегии. Чтобы поставить читателя в известность, чего следует опасаться, ниже описана пара обычных методов вскрытия паролей.
□ Если пользователь имеет обычную регистрацию в системе и хочет получить регистрацию привилегированного пользователя, он начинает с получения копии одностороннего алгоритма шифрования, который использует утилита passwd UNIX. Для этого приобретается электронный словарь. Далее пользователь копирует файл /etc/passwd на свой домашний PC и сравнивает зашифрованные версии каждого слова в словаре с зашифрованным паролем привилегированного пользователя (root). Если один из элементов словаря совпадает, можно считать, что пароль взломан! Другие обычные методы проверки паролей заключаются в проверке имен и слов, записанных наоборот. Эта техника грубой силы очень мощна, и ей можно противостоять путем просьбы к каждому пользователю выбирать неанглийский язык, необратные и нетривиальные пароли.
□ Коварный индивидуум может использовать технику перегрузки команды, описанную ранее, чтобы обмануть привилегированного пользователя при выполнении неправильной версии su. Чтобы использовать эту технику "Троянского коня", установите значение переменной окружения $ратн так, чтобы shell просматривал ваш собственный каталог bin перед стандартными каталогами bin. Затем напишите скрипт shell с именем su, который имитирует предложение регистрации привилегированному пользователю, но в действительности сохраняет его пароль в безопасном месте, выводит сообщение "Wrong password" и затем удаляет себя. Когда этот скрипт подготовлен, позвоните привилегированному пользователю и сообщите ему, что с вашим терминалом возникла проблема, которая требует установки полномочий привилегированного пользователя. Когда администратор напечатает su, чтобы войти в режим привилегированного пользователя, ваш скрипт su выполнится вместо стандартной утилиты su, и пароль привилегированного пользователя будет захвачен. Привилеги
рованный пользователь увидит сообщение "Wrong password" и попробует запустить su снова. На сей раз это у него получится, поскольку ваш скрипт "Троянского коня" уже будет удален. Пароль привилегированного пользователя теперь ваш! Способ нанести поражение этой технике — не выполнять команды с относительным путевым именем, когда вы работаете за незнакомым терминалом. Другими словами, указывайте /bin/su вместо просто su.
Лучший способ расширять свои знания о хитрых схемах — это общаться с другими системными администраторами и читать специализированную литературу, например, [Nemeth 2000J.
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
П главные задачи системного администратора;
□ способы получения полномочий привилегированного пользователя;
П запуск и остановку UNIX;
□ различия между однопользовательским и многопользовательским режимами;
□ некоторые полезные утилиты использования диска;
□ инсталляцию программного обеспечения;
П создание новой файловой системы;
□ добавление и удаление регистрационных записей пользователей;
□ обзор инсталляции устройств;
□ конфигурацию сетевого интерфейса;
П процесс создания нового ядра;
П некоторые общие проблемы безопасности.
Контрольные вопросы
1. В каких ситуациях уместно остановить систему UNIX?
2. Почему теперь большинство версий UNIX использует "теневой" файл паролей в дополнение к нормальному файлу /etc/passwd?
3. Что делает процесс getty?
4. Почему лучше использовать утилиту su, чтобы стать привилегированным пользователем, чем просто регистрироваться как root?
5. Как вы можете переключить UNIX в однопользовательский режим?
6. Когда проверяется целостность файловой системы?
7. Какие файлы должны быть модифицированы, когда вы добавляете нового пользователя?
8. Что делает утилита if config?
9. Какие подсистемы UNIX генерируют учетные записи?
10. Какие параметры ядра могут быть модифицированы?
И. Опишите технику "Троянского коня", чтобы захватить пароль привилегированного пользователя.
Упражнения
15.1. Попытайтесь, используя утилиты cpio и tar, переместить некоторые файлы на дискету и с дискеты. Какую из этих утилит вы предпочитаете? Почему? [Уровень: легкий.]
15.2. Запустите утилиту du, чтобы исследовать использование своего диска. Напишите скрипт, распечатывающий полные путевые имена ваших файлов, которые отсортированы по размеру файла. [Уровень: средний.]
15.3. Получите дискету, отформатируйте ее, на ней создайте файловую систему, установите ее и скопируйте на нее некоторые файлы. Конечно, вы будете нуждаться в помощи системного администратора, который поможет вам пройти через этот процесс. [Уровень: средний.]
15.4. Заполните функциональные возможности структурного скрипта, который вы написали в проекте 1 главы 6 так, чтобы он исполнял задачи администрирования системы в вашем управляемом при помощи меню интерфейсе. Полезные задачи для автоматизации должны включать:
• автоматическое удаление базовых файлов;
• автоматические предупреждения тем, кто использует много времени ЦП или дискового пространства;
• автоматическое архивирование.
[Уровень: средний.]
Проект
Спросите вашего системного администратора, что он думает о сильных и слабых сторонах UNIX со своей точки зрения. Возможно ли решить эти проблемы текущими релизами UNIX или другими операционными системами? [Уровень: средний.]
Глава 16
Будущее
Мотивация
Операционные системы продолжают развиваться и улучшаться по мере того, как развиваются программное обеспечение и аппаратные средства. Хотя старые, застойные системы неизбежно долгое время будут бродить вокруг, системы, которые включают лучшие концепции, и философии, в конечном счете, заменят их. UNIX существует больше, чем 30 лет, и этот возраст начинает влиять на внутреннюю архитектуру ОС. Знание тенденций операционных систем поможет читателю понять изменения, которые могут произойти в UNIX в следующие несколько лет, также как позволит примерно определить перспективную роль UNIX.
Предпосылки
Данная глава не имеет никаких предпосылок, хотя может помочь чтение главы 14.
Задачи
Глава описывает последние тенденции в проектировании операционных систем, которые влияют на развитие UNIX. Быстрый обзор главных версий ОС, находящихся сегодня в широком применении, готовит читателя к дальнейшей работе с UNIX.
Изложение
В главе исследуются темы, которые изменяют облик UNIX, и описываются некоторые примеры этих влияний в различных современных версиях UNIX и Linux.
Общие сведения
В качестве преамбулы к этой главе рассмотрим некоторые из самых последних тенденций в программном обеспечении и аппаратных средствах ЭВМ: □ объектно-ориентированное программирование;
□ программные продукты с открытым исходным текстом;
□ распределенное и параллельное программирование;
□ движение от 32- к 64-разрядным системам и сетевой адресации;
□ высокоскоростная связь и отказоустойчивые системы.
Эти тенденции представляют волнующее и интересное будущее для UNIX и вычислительной техники вообще. Чтобы воспользоваться данными преимуществами, программное обеспечение, которым является UNIX, также как платформы аппаратных средств, на которых она работает, обязаны приспособиться к изменяющимся обстоятельствам.
Влияние настоящего и будущего на UNIX
Много современных тем в теории вычислительных систем и усовершенствованиях аппаратных средств будут иметь сильное влияние на будущие сферы UNIX-систем. Некоторые уже повлияли и продолжают это делать. Другие лишь теперь входят в поле зрения.
Объектно-ориентированное программирование
Объекты ответственны за большую деловую суету в компьютерной промышленности в течение многих последних лет. Наиболее популярные объектно-ориентированные языки, которые сегодня используются в окружении UNIX, — это C++ и Java. С одной стороны, во многих ситуациях объектно-ориентированная парадигма может сильно увеличивать производительность разработки и сопровождения программных проектов. С другой стороны, использованные просто потому, что они ’’крутые", объекты могут фактически вызывать хлопоты.
Давайте бросим беглый взгляд на объектно-ориентированное программирование. Очевидно, все, что мы скажем, будет чрезвычайным упрощением. Целые тома были написаны об объектах и философии их использования; надежда сделать больше, чем просто разжечь аппетит читателя в нескольких разделах, была бы безрассудна.
Что такое объект?
Объект — это абстракция, способ описать цель и использование данных. В традиционном процедурном программировании определяются структуры данных и затем выполняются действия над этими данными. Программа должна была "знать”, какие данные были применимы к каким функциям, и какие действия могли быть выполнены над данными.
Объект создается в соответствии с определением класса объекта. Думайте о классе, как о проекте дома —- как вы собираетесь строить его — и объекте, как о доме. С помощью единственного проекта можно построить много зданий. В своем коде вы определяете класс, или проект объекта, а затем, т. к. вы должны работать с данными, создаете, или instantiate, так мало или так много объектов этого класса, как необходимо.
Идея объектно-ориентированного программирования состоит в том, что вместо простого выполнения процедурных действий на данных вы концептуально заключаете, или инкапсулируете, данные в объекте. Внутри этого объекта вы определяете набор функций, или методов, которые могут работать на определенных данных, поддержанных в объекте. Вызывая метод объекта, можно потребовать, чтобы объект выполнил одну из его функций, но нельзя получить доступ к данным непосредственно. Это защищает данные от любого вида случайной модификации, которая могла бы произойти, потому что модифицирующий код "думает", что он "знает" формат данных, но есть ошибка в коде или изменился формат данных.
Как объект используется
В дополнение к любым специфическим методам один определен для любого объекта, два других метода всегда определяются. Каждый объект должен иметь способ создания и удаления. В большинстве объектно-ориентированных языков конструкции, которые выполняют эти задачи, называются соответственно конструкторами и деструкторами)
Конструктор — это специальный метод, который выполняется, когда создается новый экземпляр объекта. В C++ и Java это происходит, когда функция new вызывается на тип объекта. Конструктор создает и инициализирует любые данные, используемые объектом.
Деструктор, как вы могли бы догадаться, делает противоположные конструктору действия. Деструктор — это специальный метод, который наводит порядок, когда объект удаляется. Выполняется любая требуемая завершающая обработка, и все ресурсы, которые были выделены, освобождаются. В С ++ это происходит, когда функция delete вызывается на объекте.
1 Java не предусматривает деструкторы, но возвращает память, используемую объектом во время "сборки мусора", когда объект больше не находится в использовании.
Так чем же хорошо все это?
В качестве простого примера рассмотрим принтер, который способен находиться в режиме online (печать) или offline (автономно, не принимать данные для печати). Принтер мог бы иметь байт, который определяет текущий режим (скажем, 1 — для режима online, 0 — для автономного). Можно, конечно, написать программу, которая устанавливает значение 2 в этом байте. Что бы сделал принтер? Это зависит от него самого, но, предположим, 2 означает 'взрываться!”
Если вы описали объект принтер в программе, которая скрыла байт статуса принтера, и определили методы printer-on() и printer-off о, то не смогли бы установить 2 в этом байте. Вы в силах вызвать printer-on о, чтобы установить байт в 1, или printer-off о, чтобы установить его в 0. Как видно, состояние в объекте является несущественным вне объекта.
Поэтому объекты помогают конкретно описать, какие действия могут быть выполнены и на какие данные можно воздействовать и предотвращать изменение данных способами, не имеющими смысла, t
Наследование
Можно также создавать новые объекты, основанные на существующих объектах. Если бы был новый принтер, имеющий другую переменную статуса, помимо переменной online/offline, можно было бы создать новый класс объекта, основанный на объекте принтер, который унаследует признаки первоначального объекта принтер. Затем можно добавить любые новые методы в код. Получился бы новейший объект принтер. И нет нужды переписывать весь код, который является общим.
Если мой новый объект принтер требовал иной механизм его выключения и включения, я мог бы также перегрузить методы printer-on о и printer-off о и определить собственный метод, который использовался бы в этом объекте вместо методов в родительском объекте. Этим способом подкласс может включать все полезное от родительского класса объекта и реализовать только те части, которые являются новыми и уникальными в подклассе. Другое преимущество состоит в том, что, если изменение сделано в базовом классе (например, исправление ошибки или другое улучшение), подкласс извлечет выгоду из изменения.
В искусстве программирования объекты являются революционными. Применяемое должным образом объектно-ориентированное программирование может уменьшить время разработки, способствовать повторному использованию кода и уменьшить ошибки.
Открытые программные средства
Сообщество UNIX имеет богатую традицию доступности программного обеспечения в исходной кодовой форме либо бесплатно, либо за разумную плату, позволяя людям учиться на коде или улучшать его далее. Сама ОС UNIX начала этот путь, и много компонентов, связанных с UNIX, разделяют эту традицию. Поэтому не сюрприз, что в мире иных собственников упакованного программного обеспечения, где вы покупаете доступное и приспосабливаете к своим требованиям, люди, поддерживающие идею о свободной доступности исходного кода, объединились, чтобы сохранить живой эту философию.
Два главных события имели огромное воздействие на эволюцию идеи открытого программного обеспечения: создание Free Software Foundation и появления Linux на фоне UNIX. В [Fink 2003] приводится превосходная экспертиза феномена открытых программных средств, причины его возникновения, объясняется, где он работает и не работает.
Free Software Foundation
Одним из первых сторонников идеи свободно доступного программного обеспечения был Ричард Сталлман (Richard Stallman), основатель Free Software Foundation (FSF) в середине 1980-х годов. Сталлман полагал, что каждый должен иметь право получать, использовать, рассматривать и изменять программное обеспечение. Он начал проект GNU2, цель которого состояла в том, чтобы воспроизвести популярные инструменты UNIX и, в конечном счете, полную UNIX-подобную операционную систему в новом коде, который мог быть свободно распространяемым, потому что он не содержал никакого лицензированного кода. Ранние продукты включали версию популярного редактора текста emacs и GNU-компилятор С.
"Свободный" в представлении свободного программного обеспечения не обязательно подразумевает, что программное обеспечение доступно бесплатно, а скорее, что его можно свободно использовать, рассматривать и изменять. Чтобы сохранять авторские права на программное обеспечение GNU, но все же обеспечить его использование наиболее широкой аудиторией, FSF разработал GNU-лицензию General Public License (GPL), согласно которой программное обеспечение GNU лицензировано для всего мира. GNU GPL предусматривает копирование, использование, модификацию и повторное распространение программного обеспечения GNU при условии, что та же самая свобода использовать, изменять и распределять его переходит к любому, кто берет вашу версию программного обеспечения. Авторское
2 GNU — это рекурсивный акроним, происходящий от "GNU’s not UNIX" и произносится "guh-NEW".
право (copyright) служит для защиты прав владельца. Здесь цель заключалась в защите прав получателя программного обеспечения. Таким образом, FSF выдумала термин copyleft, чтобы описать это несколько инвертированное значение.
Для получения дополнительной информации о Free Software Foundation см. Web-узел http://www.fsf.org.
Для получения дополнительной информации о проекте GNU или GNU General Public License посетите сайт http://www.gnu.org.
Linux
Окончательная цель проекта GNU состояла в том, чтобы обеспечить полную повторную реализацию UNIX, включая ядро. Но в то время, как GNU-приложения были многочисленны и популярны, само ядро требовало большего напряжения сил. Работа продолжается на GNU Hurd — UNIX-подобном ядре. Тем временем, в 1991 г. Линус Торвальдс (Linus Torvalds), студент Хельсинкского университета в Финляндии (University of Helsinki in Finland) написал собственное UNIX-ядро, которое соответствовало стандарту POSIX3. Все началось, как хобби. Но он чувствовал, что мир нуждался в версии UNIX, которая могла бы распространяться свободно без необходимости волноваться об ограничениях лицензирования. Его законченная работа почти совершенно дополняла работу проекта GNU.
Сначала Линус и несколько его друзей поддерживали, внося изменения в исходный код, Linux. Сегодня разработчики во всем мире создают новый код и вносят исправления. Комбинация Linux- и GNU-утилит позволяет создавать полную UNIX-подобную операционную систему, работающую на многих различных аппаратных платформах и доступную в исходной форме. Так что можете делать собственные исправления ошибок и усовершенствования в ней.
Параллельные, распределенные и многопроцессорные системы
Исторически компьютер имел единственный ЦП^ располагался на столе (или в компьютерной комнате) и обрабатывал данные, которые были в него введены. По мере того как растут сети, компьютеры связываются вместе для разделения данных и сотрудничества при совместной обработке. Благодаря развитию микропроцессорной технологии в одном компьютере можно разместить несколько процессоров.
3 Portable Operating System Interface for Computing Environment, переносимый интерфейс операционной системы для вычислительной среды. — Ред.
Параллельная обработка
Если задача может быть разделена на отдельные и несвязанные части, эти части способны работать отдельно. Таким образом, задача решается быстрее, чем в случае последовательного выполнения частей на единственном компьютере. Этот подход известен как параллельная обработка (выполнение нескольких задач одновременно). Она может быть выполнена либо различными компьютерами, либо различными процессорами внутри одного и того же компьютера, как мы вскоре увидим.
Истинная параллельная обработка является чрезвычайно трудной. Многие задачи имеют некоторые отношения друг с другом и не могут быть легко разделены. Объектно-ориентированное программирование помогает, потому что обработка некоторого объекта может быть отделена от таковой для других, и объектно-ориентированная парадигма поощряет программистов применять методы, увеличивающие это разделение. Многопользовательские системы также извлекают выгоду из параллельных процессоров. Если в системе зарегистрированы десять пользователей, и процессы shell каждого пользователя могут быть выполнены на различных процессорах, то достаточно легко предоставить массу процессорной мощности отдельным пользователям. Но разделение единственной прикладной программы на слабосвязанные части, которые могут работать независимо, является серьезной проблемой. Еще более многообещающая задача состоит в том, чтобы написать компилятор, который может автоматически определять несвязанные части программы и разбивать код во время компиляции так, чтобы различные части могли быть обработаны на разных процессорах во время выполнения программы.
Распределенные системы
Один из способов распараллеливания отделенных задач заключается в том, чтобы выполнять их на различных компьютерах в одно и то же время. Некая централизованная программа может раздавать части задачи компьютерам и собирать их вывод по мере того, как они будут заканчивать свою работу. Некоторые накладные расходы вовлечены в управление разделением и связью, но если задачи достаточно сложны, параллельное выполнение станет причиной значительного уменьшения общего времени выполнения по сравнению со случаем, когда задачи выполняются последовательно на одном компьютере.
Этот тип архитектуры часто упоминается как архитектура, не предусматривающая разделения ресурсов, потому что ни один процессор не разделяет никакие ресурсы с другими. Каждая система имеет собственные память, диск и путь данных к сети. Наряду с тем, что существует возможность для процессов на различных компьютерах разделять блоки памяти (так же, как это
могут делать два процесса, работающие на одном и том же компьютере), накладные расходы будут весьма небольшие, т. к. разделение происходит через сеть.
Многопроцессорные системы
Другой способ распараллеливания отдельных процессов состоит в том, чтобы выполнять их на одном компьютере. Если машина имеет единственный ЦП, тогда он должен разделить свое время между различными процессами, что не несет выгоду (фактически это приводит к потере времени, с накладными расходами множественных процессов) по сравнению с традиционным программированием единственного процесса. Однако, если компьютер имеет несколько процессоров, каждый отдельный процесс может быть выполнен на его собственном процессоре.
Многочисленные процессы, работающие на одном компьютере, разделяют ресурсы диска. Они могут также без труда разделять сегменты памяти при помощи методов операционной системы для доступа к разделяемой памяти. Поэтому данный тип архитектуры часто называется архитектурой с разделяемой памятью или разделяемыми ресурсами.
Sequent был одним из первых продавцов UNIX, которые предусматривали мультипроцессорную систему, специально разработанную, чтобы позволить писать параллельные программы и выполнять их на множественных процессорах. Сегодня многие UNIX-платформы доступны для мультипроцессорной архитектуры. Тем не менее, здесь применяются методы, вовлеченные в параллельное программирование, но обходятся дополнительные сложности распределения процессов на различные компьютеры.
Поскольку скорости ЦП продолжают увеличиваться, преимущество мульти-пррцессорных систем не очевидно для обычного пользователя. Однако всегда будут существовать приложения, которые нуждаются в производительности, предлагаемой параллельным программированием.
"Ошибка" 2000 года
Даже притом, что 31 декабря 1999 г. прошло без больших потрясений, это все еще является достойной обсуждения проблемой, даже если нет другой причины, которая, вероятно, может повториться 31 декабря 2099 г. Я взял в кавычки слово "ошибка”, потому что, хотя проблема была упомянута, как ошибка, в действительности проявилось плохое проектирование программы, а не ошибка в кодировании. Недавно я видел "Фольксваген Жук" (Volkswagen Beetle) с номерным знаком "Y2K BUG". Я понял, что 2000-я модель "Жука" была единственным истинным Y2K Жуком (ошибкой)4!
4 Игра слов. Bug имеет при переводе значения* "жук" и "ошибка". — Ред.
Что же это в действительности?
Проблема в том, что мы, люди, настаиваем на определении года в двух цифрах. Мы полагаем, что номер столетия будет очевиден либо из контекста, либо просто потому, что мы говорим об этом годе в текущем столетии. Человек это понимает, но компьютер — не человек.
До 1 января 2000 г. все компьютерные программы были написаны в XX столетии. Поэтому имевшие дело с датами в двух цифрах программисты предполагали, что другие две цифры были "19". С этим предположением мы попали в плохое положение просто потому, что оно никогда нас не подводило. Очевидно, что предположение было неверным.
Это была бы "ошибка компьютера", если бы сама система не могла представить 2000 год, но она может. Проблема заключается в предположении, сделанном программистом приложения.
Год в две цифры
Рассмотрим утилиту UNIX cal.
Синтаксис
cal [месяц год]
Утилита cal выводит календарь для текущего месяца. Если месяц и год определены, cal печатает календарь для указанного месяца.
Например, чтобы получить календарь на июнь 1998 г., надо сделать следующее: $ cal 6 1998
Результат такой:
June 1998
Su Mo Tu We Th Fr Sa
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30
$
Обратите внимание, что произойдет, если указать год двумя цифрами:
$ cal 6 98
June 98
Su Mo Tu We Th Fr Sa
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
$ _
Этот календарь не выглядит правильным, не так ли? Но он есть. Это календарь на июнь 98 года нашей эры5! Является ли это ошибкой cal, или это моя ошибка? Конечно, это моя ошибка; утилита cal сделала буквально то, что я попросил.
Рассмотрим другой пример. Скажем, вы рассматриваете форму страхования пациента, но пациент отсутствует. Дата рождения на форме читается 06/06/99. Действительно ли пациент является ребенком или старым гражданином? Конечно, вы будете иметь достаточно информации, чтобы это понять, если пациент сидит в это время в комнате вместе с вами. Но компьютер не способен использовать другую информацию, чтобы сделать вывод. Отсутствуют необходимые данные, доступные для компьютера, чтобы не предположить, будто дата современна. Поэтому он "решит", что пациент — ребенок. И это может стать реальной проблемой, если цель компьютера состоит в том, чтобы выписать дозу лекарства пациенту!
Решение для программного обеспечения кроется в сохранении и отображении даты четырьмя цифрами6. Ускорения, которые позволяют специфицировать дату двумя цифрами, прекрасны, пока пользователь знает, что подразумеваются сокращения, и уверен в существовании лишь небольшой вероятности двусмысленности. Иногда, тем не менее, это предположение не будет работать. Тогда должен быть способ определить полную дату.
Годы, начиная с 1900
Проблема также проявляется в программах и функциях, которые возвращают значение "года, начиная с 1900". Для даты в XX столетии они возвращают значение с двумя цифрами. Но в 2002 г. функция, которая возвращает количество лет с 1900 г, вернет 102. Если некоторое приложение предпола
5 То есть на июнь 98 г. — Ред.
6 Если бы вы действительно думаете наперед, то могли бы использовать пять цифр, но было бы разумно предположить, что код не будет применяться через 8000 лет.
гает, что оно может дописывать значение "19" возвращаемым значением, то программа будет печатать для года результат "19102" (и существуют программы, делающие это сегодня).
И опять здесь неправильное употребление функции, а не действительная ошибка системы. Ее даже просто исправить, т. к. следует прибавить возвращаемое значение к 1900 г. и вывести результат. В таком случае все работает просто прекрасно.
UNIX и XXI столетие
Непосредственно UNIX никогда не имел проблем 2000 года. Даты в UNIX хранятся как 32-битовые целочисленные значения, представляющие количество секунд, прошедших с полуночи 1 января 1970 г. (иначе известная как "эра" в сообществе UNIX). Поэтому значение 12:00:01 a.m. 1 января 2000 г.7 является просто целым числом, которое на 2 больше, чем значение 11:59:59 р.щ. 31 декабря 1999 г.8
Однако нельзя сказать, что UNIX никогда не будет иметь проблемы. Проницательные читатели поймут, что даже 32-битовое значение имеет предел. В 2038 г. значение даты UNIX перейдет через ноль (все 32 бита будут равны 1, и когда значение увеличится на единицу, все биты будут снова 0). В этот момент все UNIX-машины снова зарегистрируют 1 января 1970 г.
Хорошо, что у нас есть масса времени, чтобы приготовиться к такому событию. Я чувствую себя уверенным, высказывая следующее: если мы будем использовать операционную систему в 2038 г., даже с именем UNIX, эта проблема не будет к ней относиться.
64-разрядные системы
Первые маленькие компьютеры были 8-битовыми системами. То есть шина, которая соединяла ЦП с памятью, имела 8-битовый канал данных. Слова памяти имели длину 8 битов. Максимальный адрес памяти — 16 битов (т. к. 8 битов могут представить только 256 различных значений). Но в аппаратуре было сделано усложнение для объединения двух слов памяти для организации адресной ссылки.
Позже были внедрены 16-битовые системы, позволяя одновременно передавать большее количество данных через шину. 16-битовое значение представляет максимум 65 536 или 64 Кбайт. В то время люди действительно думали, что 64 Кбайт памяти будет достаточно для всего!
Наконец, когда возникли 32-битовые системы, адресовались 4 Гбайт памяти. Вновь большее количество данных могло быть послано через 32-битовую
7 Для нас это 00:00:01 1 января 2000 г. — Ред.
8 Для нас это 23:59:59 31 декабря 1999 г. — Ред.
27 Зак. 786
шину. Каждый думал, что настал предел. В конце концов, почему бы ни быть достаточным 4 Гбайт адресуемого диска или памяти?
64-битовые процессоры и системы сегодня стали обычными. Более широкий канал шины позволяет еще большему количеству данных перемещаться по ней. Адресация упрощена, потому что 64-битовый адрес может быть сохранен в единственном слове памяти. Теперь легко превзойти 32-битовый предел в 4 Гбайт для адресов диска и памяти. Если я скажу, что 64-битовая архитектура — это точка, в которой мы остановимся, конечно, я буду не прав, так что я не буду это говорить!
Интернет-адресация: IPv6
Текущая реализация протокола IP, версия 4 (IPv4), обеспечивает поддержку 32-битовых адресов. Однако с ростом Интернета данное значение быстро становится недостаточным, чтобы поддержать все машины, подключаемые к сети. Чем больше мы находим применений, тем больше требуется устройств, IP-адресов. Многие принтеры также имеют собственные IP-адреса, и некоторые портативные компьютеры обладают множественными IP-адресами для использования в различных местах.
В начале 1990-х гг. стало ясно, что будет необходимо новое поколение IP, которое позволит иметь намного больше адресов. Началась работа по определению IPng (IP next generation, следующее поколение IP) и формальное предложение о версии 6 IP-протокола появилось в 1995 г.
Стандарт IPv69 определяет адреса длиной 128 битов. Хотя эти протоколы IPv4 и IPv6 используют адреса различной длины, оба могут применяться в одной и той же сети. Это необходимо потому, что Интернет слишком велик для координации "вырубки" по новому протоколу. Гладкий переход к новой схеме адресации должен быть постепенным, а не требовать, чтобы все мы проснулись однажды с использованием более нового протокола.
Пакеты IP (обеих версий) определяют версию в первых 4-х битах пакета. Поэтому компьютер, который "говорит" на IPv6, должен признавать и обрабатывать пакеты с IPv4 (если он сконфигурирован для двух протоколов). Это позволяет двум протоколам сосуществовать в одной сети. Старые машины могут быть модернизированы к IPv6 по мере того, как реализации станут доступными или системные администраторы получат возможность модернизировать их без спешки.
Как уже обсуждалось в главе 9, адрес IPv4 — это 32-битовое значение, выраженное через четыре значения, каждое десятичное число представляет 8-битовое значение типа
192.127.63.141
9 IP version 6. — Ред.
В IPv6 128-битовый адрес был бы тяжел, чтобы выразить его тем же самым способом. Можете вы вообразить адрес, подобный этому?
192.127.63.141.241.27.88.16.1.77.34.8.191.253.27.61
Это направило бы администраторов сети на другую линию работы!
В IPv6 значения выражены в шестнадцатеричном формате, требуя двух шестнадцатеричных цифр для каждых 8 битов. Вместо разграничения через каждые 8 битов, они разделяются через каждые 16 битов. Другое изменение заключается в том, что разделителем между частями адреса служит двоеточие, а не точка. Таким образом, длинный адрес, представленный выше, может быть выражен в IPv6 как
C07F:3F8D:F11B:5810:0140:2208:BFFD:1B3D
Воистину, это значительно короче, но это самый длинный 1Р\'6-адрес, какой может быть (принимая во внимание, что десятичный пример перед этим был фактически на несколько цифр длиннее!). Практически, многие IP-адреса имеют 8-битовые или даже 16-битовые значения, равные нулю. IPv6 также учитывает пропуск ведущих нулей и устраняет смежные 16-битовые нулевые значения.
В дополнение к изменениям адресации IPv6 также предусматривает усовершенствования в маршрутизации и автоматической конфигурации. В то время, как IPv6 широко не распространен, продавцы реализуют и проверяют новый протокол. В ближайшие несколько лет IPv6 будет развернут в Интернете. Если все пойдет хорошо, пользователи, вероятно, даже и не заметят перехода на новый стандарт. Для получения дополнительной информации о IPv6 посетите узел сети http://www.ipv6.org.
Сети с высокой пропускной способностью
Изначально для Ethernet-стандарта скорость передачи 1 Мбит/с была высокой. Сегодня в локальной сети обычны скорости в 100 Мбит/с. С применением волоконной оптики и других цифровых средств информации через сеть может быть передано намного больше данных, чем когда-либо прежде.
Из-за бума сетевого просмотра в Интернете передаются большие объемы данных. Сообщения электронной почты были малы по сравнению с изображениями, видео и звуком, которые составляют сегодняшние страницы сети. К счастью, полоса пропускания сети увеличивается с такой же скоростью, как скорость ЦП и объем диска. Как только появляются новые, быстрые, лучшие способы делать что-нибудь, человечество находит способы использовать это. Помните, как никто не мог вообразить нехватку 64 Кбайт памяти?
Отказоустойчивые системы
Поскольку корпорации все более полагаются на компьютерные системы, время простоя становится серьезной проблемой. В некоторых ситуациях (например, маршрутизаторы в телефонной сети) почти любое время простоя недопустимо.
Традиционно решение состояло в том, чтобы иметь системы "горячего" резервирования. Эти системы работают в параллель с системой, выполняющей основную обработку, обновляя одни и те же данные и находясь при этом "в тени". Когда основная система выходит из строя, дублирующая система может почти немедленно подхватить ее функции, пока инженеры будут исправлять первую систему.
Отказоустойчивые системы пробуют достичь этого в рамках единственной системы. Система с резервными ЦП, памятью и устройствами может использовать резервный ресурс, если основной ресурс неисправен.
Несколько компаний, из которых Tandem (теперь часть Hewlett-Packard) наиболее известна, исследовали и изготовили отказоустойчивые UNIX-системы. Хотя компоненты аппаратуры теперь более надежны, чем десятилетие назад, некоторые приложения будут всегда требовать такой близости к 100% работоспособному состоянию, какой возможно достигнуть.
Обзор современных популярных версий UNIX
Хотя ОС UNIX "родилась" в компьютерной лаборатории Bell Laboratories, с тех пор путь ее развития длинен и замысловат. Серьезное обсуждение истории развития UNIX лежит за рамками данной книги, но в [Salus 1994] представлен превосходный обзор богатой истории этой ОС.
Часть истории UNIX — это соревнование между Berkeley UNIX (BSD) и System III (позже, System V UNIX, как она называлась в AT&T). Много лет мир UNIX был разделен на два лагеря. Большинство реализаций UNIX было основано на одной из двух систем. Различия заключались, главным образом, в архитектуре ядра и низкоуровневых алгоритмах операционной системы (например, BSD и System V использовали радикально различные алгоритмы управления памятью). Для пользователей различия были почти незаметны.
Когда Sun Microsystems и AT&T объединили силы, чтобы слить миры BSD и System V вместе, родились System V Release 4 (SVR4) и Solaris. SVR4 со
единила лучшее из обоих миров.10 Когда любители BSD получили большинство их любимых возможностей в базирующихся на SVR4 версиях UNIX, "UNIX-войны" начали стихать. Вскоре несколькими компаниями (наиболее памятны HP и DEC) была сформирована организация Open Software Foundation (OSF), чтобы создать собственную версию UNIX. Это была попытка помешать AT&T и Sun обладать абсолютными правами полученной собственности и, следовательно, будущим управлением UNIX. Поскольку системы, базирующиеся на SVR4, доказали возможность удовлетворения потребностей клиента, а AT&T и Sun не имели всех прав обладания UNIX, как многие боялись, эта UNIX-война также прекратилась, и OSF заняла свое место в истории.
Сегодня, в то время как есть все еще некоторые нацеленные на BSD версии UNIX, главные различия связаны с аппаратными платформами и эффективностью. Другие различия преимущественно внешние. Основная UNIX-система и интерфейсы в значительной степени переходят от одной версии к другой (но, правда, достаточно неодинаковы, чтобы доставлять пользователю неприятности время от времени). Продавцы, поставляющие собственные дистрибутивы UNIX, предусматривают свои "дополнительные" команды и возможности, реализованные по требованиям клиентов. Перенос программного обеспечения с одной версии на другую в зависимости от глубины функций операционной системы, которые могло бы использовать приложение, все еще является нетривиальной задачей. Но сейчас это не такая серьезная задача, как раньше.
В настоящее время существует много различных версий UNIX. Большинство нацелено на определенные приложения (типа вычислений в реальном времени), конкретную редкую аппаратуру или исследования, основанные на предыдущей работе с UNIX. Когда пользователь изучает "господствующие" версии UNIX, которые легкодоступны на автоматизированном рабочем месте или аппаратуре маленького сервера, то в результате их количество оказывается небольшим. Версии, обсуждаемые в следующих разделах, не составляют исчерпывающий список, но они представляют большинство версии, с которыми, вероятно, столкнется читатель в типичном окружении UNIX. Они обеспечивают возможности (в различной реализации), рассмотренные в предыдущих главах книги (т. е. X Window System, организацию сети TCP/IP, большинство "стандартных" команд UNIX и т. д.).
10 Конечно, "наилучший" является объективным термином. Вы можете найти людей, которые будут оспаривать этот факт. Намерение состояло в том, чтобы объединить лучшее от обеих версий.
-----------------------------------------------------7--------------
AIX
Advanced Interactive executive (AIX) — это реализация UNIX от фирмы IBM, работающая на ее RISC System/6000 рабочей станции и серверных платформах. Она базируется на System V UNIX с расширениями SVR4 и BSD. Платформы RS/6000 предлагают мультипроцессорные системы, также как и 64-разрядные системы.
Если читатель в прошлом использовал другие системы IBM, части- AIX покажутся более знакомыми, чем другие версии UNIX. AIX имеет более многословные сообщения об ошибках, чем другие версии. Большинство сообщений индексировано кодами, чтобы направить пользователя к информации в руководстве. В то время, как сначала такая ситуация кажется тяжелой, особенно по сравнению с кратким характером первоначальных версий UNIX, время от времени это доказывает свою полезность.
Дополнительная информации об AIX доступна в сети по адресу
http: //www.ibm.com/servers/aix.
Caldera SCO/Unixware
Много лет компания Santa Cruz Operation (SCO) была лидером среди продавцов программного обеспечения UNIX. Версия SCO UNIX работала на аппаратуре низкой производительности типа PC и предпочиталась маленькими компаниями, которые не могли позволить себе дорогостоящие рабочие станции. За свою историю SCO приобрела Unix Systems Laboratories, подразделение UNIX компании AT&T, которое разработало UnixWare, истинную UNIX System V.
Теперь компания Caldera приобрела подразделение UNIX компании Santa Cruz Operation и продолжает использовать оба названия в своих коммерческих UNIX-предложениях: SCO OpenServer и UnixWare 7.
Для получения дополнительной информации о семействе UNIX-продуктов компании Caldera посетите http://www.caldera.com/products/unix.
FreeBSD
FreeBSD, как можно предположить, является бесплатной реализацией версии UNIX компании Berkeley Standard Distribution. Это один из нескольких UNIX-проектов Open Source, доступных сегодня. FreeBSD работает на совместимой с PC аппаратуре (386, 486, Pentium и большинстве PC со стандартной архитектурой).
Программисты во всем мире исправляют и улучшают существующий код FreeBSD. Узел сети FreeBSD предоставляет информацию об участниках и правилах участия.
FreeBSD может быть загружена из сети (но она большая) или получена на CD-ROM за небольшую плату.
За дополнительной информацией о FreeBSD обратитесь на сайт http://www.freebsd.org.
HP-UX
Вклад компании Hewlett-Packard в развитие UNIX известен как HP-UX, и эта версия работает на РА-RISC аппаратной платформе HP, также как на новой архитектуре Intel IA-64 Itanium11. HP-UX базируется на System V с заимствованием лучших возможностей из SVR4 и BSD.
HP-UX — это 64-разрядная версия UNIX, которая соответствует всем популярным UNIX-стандартам. В настоящее время она является версией номер один или номер два среди поставляемых продавцами UNIX в зависимости от того, чью статистику вы читаете. Для компании, которая не была вовлечена в начальную эволюцию UNIX, HP сделала хорошую работу по адаптации "философии UNIX" и истинного следования ей в разработке HP-UX.
Для получения дополнительной информации о HP-UX обратитесь к http://www.hp.com/go/hpux.
IRIX
Компания Silicon Graphics, Inc. установила стандарт для быстродействующих графических аппаратных средств с высоким разрешением. Версия SGI's UNIX, известная как IRIX, базировалась на System V в те дни, когда большинство продавцов предлагали системы на основе BSD, поэтому совместимость в смешанных окружающих средах была проблематична. Можно приобрести UNIX на платформе SGI, если вам необходимо невероятное графическое автоматизированное рабочее место.
Ввиду того, что мир стандартизировался на SVR4, IRIX стал новой господствующей тенденцией, расставив "правильные" акценты в приоритете. IRIX включает большинство лучших особенностей SVR4, также как BSD UNIX, и является 64-разрядной операционной системой.
Для получения дополнительной информации об IRIX посетите Web-страницу http://www.sgi.com/developers/technology/irix.html.
11 Процессор Intel Itanium был совместно создан компаниями Intel и HP.
Linux
Linux является несомненно наиболее популярной из Open Source версий UNIX лля архитектуры PC. Кроме того, она была перенесена на платформу Digital Equipment Corporation (DEC)/Compaq/HP Alpha, SPARC-платфор-мы Sun, процессор Intel Itanium и платформы Power PC фирмы Motorola.
Хоть Linux и походит на UNIX и полезна даже для наиболее опытных пользователей, однако это не UNIX, потому что не разделяет никакой общий исходный код с любым UNIX-дистрибутивом. Она является повторной реализацией UNIX с теми же самыми интерфейсом и командами. Поскольку Linux не содержит никакой лицензированный исходный код, принадлежащий AT&T, Калифорнийскому университету в Беркли или кому-либо еще, она может распространяться с исходным кодом. Если необходимо узнать о ее внутренних действиях или настроить под себя, такой вариант возможен.
Linux может быть изменена, повторно распространена и даже продана, пока исходный код остается доступным. Несколько компаний осуществляют продажу средств информации, документации и поддержки для собственных дистрибутивов Linux. Ниже представлен список некоторых продавцов, обеспечивающих распространение Linux (одни — по номинальной стоимости, другие — бесплатно):
□ Caldera OpenLinux;
□ Corel Linux;
□ Debian GNU/Linux;
□ Mandrake Linux;
□ RedHat Linux;
□ Slackware Linux;
□ SuSE Linux.
В дополнение к этим отдельным распространителям Linux традиционные UNIX-продавцы, такие как HP, IBM, SGI и Sun, реализуют Linux на их собственных аппаратных платформах.
Для получения дополнительной информации об основах операционной системы Linux (включая информацию относительно всех различных поставщиков дистрибутивов) посетите сайт http://www.liniix.org.
NetBSD
NetBSD часто путают с FreeBSD. Однако они являются двумя отдельными проектами, но с похожими целями: обеспечить свободную реализацию BSD UNIX.
Проект NetBSD является, как и другие проекты Open Source, совместным усилием разработчиков со всего мира в поддержке и улучшении операционной системы. NetBSD также называется UNIX-подобной операционной системой, но основанной на коде от 4.4 BSD Lite, подмножестве BSD. Подобно Linux, NetBSD распространяется с исходным кодом.
NetBSD работает на многих различных платформах, включая PC, DEC Alpha и VAX, HP 9000, Macintosh, рабочие станции Sun SPARC, и даже на некоторых переносных устройствах.
Для дополнительной информации о NetBSD посетите узел сети по адресу http: //www.netbsd.org.
OpenBSD
OpenBSD — это другой проект, предназначенный обеспечить свободную реализацию BSD UNIX, но он больше, чем другие, предусматривает обеспечение более надежных механизмов безопасности. Подобно другим проектам Open Source, OpenBSD базируется на 4.4 BSD UNIX.
Данная версия гордится двоичной эмуляцией программ со многих UNIX-платформ, включая FreeBSD, HP-UX, Linux и SunOS/Solaris.
Для дополнительной информации об OpenBSD посетите http://www.openbsd.org.
Tru64 UNIX
Компания DEC сделала несколько "набегов" в мире UNIX. Первоначальное предложение компании — это Ultrix, базирующаяся на BSD. Ultrix работала на VAX-линии аппаратуры DEC. DEC позже адаптировал ядро, базирующееся на 0SF/1, и создал Digital UNIX, 64-разрядную операционную систему, которая работает на платформе Alpha. Digital UNIX была переименована в Tru64 UNIX, когда компания Compaq приобрела DEC.
Для получения дополнительной информации о Tru64 UNIX посетите http://www.tru64unix.Compaq.com.
Solaris
В начале 1980-х гг. большинство дистрибутивов поступало непосредственно от AT&T или Калифорнийского университета в Беркли и работало на любой имевшейся у пользователя аппаратуре, которую поддерживали эти версии. Возникли мелкие компании для распространения основных дистрибутивов и поддержки UNIX-систем, в основном базирующихся на ЦП Motorola 68000.
Вначале SunOS работала на МС68010 и MC68020. В конечном счете, компания Sun Microsystems, Inc. решила, что может лучше обслуживать своих клиентов, если она также разработает аппаратуру, специально предназначенную для выполнения UNIX. (Motorola разработала семейство 68000 не специально для работы UNIX.) Sun стала одним из первых лидеров в развитии и улучшении системы UNIX.
Solaris — это текущая точка в развитии Sun UNIX. Оригинал SunOS базировался на BSD UNIX, потому что некоторые из основателей Sun — наиболее заметный, Билл Джой (Bill Joy), автор редактора vi — прибыли из Беркли. Sun сделала прыжок от SunOS до Solaris, когда начала сотрудничать с AT&T, чтобы стандартизировать System V. Конечно, Solaris включает все лучшие особенности из BSD и SunOS, к которым привыкли клиенты Sun.
Solaris работает на SPARC, 32- и 64-разрядных платформах фирмы Sun, также как и на платформах Intel (PC).
Для получения дополнительной информации о Solaris см.
http://www.sun.com/software/solaris.
Обзор главы
Перечень тем
В этой главе мы рассмотрели:
□ объектно-ориентированное программирование;
□ открытые программные средства;
□ параллельные и распределенные системы;
□ микропроцессорные системы;
□ проблему 2000 года;
□ 64-разрядные архитектуры;
□ сети с высокой пропускной способностью;
□ отказоустойчивые системы;
□ версии UNIX, которые можно использовать.
Контрольные вопросы
1. Какие версии UNIX бесплатны?
2. Как компания может заработать, продавая проекты Open Source, когда они доступны бесплатно?
3. Как данные, связанные с объектом, отличаются от традиционных данных в компьютерной программе?
4. Сколько битов представляет из себя IP-адрес в IPv6?
Упражнение
Загрузите одну из бесплатных версий UNIX из Интернета и установите ее. [Уровень: средний.]
Проект
Определите последнюю дату и время в 2038 г., которую будет способен представить UNIX. [Уровень: средний.]
Приложение
Регулярные выражения
Регулярные выражения — это последовательности символов, которые описывают систему соответствия строкам. Они принимаются как аргументы многим утилитам UNIX, такими как grep, egrep, awk, sed и vi. Обратите внимание, что групповые символы замены имени файла, используемые shell, отсутствуют в примерах допустимых выражений, т. к. они используют другие правила соответствия.
Регулярные выражения формируются из последовательностей нормальных и специальных символов. В табл. Ш перечислены некоторые специальные символы, иногда называемые метасимволами, вместе с их значениями.
Таблица П1. Метасимволы регулярных выражений
Метасимвол Описание
Соответствует любому одиночному символу
[ ] Соответствует любому отдельному символу, указанному в скобках. Может использоваться дефис, чтобы представить диапазон символов. Если первый символ после [ — это А, то имеется в виду любой символ, неуказанный в скобках. Метасимволы *, А, $, и \ теряют свои специальные значения, когда используются внутри скобок
* Может следовать за любым символом и обозначает 0 или большее
количество появлений символа, который предшествует ему
А Соответствует только началу строки
$ Соответствует только концу строки
\ Значение любого метасимвола может быть отменено путем предше-
ствования ему \
Регулярное выражение соответствует самому длинному шаблону, который может быть. Например, когда образец у.*Ьа разыскивается в строке yabadabadoo, совпадение ПРОИСХОДИТ С подстрокой yabadaba, а не С yaba.
Чтобы проиллюстрировать использование метасимволов, рассмотрим представленный ниже фрагмент текста.
Well you know it’s your bedtime,
So turn off the light,
Say all your prayers and then,
Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea, And you will be swimming there too.
Шаблоны
В табл. П2 продемонстрированы строки текста, которые соответствовали бы различным регулярным выражениям. Часть каждой строки, удовлетворяющая регулярному выражению, выделена курсивом.
Таблица П2. Строки, соответствующие шаблонам регулярных выражений
Шаблон Строки, которые соответствуют
the So turn off the light, Say all your prayers and then, Beautiful mermaids will swim through the sea, And you will be swimming there too.
. nd Say all your prayers and then,
Oh you sleepy young heads dream of wonderful things, And you will be swimming there too.
л. nd And you will be swimming there too.
sw.*ng And you will be swimming there too.
[А-D] Beautiful mermaids will swim through the sea, And you will be swimming there too.
\ , And you will be swimming there too.
a. Say all your prayers and then,
Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea,
a. $ Beautiful mermaids will swim through the sea,
[a-m] nd Say all your prayers and then,
[ла-т]nd Oh you sleepy young heads dream of wonderful things,
Расширенные регулярные выражения
Некоторые утилиты, типа egrep, поддерживают расширенный набор метасимволов, описанных в табл. ПЗ. В та§л. П4 представлены некоторые примеры полных регулярных выражений с использованием текстового файла.
Таблица ПЗ. Метасимволы расширенных регулярных выражений
Метасимвол Описание
+ Соответствует одному или нескольким появлениям отдельного предшествующего символа
Соответствует 0 или одному появлению отдельного предшествующего символа
| (символ конвейера) 0 Если вы помещаете символ конвейера между двумя регулярными выражениями, будет принята строка, которая соответствует любому выражению. Другими словами, | действует подобно оператору ИЛИ Если вы помещаете регулярное выражение в круглые скобки, то можете использовать метасимволы *, + или ?, чтобы повлиять на полное выражение, а не только на отдельный символ Таблица П4. Строки, соответствующие шаблонам расширенных регулярных выражений
Шаблон Строки, которые соответствуют
S . *w Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea, And you will be swimming there too.
S . +w Oh you sleepy young heads dream of wonderful things, Beautiful mermaids will swim through the sea,
off|will So turn off the light, Beautiful mermaids will swim through the sea, And you will be swimming there too.
im*ing And you will be swimming.there too.
im?ing Нет совпадений
Модифицированная
для UNIX нотация Бэкуса—Наура
Синтаксис утилит UNIX и системных вызовов в данной книге представлен в измененной версии языка, известного как форма Бэкуса—Наура (Backus-Naur FORM, BNF). В описании BNF последовательности, приведенные в табл. П5, имеют специальное значение. Последняя последовательность — это ориентированная на UNIX модификация, которая позволяет избежать
использования большого числа скобок вокруг опций командной строки. Чтобы указать символы [, { или - без их специального значения, им предшествует \.
Некоторые разновидности команд зависят от опции, которую вы выбираете. Эта зависимость указана в представлении отдельного описания синтаксиса для каждой разновидности. Например, посмотрите на описание синтаксиса утилиты at, показанной ниже.
Таблица П5. Нотации BNF
Последовательность Описание
[ строки ] Строки могут появляться ноль или один раз
{ строки }* Строки могут появляться ноль или больше раз
{ строки }+ Строки могут появляться один или больше раз
строка 11строка2 Может появиться строка 1 или строка2
-списокОпций Ноль или большее количество опций могут следовать за дефисом
Синтаксис
at -csm время [дата [, год]] [+ приращение] [скрипт] at -г {10_задания} +
at -1 (ID задания}*
Первая версия утилиты выбирается любой комбинацией опций командной строки -с, -s и -т. Они должны затем сопровождаться временем и дополнительным спецификатором даты. Дополнительный спецификатор даты может сопровождаться дополнительным спецификатором года. Кроме того, приращение может быть специфицировано с именем скрипта или без него.
Вторая версия утилиты at выбирается с опцией -г,\ и может сопровождаться одним или более номерами ID заданий. Третья версия at выбирается с опцией -1 и может сопровождаться нулем или большим числом номеров ID заданий.
Библиография
1. [Anderson 1986]
Anderson, Gail, and Paul Anderson. The UNIX C Shell Field Guide. — Prentice Hall, 1986.
2. [Anderson 1995]
Anderson, Bart (ed.), Bryan Costales, and Harry Henderson. The Waite Group's UNIX Communications and the Internet. — Sams, 1995.
3. [Andleigh 1990]
Andleigh, Prabhat K. UNIX System Architecture. — Prentice Hall, 1990.
4. [Bach 1987]
Bach, Maurice J. The Design of the UNIX Operating System. — Prentice Hall PTR, 1987.
5. [Bolsky 1995]
Bolsky, Morris I., and David G. Korn. The New KornShell Command and Programming Language, 2d ed. — Prentice Hall PTR, 1995.
6. [Cheswick 1994]
Cheswick, William R., and Steven M. Bellovin. Firewalls and Internet Security. — Addison-Wesley, 1994.
7. [Christian 1988]
Christian, Kaare. The UNIX Operating System, 2d ed. — Wiley, 1988.
8. [Curry 1992]
Curry, David A. UNIX System Security: A Guide for Users and System Administrators. — Addison-Wesley, 1992. '
9. [Fink 2003]
Fink, Marlin. The Business and Economics of Linux and Open Source. — Prentice Hall, 2003.
10. [Fountain 2000]
Fountain, Anthony, Paula Ferguson, and Dan Heller. Motif Reference Manual, 2d ed. — O'Reilly & Associates, 2000.
11. [Garfinkel 1996]
Garfinkel, Simson, and Gene Spafford. Practical UNIX and Internet Security, 2d ed. — O’Reilly & Associates, 1996.
12. [Horspool 1992]
Horspool, R. Nigel. The Berkeley UNIX Environment, 2d ed. — Prentice Hall, 1992.
13. [Kernighan 1992]
Kernighan, Brian, and Rob Pike. The UNIX Programming Environment. — Prentice Hall, 1992.
14. [Leffler 1989]
Leffler, Samuel I, Marshall Kirk McKusick, Michael J. Karels, and John S. Quarterman. The Design and Implementation of the 4.3 BSD UNIX Operating System. — Addison-Wesley, 1989.
15. [McNulty 1986]
McNulty Development. UNIX Ref Guide. — Prentice Hall, 1986.
16. [Medinets 1996]
Medinets, David. Perl 5 by Example. — Que, 1996.
17. [Nemeth 2000]
Nemeth, Evi, Garth Snyder, Scott Seebass, and Trent R. Hein. UNIX System Administration Handbook, 3d ed. — Prentice Hall PTR, 2000.
18. [OSF 1992]
Open Software Foundation (OSF). OSF/Motif User's Guide. — Prentice Hall PTR, 1992.
19. [Quercia 1993]
Quercia, Valerie, and Tim O'Reilly. X Window System User’s Guide — OSF/Motif Edition, 2d ed. — O'Reilly & Associates, 1993.
20. [Roberts 1991]
Roberts, Ralph, Mark Boyd, Stephen G. Kochan, and Patrick H. Wood. UNIX Desktop Guide to EMACS. — Sams, 1991.
21. [Rochkind 1986]
Rochkind, Marc J. Advanced UNIX Programming. — Prentice Hall PTR, 1986.
22. [Sage 1986]
Sage, Russell G. Tricks of the UNIX Masters. — Sams, 1986.
23. [Salus 1994]
Salus, Peter H. A Quarter Century of UNIX. — Addison-Wesley, 1994.
24. [Seyer 1986]
Seyer, Martin D., and William J. Mills. DOS/UNIX — Becoming a Super User. — Prentice Hall, 1986.
25. [Sobell 1994]
Sobell, Mark G. A Practical Guide to the UNIX System, 3d ed. — Addison-Wesley, 1994.
26. [Stevens 1992]
Stevens, W. Richard. Advanced Programming in the UNIX Environment. — Addison-Wesley, 1992.
27. [Stevens 1998]
Stevens, W. Richard. UNIX Network Programming, 2d ed. — Prentice Hall PTR, 1998.
28. [Vahalia 1995]
Vahalia, Uresh. UNIX Internals: The New Frontiers. — Prentice Hall, 1995.
29. [Wait 1987]
Waite Group and Michael Waite (ed.). UNIX Papers. — Sams, 1987.
30. [Wall 1996]
Wall, Larry, Tom Christiansen, Randal L. Schwartz, and Stephen Potter. Programming Perl, 2d ed. — O'Reilly & Associates, 1996.
31. [Young 1994]
Young, Douglas A. The X Window System: Programming and Applications with XT — OSF/Motif. — Prentice Hall, 1994.
Предметный указатель
А
Active inode table 728
Advanced Interactive
executive (AIX) 794
Advanced Research Projects Agency
(ARPA) 404
Age 714
American National Standards Institute (ANSI) 454
Application Programming Interface (API) 434
ARPANET 405
В
Backbone 376
Backus-Naur FORM (BNF) 31, 631, 803
Berkeley Internet Name Daemon
(BIND) 409
Berkeley Standard Distribution (BSD) 23
Block device switch table 739
Block oriented interface 738
Bourne Again shell (Bash) 172, 344
автозаполнение 356
запуск 345
история 353
команда:
367
alias 352
builtin 366
case 361
declare 347, 357
dirs 364
export 365
for 362
history 353
if 361
jobs 365
kill 365
local 366
popd 364
команда pushd 363
readonly 366
select 366
set 346, 351, 355, 367
source 367
unalias 353
unset 350
until 363
while 363
массив 347
метасимволы 353
опции командной строки 367
операторы:
арифметические 356
арифметические условные 357
строковые условные 358
файловые условные 358
переменные 346
предопределенные 351
списочные 347
получение 345
псевдонимы 352
редактирование команды 355
стек каталогов 363
Bourne shell 172
закрытие стандартного ввода/вывода 240
запуск 212
команда:
case 226
export 192, 217
for 228
if 229
null 238
read 216
readonly 218
set 238
sh 212
trap 230
until 231
while 232 точка (.) 237 опции командной строки 241 переменные 213 локальные 219 окружения 221 специальные 214 переназначение 240 последовательности команд 240 Bridge 374 BSD 792, 793, 794, 795 конвейер 748 Buffer pool 725 unalias 313 unhash 339 while 326 конвейер 332 метасимволы {} 330 модификатор: замены 318 имени файла 318 истории 317 операторы: арифметические 307 строковые 307 опции командной строки 340 переменные:
С локальные 300, 305 простые 300
С shell 172, 299 дописывание имени 311 замещение имени файла 330 запуск 299 защита файлов от перезаписи 332 история 314 команда: список 300 окружения 306 перенапраление стандартного канала ошибки 331 повторное выполнение команд 316, 330 построение списков 304
@ 308 alias 312 chdir 336 csh 299 dirs 338 foreach 320 glob 336 goto 320 hashstat 339 history 315 if 321 logout 335 nice 334 notify 334 onintr 322 popd 338 pushd 337 rehash 339 repeat 323 set 301, 302 setenv 306 source 337 stop 333 switch 323 псевдонимы 311 параметризованные 314 полезные 313 разделение 314 стек каталогов 337 файловые выражения 310 хеш-таблица 339 CD-ROM Drive 13 Central Processing Unit (CPU) 12, 13 Character device switch table 739 Character oriented interface 738 Collision 373 Common Desktop Environment (CDE) 433, 449 Context switch 704 Control terminal 745 Copyleft 784 Copy-on-write bit 711, 717 Copyright 418, 784 С-компилятор 455 С-программа: выполнение 458 имя исполняемого файла 459 компиляция 456
D ID пользователя 58 реальный 61
Daemons 378 Delayed-write flag 726 Department of Defense (DOD) 409 Digital UNIX 797 Disk 13 Domain Name Service (DNS) 409 эффективный 61 Inode 359, 688 буферизация 691 список 688, 691 текущий 694 Interface Message Processor (IMP) 405
E Internet Service Provider (ISP) 413 Interprocess communication (IPC) 377,
errno, глобальная переменная 511 Ethernet 373 Ethernet interface 14 Ethernet-интерфейс 14 External data representation (XDR) 399 509, 510, 577, 596, 628, 674, 675 IPv4 377, 790 IPv6 377, 790 IP-адресация 377 IRIX 795
F к
FIFO 601, 602 Firewall 411 Free Software Foundation (FSF) 343, 783 FreeBSD 794, 796 К Desktop Environment (KDE) 433, 449 Kernel 675 Keyboard 14 Korn shell 172
G замена тильды 261 замещение команды 274
Gateway 375 General Public License (GPL) 783 Globbing 180 Graphical User Interface (GUI) 426, 450 Graphics card 13 запуск 246 история 252 команда: alias 248 bg 271 cd 283
H exit 265 fc 253, 254
Hardware 13 Hash table 716 High-water mark 714 HP-UX 795 HyperText Markup Language (HTML) 414 fg 271 jobs 269 kill 272 ksh 246 let 259 print 286 read 287
I return 265 select 262
ID группы 58 реальный 61 эффективный 61, 67 set 284 test 287 trap 289
typeset 266, 278
unalias 249
точка (.) 268
конвейер 274
массивы 278
ограниченный 293
опции командной строки 294
переменные 275
локальные 262, 266, 276
перенаправление 273
псевдонимы 248
полезные 250
предопределенные 250
путей 251
экспортируемые 251
функция 263
рекурсивная 267
L
LIFO 745
Lightweight processes 576
Line discipline 743
cbreak mode 743
cooked mode 743
raw mode 743
Linux 23, 779, 783, 784, 796
Local area network (LAN) 372
Low-water mark 714
M
Magic number 697
Маке-правило 467, 469
Маке-файл 466
Memory management unit (MMU) 709
Modem 14
Modified bit 710, 714
Monitor 13
Mosaic 414, 415
Motif 432, 433, 436, 445, 448, 449
Mount point 735
Mount table 735
Mouse 14
Multiuser mode 755
N
Named pipe 746
National Science Foundation (NSF) 413
NetBSD 796
Network File System (NFS) 399, 767
Network Information Center
(NIC) 407, 422
Network Object Model Environment
(Gnome) 449
NSFNET 413
О
Open file table 728
Open Software Foundation
(OSF) 432, 793
Open Software product 343
OpenBSD 797
OpenLook 433
p
Page daemon 714, 715
Page stealer 714
Pages 706
Parent PID (PPID) 558
Pending signal bitmap 721
Peripherals 14
Perl 154
AND 158
exit() 163
for 161
foreach 161
gmtime() 164
if 160
index() 164
length() 163
keys() 158
OR 158
split() 164
ключи к массиву 158
конкатенация строк 159
массивы 156
ассоциативные 157
(окончание рубрики см. на с. 812)
Perl (окончание)’. замещение команды 183
оператор: кавычки 193
диапазона 155 конкатенации 156 сравнения 160 печать текста 155 строки 156 PID 526, 560, 587, 632, 637, 651, 652 Pipe 20, 596 named 601 unnamed 597 Pipeline 181 POSIX 19, 344, 761, 784 Printer 14 переменные: встроенные 193 локальные 191 окружения 191 перенаправление ввода в буфер 194 подмена стандартных утилит 203 последовательности команд 184 родительский 190 условные последовательности 185 фоновое выполнение процессов 186 Signal handler array 721 Signals 721
Proccess: idle 700 runnable 700 running 700 sleeping 700 suspended 700 "zombified" 700 Process ID (PID) 558 Single-user mode 755 Socket 18 Solaris 792, 798 Source code control system (SCCS) 479 Sparse file 530, 730 Spoofing 418 Sticky bit 359 Strategy 739
R STREAMS 556, 748 Suitable username 29
RAM table 708 Random Access Memory (RAM) 13 Raw interface 738 Read Only Memory (ROM) 13 Referenced bit 710, 714 Region 707 Remote Procedure Call (RPC) 399 Revision Control System (RCS) 480 Root 22, 31, 66, 755 Root menu 436 Router 375 Run levels 756 Swap map 714 Swap space 714 System V 792, 794, 795 System V Release 4 (SVR4) 792, 794, 795 T Tape 14 Thrashing 720 Thread 576 Time quanta 703 Token Ring 377 Transport Layer Interface (TLI) 556
s Tru64 UNIX 797
Shadow-файл 37 Shared library 478 Shell 30, 172 subshell 190 группирование команд 185 дочерний 190 u UID 525 umask 207 Uniform Resource Locator (URL) 420 Unnamed pipe 746
V
Valid bit 711, 715
Visual User Environment
(VUE) 433, 448, 450
w
Web-браузер 419
Web-страница 420
Wide area network (WAN) 375
Widget 433
X Window System 425, 427
XI1 427
X11R6 428
Х-клиент 428, 438
-background 441
-foreground 441
-geometry 440
-iconic 441
-title 441
копирование и вставка 441
Х-ресурс 444
Х-сервер 427, 428
А
Авторское право 418
Адрес IP 377
Американский национальный
институт стандартов (ANSI) 454
Аппаратные средства 13
Архив 472
файлов 116
Б
Базовый класс 782
Безопасность 774
Библиотека, разделяемая 478
Библиотечная процедура:
alarm() 583
bzero() 626
gethostbyname() 625
htonl 627
htons 627
inet_addr() 625
inet_ntoa() 626
nice() 570
ntoh 627
ntohs 627
pause() 585
perror() 511
setegid() 572
seteuid() 572
setgid() 572
setuid() 572
signal() 584
семейства exec() 568
Библиотечная функция printf() 514
Блок:
косвенный 747
прямой 747
Брандмауэр 411
Буферный пул 725, 742
В
Ввод/вывод 724
блочный 687
буферизация 725
каталог 734
обычный файл 728
сокет 749
специальный файл 737
терминал 743
Взаимодействие процессов 509, 510, 596
Видеокарта 13
Виджет 433, 443, 444, 448, 450
Внешнеее представление данных 399
Выполнение программы 497
г
Геометрия экрана 428
Гиперсвязь 414, 421
Глобальная сеть 375
"Горячее" резервирование 792
Графический пользовательский
интерфейс (GUI) 426
Интернет-сервер 627
Интерсеть 376
Интерфейс устройства 738
блочный 738
низкого уровня 738
символьный 738
к
Дезинформация 418
Демон 378, 381
страниц 714, 715
Дескриптор:
индексный 359, 688
файла 513
Деструктор 781
Диалоговое окно 434
Диск 13
архитектура 684
блок 684
загрузочный 691
дорожка 684
квоты 763
контроллер 687
переполнение 760
пространство обмена 714
сектор 684
суперблок 691, 692
фрагментация 687
цилиндр 685
Диспетчер окна 430
Дисциплина линии 743
cbreak-режим 743
канонический режим 743
низкоуровневый режим 743
режим с обработкой 743
Домен 379
Драйвер устройства 738
И
Имитация соединения 418
Инкапсуляция 781
Интернет 403
безопасность 417
Карта обмена 714
Каталог 734
домашний 39
текущий рабочий 39, 569
Квант времени 703
Клавиатура 14
Класс объекта 781
Клиент-серверная модель 18, 606
Коллизия 373
Команда:
bg 589
cd 48
echo 175, 176
eval 205
exec 205
exit 204
fg 589
kill 199
shift 206
stop 589
trace 498
umask 208
wait 201
меню 434
Командная кнопка 434
Командный интерпретатор 30
Коммутация пакетов 376
Конвейер 20, 181, 274, 332, 596, 746
безымянный 597, 746
именованный 597, 601, 746
Конструктор 781
Контроллер диска 684
Корневое устройство 696
Коэффициент чередования 686
л
Лента 14
Локальная сеть 372
м п
Магистраль сети 376 Маршрутизатор 375 Маршрутизация 791 динамическая 378 статическая 378 Менеджер памяти 697 Меню: Пакет 406 Палиндром 459 Параллельная обработка 785 Перегрузка методов 782 Переключатель 435 Переключение контекста 704 Переменная:
выпадающее 431 корневое 436 окна 437 Метасимвол 176, 801 Метод 781 Многозадачность 195 Модем 14 Модуль 556 Монитор 13 Монтирование файловых систем 696 Мост 374 Мышь 14 $РАТН 568, 573 PATH 202, 251, 299 TERM 299 Переназначение 32 ввода 178, 179 вывода 42 Перенаправление 578 вывода 178 Планировщик 697, 703 Подкласс 782 Поисковая Web-машина 421 Политика приемлемого использования 419 Полоса прокрутки 435
н Постоянное запоминающее устройство (ПЗУ) 13
Накопитель CD-ROM 13 Наследование 782 Нить 576 Поток 745 восходящий 557 заголовок 745 нисходящий 557
Номер устройства: младший 739 старший 739 Потоковое сообщение 557 Право на секретность 418 Прерывание 580, 680
О аппаратное 675 обработчик 681 приоритет 680
Обработчик сигнала 580 Объединение сетей 376 Объект 781 mutex 577 Оперативное запоминающее устройство (ОЗУ) 13 Операционная система (ОС) 15 Опережающий ввод с клавиатуры 184 Отказоустойчивые системы 792 Отладчик 494 Очередь многоуровневых приоритетов 703 Привилегированный пользователь 22, 31, 66, 554, 755 Принтер 14 Пробуксовка 720 Программа 16 Программный интерфейс приложения (API) 434 Протокол: FTP 390 HTTP 420 IP 377, 406, 790 TCP 377, 406 UDP 407
Протокол Интернета 377 Протокол управления передачей 377 Процесс 16, 558, 675 getty 757, 770 init 558, 698, 756 login 757 pageout 699 sched 699 владелец 16 готовый 700 группа 591 зомби 564, 565, 588, 700, 723, 772 клиентский 606, 617 код выхода 203 легкий 576 область: Регулярное выражение 801 Редактор emacs 73, 84 буфер уничтожения 88 ввод текста 87 загрузка файла 90 запуск 84 инкрементный поиск 89 поиск и замена текста 90 перемещение курсора 87 помощь 86 редактирование текста 85 сохранение файла 90 Редактор vi 73, 256 буфер памяти 76 загрузка файла 81 замена текста 78, 80
данных 701 кода 701 пользователя 701 стека 701 ожидающий 700 приоритетный 592 приостановленный 700 работающий 700 реальный ID 572 серверный 606, 613 спящий 700 таблица 702 страниц 701 управления 591 фоновый 186 перенаправление ввода 188 перенаправление вывода 187 эффективный ID 572 ядра 699 Путь 40 абсолютный 40 полный 40 запуск 74 копирование и вставка текста 79 настройка 83 перемещение курсора 77 поиск 80 режим: ввода команд 74, 75 ввода текста 74 сохранение файла 81 удаление текста 77 Режим: многопользовательский 755 однопользовательский 755 пользовательский 678 ядра 678 Ретранслятор страниц 714 С Связь: жесткая 62, 134, 136, 531, 552, 689, 693, 728, 733, 747 символическая 134, 136, 288, 547,
р 689, 694 Семафор 629 бинарный 630
Рабочий стол 426 виртуальный 432 Разделение ограниченных ресурсов 16 Разделение сегмента памяти 628 Распределенная система 393 набор 630 Сеть 372 Сигнал 721 CONT 272 EXIT 289
HUP 198
KILL 200
SIGABRT581
SIGALRM 582-584
SIGBUS 582
SIGCHLD 564, 582, 584, 587, 617, 723, 757
SIGCONT 582, 589, 700
SIGEMT 581
SIGFPE 581
SIGHUP 581, 757
SIGILL 581
SIGINT 241, 322, 340, 581, 583, 586, 588, 593, 722
SIGIO 515, 551
SIGKILL 581, 584
SIGPIPE 582, 598
SIGPOLL 582
SIGPROF 582
SIGPWR 582
SIGQUIT 241, 340, 581
SIGSEGV 582
SIGSTOP 582, 589, 700
SIGSTP 582, 584
S1GSYS 582
SIGTERM 241, 340, 365, 582, 757, 758
SIGTRAP 581
SIGTSTP 757
SIGTTIN 582, 592, 595
SIGTTOU 582
SIGURG 551, 582
SIGUSR1 582
SIGUSR2 582
SIGVTALRM 582
SIGWINCH 582
SIGXCPU 582
SIGXFSZ 582
TERM 198, 200, 272 битовая карта ожидающих сигналов 721
массив обработчиков сигнала 721
ошибки 188
Система управления исходным кодом 479
Системный вызов 508, 675, 676 accept() 615 chdirQ 569
chmod 33, 62 chmod() 548 chown() 547 closeQ 514, 531, 742 connect() 618 dup() 549, 733 dup2() 549 exit() 564 fchmod() 548 fchown() 547 fcntlO 515, 550 forkQ 560 ftruncate() 555 getdents() 545 getegid() 572 gethostname() 625 getgid() 572 getpgid() 593 getpid() 561 getppid() 561 getuid() 572 ioctl() 552, 742 killO 587, 724 lchown() 547 link() 552, 735 listenO 615 lseek() 529, 684, 730 mknod() 554, 734 mountO 735 open() 207, 515, 525, 741 pipe() 597 read() 527, 687 setpgid() 592 setpgrpO 721 signal() 722 stat() 544 sync() 554, 727 truncateO 555 unlinkO 531, 733 wait() 562, 566, 723 write() 528
Скрипт 188 junk 327 track 234 загрузки системы 756
Служба доменных имен (DNS) 409 Сокет 18, 605
Стандартный вход 32, 42
Стандартный выход 32, 42, 163
Стандартный канал вывода
сообщений об ошибках 32
Страница памяти 706
Стратегия 739, 742
Структура каталогов 683
Суперпользователь 22
Счетчик ссылок 731
т
Таблица:
активных inode 728
векторов прерываний 681
векторов системных вызовов 678
монтирования 735
мусора 716
ОЗУ 708
открытых файлов 677, 728
переключения блочных
устройств 739
переключения символьных
устройств 739
процессов 677
страниц 707
бит копирования при
записи 711, 717
бит модификации 710, 714
бит обращения 710, 714
бит применимости 711, 715
возраст 714
Терминал:
жестко замонтированный 69
файл 770
управления 591, 745
Точка монтирования 735
Трассировка программы 497
У
Удаленный вызов процедуры 399
Универсализация файловых имен 180
Уровень управления 756
Устройство управления памятью 709
Утилита 67
ас 773
accton 773
admin 480 аг 472
at 126
awk 128, 182
biff 138 cal 787 cancel 53 cat 42, 44 chgrp 63
chmod 28, 33, 62, 64 chown 66
chsh 174, 188 clear 28, 31 cmp 110 comb 490
compress 140 config 774 cp 49
cpio 50, 116, 768 cron 772
crontab 124 crypt 141 date 28, 31, 379 dbx 495
delta 481, 484 df 760, 773 diff 111 du 762
dump 122 echo 190
egrep 102, 773
emacs 41, 49, 73, 783 env 217
expr 222, 356
fgrep 102 file 59
find 58, 113, 186 finger 384
fsck 756, 759
ftp 391, 408 get 481
grep 101, 121, 184 groups 63
gunzip 141
gzip 141 halt 758 head 45
help 480, 481, 496
hostname 383
ifconfig 771
kill 199
last 773
Id 462, 478
lint 493
In 134
Ip 52
Ipr 54
Iprm 55
Is 42, 47, 57, 181
mail 36, 91, 125, 179, 188
make 58, 774
man 28, 32, 149
mesg 386
mkdir 46
mkfs 763
mknod 769
monitor 532
more 44
mount 151
mv 46
netstat 771
newfs 764
nohup 198
nroff 23
nsiookup 411
od 149
рас 773
page 45
passwd 37, 775
prof 492
prs 485
ps 196
pwd 39, 48
quota 773
ranlib 477
rep 390
reboot 759
restore 123
reverse 516
riogin 394
rm 51
rmdei 489
rmdir 50 route 771 rsh 379, 395 rusers 381 rwho 383 sa 773 sact 482 sed 142 shutdown 758 sleep 196
sort 16, 21, 106, 182
strip 504
stty 34, 71
su 137, 755, 775
tail 45
talk 388
tar 119, 768
tee 182
telnet 380, 396, 408
test 224
time 153
touch 470
tr 147
troff 23
tset 68
tty 69, 152
ul 148
umount 151
uncompress 140
unget 483
uniq 105
users 381
uucp 773
vi 41, 49, 73
w 383
wall 389
wc 56, 181, 597
who 21, 183, 382, 442, 597
whoami 137
write 387
xbiff 439
xciock 438
xhost 429
xrdb 445
xterm 440
Учетное имя пользователя 29
ф
Файл 15, 675, 683
атрибуты 56
блок:
двойной косвенный 690
косвенный 690
блочный 545
владелец 58
волшебное число 697
время модификации 58
групп 766
каталог 683
обычный 545, 683
параметры полномочий 60
паролей 765
разбросанный 530, 730
размер 57
символьный 545
скрытый 526
специальный 554, 675, 683, 735
схема доступа:
косвенная 690
двойная косвенная 690
Файловая система:
резервное копирование 764
сетевая 399, 767
создание 763
Файловый указатель 529
Флаг отложенной записи 726
Флажок 435
Фокус окна 430
Фонд открытых программных средств 343
Форма Бэкуса—Наура (BNF) 31, 803
Фрагментация, внутренняя 751
Функции, многократно используемые 459
Ц
Цензура 418
Центральный процессор (ЦП) 12, 13
Шина 789
Шлюз 375
э
Эквивалентность машин 379
я
Ядро 674, 675, 677, 773
Язык гипертекстовой разметки документа 414
Язык программирования С 454
И* для 3-е изд»»
программистов о пользователей
Грэм Гласс • Кинг Эйблс
В доступной и наглядной форме изложены все аспекты работы с ОС UNIX, включая обсуждение основных концепций ОС, основных утилит, различных оболочек, сетевой организации, оконных систем, системного программирования, свойств и администрирования системы.
Книга будет полезна как для студентов компьютерных специальностей, так и для опытных программистов и пользователей.
В третьем, обновленном и дополненном, издании выделяются следующие темы.
• Описаны важные особенности UNIX и Linux
• Включена новая глава про командный интерпретатор Borne Again shell (Bash) и описаны все четыре главные оболочки UNIX shells
• Представлено более 100 утилит и их основные опции, включая awk, grep, sed, Perl, vi и emacs
• Приведен полный текст программы Internet shell для поддержки перенаправления и конвейеризации с другими командными интерпретаторами на удаленных хостах
Многочисленные иллюстрации, примеры, резюме, контрольные вопросы, упражнения и большое количество исходных кодов дополняют описание и помогают изучить любую версию UNIX.
БХВ-Петербург
1 j0005, Санкт-Петербург, Измайловский пр., 29
E-mail: mail bhv.ru internet www.bhv.ru тел. (812)251-42-44 факс: (812) 251-12-95