/









































































































































































































































































































































































































































































































































































































































































































































































































Автор: Yosifovich P. Ionescu A. Russinovich M.E. Solomon D.A.
Теги: windows informatik betriebssysteme
ISBN: 978-3-86490-538-4
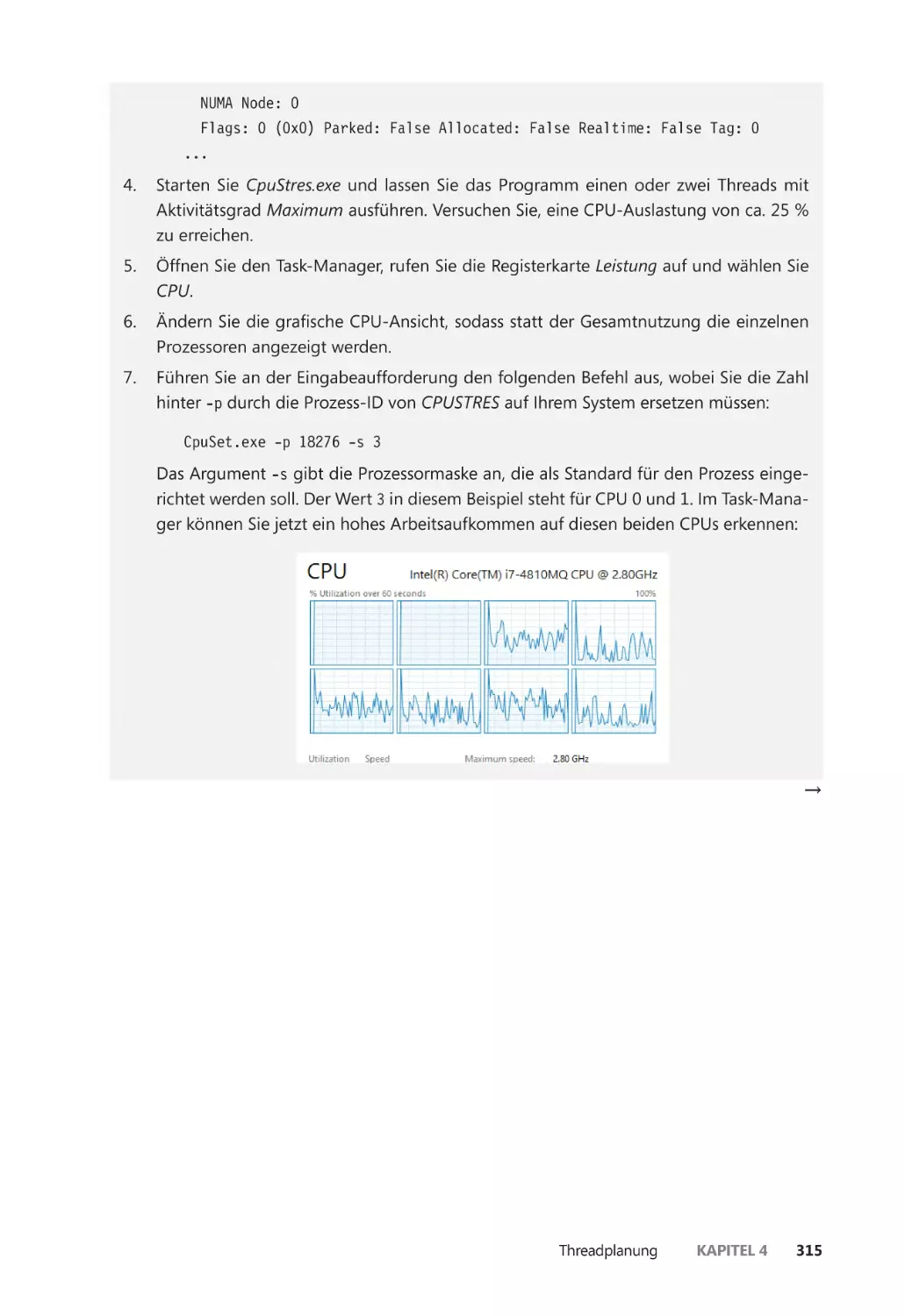
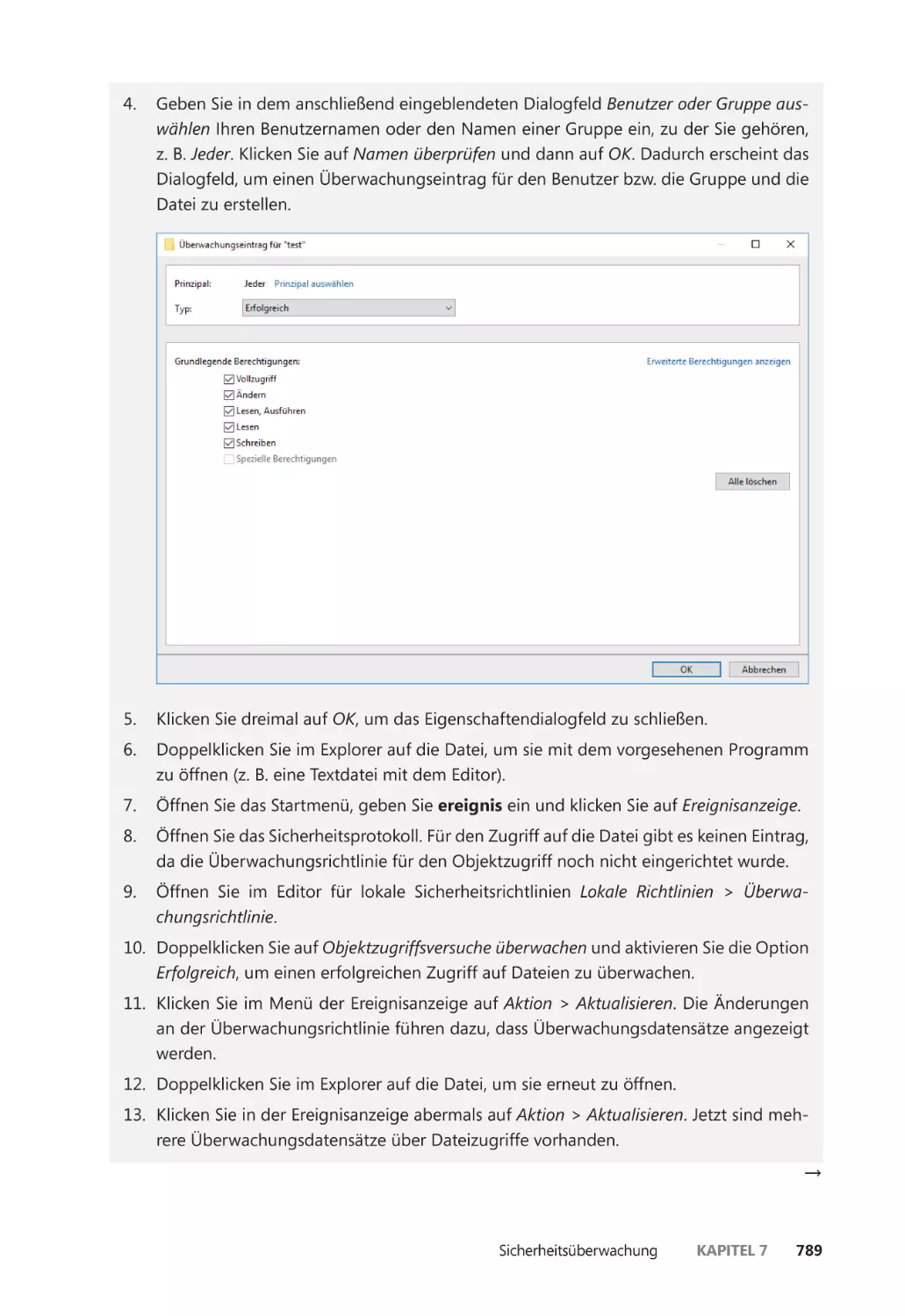
Год: 2018




Текст
Zu diesem Buch – sowie zu vielen weiteren dpunkt.büchern –
können Sie auch das entsprechende E-Book im PDF-Format
herunterladen. Werden Sie dazu einfach Mitglied bei dpunkt.plus+:
www.dpunkt.plus
Für meine Familie: meine Frau Idit und unsere Kinder Danielle, Amit und Yoav.
Danke für eure Geduld und eure Ermutigung während dieser anspruchsvollen
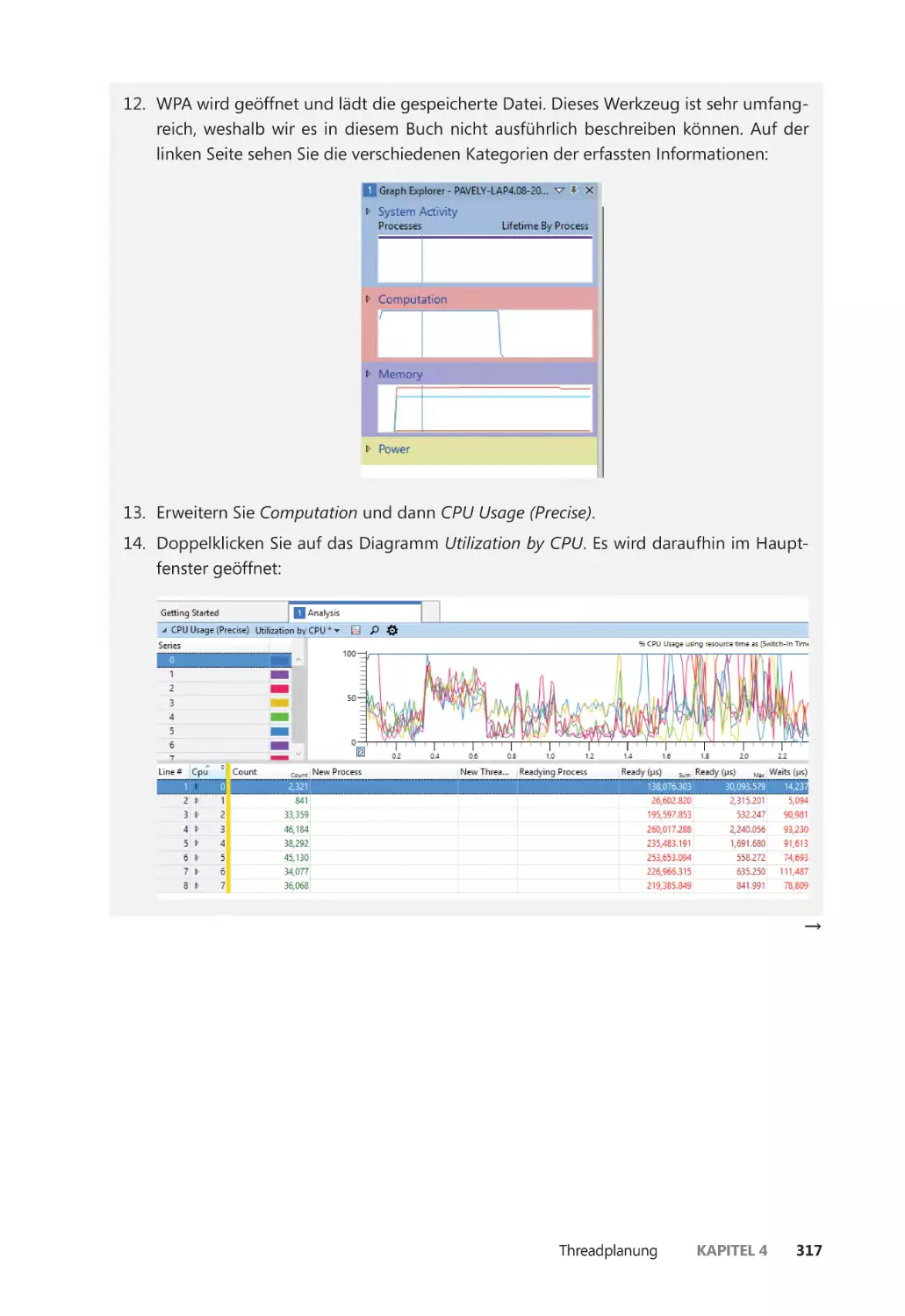
Arbeit.
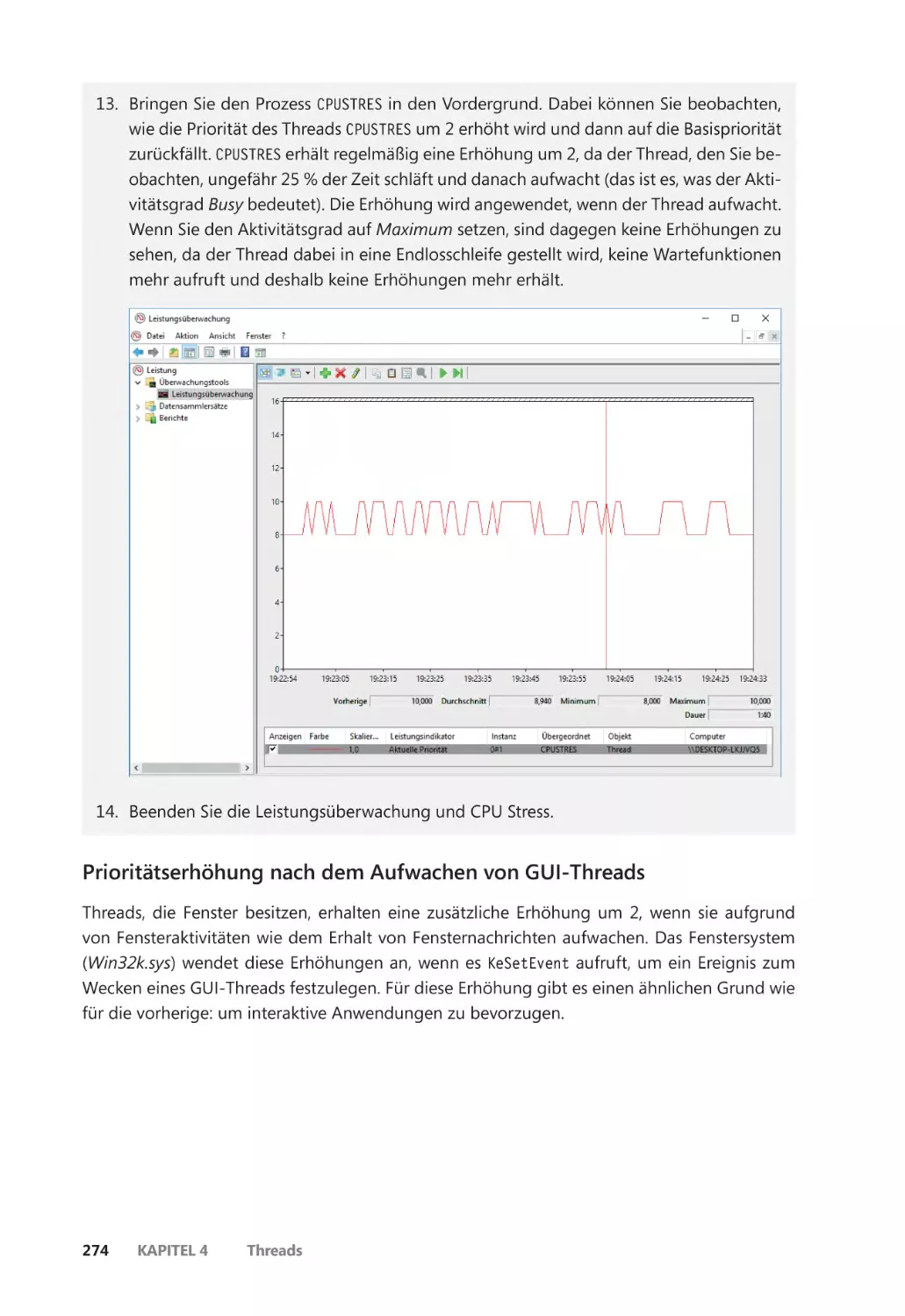
– Pavel Yosifovich
Für meine Eltern, die mich angeleitet und angeregt haben, meine Träume zu verfolgen, und für meine Familie, die während all dieser zahllosen Abende hinter mir
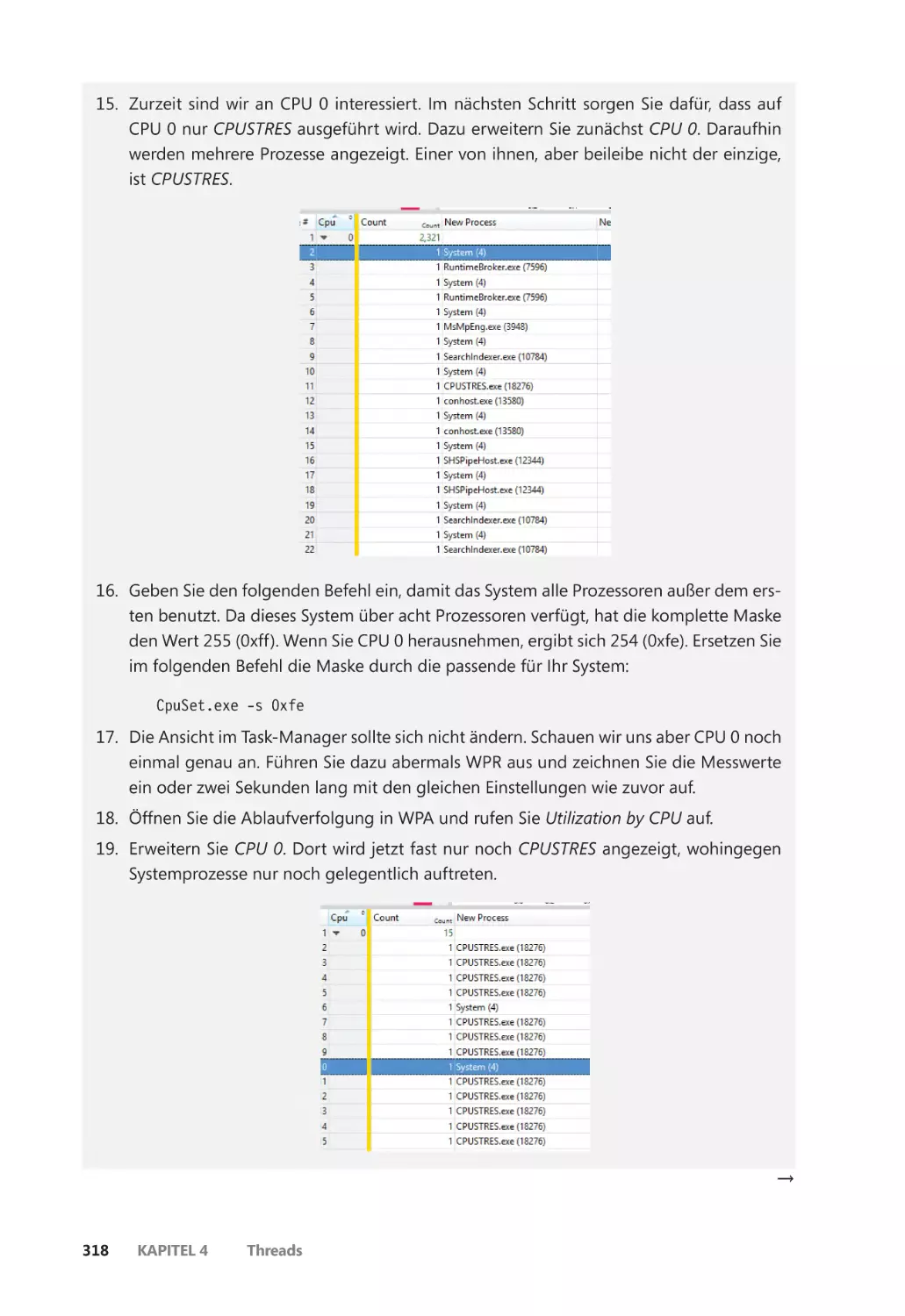
gestanden hat.
– Alex Ionescu
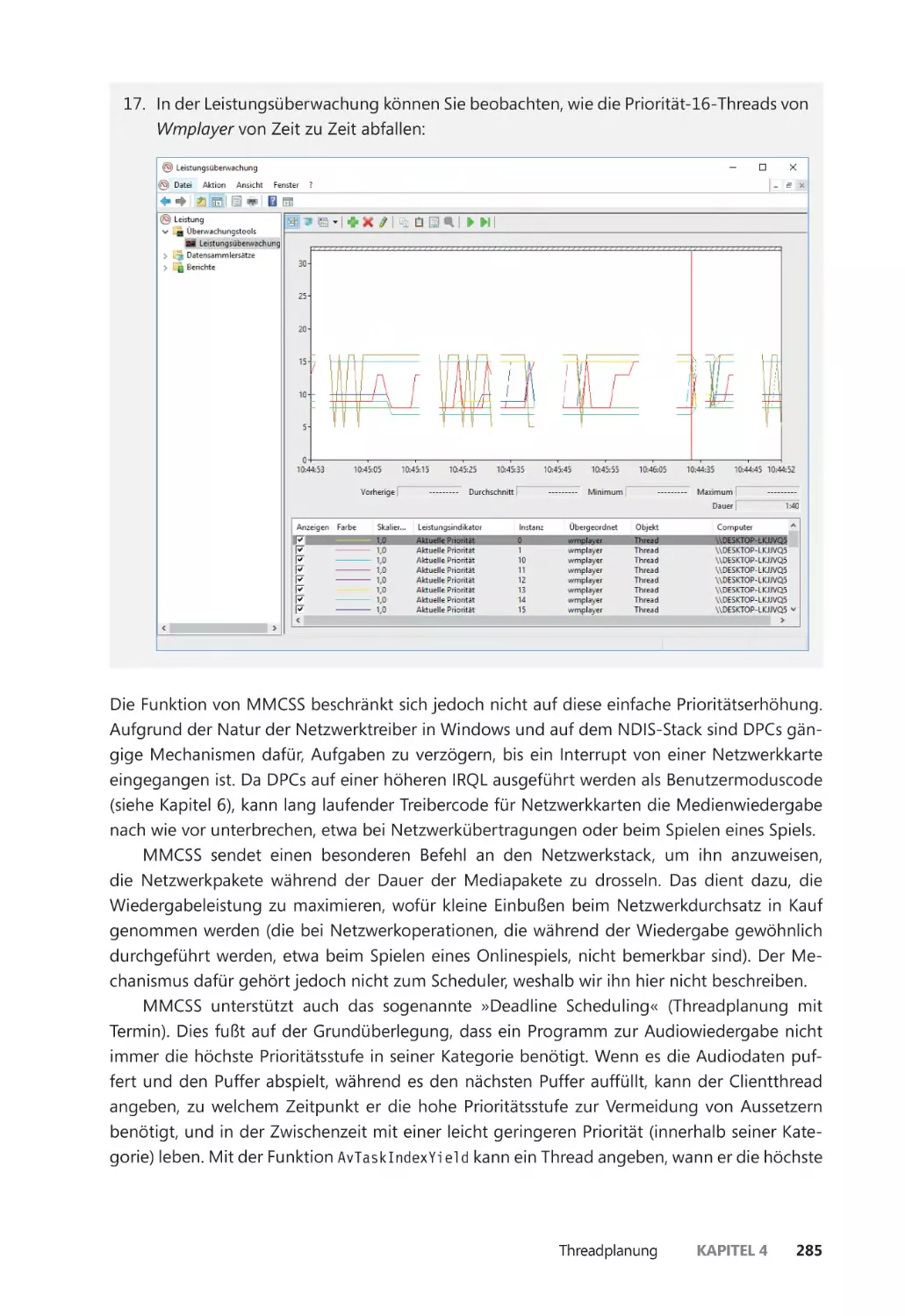
Für unsere Eltern, die uns angeleitet und angeregt haben, unsere Träume zu verfolgen.
– Mark E. Russinovich und David A. Solomon
Windows Internals
Band 1: Systemarchitektur, Prozesse, Threads,
Speicherverwaltung, Sicherheit und mehr
Übersetzung der 7. englischsprachigen Auflage
Pavel Yosifovich
Alex Ionescu
Mark E. Russinovich
David A. Solomon
Pavel Yosifovich
Alex Ionescu
Mark E. Russinovich
David A. Solomon
Lektorat: Sandra Bollenbacher
Übersetzung: G&U Language & Publishing Services GmbH, www.gundu.com
Copy-Editing: Petra Heubach-Erdmann
Satz: G&U Language & Publishing Services GmbH, www.gundu.com
Umschlaggestaltung: Helmut Kraus, exclam.de
Druckerei: C.H.Beck
ISBN:
Print
PDF
ePub
mobi
978-3-86490-538-4
978-3-96088-338-8
978-3-96088-339-5
978-3-96088-340-1
Translation Copyright für die deutschsprachige Ausgabe © 2018 dpunkt.verlag GmbH
Wieblinger Weg 17
69123 Heidelberg
Authorized translation from the English language edition, entitled WINDOWS INTERNALS, PART 1:
SYSTEM ARCHITECTURE, PROCESSES, THREADS, MEMORY MANAGEMENT, AND MORE, 7th Edition
by PAVEL YOSIFOVICH, ALEX IONESCU, MARK RUSSINOVICH, DAVID SOLOMON, published by
Pearson Education, Inc, publishing as Microsoft Press, Copyright © 2017 by Pavel Yosifovich, Alex
Ionescu, Mark E. Russinovich and David A. Solomon
All rights reserved. No part of this book may be reproduced or transmitted in any form or by any
means, electronic or mechanical, including photocopying, recording or by any information storage
retrieval system, without permission from Pearson Education, Inc.
German language edition published by dpunkt.verlag GmbH, Copyright © 2018
ISBN of the English language edition: 978-0-7356-8418-8
Die vorliegende Publikation ist urheberrechtlich geschützt. Alle Rechte vorbehalten. Die Verwendung der Texte und Abbildungen, auch auszugsweise, ist ohne die schriftliche Zustimmung des
Verlags urheberrechtswidrig und daher strafbar. Dies gilt insbesondere für die Vervielfältigung,
Übersetzung oder die Verwendung in elektronischen Systemen.
Es wird darauf hingewiesen, dass die im Buch verwendeten Soft- und Hardware-Bezeichnungen
sowie Markennamen und Produktbezeichnungen der jeweiligen Firmen im Allgemeinen warenzeichen-, marken- oder patentrechtlichem Schutz unterliegen.
Alle Angaben und Programme in diesem Buch wurden mit größter Sorgfalt kontrolliert. Weder
Autor noch Verlag können jedoch für Schäden haftbar gemacht werden, die in Zusammenhang mit
der Verwendung dieses Buchs stehen.
543210
Inhaltsverzeichnis
Einleitung xvii
Kapitel 1
Begriffe und Werkzeuge 1
Versionen des Betriebssystems Windows ����������������������������������������������������������������������� 1
Windows 10 und zukünftige Windows-Versionen ������������������������������������������������� 3
Windows 10 und OneCore ����������������������������������������������������������������������������������������� 3
Grundprinzipien und -begriffe ����������������������������������������������������������������������������������������� 4
Die Windows-API ��������������������������������������������������������������������������������������������������������� 4
Dienste, Funktionen und Routinen ��������������������������������������������������������������������������� 7
Prozesse ������������������������������������������������������������������������������������������������������������������������ 8
Threads ����������������������������������������������������������������������������������������������������������������������� 20
Jobs ����������������������������������������������������������������������������������������������������������������������������� 23
Virtueller Arbeitsspeicher ����������������������������������������������������������������������������������������� 23
Kernel- und Benutzermodus ����������������������������������������������������������������������������������� 26
Hypervisor ������������������������������������������������������������������������������������������������������������������ 30
Firmware ��������������������������������������������������������������������������������������������������������������������� 32
Terminaldienste und mehrere Sitzungen ��������������������������������������������������������������� 32
Objekte und Handles ����������������������������������������������������������������������������������������������� 33
Sicherheit ������������������������������������������������������������������������������������������������������������������� 34
Die Registrierung ������������������������������������������������������������������������������������������������������� 36
Unicode ����������������������������������������������������������������������������������������������������������������������� 37
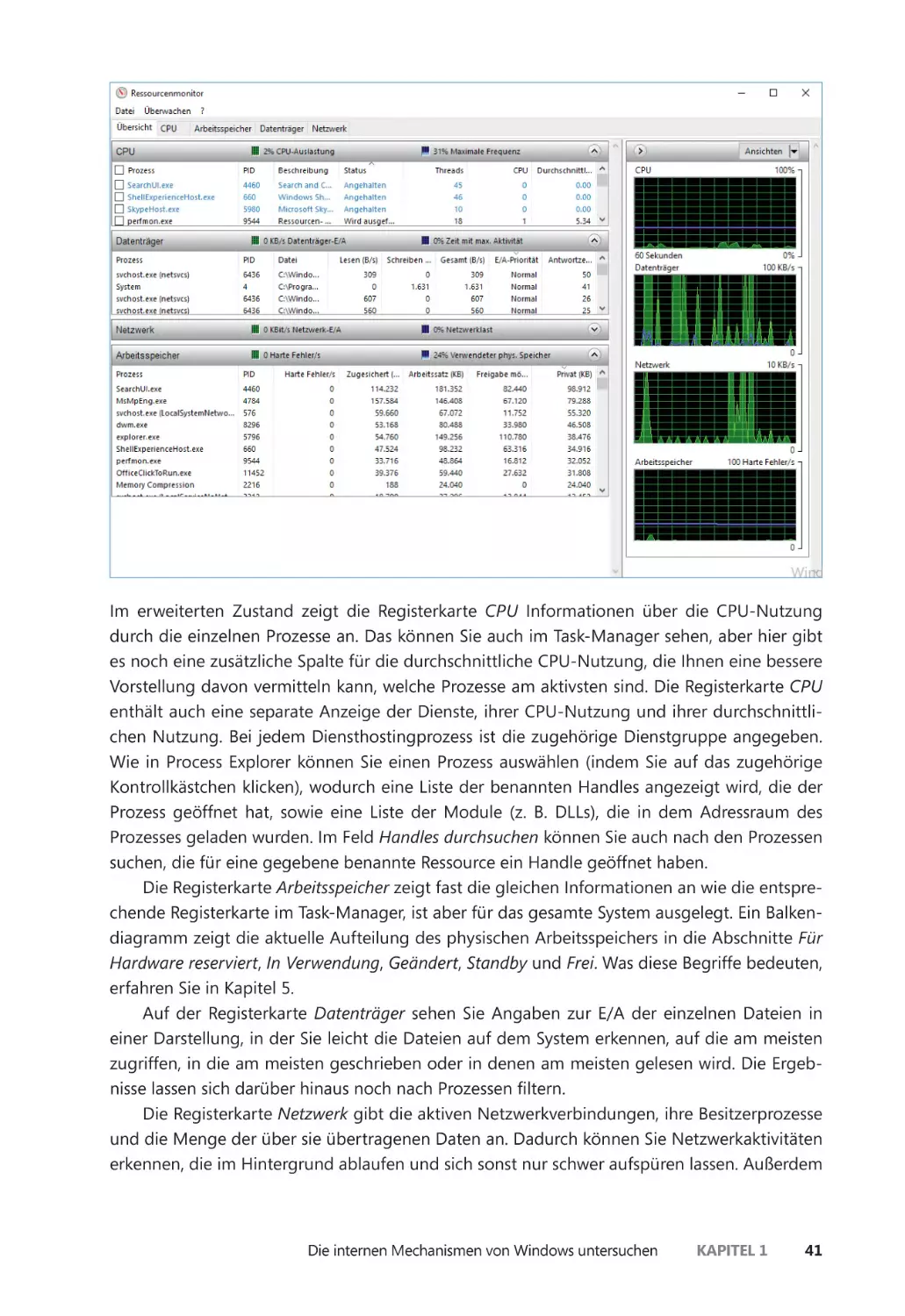
Die internen Mechanismen von Windows untersuchen ��������������������������������������������� 39
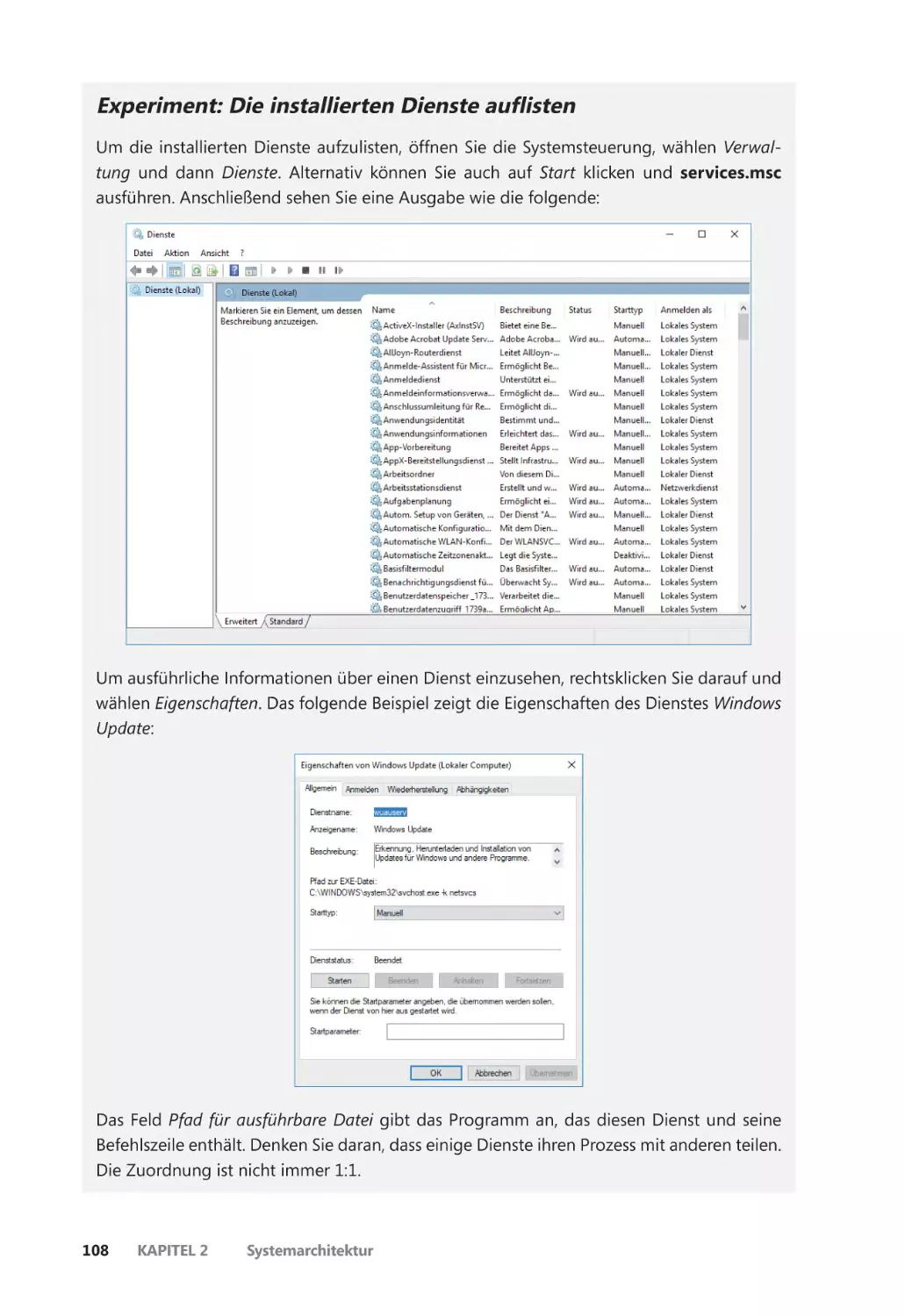
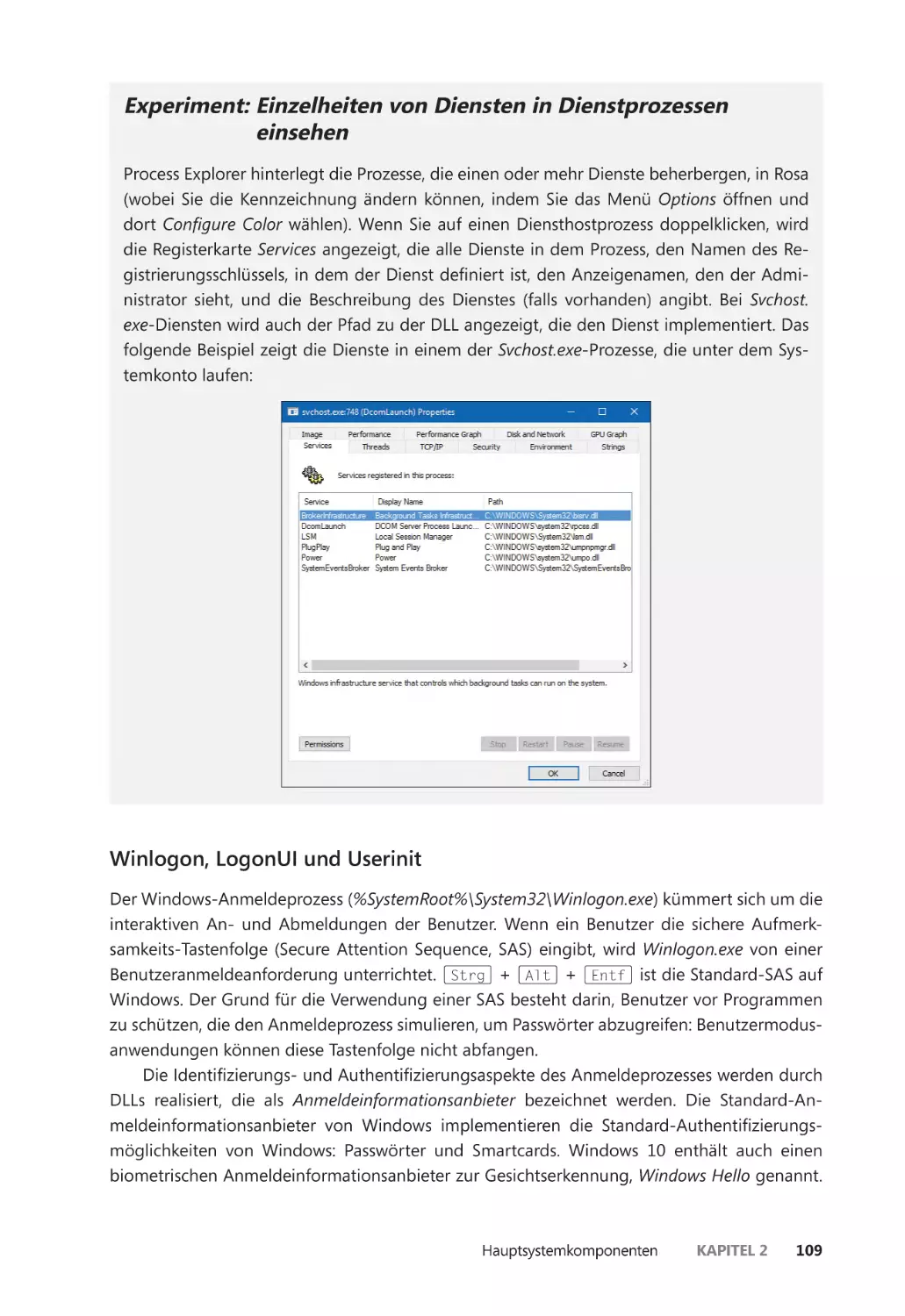
Leistungsüberwachung und Ressourcenmonitor ������������������������������������������������� 40
Kernel-Debugging ����������������������������������������������������������������������������������������������������� 42
Windows Software Development Kit ��������������������������������������������������������������������� 48
Windows Driver Kit ��������������������������������������������������������������������������������������������������� 49
Sysinternals-Werkzeuge ������������������������������������������������������������������������������������������� 49
Zusammenfassung ����������������������������������������������������������������������������������������������������������� 50
vii
Kapitel 2
Systemarchitektur 51
Anforderungen und Designziele ����������������������������������������������������������������������������������� 51
Das Modell des Betriebssystems ������������������������������������������������������������������������������������� 52
Die Architektur im Überblick ����������������������������������������������������������������������������������������� 53
Portierbarkeit ������������������������������������������������������������������������������������������������������������� 56
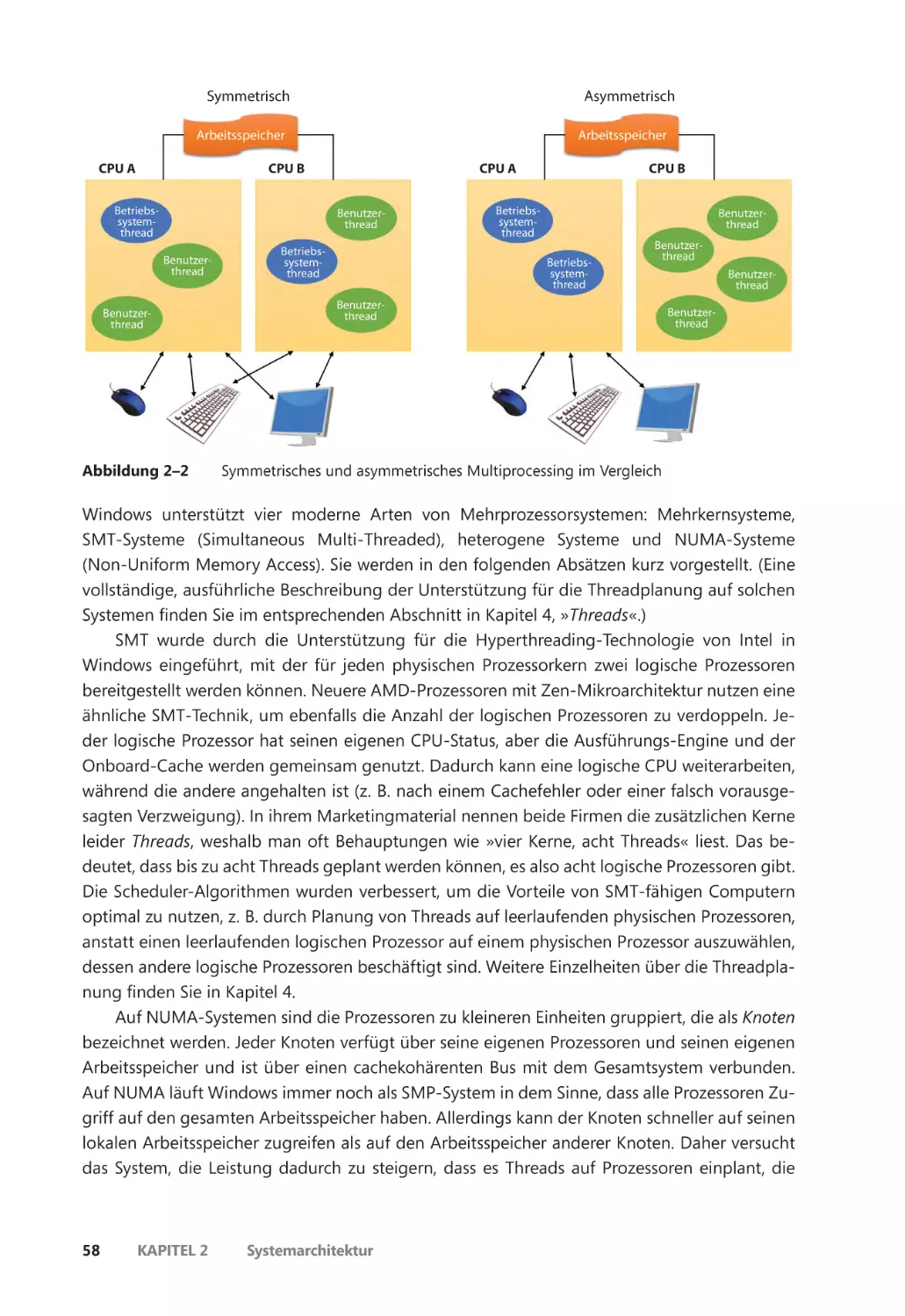
Symmetrisches Multiprocessing ����������������������������������������������������������������������������� 57
Skalierbarkeit ������������������������������������������������������������������������������������������������������������� 60
Unterschiede zwischen den Client- und Serverversionen ����������������������������������� 61
Testbuild ��������������������������������������������������������������������������������������������������������������������� 64
Die virtualisierungsgestützte Sicherheitsarchitektur im Überblick ��������������������������� 66
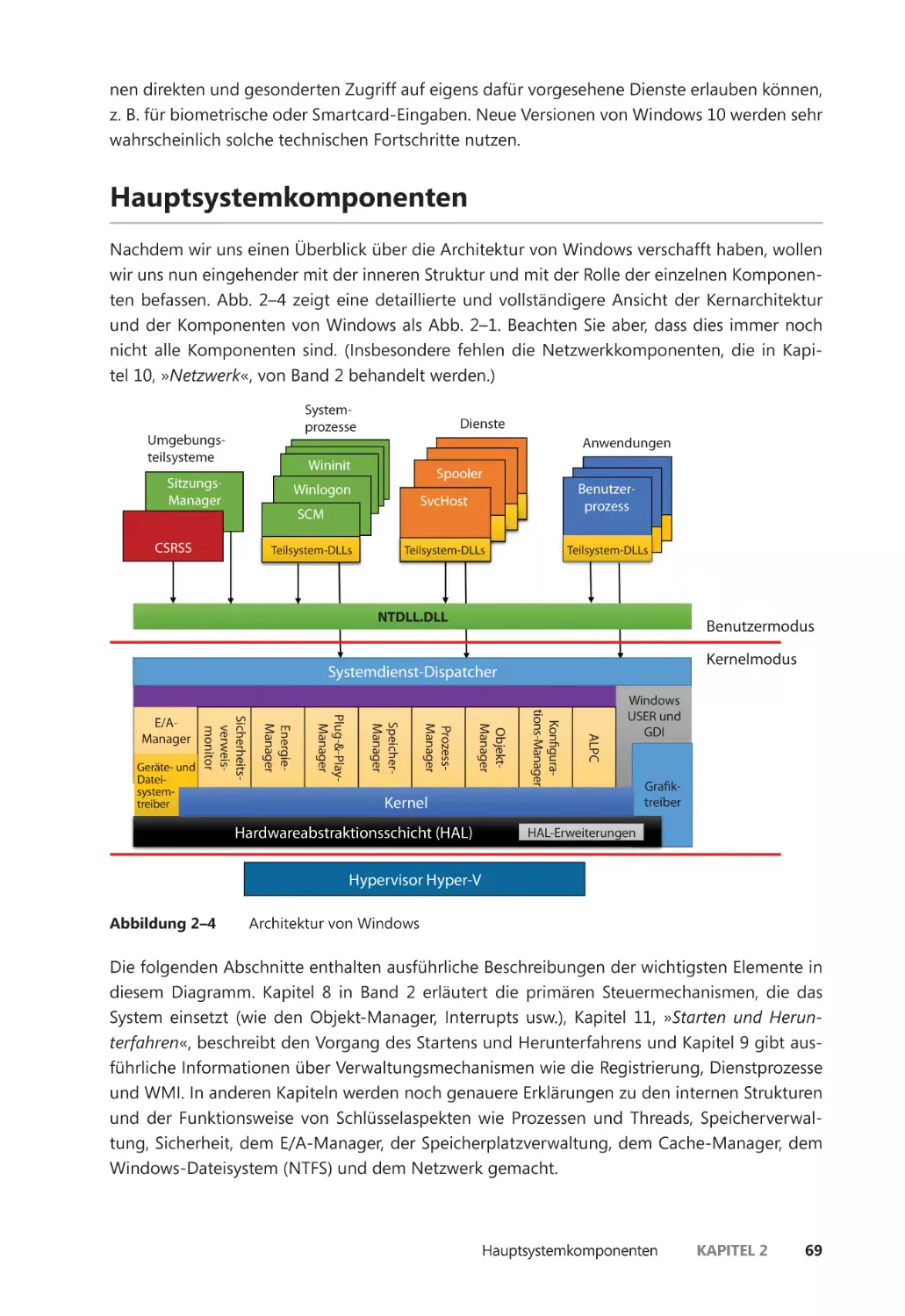
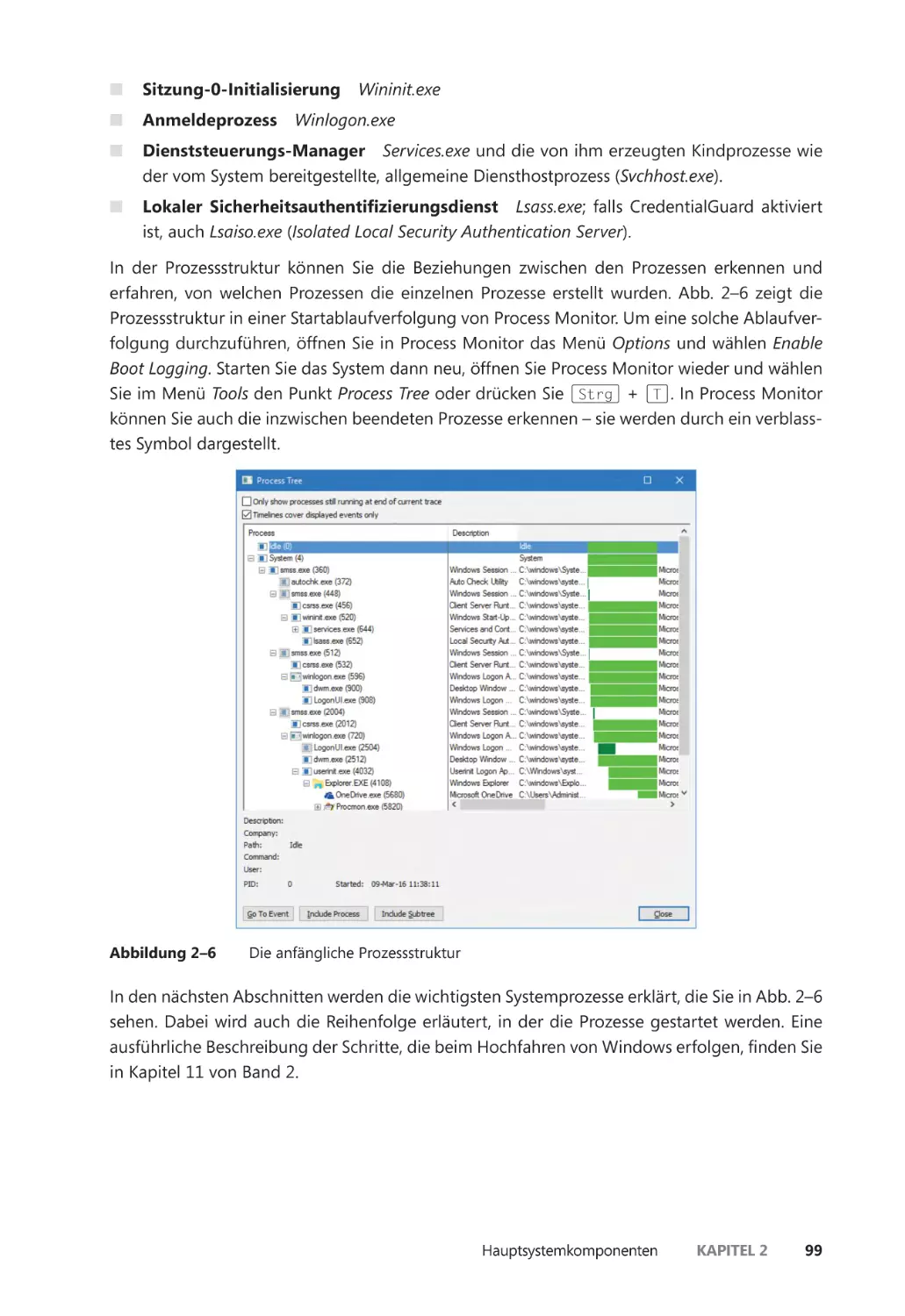
Hauptsystemkomponenten ��������������������������������������������������������������������������������������������� 69
Umgebungsteilsysteme und Teilsystem-DLLs ������������������������������������������������������� 70
Weitere Teilsysteme ��������������������������������������������������������������������������������������������������� 76
Exekutive ��������������������������������������������������������������������������������������������������������������������� 81
Der Kernel ������������������������������������������������������������������������������������������������������������������� 84
Die Hardwareabstraktionsschicht ��������������������������������������������������������������������������� 88
Gerätetreiber ������������������������������������������������������������������������������������������������������������� 92
Systemprozesse ��������������������������������������������������������������������������������������������������������� 98
Zusammenfassung ��������������������������������������������������������������������������������������������������������� 111
Kapitel 3
Prozesse und Jobs 113
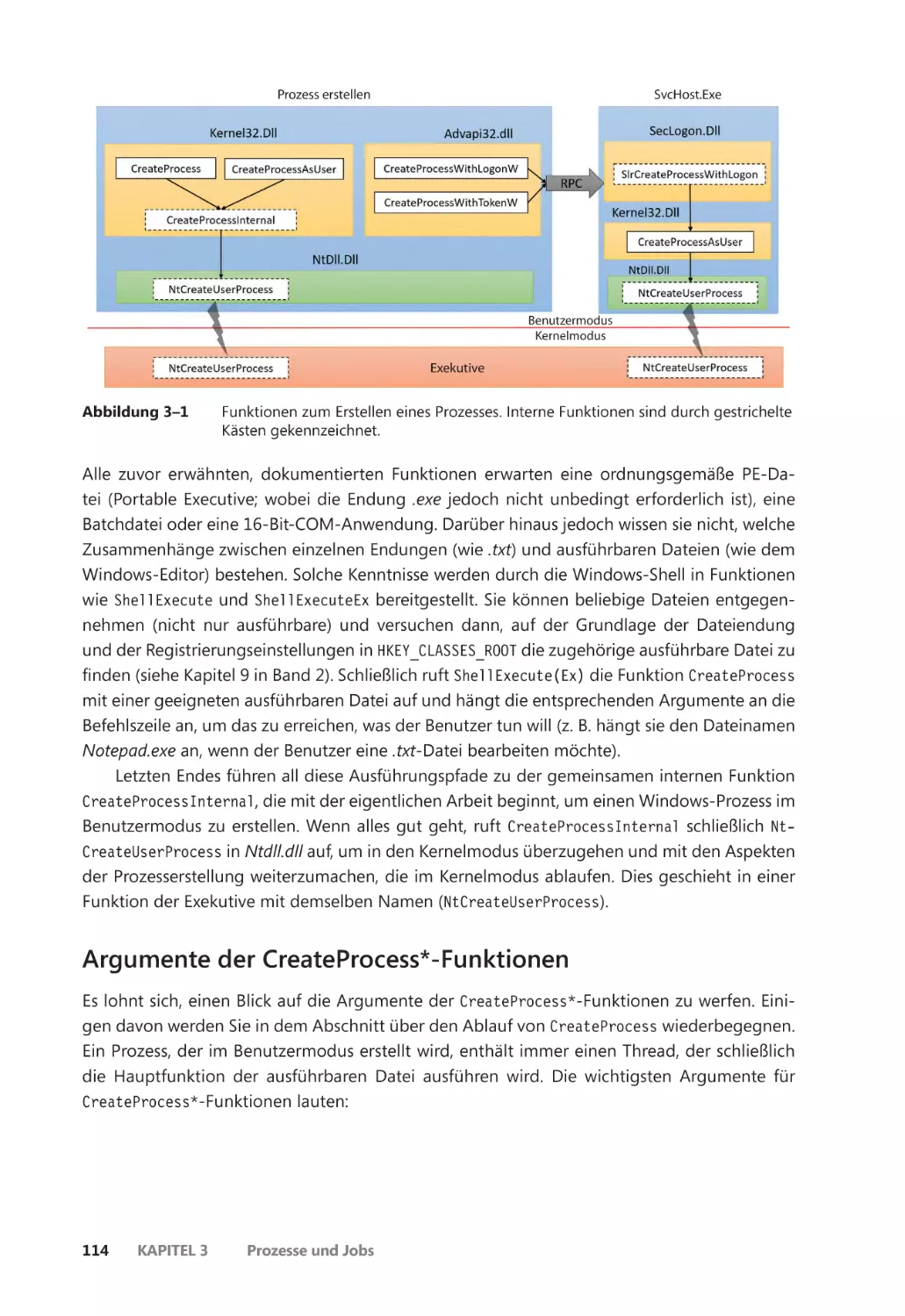
Prozesse erstellen ����������������������������������������������������������������������������������������������������������� 113
Argumente der CreateProcess*-Funktionen ������������������������������������������������������� 114
Moderne Windows-Prozesse erstellen ����������������������������������������������������������������� 115
Andere Arten von Prozessen erstellen ����������������������������������������������������������������� 116
Interne Mechanismen von Prozessen ������������������������������������������������������������������������� 117
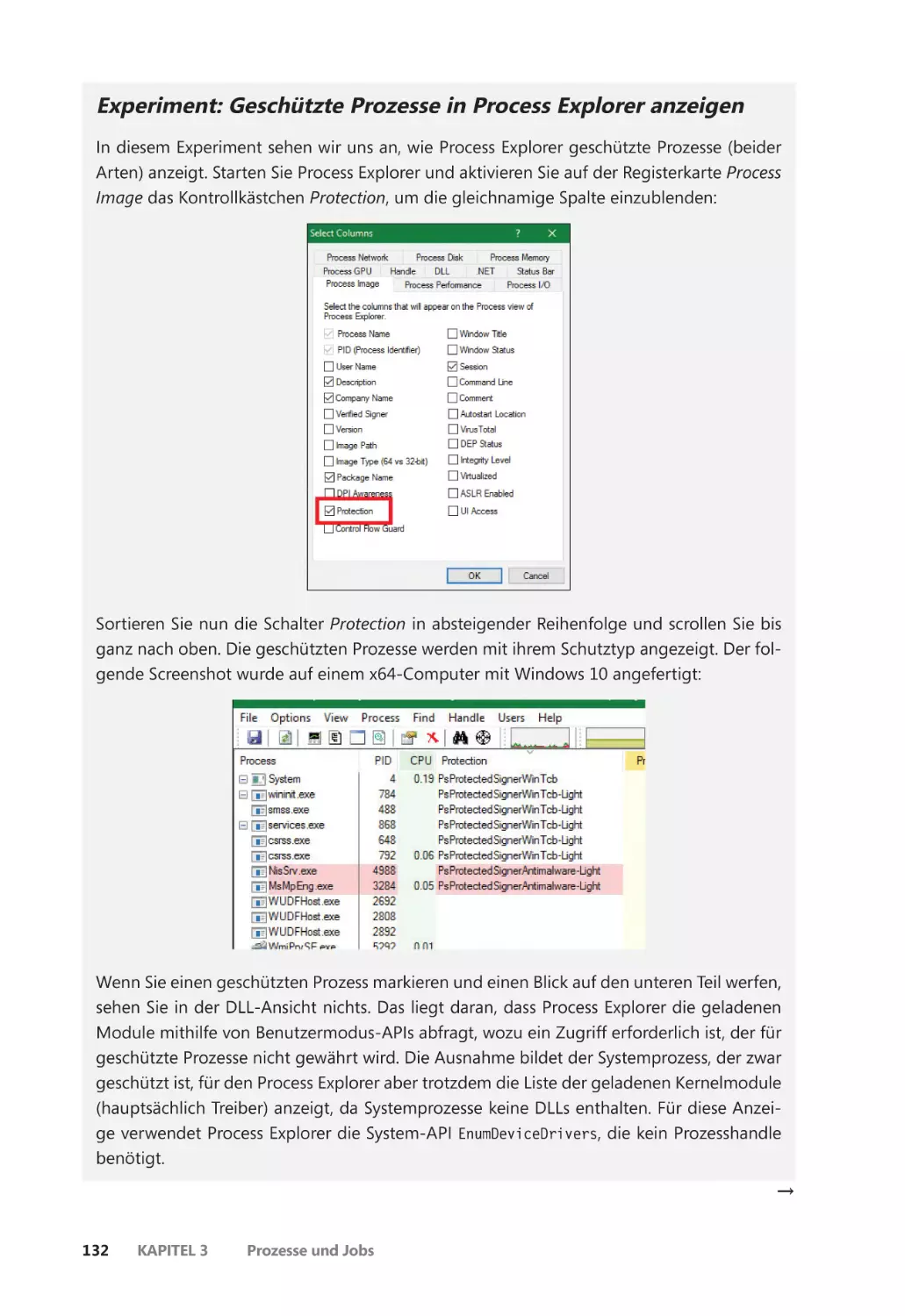
Geschützte Prozesse ������������������������������������������������������������������������������������������������������� 126
Protected Process Light (PPL) ������������������������������������������������������������������������������� 128
Unterstützung für Drittanbieter-PPLs ������������������������������������������������������������������� 133
Minimale und Pico-Prozesse ����������������������������������������������������������������������������������������� 134
Minimale Prozesse ��������������������������������������������������������������������������������������������������� 134
Pico-Prozesse ����������������������������������������������������������������������������������������������������������� 134
viii
Inhaltsverzeichnis
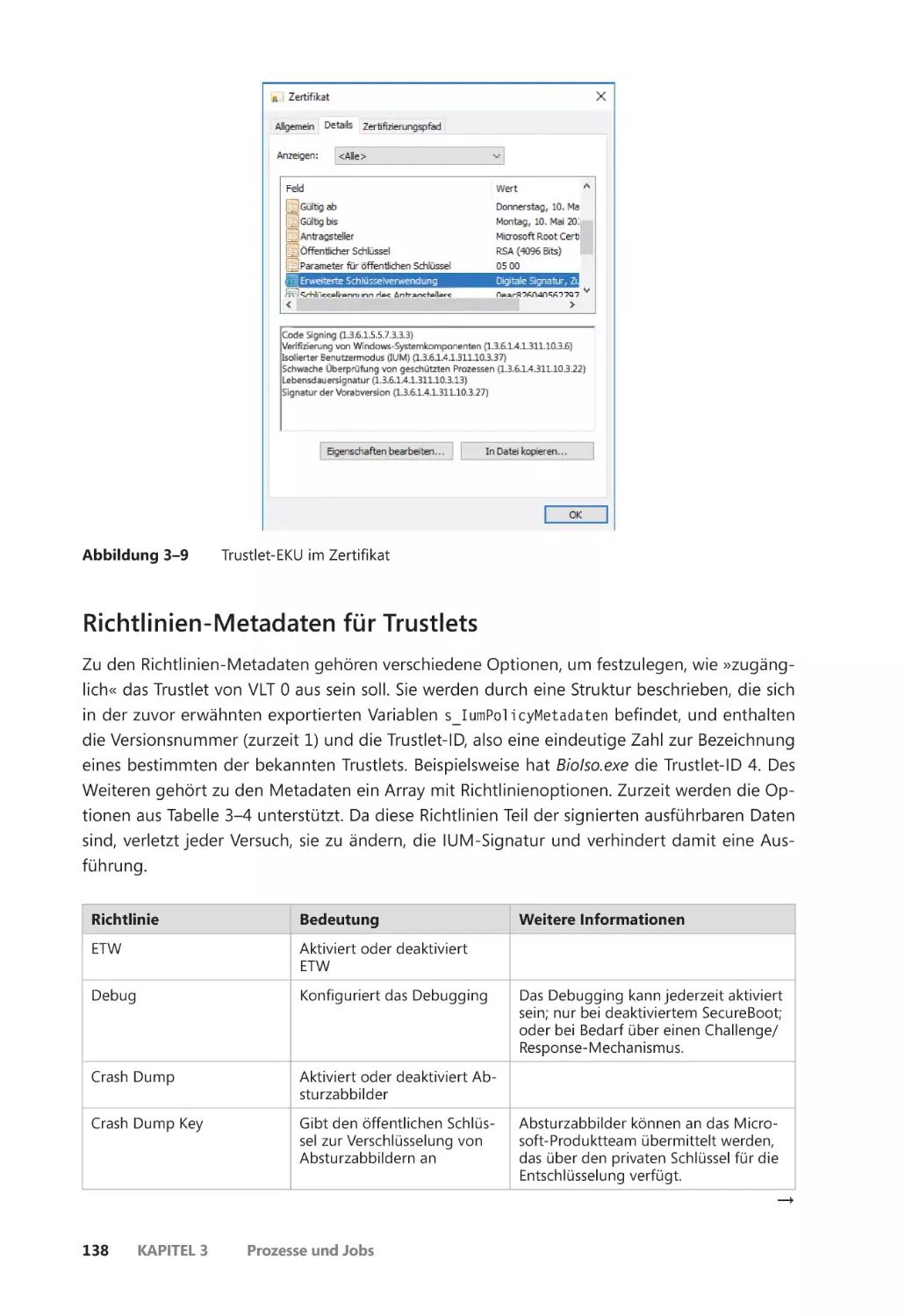
Trustlets (sichere Prozesse) ������������������������������������������������������������������������������������������� 137
Der Aufbau von Trustlets ��������������������������������������������������������������������������������������� 137
Richtlinien-Metadaten für Trustlets ��������������������������������������������������������������������� 138
Attribute von Trustlets �������������������������������������������������������������������������������������������� 139
Integrierte System-Trustlets ����������������������������������������������������������������������������������� 140
Trustlet-Identität ����������������������������������������������������������������������������������������������������� 140
IUM-Dienste ������������������������������������������������������������������������������������������������������������� 141
Für Trustlets zugängliche Systemaufrufe ������������������������������������������������������������� 142
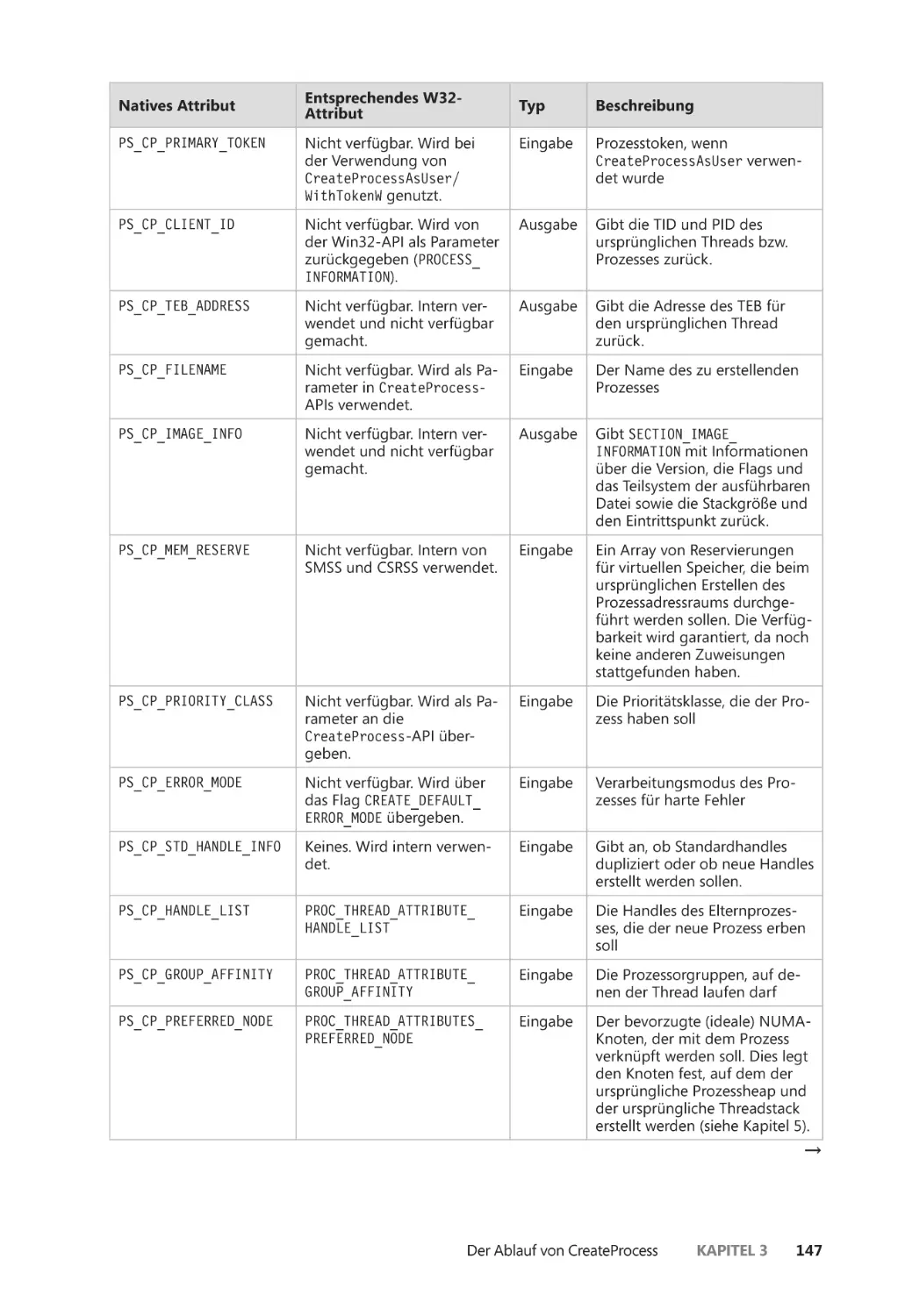
Der Ablauf von CreateProcess ��������������������������������������������������������������������������������������� 144
Phase 1: Parameter und Flags konvertieren und validieren ����������������������������� 145
Phase 2: Das auszuführende Abbild öffnen ��������������������������������������������������������� 151
Phase 3: Das Windows-Exekutivprozessobjekt erstellen ����������������������������������� 154
Phase 4: Den ursprünglichen Thread mit seinem Stack und Kontext
erstellen ����������������������������������������������������������������������������������������������������� 160
Phase 5: Spezifische Prozessinitialisierung für das Windows-Teilsystem
durchführen ��������������������������������������������������������������������������������������������� 162
Phase 6: Ausführung des ursprünglichen Threads starten ������������������������������� 164
Phase 7: Prozessinitialisierung im Kontext des neuen Prozesses
durchführen ��������������������������������������������������������������������������������������������� 165
Einen Prozess beenden ������������������������������������������������������������������������������������������������� 172
Der Abbildlader ��������������������������������������������������������������������������������������������������������������� 173
Frühe Prozessinitialisierung ����������������������������������������������������������������������������������� 176
DLL-Namensauflösung und -Umleitung ������������������������������������������������������������� 179
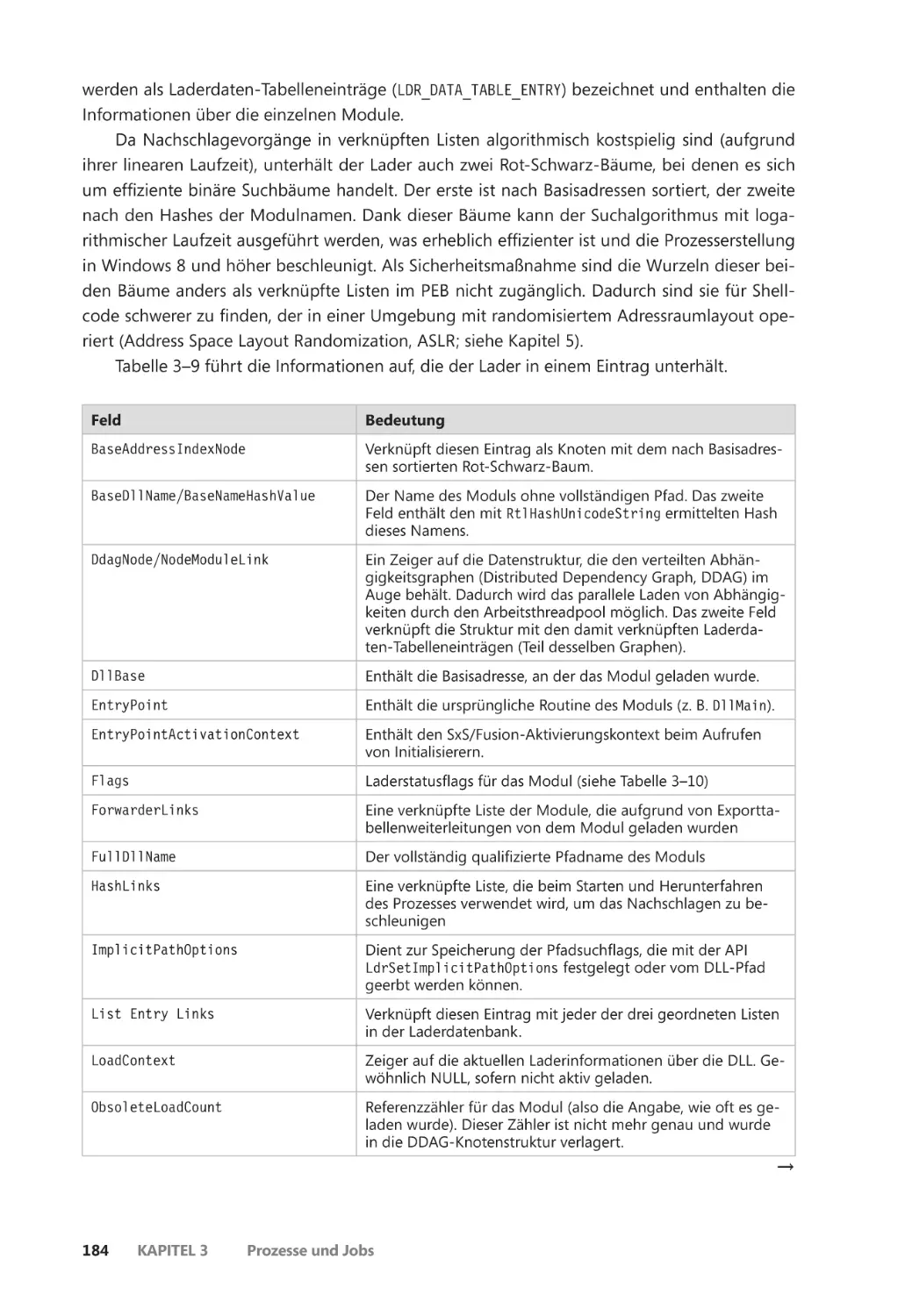
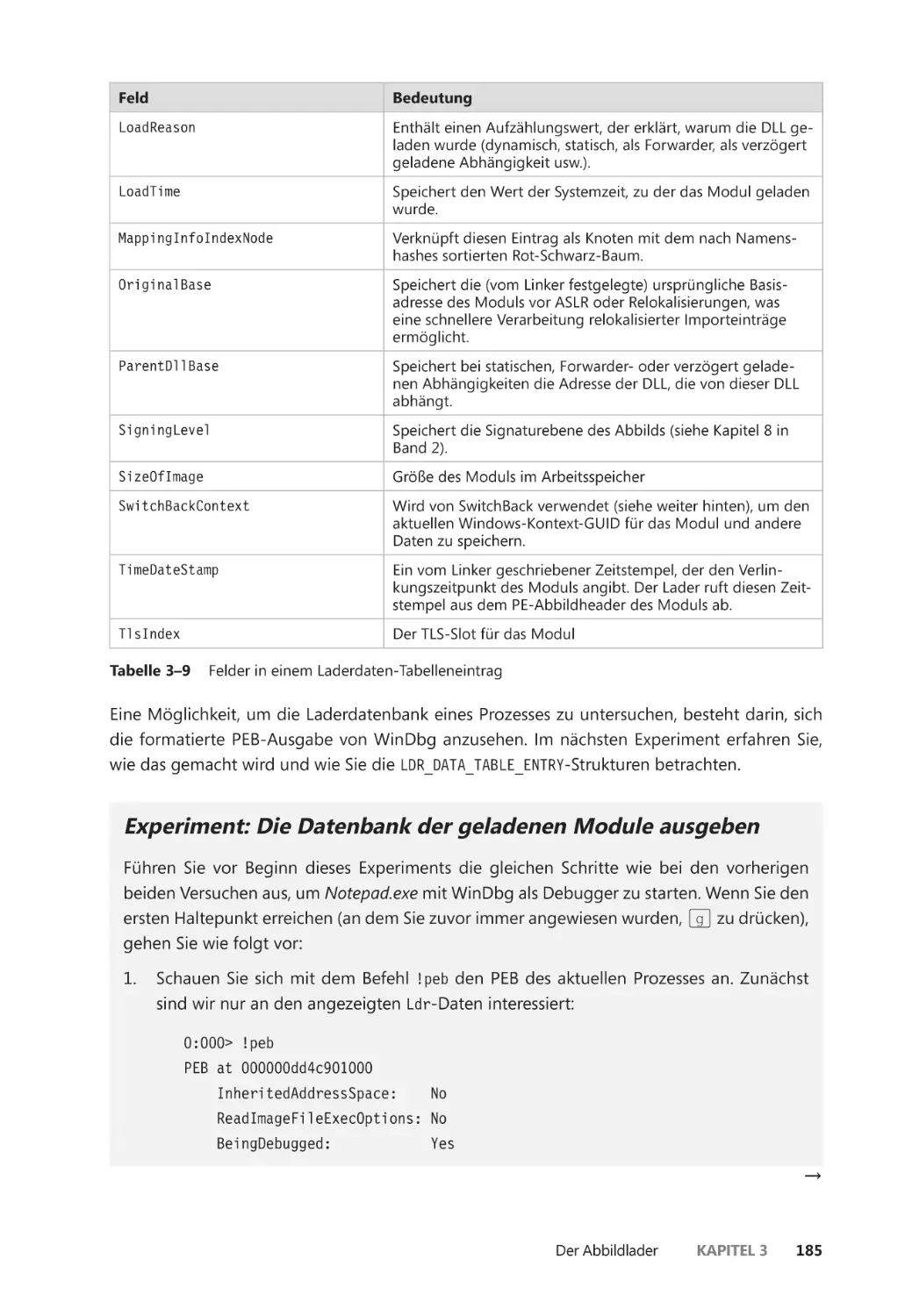
Die Datenbank der geladenen Module ��������������������������������������������������������������� 183
Importanalyse ��������������������������������������������������������������������������������������������������������� 188
Prozessinitialisierung nach dem Import ��������������������������������������������������������������� 190
SwitchBack ��������������������������������������������������������������������������������������������������������������� 191
API-Sets ��������������������������������������������������������������������������������������������������������������������� 194
Jobs ����������������������������������������������������������������������������������������������������������������������������������� 196
Grenzwerte für Jobs ����������������������������������������������������������������������������������������������� 197
Umgang mit Jobs ��������������������������������������������������������������������������������������������������� 199
Verschachtelte Jobs ������������������������������������������������������������������������������������������������� 199
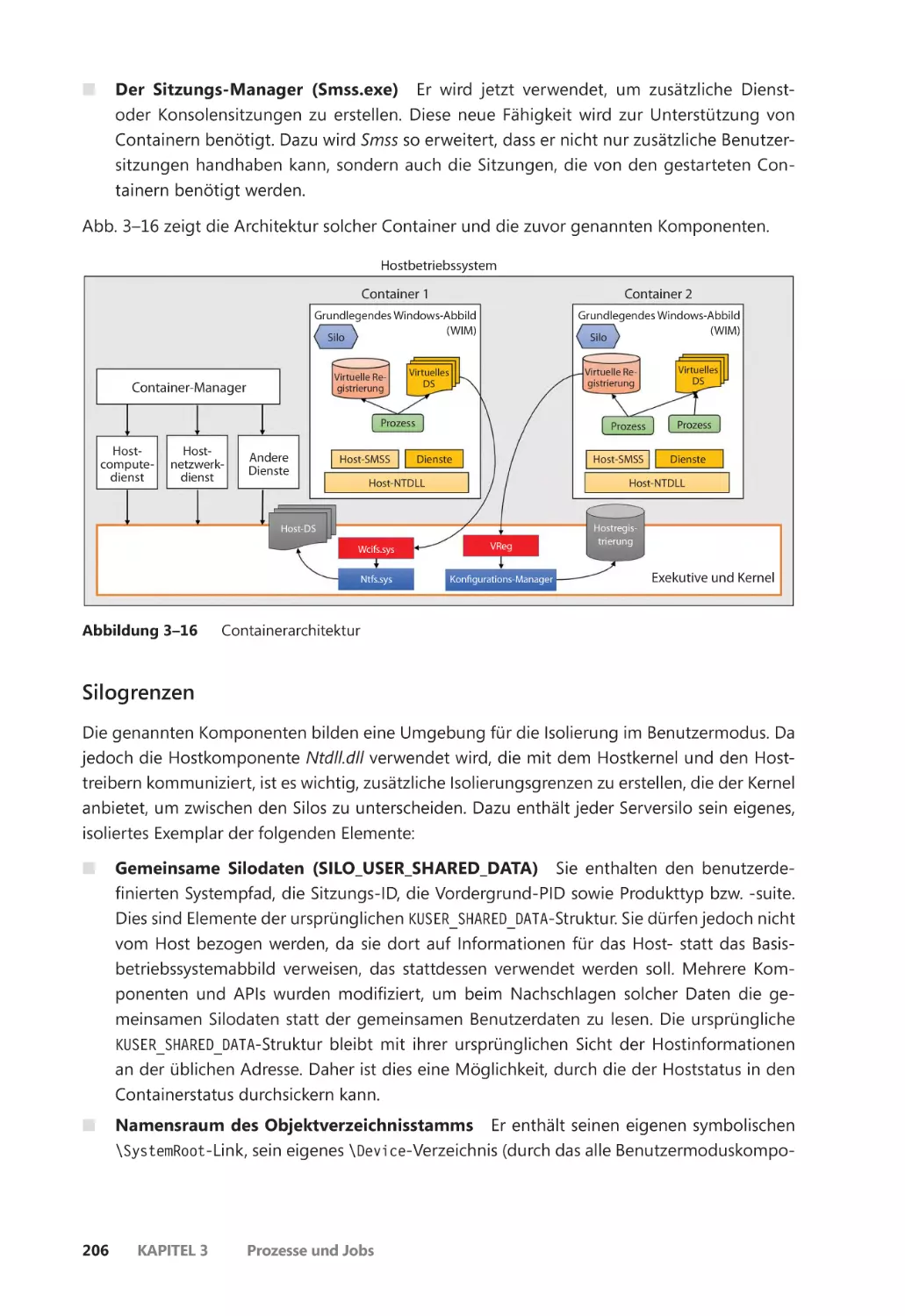
Windows-Container (Serversilos) ������������������������������������������������������������������������� 204
Zusammenfassung ��������������������������������������������������������������������������������������������������������� 213
Inhaltsverzeichnis
ix
Kapitel 4
Threads 215
Threads erstellen ������������������������������������������������������������������������������������������������������������� 215
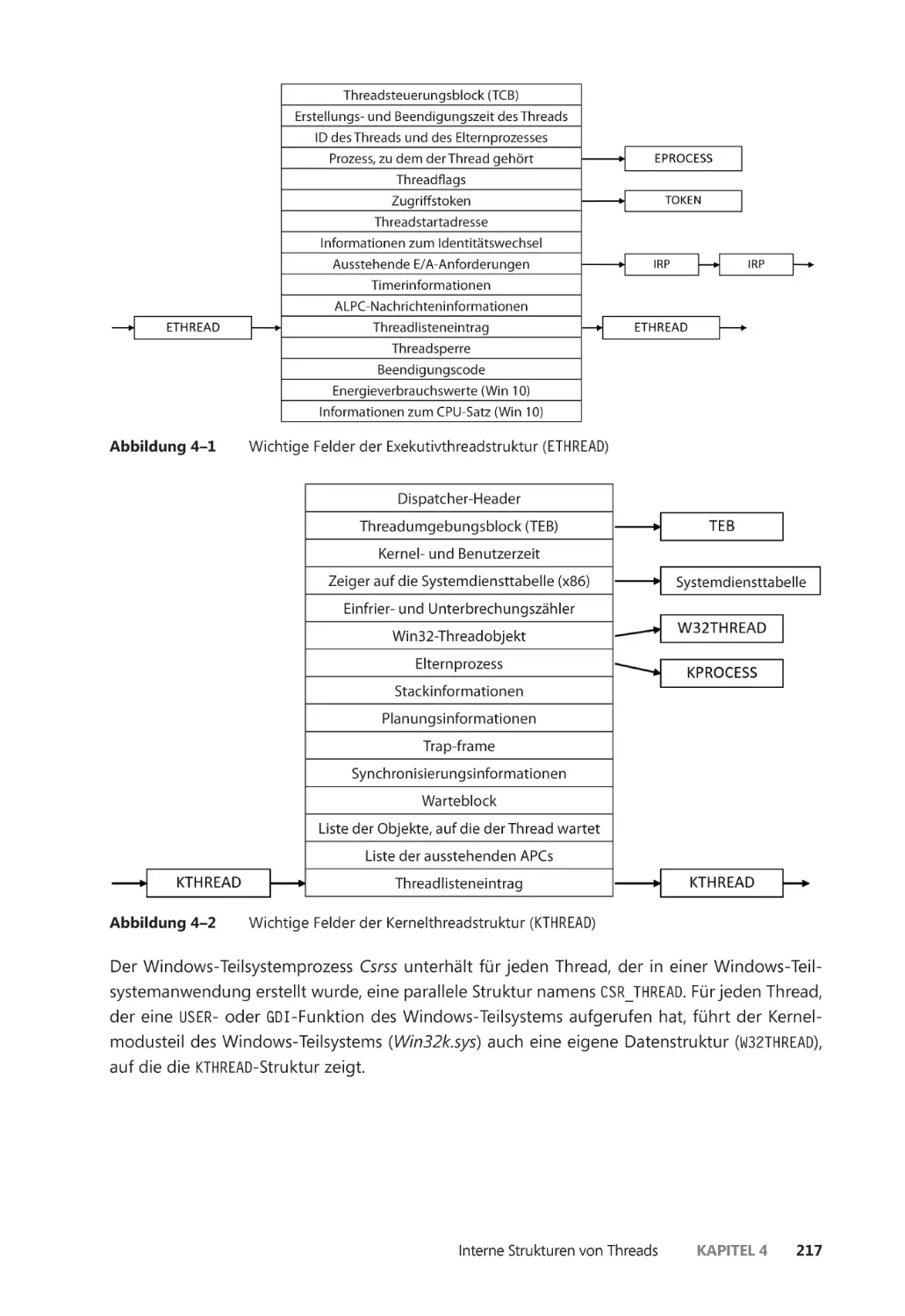
Interne Strukturen von Threads ����������������������������������������������������������������������������������� 216
Datenstrukturen ������������������������������������������������������������������������������������������������������� 216
Geburt eines Threads ��������������������������������������������������������������������������������������������� 230
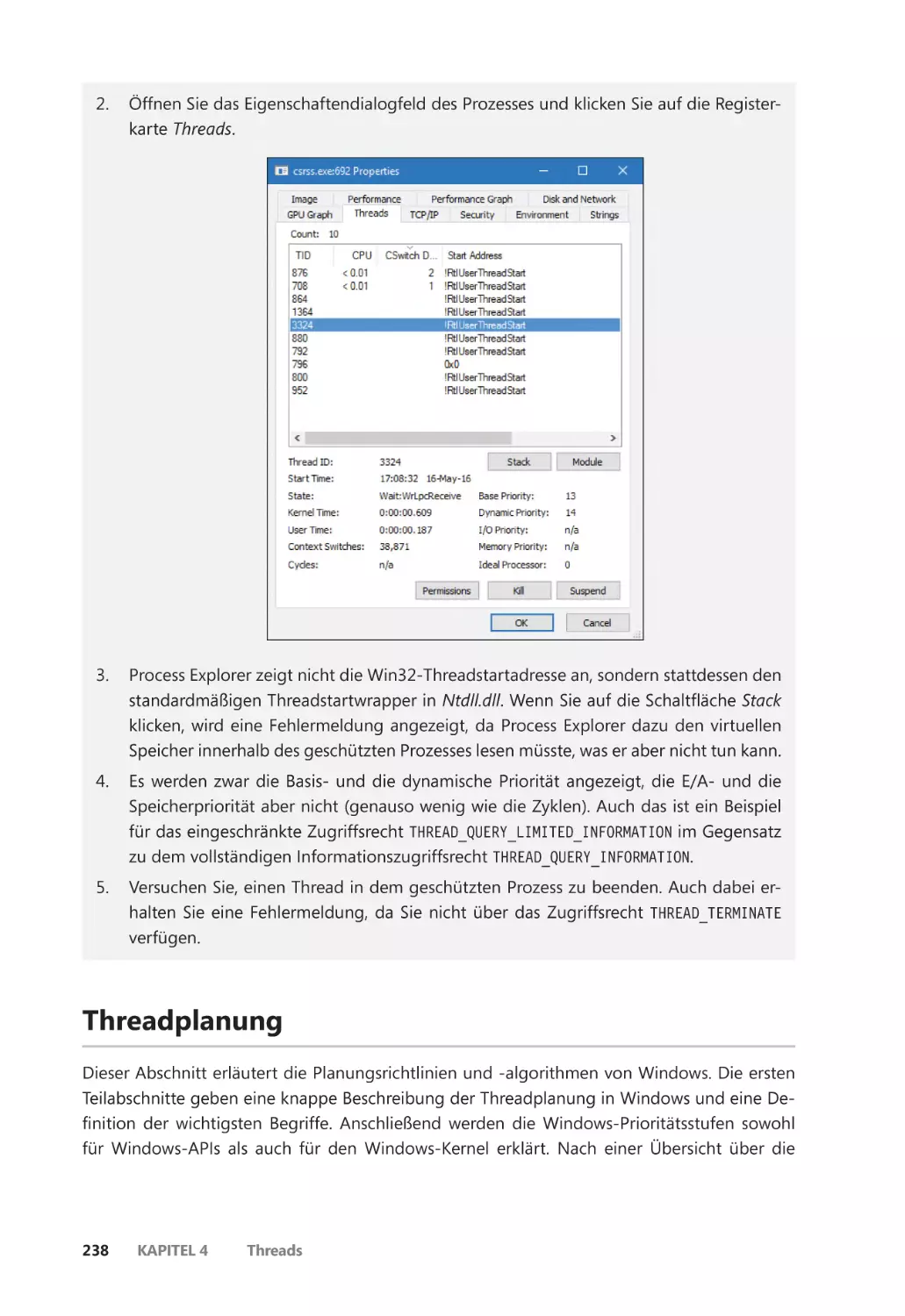
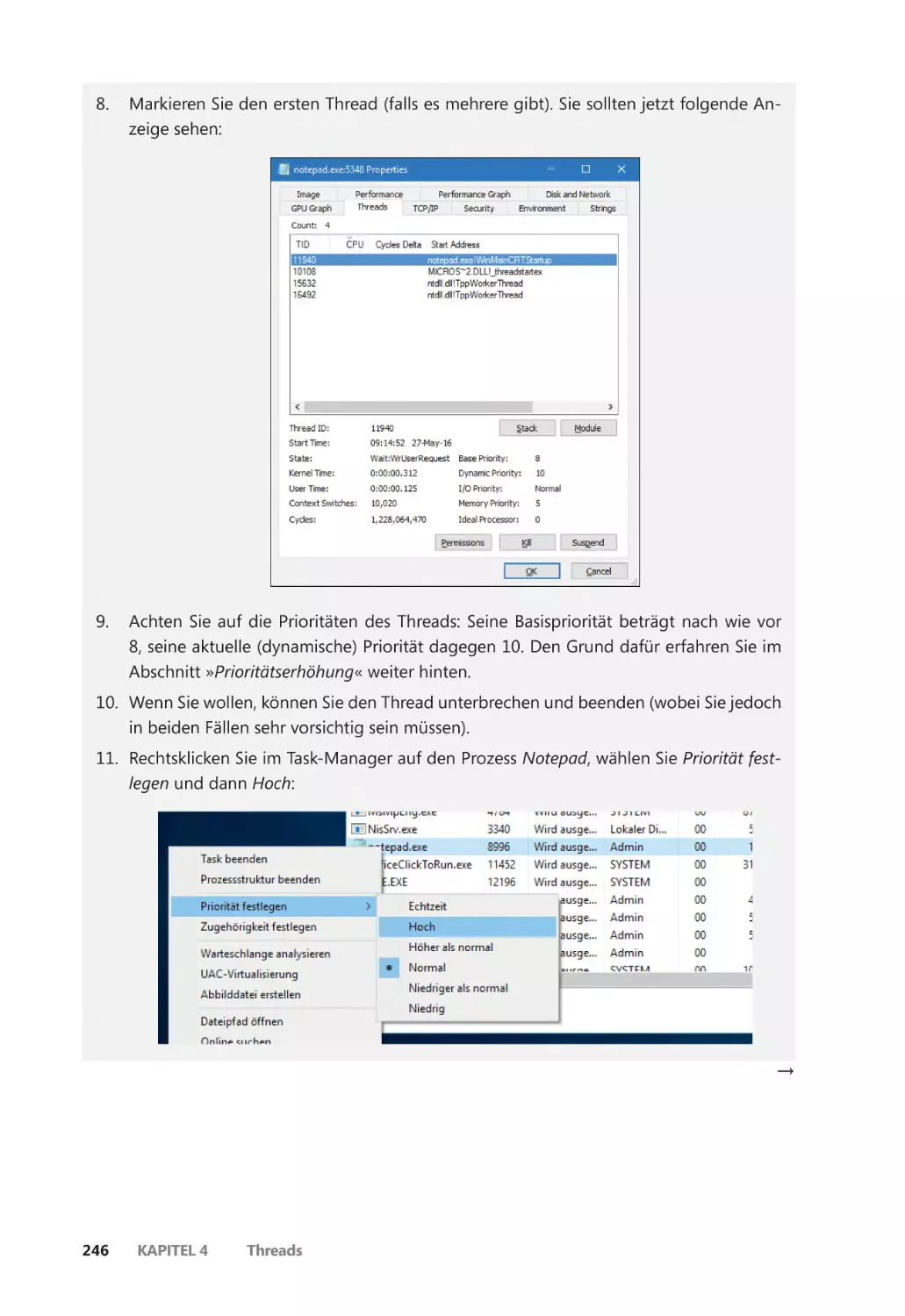
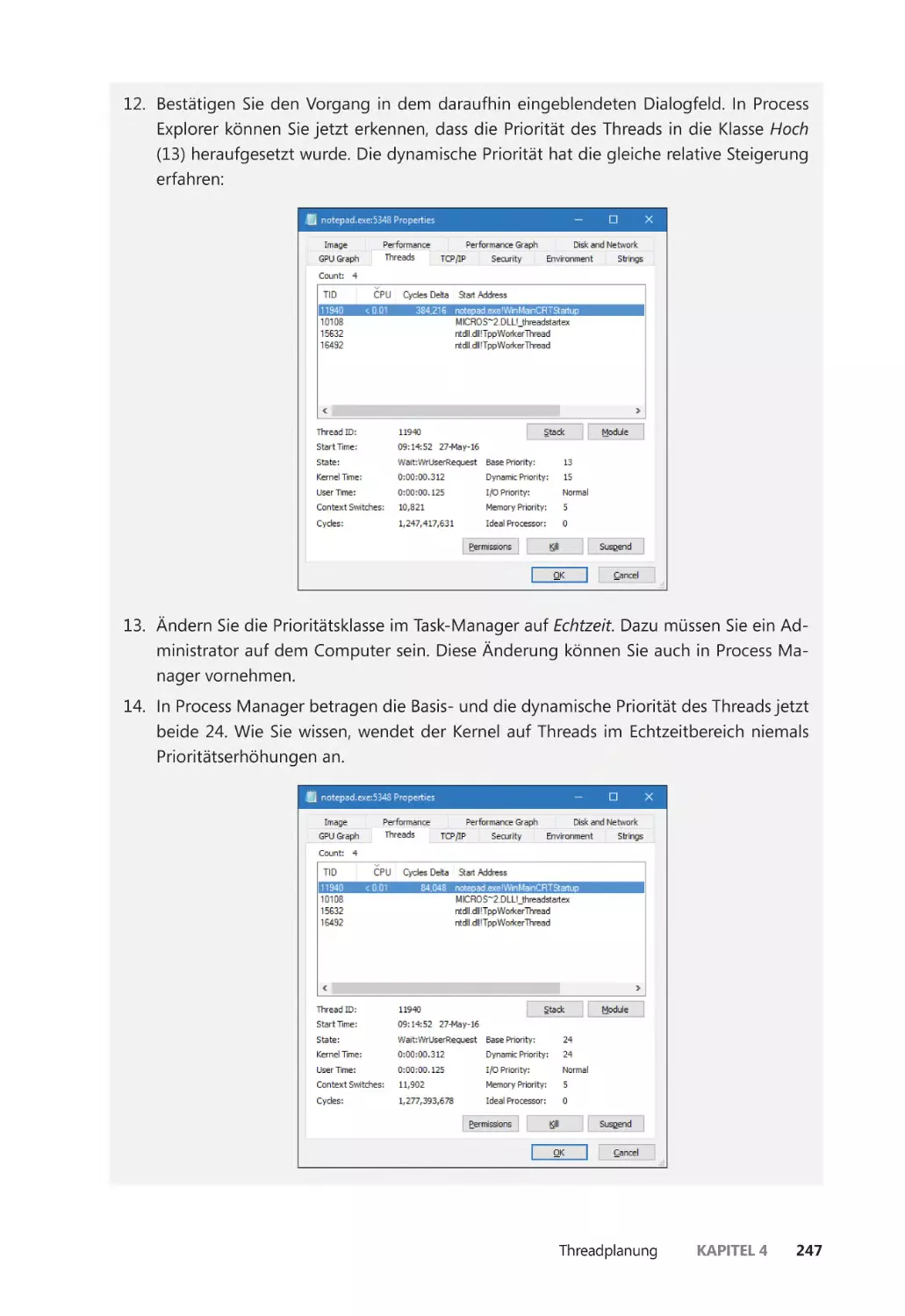
Die Threadaktivität untersuchen ��������������������������������������������������������������������������������� 231
Einschränkungen für Threads in geschützten Prozessen ����������������������������������� 237
Threadplanung ��������������������������������������������������������������������������������������������������������������� 238
Überblick über die Threadplanung in Windows ������������������������������������������������� 239
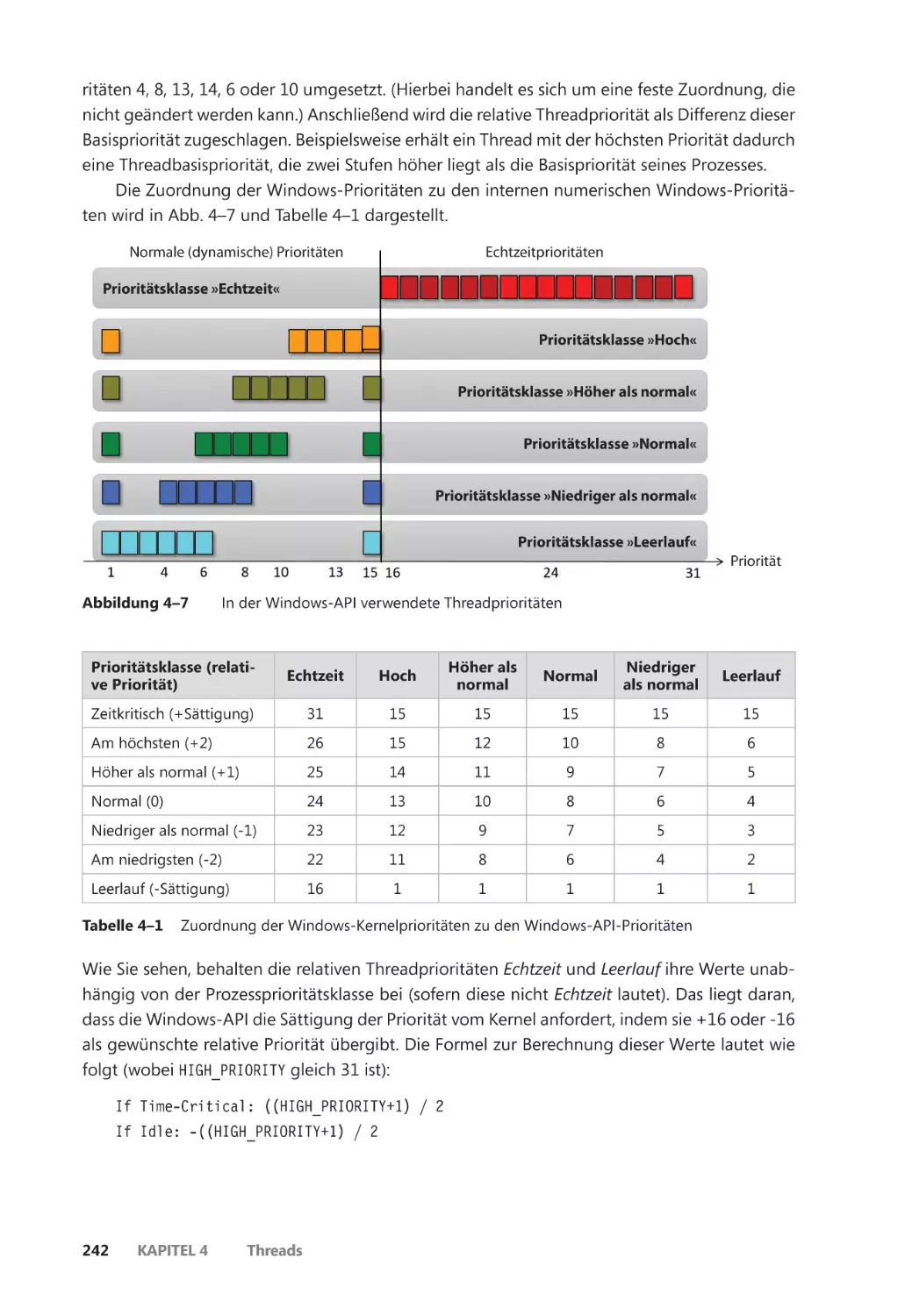
Prioritätsstufen ��������������������������������������������������������������������������������������������������������� 240
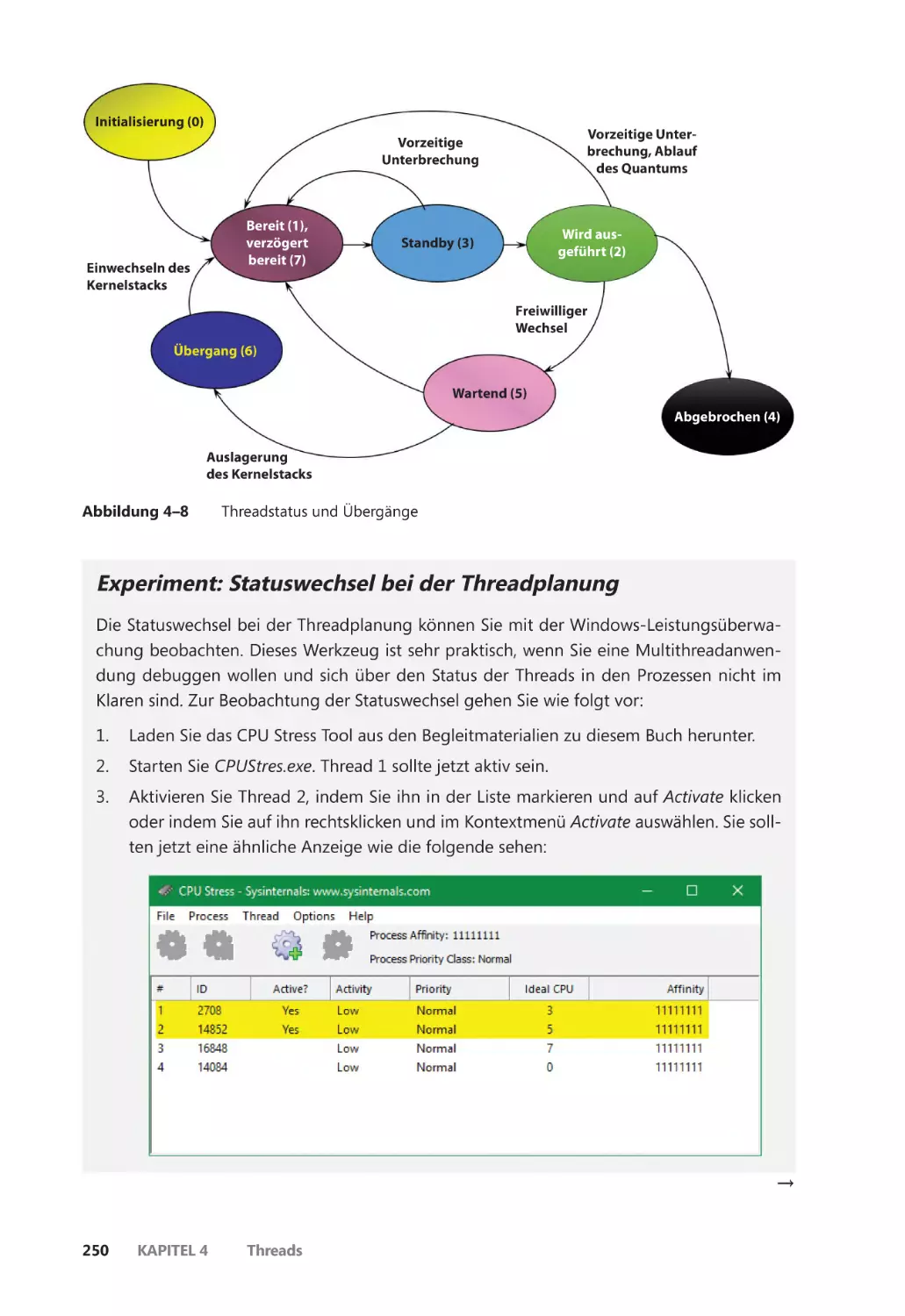
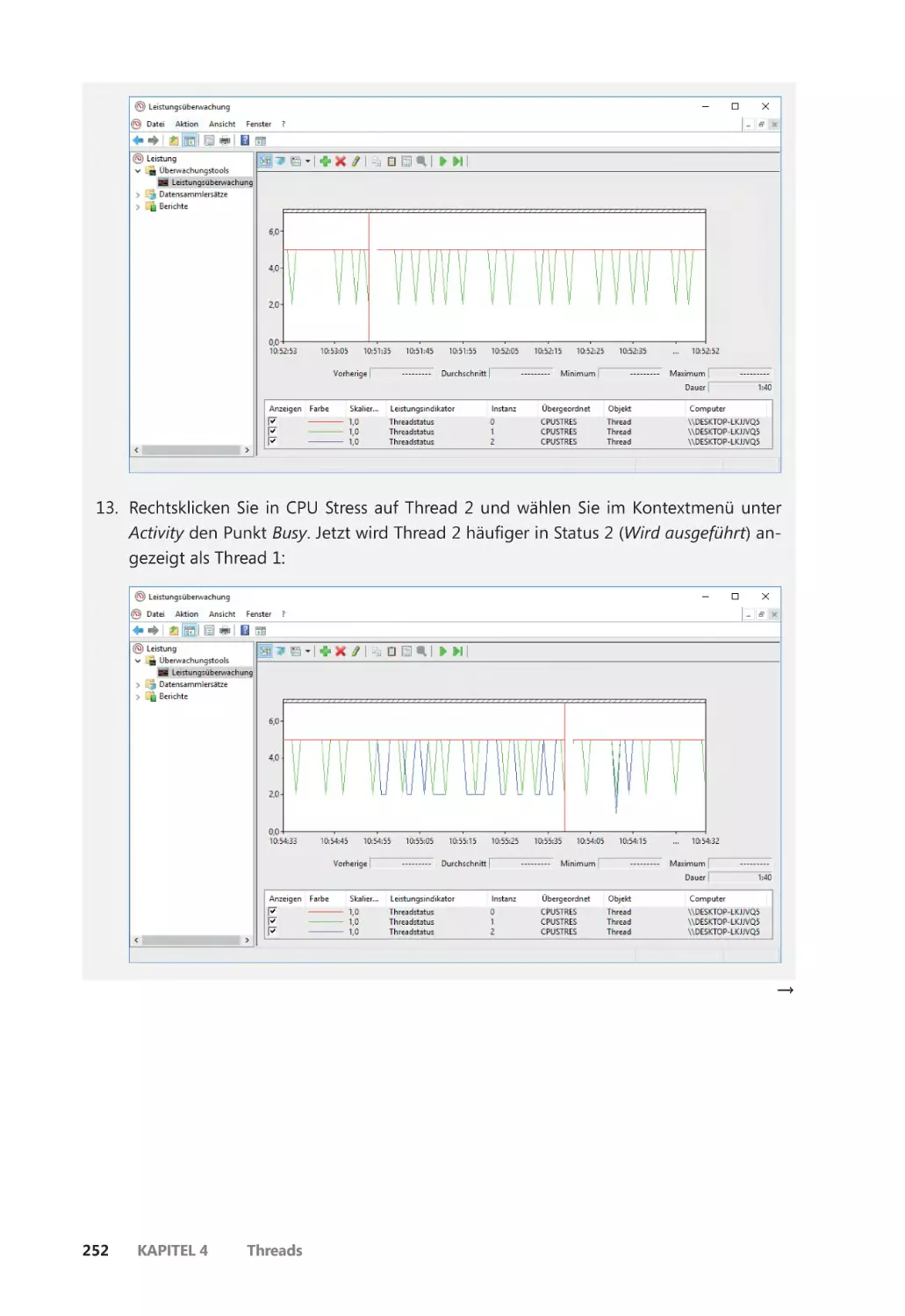
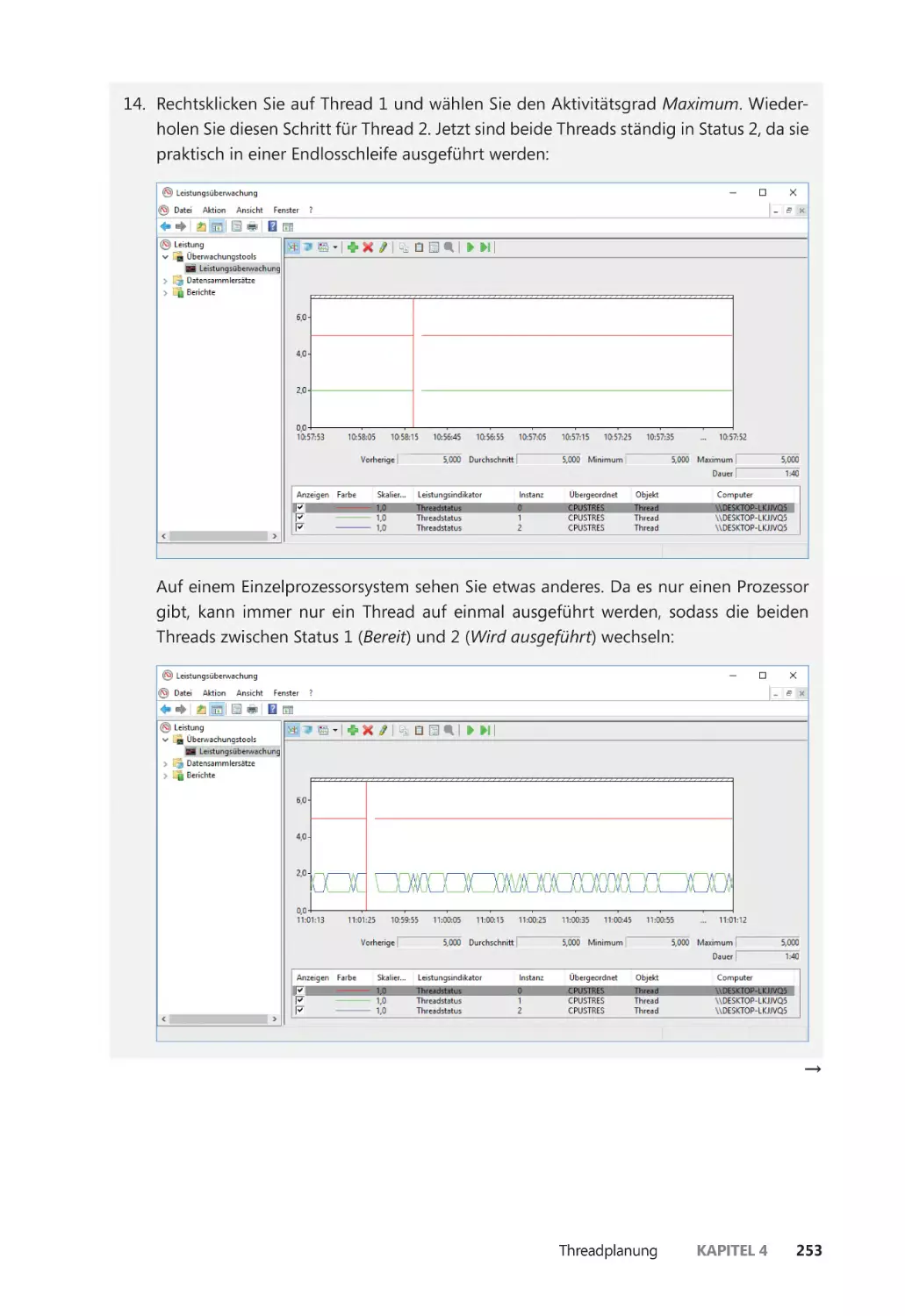
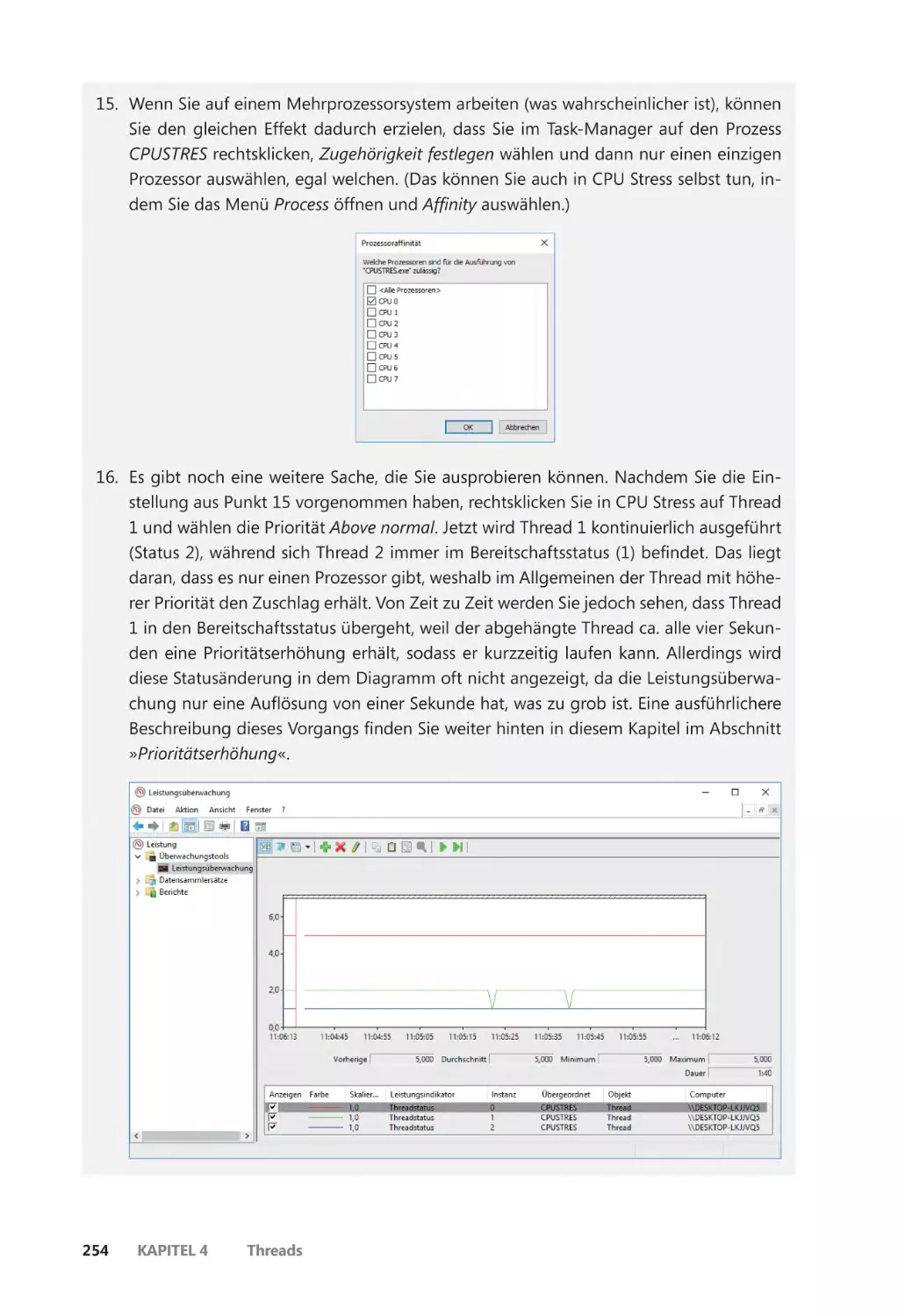
Threadstatus ������������������������������������������������������������������������������������������������������������� 248
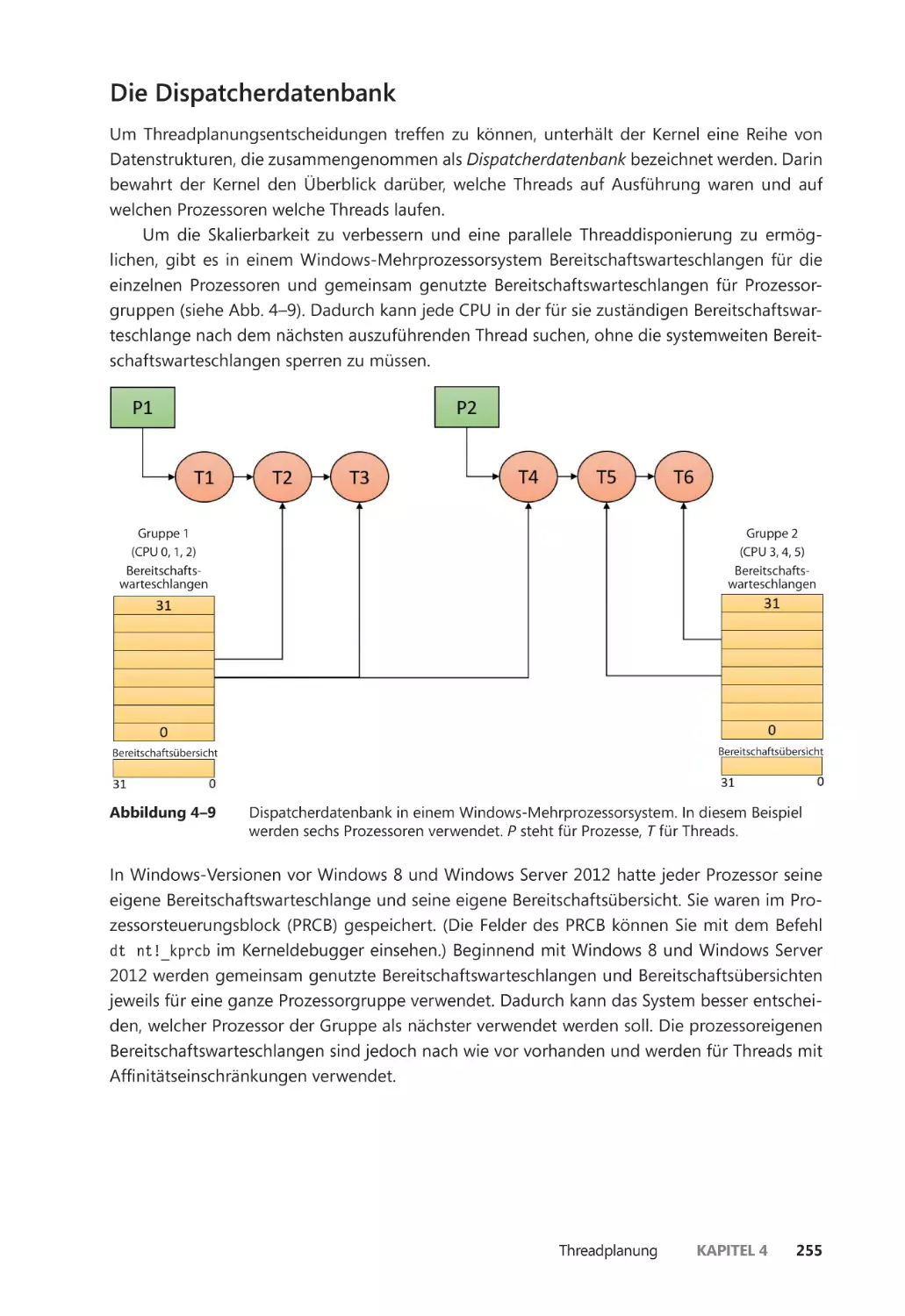
Die Dispatcherdatenbank ��������������������������������������������������������������������������������������� 255
Das Quantum ����������������������������������������������������������������������������������������������������������� 258
Prioritätserhöhung ������������������������������������������������������������������������������������������������� 266
Kontextwechsel ������������������������������������������������������������������������������������������������������� 286
Mögliche Fälle bei der Threadplanung ��������������������������������������������������������������� 288
Leerlaufthreads ������������������������������������������������������������������������������������������������������� 292
Anhalten von Threads ��������������������������������������������������������������������������������������������� 296
Einfrieren und Tiefgefrieren ����������������������������������������������������������������������������������� 296
Threadauswahl ��������������������������������������������������������������������������������������������������������� 299
Mehrprozessorsysteme ������������������������������������������������������������������������������������������� 301
Threadauswahl auf Mehrprozessorsystemen ����������������������������������������������������� 319
Prozessorauswahl ����������������������������������������������������������������������������������������������������� 320
Heterogene Threadplanung (big.LITTLE) ������������������������������������������������������������� 322
Gruppengestützte Threadplanung ������������������������������������������������������������������������������� 324
Dynamische gleichmäßige Planung (DFSS) ��������������������������������������������������������� 326
Grenzwerte für die CPU-Rate ������������������������������������������������������������������������������� 330
Dynamisches Hinzufügen und Ersetzen von Prozessoren ��������������������������������� 333
Arbeitsfactories (Threadpools) ������������������������������������������������������������������������������������� 335
Erstellen von Arbeitsfactories �������������������������������������������������������������������������������� 337
Zusammenfassung ��������������������������������������������������������������������������������������������������������� 339
x
Inhaltsverzeichnis
Kapitel 5
Speicherverwaltung 341
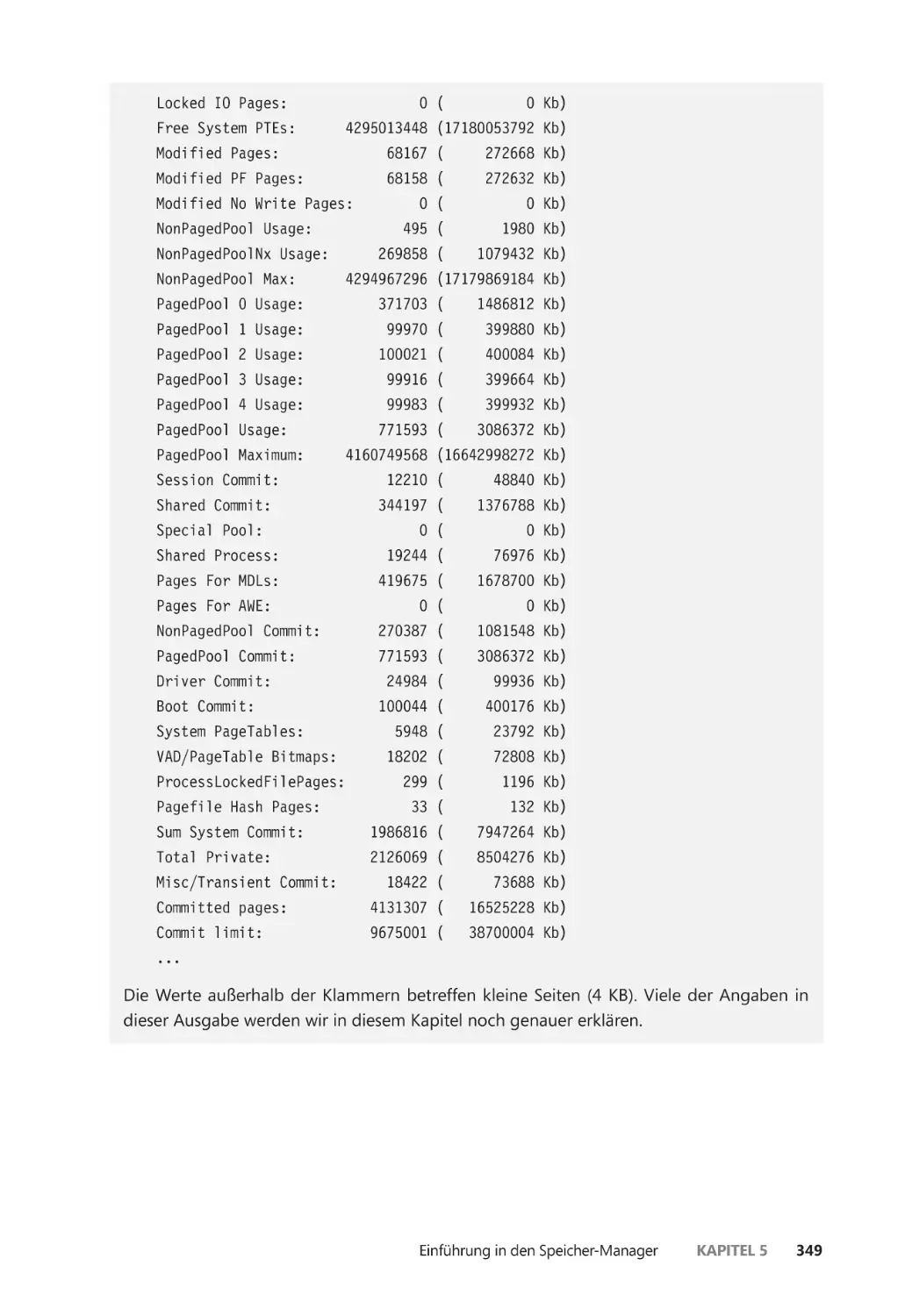
Einführung in den Speicher-Manager ������������������������������������������������������������������������� 341
Komponenten des Speicher-Managers ��������������������������������������������������������������� 342
Große und kleine Seiten ����������������������������������������������������������������������������������������� 343
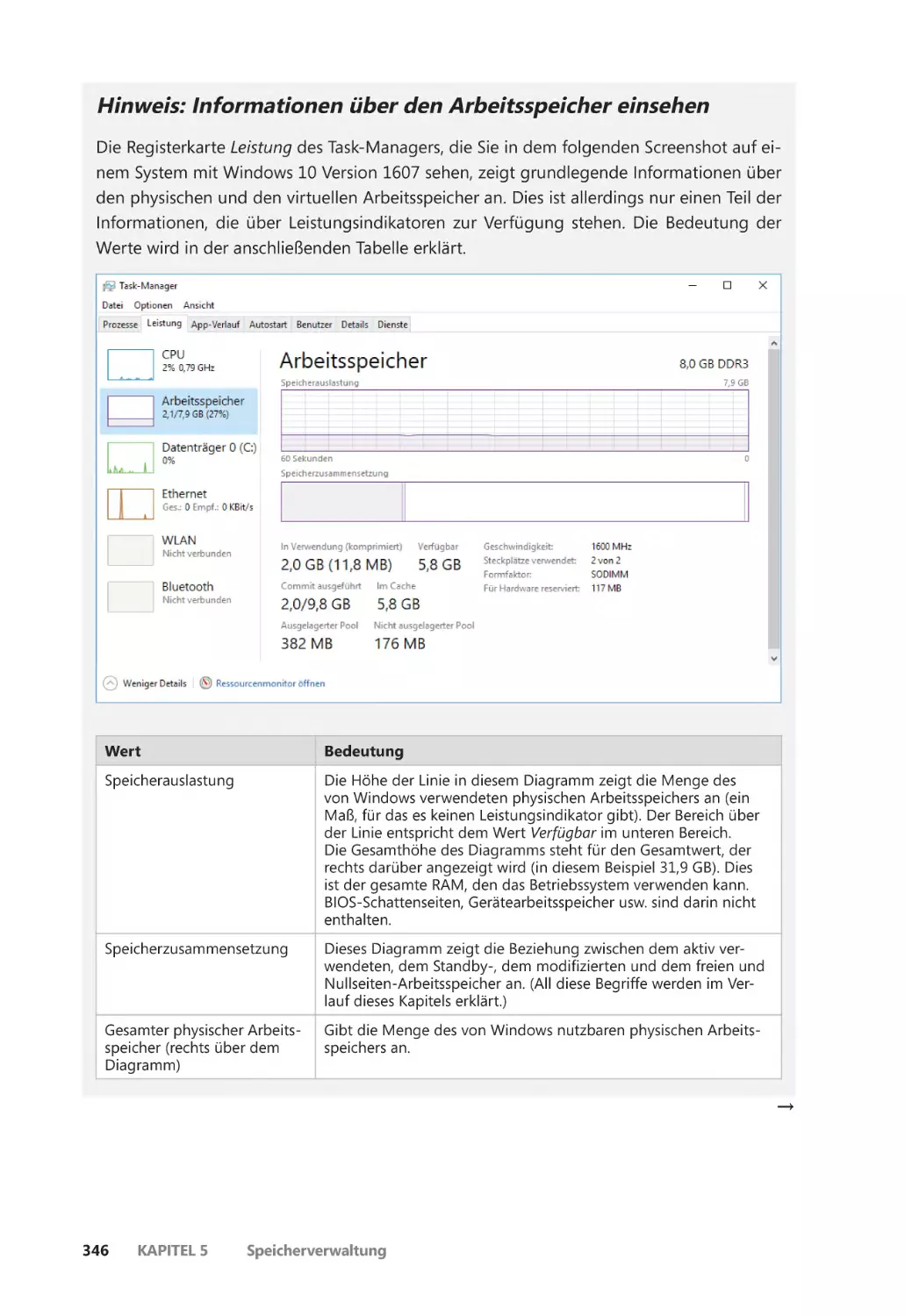
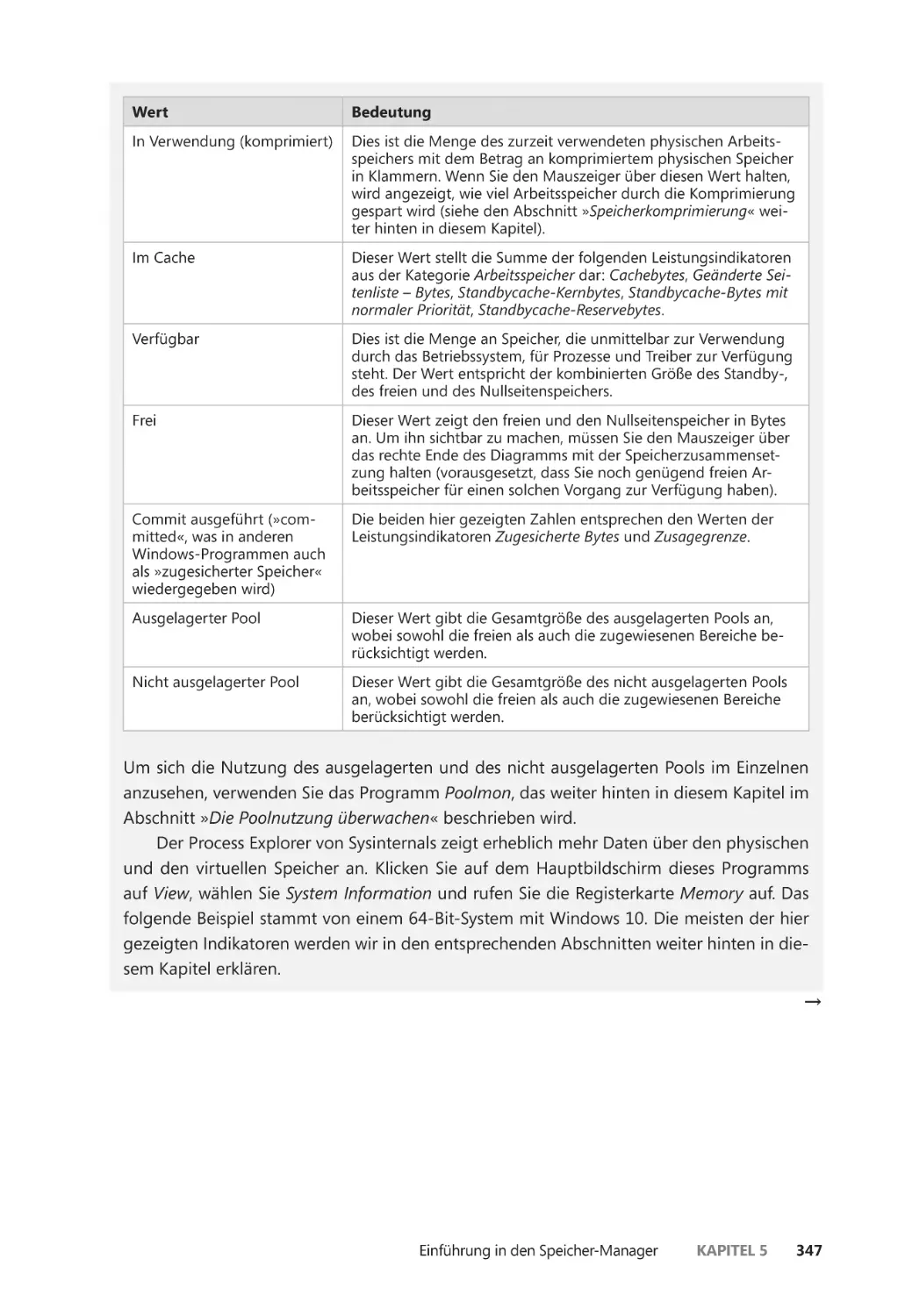
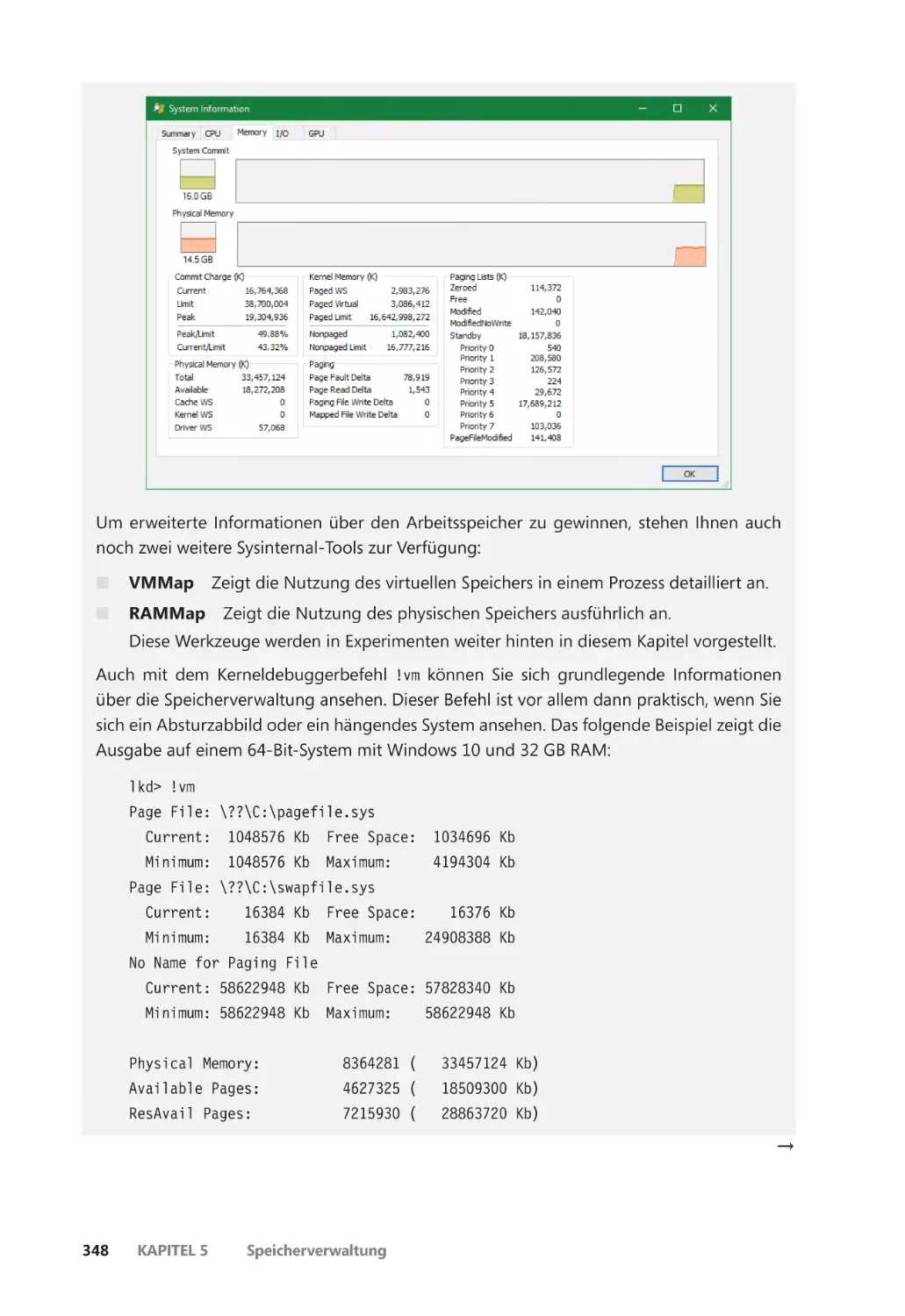
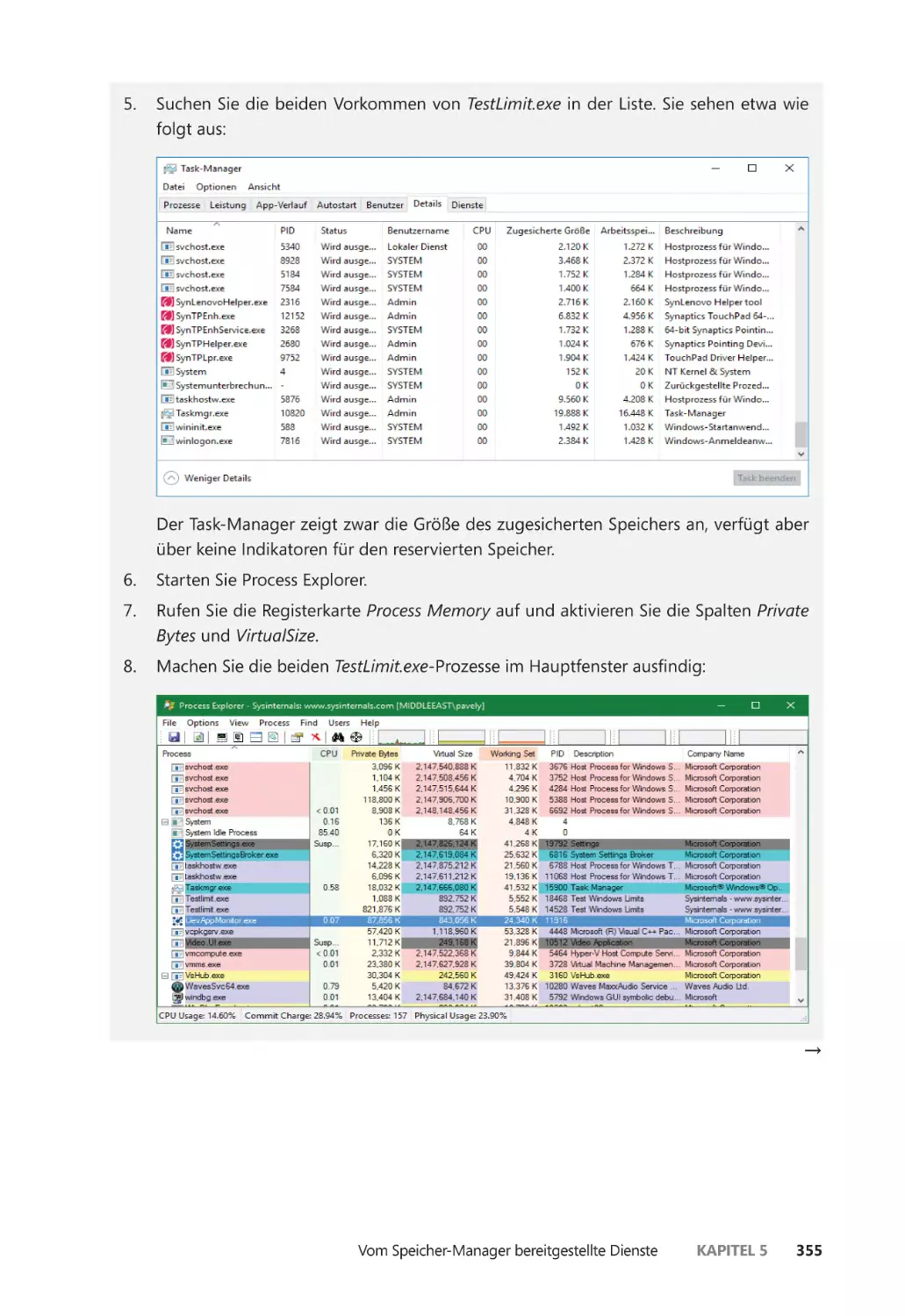
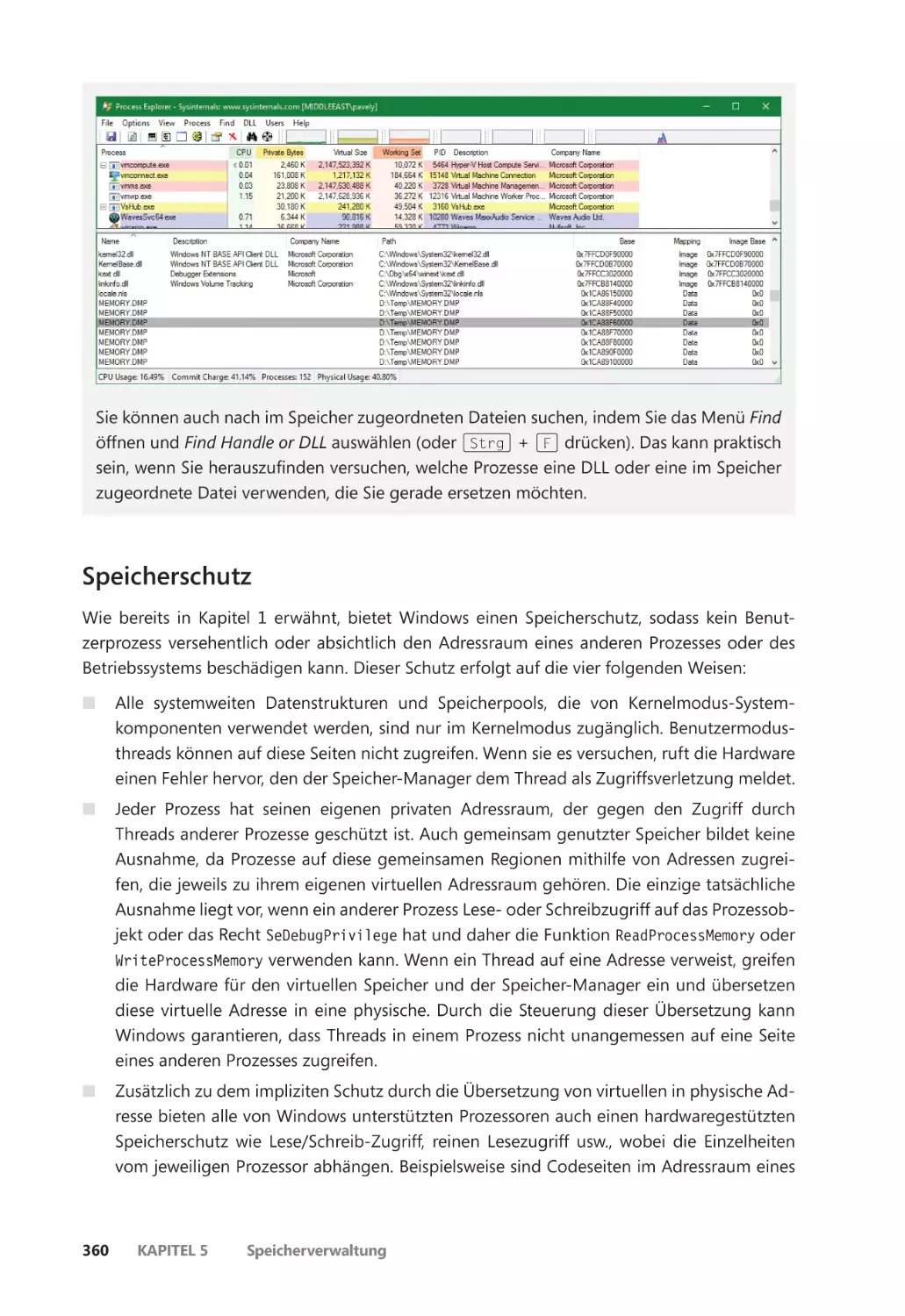
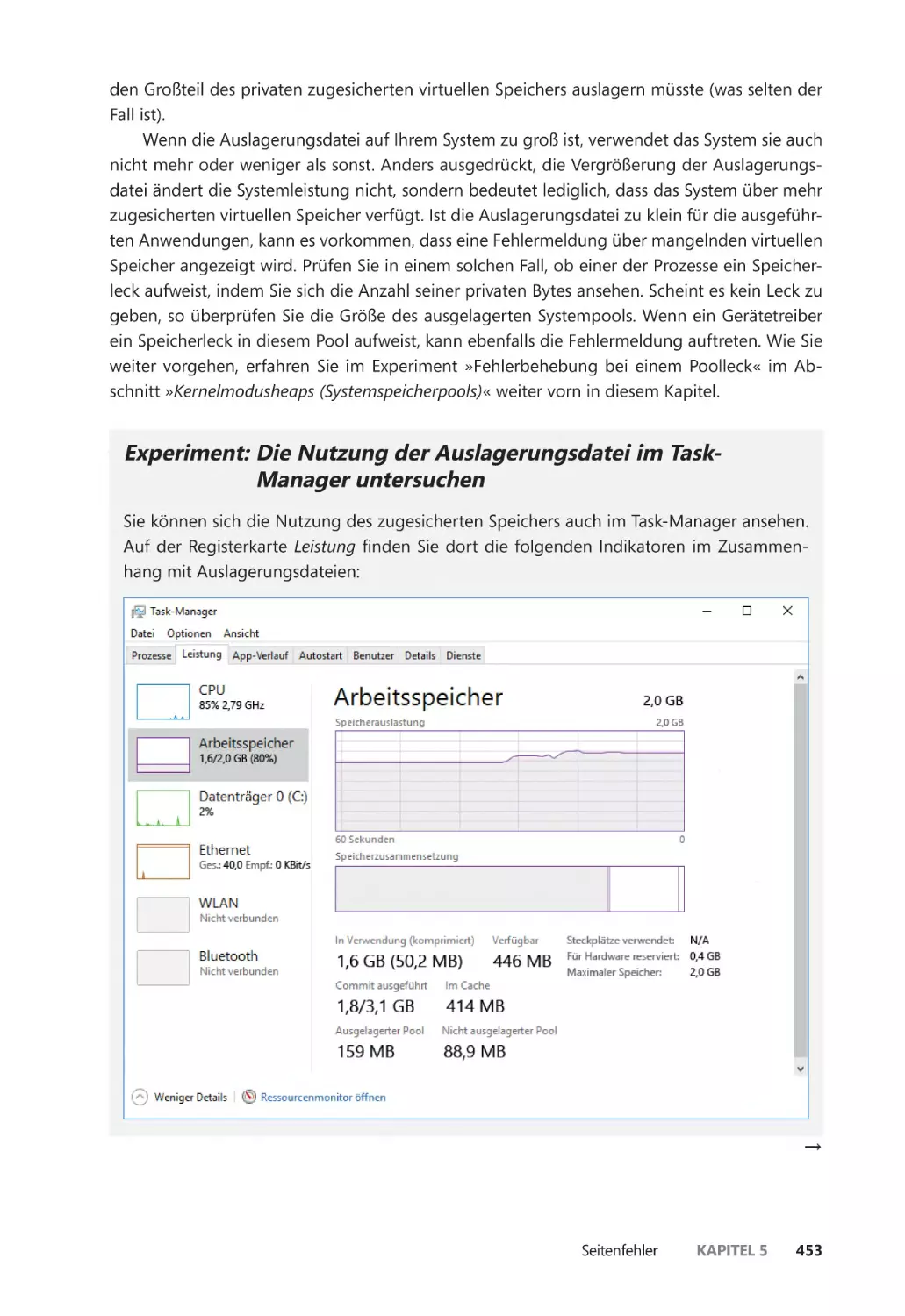
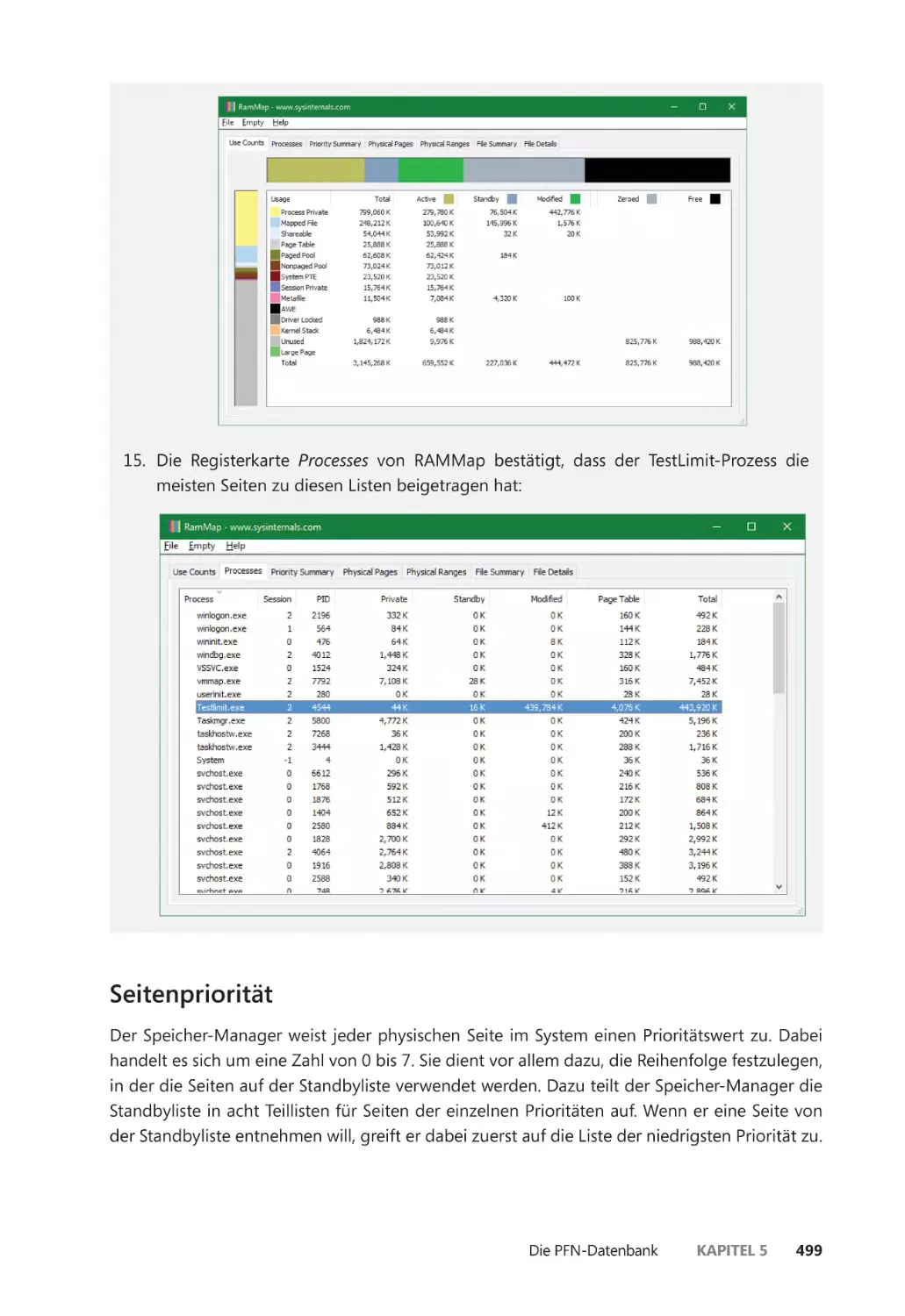
Die Speichernutzung untersuchen ����������������������������������������������������������������������� 345
Interne Synchronisierung ��������������������������������������������������������������������������������������� 350
Vom Speicher-Manager bereitgestellte Dienste ������������������������������������������������������� 350
Seitenstatus und Speicherzuweisungen ��������������������������������������������������������������� 352
Gesamter zugesicherter Speicher und Zusicherungsgrenzwert ����������������������� 356
Seiten im Arbeitsspeicher festhalten ������������������������������������������������������������������� 356
Granularität der Zuweisung ����������������������������������������������������������������������������������� 357
Gemeinsam genutzter Arbeitsspeicher und zugeordnete Dateien ����������������� 357
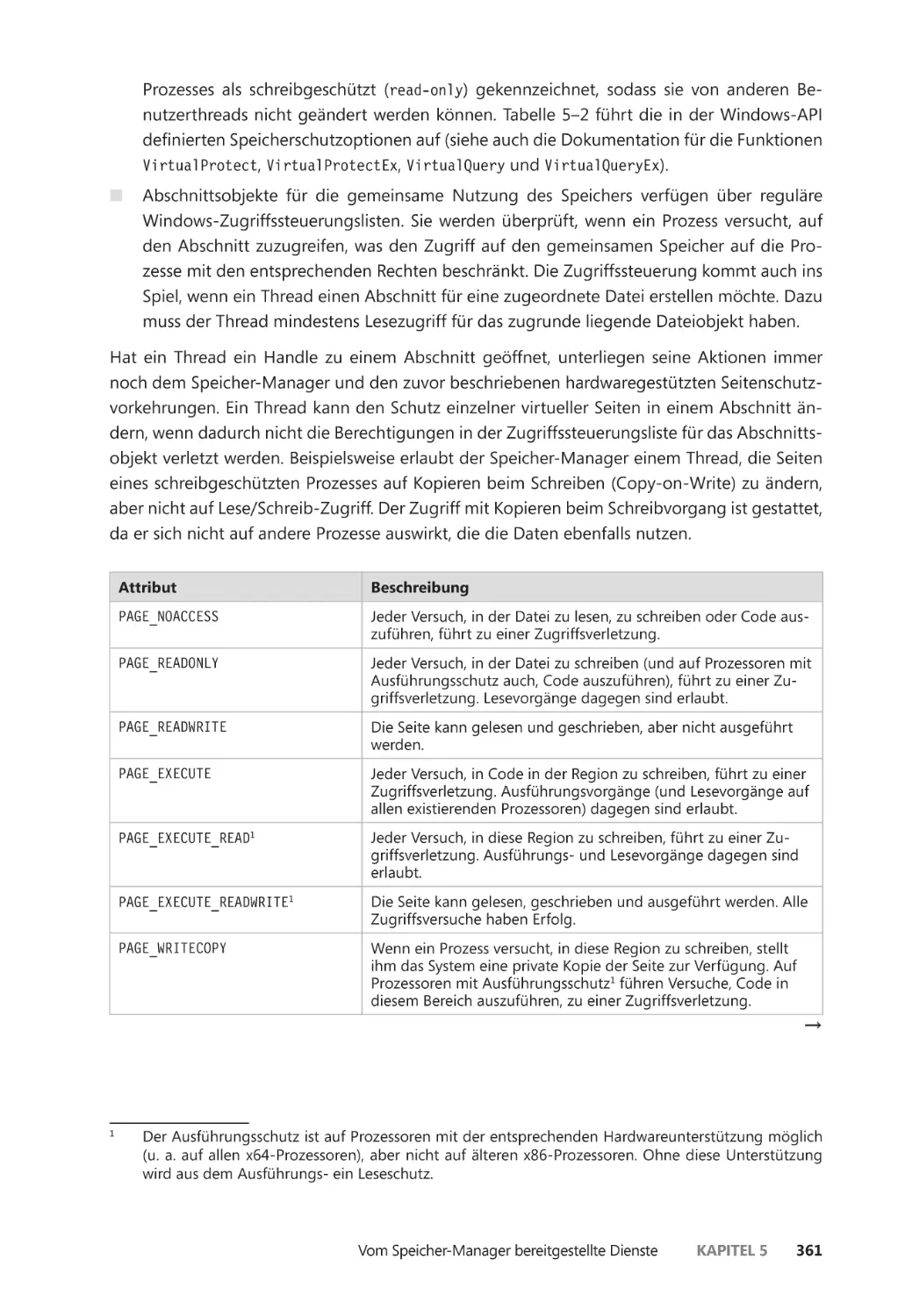
Speicherschutz ��������������������������������������������������������������������������������������������������������� 360
Datenausführungsverhinderung ��������������������������������������������������������������������������� 362
Kopieren beim Schreiben ��������������������������������������������������������������������������������������� 366
AWE (Address Windowing Extensions) ����������������������������������������������������������������� 367
Kernelmodusheaps (Systemspeicherpools) ����������������������������������������������������������������� 370
Poolgrößen ��������������������������������������������������������������������������������������������������������������� 370
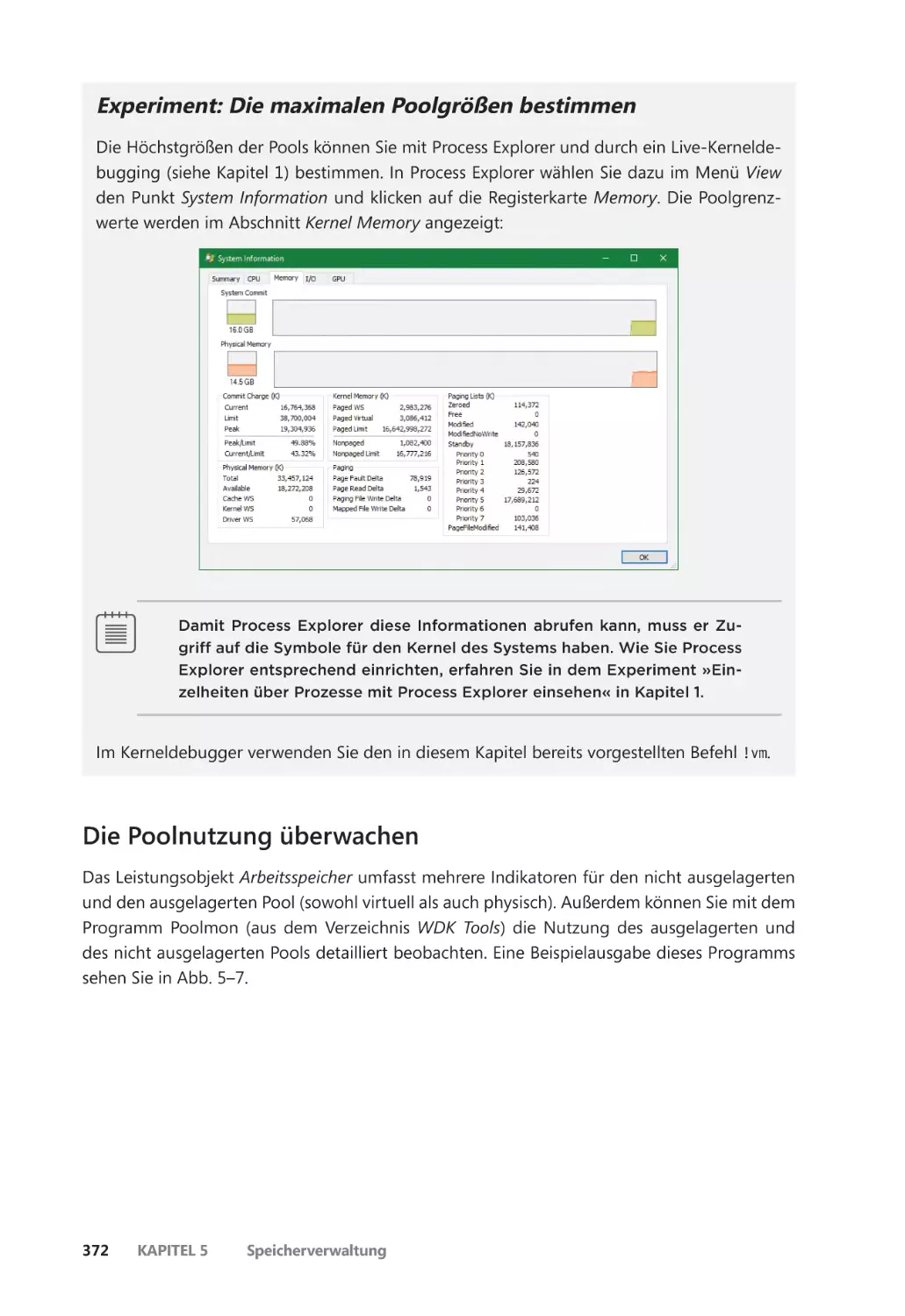
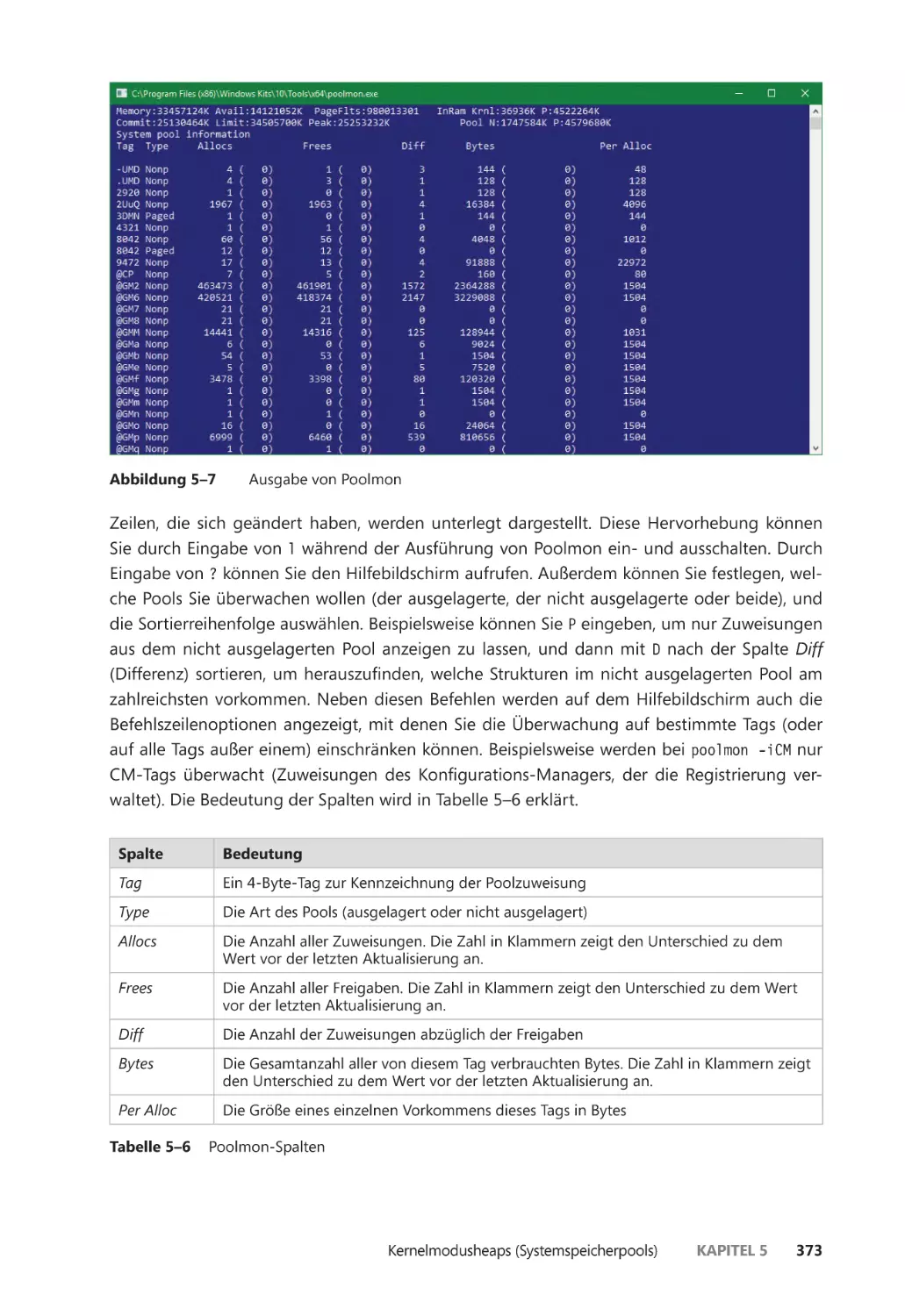
Die Poolnutzung überwachen ������������������������������������������������������������������������������� 372
Look-Aside-Listen ��������������������������������������������������������������������������������������������������� 377
Der Heap-Manager ��������������������������������������������������������������������������������������������������������� 378
Prozessheaps ����������������������������������������������������������������������������������������������������������� 379
Arten von Heaps ����������������������������������������������������������������������������������������������������� 380
NT-Heaps ����������������������������������������������������������������������������������������������������������������� 380
Heapsynchronisierung ������������������������������������������������������������������������������������������� 381
Der Low-Fragmentation-Heap ����������������������������������������������������������������������������� 381
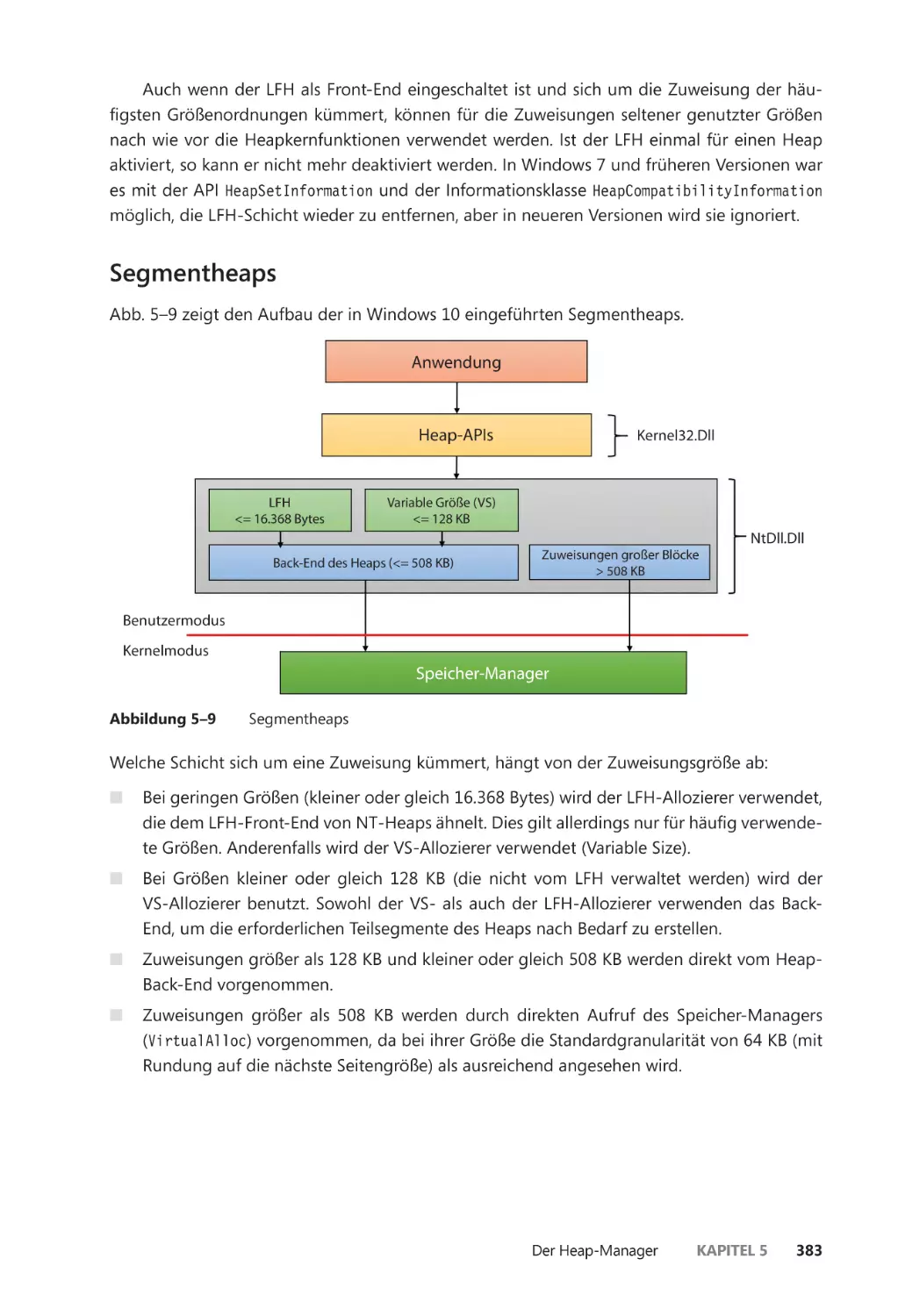
Segmentheaps ��������������������������������������������������������������������������������������������������������� 383
Sicherheitseinrichtungen von Heaps ������������������������������������������������������������������� 388
Debugging einrichten für Heaps ��������������������������������������������������������������������������� 390
Der Seitenheap ��������������������������������������������������������������������������������������������������������� 391
Der fehlertolerante Heap ��������������������������������������������������������������������������������������� 394
Layouts für virtuelle Adressräume ������������������������������������������������������������������������������� 396
x86-Adressraumlayouts ����������������������������������������������������������������������������������������� 397
Das Layout des x86-Systemadressraums ������������������������������������������������������������� 401
Inhaltsverzeichnis
xi
x86-Sitzungsraum ��������������������������������������������������������������������������������������������������� 401
System-Seitentabelleneinträge ����������������������������������������������������������������������������� 404
ARM-Adressraumlayout ����������������������������������������������������������������������������������������� 405
64-Bit-Adressraumlayout ��������������������������������������������������������������������������������������� 406
Einschränkungen bei der virtuellen Adressierung auf x64-Systemen ������������� 408
Dynamische Verwaltung des virtuellen Systemadressraums ��������������������������� 408
Kontingente für den virtuellen Systemadressraum ������������������������������������������� 415
Layout des Benutzeradressraums ������������������������������������������������������������������������� 416
Adressübersetzung ��������������������������������������������������������������������������������������������������������� 422
Übersetzung virtueller Adressen auf x86-Systemen ����������������������������������������� 422
Der Look-Aside-Übersetzungspuffer für die Übersetzung ������������������������������� 429
Übersetzung virtueller Adressen auf x64-Systemen ����������������������������������������� 433
Übersetzung virtueller Adressen auf ARM-Systemen ��������������������������������������� 434
Seitenfehler ��������������������������������������������������������������������������������������������������������������������� 435
Ungültige PTEs ��������������������������������������������������������������������������������������������������������� 436
Prototyp-PTEs ����������������������������������������������������������������������������������������������������������� 438
Einlagerungs-E/A ����������������������������������������������������������������������������������������������������� 440
Seitenfehlerkollisionen ������������������������������������������������������������������������������������������� 440
Seitencluster ������������������������������������������������������������������������������������������������������������� 441
Auslagerungsdateien ��������������������������������������������������������������������������������������������� 442
Gesamter zugesicherter Speicher und systemweiter
Zusicherungsgrenzwert ����������������������������������������������������������������������������������������� 448
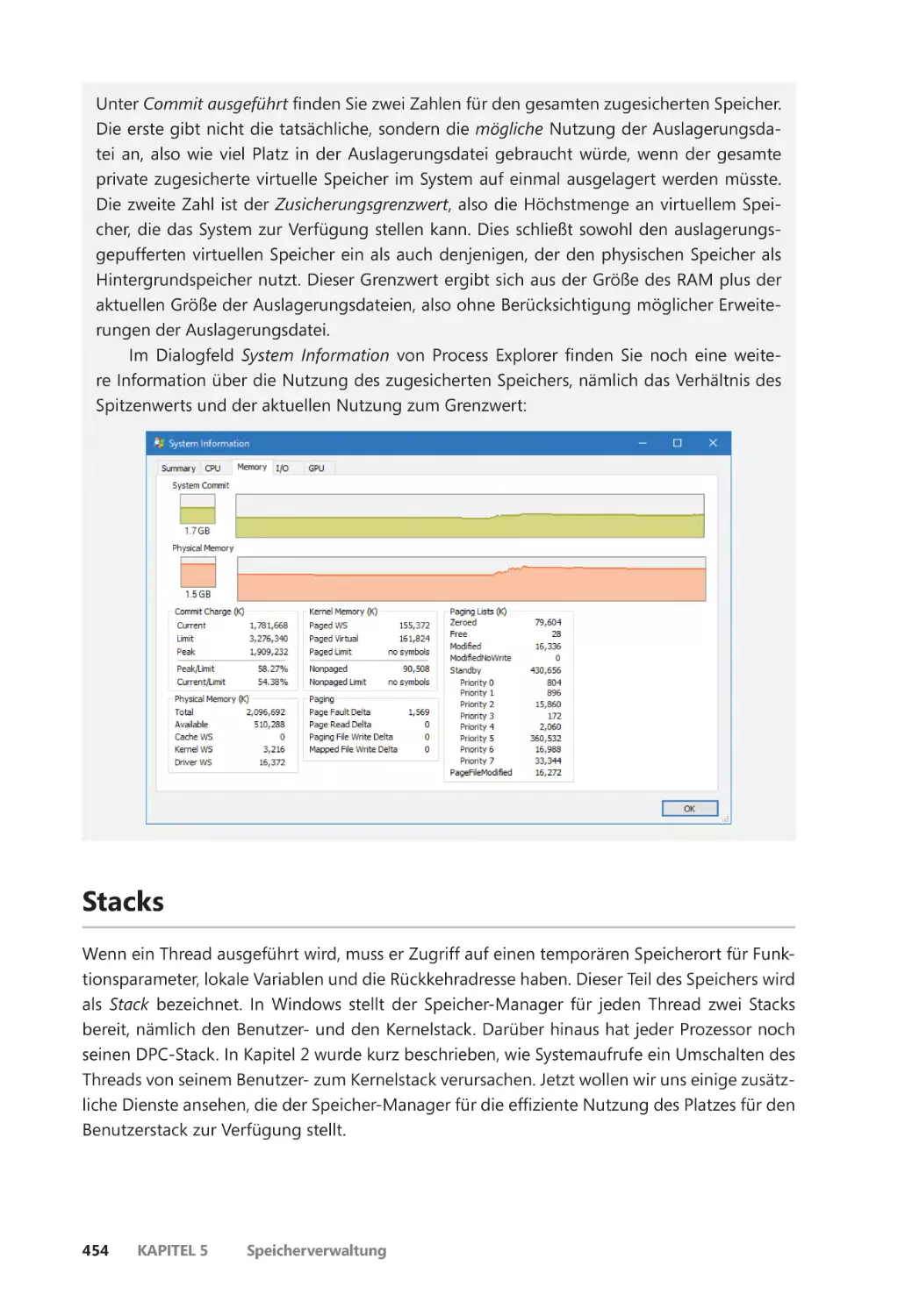
Der Zusammenhang zwischen dem gesamten zugesicherten Speicher
und der Größe der Auslagerungsdatei ����������������������������������������������������������������� 452
Stacks ������������������������������������������������������������������������������������������������������������������������������� 454
Benutzerstacks ��������������������������������������������������������������������������������������������������������� 455
Kernelstacks ������������������������������������������������������������������������������������������������������������� 456
Der DPC-Stack ��������������������������������������������������������������������������������������������������������� 457
VADs ��������������������������������������������������������������������������������������������������������������������������������� 457
Prozess-VADs ����������������������������������������������������������������������������������������������������������� 458
Umlauf-VADs ����������������������������������������������������������������������������������������������������������� 460
NUMA ������������������������������������������������������������������������������������������������������������������������������� 461
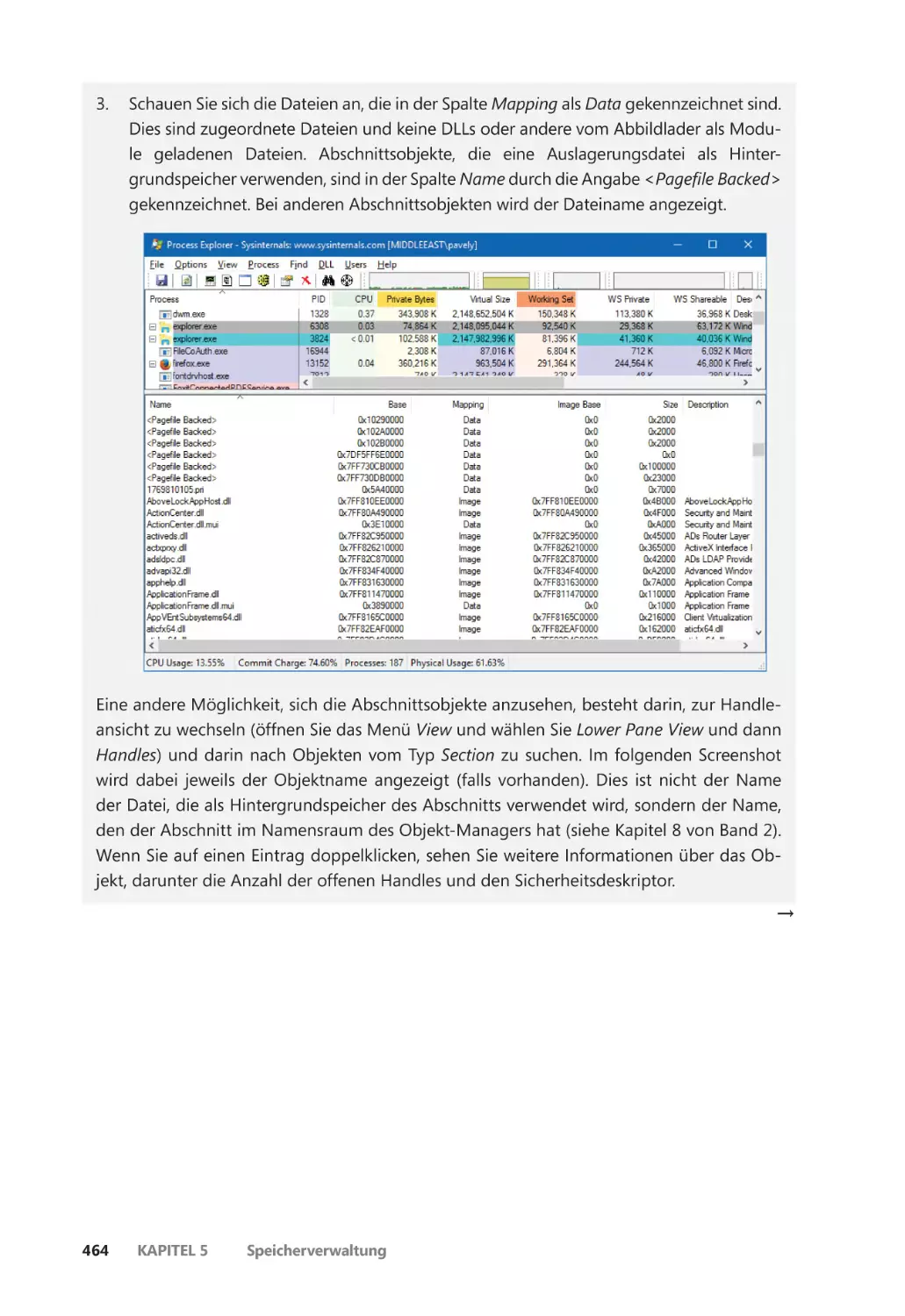
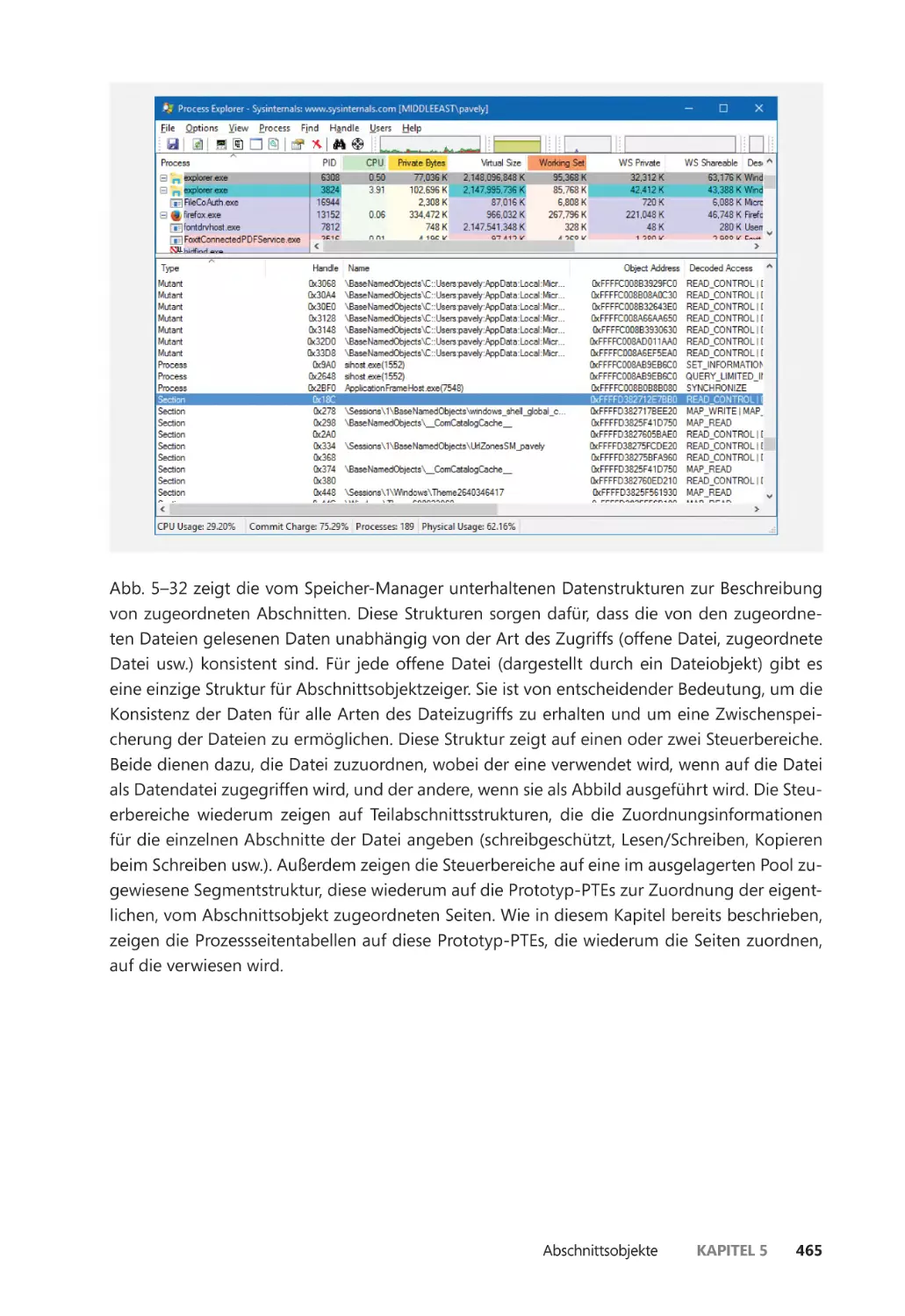
Abschnittsobjekte ����������������������������������������������������������������������������������������������������������� 462
Arbeitssätze ��������������������������������������������������������������������������������������������������������������������� 472
Auslagerung bei Bedarf ����������������������������������������������������������������������������������������� 472
Der logische Prefetcher und ReadyBoot ������������������������������������������������������������� 473
xii
Inhaltsverzeichnis
Platzierungsrichtlinien ������������������������������������������������������������������������������������������� 477
Verwaltung von Arbeitssätzen ������������������������������������������������������������������������������� 477
Der Balance-Set-Manager und der Swapper ������������������������������������������������������ 482
Systemarbeitssätze ������������������������������������������������������������������������������������������������� 483
Speicherbenachrichtigungsereignisse ����������������������������������������������������������������� 485
Die PFN-Datenbank ������������������������������������������������������������������������������������������������������� 487
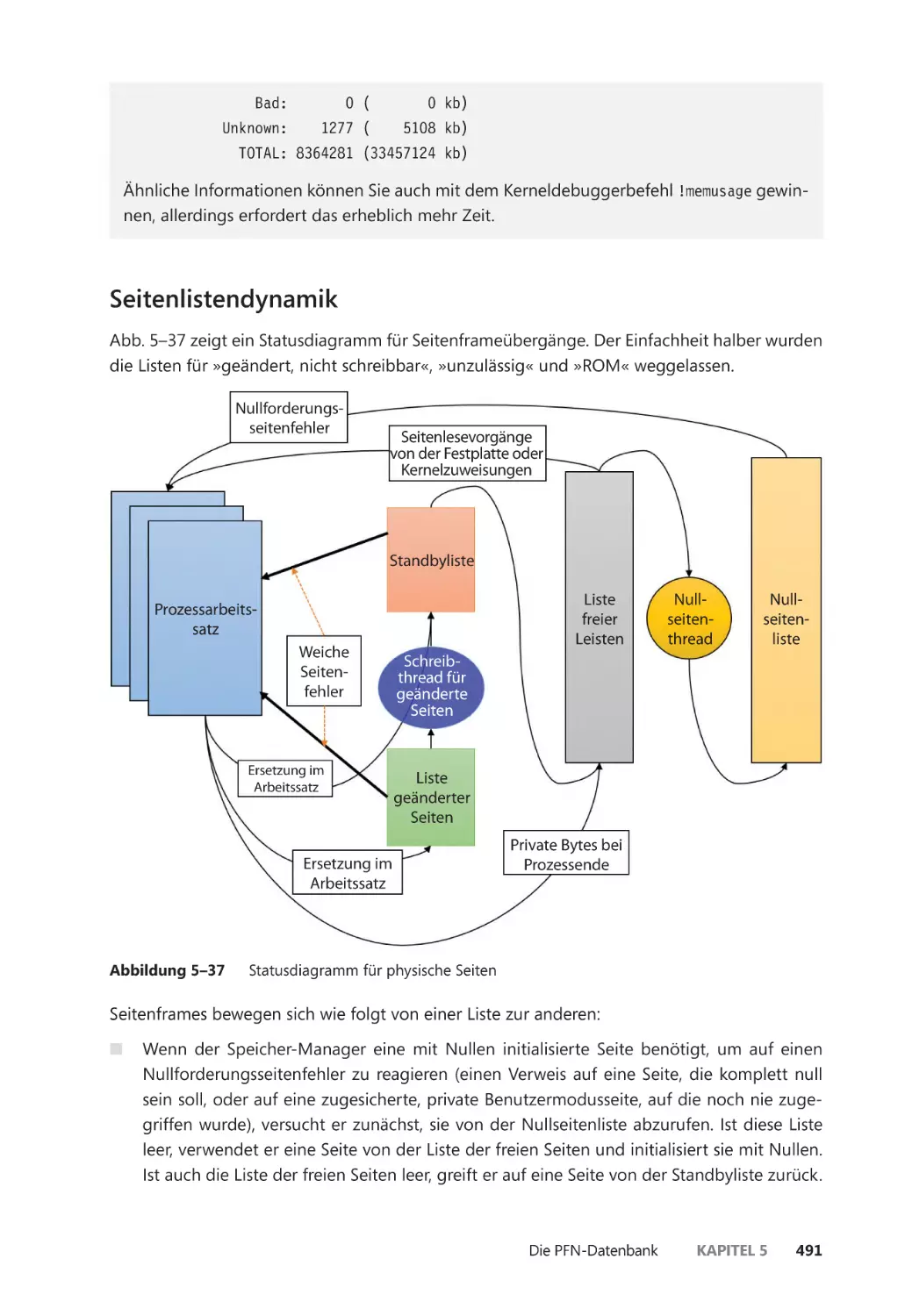
Seitenlistendynamik ����������������������������������������������������������������������������������������������� 491
Seitenpriorität ���������������������������������������������������������������������������������������������������������� 499
Die Schreibthreads für geänderte und für zugeordnete Seiten ����������������������� 502
PFN-Datenstrukturen ��������������������������������������������������������������������������������������������� 504
Reservierungen in der Auslagerungsdatei ����������������������������������������������������������� 509
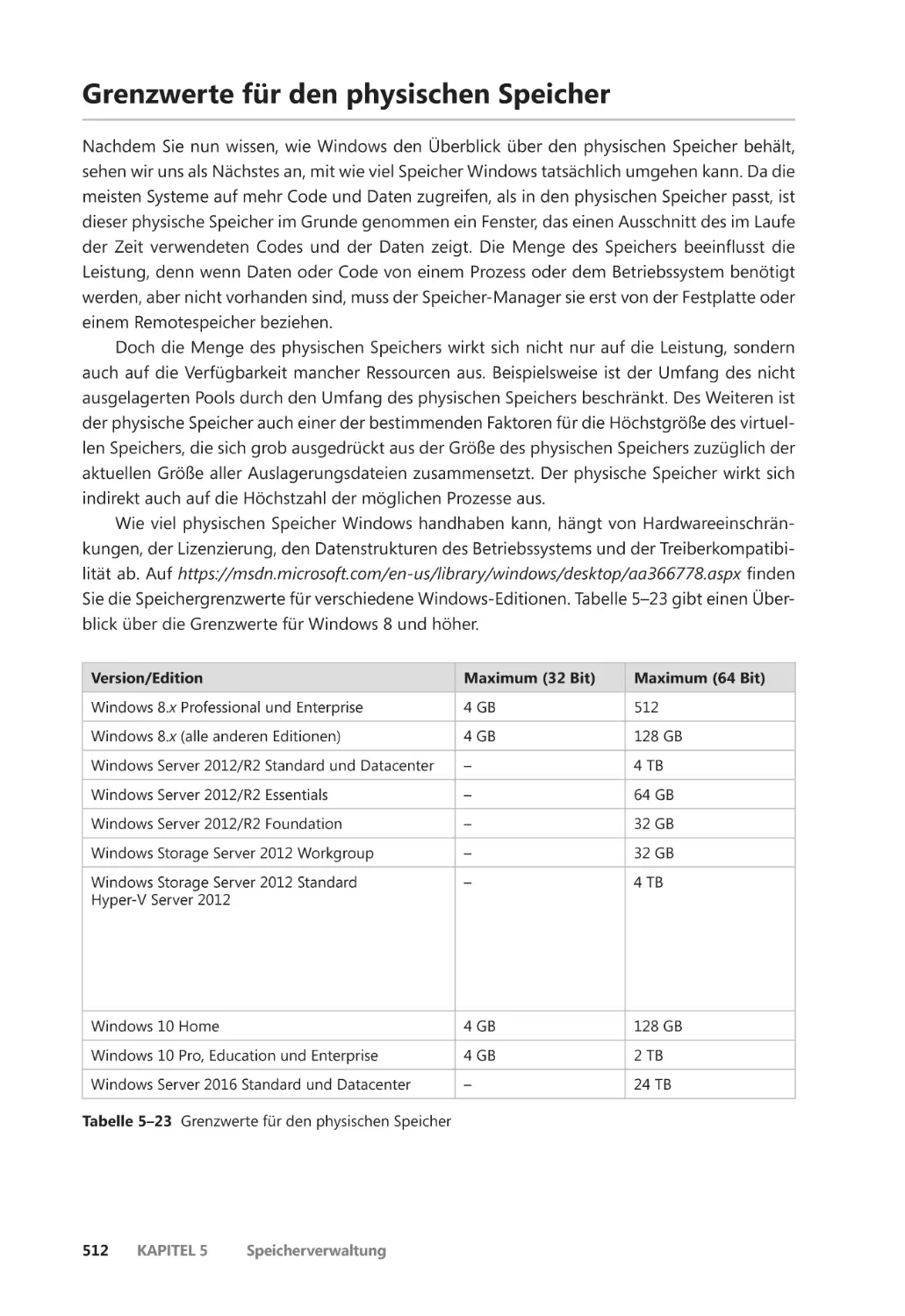
Grenzwerte für den physischen Speicher ������������������������������������������������������������������� 512
Speichergrenzwerte für Windows-Clienteditionen ������������������������������������������� 513
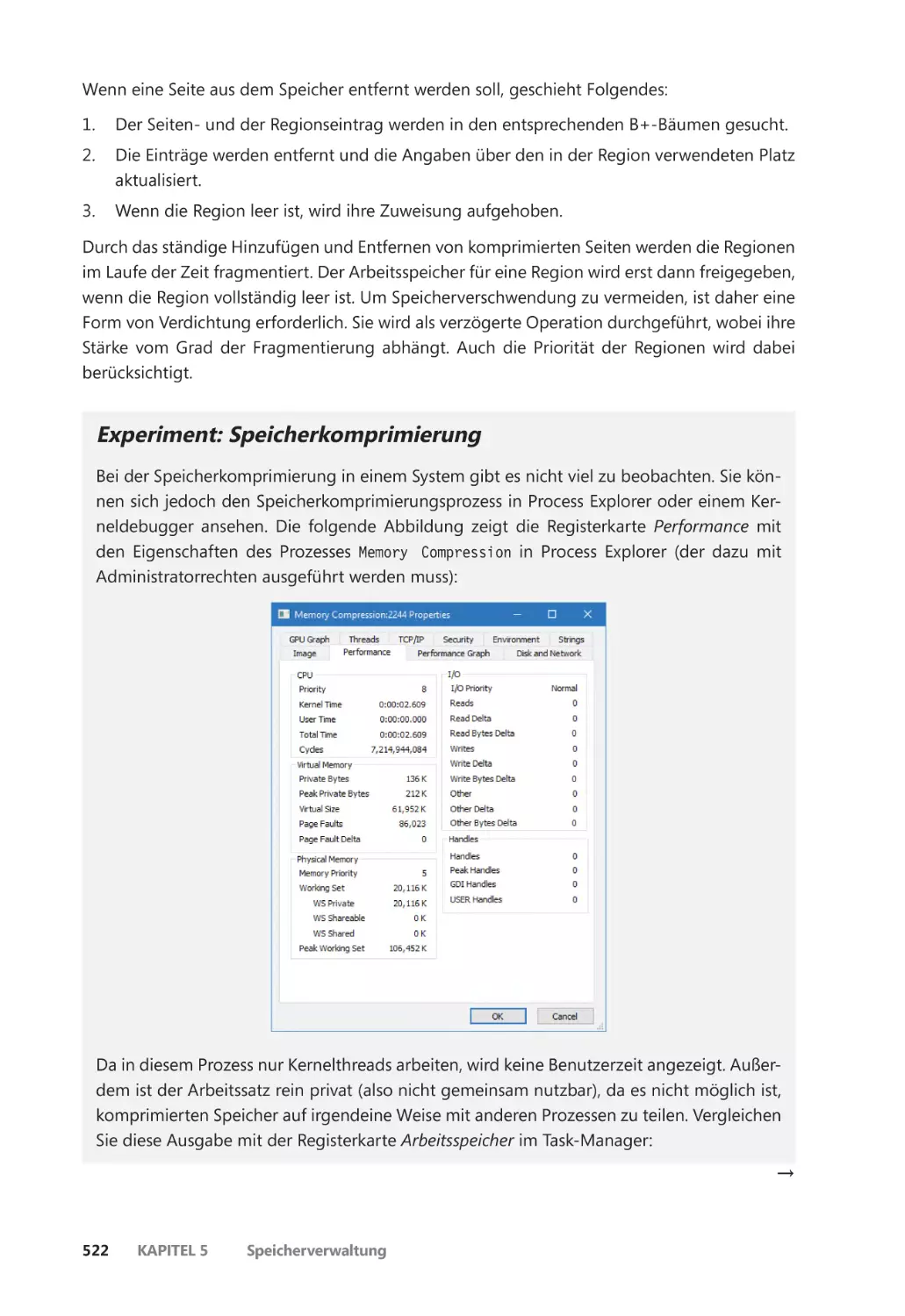
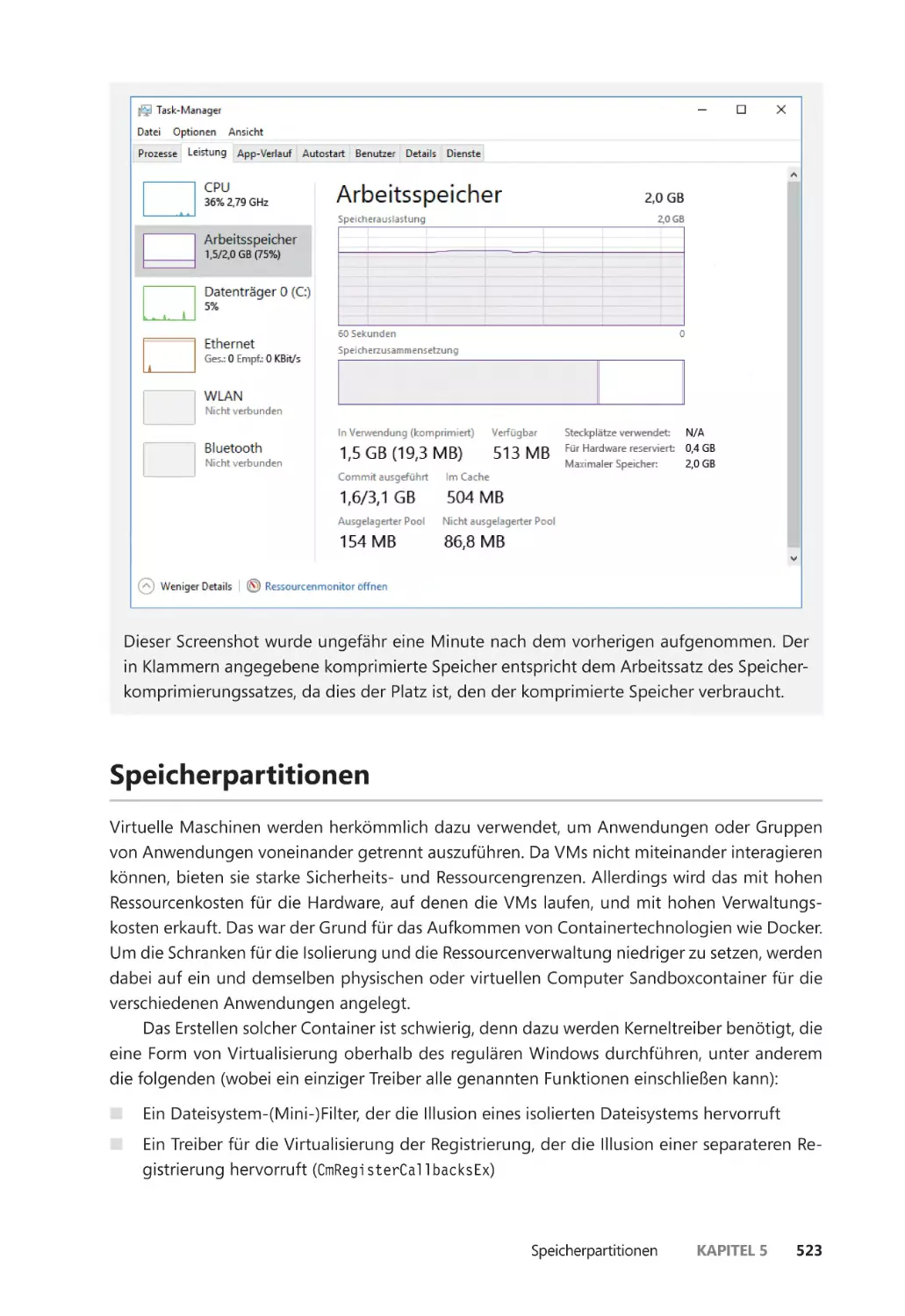
Speicherkomprimierung ����������������������������������������������������������������������������������������������� 515
Ablauf der Komprimierung ����������������������������������������������������������������������������������� 516
Komprimierungsarchitektur ����������������������������������������������������������������������������������� 520
Speicherpartitionen ������������������������������������������������������������������������������������������������������� 523
Speicherzusammenführung ����������������������������������������������������������������������������������������� 526
Die Suchphase ��������������������������������������������������������������������������������������������������������� 528
Die Klassifizierungsphase ��������������������������������������������������������������������������������������� 529
Die Zusammenführungsphase ������������������������������������������������������������������������������� 530
Vom privaten zum gemeinsamen PTE ����������������������������������������������������������������� 530
Freigabe von zusammengeführten Seiten ����������������������������������������������������������� 533
Speicherenklaven ����������������������������������������������������������������������������������������������������������� 536
Programmierschnittstellen ������������������������������������������������������������������������������������� 538
Initialisierung von Speicherenklaven ������������������������������������������������������������������� 538
Aufbau von Enklaven ��������������������������������������������������������������������������������������������� 539
Daten in eine Enklave laden ���������������������������������������������������������������������������������� 541
Eine Enklave initialisieren ��������������������������������������������������������������������������������������� 542
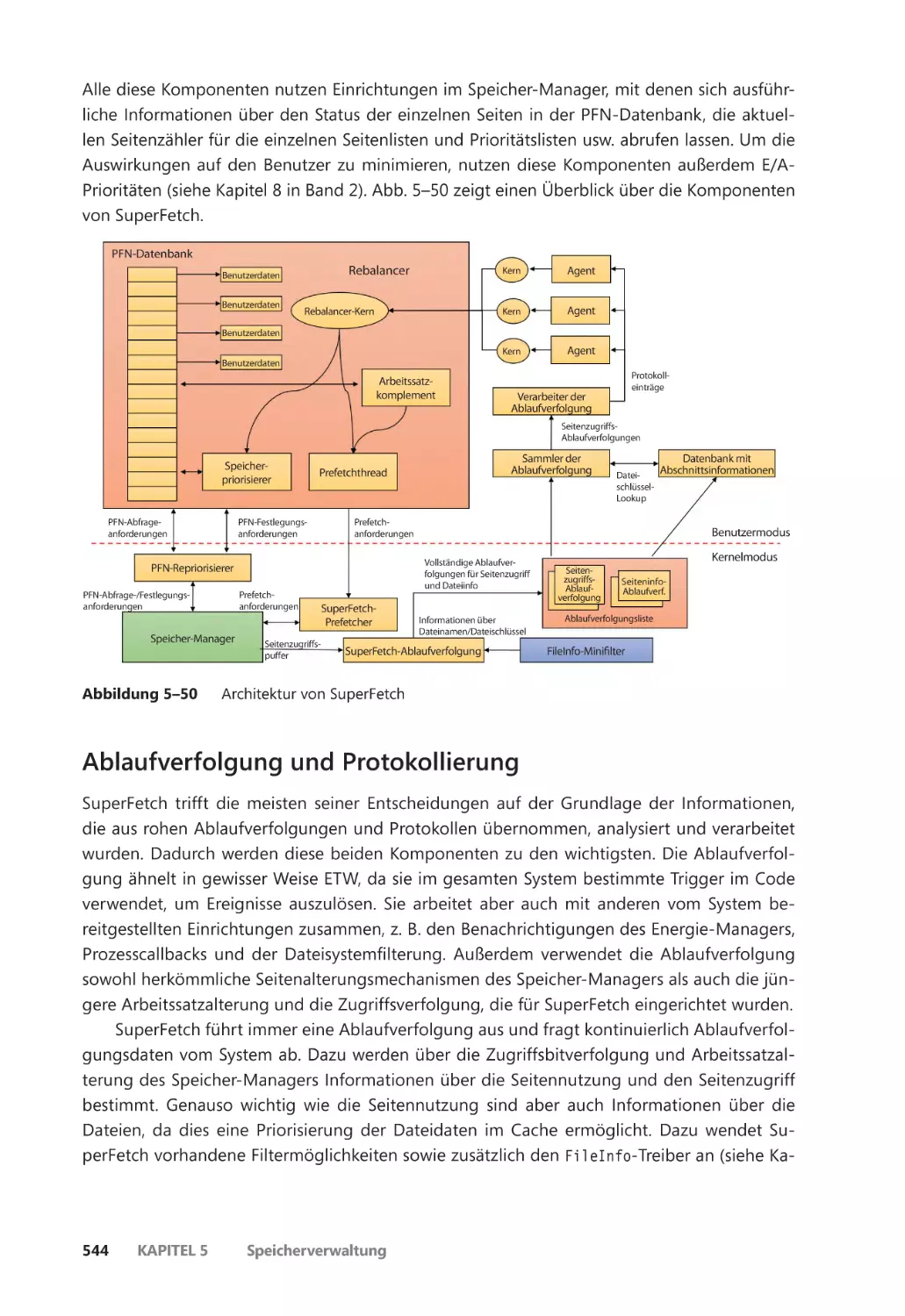
Vorausschauende Speicherverwaltung (SuperFetch) ����������������������������������������������� 542
Komponenten ��������������������������������������������������������������������������������������������������������� 543
Ablaufverfolgung und Protokollierung ��������������������������������������������������������������� 544
Szenarien ������������������������������������������������������������������������������������������������������������������� 545
Seitenpriorität und Rebalancing ��������������������������������������������������������������������������� 546
Leistungsstabilisierung ������������������������������������������������������������������������������������������� 549
Inhaltsverzeichnis
xiii
ReadyBoost ��������������������������������������������������������������������������������������������������������������� 550
ReadyDrive ��������������������������������������������������������������������������������������������������������������� 551
Prozessreflexion ������������������������������������������������������������������������������������������������������� 552
Zusammenfassung ��������������������������������������������������������������������������������������������������������� 554
Kapitel 6
Das E/A-System 555
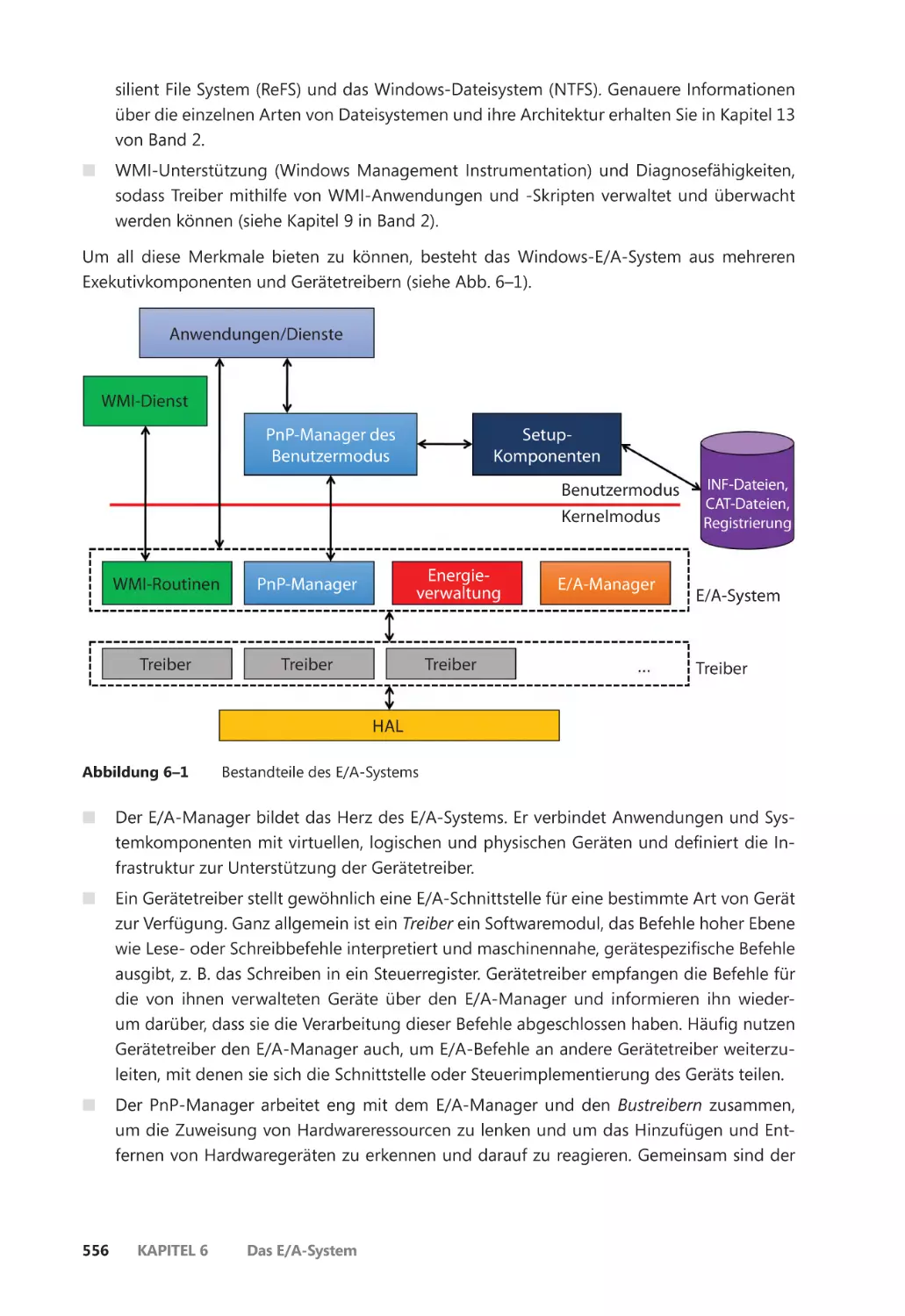
Komponenten des E/A-Systems ����������������������������������������������������������������������������������� 555
Der E/A-Manager ��������������������������������������������������������������������������������������������������� 557
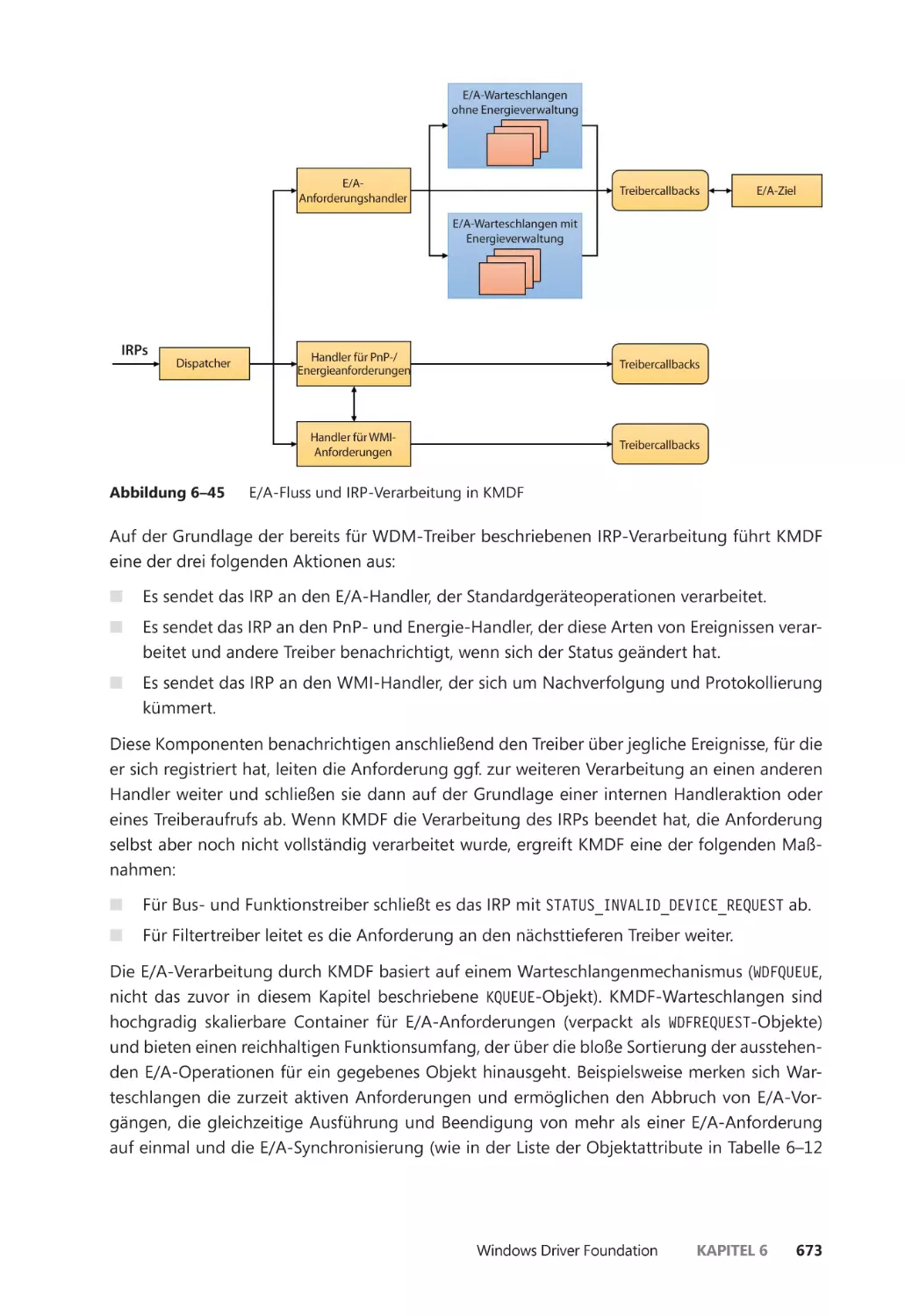
Typische E/A-Verarbeitung ������������������������������������������������������������������������������������ 558
IRQ-Ebenen und verzögerte Prozeduraufrufe ����������������������������������������������������������� 560
IRQ-Ebenen ������������������������������������������������������������������������������������������������������������� 561
Verzögerte Prozeduraufrufe ��������������������������������������������������������������������������������� 563
Gerätetreiber ������������������������������������������������������������������������������������������������������������������� 564
Arten von Gerätetreibern ��������������������������������������������������������������������������������������� 565
Aufbau eines Treibers ��������������������������������������������������������������������������������������������� 572
Treiber- und Geräteobjekte ����������������������������������������������������������������������������������� 574
Geräte öffnen ����������������������������������������������������������������������������������������������������������� 582
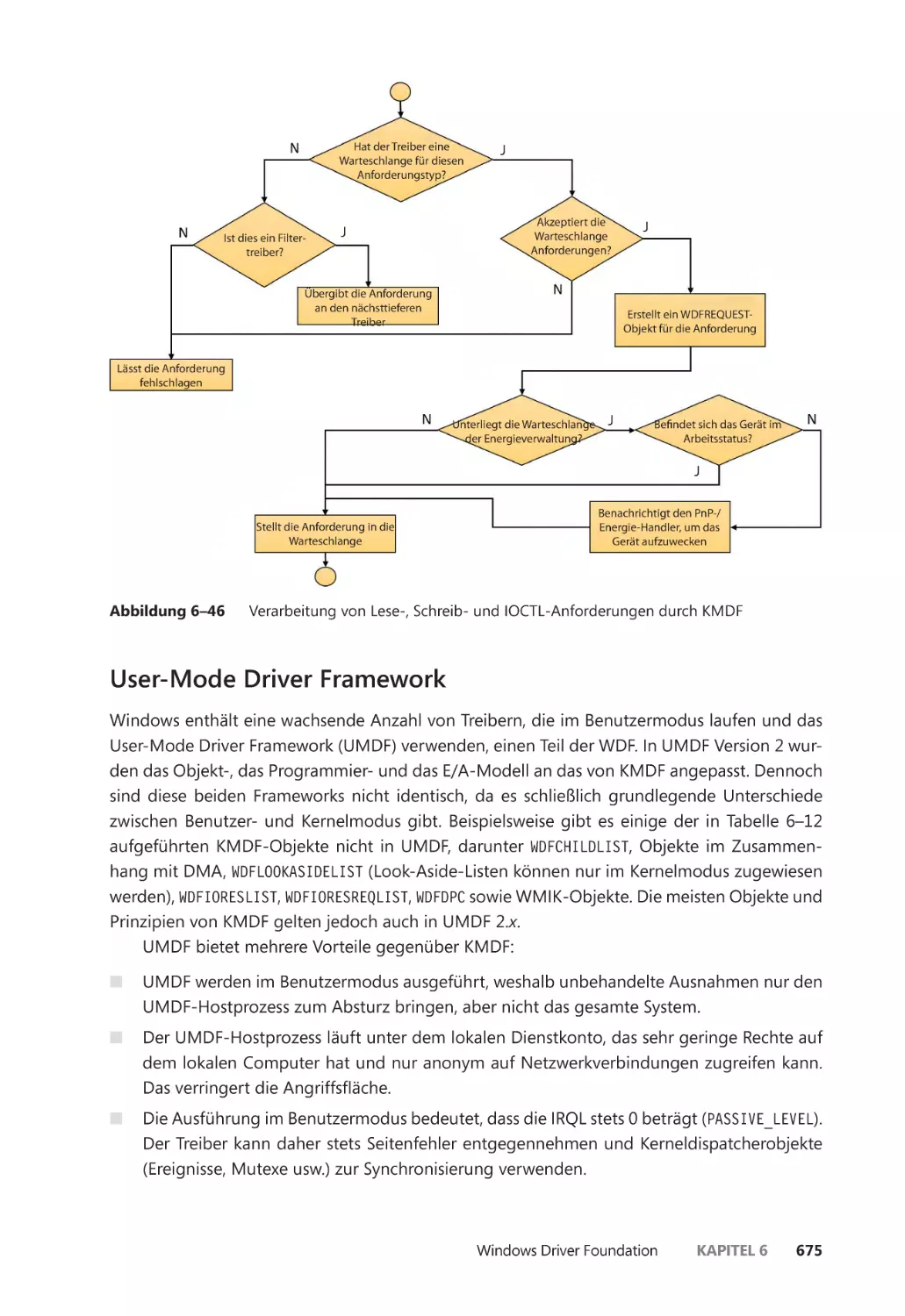
E/A-Verarbeitung ����������������������������������������������������������������������������������������������������������� 586
Verschiedene Arten der E/A ����������������������������������������������������������������������������������� 586
E/A-Anforderungspakete ��������������������������������������������������������������������������������������� 590
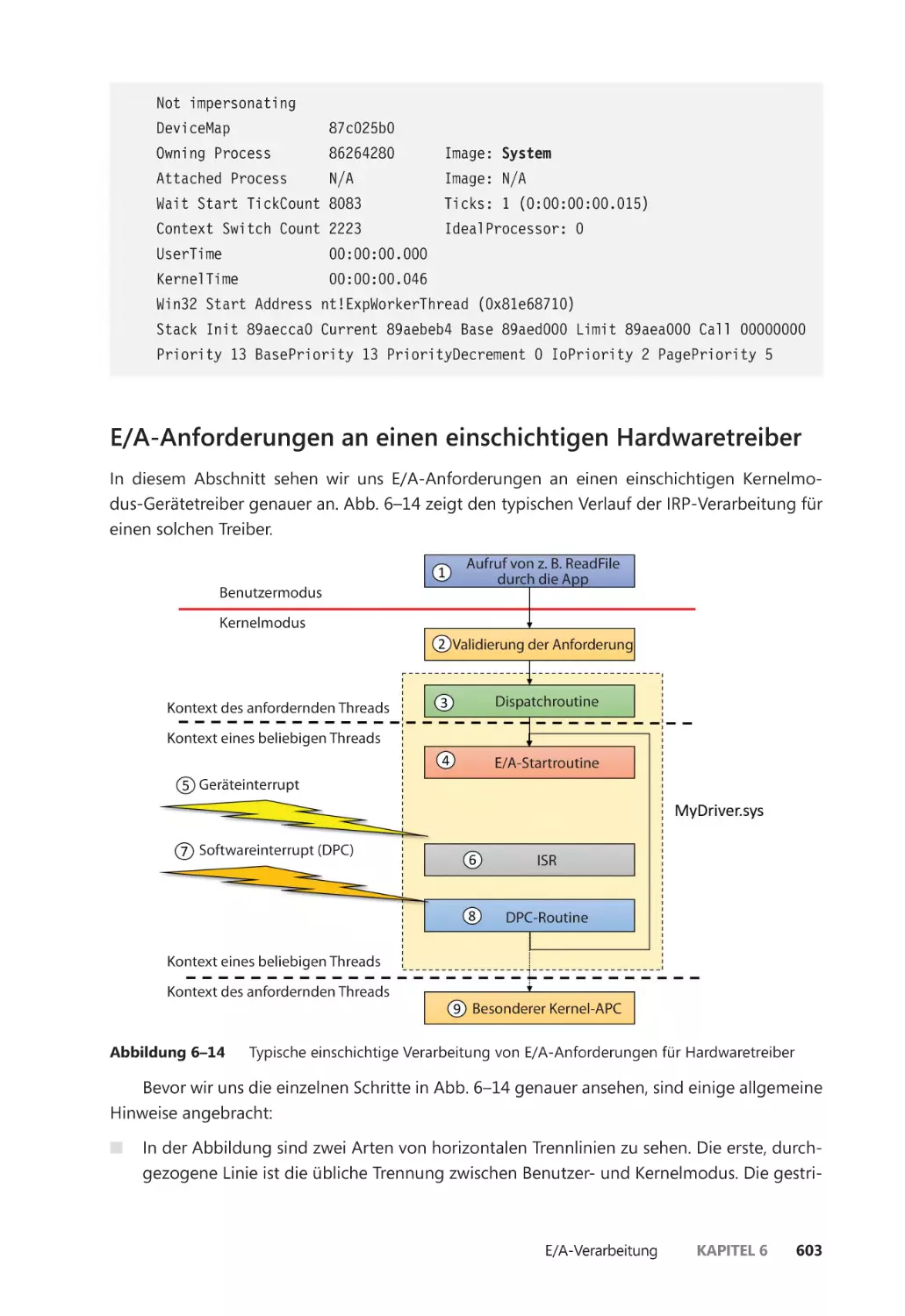
E/A-Anforderungen an einen einschichtigen Hardwaretreiber ����������������������� 603
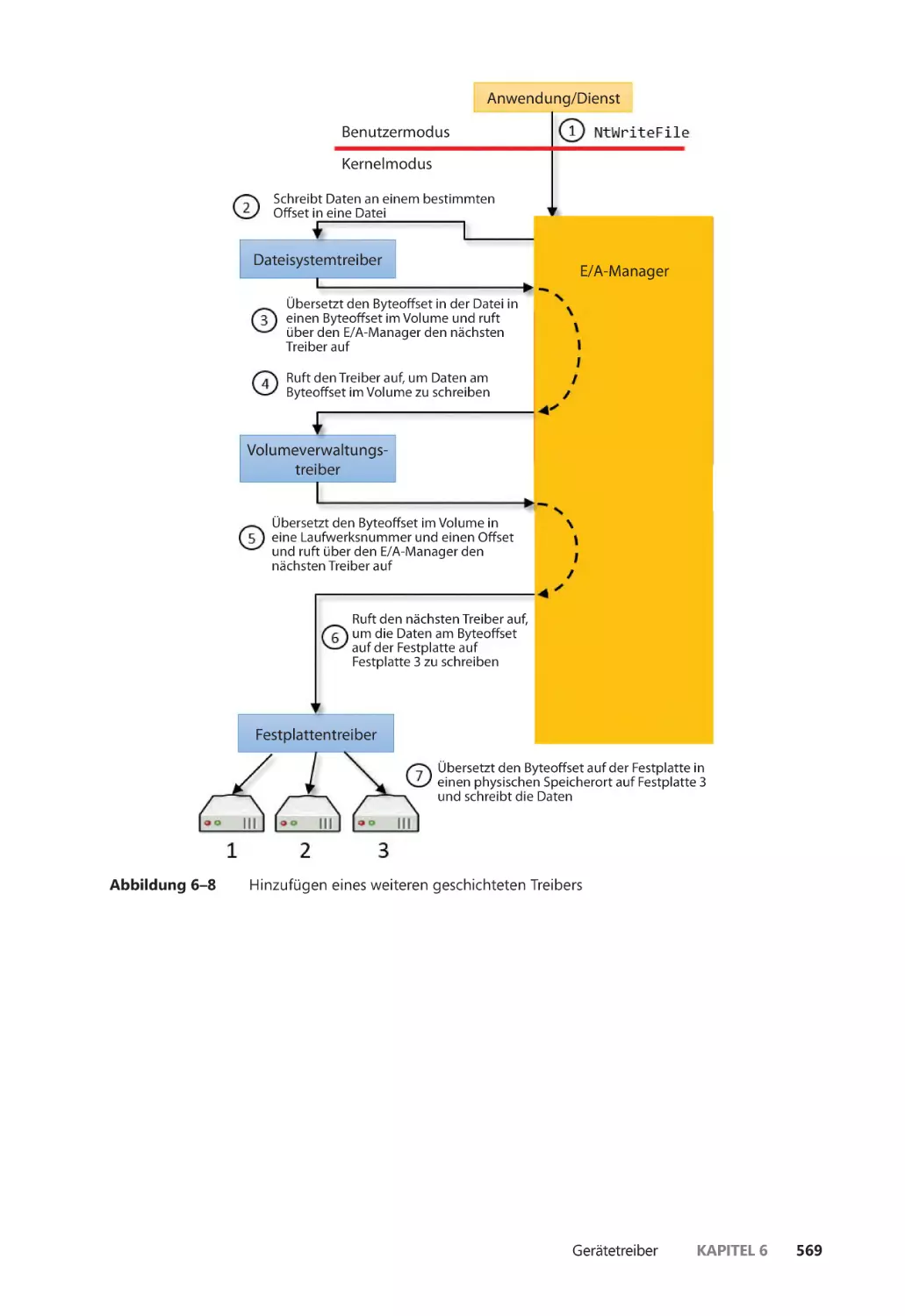
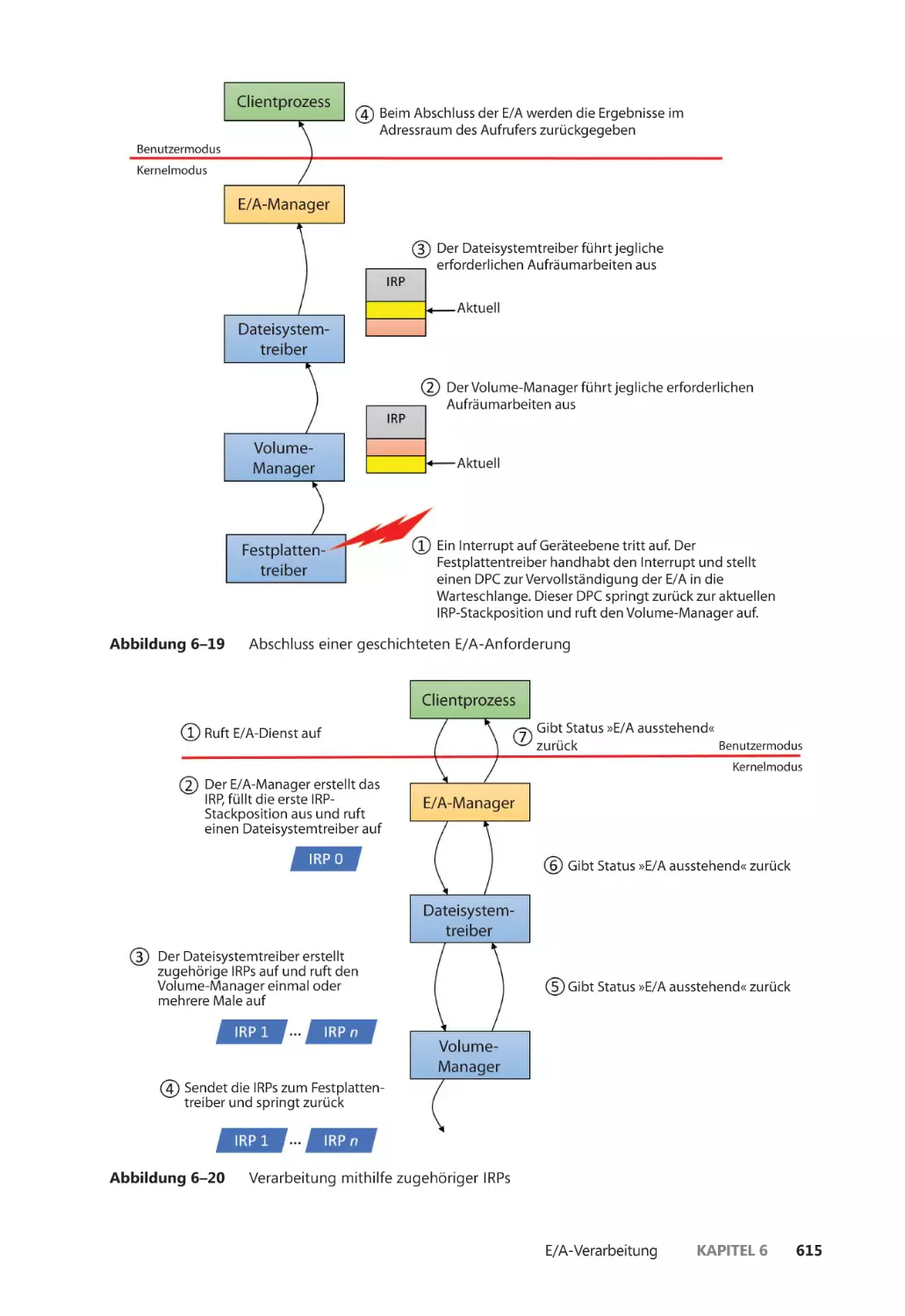
E/A-Anforderungen an geschichtete Treiber ����������������������������������������������������� 613
Threadagnostische E/A ������������������������������������������������������������������������������������������� 616
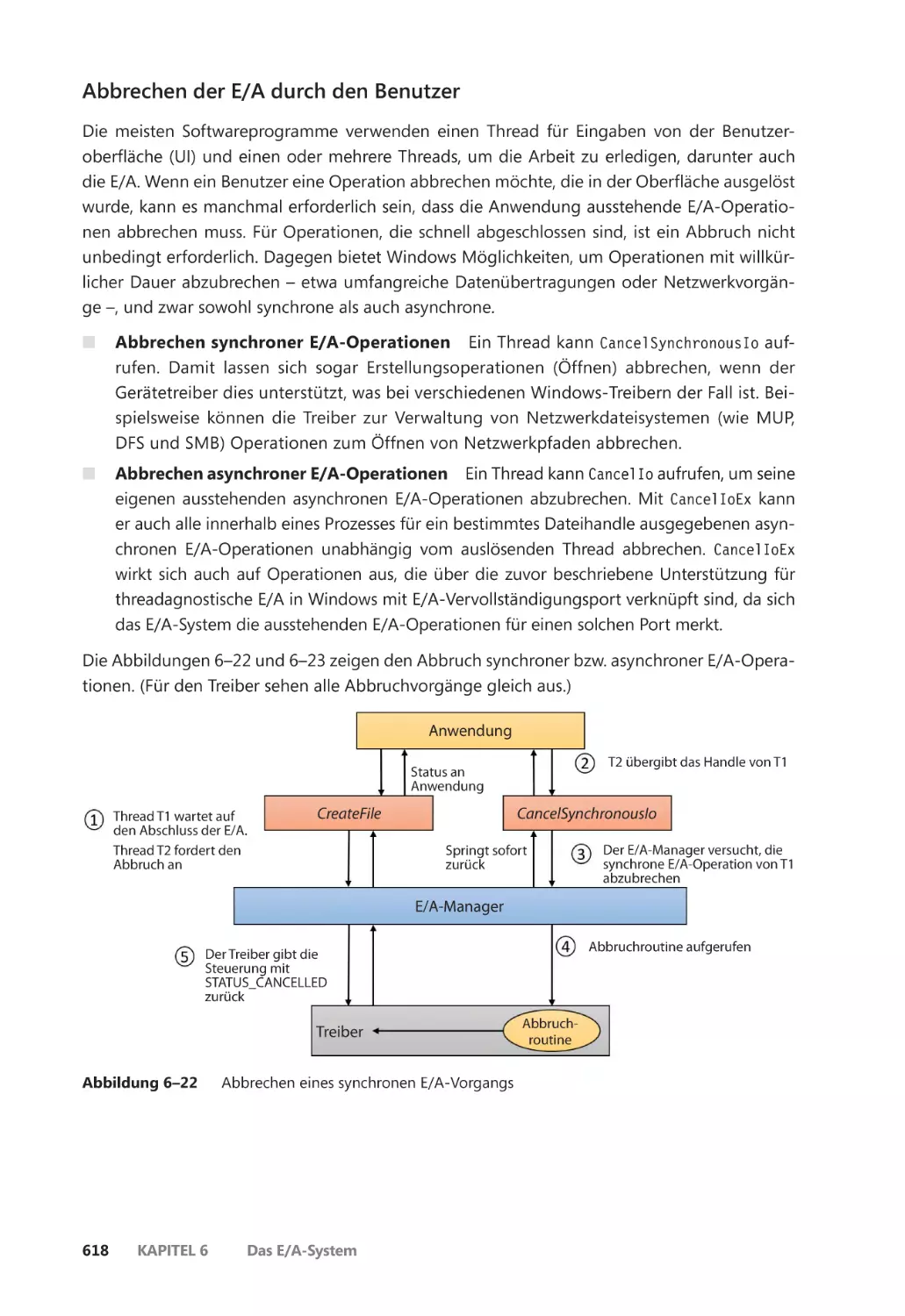
Abbrechen der E/A ������������������������������������������������������������������������������������������������� 617
E/A-Vervollständigungsports ��������������������������������������������������������������������������������� 622
E/A-Priorisierung ����������������������������������������������������������������������������������������������������� 627
Containerbenachrichtigungen ������������������������������������������������������������������������������� 634
Treiberüberprüfung ������������������������������������������������������������������������������������������������������� 635
E/A-Überprüfungsoptionen ����������������������������������������������������������������������������������� 638
Speicherüberprüfungsoptionen ��������������������������������������������������������������������������� 638
Der PnP-Manager ����������������������������������������������������������������������������������������������������������� 643
Der Grad der Unterstützung für Plug & Play ����������������������������������������������������� 644
Geräteauflistung ����������������������������������������������������������������������������������������������������� 645
Gerätestacks ������������������������������������������������������������������������������������������������������������� 649
xiv
Inhaltsverzeichnis
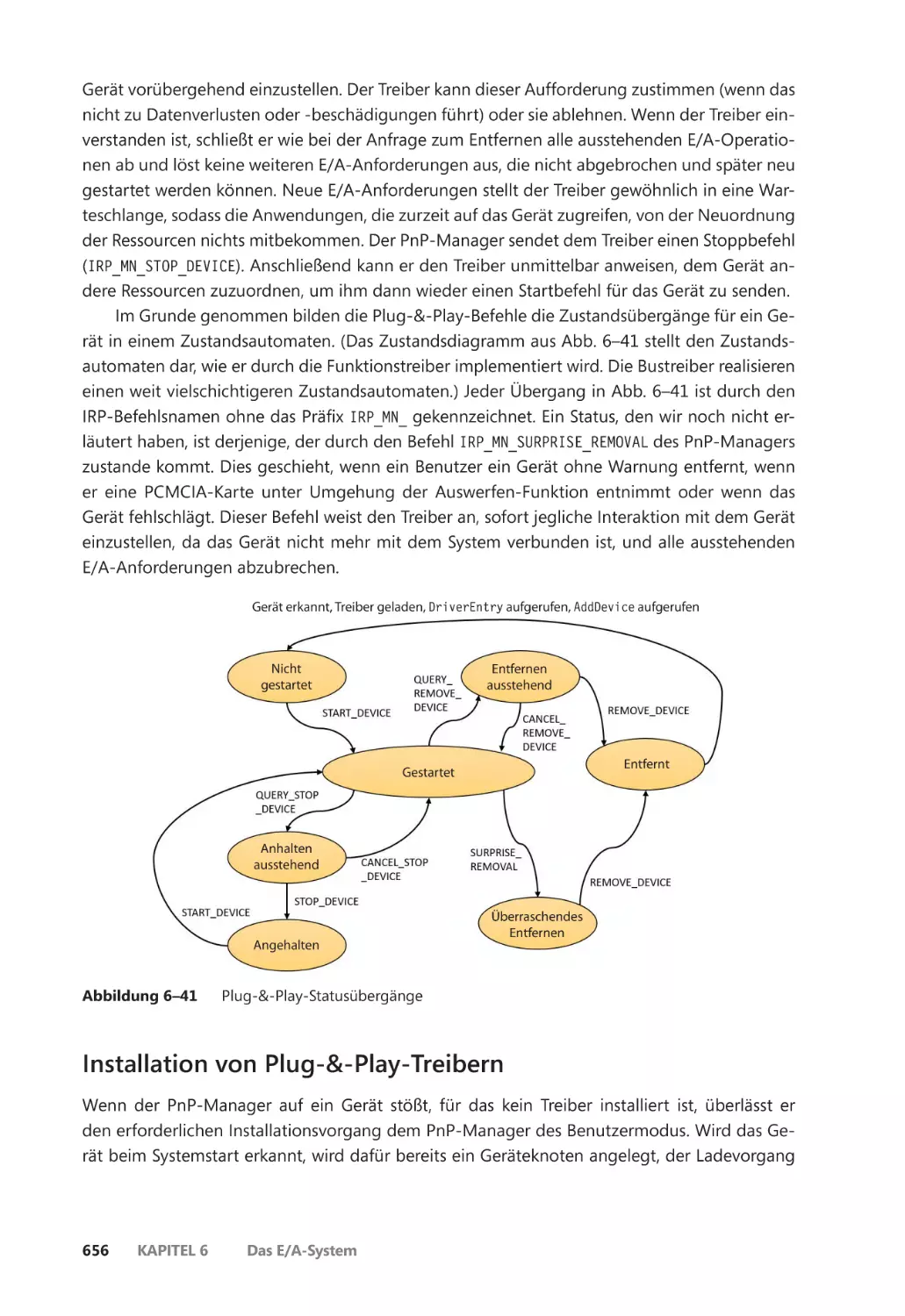
Treiberunterstützung für Plug & Play ������������������������������������������������������������������� 655
Installation von Plug-&-Play-Treibern ����������������������������������������������������������������� 656
Laden und Installieren von Treibern ��������������������������������������������������������������������������� 661
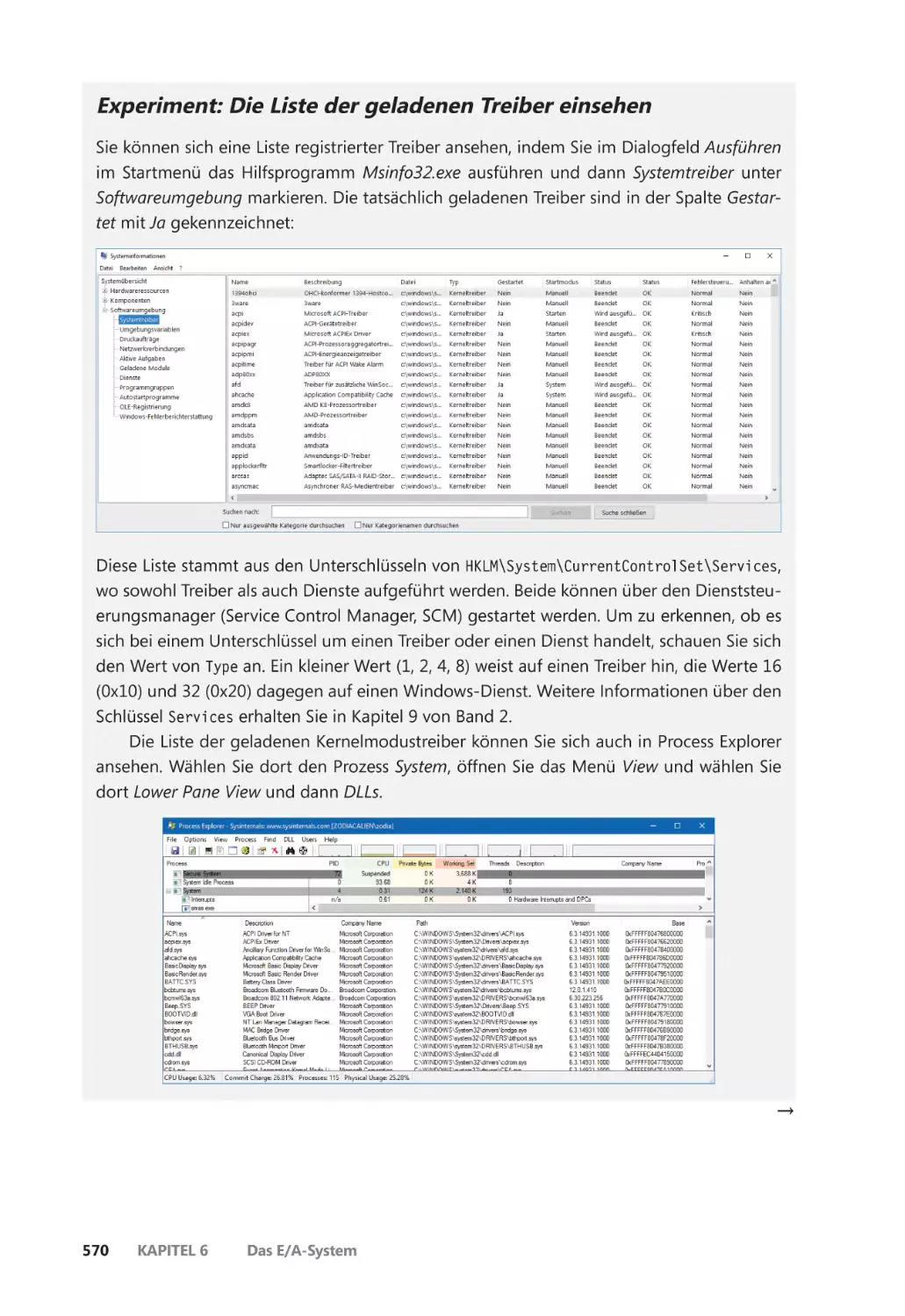
Treiber laden ������������������������������������������������������������������������������������������������������������� 661
Treiberinstallation ��������������������������������������������������������������������������������������������������� 663
Windows Driver Foundation ����������������������������������������������������������������������������������������� 664
Kernel-Mode Driver Framework ��������������������������������������������������������������������������� 665
Das E/A-Modell von KMDF ����������������������������������������������������������������������������������� 672
User-Mode Driver Framework ������������������������������������������������������������������������������� 675
Energieverwaltung ��������������������������������������������������������������������������������������������������������� 679
Verbundener und moderner Standbymodus ����������������������������������������������������� 683
Funktionsweise der Energieverwaltung ��������������������������������������������������������������� 684
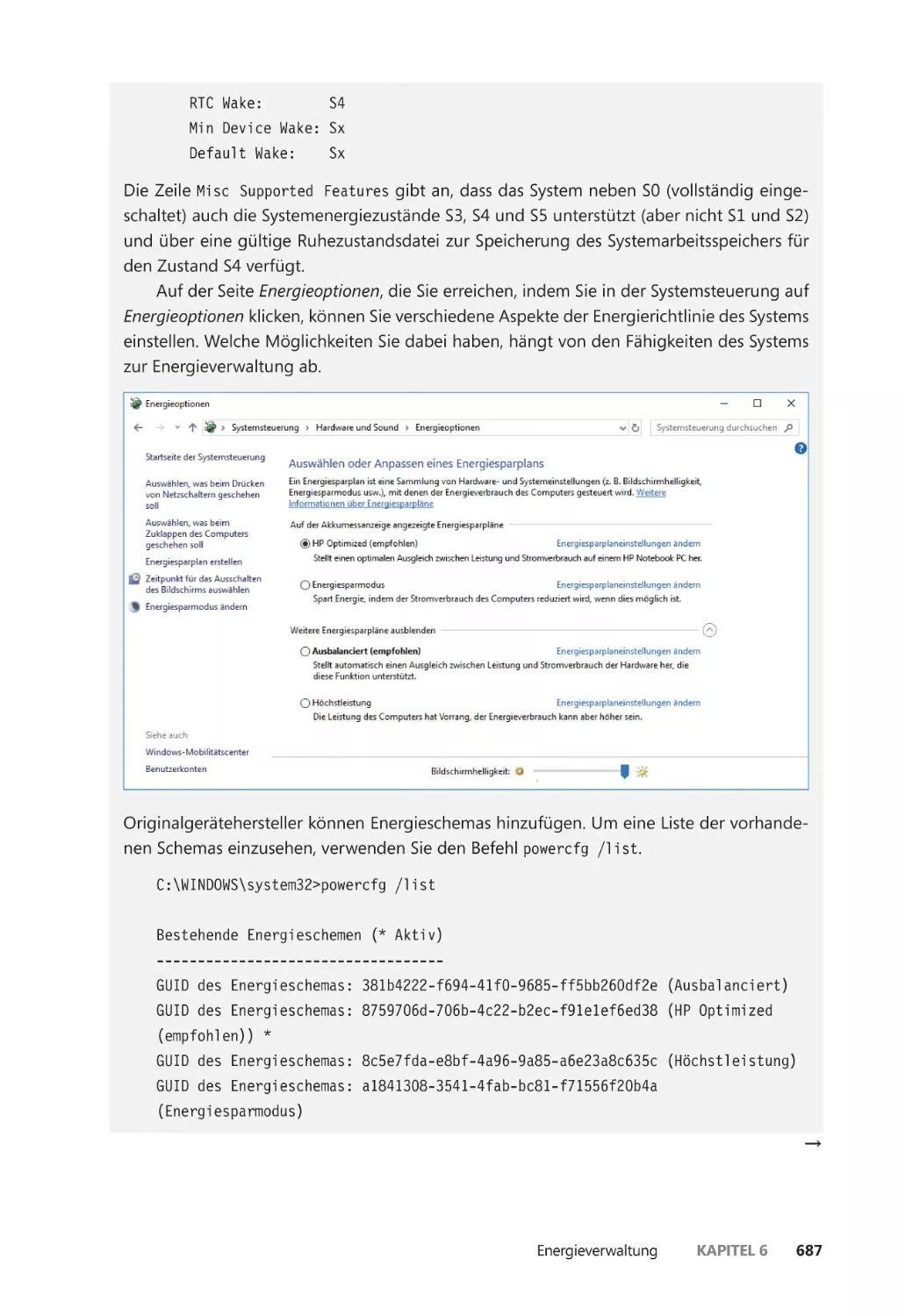
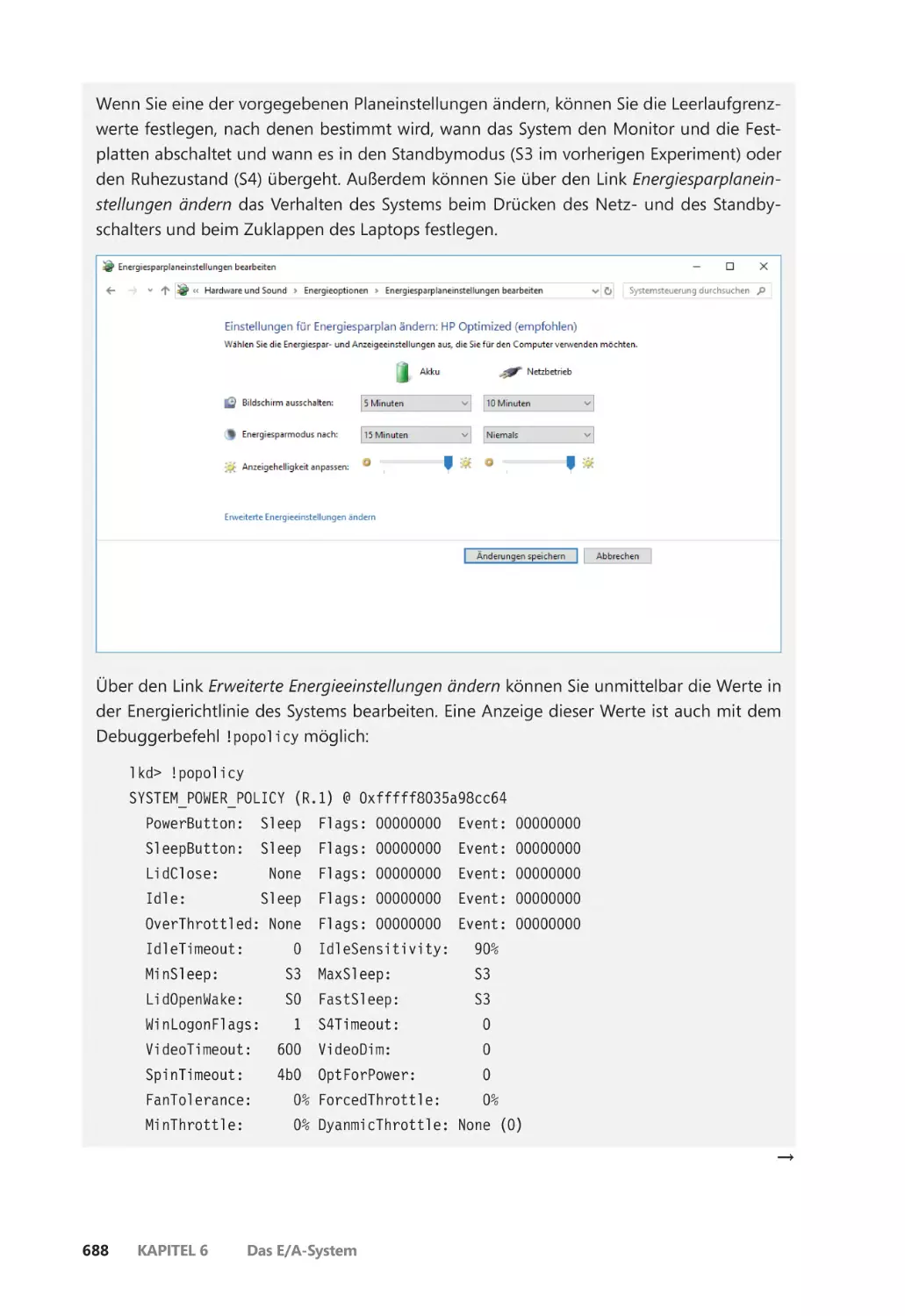
Energieverwaltung durch die Treiber ������������������������������������������������������������������� 686
Steuerung der Geräteenergiezustände durch den Treiber und die
Anwendung ������������������������������������������������������������������������������������������������������������� 689
Das Framework für die Energieverwaltung ��������������������������������������������������������� 690
Energieverfügbarkeitsanforderungen ����������������������������������������������������������������� 692
Zusammenfassung ��������������������������������������������������������������������������������������������������������� 694
Kapitel 7
Sicherheit 697
Sicherheitseinstufungen ����������������������������������������������������������������������������������������������� 697
Trusted Computer System Evaluation Criteria ����������������������������������������������������� 697
Common Criteria ����������������������������������������������������������������������������������������������������� 699
Systemkomponenten für die Sicherheit ��������������������������������������������������������������������� 700
Virtualisierungsgestützte Sicherheit ��������������������������������������������������������������������������� 704
Credential Guard ����������������������������������������������������������������������������������������������������� 705
Device Guard ����������������������������������������������������������������������������������������������������������� 712
Objekte schützen ����������������������������������������������������������������������������������������������������������� 714
Zugriffsprüfungen ��������������������������������������������������������������������������������������������������� 716
Sicherheitskennungen ��������������������������������������������������������������������������������������������� 720
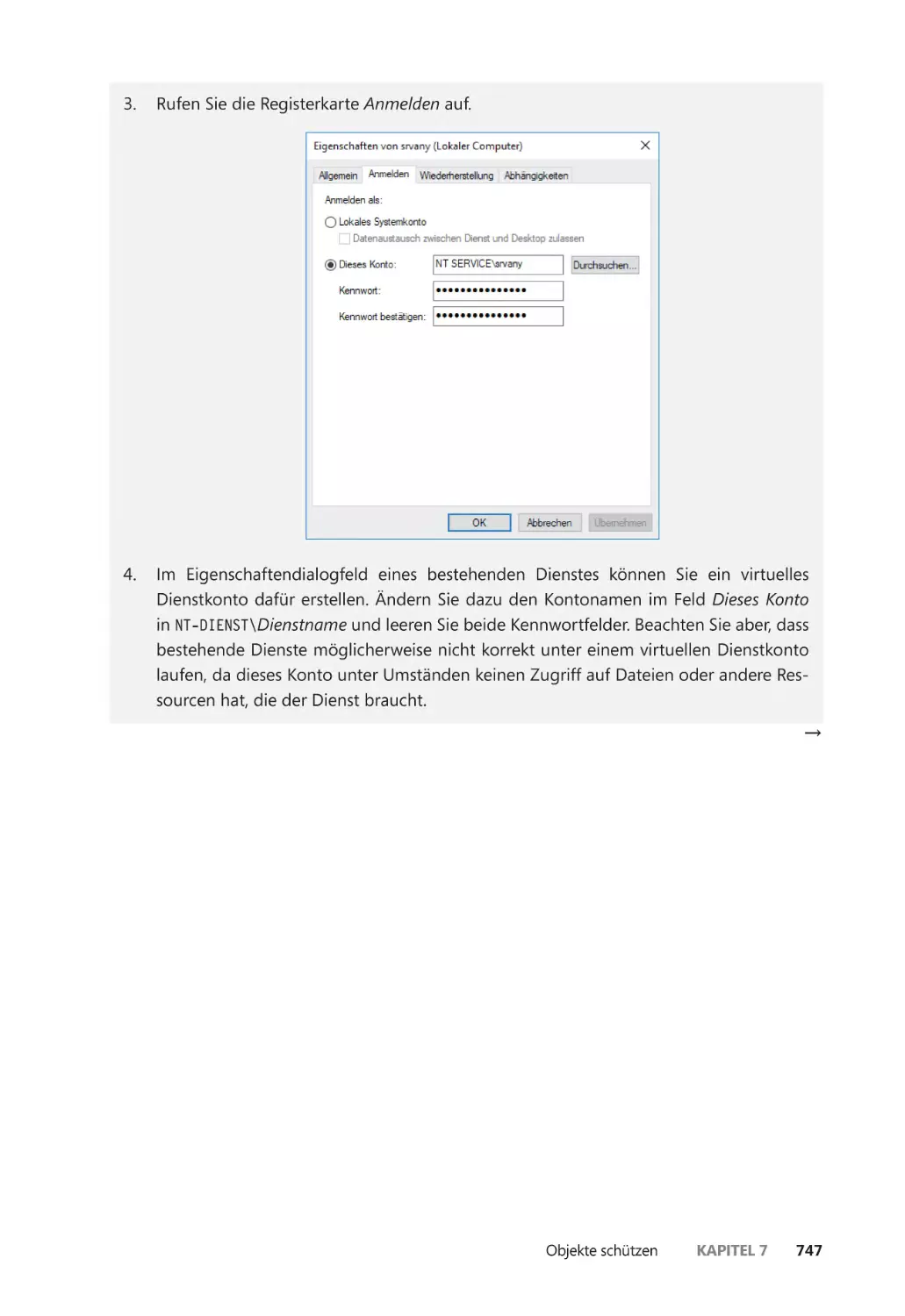
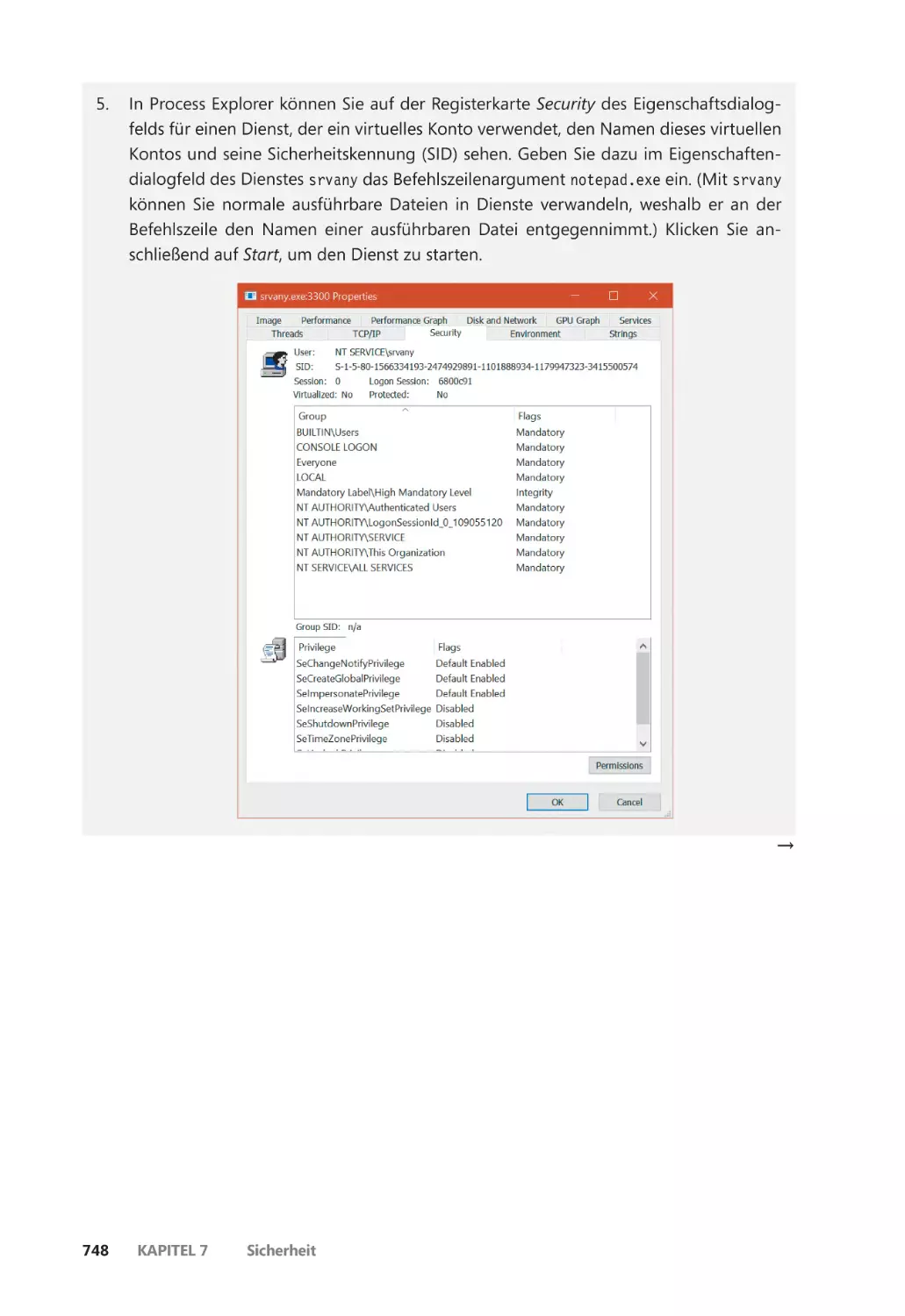
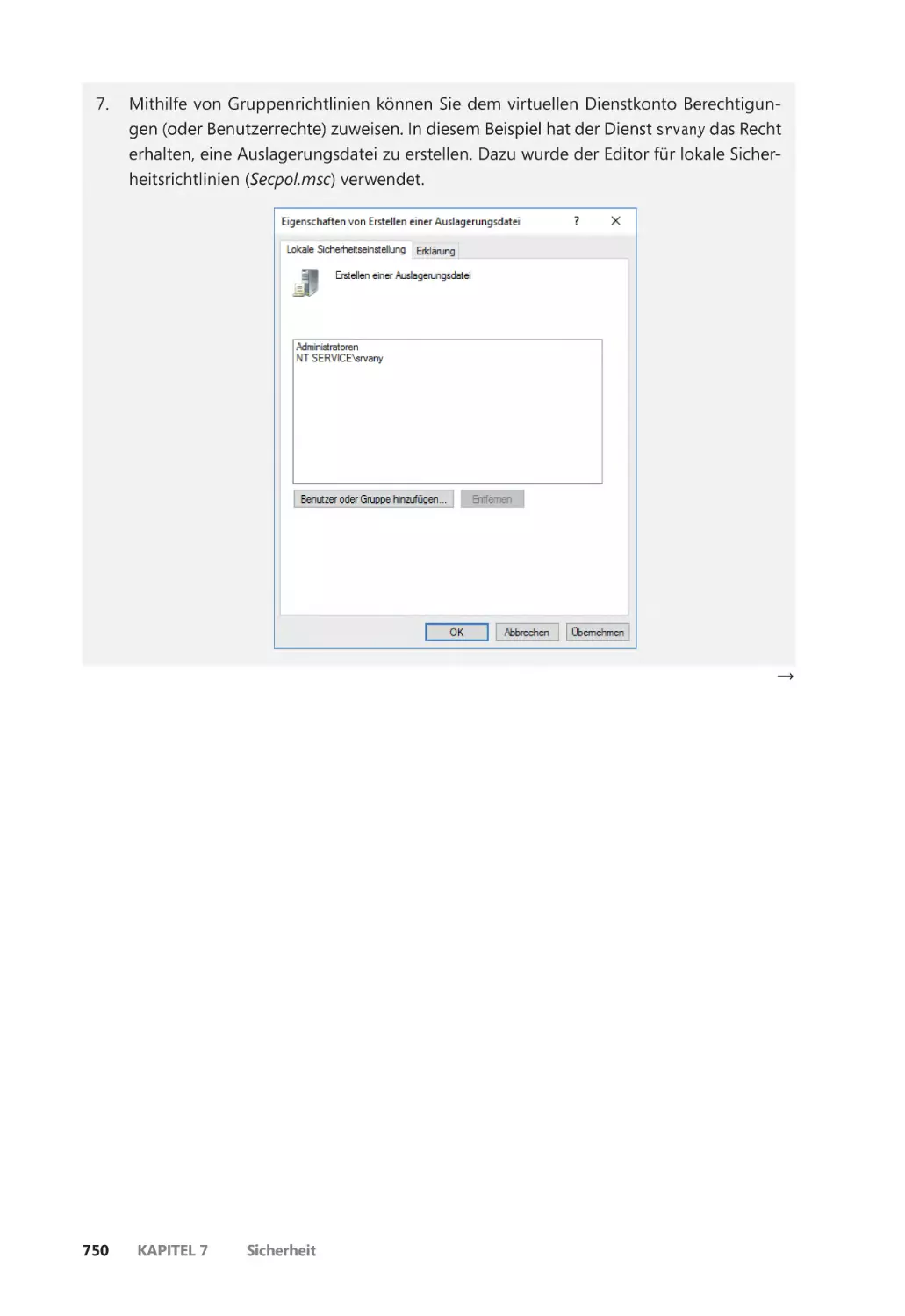
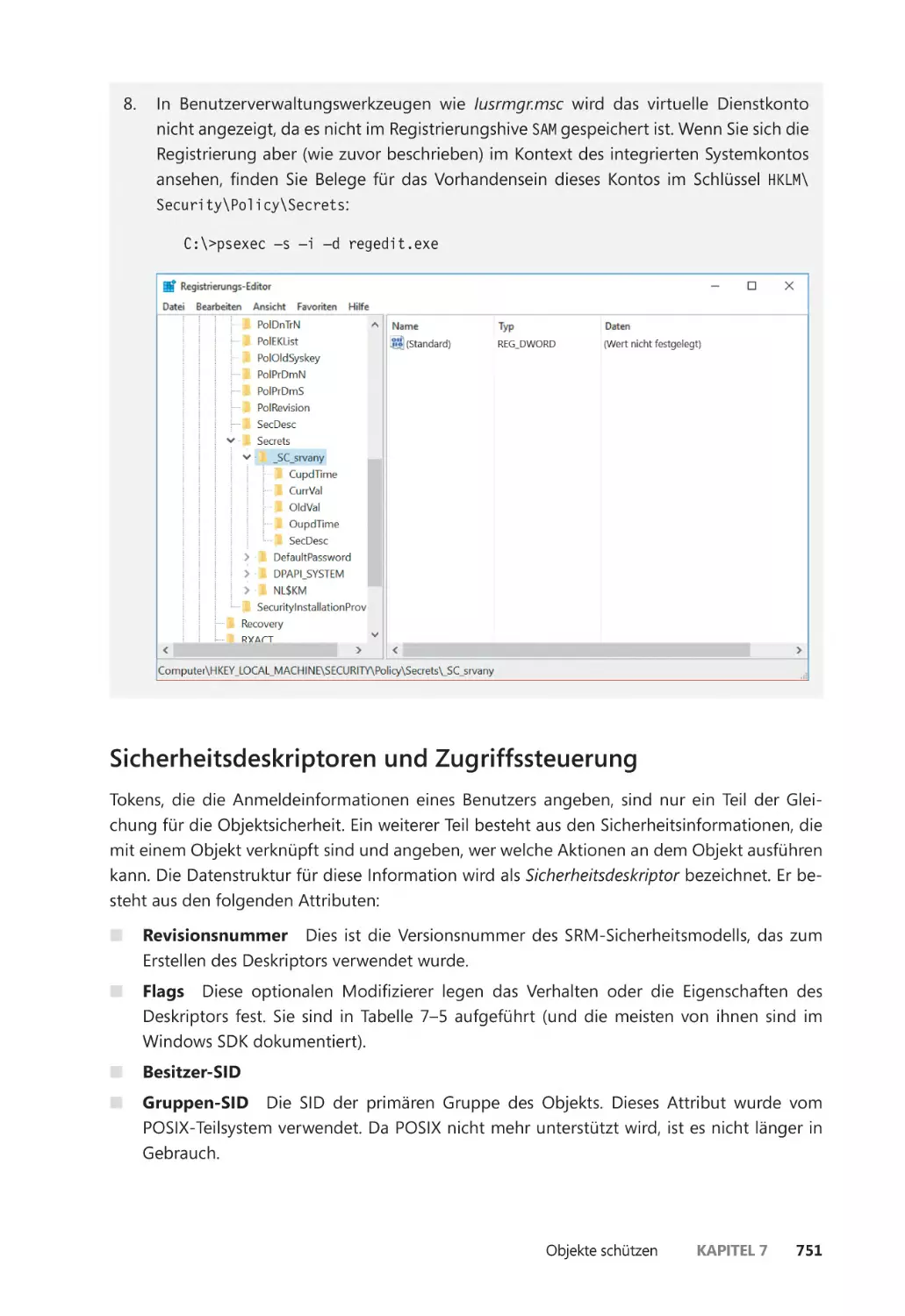
Virtuelle Dienstkonten ������������������������������������������������������������������������������������������� 745
Sicherheitsdeskriptoren und Zugriffssteuerung ������������������������������������������������� 751
Dynamische Zugriffssteuerung ����������������������������������������������������������������������������� 770
Inhaltsverzeichnis
xv
Die AuthZ-API ����������������������������������������������������������������������������������������������������������������� 771
Bedingte Zugriffssteuerungseinträge ������������������������������������������������������������������� 772
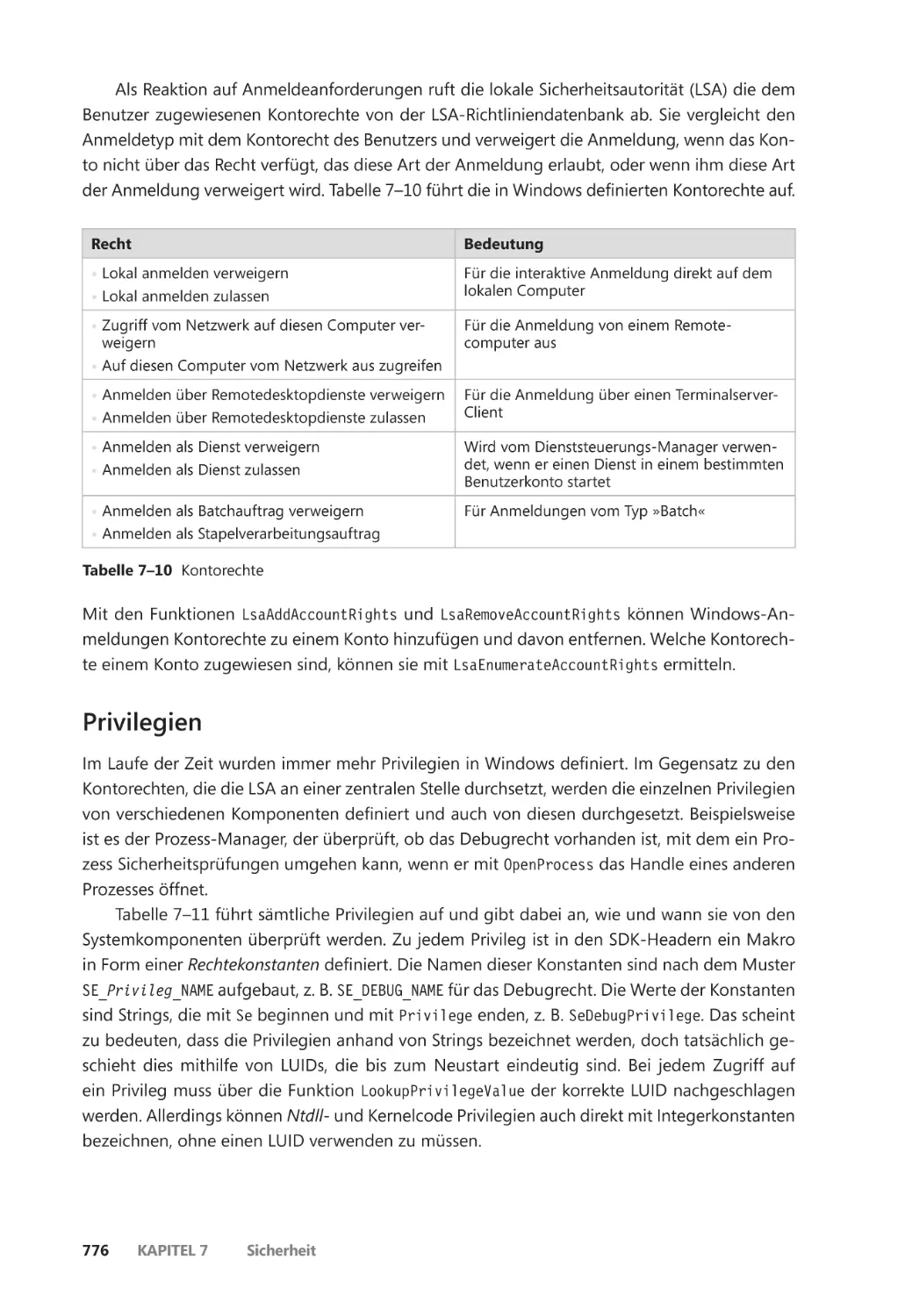
Privilegien und Kontorechte ����������������������������������������������������������������������������������������� 773
Kontorechte ������������������������������������������������������������������������������������������������������������� 775
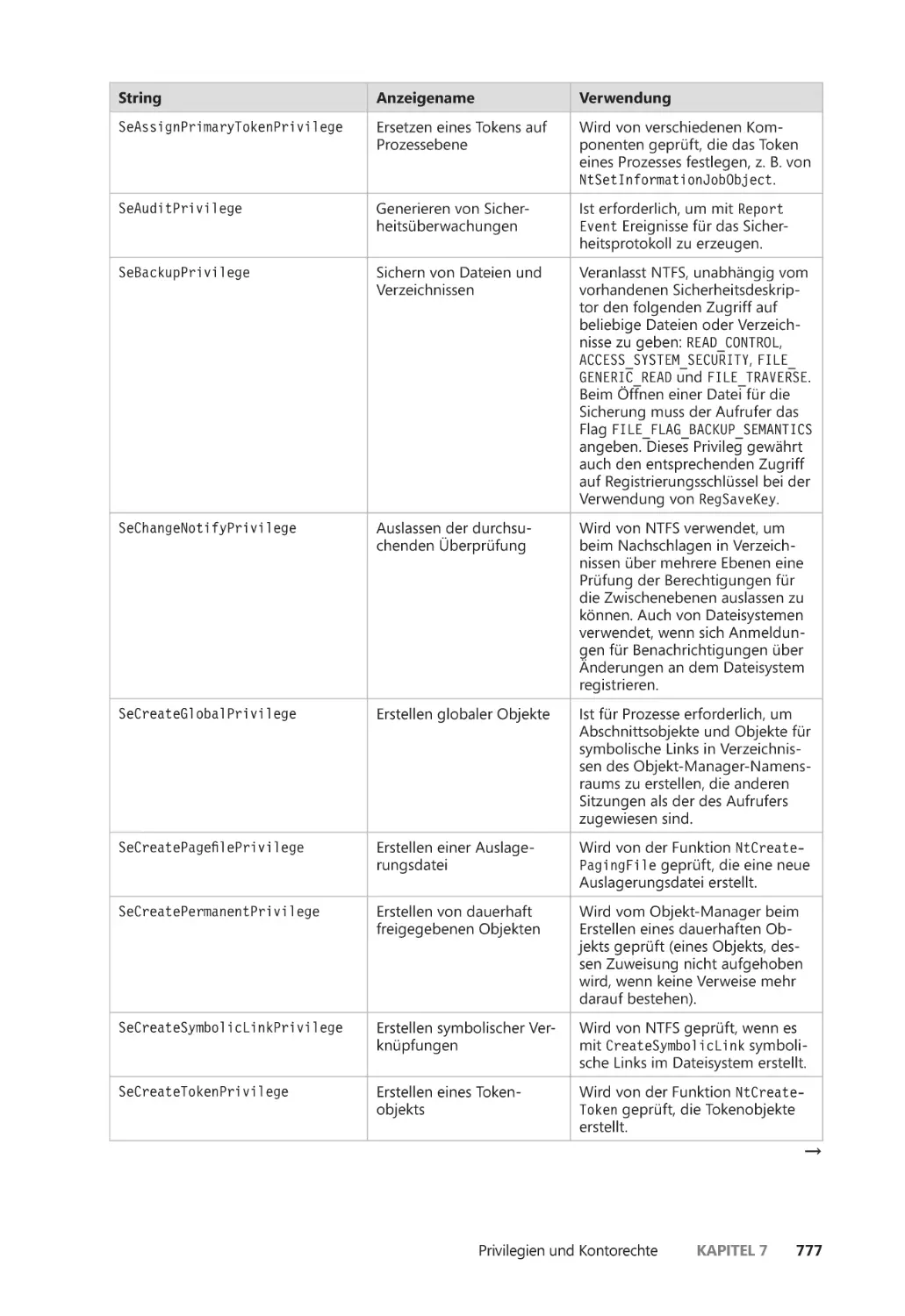
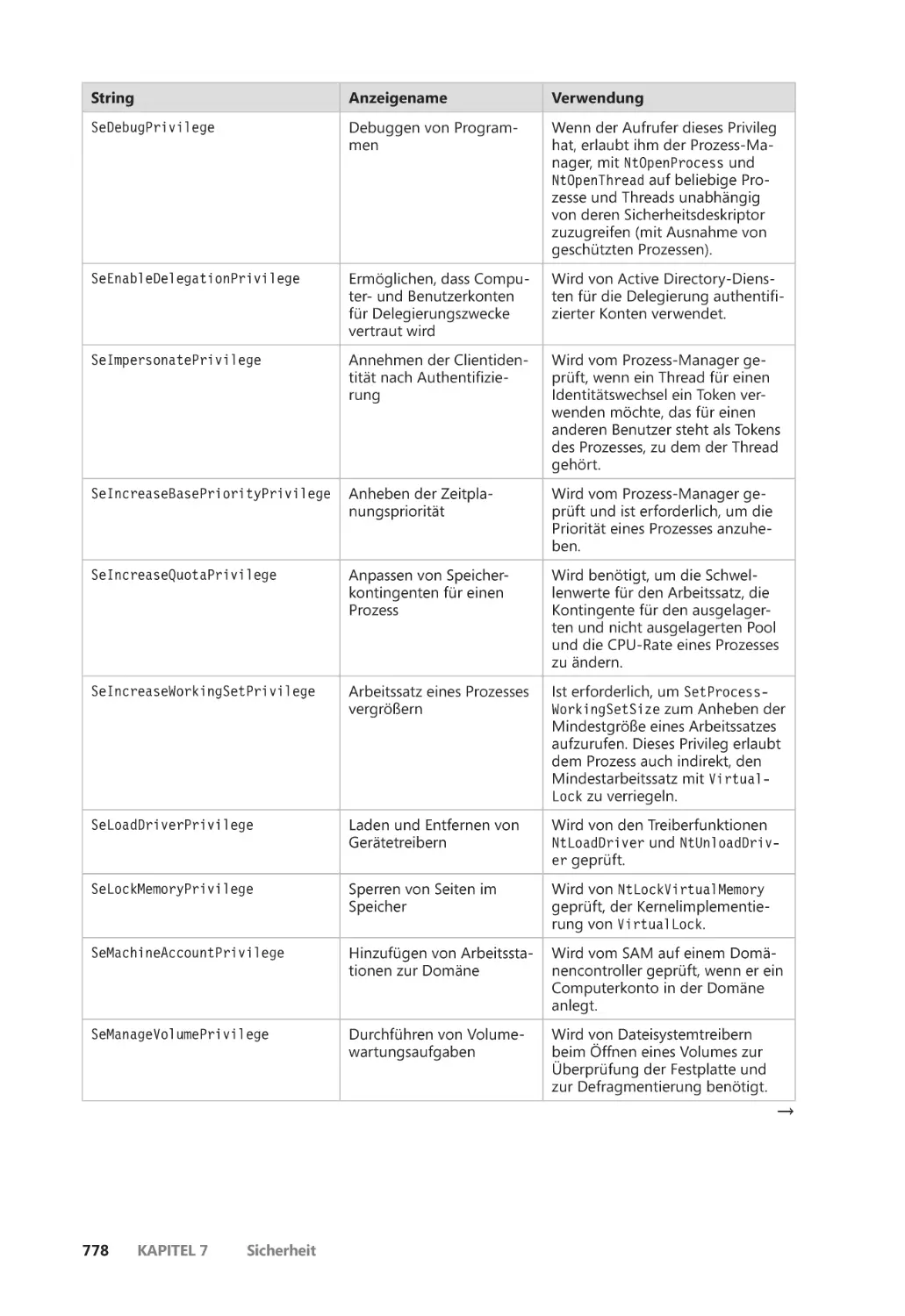
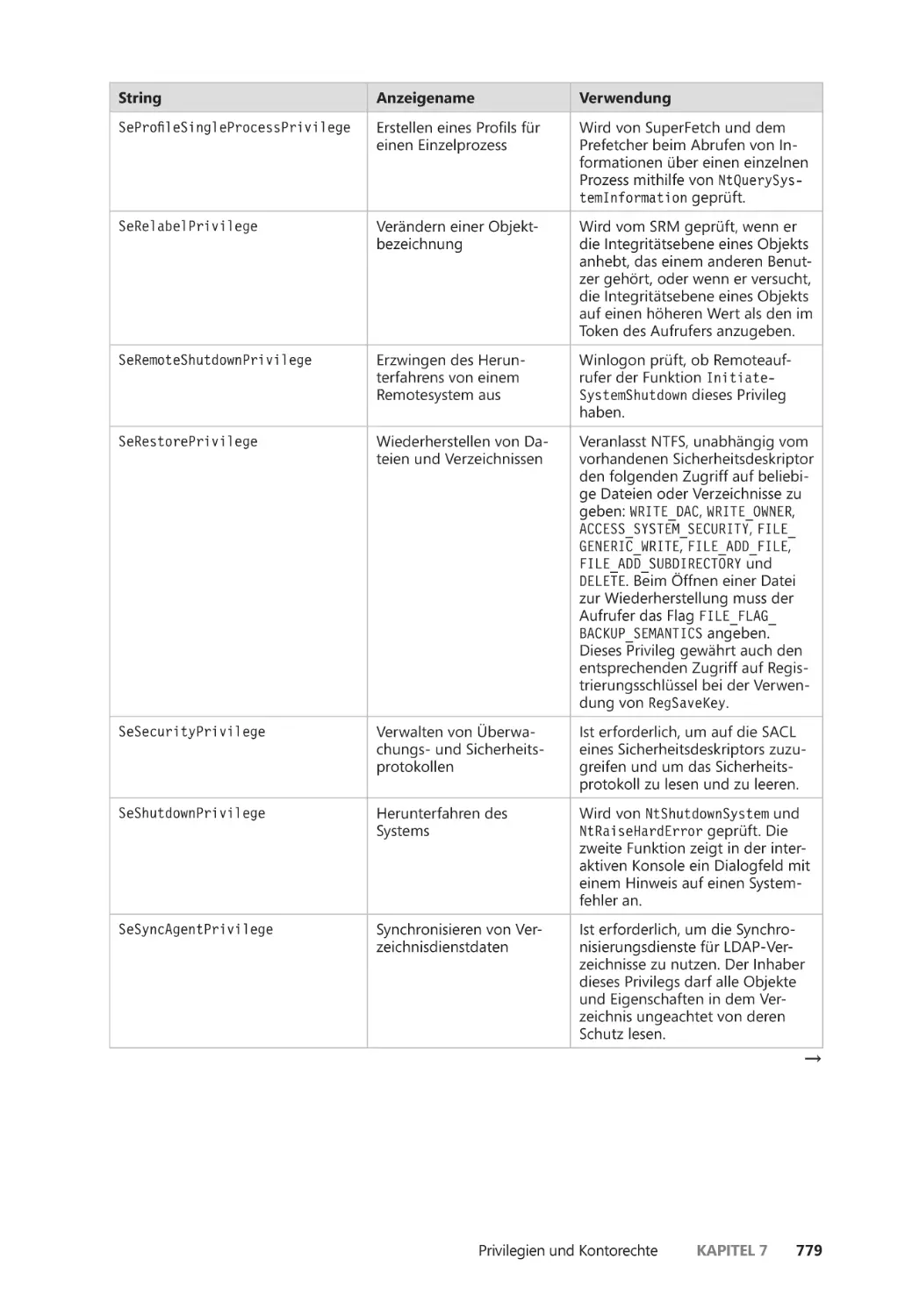
Privilegien ����������������������������������������������������������������������������������������������������������������� 776
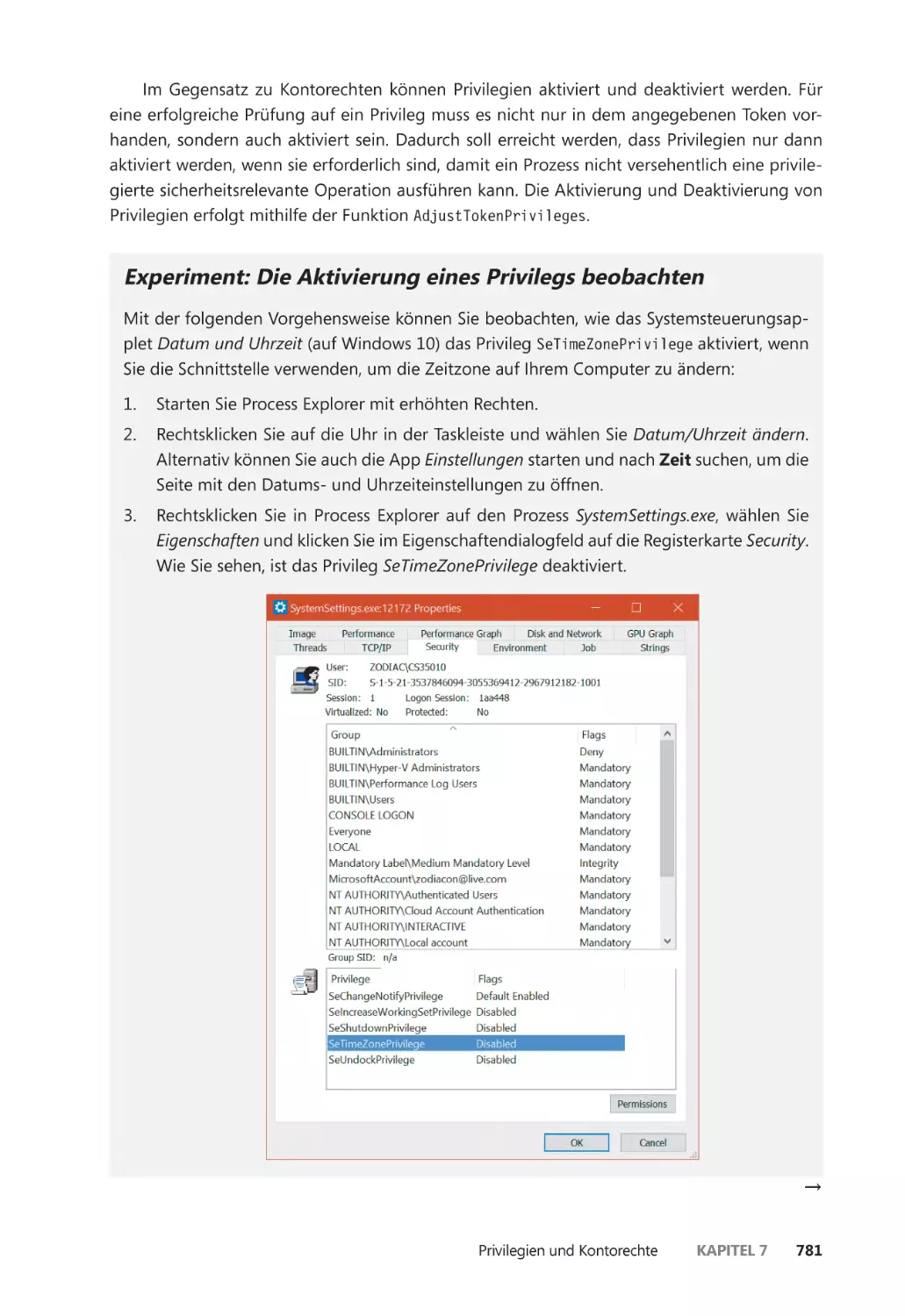
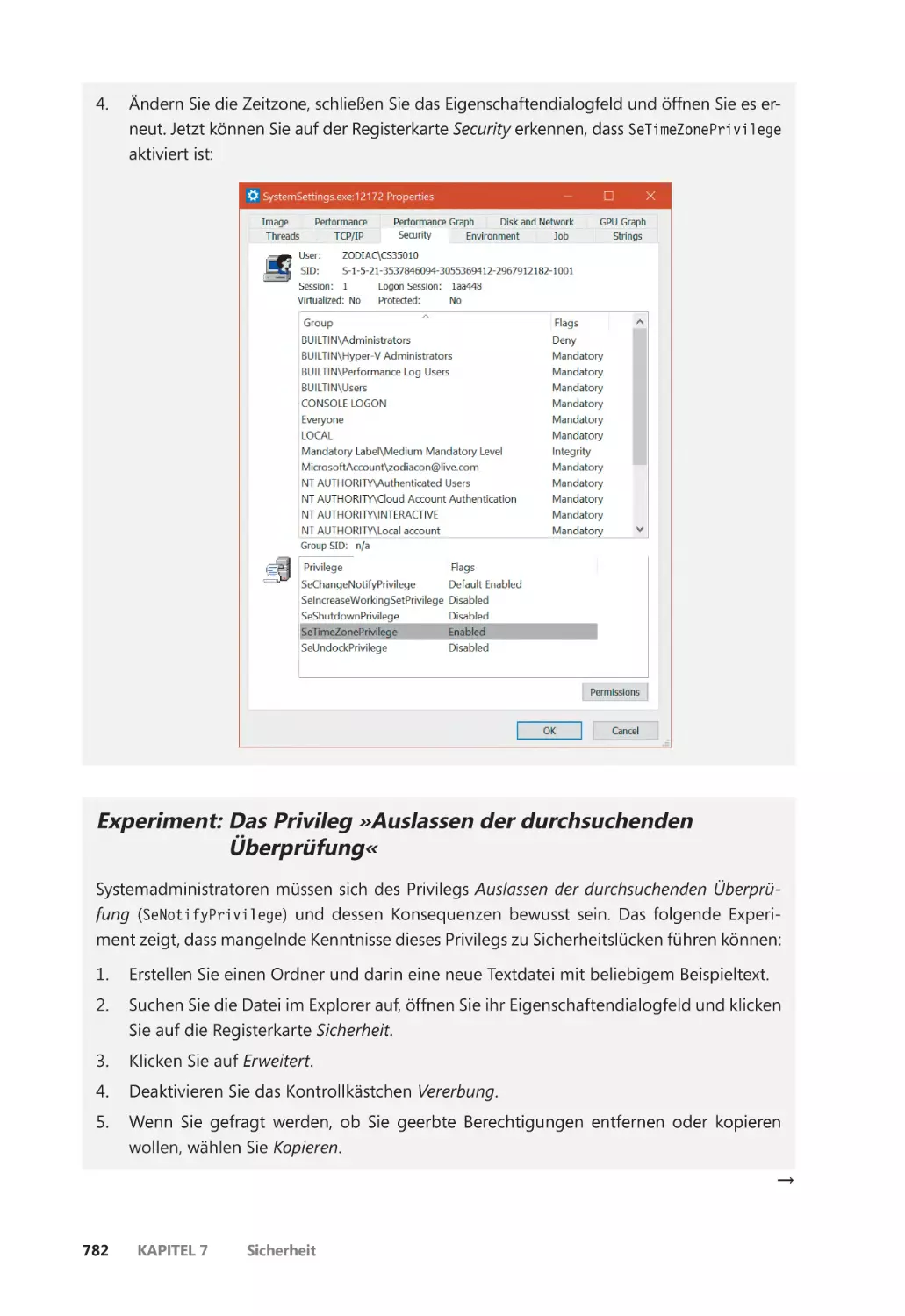
Superprivilegien ������������������������������������������������������������������������������������������������������� 783
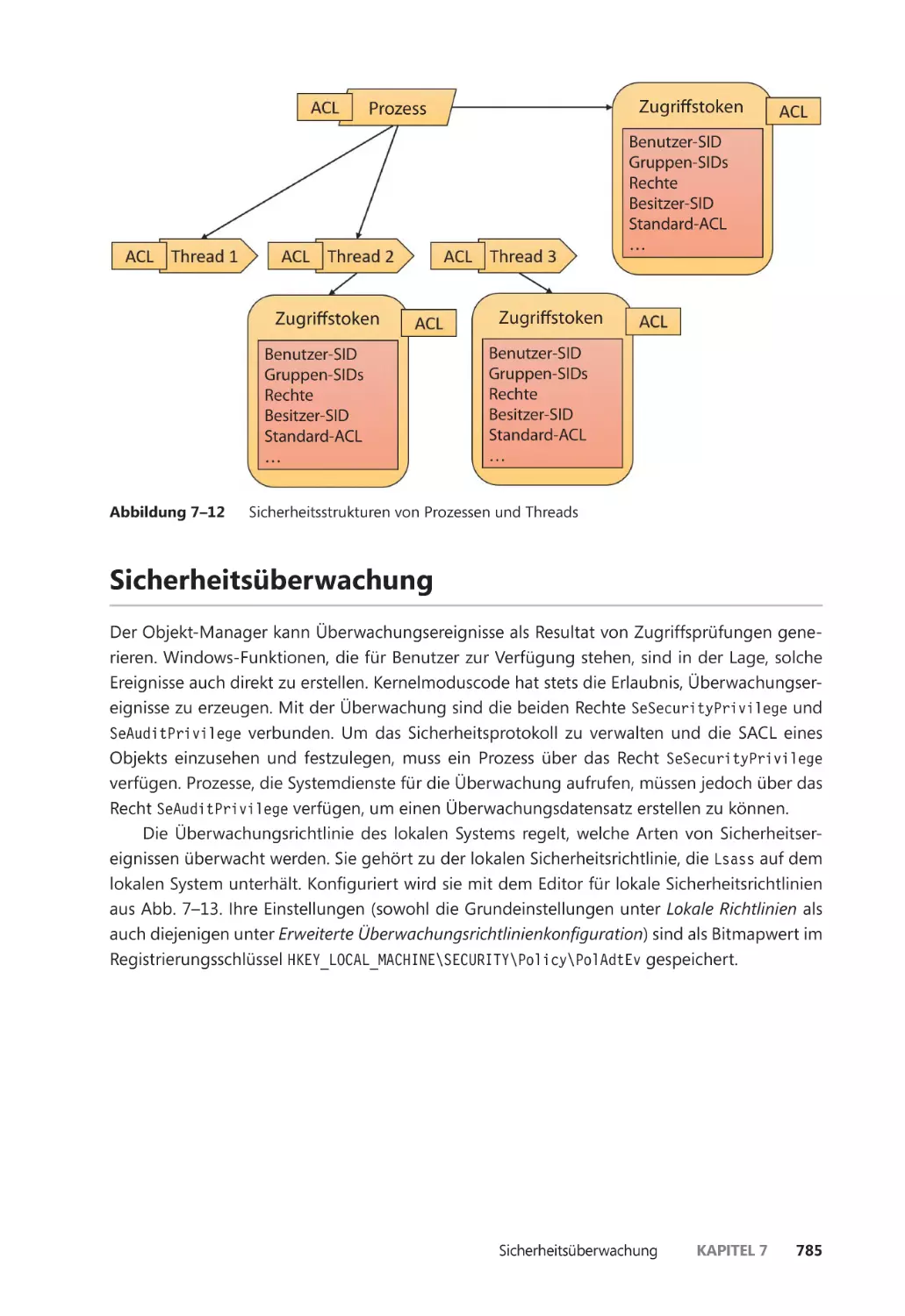
Zugriffstokens von Prozessen und Threads ��������������������������������������������������������������� 784
Sicherheitsüberwachung ����������������������������������������������������������������������������������������������� 785
Überwachung des Objektzugriffs ������������������������������������������������������������������������� 787
Globale Überwachungsrichtlinie ��������������������������������������������������������������������������� 790
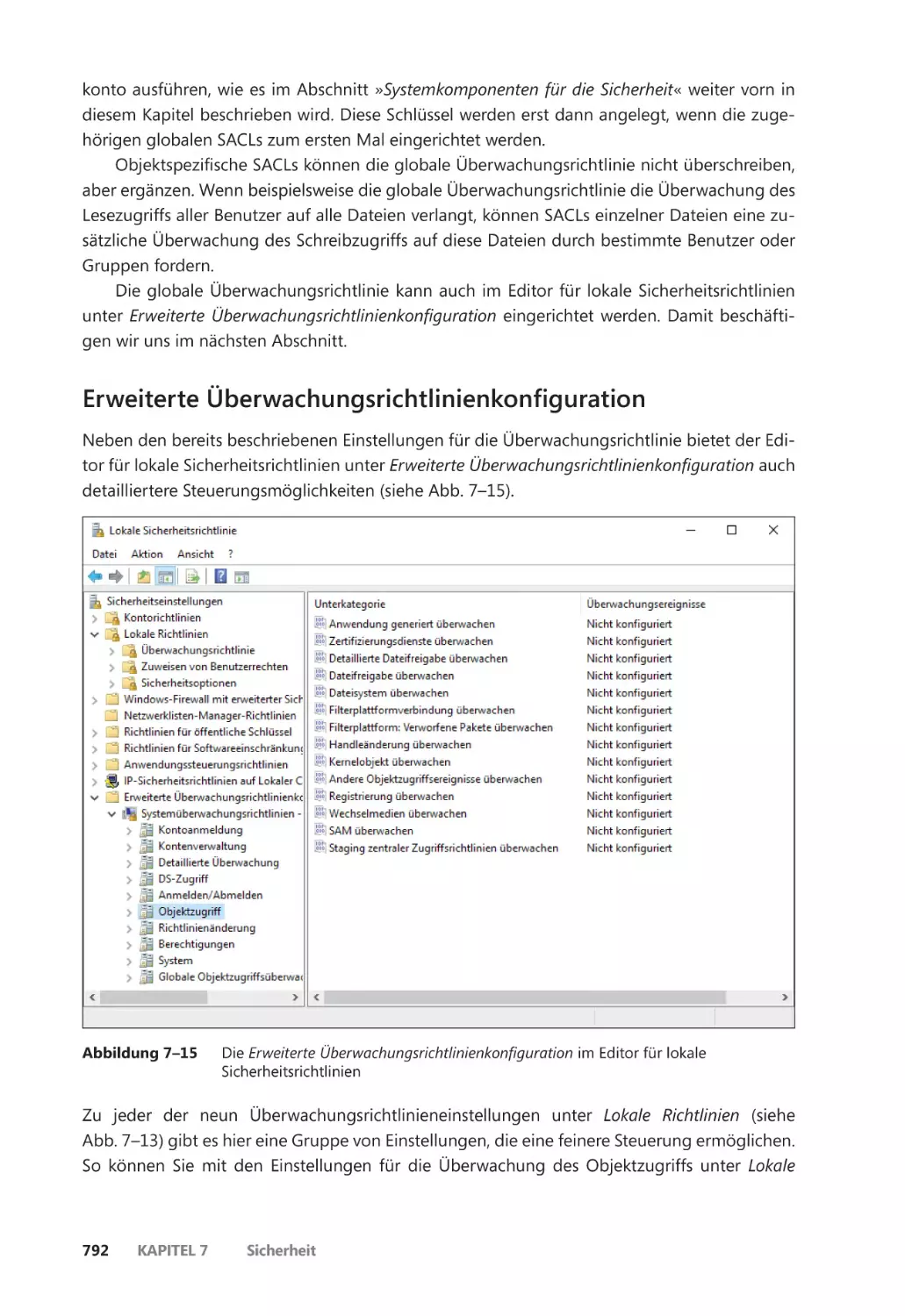
Erweiterte Überwachungsrichtlinienkonfiguration ������������������������������������������� 792
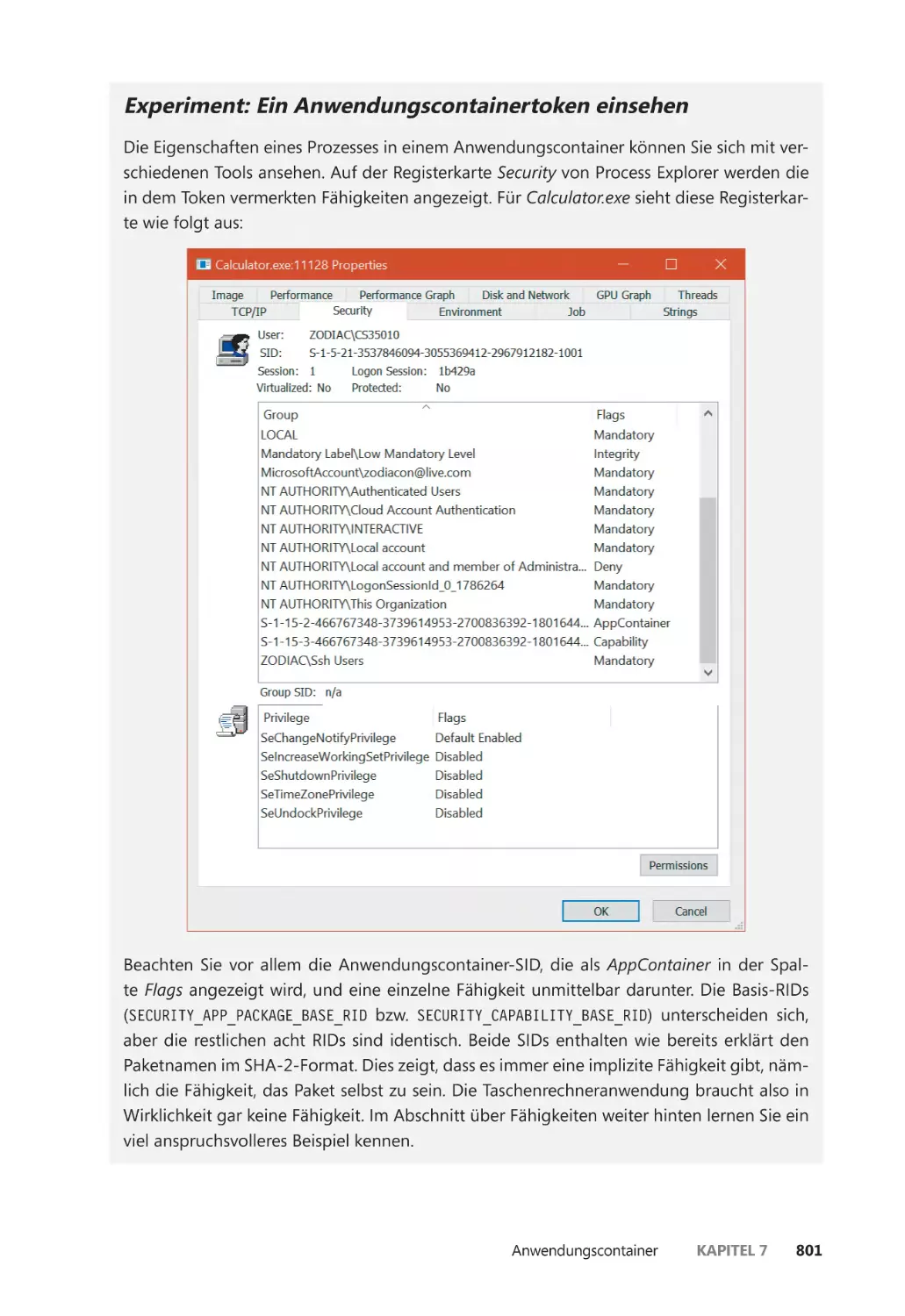
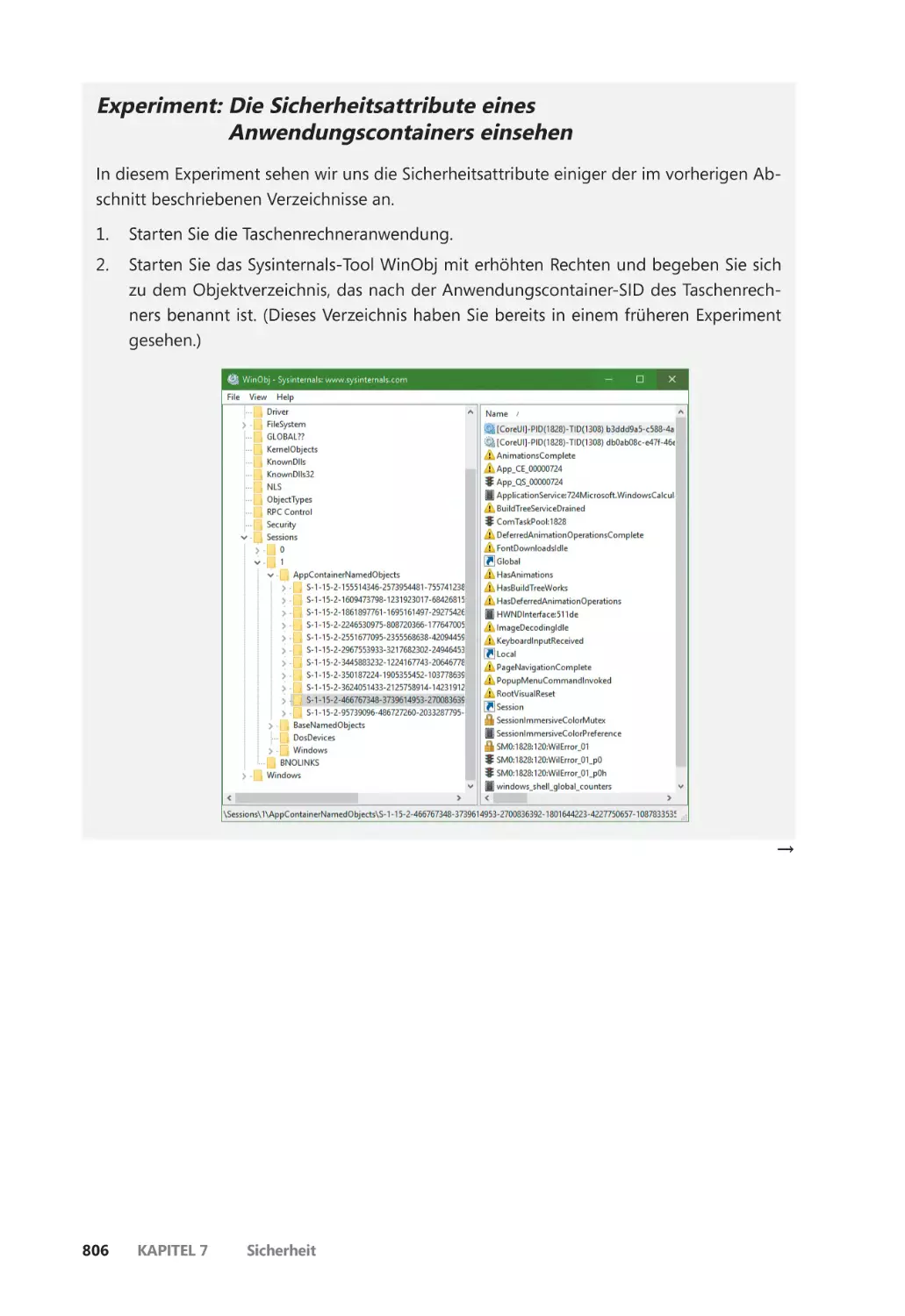
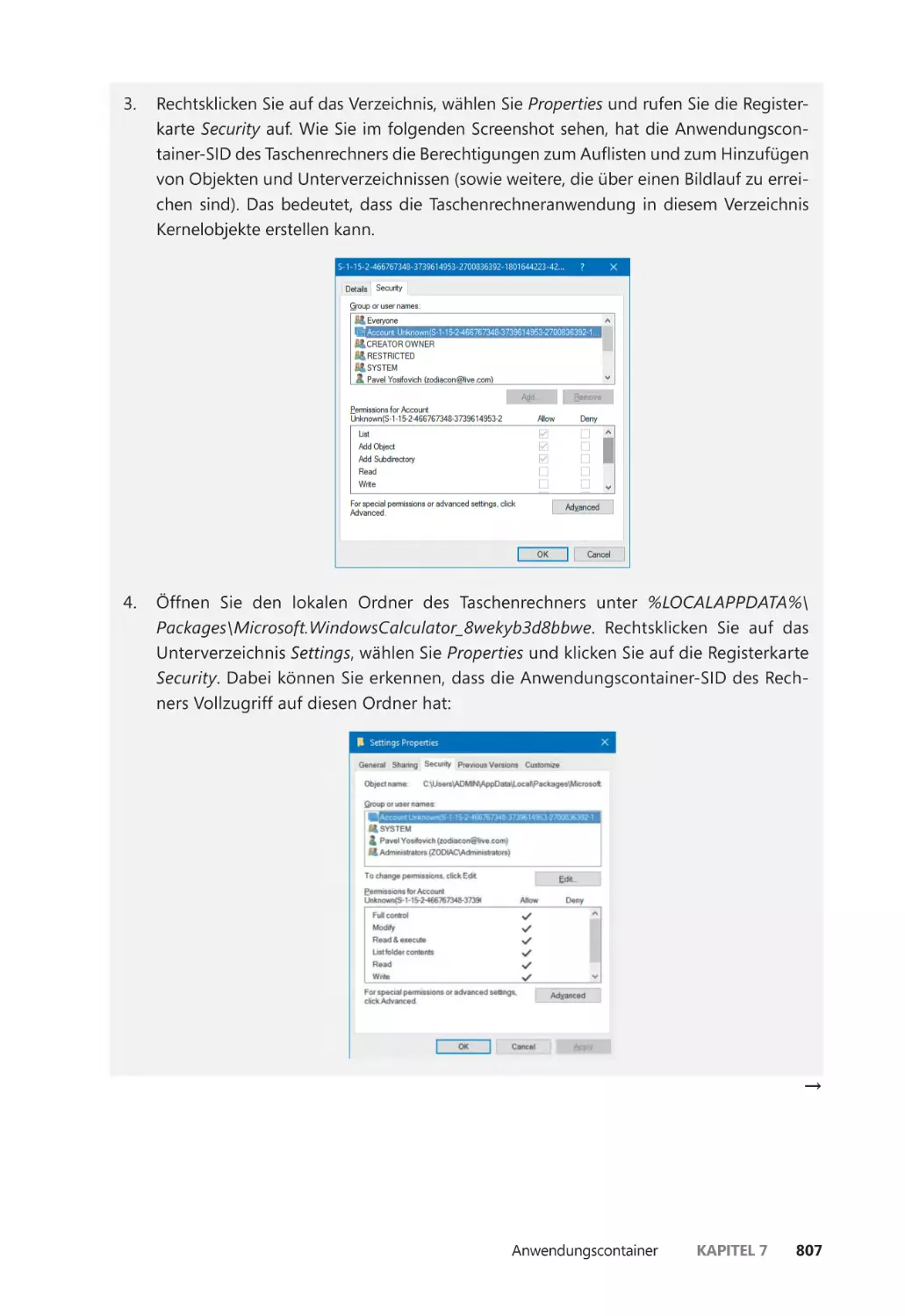
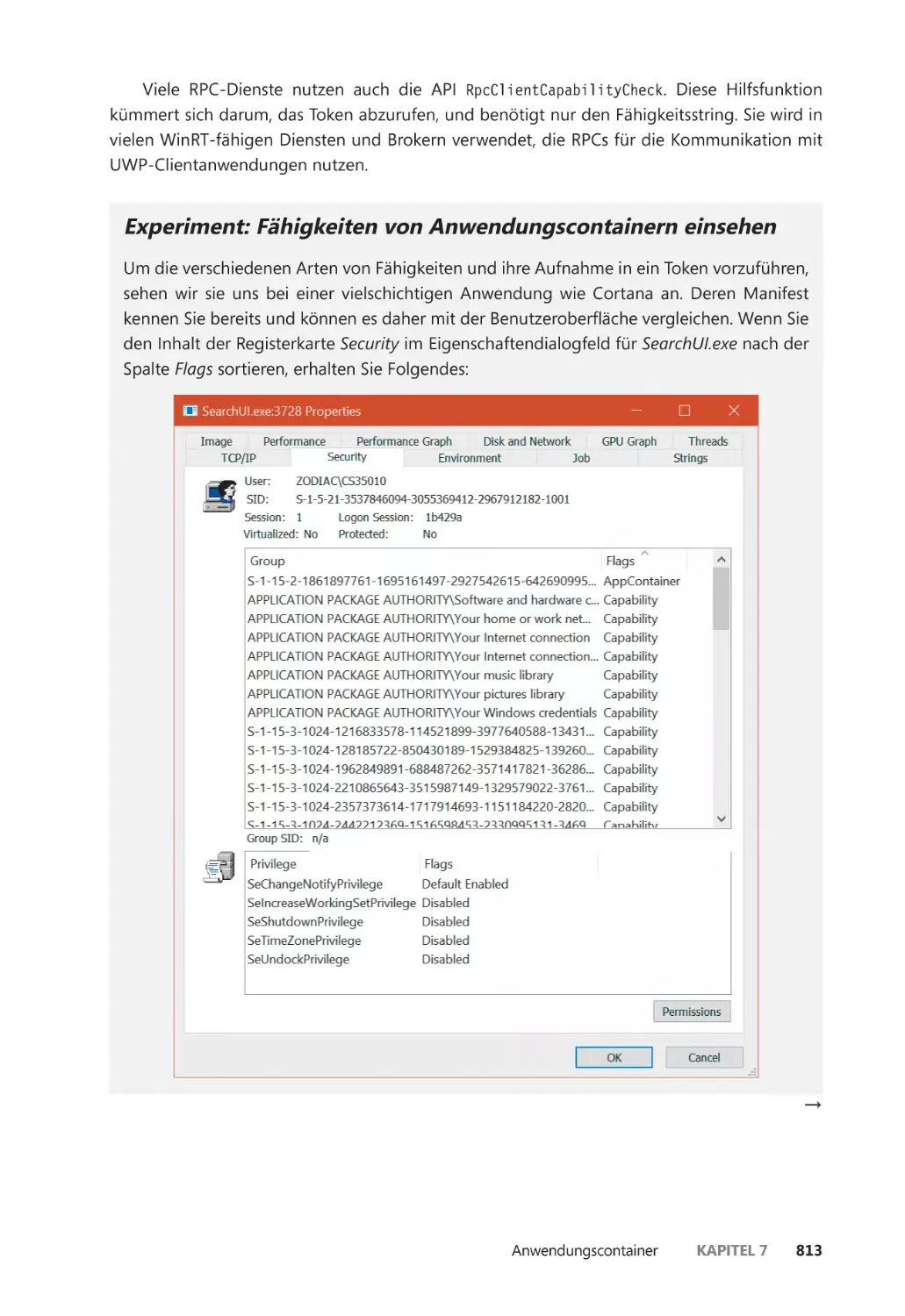
Anwendungscontainer ��������������������������������������������������������������������������������������������������� 793
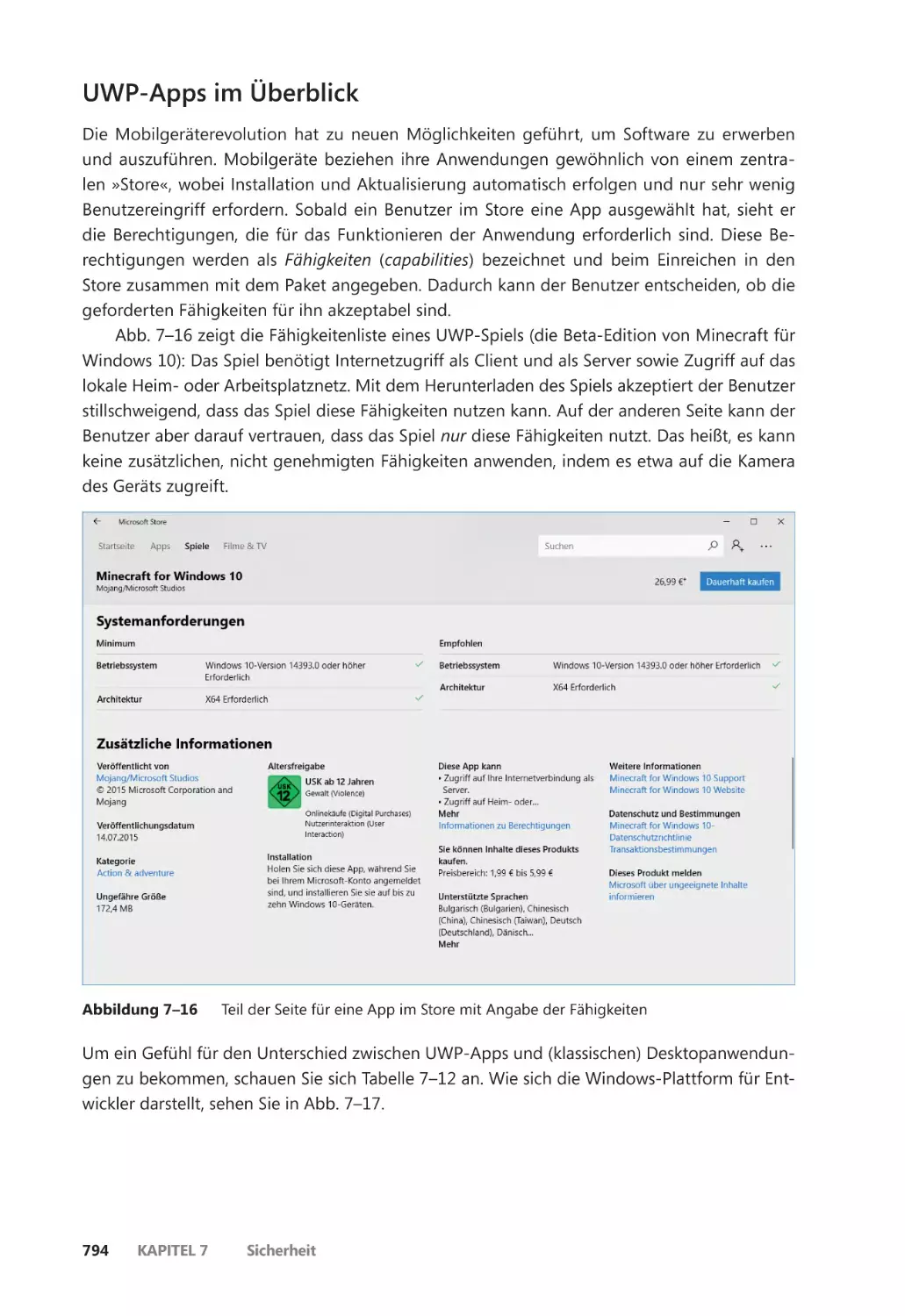
UWP-Apps im Überblick ����������������������������������������������������������������������������������������� 794
Anwendungscontainer ������������������������������������������������������������������������������������������� 796
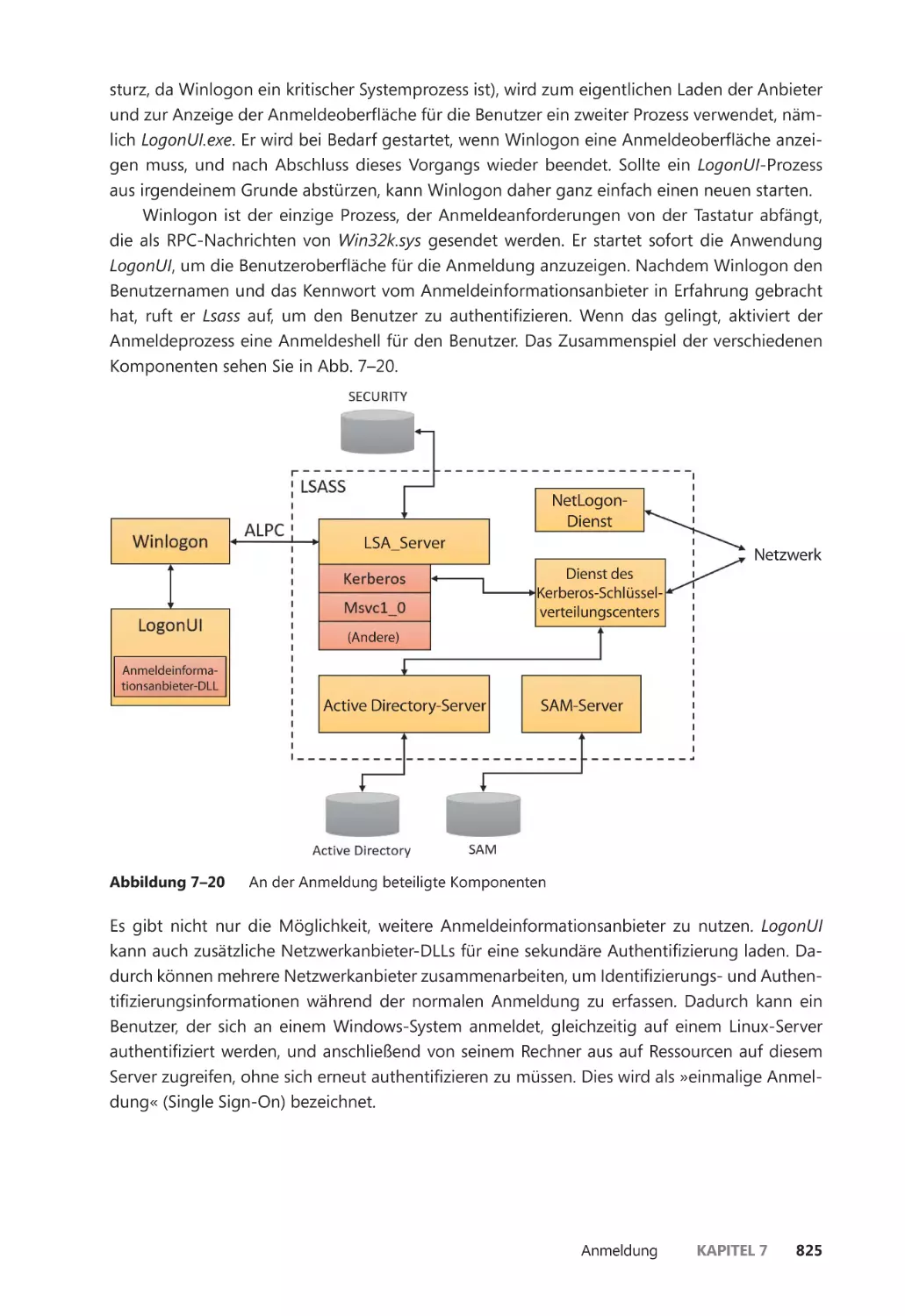
Anmeldung ��������������������������������������������������������������������������������������������������������������������� 824
Initialisierung durch Winlogon ����������������������������������������������������������������������������� 826
Die einzelnen Schritte der Benutzeranmeldung ������������������������������������������������� 827
Sichere Authentifizierung ��������������������������������������������������������������������������������������� 833
Das Windows-Biometrieframework ��������������������������������������������������������������������� 835
Windows Hello ��������������������������������������������������������������������������������������������������������� 837
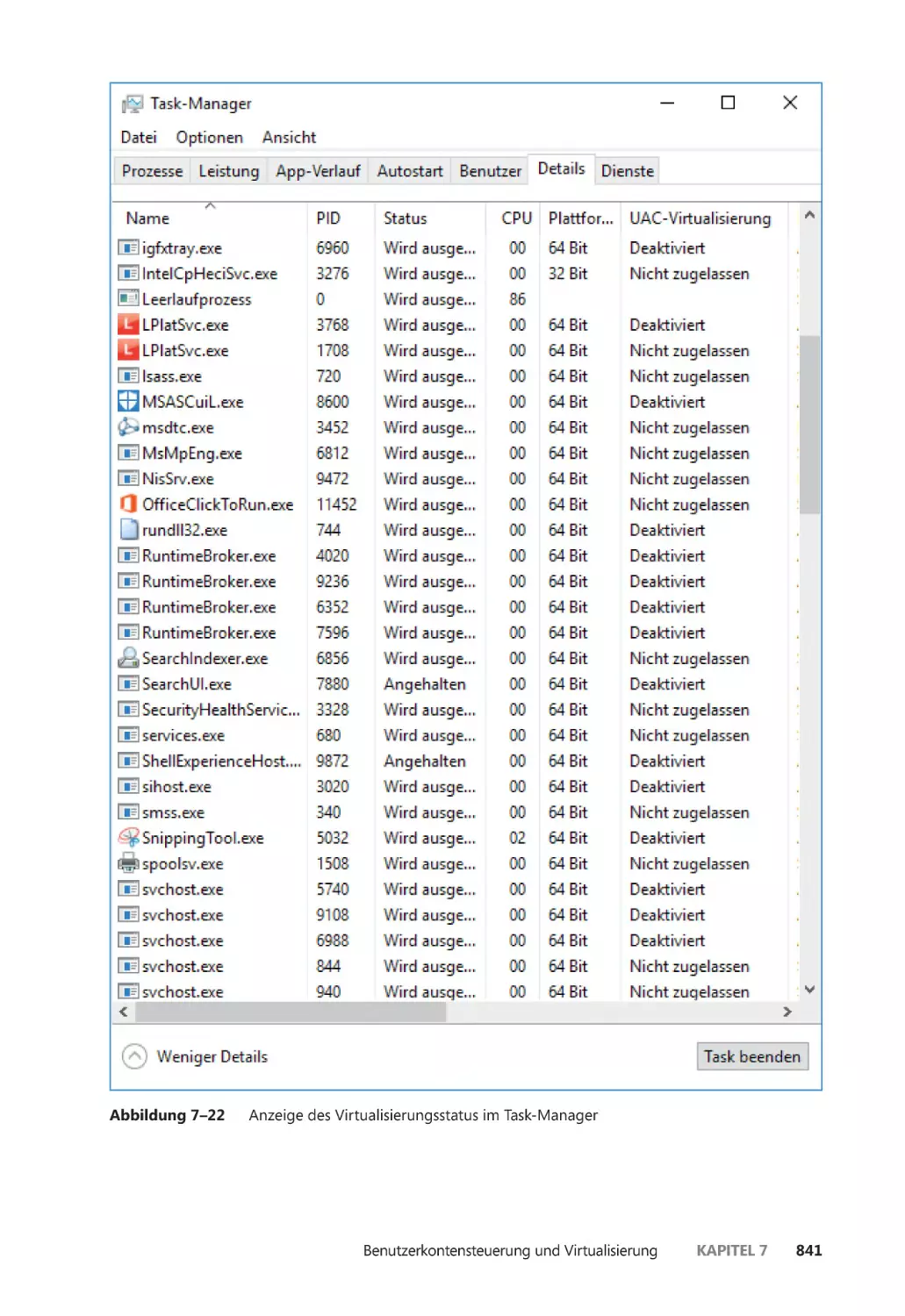
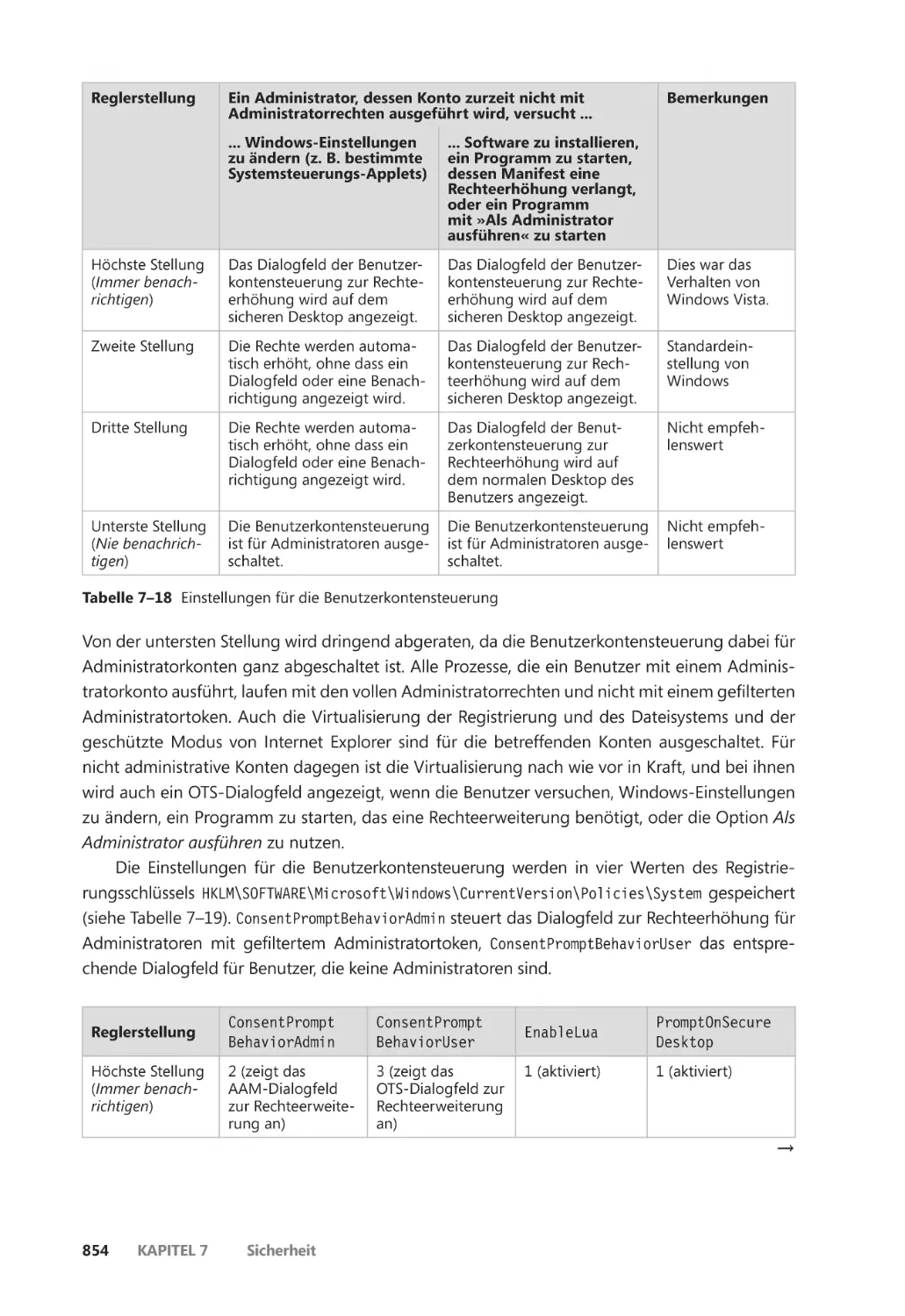
Benutzerkontensteuerung und Virtualisierung ��������������������������������������������������������� 838
Virtualisierung des Dateisystems und der Registrierung ����������������������������������� 839
Rechteerhöhung ����������������������������������������������������������������������������������������������������� 847
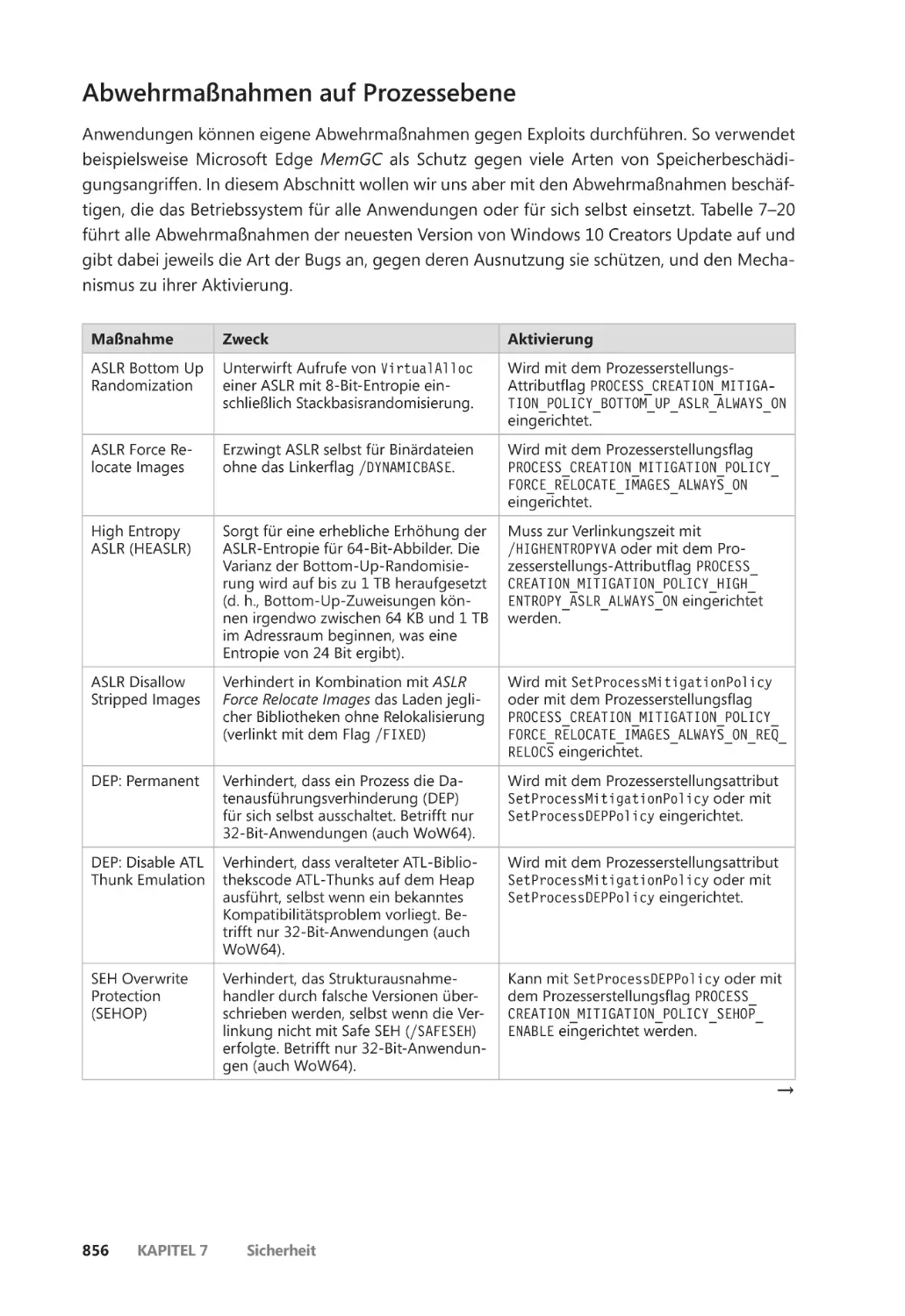
Schutz gegen Exploits ��������������������������������������������������������������������������������������������������� 855
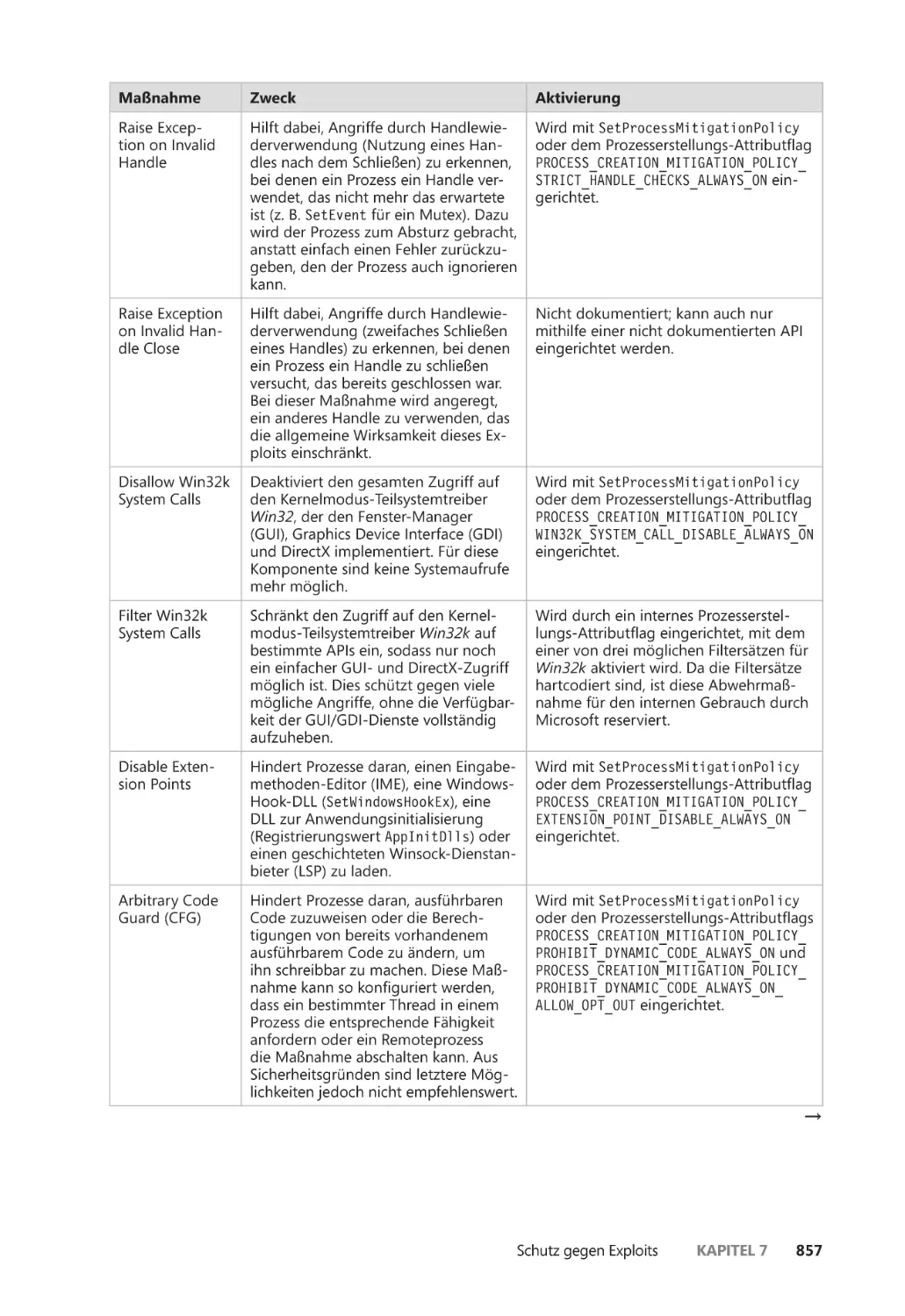
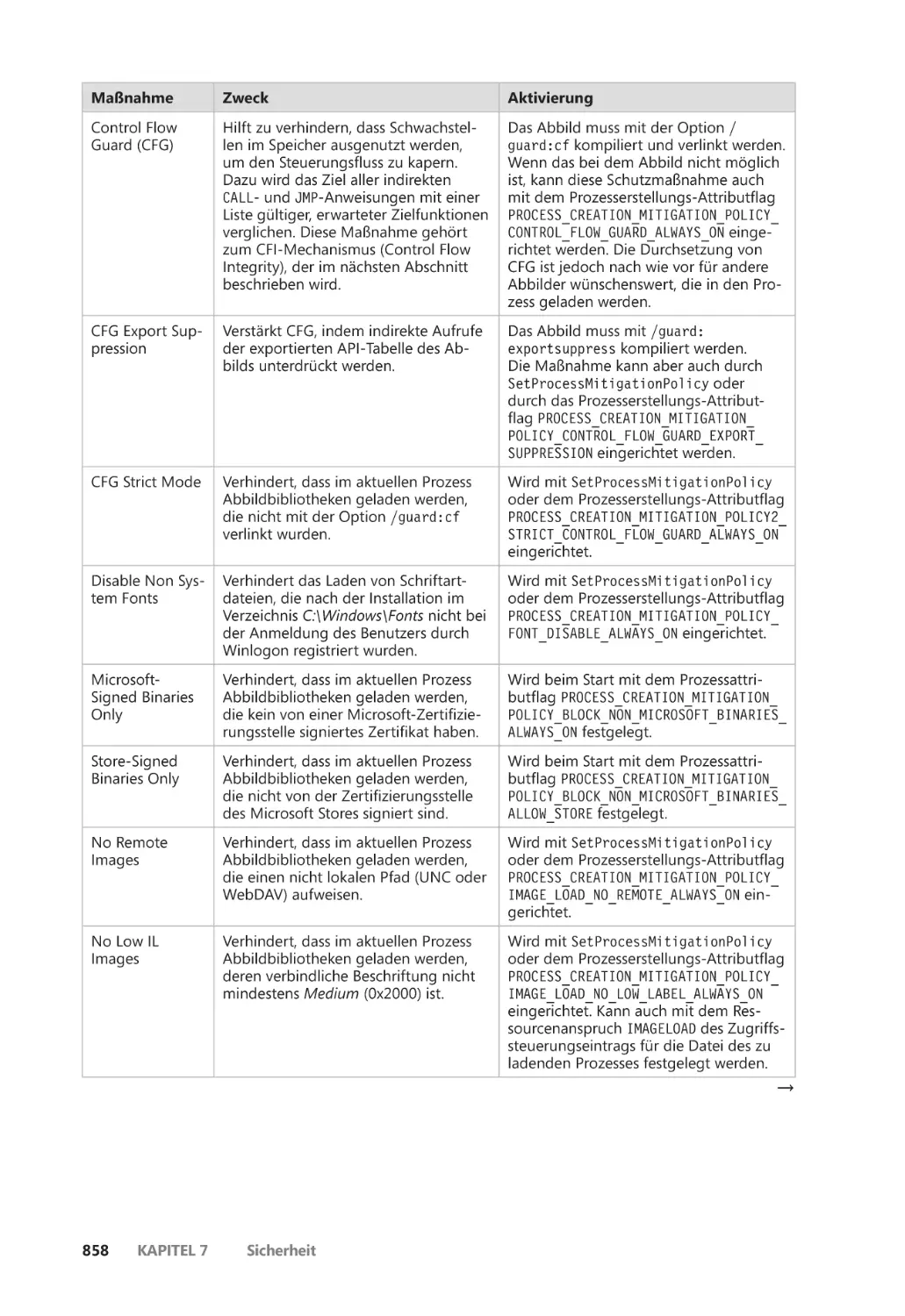
Abwehrmaßnahmen auf Prozessebene ��������������������������������������������������������������� 856
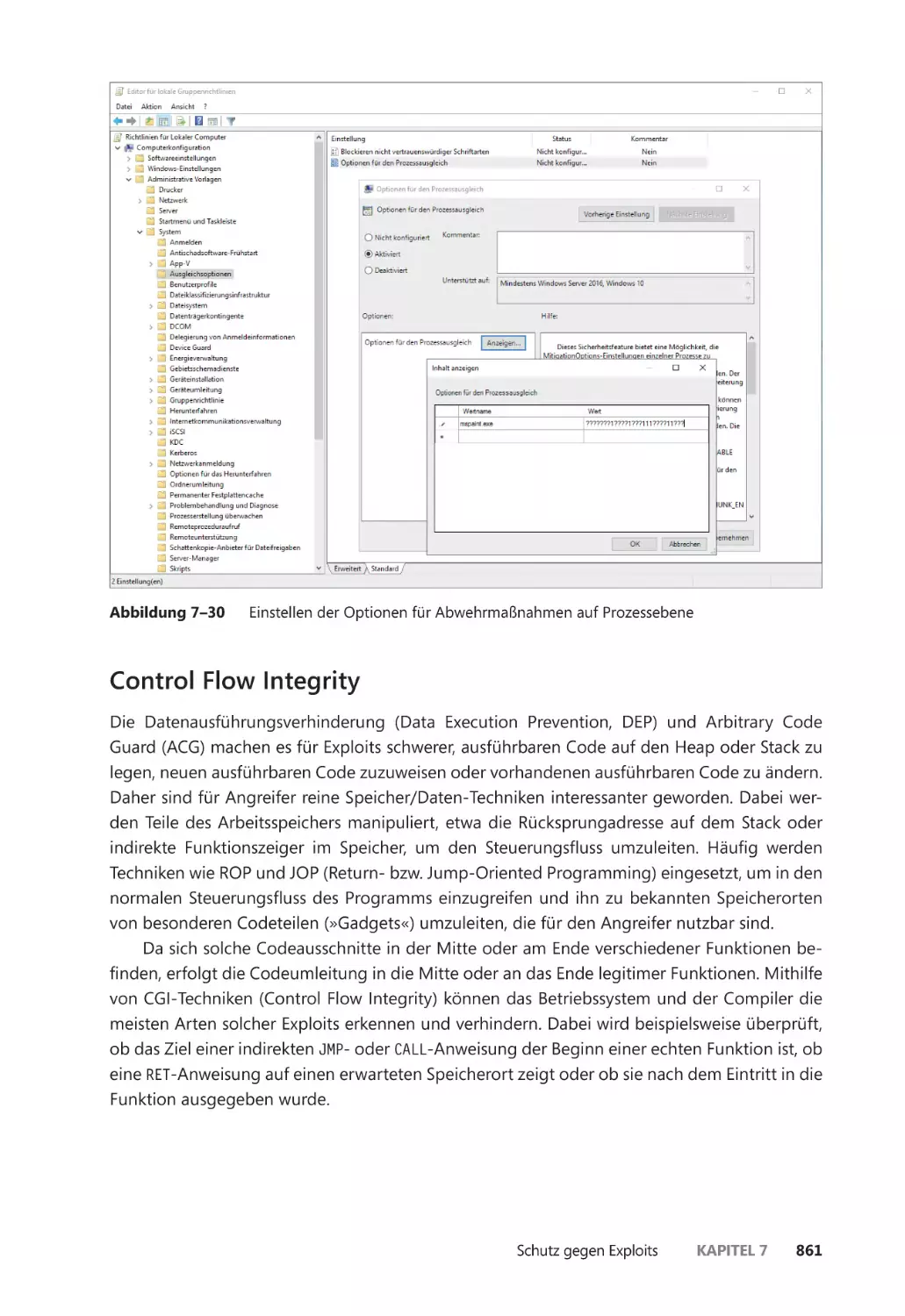
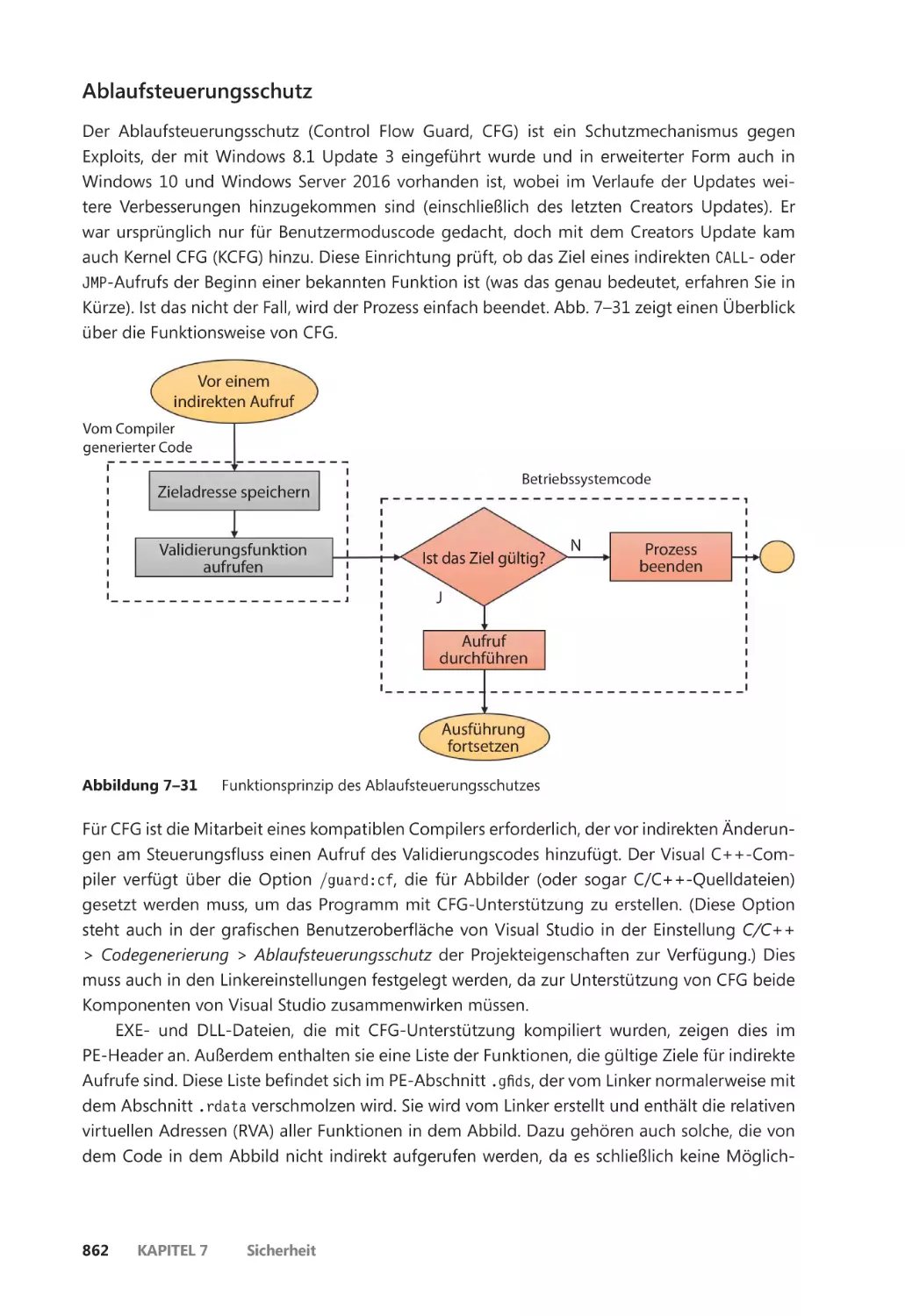
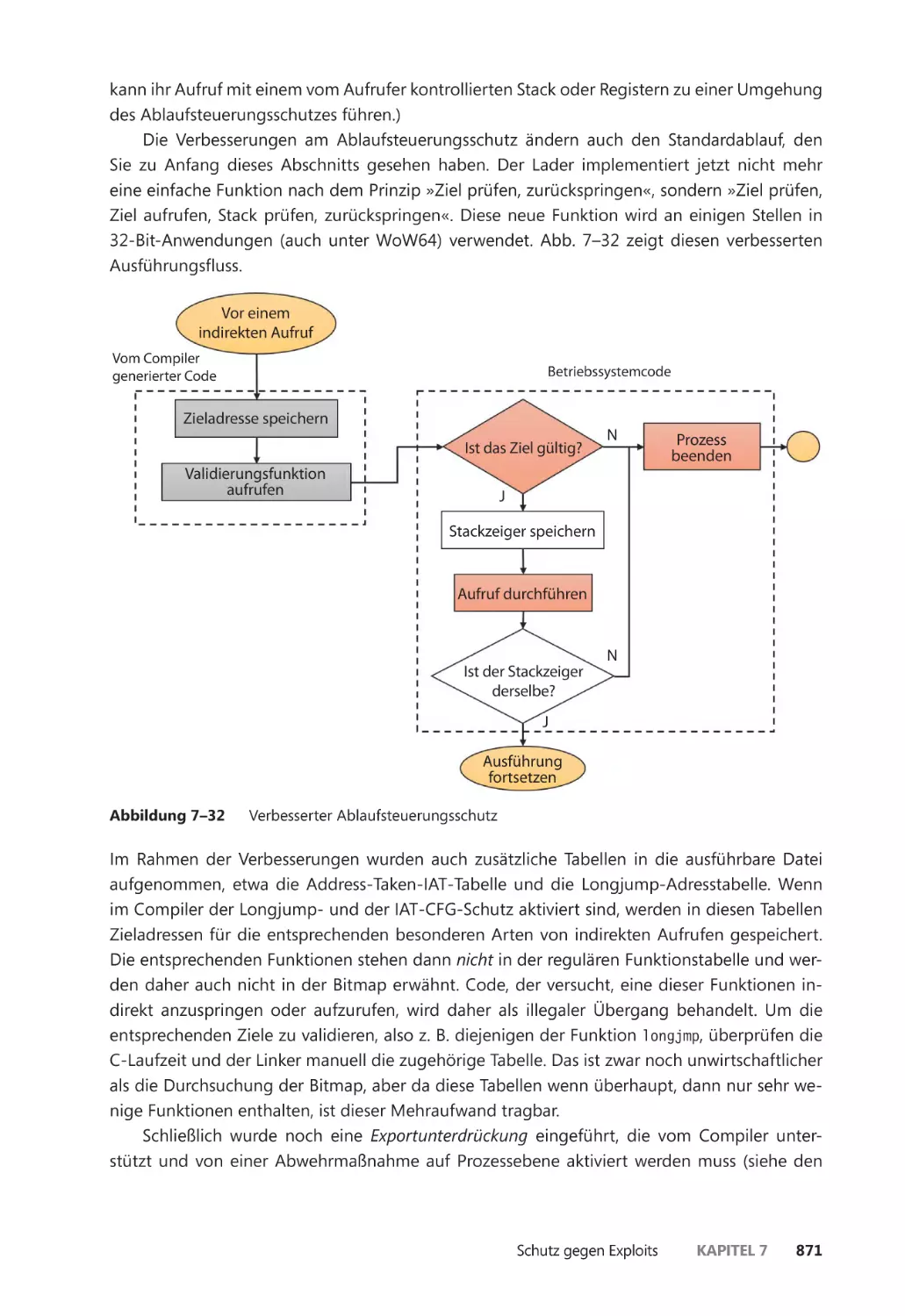
Control Flow Integrity ��������������������������������������������������������������������������������������������� 861
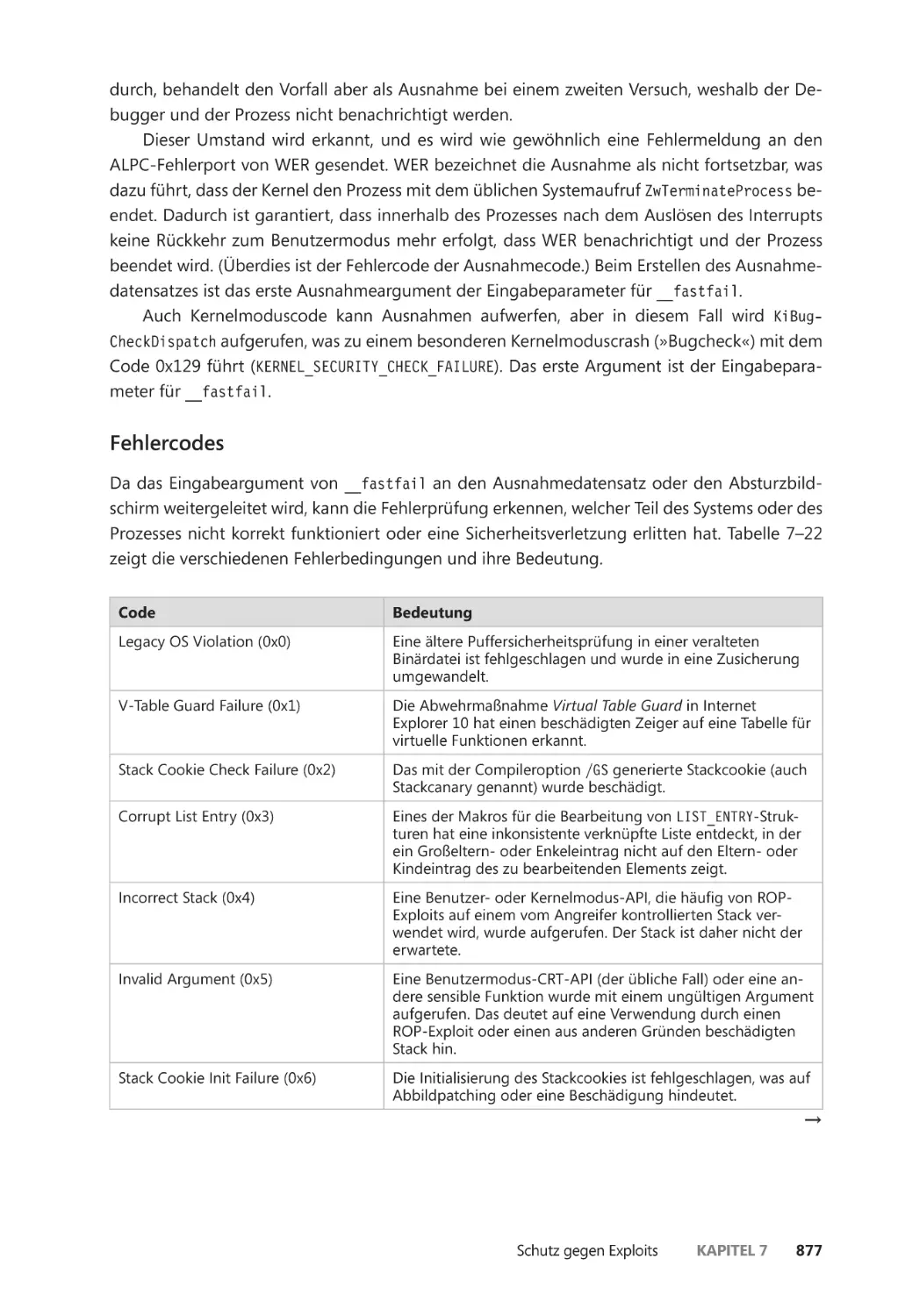
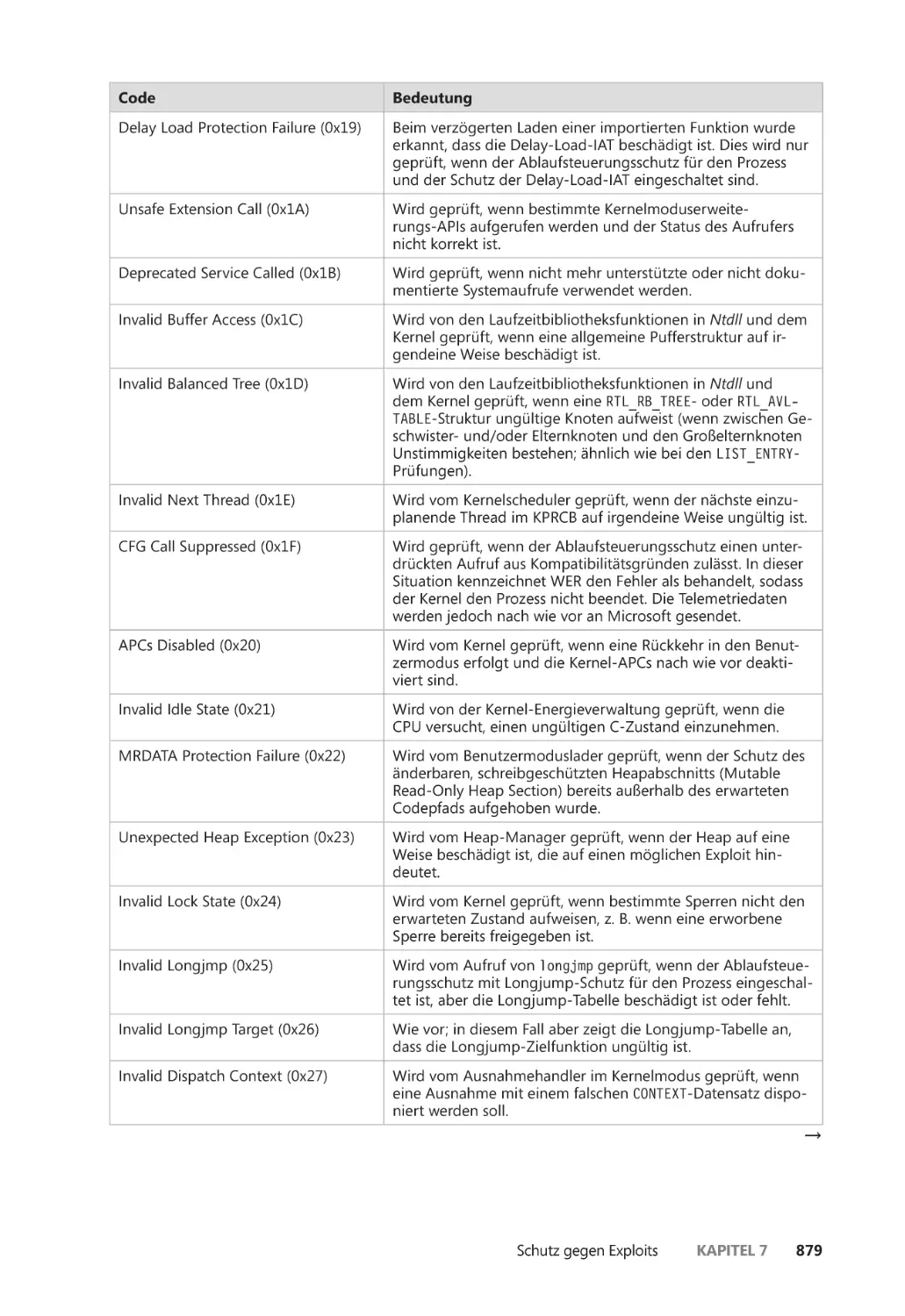
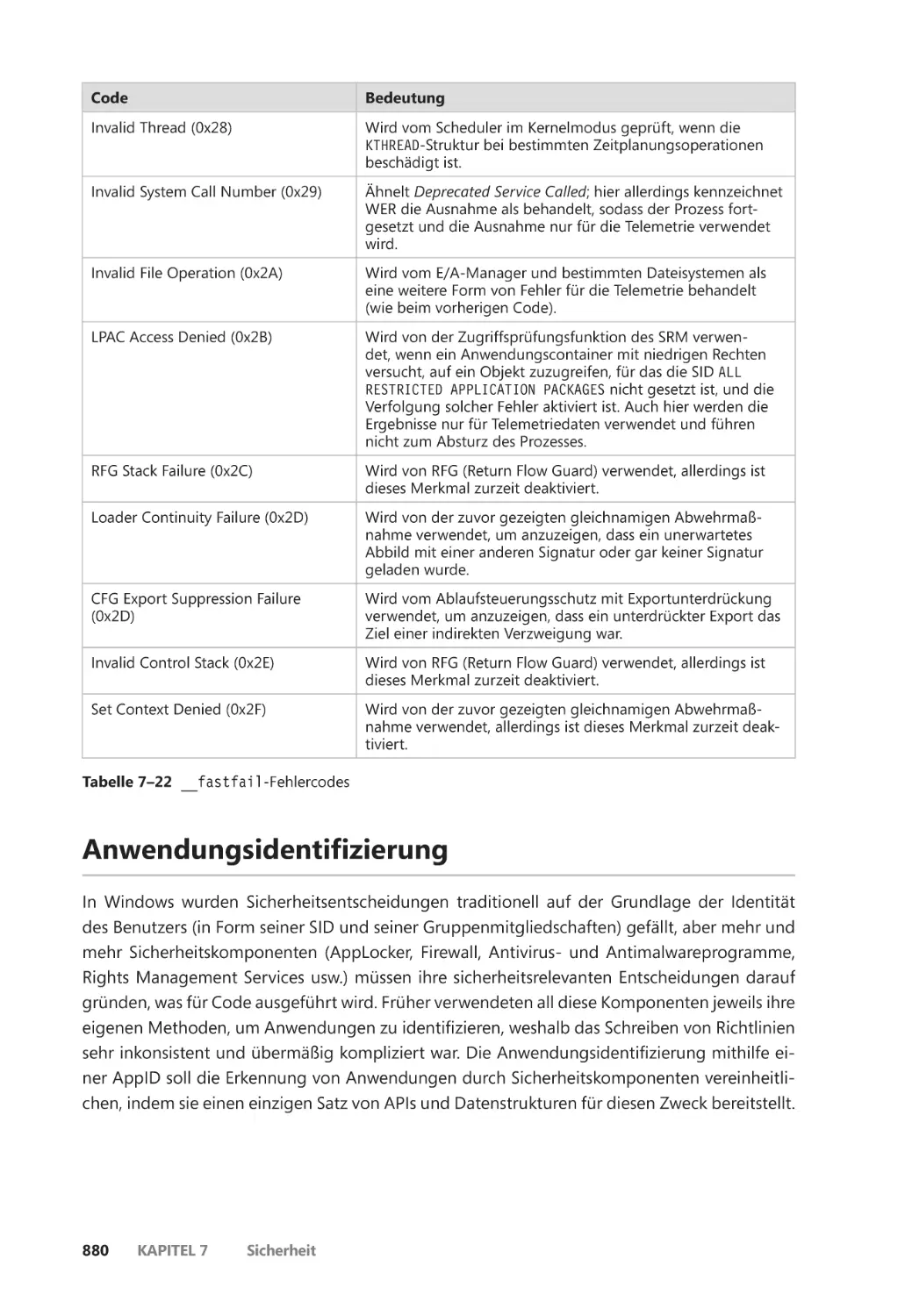
Zusicherungen ��������������������������������������������������������������������������������������������������������� 875
Anwendungsidentifizierung ����������������������������������������������������������������������������������������� 880
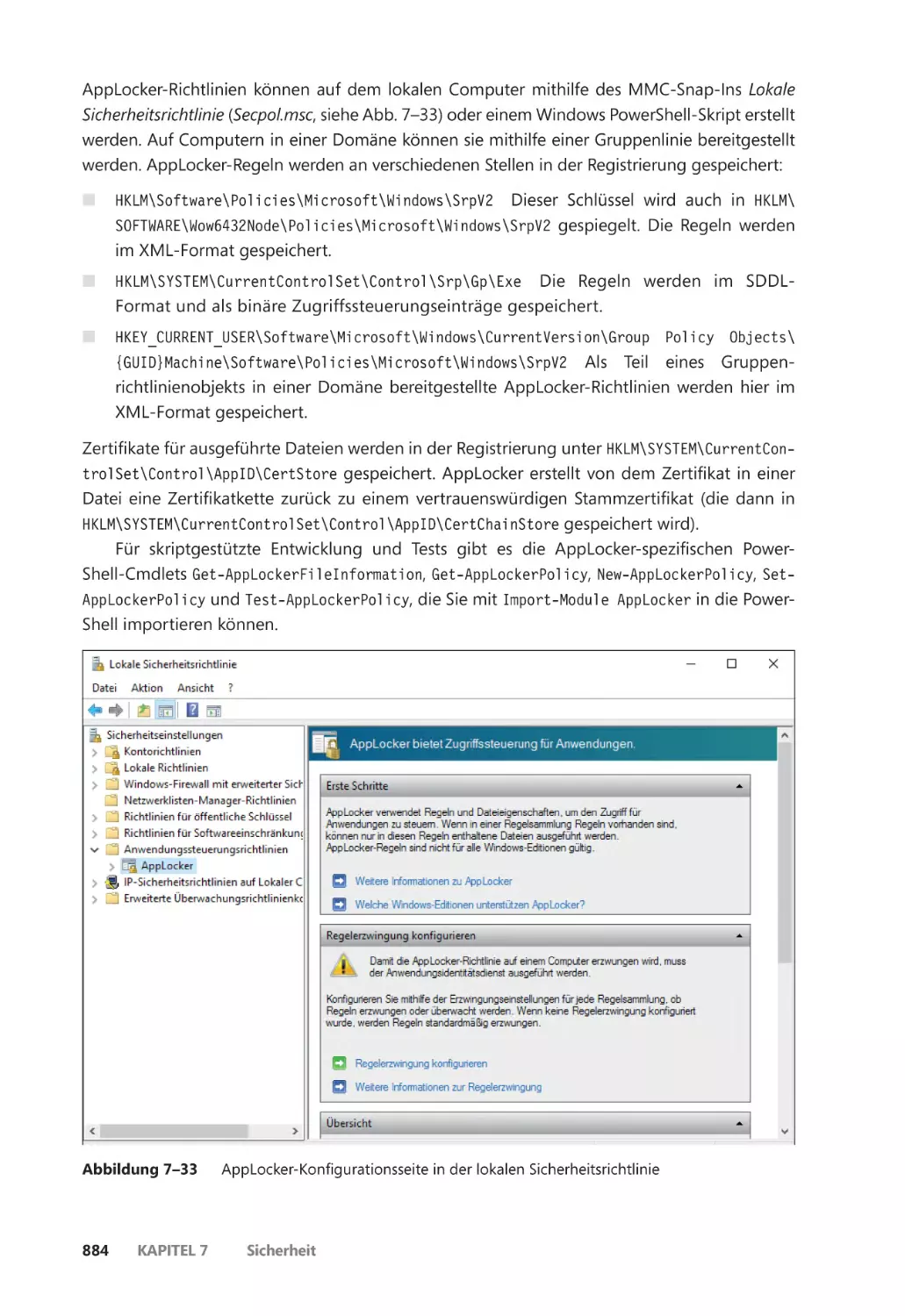
AppLocker ����������������������������������������������������������������������������������������������������������������������� 882
Richtlinien für Softwareeinschränkung ����������������������������������������������������������������������� 887
Kernelpatchschutz ����������������������������������������������������������������������������������������������������������� 889
PatchGuard ��������������������������������������������������������������������������������������������������������������� 890
HyperGuard ������������������������������������������������������������������������������������������������������������� 894
Zusammenfassung ��������������������������������������������������������������������������������������������������������� 896
Index 897
xvi
Inhaltsverzeichnis
Einleitung
Dieses Buch ist für Computerexperten (Entwickler, Sicherheitsforscher und Systemadministratoren) gedacht, die die Funktionsweise der Kernkomponenten von Microsoft Windows 10 und
Windows Server 2016 kennenlernen möchten. Mit diesen Kenntnissen können Entwickler beim
Schreiben von Anwendungen für die Windows-Plattform die Gründe für bestimmte Designentscheidungen besser verstehen. Sie helfen ihnen auch beim Debugging komplizierter Probleme. Auch Systemadministratoren profitieren von diesen Informationen, da das Wissen, wie das
System in seinem Inneren »tickt«, sein Verhalten verständlicher macht und die Störungssuche
erleichtert. Sicherheitsforscher erfahren hier, welche Fehlverhalten Softwareanwendungen und
das Betriebssystem an den Tag legen können, wie sie missbraucht werden können und welche
Schutzmaßnahmen und Sicherheitsfunktionen moderne Windows-Versionen dagegen bieten.
Nach der Lektüre dieses Buches haben Sie ein besseres Verständnis darüber, wie Windows funktioniert und welche Gründe hinter seinem Verhalten stehen.
Die Geschichte dieses Buches
Dies ist die siebente Ausgabe eines Buches, das ursprünglich Inside Windows NT hieß (Microsoft Press, 1992) und noch vor der Erstveröffentlichung von Windows NT 3.1 von Helen Custer
geschrieben wurde. Es war das erste Buch, das es je über Windows NT gab, und es bot wichtige
Einsichten in die Architektur und das Design des Systems. Inside Windows NT, Second Edition
(Microsoft Press, 1998) wurde von David Solomon geschrieben. Es deckte auch Windows NT 4.0
ab und ging weit tiefer in die technischen Details.
Inside Windows 2000, Third Edition (Microsoft Press, 2000) wurde von David Solomon und
Mark Russinovich geschrieben. Hier kamen viele neue Themen wie Starten und Herunterfahren,
interne Mechanismen von Diensten und der Registrierung, Dateisystemtreiber und Netzwerkanbindung hinzu. Auch die Änderungen am Kernel in Windows 2000 wurden erläutert, darunter das Windows Driver Model (WDM), Plug & Play, Energieverwaltung, Windows-Verwaltungsinstrumentation (Windows Management Instrumentation, WMI), Verschlüsselung, Jobobjekte
und Terminaldienste. Windows Internals, Fourth Edition (Microsoft Press, 2004) war die neue
Ausgabe für Windows XP und Windows Server 2003 mit zusätzlichen Inhalten, um IT-Fachleuten zu helfen, ihre Kenntnisse über die internen Mechanismen von Windows praktisch anzuwenden, z. B. durch die Werkzeuge von Sysinternals und die Analyse von Absturzabbildern.
Mit Windows Internals, Fifth Edition (Microsoft Press, 2009) wurde das Buch auf Windows
Vista und Windows Server 2008 aktualisiert. Da Mark Russinovich eine Vollzeitstelle bei Microsoft annahm (wo er jetzt als CTO für Azure arbeitet), kam der neue Co-Autor Alex Ionescu
hinzu. Zu den neuen Inhalten gehörten der Abbildlader, Einrichtungen für das Debugging im
Benutzermodus, ALPC (Advanced Local Procedure Call) und Hyper-V. Die nächste Ausgabe,
xvii
Windows Internals, Sixth Edition (Microsoft Press, 2012) war komplett aktualisiert, um viele
Änderungen am Kernel in Windows 7 und Windows Server 2008 R2 abzudecken. Außerdem
kamen viele neue praktische Experimente hinzu, um die Änderungen an den Werkzeugen
deutlich zu machen.
Änderungen in dieser Auflage
Seit der letzten Aktualisierung dieses Buches hat Windows mehrere neue Releases durchlaufen
und ist jetzt bei Windows 10 und Windows Server 2016 angekommen. Dabei ist Windows 10
jetzt praktisch der neue Name für Windows. Seit der Produktionsfreigabe hat es wiederum
mehrere Releases gegeben. Bezeichnet werden sie jeweils mit einer vierstelligen Zahl, die sich
aus dem Jahr und dem Monat der Veröffentlichung zusammensetzt, also z. B. Windows 10
Version 1703 für die Version vom März 2017. Zum Zeitpunkt der Abfassung dieses Buches hat
Windows also seit Windows 7 mindestens sechs Versionen durchlaufen.
Beginnend mit Windows 8 hat Microsoft mit einer Zusammenführung seiner Betriebssysteme begonnen, was für die Entwicklung und für das Windows-Konstruktionsteam von Vorteil
ist. Windows 8 und Windows Phone 8 verwendeten bereits einen gemeinsamen Kernel, und
mit Windows 8.1 und Windows Phone 8.1 kam auch eine Vereinheitlichung bei modernen Apps
hinzu. Mit Windows 10 war die Zusammenführung abgeschlossen: Dieses Betriebssystem läuft
auf Desktops, Laptops, Servern, der Xbox One, Smartphones (Windows Mobile 10), der HoloLens und verschiedenen IoT-Geräten (Internet of Things).
Angesichts dieser großen Vereinheitlichung war die Zeit reif für eine neue Ausgabe dieses
Buches, um die Änderungen von fast einem halben Jahrzehnt aufzuarbeiten, die zu einer stabileren Kernelarchitektur geführt haben. Daher deckt dieses Buch verschiedene Aspekte des
Betriebssystems von Windows 8 bis Windows 10 Version 1703 ab. Des Weiteren heißen wir
Pavel Yosifovich als neuen Co-Autor willkommen.
Praktische Experimente
Auch ohne Zugriff auf den Windows-Quellcode können Sie mithilfe des Kerneldebuggers, der
Sysinternals-Tools und der eigens für dieses Buch entwickelten Werkzeuge viel über die internen Mechanismen von Windows herausfinden. Immer wenn ein Aspekt des internen Verhaltens
von Windows mit einem der Tools sichtbar gemacht oder veranschaulicht werden kann, erfahren Sie in den mit »Experiment« betitelten Abschnitten, wie Sie dieses Tool selbst ausprobieren
können. Diese Abschnitte sind über das ganze Buch verteilt, und wir raten Ihnen dazu, diese
Experimente bei der Lektüre auszuführen. Es ist viel eindrucksvoller, die sichtbaren Auswirkungen der internen Mechanismen von Windows zu beobachten, als nur darüber zu lesen.
Nicht behandelte Themen
Windows ist ein umfangreiches und vielschichtiges Betriebssystem. In diesem Buch können wir
nicht sämtliche internen Mechanismen von Windows abdecken, sondern konzentrieren uns auf
xviii
Einleitung
die grundlegenden Systemkomponenten. Beispielsweise werden COM+, die verteilte objekt
orientierte Programmierinfrastruktur von Windows, und Microsoft .NET Framework, die Grundlage für Anwendungen mit verwaltetem Code, in diesem Buch nicht behandelt. Da es ein Buch
über die »Interna« von Windows ist und kein Leitfaden für die Benutzung, die Programmierung
oder die Systemadministration, erfahren Sie hier auch nicht, wie Sie Windows verwenden, programmieren oder konfigurieren.
Warnung
Dieses Buch beschreibt nicht dokumentierte Aspekte der internen Architektur und Funktionsweise von Windows (wie interne Kernelstrukturen und -funktionen), die sich zwischen den einzelnen Releases ändern können.
Das soll nicht heißen, dass sie sich zwangsläufig ändern, sondern nur, dass Sie sich nicht auf
ihre Unveränderbarkeit verlassen können. Software, die sich auf solche nicht dokumentierten
Schnittstellen oder auf Insiderkenntnisse über das Betriebssystem verlässt, kann in zukünftigen
Releases von Windows unter Umständen nicht mehr funktionieren. Software, die im Kernelmodus läuft (z. B. Gerätetreiber) und diese nicht dokumentierten Schnittstellen nutzt, kann
bei der Ausführung in einer neueren Windows-Version sogar einen Systemabsturz und damit
möglicherweise einen Datenverlust für den Benutzer hervorrufen.
Kurz: Bei der Entwicklung von Software für Endbenutzersysteme und allgemein für jegliche Zwecke außer Forschung und Dokumentation sollten Sie niemals auf die in diesem Buch
erwähnten internen Windows-Einrichtungen, Registrierungsschlüssel, Verhaltensweisen, APIs
oder sonstigen nicht dokumentierten Elemente zurückgreifen. Suchen Sie immer erst auf
MSDN (Microsoft Software Developer Network) nach einer offiziellen Dokumentation.
Zielgruppe
In diesem Buch wird vorausgesetzt, dass die Leser mit Windows auf dem Niveau von »Power-
Usern« vertraut sind und Grundkenntnisse über Betriebssystem- und Hardwareelemente wie
CPU-Register, Arbeitsspeicher, Prozesse und Threads mitbringen. In einigen Abschnitten sind
auch Grundkenntnisse über Funktionen, Zeiger und ähnliche Konstrukte der Programmiersprache C von Nutzen.
Der Aufbau dieses Buches
Ebenso wie die sechste Ausgabe ist auch diese in zwei Bände aufgeteilt, von denen Sie den
ersten in Händen halten.
QQ Kapitel 1, »Begriffe und Werkzeuge«, gibt eine allgemeine Einführung in die Grundbegriffe
von Windows und in die wichtigsten Werkzeuge, die wir in diesem Buch einsetzen werden.
Es ist sehr wichtig, dieses Kapitel als erstes zu lesen, da es die Hintergrundinformationen
für das Verständnis des Restes gibt.
Einleitung
xix
QQ Kapitel 2, »Systemarchitektur«, zeigt die Architektur und die Hauptkomponenten auf, aus
denen Windows besteht, und erläutert sie. Mehrere dieser Komponenten werden in den
folgenden Kapiteln noch ausführlicher beschrieben.
QQ Kapitel 3, »Prozesse und Jobs«, erklärt, wie Prozesse in Windows implementiert sind, und
zeigt die verschiedenen Vorgehensweisen zu ihrer Bearbeitung auf. Des Weiteren werden
Jobs beschrieben, die eine Möglichkeit bieten, um eine Gruppe von Prozessen zu steuern
und die Containerunterstützung von Windows zu aktivieren.
QQ Kapitel 4, »Threads«, beschreibt ausführlich, wie Threads verwaltet, geplant und auf sonstige Weise in Windows bearbeitet werden.
QQ Kapitel 5, »Speicherverwaltung«, zeigt, wie der Speicher-Manager physischen und virtuellen Arbeitsspeicher verwendet, und erklärt die verschiedenen Möglichkeiten, mit denen
Prozesse und Treiber den Arbeitsspeicher bearbeiten und nutzen können.
QQ Kapitel 6, »Das E/A-System«, beschreibt, wie das E/A-System von Windows funktioniert
und wie es mit den Gerätetreibern zusammenwirkt, um die Mechanismen für E/A-Peripheriegeräte bereitzustellen.
QQ Kapitel 7, »Sicherheit«, beschreibt ausführlich die verschiedenen Sicherheitsmechanismen
von Windows einschließlich systemeigener Schutzmaßnahmen gegen Exploits.
Schreibweisen
In diesem Buch gelten die folgenden Schreibweisen:
QQ Fettschrift wird für Text verwendet, den Sie in einer Schnittstelle eingeben müssen.
QQ Kursivschrift kennzeichnet neue Begriffe sowie die Bezeichnungen von GUI-Elementen,
Dateinamen und Webadressen.
QQ Codeelemente stehen in nichtproportionaler Schrift.
QQ Bei Tastaturkürzeln steht ein Pluszeichen zwischen den Bezeichnungen der einzelnen Tasten. Beispielsweise bedeutet (Strg) + (Alt) + (Entf), dass Sie gleichzeitig die Tasten
(Strg), (Alt) und (Entf) drücken müssen.
Begleitmaterial
Damit Sie aus diesem Buch noch größeren Nutzen ziehen können, haben wir Begleitmaterial
zusammengestellt, das Sie von der folgenden Seite herunterladen können:
https://dpunkt.de/windowsinternals1
Den Quellcode der Tools, die wir eigens für dieses Buch geschrieben haben, finden Sie auf
https://github.com/zodiacon/windowsinternals.
xx
Einleitung
Danksagungen
Als Erstes möchten wir Pavel Yosifovich dafür danken, dass er sich uns für dieses Projekt angeschlossen hat. Seine Beteiligung war für die Veröffentlichung entscheidend. Die vielen Nächte,
die er damit zugebracht hat, Einzelheiten von Windows zu studieren und über Änderungen
während der Zeit von sechs Releases zu schreiben, haben dieses Buch erst möglich gemacht.
Ohne die Rückmeldungen und die Unterstützung von wichtigen Mitgliedern des
Windows-Entwicklungsteams und anderer Fachleute von Microsoft wäre dieses Buch auch
technisch nicht so tief schürfend und nicht so präzise geworden, wie es ist. Daher möchten wir
den folgenden Personen danken, die es auf technische Korrektheit durchgesehen, Informa
tionen gegeben oder die Autoren auf andere Weise unterstützt haben: Akila Srinivasan, Alessandro Pilotti, Andrea Allievi, Andy Luhrs, Arun Kishan, Ben Hillis, Bill Messmer, Chris Kleynhans,
Deepu Thomas, Eugene Bak, Jason Shirk, Jeremiah Cox, Joe Bialek, John Lambert, John Lento,
Jon Berry, Kai Hsu, Ken Johnson, Landy Wang, Logan Gabriel, Luke Kim, Matt Miller, Matthew
Woolman, Mehmet Iyigun, Michelle Bergeron, Minsang Kim, Mohamed Mansour, Nate Warfield, Neeraj Singh, Nick Judge, Pavel Lebedynskiy, Rich Turner, Saruhan Karademir, Simon Pope,
Stephen Finnigan und Stephen Hufnagel.
Wir möchten auch Ilfak Guilfanov von Hex-Rays (http://www.hex-rays.com) für die IDA Pro
Advanced- und Hey-Rays-Lizenzen danken, die er Alex Ionescu vor mehr als einem Jahrzehnt zur
Verfügung gestellt hat, um das Reverse-Engineering des Windows-Kernels zu beschleunigen, und
für die fortlaufende Unterstützung und Entwicklung der Decompilerfeatures, die es überhaupt
erst möglich gemacht haben, ein solches Buch ohne Zugriff auf den Quellcode zu schreiben.
Zu guter Letzt möchten die Autoren den großartigen Mitarbeitern bei Microsoft Press
denken, die dieses Buch verwirklicht haben. Devon Musgrave hat zum letzten Mal als unser
Akquiseleiter gearbeitet, während Kate Shoup den Titel als Projektleiterin beaufsichtigt hat.
Auch Shawn Morningstar, Kelly Talbot und Corina Lebegioara haben zu der Qualität dieses
Buches beigetragen.
Errata
Wir haben uns gewissenhaft darum bemüht, dieses Buch und das Begleitmaterial so korrekt wie
möglich zu gestalten. Jegliche Fehler in der englischen Originalausgabe, die seit der Veröffentlichung des Buches gemeldet wurden, sind auf der Website von Microsoft Press unter folgender
Adresse aufgeführt:
https://aka.ms/winint7ed/errata
Mit Anmerkungen, Fragen oder Verbesserungsvorschlägen zu diesem Buch können Sie sich
aber auch an den deutschen dpunkt.verlag wenden:
hallo@dpunkt.de
Bitte beachten Sie, dass über unsere E-Mail-Adressen kein Support für Software und Hardware
angeboten wird.
Für Supportinformationen bezüglich der Soft- und Hardwareprodukte besuchen Sie die
Microsoft-Website http://support.microsoft.com.
Einleitung
xxi
Kontakt
Bei Microsoft Press steht Ihre Zufriedenheit an oberster Stelle. Daher ist Ihr Feedback für uns
sehr wichtig. Lassen Sie uns auf dieser englischsprachigen Website wissen, wie Sie dieses Buch
finden:
https://aka.ms/tellpress
Wir wissen, dass Sie viel zu tun haben. Darum finden Sie auf der Webseite nur wenige Fragen.
Ihre Antworten gehen direkt an das Team von Microsoft Press. (Es werden keine persönlichen
Informationen abgefragt.) Im Voraus vielen Dank für Ihre Unterstützung.
Über Ihr Feedback per E-Mail freut sich außerdem der dpunkt.verlag über:
hallo@dpunkt.de
Falls Sie News, Updates usw. zu Microsoft Press-Büchern erhalten möchten, können Sie uns auf
Twitter folgen:
http://twitter.com/MicrosoftPress (Englisch)
https://twitter.com/dpunkt_verlag (Deutsch)
xxii
Einleitung
K apite l 1
Begriffe und Werkzeuge
In diesem Kapitel führen wir Kernbegriffe des Betriebssystems Microsoft Windows ein, die wir in
dem gesamten Buch verwenden werden, z. B. Windows-API, Prozesse, Threads, virtueller Speicher, Kernel- und Benutzermodus, Objekte, Handles, Sicherheit und Registrierung. Außerdem
stellen wir die Werkzeuge vor, mit denen Sie die inneren Mechanismen von Windows erkunden
können, darunter den Kernel-Debugger, die Leistungsüberwachung und die wichtigsten Werkzeuge aus Windows Sysinternals (http://www.microsoft.com/technet/sysinternals). Des Weiteren
erklären wir, wie Sie das Windows Driver Kit (WDK) und das Windows Software Developer Kit
(SDK) verwenden können, um mehr über Windows-Interna zu erfahren.
In dem Rest dieses Buches wird vorausgesetzt, dass Sie die in diesem Kapitel eingeführten
Begriffe kennen.
Versionen des Betriebssystems Windows
In diesem Buch geht es um die neueste Version der Client- und Serverbetriebssysteme von
Microsoft, nämlich Windows 10 (eine 32-Bit-Version für x86 und ARM sowie eine 64-Bit-Version für x64) und Windows Server 2016 (wovon es nur eine 64-Bit-Version gibt). Sofern nicht
ausdrücklich anders angegeben, bezieht sich der Text auf alle diese Versionen. Als Hintergrundinformation finden Sie in Tabelle 1–1 die Produktnamen, internen Versionsnummern und Veröffentlichungsdaten der bisherigen Windows-Versionen.
Produktname
Interne Versionsnummer
Veröffentlichungsdatum
Windows NT 3.1
3.1
Juli 1993
Windows NT 3.5
3.5
September 1994
Windows NT 3.51
3.51
Mai 1995
Windows NT 4.0
4.0
Juli 1996
Windows 2000
5.0
Dezember 1999
Windows XP
5.1
August 2001
Windows Server 2003
5.2
März 2003
Windows Server 2003 R2
5.2
Dezember 2005
Windows Vista
6.0
Januar 2007
Windows Server 2008
6.0 (Service Pack 1)
März 2008
Windows 7
6.1
Oktober 2009
Windows Server 2008 R2
6.1
Oktober 2009
→
1
Produktname
Interne Versionsnummer
Veröffentlichungsdatum
Windows 8
6.2
Oktober 2012
Windows Server 2012
6.2
Oktober 2012
Windows 8.1
6.3
Oktober 2013
Windows Server 2012 R2
6.3
Oktober 2013
Windows 10
10.0 (Build 10240)
Juli 2015
Windows 10 Version 1511
10.0 (Build 10586)
November 2015
Windows 10 Version 1607 (Anniversary Update)
10.0 (Build 14393)
Juli 2016
Windows Server 2016
10.0 (Build 14393)
Oktober 2016
Tabelle 1–1
Windows-Betriebssysteme
Beginnend mit Windows 7 scheint bei der Vergabe der Versionsnummern von einem wohldefinierten Muster abgewichen worden zu sein. Die Versionsnummer dieses Betriebssystems
lautete nicht 7, sondern 6.1. Als mit Windows Vista die Versionsnummer auf 6.0 erhöht wurde,
konnten manche Anwendungen das richtige Betriebssystem nicht erkennen. Das lag daran,
dass die Entwickler aufgrund der Beliebtheit von Windows XP nur auf eine Überprüfung auf
Hauptversionsnummern größer oder gleich 5 und Nebenversionsnummern größer oder gleich
1 durchführten. Diese Bedingung aber war bei Windows Vista nicht gegeben. Microsoft hatte
die Lektion daraus gelernt und im Folgenden die Hauptversion bei 6 belassen und die Nebenversionsnummer auf mindestens 2 (größer 1) festgelegt, um solche Inkompatibilitäten zu
minimieren. Mit Windows 10 wurde die Versionsnummer jedoch auf 10.0 heraufgesetzt.
Beginnend mit Windows 8 gibt die Funktion GetVersionEx der Windows-API als
Betriebssystemnummer unabhängig vom tatsächlich vorhandenen Betriebssystem
standardmäßig 6.2 (Windows 8) zurück. (Diese Funktion ist außerdem als unerwünscht eingestuft.) Das dient zur Minimierung von Kompatibilitätsproblemen,
zeigt aber auch, dass die Überprüfung der Betriebssystemversion in den meisten
Fällen nicht die beste Vorgehensweise ist, weil manche Komponenten unabhängig von einem bestimmten offiziellen Windows-Release installiert werden können.
Wenn Sie dennoch die tatsächliche Betriebssystemversion benötigen, können Sie
sie indirekt bestimmen, indem Sie die Funktion VerifyVersionInfo oder die neuen
Hilfs-APIs für die Versionsbestimmung wie IsWindows80rGreater, IsWindows8Point
10rGreater, IsWindows100rGreater, IsWindowsServer u. Ä. verwenden. Außerdem
lässt sich die Betriebssystemkompatibilität im Manifest der ausführbaren Datei angeben, was die Ergebnisse dieser Funktion ändert. (Einzelheiten entnehmen Sie
bitte Kapitel 8, »Systemmechanismen«, in Band 2.)
Informationen über die Windows-Version können Sie mit dem Befehlszeilenwerkzeug ver oder
grafisch durch Ausführen von winver einsehen. Der folgende Screenshot zeigt das Ergebnis von
winver in Windows 10 Enterprise Version 1511:
2
Kapitel 1
Begriffe und Werkzeuge
Das Dialogfeld zeigt auch die Buildnummer (hier 10586.218), die für Windows-Insider hilfreich
sein mag (also für diejenigen, die sich registriert haben, um Vorabversionen von Windows zu
erhalten). Sie ist auch praktisch für die Verwaltung von Sicherheitsaktualisierungen, da sie zeigt,
welche Patches installiert sind.
Windows 10 und zukünftige Windows-Versionen
Mit dem Erscheinen von Windows 10 hat Microsoft angekündigt, Windows jetzt in schnellerer
Folge zu aktualisieren als zuvor. Es wird kein offizielles Windows 11 geben. Stattdessen wird
Windows Update (oder ein anderes Bereitstellungsmodell) das vorhandene Windows 10 auf
eine neue Version aktualisieren. Zurzeit hat es schon zwei solcher Aktualisierungen gegeben,
nämlich im November 2015 (Version 1511, wobei sich die Nummer auf Jahr und Monat der
Bereitstellung bezieht) und im Juli 2016 (Version 1607, die auch unter der Bezeichnung Anniversary Update vermarktet wurde).
Intern wird Windows nach wie vor phasenweise weiterentwickelt. Beispielsweise
trug das ursprüngliche Release von Windows 10 den Codenamen Threshold 1 und
die Aktualisierung von November 2015 die Bezeichnung Threshold 2. Die nächsten
drei Phasen sind Redstone 1 (Version 1607), auf die Redstone 2 und Redstone 3
folgen werden.
Windows 10 und OneCore
Mit den Jahren wurden verschiedene Geschmacksrichtungen von Windows entwickelt. Neben
dem Standard-Windows für PCs gibt es auch das Betriebssystem für die Spielkonsole Xbox
360, bei dem es sich um eine Fork von Windows 2000 handelt. Die Variante Windows Phone 7
basierte auf Windows CE (dem Echtzeit-Betriebssystem von Microsoft). Die Pflege und Erweiterung all dieses Codes ist naturgemäß nicht einfach. Daher hat man bei Microsoft entschieden,
die Kernels und die Binärdateien für die grundlegende Plattform in einer einzigen zusammenfassen. Das begann bei Windows 8 und Windows Phone 8, die bereits über einen gemeinsamen Kernel verfügten (wobei Window 8.1. und Windows Phone 8.1 auch eine gemeinsame
Versionen des Betriebssystems Windows
Kapitel 1
3
Windows-Laufzeit-API hatten). Mit Windows 10 ist diese Zusammenlegung abgeschlossen. Die
gemeinsame Plattform heißt OneCore und läuft auf PCs, Smartphones, der Spielkonsole Xbox
One, der HoloLens und auf IoT-Geräten (für das »Internet der Dinge«) wie dem Raspberry Pi 2.
Diese Geräte unterscheiden sich in ihrer physischen Gestalt sehr stark voneinander, weshalb
einige Merkmale nicht überall zur Verfügung stehen. So ist es beispielsweise nicht sinnvoll, für
HoloLens-Geräte eine Unterstützung für Maus und Tastatur anzubieten, weshalb diese Teile in
der Windows 10-Version dafür nicht vorhanden sind. Aber der Kernel, die Treiber und die Binärdateien der grundlegenden Plattform sind im Prinzip identisch (mit registrierungs- oder richtliniengestützten Einstellungen, wo dies für die Leistung oder aus anderen Gründen sinnvoll ist). Ein
Beispiel für solche Richtlinien finden Sie im Abschnitt »API-Sets« in Kapitel 3, »Prozesse und Jobs«.
In diesem Buch geht es um die inneren Mechanismen des OneCore-Kernels unabhängig
von dem Gerät, auf dem er läuft. Die Experimente in diesem Buch sind jedoch für Desktop-Computer mit Maus und Tastatur ausgelegt, allerdings hauptsächlich aus praktischen Gründen, da
es nicht einfach (und manchmal sogar unmöglich) ist, die gleichen Versuche auf Geräten wie
Smartphones oder Xbox One durchzuführen.
Grundprinzipien und -begriffe
In den folgenden Abschnitten geben wir eine Einführung in die Grundprinzipien und -begriffe
von Windows, deren Kenntnis für das Verständnis dieses Buches unverzichtbar ist. Viele der hier
genannten Elemente wie Prozesse, Threads und virtueller Speicher werden in den nachfolgenden Kapiteln noch ausführlicher dargestellt.
Die Windows-API
Die Windows-API ist die Systemprogrammierschnittstelle der Windows-Betriebssystemfamilie
für den Benutzermodus. Vor der Einführung der 64-Bit-Versionen von Windows wurde die
32-Bit-APi als Win32API bezeichnet, um sie von der ursprünglichen 16-Bit-API zu unterscheiden. Die Bezeichnung Windows-API in diesem Buch bezieht sich sowohl auf die 32- als auch die
64-Bit-Programmierschnittstelle von Windows.
Manchmal verwenden wir auch den Begriff Win32API statt Windows-API. Aber
auch dann ist sowohl die 32- als auch die 64-Bit-Variante gemeint.
Die Windows-API wird in der Dokumentation des Windows-SDK beschrieben
(siehe den Abschnitt »Windows Software Development Kit« weiter hinten in diesem Kapitel), die kostenlos auf https://developer.microsoft.com/en-us/windows/
desktop/develop zur Verfügung steht und in allen Abonnements von MSDN, dem
Microsoft-Unterstützungsprogramm für Entwickler, eingeschlossen ist. Eine hervorragende Beschreibung der Programmierung für die grundlegende WindowsAPI finden Sie in dem Buch Windows via C/C++, Fifth Edition von Jeffrey Richter
und Christophe Nasarre (Microsoft Press, 2007).
4
Kapitel 1
Begriffe und Werkzeuge
Varianten der Windows-API
Die Windows-API bestand ursprünglich nur aus C-artigen Funktionen. Heutzutage können Entwickler auf Tausende solcher Funktionen zurückgreifen. Bei der Erfindung von Windows bot
sich die Sprache C an, da sie den kleinsten gemeinsamen Nenner darstellte (weil sie auch von
anderen Sprachen aus zugänglich war) und maschinennah genug, um Betriebssystemdienste
bereitzustellen. Der Nachteil bestand in einer ungeheuren Menge von Funktionen ohne konsistente Benennung und logische Gruppierung (etwa durch einen Mechanismus wie die Namespaces von C++). Aufgrund dieser Schwierigkeiten wurden schließlich neuere APIs verwendet,
die einen anderen API-Mechanismus einsetzten, nämlich das Component Object Model (COM).
COM wurde ursprünglich entwickelt, um Microsoft Office-Anwendungen die Kommunikation und den Datenaustausch zwischen Dokumenten zu ermöglichen (z. B. die Einbettung
eines Excel-Diagramms in ein Word-Dokument oder eine PowerPoint-Präsentation). Diese Fähigkeit wird als OLE (Object Linking and Embedding) bezeichnet und wurde ursprünglich mit
dem alten Windows-Messagingmechanismus DDE (Dynamic Data Exchange) implementiert.
Aufgrund der Einschränkungen, die DDE zu eigen waren, wurde allerdings eine neue Kommunikationsmöglichkeit entwickelt, und das war COM. Als COM um 1993 veröffentlicht wurde,
hieß es sogar ursprünglich OLE 2.
COM basiert auf zwei Grundprinzipien: Erstens kommunizieren Clients mit Objekten
(manchmal COM-Serverobjekte genannt) über Schnittstellen. Dies sind wohldefinierte Kontrakte mit einem Satz logisch verwandter Methoden, die durch einen Zuteilungsmechanismus
für virtuelle Tabellen gruppiert werden. Dies ist eine übliche Vorgehensweise von C++-Compilern zur Implementierung einer Zuteilung für virtuelle Funktionen. Sie resultiert in Binärkompatibilität und verhindert Probleme durch Namensverstümmelung im Compiler. Dadurch wird
es möglich, die Methoden von vielen Sprachen (und Compilern) aufzurufen, z. B. C, C++, Visual
Basic, .NET-Sprachen, Delphi usw. Das zweite Prinzip lautet, dass die Implementierung von
Komponenten dynamisch geladen und nicht statisch mit dem Client verlinkt wird.
Der Begriff COM-Server bezieht sich gewöhnlich auf eine DLL (Dynamic Link Library) oder
eine ausführbare Datei (EXE), in der die COM-Klassen implementiert sind. COM weist noch
weitere wichtige Merkmale zu Sicherheit, prozessübergreifendem Marshalling, Threading usw.
auf. Eine umfassende Darstellung von COM können wir in diesem Buch nicht leisten. Eine hervorragende Abhandlung über COM finden Sie in dem Buch Essential COM von Don Box (Addison-Wesley, 1998).
Über COM zugängliche APIs sind beispielsweise DirectShow, Windows Media
Foundation, DirectX, DirectComposition, WIC (Windows Imaging Component)
und BITS (Background Intelligent Transfer Service).
Die Windows-Laufzeitumgebung
Mit Windows 8 wurden eine neue API und eine neue Laufzeitumgebung eingeführt, die Windows
Runtime (manchmal auch als WinRT abgekürzt; nicht zu verwechseln mit dem inzwischen eingestellten Betriebssystem Windows RT für ARM-Prozessoren). Die Windows-Laufzeitumgebung
Grundprinzipien und -begriffe
Kapitel 1
5
besteht aus Plattformdiensten für die Entwickler von sogenannten Windows-Apps (die früher
auch als Metro Apps, Modern Apps, Immersive Apps und Windows Store Apps bezeichnet wurden). Windows-Apps können auf unterschiedlichen physischen Geräten ausgeführt werden,
von kleinen IoT-Geräten über Telefone und Tablets bis zu Laptop- und Desktop-Computern
und sogar auf Geräten wie die Xbox One und die Microsoft HoloLens.
Aus der Sicht der API setzt WinRT auf COM auf und erweitert die grundlegende COM-In
frastruktur. Beispielsweise sind in WinRT vollständige Typmetadaten verfügbar (die im .NET-Metadatenformat in WINMDF-Dateien gespeichert werden), was die COM-Typbibliotheken erweitert. Mit Namespace-Hierarchien, konsistenter Benennung und Programmiermustern ist WinRT
auch viel zusammenhängender gestaltet als klassische Windows-API-Funktionen.
Anders als normale Windows-Anwendungen (die jetzt als Windows-Desktop-Anwendungen oder klassische Windows-Anwendungen bezeichnet werden) unterliegen Windows-Apps
neuen Regeln. Diese Regeln werden in Kapitel 9, »Verwaltungsmechanismen«, von Band 2 beschrieben.
Die Beziehungen zwischen den verschiedenen APIs und Anwendungen sind nicht offensichtlich. Desktop-Anwendungen können einen Teil der WinRT-APIs verwenden, WindowsApps dagegen eine der Win32- und COM-APIs. Um jeweils genau zu erfahren, welche APIs für
welche Anwendungsplattformen zur Verfügung stehen, schlagen Sie bitte in der MSDN-Dokumentation nach. Beachten Sie jedoch, dass die WinRT-API auf der grundlegenden binären
Ebene immer noch auf den älteren Binärdateien und APIs von Windows basiert, auch wenn
bestimmte APIs nicht unterstützt werden und ihre Verfügbarkeit nicht dokumentiert ist. Es gibt
keine neue »native« API für das System. Das ist vergleichbar mit .NET, das nach wie vor auf die
traditionelle Windows-API zurückgreift.
Anwendungen, die in C++, C#, anderen .NET-Sprachen oder JavaScript geschrieben sind,
können WinRT-APIs dank der für diese Plattformen entwickelten Sprachprojektionen leicht nutzen. Für C++ hat Microsoft eine nicht standardmäßige Erweiterung namens C++/CX erstellt,
die die Verwendung von WinRT-Typen vereinfacht. Die normale COM-Interop-Schicht für .NET
(zusammen mit einigen unterstützenden Laufzeiterweiterungen) erlaubt allen .NET-Sprachen
die natürliche und einfache Nutzung von WinRT-APIs wie in reinem .NET. Für JavaScript-Entwickler gibt es die Erweiterung WinJS für den Zugriff auf WinRT. Für die Gestaltung der Benutzeroberfläche müssen JavaScript-Entwickler allerdings nach wie vor HTML einsetzen.
HTML kann zwar in Windows-Apps eingesetzt werden, allerdings handelt es sich
dabei immer noch um eine lokale Client-App und nicht um eine von einem Webserver abgerufene Webanwendung.
.NET Framework
.NET Framework gehört zu Windows. Tabelle 1–2 gibt an, welche Version davon jeweils in den
einzelnen Windows-Versionen installiert ist. Es ist jedoch immer möglich, auch eine neuere
Version zu installieren.
6
Kapitel 1
Begriffe und Werkzeuge
Windows-Version
.NET Framework-Version
Windows 8
4.5
Windows 8.1
4.5.1
Windows 10
4.6
Windows 10 Version 1511
4.6.1
Windows 10 Version 1607
4.6.2
Tabelle 1–2
.NET Framework-Standardinstallation in Windows
.NET Framework besteht aus den beiden folgenden Hauptkomponenten:
QQ CLR (Common Language Runtime) Dies ist die Laufzeit-Engine für .NET. Sie umfasst
einen JIT-Compiler (Just In Time), der CIL-Anweisungen (Common Intermediate Language)
in die Maschinensprache der CPU übersetzt, einen Garbage Collector, Typverifizierung,
Codezugriffssicherheit usw. Sie ist als In-Process-COM-Server (DLL) implementiert und
nutzt verschiedene Einrichtungen, die von der Windows-API bereitgestellt werden.
QQ .NET Framework-Klassenbibliothek (FCL) Dies ist eine umfangreiche Sammlung von
Typen für die Funktionalität, die Client- und Serveranwendungen gewöhnlich benötigen,
z. B. Benutzerschnittstellendienste, Netzwerkzugriff, Datenbankzugriff usw.
Durch diese und weitere Merkmale, darunter neue High-Level-Programmiersprachen (C#, Visual Basic, F#) und Unterstützungswerkzeuge, steigert .NET Framework die Produktivität von
Entwicklern und erhöht Sicherheit und Zuverlässigkeit der Anwendungen. Abb. 1–1 zeigt die
Beziehung zwischen .NET Framework und dem Betriebssystem.
Benutzermodus
(verwalteter Code)
.NET-App (EXE)
FCL (.NET-Assemblies) (DLLs)
Benutzermodus
(nativer Code)
CLR (COM-DLL-Server)
Windows-API-DLLs
Kernelmodus
Abbildung 1–1
Windows-Kernel
Die Beziehung zwischen .NET und Windows
Dienste, Funktionen und Routinen
Mehrere Begriffe in der Windows-Dokumentation für Benutzer und für Programmierer haben
je nach Kontext eine unterschiedliche Bedeutung. Beispielsweise kann es sich bei einem Dienst
um eine aufrufbare Routine im Betriebssystem, um einen Gerätetreiber oder um einen Server-
Grundprinzipien und -begriffe
Kapitel 1
7
prozess handeln. Die folgende Aufstellung gibt an, was in diesem Buch mit den genannten
Begriffen gemeint ist:
QQ Windows-API-Funktionen Dies sind dokumentierte, aufrufbare Subroutinen in der
Windows-API, beispielsweise CreateProcess, CreateFile und GetMessage.
QQ Native Systemdienste (Systemaufrufe) Dies sind nicht dokumentierte, zugrunde liegende Dienste im Betriebssystem, die vom Benutzermodus aus aufgerufen werden können.
Beispielsweise ist NtCreateUserProcess der interne Systemdienst, den die Windows-Funk
tion CreateProcess aufruft, um einen neuen Prozess zu erstellen.
QQ Kernelunterstützungsfunktionen (Routinen) Dies sind Subroutinen in Windows, die
ausschließlich im Kernelmodus aufgerufen werden können (der weiter hinten in diesem
Kapitel erklärt wird). Beispielsweise ist ExAllocatePoolWithTag die Routine, die Gerätetreiber aufrufen, um Speicher von den Windows-Systemheaps (den sogenannten Pools) zuzuweisen.
QQ Windows-Dienste Dies sind Prozesse, die vom Dienststeuerungs-Manager von Windows
gestartet werden. Beispielsweise wird der Taskplaner-Dienst in einem Benutzermodusprozess ausgeführt, der den Befehl schtasks unterstützt (der den UNIX-Befehlen at und cron
ähnelt). (In der Registrierung werden Windows-Gerätetreiber zwar als »Dienste« bezeichnet, nicht aber in diesem Buch.)
QQ DLLs (Dynamic Link Libraries) Eine DLL ist eine Binärdatei, zu der aufrufbare Subroutinen verknüpft worden sind und die von Anwendungen, die diese Subroutinen nutzen,
dynamisch geladen werden kann, beispielsweise Msvcrt.dll (die C-Laufzeitbibliothek)
und Kernel32.dll (eine der Teilsystem-Bibliotheken der Windows-API). Komponenten des
Windows-Benutzermodus und Anwendungen nutzen DLLs ausgiebig. Der Vorteil von DLLs
gegenüber statischen Bibliotheken besteht darin, dass Anwendungen sie gemeinsam nutzen, wobei Windows dafür sorgt, dass es im Arbeitsspeicher nur ein einziges Exemplar des
DLL-Codes gibt, auf die alle Anwendungen zugreifen. Bibliotheks-Assemblies von .NET
werden als DLLs kompiliert, aber ohne nicht verwaltete, exportierte Subroutinen. Stattdessen parst die CLR die kompilierten Metadaten, um auf die entsprechenden Typen und
Elemente zuzugreifen.
Prozesse
Programme und Prozesse scheinen zwar oberflächlich gesehen ähnlich zu sein, unterscheiden
sich aber grundlegend voneinander. Ein Programm ist eine statische Folge von Anweisungen,
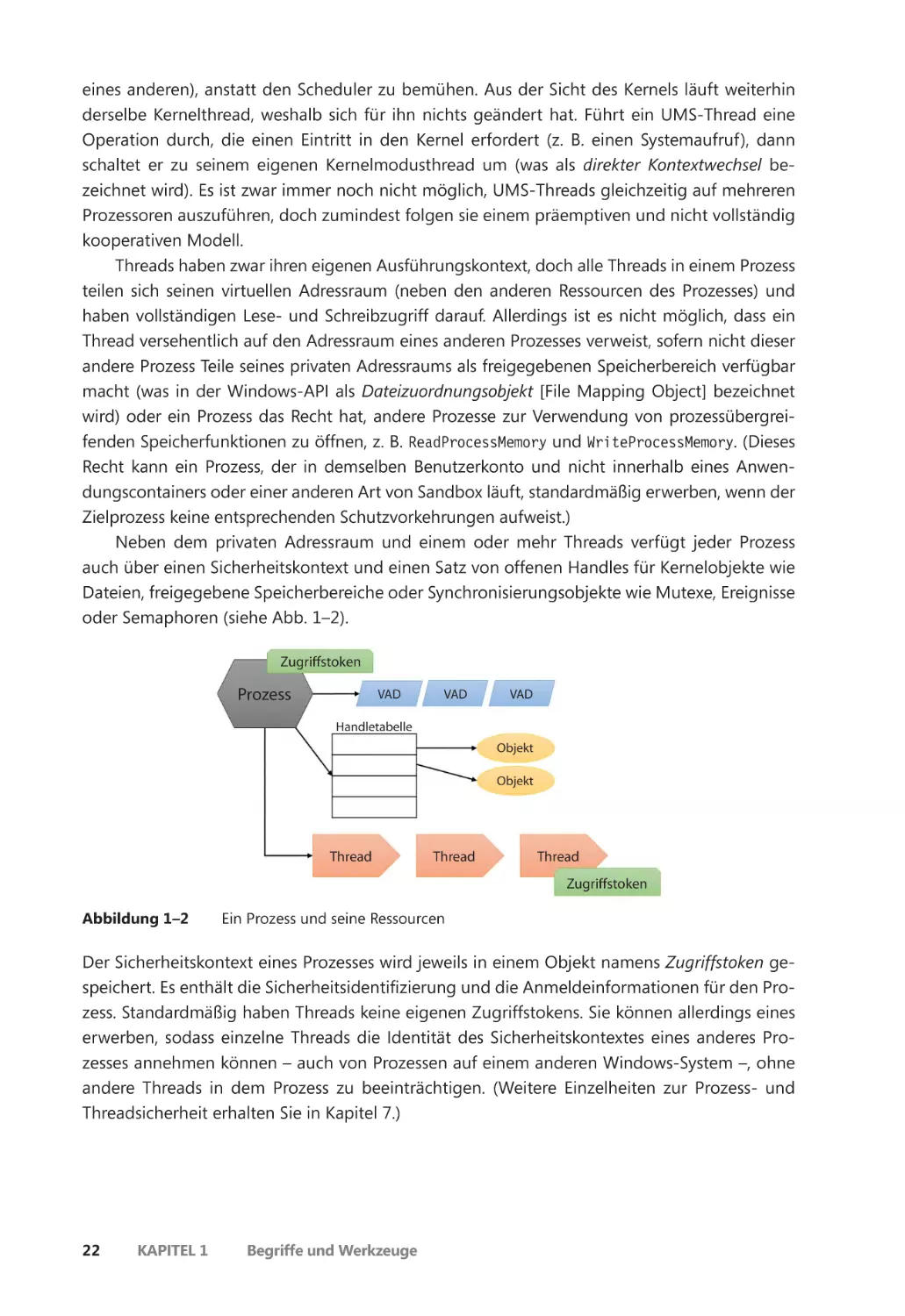
wohingegen es sich bei einem Prozess um einen Container für einen Satz von Ressourcen handelt, die bei der Ausführung einer Instanz des Programms genutzt werden. Grob gesehen,
besteht ein Windows-Prozess aus folgenden Elementen:
QQ Privater virtueller Adressraum Dies ist ein Satz von virtuellen Speicheradressen, die der
Prozess nutzen kann.
QQ Ausführbares Programm Das Programm definiert den ursprünglichen Code und die
Daten und wird auf den virtuellen Adressraum des Prozesses abgebildet.
8
Kapitel 1
Begriffe und Werkzeuge
QQ Ein Satz offener Handles Diese Handles werden verschiedenen Systemressourcen zugeordnet, z. B. Semaphoren, Synchronisierungsobjekten und Dateien, und sind von allen
Threads im Prozess aus zugänglich.
QQ Sicherheitskontext Hierbei handelt es sich um ein Zugriffstoken, das den Benutzer, die
Sicherheitsgruppen, die Rechte, Attribute, Claims und Fähigkeiten, den Virtualisierungsstatus der Benutzerkontensteuerung, die Sitzung und den Zustand des eingeschränkten Benutzerzugriffs angibt, die mit dem Prozess verbunden sind. Des Weiteren legt der Kontext
den Bezeichner des Anwendungscontainers fest und enthält Angaben über die zugehörige
Sandbox.
QQ Prozesskennung Dieser eindeutige Bezeichner ist Teil eines weiteren Bezeichners, nämlich der Clientkennung.
QQ Mindestens ein Ausführungsthread
tens) nicht sinnvoll.
Ein »leerer« Prozess ist zwar möglich, aber (meis-
Es gibt eine Reihe von Werkzeugen, um Prozesse und Prozessinformationen einzusehen und zu
bearbeiten. Die folgenden Experimente zeigen die verschiedenen Ansichten von Prozessinformationen, die Sie mit einigen dieser Tools gewinnen können. Manche dieser Werkzeuge sind
in Windows selbst, im Debugging Tool for Windows oder im Windows SDK enthalten, während
es sich bei anderen um eigenständige Programme von Sysinternals handelt. Viele dieser Werkzeuge zeigen die gleichen Kerninformationen über Prozesse und Threads an, manchmal jedoch
unter unterschiedlichen Bezeichnungen.
Das wahrscheinlich am häufigsten verwendete Werkzeug zur Untersuchung von Prozessaktivitäten ist der Task-Manager. (Der Name ist allerdings etwas eigenartig, da es im
Windows-Kernel keine »Tasks« gibt.) Das folgende Experiment führt einige der Grundfunktionen dieses Programms vor.
Experiment: Prozessinformationen im Task-Manager einsehen
Der im Lieferumfang von Windows enthaltene Task-Manager gibt eine Übersicht über die
Prozesse im System. Sie können ihn auf vier verschiedene Weisen starten:
QQ Drücken Sie (Strg) + (Umschalt) + (Esc).
QQ Rechtsklicken Sie auf die Taskleiste und wählen Sie Task-Manager starten.
QQ Drücken Sie (Strg) + (Alt) + (Entf) und klicken Sie auf die Schaltfläche Task-Manager starten.
QQ Starten Sie die ausführbare Datei Taskmgr.exe.
→
Grundprinzipien und -begriffe
Kapitel 1
9
Wenn Sie den Task-Manager zum ersten Mal starten, befindet er sich im Übersichtsmodus,
in dem nur die Prozesse angezeigt werden, für die es ein sichtbares Fenster gibt:
In diesem Fenster können Sie allerdings nicht viel sehen. Klicken Sie daher auf die Erweiterungsschaltfläche Details, um in die Vollansicht zu wechseln. Dabei liegt standardmäßig die
Registerkarte Prozesse oben:
Die Registerkarte Prozesse zeigt eine Liste der Prozesse mit vier Spalten: CPU, Arbeitsspeicher, Datenträger und Netzwerk. Wenn Sie auf die Kopfzeile rechtsklicken, können Sie noch
weitere Spalten einblenden lassen. Zur Verfügung stehen Prozessname (Abbild), Prozess-ID,
Typ, Status, Herausgeber und Befehlszeile. Einige Prozesse können erweitert werden, sodass
Sie erkennen können, welche sichtbaren Fenster von ihnen erstellt werden.
Um noch mehr Einzelheiten zu den Prozessen einzusehen, klicken Sie auf die Registerkarte Details. Sie können auch auf einen Prozess rechtsklicken und Zu Details wechseln auswählen. Dadurch gelangen Sie auf die Registerkarte Details, wobei der betreffende Prozess
schon ausgewählt ist.
→
10
Kapitel 1
Begriffe und Werkzeuge
Die Registerkarte Prozesse im Task-Manager von Windows 7 entspricht
ungefähr der Registerkarte Details im Task-Manager von Windows 8 und
höher. Im Task-Manager von Windows 7 zeigt die Registerkarte Anwendungen nur Prozesse mit sichtbaren Fenstern, und nicht sämtliche Prozesse. Diese Angaben sind jetzt auf der Registerkarte Prozesse des neuen
Task-Managers von Windows 8 und höher enthalten.
Die Registerkarte Details zeigt ebenfalls Prozesse, aber auf kompaktere Art und Weise. Sie
gibt die von den Prozessen erstellten Fenster nicht an, enthält aber eine breitere Auswahl
von Informationsspalten.
Prozesse werden anhand ihres Namens bezeichnet und mit einem Symbol dargestellt,
das angibt, wovon sie eine Instanz darstellen. Anders als viele andere Objekte in Windows
können Prozesse keine globalen Namen bekommen. Um weitere Einzelheiten einzublenden, rechtsklicken Sie auf die Kopfzeile und wählen Spalten auswählen. Dadurch wird eine
Liste von Spalten angezeigt:
→
Grundprinzipien und -begriffe
Kapitel 1
11
Unter anderem gibt es folgende wichtige Spalten:
QQ Threads Die Spalte Threads zeigt die Anzahl der Threads in jedem Prozess. Normalerweise sollte sie mindestens eins betragen, da es keine unmittelbare Möglichkeit gibt,
um einen Prozess ohne Thread zu erstellen (und ein solcher Prozess auch nicht sehr
sinnvoll wäre). Werden für einen Prozess null Threads angezeigt, so bedeutet das gewöhnlich, dass der Prozess aus irgendeinem Grund nicht gelöscht werden kann, wahrscheinlich, weil der Treibercode fehlerhaft ist.
QQ Handles Die Spalte Handles zeigt die Anzahl der Handles von Kernelobjekten, die die
Threads in dem Prozess geöffnet haben. (Dieser Vorgang wird weiter hinten in diesem
Kapitel sowie ausführlich in Kapitel 8 von Band 2 beschrieben.)
QQ Status Die Spalte Status ist etwas knifflig. Bei Prozessen ohne Benutzerschnittstelle sollte hier normalerweise Wird ausgeführt angezeigt werden, wobei es jedoch sein
kann, dass alle Threads auf irgendetwas warten, etwa auf ein Signal an ein Kernelobjekt
oder den Abschluss einer E/A-Operation. Die andere Möglichkeit für einen solchen
Prozess ist Angehalten, was angezeigt wird, wenn alle Threads in dem Prozess angehalten sind. Es ist sehr unwahrscheinlich, dass dies durch den Prozess selbst verursacht
wird, lässt sich aber programmgesteuert durch den Aufruf der nicht dokumentierten
nativen API NtSuspendProcess für den Prozess erreichen, gewöhnlich mithilfe eines
Tools (beispielsweise gibt es in dem weiter hinten beschriebenen Process Explorer eine
solche Option). Für Prozesse mit Benutzerschnittstelle bedeutet der Statuswert Wird
ausgeführt, dass die Benutzerschnittstelle reagiert. Mit anderen Worten, der Thread,
der die Fenster erstellt hat, wartet auf Benutzereingaben (technisch gesehen auf die mit
ihm verbundene Nachrichtenwarteschlange). Der Zustand Angehalten ist ebenso möglich wie bei Prozessen ohne Benutzerschnittstelle, allerdings tritt er bei Windows-Apps
(also denen mit Windows Runtime) gewöhnlich auf, wenn die Anwendung vom Benutzer minimiert wird und dadurch ihren Vordergrundstatus einbüßt. Solche Prozesse
werden nach fünf Sekunden angehalten, damit sie keine CPU- und Netzwerkressourcen
verbrauchen. Dadurch kann die neue Vordergrundanwendung alle Computerressourcen erhalten. Das ist insbesondere auf akkubetriebenen Geräten wie Tablets und Smartphones wichtig. Dieser und ähnliche Mechanismen werden ausführlich in Kapitel 9 von
Band 2 beschrieben. Der dritte mögliche Wert für Status lautet Reagiert nicht. Das kann
geschehen, wenn ein Thread in dem Prozess für die Benutzerschnittstelle seine Nachrichtenwarteschlange für Aktivitäten im Zusammenhang mit der Schnittstelle mindestens fünf Sekunden lang nicht überprüft hat. Der Prozesse (eigentlich der Thread, dem
das Fenster gehört) kann mit irgendwelchen CPU-intensiven Arbeiten beschäftigt sein
oder auf etwas völlig anderes warten (z. B. auf den Abschluss einer E/A-Operation). In
jedem Fall friert die Benutzeroberfläche ein, was Windows dadurch kennzeichnet, dass
die fraglichen Fenster blasser dargestellt und ihren Titeln der Zusatz (reagiert nicht)
hinzugefügt wird.
12
Kapitel 1
Begriffe und Werkzeuge
Jeder Prozess verweist außerdem auf seinen Elternprozess (bei dem es sich um seinen Erstellerprozess handeln kann, aber nicht muss). Existiert der Elternprozess nicht mehr, so wird diese
Angabe auch nicht mehr aktualisiert. Daher kann es sein, dass ein Prozess auf einen Elternprozess verweist, den es nicht mehr gibt. Das ist jedoch kein Problem, da es nichts gibt, was
eine aktuelle Angabe darüber benötigt. Dieses Verhalten wird durch das folgende Experiment
veranschaulicht. (Im Tool Process Explorer wird der Startzeitpunkt des Elternprozesses berücksichtigt, um zu verhindern, dass ein Kindprozess auf der Grundlage einer wiederverwendeten
Prozesskennung angefügt wird.)
Wann ist der Elternprozess nicht mit dem Erstellerprozess identisch? Bei einigen
Prozessen, die von bestimmten Benutzeranwendungen erstellt werden, kann die
Hilfe eines Makler- oder Hilfsprozesses erforderlich sein, der die API zur Prozesserstellung aufruft. In einem solchen Fall wäre es verwirrend (oder sogar falsch, wenn
eine Vererbung von Handles oder Adressräumen erforderlich ist), den Maklerprozess als Ersteller anzuzeigen, weshalb eine Umdefinition des Elternprozesses erfolgt. Mehr darüber erfahren Sie in Kapitel 7, »Sicherheit«.
Experiment: Die Prozessstruktur einsehen
Die meisten Werkzeuge zeigen für einen Prozess nicht die ID des Eltern- oder des Erstellerprozesses an. Diesen Wert können Sie jedoch in der Leistungsüberwachung (oder programmgesteuert) gewinnen, indem Sie Prozesskennung erstellen abrufen (was eigentlich
»Kennung des erstellenden Prozesses« heißen müsste). In Tlist.exe aus den Debugging Tools
for Windows können Sie die Prozessstruktur mithilfe des Optionsschalters /t anzeigen lassen. Im Folgenden sehen Sie eine Beispielausgabe von tlist /t:
System Process (0)
System (4)
smss.exe (360)
csrss.exe (460)
wininit.exe (524)
services.exe (648)
svchost.exe (736)
unsecapp.exe (2516)
WmiPrvSE.exe (2860)
WmiPrvSE.exe (2512)
RuntimeBroker.exe (3104)
SkypeHost.exe (2776)
ShellExperienceHost.exe (3760) Windows Shell Experience Host
ApplicationFrameHost.exe (2848) OleMainThreadWndName
SearchUI.exe (3504) Cortana
WmiPrvSE.exe (1576)
→
Grundprinzipien und -begriffe
Kapitel 1
13
TiWorker.exe (6032)
wuapihost.exe (5088)
svchost.exe (788)
svchost.exe (932)
svchost.exe (960)
svchost.exe (976)
svchost.exe (68)
svchost.exe (380)
VSSVC.exe (1124)
svchost.exe (1176)
sihost.exe (3664)
taskhostw.exe (3032) Task Host Window
svchost.exe (1212)
svchost.exe (1636)
spoolsv.exe (1644)
svchost.exe (1936)
OfficeClickToRun.exe (1324)
MSOIDSVC.EXE (1256)
MSOIDSVCM.EXE (2264)
MBAMAgent.exe (2072)
MsMpEng.exe (2116)
SearchIndexer.exe (1000)
SearchProtocolHost.exe (824)
svchost.exe (3328)
svchost.exe (3428)
svchost.exe (4400)
svchost.exe (4360)
svchost.exe (3720)
TrustedInstaller.exe (6052)
lsass.exe (664)
csrss.exe (536)
winlogon.exe (600)
dwm.exe (1100) DWM Notification Window
explorer.exe (3148) Program Manager
OneDrive.exe (4448)
cmd.exe (5992) C:\windows\system32\cmd.exe - tlist /t
conhost.exe (3120) CicMarshalWnd
tlist.exe (5888)
SystemSettingsAdminFlows.exe (4608)
→
14
Kapitel 1
Begriffe und Werkzeuge
Die Einrückungen in der Liste zeigen die Beziehungen zwischen Eltern- und Kindprozessen.
Prozesse, deren Elternprozesse nicht mehr existieren, sind nicht eingerückt (wie explorer.exe
im vorstehenden Beispiel), denn selbst wenn der Großelternprozess noch vorhanden wäre,
gäbe es keine Möglichkeit, diese Beziehung herauszufinden. Windows führt nur die Kennungen der Erstellerprozesse, aber keine Verbindungen zurück zu den Erstellern der Ersteller usw.
Die Zahl in Klammern ist die Prozesskennung, der bei einigen Prozessen folgende Test
der Titel des Fensters, das von dem Prozess angelegt wurde.
Um zu beweisen, dass Windows sich nicht mehr merkt als die Kennung des Elternprozesses, führen Sie die folgenden Schritte aus:
1.
Drücken Sie (Windows) + (R), geben Sie cmd ein und drücken Sie (Eingabe), um eine
Eingabeaufforderung zu öffnen.
2.
Geben Sie titel Parent ein, um den Titel des Fensters in Parent zu ändern.
3.
Geben Sie start cmd ein, um eine zweite Eingabeaufforderung zu öffnen.
4.
Geben Sie titel Child an der zweiten Eingabeaufforderung ein.
5.
Geben Sie an der zweiten Eingabeaufforderung mspaint ein, um Microsoft Paint zu
starten.
6.
Kehren Sie wieder zu der zweiten Eingabeaufforderung zurück und geben Sie exit ein.
Paint wird weiterhin ausgeführt.
7.
Drücken Sie (Strg) + (Umschalt) +(Esc), um den Task-Manager zu öffnen.
8.
Wenn sich der Task-Manager im Übersichtsmodus befindet, klicken Sie auf Details.
9.
Klicken Sie auf die Registerkarte Prozesse.
10. Suchen Sie die Anwendung Windows Command Processor und erweitern Sie ihren Knoten. Wie im folgenden Screenshot sollten Sie jetzt den Titel Parent sehen.
11. Rechtsklicken Sie auf Windows Command Processor und wählen Sie Zu Details wechseln.
→
Grundprinzipien und -begriffe
Kapitel 1
15
12. Rechtsklicken Sie auf diesen cmd.exe-Prozess und wählen Sie Prozessstruktur beenden.
13. Klicken Sie im Bestätigungsdialogfeld des Task-Managers auf Prozessstruktur beenden.
Das Fenster mit der ersten Eingabeaufforderung verschwindet, aber das Paint-Fenster wird
nach wie vor angezeigt, da es nur der Enkel des beendeten Eingabeaufforderungsprozesses
ist. Da der Zwischenprozess (der Elternprozess von Paint) beendet wurde, gibt es keine Verbindung mehr zwischen dem Elternprozess und seinem Enkel.
Der Process Explorer aus Sysinternals zeigt mehr Einzelheiten über Prozesse und Threads an
als jedes andere verfügbare Werkzeug, weshalb wir ihn in vielen Experimenten in diesem Buch
verwenden. Unter anderem gibt Ihnen Process Explorer die folgenden einzigartigen Angaben
und Möglichkeiten:
QQ Ein Prozesssicherheitstoken, z. B. Listen von Gruppen und Rechten und des Virtualisierungszustands
QQ Hervorhebungen von Veränderungen in der Liste der Prozesse, Threads, DLLs und Handles
QQ Eine Liste der Dienste in Diensthostingprozessen einschließlich Anzeigename und Beschreibung
QQ Eine Liste zusätzlicher Prozessattribute wie Abschwächungsrichtlinien und deren Prozessschutzebene
QQ Prozesse, die zu einem Job gehören, und Angaben zu dem Job
QQ Prozesse für .NET-Anwendungen mit .NET-spezifischen Angaben wie die Aufzählung der
Anwendungsdomänen, der geladenen Assemblies sowie CLR-Leistungsindikatoren
QQ Prozesse für Windows Runtime (immersive Prozesse)
QQ Startzeitpunkt von Prozessen und Threads
QQ Vollständige Liste aller Dateien, die im Speicher zugeordnet wurden (nicht nur der DLLs)
QQ Die Möglichkeit, einen Prozess oder Thread anzuhalten
QQ Die Möglichkeit, einen einzelnen Thread zwangsweise zu beenden
QQ Leichte Identifizierung der Prozesse, die im Laufe der Zeit die meisten CPU-Ressourcen
verbrauchen
Die Leistungsüberwachung kann die CPU-Nutzung eines Satzes von Prozessen
darstellen, zeigt dabei aber nicht automatisch auch Prozesse an, die nach dem
Start dieser Überwachungssitzung erstellt wurden. Das können Sie nur mit einer
manuellen Ablaufverfolgung im binären Ausgabeformat erreichen.
Des Weiteren bietet Process Explorer leichten, zentralen Zugriff auf Informationen wie die folgenden:
QQ Die Prozessstruktur, wobei es möglich ist, einzelne Teile davon reduziert darzustellen
QQ Offene Handles in einem Prozess, einschließlich nicht benannter Handles
16
Kapitel 1
Begriffe und Werkzeuge
QQ Liste der DLLs (und im Arbeitsspeicher zugeordneten Dateien) in einem Prozess
QQ Threadaktivität in einem Prozess
QQ Thread-Stacks im Benutzer- und im Kernelmodus, einschließlich der Zuordnung von Adressen zu Namen mithilfe der Dbghelp.dll, die in den Debugging Tools for Windows enthalten ist
•
Genauere Angabe des prozentualen CPU-Anteils mithilfe des Threadzykluszählers –
eine noch bessere Darstellung der genauen CPU-Aktivität (siehe Kapitel 4, »Threads«)
•
Integritätsebene
QQ Einzelheiten des Speicher-Managers wie Spitzenwert des festgelegten virtuellen Speichers
und Grenzwerte für ausgelagerte und nicht ausgelagerte Pools des Kernelspeichers (während andere Werkzeuge nur die aktuelle Größe zeigen)
Das folgende Experiment dient zur Einführung in Process Explorer.
Experiment: Einzelheiten über Prozesse mit Process Explorer
einsehen
Laden Sie die neueste Version von Process Explorer von Sysinternals herunter und führen
Sie sie aus. Das können Sie mit Standardbenutzerrechten tun, aber alternativ auch auf die
ausführbare Datei rechtsklicken und Als Administrator ausführen wählen. Wenn Sie Process
Explorer mit Administratorrechten ausführen, wird ein Treiber installiert, der mehr Funktionen bietet. Die folgende Beschreibung funktioniert jedoch unabhängig davon, wie Sie
Process Explorer starten.
Bei der ersten Ausführung von Process Explorer sollten Sie die Symbole konfigurieren,
da Sie anderenfalls eine entsprechende Meldung bekommen, wenn Sie auf einen Prozess
doppelklicken und die Registerkarte Threads wählen. Bei ordnungsgemäßer Konfiguration
kann Process Explorer auf Symbolinformationen zugreifen, um die Symbolnamen für die
Startfunktion des Threads sowie die Funktion auf seinem Aufrufstack anzuzeigen. Das ist
praktisch, um zu ermitteln, was die Threads innerhalb eines Prozesses tun. Für den Zugriff
auf Symbole müssen die Debugging Tools for Windows installiert sein (siehe die Beschreibung weiter hinten in diesem Kapitel). Klicken Sie auf Options, wählen Sie Configure Symbols und geben Sie den Pfad zu Dbghelp.dll im Ordner von Debugging Tools sowie einen
gültigen Symbolpfad an. Wenn die Debugging Tools for Windows auf einem 64-Bit-System
im Rahmen des WDK im Standardspeicherort installiert sind, können Sie beispielsweise folgende Konfiguration verwenden:
→
Grundprinzipien und -begriffe
Kapitel 1
17
Hier wird der Symbolserver verwendet, um auf Symbole zuzugreifen, und die Symboldateien werden auf dem lokalen Computer im Ordner C:\symbols gespeichert. (Wenn
Sie Speicherplatz sparen müssen, können Sie diesen Ordner auch durch einen anderen
Ordner ersetzen, auch durch einen auf einem anderen Laufwerk.) Weitere Informationen
darüber, wie Sie die Verwendung des Symbolservers einrichten, erhalten Sie auf https://
msdn.microsoft.com/en-us/library/windows/desktop/ee416588.aspx.
Sie können den Microsoft-Symbolserver einrichten, indem Sie die Umgebungsvariable _NT_SYMBOL_PATH auf den Wert aus der vorstehenden
Abbildung setzen. Mehrere Werkzeuge suchen automatisch nach dieser
Variablen, darunter Process Explorer, die Debugger aus den Debugging
Tools for Windows, Visual Studio u. a. Dadurch können Sie es sich ersparen, jedes Tool einzeln zu konfigurieren.
Beim Start zeigt Process Explorer standardmäßig die Prozessstruktur an. Sie können den
unteren Bereich erweitern, um die offenen Handles oder die im Arbeitsspeicher zugeordneten DLLs und anderen Dateien anzuzeigen (siehe auch Kapitel 5, »Speicherverwaltung«,
und Kapitel 8 von Band 2). Wenn Sie den Mauszeiger über den Namen eines Prozesses
halten, werden auch QuickInfos über die Prozessbefehlszeile und den Pfad eingeblendet.
Bei einigen Arten von Prozessen enthält die QuickInfo auch zusätzliche Angaben, darunter
die folgenden:
QQ Die Dienste innerhalb eines Diensthostingprozesses (z. B. Svchost.exe)
QQ Die Tasks innerhalb eines Taskhostingprozesses (z. B. TaskHostw.exe)
QQ Das Ziel eines Runddl32.exe-Prozesses für Elemente der Systemsteuerung und andere
Merkmale
QQ Angaben zur COM-Klasse, wenn sich der Prozess in einem Dllhost.exe-Prozess befindet (auch Standard-COM+-Ersatz genannt)
QQ Anbieterinformationen für WMI-Hostprozesse (Windows Management Instrumenta
tion) wie WMIPrvSE.exe (siehe Kapitel 8 in Band 2)
QQ Paketinformationen für Windows-Apps-Prozesse (Prozesse mit Windows Runtime, die
weiter vorn in diesem Kapitel im Abschnitt »Die Windows-Laufzeitumgebung« vorgestellt wurden)
→
18
Kapitel 1
Begriffe und Werkzeuge
Führen Sie die folgenden Schritte aus, um einige Grundfunktionen von Process Explorer
kennenzulernen:
1.
Machen Sie sich mit den farbigen Hervorhebungen vertraut: Prozesse für Dienste werden standardmäßig rosa hinterlegt, Ihre eigenen Prozesse dagegen blau. Diese Farben
können Sie ändern, indem Sie das Dropdownmenü öffnen und Options > Configure
Colors auswählen.
2.
Halten Sie den Mauszeiger über den Imagenamen eines Prozesses. In einer QuickInfo
wird der vollständige Pfad angezeigt. Wie zuvor erwähnt, enthält die QuickInfo bei
bestimmten Arten von Prozessen weitere Angaben.
3.
Klicken Sie auf der Registerkarte Process Image auf View und wählen Sie Select Columns,
um den Imagepfad hinzuzufügen.
4.
Klicken Sie auf den Kopf der Spalte Process, um die Prozesse zu sortieren. Dabei verschwindet die Strukturansicht. (Sie können nur entweder die Struktur anzeigen lassen
oder eine Sortierung nach einer der Spalten durchführen.) Klicken Sie erneut auf den
Kopf von Process, um eine Sortierung von Z zu A zu erreichen. Klicken Sie ein drittes
Mal darauf, um wieder die Strukturansicht anzuzeigen.
5.
Öffnen Sie das Menü View und deaktivieren Sie Show Processes from All Users, damit
nur Ihre Prozesse angezeigt werden.
→
Grundprinzipien und -begriffe
Kapitel 1
19
6.
Klicken Sie auf das Menü Options, wählen Sie Difference Highlight Duration und ändern
Sie den Wert auf drei Sekunden. Starten Sie dann einen (beliebigen) neuen Prozess.
Dabei wird der neue Prozess drei Sekunden lang grün hervorgehoben. Beenden Sie
den neuen Prozess. Dabei wird er drei Sekunden lang rot hervorgehoben, bevor er aus
der Anzeige verschwindet. Diese Funktion ist nützlich, um sich einen Überblick über die
Prozesse zu verschaffen, die auf dem System erstellt und beendet werden.
7.
Doppelklicken Sie auf einen Prozess und schauen Sie sich die verschiedenen Registerkarten an, die in der Anzeige der Prozesseigenschaften zur Verfügung stehen. (In
verschiedenen Experimenten in diesem Buch werden wir auf diese Registerkarten hinweisen und die darauf befindlichen Angaben erklären.)
Threads
Ein Thread ist eine Entität in einem Prozess, die Windows zur Ausführung einplant. Ohne einen
Thread kann das Programm des Prozesses nicht ausgeführt werden. Ein Thread schließt die
folgenden grundlegenden Komponenten ein:
QQ Den Inhalt eines Satzes von CPU-Registern, die den Zustand des Prozessors darstellen
QQ Zwei Stacks: einen für Kernel- und einen für den Benutzermodus
QQ Einen privaten Speicherbereich, der als lokaler Threadspeicher (Thread-Local Storage, TLS)
bezeichnet und von Teilsystemen, Laufzeitbibliotheken und DLLs verwendet wird
QQ Einen eindeutigen Bezeichner, der als Threadkennung oder Thread-ID bezeichnet wird
(und der zu einer internen Struktur namens Client-ID gehört; Prozess- und Thread-IDs
werden aus demselben Namespace generiert, weshalb sie niemals überlappen)
Darüber hinaus haben Threads manchmal auch einen eigenen Sicherheitskontext oder ein Token, das häufig von Multithread-Serveranwendungen verwendet wird, um den Sicherheitskontext der Clients anzunehmen, deren Anforderungen sie verarbeiten.
Die flüchtigen Register, die Stacks und der private Speicherbereich bilden den sogenannten Kontext des Threads. Da sie sich zwischen den einzelnen Maschinenarchitekturen unterscheiden, auf denen Windows läuft, ist diese Struktur notgedrungen architekturspezifisch. Die
Windows-Funktion GetThreadContext bietet Zugriff auf diese architekturspezifischen Informa
tionen (den sogenannten CONTEXT-Block).
Da an der Umschaltung der Ausführung von einem Thread zu einem anderen der Kernelscheduler beteiligt ist, kann dieser Vorgang sehr kostspielig sein, insbesondere wenn dies
häufig zwischen immer denselben Threads geschieht. In Windows gibt es zwei Mechanismen,
um die Kosten dafür zu senken, nämlich Fibers und UMS (User-Mode Scheduling).
20
Kapitel 1
Begriffe und Werkzeuge
Die Threads einer 32-Bit-Anwendung, die auf einer 64-Bit-Version von Windows
läuft, enthalten sowohl 32- als auch 64-Bit-Kontexte, was Wow64 (Windows on
Windows) dazu verwendet, die Anwendung bei Bedarf vom 32- in den 64-Bit-Modus
umzuschalten. Diese Threads haben zwei Benutzerstacks und zwei CONTEXT-Blöcke.
Die üblichen Windows-API-Funktionen geben stattdessen aber den 64-Bit-Kontext
zurück, die Funktion Wow64GetThreadContext dagegen den 32-Bit-Kontext. Mehr Informationen über Wow64 erhalten Sie in Kapitel 8 in Band 2.
Fibers
Fibers ermöglichen es einer Anwendung, ihre eigenen Ausführungsthreads zu planen, anstatt
sich auf den prioritätsgestützten Mechanismus von Windows zu verlassen. Sie werden oft auch
als schlanke Threads (»lightweight threads«) bezeichnet. Da sie in Kernel32.dll im Benutzermodus implementiert sind, sind sie für den Kernel nicht sichtbar. Um Fibers zu nutzen, müssen Sie
zunächst die Windows-Funktion ConvertThreadToFiber aufrufen, die den Thread in eine laufende Fiber umwandelt. Anschließend können Sie die neue Fiber nutzen, um mit der Funktion
CreateFiber weitere Fibers zu erstellen. (Jede Fiber kann ihren eigenen Satz von Fibers haben.)
Anderes als bei einem Thread jedoch beginnt die Ausführung einer Fiber erst dann, wenn sie
über einen Aufruf der Funktion SwitchToFiber manuell ausgewählt wird. Die neue Fiber wird
ausgeführt, bis sie mit einem Aufruf von SwitchToFiber beendet wird, der eine andere Fiber
zur Ausführung auswählt. Weitere Informationen entnehmen Sie bitte der Dokumentation des
Windows SDK über Fiberfunktionen.
Es ist gewöhnlich nicht gut, Fibers zu verwenden, da sie für den Kernel nicht
sichtbar sind. Außerdem gibt es bei ihnen Probleme durch die gemeinsame Nutzung des lokalen Threadspeichers (TLS), da in einem Thread mehrere Fibers laufen können. Es gibt zwar auch lokalen Fiberspeicher (FLS), der allerdings nicht
alle Probleme der gemeinsamen Verwendung löst. An die E/A gebundene Fibers
zeigen auch bei der Verwendung von FLS eine schlechte Leistung. Des Weiteren
können Fiber nicht gleichzeitig auf mehreren Prozessoren laufen und sind auf kooperatives Multitasking beschränkt. In den meisten Situationen ist es besser, dem
Windows-Kernel die Planung zu überlassen, indem Sie die geeigneten Threads für
die vorliegende Aufgabe auswählen.
UMS-Threads
UMS-Threads (User-Mode Scheduling) stehen nur in den 64-Bit-Versionen von Windows zur
Verfügung. Sie bieten die gleichen grundlegenden Vorteile wie Fibers, aber nur wenige von
deren Nachteilen. UMS-Threads haben ihren eigenen Kernelthreadstatus und sind daher für
den Kernel sichtbar, was es ermöglicht, dass mehrere UMS-Threads Ressourcen gemeinsam
nutzen, darum konkurrieren und blockierende Systemaufrufe ausgeben. Wenn zwei oder mehr
UMS-Threads Arbeit im Benutzermodus verrichten müssen, können sie regelmäßig den Ausführungskontext im Benutzermodus wechseln (durch Zurücktreten eines Threads zugunsten
Grundprinzipien und -begriffe
Kapitel 1
21
eines anderen), anstatt den Scheduler zu bemühen. Aus der Sicht des Kernels läuft weiterhin
derselbe Kernelthread, weshalb sich für ihn nichts geändert hat. Führt ein UMS-Thread eine
Operation durch, die einen Eintritt in den Kernel erfordert (z. B. einen Systemaufruf), dann
schaltet er zu seinem eigenen Kernelmodusthread um (was als direkter Kontextwechsel bezeichnet wird). Es ist zwar immer noch nicht möglich, UMS-Threads gleichzeitig auf mehreren
Prozessoren auszuführen, doch zumindest folgen sie einem präemptiven und nicht vollständig
kooperativen Modell.
Threads haben zwar ihren eigenen Ausführungskontext, doch alle Threads in einem Prozess
teilen sich seinen virtuellen Adressraum (neben den anderen Ressourcen des Prozesses) und
haben vollständigen Lese- und Schreibzugriff darauf. Allerdings ist es nicht möglich, dass ein
Thread versehentlich auf den Adressraum eines anderen Prozesses verweist, sofern nicht dieser
andere Prozess Teile seines privaten Adressraums als freigegebenen Speicherbereich verfügbar
macht (was in der Windows-API als Dateizuordnungsobjekt [File Mapping Object] bezeichnet
wird) oder ein Prozess das Recht hat, andere Prozesse zur Verwendung von prozessübergreifenden Speicherfunktionen zu öffnen, z. B. ReadProcessMemory und WriteProcessMemory. (Dieses
Recht kann ein Prozess, der in demselben Benutzerkonto und nicht innerhalb eines Anwendungscontainers oder einer anderen Art von Sandbox läuft, standardmäßig erwerben, wenn der
Zielprozess keine entsprechenden Schutzvorkehrungen aufweist.)
Neben dem privaten Adressraum und einem oder mehr Threads verfügt jeder Prozess
auch über einen Sicherheitskontext und einen Satz von offenen Handles für Kernelobjekte wie
Dateien, freigegebene Speicherbereiche oder Synchronisierungsobjekte wie Mutexe, Ereignisse
oder Semaphoren (siehe Abb. 1–2).
Zugriffstoken
Prozess
VAD
VAD
VAD
Handletabelle
Objekt
Objekt
Thread
Thread
Thread
Zugriffstoken
Abbildung 1–2
Ein Prozess und seine Ressourcen
Der Sicherheitskontext eines Prozesses wird jeweils in einem Objekt namens Zugriffstoken gespeichert. Es enthält die Sicherheitsidentifizierung und die Anmeldeinformationen für den Prozess. Standardmäßig haben Threads keine eigenen Zugriffstokens. Sie können allerdings eines
erwerben, sodass einzelne Threads die Identität des Sicherheitskontextes eines anderes Prozesses annehmen können – auch von Prozessen auf einem anderen Windows-System –, ohne
andere Threads in dem Prozess zu beeinträchtigen. (Weitere Einzelheiten zur Prozess- und
Threadsicherheit erhalten Sie in Kapitel 7.)
22
Kapitel 1
Begriffe und Werkzeuge
Die VADs (Virtual Address Descriptors) sind Datenstrukturen, die der Speicher-Manager
nutzt, um sich über die vom Prozess verwendeten virtuellen Adressen auf dem neuesten Stand
zu halten. Diese Datenstrukturen werden in Kapitel 5 ausführlicher beschrieben.
Jobs
In Windows gibt es Jobs als Erweiterung des Prozessmodells. Der Hauptzweck von Jobs besteht
darin, die Verwaltung und Bearbeitung von Prozessgruppen als eine Einheit zu ermöglichen.
Diese Objekte erlauben es, bestimmte Attribute zu steuern, und bieten Grenzwerte für die mit
ihnen verknüpften Prozesse. Sie zeichnen auch grundlegende Buchführungsinformationen für
alle verknüpften Prozesse auf, sowohl die aktuellen als auch diejenigen, die bereits beendet
wurden. In gewisser Hinsicht bilden Jobs einen Ersatz für den fehlenden strukturierten Prozessbaum in Windows. In manchen Aspekten sind sie jedoch leistungsfähiger als ein Prozessbaum
nach Art von UNIX.
Der Process Explorer kann die von einem Job verwalteten Prozesse anzeigen
(standardmäßig in Braun), aber diese Funktion müssen Sie erst aktivieren. Dazu
öffnen Sie das Menü Options und wählen Configure Colors. Auf den Eigenschaftenseite solcher Prozesse gibt es außerdem die zusätzliche Registerkarte Jobs, auf
der Sie Informationen über das zugehörige Jobobjekt finden.
Weitere Informationen über die interne Struktur von Prozessen und Jobs erhalten Sie in Kapitel 3. Threads und Algorithmen zu ihrer Planung sind Thema von Kapitel 4.
Virtueller Arbeitsspeicher
Windows richtet ein virtuelles Speichersystem auf der Grundlage eines linearen Adressraums
ein, das jedem Prozess die Illusion gibt, über einen riesigen, privaten Adressraum für sich selbst
zu verfügen. Der virtuelle Speicher bietet eine logische Sicht des Arbeitsspeichers, die nicht
unbedingt mit dem physischen Aufbau übereinstimmen muss. Zur Laufzeit bildet der Speicher-Manager, unterstützt von der Hardware, die virtuellen Adressen auf die physischen Adressen ab (oder ordnet sie ihnen zu), an denen die Daten tatsächlich gespeichert werden. Durch
Schutzvorkehrungen und durch Steuern dieser Zuordnung sorgt das Betriebssystem dafür, dass
einzelne Prozesse nicht kollidieren und gegenseitig Betriebssystemdaten überschreiben.
Da der physische Arbeitsspeicher auf den meisten Systemen viel kleiner ist als der gesamte virtuelle Arbeitsspeicher, der von den laufenden Prozessen genutzt wird, lagert der Speicher-Manager einige Speicherinhalte auf die Festplatte aus. Wenn ein Thread auf eine virtuelle
Adresse zugreift, die ausgelagert wurde, lädt der Speicher-Manager die Informationen von der
Festplatte zurück in den Arbeitsspeicher.
Um die Auslagerung nutzen zu können, ist keinerlei Anpassung der Anwendungen erforderlichen, da die Hardware dem Speicher-Manager die Auslagerung ermöglicht, ohne dass
die Prozesse oder Threads das wissen oder unterstützen müssen. Abb. 1–3 zeigt zwei Prozesse, die virtuellen Arbeitsspeicher nutzen. Teilweise ist er auf den physischen Speicher (RAM)
abgebildet und teilweise ausgelagert. Beachten Sie, dass zusammenhängende virtuelle Spei-
Grundprinzipien und -begriffe
Kapitel 1
23
cherbereiche auf nicht zusammenhängende Bereiche im physischen Speicher abgebildet
werden können. Diese Bereiche werden als Seiten bezeichnet und haben eine Standardgröße
von 4 KB.
Virtueller
Arbeitsspeicher
Physischer
Arbeitsspeicher
Prozess A
Virtueller
Arbeitsspeicher
Prozess B
Festplatte
Abbildung 1–3
Zuweisung von virtuellem zu physischem Speicher mit Auslagerung
Die Größe des virtuellen Adressraums hängt von der Hardwareplattform ab. Auf 32-Bit-x86-
Systemen hat der gesamte virtuelle Adressraum eine theoretische Maximalgröße von 4 GB.
Standardmäßig weist Windows die untere Hälfte dieses Adressraums (Adressen 0x00000000
bis 0x7FFFFFFF) für den privaten Speicher der Prozesse zu und die obere Hälfte (0x80000000
bis 0xFFFFFFFF) für seinen eigenen geschützten Betriebssystemspeicher. Die Zuordnungen der
unteren Hälfte ändern sich mit dem jeweils ausgeführten Prozess, aber die Zuordnungen der
oberen Hälfte (zumindest der Großteil davon) besteht immer aus dem virtuellen Speicher für
das Betriebssystem. In Windows können auch Bootoptionen eingesetzt werden, z. B. der Qualifizierer increaseuserva aus der Bootkonfigurationsdatenbank (siehe Kapitel 5), der Prozessen
für besonders gekennzeichnete Programme die Möglichkeit einräumt, bis zu 3 GB privaten
Adressraum zu verwenden, wobei für das Betriebssystem 1 GB übrig bleibt. (»Besonders gekennzeichnet« bedeutet, dass im Header des ausführbaren Images das Flag für großen Adressraum gesetzt ist.) Diese Option ermöglicht Anwendungen wie Datenbankservern, größere
Teile der Datenbank im Prozessadressraum zu belassen, was die Notwendigkeit der Auslagerung von Teilsichten verringert und damit die Leistung erhöht (wobei jedoch der Verlust von
1 GB für das System in manchen Fällen zu deutlichen systemweiten Leistungsverlusten führen
kann). Abb. 1–4 zeigt die beiden typischen Adressraumanordnungen in 32-Bit-Versionen von
Windows. (Die Option increaseuserva ermöglicht ausführbaren Images mit dem Flag für großen Adressraum, einen Bereich mit einer beliebigen Größe zwischen 2 bis 3 GB zu nutzen.)
24
Kapitel 1
Begriffe und Werkzeuge
Hohe Adressen
32 Bit (Standard)
2 GB
Systemraum
2 GB
Benutzerprozessraum
32 Bit (optional)
1 GB
Systemraum
3 GB
Benutzerprozessraum
Niedrige Adressen
Abbildung 1–4
Typische Adressraumaufteilungen für 32-Bit-Windows
3 GB ist zwar schon besser als 2 GB, aber das ist immer noch nicht genügend virtueller Adressraum
zur Zuordnung von sehr großen Datenbanken (von mehreren Gigabytes). Um dieses Problem auf
32-Bit-Systemen anzugehen, verwendet Windows den sogenannten AWE-Mechanismus (Address
Windowing Extension), der es einer 32-Bit-Anwendung möglich macht, bis zu 64 GB physischen
Arbeitsspeicher zuzuweisen und dann Sichten oder Fenster auf seinen 2 GB großen virtuellen Adressenraum abzubilden. Diese Vorgehensweise bürdet die Abbildung des virtuellen Adressraums
auf den physischen zwar dem Entwickler auf, erfüllt aber das Bedürfnis, mehr physischen Arbeitsspeicher direkt zuzuweisen, als in einem 32-Bit-Prozessraum abgebildet werden kann.
In 64-Bit-Windows steht den Prozessen ein viel größerer Adressraum zur Verfügung, nämlich 128 TB auf Windows 8.1, Server 2012 R2 und höher. Abb. 1–5 zeigt eine vereinfachte
Darstellung des 64-Bit-Systemadressraums. (Eine ausführliche Beschreibung finden Sie in Kapitel 5.) Beachten Sie, dass die angegebenen Größen nicht die von der Architektur vorgegebenen Grenzwerte darstellen. 64 Bit Adressraum entsprechen 264 oder 16 EB (wobei 1 EB gleich
1024 PB oder 1.048.576 TB ist), doch die aktuelle 64-Bit-Hardware beschränkt dies auf kleinere
Werte. Der als »nicht zugeordnet« gekennzeichnete Bereich in Abb. 1–5 ist viel größer als der
Bereich, der zugeordnet sein kann (auf Windows 8 ungefähr eine Million Mal größer). Die Darstellung ist also bei Weitem nicht maßstabsgerecht.
64 Bit (Windows 8)
64 Bit (Windows 8.1+)
Hohe Adressen
8 TB
Systemraum
Nicht zugeordnet
Niedrige Adressen
Abbildung 1–5
8 TB
Benutzerprozessraum
128 TB
Systemraum
Nicht zugeordnet
128 TB
Benutzerprozessraum
Adressraumaufteilungen für 64-Bit-Windows
Die Implementierung des Speicher-Managers, die Adressabbildung und die Verwaltung des
physischen Arbeitsspeichers durch Windows werden in Kapitel 5 ausführlicher beschrieben.
Grundprinzipien und -begriffe
Kapitel 1
25
Kernel- und Benutzermodus
Um zu verhindern, dass Benutzeranwendungen auf kritische Betriebssystemdaten zugreifen
und sie vielleicht sogar ändern, verwendet Windows zwei verschiedene Prozessorzugriffsmodi
(auch wenn der Prozessor, auf denen Windows läuft, mehr als zwei unterstützen kann), nämlich
den Benutzermodus und den Kernelmodus. Benutzeranwendungen laufen im Benutzermodus,
Betriebssystemcode (wie Systemdienste und Gerätetreiber) dagegen im Kernelmodus, der Zugriff auf den gesamten Systemspeicher und alle CPU-Anweisungen gewährt. Zur Unterscheidung dieser Modi werden bei manchen Prozessoren die Begriffe Code Privilege Level und Ring
Level und bei anderen Supervisor Mode und Application Mode verwendet. Unabhängig von
der Bezeichnung gestatten sie dem Betriebssystemkernel höhere Rechte als Benutzeranwendungen, wodurch Betriebssystementwickler die erforderliche Grundlage bekommen, um sicherzustellen, dass eine nicht ordnungsgemäß funktionierende Anwendung die Stabilität des
Gesamtsystems nicht beeinträchtigen kann.
Die Architekturen von x86- und x64-Prozessoren definieren vier Rechteebenen
(Ringe), um Systemcode und -daten gegen versehentliches oder böswilliges Überschreiben durch Code mit geringeren Rechten zu schützen. Windows verwendet
Rechteebene 0 (Ring 0) für den Kernel- und Rechteebene 3 (Ring 3) für den Benutzermodus. Der Grund dafür, dass Windows nur zwei Ebenen nutzt, besteht
darin, dass einige Hardwarearchitekturen, wie ARM oder früher MIPS/Alpha, nur
zwei implementiert hatten. Die Entscheidung für diesen kleinsten gemeinsamen
Nenner ermöglichte eine effizientere und portierbare Architektur, insbesondere da
die anderen Ringebenen von x86/x64 nicht die gleichen Garantien bieten wie die
Unterscheidung zwischen Ring 0 und Ring 3.
Alle Windows-Prozesse haben zwar jeweils ihren eigenen privaten Arbeitsspeicher, doch der
Kernelmoduscode des Betriebssystems und der Gerätetreiber teilen sich denselben virtuellen
Adressraum. Jede Seite im virtuellen Speicher wird mit dem Zugriffsmodus gekennzeichnet,
den der Prozessor haben muss, um sie zu lesen bzw. zu schreiben. Seiten im Systemadressraum
sind nur vom Kernelmodus aus zugänglich, Seiten im Benutzeradressraum dagegen vom Benutzer- und vom Kernelmodus aus. Schreibgeschützte Seiten (z. B. solche, die statische Daten
enthalten) sind in keinem Modus schreibbar. Auf Prozessoren mit Ausführungsschutz für den
Arbeitsspeicher kann Windows außerdem Seiten mit Daten als nicht ausführbar kennzeichnen
und dadurch die unabsichtliche oder böswillige Codeausführung in Datenbereichen verhindern (wenn die Funktion der Datenausführungsverhinderung eingeschaltet ist).
Windows bietet keinen Schutz für privaten les- und schreibbaren Systemspeicher, der von
Komponenten im Kernelmodus genutzt wird. Anders ausgedrückt, im Kernelmodus hat der
Betriebssystem- und Gerätetreibercode vollständigen Zugriff auf den Systemarbeitsspeicher
und kann die Windows-Sicherheit umgehen, um auf Objekte zuzugreifen. Da der Großteil des
Windows-Betriebssystemcodes im Kernelmodus läuft, ist es unverzichtbar, die im Kernelmodus
ausgeführten Komponenten sorgfältig zu entwerfen und zu testen, damit sie die Systemsicherheit nicht gefährden und keine Instabilitäten des Systems hervorrufen.
26
Kapitel 1
Begriffe und Werkzeuge
Aufgrund des mangelnden Schutzes ist es auch wichtig, beim Laden von Drittanbieter-Gerätetreibern besonders achtsam zu sein, insbesondere wenn diese nicht signiert sind, denn
wenn sich der Treiber erst einmal im Kernelmodus befindet, hat er kompletten Zugriff auf
sämtliche Betriebssystemdaten. Dieses Risiko war einer der Gründe für die Einführung eines
Mechanismus zur Treibersignierung in Windows 2000. Dabei wird bei dem Versuch, einen nicht
signierten Plug-&-Play-Treiber hinzuzufügen, der Benutzer gewarnt und bei entsprechender
Einstellung der Vorgang blockiert. (Weitere Informationen über Treibersignierung erhalten Sie
in Kapitel 6, »Das E/A-System«.) Andere Arten von Treibern sind davon jedoch nicht betroffen.
Die Treiberüberprüfung hilft Treiberautoren außerdem, Bugs zu finden, die die Sicherheit oder
Zuverlässigkeit gefährden, z. B. Pufferüberläufe und Speicherlecks. (Die Treiberüberprüfung
wird ebenfalls in Kapitel 6 erläutert.)
In der 64-Bit- und der ARM-Version von Windows 8.1 schreibt die Richtlinie zur Kernelmodus-Codesignierung (KMCS) vor, dass alle Gerätetreiber (nicht nur Plug-&-Play-Treiber) mit
einem kryptografischen Schlüssel von einer der namhaften Zertifizierungsstellen signiert sein
müssen. Dadurch können die Benutzer die Installation eines nicht signierten Treibers nicht erzwingen, nicht einmal mit Administratorrechten. Die Einschränkung kann einmalig manuell
deaktiviert werden, um Treiber selbst zu signieren und zu testen. Dabei wird auf dem Desktophintergrund jedoch das Wasserzeichen »Test Mode« angezeigt, und es werden bestimmte
Funktionen der digitalen Rechteverwaltung (DRM) ausgeschaltet.
In Windows 10 hat Microsoft eine noch stärkere Änderung umgesetzt, die ein Jahr nach
der Veröffentlichung im Rahmen des Anniversary Updates im Juli durchgesetzt wurde (Version
1607). Seit diesem Zeitpunkt müssen alle neuen Windows 10-Treiber von einer der beiden akzeptierten Zertifizierungsstellen mit einem SHA-2-EV-Hardwarezertifikat (Extended Validation)
signiert werden. Das reguläre dateigestützte SHA-1-Zertifikat, das von 20 Stellen ausgegeben
wird, reicht also nicht mehr aus. Nach der EV-Signierung muss der Hardwaretreiber außerdem
durch das Systemgeräteportal (SysDev) zur Bescheinigung eingereicht werden, bei der der Treiber eine Microsoft-Signatur erhält. Der Kernel signiert nun nur noch von Microsoft signierte
Windows 10-Treiber. Außer dem zuvor erwähnten Testmodus gibt es keine Ausnahmen. Treiber,
die vor dem Veröffentlichungsdatum von Windows 10 (Juli 2015) signiert wurden, können vorläufig jedoch weiterhin mit der regulären Signatur geladen werden.
Die strengsten Anforderungen stellt zurzeit Windows Server 2016. Die bereits genannte
EV-Signierung ist nach wie vor erforderlich, aber hier reicht die anschließende reine Bescheinigungssignierung nicht mehr aus. Damit ein Windows 10-Treiber auf einem Serversystem geladen werden kann, muss er die strenge WHQL-Zertifizierung (Windows Hardware Quality Labs)
im Rahmen des Hardware Compatibility Kit (HCK) durchlaufen und zur formalen Evaluierung
eingereicht werden. Nur Treiber mit WHQL-Signierung – die Systemadministratoren gewisse
Kompatibilitäts-, Sicherheits-, Leistungs- und Stabilitätsgarantien gibt – dürfen auf solchen Systemen geladen werden. Unter dem Strich sollte die Beschränkung der Drittanbietertreiber, die
in den Kernelmodusspeicher geladen werden dürfen, für erhebliche Verbesserungen bei der
Stabilität und Sicherheit sorgen.
Bei einzelnen Hersteller-, Plattform- und sogar Unternehmenskonfigurationen von Win
dows können diese Signierungsrichtlinien angepasst werden, z. B. durch die DeviceGuard-
Technologie, die wir weiter hinten in diesem Kapitel im Abschnitt »Hypervisor« sowie in Kapitel 7 noch kurz erläutern werden. Damit kann ein Unternehmen WHQL-Signaturen auch
Grundprinzipien und -begriffe
Kapitel 1
27
auf Windows 10-Clientsystemen verlangen oder diese Anforderung auf Windows Server
2016-Systemen aussetzen.
Wie Sie in Kapitel 2, »Systemarchitektur«, sehen werden, wechseln Benutzeranwendungen
vom Benutzer- in den Kernelmodus, wenn sie einen Systemdienst aufrufen. So muss beispielsweise die Windows-Funktion ReadFile irgendwann die interne Windows-Routine aufrufen, die
sich eigentlich um das Lesen der Daten in einer Datei kümmert. Da diese Routine auf interne
Systemdatenstrukturen zugreift, muss sie im Kernelmodus laufen. Durch eine besondere Prozessoranweisung wird der Wechsel vom Benutzer- in den Kernelmodus ausgelöst, wobei der
Prozessor in den Zuteilungscode für Systemdienste im Kernel eintritt. Dieser Code wiederum
ruft die entsprechende interne Funktion in Ntoskrnl.exe oder Win32k.sys auf. Vor der Rückgabe
der Steuerung an den Benutzerthread wird der Prozessormodus wieder zurück in den Benutzermodus geschaltet. Dadurch schützt das Betriebssystem sich selbst und seine Daten vor der
Verwendung und Bearbeitung durch Benutzerprozesse.
Der Wechsel vom Benutzer- in den Kernelmodus (und umgekehrt) wirkt sich nicht
per se auf die Threadplanung aus. Ein Moduswechsel ist kein Kontextwechsel. Nähere Einzelheiten zur Systemdienstzuteilung finden Sie in Kapitel 2.
Es ist daher normal, wenn ein Benutzerthread manchmal im Benutzer- und manchmal im Kernelmodus ausgeführt wird. Da der Großteil des Grafik- und Fenstersystems auch im Kernelmodus
läuft, verbringen grafikintensive Anwendungen sogar mehr Zeit im Kernel- als im Benutzermodus. Das können Sie leicht beobachten, indem Sie eine grafikintensive Anwendung wie Microsoft
Paint ausführen und die zeitliche Aufteilung zwischen Benutzer- und Kernelmodus anhand der in
Tabelle 1–3 aufgeführten Leistungsindikatoren messen. Anspruchsvollere Anwendungen können
auch modernere Technologien wie Direct2D und DirectComposition nutzen, die Massenberechnungen im Benutzermodus durchführen und nur die Oberflächenrohdaten an den Kernel senden, was die erforderliche Zeit für den Wechsel zwischen Benutzer- und Kernelmodus verringert.
Objekt: Indikator
Bedeutung
Prozessor: Privilegierte Zeit (%)
Prozentualer Anteil der Zeit, in der eine einzelne CPU (oder alle
CPUs) während eines gegebenen Zeitraums im Kernelmodus lief
Prozessor: Benutzerzeit (%)
Prozentualer Anteil der Zeit, in der eine einzelne CPU (oder alle
CPUs) während eines gegebenen Zeitraums im Benutzermodus lief
Prozess: Privilegierte Zeit (%)
Prozentualer Anteil der Zeit, in der die Threads in einem Prozess
während eines gegebenen Zeitraums im Kernelmodus ausgeführt
wurden
Prozess: Benutzerzeit (%)
Prozentualer Anteil der Zeit, in der die Threads in einem Prozess
während eines gegebenen Zeitraums im Benutzermodus ausgeführt wurden
Thread: Privilegierte Zeit (%)
Prozentualer Anteil der Zeit, in der ein Thread während eines gegebenen Zeitraums im Kernelmodus ausgeführt wurde
Thread: Benutzerzeit (%)
Prozentualer Anteil der Zeit, in der ein Thread während eines gegebenen Zeitraums im Benutzermodus ausgeführt wurde
Tabelle 1–3
28
Leistungsindikatoren im Zusammenhang mit Benutzer- und Kernelmodus
Kapitel 1
Begriffe und Werkzeuge
Experiment: Kernel- und Benutzermodus
Mit der Leistungsüberwachung können Sie sich ansehen, wie viel Zeit Ihr System im Kernelund im Benutzermodus jeweils verbringt. Gehen Sie dazu wie folgt vor:
1.
Öffnen Sie das Startmenü und geben Sie Run Performance Monitor ein, um die Leistungsüberwachung auszuführen. (Der vollständige Befehl sollte schon angezeigt werden, bevor Sie die Eingabe abgeschlossen haben.)
2.
Wählen Sie in der Struktur auf der linken Seite die Leistungsüberwachung unter Leistungs-/Überwachungstools aus.
3.
Um den Standardindikator für die CPU-Gesamtzeit zu entfernen, klicken Sie auf die
Schaltfläche Löschen in der Systemleiste oder drücken die Taste (Entf).
4.
Klicken Sie in der Symbolleiste auf die Schaltfläche Hinzufügen (die mit dem großen
Pluszeichen).
5.
Erweitern Sie den Indikatorbereich Prozessor, klicken Sie auf Privilegierte Zeit (%) und
bei gedrückter (Strg)-Taste auf Benutzerzeit (%).
6.
Klicken Sie auf Hinzufügen und dann auf OK.
7.
Öffnen Sie eine Eingabeaufforderung und geben Sie dir\\%computername\c$ /s ein,
um einen Verzeichnisscan von Laufwerk C zu starten.
8.
Schließen Sie das Tool, wenn Sie fertig sind.
→
Grundprinzipien und -begriffe
Kapitel 1
29
Sie können sich diesen Überblick auch mit dem Task-Manager verschaffen. Klicken Sie dort
einfach auf die Registerkarte Leistung und dann auf das CPU-Diagramm und wählen Sie
Kernel-Zeiten anzeigen. Die CPU-Leistungsanzeige zeigt jetzt in einem dunkleren Hellblau
die CPU-Nutzung im Kernelmodus.
Um zu sehen, wie die Verteilung zwischen Benutzer- und Kernelmodus bei einzelnen
Prozessen aussieht, führen Sie das Tool erneut aus, fügen aber die Prozessindikatoren Benutzerzeit (%) und Privilegierte Zeit (%) für die gewünschten Prozesse im System hinzu:
1.
Starten Sie die Leistungsüberwachung ggf. neu. (Falls sie noch läuft, rechtsklicken Sie
auf den Grafikbereich und wählen Sie Alle Leistungsindikatoren entfernen, um mit einer
leeren Anzeige beginnen zu können.)
2.
Klicken Sie in der Symbolleiste auf die Schaltfläche mit dem Pluszeichen.
3.
Erweitern Sie im Bereich der verfügbaren Indikatoren den Abschnitt Prozess.
4.
Wählen Sie die Indikatoren Benutzerzeit (%) und Privilegierte Zeit (%) aus.
5.
Wählen Sie im Feld Instanz einige Prozesse aus (z. B. mmc, csrss und Leerlauf).
6.
Klicken Sie auf Hinzufügen und dann auf OK.
7.
Bewegen Sie den Mauszeiger rasch hin und her.
8.
Drücken Sie (Strg) + (H), um den Hervorhebungsmodus einzuschalten. Dadurch wird
der zurzeit ausgewählte Indikator schwarz hervorgehoben.
9.
Scrollen Sie durch die Liste am unteren Rand der Anzeige, um die Prozesse zu erkennen, die ausgeführt wurden, als Sie die Maus bewegt haben. Achten Sie darauf, ob sie
im Benutzer- oder im Kernelmodus ausgeführt wurden.
Bei der Bewegung der Maus sollten Sie in der Spalte Instanz für den Prozess mmc eine
Zunahme der Zeit sowohl im Kernel- als auch im Benutzermodus sehen, da der Prozess
Anwendungscode im Benutzermodus ausführt und Windows-Funktionen aufruft, die im
Kernelmodus laufen. Bei der Bewegung der Maus werden Sie auch eine Threadaktivität im
Kernelmodus für den Prozess csrss feststellen. Ursache dafür ist der Kernelmodusthread des
Windows-Teilsystems für Roheingaben von der Tastatur und die Maus, der mit diesem Prozess verknüpft ist. (Mehr über Systemthreads und Teilsysteme erfahren Sie in Kapitel 2.) Der
Leerlaufprozess, der fast 100 % seiner Zeit im Kernelmodus verbringt, ist kein echter Prozess, sondern stellt nur eine Möglichkeit dar, die Leerlaufzyklen der CPU zu berücksichtigen.
Wenn Windows nichts zu tun hat, so tut es das dieser Anzeige zufolge im Kernelmodus.
Hypervisor
Jüngste Entwicklungen bei den Anwendungs- und Softwaremodellen wie die Einführung von
Clouddiensten und die weite Verbreitung von IoT-Geräten haben dazu geführt, dass Betriebssystem- und Hardwarehersteller effizientere Möglichkeiten finden müssen, um virtuelle Gastbetriebssysteme auf der Hosthardware eines Computers auszuführen, entweder um mehrere
Systeme auf einer Serverfarm unterzubringen und 100 isolierte Websites auf einem einzigen
Server auszuführen oder um Entwicklern zu erlauben, Dutzende von verschiedenen Betriebs-
30
Kapitel 1
Begriffe und Werkzeuge
systemvarianten zu testen, ohne spezialisierte Hardware dafür kaufen zu müssen. Der Bedarf
für schnelle, effiziente und sichere Virtualisierung hat neue Modelle des Computerwesens und
neue Ansichten über Software gefördert. Heute wird besondere Software – beispielsweise Docker, das in Windows 10 und Windows Server 2016 unterstützt wird – in Containern ausgeführt,
um komplett isolierte virtuelle Maschinen zu bilden, die ausschließlich dafür da sind, einen
einzelnen Anwendungsstack oder ein Framework auszuführen, was die Grenzen zwischen Gast
und Host mehr und mehr verschwimmen lässt.
Um solche Virtualisierungsdienste anzubieten, nutzen fast alle modernen Lösungen einen Hypervisor. Dabei handelt es sich um eine spezialisierte und mit hohen Rechten ausgestattete Komponente, die die Virtualisierung und Isolierung aller Ressourcen des Computers
erlaubt – vom virtuellen und physischen Arbeitsspeicher über Geräteinterrupts bis zu PCI- und
USB-Geräten. Ein Beispiel für einen Hypervisor ist Hyper-V, das die Hyper-V-Clientfunktionen
von Windows 8.1 und höher ermöglicht. Konkurrenzprodukte wie Xen, KVM, VMware und
VirtualBox haben ihre eigenen Hypervisors mit ihren jeweiligen Stärken und Schwächen.
Da ein Hypervisor hohe Rechte und stärkeren Zugriff als der Kernel selbst hat, bietet er
einen erheblichen Vorteil gegenüber der reinen Möglichkeit, mehrere Gastinstanzen anderer
Betriebssysteme auszuführen: Er kann einzelne Hostinstanzen schützen und überwachen, um
mehr Garantien zu geben, als es der Kernel vermag. In Windows 10 nutzt Microsoft jetzt den
Hypervisor Hyper-V, um die neuen VBS-Dienste (Virtualization-Based Security) anzubieten:
QQ DeviceGuard Bietet Hypervisor-Codeintegrität (HVCI) für eine stärkere Codesignierungsgarantie als nur mit KMCS und ermöglicht die Anpassung der Signaturrichtlinie von
Windows sowohl für Benutzer- als auch für Kernelmoduscode.
QQ HyperGuard
visors.
Schützt wichtige Datenstrukturen und Code des Kernels und des Hyper
QQ CredentialGuard Verhindert den nicht autorisierten Zugriff auf Anmeldeinformationen
und Geheimnisse für Domänenkonten in Kombination mit biometrischer Sicherheit.
QQ ApplicationGuard Stellt eine noch stärkere Sandbox für den Browser Microsoft Edge zur
Verfügung.
QQ HostGuardian und ShieldedFabric Sie nutzen virtuelles TPM (v-TPM), um eine virtuelle
Maschine vor der Infrastruktur zu schützen, auf der sie ausgeführt wird.
Außerdem ermöglicht Hyper-V einige wichtige Vorsorgemaßnahmen des Kernels gegen Exploits und ähnliche Angriffe. Der Hauptvorteil all dieser Technologien besteht darin, dass sie
anders als vorherige kernelgestützte Sicherheitsvorkehrungen nicht anfällig für bösartige oder
schlecht geschriebene Treiber sind, ob signiert oder nicht. Das gibt ihnen eine hohe Widerstandsfähigkeit gegen die anspruchsvollen modernen Angriffe. Möglich wird dies durch die
Implementierung von virtuellen Vertrauensebenen (Virtual Trust Levels, VTL) durch den Hypervisor. Da das normale Betriebssystem und seine Komponenten in einem weniger privilegierten
Modus laufen (VTL 0), die VBS-Technologien aber auf VTL 1 (mit höheren Rechten), können
sie durch Kernelmoduscode nicht beeinträchtigt werden. Der Code verbleibt daher im Rechteraum von VTL 0. In dieser Hinsicht können Sie sich VTLs als orthogonal zu den Rechteebenen
des Prozessors vorstellen: Kernel- und Benutzermodus existieren innerhalb der einzelnen VTLs
und der Hypervisor verwaltete die Rechte über die VTLs hinweg. Kapitel 2 behandelt weitere
Grundprinzipien und -begriffe
Kapitel 1
31
Einzelheiten über hypervisorunterstützte Architektur. In Kapitel 7 werden die VBS-Sicherheitsmechanismen ausführlich erläutert.
Firmware
Windows-Komponenten verlassen sich zunehmend auf die Sicherheit des Betriebssystems und
seines Kernels, wobei sich Letzterer wiederum auf den Schutz des Hypervisors verlässt. Es stellt
sich jedoch die Frage, was dafür sorgt, dass diese Komponenten sicher geladen und ihre Inhalt
authentifiziert werden können. Das ist gewöhnlich die Aufgabe des Bootloaders, aber auch er
benötigt irgendeine Form von Authentifizierungsprüfung. Auf diese Weise entsteht eine immer
kompliziertere Vertrauenshierarchie.
Was also bildet den Anfang dieser Vertrauenskette, um einen ungestörten Startvorgang zu
garantieren? In modernen Systemen mit Windows 8 und höher fällt dies in die Zuständigkeit
der Systemfirmware, die auf zertifizierten Systemen auf UEFI basieren muss. Als Teil des von
Windows vorgeschriebenen UEFI-Standards (UEFI 2.3.1b; siehe http://www.uefi.org) muss eine
sichere Bootimplementierung mit starken Garantien und Anforderungen zur Signierung von
bootrelevanter Software vorhanden sein. Aufgrund dieser Verifizierung besteht die Garantie,
dass Windows-Komponenten vom Anfang des Vorgangs an sicher geladen werden. Außerdem können Technologien wie TPM (Trusted Platform Module) den Prozess messen, um eine
Bescheinigung (sowohl lokal als auch im Netzwerk) zu bieten. Durch Branchenpartnerschaften
unterhält Microsoft eine Whitelist und eine Blacklist von UEFI-sicheren Bootkomponenten für
den Fall von Bootsoftwarefehlern oder -angriffen. In Windows-Updates sind jetzt auch Firm
wareaktualisierungen enthalten. Wir werden zwar erst in Kapitel 11, »Starten und Herunterfahren«, von Band 2 wieder auf Firmware kommen, doch es ist wichtig, schon hier auf die Bedeutung hinzuweisen, die sie durch ihre Garantien für die moderne Windows-Architektur bietet.
Terminaldienste und mehrere Sitzungen
Terminaldienste bezieht sich auf die Unterstützung, die Windows für mehrere interaktive Benutzersitzungen auf einem einzelnen System bietet. Mit den Windows-Terminaldiensten kann
ein Remotebenutzer eine Sitzung auf einem anderen Computer einrichten, sich anmelden
und Anwendungen auf dem Server ausführen. Der Server überträgt die grafische Benutzeroberfläche (sowie andere auswählbare Ressourcen wie Audio und die Zwischenablage) an den
Client, und der Client überträgt die Benutzereingabe zurück an den Server. (Ähnlich wie das
X-Window-System erlaubt Windows die Ausführung einzelner Anwendungen auf einem Serversystem so, dass nur deren Anzeige und nicht der gesamte Desktop an den Client übertragen
wird.)
Die erste Sitzung wird als Dienstesitzung oder Sitzung 0 angesehen und enthält Prozesse,
die Systemdienste beherbergen (mehr darüber in Kapitel 9 von Band 2). Die erste Anmeldesitzung an der physischen Konsole des Computers ist Sitzung 1. Weitere Sitzungen können
durch die Verwendung eines Programms für Remotedesktopverbindungen (Mstsc.exe) oder
den schnellen Benutzerwechsel erstellt werden.
Die Clientausgaben von Windows erlauben einem einzelnen Remotebenutzer, Verbindung
mit dem Computer aufzunehmen, aber wenn schon jemand an der Konsole angemeldet ist, so
32
Kapitel 1
Begriffe und Werkzeuge
ist die Arbeitsstation gesperrt. Das bedeutet, dass System kann entweder lokal oder über das
Netzwerk genutzt werden, aber nicht beides zugleich. Windows-Ausgaben mit Windows Media
Center gestatten eine interaktive und bis zu vier Windows Media Center Extender-Sitzungen.
Windows-Serversysteme ermöglichen zwei Remoteverbindungen zur selben Zeit. Das
dient zur Erleichterung der Remoteverwaltung, also etwa die Verbindung von Verwaltungswerkzeugen, für deren Nutzung sie an dem zu verwaltenden Computer angemeldet sein müssen. Außerdem unterstützen diese Systeme bis zu zwei Remotesitzungen, falls sie entsprechend
lizenziert und als Terminalserver eingerichtet sind.
Alle Clientausgaben von Windows ermöglichen mehrere Sitzungen, die lokal durch den
schnellen Benutzerwechsel erstellt werden. Von diesen Sitzungen kann jedoch immer nur eine
auf einmal ausgeführt werden. Anstatt sich abzumelden, kann ein Benutzer auch nur seine Sitzung trennen. Dazu klickt er auf die Startschaltfläche und dann auf den aktuellen Benutzer und
wählt in dem daraufhin erscheinenden Untermenü Benutzer wechseln. Er kann auch (Windows)
+ (L) drücken und dann unten links auf einen anderen Benutzer klicken. In jedem Fall bleibt
die aktuelle Sitzung – d. h., die Prozesse, die darin laufen, und alle sitzungsweiten Datenstrukturen, die sie beschreiben – im System aktiv, während das System zum Hauptanmeldebildschirm
zurückkehrt (falls es sich nicht bereits dort befindet). Wenn sich ein neuer Benutzer anmeldet,
wird eine neue Sitzung erstellt.
Für Anwendungen, die wissen sollen, dass sie in einer Terminalserversitzung laufen, gibt es
eine Reihe von Windows-APIs, um diesen Umstand programmgesteuert zu ermitteln und um
verschiedene Aspekte der Terminaldienste zu steuern. (Einzelheiten entnehmen Sie bitte dem
Windows SDK und der Remote Desktop Service API.)
Kapitel 2 beschreibt kurz, wie Sitzungen erstellt werden, und enthält einige Experimente,
die zeigen, wie Sie sich Sitzungsinformationen mithilfe verschiedener Werkzeuge ansehen können, u. a. mit dem Kerneldebugger. Der Abschnitt »Objekt-Manager« in Kapitel 8 von Band 2
beschreibt, wie der Systemnamensraum für Objekte sitzungsweise instanziiert wird und wie Anwendungen, die über andere Instanzen auf demselben System Bescheid wissen müssen, diese
Kenntnisse gewinnen können. In Kapitel 5 schließlich erfahren Sie, wie der Speicher-Manager
sitzungsweite Daten einrichtet und verwaltet.
Objekte und Handles
Ein Kernelobjekt in Windows ist eine einzelne Laufzeitinstanz eines statisch definierten Objekttyps. Ein Objekttyp wiederum besteht aus einem im System definierten Datentyp, Funktionen für Instanzen dieses Datentyps sowie Objektattribute. Wenn Sie Windows-Anwendungen
schreiben, werden Sie Prozess-, Thread-, Datei-, Ereignis- und sonstigen Objekten begegnen.
All diese Objekte gehen auf maschinennähere Objekte zurück, die von Windows erstellt und
verwaltet werden. Ein Prozess ist in Windows eine Instanz des Objekttyps für Prozesse, eine
Datei eine Instanz des Objekttyps für Dateien usw.
Ein Objektattribut ist ein Datenfeld in einem Objekt, das einen Teil des Objektzustands definiert. Beispielsweise hat ein Objekt vom Typ »Prozess« Attribute wie die Prozesskennung, eine
grundlegende Planungspriorität und einen Zeiger auf ein Zugriffstokenobjekt. Objektmethoden
sind die Vorkehrungen zur Bearbeitung von Objekten und lesen oder ändern gewöhnlich die
Grundprinzipien und -begriffe
Kapitel 1
33
Objektattribute. Beispielsweise nimmt die Methode open für einen Prozess eine Prozesskennung
als Eingabe entgegen und gibt einen Zeitpunkt auf das Objekt als Ausgabe zurück.
Es gibt auch den Parameter ObjectAttributes, den ein Aufrufer angibt, wenn er
mit den Objekt-Manager-APIs des Kernels ein Objekt erstellt. Dieser Parameter
darf nicht mit der breiteren Bedeutung des Wortes »Objektattribute« verwechselt
werden.
Der grundlegendste Unterschied zwischen einem Objekt und einer gewöhnlichen Datenstruktur besteht darin, dass die interne Struktur eines Objekts undurchsichtig ist. Um Daten aus
einem Objekt zu gewinnen oder darin abzulegen, müssen Sie einen Objektdienst aufrufen. Es
ist nicht möglich, die Daten in einem Objekt direkt zu lesen oder zu ändern. Dadurch wird die
zugrunde liegende Implementierung des Objekts von dem Code, der es lediglich benutzt, getrennt, was es ermöglicht, Objektimplementierungen im Lauf der Zeit leicht zu ändern.
Mithilfe des Objekt-Managers, einer Kernelkomponente, bieten Objekte eine bequeme
Möglichkeit, um die folgenden wichtigen Betriebssystemaufgaben zu erfüllen:
QQ Systemressourcen mit Namen versehen, die für Menschen lesbar sind
QQ Ressourcen und Daten von Prozessen gemeinsam nutzen lasen
QQ Ressourcen vor nicht autorisiertem Zugriff schützen
QQ Verfolgen von Verweisen, wodurch das System es erkennt, wenn ein Objekt nicht mehr
gebraucht wird, sodass seine Zuweisung automatisch aufgehoben werden kann
Nicht alle Datenstrukturen in Windows sind Objekte. Nur Daten, die gemeinsam genutzt, geschützt, benannt oder (mithilfe von Systemdiensten) für Benutzermodusprogramme sichtbar
gemacht werden müssen, werden in Objekte gestellt. Strukturen, die nur von einer Betriebssystemkomponente verwendet werden, um interne Funktionen zu implementieren, sind keine
Objekte. Objekte und Handles (Verweise auf Objektinstanzen) werden ausführlicher in Kapitel 8
von Band 2 beschrieben.
Sicherheit
Windows wurde von Anfang an auf Sicherheit und auf die Erfüllung verschiedener formaler
staatlicher und Branchensicherheitseinstufungen ausgelegt, darunter der CCITSE-Spezifikation
(Common Criteria for Information Technology Security Evaluation). Eine staatlich anerkannte
Sicherheitseinstufung macht ein Betriebssystem konkurrenzfähig. Natürlich sind viele der geforderten Eigenschaften für jedes Mehrbenutzersystem von Vorteil.
Zu den wichtigsten Sicherheitseigenschaften von Windows gehören:
QQ Bedingter (Kenntnis nur, wenn nötig) und verbindlicher Schutz für alle gemeinsam nutzbaren Systemobjekte wie Dateien, Verzeichnisse, Prozesse, Threads usw.
QQ Sicherheitsüberwachung für die Verantwortlichkeit von Subjekten oder Benutzern und den
von ihnen ausgelösten Aktionen
34
Kapitel 1
Begriffe und Werkzeuge
QQ Benutzerauthentifizierung bei der Anmeldung
QQ Verhindern des Zugriffs eines Benutzers auf nicht initialisierte Ressourcen wie freien Arbeitsspeicher oder Festplattenplatz, deren Zuweisung ein anderer Benutzer aufgehoben hat
Windows bietet drei Arten der Zugriffssteuerung für Objekte:
QQ Bedingte Zugriffssteuerung Dies ist der Schutzmechanismus, an den die meisten Menschen beim Thema Betriebssystemsicherheit denken. Mit dieser Methode gewähren oder
verweigern die Besitzer von Objekten (wie Dateien oder Druckern) den Zugriff für andere.
Wenn sich ein Benutzer anmeldet, erhalt er einen Satz von Sicherheitsanmeldeinforma
tionen oder einen Sicherheitskontext. Beim Versuch, auf ein Objekt zuzugreifen, wird dieser
Sicherheitszugriff mit der Zugriffssteuerungsliste für das Objekt verglichen, um zu bestimmen, ob er über die erforderlichen Berechtigungen für die verlangte Operation verfügt. In
Windows Server 2012 und Windows 8 wurde diese Art der bedingten Zugriffssteuerung
durch die Einführung einer attributgestützten Zugriffssteuerung (oder »dynamischen Zugriffssteuerung«) noch verbessert. Dabei muss die Zugriffssteuerungsliste einer Ressource
nicht mehr unbedingt einzelne Benutzer und Gruppen nennen, sondern kann auch die
Attribute oder Claims angeben, die für den Zugriff auf die Ressource erforderlich sind, z. B.
»Zugangsstufe: Top Secret« oder »Dienstalter: 10 Jahre«. Durch die Möglichkeit, SQL-Datenbanken und Schemata mit Aktive Directory durchsuchen und dadurch solche Attribute
automatisch ausfüllen zu lassen, bietet diese Vorgehensweise ein erheblich eleganteres
und flexibleres Sicherheitsmodell, bei dem sich Organisationen nicht mehr mühevoll um
die manuelle Verwaltung von Gruppen und die Gruppenhierarchien kümmern müssen.
QQ Privilegierte Zugriffssteuerung Sie ist dann erforderlich, wenn die bedingte Zugriffssteuerung nicht ausreicht. Mit dieser Methode wird dafür gesorgt, dass jemand an geschützte Objekte gelangen kann, wenn der Besitzer nicht verfügbar ist. Nehmen wir an,
ein Angestellter scheidet aus einem Unternehmen aus. Der Administrator benötigt dann
eine Möglichkeit, um Zugriff auf die Dateien zu bekommen, die nur für diesen Mitarbeiter
zugänglich waren. In einem solchen Fall kann der Administrator unter Windows den Besitz
der Datei übernehmen, um deren Rechte nach Bedarf einzurichten.
QQ Verbindliche Zugriffssteuerung Diese Methode wird angewendet, wenn zusätzliche Sicherheitsvorkehrungen erforderlich sind, um Objekte zu schützen, auf die aus demselben
Benutzerkonto heraus zugegriffen wird. Sie wird für verschiedene Zwecke eingesetzt, von
einzelnen Aspekten der Sandboxtechnologie für Windows-Apps (siehe die nachfolgende
Erörterung) über die Isolierung von Internet Explorer im geschützten Modus (und anderen
Browsern) von der Benutzerkonfiguration bis zum Schutz von Objekten, die von einem
Administratorkonto mit erhöhten Rechten erstellt wurden, vor dem Zugriff von Nicht-
Administratorkonten ohne erhöhte Rechte. (Weitere Informationen über die Benutzerkontensteuerung erhalten Sie in Kapitel 7.)
Ab Windows 8 wird eine als Anwendungscontainer (AppContainer) bezeichnete Sandbox für
Windows-Apps verwendet. Sie bietet eine Trennung von anderen Anwendungscontainern
und nicht zu Windows-Apps gehörenden Prozessen. Über wohldefinierte, von der WindowsLaufzeitumgebung bereitgestellte Kontrakte kann Code in Anwendungscontainern mit Maklern
(nicht isolierten Prozessen, die mit den Anmeldeinformationen des Benutzers ausgeführt wer-
Grundprinzipien und -begriffe
Kapitel 1
35
den) und manchmal auch mit anderen Anwendungscontainern oder Prozessen kommunizieren.
Ein kanonisches Beispiel dafür ist der Browser Microsoft Edge; er läuft in einem Anwendungscontainer und bietet dadurch einen besseren Schutz gegen Schadcode, der in seinen Grenzen
ausgeführt wird. Des Weiteren können Drittentwickler Anwendungscontainer auf ähnliche Weise zur Isolierung eigener Anwendungen nutzen, die keine Windows-Apps sind. Das Modell der
Anwendungscontainer erzwingt einen erheblichen Wandel der herkömmlichen Programmierparadigmen, weg von der traditionellen Implementierung von Einzelprozess-Anwendungen mit
mehreren Threads hin zu Anwendungen mit mehreren Prozessen.
Sicherheit ist in der Windows-API allgegenwärtig. Das Windows-Teilsystem implementiert
die objektgestützte Sicherheit auf die gleiche Weise wie das Betriebssystem: Es schützt gemeinsam genutzte Windows-Objekte vor nicht autorisiertem Zugriff, indem es sie mit Windows-Sicherheitsdeskriptoren versieht. Wenn eine Anwendung zum ersten Mal auf ein gemeinsam
genutztes Objekt zugreift, überprüft das Windows-Teilsystem, ob sie das Recht dazu hat. Bei
einem positiven Ausgang dieser Sicherheitsprüfung erlaubt das Windows-Teilsystem der Anwendung, fortzufahren.
Eine ausführliche Beschreibung der Sicherheit in Windows erhalten Sie in Kapitel 7.
Die Registrierung
Bei der Arbeit mit Windows-Betriebssystemen haben Sie vielleicht schon einmal einen Blick in
die Registrierung geworfen. Es ist schlecht möglich, die internen Mechanismen von Windows zu
erläutern, ohne die Registrierung zu erwähnen, denn diese Systemdatenbank enthält Informa
tionen über den Start und die Konfiguration des Systems, systemweite Softwareeinstellungen,
die den Betrieb von Windows steuern, die Sicherheitsdatenbank und Konfigurationseinstellungen für die einzelnen Benutzer, beispielsweise den zu verwendenden Bildschirmschoner. Außerdem gewährt die Registrierung Einblicke in flüchtige Daten im Arbeitsspeicher, darunter den
aktuellen Hardwarezustand des Systems (welche Gerätetreiber geladen sind, welche Ressourcen
sie nutzen usw.) und in die Windows-Leistungsindikatoren. Diese Indikatoren befinden sich zwar
nicht in der Registrierung, sind aber über Registrierungsfunktionen zugänglich (wobei es jedoch
für den Zugriff auf sie eine neue, bessere API gibt). Wie Sie Informationen über Leistungsindikatoren über die Registrierung gewinnen, erfahren Sie in Kapitel 9 von Band 2.
Windows-Benutzer und -Administratoren müssen nur selten einen Blick in die Registrierung werfen (da sich die meisten Konfigurationseinstellungen mit Standardverwaltungsprogrammen einsehen und ändern lassen), aber dennoch bildet sie eine nützliche Informationsquelle für Windows-Interna, da sie viele Einstellungen einschließt, die sich auf die Leistung
und das Verhalten des Systems auswirken. Bei der Beschreibung einzelner Komponenten
finden Sie in diesem Buch auch jeweils Hinweise auf die zugehörigen Registrierungsschlüssel.
Die meisten der erwähnten Schlüssel befinden sich im Hive für die systemweite Konfigura
tion – HKEY_LOCAL_MACHINE oder kurz HKLM.
Wenn Sie Registrierungseinstellungen ändern, müssen Sie außerordentlich umsichtig vorgehen. Unsachgemäße Änderungen können die Systemleistung beeinträchtigen oder sogar dazu führen, dass das System nicht mehr hochgefahren werden kann.
36
Kapitel 1
Begriffe und Werkzeuge
Weitere Informationen über die Registrierung und ihren inneren Aufbau erhalten Sie in Kapitel 9 von Band 2.
Unicode
Windows unterscheidet sich von der Mehrzahl der anderen Betriebssysteme dadurch, dass seine meisten internen Textstrings als 16 Bit breite Unicode-Zeichen gespeichert und verarbeitet
werden (genauer, im Format UTF-16LE; wenn in diesem Buch Unicode erwähnt wird, ist damit,
sofern nicht anders angegeben, UTF-16LE gemeint). Unicode ist ein internationaler Zeichensatzstandard, der eindeutige Werte für die meisten Zeichensätze der Welt definiert und 8-,
16- und 32-Bit-Codierungen für jedes Zeichen bietet.
Da viele Anwendungen ANSI-Zeichenstrings von 8 Bit (1 Byte) verarbeiten, nehmen viele
Windows-Funktionen Stringparameter mit zwei Eintrittspunkten entgegen, einer Unicode-Version (breit, 16 Bit) und einer ANSI-Version (schmal, 8 Bit). Wenn Sie die schmale Version einer
Windows-Funktion aufrufen, gibt es eine kleine Leistungseinbuße, da die Eingabestringparameter vor der Verarbeitung durch das System erst in Unicode und die Ausgabeparameter
vor der Rückgabe an die Anwendung erst in ANSI umgewandelt werden. Bei älterem Code,
der auf Windows laufen muss, aber noch mit ANSI-Zeichenstrings geschrieben ist, konvertiert
Windows die ANSI-Zeichen für den eigenen Gebrauch in Unicode, aber niemals die Daten innerhalb von Dateien. Ob solche Daten als Unicode oder ANSI gespeichert werden, entscheidet
die Anwendung.
Unabhängig von der Sprache enthalten alle Versionen von Windows dieselben Funktionen.
Anstelle von eigenständigen Sprachversionen hat Windows nur eine einzige, weltweit gültige
Binärdatei, sodass eine einzelne Installation mehrere Sprachen unterstützen kann (durch Hinzufügen von Sprachpaketen). Es ist auch möglich, Windows-Funktionen zu nutzen, um eine
Anwendung in Form einer einzigen, weltweiten Binärdatei bereitzustellen, die mehrere Sprachen unterstützt.
Die alten Windows 9x-Betriebssysteme boten keine native Unterstützung für Unicode. Dies war ein weiterer Grund dafür, immer zwei Versionen einer Funktion jeweils
für ANSI und für Unicode zu erstellen. So ist beispielsweise die Windows-API-Funktion CreateFile im Grunde genommen gar keine Funktion, sondern ein Makro, das
entweder zu der Funktion CreateFileA (ANSI) oder CreateFileW (Unicode, wobei
das W für »wide«, also »breit« steht) erweitert wird. Diese Erweiterung erfolgt aufgrund der Kompilierungskonstanten UNICODE, die in Visual Studio C++-Projekten
standardmäßig gesetzt ist, da es vorteilhafter ist, mit Unicode-Funktionen zu arbeiten. Es ist jedoch möglich, statt des Makros auch ausdrücklich den Funktionsnamen
zu verwenden. Das folgende Experiment führt diese Funktionspaare vor.
Grundprinzipien und -begriffe
Kapitel 1
37
Experiment: Exportierte Funktionen einsehen
In diesem Experiment sehen wir uns die aus einer Windows-Teilsystem-DLL exportierten
Funktionen mit dem Tool Dependency Walker an.
1.
Laden Sie Dependency Walker von http://dependencywalker.com herunter, je nach
Ihrem System die 32- oder die 64-Bit-Version. Entpacken Sie die heruntergeladene
ZIP-Datei in einem Ordner Ihrer Wahl.
2.
Führen Sie das Tool aus (depends.exe). Öffnen Sie das Menü File, wählen Sie Open,
wechseln Sie zum Ordner C:\Windows\System32 (sofern Windows bei Ihnen auf C in
stalliert ist), markieren Sie die Datei kernel32.dll und klicken Sie auf Öffnen.
3.
Möglicherweise zeigt Dependency Walker eine Warnung an. Sie können sie getrost
ignorieren und schließen.
4.
Es werden jetzt mehrere Ansichten mit vertikalen und horizontalen Trennleisten angezeigt. Stellen Sie sicher, dass in der Baumansicht oben links kernel32.dll markiert ist.
5.
Schauen Sie sich die zweite Ansicht von oben auf der rechten Seite an. Dort sind die
exportierten Funktionen aus kernel32.dll aufgeführt. Klicken Sie auf den Spaltenkopf
Function, um die Liste nach Namen zu sortieren. Suchen Sie die Funktion CreateFileA.
Nicht weit darunter finden Sie auch CreateFileW:
6.
Wie Sie sehen, handelt es sich bei den meisten Funktionen, die mindestens ein
Stringtype-Argument haben, in Wirklichkeit um Funktionspaare. In der vorstehenden
Abbildung sehen Sie CreateFileMappingA/W, CreateFileTransactedA/W und CreateFileMappingNumaA/W.
7.
Scrollen Sie durch die Liste, um weitere Funktionspaare zu finden. Sie können auch
andere Systemdateien öffnen, z. B. user32.dll und advapi32.dll.
38
Kapitel 1
Begriffe und Werkzeuge
Die COM-gestützten APIs in Windows verwenden gewöhnlich Unicode-Strings,
manchmal vom Typ BSTR. Dabei handelt es sich im Grunde genommen um ein mit
NULL abgeschlossenes Array aus Unicode-Zeichen, bei dem die Stringlänge in vier
Bytes vor dem Beginn des Arrays im Arbeitsspeicher gespeichert ist. Windows
Runtime-APIs nutzen nur Unicode-Strings vom Typ HSTRING, bei denen es sich um
unveränderliche Unicode-Zeichenarrays handelt.
Weitere Informationen über Unicode erhalten Sie auf http://www.unicode.org und in der Programmierdokumentation der MSDN Library.
Die internen Mechanismen von Windows untersuchen
Viele der Informationen, die wir in diesem Buch geben, gehen auf die Lektüre von Windows-Quellcode und Gespräche mit Entwicklern zurück. Sie müssen uns aber nicht alles ungeprüft glauben.
Viele Einzelheiten der internen Mechanismen von Windows lassen sich durch eine Reihe von
Werkzeugen sichtbar machen und vorführen, unter anderem auch mit den Tools, die im Lieferumfang von Windows und den Windows-Debuggingtools enthalten sind. Diese Werkzeugpakete werden wir weiter hinten in diesem Abschnitt noch kurz behandeln.
Um Sie dazu zu ermutigen, die internen Mechanismen von Windows selbst zu erkunden,
geben wir überall in diesem Buch Anleitungen zu »Experimenten«, mit denen Sie sich jeweils
einen bestimmten Aspekt des internen Verhaltens von Windows ansehen können. Einige dieser
Experimente haben Sie in diesem Kapitel schon gesehen. Führen Sie diese Experimente aus, um
die in diesem Buch beschriebenen Vorgänge in Aktion zu erleben.
Tabelle 1–4 nennt die wichtigsten in diesem Buch verwendeten Werkzeuge und ihren Ursprung.
Werkzeug
Image
Herkunft
Startup Programs Viewer
AUTORUNS
Sysinternals
Access Check
ACCESSCHK
Sysinternals
Dependency Walker
DEPENDS
www.dependencywalker.com
Global Flags
GFLAGS
Debugging Tools
Handle Viewer
HANDLE
Sysinternals
Kernel Debuggers
WINDBG, KD
WDK, Windows SDK
Object Viewer
WINOBJ
Sysinternals
Leistungsüberwachung
PERFMON.MSC
In Windows enthalten
Pool Monitor
POOLMON
WDK
Process Explorer
PROCEXP
Sysinternals
Process Monitor
PROCMON
Sysinternals
Task (Process) List
TLIST
Debugging tools
Task-Manager
TASKMGR
In Windows enthalten
Tabelle 1–4
Werkzeuge zur Untersuchung der internen Mechanismen von Windows
Die internen Mechanismen von Windows untersuchen
Kapitel 1
39
Leistungsüberwachung und Ressourcenmonitor
In diesem Buch werden wir häufig die Leistungsüberwachung verwenden, die Sie über den
Ordner Verwaltung in der Systemsteuerung oder durch die Eingabe von perfmon in das Dia
logfeld Ausführen erreichen. Insbesondere konzentrieren wir uns dabei auf die Werkzeuge Leistungsüberwachung und Ressourcenmonitor.
Die Leistungsüberwachung hat drei Funktionen: Systemüberwachung, Anzeige
von Leistungsindikatorenprotokollen und Einrichten von Warnungen (mithilfe von
Datensammlersätzen, die wiederum Leistungsindikatorenprotokolle sowie Ablaufverfolgungs- sowie Konfigurationsdaten nutzen). Der Einfachheit halber schreiben
wir Leistungsüberwachung, wenn wir die darin enthaltene Funktion zur Systemüberwachung meinen.
Die Leistungsüberwachung bietet mehr Informationen über das Funktionieren des Systems als
jedes andere einzelne Werkzeug. Sie finden Hunderte von grundlegenden und erweiterbaren
Indikatoren für verschiedene Objekte. Bei jedem Thema, das wir in diesem Buch beschreiben,
geben wir auch jeweils eine Tabelle der entsprechenden Windows-Leistungsindikatoren an. In
der Leistungsüberwachung finden Sie eine kurze Beschreibung der einzelnen Indikatoren. Um
sie einzusehen, markieren Sie im Fenster Leistungsindikatoren hinzufügen einen Indikator und
aktivieren das Kontrollkästchen Beschreibung anzeigen.
Obwohl sich die gesamte maschinennahe Überwachung, die wir in diesem Buch durchführen, mit der Leistungsüberwachung erledigen lässt, bietet Windows noch ein weiteres Instrument, nämlich den Ressourcenmonitor (den Sie über das Startmenü oder die Registerkarte Leistung des Task-Managers erreichen). Er zeigt die vier wichtigsten Systemressourcen an, nämlich
CPU, Festplatte, Netzwerk und Arbeitsspeicher. In der Grundansicht werden dazu die gleichen
Informationen angezeigt wie im Task-Manager. Die einzelnen Abschnitte können jedoch auch
erweitert werden, um zusätzliche Angaben einzusehen. Die folgende Abbildung zeigt eine typische Ansicht des Ressourcenmonitors:
40
Kapitel 1
Begriffe und Werkzeuge
Im erweiterten Zustand zeigt die Registerkarte CPU Informationen über die CPU-Nutzung
durch die einzelnen Prozesse an. Das können Sie auch im Task-Manager sehen, aber hier gibt
es noch eine zusätzliche Spalte für die durchschnittliche CPU-Nutzung, die Ihnen eine bessere
Vorstellung davon vermitteln kann, welche Prozesse am aktivsten sind. Die Registerkarte CPU
enthält auch eine separate Anzeige der Dienste, ihrer CPU-Nutzung und ihrer durchschnittlichen Nutzung. Bei jedem Diensthostingprozess ist die zugehörige Dienstgruppe angegeben.
Wie in Process Explorer können Sie einen Prozess auswählen (indem Sie auf das zugehörige
Kontrollkästchen klicken), wodurch eine Liste der benannten Handles angezeigt wird, die der
Prozess geöffnet hat, sowie eine Liste der Module (z. B. DLLs), die in dem Adressraum des
Prozesses geladen wurden. Im Feld Handles durchsuchen können Sie auch nach den Prozessen
suchen, die für eine gegebene benannte Ressource ein Handle geöffnet haben.
Die Registerkarte Arbeitsspeicher zeigt fast die gleichen Informationen an wie die entsprechende Registerkarte im Task-Manager, ist aber für das gesamte System ausgelegt. Ein Balkendiagramm zeigt die aktuelle Aufteilung des physischen Arbeitsspeichers in die Abschnitte Für
Hardware reserviert, In Verwendung, Geändert, Standby und Frei. Was diese Begriffe bedeuten,
erfahren Sie in Kapitel 5.
Auf der Registerkarte Datenträger sehen Sie Angaben zur E/A der einzelnen Dateien in
einer Darstellung, in der Sie leicht die Dateien auf dem System erkennen, auf die am meisten
zugriffen, in die am meisten geschrieben oder in denen am meisten gelesen wird. Die Ergebnisse lassen sich darüber hinaus noch nach Prozessen filtern.
Die Registerkarte Netzwerk gibt die aktiven Netzwerkverbindungen, ihre Besitzerprozesse
und die Menge der über sie übertragenen Daten an. Dadurch können Sie Netzwerkaktivitäten
erkennen, die im Hintergrund ablaufen und sich sonst nur schwer aufspüren lassen. Außerdem
Die internen Mechanismen von Windows untersuchen
Kapitel 1
41
werden die aktiven TCP-Verbindungen angezeigt, geordnet nach Prozessen und mit Daten wie
Remoteport, lokaler Port, Remoteadresse, lokale Adresse, Paketverluste und Latenz. Des Weiteren befindet sich hier eine nach Prozessen geordnete Liste der Ports, die es Administratoren
ermöglicht, zu erkennen, welche Dienste oder Anwendungen gerade an einem gegebenen
Port auf eine Verbindung warten. Für die einzelnen Ports und Prozesse sind auch jeweils das
Protokoll und die Firewallrichtlinie angegeben.
Alle Windows-Leistungsindikatoren sind in Programmen zugänglich. Um weitere
Informationen darüber zu erhalten, suchen Sie in der MSDN-Dokumentation nach
»performance counters«.
Kernel-Debugging
Kernel-Debugging bedeutet, die internen Datenstrukturen des Kernels zu untersuchen und die
Funktionen im Kernel schrittweise zu durchlaufen. Das ist eine praktische Vorgehensweise, um
die internen Mechanismen von Windows zu untersuchen, da Sie damit interne Systeminformationen einsehen können, die über andere Werkzeugen nicht verfügbar sind, und eine bessere
Vorstellung des Codeflusses innerhalb des Kernels erhalten. Bevor wir die verschiedenen Möglichkeiten für das Kernel-Debugging beschreiben, wollen wir uns einige Dateien ansehen, die
Sie dafür brauchen.
Symbole für das Kernel-Debugging
Symboldateien enthalten die Namen von Funktionen und Variablen und das Layout und Format von Datenstrukturen. Sie werden vom Linker erstellt und von Debuggern genutzt, um
beim Debugging auf diese Namen zu verweisen und sie anzuzeigen. Diese Informationen sind
gewöhnlich nicht im Binärabbild gespeichert, da sie zur Ausführung des Codes nicht erforderlich sind. Dadurch können die Binärdateien kleiner und schneller gemacht werden. Allerdings
müssen Sie beim Debugging dafür sorgen, dass der Debugger auf die Symboldateien für die
Images zugreifen kann, mit denen Sie arbeiten wollen.
Um irgendeines der Kernel-Debugging-Tools verwenden zu können, um interne Daten
strukturen des Windows-Kernels wie die Prozessliste, Threadblockierungen, die Liste der geladenen Treiber, Angaben über die Speichernutzung usw. zu untersuchen, brauchen Sie die Symboldateien mindestens für das Kernelabbild Ntoskrnl.exe. (Mehr über diese Datei erfahren Sie im
Abschnitt »Die Architektur im Überblick« in Kapitel 2.) Die Symboltabellendateien müssen dabei
jeweils der Version des Images entsprechen, das Sie untersuchen. Wenn Sie beispielsweise den
Kernel mit einem Windows-Servicepack oder einem Hotfix aktualisiert haben, müssen Sie auch
entsprechend aktualisierte Symboldateien verwenden.
Es ist zwar möglich, die Symbole für verschiedene Windows-Versionen herunterzuladen
und zu installieren, doch aktualisierte Versionen für Hotfixes sind nicht immer verfügbar. Die
einfachste Möglichkeit, um die korrekte Version der Symbole für das Debugging zu bekommen, besteht darin, einen Microsoft-Symbolserver zu nutzen, indem Sie im Debugger eine
besondere Syntax für den Symbolpfad angeben. Beispielsweise sorgt der folgende Symbolpfad
42
Kapitel 1
Begriffe und Werkzeuge
dafür, dass der Debugger die erforderlichen Symbole von dem Symbolserver im Internet herunterlädt und eine lokale Kopie im Ordner C:\symbols ablegt:
srv*c:\symbols*http://msdl.microsoft.com/download/symbols
Debugging Tools for Windows
Das Paket Debugging Tools for Windows enthält ausgefeilte Debugging-Werkzeuge, die wir in
diesem Buch zur Untersuchung der inneren Mechanismen von Windows einsetzen. Die neueste Version ist im Windows SDK enthalten. (Weitere Informationen über die verschiedenen
Installationsarten finden Sie auf https://msdn.microsoft.com/en-us/library/windows/hardware/
ff551063.aspx.) Die Werkzeuge eignen sich zum Debugging von Prozessen sowohl im Benutzer- als auch im Kernelmodus.
In dem Paket sind die vier Debugger cdb, ntsd, kd und WindDbg enthalten. Sie alle basieren
auf derselben Debugging-Engine, die in DbgEng.dll implementiert und in der Hilfedatei für das
Paket ziemlich gut dokumentiert ist. Die Debugger weisen folgende Eigenschaften auf:
QQ cdb und ntsd sind Debugger für den Benutzermodus, die in einer Konsole ausgeführt werden. Der einzige Unterschied zwischen ihnen besteht darin, dass ntsd ein neues Konsolenfenster öffnet, wenn er von einem bereits vorhandenen Konsolenfenster aus aufgerufen
wird, was bei cdb nicht der Fall ist.
QQ kd ist ein Debugger für den Kernelmodus, der in einer Konsole ausgeführt wird.
QQ WinDbg kann sowohl für den Benutzer- als auch den Kernelmodus verwendet werden,
aber nicht gleichzeitig. Er verfügt über eine grafische Benutzeroberfläche.
QQ Die Benutzermodus-Debugger (cdb, ntsd und WinDbg) sind im Grunde genommen gleichwertig. Welchen Sie davon bevorzugen, ist Geschmackssache.
QQ Auch die Kernelmodus-Debugger (kd und WinDbg) sind gleichwertig.
Debugging im Benutzermodus Mit den Debugging-Tools können Sie sich auch in einen
Benutzermodus-Prozess einklinken und den Prozessarbeitsspeicher untersuchen und ändern.
Dabei gibt es zwei Vorgehensweisen:
QQ Invasiv Wenn Sie sich in einen laufenden Prozess einklinken, verwenden Sie standardmäßig die Windows-Funktion DebugActiveProcess, um eine Verbindung zwischen dem
Debugger und dem zu untersuchenden Prozess herzustellen. Dadurch können Sie den
Prozessspeicher untersuchen und ändern, Haltepunkte setzen und andere Debuggingfunktionen ausführen. Wenn Sie den Debugger nur trennen und nicht ausschalten, können
Sie den Debuggingvorgang abbrechen, ohne den Zielprozess zu beenden.
QQ Nicht invasiv Bei dieser Option öffnet der Debugger den Prozess mit der Funktion
OpenProcess, ohne sich in ihn einzuklinken. Dadurch können Sie den Arbeitsspeicher des
Zielprozesses untersuchen und ändern, aber keine Haltepunkte setzen. Die nicht invasive
Vorgehensweise ist auch dann möglich, wenn sich ein anderer Debugger invasiv eingeklinkt hat.
Die internen Mechanismen von Windows untersuchen
Kapitel 1
43
Mit den Debugging-Tools können Sie auch Dumpdateien von Benutzermodus-Prozessen öffnen. Diese Dateien werden in Kapitel 8 von Band 2 im Abschnitt über Ausnahmezuteilung
erklärt.
Debugging im Kernelmodus Wie bereits erwähnt, sind zwei der Tools auch für das
Kerneldebugging geeignet, nämlich das Befehlszeilenwerkzeug Kd.exe und das GUI-Programm
WinDbg.exe. Damit können Sie drei verschiedene Arten von Kerneldebugging durchführen:
QQ Öffnen einer Absturzabbilddatei, die infolge eines Windows-Systemabsturzes erstellt wurde. (Mehr über Kernelabsturzabbilder erfahren Sie in Kapitel 15, »Analyse von Absturzabbildern«, von Band 2.)
QQ Verbindung zu einem laufenden System und Untersuchung von dessen Status (bzw. Setzen
von Haltepunkten, wenn Sie Gerätetreibercode debuggen). Für diesen Vorgang brauchen
Sie zwei Computer, nämlich das Ziel (das zu debuggende System) und den Host (das System, auf dem der Debugger ausgeführt wird). Die Verbindung kann über ein Nullmodemkabel, ein IEEE-1394-Kabel, ein USB-2.0/3.0-Debuggingkabel oder das lokale Netzwerk
erfolgen. Das Zielsystem muss im Debugmodus gestartet werden. Dafür können Sie Bcdedit.exe oder msconfig.exe entsprechend einrichten. (Möglicherweise müssen Sie dabei auf
den sicheren Start in den UEFI-BIOS-Einstellungen verzichten.) Wenn Sie Windows 7 oder
frühere Versionen über ein Virtualisierungsprodukt wie Hyper-V, VirtualBox oder VMware
Workstation debuggen, können Sie auch den seriellen Port des Gastbetriebssystems als
benannte Pipe verfügbar machen und darüber eine Verbindung herstellen. Für Gastbetriebssysteme ab Windows 8 sollten Sie jedoch das Debugging über das lokale Netzwerk
durchführen, indem Sie das Hostnetzwerk über eine virtuelle Netzwerkkarte im Gastbetriebssystem bereitstellen. Das führt zu einem Leistungsgewinn um den Faktor 1000.
QQ Bei Windows-Systemen können Sie auch Verbindung zum lokalen System aufnehmen und
dessen Zustand untersuchen. Diese Vorgehensweise wird lokales Kerneldebugging genannt. Für das Debugging mit WinDbg müssen Sie das System erst in den Debugmodus
versetzen (etwa indem Sie Msconfig.exe ausführen, die Registerkarte Start aufrufen, dort
auf Erweiterte Optionen klicken, Debug aktivieren und Windows neu starten). Starten Sie
anschließend WinDbg mit Administratorrechten, öffnen Sie das Menü File, wählen Sie Kernel Debug, klicken Sie auf die Registerkarte Local und dann auf OK (oder verwenden Sie
Bcdedit.exe). Abb. 1–6 zeigt eine Beispielausgabe auf einem Computer mit der 64-Bit-Version von Windows 10. Im lokalen Kerneldebuggingmodus funktionieren einige der Befehle
für das Kerneldebugging nicht. Unter anderem können Sie keine Haltepunkte setzen und
mit dem Befehl .dump keinen Speicherauszug erstellen. Letzteres ist allerdings mit LiveKd
möglich, das weiter hinten in diesem Abschnitt beschrieben wird.
44
Kapitel 1
Begriffe und Werkzeuge
Abbildung 1–6
Lokales Kerneldebugging
Sobald die Verbindung im Kerneldebuggingmodus hergestellt ist, können Sie eine der vielen
Debuggererweiterungen nutzen – der sogenannten Bang-Befehle, weil sie mit einem Ausrufezeichen beginnen –, um den Inhalt von internen Datenstrukturen wie Threads, Prozessen
und E/A-Anforderungspaketen sowie Speicherverwaltungsinformationen anzuzeigen. In diesem Buch sind immer die zum jeweiligen Thema passenden Kerneldebuggerbefehle und deren
Ausgaben angegeben. Eine hervorragende Möglichkeit zum Nachschlagen bietet die Hilfedatei Debugger.chm, die im Installationsordner von WinDbg enthalten ist und den gesamten
Funktionsumfang des Kerneldebuggers und seiner Erweiterungen dokumentiert. Außerdem
können Sie mit dem Befehl dt (display type) für mehr als 1000 Kernelstrukturen Typinformationen anzeigen lassen, die in der Kernelsymboldatei für Windows enthalten sind.
Experiment: Typinformationen über Kernelstrukturen
Um sich die Liste der Kernelstrukturen anzusehen, deren Typinformationen in den Kernelsymbolen enthalten sind, geben Sie im Kerneldebugger dt nt!_* ein. Dadurch erhalten Sie
die folgende (hier gekürzt wiedergegebene) Ausgabe:
lkd> dt nt!_*
ntkrnlmp!_KSYSTEM_TIME
ntkrnlmp!_NT_PRODUCT_TYPE
ntkrnlmp!_ALTERNATIVE_ARCHITECTURE_TYPE
ntkrnlmp!_KUSER_SHARED_DATA
ntkrnlmp!_ULARGE_INTEGER
ntkrnlmp!_TP_POOL
ntkrnlmp!_TP_CLEANUP_GROUP
ntkrnlmp!_ACTIVATION_CONTEXT
ntkrnlmp!_TP_CALLBACK_INSTANCE
→
Die internen Mechanismen von Windows untersuchen
Kapitel 1
45
ntkrnlmp!_TP_CALLBACK_PRIORITY
ntkrnlmp!_TP_CALLBACK_ENVIRON_V3
ntkrnlmp!_TEB
Dabei ist ntkrnlmp der interne Dateiname des 64-Bit-Kernels (siehe Kapitel 2).
Mit dem Befehl dt können Sie auch mit Jokerzeichen nach bestimmten Strukturen suchen. Wenn Sie beispielsweise den Namen der Struktur für ein Interruptobjekt benötigen,
können Sie dt nt!_*interrupt* eingeben:
lkd> dt nt!_*interrupt*
ntkrnlmp!_KINTERRUPT_MODE
ntkrnlmp!_KINTERRUPT_POLARITY
ntkrnlmp!_PEP_ACPI_INTERRUPT_RESOURCE
ntkrnlmp!_KINTERRUPT
ntkrnlmp!_UNEXPECTED_INTERRUPT
ntkrnlmp!_INTERRUPT_CONNECTION_DATA
ntkrnlmp!_INTERRUPT_VECTOR_DATA
ntkrnlmp!_INTERRUPT_HT_INTR_INFO
ntkrnlmp!_INTERRUPT_REMAPPING_INFO
Wenn Sie bei dt wie folgt den Namen einer einzelnen Struktur angeben (wobei nicht zwischen Groß- und Kleinschreibung unterschieden wird), können Sie genauere Informationen
darüber einsehen:
lkd> dt nt!_KINTERRUPT
+0x000 Type
: Int2B
+0x002 Size
: Int2B
+0x008 InterruptListEntry
: _LIST_ENTRY
+0x018 ServiceRoutine
: Ptr64 unsigned char
+0x020 MessageServiceRoutine : Ptr64 unsigned char
+0x028 MessageIndex
: Uint4B
+0x030 ServiceContext
: Ptr64 Void
+0x038 SpinLock
: Uint8B
+0x040 TickCount
: Uint4B
+0x048 ActualLock
: Ptr64 Uint8B
+0x050 DispatchAddress
: Ptr64 void
+0x058 Vector
: Uint4B
+0x05c Irql
: UChar
+0x05d SynchronizeIrql
: UChar
+0x05e FloatingSave
: UChar
+0x05f Connected
: UChar
+0x060 Number
: Uint4B
+0x064 ShareVector
: UChar
+0x065 EmulateActiveBoth
: UChar
→
46
Kapitel 1
Begriffe und Werkzeuge
+0x066 ActiveCount
: Uint2B
+0x068 InternalState
: Int4B
+0x06c Mode
: _KINTERRUPT_MODE
+0x070 Polarity
: _KINTERRUPT_POLARITY
+0x074 ServiceCount
: Uint4B
+0x078 DispatchCount
: Uint4B
+0x080 PassiveEvent
: Ptr64 _KEVENT
+0x088 TrapFrame
: Ptr64 _KTRAP_FRAME
+0x090 DisconnectData
: Ptr64 Void
+0x098 ServiceThread
: Ptr64 _KTHREAD
+0x0a0 ConnectionData
: Ptr64 _INTERRUPT_CONNECTION_DATA
+0x0a8 IntTrackEntry
: Ptr64 Void
+0x0b0 IsrDpcStats
: _ISRDPCSTATS
+0x0f0 RedirectObject
: Ptr64 Void
+0x0f8 Padding
: [8] UChar
Standardmäßig zeigt dt keine Unterstrukturen an. Dazu müssen Sie den Schalter -r oder
-b verwenden. (Den genauen Unterschied zwischen diesen beiden Schaltern entnehmen
Sie bitte der Dokumentation.) Beispielsweise können Sie diese Schalter bei der Anzeige des
Kernelinterruptobjekts angeben, um sich das Format der Struktur _LIST_ENTRY anzeigen zu
lassen, die im Feld InterruptListEntry gespeichert ist:
lkd> dt nt!_KINTERRUPT -r
+0x000 Type
: Int2B
+0x002 Size
: Int2B
+0x008 InterruptListEntry : _LIST_ENTRY
+0x000 Flink
: Ptr64 _LIST_ENTRY
+0x000 Flink
+0x008 Blink
+0x008 Blink
: Ptr64 _LIST_ENTRY
: Ptr64 _LIST_ENTRY
: Ptr64 _LIST_ENTRY
+0x000 Flink
+0x008 Blink
+0x018 ServiceRoutine
: Ptr64 _LIST_ENTRY
: Ptr64 _LIST_ENTRY
: Ptr64 unsigned char
Bei dt können Sie sogar die Verschachtelungstiefe der anzuzeigenden Strukturen festlegen,
indem Sie hinter dem Schalter -r eine Zahl angeben. Mit dem Befehl im folgenden Beispiel
wählen Sie eine Verschachtelungstiefe von einer Ebene aus:
lkd> dt nt!_KINTERRUPT -r1
Die Hilfedatei zu den Debugging Tools for Windows erklärt Ihnen, wie Sie die Kerneldebugger
einrichten und verwenden. Weitere Einzelheiten darüber, die vor allem für die Autoren von
Gerätetreibern interessant sind, finden Sie in der WDK-Dokumentation.
Die internen Mechanismen von Windows untersuchen
Kapitel 1
47
LiveKd
LiveKd ist ein kostenloses Tool von Sysinternals, mit dem es möglich ist, das laufende System
mit den zuvor beschriebenen Kerneldebuggern von Microsoft zu untersuchen, ohne es im Debugmodus zu starten. Das kann erforderlich sein, wenn Sie eine Störungssuche auf Kernelebene
an einem Computer durchführen müssen, der nicht im Debugmodus läuft. Da sich manche
Probleme nur schwer zuverlässig reproduzieren lassen, kann es sein, dass sich der Fehler nach
einem Neustart mit der Debugoption nicht mehr so deutlich zeigt.
LiveKd führen Sie genauso aus wie WinDbg und kd. Es übergibt alle von Ihnen eingegebenen Befehlszeilenoptionen an den Debugger Ihrer Wahl. Standardmäßig führt LiveKd die
Befehlszeilenversion des Kerneldebuggers aus (kd), doch mit der Option -w können Sie auf
WinDbg umschalten. Um die Hilfedateien für die Befehlszeilenoptionen von LiveKd einzusehen, verwenden Sie den Schalter -?.
LiveKd stellt dem Debugger eine simulierte Absturzabbilddatei bereit. Daher können Sie in
LiveKd jegliche Operationen durchführen, die auch bei einem Absturzabbild möglich sind. Da
LiveKd für dieses Abbild auf den physischen Arbeitsspeicher zurückgreift, kann der Debugger
auf Datenstrukturen stoßen, die gerade geändert werden und daher inkonsistent sind. Jedes
Mal, wenn der Debugger neu gestartet wird, sieht er eine aktuelle Ansicht des Systemzustands.
Sie können diese Momentaufnahme auch aktualisieren, indem Sie den Befehl q eingeben, um
den Debugger zu beenden. LiveKd fragt Sie dann, ob Sie ihn neu starten wollen. Wenn der Debugger bei der Ausgabe in eine Schleife gerät, können Sie sie mit (Strg) + (C) abbrechen und
beenden. Hängt der Debugger, drücken Sie (Strg) + (Untbr), wodurch der Debuggerprozess
beendet wird. LiveKd fragt Sie hier ebenfalls, ob Sie ihn neu starten wollen.
Windows Software Development Kit
Das Windows Software Development Kit (SDK) ist im Rahmen des MSDN-Abonnementprogramms erhältlich. Sie können es kostenlos von https://developer.microsoft.com/en-US/
windows/downloads/windows-10-sdk herunterladen. Auch bei der Installation von Visual Studio haben Sie die Möglichkeit, das SDK zu installieren. Im Abonnement erhalten Sie immer die
neueste Version, wohingegen in Visual Studio auch eine ältere Version enthalten sein kann, die
beim Kauf von VS gerade aktuell war. Neben den Debugging Tools for Windows enthält das
SDK auch die erforderlichen C-Headerdateien und Bibliotheken zum Kompilieren und Verlinken von Windows-Anwendungen. Für unsere Zwecke sind vor allem die Windows-API-Headerdateien (z. B. C:\Program Files (x86)\Windows Kits\10\Include) und die SDK-Tools (im Ordner
Bin) von Bedeutung. Ebenso von Interesse ist die Dokumentation, die online zur Verfügung
steht und für den Offlinezugriff heruntergeladen werden kann. Einige der Werkzeuge sind auch
als Beispielquellcode sowohl im Windows SDK als auch in MSDN Library erhältlich.
48
Kapitel 1
Begriffe und Werkzeuge
Windows Driver Kit
Das Windows Driver Kit (WDK) ist ebenfalls im MSDN-Abonnementprogramm verfügbar und
kann kostenlos heruntergeladen werden. Die WDK-Dokumentation finden Sie in MSDN Library.
Das WDK ist zwar vor allem für Entwickler von Gerätetreibern gedacht, bietet aber auch
eine Fülle von Informationen über interne Windows-Mechanismen. Um Ihnen ein Beispiel
zu geben: Kapitel 6 erklärt zwar die Architektur des E/A-Systems, das Treibermodell und die
grundlegenden Datenstrukturen von Gerätetreibern, aber nicht die einzelnen Kernelunterstützungsfunktionen. Eine ausführliche Beschreibung dieser Funktionen und der von den Gerätetreibern verwendeten Mechanismen finden Sie jedoch in der WDK-Dokumentation, sowohl in
Form von Tutorials als auch eines Nachschlagewerks.
Außer dieser Dokumentation enthält das WDK Headerdateien (insbesondere ntddk.h,
ntifs.h und wdm.h), die entscheidende interne Datenstrukturen und Konstanten sowie Schnittstellen zu vielen internen Systemroutinen definieren. Diese Dateien sind praktisch, wenn Sie die
internen Datenstrukturen von Windows mit einem Kerneldebugger untersuchen, da in diesem
Buch zwar das allgemeine Layout und der Inhalt dieser Strukturen angegeben wird, aber keine
Beschreibungen der einzelnen Felder (z. B. Angaben über Größe und Datentyp). Zahlreiche
dieser Datenstrukturen – etwa Objektdispatcherheader, Warteblöcke, Ereignisse, Mutanten, Semaphoren usw. – sind jedoch ausführlich im WDK beschrieben.
Wenn Sie über die Darstellung in diesem Buch noch tiefer in das E/A-System und das Treibermodell einsteigen möchten, sollten Sie die WDK-Dokumentation lesen, insbesondere die
Handbücher Kernel-Mode Driver Architecture Design Guide und Kernel-Mode Driver Reference.
Ebenfalls nützlich sind die Bücher Programming the Microsoft Windows Driver Model, Second
Edition von Walter Oney (Microsoft Press, 2002) und Developing Drivers with the Windows Driver
Foundation von Penny Orwick und Guy Smith (Microsoft Press, 2007).
Sysinternals-Werkzeuge
Für viele Experimente in diesem Buch werden Freeware-Tools verwendet, die Sie von Sysinternals herunterladen können. Die meisten davon hat Mark Russinovich geschrieben, einer der
Autoren dieses Buches. Die am häufigsten genutzten dieser Werkzeuge sind Process Explorer
und Process Monitor. Beachten Sie, dass Sie für viele dieser Tools Kernelmodus-Gerätetreiber
installieren und ausführen müssen, wofür Administrator- oder erhöhte Rechte erforderlich sind.
Einige der Werkzeuge können jedoch auch mit eingeschränktem Funktionsumfang und eingeschränkter Ausgabe von Standardbenutzerkonten ohne erhöhte Rechte ausgeführt werden.
Die Sysinternals-Tools werden regelmäßig aktualisiert. Achten Sie daher darauf, dass Sie
die neueste Version verwenden. Um sich über Aktualisierungen zu informieren, folgen Sie dem
Blog auf der Sysinternals-Website (für die es auch einen RSS-Feed gibt). Eine Beschreibung
all dieser Werkzeuge und ihrer Verwendung sowie Fallstudien über damit gelöste Probleme
finden Sie in Windows Sysinternals Administrator’s Reference von Mark Russinovich und Aaron
Margosis (Microsoft Press, 2011). Wenn Sie Fragen über die Tools stellen oder darüber diskutieren möchten, nutzen Sie das Sysinternals-Forum.
Die internen Mechanismen von Windows untersuchen
Kapitel 1
49
Zusammenfassung
In diesem Kapitel haben Sie eine Einführung in wichtige technische Prinzipien und Grundbegriffe von Windows erhalten, die im weiteren Verlauf dieses Buches verwendet werden. Des
Weiteren haben Sie einen Eindruck von den vielen praktischen Tools bekommen, mit denen Sie
die inneren Mechanismen von Windows untersuchen können. Damit sind Sie jetzt gewappnet,
die interne Gestaltung des Systems zu erkunden. Dabei beginnen wir mit einem Überblick über
die Systemarchitektur und ihre Hauptkomponenten.
50
Kapitel 1
Begriffe und Werkzeuge
K apite l 2
Systemarchitektur
Nachdem Sie die erforderlichen Grundbegriffe, Prinzipien und Werkzeuge kennengelernt haben, können Sie nun damit beginnen, die Designziele und internen Strukturen des Betriebssystems Microsoft Windows zu erkunden. In diesem Kapitel geht es um die Gesamtarchitektur des
Systems – die Hauptkomponenten, ihre Wechselbeziehungen zueinander und den Kontext, in
dem sie ausgeführt werden. Um Ihnen ein Gerüst für das Verständnis der inneren Mechanismen
von Windows zu geben, wollen wir uns zunächst die Anforderungen und Ziele ansehen, die das
ursprüngliche Design und die Spezifikation des Systems bestimmt haben.
Anforderungen und Designziele
Die folgenden Anforderungen bestimmten die Spezifikation von Windows NT im Jahr 1989:
QQ Es sollte ein präemptives, eintrittsvariantes echtes 32-Bit-Betriebssystem mit virtuellem
Speicher entwickelt werden.
QQ Das Betriebssystem sollte auf mehreren Hardwarearchitekturen und -plattformen laufen.
QQ Es sollte auf Systemen mit symmetrischem Multiprocessing laufen und gut skalierbar sein.
QQ Es sollte eine hervorragende Plattform für verteilte Verarbeitung bilden, sowohl als Netzwerkclient als auch als Server.
QQ Es sollte die meisten vorhandenen 16-Bit-MS-DOS- und Microsoft Windows 3.1-Anwendungen ausführen.
QQ Es sollte die staatlichen Anforderungen für POSIX-1003.1-Konformität erfüllen.
QQ Es sollte die staatlichen und die Branchenanforderungen für Betriebssystemsicherheit erfüllen.
QQ Es sollte Unicode unterstützen, um leicht an den weltweiten Markt angepasst werden zu
können.
Um ein System zu erschaffen, das all diese Anforderungen erfüllte, mussten Tausende von Entscheidungen getroffen werden. Um diesen Vorgang zu steuern, stellte das Designteam von
Windows NT zu Beginn des Projekts die folgenden Designziele auf:
QQ Erweiterbarkeit Der Code muss so geschrieben werden, dass er bequem ergänzt und
geändert werden kann, wenn sich die Marktanforderungen wandeln.
QQ Portierbarkeit Das System muss auf verschiedenen Hardwarearchitekturen lauffähig
und auch relativ einfach auf neue Architekturen übertragbar sein, wenn der Markt dies
verlangt.
51
QQ Zuverlässigkeit und Stabilität Das System muss sich selbst sowohl gegen interne Fehlfunktionen als auch gegen externe Manipulation schützen. Es darf nicht möglich sein, dass
Anwendungen das Betriebssystem oder andere Anwendungen schädigen.
QQ Kompatibilität Windows NT soll zwar die vorhandene Technologie erweitern, seine Benutzerschnittstelle und die APIs sollen aber mit älteren Versionen von Windows und MSDOS kompatibel sein. Es soll auch gut mit anderen Systemen wie UNIX, OS/2 und NetWare
zusammenwirken können.
QQ Leistung Das System soll im Rahmen der Vorgaben durch die anderen Designziele auf
jeder Hardwareplattform so schnell und reaktiv sein wie möglich.
Wenn wir die internen Strukturen und Vorgänge von Windows untersuchen, werden Sie noch
sehen, wie diese Designziele und die Marktanforderungen in der Konstruktion erfolgreich ver
knüpft wurden. Bevor wir unsere Erforschung beginnen, wollen wir jedoch das allgemeine
Designmodell von Windows betrachten und mit dem anderer moderner Betriebssysteme vergleichen.
Das Modell des Betriebssystems
In den meisten Mehrbenutzer-Betriebssystemen sind die Anwendungen vom Betriebssystem
getrennt. Der Kernelcode des Betriebssystems läuft in einem privilegierten Prozessormodus
(der in diesem Buch als Kernelmodus bezeichnet wird) und hat Zugriff auf die Systemdaten und
die Hardware. Der Anwendungscode dagegen wird in einem nicht privilegierten Prozessormodus ausgeführt (dem Benutzermodus), in dem nur eine begrenzte Menge der Schnittstellen zur
Verfügung steht, der Zugriff auf Systemdaten eingeschränkt ist und es keinen direkten Zugriff
auf die Hardware gibt. Wenn ein Benutzermodusprogramm einen Systemdienst aufruft, führt
der Prozesse eine besondere Anweisung aus, die den aufrufenden Thread in den Kernelmodus
umschaltet. Hat der Systemdienst seine Arbeit abgeschlossen, schaltet das Betriebssystem den
Threadkontext wieder in den Benutzermodus und erlaubt dem Aufrufer, fortzufahren.
Windows ähnelt den meisten UNIX-Systemen in der Hinsicht, dass es sich um ein monoli
thisches Betriebssystem handelt, d. h., dass sich der Großteil des Betriebssystems und der Gerätetreibercode denselben geschützten Kernelmodus-Arbeitsspeicherbereich teilen. Dadurch ist
jede Betriebssystemkomponente und jeder Gerätetreiber theoretisch in der Lage, Daten zu beschädigen, die von anderen Systemkomponenten genutzt werden. Wie Sie in Kapitel 1 gesehen
haben, geht Windows dieses Problem jedoch dadurch an, dass es die Qualität von Drittanbietertreibern stärkt und ihre Herkunft einschränkt. Dies wird mit Programmen wie WHQL erreicht
und durch KMCS durchgesetzt. Außerdem enthält Windows weitere Kernelschutztechnologien
wie die virtualisierungsgestützte Sicherheit sowie DeviceGuard und HyperGuard. Wie all diese
Einzelteile zusammenpassen, schauen wir uns später in diesem Kapitel an. Weitere Einzelheiten
erfahren Sie in Kapitel 7, »Sicherheit«, und Kapitel 8, »Systemmechanismen«, von Band 2.
All diese Betriebssystemkomponenten sind vollständig gegen fehlgehende Anwendungen
geschützt, da Anwendungen keinen direkten Zugriff auf den Code und die Daten im privilegierten Teil des Betriebssystems haben (wobei sie jedoch andere Kerneldienste aufrufen können). Dieser Schutz ist einer der Gründe, warum Windows einen Ruf als widerstandsfähige und
52
Kapitel 2
Systemarchitektur
stabile Plattform für Anwendungsserver und Arbeitsstationen hat. Gleichzeitig ist es, was die
wichtigsten Betriebssystemdienste wie die Verwaltung des virtuellen Speichers, die Datei-E/A,
Netzwerkkommunikation und Datei- und Druckerfreigabe angeht, schnell und behände.
Die Kernelmoduskomponenten von Windows verkörpern auch die Grundprinzipien des
objektorientierten Designs. Beispielsweise langen sie im Allgemeinen nicht in die Datenstrukturen anderer Komponenten hinein, um auf deren Informationen zuzugreifen, sondern nutzen
formale Schnittstellen, um Parameter zu übergeben, auf Datenstrukturen zuzugreifen und diese zu bearbeiten.
Auch wenn zur Darstellung gemeinsam genutzter Systemressourcen überall Objekte verwendet werden, ist Windows kein objektorientiertes System im strengen Sinne. Der meiste
Kernelmoduscode des Betriebssystems ist zur leichteren Portierbarkeit in C geschrieben. Diese Programmiersprache unterstützt objektorientierte Konstrukte wie polymorphe Funktionen
und Klassenvererbung nicht direkt. Daher borgt sich die C-Implementierung von Objekten in
Windows einige Merkmale bestimmter objektorientierter Sprachen, hängt aber nicht davon ab.
Die Architektur im Überblick
Nach dem kurzen Überblick über die Designziele und das Modell von Windows wollen wir
uns nun die Hauptkomponenten ansehen, die die Architektur ausmachen. Abb. 2–1 zeigt eine
vereinfachte Darstellung der Architektur, aber nicht alles. Beispielsweise sind die Netzwerkkomponenten und die verschiedenen Gerätetreiberschichten hier nicht enthalten.
Umgebungs
teilsysteme
System
prozesse
Dienst
prozesse
Benutzerprozesse
Teilsystem-DLLs
Benutzermodus
NTDLL.DLL
Kernelmodus
Exekutive
Fenster
und Grafik
Gerätetreiber
Kernel
Hardwareabstraktionsschicht (HAL)
Hypervisor Hyper-V
Kernelmodus
(Hypervisor-Kontext)
Abbildung 2–1 Vereinfachte Darstellung der Windows-Architektur
In Abb. 2–1 sind die Teile von Windows für den Benutzer- und den Kernelmodus durch eine
horizontale Linie getrennt. Wie bereits in Kapitel 1 erwähnt, werden Benutzermodusthreads in
einem privaten Prozessadressraum ausgeführt (wobei sie jedoch bei der Ausführung im Kernelmodus auch Zugriff auf den Systemadressraum haben). Daher haben System-, Dienst- und
Benutzerprozesse sowie die Umgebungsteilsysteme jeweils ihren eigenen privaten Prozess
Die Architektur im Überblick
Kapitel 2
53
adressraum. Es gibt auch noch eine zweite Trennlinie zwischen den Teilen von Windows für den
Kernelmodus und dem Hypervisor. Der Hypervisor hat zwar dieselbe CPU-Rechteebene wie der
Kernel (0), verwendet aber besondere CPU-Anweisungen (VT-x auf Intel, SVM auf AMD) und
kann sich daher vom Kernel isolieren und ihn (und die Anwendungen) gleichzeitig überwachen. Daher werfen auch manche Leute mit dem Begriff Ring -1 um sich (der nicht korrekt ist).
Es gibt die folgenden vier grundlegenden Arten von Benutzermodusprozessen:
QQ Benutzerprozesse Dies können Prozesse der folgenden Typen sein: Windows 32 Bit oder
64 Bit (dazu gehören Windows-Apps, die oberhalb der Windows Runtime in Windows 8
und höher laufen), Windows 3.1 16 Bit, MS-DOS 16 Bit, POSIX 32 Bit und 64 Bit. Beachten
Sie, dass 16-Bit-Anwendungen nur auf 32-Bit-Windows ausgeführt werden können und
POSIX-Anwendungen ab Windows 8 nicht mehr unterstützt werden.
QQ Dienstprozesse Dies sind Hostprozesse für Windows-Dienste, z. B. den Taskplaner und
den Druckspooler. Dienste müssen generell unabhängig von Benutzeranmeldungen ausgeführt werden können. Viele Windows-Serveranwendungen, z. B. Microsoft SQL Server
und Microsoft Exchange Server, enthalten ebenfalls Komponenten, die als Dienste ausgeführt werden. Eine ausführliche Beschreibung von Diensten finden Sie in Kapitel 9, »Verwaltungsmechanismen«, von Band 2.
QQ Systemprozesse Dies sind unveränderliche oder fest verdrahtete Prozesse, z. B. der Anmeldeprozess und der Sitzungs-Manager. Es handelt sich dabei nicht um Windows-Dienste, d. h., sie werden nicht vom Dienststeuerungs-Manager gestartet.
QQ Serverprozesse des Umgebungsteilsystems Diese Prozesse implementieren die Unterstützung für die Betriebssystemumgebung (oder »Persönlichkeit«), die dem Benutzer und
Programmierer angezeigt wird. Windows NT enthielt ursprünglich drei Umgebungsteilsysteme, nämlich Windows, POSIX und OS/2. Allerdings wurde das OS/2-Teilsystem mit
Windows 2000 zum letzten Mal ausgeliefert und das POSIX-Teilsystem mit Windows XP.
Die Ultimate- und die Enterprise-Edition der Clientversion von Windows 7 sowie Windows
Server 2008 R2 enthielten noch eine Unterstützung für ein erweitertes POSIX-Teilsystem
namens SUA (Subsystem for UNIX-based Applications). SUA wurde jedoch eingestellt und
wird auch nicht mehr optional für Windows angeboten (weder für Client- noch für Serverversionen).
Windows 10 Version 1607 enthält ein Windows-Teilsystem für Linux (WSL), allerdings nur als Beta-Version ausschließlich für Entwickler. Es ist auch kein echtes
Teilsystem wie die anderen in diesem Abschnitt. WSL und die zugehörigen Pico-Provider werden in diesem Kapitel noch ausführlicher beschrieben. Weitere
Informationen über Pico-Prozesse erhalten Sie in Kapitel 3, »Prozesse und Jobs«.
Beachten Sie in Abb. 2–1 den Kasten »Teilsystem-DLLs« unter »Dienstprozesse« und »Benutzerprozesse«. In Windows rufen Benutzeranwendungen die nativen Betriebssystemdienste nicht
direkt auf, sondern nutzen eine oder mehrere Teilsystem-DLLs. Deren Aufgabe besteht darin,
eine dokumentierte Funktion in die entsprechenden internen (und in der Regel nicht dokumentierten) nativen Systemdienstaufrufe zu übersetzen, die meistens in Ntdll.dll implementiert
54
Kapitel 2
Systemarchitektur
sind. Dabei kann eine Nachricht an den Prozess des Umgebungsteilsystems gesendet werden,
der den Benutzerprozess handhabt.
Windows enthält die folgenden Kernelmoduskomponenten:
QQ Exekutive Die Windows-Exekutive umfasst die grundlegenden Betriebssystemdienste
wie Speicherverwaltung, Prozess- und Threadverwaltung, Sicherheit, E/A, Netzwerk und
Kommunikation zwischen Prozessen.
QQ Der Windows-Kernel Er besteht aus den maschinennahen Betriebssystemfunktionen
wie Threadplanung, Interrupt- und Ausnahmezuteilung und Multiprozessorsynchronisierung. Außerdem bietet er eine Reihe von Routinen und Grundobjekten, die der Rest der
Exekutive verwendet, um Konstrukte höherer Ebene zu implementieren.
QQ Gerätetreiber Dazu gehören sowohl Hardwaregerätetreiber, die E/A-Funktionsaufrufe
des Benutzers in gerätespezifische E/A-Anforderungen übersetzen, aber auch Gerätetreiber nicht für Hardware, z. B. das Dateisystem und Netzwerktreiber.
QQ Hardwareabstraktionsschicht (HAL) Diese Codeschicht schirmt den Kernel, die Gerätetreiber und den Rest der Windows-Exekutive gegen plattformspezifische Hardwareunterschiede ab (z. B. Unterschiede zwischen Motherboards).
QQ Fenster- und Grafiksystem Dieses System implementiert die GUI-Funktionen (auch bekannt als Windows USER- und GDI-Funktionen) für den Umgang mit Fenstern, die Steuer
elemente der Benutzerschnittstelle, das Zeichnen usw.
QQ Hypervisor-Schicht Diese Schicht besteht aus einer einzigen Komponente, nämlich dem
Hypervisor selbst. In dieser Umgebung gibt es keine Treiber oder anderen Module. Allerdings besteht der Hypervisor selbst aus mehreren internen Schichten und Diensten wie
seinem eigenen Speicher-Manager, dem Scheduler für den virtuellen Prozessor, einer Interrupt- und Timerverwaltung, Synchronisierungsroutinen, einer Partitionsverwaltung (für
die VM-Instanzen), Kommunikation zwischen den Partitionen (IPC) usw.
Tabelle 2–1 nennt die Dateinamen der wichtigsten Windows-Komponenten (die Sie kennen
müssen, da wir in diesem Buch mehrere Systemdateien namentlich erwähnen). Alle diese Komponenten werden in diesem oder den folgenden Kapiteln ausführlicher beschrieben.
Datei
Komponenten
Ntoskrnl.exe
Exekutive und Kernel
Hal.dll
HAL
Win32k.sys
Kernelmodusteil des Windows-Teilsystems (GUI)
Hvix64.exe (Intel), Hvax64.exe (AMD)
Hypervisor
.sys-Dateien in
\SystemRoot\System32\Drivers
Haupttreiberdateien, darunter für Direct X, Volume-
Manager, TCP/IP, TPM und ACPI-Unterstützung
Ntdll.dll
Interne Unterstützungsfunktionen und Dispatch-Stubs zur
Zuteilung von Systemdiensten an Ausführungsfunktionen
Kernel32.dll, Advapi32.dll, User32.dll,
Gdi32.dll
Haupt-DLLs des Windows-Teilsystems
Tabelle 2–1 Wichtige Windows-Systemdateien
Die Architektur im Überblick
Kapitel 2
55
Bevor wir uns diese Systemkomponenten genauer ansehen, wollen wir jedoch noch einige
Grundlagen des Windows-Kerneldesigns vorstellen. Dabei beginnen wir mit der Frage, wie
Windows die Portierbarkeit über mehrere Hardwarearchitekturen hinweg erreicht.
Portierbarkeit
Windows wurde so entworfen, dass es auf verschiedenen Hardwarearchitekturen laufen kann.
Das ursprüngliche Release von Windows NT unterstützte x86 und MIPS. Kurz darauf folgte die
Unterstützung für Alpha AXP von Digital Equipment Corporation (die von Compaq aufgekauft
wurde, das wiederum mit Hewlett-Packard fusionierte). (Alpha AXP war ein 64-Bit-Prozessor,
doch Windows NT lief im 32-Bit-Modus. Während der Entwicklung von Windows 2000 wurde
auch eine native 64-Bit-Version auf dem Alpha AXP ausgeführt, allerdings wurde sie niemals
veröffentlicht.) In Windows NT 3.51 kam die Unterstützung für eine vierte Prozessorarchitektur hinzu, nämlich den Motorola PowerPC. Aufgrund wechselnder Nachfrage am Markt wurde die Unterstützung für MIPS und PowerPC jedoch aufgegeben, bevor die Entwicklung von
Windows 2000 begann. Spät nahm Compaq die Unterstützung für die Alpha AXP-Architektur zurück, sodass Windows 2000 nur noch auf x86 lief. In Windows XP und Windows Server
2003 kam die Unterstützung für zwei 64-Bit-Prozessorfamilien hinzu, den Intel Itanium IA-64
und den AMD64 mit der gleichwertigen 64-Bit-Erweiterungstechnologie von Intel (EM64T).
Die beiden letztgenannten Implementierungen wurden als erweiterte 64-Bit-Systeme bezeichnet und werden in diesem Buch x64 genannt. (Wie 32-Bit-Anwendungen auf 64-Bit-Windows
ausgeführt werden konnten, wird in Kapitel 8 von Band 2 erklärt.) Ab Server 2008 R2 wurden
IA-64-Systeme jedoch nicht mehr von Windows unterstützt.
Bei jüngeren Windows-Editionen kam auch eine Unterstützung für die ARM-Prozessorarchitektur hinzu. Beispielsweise handelte es sich bei Windows RT um eine Version von Windows 8
für ARM, die inzwischen allerdings eingestellt wurde. Windows 10 Mobile – der Nachfolger von
Windows Phone 8.x – läuft auf ARM-Prozessoren wie den Snapdragon-Modellen von Qualcomm. Windows 10 IoT kann sowohl auf x86- als auch auf ARM-Geräten wie dem Raspberry
Pi 2 (mit dem Prozessor ARM Cortex-A7) und dem Raspberry Pi 3 (ARM Cortex-A53) ausgeführt
werden. Da es inzwischen auch 64-Bit-ARM-Hardware gibt und eine steigende Anzahl von Geräten die Prozessoren der neuen Familien AArch64 und ARM64 verwendet, wird es wahrscheinlich irgendwann auch eine Unterstützung dafür geben.
Die architektur- und plattformübergreifende Portierbarkeit erreicht Windows auf allem auf
die beiden folgenden Weisen:
QQ Geschichtetes Design Windows ist in Schichten aufgebaut. Dabei stehen die maschinennahen Teile des Systems, die von der Prozessorarchitektur oder der Plattform abhängen, in getrennten Modulen, sodass die höheren Ebenen des Systems von den Unterschieden zwischen diesen Architekturen und Plattformen abgeschirmt sind. Die beiden
Hauptkomponenten, die für die Portierbarkeit sorgen, sind der Kernel (in Ntoskrnl.exe)
und die HAL (in Hal.dll). Beide Komponenten werden weiter hinten in diesem Kapitel noch
ausführlicher behandelt. Architekturspezifische Funktionen wie Threadkontextwechsel und
Trap-Dispatching sind im Kernel implementiert, und Funktionen, die sich auf Systemen mit
derselben Architektur unterscheiden können (z. B. auf unterschiedlichen Motherboards)
56
Kapitel 2
Systemarchitektur
in der HAL. Die einzige andere Komponente mit einem erheblichen Anteil an architekturspezifischem Code ist der Speicher-Manager, aber im Vergleich zum Gesamtsystem ist
dieser Anteil sehr gering. Der Hypervisor weist einen ähnlichen Aufbau auf: Die meisten
Teile werden von der AMD- und der Intel-Implementierung (SVM bzw. VT-x) gemeinsam
genutzt, und daneben gibt es noch einige wenige prozessorspezifische Teile (daher auch
die beiden Dateinamen in Tabelle 2–1).
QQ Verwendung von C Der Großteil von Windows ist in C geschrieben, einige Teile in C++.
Eine Assemblersprache wird nur für die Teile des Betriebssystems verwendet, die direkt mit
der Systemhardware kommunizieren müssen (z. B. Interrupt-Trap-Handler) oder die äußerst leistungsempfindlich sind (z. B. Kontextwechsel). Assemblercode gibt es nicht nur im
Kernel und in der HAL, sondern auch an einigen anderen Stellen des Kernbetriebssystems
(z. B. in den Routinen für gesperrte Anweisungen und in einem Modul in der Einrichtung
für lokale Prozeduraufrufe), im Kernelmodus-Teil des Windows-Teilsystems und sogar in
einigen Benutzermodus-Bibliotheken, darunter im Prozessstartcode in Ntdll.dll (einer Systembibliothek, die weiter hinten in diesem Kapitel noch genauer beschrieben wird).
Symmetrisches Multiprocessing
Multitasking ist eine Betriebssystemtechnik, mit der sich mehrere Ausführungsthreads einen
einzigen Prozessor teilen können. Auf einem Computer mit mehreren Prozessoren können
jedoch mehrere Threads gleichzeitig ausgeführt werden. Während ein Multitasking-Betriebssystem nur vorgibt, mehrere Threads gleichzeitig auszuführen, führt ein Multiprocessing-Betriebssystem jedoch tatsächlich eine Mehrfachverarbeitung durch und führt auf jedem der Prozessoren einen Thread aus.
Wie zu Anfang dieses Kapitels erwähnt, bestand eines der wichtigsten Designziele für
Windows darin, dass es auch auf Mehrprozessorsystemen gut laufen sollte. Windows ist ein Betriebssystem mit symmetrischem Multiprocessing (SMP). Es gibt keinen Masterprozessor – das
Betriebssystem und alle Benutzerthreads können auf beliebigen Prozessoren ausgeführt werden. Außerdem teilen sich alle Prozessoren denselben Speicherbereich. Das steht im Gegensatz
zum asymmetrischen Multiprocessing (ASMP), bei dem das Betriebssystem gewöhnlich einen
Prozessor für die Ausführung des Kernelcodes auswählt, während auf den anderen Prozessoren
nur Benutzercode läuft. Die Unterschiede dieser beiden Modelle veranschaulicht Abb. 2–2.
Die Architektur im Überblick
Kapitel 2
57
Symmetrisch
Asymmetrisch
Arbeitsspeicher
CPU A
Arbeitsspeicher
CPU B
Betriebs
system
thread
CPU A
Benutzer
thread
Benutzer
thread
Benutzer
thread
Betriebs
system
thread
CPU B
Betriebs
system
thread
Benutzer
thread
Betriebs
system
thread
Benutzer
thread
Benutzer
thread
Benutzer
thread
Benutzer
thread
Abbildung 2–2 Symmetrisches und asymmetrisches Multiprocessing im Vergleich
Windows unterstützt vier moderne Arten von Mehrprozessorsystemen: Mehrkernsysteme,
SMT-Systeme (Simultaneous Multi-Threaded), heterogene Systeme und NUMA-Systeme
(Non-Uniform Memory Access). Sie werden in den folgenden Absätzen kurz vorgestellt. (Eine
vollständige, ausführliche Beschreibung der Unterstützung für die Threadplanung auf solchen
Systemen finden Sie im entsprechenden Abschnitt in Kapitel 4, »Threads«.)
SMT wurde durch die Unterstützung für die Hyperthreading-Technologie von Intel in
Windows eingeführt, mit der für jeden physischen Prozessorkern zwei logische Prozessoren
bereitgestellt werden können. Neuere AMD-Prozessoren mit Zen-Mikroarchitektur nutzen eine
ähnliche SMT-Technik, um ebenfalls die Anzahl der logischen Prozessoren zu verdoppeln. Jeder logische Prozessor hat seinen eigenen CPU-Status, aber die Ausführungs-Engine und der
Onboard-Cache werden gemeinsam genutzt. Dadurch kann eine logische CPU weiterarbeiten,
während die andere angehalten ist (z. B. nach einem Cachefehler oder einer falsch vorausgesagten Verzweigung). In ihrem Marketingmaterial nennen beide Firmen die zusätzlichen Kerne
leider Threads, weshalb man oft Behauptungen wie »vier Kerne, acht Threads« liest. Das bedeutet, dass bis zu acht Threads geplant werden können, es also acht logische Prozessoren gibt.
Die Scheduler-Algorithmen wurden verbessert, um die Vorteile von SMT-fähigen Computern
optimal zu nutzen, z. B. durch Planung von Threads auf leerlaufenden physischen Prozessoren,
anstatt einen leerlaufenden logischen Prozessor auf einem physischen Prozessor auszuwählen,
dessen andere logische Prozessoren beschäftigt sind. Weitere Einzelheiten über die Threadplanung finden Sie in Kapitel 4.
Auf NUMA-Systemen sind die Prozessoren zu kleineren Einheiten gruppiert, die als Knoten
bezeichnet werden. Jeder Knoten verfügt über seine eigenen Prozessoren und seinen eigenen
Arbeitsspeicher und ist über einen cachekohärenten Bus mit dem Gesamtsystem verbunden.
Auf NUMA läuft Windows immer noch als SMP-System in dem Sinne, dass alle Prozessoren Zugriff auf den gesamten Arbeitsspeicher haben. Allerdings kann der Knoten schneller auf seinen
lokalen Arbeitsspeicher zugreifen als auf den Arbeitsspeicher anderer Knoten. Daher versucht
das System, die Leistung dadurch zu steigern, dass es Threads auf Prozessoren einplant, die
58
Kapitel 2
Systemarchitektur
zum selben Knoten gehören wie der verwendete Arbeitsspeicher. Es bemüht sich, Speicherzuweisungsanforderungen innerhalb des Knotens zu erfüllen, weist aber auch Arbeitsspeicher auf
anderen Knoten zu, wenn dies notwendig sein sollte.
Windows bietet eine native Unterstützung für Mehrkernsysteme. Da sie über mehrere physische Kerne (im selben Gehäuse) verfügen, behandelt der SMP-Code von Windows sie als
getrennte Prozessoren. Eine Ausnahme davon bilden bestimmte Buchführungs- und Identifizierungsaufgaben (wie die in Kürze beschriebene Lizenzierung), bei denen zwischen Kernen
auf demselben Prozessor und Kernen auf verschiedenen Sockeln unterschieden wird. Das ist
insbesondere beim Umgang mit Cachetopologien zur Optimierung der gemeinsamen Datennutzung wichtig.
Die ARM-Versionen von Windows unterstützen auch das sogenannte heterogene Multiprocessing, dessen Implementierung auf solchen Prozessoren als big.LITTLE bezeichnet wird. Diese
Form des SMP-Designs weicht von der herkömmlichen darin ab, dass die Prozessorkerne nicht
alle die gleichen Fähigkeiten haben, aber anders als reines heterogenes Multiprocessing immer
noch in der Lage sind, dieselben Anweisungen auszuführen. Der Unterschied liegt in den Takt
raten und dem Verhältnis des Stromverbrauchs bei Volllast und Leerlauf, wodurch langsame
Kerne mit schnelleren kombiniert werden können.
Stellen Sie sich vor, Sie würden auf einem älteren Zweikernsystem mit 1 GHz, das an eine
moderne Internetverbindung angeschlossen ist, eine E-Mail senden. Der Vorgang würde wahrscheinlich nicht langsamer ablaufen als auf einem 8-Kern-Rechner mit 3,6 GHz, da nicht die Rechenleistung den entscheidenden Engpass bildet, sondern die Tippgeschwindigkeit eines Menschen und die Netzwerkbandbreite. Auf der anderen Seite kann ein modernes System selbst im
sparsamsten Energiesparmodus noch erheblich mehr Strom verbrauchen als ein älteres System.
Das gilt selbst dann, wenn sich das moderne System selbst auf 1 GHz herunterregeln könnte,
denn dann hätte sich das alte System vermutlich auch schon auf 200 MHz herabgestuft.
Durch die Möglichkeit, solche alten Prozessoren mit Spitzenmodellen zu kombinieren,
kann eine ARM-Plattform mit einem kompatiblen Kernelscheduler die Verarbeitungsleistung
maximieren, wenn es erforderlich ist (indem alle Kerne eingeschaltet werden), in einem extremen Energiesparmodus laufen (indem nur ein einziger kleiner Kern online gehalten wird, was
für SMS und das Senden von Push-E-Mail ausreicht) oder einen Ausgleich finden (indem einige
große Kerne und für andere Aufgaben einige kleine online sind). Durch die Unterstützung der
Richtlinien für heterogenes Scheduling können Threads in Windows 10 die Richtlinie auswählen,
die ihre Bedürfnisse am besten erfüllt, und mit dem am besten geeigneten Scheduler und Energie-Manager arbeiten. Mehr über diese Richtlinien erfahren Sie in Kapitel 4.
Windows wurde nicht im Hinblick auf eine bestimmte Anzahl von Prozessoren entworfen.
Aus Gründen des Komforts und der Effizienz hält Windows jedoch Informationen über die
Prozessoren (Gesamtzahl, Prozessoren im Leerlauf, beschäftigte Prozessoren usw.) in einer Bitmaske (oder Affinitätsmaske) fest. Die Bitanzahl dieser Maske entspricht dem nativen Datentyp
des Computers (32 Bit oder 64 Bit), sodass der Prozessor die Bits direkt in einem Register bearbeiten kann. Daher waren Windows-Systeme ursprünglich auf die Anzahl der CPUs beschränkt,
die in ein natives Word passt, da sich die Affinitätsmaske nicht willkürlich vergrößern ließ. Um
die Kompatibilität zu erhalten und auch Systeme mit mehr Prozessoren zu unterstützen, implementiert Windows ein Konstrukt höherer Ordnung, nämlich die Prozessorgruppe. Dabei
handelt es sich um einen Satz von Prozessoren, die durch eine einzige Affinitätsmaske defi-
Die Architektur im Überblick
Kapitel 2
59
niert werden können. Bei Änderungen der Affinität können der Kernel und die Anwendungen
wählen, auf welche Gruppe sie sich beziehen. Kompatible Anwendungen können die Anzahl
der unterstützten Gruppen abfragen (zurzeit bis zu 20, wobei die maximale Anzahl logischer
Prozessoren zurzeit bei 640 liegt) und dann die Bitmasken für die einzelnen Gruppen aufzählen. Ältere Anwendungen sehen nur ihre aktuelle Gruppe, sodass sie ebenfalls funktionieren.
Wie Windows Prozessoren zu Gruppen zuweist (was auch im Zusammenhang mit NUMA steht),
erfahren Sie in Kapitel 4.
Die tatsächliche Anzahl der unterstützten lizenzierten Prozessoren hängt von der verwendeten Windows Edition ab (siehe Tabelle 2–2 weiter hinten). Diese Anzahl ist in der Lizenzrichtliniendatei %SystemRoot%\ServiceProfiles\LocalService\AppData\Local\Microsoft\WSLicense\tokens.
dat in der Variablen kernel-RegisteredProcessors gespeichert (im Grunde genommen eine Liste
von Schlüssel-Wert-Paaren).
Skalierbarkeit
Eines der Hauptprobleme von Multiprozessorsystemen ist die Skalierbarkeit. Um auf SMP-Systemen korrekt ausgeführt werden zu können, muss der Betriebssystemcode strenge Richtlinien
und Regeln erfüllen. Der Wettstreit um Ressourcen und andere Leistungsprobleme sind auf
Mehrprozessorsystemen komplizierter als auf Einzelprozessorsystemen und müssen beim Design des Systems berücksichtigt werden. Windows weist mehrere Merkmale auf, die für seinen
Erfolg als Multiprozessor-Betriebssystem von entscheidender Bedeutung waren:
QQ Die Möglichkeit, Betriebssystemcode auf einem beliebigen verfügbaren Prozessor und
auch gleichzeitig auf mehreren Prozessoren auszuführen
QQ Mehrere Ausführungsthreads in einem Prozess, die alle gleichzeitig auf verschiedenen Prozessoren laufen können
QQ Feine Synchronisierung im Kernel (z. B. Spinlocks, Warteschlangen-Spinlocks und Pushlocks, wie sie in Kapitel 8 von Band 2 beschrieben werden) und in Gerätetreibern und Serverprozessen, wodurch mehr Komponenten gleichzeitig auf mehreren Prozessoren laufen
können
QQ Programmiermechanismen wie E/A-Vervollständigungsports (siehe Kapitel 6, »Das E/A-
System«) für eine effiziente Implementierung von Multithread-Serverprozessen, die sich
auf Mehrprozessorsystemen gut skalieren lassen
Die Skalierbarkeit des Windows-Kernels hat sich im Laufe der Zeit entwickelt. Beispielsweise wurden Planungswarteschlangen für einzelne CPUs mit feinen Sperren in Windows Server
2003 eingeführt, was es ermöglichte, Entscheidungen zur Threadplanung parallel auf mehreren
Prozessoren durchzuführen. In Windows 7 und Windows Server 2008 R2 wurde die globale
Schedulersperre bei Warte-Dispatchoperationen beseitigt. Diese schrittweise Verfeinerung der
Sperrmechanismen hat auch in anderen Bereichen stattgefunden, z. B. im Speicher-, im Cacheund im Objekt-Manager.
60
Kapitel 2
Systemarchitektur
Unterschiede zwischen den Client- und Serverversionen
Windows wird sowohl als Client- als auch als Serverversion verkauft. Von Windows 10 gibt es
sechs Desktop-Clientversionen: Windows 10 Home, Windows 10 Pro, Windows 10 Education,
Windows 10 Pro Education, Windows 10 Enterprise und Windows 10 Enterprise Long Term
Serving Branch (LTSB). Des Weiteren sind Editionen für andere Geräte als Desktopcomputer
erhältlich, darunter Windows 10 Mobile, Windows 10 Mobile Enterprise, Windows 10 IoT Core,
IoT Core Enterprise und IoT Mobile Enterprise. Für den besonderen Bedarf einzelner Regionen
gibt es noch mehr Varianten, etwa die N-Serie.
Von Windows Server 2016 gibt es ebenfalls sechs Versionen: Windows Server 2016 Datacenter, Windows Server 2016 Standard, Windows Server 2016 Essentials, Windows Server 2016
MultiPoint Premium Server, Windows Storage Server 2016 und Microsoft Hyper-V Server 2016.
Zwischen den Versionen bestehen folgende Unterschiede:
QQ Preisgestaltung nach Anzahl der Kerne (statt der Prozessorsockel) bei Windows Server
2016 Datacenter und Standard
QQ Anzahl der insgesamt unterstützten logischen Prozessoren
QQ Anzahl der Hyper-V-Container, die ausgeführt werden dürfen (bei Serversystemen; in Clientsystemen können nur Windows-Container auf der Grundlage getrennter Namespaces
verwendet werden)
QQ Unterstützte Größe des physischen Arbeitsspeichers (eigentlich die höchste für den RAM
nutzbare physische Adresse; mehr über Grenzwerte für den physischen Arbeitsspeicher
erfahren Sie in Kapitel 5, »Speicherverwaltung«)
QQ Anzahl der zugelassenen gleichzeitigen Netzwerkverbindungen (beispielsweise sind in den
Clientversionen höchstens zehn gleichzeitige Verbindungen für Datei- und Druckdienste
erlaubt)
QQ Unterstützung für Multitouch und Desktopgestaltung
QQ Unterstützung für Merkmale wie BitLocker, VHD-Start, AppLocker, Hyper-V und über 100
weitere einstellbare Lizenzrichtlinienwerte
QQ Geschichtete Dienste, die in den Server-, aber nicht in den Clientversionen verfügbar sind
(z. B. Verzeichnisdienste, Host-Überwachungsdienst, direkte Speicherplätze, abgeschirmte
virtuelle Maschinen und Clusterdienste)
Tabelle 2–2 nennt die Unterschiede bei der Unterstützung für Arbeitsspeicher und Prozessoren
zwischen einigen Editionen von Windows 10, Windows Server 2012 R2 und Windows Server
2016. Eine ausführliche Vergleichstabelle für die verschiedenen Ausgaben von Windows Server 2012 R2 finden Sie auf https://www.microsoft.com/en-us/download/details.aspx?id=41703.
Speichergrenzwerte der Editionen von Windows 10 und Server 2016 sowie früherer Betriebssysteme sind auf https://msdn.microsoft.com/en-us/library/windows/desktop/aa366778.aspx
aufgeführt.
Die Client- und Servereditionen werden zwar in verschiedenen Paketen verkauft, nutzen
aber alle die gleichen Hauptsystemdateien, darunter das Kernelabbild Ntoskrnl.exe (und die
Die Architektur im Überblick
Kapitel 2
61
PAE-Version Ntkrnlpa.exe), die HAL-Bibliotheken, die Gerätetreiber, die grundlegenden Systemprogramme und die DLLs.
Anzahl
Prozessorsockel
(32-Bit-Edition)
Physischer
Arbeitsspeicher
(32-Bit-Edition)
Anzahl logischer
Prozessoren/
Sockel (64-BitEdition)
Physischer
Arbeitsspeicher
(x64-Editionen)
Windows 10
Home
1
4 GB
1 Sockel
128 GB
Windows 10 Pro
2
4 GB
2 Sockel
2 TB
Windows 10
Enterprise
2
4 GB
2 Sockel
2 TB
Windows Server
2012 R2 Essentials
–
–
2 Sockel
64 GB
Windows Server
2016 Standard
–
–
512 logische Prozessoren
24 TB
Windows Server
2016 Datacenter
–
–
512 logische Prozessoren
24 TB
Tabelle 2–2 Prozessor- und Speichergrenzwerte für einige Windows-Editionen
Woher weiß das System angesichts so vieler verschiedener Editionen, die alle dasselbe Kernelabbild verwenden, welche Edition gestartet wurde? Dazu fragt es die Registrierungswerte
ProductType und ProductSuite unter dem Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\
ProductOptions ab. Dabei dient ProductType zur Unterscheidung zwischen Client- und Serversystem (gleich welcher Variante). In die Registrierung geladen werden diese Werte auf der
Grundlage der zuvor beschriebenen Lizenzrichtliniendatei. Tabelle 2–3 führt die gültigen Werte
auf. Die Abfrage kann im Benutzermodus durch die Funktion VerifyVersionInfo erfolgen oder
von einem Gerätetreiber mit den Kernelmodusfunktionen RtlGetVersion und RtlVerifyVersionInfo durchgeführt werden, die beide im Windows Driver Kit dokumentiert sind.
Windows-Edition
Wert von ProductType
Windows-Client
WinNT
Windows-Server (Domänencontroller)
LanmanNT
Windows-Server (reiner Server)
ServerNT
Tabelle 2–3 Registrierungswerte für ProductType
Der Registrierungswert ProductPolicy enthält eine zwischengespeicherte Kopie der Daten in
der Datei tokens.dat, die zwischen den Windows-Editionen und den von diesen jeweils aktivierten Funktionen unterscheidet.
Wenn die Hauptdateien der Client- und Serverversionen im Grunde genommen identisch
sind, wie unterscheiden sich die Systeme dann im Betrieb? Kurz Serversysteme sind standardmäßig für den Durchsatz von Hochleistungs-Anwendungsservern optimiert, wohingegen die
Clientversionen (auch wenn sie einige Serverfähigkeiten haben) auf kurze Reaktionszeiten für
interaktive Desktopbenutzung ausgelegt sind. So werden beispielsweise beim Hochfahren des
62
Kapitel 2
Systemarchitektur
Systems je nach Produkttyp unterschiedliche Entscheidungen zur Ressourcenzuweisung getroffen, z. B. was die Größe und Anzahl der Betriebssystemheaps (oder -pools), die Anzahl
der internen Systemarbeitsthreads und die Größe des Systemdatencache angeht. Auch einige
Laufzeitentscheidungen, z. B. die Abwägung des Speicher-Managers zwischen den Speicheranforderungen des Systems und der Prozesse, unterscheiden sich zwischen den Server- und
den Clienteditionen. Sogar einige Einzelheiten der Threadplanung weisen in den beiden Familien jeweils ein unterschiedliches Standardverhalten auf (die Standardlänge der Zeitscheibe
oder das Threadquantum; siehe Kapitel 4). Wenn es auf einem Gebiet erhebliche Unterschiede
zwischen den beiden Produkten gibt, so wird in den entsprechenden Kapiteln dieses Buches
jeweils darauf hingewiesen. Ansonsten gilt alles, was in diesem Buch beschrieben wird, sowohl
für die Client- als auch die Serverversionen.
Experiment: Die von der Lizenzierungsrichtlinie aktivierten
Merkmale ermitteln
Wie bereits erwähnt, unterstützt Windows mehr als 100 Merkmale, die durch den Softwarelizenzierungsmechanismus aktiviert werden. Diese Richtlinieneinstellungen bestimmen
verschiedene Unterschiede nicht nur zwischen einer Client- und einer Serverinstallation,
sondern auch zwischen den einzelnen Editionen (oder SKU) des Betriebssystems, z. B. die
Unterstützung für BitLocker (verfügbar in der Serverversion und in den Editionen Pro und
Enterprise der Clientversion). Mit dem Tool SlPolicy aus den Downloads zu diesem Buch
können Sie viele dieser Richtlinienwerte anzeigen lassen.
Die Richtlinieneinstellungen sind nach Einrichtungen (»facilities«) geordnet, also nach
den Besitzermodulen, auf die die Richtlinie angewendet wird. Um eine Liste aller Einrichtungen einzusehen, die das Tool kennt, führen Sie SlPolicy.exe mit dem Schalter -f aus:
C:\>SlPolicy.exe -f
Software License Policy Viewer Version 1.0 (C)2016 by Pavel Yosifovich
Desktop Windows Manager
Explorer
Fax
Kernel
IIS
...
Wenn Sie den Namen einer Einrichtung hinter dem Schalter angeben, wird der Richtlinienwert für diese Einrichtung angezeigt. Wollen Sie sich beispielsweise die Grenzwerte für
CPUs und den Arbeitsspeicher ansehen, so müssen Sie die Kernel-Einrichtung verwenden.
Auf einem Computer mit Windows 10 Pro ergibt sich dabei folgende Ausgabe:
C:\>SlPolicy.exe -f Kernel
Software License Policy Viewer Version 1.0 (C)2016 by Pavel Yosifovich
Kernel
------
→
Die Architektur im Überblick
Kapitel 2
63
Maximum allowed processor sockets: 2
Maximum memory allowed in MB (x86): 4096
Maximum memory allowed in MB (x64): 2097152
Maximum memory allowed in MB (ARM64): 2097152
Maximum physical page in bytes: 4096
Device Family ID: 3
Native VHD boot: Yes
Dynamic Partitioning supported: No
Virtual Dynamic Partitioning supported: No
Memory Mirroring supported: No
Persist defective memory list: No
Bei Windows Server 2012 R2 Datacenter Edition dagegen sieht das Ergebnis wie folgt aus:
Kernel
-----Maximum allowed processor sockets: 64
Maximum memory allowed in MB (x86): 4096
Maximum memory allowed in MB (x64): 4194304
Add physical memory allowed: Yes
Add VM physical memory allowed: Yes
Maximum physical page in bytes: 0
Native VHD boot: Yes
Dynamic Partitioning supported: Yes
Virtual Dynamic Partitioning supported: Yes
Memory Mirroring supported: Yes
Persist defective memory list: Yes
Testbuild
Es gibt eine besondere interne Debugversion von Windows, die als Testbuild (oder manchmal
auch überprüfter Build) bezeichnet wird. (Extern erhältlich ist sie nur für Windows 8.1 und früher und nur mit MSDN-Abonnement.) Dabei handelt es sich um eine Neukompilierung des
Windows-Quellcodes mit dem Flag DBG, das dafür sorgt, dass Kompilierungszeitcode, Code
für bedingtes Debugging und Ablaufverfolgungscode eingeschlossen werden. Um den Maschinencode leichter verständlich zu machen, erfolgt keine Nachbearbeitung der Windows-Binärdateien, die sonst zur Optimierung des Codelayouts und damit für eine schnelle Ausführung
durchgeführt wird (siehe den Abschnitt »Debugging performance-optimized code« in der Hilfedatei zu den Debugging Tools for Windows).
Der Testbuild ist hauptsächlich als Hilfestellung für die Entwickler von Gerätetreibern gedacht, da er eine strengere Fehlerprüfung von Kernelmodusfunktionen durchführt, die von Gerätetreibern oder anderem Systemcode aufgerufen werden. Wenn beispielsweise ein Treiber (oder
anderer Kernelmoduscode) eine Systemfunktion auf ungültige Weise aufruft (indem er etwa ein
64
Kapitel 2
Systemarchitektur
Spinlock auf der falschen Interrupt-Anforderungsebene erwirbt) und das Problem erkannt wird,
da die Funktion die Parameter prüft, so hält das System die Ausführung an, damit keine Datenstrukturen beschädigt werden, was später zu einem Absturz führen könnte. Da ein kompletter
überprüfter Build häufig instabil ist und in den meisten Umgebungen nicht ausgeführt werden
kann, stellt Microsoft ab Windows 10 nur einen überprüften Kernel mit HAL zur Verfügung. Dadurch können Entwickler diese Einrichtungen nutzen, ohne sich mit den Problemen beschäftigen zu müssen, die ein vollständiger überprüfter Build hervorruft. Der überprüfte Kernel und die
überprüfte HAL stehen kostenlos im WDK zur Verfügung, und zwar im Verzeichnis \Debug des
Stamminstallationspfads. Ausführliche Anleitungen zu ihrer Nutzung erhalten Sie im Abschnitt
»Installing Just the Checked Operating System and HAL« in der WDK-Dokumentation.
Experiment: Wird der Testbuild ausgeführt?
Im Lieferumfang von Windows ist kein Werkzeug enthalten, mit dem Sie bestimmen können, ob Sie den Testbuild oder den Einzelhandelsbuild (freier Build) des Kernels ausführen.
Allerdings ist diese Information über die Eigenschaft Debug der WMI-Klasse Win32_OperatingSystem verfügbar (Windows Management Instrumentation).
Mit dem folgenden PowerShell-Skript können Sie diese Eigenschaft anzeigen lassen.
(Das können Sie ausprobieren, indem Sie einen PowerShell-Skripthost öffnen.)
PS C:\Users\pavely> Get-WmiObject win32_operatingsystem | select debug
debug
----False
In diesem Beispiel hat die Eigenschaft Debug den Wert False, was bedeutet, dass nicht der
Testbuild ausgeführt wird.
Eine Menge des zusätzlichen Codes in den Binärdateien des Testbuilds kommt durch die Makros ASSERT und NT_ASSERT zustande, die in der WDK-Headerdatei Wdm.h definiert sind und
in der WDK-Dokumentation erklärt werden. Diese Makros testen eine Bedingung, z. B. die
Gültigkeit einer Datenstruktur oder eines Parameters. Lautet das Ergebnis FALSE, so rufen die
Makros entweder die Kernelmodusfunktion RtlAssert auf, die wiederum DbgPrintEx aufruft,
um den Text der Debugnachricht an den Debugnachrichtenpuffer zu senden, oder sie geben
einen Assertion-Interrupt aus, bei dem es sich auf x64- und x86-Systemen um den Interrupt
0x2B handelt. Ist ein Kerneldebugger angeschlossen und sind die entsprechenden Symbole geladen, so wird die Nachricht automatisch angezeigt und der Benutzer gefragt, was wegen des
Assertionfehlers unternommen werden soll (Haltepunkt setzen, ignorieren, Prozess abbrechen
oder Thread abbrechen). Ist das System ohne Kerneldebugger gestartet worden (also ohne die
Option debug in der Bootkonfigurationsdatenbank) und ist daher kein Kerneldebugger angeschlossen, so führt der Fehlschlag eines Assertiontests zur Fehlerprüfung (und zum Absturz) des
Systems. Eine Liste der Assertionchecks, die einige der Kernelunterstützungsroutinen durchführen, finden Sie im Abschnitt »Checked Build ASSERTs« in der WDK-Dokumentation (allerdings
wird diese Liste nicht mehr gepflegt und ist veraltet).
Die Architektur im Überblick
Kapitel 2
65
Der überprüfte Build kann auch sehr nützlich zum Testen von Benutzermoduscode sein, da
das System bei diesem Build ein anderes Timing hat. (Das liegt daran, dass im Kernel zusätzliche Überprüfungen erfolgen und die Komponenten ohne Optimierung kompiliert worden
sind.) Oft hängen Fehler bei der Synchronisierung mehrerer Threads von bestimmten Timingbedingungen ab. Wenn Sie Ihre Tests auf einem System mit einem überprüften Build ausführen
(oder zumindest mit überprüftem Kernel und HAL), dann können aufgrund des veränderten
Systemtimings Bugs zutage treten, die sich auf einem normalen System nicht zeigen.
Die virtualisierungsgestützte Sicherheitsarchitektur
im Überblick
Durch die Trennung zwischen Benutzer- und Kernelmodus wird das Betriebssystem von Benutzermoduscode abgeschirmt, ob gefährlich oder nicht. Wenn unerwünschter Kernelmoduscode
es jedoch ins System schafft (durch eine noch nicht gepatchte Schwachstelle im Kernel oder
einem Treiber oder weil der Benutzer dazu verführt wurde, einen schädlichen oder angreifbaren Treiber zu installieren), ist das System im Grunde genommen bereits geknackt, da jeglicher Kernmoduscode Vollzugriff auf das gesamte System hat. Die in Kapitel 1 beschriebenen
Technologien, die den Hypervisor nutzen, um zusätzlichen Schutz gegen Angriffe zu bieten,
bilden zusammen die virtualisierungsgestützten Sicherheitseinrichtungen (Virtualization-Based
Security, VBS), die die normale, vom Prozessor durchgeführte Trennung aufgrund von Rechten
durch virtuelle Vertrauensebenen (Virtual Trust Levels, VTLs) erweitert. VTLs bieten nicht nur
eine neue, orthogonale Möglichkeit, um den Zugriff auf Speicher-, Hardware- und Prozessorressourcen zu isolieren, sondern erfordern auch, dass neuer Code und neue Komponenten mit
den höheren Vertrauensebenen umgehen können. Der reguläre Kernel und die regulären Treiber laufen auf VTL 0, weshalb ihnen nicht gestattet werden darf, VTL-1-Ressourcen zu steuern
und zu definieren.
Abb. 2–3 zeigt die Architektur von Windows 10 Enterprise und Windows Server 2016 mit
aktiver VBS. (Manchmal wird auch die Bezeichnung Virtual Secure Mode oder kurz VSM verwendet.) Bei Windows 10 Version 1607 und Server 2016 ist VBS standardmäßig aktiv, wenn
die Hardware dies zulässt. Bei älteren Versionen von Windows 10 können Sie VBS über eine
Richtlinie oder im Dialogfeld Hinzufügen von Windows-Funktionen aktivieren (wählen Sie dazu
die Option Isolierter Benutzermodus).
66
Kapitel 2
Systemarchitektur
VTL 0
VTL 1
Benutzermodus
Isolierter
Benutzermodus
(IUM)
Kernelmodus
Sicherer
Kernel
Hypervisor Hyper-V
SLAT
Hardware
I/O MMU
Abbildung 2–3 VBS-Architektur von Windows 10 und Server 2016
Wie Sie in Abb. 2–3 sehen, läuft der zuvor beschriebene Benutzer- und Kernelcode wie schon in
Abb. 2–1 oberhalb des Hypervisors Hyper-V. Der Unterschied besteht darin, dass es bei aktivierter VBS jetzt die VTL 1 gibt, die einen eigenen sicheren Kernel im privilegierten Prozessormodus
(Ring 0 auf x86/x64) enthält. Ebenso gibt es mit dem isolierten Benutzermodus (IUM) jetzt
einen Laufzeit-Benutzermodus, der im nicht privilegierten Modus (Ring 3) läuft.
Bei dieser Architektur befindet sich der sichere Kernel in seiner eigenen, separaten Binärdatei, die als securekernel.exe auf der Festplatte steht. Der IUM ist sowohl eine Umgebung,
die zulässige Systemaufrufe regulärer Benutzermodus-DLLs beschränkt (und damit auch, welche dieser DLLs geladen werden können), als auch ein Framework, das besondere, nur auf
VTL 1 ausführbare sichere Systemaufrufe hinzufügt. Diese zusätzlichen Systemaufrufe werden
auf ähnliche Weise verfügbar gemacht wie die regulären, nämlich durch eine interne Systembibliothek namens lumdll.dll (die VTL-1-Version von Ntdll.dll) und eine Bibliothek für das
Windows-Teilsystem namens lumbase.dll (die VTL-Version von Kernelbase.dll). Diese Implementierung des IUM verwendet zum größten Teil dieselben Standardbibliotheken der Win32-API,
was den Speicheroverhead von VTL-1-Benutzermodusanwendungen zu reduzieren hilft, da im
Grunde genommen derselbe Benutzermoduscode vorhanden ist wie in ihren VTL-0-Gegenstücken. Mechanismen für das Kopieren bei Schreibvorgängen (siehe Kapitel 5) verhindern, dass
VTL-0-Anwendungen Änderungen an Binärdateien vornehmen, die auf VTL 1 genutzt werden.
Bei VBS gelten die üblichen Regeln für Benutzer- und Kernelmodus, die jetzt aber noch um
VTL-Aspekte erweitert werden. Kernelmoduscode auf VTL 0 darf keinen Benutzermoduscode
auf VTL 1 anfassen, da VTL 1 höhere Rechte hat. Allerdings darf Benutzermoduscode auf VTL 1
auch keinen Kernelmoduscode auf VTL 0 anfassen, da ein solcher Zugriff vom Benutzermodus
(Ring 3) auf den Kernelmodus (Ring 0) grundsätzlich untersagt ist. VTL-1-Benutzermodusanwendungen müssen außerdem weiterhin die regulären Windows-Systemaufrufe und die zugehörigen Zugriffsprüfungen durchlaufen, um auf Ressourcen zuzugreifen.
Das können Sie sich auf folgende Weise verdeutlichen: Rechteebenen (Benutzer- oder
Kernelmodus) sorgen für Macht, VTLs dagegen für Isolierung. Eine VTL-1-Benutzermodusanwendung ist nicht mächtiger als eine VTL-0-Anwendung oder ein VTL-0-Treiber, aber davon
Die virtualisierungsgestützte Sicherheitsarchitektur im Überblick
Kapitel 2
67
isoliert. In vielen Fällen sind VTL-1-Anwendungen nicht nur nicht mächtiger, sondern sogar
weniger mächtig. Da der sichere Kernel nicht die volle Palette der Systemfähigkeiten implementiert, wählt er aus, welche Systemaufrufe er an den VTL-0-Kernel weiterleitet (weshalb der
sichere Kernel auch als Proxykernel bezeichnet wird). Jede Art von E/A, ob im Zusammenhang
mit Dateien, dem Netzwerk oder der Registrierung, ist komplett verboten. Auch Grafik kommt
nicht in Betracht, und es darf auch mit keinem einzigen Treiber kommuniziert werden.
Da der sichere Kernel jedoch auf VTL 1 und im Kernelmodus läuft, hat er vollständigen
Zugriff auf den Arbeitsspeicher und die Ressourcen auf VTL 0. Er kann den Hypervisor nutzen,
um den VTL-0-Betriebssystemzugriff auf bestimmte Speicherbereiche einzuschränken. Dies geschieht mithilfe von SLAT (Second Level Address Translation), einer CPU-Hardwaretechnologie.
Sie bildet die Grundlage von CredentialGuard, mit dem Geheimnisse in solchen Bereichen gespeichert werden. Der sichere Kernel kann SLAT auch nutzen, um die Ausführung von Speicherbereichen zu untersagen und zu steuern, was eine entscheidende Bedingung von DeviceGuard
ist.
Um zu verhindern, dass normale Gerätetreiber Hardwaregeräte für den direkten Speicherzugriff nutzen, verwendet das System noch eine weitere Hardware, nämlich die E/A-Speicherverwaltungseinheit (Memory Management Unit, MMU), die den Speicherzugriff für Geräte im
Grunde genommen virtualisiert. Damit kann verhindert werden, dass Gerätetreiber den direkten Speicherzugriff (Direct Memory Access, DMA) nutzen, um unmittelbar auf die physischen
Speicherbereiche des Hypervisors oder des sicheren Kernels zuzugreifen. Mit einer solchen Vorgehensweise könnte SLAT umgangen werden, da dabei kein virtueller Speicher verwendet wird.
Da der Hypervisor die erste Systemkomponente ist, die der Bootloader lädt, kann er die
SLAT und die I/O MMU nach seinem Bedarf programmieren und die Ausführungsumgebungen
VTL 0 und VTL 1 definieren. Dann wird der Bootloader in VTL 1 erneut ausgeführt, um den
sicheren Kernel zu laden, der das System nach seinen Bedürfnissen weiter konfiguriert. Erst
danach wird die VTL gesenkt, sodass der normale Kernel in seinem VTL-0-Gefängnis ausgeführt
wird, aus dem er nicht entkommen kann.
Da Benutzermodusprozesse auf VTL 1 isoliert sind, kann potenziell schädlicher Code zwar
keinen größeren Einfluss auf das System gewinnen, aber heimlich versuchen, sichere Systemaufrufe durchzuführen (die ihm erlauben würden, seine eigenen Geheimnisse zu signieren),
und möglicherweise schädliche Interaktionen mit anderen VTL-1-Prozessen oder dem sicheren
Kernel hervorrufen. Daher dürfen nur besonders signierte Binärdateien, sogenannte Trustlets,
auf VTL 1 ausgeführt werden. Jedes Trustlet weist einen eindeutigen Bezeichner und eine Signatur auf, und der sichere Kernel verfügt über hartcodierte Kenntnisse darüber, welche Trustlets
bisher erstellt wurden. Daher ist es unmöglich, neue Trustlets zu erstellen, ohne auf den sicheren Kernel zuzugreifen (den nur Microsoft anfassen kann). Auch vorhandene Trustlets können
nicht manipuliert werden, da dadurch ihre besondere Microsoft-Signatur verloren ginge. Weitere Informationen über Trustlets erhalten Sie in Kapitel 3.
Die Ergänzung um den sicheren Kernel und VBS ist eine spannende Entwicklung in der
modernen Betriebssystemarchitektur. Mit weiteren Hardwareänderungen an Bussen wie PCI
und USB wird es bald möglich sein, eine ganze Klasse von sicheren Geräten zu unterstützen, die
in Kombination mit einer minimalistischen sicheren HAL, einem sicheren Plug-&-Play-Manager
und einem sicheren Benutzermodus-Geräteframework bestimmten VTL-1-Anwendungen ei-
68
Kapitel 2
Systemarchitektur
nen direkten und gesonderten Zugriff auf eigens dafür vorgesehene Dienste erlauben können,
z. B. für biometrische oder Smartcard-Eingaben. Neue Versionen von Windows 10 werden sehr
wahrscheinlich solche technischen Fortschritte nutzen.
Hauptsystemkomponenten
Nachdem wir uns einen Überblick über die Architektur von Windows verschafft haben, wollen
wir uns nun eingehender mit der inneren Struktur und mit der Rolle der einzelnen Komponenten befassen. Abb. 2–4 zeigt eine detaillierte und vollständigere Ansicht der Kernarchitektur
und der Komponenten von Windows als Abb. 2–1. Beachten Sie aber, dass dies immer noch
nicht alle Komponenten sind. (Insbesondere fehlen die Netzwerkkomponenten, die in Kapitel 10, »Netzwerk«, von Band 2 behandelt werden.)
System
prozesse
Umgebungs
teilsysteme
Dienste
Anwendungen
Wininit
SitzungsManager
Spooler
SvcHost
Benutzer
prozess
Teilsystem-DLLs
Teilsystem-DLLs
Winlogon
SCM
CSRSS
Teilsystem-DLLs
NTDLL.DLL
Benutzermodus
Kernelmodus
Systemdienst-Dispatcher
ALPC
Konfigura
tions-Manager
ObjektManager
ProzessManager
SpeicherManager
Plug-&-PlayManager
EnergieManager
Geräte- und
Dateisystemtreiber
Sicherheits
verweis
monitor
E/AManager
Windows
USER und
GDI
Kernel
Hardwareabstraktionsschicht (HAL)
Grafik
treiber
HAL-Erweiterungen
Hypervisor Hyper-V
Abbildung 2–4 Architektur von Windows
Die folgenden Abschnitte enthalten ausführliche Beschreibungen der wichtigsten Elemente in
diesem Diagramm. Kapitel 8 in Band 2 erläutert die primären Steuermechanismen, die das
System einsetzt (wie den Objekt-Manager, Interrupts usw.), Kapitel 11, »Starten und Herunterfahren«, beschreibt den Vorgang des Startens und Herunterfahrens und Kapitel 9 gibt ausführliche Informationen über Verwaltungsmechanismen wie die Registrierung, Dienstprozesse
und WMI. In anderen Kapiteln werden noch genauere Erklärungen zu den internen Strukturen
und der Funktionsweise von Schlüsselaspekten wie Prozessen und Threads, Speicherverwaltung, Sicherheit, dem E/A-Manager, der Speicherplatzverwaltung, dem Cache-Manager, dem
Windows-Dateisystem (NTFS) und dem Netzwerk gemacht.
Hauptsystemkomponenten
Kapitel 2
69
Umgebungsteilsysteme und Teilsystem-DLLs
Ein Umgebungsteilsystem hat die Aufgabe, Anwendungsprogrammen einen Teil der grundlegenden Dienste bereitzustellen, die es im Exekutivsystem von Windows gibt. Jedes Teilsystem
bietet dabei Zugriff auf eine andere Auswahl der nativen Windows-Dienste. Das bedeutet, dass
eine Anwendung in einem Teilsystem Dinge tun kann, die einer Anwendung in einem anderen
Teilsystem nicht möglich sind. Beispielsweise kann eine Windows-Anwendung die SUA-Funk
tion fork nicht nutzen.
Jedes ausführbare Abbild (.exe) ist an genau ein Teilsystem gebunden. Wird das Abbild
ausgeführt, so untersucht der Code zur Prozesserstellung den Typcode für das Teilsystem im
Abbild-Header, sodass er das entsprechende Teilsystem über den neuen Prozess informieren
kann. Der Typcode wird mit der Option /SUBSYSTEM des Linkers von Microsoft Visual Studio angegeben (oder im Eintrag SubSystem auf der Seite Linker/System in den Projekteigenschaften).
Wie bereits erwähnt, rufen Benutzeranwendungen die Windows-Systemdienste nicht direkt auf, sondern durchlaufen dazu eine oder mehrere Teilsystem-DLLs. Diese Bibliotheken exportieren die dokumentierte Schnittstelle, die die mit dem Teilsystem verlinkten Programme
aufrufen können. Beispielsweise implementieren die DLLs des Windows-Teilsystems (wie Kernel32.dll, Advapi32.dll, User32.dll und Gdi32.dll) die Funktionen der Windows-API, während die
DLL des SUA-Teilsystems (Psxdll.dll) zur Implementierung der SUA-API-Funktionen dient (auf
Windows-Versionen, die POSIX unterstützen).
Experiment: Den Teilsystemtyp des Abbilds einsehen
Den Teilsystemtyp des Abbilds können Sie sich mit dem Werkzeug Dependency Walker
(Depends.exe) ansehen. In den folgenden Abbildungen sehen Sie z. B. die Typen für die
beiden Windows-Abbilder Notepad.exe (der einfache Windows-Texteditor) und Cmd.exe
(die Windows-Eingabeaufforderung):
→
70
Kapitel 2
Systemarchitektur
Dies zeigt, dass es sich bei Notepad um ein GUI-Programm handelt, bei Cmd dagegen um
ein Konsolenprogramm. Das scheint zu bedeuten, dass es zwei verschiedene Teilsysteme für
grafische und für textgestützte Programme gibt, allerdings gibt es in Wirklichkeit nur ein
Windows-Teilsystem. GUI-Programme können auch Konsolen haben (durch Aufrufen der
Funktion AllocConsole), und genauso gut können Konsolenprogramme grafische Benutzeroberflächen aufrufen.
Wenn eine Anwendung eine Funktion in einer Teilsystem-DLL aufruft, können drei verschiedene Situationen vorliegen:
QQ Die Funktion ist vollständig im Benutzermodus innerhalb der DLL implementiert. Das heißt,
es werden keine Nachrichten an den Prozess des Umgebungsteilsystems gesendet und
keine Dienste des Windows-Exekutivsystems aufgerufen. Die Funktion läuft im Benutzermodus ab, und die Ergebnisse werden an den Aufrufer zurückgegeben. Beispiele für solche
Funktionen sind GetCurrentProcess (die immer -1 zurückgibt; dieser Wert ist so definiert,
dass er in allen prozessbezogenen Funktionen auf den aktuellen Prozess verweist) und
GetCurrentProcessId. (Da sich die Prozesskennung für einen laufenden Prozess nicht ändert, wird sie von einem zwischengespeicherten Speicherort abgerufen, um einen Aufruf
im Kernel zu vermeiden.)
QQ Die Funktion erfordert einen oder mehrere Aufrufe der Windows-Exekutive. Beispielsweise
müssen die Funktionen ReadFile und WriteFile die zugrunde liegende (und für die Verwendung im Benutzermodus nicht dokumentierten) Dienste NtReadFile bzw. NtWriteFile
des E/A-Systems von Windows aufrufen.
QQ Für die Funktion muss einige Arbeit im Prozess des Umgebungsteilsystems erledigt werden. (Diese Prozesse laufen im Benutzermodus und sind dafür verantwortlich, den Status
der Clientanwendungen, die unter ihrer Kontrolle ausgeführt werden, zu erhalten.) In diesem Fall wird eine Client/Server-Anforderung an das Umgebungsteilsystem gestellt. Dazu
wird eine ALPAC-Nachricht (siehe Kapitel 8 in Band 2) an das Teilsystem gesendet, um eine
Operation auszuführen. Die Teilsystem-DLL wartet dann auf eine Antwort, bevor sie die
Steuerung an den Aufrufer zurückgibt.
Bei einigen Funktionen kann eine Kombination des zweiten und des dritten Falls vorliegen,
etwa bei den Windows-Funktionen CreateProcess und ExitWindowsEx.
Start von Teilsystemen
Teilsysteme werden vom Prozess Smss.exe, dem Sitzungs-Manager, gestartet. Die Informationen über den Start von Teilsystemen werden unter dem Registrierungsschlüssel HKLM\SYSTEM\
CurrentControlSet\Control\Session Manager\SubSystems gespeichert. Die Werte unter diesem
Schlüssel sind in Abb. 2–5 dargestellt (Screenshot von Windows 10 Pro).
Hauptsystemkomponenten
Kapitel 2
71
Abbildung 2–5 Registrierungs-Editor mit Informationen über Windows-Teilsysteme
Der Wert Required führt die Teilsysteme auf, die beim Start des Systems geladen werden. In diesem Wert stehen die beiden Strings Windows und Debug. Der Wert Windows enthält die Dateispezifikation des Windows-Teilsystems Csrss.exe, was für Client/Server Runtime Subsystem steht.
Debug dagegen ist leer (dieser Wert wird seit Windows XP nicht mehr benötigt, wird aber aus
Gründen der Kompatibilität beibehalten) und tut daher gar nichts. Der Wert Optional gibt optionale Teilsysteme an und ist hier auch leer, da SUA auf Windows 10 nicht mehr zur Verfügung
steht. Wäre das noch der Fall, würde der POSIX-Datenwert auf einen anderen Wert zeigen,
der wiederum auf Psxss.exe verweist (den Prozess für das POSIX-Teilsystem). Da dieser Wert in
Optional stehen würde, so würde er »bei Bedarf geladen«, also bei der ersten Begegnung mit
einem POSIX-Abbild. Der Registrierungswert Kmode enthält den Namen der Datei für den Kernelmodusteil des Windows-Teilsystems, Win32k.sys (die weiter hinten in diesem Kapitel noch
erklärt wird).
Sehen wir uns nun die Windows-Umgebungsteilsysteme genauer an.
Windows-Teilsystem
Windows wurde zwar dafür ausgelegt, mehrere unabhängige Umgebungsteilsysteme zu unterstützen, doch wenn jedes Teilsystem den gesamten Code zur Handhabung der Fenster und der
Anzeige-E/A implementierte, würde das zu einer erheblichen Duplizierung von Systemfunktionen führen und letzten Endes sowohl die Größe als auch die Leistung des Systems beeinträchtigen. Da Windows das primäre Teilsystem sein sollte, brachten die Designer diese Grundfunktionen dort unter, sodass andere Teilsysteme, etwa wie SUA, Dienste des Windows-Teilsystems
aufrufen mussten, um eine Anzeige-E/A durchzuführen.
Aufgrund dieser Designentscheidung ist das Windows-Teilsystem eine erforderliche Komponente für alle Windows-Systeme, selbst für Serversysteme, auf denen keine Benutzer für
interaktive Sitzungen angemeldet sind. Der Prozess ist daher als kritischer Prozess gekennzeichnet, d. h., sollte er aus irgendeinem Grund beendet werden, so stürzt das System ab.
72
Kapitel 2
Systemarchitektur
Das Windows-Teilsystem besteht aus den folgenden Hauptkomponenten:
QQ Für jede Sitzung lädt eine Instanz des Umgebungsteilsystemprozesses (Csrss.exe) vier DLLs
(Basesrv.dll, Winsrv.dll, Sxssrv.dll und Csrsrv.dll), die Unterstützung für Folgendes bieten:
•
Verschiedene Ordnungsaufgaben im Zusammenhang mit dem Erstellen und Löschen
von Prozessen und Threads
•
Herunterfahren von Windows-Anwendungen (durch die API ExitWindowsEx)
•
Bereitstellen von Zuordnungen von .ini-Dateien zu Speicherorten in der Registrierung,
um für Rückwärtskompatibilität zu sorgen
•
Senden bestimmter Kernelbenachrichtigungen (z. B. derjenigen aus dem Plug-&-PlayManager) als Windows-Nachrichten (WL_DEVICECHANGE) an Windows-Anwendungen
•
Teile der Unterstützung für 16-Bit-VDM-Prozesse (Virtual DOS Machine; nur auf 32-BitWindows)
•
Unterstützung für Side-by-Side (SxS)/Fusion und Manifestcaches
•
Verschiedene Unterstützungsfunktionen für natürliche Sprache, um eine Zwischenspeicherung zu ermöglichen
Der Kernelmoduscode für den Roheingabethread und den Desktopthread (verantwortlich für den Mauscursor, Tastatureingaben und den Umgang mit dem Desktop-Fenster) wird innerhalb der Threads ausgeführt, die in Winsrv.dll laufen. Daneben enthalten die Csrss.exe-Instanzen im Zusammenhang mit interaktiven Benutzersitzungen eine fünfte DLL namens Cdd.dll (Canonical Display Driver). Sie ist für
die Kommunikation mit der DirectX-Unterstützung im Kernel (siehe nachfolgende
Erklärung) bei jeder vertikalen Aktualisierung (VSync) zuständig, um den sichtbaren Desktop ohne herkömmliche hardwarebeschleunigte GDI-Unterstützung zu
zeichnen.
QQ Ein Kernelmodus-Gerätetreiber (Win32k.sys) mit folgendem Inhalt:
•
Der Fenster-Manager, der die Fensteranzeige steuert, die Bildschirmausgabe verwaltet,
Eingaben von der Tastatur, der Maus und anderen Geräten erfasst und Benutzernachrichten an Anwendungen übergibt
•
Die Grafikgerätschnittstelle (Graphics Device Interface, GDI), bei der es sich um eine
Bibliothek von Funktionen für grafische Ausgabegeräte handelt und die Funktionen für
das Zeichnen von Linien, Text und Formen sowie zur Bearbeitung von Grafiken enthält
•
Wrapper für die DirectX-Unterstützung, die in einem anderen Kerneltreiber implementiert ist (Dxgkrnl.sys)
QQ Der Konsolenhostprozess (Conhost.exe), der Unterstützung für Konsolenanwendung bietet
QQ Der Desktop Window Manager (Dwm.exe), der es ermöglicht, die Darstellung der sichtbaren Fenster mithilfe von CDD und DirectX zu einer einzigen Oberfläche zusammenzufassen
QQ Teilsystem-DLLs (wie Kernel32.dll, Advapi32.dll, User32.dll und Gdi32.dll), die dokumentierte Windows-API-Funktionen in die geeigneten und (für den Benutzermodus) nicht dokumentierten Kernelmodus-Systemdienstaufrufe in Ntoskrnl.exe und Win32k.sys übersetzen
Hauptsystemkomponenten
Kapitel 2
73
QQ Grafikgerätetreiber für hardwareabhängige Grafikanzeigetreiber, Druckertreiber und Video-Miniporttreiber
Nach einem Refactoring der Windows-Architektur unter der Bezeichnung MinWin
bestehen die Teilsystem-DLLs jetzt generell aus spezifischen Bibliotheken, die APISets implementieren, zu der Teilsystem-DLL verknüpft und mithilfe eines besonderen Umleitungsverfahrens aufgelöst werden. Weitere Informationen über diesen
Refactoringvorgang erhalten Sie im Abschnitt »Der Abbildlader« in Kapitel 3.
Win32k.sys in Windows 10
Die grundlegenden Anforderungen an die Fensterverwaltung in Windows 10 können je nach
vorliegendem Gerät erheblich schwanken. Beispielsweise braucht ein voll ausgestatteter Desktopcomputer alle Möglichkeiten des Fenster-Managers wie veränderliche Fenstergrößen, Besitzerfenster, Kindfenster usw. Windows Mobile 10 auf Smartphones und kleinen Tablets dagegen
braucht viele dieser Merkmale nicht, da immer nur ein Fenster im Vordergrund steht und nicht
minimiert, vergrößert, verkleinert oder auf ähnliche Weise verändert werden kann. Das Gleiche
gilt auch für IoT-Geräte, von denen viele nicht einmal eine Anzeige haben.
Aus diesem Grunde wurde der Funktionsumfang von Win32k.sys auf verschiedene Kernelmodule aufgeteilt, wobei auf einem System nicht unbedingt alle diese Module gebraucht
werden. Das reduziert die Angriffsfläche des Fenster-Managers erheblich, da der Code an Komplexität verliert und viele seiner älteren Teile entfernt wurden. Betrachten Sie dazu die folgenden Beispiele:
QQ Auf Smartphones (Windows Mobile 10) lädt Win32k.sys nur Win32kMin.sys und Win32kBase.sys.
QQ Auf Desktopsystemen lädt Win32k.sys nur Win32kBase.sys und Win32kFull.sys.
QQ Auf bestimmten IoT-Geräten braucht Win32k.sys lediglich Win32kBase.sys.
Anwendungen rufen die Standardfunktion USER auf, um Steuerelemente der Benutzerschnittstelle wie Fenster und Schaltflächen auf der Anzeige zu erstellen. Der Fenster-Manager vermittelt diese Anforderungen an die GDI, die sie wiederum an die Grafikgerätetreiber übergibt,
wo sie für das Anzeigegerät formatiert werden. Um die Unterstützung für die Videoanzeige zu
vervollständigen, wird ein Anzeigetreiber mit einem Video-Miniporttreiber gekoppelt.
Die GDI stellt einen Satz von 2-D-Standardfunktionen bereit, mit denen Anwendungen
mit Grafikgeräten kommunizieren können, ohne etwas über sie zu wissen. Die GDI-Funktionen
vermitteln zwischen Anwendungen und Grafikgeräten wie Anzeige- und Druckertreibern. Die
GDI interpretiert die Anforderungen der Anwendung für Grafikausgabe und sendet die Anforderungen an die Grafikgerätetreiber. Außerdem stellt sie eine Standardschnittstelle bereit, über
die die Anwendungen verschiedene Grafikausgabegeräte verwenden können. Diese Schnittstelle macht den Anwendungscode von den Hardwaregeräten und deren Treibern unabhängig.
Die GDI schneidet ihre Nachrichten auf die Fähigkeiten der Geräte zu, wobei sie eine Anforderung oft in handhabbare Teile zerlegt. Beispielsweise verstehen manche Geräte die Anweisung,
eine Ellipse zu zeichnen, während die GDI bei anderen den Befehl als eine Folge von Pixeln
74
Kapitel 2
Systemarchitektur
deuten muss, die an bestimmten Koordinaten zu platzieren sind. Weitere Informationen über
die Architektur von Grafik- und Videotreibern finden Sie im Abschnitt »Design Guide« des Kapitels »Display (Adapters and Monitors)« des WDK.
Da ein Großteil des Teilsystems – insbesondere die Funktionen zur Anzeige-E/A – im Kernelmodus läuft, führen nur wenige Windows-Funktionen dazu, dass eine Nachricht an den
Windows-Teilsystemprozess gesendet wird, nämlich die Erstellung und Beendigung von Prozessen und Threads und die Zuordnung von DOS-Laufwerksbuchstaben (etwa durch subst.exe).
Im Allgemeinen veranlasst eine laufende Windows-Anwendung wenn überhaupt nur wenige Kontextwechsel zum Windows-Teilsystemprozess. Ausnahmen sind lediglich die erforderlichen Kontextwechsel, um die neue Position des Mauscursors zu zeichnen, die Tastatureingaben zu verarbeiten und den Bildschirm über CDD wiederzugeben.
Konsolenfensterhost
Im ursprünglichen Design des Windows-Teilsystems war der Teilsystemprozess (Csrss.exe)
für die Verwaltung des Konsolenfensters verantwortlich, und jede Konsolenanwendung
(wie Cmd.exe, die Eingabeaufforderung) kommunizierte mit ihm. Ab Windows 7 wurde für
jedes Konsolenfenster im System ein eigener Prozess verwendet, nämlich der Konsolenfensterhost (Conhost.exe). (Ein Konsolenfenster kann von mehreren Konsolenanwendungen
gemeinsam genutzt werden. Wenn Sie beispielsweise eine Eingabeaufforderung von einer
anderen Eingabeaufforderung aus aufrufen, so verwendet die zweite Eingabeaufforderung
das Konsolenfenster der ersten.) Die Einzelheiten des Konsolenhosts von Windows 7 wurden in Kapitel 2 der sechsten Ausgabe dieses Buches erklärt.
Mit Windows 8 wurde die Konsolenarchitektur erneut geändert. Den Prozess Conhost.
exe gibt es nach wie vor, aber er wird jetzt vom Konsolentreiber (\Windows\System32\Drivers\ConDrv.sys) von dem konsolengestützten Prozess aus ausgelöst (also nicht mehr von
Csrss.exe aus wie in Windows 7). Der betreffende Prozess kommuniziert mit Conhost.exe
über den Konsolentreiber (ConDrv.sys), indem er Lese-, Schreib-, E/A-Steuerungs- und andere Arten von E/A-Anforderungen sendet. Conhost.exe fungiert als Server und der Prozess,
der die Konsole nutzt, als Client. Dank dieser Änderung ist es nicht mehr nötig, dass Csrss.
exe Tastatureingaben (im Rahmen des Roheingabethreads) empfängt, durch Win32k.sys an
Conhost.exe sendet und dann mit ALPC an Cmd.exe schickt. Stattdessen kann die Anwendung für die Eingabeaufforderung Eingaben über Lese/-Schreib-Eingaben und -Ausgaben
direkt vom Konsolentreiber empfangen, wodurch überflüssige Kontextwechsel verhindert
werden.
Der folgende Screenshot aus Process Explorer zeigt das Handle, den Conhost.exe für
das von ConDrv.sys verfügbar gemachte Geräteobjekt \Device\ConDrv geöffnet hält. (Weitere Einzelheiten zu Gerätenamen und E/A erhalten Sie in Kapitel 6.)
→
Hauptsystemkomponenten
Kapitel 2
75
Conhost.exe ist ein Kindprozess des Konsolenprozesses (hier von Cmd.exe). Ausgelöst wird
die Erzeugung von Conhost durch den Abbildlader für das Konsolenteilsystemabbild oder
auf Anforderung, wenn ein GUI-Teilsystemabbild die Windows-API AllocConsole aufruft.
(Natürlich sind das GUI- und das Konsolenteilsystem in dem Sinne identisch, dass beide
Varianten des Windows-Teilsystemtyps darstellen.) Die Hauptarbeit übernimmt die DLL, die
Conhost lädt (\Windows\SYstem32\ConhostV2.dll). Sie enthält den Großteil des Codes, der
mit dem Konsolentreiber kommuniziert.
Weitere Teilsysteme
Wie bereits erwähnt, unterstützte Windows ursprünglich POSIX- und OS/2-Teilsysteme. Da sie
jedoch nicht mehr im Lieferumfang von Windows enthalten sind, behandeln wir sie in diesem
Buch auch nicht. Das allgemeine Prinzip der Teilsysteme gibt es jedoch nach wie vor, sodass
das System durch neue Teilsysteme erweitert werden kann, sollte in Zukunft Bedarf dafür aufkommen.
Pico-Anbieter und das Windows-Teilsystem für Linux
Das herkömmliche Teilsystemmodell ist zwar erweiterbar und war offensichtlich leistungsfähig
genug, um POSIX und OS/2 ein Jahrzehnt lang zu unterstützen, weist aber zwei erhebliche
technische Nachteile auf, weshalb Nicht-Windows-Binärdateien keine breite Anwendung fanden, sondern nur in einigen Sonderfällen genutzt wurden:
QQ Da die Teilsysteminformationen aus dem PE-Header (Portable Executable) bezogen werden, muss der Quellcode der ursprünglichen Binärdatei das Teilsystem als ausführbare
Windows-PE-Datei (.exe) neu erstellen. Dadurch werden auch jegliche POSIX-Abhängigkeiten und -Systemaufrufe in Windows-Importe der Bibliothek Psxdll.dll geändert.
QQ Das Teilsystem ist durch den Funktionsumfang des Win32-Teilsystems (auf dem es manchmal aufsitzt) oder des NT-Kernels eingeschränkt. Daher emuliert es nicht das von der POSIX-Anwendung angeforderte Verhalten, sondern bildet nur einen Wrapper dafür. Das
kann manchmal zu leichten Kompatibilitätsstörungen führen.
76
Kapitel 2
Systemarchitektur
Außerdem war das POSIX-Teilsystem/SUA, wie der Name schon sagt, für POSIX/UNIX-Anwendungen ausgelegt, die vor Jahrzehnten den Servermarkt beherrschten, und nicht für die heute
gängigen Linux-Anwendungen.
Um diese Probleme zu lösen, was eine andere Herangehensweise an den Aufbau eines
Teilsystems erforderlich – eine, die keinen herkömmlicher Benutzermodus-Wrapper für die Systemaufrufe der Umgebung und die Ausführung herkömmlicher PE-Abbilder erforderte. Das
Projekt Drawbridge von Microsoft Research erwies sich als das ideale Mittel für einen neuen
Zugang zum Thema Teilsysteme. Dies führte zur Umsetzung des Pico-Modells.
Bei diesem Modell werden Pico-Anbieter verwendet. Dabei handelt es sich um benutzerdefinierte Kernelmodustreiber, die über die API PsRegisterPicoProvider Zugriff auf spezialisierte
Kernelschnittstellen erhalten. Diese spezialisierten Schnittstellen bieten die folgenden beiden
Vorteile:
QQ Sie ermöglichen dem Anbieter, Pico-Prozesse und -Threads zu erstellen und deren Ausführungskontexte, Segmente und Speicherdaten in den zugehörigen EPROCESS- bzw. ETHREAD-Strukturen anzupassen (mehr darüber in Kapitel 3 und 4).
QQ Sie ermöglichen dem Anbieter, eine breite Palette von Benachrichtigungen zu empfangen,
wenn diese Prozesse oder Threads an bestimmten Systemaktivitäten wie Systemaufrufen,
Ausnahmen, APCs, Seitenfehlern, Terminierungen, Kontextwechseln, Anhalten, Wiederaufnahmen usw. beteiligt sind.
Ab Windows 10 Version 1607 ist ein solcher Pico-Anbieter vorhanden, nämlich Lxss.sys mit seinem Partner Lxcore.sys. Diese Treiber bilden die Pico-Anbieterschnittstelle für die Komponente
WSL (Windows Subsystem for Linux).
Der Pico-Anbieter empfängt fast alle möglichen Übergänge zwischen Benutzer- und Kernelmodus (z. B. Systemaufrufe und Ausnahmen). Sofern die darunter laufenden Pico-Prozesse
über einen Adressraum verfügen, den der Anbieter erkennen kann, über Code verfügt, der
nativ darin ausgeführt werden kann, und die Übergänge komplett transparent erfolgen, spielt
der darunter liegende »echte« Kernel keine große Rolle. Wie Sie in Kapitel 3 noch sehen werden, unterscheiden sich Pico-Prozesse, die unter dem WSL-Pico-Anbieter ausgeführt werden,
erheblich von normalen Windows-Prozessen. Beispielsweise fehlt ihnen die Ntdll.dll, die in jeden normalen Prozess geladen wird. Stattdessen enthält ihr Arbeitsspeicher Strukturen wie ein
vDSO, ein besonderes Abbild, das es nur auf Linux/BSD-Systemen gibt.
Wenn die Linux-Prozesse transparent laufen sollen, müssen sie ausgeführt werden können, ohne eine Neukompilierung als ausführbare PE-Windows-Dateien zu erfordern. Da der
Windows-Kernel nicht weiß, wie er andere Abbildtypen zuordnen soll, können solche Abbilder
nicht von Windows-Prozessen über die API CreateProcess gestartet werden und solche APIs
auch nicht selbst aufrufen (denn schließlich wissen sie nicht einmal, dass sie auf Windows laufen). Die Unterstützung für eine solche Art von Interoperabilität bieten der Pico-Anbieter und
der LXSS-Manager, ein Dienst des Benutzermodus. Ersterer implementiert eine private Schnittstelle zur Kommunikation mit dem LXSS-Manager, Letzterer eine COM-Schnittstelle zur Kommunikation mit dem besonderen Startprozess Bash.exe und dem Verwaltungsprozess Lxrun.
exe. Das folgende Diagramm gibt einen Überblick über die Komponenten von WSL.
Hauptsystemkomponenten
Kapitel 2
77
Linux-Instanz
(Pico-Prozess)
Bash.exe
LXSS-MangerDienst
/bin/bash
Benutzermodus
LXCore / LXSS
Kernelmodus
Exekutive und Kernel
Unterstützung für eine breite Palette von Linux-Anwendungen zu geben, ist ein erhebliches Unterfangen. Linux umfasst Hunderte von Systemaufrufen, ungefähr so viele wie der
Windows-Kernel selbst. Der Pico-Anbieter kann zwar vorhandene Windows-Merkmale nutzen
– von denen viele zur Unterstützung des ursprünglichen POSIX-Teilsystems erstellt wurden,
z. B. für fork() –, doch manche Funktionalität muss er selbst neu implementieren. Obwohl
beispielsweise NTFS zur Speicherung des tatsächlichen Dateisystems genutzt wird (und nicht
EXTFS), verfügt der Pico-Anbieter über eine komplette Implementierung des Linux-VFS (Virtual
File System) einschließlich Unterstützung von Inodes, inotify() sowie /sys, /dev und ähnlichen Linux-Dateisystem-Namensräumen mit dem entsprechenden Verhalten. Ebenso kann der
Pico-Anbieter zwar WSK (Windows Sockets for Kernel) für die Netzwerkanbindung nutzen,
verfügt über komplexe Wrapper um das eigentliche Socketverhalten, sodass er UNIX-Domänensockets, Linux-NetLink-Sockets und Internet-Standardsockets unterstützen kann.
Manche vorhandenen Windows-Einrichtungen sind auch einfach nicht ausreichend kompatibel, wobei die Abweichungen ganz gering sein können. Beispielsweise verfügt Windows
über einen Treiber für benannte Pipes (Npfs.sys), der den herkömmlichen IPC-Pipe-Mechanismus unterstützt. Er unterscheidet sich jedoch nur ein wenig, aber doch ausreichend stark von
Linux-Pipes, um eine Anwendung funktionsunfähig zu machen. Das erfordert eine komplette
Neuimplementierung von Pipes für Linux-Anwendungen ohne Zuhilfenahme des Kerneltreibers Npfs.sys.
Da sich dieses Merkmal zurzeit noch im Beta-Stadium befindet und erheblichen Änderungen unterliegen kann, behandeln wir die internen Mechanismen dieses Teilsystems in diesem
Buch nicht. Allerdings werfen wir in Kapitel 3 noch einen weiteren Blick auf Pico-Prozesse.
Wenn das Teilsystem ausgereift ist, wird es wahrscheinlich eine offizielle Dokumentation auf
MSDN und stabile APIs für die Interaktion mit Linux-Prozessen geben.
Ntdll.dll
Ntdll.dll ist eine besondere Systemunterstützungsbibliothek, die hauptsächlich für die Verwendung durch Teilsystem-DLLs und native Anwendung da ist. (Nativ bezeichnet in diesem Zusammenhang Abbilder, die nicht an ein bestimmtes Teilsystem gebunden sind.) Sie enthält
Funktionen der beiden folgenden Arten:
78
Kapitel 2
Systemarchitektur
QQ Systemdienst-Dispatchstubs zu Systemdiensten der Windows-Exekutive
QQ Interne Unterstützungsfunktionen, die von Teilsystemen, Teilsystem-DLLs und anderen nativen Abbilder verwendet werden
Die erste Gruppe dieser Funktionen bildet eine Schnittstelle zu den Systemdiensten der
Windows-Exekutive, die vom Benutzermodus aus aufgerufen werden können. Es gibt über 450
solcher Funktionen, z. B. NtCreateFile und NtSetEvent. Die meisten Möglichkeiten, die diese
Funktionen bieten, sind über die Windows-API zugänglich. (Einige jedoch nicht; sie sind nur zur
Verwendung durch bestimmte interne Komponenten des Betriebssystems gedacht.)
Für jede dieser Funktionen enthält Ntdll.dll einen Eintrittspunkt mit demselben Namen.
Der Code in der Funktion enthält die architekturspezifische Anweisung für den Übergang in
den Kernelmodus, um den Systemdienst-Dispatcher aufzurufen. (Dies wird ausführlicher in
Kapitel 8 von Band 2 erläutert.) Nach der Überprüfung einiger Parameter ruft der Systemdienst-Dispatcher den Kernelmodus-Systemdienst auf, der den eigentlichen Code innerhalb
von Ntoskrnl.exe enthält. Das folgende Experiment zeigt, wie diese Funktionen aussehen.
Experiment: Den Systemdienst-Dispatchercode anzeigen
Öffnen Sie die Version von WinDbg für Ihre Systemarchitektur (also etwa die x64-Version
auf 64-Bit-Windows). Wählen Sie dann im Menü File den Befehl Open Executable. Wechseln
Sie zu %SystemRoot%\System32 und markieren Sie Notepad.exe.
Daraufhin wird der Editor (Notepad) gestartet. Der Debugger hält am ersten Haltepunkt an. Das geschieht schon sehr früh im Lauf des Prozesses, wovon Sie sich überzeugen können, indem Sie den Befehl k (für den Aufrufstack) ausführen. Dort sehen Sie einige Funktionen, deren Namen mit Ldr beginnen, was auf den Abbildlader hindeutet. Die
Hauptfunktion des Editors ist noch nicht ausgeführt worden, weshalb sein Fenster nicht
angezeigt wird.
Setzen Sie wie folgt einen Haltepunkt in NtCreateFile innerhalb von Ntdll.dll (der Debugger unterscheidet nicht zwischen Groß- und Kleinschreibung):
bp ntdll!ntcreatefile
Geben Sie den Befehl g (»go«) ein oder drücken Sie (F5), um die Ausführung des Editors
fortzusetzen. Der Debugger sollte sofort wieder anhalten und dabei etwas wie das Folgende (auf x64) ausgeben:
Breakpoint 0 hit
ntdll!NtCreateFile:
00007ffa'9f4e5b10 4c8bd1
mov
r10,rcx
Möglicherweise wird der Funktionsname als ZwCreateFile angezeigt. Sowohl ZwCreateFile
als auch NtCreateFile verweisen auf dasselbe Symbol im Benutzermodus. Geben Sie nun
den Befehl u ein (»unassembled«), um einige Anweisungen weiter nach vorn zu schauen:
00007ffa'9f4e5b10 4c8bd1
mov
r10,rcx
00007ffa'9f4e5b13 b855000000
mov
eax,55h
→
Hauptsystemkomponenten
Kapitel 2
79
00007ffa'9f4e5b18 f604250803fe7f01
test
byte ptr [SharedUserData+0x308
jne
ntdll!NtCreateFile+0x15
(00000000'7ffe0308)],1
00007ffa'9f4e5b20 7503
(00007ffa'9f4e5b25)
00007ffa'9f4e5b22 0f05
syscall
00007ffa'9f4e5b24 c3
ret
00007ffa'9f4e5b25 cd2e
int
00007ffa'9f4e5b27 c3
ret
2Eh
Das Register EAX wird auf die Nummer gesetzt, die der Systemdienst in dem vorliegenden
Betriebssystem hat (hier bei Windows 10 Pro x64 auf die Hexadezimalzahl 55). Erst später
folgt die Anweisung syscall. Sie veranlasst den Prozessor, in den Kernelmodus zu wechseln
und zum Systemdienst-Dispatcher zu springen, wo mithilfe von EAX der Exekutivdienst NtCreateFile ausgewählt wird. Am Offset 0x308 wird außerdem das Flag 1 in SharedUserData
geprüft (mehr über diese Struktur erfahren Sie in Kapitel 4). Ist es gesetzt, so folgt die Ausführung einem anderen Pfad und nutzt die Anweisung int 2Eh. Wenn Sie das VBS-Sondermerkmal CredentialGuard aktiviert haben (siehe Kapitel 7), wird das Flag auf dem Computer gesetzt, da der Hypervisor effizienter auf die Anweisung int reagieren kann als auf die
Anweisung syscall. Dieses Verhalten ist für CredentialGuard von Vorteil.
Weitere Einzelheiten über diesen Mechanismus (und über das Verhalten von syscall
und int) finden Sie in Kapitel 8 von Band 2. Zunächst einmal aber können Sie versuchen,
weitere native Dienste zu finden, z. B. NtReadFile, NtWriteFile und NtClose.
Im Abschnitt »Die virtualisierungsgestützte Sicherheitsarchitektur im Überblick« haben Sie bereits gelernt, dass IUM-Anwendungen eine ähnliche Binärdatei wie Ntdll.dll nutzen können,
nämlich IumDll.dll. Diese Bibliothek enthält ebenfalls Systemaufrufe, allerdings mit abweichenden Indizes. Wenn auf Ihrem System CredentialGuard aktiviert ist, können Sie das vorstehende
Experiment wiederholen, wobei Sie dieses Mal aber im Menü File von WinDbg auf Open Crash
Dump klicken und dann die Datei IumDll.dll auswählen. In der folgenden Ausgabe ist das hohe
Bit des Systemaufrufindex gesetzt. Die Überprüfung SharedUserData erfolgt jedoch nicht. Für
diese Art von Systemaufrufen, die als sichere Systemaufrufe bezeichnet werden, wird stets die
Anwendung syscall verwendet.
0:000> u iumdll!IumCrypto
iumdll!IumCrypto:
00000001'80001130 4c8bd1
mov
r10,rcx
00000001'80001133 b802000008
mov
eax,8000002h
00000001'80001138 0f05
syscall
00000001'8000113a c3
ret
Ntdll.dll enthält auch viele Unterstützungsfunktionen, z. B. den Abbildlader (Funktionen, deren Namen mit Ldr beginnen), den Heap-Manager und die Kommunikationsfunktionen des
Windows-Teilsystemprozesses (Namen mit Csr). Des Weiteren gibt es in Ntdll.dll allgemeine
Laufzeitbibliotheksroutinen (Rtl), Unterstützung für Debugging im Benutzermodus (DbgUi),
80
Kapitel 2
Systemarchitektur
Ereignisverfolgung für Windows (Etw) sowie den Dispatcher für asynchrone Prozeduraufrufe
(APC) im Benutzermodus und den Ausnahme-Dispatcher. (APCs und Ausnahmen werden kurz
in Kapitel 6 und ausführlicher in Kapitel 8 von Band 2 erklärt.)
Auch einen kleinen Teil der C-Laufzeitroutinen (CRT) finden Sie in Ntdll.dll. Die Auswahl ist
allerdings auf die Routinen beschränkt, die zur String- oder zur Standardbibliothek gehören
(wie memcpy, strcpy, sprintf usw.). Diese Routinen sind für die im Folgenden beschriebenen
nativen Anwendungen nützlich.
Native Abbilder
Einige Abbilder (ausführbare Dateien) gehören nicht zu irgendeinem Teilsystem. Sie werden
also nicht mit einem Satz von Teilsystem-DLLs verlinkt (etwa Kernel32.dll für das Windows-Teilsystem), sondern nur mit Ntdll.dll. Dies ist der kleinste gemeinsame Nenner für alle Teilsysteme. Da die von Ntdll.dll bereitgestellte native API größtenteils nicht dokumentiert ist, werden
Abbilder dieser Art gewöhnlich nur von Microsoft erstellt. Ein Beispiel dafür ist der Prozess des
Sitzungs-Managers (Smss.exe; weiter hinten in diesem Kapitel ausführlicher beschrieben). Smss.
exe ist der erste Benutzermodusprozess, der erstellt wird (direkt vom Kernel). Er kann daher
nicht vom Windows-Teilsystem abhängen, da Csrss.exe (der Prozess des Windows-Teilsystems)
noch gar nicht gestartet ist. Tatsächlich ist Smss.exe sogar dafür zuständig, Csrss.exe zu starten.
Ein weiteres Beispiel ist das Dienstprogramm Autochk, das manchmal beim Systemstart ausgeführt wird, um Datenträger zu prüfen. Da es relativ im Startprozess läuft (gestartet von Smss.
exe), kann es ebenfalls nicht von irgendeinem Teilsystem abhängen.
Der folgende Screenshot aus Dependency Walker zeigt, dass Smss.exe nur von Ntdll.dll
abhängig ist. Als Teilsystemtyp ist Native angegeben.
Exekutive
Die Windows-Exekutive bildet die obere Schicht von Ntoskrnl.exe. (Die untere Schicht ist der
Kernel.) Sie enthält Funktionen der folgenden Art:
QQ Funktionen, die exportiert werden und vom Benutzermodus aus aufgerufen werden können Diese Funktionen werden als Systemdienste bezeichnet und über Ntdll.dll
exportiert (z. B. NtCreateFile aus dem vorherigen Experiment). Die meisten dieser Dienste
sind über die Windows-API oder die APIs anderer Umgebungsteilsysteme zugänglich. Bei
einigen wenigen jedoch ist kein Zugriff über irgendeine dokumentierte Teilsystemfunk
tion möglich. (Dazu gehören beispielsweise ALPC und verschiedene Abfragefunktionen
wie NtQueryInformationProcess, Sonderfunktionen wie NtCreatePagingFile usw.)
Hauptsystemkomponenten
Kapitel 2
81
QQ Gerätetreiberfunktionen, die über die Funktion DeviceIoControl aufgerufen werden können Dies ist eine allgemeine Schnittstelle vom Benutzer- zum Kernelmodus, um
Funktionen in Gerätetreibern aufzurufen, die nichts mit Lesen oder Schreiben zu tun haben. Die Treiber für Process Explorer und Process Monitor von Sysinternals und der früher
erwähnte Konsolentreiber (ConDrv.sys) sind gute Beispiele dafür.
QQ Funktionen, die nur vom Kernelmodus aufgerufen werden können, exportiert werden und im WDK dokumentiert sind Dazu gehören mehrere Unterstützungsroutinen,
die von Gerätetreiberentwicklern gebraucht werden, z. B. der E/A-Manager (Namen, die
mit Io beginnen), allgemeine Exekutivfunktionen (Ex) usw.
QQ Funktionen, die exportiert werden und vom Kernelmodus aufgerufen werden können, aber nicht im WDK dokumentiert sind Dazu gehören die Funktionen, die vom
Bootvideotreiber aufgerufen werden und deren Namen mit Inbv beginnen.
QQ Funktionen, die als globale Symbole definiert sind, aber nicht exportiert werden
Dazu gehören interne Unterstützungsfunktionen, die innerhalb von Ntoskrnl.dll aufgerufen werden, z. B. diejenigen, deren Namen mit Iop (interne Unterstützungsfunktionen
für den E/A-Manager) oder Mi beginnen (interne Unterstützungsfunktionen für die Speicherverwaltung).
QQ Interne Funktionen eines Moduls, die nicht als globale Symbole definiert sind Diese Funktionen werden ausschließlich von der Exekutive und dem Kernel verwendet.
Die Exekutive schließt die folgenden Hauptkomponenten ein, die alle in nachfolgenden Kapiteln dieses Buches noch ausführlich behandelt werden:
QQ Konfigurations-Manager Der in Kapitel 9 von Band 2 beschriebene Konfigurations-Manager ist für die Implementierung und Verwaltung der Systemregistrierung zuständig.
QQ Prozess-Manager Der in Kapitel 3 und 4 erklärte Prozess-Manager erstellt und beendet
Prozesse und Threads. Die zugrunde liegende Unterstützung für Prozesse und Threads ist
im Windows-Kernel implementiert. Die Exekutive ergänzt diese maschinennahen Objekte
um zusätzliche Semantik und Funktionen.
QQ Security Reference Monitor (SRM) Der in Kapitel 7 beschriebene SRM setzt Sicherheitsrichtlinien auf dem lokalen Computer durch. Er schützt Betriebssystemressourcen,
führt einen Objektschutz zur Laufzeit und eine Überwachung durch.
QQ E/A-Manager Der in Kapitel 6 beschriebene E/A-Manager implementiert die geräteunabhängige Ein-/Ausgabe und ist für die Zuteilung zu den passenden Gerätetreibern für die
weitere Verarbeitung verantwortlich.
QQ Plug-&-Play-Manager Der in Kapitel 6 beschriebene PnP-Manager entscheidet, welche
Treiber für ein bestimmtes Gerät erforderlich sind, und lädt sie. Bei der Auflistung ruft er
die Hardwareressourcenanforderungen für die einzelnen Geräte ab. Auf deren Grundlage
weist er die entsprechenden Ressourcen wie E/A-Ports, IRQs, DMA-Kanäle und Speicherorte zu. Des Weiteren ist er dafür zuständig, ordnungsgemäße Ereignisbenachrichtigungen
über Geräteänderungen (Hinzufügen oder Entfernen eines Geräts) im System zu senden.
QQ Energie-Manager Der in Kapitel 6 erklärte Energie-Manager, die Prozessorenergieverwaltung (Power Process Management, PPM) und das Energieverwaltungsframework (Pow
82
Kapitel 2
Systemarchitektur
er Management Framework, PoFx) koordinieren Energieereignisse und erstellen Energieverwaltungsbenachrichtigungen für Gerätetreiber. Die PPM kann so eingerichtet werden,
dass sie die CPU im Leerlauf in den Ruhezustand versetzt und damit die Leistungsaufnahme senkt. Änderungen im Stromverbrauch einzelner Geräte werden von den Gerätetreibern gehandhabt, aber vom Energie-Manager und dem PoFx koordiniert. Bei Geräten
bestimmter Klassen verwaltet der Terminal Timeout Manager auch Zeitüberschreitungen
der physischen Anzeige auf der Grundlage der Gerätenutzung und -nähe.
QQ WDM-WMI-Routinen (Windows Driver Model / Windows Management Instrumentation) Diese in Kapitel 9 von Band 2 behandelten Routinen ermöglichen den Gerätetreibern, Leistungs- und Konfigurationsinformationen zu veröffentlichen und Befehle von
WMI-Diensten im Benutzermodus zu empfangen. Verbraucher von WMI-Informationen
können sich auf dem lokalen Computer, aber auch im Netzwerk befinden.
QQ Speicher-Manager Der in Kapitel 5 beschriebene Speicher-Manager implementiert virtuellen Arbeitsspeicher. Dieses Speicherverwaltungsverfahren stellt für jeden Prozess einen
umfangreichen privaten Adressraum zur Verfügung, der den verfügbaren physischen Arbeitsspeicher überschreiten kann. Des Weiteren bietet der Speicher-Manager auch Unterstützung für den Cache-Manager. Er wird vom Prefetcher und vom Store-Manager unterstützt, die beide ebenfalls in Kapitel 5 erläutert werden.
QQ Cache-Manager Der in Kapitel 14 von Band 2 beschriebene Cache-Manager erhöht die
Leistung der Datei-E/A, indem er dafür sorgt, dass erst vor Kurzem nachgeschlagene Daten
von der Festplatte für den schnellen Zugriff im Hauptarbeitsspeicher abgelegt werden. Als
weitere Maßnahme zur Leistungssteigerung verzögert er Schreibvorgänge auf der Festplatte, indem er Aktualisierungen für kurze Zeit im Arbeitsspeicher festhält und sie erst
dann an die Festplatte sendet. Dazu nutzt er die Unterstützung des Speicher-Managers für
zugeordnete Dateien.
Daneben enthält die Exekutive Unterstützungsfunktionen, die von den zuvor genannten Komponenten genutzt werden. Ungefähr ein Drittel dieser Funktionen sind im WDK dokumentiert,
da sie auch von den Gerätetreibern genutzt werden. Diese Unterstützungsfunktionen fallen in
die folgenden vier Hauptkategorien:
QQ Objekt-Manager Der Objekt-Manager erstellt, verwaltet und löscht Windows-Exekutivobjekte und abstrakte Datentypen, die zur Darstellung von Betriebssystemressourcen wie
Prozessen, Threads und den verschiedenen Synchronisierungsobjekten dienen. Erklärt wird
er in Kapitel 8 von Band 2.
QQ ALPC-Einrichtung (Advanced Local Procedure Call) Die in Kapitel 8 von Band 2 er
klärte ALPC-Einrichtung übergibt Nachrichten zwischen einem Client- und einem Serverprozess auf demselben Computer. Unter anderem dient sie als lokaler Transport für
Remoteprozeduraufrufe (RPCs), die Windows-Implementierung einer standardmäßigen
Kommunikationseinrichtung für Client- und Serverprozesse über ein Netzwerk.
QQ Laufzeit-Bibliotheksfunktionen Dazu gehören Stringverarbeitung, arithmetische Operationen, Datentypumwandlung und Verarbeitung von Sicherheitsstrukturen.
Hauptsystemkomponenten
Kapitel 2
83
QQ Unterstützungsroutinen der Exekutive Dazu gehören die Systemspeicherzuweisung
(ausgelagerter und nicht ausgelagerter Pool), gesperrter Speicherzugriff sowie besondere
Arten von Synchronisierungsmechanismen wie Exekutivressourcen, schnelle Mutexe und
Push-Sperren.
Die Exekutive enthält auch eine Reihe weiterer Infrastrukturroutinen, von denen einige in diesem Buch nur kurz vorgestellt werden:
QQ Kerneldebugger-Bibliothek Sie ermöglicht ein Debugging des Kernels mit einem Debugger, der KD unterstützt, ein portierbares Protokoll, das von verschiedenen Transporten
wie USB, Ethernet und IEEE 1394 unterstützt und von WinDbg und Kd.exe implementiert
wird.
QQ Debugging-Framework für den Benutzermodus Dieses Framework sendet Ereignisse
an die Debugging-API des Benutzermodus und ermöglicht Haltepunkte, ein schrittweises
Durchlaufen des Codes und Kontextwechsel laufender Threads.
QQ Hypervisor- und VBS-Bibliothek Diese Bibliotheken bieten Kernelunterstützung für die
sichere VM-Umgebung und optimieren einzelne Teile des Codes, wenn das System weiß,
dass es in einer Clientpartition (virtuellen Umgebung) läuft.
QQ Errata-Manager Der Errata-Manager stellt Notlösungen für nicht standardmäßige und
nicht konforme Hardwaregeräte zur Verfügung.
QQ Treiberverifizierer Der Treiberverifizierer implementiert optionale Integritätsprüfungen
von Treibern und Code im Kernelmodus (siehe Kapitel 6).
QQ Ereignisverfolgung für Windows (ETW) ETW stellt Hilfsroutinen für die systemweite
Ereignisverfolgung von Kernel- und Benutzermoduskomponenten bereit.
QQ Windows Diagnostic Infrastructure (WDI) Die WDI ermöglicht eine intelligente Verfolgung von Systemaktivitäten auf der Grundlage von Diagnoseszenarien.
QQ WHEA-Unterstützungsroutinen (Windows Hardware Error Architecture) Diese Routinen bilden ein allgemeines Framework für die Meldung von Hardwarefehlern.
QQ File-System Runtime Library (FSRTL)
tinen für Dateisystemtreiber.
Die FSRTL bietet allgemeine Unterstützungsrou-
QQ Kernel Shim Engine (KSE) Die KSE bietet Shims zur Treiberkompatibilität und zusätzliche Unterstützung für Gerätefehler. Sie nutzt die in Kapitel 8 von Band 2 beschriebene
Shim-Infrastruktur und -Datenbank.
Der Kernel
Der Kernel besteht aus einem Satz Funktionen in Ntoskrnl.exe, die grundlegende Mechanismen
bereitstellen. Dazu gehören die Threadplanungs- und Synchronisierungsdienste, die von den
Exekutivkomponenten genutzt werden, sowie architekturabhängige, maschinennahe Unterstützung wie Interrupt- und Ausnahme-Dispatching, das auf jeder Prozessorarchitektur anders
ausfällt. Der Kernelcode ist hauptsächlich in C geschrieben. Assemblercode ist für die Aufgaben
reserviert, die Zugriff auf besondere, über C nicht zugängliche Prozessoranweisungen und Register benötigen.
84
Kapitel 2
Systemarchitektur
Wie bei den Unterstützungsfunktionen der Exekutive aus dem vorherigen Abschnitt sind
auch eine Reihe der Funktionen im Kernel im WDK dokumentiert (und können durch eine Suche nach Funktionen gefunden werden, deren Namen mit Ke beginnen), da sie zur Implementierung von Gerätetreibern erforderlich sind.
Kernelobjekte
Der Kernel bietet eine maschinennahe Grundlage wohldefinierter, vorhersehbarer Betriebssystemprimitiva und -mechanismen, die es den Exekutivkomponenten höherer Ebene ermöglichen, ihre Aufgaben zu erfüllen. Der Kernel trennt sich selbst vom Rest der Exekutive, indem er
Betriebssystemmechanismen implementiert und eine Aufstellung von Richtlinien vermeidet. Er
überlässt nahezu alle Richtlinienentscheidungen der Exekutive. Die einzige Ausnahme bilden
die Threadplanung und das Dispatching, die der Kernel implementiert.
Außerhalb des Kernels stellt die Exekutive Threads und andere gemeinsam nutzbare Ressourcen als Objekte dar. Diese Objekte benötigen etwas Richtlinien-Overhead wie Objekthandles zu ihrer Handhabung, Sicherheitsprüfungen zu ihrem Schutz und Ressourcenkontingente, die bei ihrer Erstellung abgerufen werden müssen. Dieser Mehraufwand wird im Kernel
vermieden, der einen Satz einfacherer Objekte implementiert, nämlich die Kernelobjekte. Sie
helfen dem Kernel, die zentrale Verarbeitung zu steuern, und unterstützen die Erstellung von
Exekutivobjekten. Die meisten Exekutivobjekte kapseln ein oder mehrere Kernelobjekte und
enthalten deren im Kernel definierte Attribute.
Ein Satz von Kernelobjekten, die sogenannten Steuerobjekte, richten die Semantik für die
Steuerung verschiedener Betriebssystemfunktionen ein. Dazu gehören das APC-Objekt (Asynchronous Procedure Call), das DPC-Objekt (Deferred Procedure Call) sowie mehrere Objekte,
die der E/A-Manager verwendet, z. B. interrupt.
Einen weiteren Satz von Kernelobjekten bilden die Dispatcherobjekte. Sie enthalten Synchronisierungsfähigkeiten, die die Threadplanung ändern oder beeinflussen. Zu den Dispatcherobjekten gehören der Kernelthread, Mutexe (in der Kernelterminologie Mutanten genannt), Ereignisse,
Kernelereignispaare, Semaphoren, Timer und Timer mit Wartemöglichkeiten. Die Exekutive verwendet Kernelfunktionen, um Instanzen von Kernelobjekten zu erstellen, sie zu bearbeiten und
die komplexeren Objekte zu konstruieren, die sie im Benutzermodus bereitstellt. Objekte werden
ausführlicher in Kapitel 8 von Band 2 erklärt, Prozesse in Kapitel 3 und Threads in Kapitel 4.
Die Steuerregion und der Steuerblock des Kernelprozessors
Der Kernel verwendet eine als Steuerregion (Kernel Processor Control Region, KPCR) bezeichnete Datenstruktur, um prozessorspezifische Daten zu speichern. Die KPCR enthält grundlegende
Informationen wie die Interruptdispatchtabelle (IDT) des Prozessors, sein Taskstatussegment
(TSS) und die globale Deskriptortabelle (GDT). Außerdem schließt sie den Interruptcontroller
status ein, den sie mit anderen Modulen teilt, darunter dem ACPI-Treiber und der HAL. Um
leichten Zugang zur KPCR zu gewähren, speichert der Kernel einen Zeiger darauf, und zwar auf
32-Bit-Windows im Register fs und auf 64-Bit-Windows in gs.
Die KPCR umfasst auch eine eingebettete Datenstruktur, die als Steuerblock des Kernelprozessors bezeichnet wird (Kernel Processor Control Block, KPRCB). Im Gegensatz zur KPCR, die für
Drittanbieter-Treiber und andere interne Komponenten des Windows-Kernels dokumentiert ist,
Hauptsystemkomponenten
Kapitel 2
85
handelt es sich beim KPRCB um eine private Struktur, die nur vom Kernelcode in Ntoskrnl.exe
verwendet wird. Sie enthält Folgendes:
QQ Planungsinformationen wie den aktuellen, den nächsten sowie Leerlaufthreads, die zur
Ausführung auf dem Prozessor geplant sind
QQ Die Dispatcherdatenbank für den Prozessor, die wiederum die Bereitschaftswarteschlangen
für jede Prioritätsebene enthält
QQ Die DPC-Warteschlange
QQ Angaben zur CPU und zu ihrem Hersteller wie Modell, Stepping-Geschwindigkeit und Feature-Bits
QQ CPU- und NUMA-Topologie wie Knoteninformationen, Kerne pro Gehäuse, logische Prozessoren pro Kern usw.
QQ Cachegrößen
QQ Zeitabstimmungsinformationen wie die DPC- und die Interruptzeit
Der KPRCB enthält auch alle Prozessorstatistiken, darunter die folgenden:
QQ E/A-Statistiken
QQ Cache-Manager-Statistiken (siehe Kapitel 14 in Band 2)
QQ DPC-Statistiken
QQ Speicher-Manager-Statistiken (siehe Kapitel 5)
Manchmal wird der KPRCB dazu verwendet, am Cache ausgerichtete, prozessorweise Strukturen zur Optimierung des Speicherzugriffs zu speichern, insbesondere auf NUMA-Systemen,
beispielsweise die Look-Aside-Listen des Systems für den nicht ausgelagerten und den ausgelagerten Pool.
Experiment: KPCR und KPRCB einsehen
Mit den Kerneldebuggerbefehlen !pcr und !prcb können Sie sich den Inhalt der KPCR und
des KPRCB ansehen. Wenn Sie bei !prcb keine Flags angeben, zeigt der Debugger standardmäßig Informationen für CPU 0 an. Sie können jedoch auch eine bestimmte CPU auswählen, indem Sie eine Zahl an den Befehl anhängen, z. B. !prcb 2. Dagegen zeigt !pcr
immer Informationen über den aktuellen Prozessor an. In einer Remotedebuggingsitzung
können Sie den Prozessor wechseln. Beim lokalen Debugging können Sie die Adresse der
KPCR gewinnen, indem Sie die Erweiterung !pcr gefolgt von der CPU-Nummer verwenden,
und dann @$pcr durch diese Adresse ersetzen. Verwenden Sie keine der anderen Ausgaben
von !pcr. Diese Erweiterung ist veraltet und zeigt keine korrekten Daten an. Das folgende
Beispiel zeigt die Ausgabe von dt nt!_KPCR @$pcr und !pcrb auf Windows 10 x64:
lkd> dt nt!_KPCR @$pcr
+0x000 NtTib
: _NT_TIB
+0x000 GdtBase
: 0xfffff802'a5f4bfb0 _KGDTENTRY64
+0x008 TssBase
: 0xfffff802'a5f4a000 _KTSS64
→
86
Kapitel 2
Systemarchitektur
+0x010 UserRsp
: 0x0000009b'1a47b2b8
+0x018 Self
: 0xfffff802'a280a000 _KPCR
+0x020 CurrentPrcb
: 0xfffff802'a280a180 _KPRCB
+0x028 LockArray
: 0xfffff802'a280a7f0 _KSPIN_LOCK_QUEUE
+0x030 Used_Self
: 0x0000009b'1a200000 Void
+0x038 IdtBase
: 0xfffff802'a5f49000 _KIDTENTRY64
+0x040 Unused
: [2] 0
+0x050 Irql
: 0 ''
+0x051 SecondLevelCacheAssociativity : 0x10 ''
+0x052 ObsoleteNumber
: 0 ''
+0x053 Fill0
: 0 ''
+0x054 Unused0
: [3] 0
+0x060 MajorVersion
: 1
+0x062 MinorVersion
: 1
+0x064 StallScaleFactor
: 0x8a0
+0x068 Unused1
: [3] (null)
+0x080 KernelReserved
: [15] 0
+0x0bc SecondLevelCacheSize : 0x400000
+0x0c0 HalReserved
: [16] 0x839b6800
+0x100 Unused2
: 0
+0x108 KdVersionBlock
: (null)
+0x110 Unused3
: (null)
+0x118 PcrAlign1
: [24] 0
+0x180 Prcb
: _KPRCB
lkd> !prcb
PRCB for Processor 0 at fffff803c3b23180:
Current IRQL -- 0
Threads-- Current ffffe0020535a800 Next 0000000000000000 Idle fffff803c3b99740
Processor Index 0 Number (0, 0) GroupSetMember 1
Interrupt Count -- 0010d637
Times -- Dpc 000000f4 Interrupt 00000119
Kernel 0000d952 User 0000425d
Sie können den Befehl dt auch verwenden, um die _KPRCB-Datenstrukturen direkt abzurufen, da Ihnen der Debuggerbefehl die Adresse dieser Strukturen gibt (in der vorstehenden
Ausgabe fett hervorgehoben). Wenn Sie beispielsweise die beim Hochfahren ermittelte
Prozessorgeschwindigkeit herausfinden wollen, können Sie sich mit dem folgenden Befehl
das Feld MHz ansehen:
lkd> dt nt!_KPRCB fffff803c3b23180 MHz
+0x5f4 MHz : 0x893
lkd> ? 0x893
Evaluate expression: 2195 = 00000000'00000893
Hier lief der Prozessor beim Hochfahren also mit etwa 2,2 GHz.
Hauptsystemkomponenten
Kapitel 2
87
Hardwareunterstützung
Die andere Hauptaufgabe des Kernels besteht darin, die Exekutive und die Gerätetreiber gegen Unterschiede zwischen den Hardwarearchitekturen abzuschirmen. Das schließt es auch ein,
solche Abweichungen in Funktionen zu handhaben, z. B. für den Umgang mit Interrupts, das
Ausnahme-Dispatching und die Synchronisierung mehrerer Prozessoren.
Selbst bei solchen Funktionen, die sich auf die Hardware beziehen, wurde bei der Gestaltung des Kernels versucht, die Menge des gemeinsamen Codes zu maximieren. Der Kernel unterstützt eine Reihe von Schnittstellen, die architekturübergreifend portierbar und semantisch
identisch sind. Der Großteil des Codes, der diese portierbaren Schnittstellen implementiert, ist
ebenfalls in den verschiedenen Architekturen identisch.
Einige dieser Schnittstellen sind auf einigen Architekturen unterschiedlich implementiert
und verwenden teilweise architekturspezifischen Code. Diese architektonisch unabhängigen
Schnittstellen können auf jedem Computer aufgerufen werden und sind unabhängig von den
Codeunterschieden auf den Architekturen semantisch identisch. Manche Kernelschnittstellen,
z. B. die in Kapitel 8 von Band 2 beschriebenen Spinlock-Routinen, sind in der HAL implementiert (siehe den nächsten Abschnitt), da ihre Implementierung sich schon zwischen Systemen
derselben Architekturfamilie unterscheiden kann.
Der Kernel enthält auch etwas Code mit x86-spezifischen Schnittstellen zur Unterstützung alter 16-Bit-MS-DOS-Programme (auf 32-Bit-Systemen). Diese x86-Schnittstellen sind
nicht portierbar, allerdings nicht in dem Sinne, dass sie auf einem Computer mit einer anderen Architektur nicht aufgerufen werden können; tatsächlich sind sie dort nicht einmal
vorhanden. Dieser x86-spezifische Code unterstützt beispielsweise Aufrufe zur Verwendung
des virtuellen 8086-Modus, der zur Emulation von manchem Realmoduscode auf älteren
Videokarten erforderlich ist.
Ein weiteres Beispiel für architekturspezifischen Code im Kernel bilden die Schnittstellen für
die Unterstützung des Übersetzungspuffers und des CPU-Cache. Aufgrund der Art und Weise,
wie die Caches realisiert werden, ist dafür auf den einzelnen Architekturen jeweils unterschiedlicher Code erforderlich.
Noch ein Beispiel bilden Kontextwechsel. Für Threadauswahl und Kontextwechsel wird
zwar unabhängig von der Architektur der gleiche allgemeine Algorithmus verwendet (der Kontext des vorherigen Threads wird gespeichert, der Kontext des neuen Threads wird geladen
und der neue Thread wird gestartet), aber bei der Implementierung in den Prozessoren gibt es
architektonische Unterschiede. Da der Kontext durch den Prozessorzustand beschrieben wird
(Register usw.), hängt es von der Architektur ab, was gespeichert und geladen wird.
Die Hardwareabstraktionsschicht
Einer der entscheidenden Aspekte des Windows-Designs ist die Portierbarkeit für verschiedene Hardwareplattformen. Angesichts von OneCore und den unzähligen Gerätebauformen
ist dies heute wichtiger als je zuvor. Die Hardwareabstraktionsschicht (Hardware Abstraction
Layer, HAL) ist die entscheidende Komponente, die diese Portierbarkeit ermöglicht. Es handelt
sich dabei um ein ladbares Kernelmodusmodul (Hal.dll), das eine maschinennahe Schnittstelle
zu der Hardwareplattform bietet, auf der Windows läuft. Sie deckt hardwareabhängige Einzel-
88
Kapitel 2
Systemarchitektur
heiten wie E/A-Schnittstellen, Interrupt-Controller und Mechanismen zur Kommunikation zwischen Prozessoren zu, also alle architekturspezifischen und maschinenabhängigen Funktionen.
Die internen Windows-Komponenten und die Gerätetreiber bewahren diese Portierbarkeit,
indem sie nicht direkt auf die Hardware zugreifen, sondern HAL-Routinen aufrufen, wenn sie
plattformabhängige Informationen benötigen. Daher sind viele HAL-Routinen im WDK dokumentiert. Um mehr über die HAL und ihre Verwendung durch Gerätetreiber zu erfahren,
schlagen Sie im WDK nach.
In der Standard-Desktop-Installation von Windows sind zwei x86-HALs enthalten (siehe
Tabelle 2–4). Zum Startzeitpunkt kann Windows erkennen, welche es verwenden soll. Dadurch
wird das Problem gelöst, das bei früheren Versionen von Windows auftrat, wenn Sie versuchten,
eine Windows-Installation auf einer anderen Art von System zu starten.
HAL-Datei
Unterstützte Systeme
Halacpi.dll
ACPI-PCs (Advanced Configuration and Power Interface). Damit sind Einprozessorcomputer ohne APIC-Unterstützung gemeint. (Sind mehrere Prozessoren oder ein
APIC vorhanden, verwendet das System stattdessen die zweite HAL.)
Halmacpi.dll
APIC-PCs (Advanced Programmable Interrupt Controller) mit ACPI. Das Vorhandensein eines APIC bedeutet SMP-Unterstützung.
Tabelle 2–4 x86-HALs
Auf x64- und ARM-Computern gibt es nur ein HAL-Abbild, nämlich Hal.dll. Alle x64-Rechner
benötigen sowohl ACPI- als auch APIC-Unterstützung und verfügen daher über dieselbe
Motherboardkonfiguration, weshalb es nicht nötig ist, Computer ohne APIC oder mit einem
Standard-PIC zu unterstützen. Auch alle ARM-Systeme verfügen über eine ACPI und verwenden Interruptcontroller, die einem Standard-APIC ähneln, weshalb eine einzige HAL für sie
ausreicht.
Allerdings sind diese Interruptcontroller einem Standard-APIC nur ähnlich, aber nicht
identisch damit. Außerdem können sich die Timer und Speicher-/DMA-Controller auf einigen
ARM-Systemen von denen auf anderen unterscheiden. Bei IoT-Geräten können sogar gängige PC-Hardwarekomponenten wie der Intel-DMA-Controller fehlen, weshalb sie selbst auf
PC-gestützten Systemen Unterstützung für einen anderen Controller benötigen. Bei älteren
Windows-Versionen wurden die Hersteller gezwungen, eine eigene HAL für jede mögliche
Plattformkombination mitzuliefern. Das führt jedoch zu einer Unmenge von doppeltem Code
und ist heute nicht mehr machbar. Stattdessen unterstützt Windows jetzt HAL-Erweiterungen.
Dabei handelt es sich um zusätzliche DLLs auf der Festplatte, die der Bootloader laden kann,
wenn sie von der Hardware benötigt werden. (Dies erfolgt gewöhnlich durch die ACPI und die
Konfiguration in der Registrierung.) Ein Desktop-System mit Windows 10 verfügt gewöhnlich
über die Erweiterungen HalExtPL080.dll und HalExtIntcLpioDMA.dll, wobei Letztere auf bestimmten Intel-Plattformen mit geringer Leistungsaufnahme verwendet wird.
Die Entwicklung von HAL-Erweiterungen ist nur in Zusammenarbeit mit Microsoft möglich. Die Dateien müssen mit einem besonderen Zertifikat für HAL-Erweiterungen signiert
werden, das es nur für Hardwarehersteller gibt. Außerdem ist die Auswahl der APIs, die sie
nutzen können, stark eingeschränkt. Auch die Interaktion mit diesen APIs erfolgt durch einen eingeschränkten Import/Export-Tabellenmechanismus, der nicht den herkömmlichen PE-
Hauptsystemkomponenten
Kapitel 2
89
Abbildmechanismus verwendet. Wenn Sie das folgende Experiment mit einer HAL-Erweiterung
ausführen, werden daher keine Funktionen angezeigt.
Experiment: Abhängigkeiten von Ntoskrnl.exe
und der HAL-Abbilder einsehen
Sie können sich die Beziehung zwischen dem Kernel und den HAL-Abbildern mit Dependency Walker (Depends.exe) ansehen und ihre Export- und Importtabellen untersuchen.
Öffnen Sie dazu in Dependency Walker das Menü File, klicken Sie auf Open und wählen Sie
die gewünschte Abbilddatei aus.
Die folgende Beispielausgabe zeigt die Abhängigen von Ntoskrnl.exe. (Ignorieren Sie
zunächst die Fehlermeldungen, die dadurch zustande kommen, dass Dependency Walker
nicht in der Lage ist, API-Sets zu analysieren.)
Wie Sie sehen, ist Ntoskrnl.exe mit der HAL verknüpft und diese wiederum mit Ntoskrnl.exe.
(Beide nutzen Funktionen der jeweils anderen Datei.) Außerdem ist Notskrnl.exe mit den
folgenden Binärdateien verknüpft:
QQ Pshed.dll Der PSHED (Platform-Specific Hardware Error Driver) bietet eine Abstraktion der Einrichtungen, die auf der zugrunde liegenden Plattform für die Meldung
von Hardwarefehlern vorhanden sind. Dazu verbirgt er die Einzelheiten der Fehlerbehandlungsmechanismen der Plattform vor dem Betriebssystem und stellt diesem eine
einheitliche Schnittstelle bereit.
QQ Bootvid.dll Der Bootvideotreiber auf x86-Systemen (Bootvid) bietet Unterstützung
für die VGA-Befehle, die erforderlich sind, um beim Hochfahren den Starttext und das
Startlogo anzuzeigen.
QQ Kdcom.dll Dies ist die Kommunikationsbibliothek des Kerneldebuggerprotokolls (KD).
QQ Ci.dll
Dies ist die Integritätsbibliothek (siehe Kapitel 8 in Band 2).
→
90
Kapitel 2
Systemarchitektur
QQ Msrpc.sys Der Microsoft-RPC-Clienttreiber für den Kernelmodus ermöglicht dem
Kernel (und anderen Treibern) die Kommunikation mit Benutzermodusdiensten über
Remoteprozeduraufrufe (Remote Procedure Calls, RPCs) und das Marshalling von
MES-codierten Daten. Beispielsweise nutzt der Kernel diesen Treiber für das Marshalling von Daten zum und vom Plug-&-Play-Dienst des Benutzermodus.
Eine ausführliche Beschreibung der Informationen, die Dependency Walker ausgibt, finden
Sie in der Hilfedatei dieses Tools (Depends.hlp).
Wir haben Sie gebeten, die Fehlermeldungen zu ignorieren, die zustande kommen,
da Dependency Walker keine API-Sets analysieren kann (die im Abschnitt über den Abbildlader in Kapitel 3 beschrieben werden). Das liegt daran, dass der Autor das Programm
noch nicht aktualisiert hat, damit es auch diesen Mechanismus korrekt handhaben kann.
Allerdings können Sie Dependency Walker immer noch nutzen, um sich anzusehen, welche
Abhängigkeiten der Kernel je nach SKU noch haben kann, da die API-Sets auf echte Module
verweisen. API-Sets sind keine DLLs oder Bibliotheken, sondern Kontrakte. Es kann durchaus sein, dass einige dieser Kontrakte (oder sogar alle) auf Ihrem Computer nicht vorhanden
sind. Ihre Gegenwart hängt von SKU, Plattform und Hersteller ab.
QQ Werkernel-Kontrakt Bietet Unterstützung für Windows Error Reporting (WER) im
Kernel, z. B. beim Erstellen eines Live-Kernelauszugs.
QQ Tm-Kontrakt Dies ist der Kernel-Transaktions-Manager (KTM), der in Kapitel 8 von
Band 2 beschrieben wird.
QQ Kcminitcfg-Kontrakt Verantwortlich für benutzerdefinierte Erstkonfiguration der
Registrierung, die auf bestimmten Plattformen erforderlich sein kann.
QQ Ksr-Kontrakt Kümmert sich um Kernel Soft Reboot (KSR) und die erforderliche Persistenz einzelner Speicherbereiche zu dessen Unterstützung, insbesondere auf bestimmten Mobil- und IoT-Plattformen.
QQ Ksecurity-Kontrakt Enthält zusätzliche Richtlinien für AppContainer-Prozesse (also
Windows-Apps) auf bestimmen Geräten und SKUs, die im Benutzermodus laufen.
QQ Ksigningpolicy-Kontrakt Enthält zusätzliche Richtlinien für die Integrität von Benutzermoduscode (User-Mode Code Integrity, UMCI) zur Unterstützung von Nicht-AppContainer-Prozessen auf bestimmten SKUs oder zur ausführlicheren Konfiguration von
DeviceGuard- und AppLocker-Sicherheitsmerkmalen auf bestimmten Plattformen und
SKUs.
QQ Ucode-Kontrakt Dies ist die Mikrocode-Aktualisierungsbibliothek für Plattformen,
auf denen solche Aktualisierungen möglich sind, z. B. Intel und AMD.
QQ Clfs-Kontrakt Dies ist der CLFS-Treiber (Common Log File System), der unter anderem vom Transaktionsregister (TxR) verwendet wird (siehe Kapitel 8 in Band 2).
QQ Ium-Kontrakt Dies sind zusätzliche Richtlinien für IUM-Trustlets, die auf dem System
laufen und von bestimmten SKUs gebraucht werden können, z. B. für abgeschirmte VMs
auf einem Datacenter-Server. Trustlets werden ausführlicher in Kapitel 3 beschrieben.
Hauptsystemkomponenten
Kapitel 2
91
Gerätetreiber
Gerätetreiber werden noch ausführlich in Kapitel 6 beschrieben. Dieses Kapitel gibt einen kurzen Überblick über die möglichen Arten von Treibern und zeigt, wie Sie die auf Ihrem System
installierten und geladenen Treiber auflisten lassen können.
Windows unterstützt sowohl Kernel- als auch Benutzermodustreiber, doch in diesem Abschnitt beschäftigen wir uns nur mit den Kerneltreibern. Der Begriff Gerätetreiber scheint auf
Hardwaregeräte hinzudeuten, doch gibt es auch Gerätetreiber, die nicht direkt mit der Hardware zu tun haben (siehe die nachfolgende Liste). In diesem Abschnitt geht es hauptsächlich
um Gerätetreiber zur Steuerung von Hardwaregeräten.
Gerätetreiber sind ladbare Kernelmodusmodule (Dateien, die gewöhnlich die Endung .sys
tragen), die als Schnittstelle zwischen dem E/A-Manager und der entsprechenden Hardware
dienen. Sie werden im Kernelmodus in einem der drei folgenden Kontexte ausgeführt:
QQ Im Kontext des Benutzerthreads, der eine E/A-Funktion (beispielsweise eine Leseoperation)
ausgelöst hat
QQ Im Kontext eines Kernelmodus-Systemthreads (z. B. einer Anforderung vom Plug-&-PlayManager)
QQ Infolge eines Interrupts und daher nicht im Kontext eines bestimmten Threads, sondern
des Threads, der beim Auftreten des Interrupts gerade ausgeführt wurde
Wie bereits ausgeführt, handhaben Gerätetreiber in Windows die Hardware nicht direkt, sondern rufen Funktionen der HAL auf, um mit der Hardware zu arbeiten. Treiber sind gewöhnlich
in C oder C++ geschrieben. Dank der Nutzung der HAL ist ihr Quellcode also über alle von
Windows unterstützten CPU-Architekturen hinweg portierbar und ihre Binärdateien innerhalb
der Architekturfamilie.
Es gibt verschiedene Arten von Gerätetreibern:
QQ Hardwaregerätetreiber Sie verwenden die HAL, um die Hardware zu beeinflussen und
damit Ausgaben auf ein physisches Gerät oder das Netzwerk zu schreiben oder von dort
abzurufen. Es gibt viele verschiedene Arten von Hardwaregerätetreibern, darunter Bustreiber, Benutzerschnittstellentreiber, Massenspeichertreiber usw.
QQ Dateisystemtreiber Diese Windows-Treiber nehmen E/A-Anforderungen für Dateien
entgegen und übersetzen sie in E/A-Anforderungen für ein bestimmtes Gerät.
QQ Dateisystemfiltertreiber Dazu gehören die Treiber für Festplattenspiegelung und -verschlüsselung, die Untersuchung auf lokale Viren, das Abfangen von E/A-Anforderungen
und eine Verarbeitung von E/A vor der Übergabe an die nächste Schicht (bzw. in manchen
Fällen vor der Ablehnung einer solchen Operation).
QQ Netzwerkredirectors und -server Dies sind Dateisystemtreiber, die Dateisystem-E/AAnforderungen zu einem anderen Computer im Netzwerk übertragen bzw. solche Anforderungen von dort empfangen.
QQ Protokolltreiber Sie implementieren Netzwerkprotokolle wie TCP/IP, NetBEUI oder IPX/SPX.
QQ Kernelstreaming-Filtertreiber Diese Treiber sind verkettet, um eine Signalverarbeitung
an Datenströme durchzuführen, z. B. Audio- und Videoaufnahme und -wiedergabe.
92
Kapitel 2
Systemarchitektur
QQ Softwaretreiber Diese Kernelmodule führen im Namen von Benutzermodusprozessen
Operationen durch, die nur im Kernelmodus erledigt werden können. Viele Tools von Sys
internals wie Process Explorer und Process Monitor verwenden Treiber, um Informationen
abzurufen oder Operationen auszuführen, die mit Benutzermodus-APIs nicht zugänglich
bzw. nicht möglich sind.
Das Treibermodell von Windows
Das ursprüngliche Treibermodell wurde in der ersten NT-Version (3.1) erstellt und bot noch
keine Unterstützung für Plug & Play, da es dieses Funktionsprinzip damals noch gar nicht gab.
Das blieb so bis Windows 2000 (bzw. Windows 95/98 auf der Seite der Windows-Versionen für
Endverbraucher).
In Windows 2000 kamen Unterstützung für Plug & Play, Energieoptionen und eine Erweiterung des Treibermodells von Windows NT hinzu, die als Windows Driver Model (WDM) bezeichnet wurde. Windows 2000 und höher kann ältere Windows NT 4-Treiber ausführen, aber
da diese Treiber keine Unterstützung für Plug & Play und Energieoptionen bieten, sind die Möglichkeiten von Systemen, die diese Treiber nutzen, auf diesen beiden Gebieten eingeschränkt.
Ursprünglich bot WDM ein gemeinsames Treibermodell, das zwischen Windows 2000/XP
und Windows 98/ME (fast) quellcodekompatibel war. Dadurch wurde es einfacher, Treiber für
Hardwaregeräte zu schreiben, da nur ein einziger Codestamm benötigt wurde und nicht zwei.
Auf Windows 98/ME wurde WDM simuliert. Als diese Betriebssysteme außer Gebrauch kamen,
blieb WDM das Grundmodell zum Schreiben von Hardwaregerätetreibern für Windows 2000
und höhere Versionen.
WDM unterscheidet zwischen den drei folgenden Arten von Treibern:
QQ Bustreiber Bustreiber sind für Buscontroller, Adapter, Brücken und jegliche anderen Geräte da, die über Kindgeräte verfügen. Diese Treiber sind erforderlich und werden im Allgemeinen von Microsoft bereitgestellt. Für jede Art von Bus auf einem System (wie PCI,
PCMCIA und USB) gibt es einen eigenen Bustreiber. Drittanbieter können Bustreiber zur
Unterstützung neuer Busse schreiben, z. B. für VMEbus, Multibus und Futurebus.
QQ Funktionstreiber Ein Funktionstreiber ist der Hauptgerätetreiber, der die Betriebsschnittstelle für das zugehörige Gerät bereitstellt. Dieser Treiber ist erforderlich, sofern das
Gerät nicht »roh« verwendet wird, wobei die E/A über den Bustreiber und Busfiltertreiber
verfügt, z. B. einen SCSI-Pass-Thru-Treiber. Der Funktionstreiber ist per definitionem der
Treiber, der am meisten über das zugehörige Gerät weiß, und gewöhnlich der einzige Treiber, der auf gerätespezifische Register zugreift.
QQ Filtertreiber Filtertreiber dienen dazu, den Funktionsumfang eines Geräts oder eines vorhandenen Treibers zu erweitern oder um E/A-Anforderungen oder -Antworten von anderen
Treibern zu ändern. Sie werden gewöhnlich als Korrekturmaßnahme verwendet, wenn Hardware fehlerhafte Informationen über ihre Ressourcenanforderungen bereitstellt. Filtertreiber sind optional. Sie können in beliebiger Anzahl auftreten, oberhalb oder unterhalb eines
Funktionstreibers und oberhalb eines Bustreibers platziert werden. Gewöhnlich werden sie
von den System-OEMs oder von unabhängigen Hardwareherstellern bereitgestellt.
Hauptsystemkomponenten
Kapitel 2
93
In der WDM-Treiberumgebung steuert kein einziger Treiber sämtliche Aspekte eines Geräts.
Der Bustreiber meldet die Geräte, die sich an seinem Bus befinden, an den PnP-Manager, während der Funktionstreiber das Gerät handhabt.
In den meisten Fällen ändern die Filtertreiber niedrigerer Ebene das Verhalten der Gerätehardware. Wenn beispielsweise ein Gerät an seinen Bustreiber meldet, dass es vier E/A-Ports
benötigt, obwohl es in Wirklichkeit 16 sein müssten, kann ein gerätespezifischer Filtertreiber
auf niedrigerer Ebene die vom Bustreiber an den PnP-Manager gemeldete Liste der Hardwareressourcen abfangen und die Anzahl der E/A-Ports korrigieren.
Filtertreiber höherer Ebene dagegen dienen gewöhnlich dazu, den Funktionsumfang eines Geräts zu erweitern. Beispielsweise kann ein solcher Treiber für eine Festplatte zusätzliche
Sicherheitsprüfungen erzwingen.
Die Interruptverarbeitung wird allgemein in Kapitel 8 von Band 2 und im Zusammenhang
mit Gerätetreibern in Kapitel 6 beschrieben. Auch der E/A-Manager, WDM, Plug & Play und die
Energieverwaltung sind Thema von Kapitel 6.
Windows Driver Foundation
Die Windows Driver Foundation (WDF) vereinfacht die Entwicklung von Windows-Treibern,
indem sie zwei Frameworks bereitstellt: das Kernel-Mode Driver Framework (KMDF) und
das User-Mode Driver Framework (UMDF). Mit dem KMDF können Entwickler Treiber für
Windows 2000 SP4 und höher schreiben, während UMDF Windows XP und höher unterstützt.
KMDF stellt eine einfache Schnittstelle zum WDM bereit und verbirgt die Komplexität dieses Modells vor den Treiberautoren, ohne das zugrunde liegende Modell der Bus-, Funktionsund Filtertreiber zu ändern. KMDF-Treiber reagieren auf Ereignisse, die sie registrieren, und
rufen Funktionen der KMDF-Bibliothek auf, um Arbeiten auszuführen, die nicht auf die von
ihnen verwendete verwaltete Hardware zugeschnitten sind, z. B. allgemeine Energieverwaltung
oder Synchronisierung. (Früher musste jeder Treiber all dies selbst implementieren.) Dabei kann
ein einziger KDMF-Funktionsaufruf über 200 Zeilen WDM-Code einsparen.
Mit UMDF ist es möglich, Treiber bestimmter Klassen – vor allem Treiber für Busse auf
der Grundlage von USB oder anderen Protokollen mit hoher Latenz, z. B. für Videokameras,
MP3-Player, Handys und Drucker – als Benutzermodustreiber zu implementieren. UMDF führt
jeden Benutzermodustreiber letzten Endes in einem Benutzermodusdienst aus und verwendet
ALPC zur Kommunikation mit einem Kernelmodus-Wrappertreiber, der den eigentlichen Zugang zur Hardware gewährt. Wenn ein UMDF-Treiber abstürzt, wird der Prozess beendet und
gewöhnlich neu gestartet. Das System bleibt dabei stabil. Lediglich das Gerät ist vorübergehend nicht erreichbar, während der Dienst für den Treiber neu gestartet wird.
Es gibt zwei Hauptversionen von UMDF: Version 1.x ist für alle Betriebssystemversionen
verfügbar, die UMDF unterstützen. Die neueste Version ist 1.11 und steht in Windows 10 zur
Verfügung. Für Version 1.x wurden C++ und COM zum Schreiben der Treiber verwendet,
was für Benutzermodusprogrammierer sehr bequem ist, allerdings dazu führt, dass sich das
UMDF-Modell von KMDF unterscheidet. Version 2.0 von UMDF wurde in Windows 8.1 eingeführt und basiert auf demselben Objektmodell wie KMDF, was die Programmiermodelle der
beiden Frameworks sehr ähnlich macht. Der Quellcode des WDF wurde von Microsoft schließ-
94
Kapitel 2
Systemarchitektur
lich offengelegt und steht zurzeit auf GitHub unter https://github.com/Microsoft/Windows-
Driver-Frameworks zur Verfügung.
Universelle Windows-Treiber
Mit dem in Windows 10 eingeführten Prinzip der universellen Windows-Treiber ist es möglich,
Gerätetreiber zu schreiben, die die vom gemeinsamen Kern von Windows 10 bereitgestellten
APIs und Gerätetreiberschnittstellen (Device Driver Interface, DDI) gemeinsam nutzen. Solche
Treiber sind innerhalb einer CPU-Architektur (x86, x64 oder ARM) binärkompatibel und können
auf Geräten mit unterschiedlicher Bauform verwendet werden, von IoT-Geräten über Smartphones, die HoloLens und die Xbox One bis zu Laptop- und Desktopcomputern. Als Treibermodell können universelle Treiber KMDF, UMDF 2.x und WDM nutzen.
Experiment: Die installierten Gerätetreiber einsehen
Um die installierten Gerätetreiber aufzulisten, führen Sie das Tool Systeminformationen
(Msinfo32.exe) aus. Um es zu starten, klicken Sie auf Start und geben Msinfo32 ein. Erweitern Sie unter Systemübersicht den Knoten Softwareumgebung und darunter Systemtreiber.
Die folgende Abbildung zeigt eine Beispielausgabe mit einer Liste der installierten Treiber.
Dieses Fenster zeigt eine Liste der in der Registrierung definierten Gerätetreiber, ihres Typs
und ihres Zustands (Wird ausgeführt oder Beendet) an. Gerätetreiber und Windows-Dienstprozesse werden beide in HKLM\SYSTEM\CurrentControlSet\Services definiert, aber durch
den Typcode unterschieden. Beispielsweise handelt es sich bei Typ 1 um Kernelmodus-Gerätetreiber. Eine vollständige Liste der Informationen, die in der Registrierung über Gerätetreiber gespeichert sind, erhalten Sie in Kapitel 9 von Band 2.
→
Hauptsystemkomponenten
Kapitel 2
95
Alternativ können Sie die zurzeit geladenen Gerätetreiber auch anzeigen lassen, indem Sie in Process Explorer den Prozess System auswählen und die DLL-Ansicht öffnen.
Die folgende Abbildung zeigt eine Beispielausgabe. (Um zusätzliche Spalten anzuzeigen,
rechtsklicken Sie auf einen Spaltenkopf und klicken auf Select Columns. Dadurch werden
alle verfügbaren Spalten für die Module auf der DLL-Registerkarte angezeigt.)
Ein Blick in nicht dokumentierte Schnittstellen
Es kann sehr erhellend sein, einen genaueren Blick auf die Namen der exportierten oder
globalen Symbole in den wichtigsten Systemabbildern (wie Ntoskrnl.exe, Hal.dll oder Ntdll.
dll) zu werfen, denn dadurch erhalten Sie eine Vorstellung der Dinge, die Windows über
das, was dokumentiert ist und zurzeit unterstützt wird, hinaus tun kann. Natürlich heißt das
nicht, dass Sie diese Funktionen aufrufen können oder sollten, nur weil Sie ihre Namen kennen. Da die Schnittstellen nicht dokumentiert sind, können sie Änderungen unterworfen
sein. Sehen Sie sich diese Funktionen nur an, um zu erkennen, welche Arten von internen
Funktionen Windows ausführt, nicht um die unterstützten Schnittstellen zu umgehen.
Wenn Sie sich beispielsweise die Funktionen in Ntdll.dll ansehen, finden Sie alle Systemdienste, die Windows für Teilsystem-DLLs im Benutzermodus bereitstellt – also nicht nur die
Teilmenge, die das Teilsystem verfügbar macht. Viele dieser Funktionen sind zwar eindeutig
dokumentierten und unterstützten Windows-Funktionen zugeordnet, aber einige von ihnen stehen nicht über die Windows-API zur Verfügung.
Es ist allerdings auch interessant, sich die Importe der Windows-Teilsystem-DLLs (wie
Kernel32.dll oder Advapi32.dll) und die Funktionen anzusehen, die sie in Ntdll.dll aufrufen.
Auch eine Untersuchung von Ntoskrnl.exe ist interessant: Viele der exportierten Routinen,
die von Kernelmodus-Gerätetreibern genutzt werden, sind zwar im WDK dokumentiert, doch
eine ganze Menge von ihnen nicht. Schauen Sie sich auch die Importtabelle für Ntoskrnl.exe
und die HAL an. Sie zeigt die Funktionen in der HAL, die Ntoskrnl.exe nutzt, und umgekehrt.
→
96
Kapitel 2
Systemarchitektur
Tabelle 2–5 führt die meisten gängigen Funktionsnamenpräfixe für Komponenten der
Exekutive auf. Jede dieser Komponenten verwendet auch eine Variante des Präfixes, um
interne Funktionen zu kennzeichnen. Dabei wird an den ersten Buchstaben des Präfix
es entweder ein i (für intern) oder an das komplette Präfix ein p (für privat) angehängt.
Beispielsweise steht Ki für interne Kernelfunktionen und Psp für interne Prozessunterstützungsfunktionen.
Präfix
Komponente
Alpc
Advanced Local Procedure Calls
Cc
Gemeinsamer Cache (Common Cache)
Cm
Konfigurations-Manager
Dbg
Kernel-Debugunterstützung
Dbgk
Debugging-Framework für den Benutzermodus
Em
Errata-Manager
Etw
Ereignisverfolgung für Windows
Ex
Unterstützungsroutinen der Exekutive
FsRtl
Dateisystem-Laufzeitbibliothek
Hv
Hive-Bibliothek
Hvl
Hypervisor-Bibliothek
Io
E/A-Manager
Kd
Kerneldebugger
Ke
Kernel
Kse
Kernel Shim Engine
Lsa
Lokale Sicherheitsautorität
Mm
Speicher-Manager
Nt
NT-Systemdienste (vom Benutzermodus aus über Systemaufrufe zugänglich)
Ob
Objekt-Manager
Pf
Prefetcher
Po
Energie-Manager
PoFx
Energie-Framework
Pp
PnP-Manager
Ppm
Prozessor-Energie-Manager
Ps
Prozessunterstützung
Rtl
Laufzeitbibliothek
Se
Security Reference Monitor
Sm
Store-Manager
Tm
Transaktions-Manager
Ttm
Terminal Timeout Manager
→
Hauptsystemkomponenten
Kapitel 2
97
Präfix
Komponente
Vf
Treiberverifizierer
Vsl
Bibliothek für Virtual Secure Mode
Wdi
Windows Diagnostic Infrastructure
Wfp
Windows FingerPrint
Whea
Windows Hardware Error Architecture
Wmi
Windows Management Instrumentation
Zw
Spiegeleintrittspunkt für Systemdienste (die mit Nt beginnen). Er setzt den vorherigen Zugriffsmodus auf den Kernelmodus. Dadurch fällt die Parametervalidierung
weg, da Nt-Systemdienste Parameter nur dann überprüfen, wenn der vorherige
Zugriffsmodus der Benutzermodus war.
Tabelle 2–5 Gängige Präfixe
Die Namen der exportierten Funktionen können Sie einfacher deuten, wenn Sie die Namenskonvention für Windows-Systemroutinen kennen. Das allgemeine Format lautet:
<Präfix><Operation><Objekt>
Präfix gibt die interne Komponente an, die die Routine exportiert, Operation sagt, was mit
dem Objekt oder der Ressource geschieht, und Objekt nennt das Objekt, an dem die Operation ausgeführt wird.
Beispielsweise ist ExAllocatePoolWithTag die Unterstützungsroutine der Exekutive für
die Zuweisung vom ausgelagerten oder nicht ausgelagerten Pool und KeInitializeThread
die Routine, die ein Kernelthreadobjekt zuweist und einrichtet.
Systemprozesse
Die folgenden Systemprozesse erscheinen auf jedem Windows 10-System. Einer davon (der
Leerlaufprozess) ist in Wirklichkeit gar kein Prozess, und drei von ihnen – System, Secure System
und Speicherkomprimierung – sind keine vollständigen Prozessen, da sie nicht in einer ausführbaren Benutzermodusdatei laufen. Prozesse dieser Art werden minimale Prozesse genannt und
werden in Kapitel 3 erklärt.
QQ Leerlaufprozess
tigen.
Enthält einen Thread pro CPU, um CPU-Leerlaufzeiten zu berücksich-
QQ Systemprozess Enthält den Großteil der Kernelmodus-Systemthreads und -handles.
QQ Secure-System-Prozess
ser ausgeführt wird.
Enthält den Adressraum des sicheren Kernels in VTL 1, falls die-
QQ Speicherkomprimierungsprozess Enthält den komprimierten Arbeitsteil der Benutzermodusprozesse (siehe Kapitel 5).
QQ Sitzungs-Manager
Smss.exe
QQ Windows-Teilsystem Csrss.exe
98
Kapitel 2
Systemarchitektur
QQ Sitzung-0-Initialisierung Wininit.exe
QQ Anmeldeprozess Winlogon.exe
QQ Dienststeuerungs-Manager Services.exe und die von ihm erzeugten Kindprozesse wie
der vom System bereitgestellte, allgemeine Diensthostprozess (Svchhost.exe).
QQ Lokaler Sicherheitsauthentifizierungsdienst Lsass.exe; falls CredentialGuard aktiviert
ist, auch Lsaiso.exe (Isolated Local Security Authentication Server).
In der Prozessstruktur können Sie die Beziehungen zwischen den Prozessen erkennen und
erfahren, von welchen Prozessen die einzelnen Prozesse erstellt wurden. Abb. 2–6 zeigt die
Prozessstruktur in einer Startablaufverfolgung von Process Monitor. Um eine solche Ablaufverfolgung durchzuführen, öffnen Sie in Process Monitor das Menü Options und wählen Enable
Boot Logging. Starten Sie das System dann neu, öffnen Sie Process Monitor wieder und wählen
Sie im Menü Tools den Punkt Process Tree oder drücken Sie (Strg) + (T). In Process Monitor
können Sie auch die inzwischen beendeten Prozesse erkennen – sie werden durch ein verblasstes Symbol dargestellt.
Abbildung 2–6 Die anfängliche Prozessstruktur
In den nächsten Abschnitten werden die wichtigsten Systemprozesse erklärt, die Sie in Abb. 2–6
sehen. Dabei wird auch die Reihenfolge erläutert, in der die Prozesse gestartet werden. Eine
ausführliche Beschreibung der Schritte, die beim Hochfahren von Windows erfolgen, finden Sie
in Kapitel 11 von Band 2.
Hauptsystemkomponenten
Kapitel 2
99
Der Leerlaufprozess
Der erste in Abb. 2–6 aufgeführte Prozess ist der Leerlaufprozess (Idle). Wie in Kapitel 3 erklärt,
werden Prozesse anhand ihres Abbildnamens bezeichnet. Allerdings führt dieser Prozess –
ebenso wie der Systemprozess, der Secure-System-Prozess und der Speicherkomprimierungsprozess – kein echtes Benutzermodusabbild aus, d. h., im Verzeichnis \Windows gibt es keine
Datei namens System Idle Process.exe. Aufgrund der Art der Implementierung wird dieser Prozess (ID 0) auch je nach verwendetem Programm unter einem anderen Namen angezeigt (siehe
Tabelle 2–6). Der Leerlaufprozess dient dazu, Leerlaufzeiten zu berücksichtigen. Daher ist die
Anzahl der »Threads« in diesem »Prozess« die Anzahl der logischen Prozessoren des Systems.
In Kapitel 3 finden Sie eine ausführlichere Erklärung dieses Prozesses.
Programme
Name für den Prozess mit der ID 0
Task-Manager
Systemleerlaufprozess (System Idle process)
Process Status (Pstat.exe)
Idle process
Process Explorer (Procexp.exe)
System Idle process
Task List (Tasklist.exe)
System Idle process
Tlist (Tlist.exe)
System process
Tabelle 2–6 Namen des Prozesses mit der ID 0 in verschiedenen Programmen
Als Nächstes sehen wir uns die Systemthreads und den Zweck der einzelnen Systemprozesse
an, die echte Abbilder ausführen.
Der Systemprozess und die Systemthreads
Der Systemprozess (Prozess-ID 4) ist das Zuhause einer besonderen Art von Threads, die nur im
Kernelmodus laufen – der Kernelmodus-Systemthreads. Sie haben alle Attribute und Kontexte
regulärer Benutzermodusthreads, z. B. Hardwarekontext, Priorität usw., laufen aber ausschließlich im Kernelausführungscode, der in den Systemraum geladen ist, unabhängig davon, ob
dies in Ntoskrnl.ee oder einem anderen geladenen Gerätetreiber ist. Außerdem haben Systemthreads keinen Benutzerprozess-Adressraum und müssen zur Zuweisung von dynamischem
Speicher daher auf Speicherheaps des Betriebssystems zurückgreifen, z. B. auf den ausgelagerten oder den nicht ausgelagerten Pool.
Im Task-Manager von Windows 10 Version 1511 wird der Systemprozess als Systemspeicher und komprimierter Speicher bezeichnet. Der Grund dafür ist ein neues
Merkmal von Windows 10, das den Arbeitsspeicher komprimiert, um dort mehr
Prozessinformationen unterzubringen, anstatt sie auf die Festplatte auszulagern.
Dieser Mechanismus wird ausführlicher in Kapitel 5 beschrieben. Merken Sie sich
nur, dass sich der Begriff Systemprozess auf diesen Prozess bezieht, wie auch immer er in irgendeinem Programm angezeigt werden mag. In Windows 10 Version
1607 und Windows Server 2016 heißt der Prozess übrigens wieder einfach System,
da für die Speicherkomprimierung hier der Prozess Speicherkomprimierung verwendet wird. Auch dieser Prozess wird in Kapitel 5 ausführlicher beschrieben.
100
Kapitel 2
Systemarchitektur
Systemthreads werden von der Funktion PsCreateSystemThread oder IoCreateSystemThreads erstellt, die beide im WDK dokumentiert sind. Diese Threads können nur vom Kernelmodus aus
aufgerufen werden. Windows und verschiedene Gerätetreiber erstellen Systemthreads bei der
Systeminitialisierung, um Operationen auszuführen, die einen Threadkontext benötigen, z. B.
um Ein-/Ausgaben oder andere Objekte auszugeben und darauf zu warten oder Informationen
über ein Gerät abzufragen. So nutzt beispielsweise der Speicher-Manager Systemthreads zur
Implementierung von Funktionen, die modifizierte Seiten in die Auslagerungsdatei oder in
zugeordnete Dateien schreiben, um Prozesse aus dem Arbeitsspeicher auszulagern und wieder
dorthin zu übernehmen usw. Der Kernel erstellt den Systemthread Balance-Set-Manager, der
einmal pro Sekunde erwacht, um ggf. verschiedene Planungs- und Speicherverwaltungsereignisse auszulösen. Auch der Cache-Manager verwendet Systemthreads, nämlich für vorausschauendes Lesen und verzögertes Schreiben. Der Dateiserver-Gerätetreiber (Srv2.sys) nutzt
Systemthreads, um auf Netzwerk-E/A-Anforderungen für Dateidaten auf Netzwerkfreigaben zu
reagieren. Selbst der Plattentreiber hat einen Systemthread, um das Laufwerk abzufragen. (Die
Abfrage ist in diesem Fall effizienter, da ein interruptgesteuerter Plattentreiber große Mengen
an Systemressourcen verbraucht.) Weitere Informationen über einzelne Systemthreads finden
Sie jeweils in den Kapiteln, in denen die zugehörigen Komponenten beschrieben werden.
Standardmäßig gehören Systemthreads dem Systemprozess, doch können Gerätetreiber
Systemthreads auch in beliebigen Prozessen erstellen. Beispielsweise legt der Gerätetreiber für
das Windows-Teilsystem (Win32k.sys) einen Systemthread im kanonischen Displaytreiber (Cdd.
dll) des Windows-Teilsystemprozesses (Csrss.exe) an, sodass Daten im Benutzermodus-Adressraum leicht auf diesen Prozess zugreifen können.
Bei einer Störungssuche oder bei einer Systemanalyse ist es praktisch, die einzelnen Systemthreads zu den Treibern oder sogar den Subroutinen zurückverfolgen zu können, die den
Code enthalten. Beispielsweise verbraucht der Systemprozess auf einem schwer belasteten
Dateiserver wahrscheinlich erheblich viel CPU-Zeit. Zu wissen, dass »irgendein Systemthread«
läuft, wenn der Systemprozess ausgeführt wird, reicht nicht aus, um zu erkennen, welcher Gerätetreiber oder welche Betriebssystemkomponente läuft.
Daher müssen Sie als Erstes herausfinden, welche Systemthreads ausgeführt werden (z. B.
mit der Leistungsüberwachung oder mit Process Explorer). Sobald Sie sie gefunden haben,
können Sie nachschauen, in welchem Treiber ihre Ausführung begonnen hat. Das verrät Ihnen
zumindest, welcher Treiber den Thread wahrscheinlich erstellt hat. Beispielsweise können Sie in
Process Explorer auf den Systemprozess rechtsklicken, Properties auswählen und dann auf der
Registerkarte Threads auf den Spaltenkopf CPU klicken, damit der aktivste Thread ganz oben
angezeigt wird. Markieren Sie diesen Thread und klicken Sie auf die Schaltfläche Module, um
sich die Datei mit dem Code anzeigen zu lassen, der auf der Spitze des Stacks ausgeführt wird.
Da der Systemprozess in den neuen Versionen von Windows geschützt ist, kann Process Explorer den Aufrufstack nicht anzeigen.
Der Secure-System-Prozess
Der Secure-System-Prozess (variable Prozess-ID) ist technisch gesehen das Zuhause des Adress
raums, der Handles und Systemthreads des sicheren VLT-1-Kernels. Da Planung, Objekt- und
Speicherverwaltung jedoch im Besitz des VTL-0-Kernels sind, werden solche Entitäten in Wirk-
Hauptsystemkomponenten
Kapitel 2
101
lichkeit gar nicht diesem Prozess zugeordnet. Sein einziger tatsächlicher Zweck besteht darin,
in Werkzeugen wie dem Task-Manager oder Process Explorer einen sichtbaren Indikator dafür
bereitzustellen, dass VBS zurzeit aktiv ist (und mindestens eines der Merkmale bereitstellt, die
ihn nutzen).
Der Speicherkomprimierungsprozess
Der Speicherkomprimierungsprozess verwendet seinen Benutzermodus-Adressraum, um die
komprimierten Speicherseiten zu speichern, die dem aus den Arbeitssätzen bestimmter Prozesse getilgtem Standby-Speicher entsprechen (siehe Kapitel 5). Anders als der Secure-System-Prozess beherbergt der Speicherkomprimierungsprozess tatsächlich eine Reihe von Systemthreads, die gewöhnlich als SmKmStoreHelperWorker und SmStReadThread angezeigt werden.
Beide gehören zum Store-Manager, der sich um die Speicherkomprimierung kümmert.
Im Gegensatz zu den anderen Systemprozessen in der Liste befindet sich der Arbeitsspeicher dieses Prozesses tatsächlich im Benutzermodus-Adressraum. Daher unterliegt er der Beschneidung des Arbeitssatzes und wird in Systemüberwachungswerkzeugen möglicherweise
mit einer umfangreichen Speichernutzung angezeigt. Die Registerkarte Leistung des Task-Managers zeigt jetzt sowohl den verwendeten als auch den komprimierten Arbeitsspeicher. Dort
können Sie nun erkennen, dass der Arbeitssatz des Speicherkomprimierungsprozesses genauso
groß ist wie der komprimierte Arbeitsspeicher.
Der Sitzungs-Manager
Der Sitzungs-Manager (%SystemRoot%\System32\Smss.exe) ist der erste Benutzermodusprozess, der im System erstellt wird, und zwar von dem Kernelmodus-Systemthread, der die letzte
Phase der Initialisierung der Exekutive und des Kernels durchführt. Wie in Kapitel 3 beschrieben, wird er als PPL-Prozess angelegt (Protected Process Light).
Bei seinem Start prüft Smss.exe, ob er die erste Instanz (der Master) oder eine Instanz ist,
die der Master erzeugt hat, um eine Sitzung zu erstellen. Sind Befehlszeilenargumente vorhanden, so ist Letzteres der Fall. Wenn Smss.exe beim Hochfahren oder beim Erstellen einer Terminaldienste-Sitzung mehrere Instanzen von sich selbst anlegt, kann er dadurch mehrere Sitzungen gleichzeitig erzeugen – bis zu vier gleichzeitige plus eine zusätzliche für jede CPU, die
es über die erste hinaus noch gibt. Das verbessert die Anmeldeleistung auf Terminal-Servern,
wenn mehrere Benutzer gleichzeitig Verbindung aufnehmen. Wenn eine Sitzung die Initialisierung abgeschlossen hat, wird die Kopie von Smss.exe beendet, sodass nur der ursprüngliche
Smss.exe-Prozess aktiv bleibt. (Eine Beschreibung der Terminaldienste finden Sie im Abschnitt
»Terminaldienste und mehrere Sitzungen« von Kapitel 1.)
Der Smss.exe-Masterprozess führt folgende einmalige Initialisierungsschritte aus:
1.
Er kennzeichnet den Prozess und den ursprünglichen Thread als kritisch. Wird ein solcher
Prozess oder Thread aus irgendeinem Grunde beendet, stürzt Windows ab. Mehr darüber
erfahren Sie in Kapitel 3.
2.
Er sorgt dafür, dass der Prozess bestimmte Fehler als kritisch behandelt, z. B. die Verwendung ungültiger Handles oder eine Beschädigung des Heaps, und aktiviert den Prozess
ausgleich Disable Dynamic Code Execution.
102
Kapitel 2
Systemarchitektur
3.
Er erhöht die Basispriorität des Prozesses auf 11.
4.
Wenn das System ein Hinzufügen von Prozessoren im laufenden Betrieb erlaubt, aktiviert
er die automatische Aktualisierung der Prozessoraffinität. Wird dann ein neuer Prozessor
hinzugefügt, kann er von neuen Sitzungen genutzt werden. Mehr über das dynamische
Hinzufügen von Prozessoren erfahren Sie in Kapitel 4.
5.
Er initialisiert einen Threadpool zur Handhabung von ALPC-Befehlen und anderen Arbeitselementen.
6.
Er erstellt den ALPC-Port \SmApiPort, um Befehle zu empfangen.
7.
Er initialisiert eine lokale Kopie der NUMA-Topologie des Systems.
8.
Er erstellt den Mutex PendingRenameMutex, um Operationen zum Umbenennen von Dateien
zu synchronisieren.
9.
Er erstellt den ursprünglichen Prozessumgebungsblock und aktualisiert bei Bedarf die Variable Safe Mode.
10. Er erstellt Sicherheitsdeskriptoren für verschiedene Systemressourcen auf der Grundlage des
Wertes von ProtectionMode in HKLM\SYSTEM\CurrentControlSet\Control\Session Manager.
11. Er erstellt die beschriebenen Objekt-Manager-Verzeichnisse auf der Grundlage des Wertes
von ObjectDirectories in HKLM\SYSTEM\CurrentControlSet\Control\Session Manager, z. B.
\RPC Control und \Windows. Des Weiteren speichert er die in den Werten BootExecute,
BootExecuteNoPnpSync und SetupExecute aufgeführten Programme.
12. Er speichert den Programmpfad, der im Wert S0InitialCommand unter HKLM\SYSTEM\
CurrentControlSet\Control\Session Manager angegeben ist.
13. Er liest den Wert NumberOfInitialSessions von HKLM\SYSTEM\CurrentControlSet\Control\
Session Manager, ignoriert ihn aber, wenn sich das System im Fertigungsmodus befindet.
14. Er liest die Dateiumbenennungsoperationen, die in den Werten PendingFileRenameOperations und PendingFileRenameOperations2 von HKLM\SYSTEM\CurrentControlSet\Control\
Session Manager aufgeführt sind.
15. Er liest die Werte von AllowProtectedRenames, ClearTempFiles, TempFileDirectory und
D isableWpbtExecution in HKLM\SYSTEM\CurrentControlSet\Control\Session Manager.
16. Er liest die Liste der DLLs im Wert ExcludeFromKnownDllList von HKLM\SYSTEM\Current
ControlSet\Control\Session Manager.
17. Er liest die Informationen über die Auslagerungsdatei, die in den Werten PagingFiles
und ExistingPageFileslist und den Konfigurationswerten PagefileOnOsVolume und
WaitForPagingFiles von HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management gespeichert sind.
18. Er liest und speichert die Werte unter HKLM\SYSTEM\CurrentControlSet\Control\Session
Manager\ DOS Devices.
19. Er liest und speichert die Liste aus dem Wert KnownDlls in HKLM\SYSTEM\CurrentControlSet\
Control\Session Manager.
20. Er erstellt systemweite Umgebungsvariablen nach der Definition in HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Environment.
Hauptsystemkomponenten
Kapitel 2
103
21. Er erstellt das Verzeichnis \KnownDlls und auf 64-Bit-Systemen mit WoW64 auch \Known
Dlls32.
22. Er erstellt symbolische Links für die in HKLM\SYSTEM\CurrentControlSet\Control\Session
Manager\DOS Devices definierten Geräte im Verzeichnis \Global?? des Objekt-Manager-
Namensraums.
23. Er erstellt das Stammverzeichnis \Sessions im Namensraum des Objekt-Managers.
24. Er erstellt Präfixe für geschützte Mailslots und benannte Pipes, um Dienstanwendungen
gegen Spoofing-Angriffe zu schützen, die vorkommen können, wenn schädliche Benutzermodusanwendungen vor einem Dienst ausgeführt werden.
25. Er führt die Programme aus, die auf den zuvor analysierten Listen BootExecute und BootExecuteNoPnpSync aufgeführt sind. (Standardmäßig wird Autochk.exe ausgeführt, das die
Festplatte überprüft.)
26. Er initialisiert den Rest der Registrierung (die Hives Software, SAM und Security von HKLM).
27. Sofern sie nicht in der Registrierung deaktiviert ist, führt er die WPBT-Binärdatei (Windows
Platform Binary Table) aus, die in der zugehörigen ACPI-Tabelle registriert ist. Dies wird
oft von Diebstahlsschutzeinrichtungen genutzt, um sehr früh eine native Windows-Binärdatei auszuführen, die selbst auf frisch installierten Systemen nach Hause telefonieren oder
andere Dienste zur Ausführung einrichten kann. Diese Prozesse dürfen nur mit Ntdll.dll
verlinkt sein (also zum nativen Teilsystem gehören).
28. Er verarbeitet ausstehende Umbenennungen von Dateien, die in den zuvor untersuchten
Registrierungsschlüsseln angegeben wurden, sofern es sich nicht um einen Start in die
Windows-Wiederherstellungsumgebung handelt.
29. Er initialisiert Informationen über Auslagerungsdateien und dedizierte Dumpdateien auf
der Grundlage von HKLM\System\CurrentControlSet\Control\Session Manager\Memory
Management und HKLM\System\CurrentControlSet\Control\CrashControl.
30. Er prüft die Kompatibilität des Systems mit Speicherkühltechniken, wie sie auf NUMA-
Systemen verwendet werden.
31. Er speichert die alte Auslagerungsdatei, erstellt die dedizierte Absturzabbilddatei sowie
nach Bedarf neue Auslagerungsdateien auf der Grundlage der vorherigen Absturzinformationen.
32. Er erstellt zusätzliche dynamische Umgebungsvariablen wie PROCESSOR_ARCHITECTURE,
P ROCESSOR_LEVEL, PROCESSOR_IDENTIFIER und PROCESSOR_REVISION auf der Grundlage von
Registrierungsinformationen sowie aus dem Kernel abgerufener Systeminformationen.
33. Er führt die Programme in HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\
SetupExecute aus. Dabei gelten die gleichen Regeln wie für BootExecute in Schritt 11.
34. Er erstellt ein unbenanntes Abschnittsobjekt, das von den Kindprozessen (z. B. Csrss.exe)
für die mit Smss.exe ausgetauschten Informationen gemeinsam genutzt wird. Das Handle
für diesen Abschnitt wird durch Vererbung an die Kindprozesse übergeben. Mehr über die
Vererbung von Handles erfahren Sie in Kapitel 8 von Band 2.
104
Kapitel 2
Systemarchitektur
35. Er öffnet bekannte DLLs und ordnet sie als permanente Abschnitte (zugeordnete Dateien)
zu – bis auf diejenigen, die bei früheren Registrierungschecks als Ausnahmen aufgeführt
wurden. (Standardmäßig sind keine Ausnahmen vorhanden.)
36. Er erstellt einen Thread, um auf Anforderungen zum Erstellen von Sitzungen zu reagieren.
37. Er erstellt eine Instanz von Smss.exe, um Sitzung 0 (die nicht interaktive Sitzung) zu initialisieren.
38. Er erstellt eine Instanz von Smss.exe, um Sitzung 1 (die interaktive Sitzung) zu initialisieren. Bei entsprechender Konfiguration in der Registrierung erstellt er weitere Smss.exe-Instanzen für zusätzliche interaktive Sitzungen, um sich auf künftige Benutzeranmeldungen
vorzubereiten. Wenn Smss.exe diese Instanzen erstellt, fordert er jedes Mal mit dem Flag
PROCESS_CREATE_NEW_SESSION in NtCreateUserProcess ausdrücklich eine neue Prozess-ID
an. Dadurch wird die interne Speicher-Manager-Funktion MiSessionCreate aufgerufen.
Sie erstellt die erforderlichen Kernelmodus-Sitzungsdatenstrukturen (wie das Sitzungsobjekt) und richtet den virtuellen Sitzungsadressraum ein, der vom Kernelmodusteil des
Windows-Teilsystems (Win32k.sys) und anderen Sitzungsraum-Gerätetreibern genutzt
wird (siehe Kapitel 5).
Nach Abschluss dieser Schritte wartet Smss.exe unaufhörlich am Handle für die Instanz der Sitzung 0 auf Csrss.exe. Da Csrss.exe als kritischer Prozess gekennzeichnet ist (also als geschützter
Prozess; siehe Kapitel 3), wird dieser Wartevorgang bei einer Beendigung von Csrss.exe niemals
abgeschlossen, da das System dann abstürzt.
Eine Instanz von Smss.exe für den Start einer Sitzung macht Folgendes:
QQ Sie erstellt die Teilsystemprozesse für die Sitzung (standardmäßig den Windows-Teilsystemprozess Csrss.exe).
QQ Sie erstellt eine Instanz von Winlogon (interaktive Sitzungen) oder des Anfangsbefehls für
Sitzung 0. Bei Letzterem handelt es sich standardmäßig um Wininit, sofern in den zuvor
untersuchten Registrierungswerten nichts anderes angegeben ist. Weitere Informationen
über diese beiden Prozesse finden Sie in den folgenden Abschnitten.
Schließlich wird dieser Smss.exe-Zwischenprozess beendet und lässt die Teilsystem-Prozesse
und Winlogon oder Wininit ohne Elternprozess zurück.
Der Windows-Initialisierungsprozess
Der Prozess Wininit.exe führt die folgenden Systeminitialisierungsfunktionen aus:
1.
Er kennzeichnet sich selbst und den Hauptthread als kritisch. Wenn er vorzeitig beendet
und das System im Debugmodus gestartet wird, steigt er dadurch in den Debugger ein.
(Anderenfalls stürzt das System ab.)
2.
Er sorgt dafür, dass der Prozess bestimmte Fehler als kritisch behandelt, z. B. Verwendung
ungültiger Handles und Beschädigungen des Heaps.
3.
Er initialisiert die Unterstützung für die Statustrennung, falls die SKU dies ermöglicht.
Hauptsystemkomponenten
Kapitel 2
105
4.
Er erstellt das Ereignis Global\FirstLogonCheck (es kann in Process Explorer und WinObj im
Verzeichnis \BaseNamedObjects beobachtet werden), das die Windows-Anmeldeprozesse
nutzen können, um herauszufinden, welche Anmeldung als Erstes gestartet werden soll.
5.
Er erstellt ein WinLogonLogoff-Ereignis im Objekt-Manager-Verzeichnis BaseNamedObjects,
das von Winlogon-Instanzen verwendet werden kann. Dieses Ereignis wird gesendet, wenn
eine Abmeldeoperation beginnt.
6.
Er erhöht seine eigene Basispriorität auf 13 und die des Hauptthreads auf 15.
7.
Sofern im Registrierungswert NoDebugThread unter HKLM\Software\Microsoft\Windows NT\
CurrentVersion\Winlogon nichts anderes eingerichtet, erstellt er eine Timerwarteschlange,
die nach der Festlegung im Kerneldebugger in jeden Benutzermodusprozess einsteigt. Dadurch können Remotekerneldebugger dafür sorgen, dass sich Winlogon an andere Benutzermodusanwendungen anhängt und darin einsteigt.
8.
Er richtet den Computernamen in der Umgebungsvariablen COMPUTERNAME ein und aktualisiert und konfiguriert TCP/IP-Informationen wie den Domänen- und den Hostnamen.
9.
Er richtet die Umgebungsvariablen USERPROFILE, ALLUSERPROFILES, PUBLIC und ProgramData
für das Standardprofil ein.
10. Er erstellt das temporäre Verzeichnis, indem er %SystemRoot%\Temp erweitert (zum Beispiel C:\Windows\Temp).
11. Er richtet das Laden von Schriftarten und DWM ein, wenn Sitzung 0 interaktiv ist, was von
der SKU abhängt.
12. Er erstellt das ursprüngliche Terminal, das aus einer Windows-Station (stets mit dem Namen Winsta0) und zwei Desktops (Winlogon und Default) für Prozesse in Sitzung 0 besteht.
13. Er initialisiert den LSA-Maschinenverschlüsselungsschlüssel in Abhängigkeit davon, ob er
lokal gespeichert ist oder interaktiv eingegeben werden muss. Weitere Informationen über
die Speicherung lokaler Authentifizierungsschlüssel erhalten Sie in Kapitel 7.
14. Er erstellt den Dienststeuerungs-Manager (Services.exe). Mehr darüber erfahren Sie im folgenden Abschnitt und in Kapitel 9 von Band 2.
15. Er startet den Teilsystemdienst für die lokale Sicherheitsauthentifizierung (Lsass.exe) und,
falls CredentialGuard aktiviert ist, auch das isolierte LSA-Trustlet (Lsaiso.exe). Dazu ist es
erforderlich, den VBS-Bereitstellungsschlüssel von UEFI abzufragen. Mehr über Lsass.exe
und Lsaiso.exe erfahren Sie in Kapitel 7.
16. Wenn Setup aussteht (wenn es sich also um den ersten Start bei einer Neuinstallation oder
bei der Aktualisierung auf einen neuen Hauptbuild oder ein Insider-Preview des Betriebssystems handelt), startet er das Setupprogramm.
17. Er wartet unaufhörlich auf eine Anforderung, das System herunterzufahren oder eine
der zuvor erwähnten Systemprozesse zu beenden (sofern der Registrierungswert Dont
WatchSysProcs in dem in Schritt 7 erwähnten Winlogon-Schlüssel nicht gesetzt ist). In jedem
Fall fährt er das System herunter.
106
Kapitel 2
Systemarchitektur
Der Dienststeuerungs-Manager
Bei einem Dienst kann es sich in Windows um einen Serverprozess oder einen Gerätetreiber
handeln. In diesem Abschnitt beschäftigen wir uns mit Diensten, bei denen es sich um Benutzermodusprozesse handelt. Ebenso wie Daemon-Prozesse von Linux können Dienste so eingerichtet werden, dass sie beim Hochfahren des Systems automatisch gestartet werden, ohne
dass eine interaktive Anmeldung erforderlich wäre. Sie können auch manuell gestartet werden,
etwa in der Verwaltungskonsole Dienste, mit dem Programm Sc.exe und durch Aufrufen der
Windows-Funktion StartService. Gewöhnlich interagieren Dienste nicht mit dem angemeldeten Benutzer, wobei dies jedoch unter besonderen Umständen ebenfalls möglich ist. Die
meisten Dienste laufen unter besonderen Dienstkonten (z. B. SYSTEM und LOCAL SERVICE), doch
einige können auch im selben Sicherheitskontext wie das Konto des angemeldeten Benutzers
ausgeführt werden (siehe Kapitel 9 in Band 2).
Der Dienststeuerungs-Manager (Service Control Manager, SCM) ist ein besonderer Systemprozess, der das Abbild %SystemRoot%\System32\Services.exe ausführt. Dieses ist dafür
verantwortlich, Dienstprozesse zu starten, zu beenden und mit ihnen zu interagieren. Er ist geschützt, weshalb es nicht leicht ist, ihn zu manipulieren. Programme für Dienste sind im Grunde
genommen lediglich Windows-Abbilder, die bestimmte Windows-Funktionen aufrufen, um mit
dem SCM zu interagieren und beispielsweise den erfolgreichen Start des Dienstes zu regis
trieren, auf Statusanforderungen zu reagieren oder den Dienst anzuhalten oder zu beenden.
Dienste werden in der Registrierung unter HKLM\SYSTEM\CurrentControlSet\Services definiert.
Denken Sie daran, dass Dienste drei Namen haben: den Prozessnamen, den Sie im System
sehen, den internen Namen in der Registrierung und den Anzeigenamen in der Verwaltungskonsole Dienste. (Allerdings haben nicht alle Dienste einen Anzeigenamen. Wenn das der Fall
ist, wird in der Konsole der interne Name angegeben.) Dienste können auch ein Beschreibungsfeld mit weiteren Einzelheiten darüber enthalten, was sie jeweils tun.
Um einen Dienstprozess den darin enthaltenen Diensten zuzuordnen, verwenden Sie den
Befehl tlist /s (aus den Debugging-Tools für Windows) oder takslist /svc (in Windows
enthalten). Beachten Sie jedoch, dass es nicht immer eine 1:1-Zuordnung zwischen Dienstprozessen und laufenden Diensten gibt, da sich manche Dienste einen Prozess teilen. In der
Registrierung gibt der Wert Type im Schlüssel des Dienstes an, ob der Dienst in seinem eigenem
Prozess läuft oder ihn sich mit anderen Diensten in seinem Abbild teilt.
Eine Reihe von Windows-Komponenten sind als Dienste implementiert, z. B. der Druckspooler, das Ereignisprotokoll, der Taskplaner und einige Netzwerkkomponenten. Mehr über
Dienste erfahren Sie in Kapitel 9 von Band 2.
Hauptsystemkomponenten
Kapitel 2
107
Experiment: Die installierten Dienste auflisten
Um die installierten Dienste aufzulisten, öffnen Sie die Systemsteuerung, wählen Verwaltung und dann Dienste. Alternativ können Sie auch auf Start klicken und services.msc
ausführen. Anschließend sehen Sie eine Ausgabe wie die folgende:
Um ausführliche Informationen über einen Dienst einzusehen, rechtsklicken Sie darauf und
wählen Eigenschaften. Das folgende Beispiel zeigt die Eigenschaften des Dienstes Windows
Update:
Das Feld Pfad für ausführbare Datei gibt das Programm an, das diesen Dienst und seine
Befehlszeile enthält. Denken Sie daran, dass einige Dienste ihren Prozess mit anderen teilen.
Die Zuordnung ist nicht immer 1:1.
108
Kapitel 2
Systemarchitektur
Experiment: Einzelheiten von Diensten in Dienstprozessen
einsehen
Process Explorer hinterlegt die Prozesse, die einen oder mehr Dienste beherbergen, in Rosa
(wobei Sie die Kennzeichnung ändern können, indem Sie das Menü Options öffnen und
dort Configure Color wählen). Wenn Sie auf einen Diensthostprozess doppelklicken, wird
die Registerkarte Services angezeigt, die alle Dienste in dem Prozess, den Namen des Registrierungsschlüssels, in dem der Dienst definiert ist, den Anzeigenamen, den der Administrator sieht, und die Beschreibung des Dienstes (falls vorhanden) angibt. Bei Svchost.
exe-Diensten wird auch der Pfad zu der DLL angezeigt, die den Dienst implementiert. Das
folgende Beispiel zeigt die Dienste in einem der Svchost.exe-Prozesse, die unter dem Systemkonto laufen:
Winlogon, LogonUI und Userinit
Der Windows-Anmeldeprozess (%SystemRoot%\System32\Winlogon.exe) kümmert sich um die
interaktiven An- und Abmeldungen der Benutzer. Wenn ein Benutzer die sichere Aufmerksamkeits-Tastenfolge (Secure Attention Sequence, SAS) eingibt, wird Winlogon.exe von einer
Benutzeranmeldeanforderung unterrichtet. (Strg) + (Alt) + (Entf) ist die Standard-SAS auf
Windows. Der Grund für die Verwendung einer SAS besteht darin, Benutzer vor Programmen
zu schützen, die den Anmeldeprozess simulieren, um Passwörter abzugreifen: Benutzermodusanwendungen können diese Tastenfolge nicht abfangen.
Die Identifizierungs- und Authentifizierungsaspekte des Anmeldeprozesses werden durch
DLLs realisiert, die als Anmeldeinformationsanbieter bezeichnet werden. Die Standard-Anmeldeinformationsanbieter von Windows implementieren die Standard-Authentifizierungsmöglichkeiten von Windows: Passwörter und Smartcards. Windows 10 enthält auch einen
biometrischen Anmeldeinformationsanbieter zur Gesichtserkennung, Windows Hello genannt.
Hauptsystemkomponenten
Kapitel 2
109
Entwickler können jedoch ihre eigenen Anmeldeinformationsanbieter bereitstellen, um andere
Identifizierungs- und Authentifizierungsmechanismen als die übliche Abfrage von Name und
Kennwort umzusetzen, z. B. über Stimmerkennung oder Fingerabdrücke. Da Winlogon.exe ein
kritischer Prozess ist, den das System unbedingt braucht, läuft das Anmeldedialogfeld, das
die Anmeldeinformationsanbieter und die grafische Benutzeroberfläche anzeigt, nur in einem
Kindprozess von Winlogon.exe, nämlich LogonUI.exe. Wenn Winlogon.exe die SAS erkennt, startet er diesen Prozess, der wiederum die Anmeldeinformationsanbieter initialisiert. Gibt der Benutzer dann seine Anmeldeinformationen (wie von dem jeweiligen Anbieter verlangt) ein oder
schließt er die Anmeldeoberfläche, wird der Prozess LogonUI.exe beendet. Winlogon.exe kann
auch zusätzliche DLLs für Netzwerkanbieter laden, die eine zweite Authentifizierung erfordern.
Dadurch können während der normalen Anmeldung mehrere Netzwerkanbieter gleichzeitig
Identifizierungs- und Authentifizierungsinformationen erfassen.
Nachdem der Name und das Kennwort (oder andere vom Anmeldeinformationsanbieter
geforderten Angaben) erfasst wurden, werden sie zur Authentifizierung an den Prozess Lsass.
exe (Local Security Authentication Service; siehe Kapitel 7) gesendet. Lsass.exe ruft die DLL für
das entsprechende Authentifizierungspaket auf, um die eigentliche Überprüfung durchzuführen, also um beispielsweise zu prüfen, ob das angegebene Kennwort mit dem übereinstimmt,
das in Active Directory oder SAM (dem Teil der Registrierung, der die Definitionen der lokalen
Benutzer und Gruppen enthält) gespeichert ist. Bei einer Domänenanmeldung und aktiviertem CredentialGuard kommuniziert Lsass.exe mit dem isolierten LSA-Trustlet (Lsaiso.exe, siehe
Kapitel 7), um den Maschinenschlüssel abzurufen, der erforderlich ist, um die Gültigkeit der
Authentifizierungsanforderung zu überprüfen.
Bei erfolgreicher Authentifizierung ruft Lsass.exe eine Funktion im SRM auf (z. B. NtCreateToken), um ein Zugriffstokenobjekt mit dem Sicherheitsprofil des Benutzers zu erstellen. Wenn
die Benutzerkontensteuerung verwendet wird und der Benutzer ein Mitglied der Administratorengruppe ist oder Administratorrechte hat, legt Lsass.exe noch eine zweite, eingeschränkte
Version dieses Tokens an. Dieses Token wird anschließend von Winlogon verwendet, um die
Anfangsprozesse in der Benutzersitzung zu erstellen. Sie werden im Registrierungswert Userinit unter dem Schlüssel HKLM\SOFTWARE\Microsoft\WindowsNT\CurrentVersion\Winlogon gespeichert. Standardmäßig wird dabei der Prozess Userinit.exe erstellt, aber die Liste kann mehr als
ein Abbild enthalten.
Userinit.exe führt einige Initialisierungsarbeiten an der Benutzerumgebung aus, indem er
beispielsweise das Anmeldeskript ausführt und die Netzwerkverbindungen wiederherstellt.
Anschließend untersucht er den Registrierungswert Shell (unter dem zuvor erwähnten Winlogon-Schlüssel) und erstellt einen Prozess, um die vom System definierte Shell auszuführen
(standardmäßig Explorer.exe). Danach wird Userinit.exe beendet. Aus diesem Grund wird Explorer ohne Elternprozess angezeigt: Sein Elternprozess wurde beendet. Wie in Kapitel 1 erwähnt,
werden Prozesse, deren Elternprozesse nicht mehr laufen, in tlist.exe und Process Explorer linksbündig angezeigt. Explorer ist sozusagen ein Enkelprozess von Winlogon.exe.
Winlogon.exe ist nicht nur bei der An- und Abmeldung von Benutzern aktiv, sondern auch
immer dann, wenn er die SAS an der Tastatur erfasst. Wenn Sie etwa (Strg) + (Alt) + (Entf)
drücken, während Sie angemeldet sind, erscheint der Sicherheitsbildschirm von Windows mit
den Optionen zur Abmeldung, zum Starten des Task-Managers, zum Sperren der Arbeitsstation,
110
Kapitel 2
Systemarchitektur
zum Herunterfahren des Systems usw. Winlogon.exe und LogonUI.exe sind die Prozesse, die sich
um diese Vorgänge kümmern.
Eine ausführliche Beschreibung der Schritte, die bei der Anmeldung ablaufen, erhalten
Sie in Kapitel 11 von Band 2. Die Authentifizierung wird ausführlicher in Kapitel 7 erklärt. Einzelheiten über die aufrufbaren, mit Lsass.exe gekoppelten Funktionen (deren Namen mit Lsa
beginnen) finden Sie in der Dokumentation des Windows SDK.
Zusammenfassung
Dieses Kapitel hat einen groben Überblick über die Systemarchitektur von Windows gegeben.
Sie haben die Schlüsselkomponenten von Windows und deren Beziehungen untereinander
kennengelernt. Im nächsten Kapitel werfen wir einen genaueren Blick auf Prozesse. Sie gehören
zu den grundlegendsten Dingen in Windows.
Zusammenfassung
Kapitel 2
111
K apite l 3
Prozesse und Jobs
In diesem Kapitel erklären wir die Datenstrukturen und Algorithmen für die Prozesse und Jobs
in Windows. Als Erstes sehen wir uns dabei an, wie Prozesse erstellt werden. Anschließend untersuchen wir die internen Strukturen, die einen Prozess ausmachen. Danach werfen wir einen
Blick auf geschützte Prozesse und ihre Unterschiede zu nicht geschützten. Wir schauen uns
auch die erforderlichen Schritte an, um einen Prozess (und seinen Anfangsthread) zu erstellen.
Zum Abschluss des Kapitels befassen wir uns mit Jobs.
Da Prozesse so viele Windows-Komponenten berühren, werden in diesem Kapitel eine
Reihe von Begriffen und Datenstrukturen erwähnt (wie Arbeitssätze, Threads, Objekte, Handles, Heaps usw.), die an anderen Stellen dieses Buches ausführlich erläutert werden. Um dieses
Kapitel richtig verstehen zu können, müssen Sie mit den in Kapitel 1 und 2 vorgestellten Begriffen und Grundprinzipien vertraut sein, also z. B. die Unterschiede zwischen einem Prozess
und einem Thread und zwischen Benutzer- und Kernelmodus sowie den Aufbau des virtuellen
Adressraums von Windows kennen.
Prozesse erstellen
Die Windows-API enthält mehrere Funktionen, um Prozesse zu erstellen. Die einfachste ist CreateProcess, die versucht, einen Prozess anzulegen, der dasselbe Zugriffstoken wie der Erstellerprozess hat. Wird ein anderes Token benötigt, bietet sich CreateProcessAsUser an, der als
(erstes) zusätzliches Argument ein Handle für ein auf irgendeine Weise (z. B. durch Aufruf der
Funktion LogonUser) erworbenes Tokenobjekt entgegennimmt.
Weitere Funktionen zum Erstellen von Prozessen sind CreateProcessWithTokenW und CreateProcessWithLogonW (die beide zu Advapi32.dll gehören). CreateProcessWithTokenW ähnelt
CreateProcessAsUser, allerdings muss der Aufrufer über andere Rechte verfügen (siehe die Dokumentation des Windows SDK). CreateProcessWithLogonW ist eine praktische Möglichkeit, um
sich mit den Anmeldeinformationen eines gegebenen Benutzers anzumelden und gleichzeitig
einen Prozess mit dem abgerufenen Token zu erstellen. Um den Prozess tatsächlich zu erstellen,
rufen beide Funktionen den Dienst Secondary Logon (seclogon.dll in einem SvcHost.exe-Prozess)
über einen Remoteprozeduraufruf auf. SecLogon führt diesen Aufruf in seiner internen Funktion
SlrCreateProcessWithLogon aus und ruft, wenn alles gut geht, schließlich CreateProcessAsUser
auf. Der Dienst SecLogon ist standardmäßig für den manuellen Start eingerichtet, weshalb er
erst beim ersten Aufruf von CreateProcessWithTokenW oder CreateProcessWithLogonW gestartet
wird. Schlägt der Dienststart fehl (etwa weil ein Administrator den Dienst deaktiviert hat), so
schlagen auch diese Funktionen fehl. Das Befehlszeilenprogramm runas, das Sie wahrscheinlich
kennen, nutzt diese Funktionen.
Abb. 3–1 stellt die beschriebenen Aufrufe grafisch dar.
113
Prozess erstellen
SvcHost.Exe
Benutzermodus
Kernelmodus
Exekutive
Abbildung 3–1 Funktionen zum Erstellen eines Prozesses. Interne Funktionen sind durch gestrichelte
Kästen gekennzeichnet.
Alle zuvor erwähnten, dokumentierten Funktionen erwarten eine ordnungsgemäße PE-Datei (Portable Executive; wobei die Endung .exe jedoch nicht unbedingt erforderlich ist), eine
Batchdatei oder eine 16-Bit-COM-Anwendung. Darüber hinaus jedoch wissen sie nicht, welche
Zusammenhänge zwischen einzelnen Endungen (wie .txt) und ausführbaren Dateien (wie dem
Windows-Editor) bestehen. Solche Kenntnisse werden durch die Windows-Shell in Funktionen
wie ShellExecute und ShellExecuteEx bereitgestellt. Sie können beliebige Dateien entgegennehmen (nicht nur ausführbare) und versuchen dann, auf der Grundlage der Dateiendung
und der Registrierungseinstellungen in HKEY_CLASSES_ROOT die zugehörige ausführbare Datei zu
finden (siehe Kapitel 9 in Band 2). Schließlich ruft ShellExecute(Ex) die Funktion CreateProcess
mit einer geeigneten ausführbaren Datei auf und hängt die entsprechenden Argumente an die
Befehlszeile an, um das zu erreichen, was der Benutzer tun will (z. B. hängt sie den Dateinamen
Notepad.exe an, wenn der Benutzer eine .txt-Datei bearbeiten möchte).
Letzten Endes führen all diese Ausführungspfade zu der gemeinsamen internen Funktion
CreateProcessInternal, die mit der eigentlichen Arbeit beginnt, um einen Windows-Prozess im
Benutzermodus zu erstellen. Wenn alles gut geht, ruft CreateProcessInternal schließlich NtCreateUserProcess in Ntdll.dll auf, um in den Kernelmodus überzugehen und mit den Aspekten
der Prozesserstellung weiterzumachen, die im Kernelmodus ablaufen. Dies geschieht in einer
Funktion der Exekutive mit demselben Namen (NtCreateUserProcess).
Argumente der CreateProcess*-Funktionen
Es lohnt sich, einen Blick auf die Argumente der CreateProcess*-Funktionen zu werfen. Einigen davon werden Sie in dem Abschnitt über den Ablauf von CreateProcess wiederbegegnen.
Ein Prozess, der im Benutzermodus erstellt wird, enthält immer einen Thread, der schließlich
die Hauptfunktion der ausführbaren Datei ausführen wird. Die wichtigsten Argumente für
CreateProcess*-Funktionen lauten:
114
Kapitel 3
Prozesse und Jobs
QQ Bei CreateProcessAsUser und CreateProcessWithTokenW das Tokenhandle, unter dem der
neue Prozess ausgeführt werden soll. Bei CreateProcessWithLogonW sind der Benutzername,
die Domäne und das Kennwort erforderlich.
QQ Der Pfad der ausführbaren Datei und die Befehlszeilenargumente.
QQ Optionale Sicherheitsattribute für den neuen Prozess und das Threadobjekt.
QQ Ein boolesches Flag, das angibt, ob alle als vererbbar gekennzeichneten Handles im aktuellen Prozess (dem Erstellerprozess) vom neuen Prozess geerbt (in ihn kopiert) werden
sollen. (Mehr über Handles und die Handlevererbung erfahren Sie in Kapitel 8 von Band 2.)
QQ Mehrere Flags, die den Vorgang zum Erstellen des Prozesses steuern. Die Dokumentation
des Windows SDK enthält die vollständige Liste. Hier geben wir nur einige Beispiele:
•
CREATE_SUSPENDED Erstellt den Anfangsthread des neuen Prozesses im angehaltenen
Zustand. Der Thread wird ausgeführt, wenn Sie später ResumeThread aufrufen.
•
DEBUG_PROCESS Der Erstellerprozess deklariert sich selbst als Debugger und erstellt
den neuen Prozess unter seiner Kontrolle.
•
EXTENDED_STARTUPINFO_PRESENT
Anstelle von STARTUPINFO wird die erweiterte Struktur
STARTUPINFOEX bereitgestellt (siehe weiter unten).
QQ Optional ein Umgebungsblock für den neuen Prozess, der die Umgebungsvariablen angibt. Wird er nicht angegeben, so wird er vom Erstellerprozess geerbt.
QQ Optional das aktuelle Verzeichnis für den neuen Prozess. Wird es nicht angegeben, so wird
es vom Erstellerprozess geerbt. Der neue Prozess kann später SetCurrentDirectory aufrufen, um ein anderes Verzeichnis festzulegen. Das aktuelle Verzeichnis eines Prozesses wird
in verschiedenen Suchvorgängen ohne Angabe eines vollständigen Pfades genutzt (z. B.
beim Laden einer DLL nur mit dem Dateinamen).
QQ Eine STARTUPINFO- oder STARTUPINFOEX-Struktur, die noch mehr Konfigurationseinstellungen für den Erstellungsvorgang eines Prozesses bietet. STARTUPINFOEX enthält ein zusätzliches, undurchsichtiges Feld für einen Satz von Prozess- und Threadattributen, bei denen es
sich im Grunde genommen um ein Array aus Schlüssel-Wert-Paaren handelt. Die Attribute
werden durch den Aufruf von UpdateProcThreadAttributes für jedes benötigte Attribut
festgelegt. Einige von ihnen sind nicht dokumentiert und werden intern verwendet, z. B.
beim Erstellen von Store-Apps (siehe den nächsten Abschnitt).
QQ Eine PROCESS_INFORMATION-Struktur für die Ausgabe beim erfolgreichen Erstellen des Prozesses. Sie enthält die IDs des neuen Prozesses und des neuen Threads sowie die Handles
dafür. Diese Handles kann der Erstellerprozess nutzen, wenn er den neuen Prozess oder
Thread anschließend auf irgendeine Weise bearbeiten möchte.
Moderne Windows-Prozesse erstellen
In Kapitel 1 wurde die neue Art von Anwendungen beschrieben, die ab Windows 8 und
Windows Server 2012 zur Verfügung stehen. Die Namen solcher Anwendungen wurden im
Laufe der Zeit geändert. Wir nennen sie hier moderne Anwendungen, UWP-Anwendungen
oder immersive Prozesse, um sie von den klassischen Desktopanwendungen zu unterscheiden.
Prozesse erstellen
Kapitel 3
115
Um einen Prozess für eine moderne Anwendung zu erstellen, ist mehr erforderlich, als
einfach CreateProcess mit dem Pfad der ausführbaren Datei aufzurufen. Es sind auch einige
Befehlszeilenargumente und (mithilfe von UpdateProcThreadAttribute) ein nicht dokumentiertes Prozessattribut mit dem Schlüssel PROC_THREAD_ATTRIBUTE_PACKAGE_FULL_NAME anzugeben. Dieses Attribut ist nicht dokumentiert, aber die API bietet noch andere Möglichkeiten,
um eine Store-App auszuführen. Beispielsweise enthält die Windows-API die COM-Schnittstelle IApplicationActivationManager, die von einer COM-Klasse mit der Klassen-ID CLSID_
ApplicationActivationManager implementiert wird. Eine der Methoden in dieser Schnittstelle
ist ActivateApplication, und damit können Sie eine Store-App starten, nachdem Sie mit einem
Aufruf von GetPackageApplicationsIDs die sogenannte AppUserModelId aus dem vollständigen
Paketnamen der App abgerufen haben. (Mehr über diese APIs erfahren Sie im Windows SDK.)
Mehr über Paketnamen und darüber, wie eine Store-App erstellt wird, wenn ein Benutzer
auf die Kachel einer modernen App tippt (wobei letzten Endes ebenfalls CreateProcess aufgerufen wird), erfahren Sie in Kapitel 9 von Band 2.
Andere Arten von Prozessen erstellen
Windows-Anwendungen starten entweder klassische oder moderne Anwendungen, doch die
Exekutive bietet auch Unterstützung für andere Arten von Prozessen, die durch Umgehen der
Windows-API gestartet werden müssen. Dazu gehören native, minimale und Pico-Prozesse.
Beispielsweise ist der in Kapitel 2 vorgestellte Sitzungs-Manager (Smss) ein natives Abbild. Da er
direkt vom Kernel erstellt wird, nutzt er offensichtlich nicht die API CreateProcess, sondern ruft
direkt NtCreateUserProcess auf. Wenn Smss die Prozesse Autochk (das Programm zur Überprüfung der Festplatte) oder Csrss (den Windows-Teilsystemprozess) erstellt, steht die WindowsAPI gar nicht zur Verfügung, weshalb ebenfalls NtCreateUserProcess verwendet werden muss.
Des Weiteren können Windows-Anwendungen keine nativen Prozesse erstellen, da die Funk
tion CreateProcessInternal Abbilder mit dem Typ des nativen Teilsystems ablehnt. Um all diese
Schwierigkeiten abzumildern, enthält die native Bibliothek Ntdll.dll die exportierte Hilfsfunk
tion RtlCreateUserProcess, die einen einfachen Wrapper um NtCreateUserProcess darstellt.
Wie der Name schon sagt, dient NtCreateUserProcess dazu, Benutzermodusprozesse zu
erstellen. Wie Sie in Kapitel 2 gesehen haben, enthält Windows jedoch auch eine Reihe von
Kernelmodusprozessen wie den System- und den Speicherkomprimierungsprozess (bei denen
es sich um minimale Prozesse handelt). Es können auch Pico-Prozesse vorhanden sein, die
von einem Anbieter wie dem Windows-Teilsystem für Linux verwaltet werden. Erstellt werden
solche Prozesse durch einen Systemaufruf von NtCreateProcessEx, wobei einige Möglichkeiten
(etwa das Erstellen von minimalen Prozessen) ausschließlich für Aufrufer aus dem Kernelmodus
reserviert sind.
Pico-Anbieter rufen die Hilfsfunktion PspCreatePicoProcess auf, die sich sowohl darum
kümmert, den minimalen Prozess zu erstellen, als auch dessen Pico-Anbieterkontext zu initialisieren. Diese Funktion wird nicht exportiert und ist nur über eine besondere Schnittstelle
ausschließlich für Pico-Anbieter verfügbar.
Wie Sie in dem Abschnitt über den Ablauf weiter hinten in diesem Kapitel noch sehen werden, handelt es sich bei NtCreateProcessEx und NtCreateUserProcess um verschiedene System
aufrufe, die aber auf dieselben internen Routinen zurückgreifen, um ihre Arbeit zu erledigen,
116
Kapitel 3
Prozesse und Jobs
nämlich PspAllocateProcess und PspInsertProcess. Alle Möglichkeiten, um einen Prozess zu
erstellen, die Sie bisher betrachtet haben, und auch alle weiteren Möglichkeiten, die Sie sich
vorstellen können – von einem WMI-PowerShell-Cmdlet bis zu einem Kerneltreiber – landen
schließlich dort.
Interne Mechanismen von Prozessen
Dieser Abschnitt beschreibt die wichtigsten Datenstrukturen von Windows-Prozessen, die von
verschiedenen Teilen des Systems unterhalten werden, und die Möglichkeiten und Werkzeuge
zu ihrer Untersuchung.
Jeder Windows-Prozess wird durch eine Exekutivprozessstruktur (EPROCESS) dargestellt.
Neben vielen Prozessattributen enthält eine EPROCESS-Struktur auch weitere zugehörige Daten
strukturen bzw. verweist darauf. Beispielsweise hat jeder Prozess einen oder mehrere Threads,
die jeweils durch eine Exekutivthreadstruktur (ETHREAD) dargestellt werden. (Threaddatenstrukturen werden in Kapitel 4 erklärt.)
Die EPROCESS-Struktur und die meisten ihrer zugehörigen Datenstrukturen befinden sich im
Systemadressraum. Eine Ausnahme bildet der Prozessumgebungsblock (Process Environment
Block, PEB), der sich im Prozess- (Benutzer-) Adressraum befindet (da er Informationen enthält,
auf die Benutzermoduscode zugreifen muss). Außerdem sind einige der Prozessdatenstrukturen für die Speicherverwaltung, z. B. die Liste der Arbeitssätze, nur im Kontext des aktuellen
Prozesses gültig, da sie im prozessspezifischen Systemadressraum gespeichert sind. (Mehr über
den Prozessadressraum erfahren Sie in Kapitel 5.)
Für jeden Prozess, der ein Windows-Programm ausführt, unterhält der Prozess des
Windows-Teilsystems (Csrss) eine parallele Struktur namens CSR_PROCESS und der Kernelmodusteil des Windows-Teilsystems (Win32k.sys) die Datenstruktur W32PROCESS, die erstellt wird,
wenn ein Thread zum ersten Mal die im Kernelmodus implementierte Windows-Funktion USER
oder GDI aufruft. Das geschieht, sobald die Bibliothek User32.dll geladen ist. Typische Funktionen, die das Laden dieser Bibliothek veranlassen, sind CreateWindow(Ex) und GetMessage.
Da der Kernelmodusteil des Windows-Teilsystems starken Gebrauch von Grafiken mit DirectX-Hardwarebeschleunigung macht, veranlasst die GDI-Infrastruktur (Graphics Device Interface) den DirectX-Grafikkernel (Dxgkrnl.sys), eine eigene Struktur zu initialisieren, nämlich
DXGPROCESS. Sie enthält Informationen für DirectX-Objekte (Oberflächen, Schattierer usw.) und
die GPGPU-Zähler und Richtlinieneinstellungen für die Zeitplanung sowohl für Rechenvorgänge als auch für die Speicherverwaltung.
Außerdem wird beim Leerlaufprozess jede EPROCESS-Struktur vom Objekt-Manager der
Exekutive als ein Prozessobjekt gekapselt (siehe Kapitel 8 von Band 2). Da Prozesse keine benannten Objekte sind, werden sie im Sysinternals-Programm WinObj nicht angezeigt. Sie können sich in WinObj jedoch das Type-Objekt Process im Verzeichnis \ObjectTypes ansehen. Ein
Handle für einen Prozess ermöglicht durch die Nutzung der APIs für diesen Prozess den Zugriff
auf Daten in der EPROCESS-Struktur und einiger ihrer zugehörigen Strukturen.
Durch die Registrierung von Prozesserstellungsbenachrichtigungen können viele andere
Treiber und Systemkomponenten ihre eigenen Datenstrukturen erstellen, um die Informa
tionen, die sie prozessweise speichern, zu verfolgen. (Das ist durch die Exekutivfunktionen
Interne Mechanismen von Prozessen
Kapitel 3
117
P sSetCreateProcessNotifyRoutine(Ex, Ex2) möglich, die im WDK dokumentiert sind.) Um den
Prozessoverhead zu bestimmen, muss die Größe dieser Datenstrukturen oft berücksichtigt werden, wobei es jedoch praktisch unmöglich ist, genaue Zahlen zu ermitteln. Außerdem erlauben
einige dieser Funktionen solchen Komponenten, das Erstellen von Prozessen zu verbieten oder
zu blockieren. Dadurch erhalten Antimalware-Anbieter in der Architektur eine Möglichkeit, Sicherheitsverbesserungen am Betriebssystem vorzunehmen, z. B. durch hashgestützte Blacklists
oder andere Techniken.
Sehen wir uns als Erstes das Prozessobjekt an. Abb. 3–2 zeigt die wichtigsten Felder in einer
EProcess-Struktur.
Prozesssteuerungsblock (PCB)
Schutzsperren
ID des Prozesses und des Elternprozesses
PsActiveProcessHead
Link zum aktiven Prozess
Prozessflags
Erstellungs- und Beendigungszeit des Prozesses
Kontingentinformationen
Sitzungsobjekt
Sitzungsprozesslink
Sicherheits-/Ausnahme-/Debug-Ports
Primäres Zugriffstoken
Job, zu dem der Prozess gehört
Handletabelle
Prozessumgebungsblock (PEB)
Abbilddateiname
Abbildbasisadresse
Prozesszähler (Speicher, E/A ...)
Threadlistenkopf
Laufende Nummer
Win32k-Prozessstruktur
Wow64-Prozessstruktur (nur 64 Bit)
Trustlet-Identität (Win 10 x64)
Stromverbrauchswerte (Win 10)
Pico-Kontext (Win 10)
Schutzebene und Signatur
DirectX-Prozess
Arbeitssatz
Abschnittsobjekt
Abbildung 3–2 Wichtige Felder in der EPROCESS-Struktur
Die Datenstrukturen für einen Prozess folgen einem ähnlichen Aufbau wie die APIs und Komponenten des Kernels, die auf isolierte und geschichtete Module mit ihren eigenen Namenskonventionen verteilt sind. Wie Abb. 3–2 zeigt, ist das erste Element der EPROCESS-Struktur der
Prozesssteuerungsblock (Process Control Block, PCB). Dabei handelt es sich um eine Struktur
vom Typ KPROCESS (Kernelprozess). Routinen in der Exekutive speichern Informationen in der
EPROCESS-Struktur, doch der Dispatcher, der Scheduler und der Interrupt- und Zeiterfassungscode, die zum Betriebssystemkernel gehören, verwenden stattdessen die KPROCESS-Struktur.
Dies ermöglicht eine Abstraktionsebene zwischen der höheren Funktionalität der Exekutive
und den zugrunde liegenden Implementierungen einzelner Funktionen und hilft, unerwünschte Abhängigkeiten zwischen den Ebenen zu vermeiden. Abb. 3–3 zeigt die wichtigsten Felder
einer KPROCESS-Struktur.
118
Kapitel 3
Prozesse und Jobs
Dispatcher-Header
Stamm des Seitenverzeichnisses für den Prozess
Seitenverzeichnis
Kernelzeit
Benutzerzeit
Zykluszeit
Kontextwechsel
Threadlistenkopf
KTHREAD
Prozesssperre
Prozessaffinität
Prozessflags
Idealer Knoten
Thread-Seed
Basispriorität
KPROCESS
Prozesslisteneintrag
KPROCESS
Instrumentierungs-Callback
Sichere Prozess-ID
Abbildung 3–3 Wichtige Felder der Kernelprozessstruktur
Experiment: Das Format einer EPROCESS-Struktur anzeigen
Um sich eine Liste der Felder einer EPROCESS und ihrer Offsets im Hexadezimalformat anzusehen, geben Sie im Kerneldebugger dt nt!_eprocess ein. (Mehr über den Kerneldebugger und seine Verwendung für das Kerneldebugging auf dem lokalen System erfahren
Sie in Kapitel 1.) Das folgende Listing zeigt eine Ausgabe auf einem 64-Bit-System mit
Windows 10, die allerdings aus Platzgründen gekürzt wurde:
lkd> dt nt!_eprocess
+0x000 Pcb
: _KPROCESS
+0x2d8 ProcessLock
: _EX_PUSH_LOCK
+0x2e0 RundownProtect
: _EX_RUNDOWN_REF
+0x2e8 UniqueProcessId
: Ptr64 Void
+0x2f0 ActiveProcessLinks : _LIST_ENTRY
...
+0x3a8 Win32Process
: Ptr64 Void
+0x3b0 Job
: Ptr64 _EJOB
...
+0x418 ObjectTable
: Ptr64 _HANDLE_TABLE
+0x420 DebugPort
: Ptr64 Void
+0x428 WoW64Process
: Ptr64 _EWOW64PROCESS
...
+0x758 SharedCommitCharge : Uint8B
+0x760 SharedCommitLock
: _EX_PUSH_LOCK
→
Interne Mechanismen von Prozessen
Kapitel 3
119
+0x768 SharedCommitLinks
: _LIST_ENTRY
+0x778 AllowedCpuSets
: Uint8B
+0x780 DefaultCpuSets
: Uint8B
+0x778 AllowedCpuSetsIndirect : Ptr64 Uint8B
+0x780 DefaultCpuSetsIndirect : Ptr64 Uint8B
Das erste Element dieser Struktur (Pcb) ist eine eingebettete KPROCESS-Struktur. Dort sind
die Scheduling- und Zeiterfassungsdaten gespeichert. Das Format der KPROCESS-Struktur
können Sie sich auf die gleiche Weise anzeigen lassen wie das der EPROCESS-Struktur:
lkd> dt nt!_kprocess
+0x000 Header
: _DISPATCHER_HEADER
+0x018 ProfileListHead
: _LIST_ENTRY
+0x028 DirectoryTableBase
: Uint8B
+0x030 ThreadListHead
: _LIST_ENTRY
+0x040 ProcessLock
: Uint4B
...
+0x26c KernelTime
: Uint4B
+0x270 UserTime
: Uint4B
+0x274 LdtFreeSelectorHint
: Uint2B
+0x276 LdtTableLength
: Uint2B
+0x278 LdtSystemDescriptor
: _KGDTENTRY64
+0x288 LdtBaseAddress
: Ptr64 Void
+0x290 LdtProcessLock
: _FAST_MUTEX
+0x2c8 InstrumentationCallback : Ptr64 Void
+0x2d0 SecurePid
: Uint8B
Mit dem Befehl dt können Sie sich auch den Inhalt eines oder mehrere Felder anzeigen lassen, indem Sie hinter dem Strukturnamen den Feldnamen angeben. Beispielsweise zeigt dt
nt!_eprocess UniqueProcessId das Feld mit der eindeutigen Prozess-ID an. Wenn ein Feld
wiederum für eine Struktur steht – wie das Feld Pcb in der EPROCESS-Struktur, das selbst eine
KPROCESS-Unterstruktur enthält –, können Sie hinter dem Feldnamen einen Punkt angeben,
um den Debugger anzuweisen, die Unterstruktur anzuzeigen. Wenn Sie also beispielsweise
die KPROCESS-Struktur ansehen wollen, geben Sie dt nt!_eprocess Pcb. ein. Dahinter können
Sie wiederum die Namen von Feldern (innerhalb der KPROCESS-Struktur) angeben usw. Mit
dem Schalter -r des Befehls dt können Sie sämtliche Unterstrukturen durchlaufen. Wenn
Sie hinter dem Schalter eine Zahl angeben, legen Sie damit die Verschachtelungstiefe vor,
bis zu der sich der Befehl vorarbeitet.
In der zuvor gezeigten Verwendung zeigt der Befehl dt jedoch das Format der ausgewählten Struktur und nicht die Inhalte irgendwelcher Instanzen dieses Strukturtyps an.
Um die Instanz eines Prozesses zu sehen, geben Sie die Adresse einer EPROCESS-Struktur als
Argument von dt an. Die Adressen fast aller EPROCESS-Strukturen im System (außer für den
Leerlaufprozess) können Sie durch den Befehl !process 0 0 abrufen. Da die KPROCESS-Struktur das erste Element der EPROCESS-Struktur ist, können Sie bei dt _kprocess als Adresse der
KPROCESS-Struktur auch die Adresse der EPROCESS-Struktur angeben.
120
Kapitel 3
Prozesse und Jobs
Experiment: Der Befehl !process des Kerneldebuggers
Der Befehl !process des Kerneldebuggers zeigt einen Teil der Informationen in einem Prozessobjekt und dessen zugehörigen Strukturen an. Die Ausgabe für einen Prozess besteht
jeweils aus zwei Teilen. Als Erstes sehen Sie wie im Folgenden Angaben über den Prozess.
Wenn Sie keine Prozessadresse oder -ID angeben, gibt !process Informationen über den
Prozess aus, dem der zurzeit auf CPU 0 ausgeführte Thread gehört. Auf einem Einzelprozessorsystem kann das auch der WinDbg-Prozess selbst sein (bzw. livekd, falls Sie diesen
Debugger statt WinDbg verwenden).
lkd> !process
PROCESS ffffe0011c3243c0
SessionId: 2 Cid: 0e38 Peb: 5f2f1de000 ParentCid: 0f08
DirBase: 38b3e000 ObjectTable: ffffc000a2b22200 HandleCount: <Data Not
Accessible>
Image: windbg.exe
VadRoot ffffe0011badae60 Vads 117 Clone 0 Private 3563. Modified 228.
Locked 1.
DeviceMap ffffc000984e4330
Token
ffffc000a13f39a0
ElapsedTime
00:00:20.772
UserTime
00:00:00.000
KernelTime
00:00:00.015
QuotaPoolUsage[PagedPool]
299512
QuotaPoolUsage[NonPagedPool]
16240
Working Set Sizes (now,min,max) (9719, 50, 345) (38876KB, 200KB, 1380KB)
PeakWorkingSetSize
9947
VirtualSize
2097319 Mb
PeakVirtualSize
2097321 Mb
PageFaultCount
13603
MemoryPriority
FOREGROUND
BasePriority
8
CommitCharge
3994
Job
ffffe0011b853690
Auf diese Ausgabe von grundlegenden Prozessinformationen folgt eine Liste der Threads in
dem Prozess. Diese Ausgabe wird im Experiment »Der Befehl !thread des Kerneldebuggers«
in Kapitel 4 erläutert.
Es gibt noch weitere Befehle, die Prozessinformationen anzeigen. Dazu gehört auch
!handle, der die Prozesshandletabelle ausgibt (siehe Kapitel 8 von Band 2). Sicherheitsstrukturen von Prozessen und Threads sind Thema von Kapitel 7.
→
Interne Mechanismen von Prozessen
Kapitel 3
121
In dieser Ausgabe erhalten Sie auch die Adresse des PEB. Sie können sie im Befehl !peb
einsetzen, der im nächsten Experiment beschrieben wird, um sich den PEB eines beliebigen
Prozesses auf übersichtliche Weise anzeigen zu lassen. Es ist auch möglich, den regulären
Befehl dt mit der _PEB-Struktur zu verwenden. Da sich der PEB im Benutzeradressraum befindet, ist er jedoch nur im Kontext seines eigenen Prozesses gültig. Um sich den PEB eines
anderen Prozesses anzusehen, müssen Sie in WinDbg erst zu diesem Prozess wechseln. Das
können Sie mit dem Befehl .process /P gefolgt von dem EPROCESS-Zeiger tun.
Die Version von WinDbg im aktuellsten Windows 10 SDK zeigt unterhalb der PEB-Adresse
einen Hyperlink an, über den Sie die Befehle .process und !peb automatisch ausführen lassen
können.
Der PEB befindet sich im Benutzeradressraum des Prozesses, den er beschreibt. Er enthält
Informationen, die der Abbildlader, der Heap-Manager und andere Windows-Komponenten
benötigen, um vom Benutzermodus aus auf den Prozess zuzugreifen. Es wäre zu aufwendig,
all diese Informationen über Systemaufrufe verfügbar zu machen. Die EPROCESS- und die KPROCESS-Struktur sind nur vom Kernelmodus aus zugänglich. Die wichtigsten Felder des PEB sehen
Sie in Abb. 3–4 Eine ausführliche Erklärung folgt weiter hinten in diesem Kapitel.
Basisadresse des Abbilds
Laderdatenbank
Lokale Threadspeicherdaten
Prozessflags
Prozesserstellungsparameter
Prozessheap (Zeiger)
Prozessheap
Globale NT-Flags
Gemein genutzte GDI-Handletabelle (Zeiger)
Anzahl Prozessoren
Prozessheapinformationen
Ladersperre
Angabe der Betriebssytemversion
AppCompat-Daten
Shim-Daten
Sitzungs-ID
Lokale Fiberspeicherdaten
Assembly- und Aktivierungskontext
Gemeinsam genutzter CSRSS-Speicher (Zeiger)
Threadpoolinformationen
Abbildung 3–4 Wichtige Felder des Prozessumgebungsblocks
122
Kapitel 3
Prozesse und Jobs
Gemein genutzte
GDI-Handletabelle
Experiment: Den PEB untersuchen
Mit dem Befehl !peb des Kerneldebuggers können Sie die PEB-Struktur des Prozesses ausgeben, dem der zurzeit auf CPU 0 ausgeführte Thread gehört. Sie können auch den im
vorherigen Experiment gewonnenen PEB-Zeiger als Argument für den Befehl angeben.
lkd> .process /P ffffe0011c3243c0 ; !peb 5f2f1de000
PEB at 0000003561545000
InheritedAddressSpace:
No
ReadImageFileExecOptions: No
BeingDebugged:
No
ImageBaseAddress:
00007ff64fa70000
Ldr
00007ffdf52f5200
Ldr.Initialized:
Yes
Ldr.InInitializationOrderModuleList: 000001d3d22b3630 . 000001d3d6cddb60
Ldr.InLoadOrderModuleList:
000001d3d22b3790 . 000001d3d6cddb40
Ldr.InMemoryOrderModuleList:
000001d3d22b37a0 . 000001d3d6cddb50
Base TimeStamp Module
7ff64fa70000 56ccafdd Feb 23 21:15:41 2016 C:\dbg\x64\windbg.exe
7ffdf51b0000 56cbf9dd Feb 23 08:19:09 2016 C:\WINDOWS\SYSTEM32\ntdll.dll
7ffdf2c10000 5632d5aa Oct 30 04:27:54 2015 C:\WINDOWS\system32\KERNEL32.DLL
...
Die CSR_PROCESS-Struktur enthält spezifische Prozessinformationen des Windows-Teilsystems
(Csrss). Daher ist eine solche Struktur nur mit Windows-Anwendungen verbunden. (Beispielsweise hat Smss keine.) Da jede Sitzung ihre eigene Instanz des Windows-Teilsystems aufweist,
werden die CSR_PROCESS-Strukturen jeweils vom Csrss-Prozess der Sitzung gepflegt. Den grundlegenden Aufbau einer SCR_PROCESS-Struktur sehen Sie in Abb. 3–5. Eine ausführliche Erklärung
folgt weiter hinten in diesem Kapitel.
Interne Mechanismen von Prozessen
Kapitel 3
123
Client-ID
Prozesslink
Threadlistenkopf
Clientporthandle
Prozesshandle
Clientsichtdaten
Sitzungsdaten
Prozessflags
Referenzzähler
Nachrichtendaten
Shutdown-Ebene
Eines pro
CSR_SERVER_DLL
Flags
Prozessgruppendaten
Serverdaten
Abbildung 3–5 Felder einer CSR_PROCESS-Struktur
Experiment: Die CSR_PROCESS-Struktur untersuchen
Csrss-Prozesse sind geschützt (mehr darüber weiter hinten in diesem Kapitel), weshalb es
nicht möglich ist, einen Benutzermodusdebugger daran anzuhängen (nicht einmal mit erhöhten Rechten oder auf nicht invasive Weise). Stattdessen verwenden wir den Kerneldebugger.
Als Erstes listen wir die Csrss-Prozesse auf:
lkd> !process 0 0 csrss.exe
PROCESS ffffe00077ddf080
SessionId: 0 Cid: 02c0 Peb: c4e3fc0000 ParentCid: 026c
DirBase: ObjectTable: ffffc0004d15d040 HandleCount: 543.
Image: csrss.exe
PROCESS ffffe00078796080
SessionId: 1 Cid: 0338 Peb: d4b4db4000 ParentCid: 0330
DirBase: ObjectTable: ffffc0004ddff040 HandleCount: 514.
Image: csrss.exe
Als Nächstes ändern wir den Debuggerkontext und lassen ihn auf einen dieser Prozesse
verweisen, sodass die Benutzermodusmodule sichtbar werden:
lkd> .process /r /P ffffe00078796080
Implicit process is now ffffe000'78796080
Loading User Symbols
.............
→
124
Kapitel 3
Prozesse und Jobs
Der Schalter /p ändert den Prozesskontext des Debuggers auf den des angegebenen Prozessobjekts (EPROCESS, was hauptsächlich beim Live-Debugging benötigt wird), und /r fordert, die Benutzermodussymbole zu laden. Anschließend können Sie sich die Module mit
dem Befehl lm ansehen oder die CSR_PROCESS-Struktur betrachten:
lkd> dt csrss!_csr_process
+0x000 ClientId
: _CLIENT_ID
+0x010 ListLink
: _LIST_ENTRY
+0x020 ThreadList
: _LIST_ENTRY
+0x030 NtSession
: Ptr64 _CSR_NT_SESSION
+0x038 ClientPort
: Ptr64 Void
+0x040 ClientViewBase
: Ptr64 Char
+0x048 ClientViewBounds
: Ptr64 Char
+0x050 ProcessHandle
: Ptr64 Void
+0x058 SequenceNumber
: Uint4B
+0x05c Flags
: Uint4B
+0x060 DebugFlags
: Uint4B
+0x064 ReferenceCount
: Int4B
+0x068 ProcessGroupId
: Uint4B
+0x06c ProcessGroupSequence
: Uint4B
+0x070 LastMessageSequence
: Uint4B
+0x074 NumOutstandingMessages
: Uint4B
+0x078 ShutdownLevel
: Uint4B
+0x07c ShutdownFlags
: Uint4B
+0x080 Luid
: _LUID
+0x088 ServerDllPerProcessData : [1] Ptr64 Void
W32PROCESS ist die letzte Systemdatenstruktur im Zusammenhang mit Prozessen, die wir uns
ansehen wollen. Sie enthält alle Informationen, die der Grafik- und Fensterverwaltungscode im
Windows-Kernel (Win32k) benötigt, um die Statusinformationen über die GUI-Prozesse zu unterhalten (die weiter vorn als Prozesse mit mindestens einem USER/GDI-Systemaufruf definiert
worden sind). Den grundlegenden Aufbau einer W32PROCESS-Struktur sehen Sie in Abb. 3–6. Da
Typinformationen für Win32k-Strukturen in öffentlichen Symbolen nicht verfügbar sind, können wir Ihnen leider kein einfaches Experiment zeigen, mit dem Sie sich diese Informationen
selbst ansehen könnten. Allerdings ginge eine Erörterung von Datenstrukturen und Funktionsprinzipien für die Grafik ohnehin über den Rahmen dieses Buches hinaus.
Interne Mechanismen von Prozessen
Kapitel 3
125
Prozess
Referenzzähler
Flags
Prozess-ID
GDI-Handlezähler und -Spitzenwert
USER-Handlezähler und -Spitzenwert
Prozesslink
GDI-Listen
DirectX-Prozessdaten
DXGPROCESS (Singleton)
DirectComposition-Prozessdaten
Abbildung 3–6 Felder der W32PROCESS-Struktur
Geschützte Prozesse
Im Windows-Sicherheitsmodell kann jeder Prozess, der mit einem Token mit Debugrechten
ausgeführt wird (z. B. unter einem Administratorkonto), jegliche Zugriffsrechte für beliebige
andere Prozesse auf demselben Computer anfordern. Beispielsweise kann er willkürlich im Prozessspeicher lesen und schreiben, Code injizieren, Threads anhalten und wieder aufnehmen
und Informationen über andere Prozesse abfragen. Werkzeuge wie Process Explorer und der
Task-Manager benötigen solche Zugriffsrechte, um ihre Aufgabe zu erfüllen.
Dieses Verhalten ist sinnvoll, da es dafür sorgt, dass Administratoren stets die volle Kon
trolle über die Codeausführung in dem System haben, doch es kollidiert mit dem Systemverhalten für digitale Rechteverwaltung, das die Medienbranche für Computerbetriebssysteme
zur Wiedergabe von modernen, hochwertigen digitalen Inhalten wie Blu-Ray-Medien fordert.
Um eine zuverlässige und geschützte Wiedergabe solcher Inhalte zu ermöglichen, wurden in
Windows Vista und Windows Server 2008 geschützte Prozesse eingeführt. Sie existieren neben
den normalen Windows-Prozessen und schränken die Zugriffsrechte, die andere Prozesse auf
dem System anfordern können (selbst diejenigen mit Administratorrechten), erheblich ein.
Jede Anwendung kann geschützte Prozesse erstellen, allerdings lässt das Betriebssystem den Schutz des Prozesses nur dann zu, wenn die Abbilddatei mit einem besonderen
Windows-Medienzertifikat signiert wurde. Der Pfad für geschützte Medien (Protected Media
Path, PMP) in Windows nutzt geschützte Prozesse, um wertvolle Medien zu schützen. Entwickler von Anwendungen wie DVD-Playern können über die Media-Foundation-API (MF) geschützte Prozesse verwenden.
Der Prozess Audio Device Graph (Audiodg.exe) ist geschützt, da über ihn geschützte Musikinhalte decodiert werden können. Damit verwandt ist die Media Foundation Protected Pipeline
(Mfpmp.exe), die aus ähnlichen Gründen ein geschützter Prozess ist. (Er wird nicht standardmäßig ausgeführt.) Der Clientprozess Werfaultsecure.exe der Windows-Fehlerberichterstattung
(Windows Error Reporting, WER; siehe Kapitel 8 in Band 2) kann ebenfalls geschützt ausgeführt
126
Kapitel 3
Prozesse und Jobs
werden, da er für den Fall, dass ein geschützter Prozess ausfällt, Zugriff darauf haben muss.
Auch der Systemprozess selbst ist geschützt, da einige der Entschlüsselungsinformationen vom
Treiber Ksecdd.sys generiert und im Benutzermodusspeicher abgelegt werden. Der Schutz des
Systemprozesses erfolgt auch, um die Integrität aller Kernelhandles zu wahren (da die Handletabelle des Systemprozesses alle Kernelhandles des Systems enthält). Dass andere Treiber unter
Umständen Arbeitsspeicher im Benutzermodus-Adressraum des Systemprozesses zuordnen
können (z. B. das Codeintegritätszertifikat und Katalogdaten), ist ein weiterer Grund, den Prozess zu schützen.
Auf Kernelebene gibt es zwei Formen der Unterstützung für geschützte Prozesse. Erstens
erfolgt der Großteil der Prozesserstellung im Kernelmodul, um Injektionsangriffe zu vermeiden.
(Der Ablauf der Erstellung von normalen und von geschützten Prozessen wird ausführlich im
nächsten Abschnitt beschrieben.) Zweitens ist in der EPROCESS-Struktur von geschützten Prozessen (und ihren nächsten Verwandten, den im nächsten Abschnitt beschriebenen PPLs [Protected Processes Light]) ein besonderes Bit gesetzt, das das Verhalten von sicherheitsbezogenen
Routinen im Prozess-Manager so ändert, dass bestimmte Zugriffsrechte, die Administratoren
normalerweise erhalten, verweigert werden. Die einzigen Zugriffsrechte, die für geschützte
Prozesse vergeben werden, sind PROCESS_QUERY/SET_LIMITED_INFORMATION, PROCESS_TERMINATE
und PROCESS_SUSPEND_RESUME. Manche Zugriffsrechte werden auch für die Threads innerhalb
der geschützten Prozesse deaktiviert. Das sehen wir uns in Kapitel 4 im Abschnitt »Interne
Strukturen von Threads« genauer an.
Da das Programm Process Explorer reguläre Windows-APIs des Benutzermodus verwendet, um Informationen über Prozessinterna abzurufen, kann es bei geschützten Prozessen bestimmte Operationen nicht durchführen. Dagegen läuft WinDbg im Kerneldebuggingmodus
und nutzt daher die Kernelmodus-Infrastruktur, um Informationen zu gewinnen, weshalb es
damit möglich ist, sämtliche Informationen anzuzeigen. Das Verhalten von Process Explorer
beim Umgang mit einem geschützten Prozess wie Audiodg.exe lernen Sie in dem Experiment
im Abschnitt »Innere Mechanismen von Threads« von Kapitel 4 kennen.
Wie bereits in Kapitel 1 erwähnt, müssen Sie zum lokalen Kerneldebugging im Debuggingmodus starten (indem Sie bcdedit /debug oder die erweiterten Bootoptionen in Msconfig verwenden). Das dient dazu, die Gefahr von debuggergestützten
Angriffen auf geschützte Prozesse und den PMP zu verringern. Beim Start im Debuggingmode können High-Definition-Inhalte nicht wiedergegeben werden.
Durch die Einschränkung der Zugriffsrechte kann der Kernel geschützte Prozesse wie in einer
Sandbox zuverlässig gegen Zugriff vom Benutzermodus abschirmen. Allerdings sind geschützte Prozesse durch ein Flag in der EPROCESS-Struktur gekennzeichnet, sodass Administratoren
immer noch in der Lage sind, einen Kernelmodustreiber zu laden, der dieses Flag ändert. Das
allerdings würde eine Verletzung des PMP-Modells darstellen und als schädliches Verhalten
eingestuft, weshalb das Laden eines solchen Treibers auf einem 64-Bit-System wahrscheinlich
blockiert würde, da die Codesignierungsrichtlinie für den Kernelmodus eine digitale Signierung
von Schadcode nicht zulässt. Außerdem würden der Kernelmoduspatchschutz (PatchGuard,
siehe Kapitel 7) sowie der Treiber für geschützte Umgebung und Authentifizierung (Protected
Geschützte Prozesse
Kapitel 3
127
Environment and Authentication, Peauth.sys) solche Versuche erkennen und melden. Selbst
auf 32-Bit-Systemen muss der Treiber von der PMP-Richtlinie anerkannt werden, da die Wiedergabe sonst angehalten wird. Diese Richtlinie wird von Microsoft implementiert und nicht
von irgendeiner Kernelerkennung. Dieser Block würde ein manuelles Eingreifen von Microsoft
erfordern, um die Signatur als bösartig zu erkennen und den Kernel zu aktualisieren.
Protected Process Light (PPL)
Wie Sie gerade gesehen haben, ging es beim ursprünglichen Modell für geschützte Prozesse
vor allem um DRM-geschützte Inhalte. Ab Windows 8.1 und Windows Server 2012 R2 wurde
das Modell jedoch um Protected Process Light (PPL), also sozusagen die »Light-Version« von
geschützten Prozessen erweitert.
PPLs werden auf die gleiche Weise geschützt wie herkömmliche geschützte Prozesse:
Benutzermoduscode (selbst solcher mit erhöhten Rechten) kann nicht in sie eindringen und
Threads injizieren oder Informationen über die geladenen DLLs gewinnen. Beim PPL-Modell
kommen jedoch noch Attributwerte hinzu. Die verschiedenen Signierer haben unterschiedliche
Vertrauensebenen, was dazu führt, dass manche PPLs stärker geschützt sind als andere.
Da sich die digitale Rechteverwaltung von der reinen Multimedia-DRM auch zur WindowsLizenz-DRM und Windows-Store-DRM entwickelt hat, werden herkömmliche geschützte Prozesse jetzt auch anhand ihres Signiererwerts unterschieden. Die einzelnen anerkannten Signierer legen auch die Zugriffsrechte fest, die weniger geschützten Prozessen verweigert werden.
Beispielsweise sind normalerweise nur die Zugriffsmasken PROCESS_QUERY/SET_LIMITED_INFORMATION und PROCESS_SUSPEND_RESUME zugelassen. Dagegen ist PROCESS_TERMINATE für bestimmte
PPL-Signierer nicht zugelassen.
Tabelle 3–1 zeigt die zulässigen Werte für das Schutzflag in der EPROCESS-Struktur.
Internes Symbol für die Schutzebene des Prozesses
Schutztyp
Signierer
PS_PROTECTED_SYSTEM (0x72)
Geschützt
WinSystem
PS_PROTECTED_WINTCB (0x62)
Geschützt
WinTcb
PS_PROTECTED_WINTCB_LIGHT (0x61)
PPL
WinTcb
PS_PROTECTED_WINDOWS (0x52)
Geschützt
Windows
PS_PROTECTED_WINDOWS_LIGHT (0x51)
PPL
Windows
PS_PROTECTED_LSA_LIGHT (0x41)
PPL
Lsa
PS_PROTECTED_ANTIMALWARE_LIGHT (0x31)
PPL
Anti-malware
PS_PROTECTED_AUTHENTICODE (0x21)
Geschützt
Authenticode
PS_PROTECTED_AUTHENTICODE_LIGHT (0x11)
PPL
Authenticode
PS_PROTECTED_NONE (0x00)
Keine
Keine
Tabelle 3–1 Gültige Schutzwerte für Prozesse
Wie Sie in Tabelle 3–1 sehen, sind mehrere Signierer definiert, hier in der Reihenfolge absteigender Priorität angegeben. WinSystem ist der Signierer höchster Priorität und wird vom
Systemprozess sowie von minimalen Prozessen wie dem Speicherkomprimierungsprozess ver-
128
Kapitel 3
Prozesse und Jobs
wendet. Für Benutzermodusprozesse hat WinTCB (Windows Trusted Computer Base) die höchste
Priorität und wird zum Schutz kritischer Prozesse genutzt, die der Kernel genau kennt und für
die er seine Sicherheitsmaßnahmen reduzieren mag. Geschützte Prozesse haben stets mehr
Befugnisse als PPLs, Prozesse mit einem höherwertigen Signierer haben Zugriff auf Prozesse
mit einem Signierer geringerer Priorität, aber nicht umgekehrt. Tabelle 3–2 zeigt die Signierer
ebenen ( je höher der Wert, umso mehr Befugnisse hat der Signierer) und einige Beispiele ihrer
Nutzung. Sie können sie im Debugger mit dem Typ _PS_PROTECTED_SIGNER ausgeben.
Signierer (PS_PROTECTED_SIGNER)
Ebene
Verwendung
PsProtectedSignerWinSystem
7
System- und minimale Prozesse (einschließlich
Pico-Prozesse)
PsProtectedSignerWinTcb
6
Kritische Windows-Komponenten.
PROCESS_TERMINATE wird verweigert.
PsProtectedSignerWindows
5
Wichtige Windows-Komponenten, die mit sensiblen
Daten umgehen
PsProtectedSignerLsa
4
Lsass.exe (falls zur geschützten Ausführung eingerichtet)
PsProtectedSignerAntimalware
3
Anti-Malware-Dienste und Prozesse, auch von Dritt
anbietern. PROCESS_TERMINATE wird verweigert.
PsProtectedSignerCodeGen
2
NGEN (native .NET-Codegenerierung)
PsProtectedSignerAuthenticode
1
Hosting von DRM-Inhalten und Laden von Benutzermodus-Schriftarten
PsProtectedSignerNone
0
Ungültig (kein Schutz)
Tabelle 3–2 Signierer und ihre Ebenen
Vielleicht fragen Sie sich an dieser Stelle, was einen Schadprozess daran hindert, sich als geschützten Prozess auszugeben und sich gegen Anti-Malware-Anwendungen abzuschirmen. Da
für eine Ausführung als geschützter Prozess das Windows-Media-DRM-Zertifikat nicht mehr
erforderlich ist, hat Microsoft sein Codeintegritätsmodul so erweitert, dass es die beiden besonderen EKU-OIDs (Enhanced Key Usage) 1.3.6.1.4.1.311.10.3.22 und 1.3.6.4.1.311.10.3.20 versteht, die in Zertifikaten zur Codesignierung verwendet werden können. Ist eine dieser EKUs
vorhanden, werden die im Zertifikat hartcodierten Strings für den Signierer und den Aussteller
zusammen mit weiteren möglichen EKUs mit den verschiedenen Werten für geschützte Signierer verknüpft. Beispielsweise kann der Herausgeber Microsoft Windows den geschützten
Signiererwert PsProtectedSignerWindows gewähren, aber nur dann, wenn die EKU für Windows
System Component Verification (1.3.6.1.4.1.311.10.3.6) ebenfalls vorhanden ist. Als Beispiel
zeigt Abb. 3–7 das Zertifikat für Smss.exe, der als WinTcb-Light ausgeführt werden darf.
Die Schutzebene eines Prozesses bestimmt auch, welche DLLs er laden darf, denn ansonsten kann ein legitimer geschützter Prozess durch einen Bug oder eine einfache Dateiersetzung dazu gebracht werden, eine Drittanbieter- oder eine Schadbibliothek zu laden, die dann
mit derselben Schutzebene ausgeführt würde wie der Prozess. Dazu erhält jeder Prozess eine
»Signaturebene«, die im Feld SignatureLevel der EPROCESS-Struktur gespeichert wird. In einer
internen Nachschlagetabelle wird dann die zugehörige DLL-Signaturebene gesucht, die als
SectionSignatureLevel in der EPROCESS-Struktur steht. Jede in den Prozess geladene DLL wird
Geschützte Prozesse
Kapitel 3
129
von der Codeintegritätskomponente auf diese Weise überprüft wie die ausführbare Hauptdatei. Beispielsweise kann ein Prozess mit dem Signierer WinTcb nur DLLs mit dem Signierer
Windows oder höher laden.
Abbildung 3–7
Smss-Zertifikat
In Windows 10 und Windows Server 2016 sind die Prozesse smss.exe, csrss.exe, services.exe
und wininit.exe mit WinTcb-Lite PPL-signiert. Lsass.exe läuft in Windows für ARM-Geräte
(z. B. Windows Mobile 10) als PPL und kann auf x86/x64 als PPL ausgeführt werden, wenn er
durch eine Registrierungseinstellung oder eine Richtlinie entsprechend konfiguriert ist (siehe Kapitel 7). Außerdem sind einige Dienste so eingerichtet, dass sie als Windows-PPL oder
als geschützter Prozess laufen, z. B. sppsvc.exe (Software Protection Platform). Auch manche
Diensthostprozesse (Svchost.exe) werden mit dieser Schutzebene ausgeführt, da viele Dienste
ebenfalls geschützt sind, z. B. der AppX-Bereitstellungsdienst und der Dienst des Windows-Teilsystems für Linux. Weitere Informationen über solche geschützten Dienste erhalten Sie in Kapitel 9.
Für die Sicherheit des Systems ist es von entscheidender Bedeutung, dass diese Kernbinärdateien als TCB ausgeführt werden. So hat beispielsweise Csrss.exe Zugriff auf private APIs, die
vom Windows-Manager (Win32k.sys) implementiert werden und über die ein Angreifer mit
Administratorrechten Zugriff auf sensible Teile des Kernels gewinnen könnte. Smss.exe und
130
Kapitel 3
Prozesse und Jobs
Wininit.exe implementieren die Logik für Systemstart und -verwaltung, die unbedingt ausgeführt werden müssen, ohne dass sich ein Administrator daran zu schaffen machen kann.
Windows garantiert, dass diese Binärdateien stets als WinTcb-Lite ausgeführt werden. Dadurch
ist es beispielsweise nicht möglich, dass jemand sie startet, ohne beim Aufruf von CreateProcess
die richtige Prozessschutzebene in den Prozessattributen anzugeben. Diese Garantie wird als
Mindest-TCB-Liste bezeichnet und erzwingt für die Prozesse aus Tabelle 3–3, die sich in einem
Systempfad befinden, eine Mindestschutz- oder -signierebene unabhängig von der Eingabe
des Aufrufers.
Prozess
Mindestsignierebene
Mindestschutzebene
Smss.exe
Aus der Schutzebene abgeleitet
WinTcb-Lite
Csrss.exe
Aus der Schutzebene abgeleitet
WinTcb-Lite
Wininit.exe
Aus der Schutzebene abgeleitet
WinTcb-Lite
Services.exe
Aus der Schutzebene abgeleitet
WinTcb-Lite
Werfaultsecure.exe
Aus der Schutzebene abgeleitet
WinTcb-Full
Sppsvc.exe
Aus der Schutzebene abgeleitet
Windows-Full
Genvalobj.exe
Aus der Schutzebene abgeleitet
Windows-Full
Lsass.exe
SE_SIGNING_LEVEL_WINDOWS
0
Userinit.exe
SE_SIGNING_LEVEL_WINDOWS
0
Winlogon.exe
SE_SIGNING_LEVEL_WINDOWS
0
Autochk.exe
1
SE_SIGNING_LEVEL_WINDOWS
0
Tabelle 3–3 Mindest-TCB
1
Nur auf UEFI-Firmwaresystemen
Geschützte Prozesse
Kapitel 3
131
Experiment: Geschützte Prozesse in Process Explorer anzeigen
In diesem Experiment sehen wir uns an, wie Process Explorer geschützte Prozesse (beider
Arten) anzeigt. Starten Sie Process Explorer und aktivieren Sie auf der Registerkarte Process
Image das Kontrollkästchen Protection, um die gleichnamige Spalte einzublenden:
Sortieren Sie nun die Schalter Protection in absteigender Reihenfolge und scrollen Sie bis
ganz nach oben. Die geschützten Prozesse werden mit ihrem Schutztyp angezeigt. Der folgende Screenshot wurde auf einem x64-Computer mit Windows 10 angefertigt:
Wenn Sie einen geschützten Prozess markieren und einen Blick auf den unteren Teil werfen,
sehen Sie in der DLL-Ansicht nichts. Das liegt daran, dass Process Explorer die geladenen
Module mithilfe von Benutzermodus-APIs abfragt, wozu ein Zugriff erforderlich ist, der für
geschützte Prozesse nicht gewährt wird. Die Ausnahme bildet der Systemprozess, der zwar
geschützt ist, für den Process Explorer aber trotzdem die Liste der geladenen Kernelmodule
(hauptsächlich Treiber) anzeigt, da Systemprozesse keine DLLs enthalten. Für diese Anzeige verwendet Process Explorer die System-API EnumDeviceDrivers, die kein Prozesshandle
benötigt.
→
132
Kapitel 3
Prozesse und Jobs
In der Handleansicht werden die gesamten Handleinformationen angezeigt. Dazu
verwendet Process Explorer eine nicht dokumentierte API, die ebenfalls kein bestimmtes Prozesshandle benötigt. Das Programm kann die Prozesse identifizieren, da mit den
Informationen über die Handles auch die PIDs der zugehörigen Prozesse zurückgegeben
werden.
Unterstützung für Drittanbieter-PPLs
Der PPL-Mechanismus dehnt die Schutzmöglichkeiten für Prozesse auch auf ausführbare Dateien aus, die nicht von Microsoft entwickelt wurden. Ein Beispiel dafür bildet Anti-Malware-
Software. Typische AM-Produkte bestehen aus den folgenden drei Hauptkomponenten:
QQ Einem Kerneltreiber, der E/A-Anforderungen zum Dateisystem und zum Netzwerk abfängt
und über Objekt-, Prozess- und Thread-Callbacks Blockiermöglichkeiten einrichtet
QQ Einem Benutzermodusdienst (gewöhnlich unter einem privilegierten Konto), der die Treiberrichtlinien konfiguriert, Benachrichtigungen des Treibers über »interessante« Ereignisse
empfängt (z. B. über eine infizierte Datei) und mit einem lokalen Server oder dem Internet
kommunizieren kann
QQ Einem Benutzermodus-GUI-Prozess, der Informationen an den Benutzer vermittelt und ihn
ggf. Entscheidungen treffen lässt
Eine Angriffsmöglichkeit für Malware besteht darin, Code in einen Prozess mit erhöhten Rechten zu injizieren – am besten noch in einen Anti-Malware-Dienst, um diesen zu modifizieren
oder auszuschalten. Läuft der AM-Dienst aber als PPL, so ist weder eine Codeinjektion noch
eine Beendigung des Prozesses erlaubt. Dadurch ist die AM-Software besser gegen Malware
geschützt (sofern diese Exploits auf Kernelebene einsetzt).
Um das zu ermöglichen, muss der zuvor beschriebene AM-Kerneltreiber über einen zugehörigen ELAM-Treiber (Early-Launch Anti Malware) verfügen. ELAM wird in Kapitel 7 ausführlicher beschrieben. Lassen Sie uns hier nur betonen, dass solche Treiber ein besonderes
Anti-Malware-Zertifikat benötigen, das von Microsoft ausgestellt wird (nach eingehender
Überprüfung des Softwareherstellers). Ein solcher Treiber kann in seiner ausführbaren Hauptdatei (PE) einen benutzerdefinierten Ressourcenabschnitt namens ELAMCERTIFICATEINFO enthalten, der drei zusätzliche Signierer mit jeweils drei zusätzlichen EKUs beschreibt (wobei die
Signierer anhand ihres öffentlichen Schlüssels und die EKUs anhand ihrer OIDs bezeichnet
werden). Wenn das Codeintegritätssystem feststellt, dass eine Datei von einem dieser drei
Signierer mit einem dieser drei EKUs signiert wurde, erlaubt es dem Prozess, einen PPL von
PS_PROTECTED_ANTIMALWARE_LIGHT (0x31) anzufordern. Das Standardbeispiel dafür ist Windows
Defender, die eigene AM-Software von Microsoft. In Windows 10 ist ihr Dienst (MsMpEng.
exe) mit dem AM-Zertifikat signiert, um ihn besser gegen Malwareangriffe gegen ihn selbst
zu schützen. Das Gleiche gilt auch für den Network Inspection Server (NisSvc.exe).
Geschützte Prozesse
Kapitel 3
133
Minimale und Pico-Prozesse
Bei den Prozessen, die wir bisher betrachtet haben, sah es so aus, als seien sie zur Ausführung
von Benutzermoduscode da und würden dazu erhebliche Mengen an Datenstrukturen im Arbeitsspeicher unterbringen. Allerdings werden nicht alle Prozesse für diesen Zweck verwendet.
Wie wir bereits festgestellt haben, ist der Systemprozess lediglich ein Container für die meisten
Systemthreads, damit diese bei ihrer Ausführung keine anderen Benutzermodusprozesse kontaminieren, und für die Treiberhandles (Kernelhandles), damit auch diese nicht in den Besitz
irgendwelcher Anwendungen geraten.
Minimale Prozesse
Wenn die Funktion NtCreateProcessEx vom Kernelmodus aufgerufen wird und über ein bestimmtes Flag verfügt, verhält sie sich anders als sonst und verursacht die Ausführung der API
PsCreateMinimalProcess. Dadurch wird ein Prozess erstellt, dem viele der zuvor betrachteten
Strukturen fehlen:
QQ Es wird kein Benutzermodus-Adressraum eingerichtet, weshalb es auch den PEB und die
zugehörigen Strukturen nicht gibt.
QQ Dem Prozess wird keine NTDLL und auch keine Loader- oder API-Set-Information zugeordnet.
QQ Es wird kein Abschnittsobjekt an den Prozess gebunden. Das heißt, mit der Ausführung
oder dem Namen (der leer oder ein willkürlicher String sein kann) wird keine ausführbare
Abbilddatei verknüpft.
QQ In den EPROCESS-Flags wird das Flag Minimal gesetzt. Dadurch werden auch alle Threads zu
Minimalthreads und es werden jegliche Benutzermodus-Zuweisungen wie der TEB (siehe
Kapitel 4) oder der Benutzermodusstack vermieden.
Wie Sie in Kapitel 2 gesehen haben, gibt es in Windows 10 mindestens zwei minimale Prozesse,
nämlich den System- und den Speicherkomprimierungsprozess. Ist die virtualisierungsgestützte Sicherheit aktiviert, kann mit dem Secure-System-Prozess noch ein dritter hinzukommen
(siehe Kapitel 2 und 7).
Die zweite Möglichkeit, um minimale Prozesse auf einem Windows 10-System ausführen
zu lassen, besteht darin, das optionale Windows-Teilsystem für Linux (WSL) zu aktivieren (siehe
Kapitel 2). Dadurch wird ein im Lieferumfang von Windows enthaltener Pico-Provider installiert, der aus den Treibern Lxss.sys und LxCore.sys besteht.
Pico-Prozesse
Minimale Prozesse sind nur von beschränktem Nutzen, um Kernelkomponenten Zugriff auf den
virtuellen Benutzermodus-Adressraum zu geben und diesen zu schützen. Pico-Prozesse dagegen spielen eine wichtigere Rolle, da sie einer besonderen Komponente – dem Pico-Anbieter –
ermöglichen, die meisten Aspekte ihrer Ausführung zu steuern. Damit kann ein solcher Anbieter
letzten Endes das Verhalten eines völlig anderen Betriebssystemkernels emulieren, ohne dass die
134
Kapitel 3
Prozesse und Jobs
zugrunde liegende Benutzermodus-Binärdatei weiß, dass sie auf einem Windows-Betriebssystem läuft. Im Grunde genommen handelt es sich dabei um eine Implementierung des Microsoft
Research-Projekts Drawbridge, das auf ähnliche Weise auch SQL Server für Linux unterstützt
(wenn auch mit einem Windows-Bibliotheksbetriebssystem oberhalb des Linux-Kernels).
Um auf einem System Pico-Prozesse verwenden zu können, muss zunächst ein Anbieter
vorhanden sein. Er kann mit der API PsRegisterPicoProvider registriert werden, wobei jedoch
eine besondere Regel gilt: Der Pico-Anbieter muss vor allen anderen Drittanbietertreibern geladen werden (einschließlich der Boottreiber). Nur jeweils ein einziger aus einem eingeschränkten Satz von etwa einem Dutzend Kerntreibern darf diese API aufrufen, bevor diese Funktionalität deaktiviert wird. Diese Kerntreiber müssen mit einem Microsoft-Signiererzertifikat
und einer Windows-Komponenten-EKU signiert sein. Auf Windows-Systemen, auf denen die
optionale WSL-Komponente aktiviert ist, handelt es sich hierbei um den Treiber Lxss.sys, der
als Stubtreiber fungiert, bis etwas später der Treiber LxCore.sys geladen wird und die Verantwortung für den Pico-Anbieter übernimmt, indem er die Dispatchtabellen auf sich überträgt.
Zurzeit kann sich auch nur ein einziger Kerntreiber als Pico-Anbieter registrieren.
Wenn ein Pico-Anbieter die Registrierungs-API aufruft, erhält er eine Reihe von Funktionszeigern, mit denen er Pico-Prozesse erstellen und verwalten kann:
QQ Zwei Funktionen, um Pico-Prozesse bzw. Pico-Threads zu erstellen
QQ Eine Funktion, um den Kontext (einen willkürlichen Zeiger, mit dem der Anbieter bestimmte Daten speichern kann) eines Pico-Prozesses abzurufen, eine, um ihn festzulegen, und
zwei weitere Funktionen, um das Gleiche für Pico-Threads zu tun. Damit wird das Feld
PicoContext in der ETHREAD- bzw. EPROCESS-Struktur ausgefüllt.
QQ Eine Funktion, um die CPU-Kontextstruktur (CONTEXT) eines Pico-Threads abzurufen, und
eine, um ihn festzulegen
QQ Eine Funktion, um das FS- und GS-Segment eines Pico-Threads zu ändern. Diese Segmente
werden normalerweise von Benutzermoduscode verwendet, um auf eine lokale Threadstruktur zu verweisen (wie den TEB in Windows).
QQ Zwei Funktionen, um Pico-Threads bzw. Pico-Prozesse zu beenden
QQ Eine Funktion, um einen Pico-Thread anzuhalten, und eine weitere, um ihn wieder aufzunehmen
Mithilfe dieser Funktionen kann der Pico-Anbieter maßgeschneiderte Prozesse und Threads
erstellen, wobei deren ursprünglicher Startzustand, die Segmentregister und die zugehörigen
Daten seiner Kontrolle unterliegen. Das allein macht es aber noch nicht möglich, ein anderes Betriebssystem zu emulieren. Es gibt noch einen zweiten Satz von Funktionszeigern, die
jedoch vom Anbieter zum Kernel übertragen werden und als Callbacks fungieren, wenn ein
Pico-Thread oder -Prozess bestimmte Aktivitäten ausführt.
QQ Ein Callback für den Fall, dass ein Pico-Thread mithilfe der Anweisung SYSCALL einen Systemaufruf vornimmt
QQ Ein Callback für den Fall, dass ein Pico-Thread eine Ausnahme auslöst
QQ Ein Callback für den Fall, dass in einem Pico-Thread ein Fehler bei einer Sondierungs- und
Sperroperation an einer Speicherdeskriptorliste (MDL) auftritt
Minimale und Pico-Prozesse
Kapitel 3
135
QQ Ein Callback für den Fall, dass ein Aufrufer den Namen eines Pico-Prozesses anfordert
QQ Ein Callback für den Fall, dass die Ereignisverfolgung für Windows (ETW) die Benutzermodus-Stackablaufverfolgung eines Pico-Prozesses anfordert
QQ Ein Callback für den Fall, dass eine Anwendung versucht, ein Handle für einen Pico-Prozess
oder -Thread zu öffnen
QQ Ein Callback für den Fall, dass jemand die Beendigung eines Pico-Prozesses anfordert
QQ Ein Callback für den Fall, dass ein Pico-Prozess oder -Thread unerwartet beendet wird
Der Pico-Anbieter nutzt auch den in Kapitel 7 beschriebenen Kernelpatchschutz (Kernel Patch
Protection, KPP), um seine Callbacks und Systemaufrufe zu schützen und um zu verhindern,
dass sich gefälschte oder schädliche Pico-Anbieter oberhalb von ihm registrieren.
Angesichts dieses beispiellosen Zugriffs auf alle möglichen Benutzer-Kernel-Übergänge
und sichtbaren Kernel-Benutzer-Interaktionen zwischen sich selbst und der Welt können Pico-Prozesse und -Threads offensichtlich komplett von einem Pico-Anbieter (und entsprechenden Benutzermodusbibliotheken) gekapselt werden, um als Wrapper für eine ganz andere
Kernelimplementierung als die von Windows zu dienen. (Wobei es natürlich Ausnahmen gibt,
da nach wie vor die Regeln für Threadplanung und Speicherverwaltung gelten, z. B. für Commits.) Ordnungsgemäß geschriebene Anwendungen sollten nicht von solchen internen Algorithmen beeinflusst werden, da diese sich sogar in dem Betriebssystem ändern können, in dem
die Anwendungen normalerweise laufen.
Pico-Anbieter sind daher letzten Endes maßgeschneiderte Kernelmodule, die die notwendigen Callbacks für die Reaktion auf die von einem Pico-Prozess hervorgerufenen Ereignisse
(siehe weiter vorn) implementieren. Dadurch kann das WSL unveränderte Linux-ELF-Binärdateien im Benutzermodus ausführen. Eingeschränkt wird diese Möglichkeit durch die Vollständigkeit der Systemaufrufemulation und des damit verbundenen Funktionsumfangs.
Zur Abrundung des Themas sehen Sie in Abb. 3–8 die Strukturen von NT-, minimalen und
Pico-Prozessen.
NT-Prozess
Minimaler Prozess
Pico-Prozess
Prozessumgebungs
block (PEB)
Threadumgebungs
block (TEB)
Gemeinsame
Benutzerdaten
NTDLL.DLL
System
aufrufe
System
aufrufe
System
aufrufe
Benutzermodus
Exekutive und Kernel
Pico-Anbieter
(Lxss/LXCore)
Kernelmodus
Abbildung 3–8 Arten von Prozessen
136
Kapitel 3
Prozesse und Jobs
Trustlets (sichere Prozesse)
Wie bereits in Kapitel 2 erwähnt, enthält Windows neue VBS-Merkmale (Virtualization-Based
Security) wie DeviceGuard und CredentialGuard, die mithilfe eines Hypervisors die Sicherheit
des Betriebssystems und der Benutzerdaten verstärken. Eines dieser Merkmale, nämlich CredentialGuard (ausführlich beschrieben in Kapitel 7), läuft in der neuen Umgebung des isolierten
Benutzermodus, der zwar immer noch unprivilegiert ist (Ring 3), aber eine virtuelle Vertrauens
ebene von 1 (VTL 1) aufweist. Dadurch ist er von der regulären Ebene VTL 0 geschützt, auf der
sich sowohl der NT-Kernel (Ring 0) als auch die Anwendungen (Ring 3) befinden. Sehen wir uns
nun an, wie der Kernel solche Prozesse zur Ausführung einrichtet und welche Datenstrukturen
diese Prozesse verwenden.
Der Aufbau von Trustlets
Trustlets sind zwar reguläre PE-Dateien (Windows Portable Executables), weisen aber einige
IUM-spezifische Eigenschaften auf:
QQ Aufgrund der eingeschränkten Anzahl von Systemaufrufen, die für Trustlets zur Verfügung stehen, können sie nur Funktionen aus einer eingeschränkten Menge von Windows-
System-DLLs importieren (C/C++ Runtime, KernelBase, Advapi, RPC Runtime, CNG Base
Crypto und NTDLL). Mathematische DLLs, die nur Datenstrukturen bearbeiten (wie NTLM,
ASN.1 usw.), können jedoch ebenfalls verwendet werden, da sie keine Systemaufrufe
durchführen.
QQ Sie können Funktionen von einer IUM-spezifischen System-DLL namens Iumbase importieren, die ihnen zur Verfügung gestellt wird. Diese DLL enthält die grundlegende IUMSystem-API mit Unterstützung für Mailslots, Speicherboxen, Kryptografie usw. Diese Bibliothek führt letzten Endes Aufrufe in Iumdll.dll durch, der VTL-1-Version von Ntdll.dll, und
enthält sichere Systemaufrufe (also solche, die vom sicheren Kernel implementiert werden
und nicht an den normalen VTL-0-Kernel übergeben werden).
QQ Sie enthalten den PE-Abschnitt .tPolicy mit der exportierten globalen Variablen s_Ium
PolicyMetadata. Damit werden Metadaten für den sicheren Kernel bereitgestellt, um Richtlinieneinstellungen für den VTL-0-Zugriff des Trustlets zu implementieren (z. B. um Debugging zu erlauben, Unterstützung für Absturzabbilder bereitzustellen usw.).
QQ Sie werden mit einem Zertifikat signiert, dass die IUM-EKU enthält (1.3.6.1.4.311.10.3.37).
Abb. 3–9 zeigt die Zertifikatdaten für LsaIso.exe mit dieser EKU.
Außerdem muss beim Start von Trustlets mit CreateProcess ein besonderes Prozessattribut verwendet werden, um die Ausführung im IUM anzufordern und um besondere Starteigenschaften anzugeben. Die Richtlinien-Metadaten und die Prozessattribute beschreiben wir in den
folgenden Abschnitten.
Trustlets (sichere Prozesse)
Kapitel 3
137
Abbildung 3–9 Trustlet-EKU im Zertifikat
Richtlinien-Metadaten für Trustlets
Zu den Richtlinien-Metadaten gehören verschiedene Optionen, um festzulegen, wie »zugänglich« das Trustlet von VLT 0 aus sein soll. Sie werden durch eine Struktur beschrieben, die sich
in der zuvor erwähnten exportierten Variablen s_IumPolicyMetadaten befindet, und enthalten
die Versionsnummer (zurzeit 1) und die Trustlet-ID, also eine eindeutige Zahl zur Bezeichnung
eines bestimmten der bekannten Trustlets. Beispielsweise hat BioIso.exe die Trustlet-ID 4. Des
Weiteren gehört zu den Metadaten ein Array mit Richtlinienoptionen. Zurzeit werden die Optionen aus Tabelle 3–4 unterstützt. Da diese Richtlinien Teil der signierten ausführbaren Daten
sind, verletzt jeder Versuch, sie zu ändern, die IUM-Signatur und verhindert damit eine Ausführung.
Richtlinie
Bedeutung
ETW
Aktiviert oder deaktiviert
ETW
Debug
Konfiguriert das Debugging
Crash Dump
Aktiviert oder deaktiviert Absturzabbilder
Crash Dump Key
Gibt den öffentlichen Schlüssel zur Verschlüsselung von
Absturzabbildern an
Weitere Informationen
Das Debugging kann jederzeit aktiviert
sein; nur bei deaktiviertem SecureBoot;
oder bei Bedarf über einen Challenge/
Response-Mechanismus.
Absturzabbilder können an das Microsoft-Produktteam übermittelt werden,
das über den privaten Schlüssel für die
Entschlüsselung verfügt.
→
138
Kapitel 3
Prozesse und Jobs
Richtlinie
Bedeutung
Weitere Informationen
Crash Dump GUID
Gibt den eindeutigen Bezeichner für den Absturzabbildschlüssel an
Dadurch kann das Produktteam mehrere Schlüssel verwenden bzw. erkennen.
Parent Security Descriptor
SDDL-Format
Dient zur Validierung, dass der Besitzeroder Elternprozess der erwartete ist.
Parent Security Descriptor
Revision
Revisions-ID des SDDL-Formats
Dient zur Validierung, dass der Besitzeroder Elternprozess der erwartete ist.
SVN
Sicherheitsversion
Eine eindeutige Zahl, die das Trustlet
(zusammen mit seiner ID) bei der Verschlüsselung von AES256/GCM-Nach
richten nutzen kann.
Device ID
PCI-Bezeichner des sicheren
Geräts
Das Trustlet kann nur mit einem sicheren Gerät kommunizieren, das den entsprechenden PCI-Bezeichner aufweist.
Capability
Aktiviert VTL-1-Fähigkeiten
Aktiviert den Zugriff auf die API Create
Secure Section; DRM- und Benutzermodus-MMIO-Zugriff auf sichere
Geräte; und APIs für die sichere Speicherung.
Scenario ID
Gibt die Szenario-ID für die
Binärdatei an
Trustlets müssen diesen GUID angeben,
wenn sie sichere Abbildabschnitte erstellen, um sicherzustellen, dass es sich
um ein bekanntes Szenario handelt.
Tabelle 3–4 Trustlet-Richtlinienoptionen
Attribute von Trustlets
Der Start eines Trustlets erfordert die ordnungsgemäße Verwendung des Attributs PS_CP_
SECURE_PROCESS. Es dient zur Bestätigung, dass der Aufrufer wirklich ein Trustlet erstellen möchte, und zur Überprüfung, dass das Trustlet, das der Aufrufer auszuführen glaubt, auch tatsächlich das Trustlet ist, das ausgeführt wird. Dazu wird eine Trustlet-ID in das Attribut eingebettet.
Sie muss mit der Trustlet-ID in den Richtlinien-Metadaten übereinstimmen. Es können auch
noch weitere Attribute angegeben werden, die in Tabelle 3–5 aufgeführt sind.
Attribut
Bedeutung
Weitere Informationen
Mailbox Key
Dient zum Abrufen von Postfachdaten
Über Postfächer kann ein Trustlet Daten mit
VLT-0-Anwendungen gemeinsam nutzen, sofern
der Trustlet-Schlüssel bekannt ist.
Collaboration ID
Legt die Kollaborations-ID fest,
die zur Verwendung der IUMAPI Secure Storage benötigt
wird
Die Secure-Storage-API ermöglicht Trustlets mit
gemeinsamer Kollaborations-ID, Daten untereinander gemeinsam zu nutzen. Ist keine Kollaborations-ID vorhanden, wird stattdessen die ID
der Trustlet-Instanz verwendet.
TK Session ID
Die Sitzungs-ID, die bei kryptografischen Vorgängen verwendet wird
Tabelle 3–5 Trustlet-Attribute
Trustlets (sichere Prozesse)
Kapitel 3
139
Integrierte System-Trustlets
Zurzeit enthält Windows 10 die fünf Trustlets, die in Tabelle 3–6 aufgeführt sind. Die Trustlet-ID
0 steht für den sicheren Kernel selbst.
Binärdatei mit Trustlet-ID
in Klammern
Bezeichnung
Richtlinienoptionen
LsaIso.exe (1)
Credential and Key Guard
Trustlet
Allow ETW, Disable Debugging, Allow
Encrypted Crash Dump
Vmsp.exe (2)
Secure Virtual Machine Worker
(vTPM Trustlet)
Allow ETW, Disable Debugging, Dis
able Crash Dump, Enable Secure Storage Capability, Verify Parent Security
Descriptor is S-1-5-83-0 (NT VIRTUAL
MACHINE\Virtual Machines)
Unbekannt (3)
vTPM Key Enrollment Trustlet
Unbekannt
BioIso.exe (4)
Secure Biometrics Trustlet
Allow ETW, Disable Debugging, Allow
Encrypted Crash Dump
FsIso.exe (5)
Secure Frame Server Trustlet
Disable ETW, Allow Debugging, Enable
Create Secure Section Capability, Use
Scenario ID { AE53FC6E-8D89-44889D2E-4D008731C5FD}
Tabelle 3–6 Integrierte Trustlets
Trustlet-Identität
Trustlets verfügen über verschiedene Identitätsangaben:
QQ Trustlet-ID Dies ist ein Integerwert, der in den Richtlinien-Metadaten des Trustlets hartcodiert ist und in den Prozesserstellungsattributen für das Trustlet verwendet werden
muss. Dadurch weiß das System, dass es nur eine Handvoll Trustlets gibt. Anhand der ID
wird auch sichergestellt, dass Aufrufer tatsächlich das gewünschte Trustlet starten.
QQ Trustlet-Instanz Hierbei handelt es sich um eine kryptografisch sichere 16-Byte-Zufallszahl, die vom sicheren Kernel erstellt wird. Gibt es keine Kollaborations-ID, so wird die
Trustlet-Instanz herangezogen, um dafür zu sorgen, dass Secure-Storage-APIs nur dieser
einen Instanz des Trustlets erlauben, Daten in ihr Storage-BLOB zu stellen und von dort
abzurufen.
QQ Kollaborations-ID Diese ID wird verwendet, wenn ein Trustlet anderen Trustlets mit derselben ID oder anderen Instanzen desselben Trustlets den gemeinsamen Zugriff auf ein
Secure-Storage-BLOB erlauben möchte. Ist diese ID vorhanden, wird die Instanz-ID beim
Aufruf der Get- und Put-APIs ignoriert.
QQ Sicherheitsversion (SVN) Sie wird für Trustlets verwendet, die einen starken kryptografischen Beweis für den Ursprung signierter oder verschlüsselter Daten verlangen, etwa bei
der Verschlüsselung von AES256/GCM-Daten durch Credential- und KeyGuard und für den
Dienst Cryptograph Report.
140
Kapitel 3
Prozesse und Jobs
QQ Szenario-ID Sie wird für Trustlets verwendet, die benannte sichere Kernelobjekte erstellen, z. B. sichere Abschnitte. Diese Objekte werden im Namensraum mit diesem GUID gekennzeichnet, um zu bestätigen, dass das Trustlet sie im Rahmen eines vorherbestimmten
Szenarios erstellt hat. Andere Trustlets, die diese benannten Objekte öffnen wollen, müssen
über dieselbe Szenario-ID verfügen. Es ist zwar möglich, dass mehr als eine Szenario-ID
vorhanden ist, doch zurzeit verwenden Trustlets nicht mehr als eine.
IUM-Dienste
Die Ausführung als Trustlet bietet nicht nur den Vorteil des Schutzes gegen Angriffe aus der
normalen VLT-0-Umgebung, sondern bietet auch Zugriff auf privilegierte und geschützte sichere Systemaufrufe, die der sichere Kernel nur für Trustlets bereitstellt. Dazu gehören die folgenden Dienste:
QQ Sichere Geräte (IumCreateSecureDevice, IumDmaMapMemory, IumGetDmaEnabler,
IumMapSecureIo, IumProtectSecureIo, IumQuerySecureDeviceInformation, IopUnmapSecureIo, IumUpdateSecureDeviceState) Sie bieten Zugriff auf sichere ACPI- und
PCI-Geräte, die nicht von VTL 0 aus zugänglich sind und exklusiv dem sicheren Kernel (und
seinen Hilfsdiensten für die sichere HAL und das sichere PCI) gehören. Trustlets mit entsprechenden Fähigkeiten (siehe den Abschnitt »Richtlinien-Metadaten für Trustlets« weiter
vorn in diesem Kapitel) können die Register solcher Geräte auf den VTL-1-IUM abbilden
und auch Übertragungen mit direktem Speicherzugriff vornehmen (Direct Memory Access, DMA). Außerdem können sie als Benutzermodus-Gerätetreiber für solche Hardware
dienen, indem sie das Framework für sichere Geräte (Secure Device Framework, SDF) aus
SDFHost.dll verwenden. Diese Funktionalität wird für biometrische Verfahren in Windows
Hello verwendet, z. B. für die Verwendung von USB-Smartcards (über PCI) und von Webcams und Fingerabdrucksensoren (über ACPI).
QQ Sichere Abschnitte (IumCreateSecureSection, IumFlushSecureSectionBuffers, IumGet
ExposedSecureSection, IumOpenSecureSection) Über sichere Abschnitte ist es möglich,
physische Seiten gemeinsam mit einem VTL-0-Treiber zu nutzen (der dazu VslCreateSecureSection verwenden muss). Es können auch Daten als benannte sichere Abschnitte innerhalb
von VTL 1 mit anderen Trustlets oder anderen Instanzen desselben Trustlets geteilt werden
(wobei der zuvor im Abschnitt »Trustlet-Identität« erwähnte Identitätsmechanismus eingesetzt wird). Um dies tun zu können, müssen die Trustlets über die im Abschnitt »RichtlinienMetadaten für Trustlets« erwähnte Fähigkeit Secure Sections verfügen.
QQ Postfächer (IumPostMailbox) Damit kann sich ein Trustlet bis zu acht Slots von maximal ca. 4 KB Daten mit einer Komponente im normalen VLT-0-Kernel teilen, der dazu
VslRetrieveMailbox aufruft und die Slot-ID und den geheimen Postfachschlüssel angibt.
Dies wird unter anderem von Vid.sys in VTL 0 verwendet, um verschiedene Geheimnisse
abzurufen, die vTPM im Trustlet Vmsp.exe nutzt.
Trustlets (sichere Prozesse)
Kapitel 3
141
QQ Identitätsschlüssel (IumGetIdk) Damit kann das Trustlet einen eindeutig kennzeichnenden Entschlüsselungsschlüssel oder einen Signierschlüssel abrufen. Das Schlüssel
material bezeichnet eindeutig den Computer und kann nur von einem Trustlet bezogen
werden. Dies ist ein entscheidender Aspekt von CredentialGuard, um den Computer zu
authentifizieren und zu bestätigen, dass die Anmeldeinformationen tatsächlich aus dem
IUM kommen.
QQ Kryptografiedienste (IumCrypto) Sie erlauben einem Trustlet, Daten mit einem lokalen oder Bootsitzungsschlüssel zu verschlüsseln und zu entschlüsseln. Dieser Schlüssel wird
vom sicheren Kernel erstellt und steht nur im IUM zur Verfügung. Des Weiteren kann ein
Trustlet damit ein TPM-Bindungshandle erlangen; den FIPS-Modus des sicheren Kernels
abrufen; einen Seed des Zufallszahlengenerators gewinnen, der ausschließlich vom sicheren Kernel für IUM generiert wird; einen Bericht mit IDK-Signatur, SHA-2-Hash, Zeitstempel
und der Identität und SVN des Trustlets anlegen; eine Abbilddatei seiner Richtlinien-Metadaten unabhängig davon erstellen, ob sie jemals mit einem Debugger verknüpft wurden oder nicht; und jegliche andere angeforderten Daten generieren, die seiner Kontrolle
unterliegen. Das lässt sich als eine Art von TPM-Maßnahme nutzen, mit der das Trustlet
beweisen kann, dass es nicht manipuliert worden ist.
QQ Sicherer Speicher (IumSecureStorageGet, IumSecureStoragePut) Dadurch bekommt
das Trustlet die Fähigkeit Secure Storage (wie zuvor im Abschnitt »Richtlinien-Metadaten
für Trustlets« beschrieben), um BLOBs willkürlicher Größe zu speichern und abzurufen. Der
Zugriff auf das BLOB kann auf die jeweilige Trustlet-Instanz beschränkt sein oder anderen
Trustlets mit derselben Kollaborations-ID offenstehen.
Für Trustlets zugängliche Systemaufrufe
In dem Bemühen, seine Angriffsfläche zu reduzieren, stellt der sichere Kernel nur eine Teilmenge von weniger als fünfzig der Hunderte von Systemaufrufen zur Verfügung, die eine normale
VLT-0-Anwendung nutzen kann. Diese Aufrufe bilden das absolute Minimum für eine Kompatibilität mit den DLLs, die von Trustlets verwendet werden können (welche das sind, erfahren
Sie im Abschnitt »Der Aufbau von Trustlets«), und den Diensten, die zur Unterstützung der
RPC-Laufzeit (Rpcrt4.dll) und der ETW-Verfolgung erforderlich sind.
QQ Worker-Factory- und Thread-APIs Sie unterstützen die von RPCs verwendete Threadpool-API und die vom Lader verwendeten TLS-Slots.
QQ Prozessinformations-API Sie unterstützt TLS-Slots und die Threadstackzuweisung.
QQ Ereignis-, Semaphoren-, Warte- und Vervollständigungs-APIs
Threadpools und Synchronisierung.
Sie unterstützten
QQ ALPC-APIs (Advanced Local Procedure Calls) Sie unterstützen lokale RPCs über den
Transport ncalrpc.
QQ Systeminformations-API Sie ermöglicht das Lesen von Informationen über den sicheren Start, grundlegenden und NUMA-Systeminformationen für Kernel32.dll und die
Threadpoolskalierung, Leistungsinformationen und einigen Zeitinformationen.
QQ Token-API Sie bietet minimale Unterstützung für RPC-Identitätswechsel.
142
Kapitel 3
Prozesse und Jobs
QQ APIs für virtuelle Speicherzuweisung
Manager des Benutzermodus.
Sie unterstützen Zuweisungen durch den Heap-
QQ Abschnitts-APIs Sie unterstützen den Lader (für DLL-Abbilder) und die Funktionalität sicherer Abschnitte (sobald sie durch die zuvor angegebenen sicheren Systemaufrufe erstellt
bzw. verfügbar gemacht worden sind).
QQ Steuer-API für die Ablaufverfolgung
Sie unterstützt ETW.
QQ Ausnahme- und Fortsetzungs-API Sie unterstützt die strukturierte Ereignisbehandlung
(Structured Exception Handling, SEH).
Diese Liste zeigt deutlich, dass es keine Unterstützung für Operationen wie die folgenden gibt:
Geräte-E/A, unabhängig davon, ob es sich um Dateien oder physische Geräte handelt (es gibt
schon einmal keine CreateFile-API); Registrierungs-E/A; Erstellen anderer Prozesse; jegliche
Verwendung von Grafik-APIs (es gibt keinen Win32k.sys-Treiber in VTL 1). Trustlets sind als isolierte Arbeits-Back-Ends in VTL 1 für ihre komplexen Front-Ends in VTL 0 gedacht. Als einzige
Kommunikationsmechanismen stehen ihnen ALPC und bereitgestellte sichere Abschnitte zur
Verfügung (wobei ihnen die Handles dieser sicheren Abschnitte über ALPC vermittelt werden
müssen). In Kapitel 7 schauen wir uns die Implementierung des Trustlets LsaIso.exe genauer an,
das für CredentialGuard und KeyGuard zuständig ist.
Experiment: Sichere Prozesse identifizieren
Abgesehen von ihrem Namen können Sie sichere Prozesse im Kerneldebugger auf zwei
verschiedene Weisen erkennen. Erstens verfügt jeder sichere Prozess über eine sichere PID,
die in der Handletabelle des sicheren Kernels für sein Handle steht. Sie wird vom normalen
VLT-0-Kernel verwendet, wenn er Threads in dem Prozess erstellt oder dessen Beendigung
anfordert. Zweitens ist mit den Threads ein Threadcookie verknüpft, das ihren Index in der
Threadtabelle des sicheren Kernels angibt.
Probieren Sie Folgendes im Kerneldebugger aus:
lkd> !for_each_process .if @@(((nt!_EPROCESS*)${@#Process})->Pcb.SecurePid) {
.printf "Trustlet: %ma (%p)\n", @@(((nt!_EPROCESS*)${@#Process})
->ImageFileName), @#Process }
Trustlet: Secure System (ffff9b09d8c79080)
Trustlet: LsaIso.exe (ffff9b09e2ba9640)
Trustlet: BioIso.exe (ffff9b09e61c4640)
lkd> dt nt!_EPROCESS ffff9b09d8c79080 Pcb.SecurePid
+0x000 Pcb :
+0x2d0 SecurePid : 0x00000001'40000004
lkd> dt nt!_EPROCESS ffff9b09e2ba9640 Pcb.SecurePid
+0x000 Pcb :
+0x2d0 SecurePid : 0x00000001'40000030
→
Trustlets (sichere Prozesse)
Kapitel 3
143
lkd> dt nt!_EPROCESS ffff9b09e61c4640 Pcb.SecurePid
+0x000 Pcb :
+0x2d0 SecurePid : 0x00000001'40000080
lkd> !process ffff9b09e2ba9640 4
PROCESS ffff9b09e2ba9640
SessionId: 0 Cid: 0388 Peb: 6cdc62b000 ParentCid: 0328
DirBase: 2f254000 ObjectTable: ffffc607b59b1040 HandleCount: 44.
Image: LsaIso.exe
THREAD ffff9b09e2ba2080 Cid 0388.038c Teb: 0000006cdc62c000 Win32Thread:
0000000000000000 WAIT
lkd> dt nt!_ETHREAD ffff9b09e2ba2080 Tcb.SecureThreadCookie
+0x000 Tcb
+0x31c SecureThreadCookie : 9
Der Ablauf von CreateProcess
Wir haben uns bereits die verschiedenen Datenstrukturen für die Bearbeitung und Verwaltung
des Prozesszustands und die Werkzeuge und Debuggerbefehle angesehen, mit denen sie sich
untersuchen lassen. In diesem Abschnitt beschäftigen wir uns damit, wie diese Datenstrukturen
erstellt und ausgefüllt und wie Prozesse erstellt und beendet werden. Wie bereits erwähnt,
rufen alle Funktionen zur Prozesserstellung letzten Endes CreateProcessInternalW auf, weshalb
wir damit beginnen.
Um einen Windows-Prozess zu erstellen, werden mehrere Schritte in drei Teilen des Betriebssystems ausgeführt: in der clientseitigen Windows-Bibliothek Kernel32.dll (die eigentliche
Arbeit beginnt mit CreateProcessInternalW), in der Windows-Exekutive und im Windows-Teilsystemprozess (Csrss). Aufgrund der Teilsystemarchitektur für mehrere Umgebungen wird die
Erzeugung eines Exekutivprozessobjekts (das auch andere Teilsysteme nutzen können) von den
Arbeiten zum Erstellen eines Windows-Teilsystemprozesses getrennt. Die folgende Beschreibung des Ablaufs der Windows-Funktion CreateProcess ist zwar kompliziert, doch denken Sie
daran, dass dieser Teil der Arbeit nur für die zusätzliche Semantik des Windows-Teilsystems
erforderlich ist und nicht zu der grundlegenden Arbeit zum Erstellen eines Exekutivprozessobjekts gehört.
Die folgende Übersicht zeigt die Hauptphasen beim Erstellen eines Prozesses mit den
CreateProcess*-Funktionen von Windows. Die in den jeweiligen Phasen ausgeführten Operationen werden in den anschließenden Abschnitten ausführlich erläutert.
Viele Schritte von CreateProcess hängen mit der Einrichtung des virtuellen Adress
raums zusammen, weshalb dabei viele Begriffe und Strukturen der Speicherverwaltung erwähnt werden, deren Definition Sie in Kapitel 5 finden.
144
Kapitel 3
Prozesse und Jobs
1.
Parameter validieren; Windows-Teilsystemflags und -optionen in ihre nativen Gegenstücke
umwandeln; Attributliste analysieren, validieren und in ihr natives Gegenstück umwandeln.
2.
Die Abbilddatei (.exe) öffnen, die in dem Prozess ausgeführt werden soll.
3.
Das Windows-Exekutivprozessobjekt erstellen.
4.
Den ursprünglichen Thread erstellen (Stack, Kontext und Windows-Exekutivthreadobjekt).
5.
Spezifische Prozessinitialisierung für das Windows-Teilsystem durchführen.
6.
Ausführung des ursprünglichen Threads starten (sofern nicht das Flag CREATE_SUSPENDED
angegeben war).
7.
Initialisierung des Adressraums im Kontext des neuen Prozesses und Threads abschließen
(z. B. durch Laden der erforderlichen DLLs) und die Ausführung des Programmeintrittspunkts beginnen.
Abb. 3–10 gibt einen Überblick über die Phasen, die Windows beim Erstellen eines Prozesses
durchläuft.
Prozess erstellen
Phase 1
Parameter und Flags
konvertieren und validieren
Phase 2
EXE öffnen und
Abschnittsobjekt erstellen
Phasen 3+4
Prozess- und ThreadObjekte erstellen
Phase 5
Spezifische Prozessinitia
lisierung für das WindowsTeilsystem durchführen
Phase 6
Ausführung des ursprüng
lichen Threads starten
Windows-Teilsystem
Für neuen Prozess und
Thread einrichten
Neuer Prozess
Phase 6
Abschließende
Prozessinitialisierung
Ausführung des
Eintrittspunkts beginnen
Fertig
Abbildung 3–10 Die Hauptphasen der Prozesserstellung
Phase 1: Parameter und Flags konvertieren und validieren
Bevor die Funktion CreateProcessInternalW das auszuführende Image öffnet, führt sie folgende
Schritte aus:
1.
Die Prioritätsklasse für den neuen Prozess wird in Form unabhängiger Bits im Parameter
CreationFlags der CreateProcess*-Funktionen angegeben. Daher ist es möglich, bei einem
CreateProcess*-Aufruf mehrere Prioritätsklassen anzugeben. Windows weist dem Prozess
die Klasse mit der niedrigsten Priorität zu.
Der Ablauf von CreateProcess
Kapitel 3
145
Es sind sechs Prioritätsklassen definiert, denen jeweils eine Zahl zugeordnet ist:
•
Leerlauf oder niedrig (4)
•
Niedriger als normal (6)
•
Normal (8)
•
Höher als normal (10)
•
Hoch (13)
•
Echtzeit (24)
Die Prioritätsklasse wird als Basispriorität für die in dem Prozess erstellten Threads verwendet. Dieser Wert wirkt sich nicht direkt auf den Thread aus, sondern nur auf die enthaltenen
Threads. Eine Erläuterung der Prioritätsklassen und ihrer Auswirkung auf die Threadplanung erhalten Sie in Kapitel 4.
2.
Wurde für den neuen Prozess keine Prioritätsklasse angegeben, wird Normal verwendet.
Wurde die Prioritätsklasse Echtzeit angegeben und hat der Aufrufer des Prozesses nicht das
Recht Anheben der Zeitplanungspriorität (SE_INC_BASE_PRIORITY), dann wird stattdessen die
Klasse Hoch verwendet. Die Prozesserstellung schlägt also nicht fehl, nur weil der Aufrufer unzureichende Berechtigungen hat, um einen Prozess mit Echtzeitpriorität anzulegen.
Stattdessen erhält der neue Prozess einfach eine niedrigere Priorität.
3.
Verlangen die Erstellungsflags ein Debugging des Prozesses, so stellt Kernel32 eine Verbindung zum nativen Debuggingcode in Ntdll.dll her, indem er DbgUiConnectToDbg aufruft und
ein Handle für das Debugobjekt vom aktuellen Threadumgebungsblock (TEB) abruft.
4.
Kernel32.dll richtet den standardmäßigen harten Fehlermodus ein, wenn dies in den Erstellungsflags angegeben ist.
5.
Die vom Benutzer definierte Attributliste wird vom Format des Windows-Teilsystems in das
native Format umgewandelt und um interne Attribute ergänzt. Die möglichen zusätzlichen
Attribute finden Sie in Tabelle 3–7 zusammen mit ihren dokumentierten Windows-API-Gegenstücken, falls vorhanden.
Die an CreateProcess*-Aufrufe übergebene Attributliste ermöglicht es, an den Aufrufer Informationen zurückzugeben, die über einen einfachen Statuscode hinausgehen, z. B. die TEB-Adresse des ursprünglichen Threads oder Informationen über
den Abbildabschnitt. Das ist für geschützte Prozesse notwendig, da der Elternprozess diese Information nach dem Erstellen des Kindprozesses nicht abfragen kann.
Natives Attribut
Entsprechendes W32Attribut
Typ
Beschreibung
PS_CP_PARENT_PROCESS
PROC_THREAD_ATTRIBUTE_
PARENT_PROCESS. Auch bei
Rechteerhöhung verwendet.
Eingabe
Handle für den Elternprozess
PS_CP_DEBUG_OBJECT
Nicht verfügbar. Wird bei
der Verwendung von DEBUG_
PROCESS als Flag genutzt.
Eingabe
Debugobjekt, wenn der Prozess
im Debuggingmodus gestartet
wird
146
Kapitel 3
Prozesse und Jobs
→
Natives Attribut
Entsprechendes W32Attribut
Typ
Beschreibung
PS_CP_PRIMARY_TOKEN
Nicht verfügbar. Wird bei
der Verwendung von
CreateProcessAsUser/
WithTokenW genutzt.
Eingabe
Prozesstoken, wenn
CreateProcessAsUser verwendet wurde
PS_CP_CLIENT_ID
Nicht verfügbar. Wird von
der Win32-API als Parameter
zurückgegeben (PROCESS_
INFORMATION).
Ausgabe
Gibt die TID und PID des
ursprünglichen Threads bzw.
Prozesses zurück.
PS_CP_TEB_ADDRESS
Nicht verfügbar. Intern verwendet und nicht verfügbar
gemacht.
Ausgabe
Gibt die Adresse des TEB für
den ursprünglichen Thread
zurück.
PS_CP_FILENAME
Nicht verfügbar. Wird als Parameter in CreateProcess-
APIs verwendet.
Eingabe
Der Name des zu erstellenden
Prozesses
PS_CP_IMAGE_INFO
Nicht verfügbar. Intern verwendet und nicht verfügbar
gemacht.
Ausgabe
Gibt SECTION_IMAGE_
INFORMATION mit Informationen
über die Version, die Flags und
das Teilsystem der ausführbaren
Datei sowie die Stackgröße und
den Eintrittspunkt zurück.
PS_CP_MEM_RESERVE
Nicht verfügbar. Intern von
SMSS und CSRSS verwendet.
Eingabe
Ein Array von Reservierungen
für virtuellen Speicher, die beim
ursprünglichen Erstellen des
Prozessadressraums durchgeführt werden sollen. Die Verfügbarkeit wird garantiert, da noch
keine anderen Zuweisungen
stattgefunden haben.
PS_CP_PRIORITY_CLASS
Nicht verfügbar. Wird als Parameter an die
CreateProcess-API übergeben.
Eingabe
Die Prioritätsklasse, die der Prozess haben soll
PS_CP_ERROR_MODE
Nicht verfügbar. Wird über
das Flag CREATE_DEFAULT_
ERROR_MODE übergeben.
Eingabe
Verarbeitungsmodus des Prozesses für harte Fehler
PS_CP_STD_HANDLE_INFO
Keines. Wird intern verwendet.
Eingabe
Gibt an, ob Standardhandles
dupliziert oder ob neue Handles
erstellt werden sollen.
PS_CP_HANDLE_LIST
PROC_THREAD_ATTRIBUTE_
HANDLE_LIST
Eingabe
Die Handles des Elternprozesses, die der neue Prozess erben
soll
PS_CP_GROUP_AFFINITY
PROC_THREAD_ATTRIBUTE_
GROUP_AFFINITY
Eingabe
Die Prozessorgruppen, auf denen der Thread laufen darf
PS_CP_PREFERRED_NODE
PROC_THREAD_ATTRIBUTES_
PREFERRED_NODE
Eingabe
Der bevorzugte (ideale) NUMA-
Knoten, der mit dem Prozess
verknüpft werden soll. Dies legt
den Knoten fest, auf dem der
ursprüngliche Prozessheap und
der ursprüngliche Threadstack
erstellt werden (siehe Kapitel 5).
→
Der Ablauf von CreateProcess
Kapitel 3
147
Natives Attribut
Entsprechendes W32Attribut
Typ
Beschreibung
PS_CP_IDEAL_
PROCESSOR
PROC_THREAD_ATTTRIBUTE_
IDEAL_PROCESSOR
Eingabe
Der bevorzugte (ideale) Prozessor, auf dem der Thread eingeplant werden soll
PS_CP_UMS_THREAD
PROC_THREAD_ATTRIBUTE_
UMS_THREAD
Eingabe
Enthält die UMS-Attribute, die
Vervollständigungsliste und den
Kontext.
PS_CP_MITIGATION_
OPTIONS
PROC_THREAD_MITIGATION_
POLICY
Eingabe
Enthält Informationen über die
vorbeugenden Maßnahmen
(SEHOP, ATL-Emulation, NX), die
für den Prozess aktiviert oder
deaktiviert werden sollen.
PS_CP_PROTECTION_LEVEL
PROC_THREAD_ATTRIBUTE_
PROTECTION_LEVEL
Eingabe
Muss auf einen der zulässigen Prozessschutzwerte aus
Tabelle 3–1 oder den Wert
PROTECT_LEVEL_SAME zeigen. In
letzterem Fall erhält der Prozess
dieselbe Schutzebene wie sein
Elternprozess.
PS_CP_SECURE_PROCESS
Keines. Wird intern verwendet.
Eingabe
Gibt an, dass der Prozess als
IUM-Trustlet (Isolated User
Mode) ausgeführt werden soll
(siehe Kapitel 8 in Band 2).
PS_CP_JOB_LIST
Keines. Wird intern verwendet.
Eingabe
Weist den Prozess einer Jobliste
zu.
PS_CP_CHILD_PROCESS_
POLICY
PROC_THREAD_ATTRIBUTE_
CHILD_PROCESS_POLICY
Eingabe
Gibt an, ob der neue Prozess direkt oder indirekt Kindprozesse
erstellen darf (z. B. durch WMI).
PS_CP_ALL_APPLICATION_PACKAGES_POLICY
PROC_THREAD_ATTRIBUTE_
ALL_APPLICATION_PACKAGES_
POLICY
Eingabe
Gibt an, ob das AppContainer-
Token von Überprüfungen von
Zugriffssteuerungslisten ausgenommen werden soll, die die
Gruppe ALL APPLICATION PACKAGES enthalten. Stattdessen wird
die Gruppe ALL RESTRICTED
APPLICATION PACKAGES verwendet.
PS_CP_WIN32K_FILTER
PROC_THREAD_ATTRIBUTE_
WIN32K_FILTER
Eingabe
Gibt an, ob viele GDI/USER-Systemaufrufe des Prozesses an
Win32k.sys gefiltert (blockiert)
oder ob sie zugelassen, aber
überwacht werden sollen. Wird
vom Browser Microsoft Edge
verwendet, um die Angriffsfläche zu verringern.
PS_CP_SAFE_OPEN_
PROMPT_ORIGIN_CLAIM
Keines. Wird intern verwendet.
Eingabe
Wird von »Mark of the Web«
verwendet, um anzuzeigen,
dass die Datei aus einer nicht
vertrauenswürdigen Quelle
stammt.
148
Kapitel 3
Prozesse und Jobs
→
Natives Attribut
Entsprechendes W32Attribut
Typ
Beschreibung
PS_CP_BNO_ISOLATION
PROC_THREAD_ATTRIBUTE_
BNO_ISOLATION
Eingabe
Sorgt dafür, dass das Primärtoken des Prozesses mit
einem isolierten BaseNamedObjects-Verzeichnis verknüpft
wird (siehe Kapitel 8 in Band 2).
PS_CP_DESKTOP_APP_
POLICY
PROC_THREAD_ATTRIBUTE_
DESKTOP_APP_POLICY
Eingabe
Gibt an, ob die moderne Anwendung ältere Desktopanwendungen starten darf und wenn
ja, in welcher Weise.
PROC_THREAD_
ATTRIBUTE_SECURITY_
CAPABILITIES
Keines. Wird intern verwendet.
Eingabe
Gibt einen Zeiger auf eine
SECURITY_CAPABILITIES-
Struktur an, die dazu dient,
ein AppContainer-Token für
den Prozess zu erstellen, bevor
NtCreateUserProcess aufgerufen wird.
Tabelle 3–7 Prozessattribute
6.
Fordert das Erstellungsflag eine getrennte virtuelle DOS-Maschine (VDM) an, obwohl der
Prozess Teil eines Jobobjekts ist, so wird das Flag ignoriert.
7.
Die an die CreateProcess-Funktion übergebenen Sicherheitsattribute für den Prozess und
den ursprünglichen Thread werden in ihre interne Darstellung umgewandelt (OBJECT_
ATTRIBUTES-Strukturen; dokumentiert im WDK).
8.
CreateProcessInternalW prüft, ob der Prozess als moderner Prozess erstellt werden soll.
Das ist der Fall, wenn es in dem Attribut PROC_THREAD_ATTRIBUTE_PACKAGE_FULL_NAME mit
dem vollständigen Paketnamen so verlangt wird oder wenn der Ersteller selbst ein moderner Prozess ist (und mit dem Attribut PROC_THREAD_ATTRIBUTE_PARENT_PROCESS nicht ausdrücklich ein Elternprozess angegeben wurde). In diesem Fall wird die interne Funktion
BasepAppXExtension aufgerufen, um mehr Kontextinformationen über die Parameter der
modernen App zu ermitteln. Sie befinden sich in der Struktur APPX_PROCESS_CONTEXT, die Informationen wie den Paketnamen (intern als »package moniker« bezeichnet), die Fähigkeiten der Anwendung, das aktuelle Verzeichnis für den Prozess und die Angabe enthält, ob
der App volles Vertrauen geschenkt werden soll. Die Möglichkeit, eine voll vertrauenswürdige moderne App zu erstellen, ist nicht öffentlich verfügbar, sondern für Anwendungen
reserviert, die zwar über ein modernes Erscheinungsbild verfügen, aber Operationen auf
Systemebene durchführen. Ein wichtiges Beispiel ist die App Einstellungen in Windows 10
(SystemSettings.exe).
9.
Wird ein moderner Prozess erstellt, so wird die interne Funktion BasepCreateLowBox
aufgerufen, um die Sicherheitsfähigkeiten (sofern in PROC_THREAD_ATTRIBUTE_SECURITY_
CAPABILITIES bereitgestellt) für die Erstellung des ursprünglichen Tokens aufzuzeichnen.
Die Bezeichnung LowBox bezieht sich auf die Sandbox (den Anwendungscontainer), in der
der Prozess ausgeführt wird. Es ist zwar nicht möglich, moderne Prozesse direkt durch einen Aufruf von CreateProcess zu erstellen (stattdessen müssen die zuvor beschriebenen
COM-Schnittstellen verwendet werden), doch im Windows SDK und auf MSDN wird die
Der Ablauf von CreateProcess
Kapitel 3
149
Möglichkeit beschrieben, ältere AppContainer-Desktopanwendungen durch die Übergabe dieses Attributs zu erstellen.
10. Soll ein moderner Prozess erstellt werden, so wird ein Flag gesetzt, um anzuzeigen, dass
der Kernel die Erkennung des eingebetteten Manifests überspringen soll. Moderne Prozesse sollten kein eingebettetes Manifest haben, da es nicht benötigt wird. (Eine moderne App
hat ihr eigenes Manifest, das aber nichts mit dem hier gemeinten eingebetteten Manifest
zu tun hat.)
11. Wurde das Debugflag DEBUG_PROCESS angegeben, wird der Debugger-Wert im Registrierungsschlüssel Image File Execution Options für die ausführbare Datei (siehe den nächsten
Abschnitt) so markiert, dass er übersprungen wird. Anderenfalls könnte ein Debugger niemals den zu debuggenden Prozess erstellen, da der Vorgang in eine Endlosschleife eintritt
(es wird immer und immer wieder versucht, den Debuggerprozess anzulegen).
12. Alle Fenster werden mit Desktops verknüpft, den grafischen Darstellungen eines Arbeitsbereichs. Ist in der STARTUPINFO-Struktur kein Desktop angegeben, so wird der Prozess mit
dem aktuellen Desktop des Aufrufers verknüpft.
Die Windows 10-Funktion der virtuellen Desktops verwendet in Wirklichkeit nicht
mehrere Desktopobjekte (im Sinne von Kernelobjekten). Es gibt immer noch lediglich einen Desktop, auf dem aber die Fenster nach Bedarf angezeigt bzw. ausgeblendet werden. Anders ist es beim Sysinternals-Tools Desktops.exe, das wirklich
bis zu vier Desktopobjekte erstellt. Den Unterschied können Sie erkennen, wenn
Sie versuchen, ein Fenster von einem Desktop zu einem anderen zu verschieben.
Bei Desktops.exe geht das nicht, da eine solche Operation in Windows nicht unterstützt wird. In den virtuellen Desktops von Windows 10 ist es jedoch möglich, da
dabei in Wirklichkeit gar nichts verschoben wird.
13. Die an CreateProcessInternalW übergebene Anwendung und die Befehlszeilenargumente werden analysiert. Der Pfad der ausführbaren Datei wird in den internen NT-Namen
umgewandelt (beispielsweise wird aus c:\temp\a.exe etwas wie \device\harddiskvolume1\
temp\a.exe), da einige Funktionen auf dieses Format angewiesen sind.
14. Die meisten erfassten Informationen werden in eine einzige große Struktur vom Typ RTL_
USER_PROCESS_PARAMETERS umgewandelt.
Nach Abschluss dieser Schritte ruft CreateProcessInternalW die Funktion NtCreateUserProcess
auf, um zu versuchen, den Prozess zu erstellen. Da Kernel32.dll zu diesem Zeitpunkt noch nicht
weiß, ob der Name des Abbilds zu einer echten Windows-Anwendung oder zu einer Batchdatei
(.bat oder .cmd), einer 16-Bit- oder DOS-Anwendung gehört, kann dieser Aufruf fehlschlagen.
In diesem Fall schaut sich CreateProcessInternalW den Grund für den Fehler an und versucht,
ihn zu korrigieren.
150
Kapitel 3
Prozesse und Jobs
Phase 2: Das auszuführende Abbild öffnen
An dieser Stelle ist der erstellende Thread in den Kernelmodus gewechselt und fährt mit seiner
Arbeit in der Implementierung des Systemaufrufs NtCreateUserProcess fort.
1.
Als Erstes validiert NtCreateUserProcess die Argumente und baut eine interne Struktur für
alle Informationen zu dem Erstellungsvorgang auf. Validiert werden die Argumente, um
sicherzugehen, dass der Aufruf an die Exekutive nicht von einem Hack ausging, der den
Übergang von Ntdll.dll zum Kernel mit gefälschten oder schädlichen Argumenten simuliert.
2.
Wie Abb. 3–11 zeigt, besteht der nächste Schritt darin, das geeignete Windows-Abbild
zu finden, um die vom Aufrufer angegebene ausführbare Datei auszuführen und ein Abschnittsobjekt zu erstellen, das später im Adressraum des neuen Prozesses abgebildet wird.
Wenn dieser Aufruf aus irgendeinem Grund fehlschlägt, gibt er einen Fehlerstatus an CreateProcessInternalW zurück (siehe Tabelle 3–8). Mithilfe dieser Informationen versucht
CreateProcessInternalW es dann noch einmal.
Führt Cmd.exe aus
Führt NtVdm.exe aus
BAT- oder CMDDatei von DOS
Win16
Führt die EXE-Datei direkt aus
Windows
Um was für eine Anwendung
handelt es sich?
EXE-, COM- oder
PIF-Datei von DOS
Führt NtVdm.exe aus
Abbildung 3–11 Auswahl des zu verwendenden Windows-Abbilds
3.
Soll ein geschützter Prozess erstellt werden, so wird auch die Signierrichtlinie geprüft.
4.
Soll ein moderner Prozess erstellt werden, so erfolgt eine Lizenzierungsprüfung, um sicherzugehen, dass der Prozess lizenziert ist und ausgeführt werden darf. Anwendungen, die
zusammen mit Windows vorinstalliert wurden, dürfen unabhängig von der Lizenz immer
ausgeführt werden. Ist das Querladen zugelassen (was über Einstellungen festgelegt wird),
dann können alle signierten Anwendungen ausgeführt werden, nicht nur diejenigen aus
dem Store.
5.
Handelt es sich bei dem Prozess um ein Trustlet, so muss das Abschnittsobjekt mit einem
besonderen Flag erstellt werden, das die Verwendung durch den sicheren Kernel erlaubt.
6.
Wenn es sich bei der angegebenen ausführbaren Datei um eine Windows-EXE handelt,
versucht NtCreateUserProcess, sie zu öffnen und ein Abschnittsobjekt dafür zu erstellen.
Der Ablauf von CreateProcess
Kapitel 3
151
Dieses Objekt wird noch nicht auf den Arbeitsspeicher abgebildet, aber es ist geöffnet. Die
Tatsache, dass ein Abschnittsobjekt erstellt werden konnte, bedeutet jedoch nicht zwangsläufig, dass es sich bei der Datei um ein gültiges Windows-Abbild handelt, denn es könnte
auch eine DLL oder eine ausführbare POSIX-Datei sein. In letzterem Fall schlägt der Aufruf
fehl, da POSIX nicht mehr unterstützt wird. Bei einer DLL schlägt CreateProcessInternalW
ebenfalls fehl.
7.
Nachdem NtCreateUserProcess ein gültiges Windows-Abbild gefunden hat, schaut sie in
der Registrierung unter HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File
Execution Options nach, ob es einen Unterschlüssel mit dem Dateinamen und der Erweiterung des Abbilds gibt (allerdings ohne Verzeichnis- und Pfadangaben, also z. B. Notepad.
exe). Wenn ja, sucht PspAllocateProcess nach dem Debugger-Wert für diesen Schlüssel. Ist
er vorhanden, wird der Name des auszuführenden Abbilds zum String für diesen Wert.
CreateProcessInternalW startet dann erneut in Phase 1.
Sie können dieses Verhalten nutzen, um den Startcode von Windows-Dienstprozessen zu debuggen, bevor sie gestartet werden. Wenn Sie den Debugger erst
nach dem Start einklinken, ist ein Debugging des Startcodes nicht mehr möglich.
8.
Handelt es sich bei dem Abbild dagegen nicht um eine Windows-EXE (sondern z. B. um
eine MS-DOS- oder eine Win16-Anwendung), durchläuft CreateProcessInternalW eine Reihe von Schritten, um ein Windows-Unterstützungsabbild zur Ausführung dieser Datei zu
finden. Dieser Vorgang ist notwendig, da Nicht-Windows-Anwendungen nicht direkt ausgeführt werden. Stattdessen verwendet Windows dazu besondere Unterstützungsabbilder,
die letzten Endes für die Ausführung des Nicht-Windows-Programms verantwortlich sind.
Wenn Sie beispielsweise (auf 32-Bit-Windows) versuchen, eine ausführbare MS-DOS- oder
Win16-Datei zu öffnen, wird das Abbild Ntvdm.exe ausgeführt. Kurz: Es ist nicht möglich,
einen Nicht-Windows-Prozess direkt zu erstellen. Wenn Windows keine Möglichkeit findet,
das angegebene Abbild auszuführen, schlägt CreateProcessInternalW fehlt (siehe Tabelle 3–8).
Abbild
Statuscode
Ausgeführtes
Abbild
Ergebnis
MS-DOS-Anwendung mit der
Erweiterung .exe,
.com oder .pif
PsCreateFailOnSectionCreate
Ntvdm.exe
CreateProcessInternalW
startet neu in Phase 1.
Win16-Anwendung
PsCreateFailOnSectionCreate
Ntvdm.exe
CreateProcessInternalW
startet neu in Phase 1.
Win64-Anwendung auf einem
32-Bit-System
(oder eine PPC-,
MIPS- oder Alpha-Binärdatei)
PsCreateFailMachineMismatch
–
CreateProcessInternalW
schlägt fehl.
152
Kapitel 3
→
Prozesse und Jobs
Abbild
Statuscode
Ausgeführtes
Abbild
Ergebnis
Hat einen Debugger-Wert mit
einem anderen
Abbildnamen
PsCreateFailExeName
Im Debugger-Wert
angegebener
Name
CreateProcessInternalW
startet neu in Phase 1.
Ungültige oder
beschädigte
Windows-EXE
PsCreateFailExeFormat
–
CreateProcessInternalW
schlägt fehl.
Kann nicht geöffnet werden
PsCreateFailOnFileOpen
–
CreateProcessInternalW
schlägt fehl.
Befehlsprozedur
(Anwendung mit
der Erweiterung
.bat oder .com)
PsCreateFailOnSectionCreate
Cmd.exe
CreateProcessInternalW
startet neu in Phase 1.
Tabelle 3–8 Umgang mit verschiedenen Abbildern
CreateProcessInternalW entscheidet wie folgt, welches Abbild sie ausführen soll:
QQ Wenn x86-32-Bit-Windows ausgeführt wird und es sich bei dem Abbild um eine
MS-DOS-Anwendung mit der Erweiterung .exe, .com oder .pif handelt, wird eine Nachricht an das Windows-Teilsystem gesendet, um zu prüfen, ob für die Sitzung bereits ein
MS-DOS-Unterstützungsprozess erstellt worden ist (nämlich Ntvdm.exe, wie im Registrierungswert HKLM\SYSTEM\CurrentControlSet\Control\WOW\cmdline angegeben). Wenn ja,
wird dieser Unterstützungsprozess verwendet, um die MS-DOS-Anwendung auszuführen.
(Das Windows-Teilsystem sendet die Nachricht an den VDM-Prozess [virtuelle DOS-Maschine], um das neue Abbild auszuführen.) Danach gibt CreateProcessInternalW die Steuerung zurück. Wurde dagegen noch kein Unterstützungsprozess erstellt, wird als auszuführendes Image Ntvdm.exe angegeben, woraufhin CreateProcessInternalW mit Phase 1
neu beginnt.
QQ Trägt die auszuführende Datei die Endung .bat oder .cmd, wird die Windows-Eingabeaufforderung Cmd.com zum auszuführenden Abbild, woraufhin CreateProcessInternalW
mit Phase 1 neu beginnt. Der Name der Batchdatei wird als zweiter Parameter nach dem
Schalter /c an Cmd.exe übergeben.
QQ Findet der Vorgang auf einem x86-Windows-System statt und handelt es sich bei dem Abbild um eine ausführbare Win16-Datei (Windows 3.1), muss CreateProcessInternalW entscheiden, ob ein neuer VDM-Prozess dafür erstellt oder der standardmäßige sitzungsweit
gemeinsam genutzte VDM-Prozess verwendet werden soll (der möglicherweise noch nicht
erstellt wurde). Für diese Entscheidung werden die CreateProcess-Flags CREATE_SEPARATE_
WOW_VDM und CREATE_SHARED_WOW_VDM herangezogen. Wenn sie nicht angegeben sind, gibt
der Registrierungswert HKLM\SYSTEM\CurrentControlSet\Control\WOW\DefaultSeparateVDM
das Standardverhalten vor. Soll die Anwendung in einer eigenen VDM ausgeführt werden,
wird das auszuführende Abbild in Ntvdm.exe gefolgt von einigen Konfigurationsparametern und dem Namen des 16-Bit-Prozesses geändert, woraufhin CreateProcessInternalW
in Phase 1 neu startet. Anderenfalls sendet das Windows-Teilsystem eine Nachricht, um zu
prüfen, ob der gemeinsam genutzte VDM-Prozess vorhanden ist und verwendet werden
Der Ablauf von CreateProcess
Kapitel 3
153
kann. Läuft der VDM-Prozess auf einem anderen Desktop oder in einem anderen Sicherheitskontext als dem des Aufrufers, dann kann er nicht genutzt werden. In diesem Fall
muss ein neuer VDM-Prozess erstellt werden. Kann der gemeinsame VDM-Prozess dagegen verwendet werden, dann sendet das Windows-Teilsystem ihm eine Nachricht, damit er
das neue Abbild ausführt. CreateProcessInternalW gibt dann die Steuerung zurück. Wenn
der VDM-Prozess noch nicht gestartet wurde (oder nicht genutzt werden kann), wird das
auszuführende Abbild in das VDM-Unterstützungsabbild geändert, woraufhin CreateProcessInternalW in Phase 1 neu startet.
Phase 3: Das Windows-Exekutivprozessobjekt erstellen
NtCreateUserProcess hat jetzt eine gültige ausführbare Windows-Datei geöffnet und ein Ab-
schnittsobjekt erstellt, um sie auf den Adressraum des neuen Prozesses abzubilden. Als Nächstes erstellt die Funktion ein Windows-Exekutivprozessobjekt, um das Abbild auszuführen. Dazu
ruft sie die interne Systemfunktion PspAllocateProcess auf. Die Erstellung des Exekutivprozessobjekts (die vom Erstellerthread erledigt wird) umfasst die folgenden Teilphasen:
a.
Das EPROCESS-Objekt einrichten
b.
Den ursprünglichen Prozessadressraum erstellen
c.
Die KPROCESS-Struktur initialisieren
d.
Die Einrichtung des Prozessadressraums abschließen
e.
Den PEB einrichten
f.
Die Einrichtung des Exekutivprozessobjekts abschließen
Nur während des Systeminitialisierens (beim Erstellen des Systemprozesses) gibt
es keinen Elternprozess. Danach ist immer ein Elternprozess erforderlich, um den
Sicherheitskontext für den neuen Prozess bereitzustellen.
Phase 3a: Das EPROCESS-Objekt einrichten
Diese Teilphase umfasst die folgenden Schritte:
1.
Der neue Prozess erbt die Affinität des Elternprozesses, es sei denn, während der Prozess
erstellung wurde in der Attributliste ausdrücklich eine Affinität angegeben.
2.
Gegebenenfalls wird der NUMA-Knoten ausgewählt, der als idealer Knoten in der Attributliste angegeben wurde.
3.
Der neue Prozess erbt die E/A- und Seitenpriorität vom Elternprozess. Gibt es keinen Elternprozess, werden die Standardprioritäten verwendet, also 5 für die Seiten- und Normal
für die E/A-Priorität.
4.
Der neue Prozessbeendigungsstatus wird auf STATUS_PENDING gesetzt.
5.
Es wird der Verarbeitungsmodus für harte Fehler ausgewählt, der in der Attributliste angegeben ist. Wird dort keiner genannt, so erbt der Prozess den Modus des Elternprozesses.
154
Kapitel 3
Prozesse und Jobs
Gibt es keinen Elternprozess, wird der Standardverarbeitungsmodus genommen, bei dem
alle Fehler angezeigt werden.
6.
Die ID des Elternprozesses wird im Feld InheritedFromUniqueProcessID des neuen Prozessobjekts gespeichert.
7.
Der Schlüssel Image File Execution Objects (IFEO) wird abgefragt, um herauszufinden,
ob der Prozess auf großen Seiten abgebildet werden soll (Wert UseLargePages). Wenn der
Prozess unter Wow64 läuft, werden jedoch grundsätzlich keine großen Seiten verwendet.
Es wird auch geprüft, ob in diesem Schlüssel NTDLL als die DLL angegeben ist, die in dem
Prozess auf großen Seiten abgebildet werden soll.
8.
Der Leistungsoptionsschlüssel PerfOptions in IFEO wird abgefragt (falls vorhanden). Er
kann mehrere der folgenden Werte enthalten: IoPriority, PagePriority, CpuPriorityClass
und WorkingSetLimitInKB.
9.
Soll der Prozess unter Wow64 laufen, dann wird die Wow64-Hilfsstruktur EWOW64PROCESS
zugewiesen und im Element WoW64Process der EPROCESS-Struktur angegeben.
10. Soll der Prozess in einem Anwendungscontainer laufen (was bei einer modernen App
meistens der Fall ist), wird das mit LowBox erstellte Token validiert (siehe Kapitel 7).
11. Es wird versucht, alle erforderlichen Rechte zum Erstellen des Prozesses zu erwerben. Die
Auswahl der Prioritätsklasse Echtzeit, die Zuweisung eines Tokens zu dem neuen Prozess,
die Abbildung des Prozesses auf großen Seiten und das Erstellen des Prozesses in einer
neuen Sitzung erfordern jeweils entsprechende Rechte.
12. Das primäre Zugriffstoken des Prozesses (ein Duplikat des Primärtokens des Elternprozesses) wird erstellt. Neue Prozesse erben das Sicherheitsprofil ihrer Elternprozesse. Wird mit
CreateProcessAsUser ein anderes Zugriffstoken für den neuen Prozess angegeben, so wird
das Token entsprechend geändert. Das kann jedoch nur dann geschehen, wenn das Token
des übergeordneten Prozesses eine höhere Integritätsebene aufweist als das Zugriffstoken
des neuen Prozesses und wenn dieses Zugriffstoken ein echtes Kind oder Geschwister des
Elterntokens ist. Hat der Elternprozess das Recht SeAssignPrimaryToken, wird diese Überprüfung übersprungen.
13. Die Sitzungs-ID des neuen Prozesstokens wird geprüft, um zu bestimmen, ob der neue
Prozess sitzungsübergreifend erstellt wird. Wenn ja, so wird der Elternprozess vorübergehend an die Zielsitzung angehängt, um die Kontingente und die Adressraumerstellung
korrekt zu verarbeiten.
14. Der Kontingentblock des neuen Prozesses wird auf die Adresse des Elternkontingentblocks
gesetzt. Der Referenzzähler für den Elternkontingentblock wird heraufgesetzt. Wurde der
Prozess mit CreateProcessAsUser erstellt, wird dieser Schritt nicht ausgeführt. Stattdessen
wird das Standardkontingent erstellt oder das Kontingent aus dem Benutzerprofil ausgewählt.
15. Die Mindest- und Höchstgröße des Arbeitssatzes für den Prozess werden auf die Werte
von PspMinimumWorkingSet bzw. PspMaximumWorkingSet gesetzt. Diese Werte können überschrieben werden, wenn im IFEO-Schlüssel PerfOptions entsprechende Leistungsoptionen
angegeben wurden. In diesem Fall wird die maximale Arbeitssatzgröße aus diesem Schlüs-
Der Ablauf von CreateProcess
Kapitel 3
155
sel bezogen. Die Standardgrenzwerte für den Arbeitssatz sind im Grunde genommen nur
Empfehlungen, während es sich bei dem Maximalwert in PerfOptions um eine feste Grenze
handelt, die der Arbeitssatz nicht überschreiten kann.
16. Der Adressraum des Prozesses wird initialisiert (siehe Phase 3b). Wird der neue Prozess in
einer anderen Sitzung erstellt, so wird der Elternprozess jetzt von der Zielsitzung getrennt.
17. Wurde die Gruppenaffinität für den Prozess nicht geerbt, so wird sie jetzt ausgewählt.
Die Standardgruppenaffinität wird entweder vom Elternprozess geerbt, wenn zuvor die
NUMA-Knotenweiterleitung eingerichtet wurde (dabei wird die Gruppe verwendet, die
den NUMA-Knoten besitzt), oder mit einem Umlaufverfahren zugewiesen. Befindet sich
das System in einem erzwungenen Gruppenkenntnismodus und hat sich der Auswahlalgorithmus für Gruppe 0 entschieden, so wird stattdessen Gruppe 1 ausgewählt, falls sie
vorhanden ist.
18. Der KPROCESS-Teil des Prozessobjekts wird initialisiert (siehe Phase 3c).
19. Das Token für den Prozess wird jetzt eingerichtet.
20. Die Prioritätsklasse des Prozesses wird auf Normal gesetzt. Hatte der Elternprozess die
Klasse Leerlauf oder Niedriger als normal, so wird stattdessen diese Priorität verwendet.
21. Die Prozesshandletabelle wird initialisiert. Ist das Flag zur Handlevererbung für den Elternprozess gesetzt, werden alle vererbbaren Handles von dessen Objekthandletabelle in
die des neuen Prozesses kopiert (mehr darüber siehe Kapitel 8 in Band 2). Mit einem Prozessattribut kann jedoch auch nur eine Teilmenge der Handles angegeben werden. Das
ist praktisch, wenn Sie mit CreateProcessAsUser einschränken wollen, welche Objekte der
Kindprozess erben soll.
22. Wurden im Schlüssel PerfOptions Leistungsoptionen angegeben, so werden diese jetzt
angewendet. Dieser Schlüssel enthält Werte, mit denen die Grenzwerte für den Arbeitssatz,
die E/A-, die Seiten- und die CPU-Priorität des Prozesses überschrieben werden können.
23. Die endgültige Prioritätsklasse für den Prozess und das Standardquantum für seine Threads
werden berechnet und festgelegt.
24. Die verschiedenen Vorbeugungsoptionen im IFEO-Schlüssel (ein einzelner 64-Bit-Wert
namens Mitigation) werden gelesen und festgelegt. Läuft der Prozess in einem Anwendungscontainer, wird das Abwehrflag TreatAsAppContainer hinzugefügt.
25. Alle anderen Vorbeugungsflags werden angewendet.
Phase 3b: Den ursprünglichen Prozessadressraum erstellen
Der ursprüngliche Prozessadressraum besteht aus den folgenden Seiten:
QQ Seitenverzeichnis (auf Systemen mit Seitentabellen, die mehr als zwei Ebenen umfassen,
kann es mehr als ein Verzeichnis geben, beispielsweise auf x86-Systemen im PAE-Modus
und auf 64-Bit-Systemen)
QQ Hyperspace-Seite
QQ VAD-Bitmap-Seite
QQ Arbeitssatzliste
156
Kapitel 3
Prozesse und Jobs
Um diese Seiten zu erstellen, werden die folgenden Schritte ausgeführt:
1.
2.
In den entsprechenden Seitentabellen werden Einträge vorgenommen, um die ursprünglichen Seiten abzubilden.
Die Anzahl der Seiten wird aus der Kernelvariablen MmTotalCommittedPages ermittelt und zu
MmProcessCommit addiert.
3.
Die systemweite Mindestgröße für Arbeitssätze von Standardprozessen (PsMinimumWorkingSet) wird aus MmResidentAvailablePages ermittelt.
4.
Die Seitentabellenseiten für den globalen Systemraum (also alle außer den gerade beschriebenen prozessspezifischen Seiten und dem sitzungsspezifischen Arbeitsspeicher)
werden erstellt.
Phase 3c: Die KPROCESS-Struktur initialisieren
Die nächste Phase von PspAllocateProcess besteht darin, die KPROCESS-Struktur zu initialisieren
(das Element Pcb in EPROCESS). Diese Aufgabe erledigt KeInitializeProcess wie folgt:
1.
Die doppelt verlinkte Liste, die alle zu dem Prozess gehörenden Threads verbindet und
ursprünglich leer ist, wird initialisiert.
2.
Der Anfangswert (oder Rücksetzwert) des Standardquantums für den Prozess (siehe den
Abschnitt »Threadplanung« in Kapitel 4) wird als 6 hartcodiert, bis er später von PspComputeQuantumAndPriority initialisiert wird.
Das ursprüngliche Standardquantum ist in den Client- und den Serverversionen
von Windows unterschiedlich. Weitere Angaben dazu erhalten Sie im Abschnitt
»Threadplanung« in Kapitel 4.
3.
Die Basispriorität des Prozesses wird auf den in Phase 3a berechneten Wert gesetzt.
4.
Die Standardprozessoraffinität für die Threads in dem Prozess wird festgelegt. Die Gruppenaffinität wird auf den in Phase 3a berechneten oder auf den vom Elternprozess geerbten Wert gesetzt.
5.
Der Swapping-Status für den Prozess wird auf resident gesetzt.
6.
Der Thread-Seed wird anhand des idealen Prozessors bestimmt, den der Kernel für den
Prozess ausgewählt hat (und der wiederum auf dem idealen Prozessor des zuvor erstellten
Prozesses basiert, was letzten Endes zu einer Randomisierung in der Art eines Umlaufverfahrens führt). Beim Erstellen eines neuen Prozesses wird der Seed in KeNodeBlock (dem
ursprünglichen NUMA-Knotenblock) aktualisiert, sodass der nächste neue Prozessor einen
anderen idealen Prozessor für den Seed erhält.
7.
Bei einem sicheren Prozess (Windows 10 und Windows Server 2016) wird jetzt die sichere
ID durch einen Aufruf von HvlCreateSecureProcess erstellt.
Der Ablauf von CreateProcess
Kapitel 3
157
Phase 3d: Die Einrichtung des Prozessadressraums abschließen
Die Einrichtung des Adressraums für einen neuen Prozess ist recht kompliziert, weshalb wir uns
diesen Vorgang Schritt für Schritt ansehen. Für das Verständnis dieses Abschnitts sind Kenntnisse des in Kapitel 5 beschriebenen Speicher-Managers von Nutzen.
Den Großteil der Arbeit zum Einrichten des Adressraums erledigt die Routine MmInitializeProcessAddressSpace. Sie ermöglicht es auch, den Adressraum eines anderen Prozesses zu
klonen. Diese Möglichkeit war früher praktisch, um den POSIX-Systemaufruf fork zu implementieren, und kann sich in Zukunft vielleicht auch wieder als nützlich erweisen, um andere
fork-Aufrufe nach Art von Unix zu unterstützen. (Auf diese Weise wird fork im Windows-Teilsystem für Linux in Redstone 1 implementiert.) In den folgenden Schritten wird dieser Klonvorgang jedoch nicht beschrieben, sondern die normale Initialisierung des Prozessadressraums:
1.
Der Manager für den virtuellen Speicher setzt den Wert für den letzten Kürzungszeitpunkt
des Prozesses auf die aktuelle Zeit. Der Arbeitssatz-Manager (der im Kontext des Systemthreads für den Ausgleichssatz-Manager läuft) bestimmt anhand dieses Wertes, wann er
die Kürzung des Arbeitssatzes auslösen soll.
2.
Der Speicher-Manager initialisiert die Arbeitssatzliste des Prozesses. Jetzt können Seitenfehler entgegengenommen werden.
3.
Der Abschnitt (der beim Öffnen der Abbilddatei erstellt wurde) wird jetzt im Adressraum
des neuen Prozesses abgebildet. Die Basisadresse des Prozessabschnitts wird auf die Basis
adresse des Abbilds gesetzt.
4.
Der Prozessumgebungsblock (PEB) wird erstellt und initialisiert (siehe Phase 3e).
5.
Ntdll.dll wird dem Prozess zugeordnet, und bei einem Wow64-Prozess auch die 32-Bit-Version von Ntdll.dll.
6.
Falls verlangt, wird eine neue Sitzung für den Prozess erstellt. Dieser Schritt ist hauptsächlich für den Sitzungs-Manager (Smss) bei der Initialisierung einer neuen Sitzung da.
7.
Die Standardhandles werden dupliziert und die neuen Werte werden in die Prozessparameterstruktur geschrieben.
8.
Alle in der Attributliste aufgeführten Speicherreservierungen werden jetzt verarbeitet. Zwei
Flags erlauben auch eine Massenreservierung der ersten 1 oder 16 MB des Adressraums.
Diese Flags werden intern verwendet, um beispielsweise Realmodusvektoren und ROMCode zuzuordnen (die sich im unteren Bereich des virtuellen Adressraums befinden müssen, wo normalerweise der Heap oder andere Prozessstrukturen angeordnet werden).
9.
Die Benutzerprozessparameter werden in den Prozess geschrieben, kopiert und von der
absoluten in eine relative Form umgewandelt, sodass nur ein einziger Speicherblock dafür
erforderlich ist.
10. Die Affinitätsinformationen werden in den PEB geschrieben.
11. Der API-Umleitungssatz MinWin wird in dem Prozess abgebildet. Sein Zeiger wird im PEB
gespeichert.
12. Die eindeutige Prozess-ID wird ermittelt und gespeichert. Der Kernel unterscheidet nicht
zwischen eindeutigen Prozess- und Thread-IDs und Handles. Prozess- und Thread-IDs
158
Kapitel 3
Prozesse und Jobs
(Handles) werden in der globalen Handletabelle PspCidTable gespeichert, die nicht mit
einem Prozess verknüpft ist.
13. Wenn es sich um einen sicheren Prozess handelt (wenn er also im IUM läuft), so wird er
initialisiert und mit dem Kernelprozessobjekt verknüpft.
Phase 3e: Den PEB einrichten
NtCreateUserProcess ruft MmCreatePeb auf, die als Erstes die systemweiten Sprachunterstüt-
zungstabellen (National Language Support, NLS) in den Prozessadressraum abbildet. Anschließend ruft sie MiCreatePeb=rTeb auf, um eine Seite für den PEB zuzuweisen, und initialisiert dann
eine Reihe von Feldern, größtenteils auf der Grundlage von internen Variablen, die über die
Registrierung eingestellt wurden, z. B. MmHeap*-Werte, MmCriticalSectionTimeout und MmMinimumStackCommitInBytes. Einige dieser Felder können durch Einstellungen im verlinkten ausführbaren Image überschrieben werden, z. B. die Windows-Version im PE-Header und die Affinitätsmaske in dessen Ladekonfigurationsverzeichnis.
Ist das Abbildheader-Flag IMAGE_FILE_UP_SYSTEM_ONLY gesetzt (was bedeutet, dass das Abbild nur auf einem Einzelprozessorsystem ausgeführt werden kann), so wird für alle Threads
in diesem Prozess eine einzige CPU ausgewählt (MmRotatingUniprocessorNumber). Die Auswahl
erfolgt einfach durch Durchlaufen aller verfügbaren Prozessoren. Jedes Mal, wenn ein Abbild
dieser Art ausgeführt wird, kommt der nächste Prozessor an die Reihe. Dadurch werden solche
Abbilder gleichmäßig auf die Prozessoren verteilt.
Phase 3f: Die Einrichtung des Exekutivprozessobjekts abschließen
Bevor das Handle für den neuen Prozess zurückgegeben werden kann, müssen noch einige
letzte Einrichtungsschritte abgeschlossen werden. Ausgeführt werden sie von PspInsertProcess
und ihren Hilfsfunktionen:
1.
Ist die systemweite Prozessüberwachung aktiviert (aufgrund einer lokalen Richtlinieneinstellung oder einer Gruppenrichtlinieneinstellung auf einem Domänencontroller), so wird
das Erstellen des Prozesses im Sicherheitsprotokoll vermerkt.
2.
War der Elternprozess in einem Job enthalten, so wird dieser Job aus dem Jobsatz des
Elternprozesses wiederhergestellt und an die Sitzung des neuen Prozesses gebunden.
Schließlich wird der neue Prozess zu dem Job hinzugefügt.
3.
Das neue Prozessobjekt wird am Ende der Windows-Liste aktiver Prozesse eingefügt (PsActiveProcessHead). Jetzt ist der Prozess für Funktionen wie EnumProcess und OpenProcess
zugänglich.
4.
Der Prozessdebugport des Elternprozesses wird in den neuen Kindprozess kopiert, es sei
denn, das Flag NoDebugInherit ist gesetzt (das beim Erstellen des Prozesses angefordert
werden kann). Wurde ein Debugport angegeben, so wird dieser mit dem neuen Prozess
verknüpft.
5.
Jobobjekte können die möglichen Gruppen beschränken, in denen die Threads in den
Prozessen des Jobs ausgeführt werden können. Daher vergewissert sich PspInsertProcess,
dass die Gruppenaffinität des Prozesses nicht die Gruppenaffinität des Jobs verletzt. Ein
Der Ablauf von CreateProcess
Kapitel 3
159
weiteres interessantes Problem liegt vor, wenn die Berechtigungen des Jobs es erlauben,
die Affinitätsberechtigungen des Prozesses zu ändern, da ein Jobobjekt mit geringeren
Rechten dann die Affinitätsanforderungen eines höher privilegierten Prozesses manipulieren könnte.
6.
Schließlich ruft PspInsertProcess die Funktion ObOpenObjectByPointer auf, um ein Handle
für den neuen Prozess zu erstellen, und gibt dieses Handle dann an den Aufrufer zurück.
Es wird erst dann ein Prozesserstellungscallback gesendet, wenn der erste Thread in dem
Prozess angelegt wurde. Der Code sendet Prozesscallbacks immer vor Callbacks zur Objektverwaltung.
Phase 4: Den ursprünglichen Thread mit seinem Stack und
Kontext erstellen
Das Windows-Exekutivprozessobjekt ist jetzt fast vollständig eingerichtet. Es hat jedoch noch
keinen Thread und kann daher nichts tun. Für alle Aspekte der Threaderstellung ist normalerweise die Routine PspCreateThread zuständig, die von NtCreateThread aufgerufen wird, um
einen neuen Thread anzulegen. Da der ursprüngliche Thread jedoch intern vom Kernel ohne
Eingaben vom Benutzermodus erstellt wird, kommen stattdessen die beiden Hilfsroutinen
PspAllocateThread und PspInsertThread zum Einsatz, auf die sich auch PspCreateThread stützt.
Dabei kümmert sich PspAllocateThread darum, das Exekutivthreadobjekt zu erstellen und zu
initialisieren, während PspInsertHandle den Threadhandle und die Sicherheitsattribute anlegt
und KeStartThread aufruft, um aus dem Exekutivobjekt einen planbaren Thread zu machen. Allerdings tut der Thread danach immer noch nichts, da er in angehaltenem Zustand erstellt wird.
Er wird erst wieder aufgenommen, wenn der Prozess vollständig initialisiert ist (siehe Phase 5).
Der Threadparameter (der nicht in CreateProcess, sondern in CreateThread gesetzt
werden kann) gibt die Adresse des PEB an. Verwendet wird dieser Parameter von
dem Initialisierungscode, der im Kontext des neuen Threads ausgeführt wird (siehe Phase 6).
PspAllocateThread führt die folgenden Schritte aus:
1.
Sie verhindert, dass in Wow64-Prozessen UMS-Threads (User-Mode Scheduling) erstellt
werden und dass Aufrufer aus dem Benutzermodus Threads in Systemprozessen anlegen.
2.
Sie erstellt und initialisiert ein Exekutivthreadobjekt.
3.
Sind für das System Energieabschätzungen aktiviert (auf der Xbox sind sie immer deaktiviert), weist sie die THREAD_ENERGY_VALUES-Struktur zu, auf die das ETHREAD-Objekt zeigt, und
initialisiert sie.
4.
Sie initialisiert die Listen, die von LPC, der E/A-Verwaltung und der Exekutive verwendet
werden.
5.
Sie legt die Threaderstellungszeit fest und richtet die Thread-ID ein.
160
Kapitel 3
Prozesse und Jobs
6.
Bevor der Thread ausgeführt werden kann, braucht er einen Stack und einen Ausführungskontext, die jetzt von der Routine eingerichtet werden. Die Stackgröße für den ursprünglichen Thread wird aus dem Abbild bezogen. Es gibt keine Möglichkeit, eine andere Größe
anzugeben. Bei einem Wow64-Prozess wird auch der Wow64-Threadkontext initialisiert.
7.
Sie weist den Threadumgebungsblock (TEB) für den neuen Thread zu.
8.
Die Benutzermodus-Startadresse für den Thread wird im Feld StartAddress der ETHREAD-Struktur gespeichert. Dies ist die vom System bereitgestellte Threadstartfunktion
RtlUserThreadStart aus Ntdll.dll. Die vom Benutzer angegebene Windows-Startadresse
wird ebenfalls in der ETHREAD-Struktur gespeichert, aber an anderer Stelle, nämlich im Feld
Win32StartAddress. Dadurch sind Debuggingwerkzeuge wie Process Explorer in der Lage,
diese Information anzuzeigen.
9.
Um die KTHREAD-Struktur einzurichten, wird KeInitThread aufgerufen. Die ursprüngliche
und die aktuelle Basispriorität des Threads, seine Affinität und sein Quantum werden auf
die Basispriorität des Prozesses gesetzt. Danach weist KeInitThread einen Kernelstack für
den Thread zu und initialisiert den maschinenabhängigen Hardwarekontext für den
Thread einschließlich Kontext-, Trap- und Ausnahmeframes. Der Threadkontext wird so
eingerichtet, dass der Thread in KiThreadStartup im Kernelmodus gestartet wird. Schließlich setzt KeInitThread den Threadstatus auf Initialized und gibt die Steuerung an
PspAllocateThread zurück.
10. Bei einem UMS-Thread wird PspUmsInitThread aufgerufen, um den UMS-Status zu initialisieren.
Nachdem diese Aufgaben erledigt sind, ruft NtCreateUserProcess die Funktion PspInsertThread
auf, um die folgenden Schritte auszuführen:
1.
Sofern in einem Attribut ein idealer Prozessor für den Thread angegeben wurde, wird er
jetzt initialisiert.
2.
Sofern in einem Attribut eine Gruppenaffinität für den Thread angegeben wurde, wird sie
jetzt initialisiert.
3.
Gehört der Prozess zu einem Job, wird eine Überprüfung durchgeführt, um sicherzustellen,
dass die Gruppenaffinität des Threads die Einschränkungen des Jobs nicht verletzt (siehe
die Beschreibung weiter vorn).
4.
Es wird geprüft, ob der Prozess oder der Thread bereits beendet wurde und ob der Thread
schon lauffähig war. Wenn irgendetwas davon zutrifft, schlägt die Threaderstellung fehl.
5.
Wenn der Thread zu einem sicheren Prozess (IUM) gehört, wird ein sicheres Threadobjekt
erstellt und initialisiert.
6.
Der KTHREAD-Teil des Threadobjekts wird durch einen Aufruf von KeStartThread initialisiert.
Dazu werden die Schedulereinstellungen vom Besitzerprozess geerbt, der ideale Knoten
und Prozessor festgelegt, die Gruppenaffinität aktualisiert, die Basis- und die dynamische
Priorität gesetzt (durch Kopieren vom Prozess), das Threadquantum bestimmt und der
Thread in die von KPROCESS gepflegte Prozessliste eingefügt (wobei es sich um eine andere
Liste als die in EPROCESS handelt).
Der Ablauf von CreateProcess
Kapitel 3
161
7.
Ist der Prozess »tiefgefroren« (dürfen in ihm also keine Threads ausgeführt werden, auch
keine neuen), so wird auch der Thread eingefroren.
8.
Wenn es sich auf einem Nicht-x86-System um den ersten Thread eines Prozesses handelt
(und dieser wiederum nicht der Leerlaufprozess ist), wird der Prozess in eine weitere systemweite Prozessliste eingefügt, die von der globalen Variablen PiProcessListHead gepflegt wird.
9.
Der Threadzähler des Prozessobjekts wird erhöht und die E/A- und Seitenpriorität des
Besitzerprozesses werden geerbt. Ist die neue Threadanzahl die höchste, die es in dem Prozess bisher gegeben hat, wird auch der Threadspitzenzähler aktualisiert. Bei dem zweiten
Thread eines Prozesses wird das Primärtoken eingefroren, sodass es nicht mehr geändert
werden kann.
10. Der Thread wird in die Threadliste des Prozesses eingefügt und angehalten, wenn der Erstellerprozess dies verlangt hat.
11. Das Threadobjekt wird in die Prozesshandletabelle eingefügt.
12. Handelt es sich um den ersten Thread des Prozesses (wurde er also im Rahmen eines
CreateProcess*-Aufrufs erstellt), werden alle registrierten Callbacks für die Prozesserstellung und danach alle registrierten Callbacks für die Threaderstellung aufgerufen. Wenn
irgendeiner dieser Callbacks ein Veto gegen den Erstellungsvorgang einlegt, schlägt er
fehl, woraufhin ein entsprechender Status an den Aufrufer zurückgegeben wird.
13. Wurde über ein Attribut eine Jobliste angegeben und ist dies der erste Thread in dem
Prozess, so wird der Prozess allen Jobs auf der Liste zugewiesen.
14. Der Thread wird durch einen Aufruf von KeReadyThread zur Ausführung bereit gemacht
und tritt in den verzögerten Bereitschaftsstatus ein (siehe Kapitel 4).
Phase 5: Spezifische Prozessinitialisierung für das WindowsTeilsystem durchführen
Wenn NtCreateUserProcess einen Erfolgscode zurückgibt, sind die erforderlichen Exekutivprozess- und Exekutivthreadobjekte erstellt worden. Anschließend führt CreateProcessInternalW
einige spezifische Operationen für das Windows-Teilsystem aus, um die Prozessinitialisierung
abzuschließen.
1.
Es wird geprüft, ob Windows die Ausführung der ausführbaren Datei erlauben soll. Dazu
wird die Abbildversion im Header validiert und nachgeforscht, ob die Windows-Anwendungszertifizierung den Prozess durch eine Gruppenrichtlinie blockiert hat. Bei besonderen Ausgaben von Windows Server 2012 R2, z. B. Windows Storage Server 2012 R2,
erfolgen noch weitere Prüfungen, um zu sehen, ob die Anwendung unzulässige APIs
importiert.
2.
Wenn es von Softwareeinschränkungsrichtlinien vorgeschrieben ist, wird für den neuen
Prozess ein eingeschränktes Token erstellt. Anschließend wird die Anwendungskompatibilitätsdatenbank danach abgefragt, ob es für den Prozess einen Eintrag in der Registrierung oder der Anwendungsdatenbank des Systems gibt. Zu diesem Zeitpunkt werden noch
162
Kapitel 3
Prozesse und Jobs
keine Kompatibilitätsshims angewendet. Die Informationen werden im PEB gespeichert,
sobald der ursprüngliche Start mit der Ausführung beginnt (Phase 6).
3.
CreateProcessInternalW ruft (für nicht geschützte Prozesse) einige interne Funktionen
auf, um SxS-Informationen wie Manifestdateien und DLL-Umleitungspfade (siehe den Abschnitt »DLL-Namensauflösung und -Umleitung« weiter hinten in diesem Kapitel) sowie
weitere Informationen zu gewinnen, z. B. ob sich die EXE-Datei auf einem Wechselmedium
befindet und welche Installererkennungsflags gesetzt sind. Für immersive Prozesse werden
auch Versionsinformationen und die Angabe der Zielplattform aus dem Paketmanifest zurückgegeben.
4.
Aus den folgenden gesammelten Informationen wird eine Nachricht an das Windows-Teilsystem (Csrss) zusammengestellt:
•
Name des Pfades und des SxS-Pfades
•
Prozess- und Threadhandles
•
Abschnittshandle
•
Zugriffstokenhandle
•
Medieninformationen
•
AppCompat- und Shim-Daten
•
Informationen über immersive Prozesse
•
PEB-Adresse
•
Verschiedene Flags, z. B. zur Angabe, ob der Prozess geschützt ist oder mit erhöhten
Rechten ausgeführt werden soll
•
Ein Flag zur Angabe, ob der Prozess zu einer Windows-Anwendung gehört (damit
Csrss bestimmen kann, ob der Startcursor angezeigt werden soll)
•
Sprachinformationen für die Benutzeroberfläche
•
DLL-Umleitungs- und .local-Flags (siehe den Abschnitt »Der Abbildlader« weiter hinten in diesem Kapitel)
•
Informationen aus der Manifestdatei
Wenn das Windows-Teilsystem diese Nachricht erhält, führt es die folgenden Schritte aus:
1.
CsrCreateProcess dupliziert ein Handle für den Prozess und den Thread. In diesem Schritt
wird der Verwendungszähler des Prozesses und des Threads von dem bei der Erstellung
festgelegten Wert 1 auf 2 hochgesetzt.
2.
Die CSR_PROCESS-Struktur wird zugewiesen.
3.
Der Ausnahmeport des neuen Prozesses wird auf den allgemeinen Funktionsport für das
Windows-Teilsystem gesetzt, sodass das Teilsystem eine Nachricht empfängt, wenn in dem
Prozess eine Zweite-Chance-Ausnahme auftritt (zur Ausnahmebehandlung siehe Kapitel 8
in Band 2).
4.
Wird eine neue Prozessgruppe mit dem neuen Prozess als Stammprozess erstellt (Flag
CREATE_NEW_PROCESS_GROUP in CreateProcess), dann wird sie in CSR_PROCESS eingerichtet.
Prozessgruppen sind praktisch, um Steuerereignisse an mehrere Prozesse zu senden, die
Der Ablauf von CreateProcess
Kapitel 3
163
sich eine Konsole teilen. Weitere Informationen finden Sie in der Dokumentation des
Windows SDK über CreateProcess und GenerateConsoleCtrlEvent.
5.
Die CSR_THREAD-Struktur wird zugewiesen und initialisiert.
6.
CsrCreateThread fügt den Thread in die Threadliste für den Prozess ein.
7.
Der Prozesszähler der Sitzung wird heraufgesetzt.
8.
Die Prozessbeendigungsebene wird auf den Standardwert 0x280 (siehe SetProcessShut
downParameters in der Dokumentation des Windows SDK).
9.
Die neue CSR_PROCESS-Struktur wird in die Liste der Prozesse für das gesamte Windows-Teilsystem eingefügt.
Nachdem Csrss diese Schritte durchgeführt hat, prüft CreateProcessInternalW, ob der Prozess mit erhöhten Rechten ausgeführt wurde (was bedeutet, dass er über ShellExecute ausgeführt wurde und vom AppInfo-Dienst höhere Rechte erhalten hat, nachdem dem Benutzer
das Bestätigungsdialogfeld angezeigt wurde). Dazu wird unter anderem nachgesehen, ob es
sich bei dem Prozess um ein Setupprogramm handelt. Wenn ja, wird das Prozesstoken geöffnet und das Virtualisierungsflag eingeschaltet, damit die Anwendung virtualisiert wird (siehe
die Informationen zur Benutzerkontensteuerung und Virtualisierung in Kapitel 7). Enthält die
Anwendung Shims zur Rechteerhöhung oder hat sie in ihrem Manifest eine höhere Rechte
ebene angefordert, wird der Prozess zerstört und eine Anforderung zur Rechteerhöhung an
den AppInfo-Dienst gesendet.
Für geschützte Prozesse entfallen die meisten dieser Überprüfungen. Da diese Prozesse für
Windows Vista oder höher entworfen sein müssen, besteht keinerlei Grund für eine Überprüfung auf Rechteerhöhung, Virtualisierung und Anwendungskompatibilität. Außerdem könnte
es zu Sicherheitslücken führen, wenn Mechanismen wie die Shim-Engine ihre üblichen Hookund Speicherpatch-Techniken bei geschützten Prozessen anwenden dürften, denn dann wäre
es Angreifern möglich, eigene Shims einzufügen, die das Verhalten der geschützten Prozesse ändern. Da die Shim-Engine vom Elternprozess installiert wird, der möglicherweise keinen
Zugriff auf seinen geschützten Kindprozess hat, würde selbst eine legitime Verwendung von
Shims unter Umständen nicht funktionieren.
Phase 6: Ausführung des ursprünglichen Threads starten
Jetzt ist die Prozessumgebung festgelegt, die Ressourcen für den Thread sind zugewiesen, der
Prozess hat einen Thread und das Windows-Teilsystem weiß über den neuen Prozess Bescheid.
Sofern der Aufrufer nicht das Flag CREATE_SUSPENDED angegeben hat, wird der ursprüngliche
Thread jetzt wieder aufgenommen, sodass er mit der Ausführung beginnen und die restlichen
Arbeiten zur Prozessinitialisierung ausführen kann, die im Kontext des neuen Prozesses nötig
sind (Phase 7).
164
Kapitel 3
Prozesse und Jobs
Phase 7: Prozessinitialisierung im Kontext des neuen Prozesses
durchführen
Als Erstes führt der neue Thread die Kernelmodus-Threadstartroutine KiStartUserThread aus. Sie
senkt die IRQL-Ebene des Threads von DPC (Deferred Procedure Call, verzögerter Prozeduraufruf)
in APC und ruft dann die ursprüngliche Threadroutine des Systems auf, PspUserThreadStartup.
Dieser Routine wird die vom Benutzer angegebene Threadstartadresse als Parameter übergeben.
PspUserThreadStartup führt dann die folgenden Aktionen aus:
1.
Auf einer x86-Architektur installiert sie eine Ausnahmekette. (Auf anderen Architekturen
weicht die Vorgehensweise ab; siehe Kapitel 8 in Band 2.)
2.
Sie senkt die IRQL-Ebene auf PASSIVE_LEVEL (Ebene 0, was die einzige IRQL-Ebene ist, auf
der Benutzercode ausgeführt werden darf).
3.
Sie deaktiviert die Möglichkeit, das primäre Prozesstoken zur Laufzeit auszutauschen.
4.
Wurde der Thread beim Start aus irgendeinem Grund abgebrochen, so wird er beendet. Es
werden dann keine weiteren Maßnahmen unternommen.
5.
Sie legt aufgrund der Informationen in den Kernelmodus-Datenstrukturen die Gebietsschema-ID und den idealen Prozessor im TEB fest und prüft, ob die Threaderstellung fehlgeschlagen ist.
6.
Sie ruft DbgkCreateThread auf, die prüft, ob Abbildbenachrichtigungen für den neuen Prozess gesendet wurden. Wenn das nicht der Fall ist, Benachrichtigungen aber aktiviert sind,
wird eine Abbildbenachrichtigung erst für den Prozess und dann für den Abbildladevorgang von Ntdll.dll gesendet.
Dieser Vorgang erfolgt in dieser Phase und nicht bei der ursprünglichen Zuordnung der Abbilder, da die für Kernel-Callouts notwendige Prozess-ID dann noch
gar nicht zugewiesen ist.
7.
Danach folgt eine weitere Überprüfung, um zu sehen, ob es sich um einen zu debuggenden Prozess handelt. Wenn das der Fall ist, aber noch keine Debuggerbenachrichtigungen
gesendet wurden, wird durch das Debugobjekt (falls vorhanden) eine Prozesserstellungsnachricht gesendet, sodass das Prozessstart-Debugereignis (CREATE_PROCESS_DEBUG_INFO)
an den entsprechenden Debuggerprozess gesendet werden kann. Darauf folgt ein ähnliches Threadstart-Debugereignis sowie ein weiteres Debugereignis für den Abbildladevorgang von Ntdll.dll. Anschließend wartet DbgkCreateThread auf eine Antwort des Debuggers
(über die Funktion ContinueDebugEvent).
8.
Sie prüft, ob das Anwendungs-Prefetching auf dem System aktiviert ist. Wenn ja, ruft sie
den Prefetcher (und SuperFetch) auf, um die Prefetch-Anweisungsdatei (falls vorhanden)
und die während der ersten zehn Sekunden der letzten Prozessausführung referenzierten
Prefetchseiten zu verarbeiten. (Mehr über den Prefetcher und SuperFetch erfahren Sie in
Kapitel 5.)
Der Ablauf von CreateProcess
Kapitel 3
165
9.
Sie prüft, ob das systemweite Cookie in der Struktur SharedUserData eingerichtet wurde.
Wenn nicht, generiert sie es auf der Grundlage eines Hashs von Systeminformationen wie
der Anzahl der verarbeiteten Interrupts, der DPC-Auslieferungen, der Seitenfehler, der Interruptzeit und einer Zufallszahl. Dieses systemweite Cookie wird als Schutz gegen bestimmte Arten von Exploits bei der internen Codierung und Decodierung von Zeigern verwendet, u. a. im Heap-Manager. (Mehr über die Sicherheit des Heap-Managers erfahren
Sie in Kapitel 5.)
10. Bei einem sicheren Prozess (IUM-Prozess) wird HvlStartSecureThread aufgerufen, um die
Steuerung für den Start der Threadausführung an den sicheren Kernel zu übertragen. Diese
Funktion gibt die Steuerung nur zurück, wenn der Thread vorhanden ist.
11. Sie richtet den ursprünglichen Thunkkontext zur Ausführung der Initialisierungsroutine
des Abbildladers (LdrInitializeThunk in Ntdll.dll) und den systemweiten Threadstartstub
ein (RtlUserThreadStart in Ntdll.dll). Dazu wird der Kontext des Threads direkt bearbeitet
und dann eine Beendigung des Systemdienstbetriebs verlangt, wodurch dieser spezielle
Benutzerkontext geladen wird. Die Routine LdrInitializeThunk initialisiert den Lader, den
Heap-Manager, die NLS-Tabellen, die Arrays für den lokalen Threadspeicher (TLS) und
den lokalen Fiberspeicher (FLS) sowie kritische Abschnittsstrukturen. Anschließend lädt
sie alle erforderlichen DLLs und ruft die DLL-Eintrittspunkte mit dem Funktionscode von
DLL_PROCESS_ATTACH auf.
Sobald die Funktion die Steuerung zurückgibt, stellt NtContinue den neuen Benutzerkontext
wieder her und kehrt in den Benutzermodus zurück. Jetzt beginnt die echte Threadausführung.
RtlUserThreadStart verwendet die Adresse des eigentlichen Abbildeintrittspunktes und
den Startparameter und ruft den Eintrittspunkt der Anwendung auf. Diese beiden Parameter
wurden bereits vom Kernel auf den Stack gelegt. Für diesen komplizierten Ablauf gibt es zwei
Gründe:
QQ Der Abbildlader in Ntdll.dll wird dadurch in die Lage versetzt, den Prozess intern und hinter
den Kulissen einzurichten, sodass anderer Benutzermoduscode ordnungsgemäß ausgeführt werden kann. (Andernfalls gäbe es keinen Heap, keinen lokalen Threadspeicher usw.)
QQ Wenn alle Threads in einer gemeinsamen Routine beginnen, können sie mit einer Ausnahmebehandlung versehen werden. Dadurch kann Ntdll.dll es erkennen, wenn sie abstürzen,
und den Filter für nicht behandelte Ausnahmen in Kernel32.dll aufrufen. Außerdem kann
Ntdll.dll die Threadbeendigung beim Rücksprung von der Startroutine des Threads koordinieren und verschiedene Aufräumarbeiten durchführen. Anwendungsentwickler können
SetUnhandledExceptionFilter aufrufen, um ihren eigenen Code für den Umgang mit nicht
behandelten Ausnahmen hinzuzufügen.
166
Kapitel 3
Prozesse und Jobs
Experiment: Den Prozessstart verfolgen
Sie haben jetzt in allen Einzelheiten gesehen, wie ein Prozess startet und welche verschiedenen Operationen erforderlich sind, um mit der Ausführung einer Anwendung zu beginnen.
Nun wollen wir uns mit Process Monitor einige der Dateieingaben und -ausgaben ansehen,
die bei diesen Vorgängen erfolgen, sowie einige der Registrierungsschlüssel, auf die dabei
zugegriffen wird.
Dieses Experiment vermittelt zwar keine Gesamtansicht aller internen Schritte, die wir
zuvor beschrieben haben, doch Sie können dabei verschiedene Teile des Systems in Aktion
erleben, vor allem den Prefetcher und SuperFetch, die Überprüfung der Optionen zur Ausführung der Abbilddatei, weitere Kompatibilitätsprüfungen sowie die Zuordnung der DLL
des Abbildladers.
Als Beispiel verwenden wir eine sehr einfache ausführbare Datei, nämlich Notepad.exe
(den Windows-Editor), die wir an einer Eingabeaufforderung (Cmd.exe) starten. Beachten
Sie, dass wir uns dabei sowohl die Operationen innerhalb von Cmd.exe als auch die in Notepad.exe ansehen. Wie Sie bereits wissen, wird ein Großteil der Arbeiten im Benutzermodus
von der Funktion CreateProcessInternalW erledigt, die von dem Elternprozess aufgerufen
wird, bevor der Kernel das neue Prozessobjekt erstellt hat.
Gehen Sie zur Vorbereitung wie folgt vor:
1.
Fügen Sie im Process Monitor zwei Filter hinzu, einen für Cmd.exe und einen für Notepad.exe. Dies sind die beiden einzigen Prozesse, die Sie einschließen sollten. Sorgen Sie
dafür, dass zurzeit keine Instanzen dieser beiden Prozesse laufen, damit sichergestellt
ist, dass Sie sich auch die richtigen Ereignisse ansehen. Das Filterfenster sollte wie folgt
aussehen:
2.
Vergewissern Sie sich, dass die Ereignisprotokollierung zurzeit deaktiviert ist (öffnen Sie
File und deaktivieren Sie Capture Events). Starten Sie dann die Eingabeaufforderung.
3.
Aktivieren Sie die Ereignisprotokollierung (öffnen Sie File und wählen Sie Event Logging,
drücken Sie (Strg) + (E) oder klicken Sie auf das Lupensymbol auf der Symbolleiste).
Geben Sie dann Notepad.exe ein und drücken Sie die Eingabetaste. Auf einem typischen Windows-System erscheinen nun etwa 500 bis 3500 Ereignisse.
→
Der Ablauf von CreateProcess
Kapitel 3
167
4.
Stoppen Sie die Erfassung und blenden Sie die Spalten Sequence und Time of Day aus,
sodass Sie sich besser auf die für unser Experiment interessanten Spalten konzentrieren
können. Das Fenster sollte jetzt so ähnlich wie in dem folgenden Screenshot aussehen.
Wie in Phase 1 des Ablaufs von CreateProcess beschrieben, liest Cmd.exe, kurz bevor
der Prozess gestartet und der erste Thread erstellt wird, in der Registrierung, und zwar
in HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options\
Notepad.exe. Da mit Notepad.exe keine Optionen zur Ausführung des Abbilds verbunden
sind, wird der Prozess regulär erstellt.
Wie bei anderen Ereignissen im Protokoll von Process Monitor können Sie auch hier
durch Untersuchung des Ereignisstacks erkennen, welche Teile des Ablaufs zur Prozesserstellung im Benutzer- und welche im Kernelmodus durchgeführt wurden und durch welche Routinen das geschah. Dazu doppelklicken Sie auf das Ereignis RegOpenKey und wechseln zur Registerkarte Stack. Der folgende Screenshot zeigt den Standardstack auf einem
64-Bit-Computer mit Windows 10.
→
168
Kapitel 3
Prozesse und Jobs
Der Stack zeigt, dass Sie bereits den Teil der Prozesserstellung erreicht haben, der im Kernelmodus ausgeführt wird (durch NtCreateUserProcess) und dass die Hilfsroutine PspAllocateProcess für die vorliegende Überprüfung verantwortlich ist.
Wenn Sie sich die Liste der Ereignisse nach dem Erstellen des Threads und des Prozesses ansehen, werden Ihnen drei Gruppen von Ereignissen auffallen:
QQ Eine einfache Überprüfung von Flags zur Anwendungskompatibilität, durch die der
Prozesserstellungscode des Benutzermodus erkennen kann, ob eine Überprüfung in
der Anwendungskompatibilitätsdatenbank durch die Shim-Engine erforderlich ist.
QQ Mehrere Lesevorgänge in den SxS- (Side-By-Side), Manifest- und MUI-/Sprachschlüsseln, die zu dem zuvor erwähnten Assemblyframework gehören.
QQ Datei-E/A für eine oder mehrere .sdb-Dateien, bei denen es sich um die Anwendungskompatibilitätsdatenbanken auf dem System handelt. Bei diesen Ein-/Ausgaben finden
zusätzliche Überprüfungen statt, um herauszufinden, ob für die Shim-Engine diese Anwendung aufgerufen werden muss. Da der Editor ein gutwilliges Microsoft-Programm
ist, sind hier keine Shims nötig.
→
Der Ablauf von CreateProcess
Kapitel 3
169
Der folgende Screenshot zeigt die nächsten Ereignisse, die innerhalb des Notepad-Prozesses selbst auftreten. Dies sind die Aktionen, die der Benutzermodus-Threadstartwrapper
im Kernelmodus ausgelöst hat. Die ersten beiden sind Debugbenachrichtigungen über das
Laden von Abbildern von Notepad.exe und Ntdll.dll. Diese Nachrichten können erst jetzt
generiert werden, da der Code im Prozesskontext des Editors läuft und nicht mehr im Kontext der Eingabeaufforderung.
Als Nächstes greift der Prefetcher ein und sucht nach einer Prefetch-Datenbankdatei, die
bereits für den Editor generiert wurde. (Weitere Informationen über den Prefetcher erhalten Sie in Kapitel 5.) Wurde der Editor auf dem System schon mindestens einmal ausgeführt,
so ist diese Datenbank vorhanden, sodass der Prefetcher nun beginnt, die darin angegebenen Befehle auszuführen. In diesem Fall sehen Sie, wenn Sie weiter nach unten scrollen, wie
verschiedene DLLs gelesen und abgefragt werden. Anders als beim gewöhnlichen Laden
von DLLs – durch den Abbildlader des Benutzermodus, der sich die Importtabellen ansieht,
oder manuell durch Anwendungen – werden die Ereignisse hier vom Prefetcher hervorgerufen, der die vom Editor benötigten Bibliotheken kennt. Das gewöhnliche Laden von DLLs
folgt jedoch als Nächstes, und dabei werden Sie ähnliche Ereignisse wie hier sehen.
→
170
Kapitel 3
Prozesse und Jobs
Die Ereignisse werden jetzt von Benutzermoduscode generiert, der aufgerufen wurde, als
die Kernelmodus-Wrapperfunktion ihre Arbeit beendet hatte. Daher stammen die ersten
Ereignisse von LdrpInitializeProcess, die von LdrInitializeThunk für den ersten Thread
des Prozesses aufgerufen wurde. Das können Sie bestätigen, indem Sie sich den Ereignisstack ansehen – beispielsweise das Abbildladeereignis für Kernel32.dll, das im folgenden
Screenshot zu sehen ist.
→
Der Ablauf von CreateProcess
Kapitel 3
171
Es folgen weitere Ereignisse, die von dieser Routine und ihren Hilfsfunktionen hervorgerufen wurden. Schließlich gelangen Sie zu den Ereignissen der Funktion WinMain des Editors, in
der der Code ausgeführt wird, der der Kontrolle des Entwicklers unterliegt. Die ausführliche
Beschreibung aller Ereignisse und Benutzermoduskomponenten, die bei der Prozessausführung auftreten, würde ein ganzes Kapitel füllen. Die Untersuchung weiterer Ereignisse
überlassen wir Ihnen daher als Übungsaufgabe.
Einen Prozess beenden
Ein Prozess ist ein Container und eine Grenze. Das bedeutet, dass Ressourcen, die von einem
Prozess verwendet werden, in anderen Prozessen nicht unbedingt sichtbar sind. Um Informa
tionen zwischen Prozessen auszutauschen, ist daher ein Kommunikationsmechanismus erforderlich. Es ist auch nicht möglich, dass ein Prozess versehentlich willkürliche Bytes im Arbeitsspeicher eines anderen Prozesses überschreibt, denn das würde den ausdrücklichen Aufruf einer
Funktion wie WriteProcessMemory erfordern. Dazu wiederum müsste ausdrücklich ein Handle
mit der korrekten Zugriffsmaske (PROCESS_VM_WRITE) geöffnet werden, wobei nicht einmal sichergestellt ist, dass dieser Zugriff auch gewährt wird. Diese natürliche Isolation der Prozesse
bedeutet auch, dass eine Ausnahme in einem Prozess keine Auswirkungen auf andere Prozesse
hat. Schlimmstenfalls stürzt der Prozess ab, aber der Rest des Systems bleibt intakt.
Ein Prozess kann durch den Aufruf der Funktion ExitProcess ordnungsgemäß beendet
werden. Für viele Prozesse – je nach Linkereinstellung – ruft der Prozessstartcode für den ersten Thread ExitProcess im Namen des Prozesses auf, wenn der Thread von der Hauptfunktion zurückspringt. Ordnungsgemäß bedeutet hier, dass die in den Prozess geladenen DLLs
über die anstehende Beendigung des Prozesses benachrichtigt werden, damit sie die Gele-
172
Kapitel 3
Prozesse und Jobs
genheit bekommen, noch etwas zu tun. Diese Benachrichtigung erfolgt durch den Aufruf ihrer
D llMain-Funktion mit DLL_PROCESS_DETACH.
ExitProcess kann nur von dem zu beendenden Prozess selbst aufgerufen werden. Eine
nicht ordnungsgemäße Beendigung eines Prozesses ist mit der Funktion TerminateProcess
möglich, die von außerhalb des Prozesses aufgerufen werden kann. (Process Explorer und der
Task-Manager verwenden diese Funktion, wenn sie dazu aufgefordert werden.) TerminateProcess benötigt ein Handle für den Prozess, der mit der Zugriffsmaske PROCESS_TERMINATE
geöffnet wird. Allerdings wird dieser Zugriff nicht zwangsläufig gewährt. Daher ist es nicht
einfach und manchmal sogar unmöglich, bestimmte Prozesse zu beenden (z. B. Csrss). Nicht
ordnungsgemäß bedeutet hier, dass die DLLs keine Chance mehr haben, irgendwelchen Code
auszuführen (DLL_PROCESS_DETACH wird nicht gesendet), und alle Threads abrupt abgebrochen
werden. Das kann zu Datenverlusten führen, etwa wenn ein Dateicache keine Möglichkeit mehr
hat, seine Daten in die Zieldatei zu übertragen.
Wie auch immer ein Prozess beendet wird, es kann keine Lecks geben. Der gesamte private Arbeitsspeicher des Prozesses wird automatisch vom Kernel freigegeben, der Adressraum
wird zerstört, alle Handles zu Kernelobjekten werden geschlossen usw. Solange es noch offene
Handles zu dem Prozess gibt (weil die EPROCESS-Struktur nach wie vor existiert), können andere
Prozesse Zugriff auf einige der Prozessverwaltungsinformationen bekommen, z. B. auf den
Prozessbeendigungscode (GetExitCodeProcess). Nach dem Schließen dieser Handles wird die
EPROCESS-Struktur jedoch zerstört, sodass wirklich nichts mehr von dem Prozess übrig ist.
Allerdings können Drittanbietertreiber im Namen des Prozesses Zuweisungen im Kernelspeicher vornehmen, etwa aufgrund einer IOCTL (siehe Kapitel 6) oder einfach einer Prozessbenachrichtigung. Es liegt dann in ihrer Verantwortung, diesen Poolarbeitsspeicher freizugeben.
Windows hält sich nicht über den Kernelspeicher auf dem Laufenden, den ein Prozess besitzt,
und räumt ihn auch nicht auf (abgesehen von Arbeitsspeicher, der aufgrund vom Prozess erstellter Handles mit Objekten belegt ist). Damit der Treiber seinen Freigabepflichten nachkommen kann, wird er gewöhnlich über eine IRP_MJ_CLOSE-, IRP_MJ_CLEANUP- oder Prozessbeendigungsnachricht darüber informiert, dass das Handle für das Geräteobjekt geschlossen wurde.
Der Abbildlader
Wenn auf dem System ein Prozess gestartet wird, erstellt der Kernel ein Prozessobjekt dafür
und führt verschiedene Initialisierungstätigkeiten aus. Dies führt jedoch nicht zur Ausführung
der Anwendung, sondern bereitet lediglich den Kontext und die Umgebung vor. Im Gegensatz
zu Treibern, bei denen es sich um Kernelmoduscode handelt, werden Anwendungen im Benutzermodus ausgeführt. Der Großteil der eigentlichen Initialisierungsarbeit erfolgt außerhalb des
Kernels. Sie wird durch den Abbildlader erledigt, der intern als Ldr bezeichnet wird.
Der Abbildlader befindet sich in der Benutzermodus-System-DLL Ntdll.dll und nicht in der
Kernelbibliothek. Daher verhält er sich wie Standardcode aus einer DLL und unterliegt denselben Einschränkungen für den Speicherzugriff und die Sicherheitsrechte. Das Besondere an diesem Code ist, dass er im laufenden Prozess garantiert vorhanden ist (da Ntdll.dll stets geladen
wird) und als erster Benutzermoduscode eines neuen Prozesses ausgeführt wird.
Der Abbildlader
Kapitel 3
173
Da der Lader vor dem eigentlichen Anwendungscode ausgeführt wird, ist er für Benutzer
und Entwickler gewöhnlich nicht sichtbar. Obwohl seine Initialisierungsaufgaben verborgen
sind, kann ein Programm zur Laufzeit mit den Schnittstellen des Laders kommunizieren, z. B.
beim Laden oder Entladen einer DLL oder beim Abfragen der Basisadresse einer DLL. Der Lader
ist unter anderem für die folgenden Aufgaben zuständig:
QQ Initialisierung des Benutzermodusstatus der Anwendung, z. B. durch Erstellen des ursprünglichen Heaps und Einrichten der Slots für den lokalen Thread- und Fiberspeicher
(TLS bzw. FLS).
QQ Analyse der Importtabelle (IAT) der Anwendung, um nach allen erforderlichen DLLs zu
suchen (mit anschließender rekursiver Analyse der IATs der einzelnen DLLs), gefolgt von
der Analyse der Exporttabellen der DLLs, um sicherzustellen, dass die Funktion tatsächlich
vorhanden ist. (Mit besonderen Forwarder-Einträgen kann ein Export zu einer anderen DLL
umgeleitet werden.)
QQ Laden und Entladen von DLLs zur Laufzeit und bei Bedarf und Pflege einer Liste aller geladenen Module (Moduldatenbank).
QQ Handhabung von Manifestdateien für die SxS-Unterstützung (Side-by-Side) sowie von
MUI-Dateien und -Ressourcen (Multiple Language User Interface).
QQ Durchsuchen der Anwendungskompatibilitätsdatenbank nach Shims und ggf. Laden der
DLL für die Shim-Engine.
QQ Aktivieren der Unterstützung für API-Sets und API-Umleitung, einem Kernbestandteil der
One Core-Funktionalität, die es ermöglicht, UWP-Anwendungen zu erstellen (Universal
Windows Platform).
QQ Aktivieren von Vorbeugungsmaßnahmen zur dynamischen Laufzeitkompatibilität durch
SwitchBack-Mechanismen sowie Interaktion mit der Shim-Engine und den Anwendungsverifizierungsmechanismen.
Die meisten dieser Aufgaben sind unverzichtbar, um es der Anwendung zu ermöglichen, ihren
eigenen Code auszuführen. Ohne sie würden alle Vorgänge vom Aufruf externer Funktionen
bis zur Verwendung des Heaps sofort fehlschlagen. Nachdem der Prozess erstellt ist, ruft der
Lader die native API NtContinue auf, um die Ausführung gemäß dem Ausnahmeframe fortzusetzen, der auf dem Stack liegt, wie es auch jeder andere Ausnahmehandler tun würde. Dieser
Ausnahmeframe wurde vom Kernel erstellt und enthält den eigentlichen Eintrittspunkt der
Anwendung. Da der Lader keinen Standardaufruf ausführt oder in die laufende Anwendung
hineinspringt, sind die Initialisierungsfunktionen des Laders im Aufrufbaum der Stackablaufverfolgung für einen Thread niemals zu sehen.
174
Kapitel 3
Prozesse und Jobs
Experiment: Den Abbildlader beobachten
In diesem Experiment verwenden Sie globale Flags, um die Debuggerfunktion der Lader
snapshots zu aktivieren. Damit können Sie beim Debuggen des Anwendungsstarts die Debugausgabe des Abbildladers einsehen.
1.
Starten Sie in dem Verzeichnis, in dem Sie WinDbg installiert haben, die Anwendung
Gflags.exe und klicken Sie auf die Registerkarte Image File.
2.
Geben Sie Notepad.exe in das Feld Image ein und drücken Sie (Tab). Dadurch werden
die verschiedenen Optionen aktiviert. Wählen Sie Show Loader Snaps aus und klicken
Sie auf OK oder Apply.
3.
Starten Sie WinDbg, öffnen Sie das Menü File, wählen Sie Open Executable und suchen
Sie C:\Windows\System32\Notepad.exe, um sie zu starten. Es werden jetzt Debuginformationen wie die folgenden angezeigt:
0f64:2090 @ 02405218 - LdrpInitializeProcess - INFO: Beginning execution of
notepad.exe (C:\WINDOWS\notepad.exe)
Current directory: C:\Program Files (x86)\Window Kits\10\Debuggers\
Package directories: (null)
0f64:2090 @ 02405218 - LdrLoadDll - ENTER: DLL name: KERNEL32.DLL
0f64:2090 @ 02405218 - LdrpLoadDllInternal - ENTER: DLL name: KERNEL32.DLL
0f64:2090 @ 02405218 - LdrpFindKnownDll - ENTER: DLL name: KERNEL32.DLL
0f64:2090 @ 02405218 - LdrpFindKnownDll - RETURN: Status: 0x00000000
0f64:2090 @ 02405218 - LdrpMinimalMapModule - ENTER: DLL name: C:\WINDOWS\
System32\KERNEL32.DLL
ModLoad: 00007fff'5b4b0000 00007fff'5b55d000 C:\WINDOWS\System32\KERNEL32.
DLL
0f64:2090 @ 02405218 - LdrpMinimalMapModule - RETURN: Status: 0x00000000
0f64:2090 @ 02405218 - LdrpPreprocessDllName - INFO: DLL api-ms-wincorertlsupportl1-2-0.dll was redirected to C:\WINDOWS\SYSTEM32\ntdll.dll by API set
0f64:2090 @ 02405218 - LdrpFindKnownDll - ENTER: DLL name: KERNELBASE.dll
0f64:2090 @ 02405218 - LdrpFindKnownDll - RETURN: Status: 0x00000000
0f64:2090 @ 02405218 - LdrpMinimalMapModule - ENTER: DLL name: C:\WINDOWS\
System32\KERNELBASE.dll
ModLoad: 00007fff'58b90000 00007fff'58dc6000 C:\WINDOWS\System32\KERNELBASE.
dll
0f64:2090 @ 02405218 - LdrpMinimalMapModule - RETURN: Status: 0x00000000
0f64:2090 @ 02405218 - LdrpPreprocessDllName - INFO: DLL api-ms-wineventingprovider-l1-1-0.dll was redirected to C:\WINDOWS\SYSTEM32\
kernelbase.dll by API set
0f64:2090 @ 02405218 - LdrpPreprocessDllName - INFO: DLL api-ms-wincoreapiqueryl1-1-0.dll was redirected to C:\WINDOWS\SYSTEM32\ntdll.dll by API set
→
Der Abbildlader
Kapitel 3
175
4.
Der Debugger hält schließlich mitten im Ladercode an. Dies geschieht an der Stelle, an
der der Imagelader prüft, ob ein Debugger angeschlossen ist, und einen Haltepunkt
auslöst. Wenn Sie (g) drücken, um die Ausführung fortzusetzen, werden weitere Meldungen des Laders angezeigt. Schließlich erscheint der Windows-Editor.
5.
Arbeiten Sie mit dem Editor. Dabei können Sie beobachten, dass bei bestimmten Operationen der Lader aufgerufen wird, z. B. wenn Sie das Dialogfeld Speichern oder Öffnen aufrufen. Das zeigt, dass der Lader nicht nur beim Start ausgeführt wird, sondern
weiterhin auf Threadanforderungen reagiert, die das verzögerte Laden weiterer Module
verursachen können (die dann nach Gebrauch wieder entladen werden).
Frühe Prozessinitialisierung
Der Lader befindet sich in Ntdll.dll, also einer nativen DLL, die nicht mit einem bestimmten
Teilsystem verbunden ist. Daher unterliegen alle Prozesse demselben Laderverhalten (mit einigen kleinen Unterschieden). Wir haben uns bereits ausführlich die Schritte angesehen, die zum
Erstellen eines Prozesses im Kernelmodus führen, und einige der Aufgaben beschrieben, die
die Windows-Funktion CreateProcess erledigt. Jetzt wollen wir uns mit den weiteren Arbeiten
beschäftigen, die unabhängig vom Teilsystem im Benutzermodus stattfinden, sobald die Ausführung der ersten Benutzermodusanweisung beginnt.
Beim Start eines Prozesses führt der Lader die folgenden Schritte aus:
1.
Er prüft, ob LdrpProcessInitialized bereits auf 1 eingestellt oder das Flag SkipLoaderInit
im TEB gesetzt wurde. Wenn ja, überspringt er die gesamte Initialisierung und wartet drei
Sekunden lang darauf, dass LdrpProcessInitializationComplete aufgerufen wird. Dies geschieht etwa, wenn die Windows-Fehlerberichterstattung Prozessreflexion einsetzt, oder bei
anderen Prozessabspaltungen, bei denen keine Laderinitialisierung benötigt wird.
2.
Er setzt LdrInitState auf 0, was bedeutet, dass der Lader nicht initialisiert ist, sowie das
PEB-Flag ProcessInitializing und das TEB-Flag RanProcessInit auf 1.
3.
Er initialisiert die Ladersperre im PEB.
4.
Er initialisiert die dynamische Funktionstabelle für die Abwicklungs- und Ausnahmeunterstützung in JIT-Code.
5.
Er initialisiert den veränderlichen, schreibgeschützten Heap-Abschnitt MRDATA (Mutable
Read Only), in dem sicherheitsrelevante globale Variablen gespeichert werden, die von
Exploits nicht bearbeitet werden dürfen (siehe Kap. 7).
6.
Er initialisiert die Laderdatenbank im PEB.
7.
Er unterstützt die Sprachunterstützungstabellen (National Language Support, NLS) für den
Prozess.
8.
Er stellt den Abbildpfadnamen für die Anwendung zusammen.
9.
Er erfasst die SEH-Ausnahmehandler aus dem Abschnitt .pdata und erstellt die internen
Ausnahmetabellen.
176
Kapitel 3
Prozesse und Jobs
10. Er erfasst die Systemaufrufthunks für die fünf kritischen Laderfunktionen NtCreateSection,
NtOpenFile, NtQueryAttributesFile, NtOpenSection und NtMapViewOfSection.
11. Er liest die Vorbeugeoptionen für die Anwendung (die vom Kernel über die exportierte
Variable LdrSystemDllInitBlock übergeben wurden). Sie werden ausführlich in Kapitel 7
beschrieben.
12. Er fragt den Registrierungsschlüssel Image File Execution Options für die Anwendung ab.
Dazu gehören Optionen wie die globalen Flags (gespeichert in GlobalFlags), Debuggingoptionen für den Heap (DisableHeapLookaside, ShutdownFlags und FrontEndHeapDebugOptions),
Ladereinstellungen (UnloadEventTraceDepth, MaxLoaderThreads, UseImpersonatedDeviceMap),
ETW-Einstellungen (TracingFlags) sowie weitere Optionen wie MinimumStackCommitInBytes
und MaxDeadActivationContexts. Im Rahmen dieser Arbeiten werden auch das Paket Application Verifier und die zugehörigen Verifizierungs-DLLs initialisiert und die ControlFlow
Guard-Optionen (CFG) von CFGOptions gelesen.
13. Er schaut im Header der ausführbaren Datei nach, ob es sich um eine .NET-Anwendung
handelt (was durch das Vorhandensein eines .NET-spezifischen Abbildverzeichnisses angezeigt wird) und ob das Abbild im 32-Bit-Format vorliegt. Außerdem fragt er den Kernel ab,
um zu ermitteln, ob der Prozess ein Wow64-Prozess ist. Bei Bedarf kann er auch mit einem
reinen Abbildlader-Abbild von 32 Bit umgehen, für das Wow64 nicht benötigt wird.
14. Er lädt die im Ladekonfigurationsverzeichnis der ausführbaren Datei angegebenen Konfigurationsoptionen. Diese Optionen werden vom Entwickler bei der Kompilierung der
Anwendung definiert und können vom Compiler und vom Linker genutzt werden, um
bestimmte Sicherheits- und Vorbeugemerkmale wie CFG einzurichten. Sie steuern das Verhalten der ausführbaren Datei.
15. Er nimmt eine Minimalinitialisierung des FLS und TLS vor.
16. Er richtet die Debuggingoptionen für kritische Abschnitte ein, erstellt eine Datenbank für
die Ablaufverfolgung des Benutzermodusstacks (sofern das entsprechende globale Flag
gesetzt war) und ruft StackTraceDatabaseSizeInMb von Image File Execution Options ab.
17. Er initialisiert den Heap-Manager für den Prozess und erstellt den ersten Prozessheap. Um
die erforderlichen Parameter einzurichten, zieht dieser Heap verschiedene Optionen für
die Ladekonfiguration, die Abbilddateiausführung, die globalen Flags und den Header der
ausführbaren Datei heran.
18. Er aktiviert den Prozess Terminate für die Vorbeugemaßnahme gegen Heapbeschädigung,
falls diese eingeschaltet ist.
19. Er initialisiert das Ausnahme-Dispatchprotokoll, falls das entsprechende globale Flag gesetzt ist.
20. Er initialisiert das Threadpoolpaket, das die Threadpool-API unterstützt. Es fragt NUMA-
Informationen ab und berücksichtigt sie.
21. Er initialisiert und konvertiert den Umgebungs- und den Parameterblock, vor allem zur
Unterstützung von WoW64-Prozessen.
22. Er öffnet das Objektverzeichnis \KnownDlls und erstellt den Pfad für bekannte DLLs. Für
einen WoW64-Prozess wird stattdessen \KnownDlls32 verwendet.
Der Abbildlader
Kapitel 3
177
23. Für Store-Anwendungen liest er die Optionen der Anwendungsmodellrichtlinie, die in den
Claims WIN://PKG und P://SKUID des Tokens codiert sind (siehe den Abschnitt »Anwendungscontainer« in Kapitel 7).
24. Er bestimmt das aktuelle Verzeichnis, den Systempfad und den Standardladepfad (zum
Laden von Abbildungen und Öffnen von Dateien) des Prozesses sowie die Regeln für die
Standardreihenfolge bei der DLL-Suche. Dazu gehört es, die aktuellen Richtlinieneinstellungen für Universal- (UWP), Desktop-Bridge- (Centennial) bzw. Silverlight-Anwendungen
(Windows Phone 8) oder -Dienste zu lesen.
25. Er erstellt den ersten Eintrag in der Laderdatentabelle für Ntdll.dll und fügt ihn in die Moduldatenbank ein.
26. Er erstellt die Tabelle für den Abwicklungsverlauf.
27. Er initialisiert den Parallellader, der mithilfe des Threadpools und gleichzeitiger Threads alle
Abhängigkeiten lädt, die keine Kreuzabhängigkeiten aufweisen.
28. Er erstellt den nächsten Eintrag in der Laderdatentabelle für die ausführbare Hauptdatei
und fügt ihn in die Moduldatenbank ein.
29. Bei Bedarf verlagert er das Abbild der ausführbaren Hauptdatei.
30. Er initialisiert die Anwendungsverifizierung, falls sie aktiviert ist.
31. Bei einem Wow64-Prozess initialisiert er die Wow64-Engine. Der 64-Bit-Lader schließt dabei seine Initialisierung ab und der 32-Bit-Lader übernimmt die Kontrolle und startet die
meisten bis jetzt beschriebenen Operationen neu.
32. Wenn es sich um ein .NET-Abbild handelt, validiert der Lader es. Anschließend lädt er
Mscoree.dll (ein .NET-Laufzeit-Shim) und ruft den Eintrittspunkt der ausführbaren Hauptdatei ab (_CorExeMain). Damit überschreibt er den Ausnahmedatensatz, sodass dieser Eintrittspunkt statt der regulären main-Funktion verwendet wird.
33. Er initialisiert die TLS-Slots des Prozesses.
34. Für Windows-Teilsystem-Anwendungen lädt er manuell Kernel32.dll und Kernelbase.dll unabhängig von den tatsächlichen Importen des Prozesses. Er verwendet diese Bibliotheken
nach Bedarf, um den SRP/Safer-Mechanismus zu initialisieren (Software Restriction Policies)
und um die Thunkfunktion für die Initialisierung des Windows-Teilsystemthreads abzufangen. Schließlich löst er jegliche API-Set-Abhängigkeiten zwischen diesen beiden Bibliotheken auf.
35. Er initialisiert die Shim-Engine und parst die Shim-Datenbank.
36. Er aktiviert den parallelen Abbildlader, sofern mit den zuvor gescannten Kernladerfunk
tionen keine Systemaufruf-Hooks oder »Umleitungen« verbunden sind. Dies geschieht auf
der Grundlage der Anzahl von Laderthreads, die durch Richtlinien und Optionen zur Abbildausführung festgelegt wurden.
37. Er setzt die Variable LdrInitState auf 1, was »Importladevorgang läuft« bedeutet.
Jetzt ist der Abbildlader bereit, die Importtabelle der ausführbaren Datei für die Anwendung
zu analysieren und jegliche DLLs zu laden, die beim Kompilieren der Anwendung dynamisch
verlinkt wurden. Das geschieht sowohl bei .NET-Images, deren Importe durch Aufrufe in der
178
Kapitel 3
Prozesse und Jobs
.NET-Laufzeitumgebung verarbeitet werden, als auch für reguläre Abbilder. Da jede importierte DLL wiederum ihre eigene Importtabelle haben kann, wurde diese Operation früher rekursiv
durchgeführt, bis alle DLLs berücksichtigt und alle zu importierenden Funktionen gefunden
waren. Beim Laden der einzelnen Dateien behielt der Lader Statusinformationen dafür bei und
stellte die Moduldatenbank auf.
In neueren Windows-Versionen erstellt der Lader stattdessen im Voraus eine Abhängigkeitsstruktur mit Knoten für die einzelnen DLLs und einem Abhängigkeitsgraphen. Dabei
kann er Knoten herausarbeiten, die parallel geladen werden können. Wird eine Serialisierung
benötigt, wird die Arbeitswarteschlange des Threadpools geleert, was als Synchronisierungspunkt fungiert. Ein solcher Punkt tritt auf dem Aufruf aller DLL-Initialisierungsroutinen für die
statischen Importe auf, was einer der letzten Schritte des Laders ist. Nachdem dies erledigt
ist, werden die statischen TLS-Initialisierer aufgerufen. Bei Windows-Anwendungen wird zwischen diesen beiden Schritten zu Anfang die Thunkfunktionen für die Initialisierung des Kernel32-Threads (BaseThreadInitThunk) und am Ende die Post-Prozessinitialisierungsroutine von
Kernel32 aufgerufen.
DLL-Namensauflösung und -Umleitung
Bei der Namensauflösung ermittelt das System aus dem Namen einer PE-Binärdatei die physische Datei, wenn der Aufrufer keine eindeutige Dateikennung angegeben hat oder es nicht
kann. Da die Speicherorte der verschiedenen Verzeichnisse (Anwendungsverzeichnis, Systemverzeichnis usw.) zur Verlinkungszeit nicht hartcodiert werden können, schließt dies die Auflösung aller Abhängigkeiten von Binärdateien sowie LoadLibrary-Operationen ein, in denen der
Aufrufer keinen vollständigen Pfad angeben kann.
Zum Auflösen der Abhängigkeiten von Binärdateien wird im grundlegenden Windows-Anwendungsmodell versucht, die Dateien in einem Suchpfad zu finden. Dies ist eine Liste von
Speicherorten, die nacheinander nach einer Datei mit dem verlangten Grundnamen abgesucht werden. Dieser Suchpfadmechanismus kann jedoch von verschiedenen Systemkomponenten überschrieben werden, um das reguläre Anwendungsmodell zu erweitern. Das Prinzip
des Suchpfads stammt noch aus dem Zeitalter der Befehlszeile, als der Begriff des »aktuellen
Verzeichnisses« einer Anwendung tatsächlich eine sinnvolle Bedeutung hatte. Für moderne
GUI-Anwendungen wirkt er dagegen etwas anachronistisch.
Da sich das aktuelle Verzeichnis in diesem Suchpfad befand, konnten Angreifer jedoch
die Ladeoperationen für Systembinärdateien überschreiben, indem sie schädliche Binärdateien
desselben Namens in das aktuelle Verzeichnis der Anwendung stellten. Diese Technik wurde als Binary Planting bezeichnet. Um dieses Sicherheitsrisiko zu vermeiden, wurde die Such
pfadberechnung um den sicheren DLL-Suchmodus ergänzt, der für alle Prozesse standardmäßig
aktiviert ist. In diesem Modus wird das aktuelle Verzeichnis hinter die drei Systemverzeichnisse
verlagert, was zu der folgenden Suchpfadreihenfolge führt:
1.
Das Verzeichnis, in dem die Anwendung gestartet wurde
2.
Das native Windows-Systemverzeichnis (z. B. C:\Windows\System32)
3.
Da 16-Bit-Windows-Systemverzeichnis (z. B. C:\Windows\System)
4.
Das Windows-Verzeichnis (z. B. C:\Windows)
Der Abbildlader
Kapitel 3
179
5.
Das aktuelle Verzeichnis zum Startzeitpunkt der Anwendung
6.
Jegliche in der Umgebungsvariablen %PATH% angegebenen Verzeichnisse
Der DLL-Suchpfad wird für jede DLL-Ladeoperation neu berechnet. Der Algorithmus für diese
Berechnung ist derselbe wie für den Standardsuchpfad, aber die Anwendung kann einzelne
Pfadelemente überschreiben, indem sie die Variable %PATH% mit SetEnvironmentVariable bearbeitet, das aktuelle Verzeichnis mit SetCurrentDirectory ändert oder mit SetDllDirectoryAPI ein
DLL-Verzeichnis für den Prozess angibt. In letzterem Fall ersetzt das DLL-Verzeichnis das aktuelle
Verzeichnis im Suchpfad. Der Lader ignoriert dann die Einstellung des sicheren DLL-Suchmodus
für den Prozess.
Aufrufer können den DLL-Suchpfad auch für einzelne Ladeoperationen ändern, indem
sie der API LoadLibraryEx das Flag LOAD_WITH_ALTERED_SEARCH_PATH übergeben. Ist dieses Flag
gesetzt und enthält der an die API übergebene DLL-Name den String für einen vollständigen Pfad, dann wird bei der Berechnung des Suchpfads für die Operation der Pfad mit der
DLL-Datei anstelle des Anwendungsverzeichnisses verwendet. Bei einem relativen Pfad ist das
Verhalten nicht definiert, was gefährlich sein kann. Beim Laden von Desktop-Bridge-Anwendungen (Centennial) wird dieses Flag ignoriert.
Neben LOAD_WITH_ALTERED_SEARCH_PATH können Anwendungen auch die Flags LOAD_
LIBRARY_SEARCH_DLL_LOAD_DIR, LOAD_LIBRARY_SEARCH_APPLICATION_DIR, LOAD_LIBRARY_SEARCH_
SYSTEM32 und LOAD_LIBRARY_SEARCH_USER_DIRS an LoadLibraryEx übergeben. Sie alle ändern
die Suchreihenfolge, sodass nur in den Verzeichnissen gesucht wird, auf die sie verweisen.
Beispielsweise wird bei LOAD_LIBRARY_SEARCH_DEFAULT_DIRS im Anwendungsverzeichnis, in System32 und im Benutzerverzeichnis gesucht. Die Flags können auch kombiniert werden, um
mehrere Speicherorte zu durchsuchen. Mit SetDefaultDllDirectories können die Flags auch
global gesetzt werden, sodass sie sich auf alle zukünftigen Bibliotheksladevorgänge auswirken.
Bei Paketanwendungen und bei Anwendungen, die weder ein Paketdienst noch eine
veraltete Anwendung für Silverlight 8.0 auf Windows Phone sind, gibt es noch eine weitere Möglichkeit, um die Suchreihenfolge zu beeinflussen. Unter diesen Umständen werden
zur DLL-Suche nicht der herkömmliche Mechanismus und die APIs herangezogen, sondern
eine paketgestützte Graphensuche. Das gilt auch, wenn statt der regulären Funktion Load
LibraryEx die API LoadPackagedLibrary verwendet wird. Der paketgestützte Graph basiert
auf den <PackageDependency>-Einträgen im Abschnitt <Dependencies> der Manifestdatei einer
UWP-Anwendung und garantiert, dass in dem Paket keine willkürlichen DLLs geladen werden können.
Beim Laden einer Paketanwendung (mit Ausnahme von Desktop-Bridge-Anwendungen)
werden alle von der Anwendung konfigurierbaren APIs zur Änderung des DLL-Suchpfads (wie
diejenigen, die Sie zuvor gesehen haben) deaktiviert. Nur das Standardverhalten des Systems
wird verwendet (wobei für die meisten UWP-Anwendungen auch wie zuvor beschrieben die
Paketabhängigkeiten untersucht werden).
Doch selbst mit dem sicheren Suchmodus und den Standardpfad-Suchalgorithmen für
ältere Anwendungen, bei denen das Anwendungsverzeichnis immer an erster Stelle steht, ist
es leider immer noch möglich, dass eine Binärdatei von ihrem üblichen Speicherort an einen
kopiert wird, der für die Benutzer zugänglich ist (beispielsweise von C:\Windows\System32\
Notepad.exe in C:\temp\Notepad.exe, wozu nicht einmal Administratorrechte erforderlich
180
Kapitel 3
Prozesse und Jobs
sind). In einer solchen Situation kann ein Angreifer eine besonders gestaltete DLL im Verzeichnis der Anwendung platzieren, wo sie aufgrund der zuvor aufgezeigten Reihenfolge
Vorrang vor der System-DLL hat. Dies lässt sich dann zur Persistenz oder zu einer anderen Beeinflussung der Anwendung nutzen, die möglicherweise höhere Rechte hat (vor allem wenn
der Benutzer, der nichts von dem Austausch ahnt, ihre Rechte über die Benutzerkontensteuerung erhöht hat). Als Schutz dagegen können Prozesse und Administratoren die Prozessvorbeugungsrichtlinie Prefer System32 Images nutzen (siehe Kapitel 7), die die Reihenfolge von
Punkt 1 und 2 umkehrt.
DLL-Namensumleitung
Bevor sich der Lader daranmacht, einen DLL-Namensstring zu einer Datei aufzulösen, versucht er, Regeln zur DLL-Namensumleitung anzuwenden. Diese Regeln dienen dazu, Teile des
DLL-Namensraums – der gewöhnlich dem Namensraum des Win32-Dateisystems entspricht –
zu erweitern oder zu überschreiben, um damit das Windows-Anwendungsmodell zu erweitern.
In der Reihenfolge der Anwendung sind dies folgende Regeln:
QQ MinWin-API-Set-Umleitung Der Mechanismus der API-Sets beruht auf dem Prinzip
von Kontrakten. Damit können verschiedene Versionen oder Editionen von Windows die
Binärdatei, die eine bestimmte System-API exportiert, für die Anwendungen transparent
ändern. Dieser Mechanismus wurde bereits kurz in Kapitel 2 erwähnt und wird in einem
Abschnitt weiter hinten ausführlicher erklärt.
QQ .LOCAL-Umleitung Mit dem .LOCAL-Umleitungsmechanismus können Anwendungen
alle Ladevorgänge für einen gegebenen DLL-Basisnamen zu einer lokalen Kopie der DLL
im Anwendungsverzeichnis umleiten, und zwar unabhängig davon, ob ein vollständiger
Pfad angegeben wurde oder nicht. Dazu wird entweder eine Kopie der DLL mit demselben Basisnamen und der Endung .local erstellt (z. B. MyLibrary.dll.local) oder ein Dateiordner namens .local im Anwendungsverzeichnis erstellt und eine Kopie der lokalen DLL
dort hineingelegt (z. B. C:\\MyApp\.LOCAL\MyLibrary.dll). Die von diesem Mechanismus
umgeleiteten DLLs werden genauso behandelt wie die von SxS umgeleiteten (siehe den
nächsten Punkt). Der Lader berücksichtigt die .LOCAL-Umleitung von DLLs nur, wenn die
ausführbare Datei kein Manifest hat, weder ein eingebettetes noch ein externes. Diese Regel ist nicht standardmäßig aktiviert. Um sie global einzuschalten, fügen Sie den
DWORD-Wert DevOverrideEnable zum IFEO-Schlüssel hinzu (HKLM\Software\Microsoft\
WindowsNT\CurrentVersion\Image File Execution Options) und setzen ihn auf 1.
QQ Fusion-Umleitung (SxS) Fusion (auch Side-by-Side oder SxS genannt) ist eine Erweiterung des Windows-Anwendungsmodells, die es Komponenten ermöglicht, ausführlichere
Informationen über Abhängigkeiten von Binärdateien auszudrücken (meistens Versionsinformationen). Dazu werden als Manifeste bezeichnete Binärressourcen eingebettet. Der
Fusion-Mechanismus wurde ursprünglich verwendet, damit Anwendungen die richtige
Version des Pakets Windows Common Controls (Comctl32.dll) laden konnten, nachdem
die Binärdatei auf zwei verschiedene Versionen aufgeteilt worden war, die sich nebeneinander installieren ließen. Inzwischen wurde eine ähnliche Versionsverwaltung auch für
andere Binärdateien eingeführt. In Visual Studio 2005 mit dem Microsoft-Linker erstellte
Der Abbildlader
Kapitel 3
181
Anwendungen verwenden Fusion, um die richtige Version der C-Laufzeitbibliotheken zu
finden, während ab Visual Studio 2015 eine API-Set-Umleitung eingesetzt wird, um eine
universelle CRT umzusetzen.
Das Fusion-Laufzeitwerkzeug liest mithilfe des Windows Ressourcenladers die eingebetteten Abhängigkeitsinformationen im Ressourcenabschnitt der Binärdatei und verpackt sie
in Nachschlagestrukturen, die als Aktivierungskontexte bezeichnet werden. Beim Systemund Prozessstart erstellt das System Aktivierungskontexte auf System- bzw. Prozessebene.
Außerdem ist mit jedem Thread ein Aktivierungskontextstack verknüpft, wobei die Aktivierungskontextstruktur auf seiner Spitze als die aktive angesehen wird. Dieser threadweise
Aktivierungskontextstack wird explizit über die APIs ActivateActCtx und DeactivacteActCtx
und an einigen Stellen auch implizit vom System verwaltet, etwa wenn die DLL-Hauptroutine einer Binärdatei mit eingebetteten Abhängigkeitsinformationen aufgerufen wird.
Beim Nachschlagen einer Fusion-DLL-Namensumleitung sucht das System nach Umleitungsinformationen in dem Aktivierungskontext oben auf dem Aktivierungskontextstack
des Threads und danach nach den Prozess- und Systemaktivierungskontexten. Sind solche
Umleitungsinformationen vorhanden, wird die in dem Aktivierungskontext angegebene
Dateikennung für den Ladevorgang verwendet.
QQ Umleitung zu bekannten DLLs (Known-DLL-Umleitung) Dieser Mechanismus ordnet
bestimmte DLL-Basisnamen den Dateien im Systemverzeichnis zu, um zu verhindern, dass
DLLs durch eine alternative Version an einem anderen Speicherort ersetzt werden.
Die DLL-Versionsprüfung für 64-Bit- und Wow64-Anwendungen stellt einen Grenzfall des
DLL-Suchpfadalgorithmus dar. Wenn eine DLL mit einem entsprechenden Basisnamen gefunden wurde, nachträglich aber erkannt wird, dass sie für die falsche Architektur kompiliert wurde – z. B. ein 64-Bit-Abbild in einer 32-Bit-Anwendung –, dann ignoriert der Lader
den Fehler und nimmt die Suchpfadoperation wieder auf, wobei er mit dem Pfadelement
hinter demjenigen beginnt, das zu der falschen Datei geführt hat. Dieses Verhalten erlaubt Anwendungen, in der globalen Umgebungsvariablen %PATH% sowohl 64- als auch
32-Bit-Einträge vorzunehmen.
Experiment: Die DLL-Suchreihenfolge beobachten
Mit dem Process Monitor von Sysinternals können Sie beobachten, wie der Lader nach DLLs
sucht. Wenn er versucht, eine DLL-Abhängigkeit aufzulösen, ruft er CreateFile auf, um jeden Speicherort in der Suchreihenfolge zu sondieren, bis er entweder die angegebene DLL
gefunden hat oder der Ladevorgang fehlschlägt.
Die nachstehende Abbildung zeigt die Suche des Laders nach der ausführbaren Datei
OneDrive.exe. Um dieses Experiment nachzuvollziehen, gehen Sie wie folgt vor:
1.
Wenn OneDrive ausgeführt wird, schließen Sie es über sein Symbol in der Taskleiste.
Schließen Sie alle Explorer-Fenster, die zurzeit auf OneDrive zugreifen.
2.
Öffnen Sie Process Monitor und fügen Sie Filter hinzu, um nur den Prozess OneDrive.
exe oder optional nur die CreateFile-Operationen anzuzeigen.
→
182
Kapitel 3
Prozesse und Jobs
3.
Wechseln Sie zu %LocalAppData%\Microsoft\OneDrive und starten Sie OneDrive.exe
oder OneDrivePersonal.cmd (wodurch die Personal- statt der Business-Version von
OneDrive gestartet wird). Sie sehen jetzt eine Ausgabe wie die folgende (beachten Sie
dabei, dass OneDrive ein 32-Bit-Prozess ist, der hier auf einem 64-Bit-System läuft):
Hier sind einige der Aufrufe aus dem zuvor beschriebenen Suchvorgang zu sehen:
QQ Bekannte DLLs werden aus dem Systemspeicherort geladen (ole32.dll im Screenshot).
QQ LoggingPlatform.dll wird aus einem Versionsunterverzeichnis geladen, wahrscheinlich,
weil OneDrive SetDllDirectory aufruft, um Suchvorgänge zur letzten Version umzuleiten (17.3.6743.1212 im Screenshot).
QQ Im Verzeichnis der ausführbaren Datei wird erfolglos nach MSVCR120.dll (MSVC-Laufzeitversion 12) gesucht. Anschließend wird die Suche im Versionsunterverzeichnis fortgesetzt, wo sich die DLL tatsächlich befindet.
QQ Wsock32.dll (WinSock) wird erst im Pfad der ausführbaren Datei und dann im Versionsunterverzeichnis gesucht und schließlich im Systemverzeichnis gefunden (SysWow64).
Beachten Sie, dass es sich hierbei nicht um eine bekannte DLL handelt.
Die Datenbank der geladenen Module
Der Lader führt eine Liste aller Module (DLLs und die primäre ausführbare Datei), die der Prozess geladen hat. Diese Informationen werden im PEB gespeichert, und zwar in einer Unterstruktur namens PEB_LDR_DATA. Dort unterhält der Lader drei doppelt verknüpfte Listen, die
alle dieselben Informationen enthalten, jedoch in unterschiedlicher Anordnung (sortiert nach
Laderreihenfolge, Speicherort und Initialisierungsreihenfolge). Die Strukturen in den Listen
Der Abbildlader
Kapitel 3
183
werden als Laderdaten-Tabelleneinträge (LDR_DATA_TABLE_ENTRY) bezeichnet und enthalten die
Informationen über die einzelnen Module.
Da Nachschlagevorgänge in verknüpften Listen algorithmisch kostspielig sind (aufgrund
ihrer linearen Laufzeit), unterhält der Lader auch zwei Rot-Schwarz-Bäume, bei denen es sich
um effiziente binäre Suchbäume handelt. Der erste ist nach Basisadressen sortiert, der zweite
nach den Hashes der Modulnamen. Dank dieser Bäume kann der Suchalgorithmus mit logarithmischer Laufzeit ausgeführt werden, was erheblich effizienter ist und die Prozesserstellung
in Windows 8 und höher beschleunigt. Als Sicherheitsmaßnahme sind die Wurzeln dieser beiden Bäume anders als verknüpfte Listen im PEB nicht zugänglich. Dadurch sind sie für Shellcode schwerer zu finden, der in einer Umgebung mit randomisiertem Adressraumlayout operiert (Address Space Layout Randomization, ASLR; siehe Kapitel 5).
Tabelle 3–9 führt die Informationen auf, die der Lader in einem Eintrag unterhält.
Feld
Bedeutung
BaseAddressIndexNode
Verknüpft diesen Eintrag als Knoten mit dem nach Basisadressen sortierten Rot-Schwarz-Baum.
BaseDllName/BaseNameHashValue
Der Name des Moduls ohne vollständigen Pfad. Das zweite
Feld enthält den mit RtlHashUnicodeString ermittelten Hash
dieses Namens.
DdagNode/NodeModuleLink
Ein Zeiger auf die Datenstruktur, die den verteilten Abhängigkeitsgraphen (Distributed Dependency Graph, DDAG) im
Auge behält. Dadurch wird das parallele Laden von Abhängigkeiten durch den Arbeitsthreadpool möglich. Das zweite Feld
verknüpft die Struktur mit den damit verknüpften Laderdaten-Tabelleneinträgen (Teil desselben Graphen).
DllBase
Enthält die Basisadresse, an der das Modul geladen wurde.
EntryPoint
Enthält die ursprüngliche Routine des Moduls (z. B. DllMain).
EntryPointActivationContext
Enthält den SxS/Fusion-Aktivierungskontext beim Aufrufen
von Initialisierern.
Flags
Laderstatusflags für das Modul (siehe Tabelle 3–10)
ForwarderLinks
Eine verknüpfte Liste der Module, die aufgrund von Exporttabellenweiterleitungen von dem Modul geladen wurden
FullDllName
Der vollständig qualifizierte Pfadname des Moduls
HashLinks
Eine verknüpfte Liste, die beim Starten und Herunterfahren
des Prozesses verwendet wird, um das Nachschlagen zu beschleunigen
ImplicitPathOptions
Dient zur Speicherung der Pfadsuchflags, die mit der API
LdrSetImplicitPathOptions festgelegt oder vom DLL-Pfad
geerbt werden können.
List Entry Links
Verknüpft diesen Eintrag mit jeder der drei geordneten Listen
in der Laderdatenbank.
LoadContext
Zeiger auf die aktuellen Laderinformationen über die DLL. Gewöhnlich NULL, sofern nicht aktiv geladen.
ObsoleteLoadCount
Referenzzähler für das Modul (also die Angabe, wie oft es geladen wurde). Dieser Zähler ist nicht mehr genau und wurde
in die DDAG-Knotenstruktur verlagert.
→
184
Kapitel 3
Prozesse und Jobs
Feld
Bedeutung
LoadReason
Enthält einen Aufzählungswert, der erklärt, warum die DLL geladen wurde (dynamisch, statisch, als Forwarder, als verzögert
geladene Abhängigkeit usw.).
LoadTime
Speichert den Wert der Systemzeit, zu der das Modul geladen
wurde.
MappingInfoIndexNode
Verknüpft diesen Eintrag als Knoten mit dem nach Namenshashes sortierten Rot-Schwarz-Baum.
OriginalBase
Speichert die (vom Linker festgelegte) ursprüngliche Basis
adresse des Moduls vor ASLR oder Relokalisierungen, was
eine schnellere Verarbeitung relokalisierter Importeinträge
ermöglicht.
ParentDllBase
Speichert bei statischen, Forwarder- oder verzögert geladenen Abhängigkeiten die Adresse der DLL, die von dieser DLL
abhängt.
SigningLevel
Speichert die Signaturebene des Abbilds (siehe Kapitel 8 in
Band 2).
SizeOfImage
Größe des Moduls im Arbeitsspeicher
SwitchBackContext
Wird von SwitchBack verwendet (siehe weiter hinten), um den
aktuellen Windows-Kontext-GUID für das Modul und andere
Daten zu speichern.
TimeDateStamp
Ein vom Linker geschriebener Zeitstempel, der den Verlinkungszeitpunkt des Moduls angibt. Der Lader ruft diesen Zeitstempel aus dem PE-Abbildheader des Moduls ab.
TlsIndex
Der TLS-Slot für das Modul
Tabelle 3–9 Felder in einem Laderdaten-Tabelleneintrag
Eine Möglichkeit, um die Laderdatenbank eines Prozesses zu untersuchen, besteht darin, sich
die formatierte PEB-Ausgabe von WinDbg anzusehen. Im nächsten Experiment erfahren Sie,
wie das gemacht wird und wie Sie die LDR_DATA_TABLE_ENTRY-Strukturen betrachten.
Experiment: Die Datenbank der geladenen Module ausgeben
Führen Sie vor Beginn dieses Experiments die gleichen Schritte wie bei den vorherigen
beiden Versuchen aus, um Notepad.exe mit WinDbg als Debugger zu starten. Wenn Sie den
ersten Haltepunkt erreichen (an dem Sie zuvor immer angewiesen wurden, (g) zu drücken),
gehen Sie wie folgt vor:
1.
Schauen Sie sich mit dem Befehl !peb den PEB des aktuellen Prozesses an. Zunächst
sind wir nur an den angezeigten Ldr-Daten interessiert:
0:000> !peb
PEB at 000000dd4c901000
InheritedAddressSpace:
No
ReadImageFileExecOptions: No
BeingDebugged:
Yes
→
Der Abbildlader
Kapitel 3
185
ImageBaseAddress:
00007ff720b60000
Ldr
00007ffe855d23a0
Ldr.Initialized:
Yes
Ldr.InInitializationOrderModuleList: 0000022815d23d30 . 0000022815d24430
Ldr.InLoadOrderModuleList:
0000022815d23ee0 . 0000022815d31240
Ldr.InMemoryOrderModuleList:
0000022815d23ef0 . 0000022815d31250
Base TimeStamp Module
7ff720b60000 5789986a Jul 16 05:14:02 2016 C:\Windows\System32\
notepad.exe
7ffe85480000 5825887f Nov 11 10:59:43 2016 C:\WINDOWS\SYSTEM32\
ntdll.dll
7ffe84bd0000 57899a29 Jul 16 05:21:29 2016 C:\WINDOWS\System32\
KERNEL32.DLL
7ffe823c0000 582588e6 Nov 11 11:01:26 2016 C:\WINDOWS\System32\
KERNELBASE.dll
...
2.
Die Adresse, die in der Ldr-Zeile gezeigt wird, ist ein Zeiger auf die zuvor beschriebene
PEB_LDR_DATA-Struktur. WinDbg zeigt die Adressen der drei Listen an und gibt die Liste
in der Initialisierungsreihenfolge aus, wobei für jedes Modul der vollständige Pfad, der
Zeitstempel und die Basisadresse angegeben werden.
3.
Sie können auch die einzelnen Moduleinträge jeweils für sich selbst analysieren, indem
Sie die Modulliste durchgehen und dann die Daten an jeder Adresse in Form einer LDR_
DATA_TABLE_ENTRY-Struktur ausgeben. Anstatt das für jeden Eintrag selbst zu machen,
können Sie sich den Großteil der Arbeit auch von WinDbg abnehmen lassen, indem Sie
die Erweiterung !list und die folgende Syntax verwenden:
!list –x "dt ntdll!_LDR_DATA_TABLE_ENTRY" @@C++(&@$peb->Ldr>InLoadOrderModuleList)
4.
Nun sehen Sie die Einträge für die einzelnen Module:
+0x000 InLoadOrderLinks
: _LIST_ENTRY [ 0x00000228'15d23d10 -
+0x010 InMemoryOrderLinks
: _LIST_ENTRY [ 0x00000228'15d23d20 -
0x00007ffe'855d23b0 ]
0x00007ffe'855d23c0 ]
+0x020 InInitializationOrderLinks : _LIST_ENTRY [ 0x00000000'00000000 0x00000000'00000000 ]
+0x030 DllBase
: 0x00007ff7'20b60000 Void
+0x038 EntryPoint
: 0x00007ff7'20b787d0 Void
+0x040 SizeOfImage : 0x41000
+0x048 FullDllName : _UNICODE_STRING "C:\Windows\System32\notepad.exe"
+0x058 BaseDllName : _UNICODE_STRING "notepad.exe"
186
+0x068 FlagGroup
: [4] "???"
+0x068 Flags
: 0xa2cc
Kapitel 3
Prozesse und Jobs
In diesem Abschnitt geht es um den Benutzermodus-Lader aus Ntdll.dll. Der Kernel aber hat seinen eigenen Lader für Treiber und abhängige DLLs. Dieser Kernelmoduslader hat eine ähnliche
Eintragsstruktur, die als KLDR_DATA_TABLE_ENTRY bezeichnet wird, und seine eigene Datenbank
aus diesen Einträgen, die über die globale Datenvariable PsActiveModuleList direkt zugänglich
ist. Um die Datenbank der geladenen Module des Kernels auszugeben, können Sie einen ähnlichen !list-Befehl wie im vorstehenden Experiment verwenden, wobei Sie allerdings den Zeiger am Ende des Befehls durch nt!PsActiveModuleList ersetzen und den neuen Struktur- bzw.
Modulnamen angeben müssen, also !list nt!_KLDR_DATA_TABLE_ENTRY nt!PsActiveModuleList.
Wenn Sie sich die Liste in diesem rohen Format ansehen, erhalten Sie einige besondere
Einblicke in die Interna des Laders. So sehen Sie dabei beispielsweise das Feld Flags mit Statusinformationen, die Ihnen der reine !peb-Befehl nicht anzeigt. Die Bedeutung dieser Flags
finden Sie in Tabelle 3–10. Da sowohl der Kernel- als auch der Benutzermoduslader diese Struktur verwendet, können die Flags unterschiedliche Bedeutung haben. In der Tabelle werden
lediglich die Benutzermodusflags beschrieben (von denen einige auch in der Kernelstruktur
vorhanden sein können).
Flag
Bedeutung
Packaged Binary (0x1)
Das Modul ist Teil einer Paketanwendung (kann nur für das
Hauptmodul eines AppX-Pakets gesetzt werden).
Marked for Removal (0x2)
Das Modul wird entladen, sobald alle Referenzen (z. B. von
einem ausführenden Arbeitsthread) entfernt wurden.
Image DLL (0x4)
Das Modul ist eine Abbild-DLL (also keine Daten-DLL und keine ausführbare Datei).
Load Notifications Sent (0x8)
Die registrierten DLL-Benachrichtigungscallouts wurden bereits über dieses Abbild benachrichtigt.
Telemetry Entry Processed (0x10)
Telemetriedaten wurden bereits für dieses Abbild verarbeitet.
Process Static Import (0x20)
Das Modul ist ein statischer Import der binären Hauptdatei
der Anwendung.
In Legacy Lists (0x40)
Der Abbildeintrag befindet sich in den doppelt verknüpften
Listen des Laders.
In Indexes (0x80)
Der Abbildeintrag befindet sich in den Rot-Schwarz-Bäumen
des Laders.
Shim DLL (0x100)
Der Abbildeintrag steht für den DLL-Teil der Shim-Engine-/
Anwendungskompatibilitätsdatenbank.
In Exception Table (0x200)
Die .pdata-Ausnahmehandler des Moduls wurden von der
invertierten Funktionstabelle des Laders erfasst.
Load In Progress (0x800)
Das Modul wird zurzeit geladen.
Load Config Processed (0x1000)
Das Ladekonfigurationsverzeichnis des Moduls wurde gefunden und verarbeitet.
Entry Processed (0x2000)
Der Lader hat die Verarbeitung des Moduls komplett abgeschlossen.
Protect Delay Load (0x4000)
ControlFlowGuard-Merkmale für diese Binärdatei haben den
Schutz der Ladeverzögerungs-IAT angefordert (siehe Kapitel 7).
Der Abbildlader
Kapitel 3
→
187
Flag
Bedeutung
Process Attach Called (0x20000)
Die Benachrichtigung DLL_PROCESS_ATTACH wurde bereits an
die DLL gesendet.
Process Attach Failed (0x40000)
Bei der DllMain-Routine der DLL ist die Benachrichtigung
DLL_PROCESS_ATTACH fehlgeschlagen.
Don't Call for Threads (0x80000)
Zu dieser DLL soll keine DLL_THREAD_ATTACH/DETACH-Benachrichtigung gesendet werden. Dieses Flag kann mit Disable
ThreadLibraryCalls gesetzt werden.
COR Deferred Validate (0x100000)
Die Common Object Runtime (COR) wird dieses .NET-Abbild
später validieren.
COR Image (0x200000)
Das Modul ist eine .NET-Anwendung.
Don't Relocate (0x400000)
Das Abbild darf weder relokalisiert noch randomisiert werden.
COR IL Only (0x800000)
Dies ist eine reine (Abbildlader-) .NET-Zwischensprachenbibliothek, die keinen nativen Assemblycode enthält.
Compat Database Processed
(0x40000000)
Die Shim-Engine hat die DLL verarbeitet.
Tabelle 3–10 Flags für Laderdaten-Tabelleneinträge
Importanalyse
Da Sie jetzt wissen, wie der Lader den Überblick über alle für einen Prozess geladenen Module
behält, können Sie nun mit der Analyse der vom Lader durchgeführten Startinitialisierungsaufgaben fortfahren. In diesem Schritt erledigt der Lader Folgendes:
1.
Er lädt die in der Importtabelle des ausführbaren Abbilds für den Prozess angegebenen
DLLs.
2.
Er prüft jeweils, ob die DLL bereits geladen wurde, indem er die Moduldatenbank abfragt.
Steht die DLL nicht auf der Liste, öffnet der Lader sie und ordnet sie im Arbeitsspeicher zu.
3.
Während der Zuordnung schaut sich der Lader zunächst die verschiedenen Pfade an, in
denen die DLL zu finden sein könnte, und prüft, ob es sich um eine bekannte DLL handelt,
also um eine, die das System bereits beim Start geladen und für die es eine im Arbeitsspeicher zugeordnete globale Datei für den Zugriff bereitgestellt hat. Es können dabei
Abweichungen vom normalen Suchalgorithmus vorkommen, beispielsweise durch eine
.local-Datei, die den Lader zwingt, die DLLs im lokalen Pfad zu verwenden, oder eine Manifestdatei, die eine umgeleitete DLL angibt, um die Verwendung einer bestimmten Version
zu garantieren.
4.
Nachdem der Lader die DLL auf der Festplatte gefunden und zugeordnet hat, prüft er, ob
der Kernel sie an anderer Stelle geladen hat (Relokalisierung). Ist das der Fall, durchsucht
der Lader die Relokalisierungsinformationen in der DLL und führt die erforderlichen Operationen aus. Stehen keine Relokalisierungsinformationen bereit, schlägt das Laden der DLL
fehl.
5.
Anschließend erstellt der Lader einen Laderdaten-Tabelleneintrag für die DLL und führt ihn
in die Datenbank ein.
188
Kapitel 3
Prozesse und Jobs
6.
Nach der Zuordnung einer DLL wird der Vorgang für die DLL wiederholt, um ihre Importtabelle und ihre gesamten Abhängigkeiten zu analysieren.
7.
Nachdem alle DLLs geladen wurden, untersucht der Lader die IAT auf besondere Funktionen, die importiert wurden. Dies geschieht gewöhnlich nach Namen, kann aber auch
nach Indexzahlen geschehen. Für jeden Namen durchläuft der Lader die Exporttabelle der
importierten DLL und versucht, eine Übereinstimmung zu finden. Gibt es keine Übereinstimmung, wird die Operation abgebrochen.
8.
Auch die Importtabelle eines Abbilds kann gebunden werden. Das bedeutet, dass die Entwickler zur Verlinkungszeit statische Adressen zuweisen, die auf importierte Funktionen in
externen DLLs zeigen. Dadurch entfällt die Notwendigkeit, jeden Namen nachzuschlagen,
allerdings wird vorausgesetzt, dass sich die DLLs, auf die die Anwendung zurückgreift, immer an derselben Adresse befinden. Da Windows eine Adressraumrandomisierung durchführt (siehe Kapitel 5), ist dies für Systemanwendungen und Bibliotheken gewöhnlich nicht
der Fall.
9.
Die Exporttabelle einer importierten DLL kann einen Forwarder-Eintrag haben, was bedeutet, dass die eigentliche Funktion in einer anderen DLL implementiert ist. Dieser Fall muss
im Grunde genommen wie ein Import oder eine Abhängigkeit behandelt werden. Nach
der Untersuchung der Exporttabelle muss daher jede DLL geladen werden, auf die ein
Forwarder verweist. Der Lader kehrt danach zu Schritt 1 zurück.
Nachdem alle importierten DLLs (und ihre eigenen Abhängigkeiten oder Importe) geladen, alle
erforderlichen importierten Funktionen nachgeschlagen und gefunden und auch alle Forwarder geladen und verarbeitet wurden, ist der Schritt abgeschlossen: Alle von der Anwendung
und ihren DLLs zur Kompilierungszeit definierten Abhängigkeiten sind erfüllt. Bei der Ausführung können verzögert geladene Abhängigkeiten und Laufzeitoperationen (wie der Aufruf von
LoadLibrary) den Lader aufrufen und praktisch die gleichen Aufgaben erneut ausführen. Wenn
diese Schritte beim Start des Prozesses ausgeführt werden, führt ein Fehlschlag dabei jedoch
zu einem Fehler beim Starten der Anwendung. Wenn Sie beispielsweise versuchen, eine Anwendung auszuführen, die eine in der aktuellen Version des Betriebssystems nicht vorhandene
Funktion benötigt, kann das zu einer Meldung wie der aus Abb. 3–12 führen.
Abbildung 3–12 Das Dialogfeld, das erscheint, wenn eine erforderliche (importierte) Funktion in einer
DLL nicht vorhanden ist
Der Abbildlader
Kapitel 3
189
Prozessinitialisierung nach dem Import
Nachdem die erforderlichen Abhängigkeiten geladen worden sind, müssen noch verschiedene
Initialisierungsaufgaben ausgeführt werden, bevor die Anwendung endlich gestartet werden
kann. In dieser Phase erledigt der Lader Folgendes:
1.
Diese Schritte beginnen an der Stelle, an der die Variable LdrInitState auf 2 gesetzt wird,
was bedeutet, dass die Importe geladen sind.
2.
Wenn Sie einen Debugger wie WinDbg benutzen, trifft er schließlich auf den ersten Haltepunkt. Hier müssen Sie wie in den früheren Experimenten (g) drücken, um mit der Ausführung fortzufahren.
3.
Es wird geprüft, ob es sich um eine Anwendung des Windows-Teilsystems handelt. Wenn
ja, sollte in den ersten Schritten zur Prozessinitialisierung die Funktion BaseThreadInitThunk
erfasst worden sein. Jetzt wird sie aufgerufen und auf Erfolg geprüft. Auch die Funktion
TermsrvGetWindowsDirectoryW, die (auf einem Gerät mit Unterstützung für Terminaldienste)
bereits erfasst worden sein sollte, wird jetzt aufgerufen und setzt den System- und den
Windows-Verzeichnispfad zurück.
4.
Mithilfe des Verteilungsgraphen durchläuft der Lader rekursiv alle Abhängigkeiten und
führt die Initialisierer für alle statischen Importe des Abbilds aus. Bei diesem Schritt wird
die Routine DllMain für jede DLL aufgerufen, sodass jede DLL ihre eigenen Initialisierungsarbeiten durchführen kann, wozu auch das Laden weiterer DLLs zur Laufzeit gehören kann.
Außerdem werden die TLS-Initialisierer der einzelnen DLLs verarbeitet. Dies ist einer der
letzten Schritte, bei denen das Laden einer Anwendung fehlschlagen kann. Sämtliche geladenen DLLs müssen nach dem Abschluss ihrer DllMain-Routinen einen Erfolgscode zurückgeben. Anderenfalls bricht der Lader den Start der Anwendung ab.
5.
Falls das Abbild TLS-Slots verwendet, wird sein TLS-Initialisierer aufgerufen.
6.
Der Lader führt den Postinitialisierungs-Callback für die Shim-Engine aus, wenn das Modul
aus Kompatibilitätsgründen Shims verwendet.
7.
Der Lader führt die Postprozessinitialisierungsroutine für die zugehörige Teilsystem-DLL
aus, die im PEB registriert ist. Bei Windows-Anwendungen werden dabei beispielsweise
Überprüfungen für Terminaldienste ausgeführt.
8.
Jetzt wird ein ETW-Ereignis geschrieben, um anzugeben, dass der Prozess erfolgreich geladen wurde.
9.
Wenn es eine Mindestzusicherung für den Stack gibt, wird der Threadstack berührt, um
eine Einlagerung der zugesicherten Seiten zu erzwingen.
10. LdrInitState wird auf 3 gesetzt, was bedeutet, dass die Initialisierung abgeschlossen ist.
Anschließend wird das Feld ProcessInitializing des PEB auf 0 zurückgesetzt und die Variable LdrpProcessInitialized aktualisiert.
190
Kapitel 3
Prozesse und Jobs
SwitchBack
In jeder neuen Version von Windows werden Bugs wie Race Conditions und falsche Parametervalidierung in vorhandenen API-Funktionen korrigiert. Wie klein diese Änderungen auch sein
mögen, es besteht dabei immer die Gefahr von Inkompatibilitäten mit Anwendungen. Mithilfe
der SwitchBack-Technologie, die im Lader implementiert ist, können Softwareentwickler jedoch
im Manifest ihrer ausführbaren Dateien einen GUID für die Windows-Version einbetten, für die
sie ihre Anwendung geschrieben haben.
Nehmen wir an, ein Entwickler möchte die Verbesserungen nutzen, die in Windows 10 zu
einer bestimmten API hinzugefügt wurden. Er könnte dann in dem Manifest den GUID von
Windows 10 angeben. Bei einer älteren Anwendung, die von einem bestimmten Verhalten von
Windows 7 abhängt, würde er dagegen den Windows 7-GUID in das Manifest aufnehmen.
SwitchBack durchsucht diese Angaben und vergleicht sie mit den eingebetteten Informa
tionen in SwitchBack-kompatiblen DLLs (im Abschnitt .sb_data des Abbilds), um zu bestimmen,
welche Version der betreffenden API das Modul aufrufen soll. Da SwitchBack auf der Ebene der
geladenen Module arbeitet, ist es dadurch möglich, dass in einem Prozess ältere und aktuelle
DLLs dieselbe API aufrufen und dabei unterschiedliche Ergebnisse erzielen.
SwitchBack-GUIDs
Zurzeit sind GUIDs für die Kompatibilität mit allen Versionen ab Windows Vista definiert:
QQ {e2011457-1546-43c5-a5fe-008deee3d3f0} für Windows Vista
QQ {35138b9a-5d96-4fbd-8e2d-a2440225f93a} für Windows 7
QQ {4a2f28e3-53b9-4441-ba9c-d69d4a4a6e38} für Windows 8
QQ {1f676c76-80e1-4239-95bb-83d0f6d0da78} für Windows 8.1
QQ {8e0f7a12-bfb3-4fe8-b9a5-48fd50a15a9a} für Windows 10
Diese GUIDs müssen in der Manifestdatei der Anwendung unter dem Abschnitt <SupportedOS>
im ID-Attribut des Eintrags für das Kompatibilitätsattribut vorhanden sein. Enthält das Manifest
keinen GUID, wird als Standardkompatibilitätsmodus Windows Vista ausgewählt. Auf der Registerkarte Details des Task-Managers können Sie die Spalte Betriebssystemkontext einblenden,
in der angezeigt wird, ob eine Anwendung in einem bestimmten Betriebssystemkontext läuft.
Ein leerer Wert bedeutet dabei gewöhnlich, dass die Anwendung im Windows 10-Modus ausgeführt wird. Abb. 3–13 zeigt einige Beispielanwendungen, die auf einem Windows 10-System
im Windows Vista- bzw. Windows 7-Modus ausgeführt werden.
Im folgenden Beispielmanifest ist die Kompatibilität auf Windows 10 festgelegt:
<compatibility xmlns="urn:schemas-microsoft-com:compatibility.v1">
<application>
<!-- Windows 10 -->
<supportedOS Id="{8e0f7a12-bfb3-4fe8-b9a5-48fd50a15a9a}" />
</application>
</compatibility>
Der Abbildlader
Kapitel 3
191
Abbildung 3–13 Prozesse mit abweichenden Kompatibilitätsmodi
SwitchBack-Kompatibilitätsmodi
Um Ihnen eine Vorstellung davon zu geben, was SwitchBack tun kann, sehen Sie hier, was die
Ausführung im Windows 7-Kontext mit sich bringt:
QQ RPC-Komponenten verwenden den Windows-Threadpool statt einer privaten Implementierung.
QQ Für den primären Puffer kann keine DirectDraw-Sperre eingerichtet werden.
QQ Blitting auf dem Desktop ist ohne Clippingfenster nicht erlaubt.
QQ Eine Race Condition in GetOverlappedResult ist korrigiert.
QQ Aufrufe von CreateFile dürfen ein Herabstufungsflag übergeben, um eine Datei auch
dann exklusiv zu öffnen, wenn der Aufrufer keine Schreibrechte hat. Infolgedessen erhält
NtCreateFile nicht das Flag FILE_DISALLOW_EXCLUSIVE.
Die Ausführung im Windows 10-Modus dagegen betrifft das LFH-Verhalten (Low Fragmentation Heap). Ist kein Windows 10-GUID angegeben, werden alle LFH-Teilsegmente zwangsweise zugesichert und alle Zuweisungen mit einem Headerblock aufgefüllt. In Windows 10 wird
192
Kapitel 3
Prozesse und Jobs
zusätzlich die Vorbeugemaßnahme Raise Exception on Invalid Handle Close (siehe Kapitel 7)
verwendet, sodass CloseHandle und RegCloseKey das Verhalten respektieren. Bei früheren Betriebssystemen dagegen wird dieses Verhalten vor dem Aufruf von NtClose deaktiviert und
anschließend wieder aktiviert (sofern kein Debugger angeschlossen ist).
Ein weiteres Beispiel ist die Einrichtung zur Rechtschreibprüfung, die für Sprachen ohne
Rechtschreibprüfung NULL zurückgibt, in Windows 8.1 aber eine »leere« Rechtschreibprüfung.
Die Implementierung der Funktion IShellLink::Resolve gibt bei der Übergabe eines relativen
Pfads im Windows 8-Kompatibilitätsmodus E_INVALIDARG zurück, wohingegen die entsprechende Überprüfung im Windows 7-Modus nicht stattfindet.
Aufrufe von GetVersionEx oder ähnlichen NtDll-Funktionen wie RtlVerifyVersionInfo geben die höchste zurück, die mit der angegebenen SwitchBack-Kontext-GUID übereinstimmt.
Diese APIs sind veraltet und mittlerweile unerwünscht. Aufrufe von GetVersionEX
geben jetzt auf allen Versionen von Windows 8 und höher 6.2 zurück, sofern kein
höherer SwitchBack-GUID angegeben wurde.
SwitchBack-Verhalten
Bei Änderungen an einer Windows-API, die die Kompatibilität gefährden können, ruft der Eintrittscode die Funktion SbSwitchProcedure auf, um die SwitchBack-Logik zu starten. Dabei übergibt er einen Zeiger auf die SwitchBack-Modultabelle, die Informationen über den von dem
Modul genutzten SwitchBack-Mechanismus sowie einen Zeiger auf ein Array mit Einträgen für
die einzelnen SwitchBack-Punkte enthält Die Verzweigungspunkte werden dabei mit symbolischen Namen bezeichnet und mit einer ausführlichen Beschreibung und einem zugehörigen
Vorbeugetag versehen. Gewöhnlich gibt es in einem Modul mehrere Verzweigungspunkte –
einen für Windows Vista-Verhalten, einen für Windows 7-Verhalten usw.
Für jeden Verzweigungspunkt wird der erforderliche SwitchBack-Kontext angegeben, der
bestimmt, welche der Verzweigungen zur Laufzeit genommen wird. Die einzelnen Deskriptoren
enthalten auch jeweils einen Funktionszeiger auf den Code, der in der Verzweigung ausgeführt werden soll. Läuft die Anwendung mit dem Windows 10-GUID, gehört dieser Zeiger zum
SwitchBack-Kontext. Bei der Analyse der Modultabelle führt die API SbSelectProcedure einen
Abgleich durch. Sie findet den Moduleintragsdeskriptor für den Kontext und ruft den darin
enthaltenen Funktionszeiger auf.
SwitchBack nutzt ETW, um die Auswahl des SwitchBack-Kontexts und der Verzweigungspunkte zu verfolgen und die Daten in den AIT-Logger von Windows einzuspeisen (Applica
tion Impact Telemetry). Die Daten können regelmäßig von Microsoft abgefragt werden, um
zu bestimmen, in welchem Umfang die einzelnen Kompatibilitätseinträge genutzt werden, die
entsprechenden Anwendungen zu identifizieren (das Protokoll enthält eine vollständige Stack
ablaufverfolgung) und Drittanbieterhersteller zu informieren.
Wie bereits erwähnt, wird die Kompatibilitätsstufe der Anwendung in deren Manifest
gespeichert. Wenn der Lader die Manifestdatei zum Ladezeitpunkt analysiert, erstellt er eine
Kontextdatenstruktur und speichert sie im Element pShimData des PEB zwischen. Diese Kontextdaten enthalten die Kompatibilitäts-GUIDs, mit denen der Prozess ausgeführt wird, und
Der Abbildlader
Kapitel 3
193
bestimmen, welche Version der Verzweigungspunkte in den aufgerufenen SwitchBack-fähigen
APIs ausgeführt wird.
API-Sets
SwitchBack verwendet eine API-Umleitung, um für Anwendungskompatibilität zu sorgen.
Es gibt jedoch auch einen allgemeineren Umleitungsmechanismus, der in Windows für alle
Anwendungen verwendet wird – die API-Sets. Sie ermöglichen eine feine Zuordnung von
Windows-APIs zu Teil-DLLs, sodass es nicht nötig ist, riesige Mehrzweck-DLLs mit Tausenden
von APIs zu handhaben, die bei den heutigen und zukünftigen Windows-Systemen nicht alle
erforderlich sind. Diese Technologie wurde hauptsächlich entwickelt, um das Refactoring der
untersten Schichten der Windows-Architektur zu ermöglichen und diese besser von den höheren Schichten zu trennen. Sie geht Hand in Hand mit der Aufteilung von u. a. Kernel32.dll und
Advapi32.dll in mehrere virtuelle DLL-Dateien.
So zeigt der Dependency-Walker-Screenshot aus Abb. 3–14, wie die Windows-Kernbibliothek Kernel32.dll Funktionen aus vielen anderen DLLs importiert, beginnend mit API-MS-WIN.
Jede dieser DLLs enthält einen kleinen Teil der APIs, die Kernel32 normalerweise bereitstellt.
Zusammen bilden sie die gesamte API-Oberfläche, die von Kernel32.dll verfügbar gemacht
wird. Beispielsweise trägt die Bibliothek CORE-STRING nur die grundlegenden Stringfunktionen
von Windows bei.
Abbildung 3–14 API-Sets für Kernel32.dll
194
Kapitel 3
Prozesse und Jobs
Durch die Aufteilung der Funktionen auf mehrere Dateien werden zwei Ziele erreicht: Erstens
sind künftige Anwendungen dadurch in der Lage, eine Verlinkung nur mit den API-Bibliotheken
herzustellen, deren Funktionen sie tatsächlich benötigen. Zweitens: Nehmen wir an, Microsoft
wollte eine Windows-Version herausgeben, die eine bestimmte Funktionalität nicht unterstützt,
beispielsweise die Lokalisierung (etwa ein rein englisches eingebettetes System ohne Benutzerinteraktion). In diesem Fall könnte das Unternehmen einfach die entsprechenden Teil-DLLs
herausnehmen und das Schema der API-Sets ändern. Dadurch würde die Binärdatei Kernel32
kleiner, und jegliche Anwendungen, die keine Lokalisierung benötigen, könnten immer noch
ausgeführt werden.
Mithilfe dieser Technologie wurde das »grundlegende« Windows-System MinWin definiert (und der Quellcode dafür erstellt). Es enthält nur ein Minimum an Diensten, zu denen der
Kernel und die Kerntreiber gehören (einschließlich Dateisystemen, grundlegenden Systemprozessen wie Csrss und dem Dienststeuerungs-Manager sowie einer Handvoll Windows-Dienste).
Windows Embedded und der Platform Builder bieten eine scheinbar ähnliche Technologie, da
Systementwickler hier in der Lage sind, einzelne Windows-Komponenten wie die Shell oder
den Netzwerkstack zu entfernen. Dadurch aber bleiben hängende Abhängigkeiten zurück, also
Codepfade, die fehlschlagen, wenn sie ausgeführt werden, da sie die entfernten Komponenten
benötigen. Die Abhängigkeiten von MinWin sind dagegen in sich abgeschlossen.
Bei der Initialisierung ruft der Prozess-Manager die Funktion PspInitializeApiSetMap auf.
Sie ist dafür zuständig, das Abschnittsobjekt der API-Set-Umleitungstabelle zu erstellen, die
in %SystemRoot%\System32\ApiSetSchema.dll gespeichert ist. Diese DLL enthält keinen ausführbaren Code, verfügt aber über den Abschnitt .apiset mit den Daten zur Zuordnung der
virtuellen API-Set-DLLs zu den logischen DLLs, die die APIs implementieren. Wird ein neuer
Prozess gestartet, ordnet der Prozess-Manager das Abschnittsobjekt im Prozessadressraum zu
und richtet das Feld ApiSetMap im PEB des Prozesses so ein, dass es auf die Basisadresse dieser
Zuordnung zeigt.
Die Laderfunktion LdrpApplyFileNameRedirection, die normalerweise für die weiter vorn
beschriebene .local- und SxS/Fusion-Manifestumleitung zuständig ist, führt auch eine Überprüfung auf API-Set-Umleitungsdaten durch, wenn eine neue Importbibliothek geladen wird
(dynamisch oder statisch), deren Name mit API beginnt. Die API-Set-Tabelle ist nach Bibliotheken geordnet, wobei jeder Eintrag beschreibt, in welcher logischen DLL die Funktion gefunden
werden kann. Diese DLL ist es, die geladen wird. Die Schemadaten liegen zwar im Binärformat
vor, doch mit dem Sysinternals-Programm Strings können Sie die zugehörigen Strings ausgeben, um sich anzusehen, welche DLLs zurzeit definiert sind:
C:\Windows\System32>strings apisetschema.dll
...
api-ms-onecoreuap-print-render-l1-1-0
printrenderapihost.dllapi-ms-onecoreuap-settingsync-status-l1-1-0
settingsynccore.dll
api-ms-win-appmodel-identity-l1-2-0
kernel.appcore.dllapi-ms-win-appmodel-runtime-internal-l1-1-3
api-ms-win-appmodel-runtime-l1-1-2
api-ms-win-appmodel-state-l1-1-2
Der Abbildlader
Kapitel 3
195
api-ms-win-appmodel-state-l1-2-0
api-ms-win-appmodel-unlock-l1-1-0
api-ms-win-base-bootconfig-l1-1-0
advapi32.dllapi-ms-win-base-util-l1-1-0
api-ms-win-composition-redirection-l1-1-0
...
api-ms-win-core-com-midlproxystub-l1-1-0
api-ms-win-core-com-private-l1-1-1
api-ms-win-core-comm-l1-1-0
api-ms-win-core-console-ansi-l2-1-0
api-ms-win-core-console-l1-1-0
api-ms-win-core-console-l2-1-0
api-ms-win-core-crt-l1-1-0
api-ms-win-core-crt-l2-1-0
api-ms-win-core-datetime-l1-1-2
api-ms-win-core-debug-l1-1-2
api-ms-win-core-debug-minidump-l1-1-0
...
api-ms-win-core-firmware-l1-1-0
api-ms-win-core-guard-l1-1-0
api-ms-win-core-handle-l1-1-0
api-ms-win-core-heap-l1-1-0
api-ms-win-core-heap-l1-2-0
api-ms-win-core-heap-l2-1-0
api-ms-win-core-heap-obsolete-l1-1-0
api-ms-win-core-interlocked-l1-1-1
api-ms-win-core-interlocked-l1-2-0
api-ms-win-core-io-l1-1-1
api-ms-win-core-job-l1-1-0
...
Jobs
Ein Job (oder Auftrag) ist ein Kernelobjekt, das benannt, abgesichert und gemeinsam genutzt
werden kann und es ermöglicht, eine Gruppe von Prozessen als eine Einheit zu verwalten und
zu bearbeiten. Ein Prozess kann zwar zu beliebig vielen Jobs gehören, ist gewöhnlich aber nur
Element eines einzigen. Die Verbindung eines Prozesses mit einem Job kann nicht aufgehoben
werden, und alle von dem Prozess und seinen Abkömmlingen erstellten Prozesse werden mit
demselben Jobobjekt verknüpft (es sei denn, die Kindprozesse wurden mit dem Flag CREATE_
BREAKAWAY_FROM_JOB erstellt und der Job hat dies nicht eingeschränkt). Das Jobobjekt zeichnet
auch grundlegende Buchführungsinformationen für alle mit ihm verbundenen Prozesse auf,
einschließlich derer, die bereits beendet wurden.
196
Kapitel 3
Prozesse und Jobs
Jobs können auch mit einem E/A-Abschlussportobjekt verbunden werden, auf das andere
Threads mit der Windows-Funktion GetQueuedCompletionStatus oder durch Verwendung der
Threadpool-API warten (native Funktion TpAllocJobNotification). Dadurch können daran interessierte Parteien (gewöhnlich der Ersteller des Jobs) nach Verletzungen der Grenzwerte und
nach Ereignissen suchen, die die Sicherheit des Jobs gefährden, z. B. nach der Schaffung eines
neuen Prozesses oder der unnatürlichen Beendigung eines Prozesses.
Jobs spielen bei verschiedenen Systemmechanismen eine wichtige Rolle:
QQ Sie verwalten moderne Apps (UWP-Prozesse), wie in Kapitel 9 von Band 2 noch genauer
erklärt wird. Jede moderne App wird in einem Job ausgeführt. Das können Sie sich mithilfe
von Process Explorer ansehen, was im Experiment »Das Jobobjekt anzeigen« weiter hinten
in diesem Kapitel erklärt wird.
QQ Sie dienen zur Implementierung der Windows-Unterstützung für Container. Das geschieht
mithilfe des Mechanismus der Serversilos, der weiter hinten in diesem Abschnitt beschrieben wird.
QQ Sie bilden die wichtigste Einrichtung, durch die der Desktop Activity Moderator (DAM)
Drosselung, Timervirtualisierung, das Einfrieren von Timern und andere Leerlaufverhalten
für Win32-Anwendungen und -Dienste verwaltet. Der DAM wird in Kapitel 8 von Band 2
beschrieben.
QQ Sie ermöglichen die Definition und Verwaltung von Planungsgruppen für die in Kapitel 4
beschriebene dynamische gleichmäßige Planung (Dynamic Fair-Share Scheduling, DFSS).
QQ Sie ermöglichen die Angabe einer benutzerdefinierten Speicherpartition, die wiederum
die Verwendung der in Kapitel 5 beschriebenen API zur Speicherpartitionierung erlaubt.
QQ Sie dienen als entscheidende Voraussetzung für Merkmale wie Ausführen als (sekundäre
Anmeldung), Anwendungs-Boxing und den Programmkompatibilitäts-Assistenten.
QQ Sie stellen einen Teil der Sicherheitssandbox für Anwendungen wie Google Chrome und
den Microsoft Office-Dokumentkonverter sowie einen Schutz gegen DoS-Angriffe durch
WMI-Anforderungen (Windows Management Instrumentation) bereit.
Grenzwerte für Jobs
Für einen Job können Sie unter anderem die folgenden CPU-, Speicher- und E/A-Grenzwerte
festlegen:
QQ Maximale Anzahl aktiver Prozesse Schränkt die Anzahl der gleichzeitig vorhandenen
Prozesse im Job ein. Sobald dieser Grenzwert erreicht ist, wird die Erstellung neuer Prozesse, die diesem Job zugewiesen werden sollen, blockiert.
QQ Grenzwert für die CPU-Zeit im Benutzermodus für den gesamten Job Schränkt
die CPU-Zeit im Benutzermodus ein, die die Prozesse im Job verbrauchen dürfen (einschließlich der Prozesse, die bereits ausgeführt wurden und beendet sind). Sobald der
Grenzwert erreicht ist, werden standardmäßig alle Prozesse im Job mit einem Fehlercode
beendet. Es ist dann auch nicht mehr möglich, neue Prozesse in dem Job zu erstellen
(sofern der Grenzwert nicht zurückgesetzt wird). Es wird ein Signal über dieses Jobobjekt
Jobs
Kapitel 3
197
gesendet, damit jegliche Threads, die auf den Job warten, freigegeben werden können.
Dieses Standardverhalten können Sie mit einem Aufruf von EndOfJobTimeAction in der
Struktur JOBOBJECT_END_OF_JOB_TIME_INFORMATION ändern, die mit der Informationsklasse
JobObjectEndOfJobTimeInformation übergeben wird, sodass stattdessen eine Benachrichtigung durch den Abschlussport des Jobs gesendet wird.
QQ Grenzwert für die CPU-Zeit im Benutzermodus für einzelne Prozesse Ist dieser Wert
angegeben, können die einzelnen Prozesse im Job nur jeweils begrenzte CPU-Zeit im Benutzermodus verbrauchen. Ist der Grenzwert erreicht, wird der Prozess beendet, wobei es
keine Möglichkeiten für Aufräumarbeiten mehr gibt.
QQ Prozessoraffinität des Jobs Richtet die Prozessoraffinitätsmaske für jeden Prozess im
Job ein. Einzelne Threads können ihre Affinität auf eine Teilmenge der Jobaffinität einschränken, doch Prozesse können ihre Prozessaffinitätseinstellungen nicht ändern.
QQ Gruppenaffinität des Jobs Stellt eine Liste von Gruppen auf, denen die Prozesse im Job
zugeordnet werden können. Affinitätsänderungen erfolgen dann durch Auswahl der entsprechenden Gruppen. Diese Angabe dient als gruppengesteuerte Version der (veralteten)
Festlegung der Jobprozessoraffinität und verhindert, dass Letztere verwendet wird.
QQ Prioritätsklasse der Jobprozesse Legt die Prioritätsklasse für jeden Prozess im Job fest.
Anders als sonst können Threads ihre Priorität dabei nicht erhöhen. Jegliche Versuche dazu
werden ignoriert. Bei einem Aufruf von SetThreadPriority wird zwar kein Fehler zurückgegeben, doch die Priorität wird nicht erhöht.
QQ Standardminimum und -maximum für den Arbeitssatz Legt das Minimum und Maximum des Arbeitssatzes für jeden Prozess im Job fest. Dies ist jedoch keine jobweite Einstellung: Jeder Prozess hat seinen eigenen Arbeitssatz, wobei für alle Arbeitssätze dieselben
Minimum- und Maximumwerte gelten.
QQ Grenzwert für den zugesicherten virtuellen Speicher der Prozesse und des Jobs Legt
die Höchstmenge des virtuellen Adressraums fest, der von einem einzelnen Prozess oder
dem gesamten Job zugesichert werden kann.
QQ Steuerung der CPU-Rate Legt das Maximum an CPU-Zeit fest, das der Job benutzen
darf, bevor er gedrosselt wird. Diese Einstellung wird für die in Kapitel 4 beschriebene Unterstützung von Planungsgruppen verwendet.
QQ Steuerung der Netzwerkbandbreitenrate Legt das Maximum an Bandbreite fest, das
dem gesamten Job für ausgehende Verbindungen zur Verfügung steht, bevor eine Drosselung auftritt. Damit kann für die von dem Job gesendeten Netzwerkpakete auch ein
DSCP-Wert (Differentiated Services Code Point) für QoS-Zwecke festgelegt werden. Dies
lässt sich nur für einen Job in einer Hierarchie einstellen und wirkt sich auf den Job und
jegliche Kindjobs aus.
QQ Steuerung der Bandbreitenrate für Festplatten-E/A Entspricht der Steuerung der
Netzwerkbandbreitenrate, allerdings für Festplatten-E/A. Damit lässt sich die Bandbreite
selbst oder die Anzahl der E/A-Operationen pro Sekunde (IOPS) steuern. Die Einstellung
kann für ein bestimmtes Volume oder für alle Volumes auf dem System vorgenommen
werden.
198
Kapitel 3
Prozesse und Jobs
Für viele dieser Einstellungen kann der Besitzer des Jobs Schwellenwerte angeben, bei deren
Erreichen eine Benachrichtigung gesendet wird. (Ist keine Benachrichtigung registriert, wird
der Job einfach beendet.) Dazu werden die Benachrichtigungen in eine Warteschlange am
E/A-Abschlussport des Jobs gestellt (siehe Dokumentation des Windows SDK). Bei den Ratensteuerungswerten können auch Toleranzbereiche mit Intervallen angegeben werden, sodass
ein Prozess beispielsweise alle fünf Minuten bis zu zehn Sekunden lang den Grenzwert für die
Netzwerkbandbreite um 20 % überschreiten darf.
Für die Prozesse in einem Job können Sie auch Einschränkungen in Bezug auf die Benutzeroberfläche einrichten. Beispielsweise können Sie Prozesse daran hindern, Handles für
Fenster zu öffnen, die Threads außerhalb des Jobs gehören, in der Zwischenablage zu lesen
und zu schreiben und Systemparameter der Benutzerschnittstelle über die Windows-Funk
tion SystemParametersInfo zu ändern. Diese Einschränkungen werden vom GDI/USER-Treiber
Win32k.sys des Windows-Teilsystems verwaltet und durch den Job-Callout durchgesetzt, den
dieser Treiber im Prozess-Manager registriert. Um allen Prozessen in einem Job Zugriff auf
bestimmte Benutzerhandles (z. B. Fensterhandles) zu gewähren, können Sie die Funktion
UserHandleGrantAccess aufrufen. Sie kann jedoch (logischerweise) nur von einem Prozess
aufgerufen werden, der nicht zu dem betreffenden Job gehört.
Umgang mit Jobs
Ein Jobobjekt erstellen Sie mit der API CreateJobObject. Zu Anfang befinden sich keinerlei Prozesse in dem Job. Um ihn mit einem Prozess zu versehen, rufen Sie AssignProcessToJobObject
auf. Sie kann mehrmals verwendet werden, um einem Job mehrere Prozesse oder einen Prozess
zu mehreren Jobs hinzuzufügen. Bei der zweiten Möglichkeit entsteht ein verschachtelter Job,
was wir uns im nächsten Abschnitt ansehen werden. Sie können einen Prozess auch dadurch
zu einem Job hinzufügen, dass Sie mit dem weiter vorn behandelten Prozesserstellungsattribut
PS_CP_JOB_LIST manuell ein Handle zu dem Jobobjekt angeben. Dabei können Sie auch Handles für mehrere Jobobjekte angeben, die alle verknüpft werden.
Die interessanteste API für Jobs ist SetInformationJobObject, mit der Sie die im vorherigen Abschnitt erwähnten Grenzwerte und Einstellungen einrichten können. Des Weiteren
umfasst sie die internen Informationsklassen, die von Mechanismen wie Containern (Silos),
dem DAM oder Windows-UWP-Anwendungen genutzt werden. Diese Werte können mit
QueryInformationJobObject wieder gelesen werden, um daran interessierten Parteien die für
den Job festgelegten Grenzwerte mitzuteilen. Diese Funktion muss auch aufgerufen werden,
wenn Benachrichtigungen über Grenzwerte eingerichtet sind, damit der Aufrufer genau erfährt, welche Grenzwerte verletzt wurden. Ebenfalls oft nützlich ist die Funktion TerminateJobObject, die alle Prozesse in dem Job beendet (so, als wäre TerminateProcess für jeden
einzelnen dieser Prozesse aufgerufen worden).
Verschachtelte Jobs
Bis Windows 7 und Windows Server 2008 R2 konnte ein Prozess immer nur mit einem einzigen
Job verbunden sein. Dadurch waren Jobs weniger nützlich, als sie hätten sein können, da eine
Anwendung manchmal im Voraus gar nicht wissen konnte, ob ein Prozess, den sie verwalten
Jobs
Kapitel 3
199
musste, zu einem Job gehörte oder nicht. Ab Windows 8 und Windows Server 2012 kann ein
Prozess jedoch mit mehreren Jobs verbunden sein, wodurch im Grunde genommen eine Jobhierarchie entsteht.
Ein Kindjob unterhält einen Teil der Prozesse seines Elternjobs. Sobald ein Prozess zu mehr
als einem Job hinzugefügt wurde, versucht das System, eine Hierarchie zu bilden. Zurzeit ist der
Aufbau einer solchen Hierarchie nicht möglich, falls einer der fraglichen Jobs Einschränkungen
für die Benutzeroberfläche festlegt (SetInformationJobObject mit dem Argument JobObjectBasicUIRestrictions).
Die Einschränkungen eines Kindjobs können restriktiver sein als die seines Elternjobs, aber
nicht weniger streng. Wenn beispielsweise ein Elternjob einen Speichergrenzwert von 100 MB
hat, dann kann ein Kindjob für seine Prozesse (und seine eigenen Kindjobs) keinen höheren
Grenzwert festlegen (entsprechende Anforderungen schlagen einfach fehl), aber durchaus einen niedrigeren, z. B. 80 MB. Benachrichtigungen an den E/A-Abschlussport des Jobs werden
an den Job und alle seine Vorfahren gesendet. Damit eine Benachrichtigung an die Vorfahrenjobs gesendet wird, muss der Job selbst nicht über einen E/A-Abschlussport verfügen.
Die Ressourcen für einen Elternjob schließen die gesammelten Ressourcen ein, die von
seinen direkt verwalteten Prozessen sowie sämtlichen Prozessen in Kindjobs genutzt werden.
Wird ein Job beendet (TerminateJobObject), dann werden alle Prozesse in ihm und in seinen
Kindjobs beendet, wobei der Vorgang bei den Kindjobs am unteren Ende der Hierarchie beginnt. Abb. 3–15 zeigt vier Prozesse, die in einer Jobhierarchie verwaltet werden.
Abbildung 3–15 Eine Jobhierarchie
Um diese Hierarchie zu erstellen, müssen die Prozesse vom Stammjob aus zu den einzelnen
Jobs hinzugefügt werden:
1.
Prozess 1 wird zu Job 1 hinzugefügt.
2.
Prozess 2 wird zu Job 2 hinzugefügt. Dadurch entsteht die erste Verschachtelung.
3.
Prozess 2 wird zu Job 1 hinzugefügt.
4.
Prozess 2 wird zu Job 3 hinzugefügt. Dadurch entsteht die zweite Verschachtelung.
5.
Prozess 3 wird zu Job 2 hinzugefügt.
6.
Prozess 4 wird zu Job 1 hinzugefügt.
200
Kapitel 3
Prozesse und Jobs
Experiment: Das Jobobjekt anzeigen
Sie können sich benannte Jobobjekte in der Leistungsüberwachung ansehen. Halten Sie
dabei nach dem Kategorien Auftragsobjekt und Auftragsobjektdetails Ausschau. Unbenannte Jobs können Sie mit den Befehlen !job und dt nt!_ejob des Kerneldebuggers einsehen.
Ob ein Prozess mit einem Job verbunden ist, können Sie sich mithilfe des Kerneldebuggerbefehls !process und in Process Explorer ansehen. Um ein unbenanntes Jobobjekt zu
erstellen und anzuzeigen, gehen Sie wie folgt vor:
1.
Führen Sie an einer Eingabeaufforderung den Befehl runas aus, um einen Prozess zu
erstellen, der innerhalb der Eingabeaufforderung (Cmd.exe) läuft, z. B. runas /user:
<Domäne>\<Benutzername> cmd.
2.
Sie werden nach Ihrem Kennwort gefragt. Nachdem Sie es eingegeben haben, erscheint
ein Fenster mit einer Eingabeaufforderung. Der Windows-Dienst zur Ausführung von
runas-Befehlen erstellt einen unbenannten Job, der alle Prozesse enthält (damit er diese Prozesse bei der Abmeldung beenden kann).
3.
Starten Sie Process Explorer, öffnen Sie das Menü Options, wählen Sie Configure Colors
und aktivieren Sie den Eintrag Jobs. Der Prozess Cmd.exe und sein Kindprozess ConHost.exe werden als Teil eines Jobs hervorgehoben:
4.
Doppelklicken Sie auf den Prozess Cmd.exe oder ConHost.exe, um sein Eigenschaftendialogfeld zu öffnen. Klicken Sie dort auf die Registerkarte Job, um sich Informationen
über den Job anzusehen, zu dem der Prozess gehört:
→
Jobs
Kapitel 3
201
5.
Führen Sie an der Befehlszeile Notepad.exe aus.
6.
Öffnen Sie den Prozess für den Editor und rufen Sie dessen Registerkarte Job auf. Wie
Sie sehen, läuft der Editor in demselben Job wie die Eingabeaufforderung, da Cmd.exe
nicht das Flag CREATE_BREAKAWAY_FROM_JOB verwendet. Bei verschachtelten Jobs zeigt
die Registerkarte Job die Prozesse in dem Job an, zu dem der Prozess unmittelbar gehört, sowie in allen Kindjobs.
7.
Führen Sie den Kerneldebugger auf einem aktiven System aus und geben Sie den Befehl !process ein, um Notepad.exe zu finden und die folgenden grundlegenden Informationen darüber anzuzeigen:
lkd> !process 0 1 notepad.exe
PROCESS ffffe001eacf2080
SessionId: 1 Cid: 3078 Peb: 7f4113b000 ParentCid: 05dc
DirBase: 4878b3000 ObjectTable: ffffc0015b89fd80
HandleCount: 188.
Image: notepad.exe
...
8.
BasePriority
8
CommitCharge
671
Job
ffffe00189aec460
Beachten Sie den von null verschiedenen Jobzeiger. Um eine Übersicht über den Job zu
bekommen, geben Sie den Debuggerbefehl !job ein:
lkd> !job ffffe00189aec460
Job at ffffe00189aec460
Basic Accounting Information
TotalUserTime:
0x0
TotalKernelTime:
0x0
TotalCycleTime:
0x0
ThisPeriodTotalUserTime:
0x0
ThisPeriodTotalKernelTime: 0x0
TotalPageFaultCount:
0x0
TotalProcesses:
0x3
ActiveProcesses:
0x3
FreezeCount:
0
BackgroundCount:
0
TotalTerminatedProcesses:
0x0
PeakJobMemoryUsed:
0x10db
PeakProcessMemoryUsed:
0xa56
Job Flags
Limit Information (LimitFlags: 0x0)
Limit Information (EffectiveLimitFlags: 0x0)
→
202
Kapitel 3
Prozesse und Jobs
9.
Wie Sie sehen, ist ActiveProcesses auf 3 gesetzt (Cmd.exe, ConHost.exe und Notepad.
exe). Um sich eine Liste der Prozesse anzusehen, die Teil des Jobs sind, geben Sie hinter
dem Befehl !job das Flag 2 an:
lkd> !job ffffe00189aec460 2
...
Processes assigned to this job:
PROCESS ffff8188d84dd780
SessionId: 1 Cid: 5720 Peb: 43bedb6000 ParentCid: 13cc
DirBase: 707466000 ObjectTable: ffffbe0dc4e3a040
HandleCount: <Data Not Accessible>
Image: cmd.exe
PROCESS ffff8188ea077540
SessionId: 1 Cid: 30ec Peb: dd7f17c000 ParentCid: 5720
DirBase: 75a183000 ObjectTable: ffffbe0dafb79040
HandleCount: <Data Not Accessible>
Image: conhost.exe
PROCESS ffffe001eacf2080
SessionId: 1 Cid: 3078 Peb: 7f4113b000 ParentCid: 05dc
DirBase: 4878b3000 ObjectTable: ffffc0015b89fd80
HandleCount: 188.
Image: notepad.exe
10. Sie können auch den Befehl dt verwenden, um sich das Jobobjekt und zusätzliche
Felder mit Informationen über den Job anzusehen, z. B. seine Elementebene und seine
Beziehungen zu anderen Jobs (Elternjob, Geschwisterjobs und Stammjob).
lkd> dt nt!_ejob ffffe00189aec460
+0x000 Event
: _KEVENT
+0x018 JobLinks
: _LIST_ENTRY [ 0xffffe001'8d93e548 -
0xffffe001'df30f8d8 ]
+0x028 ProcessListHead : _LIST_ENTRY [ 0xffffe001'8c4924f0 0xffffe001'eacf24f0 ]
+0x038 JobLock
: _ERESOURCE
+0x0a0 TotalUserTime
: _LARGE_INTEGER 0x0
+0x0a8 TotalKernelTime : _LARGE_INTEGER 0x2625a
+0x0b0 TotalCycleTime
: _LARGE_INTEGER 0xc9e03d
...
+0x0d4 TotalProcesses
: 4
+0x0d8 ActiveProcesses : 3
+0x0dc TotalTerminatedProcesses : 0
...
→
Jobs
Kapitel 3
203
+0x428 ParentJob
: (null)
+0x430 RootJob
: 0xffffe001'89aec460 _EJOB
...
+0x518 EnergyValues
: 0xffffe001'89aec988 _PROCESS_ENERGY_VALUES
+0x520 SharedCommitCharge : 0x5e8
Windows-Container (Serversilos)
Das Aufkommen des billigen, allgegenwärtigen Cloudcomputings hat zu einer weiteren erheblichen Umwälzung des Internets geführt. Für den Aufbau von Onlinediensten und Back-EndServern für mobile Anwendungen ist jetzt kaum mehr erforderlich, als bei einem der vielen
Cloudanbieter auf eine Schaltfläche zu klicken. Allerdings hat sich die Konkurrenz zwischen
diesen Anbietern verschärft, und der Bedarf für einen Wechsel von einem Cloudanbieter zu
einem anderen, von einem Cloudanbieter zu einem Rechenzentrum oder von einem Rechenzentrum zu einem persönlichen High-End-Server ist gestiegen. Aufgrund dieser Entwicklung
werden portierbare Back-Ends immer wichtiger, die nach Bedarf bereitgestellt und verlagert
werden können, ohne dafür den Mehraufwand in Kauf nehmen zu müssen, den die Ausführung
in einer virtuellen Maschine mit sich bringt.
Um diesen Bedarf zu befriedigen, wurden Technologien wie Docker entwickelt. Sie ermöglichen die Verlagerung einer »Paketanwendung« von einer Linux-Distribution auf eine andere,
ohne sich dabei um die Feinheiten der Bereitstellung einer lokalen Installation oder um den
Ressourcenverbrauch einer virtuellen Maschine sorgen zu müssen. Dies war ursprünglich eine
reine Linux-Technologie, doch im Rahmen des Anniversary-Updates hat Microsoft Docker auch
für Windows 10 verfügbar gemacht. Dabei gibt es zwei verschiedene Betriebsmodi:
QQ Durch Bereitstellung einer Anwendung in einem schweren, aber vollständig isolierten
Hyper-V-Container, was sowohl für Server als auch für Clients möglich ist
QQ Durch Bereitstellung einer Anwendung in einem schlanken, betriebssystemisolierten Silocontainer, was aus Lizenzgründen nur für Server möglich ist
In diesem Abschnitt sehen wir uns den zweiten Fall an. Um dies möglich zu machen, mussten
tief greifende Änderungen am Betriebssystem vorgenommen werden. Clientsysteme haben
zwar prinzipiell auch die Möglichkeit, Serversilocontainer zu erstellen, doch diese Funktion
ist zurzeit deaktiviert. Im Gegensatz zu Hyper-V-Containern, die auf eine echte virtualisierte
Umgebung zurückgreifen, bietet ein Serversilocontainer eine zweite »Instanz« aller Benutzermoduskomponenten, läuft aber oberhalb desselben Kernels und derselben Treiber. Dadurch
kommt eine weit schlankere Containerumgebung zustande, was aber auf Kosten der Sicherheit
geht.
Jobobjekte und Silos
Die Möglichkeiten zum Erstellen eines Silos hängen von mehreren nicht dokumentierten Unterklassen ab, die zur API SetJobObjectInformation gehören. Ein Silo ist also im Grunde genom-
204
Kapitel 3
Prozesse und Jobs
men ein Superjob mit zusätzlichen Regeln und Fähigkeiten. Ein Jobobjekt kann nicht nur für die
bisher betrachteten Zwecke der Isolierung und des Ressourcenmanagements verwendet werden, sondern auch, um einen Silo zu erstellen. Solche Jobs werden als Hybridjobs bezeichnet.
Jobobjekte können zwei Arten von Silos beherbergen, nämlich Anwendungssilos (die zurzeit
zur Implementierung von Desktop Bridge verwendet werden und in Kapitel 9 von Band 2 erläutert werden) und Serversilos. Letztere ermöglichen die Verwendung von Docker-Containern.
Siloisolierung
Das erste Element zur Definition eines Serversilos ist ein benutzerdefiniertes Stammverzeichnisobjekt (\) des Objekt-Managers. (Der Objekt-Manager wird in Kapitel 8 von Band 2 behandelt.)
Diesen Mechanismus haben Sie zwar noch nicht kennengelernt, aber wir wollen hier nur erwähnen, dass sich alle für die Anwendung sichtbaren benannten Objekte (wie Dateien, Regis
trierungsschlüssel, Ereignisse, Mutexe, RPC-Ports usw.) in einem Stammnamensraum befinden.
Dadurch können Anwendungen solche Objekte erstellen, finden und gemeinsam nutzen.
Da ein Serversilo seinen eigenen Stamm haben kann, ist es möglich, den Zugriff auf jegliche benannten Objekte zu steuern. Dies kann auf dreierlei Weise geschehen:
QQ Durch Erstellen einer neuen Kopie eines vorhandenen Objekts, um innerhalb des Silos eine
alternative Zugriffsmöglichkeit darauf zu bieten
QQ Durch Erstellen einer symbolischen Verknüpfung zu einem vorhandenen Objekt, um den
direkten Zugriff darauf zu ermöglichen
QQ Durch Erstellen eines ganz neuen Objekts, das nur innerhalb des Silos existiert, ähnlich wie
die Objekte, die eine Containeranwendung nutzt
Diese grundlegenden Möglichkeiten werden dann mit dem von Docker verwendeten Dienst
Vmcompute (Virtual Machine Computer) kombiniert, der mit weiteren Komponenten zusammen-
arbeitet, um eine vollständige Isolierschicht zu bilden:
QQ Eine grundlegende WIM-Datei (Windows Image) als Basisbetriebssystem Dadurch
wird eine separate Kopie des Betriebssystems bereitgestellt. Zurzeit bietet Microsoft sowohl ein Server Core- als auch ein Nano Server-Abbild an.
QQ Die Bibliothek Ntdll.dll des Hostbetriebssystems Sie überschreibt die gleichnamige
Bibliothek im Abbild des Basisbetriebssystems. Das liegt daran, dass Serversilos denselben Kernel und dieselben Treiber nutzen. Da Ntdll.dll Systemaufrufe verarbeitet, ist sie die
einzige Benutzermoduskomponente, die das Hostbetriebssystem wiederverwenden muss.
QQ Ein virtuelles Sandbox-Dateisystem, bereitgestellt vom Filtertreiber Wcifs.sys Dadurch wird es möglich, dass der Container vorübergehende Änderungen am Dateisystem
vornimmt, ohne dass sich dies auf das zugrunde liegende NTFS-Laufwerk auswirkt. Nach
dem Herunterfahren des Containers können diese Änderungen gelöscht werden.
QQ Eine virtuelle Sandbox-Registrierung, bereitgestellt von der Kernelkomponente
VReg Dadurch kann ein vorübergehender Satz von Registrierungshives bereitgestellt
werden. Außerdem bildet dies eine weitere Schicht zur Namensraumisolierung, da der
Stammnamensraum des Objekt-Managers nur den Registrierungsstamm isolieren kann,
nicht aber die Hives.
Jobs
Kapitel 3
205
QQ Der Sitzungs-Manager (Smss.exe) Er wird jetzt verwendet, um zusätzliche Dienstoder Konsolensitzungen zu erstellen. Diese neue Fähigkeit wird zur Unterstützung von
Containern benötigt. Dazu wird Smss so erweitert, dass er nicht nur zusätzliche Benutzer
sitzungen handhaben kann, sondern auch die Sitzungen, die von den gestarteten Con
tainern benötigt werden.
Abb. 3–16 zeigt die Architektur solcher Container und die zuvor genannten Komponenten.
Hostbetriebssystem
Container 1
Container 2
Grundlegendes Windows-Abbild
(WIM)
Grundlegendes Windows-Abbild
(WIM)
Silo
Silo
Virtuelle Registrierung
Container-Manager
Virtuelle Registrierung
Virtuelles
DS
Prozess
Host
compute
dienst
Host
netzwerk
dienst
Andere
Dienste
Host-SMSS
Prozess
Dienste
Host-SMSS
Host-NTDLL
Virtuelles
DS
Prozess
Dienste
Host-NTDLL
Host-DS
Wcifs.sys
VReg
Ntfs.sys
Konfigurations-Manager
Hostregis
trierung
Exekutive und Kernel
Abbildung 3–16 Containerarchitektur
Silogrenzen
Die genannten Komponenten bilden eine Umgebung für die Isolierung im Benutzermodus. Da
jedoch die Hostkomponente Ntdll.dll verwendet wird, die mit dem Hostkernel und den Hosttreibern kommuniziert, ist es wichtig, zusätzliche Isolierungsgrenzen zu erstellen, die der Kernel
anbietet, um zwischen den Silos zu unterscheiden. Dazu enthält jeder Serversilo sein eigenes,
isoliertes Exemplar der folgenden Elemente:
QQ Gemeinsame Silodaten (SILO_USER_SHARED_DATA) Sie enthalten den benutzerdefinierten Systempfad, die Sitzungs-ID, die Vordergrund-PID sowie Produkttyp bzw. -suite.
Dies sind Elemente der ursprünglichen KUSER_SHARED_DATA-Struktur. Sie dürfen jedoch nicht
vom Host bezogen werden, da sie dort auf Informationen für das Host- statt das Basisbetriebssystemabbild verweisen, das stattdessen verwendet werden soll. Mehrere Komponenten und APIs wurden modifiziert, um beim Nachschlagen solcher Daten die gemeinsamen Silodaten statt der gemeinsamen Benutzerdaten zu lesen. Die ursprüngliche
KUSER_SHARED_DATA-Struktur bleibt mit ihrer ursprünglichen Sicht der Hostinformationen
an der üblichen Adresse. Daher ist dies eine Möglichkeit, durch die der Hoststatus in den
Containerstatus durchsickern kann.
QQ Namensraum des Objektverzeichnisstamms Er enthält seinen eigenen symbolischen
\SystemRoot-Link, sein eigenes \Device-Verzeichnis (durch das alle Benutzermoduskompo-
206
Kapitel 3
Prozesse und Jobs
nenten indirekt auf die Gerätetreiber zugreifen), eigene Geräte- und DOS-Geräte-Zuordnungen (über die Benutzermodusanwendungen beispielsweise auf Treiber zugreifen, die
im Netzwerk zugeordnet sind), ein eigenes \Sessions-Verzeichnis usw.
QQ API-Set-Zuordnung Sie basiert auf dem API-Set-Schema des Basisbetriebssystemabbilds, also nicht auf dem Schema, das im Dateisystem des Hostbetriebssystems gespeichert
ist. Wie Sie wissen, nutzt der Lader API-Set-Zuordnungen, um zu bestimmen, welche DLL
eine bestimmte Funktion implementiert. Dies kann sich von einer SKU zur anderen unterscheiden. Anwendungen müssen daher die SKU des Basis- und nicht des Hostbetriebssystems erkennen können.
QQ Anmeldesitzung Sie ist mit den lokal eindeutigen IDs (Local Unique ID, LUID) SYSTEM und
Anonymous sowie der LUID des virtuellen Dienstkontos verbunden, das den Benutzer im Silo
beschreibt. Im Grunde genommen steht die für das Token der Dienste und der Anwendung, die innerhalb der von Smss erstellten Containerdienstsitzung ausgeführt werden.
Weitere Informationen über LUIDs und Anmeldesitzungen erhalten Sie in Kapitel 7.
QQ ETW-Verfolgung und Loggerkontexte Sie dienen zur Isolierung von ETW-Operationen im Silo, damit die Status nicht zum Container oder Hostbetriebssystem durchsickern
(siehe Kapitel 9 in Band 2).
Silokontexte
Neben diesen Isoliergrenzen, die der Kernelkern des Hostbetriebssystems bereitstellt, können
andere Komponenten innerhalb des Kernels sowie Treiber (auch von Drittanbietern) zusätzliche
Kontextdaten für Silos bereitstellen. Dazu richten Sie mit der API PsCreateSiloContext benutzerdefinierte Daten für einen Silo ein oder verknüpfen ein bestehendes Objekt mit einem Silo.
Jeder Silokontext dieser Art nutzt einen Siloslotindex, der in alle laufenden und künftigen Serversilos eingefügt wird und einen Zeiger auf den Kontext enthält. Im Lieferumfang des Systems
sind 32 systemweite Speicherslotindizes sowie 256 Erweiterungsslots enthalten, was sehr viele
Möglichkeiten zur Erweiterung bietet.
Wenn ein Serversilo erstellt wird, erhält er ein Array für seinen lokalen Silospeicher (Silo-Local Storage, SLS), der vergleichbar mit dem lokalen Threadspeicher eines Threads ist (TLS).
Die Einträge in diesem Array geben die Slotindizes an, die zur Speicherung von Silokontexten
zugewiesen sind. Die einzelnen Silos haben am selben Slotindex jeweils einen anderen Zeiger,
speichern dort aber stets einen gleichartigen Kontext. (Beispielsweise kann dem Treiber Foo
in allen Silos der Index 5 gehören, an dem er dann in jedem Silo einen anderen Zeiger bzw.
Kontext speichert.) Einige dieser Slots werden auch von integrierten Kernelkomponenten wie
dem Objekt-Manager, dem Security Reference Monitor (SRM) und dem Konfigurations-Manager genutzt, andere von mitgelieferten Treibern (wie Afd.sys, dem Treiber für zusätzliche
WinSock-Funktionen).
Wie für den Umgang mit gemeinsamen Silodaten wurden mehrere Komponenten und
APIs modernisiert, um die Daten von dem entsprechenden Silokontext abzurufen statt von
dem, was einmal eine globale Kernelvariable war. Beispielsweise hat jeder Container jetzt seinen eigenen Lsass.exe-Prozess, und da der SRM des Kernels ein eigenes Handle für diesen
Prozess benötigt (siehe Kapitel 7), kann dies nicht mehr ein Singleton in einer globalen Varia-
Jobs
Kapitel 3
207
blen sein. Daher greift der SRM jetzt auf das Handle zu, indem er den Silokontext des aktiven
Serversilos abfragt und die Variable dann aus der zurückgegebenen Datenstruktur entnimmt.
Doch was geschieht mit dem Lsass.exe-Prozess, der auf dem Hostbetriebssystem ausgeführt wird? Wie kann der SRM auf sein Handle zugreifen, da es doch keinen Serversilo für diese
Prozesse und diese Sitzung (Sitzung 0) gibt? Für diesen Zweck unterhält der Kernel jetzt einen
Stammhostsilo. Anders ausgedrückt, der Host selbst wird als Teil eines Silos betrachtet. Dabei
handelt es sich jedoch nicht um einen Silo in der eigentlichen Bedeutung, sondern um einen
Klick, damit Kontextabfragen für den aktuellen Silo auch dann funktionieren, wenn es gar keinen aktuellen Silo gibt. Dazu wird die globale Kernelvariable PspHostSiloGlobals gespeichert,
die über ein eigenes Array für den lokalen Silospeicher sowie über andere Silokontexte verfügt,
die von den integrierten Kernelkomponenten verwendet werden. Bei verschiedenen Silo-APIs
wird ein Aufruf mit dem NULL-Zeiger als »kein Silo – verwende den Hostsilo« gedeutet.
Experiment: Den SRM-Silokontext für den Hostsilo ausgeben
Auch ein Windows 10-System muss nicht unbedingt Serversilos unterhalten, insbesondere
wenn es sich um ein Clientsystem handelt. Es ist jedoch stets ein Hostsilo vorhanden, der die
isolierten Silokontexte für den Kernel enthält. Die Windows-Debuggererweiterung !silo
können Sie zusammen mit dem Parameter -g Host verwenden, um eine Ausgabe wie die
folgende zu bekommen:
lkd> !silo -g Host
Server silo globals fffff801b73bc580:
Default Error Port: ffffb30f25b48080
ServiceSessionId
: 0
Root Directory
: 00007fff00000000 ''
State
: Running
In der Ausgabe bildet der Zeiger auf die globalen Silovariablen einen Hyperlink. Wenn Sie
darauf klicken, sehen Sie die folgende Befehlsausführung als Ausgabe:
lkd> dx -r1 (*((nt!_ESERVERSILO_GLOBALS *)0xfffff801b73bc580))
(*((nt!_ESERVERSILO_GLOBALS *)0xfffff801b73bc580)) [Type:
_ESERVERSILO_GLOBALS]
[+0x000] ObSiloState
[Type: _OBP_SILODRIVERSTATE]
[+0x2e0] SeSiloState
[Type: _SEP_SILOSTATE]
[+0x310] SeRmSiloState [Type: _SEP_RM_LSA_CONNECTION_STATE]
[+0x360] CmSiloState
: 0xffffc308870931b0 [Type: _CMP_SILO_CONTEXT *]
[+0x368] EtwSiloState
: 0xffffb30f236c4000 [Type: _ETW_SILODRIVERSTATE *]
...
Wenn Sie jetzt auf das Feld SeRmSiloState klicken, wird es erweitert und zeigt unter anderem einen Zeiger auf den Prozess Lsass.exe:
lkd> dx -r1 ((ntkrnlmp!_SEP_RM_LSA_CONNECTION_STATE *)0xfffff801b73bc890)
((ntkrnlmp!_SEP_RM_LSA_CONNECTION_STATE *)0xfffff801b73bc890) :
→
208
Kapitel 3
Prozesse und Jobs
0xfffff801b73bc890 [Type: _SEP_RM_LSA_CONNECTION_STATE *]
[+0x000] LsaProcessHandle
: 0xffffffff80000870 [Type: void *]
[+0x008] LsaCommandPortHandle : 0xffffffff8000087c [Type: void *]
[+0x010] SepRmThreadHandle
: 0x0 [Type: void *]
[+0x018] RmCommandPortHandle
: 0xffffffff80000874 [Type: void *]
Siloüberwachung
Kerneltreiber können sich mit ihrem eigenen Silokontext versehen. Woher aber wissen sie, welche Silos ausgeführt werden und welche neuen Silos als Container erstellt und gestartet werden? Dazu ist die Siloüberwachung da. Sie stellt APIs für Benachrichtigungen darüber bereit,
dass ein Serversilo erstellt oder beendet wurde (PsRegisterSiloMonitor, PsStartSiloMonitor,
PsUnregisterSiloMonitor), sowie über jegliche bereits existierenden Silos. Jede Siloüberwachung kann durch den Aufruf von PsGetSiloMonitorContextSlot ihren eigenen Slotindex abrufen und dann nach Bedarf in den Funktionen PsInsertSiloContext, PsReplaceSiloContext
und PsRemoveSiloContext nutzen. Mit PsAllocSiloContextSlot lassen sich auch weitere Slots
zuweisen, was allerdings nur dann erforderlich ist, wenn eine Komponente aus irgendeinem
Grund zwei Kontexte speichern möchte. Treiber können auch die APIs PsInsertPermanentSiloContext oder PsMakeSiloContextPermanent nutzen, um dauerhafte Silokontexte anzulegen, bei
denen keine Referenzzählung stattfindet und die nicht an die Lebensdauer des Serversilos oder
die Anzahl der Get-Funktionen für Silokontexte gebunden sind. Ein solcher dauerhafter Kontext
kann mit PsGetSiloContext und PsGetPermanentSiloContext abgerufen werden.
Experiment: Siloüberwachung und -kontext
Damit Sie ein Bild von der Verwendung der Siloüberwachung und der Speicherung von
Silokontexten bekommen, schauen wir uns den Treiber für zusätzliche WinSock-Funktionen
(Afd.sys) und die zugehörige Überwachung an. Als Erstes geben wir die Datenstruktur für
die Überwachung aus. Leider befindet sie sich nicht in den Symboldateien, weshalb wir dies
in Form von Rohdaten tun müssen.
lkd> dps poi(afd!AfdPodMonitor)
ffffe387'a79fc120 ffffe387'a7d760c0
ffffe387'a79fc128 ffffe387'a7b54b60
ffffe387'a79fc130 00000009'00000101
ffffe387'a79fc138 fffff807'be4b5b10 afd!AfdPodSiloCreateCallback
ffffe387'a79fc140 fffff807'be4bee40 afd!AfdPodSiloTerminateCallback
Als Nächstes rufen wir den Slot (in diesem Beispiel 9) vom Hostsilo ab. Silos speichern ihren
SLS im Feld Storage. Es umfasst ein Array aus Datenstrukturen (Sloteinträgen), die wiederum
jeweils einen Zeiger enthalten, sowie einige Flags. Um den Offset für den richtigen Sloteintrag zu bekommen, multiplizieren wir den Index mit 2. Anschließend greifen wir auf das
zweite Feld (+1) zu, damit wir den Zeiger auf den Kontextzeiger erhalten:
→
Jobs
Kapitel 3
209
lkd> r? @$t0 = (nt!_ESERVERSILO_GLOBALS*)@@masm(nt!PspHostSiloGlobals)
lkd> ?? ((void***)@$t0->Storage)[9 * 2 + 1]
void ** 0xffff988f'ab815941
Das Permanenzflag (0x2) wird mit einer OR-Verknüpfung in den Zeiger eingeschlossen.
Maskieren Sie es und vergewissern Sie sich dann mit dem Ausdruck !object, dass das Ergebnis wirklich ein Silokontext ist:
lkd> !object (0xffff988f'ab815941 & -2)
Object: ffff988fab815940 Type: (ffff988faaac9f20) PsSiloContextNonPaged
Serversilos erstellen
Da Silos, wie bereits erwähnt, ein Merkmal von Jobobjekten sind, müssen Sie zum Erstellen eines Serversilos zunächst ein Jobobjekt anlegen. Dazu verwenden Sie die API CreateJobObject,
die im Rahmen des Anniversary-Updates so modifiziert wurde, dass Jobs jetzt eine Job-ID (JID)
haben. Sie stammt aus demselben Wertebereich wie die Prozess- und die Thread-ID, nämlich
aus der Client-ID-Tabelle. Dadurch ist die JID nicht nur unter den anderen Jobs, sondern auch
unter den Prozessen und Threads einzigartig. Außerdem wird automatisch ein Container-GUID
erstellt.
Anschließend wird die API SetInformationJobObject mit der Informationsklasse Siloerstellung verwendet. Dadurch wird im EJOB-Exekutivobjekt für den Job das Flag Silo gesetzt und
das SLS-Slotarray im Element Storage zugewiesen. Damit liegt jetzt ein Anwendungssilo vor.
Danach wird mit einem weiteren Aufruf von SetInformationJobObject, aber einer anderen
Informationsklasse, der Namensraum für das Stammobjektverzeichnis erstellt. Für die neue
Klasse ist das Recht Trusted Computing Base (TCB) erforderlich. Da Silos normalerweise nur
vom Dienst Vmcompute erstellt werden, wird dadurch sichergestellt, dass virtuelle Objektnamensräume nicht böswillig verwendet werden, um Anwendungen zu verwirren oder sogar
funktionsunfähig zu machen. Beim Anlegen des Namensraums erstellt oder öffnet der Objekt-
Manager ein neues Siloverzeichnis unter dem echten Hoststamm (\) und hängt die JID an, um
einen neuen virtuellen Stamm zu bilden (z. B. \Silos\148\). Anschließend erstellt er die Objekte
KernelObjects, ObjectTypes, GLOBALROOT und DosDevices. Der Stamm wird dann als Silokontext
mit dem Slotindex gespeichert, der sich in PsObjectDirectorySiloContextSlot befindet und
vom Objekt-Manager beim Start zugewiesen wurde.
Der nächste Schritt besteht darin, den Silo zu einem Serversilo zu machen. Dazu wird wiederum SetInformationJobObject mit einer weiteren Informationsklasse aufgerufen. Im Kernel
wird die Funktion PspConvertSiloToServerSilo ausgeführt, die die ESERVERSILO_GLOBALS-Struktur initialisiert (die Sie schon in dem Experiment gesehen haben, in dem Sie PspHostSiloGlobals
mit dem Befehl !silo ausgegeben haben). Dadurch werden die gemeinsamen Silodaten, die
API-Set-Zuordnung, der Systemstamm und diverse Silokontexte initialisiert, z. B. derjenige, mit
dem die SRM den Lsass.exe-Prozess erkennt. Während des Konvertierungsvorgangs erhalten
die Siloüberwachungen, die Callbacks registriert und gestartet haben, entsprechende Nachrichten, z. B. dass sie ihre eigenen Silokontextdaten hinzufügen können.
210
Kapitel 3
Prozesse und Jobs
Der letzte Schritt besteht darin, den Serversilo durch Initialisieren einer neuen Dienstsitzung
zu starten, also praktisch Sitzung 0 für den Serversilo. Dies erfolgt durch eine ALPC-Nachricht,
die an den Smss-Port SmApiPort gesendet wird und ein Handle für das von Vmcompute erstellte
und nun zu einem Serversilo umgewandelte Jobobjekt enthält. Wie beim Erstellen einer normaler Benutzersitzung klont sich Smss selbst, wobei der Klon diesmal jedoch mit dem Jobobjekt verbunden wird. Dadurch wird die neue Smss-Kopie an Containerelemente des Serversilos
angehängt. Smss glaubt, dass dies Sitzung 0 ist, und führt seine üblichen Pflichten aus, z. B.
den Start von Scrss.exe, Wininit.exe, Lsass.exe usw. Dieser »Startprozess« fährt wie gewöhnlich
fort, wobei Wininit.exe als Nächstes den Dienststeuerungsmanager (Services.exe) startet, der
wiederum alle Dienste mit automatischem Start in Gang setzt usw. Im Serversilo können jetzt
auch neue Anwendungen ausgeführt werden. Wie zuvor beschrieben, werden sie mit einer
Anmeldesitzung ausgeführt, die mit einem LUID für ein virtuelles Dienstkonto verbunden ist.
Hilfsfunktionen
Vielleicht ist Ihnen aufgefallen, dass ein Startprozess wie in der vorstehenden kurzen Beschreibung nicht erfolgreich sein kann. Beispielsweise würde er im Rahmen der Initialisierung versuchen, die benannte Pipe ntsvcs zu erstellen, für die eine Kommunikation mit \Device\NamedPipe bzw. aus der Sicht von Services.exe mit \Silos\JID\Device\NamedPipe erforderlich wäre. Ein
solches Geräteobjekt gibt es aber nicht!
Damit Gerätetreiber auf Funktionen zugreifen können, müssen sie daher Informationen
bekommen und ihre eigenen Siloüberwachungen registrieren, die dann Benachrichtigungen
nutzen, um ihre eigenen Geräteobjekte für die einzelnen Silos zu erstellen. Der Kernel bietet
die API PsAttachSiloToCurrentThread (und das Pendant PsDetachSiloFromCurrentThread), die
vorübergehend das Feld Silo in der ETHREAD-Struktur des übergebenen Jobobjekts ausfüllt. Dadurch wird jeglicher Zugriff, z. B. auf den Objekt-Manager, so behandelt, als käme er von dem
Silo. Beispielsweise kann der Treiber für benannte Pipes diesen Mechanismus nutzen, um ein
NamedPipe-Objekt im Namensraum \Device zu erstellen, der jetzt zu \Silos\JID\ gehört.
Des Weiteren stellt sich die Frage, wie Anwendungen, die im Grunde genommen in einer
»Dienstsitzung« gestartet werden, interaktiv sein und Ein- und Ausgaben verarbeiten können. Beim Start in einem Windows-Container sind weder grafische Benutzeroberflächen noch
die Verwendung eines Remotedesktops für den Zugriff auf einen Container möglich. Daher
können nur Befehlszeilenanwendungen ausgeführt werden. Doch auch sie brauchen gewöhnlich eine interaktive Sitzung. Wie also können sie funktionieren? Das Geheimnis liegt in
dem besonderen Hostprozess CExecSvc.exe, der den Containerausführungsdienst implementiert. Dieser Dienst verwendet eine benannte Pipe zur Kommunikation mit dem Docker- und
dem Vmcompute-Dienst auf dem Host und startet die eigentlichen Containeranwendungen
in der Sitzung. Er emuliert auch die Konsolenfunktion, die normalerweise von Conhost.exe
bereitgestellt wird, indem er die Ein- und Ausgabe durch eine benannte Pipe zum Fenster der
eigentlichen Eingabeaufforderung (oder PowerShell) leitet, das ursprünglich zur Ausführung
des Befehls docker auf dem Host verwendet wurde. Dieser Dienst wird auch für Befehle wie
docker cp zur Übertragung von Dateien vom oder zum Container verwendet.
Jobs
Kapitel 3
211
Die Containervorlage
Neben den Geräteobjekten, die beim Erstellen eines Silos von den Treibern angelegt werden,
gibt es noch zahllose weitere Objekte, die vom Kernel und anderen Komponenten gebildet
werden. Die Dienste, die in Sitzung 0 laufen, erwarten, mit all diesen Objekten zu kommunizieren, und umgekehrt. Im Benutzermodus gibt es kein Siloüberwachungssystem, das diesen
Bedarf befriedigen könnte. Es wäre auch nicht sinnvoll, jeden Treiber zu zwingen, immer ein
besonderes Geräteobjekt zur Darstellung jedes Silos zu erstellen.
Wenn ein Silo Musik auf der Soundkarte abspielen möchte, sollte er kein separates Geräteobjekt zur Darstellung derselben Karte verwenden müssen, die auch von allen anderen Silos
und dem Host selbst verwendet wird. Das wäre nur dann erforderlich, wenn eine Klangisolierung zwischen den einzelnen Silos nötig wäre. Ein weiteres Beispiel ist der AFD. Er verwendet
zwar eine Siloüberwachung, mit der er aber nur ermittelt, welcher Benutzermodusdienst den
DNS-Client beherbergt, mit dem der AFD sprechen muss, um Kernelmodus-DNS-Anforderungen zu erfüllen. Diese Information gilt jeweils für einen Silo. Die Überwachung dient nicht dazu,
separate \Silos\JID\Device\Afd-Objekte zu erstellen, da es in dem System nur einen einzigen
Netzwerk-/WinSock-Stack gibt.
Neben Treibern und Objekten enthält die Registrierung auch verschiedene globale Informationen, die in allen Silos vorhanden und sichtbar sein müssen. Um diese Informationen herum kann dann die Komponente VReg eine Sandbox einrichten.
Um all diese Bedürfnisse zu erfüllen, werden der Silonamensraum, die Registrierung und
das Dateisystem in einer besonderen Containervorlagendatei definiert, die sich standardmäßig
in %SystemRoot%\System32\Containers\wsc.def befindet, wenn das Merkmal Windows-Con
tainer im Dialogfeld Features hinzufügen/entfernen aktiviert wurde. Diese Datei beschreibt den
Namensraum für den Objekt-Manager und die Registrierung und die zugehörigen Regeln, was
die bedarfsweise Definition von symbolischen Verknüpfungen zu den echten Objekten auf dem
Host ermöglicht. Außerdem gibt sie an, welches Jobobjekt, welche Volumebereitstellungspunkte und welche Netzwerkisolierungsrichtlinien verwendet werden sollen. Theoretisch kann in
zukünftigen Windows-Versionen auch die Verwendung anderer Vorlagendateien zugelassen
sein, um andere Arten von Containerumgebungen möglich zu machen. Das folgende Listing
zeigt einen Auszug aus Wsc.def auf einem System mit aktivierten Containern:
<!-- Silodefinitionsdatei für Cmdserver.exe -->
<container>
<namespace>
<ob shadow="false">
<symlink name="FileSystem" path="\FileSystem" scope="Global" />
<symlink name="PdcPort" path="\PdcPort" scope="Global" />
<symlink name="SeRmCommandPort" path="\SeRmCommandPort" scope="Global" />
<symlink name="Registry" path="\Registry" scope="Global" />
<symlink name="Driver" path="\Driver" scope="Global" />
<objdir name="BaseNamedObjects" clonesd="\BaseNamedObjects" shadow="false"/>
<objdir name="GLOBAL??" clonesd="\GLOBAL??" shadow="false">
212
Kapitel 3
Prozesse und Jobs
<!-- Verzeichnisse müssen vom Host zugeordnet werden -->
<symlink name="ContainerMappedDirectories" path="\
ContainerMappedDirectories" scope="Local" />
<!-- Gültige Links zu \Device -->
<symlink name="WMIDataDevice" path="\Device\WMIDataDevice" scope="Local" />
<symlink name="UNC" path="\Device\Mup" scope="Local" />
...
</objdir>
<objdir name="Device" clonesd="\Device" shadow="false">
<symlink name="Afd" path="\Device\Afd" scope="Global" />
<symlink name="ahcache" path="\Device\ahcache" scope="Global" />
<symlink name="CNG" path="\Device\CNG" scope="Global" />
<symlink name="ConDrv" path="\Device\ConDrv" scope="Global" />
...
<registry>
<load
key="$SiloHivesRoot$\Silo$TopLayerName$Software_Base"
path="$TopLayerPath$\Hives\Software_Base"
ReadOnly="true"
/>
...
<mkkey
name="ControlSet001"
clonesd="\REGISTRY\Machine\SYSTEM\ControlSet001"
/>
<mkkey
name="ControlSet001\Control"
clonesd="\REGISTRY\Machine\SYSTEM\ControlSet001\Control"
/>
Zusammenfassung
Dieses Kapitel hat die Struktur von Prozessen, ihre Erstellung und Zerstörung gezeigt. Wir haben uns angesehen, wie Jobs verwendet werden können, um eine Gruppe von Prozessen als
eine Einheit zu verwalten, und wie Serversilos eine neue Ära der Containerunterstützung in
Windows Server-Versionen einläuten. Im nächsten Kapitel geht es um Threads – um ihre Struktur und ihre Operation, ihre Einplanung zur Ausführung und die verschiedenen Möglichkeiten,
um sie zu bearbeiten und zu nutzen.
Zusammenfassung
Kapitel 3
213
K apite l 4
Threads
Dieses Kapitel erklärt die Datenstrukturen und Algorithmen im Zusammenhang mit Threads
und der Threadplanung in Windows. Im ersten Abschnitt geht es darum, wie Threads erstellt
werden. Danach werden die internen Mechanismen von Threads und der Threadplanung beschrieben. Abgeschlossen wird das Kapitel mit einer Erörterung von Threadpools.
Threads erstellen
Bevor wir uns mit den internen Strukturen zur Verwaltung von Threads beschäftigen, wollen wir
uns ansehen, wie Threads erstellt werden und welche Schritte und Argumente dazu erforderlich
sind.
Die einfachste Möglichkeit, um im Benutzermodus einen Thread zu erstellen, bietet die
Funktion CreateThread. Sie legt einen Thread im aktuellen Prozess an und nimmt die folgenden
Argumente entgegen:
QQ Eine optionale Struktur mit Sicherheitsattributen Sie nennt den Sicherheitsdeskriptor,
der mit dem neuen Thread verbunden werden soll, und gibt an, ob das Threadhandle vererbbar sein soll. (Die Handlevererbung wird in Kapitel 8 von Band 2 behandelt.)
QQ Eine optionale Stackgröße Wird hier 0 angegeben, so wird der Standardwert aus dem
Header der ausführbaren Datei verwendet. Dies gilt stets für den ersten Thread in einem
Benutzermodusprozess. (Der Threadstack wird in Kapitel 5 ausführlicher beschrieben.)
QQ Ein Funktionszeiger
Er dient als Eintrittspunkt für die Ausführung des neuen Threads.
QQ Ein optionales Argument
übergeben.
Dies dient dazu, Argumente an die Funktion des Threads zu
QQ Zwei optionale Flags Eines dieser Flags gibt an, ob der Thread im angehaltenen Zustand
gestartet wird (CREATE_SUSPENDED). Das andere steuert die Interpretation des Stackgrößenarguments (ursprüngliche zugesicherte Größe oder maximale reservierte Größe).
Nach erfolgreichem Abschluss werden ein von null verschiedenes Handle für den neuen Thread
und, falls vom Aufrufer angefordert, eine eindeutige Thread-ID zurückgegeben.
Mit CreateRemoteThread steht eine erweiterte Funktion zur Threaderstellung zur Verfügung.
Sie nimmt als zusätzliches erstes Argument ein Handle für den Zielprozess entgegen, in dem
der Thread erstellt wird. Damit können Sie einen Thread in einen anderen Prozess injizieren.
Diese Technik wird häufig in Debuggern genutzt, um ein Anhalten in einem zu debuggenden
Prozess zu erzwingen. Dabei injiziert der Debugger den Thread, der sofort die Funktion DebugBreak aufruft und damit einen Haltepunkt einrichtet. Eine weitere gängige Anwendung dieser
Technik besteht darin, einen Prozess interne Informationen eines anderen Prozesses gewinnen
215
zu lassen. Das geht leichter, wenn der Thread im Kontext des Zielprozesses ausgeführt wird
(unter anderem ist dabei der gesamte Adressraum sichtbar). Dies kann sowohl für legitime als
auch für schädliche Zwecke eingesetzt werden.
Damit CreateRemoteThread funktioniert, muss das Prozesshandle mit ausreichend Zugriffsrechten für eine solche Operation versehen sein. Eine Injektion in geschützte Prozesse ist damit
nicht möglich, da Handles für solche Prozesse nur stark eingeschränkte Rechte haben.
Als letzte Funktion wollen wir hier noch CreateRemoteThreadEx erwähnen, die den beiden zuvor erwähnten übergeordnet ist. Die Implementierungen von CreateThread und Create
RemoteThread rufen einfach CreateRemoteThreadEx mit den entsprechenden Standardwerten
auf. CreateRemoteThreadEx bietet darüber hinaus die Möglichkeit, eine Attributliste anzugeben
(ähnlich wie bei der STARTUPINFOEX-Struktur beim Erstellen von Prozessen, die gegenüber der
STARTUPINFO-Struktur ein zusätzliches Element enthält). Zu diesen Attributen gehören beispielsweise Einstellungen für den idealen Prozessor und die Gruppenaffinität (die beide weiter hinten
in diesem Kapitel behandelt werden).
Wenn alles gut geht, ruft CreateRemoteThreadEx schließlich NtCreateThreadEx in Ntdll.dll
auf. Dabei erfolgt der übliche Übergang in den Kernelmodus, wobei die Ausführung in der
Exekutivfunktion NtCreateThreadEx fortgesetzt wird. Die Kernelmodusaspekte der Threaderstellung laufen dort ab (siehe weiter hinten in diesem Kapitel im Abschnitt »Geburt eines Threads«).
Die Threaderstellung im Kernelmodus wird durch die Funktion PsCreateSystemThread erreicht (die im WDK dokumentiert ist). Das ist praktisch für Treiber, die als unabhängige Prozesse
innerhalb des Systemprozesses laufen müssen (das heißt, sie sind nicht mit einem bestimmten
Prozess verbunden). Die Funktion kann einen Thread auch unter einem beliebigen Prozess
erstellen, was für Treiber jedoch nicht von Bedeutung ist.
Bei der Beendigung der Funktion eines Kernelthreads wird das Threadobjekt nicht automatisch zerstört. Stattdessen müssen die Treiber PsTerminateSystemThread aus der Threadfunktion
heraus aufrufen, um den Thread ordnungsgemäß zu beenden. Diese Funktion springt logischerweise nie zurück.
Interne Strukturen von Threads
In diesem Abschnitt geht es um die internen Strukturen, die im Kernel (und manchmal auch im
Benutzermodus) verwendet werden, um Threads zu verwalten. Sofern nicht ausdrücklich anders angegeben, gilt alles, was in diesem Abschnitt beschrieben wird, sowohl für Benutzer- als
auch für Kernelmodusthreads.
Datenstrukturen
Auf Betriebssystemebene wird ein Windows-Thread als ein Exekutivthreadobjekt dargestellt. Es
schließt eine ETHREAD-Struktur (siehe Abb. 4–1) ein, die wiederum eine KTHREAD-Struktur (siehe
Abb. 4–2) als erstes Element enthält. Die ETHREAD-Struktur und die Strukturen, auf die sie zeigt,
befinden sich im Systemadressraum. Die einzige Ausnahme bildet der Threadumgebungsblock
(TEB), der im Prozessadressraum steht (ähnlich wie der PEB, da die Benutzermoduskomponenten darauf zugreifen müssen).
216
Kapitel 4
Threads
Threadsteuerungsblock (TCB)
Erstellungs- und Beendigungszeit des Threads
ID des Threads und des Elternprozesses
Prozess, zu dem der Thread gehört
Threadflags
Zugriffstoken
Threadstartadresse
Informationen zum Identitätswechsel
Ausstehende E/A-Anforderungen
Timerinformationen
ALPC-Nachrichteninformationen
Threadlisteneintrag
Threadsperre
Beendigungscode
Energieverbrauchswerte (Win 10)
Informationen zum CPU-Satz (Win 10)
Abbildung 4–1 Wichtige Felder der Exekutivthreadstruktur (ETHREAD)
Dispatcher-Header
Threadumgebungsblock (TEB)
Kernel- und Benutzerzeit
Zeiger auf die Systemdiensttabelle (x86)
Systemdiensttabelle
Einfrier- und Unterbrechungszähler
Win32-Threadobjekt
Elternprozess
Stackinformationen
Planungsinformationen
Trap-frame
Synchronisierungsinformationen
Warteblock
Liste der Objekte, auf die der Thread wartet
Liste der ausstehenden APCs
Threadlisteneintrag
Abbildung 4–2 Wichtige Felder der Kernelthreadstruktur (KTHREAD)
Der Windows-Teilsystemprozess Csrss unterhält für jeden Thread, der in einer Windows-Teilsystemanwendung erstellt wurde, eine parallele Struktur namens CSR_THREAD. Für jeden Thread,
der eine USER- oder GDI-Funktion des Windows-Teilsystems aufgerufen hat, führt der Kernelmodusteil des Windows-Teilsystems (Win32k.sys) auch eine eigene Datenstruktur (W32THREAD),
auf die die KTHREAD-Struktur zeigt.
Interne Strukturen von Threads
Kapitel 4
217
Die Win32k-Threadstruktur gehört zur Exekutive, ist eine Struktur höherer Ebene
und steht im Zusammenhang mit der Grafikdarstellung. Dass sich der Zeiger da
rauf in der KTHREAD- und nicht in der ETHREAD-Struktur befindet, scheint Schichtverletzung oder ein Versehen in der Abstraktionsarchitektur des Standardkernels zu
sein. Der Scheduler und andere maschinennahe Komponenten verwenden dieses
Feld nicht.
Die meisten Felder in Abb. 4–1 sind selbsterklärend. Das erste Element der ETHREAD-Struktur ist
der Threadsteuerungsblock (TCB), bei dem es sich um eine Struktur vom Typ KTHREAD handelt.
Auf ihn folgen Angaben zur Bezeichnung des Threads und des Prozesses (unter anderem ein
Zeiger auf den Besitzerprozess, sodass Zugriff auf dessen Umgebungsinformationen besteht),
Sicherheitsinformationen in Form eines Zeigers auf das Zugriffstoken und Angaben für Identitätswechsel, Felder für ALPC-Nachrichten (Advanced Local Procedure Calls) und ausstehende
E/A-Anforderungen (IRPs) sowie Windows 10-spezifische Felder zur Energieverwaltung (siehe
Kapitel 6) und zu CPU-Sätzen (weiter hinten in diesem Kapitel erklärt). Einige dieser Felder werden in diesem Buch noch ausführlicher erläutert. Um sich den Aufbau einer ETHREAD-Struktur
genau anzusehen, können Sie mit dem Kerneldebuggerbefehl dt ihr Format anzeigen lassen.
Sehen wir uns nun zwei der bereits erwähnten wichtigen Threaddatenstrukturen genauer
an, nämlich die ETHREAD- und die KTHREAD-Struktur. Die KTHREAD-Struktur ist das Element Tcb der
ETHREAD-Struktur und enthält Informationen, die der Windows-Kernel benötigt, um Threadplanungs-, Synchronisierungs- und Zeiteinhaltungsfunktionen auszuführen.
Experiment: ETHREAD- und KTHREAD-Strukturen anzeigen
Die ETHREAD- und KTHREAD-Strukturen können Sie mit dem Befehl dt des Kerneldebuggers einsehen. Die folgende Ausgabe zeigt das Format einer ETHREAD-Struktur auf einem
64-Bit-System mit Windows 10:
lkd> dt nt!_ethread
+0x000 Tcb
: _KTHREAD
+0x5d8 CreateTime
: _LARGE_INTEGER
+0x5e0 ExitTime
: _LARGE_INTEGER
...
+0x7a0 EnergyValues
: Ptr64 _THREAD_ENERGY_VALUES
+0x7a8 CmCellReferences
: Uint4B
+0x7b0 SelectedCpuSets
: Uint8B
+0x7b0 SelectedCpuSetsIndirect : Ptr64 Uint8B
+0x7b8 Silo
: Ptr64 _EJOB
Die KTHREAD-Struktur können Sie mit einem ähnlichen Befehl ausgeben lassen. Sie können
jedoch auch wie im Experiment »Das Format einer EPROCESS-Struktur anzeigen« aus Kapitel 3 den Befehl dt nt!_ETHREAD Tcb verwenden:
→
218
Kapitel 4
Threads
lkd> dt nt!_kthread
+0x000 Header
: _DISPATCHER_HEADER
+0x018 SListFaultAddress
: Ptr64 Void
+0x020 QuantumTarget
: Uint8B
+0x028 InitialStack
: Ptr64 Void
+0x030 StackLimit
: Ptr64 Void
+0x038 StackBase
: Ptr64 Void
+0x040 ThreadLock
: Uint8B
+0x048 CycleTime
: Uint8B
+0x050 CurrentRunTime
: Uint4B
...
+0x5a0 ReadOperationCount
: Int8B
+0x5a8 WriteOperationCount : Int8B
+0x5b0 OtherOperationCount : Int8B
+0x5b8 ReadTransferCount
: Int8B
+0x5c0 WriteTransferCount
: Int8B
+0x5c8 OtherTransferCount
: Int8B
+0x5d0 QueuedScb
: Ptr64 _KSCB
Experiment: Der Befehl !thread des Kerneldebuggers
Der Befehl !thread des Kerneldebuggers gibt einen Teil der Informationen in den Threaddatenstrukturen aus. Einige davon können von keinem anderen Programm angezeigt werden, darunter die folgenden:
QQ Adressen von internen Strukturen
QQ Angaben zur Priorität
QQ Informationen über den Stack
QQ Liste der ausstehenden E/A-Anforderungen
QQ Liste der Objekte, auf die ein Thread wartet
Um Threadinformationen einzusehen, verwenden Sie den Befehl !process, der zuerst Informationen über den Prozess und dann über alle darin enthaltenen Threads ausgibt, oder
den Befehl !thread mit der Adresse eines Threadobjekts, wenn Sie nur einen bestimmten
Thread anzeigen lassen wollen.
Im folgenden Beispiel sehen wir uns zunächst alle Instanzen von Explorer.exe an:
lkd> !process 0 0 explorer.exe
PROCESS ffffe00017f3e7c0
SessionId: 1 Cid: 0b7c Peb: 00291000 ParentCid: 0c34
DirBase: 19b264000 ObjectTable: ffffc00007268cc0 HandleCount: 2248.
Image: explorer.exe
→
Interne Strukturen von Threads
Kapitel 4
219
PROCESS ffffe00018c817c0
SessionId: 1 Cid: 23b0 Peb: 00256000 ParentCid: 03f0
DirBase: 2d4010000 ObjectTable: ffffc0001aef0480 HandleCount: 2208.
Image: explorer.exe
Anschließend wählen wir eine dieser Instanzen aus und lassen deren Threads anzeigen:
lkd> !process ffffe00018c817c0 2
PROCESS ffffe00018c817c0
SessionId: 1 Cid: 23b0 Peb: 00256000 ParentCid: 03f0
DirBase: 2d4010000 ObjectTable: ffffc0001aef0480 HandleCount: 2232.
Image: explorer.exe
THREAD ffffe0001ac3c080 Cid 23b0.2b88 Teb: 0000000000257000
Win32Thread: ffffe0001570ca20 WAIT: (UserRequest) UserMode Non-Alertable
ffffe0001b6eb470 SynchronizationEvent
THREAD ffffe0001af10800 Cid 23b0.2f40 Teb: 0000000000265000
Win32Thread: ffffe000156688a0 WAIT: (UserRequest) UserMode Non-Alertable
ffffe000172ad4f0 SynchronizationEvent
ffffe0001ac26420 SynchronizationEvent
THREAD ffffe0001b69a080 Cid 23b0.2f4c Teb: 0000000000267000
Win32Thread: ffffe000192c5350 WAIT: (UserRequest) UserMode Non-Alertable
ffffe00018d83c00 SynchronizationEvent
ffffe0001552ff40 SynchronizationEvent
...
THREAD ffffe00023422080 Cid 23b0.3d8c Teb: 00000000003cf000
Win32Thread: ffffe0001eccd790 WAIT: (WrQueue) UserMode Alertable
ffffe0001aec9080 QueueObject
THREAD ffffe00023f23080 Cid 23b0.3af8 Teb: 00000000003d1000
Win32Thread: 0000000000000000 WAIT: (WrQueue) UserMode Alertable
ffffe0001aec9080 QueueObject
THREAD ffffe000230bf800 Cid 23b0.2d6c Teb: 00000000003d3000
Win32Thread: 0000000000000000 WAIT: (WrQueue) UserMode Alertable
ffffe0001aec9080 QueueObject
THREAD ffffe0001f0b5800 Cid 23b0.3398 Teb: 00000000003e3000
Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode Alertable
ffffe0001d19d790 SynchronizationEvent
ffffe00022b42660 SynchronizationTimer
Die Threadliste ist hier aus Platzgründen gekürzt. Für jeden Thread wird die Adresse (ETHREAD) angezeigt, die an den Befehl !thread übergeben werden kann; die Client-ID (Cid), also
die Prozess- und Thread-ID (wobei die Prozess-ID bei allen hier gezeigten Threads identisch
ist, da sie alle zum selben Explorer.exe-Prozess gehören); der Threadumgebungsblock (TEB;
Erklärung folgt in Kürze); und der Threadstatus (meistens Wait, wobei der Grund für den
Wartevorgang in Klammern angegeben ist). In der anschließenden Zeile können die Synchronisierungsobjekte angezeigt werden, auf die der Thread wartet.
→
220
Kapitel 4
Threads
Um mehr Informationen über einen bestimmten Thread zu gewinnen, übergeben Sie
mit dem Befehl !thread seine Adresse:
lkd> !thread ffffe0001d45d800
THREAD ffffe0001d45d800 Cid 23b0.452c Teb: 000000000026d000 Win32Thread:
ffffe0001aace630 WAIT: (UserRequest) UserMode Non-Alertable
ffffe00023678350 NotificationEvent
ffffe00022aeb370 Semaphore Limit 0xffff
ffffe000225645b0 SynchronizationEvent
Not impersonating
DeviceMap
ffffc00004f7ddb0
Owning Process
ffffe00018c817c0 Image: explorer.exe
Attached Process
N/A
Image: N/A
Wait Start TickCount
7233205
Ticks: 270 (0:00:00:04.218)
Context Switch Count
6570
IdealProcessor: 7
UserTime
00:00:00.078
KernelTime
00:00:00.046
Win32 Start Address 0c
Stack Init ffffd000271d4c90 Current ffffd000271d3f80
Base ffffd000271d5000 Limit ffffd000271cf000 Call 0000000000000000
Priority 9 BasePriority 8 PriorityDecrement 0 IoPriority 2 PagePriority 5
GetContextState failed, 0x80004001
Unable to get current machine context, HRESULT 0x80004001
Child-SP
RetAddr
: Args to Child
: Call Site
ffffd000'271d3fc0 fffff803'bef086ca : 00000000'00000000 00000000'00000001
00000000'00000000 00000000'00000000 : nt!KiSwapContext+0x76
ffffd000'271d4100 fffff803'bef08159 : ffffe000'1d45d800 fffff803'00000000
ffffe000'1aec9080 00000000'0000000f : nt!KiSwapThread+0x15a
ffffd000'271d41b0 fffff803'bef09cfe : 00000000'00000000 00000000'00000000
ffffe000'0000000f 00000000'00000003 : nt!KiCommitThreadWait+0x149
ffffd000'271d4240 fffff803'bf2a445d : ffffd000'00000003 ffffd000'271d43c0
00000000'00000000 fffff960'00000006 : nt!KeWaitForMultipleObjects+0x24e
ffffd000'271d4300 fffff803'bf2fa246 : fffff803'bf1a6b40 ffffd000'271d4810
ffffd000'271d4858 ffffe000'20aeca60 : nt!ObWaitForMultipleObjects+0x2bd
ffffd000'271d4810 fffff803'befdefa3 : 00000000'00000fa0 fffff803'bef02aad
ffffe000'1d45d800 00000000'1e22f198 : nt!NtWaitForMultipleObjects+0xf6
ffffd000'271d4a90 00007ffe'f42b5c24 : 00000000'00000000 00000000'00000000
00000000'00000000 00000000'00000000 : nt!KiSystemServiceCopyEnd+0x13 (TrapFrame
@ ffffd000'271d4b00)
00000000'1e22f178 00000000'00000000 : 00000000'00000000 00000000'00000000
00000000'00000000 00000000'00000000 : 0x00007ffe'f42b5c24
Es wird eine Menge an Informationen über den Thread angezeigt, darunter seine Priorität,
Angaben zum Stack, Benutzer- und Kernelzeiten usw. Viele dieser Informationen werden
Sie in diesem Kapitel sowie in Kapitel 5 und 6 noch näher betrachten.
Interne Strukturen von Threads
Kapitel 4
221
Experiment: Threadinformationen mit tlist einsehen
Das folgende Listing ist die ausführliche Anzeige eines Prozesses, wie sie tlist in den Debugging Tools for Windows ausgibt. (Achten Sie darauf, die passende tlist-Version für die
Bitversion des Zielprozesses zu verwenden.) Hier wird in der Threadliste Win32StartAddr
angezeigt, was die Adresse ist, die die Anwendung an die Funktion CreateThread übergeben hat. Alle anderen Programme (außer Process Explorer) zeigen als Threadstartadresse
jedoch wirklich die tatsächliche Adresse an (eine Funktion in Ntdll.dll) und nicht die von der
Anwendung angegebene.
Im Folgenden sehen Sie die gekürzte Ausgabe von tlist für Word 2016:
C:\Dbg\x86>tlist winword
120 WINWORD.EXE Chapter04.docm - Word
CWD: C:\Users\pavely\Documents\
CmdLine: "C:\Program Files (x86)\Microsoft Office\Root\Office16\WINWORD.
EXE" /n
"D:\OneDrive\WindowsInternalsBook\7thEdition\Chapter04\Chapter04.docm
VirtualSize: 778012 KB PeakVirtualSize: 832680 KB
WorkingSetSize:185336 KB PeakWorkingSetSize:227144 KB
NumberOfThreads: 45
12132 Win32StartAddr:0x00921000 LastErr:0x00000000 State:Waiting
15540 Win32StartAddr:0x6cc2fdd8 LastErr:0x00000000 State:Waiting
7096 Win32StartAddr:0x6cc3c6b2 LastErr:0x00000006 State:Waiting
17696 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
17492 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
4052 Win32StartAddr:0x70aa5cf7 LastErr:0x00000000 State:Waiting
14096 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
6220 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
7204 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
1196 Win32StartAddr:0x6ea016c0 LastErr:0x00000057 State:Waiting
8848 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
3352 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
11612 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
17420 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
13612 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
15052 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
...
12080 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
9456 Win32StartAddr:0x77c1c6d0 LastErr:0x00002f94 State:Waiting
9808 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
16208 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
9396 Win32StartAddr:0x77c1c6d0 LastErr:0x00000000 State:Waiting
2688 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
→
222
Kapitel 4
Threads
9100 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
18364 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
11180 Win32StartAddr:0x70aa41d4 LastErr:0x00000000 State:Waiting
16.0.6741.2037 shp 0x00920000 C:\Program Files (x86)\Microsoft Office\Root\
Office16\WINWORD.EXE
10.0.10586.122 shp 0x77BF0000 C:\windows\SYSTEM32\ntdll.dll
10.0.10586.0 shp 0x75540000 C:\windows\SYSTEM32\KERNEL32.DLL
10.0.10586.162 shp 0x77850000 C:\windows\SYSTEM32\KERNELBASE.dll
10.0.10586.63 shp 0x75AF0000 C:\windows\SYSTEM32\ADVAPI32.dll
...
10.0.10586.0 shp 0x68540000 C:\Windows\SYSTEM32\VssTrace.DLL
10.0.10586.0 shp 0x5C390000 C:\Windows\SYSTEM32\adsldpc.dll
10.0.10586.122 shp 0x5DE60000 C:\Windows\SYSTEM32\taskschd.dll
10.0.10586.0 shp 0x5E3F0000 C:\Windows\SYSTEM32\srmstormod.dll
10.0.10586.0 shp 0x5DCA0000 C:\Windows\SYSTEM32\srmscan.dll
10.0.10586.0 shp 0x5D2E0000 C:\Windows\SYSTEM32\msdrm.dll
10.0.10586.0 shp 0x711E0000 C:\Windows\SYSTEM32\srm_ps.dll
10.0.10586.0 shp 0x56680000 C:\windows\System32\OpcServices.dll
0x5D240000 C:\Program Files (x86)\Common Files\Microsoft
Shared\Office16\WXPNSE.DLL
16.0.6701.1023 shp 0x77E80000 C:\Program Files (x86)\Microsoft Office\Root\
Office16\GROOVEEX.DLL
10.0.10586.0 shp 0x693F0000 C:\windows\system32\dataexchange.dll
Der TEB aus Abb. 4–3 ist eine der Datenstrukturen, die sich nicht im System-, sondern im Prozessadressraum befinden. Sein Header ist der Threadinformationsblock (TIB), der hauptsächlich
zur Kompatibilität mit OS/2- und Win9x-Anwendungen da ist. Durch die Verwendung eines
Anfangs-TIBs ist es auch möglich, Ausnahme- und Stackinformationen beim Erstellen von neuen Threads in kleineren Strukturen unterzubringen.
Interne Strukturen von Threads
Kapitel 4
223
Stackbasis
Stackgrenzwert
Threadinformationsblock (TIB)
Teilsystem-TIB
Client-ID
Fiberarten
Aktives RPC-Handle
Ausnahmeliste
TLS-Slots (lokaler Threadspeicher)
Zeiger auf sich selbst
Letzter Fehlerwert
PEB des Elternprozesses
PEB
GDI-Informationen
User32-Clientinformationen
OpenGL-Informationen
Winsock-Daten
Idealer Prozessor
ETW-Ablaufverfolgungsdaten
COM/OLE-Daten
Instrumentierungsdaten
WDF-Daten
TxF-Daten
Zähler für Sperren im eigenen Besitz
Abbildung 4–3 Wichtige Felder des Threadumgebungsblocks
Im TEB sind Kontextinformationen für den Abbildlader und verschiedene Windows-DLLs gespeichert. Da diese Komponenten im Benutzermodus laufen, brauchen Sie eine Datenstruktur,
die vom Benutzermodus aus schreibbar ist. Aus diesem Grund ist diese Struktur im Prozess- und
nicht im Systemadressraum untergebracht, wo sie nur im Kernelmodus schreibbar wäre. Die
Adresse des TEB können Sie mit dem Kerneldebuggerbefehl !thread herausfinden.
Experiment: Den TEB untersuchen
Mit dem Befehl !teb des Kernel- oder Benutzermodusdebuggers können Sie die TEB-Struktur ausgeben. Ohne weitere Angaben wird dabei der TEB für den aktuellen Thread des Debuggers angezeigt. Um den TEB eines anderen Threads einzusehen, geben Sie die TEB-Adresse an. Wenn Sie den Kerneldebugger einsetzen, muss der aktuelle Prozess festgelegt
sein, bevor Sie den Befehl an die TEB-Adresse ausgeben, damit der richtige Prozesskontext
verwendet wird.
Wie Sie den TEB mit dem Kerneldebugger ausgeben, erfahren Sie im nächsten Experiment. Zur Anzeige des TEB mit dem Benutzermodusdebugger gehen Sie wie folgt vor:
→
224
Kapitel 4
Threads
1.
Öffnen Sie WinDbg.
2.
Öffnen Sie das Menü File und wählen Sie Run Executable.
3.
Wechseln Sie zu C:\Windows\System32\Notepad.exe. Der Debugger sollte am ersten
Haltepunkt anhalten.
4.
Geben Sie den Befehl !teb ein, um sich den TEB des einzigen zurzeit existierenden Threads anzusehen. Das folgende Beispiel zeigt die Ausgabe auf einem 64-BitWindows-System:
0:000> !teb
TEB at 000000ef125c1000
ExceptionList:
0000000000000000
StackBase:
000000ef12290000
StackLimit:
000000ef1227f000
SubSystemTib:
0000000000000000
FiberData:
0000000000001e00
ArbitraryUserPointer: 0000000000000000
Self:
000000ef125c1000
EnvironmentPointer:
0000000000000000
ClientId:
00000000000021bc . 0000000000001b74
RpcHandle:
0000000000000000
Tls Storage:
00000266e572b600
PEB Address:
000000ef125c0000
LastErrorValue:
0
LastStatusValue:
0
Count Owned Locks:
0
HardErrorMode:
0
5.
Geben Sie den Befehl g ein oder drücken Sie (F5), um die Ausführung des Editors
fortzusetzen.
6.
Klicken Sie im Editor auf Datei und Öffnen und dann auf Abbrechen, um das Öffnen-Dialogfeld zu schließen.
7.
Drücken Sie (Strg) + (Untbr) oder öffnen Sie das Menü Debug und wählen Sie Break,
um den Prozess zwangsweise anzuhalten.
8.
Geben Sie den Befehl ~ (Tilde) ein, um alle Threads in dem Prozess anzuzeigen. Dadurch ergibt sich folgende Ausgabe:
0:005> ~
0 Id: 21bc.1b74 Suspend: 1 Teb: 000000ef'125c1000 Unfrozen
1 Id: 21bc.640 Suspend: 1 Teb: 000000ef'125e3000 Unfrozen
2 Id: 21bc.1a98 Suspend: 1 Teb: 000000ef'125e5000 Unfrozen
3 Id: 21bc.860 Suspend: 1 Teb: 000000ef'125e7000 Unfrozen
4 Id: 21bc.28e0 Suspend: 1 Teb: 000000ef'125c9000 Unfrozen
→
Interne Strukturen von Threads
Kapitel 4
225
.
5 Id: 21bc.23e0 Suspend: 1 Teb: 000000ef'12400000 Unfrozen
6 Id: 21bc.244c Suspend: 1 Teb: 000000ef'125eb000 Unfrozen
7 Id: 21bc.168c Suspend: 1 Teb: 000000ef'125ed000 Unfrozen
8 Id: 21bc.1c90 Suspend: 1 Teb: 000000ef'125ef000 Unfrozen
9 Id: 21bc.1558 Suspend: 1 Teb: 000000ef'125f1000 Unfrozen
10 Id: 21bc.a64 Suspend: 1 Teb: 000000ef'125f3000 Unfrozen
11 Id: 21bc.20c4 Suspend: 1 Teb: 000000ef'125f5000 Unfrozen
12 Id: 21bc.1524 Suspend: 1 Teb: 000000ef'125f7000 Unfrozen
13 Id: 21bc.1738 Suspend: 1 Teb: 000000ef'125f9000 Unfrozen
14 Id: 21bc.f48 Suspend: 1 Teb: 000000ef'125fb000 Unfrozen
15 Id: 21bc.17bc Suspend: 1 Teb: 000000ef'125fd000 Unfrozen
9.
Für jeden Thread wird die TEB-Adresse angezeigt. Um sich einen bestimmten Thread
anzusehen, übergeben Sie mit dem Befehl !teb seine TEB-Adresse. Für Thread 9 aus der
vorherigen Ausgabe sieht das wie folgt aus:
0:005> !teb 000000ef'125f1000
TEB at 000000ef125f1000
ExceptionList:
0000000000000000
StackBase:
000000ef13400000
StackLimit:
000000ef133ef000
SubSystemTib:
0000000000000000
FiberData:
0000000000001e00
ArbitraryUserPointer: 0000000000000000
Self:
000000ef125f1000
EnvironmentPointer:
0000000000000000
ClientId:
00000000000021bc . 0000000000001558
RpcHandle:
0000000000000000
Tls Storage:
00000266ea1af280
PEB Address:
000000ef125c0000
LastErrorValue:
0
LastStatusValue:
c0000034
Count Owned Locks:
0
HardErrorMode:
0
10. Natürlich ist es auch möglich, sich die tatsächliche Struktur an der TEB-Adresse anzusehen (hier aus Platzgründen gekürzt):
0:005> dt ntdll!_teb 000000ef'125f1000
+0x000 NtTib
: _NT_TIB
+0x038 EnvironmentPointer
: (null)
+0x040 ClientId
: _CLIENT_ID
+0x050 ActiveRpcHandle
: (null)
+0x058 ThreadLocalStoragePointer : 0x00000266'ea1af280 Void
→
226
Kapitel 4
Threads
+0x060 ProcessEnvironmentBlock
+0x068 LastErrorValue
: 0x000000ef'125c0000 _PEB
: 0
+0x06c CountOfOwnedCriticalSections : 0
...
+0x1808 LockCount
: 0
+0x180c WowTebOffset
: 0n0
+0x1810 ResourceRetValue
: 0x00000266'ea2a5e50 Void
+0x1818 ReservedForWdf
: (null)
+0x1820 ReservedForCrt
: 0
+0x1828 EffectiveContainerId : _GUID {00000000-0000-0000-0000000000000000}
Experiment: Den TEB mit einem Kerneldebugger untersuchen
Um sich den TEB mit dem Kerneldebugger anzusehen, gehen Sie wie folgt vor:
1.
Suchen Sie den Prozess des Threads, für dessen TEB Sie sich interessieren. Beispielsweise gibt der folgende Befehl die Prozesse von Explorer.exe jeweils mit einer Liste ihrer
Threads und einigen grundlegenden Informationen dazu aus (hier gekürzt):
lkd> !process 0 2 explorer.exe
PROCESS ffffe0012bea7840
SessionId: 2 Cid: 10d8 Peb: 00251000 ParentCid: 10bc
DirBase: 76e12000 ObjectTable: ffffc000e1ca0c80 HandleCount: <Data Not
Accessible>
Image: explorer.exe
THREAD ffffe0012bf53080 Cid 10d8.10dc Teb: 0000000000252000
Win32Thread: ffffe0012c1532f0 WAIT: (WrUserRequest) UserMode Non-Alertable
ffffe0012c257fe0 SynchronizationEvent
THREAD ffffe0012a30f080 Cid 10d8.114c Teb: 0000000000266000
Win32Thread: ffffe0012c2e9a20 WAIT: (UserRequest) UserMode Alertable
ffffe0012bab85d0 SynchronizationEvent
THREAD ffffe0012c8bd080 Cid 10d8.1178 Teb: 000000000026c000
Win32Thread: ffffe0012a801310 WAIT: (UserRequest) UserMode Alertable
ffffe0012bfd9250 NotificationEvent
ffffe0012c9512f0 NotificationEvent
ffffe0012c876b80 NotificationEvent
ffffe0012c010fe0 NotificationEvent
ffffe0012d0ba7e0 NotificationEvent
ffffe0012cf9d1e0 NotificationEvent
...
→
Interne Strukturen von Threads
Kapitel 4
227
THREAD ffffe0012c8be080 Cid 10d8.1180 Teb: 0000000000270000
Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode Alertable
fffff80156946440 NotificationEvent
THREAD ffffe0012afd4040 Cid 10d8.1184 Teb: 0000000000272000
Win32Thread: ffffe0012c7c53a0 WAIT: (UserRequest) UserMode Non-Alertable
ffffe0012a3dafe0 NotificationEvent
ffffe0012c21ee70 Semaphore Limit 0xffff
ffffe0012c8db6f0 SynchronizationEvent
THREAD ffffe0012c88a080 Cid 10d8.1188 Teb: 0000000000274000
Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode Alertable
ffffe0012afd4920 NotificationEvent
ffffe0012c87b480 SynchronizationEvent
ffffe0012c87b400 SynchronizationEvent
...
2.
Gibt es mehr als einen Explorer.exe-Prozess, wählen Sie für die folgenden Schritte einen
davon nach Belieben aus.
3.
Für jeden Thread wird die TEB-Adresse angezeigt. Da sich der TEB im Benutzerraum
befindet, hat diese Adresse nur im Kontext des zugehörigen Prozesses eine Bedeutung.
Sie müssen zu dem Prozess/Thread umschalten, den der Debugger sieht. Wählen Sie
den ersten Explorerthread aus, da sich dessen Kernelstack wahrscheinlich im physischen Arbeitsspeicher befindet. Bei einem Thread, bei dem das nicht der Fall ist, erhalten Sie eine Fehlermeldung.
lkd> .thread /p ffffe0012bf53080
Implicit thread is now ffffe001'2bf53080
Implicit process is now ffffe001'2bea7840
4.
Dadurch wird der Kontext auf den angegebenen Thread umgeschaltet (und damit auch
auf den entsprechenden Prozess). Jetzt können Sie den Befehl !teb mit der für den
Thread angegebenen TEB-Adresse verwenden:
lkd> !teb 0000000000252000
TEB at 0000000000252000
ExceptionList:
0000000000000000
StackBase:
00000000000d0000
StackLimit:
00000000000c2000
SubSystemTib:
0000000000000000
FiberData:
0000000000001e00
ArbitraryUserPointer: 0000000000000000
Self:
0000000000252000
EnvironmentPointer:
0000000000000000
ClientId:
00000000000010d8 . 00000000000010dc
RpcHandle:
0000000000000000
Tls Storage:
0000000009f73f30
→
228
Kapitel 4
Threads
PEB Address:
0000000000251000
LastErrorValue:
0
LastStatusValue:
c0150008
Count Owned Locks:
0
HardErrorMode:
0
Die CSR_THREAD-Struktur aus Abb. 4–4 entspricht der CSR_PROCESS-Struktur, allerdings für Threads.
Wie Sie wissen, wird Letztere von jedem Csrss-Prozess in einer Sitzung unterhalten und gibt
die Windows-Teilsystemthreads an, die darin laufen. In der CSR_THREAD-Struktur befinden sich
ein Handle, den Csrss für den Thread verwendet, mehrere Flags, die Client-ID (Thread- und
Prozess-ID) sowie die Angabe der Threaderstellungszeit. Threads werden bei Csrss registriert,
wenn sie ihre erste Nachricht an Csrss senden, gewöhnlich, weil eine API die Benachrichtigung
von Scrss über eine Operation oder Bedingung erfordert.
Erstellungszeit
Threadlink
Hashlinks
Client-ID
Threadhandle
Flags
Referenzzähler
Zähler für Identitätswechsel
Abbildung 4–4 Felder der CSR_THREAD-Struktur
Experiment: Die CSR_THREAD-Struktur untersuchen
Sie können die CSR_THREAD-Struktur mit dem Befehl dt des Kernelmodusdebuggers ausgeben, wenn sich der Debugger im Kontext des Csrss-Prozesses befindet. Befolgen Sie dazu
die Anweisungen aus dem Experiment »Die CSR_PROZESS-Struktur untersuchen« aus Kapitel 3. Die folgende Beispielausgabe stammt von einem x64-System mit Windows 10:
lkd> dt csrss!_csr_thread
+0x000 CreateTime
: _LARGE_INTEGER
+0x008 Link
: _LIST_ENTRY
+0x018 HashLinks
: _LIST_ENTRY
+0x028 ClientId
: _CLIENT_ID
+0x038 Process
: Ptr64 _CSR_PROCESS
+0x040 ThreadHandle
: Ptr64 Void
+0x048 Flags
: Uint4B
+0x04c ReferenceCount
: Int4B
+0x050 ImpersonateCount : Uint4B
Interne Strukturen von Threads
Kapitel 4
229
Die W32THREAD-Struktur aus Abb. 4–5 entspricht der W32PROCESS-Struktur, allerdings für Threads.
Sie enthält hauptsächlich Informationen für das GDI-Teilsystem (Pinsel- und Gerätekontextattribute) und DirectX, aber auch für das UMPD-Framework (User-Mode Print Driver), mit dem
Hersteller Benutzermodus-Druckertreiber schreiben. Des Weiteren enthält sie den RenderingStatus, der für Desktop-Compositing und Antialiasing genutzt wird.
Thread
Referenzzähler
Pinsel/DC-Attribute
Benutzermodus-Druckdaten
Spritestatus
Flags
Rendering-/AA-Daten
Threadsperre
DirectX-Thread
Abbildung 4–5 Felder der W32THREAD-Struktur
Geburt eines Threads
Der Lebenszyklus eines Threads beginnt, wenn ein Prozess (im Kontext eines Threads, z. B. des
Threads, der die main-Funktion ausführt) einen neuen Thread erstellt. Die Anforderung geht
schließlich an die Windows-Exekutive, wo der Prozess-Manager Speicherplatz für ein Threadobjekt zuweist und den Kernel aufruft, um den Threadsteuerungsblock (KTHREAD) zu initialisieren. Wie bereits erwähnt, führen die verschiedenen Threaderstellungsfunktionen letzten Endes
dazu, dass CreateRemoteThreadEx ausgeführt wird. Innerhalb dieser Funktion in Kernel32.dll
werden dann die folgenden Schritte ausgeführt, um einen Windows-Thread zu erstellen:
1.
Die Funktion wandelt die Windows-API-Parameter in native Flags um und erstellt eine
native Struktur, die die Objektparameter beschreibt (OBJECT_ATTRIBUTES, siehe Kapitel 8 in
Band 2).
2.
Sie erstellt eine Attributliste mit zwei Einträgen, nämlich der Client-ID und der TEB-Adresse
(siehe »Der Ablauf von CreateProcess« in Kapitel 3).
3.
Sie bestimmt, ob der Thread im aufrufenden Prozess oder in einem anderen Prozess erstellt
wird, der durch ein übergebenes Handle bestimmt wird. Ist das Handle gleich dem von
GetCurrentProcess zurückgegebenen Pseudohandle (Wert -1), dann ist es derselbe Prozess. Ein anderes Handle kann immer noch ein gültiges Handle für denselben Prozess sein,
weshalb NtQueryInformationProcess (in Ntdll) aufgerufen wird, um herauszufinden, ob das
der Fall ist.
4.
Sie ruft NtCreateThreadEx (in Ntdll) auf, um den Wechsel zur Exekutive im Kernelmodus
vorzunehmen. Der Vorgang wird dann in einer Funktion mit demselben Namen und denselben Argumenten fortgesetzt.
230
Kapitel 4
Threads
5.
NtCreateThreadEx (in der Exekutive) erstellt und initialisiert den Benutzermodus-Threadkontext (dessen Struktur von der Architektur abhängt) und ruft dann PspCreateThread auf,
um ein angehaltenes Exekutivthreadobjekt zu erstellen. (Eine Beschreibung der Schritte,
die diese Funktion ausführt, finden Sie in den Phasen 3 und 5 unter »Der Ablauf von Cre
ateProcess« in Kapitel 3.) Danach gibt die Funktion die Steuerung zurück und landet wieder im Benutzermodus bei CreateRemoteThreadEx.
6.
CreateRemoteThreadEx weist einen Aktivierungskontext für den Thread zu, der von der Side-
by-Side-Assemblyunterstützung verwendet wird. Anschließend fragt sie den Aktivierungsstack ab, um zu sehen, ob eine Aktivierung erforderlich ist, und führt diese bei Bedarf
durch. Der Aktivierungsstackzeiger wird im TEB des neuen Threads gespeichert.
7.
Sofern der Aufrufer den Thread nicht mit dem Flag CREATE_SUSPENDED erstellt hat, wird der
Thread jetzt aufgenommen, sodass er zur Ausführung eingeplant werden kann. Wenn ein
Thread zu laufen beginnt, werden die im Abschnitt »Phase 7: Prozessinitialisierung im Kontext des neuen Prozesses durchführen« von Kapitel 3 beschriebenen Schritte ausgeführt,
bevor die angegebene Startadresse des eigentlichen Benutzers aufgerufen wird.
8.
Das Threadhandle und die Thread-ID werden an den Aufrufer zurückgegeben.
Die Threadaktivität untersuchen
Eine Untersuchung der Threadaktivität ist vor allem dann wichtig, wenn Sie herauszufinden
versuchen, warum ein Hostprozess für mehrere Dienste (wie Svchost.exe, Dllhosts.exe oder
Lsass.exe) läuft oder warum ein Prozess nicht mehr reagiert.
Es gibt eine Reihe von Werkzeugen, die einen Blick auf verschiedene Elemente des Status
von Windows-Threads zulassen, z. B. WinDbg (beim Anschluss an einen Benutzerprozess und
im Kerneldebuggingmodus), die Leistungsüberwachung und Process Explorer. (Werkzeuge zur
Anzeige von Threadplanungsinformationen sind im Abschnitt »Threadplanung« angegeben.)
Um mit Process Explorer die Threads in einem Prozess einzusehen, doppelklicken Sie auf
den Prozess, um sein Eigenschaftendialogfeld zu öffnen. Alternativ können Sie auch auf den
Prozess rechtsklicken und Properties wählen. Wechseln Sie anschließend zur Registerkarte
Threads. Sie zeigt eine Liste der Threads in dem Prozess sowie vier Spalten mit Informationen
darüber an: die ID des Threads, seinen prozentualen Anteil der CPU-Nutzung (auf der Grundlage des eingestellten Aktualisierungsintervalls), die Anzahl der ihm zugeschlagenen Zyklen und
seine Startadresse. Sie können die Anzeige nach allen vier Spalten sortieren.
Neu erstellte Threads werden grün hervorgehoben, Threads, die beendet werden, in Rot.
(Die Dauer dieser Hervorhebung können Sie im Menü Options mit Difference Highlight Dura
tion ändern.) Das kann praktisch sein, um eine unnötige Threaderstellung in einem Prozess
aufzuspüren. (Im Allgemeinen sollten Threads beim Start des Prozesses erstellt werden und
nicht jedes Mal, wenn in einem Prozess eine Anforderung verarbeitet wird.)
Wenn Sie einen Thread in der Liste auswählen, zeigt Process Explorer jeweils die Thread-ID,
den Startzeitpunkt, den Status, die CPU-Zeit, die Anzahl der Zyklen, die Anzahl der Kontextwechsel, den idealen Prozessor und seine Gruppe sowie die E/A-, die Speicher-, die Basis- und
die aktuelle (dynamische) Priorität an. Mit der Schaltfläche Kill können Sie einen einzelnen
Die Threadaktivität untersuchen
Kapitel 4
231
Thread beenden, allerdings sollten Sie dabei äußerste Vorsicht walten lassen. Die Schaltfläche
Suspend unterbindet die fortgesetzte Ausführung eines Threads und verhindert so, dass ein
außer Kontrolle geratener Thread CPU-Zeit in Anspruch nimmt. Dies kann jedoch zu Deadlocks
führen, weshalb auch diese Schaltfläche ebenso mit Vorsicht zu genießen ist wie Kill. Mit der
Schaltfläche Permissions schließlich können Sie den Sicherheitsdeskriptor des Threads einsehen
(siehe Kapitel 7).
Anders als der Task-Manager und andere Prozess- und Prozessorüberwachungswerkzeuge verwendet der Process Explorer einen Taktzykluszähler für die Threadlaufzeitbestimmung
(weiter hinten in diesem Kapitel erklärt) statt eines Taktintervalltimers. Daher wird im Process
Explorer eine erheblich abweichende Sicht der CPU-Nutzung angezeigt. Viele Threads laufen
so kurz, dass nur selten (wenn überhaupt) der gerade ausgeführte Thread gesehen wird, wenn
ein Interrupt für einen Taktintervalltimer auftritt. Daher werden sie für einen Großteil ihrer CPUZeit gar nicht berücksichtigt, weshalb Werkzeuge mit solchen Timern eine CPU-Zeit von 0 %
messen. Die Gesamtzahl der Taktzyklen dagegen entspricht der Anzahl der Prozessorzyklen,
die für die Threads in dem Prozess aufgelaufen sind. Sie hängt von der Auflösung des Taktintervalltimers an, da der Zähler bei jedem Zyklus intern vom Prozessor geführt und bei jedem
Interrupt von Windows aktualisiert wird. (Vor einem Kontextwechsel erfolgt eine abschließende
Akkumulation.)
Die Threadstartadresse wird im Format Modul! Funktion angezeigt, wobei es sich bei Modul um den Namen der .exe- oder .dll-Datei handelt. Für den Funktionsnamen ist ein Zugriff auf
die Symboldateien für das Modul erforderlich (siehe das Experiment »Einzelheiten über Prozesse mit Process Explorer einsehen« in Kapitel 1). Wenn Ihnen nicht klar ist, worum es sich bei
dem Modul handelt, klicken Sie auf die Schaltfläche Module, um das Eigenschaftendialogfeld
für die Explorerdatei des Moduls mit der Startadresse des Threads zu öffnen (z. B. die .exe- oder
.dll-Datei).
Bei Threads, die mit der Windows-Funktion CreateThread erstellt wurden, zeigt
Process Explorer die an CreateThread übergebene Funktion und nicht die tatsächliche Startfunktion des Threads an. Das liegt daran, dass Windows-Threads mit
einer gemeinsamen Threadstart-Wrapperfunktion beginnen (TrlUserThreadStart
in Ntdll.dll). Würde Process Explorer die tatsächliche Startadresse anzeigen, dann
sähe es so aus, als begännen die meisten Threads in den Prozessen an derselben
Adresse, und das wäre nicht sehr hilfreich, um herauszufinden, welchen Code der
Thread ausführt. Falls Process Explorer die vom Benutzer angegebene Startadresse nicht abrufen kann (etwa bei einem geschützten Prozess), zeigt er jedoch die
Wrapperfunktion RtlUserThreadStart an.
Die angezeigte Threadstartadresse reicht unter Umständen nicht aus, um genau festzustellen,
was der Thread tut und welche Komponenten in dem Prozess für seinen CPU-Verbrauch verantwortlich sind. Das ist vor allem dann der Fall, wenn die Threadstartadresse eine generische
Startfunktion ist, etwa wenn der Funktionsname nicht angibt, was der Thread tatsächlich macht.
In diesem Fall kann eine Untersuchung des Threadstacks die Antwort liefern. Dazu doppelklicken Sie auf den betreffenden Thread (oder wählen ihn aus und klicken auf die Schaltfläche
232
Kapitel 4
Threads
Stack). Process Explorer zeigt dann den Stack des Threads an (bei einem Thread im Kernelmodus sowohl den Benutzer- als auch den Kernelstack).
Einen Benutzermodusdebugger (WinDbg, Ntsd und Cdb) können Sie an einen Prozess anhängen, um sich den Benutzerstack eines Threads anzeigen zu lassen. In
Process Explorer dagegen müssen Sie lediglich auf eine Schaltfläche klicken, um
sowohl den Benutzer- als auch den Kernelstack zu sehen. Wie die beiden nächsten
Experimente zeigen, können Sie den Benutzer- und den Kernelthreadstack auch
mit WinDbg im lokalen Kerneldebuggingmodus untersuchen.
Bei der Untersuchung von 32-Bit-Prozessen, die als Wow64-Prozesse auf 64-Bit-Systemen laufen (siehe Kapitel 8 in Band 2), zeigt Process Explorer sowohl den 32- als auch den 64-Bit-Stack
für die Threads an. Da ein Thread zum Zeitpunkt des echten (64-Bit-)Systemaufrufs bereits zum
64-Bit-Stack und -Kontext gewechselt ist, würde die Betrachtung des 64-Bit-Stacks nur die halbe Geschichte zeigen, nämlich den 64-Bit-Part des Threads mit dem Thunkcode von Wow64.
Bei der Untersuchung von Wow64-Prozessen müssen Sie daher auf jeden Fall sowohl den 32als auch den 64-Bit-Stack berücksichtigen.
Experiment: Einen Threadstack mit einem
Benutzermodusdebugger anzeigen
Gehen Sie wie folgt vor, um WinDbg an einen Prozess anzuhängen und Informationen über
den Thread und dessen Stack einzusehen:
1.
Führen Sie Notepad.exe und WinDbg.exe aus.
2.
Öffnen Sie in WinDbg das Menü File und wählen Sie Attach to Process.
3.
Suchen Sie die Notepad.exe-Instanz und klicken Sie auf OK, um den Debugger anzuhängen. Der Debugger sollte jetzt die Ausführung des Editors anhalten.
4.
Führen Sie die Threads in dem Prozess mit dem Befehl ~ auf. Für jeden Thread werden die Debugger-ID, die Client-ID (Prozess-ID.Thread-ID), der Unterbrechungszähler
(dieser Wert sollte meistens 1 lauten, da der Thread aufgrund des Haltepunktes unterbrochen wurde), die TEB-Adresse und die Angabe angezeigt, ob der Thread mit einem
Debuggerbefehl eingefroren wurde.
0:005> ~
0 Id: 612c.5f68 Suspend: 1 Teb: 00000022'41da2000 Unfrozen
1 Id: 612c.5564 Suspend: 1 Teb: 00000022'41da4000 Unfrozen
2 Id: 612c.4f88 Suspend: 1 Teb: 00000022'41da6000 Unfrozen
3 Id: 612c.5608 Suspend: 1 Teb: 00000022'41da8000 Unfrozen
4 Id: 612c.cf4 Suspend: 1 Teb: 00000022'41daa000 Unfrozen
.
5 Id: 612c.9f8 Suspend: 1 Teb: 00000022'41db0000 Unfrozen
→
Die Threadaktivität untersuchen
Kapitel 4
233
5.
Beachten Sie den Punkt, der in der Ausgabe vor Thread 5 steht. Er kennzeichnet den
aktuellen Debuggerthread. Um den Aufrufstack einzusehen, geben Sie den Befehl k
ein:
0:005> k
#
Child-SP
RetAddr
Call Site
00 00000022'421ff7e8 00007ff8'504d9031 ntdll!DbgBreakPoint
01 00000022'421ff7f0 00007ff8'501b8102 ntdll!DbgUiRemoteBreakin+0x51
02 00000022'421ff820 00007ff8'5046c5b4 KERNEL32!BaseThreadInitThunk+0x22
03 00000022'421ff850 00000000'00000000 ntdll!RtlUserThreadStart+0x34
6.
Der Debugger hat in den Notepad-Prozess einen Thread injiziert, der eine Haltepunktanweisung ausgibt (DbgBreakPoint). Um sich den Aufrufstack eines anderen Threads
anzusehen, verwenden Sie den Befehl ~nk, wobei n die in WinDbg angezeigte Threadnummer ist. (Der aktuelle Debuggerthread wird dadurch nicht geändert.) Das folgende
Beispiel zeigt die Ausgabe für Thread 2:
0:005> ~2k
#
Child-SP
RetAddr
Call Site
00 00000022'41f7f9e8 00007ff8'5043b5e8
ntdll!ZwWaitForWorkViaWorkerFactory+0x14
01 00000022'41f7f9f0 00007ff8'501b8102 ntdll!TppWorkerThread+0x298
02 00000022'41f7fe00 00007ff8'5046c5b4 KERNEL32!BaseThreadInitThunk+0x22
03 00000022'41f7fe30 00000000'00000000 ntdll!RtlUserThreadStart+0x34
7.
Um den Debugger auf einen anderen Thread umzuschalten, verwenden Sie den Befehl
~ns (wobei n wiederum die Threadnummer ist). Im folgenden Beispiel schalten wir zu
Thread 0 um und zeigen dessen Stack an:
0:005> ~0s
USER32!ZwUserGetMessage+0x14:
00007ff8'502e21d4 c3 ret
0:000> k
#
Child-SP
RetAddr
Call Site
00 00000022'41e7f048 00007ff8'502d3075 USER32!ZwUserGetMessage+0x14
01 00000022'41e7f050 00007ff6'88273bb3 USER32!GetMessageW+0x25
02 00000022'41e7f080 00007ff6'882890b5 notepad!WinMain+0x27b
03 00000022'41e7f180 00007ff8'341229b8 notepad!__mainCRTStartup+0x1ad
04 00000022'41e7f9f0 00007ff8'5046c5b4 KERNEL32!BaseThreadInitThunk+0x22
05 00000022'41e7fa20 00000000'00000000 ntdll!RtlUserThreadStart+0x34
8.
234
Auch wenn sich der Thread zurzeit im Kernelmodus befindet, zeigt ein Benutzermodusdebugger die letzte Funktion im Benutzermodus an (ZwUserGetMessage in der vorstehenden Ausgabe).
Kapitel 4
Threads
Experiment: Einen Threadstack mit einem lokalen
Kernelmodusdebugger anzeigen
In diesem Experiment verwenden wir einen lokalen Kerneldebugger, um den Benutzer- und
den Kernelmodusstack eines Threads einzusehen. Als Beispiel nutzen wir dafür einen der
Threads des Explorers, aber Sie können dieses Experiment auch mit anderen Prozessen und
Threads ausprobieren.
1.
Zeigen Sie alle Prozesse an, die im Abbild Explorer.exe ausgeführt werden. (Wenn Sie
die Explorer-Option Ordnerfenster in eigenem Prozess starten gewählt haben, wird
mehr als eine Instanz des Explorers angezeigt. Ein Prozess verwaltet den Desktop und
die Taskleiste, der andere die Explorer-Fenster.)
lkd> !process 0 0 explorer.exe
PROCESS ffffe00197398080
SessionId: 1 Cid: 18a0 Peb: 00320000 ParentCid: 1840
DirBase: 17c028000 ObjectTable: ffffc000bd4aa880 HandleCount: <Data Not
Accessible>
Image: explorer.exe
PROCESS ffffe00196039080
SessionId: 1 Cid: 1f30 Peb: 00290000 ParentCid: 0238
DirBase: 24cc7b000 ObjectTable: ffffc000bbbef740 HandleCount: <Data Not
Accessible>
Image: explorer.exe
2.
Wählen Sie eine Instanz aus und lassen Sie sich die Threadübersicht dafür anzeigen:
lkd> !process ffffe00196039080 2
PROCESS ffffe00196039080
SessionId: 1 Cid: 1f30 Peb: 00290000 ParentCid: 0238
DirBase: 24cc7b000 ObjectTable: ffffc000bbbef740 HandleCount: <Data Not
Accessible>
Image: explorer.exe
THREAD ffffe0019758f080 Cid 1f30.0718 Teb: 0000000000291000
Win32Thread: ffffe001972e3220 WAIT: (UserRequest) UserMode Non-Alertable
ffffe00192c08150 SynchronizationEvent
THREAD ffffe00198911080 Cid 1f30.1aac Teb: 00000000002a1000
Win32Thread: ffffe001926147e0 WAIT: (UserRequest) UserMode Non-Alertable
ffffe00197d6e150 SynchronizationEvent
ffffe001987bf9e0 SynchronizationEvent
→
Die Threadaktivität untersuchen
Kapitel 4
235
THREAD ffffe00199553080 Cid 1f30.1ad4 Teb: 00000000002b1000
Win32Thread: ffffe0019263c740 WAIT: (UserRequest) UserMode Non-Alertable
ffffe0019ac6b150 NotificationEvent
ffffe0019a7da5e0 SynchronizationEvent
THREAD ffffe0019b6b2800 Cid 1f30.1758 Teb: 00000000002bd000
Win32Thread: 0000000000000000 WAIT: (Suspended) KernelMode Non-Alertable
SuspendCount 1
ffffe0019b6b2ae0 NotificationEvent
...
3.
Wechseln Sie in den Kontext des ersten Threads in dem Prozess (Sie können auch andere Threads auswählen):
lkd> .thread /p /r ffffe0019758f080
Implicit thread is now ffffe001'9758f080
Implicit process is now ffffe001'96039080
Loading User Symbols
..............................................
4.
Schauen Sie sich jetzt den Thread an, um seine Einzelheiten und seinen Aufrufstack zu
untersuchen (Adressen hier gekürzt):
lkd> !thread ffffe0019758f080
THREAD ffffe0019758f080 Cid 1f30.0718 Teb: 0000000000291000 Win32Thread :
ffffe001972e3220 WAIT : (UserRequest)UserMode Non - Alertable
ffffe00192c08150 SynchronizationEvent
Not impersonating
DeviceMap
ffffc000b77f1f30
Owning Process
ffffe00196039080 Image : explorer.exe
Attached Process
N / A
Image : N / A
Wait Start TickCount 17415276 Ticks : 146 (0:00 : 00 : 02.281)
Context Switch Count 2788
UserTime
00 : 00 : 00.031
KernelTime
00 : 00 : 00.000
IdealProcessor : 4
*** WARNING : Unable to verify checksum for C : \windows\explorer.exe
Win32 Start Address explorer!wWinMainCRTStartup(0x00007ff7b80de4a0)
Stack Init ffffd0002727cc90 Current ffffd0002727bf80
Base ffffd0002727d000 Limit ffffd00027277000 Call 0000000000000000
Priority 8 BasePriority 8 PriorityDecrement 0 IoPriority 2 PagePriority 5
→
236
Kapitel 4
Threads
... Call Site
... nt!KiSwapContext + 0x76
... nt!KiSwapThread + 0x15a
... nt!KiCommitThreadWait + 0x149
... nt!KeWaitForSingleObject + 0x375
... nt!ObWaitForMultipleObjects + 0x2bd
... nt!NtWaitForMultipleObjects + 0xf6
... nt!KiSystemServiceCopyEnd + 0x13 (TrapFrame @ ffffd000'2727cb00)
... ntdll!ZwWaitForMultipleObjects + 0x14
... KERNELBASE!WaitForMultipleObjectsEx + 0xef
... USER32!RealMsgWaitForMultipleObjectsEx + 0xdb
... USER32!MsgWaitForMultipleObjectsEx + 0x152
... explorerframe!SHProcessMessagesUntilEventsEx + 0x8a
... explorerframe!SHProcessMessagesUntilEventEx + 0x22
... explorerframe!CExplorerHostCreator::RunHost + 0x6d
... explorer!wWinMain + 0xa04fd
... explorer!__wmainCRTStartup + 0x1d6
Einschränkungen für Threads in geschützten Prozessen
Wie bereits in Kapitel 3 erwähnt, bestehen bei geschützten Prozessen (was sowohl klassische
geschützte Prozesse als auch PPLs einschließt) starke Einschränkungen, was die Zugriffsrechte
angeht, selbst für Benutzer mit den höchsten Rechten auf dem System. Diese Einschränkungen
gelten auch für die Threads in diesen Prozessen. Dadurch wird sichergestellt, dass der Code,
der in einem geschützten Prozess läuft, durch Windows-Standardfunktionen nicht gekapert
oder auf andere Weise beeinträchtigt werden kann, denn dazu müssten diese Funktionen Zugriffsrechte bekommen, die für Threads in geschützten Prozessen nicht vergeben werden. Die
einzigen gewährten Berechtigungen sind THREAD_SUSPEND_RESUME und THREAD_SET/QUERY_LIMITED_INFORMATION.
Experiment: Informationen über Threads in geschützten
Prozessen mit Process Explorer anzeigen
In diesem Experiment schauen Sie sich Informationen über die Threads in einem geschützten Prozess an. Gehen Sie dazu wie folgt vor:
1.
Suchen Sie in der Prozessliste einen geschützten oder einen PPL-Prozess, z. B. Audiodg.
exe oder Csrss.exe.
→
Die Threadaktivität untersuchen
Kapitel 4
237
2.
Öffnen Sie das Eigenschaftendialogfeld des Prozesses und klicken Sie auf die Registerkarte Threads.
3.
Process Explorer zeigt nicht die Win32-Threadstartadresse an, sondern stattdessen den
standardmäßigen Threadstartwrapper in Ntdll.dll. Wenn Sie auf die Schaltfläche Stack
klicken, wird eine Fehlermeldung angezeigt, da Process Explorer dazu den virtuellen
Speicher innerhalb des geschützten Prozesses lesen müsste, was er aber nicht tun kann.
4.
Es werden zwar die Basis- und die dynamische Priorität angezeigt, die E/A- und die
Speicherpriorität aber nicht (genauso wenig wie die Zyklen). Auch das ist ein Beispiel
für das eingeschränkte Zugriffsrecht THREAD_QUERY_LIMITED_INFORMATION im Gegensatz
zu dem vollständigen Informationszugriffsrecht THREAD_QUERY_INFORMATION.
5.
Versuchen Sie, einen Thread in dem geschützten Prozess zu beenden. Auch dabei erhalten Sie eine Fehlermeldung, da Sie nicht über das Zugriffsrecht THREAD_TERMINATE
verfügen.
Threadplanung
Dieser Abschnitt erläutert die Planungsrichtlinien und -algorithmen von Windows. Die ersten
Teilabschnitte geben eine knappe Beschreibung der Threadplanung in Windows und eine Definition der wichtigsten Begriffe. Anschließend werden die Windows-Prioritätsstufen sowohl
für Windows-APIs als auch für den Windows-Kernel erklärt. Nach einer Übersicht über die
238
Kapitel 4
Threads
Windows-Hilfsprogramme und -Werkzeuge rund um die Threadplanung werden die Datenstrukturen und Algorithmen des Windows-Planungssystems ausführlich vorgestellt. Dabei
werden auch gängige Planungssituationen beschrieben und erklärt, wie die Thread- und die
Prozessorauswahl erfolgen.
Überblick über die Threadplanung in Windows
Windows verwendet ein prioritätsgesteuertes, präemptives Planungssystem. Es wird immer
mindestens einer der ausführbaren (betriebsbereiten) Threads höchster Priorität ausgeführt,
wobei einige davon jedoch nur auf bestimmten Prozessoren laufen dürfen oder bevorzugt auf
bestimmten Prozessoren ausgeführt werden sollten, was als Prozessoraffinität bezeichnet wird.
Eine solche Affinität besteht immer zu einer ganzen Gruppe von Prozessoren, die bis zu 64
Prozessoren umfassen kann. Normalerweise können Threads nur auf verfügbaren Prozessoren
in der mit dem Prozess verbundenen Gruppe ausgeführt werden. (Dies dient zur Kompatibilität
mit älteren Windows-Versionen, die nur 64 Prozessoren unterstützen.) Entwickler können die
Prozessoraffinität durch entsprechende APIs sowie über die Affinitätsmaske im Abbildheader
ändern. Benutzer können Werkzeuge einsetzen, um die Affinität zur Laufzeit oder beim Erstellen des Prozesses zu ändern. Threads in einem Prozess können zwar unterschiedlichen Gruppen
zugeordnet werden, doch ein Thread kann nur auf den Prozessoren seiner Gruppe ausgeführt
werden. Entwickler haben auch die Möglichkeit, Anwendungen zu schreiben, die mithilfe einer
erweiterten Planungs-API die Affinitäten ihrer Threads mit logischen Prozessoren in verschiedenen Gruppen verknüpfen. Dadurch wird aus dem Prozess ein Mehrgruppenprozess, dessen
Threads theoretisch auf jedem verfügbaren Prozessor auf dem Computer ausgeführt werden
können.
Nachdem ein Thread ausgewählt wurde, wird er eine bestimmte Zeit lang ausgeführt, bis
ein anderer Thread derselben Priorität an der Reihe ist. Dieser Zeitraum wird als Quantum bezeichnet, wobei sich die Quantumswerte zwischen den einzelnen Systemen und Prozessen aus
drei Gründen unterscheiden:
QQ Systemkonfigurationseinstellungen (langes oder kurzes Quantum, festes oder variables,
Trennung von Prioritäten)
QQ Vordergrund- oder Hintergrundstatus des Prozesses
QQ Änderung des Quantums durch das Jobobjekt
Diese Einzelheiten werden im Abschnitt über Quanten weiter hinten in diesem Kapitel ausführlich erklärt.
Es kann jedoch sein, dass ein Thread gar nicht dazu kommt, sein Quantum komplett auszufüllen, da Windows einen präemptiven Scheduler verwendet. Wenn ein Thread mit höherer
Priorität zur Ausführung bereitsteht, kann der aktuelle Thread vorzeitig unterbrochen werden,
bevor er eine Zeitscheibe komplett genutzt hat. Es ist sogar möglich, dass ein Thread zur Ausführung ausgewählt, aber schon vor Beginn seines Quantums abgebrochen wird.
Der Windows-Planungscode ist im Kernel implementiert. Es gibt jedoch kein eigenes Modul und keine eigene Routine dafür. Der Code ist über die Stellen im Kernel verstreut, in denen
Ereignisse rund um die Threadplanung auftreten können. Die Routinen für diese Aufgaben
Threadplanung
Kapitel 4
239
werden gesammelt als Dispatcher des Kernels bezeichnet. Die folgenden Ereignisse können
eine solche Threaddisponierung erfordern:
QQ Ein Thread ist zur Ausführung bereit. Das kann etwa der Fall sein, wenn ein Thread neu
erstellt wurde oder einen Wartezustand verlassen hat.
QQ Ein Thread verlässt den Ausführungsstatus, da sein Zeitquantum abgelaufen ist, er beendet
wird, er die Ausführung aufgebt oder er in einen Wartezustand eintritt.
QQ Die Priorität eines Threads ändert sich, entweder aufgrund eines Systemdienstaufrufs oder
weil Windows selbst den Prioritätswert geändert hat.
QQ Die Prozessoraffinität eines Threads ändert sich, sodass er nicht mehr auf dem Prozessor
ausgeführt werden kann, auf dem er läuft.
Bei jedem dieser Ereignisse muss Windows entscheiden, welcher Thread als Nächstes auf dem
logischen Prozessor ausgeführt werden soll, auf dem der betreffende Thread lief, bzw. auf welchem logischen Prozessor der Thread jetzt laufen soll. Nachdem ein logischer Prozessor für den
neuen Thread ausgewählt wurde, erfolgt dort schließlich ein Kontextwechsel zu diesem Thread.
Dabei wird der flüchtige Prozessorstatus des laufenden Threads gespeichert, der flüchtige Status eines anderen Threads geladen und die Ausführung des neuen Threads gestartet.
Windows nimmt die Planung für einzelne Threads vor. Das ist sinnvoll, da Prozesse nicht
ausgeführt werden, sondern nur die Ressourcen und den Kontext für die Ausführung ihrer
Threads liefern. Da Planungsentscheidungen rein auf Threadebene erfolgen, wird dabei nicht
berücksichtigt, zu welchen Prozessen die Threads gehören. Wenn beispielsweise Prozess A über
zehn ausführbare Threads verfügt und Prozess B über zwei, wobei alle zwölf Threads dieselbe Priorität haben, dann kann jeder Thread theoretisch ein Zwölftel der CPU-Zeit erhalten.
Windows vergibt also nicht 50 % der CPU-Zeit an Prozess A und die anderen 50 % an Prozess B.
Prioritätsstufen
Für ein Verständnis der Threadplanungsalgorithmen sind zunächst einmal Kenntnisse der Prioritätsstufen in Windows erforderlich. Wie Abb. 4–6 zeigt, verwendet Windows intern 32 Prioritätsstufen von 0 bis 31 (wobei 31 die höchste Priorität dargestellt). Die Werte sind in folgende
Bereiche aufgeteilt:
QQ 16 Echtzeitstufen (16 bis 31)
QQ 16 variable Stufen (0 bis 15), wobei Stufe 0 für den Nullseitenthread reserviert ist (siehe
Kapitel 5)
240
Kapitel 4
Threads
Echtzeit
Dynamisch (normal)
Nullseitenthread
Abbildung 4–6 Threadprioritätsstufen
Threadprioritätsstufen werden von der Windows-API und vom Windows-Kernel zugewiesen.
Die Windows-API ordnet die Prozesse zunächst nach der Prioritätsklasse, der sie bei ihrer Erstellung zugeordnet wurden (wobei die Zahl in Klammern der interne PROCESS_PRIORITY_CLASS-Index ist, den der Kernel erkennt):
QQ Echtzeit (4)
QQ Hoch (3)
QQ Höher als normal (6)
QQ Normal (2)
QQ Niedriger als normal (5)
QQ Leerlauf (1)
Mit der Windows-API SetPriorityClass kann die Prioritätsklasse eines Prozesses auf einen dieser Werte eingestellt werden.
Anschließend wird den einzelnen Threads in den Prozessen eine relative Priorität zugewiesen. Hier stehen die Zahlen für den Abstand zur Basispriorität des Prozesses:
QQ Zeitkritisch (15)
QQ Am höchsten (2)
QQ Höher als normal (1)
QQ Normal (0)
QQ Niedriger als normal (-1)
QQ Am niedrigsten (-2)
QQ Leerlauf (-15)
Die Prioritätsstufen Zeitkritisch und Leerlauf (+15 und -15) werden als Sättigungswerte bezeichnet und stellen besondere Stufen dar und keine echten Offsets. Diese Werte können an die
Windows-API SetThreadPriority übergeben werden, um die relative Priorität eines Threads zu
ändern.
In der Windows-API hat daher jeder Thread eine Basispriorität, die von der Prozessprioritätsklasse und seiner relativen Threadpriorität abhängt. Im Kernel werden die bereits erwähnten
PROCESS_PRIORITY_CLASS-Indizes mithilfe des globalen Arrays PspPriorityTable in die Basisprio-
Threadplanung
Kapitel 4
241
ritäten 4, 8, 13, 14, 6 oder 10 umgesetzt. (Hierbei handelt es sich um eine feste Zuordnung, die
nicht geändert werden kann.) Anschließend wird die relative Threadpriorität als Differenz dieser
Basispriorität zugeschlagen. Beispielsweise erhält ein Thread mit der höchsten Priorität dadurch
eine Threadbasispriorität, die zwei Stufen höher liegt als die Basispriorität seines Prozesses.
Die Zuordnung der Windows-Prioritäten zu den internen numerischen Windows-Prioritäten wird in Abb. 4–7 und Tabelle 4–1 dargestellt.
Normale (dynamische) Prioritäten
Echtzeitprioritäten
Prioritätsklasse »Echtzeit«
Prioritätsklasse »Hoch«
Prioritätsklasse »Höher als normal«
Prioritätsklasse »Normal«
Prioritätsklasse »Niedriger als normal«
Prioritätsklasse »Leerlauf«
Priorität
Abbildung 4–7 In der Windows-API verwendete Threadprioritäten
Prioritätsklasse (relative Priorität)
Echtzeit
Hoch
Höher als
normal
Normal
Niedriger
als normal
Leerlauf
Zeitkritisch (+Sättigung)
31
15
15
15
15
15
Am höchsten (+2)
26
15
12
10
8
6
Höher als normal (+1)
25
14
11
9
7
5
Normal (0)
24
13
10
8
6
4
Niedriger als normal (-1)
23
12
9
7
5
3
Am niedrigsten (-2)
22
11
8
6
4
2
Leerlauf (-Sättigung)
16
1
1
1
1
1
Tabelle 4–1 Zuordnung der Windows-Kernelprioritäten zu den Windows-API-Prioritäten
Wie Sie sehen, behalten die relativen Threadprioritäten Echtzeit und Leerlauf ihre Werte unabhängig von der Prozessprioritätsklasse bei (sofern diese nicht Echtzeit lautet). Das liegt daran,
dass die Windows-API die Sättigung der Priorität vom Kernel anfordert, indem sie +16 oder -16
als gewünschte relative Priorität übergibt. Die Formel zur Berechnung dieser Werte lautet wie
folgt (wobei HIGH_PRIORITY gleich 31 ist):
If Time-Critical: ((HIGH_PRIORITY+1) / 2
If Idle: -((HIGH_PRIORITY+1) / 2
242
Kapitel 4
Threads
Diese Werte werden vom Kernel als Anforderung zur Sättigung erkannt, sodass das Feld
Saturation in der KTHREAD-Struktur ausgefüllt wird. Bei positiver Sättigung erhält der Thread
dadurch die höchstmögliche Priorität in seiner Prioritätsklasse (dynamisch oder Echtzeit), bei
negativer Sättigung die niedrigste. Spätere Anforderungen zur Änderung der Basispriorität des
Prozesses haben keine Auswirkungen mehr auf die Basispriorität dieser Threads, da gesättigte
Threads im Verarbeitungscode übersprungen werden.
Wie Tabelle 4–1 zeigt, gibt es für Threads sieben mögliche Windows-API-Prioritätsstufen
(sechs bei der Prioritätsklasse Hoch). In der Prioritätsklasse Echtzeit können Sie sogar alle Prioritätsstufen zwischen 16 und 31 einstellen (siehe Abb. 4–7). Die Werte, die nicht von den in der
Tabelle gezeigten Konstanten abgedeckt werden, können mit den Argumenten -7, -6, -5, -4, -3,
3, 4, 5 und 6 für SetThreadPriority festgelegt werden. (Weitere Informationen erhalten Sie im
Abschnitt »Echtzeitprioritäten« weiter hinten.)
Für den Scheduler spielt es jedoch keine Rolle, wie die Priorität (als Kombination der Prozessprioritätsklasse und der relativen Threadpriorität) durch die Windows-API gebildet wurde.
Für ihn zählt nur das Endergebnis. Beispielsweise gibt es zwei Möglichkeiten, die Prioritätsstufe
10 zu erreichen, nämlich erstens durch einen Prozess der Prioritätsklasse Normal (8) und einen
Thread mit der relativen Priorität Am höchsten (+2) und zweitens durch einen Prozess der Prioritätsklasse Höher als normal (10) und einen Thread mit der relativen Priorität Normal (0). Der
Scheduler sieht nur den Wert 10, weshalb die Threads für ihn die gleiche Priorität aufweisen.
Ein Prozess hat nur einen Basisprioritätswert, ein Thread dagegen eine aktuelle (dynamische) und eine Basispriorität. Planungsentscheidungen werden aufgrund der aktuellen Priorität
getroffen. Wie in dem Abschnitt »Prioritätserhöhung« weiter hinten erklärt, kann das System
unter bestimmten Umständen die Priorität eines Threads kurzzeitig im dynamischen Bereich (1
bis 15) heraufsetzen. Dagegen ändert Windows niemals die Threadpriorität im Echtzeitbereich
(16 bis 31), weshalb bei solchen Threads die Basis- und die aktuelle Priorität stets identisch sind.
Ein Thread erbt seine ursprüngliche Basispriorität von seinem Prozess, der seine Basispriorität wiederum standardmäßig von seinem Erstellerprozess erbt. Dieses Verhalten können Sie in
der Funktion CreateProcess und mit dem Befehl start ändern. Es ist auch möglich, die Priorität
eines Prozesses nachträglich zu ändern. Dazu können Sie die Funktion SetPriorityClass sowie
verschiedene Werkzeuge verwenden, in denen sie zur Verfügung steht, darunter der Task-Manager und Process Explorer. (Dazu rechtsklicken Sie auf den Prozess und wählen die neue Prioritätsklasse aus.) Beispielsweise können Sie die Priorität eines CPU-intensiven Prozesses verringern, damit er die normalen Systemaktivitäten nicht beeinträchtigt. Bei der Änderung der
Prozesspriorität wird die Priorität seiner Threads entsprechend herauf- oder heruntergesetzt,
wobei deren relative Prioritäten jedoch bestehen bleiben.
Anwendungen und Dienste starten gewöhnlich mit der Basispriorität Normal, weshalb
ihr ursprünglicher Thread normalerweise auf der Prioritätsstufe 8 ausgeführt wird. Einige
Windows-Systemprozesse (wie der Sitzungs-Manager, der Dienststeuerungs-Manager und der
lokale Sicherheitsauthentifizierungsprozess haben jedoch eine leicht höhere Basisprozesspriorität als Normal, weshalb auch die darin enthaltenen Threads mit einer höheren Priorität als
dem Standardwert 8 starten.
Threadplanung
Kapitel 4
243
Echtzeitprioritäten
In jeder Anwendung können Sie die Threadprioritäten im dynamischen Bereich erhöhen oder
senken. Um in den Echtzeitbereich vorzudringen, müssen Sie allerdings das Recht für die Planungspriorität erhöhen (SetIncreaseBasePriorityPrivilege). Beachten Sie aber, dass im Echtzeitprioritätsbereich viele wichtige Kernelmodus-Systemthreads von Windows laufen. Wenn
Ihre Threads erheblich viel Zeit in diesem Bereich verbringen, können sie dadurch wichtige
Systemfunktionen blockieren (etwa den Speicher-Manager, den Cache-Manager oder einige
Gerätetreiber).
Wenn ein Prozess mit den Standard-Windows-APIs in den Echtzeitbereich verlegt wurde,
müssen alle seine Threads (selbst Leerlaufthreads) auf einer der Echtzeitprioritätsstufen laufen.
Mit den Standardschnittstellen ist es daher nicht möglich, in einem Prozess Echtzeit- und dynamische Threads zu kombinieren. Das liegt daran, dass die API SetThreadPriority die native
API NtSetInformationThread mit der Informationsklasse ThreadBasePriority aufruft, bei der
Prioritäten im selben Bereich bleiben müssen. Außerdem dürfen Prioritätsänderungen bei der
Verwendung dieser Informationsklasse nur die von Windows-APIs verstandenen Abstände von
-2 bis 2 (oder zeitkritisch/Leerlauf) umfassen, es sei denn, die Anforderung kommt von Csrss
oder einem anderen Echtzeitprozess. Anders ausgedrückt, ein Echtzeitprozess kann beliebige
Threadprioritäten zwischen 16 und 31 auswählen, auch wenn die relativen Threadprioritäten
der Windows-Standard-API die Auswahl auf die Werte aus der zuvor gezeigten Tabelle einzuschränken scheinen.
Wie bereits erwähnt, führt ein Aufruf von SetThreadPriority mit einigen besonderen Werten dazu, dass NtSetInformationThread mit der Informationsklasse ThreadActualBasePriority
aufgerufen wird. Die Kernelbasispriorität für den Thread kann dann direkt festgelegt werden,
wobei es auch möglich ist, die Priorität eines Threads in einem Echtzeitprozess im dynamischen
Bereich einzustellen.
Die Bezeichnung Echtzeit bedeutet nicht, dass es sich bei Windows um ein Echtzeitbetriebssystem im üblichen Sinne des Wortes handelt. Schließlich bietet es
keine Echtzeitfunktionen wie garantierte Interruptlatenz oder eine garantierte
Ausführungszeit für Threads an. Echtzeit bedeutet hier nur »mit einer höheren
Priorität als alle anderen«.
Werkzeuge für den Umgang mit Prioritäten
Die Basisprozesspriorität können Sie im Task-Manager und Process Explorer einsehen und ändern. In Process Manager können Sie auch einzelne Threads in einem Prozess beenden (wobei
Sie natürlich äußerste Vorsicht walten lassen müssen).
Die Prioritäten einzelner Prozesse können Sie in der Leistungsüberwachung, in Process
Explorer und WinDbg einsehen. Es kann durchaus sinnvoll sein, die Priorität eines Prozesses
zu erhöhen oder zu verringern, aber die Einstellung der Priorität einzelner Threads in einem
Prozess ist nicht sinnvoll, weil nur jemand, der das Programm in allen Einzelheiten kennt (also
der Entwickler), die relative Wichtigkeit der Threads innerhalb des Prozesses überblicken kann.
244
Kapitel 4
Threads
Die einzige Möglichkeit, um die Anfangsprioritätsklasse für einen Prozess anzugeben, bietet der Befehl start in der Windows-Eingabeaufforderung. Wenn Sie ein Programm immer mit
einer bestimmten Priorität starten lassen wollen, können Sie einen Kurzbefehl definieren, um
immer den Befehl start zu verwenden. Dieser Kurzbefehl muss mit cmd /c beginnen, um die
Eingabeaufforderung zu starten. Anschließend führt er den angegebenen Befehl aus und beendet die Eingabeaufforderung. Um beispielsweise den Editor mit der Leerlauf-Prozesspriorität
auszuführen, verwenden Sie den Befehl cmd /c start /low Notepad.exe.
Experiment: Prozess- und Threadprioritäten untersuchen und
festlegen
Um Prozess- und Threadprioritäten zu untersuchen und festzulegen, gehen Sie wie folgt
vor:
1.
Führen Sie Notepad.exe ganz normal aus, etwa indem Sie an der Eingabeaufforderung
notepad eingeben.
2.
Öffnen Sie den Task-Manager und klicken Sie auf die Registerkarte Details.
3.
Fügen Sie die Spalte Basispriorität hinzu. Das ist die Bezeichnung der Prioritätsklasse im
Task-Manager.
4.
Suchen Sie in der Liste nach Notepad:
5.
Wie Sie sehen, läuft der Notepad-Prozess mit der Prioritätsklasse Normal (8). Die Prioritätsklasse Leerlauf wird im Task-Manager als Niedrig angezeigt.
6.
Öffnen Sie Process Explorer.
7.
Doppelklicken Sie auf den Prozess Notepad, um sein Eigenschaftendialogfeld aufzurufen, und klicken Sie auf die Registerkarte Threads.
→
Threadplanung
Kapitel 4
245
8.
Markieren Sie den ersten Thread (falls es mehrere gibt). Sie sollten jetzt folgende Anzeige sehen:
9.
Achten Sie auf die Prioritäten des Threads: Seine Basispriorität beträgt nach wie vor
8, seine aktuelle (dynamische) Priorität dagegen 10. Den Grund dafür erfahren Sie im
Abschnitt »Prioritätserhöhung« weiter hinten.
10. Wenn Sie wollen, können Sie den Thread unterbrechen und beenden (wobei Sie jedoch
in beiden Fällen sehr vorsichtig sein müssen).
11. Rechtsklicken Sie im Task-Manager auf den Prozess Notepad, wählen Sie Priorität festlegen und dann Hoch:
→
246
Kapitel 4
Threads
12. Bestätigen Sie den Vorgang in dem daraufhin eingeblendeten Dialogfeld. In Process
Explorer können Sie jetzt erkennen, dass die Priorität des Threads in die Klasse Hoch
(13) heraufgesetzt wurde. Die dynamische Priorität hat die gleiche relative Steigerung
erfahren:
13. Ändern Sie die Prioritätsklasse im Task-Manager auf Echtzeit. Dazu müssen Sie ein Administrator auf dem Computer sein. Diese Änderung können Sie auch in Process Manager vornehmen.
14. In Process Manager betragen die Basis- und die dynamische Priorität des Threads jetzt
beide 24. Wie Sie wissen, wendet der Kernel auf Threads im Echtzeitbereich niemals
Prioritätserhöhungen an.
Threadplanung
Kapitel 4
247
Der Windows-Systemressourcen-Manager
Windows Server 2012 R2 Standard Edition und höhere SKUs enthalten den optional in
stallierbaren Windows-Systemressourcen-Manager (WSRM). Damit können Administratoren
Richtlinien aufstellen, um Affinitätseinstellungen und Grenzwerte für die CPU- und Speichernutzung (sowohl physisch als auch virtuell) durch Prozesse festzulegen. Darüber hinaus
kann WSRM Ressourcennutzungsberichte erstellen, die sich zur Buchführung und als Nachweis für Dienstleistungsverträge mit Benutzern nutzen lassen.
Die Richtlinien können auf bestimmte Anwendungen angewandt werden (durch Vergleich des Abbildnamens mit oder ohne Befehlszeilenargumente), aber auch auf Benutzer
oder Gruppen. Sie lassen sich auch zeitlich planen, sodass sie nur zu bestimmten Zeiten in
Kraft treten oder ständig gelten.
Nachdem Sie eine Ressourcenzuweisungsrichtlinie aufgestellt haben, überwacht der
WSRM-Dienst die CPU-Nutzung der darüber verwalteten Prozesse und passt deren Basisprioritäten an, wenn sie ihre Sollwerte nicht erfüllen.
Bei den Grenzwerten für den physischen Arbeitsspeicher wird mit der Funktion SetProcessWorkingSetSizeEx ein harter Höchstwert für die Größe des Arbeitssatzes festgelegt. Beim Grenzwert für den virtuellen Arbeitsspeicher prüft der Dienst, wie viel privaten
virtuellen Arbeitsspeicher die Prozesse verbrauchen (siehe Kapitel 5). Wird der Grenzwert
überschritten, kann WSRM je nach Einstellung entweder den betreffenden Prozess beenden oder einen Eintrag in das Ereignisprotokoll schreiben. Damit lässt sich ein Prozess mit
einem Speicherleck aufspüren, bevor er den gesamten verfügbaren, zugesicherten Speicher auf dem System verbraucht. Die WSRM-Speichergrenzwerte gelten jedoch nicht für
AWE-Speicher (Address Windowing Extensions), Arbeitsspeicher mit großen Seiten und den
Kernelspeicher (nicht ausgelagerter und ausgelagerter Pool). Mehr darüber erfahren Sie in
Kapitel 5.
Threadstatus
Bevor wir uns mit den Threadplanungsalgorithmen beschäftigen, müssen wir zunächst die verschiedenen Ausführungsstatus ansehen, in denen sich ein Thread befinden kann:
QQ Bereit (Ready) Ein Thread in diesem Status wartet darauf, dass er ausgeführt oder nach
Abschluss eines Wartevorgangs wieder eingewechselt wird. Bei der Suche nach auszuführenden Threads berücksichtigt der Dispatcher nur solche, die bereit sind.
QQ Verzögert bereit (Deferred Ready) Dieser Status wird für Threads verwendet, die auf
einem bestimmten Prozessor ausgewählt wurden, aber noch nicht begonnen haben, dort
zu laufen. Dieser Status ist dazu da, dass der Kernel die Zeit verkürzen kann, die eine prozessorweise Sperre für die Planungsdatenbank aufrechterhalten wird.
QQ Standby Ein Thread in diesem Zustand wurde dazu ausgewählt, als nächster auf einem
bestimmten Prozessor zu laufen. Wenn die erforderlichen Bedingungen hergestellt sind,
führt der Dispatcher einen Kontextwechsel zu diesem Thread durch. Auf jedem Prozessor
des Systems kann sich immer nur ein Thread auf einmal im Standby-Zustand befinden.
248
Kapitel 4
Threads
Es ist übrigens möglich, dass ein Thread noch im Standby-Status unterbrochen wird, also
bevor er mit der Ausführung begonnen hat (etwa wenn ein Thread mit höherer Priorität
inzwischen lauffähig wurde).
QQ Wird ausgeführt (Running) Nachdem der Dispatcher einen Kontextwechsel zu einem
Thread durchgeführt hat, geht dieser Thread in den Zustand Wird ausgeführt über. Der
Thread wird so lange ausgeführt, bis sein Quantum abläuft (und ein anderer Thread derselben Priorität bereit zur Ausführung ist), er durch einen Thread höherer Priorität unterbrochen wird, er beendet wird, er die Ausführung abgibt oder er freiwillig in einen
Wartezustand eintritt.
QQ Wartend (Waiting) Ein Thread kann auf verschiedene Weisen in den Wartezustand
übergehen: Er kann freiwillig auf ein Objekt warten, um die Ausführung zu synchronisieren;
das Betriebssystem kann für den Thread warten (etwa um eine Auslagerungs-E/A durchzuführen); und ein Umgebungsteilsystem kann den Thread anweisen, sich selbst anzuhalten.
Wenn die Wartezeit des Threads endet, wird er je nach seiner Priorität entweder sofort
weiter ausgeführt oder in den Status Bereit versetzt.
QQ Übergang (Transition) Ein Thread tritt in den Übergangsstatus ein, wenn er zur Ausführung bereit ist, sein Kernelstack aber aus dem Arbeitsspeicher ausgelagert wurde. Nachdem der Kernelstack wieder in den Arbeitsspeicher zurückgebracht wurde, nimmt der
Thread den Status Bereit an. (Threadstacks werden in Kapitel 5 erklärt.)
QQ Abgebrochen (Terminated) Wenn ein Thread die Ausführung beendet, tritt er in diesen Status ein. Ob nach seiner Beendigung die Zuweisung des Exekutivthreadobjekts (der
Datenstruktur im Systemarbeitsspeicher, die den Thread beschreibt) aufgehoben wird oder
nicht, bestimmt der Objekt-Manager. Beispielsweise bleibt das Objekt bestehen, wenn es
noch offene Handles zu dem Thread gibt. Ein Thread kann auch in den Status Abgebrochen
übergehen, wenn er ausdrücklich von einem anderen Thread beendet wird, etwa durch
den Aufruf der Windows-API TerminateThread.
QQ Initialisiert (Initialized)
verwendet.
Dieser Status wird intern während der Erstellung des Threads
Abb. 4–8 zeigt die wichtigsten Statusübergänge für Threads. Die Zahlen stehen für die internen
Werte der einzelnen Zustände, die in Werkzeugen wie der Leistungsüberwachung angezeigt
werden. Bereit und Verzögert bereit werden als ein Status dargestellt, da Verzögert bereit lediglich als vorübergehender Platzhalter für Planungsroutinen dient. Das gilt auch für den Status
Standby. Diese Zustände sind fast immer sehr kurzlebig. Threads in diesem Status gehen immer
schnell in Bereit, Wird ausgeführt oder Wartend über.
Threadplanung
Kapitel 4
249
Initialisierung (0)
Vorzeitige Unterbrechung, Ablauf
des Quantums
Vorzeitige
Unterbrechung
Bereit (1),
verzögert
bereit (7)
Einwechseln des
Kernelstacks
Wird ausgeführt (2)
Standby (3)
Freiwilliger
Wechsel
Übergang (6)
Wartend (5)
Abgebrochen (4)
Auslagerung
des Kernelstacks
Abbildung 4–8 Threadstatus und Übergänge
Experiment: Statuswechsel bei der Threadplanung
Die Statuswechsel bei der Threadplanung können Sie mit der Windows-Leistungsüberwachung beobachten. Dieses Werkzeug ist sehr praktisch, wenn Sie eine Multithreadanwendung debuggen wollen und sich über den Status der Threads in den Prozessen nicht im
Klaren sind. Zur Beobachtung der Statuswechsel gehen Sie wie folgt vor:
1.
Laden Sie das CPU Stress Tool aus den Begleitmaterialien zu diesem Buch herunter.
2.
Starten Sie CPUStres.exe. Thread 1 sollte jetzt aktiv sein.
3.
Aktivieren Sie Thread 2, indem Sie ihn in der Liste markieren und auf Activate klicken
oder indem Sie auf ihn rechtsklicken und im Kontextmenü Activate auswählen. Sie sollten jetzt eine ähnliche Anzeige wie die folgende sehen:
→
250
Kapitel 4
Threads
4.
Klicken Sie auf die Startschaltfläche und geben Sie perfmon ein, um die Leistungsüberwachung zu starten.
5.
Wählen Sie ggf. die Diagrammansicht aus und entfernen Sie den vorhandenen CPU-Indikator.
6.
Rechtsklicken Sie auf das Diagramm und wählen Sie Eigenschaften.
7.
Klicken Sie auf die Registerkarte Grafik und ändern Sie das Maximum für die vertikale
Skalierung auf 7 (da die einzelnen Status mit den Zahlen 0 bis 7 bezeichnet werden).
Klicken Sie auf OK.
8.
Klicken Sie in der Symbolleiste auf Hinzufügen, um das Dialogfeld Leistungsindikatoren
hinzufügen zu öffnen.
9.
Wählen Sie das Leistungsobjekt Thread und darunter den Indikator Threadstatus aus.
10. Aktivieren Sie das Kontrollkästchen Beschreibung anzeigen, um eine Definition der
Werte einzublenden:
11. Wählen Sie <Alle Instanzen> im Feld Instanzen. Geben Sie dann cpustres ein und klicken Sie auf Suchen.
12. Wählen Sie die ersten drei Threads von cpustres aus (cpustres/0, cpustres/1 und cpu
stres/2), klicken Sie auf Hinzufügen >> und dann auf OK. Thread 0 befindet sich im
Status 5 (Wartend), da dies der GUI-Thread ist, der auf Benutzereingaben wartet. Die
Threads 1 und 2 wechseln ständig zwischen den Status 2 und 5 (Wird ausgeführt und
Wartend). Es kann sein, dass Thread 2 hinter Thread 1 verborgen ist, da beide mit derselben Priorität und derselben Aktivität laufen.
→
Threadplanung
Kapitel 4
251
13. Rechtsklicken Sie in CPU Stress auf Thread 2 und wählen Sie im Kontextmenü unter
Activity den Punkt Busy. Jetzt wird Thread 2 häufiger in Status 2 (Wird ausgeführt) angezeigt als Thread 1:
→
252
Kapitel 4
Threads
14. Rechtsklicken Sie auf Thread 1 und wählen Sie den Aktivitätsgrad Maximum. Wiederholen Sie diesen Schritt für Thread 2. Jetzt sind beide Threads ständig in Status 2, da sie
praktisch in einer Endlosschleife ausgeführt werden:
Auf einem Einzelprozessorsystem sehen Sie etwas anderes. Da es nur einen Prozessor
gibt, kann immer nur ein Thread auf einmal ausgeführt werden, sodass die beiden
Threads zwischen Status 1 (Bereit) und 2 (Wird ausgeführt) wechseln:
→
Threadplanung
Kapitel 4
253
15. Wenn Sie auf einem Mehrprozessorsystem arbeiten (was wahrscheinlicher ist), können
Sie den gleichen Effekt dadurch erzielen, dass Sie im Task-Manager auf den Prozess
CPUSTRES rechtsklicken, Zugehörigkeit festlegen wählen und dann nur einen einzigen
Prozessor auswählen, egal welchen. (Das können Sie auch in CPU Stress selbst tun, indem Sie das Menü Process öffnen und Affinity auswählen.)
16. Es gibt noch eine weitere Sache, die Sie ausprobieren können. Nachdem Sie die Einstellung aus Punkt 15 vorgenommen haben, rechtsklicken Sie in CPU Stress auf Thread
1 und wählen die Priorität Above normal. Jetzt wird Thread 1 kontinuierlich ausgeführt
(Status 2), während sich Thread 2 immer im Bereitschaftsstatus (1) befindet. Das liegt
daran, dass es nur einen Prozessor gibt, weshalb im Allgemeinen der Thread mit höherer Priorität den Zuschlag erhält. Von Zeit zu Zeit werden Sie jedoch sehen, dass Thread
1 in den Bereitschaftsstatus übergeht, weil der abgehängte Thread ca. alle vier Sekunden eine Prioritätserhöhung erhält, sodass er kurzzeitig laufen kann. Allerdings wird
diese Statusänderung in dem Diagramm oft nicht angezeigt, da die Leistungsüberwachung nur eine Auflösung von einer Sekunde hat, was zu grob ist. Eine ausführlichere
Beschreibung dieses Vorgangs finden Sie weiter hinten in diesem Kapitel im Abschnitt
»Prioritätserhöhung«.
254
Kapitel 4
Threads
Die Dispatcherdatenbank
Um Threadplanungsentscheidungen treffen zu können, unterhält der Kernel eine Reihe von
Datenstrukturen, die zusammengenommen als Dispatcherdatenbank bezeichnet werden. Darin
bewahrt der Kernel den Überblick darüber, welche Threads auf Ausführung waren und auf
welchen Prozessoren welche Threads laufen.
Um die Skalierbarkeit zu verbessern und eine parallele Threaddisponierung zu ermöglichen, gibt es in einem Windows-Mehrprozessorsystem Bereitschaftswarteschlangen für die
einzelnen Prozessoren und gemeinsam genutzte Bereitschaftswarteschlangen für Prozessorgruppen (siehe Abb. 4–9). Dadurch kann jede CPU in der für sie zuständigen Bereitschaftswarteschlange nach dem nächsten auszuführenden Thread suchen, ohne die systemweiten Bereitschaftswarteschlangen sperren zu müssen.
Gruppe 1
(CPU 0, 1, 2)
Bereitschaftswarteschlangen
Gruppe 2
(CPU 3, 4, 5)
Bereitschaftswarteschlangen
Bereitschaftsübersicht
Bereitschaftsübersicht
Abbildung 4–9 Dispatcherdatenbank in einem Windows-Mehrprozessorsystem. In diesem Beispiel
werden sechs Prozessoren verwendet. P steht für Prozesse, T für Threads.
In Windows-Versionen vor Windows 8 und Windows Server 2012 hatte jeder Prozessor seine
eigene Bereitschaftswarteschlange und seine eigene Bereitschaftsübersicht. Sie waren im Prozessorsteuerungsblock (PRCB) gespeichert. (Die Felder des PRCB können Sie mit dem Befehl
dt nt!_kprcb im Kerneldebugger einsehen.) Beginnend mit Windows 8 und Windows Server
2012 werden gemeinsam genutzte Bereitschaftswarteschlangen und Bereitschaftsübersichten
jeweils für eine ganze Prozessorgruppe verwendet. Dadurch kann das System besser entscheiden, welcher Prozessor der Gruppe als nächster verwendet werden soll. Die prozessoreigenen
Bereitschaftswarteschlangen sind jedoch nach wie vor vorhanden und werden für Threads mit
Affinitätseinschränkungen verwendet.
Threadplanung
Kapitel 4
255
Die gemeinsamen Datenstrukturen müssen (durch ein Spinlock) geschützt werden. Damit die Konkurrenz um die Warteschlangen auf einem unerheblichen
Niveau bleibt, dürfen die Gruppen daher nicht zu groß werden. In der aktuellen
Implementierung beträgt die maximale Gruppengröße vier Prozessoren. Gibt es
mehr als vier logische Prozessoren, so werden weitere Gruppen gebildet und die
verfügbaren Prozessoren gleichmäßig darauf verteilt. Beispielsweise werden auf
einem Sechs-Prozessor-System zwei Gruppen zu je drei Prozessoren angelegt.
Die Bereitschaftswarteschlangen, die Bereitschaftsübersichten und einige andere Informationen werden in einer Kernelstruktur namens KSHARED_READY_QUEUE gespeichert, die sich wiederum im PRCB befindet. Es gibt sie zwar für jeden Prozessor, doch es wird immer nur die Struktur
auf dem jeweils ersten Prozessor einer Gruppe von allen Prozessoren der Gruppe gemeinsam
verwendet.
Die Bereitschaftswarteschlangen (ReadListHead in KSHARED_READY_QUEUE) enthalten die
Threads, die sich im Bereitschaftszustand befinden und darauf warten, dass sie zur Ausführung
eingeplant werden. Es gibt eine Warteschlange für jede der 32 Prioritätsstufen. Um die Auswahl
der auszuführenden oder zu unterbrechenden Threads zu beschleunigen, unterhält Windows
eine 32-Bit-Maske, die als Bereitschaftsübersicht (ReadySummary) bezeichnet wird. Jedes gesetzte
Bit darin steht für einen oder mehr Threads in der Bereitschaftswarteschlange für die jeweilige
Prioritätsstufe (Bit 0 steht für Priorität 0, Bit 1 für Priorität 1 usw.).
Anstatt die einzelnen Bereitschaftslisten darauf zu untersuchen, ob sie leer sind oder nicht
(was die Planungsentscheidungen von der Anzahl an Threads mit unterschiedlicher Priorität
abhängig machen würde), wird mit einem nativen Prozessorbefehl ein einziger Bitscan durchgeführt, um das höchste gesetzte Bit zu finden. Dieser Vorgang dauert unabhängig von der
Anzahl der Threads in der Bereitschaftswarteschlange immer gleich lang.
Die Dispatcherwarteschlange wird durch Erhöhung der IRQL auf DISPATCH_LEVEL (2) synchronisiert. (Eine Beschreibung der Interrupt-Prioritätsstufen oder IRQLs finden Sie in Kapitel 6.)
Dadurch wird verhindert, dass andere Threads die Threaddisponierung auf dem Prozessor unterbrechen, da Threads normalerweise auf IRQL 0 oder 1 laufen. Es ist jedoch noch mehr erforderlich, als nur die IRQL hochzusetzen, denn es kann sein, dass andere Prozessoren gleichzeitig
eine Erhöhung auf dieselbe IRQL vornehmen, um ihre eigene Dispatcherdatenbank zu bearbeiten. Wie Windows den Zugriff auf die Dispatcherdatenbank synchronisiert, wird weiter hinten
in diesem Kapitel im Abschnitt »Mehrprozessorsysteme« erklärt.
Experiment: Ausführungsbereite Threads anzeigen
Mit dem Kerneldebuggerbefehl !ready können Sie sich eine Liste der Threads anzeigen lassen, die auf den einzelnen Prioritätsstufen zur Ausführung bereit sind. Das folgende Beispiel
wurde auf einem 32-Bit-Computer mit vier logischen Prozessoren erstellt:
0: kd> !ready
KSHARED_READY_QUEUE 8147e800: (00) ****----------------------------
→
256
Kapitel 4
Threads
SharedReadyQueue 8147e800: Ready Threads at priority 8
THREAD 80af8bc0 Cid 1300.15c4 Teb: 7ffdb000 Win32Thread: 00000000 READY on
processor 80000002
THREAD 80b58bc0 Cid 0454.0fc0 Teb: 7f82e000 Win32Thread: 00000000 READY on
processor 80000003
SharedReadyQueue 8147e800: Ready Threads at priority 7
THREAD a24b4700 Cid 0004.11dc Teb: 00000000 Win32Thread: 00000000 READY on
processor 80000001
THREAD a1bad040 Cid 0004.096c Teb: 00000000 Win32Thread: 00000000 READY on
processor 80000001
SharedReadyQueue 8147e800: Ready Threads at priority 6
THREAD a1bad4c0 Cid 0004.0950 Teb: 00000000 Win32Thread: 00000000 READY on
processor 80000002
THREAD 80b5e040 Cid 0574.12a4 Teb: 7fc33000 Win32Thread: 00000000 READY on
processor 80000000
SharedReadyQueue 8147e800: Ready Threads at priority 4
THREAD 80b09bc0 Cid 0004.12dc Teb: 00000000 Win32Thread: 00000000 READY on
processor 80000003
SharedReadyQueue 8147e800: Ready Threads at priority 0
THREAD 82889bc0 Cid 0004.0008 Teb: 00000000 Win32Thread: 00000000 READY on
processor 80000000
Processor 0: No threads in READY state
Processor 1: No threads in READY state
Processor 2: No threads in READY state
Processor 3: No threads in READY state
Zu den Prozessornummern wurde 0x8000000 addiert, doch die eigentlichen Prozessornummern lassen sich leicht erkennen. Die erste Zeile zeigt die Adresse der Struktur KSHARED_READY_
QUEUE mit der Gruppennummer in Klammern an (00 in der vorstehenden Ausgabe). Darauf
folgt eine grafische Darstellung der Prozessoren in dieser Gruppe (die vier Sternchen).
Kurioserweise geben die letzten vier Zeilen an, dass es keine ausführungsbereiten
Threads gibt, was der vorstehenden Ausgabe widerspricht. Diese Zeilen beziehen sich jedoch auf die ausführungsbereiten Threads in dem alten PRCB-Element DispatcherReadyListHead, da für Threads mit eingeschränkter Affinität (die nur auf einigen der Prozessoren
in der Gruppe laufen dürfen) die Bereitschaftswarteschlangen der einzelnen Prozessoren
herangezogen werden.
Sie können auch KSHARED_READY_QUEUE anzeigen lassen, indem Sie die Adresse angeben,
die Sie bei der Ausführung des Befehls !ready gewonnen haben:
0: kd> dt nt!_KSHARED_READY_QUEUE 8147e800
+0x000 Lock
: 0
+0x004 ReadySummary
: 0x1d1
+0x008 ReadyListHead
: [32] _LIST_ENTRY [ 0x82889c5c - 0x82889c5c ]
→
Threadplanung
Kapitel 4
257
+0x108 RunningSummary : [32] "???"
+0x128 Span
: 4
+0x12c LowProcIndex
: 0
+0x130 QueueIndex
: 1
+0x134 ProcCount
: 4
+0x138 Affinity
: 0xf
Das Element ProcCount gibt die Anzahl der Prozessoren in der Gruppe an (in diesem Beispiel sind es vier). Beachten Sie auch den Wert von ReadySummary. Er lautet hier 0x1d1, was
im Binärformat 111010001 beträgt. Wenn Sie die Bits von rechts nach links lesen, können Sie
erkennen, dass es ausführungsbereite Threads auf den Prioritätsstufen 0, 4, 6, 7 und 8 gibt,
was der vorherigen Ausgabe entspricht.
Das Quantum
Wie bereits erwähnt, ist das Quantum die Dauer, für die ein Thread laufen darf, bevor Windows
prüft, ob ein anderer Thread derselben Priorität auf Ausführung wartet. Wenn ein Thread
sein Quantum ausgeschöpft hat und es keine anderen Threads seiner Priorität gibt, erlaubt
Windows ihm, für ein weiteres Quantum zu laufen.
Auf Clientversionen von Windows werden Threads standardmäßig zwei Taktintervalle lang
ausgeführt, auf Serversystemen zwölf Taktintervalle lang. (Wie Sie diese Werte ändern, erfahren Sie im Abschnitt »Das Quantum steuern«.) Der Grund für den längeren Standardwert auf
Serversystemen ist die Reduzierung von Kontextwechseln. Aufgrund des längeren Quantums
haben Serveranwendungen, die durch Clientanforderungen aufgeweckt werden, eine größere
Chance, die Anforderung abzuschließen und wieder in den Wartezustand zu wechseln, bevor
ihr Quantum endet.
Die Länge der Taktintervalle hängt von der Hardwareplattform ab. Die Frequenz der Taktinterrupts wird von der HAL bestimmt, nicht vom Kernel. So beträgt das Taktintervall auf den
meisten x86-Einzelprozessorsystemen etwa 10 ms (wobei Windows auf solchen Computern nicht
mehr läuft; wir erwähnen sie hier nur als Beispiel) und auf den meisten x86- und x64-Mehrprozessorsystemen etwa 15 ms. Das Taktintervall wird in der Kernelvariablen KeMaximumIncrement in
der Einheit von hundert Nanosekunden gespeichert.
Threads laufen zwar in Einheiten von Taktintervallen, doch das System zieht die Anzahl
der Ticks nicht als Maß dafür heran, wie lange ein Thread schon ausgeführt wird und ob sein
Quantum erschöpft ist. Das liegt daran, dass die Laufzeitverwaltung eines Threads auf Prozessorzyklen basiert. Wenn das System startet, multipliziert es die Prozessorgeschwindigkeit
(CPU-Taktzyklen pro Sekunde) in Hertz mit der Anzahl der Sekunden für einen Tick (auf der
Grundlage des zuvor beschriebenen Wertes von KeMaximumIncrement), um die Anzahl der
Taktzyklen eines Quantums zu berechnen. Dieser Wert wird in der Kernelvariablen KiCyclesPerClockQuantum gespeichert.
Daher werden Threads nicht eine bestimmte Anzahl von Ticks lang ausgeführt. Ihre Laufzeit richtet sich nach einem Quantumssollwert. Dabei handelt es sich um einen Schätzwert
dafür, wie viele CPU-Taktzyklen der Thread verbraucht haben wird, wenn seine Zeit abgelaufen
258
Kapitel 4
Threads
ist. Dieser Zielwert sollte gleich einer entsprechenden Anzahl von Taktintervall-Timerticks sein,
da die Berechnung der Taktzyklen pro Quantum auf der Taktintervall-Timerfrequenz beruht.
Das können Sie im folgenden Experiment überprüfen. Beachten Sie jedoch, dass Interruptzyklen nicht dem Thread zugeschlagen werden, sodass die tatsächliche Taktzeit länger sein kann.
Experiment: Die Taktintervallfrequenz bestimmen
Die Windows-Funktion GetSystemTimeAdjustment gibt das Taktintervall zurück. Um es zu
bestimmen, führen Sie das Sysinternals-Tool clockres aus. Die folgende Ausgabe wurde auf
einem 64-Bit-Quadcore-System mit Windows 10 erstellt:
C:\>clockres
ClockRes v2.0 - View the system clock resolution
Copyright (C) 2009 Mark Russinovich
SysInternals - www.sysinternals.com
Maximum timer interval: 15.600 ms
Minimum timer interval: 0.500 ms
Current timer interval: 1.000 ms
Aufgrund von Multimedia-Timern kann das aktuelle Intervall kleiner ausfallen als das maximale (Standard-)Intervall. Solche Timer werden bei Funktionen wie timeBeginPeriod und
timeSetEvent verwendet, die dazu dienen, Callbacks in Intervallen von bestenfalls 1 ms
zu empfangen. Das verursacht eine globale Umprogrammierung des Kernelintervalltimers,
sodass der Scheduler häufiger aufwacht, was die Systemleistung herabsetzen kann. Wie
Sie im nächsten Abschnitt sehen werden, hat das jedoch keinerlei Auswirkungen auf die
Quantumslängen.
Es ist auch möglich, den Wert wie folgt in der globalen Kernelvariablen KeMaximum
Increment zu lesen (wobei dieses Beispiel auf einem anderen System erstellt wurde als das
vorherige):
0: kd> dd nt!KeMaximumIncrement L1
814973b4 0002625a
0: kd> ? 0002625a
Evaluate expression: 156250 = 0002625a
Dies entspricht dem Standardwert von 15,6 ms.
Die Bestimmung der Quantumslänge
Im Prozesssteuerungsblock (KPROCESS) jedes Prozesses ist ein Quantumsrücksetzwert angegeben. Er wird verwendet, wenn in dem Prozess neue Threads erstellt werden, und wird in
den Threadsteuerungsblock (KTHREAD) kopiert, der dann dazu herangezogen wird, um dem
Thread einen neuen Quantumssollwert zu geben. Gespeichert wird der Rücksetzwert in Form
Threadplanung
Kapitel 4
259
von Quantumseinheiten (mehr darüber in Kürze), die dann mit der Anzahl der Taktzyklen pro
Quantum multipliziert werden, um den Quantumssollwert zu berechnen.
Während der Ausführung eines Threads werden bei den verschiedenen Ereignissen wie
Kontextwechseln, Interrupts und bestimmten Planungsentscheidungen CPU-Taktzyklen angerechnet. Wenn bei einem Interrupt des Taktintervalltimers die Anzahl dieser angerechneten
CPU-Taktzyklen den Quantumssollwert erreicht oder überschreitet, wird die Quantumsendverarbeitung ausgelöst. Wartet ein anderer Thread mit der gleichen Priorität auf Ausführung, so
erfolgt ein Kontextwechsel zum nächsten Thread in der Bereitschaftswarteschlange.
Intern wird eine Quantumseinheit als ein Drittel eines Ticks dargestellt. Ein Tick entspricht
also drei Quanten. Das bedeutet, dass Threads auf Windows-Clientsystemen einen Quantumsrücksetzwert von 6 haben (2 * 3) und auf Serversystemen von 36 (12 * 3). Aus diesem Grund
wird der Wert n KiCyclesPerClockQuantum am Ende der zuvor beschriebenen Berechnung durch
3 geteilt, da der ursprüngliche Wert nur die CPU-Taktzyklen pro Taktintervall-Timertick angibt.
Quanten werden intern als Bruchteil eines Ticks statt eines gesamten Ticks gespeichert,
damit auf Versionen vor Windows Vista ein »Verfall beim Warten« in Teilquanten abgeschlossen werden kann. In früheren Zeiten wurde der Taktintervalltimer benutzt, um den Ablauf
von Quanten zu bestimmen. Ohne diese Anpassung wäre es unter Umständen möglich gewesen, dass das Quantum eines Threads niemals abnimmt. Stellen Sie sich beispielsweise vor,
ein Thread wird ausgeführt, geht in einen Wartezustand über, wird erneut ausgeführt und
geht abermals in einen Wartezustand über, wobei er aber niemals gerade dann läuft, wenn
der Taktintervalltimer ausgelöst wird. In diesem Fall würde sein Quantum niemals um die Zeit
verringert, in der er tatsächlich ausgeführt wurde. Da den Threads jetzt CPU-Taktzyklen statt
Quanten angerechnet werden und der Vorgang nicht mehr vom Taktintervalltimer abhängt, ist
diese Anpassung jedoch nicht mehr nötig.
Experiment: Die Taktzyklen pro Quantum bestimmen
Windows macht die Anzahl der Taktzyklen pro Quantum in keiner Funktion zugänglich.
Mithilfe der angegebenen Berechnungen und Beschreibungen können Sie diesen Wert jedoch auf die folgende Weise selbst herausfinden. Dazu benötigen Sie einen Kerneldebugger wie WinDbg im lokalen Debuggingmodus.
1.
Bestimmen Sie die von Windows erkannte Prozessorfrequenz. Dazu können Sie mit
dem Befehl !cpuinfo den Wert des Feldes MHz im PRCB ausgeben. Das folgende Beispiel
stammt von einem Vier-Prozessor-System mit 2794 MHz:
lkd> !cpuinfo
CP F/M/S
Manufacturer MHz
PRCB Signature
MSR 8B Signature
Features
0 6,60,3 GenuineIntel 2794 ffffffff00000000 >ffffffff00000000< a3cd3fff
1 6,60,3 GenuineIntel 2794 ffffffff00000000
a3cd3fff
2 6,60,3 GenuineIntel 2794 ffffffff00000000
a3cd3fff
3 6,60,3 GenuineIntel 2794 ffffffff00000000
a3cd3fff
→
260
Kapitel 4
Threads
2.
Rechnen Sie den Wert in Hertz um. Dadurch erhalten Sie die Anzahl der CPU-Takt
zyklen pro Sekunde, in diesem Fall 2.794.000.000.
3.
Rufen Sie mithilfe von clockres das Taktintervall auf Ihrem System ab. Es gibt an, wie
lange es dauert, bis der Timer ausgelöst wird. Auf unserem Beispielsystem betrug der
Wert 15,625 ms.
4.
Rechnen Sie diesen Wert in die Anzahl von Auslösungen des Taktintervalltimers pro
Sekunde um. Da eine Sekunde 1000 ms umfasst, müssen Sie die in Schritt 3 gewonnene
Zahl durch 1000 teilen. In unserem Fall wird der Timer also alle 0,015625 s ausgelöst.
5.
Multiplizieren Sie das Ergebnis mit der Anzahl der Zyklen pro Sekunde, die Sie in
Schritt 2 ermittelt haben. In unserem Beispiel vergehen mit jedem Taktintervall
43.656.250 Zyklen.
6.
Da jede Quantumseinheit einem Drittel Taktintervall entspricht, dividieren Sie als
Nächstes die Anzahl der Zyklen durch 3. Dadurch erhalten Sie den Wert 14.528.083,
was der Hexadezimalzahl 0xDE0C13 entspricht. Dies ist die Anzahl der Taktzyklen, die
eine Quantumseinheit auf einem System mit 2794 Mhz und einem Taktintervall von
15,6 ms umfasst.
7.
Um die Berechnung zu überprüfen, geben Sie den Wert von KiCyclesPerClockQuantum
auf Ihrem System aus. Er sollte übereinstimmen (oder aufgrund von Rundungsfehlern
zumindest nah genug sein).
lkd> dd nt!KiCyclesPerClockQuantum L1
8149755c 00de0c10
Das Quantum steuern
Sie können das Threadquantum für sämtliche Prozesse ändern, wobei Sie allerdings nur die
Wahl zwischen zwei Möglichkeiten haben: kurzes Quantum (zwei Ticks, was der Standardwert
für Clientcomputer ist) und langes Quantum (zwölf Ticks, der Standard für Serversysteme).
In einem Jobobjekt auf einem System mit langem Quantum können Sie auch andere Quantumswerte für die Prozesse in dem Job auswählen.
Um diese Einstellung zu ändern, müssen Sie auf dem Desktop oder im Windows-Explorer auf
das Symbol Dieser PC rechtsklicken, Eigenschaften wählen, auf Erweiterte Systemeinstellungen
klicken, die Registerkarte Erweitert aufrufen, auf die Schaltfläche Einstellungen im Abschnitt
Leistung klicken und dann wiederum Erweitert aufrufen. Abb. 4–10 zeigt das resultierende Dialogfeld.
Threadplanung
Kapitel 4
261
Abbildung 4–10 Einstellung des Quantums im Dialogfeld
In diesem Dialogfeld haben Sie die beiden folgenden Wahlmöglichkeiten:
QQ Programme Diese Einstellung schreibt die Verwendung kurzer, variabler Quanten vor.
Dies ist die Standardeinstellung für die Clientversionen von Windows (und clientartige
Versionen wie Mobilgeräte, die Xbox, die HoloLens usw.). Wenn Sie Terminaldienste auf
einem Serversystem installieren und den Rechner als Anwendungsserver einrichten, wird
ebenfalls diese Einstellung ausgewählt, damit die Benutzer auf dem Terminalserver die
gleichen Quantumseinstellungen haben, die auf ihrem Desktop- oder Clientsystem laufen.
Sie können diese Einstellung auch manuell wählen, wenn Sie Windows Server als Desktopbetriebssystem ausführen.
QQ Hintergrunddienste Bei dieser Einstellung wird das lange, feste Quantum verwendet.
Dies ist die Standardeinstellung für Serversysteme. Auf einer Arbeitsstation gibt es nur
einen Grund dafür, diese Option zu wählen, nämlich wenn Sie sie als Serversystem verwenden wollen. Da Änderungen an dieser Option sofort in Kraft treten, kann es jedoch
auch sinnvoll sein, sie zu verwenden, wenn der Computer eine Hintergrund- oder serverartige Arbeitslast ausführen soll. Wenn beispielsweise eine lang andauernde Berechnung,
Verschlüsselung oder Modellsimulation über Nacht laufen soll, können Sie am Abend die
Option Hintergrunddienste wählen und am Morgen zu Programme zurückkehren.
Variable Quanten
Werden variable Quanten verwendet, so wird die Tabelle für variable Quanten (PspVariableQuantums), die ein Array aus sechs Quantenzahlen enthält, in die Tabelle PspForegroundQuantum
(ein Array mit drei Elementen) geladen, die von der Funktion PspComputeQuantum genutzt wird.
262
Kapitel 4
Threads
Deren Algorithmus wählt den angemessenen Quantumsindex danach aus, ob es sich bei dem
Prozess um einen Vordergrundprozess handelt, also ob er den Thread enthält, dem das Vordergrundfenster auf dem Desktop gehört. Ist das nicht der Fall, so wird der Index 0 gewählt, der
zu dem zuvor beschriebenen Threadquantum gehört. Bei einem Vordergrundprozess dagegen
wird der Quantumsindex entsprechend der Prioritätsaufteilung gewählt.
Der Prioritätsaufteilungswert bestimmt die Prioritätserhöhung (siehe den entsprechenden
Abschnitt weiter hinten), die der Scheduler auf Vordergrundthreads anwendet. Mit dieser Erhöhung ist auch eine entsprechende Erweiterung des Quantums verbunden. Für jede zusätzliche
Prioritätsstufe (bis zu zwei) erhält der Thread ein weiteres Quantum. Wird der Thread beispielsweise um eine Prioritätsstufe erhöht, so erhält er dabei auch ein zusätzliches Quantum.
Standardmäßig wendet Windows auf Vordergrundthreads die maximal mögliche Prioritätserhöhung an. Dabei beträgt die Prioritätsaufteilung 2, weshalb in der Tabelle für variable Quanten der Index 2 ausgewählt wird. Das wiederum führt dazu, dass der Thread zwei zusätzliche
Quanten erhält, insgesamt also drei Quanten zur Verfügung hat.
Tabelle 4–2 zeigt die genauen Quantumswerte (in Einheiten von einem Drittel Tick), die
bei den verschiedenen Quantumsindizes und Quantumskonfigurationen ausgewählt werden.
Index bei kurzem Quantum
Index bei langem Quantum
Variabel
6
12
18
12
24
36
Fest
18
18
18
36
36
36
Tabelle 4–2 Quantumswerte
Wird auf einem Clientsystem ein Fenster in den Vordergrund gebracht, so werden die Quanten
aller Threads in dem Prozess, der den Thread mit dem Vordergrundfenster enthält, verdreifacht.
Threads im Vordergrundprozess laufen mit einem Quantum von sechs Ticks, Threads in anderen Prozessen mit dem Client-Standardquantum von zwei Ticks. Wenn Sie von einem CPU-intensiven Prozess zu einem anderen umschalten, erhält der neue Vordergrundprozess einen
höheren Anteil der CPU, da seine Threads länger ausgeführt werden als die Hintergrundthreads
(wobei auch hier wieder vorausgesetzt ist, dass die Vordergrund- und Hintergrundprozesse die
gleiche Threadpriorität aufweisen).
Der Registrierungswert für die Quantumseinstellungen
Das zuvor beschriebene Dialogfeld zur Änderung der Quantumseinstellungen ändert den Registrierungswert Win32PrioritySeparation im Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\
PriorityControl. Dieser Wert gibt jedoch nicht nur die relative Länge des Threadquantums an
(kurz oder lang), sondern legt auch fest, ob variable Quanten verwendet werden sollen, und
bestimmt die Prioritätsaufteilung (die bei variablen Quanten zur Auswahl des Quantumsindex
herangezogen wird). Der Wert setzt sich aus sechs Bits in drei 2-Bit-Feldern zusammen (siehe
Abb. 4–11).
Threadplanung
Kapitel 4
263
kurz/lang
variabel/fest
Prioritäts
aufteilung
Abbildung 4–11 Die Felder des Registrierungswerts Win32PrioritySeparation
Die Felder in Abb. 4–11 werden wie folgt verwendet:
QQ Kurz/lang Der Wert 1 steht für lange Quanten, der Wert 2 für kurze. Die Einstellungen 0
und 3 besagen, dass der passende Standard für das System verwendet werden soll (kurze
Quanten für Clientsysteme, lange für Serversysteme).
QQ Variabel/fest Der Wert 1 bedeutet, dass die Tabelle für variable Quanten mit dem Algorithmus aus dem Abschnitt »Variable Quanten« verwendet werden soll. Die Einstellungen 0
und 3 besagen, dass der passende Standard für das System verwendet werden soll (variable
Quanten für Clientsysteme, feste für Serversysteme).
QQ Prioritätsaufteilung Dieses Feld (das in der Kernelvariablen PsPrioritySeparation gespeichert wird) legt die Prioritätsaufteilung (bis zu 2) fest (siehe den Abschnitt »Variable
Quanten«).
Im Dialogfeld Leistungsoptionen (siehe Abb. 4–10) können Sie nur zwischen den beiden folgenden Kombinationen wählen: kurze Quanten mit verdreifachtem Vordergrundquantum oder
lange Quanten ohne Quantumsänderung für Vordergrundthreads. Durch direkte Bearbeitung
des Registrierungswerts Win32PrioritySeparation können Sie jedoch auch andere Kombina
tionen auswählen.
Threads von Prozessen mit der Prozessprioritätsklasse Leerlauf erhalten stets ein einziges
Threadquantum. Jegliche Quantumseinstellungen – ob standardmäßig oder in der Registrierung festgelegt – werden registriert.
Auf Windows Server-Systemen, die als Anwendungsserver eingerichtet sind, beträgt der
Anfangswert von Win32PrioritySeparation 26 (hexadezimal), was identisch mit dem Wert ist,
den Sie durch die Option Programme im Dialogfeld Leistungsoptionen festlegen. Dadurch wird
ein Quantumserweiterungs- und Prioritätserhöhungsverhalten wie auf Windows-Clientsystemen ausgewählt, was für Server, auf denen hauptsächlich Benutzeranwendungen liegen, passend ist.
Auf Windows-Clientsystemen und auf Servern, die nicht als Anwendungsserver eingerichtet sind, beträgt der Anfangswert von Win32PrioritySeparation 2, was einen Wert von 0 für die
Bitfelder für kurze oder lange und variable oder feste Quanten ergibt. Die tatsächliche Einstellung richtet sich daher nach dem Standardverhalten des Systems (also danach, ob es sich um
ein Client- oder Serversystem handelt). Das Feld für die Prioritätsaufteilung dagegen bekommt
den Wert 2. Nachdem der Registrierungswert über das Dialogfeld Leistungsoptionen geändert
wurde, können Sie den Originalwert nur noch durch eine direkte Bearbeitung der Registrierung
wiederherstellen.
264
Kapitel 4
Threads
Experiment: Auswirkungen einer Änderung der
Quantumskonfiguration
Mit einem lokalen Kerneldebugger können Sie sich ansehen, wie sich die beiden Quantumskonfigurationseinstellungen Programme und Hintergrunddienste auf die Tabellen
PsPrioritySeparation und PspForegroundQuantum und auf den QuantumReset-Wert der
Threads auf dem System auswirken. Gehen Sie dazu wie folgt vor:
1.
Öffnen Sie in der Systemsteuerung das Programm System oder rechtsklicken Sie auf
dem Desktop auf Dieser PC und wählen Sie Eigenschaften.
2.
Klicken Sie auf Erweiterte Systemeinstellungen, rufen Sie die Registerkarte Erweitert auf,
klicken Sie im Abschnitt Leistung auf Einstellungen und rufen Sie in dem daraufhin eingeblendeten Dialogfeld wiederum die Registerkarte Erweitert auf.
3.
Aktivieren Sie die Option Programme und klicken Sie auf Übernehmen. Halten Sie das
Dialogfeld während des gesamten Experiments geöffnet.
4.
Geben Sie die Werte von PsPrioritySeparation und PspForegroundQuantum wie hier gezeigt aus. Wie Sie sehen, werden kurze Quanten und die Tabelle für variable Quanten
verwendet und Vordergrundanwendungen mit einer Prioritätserhöhung von 2 versehen:
lkd> dd nt!PsPrioritySeparation L1
fffff803'75e0e388 00000002
lkd> db nt!PspForegroundQuantum L3
fffff803'76189d28 06 0c 12
5.
Schauen Sie sich den QuantumReset-Wert eines beliebigen Prozesses auf Ihrem System
an. Wie bereits erklärt, ist dies das vollständige Standardquantum für jeden neu erstellten Thread auf dem System. Er wird in jedem Thread des Prozesses zwischengespeichert, aber es ist einfacher, ihn in der KPROCESS-Struktur einzusehen. In diesem Fall
beträgt er 6, da das Quantum bei WinDbg wie bei den meisten anderen Anwendungen
im ersten Eintrag der Tabelle PspForegroundQuantum festgelegt wird:
lkd> .process
Implicit process is now ffffe001'4f51f080
lkd> dt nt!_KPROCESS ffffe001'4f51f080 QuantumReset
+0x1bd QuantumReset : 6 ''
6.
Ändern Sie die Leistungsoption in dem Dialogfeld aus Schritt 1 und 2 auf Hintergrunddienste.
7.
Geben Sie erneut die in Schritt 4 und 5 gezeigten Befehle ein. Jetzt haben sich die
Werte wie in diesem Abschnitt beschrieben geändert:
lkd> dd nt!PsPrioritySeparation L1
fffff803'75e0e388 00000000
→
Threadplanung
Kapitel 4
265
lkd> db nt!PspForegroundQuantum L3
fffff803'76189d28 24 24 24
lkd> dt nt!_KPROCESS ffffe001'4f51f080 QuantumReset
+0x1bd QuantumReset : 36 '$'
Prioritätserhöhung
Der Windows-Scheduler passt die aktuelle (dynamische) Priorität von Threads regelmäßig
durch einen internen Mechanismus zur Prioritätserhöhung an. Oft macht er das, um Latenzen zu verringern (das heißt, damit Threads schneller auf die Ereignisse reagieren, auf die sie
warten) und um die Reaktivität zu erhöhen. In anderen Fällen dienen Erhöhungen dazu, Prioritätsumkehrungen und Aushungern zu vermeiden. In diesem Abschnitt beschreiben wir unter
anderem die folgenden Situationen:
QQ Erhöhung aufgrund von Scheduler-/Dispatcherereignissen (zur Latenzverringerung)
QQ Erhöhung nach einem E/A-Abschluss (zur Latenzverringerung)
QQ Erhöhung aufgrund von Eingaben von der Benutzeroberfläche (zur Latenzverringerung
und Reaktivitätssteigerung)
QQ Erhöhung, weil ein Thread zu lange auf eine Exekutivressource (ERESOURCE) wartet (Vermeidung des Aushungerns)
QQ Erhöhung, wenn ein ausführungsbereiter Thread schon einige Zeit lang nicht ausgeführt
wurde (Vermeidung von Aushungern und Prioritätsumkehrung)
Wie alle Planungsalgorithmen sind auch diese Vorgehensweisen nicht perfekt und nicht für alle
Anwendungen von Nutzen.
Windows erhöht niemals die Priorität von Threads im Echtzeitbereich (16 bis 31).
Daher ist die Planung für andere Threads in diesem Bereich stets vorhersehbar. Es
wird vorausgesetzt, dass Sie bei der Verwendung von Echtzeitprioritäten wissen,
was Sie tun.
Windows-Clientversionen verfügen auch über einen Pseudo-Erhöhungsmechanismus, der bei
der Multimediawiedergabe verwendet wird. Anders als andere Prioritätserhöhungen wird diese
Art durch den Kernelmodustreiber Mmcss.sys (Multimedia Class Scheduler Service) verwaltet.
Dabei treten jedoch keine echten Erhöhungen auf. Stattdessen legt der Treiber nach Bedarf
neue Prioritäten für die Threads fest. Die Regeln für Prioritätserhöhungen finden dabei keine Anwendung. Im Folgenden beschreiben wir zunächst die regulären Prioritätserhöhungen
durch den Kernel und erst danach die »Erhöhungen«, die MMCSS vornimmt.
266
Kapitel 4
Threads
Erhöhung aufgrund von Scheduler-/Dispatcherereignissen
Beim Auftreten eines Dispatchereignisses wird die Routine KiExitDispatcher aufgerufen. Ihre
Aufgabe besteht darin, die Liste der Threads im Status Verzögert bereit aufzurufen, wozu sie
KiProcessThreadWaitList aufruft. Anschließend prüft sie mit KzCheckForThreadDispatch, ob
irgendwelche Threads auf dem aktuellen Prozessor nicht eingeplant werden sollten. Bei einem solchen Ereignis kann der Aufrufer auch angeben, welche Art von Erhöhung auf den
Threads angewandt werden soll und welches Prioritätsinkrement dabei zu verwenden ist. Die
folgenden Situationen werden als AdjustUnwait-Dispatchereignisse betrachtet, da dabei ein
Dispatcher-(Synchronisierungs-)Objekt in einen signalisierten Status eintritt, was dazu führen
kann, dass ein oder mehrere Threads aufwachen:
QQ Ein asynchroner Prozeduraufruf (APC; siehe Kapitel 6 sowie Kapitel 8 in Band 2) wird in die
Warteschlange für einen Thread gestellt.
QQ Ein Ereignis wird festgelegt oder gepulst.
QQ Ein Timer wurde gesetzt oder die Systemzeit wurde geändert, sodass die Timer zurückgesetzt werden mussten.
QQ Ein Mutex wurde freigegeben oder aufgegeben.
QQ Ein Prozess wurde beendet.
QQ Es wurde ein Eintrag in eine Warteschlange (KQUEUE) aufgenommen oder die Warteschlange wurde geleert.
QQ Ein Semaphor wurde freigegeben.
QQ Ein Thread wurde alarmiert, angehalten, wieder aufgenommen, eingefroren oder aufgetaut.
QQ Ein primärer UMS-Thread wartet auf die Umschaltung zu einem geplanten UMS-Thread.
Bei Planungsereignissen im Zusammenhang mit einer öffentlichen API (wie SetEvent) wird das
Erhöhungsinkrement vom Aufrufer angegeben. In Windows werden Entwicklern bestimmte
Werte empfohlen, die wir weiter hinten beschreiben. Bei Alarmen wird eine Erhöhung um 2
angewandt (es sei denn, der Thread wurde durch einen Aufruf von KeAlertThreadByThreadId
in einen Alarmwartezustand versetzt; in diesem Fall beträgt die Erhöhung 1), da die Alarm-API
nicht über Parameter verfügt, in denen der Aufrufer ein eigenes Inkrement festlegen kann.
Der Scheduler hat auch zwei besondere AdjustBoost-Dispatchereignisse, die zum Sperrbesitz-Prioritätsmechanismus gehören. Damit sollen Situationen korrigiert werden, in denen ein
Aufrufer, der eine Sperre der Priorität x besitzt, die Sperre für einen wartenden Thread mit einer
Priorität kleiner oder gleich x freigibt. In diesem Fall muss der neue Besitzerthread warten, bis
er an der Reihe ist (wenn er mit Priorität x ausgeführt wird), oder er kommt gar nicht erst ans
Laufen (bei einer Priorität kleiner x). Daher fährt der freigebende Thread mit der Ausführung
fort, obwohl er den neuen Besitzerthread aufwecken und ihm die Kontrolle über den Prozessor
überlassen sollte. Die beiden folgenden Ereignisse rufen einen AdjustBoost-Dispatcherausstieg
hervor:
Threadplanung
Kapitel 4
267
QQ Mit der Schnittstelle KeSetEventBoostPriority, die von der Lese/Schreib-Kernelsperre
ERESOURCE verwendet wird, wird ein Ereignis festgelegt.
QQ Mit der Schnittstelle KeSignalGateInterface, die beim Freigeben einer Gatesperre von verschiedenen internen Mechanismen verwendet wird, wird ein Gate festgelegt.
Unwait-Erhöhung
Mit Unwait-Erhöhungen wird versucht, die Latenz zwischen zwei Threads zu verringern, von
denen der eine aufwacht, weil ein Objekt signalisiert wird (weshalb er in den Zustand Bereit
übergeht), und der andere mit der Ausführung beginnt, um das Ende des Wartevorgangs zu
verarbeiten (weshalb er in den Zustand Wird ausgeführt) übergeht. Allgemein ist es wünschenswert, dass der Thread, der aus dem Wartezustand aufwacht, so bald wie möglich ausgeführt
werden kann.
In den Windows-Headerdateien sind empfohlene Werte angegeben, die Kernelmodusaufrufer von APIs wie KeReleaseMutex, KeSetEvent und KeReleaseSemaphore verwenden sollten.
Diese Werte entsprechen Definitionen wie MUTANT_INCREMENT, SEMAPHORE_INCREMENT und EVENT_
INCREMENT. Diese drei Definitionen sind in den Headern immer auf 1 gesetzt, weshalb wir davon
ausgehen können, dass das Ende eines Wartevorgangs auf diese Objekte meistens zu einer
Erhöhung um 1 führt. In der Benutzermodus-API kann kein Inkrement angegeben werden, und
auch native Systemaufrufe wie NtSetEvent verfügen nicht über die Parameter zur Festlegung
einer Erhöhung. Wenn diese APIs die zugrunde liegende Ke-Schnittstelle aufrufen, verwenden
sie stattdessen automatisch die _INCREMENT-Standarddefinition. Das ist auch der Fall, wenn Mutexe aufgegeben oder Timer aufgrund einer Systemzeitänderung zurückgesetzt werden: Das
System verwendet die Standarderhöhung, die normalerweise bei der Freigabe des Mutexes
angewandt worden wäre. Die APC-Erhöhung liegt vollständig in der Verantwortung des Aufrufers. Sie werden in Kürze noch eine besondere Anwendung der APC-Erhöhung im Zusammenhang mit einem E/A-Abschluss sehen.
Mit einigen Dispatcherereignissen sind keine Erhöhungen verbunden. Beispielsweise findet keine Erhöhung statt, wenn ein Timer gestellt wird oder abläuft oder
wenn ein Prozess signalisiert wird.
Mit all diesen Erhöhungen um 1 soll das ursprüngliche Problem gelöst werden, wobei vorausgesetzt wird, dass sowohl der freigebende als auch der wartende Thread mit derselben Priorität
ausgeführt wird. Durch die Erhöhung der Priorität des wartenden Threads um eine Stufe wird
dafür gesorgt, dass der wartende Thread den freigebenden Thread unterbricht, sobald die Operation abgeschlossen ist. Doch leider bringt diese Erhöhung auf Einprozessorsystemen nicht
viel, wenn die Voraussetzung nicht erfüllt ist. Wenn beispielsweise der wartende Thread die
Priorität 4 und der freigebende die Priorität 8 hat, dann führt eine Erhöhung auf 5 nicht dazu,
dass die Latenz verringert und die vorzeitige Unterbrechung erzwungen wird. Auf Mehrprozessorsystemen dagegen kann der Thread mit erhöhter Priorität aufgrund der Übernahme- und
Ausgleichsalgorithmen eine bessere Chance haben, von einem anderen logischen Prozessor
aufgegriffen zu werden. Der Grund dafür ist eine Designentscheidung bei der ursprünglichen
268
Kapitel 4
Threads
NT-Architektur, durch die der Besitz von Sperren bis auf wenige Ausnahmen nicht verfolgt wird.
Der Scheduler kann also nicht sicher sein, wer nun wirklich der Besitzer eines Ereignisses ist
und ob es tatsächlich als Sperre verwendet wird. Selbst bei einer Verfolgung des Sperrbesitzes
wird (zur Vermeidung von Konvoiproblemen) die Besitzinformation nicht übergeben (außer bei
Exekutivressourcen, worüber es weiter hinten noch gehen wird).
Für bestimmte Arten von Sperrobjekten, die Ereignisse oder Gates als Synchronisierungsobjekte verwenden, kann das Problem durch eine Sperrbesitzerhöhung gelöst werden. Auf
Mehrprozessorsystemen kann der ausführungsbereite Thread außerdem aufgrund der weiter
hinten erläuterten Prozessorverteilungs- und Lastenausgleichverfahren von einem anderen
Prozessor aufgegriffen werden, wobei seine erhöhte Priorität die Wahrscheinlichkeit für die
Ausführung auf diesem zweiten Prozessor erhöht.
Sperrbesitzerhöhung
Da Sperren für Exekutivressourcen (ERESOURCE) und kritische Abschnitte zugrunde liegende
Dispatcherobjekte verwenden, kann eine Freigabe dieser Sperren zu einer Unwait-Erhöhung
wie im vorherigen Abschnitt führen. Da die Implementierung dieser Objekte Informationen
über den Besitzer der Sperre verfolgt, kann der Kernel jedoch auch fundiertere Entscheidung
darüber fällen, welche Art von Erhöhung bei AdjustBoost angewandt werden soll. Dabei wird
AdjustIncrement auf die aktuelle Priorität des Threads gesetzt, der die Sperre freigibt (oder
einrichtet), abzüglich jeglicher Erhöhungen aufgrund der Prioritätsaufteilung für den GUI-Vordergrund. Außerdem wird vor dem Aufruf von KiExitDispatcher die Funktion KiRemoveBoostThread vom Ereignis- und Gatecode aufgerufen, um den freigebenden Thread wieder auf seine
reguläre Priorität zurückzusetzen. Das ist notwendig, um einen Sperrenkonvoi zu vermeiden,
bei dem zwei Threads, die sich ständig gegenseitig eine Sperre übergeben, eine immer stärkere
Erhöhung bekommen.
Pushlocks sind unfaire Sperren, da der Sperrbesitz in einem umkämpften Erwerbspfad nicht vorhersehbar ist (sondern wie bei einem Spinlock zufällig). Bei ihnen
werden keine Prioritätserhöhungen aufgrund des Sperrbesitzes angewendet, denn
das würde nur vorzeitige Unterbrechungen und eine Ausuferung der Prioritäten
fördern. Es ist auch nicht nötig, denn die Sperre kommt nach der Freigabe sofort
frei, weil der normale Pfad mit Wartezustand/Beendigung des Wartezustands umgangen wird.
Zwischen Sperrbesitz- und Unwait-Erhöhung gibt es noch weitere Unterschiede in der Art, wie
der Scheduler die Erhöhung anwendet. Das ist Thema des nächsten Abschnitts.
Erhöhung nach E/A-Abschluss
Nach Abschluss bestimmter E/A-Operationen wendet Windows vorübergehende Prioritätserhöhungen an, damit Threads, die auf die E/A gewartet haben, eine größere Chance haben,
sofort ausgeführt zu werden und das zu verarbeiten, auf das sie gewartet haben. In den
Headerdateien des Windows Driver Kit (WDK) finden Sie zwar empfohlene Erhöhungswerte
Threadplanung
Kapitel 4
269
(suchen Sie dazu in Wdm.h oder Ntddk.h nach #define IO_; siehe auch Tabelle 4–3), doch den
tatsächlichen Wert für die Erhöhung vergibt der Gerätetreiber, wenn er mit seinem Aufruf
der Kernelfunktion IoCompleteRequest eine E/A-Anforderung abschließt. Wie Sie in Tabelle 4–3 sehen, haben E/A-Anforderungen an Geräte mit höherer Reaktivität einen größeren
Erhöhungswert.
Gerät
Erhöhung
Festplatte, CD-ROM, parallele Schnittstelle, Video
1
Netzwerk, Mailslot, benannte Pipes, serielle Schnittstelle
2
Tastatur, Maus
6
Soundkarte
8
Tabelle 4–3 Empfohlene Erhöhungswerte
Rein intuitiv erwartet man von seiner Videokarte oder Festplatte eine bessere Reaktivität, als eine Erhöhung von 1 bringen kann. Allerdings versucht der Kernel, die
Latenz zu optimieren, auf die einige Geräte (und menschliche Sinne) empfindlicher reagieren als andere. Beispielsweise erwartet die Soundkarte etwa jede Millisekunde Daten, um Musik ohne wahrnehmbare Aussetzer abspielen zu können,
wohingegen eine Videokarte nur eine Ausgabe von 24 Einzelbildern pro Sekunde
leistet und daher nur alle 40 ms Daten benötigt, bevor Unregelmäßigkeiten zu
erkennen sind.
Wie bereits angedeutet, beruhen diese E/A-Abschlusserhöhungen auf den zuvor beschriebenen
Unwait-Erhöhungen. In Kapitel 6 wird der E/A-Abschlussmechanismus ausführlich beschrieben.
Für unsere jetzige Erörterung ist wichtig, dass der Kernel den Signalisierungscode in der API
IoCompleteRequest entweder durch einen APC (für asynchrone E/A) oder durch ein Ereignis (für
synchrone E/A) implementiert. Wenn ein Treiber beispielsweise IO_DISK_INCREMENT für einen
asynchronen Lesevorgang auf der Festplatte an IoCompleteRequest übergibt, ruft der Kernel
KeInsertQueueApc mit IO_DISK_INCREMENT als Boostparameter auf. Wird der Wartezustand des
Threads aufgrund des APCs unterbrochen, erhält er schließlich die Erhöhung um 1.
Beachten Sie, dass die Erhöhungswerte aus Tabelle 4–3 nur Empfehlungen von Microsoft darstellen. Treiberentwickler können sie auch ignorieren, und für besondere Treiber können eigene Werte benutzt werden. Beispielsweise wird für einen Treiber, der Ultraschalldaten
eines medizinischen Instruments verarbeiten und eine Visualisierungsanwendung im Benutzermodus über neue Daten benachrichtigen muss, auch einen Erhöhungswert von 8 verwendet, um die gleiche Latenz zu erreichen wie eine Soundkarte. Aufgrund der Art und Weise,
in der Windows-Treiberstacks aufgebaut sind (siehe Kapitel 6), schreiben Treiberentwickler
jedoch meistens Minitreiber, die einen Microsoft-Treiber mit einem eigenen Erhöhungswert
für IoCompleteRequest aufrufen. Beispielsweise rufen Treiber für RAID- und SATA-Controllerkarten gewöhnlich StorPortCompleteRequest auf, um die Verarbeitung ihrer Anforderungen
abzuschließen. Dieser Aufruf hat keinen Parameter für einen Erhöhungswert, da der Treiber
Storport.sys den richtigen Wert beim Aufruf des Kernels einfügt. Außerdem wird jedes Mal,
270
Kapitel 4
Threads
wenn ein Dateisystemtreiber (der an dem Gerätetyp FILE_DEVICE_DISK_FILE_SYSTEM oder FILE_
DEVICE_NETWORK_FILE_SYSTEM zu erkennen ist) seine Anforderung abschließt, eine Erhöhung um
IO_DISK_INCREMENT angewendet, falls der Treiber stattdessen IO_NO_INCREMENT (0) übergeben
hat. Dadurch ist dieser Erhöhungswert von einer Empfehlung mehr oder weniger zu einer Anforderung geworden, die der Kernel durchsetzt.
Erhöhung durch Warten auf Exekutivressourcen
Wenn ein Thread versucht, eine Exekutivressource zu erwerben (ERESOURCE; siehe Kapitel 8 in
Band 2), die sich bereits im exklusiven Besitz eines anderen Threads befindet, muss er in den
Wartezustand übergeben, bis der andere Thread die Ressource freigibt. Um die Gefahr von
Deadlocks zu verringern, führt die Exekutive diese Wartevorgänge in Intervallen von 500 ms
durch, anstatt endlos auf die Ressource zu warten. Ist die Ressource nach diesen 500 ms immer noch im Besitz des anderen Threads, versucht die Exekutive, ein Aushungern der CPU zu
verhindern, indem sie die Dispatchersperre erwirbt und die Priorität der Besitzerthreads auf 15
erhöht (falls die ursprüngliche Priorität des wartenden Threads nicht bereits 15 beträgt), ihre
Quanten zurücksetzt und einen weiteren Wartevorgang durchführt.
Exekutivressourcen können entweder gemeinsam oder exklusiv genutzt werden. Der Kernel versucht zuerst, die Priorität des exklusiven Besitzers zu erhöhen, und prüft dann, ob es
gemeinsame Besitzer gibt, um deren Prioritäten zu erhöhen. Wenn der wartende Thread wieder in den Wartezustand eintritt, besteht die Hoffnung, dass der Scheduler einen der Besitzerthreads einplant, der dann genug Zeit hat, um seine Arbeit abzuschließen und die Ressource
freizugeben. Dieser Erhöhungsmechanismus wird nur dann verwendet, wenn das Flag Disable
Boost für die Ressource nicht gesetzt ist. Entwickler können dieses Flag setzen, wenn der hier
beschriebene Prioritätsumkehrungsmechanismus bei ihrer Art der Ressourcenverwendung gut
funktioniert.
Dieser Mechanismus ist nicht perfekt. Hat die Ressource beispielsweise mehrere gemeinsame Besitzer, erhöht die Exekutive die Prioritäten all dieser Threads auf 15, was zu einer plötzlichen Spitze von Threads hoher Priorität auf dem System führt, die obendrein noch alle ein vollständiges Quantum haben. Der ursprüngliche Besitzerthread wird zwar als erster ausgeführt
(da er der erste war, dessen Priorität erhöht wurde, und er daher am Anfang der Bereitschaftsliste steht), doch die anderen gemeinsamen Besitzer folgen als Nächstes, da die Priorität des
Wartethreads nicht erhöht wurde. Erst nachdem alle gemeinsamen Besitzer die Gelegenheit
zur Ausführung erhalten haben und ihre Priorität unter die des Wartethreads abgesenkt wurde,
erhält Letzterer endlich die Chance, die Ressource zu erwerben. Da gemeinsame Besitzer ihren
gemeinsamen in einen exklusiven Besitz umwandeln können, sobald der exklusive Besitzer die
Ressource freigegeben hat, kann es sein, dass der Mechanismus nicht wie vorgesehen funk
tioniert.
Prioritätserhöhung für Vordergrundthreads nach Wartevorgängen
Wenn ein Thread in einem Vordergrundprozess einen Wartevorgang auf ein Kernelobjekt abschließt, erhöht der Kernel die aktuelle Priorität (nicht die Basispriorität) dieses Threads um den
aktuellen Wert von PsPrioritySeparation (wobei das Fenstersystem bestimmt, welcher Prozess
Threadplanung
Kapitel 4
271
als Vordergrundprozess angesehen wird). Wie zuvor in diesem Kapitel im Abschnitt »Das Quantum steuern« erklärt, spiegelt PsPrioritySeparation den Quantumstabellenindex wider, der zur
Auswahl des Quantums für die Threads von Vordergrundanwendungen herangezogen wird. In
diesem Fall dient er jedoch als Wert für die Prioritätserhöhung.
Diese Erhöhung wird vorgenommen, um die Reaktivität interaktiver Anwendungen zu verbessern. Durch die kleine Prioritätserhöhung nach dem Abschluss eines Wartevorgangs hat die
Vordergrundanwendung eine bessere Chance, sofort ausgeführt zu werden, vor allem dann,
wenn im Hintergrund weitere Prozesse mit der gleichen Basispriorität laufen.
Experiment: Erhöhungen und Verringerungen der
Vordergrundpriorität beobachten
Mit dem Werkzeug CPU Stress können Sie Prioritätserhöhungen in Aktion beobachten.
Gehen Sie dazu wie folgt vor:
1.
Öffnen Sie in der Systemsteuerung das Programm System oder rechtsklicken Sie auf
dem Desktop auf Dieser PC und wählen Sie Eigenschaften.
2.
Klicken Sie auf Erweiterte Systemeinstellungen, rufen Sie die Registerkarte Erweitert auf,
klicken Sie im Abschnitt Leistung auf Einstellungen und rufen Sie in dem daraufhin eingeblendeten Dialogfeld wiederum die Registerkarte Erweitert auf.
3.
Aktivieren Sie die Option Programme. Dadurch erhält PsPrioritySeparation den
Wert 2.
4.
Starten Sie CPU Stress, rechtsklicken Sie auf Thread 1 und wählen Sie Busy aus dem
Kontextmenü.
5.
Starten Sie die Leistungsüberwachung.
6.
Klicken Sie in der Symbolleiste auf Hinzufügen oder drücken Sie (Strg) + (I), um das
Dialogfeld Leistungsindikatoren hinzufügen zu öffnen.
7.
Wählen Sie das Leistungsobjekt Thread und darunter den Indikator Aktuelle Priorität
aus.
8.
Wählen Sie im Feld Instanzen den Eintrag <Alle Instanzen> und klicken Sie auf Suchen.
→
272
Kapitel 4
Threads
9.
Scrollen Sie zum Prozess CPUSTRES, markieren Sie den zweiten Thread (das ist Thread 1;
beim ersten Thread handelt es sich um den GUI-Thread) und klicken Sie auf Hinzufügen.
Jetzt sehen Sie Folgendes:
10. Klicken Sie auf OK.
11. Rechtsklicken Sie auf den Indikator und wählen Sie Eigenschaften.
12. Klicken Sie auf die Registerkarte Grafik und ändern Sie den Maximalwert für die vertikale Skalierung auf 16. Klicken Sie auf OK.
→
Threadplanung
Kapitel 4
273
13. Bringen Sie den Prozess CPUSTRES in den Vordergrund. Dabei können Sie beobachten,
wie die Priorität des Threads CPUSTRES um 2 erhöht wird und dann auf die Basispriorität
zurückfällt. CPUSTRES erhält regelmäßig eine Erhöhung um 2, da der Thread, den Sie beobachten, ungefähr 25 % der Zeit schläft und danach aufwacht (das ist es, was der Aktivitätsgrad Busy bedeutet). Die Erhöhung wird angewendet, wenn der Thread aufwacht.
Wenn Sie den Aktivitätsgrad auf Maximum setzen, sind dagegen keine Erhöhungen zu
sehen, da der Thread dabei in eine Endlosschleife gestellt wird, keine Wartefunktionen
mehr aufruft und deshalb keine Erhöhungen mehr erhält.
14. Beenden Sie die Leistungsüberwachung und CPU Stress.
Prioritätserhöhung nach dem Aufwachen von GUI-Threads
Threads, die Fenster besitzen, erhalten eine zusätzliche Erhöhung um 2, wenn sie aufgrund
von Fensteraktivitäten wie dem Erhalt von Fensternachrichten aufwachen. Das Fenstersystem
(Win32k.sys) wendet diese Erhöhungen an, wenn es KeSetEvent aufruft, um ein Ereignis zum
Wecken eines GUI-Threads festzulegen. Für diese Erhöhung gibt es einen ähnlichen Grund wie
für die vorherige: um interaktive Anwendungen zu bevorzugen.
274
Kapitel 4
Threads
Experiment: Prioritätserhöhungen von GUI-Threads beobachten
Sie können sich ansehen, wie das Fenstersystem die Priorität von GUI-Threads, die zur Verarbeitung von Fensternachrichten aufwachen, um 2 erhöht, indem Sie die aktuelle Priorität
einer GUI-Anwendung beobachten und dabei die Maus über das Fenster bewegen. Gehen
Sie dazu wie folgt vor:
1.
Öffnen Sie in der Systemsteuerung das Programm System.
2.
Klicken Sie auf Erweiterte Systemeinstellungen, rufen Sie die Registerkarte Erweitert auf,
klicken Sie im Abschnitt Leistung auf Einstellungen und rufen Sie in dem daraufhin eingeblendeten Dialogfeld wiederum die Registerkarte Erweitert auf.
3.
Aktivieren Sie die Option Programme. Dadurch erhält PsPrioritySeparation den
Wert 2.
4.
Starten Sie den Editor.
5.
Starten Sie die Leistungsüberwachung.
6.
Klicken Sie in der Symbolleiste auf Hinzufügen oder drücken Sie (Strg) + (I), um das
Dialogfeld Leistungsindikatoren hinzufügen zu öffnen.
7.
Wählen Sie das Leistungsobjekt Thread und darunter den Indikator Aktuelle Priorität
aus.
8.
Geben Sie Notepad in das Feld Instanzen ein und klicken Sie auf Suchen.
9.
Scrollen Sie zum Eintrag Notepad/0 herunter, klicken Sie darauf, klicken Sie auf Hinzufügen und dann auf OK.
10. Ändern Sie wie im vorherigen Experiment den Maximalwert für die vertikale Skalierung
auf 16. Als Priorität für Thread 0 des Editors wird jetzt 8 oder 10 angezeigt. Da der
Editor kurz nach dem Erhalt der Prioritätserhöhung um 2 für Vordergrundprozesse in
einen Wartezustand eingetreten ist, kann es sein, dass seine Priorität noch nicht wieder
von 10 auf 8 gesunken ist.
11. Bewegen Sie den Mauszeiger über das Editorfenster, während die Leistungsüberwachung im Vordergrund ist. (Sorgen Sie dafür, dass beide Fenster auf dem Bildschirm zu
sehen sind.) Aus den zuvor genannten Gründen bleibt die Priorität manchmal bei 10
und fällt manchmal auf 9 ab.
Es ist nicht sehr wahrscheinlich, dass Sie den Prioritätswert von 8 sehen,
da der Editor nach dem Erhalt der Prioritätserhöhung für GUI-Threads um
2 nur so kurz läuft, dass die Priorität vor dem nächsten Erwachen kaum
um mehr als eine Stufe sinken kann. (Dies liegt an zusätzlichen Fensteraktivitäten und der Tatsache, dass er erneut eine Erhöhung um 2 erhält.)
→
Threadplanung
Kapitel 4
275
12. Bringen Sie den Editor in den Vordergrund. Dabei können Sie beobachten, wie die
Priorität auf 12 erhöht wird und dann bei diesem Wert bleibt. Das liegt daran, dass
der Thread zwei Erhöhungen erhält: einmal die Erhöhung um 2 für erwachende GUIThreads und eine weitere Erhöhung um 2, da der Editor jetzt im Vordergrund ist. (Unter
Umständen können Sie auch beobachten, wie die Priorität wieder auf 11 fällt, wenn der
Thread die übliche Prioritätssenkung erfährt, die bei Threads mit erhöhter Priorität am
Ende des Quantums auftritt.)
13. Bewegen Sie den Mauszeiger über das Editorfenster, während es im Vordergrund ist.
Bringen Sie den Editor in den Vordergrund. Dabei können Sie unter Umständen beobachten, wie die Priorität auf 11 oder möglicherweise sogar 10 fällt, wenn der Thread die
übliche Prioritätssenkung erfährt, die bei Threads mit erhöhter Priorität am Ende des
Quantums auftritt. Die Erhöhung um 2, die der Editor erhalten hat, weil er der Vordergrundprozess ist, bleibt jedoch so lange bestehen, wie sich der Editor im Vordergrund
befindet.
14. Beenden Sie die Leistungsüberwachung und den Editor.
Prioritätserhöhung gegen CPU-Aushungerung
Stellen Sie sich folgende Situation vor: Ein Thread mit Priorität 7 wird ausgeführt und verhindert, dass ein Thread mit Priorität 4 jemals CPU-Zeit zugeteilt bekommt. Allerdings wartet
ein Thread der Priorität 11 auf eine Ressource, die der Priorität-4-Thread gesperrt hat. Da der
Priorität-7-Thread aber die gesamte CPU-Zeit verbraucht, läuft der Priorität-4-Thread nie lange
genug, um das zu erledigen, was er tun muss, und die Ressource freizugeben, die den Priorität-11-Thread blockiert. Eine solche Situation wird als Prioritätsumkehrung oder Prioritätsinversion bezeichnet.
Wie geht Windows mit dieser Situation um? Die ideale Lösung (zumindest in der Theorie)
besteht darin, den Überblick über alle Sperren und ihre Besitzer zu bewahren und die Priorität der passenden Threads zu erhöhen, damit die Verarbeitung voranschreiten kann. Diese
Idee wird in der Autoboost-Einrichtung umgesetzt, die weiter hinten in diesem Kapitel in dem
gleichnamigen Abschnitt erläutert wird. Gegen Aushungerungssituationen im Allgemeinen
wird jedoch die folgende Schutzmaßnahme angewendet.
Sie haben bereits gesehen, dass der Code für Exekutivressourcen in einer solchen Situation
die Priorität der Besitzerthreads erhöht, sodass sie die Chance bekommen, zu laufen und die
Ressource freizugeben. Exekutivressourcen sind jedoch nur eine von vielen Synchronisierungsstrukturen, die Entwicklern zur Verfügung stehen, und diese Prioritätsverstärkungstechnik lässt
sich auf keines der anderen Primitiva anwenden. Daher gibt es in Windows einen allgemeinen
Mechanismus gegen CPU-Aushungerung, der zu einem Thread namens Ausgleichssatz-Manager gehört. (Dies ist ein Systemthread, der hauptsächlich für Speicherverwaltungsfunktionen
da ist und ausführlicher in Kapitel 5 beschrieben wird.) Dieser Thread durchsucht die Bereitschaftswarteschlange jede Sekunde nach Threads, die sich seit ca. vier Sekunden im Zustand
Bereit befinden (also noch nicht ausgeführt wurden). Wenn der Ausgleichssatz-Manager einen
solchen Thread findet, erhöht er dessen Priorität auf 15 und setzt den Quantumssollwert ent-
276
Kapitel 4
Threads
sprechend auf drei Quantumseinheiten. Nach Ablauf dieses Quantums fällt die Priorität des
Threads sofort wieder auf die ursprüngliche Basispriorität zurück. Hat der Thread seine Arbeit
noch nicht beendet und steht ein Thread höherer Priorität zur Ausführung bereit, so kehrt der
Thread in die Bereitschaftswarteschlange zurück, wo er nach weiteren vier Sekunden wieder die
Berechtigung für einen weiteren Prioritätsschub erhält.
Um CPU-Zeit zu sparen, untersucht der Ausgleichssatz-Manager jedoch nicht jedes Mal
sämtliche ausführungsbereiten Threads, sondern immer nur 16. Gibt es mehr Threads auf derselben Prioritätsstufe, merkt er sich, wo er aufgehört hat, und fährt beim nächsten Durchgang
dort fort. Außerdem verstärkt er in jedem Durchgang nur die Priorität von höchsten zehn
Threads. Sind mehr als zehn für einen solchen Prioritätsschub berechtigt (was schon auf ein
ungewöhnlich stark beschäftigtes System hindeutet), so fährt er beim nächsten Durchgang mit
den restlichen fort.
Wir hatten zuvor betont, dass die Planungsentscheidungen in Windows nicht von
der Anzahl der Threads abhängen und stets gleich viel Zeit erfordern. Da der Ausgleichssatz-Manager jedoch manuell die Bereitschaftswarteschlangen untersuchen muss, hängt die Dauer dieser Operation von der Anzahl der Threads ab: Je
mehr Threads es gibt, umso mehr Zeit erfordert die Untersuchung. Allerdings gilt
der Ausgleichssatz-Manager nicht als Teil des Schedulers oder dessen Algorithmen, sondern als Erweiterungsmechanismus zur Steigerung der Zuverlässigkeit.
Da es überdies eine Obergrenze für die Anzahl der zu untersuchenden Threads
und Warteschlangen gibt, ist die Leistungseinbuße minimal und ihr höchster Wert
berechenbar.
Experiment: Prioritätserhöhungen gegen CPU-Aushungerung
beobachten
Mit dem Werkzeug CPU Stress können Sie Prioritätserhöhungen beobachten. In diesem
Experiment werden Sie sehen, wie sich die CPU-Nutzung ändert, wenn die Priorität eines
Threads heraufgesetzt wird. Gehen Sie dazu wie folgt vor:
1.
Führen Sie CPUStres.exe aus.
2.
Der Aktivitätsgrad von Thread 1 ist Low. Ändern Sie ihn auf Maximum.
3.
Die Threadpriorität von Thread 1 ist Normal. Ändern Sie ihn auf Lowest.
4.
Klicken Sie auf Thread 2. Sein Aktivitätsgrad ist Low. Ändern Sie ihn auf Maximum.
→
Threadplanung
Kapitel 4
277
5.
Ändern Sie die Prozessaffinitätsmaske auf Affinität mit einem einzigen logischen Prozessor. Öffnen Sie dazu das Menü Process und wählen Sie Affinity. (Es spielt keine
Rolle, welchen Prozessor Sie dabei auswählen.) Alternativ können Sie diese Änderung
auch im Task-Manager vornehmen. Das Fenster von CPU Stress sollte jetzt wie folgt
aussehen:
6.
Starten Sie die Leistungsüberwachung.
7.
Klicken Sie in der Symbolleiste auf Leistungsindikator hinzufügen oder drücken Sie
(Strg) + (I), um das Dialogfeld Leistungsindikatoren hinzufügen zu öffnen.
8.
Wählen Sie das Objekt Thread und darunter den Indikator Aktuelle Priorität aus.
9.
Geben Sie CPUSTRES in das Feld Instanzen ein und klicken Sie auf Suchen.
10. Wählen Sie die Threads 1 und 2 aus (Thread 0 ist der GUI-Thread), klicken Sie auf Hinzufügen und dann auf OK.
11. Ändern Sie das Maximum der vertikalen Skalierung für beide Indikatoren auf 16.
12. Da die Leistungsüberwachung nur einmal pro Sekunde aktualisiert wird, kann es sein,
dass Sie die Prioritätsschübe dabei verpassen. Als Abhilfemaßnahme frieren Sie die Anzeige mit (Strg) + (F) ein und halten dann (Strg) + (U) gedrückt, um häufigere Aktualisierungen zu erzwingen. Mit etwas Glück können Sie dann eine Prioritätserhöhung
des Threads niedriger Priorität auf etwa 15 sehen:
→
278
Kapitel 4
Threads
13. Beenden Sie die Leistungsüberwachung und CPU Stress.
Prioritätserhöhungen anwenden
Bei der Beschreibung von KiExitDispatcher haben Sie gesehen, dass KiProcessThreadWait aufgerufen wird, um Threads in der Liste von Threads mit verzögerter Bereitschaft zu verarbeiten.
Hier werden die vom Aufrufer übergebenen Informationen über die Prioritätserhöhung verarbeitet. Dazu werden alle Threads mit verzögerter Bereitschaft in einer Schleife durchlaufen, die
Verknüpfung zu ihren Warteblöcken aufgehoben ( jedoch nur für Active- und Bypassed-Blöcke)
und die beiden Schlüsselwerte AdjustReason und AdjustIncrement im Threadsteuerungsblock
des Kernels gesetzt. Als Grund (AdjustReason) wird eine der beiden zuvor beschriebenen
A djust-Möglichkeiten angegeben, während das Inkrement dem Erhöhungswert entspricht. Anschließend wird KiDeferredReady aufgerufen. Diese Funktion bereitet den Thread zur Ausführung vor, indem sie den (im Folgenden beschriebenen) Quantums- und Prioritätsauswahlalgorithmus und den Prozessorauswahlalgorithmus (beschrieben im Abschnitt »Prozessorauswahl«
weiter hinten in diesem Kapitel) ausführt.
Sehen wir uns zunächst den Fall an, dass der Algorithmus eine Prioritätserhöhung anwendet, was nur bei Threads geschieht, die sich nicht im Echtzeit-Prioritätsbereich befinden.
Eine AdjustUnwait-Erhöhung erfolgt nur dann, wenn der Thread noch keinen ungewöhnlichen
Prioritätsschub erhalten hat und wenn die Prioritätserhöhung nicht deaktiviert wurde. Letzteres kann durch Setzen des Flags DisableBoost in KTHREAD mithilfe von SetThreadPriorityBoost
geschehen oder wenn der Kernel erkennt, dass der Thread sein Quantum bereits erschöpft hat
(aber der Taktinterrupt nicht ausgelöst wurde, um es zu verbrauchen) und seinen Wartezustand
nach weniger als zwei Ticks verlässt.
Threadplanung
Kapitel 4
279
Wenn keiner dieser Umstände vorliegt, wird die neue Priorität des Threads durch Addi
tion von AdjustIncrement zur aktuellen Basispriorität des Threads bestimmt. Gehört der Thread
zu einem Vordergrundprozess (ist also seine Speicherpriorität auf MEMORY_PRIORITY_FOREGROUND
gesetzt, was Win32k.sys bei einer Änderung des Fokus erledigt), wird auf die neue Priorität außerdem die Erhöhung aufgrund der Prioritätsaufteilung (PsPrioritySeparation) aufgeschlagen,
also der zuvor beschriebene Vordergrund-Prioritätsschub.
Anschließend prüft der Kernel noch, ob die neue Priorität höher ist als die aktuelle Priorität des Threads, und begrenzt den Wert auf maximal 15, um zu verhindern, dass er in den
Echtzeitbereich wechselt. Anschließend legt der Kernel den Wert als neue aktuelle Priorität des
Threads fest. Wurde ein Vordergrundschub angewendet, wird dieser Wert auch in das Feld
ForegroundBoost von KTHREAD eingetragen, was zu einem PriorityDecrement-Wert gleich dem
Vordergrundschub führt.
Bei AdjustBoost-Erhöhungen prüft der Kernel, ob die aktuelle Threadpriorität kleiner als
AdjustIncrement (die Priorität des festlegenden Threads) und kleiner als 13 ist. Ist das der Fall
und wurden Prioritätserhöhungen für den Thread nicht deaktiviert, wird die AdjustIncrement-
Priorität als neue aktuelle Priorität verwendet, allerdings begrenzt auf einen Maximalwert
von 13. Das KTHREAD-Feld UnusualBoost enthält den Erhöhungswert, was dazu führt, dass
PriorityDecrement auf einen Wert gleich der Sperrbesitzerhöhung gesetzt wird.
In allen Fällen, in denen PriorityDecrement vorhanden ist, wird das Quantum des Threads
auf einen Tick auf der Grundlage des Wertes von KiLockQuantumTarget gesetzt. Dadurch wird sichergestellt, dass Vordergrund- und ungewöhnliche Erhöhungen schon nach einem statt nach
den üblichen zwei Ticks (oder welcher Wert sonst eingestellt ist) wieder zurückgenommen
werden (siehe den nächsten Abschnitt). Dies geschieht auch, wenn eine AdjustBoost-Erhöhung
angefordert wird, der Thread aber bereits mit einer Priorität von 13 oder 14 läuft oder die Erhöhung deaktiviert ist.
Nachdem diese Arbeiten erledigt sind, wird AdjustReason auf AdjustNone gesetzt.
Erhöhungen zurücknehmen
Die Rücknahme von Erhöhungen erfolgt in KiDeferredReadyThread während der im vorherigen
Abschnitt gezeigten Prioritäts- und Quantumsneuberechnungen. Als Erstes prüft der Algorithmus die Art der Anpassung, die erfolgen soll.
Im Fall von AdjustNone – was bedeutet, dass der Thread ausführungsbereit wurde, möglicherweise aufgrund einer vorzeitigen Unterbrechung – wird das Quantum des Threads neu berechnet, falls es bereits den Sollwert erreicht hat, der Taktinterrupt dies aber noch nicht bemerkt
hat. (Dies gilt, wenn der Thread auf einer der dynamischen Prioritätsstufen ausgeführt wurde.)
Auch die Threadpriorität wird neu berechnet. Bei AdjustUnwait und AdjustBoost (und ebenfalls
außerhalb des Echtzeitbereichs) prüft der Kernel, ob der Thread sein Quantum stillschweigend
erschöpft hat (wie im vorherigen Abschnitt). Wenn das der Fall ist oder wenn der Thread mit
einer Basispriorität von 14 oder höher lief oder wenn kein PriorityDecrement-Wert angegeben
ist und der Thread einen Wartezustand von weniger als zwei Ticks beendet hat, dann werden
das Quantum und die Priorität des Threads neu berechnet.
280
Kapitel 4
Threads
Eine Neuberechnung der Priorität erfolgt nur bei Threads außerhalb des Echtzeitbereichs.
Dazu werden von der aktuellen Priorität des Threads die Vordergrunderhöhung, die ungewöhnliche Erhöhung (die Kombination dieser beiden Elemente ergibt PriorityDecrement) und
1 subtrahiert. Dabei bildet die Basispriorität die Untergrenze für die neue Priorität. Jegliche
vorhandenen Prioritätsdekremente werden auf null gesetzt (wodurch alle ungewöhnlichen
und Vordergrunderhöhungen entfernt werden). Bei einer Sperrbesitz- oder anderen ungewöhnlichen Erhöhung geht dadurch der gesamte Erhöhungswert verloren. Bei einer regulären
A djustUnwait-Erhöhung dagegen sinkt die Priorität langsam durch Subtraktion von 1, bis die
Basispriorität als untere Grenze erreicht ist.
Es gibt noch eine andere Situation, in der Erhöhungen zurückgenommen werden müssen,
nämlich aufgrund der Regel für Sperrbesitzerhöhungen, nach der der festlegende Thread seine
Erhöhung verlieren muss, wenn er dem aufwachenden Thread seine aktuelle Priorität gespendet
hat (um einen Sperrenkonvoi zu verhindern). Dazu wird die Funktion KiRemoveBoostThread verwendet. Sie dient auch dazu, Prioritätserhöhungen aufgrund von verzögerten Prozeduraufrufen
(Deferred Procedure Calls, DPCs) und gegen ERESOURCE-Sperrenaushungerung zurückzunehmen. Das einzig Besondere an dieser Routine ist, dass beim Berechnen der neuen Priorität die
Trennung der ForegroundBoost- und UnusualBoost-Bestandteile von PriorityDecrement getrennt
berücksichtigt werden, um GUI-Vordergrunderhöhungen aufrechtzuerhalten, die der Thread
erworben hat. Diese Vorgehensweise wurde mit Windows 7 eingeführt und sorgt dafür, dass
sich Threads mit Sperrbesitzerhöhung nicht unvorhersehbar verhalten, wenn sie im Vordergrund
laufen, und umgekehrt.
Abb. 4–12 zeigt, wie normale Erhöhungen am Ende des Quantums von einem Thread
entfernt werden.
Quantum
Erhöhung am Ende
Priorität des Wartevorgangs
Prioritätsabfall am Ende
des Quantums
Vorzeitiges
Unterbrechen
(vor Ende des
Quantums)
Basispriorität
Ausführen
Warten Ausführen
Umlaufverfahren auf
Basispriorität
Ausführen
Zeit
Abbildung 4–12 Erhöhung und Senkung der Priorität
Threadplanung
Kapitel 4
281
Prioritätserhöhung für Multimediaanwendungen und Spiele
Die Prioritätserhöhungen gegen CPU-Aushungerung können zwar ausreichen, um einen
Thread aus einem abnorm langen Wartezustand oder einem möglichen Deadlock herauszuholen, aber mit den Ressourcenanforderungen einer CPU-intensiven Anwendung wie Windows
Media Player oder einem 3-D-Computerspiel werden sie nicht fertig.
Aussetzer und andere Audiofehler haben Windows-Benutzer lange gestört. Der Benutzermodus-Audiostack von Windows hat die Situation sogar verschärft, da er noch mehr Möglichkeiten für vorzeitige Unterbrechungen bot. Als Gegenmaßnahmen verwenden Clientversionen
den MMCSS-Treiber, der in %SystemRoot%\System32\Drivers\MMCSS.sys implementiert ist
(und weiter vorn in diesem Kapitel beschrieben wurde). Er soll für eine fehlerfreie Multimediawiedergabe in Anwendungen sorgen, die sich bei ihm registrieren.
In Windows 7 ist MMCSS als Dienst und nicht als Treiber implementiert. Das bietet jedoch eine gewisse Gefahr: Wenn der Thread zur Verwaltung von MMCSS
aus irgendeinem Grund blockiert sein sollte, behalten die von ihm verwalteten
Threads ihre Echtzeitpriorität, was zu einer systemweiten Aushungerung führen
kann. Zur Lösung dieses Problems wurde der Code in den Kernel verschoben, wo
der Verwaltungsthread (und andere von MMCSS verwendete Ressourcen) nicht
beeinträchtigt werden kann. Die Implementierung als Kerneltreiber bietet noch
andere Vorteile, z. B. die Verwendung eines direkten Zeigers auf das Prozess- und
das Threadobjekt anstelle von IDs und Handles. Dadurch werden Suchvorgänge
nach den IDs und Handles vermieden und eine schnellere Kommunikation mit dem
Scheduler und dem Energie-Manager ermöglicht.
Clientanwendungen können sich bei MMCSS registrieren, indem sie AvSetMmThreadCharacteristics mit einem Tasknamen aufrufen, der einem der Unterschlüssel von HKLM\Software\
Microsoft\Windows NT\CurrentVersion\Multimedia\SystemProfile\Tasks entspricht. (Die Liste
kann von OEMs bearbeitet werden, um nach Bedarf weitere Tasks hinzuzufügen.) Im Lieferzustand sind die folgenden Tasks vorhanden:
QQ Audio
QQ Capture
QQ Distribution
QQ Games
QQ Low Latency
QQ Playback
QQ Pro Audio
QQ Window Manager
282
Kapitel 4
Threads
Jeder dieser Tasks schließt Informationen über die Eigenschaften ein, durch die sie sich unterscheiden. Die wichtigste Eigenschaft für die Threadplanung ist die Zeitplanungskategorie, die
einer der wichtigsten Faktoren dafür ist, die Priorität der bei MMCSS registrierten Threads zu
bestimmen. Tabelle 4–4 zeigt die verschiedenen Planungskategorien.
Kategorie
Priorität
Beschreibung
Hoch
23–26
Pro-Audio-Threads, die mit einer höheren Priorität als alle anderen
Threads auf dem System laufen (ausgenommen kritische Systemthreads)
Mittel
16–22
Threads einer Vordergrundanwendung wie Windows Media Player
Niedrig
8–15
Alle anderen Threads, die nicht zu einer der vorherigen Kategorien gehören
Erschöpft
4–6
Threads, die ihren Anspruch auf die CPU erschöpft haben und nur dann
weiter ausgeführt werden, wenn keine Threads höherer Priorität auf der
CPU laufen
Tabelle 4–4 Zeitplanungskategorien
Der Hauptmechanismus, der hinter MMCSS steht, erhöht die Priorität der Threads in einem
registrierten Prozess für einen garantierten Zeitraum auf die Stufe, die ihrer Zeitplanungskategorie und ihrer relativen Priorität in dieser Kategorie entspricht. Danach versetzt er die Threads
in die Kategorie Erschöpft, sodass andere, Nicht-Multimediathreads auf dem System eine Gelegenheit zur Ausführung bekommen.
Standardmäßig erhalten Multimediathreads 80 % der verfügbaren CPU-Zeit, während andere Threads 20 % erhalten. (Bei einer Stichprobe von 10 ms wären das 8 bzw. 2 ms.) Diese
Verteilung können Sie in dem Registrierungswert SystemResponsiveness unter HKLM\SOFTWARE\
Microsoft\Windows NT\CurrentVersion\Multimedia\SystemProfile ändern. Der Wert lässt sich im
Bereich von 10 bis 100 % einstellen (wobei 20 der Standardwert ist). Bei Angabe eines niedrigeren Wertes als 10 wird 10 festgelegt. Der Wert gibt den prozentualen Anteil an der CPU an,
der dem System (also nicht den registrierten Audio-Apps) garantiert ist. Der MMCSS-Planungsthread läuft auf einer Priorität von 27, da er jeden Pro-Audio-Thread vorzeitig unterbrechen
muss, um dessen Priorität auf die Kategorie Erschöpft abzusenken.
Wie bereits erwähnt, ist es gewöhnlich nicht sinnvoll, die relativen Prioritäten der Threads
innerhalb eines Prozesses zu ändern. Es gibt auch kein Werkzeug, mit dem das möglich wäre,
da nur die Entwickler die Wichtigkeit der einzelnen Threads in ihren Programmen genau kennen. Da sich Anwendungen manuell bei MMCSS registrieren und Informationen über die Art
ihres Threads angeben müssen, hat MMCSS dagegen die erforderlichen Daten, um die relativen Threadprioritäten zu ändern. Die Entwickler sind sich auch im Klaren darüber, dass dies
geschehen kann.
Threadplanung
Kapitel 4
283
Experiment: Prioritätserhöhung durch MMCSS
In diesem Experiment sehen Sie sich die Auswirkungen der MMCSS-Prioritätserhöhung an.
1.
Führen Sie den Windows Media Player (Wmplayer.exe) aus. (Andere Abspielprogramme
nutzen möglicherweise nicht die API-Aufrufe, die zur Registrierung bei MMCSS erforderlich sind.)
2.
Spielen Sie einige Audioinhalte ab.
3.
Richten Sie mit dem Task-Manager oder mit Process Explorer die Affinität des Wmplayer.
exe-Prozesses so ein, dass er nur auf einer CPU ausgeführt wird.
4.
Starten Sie die Leistungsüberwachung.
5.
Ändern Sie die Prioritätsklasse der Leistungsüberwachung im Task-Manager auf Echtzeit, sodass sie die Aktivitäten besser aufzeichnen kann.
6.
Klicken Sie in der Symbolleiste auf Leistungsindikator hinzufügen oder drücken Sie
(Strg) + (I), um das Dialogfeld Leistungsindikatoren hinzufügen zu öffnen.
7.
Wählen Sie das Objekt Thread und darunter den Indikator Aktuelle Priorität aus.
8.
Geben Sie Wmplayer in das Feld Instanzen ein, klicken Sie auf Suchen und markieren
Sie alle Threads dieses Prozesses.
9.
Klicken Sie auf Hinzufügen und dann auf OK.
10. Klicken Sie auf das Aktionsmenü und wählen Sie Eigenschaften.
11. Ändern Sie auf der Registerkarte Grafik das Maximum der vertikalen Skalierung auf 32.
Es sollten ein oder mehrere Priorität-16-Threads innerhalb von Wmplayer angezeigt
werden, die ständig ausgeführt werden, sofern kein Thread höherer Priorität die CPU
beansprucht, nachdem er in die Kategorie Erschöpft gefallen ist.
12. Starten Sie CPU Stress.
13. Setzen Sie den Aktivitätsgrad von Thread 1 auf Maximum.
14. Die Priorität von Thread 1 beträgt Normal. Ändern Sie sie in Time Critical.
15. Ändern Sie die Prioritätsklasse von CPUSTRES in High.
16. Ändern Sie die Affinität von CPUSTRES auf dieselbe CPU wie für Wmplayer. Das System
sollte jetzt erheblich langsamer werden, doch die Musikwiedergabe sollte fortfahren.
Das System wird ab und zu wieder reagieren.
→
284
Kapitel 4
Threads
17. In der Leistungsüberwachung können Sie beobachten, wie die Priorität-16-Threads von
Wmplayer von Zeit zu Zeit abfallen:
Die Funktion von MMCSS beschränkt sich jedoch nicht auf diese einfache Prioritätserhöhung.
Aufgrund der Natur der Netzwerktreiber in Windows und auf dem NDIS-Stack sind DPCs gängige Mechanismen dafür, Aufgaben zu verzögern, bis ein Interrupt von einer Netzwerkkarte
eingegangen ist. Da DPCs auf einer höheren IRQL ausgeführt werden als Benutzermoduscode
(siehe Kapitel 6), kann lang laufender Treibercode für Netzwerkkarten die Medienwiedergabe
nach wie vor unterbrechen, etwa bei Netzwerkübertragungen oder beim Spielen eines Spiels.
MMCSS sendet einen besonderen Befehl an den Netzwerkstack, um ihn anzuweisen,
die Netzwerkpakete während der Dauer der Mediapakete zu drosseln. Das dient dazu, die
Wiedergabeleistung zu maximieren, wofür kleine Einbußen beim Netzwerkdurchsatz in Kauf
genommen werden (die bei Netzwerkoperationen, die während der Wiedergabe gewöhnlich
durchgeführt werden, etwa beim Spielen eines Onlinespiels, nicht bemerkbar sind). Der Mechanismus dafür gehört jedoch nicht zum Scheduler, weshalb wir ihn hier nicht beschreiben.
MMCSS unterstützt auch das sogenannte »Deadline Scheduling« (Threadplanung mit
Termin). Dies fußt auf der Grundüberlegung, dass ein Programm zur Audiowiedergabe nicht
immer die höchste Prioritätsstufe in seiner Kategorie benötigt. Wenn es die Audiodaten puffert und den Puffer abspielt, während es den nächsten Puffer auffüllt, kann der Clientthread
angeben, zu welchem Zeitpunkt er die hohe Prioritätsstufe zur Vermeidung von Aussetzern
benötigt, und in der Zwischenzeit mit einer leicht geringeren Priorität (innerhalb seiner Kategorie) leben. Mit der Funktion AvTaskIndexYield kann ein Thread angeben, wann er die höchste
Threadplanung
Kapitel 4
285
Priorität in seiner Kategorie erhalten muss, um das nächste Mal ausgeführt zu werden. Bis dieser Zeitpunkt gekommen ist, erhält er die geringste Priorität in seiner Kategorie, sodass mehr
CPU-Zeit für das System zur Verfügung steht.
Autoboost
Das Autoboost-Framework soll das zuvor beschriebene Problem der Prioritätsumkehrung angehen. Dabei werden die Threads verfolgt, die Sperren besitzen, und diejenigen, die darauf
warten, sodass es möglich ist, die Prioritäten der passenden Threads zu steigern (bei Bedarf
auch die E/A-Prioritäten), um die Verarbeitung voranzubringen. Die Informationen über die
Sperren werden in der KTHREAD-Struktur in einem statischen Array aus KLOCK_ENTRY-Objekten
gespeichert. Bei der aktuellen Implementierung gibt es höchstens sechs solcher Einträge, von
denen jeder zwei Binärbäume unterhält, einen für die Sperren, die der Thread besitzt, und einen
für die Sperren, auf die der Thread wartet. Diese Bäume sind mit Schlüsseln nach ihrer Priorität
versehen, weshalb zur Bestimmung der höchsten Priorität, auf die eine Erhöhung angewendet
werden soll, stets eine konstante Zeit erforderlich ist. Wird eine Erhöhung benötigt, so wird
die Priorität des Besitzerthreads auf die des wartenden Threads gesetzt. Auch die E/A-Priorität
kann erhöht werden, wenn sie zu niedrig ist (siehe Kapitel 6). Wie bei allen Prioritätserhöhungen kann auch mit Autoboost maximal eine Priorität von 15 erreicht werden. (Die Priorität von
Echtzeitthreads wird nicht erhöht.)
In der aktuellen Implementierung wird Autoboost für Pushlocks und abgesicherte Mutexsynchronisierungsprimitiva verwendet, die nur für Kernelcode verfügbar gemacht werden
(siehe Kapitel 8 in Band 2). Des Weiteren wird dieses Framework von einigen Komponenten der
Exekutive für besondere Fälle genutzt. In zukünftigen Versionen von Windows kann Autoboost
auch für Objekte implementiert werden, die vom Benutzermodus aus zugänglich sind und bei
denen es das Prinzip des Besitzes gibt, z. B. für kritische Abschnitte.
Kontextwechsel
Der Kontext eines Threads und die Prozedur für den Kontextwechsel hängen von der Architektur des Prozessors ab. Gewöhnlich ist es bei einem Kontextwechsel erforderlich, folgende Daten
zu speichern und neu zu laden:
QQ Anweisungszeiger
QQ Kernelstackzeiger
QQ Zeiger auf den Adressraum, in dem der Thread ausgeführt wird (Seitentabellenverzeichnis
des Prozesses)
Der Kernel speichert diese Informationen des alten Threads, indem er sie auf den aktuellen
Kernelmodusstack legt (den des alten Threads), den Stackzeiger aktualisiert und diesen dann in
der KTHREAD-Struktur des alten Threads speichert. Anschließend wird der Kernelstackzeiger auf
den Kernelstack des neuen Threads gesetzt und der Kontext dieses Threads geladen. Befindet
sich der neue Thread in einem anderen Prozess, so wird die Adresse von dessen Seitentabellenverzeichnis in ein besonderes Prozessorregister geladen, damit der Adressraum zur Verfügung
steht (siehe die Beschreibung der Adressübersetzung in Kapitel 5). Bei einem ausstehenden
286
Kapitel 4
Threads
Kernel-APC wird ein Interrupt auf IRQL 1 angefordert. (Mehr über APCs erfahren Sie in Kapitel 8
von Band 2.) Anderenfalls geht die Steuerung an den wiederhergestellten Anweisungszeiger
des neuen Threads über, woraufhin der neue Thread mit der Ausführung beginnt.
Direct Switch
In Windows 8 und Windows Server 2012 wurde die Optimierung Direct Switch eingeführt,
die es einem Thread ermöglicht, sein Quantum und seine Prioritätserhöhung einem anderen
Thread zu spenden, der dann sofort auf demselben Prozessor ausgeführt wird. Bei synchroner
Client/Server-Verarbeitung kann dieser direkte Wechsel zu einer erheblichen Verbesserung des
Durchsatzes führen, da die Client- und Serverthreads nicht zu anderen Prozessoren verlegt werden, die sich im Leerlauf befinden oder geparkt sein können. Anderes ausgedrückt, kann immer
nur ein Client- oder Serverthread ausgeführt werden, weshalb der Scheduler sie als einen einzigen logischen Thread behandeln sollte. Abb. 4–13 zeigt die Auswirkungen von Direct Switch.
Ohne Direct Switch
T1 geht in den
Wartezustand über
und weckt T2 auf
Mit Direct Switch
T1 geht in den
Wartezustand über
und weckt T2 auf
Abbildung 4–13 Direct Switch
Der Scheduler kann nicht wissen, dass der erste Thread (T1 in Abb. 4–13) in einen Wartezustand
eintritt, nachdem er ein Synchronisierungsobjekt signalisiert hat, auf das der zweite Thread (T2)
wartet. Daher muss eine besondere Funktion aufgerufen werden, um den Scheduler darüber zu
informieren (atomares Signalisieren und Warten).
Wenn möglich, führt die Funktion KiDirectSwitchThread den eigentlichen Kontextwechsel
aus. Sie wird von KiExitDispatcher aufgerufen, wenn ein Flag übergeben wird, das die Möglichkeit eines direkten Wechsels anzeigt. Der erste Thread spendet seine Priorität dem zweiten
(sofern dessen Priorität niedriger ist als die des ersten), wenn dies KiExitDispatcher in einem
weiteren Bitflag angezeigt wird. In der aktuellen Implementierung werden immer entweder
beide Flags oder keines angegeben, was bedeutet, dass bei jedem direkten Wechsel auch eine
Prioritätsspende erfolgt. Der direkte Wechsel kann jedoch fehlschlagen, etwa wenn die Affinität
des Zielthreads verhindert, dass er auf dem aktuellen Prozessor ausgeführt wird. Hat er jedoch
Threadplanung
Kapitel 4
287
Erfolg, so wird das Quantum des ersten Threads auf den zweiten übertragen, wobei der erste
Thread sein restliches Quantum einbüßt.
Direkte Kontextwechsel werden zurzeit in folgenden Situationen verwendet:
QQ Wenn ein Thread die Windows-API SignalObjectAndWait (oder ihr Gegenstück NtSignal
AndWaitForSingleObject im Kernel) aufruft
QQ ALPCs (siehe Kapitel 8 in Band 2)
QQ Synchrone Remoteprozeduraufrufe (RPCs)
QQ COM-Remoteaufrufe (zurzeit nur von MTA zu MTA [Multithreadapartment])
Mögliche Fälle bei der Threadplanung
Windows entscheidet aufgrund der Threadpriorität, welcher Thread als Nächstes die CPU bekommt. Wie aber funktioniert das in der Praxis? In diesem Abschnitt sehen wir uns an, wie das
prioritätsgestützte präemptive Multitasking auf Threadebene abläuft.
Freiwilliger Wechsel
Ein Thread kann den Prozessor freiwillig aufgeben, wenn er auf ein Objekt wartet (z. B. ein
Ereignis, einen Mutex, einen Semaphor, einen E/A-Abschlussport, einen Prozess, einen Thread
usw.) und eine der Windows-Wartefunktionen wie WaitForSingleObject oder WaitForMultipleObjects aufruft (siehe Kapitel 8 in Band 2).
Abb. 4–14 zeigt, wie ein Thread in einen Wartezustand eintritt und Windows einen neuen
Thread zur Ausführung auswählt. Der oberste Kasten (Thread) in dieser Abbildung gibt den
Prozessor freiwillig auf, sodass der nächste Thread in der Bereitschaftswarteschlange ausgeführt werden kann (angezeigt durch den »Heiligenschein« in der Spalte Wird ausgeführt). In
dieser Abbildung mag es zwar so aussehen, als würde die Priorität des ersten Threads verringert, doch das ist nicht der Fall. Er wird einfach in die Warteschlange für die Objekte verlagert,
auf die er wartet.
Priorität
Wird ausgeführt
Bereit
Zum Wartezustand
Abbildung 4–14 Freiwilliger Kontextwechsel
288
Kapitel 4
Threads
Vorzeitige Unterbrechung
In dieser Situation wird ein Thread unterbrochen, weil ein Thread mit höherer Priorität ausführungsbereit weit. Dies kann aus den beiden folgenden Gründen geschehen:
QQ Der Thread höherer Priorität beendet seinen Wartezustand (weil das Ereignis, auf das er
gewartet hat, eingetreten ist)
QQ Die Priorität eines Threads wurde erhöht oder verringert.
In jedem dieser beiden Fälle muss Windows herausfinden, ob der zurzeit laufende Thread weiterhin ausgeführt oder vorzeitig unterbrochen werden soll, um einem Thread höherer Priorität
das Feld zu überlassen.
Threads im Benutzermodus können Threads im Kernelmodus vorzeitig unterbrechen. Der Modus des Threads spielt keine Rolle; es kommt nur auf die Priorität an.
Wird ein Thread vorzeitig beendet, so wird er an den Anfang der Bereitschaftswarteschlange
für seine Priorität gestellt (siehe Abb. 4–15).
Priorität
Wird ausgeführt
Bereit
Zum Wartezustand
Abbildung 4–15 Präemptive Threadplanung
In Abb. 4–15 kehrt ein Thread mit der Priorität 18 aus seinem Wartezustand zurück und übernimmt die CPU, weshalb der zuvor laufende Thread mit Priorität 16 an den Anfang der Bereitschaftswarteschlange gestellt wird – nicht ans Ende! Wenn der Thread höherer Priorität
ausgeführt ist, kann der unterbrochene Thread dadurch weitermachen.
Ablauf des Quantums
Wenn der laufende Thread sein CPU-Quantum erschöpft hat, muss Windows ermitteln, ob
seine Priorität verringert und ob ein anderer Thread auf dem Prozessor eingeplant werden soll.
Wird die Threadpriorität gesenkt (z. B. weil der Thread zuvor einen Prioritätsschub erhalten
hat), so sucht Windows nach einem geeigneteren Thread, z. B. einem Thread in einer Bereitschaftswarteschlange mit einer höheren Priorität als der neuen Priorität des laufenden Threads.
Threadplanung
Kapitel 4
289
Wird die Threadpriorität dagegen nicht gesenkt, so wählt Windows den nächsten Thread aus
der Bereitschaftswarteschlange für die betreffende Priorität aus. Anschließend stellt es den bisherigen Thread ans Ende der Warteschlange, gibt ihm einen neuen Quantumswert und ändert
seinen Status von Wird ausgeführt in Bereit (siehe Abb. 4–16). Steht kein Thread derselben
Priorität bereit, dann darf der Thread noch ein weiteres Quantum lang laufen.
Priorität
Wird ausgeführt
Bereit
Abbildung 4–16 Threadplanung nach Ablauf eines Quantums
Wie Sie bereits gesehen haben, verlässt sich Windows zur Planung der Threads nicht auf ein
Quantum auf der Grundlage des Taktintervalltimers, sondern bestimmt die Quantumssollwerte
anhand des genauen CPU-Taktzykluszählers. Diesen Zähler nutzt es auch, um zu bestimmen,
ob es überhaupt angemessen ist, das Quantum eines Threads für beendet zu erklären. Eine
unangemessene Beendigung konnte früher vorkommen. Dies ist ein wichtiges Thema, das wir
erörtern müssen.
Bei der Planung auf der Grundlage des Taktintervalltimers kann folgende Situation auftreten:
1.
Die Threads A und B werden in der Mitte eines Intervalls ausführungsbereit. Da der Planungscode nicht nur bei jedem Taktintervall ausgeführt wird, tritt diese Situation häufig
auf.
2.
Thread A beginnt mit der Ausführung, wird aber eine Zeit lang unterbrochen. Die Zeit für
die Handhabung des Interrupts wird dem Thread zugeschlagen.
3.
Die Interruptverarbeitung endet, sodass Thread A wieder zu laufen beginnt. Dabei erreicht
er jedoch schnell das nächste Taktintervall. Der Scheduler muss annehmen, dass Thread A
die ganze Zeit ausgeführt worden ist, und schaltet zu Thread B um.
4.
Thread B beginnt mit der Ausführung und darf ein ganzes Taktintervall lang laufen (sofern
es nicht zu vorzeitiger Unterbrechung oder zu einem Interrupt kommt).
In diesem Beispiel wurde Thread A gleich zweifach ungerecht bestraft. Erstens wurde die Zeit
für die Handhabung eines Geräteinterrupts auf seine CPU-Zeit angerechnet, auch wenn der
Thread mit diesem Interrupt wahrscheinlich gar nichts zu tun hatte. (Interrupts werden immer
im Kontext des aktuellen Threads gehandhabt, wie Sie in Kapitel 6 noch sehen werden.) Außerdem wurde er für die Zeit bestraft, die das System vor seiner Einplanung in demselben Intervall
im Leerlauf zugebracht hat. Abb. 4–17 stellt diese Situation dar.
290
Kapitel 4
Threads
Threads A und B werden
bereit zur Ausführung
Thread A
Leerlauf
Thread B
Interrupt
Intervall 1
Intervall 2
Abbildung 4–17 Unfaire Zeitaufteilung in Windows-Versionen vor Vista
Moderne Windows-Versionen führen einen genauen Zähler der CPU-Taktzyklen, die der Thread
für die Arbeiten verwendet, für die er eingeplant wurde (was bedeutet, dass die Verarbeitung
von Interrupts dabei nicht mitgezählt wird). Sie merken sich auch einen Sollwert von Taktzyklen,
die der Thread am Ende seines Quantums verbraucht haben soll. Daher können die beiden unfairen Entscheidungen zulasten von Threads in dem vorherigen Abschnitt nicht mehr auftreten.
Stattdessen geschieht Folgendes:
1.
Die Threads A und B werden in der Mitte eines Intervalls ausführungsbereit.
2.
Thread A beginnt mit der Ausführung, wird aber eine Zeit lang unterbrochen. Die CPU-Taktzyklen für die Handhabung des Interrupts werden dem Thread nicht angerechnet.
3.
Die Interruptverarbeitung endet, sodass Thread A wieder zu laufen beginnt. Dabei erreicht
er jedoch schnell das nächste Taktintervall. Der Scheduler vergleicht die dem Thread angerechneten CPU-Taktzyklen mit dem Sollwert für das Ende des Quantums.
4.
Da die Anzahl der Taktzyklen viel kleiner ist, als sie sein sollte, geht der Scheduler davon
aus, dass Thread A in der Mittel eines Taktintervalls mit der Ausführung begonnen und
möglicherweise auch noch unterbrochen wurde.
5.
Das Quantum von Thread A wird um ein weiteres Taktintervall verlängert. Der Quantumssollwert wird neu berechnet. Jetzt hat Thread A die Chance, für ein komplettes Taktintervall
zu laufen.
6.
Am Ende des nächsten Taktintervalls hat Thread A sein Quantum erschöpft, weshalb
Thread B an die Reihe kommt.
Diesen Ablauf veranschaulicht Abb. 4–18.
Threads A und B werden
bereit zur Ausführung
Leerlauf
Thread A
Thread B
Intervall 2
Intervall 3
Interrupt
Intervall 1
Abbildung 4–18 Unfaire Zeitaufteilung in Windows-Versionen vor Vista
Threadplanung
Kapitel 4
291
Terminierung
Wenn die Ausführung eines Threads endet (weil er von seiner Hauptroutine zurückgesprungen
ist, ExitThread ausgerufen hat oder durch TerminateThread beendet wurde), wechselt er vom
Status Wird ausgeführt zu Abgebrochen. Sind keine Handles für das Threadobjekt mehr geöffnet, wird der Thread aus der Threadliste des Prozesses entfernt. Die Zuweisung der zugehörigen Datenstrukturen wird aufgehoben.
Leerlaufthreads
Wenn es auf einer CPU keinen ausführbaren Thread gibt, disponiert Windows den Leerlaufthread der CPU. Jede CPU hat ihren eigenen Leerlaufthread, da es auf einem Mehrprozessorsystem passieren kann, dass eine CPU einen Thread ausführt, während auf den anderen keine
Threads zur Verfügung stehen. Der Leerlaufthread einer CPU wird über einen Zeiger in ihrem
PRCB gefunden.
Alle Leerlaufthreads gehören zum Leerlaufprozess. Sowohl die Leerlaufthreads als auch
der Leerlaufprozess sind Sonderfälle, und das in mehrerer Hinsicht. Sie werden zwar durch
EPROCESS- und KPROCESS- bzw. ETHREAD- und KTHREAD-Strukturen dargestellt, aber es handelt
sich bei ihnen nicht um Exekutivprozesse und Threadobjekte. Der Leerlaufprozess steht auch
nicht in der Prozessliste des Systems. (Das ist auch der Grund, warum er in der Ausgabe des
Kerneldebuggerbefehls !process 00 nicht erscheint.) Allerdings lassen sich Leerlaufthreads und
ihr Prozess auf andere Weise finden.
Experiment: Die Strukturen der Leerlaufthreads und des
Leerlaufprozesses anzeigen
Die Strukturen der Leerlaufthreads und des Leerlaufprozesses können Sie im Kerneldebugger mit dem Befehl !pcr einsehen (Process Control Region). Er zeigt einen Teil der Informationen der PCR und des zugehörigen PRCBs an. !pcr nimmt ein einziges numerisches
Argument entgegen, nämlich die Nummer der CPU, deren PCR angezeigt werden soll. Der
Bootprozessor ist dabei Prozessor 0. Da er stets vorhanden ist, sollte !pcr 0 immer funk
tionieren. Die folgende Ausgabe zeigt das Ergebnis dieses Befehls auf einem 64-Bit-System
mit acht Prozessoren:
lkd> !pcr
KPCR for Processor 0 at fffff80174bd0000:
Major 1 Minor 1
NtTib.ExceptionList: fffff80176b4a000
NtTib.StackBase: fffff80176b4b070
NtTib.StackLimit: 000000000108e3f8
NtTib.SubSystemTib: fffff80174bd0000
NtTib.Version: 0000000074bd0180
NtTib.UserPointer: fffff80174bd07f0
NtTib.SelfTib: 00000098af072000
→
292
Kapitel 4
Threads
SelfPcr: 0000000000000000
Prcb: fffff80174bd0180
Irql: 0000000000000000
IRR: 0000000000000000
IDR: 0000000000000000
InterruptMode: 0000000000000000
IDT: 0000000000000000
GDT: 0000000000000000
TSS: 0000000000000000
CurrentThread: ffffb882fa27c080
NextThread: 0000000000000000
IdleThread: fffff80174c4c940
DpcQueue:
Zu dem Zeitpunkt, an dem dieser Speicherauszug aufgenommen wurde, hat CPU 0 einen
anderen als den Leerlaufthread ausgeführt, was Sie daran erkennen können, dass sich die
Zeiger CurrentThread und IdleThread unterscheiden. Auf einem Mehrprozessorsystem können Sie auch !pcr 1, !pcr 2 usw. ausprobieren, bis Sie alle Prozessoren durchlaufen haben.
Dabei werden Sie feststellen, dass sich die einzelnen IdleThread-Zeiger unterscheiden.
Wenden Sie nun den Befehl !thread auf die hervorgehobene Adresse des Leerlaufthreads an:
lkd> !thread fffff80174c4c940
THREAD fffff80174c4c940 Cid 0000.0000 Teb: 0000000000000000 Win32Thread:
0000000000000000 RUNNING on processor 0
Not impersonating
DeviceMap
ffff800a52e17ce0
Owning Process
fffff80174c4b940 Image: Idle
Attached Process
ffffb882e7ec7640 Image: System
Wait Start TickCount
1637993 Ticks: 30 (0:00:00:00.468)
Context Switch Count
25908837 IdealProcessor: 0
UserTime
00:00:00.000
KernelTime
05:51:23.796
Win32 Start Address nt!KiIdleLoop (0xfffff801749e0770)
Stack Init fffff80176b52c90 Current fffff80176b52c20
Base fffff80176b53000 Limit fffff80176b4d000 Call 0000000000000000
Priority 0 BasePriority 0 PriorityDecrement 0 IoPriority 0 PagePriority 5
Als Letztes wenden Sie den Befehl !process auf den Besitzerprozess an, der in der vorstehenden Ausgabe gezeigt wird. Der Kürze halber haben wir im folgenden Beispiel einen
zweiten Parameter mit dem Wert 3 angegeben, damit !process nur ein Minimum an Informationen über jeden Thread anzeigt:
lkd> !process fffff80174c4b940 3
PROCESS fffff80174c4b940
→
Threadplanung
Kapitel 4
293
SessionId: none Cid: 0000 Peb: 00000000 ParentCid: 0000
DirBase: 001aa000 ObjectTable: ffff800a52e14040 HandleCount: 2011.
Image: Idle
VadRoot ffffb882e7e1ae70 Vads 1 Clone 0 Private 7. Modified 1627.
Locked 0.
DeviceMap 0000000000000000
Token
ffff800a52e17040
ElapsedTime
07:07:04.015
UserTime
00:00:00.000
KernelTime
00:00:00.000
QuotaPoolUsage[PagedPool]
0
QuotaPoolUsage[NonPagedPool]
0
Working Set Sizes (now,min,max) (7, 50, 450) (28KB, 200KB, 1800KB)
PeakWorkingSetSize
1
VirtualSize
0 Mb
PeakVirtualSize
0 Mb
PageFaultCount
2
MemoryPriority
BACKGROUND
BasePriority
0
CommitCharge
0
THREAD fffff80174c4c940 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 0
THREAD ffff9d81e230ccc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 1
THREAD ffff9d81e1bd9cc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 2
THREAD ffff9d81e2062cc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 3
THREAD ffff9d81e21a7cc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 4
THREAD ffff9d81e22ebcc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 5
THREAD ffff9d81e2428cc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 6
THREAD ffff9d81e256bcc0 Cid 0000.0000 Teb: 0000000000000000
Win32Thread: 0000000000000000 RUNNING on processor 7
Diese Prozess- und Threadadressen können Sie auch für dt nt!_EPROCESS, dt nt!_KTHREAD
und ähnliche Befehle verwenden.
Das vorstehende Experiment zeigt einige der Anomalien im Zusammenhang mit dem Leerlaufprozess und seinen Threads. Im Debugger wird der Abbildname Idle angezeigt (der
294
Kapitel 4
Threads
aus dem Element ImageFileName der EPROCESS-Struktur entnommen ist), doch verschiedene
Windows-Hilfsprogramme geben andere Namen an – etwa System Idle Process (oder Leerlaufprozess) im Task-Manager und in Process Explorer oder System Process in tlist. Die Prozess-ID
und die Thread-IDs (die Client-IDs oder Cid-Werte in der Ausgabe des Debuggers) sind 0,
ebenso die PEB- und TEB-Zeiger und möglicherweise auch noch viele andere Felder des Leerlaufprozesses und seiner Threads. Da der Leerlaufprozess keinen Benutzermodus-Adressraum
hat und seine Threads keinen Benutzermoduscode ausführen, werden auch die sonst erforderlichen Daten zur Verwaltung einer Benutzermodusumgebung nicht gebraucht. Der Leerlaufprozess ist auch kein Prozessobjekt des Objekt-Managers, und die Leerlaufthreads sind
keine Threadobjekte. Stattdessen werden die Strukturen für den ersten Leerlaufthread und den
Leerlaufprozess statisch zugewiesen und zum Hochfahren des Systems verwendet, bevor der
Prozess- und der Objekt-Manager initialisiert sind. Die Strukturen der nachfolgenden Leerlaufthreads werden dynamisch zugewiesen (als einfache Zuweisungen vom nicht ausgelagerten
Pool, wobei der Objekt-Manager umgangen wird), wenn weitere Prozessoren online kommen.
Nachdem die Prozessverwaltung initialisiert ist, verwendet sie die besondere Variable PsIdleProcess, um auf den Leerlaufprozess zu verweisen.
Die vielleicht bemerkenswerteste Anomalie besteht darin, dass Windows als Priorität des
Leerlaufprozesses 0 angibt. In der Praxis sind die Prioritätswerte der Leerlaufthreads jedoch
ohne Bedeutung, da diese Threads nur dann ausgewählt werden, wenn keine anderen Threads
zur Ausführung anstehen. Ihre Priorität wird niemals mit der von anderen Threads verglichen
oder dazu herangezogen, einen Leerlaufthread in eine Bereitschaftswarteschlange zu stellen.
(Auf einem Windows-System läuft tatsächlich immer nur ein Thread mit der Priorität 0, nämlich
der Nullseitenthread, der in Kapitel 5 ausführlicher erläutert wird.)
Leerlaufthreads bilden nicht nur einen Sonderfall bei der Auswahl zur Ausführung, sondern
auch bei der vorzeitigen Unterbrechung. Die Routine KiIdleLoop eines Leerlaufthreads führt
eine Reihe von Operationen durch, die verhindern, dass er von einem anderen Thread auf die
übliche Weise vorzeitig unterbrochen wird. Stehen Nicht-Leerlaufthreads zur Ausführung auf
einem Prozessor bereit, wird der Prozessor in seinem PRCB als unbeschäftigt gekennzeichnet.
Wird ein Thread zur Ausführung auf diesem Prozessor ausgewählt, so wird seine Adresse im
Zeiger NextThread des PRCBs für diesen Prozessor gespeichert. Bei jedem Schleifendurchlauf
überprüft der Leerlaufthread diesen Zeiger.
Der grundlegende Ablauf der Operationen eines Leerlaufthreads sieht wie folgt aus, wobei
einige Einzelheiten jedoch von der jeweiligen Architektur abhängen (dies ist eine der wenigen
Routinen, die in Assembler statt in C geschrieben sind):
1.
Der Leerlaufthread lässt kurzzeitig Interrupts zu, damit ausstehende Interrupts ausgeliefert
werden können, und deaktiviert sie dann wieder (mit den Anweisungen STI und CLI auf
x86- und x64-Prozessoren). Das ist sinnvoll, da große Teile des Leerlaufthreads mit deaktivierten Interrupts ausgeführt werden.
2.
Im Testbuild auf einigen Architekturen prüft der Leerlaufthread, ob ein Kerneldebugger
versucht, einen Haltepunkt in dem System auszulösen. Wenn ja, gibt er ihm Zugriff.
3.
Der Leerlaufthread prüft, ob es auf dem Prozessor ausstehende DPCs gibt (siehe Kapitel 6).
Das kann der Fall sein, wenn die DPCs in eine Warteschlange gestellt, dabei aber keine
DPC-Interrupts generiert wurden. Sind ausstehende DPCs vorhanden, ruft die Leerlauf-
Threadplanung
Kapitel 4
295
schleife KiRetireDpcList auf, um sie auszuliefern. Das führt auch zu einem Ablauf der Timer und zur Verarbeitung der Liste von Threads mit dem Status Verzögert bereit (siehe den
Abschnitt »Mehrprozessorsysteme« weiter hinten). Der Start von KiRetireDpcList muss mit
deaktivierten Interrupts erfolgen, weshalb dieser Zustand am Ende von Schritt 1 hergestellt
wird. Auch bei der Beendigung von KiRetireDpcList sind Interrupts deaktiviert.
4.
Der Leerlaufthread prüft, ob die Verarbeitung des Quantumsendes angefordert worden ist.
Wenn ja, wird KiQuantumEnd aufgerufen, um diesen Vorgang durchzuführen.
5.
Der Leerlaufthread prüft, ob ein Thread zur Ausführung auf dem Prozessor ausgewählt
worden ist. Wenn ja, disponiert er den Thread. Das kann beispielsweise der Fall sein, wenn
ein in Schritt 3 verarbeiteter DPC oder Timerablauf den Wartevorgang eines Threads beendet hat oder wenn ein anderer Prozessor einen Thread für diesen Prozessor ausgewählt
hat, während die Leerlaufschleife ausgeführt wurde.
6.
Falls verlangt, prüft der Leerlaufthread, ob Threads auf anderen Prozessoren ausführungsbereit sind, und plant wenn möglich einen davon lokal ein. Dieser Vorgang wird im Abschnitt »Der Leerlaufscheduler« weiter hinten erklärt.
7.
Der Leerlaufthread ruft die registrierte Energieverwaltungsroutine des Prozessors auf (falls
Energieverwaltungsfunktionen ausgeführt werden müssen). Dabei handelt es sich entweder um den Prozessorenergietreiber (wie Intelppm.sys) oder, falls kein solcher Treiber zur
Verfügung steht, die HAL.
Anhalten von Threads
Mit den API-Funktionen SuspendThread und ResumeThread können Threads ausdrücklich angehalten und wieder aufgenommen werden. Jeder Thread verfügt über einen Anhaltezähler,
der durch Anhalten erhalten bleibt und durch Wiederaufnehmen verringert wird. Beträgt der
Zähler 0, kann der Thread ausgeführt werden, anderenfalls nicht.
Beim Anhalten wird dem Thread ein Kernel-APC vorangestellt. Wechselt der Thread zur
Ausführung, so wird zunächst dieser APC ausgeführt, der den Thread veranlasst, auf ein Ereignis zu warten, das bei der Wiederaufnahme des Threads signalisiert wird.
Dieser Anhaltemechanismus hat jedoch einen merklichen Nachteil, wenn sich der Thread
schon in einem Wartezustand befindet, während die Anforderung zum Anhalten hereinkommt,
denn dadurch muss der Thread erst aufwachen, damit er angehalten werden kann. Dabei kann
obendrein der Kernelstack des Threads wieder eingewechselt werden, falls er ausgelagert war.
In Windows 8.1 und Windows Server 2012 R2 wurde ein schlanker Anhaltemechanismus (Lightweight Suspend) eingeführt, damit ein Thread im Wartezustand nicht durch den APC-Mechanismus angehalten wird, sondern dadurch, dass das Threadobjekt im Arbeitsspeicher direkt
bearbeitet und als »angehalten« gekennzeichnet wird.
Einfrieren und Tiefgefrieren
Beim Einfrieren werden Prozesse in einen angehaltenen Zustand versetzt, aus dem sie durch
den Aufruf von ResumeThread für ihre Threads nicht hervorgeholt werden können. Das ist sinnvoll, wenn das System eine UWP-App anhalten muss. Dies geschieht, wenn eine Windows-
296
Kapitel 4
Threads
Anwendung in den Hintergrund verlagert wird. Im Tablet-Modus kann das passieren, wenn
eine andere Anwendung in den Vordergrund geholt wird, und im Desktop-Modus, wenn die
Anwendung minimiert wird. In einem solchen Fall räumt das System der Anwendung etwa fünf
Sekunden ein, um noch gewisse Arbeiten zu verrichten, gewöhnlich um den Anwendungsstatus
zu speichern. Das ist wichtig, da Windows-Apps ohne Vorwarnung beendet werden können,
wenn die Speicherressourcen zur Neige gehen. Beim nächsten Start der Anwendung kann dieser Status dann wieder geladen werden, sodass es für den Benutzer aussieht, als wäre sie gar
nicht weg gewesen. Beim Einfrieren eines Prozesses werden alle Threads so angehalten, dass
sie mit ResumeThread nicht wieder aufgeweckt werden können. Ein Flag in der KTHREAD-Struktur
gibt an, ob der Thread eingefroren ist. Damit ein Thread ausgeführt werden kann, muss sein
Anhaltezähler 0 betragen und das Flag frozen darf nicht gesetzt sein.
Beim Tiefgefrieren können auch neu erstellte Threads in dem Prozess nicht gestartet werden. Wenn Sie beispielsweise CreateRemoteThreadEx aufrufen, um einen neuen Thread in einem
tiefgefrorenen Prozess anzulegen, so wird dieser Thread schon eingefroren, bevor er startet.
Das ist die übliche Vorgehensweise beim Einfrieren.
Die Möglichkeiten zum Einfrieren von Prozessen und Threads werden im Benutzermodus
nicht direkt bereitgestellt, sondern intern vom PSM-Dienst genutzt (Process State Manager),
der dafür zuständig ist, die Anforderungen zum Tiefgefrieren und Auftauen an den Kernel zu
senden.
Prozesse können Sie auch über die Jobs einfrieren. Die Möglichkeit, einen Job einzufrieren
und aufzutauen, ist nicht öffentlich dokumentiert, steht aber mit dem Standardsystemaufruf
NtSetInformationJobObject zur Verfügung. Er wird gewöhnlich für Windows-Anwendungen
genutzt, da alle Prozesse solcher Anwendungen in Jobs enthalten sind. Ein Job kann einen
einzigen Prozess enthalten (die Windows-Anwendung selbst), aber auch Hintergrundprozesse
für die Anwendung. Mit dem genannten Aufruf können alle Prozesse in dem Job auf einmal
eingefroren oder aufgetaut werden. (Mehr über Windows-Anwendungen erfahren Sie in Kapitel 8 von Band 2.)
Experiment: Tiefgefrieren
In diesem Experiment debuggen Sie eine virtuelle Maschine und beobachten dabei einen
Tiefgefriervorgang.
1.
Öffnen Sie WinDbg mit Administratorrechten und verbinden Sie den Debugger mit
einer virtuellen Maschine mit Windows 10.
2.
Drücken Sie (Strg) + (Untbr), um sich in die Ausführung der VM einzuklinken.
3.
Setzen Sie einen Haltepunkt an der Stelle, an der das Tiefgefrieren beginnt. Verwenden
Sie dazu einen Befehl, der zeigt, dass der Prozess eingefroren ist:
bp nt!PsFreezeProcess "!process -1 0; g"
4.
Geben Sie den Befehl g ein (go) oder drücken Sie (F5). Sie sollten jetzt viele Vorkommen von Tiefgefriervorgängen sehen.
→
Threadplanung
Kapitel 4
297
5.
Starten Sie die Cortana-Benutzeroberfläche über die Taskleiste und schließen Sie sie.
Nach ungefähr fünf Sekunden sollten Sie folgende Ausgabe sehen:
PROCESS 8f518500 SessionId: 2 Cid: 12c8 Peb: 03945000 ParentCid: 02ac
DirBase: 054007e0 ObjectTable: b0a8a040 HandleCount: 988.
Image: SearchUI.exe
6.
Wechseln Sie wieder in den Debugger und lassen Sie sich weitere Informationen über
den Prozess anzeigen:
1: kd> !process 8f518500 1
PROCESS 8f518500 SessionId: 2 Cid: 12c8 Peb: 03945000 ParentCid: 02ac
DeepFreeze
DirBase: 054007e0 ObjectTable: b0a8a040 HandleCount: 988.
Image: SearchUI.exe
VadRoot 95c1ffd8 Vads 405 Clone 0 Private 7682.
Modified 201241. Locked 0.
DeviceMap a12509c0
Token
b0a65bd0
ElapsedTime
04:02:33.518
UserTime
00:00:06.937
KernelTime
00:00:00.703
QuotaPoolUsage[PagedPool]
562688
QuotaPoolUsage[NonPagedPool]
34392
Working Set Sizes (now,min,max) (20470, 50, 345) (81880KB, 200KB,
1380KB)
7.
PeakWorkingSetSize
25878
VirtualSize
367 Mb
PeakVirtualSize
400 Mb
PageFaultCount
307764
MemoryPriority
BACKGROUND
BasePriority
8
CommitCharge
8908
Job
8f575030
Beachten Sie das Attribut DeepFreeze, das der Debugger schreibt. Da der Prozess Teil eines Jobs ist, können Sie sich mit dem Befehl !job weitere Einzelheiten anzeigen lassen:
1: kd> !job 8f575030
Job at 8f575030
Basic Accounting Information
TotalUserTime:
0x0
TotalKernelTime:
0x0
TotalCycleTime:
0x0
ThisPeriodTotalUserTime:
0x0
→
298
Kapitel 4
Threads
ThisPeriodTotalKernelTime: 0x0
TotalPageFaultCount:
0x0
TotalProcesses:
0x1
ActiveProcesses:
0x1
FreezeCount:
1
BackgroundCount:
0
TotalTerminatedProcesses:
0x0
PeakJobMemoryUsed:
0x38e2
PeakProcessMemoryUsed:
0x38e2
Job Flags
[cpu rate control]
[frozen]
[wake notification allocated]
[wake notification enabled]
[timers virtualized]
[job swapped]
Limit Information (LimitFlags: 0x0)
Limit Information (EffectiveLimitFlags: 0x3000)
CPU Rate Control
Rate = 100.00%
Scheduling Group: a469f330
8.
Der Job unterliegt der CPU-Ratensteuerung (siehe den Abschnitt »Grenzwerte für die
CPU-Rate« weiter hinten in diesem Kapitel) und ist eingefroren. Lösen Sie die Verbindung zur VM und schließen Sie den Debugger.
Threadauswahl
Wenn ein logischer Prozessor den nächsten auszuführenden Thread auswählen muss, ruft er die
Schedulerfunktion KiSelectNextThread auf. Das kann in verschiedenen Situationen geschehen:
QQ Ein harter Affinitätswechsel ist aufgetreten, sodass der zurzeit laufende Thread oder der
Standbythread nicht mehr auf dem betreffenden logischen Prozessor ausgeführt werden
kann. Aus diesem Grund muss ein anderer ausgewählt werden.
QQ Der zurzeit laufende Thread ist am Ende seines Quantums angekommen, und der SMTSatz, auf dem er ausgeführt wurde, ist beschäftigt, während sich andere SMT-Sätze innerhalb des idealen Knotens im Leerlauf befinden. (SMT oder symmetrisches Multithreading
ist die technische Bezeichnung für die in Kapitel 2 beschriebene Hyperthreading-Technologie.) Der Scheduler verlagert den Thread, da sein Quantum erschöpft ist, weshalb ein
neuer ausgewählt werden muss.
QQ Ein Wartevorgang ist beendet, und im Wartestatusregister befinden sich ausstehende Planungsoperationen (anders ausgedrückt, die Prioritäts- und/oder Affinitätsbits sind gesetzt).
Threadplanung
Kapitel 4
299
In diesen Situationen geht der Scheduler wie folgt vor:
QQ Der Scheduler ruft KiSelectReadyThreadEx auf, um nach dem nächsten ausführungsbereiten Thread zu suchen, der auf dem Prozessor ausgeführt werden kann, und um zu prüfen,
ob einer gefunden wurde.
QQ Wurde kein ausführungsbereiter Thread gefunden, wird der Leerlaufscheduler eingeschaltet und der Leerlaufthread zur Ausführung ausgewählt. Anderenfalls wird der ausführungsbereite Thread in die lokale oder die gemeinsam genutzte Bereitschaftswarteschlange gestellt.
Die Operation KiSelectNextThread wird nur dann ausgeführt, wenn der logische Prozessor den
nächsten planbaren Thread auswählen, aber noch nicht ausführen muss (weshalb der Thread
in die Bereitschaftswarteschlange gestellt wird). Es kann jedoch auch sein, dass der logische
Prozessor den nächsten Thread sofort ausführen oder, falls kein solcher verfügbar ist, eine andere Aktion erledigen möchte, anstatt in den Leerlauf überzugehen. Das kann unter folgenden
Umständen geschehen:
QQ Aufgrund eines Prioritätswechsels ist der Standbythread oder der laufende Thread nicht
mehr der ausführungsbereite Thread mit höchster Priorität auf dem logischen Prozessor.
Das bedeutet, dass jetzt ein ausführungsbereiter Thread mit höherer Priorität ausgeführt
werden muss.
QQ Der Thread hat den Prozessor mit YieldProcessor oder NtYieldExecution ausdrücklich aufgegeben und es steht möglicherweise ein anderer Thread zur Ausführung bereit.
QQ Das Quantum des aktuellen Threads ist abgelaufen und andere Threads auf derselben
Prioritätsstufe müssen die Gelegenheit zur Ausführung bekommen.
QQ Ein Thread hat seine Prioritätserhöhung verloren, was zu einer ähnlichen Prioritätserhöhung führt wie im ersten Punkt.
QQ Der Leerlaufscheduler läuft und prüft, ob zwischen der Anforderung und der Ausführung
der Leerlaufplanung ein ausführungsbereiter Thread erschienen ist.
Um herauszufinden, welche Routine jeweils eingesetzt wird, müssen Sie überlegen, ob der logische Prozessor einen anderen Thread ausführen muss (wobei KiSelectNextThread aufgerufen
wird) oder ob ein anderer Thread nach Möglichkeit ausgeführt werden soll (in diesem Fall wird
KiSelectReadyThreadEx verwendet). Da jeder Prozessor zu einer gemeinsamen Bereitschaftswarteschlange gehört (auf die der KPRCB zeigt), kann KiSelectReadyThreadEx in jedem Fall
einfach die Warteschlangen des aktuellen logischen Prozessors prüfen und den ersten Thread
höchster Priorität entnehmen, den sie findet, sofern seine Priorität geringer als diejenige des
laufenden Threads ist (sofern der laufende Thread immer noch ausgeführt werden darf, was bei
der Verwendung von KiSelectNextThread nicht der Fall ist). Gibt es keinen Thread höherer Priorität (oder überhaupt keine ausführungsbereiten Threads), wird kein Thread zurückgegeben.
300
Kapitel 4
Threads
Der Leerlaufscheduler
Wenn der Leerlaufthread läuft, prüft er, ob die Leerlaufplanung aktiviert worden ist. Wenn ja,
ruft er KiSearchForNewThread auf, um die Bereitschaftswarteschlangen der anderen Prozessoren
nach Threads zu durchsuchen, die ausgeführt werden können. Die Laufzeitkosten für diese
Operation werden nicht als Zeit für den Leerlaufthread angerechnet, sondern dem Prozessor
als Interrupt- und DPC-Zeit. Die Leerlaufplanungszeit wird also als Systemzeit betrachtet. Der
Algorithmus von KiSearchForNewThread basiert auf den zuvor in diesem Abschnitt beschriebenen Funktionen und wird in Kürze erklärt.
Mehrprozessorsysteme
Auf einem Einprozessorsystem ist die Threadplanung relativ einfach: Es wird stets derjenige der
bereitstehenden Threads ausgeführt, der die höchste Priorität aufweist. Bei einem Mehrprozessorsystem ist die Lage jedoch etwas kniffliger, da Windows versucht, einen Thread auf dem
am besten für ihn geeigneten Prozessor einzuplanen, wobei der bevorzugte und der vorherige
Prozessor des Threads und die Konfiguration des Systems berücksichtigt werden. Windows
versucht zwar nach wie vor, auf allen verfügbaren CPUs jeweils den lauffähigen Thread mit der
höchsten Priorität auszuführen, kann aber nur garantieren, dass einer der Threads höchster Priorität irgendwo ausgeführt wird. Bei der Verwendung gemeinsamer Bereitschaftswarteschlangen (für Threads ohne Affinitätseinschränkungen) ist die Garantie stärker: Auf jeder Gruppe
von Prozessoren wird mindestens einer der Threads höchster Priorität ausgeführt.
Bevor wir den Algorithmus beschreiben, der auswählt, welche Threads wann und wo ausgeführt werden, schauen wir uns jedoch die zusätzlichen Informationen an, mit denen Windows
auf den drei unterstützten Arten von Mehrprozessorsystemen (SMT, Mehrkernsysteme und
NUMA) den Überblick über die Thread- und Prozessorstatus behält.
Paket- und SMT-Sätze
In Topologien mit logischen Prozessoren zieht Windows fünf Felder im KPRCB heran, um
Threadplanungsentscheidungen zu treffen. Das erste Feld, CoresPerPhysicalProcessor, gibt
an, ob der logische Prozessor Teil eines Mehrkernpakets ist. Es wird aus der vom Prozessor
zurückgegebenen CPU-ID berechnet und auf eine Zweierpotenz gerundet. Das zweite Feld,
LogicalProcessorsPerCore, gibt an, ob der logische Prozessor zu einem SMT-Satz gehört, wie
es bei Intel-Prozessoren mit aktiviertem Hyperthreading der Fall ist. Es wird ebenfalls aufgrund
der CPU-ID bestimmt und gerundet. Die Multiplikation dieser beiden Felder ergibt die Anzahl
der logischen Prozessoren pro Paket, also pro physischem Prozessor auf einem Sockel. Damit
füllt der PRCB sein Feld PackageProcessorSet aus. Dies ist die Affinitätsmaske, die angibt, welche
anderen logischen Prozessoren in der Gruppe (Pakete sind auf eine Gruppe beschränkt) zum
selben physischen Prozessor gehören. Auf ähnliche Weise werden logische Prozessoren über
den Wert CoreProcessorSet mit demselben Kern verbunden, was als SMT-Satz bezeichnet wird.
Der Wert GroupSetMember schließlich legt fest, welche Bitmaske in der aktuellen Prozessorgruppe für den vorliegenden logischen Prozessor steht. Beispielsweise hat der logische Prozessor 3
normalerweise den GroupSetMember-Wert 8 (23).
Threadplanung
Kapitel 4
301
Experiment: Informationen über logische Prozessoren einsehen
Mit dem Kerneldebuggerbefehl !smt können Sie sich ansehen, welche Informationen
Windows über SMT-Prozessoren führt. Die folgende Ausgabe stammt von einem Intel Core
i7-Vierkernsystem mit SMT und acht logischen Prozessoren:
lkd> !smt
SMT Summary:
-----------KeActiveProcessors:
********-------------------------------------------------------(00000000000000ff)
IdleSummary:
-****--*-------------------------------------------------------(000000000000009e)
No PRCB SMT Set APIC Id
0 fffff803d7546180 **------------------------------- (0000000000000003)
0x00000000
1 ffffba01cb31a180 **------------------------------- (0000000000000003)
0x00000001
2 ffffba01cb3dd180 --**----------------------------- (000000000000000c)
0x00000002
3 ffffba01cb122180 --**----------------------------- (000000000000000c)
0x00000003
4 ffffba01cb266180 ----**--------------------------- (0000000000000030)
0x00000004
5 ffffba01cabd6180 ----**--------------------------- (0000000000000030)
0x00000005
6 ffffba01cb491180 ------**------------------------- (00000000000000c0)
0x00000006
7 ffffba01cb5d4180 ------**------------------------- (00000000000000c0)
0x00000007
Maximum cores per physical processor: 8
Maximum logical processors per core: 2
NUMA-Systeme
Windows unterstützt auch Mehrprozessorsysteme mit nicht gleichförmiger Speicherarchitektur
(Non-Uniform Memory Architecture, NUMA). Dabei sind die Prozessoren zu Einheiten gruppiert, die als Knoten bezeichnet werden. Jeder Knoten verfügt über seine eigenen Prozessoren
und seinen eigenen Arbeitsspeicher und ist über einen cachekohärenten Bus mit dem umfas-
302
Kapitel 4
Threads
senderen System verbunden. Die Systeme werden als nicht gleichförmig bezeichnet, da jeder
Knoten über seinen eigenen Hochgeschwindigkeitsspeicher verfügt. Jeder Prozessor kann zwar
unabhängig von seinem Knoten auf den gesamten Arbeitsspeicher zugreifen, doch lokaler
Knotenspeicher ist viel schneller zugänglich.
Die Informationen über die einzelnen Knoten eines NUMA-Systems führt der Kernel
in KNODE-Datenstrukturen. Die Kernelvariable KeNodeBlock ist ein Array aus Zeigern auf die
KNODE-Strukturen der einzelnen Knoten. Das KNODE-Format können Sie mit dem Kerneldebuggerbefehl dt wie folgt ermitteln:
lkd> dt nt!_KNODE
+0x000 IdleNonParkedCpuSet
: Uint8B
+0x008 IdleSmtSet
: Uint8B
+0x010 IdleCpuSet
: Uint8B
+0x040 DeepIdleSet
: Uint8B
+0x048 IdleConstrainedSet
: Uint8B
+0x050 NonParkedSet
: Uint8B
+0x058 ParkLock
: Int4B
+0x05c Seed
: Uint4B
+0x080 SiblingMask
: Uint4B
+0x088 Affinity
: _GROUP_AFFINITY
+0x088 AffinityFill
: [10] UChar
+0x092 NodeNumber
: Uint2B
+0x094 PrimaryNodeNumber
: Uint2B
+0x096 Stride
: UChar
+0x097 Spare0
: UChar
+0x098 SharedReadyQueueLeaders : Uint8B
+0x0a0 ProximityId
: Uint4B
+0x0a4 Lowest
: Uint4B
+0x0a8 Highest
: Uint4B
+0x0ac MaximumProcessors
: UChar
+0x0ad Flags
: _flags
+0x0ae Spare10
: UChar
+0x0b0 HeteroSets
: [5] _KHETERO_PROCESSOR_SET
Experiment: NUMA-Informationen anzeigen
Die Informationen, die Windows über die einzelnen Knoten eines NUMA-Systems führt,
können Sie mit dem Kerneldebuggerbefehl !numa einsehen. Wenn Sie keine NUMA-Hardware haben, können Sie zur Durchführung dieses Experiments in Hyper-V eine virtuelle
Maschine so einrichten, dass sie mehr als einen NUMA-Knoten verwendet. Allerdings benötigen Sie dazu einen Hostcomputer mit mehr als vier logischen Prozessoren. Gehen Sie
wie folgt vor:
→
Threadplanung
Kapitel 4
303
1.
Klicken Sie auf Start, geben Sie hyper ein und klicken Sie auf Hyper-V-Manager.
2.
Vergewissern Sie sich, dass die VM ausgeschaltet ist, da Sie die folgenden Änderungen
sonst nicht vornehmen können.
3.
Rechtsklicken Sie im Hyper-V-Manager auf die VM und wählen Sie Einstellungen.
4.
Klicken Sie auf Arbeitsspeicher und deaktivieren Sie Dynamischer Arbeitsspeicher.
5.
Klicken Sie auf Prozessor und geben Sie 4 in das Feld Anzahl virtueller Prozessoren ein.
6.
Erweitern Sie Prozessor und wählen Sie NUMA.
7.
Geben Sie in die Felder Maximale Prozessoranzahl und Maximale Anzahl von NUMA-
Knoten in einem Socket jeweils 2 ein.
8.
Klicken Sie auf OK, um die Einstellungen zu speichern.
9.
Starten Sie die VM.
10. Geben Sie in einem Kerneldebugger den Befehl !numa ein. Die folgende Ausgabe
stammt von der in diesem Experiment eingerichteten VM:
2: kd> !numa
NUMA Summary:
-----------Number of NUMA nodes : 2
Number of Processors : 4
unable to get nt!MmAvailablePages
MmAvailablePages
: 0x00000000
KeActiveProcessors
:
****---------------------------- (0000000f)
→
304
Kapitel 4
Threads
NODE 0 (FFFFFFFF820510C0):
Group
: 0 (Assigned, Committed, Assignment Adjustable)
ProcessorMask : **------------------------------ (00000003)
ProximityId
: 0
Capacity
: 2
Seed
: 0x00000001
IdleCpuSet
: 00000003
IdleSmtSet
: 00000003
NonParkedSet
: 00000003
Unable to get MiNodeInformation
NODE 1 (FFFFFFFF8719E0C0):
Group
: 0 (Assigned, Committed, Assignment Adjustable)
ProcessorMask : --**---------------------------- (0000000c)
ProximityId
: 1
Capacity
: 2
Seed
: 0x00000003
IdleCpuSet
: 00000008
IdleSmtSet
: 00000008
NonParkedSet
: 0000000c
Unable to get MiNodeInformation
Anwendungen, die aus einem NUMA-System die bestmögliche Leistung herausholen wollen,
bemühen sich, einen Prozess auf die Prozessoren eines bestimmten Knotens zu beschränken,
indem sie die Affinitätsmaske entsprechend festlegen. Allerdings beschränkt Windows aufgrund seines NUMA-fähigen Threadplanungsalgorithmus ohnehin fast alle Threads auf einen
einzigen NUMA-Knoten.
Wie die Planungsalgorithmen die Besonderheiten eines NUMA-Systems berücksichtigen,
beschreiben wir weiter hinten in diesem Kapitel im Abschnitt »Prozessorauswahl«. Die Optimierungen, mit denen der Speicher-Manager die Vorteile des lokalen Knotenspeichers nutzt,
werden in Kapitel 5 behandelt.
Prozessorgruppenzuweisung
Windows fragt die Topologie des Systems ab, um die Beziehungen zwischen den logischen
Prozessoren, SMT-Sätzen, Mehrkernpaketen und physischen Sockeln aufzubauen. Dabei weist
es die Prozessoren ihren Gruppen zu, die zur Beschreibung der Affinität herangezogen werden
(durch die bereits vorgestellte erweiterte Affinitätsmaske). Diese Arbeit erledigt die Routine
KePerformGroupConfiguration, die bei der Initialisierung noch vor jeglichen anderen Arbeiten in
Phase 1 aufgerufen wird. Der Vorgang läuft in folgenden Schritten ab:
1.
Die Funktion fragt alle erkannten Knoten ab (KeNumberNodes) und berechnet jeweils deren
Kapazität, also die Anzahl der logischen Prozessoren, die sie aufnehmen können. Dieser
Wert wird im Array KeNodeBlock, das alle NUMA-Knoten auf dem System beschreibt, in
Threadplanung
Kapitel 4
305
MaximumProcessors gespeichert. Ermöglicht das System die Verwendung von NUMA-NäheIDs, so wird auch die Nähe-ID eines jeden Knotens abgefragt und in dem Knotenblock
gespeichert.
2.
Das NUMA-Abstandsarray wird zugewiesen (KeNodeDistance) und die Abstände zwischen
den einzelnen NUMA-Knoten werden berechnet.
Die nächsten Schritte betreffen Benutzerkonfigurationsoptionen, die die NUMA-Standardzuordnungen überschreiben können. Stellen Sie sich beispielsweise ein System mit Hyper-V
vor, auf dem der Hypervisor für den automatischen Start eingerichtet ist. Wenn die CPU
die erweiterte Hypervisorschnittstelle nicht unterstützt, wird nur eine Prozessorgruppe aktiviert. Alle NUMA-Knoten (so viele, wie passen) werden Gruppe 0 zugeordnet. In diesem
Fall kann Hyper-V daher die Vorteile von Computern mit mehr als 64 Prozessoren nicht
nutzen.
3.
Die Funktion prüft, ob Daten für statische Gruppenzuweisungen vom Lader übergeben
wurden (was bedeutet, dass sie vom Benutzer konfiguriert wurden). Diese Daten geben die
Näheinformationen und die Gruppenzuordnungen für die einzelnen NUMA-Knoten an.
Wenn Sie auf großen NUMA-Servern eine genauere Kontrolle über die Näheinformationen und Gruppenzuordnungen benötigen, etwa für Tests oder Validierungen,
können Sie diese Daten über die Registrierungswerte Group Assignment und Node
Distance im Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\NUMA festlegen. Das
Format dieser Daten schließt einen Zähler ein, auf den das Array mit den Nähe-IDs
und Gruppenzuordnungen folgt. Die Arrayelemente sind allesamt 32-Bit-Werte.
4.
Bevor der Kernel die Daten als gültig einstuft, vergleicht er die Nähe-ID mit der Knotennummer. Anschließend ordnet er die Gruppennummern wie verlangt zu. Er sorgt dafür,
dass der NUMA-Knoten 0 der Gruppe 0 zugeordnet wird und dass die Kapazität aller
NUMA-Knoten der Gruppengröße entspricht. Schließlich prüft die Funktion, wie viele
Gruppen noch Kapazitäten frei haben.
Der NUMA-Knoten 0 wird unter allen Umständen Gruppe 0 zugeordnet.
5.
306
Der Kernel versucht, die NUMA-Knoten dynamisch zu den Gruppen zuzuweisen, wobei er
jedoch jegliche statischen Konfigurationen berücksichtigt, die ihm wie zuvor beschrieben
übergeben wurden. Normalerweise bemüht sich der Kernel, die Anzahl der Gruppen zu
minimieren, indem er jeweils so viele NUMA-Knoten wie möglich in eine Gruppe aufnimmt. Wenn dieses Verhalten nicht erwünscht ist, können Sie es jedoch mit dem Laderparameter /MAXGROUP ändern, der über die BCD-Option maxgroup eingestellt wird. Damit
wird das Standardverhalten überschrieben, sodass der Algorithmus nun versucht, so viele
NUMA-Knoten wie möglich auf so viele Gruppen wie möglich zu verteilen, wobei jedoch
ein Grenzwert von maximal 20 Gruppen gilt. Gibt es nur einen Knoten oder passen alle
Knoten in eine einzige Gruppe (und ist maxgroup ausgeschaltet), ordnet das System alle
Knoten standardmäßig der Gruppe 0 zu.
Kapitel 4
Threads
6.
Bei mehr als einem Knoten prüft Windows die statischen NUMA-Knotenabstände (falls
vorhanden) und sortiert die Knoten nach ihrer Kapazität, wobei die größten Knoten am
Anfang stehen. Im Modus mit Minimierung der Gruppenanzahl ermittelt der Kernel die
maximale Anzahl der möglichen Prozessoren, indem er alle Kapazitäten addiert. Das Ergebnis teilt der Kernel durch die Anzahl der Prozessoren pro Gruppe und erhält dadurch
die Gesamtanzahl der Gruppen auf dem Computer (die allerdings auf einen Höchstwert
von 20 begrenzt ist). Im Modus mit Maximierung der Gruppenanzahl geht der Kernel
zunächst davon aus, dass es ebenso viele Gruppen wie Knoten gibt (wiederum bis zum
Höchstwert von 20).
7.
Der Kernel beginnt mit dem endgültigen Zuordnungsvorgang. Alle früheren festen Zuordnungen werden jetzt bestätigt, und die Gruppen für diese Zuordnungen werden erstellt.
8.
Alle NUMA-Knoten werden neu gemischt, um die Abstände zwischen den Knoten in einer
Gruppe zu minimieren. Das heißt, nah beieinander stehende Knoten werden in dieselbe
Gruppe gestellt und nach Abstand geordnet.
9.
Der gleiche Vorgang wird für alle dynamischen Zuordnungen von Knoten zu Gruppen
durchgeführt.
10. Alle restlichen leeren Knoten werden Gruppe 0 zugeordnet.
Anzahl der logischen Prozessoren pro Gruppe
Gewöhnlich weist Windows einer Gruppe 64 Prozessoren zu. Dies können Sie jedoch mithilfe
der Laderoptionen /GROUPSIZE ändern, die über das BCD-Element groupsize eingestellt wird.
Durch die Angabe einer Zweierpotenz können Sie dafür sorgen, dass die Gruppen weniger
Prozessoren als üblich enthalten, etwa um die Gruppennutzung des Systems zu testen. Auf einem System mit acht logischen Prozessoren können Sie dadurch eine, zwei oder vier Gruppen
einrichten. Darüber hinaus können Sie mit der Option /FORCEGROUPAWARE (BCD-Element groupaware) dafür sorgen, dass der Kernel Gruppe 0 nach Möglichkeit vermeidet, sondern stattdessen
bei Tätigkeiten wie der Affinitätsauswahl für Threads und DPCs und die Gruppenzuweisung
von Prozessen die höchste verfügbare Gruppennummer vergibt. Vermeiden Sie es aber, eine
Gruppengröße von 1 anzugeben, da Sie dadurch praktisch alle Anwendungen auf dem System
dazu zwingen würden, sich so zu verhalten, als liefen sie auf einem Einzelprozessorcomputer.
Das liegt daran, dass der Kernel die Affinitätsmaske eines Prozesses bei dieser Einstellung so
einrichtet, dass sie nur eine einzige Gruppe einschließt, sofern die Anwendung nichts anderes
verlangt (was die meisten nicht tun).
Wenn die Anzahl der logischen Prozessoren auf einem Paket nicht in eine einzige Gruppe passt, ändert Windows diese Anzahl, um sie passend zu machen. Dazu verkleinert es
den Wert von CoresPerPhysicalProcessor und, falls der SMT-Satz nicht passt, auch den von
LogicalProcessorsPerCore. Eine Ausnahme besteht, wenn das System mehrere NUMA-Knoten in einem Paket enthält (was zwar unüblich, aber durchaus möglich ist). In solchen Multichipmodulen (MCMs) befinden sich zwei Sätze von Kernen sowie zwei Speichercontroller
auf demselben Die/Paket. Wenn die ACPI-SRAT (statische Ressourcenaffinitätstabelle) angibt,
dass das MCM über zwei NUMA-Knoten verfügt, kann Windows die beiden Knoten zwei
Threadplanung
Kapitel 4
307
verschiedenen Gruppen zuordnen (was vom Gruppenkonfigurationsalgorithmus abhängt).
In einem solchen Fall ist es möglich, dass das MCM-Paket mehr als eine Gruppe überspannt.
Diese Optionen können erhebliche Treiber- und Anwendungskompatibilitätsprobleme
hervorrufen. Tatsächlich sind sie zur Verwendung durch Entwickler gedacht, um solche Probleme zu erkennen und auszumerzen. Darüber hinaus haben diese Optionen jedoch noch
eine starke Auswirkung auf den Computer, denn sie erzwingen NUMA-Verhalten auch auf
Nicht-NUMA-Rechnern. Wie Sie im Zuordnungsalgorithmus gesehen haben, lässt Windows es
niemals zu, dass ein NUMA-Knoten mehrere Gruppen überspannt. Wenn der Kernel nun aber
künstlich kleine Gruppen erstellt, müssen die Gruppen jeweils über ihren eigenen NUMA-Knoten verfügen. Beispielsweise werden auf einem Vierkernprozessor mit der Gruppengröße 2 zwei
Gruppen und damit auch zwei NUMA-Knoten als Unterknoten des Hauptknotens erstellt. Das
beeinflusst die Richtlinien zur Threadplanung und Speicherverwaltung auf die gleiche Weise
wie eine echte NUMA-Architektur, was für Testzwecke praktisch sein kann.
Status der logischen Prozessoren
Neben den gemeinsamen und lokalen Bereitschaftswarteschlangen und -übersichten unterhält
Windows die beiden folgenden zwei Bitmasken, die den Status der Prozessoren auf dem System verfolgen (siehe den Abschnitt »Prozessorauswahl« weiter hinten):
QQ KeActiveProcessors Dies ist die Maske der aktiven Prozessoren, in der für jeden verwendbaren Prozessor auf dem System ein Bit gesetzt wird. Dies können weniger Prozessoren sein, als der Computer tatsächlich hat, wenn die Lizenzierungsgrenzwerte von Windows
nur eine geringere Anzahl von Prozessoren zulassen. Anhand der Variablen KeRegisteredProcessors können Sie nachschauen, wie viele Prozessoren auf dem Computer tatsächlich
lizenziert sind. Mit dem Begriff »Prozessor« sind hier die physischen Pakete gemeint.
QQ KeMaximumProcessors Dies ist die Höchstzahl an gebundenen logischen Prozessoren
innerhalb der Lizenzierungsgrenzen (einschließlich aller möglichen zukünftigen dynamischen Prozessorergänzungen). Sie gibt auch Plattformbeschränkungen an, die ggf. durch
einen Aufruf der HAL und die Überprüfung der ACPI-SRAT abgefragt werden können.
Zu den Knotendaten (KNODE) gehören auch Angaben über die im Leerlauf befindlichen CPUs
in dem Knoten (IdleCpuSet), über die nicht geparkten CPUs (IdleNonParkedCpuSet) und über
SMT-Sätze im Leerlauf (IdleSmtSet).
Skalierbarkeit des Schedulers
Auf einem Mehrprozessorsystem kann es vorkommen, dass ein Prozessor Datenstrukturen für
die Threadplanung eines anderen Prozessors ändern muss, etwa wenn er einen Thread einfügt,
der nur auf einem bestimmten Prozessor laufen kann. Aus diesem Grund werden die Strukturen
durch Warteschlangen-Spinlocks auf der Ebene DISPATCH_LEVEL für die einzelnen PRCBs synchronisiert. Die Threadauswahl kann daher weitergehen, während nur der PRCB des Prozessors
gesperrt ist. Bei Bedarf kann auch der PRCB eines weiteren Prozessors gesperrt werden, etwa
beim Threaddiebstahl (siehe die Erklärung weiter hinten). Threadkontextwechsel werden auch
durch feinere Spinlocks für einzelne Threads synchronisiert.
308
Kapitel 4
Threads
Es gibt auch für jede CPU eine Liste von Threads im Status Verzögert bereit (DeferredReadyListHead). Diese Threads sind zum Laufen bereit, wurden aber noch nicht zur Ausführung fertig
gemacht. Die tatsächliche Bereitstellungsoperation wurde auf einen späteren Zeitpunkt verschoben. Da jeder Prozessor seine eigene Liste von Threads mit verzögerter Bereitschaft führt,
wird sie nicht von dem PRCB-Spinlock synchronisiert. Sie wird von KiProcessDeferredReadyList
verarbeitet, nachdem eine Funktion bereits Änderungen an der Prozess- oder Threadaffinität,
an der Priorität (einschließlich Prioritätserhöhungen) oder den Quantumswerten vorgenommen hat.
Diese Funktion ruft für jeden Thread auf der Liste KiDeferredReadyThread auf, die den weiter hinten im Abschnitt »Prozessorauswahl« vorgestellten Algorithmus durchführt. Dadurch
kann es dazu kommen, dass der Thread sofort ausgeführt, in die Bereitschaftsliste des Prozessors aufgenommen oder, falls der Prozessor unerreichbar ist, auf die Verzögert-bereit-Liste
eines anderen Prozessors gesetzt wird, wo er in den Zustand Standby übergehen oder sofort
ausgeführt werden kann. Diese Eigenschaft wird von der Parking-Engine beim Parken eines
Kerns genutzt: Alle Threads werden auf die Verzögert-bereit-Liste gesetzt, die dann verarbeitet
wird. Da KiDeferredReadyThread geparkte Kerne überspringt (wie wir noch zeigen werden), landen alle Threads dieses Prozessors daher auf anderen Prozessoren.
Affinität
Jeder Thread hat eine Affinitätsmaske, die die Prozessoren angibt, auf denen er laufen darf.
Diese Maske erbt er von der Prozessaffinitätsmaske. Normalerweise haben alle Prozesse (und
daher auch alle Threads) zu Anfang eine Affinitätsmaske, die alle aktiven Prozessoren ihrer
Gruppe einschließt. Das System kann die Threads also auf sämtlichen verfügbaren Prozessoren
in der ihrem Prozess zugeordneten Gruppe einplanen. Um den Durchsatz zu optimieren, die
Arbeitslasten für einen bestimmten Satz von Prozessoren zu partitionieren oder beides, kann
eine Anwendung die Affinitätsmaske für einen Thread jedoch ändern. Das kann auf verschiedenen Ebenen geschehen:
QQ Durch einen Aufruf von SetThreadAffinityMask wird die Affinität für einen einzelnen Thread
festgelegt.
QQ Durch einen Aufruf von SetProcessAffinityMask wird die Affinität für alle Threads in einem
Prozess festgelegt.
Task-Manager und Process Explorer bieten eine grafische Oberfläche für diese Aufgabe an.
Dazu rechtsklicken Sie auf einen Prozess und wählen Zugehörigkeit festlegen bzw. Set Affinity. Im Sysinternals-Werkzeug Psexec gibt es eine Befehlszeilenschnittstelle dafür (siehe
den Schalter -a in der Ausgabe der Hilfe).
QQ Wenn der Prozess zu einem Job gehört, können Sie eine jobweite Affinitätsmaske mit der
Funktion SetInformationJobObject festlegen (siehe Kapitel 3).
QQ Beim Kompilieren der Anwendung können Sie eine Affinitätsmaske im Abbildheader festlegen.
Threadplanung
Kapitel 4
309
Eine ausführliche Spezifikation des Windows-Abbildformats können Sie sich ansehen, indem Sie auf http://msdn.microsoft.com nach Portable Executable and Common Object File Format Specification suchen.
Bei einem Abbild kann zur Verlinkungszeit auch das Flag uniprocessor gesetzt werden. Wenn
das der Fall ist, wählt das System bei der Prozesserstellung einen einzelnen Prozessor aus
(MmRotatingProcessorNumber) und weist diesen in der Prozessaffinitätsmaske zu. Dabei beginnt
das System mit dem ersten Prozessor und durchläuft dann alle Prozessoren in der Gruppe.
Wird beispielsweise auf einem Zwei-Prozessor-System ein mit dem Flag uniprocessor gekennzeichnetes Abbild zum ersten Mal gestartet, so wird ihm CPU 0 zugewiesen, beim zweiten
Mal CPU 1, beim dritten Mal CPU 0, beim vierten Mal CPU 1 usw. Dieses Flag bildet eine
praktische Notlösung für Programme mit Bugs bei der Multithreadsynchronisierung, die auf
Mehrprozessorsystemen aufgrund von Race Conditions auftreten, aber nicht auf Einzelprozessorsystemen. Wenn ein Abbild solche Symptome zeigt und nicht signiert ist, können Sie das
Flag manuell hinzufügen, indem Sie den Abbildheader mit einem PE-Bearbeitungswerkzeug
ändern. Eine bessere Lösung, die sich auch für signierte ausführbare Dateien eignet, besteht
darin, mit dem Microsoft Application Compatibility Toolkit ein Shim hinzuzufügen, das die
Kompatibilitätsdatenbank zwingt, das Abbild zur Startzeit als reine Einzelprozessoranwendung zu kennzeichnen.
Experiment: Die Prozessaffinität einsehen und ändern
In diesem Experiment ändern Sie die Affinitätseinstellungen für einen Prozess und beobachten, wie diese Affinität von neuen Prozessen geerbt wird.
1.
Starten Sie die Eingabeaufforderung (Cmd.exe).
2.
Starten Sie den Task-Manager oder Process Explorer und machen Sie Cmd.exe in der
Prozessliste ausfindig.
3.
Rechtsklicken Sie auf den Prozess und wählen Sie Zugehörigkeit festlegen bzw. Set Affinity. Daraufhin wird eine Liste der Prozessoren angezeigt. Auf einem System mit acht
logischen Prozessoren sehen Sie beispielsweise Folgendes:
→
310
Kapitel 4
Threads
4.
Wählen Sie einen Teil der verfügbaren Prozessoren auf dem System aus und klicken Sie
auf OK. Die Threads des Prozesses können jetzt nur auf den ausgewählten Prozessoren
ausgeführt werden.
5.
Geben Sie an der Eingabeaufforderung Notepad ein, um den Editor zu starten.
6.
Suchen Sie im Task-Manager oder in Process Explorer den Prozess Notepad.
7.
Rechtsklicken Sie auf den Prozess und wählen Sie Zugehörigkeit bzw. Affinity. Es werden
jetzt die Prozessoren angezeigt, die Sie für den Prozess der Eingabeaufforderung ausgewählt haben, da Prozesse ihre Affinitätseinstellungen vom Elternprozess erben.
Wenn ein laufender Thread auch auf einem anderen Prozessor ausgeführt werden könnte,
verschiebt Windows ihn jedoch trotzdem nicht, um einem Thread Platz zu machen, der nur
auf dem von ihm belegten Prozessor laufen kann. Nehmen wir an, auf CPU 0 läuft ein Thread
der Priorität 8, der auf einem beliebigen Prozessor ausgeführt werden kann, und auf CPU 1 ein
Thread der Priorität 4, der ebenfalls keinen Prozessoreinschränkungen unterliegt. Nun wird ein
Thread der Priorität 6, der nur auf CPU 0 laufen darf, zur Ausführung bereit. Was geschieht? Der
Priorität-8-Thread wird nicht von CPU 0 zu CPU 1 verschoben (wodurch der Priorität-4-Thread
vorzeitig unterbrochen würde), damit der Priorität-6-Thread laufen kann. Letzterer bleibt weiterhin im Zustand Bereit. Eine Änderung der Affinitätsmaske für einen Prozess oder Thread
kann daher dazu führen, dass den Threads weniger CPU-Zeit zur Verfügung steht als normal,
da Windows den Thread nur auf bestimmten Prozessoren ausführen kann. Daher müssen Sie
bei der Festlegung von Affinitäten äußerste Vorsicht walten lassen. Meistens ist es am besten,
Windows entscheiden zu lassen, welche Threads wo laufen sollen.
Erweiterte Affinitätsmaske
Um mehr als die 64 Prozessoren unterstützen zu können, die bei der ursprünglichen Struktur
der Affinitätsmaske (64 Bits auf einem 64-Bit-System) möglich sind, verwendet Windows die erweiterte Affinitätsmaske KAFFINITY_EX. Dabei handelt es sich um ein Array aus Affinitätsmasken
für die einzelnen Prozessorgruppen (zurzeit maximal 20).
Wenn der Scheduler auf einen Prozessor in der erweiterten Affinitätsmaske verweisen
muss, bestimmt er zunächst die zugehörige Bitmaske anhand der Gruppennummer und greift
dann direkt auf die Affinität zu. In der Kernel-API werden die erweiterten Affinitätsmasken
nicht verfügbar gemacht. Stattdessen übergibt der Aufrufer der API die Gruppennummer als
Parameter und erhält die klassische Affinitätsmaske für die Gruppe zurück. In der Windows-API
dagegen können gewöhnlich nur Informationen über eine einzelne Gruppe abgefragt werden,
nämlich die Gruppe des zurzeit laufenden Threads (die fest ist).
Die erweiterte Affinitätsmaske und ihre zugrunde liegenden Mechanismen bieten einem
Prozess auch die Möglichkeit, die Grenzen der Prozessorgruppe zu überschreiten, der er ursprünglich zugewiesen wurde. Durch die Verwendung von APIs für erweiterte Affinität können
die Threads in einem Prozess Affinitätsmasken anderer Prozessorgruppen auswählen. Stellen
Sie sich einen Computer mit 256 Prozessoren und dort einen Prozess mit vier Threads vor.
Wenn die Threads nun alle die Affinitätsmaske 0x10 (binär 0b10000) verwenden, aber jeweils
Threadplanung
Kapitel 4
311
für eine andere Gruppe, dann kann Thread 1 auf Prozessor 4 laufen, 2 auf 68, 3 auf 132 und 4
auf 196. Es ist auch möglich, dass alle Bits der Affinitätsmasken für die gegebenen Gruppen auf
1 gesetzt werden (0xFFFF...), sodass der Prozess seine Threads auf allen verfügbaren Prozessoren des Systems ausführen kann (wobei jeder Thread jedoch nur auf Prozessoren seiner eigenen
Gruppe laufen darf).
Um die Vorteile dieser erweiterten Affinität zu nutzen, können Sie beim Erstellen eines neuen Threads oder beim Aufrufen von SetThreadGroupAffinity für einen vorhandenen Thread eine
Gruppennummer in der Threadattributliste angeben (PROC_THREAD_ATTRIBUTE_GROUP_AFFINITY).
Die Systemaffinitätsmaske
Windows-Treiber werden gewöhnlich im Kontext des aufrufenden oder eines willkürlichen
Threads ausgeführt (also nicht in der sicheren Begrenzung des Systemprozesses). Daher kann
der zurzeit laufende Treibercode den vom Entwickler der Anwendung festgelegten Affinitätsregeln unterworfen sein, auch wenn diese Regeln für den Treibercode eigentlich nicht von
Bedeutung sind und ihn sofort von der richtigen Verarbeitung von Interrupts und anderen
Arbeiten in der Warteschlange abhalten können. Treiberentwicklern steht daher mit den APIs
KeSetSystemAffinityThread(Ex)/KeSetSystemGroupAffinityThread und KeRevertToUser-AffinityThread(Ex)/KeRevertToUserGroupAffinityThread ein Mechanismus zur Verfügung, um die Affinitätseinstellungen für den Benutzerthread vorübergehend zu umgehen.
Idealer und letzter Prozessor
Bei jedem Thread sind im Kernel-Threadsteuerungsblock drei CPU-Nummern gespeichert:
QQ Idealer Prozessor
Dies ist der bevorzugte Prozessor, auf dem der Thread laufen sollte.
QQ Letzter Prozessor Dies ist der Prozessor, auf dem der Thread beim letzten Mal ausgeführt wurde.
QQ Nächster Prozessor Dies ist der Prozessor, auf dem der Thread ausgeführt werden wird
oder bereits läuft.
Der ideale Prozessor wird beim Erstellen des Threads mithilfe eines Grundwerts im Prozesssteuerungsblock ausgewählt. Dieser Grundwert wird jedes Mal erhöht, wenn ein Thread angelegt
wird, sodass der Wert nach und nach alle verfügbaren Prozessoren des Systems durchläuft. Beispielsweise wird dem ersten Thread im ersten Prozess auf dem System der Wert 0 für den idealen Prozessor zugewiesen, dem zweiten Thread der Wert 2 usw. Dadurch werden die Threads
eines Prozesses gleichmäßig über die Prozessoren verteilt. Auf SMT-Systemen (Hyperthread
ing) wird der nächste ideale Prozessor aus dem nächsten SMT-Satz ausgewählt. Beispielsweise
können die Threads in einem Prozess auf einem Quadcore-System mit Hyperthreading die
idealen Prozessoren 0, 2, 4, 6, 0, ...; 3, 5, 7, 1, 3, ... usw. bekommen. Dadurch werden die Threads
eines Prozesses gleichmäßig über die physischen Prozessoren verteilt.
Dabei wird jedoch vorausgesetzt, dass die Threads in einem Prozess jeweils die gleiche
Menge Arbeit verrichten. Meistens jedoch enthält ein Prozess einen oder mehrere »Haushaltungs-« und zahlreiche Arbeitsthreads. Um die Vorteile der Mehrprozessorplattform voll auszuschöpfen, kann für eine Multithreadanwendung daher von Vorteil sein, die idealen Prozessoren
312
Kapitel 4
Threads
für ihre Threads mit der Funktion SetThreadIdealProcessor festzulegen. Um auch die Vorteile
von Prozessorgruppen zu nutzen, sollten Entwickler stattdessen SetThreadIdealProcessorEx
aufrufen, bei der es möglich ist, eine Gruppennummer für die Affinität auszuwählen.
In 64-Bit-Versionen von Windows wird das Feld Stride in der KNODE-Struktur verwendet,
um die Zuordnung neu erstellter Threads in einem Prozess auszugleichen. Dieser »Schritt«
gibt die Anzahl der Affinitätsbits an, die in einem gegebenen NUMA-Knoten übersprungen
werden müssen, um einen neuen unabhängigen Bereich logischer Prozessoren zu erreichen.
Dabei bedeutet »unabhängig«, dass sich diese Prozessoren in einem anderen Kern (auf SMT-
Systemen) oder einem anderen Paket (bei Mehrkernsystemen ohne SMT) befinden müssen. Da
32-Bit-Windows-Versionen ohnehin keine Systeme mit umfangreicher Prozessorausstattung
unterstützen, verwenden sie keinen Schrittwert. Stattdessen wählen sie einfach den Prozessor
der nächsten Nummer aus, wobei sie jedoch nach Möglichkeit vermeiden, dabei wieder denselben SMT-Satz zu verwenden.
Der ideale Knoten
Wenn auf einem NUMA-System ein Prozess erstellt wird, so wird für ihn ein idealer Knoten
ausgewählt. Der erste Prozess wird Knoten 0 zugewiesen, der zweite Knoten 1 usw. Die idealen
Prozessoren für die Threads in dem Prozess werden dann unter denen im idealen Knoten ausgewählt. Der erste Thread erhält den ersten Prozessor des Knotens usw.
CPU-Sätze
Die Affinität (die manchmal auch als harte Affinität bezeichnet wird) schränkt Threads auf
bestimmte Prozessoren ein, was der Scheduler stets berücksichtigt. Der Mechanismus, der
versucht, Threads auf ihrem idealen Prozessor auszuführen (zuweilen auch weiche Affinität genannt) erwartet im Allgemeinen, dass sich der Status des Threads im Cache dieses Prozessors
befindet. Es ist jedoch nicht garantiert, dass der ideale Prozessor verwendet wird; der Thread
kann auch auf anderen Prozessoren eingeplant werden. Beide Mechanismen gelten nicht für
Systemaktivitäten wie die von Systemthreads. Es gibt auch keine einfache Möglichkeit, die
harte Affinität für alle Prozesse auf einem System auf einmal festzulegen. Systemprozesse sind
im Allgemeinen gegen externe Affinitätsänderungen geschützt, da dafür das Zugriffsrecht
PROCESS_SET_INFORMATION erforderlich ist, das für geschützte Prozesse nicht gewährt wird.
In Windows 10 und Windows Server 2016 wurden CPU-Sätze eingeführt. Dabei handelt es
sich um eine Form von Affinität, die Sie auch für das System als Ganzes (einschließlich Systemthreadaktivitäten), für Prozesse und sogar für einzelne Threads einrichten können. Beispielsweise kann es sich anbieten, dass eine Audioanwendung mit geringer Latenz einen Prozessor ganz
für sich allein nutzt, während der Rest des Systems auf andere Prozessoren umgeleitet wird. Das
lässt sich mithilfe von CPU-Sätzen erreichen.
Zurzeit sind die Möglichkeiten der dokumentierten Benutzermodus-API recht eingeschränkt. GetSystemCpuSetInformation gibt ein Array mit SYSTEM_CPU_SET_INFORMATION-Strukturen
zurück, die Daten über die einzelnen CPU-Sätze enthalten. In der aktuellen Implementierung
entspricht ein CPU-Satz einer einzelnen CPU. Daher entspricht die Länge des zurückgegebenen
Arrays der Anzahl logischer Prozessoren auf dem System. Jeder CPU-Satz wird durch seine ID
Threadplanung
Kapitel 4
313
bezeichnet, die sich aus 256 (0x100) und dem CPU-Index (0, 1, ...) zusammensetzt. Dies sind die
IDs, die Sie an SetProcessDefaultCpuSets und SetThreadSelectedCpuSets übergeben müssen,
um die CPU-Standardsätze für einen Prozess bzw. einen CPU-Satz für einen bestimmten Thread
festzulegen.
Einen CPU-Satz für einen Thread legen Sie beispielsweise fest, wenn der Thread so wichtig
ist, dass er nach Möglichkeit nicht unterbrochen werden soll. Diesem Thread können Sie einen
CPU-Satz mit einer einzigen CPU zuordnen, während Sie in den CPU-Standardsatz für den Prozess alle anderen CPUs aufnehmen.
In der Windows-API fehlt jedoch die Möglichkeit, den System-CPU-Satz zu verkleinern.
Dies können Sie mit dem Systemaufruf NtSetSystemInformation erledigen, für den der Aufrufer
das Recht SeIncreaseBasePriorityPrivilege benötigt.
Experiment: CPU-Sätze
In diesem Experiment schauen Sie sich CPU-Sätze an, ändern sie und beobachten die Auswirkungen.
1.
Laden Sie das Werkzeug CpuSet.exe von den Begleitressourcen zu diesem Buch herunter.
2.
Öffnen Sie eine Eingabeaufforderung mit Administratorrechten und wechseln Sie dort
zu dem Verzeichnis, in dem sich CpuSet.exe befindet.
3.
Geben Sie in der Befehlszeile cpuset.exe ohne Argumente ein, um sich die aktuellen
CPU-Sätze des Systems anzusehen. Sie erhalten dabei eine Ausgabe wie die folgende:
System CPU Sets
--------------Total CPU Sets: 8
CPU Set 0
Id: 256 (0x100)
Group: 0
Logical Processor: 0
Core: 0
Last Level Cache: 0
NUMA Node: 0
Flags: 0 (0x0) Parked: False Allocated: False Realtime: False Tag: 0
CPU Set 1
Id: 257 (0x101)
Group: 0
Logical Processor: 1
Core: 0
Last Level Cache: 0
→
314
Kapitel 4
Threads
NUMA Node: 0
Flags: 0 (0x0) Parked: False Allocated: False Realtime: False Tag: 0
...
4.
Starten Sie CpuStres.exe und lassen Sie das Programm einen oder zwei Threads mit
Aktivitätsgrad Maximum ausführen. Versuchen Sie, eine CPU-Auslastung von ca. 25 %
zu erreichen.
5.
Öffnen Sie den Task-Manager, rufen Sie die Registerkarte Leistung auf und wählen Sie
CPU.
6.
Ändern Sie die grafische CPU-Ansicht, sodass statt der Gesamtnutzung die einzelnen
Prozessoren angezeigt werden.
7.
Führen Sie an der Eingabeaufforderung den folgenden Befehl aus, wobei Sie die Zahl
hinter -p durch die Prozess-ID von CPUSTRES auf Ihrem System ersetzen müssen:
CpuSet.exe -p 18276 -s 3
Das Argument -s gibt die Prozessormaske an, die als Standard für den Prozess eingerichtet werden soll. Der Wert 3 in diesem Beispiel steht für CPU 0 und 1. Im Task-Manager können Sie jetzt ein hohes Arbeitsaufkommen auf diesen beiden CPUs erkennen:
→
Threadplanung
Kapitel 4
315
8.
Als Nächstes sehen wir uns CPU 0 genauer an, um herauszufinden, welche Threads
dort laufen. Dazu verwenden Sie den Windows Performance Recorder (WPR) und den
Windows Performance Analyzer (WPA) aus dem Windows SDK. Klicken Sie auf Start,
geben Sie wpr ein und wählen Sie Windows Performance Recorder. Bestätigen Sie die
Rechteerhöhung. Jetzt wird folgendes Dialogfeld angezeigt:
9.
In der Standardeinstellung wird die CPU-Nutzung aufgezeichnet, was auch genau das
ist, was wir tun wollen. Dieses Werkzeug zeichnet ETW-Ereignisse auf (Event Tracking
for Windows, siehe Kapitel 8 in Band 2). Klicken Sie in dem Dialogfeld auf die Schaltfläche Start und nach ein oder zwei Sekunden, wenn sie mittlerweile die Bezeichnung
Save beträgt, erneut darauf.
10. WPR schlägt einen Speicherort für die aufgezeichneten Daten vor. Akzeptieren Sie ihn
oder geben Sie einen Datei- oder Ordnernamen nach Ihrem Geschmack an.
11. Wenn die Datei gespeichert ist, schlägt Ihnen WPR vor, sie mit WPA zu öffnen. Akzeptieren Sie diesen Vorschlag.
→
316
Kapitel 4
Threads
12. WPA wird geöffnet und lädt die gespeicherte Datei. Dieses Werkzeug ist sehr umfangreich, weshalb wir es in diesem Buch nicht ausführlich beschreiben können. Auf der
linken Seite sehen Sie die verschiedenen Kategorien der erfassten Informationen:
13. Erweitern Sie Computation und dann CPU Usage (Precise).
14. Doppelklicken Sie auf das Diagramm Utilization by CPU. Es wird daraufhin im Hauptfenster geöffnet:
→
Threadplanung
Kapitel 4
317
15. Zurzeit sind wir an CPU 0 interessiert. Im nächsten Schritt sorgen Sie dafür, dass auf
CPU 0 nur CPUSTRES ausgeführt wird. Dazu erweitern Sie zunächst CPU 0. Daraufhin
werden mehrere Prozesse angezeigt. Einer von ihnen, aber beileibe nicht der einzige,
ist CPUSTRES.
16. Geben Sie den folgenden Befehl ein, damit das System alle Prozessoren außer dem ersten benutzt. Da dieses System über acht Prozessoren verfügt, hat die komplette Maske
den Wert 255 (0xff). Wenn Sie CPU 0 herausnehmen, ergibt sich 254 (0xfe). Ersetzen Sie
im folgenden Befehl die Maske durch die passende für Ihr System:
CpuSet.exe -s 0xfe
17. Die Ansicht im Task-Manager sollte sich nicht ändern. Schauen wir uns aber CPU 0 noch
einmal genau an. Führen Sie dazu abermals WPR aus und zeichnen Sie die Messwerte
ein oder zwei Sekunden lang mit den gleichen Einstellungen wie zuvor auf.
18. Öffnen Sie die Ablaufverfolgung in WPA und rufen Sie Utilization by CPU auf.
19. Erweitern Sie CPU 0. Dort wird jetzt fast nur noch CPUSTRES angezeigt, wohingegen
Systemprozesse nur noch gelegentlich auftreten.
→
318
Kapitel 4
Threads
20. Die in der Spalte CPU Usage (in View) (ms) angegebene Zeit für den Systemprozess
ist sehr gering (im Bereich von Mikrosekunden). CPU 0 ist fast ausschließlich für den
Prozess CPUSTRES da.
21. Führen Sie CpuSet.exe erneut aus, aber diesmal ohne Argumente. Der erste Satz (CPU 0)
wird als Allocated: True gekennzeichnet, da er nicht mehr für den allgemeinen Gebrauch im System zur Verfügung steht, sondern einem bestimmten Prozess zugeordnet
ist.
22. Schließen Sie CPU Stress.
23. Geben Sie den folgenden Befehl ein, um den System-CPU-Satz wieder auf die Standardeinstellung zurückzusetzen:
Cpuset -s 0
Threadauswahl auf Mehrprozessorsystemen
Bevor wir uns weiter mit den Einzelheiten von Mehrprozessorsystemen beschäftigen, wollen
wir Ihnen noch einmal einen Überblick über die im Abschnitt »Threadauswahl« vorgestellten
Algorithmen verschaffen. Diese Algorithmen setzen entweder die Ausführung des aktuellen
Threads fort (wenn kein neuer Kandidat gefunden wurde) oder starten den Leerlaufthread
(wenn der aktuelle Thread blockiert ist). Es gibt jedoch mit KiSearchForNewThread noch einen
dritten Algorithmus für die Threadauswahl. Er wird verwendet, wenn der aktuelle Thread kurz
vor der Blockierung steht, weil er auf ein Objekt warten muss, oder wenn NtDelayExecutionThread aufgerufen wurde, die sogenannte Sleep-API.
Hier zeigt sich ein feiner Unterschied zwischen dem üblichen Aufruf von Sleep(21),
bei dem der aktuelle Thread bis zum nächsten Tick blockiert wird, und dem zuvor
gezeigten Aufruf von SwitchToThread. Bei Sleep(1) wird der im Folgenden erklärte
Algorithmus verwendet, bei SwitchToThread dagegen die zuvor vorgeführte Logik.
KiSearchForNewThread liest das Feld NextThread, um herauszufinden, ob für diesen Prozessor
bereits ein Thread ausgewählt wurde. Wenn ja, überführt die Funktion diesen Thread sofort
in den Zustand Wird ausgeführt. Anderenfalls ruft sie zunächst KiSelectReadyThreadEx auf, um
einen Thread zu finden und danach die gleichen Schritte wie zuvor auszuführen.
Wurde kein Thread gefunden, wird der Prozessor als unbeschäftigt gekennzeichnet (auch
wenn der Leerlaufthread noch nicht ausgeführt wird). Außerdem werden die (gemeinsamen)
Warteschlangen der anderen logischen Prozessoren untersucht (im Unterschied zu den anderen Standardalgorithmen, die an dieser Stelle aufgeben). Allerdings wird auf diese Untersuchung verzichtet, wenn der Prozessorkern geparkt ist, da es zu bevorzugen ist, dass der Kern in
den Parkzustand übergeht, anstatt ihn mit neuer Arbeit beschäftigt zu halten.
Außer in diesen beiden Sonderfällen wird jetzt die Schleife für den »Threaddiebstahl«
ausgeführt. Der Code schaut sich den aktuellen NUMA-Knoten an und entfernt die unbeschäftigten Prozessoren daraus (da sie keine Threads enthalten, die gestohlen werden könn-
Threadplanung
Kapitel 4
319
ten). Anschließend sieht er sich die gemeinsame Bereitschaftswarteschlange der aktuellen
CPU an und ruft KiSearchForNewThreadOnProcessor in einer Schleife auf. Wird dabei kein
Thread gefunden, wird die Affinität auf die nächste Gruppe geändert und die Funktion erneut aufgerufen. Diesmal aber zeigt die Ziel-CPU auf die gemeinsame Warteschlange der
nächsten Gruppe statt der aktuellen, sodass der Prozessor den besten ausführungsbereiten
Thread in der Warteschlange der anderen Prozessorgruppe finden kann. Findet sich auch
dabei kein geeigneter Thread, werden die lokalen Warteschlangen der Prozessoren in der
Gruppe auf dieselbe Weise durchsucht. Hat auch dies keinen Erfolg und ist DFSS aktiviert,
wird stattdessen ein Thread aus der Leerlauf-Warteschlange des anderen logischen Prozessors auf dem aktuellen Prozessor bereitgestellt, falls das möglich ist.
Wurde immer noch kein Kandidat gefunden, versucht der Algorithmus es mit dem logischen Prozessor der nächstniedrigen Nummer. So geht es weiter, bis er alle logischen Prozessoren des aktuellen NUMA-Knotens durchlaufen hat. Danach fährt er mit dem nächstliegenden
Knoten fort usw., bis er alle Knoten der aktuellen Gruppe untersucht hat. (Denken Sie daran,
dass die Affinität eines Threads in Windows immer nur auf eine Gruppe beschränkt ist.) Wird
dadurch immer noch kein geeigneter Thread gefunden, gibt die Funktion NULL zurück. Im
Falle eines Wartevorgangs führt der Prozessor den Leerlaufthread aus (wodurch die Leerlaufplanung übersprungen wird). Wurde diese Arbeit bereits vom Leerlaufscheduler ausgeführt,
tritt der Prozessor in einen Ruhezustand ein.
Prozessorauswahl
Wir haben bereits beschrieben, wie Windows einen Thread aussucht, wenn ein logischer Prozessor eine Auswahl treffen oder wenn diese Auswahl für ihn vorgenommen werden muss.
Dabei haben wir die Existenz einer Datenbank ausführungsbereiter Threads vorausgesetzt,
die zur Auswahl bereitstehen. Jetzt sehen wir uns an, wie diese Datenbank gefüllt wird, also
wie Windows den logischen Prozessor auswählt, mit dessen Bereitschaftswarteschlange es
den ausführungsbereiten Thread verknüpft. Nachdem Sie bereits die verschiedenen Arten
von Mehrprozessorsystemen sowie die Einstellungen für Threadaffinität und den idealen Prozessor kennengelernt haben, schauen wir uns nun an, wie diese Informationen für diesen
Zweck genutzt werden.
Prozessorauswahl bei Vorhandensein von unbeschäftigten Prozessoren
Wird ein Thread ausführungsbereit, so wird die Schedulerfunktion KiDeferredReadyThread aufgerufen. Windows muss dann die beiden folgenden Aufgaben ausführen:
QQ Nach Bedarf die Prioritäten anpassen und die Quanten aktualisieren (siehe den Abschnitt
»Prioritätserhöhung«)
QQ Den geeignetsten logischen Prozessor für den Thread auswählen
Windows schlägt als Erstes den idealen Prozessor des Threads nach und ermittelt dann, welche
Prozessoren in der Maske für die harte Affinität des Threads unbeschäftigt sind. Diese Menge
wird anschließend noch wie folgt verkleinert:
320
Kapitel 4
Threads
1.
Alle unbeschäftigten logischen Prozessoren, die geparkt wurden, werden aus der Auswahl
entfernt. (Mehr über das Parken von Prozessorkernen erfahren Sie in Kapitel 6.) Bleiben
dann keine unbeschäftigten Prozessoren mehr übrig, wird die Auswahl abgebrochen. Der
Scheduler verhält sich dann so, als stünden keine unbeschäftigten Prozessoren zur Verfügung (siehe den nächsten Abschnitt).
2.
Jegliche unbeschäftigten logischen Prozessoren, die sich nicht im idealen Knoten (also
dem Knoten mit dem idealen Prozessor) befinden, werden entfernt (es sei denn, dass dadurch keine unbeschäftigten Prozessoren mehr übrig blieben).
3.
Auf einem SMT-System werden alle beschäftigten SMT-Sätze entfernt, auch wenn dadurch
der ideale Prozessor selbst wegfällt. Windows bevorzugt also einen nicht idealen unbeschäftigten SMT-Satz gegenüber einem idealen Prozessor.
4.
Windows prüft, ob sich der ideale Prozessor unter den übrig gebliebenen unbeschäftigten
Prozessoren befindet. Ist das nicht der Fall, muss es den geeignetsten unbeschäftigten
Prozessor ermitteln. Dazu sieht es zunächst nach, ob die Auswahl den Prozessor enthält,
auf dem der Thread beim letzten Mal ausgeführt wurde. Wenn ja, so wird er als temporärer
idealer Prozessor angesehen und ausgewählt. (Durch die Nutzung des idealen Prozessors
soll die Anzahl der Prozessorcachetreffer erhöht werden, und dieses Ziel lässt sich durch
die Auswahl des zuletzt verwendeten Prozessors gut erreichen.) Befindet sich der zuletzt
verwendete Prozessor jedoch nicht in der verbliebenen Auswahl an unbeschäftigten Prozessoren, prüft Windows, ob der aktuelle Prozessor (also derjenige, der zurzeit den Threadplanungscode ausführt) darin enthalten ist. Wenn ja, wird die gleiche Logik angewendet
wie zuvor.
5.
Ist weder der zuletzt verwendete noch der aktuelle Prozessor unbeschäftigt, entfernt
Windows aus der Auswahl noch jegliche unbeschäftigten logischen Prozessoren, die sich
nicht im selben SMT-Satz befinden wie der ideale Prozessor. Sind keine solche Prozessoren übrig, entfernt Windows stattdessen jegliche Prozessoren, die sich nicht im SMT-Satz
des aktuellen Prozessors befinden (es sei denn, dadurch würden keine unbeschäftigten
Prozessoren übrig bleiben). Anders ausgedrückt, Windows bevorzugt unbeschäftigte Prozessoren aus demselben SMT-Satz gegenüber einem nicht erreichbaren idealen oder zuletzt verwendeten Prozessor. Da der Cache bei SMT-Implementierungen im gesamten Kern
gemeinsam verwendet wird, hat das für die Anzahl der Cachetreffer etwa die gleichen
Auswirkungen wie die Auswahl des idealen oder zuletzt verwendeten Prozessors.
6.
Enthält die Auswahl nach dem letzten Schritt noch mehr als einen Prozessor, wählt Windows
den mit der niedrigsten Nummer für den Thread aus.
Nach der Auswahl des Prozessors wird der Thread in den Standbyzustand versetzt und der
PRCB des unbeschäftigten Prozessors so aktualisiert, dass er auf den Thread zeigt. Ist der Prozessor unbeschäftigt, aber nicht angehalten, wird ein DPC-Interrupt gesendet, sodass sich der
Prozessor sofort um die Threadplanungsoperation kümmert. Beim Auslösen einer solchen
Operation wird immer KiCheckForThreadDispatch ausgewählt. Sie erkennt, dass auf dem Prozessor ein neuer Thread eingeplant wurde, verursacht nach Möglichkeit einen sofortigen Kontextwechsel, informiert Autoboost über den Wechsel und liefert ausstehende APCs aus. Gibt es
keinen ausstehenden Thread, sorgt sie stattdessen dafür, dass ein DPC-Interrupt gesendet wird.
Threadplanung
Kapitel 4
321
Prozessorauswahl ohne Vorhandensein von unbeschäftigten Prozessoren
Wenn ein Thread ausgeführt werden will und keine unbeschäftigten, nicht geparkten Prozessoren vorhanden sind, prüft Windows als Erstes, ob einer der geparkten verwendet werden
kann. Dazu ruft der Scheduler KiSelectCandidateProcessor auf, um die Parking-Engine nach
dem geeignetsten Kandidaten zu fragen. Die Engine wählt den nicht geparkten Prozessor mit
der höchsten Nummer im idealen Knoten aus. Gibt es keine solchen Prozessoren, hebt sie
den Parkstatus des idealen Prozessors zwangsweise auf. Wenn der Scheduler die Steuerung
zurückerhält, prüft er, ob der empfangene Kandidat unbeschäftigt ist. Wenn ja, wählt er diesen
Prozessor für den Thread aus, wobei er ebenso vorgeht wie in dem zuvor geschilderten Fall.
Wenn das nicht funktioniert, muss Windows entscheiden, ob es den zurzeit laufenden
Thread vorzeitig unterbrechen soll. Als Erstes muss es dazu einen Zielprozessor auswählen.
Dies geschieht, abgesehen von Affinitätseinschränkungen, in der Reihenfolge der Präferenz:
An erster Stelle steht der ideale Prozessor für den Thread, gefolgt vom zuletzt verwendeten
Prozessor, dem ersten verfügbaren Prozessor im aktuellen NUMA-Knoten und schließlich der
nächstgelegene Prozessor in einem anderen NUMA-Knoten.
Nach der Auswahl eines Prozessors stellt sich als Nächstes die Frage, ob der neue Thread
denjenigen vorzeitig unterbrechen soll, der zurzeit auf dem Prozessor läuft. Dazu wird der Rang
der beiden Threads verglichen. Dies ist ein interner Wert für die Threadplanung, der die relative
Bedeutung eines Threads auf der Grundlage seiner Planungsgruppe und anderer Faktoren angibt (siehe den Abschnitt »Gruppengestützte Threadplanung« weiter hinten in diesem Kapitel).
Hat der neue Thread den Rang 0 (was den höchsten Rang bezeichnet) oder eine kleinere Rangnummer als der laufende Thread oder hat er den gleichen Rang, aber eine höhere Priorität, so
erfolgt eine vorzeitige Unterbrechung. Der laufende Thread wird zur Unterbrechung markiert
und Windows stellt einen DPC-Interrupt an den Zielprozessor in die Warteschlange, um den
laufenden Thread zugunsten des neuen Threads zu unterbrechen.
Wenn der ausführungsbereite Thread nicht sofort ausgeführt werden kann, wird er ( je
nach den Affinitätseinschränkungen) in die gemeinsame oder lokale Bereitschaftswarteschlange gestellt, wo er wartet, bis er an der Reihe ist. Wie Sie bei den vorherigen Fällen gesehen haben, wird er je nachdem, ob er aufgrund einer vorzeitigen Unterbrechung in die Warteschlange
gestellt wurde, an deren Anfang oder Ende gesetzt.
Unabhängig vom vorliegenden Planungsszenario werden Threads meistens in die
lokale Bereitschaftswarteschlange ihres idealen Prozessors gestellt, was die Konsistenz der Algorithmen für die Auswahl des logischen Prozessors garantiert.
Heterogene Threadplanung (big.LITTLE)
Der Kernel geht davon aus, dass ein SMP-System vorliegt, wie wir es eben beschrieben haben.
ARM-Prozessoren können jedoch ungleiche Kerne enthalten. Eine typische ARM-CPU (z. B. von
Qualcomm) enthält einige leistungsfähige Kerne, die immer nur für kurze Zeit ausgeführt werden und mehr Strom verbrauchen, sowie einige schwächere, die länger laufen und dabei weniger Strom ziehen. Diese Konstruktionsweise wird auch als big.LITTLE bezeichnet.
322
Kapitel 4
Threads
Seit Windows 10 ist es möglich, zwischen diesen Kernen zu unterscheiden und die Threads
aufgrund der Größe der Kerne und ihrer Richtlinien z. B. im Hinblick auf den Vordergrundstatus des Threads, seine Priorität und die erwartete Laufzeit zu verteilen. Bei der Initialisierung
des Energie-Managers und beim Hinzufügen von Prozessoren im laufenden Betrieb initialisiert Windows den Prozessorsatz durch einen Aufruf von PopInitializeHeteroProcessors. Diese
Funktion kann ein Heterosystem simulieren (etwa zu Testzwecken), indem sie wie folgt Registrierungsschlüssel unter HKLM\System\CurrentControlSet\Control\SessionManager\Kernel\
KGroups hinzufügt:
QQ Im Namen des Schlüssels wird die Prozessorgruppennummer mithilfe einer zweistelligen
Dezimalzahl angegeben. (Denken Sie daran, dass eine Gruppe höchstens 64 Prozessoren
enthalten kann.) Beispielsweise steht 00 für die erste Gruppe, 01 für die zweite usw. Auf den
meisten Systemen sollte eine Gruppe ausreichen.
QQ Jeder Schlüssel enthält den DWORD-Wert SmallProcessorMask. Dies ist die Maske für die Prozessoren, die als »klein« betrachtet werden. Lautet der Wert beispielsweise 3 (die ersten
beiden Bits sind gesetzt) und enthält die Gruppe sechs Prozessoren, sind die Prozessoren
0 und 1 klein, die anderen vier dagegen groß. Dies ist im Grunde genommen das Gleiche
wie eine Affinitätsmaske.
Der Kernel verfügt auch über einige Richtlinienoptionen, die sich für Heterosysteme anpassen
lassen. Gespeichert sind sie in globalen Variablen. Tabelle 4–5 nennt einige dieser Variablen und
ihre Bedeutung.
Variablenname
Bedeutung
Standardwert
KiHeteroSystem
Ist das System heterogen?
False
PopHeteroSystem
Heterotyp des Systems:
None (0)
Simulated (1)
EfficiencyClass (2)
FavoredCore (3)
None (0)
PpmHeteroPolicy
Threadplanungsrichtlinie:
None (0)
Manual (1)
SmallOnly (2)
LargeOnly (3)
Dynamic (4)
Dynamic (4)
KiDynamicHeteroCpuPolicyMask
Bestimmt, was bei der Beurteilung
der Wichtigkeit eines Threads berücksichtigt wird.
7 (Vordergrundstatus = 1,
Priorität = 2,
erwartete Laufzeit = 4)
→
Threadplanung
Kapitel 4
323
Variablenname
Bedeutung
Standardwert
KiDefaultDynamicHeteroCpuPolicy
Verhalten der Heterorichtlinie Dynamic (siehe oben):
All (0) (alle verfügbaren Prozessoren)
Large (1)
LargeOrIdle (2)
Small (3)
SmallOrIdle (4)
Dynamic (5) (zieht Priorität und
andere Maße zur Entscheidung
heran)
BiasedSmall (6) (zieht Priorität
und andere Maße zur Entscheidung heran, bevorzugt aber kleine
Prozessoren)
BiasedLarge (7)
Small (3)
KiDynamicHeteroCpuPolicyImportant
Richtlinie für einen als wichtig
eingestuften dynamischen Thread
(siehe mögliche Werte oben)
LargeOrIdle
(2)
KiDynamicHeteroCpuPolicyImportantShort
Richtlinie für einen dynamischen
Thread, der als wichtig eingestuft
ist, aber nur kurzzeitig läuft
Small (3)
KiDynamicCpuPolicyExpectedRuntime
Der Echtzeitwert, der als »schwer«
betrachtet wird
5200 ms
KiDynamicHeteroCpuPolicyImportantPriority
Die Priorität, über die Threads bei
der Auswahl der prioritätsgestützten Richtlinie als wichtig eingestuft
werden
8
Tabelle 4–5 Kernelvariablen für Heterosysteme
Dynamische Richtlinien (siehe Tabelle 4–5) müssen in einen Wichtigkeitswert auf der Grundlage
von KiDynamicHeteroPolicyMask und des Threadstatus übersetzt werden. Dies erledigt die Funktion KiConvertDynamicHeteroPolicy, die nacheinander den Vordergrundstatus des Threads, seine Priorität relativ zu KiDynamicHeteroCpuPolicyImportantPriority und seine erwartete Laufzeit
prüft. Wird der Thread als wichtig angesehen (wenn die Laufzeit der entscheidende Faktor ist,
kann dies auch ein kurzer Thread sein), so wird für Planungsentscheidungen eine Richtlinie auf
der Grundlage der Wichtigkeit herangezogen. (In Tabelle 4–5 wäre das KiDynamicHeteroCpuPolicyImportantShort oder KiDynamicHeteroCpuPolicyImportant.)
Gruppengestützte Threadplanung
Im vorigen Abschnitt haben Sie die Standardimplementierung der Threadplanung in Windows
kennengelernt. Seit ihrer Einführung im ersten Release von Windows NT hat sie sich sowohl
im Benutzer- als auch im Serverbereich als zuverlässig erwiesen, wobei die Skalierbarkeit mit
jedem neuen Release verbessert wurde. Da bei dieser Vorgehensweise jedoch versucht wird,
die Prozessorenressourcen gleichmäßig auf konkurrierende Threads gleicher Priorität aufzuteilen, ist es damit nicht möglich, Anforderungen einer höheren Ebene wie eine gleichmäßige
Verteilung der Threads auf Benutzer zu erfüllen oder die Möglichkeit zu berücksichtigen, dass
324
Kapitel 4
Threads
einzelnen Benutzern auf Kosten der anderen mehr CPU-Zeit zur Verfügung gestellt wird. Letzteres kann sich bei Terminalumgebungen als problematisch erweisen, in denen Dutzende von
Benutzern um CPU-Zeit konkurrieren. Erfolgt die Planung ausschließlich auf der Ebene der einzelnen Threads, kann ein einziger Thread hoher Priorität eines einzelnen Benutzers die Threads
aller anderen Benutzer auf dem Computer aushungern.
In Windows 8 und Windows Server 2012 wurde ein gruppengestützter Planungsmechanismus auf der Grundlage von Planungsgruppen (KSCHEDULING_GROUP) eingeführt. Eine solche
Gruppe schließt eine Richtlinie, Planungsparameter und je einen Kernelblock zur Planungssteuerung (Kernel Scheduling Control Block, KSCB) pro Prozessor in der Gruppe ein. Der Nachteil
ist, dass ein Thread auf die Planungsgruppe zeigt, zu der er gehört. Ist dieser Zeiger NULL, wird
der Thread von keiner Planungsgruppe gesteuert. Abb. 4–19 zeigt den Aufbau einer Planungsgruppe. In diesem Beispiel gehören die Threads T1 bis T3 zu der Gruppe, T4 dagegen nicht.
Richtlinie
Planungsgruppe
Zähler
Abbildung 4–19 Eine Planungsgruppe
Im Zusammenhang mit der gruppengestützten Planung werden Ihnen die folgenden Begriffe
begegnen:
QQ Generation Dies ist der Zeitraum, über den die CPU-Nutzung verfolgt wird.
QQ Kontingent
laubt ist.
Dies ist der Umfang der CPU-Nutzung, der der Gruppe pro Generation er-
QQ Gewicht Die relative Wichtigkeit einer Gruppe. Dies ist ein Wert zwischen 1 und 9, wobei
der Standardwert 5 beträgt.
QQ Gleichmäßige Planung Hierbei können Leerlaufzyklen auf Threads übertragen werden,
die ihr Kontingent schon erfüllt haben, wenn keine Threads ausgeführt werden wollen, die
noch einen Teil ihres Kontingents zur Verfügung haben.
Die KSCB-Struktur enthält folgende Informationen über die CPU:
QQ Zyklusnutzung in der Generation
QQ Langfristige durchschnittliche Zyklusnutzung. Dadurch können Spitzen bei der Threadaktivität von einem echten Anstieg unterschieden werden.
QQ Steuerungsflags etwa für feste Obergrenzen, bei denen ein Thread auch dann keine zusätzliche CPU-Zeit erhält, wenn sie über das zugewiesene Kontingent hinaus zur Verfügung
steht.
QQ Bereitschaftswarteschlangen für die Standardprioritäten (also die Prioritäten 0 bis 15, da
Echtzeitthreads niemals Teil einer Planungsgruppe sind).
Gruppengestützte Threadplanung
Kapitel 4
325
Ein wichtiger Parameter einer Planungsgruppe ist der Rang, der als Planungspriorität für die
gesamte Gruppe der Threads angesehen werden kann. Dabei kennzeichnet 0 den höchsten
Rang. Eine höhere Rangnummer bedeutet, dass die Gruppe mehr CPU-Zeit verbraucht hat,
weshalb es weniger wahrscheinlich ist, dass sie weitere CPU-Zeit erhält.
Der Rang hat immer Vorrang vor der Priorität. Bei zwei Threads mit unterschiedlichem
Rang wird unabhängig von der Priorität derjenige mit der niedrigeren Rangnummer bevorzugt. Bei gleichrangigen Threads dagegen wird die Priorität verglichen. Der Rang wird regelmäßig an die Zyklusnutzung angepasst.
Rang 0 ist der höchste, weshalb er jede andere Rangnummer aussticht. Er wird stillschweigend folgenden Arten von Threads zugeteilt:
QQ Threads, die nicht zu einer Planungsgruppe gehören (»normale« Threads)
QQ Threads, deren Kontingent nicht ausgeschöpft ist
QQ Threads mit Echtzeitpriorität (16 bis 31)
QQ Threads, die auf der IRQL APC_LEVEL (1) in einem kernelkritischen oder geschützten Bereich
ausgeführt werden (siehe Kapitel 8 in Band 2).
Bei verschiedenen Planungsentscheidungen (z. B. KiQuantumEnd) wird die Planungsgruppe (falls
vorhanden) des aktuellen und des ausführungsbereiten Threads berücksichtigt. Gibt es eine
Planungsgruppe, so gewinnt der Thread mit der niedrigsten Rangnummer, wobei bei gleichen Rangnummern nach Priorität entschieden wird und bei gleicher Priorität danach, welcher
Thread als erster ankam (Umlaufverfahren am Ende des Quantums).
Dynamische gleichmäßige Planung (DFSS)
Die dynamische gleichmäßige Planung (Dynamic Fair-Share Scheduling, DFSS) ist ein Mechanismus, um die CPU-Zeit gleichmäßig auf die Sitzungen auf einem Computer zu verteilen.
Dadurch wird verhindert, dass eine Sitzung die CPU komplett mit Beschlag belegt, wenn einige
ihrer Threads eine relativ hohe Priorität haben und oft laufen. Auf Windows Server-Systemen
mit der Rolle Remotedesktop ist dieser Mechanismus standardmäßig aktiviert. Sie können ihn
jedoch auch auf jedem anderen Server- und Clientsystem einrichten. Die Implementierung
beruht auf der im vorherigen Abschnitt beschriebenen gruppengestützten Planung.
Wenn der Registrierungshive SOFTWARE im letzten Teil der Systeminitialisierung von Smss.
exe initialisiert wird, löst der Prozess-Manager die endgültige Post-Boot-Initialisierung in
P sBootPhaseComplete aus, die wiederum PspIsDfssEnabled aufrufen. An dieser Stelle entscheidet das System, welcher der beiden CPU-Kontingentmechanismen verwendet werden soll (der
herkömmliche oder DFSS). Um DFSS zu aktivieren, muss der Registrierungswert EnableCpuQuota
in beiden Kontingentschlüsseln auf einen von null verschiedenen Wert gesetzt werden. Der
erste dieser Schlüssel ist HKLM\SOFTWARE\Policies\Microsoft\Windows\Session Manager\Quota
System für die richtliniengestützte Einstellung, der zweite ist HKLM\SYSTEM\CurrentControlSet\
Control\Session Manager\Quota System unter dem Systemschlüssel. Letzterer legt fest, ob das
System DFSS unterstützt (und ist auf Windows Server-Computern mit der Rolle Remotedesktop
standardmäßig auf TRUE gesetzt).
326
Kapitel 4
Threads
Ist DFSS aktiviert, wird die globale Variable PsCpuFairShareEnabled auf TRUE gesetzt, wodurch alle Threads Planungsgruppen zugewiesen werden (außer denen in den Prozessen von
Sitzung 0). Die DFSS-Konfigurationsparameter werden durch einen Aufruf von PspReadDfssConfigurationValues in den zuvor erwähnten Registrierungsschlüsseln gelesen und in globalen
Variablen gespeichert. Das System überwacht diese Schlüssel. Werden sie verändert, ruft der
Benachrichtigungscallback erneut PspReadDfssConfigurationValues auf, um die Konfigurationswerte zu aktualisieren. Tabelle 4–6 zeigt die Werte und ihre Bedeutung.
Registrierungswert
Kernelvariable
Bedeutung
Standard
wert
DfssShortTermSharingMS
PsDfssShortTermSharingMS
Die erforderliche Zeit
für die Erhöhung des
Gruppenrangs in einem
Generationszyklus
30 ms
DfssLongTermSharingMS
PsDfssLongTermSharingMS
Die erforderliche Zeit, um
von Rang 0 zu einem von
null verschiedenen Rang
zu kommen, wenn die
Threads in einem Generationszyklus ihr Kontingent überschreiten
15 ms
DfssGenerationLengthMS
PsDfssGenerationLengthMS
Die Dauer der Generation, in der die CPU-Nutzung beobachtet wird
600 ms
DfssLongTermFraction1024
PsDfssLongTermFraction1024
Der Wert, der in der
Formel für einen exponentiellen gleitenden
Durchschnitt zur Berechnung langfristiger Zyklen
verwendet wird
512
Tabelle 4–6 DFSS-Konfigurationsparameter in der Registrierung
Wird bei aktivierter DFSS eine neue Sitzung erstellt (abgesehen von Sitzung 0), verknüpft MiSessionObjectCreate mit dieser Sitzung eine Planungsgruppe mit dem Standardgewicht 5,
also dem Mittel zwischen dem Mindestwert von 1 und dem Höchstwert von 9. Die Planungsgruppe verwaltet je nach Einstellung im Element Type ihrer Richtlinienstruktur (KSCHEDULING_
GROUP_POLICY) entweder DFSS-Informationen (WeightBased=0) oder Informationen zur CPU-
Ratensteuerung (RateControl=1; siehe den nächsten Abschnitt). MiSessionObjectCreate ruft
KeInsertSchedulingGroup auf, um die Planungsgruppe in die globale Systemliste einzufügen,
die in der globalen Variablen KiSchedulingGroupList geführt wird und zur Neuberechnung der
Gewichte beim Hinzufügen von Prozessoren im laufenden Betrieb benötigt wird. Die SESSION_
OBJECT-Struktur der betreffenden Sitzung zeigt ebenfalls auf die resultierende Planungsgruppe.
Gruppengestützte Threadplanung
Kapitel 4
327
Experiment: DFSS in Aktion
In diesem Experiment richten Sie ein System zur Verwendung von DFSS ein und beobachten, wie es diesen Mechanismus nutzt.
1.
Fügen Sie die in diesem Abschnitt beschriebenen Registrierungsschlüssel und -werte
hinzu, um DFSS auf dem System zu aktivieren. (Sie können dieses Experiment auch auf
einer VM ausführen.) Starten Sie das System dann neu, damit die Änderungen in Kraft
treten.
2.
Um sich zu vergewissern, dass DFSS aktiv ist, öffnen Sie eine Kerneldebugsitzung und
untersuchen Sie den Wert von PsCpuFairShareEnabled, indem Sie den folgenden Befehl
eingeben. Der Wert 1 bedeutet, dass DFSS aktiv ist.
lkd> db nt!PsCpuFairShareEnabled L1
fffff800'5183722a 01
3.
Schauen Sie sich den aktuellen Thread im Debugger an. (Es sollte einer der Threads
sein, die WinDbg ausführen.) Dabei können Sie sehen, dass der Thread zu einer Planungsgruppe gehört und dass sein KSCB nicht NULL ist, da der Thread zum Zeitpunkt
der Anzeige ausgeführt wurde:
lkd> !thread
THREAD ffffd28c07231640 Cid 196c.1a60 Teb: 000000f897f4b000 Win32Thread:
ffffd28c0b9b0b40 RUNNING on processor 1
IRP List:
ffffd28c06dfac10: (0006,0118) Flags: 00060000 Mdl: 00000000
Not impersonating
DeviceMap
ffffac0d33668340
Owning Process
ffffd28c071fd080 Image: windbg.exe
Attached Process
N/A Image: N/A
Wait Start TickCount 6146 Ticks: 33 (0:00:00:00.515)
Context Switch Count 877 IdealProcessor: 0
UserTime
00:00:00.468
KernelTime
00:00:00.156
Win32 Start Address 0x00007ff6ac53bc60
Stack Init ffffbf81ae85fc90 Current ffffbf81ae85f980
Base ffffbf81ae860000 Limit ffffbf81ae85a000 Call 0000000000000000
Priority 8 BasePriority 8 PriorityDecrement 0 IoPriority 2 PagePriority 5
Scheduling Group: ffffd28c089e7a40 KSCB: ffffd28c089e7c68 rank 0
4.
Geben Sie den Befehl dt ein, um sich die Planungsgruppe anzusehen:
lkd> dt nt!_kscheduling_group ffffd28c089e7a40
+0x000 Policy
: _KSCHEDULING_GROUP_POLICY
+0x008 RelativeWeight
: 0x80
→
328
Kapitel 4
Threads
+0x00c ChildMinRate
: 0x2710
+0x010 ChildMinWeight
: 0
+0x014 ChildTotalWeight
: 0
+0x018 QueryHistoryTimeStamp
: 0xfed6177
+0x020 NotificationCycles
: 0n0
+0x028 MaxQuotaLimitCycles
: 0n0
+0x030 MaxQuotaCyclesRemaining : 0n-73125382369
+0x038 SchedulingGroupList
: _LIST_ENTRY [ 0xfffff800'5179b110 -
0xffffd28c'081b7078 ]
+0x038 Sibling : _LIST_ENTRY [ 0xfffff800'5179b110 0xffffd28c'081b7078 ]
+0x048 NotificationDpc : 0x0002eaa8'0000008e _KDPC
+0x050 ChildList : _LIST_ENTRY [ 0xffffd28c'062a7ab8 0xffffd28c'05c0bab8 ]
+0x060 Parent : (null)
+0x080 PerProcessor : [1] _KSCB
5.
Erstellen Sie einen weiteren lokalen Benutzer auf dem Computer.
6.
Führen Sie CPU Stress in der laufenden Sitzung aus.
7.
Lassen Sie einige Threads mit maximaler Aktivität laufen, aber ohne den Computer
damit zu überlasten. Im folgenden Beispiel verwenden wir zwei Threads mit maximaler
Aktivität auf einer VM mit drei Prozessoren:
8.
Drücken Sie (Strg) + (Alt) + (Entf) und wählen Sie Benutzer wechseln. Wählen Sie
das Konto für den in Schritt 5 erstellten Benutzer aus und melden Sie sich an.
9.
Führen Sie erneut CPU Stress aus und lassen Sie dabei die gleiche Anzahl von Threads
mit maximaler Aktivität laufen.
10. Öffnen Sie für den Prozess CPUSTRES das Menü Process, wählen Sie Priority Class und
dann High, um seine Prioritätsklasse zu ändern. Ohne DFSS würde dieser Prozess höherer Priorität die CPU fast komplett mit Beschlag belegen, da es vier Threads gibt, die
um drei Prozessoren konkurrieren. Einer dieser Threads muss dabei verlieren, und zwar
derjenige mit der niedrigen Priorität.
11. Öffnen Sie Process Explorer, doppelklicken Sie auf beide CPUSTRES-Prozesse und rufen
Sie die Registerkarte Performance Graph auf.
→
Gruppengestützte Threadplanung
Kapitel 4
329
12. Ordnen Sie die Fenster nebeneinander an. Wie Sie sehen, wird die CPU ungefähr gleichmäßig von den Prozessen genutzt, obwohl sie unterschiedliche Prioritäten aufweisen:
13. Deaktivieren Sie DFSS, indem Sie die Registrierungsschlüssel entfernen. Starten Sie das
System neu.
14. Führen Sie das Experiment erneut durch. Jetzt sollten Sie erkennen, dass der Prozess
mit höherer Priorität erheblich mehr CPU-Zeit erhält.
Grenzwerte für die CPU-Rate
DFSS platziert neue Threads automatisch in der Planungsgruppe der Sitzung. Das ist für Terminaldienste zwar sehr gut geeignet, reicht aber als allgemeiner Mechanismus zur Begrenzung
der CPU-Zeit von Threads oder Prozessen nicht aus.
Durch die Verwendung eines Jobobjekts lässt sich die Infrastruktur der Planungsgruppen
auch auf eine feinere Weise nutzen. Wie Sie in Kapitel 3 gelernt haben, kann ein Job einen oder
mehrere Prozesse verwalten. Eine der Einschränkungen, die Sie einem Job auferlegen können,
ist die CPU-Ratensteuerung. Dazu rufen Sie SetInformationJobObject mit JobObjectCpuRateControlInformation als Informationsklasse und einer Struktur vom Typ JOBOBJECT_CPU_RATE_
CONTROL_INFORMATION mit den eigentlichen Steuerdaten auf. Die Struktur enthält eine Reihe von
Flags, mit denen Sie drei verschiedene Einstellungen zur Begrenzung der CPU-Zeit einrichten
können:
QQ CPU-Rate Dieser Wert kann zwischen 1 und 10.000 liegen und stellt den mit 100 multiplizierten prozentualen Anteil dar. (Beispielsweise müssen Sie für 40 % den Wert 4000
angeben.)
QQ Gewichtsgestützte Begrenzung Dies ist ein Wert zwischen 1 und 9 relativ zum Gewicht
anderer Jobs. (DFSS ist mit dieser Einstellung vorkonfiguriert.)
QQ Minimale und maximale CPU-Rate Diese Werte werden ähnlich angegeben wie bei
der ersten Option. Wenn die Threads in einem Job den maximalen Prozentsatz für das
Messintervall erreichen (standardmäßig 600 ms), können sie vor Beginn des nächsten Intervalls keine weitere CPU-Zeit mehr erhalten. Mit einem Steuerungsflag können Sie angeben, ob dies ein harter Grenzwert sein soll, sodass er auch dann gilt, wenn freie CPU-Zeit
zur Verfügung steht.
330
Kapitel 4
Threads
Diese Grenzwerte führen unter dem Strich dazu, dass alle Threads sämtlicher Prozesse in dem
Job in eine neue Planungsgruppe gestellt werden und die Gruppe wie angegeben konfiguriert
wird.
Experiment: Grenzwert für die CPU-Rate
In diesem Experiment richten Sie mithilfe eines Jobobjekts einen Grenzwert für die
CPU-Rate ein. Da der Debugger zurzeit noch einen Bug aufweist, ist es am besten, dieses
Experiment in einer VM durchzuführen und eine Verbindung zu deren Kernel herzustellen.
1.
Starten Sie CPU Stress auf der Test-VM und richten Sie einige Threads so ein, dass
sie etwa 50 % der CPU-Zeit verbrauchen. Beispielsweise müssen Sie dazu auf einem
Acht-Prozessor-System vier Threads mit maximaler Aktivität laufen lassen:
2.
Öffnen Sie Process Explorer, öffnen Sie die Eigenschaften von CPUSTRES und rufen Sie
die Registerkarte Performance Graph auf. Die CPU-Nutzung sollte etwa 50 % betragen.
3.
Laden Sie das Programm CpuLimit aus den Begleitmaterialien zu diesem Buch herunter.
Mit diesem einfachen Werkzeug können Sie die CPU-Nutzung eines einzelnen Prozesses durch Angabe eines harten Grenzwerts beschränken.
4.
Führen Sie den folgenden Befehl aus, um die CPU-Nutzung durch den Prozess CPUSTRES auf 20 % zu begrenzen. (Ersetzen Sie dabei 6324 durch die Prozess-ID auf Ihrem
System.) Das Werkzeug erstellt einen Job (CreateJobObject), fügt ihm den Prozess hinzu (AssignProcessTokenJobObject) und ruft SetInformationJobObject mit der Informa
tionsklasse für die CPU-Rate und dem Wert 2000 (20 %) auf.
CpuLimit.exe 6324 20
5.
In Process Explorer können Sie jetzt einen Abfall auf ca. 20 % erkennen:
6.
Öffnen Sie WinDbg auf dem Hostsystem.
→
Gruppengestützte Threadplanung
Kapitel 4
331
7.
Stellen Sie eine Verbindung zum Kernel des Testsystems her und klinken Sie sich darin
ein.
8.
Geben Sie den folgenden Befehl ein, um den Prozess CPUSTRES zu finden:
0: kd> !process 0 0 cpustres.exe
PROCESS ffff9e0629528080
SessionId: 1 Cid: 18b4 Peb: 009e4000 ParentCid: 1c4c
DirBase: 230803000 ObjectTable: ffffd78d1af6c540 HandleCount: <Data Not
Accessible>
Image: CPUSTRES.exe
9.
Geben Sie den folgenden Befehl ein, um grundlegende Informationen über den Prozess einzusehen:
0: kd> !process ffff9e0629528080 1
PROCESS ffff9e0629528080
SessionId: 1 Cid: 18b4 Peb: 009e4000 ParentCid: 1c4c
DirBase: 230803000 ObjectTable: ffffd78d1af6c540 HandleCount: <Data Not
Accessible>
Image: CPUSTRES.exe
VadRoot ffff9e0626582010 Vads 88 Clone 0 Private 450. Modified 4. Locked 0.
DeviceMap ffffd78cd8941640
Token
ffffd78cfe3db050
ElapsedTime
00:08:38.438
UserTime
00:00:00.000
KernelTime
00:00:00.000
QuotaPoolUsage[PagedPool]
209912
QuotaPoolUsage[NonPagedPool]
11880
Working Set Sizes (now,min,max) (3296, 50, 345) (13184KB, 200KB, 1380KB)
PeakWorkingSetSize
3325
VirtualSize
108 Mb
PeakVirtualSize
128 Mb
PageFaultCount
3670
MemoryPriority
BACKGROUND
BasePriority
8
CommitCharge
568
Job
ffff9e06286539a0
→
332
Kapitel 4
Threads
10. Wie Sie sehen, gibt es ein Jobobjekt, das nicht NULL ist. Lassen Sie sich mit dem Befehl
!job seine Eigenschaften anzeigen:
0: kd> !job ffff9e06286539a0
Job at ffff9e06286539a0
Basic Accounting Information
TotalUserTime:
0x0
TotalKernelTime:
0x0
TotalCycleTime:
0x0
ThisPeriodTotalUserTime:
0x0
ThisPeriodTotalKernelTime: 0x0
TotalPageFaultCount:
0x0
TotalProcesses:
0x1
ActiveProcesses:
0x1
FreezeCount:
0
BackgroundCount:
0
TotalTerminatedProcesses:
0x0
PeakJobMemoryUsed:
0x248
PeakProcessMemoryUsed:
0x248
Job Flags
[close done]
[cpu rate control]
Limit Information (LimitFlags: 0x0)
Limit Information (EffectiveLimitFlags: 0x800)
CPU Rate Control
Rate = 20.00%
Hard Resource Cap
Scheduling Group: ffff9e0628d7c1c0
11. Führen Sie CpuLimit für denselben Prozess aus und setzen Sie die CPU-Rate erneut auf
20 %. Daraufhin fällt der CPU-Verbrauch von CPUSTRES auf ca. 4 %. Das liegt daran,
dass der neue Job und der ihm zugewiesene Prozess in dem ersten Job verschachtelt
werden. Dadurch wird jetzt ein Grenzwert von 20 % verlangt, also 4 %.
Dynamisches Hinzufügen und Ersetzen von Prozessoren
Wie Sie in den bisherigen Ausführungen gesehen haben, können Entwickler genau festlegen,
welche Threads auf welchen Prozessoren laufen dürfen (und im Falle von idealen Prozessoren,
welche darauf laufen sollen). Auf Systemen, bei denen die Anzahl der Prozessoren zur Laufzeit
unverändert bleibt, funktioniert das sehr gut, beispielsweise auf Desktopcomputern, bei denen
es für jegliche Änderungen an der Anzahl der Prozessoren erforderlich ist, den Rechner herunterzufahren. Die Betreiber moderner Serversysteme können sich jedoch keine Ausfallzeiten
leisten, um eine CPU auszutauschen oder hinzuzufügen. Es kann sogar sein, dass CPUs gerade
dann hinzugefügt werden müssen, wenn der Computer so stark belastet ist, dass er nicht mehr
Gruppengestützte Threadplanung
Kapitel 4
333
die übliche Leistung bringt. Den Server gerade während einer solchen Spitzenauslastung herunterzufahren, wäre jedoch widersinnig.
Daher ist es bei den neuesten Generationen von Servermotherboards und -systemen möglich, Prozessoren im laufenden Betrieb hinzuzufügen und auszutauschen. Das ACPI-BIOS und
die zugehörige Hardware auf solchen Computern wurden entsprechend konstruiert, aber damit es funktioniert, muss auch das Betriebssystem mitspielen.
Unterstützung für eine dynamische Prozessorauslegung wird durch die HAL bereitgestellt,
die den Kernel mithilfe der Funktion KeStartDynamicProcessor über einen neuen Prozessor auf
dem System informiert. Diese Routine führt ähnliche Arbeiten aus wie diejenigen, die anfallen,
wenn das System beim Start mehr als einen Prozessor erkennt und die mit ihnen verknüpften
Strukturen initialisieren muss. Beim dynamischen Hinzufügen eines Prozessors erledigen mehrere Systemkomponenten noch zusätzliche Aufgaben. Beispielsweise weist der Speicher-Manager neue Seiten und Speicherstrukturen zu, die für die CPU optimiert sind, und initialisiert
einen neuen DPC-Kernelstack, während der Kernel die globale Deskriptortabelle (GDT), die
Interruptdispatchtabelle (IDT), die Prozessorsteuerungsregion (PCR), den Prozessorsteuerungsblock (PRCB) und ähnliche Strukturen für den Prozessor initialisiert.
Es werden auch andere Exekutivelemente des Kernels aufgerufen, hauptsächlich um die
Look-Aside-Listen für den hinzugefügten Prozessor zu initialisieren. Unter anderem nutzen
der E/A-Manager, der Exekutivcode für Look-Aside-Listen, der Cache-Manager und der Objekt-Manager solche Listen für ihre häufig zugewiesenen Strukturen.
Schließlich initialisiert der Kernel die DPC-Threadunterstützung für den Prozessor und
passt die exportierten Kernelvariablen an, sodass sie den neuen Prozessor angeben. Es werden
auch einige Masken im Speicher-Manager und Prozessseeds aktualisiert, die auf der Anzahl
der Prozessoren beruhen. Einzelne Merkmale des neuen Prozessors müssen ebenfalls an den
Rest des Systems angepasst werden, beispielsweise indem auf ihm die Unterstützung für die
Virtualisierung aktiviert wird. Zum Abschluss der Initialisierung wird die WHEA-Komponente
(Windows Hardware Error Architecture) darüber informiert, dass ein neuer Prozessor online ist.
Auch die HAL ist an diesem Vorgang beteiligt. Sie wird einmal aufgerufen, um den dynamisch hinzugefügten Prozessor zu starten, wenn der Kernel über ihn Bescheid weiß, und ein
weiteres Mal, wenn der Kernel die Initialisierung dieses Prozessors abgeschlossen hat. Allerdings sorgen diese Benachrichtigungen und Callbacks nur dafür, dass der Kernel über Prozessoränderungen informiert ist und darauf reagiert. Ein zusätzlicher Prozessor erhöht zwar den
Durchsatz des Kernels, hilft aber nicht den Treibern.
Für den Umgang mit den Treibern verwendet das System das Standard-Callbackobjekt
ProcessorAdd, mit dem sich Treiber für Benachrichtigungen registrieren können. Ähnlich wie die
Callbacks, die Treiber über den Energiestatus oder über Änderungen der Systemzeit informieren, ermöglicht dieser Callback dem Treibercode, z. B. einen neuen Arbeitsthread zu erstellen,
wenn das gewünscht ist, um mehr Arbeit zur selben Zeit zu erledigen.
Nachdem die Treiber benachrichtigt sind, wird als letzte Kernelkomponente der Plug-andPlay-Manager aufgerufen, der den Prozessor zum Geräteknoten des Systems hinzufügt und die
Interrupts neu verteilt, damit der neue Prozessor die bereits für andere Prozessoren registrierten Interrupts handhaben kann. CPU-hungrige Anwendungen können den neuen Prozessor
ebenfalls nutzen.
334
Kapitel 4
Threads
Eine plötzliche Änderung der Affinität kann sich auf eine laufende Anwendung jedoch
störend auswirken, insbesondere beim Übergang von einem Einzel- zu einem Mehrprozessorsystem, denn dadurch können Race Conditions auftreten oder die Arbeit falsch verteilt werden
(da der Prozess möglicherweise beim Start die idealen Verhältnisse auf der Grundlage der ihm
bekannten Anzahl von Prozessoren berechnet hat). Daher nutzen Anwendungen die Vorteile
eines dynamisch hinzugefügten Prozessors standardmäßig nicht, sondern müssen ihn anfordern.
Mit den Windows-APIs SetProcessAffinityUpdateMode und QueryProcessAffinityUpdateMode,
die den nicht dokumentierten Systemaufruf NtSet/QueryInformationProcess nutzen, teilen Anwendungen dem Prozess-Manager mit, ob ihre Affinität aktualisiert werden soll (durch das Flag
AffinityUpdateEnable in der EPROCESS-Struktur) oder nicht (durch das Flag AffinityPermanent).
Diese Einstellung wird einmalig vorgenommen. Wenn eine Anwendung dem System mitgeteilt
hat, dass ihre Affinität dauerhaft sein soll, kann sie nicht später ihre Meinung ändern und Affinitätsaktualisierungen anfordern.
Im Rahmen von KeStartDynamicProcessor wurde nach der Neuverteilung der Interrupts
ein neuer Schritt hinzufügt, nämlich ein Aufruf des Prozess-Managers, um über PsUpdate
ActiveProcessAffinity Affinitätsaktualisierungen durchzuführen. Bei einigen Kernprozessen
und -diensten von Windows ist die Möglichkeit für Affinitätsaktualisierungen bereits aktiviert, wohingegen Drittanbietersoftware neu kompiliert werden muss, um diesen neuen
API-Aufruf nutzen zu können. Der Systemprozess, die Svchost-Prozesse und Smss sind mit der
dynamischen Ergänzung von Prozessoren kompatibel.
Arbeitsfactories (Threadpools)
Arbeitsfactories sind der interne Mechanismus zur Implementierung der Threadpools des Benutzermodus. Früher waren die Threadpoolroutinen komplett im Benutzermodus in der Bibliothek Ntdll.dll implementiert. Die Windows-API enthielt außerdem verschiedene Funktionen für
Timer mit Wartemöglichkeiten (CreateTimerQueue, CreateTimerQueueTimer usw.), Wartecallbacks
(RegisterWaitForSingleObject) und die Verarbeitung von Arbeitselementen mit automatischer
Threaderstellung und -löschung in Abhängigkeit vom Umfang der zu erledigenden Arbeit
(QueueUserWorkItem).
Ein Problem bei der alten Implementierung bestand darin, dass in einem Prozess nur ein
Threadpool erstellt werden konnte, wodurch sich manche Szenarien schwer umsetzen ließen.
So war es beispielsweise nicht direkt möglich, Prioritäten für Arbeitselemente durch den Aufbau
von zwei Threadpools für unterschiedliche Anforderungen aufzustellen. Das andere Problem
betraf die Tatsache, dass sich die Implementierung im Benutzermodus (in Ntdll.dll) befand. Da
der Kernel die direkte Kontrolle über Planung, Erstellung und Beendigung von Threads ohne die
Kosten übernehmen kann, die für diese Operationen im Benutzermodus gewöhnlich anfallen,
befindet sich der Großteil der Funktionalität zur Unterstützung von Benutzermodus-Threadpools jetzt im Kernel. Das vereinfacht auch den Code, den Entwickler schreiben müssen. So lässt
sich ein Arbeitspool in einem Remoteprozess jetzt mit einem einzigen API-Aufruf erstellen statt
mit der komplizierten Folge von Aufrufen im virtuellen Arbeitsspeicher, die sonst erforderlich
Arbeitsfactories (Threadpools)
Kapitel 4
335
waren. Bei dem neuen Modell stellt Ntdll.dll nur noch die Schnittstellen und die APIs höherer
Ebene bereit, die für den Umfang mit dem Kernelcode der Arbeitsfactories erforderlich sind.
Bereitgestellt wird diese Threadpool-Funktionalität des Kernels von dem Objekt-Manager-Typ TpWorkerFactory, vier nativen Systemaufrufen für die Verwaltung der Factory und
ihrer Arbeitsthreads (NtCreateWorkerFactory, NtWorkerFactoryWorkerReady, NtReleaseWorker
FactoryWorker und NtShutdownWorkerFactory), zwei nativen Aufrufen zum Abfragen und
Festlegen (NtQueryInformationWorkerFactory und NtSetInformationWorkerFactory) und einem Warteaufruf (NtWaitForWorkViaWorkerFactory). Wie andere native Systemaufrufe stellen auch diese im Benutzermodus ein Handle für das TpWorkerFactory-Objekt bereit, das
Informationen wie den Namen und die Objektattribute, die gewünschte Zugriffsmaske und
einen Sicherheitsdeskriptor enthält. Anders als bei anderen in die Windows-API eingepackten Systemaufrufen erfolgt die Verwaltung der Threadpools jedoch durch den nativen Code
von Ntdll.dll. Entwickler müssen also mit undurchsichtigen Deskriptoren arbeiten: einem
TP_POOL-Zeiger für einen Threadpool und anderen undurchsichtigen Zeigern für Objekte, die
aus einem Pool erstellt wurden, u. a. TP_WORK (Arbeitscallback), TP_TIMER (Timercallback) und
TP_WAIT (Wartecallback). Diese Strukturen enthalten verschiedene Informationen, darunter
das Handle auf das TpWorkFactory-Objekt.
Die Implementierung der Arbeitsfactory ist dafür zuständig, die Arbeitsthreads zuzuweisen, den Eintrittspunkt eines Arbeitsthreads im Benutzermodus aufzurufen und einen Zähler
für Mindest- und Höchstanzahl von Threads zu führen (um permanente komplett dynamische
Arbeitspools zu ermöglichen) sowie andere Buchführungsinformationen zu verfolgen. Dadurch
können Operationen wie das Herunterladen des Threadpools mit einem einzigen Kernelaufruf
erledigt werden, da der Kernel als einzige Komponente für das Erstellen und Beenden der
Threads zuständig ist.
Die Tatsache, dass der Kernel neue Threads auf der Grundlage der Mindest- und Höchstzahlen nach Bedarf dynamisch erstellt, verbessert die Skalierbarkeit von Anwendungen, die
diese neue Implementierung von Threadpools nutzen. Eine Arbeitsfactory erstellt einen neuen
Thread, wenn sämtliche der folgenden Bedingungen erfüllt sind:
QQ Die dynamische Threaderstellung ist aktiviert.
QQ Die Anzahl der verfügbaren Arbeitsthreads ist geringer als die für die Factory eingestellte
Höchstzahl von Arbeitsthreads (wobei der Standardwert 500 beträgt).
QQ Die Arbeitsfactory verfügt über gebundene Objekte (z. B. einen ALPC-Port, auf den der
Arbeitsthread wartet), oder ein Thread wurde aktiviert und in den Pool gestellt.
QQ Mit einem Arbeitsthread sind ausstehende E/A-Anforderungspakete verknüpft (IRPS; siehe
Kapitel 6).
Des Weiteren beendet die Factory Threads, wenn sie länger als zehn Sekunden (Standardeinstellung) unbeschäftigt sind, also keine Arbeitselemente verarbeitet haben. Auch bei der alten
Implementierung konnten Entwickler stets so viele Threads wie möglich verwenden (was durch
die Anzahl der Prozessoren auf dem System bestimmt wurde), doch jetzt können Anwendungen, die Threadpools nutzen, automatisch die Vorteile neuer Prozessoren nutzen, die zur Laufzeit hinzugefügt werden. Das ist dank der im vorherigen Abschnitt erläuterten Unterstützung
für dynamisch hinzugefügte Prozessoren möglich.
336
Kapitel 4
Threads
Erstellen von Arbeitsfactories
Die Einrichtung von Arbeitsfactories ist lediglich ein Wrapper für den Umgang mit alltäglichen Aufgaben, die ansonsten auf Kosten der Leistung im Benutzermodus ausgeführt werden
müssten. Ein Großteil des neuen Threadpoolcodes verbleibt in Ntdll.dll. (Bei der Nutzung nicht
dokumentierter Funktionen ließe sich auf der Grundlage der Arbeitsfactories auch eine andere
Threadpoolimplementierung aufbauen.) Es ist auch nicht der Code für Arbeitsfactories, der für
Skalierbarkeit, die internen Wartemechanismen und eine effiziente Verarbeitung sorgt, sondern eine viel ältere Windows-Komponente, nämlich die E/A-Abschlussports oder genauer die
Kernelwarteschlangen (KQUEUE). Um eine Arbeitsfactory zu erstellen, muss bereits ein E/A-Abschlussport im Benutzermodus angelegt und das Handle übergeben werden.
Dieser E/A-Abschlussport sorgt dafür, dass die Benutzermodusimplementierung auf Arbeit
wartet – allerdings nicht durch die APIs für den Port, sondern durch Systemaufrufe der Arbeitsfactory. Bei dem »Freigabe«-Aufruf der Arbeitsfactory (der Arbeit in eine Warteschlange stellt)
handelt es sich intern jedoch um einen Wrapper um IoSetIoCompletionEx, die die ausstehende
Arbeit erweitert, und bei dem »Warte«-Aufruf um einen Wrapper um IoRemoveIoCompletion.
Beide Routinen rufen die Implementierung der Kernelwarteschlange auf. Die Aufgabe des Arbeitsfactorycodes besteht also darin, einen dauerhaften statischen oder einen dynamischen
Threadpool zu verwalten; das E/A-Abschlussmodell in die Schnittstellen einzupacken, die automatisch dynamische Threads erstellen, um einen Stillstand der Arbeitswarteschlangen zu verhindern; und die globalen Aufräum- und Beendigungsoperationen beim Herunterfahren einer
Factory zu vereinfachen sowie neue Anforderungen an die Factory in einer solchen Situation
zu blockieren.
Die Exekutivfunktion, die die Arbeitsfactory erstellt, ist NtCreateWorkerFactory. Sie nimmt
mehrere Argumente zur Gestaltung des Threadpools entgegen, z. B. die maximale Anzahl zu
erstellender Threads und die ursprüngliche Größe des zugesicherten und des reservierten
Stacks. Die Windows-API CreateThreadpool verwendet dagegen die Standardstackgrößen, die
in das Abbild der ausführbaren Datei eingebettet sind – ebenso wie die Standardfunktion
CreateThread. Allerdings ist es bei der Windows-API nicht möglich, diese Standardwerte zu
überschreiben. Das ist kein sehr glücklicher Umstand, denn oft sind für Threads aus Threadpools keine tiefen Aufrufstacks erforderlich, weshalb es von Vorteil wäre, wenn man kleine
Stacks zuweisen könnte.
Die von der Implementierung der Arbeitsfactory verwendeten Datenstrukturen befinden
sich nicht unter den öffentlichen Symbolen, doch wie Sie im nächsten Experiment sehen werden, ist es trotzdem möglich, sich einige der Arbeitspools anzusehen. Außerdem gibt die API
NtQueryInformationWorkerFactory fast sämtliche Felder der Arbeitsfactorystruktur aus.
Arbeitsfactories (Threadpools)
Kapitel 4
337
Experiment: Threadpools einsehen
Aufgrund seiner Vorteile wird der Threadpoolmechanismus von vielen Systemkomponenten und Anwendungen genutzt, vor allem für den Umgang mit Ressourcen wie ALPC-Ports
(um eingehende Anforderungen auf passende und skalierbare Weise dynamisch zu verarbeiten). Eine der Möglichkeiten, um herauszufinden, welche Prozesse eine Arbeitsfactory
nutzen, besteht darin, sich die Handleliste in Process Explorer anzusehen. Gehen Sie dazu
wie folgt vor:
1.
Starten Sie Process Explorer.
2.
Öffnen Sie das Menü View und wählen Sie Show Unnamed Handles and Mappings. Da
Arbeitsfactories von Ntdll.dll leider nicht benannt werden, ist dieser Schritt erforderlich,
um die Handles sehen zu können.
3.
Markieren Sie in der Prozessliste eine Instanz von Svchost.exe.
4.
Öffnen Sie das Menü View und wählen Sie Show Lower Pane, um den unteren Bereich
der Handletabelle einzublenden.
5.
Öffnen Sie das Menü View, wählen Sie Lower Pane View und dann Handles, um die
Tabelle im Handlemodus anzuzeigen.
6.
Rechtsklicken Sie auf die Spaltenköpfe im unteren Bereich und wählen Sie Select Columns.
7.
Sorgen Sie dafür, dass die Spalten Type und Handle Value mit einem Häkchen versehen
sind.
8.
Klicken Sie auf den Spaltenkopf Type, um die Tabelle nach dem Typ zu sortieren.
9.
Scrollen Sie nach unten, bis Sie ein Handle vom Typ TpWorkerFactory finden.
10. Klicken Sie auf den Spaltenkopf Handle, um die Tabelle nach dem Handlewert zu sortieren. Dadurch erhalten Sie die Anzeige aus dem folgenden Screenshot. Beachten Sie,
dass dem TpWorkerFactory-Handle unmittelbar ein IoCompletion-Handle vorausgeht.
Wie bereits erwähnt, muss vor dem Erstellen einer Arbeitsfactory ein Handle für einen
E/A-Abschlussport angelegt werden, zu dem die Arbeit gesendet wird.
→
338
Kapitel 4
Threads
11. Doppelklicken Sie in der Prozessliste auf den ausgewählten Prozess, rufen Sie die Registerkarte Threads auf und klicken Sie auf die Spalte Start Address. Dadurch erhalten
Sie die Anzeige aus dem folgenden Screenshot. Arbeitsfactorythreads lassen sich leicht
an ihrem Ntdll.dll-Eintrittspunkt TppWorkerThread erkennen (wobei Tpp für Thread Pool
Private steht).
Wenn Sie sich andere Arbeitsthreads ansehen, werden Sie feststellen, dass einige davon auf
Objekte wie Ereignisse warten. Ein Prozess kann über mehrere Threadpools verfügen, wobei
jeder davon Threads für völlig unterschiedliche Aufgaben haben kann. Der Entwickler ist dafür
zuständig, die Arbeit zuzuweisen und die Threadpool-APIs aufzurufen, um diese Arbeit über
Ntdll.dll zu registrieren.
Zusammenfassung
In diesem Kapitel ging es um die Struktur von Threads. Wir haben uns angesehen, wie sie erstellt und verwaltet werden und wie Windows entscheidet, welche Threads wie lange auf welchen Prozessoren ausgeführt werden sollen. Im nächsten Kapitel werfen wir einen genaueren
Blick auf einen der wichtigsten Aspekte eines jeden Betriebssystems, nämlich die Speicherverwaltung.
Zusammenfassung
Kapitel 4
339
K apite l 5
Speicherverwaltung
In diesem Kapitel lernen Sie, wie Windows den virtuellen Arbeitsspeicher implementiert und
den Teil davon verwaltet, der sich im physischen Arbeitsspeicher befindet. Auch die internen
Datenstrukturen, Komponenten und Algorithmen des Speicher-Managers werden beschrieben.
Bevor wir diese Mechanismen untersuchen, sehen wir uns jedoch noch einmal die grundlegenden Dienste an, die der Speicher-Manager zur Verfügung stellt, sowie wichtige Begriffe wie
reservierter, zugesicherter und gemeinsam genutzter Speicher.
Einführung in den Speicher-Manager
Die virtuelle Größe eines Prozesses beträgt auf 32-Bit-Windows standardmäßig 2 GB. Wenn
das Abbild so gekennzeichnet ist, dass es mit großen Adressräumen umgehen kann, und das
System mit einer besonderen Option gestartet wird (die weiter hinten in diesem Kapitel im Abschnitt »x86-Adressraumlayouts« erklärt wird), kann ein 32-Bit-Prozess auf 32-Bit-Windows auf
3 GB und auf 64-Bit-Windows auf 4 GB anwachsen. Auf den 64-Bit-Versionen von Windows 8
und Windows Server 2012 beträgt die Größe des virtuellen Prozessadressraums 8192 GB (8 TB)
und auf den 64-Bit-Versionen von Windows 8.1 und Windows Server 2012 R2 (und höher)
128 TB.
Wie Sie in Kapitel 2 und dort insbesondere in Tabelle 2–2 gesehen haben, unterstützt
Windows je nach Version und Edition physischen Arbeitsspeicher im Umfang von 2 GB bis
24 TB. Da der virtuelle Adressraum größer oder kleiner sein kann als der physische Arbeitsspeicher des Computers, hat der Speicher-Manager die beiden folgenden Hauptaufgaben:
QQ Er muss den virtuellen Adressraum eines Prozesses auf den physischen Arbeitsspeicher
abbilden (oder ihm zuordnen), damit die richtigen physischen Adressen referenziert werden, wenn ein Thread, der im Kontext dieses Prozesses läuft, in dem virtuellen Adressraum
liest oder schreibt. Der Teil des virtuellen Adressraums eines Prozesses, der sich im physischen Arbeitsspeicher befindet, wird Arbeitssatz genannt. Mehr darüber erfahren Sie im
Abschnitt »Arbeitssätze« weiter hinten in diesem Kapitel.
QQ Er muss einen Teil der Inhalte des Arbeitsspeichers auf die Festplatte auslagern, wenn
Threads versuchen, mehr physischen Arbeitsspeicher zu verwenden, als verfügbar ist, und
diese Inhalte bei Bedarf wieder in den physischen Arbeitsspeicher zurückholen.
Der Speicher-Manager kümmert sich jedoch nicht nur um die Verwaltung des virtuellen Arbeitsspeichers, sondern stellt auch grundlegende Dienste bereit, auf denen verschiedene
Windows-Umgebungsteilsysteme aufbauen. Dazu gehören im Speicher abgebildete oder zugeordnete Dateien (die intern als Abschnittsobjekte bezeichnet werden), Copy-on-Write-Speicher
(Kopieren beim Schreiben) sowie Unterstützung für Anwendungen, die einen umfangreichen,
341
dünn besetzten Adressraum nutzen. Des Weiteren bietet der Speicher-Manager Prozessen eine
Möglichkeit, größere Mengen des physischen Speichers zuzuweisen und zu verwenden, als auf
einmal in ihrem virtuellen Adressraum zugeordnet werden können, etwa auf 32-Bit-Systemen
mit mehr als 3 GB physischem Speicher. Dies wird im Abschnitt »AWE (Address Windowing
Extensions))« weiter hinten in diesem Kapitel erklärt.
Das Systemsteuerungsapplet System bietet die Möglichkeit, Größe, Anzahl und
Speicherort von Auslagerungsdateien festzulegen. Die dabei verwendeten Begriffe scheinen darauf hinzudeuten, dass der virtuelle Arbeitsspeicher das Gleiche ist
wie die Auslagerungsdatei. Das ist aber nicht der Fall. Die Auslagerungsdatei ist
nur ein Aspekt des virtuellen Speichers. Selbst wenn Sie gar keine Auslagerungsdatei verwenden, kann Windows immer noch virtuellen Speicher nutzen. Diese
Unterscheidung wird in diesem Kapitel noch ausführlich erklärt.
Komponenten des Speicher-Managers
Der Speicher-Manager gehört zur Windows-Exekutive und befindet sich daher in der Datei
Ntoskrnl.exe. Er bildet die größte Komponente der Exekutive, was schon auf seine Wichtigkeit
und Vielschichtigkeit hindeutet. Kein Teil des Speicher-Managers liegt in der HAL. Er besteht
aus den folgenden Komponenten:
QQ Ein Satz von Exekutiv-Systemdiensten, um virtuellen Speicher zuzuweisen und zu verwalten
und die Zuweisung aufzuheben. Die meisten dieser Dienste werden durch die WindowsAPI oder durch die Schnittstellen von Kernelmodus-Gerätetreibern bereitgestellt.
QQ Ein Traphandler für ungültige Zuordnungen und Zugriffsfehler, um von der Hardware erkannte Speicherverwaltungsausnahmen aufzulösen und virtuelle Seiten im Namen eines
Prozesses speicherresident zu machen.
QQ Sechs Routinen oberster Ebene, die jeweils in einem von sechs Kernelmodusthreads im
Systemprozess laufen:
342
•
Der Balance-Set-Manager (KeBalanceSetManager, Priorität 17) Einmal pro Sekunde und sowie dann, wenn der freie Arbeitsspeicher unter einen festgelegten Schwellenwert fällt, ruft der Balance-Set-Manager den Arbeitssatz-Manager (MwWorkingSetManager)
auf, eine innere Routine, die sich um die Richtlinien zur Speicherverwaltung wie Verkleinerung des Arbeitssatzes, Alterung und das Schreiben von modifizierten Seiten kümmert.
•
Der Prozess-/Stack-Umlagerer (KeSwapProcessOrStack, Priorität 23) Diese Komponente führt die Auslagerung und Einlagerung des Prozess- und des Kernelthread
stacks durch. Der Balance-Set-Manager und der Threadplanungscode im Kernel wecken
diesen Thread auf, wenn eine entsprechende Operation erforderlich ist.
•
Der Schreibthread für geänderte Seiten (MiModifiedPageWriter, Priorität 18) Er
schreibt die geänderten Seiten, die auf der entsprechenden Liste vermerkt sind, wieder
in die zugehörigen Auslagerungsdateien. Dieser Thread wird aufgeweckt, wenn die
Liste der modifizierten Seiten verkleinert werden muss.
Kapitel 5
Speicherverwaltung
•
Der Schreibthread für zugeordnete Seiten (MiMappedPageWriter, Priorität 18) Er schreibt geänderte Seiten in zugeordneten Dateien auf die Festplatte oder
einen Remotespeicherplatz. Aufgeweckt wird er, wenn die Liste der modifizierten Seiten
verkleinert werden muss oder wenn sich Seiten für zugeordnete Dateien schon länger
als fünf Minuten auf dieser Liste befinden. Dieser zweite Schreibthread für geänderte
Seiten ist notwendig, da er Seitenfehler hervorrufen kann, die zu Anforderungen freier
Seiten führen. Gäbe es in einer Situation, in der keine freien Seiten vorhanden sind, nur
einen einzigen Schreibthread für geänderte Seiten, so könnte das System beim Warten
auf freie Seiten in ein Deadlock eintreten.
•
Der Segmentdereferenzierungsthread (MiDereferenceSegmentThread, Priorität 19) Dieser Thread ist für die Cachereduzierung und für das Wachstum und die
Verkleinerung der Auslagerungsdatei zuständig. Wenn es beispielsweise keinen virtuellen Adressraum für das Wachstum des ausgelagerten Pools gibt, verkleinert dieser
Thread den Seitencache, sodass der als sein Anker genutzte ausgelagerte Pool zur Wiederverwendung freigegeben werden kann.
•
Der Nullseitenthread (MiZeroPageThread, Priorität 0) Dieser Thread setzt die
Seiten auf der Liste der freien Seiten auf null, sodass ein Cache aus Nullseiten für spätere Nullforderungsseitenfehler zur Verfügung steht. In einigen Fällen erfolgt diese
Nullsetzung durch die schnellere Funktion MiZeroInParallel. Mehr zu diesem Thema
erfahren Sie im Abschnitt »Seitenlistendynamik« weiter hinten in diesem Kapitel.
Jede dieser Komponenten wird weiter hinten in diesem Kapitel noch ausführlich behandelt. Die
einzige Ausnahme bildet der Segmentdereferenzierungsthread, der in Kapitel 14 von Band 2
beschrieben wird.
Große und kleine Seiten
Die Speicherverwaltung erfolgt in fest umrissenen Teilstücken, die als Seiten bezeichnet werden. Die Hardwareeinheit zur Speicherverwaltung übersetzt die virtuellen Adressen mit der Genauigkeit von Seiten in physische Adressen. Eine Seite ist daher die kleinste Einheit des Schutzes
auf Hardwareebene. (Die Möglichkeiten für den Seitenschutz werden im Abschnitt »Speicherschutz« weiter hinten in diesem Kapitel beschrieben.) Die Prozessoren, auf denen Windows
laufen kann, lassen zwei Arten von Seiten zu, kleine und große, wobei die konkrete Größe von
der Prozessorarchitektur abhängt (siehe Tabelle 5–1).
Architektur
Kleine Seite
Große Seite
Kleine Seiten pro
großer Seite
x86 (PAE)
4 KB
2 MB
512
x64
4 KB
2 MB
512
ARM
4 KB
4 MB
1024
Tabelle 5–1 Seitengrößen
Einführung in den Speicher-Manager
Kapitel 5
343
Bei einigen Prozessoren kann die Seitengröße eingestellt werden, allerdings nutzt
Windows diese Möglichkeit nicht.
Der Hauptvorteil, den große Seiten bieten, ist die Geschwindigkeit der Adressübersetzung für
Verweise auf Daten auf solchen Seiten. Beim ersten Verweis auf irgendein Byte auf einer großen
Seite werden die Informationen, die auch zur Übersetzung von Verweisen auf jegliche anderen
Bytes auf dieser Seite nötig sind, in den Look-Aside-Puffer für die Übersetzung gestellt (Translation Look-Aside Buffer, TLB; siehe den Abschnitt »Adressübersetzung« weiter hinten in diesem
Kapitel). Bei kleinen Seiten sind für denselben Bereich virtueller Adressen mehr TLB-Einträge
erforderlich, wodurch Einträge häufiger überschrieben werden und neue virtuelle Adressen
übersetzt werden müssen. Das wiederum bedeutet, dass bei Verweisen auf virtuelle Adressen
außerhalb der kleinen Seite, deren Übersetzung zwischengespeichert wurde, wieder ein Zugriff
auf die Seitentabellenstrukturen erfolgen muss. Der TLB ist ein sehr kleiner Cache, der bei der
Verwendung großer Seiten besser genutzt wird.
Um auf Systemen mit mehr als 2 GB RAM die Vorteile großer Seiten genießen zu können, ordnet Windows sowohl Kernelabbilder (Ntoskrnl.exe und Hal.dll) als auch Kerndaten des
Betriebssystems (wie den ursprünglichen Teil des nicht ausgelagerten Pools und die Daten
strukturen, die den Status der einzelnen physischen Speicherseiten beschreiben) großen Seiten zu. Auch E/A-Adressraumanforderungen (Aufrufe von MmMapIoSpace durch Gerätetreiber)
werden automatisch großen Seiten zugeordnet, wenn sie eine ausreichende Länge und eine
passende Ausrichtung aufweisen. Des Weiteren erlaubt Windows Anwendungen, ihre eigenen Abbilder, ihren privaten Arbeitsspeicher und auslagerungsgepufferte Abschnitte in großen Seiten zuzuordnen (mithilfe des Flags MEM_LARGE_PAGES in den Funktionen VirtualAlloc,
V irtualAllocEx und VirtualAllocExNuma). Außerdem können Sie weitere Gerätetreiber angeben,
die in großen Seiten zugeordnet werden sollen, indem Sie dem Registrierungsschlüssel HKLM\
SYSTEM\
CurrentControlSet\Control\Session Manager\Memory Management den Mehrfachstringwert LargePageDrivers hinzufügen und darin die Namen der Treiber als separate, mit NULL
angeschlossene Strings angeben.
Die Zuordnung großer Seiten kann fehlschlagen, wenn das Betriebssystem schon längere
Zeit läuft, da der physische Speicher für jede dieser Seiten eine hohe Anzahl physisch benachbarter kleiner Seiten umfassen muss (siehe Tabelle 5–1). Des Weiteren müssen physische
Seiten an bestimmten Grenzen beginnen. Beispielsweise können auf einem x64-System die
physischen Seiten 0 bis 511 und 512 bis 1023 für große Seiten verwendet werden, die Seiten
10 bis 521 aber nicht. Wenn das System in Betrieb ist, wird der freie physische Speicher jedoch
fragmentiert. Das ist bei der Zuweisung kleiner Seiten kein Problem, kann aber dazu führen,
dass die Zuweisung großer Seiten fehlschlägt.
Große Seiten können auch nicht ausgelagert werden. Zur Zuordnung in großen Seiten
muss der Aufrufer daher über das Recht SeLockMemoryPrivilege verfügen. Außerdem wird der
auf diese Weise zugeordnete Arbeitsspeicher nicht als Bestandteil des Prozessarbeitssatzes angesehen (siehe den Abschnitt »Arbeitssätze« weiter hinten in diesem Kapitel) und unterliegt
auch nicht den Jobeinschränkungen für die Verwendung des virtuellen Speichers.
Auf x64-Systemen mit Windows 10 Version 1607 und Windows Server 2016 können bei der
Zuordnung von großen Seiten auch riesige Seiten von 1 GB verwendet werden. Das geschieht
344
Kapitel 5
Speicherverwaltung
automatisch, wenn die angeforderte Zuweisung mehr als 1 GB beträgt, aber sie muss kein
Mehrfaches davon betragen. Um beispielsweise 1040 MB zuzuweisen, werden eine Riesenseite
(1024 MB) und acht große Seiten (8 x 2 MB = 16 MB) verwendet.
Große Seiten haben jedoch eine unangenehme Nebenwirkung. Jede Seite (ob riesig, groß
oder klein) muss mit einem Schutz zugeordnet werden, der für die gesamte Seite gilt, da der
Hardwarespeicherschutz seitenweise erfolgt. Wenn eine große Seite sowohl schreibgeschützten Code als auch les- und schreibbare Daten enthält, muss die Seite als les- und schreibbar
gekennzeichnet werden, wodurch auch der Code schreibbar wird. In einem solchen Fall können
Gerätetreiber und Kernelmoduscode – sei es aus böser Absicht oder aufgrund eines Bugs – den
Betriebssystem- oder Treibercode, der eigentlich schreibgeschützt sein soll, ohne Zugriffsverletzung überschreiben. Werden dagegen kleine Seiten verwendet, um den Kernelmoduscode
des Betriebssystems zuzuordnen, dann können die schreibgeschützten Teile von Ntoskrnl.exe
und Hal.dll als schreibgeschützte Seiten zugeordnet werden. Die Verwendung kleiner Seiten
verringert zwar die Effizienz der Adressübersetzung, doch wenn ein Gerätetreiber oder anderer
Kernelmoduscode versucht, den schreibgeschützten Teil des Betriebssystems zu ändern, stürzt
das System sofort ab, wobei die Ausnahmeinformationen auf die dafür verantwortliche Anweisung im Treiber hinweisen. Wäre der Schreibvorgang dagegen zulässig, würde das System
später auf eine schwerer zu diagnostizierende Weise abstürzen, nachdem eine andere Komponente versucht hat, die beschädigten Daten zu verwenden.
Wenn Sie befürchten, dass der Kernelcode beschädigt werden könnte, aktivieren Sie den
Treiberverifizierer (siehe Kapitel 6), der die Verwendung großer Seiten unterbindet.
In diesem und den folgenden Kapiteln bezeichnen wir mit Seite immer eine kleine
Seite, sofern nicht ausdrücklich etwas anderes angegeben oder durch den Zusammenhang deutlich gemacht wird.
Die Speichernutzung untersuchen
Die Leistungsobjekte Arbeitsspeicher und Prozess bieten Zugriff auf die meisten Informationen zur Speichernutzung durch das System und die Prozesse. In diesem Kapitel verweisen
wir häufig auf Leistungsindikatoren zu den jeweils beschriebenen Komponenten und geben
Beispiele und Anleitungen für eigene Experimente. Beachten Sie aber, dass die verschiedenen
Werkzeuge bei der Anzeige von Informationen über den Arbeitsspeicher oft unterschiedliche
und manchmal uneinheitliche oder irreführende Bezeichnungen verwenden. Das folgende Experiment macht dies deutlich. (Die in diesem Beispiel erwähnten Begriffe werden übrigens in
nachfolgenden Abschnitten erläutert.)
Einführung in den Speicher-Manager
Kapitel 5
345
Hinweis: Informationen über den Arbeitsspeicher einsehen
Die Registerkarte Leistung des Task-Managers, die Sie in dem folgenden Screenshot auf einem System mit Windows 10 Version 1607 sehen, zeigt grundlegende Informationen über
den physischen und den virtuellen Arbeitsspeicher an. Dies ist allerdings nur einen Teil der
Informationen, die über Leistungsindikatoren zur Verfügung stehen. Die Bedeutung der
Werte wird in der anschließenden Tabelle erklärt.
Wert
Bedeutung
Speicherauslastung
Die Höhe der Linie in diesem Diagramm zeigt die Menge des
von Windows verwendeten physischen Arbeitsspeichers an (ein
Maß, für das es keinen Leistungsindikator gibt). Der Bereich über
der Linie entspricht dem Wert Verfügbar im unteren Bereich.
Die Gesamthöhe des Diagramms steht für den Gesamtwert, der
rechts darüber angezeigt wird (in diesem Beispiel 31,9 GB). Dies
ist der gesamte RAM, den das Betriebssystem verwenden kann.
BIOS-Schattenseiten, Gerätearbeitsspeicher usw. sind darin nicht
enthalten.
Speicherzusammensetzung
Dieses Diagramm zeigt die Beziehung zwischen dem aktiv verwendeten, dem Standby-, dem modifizierten und dem freien und
Nullseiten-Arbeitsspeicher an. (All diese Begriffe werden im Verlauf dieses Kapitels erklärt.)
Gesamter physischer Arbeitsspeicher (rechts über dem
Diagramm)
Gibt die Menge des von Windows nutzbaren physischen Arbeitsspeichers an.
→
346
Kapitel 5
Speicherverwaltung
Wert
Bedeutung
In Verwendung (komprimiert)
Dies ist die Menge des zurzeit verwendeten physischen Arbeitsspeichers mit dem Betrag an komprimiertem physischen Speicher
in Klammern. Wenn Sie den Mauszeiger über diesen Wert halten,
wird angezeigt, wie viel Arbeitsspeicher durch die Komprimierung
gespart wird (siehe den Abschnitt »Speicherkomprimierung« weiter hinten in diesem Kapitel).
Im Cache
Dieser Wert stellt die Summe der folgenden Leistungsindikatoren
aus der Kategorie Arbeitsspeicher dar: Cachebytes, Geänderte Seitenliste – Bytes, Standbycache-Kernbytes, Standbycache-Bytes mit
normaler Priorität, Standbycache-Reservebytes.
Verfügbar
Dies ist die Menge an Speicher, die unmittelbar zur Verwendung
durch das Betriebssystem, für Prozesse und Treiber zur Verfügung
steht. Der Wert entspricht der kombinierten Größe des Standby-,
des freien und des Nullseitenspeichers.
Frei
Dieser Wert zeigt den freien und den Nullseitenspeicher in Bytes
an. Um ihn sichtbar zu machen, müssen Sie den Mauszeiger über
das rechte Ende des Diagramms mit der Speicherzusammensetzung halten (vorausgesetzt, dass Sie noch genügend freien Arbeitsspeicher für einen solchen Vorgang zur Verfügung haben).
Commit ausgeführt (»committed«, was in anderen
Windows-Programmen auch
als »zugesicherter Speicher«
wiedergegeben wird)
Die beiden hier gezeigten Zahlen entsprechen den Werten der
Leistungsindikatoren Zugesicherte Bytes und Zusagegrenze.
Ausgelagerter Pool
Dieser Wert gibt die Gesamtgröße des ausgelagerten Pools an,
wobei sowohl die freien als auch die zugewiesenen Bereiche berücksichtigt werden.
Nicht ausgelagerter Pool
Dieser Wert gibt die Gesamtgröße des nicht ausgelagerten Pools
an, wobei sowohl die freien als auch die zugewiesenen Bereiche
berücksichtigt werden.
Um sich die Nutzung des ausgelagerten und des nicht ausgelagerten Pools im Einzelnen
anzusehen, verwenden Sie das Programm Poolmon, das weiter hinten in diesem Kapitel im
Abschnitt »Die Poolnutzung überwachen« beschrieben wird.
Der Process Explorer von Sysinternals zeigt erheblich mehr Daten über den physischen
und den virtuellen Speicher an. Klicken Sie auf dem Hauptbildschirm dieses Programms
auf View, wählen Sie System Information und rufen Sie die Registerkarte Memory auf. Das
folgende Beispiel stammt von einem 64-Bit-System mit Windows 10. Die meisten der hier
gezeigten Indikatoren werden wir in den entsprechenden Abschnitten weiter hinten in diesem Kapitel erklären.
→
Einführung in den Speicher-Manager
Kapitel 5
347
Um erweiterte Informationen über den Arbeitsspeicher zu gewinnen, stehen Ihnen auch
noch zwei weitere Sysinternal-Tools zur Verfügung:
QQ VMMap
QQ RAMMap
Zeigt die Nutzung des virtuellen Speichers in einem Prozess detailliert an.
Zeigt die Nutzung des physischen Speichers ausführlich an.
Diese Werkzeuge werden in Experimenten weiter hinten in diesem Kapitel vorgestellt.
Auch mit dem Kerneldebuggerbefehl !vm können Sie sich grundlegende Informationen
über die Speicherverwaltung ansehen. Dieser Befehl ist vor allem dann praktisch, wenn Sie
sich ein Absturzabbild oder ein hängendes System ansehen. Das folgende Beispiel zeigt die
Ausgabe auf einem 64-Bit-System mit Windows 10 und 32 GB RAM:
lkd> !vm
Page File: \??\C:\pagefile.sys
Current:
1048576 Kb
Free Space:
1034696 Kb
Minimum:
1048576 Kb
Maximum:
4194304 Kb
Page File: \??\C:\swapfile.sys
Current:
16384 Kb
Free Space:
Minimum:
16384 Kb
Maximum:
16376 Kb
24908388 Kb
No Name for Paging File
Current: 58622948 Kb
Free Space: 57828340 Kb
Minimum: 58622948 Kb
Maximum:
58622948 Kb
Physical Memory:
8364281 (
33457124 Kb)
Available Pages:
4627325 (
18509300 Kb)
ResAvail Pages:
7215930 (
28863720 Kb)
→
348
Kapitel 5
Speicherverwaltung
Locked IO Pages:
Free System PTEs:
0 (
0 Kb)
4295013448 (17180053792 Kb)
Modified Pages:
68167 (
272668 Kb)
Modified PF Pages:
68158 (
272632 Kb)
0 (
0 Kb)
Modified No Write Pages:
NonPagedPool Usage:
NonPagedPoolNx Usage:
NonPagedPool Max:
495 (
1980 Kb)
269858 (
1079432 Kb)
4294967296 (17179869184 Kb)
PagedPool 0 Usage:
371703 (
1486812 Kb)
PagedPool 1 Usage:
99970 (
399880 Kb)
PagedPool 2 Usage:
100021 (
400084 Kb)
PagedPool 3 Usage:
99916 (
399664 Kb)
PagedPool 4 Usage:
99983 (
399932 Kb)
771593 (
3086372 Kb)
PagedPool Usage:
PagedPool Maximum:
4160749568 (16642998272 Kb)
Session Commit:
12210 (
48840 Kb)
Shared Commit:
344197 (
1376788 Kb)
Special Pool:
0 (
0 Kb)
Shared Process:
19244 (
76976 Kb)
Pages For MDLs:
419675 (
1678700 Kb)
0 (
0 Kb)
NonPagedPool Commit:
270387 (
1081548 Kb)
PagedPool Commit:
771593 (
3086372 Kb)
Pages For AWE:
Driver Commit:
Boot Commit:
System PageTables:
24984 (
99936 Kb)
100044 (
400176 Kb)
5948 (
23792 Kb)
18202 (
72808 Kb)
299 (
1196 Kb)
33 (
132 Kb)
Sum System Commit:
1986816 (
7947264 Kb)
Total Private:
2126069 (
8504276 Kb)
VAD/PageTable Bitmaps:
ProcessLockedFilePages:
Pagefile Hash Pages:
Misc/Transient Commit:
18422 (
73688 Kb)
Committed pages:
4131307 (
16525228 Kb)
Commit limit:
9675001 (
38700004 Kb)
...
Die Werte außerhalb der Klammern betreffen kleine Seiten (4 KB). Viele der Angaben in
dieser Ausgabe werden wir in diesem Kapitel noch genauer erklären.
Einführung in den Speicher-Manager
Kapitel 5
349
Interne Synchronisierung
Wie die anderen Komponenten der Windows-Exekutive ist auch der Speicher-Manager vollständig eintrittsinvariant und ermöglicht die gleichzeitige Ausführung auf Mehrprozessorsystemen. Das heißt, zwei Threads können Ressourcen auf solche Weise erwerben, dass sie nicht
gegenseitig die Daten des anderen beschädigen. Dazu setzt der Speicher-Manager verschiedene interne Synchronisierungsmechanismen ein, z. B. Spinlocks und ineinandergreifende Anweisungen, um den Zugriff auf seine eigenen internen Datenstrukturen zu steuern. (Synchronisierungsobjekte werden in Kapitel 8 von Band 2 beschrieben.)
Unter anderem muss der Speicher-Manager den Zugriff auf die folgenden systemweiten
Ressourcen synchronisieren:
QQ Dynamisch zugewiesene Teile des virtuellen Systemadressraums
QQ Systemarbeitssätze
QQ Kernelspeicherpools
QQ Liste der geladenen Treiber
QQ Liste der Auslagerungsdateien
QQ Listen des physischen Speichers
QQ Abbildgestützte Strukturen für die Randomisierung des Adressraumlayouts (Address Space
Layout Randomization, ASLR)
QQ Die Einträge in der Datenbank der Seitenframenummern (Page Frame Number, PFN)
Folgende prozesseigenen Datenstrukturen zur Speicherverwaltung bedürfen der Synchronisierung:
QQ Arbeitssatzsperre Diese Sperre wird eingerichtet, wenn Änderungen an den Arbeitssätzen vorgenommen werden.
QQ Adressraumsperre
Diese Sperre wird bei Änderungen am Adressraum eingerichtet.
Für beide Sperren werden Pushlocks verwendet. Eine Beschreibung finden Sie in Kapitel 8 von
Band 2.
Vom Speicher-Manager bereitgestellte Dienste
Der Speicher-Manager stellt eine Reihe von Systemdiensten bereit, um virtuellen Arbeitsspeicher zuzuweisen und freizugeben, Arbeitsspeicher von mehreren Prozessen gemeinsam nutzen
zu lassen, Dateien im Arbeitsspeicher abzubilden, virtuelle Seiten auf die Festplatte zu entleeren, Informationen über einen Bereich virtueller Seiten abzurufen, den Schutz virtueller Seiten
zu ändern und virtuelle Seiten im Speicher zu sperren.
Wie bei anderen Diensten der Windows-Exekutive kann der Aufrufer auch bei den Speicherverwaltungsdiensten ein Prozesshandle übergeben, um den Prozess anzugeben, dessen
virtueller Speicher bearbeitet werden soll. Dadurch kann der Aufrufer seinen eigenen Arbeitsspeicher oder – sofern er über die entsprechenden Berechtigungen verfügt – den eines anderen Prozesses ändern. Beispielsweise hat ein Prozess standardmäßig das Recht, den virtuellen
Speicher seiner Kindprozesse zu bearbeiten. Er kann im Namen des Kindprozesses Arbeitsspei-
350
Kapitel 5
Speicherverwaltung
cher zuweisen, darin lesen und schreiben und die Zuweisung aufheben, indem er die Dienste
für den virtuellen Speicher aufruft und dabei ein Handle für den Kindprozess als Argument
übergibt. Diese Möglichkeit wird von Teilsystemen verwendet, um den Arbeitsspeicher ihrer
Clientprozesse zu verwalten. Sie ist auch für Debugger unverzichtbar, da diese Programme
in der Lage sein müssen, im Arbeitsspeicher des zu debuggenden Prozesses zu lesen und zu
schreiben.
Die meisten dieser Dienste werden durch die Windows-API bereitgestellt. Wie Sie in
Abb. 5–1 sehen, enthält diese API vier Gruppen von Funktionen für die Speicherverwaltung in
Anwendungen:
QQ API für virtuellen Speicher Dies ist die maschinennächste API für allgemeine Speicherzuweisungen und Aufhebungen der Zuweisung. Sie bearbeitet grundsätzlich einzelne Seiten. Gleichzeitig ist sie die leistungsfähigste API, da sie sämtliche Möglichkeiten
des Speicher-Managers zur Verfügung stellt. Zu ihren Funktionen gehören VirtualAlloc,
V irtualFree, VirtualProtect, VirtualLock usw.
QQ Heap-API Diese API bietet Funktionen für kleine Zuweisungen (gewöhnlich weniger als
eine Seite). Sie greift intern auf die API für virtuellen Speicher zurück, setzt aber eine Verwaltungsschicht darauf. Zu den Heap-Manager-Funktionen gehören HeapAlloc, HeapFree,
HeapCreate, HeapReAlloc usw. Der Heap-Manager wird im gleichnamigen Abschnitt weiter
hinten in diesem Kapitel behandelt.
QQ Lokale/globale APIs Dies sind Überbleibsel aus den 16-Bit-Versionen von Windows, die
jetzt mithilfe der Heap-API implementiert sind.
QQ API für im Speicher zugeordnete Dateien Diese Funktionen ermöglichen die Zuordnung von Dateien im Speicher und die gemeinsame Nutzung des Speichers durch kooperierende Prozesse. Dazu gehören CreateFileMapping, OpenFileMapping, MapViewOfFile usw.
Lokale/globale APIs
C/C++-Laufzeit
Heap-API
API für virtuellen
Speicher
Dateizuordnungs-API
Benutzermodus
Kernelmodus
Speicher-Manager
Abbildung 5–1 Gruppen von Speicher-APIs im Benutzermodus
Der gestrichelte Kasten steht für eine typische C/C++-Laufzeitimplementierung der Speicherverwaltung (Funktionen wie malloc, free, realloc und C++-Operatoren wie new und delete),
die auf die Heap-API zurückgreift. Durch die gestrichelte Darstellung wird angedeutet, dass
diese Implementierung compilerabhängig und nicht obligatorisch ist (allerdings ist sie häufig
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
351
anzutreffen). Die in Ntdll.dll implementierten Gegenstücke für die C-Laufzeitumgebung verwenden die Heap-API.
Der Speicher-Manager stellt auch verschiedene Dienste für andere Kernelmoduskomponenten in der Exekutive und für Gerätetreiber zur Verfügung. Dazu gehören die Zuweisung von
physischem Speicher und die Aufhebung dieser Zuweisung sowie das Sperren von Seiten im
physischen Speicher für den direkten Speicherzugriff (Direct Memory Access, DMA). Die Namen dieser Funktionen beginnen mit dem Präfix Mm. Darüber hinaus werden noch einige Exekutiv-Unterstützungsroutinen verwendet, die streng genommen kein Teil des Speicher-Managers
sind. Ihre Namen beginnen mit Ex, und sie dienen zur Zuweisung von System-Heaps (ausgelagerter und nicht ausgelagerter Pool), zur Aufhebung dieser Zuweisung und zur Bearbeitung
von Look-Aside-Listen. Damit werden wir uns weiter hinten in diesem Kapitel im Abschnitt
»Kernelmodusheaps (Systemspeicherpools)« noch eingehend beschäftigen.
Seitenstatus und Speicherzuweisungen
Die Seiten im virtuellen Adressraum eines Prozesses sind entweder frei, reserviert, zugesichert
oder gemeinsam nutzbar. Wird auf zugesicherte und gemeinsam nutzbare Seiten zugegriffen,
so werden sie letzten Endes in gültige Seiten im physischen Speicher übersetzt. Zugesicherte
Seiten werden auch als private Seiten bezeichnet, da sie nicht mit anderen Prozessen geteilt
werden können, was bei gemeinsam nutzbaren Seiten möglich ist.
Private Seiten werden mithilfe der Windows-Funktionen VirtualAlloc, VirtualAllocEx und
VirtualAllocExNuma zugewiesen. Dabei wird letzten Endes die Funktion NtAllocateVirtualMemory
im Speicher-Manager ausgeführt. Diese Funktionen können Speicher sowohl zusichern als auch
reservieren. Beim Reservieren wird ein zusammenhängender Bereich von virtuellen Adressen
für die zukünftige Nutzung beiseite gestellt (z. B. für ein Array), wodurch nur vernachlässigbare Systemressourcen verbraucht werden. Im Verlauf der Anwendung werden dann nach Bedarf
Teile dieses reservierten Adressraums zugesichert. Wenn die Größenanforderungen im Voraus
bekannt sind, kann ein Prozess die Reservierung und Zusicherung auch im selben Funktionsaufruf
durchführen. In jedem Fall sind die resultierenden zugesicherten Seiten für jeden Thread in dem
Prozess zugänglich. Der Versuch, auf freien oder reservierten Speicher zuzugreifen, führt dagegen zu einer Ausnahme aufgrund einer Zugriffsverletzung, da die Seite keinem Speicherbereich
zugeordnet ist, zu dem der Verweis aufgelöst werden kann.
Zugesicherte (private) Seiten werden als Nullforderungsseiten erstellt, wenn zum ersten Mal
auf sie zugegriffen wird. Wenn es die Nachfrage nach physischem Speicher erfordert, kann das
Betriebssystem sie später automatisch in die Auslagerungsdatei schreiben. »Privat« bedeutet
hier, dass diese Seiten für andere Prozesse normalerweise unzugänglich sind.
Einige Funktionen, z. B. ReadProcessMemory und WriteProcessMemory, scheinen einen
prozessübergreifenden Speicherzugriff zuzulassen, allerdings führen sie Kernelmoduscode im Kontext des Zielprozesses aus. Außerdem ist es erforderlich, dass
der Sicherheitsdeskriptor des Zielprozesses dem zugreifenden Prozess das Recht
PROCESS_VM_READ bzw. PROCESS_VM_WRITE gewährt oder dass der zugreifende Prozess
das Recht SeDebugPrivilege hat, das standardmäßig nur Mitgliedern der Adminis
tratorengruppe gewährt wird.
352
Kapitel 5
Speicherverwaltung
Gemeinsam genutzte Seiten werden gewöhnlich auf eine Sicht des Abschnitts abgebildet. Dies
wiederum ist ein Teil einer Datei oder eine ganze Datei, kann aber auch ein Teil der Auslagerungsdatei sein. Alle gemeinsam genutzten Seiten können mit anderen Prozessen geteilt werden. Abschnitte werden in der Windows-API als Dateizuordnungsobjekte verfügbar gemacht.
Beim ersten Zugriff irgendeines Prozesses auf eine gemeinsam genutzte Seite wird sie in
der zugehörigen Datei gelesen, es sei denn, dass sie mit der Auslagerungsdatei verknüpft ist. In
letzterem Fall wird sie als Nullforderungsseite erstellt. Während sich die Seite im physischen Arbeitsspeicher befindet, können weitere Prozesse, die auf sie zugreifen, einfach die Seiteninhalte
verwenden, die bereits im Arbeitsspeicher sind. Gemeinsam genutzte Seiten können auch vom
System vorab abgerufen werden.
In zwei späteren Abschnitten dieses Kapitels – »Gemeinsam genutzter Arbeitsspeicher und
zugeordnete Dateien« und »Abschnittsobjekte« – werden gemeinsam genutzte Seiten ausführlicher erläutert. Ein Mechanismus, der als Schreiben von geänderten Seiten bezeichnet wird,
schreibt Seiten auf die Festplatte oder in einen Remotespeicher, wenn sie aus dem Arbeitssatz
des Prozesses in die systemweite Liste der geänderten Seiten verschoben werden. (In den deutschen Versionen von Windows wird sie unglücklicherweise als »geänderte Seitenliste« bezeichnet. Diese Liste sowie Arbeitssätze werden weiter hinten in diesem Kapitel erklärt.) Die Seiten
im Speicher zugeordneter Dateien können auch mit einem ausdrücklichen Aufruf von FlushViewOfFile oder mit dem Schreibthread für zugeordnete Seiten wieder zurück in die ursprünglichen Dateien auf der Festplatte geschrieben werden, wenn der Speicherbedarf dies erfordert.
Mit den Funktionen VirtualFree und VirtualFreeEx können Sie die Zusicherung privater
Seiten aufheben bzw. den Adressraum freigeben. Der Unterschied besteht darin, dass Speicher
mit aufgehobener Zusicherung immer noch reserviert ist, wohingegen freigegebener Speicher
weder zugesichert noch reserviert ist.
Der zweistufige Vorgang, bei dem virtueller Arbeitsspeicher erst reserviert und dann zugesichert wird, verzögert die Zusicherung von Seiten (und damit auch die Anrechnung auf den
gesamten zugesicherten Speicher des Systems, was im nächsten Abschnitt beschrieben wird),
bis sie notwendig wird, bewahrt aber den Zusammenhang des virtuellen Adressraums. Die Reservierung von Speicher ist eine relativ billige Operation, da dabei sehr wenig Arbeitsspeicher
verbraucht wird. Es müssen lediglich einige vergleichsweise kleine interne Datenstrukturen für
den Status des Prozessadressraums aktualisiert oder erstellt werden. Diese Datenstrukturen –
die Seitentabellen und VADs (Virtual Address Descriptors) – werden weiter hinten in diesem
Kapitel erklärt.
Ein sehr häufig anzutreffendes Beispiel für die Reservierung eines umfangreichen Adressraums und die bedarfsweise Zusicherung kleiner Teile daraus bildet der Benutzermodusstack
für einen Thread. Wird ein Thread erstellt, so wird sein Stack dadurch angelegt, dass ein zusammenhängender Teil des Prozessadressraums reserviert wird. (Die Standardgröße beträgt 1 MB,
aber diesen Wert können Sie mit den Funktionen CreateThread und CreateRemoteThread(Ex)
überschreiben oder mit dem Linkerflag /STACK für das gesamte ausführbare Abbild ändern.)
Standardmäßig wird die erste Seite des Stacks zugesichert und die nächste Seite als Wächterseite gekennzeichnet (aber nicht zugesichert), um Verweise abzufangen, die über den zugesicherten Teil des Stacks hinausgehen, und diesen zu erweitern.
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
353
Experiment: Der Unterschied zwischen reservierten und
zugesicherten Seiten
Mit dem Sysinternals-Programm TestLimit können Sie große Menge an reserviertem und an
privatem, zugesichertem virtuellen Arbeitsspeicher zuweisen. Die Unterschiede zwischen
diesen Vorgängen können Sie dann in Process Explorer beobachten. Gehen Sie dazu wie
folgt vor:
1.
Öffnen Sie zwei Eingabeaufforderungen.
2.
Rufen Sie an einer der Eingabeaufforderungen TestLimit auf, um eine große Menge an
Speicher zu reservieren:
C:\temp>testlimit -r 1 -c 800
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - wwww.sysinternals.com
Process ID: 18468
Reserving private bytes 1 MB at a time ...
Leaked 800 MB of reserved memory (800 MB total leaked). Lasterror: 0
The operation completed successfully.
3.
Sichern Sie an der anderen Eingabeaufforderung die gleiche Menge an Arbeitsspeicher
zu:
C:\temp>testlimit -m 1 -c 800
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - wwww.sysinternals.com
Process ID: 14528
Leaking private bytes 1 KB at a time ...
Leaked 800 MB of private memory (800 MB total leaked). Lasterror: 0
The operation completed successfully.
4.
Starten Sie den Task-Manager, rufen Sie die Registerkarte Details auf und fügen Sie die
Spalte Zugesicherte Größe hinzu.
→
354
Kapitel 5
Speicherverwaltung
5.
Suchen Sie die beiden Vorkommen von TestLimit.exe in der Liste. Sie sehen etwa wie
folgt aus:
Der Task-Manager zeigt zwar die Größe des zugesicherten Speichers an, verfügt aber
über keine Indikatoren für den reservierten Speicher.
6.
Starten Sie Process Explorer.
7.
Rufen Sie die Registerkarte Process Memory auf und aktivieren Sie die Spalten Private
Bytes und VirtualSize.
8.
Machen Sie die beiden TestLimit.exe-Prozesse im Hauptfenster ausfindig:
→
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
355
Die virtuellen Größen der beiden Prozesse sind gleich, aber nur bei einem von ihnen hat Private Bytes einen ähnlichen Wert wie Virtual Size. Der riesige Unterschied
bei dem anderen TestLimit-Prozess (Prozess-ID 18468) kommt durch den reservierten
Speicher zustande. Diesen Vergleich können Sie auch in der Leistungsüberwachung
durchführen, indem Sie sich die Indikatoren Virtuelle Bytes und Private Bytes in der
Kategorie Prozess ansehen.
Gesamter zugesicherter Speicher und Zusicherungsgrenzwert
Auf der Seite Arbeitsspeicher der Registerkarte Leistung im Task-Manager finden Sie den Abschnitt Commit ausgeführt. (In der deutschen Version von Windows wird der Begriff »committed« leider sehr uneinheitlich übersetzt. Neben der hier verwendeten Bezeichnung »Commit
ausgeführt« werden Sie auch »zugesagt«, »festgelegt« und vor allem »zugesichert« finden.)
Darunter stehen zwei Zahlen, von denen die erste den gesamten zugesicherten virtuellen Speicher auf dem System angibt (in Windows nicht sehr aussagekräftig einfach »festgelegter virtueller Speicher« genannt).
Es gibt einen systemweiten Grenzwert (»Zusagegrenze«) für die Menge des zugesicherten
virtuellen Speichers. Er entspricht der aktuellen Gesamtgröße aller Auslagerungsdateien zuzüglich der Menge an RAM, die das Betriebssystem nutzen kann. Dies ist die zweite der beiden
Zahlen unter Commit ausgeführt. Der Speicher-Manager kann diesen Grenzwert automatisch
erhöhen, indem er eine oder mehrere Auslagerungsdateien erweitert, die noch nicht ihre festgelegte Höchstgröße erreicht haben.
Der gesamte zugesicherte Speicher und der systemweite Zusicherungsgrenzwert werden
im Abschnitt »Gesamter zugesicherter Speicher und systemweiter Zusicherungsgrenzwert« weiter hinten in diesem Kapitel noch genauer erklärt.
Seiten im Arbeitsspeicher festhalten
Im Allgemeinen ist es besser, den Speicher-Manager entscheiden zu lassen, welche Seiten im
physischen Speicher verbleiben sollen. Unter besonderen Umständen kann es für eine Anwendung oder einen Gerätetreiber jedoch notwendig sein, Seiten im physischen Speicher festzuhalten. Das kann auf zwei Weisen geschehen:
QQ Windows-Anwendungen können die Funktion VirtualLock aufrufen, um Seiten im Arbeitssatz ihres Prozesses zu verriegeln. Die Seiten verbleiben dann im Speicher, bis sie ausdrücklich entriegelt werden oder der Prozess, der sie verriegelt hat, beendet wird. Die Anzahl
der Seiten, die ein Prozess verriegeln kann, ist auf die Mindestgröße seines Arbeitssatzes
abzüglich acht Seiten beschränkt. Muss er mehr Seiten im Speicher festhalten, kann er die
Mindestgröße seines Arbeitssatzes mit der Funktion SetProcessWorkingSetSizeEx erhöhen
(siehe den Abschnitt »Verwaltung von Arbeitssätzen« weiter hinten in diesem Kapitel).
QQ Gerätetreiber können die Kernelmodusfunktionen MmProbeAndLockPages, MmLockPagableCodeSection, MmLockPagableDataSection und MmLockPagableSectionByHandle aufrufen. Mit
diesem Mechanismus verriegelte Seiten verbleiben im Arbeitsspeicher, bis sie ausdrücklich
356
Kapitel 5
Speicherverwaltung
entriegelt werden. Bei den letzten drei dieser APIs gibt es keine Einschränkungen für die
Anzahl der Seiten, die im Speicher festgehalten werden können, da die Gesamtmenge der
residenten, verfügbaren Seiten beim ersten Laden des Treibers bestimmt wird. Dadurch ist
sichergestellt, dass es niemals zu einem Systemabsturz aufgrund von übermäßiger Verriegelung kommen kann. Bei der ersten API muss der Grenzwert für die Anzahl verriegelbarer
Seiten abgerufen werden, da sie sonst einen Fehlerstatus zurückgibt.
Granularität der Zuweisung
Windows richtet die Regionen des reservierten Prozessadressraums an den Grenzen aus, die
durch die systemweite Zuweisungsgranularität bestimmt sind. Deren Wert können Sie mit den
Funktionen WindowsGetSystemInfo und GetNativeSystemInfo abrufen. Er beträgt 64 KB. Bei
dieser Granularität kann der Speicher-Manager Metadaten zur Unterstützung verschiedener
Prozessoperationen effizient zuweisen (z. B. VADs, Bitmaps usw.). Dieser Wert verringert auch
die Gefahr, dass Anwendungen, die Annahmen für die Ausrichtung der Zuweisung treffen,
geändert werden müssen, falls eine Unterstützung für zukünftige Prozessoren mit großen Seiten (etwa bis zu 64 KB) oder mit virtuell indizierten Caches hinzukommt, die eine systemweite
Ausrichtung des physischen und virtuellen Speichers erfordern würde.
Der Kernelmoduscode von Windows unterliegt nicht denselben Einschränkungen,
sondern kann Arbeitsspeicher in der Größenordnung einzelner Seiten reservieren
(wobei diese Möglichkeit aus den zuvor genannten Gründen nicht für Gerätetreiber verfügbar gemacht wird). Diese Granularität wird hauptsächlich verwendet,
um TEB-Zuweisungen dichter packen zu können. Da es sich ausschließlich um einen internen Mechanismus handelt, kann der Code leicht geändert werden, wenn
bei einer zukünftigen Plattform andere Werte erforderlich sein sollten. Zur Unterstützung von 16-Bit- und MS-DOS-Anwendungen auf x86-Systemen bietet der
Speicher-Manager das Flag MEM_DOS_LIM für die API MapViewOfFileEx an, mit dem
eine Granularität einer einzelnen Seite erzwungen werden kann.
Wenn eine Region im Adressraum reserviert ist, stellt Windows sicher, dass die Größe und die
Basisadresse dieser Region Vielfache der systemweiten Seitengröße sind. Wenn Sie beispielsweise eine Region von 18 KB reservieren wollen, werden daher auf einem x86-System, das
4-KB-Seiten verwendet, in Wirklichkeit 20 KB reserviert. Geben Sie für eine 18-KB-Region eine
Basisadresse von 3 KB an, so werden 24 KB reserviert. Der VAD für die Zuweisung wird ebenfalls
auf die 64-KB-Begrenzung gerundet, sodass der Rest unzugänglich ist.
Gemeinsam genutzter Arbeitsspeicher und zugeordnete
Dateien
Wie die meisten modernen Betriebssysteme bietet auch Windows einen Mechanismus, um Arbeitsspeicher zwischen Prozessen und dem Betriebssystem zu teilen. Der gemeinsam genutzte
Speicher kann als der Arbeitsspeicher definiert werden, der für mehr als einen Prozess sichtbar
oder im virtuellen Adressraum mehr als eines Prozesses vorhanden ist. Wenn beispielsweise
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
357
zwei Prozesse dieselbe DLL nutzen, ist es sinnvoll, die referenzierten Codeseiten für diese DLL
nur einmal in den physischen Speicher zu laden und diese Seiten unter allen Prozessen zu teilen, die die DLL verwenden (siehe Abb. 5–2).
Code in Kernel32.dll
Code in Kernel32.dll
Code in Kernel32.dll
Prozess A
RAM
Prozess B
Code von Prozess B
EXE-Code
Code von Prozess A
EXE-Code
Abbildung 5–2 Von zwei Prozessen gemeinsam genutzter Speicher
Jeder Prozess hat hier nach wie vor seinen privaten Speicherbereich für seine privaten Daten,
doch der DLL-Code und nicht modifizierte Datenseiten können gefahrlos gemeinsam genutzt
werden. Wie Sie später noch sehen werden, erfolgt diese Form von gemeinsamer Nutzung
automatisch, da Codeseiten in ausführbaren Abbildern – EXE- und DLL-Dateien sowie verschiedenen anderen Typen, z. B. Bildschirmschonern (SCR), bei denen es sich im Grunde genommen
um DLLs unter einem anderen Namen handelt – als »nur ausführbar« zugeordnet werden und
schreibbare Seiten als »Kopieren beim Schreiben« (Copy-on-Write; siehe den Abschnitt »Kopieren beim Schreiben« weiter hinten in diesem Kapitel).
Abb. 5–2 zeigt zwei Prozesse, die sich eine nur einmal im physischen Arbeitsspeicher zugeordnete DLL teilen. Der Code im Abbild (EXE) wird dagegen nicht gemeinsam genutzt, da die
beiden Prozesse unterschiedliche Abbilder ausführen. Prozesse, die dasselbe Abbild ausführen
– etwa zwei oder mehr Notepad-Prozesse –, teilen sich jedoch auch den EXE-Code.
Die Grundelemente, die der Speicher-Manager zur Einrichtung des gemeinsam genutzten
Speichers verwendet, werden als Abschnittsobjekte bezeichnet und als Dateizuordnungsobjekte
in der Windows-API verfügbar gemacht. Die interne Struktur und Implementierung dieser Objekte wird weiter hinten in diesem Kapitel im Abschnitt »Abschnittsobjekte« erläutert.
Mit diesen Grundelementen des Speicher-Managers werden virtuelle Adressen so zugeordnet, als befänden sie sich im Hauptspeicher, unabhängig davon, ob sie sich tatsächlich dort,
in der Auslagerungsdatei oder in einer anderen Datei befinden, auf die die Anwendung zugreifen möchte. Ein Abschnitt kann von einem oder mehreren Prozessen geöffnet werden.
Abschnittsobjekte stehen also nicht unbedingt für gemeinsam genutzten Speicher.
Ein Abschnittsobjekt kann mit einer offenen Datei auf der Festplatte (einer zugeordneten
Datei) oder mit zugesichertem Speicher verbunden sein (für gemeinsam genutzten Speicher).
In letzterem Fall spricht man von auslagerungsgepufferten Abschnitten (»page-file backed«),
da die Seiten nicht in eine zugeordnete Datei, sondern in die Auslagerungsdatei geschrieben
werden, wenn der Speicherbedarf dies erfordert. (Da Windows auch ohne Auslagerungsdatei
ausgeführt werden kann, ist es möglich, dass diese Abschnitte in Wirklichkeit nur vom physischen Speicher »gepuffert« werden.) Wie andere leere Seiten, die im Benutzermodus sichtbar
358
Kapitel 5
Speicherverwaltung
gemacht werden (z. B. private zugesicherte Seiten), werden auch gemeinsam genutzte zugesicherte Seiten beim ersten Zugriff immer mit Nullen gefüllt, damit keine sensiblen Daten
austreten können.
Um ein Abschnittsobjekt zu erstellen, rufen Sie die Windows-Funktion CreateFileMapping,
CreateFileMappingFromApp oder CreateFileMappingNuma(Ex) auf. Geben Sie ein Handle zu einer
zuvor geöffneten Datei an, um den Abschnitt dieser Datei zuzuordnen, oder INVALID_HANDLE_
VALUE, um einen auslagerungsgepufferten Abschnitt anzulegen. Optional können Sie auch einen Namen und einen Sicherheitsdeskriptor angeben. Hat der Abschnitt einen Namen, so können andere Prozesse ihn mit OpenFileMapping und den CreateFileMapping*-Funktionen öffnen.
Es ist auch möglich, den Zugriff auf Abschnittsobjekte durch Handlevererbung zu gewähren
(indem Sie beim Öffnen oder Erstellen des Handles angeben, dass es vererbbar sein soll) oder
durch Handleduplizierung (mit DuplicateHandle). Gerätetreiber können Abschnittsobjekte auch
mit den Funktionen ZwOpenSection, ZwMapViewOfSection und ZwUnmapViewOfSection bearbeiten.
Ein Abschnittsobjekt kann auf Dateien verweisen, die zu groß für den Adressraum des
Prozesses sind. (Bei auslagerungsgepufferten Abschnittsobjekten muss jedoch in der Auslagerungsdatei oder im RAM ausreichend Platz dafür vorhanden sein.) Wenn ein Prozess auf
ein solches sehr großes Abschnittsobjekt zugreifen will, darf er nur den Teil zuordnen, den
er benötigt (was als eine Sicht des Abschnitts bezeichnet wird), indem er MapViewOfFile(Ex),
MapViewOfFileFromApp oder MapViewOfFileExNuma aufruft und den gewünschten Bereich angibt.
Durch die Zuordnung einer Sicht spart der Prozess Adressraum.
Windows-Anwendungen können zugeordnete Dateien verwenden, um die Datei-E/A zu
vereinfachen, da die Dateien dabei im Adressraum der Anwendung im Arbeitsspeicher erscheinen. Abschnittsobjekte werden jedoch nicht nur von Benutzeranwendungen genutzt. Der Abbildlader ordnet damit ausführbare Abbilder, DLLs und Gerätetreiber im Speicher zu, und der
Cache-Manager verwendet sie für den Zugriff auf Daten in zwischengespeicherten Dateien.
(Weitere Informationen über den Cache-Manager erhalten Sie in Kapitel 14 von Band 2.) Die
Implementierung gemeinsam genutzter Speicherabschnitte, insbesondere was die Adressübersetzung und die internen Datenstrukturen angeht, wird im Abschnitt »Abschnittsobjekte« weiter
hinten in diesem Kapitel erläutert.
Experiment: Im Speicher zugeordnete Dateien einsehen
Die im Speicher zugeordneten Dateien in einem Prozess können Sie sich von Process Explorer auflisten lassen. Schalten Sie dazu den unteren Bereich in die DLL-Ansicht um (indem Sie
View > Lower Pane View > DLLs wählen). Was Sie dann sehen, ist jedoch nicht nur eine Liste
von DLLs, sondern aller im Speicher zugeordneten Dateien im Prozessadressraum. Einige
davon sind DLLs, eine ist die ausgeführte Abbilddatei (EXE), und darüber hinaus kann es
noch weitere Einträge für im Speicher zugeordnete Datendateien geben.
Die folgende Ausgabe von Process Explorer zeigt einen WinDbg-Prozess, der mehrere Speicherzuordnungen verwendet, um auf die untersuchte Speicherauszugsdatei zuzugreifen. Wie die meisten Windows-Programme verwendet auch WinDb (oder eine der
Windows-DLLs, die es verwendet) die Speicherzuordnung, um auf die Windows-Datendatei
Locale.nls zuzugreifen, die zur Windows-Unterstützung für die Internationalisierung gehört.
→
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
359
Sie können auch nach im Speicher zugeordneten Dateien suchen, indem Sie das Menü Find
öffnen und Find Handle or DLL auswählen (oder (Strg) + (F) drücken). Das kann praktisch
sein, wenn Sie herauszufinden versuchen, welche Prozesse eine DLL oder eine im Speicher
zugeordnete Datei verwenden, die Sie gerade ersetzen möchten.
Speicherschutz
Wie bereits in Kapitel 1 erwähnt, bietet Windows einen Speicherschutz, sodass kein Benutzerprozess versehentlich oder absichtlich den Adressraum eines anderen Prozesses oder des
Betriebssystems beschädigen kann. Dieser Schutz erfolgt auf die vier folgenden Weisen:
QQ Alle systemweiten Datenstrukturen und Speicherpools, die von Kernelmodus-Systemkomponenten verwendet werden, sind nur im Kernelmodus zugänglich. Benutzermodus
threads können auf diese Seiten nicht zugreifen. Wenn sie es versuchen, ruft die Hardware
einen Fehler hervor, den der Speicher-Manager dem Thread als Zugriffsverletzung meldet.
QQ Jeder Prozess hat seinen eigenen privaten Adressraum, der gegen den Zugriff durch
Threads anderer Prozesse geschützt ist. Auch gemeinsam genutzter Speicher bildet keine
Ausnahme, da Prozesse auf diese gemeinsamen Regionen mithilfe von Adressen zugreifen, die jeweils zu ihrem eigenen virtuellen Adressraum gehören. Die einzige tatsächliche
Ausnahme liegt vor, wenn ein anderer Prozess Lese- oder Schreibzugriff auf das Prozessobjekt oder das Recht SeDebugPrivilege hat und daher die Funktion ReadProcessMemory oder
WriteProcessMemory verwenden kann. Wenn ein Thread auf eine Adresse verweist, greifen
die Hardware für den virtuellen Speicher und der Speicher-Manager ein und übersetzen
diese virtuelle Adresse in eine physische. Durch die Steuerung dieser Übersetzung kann
Windows garantieren, dass Threads in einem Prozess nicht unangemessen auf eine Seite
eines anderen Prozesses zugreifen.
QQ Zusätzlich zu dem impliziten Schutz durch die Übersetzung von virtuellen in physische Adresse bieten alle von Windows unterstützten Prozessoren auch einen hardwaregestützten
Speicherschutz wie Lese/Schreib-Zugriff, reinen Lesezugriff usw., wobei die Einzelheiten
vom jeweiligen Prozessor abhängen. Beispielsweise sind Codeseiten im Adressraum eines
360
Kapitel 5
Speicherverwaltung
Prozesses als schreibgeschützt (read-only) gekennzeichnet, sodass sie von anderen Benutzerthreads nicht geändert werden können. Tabelle 5–2 führt die in der Windows-API
definierten Speicherschutzoptionen auf (siehe auch die Dokumentation für die Funktionen
VirtualProtect, VirtualProtectEx, VirtualQuery und VirtualQueryEx).
QQ Abschnittsobjekte für die gemeinsame Nutzung des Speichers verfügen über reguläre
Windows-Zugriffssteuerungslisten. Sie werden überprüft, wenn ein Prozess versucht, auf
den Abschnitt zuzugreifen, was den Zugriff auf den gemeinsamen Speicher auf die Prozesse mit den entsprechenden Rechten beschränkt. Die Zugriffssteuerung kommt auch ins
Spiel, wenn ein Thread einen Abschnitt für eine zugeordnete Datei erstellen möchte. Dazu
muss der Thread mindestens Lesezugriff für das zugrunde liegende Dateiobjekt haben.
Hat ein Thread ein Handle zu einem Abschnitt geöffnet, unterliegen seine Aktionen immer
noch dem Speicher-Manager und den zuvor beschriebenen hardwaregestützten Seitenschutzvorkehrungen. Ein Thread kann den Schutz einzelner virtueller Seiten in einem Abschnitt ändern, wenn dadurch nicht die Berechtigungen in der Zugriffssteuerungsliste für das Abschnittsobjekt verletzt werden. Beispielsweise erlaubt der Speicher-Manager einem Thread, die Seiten
eines schreibgeschützten Prozesses auf Kopieren beim Schreiben (Copy-on-Write) zu ändern,
aber nicht auf Lese/Schreib-Zugriff. Der Zugriff mit Kopieren beim Schreibvorgang ist gestattet,
da er sich nicht auf andere Prozesse auswirkt, die die Daten ebenfalls nutzen.
1
Attribut
Beschreibung
PAGE_NOACCESS
Jeder Versuch, in der Datei zu lesen, zu schreiben oder Code auszuführen, führt zu einer Zugriffsverletzung.
PAGE_READONLY
Jeder Versuch, in der Datei zu schreiben (und auf Prozessoren mit
Ausführungsschutz auch, Code auszuführen), führt zu einer Zugriffsverletzung. Lesevorgänge dagegen sind erlaubt.
PAGE_READWRITE
Die Seite kann gelesen und geschrieben, aber nicht ausgeführt
werden.
PAGE_EXECUTE
Jeder Versuch, in Code in der Region zu schreiben, führt zu einer
Zugriffsverletzung. Ausführungsvorgänge (und Lesevorgänge auf
allen existierenden Prozessoren) dagegen sind erlaubt.
PAGE_EXECUTE_READ1
Jeder Versuch, in diese Region zu schreiben, führt zu einer Zugriffsverletzung. Ausführungs- und Lesevorgänge dagegen sind
erlaubt.
PAGE_EXECUTE_READWRITE1
Die Seite kann gelesen, geschrieben und ausgeführt werden. Alle
Zugriffsversuche haben Erfolg.
PAGE_WRITECOPY
Wenn ein Prozess versucht, in diese Region zu schreiben, stellt
ihm das System eine private Kopie der Seite zur Verfügung. Auf
Prozessoren mit Ausführungsschutz1 führen Versuche, Code in
diesem Bereich auszuführen, zu einer Zugriffsverletzung.
→
Der Ausführungsschutz ist auf Prozessoren mit der entsprechenden Hardwareunterstützung möglich
(u. a. auf allen x64-Prozessoren), aber nicht auf älteren x86-Prozessoren. Ohne diese Unterstützung
wird aus dem Ausführungs- ein Leseschutz.
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
361
Attribut
Beschreibung
PAGE_EXECUTE_WRITECOPY
Wenn ein Prozess versucht, in diese Region zu schreiben, stellt
ihm das System eine private Kopie der Seite zur Verfügung. Leseund Ausführungsversuche sind dagegen zulässig. Dabei wird
keine Kopie erstellt.
PAGE_GUARD
Jeglicher Versuch, in einer Wächterseite zu lesen oder zu schreiben, löst die Ausnahme EXCEPTION_GUARD_PAGE aus und schaltet
den Wächterseitenstatus ab. Dadurch können Wächterseiten als
einmalige Alarmierungsmöglichkeit genutzt werden. Dieses Flag
kann mit allen anderen Seitenschutzeinstellungen außer PAGE_
NOACCESS kombiniert werden.
PAGE_NOCACHE
Hierbei wird physischer Arbeitsspeicher genutzt, der nicht zwischengespeichert wird. Zur allgemeinen Verwendung wird diese
Vorgehensweise nicht empfohlen. Sie kann allerdings für Gerätetreiber nützlich sein, etwa um einen Videoframepuffer ohne
Zwischenspeicherung zuzuordnen.
PAGE_WRITECOMBINE
Hiermit wird das kombinierte Schreiben eingeschaltet. Bei dieser
Einstellung führt der Prozessor keine Schreibvorgänge im Cache
aus. Zwar kann dadurch der Datenverkehr im Arbeitsspeicher
erheblich ansteigen, doch dafür wird versucht, Schreibanforderungen zu bündeln, um die Leistung zu optimieren. Soll beispielsweise mehrmals an derselben Adresse geschrieben werden,
so wird nur der letzte dieser Schreibvorgänge ausgeführt. Auch
Schreibvorgänge in benachbarten Adressen können dadurch zu
einem einzigen langen Schreibvorgang zusammengefasst werden. Für allgemeine Anwendungen wird diese Möglichkeit nicht
genutzt, sie kann aber für Gerätetreiber sehr praktisch sein, etwa
um einen Videoframepuffer so zuzuordnen, dass kombinierte
Schreibvorgänge zulässig sind.
PAGE_TARGETS_INVALID und PAGE_
TARGETS_NO_UPDATE (Windows 10
und Windows Server 2016)
Diese Werte steuern das Verhalten des Control Flow Guard (CFG)
für ausführbaren Code in den betreffenden Seiten. Beide Konstanten haben denselben Wert, allerdings werden sie in unterschiedlichen Aufrufen verwendet. Im Grunde genommen stellen
sie einen Umschalter dar. PAGE_TARGETS_INVALID gibt an, dass
CFG bei indirekten Aufrufen fehlschlagen und der Prozess abstürzen soll. PAGE_TARGETS_NO_UPDATE lässt VirtualProtect-Aufrufe
zu, die den Seitenbereich ändern, um eine Ausführung zuzulassen, bei der der CFG-Status nicht aktualisiert wird. Weitere Informationen über CFG erhalten Sie in Kapitel 7.
Tabelle 5–2 In der Windows-API definierte Speicherschutzoptionen
Datenausführungsverhinderung
Die Datenausführungsverhinderung (Date Execution Prevention, DEP) oder der Ausführungsschutz (No Execute, NX) ruft bei dem Versuch, die Steuerung an eine Anweisung auf einer als
nicht ausführbar gekennzeichneten Seite zu übergeben, einen Zugriffsfehler hervor. Dadurch
werden bestimmte Arten von Malware daran gehindert, Schwachstellen im System auszunutzen, indem sie Code auf einer Datenseite wie dem Stack ausführen. Mithilfe der Datenausführungsverhinderung können Sie auch erkennen, wenn unsauber geschriebene Programme die
Berechtigungen für Seiten, auf denen Code ausgeführt werden soll, nicht korrekt festlegen.
Wird im Kernelmodus versucht, Code auf einer als nicht ausführbar gekennzeichneten Seite auszuführen, stürzt das System mit dem Fehlerprüfcode ATTEMPTED_EXECUTE_OF_NOEXECUTE_
362
Kapitel 5
Speicherverwaltung
MEMORY (0xFC) ab. (Eine Erklärung dieser Codes erhalten Sie in Kapitel 15 von Band 2.) Geschieht
dies im Benutzermodus, wird die Ausnahme STATUS_ACCESS_VIOLATION (0xC0000005) an den
Thread gesendet, der den ungültigen Verweis versucht. Wenn ein Prozess Speicher zuweist, der
ausführbar sein soll, muss er die Seiten entsprechend kennzeichnen, indem er bei den Speicherzuweisungsfunktionen auf Seitenebene das Flag PAGE_EXECUTE, PAGE_EXECUTE_READ, PAGE_
EXECUTE_READWRITE oder PAGE_EXECUTE_WRITECOPY angibt.
Auf 32-Bit-x86-Systemen, die die Datenausführungsverhinderung unterstützen, dient Bit
63 im Seitentabelleneintrag (Page Table Entry, PTE) dazu, eine Seite als nicht ausführbar zu
kennzeichnen. Daher steht die Datenausführungsverhinderung nur dann zur Verfügung, wenn
der Prozessor im PAE-Modus läuft (physische Adresserweiterung), da die Seitentabelleneinträge sonst nur 32 Bits breit sind (siehe den Abschnitt »Übersetzung virtueller Adressen auf
x86-Systemen« weiter hinten in diesem Kapitel). Daher erfordert die Unterstützung für Hardware-DEP auf 32-Bit-Systemen, dass der PAE-Kernel geladen wird (%SystemRoot%\System32\
Ntkrnlpa.exe), der zurzeit der einzige unterstützte Kernel auf x86-Systemen ist.
Auf ARM-Systemen ist die Datenausführungsverhinderung stets eingeschaltet.
Auf 64-Bit-Versionen von Windows wird der Ausführungsschutz automatisch auf alle
64-Bit-Prozesse und Gerätetreiber angewendet. Ausschalten können Sie ihn nur, indem Sie die
BCD-Option nx auf AlwaysOff setzen. Der Ausführungsschutz für 32-Bit-Programme hängt von
der im nächsten Absatz beschriebenen Systemkonfiguration ab. Auf 64-Bit-Windows wird der
Ausführungsschutz auf Threadstacks (sowohl im Benutzer- als auch im Kernelmodus), auf nicht
eigens als ausführbar gekennzeichnete Benutzermodusseiten, auf den ausgelagerten Kernelpool und den Kernelsitzungspool angewendet. Eine Beschreibung von Kernelspeicherpools
finden Sie im Abschnitt »Kernelmodusheaps (Systemspeicherpools)«. Auf 32-Bit-Windows dagegen wird der Ausführungsschutz nur auf Threadstacks und Benutzermodusseiten angewendet,
nicht aber auf den ausgelagerten und den Sitzungspool.
Die Anwendung des Anwendungsschutzes auf 32-Bit-Prozesse hängt von dem Wert der
BCD-Option nx ab. Um diese Einstellung zu ändern, rufen Sie die Registerkarte Datenausführungsverhinderung im Dialogfeld Leistungsoptionen auf (siehe Abb. 5–3). Dieses Dialogfeld erreichen Sie, indem Sie auf Computer rechtsklicken, Eigenschaften auswählen, auf Erweiterte
Systemeinstellungen klicken und dann Leistungseinstellungen wählen. Wenn Sie in diesem Dialogfeld den Ausführungsschutz einrichten, wird die BCD-Option nx auf den entsprechenden
Wert gesetzt. Tabelle 5–3 zeigt, welche Einstellungen auf der Registerkarte Datenausführungsverhinderung welchen nx-Werten entsprechen. 32-Bit-Anwendungen, die von dem Ausführungsschutz ausgenommen sind, werden im Registrierungsschlüssel HKLM\SOFTWARE\Microsoft\
Windows NT\CurrentVersion\AppCompatFlags\Layers aufgeführt, wobei als Name des Wertes der
vollständige Pfad der ausführbaren Datei angegeben ist und als Wert DisableNXShowUI.
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
363
Abbildung 5–3 Einstellungen auf der Registerkarte Datenausführungsverhinderung
nx-Wert
Option auf der Registerkarte
Datenausführungsverhinderung
Bedeutung
OptIn
Datenausführungsverhinderung nur
für erforderliche Windows-Programme
und -Dienste aktivieren
Die Datenausführungsverhinderung wird
für die Kernsystemabbilder von Windows
aktiviert. 32-Bit-Prozesse können die Datenausführungsverhinderung für ihre gesamte
Lebensdauer dynamisch einstellen.
OptOut
Datenausführungsverhinderung für
alle Programme und Dienste mit Ausnahme der ausgewählten aktivieren
Die Datenausführungsverhinderung wird für
ausführbare Dateien mit Ausnahme der eigens angegebenen aktiviert. 32-Bit-Prozesse
können die Datenausführungsverhinderung
für ihre gesamte Lebensdauer dynamisch
einstellen. Diese Einstellung aktiviert auch
Systemkompatibilitätskorrekturen für die Datenausführungsverhinderung.
AlwaysOn
Für diese Einstellung gibt es keine
Option in dem Dialogfeld.
Die Datenausführungsverhinderung wird für
alle Komponenten aktiviert, wobei es keine
Möglichkeit gibt, einzelne Anwendungen
auszunehmen. Die dynamische Konfiguration
für 32-Bit-Prozesse und die Systemkompatibilitätskorrekturen werden ausgeschaltet.
AlwaysOff
Für diese Einstellung gibt es keine
Option in dem Dialogfeld.
Die Datenausführungsverhinderung wird ausgeschaltet. (Von dieser Einstellung wird abgeraten.) Auch die dynamische Konfiguration für
32-Bit-Prozesse wird ausgeschaltet.
Tabelle 5–3 Werte der BCD-Option nx
364
Kapitel 5
Speicherverwaltung
Auf Windows-Clientversionen (sowohl 64 als auch 32 Bit) wird der Ausführungsschutz für
32-Bit-Prozesse in der Standardeinstellung nur auf ausführbare Dateien des Betriebssystems angewendet. Die Option nx ist also auf OptIn gesetzt. Dadurch ist dafür gesorgt, dass
32-Bit-Anwendungen, die Code auf nicht ausdrücklich als ausführbar gekennzeichneten Seiten
ausführen müssen, korrekt funktionieren, beispielsweise selbstextrahierende oder gepackte Anwendungen. Auf Windows-Serversystemen dagegen gilt der Ausführungsschutz für 32-Bit-Anwendungen für alle 32-Bit-Programme, hier ist die Option nx auf OptOut gesetzt.
Auch wenn Sie die Aktivierung der Datenausführungsverhinderung erzwingen, können
Anwendungen diese Einrichtung für ihre eigenen Abbilder ausschalten. Beispielsweise überprüft der Abbildlader unabhängig von den festgelegten Ausführungsschutzoptionen die Sig
natur einer ausführbaren Datei auf bekannte Kopierschutzmechanismen (wie SafeDisc oder
SecuROM) und deaktiviert den Ausführungsschutz, um die Kompatibilität mit älterer kopiergeschützter Software (z. B. älteren Computerspielen) zu gewährleisten. (Mehr über den Abbildlader erfahren Sie in Kapitel 3.)
Experiment: Die Einstellungen für die
Datenausführungsverhinderung ermitteln
Process Explorer kann den aktuellen Status der Datenausführungsverhinderung für alle Prozesse auf Ihrem System anzeigen. Dabei können Sie auch erkennen, ob ein Prozess standardmäßig geschützt ist oder ob der Schutz für ihn ausdrücklich aktiviert wurde. Rechtsklicken Sie auf den Prozessbaum, wählen Sie Select Columns und dann auf der Registerkarte
Process Image die Spalte DEP Status. Sie kann die folgenden drei Werte haben:
QQ DEP (permanent) Die Datenausführungsverhinderung ist für den Prozess aktiviert,
weil er zu den erforderlichen Windows-Programmen oder -Diensten gehört.
QQ DEP Die Datenausführungsverhinderung wurde für den Prozess ausführlich eingeschaltet. Das kann aufgrund einer systemweiten Richtlinie für alle 32-Bit-Prozesse geschehen sein, durch einen API-Aufruf wie SetProcessDEPPolicy oder durch Setzen des
Linkerflags /NXCOMPAT beim Erstellen des Abbilds.
QQ Keine Anzeige Wenn in der Spalte keine Informationen über den Prozess angezeigt
werden, ist die Datenausführungsverhinderung aufgrund einer systemweiten Richtlinie,
eines ausdrücklichen API-Aufrufs oder eines Shims ausgeschaltet.
Um Kompatibilität mit älteren Versionen (Version 7.1 oder früher) des ATL-Frameworks zu bieten (Active Template Library), bietet der Windows-Kernel auch eine Umgebung zur ATL-Thunk
emulation. Sie erkennt ATL-Thunkcodesequenzen, die eine DEP-Ausnahme ausgelöst haben,
und emuliert die erwartete Operation. Bei der Verwendung des neuesten Microsoft-C++-Compilers können Anwendungsentwickler durch Angabe des Flags /NXCOMPAT (das wiederum das
Flag IMAGE_DLLCHARACTERISTICS_NX_COMPAT im PE-Header setzt) verhindern, dass die ATL-Thunk
emulation angewendet wird. Dieses Flag teilt dem System mit, dass die ausführbare Datei die
Datenausführungsverhinderung vollständig unterstützt. Bei der Einstellung AlwaysOn ist die
ATL-Thunkemulation komplett ausgeschaltet.
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
365
Wenn das System bei der Einstellung OptIn oder OptOut einen 32-Bit-Prozess ausführt,
kann dieser die Datenausführungsverhinderung mit der Funktion SetProcessDEPPolicy dynamisch ausschalten oder dauerhaft einschalten. Wird die Datenausführungsverhinderung durch
diese API eingeschaltet, kann sie während der Lebensdauer des Prozesses nicht programmgesteuert ausgeschaltet werden. Mit dieser Funktion ist es auch möglich, die ATL-Thunkemulation
dynamisch auszuschalten, wenn das Abbild nicht mit dem Flag /NXCOMPAT kompiliert wurde.
Bei 64-Bit-Prozessen und auf Systemen, die mit der Einstellung AlwaysOff oder AlwaysOn gestartet wurden, schlägt die Funktion immer fehl. Die Funktion GetProcessDEPPolicy gibt die
32-Bit-DEP-Richtlinie für einen Prozess zurück. Auf 64-Bit-Systemen schlägt sie fehl, aber dort
ist die Richtlinie auch immer gleich – die Datenausführungsverhinderung ist stets eingeschaltet.
Mit GetSystemDEPPolicy können Sie die systemweiten Richtlinienwerte aus Tabelle 5–3 abrufen.
Kopieren beim Schreiben
Zum Kopieren beim Schreiben (Copy-on-Write) wendet der Speicher-Manager eine Optimierung an, um physischen Arbeitsspeicher zu sparen. Wenn ein Prozess eine entsprechend geschützte Sicht eines Abschnittsobjekts zuordnet, die les- und schreibbare Seiten enthält, verzögert der Speicher-Manager das Kopieren der Seiten, bis tatsächlich auf die Seite geschrieben
wird, anstatt schon gleich bei der Zuordnung der Sicht eine private Kopie für den Prozess
anzulegen. In dem Beispiel aus Abb. 5–4 sehen Sie zwei Prozesse, die sich drei Seiten teilen. Alle
drei Seiten sind für das Kopieren beim Schreiben gekennzeichnet, aber zurzeit hat noch keiner
der beiden Prozesse versucht, irgendwelche Daten auf diesen Seiten zu ändern.
Prozess A
RAM
Seite 1
Originaldaten
Seite 2
Prozess B
Originaldaten
Originaldaten
Originaldaten
Originaldaten
Originaldaten
Seite 3
Abbildung 5–4 Kopieren beim Schreiben – vorher
Wenn ein Thread in einem der beiden Prozesse auf eine Seite schreibt, wird ein Speicherverwaltungsfehler ausgelöst. Der Speicher-Manager erkennt, dass es sich um eine Copy-on-Write-
Seite handelt, weshalb er den Fehler nicht als Zugriffsverletzung meldet, sondern wie folgt
vorgeht:
1.
Er weist eine neue les- und schreibbare Seite im physischen Arbeitsspeicher zu.
2.
Er kopiert den Inhalt der Originalseite in die neue Seite.
366
Kapitel 5
Speicherverwaltung
3.
Er aktualisiert die zugehörigen Seitenzuordnungsinformationen in dem Prozess (mehr darüber weiter hinten in diesem Kapitel), sodass sie auf den neuen Speicherort zeigen.
4.
Er verwirft die Ausnahme und sorgt dafür, dass die Anweisung, die den Fehler hervorgerufen hat, erneut ausgeführt wird.
Bei diesem zweiten Versuch hat die Schreiboperation Erfolg. Wie Sie in Abb. 5–5 sehen, ist die
Kopie aber eine private Seite des schreibenden Prozesses und daher für den anderen Prozess
nicht sichtbar, der immer noch die gemeinsam genutzte Originalseite verwendet. Jeder weitere
Prozess, der auf dieselbe gemeinsame Seite schreibt, erhält ebenfalls seine private Kopie.
Prozess A
RAM
Seite 1
Originaldaten
Seite 2
Prozess B
Originaldaten
Geänderte Daten
Originaldaten
Originaldaten
Originaldaten
Seite 3
Kopie von Seite 2
mit Änderungen
Abbildung 5–5 Kopieren beim Schreiben – nachher
Das Kopieren beim Schreiben wird unter anderem verwendet, um Haltepunkte in Debuggern
zu ermöglichen. Beispielsweise sind Codeseiten zu Anfang standardmäßig rein für die Ausführung da. Wenn ein Programmierer beim Debuggen einen Haltepunkt setzt, muss der Debugger
die Anweisung dafür in den Code einfügen. Dazu stellt er zunächst den Schutz der Seite auf
PAGE_EXECUTE_READWRITE um und ändert dann den Anweisungsstream. Da die Codeseite zu einem zugeordneten Bereich gehört, erstellt der Speicher-Manager für den Prozess eine private
Kopie, in der der Haltepunkt gesetzt ist, während die anderen Prozesse mit der nicht geänderten Codeseite weitermachen.
Das Kopieren beim Schreiben ist ein Beispiel für die Technik der verzögerten Auswertung,
die der Speicher-Manager so oft wie möglich einsetzt. Algorithmen, die diese Technik nutzen,
vermeiden kostspielige Operationen, bis sie absolut notwendig sind. Wird die Operation niemals erforderlich, so wird keine Zeit darauf verschwendet.
Um die durch Kopieren beim Schreiben hervorgerufenen Fehler zu untersuchen, schauen
Sie sich in der Leistungsüberwachung den Leistungsindikator Schreibkopien/s aus der Kategorie
Arbeitsspeicher an.
AWE (Address Windowing Extensions)
Die 32-Bit-Version von Windows unterstützt zwar bis zu 64 GB an physischem Arbeitsspeicher
(siehe Tabelle 2–2), doch die einzelnen 32-Bit-Benutzerprozesse verfügen standardmäßig nur
über einen virtuellen Adressraum von jeweils 2 GB. (Wie im Abschnitt »Layouts für virtuelle
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
367
Adressräume« weiter hinten in diesem Kapitel erklärt, können Sie diesen Wert mit der BCD-Option increaseuserva auf bis zu 3 GB anheben.) Eine Anwendung, die mehr als 2 GB (bzw. 3 GB)
an leicht verfügbaren Daten in einem einzigen Prozess benötigt, kann dazu die Dateizuordnung nutzen und immer wieder Teile ihres Adressraums verschiedenen Teilen einer großen
Datei zuordnen. Allerdings ist jede dieser Neuzuordnungen mit einer erheblichen Auslagerung
verbunden.
Um eine höhere Leistung und eine feinere Steuerung zu ermöglichen, bietet Windows die
sogenannten AWE-Funktionen an (Address Windowing Extensions). Damit ist ein Prozess in der
Lage, mehr physischen Arbeitsspeicher zuzuweisen, als sein virtueller Adressraum darstellen
kann. Der Zugriff auf den physischen Speicher erfolgt dann, indem der Prozess Teile seines
virtuellen Adressraums im Laufe der Zeit verschiedenen Teilen des physischen Arbeitsspeichers
zuweist.
Um Arbeitsspeicher mithilfe der AWE-Funktionen zuzuweisen und zu nutzen, müssen Sie
die drei folgenden Schritte ausführen:
1.
Sie weisen den zu verwendenden physischen Arbeitsspeicher zu. Die Anwendung verwendet dazu die Windows-Funktion AllocateUserPhysicalPages oder AllocateUserPhysicalPagesNuma, für die das Recht SeLockMemoryPrivilege erforderlich ist.
2.
Sie erstellen im virtuellen Adressraum eine oder mehrere Regionen, die als Fenster zur
Zuordnung von Sichten des physischen Arbeitsspeichers dienen. Dazu verwendet die Anwendung die Win32-Funktion VirtualAlloc, VirtualAllocEx oder VirtualAllocExNuma mit
dem Flag MEM_PHYSICAL.
3.
Schritt 1 und 2 bilden allgemein ausgedrückt die Initialisierung. Um den Speicher tatsächlich nutzen zu können, ordnet die Anwendung mit MapUserPhysicalPages oder MapUserPhysicalPagesScatter einen Teil der in Schritt 1 zugewiesenen physischen Region zu einer
der in Schritt 2 zugewiesenen virtuellen Regionen oder Fenster zu.
Ein Beispiel dafür sehen Sie in Abb. 5–6. Hier hat die Anwendung in ihrem Adressraum ein
Fenster von 256 MB erstellt und 4 GB physischen Arbeitsspeicher zugeordnet. Mit MapUserPhy
sicalPages oder MapUserPhysicalPagesScatter kann sie nun auf jeden Teil des physischen Speichers zugreifen, indem sie den gewünschten Teil des Arbeitsspeichers in dem 256-MB-Fenster
zuordnet. Die Größe des Fensters bestimmt die Menge des physischen Speichers, auf den die
Anwendung in einer gegebenen Zuordnung zugreifen kann. Um Zugang zu einem anderen
Teil des zugewiesenen RAM zu erhalten, ordnet die Anwendung den Bereich einfach neu zu.
368
Kapitel 5
Speicherverwaltung
Systemadressraum
AWE-Speicher
AWE-Fenster
Benutzer
adressraum
Abbildung 5–6 Zuweisung von physischem Arbeitsspeicher mit AWE
Die AWE-Funktionen sind in allen Windows-Editionen vorhanden und können unabhängig davon genutzt werden, über wie viel physischen Speicher das System verfügt. Besonders nützlich
ist AWE allerdings auf 32-Bit-Systemen mit mehr als 2 GB physischem Arbeitsspeicher, da es
32-Bit-Prozessen die Möglichkeit gibt, mehr RAM zuzuweisen, als ihr virtueller Adressraum
normalerweise zulässt. AWE wird auch aus Sicherheitsgründen eingesetzt. Da AWE-Speicher
niemals ausgelagert wird, werden Daten im AWE-Speicher niemals in die Auslagerungsdatei
kopiert, die jemand durch einen Neustart in einem anderen Betriebssystem einsehen könnte.
(VirtualLock bietet dieselbe Garantie für Seiten im Allgemeinen.)
Arbeitsspeicher, der mit AWE-Funktionen zugewiesen und zugeordnet wurde, unterliegt
jedoch folgenden Einschränkungen:
QQ Die Seiten können nicht von mehreren Prozessen gemeinsam genutzt werden.
QQ Eine physische Seite kann nicht zu mehr als einer virtuellen Adresse zugeordnet werden.
QQ Der Seitenschutz ist auf »Lesen und Schreiben«, »nur Lesen« und »kein Zugriff« eingeschränkt.
Auf 64-Bit-Systemen darf jeder Prozess einen virtuellen Adressraum von 128 TB haben, aber
nur 24 TB RAM (auf Windows Server 2016). Daher wird AWE hier nicht gebraucht, um einer
Anwendung mehr RAM zu erlauben, als in ihren virtuellen Adressraum passt, denn schließlich
ist der RAM für einen Prozess immer kleiner als sein virtueller Prozessraum. Allerdings ist AWE
nach wie vor nützlich, um im Adressraum des Prozesses Regionen festzulegen, die nicht ausgelagert werden sollen. AWE bietet auch eine feinere Granularität als die Dateizuordnungs-APIs
(da die Systemseitengröße 4 KB statt 64 KB beträgt).
Eine Beschreibung der Datenstrukturen für die Seitentabellen, die zur Zuordnung von Arbeitsspeichern auf Systemen mit mehr als 4 GB an physischem Arbeitsspeicher verwendet werden, finden Sie im Abschnitt »Übersetzung virtueller Adressen auf x86-Systemen«.
Vom Speicher-Manager bereitgestellte Dienste
Kapitel 5
369
Kernelmodusheaps (Systemspeicherpools)
Bei der Initialisierung des Systems erstellt der Speichermanager zwei Speicherpools dynamischer Größe (Heaps), die von den meisten Kernelmoduskomponenten zur Zuordnung von Systemarbeitsspeicher verwendet werden:
QQ Nicht ausgelagerter Pool Er besteht aus einem Bereich von virtuellen Systemadressen,
die sich garantiert ständig im physischen Arbeitsspeicher befinden und daher jederzeit zugänglich sind, ohne Seitenfehler hervorzurufen. Das heißt, der Zugriff auf sie kann von jeder IRQL aus erfolgen. Ein nicht ausgelagerter Pool ist unter anderem deshalb erforderlich,
da Seitenfehler auf DPC-/Dispatchebene und darüber nicht gehandhabt werden können.
Daher müssen sich jeglicher Code und jegliche Daten, die auf dieser Ebene oder darüber
ausgeführt oder abgerufen werden sollen, in einem Teil des Arbeitsspeichers befinden, der
nicht ausgelagert werden kann.
QQ Ausgelagerter Pool Diese Region im virtuellen Arbeitsspeicher des Systems kann ausgelagert und wieder zurückgeholt werden. Gerätetreiber, die keinen Speicherzugriff auf
DPC-/Dispatchebene oder darüber benötigen, können den ausgelagerten Pool verwenden. Er ist von jedem Prozesskontext aus zugänglich.
Beide Speicherpools befinden sich im Systemteil des Adressraums und werden im virtuellen
Adressraum jedes Prozesses zugeordnet. Die Exekutive stellt Routinen für die Zuweisung aus
diesen Pools und die Aufhebung der Zuweisung bereit. Um mehr darüber zu erfahren, suchen
Sie in der Dokumentation des WDK nach Funktionen, deren Namen mit ExAllocatePool und
ExFreePool beginnen.
Zu Anfang verfügt ein System über vier ausgelagerte Pools, die zum gesamten ausgelagerten Pool des Systems kombiniert werden, sowie zwei nicht ausgelagerte Pools. Je nach Anzahl der NUMA-Knoten auf dem System werden weitere Pools bis zu einer Höchstzahl von 64
erstellt. Das Vorhandensein von mehr als einem ausgelagerten Pool verringert die Häufigkeit
von Systemcodeblockierungen bei gleichzeitigem Aufruf von Poolroutinen. Außerdem werden
die Pools verschiedenen virtuellen Adressbereichen zugeordnet, die den NUMA-Knoten des
Systems entsprechen. Auch die Datenstrukturen zur Beschreibung der Poolzuweisungen, z. B.
die umfangreichen Look-Aside-Listen, werden den einzelnen NUMA-Knoten zugeordnet.
Neben den ausgelagerten und nicht ausgelagerten Pools gibt es noch weitere Pools mit
besonderen Eigenschaften oder Verwendungszwecken. Beispielsweise gibt es im Sitzungsraum
eine Poolregion für Daten, die von allen Prozessen einer Sitzung gemeinsam genutzt werden.
Ein anderes Beispiel ist der besondere Pool. Zuweisungen daraus sind von Seiten umgeben, die
mit »kein Zugriff« gekennzeichnet sind, um Probleme in dem Code zu isolieren, der auf Speicher zugreift, bevor oder nachdem die Region des Pools zugewiesen wurde.
Poolgrößen
Ein nicht ausgelagerter Pool hat zu Anfang eine Größe, die vom physischen Arbeitsspeicher auf
dem System abhängt, und wächst dann nach Bedarf. Die Anfangsgröße beträgt gewöhnlich
3 % des System-RAM. Wenn das jedoch einen Wert von weniger als 40 MB ergibt, verwendet
das System 40 MB als Anfangsgröße. Sollten diese 40 MB jedoch auch mehr als 10 % sein,
370
Kapitel 5
Speicherverwaltung
bekommt der Pool eine Anfangsgröße von 10 % des RAM. Windows bestimmt dynamisch die
Maximalgröße und erlaubt jedem Pool, von seiner Anfangsgröße bis zu dem in Tabelle 5–4
genannten Maximum zu wachsen.
Maximum auf
64-Bit-Systemen
(Windows 8.1,
Windows 10, Windows
Server 2012 R2,
Windows Server 2016)
Art des Pools
Maximum auf 32-BitSystemen
Maximum auf 64-BitSystemen (Windows 8,
Windows Server 2012)
Nicht ausgelagert
75 % des physischen
Speichers oder 2 GB
(der kleinere Wert)
75 % des physischen
Speichers oder 128 GB
(der kleinere Wert)
16 TB
Ausgelagert
2 GB
384 GB
15,5 TB
Tabelle 5–4 Maximale Poolgrößen
Vier dieser berechneten Werte werden in Windows 8.x und in Windows Server 2012 und 2012
R2 in Kernelvariablen gespeichert. Drei davon können über Leistungsindikatoren eingesehen
werden, und einer wird als Leistungsindikatorenwert berechnet. In Windows 10 und Windows
Server 2016 wurden die globalen Variablen in Felder der globalen Speicherverwaltungsstruktur
MiState (vom Typ MI_SYSTEM_INFORMATION) verlagert. Darin befindet sich die Variable Vs (vom
Typ _MI_VISIBLE_STATE) mit den Informationen. Die globale Variable MiVisibleState zeigt ebenfalls auf das Element Vs. Tabelle 5–5 gibt einen Überblick über diese Variablen und Indikatoren.
Kernelvariable
Leistungsindikator
Beschreibung
MmSizeOfNonPagedPoolInBytes
Arbeitsspeicher:
Nicht-Auslagerungsseiten (Bytes)
Dies ist die Größe des ursprünglich
nicht ausgelagerten Pools. Er kann vom
System je nach den Speicheranforderungen automatisch verkleinert oder
vergrößert werden. Der Leistungsindikator spiegelt diese Änderungen wider,
die Kernelvariable jedoch nicht.
MmMaximumNonPagedPoolInBytes
(Windows 8.x und Server 2012/R2)
Nicht verfügbar
Dies ist die maximale Größe eines nicht
ausgelagerten Pools.
MiVisibleState->MaximumNonPagePoolInBytes (Windows 10 und Server
2016)
Nicht verfügbar
Dies ist die maximale Größe eines nicht
ausgelagerten Pools.
Nicht verfügbar
Arbeitsspeicher:
Auslagerungsseiten
(Bytes)
Dies ist die aktuelle virtuelle Gesamtgröße des ausgelagerten Pools.
WorkingSetSize (Anzahl der Seiten)
in der Struktur MmPagedPoolWs (Typ
MMSUPPORT)
(Windows 8.x und Server 2012/R2)
Arbeitsspeicher:
Auslagerungsseiten:
Residente Bytes
Dies ist die aktuelle physische (residente) Größe des ausgelagerten Pools.
MmSizeOfPagedPoolInBytes
(Windows 8.x und Server 2012/R2)
Nicht verfügbar
Dies ist die maximale (virtuelle) Größe
eines ausgelagerten Pools.
MiState.Vs.SizeOfPagedPoolInBytes
(Windows 10 und Server 2016)
Nicht verfügbar
Dies ist die maximale (virtuelle) Größe
eines ausgelagerten Pools.
Tabelle 5–5 Variablen und Leistungsindikatoren für die Systempoolgrößen
Kernelmodusheaps (Systemspeicherpools)
Kapitel 5
371
Experiment: Die maximalen Poolgrößen bestimmen
Die Höchstgrößen der Pools können Sie mit Process Explorer und durch ein Live-Kerneldebugging (siehe Kapitel 1) bestimmen. In Process Explorer wählen Sie dazu im Menü View
den Punkt System Information und klicken auf die Registerkarte Memory. Die Poolgrenz
werte werden im Abschnitt Kernel Memory angezeigt:
Damit Process Explorer diese Informationen abrufen kann, muss er Zugriff auf die Symbole für den Kernel des Systems haben. Wie Sie Process
Explorer entsprechend einrichten, erfahren Sie in dem Experiment »Einzelheiten über Prozesse mit Process Explorer einsehen« in Kapitel 1.
Im Kerneldebugger verwenden Sie den in diesem Kapitel bereits vorgestellten Befehl !vm.
Die Poolnutzung überwachen
Das Leistungsobjekt Arbeitsspeicher umfasst mehrere Indikatoren für den nicht ausgelagerten
und den ausgelagerten Pool (sowohl virtuell als auch physisch). Außerdem können Sie mit dem
Programm Poolmon (aus dem Verzeichnis WDK Tools) die Nutzung des ausgelagerten und
des nicht ausgelagerten Pools detailliert beobachten. Eine Beispielausgabe dieses Programms
sehen Sie in Abb. 5–7.
372
Kapitel 5
Speicherverwaltung
Abbildung 5–7 Ausgabe von Poolmon
Zeilen, die sich geändert haben, werden unterlegt dargestellt. Diese Hervorhebung können
Sie durch Eingabe von l während der Ausführung von Poolmon ein- und ausschalten. Durch
Eingabe von ? können Sie den Hilfebildschirm aufrufen. Außerdem können Sie festlegen, welche Pools Sie überwachen wollen (der ausgelagerte, der nicht ausgelagerte oder beide), und
die Sortierreihenfolge auswählen. Beispielsweise können Sie P eingeben, um nur Zuweisungen
aus dem nicht ausgelagerten Pool anzeigen zu lassen, und dann mit D nach der Spalte Diff
(Differenz) sortieren, um herauszufinden, welche Strukturen im nicht ausgelagerten Pool am
zahlreichsten vorkommen. Neben diesen Befehlen werden auf dem Hilfebildschirm auch die
Befehlszeilenoptionen angezeigt, mit denen Sie die Überwachung auf bestimmte Tags (oder
auf alle Tags außer einem) einschränken können. Beispielsweise werden bei poolmon -iCM nur
CM-Tags überwacht (Zuweisungen des Konfigurations-Managers, der die Registrierung verwaltet). Die Bedeutung der Spalten wird in Tabelle 5–6 erklärt.
Spalte
Bedeutung
Tag
Ein 4-Byte-Tag zur Kennzeichnung der Poolzuweisung
Type
Die Art des Pools (ausgelagert oder nicht ausgelagert)
Allocs
Die Anzahl aller Zuweisungen. Die Zahl in Klammern zeigt den Unterschied zu dem
Wert vor der letzten Aktualisierung an.
Frees
Die Anzahl aller Freigaben. Die Zahl in Klammern zeigt den Unterschied zu dem Wert
vor der letzten Aktualisierung an.
Diff
Die Anzahl der Zuweisungen abzüglich der Freigaben
Bytes
Die Gesamtanzahl aller von diesem Tag verbrauchten Bytes. Die Zahl in Klammern zeigt
den Unterschied zu dem Wert vor der letzten Aktualisierung an.
Per Alloc
Die Größe eines einzelnen Vorkommens dieses Tags in Bytes
Tabelle 5–6 Poolmon-Spalten
Kernelmodusheaps (Systemspeicherpools)
Kapitel 5
373
Was die von Windows verwendeten Pooltags bedeuten, erfahren Sie in der Datei Pooltag.
txt. Sie befindet sich im Unterverzeichnis Triage des Speicherorts für die Debugging-Tools für
Windows. Die Pooltags der Gerätetreiber von Drittanbietern sind darin jedoch nicht verzeichnet, allerdings können Sie bei der im WDK enthaltenen 32-Bit-Version von Poolmon mit dem
Schalter -c die lokale Pooltagdatei Localtag.txt erstellen, die sämtliche von Treibern auf dem
System verwendeten Pooltags enthält, einschließlich derjenigen von Drittanbietertreibern.
Wurde die Binärdatei eines Gerätetreibers nach dem Laden gelöscht, werden ihre Pooltags
jedoch nicht mehr erkannt.
Alternativ können Sie auch mit dem Sysinternals-Tool Strings.exe nach den Gerätetreibern
für ein Pooltag suchen. Beispielsweise gibt der folgende Befehl die Namen der Treiber aus, die
den String "abcd" enthalten:
strings %SYSTEMROOT%\system32\drivers\*.sys | findstr /i "abcd"
Gerätetreiber müssen sich nicht unbedingt in %SystemRoot%\System32\Drivers befinden, sondern können in jedem beliebigen Ordner stecken. Um die vollständigen Pfade aller geladenen
Treiber aufzulisten, gehen Sie wie folgt vor:
1.
Öffnen Sie das Startmenü und geben Sie Msinfo32 ein. Daraufhin wird Systeminforma
tionen angezeigt.
2.
Führen Sie Systeminformationen aus.
3.
Erweitern Sie Softwareumgebung.
4.
Markieren Sie Systemtreiber. Gerätetreiber, die zwar geladen, aber vom System gelöscht
wurden, werden hier nicht aufgeführt.
Eine andere Möglichkeit, um die Nutzung der Pools durch die Gerätetreiber zu beobachten,
bietet die in Kapitel 6 erklärte Poolverfolgungsfunktion der Treiberüberprüfung. Dabei ist es
zwar nicht mehr nötig, die Pooltags mit den Gerätetreibern zu verknüpfen, allerdings ist ein
Neustart erforderlich, um die Treiberüberprüfung für die gewünschten Treiber einzuschalten.
Nach dem Neustart mit aktivierter Poolverfolgung können Sie den grafischen Treiberüberprüfungs-Manager (%SystemRoot%\System32\Verifier.exe) verwenden, Informationen über die
Poolnutzung aber auch mit dem Befehl Verifier /Log in eine Datei schreiben.
Auch mit dem Kerneldebuggerbefehl !poolused können Sie sich einen Überblick über die
Poolnutzung verschaffen. Der Befehl !poolused 2 zeigt die Nutzung des nicht ausgelagerten
Pools an, wobei die Tags mit der stärksten Nutzung oben stehen. Mit !poolused 4 geben Sie die
Nutzung des ausgelagerten Pools in der gleichen Sortierung an. Das folgende Beispiel zeigt
Teilausgaben beider Befehle:
lkd> !poolused 2
........
Sorting by NonPaged Pool Consumed
NonPaged Paged
Tag
374
Allocs Used
Allocs
Used
File 626381 260524032
0
0 File objects
Ntfx 733204 227105872
0
0 General Allocation , Binary: ntfs.sys
Kapitel 5
Speicherverwaltung
MmCa 513713 148086336
0
0 Mm control areas for mapped files,
FMsl 732490 140638080
0
0 STREAM_LIST_CTRL structure , Binary:
Binary: nt!mm
fltmgr.sys
CcSc 104420 56804480
0
0 Cache Manager Shared Cache Map, Binary:
SQSF 283749 45409984
0
0 UNKNOWN pooltag 'SQSF', please update
nt!cc
pooltag.txt
FMfz 382318 42819616
0
0 FILE_LIST_CTRL structure, Binary:
FMsc
0
0 SECTION_CONTEXT structure, Binary:
fltmgr.sys
36130 32950560
fltmgr.sys
EtwB
517 31297568
107 105119744 Etw Buffer , Binary: nt!etw
DFmF 382318 30585440 382318
91756320 UNKNOWN pooltag 'DFmF', please update
pooltag.txt
DFmE 382318 18351264
0
0 UNKNOWN pooltag 'DFmE', please update
FSfc 382318 18351264
0
0 Unrecoginzed File System Run Time
pooltag.txt
allocations (update pooltag.w), Binary:
nt!fsrtl
smNp
4295 17592320
0
0 ReadyBoost store node pool allocations,
Thre
5780 12837376
0
0 Thread objects , Binary: nt!ps
Pool
8 12834368
0
0 Pool tables, etc.
Binary: nt!store or rdyboost.sys
Experiment: Fehlerbehebung bei einem Poolleck
In diesem Experiment spüren Sie ein Leck im ausgelagerten Pool Ihres Systems mithilfe
der in diesem Abschnitt beschriebenen Techniken auf und reparieren es. Um das Leck zu
verursachen, verwenden Sie das Sysinternals-Tool Notmyfault. Gehen Sie dazu wie folgt vor:
1.
Führen Sie die passende Bitversion von Notmyfault.exe für Ihr System aus.
2.
Notmyfault.exe lädt den Gerätetreiber Myfault.sys und zeigt das Dialogfeld Not My
Fault an, wobei die Registerkarte Crash ausgewählt ist. Klicken Sie stattdessen auf die
Registerkarte Leak. Dabei sehen Sie jetzt Folgendes:
→
Kernelmodusheaps (Systemspeicherpools)
Kapitel 5
375
3.
Vergewissern Sie sich, dass die Einstellung von Leak/Second den Wert 1000 KB hat.
4.
Klicken Sie auf Leak Paged. Dadurch sendet Notmyfault so lange Anforderungen zur
Zuweisung aus dem ausgelagerten Pool an Myfault, bis Sie auf Stop Paged klicken.
Normalerweise wird der ausgelagerte Pool auch dann nicht freigegeben, wenn Sie das
Programm beenden, das seine Entstehung ausgelöst hat (durch Interaktion mit einem
fehlerhaften Gerätetreiber). Der Pool bleibt leck, bis Sie das System neu starten. Um
den Testvorgang zu vereinfachen, erkennt Myfault jedoch, dass der Prozess geschlossen wurde, und gibt seine Zuweisungen frei.
5.
Öffnen Sie den Task-Manager, während der Pool leckt, rufen Sie die Registerkarte Leistung auf und klicken Sie auf Arbeitsspeicher. Sie können jetzt beobachten, dass der
Wert von Ausgelagerter Pool ansteigt. Das können Sie auch in der Anzeige System Information von Process Explorer erkennen. Öffnen Sie dazu das Menü View, wählen Sie
System Information und klicken Sie auf die Registerkarte Memory.
6.
Um zu ermitteln, welcher Pool leckt, führen Sie Poolmon aus und drücken (B), um die
Ausgabe nach der Anzahl der Bytes zu sortieren.
7.
Drücken Sie zweimal (P), damit Poolmon nur den ausgelagerten Pool anzeigt. Das Tag
Leak klettert an die Spitze der Liste. Poolmon hebt geänderte Zeilen hervor, um Sie auf
Änderungen bei den Poolzuweisungen hinzuweisen.
8.
Klicken Sie auf Stop Paged, damit Sie den ausgelagerten Pool auf Ihrem System nicht
erschöpfen.
9.
Führen Sie das Sysinternals-Tool Strings aus, um nach den Binärdateien der Treiber zu
suchen, die das Pooltag Leak enthalten. Als Ergebnis wird die Datei Myfault.sys angezeigt, womit bestätigt ist, dass dieser Treiber das Leck hervorruft.
Strings %SystemRoot%\system32\drivers\*.sys | findstr Leak
376
Kapitel 5
Speicherverwaltung
Look-Aside-Listen
Mit den Look-Aside-Lists bietet Windows einen Mechanismus zur schnellen Speicherzuweisung.
Der grundlegende Unterschied zwischen Pools und Look-Aside-Listen besteht darin, dass Poolzuweisungen unterschiedliche Größen aufweisen können, wohingegen Look-Aside-Listen nur
Blöcke fester Größe enthalten. Pools bieten zwar mehr Flexibilität, doch Look-Aside-Listen sind
schneller, da sie keine Spinlocks verwenden.
Exekutivkomponenten und Gerätetreiber können Look-Aside-Listen mit passenden Blockgrößen für häufig zugewiesene Datenstrukturen erstellen, indem sie die im WDK dokumentierte Funktion ExInitializeNPagedLookasideList (für nicht ausgelagerte Zuweisungen) bzw.
ExInitializePagedLookasideList (für auslagerungsfähige Zuweisungen) verwenden. Um den
Mehraufwand für die Prozessorsynchronisierung zu vermeiden, können mehrere Exekutivteilsysteme wie der E/A-Manager, der Cache-Manager und der Objekt-Manager für die einzelnen
Prozesse separate Look-Aside-Listen für die jeweils besonders häufig verwendeten Datenstrukturen anlegen. Die Exekutive erstellt auch eine allgemeine prozessorweise Look-Aside-Liste
für kleine Zuweisungen (bis zu 256) unabhängig davon, ob diese Zuweisungen ausgelagert
werden können oder nicht.
Wenn eine Look-Aside-Liste leer ist (was immer der Fall ist, wenn sie neu erstellt wurde),
muss das System Zuweisungen aus dem ausgelagerten oder nicht ausgelagerten Pool vornehmen. Enthält die Liste einen freigegebenen Block, kann die Zuweisung jedoch sehr schnell
erfüllt werden. Die Liste wächst dadurch, dass ihr Blöcke zurückgegeben werden. Die Routinen
zur Poolzuweisung passen die Anzahl der freigegebenen Blöcke, die in den Look-Aside-Listen
gespeichert sind, automatisch daran an, wie oft ein Gerätetreiber oder ein Exekutivteilsystem
Zuweisungen aus der Liste vornimmt: Je häufiger die Zuweisungen geschehen, umso mehr
Blöcke werden in der Liste gespeichert. Erfolgen keine Zuweisungen aus einer Liste, so wird sie
automatisch verkleinert. Diese Überprüfung wird einmal pro Sekunde durchgeführt, wenn der
Systemthread des Balance-Set-Managers aufwacht und die Funktion ExAdjustLookasideDepth
aufruft.
Experiment: Die Look-Aside-Listen des Systems einsehen
Inhalt und Größe der einzelnen Look-Aside-Listen des Systems können Sie sich mit dem
Kerneldebuggerbefehl !lookaside anzeigen lassen. Das folgende Beispiel zeigt einen Auszug aus der Ausgabe dieses Befehls:
lkd> !lookaside
Lookaside "nt!CcTwilightLookasideList" @ 0xfffff800c6f54300 Tag(hex):
0x6b576343 "CcWk"
Type
=
0200
NonPagedPoolNx
Current Depth
=
0
Max Depth
=
4
Size
=
128
Max Alloc
=
512
AllocateMisses =
728323
FreeMisses =
728271
→
Kernelmodusheaps (Systemspeicherpools)
Kapitel 5
377
TotalAllocates = 1030842
Hit Rate
=
TotalFrees = 1030766
29% Hit Rate
=
29%
Lookaside "nt!IopSmallIrpLookasideList" @ 0xfffff800c6f54500 Tag(hex):
0x73707249 "Irps"
Type
=
0200
Current Depth
=
0
Max Depth
=
4
Size
=
280
Max Alloc
=
1120
AllocateMisses =
44683
FreeMisses =
43576
TotalAllocates = 232027
Hit Rate
=
NonPagedPoolNx
TotalFrees = 230903
80% Hit Rate
=
81%
Lookaside "nt!IopLargeIrpLookasideList" @ 0xfffff800c6f54600 Tag(hex):
0x6c707249 "Irpl"
Type
=
0200
Current Depth
=
0
NonPagedPoolNx
Max Depth
=
4
Size
=
1216
Max Alloc
=
4864
AllocateMisses = 143708
FreeMisses = 142551
TotalAllocates = 317297
TotalFrees = 316131
Hit Rate
=
54% Hit Rate
=
54%
...
Total NonPaged currently allocated for above lists =
0
Total NonPaged potential for above lists
= 13232
Total Paged currently allocated for above lists
=
0
Total Paged potential for above lists
=
4176
Der Heap-Manager
Die meisten Anwendungen müssen Blöcke zuweisen, die kleiner als das bei der Verwendung
von Funktionen mit Seitengranularität wie VirtualAlloc mögliche Minimum von 64 KB sind.
Die Zuweisung eines so großen Bereichs für einen relativ kleinen Block ist für die Ausnutzung
des Speichers und die Leistung alles andere als optimal. Um dieses Problem zu lösen, gibt es
in Windows den Heap-Manager, der sich um Zuweisungen innerhalb der von Funktionen mit
Seitengranularität reservierten größeren Speicherbereiche kümmert. Die Zuweisungsgranularität des Speicher-Managers ist relativ klein: 8 Bytes auf 32- und 16 Bytes auf 64-Bit-Systemen.
Der Heap-Manager befindet sich in Ntdll.dll und in Ntoskrnl.exe. Die Teilsystem-APIs (wie die
Windows-Heap-APIs) rufen die Funktionen in Ntdll.dll auf, verschiedene Exekutivkomponenten
und Gerätetreiber dagegen verwenden die Funktionen aus Ntoskrnl.exe. Die nativen Schnittstellen des Heap-Managers (mit dem Präfix Rtl) stehen nur für interne Windows-Komponenten
und Kernelmodus-Gerätetreiber zur Verfügung. Die dokumentierten Windows-API-Schnittstellen für den Heap (mit dem Präfix Heap) sind Forwarder zu den nativen Funktionen in Ntdll.dll.
Darüber hinaus werden ältere APIs (mit dem Präfix Local oder Global) zur Unterstützung älterer
378
Kapitel 5
Speicherverwaltung
Windows-Anwendungen bereitgestellt. Auch sie rufen intern den Heap-Manager auf, wobei sie
einige seiner besonderen Schnittstellen für ältere Verhaltensweisen nutzen. Zu den am häufigsten verwendeten Windows-Heapfunktionen gehören die folgenden:
QQ HeapCreate und HeapDestroy Sie erstellen bzw. entfernen einen Heap. Beim Erstellen
kann die ursprünglich reservierte und zugesicherte Größe angegeben werden.
QQ HeapAlloc Diese Funktion weist einen Heapblock zu und wird zu RtlAllocateHeap in
Ntdll.dll weitergeleitet.
QQ HeapFree
Gibt einen zuvor mit HeapAlloc zugewiesenen Block frei.
QQ HeapReAlloc Ändert die Größe einer bestehenden Zuweisung; das heißt, der vorhandene Block wird vergrößert oder verkleinert. Diese Funktion wird zu RtlReAllocateHeap in
Ntdll.dll weitergeleitet.
QQ HeapLock und HeapUnlock
seitig ausschließen.
QQ HeapWalk
Diese Funktion steuern Heapoperationen, die sich gegen-
Zählt sämtliche Einträge und Regionen in einem Heap auf.
Prozessheaps
Jeder Prozess verfügt über mindestens einen Heap, nämlich seinen Standardprozessheap, der
beim Prozessstart erstellt und während der Lebensdauer des Prozesses niemals gelöscht wird.
Die Standardgröße beträgt 1 MB, aber Sie können ihn auch größer machen, indem Sie in der
Abbilddatei mit dem Linkerflag /HEAP eine Anfangsgröße angeben. Bei diesem Wert handelt es
sich jedoch lediglich um die ursprünglich reservierte Größe. Der Heap wird automatisch nach
Bedarf erweitert. In der Abbilddatei können Sie auch eine ursprünglich zugesicherte Größe
angeben.
Der Standardheap kann ausdrücklich von einem Programm und stillschweigend durch einige interne Windows-Funktionen verwendet werden. Um den Standardprozessheap abzufragen, kann eine Anwendung die Windows-Funktion GetProcessHeap aufrufen. Mit HeapCreate
können Prozesse auch zusätzliche private Heaps erstellen. Wenn ein Prozess einen privaten
Heap nicht mehr benötigt, kann er den virtuellen Adressraum zurückgewinnen, indem er HeapDestroy aufruft. In jedem Prozess wird ein Array mit allen Heaps unterhalten. Threads können
diese Heaps mit der Windows-Funktion GetProcessHeaps abfragen.
Ein UWP-Prozess (Universal Windows Platform) schließt mindestens drei Heaps ein:
QQ Den Standardprozessheap.
QQ Einen gemeinsam genutzten Heap, um umfangreiche Argumente an die Csrss.exe-Instanz
der Prozesssitzung zu übergeben. Er wird von der Ntdll.dll-Funktion CsrClientConnectToServer erstellt, die zu einem frühen Zeitraum der Prozessinitialisierung durch Ntdll.dll
ausgeführt wird. Das Heaphandle steht in der globalen Variablen CsrPortHeap (in Ntdll.dll)
zur Verfügung.
QQ Ein von der C-Laufzeitbibliothek von Microsoft erstellter Heap. Sein Handle wird in der
globalen Variablen _crtheap im Modul msvcrt gespeichert. Dies ist der Heap, der intern
von den C/C++-Speicherzuweisungsfunktionen wie malloc, free, operator new/delete usw.
verwendet wird.
Der Heap-Manager
Kapitel 5
379
QQ Ein Heap kann Zuweisungen in großen Speicherregionen vornehmen, die über VirtualAlloc vom Speicher-Manager reserviert wurden, aber auch in Dateiobjekten, die im Prozess
adressraum zugeordnet wurden. Letzteres wird nur selten verwendet, und die WindowsAPI bietet auch keine Möglichkeit dafür. Allerdings ist diese Vorgehensweise für Situationen
geeignet, in denen der Inhalt der Blöcke von zwei Prozessen oder von einer Kernel- und
einer Benutzermoduskomponente gemeinsam genutzt werden muss. Der Win32-GUI-Teilsystemtreiber (Win32k.sys) verwendet einen solchen Heap, um GDI- und USER-Objekte mit
dem Benutzermodus zu teilen. Ein Heap, der auf der Region einer im Speicher zugeordneten Datei aufbaut, unterliegt gewissen Einschränkungen:
QQ Die internen Heapstrukturen verwenden Zeiger, weshalb eine Neuzuordnung zu anderen
Adressen in anderen Prozessen nicht erlaubt ist.
QQ Die Heapfunktionen ermöglichen keine Synchronisierung zwischen mehreren Prozessoren
oder zwischen einer Kernelkomponente und einem Benutzerprozess.
QQ Wird der Heap vom Benutzer- und vom Kernelmodus gemeinsam genutzt, sollte die Benutzermoduszuordnung schreibgeschützt sein, um zu verhindern, dass Benutzermoduscode
die internen Strukturen des Heaps beschädigt, was das System zum Absturz bringen würde.
Der Kernelmodustreiber muss außerdem darauf achten, dass keine sensiblen Daten auf
einen gemeinsam genutzten Heap gelegt werden, damit sie nicht in den Benutzermodus
durchsickern können.
Arten von Heaps
Bis zu Windows 10 und Windows Server 2016 gab es nur einen Typ von Heap, nämlich den
NT-Heap. Er kann durch eine optionale Front-End-Schicht erweitert werden, die aus dem
Low-Fragmentation-Heap (LFH) besteht.
In Windows 10 wurde Segmentheaps eingeführt. Die beiden Heaptypen bestehen aus den
gleichen Elementen, sind aber unterschiedlich aufgebaut und implementiert. Standardmäßig
werden Segmentheaps von allen UWP-Apps und einigen Systemprozessen verwendet, NT-
Heaps dagegen von allen übrigen Prozessen. Wie im Abschnitt »Segmentheaps« weiter hinten
gezeigt, können Sie dies in der Registrierung ändern.
NT-Heaps
Wie Sie in Abb. 5–8 sehen, bestehen NT-Heaps im Benutzermodus aus zwei Schichten, nämlich
einem Front-End und einem Back-End (wobei Letzteres auch als Heapkern bezeichnet wird).
Das Back-End kümmert sich um die grundlegende Funktionalität wie die Verwaltung der Blöcke in den Segmenten, die Verwaltung der Segmente, die Richtlinien für die Erweiterung des
Heaps, Zusicherung von Arbeitsspeicher und Aufheben der Zusicherung sowie die Verwaltung
großer Blöcke.
380
Kapitel 5
Speicherverwaltung
Anwendung
Heap-APIs
Kernel32.Dll
Front-End-Schicht des Heaps
NtDll.Dll
Back-End des Heaps
Benutzermodus
Kernelmodus
Speicher-Manager
Abbildung 5–8 Aufbau von NT-Heaps im Benutzermodus
Nur bei Heaps im Benutzermodus kann es über dieser Kernfunktionalität noch eine Front-EndSchicht geben. Windows unterstützt eine einzige dieser optionalen Schichten, die LFH, die in
dem Abschnitt »Der Low-Fragmentation-Heap« weiter hinten beschrieben wird.
Heapsynchronisierung
Der Heap-Manager unterstützt standardmäßig den gleichzeitigen Zugriff durch mehrere
Threads. Ein Prozess, der nur einen einzigen Thread hat oder einen externen Mechanismus zur
Synchronisierung verwendet, kann den Heap-Manager jedoch anweisen, auf den Mehraufwand für die Synchronisierung zu verzichten, indem er beim Erstellen des Heaps oder für einzelne Zuweisungen das Flag HEAP_NO_SERIALIZE angibt. Bei aktivierter Heapsynchronisierung
werden alle internen Heapstrukturen durch eine einzige Sperre pro Heap geschützt.
Wenn ein Prozess Operationen ausführt, die einen über mehrere Heapaufrufe hinweg konsistenten Zustand erfordern, kann er auch den gesamten Heap sperren, sodass andere Threads
keine Heapoperationen durchführen können. Beispielsweise ist es für die Aufzählung der Blöcke in einem Heap mithilfe der Windows-Funktion HeapWalk erforderlich, den Heap zu sperren, wenn andere Threads gleichzeitig ebenfalls Operationen an ihm vornehmen könnten. Das
Sperren und Entsperren eines Heaps erfolgt mit den Funktionen HeapLock und HeapUnlock.
Der Low-Fragmentation-Heap
Viele Anwendungen nutzen nur relativ wenig Heapspeicher, gewöhnlich weniger als 1 MB. Die
»Passgenauigkeitsrichtlinie« des Heap-Managers hilft, den Speicherverbrauch für die Prozesse
solcher Anwendungen gering zu halten. Für umfangreiche Prozesse und Mehrprozessorcomputer ist diese Vorgehensweise jedoch nicht geeignet, denn dabei kann der für die Heaps verfügbare Arbeitsspeicher aufgrund der Heapfragmentierung verringert werden. Wenn Threads,
die auf verschiedenen Prozessoren laufen, ständig gleichzeitig Speicher der gleichen Größe
verwenden, kann die Leistung leiden, da die Prozessoren gleichzeitig dieselben Stellen im Ar-
Der Heap-Manager
Kapitel 5
381
beitsspeicher bearbeiten müssen (z. B. den Anfang der Look-Aside-Liste für die betreffende
Größe), wodurch eine starke Konkurrenz um die entsprechende Cachezeile entsteht.
Der Low-Fragmentation-Heap verringert die Fragmentierung dadurch, dass er für Zuweisungen sogenannte Buckets verwendet. Dabei handelt es sich um vordefinierte Bereiche mit
unterschiedlichen Blockgrößen. Wenn ein Prozess Speicher vom Heap zuweist, wählt der LFH
den Bucket mit den kleinsten Blöcken aus, in die die gewünschte Zuweisung noch passt. Die
kleinste Blockgröße beträgt 8 Bytes. Der erste Bucket wird daher für Zuweisungen zwischen
1 und 8 Bytes verwendet, der zweite für Zuweisungen zwischen 9 und 16 Bytes usw. bis zum
32. Bucket für Zuweisungen zwischen 249 und 256 Bytes. Der anschließende 33. Bucket ist für
Zuweisungen zwischen 257 und 272 Bytes da usw. Der letzte Bucket ist der 128. und wird für
Zuweisungen zwischen 15.873 und 16.384 Bytes verwendet. Bei Zuweisungen von mehr als
16.384 Bytes leitet der LFH die Anforderung einfach an das unter ihm liegende Back-End des
Heaps weiter. Tabelle 5–7 gibt einen Überblick über die Buckets mit ihrer jeweiligen Granularität und den Größenbereichen, für die sie verwendet werden.
Buckets
Granularität
Bereich
1–32
8
1–256
33–48
16
257–512
49–64
32
513–1024
65–80
64
1025–2048
81–96
128
2049–4096
97–112
256
4097–8192
113–128
512
8193–16.384
Tabelle 5–7 LFH-Buckets
Um das zu erreichen, greift der LFH auf den Kern des Heap-Managers und auf Look-Aside-Listen
zurück. Der Heap-Manager enthält einen automatischen Optimierungsmechanismus, der unter
bestimmten Bedingungen automatisch den LFH verwendet, z. B. bei Konkurrenz um Sperren
oder beim Vorhandensein von Zuweisungen häufig verwendeter Größen, die erfahrungsgemäß
eine bessere Leistung zeigen, wenn der LFH eingeschaltet ist. Bei großen Heaps fällt ein erheblicher Anteil der Zuweisungen auf eine relativ kleine Anzahl von Buckets bestimmter Größen. Das
vom LFH verwendete Verfahren dient dazu, Zuweisungen, die einem solchen Muster folgen,
durch die effiziente Handhabung von Blöcken gleicher Größe zu optimieren.
Um Skalierbarkeit zu erreichen, erweitert der LFH die internen Strukturen, auf die häufig zugegriffen wird, zu doppelt so vielen Slots, wie es zurzeit Prozessoren in dem Computer
gibt. Die Zuweisung von Threads zu diesen Slots erfolgt durch eine LFH-Komponente, die als
Affinitäts-Manager bezeichnet wird. Zu Anfang verwendet der LFH den ersten Slot für Heapzuweisungen, doch wenn er beim Zugriff auf interne Daten Konkurrenzbedingungen erkennt,
schaltet er den aktuellen Thread zu einem anderen Slot um. Mehr Konkurrenzbedingungen
führen dazu, dass die Threads auf mehr Slots verteilt werden. Für jede Bucketgröße gibt es
eigene Slots, um die Lokalität zu verbessern und den Gesamtverbrauch an Arbeitsspeicher zu
minimieren.
382
Kapitel 5
Speicherverwaltung
Auch wenn der LFH als Front-End eingeschaltet ist und sich um die Zuweisung der häufigsten Größenordnungen kümmert, können für die Zuweisungen seltener genutzter Größen
nach wie vor die Heapkernfunktionen verwendet werden. Ist der LFH einmal für einen Heap
aktiviert, so kann er nicht mehr deaktiviert werden. In Windows 7 und früheren Versionen war
es mit der API HeapSetInformation und der Informationsklasse HeapCompatibilityInformation
möglich, die LFH-Schicht wieder zu entfernen, aber in neueren Versionen wird sie ignoriert.
Segmentheaps
Abb. 5–9 zeigt den Aufbau der in Windows 10 eingeführten Segmentheaps.
Anwendung
Heap-APIs
LFH
<= 16.368 Bytes
Kernel32.Dll
Variable Größe (VS)
<= 128 KB
NtDll.Dll
Back-End des Heaps (<= 508 KB)
Zuweisungen großer Blöcke
> 508 KB
Benutzermodus
Kernelmodus
Speicher-Manager
Abbildung 5–9 Segmentheaps
Welche Schicht sich um eine Zuweisung kümmert, hängt von der Zuweisungsgröße ab:
QQ Bei geringen Größen (kleiner oder gleich 16.368 Bytes) wird der LFH-Allozierer verwendet,
die dem LFH-Front-End von NT-Heaps ähnelt. Dies gilt allerdings nur für häufig verwendete Größen. Anderenfalls wird der VS-Allozierer verwendet (Variable Size).
QQ Bei Größen kleiner oder gleich 128 KB (die nicht vom LFH verwaltet werden) wird der
VS-Allozierer benutzt. Sowohl der VS- als auch der LFH-Allozierer verwenden das BackEnd, um die erforderlichen Teilsegmente des Heaps nach Bedarf zu erstellen.
QQ Zuweisungen größer als 128 KB und kleiner oder gleich 508 KB werden direkt vom HeapBack-End vorgenommen.
QQ Zuweisungen größer als 508 KB werden durch direkten Aufruf des Speicher-Managers
(VirtualAlloc) vorgenommen, da bei ihrer Größe die Standardgranularität von 64 KB (mit
Rundung auf die nächste Seitengröße) als ausreichend angesehen wird.
Der Heap-Manager
Kapitel 5
383
Die beiden Heapimplementierungen unterscheiden sich wie folgt:
QQ In manchen Situationen können Segmentheaps etwas langsamer sein als NT-Heaps. Sehr
wahrscheinlich werden sie jedoch in zukünftigen Versionen von Windows mit den NT-
Heaps gleichziehen.
QQ Segmentheaps verbrauchen weniger Speicher für ihre Metadaten, weshalb sie sich für Geräte mit wenig Speicher besser eignen, z. B. für Telefone.
QQ Bei Segmentheaps sind die Metadaten von den eigentlichen Daten getrennt, während sie
bei NT-Heaps mit den Daten vermischt sind. Dadurch ist ein Segmentheap sicherer, da es
bei ihm schwieriger ist, allein aufgrund der Blockadresse an die Metadaten einer Zuweisung zu gelangen.
QQ Ein Segmentheap lässt sich nur für einen Heap verwenden, der wachsen kann, aber nicht
für eine vom Benutzer bereitgestellte im Speicher zugeordnete Datei. Wird versucht, in
letzterem Fall einen Segmentheap zu erstellen, wird stattdessen ein NT-Heap angelegt.
QQ Beide Arten von Heaps unterstützen LFH-Zuweisungen, allerdings mit völlig unterschiedlicher interner Implementierung. Was Speicherverbrauch und Leistung angeht, ist die Implementierung in Segmentheaps effizienter.
Wie bereits erwähnt, verwenden UWP-Anwendungen standardmäßig Segmentheaps, hauptsächlich, weil sie aufgrund ihrer geringen Speicheranforderungen besonders gut für Geräte mit
wenig Speicher geeignet sind. Segmentheaps werden auch von einigen Systemprozessen wie
Ccrss.exe, Lsass.exe, Runtimebroker.exe, Services.exe, Smss.exe und Svchost.exe verwendet.
Für Desktop-Anwendungen sind Segmentheaps jedoch nicht die Standardheaps, da es
bei bestehenden Anwendungen zu Kompatibilitätsproblemen kommen könnte. Es ist jedoch
wahrscheinlich, dass sie in zukünftigen Versionen zum Standard werden. Um die Verwendung
von Segmentheaps für eine bestimmte ausführbare Datei zu aktivieren oder zu deaktivieren,
setzen Sie wie folgt den IFEO-DWORD-Wert FrontEndHeapDebugOptions:
QQ Bit 2 (4) zur Deaktivierung der Verwendung von Segmentheaps
QQ Bit 3 (8) zur Aktivierung der Verwendung von Segmentheaps
Die Verwendung von Segmentheaps können Sie auch global aktivieren und deaktivieren, indem
Sie den DWORD-Wert Enabled zum Registrierungsschlüssel HKLM\SYSTEM\CurrentControlSet\
Control\Session Manager\Segment Heap hinzufügen. Bei einem Wert von 0 wird die Verwendung von Segmentheaps deaktiviert, bei einem von 0 verschiedenen Wert wird sie aktiviert.
Experiment: Grundlegende Informationen über Heaps einsehen
In diesem Experiment untersuchen wir einige Heaps eines UWP-Prozesses.
1.
Starten Sie den Taschenrechner von Windows 10. Um ihn zu finden, klicken Sie auf Start
und geben Calculator ein.
2.
In Windows 10 ist der Taschenrechner eine UWP-App (Calculator.exe). Starten Sie
WinDbg und verbinden Sie den Debugger mit dem Rechnerprozess.
→
384
Kapitel 5
Speicherverwaltung
3.
WinDbg klinkt sich in den Prozess ein. Geben Sie den Befehl !heap ein, um sich einen
Überblick über die Heaps in dem Prozess zu verschaffen:
0:033> !heap
Heap Address
NT/Segment Heap
2531eb90000
Segment Heap
2531e980000
NT Heap
2531eb10000
Segment Heap
25320a40000
Segment Heap
253215a0000
Segment Heap
253214f0000
Segment Heap
2531eb70000
Segment Heap
25326920000
Segment Heap
253215d0000
NT Heap
4.
Die einzelnen Heaps werden mit ihrem Handle und Typ (Segment- oder NT-Heap) angezeigt. Der erste Heap ist der Standardheap des Prozesses. Da er wachsen kann und
keinen zuvor vorhandenen Speicherblock verwendet, wird er als Segmentheap erstellt.
Der zweite Heap dagegen verwendet einen vom Benutzer definierten Speicherblock
(siehe die Beschreibung im Abschnitt »Prozessheaps« weiter vorn), was zurzeit nicht
von Segmentheaps unterstützt wird. Daher wird er als NT-Heap angelegt.
5.
Ein NT-Heap wird von der NtDll!_HEAP-Struktur verwaltet. Schauen Sie sich diese Struktur für den zweiten Heap an:
0:033> dt ntdll!_heap 2531e980000
+0x000 Segment
: _HEAP_SEGMENT
+0x000 Entry
: _HEAP_ENTRY
+0x010 SegmentSignature : 0xffeeffee
+0x014 SegmentFlags
: 1
+0x018 SegmentListEntry : _LIST_ENTRY [ 0x00000253'1e980120 0x00000253'1e980120 ]
+0x028 Heap
: 0x00000253'1e980000 _HEAP
+0x030 BaseAddress
: 0x00000253'1e980000 Void
+0x038 NumberOfPages
: 0x10
+0x040 FirstEntry
: 0x00000253'1e980720 _HEAP_ENTRY
+0x048 LastValidEntry
: 0x00000253'1e990000 _HEAP_ENTRY
+0x050 NumberOfUnCommittedPages
: 0xf
+0x054 NumberOfUnCommittedRanges
: 1
+0x058 SegmentAllocatorBackTraceIndex : 0
+0x05a Reserved
: 0
+0x060 UCRSegmentList
: _LIST_ENTRY [ 0x00000253'1e980fe0 -
0x00000253'1e980fe0 ]
+0x070 Flags
: 0x8000
→
Der Heap-Manager
Kapitel 5
385
+0x074 ForceFlags
: 0
+0x078 CompatibilityFlags : 0
+0x07c EncodeFlagMask
: 0x100000
+0x080 Encoding
: _HEAP_ENTRY
+0x090 Interceptor
: 0
+0x094 VirtualMemoryThreshold : 0xff00
+0x098 Signature
: 0xeeffeeff
+0x0a0 SegmentReserve
: 0x100000
+0x0a8 SegmentCommit
: 0x2000
+0x0b0 DeCommitFreeBlockThreshold : 0x100
+0x0b8 DeCommitTotalFreeThreshold : 0x1000
+0x0c0 TotalFreeSize
: 0x8a
+0x0c8 MaximumAllocationSize : 0x00007fff'fffdefff
+0x0d0 ProcessHeapsListIndex : 2
...
+0x178 FrontEndHeap
: (null)
+0x180 FrontHeapLockCount : 0
+0x182 FrontEndHeapType : 0 ''
+0x183 RequestedFrontEndHeapType : 0 ''
+0x188 FrontEndHeapUsageData
: (null)
+0x190 FrontEndHeapMaximumIndex
: 0
+0x192 FrontEndHeapStatusBitmap
: [129] ""
+0x218 Counters
: _HEAP_COUNTERS
+0x290 TuningParameters : _HEAP_TUNING_PARAMETERS
6.
Das Feld FrontEndHeap gibt an, ob eine Front-End-Schicht vorhanden ist. In der Beispielausgabe ist dieses Feld null, was bedeutet, dass es diese Schicht hier nicht gibt.
Jeder andere Wert weist auf eine LFH-Front-End-Schicht hin, weil dies die einzige definierte Front-End-Schicht ist.
7.
Ein Segmentheap wird durch eine Ntdll!_SEGMENT_HEAP-Struktur definiert. Sehen Sie
sich diese Struktur für den Standardheap des Prozesses an:
0:033> dt ntdll!_segment_heap 2531eb90000
+0x000 TotalReservedPages
: 0x815
+0x008 TotalCommittedPages
: 0x6ac
+0x010 Signature
: 0xddeeddee
+0x014 GlobalFlags
: 0
+0x018 FreeCommittedPages
: 0
+0x020 Interceptor
: 0
+0x024 ProcessHeapListIndex : 1
+0x026 GlobalLockCount
: 0
+0x028 GlobalLockOwner
: 0
→
386
Kapitel 5
Speicherverwaltung
+0x030 LargeMetadataLock
: _RTL_SRWLOCK
+0x038 LargeAllocMetadata
: _RTL_RB_TREE
+0x048 LargeReservedPages
: 0
+0x050 LargeCommittedPages
: 0
+0x058 SegmentAllocatorLock : _RTL_SRWLOCK
+0x060 SegmentListHead
: _LIST_ENTRY [ 0x00000253'1ec00000 -
0x00000253'28a00000 ]
+0x070 SegmentCount
: 8
+0x078 FreePageRanges
: _RTL_RB_TREE
+0x088 StackTraceInitVar
: _RTL_RUN_ONCE
+0x090 ContextExtendLock
: _RTL_SRWLOCK
+0x098 AllocatedBase
: 0x00000253'1eb93200 ""
+0x0a0 UncommittedBase
: 0x00000253'1eb94000 "--- memory read error
at address 0x00000253'1eb94000 ---"
+0x0a8 ReservedLimit
: 0x00000253'1eba5000 "--- memory read error
at address 0x00000253'1eba5000 ---"
+0x0b0 VsContext
: _HEAP_VS_CONTEXT
+0x120 LfhContext
: _HEAP_LFH_CONTEXT
8.
Mit dem Feld Signature wird zwischen den beiden Arten von Heaps unterschieden.
9.
In der Struktur für den NT-Heap befand sich am selben Offset (0x010) das Feld Segment
Signature. Dadurch können Funktionen wie RtlAllocateHeap allein am Heaphandle (an
der Adresse) erkennen, welche der beiden Implementierungen sie einschalten müssen.
10. Die letzten beiden Felder der _SEGMENT_HEAP-Struktur enthalten Angaben zum VS- und
zum LFH-Allozierer.
11. Um weitere Informationen über die einzelnen Heaps zu gewinnen, verwenden Sie den
Befehl !heap -s:
0:033> !heap -s
Process
Global
Heap Address Signature
Flags
Total
Total
Heap Reserved Committed
List
Bytes
Bytes
Index
(K)
(K)
2531eb90000
ddeeddee
0
1
8276
6832
2531eb10000
ddeeddee
0
3
1108
868
25320a40000
ddeeddee
0
4
1108
16
253215a0000
ddeeddee
0
5
1108
20
253214f0000
ddeeddee
0
6
3156
816
2531eb70000
ddeeddee
0
7
1108
24
25326920000
ddeeddee
0
8
1108
32
→
Der Heap-Manager
Kapitel 5
387
****************************************************************************
*************
NT HEAP STATS BELOW
****************************************************************************
*************
LFH Key
: 0xd7b666e8f56a4b98
Termination on corruption : ENABLED
Affinity manager status:
- Virtual affinity limit 8
- Current entries in use 0
- Statistics: Swaps=0, Resets=0, Allocs=0
Heap
Flags Reserv Commit Virt Free List UCR Virt Lock Fast
(k)
(k)
(k)
(k) length blocks cont. heap
-----------------------------------------------------------------------------------000002531e980000 00008000
64
4
64
2
1
1 0 0
00000253215d0000 00000001
16
16
16
10
1
1 0 N/A
------------------------------------------------------------------------------------
12. Der erste Teil der Ausgabe zeigt ausführliche Informationen über die Segmentheaps im
Prozess (falls vorhanden), der zweite über die NT-Heaps.
Der Debuggerbefehl !heap bietet viele Optionen zur Anzeige und Untersuchung von H
eaps.
Mehr darüber erfahren Sie in der Dokumentation zu den Debugger-Tools für Windows.
Sicherheitseinrichtungen von Heaps
Im Laufe seiner Entwicklung hat der Heap-Manager eine immer größere Rolle bei der frühzeitigen Erkennung von Heapnutzungsfehlern und bei der Eindämmung der Auswirkungen von
Heapexploits übernommen. Sowohl NT- als auch Segmentheaps verfügen über Mechanismen,
um die Wahrscheinlichkeit einer Einflussnahme auf den Speicher zu verringern.
Die von den Heaps zur internen Verwaltung verwendeten Metadaten werden mit einer
starken Randomisierung gepackt, sodass es Angreifern schwerer fällt, die internen Strukturen zu manipulieren, um einen Absturz zu vermeiden oder einen Angriff zu verschleiern. Die
Header der entsprechenden Blöcke unterliegen auch einer Integritätsprüfung, um einfache
Beschädigungen wie Pufferüberläufe zu finden. Des Weiteren nutzt der Heap auch eine gewisse Randomisierung bei den Basisadressen und Handles. Durch die Verwendung der API
HeapSetInformation mit der Klasse HeapEnableTerminationOnCorruption können Prozesse eine
automatische Beendigung verlangen, wenn Inkonsistenzen festgestellt werden, sodass kein unbekannter Code ausgeführt wird.
Die Randomisierung der Blockmetadaten führt jedoch auch dazu, dass es nicht viel bringt,
mit einem Debugger einen Blockheader als Speicherbereich auszugeben. Beispielsweise lassen
388
Kapitel 5
Speicherverwaltung
sich die Größe des Blocks und die Angabe, ob er beschäftigt ist oder nicht, in der regulären
Ausgabe nicht so leicht erkennen. Das Gleiche gilt auch für LFH-Blöcke. Bei ihnen sind im
Header andere Arten von Metadaten gespeichert, die ebenfalls teilweise randomisiert sind.
Um diese Informationen auszugeben, ruft der Debuggerbefehl !heap -i alle Metadatenfelder
eines Blocks ab und macht ggf. auf vorhandene Inkonsistenzen bei der Prüfsumme und bei
den Listen der freien Blöcke aufmerksam. Dieser Befehl funktioniert sowohl für LFH- als auch
für reguläre Heapblöcke. Die Gesamtgröße der Blöcke, die vom Benutzer angeforderte Größe,
das Segment, das den Block besitzt, und die Teilprüfsumme des Headers stehen wie im folgenden Beispiel gezeigt in der Ausgabe zur Verfügung. Da der Randomisierungsalgorithmus die
Heapgranularität verwendet, sollte der Befehl !heap -i nur im Kontext des Heaps angewendet
werden, der den Block enthält. In dem folgenden Beispiel lautet das Heaphandle 0x001a0000.
Bei einem anderen Heapkontext würde der Header falsch decodiert. Um den richtigen Kontext
festzulegen, müssen Sie den Befehl !heap -i mit dem Heaphandle als Argument vorab schon
einmal ausführen.
0:004> !heap -i 000001f72a5e0000
Heap context set to the heap 0x000001f72a5e0000
0:004> !heap -i 000001f72a5eb180
Detailed information for block entry 000001f72a5eb180
Assumed heap
: 0x000001f72a5e0000 (Use !heap -i NewHeapHandle to change)
Header content
: 0x2FB544DC 0x1000021F (decoded : 0x7F01007E 0x10000048)
Owning segment
: 0x000001f72a5e0000 (offset 0)
Block flags
: 0x1 (busy )
Total block size
: 0x7e units (0x7e0 bytes)
Requested size
: 0x7d0 bytes (unused 0x10 bytes)
Previous block size: 0x48 units (0x480 bytes)
Block CRC
: OK - 0x7f
Previous block
: 0x000001f72a5ead00
Next block
: 0x000001f72a5eb960
Besondere Sicherheitseinrichtungen von Segmentheaps
Segmentheaps nutzen viele Sicherheitsmechanismen, die es schwerer machen, den Speicher zu
beschädigen oder Code zu injizieren, darunter die folgenden:
QQ Sofortige Beendigung bei beschädigten Listenknoten Segmentheaps verwenden
verknüpfte Listen, um den Überblick über Segmente und Teilsegmente zu wahren. Wie
bei NT-Heaps werden beim Hinzufügen und Entfernen von Listenknoten Überprüfungen
durchgeführt, um willkürliche Schreibvorgänge im Arbeitsspeicher aufgrund von beschädigten Listenknoten zu verhindern. Wird ein beschädigter Knoten entdeckt, wird der Prozess mit einem Aufruf von RtlFailFast beendet.
QQ Sofortige Beendigung bei Schädigung von Schwarz-Rot-Baumknoten Segment
heaps verwenden Schwarz-Rot-Bäume, um den Überblick über Back-End- und VS-Zuweisungen zu wahren. Die Funktionen zum Hinzufügen und Entfernen von Knoten führen eine
Der Heap-Manager
Kapitel 5
389
Validierung durch und rufen den Mechanismus für die sofortige Beendigung auf, wenn sie
beschädigte Knoten feststellen.
QQ Funktionszeigerdecodierung Bei einigen Aspekten von Segmentheaps sind Callbacks
zulässig (in den Strukturen VsContext und LfhContext, die zur _SEGMENT_HEAP-Struktur gehören). Ein Angreifer kann diese Callbacks überschreiben, sodass sie auf seinen eigenen
Code zeigen. Die Funktionszeiger werden jedoch mit einer XOR-Funktion mit einem internen, zufälligen Heapschlüssel und der Kontextadresse codiert, die sich beide nicht vorab
raten lassen.
QQ Wächterseiten Bei der Zuweisung von LFH- und VS-Teilsegmenten und großen Blöcken
wird am Ende eine Wächterseite hinzugefügt. Sie hilft dabei, Überläufe und Beschädigungen angrenzender Daten zu erkennen. Weitere Informationen über Wächterseiten erhalten
Sie im Abschnitt »Stacks« weiter hinten.
Debugging einrichten für Heaps
Der Heap-Manager enthält verschiedene Einrichtungen, um Bugs zu erkennen:
QQ Blockendeüberprüfung Das Ende jedes Blocks enthält eine Signatur, die bei der Freigabe des Blocks überprüft wird. Wurde die Signatur durch einen Pufferüberlauf ganz oder
teilweise zerstört, meldet der Heap diesen Fehler.
QQ Überprüfung freier Blöcke Ein freier Block wird mit einem Muster gefüllt, das bei verschiedenen Gelegenheiten überprüft wird, bei denen der Heap-Manager auf den Block
zugreifen muss, etwa wenn er ihn von der Liste der freien Blöcke entfernt, um eine Zuweisung durchzuführen. Wenn der Prozess nach der Freigabe eines Blocks weiterhin in
diesen schreibt, erkennt der Heap-Manager die Änderungen an dem Muster und meldet
den Fehler.
QQ Parameterprüfung Hierbei erfolgt eine ausführliche Prüfung der an die Heapfunktionen
übergebenen Parameter.
QQ Heapvalidierung
Bei jedem Heapaufruf wird der gesamte Heap validiert.
Unterstützung für Heaptags und Stackablaufverfolgung Damit ist es möglich, Tags für
die Zuweisung anzugeben bzw. eine Ablaufverfolgung des Benutzermodusstacks für Heapaufrufe zu erfassen, um die möglichen Ursachen von Heapfehlern einzuschränken.
Die ersten drei Einrichtungen sind standardmäßig aktiviert, wenn der Lader erkennt, dass
ein Prozess unter der Kontrolle eines Debuggers gestartet wurde (wobei der Debugger dieses
Standardverhalten überschreiben und diese Einrichtungen ausschalten kann). Um die Heap
debuggingeinrichtungen für ein ausführbares Abbild anzugeben, setzen Sie mit dem Tool
Gflags verschiedene Debuggingflags im Abbildheader (siehe das nächste Experiment und den
Abschnitt »Globale Windows-Flags« in Kapitel 8 von Band 2). Alternativ können Sie die Heapdebuggingoptionen auch mit dem Befehl !heap in Windows-Standarddebuggern einschalten
(siehe die Hilfeseiten im Debugger).
Die Aktivierung der Heapdebuggingoptionen gilt für alle Heaps in dem Prozess. Außerdem
wird automatisch der LFH deaktiviert und der Kernheap verwendet, wenn auch nur eine dieser
Optionen eingeschaltet ist. Der LFH wird auch nicht für Heaps verwendet, die nicht erweiter-
390
Kapitel 5
Speicherverwaltung
bar sind (aufgrund des Zusatzaufwands, der noch zu den vorhandenen Heapstrukturen hinzukommt), und ebenso nicht für Heaps, die keine Serialisierung erlauben.
Der Seitenheap
Da die Überprüfung des Blockendes und der freien Blöcke Beschädigungen aufdecken können,
die lange zuvor erfolgt sind, gibt es mit dem Seitenheap noch eine zusätzliche Debuggingeinrichtung für Heaps. Er leitet einige oder alle Heapaufrufe an einen anderen Heapmanager weiter. Den Seitenheap können Sie mit Gflags aktivieren, das zu den Debugging-Tools für Windows
gehört. Der Heap-Manager platziert Zuweisungen dann am Ende von Seiten und reserviert die
unmittelbar folgende Seite. Da die reservierten Seiten nicht zugänglich sind, verursacht jeder
Pufferüberlauf eine Zugriffsverletzung, was es einfacher macht, den Verursachercode zu finden.
Optional können Blöcke auch am Anfang der Seiten platziert und die vorhergehende Seite
reserviert werden, um Pufferunterläufe zu erkennen (die seltener vorkommen). Mit dem Seitenheap lassen sich auch freigegebene Seiten gegen jeglichen Zugriff schützen, um Verweise
auf Heapblöcke nach deren Freigabe zu erkennen.
Aufgrund der erheblichen Mehrbelegung selbst bei kleinen Zuweisungen kann die Verwendung des Seitenheaps bei 32-Bit-Prozessen dazu führen, dass Ihnen der Adressraum ausgeht. Durch die Zunahme an Verweisen auf Nullforderungsseiten, den Verlust der Lokalität und
den Mehraufwand für häufige Aufrufe zur Validierung von Heapstrukturen kann außerdem
die Leistung leiden. Ein Prozess kann diese Auswirkungen dadurch verringern, dass er festlegt,
dass der Seitenheap nur für Blöcke bestimmter Größen, Adressbereiche oder Ursprungs-DLLs
eingesetzt werden soll.
Experiment: Den Seitenheap verwenden
In diesem Experiment schalten Sie den Seitenheap für Notepad.exe ein und beobachten die
Auswirkungen.
1.
Starten Sie Notepad.exe.
2.
Öffnen Sie den Task-Manager, rufen Sie die Registerkarte Details auf und fügen Sie die
Spalte Zugesicherte Größe zur Anzeige hinzu.
3.
Merken Sie sich die zugesicherte Größe der Notepad-Instanz.
4.
Starten Sie Gflags.exe in dem Ordner mit den Debugging-Tools für Windows (erhöhte
Rechte erforderlich).
5.
Klicken Sie auf die Registerkarte Image File.
6.
Geben Sie notepad.exe in das Textfeld Image ein und drücken Sie (Tab).
→
Der Heap-Manager
Kapitel 5
391
7.
Aktivieren Sie das Kontrollkästchen Enable Page Heap, sodass das Dialogfeld wie folgt
aussieht:
8.
Klicken Sie auf Übernehmen.
9.
Starten Sie eine weitere Instanz von Notepad, ohne die erste zu schließen.
10. Vergleichen Sie im Task-Manager die zugesicherten Größen der beiden Notepad-In
stanzen. Der Wert ist bei der zweiten Instanz viel größer, obwohl beide Notepad-Prozesse leer sind. Das liegt an den zusätzlichen Zuweisungen, die der Seitenheap vornimmt. Der folgende Screenshot zeigt diese Situation auf einem 32-Bit-Computer mit
Windows 10:
→
392
Kapitel 5
Speicherverwaltung
11. Um sich eine bessere Vorstellung von dem zusätzlich zugewiesenen Speicher zu machen, verwenden Sie das Sysinternals-Tool VMMap. Öffnen Sie VMMap.exe und markieren Sie die Notepad-Instanz, die den Seitenheap verwendet:
12. Öffnen Sie eine weitere Instanz von VMMap und markieren Sie darin die andere Notepad-Instanz. Ordnen Sie die beiden Fenster nebeneinander an, um beide überblicken
zu können:
Der Unterschied bei der zugesicherten Größe wird im Bereich Private Data (gelb) besonders deutlich.
→
Der Heap-Manager
Kapitel 5
393
13. Klicken Sie in beiden VMMap-Fenstern jeweils im mittleren Teil der Anzeige auf die
Zeile Private Data, um sich die Einzelheiten in der unteren Anzeige anzusehen. Im
Screenshot sind die Daten nach Größe sortiert.
14. Der Prozess im linken Screenshot (Notepad mit Seitenheap) verbraucht deutlich mehr
Speicher. Öffnen Sie einen der 1024-KB-Abschnitte. Dabei sehen Sie Folgendes:
15. Jetzt können Sie zwischen den zugesicherten Seiten deutlich die vom Seitenheap reservierten Seiten sehen, die dazu dienen, Pufferüberläufe und -unterläufe abzufangen. Deaktivieren Sie die Option Enable Page Heap in Gflags und klicken Sie auf Übernehmen, damit später aufgerufene Instanzen des Editors wieder ohne Seitenheap gestartet werden.
Weitere Informationen über den Seitenheap finden Sie in der Hilfedatei zu den Debugging-Tools für Windows.
Der fehlertolerante Heap
Microsoft hat die Beschädigung von Heapmetadaten als eine der häufigsten Ursachen von Anwendungsversagen erkannt. Um dieses Problem einzudämmen und Anwendungsentwicklern
bessere Möglichkeiten zur Problembehebung zur Verfügung zu stellen, gibt es in Windows den
fehlertoleranten Heap (FTH). Er besteht aus den beiden folgenden Hauptkomponenten:
QQ Die Erkennungskomponente (FTH-Server)
QQ Die Eindämmungskomponente (FTH-Client)
Bei der Erkennungskomponente handelt es sich um die DLL Fthsvc.dll, die vom Dienst des
Windows-Sicherheitscenters (Wscsvc.dll) geladen wird. Dieser Dienst wiederum läuft in einem der gemeinsam genutzten Dienstprozesse unter dem lokalen Dienstkonto und wird vom
Windows-Fehlerberichterstattungsdienst (Windows Error Reporting, WER) über Abstürze von
Anwendungen informiert.
Nehmen wir an, eine Anwendung stürzt in Ntdll.dll mit einem Fehlerstatus ab, der auf
eine Zugriffsverletzung oder eine Ausnahme aufgrund einer Heapbeschädigung hindeutet.
394
Kapitel 5
Speicherverwaltung
Wenn sich diese Anwendung noch nicht auf der Überwachungsliste des FTH-Dienstes befindet, erstellt dieser für sie ein »Ticket«, um die FTH-Daten festzuhalten. Stürzt die Anwendung
anschließend mehr als vier Mal in einer Stunde ab, richtet der FTH-Dienst sie so ein, dass sie in
Zukunft den FTH-Client verwendet.
Der FTH-Client ist ein Anwendungskompatibilitätsshim. Dieser Mechanismus wird seit
Windows XP verwendet, damit Anwendungen, die auf ein bestimmtes Verhalten älterer
Windows-Systeme angewiesen sind, auch auf moderneren Systemen ausgeführt werden können. In diesem Fall fängt der Shimmechanismus Aufrufe an die Heaproutinen ab und leitet sie
zu seinem eigenen Code weiter. Dieser FTH-Code implementiert verschiedene Abhilfemaßnahmen, die es der Anwendung erlauben, trotz der Heapfehler weiterzumachen.
Beispielsweise fügt FTH als Schutz gegen kleine Pufferüberlauffehler allen Zuweisungen
eine Aufpolsterung von 8 Bytes sowie einen reservierten FTH-Bereich hinzu. Um das häufig auftretende Problem zu lösen, dass ein Zugriff auf einen bereits freigegebenen Heapblock erfolgt,
werden HeapFree-Aufrufe erst nach einer gewissen Verzögerung umgesetzt. Die zur Freigabe
vorgemerkten Blöcke werden auf eine Liste gesetzt und erst dann tatsächlich freigegeben,
wenn die Gesamtgröße der Blöcke auf dieser Liste 4 MB übersteigt. Versuche, Regionen freizugeben, die nicht zu dem Heap oder zu dem Teil des Heaps gehören, der im Handleargument
von HeapFree angegeben wurde, werden einfach ignoriert. Des Weiteren werden nach dem
Aufruf von exit oder RtlExitUserProcess keine Blöcke mehr tatsächlich freigegeben.
Der FTH-Server beobachtet die Ausfallrate der Anwendung nach der Einrichtung der Abhilfemaßnahmen. Verbessert sich die Ausfallrate nicht, werden die Abhilfemaßnahmen wieder
entfernt.
Die Aktivitäten des FTH können Sie in der Ereignisanzeige beobachten. Gehen Sie dazu
wie folgt vor:
1.
Öffnen Sie das Dialogfeld Ausführen und geben Sie eventvwr.msc ein.
2.
Erweitern Sie im linken Bereich Ereignisanzeige > Anwendungs- und Dienstprotokolle >
Microsoft > Windows > Fault-Tolerant-Heap.
3.
Klicken Sie auf das Protokoll Betriebsbereit.
4.
Wenn Sie den FTH komplett deaktivieren wollen, setzen Sie den Wert Enabled im Registrierungsschlüssel HKLM\Software\Microsoft\FTH auf 0.
Dieser Registrierungsschlüssel enthält auch verschiedene FTH-Einstellungen, z. B. die bereits
erwähnte Verzögerung und eine Ausnahmeliste von ausführbaren Dateien (auf der sich u. a.
Standardsystemprozesse wie Smss.exe, Ccrss.exe, Wininit.exe, Services.exe, Winlogon.exe und
Taskhost.exe befinden). Im Wert RuleList gibt es außerdem eine Regelliste, die die Module und
Ausnahmetypen sowie einige Flags angibt, die überwacht werden müssen, um zu entscheiden,
ob der FTH zugeschaltet werden soll oder nicht. Standardmäßig wird hier nur eine einzige
Regel aufgeführt, um Heapprobleme vom Typ STATUS_ACCESS_VIOLATION (0xc0000005) in Ntdll.
dll zu erkennen.
Der FTH wird normalerweise nicht auf Dienste angewendet. In den Windows-Serversystemen ist er aus Leistungsgründen deaktiviert. Mit dem Application Compatibility Toolkit können
Systemadministratoren das Shim manuell auf die ausführbare Datei einer Anwendung oder
eines Dienstes anwenden.
Der Heap-Manager
Kapitel 5
395
Layouts für virtuelle Adressräume
In diesem Abschnitt geht es um die Komponenten im Benutzer- und im Systemadressraum und
die besonderen Layouts auf 32-Bit-Systemen (x86 und ARM) und 64-Bit-Systemen (x64). Dadurch wird deutlich, welche Einschränkungen auf diesen Plattformen jeweils für den virtuellen
Prozess- und Systemarbeitsspeicher gelten.
In Windows werden vor allem die drei folgenden Arten von Daten im virtuellen Adressraum zugeordnet:
QQ Privater Code und private Daten der einzelnen Prozesse Wie bereits in Kapitel 1 erwähnt, kann jeder Prozess über einen privaten Adressraum verfügen, der für andere Prozesse nicht zugänglich ist. Diese virtuellen Adressen werden also stets im Kontext des aktuellen
Prozesses ausgewertet und können nicht auf Adressen verweisen, die von anderen Prozessen definiert wurden. Threads innerhalb des Prozesses können daher niemals auf virtuelle
Adressen außerhalb dieses privaten Adressraums zugreifen. Auch der gemeinsam genutzte
Speicher bildet keine Ausnahme von dieser Regel, da die entsprechenden Speicherbereiche
den einzelnen teilnehmenden Prozessen zugeordnet werden, sodass jeder Prozess mithilfe
seiner prozesseigenen Adressen darauf zugreift. Auch prozessübergreifende Speicherfunktionen (ReadProcessMemory und WriteProcessMemory) führen Kernelmoduscode im Kontext
des Zielprozesses aus. Der virtuelle Adressraum des Prozesses – die Seitentabellen – wird im
Abschnitt »Adressübersetzung« beschrieben. Diese Tabellen werden auf Seiten gespeichert,
die nur vom Kernelmodus aus zugänglich sind, weshalb die Benutzermodusthreads eines
Prozesses nicht in der Lage sind, das Layout des eigenen Prozessraums zu ändern.
QQ Code und Daten der Sitzung Der Sitzungsraum enthält Informationen, die für die gesamte Sitzung gelten (siehe Kapitel 2). Eine Sitzung besteht aus den Prozessen und anderen Systemobjekten, die eine einzelne Anmeldesitzung eines Benutzers ausmachen,
zum Beispiel der Arbeitsstation, den Desktops und den Fenstern. Jede Sitzung verfügt über
ihren eigenen Bereich im ausgelagerten Pool, der vom Kernelmodusteil des Windows-Teilsystems (Win32k.sys) für die Zuweisung privater GUI-Datenstrukturen der Sitzung verwendet wird. Außerdem hat jede Sitzung ihre eigene Kopie des Windows-Teilsystemprozesses
(Csrss.exe) und des Anmeldeprozesses (Winlogon.exe). Der Prozess des Sitzungs-Managers
(Smss.exe) ist dafür zuständig, neue Sitzungen zu erstellen. Dazu gehört es, die private
Win32k.sys-Kopie der Sitzung zu laden, den privaten Objekt-Manager-Namensraum der
Sitzung anzulegen (siehe Kapitel 8 von Band 2) und die sitzungsspezifischen Instanzen
von Csrss.exe und Winlogon.exe zu erstellen. Zur Virtualisierung von Sitzungen werden alle
sitzungsweiten Datenstrukturen in einer Region des Systemraums zugeordnet, die als Sitzungsraum bezeichnet wird. Beim Erstellen eines Prozesses wird dieser Adressbereich den
Seiten der Sitzung zugeordnet, zu der der Prozess gehört.
QQ Code und Daten des Systems Der Systemraum enthält globalen Betriebssystemcode
und globale Datenstrukturen, die der Kernelmoduscode unabhängig davon sehen kann,
welcher Prozess zurzeit ausgeführt wird. Er besteht aus den folgenden Komponenten:
•
396
Systemcode Dies schließt das Betriebssystemabbild, die HAL und die Gerätetreiber
zum Starten des Systems ein.
Kapitel 5
Speicherverwaltung
•
Nicht ausgelagerter Pool Dies ist der nicht auslagerungsfähige Systemspeicher
heap.
•
Ausgelagerter Pool
•
Systemcache Dies ist der virtuelle Adressraum zur Zuordnung von Dateien, die im
Systemcache geöffnet sind (siehe Kapitel 11 in Band 2).
•
Systemweite Seitentabelleneinträge (Page Entry Tables, PTEs) Dies ist der Pool
der System-PTEs, die zur Zuordnung von Systemseiten wie dem E/A-Raum, Kernel
stacks und Speicherdeskriptorlisten verwendet werden. Mit dem Leistungsindikator Arbeitsspeicher:Freie Seitentabelleneinträge in der Leistungsüberwachung können Sie sich
ansehen, wie viele System-PTEs verfügbar sind.
•
Systemweite Arbeitssatzlisten Dies sind die Datenstrukturen für die Arbeitssatzlisten, die die drei Arbeitssätze Systemcache, ausgelagerter Pool und System-PETs beschreiben.
•
Zugeordnete Systemsichten Sie werden verwendet, um Win32k.sys – den ladbaren
Kernelmodusteil des Windows-Teilsystems – sowie die davon verwendeten Kernelmodus-Grafiktreiber zuzuordnen.
•
Hyperspace Dies ist ein besonderer Bereich zur Zuordnung der Arbeitssatzliste und
anderen prozessweisen Daten, die nicht in einem willkürlichen Prozesskontext zugänglich sein müssen. Hyperspace wird auch zur vorübergehenden Zuordnung von physischen Seiten im Systemraum verwendet. Ein Beispiel dafür ist die Aufhebung von
Einträgen in den Seitentabellen von Prozessen außer dem aktuellen, z. B. wenn eine
Seite von der Standbyliste entfernt wird.
•
Absturzabbildinformationen Dies ist zur Aufzeichnung von Informationen über
den Status eines Systemabsturzes reserviert.
•
HAL-Nutzung
Dies ist der auslagerungsfähige Systemspeicherheap.
Dies ist der für HAL-spezifische Strukturen reservierte Systemspeicher.
Nachdem Sie nun die Grundbestandteile des virtuellen Adressraums in Windows kennen, wollen wir uns die jeweiligen Layouts für die x86-, die ARM- und die x64-Plattform ansehen.
x86-Adressraumlayouts
In den 32-Bit-Versionen von Windows verfügt jeder Benutzerprozess standardmäßig über einen privaten Adressraum von 2 GB (wobei das Betriebssystem die restlichen 2 GB in Anspruch
nimmt). Allerdings können x86-Systeme mit der BCD-Startoption increaseuserva mit Benutzeradressräumen von bis zu 3 GB eingerichtet werden. Die beiden möglichen Adressraumlayouts sehen Sie in Abb. 5–10.
Diese Möglichkeit wurde eingeführt, um den Bedarf von 32-Bit-Anwendungen zu befriedigen, mehr Daten im Speicher zu halten, als es bei einem Adressraum von 2 GB möglich ist.
64-Bit-Systeme bieten natürlich einen weit umfangreicheren Adressraum.
Layouts für virtuelle Adressräume
Kapitel 5
397
Für HAL reserviert (4MB)
Systemcache
Ausgelagerter Pool
Nicht ausgelagerter Pool
1 GB Systemraum
Hyperspace (4 MB)
Prozessseitentabellen (8 MB)
Kernel und Exekutive
HAL
Treiber
Kein Zugriff (64 KB)
3 GB Benutzeradressraum
EXE-Code
Globale Variablen
Threadstacks
DLL-Code
(2 GB – 64 KB)
Abbildung 5–10 Layouts für den virtuellen Adressraum auf x86-Systemen (links 2 GB, rechts 3 GB)
Damit ein Prozess über einen Adressraum von 2 GB hinausgehen kann, muss neben der globalen Einstellung increaseuserva auch das Flag IMAGE_FILE_LARGE_ADDRESS_AWARE im Header
der Abbilddatei gesetzt sein, da Windows den zusätzliche Adressraum für den Prozess sonst
nur reserviert, sodass die Anwendung keine virtuellen Adressen größer als 0x7FFFFFFF sieht.
Der Zugriff auf den zusätzlichen virtuellen Speicher muss ausdrücklich verlangt werden, da
manche Anwendungen davon ausgehen, dass ihnen höchstens ein Adressraum von 2 GB zur
Verfügung gestellt wird. Da das hohe Bit eines Zeigers, der auf Adressen unterhalb von 2 GB
verweist, stets 0 ist (für Verweise in einem 2-GB-Adressraum sind nur 31 Bits erforderlich), wird
es von diesen Anwendungen als Flag für ihre eigenen Daten verwendet; wobei es natürlich vor
dem Verweis auf die Daten zurückgesetzt wird. Wenn solche Anwendungen einen Adressraum
von 3 GB verwendeten, würden sie dank dieses Verhaltens Zeiger für Werte oberhalb von 2 GB
abschneiden, was zu Programmfehlern einschließlich Datenbeschädigungen führte. Das Flag
IMAGE_FILE_LARGE_ADDRESS_AWARE setzen Sie, indem Sie beim Erstellen der ausführbaren Datei
das Linkerflag /LARGEADDRESSAWARE angeben. Alternativ können Sie auf der Eigenschaftenseite
in Visual Studio auch Linker und dann System auswählen und auf Große Adressen aktivieren
klicken. Mit einem Werkzeug wie Editbin.exe, das zu den Windows SDK-Tools gehört, ist es auch
möglich, das Flag zu einem ausführbaren Image hinzuzufügen, ohne dieses neu zu erstellen,
also ohne dass Sie den Quellcode benötigen, zumindest sofern die Datei nicht signiert ist. Wird
die Anwendung auf einem System mit einem Benutzeradressraum von 2 GB ausgeführt, hat
dieses Flag keine Auswirkung.
398
Kapitel 5
Speicherverwaltung
Mehrere Systemabbilder verfügen bereits über diese Kennzeichnung zur Verwendung großer Adressräume, sodass sie von der 3-GB-Einstellung profitieren können. Dazu gehören:
QQ Lsass.exe
Das Teilsystem der lokalen Sicherheitsautorität
QQ Inetinfo.exe
QQ Chkdsk.exe
QQ Smss.exe
Internet Information Server
Das Hilfsprogramm Check Disk
Der Sitzungs-Manager
QQ Dllhst3g.exe
Eine besondere Version von Dllhost.exe für COM+-Anwendungen
Experiment: Die Bereitschaft einer Anwendung zur Verwendung
großer Adressräume prüfen
Mit dem Programm Dumpbin aus den Visual Studio Tools (und älteren Versionen des
Windows SDK) können Sie ausführbare Dateien darauf überprüfen, ob sie große Adressräume nutzen können. Geben Sie zur Anzeige der Ergebnisse den Schalter /headers an. Bei der
Anwendung von Dumpbin auf den Sitzungs-Manager ergibt sich die folgende Ausgabe:
dumpbin /headers c:\windows\system32\smss.exe
Microsoft (R) COFF/PE Dumper Version 14.00.24213.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\windows\system32\smss.exe
PE signature found
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
14C machine (x86)
5 number of sections
57898F8A time date stamp Sat Jul 16 04:36:10 2016
0 file pointer to symbol table
0 number of symbols
E0 size of optional header
122 characteristics
Executable
Application can handle large (>2GB) addresses
32 bit word machine
Speicherzuweisungen mit VirtualAlloc, VirtualAllocEx und VirtualAllocExNuma beginnen
standardmäßig bei niedrigen virtuellen Adressen und gehen dann immer höher. Ein Prozess
erhält höchstens dann hohe virtuelle Adressen, wenn er sehr viel Speicher zuweist oder sein
virtueller Adressraum sehr stark fragmentiert ist. Zu Testzwecken können Sie daher erzwingen, dass die Speicherzuweisungen bei hohen Adressen beginnen, indem Sie bei den Virtual
Alloc*-Funktionen das Flag MEM_TOP_DOWN verwenden oder den DWORD-Registrierungswert
AllocationPreference zum Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\
Memory Management hinzufügen und auf 0x10000000 setzen.
Layouts für virtuelle Adressräume
Kapitel 5
399
Die folgende Ausgabe zeigt einen Testlauf des schon in früheren Experimenten verwendeten Programms TestLimit, bei dem es auf einem mit der Option increaseuserva gestarteten
32-Bit-Windows-Computer zu Speicherlecks kommt:
Testlimit.exe -r
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 5500
Reserving private bytes (MB)...
Leaked 1978 MB of reserved memory (1940 MB total leaked). Lasterror: 8
Der Prozess hat es geschafft, fast – aber nicht ganz – 2 GB zu reservieren. Da der EXE-Code und
verschiedene DLLs im Prozessadressraum zugeordnet werden, ist es nicht möglich, dass ein
normaler Prozess den gesamten Adressraum reserviert.
Auf demselben System können Sie nun zu einem Adressraum von 3 GB wechseln, indem
Sie an einer Eingabeaufforderung mit erhöhten Rechten den folgenden Befehl eingeben:
C:\WINDOWS\system32>bcdedit /set increaseuserva 3072
The operation completed successfully.
Bei diesem Befehl können Sie eine beliebige Größe (in MB) zwischen 2048 MB (dem Standardwert von 2 GB) und 3072 MB (dem Maximum von 3 GB) angeben. Starten Sie das System neu,
damit die Änderung in Kraft tritt, und führen Sie TestLimit erneut aus. Jetzt sehen Sie folgendes
Ergebnis:
Testlimit.exe -r
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 2308
Reserving private bytes (MB)...
Leaked 2999 MB of reserved memory (2999 MB total leaked). Lasterror: 8
Wie erwartet, hat TestLimit jetzt fast 3 GB mit Beschlag belegt. Dies ist nur möglich, da das
Programm bei der Verlinkung mit dem Flag /LARGEADDRESSAWARE gekennzeichnet worden ist.
Anderenfalls hätte sich das Ergebnis nicht von dem auf einem System ohne die Einstellung
increaseuserva unterschieden.
400
Kapitel 5
Speicherverwaltung
Um ein System wieder auf die normale Adressraumgröße von 2 GB pro Prozess
zurückzusetzen, führen Sie den Befehl bcdedit /deletevalue increaseuserva aus.
Das Layout des x86-Systemadressraums
Die 32-Bit-Versionen von Windows verwenden ein dynamisches Layout für den Systemadressraum (wobei wir uns den dafür eingesetzten Zuweisungsmechanismus weiter hinten noch
genauer ansehen). Wie Sie in Abb. 5–10 sehen, gibt es zwar nach wie vor einige besondere
reservierte Bereiche, doch viele Kernelmodusstrukturen nutzen die dynamische Adressraumzuweisung. Daher sind diese Strukturen nicht unbedingt zusammenhängend, sondern können auf
verschiedene Bereiche des Systemadressraums verstreut sein. Der auf diese Weise zugewiesene
Systemadressraum wird von folgenden Komponenten genutzt:
QQ Nicht ausgelagerter Pool
QQ Ausgelagerter Pool
QQ Besonderer Pool
QQ System-PTEs
QQ Zugeordnete Systemsichten
QQ Dateisystemcache
QQ PFN-Datenbank
QQ Sitzungsraum
x86-Sitzungsraum
Da Sitzung 0 von den Systemprozessen und -diensten verwendet wird und Sitzung 1 für den
ersten angemeldeten Benutzer, gibt es praktisch auf jedem System mehrere Sitzungen. Der
Code und die Daten der einzelnen Sitzungen werden dabei im Systemadressraum zugeordnet,
aber immer nur von den Prozessen in der jeweiligen Sitzung gemeinsam genutzt. Abb. 5–11
zeigt den allgemeinen Aufbau des Sitzungsraums. Die Größen der Bestandteile des Sitzungsraums werden ebenso wie im Rest des Kernel-Systemadressraums dynamisch bestimmt und
vom Speicher-Manager nach Bedarf angepasst.
Sitzungsdatenstrukturen und
Arbeitssatz
Zuordnungen der
Sitzungssicht
Ausgelagerter Pool der
Sitzung
Sitzungstreiberabbilder
Win32k.sys
Abbildung 5–11 Layout des x86-Sitzungsraums (Darstellung nicht proportional)
Layouts für virtuelle Adressräume
Kapitel 5
401
Experiment: Sitzungen anzeigen
Durch die Untersuchung der Sitzungs-ID können Sie erkennen, welche Prozesse zu welchen
Sitzungen gehören. Das können Sie im Task-Manager, in Process Explorer und im Kerneldebugger tun. Im Kerneldebugger können Sie die aktiven Sitzungen wie folgt mit dem Befehl
!session auflisten:
lkd> !session
Sessions on machine: 3
Valid Sessions: 0 1 2
Current Session 2
Anschließend können Sie mit dem Befehl !session -s die aktive Sitzung festlegen und die
Adressen der Sitzungsdatenstrukturen und Prozesse mit !sprocess anzeigen lassen:
lkd> !session -s 1
Sessions on machine: 3
Implicit process is now d4921040
Using session 1
lkd> !sprocess
Dumping Session 1
_MM_SESSION_SPACE d9306000
_MMSESSION d9306c80
PROCESS d4921040 SessionId: 1 Cid: 01d8 Peb: 00668000 ParentCid: 0138
DirBase: 179c5080 ObjectTable: 00000000 HandleCount: 0.
Image: smss.exe
PROCESS d186c180 SessionId: 1 Cid: 01ec Peb: 00401000 ParentCid: 01d8
DirBase: 179c5040 ObjectTable: d58d48c0 HandleCount: <Data Not Accessible>
Image: csrss.exe
PROCESS d49acc40 SessionId: 1 Cid: 022c Peb: 03119000 ParentCid: 01d8
DirBase: 179c50c0 ObjectTable: d232e5c0 HandleCount: <Data Not Accessible>
Image: winlogon.exe
PROCESS dc0918c0 SessionId: 1 Cid: 0374 Peb: 003c4000 ParentCid: 022c
DirBase: 179c5160 ObjectTable: dc28f6c0 HandleCount: <Data Not Accessible>
Image: LogonUI.exe
PROCESS dc08e900 SessionId: 1 Cid: 037c Peb: 00d8b000 ParentCid: 022c
DirBase: 179c5180 ObjectTable: dc249640 HandleCount: <Data Not Accessible>
Image: dwm.exe
→
402
Kapitel 5
Speicherverwaltung
Um Einzelheiten über die Sitzung einzusehen, geben Sie die MM_SESSION_SPACE-Struktur wie
folgt mit dem Befehl dt aus:
lkd> dt nt!_mm_session_space d9306000
+0x000 ReferenceCount
: 0n4
+0x004 u
: <unnamed-tag>
+0x008 SessionId
: 1
+0x00c ProcessReferenceToSession : 0n6
+0x010 ProcessList
: _LIST_ENTRY [ 0xd4921128 - 0xdc08e9e8 ]
+0x018 SessionPageDirectoryIndex : 0x1617f
+0x01c NonPagablePages
: 0x28
+0x020 CommittedPages
: 0x290
+0x024 PagedPoolStart
: 0xc0000000 Void
+0x028 PagedPoolEnd
: 0xffbfffff Void
+0x02c SessionObject
: 0xd49222b0 Void
+0x030 SessionObjectHandle : 0x800003ac Void
+0x034 SessionPoolAllocationFailures : [4] 0
+0x044 ImageTree
: _RTL_AVL_TREE
+0x048 LocaleId
: 0x409
+0x04c AttachCount
: 0
+0x050 AttachGate
: _KGATE
+0x060 WsListEntry
: _LIST_ENTRY [ 0xcdcde060 - 0xd6307060 ]
+0x080 Lookaside
: [24] _GENERAL_LOOKASIDE
+0xc80 Session
: _MMSESSION
...
Experiment: Die Nutzung des Sitzungsraums untersuchen
Die Nutzung des Sitzungsraums können Sie sich mit dem Kerneldebuggerbefehl !vm 4
ansehen. Die folgende Ausgabe stammt von einem 32-Bit-Windows-Client-System mit
Remotedesktopverbindung, sodass wir insgesamt drei Sitzungen haben – die beiden
Standardsitzungen und die Remotesitzung. (Die Adressen sind die der zuvor vorgestellten
MM_SESSION_SPACE-Objekte.)
lkd> !vm 4
...
Terminal Server Memory Usage By Session:
Session ID 0 @ d6307000:
Paged Pool Usage:
NonPaged Usage:
Commit Usage:
2012 Kb
108 Kb
2292 Kb
→
Layouts für virtuelle Adressräume
Kapitel 5
403
Session ID 1 @ d9306000:
Paged Pool Usage:
NonPaged Usage:
Commit Usage:
2288 Kb
160 Kb
2624 Kb
Session ID 2 @ cdcde000:
Paged Pool Usage:
NonPaged Usage:
Commit Usage:
7740 Kb
208 Kb
8144 Kb
Session Summary
Paged Pool Usage: 12040 Kb
NonPaged Usage:
Commit Usage:
476 Kb
13060 Kb
System-Seitentabelleneinträge
System-Seitentabelleneinträge (Page Table Entries, PTEs) werden verwendet, um Systemseiten wie den E/A-Raum, Kernelstacks und Speicherdeskriptorlisten (Memory Descriptor
Lists, MDLs; siehe Kapitel 6) dynamisch zuzuordnen. Ihr Vorrat jedoch ist beschränkt. Auf
32-Bit-Windows-Systemen stehen so viele System-PTEs zur Verfügung, um theoretisch einen zusammenhängenden virtuellen Systemadressraum von 2 GB zu beschreiben. Auf der
64-Bit-Version von Windows 10 und auf Windows Server 2016 reichen die System-PTEs für
einen zusammenhängenden virtuellen Systemadressraum von 16 TB aus.
Experiment: Informationen über System-PTEs einsehen
Wie viele System-PTEs zur Verfügung stehen, können Sie sich in der Leistungsüberwachung
mit dem Indikator Arbeitsspeicher:Freie Seitentabelleneinträge und mit den Kerneldebuggerbefehlen !sysptes und !vm ansehen. Es ist auch möglich, die _MI_SYSTEM_PTE_TYPE-Struktur als Teil der Speicherstatusvariablen MiState auszugeben (oder der globalen Variablen
MiSystemPteInfo auf Windows 8.x/2012/R2). Darin können Sie außerdem erkennen, wie
viele PTE-Zuweisungsfehler in dem System aufgetreten sind. Eine hohe Anzahl stellt ein
Problem dar und weist auf ein mögliches System-PTE-Leck hin.
kd> !sysptes
System PTE Information
Total System Ptes 216560
starting PTE: c0400000
free blocks: 969 total free: 16334 largest free block: 264
→
404
Kapitel 5
Speicherverwaltung
kd> ? MiState
Evaluate expression: -2128443008 = 81228980
kd> dt nt!_MI_SYSTEM_INFORMATION SystemPtes
+0x3040 SystemPtes : _MI_SYSTEM_PTE_STATE
kd> dt nt!_mi_system_pte_state SystemViewPteInfo 81228980+3040
+0x10c SystemViewPteInfo : _MI_SYSTEM_PTE_TYPE
kd> dt nt!_mi_system_pte_type 81228980+3040+10c
+0x000 Bitmap
: _RTL_BITMAP
+0x008 BasePte
: 0xc0400000 _MMPTE
+0x00c Flags
: 0xe
+0x010 VaType
: c ( MiVaDriverImages )
+0x014 FailureCount
: 0x8122bae4 -> 0
+0x018 PteFailures
: 0
+0x01c SpinLock
: 0
+0x01c GlobalPushLock
: (null)
+0x020 Vm
: 0x8122c008 _MMSUPPORT_INSTANCE
+0x024 TotalSystemPtes
: 0x120
+0x028 Hint
: 0x2576
+0x02c LowestBitEverAllocated : 0xc80
+0x030 CachedPtes
: (null)
+0x034 TotalFreeSystemPtes
: 0x73
Werden viele System-PTE-Fehler angezeigt, können Sie die System-PTE-Verfolgung einschalten, indem Sie im Registrierungsschlüssel HKLM\SYSTEM\CurrentControlSet\Control\
Session Manager\Memory Management den DWORD-Wert TrackPtes erstellen und auf 1 setzen. Mit !sysptes 4 können Sie sich eine Liste der Allozierer ansehen.
ARM-Adressraumlayout
Wie Sie vin Abb. 5–12 sehen, ist das Adressraumlayout von ARM-Systemen fast mit dem
von x86-Systemen identisch. Was die reine Speicherverwaltung angeht, behandelt der Speicher-Manager ARM-Systeme genauso wie x86-Systeme. Die Unterschiede zeigen sich bei der
Adressübersetzung, was in dem gleichnamigen Abschnitt weiter hinten in diesem Kapitel
erklärt wird.
Layouts für virtuelle Adressräume
Kapitel 5
405
Für HAL reserviert (4MB)
Systemcache
Ausgelagerter Pool
Nicht ausgelagerter Pool
Hyperspace (4 MB)
Prozessseitentabellen (4 MB)
Kernel und Exekutive
HAL
Treiber
Kein Zugriff (64 KB)
EXE-Code
Globale Variablen
Threadstacks
DLL-Code
(2 GB – 64 KB)
Abbildung 5–12 Layout des virtuellen Adressraums auf ARM-Systemen
64-Bit-Adressraumlayout
Theoretisch kann der virtuelle 64-Bit-Adressraum 16 Exabytes oder 18.446.744.073.709.551.616
Bytes umfassen. Heutige Prozessoren erlauben jedoch nur 48 Adresszeilen, was den möglichen
Adressraum auf 256 TB (248) beschränkt. Dieser Adressraum ist in der Mitte geteilt, wobei die unteren 128 TB für private Benutzerprozesse und die oberen für das System zur Verfügung stehen.
Bei Windows 10 und Windows Server 2016 ist der Systemraum wiederum in mehrere Regionen
unterschiedlicher Größe aufgeteilt, wie Sie in Abb. 5–13 sehen. Es ist deutlich zu erkennen, dass
die 64-Bit-Technik einen enorm viel größeren Adressraum bietet als die 32-Bit-Technik. Die
einzelnen Kernelabschnitte müssen allerdings nicht an den gezeigten Stellen beginnen, da in
den neuesten Windows-Versionen ASLR im Kernelraum verwendet wird.
406
Kapitel 5
Speicherverwaltung
Für die HAL reserviert
512 GB – 16 TB
Nicht ausgelagerter Pool
PFN-Datenbank
16 TB
System-PTEs
Vom Lader initialisierte Zuordnungen
Kernel, HAL und alle Nicht-SitzungsTreiber (512 GB)
1 TB Arbeitssatzlisten und
Hashtabellen für Systemcache
und ausgelagerten Pool
512 GB
Besonderer Pool (ausgelagert
und nicht ausgelagert)
512 GB – 256 TB
Ausgelagerter Pool
16 TB
Systemcache
Beginn des Systemraums
512 GB – 4 KB
WS-Info der System-PTEs
Gemeinsame Systemseite (4 KB)
512 GB
Seitentabellenzuordnung
mit vier Ebenen
16 TB
Ultra Zero
1 TB
Kernel-CFG-Bitmap
Kein Zugriff
(nicht kanonische Adressen)
1 TB
Hyperspace
Kein Zugriff (64 KB)
512 GB
Win32k.sys
Sitzungsdaten
Treiberabbilder
Ausgelagerter Pool und Sichten
Einzelne Prozesse
(128 TB – 64 KB)
Abbildung 5–13 Layout des virtuellen Adressraums auf x64-Systemen
Windows 8 und Windows Server 2012 sind auf einen Adressraum von 16 TB beschränkt. Das liegt an Einschränkungen bei der Implementierung von Windows,
die in Kapitel 10 der 6. Ausgabe von Band 2 erklärt wurden. Von diesen 16 TB entfallen je acht auf den Prozess- und den Systemraum.
32-Bit-Abbilder, die den großen Adressraum verwenden können, genießen bei der Ausführung auf 64-Bit-Windows (unter Wow64) einen besonderen Vorteil, denn daher erhalten sie die
kompletten 4 GB des verfügbaren Benutzeradressraums. Wenn das Abbild schon 3-GB-Zeiger
unterstützt, sollten 4-GB-Zeiger keinen großen Unterschied mehr ausmachen, da hierbei anders als beim Wechsel von 2 GB zu 3 GB keine zusätzlichen Bits benötigt werden. Die folgende
Ausgabe zeigt, wie TestLimit auf einem 64-Bit-Computer als 32-Bit-Anwendung läuft und dabei
Adressraum reserviert:
C:\Tools\Sysinternals>Testlimit.exe -r
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Layouts für virtuelle Adressräume
Kapitel 5
407
Process ID: 264
Reserving private bytes (MB)...
Leaked 4008 MB of reserved memory (4008 MB total leaked). Lasterror: 8
Not enough storage is available to process this command.
Das Ergebnis hängt davon ab, ob beim Verlinken von TestLimit die Option /LARGEADDRESSAWARE
angegeben wurde. Wäre das nicht der Fall, würde sich für beide Werte 2 GB ergeben. Ohne
/LARGEADDRESSAWARE verlinkte 64-Bit-Anwendungen sind ebenso wie 32-Bit-Anwendungen auf
die ersten 2 GB des virtuellen Prozessadressraums beschränkt. In Visual Studio wird dieses Flag
beim Erstellen von 64-Bit-Anwendungen standardmäßig gesetzt.
Einschränkungen bei der virtuellen Adressierung auf
x64-Systemen
Wie bereits erwähnt, erlaubt die 64-Bit-Technik einen virtuellen Adressraum von bis zu 16 EB,
was eine erhebliche Steigerung gegenüber den 4 GB bei der 32-Bit-Adressierung bietet. Weder heute noch in der nahen Zukunft brauchen Computer jedoch auch nur annähernd so viel
Speicher.
Um die Chiparchitektur zu vereinfachen und einen unnötigen Mehraufwand zu verhindern – insbesondere bei der weiter hinten beschriebenen Adressübersetzung –, verwenden
die aktuellen x64-Prozessoren von AMD und Intel lediglich einen virtuellen Adressraum von
256 TB, also nur die unteren 48 Bits der 64-Bit-Adressen. Allerdings sind die Adressen immer
noch 64 Bits breit und nehmen 8 Bytes im Register oder im Arbeitsspeicher ein. Ähnlich wie bei
der Vorzeichenerweiterung im Zweierkomplement müssen die oberen 16 Bits (Bit 48 bis 64) so
gesetzt sein wie das höchste verwendete Bit (Bit 47). Eine Adresse, die diese Regel erfüllt, wird
als kanonisch bezeichnet.
Die untere Hälfte des Adressraums beginnt bei 0x0000000000000000 und endet bei 0x00007FFFFFFFFFFF, während die obere Hälfte von 0xFFFF800000000000 bis
0xFFFFFFFFFFFFFFFF verläuft. Jeder dieser beiden kanonischen Teile umfasst 128 TB. Wenn
moderne Prozessoren mehr Adressbits verwenden, wird die untere Hälfte nach oben bis
0x7FFFFFFFFFFFFFFF ausgedehnt und die obere nach unten bis 0x8000000000000000.
Dynamische Verwaltung des virtuellen Systemadressraums
Die 32-Bit-Versionen von Windows verwalten den Systemadressraum durch einen internen
Kernelallozierer. Die 64-Bit-Versionen benötigen einen solchen Allozierer nicht und können
sich deshalb den Aufwand dafür sparen, da alle Regionen im virtuellen Adressraum statisch
definiert werden (siehe Abb. 5–13).
Bei der Initialisierung des Systems richtet die Funktion MiInitializeDynamicVa die grundlegenden dynamischen Bereiche ein und legt den gesamten verfügbaren Kernelraum als verfügbare virtuelle Adressen fest. Anschließend initialisiert sie die Adressraumbereiche für Bootloaderabbilder, den Prozessraum (Hyperraum) und die HAL. Dazu verwendet sie die Funktion
MiInitializeSystemVaRange, die hartcodierte Adressbereiche festlegt (nur auf 32-Bit-Systemen).
408
Kapitel 5
Speicherverwaltung
Bei der später erfolgenden Initialisierung des nicht ausgelagerten Pools wird diese Funktion
erneut eingesetzt, um die virtuellen Adressbereiche für den Pool zu reservieren. Wird ein Treiber geladen, so wird die Bezeichnung des Adressbereichs von einem Bootloader- zu einem
Treiberabbildbereich geändert.
Anschließend kann der Rest des virtuellen Systemadressraums durch MiObtainSystemVa
(und ihr Gegenstück MiObtainSessionVa) und MiReturnSystemVa dynamisch angefordert bzw.
freigegeben werden. Operationen wie die Erweiterung des Systemcache, der System-PTEs sowie des nicht ausgelagerten, des ausgelagerten und des besonderen Pools, die Zuordnung von
großen Seiten, das Erstellen der PFN-Datenbank und das Anlegen einer neuen Sitzung führen
alle zu dynamischen Zuweisungen von virtuellen Adressen für einen bestimmten Bereich.
Jedes Mal, wenn der Kernelallozierer virtuelle Speicherbereiche für die Verwendung durch
eine bestimmte Art von Adressen bezieht, aktualisiert er das Array MiSystemVaType, das den
virtuellen Adresstyp für den neu zugewiesenen Bereich angibt. Tabelle 5–8 zeigt die Werte, die
in diesem Array auftreten können.
Region
Beschreibung
Begrenzbar
MiVaUnused (0)
Nicht verwendet
–
MiVaSessionSpace (1)
Adressen für den Sitzungsraum
Ja
MiVaProcessSpace (2)
Adressen für den Prozessadressraum
Nein
MiVaBootLoaded (3)
Adressen für Abbilder, die vom Bootloader geladen wurden
Nein
MiVaPfnDatabase (4)
Adressen für die PFN-Datenbank
Nein
MiVaNonPagedPool (5)
Adressen für den nicht ausgelagerten Pool
Ja
MiVaPagedPool (6)
Adressen für den ausgelagerten Pool
Ja
MiVaSpecialPoolPaged (7)
Adressen für den besonderen Pool (ausgelagert)
Nein
MiVaSystemCache (8)
Adressen für den Systemcache
Nein
MiVaSystemPtes (9)
Adressen für System-PTEs
Ja
MiVaHal (10)
Adressen für die HAL
Nein
MiVaSessionGlobalSpace (11)
Adressen für den globalen Sitzungsraum
Nein
MiVaDriverImages (12)
Adressen für geladene Treiberabbilder
Nein
MiVaSpecialPoolNonPaged (13)
Adressen für den besonderen Pool (nicht ausgelagert)
Ja
MiVaSystemPtesLarge (14)
Adressen für PTEs großer Seiten
Ja
Tabelle 5–8 Arten von virtuellen Systemadressen
Die Möglichkeit, virtuellen Adressraum nach Bedarf dynamisch zu reservieren, ermöglicht zwar
eine bessere Verwaltung des virtuellen Speichers, aber wäre nutzlos, wenn nicht auch die Möglichkeit bestünde, diesen Speicher wieder freizugeben. Wenn der ausgelagerte Pool oder der
Systemcache verkleinert werden kann oder wenn der besondere Pool und die Zuordnungen
großer Seiten freigegeben werden können, werden daher die zugehörigen virtuellen Adressen
freigegeben. Ein weiterer solcher Fall liegt vor, wenn die Bootregistrierung freigegeben wird.
Layouts für virtuelle Adressräume
Kapitel 5
409
Dadurch ist eine dynamische Verwaltung des Speichers nach der Nutzung der einzelnen Komponenten möglich. Außerdem können Komponenten Arbeitsspeicher über MiReclaimSystemVa
zurückfordern. Diese Funktion verlangt, dass die mit dem Systemcache verbundenen virtuellen
Adressen durch den Thread zur Dereferenzierung auf die Festplatte geleert werden, wenn der
verfügbare virtuelle Adressbereich auf unter 128 MB gefallen ist. Die Zurückforderung kann
auch erfüllt werden, wenn der ursprünglich nicht ausgelagerte Pool freigegeben wurde.
Neben einer besseren Aufteilung und Verwaltung von virtuellen Adressen für die verschiedenen Verbraucher von Kernelspeicherstrukturen bietet die dynamische Zuweisung von virtuellen Adressen auch Vorteile bei der Verringerung des Speicherbedarfs. Anstatt statische Seitentabelleneinträge und Seitentabellen vorab manuell zuzuweisen, werden die entsprechenden
Strukturen bei Bedarf zugewiesen. Sowohl auf 32- als auch auf 64-Bit-Systemen verringert das
die Speichernutzung beim Hochfahren, da für nicht verwendete Adressen keine Seitentabellen
zugewiesen werden müssen. Auf 64-Bit-Systemen müssen auch die Seitentabellen für reservierte große Adressregionen nicht im Speicher zugeordnet werden. Dadurch können sie willkürlich
große Grenzwerte haben, was insbesondere auf Systemen von Vorteil ist, auf denen wenig
physischer RAM zur Unterstützung der resultierenden Seitenstrukturen zur Verfügung steht.
Experiment: Die Nutzung der virtuellen Systemadressen
untersuchen (Windows 10 und Windows Server 2016)
Die laufende und die Spitzennutzung der einzelnen Arten von virtuellen Systemadressen
können Sie sich mit dem Kerneldebugger ansehen. Die globale Variable MiVisibleState
(vom Typ MI_VISIBLE_STATE) stellt die in öffentlichen Symbolen verfügbaren Informationen
bereit. Das folgende Beispiel stammt von einer x86-Version von Windows 10.
1.
Um sich ein Bild der Daten zu machen, die MiVisibleState enthält, geben Sie die Struktur mit Werten aus:
lkd> dt nt!_mi_visible_state poi(nt!MiVisibleState)
+0x000 SpecialPool
: _MI_SPECIAL_POOL
+0x048 SessionWsList
: _LIST_ENTRY [ 0x91364060 - 0x9a172060 ]
+0x050 SessionIdBitmap
: 0x8220c3a0 _RTL_BITMAP
+0x054 PagedPoolInfo
: _MM_PAGED_POOL_INFO
+0x070 MaximumNonPagedPoolInPages : 0x80000
+0x074 SizeOfPagedPoolInPages
+0x078 SystemPteInfo
: 0x7fc00
: _MI_SYSTEM_PTE_TYPE
+0x0b0 NonPagedPoolCommit : 0x3272
+0x0b4 BootCommit
: 0x186d
+0x0b8 MdlPagesAllocated
: 0x105
+0x0bc SystemPageTableCommit : 0x1e1
+0x0c0 SpecialPagesInUse
: 0
+0x0c4 WsOverheadPages
: 0x775
+0x0c8 VadBitmapPages
: 0x30
→
410
Kapitel 5
Speicherverwaltung
+0x0cc ProcessCommit
: 0xb40
+0x0d0 SharedCommit
: 0x712a
+0x0d4 DriverCommit
: 0n7276
+0x100 SystemWs
: [3] _MMSUPPORT_FULL
+0x2c0 SystemCacheShared
: _MMSUPPORT_SHARED
+0x2e4 MapCacheFailures
: 0
+0x2e8 PagefileHashPages
: 0x30
+0x2ec PteHeader
: _SYSPTES_HEADER
+0x378 SessionSpecialPool : 0x95201f48 _MI_SPECIAL_POOL
+0x37c SystemVaTypeCount
: [15] 0
+0x3b8 SystemVaType
: [1024] ""
+0x7b8 SystemVaTypeCountFailures : [15] 0
+0x7f4 SystemVaTypeCountLimit
: [15] 0
+0x830 SystemVaTypeCountPeak
: [15] 0
+0x86c SystemAvailableVa
2.
: 0x38800000
Am Ende dieses Listings sehen Sie mehrere Arrays mit jeweils 15 Elementen, die die Systemadresstypen aus Tabelle 5–8 angeben. Lassen Sie sich die Arrays SystemVaTypeCount
und SystemVaTypeCountPeak anzeigen:
lkd> dt nt!_mi_visible_state poi(nt!mivisiblestate) -a SystemVaTypeCount
+0x37c SystemVaTypeCount :
[00] 0
[01] 0x1c
[02] 0xb
[03] 0x15
[04] 0xf
[05] 0x1b
[06] 0x46
[07] 0
[08] 0x125
[09] 0x38
[10] 2
[11] 0xb
[12] 0x19
[13] 0
[14] 0xd
lkd> dt nt!_mi_visible_state poi(nt!mivisiblestate) -a SystemVaTypeCountPeak
+0x830 SystemVaTypeCountPeak :
[00] 0
[01] 0x1f
[02] 0
→
Layouts für virtuelle Adressräume
Kapitel 5
411
[03] 0x1f
[04] 0xf
[05] 0x1d
[06] 0x51
[07] 0
[08] 0x1e6
[09] 0x55
[10] 0
[11] 0xb
[12] 0x5d
[13] 0
[14] 0xe
Die Nutzung der virtuellen Systemadressen untersuchen
(Windows 8.x und Windows Server 2012/R2)
Die laufende und die Spitzennutzung der einzelnen Arten von virtuellen Systemadressen
können Sie sich mit dem Kerneldebugger ansehen. Die globalen Kernelarrays MiSystemVaTypeCount, MiSystemVaTypeCountFailures und MiSystemVaTypeCountPeak enthalten die Größe, die Fehlerzähler und die Spitzengrößen für alle Adresstypen aus Tabelle 5–8. Die Größe
wird in Mehrfachen einer PDE-Zuweisung angegeben (siehe den Abschnitt »Adressübersetzung« weiter hinten in diesem Kapitel), was unter dem Strich die Größe einer großen Seite
ist (2 MB auf x86). Die folgenden Listings zeigen, wie Sie die Nutzung im System und die
Spitzennutzung ausgeben können. Eine ähnliche Technik können Sie auch für Fehlerzähler
anwenden. Dieses Beispiel stammt von einem 32-Bit-System mit Windows 8.1.
lkd> dd /c 1 MiSystemVaTypeCount L f
81c16640 00000000
81c16644 0000001e
81c16648 0000000b
81c1664c 00000018
81c16650 0000000f
81c16654 00000017
81c16658 0000005f
81c1665c 00000000
81c16660 000000c7
81c16664 00000021
81c16668 00000002
81c1666c 00000008
81c16670 0000001c
81c16674 00000000
81c16678 0000000b
→
412
Kapitel 5
Speicherverwaltung
lkd> dd /c 1 MiSystemVaTypeCountPeak L f
81c16b60 00000000
81c16b64 00000021
81c16b68 00000000
81c16b6c 00000022
81c16b70 0000000f
81c16b74 0000001e
81c16b78 0000007e
81c16b7c 00000000
81c16b80 000000e3
81c16b84 00000027
81c16b88 00000000
81c16b8c 00000008
81c16b90 00000059
81c16b94 00000000
81c16b98 0000000b
Die virtuellen Adressbereiche, die den Komponenten zugewiesen werden, können theoretisch
willkürlich wachsen, wenn ausreichend virtueller Systemadressraum zur Verfügung steht. In
der Praxis aber bietet der Kernelallozierer auf 32-Bit-Systemen die Möglichkeit, Grenzwerte für
die einzelnen Adresstypen festzulegen, um für Zuverlässigkeit und Stabilität zu sorgen. (Auf
64-Bit-Systemen ist eine Erschöpfung des Kerneladressraums zurzeit noch kein Problem.) Standardmäßig sind zwar keine Grenzwerte eingerichtet, doch Systemadministratoren können sie
mithilfe der Registrierung für die begrenzbaren Adresstypen (siehe Tabelle 5–8) angeben und
ändern.
Wenn die aktuelle Anforderung in einem Aufruf von MiObtainSystemVa einen vorhandenen
Grenzwert überschreiben würde, wird ein Fehler vermerkt (siehe das vorherige Experiment)
und unabhängig vom verfügbaren Speicher eine Rückforderungsoperation angefordert. Das
verringert die Speicherlast, sodass die Zuweisung beim nächsten Versuch funktionieren kann.
Allerdings wirkt sich die Rückforderung nur auf den Systemcache und den nicht ausgelagerten
Pool aus.
Experiment: Grenzwerte für virtuelle Systemadressen festlegen
Das Array MiSystemVaTypeCountLimit enthält die Grenzwerte für die Nutzung der einzelnen Arten von virtuellen Systemadressen. Zurzeit erlaubt der Speicher-Manager eine Begrenzung nur bei bestimmten Arten von virtuellen Adressen (siehe Tabelle 5–8). Festlegen
können Sie diese Grenzwerte mithilfe der Registrierung (siehe http://msdn.microsoft.com/
en-us/library/bb870880.aspx), aber auch dynamisch zur Laufzeit mithilfe eines nicht dokumentierten Systemaufrufs.
→
Layouts für virtuelle Adressräume
Kapitel 5
413
Um die Grenzwerte für die einzelnen Adresstypen einzusehen und festzulegen, können
Sie auf 32-Bit-Systemen außerdem das Programm MemLimit aus den Begleitmaterialien zu
diesem Buch verwenden. Es zeigt auch die laufende und die Spitzennutzung des virtuellen
Adressraums an. Die aktuellen Grenzwerte zeigen Sie mit dem Schalter -q an:
C:\Tools>MemLimit.exe -q
MemLimit v1.01 - Query and set hard limits on system VA space consumption
Copyright (C) 2008-2016 by Alex Ionescu
www.alex-ionescu.com
System Va Consumption:
Type
Current
Non Paged Pool
Peak
Limit
45056 KB
55296 KB
0 KB
Paged Pool
151552 KB
165888 KB
0 KB
System Cache
446464 KB
479232 KB
0 KB
System PTEs
90112 KB
135168 KB
0 KB
Session Space
63488 KB
73728 KB
0 KB
Zum Ausprobieren legen Sie mit dem folgenden Befehl einen Grenzwert von 100 MB für
den ausgelagerten Pool fest:
memlimit.exe -p 100M
Erstellen Sie nun mit dem Sysinternals-Programm TestLimit so viele Handles wie möglich.
Wenn ausreichend viel Platz im ausgelagerten Pool zur Verfügung steht, sollte die Höchstzahl bei etwa 16 Millionen liegen. Da der Grenzwert von 100 MB festgelegt ist, erhalten Sie
jedoch weniger:
C:\Tools\Sysinternals>Testlimit.exe -h
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 4780
Creating handles...
Created 10727844 handles. Lasterror: 1450
Weitere Informationen über Objekte, Handles und den Verbrauch des ausgelagerten Pools
erhalten Sie in Kapitel 8 von Band 2.
414
Kapitel 5
Speicherverwaltung
Kontingente für den virtuellen Systemadressraum
Die im vorigen Abschnitt beschriebenen Grenzwerte für den virtuellen Systemadressraum ermöglichen es, die Nutzung des systemweiten virtuellen Adressraums für bestimmte Kernelkomponenten einzuschränken. Auf 32-Bit-Systemen funktionieren sie jedoch nur, wenn sie
systemweit angewendet werden. Um den Wunsch von Systemadministratoren nach einer feineren Kontingentierung zu erfüllen, arbeitet der Speicher-Manager mit dem Prozess-Manager
zusammen, sodass für jeden Prozess entweder systemweite oder benutzerspezifische Kontingente durchgesetzt werden können.
Um anzugeben, wie viel Speicher jeder Adresstyp eines gegebenen Prozesses nutzen
darf, bearbeiten Sie die Werte PagedPoolQuota, NonPagedPoolQuota, PagingFileQuota bzw.
WorkingSetPagesQuota im Registrierungsschlüssel HKLM\SYSTEM\CurrentControlSet\Control\
Session Manager\Memory Management. Diese Werte werden bei der Initialisierung gelesen. Daraufhin wird der Standardblock mit dem Systemkontingent erstellt und allen Systemprozessen
zugewiesen. Benutzerprozesse erhalten eine Kopie dieses Blocks, sofern nicht wie im Folgenden erklärt Benutzerkontingente festgelegt wurden.
Um Benutzerkontingente zu ermöglichen, erstellen Sie unter dem Registrierungsschlüssel
HKLM\SYSTEM\CurrentControlSet\Session Manager\Quota System Unterschlüssel für die einzelnen Benutzer-SIDs. In diesen Unterschlüsseln wiederum legen Sie die zuvor erwähnten Werte
an, um Grenzwerte nur für die vom jeweiligen Benutzer erstellten Prozesse anzugeben. Tabelle 5–9 zeigt, wie Sie diese Werte einrichten (was auch zur Laufzeit geschehen kann) und welche
Rechte dafür erforderlich sind.
Wert
Beschreibung
Einheit
Dynamisch
Erforderliches Recht
PagedPoolQuota
Die maximale
Größe, die von
diesem Prozess aus dem
ausgelagerten
Pool zugewiesen werden
kann
Größe
in MB
Nur für
Prozesse,
die mit
dem Systemtoken
ausgeführt
werden
SeIncreaseQuotaPrivilege
NonPagedPoolQuota
Die maximale
Größe, die von
diesem Prozess aus dem
nicht ausgelagerten Pool
zugewiesen
werden kann
Größe
in MB
Nur für
Prozesse,
die mit
dem Systemtoken
ausgeführt
werden
SeIncreaseQuotaPrivilege
PagingFileQuota
Die maximale
Anzahl der
Seiten, die der
Prozess in der
Auslagerungsdatei haben
kann
Seiten
Nur für
Prozesse,
die mit
dem Systemtoken
ausgeführt
werden
SeIncreaseQuotaPrivilege
Layouts für virtuelle Adressräume
→
Kapitel 5
415
Wert
Beschreibung
Einheit
Dynamisch
Erforderliches Recht
WorkingSetPagesQuota
Die maximale
Anzahl der
Seiten, die
der Prozess
in seinem Arbeitssatz (im
physischen
Speicher)
haben kann
Seiten
Ja
SeIncreaseBasePriorityPrivilege,
es sei denn, bei der Operation handelt es sich um eine Bereinigungsanforderung
Tabelle 5–9 Registrierungswerte für Prozesskontingente
Layout des Benutzeradressraums
Ebenso wie der Kernel- ist auch der Benutzeradressraum dynamisch aufgebaut. Die Adressen
der Threadstacks, Prozessheaps und geladenen Abbilder (wie DLLs und ausführbare Dateien
der Anwendung) werden durch den ASLR-Mechanismus dynamisch berechnet (sofern die Anwendung und ihre Abbilder das zulassen).
Auf der Ebene des Betriebssystems ist der Benutzeradressraum in einige wenige genau
abgegrenzte Regionen aufgeteilt (siehe Abb. 5–14). Die ausführbaren Dateien und DLLs sind in
Form von im Speicher zugeordneten Abbilddateien vorhanden, gefolgt von den Prozessheaps
und Threadstacks. Abgesehen von diesen Regionen (und einigen reservierten Systemstrukturen wie den TEBs und dem PEB) sind alle anderen Speicherzuweisungen laufzeitabhängig und
erfolgen zur Laufzeit. An der Platzierung all dieser laufzeitabhängigen Regionen ist ASLR beteiligt. Zusammen mit der Datenausführungsverhinderung erschwert dieser Mechanismus einen
Remoteangriff auf das System durch Manipulation des Arbeitsspeichers. Da sich der Code und
die Daten von Windows an dynamisch festgelegten Orten befinden, kann ein Angreifer keinen
sinnvollen hartcodierten Offset in ein Programm oder eine DLL einschleusen.
Threadstack
Zufällig ausgewählte
Ladeadresse
Zufällig ausgewählte
Adresse
DLLs mit dynamischer
Basisadresse
Standardprozessheap
Threadstack
Threadstack
Zufällig ausgewählte
Ladeadresse
Ausführbare Datei
Abbildung 5–14 Layout des Benutzeradressraums mit ASLR
416
Kapitel 5
Speicherverwaltung
Experiment: Den virtuellen Benutzeradressraum analysieren
Das Sysinternals-Programm VMMap zeigt eine ausführliche Ansicht des virtuellen Arbeitsspeichers, den ein beliebiger Prozess auf Ihrem Computer verwendet. Diese Informationen
sind nach den einzelnen Arten von Zuweisungen in folgende Kategorien gegliedert:
QQ Image Zeigt die Speicherzuweisungen für die Zuordnung der ausführbaren Datei
und ihrer Abhängigkeiten (wie dynamischen Bibliotheken) sowie anderer im Speicher
zugeordneter Abbilddateien (PE-Format) an.
QQ Mapped File
Zeigt Zuweisungen für im Speicher zugeordnete Datendateien an.
QQ Shareable Zeigt als gemeinsam nutzbar gekennzeichnete Speicherzuweisungen an.
Dazu gehört gewöhnlich der gemeinsam genutzte Speicher (allerdings nicht die im
Speicher zugeordneten Dateien, die unter Image oder Mapped File aufgeführt werden).
QQ Heap
Zeigt Speicherzuweisungen für die Heaps an, die der Prozess besitzt.
QQ Managed Heap Zeigt Speicherzuweisungen durch die .NET-CLR an (verwaltete Objekte). Bei einem Prozess, der .NET nicht nutzt, wird hier nichts angezeigt.
QQ Stack Zeigt Speicherzuweisungen für die Stacks der einzelnen Threads in diesem Prozess an.
QQ Private Data Zeigt als privat gekennzeichnete Speicherzuweisungen außer den
Stacks und Heaps an, z. B. interne Datenstrukturen.
Der folgende Screenshot zeigt eine typische Ansicht des Explorers (64 Bit) in VMMap:
→
Layouts für virtuelle Adressräume
Kapitel 5
417
Je nach Art der Speicherzuweisung kann VMMap auch noch weitere Informationen wie
Dateiname (für zugeordnete Dateien), Heap-ID und -Typ (für Heapzuweisungen) und
Thread-ID (für Stackzuweisungen) anzeigen. Außerdem werden sowohl beim zugesicherten Speicher als auch beim Arbeitssatzspeicher die Kosten der Zuweisung angegeben.
Auch Größe und Schutz der einzelnen Zuweisungen werden gezeigt.
ASLR beginnt auf Abbildebene mit der ausführbaren Datei für den Prozess und ihren abhängigen DLLs. Sie verarbeitet sämtliche Abbilddateien, die über einen Relokalisierungsabschnitt
verfügen und in deren PE-Header die Unterstützung für ASLR angegeben ist (durch das Flag
IMAGE_DLL_CHARACTERISTICS_DYNAMIC_BASE, das gewöhnlich mit dem Linkerflag /DYNAMICBASE in
Microsoft Visual Studio gesetzt wird). Für ein solches Abbild wählt das System aus einem Bereich von 256 Werten, die alle an 64-Bit-Grenzen ausgerichtet sind, einen für den aktuellen
Boot global gültigen Abbildoffset aus.
Abbildrandomisierung
Um den Ladeoffset für ausführbare Dateien zu bestimmen, wird jedes Mal, wenn eine solche
Datei geladen wird, ein Deltawert berechnet. Dabei handelt es sich um eine 8-Bit-Pseudozufallszahl von 0x10000 bis 0xFE0000. Dazu wird der aktuelle Zeitstempelzähler (Time Stamp
Counter, TSC) des Prozessors um vier Stellen verschoben, auf das Ergebnis eine Division modulo
254 angewendet und 1 addiert. Diese Zahl wiederum wird mit der bekannten Zuweisungsgranularität von 64 KB multipliziert. Durch die Addition von 1 ist garantiert, dass der Wert
nie 0 sein kann, weshalb ausführbare Dateien bei der Verwendung von ASLR niemals an der
im PE-Header angegebenen Adresse geladen werden. Das Delta wird dann zu der bevorzugten Ladeadresse der ausführbaren Datei addiert. Damit sind 256 Stellen in einem Bereich von
16 MB von der Abbildadresse im PE-Header herum möglich.
Die Berechnung des Ladeoffsets für DLLs beginnt mit einem systemweiten Wert für den
jeweiligen Boot, der als Abbildverschiebung bezeichnet wird. Er wird von MiInitializeRelocations berechnet und in den MiState.Sections.ImageBias-Feldern in der globalen Speicherstatusstruktur (MI_SYSTEM_INFORMATION) festgehalten (bzw. in der globalen Variablen MiImageBias
in Windows 8.x/2012/R2). Bei diesem Wert handelt es sich um den TSC der aktuellen CPU beim
Aufruf dieser Funktion im Bootzyklus, der verschoben und zu einem 8-Bit-Wert maskiert wurde. Dadurch sind auf 32-Bit-Systemen 256 verschiedene Werte möglich. Ähnliche Berechnungen erfolgen auch auf 64-Bit-Systemen, wo es aufgrund des riesigen Adressraums jedoch mehr
mögliche Werte gibt. Anders als bei ausführbaren Dateien wird dieser Wert nur einmal pro
Boot berechnet und dann im gesamten System verwendet, damit DLLs weiterhin im physischen
Speicher gemeinsam genutzt werden können und nur einmal relokalisiert werden. Würden
DLLs in den einzelnen Prozessen an verschiedenen Stellen neu zugeordnet, könnte ihr Code
nicht gemeinsam genutzt werden. Der Lader müsste die Adressverweise für jeden Prozess einzeln anpassen. Aus gemeinsam nutzbarem, schreibgeschütztem Code würden dadurch private
Prozessdaten. Jeder Prozess, der eine DLL nutzt, müsste seine eigene private Kopie von ihr im
physischen Speicher haben.
418
Kapitel 5
Speicherverwaltung
Nach der Berechnung des Offsets initialisiert der Speicher-Manager die Bitmap ImageBitMap (bzw. die globale Variable MiImageBitMap in Windows 8.x/2012/R2), die zur MI_SECTION_
STATE-Struktur gehört. Diese Bitmap stellt die Bereiche von 0x50000000 bis 0x78000000 auf
32-Bit-Systemen dar (die Zahlen für 64-Bit-Systeme finden Sie weiter unten). Jedes Bit steht
dabei für eine Zuweisungseinheit (64 KB). Wenn der Speicher-Manager eine DLL lädt, wird das
entsprechende Bit gesetzt, um die Platzierung im System zu kennzeichnen. Wird dieselbe DLL
erneut geladen, verwendet der Speicher-Manager für sie das gleiche Abschnittsobjekt wie für
die bereits relokalisierten Daten.
Beim Laden einer DLL durchsucht das System die Bitmap von oben nach unten nach freien
Bits. Der zuvor berechnete ImageBias-Wert wird als Startindex von oben verwenden, damit wie
bereits angedeutet bei jedem Boot eine andere, zufällige Platzierung erreicht wird. Da die Bitmap beim Laden der ersten DLL (bei der es sich stets um Ntdll.dll handelt) leer ist, kann deren
Ladeadresse leicht berechnet werden (wobei 64-Bit-Systeme einen anderen Verschiebungswert
haben):
QQ 32 Bit
0x78000000 - (ImageBias + NtDllSizein64KBChunks) * 0x10000
QQ 64 Bit
0x7FFFFFFF0000 – (ImageBias64High + NtDllSizein64KBChunks) * 0x10000
Jede nachfolgende DLL wird dann jeweils in einem tiefer liegenden 64-KB-Teilstück geladen.
Aus diesem Grund lassen sich die Adressen der anderen DLLs leicht berechnen, wenn die Adresse von Ntdll.dll bekannt ist. Um diese Gefahr zu verringern, wird auch die Reihenfolge, in
der die Standard-DLLs vom Sitzungs-Manager während der Initialisierung zugeordnet werden,
beim Laden von Smss.exe randomisiert.
Ist in der Bitmap kein freier Platz mehr vorhanden (das heißt, wird bereits der Großteil der
für ASLR definierten Region verwendet), schaltet der DLL-Relokalisierungscode auf die Vorgehensweise für ausführbare Dateien um und lädt die DLLs in 64-KB-Teilstücken im Umkreis von
16 MB um die bevorzugte Basisadresse.
Experiment: Die Ladeadresse von Ntdll.dll berechnen
Mit den Informationen über die Ladeadresse aus der im letzten Abschnitt genannten Kernelvariablen können Sie die Ladeadresse von Ntdll.dll berechnen. Die folgende Anleitung
gilt für ein x86-System mit Windows 10:
1.
Starten Sie den lokalen Kerneldebugger.
2.
Ermitteln Sie den Wert von ImageBias:
lkd> ? nt!mistate
Evaluate expression: -2113373760 = 820879c0
lkd> dt nt!_mi_system_information sections.imagebias 820879c0
+0x500 Sections :
+0x0dc ImageBias : 0x6e
→
Layouts für virtuelle Adressräume
Kapitel 5
419
3.
Öffnen Sie den Explorer und ermitteln Sie die Größe von Ntdll.dll im Verzeichnis System32. Auf dem Beispielsystem beträgt sie 1547 KB = 0x182c00, was einem Wert von
0x19 in 64-KB-Stücken entspricht (aufgerundet). Es ergibt sich also 0x78000000 – (0x6E
+ 0x19) * 0x10000 = 0x77790000.
4.
Öffnen Sie Process Explorer und schauen Sie sich die Ladeadresse eines beliebigen Prozesses von Ntdll.dll an (in der Spalte Base oder Image Base). Es sollte der eben ermittelte
Wert angezeigt werden.
5.
Probieren Sie das Gleiche auf einem 64-Bit-System aus.
Stackrandomisierung
Sofern nicht das Flag StackRandomizationDisabled für den Prozess gesetzt ist, wird im nächsten
Schritt der ASLR der Speicherort des Stacks für den ursprünglichen Thread und später aller neuen Threads randomisiert. Dabei wird zunächst einer der 32 möglichen Stackorte ausgewählt,
die 64 KB oder 256 KB weit auseinanderliegen. Zur Auswahl dieser Grundadresse wird die erste
geeignete freie Speicherregion gesucht und dann die x-te verfügbare Region ausgewählt, wobei x wiederum auf dem aktuellen TSC des Prozessors beruht, der verschoben und zu einem
5-Bit-Wert maskiert wird, was 32 mögliche Orte ergibt.
Nach der Auswahl dieser Grundadresse wird ein neuer Wert auf der Grundlage des TSCs
berechnet, diesmal mit einer Länge von 9 Bits. Dieser Wert wird mit 4 multipliziert, um die
Ausrichtung zu erhalten. Dadurch kann der Wert maximal 2048 Bytes (eine halbe Seite) groß
werden. Um die endgültige Basisadresse des Stacks zu bestimmen, wird dieser Wert zu der
zuvor ermittelten Grundadresse addiert.
Heaprandomisierung
ASLR randomisiert auch den Speicherort des ursprünglichen und aller nachfolgenden Heaps
eines Prozesses, die im Benutzermodus erstellt wurden. Die Funktion RtlCreateHeap verwendet
einen weiteren Pseudozufallswert auf der Grundlage des TSCs, um die Grundadresse zu bestimmen. Dieser 5 Bits lange Wert wird mit 64 KB multipliziert, um die endgültige Basisadresse des
Heaps festzulegen. Der Bereich für diesen Wert beginnt bei 0, weshalb sich für den ursprünglichen Heap ein Adressbereich von 0x00000000 bis 0x001F0000 ergibt. Außerdem wird die
Zuweisung des Bereichs vor der Basisadresse des Heaps manuell aufgehoben, um bei einem
Brute-Force-Angriff über den gesamten möglichen Heapadressbereich eine Zugriffsverletzung
zu erzwingen.
ASLR im Kerneladressraum
ASLR ist auch im Kerneladressraum aktiv. Dort gibt es 64 mögliche Ladeadressen für 32-Bit-Treiber und 256 für 64-Bit-Treiber. Die Relokalisierung von Benutzerraumabbildern erfordert eine
erhebliche Menge an Rangierplatz im Kernelraum, aber wenn der Kernelraum knapp ist, kann
ASLR auch Benutzermodus-Adressraum des Systemprozesses als Rangierplatz nutzen. Auf
Windows 10 (Version 1607) und Windows Server 2016 ist ASLR für die meisten Systemspeicher-
420
Kapitel 5
Speicherverwaltung
regionen eingerichtet, z. B. den ausgelagerten und nicht ausgelagerten Pool, den Systemcache,
die Seitentabellen und die PFN-Datenbank (initialisiert von MiAssignTopLevelRanges).
Sicherheitsmaßnahmen verwalten
Wegen ihrer möglichen Auswirkungen auf die Kompatibilität sind ASLR und viele andere Sicherheitsmaßnahmen in Windows optional: ASLR wird nur auf Abbilder angewendet, in deren
Header das Bit IMAGE_DLL_CHARACTERISTICS_DYNAMIC_BASE gesetzt ist, der Hardware-Ausführungsschutz wird durch Boot- und Linkeroptionen gesteuert usw. Um sowohl Unternehmenskunden als auch Endverbrauchern einen Überblick und eine Steuerung dieser Funktionen zu
ermöglichen, hat Microsoft das Enhanced Mitigation Experience Toolkit (EMET) herausgegeben. Es ermöglicht eine zentrale Verwaltung der in Windows eingebauten Sicherheitsmaßnahmen und bietet darüber hinaus mehrere zusätzliche Maßnahmen, die in Windows noch nicht
enthalten sind. Des Weiteren kann EMET Administratoren über das Ereignisprotokoll informieren, wenn bei einer Software aufgrund der angewendeten Sicherheitsmaßnahmen Zugriffsfehler aufgetreten sind. In EMET können Sie auch einzelne Anwendungen, die in bestimmten
Umgebungen Kompatibilitätsprobleme haben, von den Sicherheitsmaßnahmen ausnehmen,
die die Entwickler für sie aktiviert haben.
Zurzeit ist EMET bei Version 5.5 angelangt. Das Ende des Supports wurde für Juli
2018 angekündigt, allerdings wurden einige Features in aktuelle Windows-Versionen aufgenommen.
Experiment: Den ASLR-Schutz für Prozesse untersuchen
Mit dem Sysinternals-Werkzeug Process Explorer können Sie sich Ihre Prozesse (und vor
allem die von ihnen geladenen DLLs) ansehen, um festzustellen, ob sie ASLR unterstützen.
Auch wenn nur eine DLL keine Randomisierung zulässt, kann das den Prozess anfälliger für
Angriffe machen.
Um sich den ASLR-Status der Prozesse anzusehen, gehen Sie wie folgt vor:
1.
Rechtsklicken Sie im Prozessbaum auf eine beliebige Spalte und wählen Sie Select
Columns.
2.
Wählen Sie auf den Registerkarten Process Image und DLL jeweils ASLR Enabled aus.
Wie Sie sehen, laufen alle im Lieferumfang von Windows enthaltenen Programme und
Dienste mit aktiviertem ASLR. Manche Drittanbieteranwendungen werden ebenfalls mit
ASLR ausgeführt, andere dagegen nicht.
In dem folgenden Beispiel ist der Prozess Notepad.exe hervorgehoben. Seine Lade
adresse lautet hier 0x7FF7D76B0000. Wenn Sie alle Instanzen von Notepad schließen und
eine neue öffnen, werden Sie eine andere Ladeadresse sehen. Wenn Sie das System herunterfahren und neu starten und das Experiment dann erneut ausführen, befinden sich die
ASLR-fähigen DLLs nach jedem Startvorgang an anderen Ladeadressen.
→
Layouts für virtuelle Adressräume
Kapitel 5
421
Adressübersetzung
Sie wissen jetzt, wie Windows den virtuellen Adressraum strukturiert. Als Nächstes sehen wir
uns an, wie es diese Adressräume physischen Seiten zuordnet. Benutzeranwendungen und Systemcode verweisen auf virtuelle Adressen. Dieser Abschnitt beginnt mit einer ausführlichen
Beschreibung der 32-Bit-x86-Adressübersetzung im PAE-Modus (der als einziger in aktuellen
Windows-Versionen unterstützt wird), gefolgt von einer Erläuterung der Unterschiede zu den
Plattformen ARM und x64. Im nächsten Abschnitt – »Seitenfehler« – wird dann erklärt, was
geschieht, wenn bei einer solchen Übersetzung die Auflösung zu einer physischen Speicheradresse nicht möglich ist, und wie Windows den physischen Arbeitsspeicher mithilfe von Arbeitssätzen und der Seitenframedatenbank verwaltet.
Übersetzung virtueller Adressen auf x86-Systemen
Angelehnt an die zur damaligen Zeit verfügbare CPU-Hardware hat der ursprüngliche x86-Kernel nicht mehr als 4 GB physischen Arbeitsspeicher unterstützt. Mit dem x86-Prozessor Intel
Pentium Pro wurde der neue Speicherzuordnungsmodus der physischen Adresserweiterung
(Physical Address Extension, PAE) eingeführt. Auf den heutigen x86-Prozessoren von Intel und
einem geeigneten Chipsatz ermöglicht dieser Modus 32-Bit-Betriebssystemen, auf bis zu 64 GB
physischen Arbeitsspeicher zuzugreifen (statt auf lediglich 4 GB ohne PAE). Auf x64-Prozessoren im Legacy-Modus wären damit sogar 1024 GB zugänglich, was von Windows zurzeit aber
auf 64 GB eingeschränkt wird, da zur Beschreibung einer solchen Menge an Speicher eine
übermäßig große PFN-Datenbank erforderlich wäre. Lange Zeit hat Windows zwei verschiedene x86-Kernels gehabt, nämlich einen mit PAE-Unterstützung und einen ohne. Seit Windows
422
Kapitel 5
Speicherverwaltung
Vista wird bei einer x86-Version von Windows immer der PAE-Kernel installiert, auch wenn
der physische Arbeitsspeicher des Systems nicht mehr als 4 GB umfasst. Die Leistungs- und
Speicherbedarfsvorteile des Nicht-PAE-Kernels sind ohnehin vernachlässigbar geworden, und
für den Hardware-Ausführungsschutz ist überdies der PAE-Kernel erforderlich. Dank dieser Entscheidung muss Microsoft nur einen einzigen x86-Kernel pflegen. Aus diesem Grund beschreiben wir hier nur die x86-Adressübersetzung im PAE-Modus. Wenn Sie sich für den Nicht-PAEFall interessieren, können Sie die entsprechenden Abschnitte in der 6. Ausgabe dieses Buches
nachlesen.
Mithilfe der vom Speicher-Manager erstellten und gepflegten Seitentabellen übersetzt die
CPU virtuelle in physische Adressen. Eine Seite des virtuellen Adressraums ist mit einem Seitentabelleneintrag (Page Table Entry, PTE) im Systemraum verknüpft, der die physische Adresse
angibt, auf die die virtuelle abgebildet wird. In dem Beispiel aus Abb. 5–15 sehen Sie drei aufeinanderfolgende Seiten, die auf einem x86-System drei unzusammenhängenden physischen
Seiten zugeordnet sind. Es kann sein, dass es für Regionen, die als reserviert oder zugesichert
gekennzeichnet sind, auf die aber noch nie zugegriffen wurde, gar keine PTEs gibt, da die
Seitentabelle selbst unter Umständen erst beim Auftreten des ersten Seitenfehlers zugewiesen
wird. Die gestrichelte Linie, die in Abb. 5–15 die virtuellen Seiten mit den PTEs verbindet, stellt
die indirekte Beziehung zwischen den virtuellen Seiten und dem physischen Speicher dar.
Seiten
tabellen
einträge
Prozessseitentabellen
Physischer Speicher
(RAM)
Virtuelle
Seiten
Abbildung 5–15 Zuordnung virtueller Adressen im physischen Speicher (x86)
Adressübersetzung
Kapitel 5
423
Selbst Kernelmoduscode (z. B. Gerätetreiber) ist nicht in der Lage, direkt auf physische Speicheradressen zu verweisen, sondern muss dies indirekt tun, indem er
erst die virtuellen Adressen erstellt, die den physischen zugeordnet sind. Weitere
Informationen finden Sie in der Beschreibung der Unterstützungsroutinen für die
Speicherdeskriptorliste (Memory Descriptor List, MDL) in der WDK-Dokumentation.
Der eigentliche Übersetzungsvorgang und der Aufbau der Seitentabellen und -verzeichnisse
werden von der CPU bestimmt. Das Betriebssystem muss diese Strukturen anschließend wie
vorgesehen im Speicher erstellen. Abb. 5–16 zeigt ein allgemeines Diagramm der x86-Adressübersetzung. Das allgemeine Prinzip ist jedoch auf allen Architekturen das gleiche.
Wie Sie in Abb. 5–16 sehen, besteht die Eingabe in das Übersetzungssystem aus einer
virtuellen 32-Bit-Adresse und einer Reihe von Speicherstrukturen wie Seitentabellen, Seitenverzeichnissen, einer einzelnen Seitenverzeichnis-Zeigertabelle (Page Directory Pointer Table,
PDPT) und Look-Aside-Übersetzungspuffern (Translation Look Aside Buffer, TLB). Die Ausgabe
ist die physische 36-Bit-Adresse im RAM, an der sich das eigentliche Byte befindet. Die Zahl
36 kommt durch die Art und Weise zustande, wie die Seitentabellen strukturiert sind, was vom
Prozessor bestimmt wird. Bei der Zuordnung kleiner Seiten (was der übliche und in Abb. 5–16
gezeigte Fall ist) werden die 12 am wenigsten signifikanten Bits der virtuellen Adresse direkt
in die resultierende physische Adresse kopiert. 12 Bits entsprechen genau 4 KB, also der Größe
einer kleinen Seite.
Seiten
verzeichniszeiger
Seiten
verzeichnisse
Virtuelle Adresse (32 Bit)
Nummer der virtuellen Seite
Adressübersetzung (CPU)
Wenn die Seite nicht gültig ist ...
Seitentabellen
Look-AsideÜbersetzungs
puffer (TLB)
Byte auf der Seite
Nummer der physischen Seite
Seitenfehler
Byte auf der Seite
Physische Adresse (36 Bit)
Abbildung 5–16 Überblick über die Übersetzung virtueller Adressen
Wenn eine Adresse nicht übersetzt werden kann (etwa wenn sich die Seite nicht im physischen
Speicher befindet, sondern in der Auslagerungsdatei), löst die CPU eine Ausnahme aus – einen
sogenannten Seitenfehler –, um dem Betriebssystem mitzuteilen, dass es die Seite nicht finden
kann. Da die CPU keine Ahnung hat, wo sich die Seite befindet (Auslagerungsdatei, zugeordnete Datei oder anderswo), wartet sie darauf, dass das Betriebssystem die Seite von dem Ort
abruft, an dem sie liegt (falls das möglich ist), und die Seitentabellen korrigiert, sodass sie
424
Kapitel 5
Speicherverwaltung
auf die Seite zeigen. Anschließend versucht die CPU erneut, die Übersetzung durchzuführen.
Seitenfehler werden weiter hinten in diesem Kapitel im gleichnamigen Abschnitt ausführlicher
erklärt.
Abb. 5–17 zeigt den kompletten Vorgang der Übersetzung von virtuellen in physische
x86-Adressen.
Virtuelle 32-Bit-Adresse
512 Einträge
SeitenverzeichnisZeigertabelle
512 Einträge
Seite
Byte auf der Seite
Seitenverzeichnisse
Seitentabellen
Abbildung 5–17 Übersetzung virtueller Adressen auf einem x86-System
Der zu übersetzende virtuelle 32-Bit-Adressraum ist logisch in vier Teile gegliedert. Wie Sie bereits gelernt haben, werden die unteren 12 Bits so wie sie sind verwendet, um ein bestimmtes
Byte auf einer Seite auszuwählen. Der Übersetzungsvorgang beginnt mit einer einzigen PDPT
pro Prozess, die sich stets im physischen Speicher befindet (denn sonst könnte das System sie
nicht finden). Ihre physische Adresse ist jeweils in der KPROCESS-Struktur ihres Prozesses gespeichert. Das besondere x86-Register CR3 hält diesen Wert für den zurzeit ausgeführten Prozess
fest (d. h. für den Prozess, zu dem der Thread gehört, der auf die virtuelle Adresse zugegriffen
hat). Wenn auf der CPU ein Kontextwechsel erfolgt und der neue Thread in einem anderen
Prozess läuft als der vorherige, muss das Register CR3 mit der PDPT-Adresse des neuen Prozesses aus dessen KPROCESS-Struktur geladen werden. Die PDPT muss an einer 32-Byte-Grenze
ausgerichtet sein und sich in den ersten 4 GB des RAM befinden (da CR3 auf x86 nach wie vor
ein 32-Bit-Register ist).
Bei einem Adressaufbau wie in Abb. 5–17 erfolgt die Übersetzung wie folgt:
1.
Die beiden signifikantesten Bits der virtuellen Adresse (Bit 30 und 31) bilden einen Index
für die PDPT. Diese Tabelle hat vier Einträge. Der ausgewählte Eintrag – also der Seitenverzeichnis-Zeigereintrag oder PDPE – zeigt auf die physische Adresse eines Seitenverzeichnisses.
2.
Ein Seitenverzeichnis enthält 512 Einträge, von denen einer durch die neun Bits von 21 bis
29 der virtuellen Adresse ausgewählt wird. Dieser Seitenverzeichniseintrag (Page Directory
Entry, PDE) zeigt auf die physische Adresse einer Seitentabelle.
Adressübersetzung
Kapitel 5
425
3.
Eine Seitentabelle enthält ebenfalls 512 Einträge, von denen einer durch die neun Bits von
12 bis 20 der virtuellen Adresse ausgewählt wird. Dieser Seitentabelleneintrag (PTE) zeigt
auf die physische Adresse des Seitenanfangs.
4.
Zu der Adresse, auf die der PTE zeigt, wird der Offset (die unteren 12 Bits) addiert, um die
endgültige, vom Aufrufer angeforderte physische Adresse zu erhalten.
Die Einträge in den verschiedenen Tabellen werden auch als Seitenframenummern (Page Frame
Numbers, PFNs) bezeichnet, da sie auf an Seitengrenzen ausgerichtete Adressen zeigen. Jeder
Eintrag ist 64 Bits breit, weshalb das Seitenverzeichnis und die Seitentabelle selbst nicht größer
als eine 4-KB-Seite sind. Um den physischen Bereich von 64 GB zu beschreiben, sind jedoch
nur 24 Bits erforderlich (wenn sie mit den 12 Bits für den Offset für einen Adressbereich von
insgesamt 36 Bits kombiniert werden). Es sind also mehr als genug Bits für die eigentlichen
PFN-Werte vorhanden.
Eines der zusätzlichen Bits ist für den gesamten Mechanismus von herausragender Bedeutung, nämlich das Gültigkeitsbit. Es gibt an, ob die PFN-Daten überhaupt gültig sind und ob die
CPU den beschriebenen Vorgang ausführen soll. Ist das Bit nicht gesetzt, bedeutet das einen
Seitenfehler. Die CPU löst eine Ausnahme aus und erwartet, dass sich das Betriebssystem auf
sinnvolle Weise um den Seitenfehler kümmert. Wenn beispielsweise die fragliche Seite auf die
Festplatte geschrieben wurde, liest der Speicher-Manager sie wieder in eine freie Seite im RAM
zurück, korrigiert den PTE und weist die CPU an, es erneut zu versuchen.
Da Windows für jeden Prozess einen privaten Adressraum bereitstellt, hat jeder Prozess
auch seine eigene PDPT, seine eigenen Seitenverzeichnisse und Seitentabellen, um diesen privaten Adressraum zuzuordnen. Die Seitenverzeichnisse und Seitentabellen, die den Systemraum beschreiben, werden jedoch von allen Prozessen gemeinsam genutzt (und die für den
Sitzungsraum von allen Prozessen der zugehörigen Sitzung). Damit nicht mehrere Seitentabellen denselben virtuellen Speicher beschreiben, werden die Seitenverzeichniseinträge für
den Systemraum beim Erstellen eines Prozesses so initialisiert, dass sie auf die vorhandenen
Systemseitentabellen zeigen. Gehört der Prozess zu einer Sitzung, zeigen seine Seitenverzeichniseinträge auf die bereits vorhandenen Seitentabellen für die Sitzung, damit diese gemeinsam
genutzt werden können.
Seitentabellen und Seitentabelleneinträge
Jeder PDE zeigt auf eine Seitentabelle. Jede Seitentabelle – und auch die PDPT – ist ein einfaches Array aus PTEs. Sie verfügt über 512 Einträge, die jeweils eine einzelne Seite (4 KB)
zuordnen. Daher kann eine Seitentabelle einen Adressraum von 2 MB (512 x 4 KB) zuordnen.
Auch ein Seitenverzeichnis besteht aus 512 Einträgen, die jeweils auf eine Seitentabelle zeigen.
Das bedeutet, dass ein Seitenverzeichnis einen Adressraum von 512 x 2 MB = 1 GB zuordnen
kann. Mit den vier PDPEs lässt sich daher der gesamte 32-Bit-Adressraum von 4 GB zuordnen.
Bei großen Seiten zeigt der PDE mit 11 Bits auf den Seitenanfang im physischen Speicher.
Der Byteoffset wird aus den unteren 21 Bits der ursprünglichen virtuellen Adresse entnommen.
Ein PDE für die Zuordnung einer großen Seite zeigt also nicht auf eine Seitentabelle.
Der Aufbau der Seitenverzeichnisse und -tabellen ist im Grunde genommen identisch. Mit
dem Kerneldebuggerbefehl !pte können Sie sich PTEs genauer ansehen (siehe das nachfolgen-
426
Kapitel 5
Speicherverwaltung
de Experiment »Adressen übersetzen«). Hier wollen wir uns mit gültigen PTEs beschäftigen und
die ungültigen auf den Abschnitt »Seitenfehler« verschieben. Gültige PTEs bestehen aus zwei
Hauptteilen, nämlich der PFN der physischen Seite mit den Daten oder der physischen Adresse
einer Seite im Arbeitsspeicher sowie einigen Flags, die den Status und den Schutz der Seite
beschreiben (siehe Abb. 5–18).
Modifiziert
Große Seite (bei PDE)
Zugriff erfolgt
Global
Cache deaktiviert
Kopieren beim Schreiben (Software)
Write-Through
Prototyp (Software)
Besitzer
Schreiben (Software)
Schreiben
Keine Ausführung
Gültig
Reserviert
Abbildung 5–18 Aufbau eines gültigen x86-Hardware-PTEs
Die in Abb. 5–18 mit »Software« und »Reserviert« gekennzeichneten Bits werden von der Speicherverwaltungseinheit (Memory Management Unit, MMU) in der CPU unabhängig davon
ignoriert, ob der PTE gültig ist. Diese Bits werden vom Speicher-Manager gespeichert und
interpretiert. Tabelle 5–10 gibt die hardwaredefinierten Bits in einem gültigen PTE an.
Bit
Bedeutung
Zugriff erfolgt (Accessed)
Es wurde auf die Seite zugegriffen.
Cache deaktiviert (Cache
disabled)
Deaktiviert die CPU-Zwischenspeicherung für die Seite.
Kopieren beim Schreiben
(Copy-on-Write)
Die Seite verwendet »Kopieren beim Schreiben«.
Modifiziert (Dirty)
Es wurde auf die Seite geschrieben.
Global
Die Übersetzung gilt für alle Prozesse. Beispielsweise wird dieser PTE
nicht davon beeinflusst, wenn ein Übersetzungspuffer auf die Festplatte
geleert wird.
Große Seite (Large page)
Gibt an, dass der PDE eine 2-MB-Seite zuordnet (siehe den Abschnitt
»Große und kleine Seiten« weiter vorn in diesem Kapitel).
Keine Ausführung (No
execute)
Gibt an, dass auf dieser Seite kein Code ausgeführt werden kann (sie
lässt sich nur für Daten verwenden).
Besitzer (Owner)
Gibt an, ob Benutzermoduscode auf die Seite zugreifen kann oder ob
die Seite auf Kernelmoduszugriff beschränkt ist.
Prototyp
Der PTE ist ein Prototyp, der als Vorlage zur Beschreibung von gemeinsam genutztem Speicher in Verbindung mit Abschnittsobjekten verwendet wird.
Gültig (Valid)
Gibt an, ob die Übersetzung die Seite im physischen Speicher zuordnet.
→
Adressübersetzung
Kapitel 5
427
Bit
Bedeutung
Write-Through
Kennzeichnet die Seite für Write-Through oder (falls der Prozessor die
Seitenattributtabelle unterstützt) für kombiniertes Schreiben. Dies wird
gewöhnlich für die Zuordnung von Arbeitsspeicher eines Videoframepuffers verwendet.
Schreiben (Write)
Teilt der MMU mit, ob auf die Seite geschrieben werden kann.
Tabelle 5–10 Status- und Schutzbits in einem PTE
Hardware-PTEs auf x86-Systemen enthalten zwei Bits, die die MMU ändern kann, nämlich »Modifiziert« und »Zugriff erfolgt«. Die MMU setzt das Zugriffsbit, wenn eine Seite gelesen oder
auf ihr geschrieben wurde (und das Bit noch nicht gesetzt ist). Das Modifizierungsbit setzt sie,
wenn eine Schreiboperation auf der Seite erfolgt. Das Betriebssystem ist dafür zuständig, diese
Bits zur richtigen Zeit wieder aufzuheben. Die MMU hebt sie niemals wieder auf.
Für den Seitenschutz verwendet die x86-MMU ein Schreibbit. Ist es nicht gesetzt, so kann
die Seite nur gelesen werden, anderenfalls gelesen und geschrieben. Versucht ein Thread, auf
eine Seite ohne Schreibbit zu schreiben, tritt eine Speicherverwaltungsausnahme auf. Der Zugriffsfehlerhandler des Speicher-Managers (siehe den Abschnitt »Seitenfehler« weiter hinten)
muss bestimmen, ob der Thread die Erlaubnis zum Schreiben auf der Seite erhalten kann (z. B.
wenn die Seite für das Kopieren beim Schreiben gekennzeichnet ist) oder ob eine Zugriffsverletzung gemeldet werden soll.
Hardware- und Softwareschreibbits in Seitentabelleneinträgen
Das zusätzliche, in der Software implementierte Schreibbit (siehe Abb. 5–18) dient dazu, die
Aktualisierung des Modifizierungsbits mit den Aktualisierungen der Windows-Speicherverwaltungsdaten zu synchronisieren. Im einfachsten Fall setzt der Speicher-Manager das Hardware-Schreibbit (Bit 1) für jede schreibbare Seite. Ein Schreibvorgang auf einer solchen Seite
führt dazu, dass die MMU das Modifizierungsbit im PTE setzt. Später teilt dieses Modifizierungsbit dem Speicher-Manager mit, dass der Inhalt der physischen Seite in den Hintergrundspeicher geschrieben werden muss, bevor die physische Seite für etwas anderes verwendet werden
kann.
In der Praxis kann dies auf Mehrprozessorsystemen jedoch zu Race Conditions führen, die
sich nur mit großem Aufwand aufheben lassen. Die MMUs der einzelnen Prozessoren können
jederzeit das Modifizierungsbit eines beliebigen PTEs setzen, dessen Hardware-Schreibbit gesetzt ist. Der Speicher-Manager muss die Arbeitssatzliste des Prozesses zu verschiedenen Zeiten
aktualisieren, damit sie den Zustand des Modifizierungsbits im PTE widerspiegeln. Um den
Zugriff auf diese Liste zu synchronisieren, verwendet der Speicher-Manager ein Pushlock. Doch
auf Mehrprozessorsystemen kann das Modifizierungsbit auch dann von den MMUs anderer
CPUs geändert werden, wenn ein Prozessor eine Sperre aufrechterhält. Dadurch ist es möglich,
dass eine Aktualisierung eines Modifizierungsbits verloren geht.
Um das zu vermeiden, initialisiert der Speicher-Manager von Windows sowohl schreibgeschützte als auch schreibbare Seiten so, dass das Hardware-Schreibbit (Bit 1) ihrer PTEs auf 0 gesetzt ist, und merkt sich die tatsächliche Schreibfähigkeit der Seite mit dem Software-Schreibbit
(Bit 11). Beim ersten Schreibzugriff auf eine solche Seite löst der Prozessor eine Speicherverwal-
428
Kapitel 5
Speicherverwaltung
tungsausnahme auf, da das Hardware-Schreibbit nicht gesetzt ist, so wie er es auch bei einer
echten schreibgeschützten Seite tut. In diesem Fall aber kann er über das Software-Schreibbit
erkennen, dass die Seite tatsächlich schreibbar ist, weshalb er ein Pushlock für den Arbeitssatz
erwirbt, das Modifizierungsbit und das Hardware-Schreibbit im PTE setzt, die Arbeitssatzliste
mit dem Hinweis auf die Änderung der Seite aktualisiert, das Pushlock freigibt und die Ausnahme verwirft. Die Hardware-Schreiboperation wird dann wie gewöhnlich fortgesetzt, aber
das Modifizierungsbit konnte gesetzt werden, während das Pushlock für die Arbeitssatzliste
bestand.
Bei nachfolgenden Schreibvorgängen auf der Seite treten keine Ausnahmen mehr auf, da
das Hardware-Schreibbit jetzt gesetzt ist. Die MMU setzt weiterhin das Modifizierungsbit, was
zwar überflüssig ist, aber nicht schadet, da in der Arbeitssatzliste bereits festgehalten ist, dass
auf die Seite geschrieben wurde. Es mag nach übermäßigem Mehraufwand aussehen, dass der
erste Schreibvorgang auf einer Seite die Ausnahmebehandlung durchlaufen muss, doch das
geschieht für jede schreibbare Seite nur einmal, solange sie gültig bleibt. Außerdem durchläuft
der erste Zugriff auf fast jede Seite ohnehin die Ausnahmebehandlung für die Speicherverwaltung, da die Seiten gewöhnlich im ungültigen Zustand initialisiert sind (das PTE-Bit 0 ist
nicht gesetzt). Wenn dieser erste Zugriff auch gleich der erste Schreibvorgang auf der Seite ist,
erfolgt die hier beschriebene Handhabung des Modifizierungsbits während der Ausnahmebehandlung für den Seitenfehler beim ersten Zugriff, weshalb nur wenig Zusatzaufwand entsteht.
Außerdem erlaubt diese Implementierung sowohl auf Einzel- als auch auf Mehrprozessorsystemen, den Look-Aside-Übersetzungspuffer auf die Festplatte zu leeren, ohne dass dabei für jede
betroffene Seite eine Sperre erforderlich wäre.
Der Look-Aside-Übersetzungspuffer für die Übersetzung
Wie Sie bereits wissen, sind für jede Hardwareadressübersetzung drei Nachschlagevorgänge
erforderlich:
QQ Suche nach dem passenden Eintrag in der PDPT
QQ Suche nach dem passenden Eintrag im Seitenverzeichnis (der den Speicherort der Seitentabelle ergibt)
QQ Suche nach dem passenden Eintrag in der Seitentabelle
Diese drei zusätzlichen Nachschlagevorgänge für jeden Verweis auf eine virtuelle Adresse würden die erforderliche Bandbreite zum Arbeitsspeicher vervierfachen und damit die Leistung
beeinträchtigen. Daher halten alle CPUs Adressübersetzungen im Cache fest, sodass Adressen,
auf die wiederholt zugegriffen wird, nicht immer wieder neu übersetzt werden müssen. Dieser
Cache ist ein assoziatives Speicherarray und wird als Look-Aside-Übersetzungspuffer (Translation Look-Aside Buffer, TLB) bezeichnet. Bei assoziativem Speicher handelt es sich um einen
Vektor, dessen Elemente gleichzeitig gelesen und mit einem Zielwert verglichen werden können. Im Fall des TLBs enthält dieser Vektor die kürzlich ermittelten Zuordnungen von virtuellen
zu physischen Seiten (siehe Abb. 5–19) sowie die Art des Seitenschutzes, die Größe, Attribute
usw. der einzelnen Seiten. Jeder Eintrag im TLB besteht aus einem Tag, das Teile der virtuellen
Adresse enthält, und den zugehörigen Daten, nämlich der Nummer der physischen Seite, dem
Adressübersetzung
Kapitel 5
429
Schutzfeld, dem Gültigkeitsbit und gewöhnlich auch einem Modifizierungsbit. Ist das Globalbit
des zugehörigen PTEs gesetzt (wie es in Windows bei Systemraumseiten der Fall ist, die für
alle Prozesse sichtbar sind), wird der TLB-Eintrag bei Prozesskontextwechseln nicht ungültig
gemacht.
Nummer der
virtuellen Seite: 17
Virtuelle Seite 5
Seitenrahmen 288
Virtuelle Seite 65
Ungültig
Virtuelle Seite 17
Seitenrahmen 1652
Virtuelle Seite 57
Ungültig
Virtuelle Seite 11
Seitenrahmen 544
Virtuelle Seite 445
Seitenrahmen 60
Gleichzeitiges Lesen
und Vergleichen
Abbildung 5–19 Zugriff auf den TLB
Für häufig verwendete virtuelle Adressen gibt es sehr wahrscheinlich einen Eintrag im TLB, was
eine äußerst schnelle Übersetzung und damit einen schnellen Speicherzugriff ermöglicht. Ist
eine virtuelle Adresse nicht im TLB verzeichnet, kann sie sich nach wie vor im Arbeitsspeicher
befinden, allerdings sind dann mehrere Speicherzugriffe erforderlich, um sie zu finden, was den
Zugriff etwas verlangsamt. Wurde eine virtuelle Seite ausgelagert oder hat der Speicher-Manager den PTE geändert, so muss der Speicher-Manager den TLB-Eintrag ausdrücklich ungültig
machen. Greift ein Prozess erneut auf die Seite zu, tritt ein Seitenfehler auf, weshalb der Speicher-Manager die Seite (falls nötig) wieder in den Arbeitsspeicher zurückholt und den PTE neu
erstellt. Dadurch kommt auch wieder ein Eintrag im TLB zustande.
Experiment: Adressen übersetzen
Um zu verdeutlichen, wie die Adressübersetzung funktioniert, sehen wir uns diesen Vorgang auf einem x86-PAE-System an. Mit den Werkzeugen, die im Kerneldebugger bereitstehen, untersuchen wir dabei die PDPT, die Seitenverzeichnisse, Seitentabellen und PTEs.
Hier verwenden wir einen Prozess mit der virtuellen Adresse 0x3166004, die zurzeit einer
gültigen physischen Adresse zugeordnet ist. In späteren Experimenten schauen wir uns an,
was bei den ungültigen Adressen geschieht.
→
430
Kapitel 5
Speicherverwaltung
Als Erstes rechnen wir die Adresse 0x3166004 ins Binärformat um, was 11.0001.0110.0
110.0000.0000.0100 ergibt. Anschließend zerlegen wir diese Adresse in die drei Felder, die
zur Übersetzung verwendet werden:
Index des Seitenverzeichnis
Seiten
index (24)
verzeichnis
zeigers
Seitentabellenindex
(0x166 or 358)
Byteoffset (4)
Um mit der Übersetzung beginnen zu können, muss die CPU die physische Adresse der
PDPT des laufenden Prozesses kennen. Diese Adresse steht im Register CR3. In der Ausgabe
des Befehls !process finden Sie sie im Feld DirBase:
lkd> !process -1 0
PROCESS 99aa3040 SessionId: 2 Cid: 1690 Peb: 03159000 ParentCid: 0920
DirBase: 01024800 ObjectTable: b3b386c0 HandleCount: <Data Not Accessible>
Image: windbg.exe
Die PDPT befindet sich also an der physischen Adresse 0x1024800. Wie Sie der vorhergehenden Abbildung entnehmen können, hat das PDPT-Indexfeld der virtuellen Adresse
in unserem Beispiel den Wert 0. Daher steht die physische Adresse des entsprechenden
Seitenverzeichnisses im ersten Eintrag der PDPT, also ebenfalls an der physischen Adresse
0x1024800.
Der Kerneldebuggerbefehl !pte zeigt den PDE und den PTE für die virtuelle Adresse an:
lkd> !pte 3166004
VA 03166004
PDE at C06000C0
PTE at C0018B30
contains 0000000056238867
contains 800000005DE61867
pfn 56238
pfn 5de61
---DA--UWEV
---DA--UW-V
Die PDPT gibt der Debugger dabei nicht aus, aber Sie können sie sich anzeigen lassen, indem Sie ihre physische Adresse übergeben:
lkd> !dq 01024800 L4
# 1024800 00000000'53c88801 00000000'53c89801
# 1024810 00000000'53c8a801 00000000'53c8d801
Hier haben wir den Debugger-Erweiterungsbefehl !dq verwendet. Er ähnelt dem Befehl dq
(Anzeige in Form von Quadwords, also 64-Bit-Werten), ermöglicht es uns aber, den Arbeitsspeicher anhand von physischen statt virtueller Adressen zu untersuchen. Da wir wissen,
dass die PDPT nur vier Einträge umfasst, haben wir das Längenargument L 4 angegeben,
um die Ausgabe übersichtlich zu halten.
→
Adressübersetzung
Kapitel 5
431
Da der PDPT-Index (die beiden signifikantesten Bits) der Beispieladresse 0 ist, handelt
es sich bei dem gewünschten PDPT-Eintrag um das erste angezeigte Quadword. PDPT-Einträge haben ein ähnliches Format wie PDEs und PTEs. Wie Sie hier sehen, enthält dieser
die PFN 0x53c88 (immer ausgerichtet an den Seitengrenzen) für die physische Adresse
0x53c88000. Das ist die physische Adresse des Seitenverzeichnisses.
Die Ausgabe von !pte zeigt die PDE-Adresse 0xC06000C0, allerdings als virtuelle und
nicht als physische Adresse. Auf x86-Systemen beginnt das Seitenverzeichnis des ersten
Prozesses bei der virtuellen Adresse 0xC0600000. In diesem Fall liegt die PDE-Adresse 0xC0,
also 24 Mal 8 Bytes (die Größe eines Eintrags) hinter der Startadresse des Seitenverzeichnisses. Der Seitenverzeichnisindex der Beispieladresse lautet also 24, weshalb wir uns den
25. PDE im Seitenverzeichnis ansehen müssen.
Der PDE gibt die PFN der gewünschten Seitentabelle an. In diesem Beispiel lautet sie
0x56238, was bedeutet, dass die Seitentabelle an der physischen Adresse 0x56238000 beginnt. Die MMU multipliziert den Seitentabellenindex aus der virtuellen Adresse (0x166)
mit 8 (der Größe eines PTEs in Byte) und addiert das Ergebnis zu der Startadresse. Dadurch
ergibt sich als physische Adresse des PTEs 0x56238B30.
Der Debugger zeigt, dass sich der PTE an der virtuellen Adresse 0xC0018B30 befindet.
Der Byteoffset (0xB30) ist der gleiche wie für die physische Adresse, was bei der Adressübersetzung immer der Fall ist. Da der Speicher-Manager Seitentabellen beginnend mit
0xC0000000 zuordnet, ergibt die Addition von 0xB30 zu 0xC0018000 (die 0x18 steht für
den Eintrag 24) die in der Ausgabe des Kerneldebuggers gezeigte virtuelle Adresse von
0xC0018B30. Das PFN-Feld des PTEs enthält, wie der Debugger ebenfalls zeigt, den Wert
0x5DE61.
Als Letztes müssen wir noch den Byteoffset in der ursprünglichen Adresse berücksichtigen. Wie bereits beschrieben, verkettet die MMU den Byteoffset mit der PFN aus dem PTE,
was die physische Adresse 0x5DE61004 ergibt. Sie entspricht der ursprünglichen virtuellen
Adresse 0x3166004 – zumindest zum jetzigen Zeitpunkt.
Rechts neben der PFN stehen im PTE auch noch Flagbits, in unserem Beispiel ---DA-UW-V. Das A steht hier für »accessed« (»Zugriff erfolgt«; die Seite wurde also gelesen), U für
»user-mode accessible« (»vom Benutzermodus aus zugänglich«, also nicht nur vom Kernelmodus aus), W für »writable« (»schreibbar«, also nicht nur lesbar) und V für »valid« (»gültig«;
der PTE beschreibt eine gültige Seite im physischen Speicher).
Um die Berechnung der physischen Adresse zu bestätigen, schauen Sie sich den fraglichen Speicher sowohl über seine virtuelle als auch über seine physische Adresse an. Als
Erstes wenden Sie den Debuggerbefehl dd (DWORD-Anzeige) auf die virtuelle Adresse an:
lkd> dd 3166004 L 10
03166004 00000034 00000006 00003020 0000004e
03166014 00000000 00020020 0000a000 00000014
→
432
Kapitel 5
Speicherverwaltung
Wenn Sie !dd auf die berechnete physische Adresse anwenden, sehen Sie denselben Inhalt:
lkd> !dd 5DE61004 L 10
#5DE61004 00000034 00000006 00003020 0000004e
#5DE61014 00000000 00020020 0000a000 00000014
Auf diese Weise können Sie auch die Inhalte an den virtuellen und physischen Adressen des
PTEs und des PDEs vergleichen.
Übersetzung virtueller Adressen auf x64-Systemen
Die Adressübersetzung auf x64-Systemen ähnelt der auf x86-Systemen, allerdings kommt noch
eine vierte Ebene hinzu. Jeder Prozess verfügt noch über ein zusätzliches primäres Seitenverzeichnis, die Seitenzuordnungstabelle vierter Ebene, die die physischen Speicherorte der 512
Strukturen dritter Ebene enthält, also der sogenannten Seitenverzeichniszeiger. Diese Seitenverzeichniszeiger entsprechen der PDPT auf x86-PAE-Systemen, allerdings gibt es 512 davon und
nicht nur einen, und jeder ist eine komplette Seite mit 512 statt lediglich vier Einträgen. Wie
die Einträge der PDPT enthalten auch diejenigen der Seitenverzeichniszeiger die physischen
Speicherorte der einzelnen Seitentabellen. Die Seitentabellen wiederum enthalten jeweils 512
Seitentabelleneinträge mit den physischen Speicherorten der Seiten. Alle »physischen Speicher
orte« sind in diesen Strukturen in Form von PFNs gespeichert.
Bei den aktuellen Implementierungen der x64-Architektur sind virtuelle Adressen auf
48 Bits beschränkt. Die Bestandteile solcher virtuellen 48-Bit-Adressen und ihre Verwendung
für die Adressübersetzung sehen Sie in Abb. 5–20. Den Aufbau eines x64-Hardware-PTEs sehen
Sie in Abb. 5–21.
Seitenzuordnung Ebene 4
Seiten
zuordnung
Ebene 4
Seitenverzeichniszeiger
Seiten
verzeichnis
zeiger
Seitenverzeichnis
Seiten
verzeichnisse
Seitentabelle
Byte auf der Seite
Seitentabellen
Abbildung 5–20 x64-Adressübersetzung
Adressübersetzung
Kapitel 5
433
Modifiziert
Große Seite
Zugriff erfolgt
Global
Cache deaktiviert
Kopieren beim Schreiben (Software)
Write-Through
Prototyp (Software)
Besitzer
Schreiben (Software)
Schreiben
Keine Ausführung
Gültig
Reserviert
Abbildung 5–21 Aufbau eines x64-Hardware-PTEs
Übersetzung virtueller Adressen auf ARM-Systemen
Für die Übersetzung virtueller Adressen auf 32-Bit-ARM-Prozessoren wird ein einziges Seitenverzeichnis mit 1024 Einträgen von je 32 Bits verwendet. Die für die Übersetzung herangezogenen Strukturen sehen Sie in Abb. 5–22.
1024 Einträge
1024 Einträge
Seite
Byte auf der Seite
Seitenverzeichnis
(eines pro Prozess)
Seitentabelle(n)
Abbildung 5–22 Strukturen zur Übersetzung virtueller Adressen auf ARM-Systemen
Jeder Prozess verfügt über ein einziges Seitenverzeichnis, dessen physische Adresse im
Register TTBR gespeichert ist (vergleichbar mit dem Register CR3 auf x86/x64-Systemen).
Die zehn signifikantesten Bits der virtuellen Adresse bezeichnen einen PDE, der auf eine der
1024 Seitentabellen zeigt. Die nächsten zehn Bits der virtuellen Adresse geben einen bestimmten PTE an. Jeder gültige PTE zeigt auf den Anfang einer Seite im physischen Arbeitsspeicher,
und der gewünschte Offset wird von den unteren 12 Bits der Adresse festgelegt (wie auf x86und x64-Systemen). Das Schema in Abb. 5–22 deutet schon an, dass der adressierbare physische Speicher 4 GB umfasst, da die einzelnen PTEs kleiner sind als bei x86/x64 (32 statt 64 Bits).
Tatsächlich werden für die PFN nur 20 Bits verwendet. ARM-Prozessoren unterstützen auch
einen PAE-Modus (ähnlich dem x86-PAE-Modus), doch Windows nutzt diese Möglichkeit nicht.
434
Kapitel 5
Speicherverwaltung
In zukünftigen Windows-Versionen mag eine Unterstützung für die 64-Bit-ARM-Architektur
hinzukommen, was die Einschränkungen bei den physischen Adressen verringern und den virtuellen Adressraum für Prozesse und das System dramatisch vergrößern wird.
Kurioserweise unterscheiden sich PTEs, PDEs und PDEs für große Seiten in ihrem Aufbau
voneinander. Abb. 5–23 zeigt den Aufbau eines gültigen PTEs für ARMv7, wie es zurzeit von
Windows verwendet wird. Weitere Informationen entnehmen Sie bitte der offiziellen ARM-Dokumentation.
Schreibbar (Software)
Kopieren beim Schreiben
(Software)
Typerweiterung
(stets 0)
Besitzer
Nicht modifiziert
Zugriff erfolgt
Große Seite (Software)
Cachetyp
Nicht global
Gültig (2 Bits)
Abbildung 5–23 Aufbau eines gültigen ARM-PTEs
Seitenfehler
Wie die Adressübersetzung bei gültigen PTEs funktioniert, wissen Sie nun bereits. Ist das Gültigkeitsbit aber nicht gesetzt, bedeutet das, dass die gewünschte Seite für den Prozess zurzeit
aus irgendeinem Grund nicht zugänglich ist. In diesem Abschnitt geht es um die verschiedenen
Arten von ungültigen PTEs und die Auflösung von solchen ungültigen Verweisen.
In diesem Abschnitt beschreiben wir nur PTEs auf x86-Systemen. Die PTEs auf 64Bit- und ARM-Systemen enthalten ähnliche Informationen, allerdings werden wir
ihren Aufbau hier nicht ausführlich erläutern.
Ein Verweis auf eine ungültige Seite wird als Seitenfehler bezeichnet. Der Kerneltraphandler
(siehe den Abschnitt »Trapdisponierung« in Kapitel 8 von Band 2) übergibt Fehler dieser Art an
den Fehlerhandler MmAccessFault des Speicher-Managers. Diese Routine wird im Kontext des
Threads ausgeführt, in dem der Fehler aufgetreten ist. Sie muss versuchen, den Fehler zu lösen,
und wenn das nicht möglich ist, eine entsprechende Ausnahme auslösen. Es gibt eine Vielzahl
von Bedingungen, die solche Fehler verursachen können (siehe Tabelle 5–11).
Seitenfehler
Kapitel 5
435
Ursache
Folge
Beschädigter PTE/PDE
Beendigungsfehler (Absturz) des Systems mit dem
Code 0x1A (MEMORY_MANAGEMENT)
Zugriff auf eine Seite, die sich nicht im Speicher,
sondern in einer Auslagerungsdatei auf der Festplatte oder in einer im Speicher zugeordneten
Datei befindet
Es wird eine physische Seite zugewiesen und die
gewünschte Seite von der Festplatte gelesen und
in den entsprechenden Arbeitssatz gestellt.
Zugriff auf eine Seite, die sich auf der Liste der
Standby- oder modifizierten Seiten befindet
Die Seite wird in den geeigneten Arbeitssatz des
Prozesses, der Sitzung oder des Systems überführt.
Zugriff auf eine Seite, die nicht zugesichert ist
(z. B. im reservierten oder nicht zugewiesenen
Adressraum)
Ausnahme aufgrund einer Zugriffsverletzung
Benutzermoduszugriff auf eine Seite, die nur vom
Kernelmodus aus zugänglich ist
Ausnahme aufgrund einer Zugriffsverletzung
Schreiben auf eine schreibgeschützte Seite
Ausnahme aufgrund einer Zugriffsverletzung
Zugriff auf eine Nullforderungsseite
Dem entsprechenden Arbeitssatz wird eine mit
Nullen gefüllte Seite hinzugefügt.
Schreiben auf eine Wächterseite
Wächterseitenverletzung (falls ein Verweis auf einen Benutzermodusstack vorhanden ist, wird eine
automatische Stackerweiterung durchgeführt)
Schreiben auf eine Copy-on-Write-Seite (Kopieren
beim Schreiben)
Es wird eine private Kopie der Seite für den
Prozess oder die Sitzung erstellt. Damit wird die
Originalseite im Arbeitssatz des Prozesses, der Sitzung oder des Systems ersetzt.
Schreiben auf eine Seite, die zwar gültig ist,
aber noch nicht in die aktuelle Kopie im Hintergrundspeicher geschrieben wurde
Das Modifizierungsbit des PTEs wird gesetzt.
Ausführen von Code auf einer als nicht ausführbar
gekennzeichneten Seite
Ausnahme aufgrund einer Zugriffsverletzung
Die PTE-Berechtigungen entsprechen nicht den
Enklavenberechtigungen (siehe den Abschnitt
»Speicherenklaven« weiter hinten in diesem
Kapitel und die Dokumentation der Funktion
CreateEnclave im Windows SDK)
• Benutzermodus: Ausnahme aufgrund einer
Zugriffsverletzung
• Kernelmodus: Beendigungsfehler mit Code 0x50
(PAGE_FAULT_IN_NONPAGED_AREA)
Tabelle 5–11 Gründe für Zugriffsfehler
In den folgenden Abschnitten sehen wir uns zunächst die vier grundlegenden Arten von ungültigen PTEs an, die der Zugriffsfehlerhandler verarbeitet, und dann den Sonderfall der Prototyp-PTEs, die zur Einrichtung von gemeinsam nutzbaren Seiten verwendet werden.
Ungültige PTEs
Wenn das Gültigkeitsbit eines PTEs bei der Adressübersetzung 0 ist, dann repräsentiert dieser
PTE eine ungültige Seite. Bei einem Verweis darauf wird eine Speicherverwaltungsausnahme
oder ein Seitenfehler ausgelöst. Die MMU ignoriert dann die restlichen Bits des PTEs, sodass
das Betriebssystem darin Informationen über die Seite speichern kann, die benötigt werden,
um den Seitenfehler zu beheben.
436
Kapitel 5
Speicherverwaltung
In der folgenden Aufstellung finden Sie die fünf Arten von ungültigen PTEs und ihren Aufbau. Sie werden oft auch als Software-PTEs bezeichnet, da sie vom Speicher-Manager statt von
der MMU interpretiert werden. Einige ihrer Flags sind identisch mit denen für Hardware-PTEs,
die Sie in Tabelle 5–10 gesehen haben, und auch einige der Bitfelder haben die gleiche oder
eine ähnliche Bedeutung wie die entsprechenden Felder in einem Hardware-PTE.
QQ Auslagerungsdatei Die gewünschte Seite befindet sich in einer Auslagerungsdatei. Wie
Abb. 5–24 zeigt, geben vier Bits im PTE an, in welcher der 16 möglichen Auslagerungsdateien die Seite steht, während weitere 32 Bits die Nummer der Seite in der Datei nennen.
Der Pager – also der Auslagerungsmechanismus – löst eine Einlagerungsoperation aus, um
die Seite wieder in den Arbeitsspeicher zu holen und gültig zu machen. Der Offset in der
Auslagerungsdatei ist immer von 0 verschieden und besteht niemals komplett aus Einsen
(die erste und die letzte Seite in der Auslagerungsdatei werden nicht zur Auslagerung verwendet). Dadurch sind die im Folgenden beschriebenen anderen Formate möglich.
In der Auslagerungsdatei reserviert
Übergang
In der Auslagerungsdatei zugewiesen
Offset in Auslagerungsdatei Nicht verwendet
(32 Bits)
(18 Bits)
Gültig
Prototyp
Schutz
Index der
Auslagerungsdatei
Abbildung 5–24 Ein PTE für eine Seite in einer Auslagerungsdatei
QQ Nullforderung Dieses PTE-Format ist mit dem für Seiten in einer Auslagerungsdatei
identisch, allerdings wird das Feld mit dem Offset in der Auslagerungsdatei auf 0 gesetzt.
Die gewünschte Seite muss in Form einer Seite bereitgestellt werden, die nur aus Nullen
besteht. Der Pager untersucht dazu die Nullseitenliste. Ist sie leer, entnimmt der Pager eine
Seite von der Liste der freien Seiten und setzt sie auf 0. Ist auch diese Liste leer, nimmt er
die Seite von den Standbylisten und setzt sie auf 0.
QQ VAD (Virtual Address Descriptor) Dieses PTE-Format ist mit dem für Seiten in einer Auslagerungsdatei identisch, allerdings wird das Feld mit dem Offset in der Auslagerungsdatei
komplett auf 1 gesetzt. Das steht für eine Seite, deren Definition und ggf. Hintergrundspeicher im VAD-Baum des Prozesses zu finden sind. Dieses Format wird für Seiten verwendet,
hinter denen Abschnitte in zugeordneten Dateien stehen. Der Pager findet den VAD, der
den virtuellen Adressbereich mit der virtuellen Seite definiert, und löst einen Einlagerungsvorgang von der in dem VAD genannten zugeordneten Datei aus. (VADs werden in dem
gleichnamigen Abschnitt weiter hinten in diesem Kapitel ausführlicher beschrieben.)
QQ Übergang Das Übergangsbit ist 1. Die gewünschte Seite befindet sich zwar im Arbeitsspeicher, aber entweder auf der Standbyliste, der Liste geänderter Seiten, der Liste geänderter und nicht schreibbarer Seiten oder auf gar keiner Liste. Der Pager nimmt die Seite
ggf. von der Liste und fügt sie dem Arbeitssatz des Prozesses hinzu. Da keine Ein-/Ausgabe
erforderlich ist, wird dies auch als weicher Seitenfehler bezeichnet.
QQ Unbekannt Der PTE ist 0 oder die Seitentabelle existiert nicht (wobei der PDE mit der
physischen Adresse der Seitentabelle 0 ist). In beiden Fällen muss der Speicher-Manager
Seitenfehler
Kapitel 5
437
die VADs untersuchen, um zu bestimmen, ob diese virtuelle Adresse zugesichert wurde.
Wenn ja, werden Seitentabellen für den neu zugesicherten Adressraum erstellt. Ist anderenfalls die Seite reserviert oder gar nicht definiert, wird der Seitenfehler als Ausnahme
aufgrund einer Zugriffsverletzung gemeldet.
Prototyp-PTEs
Wenn eine Seite von zwei Prozessen gemeinsam genutzt werden kann, ordnet der Speicher-Manager sie mithilfe von sogenannten Prototyp-PTEs zu. Für auslagerungsgepufferte Abschnitte
wird beim erstmaligen Erstellen eines Abschnittsobjekts ein Array aus Prototyp-PTEs angelegt,
und für zugeordnete Dateien werden bei der Zuordnung der einzelnen Sichten Teile des Arrays
nach Bedarf erstellt. Die Prototyp-PTEs gehören zu der Segmentstruktur (die weiter hinten in
diesem Kapitel im Abschnitt »Abschnittsobjekte« genauer beschrieben wird).
Wenn ein Prozess zum ersten Mal auf eine Seite verweist, die einer Sicht eines Abschnittsobjekts zugeordnet ist (denken Sie daran, dass VADs nur bei der Zuordnung der Sicht erstellt
werden!), nutzt der Speicher-Manager die Informationen im Prototyp-PTE, um den eigentlichen, für die Adressübersetzung verwendeten PTE in der Seitentabelle des Prozesses auszufüllen. Wird eine gemeinsam genutzte Seite gültig gemacht, so zeigen sowohl der Prozess- als
auch der Prototyp-PTE auf dieselbe physische Seite mit den Daten. Um die Anzahl der Prozess-PTEs im Auge zu behalten, die auf eine gültige gemeinsame Seite verweisen, wird ein
Zähler in deren PFN-Datenbankeintrag geführt. Der Speicher-Manager kann daher erkennen,
wenn es für eine gemeinsam genutzte Seite keine Verweise mehr in irgendeiner Seitentabelle
gibt, sodass er sie ungültig machen und auf die Übergangsliste setzen oder auf die Festplatte
schreiben kann.
Wird eine gemeinsam nutzbare Seite ungültig gemacht, so wird der PTE in der Prozessseitentabelle durch einen besonderen PTE ersetzt, der auf den Prototyp-PTE mit der Beschreibung
der Seite zeigt (siehe Abb. 5–25). Bei einem Zugriff auf die Seite kann der Speicher-Manager
daher diesen Prototyp-PTE finden.
Kombiniert
Nur Lesezugriff
Gültig
Prototyp
verwendet
Adresse des Prototyp-PTEs Nicht(16
Bits)
Schutz
Nicht verwendet
(5 Bits)
Abbildung 5–25 Aufbau eines ungültigen PTEs mit einem Zeiger auf den Prototyp-PTE
Der Prototyp-PTE gibt an, in welchem der sechs möglichen Zustände sich eine gemeinsam
genutzte Seite befindet:
QQ Aktiv/gültig (Active) Die Seite befindet sich im physischen Speicher, da ein anderer
Prozess darauf zugegriffen hat.
QQ Übergang (Transition) Die gewünschte Seite befindet sich im Arbeitsspeicher, steht
aber auf der Standbyliste oder der Liste der geänderten Seiten (oder auf gar keiner Liste).
438
Kapitel 5
Speicherverwaltung
QQ Geändert, nicht schreibbar (Modified no-write) Die gewünschte Seite befindet sich
im Arbeitsspeicher und auf der Liste der geänderten und nicht schreibbaren Seiten.
QQ Nullforderung (Demand zero)
werden.
Für die gewünschte Seite soll eine aus Nullen verwendet
QQ Auslagerungsdatei (Page file) Die gewünschte Seite befindet sich in der Auslagerungsdatei.
QQ Zugeordnete Datei (Mapped file)
ordneten Datei.
Die gewünschte Datei befindet sich in einer zuge-
Prototyp-PTEs weisen den gleichen Aufbau auf wie die zuvor beschriebenen echten PTEs, werden aber nicht für die Adressübersetzung verwendet. Sie bilden eine Schicht zwischen den
Seitentabellen und der PFN-Datenbank und erscheinen niemals direkt in Seitentabellen.
Der Speicher-Manager kann die gemeinsamen Seiten verwalten, ohne die Seitentabellen
der einzelnen Prozesse aktualisieren zu müssen, die diese Seiten nutzen, da alle zugreifenden
Prozesse zur Auflösung von Fehlern auf einen Prototyp-PTE verweisen werden. Wenn der Speicher-Manager eine gemeinsam genutzte Code- oder Datenseite abruft, die auf die Festplatte
ausgelagert wurde, muss er nur den Prototyp-PTE aktualisieren, der auf ihren neuen physischen
Standort zeigt. Die PTEs in den einzelnen Prozessen, die die Seite nutzen, bleiben unverändert.
Ihr Gültigkeitsbit ist nicht gesetzt, und sie zeigen auf den Prototyp. Wenn später Prozesse auf
die Seite verweisen, wird der echte PTE aktualisiert.
Abb. 5–26 zeigt zwei virtuelle Seiten in einer zugeordneten Sicht. Die erste Seite ist gültig,
und sowohl der Prozess- als auch der Prototyp-PTE zeigen auf sie. Die zweite Seite dagegen
befindet sich in der Auslagerungsdatei. Während der Prototyp-PTE den genauen Speicherort
angibt, zeigt der PTE des Prozesses (sowie aller anderen Prozesse, die diese Seite verwenden)
auf den Prototyp-PTE.
PFN 5
PFN 5
Gültig – PFN 5
Ungültig – zeigt auf
den Prototyp-PTE
PTE-Adresse
Gültig – PFN 5
Zähler für
gemeinsame
Nutzung = 1
Ungültig – in der
Auslagerungsdatei
PFN-Datenbankeintrag
Physischer Speicher
Seitentabelle
Prototyp-Seitentabelle
Abbildung 5–26 Prototyp-PTEs
Seitenfehler
Kapitel 5
439
Einlagerungs-E/A
Einlagerungs-E/A tritt auf, wenn eine Auslagerungs- oder zugeordnete Datei gelesen werden
muss, um einen Seitenfehler aufzulösen. Da auch Seitentabellen ausgelagert werden können,
ist es möglich, dass bei der Verarbeitung eines Seitenfehlers zusätzliche Ein-/Ausgaben erforderlich sind, falls das System erst die Seite mit der erforderlichen Seitentabelle laden muss.
Einlagerungsoperationen erfolgen synchron, das heißt, der Thread wartet, bis der Vorgang
abgeschlossen ist. Sie können auch nicht durch asynchrone Prozeduraufrufe (APCs) unterbrochen werden. Der Pager verwendet in der E/A-Anforderungsfunktion einen besonderen Modifizierer, um anzugeben, dass eine Einlagerungs-E/A erfolgt. Nach Abschluss des Vorgangs
löst das E/A-System ein Ereignis aus, das den Pager aufweckt, sodass er mit der Verarbeitung
fortfahren kann.
Während der Einlagerungsoperation besitzt der Thread, der den Fehler hervorgerufen
hat, keine kritischen Objekte zur Synchronisierung der Speicherverwaltung. Andere Threads
in demselben Prozess können jedoch Funktionen für den virtuellen Speicher aufrufen und Seitenfehler handhaben, während eine Einlagerung stattfindet. Es gibt jedoch einige besondere
Bedingungen, die der Pager bei Abschluss der E/A berücksichtigen muss:
QQ Ein anderer Thread in demselben oder einem anderen Prozess hat einen Seitenfehler aufgrund derselben Seite ausgelöst (was als Seitenfehlerkollision bezeichnet und im nächsten
Abschnitt erklärt wird).
QQ Die Seite kann gelöscht und vom virtuellen Adressraum neu zugeordnet worden sein.
QQ Der Schutz der Seite kann sich geändert haben.
QQ Der Fehler kann sich auf einen Prototyp-PTE beziehen, wobei es sein kann, dass sich die
Seite zur Zuordnung dieses PTEs nicht mehr im Arbeitssatz befindet.
Der Pager speichert so viel von dem Status im Kernelstack des Threads vor der Anforderung
der Einlagerungs-E/A, dass er diese Bedingungen nach dem Abschluss der Anforderung erkennen und den Seitenfehler ggf. verwerfen kann, ohne die Seite gültig zu machen. Wird die
Anweisung, die den Fehler hervorgerufen hat, erneut ausgeführt, so wird der Pager abermals
aufgerufen und wertet den PTE in seinem neuen Zustand aus.
Seitenfehlerkollisionen
Wenn ein anderer Thread desselben oder eines anderen Prozesses einen weiteren Seitenfehler
für genau die Seite hervorruft, die gerade eingelagert wird, liegt eine sogenannte Seitenfehlerkollision vor. Auf Multithreadsystemen kommen sie häufig vor, aber der Pager ist in der Lage, sie
zu erkennen und zu handhaben. Anhand der Informationen im PFN-Datenbankeintrag kann er
feststellen, dass sich die Seite im Übergang befindet und ein Lesevorgang stattfindet. Er kann
dann dafür sorgen, dass der zweite Thread auf das in dem PFN-Datenbankeintrag angegebene Ereignis wartet. Dieses Ereignis wurde von dem Thread initialisiert, der als Erster die zur
Auflösung des Fehlers nötige E/A ausgelöst hat. Alternativ kann der Pager auch eine parallele
E/A veranlassen, um ein Deadlock im Dateisystem zu verhindern. Dabei gewinnt die erste E/A,
während die anderen verworfen werden.
440
Kapitel 5
Speicherverwaltung
Nach Abschluss der E/A-Operation können die Threads, die auf das Ereignis gewartet haben, fortfahren. Der erste Thread, der die PFN-Datenbanksperre erworben hat, ist für die Operationen zum Abschluss der Einlagerung verantwortlich. Dazu gehört es, den E/A-Status zu
prüfen, um sicherzustellen, dass die E/A-Operation erfolgreich beendet wurde, das Bit für den
laufenden Lesevorgang in der PFN-Datenbank zurückzusetzen und den PTE zu aktualisieren.
Wenn die nachfolgenden Threads die PFN-Datenbanksperre erwerben, um ihren Seitenfehler zu verarbeiten, erkennt der Pager, dass die ursprüngliche Aktualisierung abgeschlossen
wurde, da das Bit für den laufenden Lesevorgang nicht gesetzt ist. Er prüft das Flag für Einlagerungsfehler in dem PFN-Datenbankeintrag, um sich zu vergewissern, dass die Einlagerungs-E/A
erfolgreich abgeschlossen wurde. Ist dieses Flag gesetzt, so wurde der PTE nicht aktualisiert,
weshalb in dem Thread, der den Fehler ausgelöst hat, eine Ausnahme wegen eines Einlagerungsfehlers (In-Page-Fehler) ausgelöst wird.
Seitencluster
Der Speicher-Manager ruft vorab große Seitencluster ab, um Seitenfehler verarbeiten zu können und den Systemcache zu füllen. Dabei werden die Daten direkt in den Seitencache des
Systems statt in einen Arbeitssatz im virtuellen Speicher geladen. Aus diesem Grund belegen
die vorab abgerufenen Daten keinen virtuellen Adressraum, weshalb die Operation auch nicht
auf den Umfang des verfügbaren virtuellen Adressraums beschränkt ist. Des Weiteren sind keine teuren Interprozessorinterrupts (IPIs) erforderlich, um den TLB auf die Festplatte zu leeren,
wenn die Seiten einem neuen Zweck zugeführt werden müssen. Die vorab abgerufenen Seiten
werden auf die Standbyliste gesetzt und im PTE mit »Übergang« markiert. Wird später auf eine
solche Seite verwiesen, fügt der Speicher-Manager sie zum Arbeitssatz hinzu. Sollte niemals auf
sie verwiesen werden, so werden auch keine Systemressourcen benötigt, um sie freizugeben.
Befinden sich Seiten aus dem vorab abgerufenen Cluster bereits im Speicher, liest der Speicher-Manager sie nicht erneut, sondern repräsentiert sie durch eine Platzhalterseite, sodass
eine einzige, effiziente, umfangreiche E/A möglich ist (siehe Abb. 5–27).
Physischer Speicher
Virtueller Adressraum
MDL(s)
X (ersetzt Y)
X (ersetzt Z)
Systemweite
Platzhalterseite X
Die Seiten Y und Z befinden sich bereits im Speicher, weshalb die
zugehörigen MDL-Einträge auf die systemweite Platzhalterseite zeigen
Abbildung 5–27 Verwendung einer Platzhalterseite bei der Adresszuordnung in einer MDL
Seitenfehler
Kapitel 5
441
Die Dateioffsets und virtuellen Adressen in der Abbildung, die den Seiten A, Y, Z und B entsprechen, sind logisch zusammenhängend, was aber nicht unbedingt auch für die physischen
Seiten gelten muss. Die Seiten A und B sind nicht im Arbeitsspeicher vorhanden, weshalb der
Speicher-Manager sie lesen muss. Dagegen befinden sich Y und Z bereits im Arbeitsspeicher,
sodass für sie kein Lesevorgang erforderlich ist. (Sie könnten jedoch geändert worden sein,
seit sie das letzte Mal aus dem Hintergrundspeicher geladen wurden; in diesem Fall würde ein
Überschreiben ihres Inhalts zu einem ernsten Fehler führen.) Es ist jedoch effizienter, die Seiten
A und B in einer einzigen Operation zu lesen, weshalb der Speicher-Manager eine Leseopera
tion ausgibt, die alle vier Seiten (A, Y, Z und B) im Hintergrundspeicher umfasst. Eine solche Anforderung schließt so viele Seiten ein, wie es angesichts der Menge des verfügbaren Speichers,
der aktuellen Nutzung des Systems usw. sinnvoll ist.
Wenn der Speicher-Manager die MDL zur Beschreibung der Anforderung erstellt, gibt er
gültige Zeiger auf die Seiten A und B an. Die Einträge für die Seiten Y und Z jedoch zeigen auf
dieselbe systemweite Platzhalterseite X. Diese Seite kann der Speicher-Manager mit den möglicherweise veralteten Daten aus dem Hintergrundspeicher füllen, da er X ohnehin nicht sichtbar
macht. Wenn eine Komponente jedoch auf den Y- oder Z-Offset in der MDL zugreift, sieht sie
die Platzhalterseite X statt Y bzw. Z.
Der Speicher-Manager kann eine beliebige Menge verworfener Seiten durch eine einzige
Platzhalterseite darstellen, und diese Seite kann mehrmals in einer einzigen MDL und sogar in
mehreren gleichzeitig verwendeten MDLs für unterschiedliche Treiber verwendet werden. Daher können sich auch die Inhalte an den Speicherorten, die für die verworfenen Dateien stehen,
jederzeit ändern. (Mehr über MDLs erfahren Sie in Kapitel 6.)
Auslagerungsdateien
In Auslagerungsdateien werden geänderte Seiten gespeichert, die immer noch von einigen
Prozessen verwendet werden, aber auf die Festplatte geschrieben wurden, weil sie nicht zugeordnet waren oder weil der Speicherbedarf dies erforderte. Der Platz in der Auslagerungsdatei
wird bereits reserviert, wenn die Seiten zugesichert werden, aber die tatsächlichen, optimal
gruppierten Speicherorte in der Auslagerungsdatei werden erst dann ausgewählt, wenn die
Seiten auf die Festplatte geschrieben werden.
Beim Start des Systems liest der Prozess des System-Managers (Smss.exe) die Liste der zu
öffnenden Auslagerungsdateien im Multistring-Registrierungswert HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management\PagingFiles. Dieser Wert enthält den
Namen und die Mindest- und Höchstgröße jeder Auslagerungsdatei. In Windows können auf
x86- und x64-Systemen bis zu 16 Auslagerungsdateien verwendet werden und auf ARM-Systemen bis zu zwei. Die Höchstgröße der einzelnen Auslagerungsdateien beträgt 16 TB (x86/x64)
bzw. 4 GB (ARM). Sobald eine Auslagerungsdatei geöffnet ist, kann sie nicht wieder geschlossen
werden, solange das System läuft, da der Systemprozess Handles für alle Auslagerungsdateien
offen hält.
Da die Auslagerungsdatei Teile des virtuellen Prozess- und Kernelspeichers enthält, kann
das System aus Sicherheitsgründen so eingerichtet werden, dass die Auslagerungsdatei beim
Herunterfahren geleert wird. Dazu wird der Registrierungswert ClearPageFileAtShutdown im
442
Kapitel 5
Speicherverwaltung
Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management auf 1
gesetzt. Anderenfalls bleiben in der Auslagerungsdatei nach dem Herunterfahren die Daten
enthalten, die aus dem System ausgelagert wurden. Eine Person, die physischen Zugriff auf den
Computer hat, kann auf diese Daten zugreifen.
Sind die Mindest- und Höchstgröße beide 0 (oder nicht angegeben), handelt es sich um
eine vom System verwaltete Auslagerungsdatei. In Windows 7 und Windows Server 2008 R2
wurde dafür ein einfaches Verfahren rein auf der Grundlage der RAM-Größe verwendet:
QQ Mindestgröße Wird auf den Umfang des RAM oder auf 1 GB gesetzt, je nachdem welcher Wert größer ist.
QQ Höchstgröße Wird auf das Dreifache des RAM oder auf 4 GB gesetzt, je nachdem welcher Wert größer ist.
Diese Einstellungen sind jedoch nicht ideal. Der RAM heutiger Laptop- und Desktopcomputer
kann 32 oder 64 GB umfassen und auf Servercomputern sogar Hunderte von Gigabyte betragen. Wird die Anfangsgröße der Auslagerungsdatei auf die Größe des RAM gesetzt, kann das
zu einem erheblichen Verlust an Festplattenplatz führen, insbesondere bei kleinen Festplatten
mit SSD-Technologie. Außerdem ist die Menge des RAM auf einem System nicht unbedingt ein
guter Indikator für die typische Speicherlast.
Bei der aktuellen Implementierung wird daher ein ausgefeilteres Verfahren verwendet, um
eine sinnvolle Mindestgröße für die Auslagerungsdatei zu finden, die nicht allein auf der Größe
des RAM beruht, sondern auch die bisherige Nutzung der Auslagerungsdatei und andere Faktoren berücksichtigt. Beim Erstellen und Initialisieren der Auslagerungsdatei berechnet Smss.
exe die Mindestgröße auf der Grundlage der folgenden vier in globalen Variablen gespeicherten Faktoren:
QQ RAM (SmpDesiredPfSizeBasedOnRAM)
rungsdatei auf der Grundlage des RAM.
Dies ist die empfohlene Größe der Auslage-
QQ Absturzabbild (SmpDesiredPfSizeForCrashDump) Dies ist die erforderliche Größe der
Auslagerungsdatei, um ein Absturzabbild zu speichern.
QQ Verlauf (SmpDesiredPfSizeBasedOnHistory Dies ist die empfohlene Größe der Auslagerungsdatei auf der Grundlage des Nutzungsverlaufs. Smss.exe verwendet einen Timer,
der stündlich eine Aufzeichnung über die Nutzung der Auslagerungsdatei auslöst.
QQ Apps (SmpDesiredPfSizeForApps)
tei für Windows-Apps.
Dies ist die empfohlene Größe der Auslagerungsda-
QQ Diese Werte werden wie in Tabelle 5–12 gezeigt berechnet.
Seitenfehler
Kapitel 5
443
Grundlage
Empfohlene Größe der Auslagerungsdatei
RAM
Bei einem RAM kleiner oder gleich 1 GB wird die Größe auf 1 GB gesetzt. Ist der RAM
größer als 1 GB, wird für jedes zusätzliche Gigabyte 1/8 GB bis zu einem Maximum
von 32 GB addiert.
Absturzabbild
Wenn eine dedizierte Datei für das Absturzabbild eingerichtet ist, so wird zur Speicherung keine Auslagerungsdatei verwendet, weshalb die Größe auf 0 gesetzt wird.
(Sie können die dedizierte Absturzabbilddatei einrichten, indem Sie dem Schlüssel
HKLM\System\CurrentControlSet\Control\CrashControl den Wert DedicatedDumpFile hinzufügen.)
Ist als Typ für das Absturzabbild Automatic (der Standardwert) angegeben, gilt:
Bei einem RAM von weniger als 4 GB beträgt die Größe 1/6 des RAM.
Anderenfalls wird die Größe auf 2/3 GB zuzüglich 1/8 GB für jedes Gigabyte über
4 GB bis zu einem Maximum von 32 GB gesetzt. Ist vor Kurzem ein Absturz erfolgt,
bei dem die Auslagerungsdatei nicht groß genug war, dann wird die empfohlene Größe auf den kleineren Wert von der RAM-Größe oder 32 GB erhöht.
Ist das System für ein vollständiges Absturzabbild konfiguriert, so wird als Größe der
Umfang des RAM zuzüglich des Umfangs der zusätzlichen Informationen in der Absturzabbilddatei zurückgegeben.
Ist das System für ein Kernelabsturzabbild konfiguriert, so wird als Größe der Umfang
des RAM zurückgegeben.
Verlauf
Wurden genug Stichproben aufgezeichnet, wird das 90%-Perzentil als empfohlene
Größe zurückgegeben, anderenfalls eine Empfehlung auf der Grundlage des vorhandenen RAM (siehe oben).
Apps
Bei einem Server wird 0 zurückgegeben.
Die empfohlene Größe hängt von einem Faktor ab, den der Prozesslebenszyklus-Manager (PLM) verwendet, um zu bestimmen, wann er eine Anwendung beenden soll.
Der aktuelle Faktor beträgt das 2,3-Fache des RAM und wurde für RAM-Größen von
1 GB gewählt (was ungefähr das Minimum für Mobilgeräte ist). Auf der Grundlage
dieses Faktors wird eine Größe von etwa 2,5 GB berechnet. Wenn das mehr ist als der
RAM, wird die RAM-Größe abgezogen. Anderenfalls wird 0 zurückgegeben.
Tabelle 5–12 Grundlegende Berechnungen für die Empfehlungen zur Größe der Auslagerungsdatei
Die Höchstgröße einer vom System verwalteten Auslagerungsdatei beträgt den größeren Wert
von entweder der RAM-Größe oder 4 GB. Die Mindestgröße (ursprüngliche Größe) wird wie
folgt bestimmt:
QQ Bei der ersten vom System verwalteten Auslagerungsdatei wird die Basisgröße aufgrund
des Verlaufs berechnet, anderenfalls auf der Grundlage des RAM (siehe Tabelle 5–12).
QQ Bei der ersten vom System verwalteten Auslagerungsdatei wird danach wie folgt vorgegangen:
•
Ist die Basisgröße kleiner als die berechnete Größe für Anwendungen (SmpDesiredPfSizeForApps), so wird die Basisgröße auf diese Größe gesetzt.
•
444
Ist die Basisgröße (danach) kleiner als die Größe für Absturzabbilder (SmpDesiredPfSizeForCrashDump), so wird die Basisgröße auf diese Größe gesetzt.
Kapitel 5
Speicherverwaltung
Experiment: Auslagerungsdateien einsehen
Eine Liste der Auslagerungsdateien finden Sie im Registrierungswert PagingFiles unter
HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management. Dieser Eintrag enthält die Konfigurationseinstellung für die Auslagerungsdatei, die Sie im Dialogfeld
Erweiterte Systemeinstellungen anpassen können. Um auf diese Einstellungen zuzugreifen,
gehen Sie wie folgt vor:
1.
Öffnen Sie die Systemsteuerung.
2.
Klicken Sie auf System und Sicherheit und dann auf System. Dadurch wird das Dialogfeld Systemeigenschaften geöffnet, das Sie auch durch einen Rechtsklick auf Computer
im Explorer und die Auswahl von Eigenschaften erreichen können.
3.
Klicken Sie auf Erweiterte Systemeinstellungen.
4.
Klicken Sie im Abschnitt Leistung auf Einstellungen. Dadurch wird das Dialogfeld Leistungsoptionen geöffnet.
5.
Klicken Sie auf die Registerkarte Erweitert.
6.
Klicken Sie im Abschnitt Virtueller Arbeitsspeicher auf Ändern.
Experiment: Die empfohlenen Größen für Auslagerungsdateien
einsehen
Um sich die in Tabelle 5–12 berechneten Variablen anzusehen, gehen Sie wie folgt vor (hier
auf einem x86-System mit Windows 10):
1.
Starten Sie den lokalen Kerneldebugger.
2.
Machen Sie den Prozess Smss.exe ausfindig:
lkd> !process 0 0 smss.exe
PROCESS 8e54bc40 SessionId: none Cid: 0130 Peb: 02bab000 ParentCid: 0004
DirBase: bffe0020 ObjectTable: 8a767640 HandleCount: <Data Not
Accessible>
Image: smss.exe
PROCESS 9985bc40 SessionId: 1 Cid: 01d4 Peb: 02f9c000 ParentCid: 0130
DirBase: bffe0080 ObjectTable: 00000000 HandleCount: 0.
Image: smss.exe
PROCESS a122dc40 SessionId: 2 Cid: 02a8 Peb: 02fcd000 ParentCid: 0130
DirBase: bffe0320 ObjectTable: 00000000 HandleCount: 0.
Image: smss.exe
→
Seitenfehler
Kapitel 5
445
3.
Suchen Sie die erste Instanz (mit der Sitzung-ID none), also die Master-Instanz von Smss.
exe (siehe Kapitel 2).
4.
Schalten Sie den Debugger auf den Kontext dieses Prozesses um:
lkd> .process /r /p 8e54bc40
Implicit process is now 8e54bc40
Loading User Symbols
..
5.
Lassen Sie sich die vier zuvor beschriebenen Variablen anzeigen. (Sie sind jeweils 64 Bits
groß.)
lkd> dq smss!SmpDesiredPfSizeBasedOnRAM L1
00974cd0 00000000'4fff1a00
lkd> dq smss!SmpDesiredPfSizeBasedOnHistory L1
00974cd8 00000000'05a24700
lkd> dq smss!SmpDesiredPfSizeForCrashDump L1
00974cc8 00000000'1ffecd55
lkd> dq smss!SmpDesiredPfSizeForApps L1
00974ce0 00000000'00000000
6.
Da der Computer nur ein einziges Volume hat (C:\), wird auch nur eine einzige Auslagerungsdatei erstellt. Wenn keine besondere Konfiguration vorliegt, wird sie vom
System verwaltet. Sie können sich die tatsächliche Größe von C:\PageFile.sys auf der
Festplatte ansehen oder den Debuggerbefehl !vm verwenden:
lkd> !vm 1
Page File: \??\C:\pagefile.sys
Current:
524288 Kb Free Space:
Minimum:
524288 Kb Maximum:
524280 Kb
8324476 Kb
Page File: \??\C:\swapfile.sys
Current:
262144 Kb Free Space:
Minimum:
262144 Kb Maximum:
262136 Kb
4717900 Kb
No Name for Paging File
Current: 11469744 Kb Free Space: 11443108 Kb
Minimum: 11469744 Kb Maximum:
11469744 Kb
...
Die Mindestgröße von C:\PageFile.sys beträgt 524.288 KB. (Was es mit den anderen Einträgen zur Auslagerungsdatei zu tun hat, schauen wir uns im nächsten Abschnitt an.) Wie
Sie zuvor gesehen haben, ist von den Variablen SmpDesiredPfSizeForCrashDump die größte,
weshalb sie der bestimmende Faktor ist (0x1FFECD55 = 524.211 KB). Dieser Wert liegt sehr
nah an dem angezeigten Wert. (Die Größen von Auslagerungsdateien werden auf Mehrfache von 64 MB gerundet.)
446
Kapitel 5
Speicherverwaltung
Um eine neue Auslagerungsdatei hinzuzufügen, verwendet die Systemsteuerung den internen Systemdienst NtCreatePagingFile, der in Ntdll.dll definiert ist. Auslagerungsdateien werden immer nicht komprimiert erstellt, auch wenn das Verzeichnis, in dem sie sich befinden,
komprimiert ist. Bis auf einige Ausnahmen, die im nächsten Abschnitt beschrieben werden,
tragen sie den Namen PageFile.sys. Sie werden im Stamm der Partition mit dem Dateiattribut
Versteckt erstellt, damit sie nicht unmittelbar sichtbar sind. Um zu verhindern, dass neue Auslagerungsdateien gelöscht werden, wird dem Systemprozess ein Duplikat des Handles gegeben,
sodass auch dann, wenn der Erstellerprozess sein Handle schließt, immer ein offenes Handle
vorhanden ist.
Die UWP-Auslagerungsdatei
Wenn eine UWP-App in den Hintergrund übergeht – etwa wenn sie minimiert wird –, werden
die Threads in ihrem Prozess angehalten, sodass der Prozess keine CPU-Ressourcen verbraucht.
Bei hoher Speicherbelastung kann der Arbeitssatz dieses Prozesses, also der von ihm verwendete private physische Arbeitsspeicher, auf die Festplatte ausgelagert werden, sodass andere
Prozesse den Speicher nutzen können.
In Windows 8 wurde eine besondere Auslagerungsdatei hinzugefügt, die ausschließlich
für UWP-Anwendungen verwendet wird. Im Grunde genommen unterscheidet sie sich jedoch
nicht von der regulären Auslagerungsdatei. (In der deutschen Microsoft-Terminologie wird sie
auch schlicht als »Auslagerungsdatei« bezeichnet, obwohl im englischen Windows zwischen
der regulären »page file« und dieser »swap file« unterschieden wird.) Auf Client-SKUs wird
sie nur dann erstellt, wenn es bereits mindestens eine reguläre Auslagerungsdatei gibt (was
normalerweise der Fall ist). Sie befindet sich als SwapFile.sys in der Systemstammpartition, zum
Beispiel C:\SwapFile.sys.
Nachdem die regulären Auslagerungsdateien erstellt worden sind, wird der Registrierungsschlüssel HKLM\System\CurrentControlSet\Control\SessionManager\Memory Management untersucht. Ist dort ein DWORD-Wert namens SwapFileControl vorhanden und auf 0 gesetzt, so wird
keine UWP-Auslagerungsdatei erstellt. Existiert dort dagegen ein Wert namens SwapFile, so
wird er als String mit demselben Format wie für eine reguläre Auslagerungsdatei gelesen, also
mit einem Dateinamen, einer Anfangs- und einer Höchstgröße. Der Unterschied zu dem String
für eine reguläre Auslagerungsdatei besteht darin, dass bei einem Wert von 0 für die Größen
keine UWP-Auslagerungsdatei erstellt wird. Da diese beiden Registrierungswerte standardmäßig nicht vorhanden sind, wird in der Systemstammpartition SwapFile.sys mit einer Mindestgröße von 16 MB auf schnellen (und kleinen) Festplatten (z. B. SSD) bzw. 256 MB auf langsamen
Festplatten (oder großen SSD-Festplatten) erstellt. Als Maximalgröße der UWP-Austauschdatei
wird der kleinere Wert von entweder 1,5 * RAM oder 10 % der Systemstammpartition festgelegt. Mehr über UWP-Apps erfahren Sie in Kapitel 7 dieses Buches sowie in Kapitel 8 und 9 von
Band 2.
Die UWP-Auslagerungsdatei wird bei der Höchstzahl der möglichen Auslagerungsdateien nicht mitgezählt.
Seitenfehler
Kapitel 5
447
Die virtuelle Auslagerungsdatei
In der Ausgabe des Debuggerbefehls !vm haben Sie noch eine weitere Auslagerungsdatei gesehen, die als No Name for Paging File gekennzeichnet war. Dies ist eine virtuelle Auslagerungsdatei. Wie der Name schon andeutet, ist mit ihr keine echte Datei verbunden. Stattdessen
dient sie indirekt als Hintergrundspeicher für die Speicherkomprimierung (die wir weiter hinten
in diesem Kapitel im Abschnitt »Speicherkomprimierung« eingehender betrachten werden). Sie
ist sehr groß, doch ihre Größe wird willkürlich festgelegt, damit ihr der freie Speicher nicht
ausgeht. Ungültige PTEs für Seiten, die komprimiert wurden, zeigen auf diese virtuelle Auslagerungsdatei. Dadurch kann der Komprimierungsspeicher komprimierte Daten bei Bedarf abrufen, indem er die Bits in diesen ungültigen PTEs untersucht und sich von ihnen zum richtigen
Index in der richtigen Region des richtigen Speichers führen lässt.
Experiment: Informationen über die UWP- und die virtuelle
Auslagerungsdatei einsehen
Der Debuggerbefehl !vm zeigt Informationen über alle Auslagerungsdateien an, einschließlich der UWP- und der virtuellen Auslagerungsdatei.
lkd> !vm 1
Page File: \??\C:\pagefile.sys
Current: 524288 Kb Free Space: 524280 Kb
Minimum: 524288 Kb Maximum: 8324476 Kb
Page File: \??\C:\swapfile.sys
Current: 262144 Kb Free Space: 262136 Kb
Minimum: 262144 Kb Maximum: 4717900 Kb
No Name for Paging File
Current: 11469744 Kb Free Space: 11443108 Kb
Minimum: 11469744 Kb Maximum: 11469744 Kb
Auf diesem System hat die UWP-Auslagerungsdatei eine Mindestgröße von 256 MB, da es
sich bei ihm um eine VM mit Windows 10 handelt und die VHD als langsame Festplatte angesehen wird. Der RAM auf dem System beträgt 3 GB und die Festplattenpartition umfasst
64 GB. Als Maximalgröße wird daher der kleinere Wert von 4,5 GB (1,5 * RAM) und 6,4 GB
(10 % der Festplattengröße) genommen, also 4,5 GB.
Gesamter zugesicherter Speicher und systemweiter
Zusicherungsgrenzwert
Inzwischen verfügen Sie über ausreichend Kenntnisse, um sich eingehender mit dem gesamten zugesicherten Speicher und dem systemweiten Zusicherungsgrenzwert beschäftigen zu
können.
Wenn virtueller Adressraum erstellt wird – z. B. durch VirtualAlloc für zugesicherten
Speicher oder durch MapViewOfFile –, muss das System dafür sorgen, dass entweder im RAM
448
Kapitel 5
Speicherverwaltung
oder im Hintergrundspeicher genügend Platz dafür vorhanden ist. Für zugeordneten Speicher
(außer den Abschnitten, die Auslagerungsdateien zugeordnet sind) bildet die Datei, die mit
dem im MapViewOfFile-Aufruf genannten Zuordnungsobjekt verbunden ist, den erforderlichen
Hintergrundspeicher. Bei allen anderen virtuellen Zuweisungen wird auf die vom System verwalteten gemeinsam genutzten Speicherressourcen zurückgegriffen, also den RAM und die
Auslagerungsdateien. Der gesamte zugesicherte Speicher und der systemweite Zusicherungsgrenzwert dienen dazu, die Übersicht über alle diese Ressourcen zu wahren, damit es nie zu
einer Überzusicherung kommen kann, das heißt, damit niemals mehr virtueller Adressraum
definiert wird, als Platz zur Speicherung seiner Inhalte im RAM und im Hintergrundspeicher
(auf der Festplatte) zur Verfügung steht.
In diesem Abschnitt werden häufig die Auslagerungsdateien erwähnt. Es ist durchaus möglich (im Allgemeinen aber nicht empfehlenswert), Windows ohne jegliche
Auslagerungsdateien zu betreiben. Wenn der RAM erschöpft ist, gibt es dann keinen Ausweichplatz mehr, sodass Speicherzuweisungen fehlschlagen. Das führt zu
einem Bluescreen. Bei jedem Hinweis auf eine Auslagerungsdatei können Sie im
Stillen ergänzen: »... falls mindestens eine Auslagerungsdatei vorhanden ist.«
Der systemweite Zusicherungsgrenzwert gibt an, wie viel zugesicherter virtueller Adressraum
insgesamt erstellt werden kann – neben den virtuellen Zuweisungen, die über ihren eigenen
Hintergrundspeicher verfügen, also neben den Abschnitten, die Dateien zugeordnet sind. Der
numerische Wert ist einfach die Menge des RAM, die für Windows zur Verfügung steht, zuzüglich der aktuellen Größen aller vorhandenen Auslagerungsdateien. Wird eine Auslagerungsdatei erweitert oder eine neue erstellt, so wird der Zuweisungsgrenzwert entsprechend erhöht.
Ist keine Auslagerungsdatei vorhanden, so entspricht der systemweite Zusicherungsgrenzwert
einfach der Gesamtmenge des für Windows verfügbaren RAM.
Der gesamte zugesicherte Speicher ist die systemweite Summe sämtlicher zugesicherten
Speicherzuweisungen, die im RAM oder in einer Auslagerungsdatei gehalten werden müssen.
Dazu tragen neben den privaten zugesicherten Adressräumen der Prozesse auch noch viele
andere, weniger offensichtliche Dinge bei.
Windows führt auch die Prozessquote für die Auslagerungsdatei. Viele der Zuweisungen
tragen nicht nur zum gesamten zugesicherten Speicher, sondern auch zu dieser Quote bei. Sie
steht jeweils für den privaten Beitrag des Prozesses zum gesamten zugesicherten Speicher. Allerdings gibt sie nicht die aktuelle Nutzung der Auslagerungsdatei an, sondern die potenzielle
oder maximal mögliche Nutzung, wenn alle diese Zuweisungen dort gespeichert würden.
Die folgenden Arten von Speicherzuweisungen tragen zum gesamten zugesicherten Speicher und in vielen Fällen auch zur Prozessquote für die Auslagerungsdatei bei. Einige von ihnen
sehen wir uns in späteren Abschnitten dieses Kapitels noch genauer an.
QQ Privater zugesicherter Speicher Hierbei handelt es sich um den Speicher, der mit
V irtualAlloc und der Option MEM_COMMIT zugewiesen wird. Dies sind die üblichsten Zuweisungen, die zum gesamten zugesicherten Speicher und auch zur Prozessquote für die
Auslagerungsdatei beitragen.
Seitenfehler
Kapitel 5
449
QQ Auslagerungsgepufferter, zugeordneter Speicher Dieser Speicher wird mit einem
Aufruf von MapViewOfFile zugesichert, der auf ein nicht mit einer Datei verknüpftes Abschnittsobjekt verweist. Stattdessen verwendet das System einen Teil der Auslagerungsdatei als Hintergrundspeicher. Diese Zuweisungen werden der Prozessquote für die Auslagerungsdatei nicht angerechnet.
QQ Copy-on-Write-Regionen des zugeordneten Speichers (einschließlich solcher, die
mit regulären zugeordneten Dateien verknüpft sind) Die zugeordnete Datei bildet
den Hintergrundspeicher für ihren eigenen nicht modifizierten Inhalt. Wird eine Seite in
einer Copy-on-Write-Region geändert, kann sie die ursprünglich zugeordnete Datei nicht
mehr als Hintergrundspeicher nutzen, sondern muss im RAM festgehalten oder in eine
Auslagerungsdatei gestellt werden. Diese Zuweisungen werden der Prozessquote für die
Auslagerungsdatei nicht angerechnet.
QQ Zuweisungen aus dem nicht ausgelagerten und dem ausgelagerten Pool sowie andere Zuweisungen im Systemraum, die nicht ausdrücklich über zugehörige Dateien
als Hintergrundspeicher verfügen Selbst die zurzeit freien Regionen der Systemspeicherpools tragen zum gesamten zugesicherten Speicher bei. Die nicht auslagerungsfähigen Regionen werden beim gesamten zugesicherten Speicher mitgezählt, auch wenn sie
niemals in eine Auslagerungsdatei geschrieben werden, da sie den für private auslagerungsfähige Daten verfügbaren RAM dauerhaft verringern. Diese Zuweisungen werden der
Prozessquote für die Auslagerungsdatei nicht angerechnet.
QQ Kernelstacks
Threadstacks bei der Ausführung im Kernelmodus.
QQ Seitentabellen Die meisten davon können selbst ausgelagert werden und haben keine
zugeordnete Dateien als Hintergrundspeicher. Wenn sie aber nicht auslagerungsfähig sind,
nehmen sie RAM ein. Daher trägt der für sie benötigte Platz zum gesamten zugesicherten
Speicher bei.
QQ Platz für noch nicht zugewiesene Seitentabellen Wenn große Bereiche des virtuellen
Adressraums zwar definiert wurden, aber noch kein Zugriff auf sie erfolgt ist (z. B. bei privatem zugesichertem virtuellem Adressraum), muss das System noch keine Seitentabellen
dafür erstellen. Der Platz für diese noch nicht vorhandenen Seitentabellen wird jedoch
dem gesamten zugesicherten Speicher zugeschlagen, damit die Seitentabellen bei Bedarf
angelegt werden können.
QQ Zuweisungen von physischem Speicher über AWE-APIs Wie bereits erwähnt, verbrauchen solche Zuweisungen direkt physischen Arbeitsspeicher.
Bei vielen dieser Punkte steht der Beitrag zum gesamten zugesicherten Speicher nur für eine
mögliche und nicht für die tatsächliche Nutzung des Speichers. Beispielsweise nimmt eine Seite
im privaten zugesicherten Speicher erst dann tatsächlich eine physische Seite im RAM oder den
entsprechenden Platz in der Auslagerungsdatei ein, wenn mindestens einmal auf sie verwiesen
wurde. Bis dahin handelt es sich um eine Nullforderungsseite (was weiter hinten erklärt wird).
Beim gesamten zugesicherten Speicher wird diese Seite jedoch mitgezählt, wenn der virtuelle
Speicher für sie angelegt wird. Dadurch ist garantiert, dass der physische Speicher verfügbar ist,
wenn später auf die Seite verwiesen wird.
450
Kapitel 5
Speicherverwaltung
Bei Copy-on-Write-Regionen für zugeordnete Dateien gilt Ähnliches. Bis der Prozess in die
Region schreibt, verwenden alle Seiten darin die zugeordnete Datei als Hintergrundspeicher.
Allerdings kann der Prozess jederzeit auf irgendeine dieser Seiten schreiben, und wenn das
geschieht, werden diese Seiten anschließend als private Seiten des Prozesses betrachtet, sodass
dann die Auslagerungsdatei ihren Hintergrundspeicher bildet. Da die Region beim Erstellen
dem gesamten zugesicherten Speicher zugeschlagen wird, ist garantiert, dass später bei einem
Schreibzugriff privater Speicher für sie zur Verfügung steht.
Ein besonderer Fall liegt vor, wenn privater Speicher reserviert und später zugesichert wird.
Wurde die reservierte Region mit VirtualAlloc erstellt, wird sie nicht auf den gesamten zugesicherten Speicher angerechnet. In Windows 8 und Windows Server 2012 sowie früheren Versionen wurden jedoch alle Seiten für neue Seitentabellen angerechnet, die zur Beschreibung
dieser Region erforderlich sind, auch wenn sie noch gar nicht existieren oder möglicherweise
nie benötigt werden. Ab Windows 8.1 und Windows Server 2012 R2 werden die Seitentabellenhierarchien für reservierte Regionen jedoch nicht mehr sofort angerechnet. Dadurch können
riesige reservierte Regionen ohne Seitentabellen zugewiesen werden, ohne den den Speicher
zu erschöpfen, was insbesondere für einige Sicherheitseinrichtungen wie Control Flow Guard
(siehe Kapitel 7) wichtig ist. Wird die Region oder ein Teil davon später zugesichert, so wird die
Größe dieser Region und ihrer Seitentabellen auf den gesamten zugesicherten Speicher und
die Prozessquote für die Auslagerungsdatei angerechnet.
Anders ausgedrückt: Wenn das System eine VirtualAlloc-Zusicherung oder einen
MapViewOfFile-Aufruf erfolgreich abschließt, garantiert es, dass der erforderliche Speicher bei
Bedarf verfügbar sein wird, auch wenn er zurzeit nicht gebraucht wird. Dadurch können spätere Speicherverweise auf die zugewiesene Region niemals aufgrund von Speichermangel fehlschlagen (allerdings immer noch aus anderen Gründen, z. B. den Seitenschutzeinstellungen, der
Aufhebung der Zuweisung für die Region usw.). Der Mechanismus für die Anrechnung auf den
gesamten zugesicherten Speicher ermöglicht es dem System, seine Zusicherungen einzuhalten.
In der Leistungsüberwachung wird der gesamte zugesicherte Speicher mit dem Indikator
Arbeitsspeicher: Zugesicherte Bytes angezeigt. Sie finden ihn auch als die erste der beiden Zahlen unter der Beschriftung Commit ausgeführt auf der Registerkarte Leistung des Task-Managers
(wobei die zweite Zahl den Zusicherungsgrenzwert angibt) und als Commit Charge – Current
auf der Registerkarte Memory des Dialogfelds System Information von Process Explorer.
Die Prozessquote für die Auslagerungsdatei wird in den Leistungsindikatoren Prozess: Auslagerungsdatei (Bytes) und Prozess: Private Bytes angezeigt. Keiner dieser beiden Begriffe beschreibt die Bedeutung dieses Indikators jedoch korrekt.
Wenn der gesamte zugesicherte Speicher den Zuweisungsgrenzwert erreicht, versucht der
Speicher-Manager, den Grenzwert zu erhöhen, indem er eine oder mehrere Auslagerungsdateien vergrößert. Falls das nicht möglich ist, schlagen anschließende Versuche zur Zuweisung
von virtuellem Arbeitsspeicher fehl, der auf den gesamten zugesicherten Arbeitsspeicher angerechnet wird, bis bereits vorhandener zugesicherter Speicher freigegeben wird. Mit den in
Tabelle 5–13 aufgeführten Leistungsindikatoren können Sie die Nutzung von privatem zugesichertem Speicher für das gesamte System, für einzelne Prozesse und für einzelne Auslagerungsdateien untersuchen.
Seitenfehler
Kapitel 5
451
Leistungsindikator
Beschreibung
Arbeitsspeicher: Zugesicherte Bytes
Dies ist die Größe (in Bytes) des virtuellen (nicht reservierten) Speichers, der zugesichert wurde. Sie gibt
nicht unbedingt die Nutzung der Auslagerungsdatei
wieder, da darin auch private zugesicherte Seiten
im physischen Speicher enthalten sind, die niemals
ausgelagert wurden. Tatsächlich steht sie für die angerechnete Menge des zugesicherten Speichers, für
den Platz in der Auslagerungsdatei oder im RAM zur
Verfügung stehen muss.
Arbeitsspeicher: Zusagegrenzwert
Dies ist die Größe (in Bytes) des virtuellen Speichers,
der zugesichert werden kann, ohne die Auslagerungsdateien erweitern zu müssen. Ist eine Vergrößerung
der Auslagerungsdateien möglich, so ist dies ein weicher Grenzwert.
Prozess: Quoten für Auslagerungsdatei
Dies ist der Beitrag des Prozesses zu Arbeitsspeicher:
Zugesicherte Bytes.
Prozess: Private Bytes
Identisch mit Prozess: Quoten für Auslagerungsdatei
Prozess: Arbeitsseiten – privat
Dies ist der Anteil von Prozess: Quoten für Auslagerungsdatei, der sich zurzeit im RAM befindet und auf
den ohne Seitenfehler verwiesen werden kann. Dies
ist auch ein Anteil von Prozess: Arbeitsseiten.
Prozess: Arbeitsseiten
Dies ist der Anteil von Prozess: Virtuelle Bytes, der sich
zurzeit im RAM befindet und auf den ohne Seitenfehler verwiesen werden kann.
Prozess: Virtuelle Größe
Dies ist der Gesamtumfang der virtuellen Speicherzuweisungen des Prozesses einschließlich zugeordneter,
privater zugesicherter und privater reservierter Regio
nen.
Auslagerungsdatei: Belegung (%)
Dies ist der prozentuale Anteil des Platzes in der Auslagerungsdatei, der zurzeit verwendet wird.
Auslagerungsdatei: Maximale Belegung (%)
Dies ist der höchste bisher aufgetretene Wert von
Auslagerungsdatei: Belegung (%).
Tabelle 5–13 Leistungsindikatoren für zugesicherten Speicher und Auslagerungsdateien
Der Zusammenhang zwischen dem gesamten zugesicherten
Speicher und der Größe der Auslagerungsdatei
Anhand der Zähler in Tabelle 5–13 können Sie die Größe der Auslagerungsdatei auch selbst
bestimmen. Da die Standardfestlegung auf der Größe des RAM beruht, ist er für die meisten
Rechner geeignet, doch je nach Arbeitslast kann die resultierende Auslagerungsdatei dabei
auch unnötig groß oder zu klein sein.
Um zu ermitteln, wie viel Platz in der Auslagerungsdatei wirklich für die Anwendungen
gebraucht wird, die seit dem Systemstart ausgeführt wurden, schauen Sie sich den Spitzenwert
des gesamten zugesicherten Speichers (Commit Charge – Peak) auf der Registerkarte Memory
des Dialogfelds System Information von Process Explorer an. Diese Zahl gibt die maximale Größe der Auslagerungsdatei an, die seit dem Systemstart nötig gewesen wäre, wenn das System
452
Kapitel 5
Speicherverwaltung
den Großteil des privaten zugesicherten virtuellen Speichers auslagern müsste (was selten der
Fall ist).
Wenn die Auslagerungsdatei auf Ihrem System zu groß ist, verwendet das System sie auch
nicht mehr oder weniger als sonst. Anders ausgedrückt, die Vergrößerung der Auslagerungsdatei ändert die Systemleistung nicht, sondern bedeutet lediglich, dass das System über mehr
zugesicherten virtuellen Speicher verfügt. Ist die Auslagerungsdatei zu klein für die ausgeführten Anwendungen, kann es vorkommen, dass eine Fehlermeldung über mangelnden virtuellen
Speicher angezeigt wird. Prüfen Sie in einem solchen Fall, ob einer der Prozesse ein Speicherleck aufweist, indem Sie sich die Anzahl seiner privaten Bytes ansehen. Scheint es kein Leck zu
geben, so überprüfen Sie die Größe des ausgelagerten Systempools. Wenn ein Gerätetreiber
ein Speicherleck in diesem Pool aufweist, kann ebenfalls die Fehlermeldung auftreten. Wie Sie
weiter vorgehen, erfahren Sie im Experiment »Fehlerbehebung bei einem Poolleck« im Abschnitt »Kernelmodusheaps (Systemspeicherpools)« weiter vorn in diesem Kapitel.
Experiment: Die Nutzung der Auslagerungsdatei im TaskManager untersuchen
Sie können sich die Nutzung des zugesicherten Speichers auch im Task-Manager ansehen.
Auf der Registerkarte Leistung finden Sie dort die folgenden Indikatoren im Zusammenhang mit Auslagerungsdateien:
→
Seitenfehler
Kapitel 5
453
Unter Commit ausgeführt finden Sie zwei Zahlen für den gesamten zugesicherten Speicher.
Die erste gibt nicht die tatsächliche, sondern die mögliche Nutzung der Auslagerungsdatei an, also wie viel Platz in der Auslagerungsdatei gebraucht würde, wenn der gesamte
private zugesicherte virtuelle Speicher im System auf einmal ausgelagert werden müsste.
Die zweite Zahl ist der Zusicherungsgrenzwert, also die Höchstmenge an virtuellem Speicher, die das System zur Verfügung stellen kann. Dies schließt sowohl den auslagerungsgepufferten virtuellen Speicher ein als auch denjenigen, der den physischen Speicher als
Hintergrundspeicher nutzt. Dieser Grenzwert ergibt sich aus der Größe des RAM plus der
aktuellen Größe der Auslagerungsdateien, also ohne Berücksichtigung möglicher Erweiterungen der Auslagerungsdatei.
Im Dialogfeld System Information von Process Explorer finden Sie noch eine weitere Information über die Nutzung des zugesicherten Speichers, nämlich das Verhältnis des
Spitzenwerts und der aktuellen Nutzung zum Grenzwert:
Stacks
Wenn ein Thread ausgeführt wird, muss er Zugriff auf einen temporären Speicherort für Funktionsparameter, lokale Variablen und die Rückkehradresse haben. Dieser Teil des Speichers wird
als Stack bezeichnet. In Windows stellt der Speicher-Manager für jeden Thread zwei Stacks
bereit, nämlich den Benutzer- und den Kernelstack. Darüber hinaus hat jeder Prozessor noch
seinen DPC-Stack. In Kapitel 2 wurde kurz beschrieben, wie Systemaufrufe ein Umschalten des
Threads von seinem Benutzer- zum Kernelstack verursachen. Jetzt wollen wir uns einige zusätzliche Dienste ansehen, die der Speicher-Manager für die effiziente Nutzung des Platzes für den
Benutzerstack zur Verfügung stellt.
454
Kapitel 5
Speicherverwaltung
Benutzerstacks
Beim Erstellen eines Threads reserviert der Speicher-Manager automatisch eine zuvor festgelegte Menge an virtuellem Speicher, standardmäßig 1 MB. Diesen Betrag können Sie mit den
Funktionen CreateThread und CreateRemoteThread(Ex) festlegen, aber auch beim Kompilieren
der Anwendung mit dem Schalter /STACK:reserve des C/C++-Compilers von Microsoft in den
Abbildheader aufnehmen. Es wird zwar 1 MB reserviert, doch nur die erste Seite des Stacks
sowie eine Wächterseite werden zugesichert (es sei denn, im PE-Header des Abbilds ist etwas
anderes festgelegt). Wenn der Stack so weit wächst, dass er die Wächterseite erreicht, wird eine
Ausnahme ausgelöst, durch die wiederum versucht wird, eine weitere Wächterseite zuzuweisen.
Dank dieses Mechanismus verbraucht der Stack nicht sofort alle 1 MB des zugesicherten Speichers, sondern wächst bei Bedarf. Allerdings kann er nicht wieder schrumpfen.
Experiment: Die maximale Anzahl an Threads erstellen
Während für jeden 32-Bit-Prozess nur 2 GB Benutzeradressraum zur Verfügung stehen, wird
für die Stacks der einzelnen Threads jeweils eine relativ große Menge an Speicher reserviert.
Daraus lässt sich leicht die höchstmögliche Anzahl an Threads in einem Prozess errechnen:
Es sind knapp 2048 für fast 2 GB (also ohne die Verwendung der BCD-Option increaseuserva, durch die das Abbild einen größeren Adressraum nutzen kann). Wenn wir dafür sorgen,
dass jeder neue Thread nur die kleinstmögliche Stackreservierungsgröße von 64 KB nutzt,
können wir diesen Grenzwert jedoch auf ca. 30.000 Threads erweitern. Das können Sie mit
TestLimit von Sysinternals selbst ausprobieren. Betrachten Sie die folgende Beispielausgabe:
C:\Tools\Sysinternals>Testlimit.exe -t -n 64
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 17260
Creating threads with 64 KB stacks...
Created 29900 threads. Lasterror: 8
Auf einer 64-Bit-Windows-Installation, auf der 128 TB an Benutzeradressraum zur Verfügung stehen, sollte man eigentlich Hunderttausende von Threads erwarten (sofern genügend Speicher verfügbar ist). Tatsächlich aber legt TestLimit weniger Threads an als auf
einem 32-Bit-Rechner. Das liegt daran, dass TestLimit.exe eine 32-Bit-Anwendung ist und
daher in der Wow64-Umgebung läuft (siehe Kapitel 8 in Band 2). Dabei hat jeder Thread
aber neben seinem 32-Bit-Wow64-Stack auch noch seinen 64-Bit-Stack, sodass er doppelt
so viel Speicher dafür verbraucht, während ihm gleichzeitig nur 2 GB an Adressraum zur
Verfügung stehen. Um den Grenzwert für die Threadanzahl auf 64-Bit-Windows korrekt zu
prüfen, müssen Sie daher TestLimit64.exe verwenden.
→
Stacks
Kapitel 5
455
Um TestLimit abzubrechen, müssen Sie Process Explorer oder den Task-Manager verwenden. Mit (Strg) + (C) geht es nicht, da für diese Operation selbst ein neuer Thread
angelegt werden muss, was nicht mehr möglich ist, wenn der Speicher erschöpft ist.
Kernelstacks
Während die typische Größe von Benutzerstacks 1 MB beträgt, wird für den Kernelstack erheblich weniger Speicher zur Verfügung gestellt, nämlich 12 KB auf 32- und 16 KB auf 64-Bit-Systemen. Hinzu kommt noch die Wächterseite, sodass sich insgesamt 16 bzw. 20 KB ergeben.
Im Kernel ausgeführter Code soll weniger rekursiv sein als Benutzercode, Variablen effizienter
verwenden und den Umfang der Stackpuffer gering halten. Da sich die Kernelstacks im System
adressraum befinden (der von allen Prozessen gemeinsam genutzt wird), hat ihre Speichernutzung eine stärkere Auswirkung auf das System.
Kernelcode ist zwar gewöhnlich nicht rekursiv, doch Interaktionen zwischen Grafiksystemaufrufen, die von Win32k.sys gehandhabt werden, und nachfolgenden Callbacks in den
Benutzermodus können rekursive Wiedereintrittsvorgänge in den Kernel auf demselben Kernelstack hervorrufen. Daher stellt Windows einen Mechanismus bereit, um den Kernelstack
von seiner ursprünglichen Größe zu erweitern und wieder zu schrumpfen. Bei jedem weiteren
Grafikaufruf des Threads werden weitere 16 KB Speicher für den Kernelstack zugewiesen. (Dies
kann irgendwo im Systemadressraum geschehen. Der Speicher-Manager bietet die Möglichkeit, bei der Annäherung an die Wächterseite zu einem anderen Stack zu springen.) Wenn ein
Aufruf die Steuerung an den Aufrufer zurückgibt (»abwickelt«), gibt der Speicher-Manager
den dafür zugewiesenen zusätzlichen Kernelstack wieder frei (siehe Abb. 5–28). Dieser Mechanismus ermöglicht eine zuverlässige Ausführung rekursiver Systemaufrufe bei gleichzeitiger effizienter Nutzung des Systemadressraums. Er wird von Treiberentwicklern bei rekursiven
Callouts durch die KeExpandKernelStackAndCallout(Ex)-APIs bei Bedarf zur Verfügung gestellt.
Kernelmodusstack mit 16/20 KB
Zusätzlicher Stack mit 16/20 KB
Zusätzlicher Stack mit 16/20 KB
Abbildung 5–28 Springen zwischen den Kernelstacks
456
Kapitel 5
Speicherverwaltung
Abwickeln beim Abschluss
der verschachtelten Callbacks
Experiment: Die Nutzung des Kernelstacks untersuchen
Mit dem Sysinternals-Tools RamMap können Sie sich ansehen, wie viel physischen Speicher die Kernelstacks zurzeit belegen. Der folgende Screenshot zeigt die Registerkarte Use
Counts dieses Programms:
Um sich die Nutzung der Kernelstacks anzusehen, gehen Sie wie folgt vor:
1.
Wiederholen Sie das vorherige TestLimit-Experiment, beenden Sie TestLimit aber nicht.
2.
Wechseln Sie zu RamMap.
3.
Öffnen Sie das Menü File und klicken Sie auf Refresh (oder drücken Sie (F5)). Jetzt wird
eine viel höhere Größe für die Kernelstacks angezeigt:
Wenn Sie TestLimit mehrere Male ausführen, ohne die vorherigen Instanzen zu schließen,
können Sie auf einem 32-Bit-System den physischen Speicher sehr leicht erschöpfen. Daraus ergibt sich eine der wichtigsten Beschränkungen für die systemweite Threadanzahl auf
32-Bit-Systemen.
Der DPC-Stack
Windows hält für jeden Prozessor einen DPC-Stack bereit, den das System nutzen kann, wenn
DPCs ausgeführt werden. Dadurch wird der DPC-Code vom Kernelstack des laufenden Threads
getrennt, der schließlich gar nichts mit der DPC-Operation zu tun hat, da DPCs in einem willkürlichen Threadkontext ausgeführt werden (siehe Kapitel 6). Der DPC-Stack ist auch als Anfangsstack für die Handhabung der Anweisung sysenter (x86), svc (ARM) bzw. syscall (x64)
während eines Systemaufrufs eingerichtet. Die CPU ist dafür zuständig, den Stack zu wechseln,
wenn diese Anweisungen ausgeführt werden. Dazu zieht sie ein vom Modell abhängiges Register heran (ein MSR auf x86/x64). Eine Umprogrammierung des MSR bei jedem Kontextwechsel
wäre jedoch eine ziemlich kostspielige Operation, weshalb Windows im MSR nur einen Zeiger
auf den DPC-Stack des Prozessors einrichtet.
VADs
Der Speicher-Manager verwendet einen bedarfsgesteuerten Auslagerungsmechanismus, um
zu erfahren, wann er Seiten in den Arbeitsspeicher laden soll. Dabei wartet er, bis ein Thread
auf eine Adresse verweist und einen Seitenfehler hervorruft, bevor er die Seite von der Festplatte zurückholt. Ebenso wie das Kopieren beim Schreiben ist auch dieser Mechanismus eine
VADs
Kapitel 5
457
Form von verzögerter Auswertung – die Erledigung einer Aufgabe wird bis zu dem Zeitpunkt
verschoben, an dem sie tatsächlich erforderlich ist.
Der Speicher-Manager setzt die verzögerte Auswertung nicht nur ein, um Seiten in den
Arbeitsspeicher zurückzuholen, sondern auch, um die zur Beschreibung neuer Seiten erforderlichen Seitentabellen anzulegen. Wenn ein Thread mit VirtualAlloc eine umfangreiche Region
im virtuellen Speicher zusichert, könnte der Speicher-Manager die für den Zugriff auf diese
Region erforderlichen Seitentabellen sofort erstellen. Was aber, wenn auf einige Teile dieser
Region niemals zugegriffen wird? Seitentabellen für die gesamte Region zu erstellen wäre Verschwendung. Stattdessen wartet der Speicher-Manager damit, bis ein Thread einen Seitenfehler hervorruft. Erst dann erstellt er eine Seitentabelle für die betreffende Seite. Diese Methode
führt zu einer erheblichen Leistungssteigerung von Prozessen, die sehr viel Speicher reservieren
oder zusichern, aber nur spärlich darauf zugreifen.
Der virtuelle Adressraum, der von diesen noch nicht vorhandenen Seitentabellen eingenommen werden würde, wird dem gesamten zugesicherten Speicher und der Prozessquote für
die Auslagerungsdatei zugewiesen. Dadurch ist garantiert, dass der Platz für sie vorhanden ist,
wenn sie erstellt werden. Dank der verzögerten Auswertung bildet auch die Zuweisung umfangreicher Speicherblöcke eine schnelle Operation. Wenn ein Thread Speicher zuweist, muss
der Speicher-Manager mit einem Adressbereich antworten, den der Thread nutzen kann. Dazu
unterhält der Speicher-Manager einen weiteren Satz von Datenstrukturen, in denen er sich
merkt, welche virtuellen Adressen im Adressraum des Prozesses reserviert worden sind und
welche nicht. Diese Datenstrukturen werden als Virtual Address Descriptors (VADs) bezeichnet
und aus dem nicht ausgelagerten Pool zugewiesen.
Prozess-VADs
Für jeden Prozess unterhält der Speicher-Manager einen Satz von VADs, die den Status des
Adressraums für diesen Prozess beschreiben. Die VADs sind in einem selbst ausgleichenden
AVL-Baum angeordnet (benannt nach seinen Erfindern Adelson-Velsky und Landis). Die Höhen
der beiden Kindknoten eines beliebigen Knotens dürfen darin höchstens um 1 auseinanderliegen, was Einfügen, Nachschlagen und Löschen sehr schnell macht. Dank der Verwendung eines
AVL-Baums ist bei der Suche nach einem VAD für eine virtuelle Adresse gewöhnlich nur die
Mindestanzahl von Vergleichen erforderlich. Für jeden praktisch zusammenhängenden Bereich
nicht freier virtueller Adressen derselben Art (reserviert, zugesichert oder zugeordnet, gleicher
Zugriffsschutz usw.) gibt es einen VAD. Ein Diagramm des VAD-Baums sehen Sie in Abb. 5–29.
458
Kapitel 5
Speicherverwaltung
Bereich: 20000000 bis 2000FFFF
Schutz: Lesen/Schreiben
Bereich: 000080000 bis 0000DFFF
Schutz: Nur Lesen
Bereich: 4A000000 bis 4C00FFFF
Schutz: Kopieren beim Schreiben
Bereich: 33000000 bis 3300FFFF
Schutz: Nur Lesen
Bereich: 52000000 bis 52017FFF
Schutz: Lesen/Schreiben
Abbildung 5–29 VADs
Wenn ein Prozess Adressraum reserviert oder die Sicht eines Abschnitts zuordnet, erstellt der
Speicher-Manager einen VAD, um darin jegliche Informationen festzuhalten, die bei der Zuweisungsanforderung übergeben wurden, z. B. den Bereich der reservierten Adresse, den Schutz
für die Seiten in dem Bereich, die Angabe, ob der Bereich gemeinsam nutzbar oder privat ist,
und die Angabe, ob ein Kindprozess den Inhalt des Bereichs erben kann.
Wenn zum ersten Mal ein Thread auf eine Adresse zugreift, muss der Speicher-Manager
einen PTE für die Seite erstellen, die diese Adresse enthält. Dazu sucht er den VAD, in dessen
Adressbereich sich die Adresse befindet, und füllt den PTE mit den darin aufgezeichneten Informationen aus. Wird die Adresse von keinem VAD abgedeckt oder befindet sie sich in einem
Bereich, der zwar reserviert, aber nicht zugesichert ist, weiß der Speicher-Manager, dass der
Thread versucht, auf Speicher zuzugreifen, ohne ihn vorher zugewiesen zu haben, und löst
daher eine Zugriffsverletzung aus.
Experiment: VADs einsehen
Mit dem Kerneldebuggerbefehl !vad können Sie sich die VADs eines Prozesses ansehen.
Dazu müssen Sie zunächst mit !process die Adresse für den Stamm des VAD-Baums herausfinden. Diese Adresse übergeben Sie anschließend an !vad. Das folgende Beispiel zeigt
diesen Vorgang für den VAD-Baum des Prozesses, der Explorer.exe ausführt:
lkd> !process 0 1 explorer.exe
PROCESS ffffc8069382e080
SessionId: 1 Cid: 43e0 Peb: 00bc5000 ParentCid: 0338
DirBase: 554ab7000 ObjectTable: ffffda8f62811d80 HandleCount: 823.
Image: explorer.exe
VadRoot ffffc806912337f0 Vads 505 Clone 0 Private 5088. Modified 2146.
Locked 0.
...
lkd> !vad ffffc8068ae1e470
VAD
Level
Start
End
Commit
→
VADs
Kapitel 5
459
ffffc80689bc52b0
9
640
64f
0 Mapped
READWRITE
0 Mapped
READONLY
0 Mapped
READONLY
Pagefile section, shared commit 0x10
ffffc80689be6900
8
650
651
Pagefile section, shared commit 0x2
ffffc80689bc4290
9
660
675
Pagefile section, shared commit 0x16
ffffc8068ae1f320
7
680
6ff
32 Private
READWRITE
ffffc80689b290b0
9
700
701
2 Private
READWRITE
ffffc80688da04f0
8
710
711
2 Private
READWRITE
ffffc80682795760
6
720
723
0 Mapped
READONLY
0 Mapped
READONLY
Pagefile section, shared commit 0x4
ffffc80688d85670 10
730
731
Pagefile section, shared commit 0x2
ffffc80689bdd9e0
9
740
741
2 Private
READWRITE
ffffc80688da57b0
8
750
755
0 Mapped
READONLY
\Windows\en-US\explorer.exe.mui
...
Total VADs: 574, average level: 8, maximum depth: 10
Total private commit: 0x3420 pages (53376 KB)
Total shared commit: 0x478 pages (4576 KB)
Umlauf-VADs
Videokartentreiber müssen gewöhnlich Daten von einer Grafikanwendung im Benutzermodus in verschiedene Stellen des Systemarbeitsspeichers kopieren, u. a. in den Speicher der Videokarte und des AGP-Ports, die beide andere Cacheattribute und Adressen aufweisen. Um
diese verschiedenen Speichersichten schnell einem Prozess zuordnen zu können und dabei
unterschiedliche Cacheattribute zuzulassen, verwendet der Speicher-Manager Umlauf-VADs.
Damit kann ein Videotreiber Daten direkt mithilfe der GPU übertragen und Speicher nach Bedarf durch ein Umlaufverfahren aus den Seiten der Prozesssicht herausnehmen und einfügen.
Abb. 5–30 zeigt an einem Beispiel, wie dieselbe virtuelle Adresse zwischen dem Video-RAM
und dem virtuellen Speicher gewechselt werden kann.
460
Kapitel 5
Speicherverwaltung
Video-RAM
Virtueller Adressraum
Seitentabelle
Benutzerdaten
Virtuelle
Benutzeradresse
Eintrag für
virtuelle
Benutzeradresse
Auslagerungs
gepufferte Seite
Benutzerdaten
Abbildung 5–30 Umlauf-VADs
NUMA
Bei jedem neuen Release von Windows gibt es Verbesserungen am Speicher-Manager, um
die Möglichkeiten von NUMA-Computern (Non-Uniform Memory Architecture) besser ausnutzen zu können, und zwar sowohl von Serversystemen als auch von SMP-Arbeitsstationen mit
dem Intel i7 oder dem AMD Opteron. Die NUMA-Unterstützung im Speicher-Manager bietet
Anwendungen und Treibern Informationen über die Knoten wie Standort, Topologie und Zugriffskosten, sodass sie NUMA-Fähigkeiten nutzen können, ohne sich um die Einzelheiten der
Hardware kümmern zu müssen.
Wenn der Speicher-Manager initialisiert wird, ruft er die Funktion MiComputerNumaCosts auf.
Sie führt verschiedene Seiten- und Cacheoperationen auf verschiedenen Knoten aus und ermittelt, wie viel Zeit dafür jeweils erforderlich ist. Aufgrund dieser Informationen erstellt sie einen Graphen der Zugriffskosten (Abstand eines Knotens von allen anderen Knoten im System).
Muss das System Seiten für eine bestimmte Operation anfordern, sucht es in dem Graphen
nach dem optimalen (also dem nächstgelegenen) Knoten. Ist auf diesem Knoten kein Speicher
verfügbar, wählt das System den zweitnächsten Knoten aus usw.
Der Speicher-Manager sorgt zwar dafür, dass Speicherzuweisungen nach Möglichkeit auf
dem Knoten mit dem idealen Prozessor für den Thread erfolgen, der die Zuweisung durchführt
(also auf dem idealen Knoten), bietet aber auch die APIs wie VirtualAllocExNuma, CreateFileMappingNuma, MapViewOfFileExNuma und AllocateUserPhysicalPagesNuma, mit denen Anwendungen selbst einen Knoten auswählen können.
Der ideale Knoten wird nicht nur dann verwendet, wenn Anwendungen Speicher zuweisen,
sondern auch bei Kerneloperationen und Seitenfehlern. Wenn beispielsweise ein Thread, der
nicht auf seinem idealen Prozessor läuft, einen Seitenfehler hervorruft, verwendet der Speicher-Manager nicht den aktuellen Knoten, sondern weist Speicher vom idealen Knoten des
Threads zu. Das kann zwar zu einer längeren Zugriffszeit führen, wenn der Thread nach wie vor
auf seiner nicht idealen CPU läuft, doch der Speicherzugriff wird insgesamt verbessert, wenn
der Thread zu seinem idealen Knoten zurückkehrt. Stehen auf dem idealen Knoten keine Res-
NUMA
Kapitel 5
461
sourcen mehr zur Verfügung, wird ohnehin der ihm am nächsten gelegene Knoten ausgewählt
und kein willkürlicher anderer Knoten. Ebenso wie Benutzermodusanwendungen können jedoch auch Treiber selbst einen Knoten auswählen, indem sie APIs wie MmAllocatePagesForMdlEx
und MmAllocateContinuousMemorySpecifyCacheNode verwenden.
Auch mehrere Pools und Datenstrukturen des Speicher-Managers sind zur Nutzung von
NUMA-Knoten optimiert. Der Speicher-Manager versucht, den physischen Speicher von allen
Knoten auf dem System gleichmäßig für den nicht ausgelagerten Pool zu nutzen. Bei Zuweisungen aus diesem Pool nutzt der Speicher-Manager den idealen Knoten als Index, um den
virtuellen Adressbereich im nicht ausgelagerten Pool auszuwählen, der mit dem physischen
Speicher dieses Knotens übereinstimmt. Außerdem wird für jeden NUMA-Knotenpool eine Liste der freien Seiten geführt, um diese Art von Speicherkonfiguration effizient nutzen zu können. Nicht nur der nicht ausgelagerte Pool, sondern auch der Systemcache, die System-PTEs
und die Look-Aside-Listen des Speicher-Managers werden auf diese Weise über alle Knoten
hinweg zugewiesen.
Wenn das System Nullseiten benötigt, verteilt es sie ebenfalls über verschiedene NUMA-Knoten. Dazu werden Threads mit NUMA-Affinitäten für die Knoten erstellt, in denen sich
der physische Speicher befindet. Der logische Prefetcher und SuperFetch (siehe den Abschnitt
»Vorausschauende Speicherverwaltung (SuperFetch)«) verwenden ebenfalls den idealen Knoten
des Zielprozesses. Weiche Seitenfehler können dazu führen, dass Seiten auf den idealen Knoten
für den betroffenen Thread übertragen werden.
Abschnittsobjekte
Wie bereits weiter vorn in diesem Kapitel im Abschnitt »Gemeinsam genutzter Arbeitsspeicher
und zugeordnete Dateien« beschrieben, ist das Speicherobjekt – oder Dateizuordnungsobjekt,
wie es im Windows-Teilsystem genannt wird – ein Speicherblock, den mehrere Prozesse gemeinsam nutzen können. Es kann in der Auslagerungsdatei oder einer anderen Datei auf der
Festplatte zugeordnet werden.
Die Exekutive verwendet ebenfalls Abschnitte, um ausführbare Abbilder in den Speicher zu
laden, und der Cache-Manager nutzt sie für den Zugriff auf die Daten in einer zwischengespeicherten Datei (mehr darüber in Kapitel 14 von Band 2). Mithilfe von Sitzungsobjekten können
Sie auch eine Datei im Prozessadressraum zuordnen. Der Zugriff auf die Datei kann dann in
Form eines großen Arrays erfolgen. Dazu werden die einzelnen Sichten des Abschnittsobjekts
zugeordnet und die Lese- und Schreibvorgänge im Arbeitsspeicher statt in der Datei durchgeführt. Dieser Vorgang wird E/A in einer im Speicher abgebildeten Datei genannt. Wenn das
Programm auf eine ungültige Seite zugreift (die sich nicht im physischen Speicher befindet),
tritt ein Seitenfehler auf, woraufhin der Speicher-Manager diese Seite automatisch aus der zugeordneten Datei oder der Auslagerungsdatei in den Speicher holt. Falls die Anwendung die
Seite ändert, schreibt der Speicher-Manager diese Änderungen während seiner normalen Auslagerungsoperationen in die Datei. (Alternativ kann die Anwendung eine Sicht auch ausdrücklich mithilfe der Windows-Funktion FlushViewOfFile auf die Festplatte übertragen.)
Wie andere Objekte erfolgt auch die Zuweisung und Aufheben der Zuweisung von Abschnittsobjekten durch den Objekt-Manager. Er erstellt und initialisiert einen Objektheader,
462
Kapitel 5
Speicherverwaltung
den er zur Verwaltung der Objekte verwendet. Der Rumpf des Abschnittsobjekts dagegen wird
vom Speicher-Manager definiert. (Mehr über den Objekt-Manager erfahren Sie in Kapitel 8
von Band 2.) Der Speicher-Manager implementiert auch Dienste, die Benutzermodusthreads
aufrufen können, um die im Rumpf eines Abschnittsobjekts gespeicherten Attribute abzurufen
und zu ändern. Abb. 5–31 zeigt den Aufbau eines Abschnittsobjekts. Die in Abschnittsobjekten
gespeicherten Attribute finden Sie in Tabelle 5–14.
Objekttyp
Objektrumpfattribute
Dienste
Section
Maximale Größe
Seitenschutz
Auslagerungsdatei oder zugeordnete Datei
Mit oder ohne Basisadresse
Create Section
Open Section
Extend Section
Map/Unmap View
Query Section
Abbildung 5–31 Ein Abschnittsobjekt
Attribut
Bedeutung
Maximale Größe
Die Höchstgröße in Bytes, auf die der Abschnitt wachsen kann. Bei der
Zuordnung einer Datei ist dies die Höchstgröße der Datei.
Seitenschutz
Der Speicherschutz, der allen Seiten des Abschnitts bei seiner Erstellung
zugewiesen wird.
Auslagerungsdatei oder
zugeordnete Datei
Gibt an, ob der Abschnitt leer erstellt wird (mit der Auslagerungsdatei als
Hintergrundspeicher; wie bereits erklärt, können auslagerungsgepufferte
Abschnitte nur dann Ressourcen der Auslagerungsdatei nutzen, wenn
Seiten auf die Festplatte geschrieben werden müssen) oder mit einer geladenen Datei (mit einer zugeordneten Datei als Hintergrundspeicher).
Mit oder ohne Basisadresse
Gibt an, ob sich der Abschnitt für alle Prozesse, die ihn nutzen, an derselben virtuellen Adresse befinden muss, oder ob er für die einzelnen
Prozesse jeweils an verschiedenen Adressen stehen kann.
Tabelle 5–14 Rumpfattribute von Abschnittsobjekten
Experiment: Abschnittsobjekte untersuchen
Mit Process Explorer von Sysinternals können Sie sich die von einem Prozess zugeordneten
Dateien ansehen. Gehen Sie dazu folgendermaßen vor:
1.
Öffnen Sie das Menü View und wählen Sie Lower Pane View und dann DLLs.
2.
Öffnen Sie das Menü View und wählen Sie Select Columns und dann DLLs und aktivieren Sie die Spalte Mapping Type.
→
Abschnittsobjekte
Kapitel 5
463
3.
Schauen Sie sich die Dateien an, die in der Spalte Mapping als Data gekennzeichnet sind.
Dies sind zugeordnete Dateien und keine DLLs oder andere vom Abbildlader als Module geladenen Dateien. Abschnittsobjekte, die eine Auslagerungsdatei als Hintergrundspeicher verwenden, sind in der Spalte Name durch die Angabe <Pagefile Backed>
gekennzeichnet. Bei anderen Abschnittsobjekten wird der Dateiname angezeigt.
Eine andere Möglichkeit, sich die Abschnittsobjekte anzusehen, besteht darin, zur Handleansicht zu wechseln (öffnen Sie das Menü View und wählen Sie Lower Pane View und dann
Handles) und darin nach Objekten vom Typ Section zu suchen. Im folgenden Screenshot
wird dabei jeweils der Objektname angezeigt (falls vorhanden). Dies ist nicht der Name
der Datei, die als Hintergrundspeicher des Abschnitts verwendet wird, sondern der Name,
den der Abschnitt im Namensraum des Objekt-Managers hat (siehe Kapitel 8 von Band 2).
Wenn Sie auf einen Eintrag doppelklicken, sehen Sie weitere Informationen über das Objekt, darunter die Anzahl der offenen Handles und den Sicherheitsdeskriptor.
→
464
Kapitel 5
Speicherverwaltung
Abb. 5–32 zeigt die vom Speicher-Manager unterhaltenen Datenstrukturen zur Beschreibung
von zugeordneten Abschnitten. Diese Strukturen sorgen dafür, dass die von den zugeordneten Dateien gelesenen Daten unabhängig von der Art des Zugriffs (offene Datei, zugeordnete
Datei usw.) konsistent sind. Für jede offene Datei (dargestellt durch ein Dateiobjekt) gibt es
eine einzige Struktur für Abschnittsobjektzeiger. Sie ist von entscheidender Bedeutung, um die
Konsistenz der Daten für alle Arten des Dateizugriffs zu erhalten und um eine Zwischenspeicherung der Dateien zu ermöglichen. Diese Struktur zeigt auf einen oder zwei Steuerbereiche.
Beide dienen dazu, die Datei zuzuordnen, wobei der eine verwendet wird, wenn auf die Datei
als Datendatei zugegriffen wird, und der andere, wenn sie als Abbild ausgeführt wird. Die Steuerbereiche wiederum zeigen auf Teilabschnittsstrukturen, die die Zuordnungsinformationen
für die einzelnen Abschnitte der Datei angeben (schreibgeschützt, Lesen/Schreiben, Kopieren
beim Schreiben usw.). Außerdem zeigen die Steuerbereiche auf eine im ausgelagerten Pool zugewiesene Segmentstruktur, diese wiederum auf die Prototyp-PTEs zur Zuordnung der eigentlichen, vom Abschnittsobjekt zugeordneten Seiten. Wie in diesem Kapitel bereits beschrieben,
zeigen die Prozessseitentabellen auf diese Prototyp-PTEs, die wiederum die Seiten zuordnen,
auf die verwiesen wird.
Abschnittsobjekte
Kapitel 5
465
VAD
Abschnitts
objekt
Dateiobjekt
Abschnitts
objektzeiger
Segment
Datensteuer
bereich
Teilabschnitt
Dateiobjekt
Abbildsteuerbereich
(wenn es sich bei der
Datei um ein ausführbares
Abbild handelt)
Nächster
Teilabschnitt
Prototyp-PTEs
PFN-Daten
bankeintrag
Seitentabelle
Abbildung 5–32 Interne Strukturen eines Abschnitts
Windows sorgt zwar dafür, dass alle Prozesse, die auf eine Datei zugreifen (sie liest oder
schreibt), stets konsistente Daten sehen, doch es ist möglich, dass sich zwei Kopien der Seiten
einer Datei im Arbeitsspeicher befinden. In diesem Fall erhalten jedoch alle Prozesse, die auf die
Datei zugreifen, die jüngste Kopie, sodass die Datenkonsistenz trotzdem sichergestellt ist. Diese
Duplizierung kann vorkommen, wenn eine Abbilddatei als Datendatei gelesen oder geschrieben wurde und dann als Abbild ausgeführt wird. Das ist beispielsweise möglich, wenn das Abbild verlinkt und dann ausgeführt wird. Der Linker hat die Datei für den Datenzugriff geöffnet,
und bei der Ausführung als Abbild hat der Abbildlader sie anschließend als ausführbare Datei
zugeordnet. Intern geschieht dabei Folgendes:
1.
Wenn die ausführbare Datei mithilfe der Dateizuordnungs-APIs oder des Cache-Managers
erstellt wurde, wird ein Datensteuerbereich zur Darstellung der Datenseiten in der Abbilddatei angelegt, die gelesen oder geschrieben werden.
2.
Wird das Abbild ausgeführt und das Abschnittsobjekt zur Abbildung des Abbilds als ausführbare Datei erstellt, erkennt der Speicher-Manager, dass das Abschnittsobjekt für die
Abbilddatei auf einen Datensteuerbereich zeigt, und leert den Abschnitt auf die Festplatte.
Das ist notwendig, damit jegliche geänderten Seiten auf die Festplatte geschrieben werden, bevor ein Zugriff auf das Abbild über den Abbildsteuerbereich erfolgt.
3.
Der Speicher-Manager erstellt einen Steuerbereich für die Abbilddatei.
4.
Wenn das Abbild ausgeführt wird, werden seine (schreibgeschützten) Seiten aus der Abbilddatei eingelagert oder direkt aus der Datendatei herüberkopiert, falls die zugehörige
Datenseite im Speicher vorhanden ist.
Da sich die vom Datensteuerbereich zugeordneten Seiten nach wie vor im Speicher (oder auf
der Standbyliste) befinden können, ist dies der einzige Fall, in dem zwei Exemplare derselben
Daten in zwei verschiedenen Seiten im Arbeitsspeicher vorhanden sein können. Allerdings führt
diese Duplizierung nicht zu Inkonsistenzen, weil der Datensteuerbereich wie schon erwähnt
466
Kapitel 5
Speicherverwaltung
bereits auf die Festplatte geleert wurde, sodass die aus dem Abbild gelesenen Seiten auf dem
neuesten Stand sind (und niemals wieder auf die Festplatte geschrieben werden).
Experiment: Steuerbereiche einsehen
Um die Adressen der Steuerbereichstrukturen für eine Datei zu finden, müssen Sie zunächst
die Adresse des betreffenden Dateiobjekts ermitteln, indem Sie mit dem Kerneldebuggerbefehl !handle die Prozesshandletabelle ausgeben. Anschließend untersuchen Sie das Dateiobjekt mit dt, um die Adresse der Struktur mit den Abschnittsobjektzeigern zu ermitteln.
(Der Befehl !file gibt zwar grundlegende Informationen über ein Dateiobjekt aus, aber
nicht den Zeiger auf diese Struktur.) Diese Struktur enthält drei Zeiger: einen auf den Datensteuerbereich, einen auf die gemeinsam genutzte Cachezuordnung (siehe Kapitel 14 in
Band 2) und einen auf den Abbildsteuerbereich. Wenn es also einen Steuerbereich für die
Datei gibt, können Sie seine Adresse aus dieser Zeigerstruktur ermitteln und anschließend
in den Befehl !ca einspeisen.
Öffnen Sie eine PowerPoint-Datei und lassen Sie sich mit dem Befehl !handle die Handle
tabelle für den zugehörigen Prozess anzeigen. Dabei finden Sie (mithilfe einer Textsuche) ein
offenes Handle für die PowerPoint-Datei. (Weitere Informationen über die Verwendung von
!handle finden Sie im Abschnitt »Der Objekt-Manager« in Kapitel 8 von Band 2 und in der
Dokumentation des Debuggers.)
lkd> !process 0 0 powerpnt.exe
PROCESS ffffc8068913e080
SessionId: 1 Cid: 2b64 Peb: 01249000 ParentCid: 1d38
DirBase: 252e25000 ObjectTable: ffffda8f49269c40 HandleCount: 1915.
Image: POWERPNT.EXE
lkd> .process /p ffffc8068913e080
Implicit process is now ffffc806'8913e080
lkd> !handle
...
0c08: Object: ffffc8068f56a630 GrantedAccess: 00120089 Entry: ffffda8f491d0020
Object: ffffc8068f56a630 Type: (ffffc8068256cb00) File
ObjectHeader: ffffc8068f56a600 (new version)
HandleCount: 1 PointerCount: 30839
Directory Object: 00000000 Name: \WindowsInternals\7thEdition\
Chapter05\diagrams.pptx {HarddiskVolume2}
...
Untersuchen Sie nun die Adresse des Dateiobjekts (FFFFC8068F56A630) mit dt:
lkd> dt nt!_file_object ffffc8068f56a630
+0x000 Type
: 0n5
+0x002 Size
: 0n216
→
Abschnittsobjekte
Kapitel 5
467
+0x008 DeviceObject
: 0xffffc806'8408cb40 _DEVICE_OBJECT
+0x010 Vpb
: 0xffffc806'82feba00 _VPB
+0x018 FsContext
: 0xffffda8f'5137cbd0 Void
+0x020 FsContext2
: 0xffffda8f'4366d590 Void
+0x028 SectionObjectPointer : 0xffffc806'8ec0c558 _SECTION_OBJECT_POINTERS
...
Anschließend untersuchen Sie die Adresse der Struktur mit den Abschnittsobjektzeigern
mit dt:
lkd> dt nt!_section_object_pointers 0xffffc806'8ec0c558
+0x000 DataSectionObject
: 0xffffc806'8e838c10 Void
+0x008 SharedCacheMap
: 0xffffc806'8d967bd0 Void
+0x010 ImageSectionObject : (null)
Nun können Sie mit dem Befehl !ca unter Angabe der gefundenen Adresse den Steuerbereich einsehen:
lkd> !ca 0xffffc806'8e838c10
ControlArea @ ffffc8068e838c10
Segment
ffffda8f4d97fdc0
Flink ffffc8068ecf97b8 Blink ffffc8068ecf97b8
Section Ref
1
Pfn Ref
58 Mapped Views
2
User Ref
0
WaitForDel
0 Flush Count
0
ModWriteCount
0 System Views
2
File Object ffffc8068e5d3d50
WritableRefs
0
Flags (8080) File WasPurged \WindowsInternalsBook\7thEdition\Chapter05\
diagrams.pptx
Segment @ ffffda8f4d97fdc0
ControlArea ffffc8068e838c10
Total Ptes
ExtendInfo 0000000000000000
Segment Size
80
80000
Committed
0
Flags (c0000) ProtectionMask
Subsection 1 @ ffffc8068e838c90
ControlArea ffffc8068e838c10
Starting Sector
0
Base Pte
Ptes In Subsect
58
Unused Ptes
0
0
Protection
6
Blink ffffc8068bb7fcf0
MappedViews
2
ControlArea ffffc8068e838c10
Starting Sector
58
Number Of Sectors 28
Base Pte
Ptes In Subsect
28
Unused Ptes
Flags
ffffda8f48eb6d40
d
Sector Offset
Number Of Sectors 58
Accessed
Flink
ffffc8068bb7fcf0
Subsection 2 @ ffffc8068c2e05b0
ffffda8f3cc45000
1d8
→
468
Kapitel 5
Speicherverwaltung
Flags
d
Sector Offset
0
Protection
6
MappedViews
1
Accessed
Flink
ffffc8068c2e0600
Blink ffffc8068c2e0600
Eine weitere Möglichkeit besteht darin, sich mit !memusage eine Liste aller Steuerbereiche
anzeigen zu lassen. Auf einem System mit sehr viel Arbeitsspeicher kann dieser Befehl sehr
viel Zeit in Anspruch nehmen. Das folgende Listing stellt einen Auszug aus der Ausgabe
dieses Befehls dar:
lkd> !memusage
loading PFN database
loading (100% complete)
Compiling memory usage data (99% Complete).
Zeroed:
98533 (
394132 kb)
Free:
1405 (
5620 kb)
Standby:
331221 ( 1324884 kb)
Modified:
83806 (
335224 kb)
ModifiedNoWrite:
116 (
464 kb)
Active/Valid: 1556154 ( 6224616 kb)
Transition:
5 (
20 kb)
SLIST/Bad:
1614 (
6456 kb)
Unknown:
0 (
0 kb)
TOTAL: 2072854 ( 8291416 kb)
Dangling Yes Commit:
130 (
520 kb)
Dangling No Commit: 514812 ( 2059248 kb)
Building kernel map
Finished building kernel map
(Master1 0 for 1c0)
(Master1 0 for e80)
(Master1 0 for ec0)
(Master1 0 for f00)
Scanning PFN database - (02% complete)
(Master1 0 for de80)
Scanning PFN database - (100% complete)
→
Abschnittsobjekte
Kapitel 5
469
Usage Summary (in Kb):
Control Valid Standby Dirty Shared Locked PageTables name
ffffffffd 1684540 0 0 0 1684540 0 AWE
ffff8c0b7e4797d0 64 0 0 0 0 0 mapped_file( MicrosoftWindows-Kernel-PnP%4Configuration.evtx )
ffff8c0b7e481650 0 4 0 0 0 0 mapped_file( No name for file )
ffff8c0b7e493c00 0 40 0 0 0 0 mapped_file( FSD-{ED5680AF0543-4367-A331-850F30190B44}.FSD )
ffff8c0b7e4a1b30 8 12 0 0 0 0 mapped_file( msidle.dll )
ffff8c0b7e4a7c40 128 0 0 0 0 0 mapped_file( MicrosoftWindows-Diagnosis-PCW%4Operational.evtx )
ffff8c0b7e4a9010 16 8 0 16 0 0 mapped_file( netjoin.dll
)8a04db00 ...
ffff8c0b7f8cc360 8212 0 0 0 0 0 mapped_file( OUTLOOK.EXE )
ffff8c0b7f8cd1a0 52 28 0 0 0 0 mapped_file( verdanab.ttf )
ffff8c0b7f8ce910 0 4 0 0 0 0 mapped_file( No name for file )
ffff8c0b7f8d3590 0 4 0 0 0 0 mapped_file( No name for file )
...
Die Spalte Control zeigt auf die Steuerbereichstruktur, die die zugeordnete Datei beschreibt.
Mit dem Kerneldebuggerbefehl !ca können Sie sich die Speicherbereiche, Segmente und
Teilabschnitte anzeigen lassen. Um beispielsweise die Steuerbereiche für die zugeordnete
Datei Outlook.exe in diesem Beispiel auszugeben, verwenden Sie den Befehl !ca gefolgt von
der zugehörigen Nummer in der Spalte Control:
lkd> !ca ffff8c0b7f8cc360
ControlArea @ ffff8c0b7f8cc360
Segment
ffffdf08d8a55670 Flink ffff8c0b834f1fd0 Blink ffff8c0b834f1fd0
Section Ref
1 Pfn Ref
User Ref
2 WaitForDel
File Object ffff8c0b7f0e94e0 ModWriteCount
WritableRefs
806 Mapped Views
1
0 Flush Count
c5a0
0 System Views
ffff
80000161
Flags (a0) Image File \Program Files (x86)\Microsoft Office\root\Office16\
OUTLOOK.EXE
Segment @ ffffdf08d8a55670
ControlArea ffff8c0b7f8cc360
Total Ptes
1609
Segment Size
1609000
Image Commit
f4
ProtoPtes
BasedAddress 0000000000be0000
Committed
Image Info
0
ffffdf08d8a556b8
ffffdf08dab6b000
Flags (c20000) ProtectionMask
→
470
Kapitel 5
Speicherverwaltung
Subsection 1 @ ffff8c0b7f8cc3e0
ControlArea ffff8c0b7f8cc360
Starting Sector 0
Number Of Sectors 2
Base Pte
Ptes In Subsect 1
Unused Ptes
0
Sector Offset
Protection
1
Flags
ffffdf08dab6b000
2
0
Subsection 2 @ ffff8c0b7f8cc418
ControlArea ffff8c0b7f8cc360
Starting Sector
Base Pte
Ptes In Subsect f63
Unused Ptes
0
Sector Offset
Protection
3
Flags
ffffdf08dab6b008
6
2
Number Of Sectors 7b17
0
Subsection 3 @ ffff8c0b7f8cc450
ControlArea ffff8c0b7f8cc360
Starting Sector 7b19
Number Of Sectors 19a4
Base Pte
Ptes In Subsect
Unused Ptes
0
Protection
1
Flags
ffffdf08dab72b20
2
Sector Offset
335
0
Subsection 4 @ ffff8c0b7f8cc488
ControlArea ffff8c0b7f8cc360
Starting Sector 94bd
Number Of Sectors 764
Base Pte
Ptes In Subsect
f2
Unused Ptes
0
0
Protection
5
Flags
ffffdf08dab744c8
a
Sector Offset
Subsection 5 @ ffff8c0b7f8cc4c0
ControlArea ffff8c0b7f8cc360
Starting Sector 9c21
Number Of Sectors 1
Base Pte
Ptes In Subsect
1
Unused Ptes
0
Sector Offset
0
Protection
5
Flags
ffffdf08dab74c58
a
Subsection 6 @ ffff8c0b7f8cc4f8
ControlArea ffff8c0b7f8cc360
Starting Sector 9c22
Number Of Sectors 1
Base Pte
Ptes In Subsect
1
Unused Ptes
0
Sector Offset
0
Protection
5
Flags
ffffdf08dab74c60
a
Subsection 7 @ ffff8c0b7f8cc530
ControlArea ffff8c0b7f8cc360
Starting Sector 9c23
Number Of Sectors c62
Base Pte
Ptes In Subsect
Unused Ptes
0
Protection
1
Flags
ffffdf08dab74c68
2
Sector Offset
18d
0
Subsection 8 @ ffff8c0b7f8cc568
ControlArea ffff8c0b7f8cc360
Starting Sector a885
Number Of Sectors 771
Base Pte
Ptes In Subsect
ef
Unused Ptes
0
0
Protection
1
Flags
ffffdf08dab758d0
2
Sector Offset
Abschnittsobjekte
Kapitel 5
471
Arbeitssätze
Sie haben jetzt gesehen, wie Windows den Überblick über den physischen Arbeitsspeicher
wahrt und wie viel Speicher es unterstützt. Als Nächstes beschäftigen wir uns damit, wie
Windows einen Teil der virtuellen Adressen im physischen Speicher behält.
Wie Sie wissen, wird der Teil der virtuellen Seiten, die sich im physischen Speicher befinden,
als Arbeitssatz bezeichnet. Es gibt drei Arten davon:
QQ Prozessarbeitssätze Sie enthalten die Seiten, auf die Threads innerhalb eines einzelnen
Prozesses verwiesen haben.
QQ Systemarbeitssätze Sie enthalten den speicherresidenten Teil des auslagerungsfähigen
Systemcodes (z. B. Ntoskrnl.exe und Treiber), den ausgelagerten Pool und den Systemcache.
QQ Sitzungsarbeitssätze Jede Sitzung verfügt über ihren eigenen Arbeitssatz mit dem speicherresidenten Teil der sitzungsspezifischen Kernelmodus-Datenstrukturen, die vom Kernelmodusteil des Windows-Teilsystems (Win32k.sys) zugewiesen wurden, dem ausgelagerten
Pool der Sitzung, den zugeordneten Sichten der Sitzung und anderen Gerätetreibern im
Sitzungsraum.
Bevor wir näher auf die einzelnen Arten von Arbeitssätzen eingehen, schauen wir uns an, wie
allgemein entschieden wird, welche Seiten in den physischen Arbeitsspeicher gebracht werden
und wie lange sie dort bleiben sollen.
Auslagerung bei Bedarf
Der Speicher-Manager verwendet einen bedarfsgesteuerten Auslagerungsmechanismus mit
Clustering, um Seiten in den Speicher zu laden. Wenn ein Thread einen Seitenfehler empfängt,
lädt der Speicher-Manager die fehlende Seite sowie einige wenige der vorausgehenden und/
oder nachfolgenden Seiten in den Speicher. Dadurch wird versucht, die Menge der Auslagerungs-E/A-Vorgänge in einem Thread zu minimieren. Da Programme – insbesondere umfangreiche – immer in kleinen Regionen ihres Adressraums ausgeführt werden, verringert das Laden
ganzer Cluster von virtuellen Seiten die Anzahl der Lesevorgänge auf der Festplatte. Bei Seitenfehlern aufgrund von Verweisen auf Datenseiten in Abbildern beträgt die Clustergröße drei
Seiten, bei allen anderen Seitenfehlern sieben Seiten.
Diese bedarfsgesteuerte Vorgehensweise kann jedoch zu vielen Seitenfehlern in einem
Prozess führen, wenn die Threads mit der Ausführung beginnen oder sie wieder aufnehmen.
Um den Start von Prozessen (und des Systems) zu optimieren, setzt Windows eine intelligente
Prefetch-Engine ein, den logischen Prefetcher, den wir im nächsten Abschnitt vorstellen. Eine
weitergehende Optimierung mit zusätzlichen Prefetchvorgängen wird von der Komponente
SuperFetch durchgeführt, die weiter hinten in diesem Kapitel beschrieben wird.
472
Kapitel 5
Speicherverwaltung
Der logische Prefetcher und ReadyBoot
Beim Start des Systems oder einer Anwendung werden gewöhnlich erst einige Seiten aus einem
Teil einer Datei in den Speicher geholt, dann vielleicht aus einem weiter entfernten Teil derselben Datei, danach aus einer anderen Datei, anschließend möglicherweise aus einem Verzeichnis und schließlich wieder aus der ersten Datei. Dieses Herumspringen verlangsamt den Zugriff
erheblich. Analysen haben gezeigt, dass die Suchzeiten auf der Festplatte ein entscheidender
Faktor für einen langsamen Start des Systems und der Anwendungen darstellen. Durch einen
Vorabruf von mehreren Seiten auf einmal lässt sich der Zugriff in eine vernünftigere Reihenfolge bringen, ohne dass dazu eine übermäßige Rückverfolgung erforderlich ist. Dadurch wird die
erforderliche Zeit zum Hochfahren des Systems oder zum Starten einer Anwendung insgesamt
verbessert. Aufgrund der starken Korrelation der Zugriffsvorgänge über mehrere Startvorgänge des Systems bzw. der Anwendung hinweg sind die benötigten Seiten im Voraus bekannt.
Der Prefetcher versucht, den Startvorgang zu beschleunigen, indem er beobachtet, auf
welche Daten und welchen Code beim Starten des Systems oder einer Anwendung zugegriffen
wird, und diese Informationen zu Beginn des nächsten Startvorgangs nutzt, um Code und Daten zu lesen. Der Speicher-Manager benachrichtigt den Prefetchercode im Kernel über Seitenfehler – sowohl harte, bei denen die Daten von der Festplatte gelesen werden müssen, als auch
weiche, bei denen sich die Daten bereits im Arbeitsspeicher befinden und nur zum Arbeitssatz
des Prozesses hinzugefügt werden müssen. Der Prefetcher beobachtet die ersten zehn Sekunden des Starts einer Anwendung. Das Hochfahren des Systems verfolgt er standardmäßig bis
30 Sekunden nach dem Start der Benutzershell (gewöhnlich Explorer). Ist das nicht möglich,
führt er seine Beobachtung bis 60 Sekunden nach der Initialisierung der Windows-Dienste
oder insgesamt 120 Sekunden lang durch, wobei er nach dem zuerst abgelaufenen Zeitraum
Schluss macht.
Die im Kernel aufgezeichnete Ablaufverfolgung umfasst Seitenfehler für die Metadatendatei der NTFS-Masterdateitabelle (MFT), falls die Anwendung auf Dateien oder Verzeichnisse auf
NTFS-Volumes zugreift, und für die Dateien und Verzeichnisse, auf die verwiesen wird. Nach
der Erfassung der Ablaufverfolgung wartet der Prefetchercode auf Anforderungen von der
Prefetcherkomponente des Dienstes SuperFetch (%SystemRoot%\System32\Sysmain.dll), der in
einer Instanz von Svchost läuft. Dieser Dienst ist sowohl für den logischen Prefetcher im Kernel
als auch für die SuperFetch-Komponente zuständig, mit der wir uns später noch beschäftigen werden. Der Prefetcher meldet das Ereignis \KernelObjects\PrefetchTracesReady, um den
SuperFetch-Dienst darüber zu informieren, dass die Ablaufverfolgungsdaten jetzt abgefragt
werden können.
Das Prefetching beim Start des Systems oder von Anwendungen können Sie einund ausschalten, indem Sie den DWORD-Registrierungswert EnablePrefetcher unter dem Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\Memory
Management\PrefetchParameters bearbeiten. Mit dem Wert 0 schalten Sie das Prefetching komplett ab. Mit 1 aktivieren Sie es nur für Anwendungen, mit 2 nur für
den Systemstart und mit 3 sowohl für Anwendungen als auch für den Systemstart.
Arbeitssätze
Kapitel 5
473
Der Dienst SuperFetch (der den logischen Prefetcher beherbergt, auch wenn dieser eine eigene
Komponente ist und nichts mit der eigentlichen SuperFetch-Funktionalität zu tun hat) ruft die
interne Systemfunktion NtQuerySystemInformation auf, um die Daten der Ablaufverfolgung anzufordern. Der logische Prefetcher verarbeitet diese Daten, kombiniert sie mit zuvor erfassten
Daten und schreibt sie in eine Datei im Ordner %SystemRoot%\Prefetch (siehe Abb. 5–33). Der
Name dieser Datei besteht aus dem Namen der Anwendung, für die die Ablaufverfolgung aufgenommen wurde, gefolgt von einem Bindestrich, dem Hash des Dateipfads in hexadezimaler
Form und schließlich der Endung .pf, beispielsweise NOTEPAD.EXE-9FB27C0E.pf.
Abbildung 5–33 Der Ordner Prefetch
Es gibt jedoch eine Ausnahme von dieser Regel für Dateinamen, nämlich bei Abbildern, die andere Komponenten beherbergen, etwa die Microsoft Management Console (%SystemRoot%\
System32\Mmc.exe), der Diensthostprozess (%SystemRoot%\System32\Svchost.exe), RunDLL
(%SystemRoot%\System32\Rundll32.exe) und Dllhost (%SystemRoot%\System32\Dllhost.exe).
Da bei diesen Anwendungen Add-On-Komponenten an der Befehlszeile angegeben werden,
schließt der Prefetcher die Befehlszeile in den Hash ein. Daher gibt es für Aufrufe dieser Anwendungen mit unterschiedlichen Komponenten jeweils eigene Ablaufverfolgungen.
Beim Hochfahren des Systems wird dagegen der Mechanismus ReadyBoot verwendet. Um
die E/A-Operationen zu optimieren, führt er umfangreiche und effiziente E/A-Lesevorgänge
durch und speichert die Daten im RAM. Wenn Systemkomponenten die Daten benötigen, erhalten sie diejenigen aus dem RAM. Das ist insbesondere bei mechanischen Festplatten von
Vorteil, kann sich aber auch bei SSDs als nützlich erweisen. Informationen über die Dateien, die
474
Kapitel 5
Speicherverwaltung
vorab abgerufen werden sollten, werden nach dem Hochfahren im Unterverzeichnis ReadyBoot des Verzeichnisses Prefetch aus Abb. 5–33 gespeichert. Nach Abschluss des Startvorgangs
werden die zwischengespeicherten Daten aus dem RAM gelöscht. Bei sehr schnellen SSDs ist
ReadyBoot standardmäßig ausgeschaltet, da dieser Mechanismus hier, wenn überhaupt, nur
sehr geringe Vorteile bietet.
Beim Start des Systems oder einer Anwendung wird der Prefetcher aufgerufen. Er schaut
nach, ob sich im Prefetch-Verzeichnis Ablaufverfolgungen für die vorliegende Situation befinden. Wenn ja, ruft er NTFS auf, um jegliche vorhandenen Verweise auf die MFT-Metadatendatei abzurufen, liest den Inhalt aller darin genannten Verzeichnisse und öffnet schließlich alle
Dateien, auf die verwiesen wird. Anschließend ruft er die Funktion MmPrefetchPages des Speicher-Managers auf, um jegliche Daten und jeglichen Code einzulesen, die in der Ablaufverfolgung angegeben, aber noch nicht im Speicher vorhanden sind. Der Speicher-Manager führt all
diese Lesevorgänge asynchron aus und wartet auf ihren Abschluss, bevor er den fortgesetzten
Start der Anwendung gestattet.
Experiment: Lese- und Schreibvorgänge in der Prefetchdatei
beobachten
Wenn Sie eine Ablaufverfolgung für einen Anwendungsstart mit Process Monitor von Sys
internals auf einer Windows-Clientversion erfassen (auf den Serverversionen ist das Prefetching standardmäßig ausgeschaltet), können Sie beobachten, wie der Prefetcher nach der
Prefetchdatei für die Anwendung sucht und ggf. darin liest und wie er etwa zehn Sekunden
nach dem Start der Anwendung ein neues Exemplar dieser Datei schreibt. Die folgende
Anzeige stammt von einem Start des Windows-Editors (Notepad), wobei der Filter Include
auf prefetch gesetzt wurde, sodass Process Monitor nur Zugriffe auf das Verzeichnis %SystemRoot%\Prefetch zeigt:
→
Arbeitssätze
Kapitel 5
475
In Zeile 0 bis 3 sehen Sie, dass die Prefetchdatei für Notepad im Kontext des Prozesses Notepad während seines Starts gelesen wird. In den Zeilen 7 bis 19, deren Zeitstempel eine Zeit
zehn Sekunden nach den ersten vier Zeilen angibt, schreibt der Dienst SuperFetch, der im
Kontext eines Svchost-Prozesses läuft, die aktualisierte Prefetchdatei.
Um die Suchvorgänge noch weiter zu reduzieren, stellt der Dienst SuperFetch etwa alle drei
Tage in Leerlaufzeiten eine Liste der Dateien und Verzeichnisse in der Reihenfolge zusammen,
in der beim Start des Systems oder der Anwendung auf sie verwiesen wird, und speichert sie in
%SystemRoot%\Prefetch\Layout.ini (siehe Abb. 5–34). Diese Liste enthält auch von SuperFetch
beobachtete Dateien, auf die häufig zugegriffen wurde.
Abbildung 5–34 Layoutdatei für die Defragmentierung
Anschließend startet der Dienst die Systemdefragmentierung mit einer Befehlszeilenoption,
die besagt, dass der Vorgang nicht vollständig, sondern nur aufgrund des Inhalts dieser Datei
erfolgen soll. Der Defragmentierungsmechanismus sucht in jedem Volume nach einem zusammenhängenden Bereich, der groß genug für alle in der Liste genannten Dateien und Verzeichnisse auf diesem Volume ist, und verschiebt sie komplett in diesen Bereich, sodass sie eine nach
der anderen dort gespeichert sind. Zukünftige Prefetchvorgänge laufen dadurch effizienter ab,
da sich die Daten jetzt in der Lesereihenfolge auf der Festplatte befinden. Da die Anzahl der
vorab abgerufenen Dateien gewöhnlich nur in die Hunderte geht, verläuft dieser Vorgang weit
schneller als die komplette Defragmentierung des Volumes.
476
Kapitel 5
Speicherverwaltung
Platzierungsrichtlinien
Wenn ein Thread einen Seitenfehler empfängt, muss der Speicher-Manager entscheiden, wo er
die virtuelle Seite im physischen Speicher ablegt. Die Regeln, die die ideale Position bestimmen,
werden als Platzierungsrichtlinie bezeichnet. Bei der Auswahl der Seitenframes berücksichtigt
Windows die Größe der CPU-Speichercaches, um deren unnötige Zersplitterung zu vermeiden.
Ist der physische Speicher bei Auftreten eines Seitenfehlers voll belegt, bestimmt Windows
anhand einer Ersetzungsrichtlinie, welche virtuelle Seite aus dem Speicher entfernt werden soll,
um Platz für die neue zu schaffen. Zu den gängigen Ersetzungsrichtlinien gehören LRU (Least
Recently Used) und FIFO (First In, First Out). Für den LRU-Algorithmus (in seiner Implementierung in den meisten UNIX-Versionen auch Taktalgorithmus genannt) muss sich das virtuelle
Speichersystem merken, wann eine Seite im Speicher verwendet wird. Wird ein neuer Seitenframe gebraucht, so wird die Seite, die am längsten nicht benutzt wurde, aus dem Arbeitssatz
entfernt. Die FIFO-Algorithmus ist etwas einfacher: Bei ihm wird die Seite entfernt, die sich am
längsten im physischen Speicher befindet, unabhängig davon, wie oft sie benutzt wurde.
Es wird zwischen lokalen und globalen Ersetzungsrichtlinien unterschieden. Bei einer globalen Richtlinie kann bei einem Seitenfehler auf jeden beliebigen Seitenframe zurückgegriffen
werden, auch wenn er zu einem anderen Prozess gehört. Beispielsweise wird bei einer globalen
Ersetzungsrichtlinie mit FIFO-Algorithmus einfach die Seite freigegeben, die sich am längsten im physischen Speicher befindet. Bei einer lokalen Richtlinie wird diese Suche auf Seiten
eingeschränkt, die zu dem Prozess gehören, in dem der Seitenfehler aufgetreten ist. Globale
Ersetzungsrichtlinien können Prozesse anfällig für das Verhalten anderer Prozesse machen. So
kann eine störrische Anwendung das gesamte Betriebssystem unterminieren, indem sie in allen
Prozessen eine übermäßige Auslagerung hervorruft.
Windows verwendet sowohl lokale als auch globale Ersetzungsrichtlinien. Wenn ein Arbeitssatz an seine Grenzen stößt oder aufgrund der Nachfrage nach physischem Speicher verkleinert werden muss, entfernt der Speicher-Manager aus ihm Seiten, bis genügend freie Seiten
vorhanden sind.
Verwaltung von Arbeitssätzen
Jeder Prozess hat zu Anfang eine Mindestgröße von 50 und eine Höchstgröße von 345 Seiten
für seinen Arbeitssatz. Diese Grenzwerte können Sie mit der Windows-Funktion SetProcessWorkingSetSize ändern, für die Sie das Recht SeIncreaseBasePriorityPrivilege benötigen. Sofern Sie den Prozess nicht auch so eingerichtet haben, dass er harte Grenzen für den Arbeitssatz verwendet, werden diese Grenzwerte jedoch ignoriert: Der Speicher-Manager erlaubt dem
Prozess, auch über sein Maximum hinaus zu wachsen, wenn eine starke Auslagerung stattfindet
und noch ausreichend Speicher zur Verfügung steht. Umgekehrt kann er den Arbeitssatz auch
unter sein Minimum schrumpfen lassen, wenn keine Auslagerung stattfindet, der physische
Speicher aber stark nachgefragt ist. Harte Grenzwerte können Sie mit der Funktion SetProcessWorkingSetSizeEx und dem Flag QUOTA_LIMITS_HARDWS_MAX_ENABLE festlegen, allerdings ist es
fast immer besser, die Verwaltung des Arbeitssatzes dem System zu überlassen.
Auf 32-Bit-Systemen kann die Maximalgröße des Arbeitssatzes nicht das systemweite Maximum überschreiten, das bei der Systeminitialisierung berechnet und in der Kernelvariablen
Arbeitssätze
Kapitel 5
477
MiMaximumWorkingSet gespeichert wurde. Auf x64-Systemen ist der virtuelle Adressraum so um-
fangreich, dass die Menge des physischen Speichers den praktischen oberen Grenzwert bildet.
Die Arbeitssatzhöchstgrößen für verschiedene Systeme sind in Tabelle 5–15 aufgeführt.
Windows-Version
Höchstgröße des Arbeitssatzes
x86, ARM
2 GB – 64 KB (0x7FFF0000)
x86-Versionen von Windows, gestartet mit
increaseuserva
2 GB – 64 KB + Erweiterung des virtuellen Benutzeradressraums
x64 (Windows 8, Server 2012)
8192 GB (8 TB)
x64 (Windows 8.1, 10, Server 2012 R2, 2016)
128 TB
Tabelle 5–15 Obergrenze für die Größe von Arbeitssätzen
Wenn ein Seitenfehler auftritt, werden die Grenzwerte des Arbeitssatzes für den Prozess und
die Menge an freiem Arbeitsspeicher auf dem System untersucht. Sofern die Bedingungen
es zulassen, erlaubt der Speicher-Manager einem Prozess, seinen Arbeitssatz bis zum oberen
Grenzwert zu erweitern (oder sogar darüber hinaus, wenn keine harten Grenzwerte festgelegt
sind und genügend freie Seiten zur Verfügung stehen). Ist dagegen der Speicher knapp, ersetzt
Windows bei Seitenfehlern lieber vorhandene Seiten im Arbeitssatz, anstatt neue hinzuzufügen.
Windows schreibt geänderte Seiten auf die Festplatte, um Arbeitsspeicher verfügbar zu
halten. Erfolgen solche Änderungen sehr rasch, so ist trotzdem mehr Speicher erforderlich,
um die Speicheranforderungen zu erfüllen. Wenn der physische Speicher knapp wird, löst der
Arbeitssatz-Manager – der im Kontext des Systemthreads für den Balance-Set-Manager ausgeführt wird (siehe den nächsten Abschnitt) – die automatische Verkleinerung des Arbeitssatzes
aus, um den Betrag an verfügbarem freiem Speicher im System zu erhöhen. Mit der bereits erwähnten Funktion SetProcessWorkingSetSizeEx können Sie diese Verkleinerung auch für ihren
eigenen Prozess auslösen, etwa nach der Prozessinitialisierung.
Der Arbeitssatz-Manager untersucht den verfügbaren Speicher und entscheidet, ob und
welche Arbeitssätze verkleinert werden müssen. Ist ausreichend Speicher vorhanden, berechnet
der Arbeitssatz-Manager, wie viele Seiten bei Bedarf aus den Arbeitssätzen entfernt werden
können. Wird eine Verkleinerung notwendig, wendet er sich den Arbeitssätzen zu, deren Größe
noch über dem Minimum liegt. Außerdem passt er dynamisch die Abstände an, in denen er die
Arbeitssätze untersucht, und bringt die für eine Verkleinerung der Arbeitssätze anstehenden
Prozesse in eine optimale Reihenfolge. Beispielsweise werden Prozesse mit Seiten, auf die seit
Längerem nicht mehr zugegriffen wurde, als Erstes betrachtet. Umfangreiche Prozesse, die sich
schon länger im Leerlauf befinden, werden eher berücksichtigt als kleinere Prozesse, die häufiger laufen. Prozesse, die die Vordergrundanwendung ausführen, werden als Letzte in Betracht
gezogen.
Wenn der Arbeitssatz-Manager Prozesse findet, die mehr als die Mindestgröße für ihre
Arbeitssätze verwenden, sucht er nach Seiten, die er daraus entfernen kann, um sie für andere
Zwecke zur Verfügung zu stellen. Ist der Betrag an freiem Speicher dann immer noch zu niedrig, fährt der Arbeitssatz-Manager damit fort, Seiten aus den Prozessarbeitssätzen zu entfernen, bis er die Mindestanzahl von freien Seiten auf dem System erreicht hat.
478
Kapitel 5
Speicherverwaltung
Der Arbeitssatz-Manager entfernt nach Möglichkeit Seiten, auf die nicht erst kürzlich zugegriffen wurde. Um das herauszufinden, überprüft er das Zugriffsbit im Hardware-PTE. Ist
das Bit nicht gesetzt, so wird die Seite gealtert. Dabei wird ein Zähler hochgesetzt, der angibt,
dass seit der letzten Untersuchung des Arbeitssatzes für eine mögliche Kürzung nicht auf die
Seite verwiesen wurde. Später werden anhand dieses Alters die Seiten ausgewählt, die aus dem
Arbeitssatz entfernt werden sollten.
Ist das Zugriffsbit im Hardware-PTE dagegen gesetzt, entfernt der Arbeitssatz-Manager es
und geht zur nächsten Seite im Arbeitssatz über. Wenn der Arbeitssatz-Manager sich die Seite
das nächste Mal ansieht, ist das Bit daher nicht gesetzt. Daraus kann der Manager ablesen,
dass seit seiner letzten Untersuchung nicht auf die Seite zugegriffen wurde. Diese Suche nach
zu entfernenden Seiten wird im ganzen Arbeitssatz fortgesetzt, bis entweder genügend viele
Seiten entfernt wurden oder die Untersuchung wieder am Anfangspunkt angekommen ist. Bei
der nächsten Verkleinerung des Arbeitssatzes wird sie dort wieder aufgenommen, wo sie beim
letzten Mal abgebrochen wurde.
Experiment: Größen von Prozessarbeitssätzen einsehen
In der Leistungsüberwachung können Sie sich die Größe von Arbeitssätzen mit den in der
folgenden Tabelle genannten Indikatoren ansehen. Auch mithilfe anderer Hilfsprogramme
zur Einsichtnahme in Prozesse (wie dem Task-Manager und Process Explorer) können Sie die
Größe von Prozessarbeitssätzen ermitteln.
Leistungsindikator
Beschreibung
Prozess: Arbeitsseiten
Gibt die aktuelle Größe des Arbeitssatzes für den ausgewählten
Prozess in Byte an.
Prozess: Arbeitssatz (max.)
Gibt die bisherige Spitzengröße des Arbeitssatzes für den ausgewählten Prozess in Byte an.
Prozess: Seitenfehler/s
Gibt die Anzahl der Seitenfehler an, die pro Sekunde bei diesem
Prozess auftreten.
Den Gesamtwert für sämtliche Prozessarbeitssätze erhalten Sie jeweils, indem Sie im Instanzfeld der Leistungsüberwachung _Total auswählen. Diese Instanz ist jedoch kein echter
Prozess, sondern gibt lediglich die Summe der prozessspezifischen Zähler für alle zurzeit
auf dem System laufenden Prozesse an. Die angezeigte Summe ist größer als der RAM, was
daran liegt, dass die Größen der einzelnen Prozessarbeitssätze auch gemeinsam genutzte
Seiten einschließen. Wenn mehrere Prozesse dieselbe Seite verwenden, wird sie bei den
Arbeitssätzen aller dieser Prozesse mitgezählt.
Arbeitssätze
Kapitel 5
479
Experiment: Arbeitssatz- und virtuelle Größe im Vergleich
Weiter vorn in diesem Kapitel haben Sie mit TestLimit zwei Prozesse erstellt, von denen der
eine seinen Arbeitsspeicher nur reserviert und der andere ihn privat zugesichert hatte. Die
Unterschiede haben Sie sich mit Process Explorer angesehen. Jetzt erstellen wir einen dritten TestLimit-Prozess, der den Arbeitsspeicher nicht nur zusichert, sondern auch tatsächlich
darauf zugreift, sodass er in den Arbeitssatz aufgenommen wird. Gehen Sie dazu wie folgt
vor:
1.
Erstellen Sie einen neuen TestLimit-Prozess:
C:\Users\pavely>testlimit -d 1 -c 800
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 13008
Leaking private bytes with touch 1 MB at a time...
Leaked 800 MB of private memory (800 MB total leaked). Lasterror: 0
The operation completed successfully.
2.
Öffnen Sie Process Explorer.
3.
Öffnen Sie das Menü View, wählen Sie Select Columns und klicken Sie auf die Registerkarte Process Memory.
4.
Aktivieren Sie die Indikatoren Private Bytes, Virtual Size, Working Set Size, WS Shareable
Bytes und WS Private Bytes.
5.
Suchen Sie die drei Instanzen von TestLimit:
Der neue TestLimit-Prozess ist der dritte, also derjenige mit der PID 13008. Er ist der einzige
der drei, der tatsächlich auf den zugewiesenen Speicher zugreift, und damit auch der einzige, dessen Arbeitssatzgröße die Größe der Zuweisung widerspiegelt.
→
480
Kapitel 5
Speicherverwaltung
Dieses Ergebnis ist jedoch nur bei Systemen möglich, auf denen genügend RAM zur
Verfügung steht, um den Arbeitssatz so stark wachsen zu lassen. Selbst auf diesem System
befinden sich nicht alle privaten Bytes (821.888 KB) im privaten Teil des Arbeitssatzes (WS
Private). Ein kleiner Teil der privaten Seite wurde aufgrund von Ersetzungen aus dem Arbeitssatz entfernt oder noch nicht eingelagert.
Experiment: Die Arbeitssatzliste im Debugger einsehen
Mit dem Kerneldebuggerbefehl !wsle können Sie sich die einzelnen Einträge im Arbeitssatz
ansehen. Das folgende Beispiel zeigt einen Ausschnitt aus der Ausgabe von WinDbg für die
Arbeitssatzliste auf einem 32-Bit-System:
lkd> !wsle 7
Working Set Instance @ c0802d50
Working Set Shared @ c0802e30
FirstFree
f7d
LastEntry
203d
NonDirect
0
FirstDynamic 6
NextSlot
6
LastInitialized 2063
HashTable
0
HashTableSize
0
Reading the WSLE data .......................................................
.......
Virtual Address
Age
Locked
ReferenceCount
c0603009
0
0
1
c0602009
0
0
1
c0601009
0
0
1
c0600009
0
0
1
c0802d59
6
0
1
c0604019
0
0
1
c0800409
2
0
1
c0006209
1
0
1
77290a05
5
0
1
7739aa05
5
0
1
c0014209
1
0
1
c0004209
1
0
1
72a37805
4
0
1
b50409
2
0
1
b52809
4
0
1
→
Arbeitssätze
Kapitel 5
481
7731dc05
6
0
1
bbec09
6
0
1
bbfc09
6
0
1
6c801805
4
0
1
772a1405
2
0
1
944209
1
0
1
77316a05
5
0
1
773a4209
1
0
1
77317405
2
0
1
772d6605
3
0
1
a71409
2
0
1
c1d409
2
0
1
772d4a05
5
0
1
77342c05
6
0
1
6c80f605
3
0
1
77320405
2
0
1
77323205
1
0
1
77321405
2
0
1
7ffe0215
1
0
2
a5fc09
6
0
1
7735cc05
6
0
1
...
Einige der Einträge in der Arbeitssatzliste sind Seiten von Seitentabellen (diejenigen mit
einer Adresse größer als 0xC0000000), einige gelten für System-DLLs (diejenigen im Bereich
0x7nnnnnnn) und einige für den Code von WinDbg.exe selbst.
Der Balance-Set-Manager und der Swapper
Die Erweiterung und Verkleinerung von Arbeitssätzen erfolgt im Kontext eines Systemthreads,
der als Balance-Set-Manager bezeichnet und bei der Systeminitialisierung angelegt wird (Funktion KeBalanceSetManager). Obwohl er technisch zum Kernel gehört, ruft er den Arbeitssatz-Manager des Speicher-Managers auf (MmWorkingSetManager), um die Analyse und Anpassung der
Arbeitssätze durchzuführen.
Der Balance-Set-Manager wartet auf zwei Ereignisobjekte: Das eine dieser Ereignisse wird
gemeldet, wenn ein regelmäßiger Timer einmal pro Sekunde abläuft, das andere signalisiert
der Speicher-Manager, wenn er feststellt, dass ein Arbeitssatz verändert werden muss. Treten
beispielsweise sehr viele Seitenfehler auf oder ist die Liste der freien Seiten zu klein, weckt der
Speicher-Manager den Balance-Set-Manager, sodass dieser den Arbeitssatz-Manager aufruft,
um mit der Verkleinerung von Arbeitssätzen zu beginnen. Ist reichlich Speicher vorhanden,
erlaubt der Arbeitssatz-Manager Prozessen mit Seitenfehlern, die Größe ihrer Arbeitssätze nach
und nach zu erhöhen, indem sie die fehlenden Seiten in den Speicher zurückholen. Dabei
wachsen die Arbeitssätze aber nur nach Bedarf.
482
Kapitel 5
Speicherverwaltung
Wenn der Balance-Set-Manager aufwacht, weil der 1-Sekunden-Timer abgelaufen ist,
führt er folgende Aufgaben aus:
1.
Wenn das System den sicheren virtuellen Modus (VSM) unterstützt (was auf Windows 10
und Windows Server 2016 der Fall ist), wird der sichere Kernel aufgerufen, um seine regelmäßigen Haushaltungsaufgaben zu erledigen (VslSecureKernelPeriodicTick).
2.
Der Balance-Set-Manager ruft eine Routine zur Anpassung der IRP-Credits auf, um die
Nutzung der prozesserweisen Look-Aside-Listen bei der IRP-Vervollständigung zu optimieren (IoAdjustIrpCredits). Das verbessert die Skalierbarkeit, wenn einzelne Prozessoren
einer starken E/A-Last unterliegen. (Mehr über IRPs erfahren Sie in Kapitel 6.)
3.
Er überprüft die Look-Aside-Liste und passt ggf. ihre Tiefe an, um die Zugriffszeit zu verbessern und Poolnutzung sowie Poolfragmentierung zu verringern (ExAdjustLookaside
Depth).
4.
Er passt die Größe des ETW-Pufferpools (Event Tracing for Windows) an, damit der
ETW-Speicherpuffer wirtschaftlicher genutzt werden kann (EtwAdjustTraceBuffers). (Mehr
über ETW erfahren Sie in Kapitel 8 von Band 2.)
5.
Er ruft den Arbeitssatz-Manager des Speicher-Managers auf. Der Arbeitssatz-Manager verfügt über seine eigenen internen Indikatoren, um festzulegen, wann und wie stark Arbeitssätze verkleinert werden müssen.
6.
Er setzt die Grenzwerte für die Ausführungszeit für Jobs durch (PsEnforceExecutionLimits).
7.
Wenn der Balance-Set-Manager zum achten Mal erwacht, weil der 1-Sekunden-Timer abgelaufen ist, meldet er ein Ereignis, das einen weiteren Systemthread aufweckt, nämlich
den Swapper (KeSwapProcessorStack). Der Swapper wird mit Priorität 23 ausgeführt und
versucht, die Kernelstacks von Threads, die längere Zeit nicht ausgeführt wurden, auszulagern. Dazu sucht er nach Threads, die sich schon seit 15 Sekunden in einem Benutzermodus-Wartezustand befinden. Wenn er einen solchen Thread findet, versetzt er dessen
Kernelstack in den Übergangsstatus (das heißt, er verschiebt die Seiten auf die Standbyliste
oder die Liste der geänderten Seiten), um den physischen Speicher dafür zurückzugewinnen – getreu dem Grundsatz, dass ein Thread, der schon so lange gewartet hat, noch
länger wartet. Wenn der letzte Kernelstack des letzten Threads in einem Prozess aus dem
Arbeitsspeicher entfernt wurde, wird der Prozess für die komplette Auslagerung gekennzeichnet. Das ist der Grund dafür, dass Prozesse, die sich schon lange im Leerlauf befinden
(wie Wininit oder Winlogon) eine Arbeitssatzgröße von 0 aufweisen können.
Systemarbeitssätze
Ebenso wie bei Prozessen werden auch der auslagerungsfähige Code und die auslagerungsfähigen Daten im Systemadressraum mithilfe von Arbeitssätzen verwaltet, wobei es insgesamt
drei solcher globalen Systemarbeitssätze gibt:
QQ Arbeitssatz des Systemcache
Enthält die Seiten, die sich im Systemcache befinden.
QQ Arbeitssatz des ausgelagerten Pools Enthält die Seiten, die sich im ausgelagerten Pool
befinden.
Arbeitssätze
Kapitel 5
483
QQ Arbeitssatz der System-PTEs Enthält auslagerungsfähigen Code und auslagerungsfähige Daten der geladenen Treiber sowie das Kernelabbild und die Seiten von Abschnitten,
die im Systemraum abgebildet wurden.
Tabelle 5–16 gibt an, wo diese Systemarbeitssätze gespeichert sind.
Arbeitssatz
Speicherort
(Windows 8.x, Windows
Server 2012/R2)
Speicherort (Windows 10, Windows Server
2016)
Systemcache
MmSystemCacheWs
MiState.SystemVa.SystemWs[0]
Ausgelagerter Pool
MmPagedPoolWs
MiState.SystemVa.SystemWs[2]
System-PTEs
MmSystemPtesWs
MiState.SystemVa.SystemWs[1]
Tabelle 5–16 Systemarbeitssätze
Die Größen dieser Arbeitssätze bzw. die Größen der Komponenten, die zu ihnen beitragen,
können Sie mit den in Tabelle 5–17 aufgeführten Leistungsindikatoren und Systemvariablen
untersuchen. Die Leistungsindikatoren geben die Werte in Bytes an, die Systemvariablen dagegen in Seiten.
Leistungsindikator (in
Bytes)
Systemvariabel (in Seiten)
Bedeutung
Arbeitsspeicher: Cachebytes
Arbeitsspeicher: Systemcache: Residente Bytes
WorkingSetSize
Der vom Dateisystemcache verbrauchte physische Arbeitsspeicher
Arbeitsspeicher: Cachebytes
(max.)
PeakWorkingSetSize (Windows 10
und Windows Server 2016)
Peak (Windows 8.x und Windows
Server 2012/R2)
Spitzengröße des Systemarbeitssatzes
Arbeitsspeicher: Systemtreiber: Residente Bytes
SystemPageCounts.
SystemDriverPage (global,
Windows 10 und Windows Server
2016)
MmSystemDriverPage (global,
Windows 8.x und Windows Server
2012/R2)
Der von auslagerungsfähigem
Gerätetreibercode verbrauchte
physische Arbeitsspeicher
Arbeitsspeicher: Auslagerungsseiten: Residente
Bytes
WorkingSetSize
Der vom ausgelagerten Pool
verbrauchte physische Arbeitsspeicher
Tabelle 5–17 Leistungsindikatoren und Systemvariablen für Systemarbeitssätze
Die Auslagerungsaktivität im Systemcache-Arbeitssatz können Sie sich mit dem Leistungsindikator Arbeitsspeicher: Cachefehler/s ansehen. Er gibt an, wie viele (harte und weiche) Seitenfehler im Systemcache-Arbeitssatz auftreten. Das Element PageFaultCount in der Struktur für den
Systemcache-Arbeitssatz enthält den Wert dieses Indikators.
484
Kapitel 5
Speicherverwaltung
Speicherbenachrichtigungsereignisse
Windows bietet eine Möglichkeit, um Benutzermodusprozesse und Kernelmodustreiber zu
benachrichtigen, wenn der physische Speicher, der ausgelagerte Pool, der nicht ausgelagerte
Pool oder der gesamte zugesicherte Speicher knapp bzw. reichlich vorhanden ist. Diese Informationen können dann herangezogen werden, um die Nutzung des Speichers angemessen zu
gestalten. Ist beispielsweise wenig Speicher vorhanden, kann die Anwendung den Speicherverbrauch verringern. Ist der verfügbare ausgelagerte Pool sehr groß, kann ein Treiber mehr
Speicher zuweisen. Mit einem weiteren Ereignis des Speicher-Managers sind auch Benachrichtigungen darüber möglich, dass beschädigte Seiten entdeckt wurden.
Benutzermodusprozesse können nur darüber informiert werden, dass der Speicher knapp
oder reichlich vorhanden ist. Eine Anwendung kann die Funktion CreateMemoryResourceNotification aufrufen und dabei angeben, ob sie Benachrichtigungen über niedrige oder hohe Verfügbarkeit des Speichers erhalten soll. Das zurückgegebene Handle kann an beliebige Wartefunktionen übergeben werden. Ist der Speicher knapp (oder reichlich), wird der Wartevorgang
beendet, wodurch der Thread über die Speicherverfügbarkeit informiert wird. Die Speicherverfügbarkeit auf dem System kann auch jederzeit mit QueryMemoryResourceNotification abgefragt
werden, ohne den aufrufenden Thread zu blockieren.
Treiber verwenden dagegen den Ereignisnamen, den der Speichermanager im Verzeichnis
\KernelObjects des Objekt-Managers eingerichtet hat, da Benachrichtigungen dadurch zustande kommen, dass der Speicher-Manager eines der von ihm definierten global benannten Ereignisobjekte aus Tabelle 5–18 ausgibt. Wird ein definierter Speicherzustand entdeckt, so wird das
entsprechende Signal ausgegeben und dadurch jeder wartende Thread aufgeweckt.
Ereignis
Beschreibung
HighCommitCondition
Dieses Ereignis wird ausgelöst, wenn sich der gesamte zugesicherte
Speicher dem oberen Grenzwert nähert, wenn also die Speichernutzung sehr hoch ist, sehr wenig Platz im physischen Speicher oder den
Auslagerungsdateien vorhanden ist und das Betriebssystem die Auslagerungsdateien nicht erweitern kann.
HighMemoryCondition
Dieses Ereignis wird ausgelöst, wenn die Menge des freien physischen
Speichers einen definierten Schwellenwert übersteigt.
HighNonPagedPoolCondition
Dieses Ereignis wird ausgelöst, wenn der Umfang des nicht ausgelagerten Pools einen definierten Schwellenwert übersteigt.
HighPagedPoolCondition
Dieses Ereignis wird ausgelöst, wenn der Umfang des ausgelagerten
Pools einen definierten Schwellenwert übersteigt.
LowCommitCondition
Dieses Ereignis wird ausgelöst, wenn der gesamte zugesicherte Speicher im Vergleich zum aktuellen oberen Grenzwert gering ist, wenn
also die Speichernutzung niedrig und viel Platz im physischen Speicher oder den Auslagerungsdateien vorhanden ist.
LowMemoryCondition
Dieses Ereignis wird ausgelöst, wenn die Menge des freien physischen
Speichers einen definierten Schwellenwert unterschreitet.
LowNonPagedPoolCondition
Dieses Ereignis wird ausgelöst, wenn der Umfang des nicht ausgelagerten Pools einen definierten Schwellenwert unterschreitet.
LowPagedPoolCondition
Dieses Ereignis wird ausgelöst, wenn der Umfang des ausgelagerten
Pools einen definierten Schwellenwert unterschreitet.
Arbeitssätze
Kapitel 5
→
485
Ereignis
Beschreibung
MaximumCommitCondition
Dieses Ereignis wird ausgelöst, wenn sich der gesamte zugesicherte
Speicher dem oberen Grenzwert nähert, wenn also die Speichernutzung sehr hoch ist, sehr wenig Platz im physischen Speicher oder den
Auslagerungsdateien vorhanden ist und das Betriebssystem die Größe
und Anzahl der Auslagerungsdateien nicht erhöhen kann.
MemoryErrors
Dieses Ereignis gibt an, dass eine unzulässige Seite (eine nicht mit Nullen gefüllte Nullseite) entdeckt wurde.
Tabelle 5–18 Benachrichtigungsereignisse des Speicher-Managers
Um die Standardeinstellung für den unteren oder oberen Schwellenwert zu überschreiben, fügen Sie den DWORD-Wert LowMemoryThreshold bzw. HighMemoryThresh
old zum Registrierungsschlüssel HKLM\SYSTEM\CurrentControlSet\Session Manager\
Memory Management hinzu und setzen ihn auf den gewünschten Wert in Megabyte.
Sie können auch dafür sorgen, dass das System beim Erkennen einer unzulässigen
Seite kein Speicherfehlerereignis sendet, sondern abstürzt, indem Sie den DWORD-
Registrierungswert PageValidationAction unter demselben Schlüssel auf 1 setzen.
Experiment: Benachrichtigungsereignisse über
Speicherressourcen einsehen
Um sich die Benachrichtigungsereignisse über Speicherressourcen anzusehen, führen Sie
das Sysinternals-Programm WinObj aus und klicken auf den Ordner KernelObjects. Daraufhin werden im rechten Bereich die Ereignisse für niedrigen und hohen Speicher angezeigt:
→
486
Kapitel 5
Speicherverwaltung
Wenn Sie auf eines dieser Ereignisse klicken, können Sie sehen, wie viele Handles oder Verweise auf die Objekte erfolgt sind. Um zu ermitteln, ob Prozesse in dem System Benachrichtigungen über Speicherressourcen angefordert haben, durchsuchen Sie die Handletabelle
nach Verweisen auf LowMemoryCondition oder HighMemoryCondition. Das können Sie über
das Menü Find von Process Explorer tun (wählen Sie darin Find Handle or DLL) und mit
WinDbg. (Eine Beschreibung der Handletabelle finden Sie im Abschnitt »Der Objekt-Manager« in Kapitel 8 von Band 2.)
Die PFN-Datenbank
Bislang haben wir uns häufiger mit der virtuellen Sicht eines Windows-Prozesses beschäftigt –
mit den Seitentabellen, PTEs und VADs. Im Rest dieses Kapitels wollen wir uns ansehen, wie
Windows den physischen Speicher verwaltet. Dabei beginnen wir damit, wie Windows den
Überblick über diesen physischen Speicher behält. Während Arbeitssätze die im Speicher befindlichen Seiten eines Prozesses oder des Systems beschreiben, gibt die PFN-Datenbank (Page
Frame Number) den Zustand jeder einzelnen Seite im physischen Speicher an. Die möglichen
Zustände sind in Tabelle 5–19 aufgeführt.
Status
Beschreibung
Aktiv oder gültig (Active/
valid)
Die Seite gehört zu einem Prozess-, Sitzungs- oder Systemarbeitssatz
oder zu gar keinem Arbeitssatz (z. B. eine nicht ausgelagerte Kernelseite).
Gewöhnlich zeigt ein gültiger PTE darauf.
Übergang (Transition)
Dies ist ein vorübergehender Zustand für eine Seite, die nicht zu einem
Arbeitssatz gehört und sich auch nicht auf einer Seitenliste befindet.
Eine Seite nimmt diesen Zustand ein, wenn auf ihr eine E/A stattfindet.
Der PTE ist angegeben, sodass Seitenfehlerkollisionen erkannt und ordnungsgemäß gehandhabt werden können. (Diese Bedeutung des Begriffs
»Übergang« unterscheidet sich von seiner Verwendung im Abschnitt über
ungültige PTEs. Ein ungültiger Übergangs-PTE zeigt auf eine Seite, die
sich auf der Standbyliste oder der Liste geänderter Seiten befindet.)
Standby
Die Seite gehörte zu einem Arbeitssatz, wurde aber daraus entfernt
oder wurde direkt durch Prefetching oder Clustering in die Standbyliste
aufgenommen. Seit sie zum letzten Mal auf die Festplatte geschrieben
wurde, ist sie nicht geändert worden. Der PTE verweist immer noch auf
die physische Seite, ist aber als ungültig und im Übergang befindlich
gekennzeichnet.
Geändert (Modified)
Die Seite gehörte zu einem Arbeitssatz, wurde aber daraus entfernt.
Während sie in Gebrauch war, wurde sie geändert, und ihre aktuellen
Inhalte wurden noch nicht auf die Festplatte oder einen Remotespeicher
geschrieben. Der PTE verweist immer noch auf die physische Seite, ist
aber als ungültig und im Übergang befindlich gekennzeichnet. Die Seite
muss in den Hintergrundspeicher geschrieben werden, bevor die physische Seite wiederverwendet werden kann.
→
Die PFN-Datenbank
Kapitel 5
487
Status
Beschreibung
Geändert, nicht schreibbar
(Modified no-write)
Dieser Zustand ist gleich dem einer geänderten Seite, allerdings ist sie
so gekennzeichnet, dass der Schreibthread für geänderte Seiten sie
nicht auf die Festplatte schreiben kann. Der Cache-Manager nimmt die
Kennzeichnung als geändert und nicht schreibbar auf Anforderung der
Dateisystemtreiber vor. Beispielsweise verwendet NTFS diesen Status
für Seiten mit Dateisystemmetadaten, damit es erst die Einträge des
Transaktionsprotokolls auf die Festplatte leeren kann, bevor die Seiten,
die durch diese Einträge geschützt sind, auf die Festplatte geschrieben
werden. (NTFS-Transaktionsprotokolle werden in Kapitel 13 von Band 2
erklärt.)
Frei (Free)
Die Seite ist frei, enthält aber nicht genau bestimmte modifizierte Daten.
Aus Sicherheitsgründen müssen diese Seiten zunächst mit Nullen initialisiert oder mit neuen Daten (z. B. aus einer Datei) überschrieben werden,
bevor sie als Benutzerseiten an Benutzerprozesse übergeben werden
können.
Mit Null initialisiert
(Zeroed)
Die Seite ist frei und wurde vom Nullseitenthread mit Nullen überschrieben oder als eine Seite erkannt, die bereits Nullen enthält.
ROM
Die Seite steht für schreibgeschützten Speicher (Read-Only Memory).
Unzulässig (Bad)
Die Seite hat einen Paritäts- oder einen anderen Hardwarefehler hervorgerufen und kann nicht (oder nur als Teil einer Enklave) benutzt werden.
Tabelle 5–19 Mögliche Zustände von physischen Seiten
Die PFN-Datenbank besteht aus einem Array von Strukturen, die für die einzelnen physischen
Speicherseiten auf dem System stehen. Abb. 5–35 zeigt diese Datenbank und ihre Beziehung
zu den Seitentabellen. Wie Sie dort erkennen können, zeigen gültige PTEs gewöhnlich auf
Einträge in der PFN-Datenbank (und der PFN-Index auf die entsprechende Seite im physischen
Speicher), während die Einträge in der PFN-Datenbank für Nicht-Prototyp-PTEs ggf. zurück
auf die Seitentabelle zeigen, die sie verwendet. Datenbankeinträge für Prototyp-PTEs dagegen
zeigen zurück zu dem Prototyp-PTE.
488
Kapitel 5
Speicherverwaltung
Seitentabelle von
Prozess 1
Gültig
PFN-Datenbank
Ungültig:
Festplattenzugriff
Ungültig:
Übergang
In Verwendung
Standbyliste
Seitentabelle von
Prozess 2
Gültig
In Verwendung
Ungültig:
Festplattenzugriff
In Verwendung
Gültig
Seitentabelle von
Prozess 3
Liste geänderter
Seiten
Gültig
Ungültig:
Übergang
Ungültig:
Festplattenzugriff
Vorwärtszeiger
Rückwärtszeiger
Abbildung 5–35 Seitentabellen und die PFN-Datenbank
Für sechs der Seitenzustände in Tabelle 5–19 gibt es verknüpfte Listen, sodass der Speicher-
Manager Seiten des entsprechenden Typs schnell finden kann. (Aktive/gültige Seiten, Übergangsseiten und überladene »unzulässige« Seiten werden auf keiner systemweiten Liste geführt.) Der Status Standby ist darüber hinaus mit acht nach Priorität gegliederten Listen verknüpft. (Mit der Priorität beschäftigen wir uns weiter hinten in diesem Abschnitt noch genauer.)
Abb. 5–36 zeigt ein Beispiel für die Verknüpfungen zwischen diesen Einträgen.
Die PFN-Datenbank
Kapitel 5
489
Mit Null
initialisiert
Aktiv
Frei
Standby
Unzulässig
Aktiv
Geändert
Aktiv
ROM
Geändert, nicht
schreibbar
Abbildung 5–36 Seitenlisten in der PFN-Datenbank
Experiment: Die PFN-Datenbank einsehen
Mit dem Programm MemInfo von der Website zu diesem Buch können Sie bei Angabe des
Schalters -s die Größe der einzelnen Seitenlisten ausgeben:
C:\Tools>MemInfo.exe -s
MemInfo v3.00 - Show PFN database information
Copyright (C) 2007-2016 Alex Ionescu
www.alex-ionescu.com
Initializing PFN Database... Done
PFN Database List Statistics
Zeroed:
4867 (
19468 kb)
Free:
3076 (
12304 kb)
Standby: 4669104 (18676416 kb)
Modified:
7845 (
31380 kb)
ModifiedNoWrite:
117 (
468 kb)
Active/Valid: 3677990 (14711960 kb)
Transition:
5 (
20 kb)
→
490
Kapitel 5
Speicherverwaltung
Bad:
0 (
0 kb)
Unknown:
1277 (
5108 kb)
TOTAL: 8364281 (33457124 kb)
Ähnliche Informationen können Sie auch mit dem Kerneldebuggerbefehl !memusage gewinnen, allerdings erfordert das erheblich mehr Zeit.
Seitenlistendynamik
Abb. 5–37 zeigt ein Statusdiagramm für Seitenframeübergänge. Der Einfachheit halber wurden
die Listen für »geändert, nicht schreibbar«, »unzulässig« und »ROM« weggelassen.
Nullforderungs
seitenfehler
Seitenlesevorgänge
von der Festplatte oder
Kernelzuweisungen
Standbyliste
Liste
freier
Leisten
Prozessarbeits
satz
Weiche
Seiten
fehler
Ersetzung im
Arbeitssatz
Null
seiten
thread
Null
seiten
liste
Schreib
thread für
geänderte
Seiten
Liste
geänderter
Seiten
Ersetzung im
Arbeitssatz
Private Bytes bei
Prozessende
Abbildung 5–37 Statusdiagramm für physische Seiten
Seitenframes bewegen sich wie folgt von einer Liste zur anderen:
QQ Wenn der Speicher-Manager eine mit Nullen initialisierte Seite benötigt, um auf einen
Nullforderungsseitenfehler zu reagieren (einen Verweis auf eine Seite, die komplett null
sein soll, oder auf eine zugesicherte, private Benutzermodusseite, auf die noch nie zugegriffen wurde), versucht er zunächst, sie von der Nullseitenliste abzurufen. Ist diese Liste
leer, verwendet er eine Seite von der Liste der freien Seiten und initialisiert sie mit Nullen.
Ist auch die Liste der freien Seiten leer, greift er auf eine Seite von der Standbyliste zurück.
Die PFN-Datenbank
Kapitel 5
491
Ein Grund für die Notwendigkeit einer mit Nullen initialisierten Seite können Sicherheitsanforderungen wie Common Criteria (CC) sein. Die meisten CC-Profile verlangen, dass
Benutzermodusprozesse initialisierte Seitenframes bekommen, damit sie keine Speicher
inhalte des vorherigen Prozesses lesen können. Daher gibt der Speicher-Manager Benutzermodusprozessen mit Nullen initialisierte Frames; es sei denn, dass die Seite vom
Hintergrundspeicher gelesen wurde. In letzterem Fall verwendet der Speicher-Manager
bevorzugt einen nicht mit Nullen gefüllten Frame, den er dann mit den Daten von der
Festplatte oder dem Remotespeicher initialisiert. Die Nullseitenliste wird vom Nullseiten-Systemthread (Thread 0 im Systemprozess) mit Einträgen aus der Liste der freien Seiten gefüllt. Um mit seiner Arbeit zu beginnen, wartet der Nullseitenthread auf das Signal
eines Gate-Objekts. Es wird ausgelöst, wenn die Liste der freien Seiten acht oder mehr
Seiten enthält. Allerdings wird der Nullseitenthread nur dann ausgeführt, wenn auf mindestens einem Prozessor keine anderen Threads laufen, da er die Priorität 0 hat und ein
Benutzerthread mindestens die Priorität 1.
Wenn ein Treiber mithilfe von MmAllocatePagesForMdl(Ex) oder eine Windows-Anwendung mit AllocatePhysicalPages oder AllcoateUserPhysicalPagesNuma eine
physische Seite zuweist oder wenn eine Anwendung große Seiten zuweist und
dadurch Speicher mit Nullen überschrieben werden muss, verwendet der Speicher-Manager die Funktion MiZeroInParallel, um eine bessere Leistung zu erzielen. Sie ordnet größere Regionen zu als der Nullseitenthread, der immer nur eine
Seite auf einmal bearbeitet. Auf Mehrprozessorsystemen erstellt der Speicher-Manager außerdem zusätzliche Systemthreads, um das Überschreiben mit Nullen parallel durchzuführen (bzw. um es auf NUMA-Plattformen für NUMA zu optimieren).
QQ Braucht der Speicher-Manager keine mit Nullen initialisierte Seite, wendet er sich als Erstes an die Liste der freien Seite. Wenn diese leer ist, geht er zur Nullseitenliste über, und
wenn auch diese leer ist, zu den Standbylisten. Bevor er Seitenframes von Standbylisten
verwenden kann, muss er jedoch zunächst die Verweise vom ungültigen PTE (oder Prototyp-PTE) zurückverfolgen und entfernen, die auf diese Frames zeigen. Da die Einträge
in der PFN-Datenbank Zeiger zurück auf die Seiten mit der Seitentabelle des vorherigen
Benutzers enthalten (oder auf die Seite eines Prototyp-PTE-Pools für gemeinsam genutzte
Seiten), kann der Speicher-Manager den PTE schnell finden und die entsprechenden Änderungen vornehmen.
QQ Wenn ein Prozess eine Seite aus seinem Arbeitssatz entfernen muss, weil er auf eine neue
Seite verweist und sein Arbeitssatz voll ist oder weil der Speicher-Manager den Arbeitssatz
verkleinert, wird die Seite auf die Standbyliste gesetzt, sofern sie während ihres Aufenthalts
im Speicher nicht modifiziert wurde, oder auf die Liste der geänderten Seiten.
QQ Wird ein Prozess beendet, werden alle seine privaten Seiten auf die Liste der freien Seiten
gesetzt. Wenn der letzte Verweis auf einen auslagerungsgepufferten Abschnitt geschlossen wird und dieser Abschnitt keine zugeordneten Sichten mehr enthält, werden auch
diese Seiten auf die Liste der freien Seiten übertragen.
492
Kapitel 5
Speicherverwaltung
Experiment: Die Nullseitenliste und die Liste der freien Seiten
Die Freigabe privater Seiten bei der Beendigung eines Prozesses können Sie sich im Dialogfeld System Information von Process Explorer ansehen. Erstellen Sie dazu zunächst einen
Prozess mit zahlreichen privaten Seiten im Arbeitssatz. Das haben wir bereits in einem früheren Prozess mithilfe von TestLimit getan:
C:\Tools\Sysinternals>Testlimit.exe -d 1 -c 1500
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 13928
Leaking private bytes with touch 1 MB at a time...
Leaked 1500 MB of private memory (1500 MB total leaked). Lasterror: 0
The operation completed successfully.
Die Option -d veranlasst TestLimit nicht nur, privaten, zugesicherten Speicher zuzuweisen,
sondern auch darauf zuzugreifen. Dadurch wird physischer Speicher zugewiesen und mit
dem Prozess verknüpft, um einen Bereich von privatem, zugesichertem virtuellem Arbeitsspeicher zu materialisieren. Sofern das System über ausreichend RAM verfügt, sollten sich
die gesamten 1500 MB im RAM für den Prozess befinden. Anschließend wartet der Prozess,
bis Sie ihn beenden (etwa dadurch, dass Sie in seinem Befehlsfenster (Strg) + (C) drücken).
Gehen Sie danach wie folgt vor:
1.
Starten Sie Process Explorer.
2.
Öffnen Sie das Menü View, wählen Sie System Information und klicken Sie auf die Registerkarte Memory.
3.
Schauen Sie sich die Größen der Listen Free und Zeroed an.
4.
Beenden Sie den TestLimit-Prozess.
Unter Umständen können Sie erkennen, dass die Liste der freien Seiten kurzzeitig größer
wird. Es heißt hier absichtlich »unter Umständen«, da der Nullseitenthread schon aufgeweckt wird, sobald sich acht Seiten auf dieser Liste befinden, und sehr schnell reagiert.
Process Explorer aktualisiert seine Anzeige jedoch nur einmal pro Sekunde, weshalb es sehr
wahrscheinlich ist, dass die meisten Seiten bereits mit Nullen initialisiert und auf die Nullseitenliste verschoben wurden, bevor der Status erfasst werden kann. Wenn Sie ein vorübergehendes Anwachsen der Liste der freien Seiten erkennen können, werden Sie anschließend
einen Abfall auf null und eine entsprechende Vergrößerung der Nullseitenliste sehen. Wenn
nicht, so können Sie zumindest ein Anwachsen der Nullseitenliste beobachten.
Die PFN-Datenbank
Kapitel 5
493
Experiment: Die Standbyliste und die Liste geänderter Seiten
Die Verschiebung der Seiten aus dem Arbeitssatz auf die Liste der geänderten Seiten und
dann auf die Standbyliste können Sie mit den Sysinternal-Tools VMMap und RAMMap sowie dem Kerneldebugger beobachten. Gehen Sie dazu wie folgt vor:
1.
Starten Sie RAMMap und beobachten Sie den Zustand des unbelasteten Systems. Das
folgende Beispiel stammt von einem x86-System mit 3 GB RAM. Die Spalten stehen für
die einzelnen Seitenstatus aus Abb. 5–37. Der Übersichtlichkeit halber wurden einige
für unsere Zwecke unwichtige Spalten ausgeblendet.
2.
Das System verfügt über ca. 420 MB freien RAM (die Summe der Nullseitenliste und
der Liste freier Seiten). Etwa 580 MB befinden sich auf der Standbyliste (und sind daher
»verfügbar«, enthalten aber wahrscheinlich Daten früherer Prozesse oder von SuperFetch). Ungefähr 830 MB sind aktiv, also über gültige PTEs direkt virtuellen Adressen
zugeordnet.
3.
Jede Zeile schlüsselt die Seitenstatus nach Nutzung oder Ursprung auf (z. B. privater
Speicher des Prozesses, zugeordnete Dateien usw.). Beispielsweise sind von den aktiven
830 MB zurzeit 400 MB auf private Prozesszuweisungen zurückzuführen.
4.
Erstellen Sie nun wie im vorherigen Experiment mithilfe von TestLimit einen Prozess
mit vielen Seiten im Arbeitssatz. Verwenden Sie auch hier wieder die Option -d, damit
TestLimit auf jede Seite schreibt, diesmal aber ohne Grenzwert, damit so viele private
modifizierte Seiten wie möglich erstellt werden:
→
494
Kapitel 5
Speicherverwaltung
C:\Tools\Sysinternals>Testlimit.exe -d
Testlimit v5.24 - test Windows limits
Copyright (C) 2012-2015 Mark Russinovich
Sysinternals - www.sysinternals.com
Process ID: 7548
Leaking private bytes with touch (MB)...
Leaked 1975 MB of private memory (1975 MB total leaked). Lasterror: 8
5.
TestLimit hat jetzt 1975 Zuweisungen von je 1 MB erstellt. Aktualisieren Sie die Anzeige
von RAMMap mit File > Refresh. (RAMMap aktualisiert seine Anzeige nicht kontinuierlich, da mit der Erfassung dieser Informationen hohe Kosten verbunden sind.)
6.
Wie Sie sehen, sind jetzt mehr als 2,8 GB aktiv, davon 2,4 GB in der Zeile Private Process.
Dies ist der von TestLimit zugewiesene und verwendete Speicher. Beachten Sie, dass die
Werte für die Standbyliste, die Nullseitenliste und die Liste freier Seiten jetzt viel kleiner
sind. Der Großteil des TestLimit zugewiesenen RAM stammt von diesen Listen.
→
Die PFN-Datenbank
Kapitel 5
495
7.
Untersuchen Sie nun in RAMMap die Zuweisungen physischer Seiten für den Prozess.
Wechseln Sie zur Registerkarte Physical Pages, richten Sie am unteren Bildschirmrand
den Filter Process ein und setzen Sie ihn auf Testlimit.exe. Jetzt werden die physischen
Seiten angezeigt, die zum Arbeitssatz dieses Prozesses gehören.
8.
Wir würden gern eine der physischen Seiten ermitteln, die bei der Zuweisung von virtuellem Adressraum mithilfe der TestLimit-Option -d verwendet werden. RAMMap sagt
nichts darüber aus, welche virtuellen Zuweisungen mit den VirtualAlloc-Aufrufen von
TestLimit verknüpft sind. Allerdings können wir in VMMap einen guten Hinweis darauf
erhalten. Wenn wir VMMap auf denselben Prozess anwenden, erhalten wir folgendes
Ergebnis:
→
496
Kapitel 5
Speicherverwaltung
9.
Im unteren Teil der Anzeige sehen wir Hunderte von Zuweisungen von privaten Prozessdaten von jeweils 1 MB Größe und 1 MB zugesicherter Größe. Das entspricht der
Größe der Zuweisungen durch TestLimit. Eine davon ist im vorstehenden Screenshot
markiert. Ihre Startadresse lautet 0x310000.
10. Kehren Sie wieder zur Anzeige des physischen Speichers in RAMMap zurück. Ordnen
Sie die Spalten so an, dass Sie die Spalte Virtual Address gut erkennen können, klicken
Sie darauf, um die Anzeige nach diesem Wert zu sortieren, und suchen Sie die gewünschte virtuelle Adresse:
→
Die PFN-Datenbank
Kapitel 5
497
11. Wie Sie sehen, ist die virtuelle Seite, die bei 0x310000 beginnt, zurzeit der physischen
Adresse 0x212D1000 zugeordnet. Die Option -d von TestLimit sorgt dafür, dass in das
erste Byte jeder Zuweisung jeweils der Name des Programms geschrieben wird. Das
können Sie sich mit dem Befehl !dc (display characters, also Zeichenanzeige, unter
Angabe der physischen Adresse) im lokalen Kerneldebugger anschauen:
lkd> !dc 0x212d1000
#212d1000 74736554 696d694c 00000074 00000000 TestLimit.......
#212d1010 00000000 00000000 00000000 00000000 ................
...
12. Wenn Sie nicht schnell genug sind, kann das schiefgehen, weil die Seite möglicherweise
schon aus dem Arbeitssatz entfernt wurde. Im letzten Abschnitt dieses Experiments
wollen wir zeigen, dass diese Daten intakt bleiben (zumindest eine Zeit lang), wenn der
Prozessarbeitssatz verkleinert und die Seite auf die Liste der geänderten Seiten und auf
die Standbyliste verschoben wird.
13. Markieren Sie in VMMap den Prozess TestLimit, öffnen Sie das Menü View und wählen
Sie Empty Working Set, um den Arbeitssatz des Prozesses auf das nackte Minimum zu
verkleinern. Daraufhin sehen Sie folgende Anzeige:
14. Das Balkendiagramm Working Set ist praktisch leer. Im mittleren Bereich wird für den
Prozess ein Arbeitssatz von lediglich 4 KB angezeigt, und fast alles davon wird für Seitentabellen verwendet. Kehren Sie jetzt zu RAMMap zurück und aktualisieren Sie die
Anzeige. Auf der Registerkarte Use Counts sehen Sie jetzt, dass die Anzahl aktiver Seiten erheblich abgenommen hat, während sich viele Seiten auf der Liste der geänderten
Seiten und einige auf der Standbyliste befinden:
→
498
Kapitel 5
Speicherverwaltung
15. Die Registerkarte Processes von RAMMap bestätigt, dass der TestLimit-Prozess die
meisten Seiten zu diesen Listen beigetragen hat:
Seitenpriorität
Der Speicher-Manager weist jeder physischen Seite im System einen Prioritätswert zu. Dabei
handelt es sich um eine Zahl von 0 bis 7. Sie dient vor allem dazu, die Reihenfolge festzulegen,
in der die Seiten auf der Standbyliste verwendet werden. Dazu teilt der Speicher-Manager die
Standbyliste in acht Teillisten für Seiten der einzelnen Prioritäten auf. Wenn er eine Seite von
der Standbyliste entnehmen will, greift er dabei zuerst auf die Liste der niedrigsten Priorität zu.
Die PFN-Datenbank
Kapitel 5
499
Auch jedem Thread und jedem Prozess im System ist eine Seitenpriorität zugewiesen. Die
Priorität einer Seite entspricht gewöhnlich der Seitenpriorität des Threads, der ihre Zuweisung
veranlasst hat. (Bei einer gemeinsam genutzten Seite ist dies die höchste Seitenpriorität unter
den betreffenden Threads.) Ein Thread erbt seine Seitenpriorität von dem Prozess, zu dem er
gehört. Der Speicher-Manager verwendet für Seiten, die er in Erwartung des nächsten Speicherzugriffs eines Prozesses vorausschauend von der Festplatte liest, niedrige Prioritäten.
Standardmäßig haben Prozesse einen Seitenprioritätswert von 5. Anwendungen können
die Seitenprioritäten von Prozessen und Threads jedoch mit den Benutzermodusfunktionen
SetProcessInformation und SetThreadInformation ändern, die wiederum die nativen Funktionen NtSetInformationProcess bzw. NtSetInformationThread aufrufen. Die Speicherpriorität eines Threads können Sie sich in Process Explorer ansehen. (Die Prioritäten der einzelnen Seiten
können Sie durch Untersuchung der PFN-Einträge ermitteln, wie Sie in einem Experiment weiter hinten in diesem Kapitel noch sehen werden.) Abb. 5–38 zeigt die Registerkarte Threads von
Process Explorer mit Informationen über den Hauptthread von Winlogon. Die Threadpriorität
ist zwar hoch, doch die Speicherpriorität hat nach wie vor den Standardwert 5.
Abbildung 5–38 Die Registerkarte Threads in Process Explorer
Was Speicherprioritäten wirklich leisten, wird erst klar, wenn die relativen Prioritäten der Seiten
auf einer höheren Ebene gedeutet werden. Das ist die Rolle von SuperFetch, womit wir uns am
Ende dieses Kapitels beschäftigen werden.
500
Kapitel 5
Speicherverwaltung
Experiment: Nach Prioritäten geordnete Standbylisten einsehen
Mit Process Explorer können Sie sich die Größen der einzelnen Standbylisten ansehen, indem Sie im Dialogfeld System Information die Registerkarte Memory aufrufen:
Auf dem in diesem Experiment verwendeten, erst kürzlich gestarteten x86-System sind ungefähr 9 MB Daten mit Priorität 0 zwischengespeichert, etwa 47 MB mit Priorität 1, 68 MB
mit Priorität 2 usw. Versuchen Sie jetzt, mit dem Sysinternals-Tool TestLimit so viel Speicher
wie möglich zuzusichern und darauf zuzugreifen:
C:\Tools\Sysinternals>Testlimit.exe -d
Die Standbylisten niedriger Priorität wurden zuerst verwendet und sind jetzt viel kleiner,
während die Listen hoher Priorität nach wie vor wertvolle zwischengespeicherte Daten enthalten.
Die PFN-Datenbank
Kapitel 5
501
Die Schreibthreads für geänderte und für zugeordnete Seiten
Der Speicher-Manager verwendet zwei Systemthreads, um Seiten auf die Festplatte zurückzuschreiben und auf die Standbyliste für ihre Priorität zu setzen. Der eine dieser Threads
(MiModifiedPageWriter) schreibt geänderte Seiten in die Auslagerungsdatei, der andere
(MiMappedPageWriter) in zugeordnete Dateien. Zwei Threads sind erforderlich, um Deadlocks
zu vermeiden, die auftreten können, wenn beim Schreiben in eine zugeordnete Datei ein
Seitenfehler auftritt, weshalb eine freie Seite benötigt wird und, falls keine vorhanden ist, der
Schreibthread für geänderte Seiten für weitere freie Seiten sorgen muss. Dadurch, dass der
Schreibthread für geänderte Seiten die E/A das Schreiben in zugeordneten Dateien einem
zweiten Systemthread überlässt, kann dieser zweite Thread warten, ohne das Schreiben in die
Auslagerungsdatei zu blockieren.
Beide Threads laufen mit Priorität 18. Nach der Initialisierung warten sie jeweils auf unterschiedliche Ereignisobjekte, von denen sie ausgelöst werden. Der Schreibthread für zugeordnete Seiten wartet auf die folgenden 18 Ereignisobjekte:
QQ Ein Beendigungsereignis, das dem Thread die Beendigung signalisiert (für die vorliegende
Erörterung ohne Bedeutung).
QQ Das MappedPagedWriter-Ereignis, das in der globalen Variablen MiSystemPartition.
Modwriter.MappedPageWriterEvent gespeichert ist (bzw. in MmMappedPageWriterEvent in
Windows 8.x und Windows Server 2012/R2). Dieses Ereignis wird in den folgenden Fällen
ausgelöst:
•
Bei einer Seitenlistenoperation durch MiInsertPageInList. Diese Routine fügt eine Seite
in die Listen ein, die in seinen Eingangsargumenten angegeben ist. Sie löst das Ereignis
aus, wenn die Anzahl der für das Dateisystem bestimmten Seiten in der Liste der geänderten Seiten den Wert 16 überschreitet und die Anzahl der verfügbaren Seiten unter
1024 gefallen ist.
•
Bei dem Versuch, freie Seiten zu gewinnen (MiObtainFreePages).
•
Durch den Arbeitssatz-Manager des Speicher-Managers (MmWorkingSetManager). Er löst
dieses Ereignis aus, wenn die Anzahl der für das Dateisystem bestimmten Seiten in der
Liste der geänderten Seiten den Wert 800 überschreitet.
•
Bei der Anforderung, alle geänderten Seiten auf die Festplatte zu leeren (MmFlushAllPages).
•
Bei der Anforderung, alle für das Dateisystem bestimmten geänderten Seiten auf die
Festplatte zu leeren (MmFlushAllFilesystemPages). In den meisten Fällen werden geänderte zugeordnete Seiten nicht wieder in die Dateien ihres Hintergrundspeichers
zurückgeschrieben, wenn die Anzahl der zugeordneten Seiten in der Liste der geänderten Seiten geringer ist als die Maximalgröße des Schreibclusters, also 16 Seiten. Bei
MmFlushAllFilesystemPages und MmFlushAllPages wird diese Überprüfung jedoch nicht
durchgeführt.
QQ 16 Ereignisse, die mit 16 Listen für zugeordnete Seiten verknüpft und als Array in
M iSystemPartition.PageLists.MappedPageListHeadEvent gespeichert sind (bzw. in MmMappedPageListHeadEvent in Windows 8.x und Windows Server 2012/R2). Bei jeder Än-
502
Kapitel 5
Speicherverwaltung
derung an einer zugeordneten Seite wird sie in eine dieser 16 Listen aufgenommen. Die
Auswahl der Liste erfolgt dabei aufgrund einer Bucketnummer, die in MiSystemPartition.
WorkingSetControl->CurrentMappedPageBucket gespeichert ist (bzw. in MmCurrentMappedPageBucket in Windows 8.x und Windows Server 2012/R2). Diese Nummer wird vom Arbeitssatz-Manager immer dann aktualisiert, wenn das System feststellt, dass zugeordnete
Seiten alt genug sind. Der Altersschwellenwert beträgt zurzeit 100 Sekunden. Er wird in der
Variablen WriteGapCounter in derselben Struktur gespeichert (bzw. in MiWriteGapCounter
in Windows 8.x und Windows Server 2012/R2) und bei jeder Ausführung des Arbeitssatz-Managers inkrementiert. Diese zusätzlichen Ereignisse sollen Datenverluste bei einem
Systemabsturz oder Stromausfall verringern helfen, indem geänderte zugeordnete Seiten
auch dann geschrieben werden, wenn die Liste der geänderten Seiten den Schwellenwert
von 800 Einträgen noch nicht erreicht hat.
Der Schreibthread für geänderte Seiten wartet auf zwei Ereignisse. Das erste ist das Beendigungsereignis, und bei dem zweiten handelt es sich um das Ereignis, das in MiSystemPartition.
Modwriter.ModifiedPageWriterEvent gespeichert ist (bzw. um das in MmModifiedPageWriterGate
gespeicherte Kernelgateereignis in Windows 8.x und Windows Server 2012/R2) und unter folgenden Umständen ausgelöst wird:
QQ Bei der Anforderung, alle empfangenen Seiten auf die Festplatte zu leeren.
QQ Wenn die Anzahl der verfügbaren Seiten – gespeichert in MiSystemPartition.Vp.AvailablePages (bzw. in MmAvailablePages in Windows 8.x und Windows Server 2012/R2) – unter
128 fällt.
QQ Wenn der Gesamtumfang der Nullseitenliste und der Liste freier Seiten auf unter 20.000
fällt und die Anzahl der für die Auslagerungsdatei bestimmten geänderten Seiten größer
ist als der kleinere Wert von entweder 1/16 der verfügbaren Seiten oder 64 MB (16.384
Seiten).
QQ Wenn ein Arbeitssatz verkleinert wird, um zusätzliche Seiten aufnehmen zu können, und
die Anzahl der verfügbaren Seiten kleiner als 15.000 ist.
QQ Bei einer Seitenlistenoperation durch MiInsertPageInList. Diese Routine löst das Ereignis
aus, wenn die Anzahl der für das Dateisystem bestimmten Seiten in der Liste der geänderten Seiten den Wert 16 überschreitet und die Anzahl der verfügbaren Seiten unter 1024
gefallen ist.
Nach dem Auslösen dieses Ereignisses wartet der Schreibthread für geänderte Seiten noch auf
zwei weitere Ereignisse. Das eine zeigt an, dass eine erneute Untersuchung der Auslagerungsdatei erforderlich ist (etwa wenn eine neue Auslagerungsdatei erstellt wurde) und ist in MiSystemPartition.Modwriter.RescanPageFilesEvent gespeichert (bzw. in MiRescanPageFilesEvent in
Windows 8.x und Windows Server 2012/R2). Das zweite ist ein internes Ereignis des Auslagerungsdateiheaders (MiSystemPartition.Modwriter.PagingFileHeader bzw. MmPagingFileHeader
in Windows 8.x und Windows Server 2012/R2) und ermöglicht dem System, das Leeren der
Daten in die Auslagerungsdatei bei Bedarf manuell anzufordern.
Wenn der Schreibthread für zugeordnete Seiten aufgerufen wird, versucht er, so viele Seiten wie möglich in einer einzigen E/A-Anforderung auf die Festplatte zu schreiben. Dazu untersucht er das ursprüngliche PTE-Feld des PFN-Datenbankelements auf Seiten, die auf der
Die PFN-Datenbank
Kapitel 5
503
Liste der geänderten Seiten stehen, um Seiten in zusammenhängenden Speicherorten auf der
Festplatte zu finden. Wenn eine Liste erstellt ist, werden die Seiten von der Liste der geänderten
Seiten entfernt und eine E/A-Anforderung ausgegeben. Nach deren erfolgreichem Abschluss
werden die Seiten am Ende der Standbyliste für ihre Priorität eingereiht.
Andere Threads können auf Seiten zugreifen, die gerade geschrieben werden. Wenn
das geschieht, werden der Referenzzähler und der Zähler für die gemeinsame Nutzung im
PFN-Eintrag für die physische Seite heraufgesetzt, um anzugeben, dass ein weiterer Prozess
die Seite nutzt. Ist die E/A-Operation abgeschlossen, stellt der Schreibthread für geänderte
Seiten fest, dass der Referenzzähler nicht mehr 0 beträgt, weshalb er die Seite nicht auf eine
der Standbylisten stellt.
PFN-Datenstrukturen
PFN-Datenbankeinträge haben zwar eine feste Länge, allerdings können ihre einzelnen Felder
je nach dem Seitenstatus eine unterschiedliche Bedeutung aufweisen. Abb. 5–39 zeigt den
Aufbau von PFN-Einträgen für verschiedene Zustände.
Arbeitssatzindex
PTE-Adresse | Sperre
Zähler für gemeinsame Nutzung
Priorität
Flags
Typ
Cacheattribute Referenzzähler
Ursprünglicher PTE-Inhalt
PFN des PTEs Flags Seitenfarbe
Vorwärtsverknüpfung
PTE-Adresse | Sperre
Rückwärtsverknüpfung
Flags
Typ
Priorität
Cacheattribute Referenzzähler
Ursprünglicher PTE-Inhalt
PFN des PTEs Flags Seitenfarbe
PFN für eine Seite im Arbeitssatz
PFN für eine Seite auf der Standby
liste oder der Liste geänderter Seiten
Verknüpfung zur PFN
des nächsten Stacks
PTE-Adresse | Sperre
Zähler für gemeinsame Nutzung
Priorität
Typ
Flags
Cacheattribute Referenzzähler
Ursprünglicher PTE-Inhalt
PFN des PTEs Flags Seitenfarbe
Ereignisadresse
PTE-Adresse | Sperre
Zähler für gemeinsame Nutzung
Priorität
Typ
Flags
Cacheattribute Referenzzähler
Ursprünglicher PTE-Inhalt
PFN des PTEs Flags Seitenfarbe
PFN für die Seite eines Kernelstacks
PFN für eine Seite mit laufender E/A
Kernelstackbesitzer
Abbildung 5–39 PFN-Datenbankeinträge für verschiedene Status (prinzipieller Aufbau)
Viele der Felder sind bei den verschiedenen PFN-Typen identisch, andere aber haben je nach
Art der PFN eine eigene Bedeutung. Die folgenden Felder kommen in mehr als einem PFN-Typ
vor:
QQ PTE-Adresse Dies ist die virtuelle Adresse des PTEs, der auf die Seite zeigt. Da PTE-Adressen immer an einer 4-Byte-Grenze ausgerichtet sind (bzw. 8 Byte auf 64-Bit-Systemen),
werden die beiden unteren Bits als Sperrmechanismus verwendet, um den Zugriff auf den
PFN-Eintrag zu serialisieren.
504
Kapitel 5
Speicherverwaltung
QQ Referenzzähler Dies ist die Anzahl der Verweise auf die Seite. Der Zähler wird erhöht,
wenn eine Seite zum Arbeitssatz hinzugefügt oder für die E/A im Speicher verriegelt wird
(z. B. durch einen Gerätetreiber), und erniedrigt, wenn der Zähler für die gemeinsame Nutzung auf 0 sinkt oder wenn Seiten im Speicher entriegelt werden. In ersterem Fall gehört
die Seite keinem Arbeitssatz mehr an. Wenn der Referenzzähler nun auch auf 0 sinkt, wird
der PFN-Datenbankeintrag für die Seite aktualisiert, um die Seite der Standliste, der Liste
der freien oder der geänderten Seiten hinzuzufügen.
QQ Typ Dies ist die Art der Seite, für die die PFN steht (aktiv/gültig, Standby, geändert, geändert und nicht schreibbar, frei, mit null initialisiert, unzulässig oder Übergang).
QQ Flags
Die möglichen Inhalte des Flagfeldes finden Sie in Tabelle 5–20.
QQ Priorität Dies ist die mit dieser PFN verknüpfte Priorität, über die bestimmt wird, in welche Standbyliste die Seite gestellt wird.
QQ Ursprünglicher PTE-Inhalt Alle PFN-Datenbankeinträge enthalten den ursprünglichen
Inhalt des PTEs, der auf die Seite zeigt (wobei es sich dabei auch um einen Prototyp-PTE
handeln kann). Dadurch kann der PTE-Inhalt wiederhergestellt wird, wenn die physische
Seite nicht mehr vorhanden ist. Eine Ausnahme bilden PFN-Einträge für AWE-Zuweisungen. Bei ihnen ist in diesem Feld der AWE-Referenzzähler untergebracht.
QQ PFN des PTEs Dies ist die Nummer der physischen Seite für die Seitentabelle mit dem
PTE, der auf die vorliegende Seite zeigt.
QQ Farbe PFN-Datenbankeinträge sind nicht nur über eine Liste verknüpft, sondern enthalten auch ein zusätzliches Feld, um physische Seiten anhand ihrer »Farbe« zu verknüpfen.
Dabei handelt es sich um die Nummer des NUMA-Knotens der Seite.
QQ Flags Das zweite Flagfeld dient zur Aufnahme zusätzliche Informationen über den PTE.
Diese Flags werden in Tabelle 5–21 erklärt.
Flag
Bedeutung
Laufender Schreibvorgang (Write in progress)
Gibt an, dass gerade eine Schreiboperation
ausgeführt wird. Das erste DWORD enthält die
Adresse des Ereignisobjekts, das beim Abschluss
der E/A ausgelöst wird.
Status »Geändert« (Modified state)
Gibt an, dass die Seite geändert wurde. Bevor die
Seite aus dem Arbeitsspeicher entfernt wird, muss
ihr Inhalt auf der Festplatte gesichert werden.
Laufender Lesevorgang (Read in progress)
Gibt an, dass gerade eine Leseoperation für die
Seite ausgeführt wird. Das erste DWORD enthält
die Adresse des Ereignisobjekts, das beim Abschluss der E/A ausgelöst wird.
ROM
Gibt an, dass die Seite aus der Firmware des Computers oder einem anderen schreibgeschützten
Speicher stammt, z. B. einem Geräteregister.
Einlagerungsfehler (In-page error)
Gibt an, dass bei einer Einlagerungsoperation
für diese Seite ein E/A-Fehler aufgetreten ist. In
diesem Fall enthält das erste Feld im PFN-Eintrag
den Fehlercode.
→
Die PFN-Datenbank
Kapitel 5
505
Flag
Bedeutung
Kernelstack
Gibt an, dass die Seite für einen Kernelstack verwendet wurde. In diesem Fall enthält der PFN-Eintrag den Besitzer des Stacks und die PFN des
nächsten Stacks für diesen Thread.
Entfernen angefordert (Removal requested)
Gibt an, dass die Seite das Ziel eines Entfernungsvorgangs ist (aufgrund eines ECC- oder Datenbereinigungsvorgangs oder eines Speicherausbaus
im laufenden Betrieb).
Paritätsfehler (Parity error)
Gibt an, dass die physische Seite Paritäts- oder
ECC-Fehler (Error Correction Control) enthält.
Tabelle 5–20 Flags in PFN-Datenbankeinträgen
Flag
Bedeutung
PFN-Abbild überprüft (PFN image verified)
Gibt an, dass die Codesignatur für die PFN verifiziert wurde. (Diese Signatur ist im Katalog der
kryptografischen Signaturen für das Abbild zu
dieser PFN enthalten.)
AWE-Zuweisung (AWE allocation)
Gibt an, dass diese PFN für eine AWE-Zuweisung
gilt.
Prototyp-PTE
Gibt an, dass der PTE, auf den der PFN-Eintrag
verweist, ein Prototyp-PTE ist, z. B. bei einer gemeinsam genutzten Seite.
Tabelle 5–21 Sekundäre Flags in PFN-Datenbankeinträgen
Die restlichen Felder treten nur jeweils in bestimmten Arten von PFN-Einträgen auf. Beispielsweise steht der erste Eintrag in Abb. 5–39 für eine aktive Seite, die Teil eines Arbeitssatzes ist.
Hier gibt es ein Feld mit dem Zähler der gemeinsamen Nutzung, der angibt, wie viele PTEs
auf die Seite verweisen. (Seiten, die als schreibgeschützt, für Kopieren beim Schreiben oder
für gemeinsames Lesen und Schreiben gekennzeichnet sind, können von mehreren Prozessen
gemeinsam genutzt werden.) Für die Seiten von Seitentabellen steht in dem entsprechenden
Feld dagegen die Anzahl der gültigen und Übergangs-PTEs in der Seitentabelle. Solange der
Zähler für die gemeinsame Nutzung größer als 0 ist, kann die Seite nicht aus dem Speicher
entfernt werden.
Der Arbeitssatzindex gibt den Index in der Prozessarbeitssatzliste an (bzw. in der System- oder Sitzungsarbeitssatzliste; gehört die Seite nicht zu einem Arbeitssatz, ist der Wert
0), an der sich die virtuelle Adresse zur Zuordnung dieser physischen Seite befindet. Bei einer
privaten Seite verweist das Feld mit dem Arbeitssatzindex direkt auf den Eintrag in der Arbeitssatzliste, da die Seite nur einer einzigen virtuellen Adresse zugeordnet ist. Bei einer gemeinsam genutzten Seite dagegen ist der Arbeitssatzindex ein Hinweis, dessen Richtigkeit für
den ersten Prozess, der die Seite gültig macht, garantiert wird (wobei andere Prozesse nach
Möglichkeit versuchen, denselben Index zu verwenden). Der Prozess, der das Feld ursprünglich festgelegt hat, verweist garantiert auf den richtigen Index und muss daher in seinen
Arbeitssatz-Hashbaum keinen Hasheintrag für die Arbeitssatzliste aufnehmen, auf den die
506
Kapitel 5
Speicherverwaltung
virtuelle Adresse verweist. Dank dieser Garantie kann der Arbeitssatz-Hashbaum verkleinert
werden, was Suchvorgänge für diese Einträge beschleunigt.
Der zweite PFN-Eintrag in Abb. 5–39 gilt für eine Seite auf der Standbyliste oder der Liste geänderter Seiten. Die Felder für die Vorwärts- und Rückwärtsverknüpfung verbinden die
Listenelemente miteinander. Für Seiten auf diesen Listen ist der Zähler für die gemeinsame
Nutzung definitionsgemäß 0 (da kein Arbeitssatz die Seite verwendet) und kann daher durch
die Rückwärtsverknüpfung überschrieben werden. Auch der Referenzzähler ist für Seiten auf
diesen Listen 0. Ist er nicht 0 (da eine E/A für diese Seite im Gange sein kann, etwa wenn sie auf
die Festplatte geschrieben wird), so wird die Seite von der Liste genommen.
Der dritte PFN-Eintrag in Abb. 5–39 gilt für eine Seite des Kernelstacks. Wie bereits erwähnt, werden Kernelstacks in Windows dynamisch zugewiesen, erweitert und eingefroren,
wenn ein Callback in den Benutzermodus erfolgt oder die Steuerung zurückgibt oder wenn ein
Treiber einen Callback durchführt und eine Stackerweiterung anfordert. Für diese PFNs muss
sich der Speicher-Manager den Thread merken, der tatsächlich mit dem Kernelstack verknüpft
ist, oder eine Verknüpfung zum nächsten freien Look-Aside-Stack unterhalten, wenn die Seite
frei ist.
Die vierte PFN in Abb. 5–39 gilt für eine Seite, für die gerade ein E/A-Vorgang erfolgt
(z. B. ein Lesevorgang). Dabei zeigt das erste Feld auf das Ereignisobjekt, das ausgelöst wird,
wenn der E/A-Vorgang abgeschlossen ist. Tritt ein Einlagerungsfehler auf, enthält das Feld den
entsprechenden Windows-Fehlerstatuscode. Dieser PFN-Typ dient zur Auflösung von Seitenfehlerkollisionen.
Neben der PFN-Datenbank beschreiben auch die in Tabelle 5–22 genannten Systemvariablen den Gesamtstatus des physischen Speichers.
Variable (Windows 10 und
Windows Server 2016)
Variable (Windows 8.x und
Windows Server 2012/R2)
Beschreibung
MiSystemPartition.Vp.
NumberOfPhysicalPages
MmNumberOfPhysicalPages
Gesamtzahl der auf dem System verfügbaren physischen Seiten.
MiSystemPartition.Vp.
AvailablePages
MmAvailablePages
Gesamtzahl der auf dem System
verfügbaren Seiten – die Summe
der Seiten auf der Nullseiten- und
der Standbyliste sowie der Liste der
freien Seiten.
MiSystemPartition.Vp.
ResidentAvailablePages
MmResidentAvailablePages
Gesamtzahl der physischen Seiten,
die auf dem System verfügbar wären,
wenn die Arbeitssätze aller Prozesse
auf ihre Mindestgröße geschrumpft
und alle geänderten Seiten auf die
Festplatte geleert würden.
Tabelle 5–22 Systemvariablen zur Beschreibung des physischen Speichers
Die PFN-Datenbank
Kapitel 5
507
Experiment: PFN-Einträge einsehen
Mit dem Kerneldebuggerbefehl !pfn können Sie einzelne PFN-Einträge untersuchen. Dabei
müssen Sie die PFN als Argument angeben, beispielsweise !pfn 0 für den ersten Eintrag,
!pfn 1 für den zweiten usw. Die folgende Ausgabe zeigt den PTE für die virtuelle Adresse
0xD20000, gefolgt von dem PFN-Eintrag mit dem Seitenverzeichnis und dann der eigentlichen Seite:
lkd> !pte d20000
VA 00d20000
PDE at C0600030
PTE at C0006900
contains 000000003E989867
contains 8000000093257847
pfn 3e989 ---DA--UWEV
pfn 93257 ---D---UW-V
lkd> !pfn 3e989
PFN 0003E989 at address 868D8AFC
flink
blink / share count 00000144
pteaddress C0600030
reference count 0001
00000071
Cached color
Priority
5
restore pte 00000080
containing page
Active
M
0
0696B3
Modified
lkd> !pfn 93257
PFN 00093257 at address 87218184
flink
blink / share count 00000001
pteaddress C0006900
reference count 0001
000003F9
Cached color
Priority
5
restore pte 00000080
containing page
Active
M
0
03E989
Modified
Auch mit MemInfo können Sie Informationen über eine PFN abrufen. Dabei erhalten Sie
manchmal sogar noch mehr Angaben als in der Ausgabe des Debuggers, und überdies ist
es dabei nicht nötig, im Debuggingmodus zu starten. Die MemInfo-Ausgabe für dieselben
beiden PFNs sieht wie folgt aus:
C:\Tools>MemInfo.exe -p 3e989
0x3E989000 Active
Page Table
5
N/A
0xC0006000 0x8E499480
C:\Tools>MemInfo.exe -p 93257
0x93257000 Active
Process Private 5
windbg.exe 0x00D20000 N/A
Von links nach rechts sehen Sie hier die physische Adresse, den Typ, die Seitenpriorität, den
Prozessnamen, die virtuelle Adresse sowie mögliche weitere Informationen. MemInfo hat
korrekt erkannt, dass es sich bei der ersten PFN um eine Seitentabelle handelt und dass die
zweite zu WinDbg gehört, dem aktiven Prozess, als der Befehl !pte d20000 im Debugger
verwendet wurde.
508
Kapitel 5
Speicherverwaltung
Reservierungen in der Auslagerungsdatei
Sie haben bereits einige Mechanismen kennengelernt, mit denen der Speicher-Manager versucht, den Verbrauch an physischem Speicher und damit den Zugriff auf Auslagerungsdateien
zu verringern. Dazu gehören die Verwendung der Standbyliste und der Liste geänderter Seiten
sowie die Speicherkomprimierung, die in einem eigenen Abschnitt weiter hinten in diesem
Kapitel erklärt wird. Ein weiteres Optimierungsverfahren steht in direktem Zusammenhang mit
dem Zugriff auf die Auslagerungsdateien.
Rotationsfestplatten haben einen beweglichen Kopf, der erst zum Zielsektor gefahren werden muss, bevor der eigentliche Lese- oder Schreibvorgang beginnen kann. Diese Suchzeit ist
relativ lang (in der Größenordnung von Millisekunden). Die gesamte Zeit für Festplattenaktivitäten setzt sich aus der Suchzeit und der eigentlichen Schreib- oder Lesezeit zusammen. Wenn
sehr viele Daten von der erreichten Suchposition aus in einem zusammenhängenden Gebiet
zugänglich sind, dann kann die Suchzeit vernachlässigbar werden. Muss der Kopf dagegen viel
suchen, weil die Daten über die Festplatte verstreut sind, wird die Gesamtzeit für die Suchvorgänge zum Hauptproblem.
Wenn der Sitzungs-Manager (Smss.exe) eine Auslagerungsdatei erstellt, fragt er die Festplatten- oder Dateipartition danach ab, ob er es mit einer Rotations- oder einer SSD-Festplatte
zu tun hat (Solid-State Drive). Im ersten Fall aktiviert er den Mechanismus der sogenannten
Reservierungen in der Auslagerungsdatei. Dabei wird versucht, zusammenhängende Seiten im
physischen Speicher auch in der Auslagerungsdatei zusammenhängend zu halten. Bei einem
SSD-Laufwerk (oder einem Hybridmodell, das jedoch, was diese Reservierungen angeht, ebenso behandelt wird) bringen Reservierungen in der Auslagerungsdatei keinen echten Nutzen (da
es keinen beweglichen Kopf gibt), weshalb dieser Mechanismus hier nicht genutzt wird.
Reservierungen in der Auslagerungsdatei werden an drei Stellen im Speicher-Manager
gehandhabt, nämlich im Arbeitssatz-Manager, im Schreibthread für geänderte Seiten und im
Seitenfehlerhandler. Der Arbeitssatz-Manager verkleinert Arbeitssätze, indem er die Routine
MiFreeWsleList aufruft, die eine Liste von Seiten im Arbeitssatz entgegennimmt und für jede
dieser Seiten den Zähler für die gemeinsame Nutzung heruntersetzt. Fällt dieser Zähler auf 0,
kann die Seite in die Liste der geänderten Seiten geschoben werden, wobei der zugehörige PTE
in einen Übergangs-PTE geändert wird. Der alte gültige PTE wird im PFN-Eintrag gespeichert.
Der ungültige PTE enthält zwei Bits für den Reservierungsmechanismus, nämlich für Reservierungen und für Zuweisungen in der Auslagerungsdatei (siehe Abb. 5–24). Wird eine physische Seite benötigt und wird sie aus einer der Listen für »freie« Seiten entnommen (Liste freier
Seiten, Nullseiten- oder Standbyliste) und zu einer aktiven (gültigen) Seite gemacht, wird im
PFN-Feld für den ursprünglichen PTE ein ungültiger PTE gespeichert. Dieses Feld ist von entscheidender Bedeutung, um den Überblick über Reservierungen in der Auslagerungsdatei zu
behalten.
Die Routine MiCheckReservePageFileSpace versucht, einen Reservierungscluster zu erstellen, bei der die angegebene Seite beginnt. Sie prüft, ob Reservierungen für die vorgesehene
Auslagerungsdatei deaktiviert sind und ob es bereits eine solche Reservierung für die Datei gibt
(anhand des ursprünglichen PTEs). Wenn eine dieser Bedingungen wahr ist, bricht die Funktion
die weitere Verarbeitung der Seite ab. Des Weiteren prüft die Routine, ob es sich um Benutzerseiten handelt. Ist das nicht der Fall, bricht sie ebenfalls ab. Für andere Arten von Seiten (z. B. für
Die PFN-Datenbank
Kapitel 5
509
den ausgelagerten Pool) werden keine Reservierungen versucht, da sie dafür nicht besonders
nützlich sind (u. a. aufgrund der nicht vorhersehbaren Nutzungsmuster, die zu kleinen Clustern
führen). Schließlich ruft MiCheckReservePageFileSpace die Funktion MiReservePageFileSpace auf,
um die eigentliche Arbeit zu erledigen.
Die Suche nach Reservierungen in der Auslagerungsdatei erfolgt abwärts und beginnt
beim ursprünglichen PTE. Das Ziel besteht darin, geeignete, aufeinanderfolgende Seiten zu
finden, die reserviert werden können. Wenn der PTE, der die benachbarte Seite zuordnet, zu
einer nicht zugesicherten Seite, zu einer Seite aus dem nicht ausgelagerten Pool oder zu einer
bereits reservierten Seite gehört, kann die Seite nicht genutzt werden. In diesem Fall wird
die aktuelle Seite zur unteren Grenze des Reservierungsclusters. Anderenfalls geht die Suche
nach unten weiter. Anschließend beginnt die Suche erneut von der ursprünglichen Seite aus
vorwärts, um auch dort so viele geeignete Seiten wie möglich zu erfassen. Der Cluster muss
mindestens 16 Seiten umfassen, damit die Reservierung stattfindet (wobei die maximale Clustergröße 512 Seiten beträgt). Abb. 5–40 zeigt ein Beispiel für einen Cluster, der auf der einen
Seite durch eine ungültige Seite und auf der anderen durch einen vorhandenen Cluster begrenzt ist. (Ein Cluster kann auch mehrere Seitentabellen überspannen, sofern sie zum selben
Seitenverzeichnis gehören.)
Ein weiterer Cluster für die
Reservierung in der
Auslagerungsdatei
Start-PTE
Cluster für die Reservierung
in der Auslagerungsdatei
(Der Start-PTE befindet sich
im Übergangszustand.)
UNGÜLTIG
UNGÜLTIG
UNGÜLTIG
Seitenverzeichnis für Prozess A
Nicht zugewiesene
Region
Seitentabellen für Prozess A
Abbildung 5–40 Cluster für Reservierungen in der Auslagerungsdatei
Nach der Berechnung des Reservierungsclusters muss freier Platz in der Auslagerungsdatei
gefunden werden, um ihn für diesen Cluster zu reservieren. Zuweisungen in der Auslagerungsdatei werden mithilfe einer Bitmap gehandhabt, wobei jedes gesetzte Bit für eine verwendete
Seite in der Datei steht. Für Reservierungen in der Auslagerungsdatei wird eine zweite Bitmap
verwendet, bei der die gekennzeichneten Seiten reserviert wurden. Das heißt jedoch nicht unbedingt, dass sie auch tatsächlich geschrieben wurden, denn das ist die Aufgabe der Bitmap für
die Zuweisungen in der Auslagerungsdatei. Wenn es in der Auslagerungsdatei Platz gibt, der
gemäß diesen Bitmaps weder reserviert noch zugewiesen ist, werden die zugehörigen Bits in
510
Kapitel 5
Speicherverwaltung
der Reservierungsbitmap gesetzt. Wenn der Schreibthread für geänderte Seiten den Inhalt der
Seiten auf die Festplatte schreibt, muss er die entsprechenden Bits in der Zuweisungsbitmap
setzen. Kann in der Auslagerungsdatei kein ausreichender Platz für den vorgesehenen Cluster
gefunden werden, wird versucht, die Datei zu erweitern. Falls das bereits geschehen ist (oder
falls die Auslagerungsdatei bereits die maximale Größe erreicht hat), wird der Cluster verkleinert, damit er in den vorhandenen Platz für eine Reservierung passt.
Die Seiten im Cluster (mit Ausnahme des ursprünglichen Start-PTEs) sind nicht mit
irgendeiner der Listen physischer Seiten verknüpft. Die Reservierungsinformationen werden in den ursprünglichen PTE der PFN aufgenommen.
Der Schreibthread für geänderte Seiten muss das Schreiben von Seiten mit Reservierungen als
Sonderfall behandeln. Er nutzt alle zuvor beschriebenen Informationen, um eine MDL mit den
korrekten PFNs für einen umfassenden Cluster aufzustellen, den er zum Schreiben verwendet.
Für den Aufbau dieses Schreibclusters muss er zusammenhängende Seiten finden, die alle Reservierungscluster überspannen. Bei »Lücken« zwischen den Einzelclustern wird eine Platzhalterseite eingeschaltet (in der alle Bytes den Wert 0xFF haben). Bei mehr als 32 Platzhalterseiten
ist der Schreibcluster zersplittert. Dieser Durchlauf erfolgt erst vorwärts und dann rückwärts,
um den endgültigen Schreibcluster zu erstellen. Abb. 5–41 zeigt ein Beispiel für den Seitenstatus, nachdem der Schreibthread für geänderte Seiten einen solchen Schreibcluster erstellt hat.
Ungültig
Aktiv
Ungültig
Schutz
Schutz
Ursprünglicher
PTE
Ursprünglicher
PTE
PTE-Zeiger
PTE-Zeiger
PFN 1F6
PFN 67A
Aktiv
Ungültig
Aktiv
Seitentabellen von Prozess A
Aktiv
Schutz
Ungültig
Ursprünglicher
PTE
Aktiv
PTE-Zeiger
Seitentabellen von Prozess B
PFN 89C
Reservierung 1 in der Auslagerungsdatei für Prozess A
PLATZHALTER PLATZHALTER
PFN 1F6
PLATZHALTER
PFN 53A
PLATZHALTER
Reservierung 1 in der Auslagerungsdatei für Prozess B
PFN 67A
PLATZHALTER
PFN 89C
PLATZHALTER
PFN 10F
PLATZHALTER PLATZHALTER
Zuweisungsbitmap
Reservierungsbitmap
Systemauslagerungsdatei
Abbildung 5–41 Der Schreibcluster
Schließlich bestimmt der Seitenfehlerhandler anhand der Informationen in der Reservierungsbitmap und in den PTEs die Anfangs- und Endpunkte der Cluster, um benötigte Seiten mit
minimalem Suchaufwand des mechanischen Kopfes der Festplatte zurückladen zu können.
Die PFN-Datenbank
Kapitel 5
511
Grenzwerte für den physischen Speicher
Nachdem Sie nun wissen, wie Windows den Überblick über den physischen Speicher behält,
sehen wir uns als Nächstes an, mit wie viel Speicher Windows tatsächlich umgehen kann. Da die
meisten Systeme auf mehr Code und Daten zugreifen, als in den physischen Speicher passt, ist
dieser physische Speicher im Grunde genommen ein Fenster, das einen Ausschnitt des im Laufe
der Zeit verwendeten Codes und der Daten zeigt. Die Menge des Speichers beeinflusst die
Leistung, denn wenn Daten oder Code von einem Prozess oder dem Betriebssystem benötigt
werden, aber nicht vorhanden sind, muss der Speicher-Manager sie erst von der Festplatte oder
einem Remotespeicher beziehen.
Doch die Menge des physischen Speichers wirkt sich nicht nur auf die Leistung, sondern
auch auf die Verfügbarkeit mancher Ressourcen aus. Beispielsweise ist der Umfang des nicht
ausgelagerten Pools durch den Umfang des physischen Speichers beschränkt. Des Weiteren ist
der physische Speicher auch einer der bestimmenden Faktoren für die Höchstgröße des virtuellen Speichers, die sich grob ausgedrückt aus der Größe des physischen Speichers zuzüglich der
aktuellen Größe aller Auslagerungsdateien zusammensetzt. Der physische Speicher wirkt sich
indirekt auch auf die Höchstzahl der möglichen Prozesse aus.
Wie viel physischen Speicher Windows handhaben kann, hängt von Hardwareeinschränkungen, der Lizenzierung, den Datenstrukturen des Betriebssystems und der Treiberkompatibilität ab. Auf https://msdn.microsoft.com/en-us/library/windows/desktop/aa366778.aspx finden
Sie die Speichergrenzwerte für verschiedene Windows-Editionen. Tabelle 5–23 gibt einen Überblick über die Grenzwerte für Windows 8 und höher.
Version/Edition
Maximum (32 Bit)
Maximum (64 Bit)
Windows 8.x Professional und Enterprise
4 GB
512
Windows 8.x (alle anderen Editionen)
4 GB
128 GB
Windows Server 2012/R2 Standard und Datacenter
–
4 TB
Windows Server 2012/R2 Essentials
–
64 GB
Windows Server 2012/R2 Foundation
–
32 GB
Windows Storage Server 2012 Workgroup
–
32 GB
Windows Storage Server 2012 Standard
Hyper-V Server 2012
–
4 TB
Windows 10 Home
4 GB
128 GB
Windows 10 Pro, Education und Enterprise
4 GB
2 TB
Windows Server 2016 Standard und Datacenter
–
24 TB
Tabelle 5–23 Grenzwerte für den physischen Speicher
512
Kapitel 5
Speicherverwaltung
Die maximal unterstützte Menge an Arbeitsspeicher beträgt zurzeit 4 TB auf einigen Editionen
von Windows Server 2012/R2 bzw. 24 TB auf Windows Server 2016. Diese Grenzwerte beruhen
jedoch nicht auf irgendwelchen Einschränkungen der Implementierung oder der Hardware, sondern rühren daher, dass Microsoft nur Konfigurationen unterstützt, die das Unternehmen auch
testen kann. Die genannten Speichermengen sind zurzeit die größten, die überprüft wurden.
Speichergrenzwerte für Windows-Clienteditionen
Die einzelnen 64-Bit-Clienteditionen von Windows unterscheiden sich in der Menge an unterstütztem physischem Speicher, wobei die Spanne von 4 GB bis zu 2 TB in den Enterprise- und
Professional-Editionen reicht. Für alle 32-Bit-Clienteditionen dagegen gilt ein Maximum von
4 GB, was der größte physische Speicher ist, der mit dem Standard-Speicherverwaltungsmodus
von x86-Systemen zugänglich ist.
Client-SKUs unterstützen den PAE-Adressierungsmodus auf x86, um einen Hardwareschutz
zu ermöglichen. Damit wäre es zwar möglich, auf mehr als 4 GB an physischem Speicher zuzugreifen, doch in Tests hat sich gezeigt, dass solche Systeme abstürzen, sich aufhängen oder
nicht mehr starten lassen. Das liegt daran, dass einige Gerätetreiber – hauptsächlich diejenigen
für Video- und Audiogeräte, die auf Clientcomputern gebräuchlich sind, aber nicht auf Servern
– nicht darauf programmiert wurden, physische Adressen größer als 4 GB zu erwarten. Daher
schneiden diese Treiber solche Adressen ab, was zu Speicherbeschädigungen und damit verbundenen Nebenwirkungen führt. Serversysteme verfügen dagegen über weniger spezifische
Treiber, die einfacher und stabiler sind, weshalb diese Probleme bei ihnen in der Regel nicht
auftreten. Aufgrund der problematischen Clienttreiberumgebung wurde die Entscheidung gefällt, dass Clienteditionen den physischen Speicher oberhalb von 4 GB ignorieren, auch wenn
sie ihn theoretisch adressieren könnten. Treiberentwicklern wird empfohlen, ihre Systeme mit
der BCD-Option nolowmem zu testen, um den Kernel zu zwingen, physische Adressen oberhalb
von 4 GB nur dann zu nutzen, wenn auf dem System ausreichend Speicher dazu vorhanden ist.
Dadurch können die entsprechenden Probleme in Treibern sofort erkannt werden.
Der Betrag von 4 GB stellt den Lizenzierungsgrenzwert für 32-Bit-Clienteditionen dar, doch
der tatsächliche Grenzwert kann niedriger sein und hängt vom Chipsatz des Systems und den
angeschlossenen Geräten ab. Das liegt daran, dass die Zuordnung der physischen Adressen
nicht nur den RAM, sondern auch den Gerätespeicher einschließt, wobei x86- und x64-Systeme
gewöhnlich den gesamten Gerätespeicher unterhalb der Grenze von 4 GB zuordnen, um mit
32-Bit-Systemen kompatibel zu bleiben, die nicht wissen, wie sie mit Adressen größer als 4 GB
umgehen sollen. Modernere Chipsätze unterstützen zwar eine Geräteneuzuordnung auf der
Grundlage von PAE, doch Windows-Clienteditionen machen aufgrund der erwähnten Treiberkompatibilitätsprobleme keinen Gebrauch davon. Die Treiber würden sonst 64-Bit-Zeiger zu
ihrem Gerätespeicher erhalten.
Wenn Geräte wie Video-, Audio- und Netzwerkadapter auf einem System mit 4 GB RAM
Fenster mit Ausschnitten ihres Gerätespeichers von insgesamt 500 MB in den Speicher einfügen, dann landen 500 MB der 4 GB RAM oberhalb der 4-GB-Grenze (siehe Abb. 5–42).
Grenzwerte für den physischen Speicher
Kapitel 5
513
4,5 GB
4 GB
Unzugänglicher
RAM
RAM
Gerätespeicher
RAM
Gerätespeicher
RAM
0
Abbildung 5–42 Aufbau des physischen Speichers auf einem 4-GB-System
Bei einer 32-Bit-Clientversion von Windows kann es daher sein, dass Sie auf einem System mit
3 GB oder mehr nicht den gesamten RAM nutzen können. Im Dialogfeld Systemeigenschaften
wird angezeigt, wie viel installierten RAM Windows erkannt hat, aber um den tatsächlich für
Windows verfügbaren Speicher zu ermitteln, müssen Sie auf der Registerkarte Leistung des
Task-Managers nachschauen oder das Hilfsprogramm Msinfo32 verwenden. Beispielsweise
zeigt Msinfo32 auf einer Hyper-V-VM mit 4 GB RAM und einer 32-Bit-Version von Windows 10
einen verfügbaren physischen Speicher von 3,87 GB an:
Installed Physical Memory (RAM) 4.00 GB
Total Physical Memory 3.87 GB
Den Aufbau des physischen Speichers können Sie sich mit dem Programm MemInfo ansehen.
Die folgende MemInfo-Ausgabe stammt von einem 32-Bit-System. Mit dem Schalter -r haben
wir hier die physischen Speicherbereiche ausgegeben:
C:\Tools>MemInfo.exe -r
MemInfo v3.00 - Show PFN database information
Copyright (C) 2007-2016 Alex Ionescu
www.alex-ionescu.com
Physical Memory Range: 00001000 to 0009F000 (158 pages, 632 KB)
Physical Memory Range: 00100000 to 00102000 (2 pages, 8 KB)
Physical Memory Range: 00103000 to F7FF0000 (1015533 pages, 4062132 KB)
MmHighestPhysicalPage: 1015792
In den Adressbereichen klafft eine Lücke zwischen A0000 und 100000 (384 KB) sowie eine weitere zwischen F8000000 bis FFFFFFFF (128 MB).
514
Kapitel 5
Speicherverwaltung
Mit dem Geräte-Manager können Sie sich ansehen, wer diese reservierten Speicherregionen belegt hat, die Windows nicht nutzen kann und die daher in der Ausgabe von MemInfo als
Lücken angezeigt werden. Gehen Sie dazu wie folgt vor:
1.
Führen Sie Devmgmt.msc aus.
2.
Öffnen Sie das Menü Ansicht und wählen Sie Ressourcen nach Verbindung.
3.
Erweitern Sie den Knoten Arbeitsspeicher. Auf dem Laptop, auf dem die Ausgabe aus
Abb. 5–43 erstellt wurde, ist der Hauptverbraucher des zugeordneten Gerätespeichers
wie zu erwarten die Videokarte (Hyper-V S3 Cap), die 128 MB im Bereich F8000000 bis
FBFFFFFF belegt.
Arbeitsspeicher
[00000000 - 0009FFFF] Systemplatine
[000A0000 - 000BFFFF] PCI-Bus
[000C0000 - 000DFFFF] Systemplatine
[000E0000 - 000FFFFF] Systemplatine
[00100000 - F7FFFFFF] Systemplatine
[E0000000 - FFFFFFFF] PCI-Bus
[FF800000 - FFFFFFFF] Microsoft Hyper-V Video
[F8000000 - FFFBFFFF] PCI-Bus
[F8000000 - FBFFFFFF] Microsoft Hyper-V S3 Cap
[FEBFF000 - FEBFFFFF] Intel 21140-Based PCI Fast Ethernet Adapter (Emuliert)
[FEC00000 - FEC00FFF] Hauptplatinenressourcen
[FEE00000 - FEE00FFF] Hauptplatinenressourcen
[FFFC0000 - FFFFFFFF] Systemplatine
Abbildung 5–43 Von der Hardware reservierte Speicherbereiche auf einem 32-Bit-Windows-System
Für die restlichen Lücken sind verschiedene weitere Gerätetreiber verantwortlich. Aufgrund
der vorsichtigen Schätzungen der Firmware während des Bootvorgangs reserviert der PCI-Bus
weitere Bereiche für Geräte.
Speicherkomprimierung
Der Speicher-Manager von Windows 10 verfügt über einen Mechanismus, um private und
auslagerungsgepufferte Seiten zu komprimieren, die sich auf der Liste der geänderten Seiten
befinden. Die Hauptkandidaten für diese Komprimierung sind private Seiten von UWP-Apps,
da die Komprimierung gut mit der Auslagerung und Leerung des Arbeitssatzes zusammenwirkt, die bei solchen Anwendungen ohnehin schon stattfinden, wenn der Speicher knapp ist.
Wenn eine Anwendung angehalten und ihr Arbeitssatz ausgelagert ist, ist es jederzeit möglich,
ihren Arbeitssatz zu leeren und geänderte Seiten zu komprimieren. Dadurch wird zusätzlicher
Speicher verfügbar, was schon ausreichen kann, um eine weitere Anwendung im Speicher zu
halten, ohne dass die Seiten der ersten Anwendung ihn verlassen müssen.
Experimente haben gezeigt, dass Seiten durch den Xpress-Algorithmus von
Microsoft auf ca. 30–50 % ihrer ursprünglichen Größe komprimiert werden können. Dabei wird die Geschwindigkeit für die Größe geopfert, was zu erheblichen
Speichereinsparungen führt.
Speicherkomprimierung
Kapitel 5
515
Die Speicherkomprimierung muss die folgenden Voraussetzungen erfüllen:
QQ Eine Seite darf sich nicht sowohl in komprimierter als auch in nicht komprimierter Form befinden, denn eine solche Duplizierung würde eine Verschwendung von physischem Speicher bedeuten. Wenn eine Seite komprimiert wird, muss die Originalseite anschließend
sofort freigegeben werden.
QQ Der Komprimierungsspeicher muss die komprimierten Daten so speichern und seine Datenstrukturen so unterhalten, dass sich dabei stets eine Einsparung an Speicher für das
System insgesamt ergibt. Das bedeutet, dass eine Seite, die nicht gut komprimiert werden
kann, nicht zum Speicher hinzugefügt werden sollte.
QQ Komprimierte Seiten müssen als verfügbarer Speicher angezeigt werden, denn schließlich
können sie bei Bedarf tatsächlich umgewidmet werden. Das dient dazu, die fehlerhafte
Wahrnehmung zu vermeiden, dass die Komprimierung den Speicherverbrauch erhöht.
Die Speicherkomprimierung ist auf allen Client-SKUs (Telefon, PC, Xbox usw.) standardmäßig
aktiviert. Auf Server-SKUs wird zurzeit keine Speicherkomprimierung verwendet, allerdings
wird sich das in künftigen Versionen wahrscheinlich ändern.
In Windows Server 2016 zeigt der Task-Manager in Klammern die Werte für komprimierten Speicher an, die aber immer 0 sind. Es gibt auch keinen Speicherkomprimierungsprozess.
Beim Systemstart weist der Dienst SuperFetch (Sysmain.dll, ausgeführt in einer Instanz von
Svchost.exe; siehe den Abschnitt »Vorausschauende Speicherverwaltung (SuperFetch)« weiter
hinten in diesem Kapitel) den Store-Manager in der Exekutive durch einen Aufruf von NtSetSystemInformation an, einen Systemspeicher für Nicht-UWP-Anwendungen zu erstellen. (Dies
ist stets der erste Systemspeicher, der angelegt wird.) Wird eine UWP-Anwendung gestartet,
fordert sie von SuperFetch einen Speicher für sich selbst an.
Ablauf der Komprimierung
Um Ihnen eine Vorstellung davon zu geben, wie die Speicherkomprimierung funktioniert, zeigen wir ein Beispiel zur Veranschaulichung an. Nehmen wir an, es gibt die folgenden physischen Seiten:
Null/Frei
Aktiv
Geändert
516
Kapitel 5
Speicherverwaltung
Die Nullseitenliste und die Liste der freien Seiten enthalten Seiten, die mit Abfall bzw. mit
Nullen gefüllt sind und zur Zusicherung von Speicher verwendet werden können. Für unsere Zwecke betrachten wir sie hier als eine gemeinsame Liste. Die aktiven Seiten gehören zu
verschiedenen Seiten, während die geänderten Seiten modifizierte Daten enthalten, die noch
nicht in eine Auslagerungsdatei geschrieben wurden. Wenn ein Prozess auf eine solche Seite
verweist, kann sie jedoch über einen weichen Seitenfehler in den Arbeitssatz des Prozesses
aufgenommen werden, ohne dass dabei eine E/A-Operation erforderlich wäre.
Nehmen wir nun an, dass der Speicher-Manager die Liste der geänderten Seiten verkleinern will, etwa weil sie zu groß geworden ist oder die Null/Frei-Liste zu klein. Gehen wir des
Weiteren davon aus, dass aus der Liste der geänderten Seiten drei Seiten entfernt werden sollen. Der Speicher-Manager komprimiert nun den Inhalt zu einer einzigen Seite, die der Null/
Frei-Seite entnommen wird:
Null/Frei
Aktiv
Geändert
Die Seiten 11 bis 13 sind nun in Seite 1 komprimiert. Danach ist Seite 1 nicht mehr frei, sondern
aktiv, da sie zum Arbeitssatz des Speicherkomprimierungsprozesses gehört (siehe den nächsten
Abschnitt). Nun werden die Seiten 11 bis 13 nicht mehr benötigt und können daher in die Liste
der freien Seiten verschoben werden. Durch die Komprimierung werden also unter dem Strich
zwei Seiten eingespart:
Null/Frei
Aktiv
Aktiv (Speicherkomprimierungsprozess)
Geändert
Speicherkomprimierung
Kapitel 5
517
Stellen Sie sich nun vor, dass der Vorgang ein weiteres Mal ausgeführt wird. Dieses Mal werden
die Seiten 14 bis 16 in zwei Seiten (2 und 3) komprimiert:
Null/Frei
Aktiv
Aktiv (Speicherkomprimierungsprozess)
Geändert
Dadurch gelangen die Seiten 2 und 3 in den Arbeitssatz des Speicherkomprimierungsprozesses, während die Seiten 14 bis 16 frei werden:
Null/Frei
Aktiv
Aktiv (Speicherkomprimierungsprozess)
Geändert
Wenn der Speicher-Manager später beschließt, den Arbeitssatz des Speicherkomprimierungsprozesses zu verkleinern, werden dessen Seiten in die Liste der geänderten Seiten verschoben,
da sie Daten enthalten, die noch nicht in eine Auslagerungsdatei geschrieben wurden. Natürlich können sie jederzeit durch einen weichen Seitenfehler zu ihrem ursprünglichen Prozess
zurückkehren, wobei sie unter Verwendung freier Seiten entkomprimiert werden. In der folgenden Abbildung wurden die Seiten 1 und 2 von den aktiven Seiten des Speicherkomprimierungsprozesses entfernt und in die Liste der geänderten Seiten verschoben:
518
Kapitel 5
Speicherverwaltung
Null/Frei
Aktiv
Aktiv (Speicherkomprimierungsprozess)
Geändert
Wird der Speicher knapp, kann der Speicher-Manager entscheiden, die komprimierten geänderten Dateien in eine Auslagerungsdatei zu schreiben:
Null/Frei
Aktiv
Aktiv (Speicherkomprimierungsprozess)
Geändert
Auslagerungs
datei
Danach werden diese Seiten in die Standbyliste verschoben, da ihr Inhalt gespeichert ist und
sie bei Bedarf einem anderen Zweck zugeführt werden können. Ebenso wie in der Liste der
geänderten Seiten können sie auch jetzt bei einem weichen Seitenfehler entkomprimiert werden, woraufhin die resultierenden Seiten als aktive Seiten dem Arbeitssatz des entsprechenden
Prozesses zugeschlagen werden. In der Standbyliste stehen sie jeweils in der Teilliste für ihre Priorität (siehe den Abschnitt »Seitenpriorität und Rebalancing« weiter hinten in diesem Kapitel).
Speicherkomprimierung
Kapitel 5
519
Null/Frei
Aktiv
Aktiv (Speicherkomprimierungsprozess)
Geändert
Standby
Komprimierungsarchitektur
Die Komprimierungs-Engine benötigt Speicher als »Arbeitsbereich«, um die komprimierten Seiten und die Datenstrukturen zu ihrer Verwaltung festzuhalten. In Windows 10 vor Version 1607
wurde dazu der Benutzeradressraum des Systemprozesses verwendet, ab Version 1607 dagegen
der neue, eigens dafür vorgesehene Speicherkomprimierungsprozess. Ein Grund dafür war, dass
der Speicherverbrauch des Systemprozesses bei flüchtiger Betrachtung hoch wirkte, was zu der
Schlussfolgerung Anlass gab, dass das System viel Speicher verbrauchen würde. Das ist jedoch
nicht der Fall, da der komprimierte Speicher nicht auf den Zusicherungsgrenzwert angerechnet
wird. Manchmal ist jedoch die Wahrnehmung entscheidend.
Der Speicherkomprimierungsprozess ist ein minimaler Prozess, das heißt, er lädt keine DLLs
und führt keine Abbilder aus, sondern stellt nur einen Benutzermodus-Adressraum bereit, den
der Kernel nutzen kann. (Mehr über minimale Prozesse erfahren Sie in Kapitel 3.)
In der Detailansicht des Task-Managers wird der Speicherkomprimierungsprozess
absichtlich nicht angezeigt. In Process Explorer ist er jedoch zu sehen. Im Kerneldebugger lautet der Abbildname für diesen Prozess MemCompression.
Für jeden einzelnen Speicher (»store«) weist der Store-Manager Arbeitsspeicher (»memory«)
in Regionen mit einstellbarer Größe zu, zurzeit 128 KB. Dies geschieht gewöhnlich nach Be
darf durch Aufrufe von VirtualAlloc. Die eigentlichen komprimierten Seiten werden in 16Byte-Stücken in einer Region gespeichert. Eine komprimierte Seite (4 KB) kann offensichtlich
viele solcher Stücke umfassen. Abb. 5–44 zeigt einen Speicher mit einem Array von Regionen
und einigen der Datenstrukturen, die zur Verwaltung erforderlich sind.
520
Kapitel 5
Speicherverwaltung
Regionsmetadaten
B+-Baum der Seiten
Idx
Genutzter Platz
Regionsarray
Seiteneintrag
Region 0
Seitenschlüssel
Regions-Nr.
Offset
Größe
Flags
Region 0
Nicht
verwendet
Region 1
Nicht
verwendet
Region N
Regionselement
Komprimierte Seiten
Regionseintrag
Regions-Nr.
Offset
Virtuelle Adresse
Reset-Bitmap
Seitenschlüssel
B+-Baum der Regionen
Region N
Abbildung 5–44 Speicherdatenstrukturen
Wie Sie in Abb. 5–44 sehen, werden die Seiten mit einem B+-Baum verwaltet. Im Grunde
genommen ist das ein Baum, dessen Knoten jeweils eine beliebige Anzahl von Kindknoten
aufweisen können. Darin zeigt jeder Seiteneintrag auf den zugehörigen komprimierten Inhalt
in einer der Regionen. Zu Anfang hat ein Speicher null Regionen. Die Zuweisung von Regionen
und die Aufhebung dieser Zuweisungen erfolgen nach Bedarf. Wie Sie im Abschnitt »Seitenpriorität und Rebalancing« weiter hinten in diesem Kapitel noch sehen werden, hat jede Region
eine Priorität.
Um eine Seite zu einem Speicher hinzuzufügen, sind die folgenden Hauptschritte erforderlich:
1.
Wenn es keine Region mit der Priorität der hinzuzufügenden Seite gibt, wird eine neue
Region zugewiesen, im physischen Speicher verriegelt und mit der entsprechenden Priorität versehen. Diese neu zugewiesene Region wird als aktuelle Region für diese Priorität
verwendet.
2.
Die Seite wird komprimiert und in der Region gespeichert, wobei sie auf die Granularitätseinheit (16 Bytes) aufgerundet wird. Beispielsweise nimmt eine auf 687 Bytes komprimierte
Seite 43 Einheiten zu je 16 Bytes ein. Die Komprimierung erfolgt im aktuellen Thread mit
einer niedrigen CPU-Priorität (7), um Störungen zu vermeiden. Ist eine Entkomprimierung
erforderlich, so wird sie mithilfe aller verfügbaren Prozessoren parallel ausgeführt.
3.
Die Seiten- und Regionsinformationen in den entsprechenden B+-Bäumen werden aktualisiert.
4.
Wenn der verbliebene Platz in der aktuellen Region zur Speicherung der komprimierten
Seite nicht ausreicht, wird eine neue Region mit derselben Seitenpriorität erstellt und als
aktuelle Region für diese Priorität verwendet.
Speicherkomprimierung
Kapitel 5
521
Wenn eine Seite aus dem Speicher entfernt werden soll, geschieht Folgendes:
1.
Der Seiten- und der Regionseintrag werden in den entsprechenden B+-Bäumen gesucht.
2.
Die Einträge werden entfernt und die Angaben über den in der Region verwendeten Platz
aktualisiert.
3.
Wenn die Region leer ist, wird ihre Zuweisung aufgehoben.
Durch das ständige Hinzufügen und Entfernen von komprimierten Seiten werden die Regionen
im Laufe der Zeit fragmentiert. Der Arbeitsspeicher für eine Region wird erst dann freigegeben,
wenn die Region vollständig leer ist. Um Speicherverschwendung zu vermeiden, ist daher eine
Form von Verdichtung erforderlich. Sie wird als verzögerte Operation durchgeführt, wobei ihre
Stärke vom Grad der Fragmentierung abhängt. Auch die Priorität der Regionen wird dabei
berücksichtigt.
Experiment: Speicherkomprimierung
Bei der Speicherkomprimierung in einem System gibt es nicht viel zu beobachten. Sie können sich jedoch den Speicherkomprimierungsprozess in Process Explorer oder einem Kerneldebugger ansehen. Die folgende Abbildung zeigt die Registerkarte Performance mit
den Eigenschaften des Prozesses Memory Compression in Process Explorer (der dazu mit
Administratorrechten ausgeführt werden muss):
Da in diesem Prozess nur Kernelthreads arbeiten, wird keine Benutzerzeit angezeigt. Außerdem ist der Arbeitssatz rein privat (also nicht gemeinsam nutzbar), da es nicht möglich ist,
komprimierten Speicher auf irgendeine Weise mit anderen Prozessen zu teilen. Vergleichen
Sie diese Ausgabe mit der Registerkarte Arbeitsspeicher im Task-Manager:
→
522
Kapitel 5
Speicherverwaltung
Dieser Screenshot wurde ungefähr eine Minute nach dem vorherigen aufgenommen. Der
in Klammern angegebene komprimierte Speicher entspricht dem Arbeitssatz des Speicherkomprimierungssatzes, da dies der Platz ist, den der komprimierte Speicher verbraucht.
Speicherpartitionen
Virtuelle Maschinen werden herkömmlich dazu verwendet, um Anwendungen oder Gruppen
von Anwendungen voneinander getrennt auszuführen. Da VMs nicht miteinander interagieren
können, bieten sie starke Sicherheits- und Ressourcengrenzen. Allerdings wird das mit hohen
Ressourcenkosten für die Hardware, auf denen die VMs laufen, und mit hohen Verwaltungskosten erkauft. Das war der Grund für das Aufkommen von Containertechnologien wie Docker.
Um die Schranken für die Isolierung und die Ressourcenverwaltung niedriger zu setzen, werden
dabei auf ein und demselben physischen oder virtuellen Computer Sandboxcontainer für die
verschiedenen Anwendungen angelegt.
Das Erstellen solcher Container ist schwierig, denn dazu werden Kerneltreiber benötigt, die
eine Form von Virtualisierung oberhalb des regulären Windows durchführen, unter anderem
die folgenden (wobei ein einziger Treiber alle genannten Funktionen einschließen kann):
QQ Ein Dateisystem-(Mini-)Filter, der die Illusion eines isolierten Dateisystems hervorruft
QQ Ein Treiber für die Virtualisierung der Registrierung, der die Illusion einer separateren Registrierung hervorruft (CmRegisterCallbacksEx)
Speicherpartitionen
Kapitel 5
523
QQ Ein privater Objekt-Manager-Namensraum durch Verwendung von Silos (siehe Kapitel 3)
QQ Prozessverwaltung zur Verknüpfung von Prozessen mit dem richtigen Container durch
Prozesserstellungsbenachrichtigungen (PsSetCreateNotifyRoutineExe)
Selbst wenn dieser Treiber vorhanden ist, lassen sich manche Dinge schwer virtualisieren, insbesondere die Speicherverwaltung. Unter Umständen möchte jeder Container seine eigene
PFN-Datenbank, seine eigene Auslagerungsdatei usw. verwenden. Die 64-Bit-Versionen von
Windows 10 sowie Windows Server 2016 machen dies mithilfe von Speicherpartitionen möglich.
Eine Speicherpartition besteht aus ihren eigenen Speicherverwaltungsstrukturen wie Seitenlisten (Standby, geänderte Seiten, Nullseiten, freie Seiten usw.), gesamter zugesicherter
Speicher, Arbeitssatz, Seitentrimmer, Schreibthread für geänderte Seiten, Nullseitenthread usw.,
die von denen der anderen Partitionen getrennt sind. Im System werden Speicherpartitionen
durch Partitionsobjekte dargestellt, bei denen es sich wie bei anderen Exekutivobjekten auch
um sicherungsfähige und benennbare Objekte handelt. Eine Partition ist immer vorhanden,
nämlich die Systempartition, die für das System als Ganzes steht und die Stammpartition aller
ausdrücklich erstellten Partitionen ist. Die Adresse der Systempartition ist in der globalen Variablen MiSystemPartition gespeichert. Die Partition trägt den Namen KernelObjects\Memory
Partition0, unter dem sie auch in Werkzeugen wie dem Sysinternals-Tool WinObj angezeigt
wird (siehe Abb. 5–45).
Abbildung 5–45 Die Systempartition in WinObj
Alle Partitionsobjekte sind in einer globalen Liste gespeichert. Die maximale Anzahl von Parti
tionen beträgt zurzeit 1024 (10 Bits), da der Partitionsindex für den schnellen Zugriff auf die
Partitionsinformationen in die PTEs aufgenommen werden muss. Einer dieser Indizes bezeichnet die Systempartition. Zwei weitere Werte werden als Wächter genutzt, sodass Indizes für
1021 Partitionen verbleiben.
Speicherpartitionen können im Benutzer- und im Kernelmodus mithilfe der internen, nicht
dokumentierten Funktion NtCreatePartition erstellt werden, wobei Aufrufer im Benutzermodus dazu das Recht SeLockMemory benötigen. Die Funktion kann eine Elternpartition entgegennehmen, aus der die ersten Seiten kommen und zu der sie zurückkehren, wenn die neue
524
Kapitel 5
Speicherverwaltung
Partition zerstört wird. Wird keine Elternpartition angegeben, so wird dafür die Systempartition verwendet. NtCreatePartition delegiert die eigentliche Arbeit an die interne Funktion
M iCreatePartition des Speicher-Managers.
Eine bestehende Partition kann anhand ihres Namens mit NtOpenPartition geöffnet werden. Dazu sind keine besonderen Rechte erforderlich, da das Objekt wie üblich durch Zugriffssteuerungslisten geschützt werden kann. Für die Bearbeitung der Partition ist die Funktion
NtManagePartition da. Mit ihr können Sie der Partition Speicher und Auslagerungsdateien hinzufügen, Speicher von einer Partition in eine andere kopieren und Informationen über eine
Partition abrufen.
Experiment: Speicherpartitionen einsehen
In diesem Experiment werfen wir mithilfe des Kerneldebuggers einen Blick auf Partitionsobjekte.
1.
Starten Sie den lokalen Kerneldebugger und geben Sie den Befehl !partition ein. Er
führt alle Partitionsobjekte in dem System auf.
lkd> !partition
Partition0 fffff803eb5b2480 MemoryPartition0
2.
Standardmäßig wird die stets vorhandene Systempartition angezeigt. Sie können bei
dem Befehl !partition jedoch auch die Adresse eines Partitionsobjekts angeben, um
nähere Einzelheiten darüber abzurufen:
lkd> !partition fffff803eb5b2480
PartitionObject @ ffffc808f5355920 (MemoryPartition0)
_MI_PARTITION 0 @ fffff803eb5b2480
MemoryRuns: 0000000000000000
MemoryNodeRuns: ffffc808f521ade0
AvailablePages: 0n4198472 ( 16 Gb 16 Mb 288 Kb)
ResidentAvailablePages:
0n6677702 ( 25 Gb 484 Mb 792 Kb)
0 _MI_NODE_INFORMATION @ fffff10000003800
TotalPagesEntireNode: 0x7f8885
Zeroed
1GB
0 (
2MB
41 (
Free
0)
0 (0)
82 Mb)
0 (0)
64KB
3933 ( 245 Mb 832 Kb)
0 (0)
4KB
82745 ( 323 Mb 228 Kb)
0 (0)
Node Free Memory: ( 651 Mb
36 Kb )
InUse Memory:
(
31 Gb 253 Mb 496 Kb )
TotalNodeMemory:
(
31 Gb 904 Mb 532 Kb )
→
Speicherpartitionen
Kapitel 5
525
Die Ausgabe zeigt einige der Informationen, die in der zugrunde liegenden MI_PARTITIONStruktur gespeichert sind, sowie die Adresse dieser Struktur. Die Angaben sind nach NUMA-
Knoten gegliedert, wobei es in diesem Beispiel nur einen einzigen gibt. Da dies die Systempartition ist, sollten die Zahlen für den verwendeten, den freien und den Gesamtspeicher
den Werten entsprechen, die Sie in Programmen wie dem Task-Manager und Process Explorer ermitteln können. Es ist auch möglich, die MI_PARTITION-Struktur wie üblich mit dem
Befehl dt zu untersuchen.
Es ist denkbar, dass in Zukunft besondere Prozesse jeweils mit einer Speicherpartition verknüpft
werden (mithilfe von Jobobjekten), etwa wenn eine exklusive Kontrolle über den physischen
Arbeitsspeicher von Vorteil ist. Eine Anwendung dieser Art bildet bereits der Spielmodus im
Creators Update (siehe Kapitel 8 in Band 2).
Speicherzusammenführung
Der Speicher-Manager greift auf verschiedene Mechanismen zurück, um so viel RAM wie möglich zu sparen, z. B. durch die gemeinsame Nutzung von Seiten für Images, das Kopieren beim
Schreiben für Datenseiten und die Komprimierung. In diesem Abschnitt sehen wir uns einen
weiteren solchen Mechanismus an, nämlich die Speicherzusammenführung.
Die zugrunde liegende Idee ist ganz einfach: Es wird nach mehrfach vorhandenen Seiten
im RAM gesucht, die dann zu einer Seite zusammengefasst werden, wobei die nun überflüssig
gewordenen Exemplare entfernt werden. Dabei stellen sich jedoch die folgenden Fragen:
QQ Was für Seiten sind die »besten« Kandidaten für eine Zusammenführung?
QQ Wann ist es angebracht, eine Speicherzusammenführung auszulösen?
QQ Soll die Zusammenführung für einen bestimmten Prozess, eine Speicherpartition oder das
gesamte System erfolgen?
QQ Wie kann der Zusammenführungsprozess so schnell gemacht werden, dass er die reguläre
Codeausführung nicht beeinträchtigt?
QQ Wie kann eine private Kopie erstellt werden, wenn eine schreibbare zusammengeführte
Seite später von einem ihrer Verbraucher geändert wird?
All diese Fragen beantworten wir in diesem Abschnitt, wobei wir mit der letzten beginnen. Zur
Lösung dieses Problems wird der Copy-on-Write-Mechanismus verwendet: Solange nicht auf
die zusammengeführten Seiten geschrieben wird, geschieht nichts. Versucht ein Prozess, auf
die Seite zu schreiben, wird für ihn eine Kopie erstellt, wobei das Copy-on-Write-Flag für diese
neu zugewiesene private Seite entfernt wird.
Die Seitenzusammenführung können Sie abschalten, indem Sie im Registrierungsschlüssel HKLM\System\CurrentControlSet\Control\Session Manager\Memory
Management den DWORD-Wert DisablePageCombining festlegen.
526
Kapitel 5
Speicherverwaltung
In diesem Abschnitt verwenden wir die Begriffe CRC und Hash synonym. Beide
bezeichnen eine statistisch eindeutige (zumindest mit hoher Wahrscheinlichkeit)
64-Bit-Zahl, die auf den Inhalt einer Seite verweist.
Die Initialisierungsroutine MmInitSystem des Speicher-Managers erstellt die Systempartition
(siehe den vorhergehenden Abschnitt). In der MI_PARTITION-Struktur, die eine Partition beschreibt, befindet sich ein Array aus 16 AVL-Bäumen, die die Seitendubletten bezeichnen. Das
Array ist nach den letzten vier Bits des CRC-Werts der zusammengeführten Seiten sortiert. Sie
werden in Kürze sehen, welche Rolle das für den Algorithmus spielt.
Es gibt noch zwei besondere Arten von Seiten, die als einfache Seiten bezeichnet werden.
Auf den Seiten des einen Typs sind alle Bytes 0, auf denen des anderen Typs 1 (gefüllt mit dem
Byte 0xFF). Der CRC wird nur einmal berechnet und dann gespeichert. Bei der Untersuchung
der Seiteninhalte lassen sich solche Seiten leicht erkennen.
Um eine Speicherzusammenführung auszulösen, wird die native API NtSetSystemInformation mit der Systeminformationsklasse SystemCombinePhysicalMemoryInformation aufgerufen.
Dazu muss der Aufrufer das Recht SeProfileSingleProcessPrivilege haben, das gewöhnlich
Mitgliedern der lokalen Administratorengruppe gewährt wird. Durch eine Kombination von
Argumenten für die API können folgende Optionen eingestellt werden:
QQ Speicherzusammenführung in der gesamten (System-)Partition oder nur im aktuellen
Prozess
QQ Zusammenführung nur von einfachen Seiten (komplett 0 oder 1) oder Zusammenführung
von Duplikaten ohne Berücksichtigung ihres Inhalts
Es kann optional auch ein Ereignishandle übergeben werden, wobei die Zusammenführung
abgebrochen wird, wenn ein anderer Thread das entsprechende Ereignis auslöst. Zurzeit verfügt der Dienst SuperFetch (der am Ende dieses Kapitels eingehender erklärt wird) über einen
besonderen Thread, der mit niedriger Priorität (4) läuft und die Speicherzusammenführung
für das gesamte System entweder auslöst, wenn der Benutzer nichts tut, oder anderenfalls alle
15 Minuten.
Umfasst der physische Speicher mehr als 3,5 GB (3584 MB), wird im Creators Update in
jedem Svchost-Prozess meistens ein einziger Dienst ausgeführt. Dadurch werden Dutzende von
Prozessen erzeugt, allerdings ist es dadurch nicht mehr wahrscheinlich, dass sich die Dienste
gegenseitig beeinflussen (was zu Instabilitäten oder Sicherheitsproblemen führen kann). In dieser Situation verwendet der Dienststeuerungs-Manager (Service Control Manager, SCM) eine
neue Option der API für die Speicherzusammenführung und löst alle drei Minuten eine Zusammenführung in jedem der Svchost-Prozesse aus, indem er einen Threadpooltimer mit der
Basispriorität 6 verwendet (ScPerformPageCombineOnServiceImages). Damit wird versucht, den
RAM-Verbrauch, der jetzt höher sein kann als bei der Verwendung weniger Svchost-Instanzen,
wieder zu senken. Für Dienste, die nicht in Svchost-Prozessen ausgeführt werden oder unter
benutzerweisen oder privaten Benutzerkonten laufen, erfolgt keine Seitenzusammenführung.
Die Routine MiCombineIdenticalPages ist der eigentliche Eintrittspunkt für den Seitenzusammenführungsprozess. Für jeden NUMA-Knoten der Speicherpartition weist sie eine Liste
der Seiten einschließlich ihres CRCs zu und speichert sie in der PCS-Struktur (Page Combining
Speicherzusammenführung
Kapitel 5
527
Support). Dies ist die Struktur zur Verwaltung aller erforderlichen Seitenzusammenführungsoperationen, die auch das zuvor erwähnte Array der AVL-Bäume enthält. Der anfordernde
Thread führt die eigentliche Arbeit aus. Da er auf CPUs des aktuellen NUMA-Knotens laufen
sollte, wird seine Affinität ggf. entsprechend angepasst. Um die Erklärung des Speicherzusammenführungsalgorithmus zu vereinfachen, teilen wir ihn in drei Phasen auf: Suche, Klassifizierung und eigentliche Zusammenführung. In den folgenden Abschnitten setzen wir voraus, dass
eine umfassende Seitenzusammenführung für alle Seiten angefordert wurde, also nicht nur für
den aktuellen Prozess und nicht nur für einfache Seiten. In den anderen Fällen läuft der Vorgang nach demselben Prinzip ab, ist aber einfacher.
Die Suchphase
In der ersten Phase werden die CRCs sämtlicher physischer Seiten berechnet. Der Algorithmus
analysiert jede physische Seite, die zur Liste der aktiven oder geänderten Seiten oder zur Standbyliste gehört, überspringt aber mit null initialisierte und freie Seiten, da diese letzten Endes
nicht verwendet werden.
Gute Kandidaten für eine Speicherzusammenführung sind aktive, nicht gemeinsam genutzte Seiten, die zu einem Arbeitssatz gehören und keiner Auslagerungsstruktur zugeordnet
sind. Ein Kandidat kann sich durchaus auf der Standbyliste oder der Liste der geänderten Seiten
befinden, muss aber einen Referenzzähler von 0 aufweisen. Grundsätzlich berücksichtigt das
System nur drei Arten von Seiten für die Zusammenführung, nämlich solche von Benutzerprozessen, aus dem ausgelagerten Pool und dem Sitzungsraum. Alle anderen Arten von Seiten
werden übergangen.
Um den CRC einer Seite zu berechnen, muss das System die physische Seite mithilfe eines
neuen System-PTEs einer Systemadresse zuordnen, da der Prozesskontext meistens nicht derjenige des aufrufenden Threads ist, weshalb die Seite in den niedrigen Benutzermodusadressen
unzugänglich ist. Der CRC der Seite wird dann mit einem eigenen Algorithmus berechnet (MiComputeHash64). Anschließend wird der System-PTE freigegeben, sodass die Seite nicht mehr im
Systemadressraum zugeordnet ist.
Der Seitenhashalgorithmus
Zur Berechnung des 8-Byte-Seitenhashs (CRC) verwendet das System folgenden Algorithmus: Als Ausgangspunkt wird das Produkt zweier großer 64-Bit-Primzahlen verwendet. Die
Seite wird dann vom Ende zum Anfang abgetastet, wobei der Algorithmus pro Zyklus 64
Bytes hashcodiert. Jeder auf der Seite gelesene 8-Byte-Wert wird zu dem Ausgangshash
hinzugefügt. Anschließend wird der Hash um eine primzahlige Menge von Bits nach rechts
gedreht (beginnend mit 2, dann 3, 5, 7, 11, 13, 17 und 19). Um den Hash einer Seite zu
bestimmen, sind insgesamt 512 Speicherzugriffsoperationen (4096/8) erforderlich.
528
Kapitel 5
Speicherverwaltung
Die Klassifizierungsphase
Wenn alle Hashes der Seiten eines NUMA-Knotens berechnet sind, beginnt der zweite Teil
des Algorithmus. In dieser Phase werden die CRC/PFN-Einträge in der Liste verarbeitet und
strategisch geschickt sortiert. Der Algorithmus für die eigentliche Zusammenführung muss die
Anzahl der Kontextwechsel minimieren und so schnell wie möglich ablaufen.
Als Erstes sortiert die Routine MiProcessCrcList die CRC/PFN-Liste mithilfe eines Quicksort-Algorithmus nach den Hashes. Mit dem Zusammenführungsblock, einer weiteren wichtigen Datenstruktur, wird der Überblick über alle Seiten gewahrt, die den gleichen Hash haben. Vor
allem aber wird darin der neue Prototyp-PTE für die Zuordnung der neuen, zusammengeführten Seite gespeichert. Anschließend werden die CRC/PFN-Einträge der neuen, sortierten Liste
der Reihe nach verarbeitet. Das System muss dabei jeweils prüfen, ob der betrachtete Hash ein
einfacher Hash ist, also zu einer Seite gehört, die komplett 0 oder 1 ist, und ob er gleich dem
vorhergehenden oder dem nächsten Hash ist (denken Sie daran, dass die Liste nach Hashes sortiert ist). Ist das nicht der Fall, prüft das System, ob in der PCS-Struktur bereits ein Zusammenführungsblock vorhanden ist. Wenn ja, so heißt das, dass bei einer vorherigen Ausführung des
Algorithmus oder in einem anderen Knoten des Systems bereits eine zusammengeführte Seite
identifiziert wurde. Wenn nein, ist der CRC einmalig, weshalb die Seite nicht zusammengeführt
werden kann, sodass der Algorithmus mit der nächsten Seite in der Liste fortfährt.
Wird ein einfacher Hash gefunden, der zuvor noch nicht aufgetreten ist, so weist der Algorithmus einen neuen, leeren Zusammenführungsblock für die Master-PFN zu und fügt ihn in
eine Liste ein, die dann in der nächsten Phase vom Code für die eigentliche Zusammenführung
verwendet wird. Kam der Hash bereits vor – ist die Seite also nicht das Masterexemplar –, wird
dem aktuellen CRC/PFN-Eintrag ein Verweis auf den Zusammenführungsblock hinzugefügt.
Damit sind jetzt alle Daten vorbereitet, die der Zusammenführungsalgorithmus benötigt:
eine Liste von Zusammenführungsblöcken, in denen die physischen Masterseiten und ihre Prototyp-PTEs gespeichert sind, eine Liste der CRC/PFN-Einträge, die nach ihrem Arbeitssatz sortiert sind, und etwas physischer Speicher für die Inhalte der neuen, zusammengeführten Seiten.
Anschließend ruft der Algorithmus die Adresse der physischen Seite ab, die laut der zuvor
mithilfe von MiCombineIdenticalPage durchgeführten Überprüfung tatsächlich existieren sollte,
und sucht nach einer Datenstruktur, in der alle zu dem entsprechenden Arbeitssatz gehörenden Seiten gespeichert sind. Diese Struktur nennen wir im Folgenden WS-CRC-Knoten. Falls sie
nicht vorhanden ist, weist der Algorithmus eine neue zu und fügt sie in einen weiteren AVLBaum ein. Der CRC/PFN-Eintrag und die virtuelle Adresse der Seiten werden in dem WS-CRCKnoten miteinander verknüpft.
Nachdem alle gefundenen Seiten verarbeitet wurden, weist das System mithilfe einer MDL
den physischen Speicher für die neuen Masterseiten zu und verarbeitet die einzelnen WSCRC-Knoten. Aus Leistungsgründen werden die Kandidatenseiten in den Knoten nach ihren
ursprünglichen virtuellen Adressen geordnet. Jetzt ist das System bereit für die eigentliche
Seitenzusammenführung.
Speicherzusammenführung
Kapitel 5
529
Die Zusammenführungsphase
Zu Anfang der Zusammenführungsphase stehen eine WS-CRC-Knotenstruktur mit all den Seiten, die zu einem bestimmten Arbeitssatz gehören und Kandidaten für eine Zusammenführung
sind, sowie eine Liste freier Zusammenführungsblöcke, die zur Speicherung der Prototyp-PTEs
und der Masterseiten dient. Der Algorithmus klinkt sich in den Zielprozess ein und verriegelt
seinen Arbeitssatz, wobei er dessen IRQL auf Dispatchebene anhebt. Dadurch kann er direkt auf
jeder Seite lesen und schreiben, ohne sie neu zuordnen zu müssen.
Der Algorithmus verarbeitet alle CRC/PFN-Einträge in der Liste, doch da er auf Dispatch
ebene läuft und der Vorgang einige Zeit in Anspruch nehmen kann, ruft er vor der Analyse des
nächsten Eintrags jeweils KeShouldYieldProcessor auf, um zu prüfen, ob sich DPCs oder geplante Elemente in der Warteschlange des Prozessors befinden. Wenn ja, trifft der Algorithmus
Vorsichtsmaßnahmen, um seinen Status zu erhalten, und gibt die Kontrolle über den Prozessor
vorübergehend ab.
Die Zusammenführungsstrategie geht von folgenden drei möglichen Situationen aus:
QQ Die Seite ist aktiv und gültig, enthält aber nur Nullen. Anstatt sie zusammenzuführen, wird
ihr PTE durch einen Nullforderungs-PTE ersetzt. Dies ist der ursprüngliche Zustand bei
einer Speicherzuweisung mit VirtualAlloc oder vergleichbaren Funktionen.
QQ Die Seite ist aktiv und gültig, aber nicht mit Nullen initialisiert, was bedeutet, dass sie zusammengeführt werden muss. Der Algorithmus prüft, ob die Seite zum Master befördert
wurde. Das ist der Fall, wenn der CRC/PFN-Eintrag nicht über einen Zeiger auf einen gültigen Zusammenführungsblock verfügt. In dieser Situation wird der Hash der Masterseite
erneut überprüft und eine neue physische Seite für die gemeinsame Nutzung zugewiesen.
Anderenfalls wird der vorhandene Zusammenführungsblock verwendet und dessen Referenzzähler heraufgesetzt. Das System ist jetzt bereit, die private in eine gemeinsam genutzte, zusammengeführte Seite umzuwandeln, und ruft dazu MiConvertPrivateToProto auf.
QQ Die Seite befindet sich auf der Standbyliste oder der Liste der geänderten Seiten. In diesem
Fall wird sie als gültige Seite einer Systemadresse zugeordnet und ihr Hash neu berechnet. Der Algorithmus führt dieselben Schritte aus wie in der vorherigen Situation, wobei
der PTE allerdings mit MiConvertStandbyToProto von einem gemeinsamen zu einem Prototyp-PTE umgewandelt wird.
Am Ende der Zusammenführung der aktuellen Seite führt das System den Zusammenführungsblock des Masterexemplars in die PCS-Struktur ein. Das ist wichtig, da dieser Blick die Verbindung zwischen den einzelnen privaten PTEs und der zusammengeführten Seite bildet.
Vom privaten zum gemeinsamen PTE
Die Routine MiConvertPrivateToProto dient dazu, den PTE einer aktiven und gültigen Seite
umzuwandeln. Wenn sie feststellt, dass der Prototyp-PTE im Zusammenführungsblock 0 ist,
so bedeutet das, dass die Masterseite zusammen mit dem gemeinsamen Prototyp-PTE erstellt
werden muss. Anschließend ordnet sie die freie physische Adresse einer Systemadresse zu und
kopiert den Inhalt der privaten Seite in die neue, gemeinsam genutzte. Bevor der gemeinsame
530
Kapitel 5
Speicherverwaltung
PTE erstellt wird, sollte das System alle Reservierungen in der Auslagerungsdatei freigeben
(siehe den entsprechenden Abschnitt weiter vorn in diesem Kapitel) und den PFN-Deskriptor
der gemeinsam genutzten Seite ausfüllen. In der PFN für die gemeinsam genutzte Seite ist das
Prototypbit gesetzt, und der PTE-Framezeiger verweist auf die PFN der physischen Seite mit
dem Prototyp-PTE. Vor allem aber weist der PTE-Zeiger auf den PTE innerhalb des Zusammenführungsblocks, wobei allerdings das 63. Bit auf 0 gesetzt ist. Daran kann das System erkennen,
dass die PFN zu einer zusammengeführten Seite gehört.
Als Nächstes muss das System den PTE der privaten Seite ändern, indem es die Ziel-PFN
darin auf die gemeinsam genutzte physische Seite setzt, den Schutz auf Kopieren beim Schreiben einstellt und den PTE der privaten Seite als gültig kennzeichnet. Auch der Prototyp-PTE im
Zusammenführungsblock wird als gültiger Hardware-PTE gekennzeichnet, denn der Inhalt ist
identisch mit dem neuen PTE der privaten Seite. Schließlich wird der für die private Seite zugewiesene Platz in der Auslagerungsdatei freigegeben und die ursprüngliche PFN der privaten
Seite als gelöscht markiert. Der TLB-Cache wird auf die Festplatte geleert, und der Arbeitssatz
des privaten Prozesses wird um eine Seite verkleinert.
Ist der Prototyp-PTE im Zusammenführungsblock dagegen nicht 0, so heißt das, dass die
private Seite eine Kopie der Masterseite sein soll. In diesem Fall muss nur der aktive PTE der
privaten Seite umgewandelt werden. Die PFN der gemeinsam genutzten Seite wird einer Systemadresse zugeordnet und der Inhalt der beiden Seiten wird verglichen. Das ist wichtig, da
der CRC-Algorithmus im Allgemeinen keine eindeutigen Werte hervorruft. Stimmen die beiden
Seiten nicht überein, bricht die Funktion die Verarbeitung ab und gibt die Steuerung zurück.
Anderenfalls hebt sie die Zuordnung der gemeinsam genutzten Seite auf und legt für die gemeinsam genutzte PFN die höhere der beiden Seitenprioritäten fest. Abb. 5–46 zeigt den Zustand in dem Fall, dass nur eine Masterseite existiert.
Zusammenführungsblock
Prozess A
Prototyp-PTE
PFN = 0x7ffd0
Gültig, Copy-on-Write
PTE
Seite
PFN = 0x7ffd0
Gültig, Copy-on-Write
PTE-Adresse: 0x7fffb284`74a09f48
Zähler für gemeinsame Nutzung:
Aktiv, gem. genutzt, zusammengeführt
PFN-Eintrag
Abbildung 5–46 Zusammengeführte Masterseite
Jetzt berechnet der Algorithmus den neuen ungültigen Software-Prototyp-PTE, der in die private Seitentabelle des Prozesses eingefügt werden muss. Dazu liest er im Zusammenführungsblock die Adresse des Hardware-PTEs, der die gemeinsam genutzte Seite zuordnet, verschiebt
sie und setzt das Prototyp- und das Zusammenführungsbit. Anschließend prüft er, ob der Zähler für die gemeinsame Nutzung der privaten PFN 1 ist. Wenn nein, wird die Verarbeitung ab-
Speicherzusammenführung
Kapitel 5
531
gebrochen. Der Algorithmus schreibt den neuen Software-PTE in die private Seitentabelle des
Prozesses und setzt den Zähler für die gemeinsame Nutzung in der Seitentabelle für die alte
private PFN. (Denken Sie daran, dass eine aktive PFN immer einen Zeiger auf ihre Seitentabelle
unterhält.) Der Arbeitssatz des Zielprozesses wird um eine Seite verkleinert und der TLB auf die
Festplatte geleert. Die alte private Seite wird in den Übergangszustand versetzt und ihre PFN
zur Löschung markiert. Abb. 5–47 zeigt zwei Seiten, von denen die neue auf den Prototyp-PTE
zeigt, aber noch nicht gültig ist.
Um zu verhindern, dass gemeinsam genutzte Seiten bei der Verkleinerung des Arbeitssatzes entfernt werden, wendet das System einen Trick an, nämlich die Simulation eines Seitenfehlers. Dadurch wird der Zähler für die gemeinsame Nutzung der gemeinsamen PFN wieder
erhöht, und es tritt kein Fehler auf, wenn der Prozess versucht, die gemeinsame Seite zu lesen.
Das führt letzten Endes dazu, dass der private PTE wieder ein gültiger Hardware-PTE wird.
Abb. 5–48 zeigt die Auswirkungen eines weichen Seitenfehlers auf die zweite Seite: Sie wird
dadurch gültig gemacht und ihr Zähler für die gemeinsame Nutzung wird heraufgesetzt.
Prozess B (oder A)
PTE
Seite
Nicht gültig, zusammengeführt
Proto-Adresse:
FFFFB28474A09F80
Zusammenführungsblock
Prozess A
Prototyp-PTE
PFN = 0x7ffd0
Gültig, Copy-on-Write
PTE
Seite
PFN = 0x7ffd0
Gültig, Copy-on-Write
PTE-Adresse: 0x7fffb284`74a09f48
Zähler für gemeinsame Nutzung = 1
Aktiv, gem. genutzt, zusammengeführt
PFN-Eintrag
Abbildung 5–47 Zusammengeführte Seiten vor einem simulierten Seitenfehler
532
Kapitel 5
Speicherverwaltung
Prozess B (oder A)
PTE
Seite
PFN = 0x7ffd0
Gültig, Copy-on-Write
Zusammenführungsblock
Prozess A
Prototyp-PTE
Gültig, PFN = 0x7ffd0
Gültig, Copy-on-Write
PTE
Seite
PFN = 0x7ffd0
Gültig, Copy-on-Write
PTE-Adresse: 0x7fffb284`74a09f48
Zähler für gemeinsame Nutzung = 2
Aktiv, gem. genutzt, zusammengeführt
PFN-Eintrag
Abbildung 5–48 Zusammengeführte Seiten nach einem simulierten Seitenfehler
Freigabe von zusammengeführten Seiten
Wenn das System eine bestimmte virtuelle Adresse freigeben muss, sucht es als Erstes die
Adresse des PTEs, der sie zuordnet und der wiederum auf eine PFN zeigt. Bei der PFN einer
zusammengeführten Seite sind das Prototyp- und das Zusammenführungsbit gesetzt. Die
Freigabeanforderung für eine zusammengeführte PFN wird genauso verwaltet wie die für
eine Prototyp-PFN. Der einzige Unterschied besteht darin, dass das System bei gesetztem Zusammenführungsbit nach der Verarbeitung der Prototyp-PFN noch MiDecrementCombinedPte
aufruft.
MiDecrementCombinedPte ist eine einfache Funktion, die den Referenzzähler im Zusammenführungsblock des Prototyp-PTEs heruntersetzt. (In diesem Stadium befindet sich der PTE im
Übergang, da der Speicher-Manager die Zuweisung der zugeordneten physischen Seite bereits
aufgehoben hat. Der Zähler für die gemeinsame Verwendung der physischen Seite ist bereits
auf 0 gefallen, weshalb das System den PTE in den Übergangszustand versetzt hat.) Fällt der
Referenzzähler auf 0, wird der Prototyp-PTE freigegeben, die physische Seite auf die Liste der
freien Seiten gestellt und der Zusammenführungsblock an die Liste freier zusammengeführter
Seiten in der PCS-Struktur der Speicherpartition zurückgegeben.
Speicherzusammenführung
Kapitel 5
533
Experiment: Speicherzusammenführung
In diesem Experiment beobachten Sie die Auswirkungen der Speicherzusammenführung.
Gehen Sie dazu wie folgt vor:
1.
Starten Sie eine Kerneldebuggingsitzung mit einer VM als Ziel (siehe Kapitel 4).
2.
Kopieren Sie MemCombine32.exe (für 32-Bit-Ziele) oder MemCombine64.exe (für
64-Bit-Ziele) sowie MemCombineTest.exe aus den Begleitmaterialien zu diesem Buch
auf den Zielrechner.
3.
Führen Sie auf dem Zielcomputer MemCombineTest.exe aus. Sie sehen jetzt folgende
Anzeige:
4.
Beachten Sie die beiden Adressen. Dies sind zwar Puffer, die mit zufällig generierten
Bytemustern gefüllt sind. Die Muster werden wiederholt, sodass jede Seite den gleichen
Inhalt hat.
5.
Suchen Sie im Debugger den Prozess MemCombineTest:
0: kd> !process 0 0 memcombinetest.exe
PROCESS ffffe70a3cb29080
SessionId: 2 Cid: 0728 Peb: 00d08000 ParentCid: 11c4
DirBase: c7c95000 ObjectTable: ffff918ede582640 HandleCount: <Data Not
Accessible>
Image: MemCombineTest.exe
6.
Schalten Sie zu diesem Prozess um:
0: kd> .process /i /r ffffe70a3cb29080
You need to continue execution (press 'g' <enter>) for the context to be
switched. When the debugger breaks in again, you will be in the new process
context.
0: kd> g
Break instruction exception - code 80000003 (first chance)
nt!DbgBreakPointWithStatus:
fffff801'94b691c0 cc int 3
→
534
Kapitel 5
Speicherverwaltung
7.
Suchen Sie mit !pte die PFN, in der die beiden Puffer gespeichert sind:
0: kd> !pte b80000
VA 0000000000b80000
PXE at FFFFA25128944000 PPE at FFFFA25128800000 PDE at
FFFFA25100000028 PTE at FFFFA20000005C00
contains 00C0000025BAC867 contains 0FF00000CAA2D867 contains
00F000003B22F867 contains B9200000DEDFB867
pfn 25bac ---DA--UWEV pfn caa2d ---DA--UWEV pfn 3b22f ---DA-UWEV pfn dedfb ---DA--UW-V
0: kd> !pte b90000
VA 0000000000b90000
PXE at FFFFA25128944000 PPE at FFFFA25128800000 PDE at
FFFFA25100000028 PTE at FFFFA20000005C80
contains 00C0000025BAC867 contains 0FF00000CAA2D867 contains
00F000003B22F867 contains B9300000F59FD867
pfn 25bac ---DA--UWEV pfn caa2d ---DA--UWEV pfn 3b22f ---DA-UWEV pfn f59fd ---DA--UW-V
8.
Die PFN-Werte sind unterschiedlich, was anzeigt, dass diese Seiten unterschiedlichen
physischen Adressen zugeordnet sind. Nehmen Sie die Ausführung des Ziels wieder
auf.
9.
Öffnen Sie auf dem Zielcomputer eine Eingabeaufforderung mit erhöhten Rechten,
wechseln Sie zu dem Verzeichnis, in das Sie MemCombine(32/64) kopiert haben, und
führen Sie diese Datei aus. Das Programm erzwingt eine vollständige Speicherzusammenführung, was einige Sekunden dauern kann.
10. Wenn die Speicherzusammenführung abgeschlossen ist, klinken Sie sich wieder mit
dem Debugger ein. Wiederholen Sie die Schritte 6 und 7. Jetzt sehen Sie die geänderten PFNs:
1: kd> !pte b80000
VA 0000000000b80000
PXE at FFFFA25128944000 PPE at FFFFA25128800000 PDE at
FFFFA25100000028 PTE at FFFFA20000005C00
contains 00C0000025BAC867 contains 0FF00000CAA2D867 contains
00F000003B22F867 contains B9300000EA886225
pfn 25bac ---DA--UWEV pfn caa2d ---DA--UWEV pfn 3b22f ---DA-UWEV pfn ea886 C---A--UR-V
1: kd> !pte b90000
VA 0000000000b90000
PXE at FFFFA25128944000 PPE at FFFFA25128800000 PDE at
→
Speicherzusammenführung
Kapitel 5
535
FFFFA25100000028 PTE at FFFFA20000005C80
contains 00C0000025BAC867 contains 0FF00000CAA2D867 contains
00F000003B22F867 contains BA600000EA886225
pfn 25bac ---DA--UWEV pfn caa2d ---DA--UWEV pfn 3b22f ---DA-UWEV pfn ea886 C---A--UR-V
11. Die PFN-Werte sind identisch, da die Seiten derselben Adresse im RAM zugeordnet
sind. Beachten Sie auch das Flag C in der PFN, das für Copy-on-Write steht.
12. Nehmen Sie die Ausführung des Ziels wieder auf und drücken Sie im Fenster von MemCombineTest eine beliebige Taste. Dadurch wird ein einziges Byte im ersten Puffer geändert.
13. Klinken Sie sich wieder ein und führen Sie abermals Schritt 6 und 7 aus:
1: kd> !pte b80000
VA 0000000000b80000
PXE at FFFFA25128944000 PPE at FFFFA25128800000 PDE at
FFFFA25100000028 PTE at FFFFA20000005C00
contains 00C0000025BAC867 contains 0FF00000CAA2D867 contains
00F000003B22F867 contains B9300000813C4867
pfn 25bac ---DA--UWEV pfn caa2d ---DA--UWEV pfn 3b22f ---DA-UWEV pfn 813c4 ---DA--UW-V
1: kd> !pte b90000
VA 0000000000b90000
PXE at FFFFA25128944000 PPE at FFFFA25128800000 PDE at
FFFFA25100000028 PTE at FFFFA20000005C80
contains 00C0000025BAC867 contains 0FF00000CAA2D867 contains
00F000003B22F867 contains BA600000EA886225
pfn 25bac ---DA--UWEV pfn caa2d ---DA--UWEV pfn 3b22f ---DA-UWEV pfn ea886 C---A--UR-V
14. Die PFN des ersten Puffers hat sich geändert, und das Copy-on-Write-Flag wurde entfernt. Die Seite wurde geändert und an eine andere Adresse im RAM verlegt.
Speicherenklaven
In einem Prozess ausgeführte Threads haben Zugriff auf den gesamten Prozessadressraum
( je nach Seitenschutz, der aber geändert werden kann). Das ist zwar meistens wünschenswert, doch wenn Schadcode sich in einen Prozess einschleusen kann, stehen ihm die gleichen
Möglichkeiten zur Verfügung: Er kann ungehindert Daten lesen, die möglicherweise sensible
Informationen umfassen, und sie sogar ändern.
Intel hat die SGX-Technologie entwickelt (Software Guard Extensions), mit der sich geschützte Speicherenklaven erstellen lassen. Dies sind sichere Zonen im Prozessadressraum, in
536
Kapitel 5
Speicherverwaltung
denen die CPU Code und Daten vor Code schützt, der außerhalb der Enklave läuft. Umgekehrt
jedoch hat der Code in einer Enklave den normalen Vollzugriff auf den Prozessadressraum
außerhalb. Natürlich ist die Enklave darüber hinaus auch gegen Zugriffe von anderen Prozessen und sogar von Kernelmoduscode geschützt. Abb. 5–49 zeigt eine vereinfachte Darstellung
einer Speicherenklave.
Geschützte Enklave
Geschützte Daten
Vollzugriff
Kein Zugriff
Geschützter Code
Code
Daten
Abbildung 5–49 Speicherenklaven
Intel SGX wird von Core-Prozessoren der 6. Generation (Skylake) und höher unterstützt. Intel
stellt ein eigenes SDK für Anwendungsentwickler bereit, das für Windows 7 und höhere Systeme genutzt werden kann (nur 64 Bit). Ab Windows 10 Version 1511 und Windows Server 2016
bietet Windows eine Abstraktion mithilfe von Windows-API-Funktionen, wodurch es nicht
mehr nötig ist, das Intel-SDK zu verwenden. Möglicherweise werden andere CPU-Hersteller
in Zukunft ähnliche Lösungen entwickeln, die dann über dieselbe API gehandhabt werden
können. Dadurch ergibt sich eine relativ gut portierbare Schicht, die Anwendungsentwickler
nutzen können, um Enklaven zu erstellen und zu füllen.
Nicht alle Core-Prozessoren der 6. Generation unterstützen SGX. Außerdem muss
auf dem System ein entsprechendes BIOS-Update installiert werden, damit SGX
funktionieren kann. Mehr erfahren Sie in der Dokumentation zu Intel SGX. Die
SGX-Website erreichen Sie auf https://software.intel.com/en-us/sgx.
Intel stellt zwei Versionen von SGX her (1.0 und 2.0), wobei Windows zurzeit nur
Version 1.0 unterstützt. Die Unterschiede zwischen den Versionen würden den
Rahmen dieses Buches sprengen. Schlagen Sie dazu in der SGX-Dokumentation
nach.
Bei den aktuellen SGX-Versionen sind keine Enklaven in Ring 0 (Kernelmodus)
möglich, sondern nur in Ring 3 (Benutzermodus).
Speicherenklaven
Kapitel 5
537
Programmierschnittstellen
Um in ihren Programmen Enklaven zu erstellen und zu verwenden, müssen Anwendungsentwickler wie folgt vorgehen (wobei die internen Mechanismen, die dabei ablaufen, in den folgenden Abschnitten dargestellt sind):
1.
Als Erstes muss das Programm feststellen, ob Speicherenklaven überhaupt unterstützt
werden. Dazu ruft es IsEnclaveTypeSupported auf und übergibt dabei einen Wert für die
gewünschte Enklaventechnologie. Zurzeit ist dabei nur der Wert ENCLAVE_TYPE_SGX möglich.
2.
Um eine neue Enklave zu erstellen, wird die Funktion CreateEnclave aufgerufen, die ähnliche Argumente verwendet wie VirtualAllocEx. Beispielsweise ist es möglich, eine Enklave
in einem anderen Prozess aus dem Aufruferprozess zu erstellen. Kompliziert wird die Sache dadurch, dass eine herstellerspezifische Konfigurationsstruktur benötigt wird. Für Intel
ist das eine 4 KB große SGX-Enklavensteuerungsstruktur (SGX Enclave Control Structure,
SECS), die Microsoft nicht ausdrücklich definiert. Stattdessen müssen Entwickler ihre eigene Struktur für die jeweils verwendete Technologie anhand ihrer Dokumentation erstellen.
3.
Nachdem eine leere Enklave erstellt ist, besteht der nächste Schritt darin, sie mit Code und
Daten von außerhalb zu füllen. Dazu wird die Funktion LoadEnclaveData aufgerufen, die
Daten im Speicher außerhalb der Enklave in die Enklave hineinkopiert. Es kann durchaus
mehrere Aufrufe dieser Funktion geben.
4.
Abschließend muss die Enklave mit InitializeEnclave aktiviert werden. Code, der zur Ausführung in der Enklave eingerichtet wurde, kann jetzt starten.
5.
Leider gibt es keine API für die Ausführung von Code in der Enklave. Stattdessen ist eine
unmittelbare Verwendung von Assembleranweisungen erforderlich. EENTER überträgt die
Ausführung an die Enklave, und EEXIT veranlasst den Rücksprung zur aufrufenden Funktion. Eine irreguläre Beendigung der Enklavenausführung, z. B. aufgrund eines Fehlers, ist
mit AEX möglich (Asynchronous Enclave Exit). Die Einzelheiten sind nicht Windows-spezifisch und daher nicht Thema dieses Buches. Richten Sie sich dazu nach der SGX-Dokumentation.
6.
Um eine Enklave zu zerstören, kann eine normale VirtualFree(Ex)-Funktion auf den in
CreateEnclave gewonnenen Zeiger auf die Enklave angewendet werden.
Initialisierung von Speicherenklaven
Beim Systemstart ruft Winload (der Windows-Bootloader) OslEnumerateEnclavePageRegions auf.
Diese Funktion wendet als Erstes die Funktion CPUID an, um zu prüfen, ob SGX unterstützt wird.
Wenn ja, gibt sie Anweisungen aus, um die EPC-Deskriptoren aufzulisten. Ein EPC (Enclave Page
Cache) ist der geschützte Speicher, den der Prozessor zum Erstellen und Verwenden von Enklaven bereitstellt. Für jeden aufgelisteten EPC ruft OslEnumerateEnclavePageRegions die Funktion
BlMmAddEnclavePageRange auf, um Informationen über den Seitenbereich zu einer sortierten
Liste von Speicherdeskriptoren mit dem Typwert LoaderEnclaveMemory hinzuzufügen. Diese Lis-
538
Kapitel 5
Speicherverwaltung
te wird schließlich im Element MemoryDescriptorListHead der LOADER_PARAMETER_BLOCK-Struktur
gespeichert, mit der Informationen vom Bootloader an den Kernel übergeben werden.
Während der Initialisierung wird die Speicher-Manager-Routine MiCreateEnclaveRegions
aufgerufen, um einen AVL-Baum für die ermittelten Enklavenregionen zu erstellen, sodass
sie bei Bedarf schnell nachgeschlagen werden können. Dieser Baum wird im Datenelement
MiState.Hardware.EnclaveRegions gespeichert. Der Kernel fügt eine neue Enklavenseitenliste
hinzu. Ein besonderes Flag, das an MiInsertPageInFreeOrZeroedList übergeben wird, ermöglicht es, diese neue Liste zu nutzen. Da der Speicher-Manager jedoch keine Listen-IDs mehr zur
Verfügung hat (es werden drei Bits verwendet, sodass höchstens acht Werte möglich sind, und
alle davon sind bereits verwendet), hält der Kernel diese Seiten für »unzulässige« Seiten, bei
denen ein Einlagerungsfehler aufgetreten ist. Da der Speicher-Manager niemals unzulässige
Seiten verwendet, wird er dadurch davon abgehalten, die Enklavenseiten für normale Speicherverwaltungsoperationen zu verwenden.
Aufbau von Enklaven
Die API CreateEnclave ruft schließlich NtCreateEnclave im Kernel auf. Wie bereits erwähnt, muss
eine SECS-Struktur übergeben werden. Ihr Aufbau ist in der SGX-Dokumentation von Intel beschrieben. Einen Überblick sehen Sie in Tabelle 5–24.
NtCreateEnclave prüft zunächst, ob Speicherenklaven unterstützt werden, indem sie sich
den Stamm des AVL-Baums ansieht (also nicht mithilfe der langsameren Anweisung CPUID).
Anschließend erstellt sie eine Kopie der übergebenen Struktur, wie es bei Kernelfunktionen
üblich ist, die Daten vom Benutzermodus erhalten. Falls sich die Enklave in einem anderen Prozess als dem des Aufrufers befindet, hängt sie diese Struktur an den Zielprozess an
(KeStackAttachProcess). Anschließend überträgt sie die Steuerung an MiCreateEnclave, die
die eigentliche Arbeit ausführt.
Feld
Offset (Bytes)
Größe (Bytes)
Beschreibung
SIZE
0
8
Größe der Enklave in Bytes; muss eine
Zweierpotenz sein.
BASEADDR
8
8
Lineare Basisadresse der Enklave; muss
natürlich an der Größe ausgerichtet sein.
SSAFRAMESIZE
16
4
Größe eines SSA-Frames auf den Seiten
(einschließlich XSAVE, Auffüllung, GPR
und optional MISC)
MRSIGNER
128
32
Messregister, erweitert mit dem öffentlichen Schlüssel, der die Enklave verifiziert
hat. Korrektes Format siehe SIGSTRUCT.
RESERVED
160
96
ISVPRODID
256
2
Produkt-ID der Enklave
ISVSVN
258
2
Sicherheitsversionsnummer (SVN) der
Enklave
EID
Implementierungsabhängig
8
Enklaven-ID
→
Speicherenklaven
Kapitel 5
539
Feld
Offset (Bytes)
Größe (Bytes)
Beschreibung
PADDING
Implementierungsabhängig
352
Auffüllmuster von der Signatur (verwendet für Schlüsselableitungsstrings)
RESERVED
260
3836
Schließt EID und andere von null verschiedene reservierte Felder und muss
von null verschieden sein.
Tabelle 5–24 Aufbau einer SECS-Struktur
Als Erstes weist MiCreateEnclave die AWE-Informationsstruktur zu (Address Windowing Extension), die auch die AWE-APIs nutzen, weil Enklaven ähnlich wie AWE einen direkten Zugriff
von Benutzermodusanwendungen auf physische Seiten zulassen (genauer ausgedrückt, auf die
physischen Seiten, die bei der zuvor beschriebenen Überprüfung als EPC-Seiten erkannt wurden). Wenn Benutzermodusanwendungen die direkte Kontrolle über physische Seiten haben,
müssen stets AWE-Datenstrukturen und -Sperren verwendet werden. Diese Datenstruktur wird
im Feld AweInfo der EPROCESS-Struktur gespeichert.
Als Nächstes ruft MiCreateEnclave die Funktion MiAllocateEnclaveVad auf, um einen Enklaven-VAD zuzuweisen, der den virtuellen Speicherbereich der Enklave beschreibt. Bei diesem
VAD ist wie bei allen AWE-VADs das Flag VadAwd gesetzt, aber auch das zusätzliche Flag Enclave,
was ihn von einem echten AWE-VAD unterscheidet. Im Rahmen der VAD-Zuweisung wird
schließlich auch die Benutzermodusadresse für den Arbeitsspeicher der Enklave ausgewählt
(falls sie nicht schon ausdrücklich im ursprünglichen Aufruf von CreateEnclave angegeben war).
Im nächsten Schritt erwirbt MiCreateEnclave eine Enklavenseite unabhängig von der Enklavengröße und der ursprünglichen Zusicherung, da laut der SGX-Dokumentation von Intel
alle Enklaven über eine mindestens einseitige Steuerstruktur verfügen müssen. Um die erforderliche Zuweisung zu gewinnen, wird MiGetEnclavePage verwendet. Sie untersucht die zuvor
beschriebene Enklavenseitenlisten und entnimmt ihr nach Bedarf eine Seite. Diese zurückgegebene Seite wird mit einem System-PTE zugeordnet, der im Enklaven-VAD gespeichert ist.
Die Funktion MiInitializeEnclavePfn richtet die zugehörige PFN-Datenstruktur ein und kennzeichnet sie mit Modified und ActiveAndValid.
Es gibt keine Bits, an denen man die Enklaven-PFN von einer anderen aktiven Region
im Speicher unterscheiden könnte, etwa vom nicht ausgelagerten Pool. Hier kommt der AVLBaum für Enklavenregionen ins Spiel. Wenn der Kernel prüfen muss, ob eine PFN eine EPC-
Region beschreibt, verwendet er dazu die Funktion MI_PFN_IS_ENCLAVE.
Nach der Initialisierung der PFN wird der System-PTE in einen globalen Kernel-PTE
umgewandelt und die resultierende virtuelle Adresse berechnet. Der letzte Schritt von
MiCreateEnclave besteht darin, KeCreateEnclave aufzurufen, die die maschinennahen Schritte zur Enklavenerstellung im Kernel ausführt und sich dabei auch um die Kommunikation
mit der SGX-Hardwareimplementierung kümmert. Unter anderem ist KeCreateEnclave dafür
verantwortlich, die Basisadresse anzugeben, wenn der Aufrufer keine angegeben hat. Diese Adresse muss in der SECS-Struktur vorhanden sein, bevor die Kommunikation mit der
SGX-Hardware zum Erstellen der Enklave beginnt.
540
Kapitel 5
Speicherverwaltung
Daten in eine Enklave laden
Wenn die Enklave erstellt ist, muss sie mit Informationen geladen werden. Dazu ist die Funktion
LoadEnclaveData da, die die entsprechende Anforderung aber nur an die zugrunde liegende
Exekutivfunktion NtLoadEnclaveData weiterleitet. Diese wiederum führt eine Form von Speicherkopieroperation mit einigen VirtualAlloc-Attributen durch, etwa dem Seitenschutz.
Enthält die Enklave noch keine zugesicherten Enklavenseiten, müssen diese erst erworben werden. Dadurch wird mit Nullen überschriebener Speicher zu der Enklave hinzugefügt,
der dann mit nicht mit Nullen gefülltem Speicher außerhalb der Enklave gefüllt werden kann.
Wurde dagegen eine Initialisierungsgröße mit vorab zugesicherten Seiten übergeben, können
diese unmittelbar mit Nicht-Null-Speicher außerhalb der Enklave gefüllt werden.
Da der Enklavenspeicher durch einen VAD beschrieben wird, funktionieren viele der herkömmlichen Speicherverwaltungs-APIs auch bei diesem Speicher; zumindest teilweise. Beispielsweise führt ein Aufruf von VirtualAlloc (der schließlich bei NtAllocateVirtualMemory
landet) mit dem Flag MEM_COMMIT für eine solche Adresse dazu, dass MiCommitEnclavePages aufgerufen wird. Diese Funktion wiederum überprüft, ob die Schutzmaske für die neuen Seiten
kompatibel ist (das heißt, ob sie die richtige Kombination aus Lese-, Schreib- und Ausführungsflags enthält, wobei besondere Flags für Caching und kombiniertes Schreiben nicht berücksichtigt werden), und ruft dann MiAddPagesToEnclave auf. Dabei übergibt sie einen Zeiger auf den
Enklaven-VAD für den Adressbereich, die in VirtualAlloc angegebene Schutzmaske und die
PTE-Adressen für den zuzusichernden virtuellen Adressbereich.
MiAddPagesToEnclave prüft als Erstes, ob mit dem Enklaven-VAD vorhandene EPC-Seiten
verknüpft sind und ob es genug davon gibt, um die Zusicherung zu erfüllen. Wenn nicht, wird
MiReserveEnclavePages aufgerufen, um eine ausreichende Menge zu beziehen. Diese Funktion
schaut sich die aktuelle Enklavenseitenliste an und bestimmt die Summe. Stellt der Prozessor
nicht genügend physische EPC-Seiten bereit (nach den beim Hochfahren ermittelten Informa
tionen), schlägt die Funktion fehl. Anderenfalls ruft MiReserveEnclavePages die Funktion MiGetEnclavePage in einer Schleife für die erforderliche Menge an Seiten auf.
Jeder abgerufene PFN-Eintrag wird mit dem PFN-Array im Enklaven-VAD verknüpft. Das
heißt, wenn eine Enklaven-PFN aus der Enklavenseitenliste herausgenommen und in den aktiven Status versetzt wurde, fungiert der Enklaven-VAD als Liste der aktiven Enklaven-VADs.
Sobald die erforderlichen zugesicherten Seiten bezogen wurden, übersetzt MiAddPagesToEnclave den an LoadEnclaveData übergebenen Seitenschutz in die SGX-Gegenstücke. Anschließend reserviert die Funktion die entsprechende Anzahl von System-PTEs, um Informationen
über die einzelnen erforderlichen EPC-Seiten festzuhalten. Danach ruft sie schließlich KeAddEnclavePage auf, die wiederum die SGX-Hardware aufruft, um die Seiten tatsächlich hinzuzufügen.
Das besondere Seitenschutzattribut PAGE_ENCLAVE_THREAD_CONTROL gibt an, dass der Speicher
für eine von SGX definierte Threadsteuerstruktur (Thread Control Structure, TCS) gebraucht wird.
Jede TCS steht für einen eigenen Thread, der für sich allein in der Enklave ausgeführt werden
kann.
NtLoadEnclaveData überprüft Parameter und ruft dann MiCopyPagesIntoEnclave auf, um die
eigentliche Arbeit auszuführen. Dazu kann es gehören, zugesicherte Seiten abzurufen, wie es
bereits weiter vorn erklärt wurde.
Speicherenklaven
Kapitel 5
541
Eine Enklave initialisieren
Nachdem die Enklave erstellt und mit Daten versehen wurde, ist noch ein letzter Schritt erforderlich, bevor in der Enklave Code ausgeführt werden kann. Die Funktion InitializeEnclave
muss SGX darüber benachrichtigen, dass sich die Enklave im letzten Stadium vor der Ausführung befindet. Ihr müssen die beiden SGX-spezifischen Strukturen SIGSTRUCT und EINITTOKEN
übergeben werden (siehe die SGX-Dokumentation).
Die von InitializeEnclave aufgerufene Exekutivfunktion NtInitializeEnclave überprüft
einige Parameter und stellt sicher, dass der Enklaven-VAD über die richtigen Attribute verfügt.
Anschließend übergibt sie die Strukturen an die SGX-Hardware. Beachten Sie, dass eine Enklave
nur einmal initialisiert werden kann.
Jetzt kann die Codeausführung mithilfe der Intel-Assembleranweisung EENTER gestartet
werden (siehe SGX-Dokumentation).
Vorausschauende Speicherverwaltung (SuperFetch)
Bei der herkömmlichen Speicherverwaltung in Betriebssystemen liegt der Schwerpunkt auf
dem bis jetzt beschriebenen Modell der bedarfsweisen Auslagerung mit einigen Erweiterungen wie Clustering und Prefetching, die eine Optimierung der Festplatten-E/A zum Zeitpunkt
des Seitenfehlers ermöglichen. Clientversionen von Windows enthalten jedoch noch eine erhebliche Verbesserung der Verwaltung von physischem Speicher, nämlich SuperFetch. Dabei
handelt es sich um ein Speicherverwaltungsverfahren, das das Prinzip des am weitesten zurückliegenden Zugriffs durch Verlaufsinformationen über den Dateizugriff und vorausschauende
Speicherverwaltung verstärkt.
Bei der Verwaltung der Standbyliste in älteren Windows-Versionen gab es zwei Einschränkungen. Erstens basierte die Priorität der Seiten nur auf dem unmittelbar vorausgegangenen
Verhalten der Prozesse und nahm keine künftigen Speicheranforderungen vorweg. Zweitens
waren die Daten für die Vergabe der Prioritäten auf die Seiten beschränkt, die dem Prozess zum
jeweiligen Zeitpunkt gehörten. Diese Mängel konnten dazu führen, dass auf einem Computer,
auf dem speicherintensive Systemanwendungen wie Virenscans oder eine Diskfragmentierung
ausgeführt wurden, während der Benutzer kurzzeitig nicht darauf gearbeitet hat, anschließende interaktive Anwendungen sehr langsam laufen oder langsam gestartet werden. Das kann
auch geschehen, wenn ein Benutzer eine daten- oder speicherintensive Anwendung ausführt
und dann zu anderen Programmen wechselt: Auch diese können auf einmal erheblich schlechter reagieren.
Dieser Leistungsabfall tritt auf, wenn Code und Daten, die von aktiven Anwendungen im
Speicher abgelegt wurden, von speicherintensiven Anwendungen überschrieben werden. Da
die anderen Anwendungen ihre Daten und ihren Code anschließend erst wieder von der Festplatte anfordern müssen, laufen sie nur schleppend. Durch die Lösung dieser Probleme mithilfe
von SuperFetch haben die Clientversionen von Windows einen großen Schritt nach vorn getan.
542
Kapitel 5
Speicherverwaltung
Komponenten
SuperFetch besteht aus mehreren Komponenten im System, die zusammenarbeiten, um den
Speicher vorausschauend zu verwalten, und dabei helfen, Beeinträchtigungen des Benutzers
durch die Ausführung von SuperFetch zu begrenzen:
QQ Ablaufverfolgung Die Mechanismen zur Ablaufverfolgung gehören alle zu der Kernelkomponente Pf, die es SuperFetch ermöglicht, jederzeit ausführliche Informationen
über Seitennutzung, Sitzungen und Prozesse abzurufen. Zur Verfolgung der Dateinutzung
setzt SuperFetch außerdem den Minifiltertreiber FileInfo ein (%SystemRoot%\System32\
Drivers\Fileinfo.sys).
QQ Sammler und Verarbeiter der Ablaufverfolgung Der Sammler arbeitet mit den Komponenten der Ablaufverfolgung zusammen, um ein Rohprotokoll der erfassten Ablaufverfolgungsdaten bereitzustellen. Diese Daten werden im Arbeitsspeicher gehalten und
an den Verarbeiter übergeben, der die Protokolleinträge an die Agenten weitergibt. Diese
Agenten wiederum führen die Verlaufsdateien im Arbeitsspeicher und sichern sie auf der
Festplatte, wenn der Dienst beendet wird, etwa bei einem Neustart.
QQ Agenten SuperFetch führt Informationen über den Dateiseitenzugriff in Verlaufsdateien.
Darin sind die virtuellen Offsets vermerkt. Die Agenten gruppieren die Seiten nach Attributen, u. a. den folgenden:
•
Seitenzugriff, wenn der Benutzer aktiv war
•
Seitenzugriff durch einen Vordergrundprozess
•
Harte Fehler, während der Benutzer aktiv war
•
Seitenzugriffe während des Starts einer Anwendung
•
Seitenzugriffe, wenn der Benutzer nach einer längeren Leerlaufzeit zurückkehrt
QQ Szenario-Manager Diese auch als Kontext-Manager bezeichnete Komponente verwaltet
die drei SuperFetch-Szenariopläne Ruhezustand, Standby und schneller Benutzerwechsel.
Der Kernelmodusteil des Szenario-Managers stellt APIs bereit, um diese Szenarien auszulösen und zu beenden, um den Status des aktuellen Szenarios zu verwalten und um
Ablaufverfolgungsinformationen mit diesen Szenarien zu verknüpfen.
QQ Rebalancer Aufgrund der Informationen der SuperFetch-Agenten und des aktuellen
Systemstatus (z. B. des Zustands der nach Prioritäten sortierten Seitenlisten) fragt der Rebalancer – ein besonderer Agent im Benutzermodusdienst SuperFetch – die PFN-Datenbank
ab und vergibt neue Prioritäten auf der Grundlage des zugehörigen Punktestands jeder
Seite. Dadurch stellt er die nach Prioritäten geordnete Standbyliste auf. Der Rebalancer
kann auch Befehle an den Speicher-Manager ausgeben, um die Arbeitssätze von Prozessen zu bearbeiten. Er ist der einzige Agent, der tatsächlich Maßnahmen auf dem System
ergreifen kann. Die anderen Agenten filtern lediglich die Informationen, die der Rebalancer
für seine Entscheidungen heranzieht. Des Weiteren löst der Rebalancer das Prefetching
durch den Prefetcherthread aus, der wiederum FileInfo und Kerneldienste nutzt, um den
Speicher vorab mit nützlichen Seiten zu laden.
Vorausschauende Speicherverwaltung (SuperFetch)
Kapitel 5
543
Alle diese Komponenten nutzen Einrichtungen im Speicher-Manager, mit denen sich ausführliche Informationen über den Status der einzelnen Seiten in der PFN-Datenbank, die aktuellen Seitenzähler für die einzelnen Seitenlisten und Prioritätslisten usw. abrufen lassen. Um die
Auswirkungen auf den Benutzer zu minimieren, nutzen diese Komponenten außerdem E/A-
Prioritäten (siehe Kapitel 8 in Band 2). Abb. 5–50 zeigt einen Überblick über die Komponenten
von SuperFetch.
PFN-Datenbank
Rebalancer
Benutzerdaten
Benutzerdaten
Rebalancer-Kern
Kern
Agent
Kern
Agent
Kern
Agent
Benutzerdaten
Benutzerdaten
Arbeitssatz
komplement
Protokoll
einträge
Verarbeiter der
Ablaufverfolgung
SeitenzugriffsAblaufverfolgungen
Speicher
priorisierer
PFN-Abfrage
anforderungen
PFN-Festlegungs
anforderungen
Speicher-Manager
Prefetch
anforderungen
Seitenzugriffs
puffer
Datenbank mit
Abschnittsinformationen
Datei
schlüsselLookup
Prefetch
anforderungen
Benutzermodus
Vollständige Ablaufver
folgungen für Seitenzugriff
und Dateiinfo
PFN-Repriorisierer
PFN-Abfrage-/Festlegungs
anforderungen
Sammler der
Ablaufverfolgung
Prefetchthread
SuperFetchPrefetcher
Informationen über
Dateinamen/Dateischlüssel
SuperFetch-Ablaufverfolgung
Kernelmodus
Seiten
zugriffsAblauf
verfolgung
SeiteninfoAblaufverf.
Ablaufverfolgungsliste
FileInfo-Minifilter
Abbildung 5–50 Architektur von SuperFetch
Ablaufverfolgung und Protokollierung
SuperFetch trifft die meisten seiner Entscheidungen auf der Grundlage der Informationen,
die aus rohen Ablaufverfolgungen und Protokollen übernommen, analysiert und verarbeitet
wurden. Dadurch werden diese beiden Komponenten zu den wichtigsten. Die Ablaufverfolgung ähnelt in gewisser Weise ETW, da sie im gesamten System bestimmte Trigger im Code
verwendet, um Ereignisse auszulösen. Sie arbeitet aber auch mit anderen vom System bereitgestellten Einrichtungen zusammen, z. B. den Benachrichtigungen des Energie-Managers,
Prozesscallbacks und der Dateisystemfilterung. Außerdem verwendet die Ablaufverfolgung
sowohl herkömmliche Seitenalterungsmechanismen des Speicher-Managers als auch die jüngere Arbeitssatzalterung und die Zugriffsverfolgung, die für SuperFetch eingerichtet wurden.
SuperFetch führt immer eine Ablaufverfolgung aus und fragt kontinuierlich Ablaufverfolgungsdaten vom System ab. Dazu werden über die Zugriffsbitverfolgung und Arbeitssatzalterung des Speicher-Managers Informationen über die Seitennutzung und den Seitenzugriff
bestimmt. Genauso wichtig wie die Seitennutzung sind aber auch Informationen über die
Dateien, da dies eine Priorisierung der Dateidaten im Cache ermöglicht. Dazu wendet SuperFetch vorhandene Filtermöglichkeiten sowie zusätzlich den FileInfo-Treiber an (siehe Ka-
544
Kapitel 5
Speicherverwaltung
pitel 6). Dieser Treiber befindet sich oberhalb des Dateisystem-Gerätestacks und überwacht
den Zugriff auf Dateien und Änderungen daran auf Streamebene, was detaillierte Kenntnisse
über den Dateizugriff ermöglicht. (Weitere Informationen über NTFS-Datenstreams erhalten
Sie in Kapitel 13 von Band 2.) Die Hauptaufgabe des FileInfo-Treibers besteht darin, die
Streams, die nur mit einem eindeutigen, zurzeit im FsContext-Feld des zugehörigen Dateiobjekts implementierten Schlüssel bezeichnet werden, mit Dateinamen zu verknüpfen, sodass der Benutzermodusdienst SuperFetch die jeweiligen Dateistreams und Offsets erkennen
kann, zu denen eine Seite auf der Standbyliste eines im Speicher zugeordneten Abschnitts
gehört. Außerdem bietet der Treiber eine Schnittstelle, um die Dateidaten unsichtbar vorab
abzurufen, ohne gesperrte Dateien und andere Dateisystemzustände zu stören. Des Weiteren
sorgt der Treiber dafür, dass die Informationen konsistent bleiben, indem er Löschvorgänge,
Umbenennungen, Kürzungen und die Wiederverwendung von Dateischlüsseln mithilfe von
Sequenznummern verfolgt.
Während einer Ablaufverfolgung kann der Rebalancer jederzeit aufgerufen werden, um
die Seiten neu zu füllen. Die Entscheidung dafür erfolgt aufgrund der Analyse von Informationen wie der Verteilung des Speichers auf Arbeitssätze, die Nullseitenliste, die Liste geänderter
Seiten und die Standbyliste, der Anzahl von Fehlern, des Status der PTE-Zugriffsbits, der seitenweisen Nutzungsdaten, des aktuellen Verbrauchs an virtuellen Adressen und der Arbeitssatzgrößen.
Es gibt mehrere Arten von Ablaufverfolgungen. Eine Seitenzugriffs-Ablaufverfolgung greift
auf das Zugriffsbit zurück, um sich zu merken, auf welche Seiten der Prozess zugegriffen hat
(sowohl auf Dateiseiten als auch auf privaten Speicher). Eine Ablaufverfolgung zur Namensprotokollierung beobachtet Änderungen an der Zuordnung von Dateinamen zu Dateischlüsseln
für die tatsächliche Datei auf der Festplatte. Dadurch kann SuperFetch eine Seite zuordnen, die
mit einem Dateiobjekt verknüpft ist.
Eine SuperFetch-Ablaufverfolgung merkt sich nur Seitenzugriffe, doch der Dienst SuperFetch verarbeitet diese Ablaufverfolgung im Benutzermodus und geht viel tiefer, wobei er seine
eigenen, umfassenderen Informationen hinzufügt, z. B. von wo die Seite geladen wurde (z. B.
als residente Datei im Arbeitsspeicher oder aufgrund eines harten Seitenfehlers), ob dies der
erste Zugriff auf die Seite war und wie hoch die Seitenzugriffsrate ist. Dazu kommen noch weitere Informationen wie der Systemstatus oder Informationen über nicht lang zurückliegende
Szenarien, in denen jeweils zuletzt auf die beobachteten Seiten verwiesen wurde. Diese Ablaufverfolgungsinformationen werden durch einen Logger im Arbeitsspeicher gehalten, und
zwar in Datenstrukturen, die die Ablaufverfolgungen bezeichnen und ein Paar aus virtueller
Adresse und Arbeitssatz (Ablaufverfolgung des Seitenzugriffs) bzw. aus Datei und Offset (Namensprotokollierung) angeben. Dadurch kann sich SuperFetch merken, für welchen virtuellen
Adressbereich eines gegebenen Prozesses bzw. für welchen Offsetbereich einer gegebenen
Datei es Seitenereignisse gibt.
Szenarien
Ein Aspekt von SuperFetch, der von seinen Hauptmechanismen für Seitenpriorisierung und
Prefetching abweicht (mehr darüber im nächsten Abschnitt), ist die Nutzung von Szenarien.
Vorausschauende Speicherverwaltung (SuperFetch)
Kapitel 5
545
Dabei handelt es sich um bestimmte Vorgänge auf dem Computer, die SuperFetch versucht,
möglichst angenehm für den Benutzer zu gestalten:
QQ Ruhezustand Hierbei muss sinnvoll entschieden werden, welche Seiten außer den vorhandenen Arbeitssatzseiten in der Ruhezustandsdatei gespeichert werden sollen. Damit
soll die Zeit, die das System braucht, um nach der Wiederaufnahme des Betriebs wieder
reagieren zu können, möglichst kurz gehalten werden.
QQ Standby Hierbei sollen harte Fehler nach der Wiederaufnahme völlig vermieden werden.
Da ein typisches System den Betrieb in weniger als zwei Sekunden wieder aufnehmen
kann, aber unter Umständen bis zu fünf Sekunden braucht, um die Festplatte nach einem
langen Schlaf wieder in Marsch zu setzen, kann schon ein einziger harter Seitenfehler eine
Verzögerung in dieser Größenordnung bewirken. Um das zu verhindern, priorisiert SuperFetch die nach einem Standby erforderlichen Seiten.
QQ Schneller Benutzerwechsel Hierbei müssen die Prioritäten und der Überblick über den
Arbeitsspeicher der einzelnen Benutzer genau festgehalten werden. Dadurch kann die Sitzung des neuen Benutzers nach einem Wechsel sofort verwendet werden, ohne dass erst
viel Zeit vergeht, um Seiten wieder einzulagern.
Jedes dieser Szenarien dient einem eigenen Zweck, aber allgemein geht es darum, das Auftreten harter Seitenfehler zu reduzieren oder ganz auszuschließen.
Die Szenarien sind hartcodiert. SuperFetch verwaltet sie durch die APIs NtSetSystemInformation und NtQuerySystemInformation, die den Systemstatus steuern. Für die Zwecke von
SuperFetch wird die besondere Informationsklasse SystemSuperFetchInformation verwendet,
um die Kernelmoduskomponenten zu steuern und Anforderungen zum Starten, Beenden und
Abfragen eines Szenarios oder zur Verknüpfung von Ablaufverfolgungen mit einem Szenario
zu stellen.
Jedes Szenario wird durch eine Plandatei definiert, die mindestens eine Liste der mit dem
Szenario verknüpften Seiten enthält. Es werden auch Seitenprioritätswerte nach bestimmten
Regeln zugewiesen (siehe den nächsten Abschnitt). Wenn ein Szenario beginnt, muss der Szenario-Manager auf dieses Ereignis reagieren, indem er eine Liste der Seiten aufstellt, die in den
Speicher gebracht werden sollen, und der Prioritäten, mit denen das geschehen soll.
Seitenpriorität und Rebalancing
Sie haben bereits gesehen, dass der Speicher-Manager ein System von Seitenprioritäten implementiert, um zu definieren, welche Seiten von der Standbyliste für eine gegebene Operation
umfunktioniert und in welche Listen die einzelnen Seiten jeweils aufgenommen werden. Dass
die Prozesse und Threads dadurch über Prioritäten verfügen, ist von Vorteil. Beispielsweise wird
dadurch garantiert, dass ein Defragmentierungsprozess die Standbyliste nicht verunreinigt und
keine Seiten von interaktiven Vordergrundprozessen stiehlt. Der wirkliche Nutzen dieses Mechanismus zeigt sich aber erst bei den Seitenpriorisierungsverfahren und dem Rebalancing von
SuperFetch, für das keine manuellen Anwendungseingaben und hartcodierten Angaben über
die Wichtigkeit der Prozesse erforderlich sind.
546
Kapitel 5
Speicherverwaltung
SuperFetch weist Seitenprioritäten auf der Grundlage eines internen Punktestands der einzelnen Seiten zu, der wiederum teilweise auf der Häufigkeit der Nutzung basiert. Dabei wird
gezählt, wie oft eine Seite in einem Zeitintervall verwendet wurde, z. B. in einer Stunde, einem
Tag oder einer Woche. Das System merkt sich auch den Zeitpunkt der Verwendung und zeichnet auf, wie lange der letzte Zugriff auf eine Seite zurückliegt. Auch Daten wie der Ursprung
der Seite (also die Liste, von der sie stammt) und andere Zugriffsmuster werden zur Berechnung
dieses Punktestands herangezogen.
Dieser Punktestand wird in eine Prioritätszahl von 1 bis 6 übersetzt. (Für einen anderen
Zweck wird eine Priorität von 7 verwendet; mehr darüber später.) Die Seiten auf der Standbyliste mit den niedrigeren Prioritäten werden zuerst wiederverwertet, wie Sie in dem Experiment »Nach Prioritäten geordnete Standbylisten einsehen« schon gesehen haben. Priorität
5 wird gewöhnlich für normale Anwendungen verwendet, Priorität 1 für Hintergrundanwendungen, die Drittentwickler entsprechend kennzeichnen können. Priorität 6 dient dazu, einige
sehr wichtige Seiten so spät wie möglich wiederzuverwerten. Die anderen Prioritäten kommen
durch die Punktestände der einzelnen Seiten zustande.
Da der SuperFetch-Mechanismus das System des Benutzers nach und nach kennenlernt,
kann er ohne jegliche Verlaufsdaten bei null beginnen und langsam ein Verständnis der Seitenzugriffe durch den Benutzer aufbauen. Das allerdings würde einen erheblichen Lernaufwand erfordern, wenn eine neue Anwendung, ein neuer Benutzer oder ein neues Servicepack
hinzukommt. Stattdessen hat Microsoft SuperFetch im Voraus trainiert. Dazu hat das SuperFetch-Team gängige Verwendungsweisen und Muster erfasst, die bei allen Benutzern auftreten, z. B. Klicken auf das Startmenü, Öffnen der Systemsteuerung oder die Verwendung der
Dialogfelder zum Öffnen und Speichern von Dateien, und diese Daten in Ablaufverfolgungen
umgewandelt. Diese vorgefertigten Ablaufverfolgungen wiederum wurden in Verlaufsdateien
gespeichert, die als Ressourcen in Sysmain.dll enthalten sind. Sie dienen dazu, die besondere
Liste für die Priorität 7 zu füllen. Seiten mit dieser Priorität sind Dateiseiten, die auch nach der
Beendigung eines Prozesses und sogar über einen Neustart hinweg im Speicher gehalten werden. (Letzteres bedeutet, dass die Seiten nach dem Neustart wieder in den Speicher geladen
werden.) Außerdem sind Seiten der Priorität 7 statisch. Das heißt, dass ihre Priorität nie geändert wird und dass SuperFetch niemals andere Seiten außer denen in dem vorkonfigurierten
Satz dynamisch mit Priorität 7 lädt.
Die nach Prioritäten geordnete Liste wird vom Rebalancer in den Speicher geladen (oder
vorab gefüllt), aber um das eigentliche Rebalancing kümmern sich SuperFetch und der Speicher-Manager. Wie Sie gesehen haben, erfolgt die Priorisierung der Standbyliste durch einen
internen Mechanismus des Speicher-Managers, wobei die Entscheidungen, welche Seiten als
Erste herausgenommen und welche geschützt werden sollen, aufgrund der Prioritätszahl erfolgen. Der Rebalancer verteilt den Speicher nicht neu, sondern ändert die Prioritäten, was
den Speicher-Manager veranlasst, die erforderlichen Aufgaben auszuführen. Außerdem ist der
Rebalancer dafür zuständig, die Seiten bei Bedarf von der Festplatte zu lesen, sodass sie im
Speicher vorhanden sind (Prefetching). Anschließend weist er ihnen die Priorität zu, die von den
Agenten für die Punktestände der einzelnen Seiten zugewiesen wurden. Der Speicher-Manager
sorgt dafür, dass die Seite ihrer Wichtigkeit entsprechend behandelt wird.
Der Rebalancer kann auch aktiv werden, ohne auf andere Agenten zurückzugreifen, etwa
wenn er feststellt, dass die Verteilung der Seiten über die Auslagerungsdateien nicht optimal
Vorausschauende Speicherverwaltung (SuperFetch)
Kapitel 5
547
ist oder dass die Anzahl der wiederverwerteten Seiten auf den verschiedenen Prioritätsebenen
nachteilig ist. Außerdem kann der Rebalancer die Verkleinerung von Arbeitssätzen auslösen, die
erforderlich sein kann, um ein ausreichendes Budget an Seiten für die von SuperFetch vorab
gefüllten Cachedaten zu erstellen. Gewöhnlich nimmt der Rebalancer Seiten geringer Nützlichkeit – z. B. solche, die bereits eine niedrige Priorität haben, die mit Nullen überschrieben sind
oder die zwar über gültige Inhalte verfügen, aber nicht zu einem Arbeitssatz gehören und nicht
verwendet wurden – und baut daraus einen nützlichen Satz von Seiten im Arbeitsspeicher auf,
wobei er auf das Budget zurückgreift, das er sich selbst zugewiesen hat. Nachdem der Rebalancer entschieden hat, welche Seiten er mit welcher Priorität in den Speicher laden muss und
welche er daraus entfernt, führt er die erforderlichen Lesevorgänge auf der Festplatte durch,
um die Seiten vorab zu laden. Dabei arbeitet er mit dem Priorisierungsverfahren des E/A-
Managers zusammen, damit seine Ein- und Ausgaben mit niedriger Priorität erfolgen und die
Arbeit des Benutzers nicht stören.
Für den Speicher, der für das Prefetching erforderlich ist, wird auf Standbyseiten zurückgegriffen. Wie bereits erwähnt, ist dies weiterhin verfügbarer Speicher, da er jederzeit von einem
anderen Allozierer als freier Speicher wiederverwertet werden kann. Sollte SuperFetch beim
Prefetching einmal die falschen Daten abrufen, so wird der Benutzer dadurch nicht beeinträchtigt, da der Speicher bei Bedarf wiederverwendet werden kann und keine Ressourcen
verschlingt.
Der Rebalancer wird außerdem in regelmäßigen Abständen ausgeführt, um zu prüfen, ob
Seiten mit hoher Priorität tatsächlich kürzlich verwendet wurden. Da solche Seiten selten (wenn
überhaupt) wiederverwertet werden, ist es wichtig, sie nicht für Daten zu verschwenden, bei
denen nur in einem bestimmten Zeitraum eine häufige Verwendung beobachtet wurde, obwohl in Wirklichkeit nur selten auf sie zugegriffen wird. Wird eine solche Situation erkannt, so
wird der Rebalancer erneut ausgeführt, um die betreffenden Seiten auf der Prioritätsliste nach
unten zu setzen.
An verschiedenen Prefetchingmechanismen ist der Anwendungsstart-Agent beteiligt. Er
versucht, den Start von Anwendungen vorauszusehen, und stellt ein Markow-Kettenmodell auf,
um aufgrund von gegebenen Anwendungsstarts in einem Zeitabschnitt die Wahrscheinlichkeit
für den Start bestimmter Anwendungen zu bestimmen. Als Zeitabschnitte werden dabei vier
Zeiträume von durchschnittlich sechs Stunden pro Tag verwendet – morgens, mittags, abends
und nachts –, wobei zusätzlich nach Wochenenden und regulären Arbeitstagen unterschieden
wird. Wenn ein Benutzer beispielsweise am Samstag- und Sonntagabend erst Word und danach Outlook startet, wird der Anwendungsstart-Agent an Wochenendabenden nach einem
Start von Word schon einmal Outlook vorab abrufen.
Angesichts der ausreichend großen Mengen von Arbeitsspeicher, die moderne Computer
aufweisen – durchschnittlich mehr als 2 GB –, fällt der Betrag, der benötigt wird, um häufig verwendete Prozesse aus Leistungsgründen im Speicher zu halten, kaum ins Gewicht. Häufig kann
SuperFetch sämtliche erforderlichen Seiten im RAM unterbringen (wobei SuperFetch allerdings
auch auf Systemen mit wenig Speicher funktioniert). Ist das nicht möglich, können Technologien wie ReadyBoost und ReadyDrive dabei helfen, die Nutzung der Festplatte zu verringern.
548
Kapitel 5
Speicherverwaltung
Leistungsstabilisierung
SuperFetch verfügt außerdem über eine Leistungsstabilisierung. Diese Komponente wird vom
Benutzermodusdienst SuperFetch verwaltet, ist aber letzten Endes im Kernel implementiert,
nämlich in den Pf-Routinen. Sie sucht nach Dateizugriffsvorgängen, die die Systemleistung
beeinträchtigen, indem sie Standbylisten mit nicht benötigten Daten füllt. Wenn beispielsweise
ein Prozess eine große Datei im Dateisystem kopiert, würde die Standbyliste mit dem Inhalt dieser Datei gefüllt, auch wenn nie wieder oder zumindest lange Zeit kein Zugriff mehr auf diese
Datei erfolgt. Dadurch würden andere Dateien mit der gleichen Priorität aus dem Arbeitsspeicher entfernt, und wenn die Datei zu einem interaktiven und nützlichen Programm gehört, ist
es sehr wahrscheinlich, dass diese Priorität mindestens 5 beträgt.
SuperFetch reagiert auf zwei bestimmte Arten von E/A-Zugriffsmustern:
QQ Sequenzieller Dateizugriff
Hierbei durchläuft das System alle Daten in einer Datei.
QQ Sequenzieller Verzeichniszugriff Hierbei durchläuft das System alle Dateien in einem
Verzeichnis.
Wenn die Menge an Daten, die aufgrund eines Zugriffs einer dieser Arten in die Standbyliste
aufgenommen wurden, einen internen Schwellenwert überschreitet, wendet SuperFetch eine
aggressive Prioritätssenkung auf die zur Zuordnung der Datei verwendeten Seiten an. Dies geschieht nur im Zielprozess, damit andere Anwendungen nicht bestraft werden. Die betroffenen
Seiten erhalten die neue Priorität 2.
Da diese Komponente von SuperFetch reaktiv und nicht vorausschauend arbeitet, dauert
es einige Zeit, bis sie Wirkung zeigt. SuperFetch behält diesen Prozess daher im Auge. Wenn
der Prozess immer diese Art von sequenziellem Zugriff durchführt, so kann sich SuperFetch
daran erinnern und senkt die Prioritäten der Dateiseiten schon, sobald sie zugeordnet werden,
anstatt erst nachträglich zu reagieren. Der gesamte Prozess unterliegt jetzt bereits einer Leistungsstabilisierung für zukünftige Dateizugriffe.
Dadurch aber könnte SuperFetch legitime Anwendungen beeinträchtigen, die sequenzielle Zugriffe durchführen. Beispielsweise können Sie mit dem Sysinternals-Tool Strings.exe
nach Strings in allen ausführbaren Dateien in einem Verzeichnis suchen. Wenn es viele solcher Dateien gibt, wird SuperFetch wahrscheinlich eine Leistungsstabilisierung durchführen.
Wenn Sie Strings.exe das nächste Mal mit einem anderen Suchparameter ausführen, würde das
Programm dann langsamer ausgeführt werden als beim ersten Mal. Um das zu verhindern,
unterhält SuperFetch neben der Liste der Prozesse, die beobachtet werden müssen, auch eine
interne, hartcodierte Liste von Ausnahmen. Greift ein Prozess später erneut auf leistungsstabilisierte Dateien zu, wird die Leistungsstabilisierung für ihn ausgeschaltet, um das erwartete
Verhalten wiederherzustellen.
Ein wichtiger Punkt der Leistungsstabilisierung – und von SuperFetch-Optimierungen im
Allgemeinen – ist die Tatsache, dass SuperFetch die Nutzungsmuster ständig beobachtet und
sein Verständnis des Systems ständig aktualisiert, um einen Abruf unnützer Daten zu vermeiden. Zwar können Änderungen in der Tagesroutine des Benutzers oder im Startverhalten von
Anwendungen dazu führen, dass SuperFetch den Cache mit irrelevanten Daten füllt oder vermeintlich nutzlose Daten entfernt, aber der Mechanismus kann sich rasch an solche geänderten Muster anpassen. Wenn die Aktionen des Benutzers erratisch sind, verhält sich das System
Vorausschauende Speicherverwaltung (SuperFetch)
Kapitel 5
549
schlimmstenfalls so, als wäre SuperFetch gar nicht vorhanden. Im Zweifelfall oder wenn keine
zuverlässigen Daten erfasst werden können, hält SuperFetch sich zurück und nimmt keine Änderungen an dem betreffenden Prozess oder der Seite vor.
ReadyBoost
Im Vergleich zu der Situation vor einem Jahrzehnt ist RAM heutzutage gut verfügbar und
relativ günstig, aber noch nicht billig genug, um die Kosten von Sekundarspeicher wie Festplatten zu schlagen. Leider enthalten mechanische Festplatten viele bewegliche Teile, sind störanfällig und im Vergleich zum RAM langsam, insbesondere bei Suchvorgängen. Daher ist die
Speicherung aktiver SuperFetch-Daten auf der Festplatte praktisch genauso schlecht wie die
Auslagerung einer Seite, die dann erst wieder über einen harten Seitenfehler in den Speicher
zurückgeholt werden muss.
Bei SSD- und Hybridfestplatten sind diese Nachteile weniger stark ausgeprägt, allerdings
sind die Geräte immer noch teurer und langsamer als RAM. SSD-Wechselmedien wie USBSticks, CompactFlash- und Secure-Digital-Karten stellen einen brauchbaren Kompromiss dar.
Sie sind billiger als RAM und mit größerem Speichervolumen erhältlich und weisen gleichzeitig
aufgrund ihres Mangels an beweglichen Teilen kürzere Suchzeiten auf als mechanische Festplatten.
In der Praxis werden CompactFlash- und Secure-Digital-Karten fast immer über einen USB-Adapter angeschlossen, sodass sie im System als USB-Medien erscheinen.
Wahlfreie Festplatten-E/A ist besonders langsam, da sich die Suchzeit und die Rotationslatenz
eines typischen Desktop-Festplattenlaufwerks auf insgesamt etwa 10 ms belaufen kann, was für
die heutigen Prozessoren mit 3 oder gar 4 GHz eine Ewigkeit darstellt. Flash-Speicher dagegen
kann wahlfreie Lesevorgänge bis zu zehnmal schneller erledigen als eine typische Festplatte.
Daher bietet Windows die ReadyBoot-Funktion, um die Vorteile von Flash-Speichergeräten für
den Arbeitsspeicher nutzen zu können. Dabei wird eine Cachingschicht aufgebaut, die sich
logisch zwischen dem Arbeitsspeicher und dem Flash-Medium befindet.
ReadyBoost (nicht zu verwechseln mit ReadyBoot!) wird mithilfe eines Treibers implementiert (%SystemRoot&\System32\Drivers\Rdyboost.sys), der die zwischengespeicherten Daten in
das NVRAM-Gerät (Non-Volatile RAM, »nicht flüchtiger RAM«) schreibt. Wenn Sie einen USBStick an ein System anschließen, schaut sich ReadyBoost die Leistungseigenschaften des Geräts
an und speichert den Befund in HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Emdmgmt.
Emd steht hier für »External Memory Drive«, was die Bezeichnung für ReadyBoost während der
Entwicklung war.
Wenn das neue Gerät zwischen 256 MB und 32 GB groß ist und über eine Übertragungsrate von mindestens 2,5 MB pro Sekunde für 4-KB-Lesevorgänge und von mindestens 1,75 MB
für wahlfreie 512-KB-Schreibvorgänge verfügt, fragt ReadyBoost, ob Sie einen Teil des Platzes
für die Zwischenspeicherung auf der Festplatte zur Verfügung stellen möchten. Wenn Sie zustimmen, erstellt ReadyBoost im Stamm des Geräts die Datei ReadyBoost.sfcache und verwendet diese, um zwischengespeicherte Seiten abzulegen.
550
Kapitel 5
Speicherverwaltung
Nach der Initialisierung der Zwischenspeicherung fängt ReadyBoost alle Lese- und Schreibvorgänge auf lokale Festplattenvolumes (z. B. C:\) ab und kopiert alle gelesenen oder geschriebenen Daten in die von dem Dienst erstellte Cachingdatei. Ausgenommen davon sind u. a.
Daten, die lange nicht gelesen wurden oder die zu Volume-Snapshot-Anforderungen gehören.
Die auf dem Cachelaufwerk gespeicherten Daten werden komprimiert, wobei gewöhnlich ein
Verhältnis von 2:1 erreicht wird, sodass eine 4-GB-Cachedatei 8 GB an Daten fassen kann. Jeder
Block wird beim Schreiben mit AES verschlüsselt, wobei ein für jeden Systemstart neu erstellter,
zufälliger Sitzungsschlüssel verwendet wird, um die Daten in dem Cache für den Fall zu schützen, dass das Gerät von dem Computer entfernt wird.
Wenn wahlfreie Lesevorgänge im Cache erledigt werden können, nutzt ReadyBoost dafür
tatsächlich die Cachedatei. Da der sequenzielle Lesezugriff auf Festplatten jedoch günstiger
ist als im Flash-Speicher, werden Lesevorgänge, die zu einem sequenziellen Zugriff gehören,
weiterhin direkt auf der Festplatte erledigt, auch wenn sich die entsprechenden Daten im Cache
befinden. Das Gleiche gilt auch für Lesevorgänge im Rahmen umfangreicher Ein-/Ausgaben.
Ein Nachteil der Verwendung von Flashmedien besteht darin, dass der Benutzer sie jederzeit vom Computer entfernen kann, weshalb das System kritische Daten nicht ausschließlich
dort speichern darf. (Wie Sie gesehen haben, werden Schreibvorgänge immer erst im Sekundärspeicher durchgeführt.) Die verwandte ReadyDrive-Technologie, die wir im nächsten Abschnitt erläutern, bietet zusätzliche Vorteile und löst dieses Problem.
ReadyDrive
ReadyDrive ist eine Windows-Technologie, die die Vorteile von Hybridfestplatten (Hybrid Hard
Disk Drives, H-HDD) nutzt. Dabei handelt es sich um eine Festplatte mit eingebettetem NVRAM. Gewöhnlich enthalten H-HDDs einen Cache zwischen 50 und 512 MB.
Bei der Verwendung von ReadyDrive dient der Flashspeicher des Laufwerks nicht einfach als
automatischer, transparenter Cache wie bei den meisten Festplatten. Stattdessen legt Windows
mithilfe von ATA-8-Befehlen fest, welche Daten auf der Festplatte im Flashspeicher festgehalten
werden sollen. Beispielsweise speichert Windows Bootdaten im Cache, wenn das System heruntergefahren wird, was einen schnelleren Neustart ermöglicht. Ebenso werden einige Daten der
Ruhezustandsdatei im Cache abgelegt, sodass das Aufwachen aus dem Ruhezustand schneller
erfolgt. Da der Cache auch bei abgeschalteter Festplatte aktiviert ist, kann Windows den Flashspeicher als Schreibcache verwenden und damit ein Einschalten der Festplatte bei niedrigem
Akkustand vermeiden. Dadurch lässt sich bei normalem Gebrauch sehr viel Strom sparen.
ReadyDrive wird auch von SuperFetch genutzt, da es die gleichen Vorteile wie ReadyBoost,
zusätzlich aber weitere Möglichkeiten, bietet. Beispielsweise ist kein externes Flashlaufwerk erforderlich. Außerdem kann SuperFetch den Cache dauerhaft nutzen, denn da er sich auf der
physischen Festplatte befindet, wird er gewöhnlich nicht im laufenden Betrieb entfernt. Der
Festplattencontroller muss sich daher keine Sorgen machen, dass die Daten verschwinden, und
kann Schreibvorgänge auf der eigentlichen Festplatte vermeiden, indem er ausschließlich den
Cache benutzt.
Vorausschauende Speicherverwaltung (SuperFetch)
Kapitel 5
551
Prozessreflexion
Es kann vorkommen, dass sich ein Prozess problematisch verhält, aber immer noch einen Zweck
erfüllt, weshalb es nicht angebracht ist, ihn anzuhalten, um einen kompletten Speicherauszug
zu erstellen oder ihn interaktiv zu debuggen. Der Zeitraum, in dem der Prozess angehalten
wird, um einen Speicherauszug zu erstellen, lässt sich zwar verkleinern, indem man nur einen
Miniauszug aufnimmt – bei dem nur die Threadregister und Stacks sowie die Seiten erfasst
werden, auf die die Register verweisen –, doch ein solcher Auszug bietet nur sehr eingeschränkte Informationen. Zur Diagnose von Abstürzen mögen sie oft ausreichen, aber nicht für die
Störungssuche im Allgemeinen. Bei der Prozessreflexion wird der Zielprozess nur so lange angehalten, um einen Miniauszug sowie einen angehaltenen Klon von ihm zu erstellen. Während
der Zielprozess danach weiter ausgeführt wird, kann aus dem Klon ein umfassender Auszug
erstellt werden, der den gesamten gültigen Benutzermodusspeicher des Prozesses umfasst.
Mehrere WDI-Komponenten (Windows Diagnostic Infrastructure) nutzen die Prozessreflexion, um auf diese minimalinvasive Weise Speicherauszüge der Prozesse zu erstellen, die
von ihren Heuristiken als verdächtig eingestuft werden. Beispielsweise legt der Memory Leak
Diagnoser von Windows Resource Exhaustion Detection and Resolution (RADAR genannt) auf
diese Weise einen Speicherauszug von Prozessen an, bei denen Lecks im privaten virtuellen
Arbeitsspeicher vermutet werden. Dieser Speicherauszug kann dann über die Windows-Fehlerberichterstattung zur Analyse an Microsoft gesendet werden. Die WDI-Heuristiken für hängende Prozesse gehen bei Prozessen, zwischen denen Deadlocks zu bestehen scheinen, auf die
gleiche Weise vor. Da diese Komponenten Heuristiken verwenden, können sie nicht sicher sein,
dass mit den Prozessen tatsächlich etwas nicht stimmt, weshalb sie sie nicht einfach für längere
Zeit anhalten oder gar beenden dürfen.
Die Funktion RtlCreateProcessReflection in Ntdll.dll sorgt für die Prozessreflexion:
1.
Sie erstellt einen gemeinsam genutzten Speicherabschnitt.
2.
Sie füllt diesen gemeinsam genutzten Speicherabschnitt mit Parametern.
3.
Sie ordnet den gemeinsam genutzten Speicherabschnitt dem aktuellen und dem Zielprozess zu.
4.
Sie erstellt zwei Ereignisobjekte und kopiert sie in den Zielprozess, sodass der aktuelle und
der Zielprozess ihre Operationen synchronisieren können.
5.
Mit einem Aufruf von RtlpCreateUserThreadEx injiziert sie einen Thread in den Zielprozess.
Mit der Ntdll-Funktion RtlpProcessReflectionStartup wird dieser Thread angewiesen, mit
der Ausführung zu beginnen. Da Ntdll.dll in den Adressräumen aller Prozessen an der gleichen zufällig beim Start zugeordneten Adresse zugeordnet ist, kann der aktuelle Prozess
einfach die Adresse der Funktion aus seiner eigenen Ntdll.dll-Zuordnung übergeben.
6.
Wenn der Aufrufer von RtlCreateProcessReflection ein Handle für den geklonten Prozess
verlangt hat, wartet die Funktion darauf, dass der Remotethread beendet wird. Anderenfalls gibt sie die Steuerung an den Aufrufer zurück.
7.
Der injizierte Thread im Zielprozess weist ein weiteres Ereignisobjekt für die Synchronisierung mit dem geklonten Prozess zu.
552
Kapitel 5
Speicherverwaltung
8.
Der injizierte Thread ruft RtlCloneUserProcess auf und übergibt die Parameter aus der
Speicherzuordnung, die er sich mit dem auslösenden Prozess teilt.
9.
Es gibt eine Option für RtlCreateProcessReflection, um zu verlangen, dass der Prozess nur
dann geklont wird, wenn er nicht im Lader ausgeführt wird, Heapoperationen durchführt,
den Prozessumgebungsblock (PEB) oder lokalen Fiberspeicher bearbeitet. Wenn diese Option vorhanden ist, erwirbt RtlCreateProcessReflection zunächst die entsprechenden Sperren. Das kann für das Debugging nützlich sein, da sich die Kopie der Datenstrukturen im
Speicherauszug dann in einem konsistenten Zustand befindet.
10. Abschließend ruft RtlCloneUserProcess die Benutzermodusfunktion RtlCreateUserProcess
auf, die für die Prozesserstellung im Allgemeinen zuständig ist, und übergibt dabei Flags,
um festzulegen, dass der neue Prozess ein Klon des aktuellen sein soll. RtlpCreateUserProcess wiederum ruft ZwCreateUserProcess auf, um den Kernel zu bitten, den Prozess zu
erstellen.
Beim Klonen eines Prozesses führt ZwCreateUserProcess zum Großteil denselben Code aus wie
beim Erstellen eines neuen Prozesses. Die Ausnahme besteht in der Funktion PspAllocateProcess,
die sie aufruft, um das Prozessobjekt und den ursprünglichen Thread anzulegen: Diese Funktion
ruft ihrerseits MmInitializeProcessAddressSpace mit einem Flag auf, durch das als Adresse eine
Copy-on-Write-Kopie des Zielprozesses verwendet wird und nicht ein neuer Prozessadressraum.
Der Speicher-Manager nutzt dieselbe Unterstützung, die er für die API fork für Services for Unix
Application bereitstellt, um den Adressraum effizient zu klonen. Sobald der Zielprozess die Ausführung wieder aufnimmt, werden alle Änderungen, die er an seinem Adressraum vornimmt, nur
noch von ihm selbst gesehen, nicht aber von dem Klon. Der Adressraum des Klons stellt daher
eine Momentaufnahme des Zielprozesses dar.
Die Ausführung des Klons beginnt, sobald RtlCreateUserProcess die Steuerung zurückgegeben hat. Wurde der Klon erfolgreich erstellt, empfängt sein Thread den Rückgabecode
STATUS_PROCESS_CLONED und der klonende Thread STATUS_SUCCESS. Der geklonte Prozess synchronisiert sich nun mit dem Zielprozess und ruft schließlich eine Funktion auf, die optional
an RtlCreateProcessReflection übergeben werden kann. Dabei muss es sich um eine in Ntdll.
dll implementierte Funktion handeln. Beispielsweise gibt RADAR hier RtlDetectHeapLeaks an,
die eine grundlegende heuristische Analyse der Prozessheaps durchführt und das Ergebnis
an den Thread meldet, der RtlCreateProcessReflection aufgerufen hat. Wurde keine Funktion
angegeben, hält sich der Thread je nach den an RtlCreateProcessReflection übergebenen Flags
entweder selbst an oder beendet sich.
Um die Prozessreflexion zu nutzen, rufen RADAR und WDI die Funktion RtlCreateProcessReflection auf und weisen sie an, ein Handle für den geklonten Prozess zurückzugeben und dafür zu sorgen, dass sich der Klon nach seiner Initialisierung selbst anhält. Anschließend legen Sie
einen Miniauszug des Zielprozesses an, wobei dieser für die Dauer dieses Vorgangs angehalten
wird. Danach erstellen sie aus dem geklonten Prozess einen umfassenderen Speicherauszug
und beenden den Klon schließlich. Zwischen dem Abschluss des Miniauszugs und dem Erstellen des Klons kann der Zielprozess weiterlaufen, doch in den meisten Fällen beeinträchtigen
Inkonsistenzen die Störungssuche nicht. Wenn Sie das Sysinternals-Programm Procdump mit
dem Schalter -r aufrufen, geht es auf die gleiche Weise vor, um mithilfe der Selbstreflexion
einen Speicherauszug des Zielprozesses anzulegen.
Vorausschauende Speicherverwaltung (SuperFetch)
Kapitel 5
553
Zusammenfassung
In diesem Kapitel haben Sie sich angesehen, wie der Speicher-Manager von Windows den
virtuellen Speicher verwaltet. Wie in den meisten modernen Betriebssystemen hat jeder Prozess Zugriff auf einen privaten Adressraum, wodurch der Speicher eines Prozesses geschützt
wird, andererseits aber eine gemeinsame Nutzung des Speichers durch Prozesse auf effi
ziente und sichere Weise möglich ist. Darüber hinaus gibt es noch zusätzliche Möglichkeiten
wie die Verwendung zugeordneter Dateien und von dünn zugewiesenem Arbeitsspeicher. Das
Windows-Umgebungsteilsystem stellt die meisten Fähigkeiten des Speicher-Managers über die
Windows-API für Anwendungen bereit.
Im nächsten Kapitel beschäftigen wir uns mit einem weiteren entscheidenden Bestandteil
eines jedes Betriebssystems – dem E/A-System.
554
Kapitel 5
Speicherverwaltung
K apite l 6
Das E/A-System
Das E/A-System von Windows besteht aus mehreren Exekutivkomponenten, die zusammen die
Hardwaregeräte verwalten und den Anwendungen und dem System eine Schnittstelle dazu zur
Verfügung stellen. In diesem Kapitel betrachten wir als Erstes die Designziele für das E/A-System, die die Implementierung beeinflusst haben, und dann die Komponenten, aus denen dieses
System besteht – den E/A-Manager, den PnP-Manager (Plug & Play) und die Energieverwaltung.
Anschließend untersuchen wir die wichtigsten Datenstrukturen zur Beschreibung von Geräten,
Gerätetreibern und E/A-Anforderungen und die erforderlichen Schritte, um E/A-Anforderungen
zu erfüllen und abzuschließen. Abschließend schauen wir uns die Funktionsweise der Geräteerkennung, der Treiberinstallation und der Energieverwaltung an.
Komponenten des E/A-Systems
Beim Design des Windows-E/A-Systems bestand das Ziel darin, Anwendungen eine Abstraktion
sowohl von Hardware- als auch von Softwaregeräten (physischen und logischen Geräten) mit
den folgenden Eigenschaften zur Verfügung zu stellen:
QQ Einheitliche Sicherheitsvorkehrungen und Benennung für alle Geräte, um gemeinsam
nutzbare Ressourcen zu schützen. (Eine Beschreibung des Windows-Sicherheitsmodells
finden Sie in Kapitel 7.)
QQ Asynchrone, paketgestützte Hochleistungs-E/A, um die Implementierung skalierbarer Anwendungen zu ermöglichen.
QQ Dienste, die es erlauben, Treiber in einer Hochsprache zu schreiben und von einer Maschinenarchitektur zur anderen zu übertragen.
QQ Geschichteter Aufbau und Erweiterbarkeit, um Treiber hinzufügen zu können, die das Verhalten der anderen Treiber oder der Geräte transparent verändern, ohne jegliche Änderungen an diesen anderen Treibern oder Geräten vornehmen zu müssen.
QQ Dynamisches Laden und Entladen von Gerätetreibern, sodass sie bei Bedarf geladen werden können und keine Systemressourcen verbrauchen, wenn sie nicht benötigt werden.
QQ Plug-&-Play-Unterstützung; das heißt, das System kann Treiber für neu erkannte Hardware
finden und installieren, die erforderlichen Hardwareressourcen zuweisen und es Anwendungen ermöglichen, Geräteschnittstellen zu entdecken und zu aktivieren.
QQ Unterstützung für die Energieverwaltung, sodass das gesamte System oder einzelne Geräte
in Energiesparzustände eintreten können.
QQ Unterstützung für mehrere installierbare Dateisysteme einschließlich FAT (und die Varianten FAT32 und exFAT), das CD-ROM-Dateisystem (CDFS), Universal Disk Format (UDF), Re-
555
silient File System (ReFS) und das Windows-Dateisystem (NTFS). Genauere Informationen
über die einzelnen Arten von Dateisystemen und ihre Architektur erhalten Sie in Kapitel 13
von Band 2.
QQ WMI-Unterstützung (Windows Management Instrumentation) und Diagnosefähigkeiten,
sodass Treiber mithilfe von WMI-Anwendungen und -Skripten verwaltet und überwacht
werden können (siehe Kapitel 9 in Band 2).
Um all diese Merkmale bieten zu können, besteht das Windows-E/A-System aus mehreren
Exekutivkomponenten und Gerätetreibern (siehe Abb. 6–1).
Anwendungen/Dienste
WMI-Dienst
PnP-Manager des
Benutzermodus
SetupKomponenten
Benutzermodus
Kernelmodus
WMI-Routinen
PnP-Manager
Treiber
Treiber
Energie
verwaltung
Treiber
E/A-Manager
INF-Dateien,
CAT-Dateien,
Registrierung
E/A-System
Treiber
HAL
Abbildung 6–1 Bestandteile des E/A-Systems
QQ Der E/A-Manager bildet das Herz des E/A-Systems. Er verbindet Anwendungen und Systemkomponenten mit virtuellen, logischen und physischen Geräten und definiert die In
frastruktur zur Unterstützung der Gerätetreiber.
QQ Ein Gerätetreiber stellt gewöhnlich eine E/A-Schnittstelle für eine bestimmte Art von Gerät
zur Verfügung. Ganz allgemein ist ein Treiber ein Softwaremodul, das Befehle hoher Ebene
wie Lese- oder Schreibbefehle interpretiert und maschinennahe, gerätespezifische Befehle
ausgibt, z. B. das Schreiben in ein Steuerregister. Gerätetreiber empfangen die Befehle für
die von ihnen verwalteten Geräte über den E/A-Manager und informieren ihn wiederum darüber, dass sie die Verarbeitung dieser Befehle abgeschlossen haben. Häufig nutzen
Gerätetreiber den E/A-Manager auch, um E/A-Befehle an andere Gerätetreiber weiterzuleiten, mit denen sie sich die Schnittstelle oder Steuerimplementierung des Geräts teilen.
QQ Der PnP-Manager arbeitet eng mit dem E/A-Manager und den Bustreibern zusammen,
um die Zuweisung von Hardwareressourcen zu lenken und um das Hinzufügen und Entfernen von Hardwaregeräten zu erkennen und darauf zu reagieren. Gemeinsam sind der
556
Kapitel 6
Das E/A-System
PnP-Manager und der Bustreiber dafür zuständig, bei der Entdeckung eines Geräts dessen
Treiber zu laden. Wird dem System ein Gerät hinzugefügt, für das kein geeigneter Treiber
vorhanden ist, ruft die PnP-Komponente der Exekutive die Geräteinstallationsdienste des
PnP-Managers im Benutzermodus auf.
QQ Auch die Energieverwaltung arbeitet eng mit dem E/A- und dem PnP-Manager zusammen, um das System und die einzelnen Gerätetreiber durch Statusübergänge beim Energieverbrauch zu lotsen.
QQ Gerätetreiber können indirekt als Anbieter fungieren, indem sie die WMI-Unterstützungsroutinen des WDM-WMI-Anbieters (Windows Driver Model) als Vermittler für die Kommunikation mit dem WMI-Dienst im Benutzermodus verwenden.
QQ Die Registrierung dient als Datenbank, in der eine Beschreibung der grundlegenden an
das System angeschlossenen Hardwaregeräte sowie die Initialisierungs- und Konfigura
tionseinstellungen der Treiber gespeichert werden (siehe den Abschnitt »Die Registrierung« in Kapitel 9 von Band 2).
QQ Bei den INF-Dateien handelt es sich um Treiberinstallationsdateien. Sie bilden die Verbindung zwischen einem Hardwaregerät und dem Treiber, der hauptsächlich für seine
Steuerung zuständig ist. Diese Dateien bestehen aus skriptartigen Anweisungen, die das
zugehörige Gerät beschreiben und die Quell- und Zielspeicherorte der Treiberdateien,
die zur Treiberinstallation erforderlichen Registrierungsänderungen sowie treiberspezifische Informationen angeben. Die digitalen Signaturen, mit denen Windows bestätigt, dass
eine Treiberdatei die WHQL-Tests (Windows Hardware Quality Labs) bestanden hat, sind in
CAT-Dateien gespeichert. Digitale Signaturen dienen auch als Schutz gegen eine Manipulation des Treibers oder seiner INF-Datei.
QQ Die Hardwareabstraktionsschicht (HAL) schirmt die Treiber gegen die technischen Einzelheiten des Prozessors und des Interruptcontrollers ab, indem sie APIs bereitstellt, die die
Unterschiede zwischen verschiedenen Plattformen zudecken. Im Grunde genommen ist
die HAL der Bustreiber für alle auf der Hauptplatine des Computers festgelöteten Geräte,
die nicht von anderen Treibern gesteuert werden.
Der E/A-Manager
Der E/A-Manager ist das Herz des E/A-Systems. Er definiert das Framework oder Modell zur
Auslieferung von E/A-Anforderungen an Gerätetreiber. Das E/A-System ist paketgestützt. Die
meisten E/A-Anforderungen werden durch ein E/A-Anforderungspaket (I/O Request Packet,
IRP) dargestellt. Diese Datenstruktur beschreibt die Anforderung vollständig und bewegt sich
zwischen den Komponenten des E/A-Systems. (Wie Sie im Abschnitt »Schnelle E/A« noch sehen werden, bildet die schnelle E/A eine Ausnahme, denn hierbei werden keine IRPs verwendet.) Dadurch kann ein einzelner Anwendungsthread mehrere E/A-Anforderungen gleichzeitig
handhaben. Weitere Informationen über IRPs erhalten Sie weiter hinten im Abschnitt »E/A-
Anforderungspakete«.
Der E/A-Manager erstellt im Arbeitsspeicher ein IRP, um eine E/A-Operation darzustellen,
und übergibt diesem Paket einen Zeiger auf den passenden Treiber. Wenn ein Treiber ein IRP
empfängt, führt er die darin angegebene Operation aus und gibt das Paket dann wieder an
Komponenten des E/A-Systems
Kapitel 6
557
den E/A-Manager zurück, da entweder die Operation abgeschlossen ist oder eine Weitergabe
an einen anderen Treiber für eine zusätzliche Verarbeitung erforderlich ist. Wenn die Operation
komplett abgeschlossen ist, verwirft der E/A-Manager das Paket.
Daneben stellt der E/A-Manager auch gemeinsamen Code bereit, den die verschiedenen
Treiber für ihre E/A-Verarbeitung aufrufen können. Durch die Konsolidierung dieser allgemeinen Aufgaben in den E/A-Manager lassen sich die einzelnen Treiber einfacher und kompakter
gestalten. Beispielsweise enthält der E/A-Manager eine Funktion, mit der Treiber andere Treiber
aufrufen können. Er verwaltet auch Puffer für E/A-Anforderungen, bietet eine Timeoutunterstützung für Treiber und zeichnet auf, welche installierten Dateisysteme im Betriebssystem geladen sind. Im E/A-Manager gibt es etwa 100 verschiedene Routinen, die von Gerätetreibern
aufgerufen werden können.
Des Weiteren stellt der E/A-Manager flexible E/A-Dienste bereit, mit denen Umgebungsteilsysteme wie die für Windows und POSIX (wobei Letzteres nicht mehr unterstützt wird)
ihre jeweiligen E/A-Funktionen implementieren können. Diese Dienste bieten unter anderem
Unterstützung für asynchrone E/A, womit Entwickler skalierbare Hochleistungs-Serveranwendungen erstellen können.
Die einheitliche, modulare Schnittstelle der Treiber ermöglicht dem E/A-Manager, jeden
Treiber ohne genaue Kenntnisse seines Aufbaus und seiner Interna aufzurufen. Das Betriebssystem behandelt alle E/A-Anforderungen so, als wären sie an eine Datei gerichtet. Der Treiber
wandelt diese Anforderungen an eine virtuelle Datei in hardwarespezifische Anforderungen
um. Über den E/A-Manager können sich Treiber auch gegenseitig aufrufen, um die E/A-Anforderung in unabhängigen Schichten auszuführen.
Neben den regulären Funktionen zum Öffnen, Schließen, Lesen und Schreiben bietet das
Windows-E/A-System auch noch fortgeschrittene Möglichkeiten, z. B. für asynchrone, direkte,
gepufferte und Scatter-Gather-E/A, die wir alle weiter hinten im Abschnitt »Verschiedene Arten
der E/A« genauer beschreiben werden.
Typische E/A-Verarbeitung
Meistens sind an E/A-Operationen nicht alle Komponenten des E/A-Systems beteiligt. Eine
typische E/A-Anforderung beginnt damit, dass eine Anwendung eine E/A-Funktion ausführt,
z. B. das Lesen von Daten von einem Gerät, die dann vom E/A-Manager, einem oder mehreren
Gerätetreibern und der HAL verarbeitet wird.
In Windows führen Threads Ein- und Ausgaben an virtuellen Dateien durch. Das sind jegliche Quellen oder Ziele für die E/A, die wie eine Datei behandelt werden (z. B. Geräte, Dateien, Verzeichnisse, Pipes und Mailslots). Ein typischer Benutzermodusclient ruft die Funktion
CreateFile oder CreateFile2 auf, um ein Handle zu einer virtuellen Datei zu erhalten. Diese
Funktionsnamen sind jedoch irreführend, denn es geht hier nicht nur um Dateien, sondern um
alles, was im Objekt-Manager-Verzeichnis GLOBAL?? als symbolische Verknüpfung bezeichnet
wird. Die Bezeichnung File in diesen Funktionsnamen bedeutet nur ein virtuelles Dateiobjekt
(FILE_OBJECT), das von der Exekutive als Ergebnis dieser Funktionen erstellt wird. Abb. 6–2 zeigt
das Verzeichnis GLOBAL?? in der Anzeige des Sysinternals-Tools WinObj.
Wie Sie dort erkennen können, ist ein Name wie C: lediglich eine symbolische Verknüpfung
zu einem internen Namen im Objekt-Manager-Verzeichnis Device (in diesem Fall \Device\Hard-
558
Kapitel 6
Das E/A-System
diskVolume7). (Mehr über den Objekt-Manager und seinen Namespace erfahren Sie in Kapitel 8
von Band 2.) Alle Namen im Verzeichnis GLOBAL?? sind mögliche Argumente für CreateFile(2).
Kernelmodusclients, z. B. Gerätetreiber, können die ähnliche Funktion ZwCreateFile nutzen, um
ein Handle zu einer virtuellen Datei zu bekommen.
Abbildung 6–2 Das Verzeichnis GLOBAL?? des Objekt-Managers
Abstraktionen höherer Ebene wie das .NET-Framework und die Windows-Runtime
bringen ihre eigenen APIs für die Arbeit mit Dateien und Geräten mit (z. B. die
Klassen System.IO.File in .NET und Windows.Storage.StorageFile in WinRT). Um
das eigentliche Handle zu erhalten, rufen diese APIs allerdings letztendlich CreateFile(2) auf.
Für das Verzeichnis GLOBAL?? des Objekt-Managers finden Sie manchmal auch
noch die ältere Bezeichnung DosDevices. Dieser Name funktioniert immer noch, da
er als symbolische Verknüpfung zu GLOBAL?? im Stamm des Objekt-Manager-Namespaces definiert ist. In Treibercode wird zum Verweis auf GLOBAL?? gewöhnlich
der String ?? verwendet.
Das Betriebssystem abstrahiert alle E/A-Anforderungen als Operationen auf einer virtuellen
Datei, da der E/A-Manager keinerlei Kenntnisse über irgendetwas außer über diese Dateien hat.
Daher ist der Treiber dafür verantwortlich, dateiorientierte Befehle (Öffnen, Schließen, Lesen,
Schreiben) in gerätespezifische umzuwandeln. Durch diese Abstraktion wird die Schnittstelle einer Anwendung zu den Treibern generalisiert. Benutzermodusanwendungen rufen dokumentierte Funktionen auf, die wiederum interne E/A-Systemfunktionen zum Lesen und Schreiben in
einer Datei und für andere Operationen aufrufen. Der E/A-Manager leitet diese Anforderungen
für virtuelle Dateien dynamisch an die passenden Gerätetreiber weiter. Abb. 6–3 illustriert den
Komponenten des E/A-Systems
Kapitel 6
559
grundlegenden Ablauf einer Anforderung für einen Lesevorgang. Andere Arten von E/A-Anforderungen, z. B. zum Schreiben, laufen ähnlich ab; der Unterschied besteht nur in den verwendeten APIs.
ReadFile
NtReadFile
Benutzermodus
sysenter / syscall / svc
Kernelmodus
NtReadFile
E/A-Manager
(IoCallDriver)
Treiberunter
stützungs
routinen
(Io, Ke, Ex, Mm,
Hal, FsRtl, …
Auslösen der E/A
HALZugriffsroutinen
Gerät
Abbildung 6–3 Ablauf einer typischen E/A-Anforderung
In den folgenden Abschnitten betrachten wir diese Komponenten genauer. Dabei behandeln
wir die verschiedenen Arten von Gerätetreibern und sehen uns an, wie sie geladen und initialisiert werden und wie sie E/A-Anforderungen verarbeiten. Anschließend beschäftigen wir uns
mit der Funktionsweise und dem Zweck der PNP- und der Energieverwaltung.
IRQ-Ebenen und verzögerte Prozeduraufrufe
Für unsere weitere Erörterung müssen wir zunächst zwei wichtige Elemente des Windows-Kernels vorstellen, die eine große Rolle für das E/A-System spielen, nämlich IRQ-Ebenen (Interrupt
Request Levels, IRQL) und verzögerte Prozeduraufrufe (Deferred Procedure Calls, DPCs). In Kapitel 8 von Band 2 werden diese Funktionsprinzipien ausführlicher erklärt. Hier wollen wir nur
so weit darauf eingehen, wie es für das Verständnis der E/A-Verarbeitung nötig ist.
560
Kapitel 6
Das E/A-System
IRQ-Ebenen
Der Begriff »IRQ-Ebene« (IRQL) bedeutet zweierlei, doch in bestimmten Situationen können
diese beiden Bedeutungen ein und dasselbe bezeichnen:
QQ Eine IRQL ist eine Priorität, die einer Interruptquelle auf einem Hardwaregerät zugewiesen wird Dieser Prioritätswert wird gemeinsam von der HAL und dem Interruptcon
troller festgelegt, mit dem die Geräte, die eine Interruptverarbeitung benötigen, verbunden
sind.
QQ Jede CPU verfügt über ihren eigenen IRQL-Wert Dieser Wert kann als ein Register
der CPU angesehen werden, auch wenn er in heutigen CPUs nicht auf diese Weise implementiert ist.
Die Grundregel lautet, dass Code mit höherer IRQL Code mit niedrigerer IRQL unterbrechen
kann, aber nicht umgekehrt. Beispiele dafür folgen in Kürze. In Abb. 6–4 sehen Sie eine Liste
von IRQLs für die von Windows unterstützten Architekturen. Beachten Sie, dass IRQLs und
Threadprioritäten zwei verschiedene Dinge sind. Threadprioritäten sind nur auf IRQLs kleiner
2 von Bedeutung.
Hoch (31)
Stromausfall (30)
Inter-Processor Interrupt
(IPI) (29)
Takt (28)
Profile (27)
Hoch/Profil (15)
IPI/Strom (14)
Takt (13)
Geräte-IRQL (DIRQL)
3 bis 26
Geräte-IRQL (DIRQL)
3 bis 12
Dispatch/DPC (2)
Dispatch/DPC (2)
APC (1)
APC (1)
Passiv/niedrig (0)
Passiv/niedrig (0)
x86
x64 und ARM
Thread
prioritäten
Abbildung 6–4 IRQLs
Eine IRQL ist nicht dasselbe wie ein IRQ (Interrupt Request). IRQs sind Hardwareleitungen, die Geräte mit einem Interruptcontroller verbinden. Mehr über Interrupts, IRQs und IRQLs erfahren Sie in Kapitel 8 von Band 2.
Die IRQL eines Prozessors ist normalerweise 0. Das bedeutet, dass in dieser Beziehung »nichts
Besonderes« geschieht und dass der Kernelscheduler, der Threads aufgrund ihrer Prioritäten
usw. einplant, wie in Kapitel 4 beschrieben funktioniert. Im Benutzermodus kann die IRQL nur
IRQ-Ebenen und verzögerte Prozeduraufrufe
Kapitel 6
561
0 sein. Es gibt keine Möglichkeit, die IRQL vom Benutzermodus aus anzuheben. Aus diesem
Grund wird die IRQL in der Benutzermodusdokumentation auch nie erwähnt.
Kernelmoduscode dagegen kann die IRQL der aktuellen CPU mit den Funktionen KeRaise
Irql und KeLowerIrql anheben bzw. senken. Die meisten zeitspezifischen Funktionen werden
jedoch mit einer IRQL ausgeführt, die auf einen bestimmten Wert angehoben ist, wie Sie bei
der Beschreibung der typischen E/A-Verarbeitung durch einen Treiber in Kürze noch sehen
werden.
Die wichtigsten IRQLs für unsere Erörterung der E/A sind:
QQ Passiv (0) Sie wird durch das Makro PASSIVE_LEVEL im WKD-Header wdm.h definiert.
Dies ist die Standard-IRQL, bei der der Kernelscheduler auf die übliche, in Kapitel 4 beschriebene Weise arbeitet.
QQ Dispatch/DPC (2) (DISPATCH_LEVEL) Dies ist die IRQL des Kernelschedulers selbst.
Wenn ein Thread die aktuelle IRQL auf 2 oder höher anhebt, steht ihm im Grunde genommen ein unendliches Quantum zur Verfügung, da er von keinem anderen Thread unterbrochen werden kann. Der Scheduler auf der aktuellen CPU kann erst dann wieder aufwachen,
wenn die IRQL unter 2 gefallen ist. Das hat die beiden folgenden Konsequenzen:
•
Auf IRQL 2 und höher führt jeder Wartevorgang auf Kerneldispatcherobjekte (wie Mutexe, Semaphoren und Ereignisse) zu einem Absturz des Systems, da der Thread dazu
in einen Wartezustand eintreten und ein anderer Thread auf derselben CPU eingeplant
werden müsste. Das aber kann nicht geschehen, da sich der Scheduler nicht regt, wenn
Code auf dieser Ebene ausgeführt wird. Stattdessen reagiert das System mit einem Beendigungsfehler. Die einzige Ausnahme liegt vor, wenn das Wartetimeout auf 0 gesetzt
ist, denn dies bedeutet, dass in Wirklichkeit gar keine Wartezeit erforderlich ist, sondern
nur der signalisierte Zustand des Objekts abgerufen werden muss.
•
Es können keine Seitenfehler verarbeitet werden, denn sie würden einen Kontextwechsel zu einem der Schreibthreads für geänderte Seiten erfordern. Da Kontextwechsel
aber nicht zulässig sind, stürzt das System ab. Code, der auf IRQL 2 oder höher läuft,
kann daher nur auf nicht ausgelagerten Speicher zugreifen, also gewöhnlich auf Speicher aus dem nicht ausgelagerten Pool, der sich definitionsgemäß stets im physischen
Speicher befindet.
QQ Geräte-IRQL (3 bis 26 auf x86, x bis 12 auf x64 und ARM) (DIRQL) Dies sind die Ebenen für Hardwareinterrupts. Trifft ein solcher Interrupt ein, so ruft der Trapdispatcher des
Kernels die entsprechende Interruptdienstroutine (Interrupt Service Routine, ISR) auf und
hebt deren IRQL auf den des Interrupts an. Da dieser Wert stets höher als DISPATCH_LEVEL
(also 2) ist, gelten für DIRQL auch alle Regeln von IRQL 2.
Bei der Ausführung auf einer bestimmten IRQL werden Interrupts derselben oder einer niedrigeren IRQL verdeckt. Wird beispielsweise eine ISR auf IRQL 8 ausgeführt, so kann sie auf der
vorliegenden CPU nicht von Code mit IRQL 7 und niedriger unterbrochen werden. Insbesondere kann kein Benutzermoduscode ausgeführt werden, da dessen IRQL stets 0 beträgt. Die
Ausführung auf einer hohen IRQL ist daher im Allgemeinen nicht wünschenswert. Es gibt nur
einige wenige besondere Fälle (die wir uns in diesem Kapitel noch ansehen werden), in denen
sie sinnvoll und für den Normalbetrieb des Systems auch erforderlich ist.
562
Kapitel 6
Das E/A-System
Verzögerte Prozeduraufrufe
Ein verzögerter Prozeduraufruf (Deferred Procedure Call, DPC) ist ein Objekt, das den Aufruf
einer Funktion auf IRQL 2 (DPC_LEVEL) kapselt. DPCs sind hauptsächlich für die Verarbeitung im
Anschluss an einen Interrupt da, denn bei der Ausführung auf ihrer IRQL werden alle Interrupts,
die auf Verarbeitung warten, verdeckt und damit verzögert. Eine ISR führt gewöhnlich nur das
Minimum an erforderlicher Arbeit aus – was in den meisten Fällen heißt, dass sie den Status
des Geräts liest und es anweist, sein Interruptsignal zu beenden – und verschiebt die weitere Verarbeitung dann auf eine niedrigere IRQL (2), indem sie einen DPC anfordert. Verzögert
bedeutet, dass der DPC nicht sofort ausgeführt wird; was er auch gar nicht kann, da die IRQL
zurzeit immer noch höher als 2 ist. Wenn die ISR die Steuerung zurückgibt und keine weiteren
ausstehenden Interrupts auf Verarbeitung warten, fällt die CPU-IRQL auf 2, sodass die bis dahin
angesammelten DPCs ausgeführt werden. Abb. 6–5 zeigt einen vereinfachten Überblick über
den Ablauf der Ereignisse, wenn ein Interrupt von einem Hardwaregerät auftritt (was jederzeit
geschehen kann, da diese Interrupts von Natur aus asynchron sind), während der Code auf der
regulären IRQL 0 ausgeführt wird.
Benutzer-/Kernel
moduscode (0)
ISR 1 (5)
ISR 2 (8)
DPC in Warte
schlange gestellt
DPCVerarbeitungs
schleife
DPC in Warte
schlange gestellt
DPC-Warte
schlange
DPC
DPC-Routine 1
DPC
DPC-Routine 2
Abbildung 6–5 Interrupt- und DPC-Verarbeitung
In Abb. 6–5 geschieht Folgendes:
1.
Benutzer- oder Kernelmoduscode wird ausgeführt, während sich die CPU auf IRQL 0 befindet, was meistens der Fall ist.
2.
Ein Hardwareinterrupt mit IRQL 5 trifft ein (Geräte-IRQLs sind immer mindestens 3). Da
dieser Wert höher ist als der der aktuellen IRQL, wird der CPU-Status gespeichert, die IRQL
auf 5 erhöht und die mit dem Interrupt verknüpfte ISR aufgerufen. Es findet jedoch kein
Kontextwechsel statt. Der ISR-Code wird von dem bisherigen Thread ausgeführt. Falls sich
der Thread im Benutzermodus befand, wird er beim Eintreffen eines Interrupts in den Kernelmodus umgeschaltet.
IRQ-Ebenen und verzögerte Prozeduraufrufe
Kapitel 6
563
3.
ISR 1 beginnt mit der Ausführung, während sich die CPU nach wie vor auf IRQL 5 befindet.
Interrupts auf IRQL 5 oder niedriger können jetzt keine Unterbrechung mehr hervorrufen.
4.
Ein Interrupt mit IRQL 8 trifft ein. Falls das System entscheidet, dass sich dieselbe CPU
darum kümmern soll, wird der Code erneut unterbrochen, da die IRQL 8 höher ist als die
aktuelle. Abermals wird der CPU-Status gespeichert, die IRQL wird auf 8 erhöht und die
CPU springt zu ISR 2. Die Ausführung erfolgt wiederum im selben Thread. Da der Threadscheduler auf IRQL 2 und höher nicht aufwachen kann, sind keine Kontextwechsel möglich.
5.
ISR 2 wird ausgeführt. Zur vollständigen Verarbeitung des Interrupts sind noch einige Arbeiten auf einer niedrigeren IRQL erforderlich, sodass Code mit IRQL kleiner 8 wieder verarbeitet werden kann.
6.
Als Letztes ruft ISR 2 die Funktion KeInsertQueueDpc auf, um einen DPC in die Warteschlange zu stellen. Dieser DPC zeigt auf eine Treiberroutine, die die weitere Verarbeitung nach
dem Verwerfen des Interrupts ausführt. Welche Aufgaben eine solche weitere Verarbeitung gewöhnlich einschließt, sehen wir uns im nächsten Abschnitt an. Die ISR gibt die
Steuerung zurück. Der CPU-Status vor ihrem Aufruf wird wiederhergestellt.
7.
Die IRQL fällt wieder auf den vorherigen Wert von 5, sodass die CPU mit der Ausführung
der unterbrochenen ISR 1 fortfährt.
8.
Kurz bevor ISR 1 zum Ende kommt, stellt sie einen eigenen DPC für die weitere Verarbeitung in die Warteschlange. Anschließend gibt ISR 1 die Steuerung zurück. Der CPU-Status
vor ihrem Aufruf wird wiederhergestellt.
9.
Die IRQL sollte jetzt auf den alten Wert von 0 fallen, der vor dem Eintreffen der Interrupts
vorherrschte. Der Kernel erkennt aber, dass noch ausstehende DPCs vorhanden sind, weshalb er die IRQL auf 2 senkt (DPC_LEVEL) und in eine DPC-Verarbeitungsschleife eintritt, die
die gesammelten DPCs durchläuft und nacheinander die einzelnen DPC-Routinen aufruft.
Wenn die DPC-Warteschlange komplett abgearbeitet ist, endet die DPC-Verarbeitung.
10. Jetzt kann die IRQL endlich auf 0 zurückfallen. Der ursprüngliche CPU-Zustand wird wiederhergestellt, und die Ausführung des unterbrochenen Benutzer- oder Kernelmoduscodes
wird wieder aufgenommen. Die gesamte Verarbeitung lief in demselben Thread ab. Das
bedeutet, dass ISRs und DPC-Routinen nicht auf einen bestimmten Thread (und damit
auch nicht auf einen bestimmten Prozess) angewiesen sein dürfen. Die Ausführung kann
in jedem beliebigen Thread stattfinden. Die Bedeutung dieses Umstands sehen wir uns im
nächsten Abschnitt noch an.
Gerätetreiber
Um mit dem E/A-Manager und anderen Komponenten des E/A-Systems zusammenwirken zu
können, muss ein Gerätetreiber den Implementierungsrichtlinien für die Art des Geräts genügen, die er verwaltet. In diesem Abschnitt sehen wir uns die verschiedenen von Windows
unterstützten Arten von Gerätetreibern und deren internen Aufbau an.
564
Kapitel 6
Das E/A-System
Die meisten Kernelmodus-Gerätetreiber sind in C geschrieben. Dank der besonderen Unterstützung für C++-Kernelmoduscode in den neuen Compilern können
sie beginnend mit dem Windows Driver Kit 8.0 auch gefahrlos in C++ geschrieben
werden. Von der Verwendung von Assemblersprache wird jedoch dringend abgeraten, da sie die Treiber komplizierter macht und ihre Portierung zwischen den von
Windows unterstützten Hardwarearchitekturen (x86, x64 und ARM) erschwert.
Arten von Gerätetreibern
Windows unterstützt eine breite Palette von Gerätetreibertypen und Programmierumgebungen. Selbst innerhalb einer bestimmten Art von Gerätetreiber sind je nach Gerät unterschiedliche Programmierumgebungen möglich.
Die gröbste Einteilung ist die in Benutzer- und Kernelmodustreiber. Windows unterstützt
zwei Arten von Benutzermodustreiber:
QQ Druckertreiber des Windows-Teilsystems Sie übersetzen geräteunabhängige Grafikanforderungen in druckerspezifische Befehle. Diese Befehle wiederum werden dann
an einen Kernelmodus-Porttreiber wie den für den USB-Druckeranschluss weitergeleitet
(Usbprint.sys).
QQ UMDF-Treiber (User-Mode Driver Framework) Hierbei handelt es sich um Hardwaregerätetreiber, die im Benutzermodus ausgeführt werden können und über ALPCS mit der
UMDF-Bibliothek im Kernelmodus kommunizieren. Mehr darüber erfahren Sie im Abschnitt »User-Mode Driver Framework« weiter hinten in diesem Kapitel.
In diesem Kapitel befassen wir uns jedoch hauptsächlich mit Kernelmodustreibern. Es gibt verschiedene Arten davon, die sich in die folgenden Grundkategorien einteilen lassen:
QQ Dateisystemtreiber Diese Treiber nehmen E/A-Anforderungen für Dateien entgegen
und geben zu deren Verarbeitung ihre eigenen ausdrücklichen Anforderungen an Massenspeicher- und Netzwerkgerätetreiber aus.
QQ Plug-&-Play-Treiber Diese Treiber arbeiten mit der Hardware und dem Energie- und
dem PnP-Manager zusammen. Dazu gehören Treiber für Massenspeichergeräte, Video
adapter, Eingabegeräte und Netzwerkkarten.
QQ Nicht-Plug-&-Play-Treiber Dazu gehören Kernelerweiterungen, also Treiber und Module, die den Funktionsumfang des Systems erweitern. Gewöhnlich arbeiten sie nicht mit
dem PnP-Manager und der Energieverwaltung zusammen, da sie meistens keine tatsächliche Hardware verwalten. Beispiele für diese Kategorie sind Netzwerk-API- und Protokolltreiber. Das Sysinternals-Tool Process Monitor verfügt über einen Treiber, der ebenfalls in
diese Gruppe fällt.
Die Kernelmodustreiber können auch auf der Grundlage des verwendeten Treibermodells und
ihrer Rolle bei der Verarbeitung ihrer Geräteanforderungen unterteilt werden.
Gerätetreiber
Kapitel 6
565
WDM-Treiber
Bei WDM-Treibern handelt es sich um Gerätetreiber, die dem Windows Driver Model folgen.
Dieses Modell unterstützt Energieverwaltung, Plug & Play und WMI, und die meisten Plug-&Play-Treiber folgen ihm. Es gibt drei Arten von WDM-Treibern:
QQ Bustreiber Sie verwalten einen logischen oder physischen Bus, beispielsweise PCMCIA,
PCI, USB und IEEE 1394. Ein Bustreiber erkennt an seinen Bus angeschlossene Geräte und
informiert den PnP-Manager darüber. Außerdem ist er für die Energieeinstellungen des
Busses zuständig. Diese Treiber werden gewöhnlich von Microsoft mitgeliefert.
QQ Funktionstreiber Sie verwalten jeweils eine bestimmte Art von Gerät. Der Bustreiber
zeigt das Gerät über den PnP-Manager dem Funktionstreiber an, und der Funktionstreiber
wiederum stellt die Betriebsschnittstelle des Geräts im Betriebssystem bereit. Im Allgemeinen ist der Funktionstreiber derjenige, der die meisten Kenntnisse über das Gerät hat.
QQ Filtertreiber Diese Treiber sind logisch über den Funktionstreibern (obere Filter oder
Funktionsfilter) oder dem Bustreiber angeordnet (untere Filter oder Busfilter) und erweitern oder ändern das Verhalten eines Geräts oder eines anderen Treibers. Beispielsweise
kann ein Hilfsprogramm zur Tastaturerfassung mit einem Tastaturfiltertreiber implementiert werden, der oberhalb des Tastaturfunktionstreibers liegt.
Abb. 6–6 zeigt einen Geräteknoten mit einem Bustreiber, der ein physisches Geräteobjekt erstellt (Physical Device Objekt, PDO), einem Funktionstreiber, der ein funktionales Geräteobjekt
(FDO) erstellt, sowie mit unteren und oberen Filtern. Erforderlich sind dabei nur das PDO und
das FDO. Das Vorhandensein der Filter ist optional.
Oberer Filtertreiber 3
Oberer Filtertreiber 2
Oberer Filtertreiber 1
Funktionstreiber
Unterer Filtertreiber 2
Unterer Filtertreiber 1
Bustreiber
Abbildung 6–6 WDM-Geräteknoten
In WDM ist kein Treiber für die Steuerung aller Aspekte eines Geräts alleinverantwortlich. Der
Bustreiber kümmert sich um Änderungen der Busmitgliedschaft (Hinzufügen und Entfernen
von Geräten), hilft dem PnP-Manager beim Aufzählen der Geräte am Bus, greift auf die busspezifischen Konfigurationsregister zu und verwaltet in einigen Fällen auch den Stromverbrauch
566
Kapitel 6
Das E/A-System
der Geräte am Bus. Der Funktionstreiber ist im Allgemeinen der einzige, der auf die Gerätehardware zugreift. Mehr darüber erfahren Sie im Abschnitt »Der PnP-Manager« weiter hinten
in diesem Kapitel.
Geschichtete Treiber
Die Unterstützung für ein einziges Hardwaregerät ist oft auf mehrere Treiber aufgeteilt, die
jeweils einen Teil der erforderlichen Funktionalität bereitstellen. Neben den Bus-, Funktionsund Filtertreibern von WDM kann sich die Hardwareunterstützung auch noch auf folgende
Komponenten ausdehnen:
QQ Klassentreiber Sie implementieren jeweils die E/A-Verarbeitung für eine ganze Klasse
von Geräten, z. B. Festplatten, Tastaturen oder CD-ROM-Laufwerke, bei denen die Hardwareschnittstellen standardisiert sind, sodass ein Treiber Geräte verschiedener Hersteller
steuern kann.
QQ Miniklassentreiber Sie implementieren die herstellerspezifische E/A-Verarbeitung
für jeweils eine bestimmte Geräteklasse. Obwohl es einen standardisierten Batterieklassen-Treiber von Microsoft gibt, haben beispielsweise sowohl unterbrechungsfreie Stromversorgungen (USV) als auch Laptopakkus sehr besondere und stark herstellerabhängige
Schnittstellen, weshalb ein Miniklassentreiber vom Hersteller erforderlich ist. Bei diesen
Treibern handelt es sich im Grunde genommen um Kernelmodus-DLLs, die keine direkte
IRP-Verarbeitung durchführen. Stattdessen werden sie von den Klassentreibern aufgerufen
und importieren deren Funktionen.
QQ Porttreiber Sie implementieren die Verarbeitung von E/A-Anforderungen für eine bestimmte Art von E/A-Port, z. B. SATA, und sind als Kernelmodus-Funktionsbibliotheken statt
als Gerätetreiber im eigentlichen Sinne geschrieben. Porttreiber stammen fast ausschließlich von Microsoft, da die Schnittstellen gewöhnlich so standardisiert sind, dass Geräte verschiedener Hersteller denselben Treiber nutzen können. Im Einzelnen kann es jedoch sein,
dass Dritthersteller ihren eigenen Porttreiber für besondere Hardware schreiben müssen.
Manchmal schließen die E/A-Ports auch logische Ports ein. Beispielsweise ist der NDIS-Treiber (Network Driver Interface Specification) der »Port«-Treiber für das Netzwerk.
QQ Miniporttreiber Diese Treiber ordnen eine allgemeine E/A-Anforderung für eine Art
von Port einem anderen Adaptertyp zu, beispielsweise einer bestimmten Netzwerkkarte.
Miniporttreiber sind echte Gerätetreiber, die die von einem Porttreiber bereitgestellten
Funktionen importieren. Sie werden von Drittherstellern geschrieben und stellen eine
Schnittstelle für den Porttreiber bereit. Ebenso wie Miniklassentreiber handelt es sich bei
ihnen um Kernelmodus-DLLs, die keine direkte IRP-Verarbeitung durchführen.
Abb. 6–7 gibt einen vereinfachten Überblick über die Funktionsweise und Schichtung von Gerätetreibern. Der Dateisystemtreiber nimmt hier die Anforderung entgegen, Daten an eine bestimmte Stelle einer bestimmten Datei zu schreiben, und übersetzt sie in eine Anforderung,
eine bestimmte Anzahl von Bytes an eine bestimmte (logische) Stelle auf der Festplatte zu
schreiben. Anschließend übergibt er sie über den E/A-Manager an einen einfachen Festplattentreiber, der die Stelle wiederum in einen physischen Speicherort auf der Festplatte übersetzt
und mit der Festplatte kommuniziert, um die Daten zu schreiben.
Gerätetreiber
Kapitel 6
567
Anwendung/Dienst
Benutzermodus
Kernelmodus
Schreibt Daten an einem bestimmten
Offset in eine Datei
Dateisystemtreiber
E/A-Manager
Übersetzt den Byteoffset in der Datei in
einen Byteoffset im Volume und ruft über
den E/A-Manager den nächsten Treiber auf
Ruft den Treiber auf, um Daten am
Byteoffset im Volume zu schreiben
Festplattentreiber
Übersetzt den Byteoffset im Volume in
einen Byteoffset auf der Festplatte und
schreibt die Daten
Abbildung 6–7 Schichtung eines Dateisystem- und eines Festplattentreibers
Diese Abbildung zeigt die Arbeitsteilung zwischen zwei geschichteten Treibern. Der E/A-Manager empfängt eine Schreibanforderung relativ zum Anfang einer bestimmten Datei und übergibt sie an den Dateisystemtreiber. Der wiederum übersetzt die Schreiboperation in eine Datei
an einem Anfangsspeicherort (eine Sektorengrenze auf der Festplatte) und die Anzahl der zu
schreibenden Bytes und ruft den E/A-Manager auf, um diese Anforderung an den Festplattentreiber zu übergeben. Letzterer wiederum übersetzt die Anforderung in einen Speicherort auf
der physischen Festplatte und überträgt die Daten.
Da alle Treiber – sowohl Geräte- als auch Dateisystemtreiber – dem Betriebssystem gegenüber dasselbe Framework verwenden, lässt sich in diese Hierarchie problemlos ein weiterer
Treiber einfügen, ohne dass die bestehenden Treiber oder das E/A-System geändert werden
müssten. Beispielsweise ist es durch einen zusätzlichen Treiber möglich, mehrere Festplatten
wie eine einzige große Festplatte erscheinen zu lassen. Ein solcher Treiber zur Verwaltung eines
logischen Volumes befindet sich zwischen dem Dateisystemtreiber und den Festplattentreibern, wie Sie in Abb. 6–8 sehen. (Diagramme für den eigentlichen Speichertreiber und den
Volumetreiber finden Sie in Kapitel 12 von Band 2.)
568
Kapitel 6
Das E/A-System
Anwendung/Dienst
Benutzermodus
Kernelmodus
Schreibt Daten an einem bestimmten
Offset in eine Datei
Dateisystemtreiber
E/A-Manager
Übersetzt den Byteoffset in der Datei in
einen Byteoffset im Volume und ruft
über den E/A-Manager den nächsten
Treiber auf
Ruft den Treiber auf, um Daten am
Byteoffset im Volume zu schreiben
Volumeverwaltungs
treiber
Übersetzt den Byteoffset im Volume in
eine Laufwerksnummer und einen Offset
und ruft über den E/A-Manager den
nächsten Treiber auf
Ruft den nächsten Treiber auf,
um die Daten am Byteoffset
auf der Festplatte auf
Festplatte 3 zu schreiben
Festplattentreiber
Übersetzt den Byteoffset auf der Festplatte in
einen physischen Speicherort auf Festplatte 3
und schreibt die Daten
Abbildung 6–8 Hinzufügen eines weiteren geschichteten Treibers
Gerätetreiber
Kapitel 6
569
Experiment: Die Liste der geladenen Treiber einsehen
Sie können sich eine Liste registrierter Treiber ansehen, indem Sie im Dialogfeld Ausführen
im Startmenü das Hilfsprogramm Msinfo32.exe ausführen und dann Systemtreiber unter
Softwareumgebung markieren. Die tatsächlich geladenen Treiber sind in der Spalte Gestartet mit Ja gekennzeichnet:
Diese Liste stammt aus den Unterschlüsseln von HKLM\System\CurrentControlSet\Services,
wo sowohl Treiber als auch Dienste aufgeführt werden. Beide können über den Dienststeuerungsmanager (Service Control Manager, SCM) gestartet werden. Um zu erkennen, ob es
sich bei einem Unterschlüssel um einen Treiber oder einen Dienst handelt, schauen Sie sich
den Wert von Type an. Ein kleiner Wert (1, 2, 4, 8) weist auf einen Treiber hin, die Werte 16
(0x10) und 32 (0x20) dagegen auf einen Windows-Dienst. Weitere Informationen über den
Schlüssel Services erhalten Sie in Kapitel 9 von Band 2.
Die Liste der geladenen Kernelmodustreiber können Sie sich auch in Process Explorer
ansehen. Wählen Sie dort den Prozess System, öffnen Sie das Menü View und wählen Sie
dort Lower Pane View und dann DLLs.
→
570
Kapitel 6
Das E/A-System
Process Explorer führt die geladenen Treiber mit ihren Namen, Versionsinformationen (einschließlich Hersteller und Beschreibung) und Ladeadressen auf (sofern Sie Process Explorer
zur Anzeige der entsprechenden Spalten eingerichtet haben).
Wenn Sie sich im Kerneldebugger ein Absturzabbild oder ein Live-System ansehen,
können Sie mit dem Befehl lm kv eine ähnliche Anzeige aufrufen:
kd> lm kv
start end module name
80626000 80631000 kdcom (deferred)
Image path: kdcom.dll
Image name: kdcom.dll
Browse all global symbols functions data
Timestamp:
Sat Jul 16 04:27:27 2016 (57898D7F)
CheckSum:
0000821A
ImageSize:
0000B000
Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4
81009000 81632000 nt (pdb symbols) e:\symbols\ntkrpamp.
pdb\A54DF85668E54895982F873F58C984591\ntkrpamp.pdb
Loaded symbol image file: ntkrpamp.exe
Image path: ntkrpamp.exe
Image name: ntkrpamp.exe
Browse all global symbols functions data
Timestamp:
Wed Sep 07 07:35:39 2016 (57CF991B)
CheckSum:
005C6B08
ImageSize:
00629000
Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4
81632000 81693000 hal (deferred)
Image path: halmacpi.dll
Image name: halmacpi.dll
Browse all global symbols functions data
Timestamp:
Sat Jul 16 04:27:33 2016 (57898D85)
CheckSum:
00061469
ImageSize:
00061000
Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4
8a800000 8a84b000 FLTMGR (deferred)
Image path: \SystemRoot\System32\drivers\FLTMGR.SYS
Image name: FLTMGR.SYS
Browse all global symbols functions data
Timestamp:
Sat Jul 16 04:27:37 2016 (57898D89)
CheckSum:
00053B90
ImageSize:
0004B000
Translations: 0000.04b0 0000.04e4 0409.04b0 0409.04e4
...
Gerätetreiber
Kapitel 6
571
Aufbau eines Treibers
Das E/A-System steuert die Ausführung der Gerätetreiber. Diese Treiber bestehen aus Routinen,
die aufgerufen werden, um die verschiedenen Phasen einer E/A-Anforderung zu verarbeiten.
Abb. 6–9 zeigt die Haupttreiberroutinen.
E/A-System
Initialisierungsroutine
DPC-Routine
Routine zum Hinzu
fügen von Geräten
Dispatchroutinen
ISR
E/A-Startroutine
Abbildung 6–9 Hauptroutinen von Gerätetreibern
QQ Initialisierungsroutine Wenn der Treiber in das Betriebssystem geladen wird, legt das
WDK GSDriverEntry als Initialisierungsroutine fest, die dann vom E/A-Manager ausgeführt
wird. GSDriverEntry initialisiert den Schutz des Compilers gegen Stacküberlauffehler (ein
sogenanntes Cookie) und ruft dann die Routine DriverEntry auf, die der Treiberautor implementieren muss. Sie füllt Systemdatenstrukturen aus, um die restlichen Treiberroutinen
beim E/A-Manager zu registrieren, und führt alle nötigen globalen Treiberinitialisierungsarbeiten durch.
QQ Routine zum Hinzufügen von Geräten Ein Treiber, der Plug & Play unterstützt, implementiert eine Routine zum Hinzufügen von Geräten. Über diese Routine sendet der
PnP-Manager eine Benachrichtigung an den Treiber, wenn ein Gerät erkannt wird, für das
der Treiber zuständig ist. Der Treiber erstellt in dieser Routine gewöhnlich ein Geräteobjekt
(siehe weiter hinten in diesem Kapitel), das für das Gerät steht.
QQ Dispatchroutinen Dispatchroutinen sind die Haupteintrittspunkte, die ein Gerätetreiber
bereitstellt. Darunter gibt es Routinen zum Öffnen, Schließen, Lesen und Schreiben und für
Plug & Play. Wenn der E/A-Manager aufgerufen wird, um eine E/A-Operation durchzuführen, erstellt er ein IRP und ruft einen Treiber durch eine von dessen Dispatchroutinen auf.
QQ E/A-Startroutine Mit einer E/A-Startroutine kann ein Treiber die Datenübertragung von
oder zu einem Gerät auslösen. Eine solche Routine wird nur in Treibern definiert, die ihre
eingehenden E/A-Anforderungen vom E/A-Manager in eine Warteschlange stellen lassen.
Der E/A-Manager serialisiert die IRPs für einen Treiber, indem er dafür sorgt, dass der Treiber immer nur ein IRP auf einmal ausführt. Treiber können zwar mehrere IRPs gleichzeitig
ausführen, doch bei den meisten Geräten ist eine Serialisierung erforderlich, da sie nicht in
der Lage sind, mehrere E/A-Anforderungen nebeneinander zu handhaben.
QQ Interruptdienstroutine (ISR) Wenn ein Gerät einen Interrupt auslöst, überträgt der Interruptdispatcher des Kernels die Steuerung an diese Routine. Im E/A-Modell von Windows
werden ISRs auf der Geräte-IRQL ausgeführt (DIRQL). Um Interrupts mit niedrigerer IRQL
572
Kapitel 6
Das E/A-System
nicht zu blockieren, führen sie so wenig Arbeit aus wie möglich (siehe den vorhergehenden
Abschnitt). Eine ISR stellt gewöhnlich einen DPC mit niedrigerer IRQL (DPC/Dispatch-Ebene) in die Warteschlange, um die restlichen Aufgaben zur Verarbeitung des Interrupts zu
erledigen. Nur Treiber für interruptgesteuerte Geräte verfügen über ISRs. Ein Dateisystemtreiber ist ein Beispiel für einen Treiber ohne ISRs.
QQ DPC-Routine zur Interruptverarbeitung Nach der Ausführung der ISR wird die meiste
Arbeit zur Verarbeitung eines Geräteinterrupts von einer DPC-Routine erledigt. Sie wird auf
IRQL 2 ausgeführt, was einen Kompromiss zwischen der höheren DIRQL und der passiven
Ebene 0 darstellt. Eine typische DPC-Routine löst die E/A-Vervollständigung aus und beginnt mit der nächsten E/A-Operation für das Gerät in der Warteschlange.
Auch wenn die folgenden Routinen in Abb. 6–9 nicht gezeigt wurden, sind sie in vielen Arten
von Gerätetreibern vorhanden:
QQ E/A-Vervollständigungsroutinen Ein geschichteter Treiber kann über E/A-Vervollständigungsroutinen verfügen, die ihn informieren, wenn ein Treiber niedrigerer Ebene
die Verarbeitung eines IRPs abgeschlossen hat. Beispielsweise ruft der E/A-Manager die
E/A-Vervollständigungsroutine eines Dateisystemtreibers auf, nachdem ein Gerätetreiber
die Datenübertragung zu oder von einer Datei abgeschlossen hat. Die Vervollständigungsroutine informiert den Dateisystemtreiber, ob die Operation erfolgreich war, fehlgeschlagen ist oder abgebrochen wurde, und ermöglicht ihm, Bereinigungsoperationen
auszuführen.
QQ E/A-Abbruchroutine Ein Treiber kann auch E/A-Abbruchroutinen definieren. Wenn er
ein IRP für eine E/A-Operation empfängt, die abgebrochen werden kann, so weist er diesem IRP eine Abbruchroutine zu. Während das IRP die einzelnen Phasen der Verarbeitung
durchläuft, kann sich die Routine ändern oder auch komplett verschwinden, wenn die laufende Operation nicht abgebrochen werden kann. Wird ein Thread, der eine E/A-Anforderung ausgegeben hat, vor Abschluss dieser Anforderung beendet oder wird die Operation
abgebrochen (z. B. durch die Windows-Funktionen CancelIo oder CancelIOEx), führt der
E/A-Manager ggf. die dem IRP zugewiesene Abbruchroutine aus. Diese Routine erledigt
alle erforderlichen Aufgaben, um die bei der bisherigen Verarbeitung des IRPs erworbenen
Ressourcen freizugeben und um das IRP mit dem Status »abgebrochen« abzuschließen.
QQ Schnelldispatchroutinen Treiber, die den Cache-Manager nutzen – z. B. Dateisystemtreiber – stellen gewöhnlich Routinen dieser Art bereit, damit der Kernel beim Zugriff auf
den Treiber die übliche E/A-Verarbeitung umgehen kann. (Mehr über den Cache-Manager
erfahren Sie in Kapitel 14 von Band 2.) Beispielsweise können Lese- und Schreiboperationen durch den direkten Zugriff auf die Daten im Cache schneller erledigt werden als
mit der üblichen Vorgehensweise des E/A-Managers, bei der diskrete E/A-Operationen
erfolgen. Die Schnelldispatchroutinen dienen auch als Callbacks vom Speicher- und Cache-
Manager zu den Dateisystemtreibern. Wenn der Speicher-Manager beispielsweise einen
Abschnitt erstellt, führt er einen Callback zum Dateisystemtreiber durch, um die Datei exklusiv zu erwerben.
QQ Entladeroutine Eine Entladeroutine gibt jegliche Systemressourcen frei, die ein Treiber
verwendet, sodass der E/A-Manager den Treiber aus dem Arbeitsspeicher entfernen kann.
Gerätetreiber
Kapitel 6
573
In der Initialisierungsroutine (DriverEntry) erworbene Ressourcen werden gewöhnlich in
der Entladeroutine freigegeben. Ein Treiber kann bei laufendem System geladen und entladen werden, sofern er diese Möglichkeit unterstützt, doch die Entladeroutine wird nur
dann aufgerufen, wenn alle Dateihandles für das Gerät geschlossen sind.
QQ Routine für Benachrichtigungen über das Herunterfahren des Systems Diese Routine ermöglicht eine Treiberbereinigung beim Herunterfahren des Systems.
QQ Fehlerprotokollierungsroutinen Wenn unerwartete Fehler auftreten (z. B. wenn ein
Festplattenblock beschädigt ist), bemerken die Fehlerprotokollierungsroutinen des Treibers dies und informieren den E/A-Manager, der die entsprechenden Informationen in
eine Fehlerprotokolldatei schreibt.
Treiber- und Geräteobjekte
Wenn ein Thread ein Handle für ein Dateiobjekt öffnet (siehe den Abschnitt »E/A-Verarbeitung«
weiter hinten in diesem Kapitel), muss der E/A-Manager anhand des Dateiobjektnamens bestimmen, welchen Treiber er zur Verarbeitung der Anforderung aufrufen soll. Außerdem muss
er diese Information wiederfinden, wenn später ein Thread das gleiche Filehandle verwendet.
Dazu sind folgende Objekte da:
QQ Treiberobjekt Dieses Objekt (DRIVER_OBJECT-Struktur) steht für einen einzelnen Treiber
im System. Von diesem Objekt ruft der E/A-Manager die Adressen der einzelnen Dispatchroutinen des Treibers ab (Eintrittspunkte).
QQ Geräteobjekt Dieses Objekt (DEVICE_OJBECT-Struktur) steht für ein physisches oder logisches Gerät im System und beschreibt dessen Merkmale, z. B. die erforderliche Ausrichtung
für Puffer und den Speicherort der Gerätewarteschlange für eingehende IRPs. Es ist das
Ziel für alle E/A-Operationen, da es dieses Objekt ist, mit dem das Handle kommuniziert.
Wenn ein Treiber in das System geladen wird, erstellt der E/A-Manager ein Treiberobjekt dafür.
Anschließend ruft er die Initialisierungsroutine dieses Treibers auf (DriverEntry), die die Objektattribute mit den Eintrittspunkten des Treibers füllt.
Nach dem Laden kann der Treiber jederzeit Geräteobjekte für logische oder physische
Geräte erstellen – und sogar für logische Schnittstellen und Endpunkte des Treibers –, indem er
IoCreateDevice oder IoCreateDeviceSecure aufruft. Die meisten Plug-&-Play-Treiber erstellen
Geräteobjekte jedoch in ihrer Routine zum Hinzufügen von Geräten, wenn der PnP-Manager
sie über das Vorhandensein eines Geräts informiert, für das sie zuständig sind. Nicht-Plug&-Play-Treiber dagegen legen die Geräteobjekte an, wenn der E/A-Manager ihre Initialisierungsroutine aufruft. Der E/A-Manager entlädt einen Treiber, wenn dessen letztes Geräteobjekt
gelöscht wurde und keine Verweise auf den Treiber mehr übrig sind.
Die Beziehung zwischen einem Treiberobjekt und seinen Geräteobjekten ist in Abb. 6–10
dargestellt.
574
Kapitel 6
Das E/A-System
Treiberobjekt
Geräteobjekt
Geräteobjekt
Einzelheiten der
Geräteerweiterung
Abbildung 6–10 Ein Treiberobjekt und seine Geräteobjekte
Das Element DeviceObject eines Treiberobjekts enthält einen Zeiger auf dessen erstes Geräteobjekt. In dieser DEVICE_OBJECT-Struktur befindet sich das Element NextDevice mit einem
Zeiger auf das zweite Geräteobjekt usw., bis das Element NextDevice des letzten Geräteobjekts auf NULL zeigt. Im Element DriverObject zeigt jedes Geräteobjekt zurück auf sein Zeigerobjekt. Alle Beziehungen, die in Abb. 6–10 durch Pfeile dargestellt sind, werden von den
Funktionen zur Geräteerstellung aufgebaut (IoCreateDevice und IoCreateDeviceSecure). Der
Zeiger DeviceExtension bietet einem Treiber die Möglichkeit, zusätzlichen Speicher zuzuweisen, der mit den einzelnen von ihm verwalteten Geräteobjekten verknüpft ist.
Die Unterscheidung zwischen Treiber- und Geräteobjekten ist sehr wichtig. Ein
Treiberobjekt steht für das Verhalten des Treibers, wohingegen die einzelnen Geräteobjekte die Kommunikationsendpunkte darstellen. Beispielsweise gibt es auf
einem System mit vier seriellen Endpunkten ein Treiberobjekt (und eine Binärdatei
für den Treiber), aber vier Geräteobjekte, die für die einzelnen seriellen Ports stehen und die einzeln geöffnet werden können, ohne dass sich das auf die anderen
seriellen Ports auswirken würde. Auch bei Hardwaregeräten steht jedes Geräteobjekt für einen eigenen Satz von Hardwareressourcen wie E/A-Ports, im Speicher
zugeordnete E/A und die Interruptleitung. Windows ist eher geräte- denn treiberorientiert.
Wenn ein Treiber ein Geräteobjekt erstellt, kann er es optional benennen. Mit einem solchen
Namen gelangt das Geräteobjekt in den Namensraum des Objekt-Managers. Der Treiber kann
den Namen entweder ausdrücklich festlegen oder ihn automatisch vom E/A-Manager erstellen
lassen. Vereinbarungsgemäß werden Geräteobjekte im Verzeichnis \Device des Namensraums
untergebracht, das für Anwendungen über die Windows-API nicht zugänglich ist.
Gerätetreiber
Kapitel 6
575
Manche Treiber stellen Geräteobjekte auch in andere Verzeichnisse als \Device.
Der IDE-Treiber legt z. B. Objekte für IDE-Ports und -Kanäle in \Device\Ide an. Eine
Beschreibung der Speicherarchitektur und der Speicherung von Geräteobjekten
durch Treiber erhalten Sie in Kapitel 12 von Band 2.
Muss ein Treiber Anwendungen das Öffnen eines Geräteobjekts ermöglichen, so muss er mit
der Funktion IoCreateSymbolicLink im Verzeichnis \GLOBAL?? eine symbolische Verknüpfung
zum Namen des Geräteobjekts in \Device erstellen. Nicht-Plug-&-Play-Treiber und Dateisystemtreiber legen gewöhnlich eine symbolische Verknüpfung mit einem Standardnamen an,
z. B. \Device\HarddiskVolume2. Da Standardnamen in Umgebungen, in denen Hardware dynamisch hinzukommt und wieder entfernt wird, nicht funktionieren, stellen PnP-Treiber mithilfe
von IoRegisterDeviceInterface Schnittstellen bereit, wobei sie einen global eindeutigen Bezeichner (GUID) für die betreffende Funktionalität angeben. Bei diesen GUIDs handelt es sich
um 128-Bit-Werte, die mit den im WDK und im Windows SDK enthaltenen Tools wie uuidgen
und guidgen erzeugt werden können. Angesichts des Wertebereichs, der eine Kombination von
128 Bits hat, und der Formel zur Generierung dieser GUIDs ist es statistisch praktisch sicher, dass
jeder GUID stets und überall eindeutig ist.
IoRegisterDeviceInterface generiert die symbolische Verknüpfung für die Geräteinstanz.
Ein Treiber muss jedoch IoSetDeviceInterfaceState aufrufen, um die Schnittstelle zu dem Gerät zu aktivieren, bevor der E/A-Manager die Verknüpfung tatsächlich erstellen kann. Das erledigt der Treiber gewöhnlich, wenn der PnP-Manager das Gerät startet, indem er dem Treiber
ein Gerätestart-IRP sendet, in diesem Fall IRP_MJ_PNP (Hauptfunktionscode) mit IRP_MIN_START_
DEVICE (Nebenfunktionscode). IRPs werden im Abschnitt »E/A-Anforderungspakete« weiter hinten in diesem Kapitel genauer vorgestellt.
Möchte eine Anwendung ein Geräteobjekt öffnen, dessen Schnittstellen jeweils einen
GUID aufweisen, kann sie Plug-&-Play-Einrichtungsfunktionen wie SetupDiEnumDeviceInterfaces im Benutzerraum aufrufen, um die für einen bestimmten GUID vorhandenen Schnittstellen aufzulisten und die Namen der symbolischen Links abzurufen, die sie zum Öffnen der
Geräteobjekte benötigt. Für jedes von SetupDiEnumDeviceInterfaces gemeldete Gerät führt die
Anwendung SetupDiGetDeviceInterfaceDetail aus, um zusätzliche Informationen über das Gerät abzurufen, z. B. ob es sich um einen automatisch generierten Namen handelt. Nachdem
die Anwendung den Gerätenamen von SetupDiGetDeviceInterfaceDetail erhalten hat, kann
sie die Windows-Funktion CreateFile oder CreateFile2 ausführen, um das Gerät zu öffnen und
ein Handle zu beziehen.
576
Kapitel 6
Das E/A-System
Experiment: Geräteobjekte beobachten
Mit dem Sysinternals-Tool WinObj und mit dem Kerneldebuggerbefehl !object können Sie
sich die Gerätenamen im Verzeichnis \Device des Objekt-Manager-Namensraums ansehen.
Der folgende Screenshot zeigt eine vom E/A-Manager zugewiesene symbolische Verknüpfung, die auf ein Geräteobjekt mit einem automatisch generierten Namen in \Device zeigt:
Wenn Sie den Kerneldebuggerbefehl !object ausführen und dabei das Verzeichnis \Device
angeben, erhalten Sie folgende Ausgabe:
1: kd> !object \device
Object: 8200c530 Type: (8542b188) Directory
ObjectHeader: 8200c518 (new version)
HandleCount: 0 PointerCount: 231
Directory Object: 82007d20 Name: Device
Hash
Address
Type
Name
----
-------
----
----
00
d024a448
Device
NisDrv
959afc08
Device
SrvNet
958beef0
Device
WUDFLpcDevice
854c69b8
Device
FakeVid1
8befec98
Device
RdpBus
88f7c338
Device
Beep
89d64500
Device
Ndis
8a24e250
SymbolicLink
ScsiPort2
89d6c580
Device
KsecDD
89c15810
Device
00000025
89c17408
Device
00000019
→
Gerätetreiber
Kapitel 6
577
01
02
03
04
854c6898
Device
FakeVid2
88f98a70
Device
Netbios
8a48c6a8
Device
NameResTrk
89c2fe88
Device
00000026
854c6778
Device
FakeVid3
8548fee0
Device
00000034
8a214b78
SymbolicLink
Ip
89c31038
Device
00000027
9c205c40
Device
00000041
854c6658
Device
FakeVid4
854dd9d8
Device
00000035
8d143488
Device
Video0
8a541030
Device
KeyboardClass0
89c323c8
Device
00000028
8554fb50
Device
KMDF0
958bb040
Device
ProcessManagement
97ad9fe0
SymbolicLink
MailslotRedirector
854f0090
Device
00000036
854c6538
Device
FakeVid5
8bf14e98
Device
Video1
8bf2fe20
Device
KeyboardClass1
89c332a0
Device
00000029
89c05030
Device
VolMgrControl
89c3a1a8
Device
VMBus
...
Wenn Sie bei dem Befehl !object ein Objekt-Manager-Verzeichnis angeben, gibt der Kerneldebugger den Inhalt dieses Verzeichnisses in der Weise aus, wie der Objekt-Manager
ihn intern gliedert. Um schnelles Nachschlagen zu erlauben, sind die Objekte in einem Verzeichnis in einer Hashtabelle nach dem Hash des Objektnamens abgelegt. Daher werden
die Objekte in der Ausgabe jeweils in den einzelnen Buckets dieser Hashtabelle gezeigt.
Wie Sie in Abb. 6–10 sehen, zeigt ein Geräteobjekt zurück auf sein Treiberobjekt. Dadurch kann
der E/A-Manager erkennen, welche Treiberroutine er beim Empfang einer E/A-Anforderung
aufrufen muss. Über das Geräteobjekt findet er das Treiberobjekt für den Treiber, der für das
Gerät zuständig ist. Anschließend sucht er den richtigen Index im Treiberobjekt, indem er den
in der ursprünglichen Anforderung angegebenen Funktionscode verwendet. Jeder Funktionscode entspricht einem Treibereintrittspunkt (also einer Dispatchroutine).
Mit einem Treiberobjekt sind oft mehrere Geräteobjekte verknüpft. Wird ein Treiber aus
dem System entladen, bestimmt der E/A-Manager anhand der Warteschlange der Geräteobjekte, welche Geräte vom Entfernen des Treibers betroffen sind.
578
Kapitel 6
Das E/A-System
Experiment: Treiber- und Geräteobjekte anzeigen
Mit den Kerneldebuggerbefehlen !drvobj und !devobj können Sie sich Treiber- bzw. Geräteobjekte anzeigen lassen. Im folgenden Beispiel untersuchen wir das Treiberobjekt für den
Treiber der Tastaturklasse und zeigen eines seiner Geräteobjekte an:
1: kd> !drvobj kbdclass
Driver object (8a557520) is for:
\Driver\kbdclass
Driver Extension List: (id , addr)
Device Object list:
9f509648 8bf2fe20 8a541030
1: kd> !devobj 9f509648
Device object (9f509648) is for:
KeyboardClass2 \Driver\kbdclass DriverObject 8a557520
Current Irp 00000000 RefCount 0 Type 0000000b Flags 00002044
Dacl 82090960 DevExt 9f509700 DevObjExt 9f5097f0
ExtensionFlags (0x00000c00) DOE_SESSION_DEVICE, DOE_DEFAULT_SD_PRESENT
Characteristics (0x00000100) FILE_DEVICE_SECURE_OPEN
AttachedTo (Lower) 9f509848 \Driver\terminpt
Device queue is not busy.
Der Befehl !devobj zeigt auch die Adressen und Namen jeglicher Geräteobjekte an, über
denen sich das betrachtete Objekt befindet (siehe die Zeile AttachedTo). Befinden sich Objekte oberhalb des betrachteten Objekts, werden sie in der Zeile AttachedDevice angegeben, was hier aber nicht der Fall ist.
Um sich noch mehr Informationen anzeigen zu lassen, können Sie den Befehl !devobj
auch mit einem optionalen Argument aufrufen. Im folgenden Beispiel wird damit das Maximum an verfügbaren Informationen abgerufen:
1: kd> !drvobj kbdclass 7
Driver object (8a557520) is for:
\Driver\kbdclass
Driver Extension List: (id , addr)
Device Object list:
9f509648 8bf2fe20 8a541030
DriverEntry:
8c30a010
kbdclass!GsDriverEntry
DriverStartIo: 00000000
DriverUnload:
00000000
AddDevice:
8c307250
kbdclass!KeyboardAddDevice
→
Gerätetreiber
Kapitel 6
579
Dispatch routines:
[00] IRP_MJ_CREATE
8c301d80
kbdclass!KeyboardClassCreate
[01] IRP_MJ_CREATE_NAMED_PIPE
81142342
nt!IopInvalidDeviceRequest
[02] IRP_MJ_CLOSE
8c301c90
kbdclass!KeyboardClassClose
[03] IRP_MJ_READ
8c302150
kbdclass!KeyboardClassRead
[04] IRP_MJ_WRITE
81142342
nt!IopInvalidDeviceRequest
[05] IRP_MJ_QUERY_INFORMATION
81142342
nt!IopInvalidDeviceRequest
[06] IRP_MJ_SET_INFORMATION
81142342
nt!IopInvalidDeviceRequest
[07] IRP_MJ_QUERY_EA
81142342
nt!IopInvalidDeviceRequest
[08] IRP_MJ_SET_EA
81142342
nt!IopInvalidDeviceRequest
[09] IRP_MJ_FLUSH_BUFFERS
8c303678
kbdclass!KeyboardClassFlush
[0a] IRP_MJ_QUERY_VOLUME_INFORMATION 81142342
nt!IopInvalidDeviceRequest
[0b] IRP_MJ_SET_VOLUME_INFORMATION
81142342
nt!IopInvalidDeviceRequest
[0c] IRP_MJ_DIRECTORY_CONTROL
81142342
nt!IopInvalidDeviceRequest
[0d] IRP_MJ_FILE_SYSTEM_CONTROL
81142342
nt!IopInvalidDeviceRequest
[0e] IRP_MJ_DEVICE_CONTROL
8c3076d0
kbdclass!KeyboardClassDevice
8c307ff0
kbdclass!KeyboardClassPass
[10] IRP_MJ_SHUTDOWN
81142342
nt!IopInvalidDeviceRequest
[11] IRP_MJ_LOCK_CONTROL
81142342
nt!IopInvalidDeviceRequest
[12] IRP_MJ_CLEANUP
8c302260
kbdclass!KeyboardClassCleanup
[13] IRP_MJ_CREATE_MAILSLOT
81142342
nt!IopInvalidDeviceRequest
[14] IRP_MJ_QUERY_SECURITY
81142342
nt!IopInvalidDeviceRequest
[15] IRP_MJ_SET_SECURITY
81142342
nt!IopInvalidDeviceRequest
[16] IRP_MJ_POWER
8c301440
kbdclass!KeyboardClassPower
[17] IRP_MJ_SYSTEM_CONTROL
8c307f40
kbdclass!KeyboardClassSystem
[18] IRP_MJ_DEVICE_CHANGE
81142342
nt!IopInvalidDeviceRequest
[19] IRP_MJ_QUERY_QUOTA
81142342
nt!IopInvalidDeviceRequest
[1a] IRP_MJ_SET_QUOTA
81142342
nt!IopInvalidDeviceRequest
[1b] IRP_MJ_PNP
8c301870 kbdclass!KeyboardPnP
Control
[0f] IRP_MJ_INTERNAL_DEVICE_CONTROL
Through
Control
Das Array der Dispatchroutinen ist deutlich zu sehen; wir werden es im nächsten Abschnitt
genauer erläutern. Operationen, die der Treiber nicht unterstützt, zeigen auf die Routine
IopInvalidDeviceRequest des E/A-Managers.
Bei !drvobj geben Sie die Adresse eines DRIVER_OBJECT an und bei !devobj die einer
DEVICE_OBJECT-Struktur. Im Debugger können Sie diese Strukturen auch direkt einsehen:
1: kd> dt nt!_driver_object 8a557520
+0x000 Type
: 0n4
+0x002 Size
: 0n168
+0x004 DeviceObject
: 0x9f509648 _DEVICE_OBJECT
→
580
Kapitel 6
Das E/A-System
+0x008 Flags
: 0x412
+0x00c DriverStart
: 0x8c300000 Void
+0x010 DriverSize
: 0xe000
+0x014 DriverSection
: 0x8a556ba8 Void
+0x018 DriverExtension : 0x8a5575c8 _DRIVER_EXTENSION
+0x01c DriverName
: _UNICODE_STRING "\Driver\kbdclass"
+0x024 HardwareDatabase : 0x815c2c28 _UNICODE_STRING "\REGISTRY\MACHINE\
HARDWARE\DESCRIPTION\SYSTEM"
+0x028 FastIoDispatch
: (null)
+0x02c DriverInit
: 0x8c30a010 long +ffffffff8c30a010
+0x030 DriverStartIo
: (null)
+0x034 DriverUnload
: (null)
+0x038 MajorFunction
: [28] 0x8c301d80 long +ffffffff8c301d80
1: kd> dt nt!_device_object 9f509648
+0x000 Type
: 0n3
+0x002 Size
: 0x1a8
+0x004 ReferenceCount
: 0n0
+0x008 DriverObject
: 0x8a557520 _DRIVER_OBJECT
+0x00c NextDevice
: 0x8bf2fe20 _DEVICE_OBJECT
+0x010 AttachedDevice
: (null)
+0x014 CurrentIrp
: (null)
+0x018 Timer
: (null)
+0x01c Flags
: 0x2044
+0x020 Characteristics
: 0x100
+0x024 Vpb
: (null)
+0x028 DeviceExtension
: 0x9f509700 Void
+0x02c DeviceType
: 0xb
+0x030 StackSize
: 7 ''
+0x034 Queue
: <unnamed-tag>
+0x05c AlignmentRequirement : 0
+0x060 DeviceQueue
: _KDEVICE_QUEUE
+0x074 Dpc
: _KDPC
+0x094 ActiveThreadCount
: 0
+0x098 SecurityDescriptor : 0x82090930 Void
...
In dieser Struktur gibt es einige interessante Felder, die wir uns im nächsten Abschnitt genauer ansehen.
Da Informationen über Treiber in Objekten aufgezeichnet werden, muss der E/A-Manager die
Einzelheiten der einzelnen Treiber nicht kennen, sondern lediglich einem Zeiger folgen, um
den Treiber zu finden. Das sorgt für Portierbarkeit und ermöglicht es, neue Treiber auf einfache
Weise zu laden.
Gerätetreiber
Kapitel 6
581
Geräte öffnen
Ein Dateiobjekt ist eine Kernelmodus-Datenstruktur, die für das Handle zu einem Gerät steht.
Dateiobjekte erfüllen eindeutig die Kriterien für Objekte in Windows: Es handelt sich um
Systemressourcen, die von mehreren Benutzermodusprozessen gemeinsam genutzt werden
können; sie können benannt sein; sie sind durch objektgestützte Sicherheitseinrichtungen geschützt; und sie erlauben eine Synchronisierung. Gemeinsame Ressourcen im E/A-System – wie
die anderen Komponenten der Windows-Exekutive – werden als Objekte bearbeitet. (Mehr
über Objektverwaltung erfahren Sie in Kapitel 8 von Band 2.)
Dateiobjekte bieten eine speichergestützte Darstellung von Ressourcen, die über eine
E/A-orientierte Schnittstelle gelesen und geschrieben werden können. Tabelle 6–1 führt einige
der Attribute von Dateiobjekten auf. Die Deklarationen und Größen der einzelnen Felder schlagen Sie in der Strukturdefinition für FILE_OBJECT in wdm.h nach.
Attribut
Zweck
Dateiname
Gibt die virtuelle Datei an, auf die das Dateiobjekt verweist und die
an CreateFile oder CreateFile2 übergeben wurde.
Aktueller Byteoffset
Gibt die aktuelle Stelle in der Datei an (nur gültig für synchrone
E/A).
Modi für gemeinsame Nutzung
Gibt an, ob andere Aufrufer die Datei zum Lesen, Schreiben oder
Löschen öffnen können, während der aktuelle Aufrufer sie verwendet.
Flags für offenen Modus
Gibt an, ob die E/A synchron oder asynchron, mit oder ohne Zwischenspeicherung, sequenziell oder wahlfrei erfolgt usw.
Zeiger auf das Geräteobjekt
Gibt die Art des Geräts an, auf dem sich die Datei befindet.
Zeiger auf den Volumeparameterblock (VPB)
Gibt das Volume oder die Partition an, auf dem oder der sich die
Datei befindet (bei Dateisystemdateien).
Zeiger auf Abschnittsobjektzeiger
Gibt die Stammstruktur an, die eine zugeordnete/zwischengespeicherte Datei beschreibt. Diese Struktur enthält auch die gemeinsam
genutzte Cachezuordnung, die wiederum angibt, welche Teile der
Datei vom Cache-Manager zwischengespeichert (bzw. zugeordnet)
sind und wo sie sich im Cache befinden.
Zeiger auf private Cachezuordnung
Dient zur Speicherung der Cachinginformationen eines Handles,
z. B. seine Lesemuster oder die Seitenpriorität für den Prozess. Mehr
Informationen über Seitenprioritäten erhalten Sie in Kapitel 5.
Liste der E/A-Anforderungspakete (IRPs)
Ist das Dateiobjekt bei threadagnostischer E/A mit einem Vervollständigungsport verknüpft, so ist dies eine Liste aller E/A-Operatio
nen, die mit dem Dateiobjekt verknüpft sind (siehe die Abschnitte
»Threadagnostische E/A« und »E/A-Vervollständigungsports« weiter
hinten in diesem Kapitel).
E/A-Vervollständigungskontext
Dies sind die Kontextinformationen für den aktuellen E/A-Vervollständigungsport (falls ein solcher Port aktiv ist).
Dateiobjekterweiterung
Dient zur Speicherung der E/A-Priorität für die Datei (siehe weiter
hinten in diesem Kapitel) sowie der Angabe, ob Prüfungen für den
gemeinsamen Zugriff für das Dateiobjekt durchgeführt werden sollen. Dieses Attribut enthält optionale Dateiobjekterweiterungen, in
denen kontextspezifische Informationen gespeichert werden.
Tabelle 6–1 Attribute von Dateiobjekten
582
Kapitel 6
Das E/A-System
Um gegenüber dem Treibercode, der das Dateiobjekt verwendet, eine gewisse Opazität zu
wahren, und um die Funktionalität des Dateiobjekts zu erweitern, ohne die Struktur vergrößern
zu müssen, enthält das Dateiobjekt auch ein Feld für Erweiterungen, das bis zu sechs verschiedene weitere Arten von Attributen aufnehmen kann (siehe Tabelle 6–2).
Erweiterung
Zweck
Transaktionsparameter
Enthält den Transaktionsparameterblock, der wiederum Informationen
über eine als Transaktion ausgeführte Dateioperation enthält. Wird von
IoGetTransactionParameterBlock zurückgegeben.
Geräteobjekthinweis
Bezeichnet das Geräteobjekt des Filtertreibers, mit dem die Datei verknüpft werden soll. Wird mit IoCreateFileEx oder IoCreateFileSpecifyDeviceObjectHint festgelegt.
E/A-Statusblockbereich
Ermöglicht Anwendungen, einen Benutzermoduspuffer im Kernelspeicher zu verriegeln, um asynchrone E/A zu synchronisieren. Wird mit
SetFileIoOverlappedRange festgelegt.
Allgemein
Enthält filtertreiberspezifische Informationen und erweiterte Erstellungsparameter (Extended Create Parameters, ECPs), die vom Aufrufer hinzugefügt wurden. Wird mit IoCreateFileEx festgelegt.
Geplante Datei-E/A
Speichert Angaben zur Bandbreitenreservierung einer Datei, die vom
Speichersystem verwendet werden, um den Durchsatz für Multimediaanwendungen zu optimieren und zu garantieren (siehe den Abschnitt
»Bandbreitenreservierung (geplante Datei-E/A)« weiter hinten in diesem
Kapitel). Wird mit SetFileBandwidthReservation festgelegt.
Symbolische Verknüpfung
Wird beim Erstellen des Dateiobjekts hinzugefügt, wenn ein Bereitstellungszeiger oder eine Verzeichnisverzweigung durchlaufen wird (oder ein
Filter den Pfad ausdrücklich neu analysiert). In dieser Erweiterung wird
der vom Aufrufer angegebene Pfad einschließlich dazwischen liegender
Verzweigungen gespeichert, sodass eine relative symbolische Verknüpfung über die Verzweigungen zurückverfolgt werden kann. Mehr Informationen über symbolische NTFS-Verknüpfungen, Bereitstellungspunkte
und Verzeichnisverzweigungen erhalten Sie in Kapitel 13 von Band 2.
Tabelle 6–2 Erweiterungen für Dateiobjekte
Wenn ein Aufrufer eine Datei oder ein einfaches Gerät öffnet, gibt der E/A-Manager ein Handle
für das Dateiobjekt zurück. Zuvor wird jedoch der für das betreffende Gerät zuständige Treiber
über seine Create-Dispatchroutine (IRP_MJ_CREATE) gefragt, ob es in Ordnung ist, das Gerät zu
öffnen. Außerdem wird ihm die Gelegenheit eingeräumt, jegliche Initialisierungen durchzuführen, die für ein erfolgreiches Öffnen erforderlich sind.
Dateiobjekte stehen für offene Instanzen von Dateien, nicht für die Dateien selbst.
Im Gegensatz zu UNIX-Systemen, die Vnodes verwenden, definiert Windows keine
Darstellung einer Datei. Das überlässt Windows den Dateisystemtreibern.
Ähnliche wie Exekutivobjekte sind auch Dateien durch einen Sicherheitsdeskriptor mit einer
Zugriffssteuerungsliste geschützt. Der E/A-Manager wendet sich an das Sicherheitsteilsystem,
um zu bestimmen, ob die Zugriffssteuerungsliste einer Datei den Zugriff auf die Datei in der
von dem Thread angeforderten Weise gestattet. Wenn ja, erlaubt der Objekt-Manager den Zugriff und verknüpft die gewährten Zugriffsrechte mit dem Dateihandle, das er zurückgibt. Muss
Gerätetreiber
Kapitel 6
583
der Thread oder ein anderer Thread in dem Prozess weitere Operationen durchführen, die bei
der ursprünglichen Anforderung nicht angegeben waren, so muss er dieselbe Datei mit einer
weiteren Anforderung erneut öffnen (oder das Handle mit dem angeforderten Zugriff duplizieren), um ein weiteres Handle zu erhalten, wodurch eine zweite Sicherheitsprüfung ausgelöst
wird. Mehr über den Objektschutz erfahren Sie in Kapitel 7.
Experiment: Gerätehandles einsehen
Jeder Prozess, der ein offenes Handle zu einem Gerät hat, verfügt in seiner Handletabelle
über ein Dateiobjekt für die offene Instanz. Diese Handles können Sie in Process Explorer
einsehen, indem Sie einen Prozess markieren und dann Handles im Teilmenü Lower Pane
View des Menüs View aktivieren. Sortieren Sie anschließend nach der Spalte Type und scrollen Sie zu der Stelle, an der die mit File beschrifteten Handles für die Dateiobjekte angezeigt
werden.
In diesem Beispiel hat der Prozess Desktop Windows Manager (Dwm.exe) ein offenes Handle zu einem Gerät, das der Kernelsicherheitsgerätetreiber (Ksecdd.sys) erstellt hat. Das entsprechende Dateiobjekt können Sie sich auch im Kerneldebugger ansehen, wozu Sie zunächst seine Adresse ermitteln müssen. Der folgende Befehl gibt Informationen über das
im vorherigen Screenshot hervorgehobene Handle aus (Handlewert 0xD4). Dabei handelt
es sich um den Prozess Dwm.exe mit einer Prozess-ID von 452 (dezimal):
lkd> !handle 348 f 0n452
PROCESS ffffc404b62fb780
SessionId: 1 Cid: 01c4 Peb: b4c3db0000 ParentCid: 0364
DirBase: 7e607000 ObjectTable: ffffe688fd1c38c0 HandleCount: <Data Not
Accessible>
Image: dwm.exe
→
584
Kapitel 6
Das E/A-System
Handle Error reading handle count.
0348: Object: ffffc404b6406ef0 GrantedAccess: 00100003 (Audit) Entry:
ffffe688fd396d20
Object: ffffc404b6406ef0 Type: (ffffc404b189bf20) File
ObjectHeader: ffffc404b6406ec0 (new version)
HandleCount: 1 PointerCount: 32767
Da das Objekt ein Dateiobjekt ist, können Sie Informationen darüber mit dem Befehl !file
obj gewinnen (beachten Sie, dass hier dieselbe Objektadresse gezeigt wird wie in Process
Explorer):
lkd> !fileobj ffffc404b6406ef0
Device Object: 0xffffc404b2fa7230 \Driver\KSecDD
Vpb is NULL
Event signalled
Flags: 0x40002
Synchronous IO
Handle Created
CurrentByteOffset: 0
Da ein Dateiobjekt nur die Darstellung einer gemeinsam nutzbaren Ressource im Arbeitsspeicher ist und nicht die Ressource selbst, unterscheidet es sich von anderen Exekutivobjekten. Ein
Dateiobjekt enthält ausschließlich die Daten für das zugehörige Objekthandle, während die Datei selbst die gemeinsam nutzbaren Daten oder Texte einschließt. Jedes Mal, wenn ein Thread
eine Datei öffnet, wird ein neues Dateiobjekt mit einem neuen Satz handlespezifischer Attribute
erstellt. Betrachten Sie als Beispiel eine Datei, die gleichzeitig mehrmals geöffnet ist. Das Attribut mit dem aktuellen Byteoffset in den einzelnen Dateiobjekten verweist dabei jeweils auf den
Speicherort in der Datei, an dem die nächste Lese- oder Schreiboperation über das zugehörige
Handle stattfinden wird. Jedes Dateihandle verfügt über seinen eigenen privaten Byteoffset,
obwohl die zugrunde liegende Datei dieselbe ist. Ein Dateiobjekt gehört außerdem immer nur
zu einem einzigen Prozess. Die einzigen Ausnahmen bestehen, wenn der Prozess das Handle in
einen anderen Prozess dupliziert (was mit der Windows-Funktion D uplicateHandle möglich ist)
oder wenn ein Kindprozess es von seinem Elternprozess erbt. In diesen Fällen haben die beiden
Prozesse getrennte Handles, die auf dasselbe Dateiobjekt verweisen.
Das Dateihandle gehört zwar nur zu einem einzigen Prozess, nicht aber die zugrunde liegende physische Ressource. Threads müssen daher wie bei allen anderen gemeinsam genutzten Ressourcen ihren Zugriff synchronisieren. Schreibt beispielsweise ein Thread in eine Datei,
muss er beim Öffnen dieser Datei exklusiven Schreibzugriff verlangen, damit andere Threads
nicht zur gleichen Zeit in die Datei schreiben. Mit der Windows-Funktion LockFile kann der
Thread alternativ auch einen Teil der Datei sperren, während er darin schreibt.
Gerätetreiber
Kapitel 6
585
Beim Öffnen einer Datei wird der Name des Objekts für das Gerät, auf dem sich die Da
tei befindet, in den Dateinamen eingeschlossen. Beispielsweise bezeichnet der Name \Device\
HarddiskVolume1\Myfile.dat die Datei Myfile.dat in dem Volume C:, wobei der Teilstring
\Device\HarddiskVolume1 der Name des internen Windows-Geräteobjekts für das Volume
ist. Wenn Sie Myfile.dat öffnen, erstellt der E/A-Manager ein Dateiobjekt, speichert darin
einen Zeiger auf das Geräteobjekt HarddiskVolume1 und gibt ein Dateihandle an den Aufrufer zurück. Wenn der Aufrufer dieses Handle verwendet, kann der E/A-Manager damit
unmittelbar das Geräteobjekt HarddiskVolume1 finden.
In Windows-Anwendungen können Sie die internen Windows-Gerätenamen jedoch nicht
nutzen. Stattdessen erstellen Gerätetreiber in dem besonderen Verzeichnis \GLOBAL?? im
Namensraum des Objekt-Managers symbolische Verknüpfungen zu den internen Windows-
Gerätenamen, damit ihre Geräte für Windows-Anwendungen zugänglich sind. Diese Verknüpfungen können Sie in Ihren Programmen mithilfe der Windows-Funktionen QueryDosDevice
und DefineDosDevice untersuchen bzw. ändern.
E/A-Verarbeitung
Nachdem Sie jetzt den Aufbau und die Arten von Treibern und die unterstützenden Daten
strukturen kennen, wollen wir uns den Ablauf von E/A-Anforderungen im System ansehen. Diese
Anforderungen durchlaufen mehrere vorhersehbare Verarbeitungsphasen. Welche Phasen das
sind, hängt davon ab, ob die Anforderung für ein Gerät bestimmt ist, das von einem einschichtigen oder einem mehrschichtigen Treiber gesteuert wird, und ob der Aufrufer synchrone oder
asynchrone E/A verlangt hat. Sehen wir uns daher als Erstes die verschiedenen Arten der E/A an.
Verschiedene Arten der E/A
Anwendungen können bei ihren E/A-Anforderungen zwischen mehreren Optionen wählen.
Außerdem gibt der E/A-Manager Treibern die Möglichkeit, eine E/A-Schnellschnittstelle zu implementieren, mit der sich IRP-Zuweisungen für die E/A-Verarbeitung oft verringern lassen. In
diesem Abschnitt sehen wir uns die verschiedenen Optionen für E/A-Anforderungen an.
Synchrone und asynchrone E/A
Die meisten von Anwendungen angeforderten E/A-Operationen verlaufen synchron (was die
Standardvariante ist). Dabei wartet der Anwendungsthread, während das Gerät die Operation
ausführt, und gibt einen Statuscode zurück, wenn die E/A abgeschlossen ist. Das Programm
kann dann fortfahren und unmittelbar auf die übertragenen Daten zugreifen. In ihrer einfachsten Form werden die Windows-Funktionen ReadFile und WriteFile synchron ausgeführt: Sie
schließen die E/A-Operation ab, bevor sie die Steuerung an den Aufrufer zurückgeben.
Bei der asynchronen E/A dagegen kann die Anwendung mehrere E/A-Anforderungen ausgeben und fortfahren, während das Gerät die Operation durchführt. Das kann den Durchsatz
der Anwendung erhöhen, da sich der Anwendungsthread um andere Arbeiten kümmern kann,
während die E/A-Operation abläuft. Um asynchrone E/A nutzen zu können, müssen Sie beim
Aufruf der Windows-Funktionen CreateFile und CreateFile2 das Flag FILE_FLAG_OVERLAPPED
586
Kapitel 6
Das E/A-System
angeben. Natürlich darf der Thread nach der Anforderung einer asynchronen E/A-Operation
erst dann auf die daraus resultierenden Daten zugreifen, wenn der Gerätetreiber die Operation
abgeschlossen hat. Um das zu erreichen, muss er das Handle des Synchronisierungsobjekts
überwachen, das beim Abschluss der E/A ausgegeben wird (wobei es sich um ein Ereignisobjekt, einen E/A-Vervollständigungsport oder das Dateiobjekt selbst handeln kann).
Unabhängig von der Art der E/A-Anforderung werden E/A-Operationen, die von einem
Treiber im Namen einer Anwendung verlangt wurden, asynchron ausgeführt. Das heißt, dass der
Gerätetreiber die Steuerung nach dem Auslösen einer E/A-Anforderung so schnell wie möglich
an das E/A-System zurückgeben muss. Ob das E/A-System dann die Steuerung sofort wieder an
den Aufrufer zurückgibt oder nicht, hängt davon ab, ob das Handle für synchrone oder asynchrone E/A geöffnet wurde. Abb. 6–3 zeigt den Verlauf der Steuerung beim Auslösen einer Leseoperation. Wenn ein Wartevorgang stattfindet – was von der Einstellung des OVERLAPPED-Flags
im Dateiobjekt abhängt –, erfolgt er im Kernelmodus durch die Funktion NtReadFile.
Den Status einer ausstehenden asynchronen E/A-Operation können Sie mit dem
Windows-Makro HasOverlappedIoCompleted in Erfahrung bringen. Nähere Einzelheiten lassen
sich auch mit den GetOverlappedResult(Ex)-Funktionen einsehen. Wenn Sie E/A-Vervollständigungsports einsetzen (siehe den entsprechenden Abschnitt weiter hinten in diesem Kapitel),
können Sie die GetQueuedCompletionStatus(Ex)-Funktionen nutzen.
Schnelle E/A
Die schnelle E/A ist ein besonderer Mechanismus, mit dem das E/A-System die Generierung eines IRPs umgehen und sich direkt dem Treiberstack zuwenden kann, um eine E/A-Anforderung
abzuschließen. Diese Vorgehensweise dient zur Optimierung bestimmter E/A-Pfade, die bei der
Verwendung von IRPs etwas langsamer ablaufen. (Eine ausführlichere Erklärung der schnellen
E/A finden Sie in Kapitel 13 und 14 von Band 2.) Um seine Eintrittspunkte für schnelle E/A zu
registrieren, gibt ein Treiber sie in eine Struktur ein, auf die der Zeiger PFAST_IO_DISPATCH in
seinem Treiberobjekt verweist.
Experiment: Die von einem Treiber registrierten Routinen für
schnelle E/A einsehen
Der Kerneldebuggerbefehl !drvobj kann die Routinen für schnelle E/A auflisten, die ein
Treiber in seinem Treiberobjekt registriert. Gewöhnlich haben nur Dateisystemtreiber Verwendung für solche Routinen, doch es gibt auch Ausnahmen wie Netzwerkprotokoll- und
Busfiltertreiber. Die folgende Ausgabe zeigt die Tabelle für schnelle E/A des NTFS-Dateisystemtreiberobjekts:
lkd> !drvobj \filesystem\ntfs 2
Driver object (ffffc404b2fbf810) is for:
\FileSystem\NTFS
DriverEntry:
fffff80e5663a030
NTFS!GsDriverEntry
DriverStartIo: 00000000
→
E/A-Verarbeitung
Kapitel 6
587
DriverUnload:
00000000
AddDevice:
00000000
Dispatch routines:
...
Fast I/O routines:
FastIoCheckIfPossible
fffff80e565d6750
NTFS!NtfsFastIoCheckIfPossible
FastIoRead
fffff80e56526430
NTFS!NtfsCopyReadA
FastIoWrite
fffff80e56523310
NTFS!NtfsCopyWriteA
FastIoQueryBasicInfo
fffff80e56523140
NTFS!NtfsFastQueryBasicInfo
FastIoQueryStandardInfo
fffff80e56534d20
NTFS!NtfsFastQueryStdInfo
FastIoLock
fffff80e5651e610
NTFS!NtfsFastLock
FastIoUnlockSingle
fffff80e5651e3c0
NTFS!NtfsFastUnlockSingle
FastIoUnlockAll
fffff80e565d59e0
NTFS!NtfsFastUnlockAll
FastIoUnlockAllByKey
fffff80e565d5c50
NTFS!NtfsFastUnlockAllByKey
ReleaseFileForNtCreateSection
fffff80e5644fd90
NTFS!NtfsReleaseForCreate
fffff80e56537750
NTFS!NtfsFastQueryNetwork
Section
FastIoQueryNetworkOpenInfo
OpenInfo
AcquireForModWrite
fffff80e5643e0c0
NTFS!NtfsAcquireFileForModWrite
MdlRead
fffff80e5651e950
MdlReadComplete
fffff802dc6cd844
NTFS!NtfsMdlReadA
nt!FsRtlMdlReadCompleteDev
PrepareMdlWrite
fffff80e56541a10
MdlWriteComplete
fffff802dcb76e48
NTFS!NtfsPrepareMdlWriteA
nt!FsRtlMdlWriteCompleteDev
FastIoQueryOpen
fffff80e5653a520
NTFS!NtfsNetworkOpenCreate
ReleaseForModWrite
fffff80e5643e2c0
NTFS!NtfsReleaseFileForModWrite
AcquireForCcFlush
fffff80e5644ca60
NTFS!NtfsAcquireFileForCcFlush
ReleaseForCcFlush
fffff80e56450cf0
NTFS!NtfsReleaseFileForCcFlush
Die Ausgabe zeigt, dass NTFS seine Routine NtfsCopyReadA als FastIoRead-Eintrag in der
Tabelle für schnelle E/A registriert hat. Wie der Name dieses Eintrags schon andeutet, ruft
der E/A-Manager diese Funktion auf, wenn er eine Leseanforderung für eine Datei im Cache
ausgibt. Schlägt dieser Aufruf fehl, wird der übliche Weg über IRPs gewählt.
588
Kapitel 6
Das E/A-System
E/A in zugeordneten Dateien und Zwischenspeicherung
Die E/A in zugeordneten Dateien ist eine wichtige Funktion, an der das E/A-System und der
Speicher-Manager gemeinsam beteiligt sind. (Mehr über zugeordnete Dateien erfahren Sie in
Kapitel 5.) Dabei kann eine Datei auf der Festplatte als Teil des virtuellen Speichers eines Prozesses angesehen werden. Ein Programm kann auf die Datei wie auf ein großes Array zugreifen,
ohne Daten zu puffern oder E/A auf der Festplatte auszuführen. Das Programm greift dabei auf
den Arbeitsspeicher zu, woraufhin der Speicher-Manager mithilfe seines Auslagerungsmechanismus die gewünschte Seite von der Datei auf der Festplatte lädt. Schreibt die Anwendung in
ihren virtuellen Adressraum, so schreibt der Speicher-Manager die Änderungen im Rahmen der
normalen Auslagerung in die Datei.
Mit CreateFileMapping, MapViewOfFile und ähnlichen Windows-Funktionen ist eine E/A in
zugeordneten Dateien im Benutzermodus möglich. Innerhalb des Betriebssystems wird diese Vorgehensweise für wichtige Operationen wie die Zwischenspeicherung von Dateien und
die Abbildaktivierung (Laden und Ausführen von ausführbaren Programmen) verwendet. Der
andere Hauptnutzer der E/A in zugeordneten Dateien ist der Cache-Manager. Dateisysteme
nutzen ihn, um Dateidaten im virtuellen Speicher zuzuordnen und damit die Reaktionszeit von
E/A-abhängigen Programmen zu verbessern. Während der Aufrufer die Datei nutzt, nimmt der
Speicher-Manager die betroffenen Seiten in den Arbeitsspeicher auf. Die meisten Cachingsysteme weisen eine feste Anzahl von Bytes für die Zwischenspeicherung von Dateien im Arbeitsspeicher zu, doch der Windows-Cache wächst und schrumpft je nachdem, wie viel Speicher
zur Verfügung steht. Diese Größenanpassung ist möglich, da sich der Cache-Manager darauf
verlässt, dass der Speicher-Manager den Cache durch die in Kapitel 5 erklärten Mechanismen
für Arbeitssätze automatisch erweitert und verkleinert, wobei diese Mechanismen hier auf den
Systemarbeitssatz angewendet werden. Da der Cache-Manager auf das Auslagerungssystem
des Speicher-Managers zurückgreift, vermeidet er es, die Arbeit, die der Speicher-Manager ohnehin erledigt, erneut auszuführen. (Die Funktionsweise des Cache-Managers wird ausführlich
in Kapitel 14 von Band 2 erklärt.)
Scatter-Gather-E/A
Über die Funktionen ReadFileScatter und WriteFileGather ermöglicht Windows auch eine
Form von Hochleistungs-E/A, die als Scatter-Gather-E/A bezeichnet wird. Mit diesen Funktionen kann eine Anwendung einen einzelnen Lese- oder Schreibvorgang von mehreren Puffern
im virtuellen Speicher zu einem zusammenhängenden Bereich einer Datei auf der Festplatte
anfordern, ohne für jeden Puffer eine eigene E/A-Anforderung ausgeben zu müssen. Dazu
muss die Datei für E/A ohne Caching geöffnet sein, die verwendeten Benutzerpuffer müssen an
Seitengrenzen ausgerichtet und die E/As asynchron sein. Erfolgt die E/A in einem Massenspeichergerät, muss sie außerdem an einer Gerätesektorengrenze ausgerichtet sein und eine Länge
von einem Vielfachen der Sektorengröße aufweisen.
E/A-Verarbeitung
Kapitel 6
589
E/A-Anforderungspakete
In einem E/A-Anforderungspaket (I/O Request Packet, IRP) speichert das E/A-System die Informationen, die es zur Verarbeitung einer E/A-Anforderung benötigt. Wenn ein Thread eine
E/A-API aufruft, erstellt der E/A-Manager ein IRP, das die Operation während ihres Durchlaufs
durch das E/A-System repräsentiert. Wenn möglich weist der E/A-Manager IRPs von einer der
drei vom Prozessor nicht ausgelagerten Look-Aside-Listen für IRPs zu:
QQ Look-Aside-Liste für kleine IRPs Speichert IRPs mit einer Stackposition. (Worum es sich
bei diesen Stackpositionen handelt, erklären wir in Kürze.)
QQ Look-Aside-Liste für mittlere IRPs Enthält IRPs mit vier Stackpositionen (kann aber
auch für IRPs verwendet werden, die nur zwei oder drei Stackpositionen benötigen).
QQ Look-Aside-Liste für große IRPs Enthält IRPs mit mehr als vier Stackpositionen. Standardmäßig speichert das System in dieser Liste IRPs mit 14 Stackpositionen, allerdings
passt es einmal pro Minute die Anzahl der zugewiesenen Stackpositionen an und kann
die Anzahl je nachdem, wie viele Stackpositionen kürzlich erworben wurden, auf bis zu 20
erhöhen.
Hinter diesen Listen stehen auch die globalen Look-Aside-Listen, was einen effizienten
CPU-übergreifenden IRP-Fluss ermöglicht. Wenn ein IRP mehr Stackpositionen benötigt, als die
Liste für große IRPs bietet, weist der E/A-Manager IRPs vom nicht ausgelagerten Pool zu. Zur
Zuweisung von IRPs verwendet der E/A-Manager die Funktion IoAllocateIrp, die auch für die
Entwickler von Gerätetreibern verfügbar ist, da ein Treiber unter Umständen eine E/A-Anforderung direkt dadurch auslösen muss, dass er seine eigenen IRPs erstellt und initialisiert. Nach
der Zuweisung und Initialisierung eines IRPs speichert der E/A-Manager darin einen Zeiger auf
das Dateiobjekt des Aufrufers.
Falls vorhanden, gibt der DWORD-Wert LargeIrpStackLocations im Registrierungsschlüssel HKLM\System\CurrentControlSet\Session Manager\I/O System an, wie
viele Stackpositionen die IRPs auf der Look-Aside-Liste für große IRPs enthalten.
Mit dem Wert MediumIrpStackLocations im selben Schlüssel kann die Anzahl der
Stackpositionen in der Liste für mittlere IRPs geändert werden.
Abb. 6–11 zeigt einige der wichtigen Elemente der IRP-Struktur. Sie wird stets von einem oder
mehreren IO_STACK_LOCATION-Objekten begleitet (siehe den nächsten Abschnitt).
590
Kapitel 6
Das E/A-System
MDL
MdlAddress
MasterIrp
AssociatedIrp
Aktuelle E/A-Stackposition
Zähler der E/A-Stackpositionen
IoStatus
IrpCount
SystemBuffer
Benutzerereignis
Status
Benutzerpuffer
Information
Abbruchroutine
Abbildung 6–11 Wichtige Elemente der IRP-Struktur
Diese Elemente haben folgende Bedeutung:
QQ IoStatus Dies ist der Status des IRPs. Er besteht selbst aus zwei Elementen, nämlich
S tatus mit dem eigentlichen Statuscode und dem polymorphen Wert Information, der
in einigen Fällen eine Bedeutung hat. Beispielsweise gibt dieser (vom Treiber festgelegte)
Wert bei einer Lese- oder Schreiboperation die Anzahl der gelesenen bzw. geschriebenen
Bytes an. Derselbe Wert wird von den Funktionen ReadFile und WriteFile als Ausgabewert
zurückgegeben.
QQ MdlAddress Dies ist ein optionaler Zeiger auf eine Speicherdeskriptorliste (Memory
Descriptor List, MDL), also eine Struktur mit Angaben über einen Puffer im physischen
Speicher. Die Hauptverwendung von MDLs für Gerätetreiber beschreiben wir im nächsten
Abschnitt. Wurde keine MDL angefordert, ist dieser Wert NULL.
QQ Zähler der E/A-Stackpositionen und aktuelle Stackposition Hierin sind die Gesamtzahl der nachfolgenden E/A-Stackpositionsobjekte bzw. ein Zeiger auf die aktuelle Position
gespeichert, die sich diese Treiberschicht ansehen soll. Im nächsten Abschnitt beschäftigen
wir uns eingehender mit Stackpositionen.
QQ Benutzerpuffer Dies ist ein Zeiger auf den von dem Client bereitgestellten Puffer, der
die E/A-Operation ausgelöst hat, beispielsweise der Puffer für die Funktion ReadFile oder
ReadWrite.
QQ Benutzerereignis Dies ist das Kernelereignisobjekt, das ggf. bei einer asynchronen
E/A-Operation verwendet wurde. Ein Ereignis ist eine Möglichkeit, um über den Abschluss
der E/A-Operation zu informieren.
E/A-Verarbeitung
Kapitel 6
591
QQ Abbruchroutine Dies ist die Funktion, die der E/A-Manager aufruft, wenn das IRP abgebrochen wird.
QQ AssociatedIrp Dies ist eine Vereinigung von bis zu drei Feldern: Wenn der E/A-Manager
eine gepufferte E/A-Technik verwendet, wird mit SystemBuffer der Benutzerpuffer an den
Treiber übergeben. Die gepufferte E/A sowie weitere Möglichkeiten, um Benutzermoduspuffer an Treiber zu übergeben, sind Thema des nächsten Abschnitts. Mit dem Element
MasterIrp kann ein Master-IRP erstellt werden, um die Arbeit auf Teil-IRPs aufzuteilen. Der
Master wird dabei erst dann als abgeschlossen betrachtet, wenn alle Teil-IRPs abgeschlossen sind.
E/A-Stackpositionen
Auf ein IRP folgen immer eine oder mehrere E/A-Stackpositionen, wobei die Anzahl dieser
Positionen der Anzahl der geschichteten Geräte in dem zugehörigen Geräteknoten entspricht.
Die Informationen über die E/A-Operation sind auf den IRP-Rumpf (die Hauptstruktur) und
die aktuelle E/A-Stackposition aufgeteilt, wobei aktuell hier die Position bedeutet, die für die
betreffende Geräteschicht eingerichtet ist. Abb. 6–12 zeigt die wichtigen Felder einer E/A-
Stackposition. Beim Erstellen eines IRPs wird die Anzahl der angeforderten Stackpositionen
an IoAllocateIrp übergeben. Der E/A-Manager initialisiert dann den IRP-Rumpf und die erste
Stackposition, die für das oberste Gerät im Geräteknoten da ist. Jede Schicht im Geräteknoten
ist dafür zuständig, die jeweils nächste E/A-Stackposition zu initialisieren, wenn sie den IRP an
das nächste Gerät übergibt.
Die in Abb. 6–12 gezeigten Elemente haben folgende Bedeutung:
QQ Hauptfunktion Dies ist der Hauptcode, der die Art der Anforderung angibt (Lesen,
Schreiben, Erstellen, Plug & Play usw.). Er wird auch als Dispatchroutinencode bezeichnet.
Dabei handelt es sich um eine von 28 Konstanten (0 bis 27) in wdm.h, die alle mit IRP_MJ_
beginnen. Diesen Index nutzt der E/A-Manager im Funktionszeigerarray MajorFunction,
um innerhalb des Treibers zu der benötigten Routine zu springen. In den meisten Treibern
sind Dispatchroutinen nur für einen Teil des möglichen Hauptfunktionscodes definiert, z. B.
zum Erstellen (Öffnen), Lesen und Schreiben, für die Geräte-E/A-Steuerung, für Energieverwaltung, Plug & Play, Systemsteuerung (für WMI-Befehle) und Bereinigung sowie zum
Schließen. Dateisystemtreiber füllen gewöhnlich die meisten oder alle ihrer Dispatcheintrittspunkte mit Funktionen aus. Dagegen sind in einem Treiber für ein einfaches USB-
Gerät meistens nur die Routinen zum Öffnen, Schließen, Lesen und Schreiben und zum
Senden von E/A-Steuercodes angegeben. Der E/A-Manager sorgt dafür, dass die vom
Treiber nicht ausgefüllten Dispatcheintrittspunkte auf seine eigene Funktion IopInvalid
DeviceRequest zeigen. Sie schließt das IRP mit einem Fehlerstatus ab, der angibt, dass die
im IRP angegebene Hauptfunktion für das Gerät ungültig ist.
QQ Nebenfunktion Dies dient bei einigen Funktionen zur Erweiterung des Hauptfunktionscodes. So haben zwar IRP_MJ_READ (Lesen) und IRP_MJ_WRITE (Schreiben) keine Nebenfunktionen, während die IRPs für Plug & Play und Energieverwaltung immer einen Nebenfunktionscode zur weiteren Spezialisierung des Hauptcodes enthalten. Der Hauptfunktionscode
592
Kapitel 6
Das E/A-System
IRP_MJ_PNP für Plug & Play ist so allgemein, dass die eigentliche Anweisung im Nebencode
angegeben wird, z. B. IRP_MN_START_DEVICE, IRP_MN_REMOVE_DEVICE usw.
QQ Parameter Dies ist eine riesige Vereinigung von Strukturen, die jeweils für einen bestimmten Hauptfunktionscode oder eine Kombination aus Haupt- und Nebencode gültig
sind. Beispielsweise enthält die Struktur Parameters.Read für eine Leseoperation (IRP_MJ_
READ) Informationen über die Leseanforderung, darunter die Puffergröße.
QQ FileObject und DeviceObject Diese Elemente zeigen auf die FILE_OBJECT- bzw. DEVICE_
OBJECT-Struktur für die E/A-Anforderung.
QQ CompletionRoutine Dies ist die optionale Vervollständigungsfunktion, die ein Treiber in
der DDI IoSetCompletionRoutine(Ex) registrieren kann und die aufgerufen wird, wenn das
IRP von einem Treiber einer niedrigeren Schicht abgeschlossen wird. An dieser Stelle kann
sich der Treiber den Abschlussstatus des IRPs ansehen und jegliche noch erforderliche abschließende Verarbeitung durchführen. Er kann den Abschluss sogar rückgängig machen
(indem er in der Funktion den besonderen Wert STATUS_MORE_PROCESSING_REQUIRED zurückgibt) und das IRP erneut an den Geräteknoten senden, auch mit geänderten Parametern
oder an einen anderen Geräteknoten.
QQ Kontext Dies ist ein willkürlicher Wert, der mit IoSetCompletionRoutine(Ex) festgelegt
und so wie er ist an die Vervollständigungsroutine übergeben wird.
Hauptfunktion Nebenfunktion
Parameter
FileObject
DeviceObject
CompletionRoutine
Kontext
Abbildung 6–12 Wichtige Elemente der IO_STACK_LOCATION-Struktur
Die Aufteilung der Informationen auf den IRP-Rumpf und die E/A-Stackposition macht es möglich, die Parameter in der Stackposition für das nächste Gerät im Gerätestack zu ändern und
gleichzeitig die ursprünglichen Anforderungsparameter beizubehalten. Beispielsweise wird ein
Lese-IRP für ein USB-Gerät vom Funktionstreiber oft in ein Gerätesteuerungs-IRP geändert,
bei dem das Eingabepufferargument der Gerätesteuerung auf einen USB-Anforderungsblock
(URB) zeigt, das von dem USB-Bustreiber der niedrigeren Schicht verstanden wird. Außerdem
kann jede Schicht (außer der untersten) ihre eigene Vervollständigungsroutine registrieren, wobei jede in der darunter liegenden Stackposition gespeichert wird.
E/A-Verarbeitung
Kapitel 6
593
Experiment: Dispatchroutinen von Treibern untersuchen
Um sich eine Liste der Funktionen anzeigen zu lassen, die ein Treiber für seine Dispatchroutinen definiert hat, verwenden Sie den Kerneldebuggerbefehl !drvobj mit Bit 1 (Wert 2).
Die folgende Ausgabe zeigt die Hauptfunktionscodes der vom NTFS-Treiber unterstützten
Funktionscodes. (Dies ist dasselbe Experiment wie bei der schnellen E/A.)
lkd> !drvobj \filesystem\ntfs 2
Driver object (ffffc404b2fbf810) is for:
\FileSystem\NTFS
DriverEntry:
fffff80e5663a030
NTFS!GsDriverEntry
DriverStartIo: 00000000
DriverUnload:
00000000
AddDevice:
00000000
Dispatch routines:
[00] IRP_MJ_CREATE
fffff80e565278e0 NTFS!NtfsFsdCreate
[01] IRP_MJ_CREATE_NAMED_PIPE
fffff802dc762c80 nt!IopInvalidDeviceRequest
[02] IRP_MJ_CLOSE
fffff80e565258c0 NTFS!NtfsFsdClose
[03] IRP_MJ_READ
fffff80e56436060 NTFS!NtfsFsdRead
[04] IRP_MJ_WRITE
fffff80e564461d0 NTFS!NtfsFsdWrite
[05] IRP_MJ_QUERY_INFORMATION
fffff80e565275f0 NTFS!NtfsFsdDispatchWait
[06] IRP_MJ_SET_INFORMATION
fffff80e564edb80 NTFS!NtfsFsdSetInformation
[07] IRP_MJ_QUERY_EA
fffff80e565275f0 NTFS!NtfsFsdDispatchWait
[08] IRP_MJ_SET_EA
fffff80e565275f0 NTFS!NtfsFsdDispatchWait
[09] IRP_MJ_FLUSH_BUFFERS
fffff80e5653c9a0 NTFS!NtfsFsdFlushBuffers
[0a] IRP_MJ_QUERY_VOLUME_INFORMATION fffff80e56538d10 NTFS!NtfsFsdDispatch
[0b] IRP_MJ_SET_VOLUME_INFORMATION
[0c] IRP_MJ_DIRECTORY_CONTROL
fffff80e56538d10 NTFS!NtfsFsdDispatch
fffff80e564d7080
NTFS!NtfsFsdDirectoryControl
[0d] IRP_MJ_FILE_SYSTEM_CONTROL
fffff80e56524b20
NTFS!NtfsFsdFileSystemControl
[0e] IRP_MJ_DEVICE_CONTROL
fffff80e564f9de0 NTFS!NtfsFsdDeviceControl
[0f] IRP_MJ_INTERNAL_DEVICE_CONTROL fffff802dc762c80 nt!IopInvalidDeviceRequest
[10] IRP_MJ_SHUTDOWN
fffff80e565efb50 NTFS!NtfsFsdShutdown
[11] IRP_MJ_LOCK_CONTROL
fffff80e5646c870 NTFS!NtfsFsdLockControl
[12] IRP_MJ_CLEANUP
fffff80e56525580 NTFS!NtfsFsdCleanup
[13] IRP_MJ_CREATE_MAILSLOT
fffff802dc762c80 nt!IopInvalidDeviceRequest
[14] IRP_MJ_QUERY_SECURITY
fffff80e56538d10 NTFS!NtfsFsdDispatch
[15] IRP_MJ_SET_SECURITY
fffff80e56538d10 NTFS!NtfsFsdDispatch
[16] IRP_MJ_POWER
fffff802dc762c80 nt!IopInvalidDeviceRequest
[17] IRP_MJ_SYSTEM_CONTROL
fffff802dc762c80 nt!IopInvalidDeviceRequest
→
594
Kapitel 6
Das E/A-System
[18] IRP_MJ_DEVICE_CHANGE
fffff802dc762c80 nt!IopInvalidDeviceRequest
[19] IRP_MJ_QUERY_QUOTA
fffff80e565275f0 NTFS!NtfsFsdDispatchWait
[1a] IRP_MJ_SET_QUOTA
fffff80e565275f0 NTFS!NtfsFsdDispatchWait
[1b] IRP_MJ_PNP
fffff80e56566230 NTFS!NtfsFsdPnp
Fast I/O routines:
...
Wenn ein IRP aktiv ist, wird es gewöhnlich in die IRP-Liste des Threads gestellt, der die E/A
angefordert hat. (Bei der in einem eigenen Abschnitt weiter hinten in diesem Kapitel beschriebenen threadagnostischen E/A wird es im Dateiobjekt gespeichert.) Dadurch kann das E/A-System ausstehende IRPs finden und abbrechen, wenn ein Thread mit nicht abgeschlossenen IRPs
beendet wird. IRPs für Auslagerungs-E/A sind außerdem mit dem Fehlerthread verknüpft (obwohl sie nicht abgebrochen werden können). Dadurch kann Windows die Optimierung der
threadagnostischen E/A anwenden, wenn der aktuelle Thread der auslösende Thread ist und
zur Vervollständigung der E/A kein asynchroner Prozeduraufruf (APC) eingesetzt wird. Das bedeutet, dass Seitenfehler inline auftreten und keine APC-Auslieferung erfordern.
Experiment: Die ausstehenden IRPs eines Threads anzeigen
Der Befehl !thread gibt alle mit einem Thread verknüpften IRPs aus. Auf entsprechende
Anweisung macht der Befehl !process das auch. Führen Sie im Kerneldebugger ein lokales
oder ein Live-Debugging durch und lassen Sie sich dabei die Threads eines Explorerprozesses anzeigen:
lkd> !process 0 7 explorer.exe
PROCESS ffffc404b673c780
SessionId: 1 Cid: 10b0 Peb: 00cbb000 ParentCid: 1038
DirBase: 8895f000 ObjectTable: ffffe689011b71c0 HandleCount: <Data Not
Accessible>
Image: explorer.exe
VadRoot ffffc404b672b980 Vads 569 Clone 0 Private 7260. Modified 366527.
Locked 784.
DeviceMap ffffe688fd7a5d30
Token
ffffe68900024920
ElapsedTime
18:48:28.375
UserTime
00:00:17.500
KernelTime
00:00:13.484
...
MemoryPriority BACKGROUND
BasePriority
8
CommitCharge
10789
Job
ffffc404b6075060
→
E/A-Verarbeitung
Kapitel 6
595
THREAD ffffc404b673a080 Cid 10b0.10b4 Teb: 0000000000cbc000 Win32Thread:
ffffc404b66e7090 WAIT: (WrUserRequest) UserMode Non-Alertable
ffffc404b6760740 SynchronizationEvent
Not impersonating
...
THREAD ffffc404b613c7c0 Cid 153c.15a8 Teb: 00000000006a3000 Win32Thread:
ffffc404b6a83910 WAIT: (UserRequest) UserMode Non-Alertable
ffffc404b58d0d60 SynchronizationEvent
ffffc404b566f310 SynchronizationEvent
IRP List:
ffffc404b69ad920: (0006,02c8) Flags: 00060800 Mdl: 00000000
...
In der Ausgabe sehen Sie eine Menge von Threads. Im Abschnitt IRP List der Threadinformationen werden bei den meisten dieser Threads die IRPs angezeigt. (Beachten Sie, dass
der Debugger bei einem Thread mit mehr als 17 ausstehenden E/A-Anforderungen nur die
ersten 17 IRPs ausgibt.) Wählen Sie ein IRP aus und untersuchen Sie es mit dem Befehl !irp:
lkd> !irp ffffc404b69ad920
Irp is active with 2 stacks 1 is current (= 0xffffc404b69ad9f0)
No Mdl: No System Buffer: Thread ffffc404b613c7c0: Irp stack trace.
cmd flg cl Device File Completion-Context
>[IRP_MJ_FILE_SYSTEM_CONTROL(d), N/A(0)]
5 e1 ffffc404b253cc90 ffffc404b5685620 fffff80e55752ed0-ffffc404b63c0e00
Success Error Cancel pending
\FileSystem\Npfs FLTMGR!FltpPassThroughCompletion
Args: 00000000 00000000 00110008 00000000
[IRP_MJ_FILE_SYSTEM_CONTROL(d), N/A(0)]
5 0 ffffc404b3cdca00 ffffc404b5685620 00000000-00000000
\FileSystem\FltMgr
Args: 00000000 00000000 00110008 00000000
Das IRP hat zwei Stackpositionen. Sein Ziel ist ein Gerät, das dem NPFS-Treiber gehört
(Named Pipe File System; siehe Kapitel 10 in Band 2).
596
Kapitel 6
Das E/A-System
IRP-Fluss
IRPs werden gewöhnlich vom E/A-Manager erstellt und dann an das erste Gerät des Zielgeräteknotens gesendet. Abb. 6–13 zeigt einen typischen IRP-Fluss für Hardwaregerätetreiber.
PnP-Manager
Verarbeitung auf dem
Weg nach unten
E/A-Manager
Energieverwaltung
Verarbeitung auf dem
Weg nach oben
Vervollständigungs
routine aufrufen
Vervollständigungsroutine
registrieren
Vervollständigungs
routine aufrufen
Vervollständigungsroutine
registrieren
Vollständige Anforderung
Abbildung 6–13 IRP-Fluss
Allerdings werden IRPs nicht nur vom E/A-Manager, sondern auch vom PnP-Manager und von
der Energieverwaltung angelegt, wobei der Hauptfunktionscode IRP_MJ_PNP bzw. IRP_MJ_POWER
angegeben wird.
Abb. 6–13 zeigt einen Geräteknoten mit sechs geschichteten Geräteobjekten: zwei oberen
Filtern, dem FDO, zwei unteren Filtern und dem PDO. Ein IRP für diesen Knoten wird daher mit
sechs E/A-Stackpositionen erstellt, einer für jede Schicht. IRPs werden immer zu dem Gerät der
höchsten Schicht ausgeliefert, auch wenn ein Handle zu einem benannten Gerät tiefer in dem
Stack geöffnet wurde.
Wenn ein Treiber ein IRP empfängt, kann er eine der folgenden Aktionen ausführen:
QQ Er kann das IRP sofort abschließen, indem er IoCompleteRequest aufruft. Das kann vorkommen, wenn das IRP ungültige Parameter enthält (etwa eine unzureichende Puffergröße oder
einen nicht erkannten E/A-Steuercode) oder wenn es sich bei der angeforderten Operation
um eine handelt, die sofort erledigt werden kann, z. B. um den Abruf eines Gerätestatus
oder das Lesen eines Registrierungswerts. Der Treiber ruft IoGetCurrentIrpStackLocation
auf, um einen Zeiger auf die Stackposition zu erhalten, an die er sich wenden muss.
QQ Der Treiber kann das IRP an die nächste Schicht weiterleiten (und zuvor auch optional eine
gewisse Verarbeitung durchführen). Beispielsweise kann ein oberer Filter einige Protokollierungsaufgaben ausführen und das IRP dann zur eigentlichen Ausführung weiter nach
unten leiten. Vor dieser Übergabe muss er jedoch die nächste E/A-Stapelposition vorbereiten, die der nächste Treiber in der Reihe verwenden soll. Wenn er keine Änderungen
E/A-Verarbeitung
Kapitel 6
597
vornehmen will, kann er das Makro IoSkipCurrentIprStackLocation nutzen. Anderenfalls
kann er mit IoCopyIrpStackLocationToNext eine Kopie der Stackposition erstellen und sie
ändern, indem er mit IoGetNextIrpStackLocation einen Zeiger darauf abruft. Nachdem er
die nächste E/A-Stackposition vorbereitet hat, ruft der Treiber IoCallDriver auf, um das
IRP weiterzuleiten.
QQ Als Erweiterung der vorstehenden Möglichkeit kann der Treiber auch eine Vervollständigungsroutine registrieren, indem er vor der Weitergabe des IRPs IoSetCompletionRoutine(Ex)
aufruft. Jede Schicht außer der untersten kann eine solche Vervollständigungsroutine registrieren. (In der untersten Schicht wäre das sinnlos, da dieser Treiber das IRP abschließen muss,
weshalb kein Callback erforderlich ist.) Nachdem ein Treiber einer tieferen Schicht IoCompleteRequest aufgerufen hat, wandert das IRP wieder nach oben (siehe Abb. 6–13), wobei
die vorhandenen Vervollständigungsroutinen in umgekehrter Reihenfolge der Registrierung
aufgerufen werden. Der Ursprung des IRPs (E/A-Manager, PnP-Manager oder Energieverwaltung) verwendet diesen Mechanismus, um eine abschließende Verarbeitung am IRP
durchzuführen und es schließlich freizugeben.
Da die Anzahl der Geräte auf einem Stack im Voraus bekannt ist, weist der E/A-Manager für jeden beteiligten Gerätetreiber eine Stackposition zu. Es gibt jedoch
Situationen, in denen ein IRP zu einem neuen Treiberstack weitergeleitet werden
kann. Dies kann etwa bei der Verwendung des Filter-Managers geschehen, der
es einem Filter ermöglicht, ein IRP zu einem anderen Filter umzuleiten (z. B. von
einem lokalen zu einem Netzwerkdateisystem). Der E/A-Manager stellt die API
IoAdjustStackSizeForRedirection bereit, die diese Vorgehensweise ermöglicht,
indem sie die erforderlichen Stackpositionen anhand der Geräte auf dem Umleitungsstack hinzufügt.
Experiment: Einen Gerätestack anzeigen
Der Kerneldebuggerbefehl !devstack zeigt den Gerätestack der geschichteten Geräteobjekte für das angegebene Geräteobjekt an. In dem folgenden Beispiel sehen Sie den Stack
für das Geräteobjekt \device\keyboardclass0, das dem Tastatur-Klassentreiber gehört:
lkd> !devstack keyboardclass0
!DevObj
!DrvObj
!DevExt
ObjectName
\Driver\kbdclass
ffff9c80c0424590
KeyboardClass0
ffff9c80c04247c0
\Driver\kbdhid
ffff9c80c0424910
ffff9c80c0414060
\Driver\mshidkmdf
ffff9c80c04141b0
> ffff9c80c0424440
0000003f
!DevNode ffff9c80c0414d30 :
DeviceInst is "HID\MSHW0029&Col01\5&1599b1c7&0&0000"
ServiceName is "kbdhid"
Das Zeichen > in der ersten Spalte der Ausgabe hebt den Eintrag für KeyboardClass0 hervor.
Die Einträge oberhalb dieser Zeile sind Treiber oberhalb dieser Schicht, die Zeilen darunter
Treiber unterhalb der Schicht.
598
Kapitel 6
Das E/A-System
Experiment: IRPs untersuchen
In diesem Experiment suchen Sie nach einem nicht abgeschlossenen IRP auf dem System und bestimmen des1sen Typ, das Zielgerät, den Treiber, der das Gerät verwaltet, den
Thread, der das IRP ausgegeben hat, und den Prozess, zu dem dieser Thread gehört. Am
besten führen Sie dieses Experiment auf einem 32-Bit-System mit nicht lokalem Kerneldebugging durch. Es funktioniert zwar auch mit lokalem Kerneldebugging, aber dabei kann
es sein, dass die IRPs in der Zeit zwischen der Ausgabe der einzelnen Befehle abgeschlossen
werden, sodass Sie mit uneinheitlichen Daten rechnen müssen.
Auf einem System gibt es immer einige nicht abgeschlossene IRPs, da es viele Geräte gibt, für die Anwendungen IRPs ausgeben können, und die Treiber die IRPs erst dann
abschließen, wenn ein bestimmtes Ereignis eintritt, z. B. wenn die Daten zur Verfügung
stehen. Ein Beispiel dafür ist ein blockierender Lesevorgang von einem Netzwerkendpunkt.
Mit dem Kerneldebuggerbefehl !irpfind können Sie sich die ausstehenden IRPs auf einem
System ansehen. (Dieser Befehl kann einige Zeit in Anspruch nehmen. Sie können ihn aber
anhalten, sobald einige IRPs erschienen sind.)
kd> !irpfind
Scanning large pool allocation table for tag 0x3f707249 (Irp?) (a5000000 :
a5200000)
Irp
[ Thread ] irpStack: (Mj,Mn) DevObj
[Driver]
MDL Process
9515ad68 [aa0c04c0] irpStack: ( e, 5) 8bcb2ca0 [ \Driver\AFD] 0xaa1a3540
8bd5c548 [91deeb80] irpStack: ( e,20) 8bcb2ca0 [ \Driver\AFD] 0x91da5c40
Searching nonpaged pool (80000000 : ffc00000) for tag 0x3f707249 (Irp?)
86264a20 [86262040] irpStack: ( e, 0) 8a7b4ef0 [ \Driver\vmbus]
86278720 [91d96b80] irpStack: ( e,20) 8bcb2ca0 [ \Driver\AFD] 0x86270040
86279e48 [91d96b80] irpStack: ( e,20) 8bcb2ca0 [ \Driver\AFD] 0x86270040
862a1868 [862978c0] irpStack: ( d, 0) 8bca4030 [ \FileSystem\Npfs]
862a24c0 [86297040] irpStack: ( d, 0) 8bca4030 [ \FileSystem\Npfs]
862c3218 [9c25f740] irpStack: ( c, 2) 8b127018 [ \FileSystem\NTFS]
862c4988 [a14bf800] irpStack: ( e, 5) 8bcb2ca0 [ \Driver\AFD] 0xaa1a3540
862c57d8 [a8ef84c0] irpStack: ( d, 0) 8b127018 [ \FileSystem\NTFS] 0xa8e6f040
862c91c0 [99ac9040] irpStack: ( 3, 0) 8a7ace48 [ \Driver\vmbus] 0x9517ac40
862d2d98 [9fd456c0] irpStack: ( e, 5) 8bcb2ca0 [ \Driver\AFD] 0x9fc11780
862d6528 [9aded800] irpStack: ( c, 2) 8b127018 [ \FileSystem\NTFS]
862e3230 [00000000] Irp is complete (CurrentLocation 2 > StackCount 1)
862ec248 [862e2040] irpStack: ( d, 0) 8bca4030 [ \FileSystem\Npfs]
862f7d70 [91dd0800] irpStack: ( d, 0) 8bca4030 [ \FileSystem\Npfs]
863011f8 [00000000] Irp is complete (CurrentLocation 2 > StackCount 1)
→
E/A-Verarbeitung
Kapitel 6
599
86327008 [00000000] Irp is complete (CurrentLocation 43 > StackCount 42)
86328008 [00000000] Irp is complete (CurrentLocation 43 > StackCount 42)
86328960 [00000000] Irp is complete (CurrentLocation 43 > StackCount 42)
86329008 [00000000] Irp is complete (CurrentLocation 43 > StackCount 42)
863296d8 [00000000] Irp is complete (CurrentLocation 2 > StackCount 1)
86329960 [00000000] Irp is complete (CurrentLocation 43 > StackCount 42)
89feeae0 [00000000] irpStack: ( e, 0) 8a765030 [ \Driver\ACPI]
8a6d85d8 [99aa1040] irpStack: ( d, 0) 8b127018 [ \FileSystem\NTFS] 0x00000000
8a6dc828 [8bc758c0] irpStack: ( 4, 0) 8b127018 [ \FileSystem\NTFS] 0x00000000
8a6f42d8 [8bc728c0] irpStack: ( 4,34) 8b0b8030 [ \Driver\disk] 0x00000000
8a6f4d28 [8632e6c0] irpStack: ( 4,34) 8b0b8030 [ \Driver\disk] 0x00000000
8a767d98 [00000000] Irp is complete (CurrentLocation 6 > StackCount 5)
8a788d98 [00000000] irpStack: ( f, 0) 00000000 [00000000: Could not read device
object or _DEVICE_OBJECT not found
]
8a7911a8 [9fdb4040] irpStack: ( e, 0) 86325768 [ \Driver\DeviceApi]
8b03c3f8 [00000000] Irp is complete (CurrentLocation 2 > StackCount 1)
8b0b8bc8 [863d6040] irpStack: ( e, 0) 8a78f030 [ \Driver\vmbus]
8b0c48c0 [91da8040] irpStack: ( e, 5) 8bcb2ca0 [ \Driver\AFD] 0xaa1a3540
8b118d98 [00000000] Irp is complete (CurrentLocation 9 > StackCount 8)
8b1263b8 [00000000] Irp is complete (CurrentLocation 8 > StackCount 7)
8b174008 [aa0aab80] irpStack: ( 4, 0) 8b127018 [ \FileSystem\NTFS] 0xa15e1c40
8b194008 [aa0aab80] irpStack: ( 4, 0) 8b127018 [ \FileSystem\NTFS] 0xa15e1c40
8b196370 [8b131880] irpStack: ( e,31) 8bcb2ca0 [ \Driver\AFD]
8b1a8470 [00000000] Irp is complete (CurrentLocation 2 > StackCount 1)
8b1b3510 [9fcd1040] irpStack: ( e, 0) 86325768 [ \Driver\DeviceApi]
8b1b35b0 [a4009b80] irpStack: ( e, 0) 86325768 [ \Driver\DeviceApi]
8b1cd188 [9c3be040] irpStack: ( e, 0) 8bc73648 [ \Driver\Beep]
...
Einige IRPs sind abgeschlossen, und bei anderen kann die Zuweisung bald aufgehoben
werden. Es kann auch sein, dass die Zuweisung schon aufgehoben ist, das IRP aber noch
nicht durch ein neues ersetzt wurde, da die Zuweisung von einer Look-Aside-Liste stammte.
Für jedes IRP wird die Adresse gefolgt von dem Thread angegeben, der die Anforderung ausgegeben hat. Darauf folgen der Haupt- und der Nebenfunktionscode der aktuellen
Stackposition in Klammern. Um ein IRP zu untersuchen, verwenden Sie den Befehl !irp:
kd> !irp 8a6f4d28
Irp is active with 15 stacks 6 is current (= 0x8a6f4e4c)
Mdl=8b14b250: No System Buffer: Thread 8632e6c0: Irp stack trace.
cmd flg cl Device File Completion-Context
[N/A(0), N/A(0)]
0 0 00000000 00000000 00000000-00000000
→
600
Kapitel 6
Das E/A-System
Args: 00000000 00000000 00000000 00000000
[N/A(0), N/A(0)]
0 0 00000000 00000000 00000000-00000000
Args: 00000000 00000000 00000000 00000000
[N/A(0), N/A(0)]
0 0 00000000 00000000 00000000-00000000
Args: 00000000 00000000 00000000 00000000
[N/A(0), N/A(0)]
0 0 00000000 00000000 00000000-00000000
Args: 00000000 00000000 00000000 00000000
[N/A(0), N/A(0)]
0 0 00000000 00000000 00000000-00000000
Args: 00000000 00000000 00000000 00000000
>[IRP_MJ_WRITE(4), N/A(34)]
14 e0 8b0b8030 00000000 876c2ef0-00000000 Success Error Cancel
\Driver\disk partmgr!PmIoCompletion
Args: 0004b000 00000000 4b3a0000 00000002
[IRP_MJ_WRITE(4), N/A(3)]
14 e0 8b0fc058 00000000 876c36a0-00000000 Success Error Cancel
\Driver\partmgr partmgr!PartitionIoCompletion
Args: 4b49ace4 00000000 4b3a0000 00000002
[IRP_MJ_WRITE(4), N/A(0)]
14 e0 8b121498 00000000 87531110-8b121a30 Success Error Cancel
\Driver\partmgr volmgr!VmpReadWriteCompletionRoutine
Args: 0004b000 00000000 2bea0000 00000002
[IRP_MJ_WRITE(4), N/A(0)]
4 e0 8b121978 00000000 82d103e0-8b1220d9 Success Error Cancel
\Driver\volmgr fvevol!FvePassThroughCompletionRdpLevel2
Args: 0004b000 00000000 4b49acdf 00000000
[IRP_MJ_WRITE(4), N/A(0)]
4 e0 8b122020 00000000 82801a40-00000000 Success Error Cancel
\Driver\fvevol rdyboost!SmdReadWriteCompletion
Args: 0004b000 00000000 2bea0000 00000002
[IRP_MJ_WRITE(4), N/A(0)]
4 e1 8b118538 00000000 828637d0-00000000 Success Error Cancel pending
\Driver\rdyboost iorate!IoRateReadWriteCompletion
Args: 0004b000 3fffffff 2bea0000 00000002
[IRP_MJ_WRITE(4), N/A(0)]
4 e0 8b11ab80 00000000 82da1610-8b1240d8 Success Error Cancel
\Driver\iorate volsnap!VspRefCountCompletionRoutine
Args: 0004b000 00000000 2bea0000 00000002
→
E/A-Verarbeitung
Kapitel 6
601
[IRP_MJ_WRITE(4), N/A(0)]
4 e1 8b124020 00000000 87886ada-89aec208 Success Error Cancel pending
\Driver\volsnap NTFS!NtfsMasterIrpSyncCompletionRoutine
Args: 0004b000 00000000 2bea0000 00000002
[IRP_MJ_WRITE(4), N/A(0)]
4 e0 8b127018 a6de4bb8 871227b2-9ef8eba8 Success Error Cancel
\FileSystem\NTFS FLTMGR!FltpPassThroughCompletion
Args: 0004b000 00000000 00034000 00000000
[IRP_MJ_WRITE(4), N/A(0)]
4 1 8b12a3a0 a6de4bb8 00000000-00000000 pending
\FileSystem\FltMgr
Args: 0004b000 00000000 00034000 00000000
Irp Extension present at 0x8a6f4fb4:
Dieses Monster-IRP verfügt über 15 Stackpositionen, wobei die fett hervorgehobene Position und im Debugger mit > gekennzeichnete Position 6 die aktuelle ist. Für jede Stackposition sind die Haupt- und Nebenfunktion sowie Adressen des Geräteobjekts und der
Vervollständigungsroutinen angegeben.
Der nächste Schritt besteht darin, den Befehl !devobj auf die Geräteobjektadresse in
der aktuellen Stackposition anzuwenden, um das Zielobjekt des IRP zu ermitteln:
kd> !devobj 8b0b8030
Device object (8b0b8030) is for:
DR0 \Driver\disk DriverObject 8b0a7e30
Current Irp 00000000 RefCount 1 Type 00000007 Flags 01000050
Vpb 8b0fc420 SecurityDescriptor 87da1b58 DevExt 8b0b80e8 DevObjExt 8b0b8578
Dope
8b0fc3d0
ExtensionFlags (0x00000800) DOE_DEFAULT_SD_PRESENT
Characteristics (0x00000100) FILE_DEVICE_SECURE_OPEN
AttachedDevice (Upper) 8b0fc058 \Driver\partmgr
AttachedTo (Lower) 8b0a4d10 \Driver\storflt
Device queue is not busy.
Schließlich können Sie sich mit !thread Angaben zu dem Thread und dem Prozess ansehen,
die das IRP ausgegeben haben:
kd> !thread 8632e6c0
THREAD 8632e6c0 Cid 0004.0058 Teb: 00000000 Win32Thread: 00000000 WAIT:
(Executive) KernelMode Non-Alertable
89aec20c NotificationEvent
IRP List:
8a6f4d28: (0006,02d4) Flags: 00060043 Mdl: 8b14b250
→
602
Kapitel 6
Das E/A-System
Not impersonating
DeviceMap
87c025b0
Owning Process
86264280
Image: System
Attached Process
N/A
Image: N/A
Wait Start TickCount 8083
Ticks: 1 (0:00:00:00.015)
Context Switch Count 2223
IdealProcessor: 0
UserTime
00:00:00.000
KernelTime
00:00:00.046
Win32 Start Address nt!ExpWorkerThread (0x81e68710)
Stack Init 89aecca0 Current 89aebeb4 Base 89aed000 Limit 89aea000 Call 00000000
Priority 13 BasePriority 13 PriorityDecrement 0 IoPriority 2 PagePriority 5
E/A-Anforderungen an einen einschichtigen Hardwaretreiber
In diesem Abschnitt sehen wir uns E/A-Anforderungen an einen einschichtigen Kernelmodus-Gerätetreiber genauer an. Abb. 6–14 zeigt den typischen Verlauf der IRP-Verarbeitung für
einen solchen Treiber.
Benutzermodus
Aufruf von z. B. ReadFile
durch die App
Kernelmodus
Validierung der Anforderung
Kontext des anfordernden Threads
Dispatchroutine
Kontext eines beliebigen Threads
E/A-Startroutine
Geräteinterrupt
Softwareinterrupt (DPC)
ISR
DPC-Routine
Kontext eines beliebigen Threads
Kontext des anfordernden Threads
Besonderer Kernel-APC
Abbildung 6–14 Typische einschichtige Verarbeitung von E/A-Anforderungen für Hardwaretreiber
Bevor wir uns die einzelnen Schritte in Abb. 6–14 genauer ansehen, sind einige allgemeine
Hinweise angebracht:
QQ In der Abbildung sind zwei Arten von horizontalen Trennlinien zu sehen. Die erste, durchgezogene Linie ist die übliche Trennung zwischen Benutzer- und Kernelmodus. Die gestri-
E/A-Verarbeitung
Kapitel 6
603
chelten Linien dagegen setzen den Code, der im Kontext des anfordernden Threads läuft,
von dem Code im Kontext eines beliebigen Threads ab. Definiert sind diese Kontexte wie
folgt:
•
In dem Abschnitt, der zum Kontext des anfordernden Threads gehört, ist der ausführende Thread derjenige, der ursprünglich die E/A-Operation angefordert hat. Das ist
wichtig, denn das bedeutet, dass auch der Prozesskontext derjenige des ursprünglichen Prozesses ist, weshalb der Benutzermodus-Adressraum, der den an die E/A-Operation übergebenen Benutzerpuffer enthält, direkt zugänglich ist.
•
In dem Abschnitt, der zum Kontext eines beliebigen Threads gehört, ist der Thread
sehr wahrscheinlich nicht der anfordernde Thread, weshalb der sichtbare Benutzermodus-Prozessadressraum sehr wahrscheinlich nicht der des ursprünglichen Prozesses ist.
In diesem Kontext kann der Versuch, mit einer Benutzermodusadresse auf den Benutzerpuffer zuzugreifen, katastrophale Folgen haben. Im nächsten Abschnitt erfahren Sie,
wie dieses Problem gehandhabt wird.
Die Erklärungen für die in Abb. 6–14 gezeigten Schritte machen deutlich, warum
sich die Trennlinien an den angegebenen Stellen befinden.
QQ Das große Viereck um die vier Blöcke Dispatchroutine, E/A-Startroutine, ISR und DPC-Routine kennzeichnet den vom Treiber bereitgestellten Code. Alle anderen Blöcke werden vom
System bereitgestellt.
QQ In der Abbildung ist vorausgesetzt, dass das Hardwaregerät nur eine Operation auf einmal
handhaben kann, was bei vielen Arten von Geräten der Fall ist. Selbst wenn das Gerät mit
mehreren Anforderungen umgehen kann, bleibt der grundlegende Verlauf der Operation
doch identisch.
Wie in Abb. 6–14 gezeigt, laufen die Ereignisse wie folgt ab:
1.
Eine Clientanwendung ruft eine Windows-API wie ReadFile auf, die ihrerseits die native
Funktion NtReadFile (in Ntdll.dll) aufruft. Diese wiederum überführt den Thread in den
Kernelmodus zu der Exekutivfunktion NtReadFile. (Diese Schritte wurden bereits weiter
vorn in diesem Kapitel beschrieben.)
2.
Der E/A-Manager in der Implementierung von NtReadFile führt einige Sicherheitsprüfungen an der Anforderung durch, z. B. ob der vom Client bereitgestellte Puffer mit dem richtigen Seitenschutz zugänglich ist. Anschließend sucht der E/A-Manager den zugehörigen
Treiber (mithilfe des bereitgestellten Dateihandles), weist ein IRP zu und initialisiert es und
ruft den Treiber in der passenden Dispatchroutine auf (in diesem Fall in der Routine, die
dem Index IRP_MJ_READ entspricht), indem er IoCallDriver mit dem IRP verwendet.
3.
Jetzt sieht der Treiber das IRP zum ersten Mal. Der Aufruf erfolgt gewöhnlich über den
aufrufenden Thread. Die einzige Möglichkeit, um das zu verhindern, besteht darin, einen oberen Filter auf dem IRP einzusetzen und IoCallDriver später von einem anderen
Thread aus aufzurufen. Wir gehen hier jedoch davon aus, dass das nicht der Fall ist. (Bei
den meisten Hardwaregeräten geschieht das auch tatsächlich nicht. Selbst wenn es obere
604
Kapitel 6
Das E/A-System
Filter gibt, so führen sie lediglich eine gewisse Verarbeitung aus und rufen dann sofort den
unteren Treiber aus demselben Thread heraus auf.) Der Dispatch-Lesecallback im Treiber
hat zwei Aufgaben: Erstens führt er weitere Überprüfungen durch, die der E/A-Manager
nicht leisten konnte, da er keine Vorstellung davon hatte, was die Anforderung tatsächlich
bedeuten sollte. Beispielsweise kann der Treiber prüfen, ob der für eine Lese- oder Schreib
operation bereitgestellte Puffer groß genug ist oder ob der für eine DeviceIoControl-Ope
ration angegebene E/A-Steuercode unterstützt wird. Schlägt eine dieser Überprüfungen
fehl, schließt der Treiber das IRP mit dem Status »fehlgeschlagen« ab (IoCompleteRequest)
und gibt sofort die Steuerung zurück. Bei bestandenen Überprüfungen dagegen ruft der
Treiber seine E/A-Startroutine auf, um die Operation auszulösen. Ist das Hardwaregerät
jedoch gerade beschäftigt (weil es sich um ein vorheriges IRP kümmert), wird das IRP in
eine vom Treiber verwaltete Warteschlange gestellt. In diesem Fall wird STATUS_PENDING
zurückgegeben, ohne das IRP abzuschließen. Der E/A-Manager nutzt dazu die Funktion
IoStartPacket, die das Busy-Bit im Geräteobjekt überprüft und das IRP in die Warteschlange stellt, wenn das Gerät beschäftigt ist. (Die Warteschlange ist dabei ein Teil der Struktur
für das Geräteobjekt.) Ist das Gerät nicht beschäftigt, setzt der E/A-Manager das Busy-Bit
und ruft die registrierte E/A-Startroutine auf (es gibt ein entsprechendes Element in dem
Treiberobjekt, das in DriverEntry initialisiert wurde). Selbst wenn der Treiber IoStartPacket
nicht verwendet, folgt er einer ähnlichen Logik.
4.
Wenn das Gerät nicht beschäftigt ist, wird die E/A-Startroutine unmittelbar von der
Dispatchroutine aufgerufen, was bedeutet, dass dieser Aufruf immer noch durch den anfordernden Thread erfolgt. In Abb. 6–14 dagegen wird die E/A-Startroutine im Kontext
eines beliebigen Threads aufgerufen. Wie Sie bei der Betrachtung der DPC-Routine in
Schritt 8 sehen werden, ist das im Allgemeinen der Fall. Die E/A-Startroutine ist dazu da,
das Hardwaregerät mithilfe der relevanten Parameter für das IRP zu programmieren (indem sie beispielsweise mithilfe von HAL-Hardwarezugriffsroutinen wie WRITE_PORT_UCHAR,
WRITE_REGISTER_ULONG usw. in dessen Port oder Register schreibt). Nach dem Abschluss der
E/A-Startroutine springt der Aufruf zurück. Im Treiber läuft jetzt kein besonderer Code, die
Hardware funktioniert und erledigt ihre Aufgabe. Während das Hardwaregerät arbeitet,
können weitere Anweisungen für das Gerät hereinkommen, und zwar sowohl über denselben Thread (bei Verwendung asynchroner Operationen) als auch über andere Threads,
die Handles für das Gerät geöffnet haben. Wenn das passiert, erkennt die Dispatchroutine,
dass das Gerät beschäftigt ist, und stellt das IRP in die Warteschlange. (Wie bereits erwähnt, besteht eine Möglichkeit dazu, IoStartPacket aufzurufen.)
5.
Wenn das Gerät die laufende Operation abgeschlossen hat, löst es einen Interrupt aus. Der
Traphandler des Kernels speichert den CPU-Kontext für den Thread, der gerade auf der zur
Handhabung des Interrupts ausgewählten CPU läuft, hebt die IRQL dieser CPU auf die für
den Interrupt an (DIRQL) und springt zu der registrierten ISR für das Gerät.
6.
Die ISR, die auf einer Geräte-IRQL läuft (größer 2), führt so wenig Arbeiten durch wie
möglich, weist das Gerät an, das Interruptsignal zu beenden, und ruft den Status oder andere erforderliche Informationen von dem Hardwaregerät ab. Als letzte Maßnahme stellt
die ISR einen DPC für die weitere Verarbeitung auf einer niedrigeren IRQL in eine Warteschlange. Der Vorteil der Verwendung eines DPCs für den Großteil der Geräteaufgaben
E/A-Verarbeitung
Kapitel 6
605
besteht darin, dass blockierte Interrupts mit IRQLs zwischen der Geräte-IRQL und der DPC/
Dispatch-IRQL (2) auftreten können, bevor der DPC mit niedrigerer Priorität verarbeitet
wird. Interrupts auf einer mittleren Ebene werden daher schneller verarbeitet, als es sonst
möglich wäre, was die Latenz des Systems verringert.
7.
Nachdem der Interrupt verworfen wurde, erkennt der Kernel, dass die DPC-Warteschlange
nicht leer ist, und verwendet daher einen Softwareinterrupt auf der IRQL DPC_LEVEL (2), um
zu der DPC-Verarbeitungsschleife zu springen.
8.
Schließlich wird der DPC aus der Warteschlange genommen und auf IRQL 2 ausgeführt,
wobei er gewöhnlich die beiden folgenden Hauptoperationen erledigt:
9.
•
Er ruft ggf. das nächste IRP in der Warteschlange auf und beginnt mit der neuen Operation für das Gerät. Dies geschieht als Erstes, damit das Gerät nicht zu lange im Leerlauf ist. Hat die Dispatchroutine IoStartPacket verwendet, dann hat die DPC-Routine
deren Gegenstück IoStartNextPacket aufgerufen, die die hier beschriebene Aufgabe
ausführt. Ist ein IRP verfügbar, wird die E/A-Startroutine vom DPC aufgerufen. Aus
diesem Grunde erfolgt dieser Aufruf im Allgemeinen im Kontext eines willkürlichen
Threads. Befinden sich keine IRPs in der Warteschlange, wird das Gerät als unbeschäftigt gekennzeichnet, also als bereit für die nächste eingehende Anforderung.
•
Er schließt das IRP ab, dessen Operation gerade von dem Treiber durch Aufruf von
IoCompleteRequest beendet wurde. Jetzt ist der Treiber nicht mehr für das IRP verantwortlich. Es sollte auch nicht mehr angefasst werden, da es nach dem Aufruf jeden
Augenblick freigegeben werden kann. IoCompleteRequest ruft jegliche registrierten
Beendigungsroutinen ab. Schließlich gibt der E/A-Manager das IRP frei (wozu er eine
eigene Beendigungsroutine verwendet).
Der ursprünglich anfordernde Thread muss über den Abschluss benachrichtigt werden.
Der DPC wird aber zurzeit in einem beliebigen Thread ausgeführt, also sehr wahrscheinlich nicht in dem ursprünglichen Thread mit dem ursprünglichen Prozessadressraum. Um
Code im Kontext des anfordernden Threads aufzuführen, wird ein besonderer Kernel-APC
an den Thread ausgegeben. Ein APC ist eine Funktion, die zwangsweise im Kontext eines bestimmten Threads ausgeführt wird. Wenn der anfordernde Thread CPU-Zeit erhält,
wird als Erstes der besondere Kernel-APC ausgeführt (auf der IRQL APC_LEVEL, also 1). Er
erledigt die erforderlichen Aufgaben, also z. B. die Befreiung des Threads aus dem Wartezustand, die Signalisierung eines in einer asynchronen Operation registrierten Ereignisses
usw. (Mehr über APCs erfahren Sie in Kapitel 8 von Band 2.)
Noch ein letztes Wort zur E/A-Beendigung: Die asynchronen E/A-Funktionen ReadFileEx und
WriteFileEx erlauben dem Aufrufer, eine Callbackfunktion als Parameter bereitzustellen. Wenn
der Aufrufer diese Vorkehrung nutzt, stellt der E/A-Manager im letzten Schritt der E/A-Beendigung einen Benutzermodus-APC in die APC-Warteschlange im Thread des Aufrufers. Dadurch
kann der Aufrufer eine Subroutine angeben, die aufgerufen wird, wenn eine E/A-Anforderung
abgeschlossen oder abgebrochen wird. APC-Beendigungsroutinen im Benutzermodus werden
im Kontext des anfordernden Threads ausgeführt und nur dann ausgeliefert, wenn der Thread
in einen benachrichtigungsfähigen Wartezustand eintritt (durch den Aufruf von Funktionen
wie SleepEx, WaitForSingleObjectEx und WaitForMultipleObjectsEx).
606
Kapitel 6
Das E/A-System
Zugriff auf den Benutzer-Adressraumpuffer
Wie Abb. 6–14 zeigt, sind an der Verarbeitung eines IRPs vier Haupttreiberfunktionen beteiligt.
Diese Routinen müssen unter Umständen auf den von der Clientanwendung bereitgestellten
Puffer im Benutzerraum zugreifen. Wenn eine Anwendung oder ein Gerätetreiber mithilfe der
Systemdienste NtReadFile, NtWriteFile oder NtDeviceIoControlFile (oder den entsprechenden
Windows-API-Funktionen ReadFile, WriteFile und DeviceIoFile) indirekt ein IRP erstellt, wird
der Zeiger auf den Puffer des Benutzers im Element UserBuffer des IRP-Rumpfes bereitgestellt.
Ein direkter Zugriff auf diesen Puffer kann jedoch nur im Kontext des anfordernden Threads
(in dem der Prozessadressraum des Clients sichtbar ist) und auf IRQL 0 erfolgen (auf der die
Auslagerung normal verläuft).
Wir bereits im vorherigen Abschnitt erwähnt, erfüllt nur die Dispatchroutine diese beiden
Kriterien – und das nicht einmal in jedem Fall! Es ist möglich, dass ein oberer Filter das IRP
festhält und nicht sofort nach unten übergibt, sondern später über einen anderen Thread, was
obendrein auf der CPU-IRQL 2 oder höher geschehen kann.
Die drei anderen Funktionen (E/A-Start, ISR und DPC) laufen auf jeden Fall im Kontext
eines beliebigen Threads und auf IRQL 2 (DIRQL für die ISR). Ein direkter Zugriff auf den Benutzerpuffer von einer dieser Routinen aus ist gewöhnlich katastrophal, und zwar aus folgenden
Gründen:
QQ Da der Thread auf IRQL 2 oder höher ausgeführt wird, ist keine Auslagerung erlaubt. Der
Benutzerpuffer (oder Teile davon) können aber ausgelagert sein, weshalb ein Zugriff auf
den nicht residenten Speicher zu einem Absturz führt.
QQ Da die Funktionen in einem willkürlichen Thread ausgeführt werden und daher ein zufälliger Prozessadressraum sichtbar ist, hat die ursprüngliche Benutzerraumadresse keine
Bedeutung. Ein Zugriff darauf führt sehr wahrscheinlich zu einer Zugriffsverletzung oder,
was noch schlimmer ist, zu einem Zugriff auf Daten eines willkürlichen Prozesses (des Elternprozesses des zurzeit ausgeführten Threads).
Es muss daher eine gefahrlose Vorgehensweise geben, um von diesen Routinen aus auf den
Benutzerpuffer zuzugreifen. Der E/A-Manager bietet dafür zwei Möglichkeiten, für die er die
Hauptarbeit übernimmt, nämlich gepufferte und direkte E/A. Es gibt noch eine dritte Möglichkeit, die »Weder/noch-E/A« (Neither I/O), die aber keine Vorgehensweise im Sinne des Wortes
ist. Dabei tut der E/A-Manager nichts, sondern lässt das Problem vom Treiber lösen.
Der Treiber wählt die einzusetzende Methode wie folgt aus:
QQ Für Lese- und Schreibanforderungen (IRP_MJ_READ und IRP_MJ_WRITE) setzt er das Element
Flags (in einer booleschen Oder-Operation, um andere Flags nicht zu beeinträchtigen) des
Geräteobjekts (DEVICE_OBJECT) auf DO_BUFFERED_IO (für gepufferte E/A) oder DO_DIRECT_IO
(für direkte E/A). Ist keines dieser Flags gesetzt, so bedeutet das Neither I/O. (DO steht hier
für Device Object, also Geräteobjekt.)
QQ Für Gerätesteuerungsanforderungen (IRP_MJ_DEVICE_CONTROL) werden die einzelnen Steuercodes mithilfe des Makros CTL_CODE zusammengesetzt. Einige der Bits dienen dabei zur
Angabe der Puffermethode. Dadurch kann die Puffermethode für jeden Steuercode einzeln festgelegt werden, was sehr praktisch ist.
E/A-Verarbeitung
Kapitel 6
607
Im folgenden Abschnitt werden die Puffermethoden ausführlich beschrieben.
Gepufferte E/A Bei der gepufferten E/A weist der E/A-Manager im nicht ausgelagerten
Pool einen Spiegelpuffer zu, der die gleiche Größe hat wie der Benutzerpuffer, und speichert im
Element AssociatedIrp.SystemBuffer des IRP-Rumpfes einen Zeiger auf diesen neuen Puffer.
Abb. 6–15 zeigt die Hauptphasen der gepufferten E/A für eine Leseoperation, wobei der Vorgang bei Schreiboperationen ähnlich ist.
Kernelraum
Kernelraum
Kernelpuffer
RAM
Benutzerpuffer
Benutzerpuffer
Benutzerraum
Benutzerraum
Der Benutzerclient weist den Puffer
zu und ruft die Leseoperation auf
Der E/A-Manager weist den Puffer im
nicht ausgelagerten Pool zu
Kernelraum
Kernelraum
Daten
Daten
Kopieren
RAM
Benutzerpuffer
Benutzerraum
Der Treiber schreibt Daten in
den Kernelpuffer
Daten
Daten
Benutzerraum
Nach dem Abschluss des IRPs kopiert der
E/A-Manager die Daten in den Benutzer
puffer und gibt den Kernelpuffer frei
Abbildung 6–15 Gepufferte E/A
Der Treiber kann von jedem Thread aus und auf jeder IRQL auf den Systempuffer zugreifen
(Adresse q in Abb. 6–15):
QQ Die Adresse befindet sich im Systemraum und ist daher in jedem Prozesskontext gültig.
QQ Der Puffer wird im nicht ausgelagerten Pool zugewiesen, weshalb keine Seitenfehler auftreten können.
Bei Schreiboperationen kopiert der E/A-Manager die Pufferdaten des Aufrufers in den zugewiesenen Puffer, wenn er das IRP erstellt. Bei Leseoperationen dagegen kopiert er die Daten
aus dem zugewiesenen Puffer in den Benutzerpuffer, wenn das IRP (mithilfe eines besonderen
Kernel-APCs) abgeschlossen wird, und gibt dann den zugewiesenen Puffer frei.
608
Kapitel 6
Das E/A-System
Die gepufferte E/A lässt sich sehr einfach einsetzen, da sich der E/A-Manager praktisch
um alles kümmert. Ihr größter Nachteil besteht darin, dass sie immer einen Kopiervorgang
erfordert, was bei umfangreichen Puffern ineffizient ist. Gewöhnlich wird die gepufferte E/A
nur eingesetzt, wenn der Puffer nicht größer als eine Seite ist (4 KB) und das Gerät keinen direkten Speicherzugriff (Direct Memory Access, DMA) unterstützt. DMA dient zur Übertragung
von Daten von einem Gerät in den RAM und umgekehrt ohne Umweg über die CPU, doch da
die gepufferte E/A immer einen Kopiervorgang mithilfe der CPU einschließt, würde sie DMA
sinnlos machen.
Direkte E/A Direkte E/A bietet einem Treiber die Möglichkeit, unmittelbar auf den Benutzerpuffer zuzugreifen, ohne dass ein Kopiervorgang erforderlich ist. Abb. 6–16 zeigt die
Hauptphasen der direkten E/A für Lese- und Schreiboperationen.
Kernelraum
Kernelraum
Benutzerpuffer
Benutzerpuffer
Benutzerraum
Benutzerraum
Der Benutzerclient weist den
Puffer zu und ruft die Leseoder Schreiboperation auf
Der E/A-Manager verriegelt den
Benutzerpuffer im RAM und bildet den
Puffer im Systemraum ab
Kernelraum
Daten
Daten
Daten
Benutzerraum
Der Treiber liest/schreibt unter Verwendung
der Systemadresse im Puffer
Abbildung 6–16 Direkte E/A
Wenn der E/A-Manager das IRP erstellt, ruft er die (im WDK dokumentierte) Funktion
MmProbeAndLockPages auf, um den Benutzerpuffer im Speicher zu verriegeln (sodass dieser nicht
ausgelagert werden kann). Außerdem speichert der E/A-Manager eine Speicherdeskriptorliste
(Memory Descriptor List, MDL). Dabei handelt es sich um eine Struktur, die den von einem
Puffer belegten physischen Speicher beschreibt. Ihre Adresse wird im Element MdlAddress des
IRP-Rumpfes festgehalten. Geräte, die DMA durchführen, benötigen nur physische Beschreibungen der Puffer, weshalb eine MDL für ihren Betrieb ausreicht. Muss ein Treiber dagegen auf
E/A-Verarbeitung
Kapitel 6
609
den Pufferinhalt zugreifen, so kann er den Puffer im Systemadressraum abbilden. Dazu verwendet er die Funktion MmGetSystemAddressForMdlSafe, der er die bereitgestellte MDL übergibt.
Der resultierende Zeiger (q in Abb. 6–16) kann gefahrlos in jedem Threadkontext (es handelt
sich um eine Systemadresse) und auf jeder IRQL verwendet werden (der Puffer kann nicht ausgelagert werden). Der Benutzerpuffer wird also letzten Endes doppelt zugewiesen. Die direkte
Benutzeradresse (p in Abb. 6–16) kann nur im Kontext des ursprünglichen Prozesses verwendet
werden, die zweite Zuordnung im Systemraum dagegen in jedem Kontext. Nach Abschluss des
IRPs entriegelt der E/A-Manager den Puffer (sodass dieser wieder ausgelagert werden kann),
indem er MmUnlockPages aufruft (im WDK dokumentiert).
Die direkte E/A ist für große Puffer (von mehr als einer Seite) sinnvoll, da hierbei kein Kopiervorgang stattfindet, vor allem aber auch für DMA-Übertragungen (aus demselben Grund).
Weder/noch Bei Neither I/O führt der E/A-Manager keinerlei Pufferverwaltung durch,
sondern überlässt diese Aufgabe dem Gerätetreiber. Dabei ist es möglich, dass der Treiber die
Schritte vornimmt, die der E/A-Manager bei den anderen beiden Formen der Pufferverwaltung ausführt. In manchen Fällen reicht es jedoch auch, in der Dispatchroutine auf den Puffer
zuzugreifen, sodass der Treiber nichts mehr tun muss. Der Hauptvorteil von Neither I/O ist der
fehlende Zusatzaufwand.
Treiber, die Neither I/O für den Zugriff auf möglicherweise im Benutzerraum befindliche
Puffer verwenden, müssen darauf achten, dass die Pufferadressen gültig sind und sich nicht
auf Kernelspeicher beziehen. Skalarwerte können jedoch gefahrlos übergeben werden, wobei
jedoch nur bei sehr wenigen Treibern eine Notwendigkeit dazu besteht. Eine mangelnde Überprüfung der Adressen kann zu Abstürzen und Sicherheitsproblemen führen, etwa dadurch,
dass Anwendungen Zugriff auf Kernelmodusspeicher bekommen oder Code in den Kernel einschleusen können. Die Funktionen ProbeForRead und ProbeForWrite, die der Kernel für Treiber
bereitstellt, stellen sicher, dass sich der Puffer komplett im Benutzeradressraum befindet. Um
einen Absturz aufgrund eines Verweises auf eine ungültige Benutzermodusadresse zu vermeiden, können Treiber mit strukturierter Ausnahmebehandlung (Structured Exception Handling,
SEH) auf Benutzermoduspuffer zugreifen. Diese Vorgehensweise wird in C/C++ durch __try/
__except-Blöcke dargestellt und dient dazu, Fehler aufgrund eines ungültigen Speicherzugriffs
abzufangen und in Fehlercodes zu übersetzen, die an die Anwendung zurückgegeben werden.
(Mehr über SEH erfahren Sie in Kapitel 8 von Band 2.) Außerdem können Treiber alle Eingabedaten abfangen und in einen Kernelpuffer stellen, anstatt sich auf Benutzermodusadressen zu
verlassen, da der Aufrufer auch dann die Daten hinter dem Rücken des Treibers ändern kann,
wenn die Speicheradresse selbst gültig ist.
Synchronisierung
Treiber müssen ihren Zugriff auf globale Treiberdaten und Hardwareregister aus den beiden
folgenden Gründen synchronisieren:
QQ Die Ausführung eines Treibers kann durch Threads höherer Priorität oder den Ablauf einer
Zeitscheibe (oder eines Quantums) vorzeitig abgebrochen oder durch Interrupts einer höheren IRQL unterbrochen werden.
QQ Auf Multiprozessorsystemen (die heutzutage die Norm sind) kann Windows Treibercode
gleichzeitig auf mehreren Prozessoren ausführen.
610
Kapitel 6
Das E/A-System
Ohne Synchronisierung kann eine Datenbeschädigung auftreten. Beispielsweise kann Gerätetreibercode, der auf der passiven IRQL 0 läuft (z. B. eine Dispatchroutine), wenn ein Aufrufer
eine E/A-Operation auslöst, durch einen Geräteinterrupt unterbrochen werden. Dadurch wird
die ISR des Gerätetreibers ausgeführt, während der Gerätetreiber selbst schon läuft. War der
Gerätetreiber dabei, Daten zu ändern, die auch von der ISR geändert werden – z. B. Geräteregister, Heapspeicher oder statische Daten –, dann können die Daten bei der Ausführung der
ISR beschädigt werden.
Um eine solche Situation zu verhindern, müssen für Windows geschriebene Gerätetreiber
ihren Zugriff auf jegliche Daten synchronisieren, die auf mehr als einer IRQL zugänglich sind.
Bevor der Gerätetreiber versucht, die gemeinsamen Daten zu ändern, muss er alle anderen
Threads (bzw. CPUs auf Mehrprozessorsystemen) sperren, damit sie nicht dieselbe Datenstruktur bearbeiten.
Auf einem Einzelprozessorsystem ist die Synchronisierung von zwei oder mehr Funktionen
auf verschiedenen IRQLs ganz einfach. Eine solche Funktion muss lediglich ihre IRQL auf den
höchsten Wert ändern, der für sie möglich ist (mithilfe von KeRaiseIrql). Um beispielsweise
eine Dispatchroutine (IRQL 0) und eine DPC-Routine (IRQL 2) zu synchronisieren, muss die
Dispatchroutine ihre IRQL auf 2 anheben, bevor sie auf die gemeinsamen Daten zugreift. Ist
eine Synchronisierung zwischen einem DPC und einer ISR erforderlich, hebt der DPC seine
IRQL auf die Geräte-IRQL an. (Diese Information wird dem Treiber bereitgestellt, wenn der
PnP-Manager ihn über die Hardwareressourcen informiert, mit denen das Gerät verbunden ist.)
Auf Mehrprozessorsystemen dagegen reicht eine Anhebung der IRQL nicht aus, da die andere
Routine – etwa eine ISR – auch auf einer anderen CPU ausgeführt werden kann. (Denken Sie
daran, dass die IRQL ein Attribut der CPU und keine globale Systemeigenschaft ist.)
Um eine CPU-übergreifende Synchronisierung zu ermöglichen, stellt der Kernel mit den
Spinlocks besondere Synchronisierungsobjekte bereit. Im Folgenden sehen wir uns Spinlocks
nur kurz im Zusammenhang mit der Treibersynchronisierung an. Eine ausführliche Darstellung
erhalten Sie in Kapitel 8 von Band 2. Im Prinzip ähnelt ein Spinlock einem Mutex (ebenfalls in
Kapitel 8 von Band 2 erklärt), da beide dem Code erlauben, auf gemeinsam genutzte Daten
zuzugreifen. Allerdings gibt es deutliche Unterschiede in der Funktionsweise und Anwendung.
Tabelle 6–3 gibt einen Überblick über die Unterschiede zwischen Mutexen und Spinlocks.
Mutex
Spinlock
Art der Synchronisierung
Ein Thread von vielen erhält die
Erlaubnis, in eine kritische Region
einzusteigen und auf gemeinsame
Daten zuzugreifen.
Eine CPU von vielen erhält die
Erlaubnis, in eine kritische Region
einzusteigen und auf gemeinsame
Daten zuzugreifen.
Mögliche IRQL
< DISPATCH_LEVEL (2)
>= DISPATCH_LEVEL (2)
Wartetyp
Normal, das heißt, es werden
beim Warten keine CPU-Zyklen
verbraucht.
Beschäftigt, das heißt, die CPU
prüft fortlaufend das Spinlockbit,
bis es frei ist.
Besitz
Der Besitzerthread wird festgehalten. Rekursiver Erwerb der Sperre
ist zulässig.
Der CPU-Besitzer wird nicht festgehalten. Rekursiver Erwerb der
Sperre führt zu einem Deadlock.
Tabelle 6–3 Mutexe und Spinlocks im Vergleich
E/A-Verarbeitung
Kapitel 6
611
Bei einem Spinlock handelt es sich einfach nur um ein Bit im Arbeitsspeicher, auf das eine elementare Test- und Änderungsoperation zugreift. Spinlocks können im Besitz einer CPU oder
frei (ohne Besitzer) sein. Wie Sie in Tabelle 6–3 sehen, sind Spinlocks für die Synchronisierung
auf höheren IRQLs (>= 2) erforderlich. Ein Mutex lässt sich hier nicht verwenden, da dazu ein
Scheduler nötig ist, der auf einer CPU mit einer IRQL von 2 oder höher nicht aufwachen kann.
Aus diesem Grund ist die CPU auch beim Warten auf ein Spinlock beschäftigt: Der Thread kann
nicht in einen normalen Wartezustand übergeben, da dazu ein Scheduler aufwachen und zu
einem anderen Thread umschalten müsste.
Der Erwerb eines Spinlocks durch eine CPU läuft immer in zwei Schritten ab. Als Erstes wird
die IRQL auf diejenige erhöht, auf der die Synchronisierung stattfinden soll, also auf die höchste
IRQL, auf der die zu synchronisierende Funktion ausgeführt werden kann. Beispielsweise muss
die IRQL bei der Synchronisierung einer Dispatchroutine (IRQL 0) und eines DPCs (2) auf 2 erhöht werden und bei der Synchronisierung eines DPCs (2) und einer ISR (DIRQL) auf die IRQL
(die DIRQL für den vorliegenden Interrupt). Als Zweites wird der Erwerb des Spinlocks versucht,
indem das Spinlockbit überprüft und gesetzt wird.
Die hier aufgezeigten Schritte, um ein Spinlock zu erwerben, sind vereinfacht. Einzelheiten, die für unser aktuelles Thema nicht von Belang sind, finden hier keine
Beachtung. Eine vollständige Beschreibung finden Sie in Kapitel 8 von Band 2.
Funktionen, die Spinlocks erwerben, bestimmen die IRQL für die Synchronisierung, wie Sie in
Kürze sehen werden.
Abb. 6–17 zeigt eine vereinfachte Darstellung des zweiteiligen Vorgangs zum Erwerb eines
Spinlocks.
Anheben auf die zugehörige IRQL
Testen und Setzen des Spinlockbits
Nein
War das Bit zuvor frei?
Ja
This CPU now owns
the Spinklock
Abbildung 6–17 Erwerb eines Spinlocks
Für die Synchronisierung auf IRQL 2 – etwa zwischen einer Dispatchroutine und einem DPC
oder zwischen zwei DPCs auf unterschiedlichen CPUs – stellt der Kernel die Funktionen
K eAcquireSpinLock und KeReleaseSpinLock bereit. (Es gibt noch andere Varianten, die in Ka-
612
Kapitel 6
Das E/A-System
pitel 8 von Band 2 vorgestellt werden.) Diese Funktionen führen die Schritte aus Abb. 6–17
durch, wobei die »zugehörige IRQL« 2 ist. In diesem Fall muss der Treiber ein Spinlock zuweisen
(KSPIN_LOCK; lediglich 4 Bytes auf 32-Bit- und 8 Bytes auf 64-Bit-Systemen) – gewöhnlich in der
Geräteerweiterung (wo die vom Treiber verwalteten Daten für das Gerät aufbewahrt werden) –
und es mit KeInitializeSpinLock initialisieren.
Zur Synchronisierung von beliebigen Funktionen (etwa einem DPC oder einer Dispatchroutine) mit der ISR müssen andere Funktionen verwendet werden. Jedes Interruptobjekt
(KINTERRUPT) enthält ein Spinlock, das vor der Ausführung der ISR erworben wird. (Das bringt
es mit sich, dass ein und dieselbe ISR nicht gleichzeitig auf mehreren CPUs ausgeführt werden
kann.) Die Synchronisierung erfolgt in diesem Fall mit diesem Spinlock (es muss kein weiteres
mehr zugewiesen werden), das indirekt durch die Funktion KeAcquireInterruptSpinLock erworben und mit KeReleaseInterruptSpinLock freigegeben werden kann. Eine weitere Möglichkeit
bietet die Funktion KeSynchronizeExecution, die eine vom Treiber bereitgestellte Callbackfunktion entgegennimmt. Letztere wird zwischen dem Erwerb und der Freigabe des Interrupt-Spinlocks aufgerufen.
Es sollte nun klar geworden sein, dass ISRs zwar besondere Aufmerksamkeit erfordern, aber
jegliche von einem Gerätetreiber verwendeten Daten auch für Funktionen desselben Gerätetreibers auf einem anderen Prozessor zugänglich sind. Daher ist es unverzichtbar, dass Gerätetreibercode seine Verwendung von globalen oder gemeinsamen Daten und jeglichen Zugriff
auf das physische Gerät synchronisiert.
E/A-Anforderungen an geschichtete Treiber
Im Abschnitt »IRP-Fluss« wurden die allgemeinen Möglichkeiten aufgezeigt, die Treiber für den
Umgang mit IRPs haben, wobei der Schwerpunkt auf einem standardmäßigen WDM-Geräteknoten lag. Der vorstehende Abschnitt hat gezeigt, wie eine E/A-Anforderung an ein einfaches,
von einem einzigen Treiber gesteuertes Gerät gehandhabt wird. Die E/A-Verarbeitung für da
teigestützte Geräte und für Anforderungen an andere geschichtete Treiber erfolgt sehr ähnlich.
Es lohnt sich aber trotzdem, einen genaueren Blick auf die Anforderungen an Dateisystemtreiber zu werfen. Abb. 6–18 zeigt ein vereinfachtes Beispiel dafür, wie eine asynchrone E/A-Anforderung die geschichteten Treiber für Nicht-Hardwaregeräte als Hauptziel durchlaufen kann. Als
Beispiel dient hier eine Festplatte, die von einem Dateisystem gesteuert wird.
E/A-Verarbeitung
Kapitel 6
613
Clientprozess
Gibt Status »E/A ausstehend«
Benutzermodus
zurück
Ruft E/A-Dienst auf
Kernelmodus
Der E/A-Manager erstellt das
IRP, füllt die erste IRPStackposition aus und ruft
einen Dateisystemtreiber auf
E/A-Manager
Gibt Status »E/A ausstehend« zurück
Aktuell
Der Dateisystemtreiber füllt die
zweite IRP-Stackposition aus
und ruft den VolumeManager auf
Dateisystem
treiber
Gibt Status »E/A ausstehend« zurück
VolumeManager
Aktuell
Sendet das IRP nach unten zum
Festplattentreiber (oder stellt
es in eine Warteschlange) und
springt zurück
Abbildung 6–18 Verlauf einer asynchronen Anforderung durch geschichtete Treiber
Auch hier empfängt der E/A-Manager wieder die Anforderung und erstellt ein IRP, um sie
darzustellen. Dieses Mal jedoch liefert er das Paket an einen Dateisystemtreiber, der zu diesem
Zeitpunkt großen Einfluss auf die E/A-Operation hat. Je nach Art der Anforderung kann das
Dateisystem das ursprüngliche IRP gleich an den Festplattentreiber senden oder zusätzliche
IRPs erstellen, die es dann getrennt an den Festplattentreiber schickt.
Am wahrscheinlichsten ist es, dass das Dateisystem das ursprüngliche IRP verwendet, wenn
die Anforderung einer einzelnen, einfachen Anforderung an ein Gerät entspricht. Wenn beispielsweise eine Anwendung eine Leseanforderung für die ersten 512 Bytes in einer Datei auf
einem Volume ausgibt, ruft das NTFS-Dateisystem einfach den Volume-Manager-Treiber auf
und weist ihn an, einen Sektor des Volumes beginnend an der Anfangsposition der Datei zu
lesen.
Nachdem der DMA-Adapter des Festplattencontrollers die Datenübertragung abgeschlossen hat, unterbricht der Controller den Host. Dadurch wird die ISR für den Festplattencontroller
ausgeführt und fordert einen DPC-Callback an, um das IRP abzuschließen (siehe Abb. 6–19).
Anstatt das ursprüngliche IRP zu verwenden, kann das Dateisystem auch mehrere zugehörige IRPs erstellen, die parallel für eine einzige E/A-Anforderung ausgeführt werden. Sind die
von einer Datei zu lesenden Daten beispielsweise über die Festplatte verstreut, kann der Dateisystemtreiber mehrere IRPs anlegen, die jeweils einen Teil der Anforderung in einem einzelnen
Sektor erfüllen. Dies wird in Abb. 6–20 dargestellt.
614
Kapitel 6
Das E/A-System
Clientprozess
Beim Abschluss der E/A werden die Ergebnisse im
Adressraum des Aufrufers zurückgegeben
Benutzermodus
Kernelmodus
E/A-Manager
Der Dateisystemtreiber führt jegliche
erforderlichen Aufräumarbeiten aus
Aktuell
Dateisystem
treiber
Der Volume-Manager führt jegliche erforderlichen
Aufräumarbeiten aus
VolumeManager
Festplatten
treiber
Aktuell
Ein Interrupt auf Geräteebene tritt auf. Der
Festplattentreiber handhabt den Interrupt und stellt
einen DPC zur Vervollständigung der E/A in die
Warteschlange. Dieser DPC springt zurück zur aktuellen
IRP-Stackposition und ruft den Volume-Manager auf.
Abbildung 6–19 Abschluss einer geschichteten E/A-Anforderung
Clientprozess
Gibt Status »E/A ausstehend«
Benutzermodus
zurück
Ruft E/A-Dienst auf
Kernelmodus
Der E/A-Manager erstellt das
IRP, füllt die erste IRPStackposition aus und ruft
einen Dateisystemtreiber auf
E/A-Manager
Gibt Status »E/A ausstehend« zurück
Dateisystem
treiber
Der Dateisystemtreiber erstellt
zugehörige IRPs auf und ruft den
Volume-Manager einmal oder
mehrere Male auf
Gibt Status »E/A ausstehend« zurück
VolumeManager
Sendet die IRPs zum Festplatten
treiber und springt zurück
Abbildung 6–20 Verarbeitung mithilfe zugehöriger IRPs
E/A-Verarbeitung
Kapitel 6
615
Der Dateisystemtreiber liefert die zugehörigen IRPs an den Volume-Manager, der sie wiederum
an den Festplattengerätetreiber schickt. Dieser stellt sie in die Warteschlange für das Festplattengerät. Alle IRPs werden gleichzeitig verarbeitet, wobei der Dateisystemtreiber die zurückgegebenen Daten im Auge behält. Sind alle zugehörigen IRPs abgeschlossen, schließt das
E/A-System das ursprüngliche IRP ab und kehrt zum Aufrufer zurück (siehe Abb. 6–21).
Clientprozess
Benutzermodus
Nach Beendigung aller zugehörigen IRPs wird das ursprüngliche IRP
abgeschlossen, und Status und Daten werden an den Aufrufer
zurückgegeben
Kernelmodus
E/A-Manager
Schritt 2 wird wiederholt. Dabei werden die IRPs 2 bis n
abgeschlossen. Der Dateisystemtreiber führt jegliche erforderlichen Aufräumarbeiten aus
Dateisystem
treiber
Schritt 1 wird wiederholt. Dabei werden die IRPs 2 bis n
abgeschlossen. Der Volume-Manager führt jegliche
erforderlichen Aufräumarbeiten aus
VolumeManager
Festplatten
treiber
Nach Übertragung der Daten für ein IRP tritt ein
Geräteinterrupt auf. Der Festplattentreiber handhabt den
Interrupt und stellt einen DPC in die Warteschlange.
Dieser DPC startet das nächste IRP für das Gerät und ruft
den E/A-Manager auf, um das erste IRP abzuschließen.
Abbildung 6–21 Abschluss einer E/A-Anforderung mit zugehörigen IRPs
Alle Windows-Dateisystemtreiber zur Verwaltung von Festplatten-Dateisystemen
gehören zu einem Treiberstack mit mindestens drei Ebenen – dem Dateisystemtreiber an der Spitze, einem Volume-Manager in der Mitte und einem Festplattentreiber unten. Zusätzlich können beliebig viele Filtertreiber zwischen diese Treiber
geschaltet sein. Der Übersichtlichkeit halber wurden in dem vorstehenden Beispiel
für geschichtete E/A-Anforderungen lediglich der Dateisystemtreiber und der Volume-Manager dargestellt. Weitere Informationen erhalten Sie in Kapitel 12 von
Band 2.
Threadagnostische E/A
In den bis jetzt beschriebenen E/A-Modellen werden die IRPs in die Warteschlange des Threads
gestellt, der die E/A ausgelöst hat, und von dem E/A-Manager durch die Ausgabe eines APCs an
diesen Thread abgeschlossen, sodass der prozess- und threadspezifische Kontext bei der Verarbeitung dieses Abschlusses zugänglich sind. Für die Leistungs- und Skalierbarkeitsbedürfnisse
616
Kapitel 6
Das E/A-System
der meisten Anwendungen reicht eine solche threadspezifische E/A-Verarbeitung gewöhnlich
aus. Mithilfe der beiden folgenden Mechanismen bietet Windows jedoch auch Unterstützung
für threadagnostische E/A:
QQ E/A-Vervollständigungsports. Sie werden im gleichnamigen Abschnitt weiter hinten in diesem Kapitel beschrieben.
QQ Verriegeln des Benutzerpuffers im Arbeitsspeicher und Abbilden des Puffers in den System
adressraum
Bei der Verwendung von E/A-Vervollständigungsports entscheidet die Anwendung, wann sie auf
Abschluss der E/A prüft. Daher ist es nicht von Bedeutung, welcher Thread die E/A-Anforderung
ausgegeben hat, da auch jeder andere Thread die Vervollständigungsanforderung durchführen
kann. Das IRP kann daher im Kontext eines beliebigen Threads abgeschlossen werden, der Zugriff
auf den Vervollständigungsport hat.
Auch bei der Verwendung einer verriegelten und im Kernel abgebildeten Version des Benutzerpuffers ist es nicht erforderlich, sich im selben Speicheradressraum zu befinden wie der
ausgebende Thread, da der Kernel auf Speicher beliebiger Kontexte zugreifen kann. Anwendungen können diesen Mechanismus einschalten, indem sie SetFileIoOverlappedRange verwenden, sofern sie über das Recht SeLockMemoryPrivilege verfügen.
Sind sowohl die Vervollständigsport-E/A als auch die E/A auf Dateipuffern durch SetFile
IoOverlappedRange festgelegt, verknüpft der E/A-Manager die IRPs mit dem Dateiobjekt, für
das sie ausgegeben wurden, statt mit dem ausgebenden Thread. Die Erweiterung !fileobj in
WinDbg zeigt eine Liste von IRPs für Dateiobjekte, für die dieser Mechanismus verwendet
wird.
In den nächsten Abschnitten erfahren Sie, wie die threadagnostische E/A die Zuverlässigkeit und Leistung von Anwendungen in Windows verbessert.
Abbrechen der E/A
Es gibt viele Möglichkeiten zur IRP-Verarbeitung und verschiedene Möglichkeit, um eine
E/A-Anforderung abzuschließen. Sehr viele E/A-Operationen enden jedoch nicht mit einem
Abschluss, sondern mit einem Abbruch. Beispielsweise kann es sein, dass ein Gerät entfernt
werden muss, während noch IRPs aktiv sind, oder dass der Benutzer eine langwierige Operation
an einem Gerät abbricht, z. B. eine Netzwerkoperation. Auch die Beendigung eines Threads
oder Prozesses erfordert ein Abbrechen der E/A, da die damit verbundenen E/A-Vorgänge
nicht mehr von Bedeutung sind und der Thread erst gelöscht werden kann, wenn alle ausstehenden E/A-Vorgänge abgeschlossen sind.
Der E/A-Manager von Windows arbeitet mit den Treibern zusammen und muss auf effiziente und zuverlässige Weise mit solchen Anforderungen umgehen, damit die Vorgänge für
die Benutzer reibungslos erscheinen. Für E/A-Operationen, die sich abbrechen lassen (gewöhnlich sind das solche, die sich noch in der Warteschlange befinden und noch nicht ausgeführt
werden), registrieren Treiber eine Abbruchroutine, die beim E/A-Manager aufgerufen werden
kann. Wenn ein Treiber seine Aufgaben in dieser Situation nicht erfüllt, können die Benutzer auf
nicht beendbare Prozesse stoßen, die zwar in der grafischen Oberfläche verschwunden sind,
aber immer noch im Task-Manager oder in Process Explorer angezeigt werden.
E/A-Verarbeitung
Kapitel 6
617
Abbrechen der E/A durch den Benutzer
Die meisten Softwareprogramme verwenden einen Thread für Eingaben von der Benutzeroberfläche (UI) und einen oder mehrere Threads, um die Arbeit zu erledigen, darunter auch
die E/A. Wenn ein Benutzer eine Operation abbrechen möchte, die in der Oberfläche ausgelöst
wurde, kann es manchmal erforderlich sein, dass die Anwendung ausstehende E/A-Operationen abbrechen muss. Für Operationen, die schnell abgeschlossen sind, ist ein Abbruch nicht
unbedingt erforderlich. Dagegen bietet Windows Möglichkeiten, um Operationen mit willkürlicher Dauer abzubrechen – etwa umfangreiche Datenübertragungen oder Netzwerkvorgänge –, und zwar sowohl synchrone als auch asynchrone.
QQ Abbrechen synchroner E/A-Operationen Ein Thread kann CancelSynchronousIo aufrufen. Damit lassen sich sogar Erstellungsoperationen (Öffnen) abbrechen, wenn der
Gerätetreiber dies unterstützt, was bei verschiedenen Windows-Treibern der Fall ist. Beispielsweise können die Treiber zur Verwaltung von Netzwerkdateisystemen (wie MUP,
DFS und SMB) Operationen zum Öffnen von Netzwerkpfaden abbrechen.
QQ Abbrechen asynchroner E/A-Operationen Ein Thread kann CancelIo aufrufen, um seine
eigenen ausstehenden asynchronen E/A-Operationen abzubrechen. Mit CancelIoEx kann
er auch alle innerhalb eines Prozesses für ein bestimmtes Dateihandle ausgegebenen asynchronen E/A-Operationen unabhängig vom auslösenden Thread abbrechen. CancelIoEx
wirkt sich auch auf Operationen aus, die über die zuvor beschriebene Unterstützung für
threadagnostische E/A in Windows mit E/A-Vervollständigungsport verknüpft sind, da sich
das E/A-System die ausstehenden E/A-Operationen für einen solchen Port merkt.
Die Abbildungen 6–22 und 6–23 zeigen den Abbruch synchroner bzw. asynchroner E/A-Opera
tionen. (Für den Treiber sehen alle Abbruchvorgänge gleich aus.)
Anwendung
T2 übergibt das Handle von T1
Status an
Anwendung
Thread T1 wartet auf
den Abschluss der E/A.
Thread T2 fordert den
Abbruch an
CreateFile
CancelSynchronousIo
Springt sofort
zurück
Der E/A-Manager versucht, die
synchrone E/A-Operation von T1
abzubrechen
E/A-Manager
Abbruchroutine aufgerufen
Der Treiber gibt die
Steuerung mit
STATUS_CANCELLED
zurück
Treiber
Abbildung 6–22 Abbrechen eines synchronen E/A-Vorgangs
618
Kapitel 6
Das E/A-System
Abbruch
routine
Anwendung
Übergibt Dateihandle
Status an
Anwendung
Ein Thread im Prozess
fordert den Abbruch aller
ausstehenden
Datei-E/A-Operationen
für ein bestimmtes
Handle an
Springt sofort
zurück
Der E/A-Manager versucht, alle
ausstehenden E/A-Operationen
für dieses Handle abzubrechen
E/A-Manager
Der Treiber gibt die
Steuerung mit
STATUS_CANCELLED
zurück
Abbruchroutine aufgerufen
Abbruch
routine
Treiber
Abbildung 6–23 Abbrechen eines asynchronen E/A-Vorgangs
Abbrechen der E/A zur Beendigung des Threads
Eine weitere Situation, in der E/A-Operationen abgebrochen werden müssen, liegt vor, wenn
ein Thread beendet wird, entweder direkt oder weil sein Prozess beendet wird. Der E/A-Manager durchläuft die Liste der mit dem Thread verknüpften IRPs und bricht diejenigen ab, die
abgebrochen werden können. Während CancelIoEx die Steuerung zurückgibt, ohne auf den
Abbruch eines IRPs zu warten, lässt der Prozess-Manager eine Fortsetzung der Threadbeendigung erst dann zu, wenn alle E/A-Operationen abgebrochen wurden. Wenn ein Treiber es
versäumt, ein IRP abzubrechen, bleiben das Prozess- und das Threadobjekt daher bis zum
Herunterfahren des Systems zugewiesen.
Nur IRPs, für die der Treiber eine Abbruchroutine eingerichtet hat, können abgebrochen werden. Der Prozess-Manager wartet, bis alle mit einem Thread verbundenen E/A-Operationen entweder abgebrochen oder abgeschlossen sind, und
löscht den Thread erst dann.
Experiment: Einen nicht beendbaren Prozess debuggen
In diesem Experiment erstellen wir mit Notmyfault von Sysinternals einen nicht beendbaren
Prozess. Notmyfault.exe verwendet den Treiber Myfault.sys und bringt ihn dazu, ein IRP aufrechtzuerhalten, für das keine Abbruchroutine registriert ist. (Notmyfault wird ausführlich
im Abschnitt »Analyse von Absturzabbildern« von Kapitel 15 in Band 2 beschrieben.) Gehen
Sie dazu wie folgt vor:
→
E/A-Verarbeitung
Kapitel 6
619
1.
Starten Sie Notmyfault.exe.
2.
Rufen Sie im Dialogfeld Not My Fault die Registerkarte Hang auf und aktivieren Sie wie
im folgenden Screenshot die Option Hang with IRP. Klicken Sie dann auf die Schaltfläche Hang.
3.
Eine sichtbare Auswirkung gibt es zunächst nicht. Es ist auch nach wie vor möglich, auf
Cancel zu klicken, um die Anwendung abzubrechen. Im Task-Manager und in Process
Explorer dagegen wird der Prozess Notmyfault nach wie vor angezeigt. Versuche, ihn
zu beenden, schlagen fehl, da Windows endlos auf den Abschluss des IRPs wartet, weil
der Treiber Myfault keine Abbruchroutine dafür registriert hat.
4.
Um ein solches Problem zu debuggen, können Sie sich mit WinDbg ansehen, was der
Thread gerade tut. Öffnen Sie eine lokale Kerneldebuggersitzung und lassen Sie sich
mit dem Befehl !process die Informationen über den Prozess Notmyfault.exe anzeigen.
(Der im Folgenden gezeigte Prozess notmyfault64 ist die 64-Bit-Version.)
lkd> !process 0 7 notmyfault64.exe
PROCESS ffff8c0b88c823c0
SessionId: 1 Cid: 2b04 Peb: 4e5c9f4000 ParentCid: 0d40
DirBase: 3edfa000 ObjectTable: ffffdf08dd140900 HandleCount: <Data Not
Accessible>
Image: notmyfault64.exe
VadRoot ffff8c0b863ed190 Vads 81 Clone 0 Private 493. Modified 8. Locked
0....
THREAD ffff8c0b85377300 Cid 2b04.2714 Teb:
0000004e5c808000 Win32Thread: 0000000000000000 WAIT: (UserRequest) UserMode
Non-Alertable fffff80a4c944018 SynchronizationEvent
IRP List:
ffff8c0b84f1d130: (0006,0118) Flags: 00060000 Mdl: 00000000
Not impersonating
DeviceMap
ffffdf08cf4d7d20
Owning Process ffff8c0b88c823c0 Image: notmyfault64.exe
→
620
Kapitel 6
Das E/A-System
...
Child-SP
RetAddr
: Args to Child
: Call Site
ffffb881'3ecf74a0 fffff802'cfc38a1c : 00000000'00000100
00000000'00000000 00000000'00000000 00000000'00000000 :
nt!KiSwapContext+0x76
ffffb881'3ecf75e0 fffff802'cfc384bf : 00000000'00000000
00000000'00000000 00000000'00000000 00000000'00000000 :
nt!KiSwapThread+0x17c
ffffb881'3ecf7690 fffff802'cfc3a287 : 00000000'00000000
00000000'00000000 00000000'00000000 00000000'00000000 :
nt!KiCommitThreadWait+0x14f
ffffb881'3ecf7730 fffff80a'4c941fce : fffff80a'4c944018
fffff802'00000006 00000000'00000000 00000000'00000000 :
nt!KeWaitForSingleObject+0x377
ffffb881'3ecf77e0 fffff802'd0067430 : ffff8c0b'88d2b550
00000000'00000001 00000000'00000001 00000000'00000000 : myfault+0x1fce
ffffb881'3ecf7820 fffff802'd0066314 : ffff8c0b'00000000
ffff8c0b'88d2b504 00000000'00000000 ffffb881'3ecf7b80 :
nt!IopSynchronousServiceTail+0x1a0
ffffb881'3ecf78e0 fffff802'd0065c96 : 00000000'00000000
00000000'00000000 00000000'00000000 00000000'00000000 :
nt!IopXxxControlFile+0x674
ffffb881'3ecf7a20 fffff802'cfd57f93 : ffff8c0b'85377300
fffff802'cfcb9640 00000000'00000000 fffff802'd005b32f :
nt!NtDeviceIoControlFile+0x56
ffffb881'3ecf7a90 00007ffd'c1564f34 : 00000000'00000000
00000000'00000000 00000000'00000000 00000000'00000000 :
nt!KiSystemServiceCopyEnd+0x13 (TrapFrame @ ffffb881'3ecf7b00)
5.
Diese Ablaufverfolgung zeigt, dass der Thread, der die E/A ausgelöst hat, auf Abbruch
oder Vervollständigung wartet. Der nächste Schritt besteht darin, wie in den früheren
Experimenten den Erweiterungsbefehl !irp auf den IRP-Zeiger anzuwenden, um das
Problem zu analysieren:
lkd> !irp ffff8c0b84f1d130
Irp is active with 1 stacks 1 is current (= 0xffff8c0b84f1d200)
No Mdl: No System Buffer: Thread ffff8c0b85377300: Irp stack trace.
cmd flg cl Device File Completion-Context
>[IRP_MJ_DEVICE_CONTROL(e), N/A(0)]
5 0 ffff8c0b886b5590 ffff8c0b88d2b550 00000000-00000000
\Driver\MYFAULT
Args: 00000000 00000000 83360020 00000000
→
E/A-Verarbeitung
Kapitel 6
621
6.
Diese Ausgabe zeigt klar, welcher Treiber der Schuldige ist, nämlich \Driver\MYFAULT
bzw. Myfault.sys. Der Name des Treibers deutet schon an, dass eine solche Situation
nur aufgrund eines Treiberproblems auftreten kann, nicht aufgrund einer fehlerhaften Anwendung. Obwohl Sie jetzt wissen, welcher Treiber das Problem verursacht hat,
gibt es jedoch leider keine andere Lösungsmöglichkeit, als das System neu zu starten.
Das ist notwendig, da Windows niemals davon ausgehen kann, dass sich der fehlende
Abbruch gefahrlos ignorieren lässt. Das IRP könnte jederzeit zurückspringen und den
Systemarbeitsspeicher beschädigen.
Wenn Ihnen dieses Problem in der Praxis begegnet, sollten Sie nach einer neueren Version des Treibers Ausschau halten. Möglicherweise ist der
Bug darin schon korrigiert.
E/A-Vervollständigungsports
Eine hochleistungsfähige Serveranwendung erfordert ein effizientes Threadmodell. Zu wenige,
aber auch zu viele Serverthreads zur Verarbeitung von Clientanforderungen können Leistungsprobleme verursachen. Wenn ein Server nur einen einzigen Thread zur Handhabung sämtlicher
Anforderungen erstellt, kann er immer nur eine Anforderung auf einmal verarbeiten, weshalb
die Clients ausgehungert werden können. Ein einzelner Thread könnte zwar auch gleichzeitig
mehrere Anforderungen verarbeiten, indem er bei Beginn der E/A-Operation zur nächsten umschaltet, doch eine solche Architektur ist sehr kompliziert und nutzt die Möglichkeiten von Systemen mit mehr als einem logischen Prozessor nicht richtig aus. Der andere Extremfall besteht
darin, dass ein Server einen riesigen Threadpool erstellt, sodass jede Clientanforderung von
einem eigenen Thread verarbeitet werden kann. Das führt jedoch dazu, dass viele Threads aufwachen, ein wenig auf der CPU arbeiten, dann blockiert werden, während sie auf E/A warten,
und schließlich nach dem Abschluss der Verarbeitung wiederum blockiert werden, wenn sie
auf eine neue Anforderung warten. Auf jeden Fall führen zu viele Threads zu einer erheblichen
Menge von Kontextwechseln, da der Scheduler die Prozessorzeit auf die verschiedenen aktiven
Threads aufteilen muss. Ein solches Verfahren lässt sich daher nicht gut skalieren.
Ein Server sollte so wenig Kontextwechsel wie möglich durchführen, die unnötige Blockierung von Threads vermeiden und gleichzeitig die Parallelverarbeitung durch die Verwendung
mehrerer Threads maximieren. Der Idealzustand besteht also darin, dass es auf jedem Prozessor
einen Thread gibt, der aktiv eine Clientanforderung verarbeitet, und dass diese Threads nicht
blockiert werden, wenn sie eine Anforderung abgeschlossen haben und auf weitere Anforderungen warten. Damit das funktioniert, muss die Anwendung jedoch eine Möglichkeit haben,
einen anderen Thread zu aktivieren, wenn ein Thread, der eine Clientanforderung verarbeitet,
durch E/A blockiert ist (z. B. wenn er im Rahmen der Verarbeitung in einer Datei liest).
622
Kapitel 6
Das E/A-System
Das IoCompletion-Objekt
Als Sammelpunkt für den Abschluss von E/A-Operationen mit mehreren Dateihandles verwenden Anwendungen das Exekutivobjekt IoCompletion, das als Vervollständigungsport in die
Windows-API exportiert wird. Wenn eine Datei mit einem solchen Port verknüpft ist, können
jegliche für die Datei abgeschlossenen asynchronen E/A-Operationen dazu führen, dass ein
Vervollständigungspaket in die Warteschlange für diesen Port gestellt wird. Ein Thread kann auf
den Abschluss ausstehender E/A-Operationen für mehrere Dateien warten, indem er einfach
darauf wartet, dass ein Vervollständigungspaket in die Warteschlange für den Vervollständigungsport gestellt wird. Mit der Funktion WaitForMultipleObjects bietet die Windows-API eine
ähnliche Möglichkeit. Vervollständigungsports aber bieten einen wichtigen Vorteil, nämlich
einen Parallelitätswert. Dabei handelt es sich um die Anzahl der Threads einer Anwendung, die
aktiv Clientanforderungen handhaben. Festgelegt wird er mit der Hilfe des Systems.
Wenn eine Anwendung einen Vervollständigungsport erstellt, gibt sie einen Parallelitätswert an, also die maximale Anzahl der mit diesem Port verknüpften Threads, die gleichzeitig
laufen können. Wie bereits erwähnt, besteht der Idealzustand darin, dass auf jedem Prozessor
des Systems jederzeit ein Thread aktiv ist. Windows nutzt die Parallelitätswerte der Ports, um
zu steuern, wie viele aktive Threads eine Anwendung hat. Ist die Anzahl der aktiven Threads
an einem Port gleich dem Parallelitätswert, dann wird einem Thread, auf den der Port wartet,
die Ausführung nicht erlaubt. Stattdessen beendet ein aktiver Thread die Verarbeitung seiner
laufenden Anforderung. Danach wird geprüft, ob ein weiteres Paket an dem Port wartet. Wenn
ja, greift der Thread dieses Paket auf und verarbeitet es. Dabei erfolgt kein Kontextwechsel, und
die Kapazitäten der CPUs werden nahezu vollständig ausgeschöpft.
Verwendung von Vervollständigungsports
Abb. 6–24 zeigt einen Überblick über die Funktionsweise von Vervollständigungsports. Erstellt
wird ein solcher Port über einen Aufruf der Windows-API-Funktion CreateIoCompletionPort.
Werden Threads an einem solchen Port blockiert, so werden sie mit ihm verknüpft und in
LIFO-Reihenfolge (Last In, First Out) aufgeweckt. Es ist also der zuletzt blockierte Thread, der
das nächste Paket bekommt. Die Stacks von Threads, die längere Zeit blockiert sind, können
auf die Festplatte ausgelagert werden. Sind mit einem Port mehr Threads verknüpft, als Arbeit
vorliegt, wird dadurch die Speichergröße der am längsten blockierten Threads reduziert.
Eine Serveranwendung empfängt Clientanforderungen gewöhnlich über Netzwerkendpunkte, die durch Dateihandles bezeichnet werden, zum Beispiel Winsock2-Sockets und benannte Pipes. Während der Server seine Kommunikationsendpunkte erstellt, verknüpft er sie
mit einem Vervollständigungsport und dessen Threads, die auf eingehende Anforderungen
warten. Dazu ruft er GetQueuedCompletionStatus(Ex) für den Port auf. Wenn ein Thread ein
Paket von dem Vervollständigungsport erhält, beginnt er, die Anforderung zu verarbeiten und
wird dadurch ein aktiver Thread. Während dieser Verarbeitung wird der Thread mehrmals blockiert, etwa wenn er Daten in einer Datei auf der Festplatte lesen oder schreiben oder sich mit
anderen Threads synchronisieren muss. Windows erkennt dann, dass an dem Vervollständigungsport ein Thread weniger aktiv ist. Steht dann ein weiteres Paket in der Warteschlange, so
wird ein anderer Thread aufgeweckt, der an dem Vervollständigungsport wartet.
E/A-Verarbeitung
Kapitel 6
623
Eingehende Clientanforderung
Vervollständigungsport
Am Vervollständigungsport blockierte
Threads
CPU-Verarbeitung
(aktiv)
Datei-E/A – Blockierung
(inaktiv)
CPU-Verarbeitung
(aktiv)
Abbildung 6–24 Funktionsweise von E/A-Vervollständigungsports
Nach den Richtlinien von Microsoft wird der Parallelitätswert ungefähr auf die Anzahl der Prozessoren im System gesetzt. Es ist jedoch möglich, dass die Anzahl der Threads an einem Vervollständigungsport den Parallelitätsgrenzwert übersteigt. Betrachten Sie dazu den Fall des
Grenzwerts 1:
1.
Eine Clientanforderung kommt herein. Ein Thread wird zur Verarbeitung der Anforderung
abgestellt und wird aktiv.
2.
Eine zweite Anforderung kommt herein, aber da der Parallelitätsgrenzwert bereits erreicht
ist, darf ein zweiter Thread, der an dem Port wartet, nicht weitermachen.
3.
Der erste Thread wartet auf eine Datei-E/A und wird dadurch inaktiv.
4.
Der zweite Thread wird freigegeben.
5.
Während der zweite Thread nach wie vor aktiv ist, wird die Datei-E/A des ersten Threads
abgeschlossen, sodass er wieder aktiv wird. Bis einer der beiden Threads wieder blockiert
wird, beträgt der Parallelitätswert 2, also mehr als der Grenzwert von 1. Meistens verbleibt
die Anzahl der aktiven Threads jedoch am Grenzwert oder nur knapp darüber.
Die API für Vervollständigungsports ermöglicht es einer Serveranwendung auch, privat definierte Vervollständigungspakete mit der Funktion PostQueuedCompletionStatus in eine Portwarteschlange zu stellen. Diese Funktion nutzen Server gewöhnlich, um ihre Threads über externe
Ereignisse zu informieren, z. B. über die Notwendigkeit, sich ordnungsgemäß herunterzufahren.
Anwendungen können die zuvor beschriebene threadagnostische E/A in Kombination mit
Vervollständigungsports verwenden, damit sie die Threads mit einem Vervollständigungsportobjekt statt mit ihren eigenen E/A-Operationen verknüpfen können. Außer Skalierungsvorteilen
bieten Vervollständigungsports auch den Vorteil einer Reduzierung von Kontextwechseln. Normale E/A-Abschlussvorgänge müssen von dem Thread ausgeführt werden, der die E/A-Operation ausgelöst hat, aber wenn eine mit einem Vervollständigungsport verknüpfte Operation
abgeschlossen werden muss, kann der E/A-Manager einen beliebigen wartenden Thread dafür
verwenden.
624
Kapitel 6
Das E/A-System
Funktionsweise von E/A-Vervollständigungsports
Windows-Anwendungen erstellen Vervollständigungsports, indem sie die Windows-API
C reateIoCompletionPort aufrufen und dabei einen NULL-Porthandle angeben. Dadurch wird
der Systemdienst NtCreateIoCompletion ausgeführt. Das IoCompletion-Objekt der Exekutive
enthält ein Kernelsynchronisiserungsobjekt, das als Kernelwarteschlange bezeichnet wird. Der
Systemdienst erstellt also ein Vervollständigungsportobjekt und initialisiert im zugewiesenen
Speicher des Ports ein Warteschlangenobjekt. (Ein Zeiger auf den Port verweist auch auf das
Warteschlangenobjekt, da die Warteschlange das erste Element des Ports ist.) Der Parallelitätswert eines Kernelwarteschlangenobjekts wird festgelegt, wenn ein Thread das Objekt
initialisiert. In diesem Fall wird der an CreateIoCompletionPort übergebene Wert verwendet.
Um das Warteschlangenobjekt eines Ports zu initialisieren, ruft NtCreateIoCompletion die
Funktion KeInitializeQueue auf.
Wenn eine Anwendung CreateIoCompletionPort aufruft, um ein Dateihandle mit einem
Port zu verknüpfen, wird der Systemdienst NtSetInformationFile mit dem Dateihandle als
primärem Parameter ausgeführt. Als Informationsklasse wird FileCompletionInformation festgelegt, und das Handle des Vervollständigungsports sowie der Parameter CompletionKey von
CreateIoCompletionPort sind die Datenwerte. NtSetInformationFile dereferenziert das Dateihandle, um das Dateiobjekt abzurufen, und weist eine Datenstruktur mit dem Vervollständigungskontext zu.
Schließlich richtet NtSetInformationFile das Feld CompletionContext im Dateiobjekt so ein,
dass es auf die Kontextstruktur zeigt. Wird eine asynchrone E/A-Operation für ein Dateiobjekt
abgeschlossen, prüft der E/A-Manager, ob das Feld CompletionContext im Dateiobjekt nicht
NULL ist. Wenn ja, weist er ein Vervollständigungspaket zu und stellt es in die Warteschlange für
den Port, indem er KeInsertQueue mit dem Port als die zu verwendende Warteschlange aufruft.
(Das funktioniert, da das Vervollständigungsport- und das Warteschlangenobjekt dieselbe Adresse haben.)
Wenn ein Serverthread GetQueuedCompletionStatus aufruft, wird der Systemdienst NtRe
moveIoCompletion ausgeführt. Nach der Validierung der Parameter und der Übersetzung des
Porthandles in einen Zeiger auf den Port ruft NtRemoveIoCompletion die Funktion IoRemoveIoCompletion auf, die ihrerseits KeRemoveQueueEx aufruft. Bei Hochleistungsservern ist es möglich,
dass mehrere E/A-Operationen abgeschlossen wurden. Der Thread wird zwar nicht blockiert,
wendet sich aber immer noch jedes Mal an den Kernel, um ein Element abzurufen. Die API GetQueuedCompletionStatus bzw. GetQueuedCompletionStatusEx ermöglicht Anwendungen, mehr
als einen E/A-Vervollständigungsstatus auf einmal abzurufen, was die Anzahl der Benutzer/
Kernel-Roundtrips verringert und für dauerhafte Spitzenleistung sorgt. Intern wird dies durch
die Funktion NtRemoveIoCompletionEx implementiert. Sie ruft IoRemoveIoCompletion mit einem
Zähler für Elemente in der Warteschlange auf, der an KeRemoveQueueEx übergeben wird.
Wie Sie sehen, bilden KeRemoveQueueEx und KeInsertQueue die Engine hinter den Vervollständigungsports. Diese Funktionen bestimmen, ob ein Thread, der auf ein E/A-Vervollständigungspaket wartet, aktiviert werden soll. Intern führt ein Warteschlangenobjekt einen
Zähler der zurzeit aktiven Threads sowie der Maximalzahl aktiver Threads. Wenn ein Thread
KeRemoveQueueEx aufruft und die aktuelle Anzahl der Threads gleich dem Maximum ist oder
dieses übersteigt, wird der Thread (in LIFO-Reihenfolge) auf eine Liste der Threads gesetzt,
E/A-Verarbeitung
Kapitel 6
625
die darauf warten, ein Vervollständigungspaket zu verarbeiten. Diese Threadliste hängt am
Warteschlangenobjekt. Die Steuerblockdatenstruktur eines Threads (KTHREAD) enthält einen
Zeiger, der auf das Warteschlangenobjekt der Warteschlange verweist, mit dem der Thread
verknüpft ist. Ist der Zeiger NULL, dann gehört der Thread zu keiner Warteschlange.
Mithilfe des Warteschlangenzeigers im Steuerungsblock merkt sich Windows, welche
Threads dadurch inaktiv werden, dass sie auf etwas anderes warten als den Vervollständigungsport. Die Schedulerroutinen, die möglicherweise zur Blockierung eines Threads führen
(wie KeWaitForSingleObject, KeDelayExecutionThread usw.), überprüfen den Warteschlangenzeiger des Threads. Wenn er nicht NULL ist, rufen diese Funktionen die Warteschlangenfunktion KiActivateWaiterQueue auf, die den Zähler der mit der Warteschlange verknüpften
aktiven Threads dekrementiert. Ist die resultierende Zahl kleiner als das Maximum und steht
mindestens ein Vervollständigungspaket in der Warteschlange, wird der Thread am Anfang
der Threadliste in der Warteschlange aufgeweckt und erhält das älteste Paket. Wacht dagegen ein mit der Warteschlange verknüpfter Thread nach einer Blockierung auf, führt der
Scheduler die Funktion KiUnwaitThread auf, die den Zähler aktiver Threads der Warteschlange
heraufsetzt.
Die Windows-API-Funktion PostQueuedCompletionStatus führt dazu, dass der Systemdienst
NtSetIoCompletion ausgeführt wird. Diese Funktion fügt einfach das angegebene Paket mit
KeInsertQueue in die Warteschlange des Vervollständigungsports ein.
Abb. 6–25 zeigt ein Beispiel für ein Vervollständigungsportobjekt in Betrieb. Zwar sind
beide Threads zur Verarbeitung von Vervollständigungspaketen bereit, aber aufgrund des Parallelitätswerts von 1 kann nur ein mit dem Port verknüpfter Thread aktiv sein, weshalb die
beiden Threads blockiert sind.
Wartende Threads
Aktiver Thread
Vervollstän
digungspaket
Vervollständigungsport
Warteschlange
Parallelität: 1
Vervollstän
digungspaket
Dateiobjekt
Abbildung 6–25 Ein E/A-Vervollständigungsportobjekt in Betrieb
Das Benachrichtigungsmodell eines E/A-Vervollständigungsports können Sie mit der API
SetFileCompletionNotificationModes einstellen. Dadurch können Anwendungsentwickler die
Vorteile von Verbesserungen nutzen, die gewöhnlich Codeänderungen erfordern, aber einen
noch höheren Durchsatz bieten. Es gibt drei mögliche Benachrichtigungsmodi (siehe Tabelle 6–4). Sie gelten jeweils für ein Dateihandle und können nach der Festlegung nicht mehr
geändert werden.
626
Kapitel 6
Das E/A-System
Modus
Bedeutung
Überspringen des Vervollständigungsports
bei Erfolg
(FILE_SKIP_COMPLETION_PORT_ON_SUCCESS=1)
Wenn die folgenden drei Bedingungen wahr sind,
stellt der E/A-Manager keinen Vervollständigungseintrag in die Warteschlange des Ports, auch wenn er es
normalerweise tun würde. Erstens muss der Vervollständigungsport mit dem Dateihandle verknüpft sein.
Zweitens muss die Datei für asynchrone E/A geöffnet
sein. Drittens muss die Anforderung sofort erfolgreich
zurückspringen und nicht ERROR_PENDING zurückgeben.
Festgelegtes Ereignis für das Handle überspringen
(FILE_SKIP_SET_EVENT_ON_HANDLE=2)
Der E/A-Manager legt das Ereignis für das Dateiobjekt
nicht fest, wenn eine Anforderung die Steuerung mit
einem Erfolgscode zurückgibt oder wenn der zurückgegebene Fehler ERROR_PENDING ist und es sich bei
der aufgerufenen Funktion nicht um eine synchrone
Funktion handelt. Wurde für die Anforderung ein ausdrückliches Ereignis bereitgestellt, so wird es nach wie
vor signalisiert.
Festgelegtes Benutzerereignis bei schneller
E/A überspringen
(FILE_SKIP_SET_USER_EVENT_ON_FAST_IO=4)
Der E/A-Manager legt das für die Anforderung bereitgestellte ausdrückliche Ereignis nicht fest, wenn die
Anforderung den Weg für die schnelle E/A genommen
hat und mit einem Erfolgscode zurückkehrt oder der
zurückgegebene Fehler ERROR_PENDING ist und es sich
bei der aufgerufenen Funktion nicht um eine synchrone Funktion handelt.
Tabelle 6–4 Benachrichtigungsmodi für E/A-Vervollständigungsports
E/A-Priorisierung
Ohne E/A-Priorisierung würden Hintergrundaktivitäten wie Suchindizierung, Virusscans und
Festplattendefragmentierung die Reaktivität von Vordergrundoperationen erheblich beeinträchtigen. Wenn ein Benutzer beispielsweise eine Anwendung startet oder ein Dokument
öffnet, während ein anderer Prozess eine Festplatten-E/A durchführt, kommt es zu Verzögerungen, da der Vordergrundtask auf Festplattenzugriff wartet. Diese Störungen wirken sich
auch auf die Streaming-Wiedergabe von Multimediainhalten wie Musik auf der Festplatte
aus.
In Windows gibt es zwei Arten der E/A-Priorisierung, mit denen E/A-Operationen im Vordergrund Vorrang erhalten: Priorität für einzelne E/A-Operationen und E/A-Bandbreitenreservierung.
E/A-Prioritäten
Der E/A-Manager von Windows bietet intern eine Unterstützung für fünf E/A-Prioritäten, wobei aber nur drei verwendet werden (siehe Tabelle 6–5). In zukünftigen Versionen von Windows
werden Hoch und Niedrig möglicherweise ebenfalls unterstützt.
E/A-Verarbeitung
Kapitel 6
627
E/A-Priorität
Verwendung
Kritisch
Speicher-Manager
Hoch
Nicht verwendet
Normal
Normale Anwendungs-E/A
Niedrig
Nicht verwendet
Sehr niedrig
Geplante Aufgaben, SuperFetch, Defragmentierung, Inhaltsindizierung, Hintergrundaktivitäten
Tabelle 6–5 E/A-Prioritäten
Die Standardpriorität ist Normal. Der Speicher-Manager verwendet Kritisch, wenn er bei knappem Speicher geänderte Daten auf die Festplatte schreiben möchte, um im RAM Platz für
andere Daten und Code zu schaffen. Der Taskplaner von Windows setzt die E/A-Priorität für
Aufgaben, die die Standardpriorität haben, auf Sehr niedrig. Anwendungen, die Hintergrundverarbeitung durchführen, vergeben ebenfalls die Priorität Sehr niedrig. Alle Windows-Hintergrundoperationen wie Scans von Windows Defender und die Indizierung für die Desktopsuche
verwenden die Priorität Sehr niedrig.
Priorisierungsstrategien
Intern sind die fünf E/A-Prioritäten auf zwei E/A-Priorisierungsmodi aufgeteilt, die sogenannten Strategien: Hierarchie- und Leerlaufpriorisierung. Erstere umfasst alle Prioritäten außer Sehr
niedrig. Sie setzt das folgende Verfahren um:
QQ Alle E/A-Operationen mit kritischer Priorität müssen vor denen mit hoher Priorität ausgeführt werden.
QQ Alle E/A-Operationen mit hoher Priorität müssen vor denen mit normaler Priorität ausgeführt werden.
QQ Alle E/A-Operationen mit normaler Priorität müssen vor denen mit niedriger Priorität ausgeführt werden.
QQ Alle E/A-Operationen mit niedriger Priorität werden nach denen mit irgendeiner höheren
Priorität ausgeführt.
Wenn eine Anwendung E/A-Operationen erstellt, werden die IRPs je nach ihrer Priorität in verschiedene E/A-Warteschlangen eingereiht. Die Hierarchiestrategie bestimmt die Reihenfolge
der Operationen.
Die Leerlaufstrategie dagegen verwendet eine eigene Warteschlange für E/A-Operationen
mit Leerlaufpriorität. Da das System sämtliche E/A-Operationen mit Hierarchiepriorität vor jeglicher Leerlauf-E/A verarbeitet, ist es möglich, dass E/A-Operationen in dieser Warteschlange
verhungern, solange es noch eine einzige E/A-Operation mit einer anderen als der Leerlaufpriorität in der Hierarchiewarteschlange gibt.
Um eine solche Situation zu vermeiden und um den Backoff zu steuern (die Senderate der
E/A-Übertragungen), wird die Warteschlange bei der Leerlaufstrategie mit einem Timer überwacht, um zu garantieren, dass wenigstens eine E/A-Operation pro Zeiteinheit (gewöhnlich
628
Kapitel 6
Das E/A-System
eine halbe Sekunde) verarbeitet wird. Werden Daten mit einer anderen als der Leerlaufpriorität
geschrieben, kann der Cache-Manager die Änderungen sofort auf die Festplatte schreiben,
anstatt dies auf später zu verschieben, und damit das vorausschauende Lesen für Leseopera
tionen umgehen, die sonst vorab in der betreffenden Datei lesen würden. Außerdem wartet die
Priorisierungsstrategie nach dem Abschluss des letzten Nicht-Leerlauf-E/A 50 ms lang, um die
nächste Leerlauf-E/A auszugeben, da Leerlauf-E/A-Vorgänge mitten in Nicht-Leerlauf-Streams
auftreten könnten, was kostspielige Suchvorgänge hervorrufen würde.
Wenn wir all diese Strategien zur Veranschaulichung zu einer virtuellen globalen E/A-
Warteschlange kombinieren, kann eine Momentaufnahme dieser Warteschlange wie in
Abb. 6–26 aussehen. Beachten Sie, dass in jeder Warteschlange eine FIFO-Reihenfolge gilt
(First In, First Out). Die Reihenfolge der einzelnen Vorgänge in der Abbildung ist nur ein
Beispiel.
Kritisch
Hoch
Hierarchie
Normal
Niedrig
Sehr niedrig
Leerlauf
Abbildung 6–26 Beispieleinträge in einer globalen E/A-Warteschlange
Benutzermodusanwendungen können die E/A-Priorität in drei verschiedenen Objekten einstellen. Die Funktionen SetPriorityClass (mit dem Wert PROCESS_MODE_BACKGROUND_BEGIN) und
SetThreadPriority (mit dem Wert THREAD_MODE_BACKGROUND_BEGIN) legen die Priorität für alle
E/A-Operationen fest, die vom gesamten Prozess bzw. einzelnen Threads generiert werden
(wobei die Priorität jeweils in den IRPs der einzelnen Anforderungen gespeichert wird). Diese
Funktionen wirken sich nur auf den aktuellen Prozess bzw. Thread aus und senken die E/A-Priorität auf Sehr niedrig. Darüber hinaus setzen sie auch die Planungspriorität auf 4 und die Speicherpriorität auf 1 herab. Die Funktion SetFileInformationByHandle kann die Priorität für ein
einzelnes Dateiobjekt festlegen (wobei die Priorität im Dateiobjekt gespeichert wird). Treiber
haben die Möglichkeit, die E/A-Priorität mit IoSetIoPriorityHint direkt in einem IRP einzustellen.
Die Felder für die E/A-Priorität in IRPs und Dateiobjekten sind lediglich Hinweise
(Hints). Es ist nicht garantiert, dass diese Einstellung respektiert wird, und nicht
einmal sicher, dass sie von den einzelnen Treibern im Speicherstack überhaupt
unterstützt wird.
Die beiden Priorisierungsstrategien werden durch zwei verschiedene Arten von Treibern implementiert. Die Hierarchiestrategie wird durch Speicherporttreiber umgesetzt, die jeweils für
die gesamte E/A an einem bestimmten Port zuständig sind, z. B. ATA, SCSI oder USB. Nur
der ATA-Porttreiber (Ataport.sys) und der USB-Porttreiber (Usbstor.sys) implementieren jedoch
diese Strategie; der SCSI- und der Speicherporttreiber (Scsiport.sys und Storport.sys) dagegen
nicht.
E/A-Verarbeitung
Kapitel 6
629
Alle Porttreiber prüfen ausdrücklich, ob E/A-Operationen mit kritischer Priorität
vorliegen, und verschieben sie an die Spitze ihrer Warteschlangen, selbst wenn sie
den Hierarchiemechanismus nicht komplett unterstützen. Dies dient dazu, kritische Auslagerungsoperationen des Speicher-Managers zu fördern, um die Zuverlässigkeit des Systems zu garantieren.
Massenspeichergeräte für Endverbraucher wie IDE- oder SATA-Festplatten und USB-Sticks nutzen daher die Vorteile der E/A-Priorisierung, SCSI-, Fibre-Channel- und iSCSI-Geräte dagegen
nicht.
Dagegen wird die Leerlaufstrategie vom Systemgerätetreiber für die Speicherklasse (Class
pnp.sys) durchgesetzt, sodass diese Strategie automatisch auf E/A-Vorgänge an allen Speichergeräten einschließlich SCSI-Laufwerken angewendet wird. Damit ist sichergestellt, dass Leerlauf-E/A-Operationen dem Backoffalgorithmus unterliegen, damit das System auch bei einem
starken Aufkommen von Leerlauf-E/A zuverlässig arbeitet und die Anwendungen, die diese
Art der E/A durchführen, Fortschritte machen können. Durch die Implementierung dieser Strategie in einem von Microsoft bereitgestellten Klassentreiber werden auch Leistungsprobleme
vermieden, die durch mangelnde Unterstützung in veralteten Drittanbieter-Porttreibern verursacht werden könnten.
Abb. 6–27 gibt eine vereinfachte Darstellung des Speicherstacks und zeigt, wo die Strategien jeweils implementiert sind. Weitere Informationen über den Speicherstack erhalten Sie in
Kapitel 12 von Band 2.
Benutzermodus
Kernelmodus
Anwendung
Dateisystem
Volume/Partition
Geräteklasse
Warteschlange für Leerlaufpriorität
Befehlsport
Warteschlange für Hierarchiepriorität
E/A-Bandbreitenreservierung
Speicher
Abbildung 6–27 Implementierung der E/A-Priorisierungsstrategien im Speicherstack
Prioritätsumkehrung verhindern
Um eine Umkehrung der E/A-Priorität zu verhindern, bei der ein Thread mit hoher Priorität von
einem Thread mit niedriger Priorität ausgehungert wird, wendet der Sperrmechanismus der
Exekutivressource (ERESOURCE) verschiedene Strategien an. Diese Ressource wurde eigens für die
Implementierung der E/A-Prioritätsvererbung ausgewählt, da sie häufig in Dateisystem- und
630
Kapitel 6
Das E/A-System
Speichertreibern verwendet wird, wo die meisten Probleme mit Prioritätsumkehrung auftreten
können. (Mehr über die Exekutivressource erfahren Sie in Kapitel 8 von Band 2.)
Erwirbt ein Thread mit niedriger E/A-Priorität eine Exekutivressource und warten bereits
andere Threads mit normaler oder höherer Priorität auf diese Ressource, so wird der aktuelle
Thread mithilfe der API PsBoostThreadIo, die den Zähler IoBoostCount in der ETHREAD-Struktur
inkrementiert, vorübergehend auf normale E/A-Priorität heraufgesetzt. Sie benachrichtigt auch
Autoboost, wenn die E/A-Priorität des Threads erhöht oder die Erhöhung zurückgenommen
wird. (Mehr über Autoboost erfahren Sie in Kapitel 4.)
Anschließend ruft sie die API IoBoostThreadIoPriority auf, die alle IRPs in der Warteschlange des Zielthreads auflistet (denken Sie daran, dass jeder Thread über eine Liste ausstehender IRPs verfügt) und prüft, welche davon eine niedrigere als die Zielpriorität haben (in
diesem Fall normal). Dadurch werden die ausstehenden IRPs mit Leerlaufpriorität bestimmt.
Anschließend werden die für diese IRPs jeweils verantwortlichen Geräteobjekte ermittelt. Der
E/A-Manager prüft, ob ein Prioritätscallback registriert worden ist. Eine solche Registrierung
können Treiberentwickler mit IoRegisterPriorityCallback und durch Setzen des Flags DO_
PRIORITY_CALLBACK_ENABLED im Geräteobjekt vornehmen. Je nachdem, ob es sich um ein IRP
für Auslagerungs-E/A handelt oder nicht, wird der Mechanismus für die Prioritätserhöhung
Paging Boost (Auslagerungsschub) oder Threaded Boost (Threadschub) genannt. Wenn keine
übereinstimmenden IRPs gefunden wurden, der Thread aber über ausstehende IRPs verfügt,
erhalten sie alle unabhängig vom Geräteobjekt oder ihrer Priorität einen Prioritätsschub. Dies
wird als Blanket Boost (Pauschalschub) bezeichnet.
Prioritätsschübe und -bumps
Um Aushungern, Umkehrung und andere unerwünschte Situationen im Zusammenhang mit
der E/A-Priorität zu verhindern, verwendet Windows noch einige andere feine Modifizierungen
der normalen E/A-Vorgänge. Gewöhnlich wird dabei die E/A-Priorität bei Bedarf erhöht. Das
geschieht in folgenden Situationen:
QQ Wenn ein Treiber mit einem IRP für ein bestimmtes Dateiobjekt aufgerufen wird und die
Anforderung vom Kernelmodus kommt, sorgt Windows dafür, dass das IRP auch dann die
normale Priorität verwendet, wenn das Objekt einen niedrigeren Prioritätshinweis hat. Dies
wird als Kernelbump bezeichnet.
QQ Bei Lese- oder Schreibvorgängen in der Auslagerungsdatei (durch IoPageRead bzw. IoPageWrite) prüft Windows, ob die Anforderung vom Kernelmodus stammt und nicht im Namen
von SuperFetch erfolgt (da SuperFetch ausschließlich Leerlauf-E/A durchführt). Wenn ja,
wird das IRP auch dann mit normaler Priorität ausgeführt, wenn der aktuelle Thread eine
niedrigere E/A-Priorität hat. Dies wird als Auslagerungsbump bezeichnet.
Das folgende Experiment zeigt ein Beispiel für die Priorität Sehr niedrig und führt vor, wie Sie
sich E/A-Prioritäten für verschiedene Anforderungen in Process Monitor ansehen können.
E/A-Verarbeitung
Kapitel 6
631
Experiment: Durchsatz von Threads mit sehr niedriger und
normaler E/A-Priorität
Mit der im Begleitmaterial zu diesem Buch enthaltenen Beispielanwendung IO Priority können Sie sich den Unterschied des Durchsatzes von Threads mit unterschiedlichen E/A-Prioritäten ansehen. Gehen Sie dazu wie folgt vor:
1.
Starten Sie IoPriority.exe.
2.
Aktivieren Sie in dem Dialogfeld im Bereich Thread 1 das Kontrollkästchen Low Priority.
3.
Klicken Sie auf Start I/O. Jetzt können Sie einen erheblichen Geschwindigkeitsunterschied zwischen den beiden Threads beobachten, wie der folgende Screenshot zeigt:
Wenn beide Threads auf niedriger Priorität laufen und sich das System
größtenteils im Leerlauf befindet, entspricht ihr Durchsatz ungefähr dem
eines einzelnen Threads mit normaler Priorität, da Threads mit niedriger
Priorität nicht künstlich gedrosselt oder auf andere Weise aufgehalten
werden, wenn es keine Konkurrenz durch Threads mit höherer Priorität
gibt.
4.
Öffnen Sie den Prozess in Process Explorer und schauen Sie sich den Thread mit der
niedrigen Priorität an:
→
632
Kapitel 6
Das E/A-System
5.
In Process Monitor können Sie auch die E/A-Operationen von IO Priority verfolgen und
sich ihre Prioritätshinweise ansehen. Richten Sie dazu in Process Monitor einen Filter
für IoPriority.exe ein und wiederholen Sie das Experiment. Die einzelnen Threads dieser
Anwendung lesen eine Datei, deren Name sich aus _File_ und der Thread-ID zusammensetzt.
6.
Scrollen Sie nach unten bis zu einem Schreibvorgang in _File_1. Dabei sollten Sie folgende Ausgabe sehen:
7.
In dem Screenshot haben die E/A-Operationen für die Datei _FILE_7920 eine sehr niedrige Priorität. In den Spalten Time of Day und Relative Time können Sie außerdem erkennen, dass diese E/A-Vorgänge jeweils eine halbe Sekunde auseinanderliegen. Dies
ist ein weiterer Hinweis darauf, dass die Leerlaufstrategie ausgeführt wird.
Experiment: Analysieren der Leistung bei Prioritätsschüben und
-bumps
Der Kernel führt mehrere interne Variablen, die Sie durch die nicht dokumentierte, in
NtQuerySystemInformation vorhandene Systemklasse SystemLowPriorityIoInformation
abfragen können. Sie können sich diese Zahlen auf Ihrem System aber auch mit dem
lokalen Kerneldebugger ansehen, ohne eine solche Anwendung zu schreiben oder zu
nutzen. Die folgenden Variablen stehen zur Verfügung:
QQ IoLowPriorityReadOperationCount und IoLowPriorityWriteOperationCount
QQ IoKernelIssuedIoBoostedCount
QQ IoPagingReadLowPriorityCount und IoPagingWriteLowPriorityCount
QQ IoPagingReadLowPriorityBumpedCount und IoPagingWriteHighPriorityBumpedCount
QQ IoBoostedThreadedIrpCount und IoBoostedPagingIrpCount
QQ IoBlanketBoostCount
Mit dem Speicherauszugsbefehl dd des Kerneldebuggers können Sie sich die Werte dieser
Variablen ansehen. (Es sind alles 32-Bit-Werte.)
E/A-Verarbeitung
Kapitel 6
633
Bandbreitenreservierung (geplante Datei-E/A)
Die Unterstützung von Windows für die E/A-Bandbreitenreservierung ist sehr hilfreich für
Anwendungen, die einen gleichmäßigen E/A-Durchsatz benötigen. Beispielsweise kann eine
Mediaplayeranwendung das E/A-System mit einem Aufruf von SetFileBandwidthReservation
bitten, ihr die Möglichkeit zu gewähren, Daten mit einer festgelegten Rate von einem Gerät zu
lesen. Wenn das Gerät die Daten mit der angeforderten Rate liefern kann und die bestehenden
Reservierungen es erlauben, teilt das E/A-System der Anwendung mit, wie schnell sie E/A-
Operationen ausgeben kann und wie umfangreich diese Operationen sein dürfen.
Das E/A-System führt andere E/A-Vorgänge nur dann aus, wenn es die Anforderungen der
Anwendungen, die Reservierungen für das Zielspeichergerät vorgenommen haben, erfüllen
kann. Abb. 6–28 zeigt den prinzipiellen zeitlichen Verlauf von E/A-Vorgängen in derselben
Datei. Die grauen Abschnitte sind die einzigen, die für andere Anwendungen zur Verfügung
stehen. Wenn die E/A-Bandbreite belegt ist, müssen neue E/A-Operationen bis zum nächsten
Zyklus warten.
Reservierte
Bandbreite
Freie
Band
breite
Reservierte
Bandbreite
Reservierte
Bandbreite
Freie
Band
breite
Reservierte
Bandbreite
Abbildung 6–28 Bandbreitenreservierung für E/A-Anforderungen
Wie die Hierarchiestrategie wird die Bandbreitenreservierung in den Porttreibern implementiert. Dadurch steht sie nur für IDE-, SATA- und USB-Massenspeichergeräte zur Verfügung.
Containerbenachrichtigungen
Containerbenachrichtigungen sind besondere Klassen von Ereignissen, die Treiber für einen
asynchronen Callbackmechanismus registrieren können. Dazu verwenden sie die API IoRegisterContainerNotification und wählen die gewünschte Benachrichtigungsklasse aus. Bis jetzt ist
nur eine solche Klasse in Windows implementiert, nämlich IoSessionStateNotification. Damit
können Treiber ihre registrierten Callbacks aufrufen lassen, wenn in einer gegebenen Sitzung
eine Statusänderung festgestellt wird. Folgende Änderungen werden erkannt:
QQ Eine Sitzung wird erstellt oder beendet.
QQ Ein Benutzer stellt eine Verbindung zu der Sitzung her oder trennt sie.
QQ Ein Benutzer meldet sich an einer Sitzung an oder ab.
634
Kapitel 6
Das E/A-System
Bei Angabe eines Geräteobjekts für eine bestimmte Sitzung kann der Treibercallback nur für diese Sitzung aktiv werden. Wird dagegen ein globales Geräteobjekt angegeben (oder gar keines),
so empfängt der Treiber Benachrichtigungen für alle Ereignisse im System. Das ist besonders
für Geräte nützlich, die an dem durch die Terminaldienste bereitgestellten Plug-&-Play-Geräteumleitungsmechanismus beteiligt sind. Er macht es möglich, dass ein Remotegerät auch im
Bus des PnP-Managers des Hosts zu sehen ist, der die Verbindung aufnimmt (z. B. in Form von
Audio- oder Druckerumleitung). Wenn ein Benutzer beispielsweise die Verbindung zu einer
Sitzung mit Audiowiedergabe aufhebt, muss der Gerätetreiber benachrichtigt werden, damit er
die Umleitung des Quellaudiostreams beendet.
Treiberüberprüfung
Die Treiberüberprüfung (Driver Verifier) ist ein Mechanismus, mit dem sich gängige Bugs in
Gerätetreibern und anderem Kernelmodus-Systemcode finden und isolieren lassen. Microsoft
setzt die Treiberüberprüfung selbst ein, um sowohl eigene als auch von den Herstellern für
die WHQL-Prüfung eingereichte Gerätetreiber zu untersuchen. Dadurch ist sichergestellt, dass
die eingereichten Treiber mit Windows kompatibel sind und keine der üblichen Treiberfehler
aufweisen. (Es gibt auch ein Werkzeug zur Anwendungsüberprüfung, das zu erheblichen Qualitätsverbesserungen von Benutzermoduscode in Windows geführt hat, allerdings werden wir
es in diesem Buch nicht behandeln.)
Die Treiberüberprüfung ist hauptsächlich als Werkzeug gedacht, mit dem die Entwickler von Gerätetreibern Bugs in ihrem Code aufspüren können. Es ist jedoch
auch sehr nützlich für Systemadministratoren, um Abstürze zu analysieren. Kapitel 15 beschreibt die Anwendung der Treiberüberprüfung für die Absturzanalyse.
Die Treiberüberprüfung ist auf mehrere Systemkomponenten verteilt. Im Speicher-Manager, im
E/A-Manager und in der HAL gibt es Treiberüberprüfungsoptionen, die Sie aktivieren können.
Konfiguriert werden sie mit dem Treiberüberprüfungs-Manager (%SystemRoot%\System32\
Verifier.exe). Wenn Sie ihn ohne Befehlszeilenargumente ausführen, wird eine Assistentenoberfläche wie in Abb. 6–29 angezeigt. (Sie können den Treiberüberprüfungs-Manager auch an der
Befehlszeile aktivieren und deaktivieren und seine aktuellen Einstellungen einsehen.) Um sich
die möglichen Schalter anzeigen zu lassen, geben Sie an einer Befehlszeile verifier /? ein.
Treiberüberprüfung
Kapitel 6
635
Abbildung 6–29 Der Treiberüberprüfungs-Manager
Der Treiberüberprüfungs-Manager unterscheidet zwischen Standard- und Zusatzeinstellungen.
Die Grenze ist etwas willkürlich gezogen, allerdings umfassen die Standardeinstellungen die
gängigeren Optionen, die am besten bei jedem zu testenden Treiber verwendet werden sollen,
während es sich bei den Zusatzeinstellungen um weniger gebräuchliche oder um solche handelt, die nur für bestimmte Arten von Treibern sinnvoll sind. Wenn Sie in der Hauptseite des
Assistenten Benutzerdefinierte Einstellungen erstellen wählen, werden alle Optionen in einer
Spalte angezeigt, wobei angegeben ist, welche davon Standard- und welche Zusatzeinstellungen sind (siehe Abb. 6–30).
Unabhängig davon, welche Optionen Sie ausgewählt haben, überwacht die Treiberüberprüfung stets die zur Überprüfung ausgewählten Treiber und sucht dabei nach verschiedenen
unzulässigen und grenzwertigen Operationen, z. B. nach dem Aufruf von Kernelpoolfunktionen
auf ungültigen IRQLs, nach doppelter Freigabe von Speicher, nicht ordnungsgemäßer Freigabe
von Spinlocks, mangelnder Freigabe von Timern, Verweise auf freigegebene Objekte, Verzögerung des Herunterfahrens um mehr als 20 Minuten und die Anforderung von Speicherzuweisungen der Größe 0.
636
Kapitel 6
Das E/A-System
Abbildung 6–30 Einstellungen der Treiberüberprüfung
Die Einstellungen der Treiberüberprüfung werden unter dem Registrierungsschlüssel HKLM\
SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management gespeichert. Der Wert
VerifyDriverLevel enthält eine Bitmaske, die die aktivierten Überprüfungsoptionen angibt, und
der Wert VerifyDrivers die Namen der zu überwachenden Treiber. (Diese Werte erscheinen
erst in der Registrierung, wenn Sie die Treiber im Treiberüberprüfungs-Manager auswählen.)
Wenn Sie festgelegt haben, dass Sie alle Treiber überprüfen wollen (was Sie nicht tun sollten,
da das System dadurch beträchtlich verlangsamt wird), wird VerifyDrivers auf das Zeichen *
gesetzt. Je nachdem, welche Einstellungen Sie vorgenommen haben, kann es sein, dass Sie das
System neu starten müssen, damit die ausgewählte Überprüfung vorgenommen werden kann.
Sehr früh im Bootvorgang liest der Speicher-Manager die Registrierungswerte der Treiberüberprüfung, um zu bestimmen, welche Treiber untersucht und welche Optionen aktiviert werden sollen. (Beim Start im abgesicherten Modus werden die Einstellungen für die Treiberüberprüfung ignoriert.) Anschließend gleicht der Kernel die Namen aller in den Speicher geladenen
Gerätetreiber mit der Liste der Treiber ab, die Sie zur Überprüfung ausgewählt haben. Für jeden
Treiber, für den der Kernel eine Übereinstimmung findet, ruft er die Funktion VfLoadDriver auf,
die wiederum andere interne Vf*-Funktionen aufruft, um die Verweise des Treibers auf eine
Reihe von Kernelfunktionen durch Verweise auf die entsprechenden Versionen der Treiber
überprüfung zu ersetzen. Beispielsweise wird ExAllocatePool durch VerifierAllocatePool ersetzt. Der Fenstersystemtreiber (Win32k.sys) führt ähnliche Änderungen durch, um für manche
Funktionen die Versionen der Treiberüberprüfung zu nutzen.
Treiberüberprüfung
Kapitel 6
637
E/A-Überprüfungsoptionen
Es gibt folgende Überprüfungsoptionen im Zusammenhang mit der E/A:
QQ E/A-Überprüfung Bei der Auswahl dieser Option weist der E/A-Manager IRPs für die
zu überprüfenden Treiber aus einem besonderen Pool zu und verfolgt ihre Nutzung. Außerdem lässt die Treiberüberprüfung das System abstürzen, wenn ein IRP abgeschlossen
wird, der einen ungültigen Status enthält, oder wenn ein ungültiges Geräteobjekt an den
E/A-Manager übergeben wird. Bei dieser Option werden des Weiteren alle IRPs überwacht,
um sicherzustellen, dass die Treiber sie korrekt kennzeichnen, wenn sie sie asynchron abschließen, dass sie die Gerätestackpositionen korrekt verwalten und dass sie Geräteobjekte
nur einmal löschen. Außerdem belastet die Treiberüberprüfung Treiber nach dem Zufallsprinzip, indem sie ihnen gefälschte Energieverwaltungs- und WMI-IRPs sendet, die
Reihenfolge ändert, in der die Treiber aufgelistet werden, und den Status von PnP- und
Energie-IRPs bei ihrem Abschluss anpasst. Das dient dazu, Treiber ausfindig zu machen, die
einen falschen Status von ihren Dispatchroutinen zurückgeben. Darüber hinaus erkennt
die Treiberüberprüfung es auch, wenn Sperren fälschlicherweise neu initialisiert werden,
obwohl sie aufgrund der ausstehenden Entfernung eines Geräts noch gehalten werden.
QQ DMA-Überprüfung DMA (Direct Memory Access, also »direkter Speicherzugriff«) ist ein
von der Hardware unterstützter Mechanismus, der es Geräten erlaubt, Daten unter Umgehung der CPU in den oder aus dem physischen Speicher zu übertragen. Der E/A-Manager
bietet mehrere Funktionen, mit denen Treiber DMA-Operationen auslösen und steuern
können. Bei dieser Option wird die korrekte Nutzung dieser Funktionen und der vom
E/A-Manager für DMA-Operationen bereitgestellten Puffer überprüft.
QQ Ausstehende E/A-Anforderungen erzwingen Bei vielen Geräten werden asynchrone
E/A-Operationen sofort abgeschlossen. Daher kann es sein, dass die Treiber nicht korrekt
geschrieben wurden, um gelegentliche asynchrone E/As ordnungsgemäß zu handhaben.
Ist diese Option aktiviert, gibt der E/A-Manager nach dem Zufallsprinzip STATUS_PENDING
zurück, wenn ein Treiber IoCallDriver aufruft, um den asynchronen Abschluss der E/A zu
provozieren.
QQ IRP-Protokollierung Bei dieser Option wird die Verwendung von IRPs durch den Treiber
überwacht und als WMI-Information aufgezeichnet. Anschließend können Sie mit dem
WDK-Programm Dc2wmiparser.exe diese WMI-Datensätze in eine Textdatei umwandeln.
Allerdings können für jedes Gerät nur zwanzig IRPs aufgezeichnet werden – bei jedem weiteren IRP wird der älteste vorhandene Eintrag überschrieben. Nach einem Neustart werden
die Informationen verworfen, weshalb Sie Dc2wmiparser.exe vorher ausführen müssen,
wenn Sie den Inhalt der Ablaufverfolgung später noch analysieren wollen.
Speicherüberprüfungsoptionen
Die Treiberüberprüfung bietet die folgenden Überprüfungsoptionen für den Arbeitsspeicher.
Einige davon stehen auch in Beziehung mit E/A-Operationen.
638
Kapitel 6
Das E/A-System
Spezieller Pool
Bei der Auswahl der Option Spezieller Pool werden Poolzuweisungen zwischen ungültige Seiten
eingeschlossen, sodass Verweise vor oder hinter die Zuweisungen zu einer Kernelmodus-Zugriffsverletzung führen und das System zum Absturz bringen, wobei der fehlerhafte Treiber
deutlich gemacht wird. Bei dieser Option erfolgen auch einige zusätzliche Überprüfungen,
wenn ein Treiber Speicher zuweist oder freigibt. Außerdem weisen die Poolzuweisungsroutinen
hierbei eine besondere Region des Kernelspeichers für die Verwendung durch die Treiberüberprüfung zu. Die Treiberüberprüfung leitet Speicherzuweisungsanforderungen von überwachten Treibern an diesen besonderen Poolbereich weiter, anstatt die regulären Kernelmoduspools
zu verwenden. Wenn ein Gerätetreiber Speicher aus diesem besonderen Pool zuweist, rundet
die Treiberüberprüfung diese Zuweisung auf eine gerade Anzahl von Seiten auf. Da sie ungültige Seiten vor und hinter die zugewiesenen Seiten stellt, greift ein Treiber auf eine ungültige
Seite zu, wenn er versucht, außerhalb des Puffers zu lesen oder zu schreiben, sodass der Speicher-Manager eine Kernelmodus-Zugriffsverletzung auslöst.
Abb. 6–31 zeigt ein Beispiel für den besonderen Pool, den die Treiberüberprüfung Gerätetreibern zuweist, um Überlauffehler feststellen zu können.
Ungültige Seite
Treiberpuffer
Zufällige Daten
Ungültige Seite
Seite 2 (hohe Adresse)
Seite 1
Seite 0 (niedrige Adresse)
Abbildung 6–31 Aufbau von Zuweisungen aus dem besonderen Pool
Die Treiberüberprüfung führt standardmäßig eine Untersuchung auf Überläufe durch. Dazu
platziert sie den vom Gerätetreiber verwendeten Puffer am Ende der zugewiesenen Seite und
füllt den Seitenanfang mit zufälligen Daten. Eine Untersuchung auf Unterläufe können Sie zwar
nicht im Treiberüberprüfungs-Manager einstellen, aber dadurch, dass Sie den DWORD-Registrierungswert PoolTagOverruns im Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\Session
Manager\Memory Management auf 0 setzen. (Eine weitere Möglichkeit besteht darin, das Dienstprogramm Gflags.exe auszuführen und im Abschnitt Kernel Special Pool Tag die Option Verify
Start statt der Standardoption Verify End auszuwählen.) Für die Untersuchung auf Unterläufe
weist die Treiberüberprüfung den Treiberpuffer am Anfang statt am Ende der Seite zu.
Die Überlauferkennung schließt jedoch auch einige Maßnahmen für die Unterlauferkennung ein. Wenn der Treiber seinen Puffer freigibt, um den Speicher an die Treiberüberprüfung
zurückzugeben, vergewissert diese sich, dass das dem Puffer vorausgehende Muster unverändert ist. Wurde es geändert, so hat der Gerätetreiber den Puffer unterlaufen und in den Speicher außerhalb des Puffers geschrieben.
Bei Zuweisungen aus dem besonderen Pool wird auch geprüft, ob die Zuweisung und Aufhebung der Zuweisung auf einer gültigen IRQL stattfinden. Dadurch kann ein Fehler erkannt
Treiberüberprüfung
Kapitel 6
639
werden, den manche Gerätetreiber machen: Sie weisen auslagerungsfähigen Speicher auf der
DPC- oder Dispatch-IRQL oder höher zu.
Den besonderen Pool können Sie auch manuell einrichten, indem Sie im Schlüssel HKLM\
SYSTEM\CurrentControlSet\Control\Session Manager\Memory Management den DWORD-Wert
PoolTag für die Zuweisungstags hinzufügen, die das System für den besonderen Pool nutzt.
Wenn die Treiberüberprüfung nicht zur Überwachung eines bestimmten Gerätetreibers eingerichtet ist, der Treiber den zugewiesenen Speicher mit dem Tag aus dem Wert PoolTag verknüpft, dann wird der Speicher trotzdem aus dem besonderen Pool zugewiesen. Sie können
den Wert von PoolTag auch auf 0x2a oder * setzen, sodass der gesamte Speicher, den der
Treiber zuweist, aus dem besonderen Pool genommen wird, sofern ausreichend virtueller und
physischer Speicher vorhanden ist. (Wenn es nicht genügend freie Seiten gibt, nehmen die
Treiber die Zuweisung wieder aus dem regulären Pool vor.)
Poolnachverfolgung
Wenn die Poolnachverfolgung aktiviert ist, prüft der Speicher-Manager beim Entladen des
Treibers, ob der Treiber alle von ihm vorgenommenen Speicherzuweisungen freigegeben hat.
Wenn nicht, stürzt das System ab, wobei der fehlerhafte Treiber als Ursache angegeben wird.
Die Treiberüberprüfung zeigt auch allgemeine Poolstatistiken auf der Registerkarte Poolnachverfolgung des Treiberüberprüfungs-Managers an (die angezeigt wird, wenn Sie auf der Hauptseite des Assistenten die Option Informationen über verifizierte Treiber anzeigen wählen und
dann zweimal auf Weiter klicken). Sie können auch den Kerneldebuggerbefehl !verifier verwenden. Er zeigt mehr Informationen an als die Treiberüberprüfung und ist für Treiberautoren
sehr hilfreich.
Die Poolnachverfolgung und der besondere Pool decken nicht nur ausdrückliche Zuweisungsaufrufe wie ExAllocatePoolWithTag ab, sondern auch Aufrufe anderer Kernel-APIs, die
implizit Speicher aus den Pools zuweisen: IoAllocateMdl, IoAllocateIrp und andere IRP-Zuweisungsaufrufe, verschiedene Rtl-String-APIs sowie IoSetCompletionRoutineEx.
Eine weitere Treiberüberprüfungsfunktion, die durch die Option Poolnachverfolgung aktiviert wird, hängt mit Poolkontingenten zusammen. Bei einem Aufruf von ExAllocatePoolWithQuotaTag wird die Anzahl der zugewiesenen Bytes auf das Poolkontingent des aktuellen
Threads angerechnet. Erfolgt ein solcher Aufruf von einer DPC-Routine aus, lässt sich aber nicht
sagen, auf welchen Prozess die Zuweisung angerechnet werden soll, da DPC-Routinen im Kontext eines beliebigen Prozesses ausgeführt werden können. Bei der Option Poolnachverfolgung
wird geprüft, ob diese Routine im Kontext von DPC-Routinen aufgerufen wird.
Die Treiberüberprüfung kann auch eine Seitenverfolgung im verriegelten Speicher durchführen, bei der zusätzlich ermittelt wird, ob Seiten nach dem Abschluss einer E/A-Opera
tion verriegelt geblieben sind. Wenn ja, wird statt PROCESS_HAS_LOCKED_PAGES der Absturzcode
DRIVER_LEFT_LOCKED_PAGES_IN_PROCESS angegeben, der den für den Fehler verantwortlichen
Treiber und die für die Verriegelung der Seiten verantwortliche Funktion nennt.
640
Kapitel 6
Das E/A-System
IRQL-Überprüfung
Einer der am häufigsten vorkommenden Gerätetreiberbugs tritt auf, wenn ein Treiber auf auslagerungsfähige Daten oder auslagerungsfähigen Code zugreift, während der Prozessor, auf
dem der Treiber ausgeführt wird, auf einer erhöhten IRQL arbeitet. Bei einer IRQL von DPC/
Dispatch-Ebene oder höher kann der Speicher-Manager aber keinen Seitenfehler handhaben.
Wenn sich die Daten, auf die der Treiber zugreift, gerade im physischen Speicher befinden,
erkennt das System den Fehler nicht einmal. Sind die Daten dagegen ausgelagert, kommt es
zu einem Systemabsturz mit dem Stoppcode IRQL_NOT_LESS_OR_EQUAL (das heißt, die IRQL war
nicht kleiner oder gleich der Ebene, die für die versuchte Operation erforderlich war, in diesem
Fall für den Zugriff auf auslagerungsfähigen Speicher).
Es ist gewöhnlich ziemlich schwierig, Gerätetreiber auf Bugs dieser Art zu untersuchen,
doch die Treiberüberprüfung macht es einfach. Wenn Sie die Option IRQL-Überprüfung aktivieren, entfernt die Treiberüberprüfung jeglichen auslagerungsfähigen Kernelmoduscode und alle
auslagerungsfähigen Kernelmodusdaten aus dem Systemarbeitssatz, sobald ein überwachter
Gerätetreiber die IRQL anhebt. Dazu wird die interne Funktion MiTrimAllSystemPagableMemory
verwendet. Wenn ein überwachter Gerätetreiber dann bei erhöhter IRQL auf auslagerungsfähigen Speicher zugreift, erkennt das System sofort die Verletzung. In dem resultierenden
Systemabsturz wird der fehlerhafte Treiber angegeben.
Ein weiterer häufiger Treiberabsturz aufgrund falscher IRQL-Verwendung tritt auf, wenn
auf Synchronisierungsobjekte gewartet wird, die zu ausgelagerten Datenstrukturen gehören.
Synchronisierungsobjekte sollten niemals ausgelagert werden, da der Dispatcher auch auf
höheren IRQLs auf sie zugreifen muss, bei denen es sonst zu einem Absturz kommen würde.
Die Treiberüberprüfung ermittelt, ob sich die Strukturen KTIMER, KMUTEX, KSPIN_LOCK, KEVENT,
KSEMAPHORE, ERESOURCE und FAST_MUTEX im auslagerungsfähigen Speicher befinden.
Simulierung geringer Ressourcen
Bei der Option Simulierung geringer Ressourcen lässt die Treiberüberprüfung Speicherzuweisungen durch die überwachten Gerätetreiber nach dem Zufallsprinzip fehlschlagen. Früher
wurden Gerätetreiber oft unter der Annahme geschrieben, dass der Kernelspeicher stets verfügbar ist. Wenn dieser Speicher ausging, war das für den Treiber auch kein Problem, da das
System dann ohnehin abstürzen würde. Da eine Verknappung des Speichers jedoch auch vorübergehend auftreten kann und die heutigen Mobilgeräte nicht so leistungsfähig sind wie große
Computer, müssen Gerätetreiber jedoch sauber mit Zuweisungsfehlern umgehen, die auf eine
Erschöpfung des Kernelspeichers hindeuten.
Zu den Treiberaufrufen, bei den zufällig ein Fehlschlag ausgelöst wird, gehören ExAllocatePool*, MmProbeAndLockPages, MmMapLockedPagesSpecifyCache, MmMapIoSpace, MmAllocateContiguousMemory, MmAllocatePagesForMdl, IoAllocateIrp, IoAllocateMdl, IoAllocateWorkItem,
IoAllocateErrorLogEntry, IoSetCompletionRoutineEx sowie verschiedene Rtl-String-APIs,
die Zuweisungen aus dem Pool vornehmen. Die Treiberüberprüfung lässt auch einige Zu-
Treiberüberprüfung
Kapitel 6
641
weisungen der GDI-Kernelfunktionen fehlschlagen. (Eine vollständige Liste finden Sie in der
WDK-Dokumentation.) Darüber hinaus können Sie noch Folgendes angeben:
QQ Die Wahrscheinlichkeit, mit der eine Zuweisung fehlschlägt
trägt 6 %.
QQ Die Anwendungen, die dieser Simulation unterzogen werden
sind dies alle.
QQ Die betroffenen Pooltags
Der Standardwert beNach Voreinstellung
Nach Voreinstellung sind dies alle.
QQ Die Verzögerung, bevor die Simulation beginnt Vorgegeben sind sieben Minuten
nach dem Systemstart. Das ist ausreichend Zeit, um die kritische Initialisierungsphase abzuschließen, in der knapper Speicher das Laden eines Gerätetreibers verhindern kann.
Diese Einstellungen können Sie mit den Befehlszeilenoptionen von verifier.exe ändern.
Nach Ablauf der Verzögerung beginnt die Treiberüberprüfung damit, Zuweisungsaufrufe der
überwachten Gerätetreiber zufallsgesteuert fehlschlagen zu lassen. Wenn ein Treiber mit solchen Zuweisungsfehlern nicht korrekt umgehen kann, wird sich das sehr wahrscheinlich in einem Systemabsturz zeigen.
Systematische Simulation geringer Ressourcen
Ähnlich wie bei Simulierung geringer Ressourcen lässt die Treiberüberprüfung auch bei dieser
Option bestimmte Aufrufe an den Kernel und an Ndis.sys (für Netzwerktreiber) fehlschlagen, allerdings auf systematische Weise. Dazu untersucht sie den Aufrufstack bei einem Fehler. Wenn
der Treiber ihn korrekt gehandhabt hat, wird bei diesem Stack kein weiterer Fehlschlag mehr
versucht. Dadurch können Treiberautoren die Probleme systematisch erkennen, ein gemeldetes Problem lösen und dann zum nächsten übergehen. Die Untersuchung von Aufrufstacks ist
jedoch eine sehr aufwendige Operation, weshalb davon abzuraten ist, mehr als einen Treiber
auf einmal mit dieser Einstellung zu überprüfen.
Sonstige Prüfungen
Bei einigen der Überprüfungen, die unter Sonstiges fallen, wird ermittelt, ob bestimmte Systemstrukturen im Pool freigegeben werden, obwohl sie noch aktiv sind. Beispielsweise kann die
Treiberüberprüfung nach folgenden Situationen Ausschau halten:
QQ Aktive Arbeitselemente im freigegebenen Speicher Ein Treiber ruft ExFreePool auf,
um einen Poolblock freizugeben, in dem sich noch Arbeitselemente befinden, die mit
I oQueueWorkItem in eine Warteschlange gestellt wurden.
QQ Aktive Ressourcen im freigegebenen Speicher Ein Treiber ruft ExFreePool auf, ohne
erst ExDeleteResource aufzurufen, um ein ERESOURCE-Objekt zu zerstören.
QQ Aktive Look-Aside-Listen im freigegebenen Speicher Ein Treiber ruft ExFreePool auf,
ohne erst ExDeleteNPagedLookasideList oder ExDeletePagedLookasideList aufzurufen, um
die Look-Aside-Liste zu löschen.
642
Kapitel 6
Das E/A-System
Die Treiberüberprüfung führt darüber hinaus automatisch noch weitere Untersuchungen
durch, die sich nicht einzeln aktivieren und deaktivieren lassen. Dazu gehören die Folgenden:
QQ Aufruf von MmProbeAndLockPages oder MmProbeAndLockProcessPages für eine MDL mit falschen Flags. Beispielsweise ist es falsch, MmProbeAndLockPages für eine MDL aufzurufen, die
durch den Aufruf von MmBuildMdlForNonPagedPools eingerichtet wurde.
QQ Aufruf von MmMapLockedPages für eine MDL mit falschen Flags. Beispielsweise ist es falsch,
MmMapLockedPages für eine MDL aufzurufen, die bereits auf eine Systemadresse abgebildet
wurde. Ein weiteres Beispiel für falsches Treiberverhalten ist ein Aufruf von MmMapLockedPages
für eine nicht verriegelte MDL.
QQ Aufruf von MmUnlockPages oder MmUnmapLockedPages für eine Teil-MDL (erstellt durch
IoBuildPartialMdl).
QQ Aufruf von MmUnmapLockedPages für eine MDL, die nicht auf eine Systemadresse abgebildet
wurde.
QQ Zuweisen von Synchronisierungsobjekten wie Ereignissen oder Mutexen aus dem
N onPagedPoolSession-Speicher.
Die Treiberüberprüfung ist eine wertvolle Ergänzung der Verifizierungs- und Debuggingwerkzeuge für Treiberautoren. Viele Gerätetreiber, die mit der Treiberüberprüfung untersucht
wurden, wiesen Bugs auf, die damit sichtbar gemacht werden konnten. Dadurch hat die Treiberüberprüfung zu einer allgemeinen Verbesserung des Kernelmoduscodes in Windows geführt.
Der PnP-Manager
Der PnP-Manager ist die Hauptkomponente für die Fähigkeit von Windows, geänderte Hardwarekonfigurationen zu erkennen und sich daran anzupassen. Ein Benutzer muss nichts von
den Feinheiten der Hardware oder der manuellen Konfiguration verstehen, um Geräte zu in
stallieren und zu entfernen. So ist der PnP-Manager beispielsweise auch dafür zuständig, dass
ein laufender Windows-Laptop, der in einer Dockingstation platziert wird, automatisch andere
Geräte an derselben Station erkennen und sie für den Benutzer verfügbar machen kann.
Die Unterstützung für Plug & Play erfordert Kooperation auf der Ebene der Hardware,
der Gerätetreiber und des Betriebssystems. Branchenstandards für die Auflistung und Identifizierung von Geräten an Bussen bilden die Grundlage für die Plug-&-Play-Unterstützung von
Windows. Beispielsweise legt der USB-Standard fest, wie sich Geräte an einem USB-Bus selbst
identifizieren. Auf dieser Grundlage bietet die Plug-&-Play-Unterstützung von Windows folgende Möglichkeiten:
QQ Der PnP-Manager erkennt automatisch installierte Geräte. Dazu werden die beim Start an
das System angeschlossenen Geräte aufgelistet und alle Ergänzungen und Wegnahmen
von Geräten während der weiteren Ausführung des Systems erkannt.
QQ Der PnP-Manager kümmert sich auch um die Zuweisung von Hardwareressourcen, indem
er die entsprechenden Anforderungen der angeschlossenen Geräte erfasst (Interrupts,
E/A-Speicher, E/A-Register oder busspezifische Ressourcen) und die Ressourcen durch den
Der PnP-Manager
Kapitel 6
643
Vorgang der Ressourcenvermittlung optimal zuweist, sodass jedes Gerät bekommt, was es
für seinen Betrieb benötigt. Da Hardwaregeräte auch nach der Ressourcenzuweisung beim
Start hinzugefügt werden können, muss der PnP-Manager auch in der Lage sein, Ressourcen neu zuzuweisen, um die Bedürfnisse der im laufenden Betrieb hinzugekommenen
Geräte zu erfüllen.
QQ Das Laden der geeigneten Treiber fällt ebenfalls in die Verantwortung des PnP-Managers.
Er ermittelt, ob auf dem System ein Treiber installiert ist, der in der Lage ist, das betreffende
Gerät zu verwalten. Wenn ja, weist er den E/A-Manager an, diesen Treiber zu laden. Ist kein
geeigneter Treiber vorhanden, kommuniziert der PnP-Manager im Kernelmodus mit dem
PnP-Manager im Benutzermodus, um das Gerät zu installieren, wobei er möglicherweise
den Benutzer auffordert, einen geeigneten Treiber zu suchen.
QQ Der PnP-Manager implementiert auch Mechanismen, mit denen Anwendungen und Treiber Änderungen an der Hardwarekonfiguration erkennen können. Da manche Anwendungen und Treiber für ihren Betrieb besondere Hardware benötigen, bietet Windows ihnen
die Möglichkeit, Anforderungen über das Vorhandensein, das Hinzufügen und Entfernen
von Geräten anzufordern.
QQ Der PnP-Manager stellt Platz zur Speicherung des Gerätestatus zur Verfügung und beteiligt sich an der Einrichtung, Aktualisierung und Migration des Systems sowie an der
Verwaltung von Offlineabbildern.
QQ Der PnP-Manager unterstützt über das Netzwerk angeschlossene Geräte wie Projektoren
und Drucker, indem er besonderen Bustreibern die Möglichkeit bietet, das Netzwerk als
Bus aufzufassen und Geräteknoten für die dort laufenden Geräte zu erstellen.
Der Grad der Unterstützung für Plug & Play
Windows soll Plug & Play nach Möglichkeit vollständig unterstützen, was allerdings von den
angeschlossenen Geräten und den installierten Treibern abhängt. Wenn ein einzelnes Gerät
oder ein einziger Treiber Plug & Play nicht unterstützt, kann das den Grad der Plug-&-Play-Unterstützung des Systems einschränken. Es ist sogar möglich, dass ein Treiber, der Plug & Play
nicht unterstützt, die Verwendung anderer Geräte im System verhindert. Tabelle 6–6 zeigt die
verschiedenen möglichen Kombinationen von Geräten und Treibern, die keine Unterstützung
für Plug & Play bieten.
Gerät
Plug-&-Play-Treiber
Nicht-Plug-&-Play-Treiber
Plug-&-Play-Gerät
Vollständige Plug-&-Play-
Unterstützung
Kein Plug & Play
Nicht-Plug-&-Play-Gerät
Möglicherweise eingeschränkte
Plug-&-Play-Unterstützung
Kein Plug & Play
Tabelle 6–6 Plug-&-Play-Fähigkeit von Geräten und Treibern
Nicht Plug-&-Play-fähige Geräte, beispielsweise veraltete ISA-Soundkarten, bieten keine Unterstützung für die automatische Erkennung. Da das Betriebssystem nicht weiß, wo die Hardware physisch angeschlossen ist, sind bestimmte Operationen – z. B. das Entnehmen eines
644
Kapitel 6
Das E/A-System
Laptops aus einer Dockingstation, Energiesparmodus und Ruhezustand – nicht zulässig. Wird
für das Gerät jedoch manuell ein Plug-&-Play-Treiber installiert, kann dieser zumindest eine
vom PnP-Manager gelenkte Ressourcenzuweisung für das Gerät implementieren.
Zu den nicht Plug-&-Play-fähigen Treibern gehören veraltete Treiber wie diejenigen, die
auf Windows NT 4 liefen. Sie funktionieren unter Umständen zwar auch auf neueren Versionen
von Windows, doch der PnP-Manager kann die Ressourcen, die den entsprechenden Geräten
zugewiesen wurden, nicht neu einstellen, wenn eine Neuzuweisung von Ressourcen durch das
dynamische Hinzufügen weiterer Geräte erforderlich ist. Betrachten Sie als Beispiel ein Gerät,
das die E/A-Speicherbereiche A und B nutzen kann. Während des Starts weist ihm der PnP-
Manager Bereich A zu. Wird dem System später ein Gerät hinzugefügt, das auf die Verwendung
von A angewiesen ist, kann der PnP-Managern den Treiber des ersten Geräts nicht anweisen,
sich für Bereich B umzukonfigurieren. Das hindert das zweite Gerät daran, die erforderlichen
Ressourcen zu erwerben, weshalb es vom System nicht genutzt werden kann. Veraltete Treiber
beeinträchtigen auch die Möglichkeiten des Computers, in den Energiesparmodus oder den
Ruhezustand überzugehen (siehe den Abschnitt über die Energieverwaltung weiter hinten in
diesem Kapitel).
Geräteauflistung
Eine Geräteauflistung erfolgt, wenn das System hochgefahren wird, aus dem Ruhezustand erwacht oder ausdrücklich dazu aufgefordert wird (etwa durch einen Klick auf Nach geänderter
Hardware suchen im Dialogfeld Geräte-Manager). Der PnP-Manager erstellt einen Gerätebaum
(den wir in Kürze beschreiben werden) und vergleicht ihn ggf. mit dem gespeicherten Baum
einer vorherigen Auflistung. Beim Hochfahren und beim Aufwachen aus dem Ruhezustand ist
der gespeicherte Gerätebaum leer. Neu ermittelte und entfernte Geräte benötigen eine besondere Behandlung, z. B. das Laden der passenden Treiber (für neu hinzugekommene Geräte)
bzw. die Benachrichtigung der Treiber darüber, dass das Gerät entfernt wurde.
Der PnP-Manager beginnt die Geräteauflistung mit einem virtuellen Bustreiber, der als
Stammgerät bezeichnet wird. Er steht für das gesamte Computersystem und fungiert als Bustreiber für nicht Plug-&-Play-fähige Treiber und die HAL. Die HAL wiederum dient als Bustreiber für
die Auflistung der direkt an die Hauptplatine angeschlossenen Geräte sowie von Systemkomponenten wie Akkus. Um den primären Bus (in den meisten Fällen ist das der PCI-Bus) und Geräte
wie Akkus und Lüfter zu erkennen, führt die HAL jedoch nicht selbst eine Auflistung durch,
sondern verlässt sich auf die Hardwarebeschreibung, die der Setupprozess in der Registrierung
gespeichert hat.
Der primäre Bustreiber listet die Geräte an seinem Bus auf. Möglicherweise findet er dabei
weitere Busse, für die der PnP-Manager dann Treiber initialisiert. Diese Treiber wiederum können weitere Geräte entdecken, darunter auch weitere untergeordnete Busse. Dieser rekursive
Vorgang der Auflistung, des Ladens von Treibern (falls der entsprechende Treiber nicht bereits
geladen ist) und der weiteren Auflistung wird fortgesetzt, bis alle Geräte am System ermittelt
und konfiguriert worden sind.
Wenn die Bustreiber dem PnP-Manager erkannte Geräte melden, erstellt dieser einen
internen Gerätebaum, der die Beziehungen zwischen den Geräten darstellt. Die Knoten in
diesem Baum werden als Geräteknoten oder auch kurz als Devnodes bezeichnet. Ein solcher
Der PnP-Manager
Kapitel 6
645
Knoten enthält Informationen über die Geräteobjekte, die das Gerät darstellen, sowie weitere
Plug-&-Play-Informationen, die der PnP-Manager in dem Knoten gespeichert hat. Abb. 6–32
zeigt ein vereinfachtes Beispiel eines solchen Baums. Hier fungiert ein PCI-Bus als Primärbus
des Systems und verfügt über einen USB-, einen ISA- und einen SCSI-Bus.
Kamera
Maus
Externes
Modem
Serieller
Port
USB-Hub
USBController
Tastatur
PCI-ISABrücke
ACPI-Lüfter
PCI-Bus
Festplatte
SCSIAdapter
ACPI-Akku
ACPI
Stamm
gerät
Abbildung 6–32 Beispiel für einen Gerätebaum
Der Geräte-Manager, der unter Start > Programme > Verwaltung > Computerverwaltung zur
Verfügung steht (sowie unter dem Link Geräte-Manager im Dienstprogramm System der Systemsteuerung), zeigt in seiner Standardansicht eine einfache Liste der Geräte, die auf dem
System vorhanden sind. Im Menü Ansicht des Geräte-Managers können Sie jedoch auch die
Option Geräte nach Verbindung auswählen, sodass die Geräte wie im Gerätebaum angezeigt
werden (siehe Abb. 6–33).
646
Kapitel 6
Das E/A-System
Abbildung 6–33 Der Geräte-Manager mit der Ansicht des Gerätebaums
Experiment: Den Gerätebaum ausgeben
Mit dem Kerneldebuggerbefehl !devnode können Sie sich eine ausführlichere Ansicht des
Gerätebaums anzeigen lassen, als sie der Geräte-Manager bietet. Wenn Sie die Optionen
0 1 angeben, werden die internen Geräteknotenstrukturen des Gerätebaums ausgegeben,
wobei die Einrückungen die hierarchischen Beziehungen zeigen:
lkd> !devnode 0 1
Dumping IopRootDeviceNode (= 0x85161a98)
DevNode 0x85161a98 for PDO 0x84d10390
InstancePath is "HTREE\ROOT\0"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x8515bea8 for PDO 0x8515b030
DevNode 0x8515c698 for PDO 0x8515c820
InstancePath is "Root\ACPI_HAL\0000"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x84d1c5b0 for PDO 0x84d1c738
→
Der PnP-Manager
Kapitel 6
647
InstancePath is "ACPI_HAL\PNP0C08\0"
ServiceName is "ACPI"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x85ebf1b0 for PDO 0x85ec0210
InstancePath is "ACPI\GenuineIntel_-_x86_Family_6_Model_15\_0"
ServiceName is "intelppm"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x85ed6970 for PDO 0x8515e618
InstancePath is "ACPI\GenuineIntel_-_x86_Family_6_Model_15\_1"
ServiceName is "intelppm"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x85ed75c8 for PDO 0x85ed79e8
InstancePath is "ACPI\ThermalZone\THM_"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x85ed6cd8 for PDO 0x85ed6858
InstancePath is "ACPI\pnp0c14\0"
ServiceName is "WmiAcpi"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x85ed7008 for PDO 0x85ed6730
InstancePath is "ACPI\ACPI0003\2&daba3ff&2"
ServiceName is "CmBatt"
State = DeviceNodeStarted (0x308)
Previous State = DeviceNodeEnumerateCompletion (0x30d)
DevNode 0x85ed7e60 for PDO 0x84d2e030
InstancePath is "ACPI\PNP0C0A\1"
ServiceName is "CmBatt"
...
Bei den einzelnen Geräteknoten wird u. a. der Instanzpfad (InstancePath) angezeigt. Das
ist der Name des Auflistungsschlüssels für das Gerät unter HKLM\SYSTEM\CurrentControlSet\
Enum. Ebenfalls angegeben ist der Dienstname (ServiceName), der dem Treiberschlüssel für
das Gerät unter HKLM\SYSTEM\CurrentControlSet\Services entspricht. Um die den einzelnen
Geräteknoten zugewiesenen Ressourcen wie Interrupts, Ports und Arbeitsspeicher einzusehen, geben Sie beim Befehl !devnode die Optionen 0 3 an.
648
Kapitel 6
Das E/A-System
Gerätestacks
Wenn der PnP-Manager Geräteknoten erstellt, legt er auch die Treiber- und Geräteobjekte an,
um die Verknüpfung zwischen den Geräten, die den Knoten ausmachen, zu verwalten und logisch darzustellen. Diese Verknüpfung wird als Gerätestack bezeichnet (und wurde im Abschnitt
»IRP-Fluss« weiter vorn in diesem Kapitel schon kurz erwähnt). Diesen Gerätestack können Sie
sich als geordnete Liste von Geräteobjekt-Treiber-Paaren vorstellen. Ein Gerätestack wird immer
von unten nach oben aufgebaut. Abb. 6–34 zeigt ein Beispiel für einen Geräteknoten (identisch
mit Abb. 6–6) mit sieben Geräteobjekten (die alle dasselbe physische Gerät verwalten). Jeder
Geräteknoten enthält mindestens zwei Geräte (PDO und FDO), kann aber noch mehr Geräteobjekte einschließen. Ein Gerätestack besteht aus folgenden Elementen:
QQ Ein physisches Geräteobjekt (Physical Device Object, PDO). Wenn ein Bustreiber bei der
Auflistung das Vorhandensein eines Geräts an seinem Bus meldet, weist der PnP-Manager
ihn an, dieses Objekt zu erstellen. Das PDO stellt die physische Schnittstelle zu dem Gerät
dar und befindet sich immer am Boden des Gerätestacks.
QQ Ein oder mehrere optionale Filtergeräteobjekte (FiDOs) zwischen dem PDO und dem funktionalen Geräteobjekt (FDO; siehe den nächsten Punkt). Sie werden als untere Filter bezeichnet (in Bezug auf das FDO) und können dazu verwendet werden, IRPs abzufangen,
die vom FDO zum Bustreiber laufen (und von Interesse für die Busfilter sind).
QQ Genau ein funktionales Geräteobjekt (FDO). Erstellt wird es von dem Funktionstreiber, den
der PnP-Manager zur Verwaltung des erkannten Geräts lädt. Ein FDO stellt die logische
Schnittstelle zu dem Gerät dar und hat die ausführlichsten Kenntnisse über den Funk
tionsumfang des Geräts. Ein Funktionstreiber kann auch als Bustreiber fungieren, wenn an
das Gerät, das durch das FDO dargestellt wird, andere Geräte angeschlossen sind. Häufig
erstellt der Funktionstreiber eine Schnittstelle (im Grunde genommen nur ein Name) zu
dem PDO für das FDO, damit Anwendungen und andere Treiber das Gerät öffnen und
damit arbeiten können. Manche Funktionstreiber bestehen aus einem Klassen- oder Porttreiber sowie einem Miniporttreiber, die zusammenarbeiten, um die E/A für das FDO zu
verwalten.
QQ Ein oder mehrere optionale FiDOs oberhalb des FDOs (obere Filter). Sie sind die ersten, die
mit dem IRP-Header für das FDO arbeiten dürfen.
In Abb. 6–34 haben die Geräteobjekte verschiedene Namen, um sie einfacher beschreiben zu können. Allerdings sind alle Instanzen von DEVICE_OBJECT-Strukturen.
Der PnP-Manager
Kapitel 6
649
Oberer Filtertreiber 3
Oberer Filtertreiber 2
Oberer Filtertreiber 1
Funktionstreiber
Unterer Filtertreiber 2
Unterer Filtertreiber 1
Bustreiber
Abbildung 6–34 Geräteknoten (Gerätestack)
Gerätestacks werden von unten nach oben aufgebaut und nutzen die Schichtungsmöglichkeiten des E/A-Managers, sodass IRPs von der Spitze des Stacks zum Boden fließen können. Wie
im Abschnitt »IRP-Fluss« weiter vorn in diesem Kapitel bereits erklärt, kann ein IRP aber von
jeder Schicht des Gerätestacks abgeschlossen werden.
Treiber in den Gerätestack laden
Wie findet der PnP-Manager die richtigen Treiber, um den Gerätestack aufzubauen? Die entsprechenden Informationen sind in drei Schlüsseln der Registrierung (und ihren Unterschlüsseln) verstreut, wie Sie in Tabelle 6–7 sehen. (CCS steht hier für CurrentControlSet.)
Registrierungsschlüssel
Kurzname
Beschreibung
HKLM\System\CCS\Enum
Hardwareschlüssel
Einstellungen für bekannte Hardwaregeräte
HKLM\System\CCS\Control\Class
Klassenschlüssel
Einstellungen für Gerätetypen
HKLM\System\CCS\Services
Softwareschlüssel
Einstellungen für Treiber
Tabelle 6–7 Registrierungsschlüssel zum Laden von Plug-&-Play-Treibern
Wenn ein Bustreiber eine Geräteauflistung durchführt und ein neues Gerät entdeckt, erstellt
er als Erstes ein PDO, das für das Vorhandensein dieses physischen Geräts steht. Danach informiert er den PnP-Manager, indem er die im WDK dokumentierte Funktion IoInvalidate
DeviceRelations mit dem Auflistungswert BusRelations und dem PDO aufruft. Das sagt dem
PnP-Manager, dass eine Änderung an dem Bus erkannt wurde. Der PnP-Manager reagiert
darauf, indem er den Bustreiber (durch ein IRP) nach der Gerätekennung fragt.
Diese Kennungen sind busspezifisch. Beispielsweise bestehen die Kennungen von USB-
Geräten aus der ID des Hardwareherstellers (Vendor ID, VID) und einer Produkt-ID (PID), die
dieser Hersteller dem Gerät zugewiesen hat. Bei einem PCI-Gerät wird neben einer ähnlichen
Hersteller-ID auch eine Geräte-ID benötigt, um das Gerät in der Produktpalette des Herstellers
eindeutig zu bezeichnen. (Dazu kommen noch einige optionale Komponenten. Mehr Infor-
650
Kapitel 6
Das E/A-System
mationen über das Format von Gerätekennungen finden Sie im WDK.) Zusammengenommen
ergibt sich das, was bei Plug & Play als Gerätekennung oder Geräte-ID bezeichnet wird. Der
PnP-Manager fragt den Bustreiber auch nach einer Instanz-ID, um zwischen mehreren Exemplaren der gleichen Hardware unterscheiden zu können. Die Instanz-ID kann dabei entweder
eine relative Platzierung am Bus (z. B. den USB-Anschluss) angeben oder ein global eindeutiger
Bezeichner sein (z. B. die Seriennummer).
Geräte- und Instanz-ID werden zu einer Geräteinstanz-ID (Device Instance ID, DIID) kombiniert. Darüber kann der PnP-Manager den Schlüssel für das Gerät im Hardwareschlüssel
(siehe Tabelle 6–7) finden. Die Unterschlüssel haben die Form <Bustreiber>\<Geräte-ID>\
<Instanz-ID>.
Abb. 6–35 zeigt ein Beispiel für einen Auflistungs-Unterschlüssel für eine Intel-Grafikkarte. Der Schlüssel des Geräts enthält neben beschreibenden Daten die Werte Service und
ClassGUID (die bei der Installation aus der INF-Datei des Treibers bezogen werden), mit denen
der PnP-Manager die Treiber für das Gerät wie folgt finden kann:
QQ Er schlägt den Wert von Service im Softwareschlüssel nach, wo der Pfad zu dem Treiber (SYS-Datei) im Wert ImagePath gespeichert ist. Abb. 6–36 zeigt den Softwareschlüssel
igfx, der im Eintrag Service von Abb. 6–35 angegeben war und in dem der Pfad zu dem
Intel-Grafiktreiber verzeichnet ist. Der PnP-Manager lädt den Treiber (falls das nicht bereits
geschehen ist) und ruft dessen Routine zum Hinzufügen von Geräten auf. Der Treiber erstellt dann das FDO.
QQ Der unter Umständen vorhandene Wert LowerFilters enthält mehrere Stringlisten von
Treibern, die als untere Filter geladen werden müssen. Auch sie können über den Softwareschlüssel gefunden werden. Der PnP-Manager lädt diese Filtertreiber vor dem Treiber, der
im Service-Wert angegeben ist.
Abbildung 6–35 Beispiel für einen Hardwareschlüssel
Der PnP-Manager
Kapitel 6
651
Abbildung 6–36 Beispiel für einen Softwareschlüssel
QQ Es kann auch der Wert UpperFilters mit einer Liste von Treibernamen vorhanden sein (wobei diese Treiber ebenso wie bei LowerFilters im Softwareschlüssel verzeichnet sind). Der
PnP-Manager lädt diese Treiber nach demjenigen, der im Wert Service genannt wurde.
QQ Der Wert ClassGUID steht für einen allgemeinen Gerätetyp (Anzeige, Tastatur, Festplatte
usw.) und zeigt auf einen Unterschlüssel des Klassenschlüssels (siehe Tabelle 6–7). Dieser
Schlüssel stellt die Einstellungen dar, die für alle Treiber dieses Gerätetyps gelten. Ist hier
beispielsweise der Wert LowerFilters oder UpperFilters vorhanden, so wird er genauso behandelt wie diejenigen im Hardwareschlüssel für ein bestimmtes Gerät. Dadurch ist
es beispielsweise möglich, einen oberen Filter für Tastaturgeräte unabhängig von einem
spezifischen Gerät oder Hersteller zu laden. Abb. 6–37 zeigt den Klassenschlüssel für Tastaturen. Es gibt zwar einen für Menschen verständlichen Anzeigenamen (Keyboard), aber
worauf es wirklich ankommt, ist der GUID. (Zu welcher Klasse ein Gerät gehört, wird in der
INF-Datei angegeben.) In diesem Beispiel ist der Wert UpperFilters vorhanden und gibt
die vom System bereitgestellten Tastaturklassentreiber an, die für jeden Tastaturgeräteknoten geladen werden. (Darüber hinaus gibt der Wert IconPath das Symbol an, das in der
Benutzeroberfläche des Geräte-Managers für Tastaturen verwendet werden soll.)
Abbildung 6–37 Der Klassenschlüssel für Tastaturen
Die Treiber für einen Geräteknoten werden also in folgender Reihenfolge geladen:
1.
Der Bustreiber wird geladen und erstellt das PDO.
2.
Jegliche im Hardwareschlüssel aufgeführten unteren Filter werden in der angegebenen
Reihenfolge (Multistring) geladen, wobei ihre Filtergerätobjekte erstellt werden (die FiDOs
aus Abb. 6–34).
3.
Jegliche im zugehörigen Klassenschlüssel aufgeführten unteren Filter werden in der angegebenen Reihenfolge geladen, wobei ihre FiDOs erstellt werden.
4.
Der im Wert Service genannte Treiber wird geladen und das FDO wird erstellt.
5.
Jegliche im Hardwareschlüssel aufgeführten oberen Filter werden in der angegebenen Reihenfolge geladen, wobei ihre FiDOs erstellt werden.
652
Kapitel 6
Das E/A-System
6.
Jegliche im zugehörigen Klassenschlüssel aufgeführten oberen Filter werden in der angegebenen Reihenfolge geladen, wobei ihre FiDOs erstellt werden.
Um mit Multifunktionsgeräten umgehen zu können (z. B. Multifunktionsdrucker oder Smartphones mit eingebauter Kamera und Möglichkeiten zur Musikwiedergabe), ist es in Windows
möglich, mit einem Geräteknoten auch eine Container-ID zu verknüpfen. Dieser GUID ist für
eine einzelne Instanz eines physischen Geräts eindeutig, wird aber von allen seinen Geräteknoten für die einzelnen Funktionen gemeinsam genutzt (siehe Abb. 6–38).
Windows-PC
Container für
Multi
funktionsgerät
Plug-&-Play-Geräteknoten
Multifunktionsgerät
• Drucker
• Scanner
• Fax
Abbildung 6–38 Multifunktionsdrucker mit einer eindeutigen ID aus der Sicht des PnP-Managers
Die Container-ID wird ähnlich wie die Instanz-ID von dem Bustreiber der zugehörigen Hardware gemeldet. Bei der Auflistung des Geräts teilen sich alle mit dem PDO verknüpften Geräteknoten diese Container-ID. Da Windows bereits im Lieferzustand mehrere Busse unterstützt
– z. B. PnP-X, Bluetooth und USB –, können die meisten Gerätetreiber einfach die busspezifische ID zurückgeben, aus der Windows dann die entsprechende Container-ID generiert. Bei
anderen Arten von Geräten und Bussen können die Treiber ihre eigene eindeutige ID mithilfe
von Software erstellen.
Bei Gerätetreibern, die keine Container-IDs unterstützen, kann Windows gezielt raten, indem es die Topologie für den Bus durch Mechanismen wie ACPI abfragt (sofern vorhanden).
Wenn Windows weiß, ob ein bestimmtes Gerät einem anderen untergeordnet ist, ob es sich
um ein Wechselgerät, ein im laufenden Betrieb austauschbares Gerät oder ein für den Benutzer
zugängliches Gerät (im Gegensatz zu einer internen Komponente auf dem Motherboard) handelt, kann es den Geräteknoten Container-IDs zuweisen, die die Multifunktionsgeräte korrekt
widerspiegeln.
Der Vorteil, den die Gruppierung von Geräten nach Container-IDs für den Endbenutzer
hat, wird im Dialogfeld Geräte und Drucker sichtbar, denn dadurch können die Scanner-, die
Drucker- und die Fax-Komponente eines Multifunktionsdruckers durch ein einziges grafisches
Element dargestellt werden anstatt als drei getrennte Geräte. In Abb. 6–39 ist der Multifunk
tionsdrucker HP 6860 als ein einziges Gerät angegeben.
Der PnP-Manager
Kapitel 6
653
Abbildung 6–39 Das Applet Geräte und Drucker in der Systemsteuerung
Experiment: Ausführliche Informationen über einen
Geräteknoten im Geräte-Manager anzeigen
Auf der Registerkarte Details des Geräte-Managers werden ausführliche Informationen
über einen Geräteknoten angezeigt. Hier können Sie verschiedene Felder einsehen, darunter die Geräteinstanz-ID, die Hardware-ID, den Dienstnamen, die Filter und Energiedaten
des Geräteknotens.
Der folgende Screenshot stellt das ausgeklappte Dropdownmenü der Registerkarte Details dar und zeigt, auf welche Arten von Informationen Sie hier zugreifen können:
654
Kapitel 6
Das E/A-System
Treiberunterstützung für Plug & Play
Zur Unterstützung von Plug & Play muss ein Treiber eine PnP-Dispatchroutine (IRP_MJ_PNP),
eine Dispatchroutine für die Energieverwaltung (IRP_MJ_POWER; siehe den Abschnitt »Energieverwaltung« weiter hinten in diesem Kapitel) und eine Routine zum Hinzufügen von Geräten
implementieren. Allerdings müssen Bustreiber andere Arten von Plug-&-Play-Anforderungen
unterstützen als Funktions- und Filtertreiber. Beispielsweise fragt der PnP-Manager die Bustreiber während der Geräteauflistung zum Systemstart mithilfe von PRP-IRPs nach Beschreibungen
der Geräte an ihren jeweiligen Bussen.
Funktions- und Filtertreiber bereiten die Verwaltung ihrer Geräte in den Routinen zum
Hinzufügen von Geräten vor. Sie kommunizieren jedoch nicht mit der Gerätehardware, sondern
warten darauf, dass der PnP-Manager einen Befehl zum Starten des Geräts (PnP-IRP-Nebenfunktionscode IRP_MIN_START_DEVICE) an ihre PnP-Dispatchroutine sendet. Dieser Startbefehl
enthält auch die Ressourcenzuweisung für das Gerät, die der PnP-Manager zuvor bei der Ressourcenvermittlung ermittelt hat. Wenn ein Treiber den Startbefehl erhält, kann er sein Gerät
so einrichten, dass es die angegebenen Ressourcen nutzt. Versucht eine Anwendung, ein Gerät
zu öffnen, dessen Startvorgang noch nicht abgeschlossen ist, erhält sie die Fehlermeldung, dass
das Gerät nicht existiert.
Nach dem Start eines Geräts kann der PnP-Manager dem Treiber weitere Plug-&-PlayBefehle senden, unter anderem auch, um das Gerät wieder von dem System zu entfernen oder
um die Ressourcen neu zuzuweisen. Wenn der Benutzer beispielsweise die Auswerfen-Funktion
aufruft, die über das Symbol mit dem USB-Stecker in der Taskleiste erreichbar ist, um Windows
dazu aufzufordern, einen USB-Stick auszuwerfen (siehe Abb. 6–40), sendet der PnP-Manager
an alle Anwendungen, die sich für Plug-&-Play-Benachrichtigungen für dieses Gerät registriert
haben, eine QUERY_REMOVE-Benachrichtigung. Anwendungen registrieren sich gewöhnlich für
Benachrichtigungen, die ihre Handles betreffen. Beim Eingang von QUERY_REMOVE schließen sie
diese Handles. Wenn keine Anwendung ihr Veto gegen diese Anforderung einlegt, sendet der
PnP-Manager eine entsprechende Benachrichtigung an den Treiber, dem das auszuwerfende
Gerät gehört (IRP_MIN_QUERY_REMOVE_DEVICE). Der Treiber kann jetzt das Entfernen des Geräts
verweigern oder dafür sorgen, dass alle ausstehenden E/A-Operationen im Zusammenhang
mit dem Gerät abgeschlossen und jegliche neuen E/A-Anforderungen abgelehnt werden.
Wenn der Treiber dem Entfernen zustimmt und es keine offenen Handles zu dem Gerät mehr
gibt, sendet der PnP-Manager als Nächstes einen Entfernbefehl an den Treiber (IRP_MN_REMOVE_
DEVICE), um diesen aufzufordern, nicht mehr auf das Gerät zuzugreifen und jegliche von ihm
für das Gerät zugewiesenen Ressourcen freizugeben.
Abbildung 6–40 Auswerfen eines Geräts
Wenn der PnP-Manager die Ressourcen eines Geräts neu zuweisen muss, sendet er dem Treiber
eine Anhalteanfrage (IRP_MN_QUERY_STOP_DEVICE), um ihn aufzufordern, die Aktivitäten auf dem
Der PnP-Manager
Kapitel 6
655
Gerät vorübergehend einzustellen. Der Treiber kann dieser Aufforderung zustimmen (wenn das
nicht zu Datenverlusten oder -beschädigungen führt) oder sie ablehnen. Wenn der Treiber einverstanden ist, schließt er wie bei der Anfrage zum Entfernen alle ausstehenden E/A-Operationen ab und löst keine weiteren E/A-Anforderungen aus, die nicht abgebrochen und später neu
gestartet werden können. Neue E/A-Anforderungen stellt der Treiber gewöhnlich in eine Warteschlange, sodass die Anwendungen, die zurzeit auf das Gerät zugreifen, von der Neuordnung
der Ressourcen nichts mitbekommen. Der PnP-Manager sendet dem Treiber einen Stoppbefehl
(IRP_MN_STOP_DEVICE). Anschließend kann er den Treiber unmittelbar anweisen, dem Gerät andere Ressourcen zuzuordnen, um ihm dann wieder einen Startbefehl für das Gerät zu senden.
Im Grunde genommen bilden die Plug-&-Play-Befehle die Zustandsübergänge für ein Gerät in einem Zustandsautomaten. (Das Zustandsdiagramm aus Abb. 6–41 stellt den Zustandsautomaten dar, wie er durch die Funktionstreiber implementiert wird. Die Bustreiber realisieren
einen weit vielschichtigeren Zustandsautomaten.) Jeder Übergang in Abb. 6–41 ist durch den
IRP-Befehlsnamen ohne das Präfix IRP_MN_ gekennzeichnet. Ein Status, den wir noch nicht erläutert haben, ist derjenige, der durch den Befehl IRP_MN_SURPRISE_REMOVAL des PnP-Managers
zustande kommt. Dies geschieht, wenn ein Benutzer ein Gerät ohne Warnung entfernt, wenn
er eine PCMCIA-Karte unter Umgehung der Auswerfen-Funktion entnimmt oder wenn das
Gerät fehlschlägt. Dieser Befehl weist den Treiber an, sofort jegliche Interaktion mit dem Gerät
einzustellen, da das Gerät nicht mehr mit dem System verbunden ist, und alle ausstehenden
E/A-Anforderungen abzubrechen.
Gerät erkannt, Treiber geladen, DriverEntry aufgerufen, AddDevice aufgerufen
Nicht
gestartet
Entfernen
ausstehend
Entfernt
Gestartet
Anhalten
ausstehend
Angehalten
Überraschendes
Entfernen
Abbildung 6–41 Plug-&-Play-Statusübergänge
Installation von Plug-&-Play-Treibern
Wenn der PnP-Manager auf ein Gerät stößt, für das kein Treiber installiert ist, überlässt er
den erforderlichen Installationsvorgang dem PnP-Manager des Benutzermodus. Wird das Gerät beim Systemstart erkannt, wird dafür bereits ein Geräteknoten angelegt, der Ladevorgang
656
Kapitel 6
Das E/A-System
aber bis zum Start des Benutzermodus-PnP-Managers aufgeschoben. (Der Dienst für den PnP-
Manager im Benutzermodus ist in Umpnpmgr.dll implementiert, die wiederum in einer Standardinstanz von Svchost.exe läuft.)
Die Komponenten, die an der Treiberinstallation beteiligt sind, sehen Sie in Abb. 6–42. Die
dunkel getönten Objekte sind Komponenten, die im Allgemeinen vom System bereitgestellt
werden, während es sich bei den helleren um diejenigen handelt, die in den Installationsdateien
des Treibers enthalten sind. Als Erstes informiert der Bustreiber den PNP-Treiber anhand der
Geräte-ID über ein Gerät, das er auflistet (1). Der PnP-Manager sucht in der Registrierung nach
einem zugehörigen Funktionstreiber. Wenn er keinen findet, informiert er den PnP-Manager
des Benutzermodus über das neue Gerät, wobei er ebenfalls die Geräte-ID angibt (2). Der
PnP-Manager des Benutzermodus versucht nun zuerst, eine automatische Installation ohne
Eingreifen des Benutzers durchzuführen. Wenn es für die Installation erforderlich ist, Dialogfelder anzuzeigen und den Benutzer einzubeziehen, und der zurzeit angemeldete Benutzer
über Administratorrechte verfügt, startet der PnP-Manager des Benutzermodus die Anwendung Rundll32.exe (die auch die klassischen .cpl-Systemsteuerungsprogramme beherbergt),
um den Hardwareinstallations-Assistenten %SystemRoot%\System32\Newdev.dll auszuführen
(3). Hat der angemeldete Benutzer dagegen keine Administratorrechte (oder ist kein Benutzer
angemeldet) und erfordert die Installation des Geräts ein Eingreifen des Benutzers, so schiebt
der PnP-Manager des Benutzermodus die Installation auf, bis ein Benutzer mit entsprechenden
Rechten angemeldet ist. Der Hardwareinstallations-Assistent verwendet die API-Funktionen
DSetupapi.dll und CfgMg32.dll (Konfigurations-Manager), um die INF-Dateien für Treiber zu
finden, die mit dem erkannten Gerät kompatibel sind. Bei diesem Vorgang kann es erforderlich sein, dass der Benutzer ein Installationsmedium mit den INF-Dateien des Herstellers einlegt. Es kann auch sein, dass der Assistent eine geeignete INF-Datei im Treiberspeicher findet
(%SystemRoot%\System32\DriverStore), der mit Windows ausgelieferte und über Windows
Update heruntergeladene Treiber enthält. Die Installation erfolgt in zwei Schritten. Im ersten
Schritt importiert der Drittanbieter-Treiberentwickler das Treiberpaket in den Treiberspeicher,
und im zweiten führt das System die eigentliche Installation mithilfe des Prozesses %SystemRoot%\System32\Drvinst.exe durch.
Hardwareinstallations- Setup- und CfgMgrAssistent
APIs
Klasseninstaller und
Co-Installer
PnP-Manager im
Benutzermodus
INF-Dateien,
CAT-Dateien,
Registrierung
Benutzermodus
Kernelmodus
Filtertreiber
PnP-Manager
Funktionstreiber
Filtertreiber
Bustreiber
Abbildung 6–42 An der Installation beteiligte Komponenten
Der PnP-Manager
Kapitel 6
657
Um Treiber für das neue Gerät zu finden, ruft der Installationsprozess eine Liste von Hardware-IDs (siehe die Erklärung weiter vorn) und kompatibler IDs vom Bustreiber ab. Kompatible IDs sind allgemeiner gehalten. Beispielsweise kann eine USB-Maus von einem bestimmten
Hersteller über eine besondere Taste für eine einzigartige Funktion verfügen. Ist der spezifische
Treiber nicht vorhanden, kann mit der kompatiblen ID allgemein für eine Maus jedoch auch ein
generischer, im Lieferumfang von Windows enthaltener Treiber verwendet werden, um wenigstens die grundlegende, übliche Funktionalität einer Maus bereitzustellen.
Die IDs beschreiben die verschiedenen Möglichkeiten zur Bezeichnung der Hardware in
einer Treiberinstallationsdatei (INF). Die Listen sind so geordnet, dass die spezifischste Beschreibung der Hardware an erster Stelle steht. Werden in mehreren INFs Übereinstimmungen gefunden, wird wie folgt vorgegangen:
QQ Spezifischere Übereinstimmungen werden gegenüber allgemeineren bevorzugt.
QQ Digital signierte INFs werden gegenüber nicht signierten bevorzugt.
QQ Jüngere signierte INFs werden gegenüber älteren signierten bevorzugt.
Bei einer Übereinstimmung aufgrund einer kompatiblen ID kann der Hardware
installations-Assistent für den Fall, dass zusammen mit der Hardware ein neu
erer Treiber geliefert wurde, nach einem Installationsmedium fragen.
Die INF-Datei verweist auf die Dateien des Funktionstreibers und enthält Anweisungen, um den
Auflistungs- und den Klassenschlüssel in der Registrierung auszufüllen und die erforderlichen
Dateien zu kopieren. Des Weiteren kann sie den Hardwareinstallations-Assistenten anweisen,
die DLLs für Klassen- oder Co-Installer des Geräts zu starten (4), um klassen- oder gerätespezifische Installationsschritte auszuführen, z. B. die Anzeige von Konfigurationsdialogfeldern, in
denen der Benutzer Einstellungen vornehmen kann. Beim Laden der Treiber, die den Geräteknoten bilden, wird schließlich der Geräte-/Treiberstack erstellt (5).
Experiment: Die INF-Datei eines Treibers untersuchen
Wenn ein Treiber oder eine andere Software mit einer INF-Datei installiert wird, kopiert
das System diese Datei in das Verzeichnis %SystemRoot\Inf. Eine Datei ist dort immer vorhanden, nämlich Keyboard.inf für den Tastaturklassentreiber. Ihren Inhalt können Sie sich
ansehen, indem Sie sie im Editor öffnen (wobei alles, was hinter einem Semikolon steht, ein
Kommentar ist):
;
; KEYBOARD.INF -- This file contains descriptions of Keyboard class devices
;
;
; Copyright (c) Microsoft Corporation. All rights reserved.
→
658
Kapitel 6
Das E/A-System
[Version]
Signature ="$Windows NT$"
Class
=Keyboard
ClassGUID ={4D36E96B-E325-11CE-BFC1-08002BE10318}
Provider
=%MSFT%
DriverVer =06/21/2006,10.0.10586.0
[SourceDisksNames]
3426=windows cd
[SourceDisksFiles]
i8042prt.sys = 3426
kbdclass.sys = 3426
kbdhid.sys
= 3426
...
Eine INF-Datei hat das klassische INI-Format, bei denen die Abschnittsüberschriften in eckigen Klammern stehen und darunter jeweils die Schlüssel-Wert-Paare, in denen Schlüssel
und Wert jeweils durch ein Gleichheitszeichen verbunden sind. Eine INF-Datei wird nicht
nacheinander von Anfang bis Ende abgearbeitet, sondern eher wie ein Baum: Einzelne Werte zeigen auf Abschnitte mit dem Wertnamen, an dem die Ausführung fortgesetzt werden
soll. (Einzelheiten dazu entnehmen Sie bitte dem WDK.)
Wenn Sie die Datei nach .sys durchsuchen, finden Sie die Abschnitte, die den PnP-Manager des Benutzermodus anweisen, die Klassentreiber i8042prt.sys und kbdclass.sys zu installieren:
...
[i8042prt_CopyFiles]
i8042prt.sys,,,0x100
[KbdClass.CopyFiles]
kbdclass.sys,,,0x100
...
Vor der Installation eines Treibers prüft der PnP-Manager des Benutzermodus die Treibersignierrichtlinie des Systems. Wenn sie vorsieht, dass das System die Installation nicht signierter
Treiber blockieren oder dabei zumindest eine Warnung ausgeben soll, durchsucht der PnP-
Manager des Benutzermodus die INF-Datei des Treibers nach einem Eintrag mit einem Verweis
auf einen Katalog (eine Datei mit der Erweiterung .cat), der die digitale Signatur des Treibers
enthält.
Die Windows Hardware Quality Labs (WHQL) von Microsoft prüfen die mit Windows mitgelieferten und die von Hardwareherstellern eingereichten Treiber. Wenn ein Treiber die WHQL-Tests besteht, wird er von Microsoft »signiert«. Das bedeutet, dass das WHQL einen Hash
bestimmt – einen eindeutigen Wert, der die Treiberdateien einschließlich der Abbilddatei darstellt
Der PnP-Manager
Kapitel 6
659
– und dann mit dem privaten Treibersignierschlüssel von Microsoft kryptografisch signiert. Der
signierte Hash wird in einer Katalogdatei gespeichert und in das Windows-Installationsmedium
aufgenommen bzw. an den Hersteller übermittelt, der den Treiber für sein Gerät eingereicht hat.
Experiment: Katalogdateien einsehen
Bei der Installation eines Treibers oder einer anderen Komponente, die eine Katalogdatei
enthält, kopiert Windows diese Datei in ein Unterverzeichnis von %SystemRoot%\System32\
Catroot. Wenn Sie sich dieses Verzeichnis im Explorer ansehen, finden Sie dort ein Unterverzeichnis mit den .cat-Dateien. Beispielsweise sind in Nt5.cat und Nt5ph.cat die Signaturen
und Seitenhashes für Windows-Systemdateien gespeichert.
Wenn Sie eine Katalogdatei öffnen, erscheint ein Dialogfeld mit zwei Registerkarten.
Die Registerkarte Allgemein gibt Informationen über die Signatur in der Katalogdatei, während die Registerkarte Sicherheitskatalog die Hashes der Komponenten enthält, die mit
der Katalogdatei signiert sind. Der folgende Screenshot zeigt den Hash für die .sys-Datei
eines Intel-Audiotreibers. Die anderen Hashes in dem Katalog gehören zu den Unterstützungs-DLLs, die mit dem Treiber ausgeliefert werden.
Bei der Installation eines Treibers entnimmt der PnP-Manager des Benutzermodus die Signatur
aus der zugehörigen Katalogdatei, entschlüsselt sie mit dem öffentlichen Treibersignierschlüssel von Microsoft und vergleicht den resultierenden Hash mit einem Hash der Treiberdatei,
die er installieren will. Stimmen die Hashes überein, ist damit bestätigt, dass der Treiber den
WHQL-Test bestanden hat. Schlägt die Verifizierung der Signatur dagegen fehl, handelt der
PnP-Manager des Benutzermodus, wie es in der Treibersignierrichtlinie des Systems vorgesehen ist. Dabei besteht die Möglichkeit, dass er den Installationsversuch abbricht, den Benutzer
vor dem nicht signierten Treiber warnt oder den Treiber trotzdem stillschweigend installiert.
660
Kapitel 6
Das E/A-System
Werden Treiber von Setupprogrammen installiert, die die Registrierung manuell
konfigurieren und die Treiberdateien in das System kopieren, oder werden Treiberdateien dynamisch von Anwendungen geladen, so erfolgt keine Signaturprüfung
nach der Signierrichtlinie des PnP-Managers. Stattdessen wird die Codesignierrichtlinie des Kernelmodus aus Kapitel 8 in Band 2 herangezogen. Nur bei Treibern,
die mithilfe von INF-Dateien installiert werden, wird eine Validierung anhand der
Treibersignierrichtlinie des PnP-Managers durchgeführt.
Der PnP-Manager des Benutzermodus prüft auch, ob sich der zu installierende
Treiber auf der von Windows Update unterhaltenen Treiberschutzliste befindet.
Wenn ja, wird die Installation blockiert und eine Warnung an den Benutzer ausgegeben. Diese Liste enthält Treiber, von denen bekannt ist, dass sie Inkompatibilitäten oder Bugs aufweisen.
Laden und Installieren von Treibern
Im vorhergehenden Abschnitt haben Sie gesehen, wie der PnP-Manager Treiber für Hardwaregeräte findet und lädt. Diese Treiber werden meistens bei Bedarf geladen, also erst dann, wenn
ein entsprechendes Gerät in dem System erscheint. Nachdem alle von einem Treiber verwalteten Geräte entfernt wurden, wird auch der Treiber entladen.
Der Softwareschlüssel in der Registrierung enthält die Einstellungen für Treiber – und für
Windows-Dienste, bei denen es sich aber um Benutzermodusprogramme handelt, die keine
Verbindung zu den Kerneltreibern haben (wobei der Dienststeuerungs-Manager jedoch sowohl Dienste als auch Gerätetreiber laden kann). In diesem Abschnitt konzentrieren wir uns auf
die Treiber. Eine ausführliche Erörterung der Dienste finden Sie in Kapitel 9 von Band 2.
Treiber laden
Jeder Unterschlüssel des Softwareschlüssels (HKLM\System\CurrentControlSet\Services) enthält
einen Satz von Werten, die einige statische Aspekte eines Treibers (oder Dienstes) steuern. Einen dieser Werte, nämlich ImagePath, haben Sie bereits kennengelernt, als wir uns den Ladevorgang für PnP-Treiber angesehen haben. Abb. 6–36 zeigt ein Beispiel für einen Treiberschlüssel,
und Tabelle 6–8 gibt einen Überblick über die wichtigsten Werte im Softwareschlüssel eines
Treibers. (Eine vollständige Liste erhalten Sie in Kapitel 9 von Band 2.)
Der Wert Start gibt an, in welcher Phase der Treiber (oder Dienst) geladen wird. In dieser Hinsicht unterscheiden sich Gerätetreiber und Dienste vor allem in den beiden folgenden
Punkten:
QQ Nur Gerätetreiber können die Start-Werte BOOT_START (0) und SYSTEM_START (1) aufweisen,
da es in diesen Phasen noch keinen Benutzermodus gibt, weshalb Dienste nicht geladen
werden können.
Laden und Installieren von Treibern
Kapitel 6
661
QQ Gerätetreiber können die Werte Group und Tag verwenden (in Tabelle 6–8 nicht gezeigt),
um die Reihenfolge festzulegen, in der sie in der Startphase geladen werden. Im Gegensatz
zu Diensten können sie aber die Werte DependOnGroup und DependOnService nicht nutzen.
(Mehr dazu erfahren Sie in Kapitel 9 von Band 2.)
Name des Werts
Beschreibung
ImagePath
Der Pfad zur Abbilddatei (.sys-Datei) des Treibers.
Type
Gibt an, ob der Schlüssel für einen Dienst oder einen Treiber steht. Der Wert 1
bezeichnet einen Treiber, der Wert 2 einen Dateisystem- oder Filtertreiber. Die
Werte 16 (0x10) und 30 (0x20) kennzeichnen Dienste. Mehr darüber erfahren
Sie in Kapitel 9 von Band 2.
Start
Gibt an, wann der Treiber geladen werden soll. Hierzu gibt es folgende Op
tionen:
0 (SERVICE_BOOT_START) Der Treiber wird vom Bootloader geladen.
1 (SERVICE_SYSTEM_START) Der Treiber wird nach der Initialisierung der Exekutive geladen.
2 (SERVICE_AUTO_START) Der Treiber wird vom Systemsteuerungs-Manager
geladen.
3 (SERVICE_DEMAND_START) Der Treiber wird bei Bedarf geladen.
4 (SERVICE_DISABLED) Der Treiber wird nicht geladen.
Tabelle 6–8 Wichtige Werte im Registrierungsschlüssel für einen Treiber
Kapitel 11 in Band 2 beschreibt die Phasen des Bootvorgangs. Ein Treiber, der einen Start-Wert
von 0 hat, wird vom Bootloader des Betriebssystems geladen, ein Treiber mit einem Start von
1 dagegen vom E/A-Manager, nachdem die Initialisierung des Exekutivteilsystems abgeschlossen ist. Der E/A-Manager ruft die Treiberinitialisierungsroutinen in der Reihenfolge auf, in der
die Treiber in der jeweiligen Bootphase geladen werden. Ebenso wie bei Windows-Diensten
kann auch in den Registrierungsschlüsseln von Treibern ein Group-Wert vorhanden sein, um die
Gruppe anzugeben, zu der der Treiber gehört. Der Registrierungswert HKLM\SYSTEM\CurrentControlSet\Control\ServiceGroupOrder\List bestimmt die Reihenfolge, in der die Gruppen in
der jeweiligen Bootphase geladen werden.
Um die Ladereihenfolge noch genauer zu bestimmen, kann ein Treiber seine Anordnung
innerhalb der Gruppe mit einem Tag-Wert festlegen. Der E/A-Manager sortiert die Treiber innerhalb der einzelnen Gruppen jeweils nach den Tag-Werten in den Registrierungsschlüsseln
der Treiber, wobei Treiber ohne einen solchen Wert ans Ende ihrer Gruppe gestellt werden.
Man könnte annehmen, dass der E/A-Manager Treiber mit niedrigerer Tag-Nummer vor denen mit höherer Tag-Nummer initialisiert, aber das muss nicht unbedingt der Fall sein. Der
Registrierungsschlüssel HKLM\SYSTEM\CurrentControlSet\Control\GroupOrderList definiert die
Tag-Reihenfolge innerhalb einer Gruppe. Dank dieses Schlüssels können Microsoft und Gerätetreiberentwickler jeweils ihr eigenes Nummerierungssystem definieren.
Die Werte Group und Tags stammen noch aus der Frühzeit von Windows NT. In der
Praxis werden sie heutzutage kaum noch genutzt. Die Treiber sollten nach Möglichkeit keine Abhängigkeiten von anderen Treibern haben (außer von den Kernelbibliotheken, mit denen sie verlinkt sind, z. B. NDIS.sys).
662
Kapitel 6
Das E/A-System
Der Start-Wert von Treibern wird nach den folgenden Richtlinien festgelegt:
QQ Nicht-Plug-&-Play-Treiber setzen ihren Start-Wert auf die Bootphase, in der sie geladen
werden sollen.
QQ Treiber gleich welcher Art, die beim Systemstart vom Bootloader geladen werden sollen,
müssen den Start-Wert BOOT_START (0) angeben. Dazu gehören u. a. die Systembustreiber
und die Treiber für das Bootdateisystem.
QQ Treiber, die zum Hochfahren des Systems nicht benötigt werden, sondern dazu da sind,
Geräte zu erkennen, die vom Systembustreiber nicht aufgelistet werden können, haben
den Start-Wert SYSTEM_START (1). Ein Beispiel dafür bildet der Treiber für den seriellen Port.
Er informiert den PnP-Treiber über das Vorhandensein von seriellen PC-Standardports, die
von Setup erkannt und in der Registrierung aufgezeichnet wurden.
QQ Nicht-Plug-&-Play-Treiber und Dateisystemtreiber, die beim Systemstart nicht vorhanden
sein müssen, haben den Start-Wert AUTO_START (2). Ein Beispiel dafür ist der MUP-Treiber
(Multiple UNC Provider), der Unterstützung für UNC-Pfadnamen (Universal Naming Convention) für Remoteressourcen bietet (z. B. \\Remotecomputername\Freigabename).
QQ Plug-&-Play-Treiber, die zum Hochfahren des Systems nicht benötigt werden, haben den
Start-Wert DEMAND_START (3). Das trifft beispielsweise auf Netzwerkkartentreiber zu.
Die Start-Werte für Plug-&-Play-Treiber und für die Treiber von Geräten, die aufgelistet werden können, dienen nur einem einzigen Zweck, nämlich dafür zu sorgen, dass der Lader des
Betriebssystems die Treiber lädt, die zum erfolgreichen Hochfahren des Systems erforderlich
sind. Die weitergehende Ladereihenfolge von Plug-&-Play-Treibern wird durch den Geräteauflistungsprozess des PnP-Managers bestimmt.
Treiberinstallation
Wie Sie gesehen haben, ist für die Installation von Plug-&-Play-Treibern eine INF-Datei nötig.
Sie enthält die IDs der Hardwaregeräte, mit denen der Treiber umgehen kann, sowie Anweisungen, um Dateien zu kopieren und Registrierungswerte festzulegen. Auch für andere Arten
von Treibern (wie Dateisystemtreiber, Dateisystemfilter und Netzwerkfilter) sind INF-Dateien
erforderlich, die eindeutige Werte für die jeweilige Art von Treiber enthalten.
Reine Softwaretreiber (wie derjenige, den Process Explorer nutzt) können ebenfalls eine
INF-Datei zur Installation nutzen, allerdings ist dies nicht unbedingt erforderlich. Sie lassen sich
mit einem Aufruf der API CreateService installieren (oder mithilfe eines Wrapperprogramms
wie Sc.exe), wie es die Anwendung Process Explorer macht, nachdem sie ihren Treiber aus einer Ressource innerhalb der ausführbaren Datei bezogen hat (sofern sie mit erhöhten Rechten
ausgeführt wird). Wie der Name der API schon andeutet, kann sie sowohl zur Installation von
Treibern als auch von Diensten verwendet werden, was durch eines ihrer Argumente bestimmt
wird. Die anderen Argumente geben den Start-Wert sowie weitere Parameter an (siehe die
Dokumentation des Windows SDK). Nachdem der Treiber (oder Dienst) installiert wurde, wird
er mit einem Aufruf der Funktion StartService geladen, die wiederum (für einen Treiber) wie
üblich DriverEntry aufruft.
Laden und Installieren von Treibern
Kapitel 6
663
Ein reiner Softwaretreiber erstellt gewöhnlich ein Geräteobjekt mit einem Namen, den seine Clients kennen. Beispielsweise legt Process Explorer das Gerät PROCEXP152 an, das anschließend von Process Explorer im Aufruf von CreateFile verwendet wird. Darauf folgen Aufrufe wie
DeviceIOControl, um Anforderungen an den Treiber zu senden (die vom E/A-Manager in IRPs
umgewandelt werden). Abb. 6–43 zeigt den symbolischen Link für das Process Explorer-Objekt
im Verzeichnis \GLOBAL?? (die Namen in diesem Verzeichnis sind für Clients im Benutzermodus
zugänglich), dargestellt im Sysinternals-Tool WinObj. Dieses Verzeichnis wird von der Anwendung Process Explorer erstellt, wenn sie zum ersten Mal mit erhöhten Rechten ausgeführt wird.
Wie Sie sehen, zeigt der Link auf das echte Geräteobjekt im Verzeichnis \Device und trägt denselben Namen (was nicht erforderlich ist).
Abbildung 6–43 Symbolischer Link und Gerätename für Process Explorer
Windows Driver Foundation
Die Windows Driver Foundation (WDF) ist ein Framework zur Entwicklung von Treibern, das
gängige Aufgaben wie die korrekte Handhabung von Plug-&-Play- und Energie-IRPs vereinfacht. Zu WDF gehören das Kernel-Mode Driver Framework (KMDF) und das User-Mode
Driver Framework (UMDF). WDF ist jetzt quelloffen und auf https://github.com/Microsoft/
Windows-Driver-Frameworks zu finden. Die Tabellen 6–9 und 6–10 zeigen, welche Windows-
Versionen welche KMDF- bzw. UMDF-Versionen unterstützen (ab Windows 7).
KMDF-Version
Releasemethode
Enthalten in
Treiber laufen auf
1.9
Windows 7 WDK
Windows 7
Windows XP und höher
1.11
Windows 8 WDK
Windows 8
Windows Vista und höher
1.13
Windows 8.1 WDK
Windows 8.1
Windows 8.1 und höher
1.15
Windows 10 WDK
Windows 10
Windows 10, Windows Server 2016
664
Kapitel 6
Das E/A-System
→
KMDF-Version
Releasemethode
Enthalten in
Treiber laufen auf
1.17
Windows 10 Version
1511 WDK
Windows 10 Version
1511
Windows 10 Version 1511 und höher, Windows Server 2016
1.19
Windows 10 Version
1607 WDK
Windows 10 Version
1607
Windows 10 Version 1607 und höher, Windows Server 2016
Tabelle 6–9 KMDF-Versionen
UMDF-Version
Releasemethode
Enthalten in
Treiber laufen auf
1.9
Windows 7 WDK
Windows 7
Windows XP und höher
1.11
Windows 8 WDK
Windows 8
Windows Vista und höher
2.0
Windows 8.1 WDK
Windows 8.1
Windows 8.1 und höher
2.15
Windows 10 WDK
Windows 10
Windows 10 und höher, Windows
Server 2016
2.17
Windows 10 Version
1511 WDK
Windows 10 Version
1511
Windows 10 Version 1511 und höher, Windows Server 2016
2.19
Windows 10 Version
1607 WDK
Windows 10 Version
1607
Windows 10 Version 1607 und höher, Windows Server 2016
Tabelle 6–10 UMDF-Versionen
In Windows 10 wurde das Prinzip der Universaltreiber eingeführt, das schon kurz in Kapitel 2
erwähnt wurde. Diese Treiber nutzen einen gemeinsamen Satz von DDIs, die in verschiedenen
Editionen von Windows 10 implementiert sind – von IoT Core über Mobile bis zu den Desktopversionen. Universaltreiber können mit KMDF, UMDF 2.x und WDM erstellt werden. In Visual
Studio geht das sogar relativ einfach, wenn die Einstellung Zielplattform auf Universal gesetzt
ist. In diesem Fall macht der Compiler auf jegliche DDIs aufmerksam, die für Universaltreiber
ungeeignet sind.
In UMDF 1.x wurde für die Programmierung von Treibern ein Modell auf der Grundlage von
COM verwendet, was sich sehr stark von dem Programmiermodell von KMDF (das auf Objekten
beruhendes C verwendet) unterscheidet. Mit Version 2 wurde UMDF an KMDF angepasst und
bietet nun eine fast identische API, was den Gesamtaufwand für die Treiberentwicklung in WDF
verringert. Falls nötig, lassen sich UMDF-2.x-Treiber sogar mit wenig Mühe in KMDF-Treiber
umwandeln. UMDF 1.x wird in diesem Buch nicht behandelt; weitere Informationen darüber
entnehmen Sie bitte dem WDK.
In den folgenden Abschnitten beschäftigen wir uns näher mit KMDF und UMDF. Beide
verhalten sich unabhängig von dem Betriebssystem, auf dem sie laufen, jeweils gleichartig.
Kernel-Mode Driver Framework
Einige Einzelheiten von Windows Driver Foundation (WDF) haben Sie sich bereits in Kapitel 2
angesehen. In diesem Abschnitt werfen wir einen genaueren Blick auf die Komponenten und
den Funktionsumfang von KMDF, also dem Teil des Frameworks für Kernelmodustreiber. Einige
Aspekte der Kernarchitektur von KMDF werden wir hier aber nur kurz erwähnen. Eine ausführlichere Darstellung des Themas finden Sie in der Dokumentation des Windows Driver Kits.
Windows Driver Foundation
Kapitel 6
665
Die meisten Angaben in diesem Abschnitt gelten auch für UMDF 2.x. Die Ausnahmen werden im nachfolgenden Abschnitt beschrieben.
Aufbau und Funktionsweise von KMDF-Treibern
Sehen wir uns als Erstes an, was für Treiber und Geräte von KMDF unterstützt werden. Allgemein ausgedrückt sollte das jeder WDM-konforme Treiber sein, sofern er eine reguläre
E/A-Verarbeitung und IRP-Bearbeitung durchführt. Nicht geeignet ist KMDF für Treiber, die die
Windows-Kernel-API nicht direkt nutzen, sondern stattdessen Bibliotheksaufrufe an vorhandene Port- und Klassentreiber vornehmen. Da diese Treiber nur Callbacks für die WDM-Treiber
bereitstellen, die die E/A-Verarbeitung tatsächlich durchführen, können sie KMDF nicht verwenden. Treiber, die sich nicht auf einen Port- oder Klassentreiber, IEEE1394, ISA, PCI-, PCMCIA und SD Client verlassen, sondern eigene Dispatchroutinen bereitstellen, können ebenfalls
KMDF nutzen.
KMDF bietet zwar eine Abstraktion oberhalb von WDM, doch die zuvor gezeigte grundlegende Treiberstruktur gilt auch für KMDF-Treiber. Sie müssen über folgende Funktionen verfügen:
QQ Eine Initialisierungsroutine Wie alle anderen Treiber weisen auch KMDF-Treiber eine
DriverEntry-Funktion auf, die den Treiber initialisiert. KMDF-Treiber starten das Framework
an diesem Punkt und führen jegliche Konfigurations- und Initialisierungsschritte durch, die
zu dem Treiber oder zur Beschreibung des Treibers gegenüber dem Framework gehören.
Bei Nicht-Plug-&-Play-Treibern ist dies die Stelle, an der das erste Geräteobjekt erstellt
werden sollte.
QQ Eine Routine zum Hinzufügen eines Geräts Die Funktionsweise von KMDF-Treibern
beruht auf Ereignissen und Callbacks (eine Beschreibung folgt in Kürze), wobei EvtDriverDeviceAdd der wichtigste Callback für PnP-Geräte ist, da er Benachrichtigungen empfängt,
wenn der PnP-Manager eines der Geräte, für die der Treiber zuständig ist, im Kernel auflistet.
QQ Eine oder mehrere EvtIo*-Routinen Ähnlich wie die Dispatchroutinen von WDM-Treibern kümmern sich diese Callbackroutinen um bestimmte Arten von E/A-Anforderungen
von einer bestimmten Gerätewarteschlange. Ein Treiber legt gewöhnlich eine oder mehrere Warteschlangen an, in die KMDF E/A-Anforderungen für seine Geräte einreiht. Diese
Warteschlangen können nach Anforderungs- und Dispatchtyp konfiguriert werden.
Im einfachsten Fall kann ein KMDF-Treiber auch nur aus einer Initialisierungsroutine und einer
Routine zum Hinzufügen von Geräten bestehen, da das Framework die allgemeine Funktonalität bereitstellt, die für die meisten Formen der E/A-Verarbeitung erforderlich ist, einschließlich
Energie- und Plug-&-Play-Ereignisse. Im KMDF-Modell sind Ereignisse Laufzeitzustände, auf
die ein Treiber reagieren oder an denen er teilnehmen kann. Diese Ereignisse haben nichts mit
Synchronisierungsprimitiva zu tun (siehe Kapitel 8 in Band 2), sondern sind interne Konzepte
des Frameworks.
666
Kapitel 6
Das E/A-System
Zur Handhabung von Ereignissen, die für das Funktionieren des Treibers von entscheidender Bedeutung sind oder die einer besonderen Verarbeitung bedürfen, kann der Treiber
eine Callbackroutine registrieren. In anderen Fällen kann der Treiber das Framework eine Standardaktion ausführen lassen. Beispielsweise kann ein Treiber einen eigenen Callback für ein
Auswerfen-Ereignis (EvtDeviceEject) bereitstellen, um das Auswerfen zu unterstützen, aber
auch einfach den KMDF-Standardcode nutzen, der dem Benutzer mitteilt, dass ein Auswerfen
bei dem betreffenden Gerät nicht möglich ist. Solche Standardverhalten gibt es jedoch nicht
für alle Ereignisse, weshalb der Treiber dafür Callbacks bereitstellen muss. Ein bemerkenswertes
Beispiel ist das zuvor beschriebene Ereignis EvtDriverDeviceAdd, das das Herzstück eines jeden
Plug-&-Play-Treibers bildet.
Experiment: KMDF- und UMDF-2-Treiber anzeigen
Die mit den Debugging-Tools für Windows ausgelieferte Erweiterung Wdfkd.dll bietet viele Befehle zum Debuggen und Analysieren von KMDF-Treibern und Geräten (als Ersatz
für die eingebaute Debuggingerweiterung im WDM-Stil, die nicht die gleiche Menge an
WDF-spezifischen Informationen liefert). Installierte KMDF-Treiber können Sie mit dem Debuggerbefehl !wdfkd.wdfldr anzeigen lassen. Die folgende Beispielausgabe stammt von einer 32-Bit-VM mit Windows 10 in Hyper-V und zeigt die installierten mitgelieferten Treiber:
lkd> !wdfkd.wdfldr
--------------------------------------------------------------KMDF Drivers
--------------------------------------------------------------LoadedModuleList 0x870991ec
---------------------------------LIBRARY_MODULE 0x8626aad8
Version
v1.19
Service
\Registry\Machine\System\CurrentControlSet\Services\Wdf01000
ImageName
Wdf01000.sys
ImageAddress
0x87000000
ImageSize
0x8f000
Associated Clients: 25
ImageName
Ver
umpass.sys
v1.15 0xa1ae53f8 0xa1ae52f8 0x9e5f0000 0x00008000
WdfGlobals FxGlobals ImageAddress ImageSize
peauth.sys
v1.7
mslldp.sys
v1.15 0x9aed1b50 0x9aed1a50 0x8e300000 0x00014000
vmgid.sys
v1.15 0x97d0fd08 0x97d0fc08 0x8e260000 0x00008000
monitor.sys
v1.15 0x97cf7e18 0x97cf7d18 0x8e250000 0x0000c000
tsusbhub.sys
v1.15 0x97cb3108 0x97cb3008 0x8e4b0000 0x0001b000
NdisVirtualBus.sys
v1.15 0x8d0fc2b0 0x8d0fc1b0 0x87a90000 0x00009000
vmgencounter.sys
v1.15 0x8d0fefd0 0x8d0feed0 0x87a80000 0x00008000
0x95e798d8 0x95e797d8 0x9e400000 0x000ba000
→
Windows Driver Foundation
Kapitel 6
667
intelppm.sys
v1.15 0x8d0f4cf0 0x8d0f4bf0 0x87a50000 0x00021000
vms3cap.sys
v1.15 0x8d0f5218 0x8d0f5118 0x87a40000 0x00008000
netvsc.sys
v1.15 0x8d11ded0 0x8d11ddd0 0x87a20000 0x00019000
hyperkbd.sys
v1.15 0x8d114488 0x8d114388 0x87a00000 0x00008000
dmvsc.sys
v1.15 0x8d0ddb28 0x8d0dda28 0x879a0000 0x0000c000
umbus.sys
v1.15 0x8b86ffd0 0x8b86fed0 0x874f0000 0x00011000
CompositeBus.sys
v1.15 0x8b869910 0x8b869810 0x87df0000 0x0000d000
cdrom.sys
v1.15 0x8b863320 0x8b863220 0x87f40000 0x00024000
vmstorfl.sys
v1.15 0x8b2b9108 0x8b2b9008 0x87c70000 0x0000c000
EhStorClass.sys
v1.15 0x8a9dacf8 0x8a9dabf8 0x878d0000 0x00015000
vmbus.sys
v1.15 0x8a9887c0 0x8a9886c0 0x82870000 0x00018000
vdrvroot.sys
v1.15 0x8a970728 0x8a970628 0x82800000 0x0000f000
msisadrv.sys
v1.15 0x8a964998 0x8a964898 0x873c0000 0x00008000
WindowsTrustedRTProxy.sys v1.15 0x8a1f4c10 0x8a1f4b10 0x87240000 0x00008000
WindowsTrustedRT.sys
v1.15 0x8a1f1fd0 0x8a1f1ed0 0x87220000 0x00017000
intelpep.sys
v1.15 0x8a1ef690 0x8a1ef590 0x87210000 0x0000d000
acpiex.sys
v1.15 0x86287fd0 0x86287ed0 0x870a0000 0x00019000
---------------------------------Total: 1 library loaded
Sind UMDF-2.x-Treiber geladen, so werden sie ebenfalls angezeigt. Das ist einer der Vorteile der UMDF-2.x-Bibliothek. (Mehr darüber erfahren Sie im Abschnitt über UMDF weiter
hinten in diesem Kapitel.)
Die KMDF-Bibliothek ist in Wdf01000.sys implementiert, der aktuellen Version 1.x von
KMDF. Zukünftige Versionen von KMDF können die Hauptversionsnummer 2 haben und
in einem anderen Kernelmodul implementiert sein (Wdf02000.sys). Ein solches zukünftiges
Modul kann sich parallel neben dem Modul der Version 1.x befinden, wobei beide jeweils
die Treiber laden, die mit ihnen kompiliert wurden. Dadurch ist für eine Trennung und
Unabhängigkeit von Treibern gesorgt, die mit KMDF-Bibliotheken verschiedener Hauptversionen erstellt wurden.
Das Objektmodell von KMDF
Ähnlich wie das Modell für den Kernel verwendet das Objektmodell von KMDF Eigenschaften, Methoden und Ereignisse, die in C implementiert sind, greift aber nicht auf den Objekt-Manager zurück. Stattdessen verwaltet KMDF seine eigenen Objekte intern und stellt sie
Treibern als Handles bereit, wobei es die eigentlichen Datenstrukturen verborgen hält. Für
jeden Objekttyp bietet das Framework Routinen, um Operationen an den Objekten auszuführen (Methoden), beispielsweise WdfDeviceCreate, die ein Gerät erstellt. Außerdem können
Objekte über Datenfelder und Elemente verfügen, die über Get/Set (für Änderungen, die
nicht fehlschlagen dürfen) oder Assing/Retrieve (für Änderungen, die fehlschlagen können)
zugänglich sind. Diese Felder werden als Eigenschaften bezeichnet. Beispielsweise gibt die
668
Kapitel 6
Das E/A-System
Funktion WdfInterruptGetInfo Informationen über ein gegebenes Interruptobjekt zurück
(WDFINTERRUPT).
Anders als Kernelobjekte, die alle auf individuelle, isolierte Objekttypen verweisen, gehören sämtliche KMDF-Objekte zu einer Hierarchie, in der die meisten Objekttypen an ein
Elternobjekt gebunden sind. Das Stammobjekt ist die WDFDRIVER-Struktur, die den eigentlichen
Treiber beschreibt. Diese Struktur und ihre Bedeutung entsprechen der vom E/A-Manager bereitgestellten DRIVER_OBJECT-Struktur, und alle anderen KMDF-Strukturen sind Kinder davon.
Das nächste wichtige Objekt ist WDFDEVICE. Es verweist auf eine bestimmte Instanz eines erkannten Geräts im System, das mit WdfDeviceCreate erstellt worden sein muss. Dies entspricht
wiederum der DEVICE_OBJECT-Struktur, die im WDM-Modell und vom E/A-Manager verwendet
wird. In Tabelle 6–11 sind die von KMDF unterstützten Objekttypen aufgeführt.
Objekt
Typ
Beschreibung
Kindliste
WDFCHILDLIST
Eine Liste von WDFDEVICE-Kindobjekten, die
mit dem Gerät verbunden sind. Wird nur von
Bustreibern verwendet.
Sammlung
WDFCOLLECTION
Eine Liste von Objekten ähnlichen Typs, z. B. einer Gruppe von gefilterten WDFDEVICE-Objekten.
Verzögerter Prozeduraufruf
WDFDPC
Eine Instanz eines DPC-Objekts
Gerät
WDFDEVICE
Eine Geräteinstanz
Gemeinsamer DMA-Puffer
WDFCOMMONBUFFER
Ein Bereich im Arbeitsspeicher, auf den ein Gerät
und ein Treiber für DMA zugreifen können
DMA-Aktivierung
WDFDMAENABLER
Aktiviert DMA auf einem gegebenen Kanal für
einen Treiber.
DMA-Transaktion
WDFDMATRANSACTION
Eine Instanz einer DMA-Transaktion
Treiber
WDFDRIVER
Ein Objekt für den Treiber. Es stellt den Treiber,
seine Parameter, seine Callbacks usw. dar.
Datei
WDFFILEOBJECT
Die Instanz eines Dateiobjekts, das als Kanal für
die Kommunikation zwischen einer Anwendung
und dem Treiber verwendet werden kann
Allgemeines Objekt
WDFOBJECT
Ermöglicht es, vom Treiber definierte eigene
Daten als Objekt in das Objektdatenmodell des
Frameworks einzubinden.
Interrupt
WDFINTERRUPT
Eine Instanz eines Interrupts, den der Treiber
handhaben muss.
E/A-Warteschlange
WDFQUEUE
Dieses Objekt steht für eine gegebene E/A-
Warteschlange.
E/A-Anforderung
WDFREQUEST
Dieses Objekt steht für eine gegebene Anforderung in einer WDFQUEUE.
E/A-Ziel
WDFIOTARGET
Dieses Objekt steht für den Gerätestack, der das
Ziel einer gegebenen WDFREQUEST ist.
Look-Aside-Liste
WDFLOOKASIDE
Beschreibt eine Look-Aside-Liste der Exekutive
(siehe Kapitel 5).
Windows Driver Foundation
Kapitel 6
→
669
Objekt
Typ
Beschreibung
Arbeitsspeicher
WDFMEMORY
Beschreibt eine Region des ausgelagerten oder
nicht ausgelagerten Pools.
Registrierungsschlüssel
WDFKEY
Beschreibt einen Registrierungsschlüssel.
Ressourcenliste
WDFCMRESLIST
Gibt die einem WDFDEVICE zugewiesenen Hardwareressourcen an.
Ressourcenbereichsliste
WDFIORESLIST
Gibt die möglichen Hardwareressourcenbereiche für ein WDFDEVICE an.
Ressourcenerfordernisliste
WDFIORESREQLIST
Enthält ein Array aus WDFIORESLIST-Objekten,
die alle möglichen Ressourcenbereiche für ein
WDFDEVICE beschreiben.
Spinlock
WDFSPINLOCK
Beschreibt ein Spinlock.
String
WDFSTRING
Beschreibt eine Unicode-Stringstruktur.
Timer
WDFTIMER
Beschreibt einen Exekutivtimer (siehe Kapitel 8
in Band 2).
USB-Gerät
WDFUSBDEVICE
Bezeichnet eine Instanz eines USB-Geräts.
USB-Schnittstelle
WDFUSBINTERFACE
Bezeichnet eine Schnittstelle des gegebenen
WDFUSBDEVICE.
USB-Pipe
WDFUSBPIPE
Bezeichnet eine Pipe zu einem Endpunkt auf
einem gegebenen WDFUSBDEVICE.
Wartesperre
WDFWAITLOCK
Dieses Objekt steht für ein Kerneldispatcher-Ereignisobjekt.
WMI-Instanz
WDFWMIINSTANCE
Dieses Objekt stellt einen WMI-Datenblock für
einen gegebenen WDFWMIPROVIDER dar.
WMI-Anbieter
WDFWMIPROVIDER
Beschreibt das WMI-Schema für alle von dem
Treiber unterstützten WDFWMIINSTANCE-Objekte.
Arbeitselement
WDFWORKITEM
Beschreibt ein Exekutiv-Arbeitsobjekt.
Tabelle 6–11 KMDF-Objekttypen
An jedes dieser Objekte können andere KMDF-Objekte als Kindobjekte angehängt werden.
Für einige Objekte gibt es nur ein oder zwei gültige Elternobjekte, während andere an jedes
beliebige Elternobjekt angehängt werden können. So muss ein WDFINTERRUPT-Objekt beispielsweise immer mit einem gegebenen WDFDEVICE verknüpft werden, wohingegen ein WDFSPINLOCKoder ein WDFSTRING-Objekt beliebige Elternobjekte aufweisen kann. Das ermöglicht eine feine
Steuerung ihrer Gültigkeit und Verwendung und eine Reduzierung globaler Statusvariablen.
Abb. 6–44 zeigt die gesamte KMDF-Objekthierarchie.
670
Kapitel 6
Das E/A-System
(Treiber erstellt)
(von der
Warteschlange ausgeliefert)
Vordefiniert
Standardbeziehung; der Treiber kann aber
auch zu jedem anderen Objekt wechseln
Beide können Elternobjekte sein
Abbildung 6–44 KMDF-Objekthierarchie
Diese Beziehungen zwischen den Objekten müssen nicht unbedingt direkt sein. Es muss sich
lediglich ein entsprechendes Elternobjekt in der Hierarchiekette befindet, das heißt, einer der
Vorfahrenknoten muss von diesem Typ sein. Die Einrichtung solcher Beziehungen ist sehr praktisch, da sich Objekthierarchien nicht nur auf die Platzierung eines Objekts auswirken, sondern
auch auf seine Lebensdauer. Wird ein Kindobjekt erstellt, so wird ihm über die Verknüpfung zu
seinem Elternobjekt ein Referenzzähler hinzugefügt. Wenn das Elternobjekt zerstört wird, werden daher auch alle Kindobjekte zerstört. Durch die Verknüpfung von Objekten wie WDFSTRING
und WDFMEMORY mit einem gegebenen Objekt statt mit dem standardmäßigen WDFDRIVER-Objekt
ist es daher möglich, automatisch Speicher und Statusinformationen freizugeben, wenn das
Elternobjekt zerstört wird.
Eng verwandt mit dem Prinzip der Hierarchie ist der Objektkontext in KMDF. Da KMDF-Objekte wie bereits erwähnt undurchsichtig sind und zu ihrer Platzierung mit einem Elternobjekt
verknüpft werden, ist es wichtig, dass Treiber ihre eigenen Daten an ein Objekt anhängen können, um Informationen zu verfolgen, die außerhalb der Möglichkeiten oder der Unterstützung
des Frameworks liegen. Mithilfe von Objektkontexten können alle KMDF-Objekte solche Informationen enthalten. Außerdem lassen sie mehrere Objektkontextbereiche zu, sodass verschiedene Codeschichten innerhalb eines Treibers auf unterschiedliche Weise mit demselben Objekt
umgehen können. In WDM ist es mithilfe der benutzerdefinierten Datenstruktur der Gerät
erweiterung möglich, solche Informationen mit einem gegebenen Gerät zu verknüpfen, aber
in KMDF können sogar Spinlocks und Strings Kontextbereiche enthalten. Diese Erweiterbarkeit
erlaubt es jeder Bibliothek und jeder Codeschicht, die für die Verarbeitung einer E/A-Anfor-
Windows Driver Foundation
Kapitel 6
671
derung zuständig ist, unabhängig von anderem Code auf der Grundlage des Kontextbereichs
vorzugehen, mit dem sie arbeitet.
KMDF-Objekte weisen außerdem Attribute auf (siehe Tabelle 6–12). Sie werden gewöhnlich auf ihre Standardwerte eingestellt, doch wenn der Treiber das Objekt erstellt, kann er
diese Werte durch Angabe einer WDF_OBJECT_ATTRIBUTES-Struktur überschreiben (ähnlich wie
die OBJECT_ATTRIBUTES-Struktur, die der Objekt-Manager beim Erstellen eines Kernelobjekts
verwendet).
Attribut
Beschreibung
ContextSizeOverride
Die Größe des Objektkontextbereichs
ContextTypeInfo
Der Typ des Objektkontextbereichs
EvtCleanupCallback
Der Callback, der den Treiber vor dem Löschen über die Bereinigung des Objekts informierten muss (wobei nach wie vor Verweise
vorhanden sein können)
EvtDestroyCallback
Der Callback, der den Treiber über die unmittelbar bevorstehende
Löschung des Objekts informierten muss (wobei der Referenzzähler 0 ist)
ExecutionLevel
Gibt die höchste IRQL an, auf der Callbacks von KMDF aufgerufen
werden können.
ParentObject
Gibt das Elternobjekt an.
SynchronizationScope
Gibt an, ob Callbacks mit dem Elternobjekt, einer Warteschlange,
einem Gerät oder gar nicht synchronisiert werden sollen.
Tabelle 6–12 KMDF-Objektattribute
Das E/A-Modell von KMDF
Das E/A-Modell von KMDF folgt den in diesem Kapitel bereits beschriebenen WDM-Mechanismen. Sie können sich das Framework sogar als einen WDM-Treiber vorstellen, da es Kernel-APIs und WDM-Verhalten nutzt, um KMDF zu abstrahieren und funktionaler zu machen.
Unter KMDF richtet der Frameworktreiber seine eigenen WDM-artigen IRP-Dispatchroutinen
ein und übernimmt die Kontrolle über alle an den Gerätetreiber gesendete IRPs. Nachdem er
von einem der drei E/A-Handler von KMDF behandelt wurde, verpackt er diese Anforderungen
in geeignete KMDF-Objekte, stellt diese in die entsprechenden Warteschlangen (falls erforderlich) und führt einen Treibercallback aus, falls der Gerätetreiber an diesen Ereignissen interessiert ist. Abb. 6–45 zeigt den E/A-Fluss im Framework.
672
Kapitel 6
Das E/A-System
E/A-Warteschlangen
ohne Energieverwaltung
E/AAnforderungshandler
Treibercallbacks
E/A-Ziel
E/A-Warteschlangen mit
Energieverwaltung
IRPs
Dispatcher
Handler für PnP-/
Energieanforderungen
Treibercallbacks
Handler für WMIAnforderungen
Treibercallbacks
Abbildung 6–45 E/A-Fluss und IRP-Verarbeitung in KMDF
Auf der Grundlage der bereits für WDM-Treiber beschriebenen IRP-Verarbeitung führt KMDF
eine der drei folgenden Aktionen aus:
QQ Es sendet das IRP an den E/A-Handler, der Standardgeräteoperationen verarbeitet.
QQ Es sendet das IRP an den PnP- und Energie-Handler, der diese Arten von Ereignissen verarbeitet und andere Treiber benachrichtigt, wenn sich der Status geändert hat.
QQ Es sendet das IRP an den WMI-Handler, der sich um Nachverfolgung und Protokollierung
kümmert.
Diese Komponenten benachrichtigen anschließend den Treiber über jegliche Ereignisse, für die
er sich registriert hat, leiten die Anforderung ggf. zur weiteren Verarbeitung an einen anderen
Handler weiter und schließen sie dann auf der Grundlage einer internen Handleraktion oder
eines Treiberaufrufs ab. Wenn KMDF die Verarbeitung des IRPs beendet hat, die Anforderung
selbst aber noch nicht vollständig verarbeitet wurde, ergreift KMDF eine der folgenden Maßnahmen:
QQ Für Bus- und Funktionstreiber schließt es das IRP mit STATUS_INVALID_DEVICE_REQUEST ab.
QQ Für Filtertreiber leitet es die Anforderung an den nächsttieferen Treiber weiter.
Die E/A-Verarbeitung durch KMDF basiert auf einem Warteschlangenmechanismus (WDFQUEUE,
nicht das zuvor in diesem Kapitel beschriebene KQUEUE-Objekt). KMDF-Warteschlangen sind
hochgradig skalierbare Container für E/A-Anforderungen (verpackt als WDFREQUEST-Objekte)
und bieten einen reichhaltigen Funktionsumfang, der über die bloße Sortierung der ausstehenden E/A-Operationen für ein gegebenes Objekt hinausgeht. Beispielsweise merken sich Warteschlangen die zurzeit aktiven Anforderungen und ermöglichen den Abbruch von E/A-Vorgängen, die gleichzeitige Ausführung und Beendigung von mehr als einer E/A-Anforderung
auf einmal und die E/A-Synchronisierung (wie in der Liste der Objektattribute in Tabelle 6–12
Windows Driver Foundation
Kapitel 6
673
bereits erwähnt). Ein typischer KMDF-Treiber erstellt mindestens eine Warteschlange und verknüpft mit jeder davon ein oder mehrere Ereignisse sowie einige der folgenden Optionen:
QQ Die Callbacks, die für die mit dieser Warteschlange verknüpften Ereignisse registriert sind.
QQ Der Energieverwaltungsstatus für die Warteschlange. KMDF unterstützt Warteschlangen
mit und ohne Energieverwaltung. Bei Ersteren weckt der E/A-Handler das Gerät, wenn es
erforderlich (und möglich) ist, stellt den Leerlauftimer scharf, wenn sich keine E/A-Opera
tionen für das Gerät in der Warteschlange befinden, und ruft die E/A-Abbruchroutinen des
Treibers auf, wenn das System den Arbeitszustand verlässt.
QQ Die Dispatchmethode für die Warteschlange. KMDF kann E/A-Operationen aus einer Warteschlange im sequenziellen, parallelen und manuellen Modus ausliefern. Im sequenziellen
Modus werden die E/As eine nach der anderen ausgeliefert (dabei wartet KMDF darauf,
dass der Treiber die vorherige Anforderung abschließt), im parallelen werden sie dagegen
an den Treiber geliefert, sobald es möglich ist. Im manuellen Modus muss der Treiber sie
manuell aus der Warteschlange abrufen.
QQ Die Angabe, ob die Warteschlange Puffer der Länge null akzeptiert, also etwa eingehende
Anforderungen, die keine Daten enthalten.
Die Dispatchmethode wirkt sich nur darauf aus, wie viele Anforderungen in der
Warteschlange des Treibers auf einmal aktiv sein können. Sie legt nicht fest, ob
die Ereigniscallbacks selbst gleichzeitig oder seriell aufgerufen werden. Letzteres wird durch das bereits erwähnte Objektattribut für den Synchronisierungsbereich bestimmt. Daher ist es möglich, dass bei einer parallelen Warteschlange die
Gleichzeitigkeit ausgeschaltet ist, aber dennoch mehrere Anforderungen eingehen können.
Auf der Grundlage des Warteschlangenmechanismus kann der E/A-Handler von KMDF beim
Empfang einer Erstell-, Schließungs-, Bereinigungs-, Lese- oder Gerätesteuerungsanforderung
(IOCTL) verschiedene Aufgaben ausführen:
QQ Für Erstellanforderungen kann der Treiber verlangen, sofort über das Callbackereignis
EvtDeviceFileCreate benachrichtigt zu werden. Er kann auch eine nicht manuelle Warteschlange für den Empfang von Erstellanforderungen anlegen und einen EvtIoDefault-
Callback registrieren, um die Benachrichtigungen zu erhalten. Wird keine dieser Methoden
verwendet, schließt KMDF die Anforderung einfach mit einem Erfolgscode ab. Das bedeutet, dass Anwendungen standardmäßig Handles für KMDF-Treiber öffnen können, die
keinen eigenen Code bereitstellen.
QQ Für Bereinigungs- und Schließungsanforderungen wird der Treiber unmittelbar über die
Callbacks EvtFileCleanup bzw. EvtFileClose informiert, sofern er dafür registriert ist. Anderenfalls schließt das Framework die Anforderung einfach mit einem Erfolgscode ab.
QQ Für Schreib-, Lese- und IOCTL-Anforderungen erfolgt der Vorgang aus Abb. 6–46.
674
Kapitel 6
Das E/A-System
Hat der Treiber eine
Warteschlange für diesen
Anforderungstyp?
Ist dies ein Filter
treiber?
J
J
Akzeptiert die
Warteschlange
Anforderungen?
Übergibt die Anforderung
an den nächsttieferen
Treiber
J
Erstellt ein WDFREQUESTObjekt für die Anforderung
Lässt die Anforderung
fehlschlagen
Unterliegt die Warteschlange
der Energieverwaltung?
J
Befindet sich das Gerät im
Arbeitsstatus?
J
Stellt die Anforderung in die
Warteschlange
Benachrichtigt den PnP-/
Energie-Handler, um das
Gerät aufzuwecken
Abbildung 6–46 Verarbeitung von Lese-, Schreib- und IOCTL-Anforderungen durch KMDF
User-Mode Driver Framework
Windows enthält eine wachsende Anzahl von Treibern, die im Benutzermodus laufen und das
User-Mode Driver Framework (UMDF) verwenden, einen Teil der WDF. In UMDF Version 2 wurden das Objekt-, das Programmier- und das E/A-Modell an das von KMDF angepasst. Dennoch
sind diese beiden Frameworks nicht identisch, da es schließlich grundlegende Unterschiede
zwischen Benutzer- und Kernelmodus gibt. Beispielsweise gibt es einige der in Tabelle 6–12
aufgeführten KMDF-Objekte nicht in UMDF, darunter WDFCHILDLIST, Objekte im Zusammenhang mit DMA, WDFLOOKASIDELIST (Look-Aside-Listen können nur im Kernelmodus zugewiesen
werden), WDFIORESLIST, WDFIORESREQLIST, WDFDPC sowie WMIK-Objekte. Die meisten Objekte und
Prinzipien von KMDF gelten jedoch auch in UMDF 2.x.
UMDF bietet mehrere Vorteile gegenüber KMDF:
QQ UMDF werden im Benutzermodus ausgeführt, weshalb unbehandelte Ausnahmen nur den
UMDF-Hostprozess zum Absturz bringen, aber nicht das gesamte System.
QQ Der UMDF-Hostprozess läuft unter dem lokalen Dienstkonto, das sehr geringe Rechte auf
dem lokalen Computer hat und nur anonym auf Netzwerkverbindungen zugreifen kann.
Das verringert die Angriffsfläche.
QQ Die Ausführung im Benutzermodus bedeutet, dass die IRQL stets 0 beträgt (PASSIVE_LEVEL).
Der Treiber kann daher stets Seitenfehler entgegennehmen und Kerneldispatcherobjekte
(Ereignisse, Mutexe usw.) zur Synchronisierung verwenden.
Windows Driver Foundation
Kapitel 6
675
QQ UMDF-Treiber lassen sich leichter debuggen als KMDF-Treiber, da hierzu keine zwei getrennten Computer (virtuell oder physisch) erforderlich sind.
Der Hauptnachteil von UMDF besteht in der erhöhten Latenz aufgrund der Übergänge zwischen Kernel- und Benutzermodus und der erforderlichen Kommunikation (was wir in Kürze
beschreiben werden). Außerdem sind einige Arten von Treibern, z. B. diejenigen für PCI-Hochgeschwindigkeitsgeräte, einfach nicht für die Ausführung im Benutzermodus gedacht und können daher nicht mit UMDF geschrieben werden.
UMDF ist eigens zur Unterstützung von Protokollgeräteklassen ausgelegt. Solche Klassen
umfassen jeweils alle Geräte, die dasselbe standardisierte, allgemeine Protokoll verwenden
und auf dieser Grundlage eine besondere Funktionalität anbieten. Zu den Protokollen gehören zurzeit IEEE 1394 (FireWire), USB, Bluetooth und TCP/IP; des Weiteren gibt es noch eine
Klasse für Geräte mit direkter Benutzerinteraktion (Human Interface Devices, HIDs; in Windows
Eingabegeräte genannt). Alle Geräte, die auf einem dieser Busse laufen (oder an ein Netzwerk
angeschlossen sind), sind potenzielle Kandidaten für UMDF, beispielsweise tragbare Musikabspielgeräte, Eingabegeräte, Mobiltelefone, Kameras, Webcams usw. UMDF wird außerdem von
SideShow-kompatiblen Geräten (Hilfsanzeigen) sowie dem Windows Portable Device Framework (WPD) genutzt, das USB-Wechselspeichermedien unterstützt (USB-Massenübertragungsgeräte). Wie bei KMDF ist es in UMDF außerdem auch möglich, reine Softwaretreiber zu implementieren, z. B. für ein virtuelles Gerät.
KMDF-Treiber werden als Treiberobjekte ausgeführt, die für eine SYS-Abbilddatei stehen.
Im Gegensatz dazu laufen UMDF-Treiber in einem Treiberhostprozess, der das Image %SystemRoot%\System32\WUDFHost.exe ausführt und einem Serverhostprozess ähnelt. Dieser Hostprozess enthält den Treiber selbst, das UMDF (in Form einer DLL) sowie eine Laufzeitumgebung
(zuständig für E/A-Disponierung, das Laden der Treiber, Gerätestackverwaltung, Kommunika
tion mit dem Kernel und dem Threadpool).
Wie im Kernel werden auch die einzelnen UMDF-Treiber als Teil eines Stacks ausgeführt.
Er kann mehrere Treiber für die Verwaltung eines Geräts einschließen. Da Benutzermoduscode
nicht auf den Kerneladressraum zugreifen kann, enthält UMDF auch Komponenten, die einen
solchen Zugriff über eine besondere Schnittstelle erlauben. Dies wird durch einen Kernelmodus
teil von UMDF erreicht, der ALPC einsetzt, einen Mechanismus zur Kommunikation zwischen
Prozessen, der mit der Laufzeitumgebung in den Benutzermodus-Treiberhostprozessen spricht.
(Mehr über ALPC erfahren Sie in Kapitel 8 von Band 2.) Abb. 6–47 zeigt die Architektur des
UMDF-Treibermodells.
676
Kapitel 6
Das E/A-System
UMDF-Hostprozess
Treiber-Manager
UMDF-Treiber
UMDF-Treiber
UMDF-Framework
Benutzermodus
UMDF-Laufzeit
Reflektor (Filter)
Kernelmodustreiber
UMDF-Hostprozess
Anwendungen
Win32-API
Windows-Kernel
Bereitgestellt durch:
UMDF-Framework
UMDF-Laufzeit
Reflektor (Filter)
Kernelmodustreiber
Kernelmodustreiber
Stack des logischen Geräts
Stack des logischen Geräts
Abbildung 6–47 UMDF-Architektur
Abb. 6–47 zeigt zwei Gerätestacks zur Verwaltung von zwei verschiedenen Hardwaregeräten.
In jedem davon läuft ein UMDF-Treiber jeweils in seinem eigenen Treiberhostprozess. In dem
Diagramm sind die folgenden Bestandteile der Architektur zu sehen:
QQ Anwendungen Sind die Clients des Treibers. Es handelt sich dabei um Windows-Standardanwendungen, die dieselben APIs für E/A-Vorgänge verwenden wie bei einem von
KMDF oder WDM verwalteten Gerät. Die Anwendungen wissen nicht (oder kümmern sich
nicht darum), dass sie mit einem UMDF-Gerät kommunizieren. Ihre Aufrufe werden nach
wie vor an den E/A-Manager des Kernels gesendet.
QQ Windows-Kernel (E/A-Manager) Wie auch für jedes andere Standardgerät erstellt der
E/A-Manager auf der Grundlage der E/A-APIs der Anwendungen die IRPs für die Operationen.
QQ Reflektor Der Reflektor ist der eigentliche Motor von UMDF. Es handelt sich dabei um
einen standardmäßigen WDM-Filtertreiber (%SystemRoot%\System32\Drivers\WUDFRD.
sys), der an der Spitze des Stacks für jedes von einem UMDF-Treiber verwalteten Geräts
sitzt. Der Reflektor verwaltet die Kommunikation zwischen dem Kernel und dem Benutzermodus-Treiberhostprozess. IRPs im Zusammenhang mit Energieverwaltung, Plug & Play
und Standard-E/A werden über ALPC an den Hostprozess weitergeleitet. Dadurch kann der
UMDF-Treiber auf die E/A-Vorgänge reagieren und Arbeit leisten sowie sich durch Auflistung, Installation und Verwaltung seiner Geräte am Plug-&-Play-Modell beteiligen. Überdies behält der Reflektor die Treiberhostprozesse im Auge und sorgt dafür, dass sie in angemessener Zeit auf Anforderungen reagieren, damit die Treiber und Anwendungen nicht
hängen.
QQ Treiber-Manager Der Treiber-Manager ist dafür zuständig, die Treiberhostprozesse je
nachdem zu starten und zu beenden, welche UMDF-verwalteten Geräte vorhanden sind,
und die Informationen darüber zu verwalten. Er muss auch auf Meldungen vom Reflektor
Windows Driver Foundation
Kapitel 6
677
reagieren (z. B. auf eine Geräteinstallation) und sie auf die entsprechenden Hostprozesse anwenden. Ausgeführt wird der Treiber-Manager als ein in %SystemRoot%\System32\
WUDFsvc.dll implementierter Windows-Standarddienst in einem Svchost.exe-Standardhostprozess. Er ist so eingerichtet, dass er automatisch gestartet wird, sobald der erste
UMDF-Treiber für ein Gerät installiert ist. Für sämtliche Treiberhostprozesse wird nur eine
einzige Instanz des Treiber-Managers ausgeführt (wie es bei Diensten immer der Fall ist). Er
muss stets laufen, damit die UMDF-Treiber arbeiten können.
QQ Hostprozess Der Hostprozess stellt den Adressraum und die Laufzeitumgebung für den
eigentlichen Treiber bereit (WUDFHost.exe). Obwohl er unter dem lokalen Dienstkonto
ausgeführt wird, ist er kein Windows-Dienst und wird auch nicht von SCM verwaltet, sondern nur vom Treiber-Manager. Der Hostprozess stellt den Benutzermodus-Gerätestack
für die Hardware bereit, der für alle Anwendungen im System sichtbar ist. Zurzeit hat jede
Instanz eines Geräts ihren eigenen Gerätestack in einem eigenen Hostprozess. Es kann aber
sein, dass sich in Zukunft mehrere Instanzen einen Hostprozess teilen. Hostprozesse sind
Kindprozesse des Treiber-Managers.
QQ Kernelmodustreiber Wenn für ein von einem UMDF-Treiber verwaltetes Gerät eine besondere Kernelunterstützung erforderlich ist, kann für diesen Zweck auch ein Kernelmodus-Begleittreiber geschrieben werden. Dadurch ist es möglich, das Gerät sowohl durch
einen UMDF- als auch durch einen KMDF- (oder WDM-) Treiber zu verwalten.
Um sich UMDF auf Ihrem System in Aktion anzusehen, müssen Sie lediglich einen nicht leeren
USB-Stick daran anschließen. In Process Explorer wird der Treiberhostprozess WUDFHost.exe
angezeigt. Wenn Sie zur DLL-Ansicht umschalten und nach untern scrollen, können Sie wie in
Abb. 6–48 die DLLs erkennen.
Abbildung 6–48 DLLs im UMDF-Hostprozess
678
Kapitel 6
Das E/A-System
Hier erkennen Sie drei der Hauptkomponenten aus der zuvor gegebenen Übersicht über die
Architektur wieder:
QQ WUDFHost.exe
Dies ist die ausführbare Datei für den UMDF-Hostprozess.
QQ WUDFx02000.dll
Dies ist die DLL für UMDF 2.x.
QQ WUDFPlatform.dll
Dies ist die Laufzeitumgebung.
Energieverwaltung
Die Plug-&-Play-Funktionen von Windows erfordern Unterstützung durch die Hardware des
Systems, und ebenso ist auch für Energieverwaltungsfunktionen Hardware erforderlich, die mit
der ACPI-Spezifikation (Advanced Configuration and Power Interface) übereinstimmt. Diese
Spezifikation gehört jetzt zum Unified Extensible Firmware Interface (UEFI) und steht auf http://
www.uefi.org/specifications zur Verfügung.
Der ACPI-Standard definiert verschiedene Energiezustände für Systeme und Geräte. Die
sechs Systemenergiezustände S0 (vollständig eingeschaltet) bis S5 (komplett aus) sind in Tabelle 6–13 aufgeführt. Sie zeichnen sich jeweils durch die folgenden Merkmale aus:
QQ Energieverbrauch
Der Betrag an Energie, den das System verbraucht.
QQ Wiederaufnahmestatus Dies ist der Softwarestatus, zu dem das System zurückkehrt,
wenn es zu einem »weiter eingeschalteten« Zustand wechselt.
QQ Hardwarelatenz Die Zeit, die es dauert, um das System wieder in den vollständig eingeschalteten Zustand zu versetzen.
Zustand
Energieverbrauch
Wiederaufnahmestatus
Hardwarelatenz
S0 (vollständig eingeschaltet)
Maximum
–
Keine
S1 (Energiesparmodus)
Kleiner als in S0, größer
als in S2
System nimmt den Zustand ein, den es verlassen hat (Rückkehr zu S0).
Weniger als zwei
Sekunden
S2 (Energiesparmodus)
Kleiner als in S1, größer
als in S3
System nimmt den Zustand ein, den es verlassen hat (Rückkehr zu S0).
Zwei oder mehr
Sekunden
S3 (Energiesparmodus)
Kleiner als in S2; Prozessor ist aus.
System nimmt den Zustand ein, den es verlassen hat (Rückkehr zu S0).
Zwei oder mehr
Sekunden
S4 (Ruhezustand)
Erhaltungsstrom für
Einschalttaste und Aufweckschaltung
Das System wird von der
gespeicherten Ruhezustandsdatei neu gestartet
und nimmt den Zustand
ein, den es vor dem Ruhezustand hatte.
Lang und nicht
definiert
S5 (komplett aus)
Erhaltungsstrom für
Einschalttaste
Systemstart
Lang und nicht
definiert
Tabelle 6–13 Systemenergiezustände
Energieverwaltung
Kapitel 6
679
Die Zustände S1 bis S4 sind Schlaf- oder Standbyzustände, in denen das System aufgrund
seiner geringeren Leistungsaufnahme ausgeschaltet zu sein scheint. Dabei behält es jedoch
ausreichend Informationen bei – im Arbeitsspeicher oder auf der Festplatte –, um wieder zu S0
zu wechseln. Bei den Zuständen S1 bis S3 ist der Energieverbrauch noch hoch genug, um den
Inhalt des Arbeitsspeichers zu erhalten, sodass die Energieverwaltung die Ausführung beim
Übergang zu S0 (wenn der Benutzer oder ein Gerät den Computer aufweckt) dort fortsetzt, wo
sie sie beim Übergang in den Energiesparmodus abgebrochen hat.
Beim Übergang zu S4 dagegen speichert die Energieverwaltung die komprimierten Inhalte
des Arbeitsspeichers in der Ruhezustandsdatei Hiberfil.sys im Stammverzeichnis des Systemvolumes (verborgene Datei). Diese Datei ist groß genug, um auch die nicht komprimierten Inhalte
des Arbeitsspeichers zu fassen, aber um die Festplatten-E/A zu minimieren und die Leistung
beim Wechsel in und aus dem Ruhezustand zu verbessern, wird die Komprimierung eingesetzt.
Nach diesem Speichervorgang schaltet die Energieverwaltung den Computer aus. Schaltet der
Benutzer den Computer anschließend wieder ein, erfolgt ein normaler Startvorgang, allerdings
mit der Ausnahme, dass der Boot-Manager das Speicherabbild in der Ruhezustandsdatei entdeckt. Ist in dieser Datei ein gespeicherter Systemstatus enthalten, startet der Boot-Manager
%SystemRoot%\System32\Winresume.exe, die den Inhalt der Datei in den Arbeitsspeicher einliest und die Ausführung an der Stelle im Arbeitsspeicher fortsetzt, die in der Ruhezustandsdatei aufgezeichnet wurde.
Auf Systemen mit hybridem Standbymodus resultiert die Anforderung, den Computer
schlafen zu legen, in einer Kombination aus den Zuständen S3 und S4. Der Computer geht
in den Energiesparmodus über, aber dabei wird auch eine Notfall-Ruhezustandsdatei auf die
Festplatte geschrieben. Im Gegensatz zu regulären Ruhezustandsdateien, die fast den gesamten aktiven Arbeitsspeicher enthalten, befinden sich in dieser Datei nur die Daten, die später
nicht eingelagert werden können. Da weniger Daten auf die Festplatte geschrieben werden,
erfolgt der Übergang in diesen Modus schneller als der Wechsel in den regulären Ruhezustand.
Dabei werden die Treiber darüber informiert, dass ein Übergang zu S4 ansteht, sodass sie sich
wie bei einem normalen Ruhezustand selbst konfigurieren und ihren Status speichern können.
Anschließend geht das System in den normalen Energiesparmodus über. Fällt dabei der Strom
aus, befindet sich das System praktisch in einem S4-Zustand: Wenn der Benutzer den Computer wieder einschaltet, kann Windows die Ausführung auf der Grundlage der Notfall-Ruhezustandsdatei wieder aufnehmen.
Sie können den Ruhezustand komplett ausschalten und damit etwas Festplattenplatz gewinnen, indem Sie an einer Eingabeaufforderung mit erhöhten Rechten
powercfg /h off ausführen.
Unmittelbare Übergänge zwischen den Status S1 bis S4 finden nie statt, da dazu eine Codeausführung erforderlich wäre, die CPU in diesen Zuständen aber ausgeschaltet ist. Stattdessen
muss immer erst ein Übergang zu S0 erfolgen. Ein Übergang von irgendeinem der Zustände S1
bis S5 zu S0 wird als Aufwachen bezeichnet, ein Übergang von S0 zu einem der Zustände S1 bis
S5 als Einschlafen (siehe Abb. 6–49).
680
Kapitel 6
Das E/A-System
Abbildung 6–49 Übergänge zwischen den Systemenergiezuständen
Experiment: Systemenergiezustände
Um sich die auf dem System verfügbaren Energiezustände anzusehen, öffnen Sie eine Eingabeaufforderung mit erhöhten Rechten und geben den Befehl powercfg /a ein. Dadurch
erhalten Sie eine Ausgabe wie die folgende:
C:\WINDOWS\system32>powercfg /a
Die folgenden Standbymodusfunktionen sind auf diesem System verfügbar:
Standby (S3)
Ruhezustand
Schnellstart
Die folgenden Standbymodusfunktionen sind auf diesem System nicht verfügbar:
Standby (S1)
Die Systemfirmware unterstützt diesen Standbystatus nicht.
Standby (S2)
Die Systemfirmware unterstützt diesen Standbystatus nicht.
Standby (S0 Niedriger Energiestand – Leerlauf)
Die Systemfirmware unterstützt diesen Standbystatus nicht.
Hybrider Standbymodus
Der Hypervisor unterstützt diesen Standbystatus nicht.
Hier sind der Standbystatus S3 und der Ruhezustand verfügbar. Im Folgenden schalten wir
den Ruhezustand aus und geben den Befehl dann erneut ein:
C:\WINDOWS\system32>powercfg /h off
C:\WINDOWS\system32>powercfg /a
→
Energieverwaltung
Kapitel 6
681
Die folgenden Standbymodusfunktionen sind auf diesem System verfügbar:
Standby (S3)
Die folgenden Standbymodusfunktionen sind auf diesem System nicht verfügbar:
Standby (S1)
Die Systemfirmware unterstützt diesen Standbystatus nicht.
Standby (S2)
Die Systemfirmware unterstützt diesen Standbystatus nicht.
Ruhezustand
Ruhezustand wurde nicht aktiviert.
Standby (S0 Niedriger Energiestand – Leerlauf)
Die Systemfirmware unterstützt diesen Standbystatus nicht.
Hybrider Standbymodus
Ruhezustand ist nicht verfügbar.
Der Hypervisor unterstützt diesen Standbystatus nicht.
Schnellstart
Ruhezustand ist nicht verfügbar.
Für Geräte sind in ACPI die vier Energiezustände D0 bis D3 definiert, wobei D0 »vollständig
eingeschaltet« und D3 »komplett aus« ist. Die genaue Bedeutung der Zustände D1 und D2
festzulegen, überlässt der ACPI-Standard den einzelnen Treibern und Geräten. Vorgeschrieben
ist dabei lediglich, dass der Energieverbrauch in D1 kleiner oder gleich dem in D0 und der
Energieverbrauch in D2 kleiner oder gleich dem in D1 sein muss.
In Windows 8 und höher ist D3 in die zwei Unterzustände aufgeteilt, den »heißen« und
den »kalten« D3. Im heißen D3 ist das Gerät größtenteils ausgeschaltet, aber noch nicht von
seiner Hauptstromquelle getrennt. Außerdem kann der Elternbuscontroller in diesem Zustand
das Vorhandensein des Geräts auf dem Bus erkennen. Im kalten D3 dagegen hat das Gerät
keine Verbindung mehr mit seiner Stromquelle, und der Buscontroller kann das Gerät auch
nicht mehr wahrnehmen. Dieser Zustand bietet noch eine erweiterte Gelegenheit, um Strom zu
sparen. Abb. 6–50 zeigt die Gerätezustände und die möglichen Statusübergänge.
682
Kapitel 6
Das E/A-System
heiß
kalt
Abbildung 6–50 Übergänge zwischen Gerätestatus
Vor Windows 8 konnten Geräte den heißen D3-Zustand nur dann erreichen, wenn das System
vollständig eingeschaltet war (S0). Der Übergang zum kalten D3 erfolgte implizit, wenn das
System in einen Standbymodus überging. Ab Windows 8 kann ein Gerät auch bei vollständig
eingeschaltetem System in den kalten D3-Zustand versetzt werden. Allerdings kann der Treiber,
der das Gerät steuert, dies nicht direkt tun, sondern muss es zunächst in den heißen D3 versetzen. Der Bustreiber und die Firmware können anschließend entscheiden, alle Geräte an ihrem
Bus, die sich im heißen D3-Zustand befinden, auf kalten D3 umzuschalten. Diese Entscheidung
hängt von zwei Faktoren ab, nämlich erstens, ob der Bustreiber und die Firmware überhaupt
dazu in der Lage sind, und zweitens, ob der Treiber einen Übergang in den kalten D3 vorgesehen hat, was er durch Angabe in der INF-Installationsdatei oder durch einen dynamischen
Aufruf der Funktion SetD3DColdSupport tun kann.
Zusammen mit anderen Originalgeräteherstellern hat Microsoft eine Reihe von Spezifikationen für die Energieverwaltung aufgestellt, die die für alle Geräte in einer bestimmten Klasse erforderlichen Geräteenergiezustände festlegen (für die Hauptgeräteklassen wie Anzeige,
Netzwerk, SCSI usw.). Einige Geräte können nur entweder »vollständig ein« oder »vollständig
aus« sein, weshalb jegliche Zwischenzustände bei ihnen nicht definiert sind.
Verbundener und moderner Standbymodus
In dem letzten Experiment ist Ihnen wahrscheinlich ein weiterer Systemzustand aufgefallen, der
als Standby (S0 Niedriger Energiestand – Leerlauf) angezeigt wurde. Dies ist kein offizieller
ACPI-Status, sondern eine Variante von S0, die in Windows 8.x als verbundener oder Verbindungsstandby bezeichnet wurde und in Windows 10 (sowohl in den Desktop- als auch den
Mobileditionen) zum modernen Standbymodus erweitert wurde. Der reguläre Standbymodus
S3 wird manchmal auch als veralteter oder Legacy-Standby bezeichnet.
Das Hauptproblem bei S3 besteht darin, dass das System in diesem Zustand nicht arbeitet, sodass es beispielsweise eine eingehende E-Mail nicht aufnehmen kann, ohne in den
S0-Zustand aufzuwachen, was je nach Konfiguration und den Möglichkeiten der Geräte zwar
möglich sein kann, aber nicht muss. Wenn das System tatsächlich aufwacht, um die E-Mail
abzurufen, geht es danach aber nicht wieder sofort in den Standbymodus über. Durch den
modernen Standbymodus werden beide Probleme gelöst.
Energieverwaltung
Kapitel 6
683
Systeme, die den modernen Standbymodus unterstützen, gehen in diesen Zustand über,
wenn sie angewiesen werden, in den Standby zu wechseln. Technisch befindet sich das System
immer noch im Status S0, da die CPU aktiv ist und Code ausgeführt werden kann. Allerdings
sind Desktopprozesse (Nicht-UWP-Apps) und UWP-Apps angehalten (wobei sich die meisten
UWP-Apps nicht im Vordergrund befinden und daher ohnehin angehalten sind). Von UWPApps erstellte Hintergrundtasks dagegen können weiterhin ausgeführt werden. So kann beispielsweise ein E-Mail-Client einen Hintergrundtask haben, der regelmäßig nach neuen Nachrichten Ausschau hält.
Im modernen Standbymodus kann das System auch sehr schnell zu S0 aufwachen (was
manchmal als »instant on« bezeichnet wird). Allerdings können nicht alle Systeme diesen Modus nutzen; dies hängt vom Chipset und anderen Komponenten der Plattform ab. (Das System,
auf dem wir das letzte Experiment ausgeführt haben, unterstützt den modernen Standbymodus nicht, sondern dafür den regulären S3-Standbymodus.)
Weitere Informationen über den modernen Standbymodus finden Sie in der Windows-Hardwaredokumentation auf https://msdn.microsoft.com/en-us/library/windows/hardware/mt2825
15(v=vs.85).aspx.
Funktionsweise der Energieverwaltung
Die Verantwortung für die Windows-Energierichtlinien ist auf die als Energieverwaltung (Power
Manager) bezeichnete Komponente und die einzelnen Gerätetreiber aufgeteilt. Die Energieverwaltung ist Besitzer der Systemenergierichtlinie. Das bedeutet, dass die Energieverwaltung
entscheidet, welcher Systemenergiezustand jeweils geeignet ist und wann das System in einen Energiesparmodus oder den Ruhezustand versetzt oder heruntergefahren werden soll. Sie
weist auch die dazu fähigen Geräte im System an, die entsprechenden Übergänge zwischen
den Systemenergiezuständen durchzuführen.
Um zu entscheiden, welcher Übergang angebracht ist, zieht die Energieverwaltung die
folgenden Faktoren heran:
QQ Aktivitätsgrad auf dem System
QQ Akkuladezustand
QQ Anforderungen von Anwendungen, das System herunterzufahren oder in den Ruhezustand oder Energiesparmodus zu versetzen
QQ Benutzeraktionen wie die Betätigung des Netzschalters
QQ Energieeinstellungen in der Systemsteuerung
Wenn der PnP-Manager eine Geräteauflistung durchführt, erhält er unter anderem auch Informationen über die Fähigkeiten der Geräte zur Energieverwaltung. Ein Treiber meldet es, wenn
seine Geräte die Gerätezustände D1 und D2 unterstützen, und gibt optional auch die Latenzen,
also die erforderlichen Zeiten für den Wechsel von D1 zu D3 bis D0 an.
Um der Energieverwaltung bei der Entscheidung zu helfen, wann ein Energiezustandsübergang erfolgen soll, geben die Bustreiber auch eine Tabelle mit einer Zuordnung zwischen den
Systemenergiezuständen S0 bis S5 und den vom Gerät unterstützten Geräteenergiezuständen
zurück. Diese Tabelle nennt den jeweils geringstmöglichen Geräteenergiezustand für die einzel-
684
Kapitel 6
Das E/A-System
nen Systemzustände und spiegelt unmittelbar den Zustand der verschiedenen Energieniveaus
wieder für den Energiespar- oder Ruhemodus wider. Für einen Bus, der alle vier Geräteenergiezustände unterstützt, kann beispielsweise die Zuordnungstabelle aus Tabelle 6–14 zurückgegeben
werden. Die meisten Gerätetreiber schalten ihre Geräte komplett aus (D3), wenn das System den
Zustand S0 verlässt, um den Energieverbrauch zu minimieren, während der Computer nicht in
Gebrauch ist. Andere Geräte dagegen haben die Möglichkeit, das System aus einem Standbyzustand aufzuwecken, beispielsweise Netzwerkkarten. Auch diese Fähigkeit und der niedrigste Geräteenergiezustand, bei dem sie noch vorhanden ist, werden bei der Geräteauflistung gemeldet.
Systemenergiezustand
Geräteenergiezustand
S0 (vollständig eingeschaltet)
D0 (vollständig eingeschaltet)
S1 (Energiesparmodus)
D1
S2 (Energiesparmodus)
D2
S3 (Energiesparmodus)
D2
S4 (Ruhezustand)
D3 (komplett aus)
S5 (komplett aus)
D3 (komplett aus)
Tabelle 6–14 Beispiel einer Zuordnungstabelle für System- und Energiegerätezustände
Experiment: Die Energiezustandszuordnung eines Treibers einsehen
Im Geräte-Manager können Sie die Zuordnungen zwischen System- und Geräteenergiezuständen für einen Treiber einsehen. Öffnen Sie dazu das Eigenschaftendialogfeld für ein
Gerät, klicken Sie auf die Registerkarte Details und wählen Sie im Dropdownmenü Eigenschaft den Punkt Energiedaten. Das Dialogfeld zeigt auch den aktuellen Energiezustand
des Geräts, die Fähigkeiten des Geräts zur Energieverwaltung (Energiekapazität) und die
Energiezustände an, aus denen es das System aufwecken kann:
Energieverwaltung
Kapitel 6
685
Energieverwaltung durch die Treiber
Wenn die Energieverwaltung einen Übergang zu einem anderen Systemenergiezustand durchführen will, sendet sie Energiebefehle an die Energie-Dispatchroutine eines Treibers (IRP_MJ_
POWER). Für die Verwaltung eines Geräts können mehrere Treiber zuständig sein, aber nur einer
davon ist als Besitzer der Energierichtlinie für das Gerät vorgesehen. Gewöhnlich ist dies der
Treiber, der das FDO verwaltet. Dieser Treiber bestimmt aufgrund des Systemstatus den Energiezustand des Geräts. Geht das System beispielsweise von S0 zu S3 über, kann der Treiber
entscheiden, das Gerät von D0 aus in den Zustand D1 zu versetzen.
Anstatt die anderen Treiber, die an der Verwaltung des Geräts beteiligt sind, direkt über
diese Entscheidung zu informieren, bittet der Besitzer der Energierichtlinie für das Gerät die
Energieverwaltung mithilfe der Funktion PoRequestPowerIrp, dies zu tun, indem sie einen Geräteenergiebefehl an die Energie-Dispatchroutinen dieser Treiber ausgibt. Dadurch hat die Energieverwaltung jederzeit die Kontrolle über die Anzahl der Energiebefehle, die auf dem System
aktiv sind. Beispielsweise kann es sein, dass einige Geräte erheblich viel Strom zum Starten
benötigen. Die Energieverwaltung sorgt dafür, dass solche Geräte nicht gleichzeitig hochgefahren werden.
Zu vielen Energiebefehlen gibt es auch entsprechende Abfragebefehle. Wenn das System
beispielsweise in einen Standbyzustand übergeht, fragt die Energieverwaltung die Geräte erst,
ob dies akzeptabel ist. Ein Gerät, das gerade zeitkritische Operationen durchführt oder mit Gerätehardware kommuniziert, kann diesen Befehl ablehnen, sodass das System seinen aktuellen
Energiezustand beibehält.
Experiment: Die Systemfähigkeiten und die Systemrichtlinie zur
Energieverwaltung einsehen
Mit dem Kerneldebuggerbefehl !pocaps können Sie sich die Fähigkeiten eines Systems zur
Energieverwaltung anschauen. Die folgende Ausgabe dieses Befehls stammt von einem
x64-Laptop mit Windows 10:
lkd> !pocaps
PopCapabilities @ 0xfffff8035a98ce60
Misc Supported Features: PwrButton SlpButton Lid S3 S4 S5 HiberFile FullWake
VideoDim
Processor Features:
Thermal
Disk Features:
Battery Features:
BatteriesPresent
Battery 0 - Capacity: 0 Granularity: 0
Battery 1 - Capacity: 0 Granularity: 0
Battery 2 - Capacity: 0 Granularity: 0
Wake Caps
Ac OnLine Wake: Sx
Soft Lid Wake:
Sx
→
686
Kapitel 6
Das E/A-System
RTC Wake:
S4
Min Device Wake: Sx
Default Wake:
Sx
Die Zeile Misc Supported Features gibt an, dass das System neben S0 (vollständig eingeschaltet) auch die Systemenergiezustände S3, S4 und S5 unterstützt (aber nicht S1 und S2)
und über eine gültige Ruhezustandsdatei zur Speicherung des Systemarbeitsspeichers für
den Zustand S4 verfügt.
Auf der Seite Energieoptionen, die Sie erreichen, indem Sie in der Systemsteuerung auf
Energieoptionen klicken, können Sie verschiedene Aspekte der Energierichtlinie des Systems
einstellen. Welche Möglichkeiten Sie dabei haben, hängt von den Fähigkeiten des Systems
zur Energieverwaltung ab.
Originalgerätehersteller können Energieschemas hinzufügen. Um eine Liste der vorhandenen Schemas einzusehen, verwenden Sie den Befehl powercfg /list.
C:\WINDOWS\system32>powercfg /list
Bestehende Energieschemen (* Aktiv)
----------------------------------GUID des Energieschemas: 381b4222-f694-41f0-9685-ff5bb260df2e (Ausbalanciert)
GUID des Energieschemas: 8759706d-706b-4c22-b2ec-f91e1ef6ed38 (HP Optimized
(empfohlen)) *
GUID des Energieschemas: 8c5e7fda-e8bf-4a96-9a85-a6e23a8c635c (Höchstleistung)
GUID des Energieschemas: a1841308-3541-4fab-bc81-f71556f20b4a
(Energiesparmodus)
→
Energieverwaltung
Kapitel 6
687
Wenn Sie eine der vorgegebenen Planeinstellungen ändern, können Sie die Leerlaufgrenz
werte festlegen, nach denen bestimmt wird, wann das System den Monitor und die Festplatten abschaltet und wann es in den Standbymodus (S3 im vorherigen Experiment) oder
den Ruhezustand (S4) übergeht. Außerdem können Sie über den Link Energiesparplaneinstellungen ändern das Verhalten des Systems beim Drücken des Netz- und des Standbyschalters und beim Zuklappen des Laptops festlegen.
Über den Link Erweiterte Energieeinstellungen ändern können Sie unmittelbar die Werte in
der Energierichtlinie des Systems bearbeiten. Eine Anzeige dieser Werte ist auch mit dem
Debuggerbefehl !popolicy möglich:
lkd> !popolicy
SYSTEM_POWER_POLICY (R.1) @ 0xfffff8035a98cc64
PowerButton:
Sleep
Flags: 00000000
Event: 00000000
SleepButton:
Sleep
Flags: 00000000
Event: 00000000
None
Flags: 00000000
Event: 00000000
Sleep
Flags: 00000000
Event: 00000000
OverThrottled: None
Flags: 00000000
Event: 00000000
IdleTimeout:
IdleSensitivity:
90%
LidClose:
Idle:
0
MinSleep:
S3
MaxSleep:
S3
LidOpenWake:
S0
FastSleep:
S3
1
WinLogonFlags:
S4Timeout:
0
VideoTimeout:
600
VideoDim:
0
SpinTimeout:
4b0
OptForPower:
0
FanTolerance:
0% ForcedThrottle:
0%
MinThrottle:
0% DyanmicThrottle: None (0)
→
688
Kapitel 6
Das E/A-System
Die ersten Zeilen dieser Ausgaben beziehen sich auf das Verhalten bei der Betätigung der
verschiedenen Schalter, wie es im Fenster Energieoptionen > Erweiterte Einstellungen festgelegt ist. Auf diesem System versetzen sowohl der Netz- als auch der Standbyschalter den
Computer in einen Standbymodus. Beim Zuklappen dagegen passiert nichts. Die Timeoutwerte hinten in der Anzeige sind in Sekunden und in Hexadezimalschreibweise angegeben.
Die Werte entsprechen unmittelbar denen, die im Fenster Energieoptionen eingestellt wurden. Beispielsweise beläuft sich der Videotimeoutwert auf 600, was bedeutet, dass der Monitor nach 600 s, also nach 10 Minuten abgeschaltet wird. (Aufgrund eines Bugs in den hier
verwendeten Debuggingwerkzeugen wird dieser Wert im Dezimalformat angegeben.) Das
Timeout zum Herunterfahren der Festplatte beträgt 0x4b0, also 1200 s oder 20 Minuten.
Steuerung der Geräteenergiezustände durch den Treiber und
die Anwendung
Ein Treiber kann nicht nur auf Befehle der Energieverwaltung für den Wechsel zu einem anderen Systemenergiezustand reagieren, sondern den Energiezustand seiner Geräte auch von
sich aus steuern. So kann es beispielsweise sein, dass der Treiber den Energieverbrauch eines
Geräts verringern will, das längere Zeit inaktiv war. Das kann beispielsweise bei Monitoren und
Festplatten geschehen, die ein Abdunkeln bzw. Herunterfahren zulassen. Der Treiber kann die
Inaktivität eines Geräts entweder selbst oder unter Zuhilfenahme der Einrichtungen der Energieverwaltung erkennen. In letzterem Fall muss der Treiber das Gerät durch den Aufruf der
Funktion PoRegisterDeviceForIdleDetection bei der Energieverwaltung registrieren.
Diese Funktion teilt der Energieverwaltung die Timeoutwerte mit, die bestimmen, ob sich
das Gerät im Leerlauf befindet, und gibt den Geräteenergiezustand an, den die Energieverwaltung anwenden soll. Der Treiber gibt zwei Timeouts an, nämlich einen für den Fall, dass
der Benutzer den Computer zum Energiesparen konfiguriert hat, und einen zweiten für eine
Konfiguration zur Optimierung der Leistung. Nach dem Aufruf von PoRegisterDeviceForIdleDetection muss der Treiber die Energieverwaltung durch einen Aufruf von PoSetDeviceBusy
oder PoSetDeviceBusyEx immer informieren, wenn das Gerät aktiv ist, und sich dann erneut für
die Leerlauferkennung registrieren, und sie nach Bedarf zu de- und zu reaktivieren. Es gibt auch
die APIs PoStartDeviceBusy und PoEndDeviceBusy, mit denen sich das gleiche Verhalten unter
Verwendung einer einfacheren Programmierlogik hervorrufen lässt.
Ein Gerät hat zwar die Kontrolle über seinen eigenen Energiezustand, kann aber den Systemenergiezustand nicht beeinflussen, um Zustandsübergänge zu verhindern. Wenn beispielsweise ein schlecht geschriebener Treiber keinen Standbymodus erlaubt, kann er das Gerät nur
eingeschaltet lassen oder komplett abschalten. Das ändert aber nichts an den Möglichkeiten
des Systems, in einen Standbymodus zu wechseln, da die Energieverwaltung die Treiber nur
über Zustandsübergänge informiert, aber nicht um deren Zustimmung bittet. Bevor das System
in einen Zustand mit geringerem Energieverbrauch übergeht, erhalten die Treiber ein IRP mit
einer Energieabfrage (IRP_MN_QUERY_POWER). Ein Treiber kann dagegen ein Veto einlegen, aber
die Energieverwaltung muss dieses Veto nicht berücksichtigen. Sie kann den Übergang ver-
Energieverwaltung
Kapitel 6
689
zögern, falls das möglich ist (etwa wenn die Akkuladung noch keinen kritisch niedrigen Wert
erreicht hat). Der Übergang in den Ruhezustand dagegen schlägt niemals fehl.
Für die Energieverwaltung sind primär die Treiber und der Kernel verantwortlich, doch
auch die Anwendungen können sich beteiligen. Benutzermodusprozesse können sich für verschiedene Energiebenachrichtigungen registrieren, z. B. für einen niedrigen oder kritischen
Akkuladezustand, für den Wechsel des Computers von Akku- auf Netzbetrieb oder für die
Auslösung eines Energiezustandsübergangs durch das System. Allerdings können Anwendungen kein Veto gegen solche Vorgänge einlegen. Vor dem Übergang in einen Standbymodus
wird Ihnen ein Zeitraum von zwei Sekunden für alle erforderlichen Aufräumarbeiten gewährt.
Das Framework für die Energieverwaltung
Beginnend mit Windows 8 bietet der Kernel ein Framework für die Verwaltung der Energiezustände einzelner Komponenten eines Geräts (manchmal auch Funktionen des Geräts genannt).
Beispielsweise kann ein Audiogerät Komponenten für die Wiedergabe und für die Aufnahme haben. Wenn die Wiedergabekomponente aktiv ist, die Aufnahmekomponente aber nicht,
dann wäre es vorteilhaft, Letztere in einen Zustand mit geringerem Energieverbrauch zu versetzen. Das Power Management Framework (PoFx) stellt eine API bereit, mit deren Hilfe Treiber die
Energiezustände und -erfordernisse ihrer Komponenten angeben können. Alle Komponenten
müssen den Status »vollständig eingeschaltet« (F0) unterstützen. Höhere F-Nummern stehen
für Zustände mit geringerem Energieverbrauch, wobei jeder F-Zustand weniger Energie verbraucht als der vorherige, aber dafür eine längere Übergangszeit für den Wechsel zurück zu
F0 erfordert. Diese F-Zustände haben nur eine Bedeutung, wenn sich das Gerät im Zustand D0
befindet, da es in den D-Zuständen mit höheren Nummern gar nicht arbeitet.
Der Besitzer der Energierichtlinie des Geräts (gewöhnlich das FDO) muss sich beim PoFx
registrieren, indem er die Funktion PoFxRegisterDevice aufruft. Dabei übergibt der Treiber die
folgenden Informationen:
QQ Die Anzahl der Komponenten in dem Gerät.
QQ Einen Satz von Callbacks, die der Treiber implementieren kann, um sich bei verschiedenen
Ereignissen vom PoFx benachrichtigen zu lassen, beispielsweise beim Wechsel zu einem
aktiven oder inaktiven Zustand, beim Übergang in den Zustand D0 und beim Senden von
Energiesteuercodes. (Mehr darüber erfahren Sie im WDK.)
QQ Für alle Komponenten jeweils die Anzahl der möglichen F-Zustände.
QQ Für alle Komponenten jeweils den niedrigsten F-Zustand, aus dem sie aufwachen kann.
QQ Für alle F-Zustände aller Komponenten die Zeit, die es erfordert, um zu F0 zurückzukehren;
die Mindestzeit, die diese Komponenten in dem F-Zustand verbleiben müssen, damit der
Übergang sich lohnt; und den Nennenergieverbrauch der Komponente in diesem Zustand.
Es kann auch angegeben sein, dass der Energieverbrauch vernachlässigbar ist und es sich
nicht lohnt, ihn zu berücksichtigen, wenn PoFx entscheidet, mehrere Komponenten gleichzeitig aufzuwecken.
PoFx nutzt diese Informationen – sowie weitere Energieinformationen über das Gerät und das
System, z. B. das aktuelle Energieprofil –, um eine fundierte Entscheidung zu treffen, in welchem
690
Kapitel 6
Das E/A-System
F-Zustand sich eine Komponente jeweils befinden soll. Die Kunst besteht dabei darin, zwischen
zwei einander widersprechenden Zielen abzuwägen, nämlich dafür zu sorgen, dass eine inaktive Komponente so wenig Energie verbraucht wie möglich, aber zweitens auch sicherzustellen,
dass eine Komponente schnell genug zurück in den Zustand F0 wechseln kann, sodass es so
aussieht, als wäre die Komponente stets eingeschaltet und immer verbunden.
Der Treiber muss PoFx informieren, wenn eine Komponente aktiv sein muss (F0), indem er
PoFxActivateComponent aufruft. Danach ruft PoFx schließlich den zugehörigen Callback auf, um
dem Treiber mitzuteilen, dass sich die Komponente jetzt im Zustand F0 befindet. Entscheidet der
Treiber dagegen, dass die Komponente zurzeit nicht benötigt wird, ruft er PoFxIdleComponent auf,
um dies PoFx mitzuteilen. Das Framework reagiert darauf, indem es die Komponente in einen
F-Zustand mit geringerem Energieverbrauch versetzt und den Treiber nach getaner Arbeit da
rüber informiert.
Leistungszustandsverwaltung
Der gerade beschriebene Mechanismus macht es möglich, dass eine Komponente im Leerlauf
(in einem anderen Zustand als F0) weniger Energie verbraucht als in F0. Manche Komponenten
aber können je nachdem, welche Arbeit das Gerät gerade verrichtet, selbst im Zustand F0 weniger Energie verbrauchen. Beispielsweise verbraucht eine Grafikkarte weniger Energie, wenn
sie eine größtenteils statische Anzeige darstellt, als wenn sie eine 3-D-Animation mit 60 Bildern
pro Sekunde rendert.
In Windows 8.x mussten die entsprechenden Treiber einen eigenen Algorithmus zur Auswahl eines Leistungszustands implementieren und einen Betriebssystemdienst benachrichtigen, der als Plattformerweiterung-Plug-In (PEP) bezeichnet wurde, wobei ein PEP jeweils auf
eine bestimmte Produktreihe von Prozessoren oder Ein-Chip-Systemen (System on Chip, SoC)
zugeschnitten ist. Dadurch musste der Treibercode eng an das jeweilige PEP gekoppelt sein.
In Windows 10 wurde die PoFx-API um eine Verwaltung von Leistungszuständen erweitert,
sodass der Treibercode nun Standard-APIs verwenden kann und sich nicht mehr darum kümmern muss, welches PEP auf der jeweiligen Plattform eingesetzt wird. Für jede Komponente
bietet PoFx die folgenden Arten von Leistungszuständen:
QQ Diskrete Zustandsnummern, die für bestimmte Frequenzen (Hz) oder Bandbreiten (Bit pro
Sekunde) stehen, oder Nummern, die nur für den Treiber eine Bedeutung haben
QQ Kontinuierliche Zustandsverläufe zwischen einem Minimum und einem Maximum (Frequenz, Bandbreite, benutzerdefiniert)
Beispielsweise kann für eine Grafikkarte ein Satz diskreter Frequenzen definiert werden, bei
denen sie arbeiten kann, was sich indirekt auf ihren Energieverbrauch auswirkt. Ähnliche Leistungssätze können auch für die genutzte Bandbreite aufgestellt werden, wo dies sinnvoll ist.
Um sich für die Verwaltung von Leistungszuständen bei PoFx zu registrieren, muss ein
Treiber zunächst das Gerät wie im vorherigen Abschnitt registrieren (über PoFxRegisterDevice).
Anschließend ruft er PoFxRegisterComponentPerfStates auf und übergibt dabei Angaben zur
Leistung (diskret oder kontinuierlich, Frequenz, Bandbreite oder benutzerdefiniert) und einen
Callback für den Fall, dass eine Statusänderung eintritt.
Energieverwaltung
Kapitel 6
691
Wenn ein Treiber entscheidet, dass eine Komponente ihren Leistungszustand ändern soll,
ruft er PoFxIssuePerfStateChange oder PoFxIssuePerfStatechangeMultiple auf. Dadurch wird
das PEP aufgefordert, die Komponente in den angegebenen Zustand zu versetzen (auf der
Grundlage des angegebenen Index oder Wertes, je nachdem, ob der Satz für einen diskreten
oder einen Bereichszustand gilt). Der Treiber kann auch angeben, ob der Aufruf synchron oder
asynchron erfolgen soll oder ob es ihm egal ist; in letzterem Fall trifft das PEP die Entscheidung. In jedem Fall ruft PoFX schließlich den vom Treiber registrierten Callback mit dem Leistungszustand auf. Dabei kann es sich tatsächlich um den angeforderten Zustand handeln, es
ist aber auch möglich, dass das PEP die Anforderung verweigert hat. Wurde die Anforderung
akzeptiert, nimmt der Treiber die entsprechenden Aufrufe für seine Hardware vor, um den eigentlichen Wechsel vorzunehmen. Bei einer Ablehnung der Anforderung kann der Treiber es
mit einem weiteren Aufruf einer der erwähnten Funktionen erneut versuchen. Der Callback des
Treibers erfolgt jedoch schon nach einem einzigen Aufruf.
Energieverfügbarkeitsanforderungen
Gegen Übergänge in einen Standbymodus, die bereits ausgelöst wurden, können Anwendungen und Treiber kein Veto einlegen. In manchen Situationen ist allerdings ein Mechanismus nötig, um die Auslösung eines solchen Zustandsübergangs zu verhindern, wenn der Benutzer auf
bestimmte Weise mit dem System arbeitet. Wenn sich der Benutzer beispielsweise einen Film
ansieht und der Computer so eingestellt ist, dass er nach 15 Minuten ohne Maus- oder Tastaturbetätigungen in den Standbymodus übergeht, muss die Anwendung zur Medienwiedergabe
die Möglichkeit haben, solche Übergänge auszuschließen, solange der Film läuft. Auch andere
Energiesparmaßnahmen wie ein Abschalten oder auch nur eine Verdunkelung des Bildschirms
würden die Freude an der Betrachtung des Films erheblich mindern. In älteren Windows-Ver
sionen konnte die Benutzermodus-API SetThreadExecutionStation Zustandsübergänge des
Systems und der Anwendung im Leerlauf unterbinden, indem sie die Energieverwaltung darüber informierte, dass der Benutzer den Computer nach wie vor nutzt. Allerdings bot diese API
keinerlei Diagnosemöglichkeiten und auch keine ausreichend feinen Steuerungsmöglichkeiten,
um die Verfügbarkeitsanforderung zu definieren. Des Weiteren konnten Treiber keine eigenen
Anforderungen ausgeben. Benutzeranwendungen mussten ihr Threadmodell sogar entsprechend anpassen, da diese Anforderungen auf Thread-, und nicht auf Prozess- oder System
ebene erfolgten.
Mittlerweise jedoch unterstützt Windows Objekte für Verfügbarkeitsanforderungen, die im
Kernel implementiert und im Objekt-Manager definiert sind. Mit dem Sysinternals-Tool WinObj
(mehr darüber in Kapitel 8 von Band 2) können Sie sich den Objekttyp PowerRequest im Verzeichnis \ObjectTypes ansehen. Alternativ können Sie dazu auch den Kerneldebuggerbefehl !object
auf den Objekttyp \ObjectTypes\PowerRequest anwenden.
Energieverfügbarkeitsanforderungen werden von Benutzermodusanwendungen über die
API PowerCreateRequest erstellt und mit PowerSetRequest und PowerClearRequest aktiviert bzw.
deaktiviert. Im Kernel verwenden die Treiber dazu die Funktionen PoCreatePowerRequest, PoSetPowerRequest und PoClearPowerRequest. Da hier keine Handles verwendet werden, ist außerdem
PoDeletePowerRequest erforderlich, um den Verweis auf das Objekt zu entfernen (wohingegen
im Benutzermodus einfach CloseHandle aufgerufen werden kann).
692
Kapitel 6
Das E/A-System
Über die PowerRequest-API können vier Arten von Anforderungen eingesetzt werden:
QQ Systemanforderung Bei dieser Art von Anforderung wird das System gebeten, bei Ablauf des Leerlauftimers nicht automatisch in einen Standbymodus zu wechseln (wobei der
Benutzer jedoch nach wie vor die Möglichkeit hat, etwa den Laptop zuzuklappen, um
einen Standbymodus hervorzurufen).
QQ Anzeigeanforderung Diese Art von Anforderung macht dasselbe wie die Systemanforderung, allerdings für die Anzeige.
QQ Abwesenheitsmodusanforderung Dies ist eine Änderung des normalen S3-Verhaltens
von Windows, bei der der Computer vollständig eingeschaltet bleibt, Anzeige und Soundkarte aber ausgeschaltet sind. Für den Benutzer sieht es so aus, als befände sich der Computer tatsächlich in einem Standbymodus. Dieses Verhalten wird gewöhnlich nur von besonderen Set-Top-Boxen und Mediacentergeräten verwendet, bei denen die Medienauslieferung
auch dann weitergehen muss, wenn der Benutzer etwa einen physischen Standbyschalter
betätigt hat.
QQ Anforderung für erforderliche Ausführung Mit dieser Art von Anforderung (die ab
Windows 8 und Windows Server 2012 verfügbar ist) wird verlangt, den Prozess einer UWPApp auch dann fortzusetzen, wenn der Prozesslebenszyklus-Manager (PLM) ihn normalerweise (aus welchem Grunde auch immer) beendet hätte. Wie weit die Lebensdauer verlängert wird, hängt von verschiedenen Faktoren ab, darunter den Einstellungen der Energierichtlinie. Diese Art von Anforderung wird nur auf Systemen unterstützt, die den modernen
Standbymodus bieten. Auf anderen Systemen wird sie als Systemanforderung interpretiert.
Experiment: Energieverfügbarkeitsanforderungen einsehen
Kernelobjekte für Energieanforderungen, die mit einem Aufruf wie PowerCreateRequest erstellt werden, sind in den öffentlichen Symbolen leider nicht zugänglich. Das Dienstprogramm powercfg bietet jedoch eine Möglichkeit, Energieanforderungen auch ohne Zuhilfenahme eines Kerneldebuggers anzuzeigen. Die folgende Ausgabe dieses Dienstprogramms
stammt von einem Windows 10-Laptop, der gerade einen Video- und Audiostream aus
dem Web wiedergab:
c:\WINDOWS\system32>powercfg /requests
DISPLAY:
[PROCESS] \Device\HarddiskVolume4\Program Files\WindowsApps\Microsoft.
ZuneVideo_10.16092.10311.0_x64__8wekyb3d8bbwe\Video.UI.exe
Windows-Runtime-Paket: Microsoft.ZuneVideo_8wekyb3d8bbwe
SYSTEM:
[DRIVER] Conexant ISST Audio (INTELAUDIO\
FUNC_01&VEN_14F1&DEV_50F4&SUBSYS_103C80D3&R
EV_1001\4&1a010da&0&0001)
Ein Audiostream wird derzeit verwendet.
→
Energieverwaltung
Kapitel 6
693
[PROCESS] \Device\HarddiskVolume4\Program Files\WindowsApps\Microsoft.
ZuneVideo_10.16092.10311.0_x64__8wekyb3d8bbwe\Video.UI.exe
Windows-Runtime-Paket: Microsoft.ZuneVideo_8wekyb3d8bbwe
AWAYMODE:
Keine.
EXECUTION:
Keine.
PERFBOOST:
Keine.
ACTIVELOCKSCREEN:
Keine.
Diese Ausgabe zeigt sechs verschiedene Anforderungstypen statt der zuvor beschriebenen vier. Die beiden letzten – perfboost und activelockscreen – werden im Rahmen eines
internen Energieanforderungstyps in einem Kernelheader deklariert, darüber hinaus aber
zurzeit nicht verwendet.
Zusammenfassung
Das E/A-System definiert das Modell zur E/A-Verarbeitung auf Windows und führt allgemeine
Funktionen sowie solche aus, die von mehr als einem Treiber benötigt werden. Seine Hauptaufgabe besteht darin, IRPs für E/A-Anforderungen zu erstellen, diese Pakete durch die verschiedenen Treiber zu lotsen und die Ergebnisse nach Abschluss der E/A-Operation an den
Aufrufer zurückzugeben. Mithilfe von E/A-Systemobjekten, darunter Treiber- und Geräteobjekten, kann der E/A-Manager die einzelnen Treiber und Geräte ausfindig machen. Intern
arbeitet das E/A-System von Windows asynchron, um eine hohe Leistung zu erzielen. Für
Anwendungen im Benutzermodus stellt es Vorkehrungen sowohl für synchrone als auch für
asynchrone E/A bereit.
Zu den Gerätetreibern gehören nicht nur herkömmliche Hardwaregerätetreiber, sondern auch Dateisystem-, Netzwerk- und geschichtete Filtertreiber. Alle haben eine gemeinsame Struktur und kommunizieren über gemeinsame Mechanismen miteinander und mit dem
E/A-Manager. Die Schnittstellen des E/A-Systems ermöglichen es, Treiber in einer Hochsprache
zu schreiben, um die Entwicklungszeit zu verkürzen und die Portierbarkeit zu verbessern. Da
Treiber für das Betriebssystem eine gleichartige Struktur aufweisen, können sie geschichtet
werden, um Modularität zu erreichen und eine Duplizierung einzelner Aufgaben untereinander
zu vermeiden. Durch die Verwendung von Universal-DDIs können Treiber ohne Änderungen
am Code verschiedene Geräte und Bauformen ansprechen.
694
Kapitel 6
Das E/A-System
Der PnP-Manager arbeitet mit den Gerätetreibern zusammen, um Hardwaregeräte dynamisch zu erkennen und einen internen Gerätebaum für die Geräteauflistung und Treiberinstallation aufzustellen. Die Energieverwaltung arbeitet ebenfalls mit den Gerätetreibern zusammen,
um Geräte in einen Zustand mit geringerem Energieverbrauch zu versetzen, wenn dies möglich
ist, um Energie zu sparen und die Akkubetriebsdauer zu verlängern.
Im nächsten Kapitel beschäftigen wir uns mit einem der zurzeit wichtigsten Aspekte von
Computersystemen, nämlich der Sicherheit.
Zusammenfassung
Kapitel 6
695
K apite l 7
Sicherheit
In jeder Umgebung, in der mehrere Benutzer Zugang zu denselben physischen Ressourcen
oder Netzwerkressourcen haben, ist es von entscheidender Bedeutung, einen nicht autorisierten Zugriff auf sensible Daten zu verhindern. Das Betriebssystem und die einzelnen Benutzer
müssen in der Lage sein, Dateien, den Arbeitsspeicher und Konfigurationseinstellungen vor unerwünschter Einsichtnahme und Änderung zu schützen. Die Betriebssystemsicherheit schließt
auf der Hand liegende Mechanismen wie Konten, Kennwörter und Dateischutz ein, aber auch
weniger offensichtliche Maßnahmen, wie das Betriebssystem vor Beschädigungen zu schützen, Benutzer mit geringeren Rechten von bestimmten Aktionen (wie etwa dem Neustart des
Computers) abzuhalten und nicht zuzulassen, dass Programme eines Benutzers die Programme
anderer Benutzer oder gar das Betriebssystem beeinträchtigen.
In diesem Kapitel zeigen wir, wie sämtliche Aspekte des Designs und der Implementierung
von Microsoft Windows auf die eine oder andere Weise durch strenge Anforderungen an eine
solide Sicherheit beeinflusst wurden.
Sicherheitseinstufungen
Eine Einstufung von Software einschließlich Betriebssystemen anhand wohldefinierter Standards hilft Behörden, Unternehmen und Endbenutzern, auf Computern gespeicherte firmen
eigene und persönliche Daten zu schützen. In den Vereinigten Staaten und in vielen anderen
Ländern bilden die Common Criteria (CC) zurzeit den gültigen Standard für die Sicherheitseinstufung. Um die in Windows eingebauten Sicherheitsvorkehrungen zu verstehen, ist es jedoch
sinnvoll, sich auch mit der Geschichte des Systems für Sicherheitseinstufungen zu beschäftigen,
das das Design von Windows beeinflusst hat: Trusted Computer System Evaluation Criteria
(TCSEC).
Trusted Computer System Evaluation Criteria
Das National Computer Security Center (NCSC) wurde 1981 als Teil der National Security Agency (NSA) des US-Verteidigungsministeriums eingerichtet. Ein Ziel des NCSC bestand darin, die
in Tabelle 7–1 aufgeführten Sicherheitseinstufungen aufzustellen, um den Grad des Schutzes
bestimmen zu können, den kommerzielle Betriebssysteme, Netzwerkkomponenten und vertrauenswürdige Anwendungen anbieten. Diese Sicherheitsstufen wurden 1983 definiert und als
Orange Book bezeichnet. Sie finden sie auf http://csrc.nist.gov/publications/history/dod85.pdf.
697
Einstufung
Beschreibung
A1
Verifiziertes Design
B3
Sicherheitsbereiche
B2
Strukturierter Schutz
B1
Schutz durch Sicherheitskennzeichen
C2
Schutz durch gesteuerten Zugriff
C1
Schutz durch diskreten Zugriff (veraltet)
D
Minimaler Schutz
Tabelle 7–1 TCSEC-Einstufungen
Die Einstufungen des TCSEC-Standards stellen unterschiedliche Grade an Vertrauenswürdigkeit
dar, wobei die höheren Ebenen durch Ergänzung um rigorosere Schutz- und Validierungsanforderungen aus den unteren hervorgehen. Es gibt kein Betriebssystem, das die Voraussetzungen für die A1-Einstufung (verifiziertes Design) erfüllt. Einige haben zwar B-Einstufungen
erhalten, doch C2 wird als ausreichend angesehen und ist die höchste Einstufung, die für ein
Allzweck-Betriebssystem praktisch geeignet ist.
Die folgenden Schlüsselanforderungen für die Sicherheitseinstufung C2 gelten nach wie
vor als wichtigste Erfordernisse für sichere Betriebssysteme:
QQ Eine Einrichtung für die sichere Anmeldung Dazu ist es erforderlich, dass die Benutzer
eindeutig identifiziert werden können und nur dann Zugriff auf den Computer erhalten,
wenn sie sich auf irgendeine Weise authentifiziert haben.
QQ Zugriffssteuerung im Ermessen des Besitzers Der Besitzer einer Ressource (etwa einer
Datei) kann festlegen, welche Benutzer auf die Ressource zugreifen können und was sie
damit anstellen dürfen. Er vergibt Rechte für verschiedene Arten des Zugriffs an Benutzer
oder Benutzergruppen.
QQ Sicherheitsüberwachung Dies bezeichnet die Fähigkeit, sicherheitsrelevante Ereignisse
sowie jegliche Vorgänge zu erkennen und zu melden, bei denen versucht wird, Systemressourcen zu erstellen, anzufassen oder zu löschen. Die Identitäten aller Benutzer werden
mit Anmeldekennungen festgehalten, sodass sich leicht feststellen lässt, wenn jemand eine
nicht autorisierte Aktion durchführt.
QQ Schutz vor Objektwiederverwendung Dadurch wird verhindert, dass Benutzer Daten
sehen, die ein anderer Benutzer gelöscht hat, oder auf Arbeitsspeicher zugreifen, den ein
anderer Benutzer zuvor verwendet und dann freigegeben hat. Beispielsweise ist es in manchen Betriebssystemen möglich, eine neue Datei einer bestimmten Länge zu erstellen und
dann ihren Inhalt zu untersuchen, um sich anzusehen, welche Daten sich zuvor an dem
Speicherort auf der Festplatte befanden, dem die Datei zugewiesen wurde. Diese Daten
können aber sensible Informationen aus einer inzwischen gelöschten Datei eines anderen
Benutzers umfassen. Der Schutz vor Objektwiederverwendung stopft diese Sicherheitslücke, indem er sämtliche Objekte, also auch Dateien und Arbeitsspeicher, vor der Zuweisung
zu einem Benutzer initialisiert.
698
Kapitel 7
Sicherheit
Windows erfüllt auch zwei Anforderungen für die Sicherheitsstufe B:
QQ Vertrauenswürdige Pfade Dadurch wird verhindert, dass trojanische Pferde Benutzernamen und Kennwörter bei der Anmeldung abfangen. In Windows wird diese Maßnahme
durch die Anmeldetastenfolge (Strg) + (Alt) + (Entf) umgesetzt, die von nicht privilegierten Anwendungen nicht abgefangen werden kann. Diese Tastenfolge, die auch als
Sicherheitsaufruf (Secure Attention Sequence, SAS) bezeichnet wird, zeigt immer einen
systemgesteuerten Windows-Sicherheitsbildschirm (falls der Benutzer bereits angemeldet
ist) oder den Anmeldebildschirm an, sodass trojanische Pferde leicht zu erkennen sind. (Die
SAS kann auch von einem Programm aus über die API SendSAS gesendet werden, wenn die
Gruppenrichtlinie und andere Einschränkungen das zulassen.) Ein trojanisches Pferd, das
ein gefälschtes Anmeldedialogfeld anzeigt, wird bei der Angabe der SAS umgangen.
QQ Verwaltung durch vertrauenswürdige Einrichtungen Hierzu muss es separate Kontorollen für unterschiedliche administrative Funktionen geben, also beispielsweise eigene
Konten für Administratoren, für Benutzer, die auf dem Computer Sicherungen durchführen, und für Standardbenutzer.
Durch sein Sicherheitsteilsystem und die damit zusammenhängenden Komponenten erfüllt
Windows alle diese Kriterien.
Common Criteria
Im Januar 1996 haben die USA, Großbritannien, Deutschland, Frankreich, Kanada und die Niederlande die gemeinsam entwickelte Spezifikation Common Criteria for Information Technology Security Evaluation (CCITSE) herausgegeben, üblicherweise kurz Common Criteria (CC)
genannt. Diese Kriterien bilden den anerkannten internationalen Standard zur Bewertung der
Produktsicherheit. Die Website für CC finden Sie auf http://www.niap-ccevs.org/cc-scheme.
Die CC sind flexibler als die TCSEC-Einstufungen und weisen eine Struktur auf, die sich
stärker am ITSEC- als am TCSEC-Standard orientiert. In den CC gibt es den Begriff des Schutzprofils (Protection Profile, PP), mit dem Sicherheitsanforderungen zu leicht spezifizierbaren und
vergleichbaren Sätzen gebündelt werden, und der Sicherheitsvorgabe (Security Target, ST), die
über einen Verweis auf ein PP einen Satz von anwendbaren Sicherheitsanforderungen enthält.
Außerdem definieren die CC sieben Stufen für die Vertrauenswürdigkeit der Zertifizierung, die
als »Evaluation Assurance Levels« (ELAs) bezeichnet werden. Dadurch entfernen die CC (ebenso
wie zuvor der ITSEC-Standard) die Verbindung zwischen Funktionalität und Vertrauenswürdigkeit, die es in TCSEC und früheren Zertifizierungsverfahren gab.
Windows 2000, Windows XP, Windows Server 2003 und Windows Vista Enterprise haben
eine Common-Criteria-Zertifizierung mit dem Schutzprofil für gesteuerten Zugriff (Controlled
Access Protection Profile, CAPP) erreicht, was ungefähr der TCSEC-Einstufung C2 entspricht.
Alle erhielten die Bewertung EAL 4+, wobei das Plus für »Mängelsanierung« steht. EAL 4 ist der
höchste Grad, der international anerkannt wird.
Im März 2011 wurden Windows 7 und Windows Server 2008 R2 nach den Anforderungen
von Version 1 des Schutzprofils der US-Regierung für Allzweck-Betriebssysteme in Netzwerk
umgebungen überprüft (US Government Protection Profile for General-Purpose Operating
Sicherheitseinstufungen
Kapitel 7
699
S ystems in a Networked Environment, GPOSPP; siehe http://www.commoncriteriaportal.org/
files/ppfiles/pp_gpospp_v1.0.pdf). Diese Zertifizierung schließt auch den Hypervisor Hyper-V ein.
Abermals erzielte Windows EAL 4 mit Mängelsanierung (EAL 4+). Der Validierungsbericht ist
auf http://www.commoncriteriaportal.org/files/epfiles/st_vid10390-vr.pdf zu finden, und die Beschreibung der Sicherheitsvorgänge mit Angaben zu den einzelnen erfüllten Voraussetzungen
auf http://www.commoncriteriaportal.org/files/epfiles/st_vid10390-st.pdf. Ähnliche Zertifizierungen erhielten Windows 10 und Windows Server 2012 R2 im Juni 2016. Die Berichte hierzu
stehen auf http://www.commoncriteriaportal.org/files/epfiles/cr_windows10.pdf zur Verfügung.
Systemkomponenten für die Sicherheit
Die folgenden Kernkomponenten und Datenbanken implementieren die Sicherheitsvorkehrungen von Windows. Sofern nicht anders angegeben, befinden sich alle genannten Dateien im
Verzeichnis %SystemRoot%\System32.
QQ Security Reference Monitor, SRM Diese Komponente der Windows-Exekutive (Ntoskrnl.exe) ist dafür zuständig, die Datenstruktur für ein Zugriffstoken zur Darstellung eines
Sicherheitskontexts zu definieren, Zugriffsprüfungen an Objekten durchzuführen, Benutzerrechte zu bearbeiten und jegliche aus diesen Tätigkeiten resultierenden Meldungen für
die Sicherheitsüberwachung zu generieren.
QQ Teilsystemdienst für die lokale Sicherheitsautorität (Local Security Authority Subsystem Service, Lsass) Dieser Benutzermodusprozess wird im Abbild Lsass.exe ausgeführt und kümmert sich um die lokale Systemsicherheitsrichtlinie (die u. a. festlegt, welche
Benutzer sich an dem Computer anmelden dürfen, und Kennwortrichtlinien, Rechte für
Benutzer und Gruppen und die Einstellungen für die Systemsicherheitsüberwachung umfasst), die Benutzerauthentifizierung und darum, Meldungen der Sicherheitsüberwachung
an das Ereignisprotokoll zu senden. Der Großteil dieser Funktionalität ist im Dienst der
lokalen Sicherheitsautorität (Lsasrv.dll) implementiert, einer Bibliothek, die Lsass lädt.
QQ LSAIso.exe Diese Komponente wird auch als Credential Guard (siehe den gleichnamigen
Abschnitt weiter hinten) bezeichnet. Lsass verwendet sie, um Hashes von Benutzertokens
zu speichern, anstatt sie im eigenen Arbeitsspeicher aufzubewahren. Da es sich bei Lsaiso.
exe um ein Trustlet handelt – einen IUM-Prozess (Isolated User Mode) –, das auf VTL1 ausgeführt wird, kann kein normaler Prozess auf seinen Adressraum zugreifen, nicht einmal
der normale Kernel. Lsass selbst speichert ein verschlüsseltes BLOB des Kennworthashs, der
für die Kommunikation mit Lsaiso (über ALPC) benötigt wird.
QQ Lsass-Richtliniendatenbank Diese Datenbank enthält die Einstellungen der lokalen
Systemsicherheitsrichtlinie und ist in der Registrierung in einem durch eine Zugriffssteuerungsliste geschützten Bereich unter HKLM\SECURITY gespeichert. Sie gibt beispielsweise
an, welchen Domänen die Authentifizierung von Anmeldeversuchen anvertraut wird, wer
die Berechtigung hat, in welcher Weise auf das System zuzugreifen (interaktiv, über das
Netzwerk und über Dienstanmeldungen), wem welche Rechte zugewiesen sind und welche
Form von Sicherheitsüberwachung ausgeführt wird. Außerdem sind in der Lsass-Richtliniendatenbank »Geheimnisse« wie die Anmeldeinformationen für zwischengespeicherte
700
Kapitel 7
Sicherheit
Domänenanmeldungen und Benutzerkontoanmeldungen von Windows-Diensten abgelegt. (Weitere Informationen über Windows-Dienste erhalten Sie in Kapitel 9 von Band 2.)
QQ Sicherheitskonto-Manager (Security Accounts Manager, SAM) Dieser Dienst (in älteren deutschen Versionen »Sicherheitskontoverwaltung« genannt) verwaltet die Datenbank mit den auf dem lokalen Computer definierten Benutzernamen und Gruppen. Der in
Samsrv.dll implementierte SAM-Dienst wird in den Lsass-Prozess geladen.
QQ SAM-Datenbank Diese Datenbank enthält die definierten lokalen Benutzer und Gruppen mit ihren Kennwörtern und sonstigen Attributen. Auf Domänencontrollern speichert
der Sicherheitskonto-Manager nicht die in der Domäne definierten Benutzer, sondern die
Definition und das Kennwort für das Wiederherstellungskonto des Systemadministrators.
Diese Datenbank befindet sich in der Registrierung unter HKLM\SAM.
QQ Active Directory Dieser Verzeichnisdienst enthält eine Datenbank mit Informationen
über die Objekte in einer Domäne wie Benutzer, Gruppen und Computer. In diesem Zusammenhang ist eine Domäne eine Menge von Computern und ihrer zugehörigen Sicherheitsgruppen, die als eine Einheit verwaltet werden. In Active Directory sind auch die
Kennwortinformationen und Rechte für Domänenbenutzer und Gruppen gespeichert und
werden auf die Computer repliziert, die als Domänencontroller für die Domäne eingerichtet sind. Der Active Directory-Server ist in Ntdsa.dll implementiert und wird im Lsass-
Prozess ausgeführt. Weitere Informationen über Active Directory erhalten Sie in Kapitel 10
von Band 2.
QQ Authentifizierungspakete Dazu gehörigen die DLLs (Dynamic Link Libraries), die im
Kontext sowohl des Lsass-Prozesses als auch der Clientprozesse ausgeführt werden und
die Authentifizierungsrichtlinie von Windows implementieren. Authentifizierungs-DLLs
authentifizieren Benutzer, indem sie prüfen, ob der angegebene Benutzername und das
Kennwort übereinstimmen (oder je nach dem verwendeten Mechanismus zur Angabe von
Anmeldeinformationen entsprechend vorgehen). Wenn ja, geben sie Informationen über
die Sicherheitsidentität des Benutzers an Lsass zurück, woraufhin Lsass diese Informationen wiederum nutzt, um ein Token zu erstellen.
QQ Manager für die interaktive Anmeldung (Winlogon) Dieser Benutzermodusprozess
führt Winlogon.exe aus, das dafür zuständig ist, auf die SAS zu reagieren und interaktive
Anmeldesitzungen zu verwalten. Unter anderem erstellt Winlogon bei der Anmeldung
eines Benutzers dessen ersten Prozess.
QQ Benutzerschnittstelle für die Anmeldung (LogonUI) Dieser Benutzermodusprozess
führt das Abbild LogonUI.exe aus, das den Benutzern die Oberfläche anzeigt, an der sie
sich gegenüber dem System authentifizieren können. Dabei nutzt LogonUI Anmeldeinformationsanbieter, um die verschiedenen Arten von Anmeldeinformationen von Benutzern
abzufragen.
QQ Anmeldeinformationsanbieter (Credential Providers, CPs) Hierbei handelt es sich
um prozessinterne COM-Objekte, die im Prozess LogonUI laufen (der wiederum bei Bedarf
von Winlogon gestartet wird, wenn die SAS-Tastenfolge betätigt wird) und dazu dienen,
den Benutzernamen und das Kennwort, die Smartcard-PIN, biometrische Daten (z. B. Fingerabdrücke) oder andere Identifizierungsmerkmale zu erfassen. Die Standard-Anmelde
Systemkomponenten für die Sicherheit
Kapitel 7
701
informationsanbieter sind Authui.dll, SmartcardCredentialProvider.dll, BioCredProv.dll und
FaceCredentialProvider.dll, wobei der Anbieter für die Gesichtserkennung in Windows 10
hinzugefügt wurde.
QQ Netzwerkanmeldedienst (Netlogon) Dieser Windows-Dienst (Netlogon.dll, ausgeführt
in einem regulären Svchost-Hostprozess) richtet den sicheren Kanal zu einem Domänencontroller ein, über den Sicherheitsanforderungen gesendet werden, z. B. interaktive Anmeldungen (wenn der Domänencontroller Windows NT 4 ausführt) oder eine Authentifizierungsvalidierung durch LAN Manager oder NT LAN Manager (v1 und v2). Netlogon wird
auch für die Active Directory-Anmeldung verwendet.
QQ Kernel Security Device Driver (KSecDD) Die Funktionen in dieser Kernelmodusbibliothek (%SystemRoot%\System32\Drivers\Ksecdd.sys) implementierten die Schnittstellen für
erweiterte lokale Prozeduraufrufe (Advanced Local Procedure Calls, ALPCs), die andere
Sicherheitskomponenten im Kernelmodus – etwa das verschlüsselnde Dateisystem (Encrypting File System, EFS) – zur Kommunikation mit Lsass im Benutzermodus verwenden,
QQ AppLocker Dieser Mechanismus ermöglicht Administratoren, festzulegen, welche ausführbaren Dateien, DLLs und Skripte die angegebenen Benutzer und Gruppen verwenden
dürfen. AppLocker besteht aus einem Treiber (%SystemRoot%\System32\Drivers\Appld.sys)
und einem Dienst (AppldSvc.dll), die in einem standardmäßigen SvcHost-Prozess ausgeführt werden.
Abb. 7–1 zeigt die Beziehungen zwischen einigen dieser Komponenten und den von ihnen
verwalteten Datenbanken.
Ereignisproto
kollierung
Netlogon
Active
Directory
LSA-Server
SAM-Server
LSA-Richtlinie
Benutzermodus
Kernelmodus
Exekutive
Abbildung 7–1 Sicherheitskomponenten von Windows
702
Kapitel 7
Sicherheit
Experiment: HKLM\SAM und HKLM\Security einsehen
Die mit den Registrierungsschlüsseln SAM und Security verknüpften Sicherheitsdeskriptoren verhindern, dass irgendein Konto außer dem lokalen Systemkonto auf sie zugreifen
kann. Eine Möglichkeit, um sich diese Schlüssel trotzdem anzusehen, besteht darin, ihre Sicherheitseinstellungen zurückzusetzen, was aber die Sicherheit des Systems schwächt. Eine
andere Vorgehensweise besteht darin, Regedit.exe unter dem lokalen Systemkonto auszuführen. Das können Sie wie folgt mit dem Sysinternals-Tool PsExec und der Option -s tun:
C:\>psexec –s –i –d c:\windows\regedit.exe
Der Schalter -i weist PsExec an, die angegebene ausführbare Datei in einer interaktiven
Fensterstation auszuführen. Ohne diese Angabe würde der Prozess in einer nicht interaktiven Fensterstation laufen, also auf einem unsichtbaren Desktop. Der Schalter -d gibt an,
dass PsExec nicht auf die Beendigung des Zielprozesses warten soll.
Der SRM im Kernelmodus und Lsass im Benutzermodus kommunizieren über die in Kapitel 8
von Band 2 beschriebenen ALPCs. Während der Initialisierung des Systems erstellt SRM den
Port SeRmCommandPort, mit dem Lsass Verbindung aufnimmt, und wenn der Lsass-Prozess startet, legt er den ALPC-Port SeLsaCommandPort an, mit dem wiederum der SRM Verbindung aufnimmt. Dadurch entstehen private Kommunikationsports. Der SRM erstellt einen gemeinsamen
Speicherbereich für Nachrichten, die länger als 256 Bytes sind, und übergibt im Verbindungsaufruf ein Handle. Nachdem der SRM und Lsass bei der Systeminitialisierung miteinander Verbindung aufgenommen haben, lauschen sie nicht mehr auf ihren jeweiligen Verbindungsports.
Dadurch haben Benutzerprozesse keine Möglichkeit mehr, Verbindung mit einem dieser Ports
aufzunehmen, um sie für böse Zwecke zu missbrauchen. Eine solche Verbindungsanforderung
wird niemals abgeschlossen.
Systemkomponenten für die Sicherheit
Kapitel 7
703
Virtualisierungsgestützte Sicherheit
Da der Kernel von Natur aus höhere Rechte erfordert und von Benutzermodusanwendungen
getrennt ist, wird er gemeinhin auch als vertrauenswürdig bezeichnet. Es werden jedoch jeden
Monat zahllose Drittanbietertreiber geschrieben. Laut Aussage von Microsoft sind in den Telemetriedaten jeden Monat eine Million verschiedene Treiberhashes zu erkennen. Jeder dieser
Treiber kann Schwachstellen enthalten – ganz zu schweigen von bewusst eingebautem Kernelmodus-Schadcode. Angesichts dieser Tatsachen ist die Vorstellung, dass der Kernel eine kleine,
geschützte Komponente ist und Benutzermodusanwendungen vor Angriffen aus dem Kernel
sicher sind, offensichtlich unrealistisch. Es ist nicht angebracht, dem Kernel voll zu vertrauen.
Wichtige Benutzermodusanwendungen, die sehr private Benutzerdaten enthalten können, sind
Angriffen sowohl durch schädliche Benutzermodusanwendungen (die fehlerhafte Kernelmoduskomponenten ausnutzen) als auch durch schädliche Kernelmodusprogramme ausgesetzt.
Wie bereits in Kapitel 2 erwähnt, weisen Windows 10 und Windows Server 2016 eine Architektur für virtualisierungsgestützte Sicherheit (Virtualization-Based Security, VBS) auf, die eine
zusätzliche, orthogonale Vertrauensebene ins Spiel bringt, nämlich die virtuelle Vertrauensebene (Virtual Trust Level, VTL). In diesem Abschnitt erfahren Sie, wie Credential Guard und Device
Guard VTLs nutzen, um Benutzerdaten zu schützen und eine zusätzliche Sicherheitsschicht auf
der Grundlage vertrauenswürdiger Hardware für die digitale Codesignierung bereitzustellen.
Am Endes dieses Kapitels werden Sie außerdem sehen, wie Kernel Patch Protection (KPP) durch
die Komponente PatchGuard bereitgestellt und von der VBS-gestützten HyperGuard-Technologie noch verstärkt wird.
Zur Auffrischung: Normaler Benutzer- und Kernelmoduscode läuft auf VTL 0 und weiß
nichts von VTL 1. Alles, was auf VTL 1 läuft, ist daher für VTL-0-Code unsichtbar und nicht
zugänglich. Kann Malware in den normalen Kernel vordringen, ist es ihr trotzdem nicht möglich, Zugriff auf irgendetwas zu bekommen, das auf VTL 1 gespeichert ist, nicht einmal auf
Benutzermoduscode, der auf dieser Ebene läuft (was als isolierter Benutzermodus oder Isolated
User Mode bezeichnet wird). Abb. 7–2 zeigt die wichtigsten VBS-Komponenten, die wir uns in
diesem Abschnitt ansehen werden:
QQ Hypervisor-Based Code Integrity (HVCI) und Kernel-Mode Code Integrity (KMCI), die Mechanismen hinter Device Guard
QQ LSA (Lsass.exe) und isolierte LSA (Lsaiso.exe), die Mechanismen hinter Credential Guard
Schlagen Sie auch noch einmal die Implementierung von Trustlets, die in IUM laufen, in Kapitel 3 nach.
704
Kapitel 7
Sicherheit
Kernel Mode
Code Integrity
Isolierte LSA
Apps
Windows-Plattformdienste
HVCI
Kernel
Virtueller sicherer
Modus (VSM)
Kernel
Windows (Hostbetriebssystem)
Abbildung 7–2 VBS-Komponenten
Wie jede andere vertrauenswürdige Komponente setzt auch VTL 1 voraus, dass die Komponenten, von denen sie abhängt, vertrauenswürdig sind. Daher ist es für VTL 1 erforderlich, dass
der sichere Start (und damit die Firmware) korrekt funktioniert, der Hypervisor nicht beschädigt
wurde und Hardwareelemente wie IOMMU und die Intel Management Engine keine von VTL 0
aus zugänglichen Schwachstellen aufweisen. Weitere Informationen über die Hardware-Vertrauenskette und Sicherheitstechnologien für den Start erhalten Sie in Kapitel 11 von Band 2.
Credential Guard
Um zu verstehen, welche Sicherheitsschranken und Schutzmaßnahmen Credential Guard bietet, müssen wir uns zunächst mit den einzelnen Komponenten befassen, die den Zugriff auf die
Ressourcen und Daten eines Benutzers und die Anmeldeeinrichtungen in einer Netzwerkumgebung gewähren:
QQ Kennwort Dies ist die primäre Art von Anmeldeinformation, mit der sich Benutzer interaktiv am Computer anmelden. Sie wird zur Authentifizierung und zur Ableitung der anderen Komponenten des Anmeldeinformationsmodells genutzt und bildet den entscheidenden Aspekt der Identität eines Benutzers.
QQ NT-Einwegfunktion (NT One-Way Function, OWF) Dies ist ein Hash, der von veralteten Komponenten unter Verwendung des Protokolls NT LAN Manager (NTLM) zur
Identifizierung des Benutzers verwendet wird (nach erfolgreicher Anmeldung mit einem
Kennwort). Moderne Netzwerksysteme setzen zur Benutzerauthentifizierung kein NTLM
mehr ein, doch bei vielen lokalen Komponenten und auch bei einigen Arten veralteter
Netzwerkkomponenten (wie NTLM-gestützten Authentifizierungsproxies) ist das nach wie
vor der Fall. Die NTOWF ist jedoch nur ein MD4-Hash. Aufgrund des mangelnden Schutzes
gegen Wiedereinspielen und der für moderne Hardware geringen algorithmischen Kom-
Virtualisierungsgestützte Sicherheit
Kapitel 7
705
plexität dieses Hashs führt ein Abfangen der NTOWF zu einer unmittelbaren Gefährdung
und unter Umständen sogar zu einer Ermittlung des Kennworts.
QQ Ticketgewährendes Ticket (TGT) Dies ist das Gegenstück zur NTOWF bei der Verwendung des weit moderneren Remoteauthentifizierungsmechanismus Kerberos. In Active Directory-Domänen ist Kerberos die Standardvorgehensweise, in Windows Server 2016 wird
die Verwendung von Kerberos sogar erzwungen. Das TGT und der zugehörige Schlüssel
werden dem lokalen Computer nach einer erfolgreichen Anmeldung bereitgestellt (wie die
NTOWF bei NTLM). Werden beide Komponenten abgefangen, so sind die Anmeldeinformationen des Benutzers damit unmittelbar gefährdet. Wiedereinspielung und Ermittlung
des Kennworts sind jedoch nicht möglich.
Wenn Credential Guard nicht aktiviert ist, sind einige oder alle dieser Bestandteile der Anmeldeinformationen eines Benutzers im Arbeitsspeicher von Lsass vorhanden.
Um Credential Guard in den Editionen Windows 10 Enterprises und Windows
Server 2016 zu aktivieren, öffnen Sie den Gruppenrichtlinien-Editor (gpedit.msc)
und wählen Computerkonfiguration > Administrative Vorlagen > System > Device
Guard und dann Virtualisierungsbasierte Sicherheit aktivieren. Klicken Sie im oberen linken Bereich des daraufhin eingeblendeten Dialogfelds auf Aktiviert und
wählen Sie schließlich eine der Aktiviert-Optionen im Kombinationsfeld Credential
Guard-Konfiguration aus.
Kennwortschutz
Das Kennwort wird mit einem lokalen symmetrischen Schlüssel verschlüsselt und gespeichert,
um eine einmalige Anmeldung (Single Sign-On, SSO) über Protokolle wie Digestauthentifizierung (WDigest, was seit Windows XP für die HTTP-Authentifizierung verwendet wird)
oder Terminaldienste/RDP zu ermöglichen. Da diese Protokolle eine Klartextauthentifizierung
durchführen, ist es erforderlich, diese Kennwörter im Arbeitsspeicher zu halten, der aber durch
Codeinjektion, Debugger und andere Exploittechniken zugänglich ist, und zu entschlüsseln.
Credential Guard kann diese von Natur aus unsicheren Protokolle nicht ändern. Als einzige
Lösung bleibt Credential Guard daher nur übrig, die SSO-Funktionalität für solche Protokolle
zu deaktivieren. Das führt jedoch zu einem Verlust an Kompatibilität und zwingt den Benutzer
zu einer erneuten Authentifizierung.
Eine bessere Lösung besteht offensichtlich darin, ganz auf die Verwendung von Kennwörtern zu verzichten. Mit Windows Hello, das in einem eigenen Abschnitt weiter hinten beschrieben wird, ist das möglich. Bei einer Authentifizierung über biometrische Verfahren wie
Gesichts- oder Fingerabdruckerkennung ist es nicht mehr nötig, ein Kennwort einzugeben
und die Anmeldeinformationen vor Hardware-Keyloggern, Kernelsniffern und Kernelhooking-Werkzeugen und gefälschten Benutzermodusanwendungen zu schützen. Wenn Benutzer
niemals ein Kennwort eingeben müssen, kann auch kein Kennwort mehr gestohlen werden.
Eine andere Form sicherer Anmeldeinformationen bildet die Kombination aus einer Smartcard
und der zugehörigen PIN. Die PIN kann zwar bei der Eingabe erfasst werden, aber die Smartcard ist ein physisches Element, das sich ohne einen komplizierten hardwaregestützten Angriff
706
Kapitel 7
Sicherheit
nicht abfangen lässt. Dies ist eine Form der Zwei-Faktor-Authentifizierung, die es auch noch in
vielen anderen Varianten gibt.
Schutz der NTOWF bzw. des TGT-Schlüssels
Auch wenn die interaktiven Anmeldeinformationen geschützt sind, führt eine erfolgreiche Anmeldung dazu, dass das Schlüsselverteilungscenter (Key Distribution Center, KDC) des Domänencontrollers das TGT und seinen Schlüssel sowie für ältere Anwendungen auch die NTOWF
zurückgibt. Der Benutzer verwendet die NTOWF für den Zugriff auf ältere Ressourcen und
das TGT und dessen Schlüssel, um ein Dienstticket zu erstellen, das dann für den Zugriff auf
Remoteressourcen (wie Dateien auf einer Freigabe) eingesetzt werden kann (siehe Abb. 7–3).
rer
ifizie
t
n
e
th
sel
1. Au
hlüs
+ Sc
T
G
T
T
2. TG
ssel
chlü
S
+
ket
sttic
Dien
3. Die
nsttic
ket
Dateie
n
Datei
server
Abbildung 7–3 Zugriff auf Remoteressourcen
Wenn ein Angreifer aber die NTOWF oder das TGT und dessen Schlüssel (gespeichert in Lsass)
in die Hände bekommt, kann er damit auch ohne Smartcard, PIN, das Gesicht oder die Fingerabdrücke des Benutzers auf Ressourcen zugreifen. Eine denkbare Sicherheitsmaßnahme
besteht darin, Lsass vor Zugriff durch Angreifer zu schützen, was mit der in Kapitel 3 beschriebenen PPL-Architektur (Protected Process Light) möglich ist.
Um dafür zu sorgen, dass Lsass geschützt ausgeführt wird, setzen Sie den DWORD-Wert
RunAsPPL im Registrierungsschlüssel HKLM\System\CurrentControlSet\Control\Lsa auf 1. (Dies
ist nicht die Standardoption, da auch legitime Authentifizierungsanbieter von Drittanbietern
[DLLs] im Kontext von Lsass geladen und ausgeführt werden, was nicht möglich ist, wenn
Lsass im geschützten Modus läuft.) Durch diese Maßnahme werden zwar die NTOWF und der
TGT-Schlüssel vor Angriffen aus dem Benutzermodus geschützt, aber weder vor Angriffen aus
dem Kernel noch vor Benutzermodusangriffen, die eine Schwachstelle in einem der Millionen
pro Monat produzierten Treiber ausnutzen. Credential Guard löst dieses Problem durch den
Prozess Lsaiso.exe. Er wird als Trustlet auf VTL 1 ausgeführt und speichert die Geheimnisse des
Benutzers daher in seinem Arbeitsspeicher und nicht in Lsass.
Virtualisierungsgestützte Sicherheit
Kapitel 7
707
Sichere Kommunikation
Wie bereits in Kapitel 2 erklärt, weist die Ebene VTL 1 eine geringe Angriffsfläche auf, da sie
weder über einen vollständigen regulären NT-Kernel noch über Treiber oder E/A-Zugriff auf
irgendwelche Hardware verfügt. Daher kann die isolierte LSA, bei der es sich um ein VTL-1Trustlet handelt, nicht direkt mit dem KDC kommunizieren. Dies liegt nach wie vor im Aufgabenbereich des Lsass-Prozesses, der als Proxy und Protokollimplementierer fungiert. Er
kommuniziert mit dem KDC, um den Benutzer zu authentifizieren, das TGT, den Schlüssel und
die NTOWF in Empfang zu nehmen, und kommuniziert mithilfe des Diensttickets mit dem
Dateiserver. Hier scheint jedoch ein Problem vorzuliegen: Das TGT und sein Schlüssel bzw. die
NTOWF durchlaufen während der Authentifizierung Lsass, und das TGT und sein Schlüssel
stehen Lsass auf irgendeine Weise zur Verfügung, um die Diensttickets generieren zu können.
Das führt zu den beiden folgenden Fragen: Wie kann Lsass die Geheimnisse in der isolierten
LSA senden und empfangen, und wie können wir einen Angreifer daran hindern, dies ebenfalls
zu tun?
Um die erste Frage zu beantworten, denken Sie daran, welche Dienste laut Kapitel 3 für
Trustlets zur Verfügung stehen. Einer davon ist Advanced Local Procedure Call (ALPC), den
der sichere Kernel dadurch unterstützt, dass er NtAlpc*-Aufrufe als Proxy an den normalen
Kernel weiterleitet. Außerdem implementiert der isolierte Benutzermodus (Isolated User Mode,
IUM) eine Unterstützung für die RPC-Laufzeitbibliothek (Rpcrt4.dll) über das ALPC-Protokoll,
wodurch VLT-0- und VLT-1-Anwendungen wie alle anderen Anwendungen und Dienste über
lokale RPCs kommunizieren können. Abb. 7–4 zeigt einen Screenshot von Process Explorer. Hier
sehen Sie den Prozess Lsaiso.exe mit einem ALPC-Handle für den Port LSA_ISO_RPC_SERVER, der
für die Kommunikation mit dem Prozess Lsass.exe verwendet wird. (Mehr über ALPC erfahren
Sie in Kapitel 8 von Band 2.)
Zur Beantwortung der zweiten Frage sind gewisse Kenntnisse über kryptografische Protokolle und Challenge/Response-Modelle erforderlich. Wenn Sie bereits mit den Grundprinzipien
der SSL/TLS-Technologie und ihrer Anwendung zur Verhinderung von Man-in-the-Middle-Angriffen bei der Kommunikation im Internet vertraut sind, können Sie sich das Protokoll für das
KDC und die isolierte LSA ähnlich vorstellen. Lsass befindet sich zwar wie ein Proxy in der Mitte,
sieht aber nur verschlüsselten Datenverkehr zwischen dem KDC und der isolierten LSA, ohne
die übertragenen Inhalte verstehen zu können. Die isolierte LSA richtet einen lokalen Sitzungsschlüssel ein, der nur auf VTL 1 gültig ist, verschlüsselt ihn mit einem weiteren Schlüssel, der nur
dem KDC bekannt ist, und sendet ihn über ein sicheres Protokoll. Das KDC antwortet dann mit
dem TGT und dessen Schlüssel, die er mit dem Sitzungsschlüssel der isolierten LSA verschlüsselt. Daher sieht Lsass nur eine verschlüsselte Nachricht an das KDC und eine verschlüsselte
Nachricht vom KDC, die er beide nicht entschlüsseln kann.
708
Kapitel 7
Sicherheit
Abbildung 7–4
LsaIso.exe und sein ALPC-Port
Mit diesem Modell lässt sich auch die veraltete NTLM-Authentifizierung schützen, die auf dem
Challenge/Response-Modell beruht. Wenn sich beispielsweise ein Benutzer mit Klartext-Anmeldeinformationen anmeldet, sendet LSA diese an die isolierte LSA, die sie mit ihrem Sitzungsschlüssel verschlüsselt und in dieser verschlüsselten Form an Lsass zurückgibt. Wird später ein
Challenge/Response-Vorgang für NTLM benötigt, sendet Lsass die NTLM-Challenge und die
verschlüsselten Anmeldeinformationen an die isolierte LSA. Zu diesem Zeitpunkt verfügt nur
die isolierte LSA über den Verschlüsselungsschlüssel, sodass sie die Anmeldeinformationen entschlüsseln und die passende NTLM-Antwort generieren kann.
Beachten Sie jedoch, dass bei diesem Modell vier Arten von Angriffen möglich sind:
QQ Ist der Computer bereits physisch übernommen, kann das Klartextkennwort bei der Eingabe oder beim Senden an die isolierte LSA abgefangen werden (wenn Lsass übernommen
wurde). Die Verwendung von Windows Hello kann dieses Risiko senken.
QQ Wie bereits erwähnt verfügt NTLM nicht über einen Wiedereinspielschutz. Wird die NTLM-Antwort abgefangen, kann sie daher später für die gleiche Challenge wieder eingespielt werden. Kann ein Angreifer nach der Anmeldung Lsass knacken, so kann er darüber
die verschlüsselten Anmeldeinformationen abfangen und die isolierte LSA zwingen, neue
NTLM-Antworten für beliebige NTLM-Challenges zu generieren. Dies funktioniert aber nur
bis zu einem Neustart, da die isolierte LSA danach einen neuen Sitzungsschlüssel erstellt.
QQ Bei der Kerberos-Anmeldung kann die NTOWF (die nicht verschlüsselt ist) wie bei einem
normalen Pass-the-Hash-Angriff abgefangen und wiederverwendet werden. Auch dazu ist
jedoch ein bereits geknackter Computer (oder eine physische Möglichkeit zum Abfangen
der Informationen im Netzwerk) erforderlich.
QQ Ein Benutzer mit physischem Zugang zu dem Computer kann Credential Guard abschalten
(»Downgrade-Angriff«). Danach wird das ältere Authentifizierungsmodell verwendet, weshalb sich auch ältere Angriffsmethoden wieder einsetzen lassen.
Virtualisierungsgestützte Sicherheit
Kapitel 7
709
UEFI-Sperre
Angreifer können Credential Guard auf einfache Weise ausschalten, da es sich dabei im Grunde
genommen lediglich um eine Registrierungseinstellung handelt. Als Gegenmaßnahme können
Secure Boot und UEFI eingesetzt werden, um nicht physisch anwesende Administratoren (wie
Malware mit Administratorrechten) daran zu hindern. Dazu wird Credential Guard mit UEFI-Sperre aktiviert. In diesem Modus wird eine EFI-Laufzeitvariable in den Firmware-Arbeitsspeicher geschrieben, woraufhin ein Neustart erforderlich ist. Dabei schreibt der Windows-Bootloader, der
nach wie vor im EFI-Startdienstmodus läuft, eine EFI-Bootvariable (die nach dem Verlassen des
EFI-Startdienstmodus weder les- noch schreibbar ist), um darin die Tatsache festzuhalten, dass
Credential Guard aktiviert ist. Außerdem wird eine Option in der Startkonfigurationsdatenbank
(Boot Configuration Database, BCD) aufgezeichnet.
Wenn der Kernel startet und diese BCD-Option oder die UEFI-Laufzeitvariable vorhanden
ist, schreibt er den erforderlichen Registrierungsschlüssel für Credential Guard neu. Wird die
BCD-Option von einem Angreifer gelöscht, erkennen BitLocker (falls aktiviert) und der TPM-
gestützte Remotenachweis (falls aktiviert) die Änderung, woraufhin sie die physische Eingabe
des Wiederherstellungsschlüssels des Administrators verlangen und einen Neustart ausführen.
Dabei wird die BCD-Option auf der Grundlage der UEFI-Laufzeitvariablen wiederhergestellt.
Wird die UEFI-Laufzeitvariable gelöscht, so stellt der Windows-Bootloader sie auf der Grundlage der UEFI-Startvariablen wieder her. Ohne besonderen Code zum Löschen der UEFI-Bootvariablen – was nur im EFI-Startdienstmodus geschehen kann – gibt es daher keine Möglichkeit,
Credential Guard im UEFI-Sperrmodus auszuschalten.
Der einzige existierende Code dieser Art befindet sich in der besonderen Microsoft-Binärdatei SecComp.efi. Sie muss vom Administrator herunterladen werden, und anschließend muss
der Administrator den Computer von einem anderen EFI-Gerät aus starten und die Datei manuell ausführen (wozu sowohl der BitLocker-Wiederherstellungsschlüssel als auch physischer
Zugriff erforderlich sind) oder die BDC bearbeiten (wozu der BitLocker-Wiederherstellungsschlüssel erforderlich ist). Beim Neustart verlangt SecComp.efi eine Benutzerbestätigung im
UEFI-Modus (was nur durch einen physisch anwesenden Benutzer erfolgen kann).
Authentifizierungsrichtlinien und Kerberos-Armoring
Das Sicherheitsmodell »sicher, sofern der Computer nichts bereits vor der Anmeldung geknackt
wurde oder ein Angriff durch einen physisch anwesenden Administrator erfolgt« ist sicherlich
besser als das herkömmliche Modell ohne Credential Guard. Manche Unternehmen und Organisationen benötigen jedoch eine noch stärkere Sicherheitsgarantie: Selbst ein geknackter
Computer darf nicht dazu verwendet werden können, Anmeldeinformationen eines Benutzers
zu fälschen oder wieder einzuspielen, und selbst wenn die Anmeldeinformationen eines Benutzers gestohlen wurden, dürfen sie außerhalb bestimmter Systeme nicht genutzt werden
können. Durch die Nutzung von Authentifizierungsrichtlinien – einem Merkmal von Windows
Server 2016 – und Kerberos-Armoring kann Credential Guard auch in diesem verstärkten Sicherheitsmodus ausgeführt werden.
710
Kapitel 7
Sicherheit
Dabei erfasst der sichere VLT-1-Kernel mithilfe des TPMs (es kann auch eine Datei auf der
Festplatte verwendet werden, aber das würde die Sicherheit hinfällig machen) einen besonderen Schlüssel für die Computer-ID. Mit diesem Schlüssel wird dann ein TGT-Schlüssel für den
Computer generiert, wenn der Computer beim Beitritt zu einer Domäne bereitgestellt wird.
(Bei dieser Bereitstellung ist es natürlich wichtig, sich zu vergewissern, dass sich der Computer
in einem vertrauenswürdigen Zustand befindet.) Dieser TGT-Schlüssel wiederum wird an das
KDC gesendet. Wenn sich ein Benutzer anmeldet, werden seine Anmeldeinformationen mit
denen des Computers (auf die nur die isolierte LSA Zugriff hat) zu einem Ursprungsnachweisschlüssel kombiniert. Bei dieser Vorgehensweise sind zwei Dinge garantiert:
QQ Der Benutzer authentifiziert sich an einem bekannten Computer Wenn ein Benutzer
oder ein Angreifer versucht, sich mit den richtigen Benutzeranmeldeinformationen von einem anderen Computer aus anzumelden, weichen seine Computeranmeldeinformationen
ab, da sie auf dem TPM beruhen.
QQ Die NTLM-Antwort bzw. das Benutzerticket kommt von der isolierten LSA und wurde nicht manuell von Lsass generiert Damit ist garantiert, dass Credential Guard auf
dem Computer aktiviert ist, selbst wenn ein physisch anwesender Benutzer es deaktivieren
kann.
Auch hier gilt jedoch leider wieder: Wenn der Computer schon so weit übernommen wurde,
dass die mit dem Ursprungsnachweis verschlüsselte KDC-Antwort mit dem Benutzer-TGT und
dem zugehörigen Schlüssel abgefangen werden kann, ist es möglich, sie zu speichern und dazu
zu nutzen, von der isolierten LSA Diensttickets anzufordern, die mit dem Sitzungsschlüssel verschlüsselt sind. Diese Diensttickets können dann beispielsweise an einen Dateiserver gesendet
werden, um darauf zuzugreifen, bis der Sitzungsschlüssel bei einem Neustart gelöscht wird. Für
Systeme mit Credential Guard wird daher empfohlen, jedes Mal einen Neustart auszuführen,
wenn sich ein Benutzer abmeldet, da ein Angreifer sonst auch dann noch in der Lage ist, gültige
Tickets auszugeben, wenn der Benutzer nicht mehr anwesend ist.
Zukünftige Verbesserungen
Wie bereits in Kapitel 2 und 3 erwähnt, wird der sichere Kernel auf VTL 1 zurzeit Verbesserungen unterzogen, um auch Sonderklassen für PCI- und USB-Hardware zu unterstützen, mit denen eine Kommunikation ausschließlich über den Hypervisor und VTL-1-Code mit Secure Device Framework (SDF) möglich ist. Zusammen mit den neuen Trustlets BioIso.exe und FsIso.exe
zur sicheren Erfassung von biometrischen Daten und Videoframes (von einer Webcam) sorgt
dies dafür, dass Komponenten im VTL-0-Kernelmodus die Inhalte von Windows Hello-Authentifizierungsversuchen nicht abfangen können (die wir im Gegensatz zu Klartext-Benutzerkennwörtern als sicher einstufen, obwohl sie technisch durch maßgeschneiderte, treibergestützte
Abfangaktionen erfasst werden können). Es ist auf Hardwareebene garantiert, dass Windows
Hello-Anmeldeinformationen niemals von VTL 0 aus zugänglich sind. In diesem Modus ist eine
Beteiligung von Lsass an der Windows Hello-Authentifizierung nicht erforderlich. Die isolierte
LSA ruft die Anmeldeinformationen unmittelbar von dem isolierten Biometrie- oder Video
framedienst ab.
Virtualisierungsgestützte Sicherheit
Kapitel 7
711
Secure Driver Framework (SDF) ist das Gegenstück zu WDF für VTL-1-Treiber.
Dieses Framework ist zurzeit noch nicht öffentlich zugänglich, steht aber Microsoft-Partnern zur Entwicklung von VTL-1-Treibern zur Verfügung.
Device Guard
Credential Guard dient zum Schutz der Anmeldeinformationen von Benutzern, Device G
uard
dagegen zum Schutz des Computers selbst vor verschiedenen Arten von Software- und
Hardwareangriffen. Device Guard nutzt die Windows-Codeintegritätsdienste wie Kernelmodus-Codesignierung (KMCS) und Benutzermodus-Codeintegrität (UMCI) und verstärkt sie
durch Hypervisor-Codeintegrität (HVCI). Mehr über Codeintegrität erfahren Sie in Kapitel 8
von Band 2.
Außerdem kann Device Guard vollständig konfiguriert werden. Dies geschieht mithilfe von
Custom Code Integrity (CCI) und Signierrichtlinien, die von Secure Boot geschützt und vom
Unternehmensadministrator definiert werden. Diese Richtlinien, die in Kapitel 8 erklärt werden, ermöglichen es, Einschluss- und Ausschlusslisten durchzusetzen, die auf der Grundlage
kryptografisch sinnvoller Informationen (wie dem Unterzeichner eines Zertifikats oder einem
SHA-2-Hash) und nicht wie bei AppLocker-Richtlinien aufgrund von Dateipfaden oder -namen
aufgestellt werden. (Weitere Informationen über AppLocker erhalten Sie in dem gleichnamigen
Abschnitt weiter hinten in diesem Kapitel.)
Wir werden hier nicht die verschiedenen Möglichkeiten beschreiben, um Codeintegritätsrichtlinien aufzustellen und anzupassen, sondern erklären, wie Device Guard diese Richtlinien
durchsetzt. Dabei wird Folgendes garantiert:
QQ Wird die Codesignierung im Kernelmodus durchgesetzt, kann nur signierter Code
geladen werden, selbst wenn der Kernel übernommen wurde Der Grund dafür ist,
dass der Kernelladeprozess den sicheren Kernel in VLT 1 informiert, wenn er einen Treiber
lädt, und den Ladevorgang nur dann erfolgreich abschließen kann, wenn HVCI die Signatur
validiert hat.
QQ Wird die Codesignierung im Kernelmodus durchgesetzt, kann signierter Code nach
dem Laden nicht mehr geändert werden, nicht einmal vom Kernel selbst Der Grund
dafür ist, dass die ausführbaren Codeseiten durch den SLAT-Mechanismus (Second Level
Address Translation) des Hypervisors als schreibgeschützt gekennzeichnet werden. Dies
wird ausführlicher in Kapitel 8 von Band 2 erklärt.
QQ Wird die Codesignierung im Kernelmodus durchgesetzt, ist dynamisch zugewiesener Code unzulässig (was aus den ersten beiden Punkten hervorgeht) Der Grund
dafür ist, dass der Kernel keine Möglichkeit hat, in SLAT-Tabelleneinträgen ausführbare
Einträge zuzuweisen, selbst wenn die Seitentabellen des Kernels den Code als ausführbar
kennzeichnen.
QQ Wird die Codesignierung im Kernelmodus durchgesetzt, kann UEFI-Laufzeitcode
nicht geändert werden, auch nicht von anderem UEFI-Laufzeitcode und dem Kernel selbst Außerdem sollte Secure Boot bereits überprüft haben, dass dieser Code zum
712
Kapitel 7
Sicherheit
L adezeitpunkt signiert war. (Device Guard stützt sich auf diese Annahme.) Außerdem können UEFI-Laufzeitdaten nicht ausführbar gemacht werden. Die Überprüfung erfolgt dadurch, dass der gesamte UEFI-Laufzeitcode und die UEFI-Laufzeitdaten gelesen und die
korrekten Berechtigungen durchgesetzt und in die von VTL 1 geschützten SLAT-Seitentabelleneinträge dupliziert werden.
QQ Wird die Codesignierung im Kernelmodus durchgesetzt, kann nur signierter Kernelmoduscode (Ring 0) ausgeführt werden Diese Aussage scheint aus den ersten drei
Punkten hervorzugehen. Betrachten Sie aber den Fall von signiertem Ring-3-Code. Für
UMCI ist er gültig, und er wird auch in den SLAT-Seitentabelleneinträgen als ausführbarer Code autorisiert. Der sichere Kernel stützt sich auf ein als MBEC bezeichnetes Hardwaremerkmal (Mode-Based Execution Control), das die SLAT um ein Ausführbarkeitsbit für
Benutzer- und Kernelmodus erweitert, oder auf die Softwareemulation dieses Merkmals
im Hypervisor, die eingeschränkter Benutzermodus (Restricted User Mode, RUM) genannt
wird.
QQ Wird die Codesignierung im Benutzermodus durchgesetzt, können nur signierte Benutzermodusabbilder geladen werden Das bedeutet, dass sowohl die ausführbaren
Prozesse (.exe-Dateien) als auch die Bibliotheken, die sie laden (.dll), signiert sein müssen.
QQ Wird die Codesignierung im Benutzermodus durchgesetzt, erlaubt der Kernel den
Benutzermodusanwendungen nicht, vorhandene ausführbare Codeseiten schreibbar zu machen Benutzermodus ist offensichtlich nicht in der Lage, ausführbaren Arbeitsspeicher zuzuweisen oder vorhandenen Arbeitsspeicher zu ändern, ohne den Kernel um
Erlaubnis zu bitten. Daher kann der Kernel seine üblichen Regeln anwenden. Doch selbst
wenn der Kernel übernommen wurde, sorgt die SLAT nach wie vor dafür, dass Benutzermodusseiten ohne Wissen und Genehmigung des sicheren Kernels nicht ausführbar gemacht
werden können und dass ausführbare Seiten niemals schreibbar werden.
QQ Wird die Codesignierung im Benutzermodus durchgesetzt und fordert die Signierrichtlinie harte Codegarantien an, ist eine dynamische Zuweisung von Code unzulässig Dies ist ein wichtiger Unterschied zu den Situationen mit Kernelcodesignierung.
Signierter Benutzermoduscode darf standardmäßig zusätzlichen ausführbaren Arbeitsspeicher zuweisen, um JIT-Vorgänge zu unterstützen, es sei denn, dass das Zertifikat der
Anwendung eine besondere erweiterte Schlüsselverwendung (Enhanced Key Usage, EKU)
enthält, die angibt, ob dynamische Codegenerierung zulässig ist. Zurzeit verfügt NGen.exe
(.NET Native Image Generation) über diese EKU, die es ausführbaren .NET-Dateien in reiner
IL ermöglicht, sogar in diesem Modus zu funktionieren.
QQ Wird der eingeschränkte PowerShell-Sprachmodus durchgesetzt, müssen alle PowerShell-Skripte signiert werden, die dynamische Typen, Reflexion und andere
Sprachmerkmale einsetzen, mit denen eine Ausführung, willkürlicher Code oder
ein Marshalling zu Windows- oder .NET-API-Funktionen erlaubt wird Dadurch wird
verhindert, dass möglicherweise schädliche PowerShell-Skripte aus dem eingeschränkten
Modus ausbrechen.
SLAT-Seitentabelleneinträge sind in VTL 1 geschützt und enthalten die grundlegenden Angaben darüber, welche Berechtigungen eine gegebene Seite im Arbeitsspeicher haben kann.
Virtualisierungsgestützte Sicherheit
Kapitel 7
713
Durch Zurückhalten des Ausführbarkeitsbits nach Bedarf und/oder Zurückhalten des Schreibbarkeitsbits von vorhandenen ausführbaren Seiten (ein Sicherheitsmodell, das als W^X, also W
XOR X bezeichnet wird), verschiebt Device Guard die Durchsetzung der Codesignierung komplett nach VTL 1 (in eine Bibliothek namens Skci.dll, was für Secure Kernel Code Integrity steht).
Selbst wenn Device Guard auf einem Computer nicht ausdrücklich eingerichtet ist, läuft
es in einem dritten Modus, wenn Credential Guard aktiviert ist. Dabei erzwingt es, dass alle
Trustlets über eine bestimmte Microsoft-Signatur mit einem Zertifikat verfügen, das die IUMEKU enthält. Wäre das nicht der Fall, könnte ein Widersacher mit Ring-0-Rechten den regulären KMCS-Mechanismus angreifen und ein schädliches Trustlet laden, um die isolierte LSA zu
attackieren. Darüber hinaus werden alle Aspekte der Benutzermodus-Codesignierung für das
Trustlet durchgesetzt, sodass es im Modus mit harten Codegarantien ausgeführt wird.
Um die Leistung zu optimieren, authentifiziert der HVCI-Mechanismus nicht jede einzelne
Seite neu, wenn das System aus dem Ruhezustand (S4) aufwacht. Es kann sogar sein, dass die
Zertifikatdaten nicht einmal verfügbar sind. In einem solchen Fall müssen die SLAT-Daten rekonstruiert werden, was bedeutet, dass die SLAT-Seitentabelleneinträge in der Ruhezustandsdatei gespeichert werden müssen. Daher muss der Hypervisor darauf vertrauen können, dass
die Ruhezustandsdatei nicht manipuliert wurde. Dazu wird die Ruhezustandsdatei mit dem
lokalen Computerschlüssel verschlüsselt, der im TPM gespeichert ist. Ist kein TPM vorhanden,
muss der Schlüssel leider in einer UEFI-Laufzeitvariablen abgelegt werden, was es einem lokalen Angreifer ermöglicht, die Ruhezustandsdatei zu entschlüsseln, zu ändern und wieder zu
verschlüsseln.
Objekte schützen
Objektschutz und Zugriffsprotokollierung sind das Herz der besitzerverwalteten Zugriffssteuerung und der Überwachung. Zu den Objekten, die in Windows geschützt werden können,
gehören Dateien, Geräte, Mailslots, Pipes (benannte und unbenannte), Jobs, Prozesse, Threads,
Ereignisse, mit Schlüsseln versehene Ereignisse, Ereignispaare, Mutexe, Semaphoren, gemeinsam genutzte Speicherabschnitte, E/A-Vervollständigungsports, LPC-Ports, Timer mit Wartemöglichkeit, Zugriffstokens, Volumes, Fensterstationen, Desktops, Netzwerkfreigaben, Dienste,
Registrierungsschlüssel, Drucker, Active Directory-Objekte usw. – theoretisch alles, was durch
den Objekt-Manager der Exekutive verwaltet wird. In der Praxis werden Objekte, die nicht
im Benutzermodus zugänglich gemacht werden (z. B. Treiberobjekte), üblicherweise nicht geschützt. Kernelmoduscode gilt als vertrauenswürdig und verwendet gewöhnlich Schnittstellen
zum Objekt-Manager, bei denen keine Zugriffsprüfung erfolgt. Da Systemressourcen, die in
den Benutzermodus exportiert werden (und daher eine Sicherheitsvalidierung erfordern), als
Objekte im Kernelmodus implementiert sind, spielt der Objekt-Manager von Windows eine
wichtige Rolle für die Objektsicherheit.
Den Objektschutz (von benannten Objekten) können Sie sich mit dem Sysinternals-Tool
WinObj ansehen (siehe Abb. 7–5). Abb. 7–6 zeigt die Registerkarte Sicherheit des Eigenschaftendialogfelds für ein Abschnittsobjekt in der Benutzersitzung. Dateien sind die Ressourcen,
die man am häufigsten mit dem Objektschutz in Verbindung bringt, aber Windows verwendet
auch für Exekutivobjekte dasselbe Sicherheitsmodell und dieselben Mechanismen wie für die
714
Kapitel 7
Sicherheit
Dateien im Dateisystem. Was die Zugriffssteuerung angeht, unterscheiden sich Exekutivobjekte
nur durch die jeweils unterstützten Zugriffsmethoden von Dateien.
Abbildung 7–5 Ein Abschnittsobjekt in WinObj
Abbildung 7–6 Ein Exekutivobjekt und sein Sicherheitsdeskriptor in WinObj
Objekte schützen
Kapitel 7
715
Was Sie in Abb. 7–6 sehen, ist im Grunde genommen die besitzerverwaltete Zugriffssteuerungsliste (Discretionary Access Control List, DACL) des Objekts. Im Abschnitt »Sicherheitsdeskriptoren und Zugriffssteuerung« werden wir uns ausführlicher mit DACLs beschäftigen.
In Process Explorer können Sie sich die Sicherheitseigenschaften von Objekten ansehen,
indem Sie auf ein Handle im unteren Bereich doppelklicken, sofern Sie Process Explorer zur
Anzeige von Handles eingerichtet haben, was den zusätzlichen Vorteil bietet, dass auch unbenannte Objekte ausgegeben werden. Die angezeigte Eigenschaftenseite ist in beiden Werkzeugen identisch, da die Seite selbst von Windows bereitgestellt wird.
Um festzulegen, wer ein Objekt bearbeiten darf, muss sich das Sicherheitssystem zunächst
über die Identität der einzelnen Benutzer vergewisasern. Aus diesem Grund verlangt Windows
vor dem Zugriff auf jegliche Systemressourcen eine authentifizierte Anmeldung. Wenn ein Prozess ein Handle für ein Objekt anfordert, bestimmen der Objekt-Manager und das Sicherheitssystem anhand der Sicherheitskennung des Aufrufers und des Sicherheitsdeskriptors für das
Objekt, ob dem Aufrufer das Handle übergeben werden soll, das dem Prozess Zugriff auf das
gewünschte Objekt gewährt.
Wie weiter hinten in diesem Kapitel ausführlich beschrieben wird, kann ein Thread einen
anderen Sicherheitskontext als den seines Prozesses annehmen, was als Identitätswechsel bezeichnet wird. Führt ein Thread einen Identitätswechsel durch, so verwenden die Mechanismen
zur Sicherheitsvalidierung den Sicherheitskontext des Threads, anderenfalls den seines Prozesses. Denken Sie daran, dass alle Threads in einem Prozess dieselbe Handletabelle nutzen. Wenn
ein Thread ein Objekt öffnet, haben alle anderen Threads in seinem Prozess daher ebenfalls
Zugriff auf dieses Objekt, selbst wenn der Thread einen Identitätswechsel durchgeführt hat.
Manchmal reicht die Validierung der Identität eines Benutzers nicht aus, um Zugriff auf
eine Ressource zu gewähren, die nur für ein bestimmtes Konto zugänglich sein soll. Beispielsweise besteht ein großer Unterschied zwischen einem Dienst, der unter dem Konto Alice läuft,
und einer Anwendung, die Alice aus dem Internet heruntergeladen hat. Diese Art von Benutzerseparierung wird durch den Windows-Integritätsmodus erreicht, der Integritätsebenen
einrichtet. Dieser Mechanismus wird von der Benutzerkontensteuerung, von der Benutzeroberflächen-Rechteisolierung (User Interface Privilege Isolation, UIPI) sowie von Anwendungscon
tainern genutzt, die in diesem Kapitel alle noch beschrieben werden.
Zugriffsprüfungen
Das Windows-Sicherheitsmodell verlangt, dass ein Thread schon beim Öffnen eines Objekts
angibt, welche Aktionen er daran ausführen möchte. Der Objekt-Manager ruft den SRM auf,
um diesen gewünschten Zugriff zu prüfen. Wird der Zugriff gewährt, so wird dem Prozess des
Threads ein Handle zugewiesen, mit dem der Thread (sowie andere Threads in dem Prozess)
weitere Operationen an dem Objekt ausführen können.
Wenn ein Thread ein vorhandenes Objekt anhand seines Namens öffnet, führt der Objekt-Manager eine Zugriffsvalidierung durch. Dabei schlägt er das angegebene Objekt zunächst in seinem Namensraum nach. Ist es nicht in einem der sekundären Namensräume
vorhanden, etwa im Registrierungsnamensraum des Konfigurations-Managers oder im
Dateisystemnamensraum des Dateisystemtreibers, ruft der Objekt-Manager die interne
Funktion ObpCreateHandle auf, sobald er das Objekt gefunden hat. Wie der Name schon sagt,
716
Kapitel 7
Sicherheit
erstellt ObpCreateHandle in der Handletabelle des Prozesses einen Eintrag, der mit dem Objekt verknüpft wird. ObpCreateHandle ruft zunächst ObpGrantAccess auf, um zu sehen, ob der
Thread die Berechtigung hat, auf das Objekt zuzugreifen. Wenn ja, ruft ObpCreateHandle als
Nächstes die Exekutivfunktion ExCreateHandle auf, um einen Eintrag in der Handletabelle des
Prozesses anzulegen. Um die Zugriffsprüfung durchzuführen, ruft ObpGrantAccess die Funk
tion ObCheckObjectAccess auf.
ObpGrantAccess übergibt die Sicherheitsanmeldeinformationen des Threads, die gewünschte Art des Zugriffs auf das Objekt (Lesen, Schreiben, Löschen usw. oder objektspezifische Operationen) und einen Zeiger auf das Objekt an ObCheckObjectAccess. Als Erstes sperrt
diese Funktion den Sicherheitsdeskriptor des Objekts und den Sicherheitskontext des Threads,
um zu verhindern, dass die Sicherheitseinstellungen des Objekts bzw. die Sicherheitsidentität
des Threads während der Zugriffsprüfung von einem anderen Thread in dem System geändert
werden. Anschließend ruft ObCheckObjectAccess die Sicherheitsmethode des Objekts auf, um
dessen Sicherheitseinstellungen abzurufen. (Objektmethoden werden in Kapitel 8 von Band 2
erläutert.) Durch den Aufruf der Sicherheitsmethode kann eine Funktion in einer anderen Exekutivkomponente aufgerufen werden. Viele Exekutivobjekte greifen jedoch auf die standardmäßige Unterstützung des Systems für die Sicherheitsverwaltung zurück.
Wenn eine Komponente der Exekutive ein Objekt definiert und die SRM-Standardsicherheitsrichtlinie nicht überschreiben möchte, kennzeichnet sie das Objekt als eines mit Standardsicherheit. Beim Aufruf der Sicherheitsmethode eines Objekts prüft der SRM als Erstes, ob das
Objekt über Standardsicherheit verfügt. Bei solchen Objekten werden die Sicherheitsinformationen im Header gespeichert und als Sicherheitsmethode SeDefaultObjectMethod verwendet.
Objekte, die sich nicht auf die Standardsicherheit verlassen, müssen ihre Sicherheitsinformationen selbst verwalten und eine eigene Sicherheitsmethode bereitstellen. Zu den Objekten
mit Standardsicherheit zählen Mutexe, Ereignisse und Semaphoren. Bei Dateiobjekten kann
die Standardsicherheit überschrieben werden. Der Objekt-Manager, der den Dateiobjekttyp
festlegt, überlässt es dem zuständigen Dateisystemtreiber, die Sicherheit für seine Dateien auszuwählen (oder auf ihre Implementierung zu verzichten). Wenn das System die Sicherheitsinformationen eines Dateiobjekts für eine Datei in einem NTFS-Volume abfragt, wendet sich die
Sicherheitsmethode für das Dateiobjekt daher an den NTFS-Dateisystemtreiber. Beachten Sie
aber, dass ObCheckObjectAccess nicht ausgeführt wird, wenn Dateien geöffnet werden, da sie
sich dann in sekundären Namensräumen befinden. Das System ruft die Sicherheitsmethode
eines Dateiobjekts nur dann auf, wenn ein Thread ausdrücklich die Sicherheitsinformationen
einer Datei abfragt oder festlegt (z. B. mit den Windows-Funktionen GetFileSecurity bzw.
SetFileSecurity).
Nach dem Abruf der Sicherheitsinformationen eines Objekts ruft ObCheckObjectAccess die
SRM-Funktion SeAccessCheck ab, die zum Kern des Windows-Sicherheitsmodells gehört. Zu
ihren Eingabeparametern gehören u. a. die Sicherheitsinformationen des Objekts, die Sicherheitsidentität des Threads, wie sie von ObCheckObjectAccess erfasst wurde, und die von dem
Thread angeforderte Art des Zugriffs. Je nachdem, ob dem Thread der gewünschte Zugriff
auf das Objekt gewährt wird oder nicht, gibt SeAccessCheck entweder true oder false zurück.
Nehmen wir an, ein Thread möchte wissen, wann ein bestimmter Prozess endet (oder auf
irgendeine Weise beendet wird). Dazu muss er sich ein Handle für den Zielprozess beschaffen, indem er OpenProcess aufruft und dabei zwei wichtige Argumente übergibt, nämlich die
Objekte schützen
Kapitel 7
717
eindeutige Prozesskennung (wobei wir davon ausgehen, dass er sie kennt oder auf irgendeine
Weise erworben hat) und eine Zugriffsmaske, die die gewünschten Operationen angibt. Ein
fauler Entwickler könnte nun einfach PROCESS_ALL_ACCESS als Zugriffsmaske übergeben, um alle
möglichen Zugriffsrechte für den Prozess anzufordern. Dabei können die beiden folgenden
Dinge passieren:
QQ Wenn dem aufrufenden Thread alle Berechtigungen gewährt werden können, erhält er ein
gültiges Handle zurück und kann WaitForSingleObject aufrufen, um auf die Beendigung
des Prozesses zu warten. Ein anderer Thread in dem Prozess, der möglicherweise geringere
Rechte hat, kann jedoch dasselbe Handle nutzen, um andere Operationen an dem Prozess
vorzunehmen. Beispielsweise ist er in der Lage, den Prozess mit TerminateProcess vorzeitig
zu beenden. Das ist möglich, da das Handle sämtliche Operationen an dem Prozess zulässt.
QQ Wenn der Thread keine ausreichenden Rechte hat, um ihm jede mögliche Form des Zugriffs zu gewähren, schlägt der Aufruf fehl. Das Ergebnis ist ein ungültiges Handle, also keinerlei Zugriff auf den Prozess. Das hätte jedoch nicht sein müssen, da es völlig ausreichend
gewesen wäre, einfach nur die Zugriffsmaske SYNCHRONIZE zu übergeben. Das hätte größere
Erfolgsaussichten gehabt als die Anforderung von PROCESS_ALL_ACCESS.
Daraus lässt sich die einfache Schlussfolgerung ziehen, dass ein Thread genau den gewünschten Zugriff anfordern soll – nicht mehr und nicht weniger.
Der Objekt-Manager führt eine Zugriffsvalidierung auch durch, wenn ein Prozess mit einem vorhandenen Handle auf ein Objekt verweist. Solche Verweise erfolgen oft indirekt, etwa
wenn ein Prozess eine Windows-API aufruft, um ein Objekt zu bearbeiten, und dabei ein Objekthandle übergibt. Beispielsweise kann ein Thread, der eine Datei öffnet, Leseberechtigungen
für die Datei anfordern. Hat er gemäß seinem Sicherheitskontext und der Sicherheitseinstellungen der Datei die Berechtigung, auf diese Weise auf das Objekt zuzugreifen, erstellt der
Objekt-Manager in der Handletabelle des Prozesses, zu dem der Thread gehört, ein Handle,
das für die Datei steht. Zusammen mit dem Handle speichert der Objekt-Manager auch, welche
Arten des Zugriffs die Threads in dem Prozess durchführen dürfen.
Der Thread könnte nun später versuchen, mit der Windows-Funktion WriteFile in die Datei
zu schreiben, wobei er das Dateihandle als Parameter übergibt. Der Systemdienst N tWriteFile,
den WriteFile über Ntdll.dll aufruft, gewinnt mithilfe der (im WDK dokumentierten) Objekt-Manager-Funktion ObReferenceObjectByHandle aus diesem Handle einen Zeiger auf das
Dateiobjekt. ObReferenceObjectByHandle nimmt die vom Aufrufer anforderte Art des Zugriffs
als Parameter entgegen. Nachdem sie den Eintrag für das Handle in der Handletabelle des
Prozesses gefunden hat, vergleicht diese Funktion den angeforderten Zugriff mit dem Zugriff,
der beim Öffnen der Datei gewährt wurde. In diesem Beispiel verweigert ObReferenceObjectByHandle die Schreiboperation, da der Aufrufer beim Öffnen der Datei keinen Schreibzugriff
erhalten hat.
Die Windows-Sicherheitsfunktionen ermöglichen Windows-Anwendungen auch, ihre eigenen privaten Objekte zu definieren und die SRM-Dienste aufzurufen (über die weiter hinten beschriebenen AuthZ-Benutzermodus-APIs), um das Windows-Sicherheitsmodell auf
diese Objekte anzuwenden. Viele Kernelmodusfunktionen, die der Objekt-Manager und andere Komponenten der Exekutive nutzen, um ihre eigenen Objekte zu schützen, werden als
Windows-Benutzermodus-APIs exportiert. Das Gegenstück von SeAccessCheck im Benutzermo-
718
Kapitel 7
Sicherheit
dus ist die AuthZ-API AccessCheck. Windows-Anwendungen können daher die Flexibilität des
Sicherheitsmodells nutzen und sich transparent in die Authentifizierungs- und Administrationsschnittstellen integrieren, die in Windows vorhanden sind.
Im Grunde genommen ist das SRM-Sicherheitsmodell ein Algorithmus mit drei Eingaben:
der Sicherheitsidentität eines Threads, der Art des Zugriffs auf ein Objekt, die der Thread anfordert, und den Sicherheitseinstellungen des Objekts. Die Ausgabe lautet entweder Ja oder Nein
und gibt an, ob das Sicherheitsmodell dem Thread den gewünschten Zugriff gewährt. In den
folgenden Abschnitten werden die Eingaben ausführlicher beschrieben und der Algorithmus
für die Zugriffsvalidierung erklärt.
Experiment: Zugriffsmasken einsehen
In Process Explorer können Sie sich die Zugriffsmasken für offene Handles ansehen:
1.
Starten Sie Process Explorer.
2.
Öffnen Sie das Menü View und wählen Sie Lower Pane View > Handles, damit im unteren Bereich Handles angezeigt werden.
3.
Rechtsklicken Sie auf die Spaltenköpfe im unteren Bereich und wählen Sie Select Col
umns, um das folgende Dialogfeld einzublenden:
4.
Aktivieren Sie die Kontrollkästchen Access Mask und Decoded Access Mask (wobei Letzteres erst ab Version 16.10 angezeigt wird) und klicken Sie auf OK.
→
Objekte schützen
Kapitel 7
719
5.
Markieren Sie in der Prozessliste Explorer.exe und schauen Sie sich die Handles im unteren Bereich an. Bei jedem Handle ist die Zugriffsmaske angegeben, die besagt, welche
Art von Zugriff für dieses Handle gewährt wurde. Die rechte Spalte Decoded Access
Mask zeigt für viele Arten von Objekten in Textform an, was die Bits in der Zugriffsmaske
bedeuten:
Wie Sie sehen, gibt es sowohl allgemeine Zugriffsrechte (wie READ_CONTROL und SYNCHRONIZE) als auch spezielle (z. B. KEY_READ und MODIFY_STATE). Bei den meisten der speziellen
Zugriffsrechte werden lediglich Abkürzungen der Namen angegeben, die tatsächlich in
den Windows-Headern definiert sind (wie MODIFY_STATE statt EVENT_MODIFY_STATE oder
TERMINATE statt PROCESS_TERMINATE).
Sicherheitskennungen
Anstelle von Namen (die nicht unbedingt eindeutig sein müssen) verwendet Windows Sicherheitskennungen (Security Identifiers, SIDs) zur Bezeichnung von Entitäten, die in einem System Aktionen ausführen. Benutzer, lokale und Domänengruppen, lokale Computer, Domänen,
Domänenmitglieder und Dienste – sie alle haben Sicherheitskennungen. Eine SID ist ein numerischer Wert variabler Länge, der aus der Revisionsnummer der SID-Struktur, einem 48-Bit-Wert
für die Bezeichnerautorität sowie einer variablen Anzahl von 32-Bit-Werten für die Teilautorität
oder den relativen Bezeichner (RID) besteht. Der Autoritätswert bezeichnet den Agent, der
die SID ausgegeben hat, wobei es sich gewöhnlich um ein lokales Windows-System oder eine
Domäne handelt. Teilautoritätswerte bezeichnen vertrauenswürdige Stellen relativ zur ausgebenden Autorität, und RIDs bilden einfach eine Möglichkeit, mit der Windows eindeutige
SIDs auf der Grundlage einer gemeinsamen Basis-SID erstellen kann. Da SIDs lang sind und
Windows darauf achtet, jede SID aus wirklich zufälligen Werten zusammenzusetzen, ist es praktisch unmöglich, dass Windows irgendwo auf der Welt zweimal dieselbe SID vergibt.
720
Kapitel 7
Sicherheit
In der Darstellung in Textform wird jeder SID das Präfix S vorangestellt, und die einzelnen
Bestandteile sind durch Bindestriche voneinander abgesetzt:
S-1-5-21-1463437245-1224812800-863842198-1128
Diese SID hat die Revisionsnummer 1 und den Wert 5 für die Bezeichnerautorität (was der Wert
für die Windows-Sicherheitsautorität ist). Der Rest der SID besteht aus vier Teilautoritätswerten
und einem RID (1128). Hierbei handelt es sich um eine Domänen-SID. SIDs für lokale Computer
in dieser Domäne haben dieselbe Revisionsnummer, denselben Wert für die Bezeichnerautorität und dieselbe Anzahl von Teilautoritätswerten.
Bei der Installation von Windows richtet das Setupprogramm eine Computer-SID für den
Rechner ein. Für die lokalen Konten auf dem Computer weist Windows SIDs zu, die auf der SID
des Rechners basieren und einen RID am Ende haben. Die RIDs für Benutzerkonten und Gruppen beginnen bei 1000 und werden für jeden neuen Benutzer und jede Gruppe um 1 erhöht.
Dcpromo.exe (Domain Controller Promote), das Programm zum Erstellen einer neuen Windows
Domäne verwendet die SID des Computers, der zum Domänencontroller heraufgestuft wird,
als Domänen-SID. Sollte der Rechner wieder heruntergestuft werden, so wird für ihn eine neue
Computer-SID erstellt. Für neue Domänenkonten gibt Windows SIDs aus, die auf der Domänen-SID beruhen und mit einem RID versehen sind (der wiederum bei 1000 beginnt und für
jeden neuen Benutzer und jede neue Gruppe um 1 erhöht wird). Ein RID von 1028 bedeutet,
dass es sich bei der SID um die 29. in der Domäne handelt.
Für viele vordefinierte Konten und Gruppen gibt Windows SIDs aus, die aus der Computer- oder Domänen-SID und einem vordefinierten RID bestehen. Beispielsweise wird für das
Administratorkonto der RID 500 verwendet und für das Gastkonto der RID 501. Für das Konto
des lokalen Computeradministrators wird also der RID 500 an die Computer-SID angehängt:
S-1-5-21-13124455-12541255-61235125-500
In Windows sind auch einige lokale und Domänen-SIDs für Standardgruppen vordefiniert. Beispielsweise gibt es die Jeder-SID S-1-1-0, die für »alle Konten« (außer anonymen Benutzern)
steht. Die Netzwerkgruppe, die für alle über das Netzwerk an dem Computer angemeldeten Benutzer steht, hat die SID S-1-5-2. Tabelle 7–2, entnommen aus der Dokumentation des
Windows SDK, zeigt die numerischen Werte und die Verwendung einiger der grundlegenden
Standard-SIDs. Im Gegensatz zu den Benutzer-SIDs handelt es sich hierbei um vordefinierte
Konstanten, die auf allen Windows-Systemen weltweit jeweils dieselben Werte haben. Wenn
eine Datei auf dem System, auf dem sie erstellt wurde, für die Gruppe Jeder zugänglich ist, so
ist sie auch für die Gruppe Jeder in jedem System und jeder Domäne zugänglich, in die die
Festplatte, auf der sie sich befindet, verlegt wird. Benutzer auf diesen Systemen müssen sich
jedoch erst mit einem Konto auf diesen Systemen authentifizieren, bevor sie Mitglieder der
Gruppe Jeder werden.
SID
Name
Verwendung
S-1-0-0
Niemand
Wird verwendet, wenn die SID unbekannt ist.
S-1-1-0
Jeder
Eine Gruppe, die alle Benutzer außer anonymen einschließt
S-1-2-0
Lokal
Benutzer, die sich über ein lokales (physisch mit dem System
verbundenes) Terminal anmelden
→
Objekte schützen
Kapitel 7
721
SID
Name
Verwendung
S-1-3-0
Ersteller-Besitzer
Eine Sicherheitskennung, die durch die Sicherheitskennung
des Benutzers ersetzt wird, der ein neues Objekt erstellt hat
(wird in vererbbaren Zugriffssteuerungseinträgen verwendet)
S-1-3-1
Erstellergruppe
Eine Sicherheitskennung, die durch die Sicherheitskennung
der primären Gruppe des Benutzers ersetzt wird, der ein
neues Objekt erstellt hat (wird in vererbbaren Zugriffssteu
erungseinträgen verwendet)
S-1-5-18
Lokales Systemkonto
Wird von Diensten verwendet.
S-1-5-19
Lokales Dienstkonto
Wird von Diensten verwendet.
S-1-5-20
Netzwerkdienstkonto
Wird von Diensten verwendet.
Tabelle 7–2 Eine Auswahl von Standard-SIDs
Eine Liste vordefinierter SIDs finden Sie im Artikel 243330 der Microsoft Knowledge
Base auf http://support.microsoft.com/kb/243330.
Schließlich erstellt Winlogon noch eine eindeutige Anmelde-SID für jede interaktive Anmeldesitzung. Gewöhnlich werden solche SIDs in Zugriffssteuerungseinträgen verwendet, die
den Zugriff für die Dauer der Anmeldesitzung eines Clients erlauben. Beispielsweise kann ein
Windows-Dienst mit der Funktion LogonUser eine neue Anmeldesitzung starten. Diese Funktion gibt ein Zugriffstoken zurück, aus dem der Dienst die Anmelde-SID entnehmen kann.
Anschließend kann der Dienst diese SID in einem Zugriffssteuerungseintrag verwenden (siehe
den Abschnitt »Sicherheitsdeskriptoren und Zugriffssteuerung« weiter hinten in diesem Kapitel),
mit dem der Anmeldesitzung des Clients der Zugriff auf die interaktive Fensterstation und den
Desktop gewährt wird. Die SID für eine Anmeldesitzung hat die Form S-1-5-5-X-Y, wobei die
Werte für X und Y zufällig generiert werden.
Experiment: SIDs mit PsGetSid und Process Explorer einsehen
Mit dem Sysinternals-Tool PsGetSid können Sie sich die SID aller Konten ansehen, die Sie
verwenden. Die Optionen von PsGetSid machen es möglich, die Namen von Computerund Benutzerkonten in die zugehörigen SIDs zu übersetzen und umgekehrt.
Wenn Sie das Programm PsGetSid ohne Optionen ausführen, gibt es die SID des lokalen Computers aus. Da das Administratorkonto stets den RID 500 hat, können Sie ermitteln,
welchen Namen dieses Konto hat (wenn es aus Sicherheitsgründen umbenannt wurde),
indem Sie einfach die Computer-SID mit angehängtem -500 als Befehlszeilenargument an
PsGetSid übergeben.
Um die SID eines Domänenkontos abzurufen, geben Sie den Benutzernamen mit vorangestelltem Domänennamen ein:
c:\>psgetsid redmond\johndoe
→
722
Kapitel 7
Sicherheit
Die SID einer Domäne erhalten Sie, indem Sie ihren Namen als Argument von PsGetSid
angeben:
c:\>psgetsid redmond
Aus dem RID Ihres eigenen Kontos können Sie zumindest ablesen, wie viele Sicherheitskonten in Ihrer Domäne oder auf Ihrem lokalen Computer erstellt wurden ( je nachdem, ob
Sie ein Domänen- oder ein lokales Computerkonto verwenden), indem Sie 999 vom RIDWert subtrahieren. Um zu ermitteln, welchem Konto ein bestimmter RID zugewiesen wurde,
übergeben Sie eine SID mit diesem RID an PsGetSid. Wenn PsGetSid meldet, dass der SID
kein Konto zugeordnet werden konnte, obwohl der RID kleiner ist als der für Ihr Konto,
dann bedeutet das, dass das Konto mit diesem RID gelöscht wurde.
Um beispielsweise den Namen des Kontos herauszufinden, dem der 28. RID zugewiesen wurde, übergeben Sie die Domänen-SID mit angehängtem -1027 an PsGetSid:
c:\>psgetsid S-1-5-21-1787744166-3910675280-2727264193-1027
Account for S-1-5-21-1787744166-3910675280-2727264193-1027:
User: redmond\johndoe
Informationen über Konto- und Gruppen-SIDs können Sie auch auf der Registerkarte Security von Process Explorer einsehen. Dort ist zu sehen, wer der Besitzer des untersuchten
Prozesses ist und zu welchen Gruppen dieses Konto gehört. Doppelklicken Sie dazu einfach
auf einen beliebigen Prozess (z. B. Explorer.exe) und rufen Sie dann die Registerkarte Security auf. Dadurch erhalten Sie eine Anzeige wie die folgende:
→
Objekte schützen
Kapitel 7
723
Im Feld User wird der Anzeigename des Kontos angegeben, dem der Prozess gehört. Das
Feld SID zeigt den SID-Wert, und die Liste Groups führt alle Gruppen auf, zu denen das
Konto gehört. (Gruppen werden weiter hinten in diesem Kapitel beschrieben.)
Integritätsebenen
Wie bereits erwähnt, können Integritätsebenen den besitzerverwalteten Zugriff überschreiben,
um zwischen einem Prozess und den Objekten zu unterscheiden, die als derselbe Benutzer
ausgeführt werden und ihm gehören. Dadurch ist es möglich, Code und Daten innerhalb eines
Benutzerkontos zu separieren. Mit dem MIC-Mechanismus (Mandatory Integrity Control), der
einen Aufrufer mit einer Integritätsebene verknüpft, kann der SRM ausführlichere Informationen über die Natur dieses Aufrufers gewinnen. Der Mechanismus bietet auch Informationen
über die erforderlichen Vertrauensstufen für den Zugriff auf das Objekt, indem er eine Integritätsebene dafür definiert.
Die Integritätsebene eines Tokens lässt sich mit der API GetTokenInformation und dem Auflistungswert TokenIntegrityLevel abrufen. Bezeichnet werden die Integritätsebenen anhand
einer SID. Sie können zwar beliebige Werte annehmen, aber zur Trennung von Rechteebenen
verwendet das System die sechs in Tabelle 7–3 aufgeführten Hauptebenen.
SID
Name (Ebene)
Verwendung
S-1-16-0x0
Nicht vertrauenswürdig (0)
Wird von Prozessen verwendet, die von der
Gruppe Anonym gestartet werden. Diese Ebene
blockiert die meisten Schreibzugriffe.
S-1-16-0x1000
Niedrig (1)
Wird von Anwendungscontainerprozessen (UWP)
und Internet Explorer im geschützten Modus verwendet. Diese Ebene blockiert den Schreibzugriff
auf die meisten Objekte auf dem System (darunter Dateien und Registrierungsschlüssel).
S-1-16-0x2000
Mittel (2)
Wird von normalen Anwendungen verwendet, die
bei aktiver Benutzerkontensteuerung gestartet
wurden.
S-1-16-0x3000
Hoch (3)
Wird von administrativen Anwendungen ver
wendet, die bei aktiver Benutzerkontensteuerung
mit erhöhten Rechten gestartet wurden, sowie
von normalen Anwendungen, wenn die Benutzer
kontensteuerung ausgeschaltet und der Benutzer
ein Administrator ist.
S-1-16-0x4000
System (4)
Wird von Diensten und anderen Prozessen auf
Systemebene verwendet (wie Wininit, Winlogon,
Smss usw.).
S-1-16-0x5000
Geschützt (5)
Wird zurzeit standardmäßig nicht verwendet und
kann nur von Aufrufern im Kernelmodus festgelegt werden.
Tabelle 7–3 SIDs für Integritätsebenen
724
Kapitel 7
Sicherheit
Scheinbar gibt es noch eine weitere Integritätsebene, die AppContainer genannt und von
UWP-Anwendungen verwendet wird. Tatsächlich ist sie jedoch identisch mit der Ebene Niedrig. UWP-Prozesstokens verfügen über ein Attribut, um anzugeben, dass sie in einem Anwendungscontainer laufen (siehe den entsprechenden Abschnitt weiter hinten). Diese Information
kann mit der API GetTokenInformation und dem Auflistungswert TokenIsAppContainer abgerufen werden.
Experiment: Die Integritätsebenen von Prozessen einsehen
In Process Explorer können Sie sich die Integritätsebenen von Prozessen auf Ihrem System
ansehen, wie das folgende Beispiel zeigt:
1.
Starten Sie Microsoft Edge und Calc.exe (Windows 10).
2.
Öffnen Sie eine Eingabeaufforderung mit erhöhten Rechten.
3.
Öffnen Sie den Editor auf normale Weise (also ohne erhöhte Rechte).
4.
Starten Sie Process Explorer mit erhöhten Rechten, rechtsklicken Sie auf einen beliebigen Spaltenkopf in der Prozessliste und wählen Sie Select Columns.
5.
Rufen Sie die Registerkarte Process Image auf und aktivieren Sie das Kontrollkästchen
Integrity Level. Das Dialogfeld sollte jetzt wie folgt aussehen:
→
Objekte schützen
Kapitel 7
725
6.
Process Explorer zeigt jetzt die Integritätsebenen der Prozesse auf Ihrem System an.
Der Editor (Notepad) sollte auf mittlerer Ebene ausgeführt werden (Medium), Edge
(MicrosoftEdge.exe) auf der Ebene AppContainer und die Eingabeaufforderung mit erhöhten Rechten auf High. Dienste und Systemprozesse laufen auf einer noch höheren
Integritätsebene, nämlich System.
Jeder Prozess ist einer Integritätsebene zugewiesen. Sie wird in seinem Token vermerkt und
nach den folgenden Regeln vererbt:
QQ Ein Prozess erbt normalerweise die Integritätsebene seines Elternprozesses (was beispielsweise bedeutet, dass eine Eingabeaufforderung mit erhöhten Rechten weitere Prozesse mit
erhöhten Rechten hervorruft).
QQ Wenn das Dateiobjekt für das ausführbare Abbild, zu dem der Kindprozess gehört, über
eine eigene Integritätsebene verfügt, und der Elternprozess die mittlere oder hohe Integritätsebene hat, dann erbt der Kindprozess die niedrigere der beiden Ebenen.
QQ Ein Elternprozess kann Kindprozesse erstellen, deren Integritätsebene ausdrücklich niedriger ist als seine eigene. Dazu dupliziert er sein Zugriffstoken mit DuplicateTokenEx, ändert
die Integritätsebene im neuen Token mit SetTokenInformation auf den gewünschten Wert
und ruft dann CreateProcessAsUser mit dem neuen Token auf.
In Tabelle 7–3 haben Sie die Integritätsebenen für Prozesse gesehen, aber was ist mit Objekten?
Auch in den Sicherheitsdeskriptoren von Objekten ist eine Integritätsebene gespeichert, und
zwar in einer Struktur, die als verbindliche Beschriftung bezeichnet wird.
726
Kapitel 7
Sicherheit
Um die Migration von früheren Windows-Versionen zu ermöglichen (deren Registrierungsschlüssel und Dateien keine Informationen über Integritätsebenen enthalten) und um
Anwendungsentwicklern die Arbeit zu erleichtern, verfügen alle Objekte über eine implizite
Integritätsebene, sodass es nicht erforderlich ist, eine Ebene manuell anzugeben. Diese implizite Ebene ist die mittlere, was bedeutet, dass die erforderliche Richtlinie (mit der wir uns in
Kürze genauer beschäftigen werden) für das Objekt an Tokens ausgeführt wird, die auf einer
niedrigeren als der mittleren Integritätsebene auf das Objekt zugreifen.
Wenn ein Prozess ein Objekt erstellt, ohne eine Integritätsebene anzugeben, prüft das
System die Integritätsebene in dem Token. Bei Tokens mit mittlerer oder hoher Integritätsebene bleibt die implizite mittlere Integritätsebene des Objekts erhalten. Enthält ein Token aber
eine niedrigere Integritätsebene, so wird das Objekt mit einer ausdrücklichen Integritätsebene
gleich derjenigen aus dem Token erstellt.
Objekte, die von Prozessen mit der hohen oder der Systemintegritätsebene erstellt werden, haben selbst die mittlere Integritätsebene, damit Benutzer die Benutzerkontensteuerung
aus- und einschalten können. Würden Objekte stets die Integritätsebene ihres Erstellers erben,
können Anwendungen eines Administrators fehlschlagen, der die Benutzerkontensteuerung
ausschaltet und anschließend wieder einschaltet, da der Administrator bei der Ausführung auf
der hohen Integritätsebene nicht in der Lage wäre, Registrierungseinstellungen oder Dateien
zu ändern. Objekte können auch über eine ausdrückliche Integritätsebene verfügen, die vom
System oder vom Ersteller festgelegt wird. Wenn beispielsweise der Kernel Prozesse, Threads,
Tokens und Jobs erstellt, gibt er ihnen eine solche ausdrückliche Integritätsebene. Dadurch soll
verhindert werden, dass ein Prozess desselben Benutzers, der auf einer niedrigeren Integritätsebene ausgeführt wird, auf diese Objekte zugreift und ihren Inhalt oder ihr Verhalten ändert
(z. B. durch DLL-Injektion oder Codeänderung).
Neben einer Integritätsebene haben Objekte auch eine erforderliche Richtlinie. Sie legt den
tatsächlichen Grad an Schutz fest, der aufgrund der Überprüfung der Integritätsebene angewendet wird. Wie Tabelle 7–4 zeigt, sind dabei drei Arten von Schutz möglich. Die Integritätsebene und die erforderliche Richtlinie werden zusammen im selben Zugriffssteuerungseintrag
gespeichert.
Richtlinie
Standardmäßige
Verwendung
Beschreibung
No-Write-Up
Implizit für alle Objekte
Schränkt den Schreibzugriff auf das Objekt für
Prozesse mit einer niedrigeren Integritätsebene
ein.
No-Read-Up
Nur für Prozessobjekte
Schränkt den Lesezugriff auf das Objekt für Prozesse mit einer niedrigeren Integritätsebene ein.
Die Anwendung auf Prozessobjekte schützt vor
Informationslecks, da externe Prozesse daran gehindert werden, im Adressraum zu lesen.
No-Execute-Up
Nur für Binärdateien, die
COM-Klassen implementieren
Schränkt den Ausführungszugriff auf das Objekt
für Prozesse mit einer niedrigeren Integritätsebene ein. Die Anwendung auf COM-Klassen
schränkt die Startaktivierungsberechtigungen für
diese Klassen ein.
Tabelle 7–4 Erforderliche Richtlinien von Objekten
Objekte schützen
Kapitel 7
727
Experiment: Die Integritätsebenen von Objekten einsehen
Mit dem Sysinternals-Tools AccessChk können Sie sich die Integritätsebenen von Objekten
auf Ihrem System wie Dateien, Prozessen und Registrierungsschlüsseln ansehen. Das folgende Experiment zeigt dabei, welchen Zweck das Verzeichnis LocalLow in Windows hat:
1.
Wechseln Sie an einer Eingabeaufforderung zu C:\Users\<Benutzername>, wobei Sie
für <Benutzername> Ihren Benutzernamen einsetzen.
2.
Versuchen Sie, AccessChk wie folgt für den Ordner AppData auszuführen:
C:\Users\UserName> accesschk –v appdata
3.
Beachten Sie den Unterschied zwischen den Unterordnern Local und LocalLow in der
Ausgabe:
C:\Users\UserName\AppData\Local
Medium Mandatory Level (Default) [No-Write-Up]
[...]
C:\Users\UserName\AppData\LocalLow
Low Mandatory Level [No-Write-Up]
[...]
C:\Users\UserName\AppData\Roaming
Medium Mandatory Level (Default) [No-Write-Up]
[...]
4.
Wie Sie sehen, hat das Verzeichnis LocalLow die Integritätsebene Low, während die
Verzeichnisse Local und Roaming über die Integritätsebene Medium (default) verfügen.
Die Angabe default bedeutet, dass das System die implizite Integritätsebene verwendet.
5.
Führen Sie AccessChk erneut für den Ordner AppData aus, geben Sie diesmal aber den
Schalter -e an, damit nur die ausdrücklichen Integritätsebenen angezeigt werden. Jetzt
sehen Sie nur Angaben zu LocalLow.
Mit den Schaltern -o (Objekt), -k (Registrierungsschlüssel) und -p (Prozess) können Sie sich
andere Objekte als Dateien und Verzeichnisse anzeigen lassen.
Tokens
Der SRM verwendet ein als Token (oder Zugriffstoken) bezeichnetes Objekt, um den Sicherheitskontext eines Prozesses oder Threads zu identifizieren. Ein solcher Sicherheitskontext besteht
aus den Informationen zur Beschreibung des Kontos, der Gruppen und der Rechte, die mit dem
Prozess bzw. Thread verknüpft sind. Darüber hinaus enthalten Tokens auch Informationen wie
die Sitzungs-ID, die Integritätsebene und den Virtualisierungsstatus der Benutzerkontensteuerung. (Sowohl Rechte als auch den Virtualisierungsmechanismus der Benutzerkontensteuerung
werden wir weiter hinten in diesem Kapitel noch ausführlicher beschreiben.)
728
Kapitel 7
Sicherheit
Wenn sich ein Benutzer anmeldet, erstellt Lsass ein erstes Token für ihn und ermittelt dann,
ob er ein Mitglied einer privilegierten Gruppe ist oder über ein hohes Recht verfügt. In diesem
Schritt wird nach Mitgliedschaft in einer der folgenden Gruppen gesucht:
QQ Integrierte Administratorengruppe
QQ Zertifikatadministratoren
QQ Domänenadministratoren
QQ Unternehmensadministratoren
QQ Richtlinienadministratoren
QQ Schemaadministratoren
QQ Domänencontroller
QQ Schreibgeschützte Domänencontroller der Organisation
QQ Schreibgeschützte Domänencontroller
QQ Konten-Operatoren
QQ Sicherungsoperatoren
QQ Kryptografie-Operatoren
QQ Netzwerkkonfigurations-Operatoren
QQ Druck-Operatoren
QQ System-Operatoren
QQ RAS-Server
QQ Hauptbenutzer
QQ Prä-Windows 2000-kompatibler Zugriff
Viele der hier genannten Gruppen werden ausschließlich auf Systemen verwendet, die an eine
Domäne angeschlossen sind, und räumen ihren Mitgliedern keine lokalen Administratorrechte
ein. Stattdessen ist es den Mitgliedern gestattet, domänenweite Einstellungen zu ändern.
Bei den hohen Rechten, nach denen gesucht wird, handelt es sich um folgende:
QQ SeBackupPrivilege
QQ SeCreateTokenPrivilege
QQ SeDebugPrivilege
QQ SeImpersonatePrivilege
QQ SeLabelPrivilege
QQ SeLoadDriverPrivilege
QQ SeRestorePrivilege
QQ SeTakeOwnershipPrivilege
QQ SeTcbPrivilege
Eine ausführliche Beschreibung erhalten Sie im Abschnitt »Rechte« weiter hinten in diesem
Kapitel.
Objekte schützen
Kapitel 7
729
Sind eine oder mehrere dieser Gruppen oder Rechte vorhanden, erstellt Lsass ein eingeschränktes Token für den Benutzer (ein gefiltertes Administratortoken) und eine Anmeldesitzung für beide. Das Standardbenutzertoken wird an den ersten Prozess oder die ersten
Prozesse angehängt, die Winlogon starten (standardmäßig ist das Userinit.exe).
Wurde die Benutzerkontensteuerung ausgeschaltet, so haben Administratoren ein
Token, das die Mitgliedschaft in ihren Administratorgruppen und ihre Rechte einschließt.
Da Kindprozesse standardmäßig eine Kopie des Tokens ihres Erstellers erben, laufen alle Prozesse in der Sitzung eines Benutzers unter demselben Token. Um ein Token zu generieren, können
Sie auch die Windows-Funktion LogonUser verwenden. Anschließend können Sie mit diesem
Token einen Prozess anlegen, der im Sicherheitskontext des mit LogonUser angemeldeten Benutzers läuft, indem Sie der Windows-Funktion CreateProcessAsUser dieses Token übergeben.
Die Funktion CreateProcessWithLogonW kombiniert diese beiden Vorgänge in einem einzigen
Aufruf. Auf diese Weise startet der Befehl Runas Prozesse unter alternativen Tokens.
Da Benutzerkonten über verschiedene Mengen von Rechten und zugehörigen Gruppenkonten verfügen, weisen ihre Tokens unterschiedliche Größen auf. Allerdings enthalten alle
Tokens die gleichen Arten von Informationen. Die wichtigsten Inhalte sehen Sie in Abb. 7–7.
Tokenquelle
Token-ID
Authentifizierungs-ID
Elterntoken-ID
Ablaufzeit
Tokensperre
Modifizierungs-ID
Rechte
Überwachungsrichtlinie
Sitzungs-ID
SID der primären Gruppe
Gruppen
SID Gruppe 1
SID Gruppe 2
Standard-DACLs
Eingeschränkte SIDs
Tokentyp
Eingeschränkte SID 1
Eingeschränkte SID 2
SID Fähigkeit 1
SID Fähigkeit 2
Ebene des Identitätswechsels
Flags
Anmeldesitzung
Paket-SID
Fähigkeiten
LowBox-Informationen
Abbildung 7–7 Zugriffstokens
730
Kapitel 7
Sicherheit
Die Sicherheitsmechanismen in Windows bestimmen mithilfe von zwei Komponenten, welche Objekte zugänglich sind und welche Operationen durchgeführt werden können. Die eine
dieser Komponente besteht aus den Tokenfeldern für die Benutzerkonto-SID und die Gruppen-SIDs. Der SRM ermittelt anhand der SIDs, ob ein Prozess oder Thread den angeforderten
Zugriff auf ein sicherungsfähiges Objekt (z. B. eine NTFS-Datei) erhalten kann.
Die Gruppen-SIDs in einem Token geben an, in welchen Gruppen das Benutzerkonto Mitglied ist. Dabei kann beispielsweise eine Serveranwendung bestimmte Gruppen deaktivieren,
um die Anmeldeinformation eines Tokens einzuschränken, wenn die Anwendung von einem
Client angeforderte Aktionen durchführt. Die Deaktivierung einer Gruppe wirkt sich fast genauso aus, als wäre die Gruppe in dem Token gar nicht vorhanden. (Dies führt zu einer reinen
Verweigerungsgruppe, was im Abschnitt »Eingeschränkte Tokens« beschrieben wird. Deaktivierte SIDs werden im Rahmen von Zugriffsprüfungen verwendet, die im Abschnitt »Den Zugriff
bestimmen« weiter hinten erläutert werden.) Zu den Gruppen-SIDs kann auch eine besondere
SID mit der Integritätsebene des Prozesses oder Threads gehören. Der SRM verwendet noch ein
weiteres Feld in dem Token, das die erforderliche Integritätsrichtlinie beschreibt, um die weiter
hinten in diesem Kapitel beschriebenen verbindlichen Integritätsprüfungen durchzuführen.
Die zweite Komponente, anhand der bestimmt wird, was der Thread oder Prozess tun
kann, ist das Array der Rechte, die mit dem Token verknüpft sind, beispielsweise das Recht, den
Computer herunterzufahren. Weiter hinten in diesem Kapitel werden Rechte noch ausführlicher
behandelt.
Die Standardfelder eines Tokens für die primäre Gruppe und für die besitzerverwaltete Zugriffssteuerungsliste (DACL) sind Sicherheitsattribute, die Windows auf die unter Verwendung
des Tokens von einem Prozess oder Thread erstellten Objekte anwendet. Durch die Aufnahme
der Sicherheitsinformationen in die Tokens erleichtert Windows es Prozessen und Threads, Objekte mit Standardsicherheitsattributen zu erstellen, da die Prozesse und Threads dadurch nicht
mehr gezwungen sind, diskrete Sicherheitsinformationen für jedes Objekt anzufordern, das sie
erstellen.
Beim Typ eines Tokens wird zwischen einem Primärtoken (das den Sicherheitskontext eines
Prozesses angibt) und einem Identitätswechseltoken unterschieden (das von Threads verwendet wird, um vorübergehend einen anderen Sicherheitskontext anzunehmen, gewöhnlich den
eines anderen Benutzers). Identitätswechseltokens können eine Identitätswechselebene enthalten, die angibt, welche Art von Identitätswechsel in dem Token aktiv ist. (Identitätswechsel
werden weiter hinten in diesem Kapitel beschrieben.)
Ein Token gibt auch die erforderliche Richtlinie für den Prozess oder Thread an. Sie legt
fest, wie MIC bei der Verarbeitung des Tokens vorgeht. Dabei gibt es die beiden folgenden
Richtlinien:
QQ TOKEN_MANDATORY_NO_WRITE_UP Diese Richtlinie ist standardmäßig aktiviert und
legt die Richtlinie No-Write-Up für das Token fest. Das bedeutet, dass der Prozess oder
Thread keinen Schreibzugriff auf Objekte mit einer höheren Integritätsebene hat.
QQ TOKEN_MANDATORY_NEW_PROCESS_MIN Diese Richtlinie ist ebenfalls standardmäßig aktiviert und legt fest, dass sich der SRM beim Starten eines Kindprozesses die Integritätsebene des ausführbaren Abbilds ansehen und für den Kindprozess die kleinere der
beiden Integritätsebenen des Elternprozesses und des Dateiobjekts festlegen soll.
Objekte schützen
Kapitel 7
731
Die Tokenflags schließen Parameter ein, die das Verhalten einzelner Mechanismen der Benutzerkontensteuerung und von UIPI bestimmen, z. B. Virtualisierung und Zugriff auf die Benutzerschnittstelle. Diese Mechanismen werden weiter hinten in diesem Kapitel beschrieben.
Wenn AppLocker-Regeln definiert wurden, kann jedes Token auch Attribute enthalten,
die vom Anwendungsidentifizierungsdienst (einem Teil von AppLocker) zugewiesen wurden.
AppLocker und die Verwendung von AppLocker-Attributen in Zugriffstokens werden weiter
hinten in diesem Kapitel beschrieben.
Ein Token für einen UWP-Prozess enthält auch Informationen über den Anwendungscontainer, in dem der Prozess untergebracht ist. An erster Stelle steht dabei die Paket-SID für das
UWP-Paket, aus dem der Prozess stammt. Was es mit dieser SID auf sich hat, erfahren Sie im
Abschnitt »Anwendungscontainer« weiter hinten in diesem Kapitel. Zweitens müssen UWP-Prozesse Fähigkeiten für Operationen anfordern, die einer Zustimmung des Benutzers bedürfen.
Zu diesen Fähigkeiten gehören der Netzwerkzugriff, die Verwendung der Telefonfähigkeiten
des Geräts (falls vorhanden), der Zugriff auf die Kamera des Geräts usw. Jede dieser Fähigkeiten
wird durch eine SID dargestellt, die im Token gespeichert ist. (Fähigkeiten werden ebenfalls im
Abschnitt »Anwendungscontainer« beschrieben.)
Die restlichen Felder im Token sind rein informativ. Das Feld für die Tokenquelle gibt in
Textform an, welche Entität das Token erstellt hat. Programme, die den Ursprung eines Tokens in Erfahrung bringen wollen, können anhand dieses Feldes zwischen Quellen wie dem
Windows-Sitzungs-Manager, einem Netzwerkdateiserver und einem RPC-Server unterscheiden. Die Token-ID ist ein lokal eindeutiger Bezeichner (LUID), den der SRM zuweist, wenn er das
Token erstellt. Die Windows-Exekutive führt einen monoton steigenden LUID-Zähler, um jedem
Token einen eindeutigen numerischen Wert zuzuweisen. LUIDs sind nur bis zum Herunterfahren des Systems garantiert eindeutig.
Die Authentifizierungs-ID ist ein weiterer LUID. Er wird vom Ersteller des Tokens zugewiesen, wenn er die Funktion LsaLogonUser aufruft. Gibt der Ersteller keinen LUID an, bezieht Lsass
den LUID vom LUID-Zähler der Exekutive. Lsass verwendet für alle Tokens, die von einem ursprünglichen Anmeldetoken abstammen, dieselbe Authentifizierungs-ID. Ein Programm kann
die Authentifizierungs-ID eines Tokens abrufen, um zu sehen, ob das Token zur selben Anmeldesitzung gehört wie andere Tokens, die das Programm untersucht hat.
Mithilfe des LUID-Zählers der Exekutive wird die Modifizierungs-ID jedes Mal aktualisiert,
wenn die Eigenschaften eines Tokens geändert wurden. Anwendungen können die Modifizierungs-ID überprüfen, um zu erkennen, ob der Sicherheitskontext seit seiner letzten Verwendung verändert wurde.
Tokens enthalten auch ein Feld für eine Ablaufzeit. Damit können Anwendungen eigene
Sicherheitsmaßnahmen ausführen, bei denen Tokens nach einem bestimmten Zeitraum nicht
mehr akzeptiert werden. Windows selbst erzwingt jedoch keinen Ablauf von Tokens.
Um die Sicherheit des Systems zu garantieren, sind die Felder in einem Token
nicht veränderbar (da sie sich im Kernelspeicher befinden). Zwar können einige
Felder durch besondere Systemaufrufe bearbeitet werden (sofern der Aufrufer die
entsprechenden Zugriffsrechte für das Tokenobjekt hat), doch Daten wie Rechte
und SIDs in einem Token lassen sich vom Benutzermodus aus niemals verändern.
732
Kapitel 7
Sicherheit
Experiment: Zugriffstoken einsehen
Der Kerneldebuggerbefehl dt _TOKEN zeigt das Format eines internen Tokenobjekts an.
Diese Struktur unterscheidet sich zwar von der Benutzermodus-Tokenstruktur, die von Sicherheitsfunktionen der Windows-API zurückgegeben wird, doch die Felder sind ähnlich.
Weitere Informationen über Tokens finden Sie in der Dokumentation zum Windows SDK.
In Windows 10 sieht die Tokenstruktur wie folgt aus:
lkd> dt nt!_token
+0x000 TokenSource
: _TOKEN_SOURCE
+0x010 TokenId
: _LUID
+0x018 AuthenticationId : _LUID
+0x020 ParentTokenId
: _LUID
+0x028 ExpirationTime
: _LARGE_INTEGER
+0x030 TokenLock
: Ptr64 _ERESOURCE
+0x038 ModifiedId
: _LUID
+0x040 Privileges
: _SEP_TOKEN_PRIVILEGES
+0x058 AuditPolicy
: _SEP_AUDIT_POLICY
+0x078 SessionId
: Uint4B
+0x07c UserAndGroupCount : Uint4B
+0x080 RestrictedSidCount : Uint4B
+0x084 VariableLength
: Uint4B
+0x088 DynamicCharged
: Uint4B
+0x08c DynamicAvailable : Uint4B
+0x090 DefaultOwnerIndex : Uint4B
+0x098 UserAndGroups
: Ptr64 _SID_AND_ATTRIBUTES
+0x0a0 RestrictedSids
: Ptr64 _SID_AND_ATTRIBUTES
+0x0a8 PrimaryGroup
: Ptr64 Void
+0x0b0 DynamicPart
: Ptr64 Uint4B
+0x0b8 DefaultDacl
: Ptr64 _ACL
+0x0c0 TokenType
: _TOKEN_TYPE
+0x0c4 ImpersonationLevel : _SECURITY_IMPERSONATION_LEVEL
+0x0c8 TokenFlags
: Uint4B
+0x0cc TokenInUse
: UChar
+0x0d0 IntegrityLevelIndex : Uint4B
+0x0d4 MandatoryPolicy
: Uint4B
+0x0d8 LogonSession
: Ptr64 _SEP_LOGON_SESSION_REFERENCES
+0x0e0 OriginatingLogonSession : _LUID
+0x0e8 SidHash
: _SID_AND_ATTRIBUTES_HASH
+0x1f8 RestrictedSidHash : _SID_AND_ATTRIBUTES_HASH
+0x308 pSecurityAttributes : Ptr64 _AUTHZBASEP_SECURITY_ATTRIBUTES_INFORMATION
→
Objekte schützen
Kapitel 7
733
+0x310 Package
: Ptr64 Void
+0x318 Capabilities
: Ptr64 _SID_AND_ATTRIBUTES
+0x320 CapabilityCount
: Uint4B
+0x328 CapabilitiesHash : _SID_AND_ATTRIBUTES_HASH
+0x438 LowboxNumberEntry : Ptr64 _SEP_LOWBOX_NUMBER_ENTRY
+0x440 LowboxHandlesEntry : Ptr64 _SEP_LOWBOX_HANDLES_ENTRY
+0x448 pClaimAttributes : Ptr64 _AUTHZBASEP_CLAIM_ATTRIBUTES_COLLECTION
+0x450 TrustLevelSid
: Ptr64 Void
+0x458 TrustLinkedToken : Ptr64 _TOKEN
+0x460 IntegrityLevelSidValue : Ptr64 Void
+0x468 TokenSidValues
: Ptr64 _SEP_SID_VALUES_BLOCK
+0x470 IndexEntry
: Ptr64 _SEP_LUID_TO_INDEX_MAP_ENTRY
+0x478 DiagnosticInfo
: Ptr64 _SEP_TOKEN_DIAG_TRACK_ENTRY
+0x480 SessionObject
: Ptr64 Void
+0x488 VariablePart
: Uint8B
Das Token eines Prozesses können Sie mit dem Befehl !token untersuchen. Die Adresse des
Tokens finden Sie in der Ausgabe des Befehls !process. Das folgende Beispiel zeigt den
Vorgang für den Prozess Explorer.exe:
lkd> !process 0 1 explorer.exe
PROCESS ffffe18304dfd780
SessionId: 1 Cid: 23e4 Peb: 00c2a000 ParentCid: 2264
DirBase: 2aa0f6000 ObjectTable: ffffcd82c72fcd80 HandleCount: <Data Not
Accessible>
Image: explorer.exe
VadRoot ffffe18303655840 Vads 705 Clone 0 Private 12264. Modified 376410.
Locked 18.
DeviceMap ffffcd82c39bc0d0
Token ffffcd82c72fc060
...
PROCESS ffffe1830670a080
SessionId: 1 Cid: 27b8 Peb: 00950000 ParentCid: 035c
DirBase: 2cba97000 ObjectTable: ffffcd82c7ccc500 HandleCount: <Data Not
Accessible>
Image: explorer.exe
VadRoot ffffe183064e9f60 Vads 1991 Clone 0 Private 19576. Modified 87095.
Locked 0.
DeviceMap ffffcd82c39bc0d0
Token ffffcd82c7cd9060
...
→
734
Kapitel 7
Sicherheit
lkd> !token ffffcd82c72fc060
_TOKEN 0xffffcd82c72fc060
TS Session ID: 0x1
User: S-1-5-21-3537846094-3055369412-2967912182-1001
User Groups:
00 S-1-16-8192
Attributes - GroupIntegrity GroupIntegrityEnabled
01 S-1-1-0
Attributes - Mandatory Default Enabled
02 S-1-5-114
Attributes - DenyOnly
03 S-1-5-21-3537846094-3055369412-2967912182-1004
Attributes - Mandatory Default Enabled
04 S-1-5-32-544
Attributes - DenyOnly
05 S-1-5-32-578
Attributes - Mandatory Default Enabled
06 S-1-5-32-559
Attributes - Mandatory Default Enabled
07 S-1-5-32-545
Attributes - Mandatory Default Enabled
08 S-1-5-4
Attributes - Mandatory Default Enabled
09 S-1-2-1
Attributes - Mandatory Default Enabled
10 S-1-5-11
Attributes - Mandatory Default Enabled
11 S-1-5-15
Attributes - Mandatory Default Enabled
12 S-1-11-96-3623454863-58364-18864-2661722203-1597581903-12253128352511459453-1556397606-2735945305-1404291241
Attributes - Mandatory Default Enabled
13 S-1-5-113
Attributes - Mandatory Default Enabled
14 S-1-5-5-0-1745560
Attributes - Mandatory Default Enabled LogonId
15 S-1-2-0
Attributes - Mandatory Default Enabled
16 S-1-5-64-36
Attributes - Mandatory Default Enabled
Primary Group: S-1-5-21-3537846094-3055369412-2967912182-1001
→
Objekte schützen
Kapitel 7
735
Privs:
19 0x000000013 SeShutdownPrivilege
Attributes -
23 0x000000017 SeChangeNotifyPrivilege
Attributes - Enabled Default
25 0x000000019 SeUndockPrivilege
Attributes -
33 0x000000021 SeIncreaseWorkingSetPrivilege
Attributes -
34 0x000000022 SeTimeZonePrivilege
Attributes -
Authentication ID:
(0,1aa448)
Impersonation Level:
Anonymous
TokenType:
Primary
Source: User32
TokenFlags: 0x2a00 ( Token in use )
Token ID: 1be803
ParentToken ID: 1aa44b
Modified ID:
(0, 43d9289)
RestrictedSidCount: 0
RestrictedSids: 0x0000000000000000
OriginatingLogonSession: 3e7
PackageSid: (null)
CapabilityCount: 0
Capabilities: 0x0000000000000000
LowboxNumberEntry: 0x0000000000000000
Security Attributes:
Unable to get the offset of nt!_AUTHZBASEP_SECURITY_ATTRIBUTE.ListLink
Process Token TrustLevelSid: (null)
Da der Explorer nicht in einem Anwendungscontainer läuft, gibt es für ihn keine Paket-SID.
Führen Sie Calc.exe in Windows 10 aus. Dadurch wird Calculator.exe erzeugt (was jetzt
eine UWP-Anwendung ist). Untersuchen Sie das Token:
lkd> !process 0 1 calculator.exe
PROCESS ffffe18309e874c0
SessionId: 1 Cid: 3c18 Peb: cd0182c000 ParentCid: 035c
DirBase: 7a15e4000 ObjectTable: ffffcd82ec9a37c0 HandleCount: <Data Not
Accessible>
Image: Calculator.exe
VadRoot ffffe1831cf197c0 Vads 181 Clone 0 Private 3800. Modified 3746.
Locked 503.
DeviceMap ffffcd82c39bc0d0
Token ffffcd82e26168f0
...
lkd> !token ffffcd82e26168f0
_TOKEN 0xffffcd82e26168f0
TS Session ID: 0x1
User: S-1-5-21-3537846094-3055369412-2967912182-1001
User Groups:
00 S-1-16-4096
→
736
Kapitel 7
Sicherheit
Attributes - GroupIntegrity GroupIntegrityEnabled
01 S-1-1-0
Attributes - Mandatory Default Enabled
02 S-1-5-114
Attributes - DenyOnly
03 S-1-5-21-3537846094-3055369412-2967912182-1004
Attributes - Mandatory Default Enabled
04 S-1-5-32-544
Attributes - DenyOnly
05 S-1-5-32-578
Attributes - Mandatory Default Enabled
06 S-1-5-32-559
Attributes - Mandatory Default Enabled
07 S-1-5-32-545
Attributes - Mandatory Default Enabled
08 S-1-5-4
Attributes - Mandatory Default Enabled
09 S-1-2-1
Attributes - Mandatory Default Enabled
10 S-1-5-11
Attributes - Mandatory Default Enabled
11 S-1-5-15
Attributes - Mandatory Default Enabled
12 S-1-11-96-3623454863-58364-18864-2661722203-1597581903-12253128352511459453-1556397606-2735945305-1404291241
Attributes - Mandatory Default Enabled
13 S-1-5-113
Attributes - Mandatory Default Enabled
14 S-1-5-5-0-1745560
Attributes - Mandatory Default Enabled LogonId
15 S-1-2-0
Attributes - Mandatory Default Enabled
16 S-1-5-64-36
Attributes - Mandatory Default Enabled
Primary Group: S-1-5-21-3537846094-3055369412-2967912182-1001
Privs:
19 0x000000013 SeShutdownPrivilege
Attributes -
23 0x000000017 SeChangeNotifyPrivilege
Attributes - Enabled Default
25 0x000000019 SeUndockPrivilege
Attributes -
33 0x000000021 SeIncreaseWorkingSetPrivilege
Attributes -
34 0x000000022 SeTimeZonePrivilege
Attributes -
Authentication ID:
(0,1aa448)
→
Objekte schützen
Kapitel 7
737
Impersonation Level:
Anonymous
TokenType:
Primary
Source: User32
TokenFlags: 0x4a00 ( Token in use )
Token ID: 4ddb8c0
ParentToken ID: 1aa44b
Modified ID:
(0, 4ddb8b2)
RestrictedSidCount: 0
RestrictedSids: 0x0000000000000000
OriginatingLogonSession: 3e7
PackageSid: S-1-15-2-466767348-3739614953-2700836392-1801644223-42277506571087833535-2488631167
CapabilityCount: 1
Capabilities: 0xffffcd82e1bfccd0
Capabilities:
00 S-1-15-3-466767348-3739614953-2700836392-1801644223-4227750657-10878335352488631167
Attributes - Enabled
LowboxNumberEntry: 0xffffcd82fa2c1670
LowboxNumber: 5
Security Attributes:
Unable to get the offset of nt!_AUTHZBASEP_SECURITY_ATTRIBUTE.ListLink
Process Token TrustLevelSid: (null)
Wie Sie sehen, ist für den Taschenrechner eine Fähigkeit erforderlich (die identisch mit
der RID seines Anwendungscontainers ist, wie im Abschnitt »Anwendungscontainer« weiter
hinten in diesem Kapitel noch beschrieben wird). Eine Untersuchung des Tokens für den
Cortana-Prozess (Searchui.exe) zeigt folgende Fähigkeiten:
lkd> !process 0 1 searchui.exe
PROCESS ffffe1831307d080
SessionId: 1 Cid: 29d8 Peb: fb407ec000 ParentCid: 035c
DeepFreeze
DirBase: 38b635000 ObjectTable: ffffcd830059e580 HandleCount: <Data Not
Accessible>
Image: SearchUI.exe
VadRoot ffffe1831fe89130 Vads 420 Clone 0 Private 11029. Modified 2031.
Locked 0.
DeviceMap ffffcd82c39bc0d0
Token ffffcd82d97d18f0
...
lkd> !token ffffcd82d97d18f0
_TOKEN 0xffffcd82d97d18f0
TS Session ID: 0x1
User: S-1-5-21-3537846094-3055369412-2967912182-1001
User Groups:
...
→
738
Kapitel 7
Sicherheit
Primary Group: S-1-5-21-3537846094-3055369412-2967912182-1001
Privs:
19 0x000000013 SeShutdownPrivilege
Attributes -
23 0x000000017 SeChangeNotifyPrivilege
Attributes - Enabled Default
25 0x000000019 SeUndockPrivilege
Attributes -
33 0x000000021 SeIncreaseWorkingSetPrivilege
Attributes -
34 0x000000022 SeTimeZonePrivilege
Attributes -
Authentication ID:
(0,1aa448)
Impersonation Level:
Anonymous
TokenType:
Primary
Source: User32
TokenFlags: 0x4a00 ( Token in use )
Token ID: 4483430
ParentToken ID: 1aa44b
Modified ID:
(0, 4481b11)
RestrictedSidCount: 0
RestrictedSids: 0x0000000000000000
OriginatingLogonSession: 3e7
PackageSid: S-1-15-2-1861897761-1695161497-2927542615-642690995-3278402852659745135-2630312742
CapabilityCount: 32 Capabilities: 0xffffcd82f78149b0
Capabilities:
00 S-1-15-3-1024-1216833578-114521899-3977640588-1343180512-2505059295473916851-3379430393-3088591068
Attributes - Enabled
01 S-1-15-3-1024-3299255270-1847605585-2201808924-710406709-3613095291873286183-3101090833-2655911836
Attributes - Enabled
02 S-1-15-3-1024-34359262-2669769421-2130994847-3068338639-32842714462009814230-2411358368-814686995
Attributes - Enabled
03 S-1-15-3-1
Attributes - Enabled
...
29 S-1-15-3-3633849274-1266774400-1199443125-2736873758
Attributes - Enabled
30 S-1-15-3-2569730672-1095266119-53537203-1209375796
Attributes - Enabled
31 S-1-15-3-2452736844-1257488215-2818397580-3305426111
Attributes - Enabled
LowboxNumberEntry: 0xffffcd82c7539110
LowboxNumber: 2
Security Attributes:
Unable to get the offset of nt!_AUTHZBASEP_SECURITY_ATTRIBUTE.ListLink
Process Token TrustLevelSid: (null)
→
Objekte schützen
Kapitel 7
739
Für Cortana sind 32 Fähigkeiten erforderlich. Das zeigt, dass dieser Prozess viel mehr Funktionen aufweist, die von den Endbenutzern akzeptiert und vom System validiert werden
müssen.
Den Inhalt eines Tokens können Sie sich indirekt auch auf der Registerkarte Security des
Eigenschaftendialogfelds für einen Prozess in Process Explorer ansehen. Dort werden die
Gruppen und Rechte aufgeführt, die in dem Token des betreffenden Prozesses enthalten sind.
Experiment: Ein Programm auf niedriger Integritätsebene starten
Wenn Sie die Rechte eines Programms erhöhen – entweder durch die Option Als Administrator ausführen oder weil das Programm es verlangt –, wird es ausdrücklich auf einer höheren Integritätsebene ausgeführt. Mithilfe von PsExec von Sysinternals ist es jedoch auch
möglich, ein Programm auf einer niedrigeren Integritätsebene zu starten:
1.
Starten Sie den Editor mit dem folgenden Befehl auf der niedrigen Integrationsebene:
c:\psexec –l notepad.exe
2.
Versuchen Sie, eine Datei im Verzeichnis %SystemRoot%\System32 zu öffnen (z. B. eine
der XML-Dateien). Sie werden feststellen, dass Sie das Verzeichnis durchsuchen und alle
darin enthaltenen Dateien öffnen können.
3.
Wählen Sie im Editor Datei > Neu.
4.
Geben Sie Text in das Fenster ein und versuchen Sie, die Datei im Verzeichnis %SystemRoot%\System32 zu speichern. Dabei zeigt der Editor jedoch ein Dialogfeld an, in dem
Sie auf mangelnde Berechtigungen hingewiesen werden und den Vorschlag erhalten,
die Datei im Dokumentenordner zu speichern:
5.
Akzeptieren Sie den Vorschlag des Editors. Dabei erhalten Sie jedoch wieder die gleiche
Meldung. Das gilt auch für jeden folgenden Versuch.
6.
Versuchen Sie nun, die Datei im Verzeichnis LocalLow Ihres Benutzerprofils zu speichern, das Sie in einem früheren Experiment in diesem Kapitel kennengelernt haben.
Im Verzeichnis LocalLow können Sie die Datei nun endlich speichern. Das liegt daran, dass
der Editor hier auf der niedrigen Integritätsebene ausgeführt wurde und LocalLow als einziges Verzeichnis ebenfalls dieser Ebene zugewiesen ist. Alle anderen Verzeichnisse, die Sie
ausprobiert haben, verfügen über die implizite Integrationsebene Medium. (Das können Sie
mit AccessChk überprüfen.) Das Anzeigen und Öffnen von Dateien im Verzeichnis %SystemRoot%\System32 ist jedoch trotz der impliziten mittleren Integrationsebene möglich.
740
Kapitel 7
Sicherheit
Identitätswechsel
Der Identitätswechsel ist eine erfolgreiche Vorgehensweise, die im Sicherheitsmodell und im
Client/Server-Programmiermodell von Windows häufig eingesetzt wird. Betrachten Sie als Beispiel eine Serveranwendung, die Ressourcen wie Dateien, Drucker oder Datenbanken bereitstellt. Clients, die auf eine dieser Ressourcen zugreifen wollen, senden eine Anforderung an den
Server. Wenn der Server diese Anforderung erhält, muss er sich vergewissern, dass der Client
über die Berechtigungen für den gewünschten Umgang mit der Ressource verfügt. Versucht
ein Benutzer auf einem Remotecomputer etwa, eine Datei in einer NTFS-Freigabe zu löschen,
muss der Server, der diese Freigabe bereitstellt, ermitteln, ob der Benutzer dazu berechtigt ist.
Die offensichtliche Vorgehensweise besteht darin, den Server die Konto- und die Gruppen-SIDs
des Benutzers abrufen und die Sicherheitsattribute der Datei untersuchen zu lassen. Allerdings
ist dies nur sehr mühsam zu programmieren und fehleranfällig. Außerdem wäre es bei dieser
Vorgehensweise nicht möglich, neue Sicherheitsmerkmale transparent zu unterstützen. Daher
bietet Windows Identitätswechseldienste, um dem Server die Aufgabe zu erleichtern.
Damit kann der Server dem SRM mitteilen, dass er vorübergehend das Sicherheitsprofil des
Clients annimmt, der die Ressource angefordert hat. Der Server greift im Namen des Clients
auf die Ressource zu und der SRM führt die Zugriffsvalidierung auf der Grundlage des angenommenen Sicherheitskontextes des Clients aus. Gewöhnlich hat ein Server Zugriff auf mehr
Ressourcen als ein Client, weshalb er beim Identitätswechsel einen Teil seiner Berechtigungen
verliert. Es kann jedoch auch das Gegenteil der Fall sein, nämlich dass der Server bei einem
Identitätswechsel Berechtigungen gewinnt.
Der Server übernimmt die Identität des Clients nur innerhalb des Threads, der die entsprechende Anforderung stellt. Die Datenstrukturen für die Threadsteuerung enthalten einen
optionalen Eintrag für ein Identitätswechseltoken. Das Primärtoken des Threads, das für die
echten Anmeldeinformationen des Threads steht, ist jedoch stets in der Steuerstruktur des
Prozesses zugänglich.
Windows ermöglicht Identitätswechsel durch verschiedene Mechanismen. Wenn ein Server mit einem Client über eine benannte Pipe kommuniziert, kann er die Windows-API-Funktion ImpersonateNamedPipeClient nutzen, um dem SRM mitzuteilen, dass er die Identität des
Benutzers am anderen Ende der Pipe übernehmen möchte. Bei der Kommunikation über DDE
(Dynamic Data Exchange) oder RPCs kann der Server ähnliche Anforderungen für einen Identitätswechsel mithilfe von DdeImpersonateClient bzw. RpcImpersonateClient stellen. Ein Thread
kann ein Identitätswechseltoken erstellen, indem er einfach das Prozesstoken mit der Funktion
ImpersonateSelf kopiert. Anschließend kann er dieses Identitätswechseltoken ändern, um etwa
SIDs oder Rechte zu deaktivieren. Ein SSPI-Paket (Security Support Provider Interface) kann die
Identität von Clients mit ImpersonateSecurityContext übernehmen. SSPIs implementieren ein
Netzwerkauthentifizierungsprotokoll wie LAN Manager 2 oder Kerberos. Andere Schnittstellen
wie COM ermöglichen Identitätswechsel mithilfe von eigenen APIs wie CoImpersonateClient.
Nachdem der Serverthread seine Aufgabe erledigt hat, kehrt er zu seinem eigentlichen
Sicherheitskontext zurück. Diese Art von Identitätswechsel eignet sich dafür, besondere Ak
tionen auf Anforderung eines Clients durchzuführen und dabei die korrekte Überwachung des
Objektzugriffs sicherzustellen (sodass im Überwachungsprotokoll die Identität des Clients und
nicht die des Serverprozesses vermerkt wird). Der Nachteil besteht darin, dass es hiermit nicht
Objekte schützen
Kapitel 7
741
möglich ist, ein ganzes Programm im Kontext eines Clients auszuführen. Außerdem kann ein
Identitätswechseltoken nur dann auf Dateien oder Drucker in Netzwerkfreigaben zugreifen,
wenn es sich um einen Identitätswechsel auf Delegierungsebene handelt (womit wir uns in Kürze befassen werden) und die Anmeldeinformationen des Tokens für die Authentifizierung an
dem Remotecomputer ausreichen oder die Datei- oder Druckerfreigabe Nullsitzungen erlaubt
(also Sitzungen mit anonymer Anmeldung).
Ist es erforderlich, dass eine gesamte Anwendung im Sicherheitskontext eines Clients ausgeführt wird oder ohne Identitätswechsel auf Netzwerkressourcen zugreift, dann muss der Client
am System angemeldet sein. Die Windows-API-Funktion LogonUser ermöglicht dies. Sie nimmt
einen Kontonamen, ein Kennwort, einen Domänen- oder Computernamen, einen Anmeldetyp
(wie interaktive, Batch- oder Dienstanmeldung) sowie einen Anmeldeanbieter entgegen und
gibt ein Primärtoken zurück. Ein Serverthread kann dieses Token als Identitätswechseltoken
übernehmen; er kann aber auch ein Programm starten, das die Anmeldeinformationen des Clients als sein Primärtoken verwendet. Vom Standpunkt der Sicherheit aus sieht ein Programm,
das mit einem Token von einer interaktiven Anmeldung mit LogonUser erstellt wird, genauso
aus wie ein Programm, das sich zu Anfang interaktiv am Computer anmeldet. Der Nachteil bei
dieser Vorgehensweise besteht darin, dass der Server den Kontonamen und das Kennwort des
Benutzers abrufen muss. Wenn er diese Informationen über das Netzwerk überträgt, muss er
sie sicher verschlüsseln, damit sie nicht von böswilligen Benutzern abgefangen werden können.
Um missbräuchlichen Identitätswechseln vorzubeugen, ist es in Windows nicht zulässig,
dass Server einen solchen Vorgang ohne Zustimmung des Clients vollziehen. Außerdem kann
ein Clientprozess den Grad der Identitätsübernahme einschränken, den ein Serverprozess vornehmen darf, indem er bei der Verbindungsaufnahme mit dem Server eine Sicherheitsdienstqualität (Security Quality of Service, SQOS) angibt. Beispielsweise kann ein Prozess beim Öffnen
einer benannten Pipe SECURITY_ANONYMOUS, SECURITY_IDENTIFICATION, SECURITY_IMPERSONATION
oder SECURITY_DELEGATION als Option für die Windows-Funktion CreateFile festlegen. Diese
Optionen gibt es auch für die zuvor erwähnten anderen Funktionen im Zusammenhang mit
Identitätswechseln. Auf jedem dieser Grade kann ein Server verschiedene Arten von Operationen in Abhängigkeit vom Sicherheitskontext des Clients durchführen:
QQ SecurityAnonymous Dies ist der am stärksten eingeschränkte Grad der Identitätsübernahme. Hierbei ist der Server nicht in der Lage, Informationen über die Identität des Clients
abzurufen oder die Identität zu übernehmen.
QQ SecurityIdentification Bei diesem Grad kann der Server Informationen über die Identität (die SIDs) und die Rechte des Clients abrufen, die Identität des Clients aber nicht
übernehmen.
QQ SecurityImpersonation Hierbei kann der Server Informationen über die Identität des
Clients abrufen und seine Identität auf dem lokalen System übernehmen.
QQ SecurityDelegation Dies ist der am wenigsten eingeschränkte Grad. Der Server kann
die Identität des Clients auf dem lokalen System und auf Remotesystemen übernehmen.
Andere Schnittstellen wie RPC verwenden ihre eigenen Konstanten mit ähnlichen Bedeutungen
(z. B. RPC_C_IMP_LEVEL_IMPERSONATE).
742
Kapitel 7
Sicherheit
Wenn der Client keinen Grad für den Identitätswechel festlegt, wählt Windows SecurityImpersonation. Die Funktion CreateFile akzeptiert auch die Modifikatoren SECURITY_EFFECTIVE_
ONLY und SECURITY_CONTEXT_TRACKING für die Einstellungen des Identitätswechsels:
QQ SECURITY_EFFECTIVE_ONLY Diese Angabe verhindert, dass ein Server Rechte oder
Gruppen eines Clients aktiviert oder deaktiviert, während er dessen Identität übernimmt.
QQ SECURITY_CONTEXT_TRACKING Hierbei spiegelt der Server auch alle laufenden Änderungen am Sicherheitskontext des Clients wider. Ist diese Option nicht angegeben,
übernimmt er den Kontext des Clients in dem Zustand, den er zum Zeitpunkt des Identitätswechsels hat, ohne anschließende Änderungen an dem Clientkontext zu berücksichtigen. Diese Option ist nur dann gültig, wenn sich der Server- und der Clientprozess auf
demselben System befinden.
Um zu verhindern, dass ein Prozess mit niedriger Integritätsebene eine Benutzerschnittstelle
erstellt, darüber Anmeldeinformationen eines Benutzers abfängt und anschließend das Token
des Benutzers über LogonUser abruft, wird bei Identitätswechseln eine besondere Integritätsrichtlinie angewendet: Ein Thread kann die Identität eines Tokens mit einer höheren Inte
gritätsebene als seiner eigenen nicht übernehmen. So ist es einer Anwendung mit niedriger
Integritätsebene nicht möglich, ein Dialogfeld zu fälschen, das Administratoranmeldeinformationen abruft, und anschließend Prozesse mit höheren Rechten zu starten. Die Integritätsrichtlinie für Identitätswechseltokens besagt, dass die Integritätsebene des Zugriffstokens, das
von LsaLogonUser zurückgegeben wird, nicht höher sein darf als diejenige des aufrufenden
Prozesses.
Eingeschränkte Tokens
Ein eingeschränktes Token wird mithilfe der Funktion CreateRestrictedToken aus einem Primäroder Identitätswechseltoken erstellt. Es handelte sich dabei um eine Kopie seines Ursprungstokens mit den folgenden möglichen Änderungen:
QQ Aus dem Rechtearray des Tokens können Rechte entfernt werden.
QQ SIDs in dem Token können als reine Verweigerungseinträge gekennzeichnet werden. Jeglicher Zugriff für diese SIDs, der durch einen entsprechenden Zugriffssteuerungseintrag
verweigert wird, ist tatsächlich untersagt, auch wenn er durch einen zuvor in dem Sicherheitsdeskriptor angegebenen Zugriffssteuerungseintrag für eine Gruppe, zu der die SID
gehört, erlaubt ist.
QQ SIDs in dem Token können als eingeschränkt gekennzeichnet werden. Sie durchlaufen den
Algorithmus für die Zugriffsprüfung ein zweites Mal. Die Ergebnisse des ersten und des
zweiten Durchlaufs müssen den Zugriff auf die Ressource gewähren, damit der Zugriff auf
das Objekt zugelassen wird.
Eingeschränkte Tokens sind praktisch, wenn eine Anwendung die Identität eines Clients auf
einer weniger privilegierten Ebene übernehmen möchte. Dies geschieht hauptsächlich aus
Sicherheitsgründen bei der Ausführung von nicht vertrauenswürdigem Code. Beispielsweise
kann bei einem eingeschränkten Token das Recht zum Herunterfahren des Systems entfernt
Objekte schützen
Kapitel 7
743
werden, damit Code, der in seinem Sicherheitskontext ausgeführt wird, nicht in der Lage ist,
das System neu zu starten.
Gefilterte Administratortokens
Wie Sie bereits gesehen haben, verwendet auch die Benutzerkontensteuerung eingeschränkte
Tokens, um das gefilterte Administratortoken zu erstellen, das alle Benutzeranwendungen erben. Dieses Token weist folgende Merkmale auf:
QQ Als Integritätsebene ist Medium festgelegt.
QQ Die zuvor erwähnten Administrator- und administratorähnlichen SIDs werden als reine
Verweigerungseinträge gekennzeichnet, um eine Sicherheitslücke zu vermeiden, wenn die
Gruppe komplett entfernt werden muss. Verweigert beispielsweise die Zugriffssteuerungsliste einer Datei der Administratorgruppe den Zugriff, erlaubt ihn aber für eine andere
Gruppe, zu der der Benutzer gehört, würde der Benutzer nach wie vor Zugriff haben, wenn
die Administratorgruppe aus dem Token herausgenommen wird. Dadurch hätte die Standardidentität dieses Benutzers mehr Zugriff als seine Administratoridentität.
QQ Alle Rechte außer Änderungsbenachrichtigung, Herunterfahren, Abdocken, Arbeitssatz vergrößern und Zeitzone werden entfernt.
Experiment: Gefilterte Administratortokens einsehen
Im Explorer können Sie einen Prozess mit dem Standardbenutzertoken oder dem Administratortoken ausführen. Gehen Sie dazu auf einem Computer mit aktivierter Benutzerkontensteuerung wie folgt vor:
1.
Melden Sie sich mit einem Konto an, das zur Administratorgruppe gehört.
2.
Öffnen Sie das Startmenü, geben Sie eingabe ein, rechtsklicken Sie auf die eingeblendete Option Eingabeaufforderung und wählen Sie Als Administrator ausführen, um eine
Eingabeaufforderung mit erhöhten Rechten zu starten.
3.
Starten Sie eine weitere Instanz von Cmd.exe, diesmal aber regulär, also ohne erhöhte
Rechte.
4.
Führen Sie Process Explorer mit erhöhten Rechten aus, öffnen Sie das Eigenschaftendialogfeld für die Prozesse der beiden Eingabeaufforderungen und klicken Sie jeweils
auf die Registerkarte Security. Das Standardbenutzertoken enthält eine SID für einen
reinen Verweigerungseintrag sowie die verbindliche Beschriftung Medium. Außerdem
verfügt es nur über wenige Rechte. Das Eigenschaftendialogfeld auf der rechten Seite
des folgenden Screenshots stammt von der Eingabeaufforderung mit Administratortoken, das auf der linken Seite von dem mit gefiltertem Administratortoken:
→
744
Kapitel 7
Sicherheit
Virtuelle Dienstkonten
Windows bietet eine besondere Art von Konten, die als virtuelle Dienstkonten (oder kurz virtuelle Konten) bezeichnet werden und die Isolierung und Zugriffssteuerung von Windows-Diensten mit einem Minimum an Verwaltungsaufwand verbessern. (Mehr Informationen über
Windows-Dienste erhalten Sie in Kapitel 9 von Band 2.) Ohne diesen Mechanismus müssten
Windows-Dienste unter einem der für die integrierten Dienste definierten Konten (wie Lokaler
Dienst oder Netzwerkdienst) oder unter einem regulären Domänenkonto laufen. Konten wie
Lokaler Dienst werden jedoch von vielen Diensten gemeinsam genutzt und bieten daher keine
besonders detaillierte Rechte- und Zugriffssteuerung. Außerdem lassen sie sich nicht domänenweit verwalten. Bei Domänenkonten ist es aus Sicherheitsgründen erforderlich, regelmäßig
das Kennwort zu ändern, was die Verfügbarkeit der Dienste während eines solchen Wechsels
beeinträchtigen kann. Außerdem sollte jeder Dienst zur bestmöglichen Isolierung eigentlich
unter seinem eigenen Konto laufen, was aber bei regulären Konten einen erheblichen Verwaltungsaufwand hervorrufen würde.
Bei der Verwendung virtueller Dienstkonten läuft jeder Dienst unter seinem eigenen Konto
mit seiner eigenen SID. Der Name des Kontos lautet stets NT-DIENST\, gefolgt vom internen
Namen des Dienstes. Virtuelle Dienstkonten können wie alle anderen Konten in Zugriffssteuerungslisten verwendet und über Gruppenrichtlinien mit Rechten versehen werden. Sie lassen
sich jedoch mit den üblichen Werkzeugen zur Kontoverwaltung nicht erstellen, löschen und
Gruppen zuweisen.
Objekte schützen
Kapitel 7
745
Die Kennwörter für virtuelle Dienstkonten werden von Windows automatisch eingerichtet
und regelmäßig geändert. Ähnlich wie Lokales System und andere Dienstkonten haben sie ein
Kennwort, das den Systemadministratoren aber unbekannt ist.
Experiment: Virtuelle Dienstkonten verwenden
Mit dem Hilfsprogramm Service Control (Sc.exe) können Sie einen Dienst erstellen, der unter
einem virtuellen Dienstkonto läuft. Gehen Sie dazu wie folgt vor:
1.
Starten Sie an einer Eingabeaufforderung mit erhöhten Rechten das Befehlszeilenwerkzeug Sc.exe und geben Sie darin create ein, um einen Dienst sowie ein virtuelles
Konto zu erstellen, unter dem er ausgeführt werden soll. In diesem Beispiel verwenden wir den Dienst srvany aus dem Windows 2003 Resource Kit, das Sie von https://
www.microsoft.com/en-us/download/details.aspx?id=17657 herunterladen können.
C:\Windows\system32>sc create srvany obj= "NT SERVICE\srvany" binPath="c:\
temp\srvany.exe"
[SC] CreateService SUCCESS
2.
Der vorstehende Befehl erstellt den Dienst (in der Registrierung und in der internen
Liste des Dienststeuerungs-Managers) und das virtuelle Dienstkonto. Starten Sie jetzt
das MMC-Snap-In Dienste (Services.msc), markieren Sie den neuen Dienst und öffnen
Sie sein Eigenschaftendialogfeld.
→
746
Kapitel 7
Sicherheit
3.
Rufen Sie die Registerkarte Anmelden auf.
4.
Im Eigenschaftendialogfeld eines bestehenden Dienstes können Sie ein virtuelles
Dienstkonto dafür erstellen. Ändern Sie dazu den Kontonamen im Feld Dieses Konto
in NT-DIENST\Dienstname und leeren Sie beide Kennwortfelder. Beachten Sie aber, dass
bestehende Dienste möglicherweise nicht korrekt unter einem virtuellen Dienstkonto
laufen, da dieses Konto unter Umständen keinen Zugriff auf Dateien oder andere Ressourcen hat, die der Dienst braucht.
→
Objekte schützen
Kapitel 7
747
5.
In Process Explorer können Sie auf der Registerkarte Security des Eigenschaftsdialogfelds für einen Dienst, der ein virtuelles Konto verwendet, den Namen dieses virtuellen
Kontos und seine Sicherheitskennung (SID) sehen. Geben Sie dazu im Eigenschaftendialogfeld des Dienstes srvany das Befehlszeilenargument notepad.exe ein. (Mit srvany
können Sie normale ausführbare Dateien in Dienste verwandeln, weshalb er an der
Befehlszeile den Namen einer ausführbaren Datei entgegennimmt.) Klicken Sie anschließend auf Start, um den Dienst zu starten.
→
748
Kapitel 7
Sicherheit
6.
Das virtuelle Dienstkonto kann in den Zugriffssteuerungseinträgen jeglicher Objekte
(z. B. Dateien) verwendet werden, auf die der Dienst zugreifen muss. Wenn Sie die
Registerkarte Security im Eigenschaftendialogfeld für eine Datei aufrufen und eine Zugriffssteuerungsliste erstellen, die auf das virtuelle Dienstkonto verweist, werden Sie
feststellen, dass die Funktionen zur Namensüberprüfung den von Ihnen eingegebenen
Kontonamen (z. B. NT-DIENST\srvany) in den Dienstnamen umgewandelt hat (srvany).
In dieser abgekürzten Form erscheint er auch in der Zugriffssteuerungsliste.
→
Objekte schützen
Kapitel 7
749
7.
Mithilfe von Gruppenrichtlinien können Sie dem virtuellen Dienstkonto Berechtigungen (oder Benutzerrechte) zuweisen. In diesem Beispiel hat der Dienst srvany das Recht
erhalten, eine Auslagerungsdatei zu erstellen. Dazu wurde der Editor für lokale Sicherheitsrichtlinien (Secpol.msc) verwendet.
→
750
Kapitel 7
Sicherheit
8.
In Benutzerverwaltungswerkzeugen wie Iusrmgr.msc wird das virtuelle Dienstkonto
nicht angezeigt, da es nicht im Registrierungshive SAM gespeichert ist. Wenn Sie sich die
Registrierung aber (wie zuvor beschrieben) im Kontext des integrierten Systemkontos
ansehen, finden Sie Belege für das Vorhandensein dieses Kontos im Schlüssel HKLM\
Security\Policy\Secrets:
C:\>psexec –s –i –d regedit.exe
Sicherheitsdeskriptoren und Zugriffssteuerung
Tokens, die die Anmeldeinformationen eines Benutzers angeben, sind nur ein Teil der Gleichung für die Objektsicherheit. Ein weiterer Teil besteht aus den Sicherheitsinformationen, die
mit einem Objekt verknüpft sind und angeben, wer welche Aktionen an dem Objekt ausführen
kann. Die Datenstruktur für diese Information wird als Sicherheitsdeskriptor bezeichnet. Er besteht aus den folgenden Attributen:
QQ Revisionsnummer Dies ist die Versionsnummer des SRM-Sicherheitsmodells, das zum
Erstellen des Deskriptors verwendet wurde.
QQ Flags Diese optionalen Modifizierer legen das Verhalten oder die Eigenschaften des
Deskriptors fest. Sie sind in Tabelle 7–5 aufgeführt (und die meisten von ihnen sind im
Windows SDK dokumentiert).
QQ Besitzer-SID
QQ Gruppen-SID Die SID der primären Gruppe des Objekts. Dieses Attribut wurde vom
POSIX-Teilsystem verwendet. Da POSIX nicht mehr unterstützt wird, ist es nicht länger in
Gebrauch.
Objekte schützen
Kapitel 7
751
QQ Benutzerverwaltete Zugriffssteuerungsliste (Discretionary Access Control List,
DACL) Gibt an, wer welchen Zugriff auf das Objekt hat.
QQ Systemzugriffssteuerungsliste (System Access Control List, SACL) Gibt an, welche
Operationen welcher Benutzer im Systemüberwachungsprotokoll festgehalten werden sollen, und legt die ausdrückliche Integritätsebene des Objekts fest.
Flag
Bedeutung
SE_OWNER_DEFAULTED
Kennzeichnet einen Sicherheitsdeskriptor mit einer standardmäßigen Besitzer-SID. Verwenden Sie dieses Bit, um alle Objekte zu finden, die über
standardmäßige Besitzerberechtigungen verfügen.
SE_GROUP_DEFAULTED
Kennzeichnet einen Sicherheitsdeskriptor mit einer standardmäßigen
Gruppen-SID. Verwenden Sie dieses Bit, um alle Objekte zu finden, die
über standardmäßige Gruppenberechtigungen verfügen.
SE_DACL_PRESENT
Kennzeichnet einen Sicherheitsdeskriptor mit einer DACL. Wenn dieses
Flag nicht gesetzt ist oder wenn die DACL NULL ist, gewährt der Sicher
heitsdeskriptor Vollzugriff für alle.
SE_DACL_DEFAULTED
Kennzeichnet einen Sicherheitsdeskriptor mit einer Standard-DACL.
Wenn ein Objektersteller keine DACL angibt, erhält das Objekt die
Standard-DACL vom Zugriffstoken des Erstellers. Dieses Flag wirkt sich
darauf aus, wie das System die DACL im Hinblick auf die Vererbung von
Zugriffssteuerungseinträgen behandelt. Wenn SE_DACL_PRESENT nicht
gesetzt ist, wird dieses Flag ignoriert.
SE_SACL_PRESENT
Kennzeichnet einen Sicherheitsdeskriptor mit einer SACL.
SE_SACL_DEFAULTED
Kennzeichnet einen Sicherheitsdeskriptor mit einer Standard-SACL.
Wenn ein Objektersteller keine SACL angibt, erhält das Objekt die Standard-SACL vom Zugriffstoken des Erstellers. Dieses Flag wirkt sich darauf
aus, wie das System die SACL im Hinblick auf die Vererbung von Zugriffssteuerungseinträgen behandelt. Wenn SE_SACL_PRESENT nicht gesetzt ist,
wird dieses Flag ignoriert.
SE_DACL_UNTRUSTED
Gibt an, dass die Zugriffssteuerungsliste, auf die die DACL des Sicherheitsdeskriptors zeigt, aus einer nicht vertrauenswürdigen Quelle stammt.
Wenn dieses Flag gesetzt ist, ersetzt das System Server-SIDs in zusammengesetzten Zugriffssteuerungseinträgen durch bekannte gültige SIDs.
SE_SERVER_SECURITY
Verlangt, dass der Anbieter für das von dem Sicherheitsdeskriptor geschützte Objekt eine Serverzugriffssteuerungsliste auf der Grundlage der
Zugriffssteuerungsliste in der Eingabe sein muss, und zwar unabhängig
von ihrer Quelle (explizit angegebene oder Standardzugriffssteuerungsliste). Dazu werden alle GRANT-Zugriffssteuerungseinträge durch
zusammengesetzte Einträge ersetzt, die dem aktuellen Server Zugriff
gewähren. Dieses Flag ist nur dann sinnvoll, wenn das Subjekt einen
Identitätswechsel vornimmt.
SE_DACL_AUTO_INHERIT_REQ
Verlangt, dass der Anbieter für das von dem Sicherheitsdeskriptor geschützte Objekt die DACL automatisch auf die Kindobjekte überträgt.
Wenn der Anbieter eine automatische Vererbung unterstützt, wird
die DACL auf alle vorhandenen Kindobjekte übertragen und das Bit
SE_DACL_AUTO_INHERITED in den Sicherheitsdeskriptoren des Elternund des Kindobjekts gesetzt.
SE_SACL_AUTO_INHERIT_REQ
Verlangt, dass der Anbieter für das von dem Sicherheitsdeskriptor geschützte Objekt die SACL automatisch auf die Kindobjekte überträgt.
Wenn der Anbieter eine automatische Vererbung unterstützt, wird
die SACL auf alle vorhandenen Kindobjekte übertragen und das Bit
SE_SACL_AUTO_INHERITED in den Sicherheitsdeskriptoren des Elternund des Kindobjekts gesetzt.
752
Kapitel 7
Sicherheit
→
Flag
Bedeutung
SE_DACL_AUTO_INHERITED
Kennzeichnet einen Sicherheitsdeskriptor, in dem die DACL für die automatische Übertragung vererbbarer Zugriffssteuerungseinträge an vorhandene Kindobjekte eingerichtet ist. Das System setzt dieses Bit, wenn
es den Algorithmus für die automatische Vererbung an dem Objekt und
seinen vorhandenen Kindobjekten ausführt.
SE_SACL_AUTO_INHERITED
Kennzeichnet einen Sicherheitsdeskriptor, in dem die SACL für die automatische Übertragung vererbbarer Zugriffssteuerungseinträge an vorhandene Kindobjekte eingerichtet ist. Das System setzt dieses Bit, wenn
es den Algorithmus für die automatische Vererbung an dem Objekt und
seinen vorhandenen Kindobjekten ausführt.
SE_DACL_PROTECTED
Verhindert, dass die DACL eines Sicherheitsdeskriptors durch vererbbare
Zugriffssteuerungseinträge verändert wird.
SE_SACL_PROTECTED
Verhindert, dass die SACL eines Sicherheitsdeskriptors durch vererbbare
Zugriffssteuerungseinträge verändert wird.
SE_RM_CONTROL_VALID
Gibt an, dass die Bits für den Ressourcensteuerungs-Manager in dem Sicherheitsdeskriptor gültig sind. Dabei handelt es sich um acht Bits in der
Struktur des Sicherheitsdeskriptors mit Informationen für den Ressourcen-Manager, der auf die Struktur zugreift.
SE_SELF_RELATIVE
Kennzeichnet einen Sicherheitsdeskriptor in einem selbstbezüglichen
Format, bei dem sich alle Sicherheitsinformationen in einem zusammenhängenden Speicherblock befinden. Wenn dieses Flag nicht gesetzt ist,
weist der Sicherheitsdeskriptor ein absolutes Format auf.
Tabelle 7–5 Flags für Sicherheitsdeskriptoren
Sicherheitsdeskriptoren lassen sich in Programmen mit verschiedenen Funktionen abrufen,
z. B. mit GetSecurityInfo, GetKernelObjectSecurity, GetFileSecurity, GetNamedSecurityInfo
und weiteren, noch esoterischeren Funktionen. Anschließend können Sie den Deskriptor bearbeiten und die zugehörige Set-Funktion aufrufen, um die Änderung vorzunehmen. Überdies
bietet die Sprache SDDL (Security Descriptor Definition Language) die Möglichkeit, einen Sicherheitsdeskriptor in Form eines kompakten Strings zusammenzusetzen, den Sie dann durch
einen Aufruf von ConvertStringSecurityDescriptorToSecurityDescriptor in einen echten Sicherheitsdeskriptor verwandeln können. Wie zu erwarten, gibt es auch die Umkehrfunktion
ConvertSecurityDescriptorToStringSecurityDescriptor. Eine ausführliche Beschreibung der
SDDL finden Sie im Windows SDK.
Eine Zugriffssteuerungsliste besteht aus einem Header und null oder mehr Strukturen für
Zugriffssteuerungseinträge (Access Control Entries, ACEs). Es gibt zwei Arten von Zugriffssteuerungslisten, DACLs und SACLs. In einer DACL enthält jeder Zugriffssteuerungseintrag
eine SID und eine Zugriffsmaske (einen Satz von Flags, wie wir in Kürze erklären werden). Diese Maske gibt die Zugriffsrechte (Lesen, Schreiben, Löschen usw.) an, die dem Halter der SID
gewährt oder verweigert werden. In einer DACL können neun Arten von Zugriffssteuerungseinträgen auftreten: Zugriff gewährt, Zugriff verweigert, Objekt gewährt, Objekt verweigert,
Callback gewährt, Callback verweigert, Objektcallback gewährt, Objektcallback verweigert
und bedingte Ansprüche. Wie zu erwarten, erlauben Zugriffssteuerungseinträge vom Typ
»Zugriff gewährt« einem Benutzer den Zugriff, während Einträge vom Typ »Zugriff verweigert« die in der Zugriffsmaske angegebenen Zugriffsrechte verweigern. Die Callbackeinträge
werden von Anwendungen genutzt, die die AuthZ-API verwenden, um einen Callback zu re-
Objekte schützen
Kapitel 7
753
gistrieren, den AuthZ bei der Zugriffsprüfung anhand des vorliegenden Zugriffssteuerungseintrags aufruft.
Der Unterschied zwischen »Zugriff gewährt/verweigert« und »Objekt gewährt/verweigert« besteht darin, dass die »Objekt«-Einträge nur in Active Directory verwendet werden.
Zugriffssteuerungseinträge dieser Art weisen ein GUID-Feld auf. Es bedeutet, dass der Eintrag
nur für Objekte oder Unterobjekte gilt, die über GUID, also global eindeutige Bezeichner (Globally Unique Identifier) von 128 Bit verfügen. Wenn in einem Active Directory-Container mit
Zugriffssteuerungseintrag ein Kindobjekt erstellt wird, gibt ein weiterer, optionaler GUID an,
welche Art von Kindobjekt den Eintrag erbt. Der Eintrag für bedingte Ansprüche ist in einer
ACE-Struktur von einem der Callbacktypen gespeichert und wird im Abschnitt über AuthZ beschrieben.
Die Zugriffsrechte, die durch die einzelnen Zugriffssteuerungseinträge gewährt werden,
bilden zusammen die Menge der Zugriffsrechte, die die Zugriffssteuerungsliste gewährt. Wenn
in einem Sicherheitsdeskriptor keine DACL angegeben ist (oder eine NULL-DACL), haben alle
Vollzugriff auf das Objekt. Ist die DACL leer (enthält sie also keine Einträge), hat kein Benutzer
Zugriff auf das Objekt.
Für Zugriffssteuerungseinträge in DACLs gibt es auch Flags, die die Vererbung der Einträge
regeln. In einigen Objektnamensräumen gibt es Container und Objekte, wobei ein Container
andere Container- und Blattobjekte enthalten kann, die dann seine Kindobjekte sind. Container
können beispielsweise Verzeichnisse im Namensraum des Dateisystems sein oder Schlüssel im
Namensraum der Registrierung. Bestimmte Flags in einem Zugriffssteuerungseintrag legen
fest, wie der Eintrag an die Kindobjekte des Containers vererbt wird, zu dem der Eintrag gehört. Tabelle 7–6, entnommen aus dem Windows SDK, führt einige ACE-Flags und die damit
festgelegten Vererbungsregeln auf.
Flag
Vererbungsregel
CONTAINER_INHERIT_ACE
Kindobjekte, die selbst Container sind, z. B. Verzeichnisse, erben den
Zugriffssteuerungseintrag als effektiven Zugriffssteuerungseintrag. Der
geerbte Eintrag kann weitervererbt werden, es sei denn, dass das Bit
NO_PROPAGATE_INHERIT_ACE ebenfalls gesetzt ist.
INHERIT_ONLY_ACE
Dieses Flag kennzeichnet einen reinen Vererbungs-ACE, der nicht dazu
dient, den Zugriff auf das zugehörige Objekt zu steuern.
INHERITED_ACE
Dieses Flag gibt an, dass der Zugriffssteuerungseintrag geerbt wurde.
Das System setzt dieses Bit, wenn es einen vererbbaren Eintrag auf ein
Kindobjekt überträgt.
NO_PROPAGATE_INHERIT_ACE
Wird der Zugriffssteuerungseintrag von einem Kindobjekt geerbt,
entfernt das System aus dem Eintrag die Flags OBJECT_INHERIT_ACE
und CONTAINER_INHERIT_ACE. Dadurch wird verhindert, dass er an die
nächste Objektgeneration weitervererbt wird.
OBJECT_INHERIT_ACE
Kindobjekte, die keine Container sind, erben den Zugriffssteuerungseintrag als effektiven Zugriffssteuerungseintrag. Kindobjekte, die Container sind, erben ihn dagegen als reinen Vererbungs-ACE, es sei denn,
dass das Flag NO_PROPAGATE_INHERIT_ACE ebenfalls gesetzt ist.
Tabelle 7–6 ACE-Flags für Vererbungsregeln
754
Kapitel 7
Sicherheit
Eine SACL enthält zwei Arten von Zugriffssteuerungseinträgen, nämlich Systemüberwachungs-ACEs und Systemüberwachungsobjekt-ACEs. Sie geben an, welche Operationen, die
die angegebenen Benutzer oder Gruppen an dem Objekt ausführen, überwacht werden sollen. Die Überwachungsinformationen werden im Systemüberwachungsprotokoll gespeichert.
Dabei können sowohl erfolgreiche als auch fehlgeschlagene Versuche aufgezeichnet werden.
Ebenso wie die objektspezifischen DACL-Einträge weisen auch die Systemüberwachungsobjekt-ACEs einen GUID auf, der angibt, für welche Arten von Objekten oder Unterobjekten der
Eintrag jeweils gilt, sowie einen optionalen GUID, der die Vererbung des Eintrags an bestimmte Arten von Kindobjekten regelt. Ist die SACL NULL, findet keine Überwachung statt. (Die
Sicherheitsüberwachung wird weiter hinten in diesem Kapitel beschrieben.) Die Vererbungsflags für DACL-Einträge gelten auch für Systemüberwachungs- und Systemüberwachungsobjekt-ACEs.
Abb. 7–8 gibt eine vereinfachte Darstellung eines Dateiobjekts und seiner DACL. Der erste
Zugriffssteuerungseintrag erlaubt dem Benutzer USER1, die Datei zu lesen, der zweite verweigert den Mitgliedern der Gruppe TEAM1 den Zugriff auf die Datei und der dritte gewährt allen
Benutzern (Jeder) Ausführungszugriff.
Dateiobjekt
Sicherheits
deskriptor
Zulassen
USER1
Daten lesen
Verweigern
TEAM1
Daten schreiben
Zulassen
Jeder
Datei ausführen
Abbildung 7–8 Besitzerverwaltete Zugriffssteuerungsliste (DACL)
Experiment: Einen Sicherheitsdeskriptor einsehen
Die meisten Teilsysteme der Exekutive verlassen sich zur Verwaltung der Sicherheitsdeskriptoren für ihre Objekte auf die regulären Sicherheitsfunktionen des Objekt-Managers. Um
die Sicherheitsdeskriptoren für diese Objekte zu speichern, nutzen diese Funktionen einen
entsprechenden Zeiger. Beispielsweise hinterlegt der Objekt-Manager in den Headern von
Prozess- und Threadobjekten Verweise auf die Sicherheitsdeskriptoren der Prozesse bzw.
Threads. Auch in den entsprechenden Zeigern von Ereignissen, Mutexen und Semaphoren
werden Verweise auf deren Sicherheitsdeskriptoren gespeichert. Mit einem Live-Kerneldebugging können Sie sich wie folgt die Sicherheitsdeskriptoren dieser Objekte ansehen.
Dazu müssen Sie als Erstes deren Header ausfindig machen. Sicherheitsdeskriptoren für
Prozesse können Sie sich auch in Process Explorer und mit AccessChk anzeigen lassen.
→
Objekte schützen
Kapitel 7
755
1.
Beginnen Sie mit dem lokalen Kerneldebugger.
2.
Geben Sie !process 0 0 explorer.exe ein, um Informationen über den Explorer-Prozess
abzurufen:
lkd> !process 0 0 explorer.exe
PROCESS ffffe18304dfd780
SessionId: 1 Cid: 23e4 Peb: 00c2a000 ParentCid: 2264
DirBase: 2aa0f6000 ObjectTable: ffffcd82c72fcd80 HandleCount: <Data Not
Accessible>
Image: explorer.exe
PROCESS ffffe1830670a080
SessionId: 1 Cid: 27b8 Peb: 00950000 ParentCid: 035c
DirBase: 2cba97000 ObjectTable: ffffcd82c7ccc500 HandleCount: <Data Not
Accessible>
Image: explorer.exe
3.
Wird mehr als eine Instanz des Explorers angezeigt, wählen Sie willkürlich eine davon
aus. Geben Sie !object mit der Adresse der EPROCESS-Struktur aus der Ausgabe des vorherigen Befehls als Argument ein, um sich die Objektdatenstruktur anzeigen zu lassen:
lkd> !object ffffe18304dfd780
Object: ffffe18304dfd780 Type: (ffffe182f7496690) Process
ObjectHeader: ffffe18304dfd750 (new version)
HandleCount: 15 PointerCount: 504639
4.
Geben Sie dt _OBJECT_HEADER und die Adresse des Objektheaderfelds aus der Ausgabe des vorherigen Befehls ein, um sich die Datenstruktur des Objektheaders anzusehen. Darunter befindet sich auch der Zeiger auf den Sicherheitsdeskriptor:
lkd> dt nt!_object_header ffffe18304dfd750
+0x000 PointerCount
: 0n504448
+0x008 HandleCount
: 0n15
+0x008 NextToFree
: 0x00000000'0000000f Void
+0x010 Lock
: _EX_PUSH_LOCK
+0x018 TypeIndex
: 0xe5 ''
+0x019 TraceFlags
: 0 ''
+0x019 DbgRefTrace
: 0y0
+0x019 DbgTracePermanent : 0y0
+0x01a InfoMask
: 0x88 ''
+0x01b Flags
: 0 ''
+0x01b NewObject
: 0y0
+0x01b KernelObject
: 0y0
+0x01b KernelOnlyAccess
: 0y0
+0x01b ExclusiveObject
: 0y0
→
756
Kapitel 7
Sicherheit
+0x01b PermanentObject
: 0y0
+0x01b DefaultSecurityQuota : 0y0
+0x01b SingleHandleEntry : 0y0
+0x01b DeletedInline
: 0y0
+0x01c Reserved
: 0x30003100
+0x020 ObjectCreateInfo
: 0xffffe183'09e84ac0 _OBJECT_CREATE_INFORMATION
+0x020 QuotaBlockCharged : 0xffffe183'09e84ac0 Void
+0x028 SecurityDescriptor : 0xffffcd82'cd0e97ed Void
+0x030 Body
5.
: _QUAD
Jetzt können Sie den Sicherheitsdeskriptor mit dem Debuggerbefehl !sd abrufen. Im
Objektheader werden in dem Zeiger auf den Sicherheitsdeskriptor einige der niederwertigen Bits als Flags verwendet, weshalb Sie sie erst auf null setzen müssen, bevor Sie
dem Zeiger folgen können. Auf 32-Bit-Systemen gibt es drei Flagbits. Daher müssen Sie
auf die in der Objektheaderstruktur angegebene Deskriptoradresse noch & -8 anwenden. Auf 64-Bit-Systemen mit vier Flagbits verwenden Sie stattdessen & -10.
lkd> !sd 0xffffcd82'cd0e97ed & -10
->Revision: 0x1
->Sbz1
: 0x0
->Control : 0x8814
SE_DACL_PRESENT
SE_SACL_PRESENT
SE_SACL_AUTO_INHERITED
SE_SELF_RELATIVE
->Owner
: S-1-5-21-3537846094-3055369412-2967912182-1001
->Group
: S-1-5-21-3537846094-3055369412-2967912182-1001
->Dacl
:
->Dacl
: ->AclRevision: 0x2
->Dacl
: ->Sbz1
: 0x0
->Dacl
: ->AclSize
: 0x5c
->Dacl
: ->AceCount
: 0x3
->Dacl
: ->Sbz2
: 0x0
->Dacl
: ->Ace[0]: ->AceType: ACCESS_ALLOWED_ACE_TYPE
->Dacl
: ->Ace[0]: ->AceFlags: 0x0
->Dacl
: ->Ace[0]: ->AceSize: 0x24
->Dacl
: ->Ace[0]: ->Mask : 0x001fffff
->Dacl
: ->Ace[0]: ->SID: S-1-5-21-3537846094-3055369412-2967912182-1001
->Dacl
: ->Ace[1]: ->AceType: ACCESS_ALLOWED_ACE_TYPE
->Dacl
: ->Ace[1]: ->AceFlags: 0x0
->Dacl
: ->Ace[1]: ->AceSize: 0x14
->Dacl
: ->Ace[1]: ->Mask : 0x001fffff
→
Objekte schützen
Kapitel 7
757
->Dacl
: ->Ace[1]: ->SID: S-1-5-18
->Dacl
: ->Ace[2]: ->AceType: ACCESS_ALLOWED_ACE_TYPE
->Dacl
: ->Ace[2]: ->AceFlags: 0x0
->Dacl
: ->Ace[2]: ->AceSize: 0x1c
->Dacl
: ->Ace[2]: ->Mask : 0x00121411
->Dacl
: ->Ace[2]: ->SID: S-1-5-5-0-1745560
->Sacl
:
->Sacl
: ->AclRevision: 0x2
->Sacl
: ->Sbz1
: 0x0
->Sacl
: ->AclSize
: 0x1c
->Sacl
: ->AceCount
: 0x1
->Sacl
: ->Sbz2
: 0x0
->Sacl
: ->Ace[0]: ->AceType: SYSTEM_MANDATORY_LABEL_ACE_TYPE
->Sacl
: ->Ace[0]: ->AceFlags: 0x0
->Sacl
: ->Ace[0]: ->AceSize: 0x14
->Sacl
: ->Ace[0]: ->Mask : 0x00000003
->Sacl
: ->Ace[0]: ->SID: S-1-16-8192
Der Sicherheitsdeskriptor enthält drei Zugriffssteuerungseinträge vom Typ »Zugriff gewährt«: einen für den aktuellen Benutzer (S-1-5-21-3537846094-3055369412-29679121821001), einen für das Systemkonto (S-1-5-18) und einen dritten für die Anmelde-SID (S-1-55-0-1745560). Die Systemzugriffssteuerungsliste hat nur einen Eintrag (S-1-16-8192).
Zuweisung von Zugriffssteuerungslisten
Um zu bestimmen, welche DACL es einem neuen Objekt zuweisen soll, wendet das Sicherheitssystem die erste der folgenden vier Regeln an, die in dem jeweiligen Fall geeignet ist:
1.
Wenn der Aufrufer beim Erstellen des Objekts ausdrücklich einen Sicherheitsdeskriptor
angibt, wendet das Sicherheitssystem diesen auf das Objekt an. Hat das Objekt einen Namen und befindet es sich in einem Containerobjekt (z. B. ein benanntes Ereignisobjekt
im Verzeichnis \BaseNamedObjects des Objekt-Manager-Namensraums), führt das System
alle vererbbaren Zugriffssteuerungseinträge (also solche, die vom Container des Objekts
übernommen werden können) in der DACL zusammen, es sei denn, dass das Flag SE_DACL_
PROTECTED gesetzt ist, das eine Vererbung verhindert.
2.
Wenn der Aufrufer keinen Sicherheitsdeskriptor angegeben hat, das Objekt aber benannt
ist, schaut sich das Sicherheitssystem den Sicherheitsdeskriptor des Containers an, in dem
der neue Objektname gespeichert ist. Einige der Zugriffssteuerungseinträge für das Objektverzeichnis können als vererbbar gekennzeichnet sein, was bedeutet, dass sie auf neue,
in diesem Verzeichnis erstellte Objekte angewendet werden sollten. Sind solche vererbbaren Einträge vorhanden, bildet das Sicherheitssystem daraus eine Zugriffssteuerungsliste,
die es an das neue Objekt anhängt. (Manche Einträge können durch besondere Flags auch
758
Kapitel 7
Sicherheit
so gekennzeichnet sein, dass sie nur von Containerobjekten und nicht von anderen Arten
von Objekten geerbt werden können.)
3.
Wenn kein Sicherheitsdeskriptor angegeben ist und das Objekt keine Zugriffssteuerungseinträge erbt, ruft das Sicherheitssystem die Standard-DACL vom Zugriffstoken des Aufrufers ab und wendet sie auf das neue Objekt an. Mehrere Teilsysteme von Windows
verfügen über hartcodierte DACLs, die sie beim Erstellen eines Objekts zuweisen (z. B.
Dienste, LSA- und SAM-Objekte).
4.
Wenn kein Sicherheitsdeskriptor angegeben ist, keine Zugriffssteuerungseinträge geerbt
werden und es auch keine Standard-DACL gibt, erstellt das System das Objekt ohne DACL.
Dadurch hat Jeder (also alle Benutzer und Gruppen) Vollzugriff auf das Objekt. Die dritte
Regel ist mit dieser identisch, wenn das Token eine NULL-Standard-DACL angibt.
Bei der Zuweisung einer SACL zu einem neuen Objekt wendet das System ähnliche Regeln wie
für die DACL an, allerdings mit folgenden Ausnahmen:
QQ Geerbte Systemüberwachungs-ACEs werden nicht an Objekte weitervererbt, deren Sicherheitsdeskriptoren das Flag SE_SACL_PROTECTED aufweisen (vergleichbar mit dem Flag
SE_DACL_PROTECTED zum Schutz von DACLs).
QQ Sind keine Sicherheitsüberwachungs-ACEs angegeben und wird keine SACL geerbt, so
wird auf das Objekt keine SACL angewendet. Dieses Verhalten unterscheidet sich von dem
bei DACL, bei denen im vergleichbaren Fall eine Standard-DACL verwendet wird. Das liegt
daran, dass es eine Standard-SACL nicht gibt.
Wird auf einen Container ein neuer Sicherheitsdeskriptor angewendet, der vererbbare Zugriffssteuerungseinträge enthält, so überträgt das System diese Einträge automatisch auf die
Sicherheitsdeskriptoren der Kindobjekte. (Allerdings werden solche geerbten Einträge nicht akzeptiert, wenn das Flag SE_DACL_PROTECTED bzw. SE_SACL_PROTECTED gesetzt ist.) Dabei werden
die vererbbaren Einträge so mit dem vorhandenen Sicherheitsdeskriptor des Kindobjekts zusammengeführt, dass die ausdrücklich auf die Zugriffssteuerungsliste angewendeten Einträge
vor den geerbten stehen. Zur Vererbung von Zugriffssteuerungseinträgen wendet das System
die folgenden Regeln an:
QQ Wenn ein Kindobjekt ohne DACL einen Zugriffssteuerungseintrag erbt, ergibt sich ein
Kindobjekt mit einer DACL, die nur diesen geerbten Eintrag enthält.
QQ Wenn ein Kindobjekt mit einer leeren DACL einen Zugriffssteuerungseintrag erbt, ergibt
sich ein Kindobjekt mit einer DACL, die nur diesen geerbten Eintrag enthält.
QQ Ausschließlich für Active Directory-Objekte gilt: Wenn ein vererbbarer Zugriffssteuerungseintrag von einem Objekt entfernt wird, sorgt die automatische Vererbung dafür, dass
jegliche Kopien dieses Eintrags in Kindobjekten ebenfalls entfernt werden.
QQ Ausschließlich für Active Directory-Objekte gilt: Werden durch die automatische Vererbung sämtliche Zugriffssteuerungseinträge aus der DACL eines Kindobjekts entfernt, so
hat es anschließend eine leere DACL und nicht keine DACL.
Wie Sie in Kürze sehen werden, spielt die Reihenfolge der Einträge in einer Zugriffssteuerungsliste eine wichtige Rolle im Sicherheitsmodell von Windows.
Objekte schützen
Kapitel 7
759
Von Objektspeichern wie Dateisystemen, der Registrierung und Active Directory
wird die Vererbung im Allgemeinen nicht direkt unterstützt. Windows-APIs zur
Vererbung wie SetEntriesInAcl rufen dazu entsprechende Funktionen der DLL für
die Sicherheitsvererbung auf (%SystemRoot%\System32\Ntmarta.dll), die wissen,
wie sie diese Objektspeicher durchlaufen müssen.
Vertrauenseinträge
Durch die Einführung von geschützten Prozessen und PPLs (Protected Processes Light; siehe
Kapitel 3) wurde eine Vorkehrung benötigt, um dafür zu sorgen, dass Objekte nur für geschützte Prozesse zugänglich sind. Das ist wichtig, um bestimmte Ressourcen, etwa den Registrierungsschlüssel KnownDlls, gegen Manipulation zu schützen, selbst gegen Manipulation
durch Code auf Administratorebene. Entsprechende Zugriffssteuerungseinträge werden mit
Standard-SIDs versehen, die den erforderlichen Schutzgrad und den erforderlichen Signierer
für den Zugriff angeben. Tabelle 7–7 führt dieses SIDs und ihre Bedeutung auf.
SID
Schutzgrad
Signierer
1-19-512-0
PPL
Keiner
1-19-512-4096
PPL
Windows
1-19-512-8192
PPL
WinTcb
1-19-1024-0
Geschützt
Keiner
1-19-1024-4096
Geschützt
Windows
1-19-1024-8192
Geschützt
WinTcb
Tabelle 7–7 Vertrauens-SIDs
Eine Vertrauens-SID ist Teil eines Tokenobjekts für einen geschützten oder einen PPL-Prozess.
Je höher die SID-Nummer, umso leistungsstärker ist das Token. (»Geschützt« ist ein höherer
Grad als »PPL«.)
760
Kapitel 7
Sicherheit
Experiment: Vertrauens-SIDs einsehen
In diesem Experiment schauen Sie sich die Vertrauens-SIDs in den Tokens von geschützten
Prozessen an.
1.
Starten Sie den lokalen Kerneldebugger.
2.
Lassen Sie sich grundlegende Informationen über den Prozess Csrss.exe anzeigen:
lkd> !process 0 1 csrss.exe
PROCESS ffff8188e50b5780
SessionId: 0 Cid: 0358 Peb: b3a9f5e000 ParentCid: 02ec
DirBase: 1273a3000 ObjectTable: ffffbe0d829e2040 HandleCount: <Data Not
Accessible>
Image: csrss.exe
VadRoot ffff8188e6ccc8e0 Vads 159 Clone 0 Private 324. Modified 4470.
Locked 0.
DeviceMap ffffbe0d70c15620
Token ffffbe0d829e7060
...
PROCESS ffff8188e7a92080
SessionId: 1 Cid: 03d4 Peb: d5b0de4000 ParentCid: 03bc
DirBase: 162d93000 ObjectTable: ffffbe0d8362d7c0 HandleCount: <Data Not
Accessible>Modified 462372. Locked 0.
DeviceMap ffffbe0d70c15620
Token ffffbe0d8362d060
...
3.
Wählen Sie eines der Tokens aus und lassen Sie sich die Einzelheiten anzeigen:
lkd> !token ffffbe0d829e7060
_TOKEN 0xffffbe0d829e7060
TS Session ID: 0
User: S-1-5-18
...
Process Token TrustLevelSid: S-1-19-512-8192
Wie Sie sehen, handelt es sich um einen PPL mit dem Signierer WinTcb.
Den Zugriff bestimmen
Um den Zugriff auf ein Objekt zu bestimmen, werden die beiden folgenden Methoden verwendet:
QQ Die verbindliche Integritätsprüfung, die anhand der Integritätsebene der Ressource und
der erforderlichen Richtlinie ermittelt, ob die Integritätsebene des Aufrufers für den Zugriff
auf die Ressource ausreicht.
Objekte schützen
Kapitel 7
761
QQ Die Prüfung des besitzerverwalteten Zugriffs, die den zulässigen Zugriff eines gegebenen
Benutzerkontos auf ein Objekt ermittelt.
Wenn ein Prozess versucht, ein Objekt zu öffnen, findet die Integritätsprüfung vor der regulären Windows-DACL-Prüfung in der Kernelfunktion SeAccessCheck statt, da sie schneller abläuft
und damit rasch bestimmt werden kann, ob die vollständige Prüfung des besitzerverwalteten Zugriffs überhaupt nötig ist. Ein Prozess mit den Standardintegritätsrichtlinien in seinem
Zugriffstoken (wie zuvor beschrieben TOKEN_MANDATORY_NO_WRITE_UP und TOKEN_MANDATORY_NEW_
PROCESS_MIN) kann ein Objekt für den Schreibzugriff öffnen, wenn seine Integritätsebene größer
oder gleich der des Objekts ist und die DACL dem Prozess ebenfalls den gewünschten Zugriff
gewährt. Ein Prozess mit niedriger Integritätsebene kann beispielsweise keinen Prozess mittlerer Integritätsebene für den Schreibzugriff öffnen, selbst wenn die DACL dies zulässt.
Unter den Standardintegritätsrichtlinien können Prozesse jedes Objekt – außer Prozess-,
Thread- und Tokenobjekte – für den Lesezugriff öffnen, wenn die DACL des Objekts diesen Zugriff gewährt. Ein Prozess mit niedriger Integritätsebene kann daher jegliche Dateien öffnen,
die für das Benutzerkonto, unter dem er läuft, zugänglich sind. Internet Explorer im geschützten Modus verwendet Integritätsebenen, um zu verhindern, dass Malware Benutzerkontoeinstellungen ändert. Das hält die Malware jedoch nicht davon ab, in den Dokumenten der
Benutzer zu lesen.
Prozess-, Thread- und Tokenobjekte bilden jedoch Ausnahmen, da ihre Integritätsrichtlinie
auch die Einstellung No-Read-Up enthält. Das bedeutet, dass die Integritätsebene eines Prozesses größer oder gleich der Integritätsebene des Prozesses oder Threads sein muss, den er
öffnen will, und die DACL den gewünschten Zugriff erlauben muss. Tabelle 7–8 zeigt, welche
Arten von Zugriff ein Prozess mit verschiedenen Integritätsebenen auf andere Prozesse und
Objekte hat, sofern die DACLs diesen Zugriff ebenfalls gewährt.
Zugreifender Prozess
Zugriff auf Objekte
Zugriff auf andere Prozesse
Hohe Integritätsebene
• Lese/Schreib-Zugriff auf alle Objekte mit Integritätsebene Hoch
und darunter
• Lesezugriff auf alle Objekte mit
der Integritätsebene System
• Lese/Schreib-Zugriff auf alle Prozesse mit Integritätsebene Hoch
und darunter
• Kein Lese/Schreib-Zugriff auf
Prozesse mit der Integritätsebene
System
Mittlere Integritätsebene
• Lese/Schreib-Zugriff auf alle Objekte mit mittlerer und niedriger
Integritätsebene
• Lesezugriff auf alle Objekte mit
der Integritätsebene Hoch oder
System
• Lese/Schreib-Zugriff auf alle Prozesse mit mittlerer und niedriger
Integritätsebene
• Kein Lese/Schreib-Zugriff auf
Prozesse mit der Integritätsebene
Hoch oder System
Niedrige Integritätsebene
• Lese/Schreib-Zugriff auf alle
Objekte mit niedriger Integritätsebene
• Lesezugriff auf alle Objekte mit
der Integritätsebene Mittel oder
höher
• Lese/Schreib-Zugriff auf alle
Prozesse mit niedriger Integritätsebene
• Kein Lese/Schreib-Zugriff auf
Prozesse mit der Integritätsebene
Mittel oder höher
Tabelle 7–8 Zugriff auf Objekte und Prozesse nach Integritätsebene
762
Kapitel 7
Sicherheit
Mit dem Lesezugriff auf einen Prozess ist in diesem Abschnitt ein vollständiger
Lesezugriff gemeint, also das Lesen der Inhalte im Prozessadressraum. No-ReadUp verhindert nicht, dass ein Prozess einen Prozess mit höherer Integritätsebene
für beschränkten Zugriff öffnen kann, z. B. für PROCESS_QUERY_LIMITED_INFORMATION,
wobei nur grundlegende Informationen über den Prozess abgefragt werden.
User Interface Privilege Isolation
Auch das Messaging-Teilsystem von Windows nutzt Integritätsebenen, um eine Trennung
der Rechte für die Benutzerschnittstelle (User Interface Privilege Isolation, UIPI) zu erreichen. Dabei hindert das Teilsystem Prozesse daran, Fensternachrichten an Fenster zu senden, die Prozessen mit einer höheren Integritätsebene gehören. Eine Ausnahme bilden die
folgenden rein informativen Nachrichten:
QQ WM_NULL
QQ WM_MOVE
QQ WM_SIZE
QQ WM_GETTEXT
QQ WM_GETTEXTLENGTH
QQ WM_GETHOTKEY
QQ WM_GETICON
QQ WM_RENDERFORMAT
QQ WM_DRAWCLIPBOARD
QQ WM_CHANGECBCHAIN
QQ WM_THEMECHANGED
Die Beachtung der Integrationsebenen hindert Standardbenutzerprozesse daran, Eingaben
in Fenstern von erhöhten Rechten vorzunehmen und Shatter-Angriffe durchzuführen (etwa
dadurch, einem Prozess nicht wohlgeformte Nachrichten zu senden, die einen internen Pufferüberlauf auslösen, wodurch es möglich wäre, Code mit den erhöhten Rechten des Prozesses auszuführen). UIPI lässt auch nicht zu, dass sich Fenster-Hooks (SetWindowsHookEx) auf die
Fenster von Prozessen mit höherer Integritätsebene auswirken. Dadurch ist es beispielsweise
nicht möglich, dass ein Standardbenutzerprozess die Tastatureingaben eines Benutzers in
einer Administratoranwendung aufzeichnet. Auch Journal-Hooks werden blockiert, um zu
verhindern, dass Prozesse das Verhalten von Prozessen einer höheren Integritätsebene überwachen.
→
Objekte schützen
Kapitel 7
763
Prozesse auf der mittleren und einer höheren Integritätsebene können die API
ChangeWindowsMessageFilterEx aufrufen, um zusätzliche Nachrichten durchzulassen. Das
wird gewöhnlich getan, um Nachrichten zu erlauben, die benutzerdefinierte Steuerelemente für die Kommunikation außerhalb der Standardsteuerelemente von Windows benötigen. Die ältere API ChangeWindowMessageFilter leistet Ähnliches, wirkt sich aber auf
einen ganzen Prozess aus und nicht nur auf ein bestimmtes Fenster. Bei der Verwendung
von ChangeWindowMessageFilter können zwei benutzerdefinierte Steuerelemente innerhalb eines Prozesses die gleichen internen Fensternachrichten nutzen. Dabei kann es passieren, dass eine möglicherweise schädliche Fensternachricht des einen Steuerelements
durchgelassen wird, wenn es sich bei ihm lediglich um eine reine Abfragenachricht für das
andere Steuerelement handelt.
Da Bedienhilfen wie die Bildschirmtastatur (Osk.exe) den UIPI-Einschränkungen unterliegen (die es erfordern würden, dass die Bedienhilfe für alle Integritätsebenen der auf dem
Desktop sichtbaren Prozesse ausgeführt wird), können die Prozesse dieser Anwendungen
den Zugriff auf die Benutzerschnittstelle aktivieren. Das entsprechende Flag kann in der
Manifestdatei des Abbilds vorhanden sein und führt den Prozess auf einer leicht höheren
Integritätsebene als der mittleren aus (zwischen 0x2000 und 0x3000), wenn sie von einem
Standardbenutzerkonto gestartet wurde, bzw. auf der hohen Integritätsebene, wenn sie
von einem Administratorkonto gestartet wurde. Im zweiten Fall wird die Anforderung zur
Rechteerhöhung nicht angezeigt. Damit ein Prozess dieses Flag setzen kann, muss das Abbild signiert sein und sich in einem der verschiedenen sicheren Speicherorte befinden, z. B.
%SystemRoot% oder %ProgramFiles%.
Wenn die Integritätsprüfung abgeschlossen ist und die erforderliche Richtlinie den Zugriff auf
das Objekt erlaubt, wird einer der beiden folgenden Algorithmen verwendet, um den besitzerverwalteten Zugriff auf das Objekt zu bestimmen. Das Resultat dieses Algorithmus bestimmt
dann das Gesamtergebnis der Zugriffsprüfung.
QQ Der maximal mögliche Zugriff auf das Objekt wird bestimmt. Er kann in gewisser Form
mithilfe der AuthZ-API (siehe den eigenen Abschnitt dazu weiter hinten in diesem Kapitel)
oder der älteren Funktion GetEffectiveRightsFromAcl in den Benutzermodus exportiert
werden. Diese Vorgehensweise wird auch angewendet, wenn ein Programm einen Zugriff
vom Typ MAXIMUM_ALLOWED anfordert, was ältere APIs tun, die keinen Parameter für den
gewünschten Zugriff haben.
QQ Es wird ermittelt, ob der gewünschte Zugriff zulässig ist. Dies kann mithilfe der Windows-
Funktionen AccessCheck und AccessCheckByType geschehen.
Der erste Algorithmus untersucht die Einträge in der DACL wie folgt:
1.
764
Wenn das Objekt keine DACL (eine NULL-DACL) hat, ist es nicht geschützt. Das Sicherheitssystem gewährt jeglichen Zugriff bis auf den von einem AppContainer-Prozess (siehe den
Abschnitt »Anwendungscontainer« weiter hinten in diesem Kapitel). In letzterem Fall wird
der Zugriff verweigert.
Kapitel 7
Sicherheit
2.
Wenn der Aufrufer das Recht »Besitz übernehmen« hat, gewährt das System vor der Untersuchung einen Zugriff vom Typ »Besitzer festlegen«.
3.
Wenn der Aufrufer der Besitzer des Objekts ist, sucht das System nach einer OWNER_RIGHTSSID und verwendet diese für die nächsten Schritte. Anderenfalls werden die Zugriffsrechte
»Lesezugriff« und »DACL schreiben« gewährt.
4.
Die Zugriffsmaske jedes Verweigerungseintrags mit einer SID, die derjenigen im Zugriffs
token des Aufrufers entspricht, wird von der Zulassungsmaske entfernt.
5.
Die Zugriffsmaske jedes Zulassungseintrags mit einer SID, die derjenigen im Zugriffstoken
des Aufrufers entspricht, wird der zu berechnenden Zulassungsmaske hinzugefügt, es sei
denn, dass der betreffende Zugriff bereits verweigert wurde.
Nach der Untersuchung aller Einträge in der DACL wird die berechnete Zulassungsmaske als
»maximal möglicher Zugriff« an den Aufrufer zurückgegeben. Diese Maske gibt sämtliche Arten des Zugriffs an, die der Aufrufer beim Öffnen des Objekts erfolgreich anfordern kann.
Diese Beschreibung gilt jedoch nur für die Kernelmodusform des Algorithmus. Die in
GetEffectiveRightsFromAcl implementierte Version führt Schritt 2 nicht aus und betrachtet
statt eines Zugriffstokens eine einzelne Benutzer- oder Gruppen-SID.
Besitzerrechte
Da Objektbesitzer stets die Rechte »Lesezugriff« und »DACL schreiben« für ihr Objekt haben und damit in der Lage sind, dessen Sicherheitseinstellungen zu überschreiben, gibt
es in Windows eine besondere Einrichtung, um dieses Verhalten zu steuern, nämlich die
Besitzerrechte-SID. Es gibt sie aus den beiden folgenden Hauptgründen:
QQ Höhere Sicherheit für Dienste im Betriebssystem Wenn ein Dienst zur Laufzeit ein
Objekt erstellt, wird mit diesem nicht die tatsächliche Dienst-SID als Besitzer-SID verknüpft, sondern das Konto, unter dem der Dienst läuft (also etwa das Konto des lokalen
Systems oder des lokalen Dienstes). Dadurch wäre jeder andere Dienst in diesem Konto
ebenfalls ein Besitzer und hätte Zugriff auf das Objekt. Dieses unerwünschte Verhalten
wird durch die Benutzerrechte-SID verhindert.
QQ Mehr Flexibilität für besondere Fälle Nehmen wir an, ein Administrator möchte
den Benutzern erlauben, Dateien und Ordner zu erstellen, aber nicht, die Zugriffssteuerungslisten für diese Objekte zu ändern (da die Benutzer sonst versehentlich oder
arglistig unerwünschten Konten Zugriff auf diese Dateien oder Ordner gewähren könnten). Durch die Verwendung einer vererbbaren Benutzerrechte-SID können die Benutzer daran gehindert werden, die Zugriffssteuerungslisten der von ihnen erstellten Objekte zu bearbeiten oder auch nur einzusehen. Ein weiteres Beispiel sind Änderungen
an Gruppen. Stellen Sie sich vor, ein Angestellter hat mehrere Dateien erstellt, während
er zu einer vertraulichen Gruppe gehörte, und wird nun aus geschäftlichen Gründen
aus dieser Gruppe herausgenommen. Da er nach wie vor ein Benutzer ist, könnte er
weiterhin auf die sensiblen Dateien zugreifen.
Objekte schützen
Kapitel 7
765
Mit dem zweiten Algorithmus wird ermittelt, ob eine gegebene Zugriffsanforderung auf der
Grundlage des Zugriffstokens des Aufrufers gewährt werden kann. Jede Windows-API-Funktion zum Öffnen sicherungsfähiger Objekte verfügt über einen Parameter, der die Maske für
den gewünschten Zugriff angibt. Dies ist der letzte Bestandteil der Sicherheitsgleichung. Um zu
bestimmen, ob der Aufrufer Zugriff hat, werden die folgenden Schritte ausgeführt:
1.
Wenn das Objekt keine DACL (eine NULL-DACL) hat, ist es nicht geschützt. Das Sicherheitssystem gewährt den Zugriff.
2.
Wenn der Aufrufer das Recht »Besitz übernehmen« hat, gewährt das System einen Zugriff
vom Typ »Besitzer festlegen«, falls dieser angefordert wurde. Anschließend untersucht es
die DACL, es sei denn, dass »Besitzer festlegen« der einzige angeforderte Zugriff war. Wenn
das der Fall ist, wird die DACL nicht mehr untersucht.
3.
Wenn der Aufrufer der Besitzer des Objekts ist, sucht das System nach einer OWNER_RIGHTSSID und verwendet diese für die nächsten Schritte. Anderenfalls werden die Zugriffsrechte
»Lesezugriff« und »DACL schreiben« gewährt. Wenn das die einzigen angeforderten Zugriffsrechte waren, wird der Zugriff gewährt, ohne die DACL zu untersuchen.
4.
Die einzelnen Zugriffssteuerungseinträge in der DACL werden vom ersten zum letzten
untersucht. Ein Zugriffssteuerungseintrag wird verarbeitet, wenn eine der folgenden Bedingungen erfüllt ist:
•
Es handelt sich um einen Verweigerungseintrag und die in ihm angegebene SID entspricht einer aktivierten SID (SIDs können aktiviert und deaktiviert werden) oder einer
reinen Verweigerungs-SID im Zugriffstoken des Aufrufers.
•
Es handelt sich um einen Zulassungseintrag und die in ihm angegebene SID entspricht
einer aktivierten SID im Token des Aufrufers, die keine reine Verweigerungs-SID ist.
•
Es ist der zweite Durchlauf durch den Deskriptor (also derjenige für die Überprüfung
eingeschränkter SIDs) und die SID in dem Eintrag entspricht einer eingeschränkten SID
im Zugriffstoken des Aufrufers.
•
Der Eintrag ist nicht als reiner Vererbungseintrag gekennzeichnet.
5.
Angeforderte Rechte, die sich in der Zugriffsmaske eines Zulassungseintrags befinden,
werden gewährt. Wurden alle angeforderten Zugriffsrechte gewährt, endet die Zugriffsprüfung erfolgreich. Befinden sich dagegen irgendwelche der angeforderte Rechte in der
Zugriffsmaske eines Verweigerungseintrags, wird der Zugriff abgelehnt.
6.
Wenn das Ende der DACL erreicht ist und einige der angeforderten Zugriffsrechte immer
noch nicht gewährt sind, wird der Zugriff verweigert.
7.
Wenn der gesamte Zugriff gewährt wird, das Zugriffstoken des Aufrufers aber über mindestens eine eingeschränkte SID verfügt, durchsucht das System die DACL erneut und
schaut sich dabei die Zugriffssteuerungseinträge an, deren Zugriffsmasken dem angeforderten Zugriff entsprechen und deren SIDs sich unter denen der eingeschränkten SIDs des
Aufrufers befinden. Nur wenn die angeforderten Zugriffsrechte bei beiden Durchläufen
durch die DACL gewährt werden, erhält der Benutzer Zugriff auf das Objekt.
766
Kapitel 7
Sicherheit
Das Verhalten beider Zugriffsvalidierungsalgorithmen hängt davon ab, wie die Zulassungs- und
Verweigerungseinträge relativ zueinander angeordnet sind. Stellen Sie sich ein Objekt mit nur
zwei Zugriffssteuerungseinträgen vor – einem, der dem Benutzer Vollzugriff auf das Objekt
gewährt, und einem, der den Zugriff verweigert. Steht der Zulassungseintrag vor dem Verweigerungseintrag, so erhält der Benutzer Vollzugriff, doch bei umgekehrter Reihenfolge wird ihm
der Zugriff nicht erlaubt.
Mehrere Windows-Funktionen, darunter SetSecurityInfo und SetNamedSecurityInfo, richten Zugriffssteuerungseinträge in der bevorzugten Reihenfolge ein, in der erst die ausdrücklichen Verweigerungseinträge stehen und dann die ausdrücklichen Zulassungseinträge. Diese
Funktionen werden unter anderem in den Dialogfeldern des Sicherheitseditors eingesetzt, in
denen Sie die Berechtigungen für NTFS-Dateien und Registrierungsschlüssel bearbeiten können. Darüber hinaus wenden SetSecurityInfo und SetNamedSecurityInfo auch Vererbungsregeln für Zugriffssteuerungseinträge auf den Sicherheitsdeskriptor an, für den sie aufgerufen
werden.
Abb. 7–9 zeigt ein Beispiel der Zugriffsprüfung, das die Wichtigkeit der Reihenfolge von
Zugriffssteuerungseinträgen herausstreicht. Hier wird einem Benutzer, der eine Datei öffnen
möchte, der Zugriff verweigert, obwohl es in der DACL des Objekts einen Eintrag gibt, der den
Zugriff erlaubt. Das liegt daran, dass der Eintrag, der den Zugriff für diesen Benutzer (aufgrund
seiner Mitgliedschaft in der Gruppe Autoren) verweigert, vor dem Zulassungseintrag steht.
Zugriffstoken
Benutzer: DaveC
Gruppe 1: Administratoren
Gruppe 2: Autoren
Zugriff zum Öffnen
Angefordert: Schreiben
Objekt
Sicherheits
deskriptor
Verweigern
Autoren
Lesen, Schreiben
Zulassen
DaveC
Lesen, Schreiben
Verweigert
Abbildung 7–9 Beispiel für die Zugriffsprüfung
Es wäre nicht sehr wirtschaftlich, wenn das Sicherheitssystem die DACL jedes Mal verarbeiten
würde, wenn ein Prozess ein Handle verwendet. Daher führt der SRM diese Zugriffsprüfung nur
beim Öffnen des Handles durch, nicht bei jeder Verwendung. Sobald ein Prozess ein Handle
erfolgreich geöffnet hat, kann das Sicherheitssystem die gewährten Zugriffsrechte daher nicht
mehr widerrufen – nicht einmal, wenn sich die DACL des Objekts ändert. Da Kernelmoduscode
für den Zugriff auf Objekte keine Handles verwendet, sondern Zeiger, erfolgt auch keine Zugriffsprüfung, wenn das Betriebssystem Objekte nutzt. In diesem Sinne vertraut die Windows-
Exekutive also sich selbst und allen geladenen Treibern.
Da der Besitzer eines Objekts immer den Zugriff vom Typ »DACL schreiben« auf ein Objekt
hat, können Benutzer nicht daran gehindert werden, auf die Objekte zuzugreifen, die ihnen gehören. Hat ein Objekt aus irgendeinem Grunde eine leere DACL (kein Zugriff), kann der Besitzer
das Objekt daher immer noch zum Schreiben der DACL öffnen und damit eine neue DACL mit
den gewünschten Berechtigungen einrichten.
Objekte schützen
Kapitel 7
767
Vorsicht bei der Verwendung von grafischen Sicherheitseditoren!
Wenn Sie die grafischen Berechtigungseditoren verwenden, um die Sicherheitseinstellungen für eine Datei, einen Registrierungsschlüssel, ein Active Directory-Objekt oder ein
anderes sicherungsfähiges Objekt zu bearbeiten, wird im Hauptdialogfeld möglicherweise
eine irreführende Ansicht angezeigt. Wenn Sie Vollzugriff für die Gruppe Jeder gewähren
und für die Gruppe Administratoren verweigern, sieht es so aus, als würde der Zulassungseintrag für Jeder dem Verweigerungseintrag für Administratoren vorausgehen, weil sie in
dieser Reihenfolge in der Oberfläche erscheinen. Wie wir aber bereits festgestellt haben,
platzieren die Editoren Verweigerungseinträge vor Zulassungseinträgen.
Erst die Registerkarte Berechtigungen des Dialogfelds Erweiterte Sicherheitseinstellungen
zeigt die tatsächliche Reihenfolge der Zugriffssteuerungseinträge in der DACL. Doch selbst
dieses Dialogfeld kann irreführend wirken, da bei komplizierteren DACLs erst die Verweigerungseinträge für verschiedene Arten des Zugriffs stehen können, auf die dann Zulassungseinträge für andere Arten des Zugriffs folgen.
→
768
Kapitel 7
Sicherheit
Abgesehen von Ausprobieren besteht die einzige Möglichkeit, um herauszufinden, welchen
Zugriff ein gegebener Benutzer oder eine Gruppe nun genau auf das Objekt hat, darin, einen Blick auf die Registerkarte Effektive Berechtigungen des Dialogfelds zu werfen, das nach
einem Klick auf die Schaltfläche Erweitert im Eigenschaftendialogfeld angezeigt wird. Wenn
Sie dort den Namen eines Benutzers oder einer Gruppe eingeben, können Sie anschließend
ablesen, welche Berechtigungen diesem Benutzer oder der Gruppe für das betreffende
Objekt gewährt werden.
→
Objekte schützen
Kapitel 7
769
Dynamische Zugriffssteuerung
Der in den vorherigen Abschnitten vorgestellte Mechanismus der besitzerverwalteten Zugriffssteuerung wurde schon in der ersten Version von Windows NT eingeführt und ist in vielen
Situationen nützlich. Es gibt jedoch auch Fälle, für die er nicht flexibel genug ist. Beispielsweise
ist es möglich, dass Benutzer von einem Computer an ihrem Arbeitsplatz auf eine freigegebene
Datei zugreifen können müssen, von einem Computer zu Hause aber nicht darauf zugreifen
dürfen. Mithilfe von Zugriffssteuerungseinträgen lässt sich eine solche Bedingung nicht angeben.
In Windows 8 und Windows Server 2012 wurde die dynamische Zugriffssteuerung (Dynamic Access Control, DAC) eingeführt. Dieser flexible Mechanismus macht es möglich, Regeln
der Grundlage benutzerdefinierter Attribute in Active Directory aufzustellen. DAC ersetzt den
bisherigen Mechanismus nicht, sondern ergänzt ihn. Um eine Operation zu erlauben, muss die
entsprechende Berechtigung also sowohl durch die dynamische Zugriffssteuerung als auch
durch die klassische DACL gewährt werden. Abb. 7–10 zeigt die Hauptkomponenten der dynamischen Zugriffssteuerung.
770
Kapitel 7
Sicherheit
Benutzeransprüche
Ressourcen
eigenschaften
Geräteansprüche
Zentrale Zugriffsrichtlinie
Abbildung 7–10 Bestandteile der dynamischen Zugriffssteuerung
Ein Anspruch (Claim) ist eine Information über einen Benutzer, ein Gerät (Computer in einer
Domäne) oder eine Ressource (allgemeines Attribut), die von einem Domänencontroller veröffentlicht wurde. Gültige Ansprüche sind beispielsweise der Titel eines Benutzers oder die
Abteilungsklassifizierung einer Datei. In Ausdrücken zum Aufstellen von Regeln können Ansprüche beliebig kombiniert werden. Die Gesamtheit dieser Regeln bestimmt die zentrale Zugriffsrichtlinie.
Die dynamische Zugriffssteuerung wird in Active Directory konfiguriert und durch Richtlinien durchgesetzt. Das Ticketprotokoll Kerberos wurde erweitert, um einen authentifizierten
Transport von Benutzer- und Geräteansprüchen (das sogenannte Kerberos-Armoring) zu unterstützen.
Die AuthZ-API
Die Windows-API AuthZ bietet Autorisierungsfunktionen und implementiert dasselbe Sicherheitsmodell wie der Security Reference Monitor (SRM), was allerdings vollständig im Benutzermodus geschieht, und zwar in der Bibliothek %SystemRoot%\System32\Authz.dll. Dadurch
bekommen Anwendungen, die ihre eigenen privaten Objekte schützen wollen – beispielsweise
Datenbanktabellen –, die Möglichkeit, das Windows-Sicherheitsmodell zu nutzen, ohne sich
dadurch die Kosten für die Übergänge vom Benutzer- in den Kernelmodus einzuhandeln, die
bei der Nutzung von SRM auf sie zukämen.
Die AuthZ-API verwendet standardmäßige Sicherheitsdeskriptoren, SIDs und Rechte. Zur
Repräsentation der Clients wird anstelle von Tokens jedoch AUTHZ_CLIENT_CONTEXT genutzt.
AuthZ enthält Benutzermodusvarianten aller Zugriffsprüfungs- und Windows-Sicherheitsfunktionen. Beispielsweise ist AuthzAccessCheck die AuthZ-Version der Windows-API AccessCheck,
die die SRM-Funktion SeAccessCheck verwendet.
Ein weiterer Vorteil besteht darin, dass Anwendungen AuthZ anweisen können, die Ergebnisse der Sicherheitsprüfungen zwischenzuspeichern, um kommende Prüfungen für denselben
Clientkontext und Sicherheitsdeskriptor zu vereinfachen. AuthZ ist im Windows SDK vollständig
dokumentiert.
Diese Art der Zugriffsprüfung auf der Grundlage der SID und der Mitgliedschaft in einer
Sicherheitsgruppe in einer statischen, kontrollierten Umgebung wird als identitätsgestützte Zugriffssteuerung (Identity-Based Access Control, IBAC) bezeichnet. Dazu muss das Sicherheitssys-
Die AuthZ-API
Kapitel 7
771
tem aber bereits die Identitäten aller möglichen Entitäten kennen, die auf ein Objekt zugreifen
können, wenn die DACL in den Sicherheitsdeskriptor des Objekts gestellt wird.
Windows unterstützt auch eine anspruchsgestützte Zugriffssteuerung (Claims-Based Access Control, CBAC). Dabei wird der Zugriff nicht auf der Grundlage der Identität oder Gruppenmitgliedschaft der zugreifenden Entität gewährt, sondern auf der Grundlage willkürlicher
Attribute, die ihr zugewiesen und in ihrem Zugriffstoken gespeichert werden. Diese Attribute
werden von einem Attributanbieter bereitgestellt, beispielsweise AppLocker. Der CBAC-Mechanismus bietet eine Reihe von Vorteilen. Unter anderem ist es damit möglich, eine DACL für
einen Benutzer zu erstellen, dessen Identität noch nicht bekannt ist oder dynamisch mithilfe
von Attributen bestimmt wird. CBAC-Zugriffssteuerungseinträge (auch bedingte Zugriffssteuerungseinträge genannt) werden in *-callback-Eintragsstrukturen gespeichert, die im Grunde
genommen private Strukturen von AuthZ sind und von der System-API SeAccessCheck ignoriert
werden. Die Kernelmodusroutine SeSrpAccessCheck kann bedingte Zugriffssteuerungseinträge
nicht verstehen. Nur Anwendungen, die die AuthZ-APIs aufrufen, können CBAC nutzen. App
Locker ist die einzige Systemkomponente, die CBAC verwendet, und legt damit Attribute wie
den Pfad oder den Herausgeber fest. Drittanbieteranwendungen können CBAC mithilfe der
CBAC-APIs von AuthZ nutzen.
Die Verwendung von CBAC-Sicherheitsprüfungen macht vielseitige Verwaltungsrichtlinien
möglich, beispielsweise die folgenden:
QQ Es dürfen nur Anwendungen ausgeführt werden, die von der IT-Abteilung des Unternehmens genehmigt wurden.
QQ Nur genehmigte Anwendungen dürfen auf Kontakte oder den Kalender in Microsoft Outlook zugreifen.
QQ Nur Personen auf einer bestimmten Etage eines bestimmten Gebäudes dürfen auf die
Drucker dieser Etage zugreifen.
QQ Nur Vollzeitangestellte dürfen auf eine Intranetwebsite zugreifen.
Die Attribute können in bedingten Zugriffssteuerungseinträgen verwendet werden, in denen
ihr Vorhandensein, ihr Fehlen oder ihr Wert geprüft wird. Attributnamen können beliebige
alphanumerische Unicode-Zeichen sowie Doppelpunkte, reguläre Schrägstriche und Unterstriche enthalten. Als Werte von Attributen sind 64-Bit-Integer, Unicode-Strings, Bytestrings und
Arrays möglich.
Bedingte Zugriffssteuerungseinträge
Das Format von SDDL-Strings wurde erweitert, um auch Zugriffssteuerungseinträge mit bedingten Ausdrücken zu ermöglichen. Das neue Format sieht wie folgt aus: AceType;
AceFlags;
Rights;ObjectGuid;InheritObjectGuid;AccountSid;(ConditionalExpression).
Der ACE-Typ eines bedingten Zugriffssteuerungseintrags ist entweder XA (für SDDL_
CALLBACK_ACCESS_ALLOWED) oder XD (für SDDL_CALLBACK_ACCESS_DENIED). Zugriffssteuerungseinträge mit bedingten Ausdrücken werden nur für die anspruchsgestützte Autorisierung (insbesondere die AuthZ-APIs und AppLocker) verwendet und nicht vom Objekt-Manager und von
Dateisystemen erkannt.
772
Kapitel 7
Sicherheit
In bedingten Ausdrücken können die Elemente aus Tabelle 7–9 verwendet werden.
Element
Beschreibung
AttributeName
Prüft, ob das angegebene Attribut einen von null verschiedenen
Wert hat.
exists AttributeName
Prüft, ob das angegebene Attribut im Clientkontext vorhanden
ist.
AttributeName Operator Value
Gibt das Ergebnis der angegebenen Operation zurück. In bedingten Ausdrücken können die Operatoren Contains any_of,
==, !=, <, <=, > und >= verwendet werden, um die Werte von
Attributen zu prüfen. Es handelt sich dabei ausschließlich um
binäre Operatoren (also keine unären).
ConditionalExpression ||
ConditionalExpression
Prüft, ob mindestens einer der bedingten Ausdrücke wahr ist.
ConditionalExpression &&
ConditionalExpression
Prüft, ob beide bedingten Ausdrücke wahr sind.
!(ConditionalExpression)
Negiert den bedingten Ausdruck.
Member_of {SidArray}
Prüft, ob das Array SID_AND_ATTRIBUTES des Clientkontexts alle
Sicherheitskennungen (SIDs) enthält, die in der als SidArray angegebenen kommagetrennten Liste vorhanden sind.
Tabelle 7–9 Mögliche Elemente für bedingte Ausdrücke
Ein bedingter Zugriffssteuerungseintrag kann eine beliebige Menge von Bedingungen enthalten. Wenn die Bedingung zu false ausgewertet wird, wird der Eintrag ignoriert; lautet
das Ergebnis dagegen true, wird er angewendet. Ein bedingter Eintrag kann mit der API
AddConditionalAce zu einem Objekt hinzugefügt und mit AuthzAccessCheck überprüft werden.
Mithilfe von bedingten Zugriffssteuerungseinträgen können Sie angeben, dass der Zugriff
auf einzelne Datensätze in einem Programm nur einem Benutzer gewährt werden soll, der bestimmte Bedingungen erfüllt. Das können Bedingungen wie die folgenden sein:
QQ Der Benutzer hat das Attribut Role mit dem Wert Architect, ProgramManager oder Development Lead und das Attribut Division mit dem Wert Windows.
QQ Der Benutzer hat das Attribut ManagementChain mit dem Wert John Smith.
QQ Der Benutzer hat das Attribut CommissionType mit dem Wert Officer und das Attribut
PayGrade mit einem Wert größer als 6 (was im US-Militär einem Generalsrang entspricht).
Windows enthält keine Programme, mit denen sich bedingte Zugriffssteuerungseinträge einsehen oder bearbeiten lassen.
Privilegien und Kontorechte
Bei vielen Operationen, die von Prozessen durchgeführt werden, kann die Autorisierung nicht
über den Objektzugriffsschutz erfolgen, da dabei überhaupt keine Interaktion mit einem bestimmten Objekt stattfindet. Beispielsweise ist die Möglichkeit, die Sicherheitsprüfungen beim
Öffnen von Dateien für die Datensicherung zu umgeben, ein Attribut eines Kontos und nicht
Privilegien und Kontorechte
Kapitel 7
773
eines Objekts. Mithilfe von Privilegien und Kontorechten können Systemadministratoren in
Windows steuern, welche Konten sicherheitsrelevante Vorgänge ausführen dürfen.
Ein Privileg (privilege; in der deutschen Version von Windows als »Recht« bezeichnet, hier
zur besseren Unterscheidung jedoch »Privileg« genannt) erlaubt einem Konto, eine bestimmte
Operation am System durchzuführen, z. B. den Computer herunterzufahren oder die Systemzeit zu ändern. Ein Kontorecht (account right) gewährt oder verweigert dem zugehörigen Konto
die Möglichkeit, eine bestimmte Art von Anmeldung durchzuführen, z. B. eine lokale oder
interaktive Anmeldung.
Mithilfe des MMC-Snap-Ins Active Directory-Benutzer und Gruppen für Domänenkonto
oder dem Editor für lokale Sicherheitsrichtlinien (%SystemRoot%\System32\secpol.msc) können
Systemadministratoren Gruppen und Konten Privilegien und Kontorechte zuweisen. Abb. 7–11
zeigt den Abschnitt Zuweisen von Benutzerrechten im Editor für lokale Sicherheitsrichtlinien, in
dem sämtliche auf Windows verfügbaren Privilegien und Kontorechte aufgeführt sind. In diesem Dienstprogramm wird übrigens nicht zwischen Privilegien und Kontorechten unterschieden. Die Kontorechte sind diejenigen, bei denen es um die Anmeldung geht.
774
Kapitel 7
Sicherheit
Abbildung 7–11 Zuweisung von Benutzerrechten im Editor für lokale Sicherheitsrichtlinien
Kontorechte
Kontorechte werden weder vom SRM durchgesetzt noch in Tokens gespeichert. Die für die
Anmeldung zuständige Funktion ist LsaLogonUser. Wenn sich beispielsweise ein Benutzer interaktiv an einem Computer anmeldet, ruft Winlogon die API LogonUser auf und LogonUser
wiederum LsaLogonUser. Dabei nimmt LogonUser einen Parameter entgegen, der die Art der
Anmeldung angibt, z. B. eine interaktive Anmeldung, eine Netzwerk-, Batch- oder Dienstanmeldung oder eine Anmeldung über einen Terminalserver-Client.
Privilegien und Kontorechte
Kapitel 7
775
Als Reaktion auf Anmeldeanforderungen ruft die lokale Sicherheitsautorität (LSA) die dem
Benutzer zugewiesenen Kontorechte von der LSA-Richtliniendatenbank ab. Sie vergleicht den
Anmeldetyp mit dem Kontorecht des Benutzers und verweigert die Anmeldung, wenn das Konto nicht über das Recht verfügt, das diese Art der Anmeldung erlaubt, oder wenn ihm diese Art
der Anmeldung verweigert wird. Tabelle 7–10 führt die in Windows definierten Kontorechte auf.
Recht
Bedeutung
• Lokal anmelden verweigern
• Lokal anmelden zulassen
Für die interaktive Anmeldung direkt auf dem
lokalen Computer
• Zugriff vom Netzwerk auf diesen Computer verweigern
• Auf diesen Computer vom Netzwerk aus zugreifen
Für die Anmeldung von einem Remote
computer aus
• Anmelden über Remotedesktopdienste verweigern
• Anmelden über Remotedesktopdienste zulassen
Für die Anmeldung über einen Terminalserver-
Client
• Anmelden als Dienst verweigern
• Anmelden als Dienst zulassen
Wird vom Dienststeuerungs-Manager verwendet, wenn er einen Dienst in einem bestimmten
Benutzerkonto startet
• Anmelden als Batchauftrag verweigern
• Anmelden als Stapelverarbeitungsauftrag
Für Anmeldungen vom Typ »Batch«
Tabelle 7–10 Kontorechte
Mit den Funktionen LsaAddAccountRights und LsaRemoveAccountRights können Windows-Anmeldungen Kontorechte zu einem Konto hinzufügen und davon entfernen. Welche Kontorechte einem Konto zugewiesen sind, können sie mit LsaEnumerateAccountRights ermitteln.
Privilegien
Im Laufe der Zeit wurden immer mehr Privilegien in Windows definiert. Im Gegensatz zu den
Kontorechten, die die LSA an einer zentralen Stelle durchsetzt, werden die einzelnen Privilegien
von verschiedenen Komponenten definiert und auch von diesen durchgesetzt. Beispielsweise
ist es der Prozess-Manager, der überprüft, ob das Debugrecht vorhanden ist, mit dem ein Prozess Sicherheitsprüfungen umgehen kann, wenn er mit OpenProcess das Handle eines anderen
Prozesses öffnet.
Tabelle 7–11 führt sämtliche Privilegien auf und gibt dabei an, wie und wann sie von den
Systemkomponenten überprüft werden. Zu jedem Privileg ist in den SDK-Headern ein Makro
in Form einer Rechtekonstanten definiert. Die Namen dieser Konstanten sind nach dem Muster
SE_Privileg_NAME aufgebaut, z. B. SE_DEBUG_NAME für das Debugrecht. Die Werte der Konstanten
sind Strings, die mit Se beginnen und mit Privilege enden, z. B. SeDebugPrivilege. Das scheint
zu bedeuten, dass die Privilegien anhand von Strings bezeichnet werden, doch tatsächlich geschieht dies mithilfe von LUIDs, die bis zum Neustart eindeutig sind. Bei jedem Zugriff auf
ein Privileg muss über die Funktion LookupPrivilegeValue der korrekte LUID nachgeschlagen
werden. Allerdings können Ntdll- und Kernelcode Privilegien auch direkt mit Integerkonstanten
bezeichnen, ohne einen LUID verwenden zu müssen.
776
Kapitel 7
Sicherheit
String
Anzeigename
Verwendung
SeAssignPrimaryTokenPrivilege
Ersetzen eines Tokens auf
Prozessebene
Wird von verschiedenen Komponenten geprüft, die das Token
eines Prozesses festlegen, z. B. von
NtSetInformationJobObject.
SeAuditPrivilege
Generieren von Sicherheitsüberwachungen
Ist erforderlich, um mit Report
Event Ereignisse für das Sicherheitsprotokoll zu erzeugen.
SeBackupPrivilege
Sichern von Dateien und
Verzeichnissen
Veranlasst NTFS, unabhängig vom
vorhandenen Sicherheitsdeskriptor den folgenden Zugriff auf
beliebige Dateien oder Verzeichnisse zu geben: READ_CONTROL,
ACCESS_SYSTEM_SECURITY, FILE_
GENERIC_READ und FILE_TRAVERSE.
Beim Öffnen einer Datei für die
Sicherung muss der Aufrufer das
Flag FILE_FLAG_BACKUP_SEMANTICS
angeben. Dieses Privileg gewährt
auch den entsprechenden Zugriff
auf Registrierungsschlüssel bei der
Verwendung von RegSaveKey.
SeChangeNotifyPrivilege
Auslassen der durchsuchenden Überprüfung
Wird von NTFS verwendet, um
beim Nachschlagen in Verzeichnissen über mehrere Ebenen eine
Prüfung der Berechtigungen für
die Zwischenebenen auslassen zu
können. Auch von Dateisystemen
verwendet, wenn sich Anmeldungen für Benachrichtigungen über
Änderungen an dem Dateisystem
registrieren.
SeCreateGlobalPrivilege
Erstellen globaler Objekte
Ist für Prozesse erforderlich, um
Abschnittsobjekte und Objekte für
symbolische Links in Verzeichnissen des Objekt-Manager-Namensraums zu erstellen, die anderen
Sitzungen als der des Aufrufers
zugewiesen sind.
SeCreatePagefilePrivilege
Erstellen einer Auslagerungsdatei
Wird von der Funktion NtCreatePagingFile geprüft, die eine neue
Auslagerungsdatei erstellt.
SeCreatePermanentPrivilege
Erstellen von dauerhaft
freigegebenen Objekten
Wird vom Objekt-Manager beim
Erstellen eines dauerhaften Objekts geprüft (eines Objekts, dessen Zuweisung nicht aufgehoben
wird, wenn keine Verweise mehr
darauf bestehen).
SeCreateSymbolicLinkPrivilege
Erstellen symbolischer Verknüpfungen
Wird von NTFS geprüft, wenn es
mit CreateSymbolicLink symbolische Links im Dateisystem erstellt.
SeCreateTokenPrivilege
Erstellen eines Token
objekts
Wird von der Funktion NtCreateToken geprüft, die Tokenobjekte
erstellt.
→
Privilegien und Kontorechte
Kapitel 7
777
String
Anzeigename
Verwendung
SeDebugPrivilege
Debuggen von Programmen
Wenn der Aufrufer dieses Privileg
hat, erlaubt ihm der Prozess-Manager, mit NtOpenProcess und
NtOpenThread auf beliebige Prozesse und Threads unabhängig
von deren Sicherheitsdeskriptor
zuzugreifen (mit Ausnahme von
geschützten Prozessen).
SeEnableDelegationPrivilege
Ermöglichen, dass Computer- und Benutzerkonten
für Delegierungszwecke
vertraut wird
Wird von Active Directory-Diensten für die Delegierung authentifizierter Konten verwendet.
SeImpersonatePrivilege
Annehmen der Clientidentität nach Authentifizierung
Wird vom Prozess-Manager geprüft, wenn ein Thread für einen
Identitätswechsel ein Token verwenden möchte, das für einen
anderen Benutzer steht als Tokens
des Prozesses, zu dem der Thread
gehört.
SeIncreaseBasePriorityPrivilege
Anheben der Zeitplanungspriorität
Wird vom Prozess-Manager geprüft und ist erforderlich, um die
Priorität eines Prozesses anzuheben.
SeIncreaseQuotaPrivilege
Anpassen von Speicherkontingenten für einen
Prozess
Wird benötigt, um die Schwellenwerte für den Arbeitssatz, die
Kontingente für den ausgelagerten und nicht ausgelagerten Pool
und die CPU-Rate eines Prozesses
zu ändern.
SeIncreaseWorkingSetPrivilege
Arbeitssatz eines Prozesses
vergrößern
Ist erforderlich, um SetProcessWorkingSetSize zum Anheben der
Mindestgröße eines Arbeitssatzes
aufzurufen. Dieses Privileg erlaubt
dem Prozess auch indirekt, den
Mindestarbeitssatz mit VirtualLock zu verriegeln.
SeLoadDriverPrivilege
Laden und Entfernen von
Gerätetreibern
Wird von den Treiberfunktionen
NtLoadDriver und NtUnloadDriver geprüft.
SeLockMemoryPrivilege
Sperren von Seiten im
Speicher
Wird von NtLockVirtualMemory
geprüft, der Kernelimplementierung von VirtualLock.
SeMachineAccountPrivilege
Hinzufügen von Arbeitsstationen zur Domäne
Wird vom SAM auf einem Domänencontroller geprüft, wenn er ein
Computerkonto in der Domäne
anlegt.
SeManageVolumePrivilege
Durchführen von Volumewartungsaufgaben
Wird von Dateisystemtreibern
beim Öffnen eines Volumes zur
Überprüfung der Festplatte und
zur Defragmentierung benötigt.
778
Kapitel 7
Sicherheit
→
String
Anzeigename
Verwendung
SeProfileSingleProcessPrivilege
Erstellen eines Profils für
einen Einzelprozess
Wird von SuperFetch und dem
Prefetcher beim Abrufen von Informationen über einen einzelnen
Prozess mithilfe von NtQuerySystemInformation geprüft.
SeRelabelPrivilege
Verändern einer Objekt
bezeichnung
Wird vom SRM geprüft, wenn er
die Integritätsebene eines Objekts
anhebt, das einem anderen Benutzer gehört, oder wenn er versucht,
die Integritätsebene eines Objekts
auf einen höheren Wert als den im
Token des Aufrufers anzugeben.
SeRemoteShutdownPrivilege
Erzwingen des Herunterfahrens von einem
Remotesystem aus
Winlogon prüft, ob Remoteaufrufer der Funktion Initiate
SystemShutdown dieses Privileg
haben.
SeRestorePrivilege
Wiederherstellen von Dateien und Verzeichnissen
Veranlasst NTFS, unabhängig vom
vorhandenen Sicherheitsdeskriptor
den folgenden Zugriff auf beliebige Dateien oder Verzeichnisse zu
geben: WRITE_DAC, WRITE_OWNER,
ACCESS_SYSTEM_SECURITY, FILE_
GENERIC_WRITE, FILE_ADD_FILE,
FILE_ADD_SUBDIRECTORY und
DELETE. Beim Öffnen einer Datei
zur Wiederherstellung muss der
Aufrufer das Flag FILE_FLAG_
BACKUP_SEMANTICS angeben.
Dieses Privileg gewährt auch den
entsprechenden Zugriff auf Registrierungsschlüssel bei der Verwendung von RegSaveKey.
SeSecurityPrivilege
Verwalten von Überwachungs- und Sicherheitsprotokollen
Ist erforderlich, um auf die SACL
eines Sicherheitsdeskriptors zuzugreifen und um das Sicherheitsprotokoll zu lesen und zu leeren.
SeShutdownPrivilege
Herunterfahren des
Systems
Wird von NtShutdownSystem und
NtRaiseHardError geprüft. Die
zweite Funktion zeigt in der interaktiven Konsole ein Dialogfeld mit
einem Hinweis auf einen Systemfehler an.
SeSyncAgentPrivilege
Synchronisieren von Verzeichnisdienstdaten
Ist erforderlich, um die Synchronisierungsdienste für LDAP-Verzeichnisse zu nutzen. Der Inhaber
dieses Privilegs darf alle Objekte
und Eigenschaften in dem Verzeichnis ungeachtet von deren
Schutz lesen.
→
Privilegien und Kontorechte
Kapitel 7
779
String
Anzeigename
Verwendung
SeSystemEnvironmentPrivilege
Verändern der Firmware
umgebungsvariablen
Wird von NtSetSystemEnvironmentValue und NtQuerySystem
EnvironmentValue benötigt, um
Firmwareumgebungsvariablen
mithilfe der Hardwareabstrak
tionsschicht (HAL) zu ändern und
zu lesen.
SeSystemProfilePrivilege
Erstellen eines Profils der
Systemleistung
Wird von der Funktion NtCreateProfile geprüft, die zum Erstellen
eines Systemprofils da ist und z. B.
von dem Dienstprogramm Kernprof genutzt wird.
SeSystemtimePrivilege
Ändern der Systemzeit
Ist erforderlich, um die Uhrzeit
und das Datum zu ändern.
SeTakeOwnershipPrivilege
Übernehmen des Besitzes
von Dateien und Objekten
Ist erforderlich, um den Besitz eines Objekts zu übernehmen, ohne
über besitzerverwaltete Zugriffsrechte zu verfügen.
SeTcbPrivilege
Einsetzen als Teil des
Betriebssystems
Wird vom SRM geprüft, um die
Sitzungs-ID in einem Token festzulegen; vom PnP-Manager, um
Plug-&-Play-Ereignisse zu erstellen
und zu verwalten; von BroadcastSystemMessageEx beim Aufruf mit
BSM_ALLDESKTOPS; von LsaRegisterLogonProcess; und bei der
Kennzeichnung einer Anwendung
als VDM mit NtSetInformationProcess.
SeTimeZonePrivilege
Ändern der Zeitzone
Ist erforderlich, um die Zeitzone
zu ändern.
SeTrustedCredManAccessPrivilege
Auf Anmeldeinformations-Manager als vertrauenswürdigem Aufrufer
zugreifen
Wird vom Anmeldeinformations-
Manager geprüft, um zu bestätigen, dass er einem Aufrufer mit
Anmeldeinformationen vertrauen
soll, die als Klartext abgefragt
werden können. Dieses Privileg
wird standardmäßig nur Winlogon
übertragen.
SeUndockPrivilege
Entfernen des Computers
von der Dockingstation
Wird vom PnP-Manager im Benutzermodus geprüft, wenn das Abdocken des Computers ausgelöst
oder das Auswerfen eines Geräts
angefordert wird.
SeUnsolicitedInputPrivilege
Nicht angeforderte Daten
von einem Terminalgerät
empfangen
Dieses Privileg wird in Windows
zurzeit nicht verwendet.
Tabelle 7–11 Privilegien
Um zu prüfen, ob ein Token ein bestimmtes Privileg einschließt, können Komponenten
im Benutzermodus PrivilegeCheck oder LsaEnumerateAccountRights und im Kernelmodus
S eSinglePrivilegeCheck und SePrivilegeCheck verwenden. Die Privilege-APIs verstehen
keine Kontorechte, die AccountRights-APIs aber auch Privilegien.
780
Kapitel 7
Sicherheit
Im Gegensatz zu Kontorechten können Privilegien aktiviert und deaktiviert werden. Für
eine erfolgreiche Prüfung auf ein Privileg muss es nicht nur in dem angegebenen Token vorhanden, sondern auch aktiviert sein. Dadurch soll erreicht werden, dass Privilegien nur dann
aktiviert werden, wenn sie erforderlich sind, damit ein Prozess nicht versehentlich eine privilegierte sicherheitsrelevante Operation ausführen kann. Die Aktivierung und Deaktivierung von
Privilegien erfolgt mithilfe der Funktion AdjustTokenPrivileges.
Experiment: Die Aktivierung eines Privilegs beobachten
Mit der folgenden Vorgehensweise können Sie beobachten, wie das Systemsteuerungsapplet Datum und Uhrzeit (auf Windows 10) das Privileg SeTimeZonePrivilege aktiviert, wenn
Sie die Schnittstelle verwenden, um die Zeitzone auf Ihrem Computer zu ändern:
1.
Starten Sie Process Explorer mit erhöhten Rechten.
2.
Rechtsklicken Sie auf die Uhr in der Taskleiste und wählen Sie Datum/Uhrzeit ändern.
Alternativ können Sie auch die App Einstellungen starten und nach Zeit suchen, um die
Seite mit den Datums- und Uhrzeiteinstellungen zu öffnen.
3.
Rechtsklicken Sie in Process Explorer auf den Prozess SystemSettings.exe, wählen Sie
Eigenschaften und klicken Sie im Eigenschaftendialogfeld auf die Registerkarte Security.
Wie Sie sehen, ist das Privileg SeTimeZonePrivilege deaktiviert.
→
Privilegien und Kontorechte
Kapitel 7
781
4.
Ändern Sie die Zeitzone, schließen Sie das Eigenschaftendialogfeld und öffnen Sie es erneut. Jetzt können Sie auf der Registerkarte Security erkennen, dass SeTimeZonePrivilege
aktiviert ist:
Experiment: Das Privileg »Auslassen der durchsuchenden
Überprüfung«
Systemadministratoren müssen sich des Privilegs Auslassen der durchsuchenden Überprüfung (SeNotifyPrivilege) und dessen Konsequenzen bewusst sein. Das folgende Experiment zeigt, dass mangelnde Kenntnisse dieses Privilegs zu Sicherheitslücken führen können:
1.
Erstellen Sie einen Ordner und darin eine neue Textdatei mit beliebigem Beispieltext.
2.
Suchen Sie die Datei im Explorer auf, öffnen Sie ihr Eigenschaftendialogfeld und klicken
Sie auf die Registerkarte Sicherheit.
3.
Klicken Sie auf Erweitert.
4.
Deaktivieren Sie das Kontrollkästchen Vererbung.
5.
Wenn Sie gefragt werden, ob Sie geerbte Berechtigungen entfernen oder kopieren
wollen, wählen Sie Kopieren.
→
782
Kapitel 7
Sicherheit
6.
Ändern Sie die Sicherheitseinstellungen des neuen Ordners so, dass Ihr Konto keinen
Zugriff darauf hat. Wählen Sie dazu Ihr Konto aus und aktivieren Sie in der Liste der
Berechtigungen alle Kontrollkästchen mit der Bezeichnung Verweigern.
7.
Starten Sie den Editor. Wählen Sie Datei > Öffnen und versuchen Sie, in dem daraufhin
angezeigten Dialogfeld zu dem neuen Verzeichnis zu gelangen. Der Zugriff auf dieses
Verzeichnis wird Ihnen verweigert.
8.
Geben Sie in das Feld Dateiname des Dialogfelds Öffnen den Namen der neuen Datei
mit vollständiger Pfadangabe ein. Die Datei wird geöffnet.
Wenn Ihr Konto das Privileg Auslassen der durchsuchenden Überprüfung nicht hat und Sie
versuchen, eine Datei zu öffnen, führt NFTS für jedes Verzeichnis im Pfad zu der Datei eine
Zugriffsprüfung durch. Dabei würde Ihnen in unserem Beispiel der Zugriff auf die Datei
verweigert.
Superprivilegien
Einige Privilegien sind so umfassend, dass Benutzer, die darüber verfügen, zu »Superbenutzern« mit voller Kontrolle über den Computer werden. Diese Privilegien können auf unterschiedlichste Weise verwendet werden, um nicht autorisierten Zugriff zu erlangen oder um
Beschränkungen für Ressourcen aufzuheben und nicht autorisierte Operationen durchzuführen. Wir wollen uns hier jedoch darauf konzentrieren, die Privilegien zur Ausführung von Code
zu nutzen, der dem Benutzer weitere, ihm nicht zustehende Rechte gewähren kann, denn damit kann der Benutzer letzten Endes jede beliebige Operation auf dem Computer ausführen.
In diesem Abschnitt geben wir einen Überblick über die »Superprivilegien« und erklären,
wie sie ausgenutzt werden können. Andere Privilegien können ebenfalls missbraucht werden,
z. B. Sperren von Seiten im Speicher (SeLockMemoryPrivilege) für Denial-of-Service-Angriffe auf
ein System, aber damit wollen wir uns hier nicht befassen. Auf Systemen mit eingeschalteter Benutzerkontensteuerung werden die hier vorgestellten Privilegien nur Anwendungen auf
mindestens hoher Integritätsebene zugewiesen, selbst wenn das Konto über sie verfügt.
QQ Debuggen von Programmen (SeDebugPrivilege) Ein Benutzer mit diesem Privileg
kann jegliche Prozesse im System (mit Ausnahme von geschützten Prozessen) unabhängig von deren Sicherheitsdeskriptoren öffnen. Beispielsweise könnte er ein Programm einsetzen, das den Lsass-Prozess öffnet, ausführbaren Code in dessen Adressraum schreibt
und dann mit CreateRemoteThread einen Thread erstellt, der den injizierten Code in einem
Sicherheitskontext mit höheren Rechten ausführt. Dieser Code wiederum kann dem Benutzer weitere Rechte und Gruppenmitgliedschaften gewähren.
QQ Übernehmen des Besitzes (SeTakeOwnershipPrivilege) Dieses Privileg erlaubt dem
Inhaber, den Besitz über beliebige sicherungsfähige Objekte zu übernehmen (selbst über
geschützte Prozesse und Threads), indem er seine eigene SID in das Besitzerfeld des Sicherheitsdeskriptors für das Objekt schreibt. Da der Besitzer immer die Berechtigung zum
Lesen und Ändern der DACL des Sicherheitsdeskriptors hat, kann ein Prozess mit diesem
Privileg die DACL bearbeiten, um sich selbst Vollzugriff auf das Objekt zu geben, und es
Privilegien und Kontorechte
Kapitel 7
783
dann schließen und mit Vollzugriff öffnen. Dadurch kann der Benutzer nicht nur sensible
Daten einsehen, sondern sogar Systemdateien wie Lsass, die im Rahmen des normalen
Systembetriebs ausgeführt werden, durch seine eigenen Programme ersetzen, die einem
Benutzer erhöhte Rechte gewähren.
QQ Wiederherstellen von Dateien und Verzeichnissen (SeRestorePrivilege) Ein Benutzer
mit diesem Privileg kann sämtliche Dateien auf dem System durch seine eigenen ersetzen,
sogar Systemdateien.
QQ Laden und Entfernen von Gerätetreibern (SeLoadDriverPrivilege) Böswillige Benutzer sind mit diesem Privileg in der Lage, Gerätetreiber in dem System zu laden. Da Gerätetreiber als vertrauenswürdige Bestandteile des Betriebssystems angesehen werden und
mit den Anmeldeinformationen des Systemkontos ausgeführt werden können, kann ein
solcher Treiber privilegierte Programme starten, die dem Benutzer noch weitere Rechte
zuweisen.
QQ Erstellen eines Tokenobjekts (SeCreateTokenPrivilege) Dieses Privileg lässt sich dazu
missbrauchen, Tokens für willkürliche Benutzerkonten mit willkürlichen Gruppenmitgliedschaften und Privilegien zu erstellen.
QQ Einsetzen als Teil des Betriebssystems (SeTcbPrivilege) Die Funktion LsaRegisterLogonProcess, die ein Prozess aufruft, um eine vertrauenswürdige Verbindung zu Lsass
herzustellen, prüft, ob dieses Privileg vorhanden ist. Ein böswilliger Benutzer mit diesem
Privileg kann eine vertrauenswürdige Lsass-Verbindung einrichten und dann die Funktion
LsaLogonUser ausführen, um weitere Anmeldesitzungen zu erstellen. LsaLogonUser verlangt
einen gültigen Benutzernamen und ein Kennwort und akzeptiert eine optionale Liste von
SIDs, die sie dem ursprünglichen Token für eine neue Anmeldesitzung hinzufügt. Daher
könnte der Benutzer mit seinem eigenen Benutzernamen und Kennwort eine neue Anmeldesitzung erstellen, bei der die SIDs von Gruppen und Benutzern mit höheren Rechten in
das resultierende Token eingeschlossen werden.
Die Verwendung erhöhter Rechte ist auf den lokalen Computer beschränkt und
wirkt sich nicht auf das Netzwerk aus, da jegliche Interaktion mit einem anderen
Rechner eine Authentifizierung auf einem Domänencontroller und die Überprüfung des Domänenkennworts erfordert. Da Domänenkennwörter aber weder im
Klartext noch in verschlüsselter Form auf einem lokalen Computer gespeichert
sind, sind sie für Schadcode nicht zugänglich.
Zugriffstokens von Prozessen und Threads
Abb. 7–12 gibt einen Überblick über die bis jetzt in diesem Kapitel eingeführten Begriffe und
zeigt die grundlegenden Sicherheitsstrukturen von Prozessen und Threads. Wie Sie sehen,
verfügen die Prozess-, Thread- und Zugriffstokenobjekte alle über ihre eigenen Zugriffssteu
erungslisten (Access Control Lists, ACLs). In der Abbildung haben Thread 2 und 3 jeweils ein
Identitätswechseltoken, während Thread 1 das Prozesszugriffstoken verwendet.
784
Kapitel 7
Sicherheit
Zugriffstoken
Prozess
Benutzer-SID
Gruppen-SIDs
Rechte
Besitzer-SID
Standard-ACL
…
Zugriffstoken
Benutzer-SID
Gruppen-SIDs
Rechte
Besitzer-SID
Standard-ACL
…
Zugriffstoken
Benutzer-SID
Gruppen-SIDs
Rechte
Besitzer-SID
Standard-ACL
…
Abbildung 7–12 Sicherheitsstrukturen von Prozessen und Threads
Sicherheitsüberwachung
Der Objekt-Manager kann Überwachungsereignisse als Resultat von Zugriffsprüfungen generieren. Windows-Funktionen, die für Benutzer zur Verfügung stehen, sind in der Lage, solche
Ereignisse auch direkt zu erstellen. Kernelmoduscode hat stets die Erlaubnis, Überwachungsereignisse zu erzeugen. Mit der Überwachung sind die beiden Rechte SeSecurityPrivilege und
SeAuditPrivilege verbunden. Um das Sicherheitsprotokoll zu verwalten und die SACL eines
Objekts einzusehen und festzulegen, muss ein Prozess über das Recht SeSecurityPrivilege
verfügen. Prozesse, die Systemdienste für die Überwachung aufrufen, müssen jedoch über das
Recht SeAuditPrivilege verfügen, um einen Überwachungsdatensatz erstellen zu können.
Die Überwachungsrichtlinie des lokalen Systems regelt, welche Arten von Sicherheitsereignissen überwacht werden. Sie gehört zu der lokalen Sicherheitsrichtlinie, die Lsass auf dem
lokalen System unterhält. Konfiguriert wird sie mit dem Editor für lokale Sicherheitsrichtlinien
aus Abb. 7–13. Ihre Einstellungen (sowohl die Grundeinstellungen unter Lokale Richtlinien als
auch diejenigen unter Erweiterte Überwachungsrichtlinienkonfiguration) sind als Bitmapwert im
Registrierungsschlüssel HKEY_LOCAL_MACHINE\SECURITY\Policy\PolAdtEv gespeichert.
Sicherheitsüberwachung
Kapitel 7
785
Abbildung 7–13 Die Überwachungsrichtlinie im Editor für lokale Sicherheitsrichtlinien
Bei der Systeminitialisierung und bei Änderungen der Richtlinie sendet Lsass dem SRM Nachrichten, um ihn über die Überwachungsrichtlinie zu informieren. Der SRM wiederum sendet
über seine ALPC-Verbindung Überwachungsdatensätze, die er auf der Grundlage der Überwachungsereignisse erstellt, an Lsass, und Lsass bearbeitet sie und sendet sie an die Ereignisprotokollierung. Diese Weiterleitung der Datensätze erfolgt durch Lsass und nicht durch
den SRM, da Lsass noch wichtige Einzelheiten hinzufügt, z. B. die erforderlichen Angaben, um
den überwachten Prozess vollständig identifizieren zu können.
Die Ereignisprotokollierung schreibt die Überwachungsdatensätze anschließend in das Sicherheitsprotokoll. Neben den Überwachungsdatensätzen vom SRM erstellen auch Lsass und
der SAM Überwachungsdatensätze, die Lsass direkt an die Ereignisprotokollierung sendet.
Mithilfe der AuthZ-APIs können Anwendungen selbst definierte Überwachungen erzeugen.
Abb. 7–14 zeigt den Gesamtablauf.
786
Kapitel 7
Sicherheit
Sicherheitsteilsystem
Sicherheitsprotokoll
LSA-Authentifizierung
Ereignis
protokollierung
AuthZ-API
LSA-Überwachung
Benutzermodus
Überwachungsrichtlinie
Überwachungs
datensätze
Kernelmodus
Objekt-Manager
E/A-Analyse
NTFS
Mailslots
Benannte Pipes
Konfigurations-Manager
Prozess-Manager
Abbildung 7–14 Weiterleitung von Überwachungsdatensätzen
Die Überwachungsdatensätze werden bei ihrem Eingang im SRM in eine Warteschlange zur
Übertragung an die LSA gestellt. Sie werden nicht in Stapeln gesendet. Die Verschiebung vom
SRM zum Sicherheitsteilsystem kann auf zwei verschiedene Weisen erfolgen. Kleine Überwachungsdatensätze (mit einem Umfang unter der maximalen Nachrichtengröße für ALPCs) werden als ALPC-Nachrichten gesendet. Dabei werden die Datensätze vom Adressraum des SRM
in den Adressraum des Lsass-Prozesses kopiert. Größere Überwachungsdatensätze macht der
SRM in gemeinsam genutztem Speicher für Lsass verfügbar und übergibt lediglich einen Zeiger darauf in einer ALPC-Nachricht.
Überwachung des Objektzugriffs
Eine wichtige Anwendung des Überwachungsmechanismus in vielen Umgebungen besteht
darin, ein Protokoll der Zugriffsversuche auf abgesicherte Objekte zu führen, insbesondere auf
Dateien. Dazu muss die Richtlinie Objektzugriffsversuche überwachen aktiviert sein. Außerdem
muss es in den SACLs Überwachungseinträge geben, die die Überwachung der betreffenden
Objekte erlauben.
Wenn versucht wird, das Handle eines Objekts zu öffnen, ermittelt der SRM zunächst, ob
dieser Vorgang zugelassen oder verweigert werden soll. Ist die Objektzugriffsüberwachung
eingeschaltet, untersucht der SRM anschließend die SACL des Objekts. Es gibt zwei Arten von
Überwachungseinträgen, nämlich Zulassungs- und Verweigerungseinträge. Damit ein Überwachungseintrag für den Objektzugriff erstellt wird, muss der Überwachungseintrag mit allen
Sicherheitskennungen der zugreifenden Entität und mit allen angeforderten Zugriffsmethoden
übereinstimmen und von dem Typ sein, der dem Ergebnis der Zugriffsprüfung entspricht (Zugriff erlaubt oder verweigert).
In Überwachungsdatensätzen für den Objektzugriff wird nicht nur festgehalten, ob der
Zugriff gewährt oder verweigert wurde, sondern auch der Grund für den Erfolg bzw. Fehlschlag. Das geschieht gewöhnlich in Form eines Zugriffssteuerungseintrags, der in SDDL
(Security Descriptor Definition Language) angegeben ist. Wenn der Zugriff auf ein Objekt
Sicherheitsüberwachung
Kapitel 7
787
entgegen den Erwartungen verweigert oder zugelassen wird, ist dadurch eine Diagnose
möglich, da der Zugriffssteuerungseintrag, der für den Erfolg oder Fehlschlag des Zugriffs
führte, angegeben ist.
Wie Sie in Abb. 7–13 gesehen haben, ist die Überwachung des Objektzugriffs (ebenso wie
alle anderen Überwachungsrichtlinien) standardmäßig ausgeschaltet.
Experiment: Den Objektzugriff überwachen
Die Objektzugriffsüberwachung können Sie auf folgende Weise beobachten:
1.
Begeben Sie sich im Explorer zu einer Datei, auf die Sie normalerweise Zugriff haben
(z. B. eine Textdatei), öffnen Sie ihr Eigenschaftendialogfeld, rufen Sie die Registerkarte
Sicherheit auf und klicken Sie auf Erweitert.
2.
Rufen Sie die Registerkarte Überwachung auf und klicken Sie sich durch die Warnung
über administrative Rechte. In dem schließlich angezeigten Dialogfeld können Sie zur
SACL der Datei Überwachungseinträge hinzufügen.
3.
Klicken Sie auf Hinzufügen und wählen Sie Prinzipal auswählen.
→
788
Kapitel 7
Sicherheit
4.
Geben Sie in dem anschließend eingeblendeten Dialogfeld Benutzer oder Gruppe auswählen Ihren Benutzernamen oder den Namen einer Gruppe ein, zu der Sie gehören,
z. B. Jeder. Klicken Sie auf Namen überprüfen und dann auf OK. Dadurch erscheint das
Dialogfeld, um einen Überwachungseintrag für den Benutzer bzw. die Gruppe und die
Datei zu erstellen.
5.
Klicken Sie dreimal auf OK, um das Eigenschaftendialogfeld zu schließen.
6.
Doppelklicken Sie im Explorer auf die Datei, um sie mit dem vorgesehenen Programm
zu öffnen (z. B. eine Textdatei mit dem Editor).
7.
Öffnen Sie das Startmenü, geben Sie ereignis ein und klicken Sie auf Ereignisanzeige.
8.
Öffnen Sie das Sicherheitsprotokoll. Für den Zugriff auf die Datei gibt es keinen Eintrag,
da die Überwachungsrichtlinie für den Objektzugriff noch nicht eingerichtet wurde.
9.
Öffnen Sie im Editor für lokale Sicherheitsrichtlinien Lokale Richtlinien > Überwachungsrichtlinie.
10. Doppelklicken Sie auf Objektzugriffsversuche überwachen und aktivieren Sie die Option
Erfolgreich, um einen erfolgreichen Zugriff auf Dateien zu überwachen.
11. Klicken Sie im Menü der Ereignisanzeige auf Aktion > Aktualisieren. Die Änderungen
an der Überwachungsrichtlinie führen dazu, dass Überwachungsdatensätze angezeigt
werden.
12. Doppelklicken Sie im Explorer auf die Datei, um sie erneut zu öffnen.
13. Klicken Sie in der Ereignisanzeige abermals auf Aktion > Aktualisieren. Jetzt sind mehrere Überwachungsdatensätze über Dateizugriffe vorhanden.
→
Sicherheitsüberwachung
Kapitel 7
789
14. Suchen Sie den Überwachungsdatensatz mit der Ereignis-ID 4656. Er wird mit der Beschreibung »Ein Handle zu einem Objekt wurde angefordert ...« angezeigt. Sie können
auch die Suchfunktion nutzen, um nach dem Namen der geöffneten Datei zu suchen.
15. Scrollen Sie in dem Textfeld nach unten bis zum Abschnitt Zugriffsgründe. Im folgenden Beispiel sind dort die beiden Zugriffsmethoden READ_CONTROL und SYNCHRONIZE sowie ReadAttributes, ReadEA (erweiterte Attribute) und ReadDate angefordert
worden. READ_CONTROL wurde zugelassen, da es der Besitzer der Datei war, der den
Zugriff versucht hat. Die anderen Zugriffsarten wurden aufgrund der Einstellungen
im Zugriffssteuerungseintrag gewährt.
Globale Überwachungsrichtlinie
Neben Zugriffssteuerungseinträgen für einzelne Objekte können Sie auch eine globale Überwachungsrichtlinie aufstellen, um die Objektzugriffsüberwachung für alle Objekte im Dateisystem, für alle Registrierungsschlüssel oder beides einzurichten. Damit können Sie dafür sorgen,
dass die gewünschte Überwachung stattfindet, ohne sich die SACLs aller einzelnen Objekte
ansehen zu müssen.
Administratoren können die globale Überwachungsrichtlinie mit dem Befehl AuditPol und
der Option /resourceSACL festlegen und einsehen. Innerhalb eines Programms lässt sich dies
mit einem Aufruf von AuditSetGlobalSacl bzw. AuditQueryGlobalSacl bewerkstelligen. Ebenso
wie für Änderungen an Objekt-SACLs ist auch für Änderungen an diesen globalen SACLs das
Recht SeSecurityPrivilege erforderlich.
790
Kapitel 7
Sicherheit
Experiment: Die globale Überwachungsrichtlinie einrichten
Mit dem Befehl AuditPol können Sie die globale Überwachungsrichtlinie einschalten.
1.
Öffnen Sie den Editor für lokale Sicherheitsrichtlinien, öffnen Sie die Einstellungen für
die Überwachungsrichtlinie (siehe Abb. 7–13), doppelklicken Sie auf Objektzugriffsversuche überwachen und aktivieren Sie sowohl Erfolgreich als auch Fehler. Auf den meisten Systemen gibt es nicht viele SACLs, die eine Objektzugriffsüberwachung angeben,
weshalb an dieser Stelle wenn überhaupt nur sehr wenige Überwachungsdatensätze
erzeugt werden.
2.
Geben Sie an einer Eingabeaufforderung mit erhöhten Rechten den folgenden Befehl
ein. Dadurch wird ein Überblick der Befehle zum Festlegen und Abrufen der globalen
Überwachungsrichtlinie angezeigt.
C:\> auditpol /resourceSACL
3.
Geben Sie nun an derselben Eingabeaufforderung mit erhöhten Rechten die folgenden
Befehle ein. Gewöhnlich wird dabei gemeldet, dass für die entsprechenden Ressourcentypen keine globale SACL vorhanden ist. (Beachten Sie, dass es bei den Schlüsselwörtern File und Key auf die Groß- und Kleinschreibung ankommt!)
C:\> auditpol /resourceSACL /type:File /view
C:\> auditpol /resourceSACL /type:Key /view
4.
Geben Sie an derselben Eingabeaufforderung mit erhöhten Rechten den folgenden
Befehl ein. Dadurch richten Sie eine globale Überwachungsrichtlinie ein, gemäß der
jegliche Versuche des angegebenen Benutzers, Dateien für den Schreibzugriff (FW) zu
öffnen, Überwachungsdatensätze hervorrufen, und zwar unabhängig davon, ob diese
Versuche erfolgreich waren oder nicht. Bei dem Benutzernamen kann es sich um einen einzelnen Benutzernamen auf dem System, einen Gruppennamen wie Jeder, einen
Benutzernamen mit Domänenangabe (Domänenname\Benutzername) oder eine SID
handeln.
C:\> auditpol /resourceSACL /set /type:File /user:Ihr_Benutzername /success
/failure /access:FW
5.
Öffnen Sie unter dem angegebenen Benutzernamen im Explorer oder mithilfe anderer
Programme eine Datei. Suchen Sie anschließend im Systemprotokoll nach den Überwachungsdatensätzen.
6.
Entfernen Sie nach Beendigung des Experiments die globale SACL aus Schritt 4 wieder
wie folgt mit dem Befehl auditpol:
C:\> auditpol /resourceSACL /remove /type:File /user:Ihr_Benutzername
Die globale Überwachungsrichtlinie wird in Form von zwei SACLs in den Registrierungsschlüsseln HKLM\SECURITY\Policy\GlobalSaclNameFile und HKLM\SECURITY\Policy\GlobalSaclNameKey
gespeichert. Sie können sich diese Schlüssel ansehen, indem Sie Regedit.exe unter dem System-
Sicherheitsüberwachung
Kapitel 7
791
konto ausführen, wie es im Abschnitt »Systemkomponenten für die Sicherheit« weiter vorn in
diesem Kapitel beschrieben wird. Diese Schlüssel werden erst dann angelegt, wenn die zugehörigen globalen SACLs zum ersten Mal eingerichtet werden.
Objektspezifische SACLs können die globale Überwachungsrichtlinie nicht überschreiben,
aber ergänzen. Wenn beispielsweise die globale Überwachungsrichtlinie die Überwachung des
Lesezugriffs aller Benutzer auf alle Dateien verlangt, können SACLs einzelner Dateien eine zusätzliche Überwachung des Schreibzugriffs auf diese Dateien durch bestimmte Benutzer oder
Gruppen fordern.
Die globale Überwachungsrichtlinie kann auch im Editor für lokale Sicherheitsrichtlinien
unter Erweiterte Überwachungsrichtlinienkonfiguration eingerichtet werden. Damit beschäftigen wir uns im nächsten Abschnitt.
Erweiterte Überwachungsrichtlinienkonfiguration
Neben den bereits beschriebenen Einstellungen für die Überwachungsrichtlinie bietet der Editor für lokale Sicherheitsrichtlinien unter Erweiterte Überwachungsrichtlinienkonfiguration auch
detailliertere Steuerungsmöglichkeiten (siehe Abb. 7–15).
Abbildung 7–15 Die Erweiterte Überwachungsrichtlinienkonfiguration im Editor für lokale
Sicherheitsrichtlinien
Zu jeder der neun Überwachungsrichtlinieneinstellungen unter Lokale Richtlinien (siehe
Abb. 7–13) gibt es hier eine Gruppe von Einstellungen, die eine feinere Steuerung ermöglichen.
So können Sie mit den Einstellungen für die Überwachung des Objektzugriffs unter Lokale
792
Kapitel 7
Sicherheit
Richtlinien nur dafür sorgen, dass der Zugriff auf sämtliche Objekte überwacht wird, während
die Einstellungen in diesem Abschnitt es ermöglichen, den Zugriff auf verschiedene Arten von
Objekten getrennt voneinander zu überwachen. Wenn Sie eine der Einstellungen unter Lokale
Richtlinien aktivieren, werden dadurch implizit alle zugehörigen erweiterten Einstellungen eingeschaltet. Brauchen Sie eine genauere Kontrolle über den Inhalt des Überwachungsprotokolls,
können Sie die erweiterten Einstellungen einzeln festlegen. Die Standardeinstellungen werden
dann zu einem Produkt der erweiterten Einstellungen, was im Editor für lokale Sicherheitsrichtlinien aber nicht erkennbar ist. Ein Versuch, die Überwachung sowohl mit den einfachen
als auch den erweiterten Einstellungen festzulegen, kann zu unerwarteten Ergebnissen führen.
Mit der erweiterten Option Globale Objektzugriffsüberwachung können Sie die im vorherigen Abschnitt beschriebenen globalen SACLs mit einer ähnlichen grafischen Oberfläche einrichten, wie sie im Explorer und im Registrierungseditor für Sicherheitsdeskriptoren im Dateisystem
bzw. der Registrierung verwendet wird.
Anwendungscontainer
In Windows 8 wurde die neue Sicherheits-Sandbox AppContainer eingeführt. Anwendungscontainer sind zwar hauptsächlich für UWP-Prozesse gedacht, können aber auch für »normale«
Prozesse verwendet werden (wobei es jedoch kein mitgeliefertes Tool für diesen Zweck gibt). In
diesem Abschnitt beschäftigen wir uns hauptsächlich mit Paket-Anwendungscontainern, also
denen für UWP-Prozesse mit dem .appx-Format. Eine vollständige Erörterung von UWP-Apps
würde den Rahmen dieses Kapitels sprengen. Weitere Informationen dazu finden Sie in Kapitel 3 sowie in den Kapiteln 8 und 9 von Band 2. Hier konzentrieren wir uns auf die Sicherheits
aspekte von Anwendungscontainern und ihre typische Verwendung als Hosts für UWP-Anwendungen.
UWP-App (Universal Windows Platform) ist der neueste Begriff zur Bezeichnung
von Prozessen, die die Windows-Laufzeit beherbergen. Früher wurden sie auch
Vollbild-Apps, moderne Apps, Metro-Apps und manchmal auch einfach WindowsApps genannt. Der Namensbestandteil »Universal« gibt an, dass diese Anwendungen zur Bereitstellung und Ausführung auf verschiedenen Windows 10-Editionen
und Gerätearten von IoT Core über Mobil- und Desktopgeräte und die Xbox bis hin
zur HoloLens gedacht sind. Im Grunde genommen sind sie jedoch noch mit denen
identisch, die in Windows 8 eingeführt wurden. Das Prinzip der Anwendungscontainer in diesem Abschnitt gilt dafür für Windows 8 und höher. Beachten Sie, dass
statt UWP manchmal auch die Bezeichnung UAP (für Universal Application Platform) verwendet wird. Beide Begriffe bedeuten jedoch dasselbe.
Der ursprüngliche Codename für AppContainer war LowBox. Dieser Begriff taucht
noch in vielen API-Namen und Datenstrukturen auf, die wir uns in diesem Abschnitt ansehen.
Anwendungscontainer
Kapitel 7
793
UWP-Apps im Überblick
Die Mobilgeräterevolution hat zu neuen Möglichkeiten geführt, um Software zu erwerben
und auszuführen. Mobilgeräte beziehen ihre Anwendungen gewöhnlich von einem zentralen »Store«, wobei Installation und Aktualisierung automatisch erfolgen und nur sehr wenig
Benutzereingriff erfordern. Sobald ein Benutzer im Store eine App ausgewählt hat, sieht er
die Berechtigungen, die für das Funktionieren der Anwendung erforderlich sind. Diese Berechtigungen werden als Fähigkeiten (capabilities) bezeichnet und beim Einreichen in den
Store zusammen mit dem Paket angegeben. Dadurch kann der Benutzer entscheiden, ob die
geforderten Fähigkeiten für ihn akzeptabel sind.
Abb. 7–16 zeigt die Fähigkeitenliste eines UWP-Spiels (die Beta-Edition von Minecraft für
Windows 10): Das Spiel benötigt Internetzugriff als Client und als Server sowie Zugriff auf das
lokale Heim- oder Arbeitsplatznetz. Mit dem Herunterladen des Spiels akzeptiert der Benutzer
stillschweigend, dass das Spiel diese Fähigkeiten nutzen kann. Auf der anderen Seite kann der
Benutzer aber darauf vertrauen, dass das Spiel nur diese Fähigkeiten nutzt. Das heißt, es kann
keine zusätzlichen, nicht genehmigten Fähigkeiten anwenden, indem es etwa auf die Kamera
des Geräts zugreift.
Abbildung 7–16 Teil der Seite für eine App im Store mit Angabe der Fähigkeiten
Um ein Gefühl für den Unterschied zwischen UWP-Apps und (klassischen) Desktopanwendungen zu bekommen, schauen Sie sich Tabelle 7–12 an. Wie sich die Windows-Plattform für Entwickler darstellt, sehen Sie in Abb. 7–17.
794
Kapitel 7
Sicherheit
UWP-App
(Klassische) Desktopanwendung
Geräteunterstützung
Läuft auf allen Windows-Geräten.
Nur auf PCs
APIs
Kann auf WinRT-, einen Teil der
COM- und einen Teil der Win32-APIs
zugreifen.
Kann auf COM-, Win32- und einen
Teil der WinRT-APIs zugreifen.
Identität
Starke Anwendungsidentität (statisch
und dynamisch)
Rohe EXE-Dateien und Prozesse
Information
Deklaratives APPX-Manifest
Undurchsichtige Binärdateien
Installation
Eigenständiges APPX-Paket
Lose Dateien oder MSI
Anwendungsdaten
Isolierter Speicher für einzelne Benutzer/Anwendungen (lokal und
Roaming)
Freigegebene Benutzerprofile
Lebenszyklus
Teilnahme an Anwendungsressourcenverwaltung und PLM
Lebenszyklus auf Prozessebene
Instanzen
Nur eine einzige Instanz
Beliebige Anzahl von Instanzen
Tabelle 7–12 UWP- und Desktopanwendungen im Vergleich
(Klassische) Desktopanwendungen
.NET-Sprachen
.NET-Laufzeit
UWP-Apps
Desktop Bridge („Centennial“)
Web Bridge („Westminster“)
iOS Bridge („Islandwood“)
.NETSprachen
Universal Windows Platform (Windows-Laufzeit-APIs)
DLLs des Win32-Teilsystems
Benutzermodus
Kernelmodus
Exekutive und Kernel
Abbildung 7–17 Aufbau der Windows-Plattform
Sehen wir uns einige der Elemente in Abb. 7–17 noch etwas genauer an:
QQ UWP-Apps können ebenso wie Desktopanwendungen normale ausführbare Dateien
produzieren. Als Host für UWP-App auf der Grundlage von HTML oder JavaScript wird
Wwahost.exe (%SystemRoot%\System32\wwahost.exe) verwendet, da diese Apps eine
DLL produzieren und keine ausführbare Datei.
QQ Die UWP wird durch Windows-Laufzeit-APIs implementiert, die wiederum auf einer erweiterten Version von COM basieren. Sprachprojektionen werden für C++ (durch proprietäre, als C++/CX bezeichnete Spracherweiterungen), .NET-Sprachen und JavaScript
bereitgestellt. Diese Projektionen machen es Entwicklern relativ einfach, von ihrer vertrauten Umgebung aus auf die Typen, Methoden, Eigenschaften und Ereignisse von WinRT
zuzugreifen.
Anwendungscontainer
Kapitel 7
795
QQ Es stehen verschiedene Bridge-Technologien zur Verfügung, um auch andere Arten von
Anwendungen in UWP zu übersetzen. Weitere Informationen zur Nutzung dieser Technologien finden Sie in der MSDN-Dokumentation.
QQ Die Windows-Laufzeit befindet sich ebenso wie das .NET-Framework oberhalb der DLLs
des Windows-Teilsystems. Sie hat keine Kernelkomponenten und gehört nicht zu einem
anderen Teilsystem, da sie dieselben Win32-APIs nutzt, die das System anbietet. Einige
Richtlinien und die allgemeine Unterstützung für Anwendungscontainer sind jedoch im
Kernel implementiert.
QQ Die Windows-Laufzeit-APIs sind in DLLs implementiert, die sich im Verzeichnis %SystemRoot%\System32 befinden und Namen der Form Windows.Xxx.Yyy...dll tragen, wobei der
Dateiname gewöhnlich den von der API implementierten Namensraum angibt. So stellt
beispielsweise Windows.Globalization.dll die Klassen bereit, die sich im Namensraum
Windows.Globalization befinden. (Eine vollständige Referenz der WinRT-APIs finden Sie
in der MSDN-Dokumentation.)
Anwendungscontainer
Die erforderlichen Schritte, um Prozesse zu erstellen, haben Sie bereits in Kapitel 3 kennengelernt. Außerdem haben Sie auch einige der zusätzlichen Schritte gesehen, die nötig sind,
um UWP-Prozesse anzulegen. Bei Letzteren wird der Erstellvorgang vom Dienst DCOMLaunch
ausgelöst, da UWP-Pakete unter anderem das Launch-Protokoll unterstützen. Der resultierende Prozess wird in einem Anwendungscontainer ausgeführt. Paketprozesse in einem Anwendungscontainer weisen unter anderem die folgenden Eigenschaften auf:
QQ Die Integritätsebene des Prozesses ist auf Niedrig gesetzt, was automatisch den Zugriff
auf viele Objekte sowie auf bestimmte APIs für den Prozess beschränkt, wie Sie in diesem
Kapitel schon gesehen haben.
QQ UWP-Prozesse werden immer innerhalb eines Jobs erstellt (ein Job pro UWP-App). Dieser
Job verwaltet den UWP-Prozess sowie alle Hintergrundprozesse, die für ihn ausgeführt
werden (mithilfe verschachtelter Jobs). Dadurch kann der Prozessstatus-Manager (PSM)
die App oder die Hintergrundverarbeitung auf einen Streich anhalten oder wieder aufnehmen.
QQ Das Token für einen UWP-Prozess verfügt über eine Anwendungscontainer-SID, die auf dem
SHA-2-Hash des UWP-Paketnamens basiert. Wie Sie noch sehen werden, wird diese SID
vom System und von anderen Anwendungen verwendet, um den Zugriff auf Dateien und
andere Kernelobjekte ausdrücklich zu erlauben. Die SID gehört nicht zur NT-AUTORITÄT, die
Sie in diesem Kapitel bis jetzt vor allem gesehen haben, sondern zur ZERTIFIZIERUNGSSTELLE
FÜR ANWENDUNGSPAKETE (die in der deutschen Version von Windows leider so genannt wurde,
obwohl es sich dabei nicht um eine Zertifizierungsstelle handelt). Im Stringformat beginnt
diese SID daher mit S-1-15-2, was SECURITY_AP_PACKAGE_BASE_RID (15) und SECURITY_APP_
PACKAGE_BASE_RID (2) entspricht. Da ein SHA-2-Hash 32 Bytes umfasst, umfasst der Rest
der SID insgesamt acht RIDs (wie bereits erwähnt, handelt es sich bei einem RID um einen
4-Byte-ULONG-Wert).
796
Kapitel 7
Sicherheit
QQ Das Token kann einen Satz von Fähigkeiten einschließen, die jeweils durch eine SID dargestellt werden. Diese Fähigkeiten werden im Manifest der Anwendung deklariert und auf
der Seite der Anwendung im Store angezeigt. Bei der Speicherung im Fähigkeitsabschnitt
des Manifests werden sie anhand der in Kürze beschriebenen Regeln ins SID-Format umgewandelt. Sie gehören zu der SID-Autorität aus dem vorherigen Punkt, haben aber den
Standard-RID SECURITY_CAPABILITY_BASE_RID (3). Komponenten der Windows-Laufzeit, Gerätezugriffsklassen im Benutzermodus und der Kernel können sich die Fähigkeiten ansehen, um einzelne Operationen zuzulassen oder zu verweigern.
QQ Das Token kann nur die Rechte SeChangeNotifyPrivilege, SeIncreaseWorkingSetPrivilege,
SeShutdownPrivilege, SeTimeZonePrivilege und SeUndockPrivilege enthalten. Dies ist der
Standardsatz von Rechten, die mit Standardbenutzerkonten verknüpft werden. Auf bestimmten Geräten kann darüber hinaus die Funktion AppContainerPrivilegesEnabledExt
der API-Erweiterung ms-win-ntos-ksecurity vorhanden sein, um die standardmäßig aktivierten Privilegien noch weiter einzuschränken.
QQ Das Token enthält bis zu vier Sicherheitsattribute (siehe den Abschnitt zur attributgestützten Zugriffssteuerung weiter vorn in diesem Kapitel), die angeben, dass das Token zu der
UWP-Paketanwendung gehört. Diese Attribute werden wie bereits angedeutet vom Dienst
DcomLaunch hinzugefügt, der für Aktivierung von UWP-Anwendungen zuständig ist. Es
handelt sich dabei um folgende Attribute:
•
WIN://PKG Dieses Attribut gibt an, dass das Token zu einer UWP-Paketanwendung
gehört. Es enthält einen Integerwert mit dem Ursprung der Anwendung sowie einige
Flags. Die möglichen Werte sind in Tabelle 7–13 und 7–14 aufgeführt.
•
WIN://SYSAPPID Enthält die Anwendungskennungen (oder Paket- oder String
namen) in Form eines Arrays aus Unicode-Stringwerten.
•
WIN://PKGHOSTID Gibt bei Paketen mit einem ausdrücklich festgelegten UWP-
Pakethost dessen ID in Form eines Integerwerts an.
•
WIN://BGKD Dieses Attribut wird nur für Hintergrundhosts verwendet (z. B. Back
groundTaskHost.exe für allgemeine Hintergrundtasks), die als COM-Anbieter ausgeführ
te UWP-Paketdienste speichern können. Der Name dieses Attributs soll background
bedeuten. Es enthält einen Integerwert für die Host-ID.
Das Flag TOKEN_LOWBOX (0x4000) wird im Element Flags des Tokens gesetzt, das mithilfe verschiedener Windows- und Kernel-APIs abgefragt werden kann (z. B. mit GetTokenInformation).
Das ermöglicht Komponenten, beim Vorhandensein eines Anwendungscontainertokens auf
andere Weise zu identifizieren und sich zu verhalten.
Es gibt noch eine zweite Art von Anwendungscontainer, nämlich Kindanwendungscontainer. Sie werden verwendet, wenn ein UWP-Anwendungscontainer
(oder Eltern-Anwendungscontainer) eigene verschachtelte Anwendungscontainer
erstellt. Neben den acht RIDs, die mit denen seines Elterncontainers übereinstimmen, verfügt ein Kindanwendungscontainer zur eindeutigen Identifizierung noch
über vier weitere RIDs.
Anwendungscontainer
Kapitel 7
797
Ursprung
Bedeutung
Unknown (0)
Der Ursprung des Pakets ist unbekannt.
Unsigned (1)
Das Paket ist nicht signiert.
Inbox (2)
Das Paket gehört zu einer integrierten (im Lieferumfang enthaltenen)
Windows-Anwendung.
Store (3)
Das Paket gehört zu einer aus dem Store heruntergeladenen UWP-Anwendung. Um den Ursprung zu bestätigen, wird geprüft, ob die DACL
der ausführbaren Hauptdatei der Anwendung einen Vertrauenseintrag
enthält.
Developer Unsigned (4)
Das Paket gehört zu einem nicht signierten Entwicklerschlüssel.
Developer Signed (5)
Das Paket gehört zu einem signierten Entwicklerschlüssel.
Line-of-Business (6)
Das Paket gehört zu einer quergeladenen Branchenanwendung.
Tabelle 7–13 Paketursprünge
Flag
Bedeutung
PSM_ACTIVATION_TOKEN_PACKAGED_
APPLICATION (0x1)
Gibt an, dass die UWP-Anwendung im AppX-Paketformat gespeichert ist. Dies ist die Standardeinstellung.
PSM_ACTIVATION_TOKEN_SHARED_ENTITY
(0x2)
Gibt an, dass das Token für mehrere ausführbare Dateien verwendet wird, die alle zur selben AppX-UWP-
Paketanwendung gehören.
PSM_ACTIVATION_TOKEN_FULL_TRUST
(0x4)
Gibt an, dass das Anwendungscontainertoken für das
Hosting einer Win32-Anwendung verwendet wird, die
mit der Windows-Bridge Centennial für Desktopanwendungen konvertiert wurde.
PSM_ACTIVATION_TOKEN_NATIVE_SERVICE
(0x8)
Gibt an, dass das Anwendungscontainertoken für das
Hosting eines Paketdienstes verwendet wird, der vom
Ressourcen-Manager des Dienststeuerungs-Managers
erstellt wurde. Mehr Informationen über Dienste erhalten Sie in Kapitel 9 von Band 2.
PSM_ACTIVATION_TOKEN_DEVELOPMENT_APP
(0x10)
Gibt an, dass es sich um eine interne Entwicklungsanwendung handelt. Wird auf Endbenutzersystemen
nicht verwendet.
BREAKAWAY_INHIBITED
(0x20)
Das Paket kann keine Prozesse erstellen, die nicht
selbst Pakete sind. Dieses Flag wird vom Prozesserstellungsattribut PROC_THREAD_ATTRIBUTE_DESKTOP_APP_
POLICY festgelegt (siehe Kapitel 3).
Tabelle 7–14 Paketflags
798
Kapitel 7
Sicherheit
Experiment: Informationen über UWP-Prozesse einsehen
Es gibt mehrere Möglichkeiten, um sich UWP-Prozesse anzusehen. Process Explorer kann
Prozesse, die die Windows-Laufzeit nutzen, farbig hervorheben (in der Grundeinstellung
hellblau). Um das auszuprobieren, starten Sie Process Explorer, öffnen das Menü Options
und wählen Configure Colors. Aktivieren Sie das Kontrollkästchen Immersive Processes.
»Immersive processes« (in der deutschen Lokalisierung »Vollbildprozesse« genannt) war
der ursprüngliche Begriff zur Beschreibung von WinRT-Apps (den heutigen UWP-Apps)
in Windows 8. (Der Begriff rührt daher, dass es sich dabei meistens um Vollbildanwendungen handelte.) Die Unterscheidung zwischen Vollbild- und anderen Prozessen erfolgt durch
Aufruf der API IsImmersiveProcess.
Starten Sie Calc.exe und schalten Sie wieder zu Process Explorer um. Jetzt werden mehrere Prozesse hellblau hervorgehoben, darunter Calculator.exe. Wenn Sie die Rechner-Anwendung minimieren, wird die hellblaue Hervorhebung grau, weil der Taschenrechner angehalten wurde. Stellen Sie das Taschenrechnerfenster wieder her, und die Hervorhebung
wird wieder hellblau angezeigt.
Das Gleiche können Sie auch bei anderen Apps feststellen, etwa bei Cortana (SearchUI.
exe). Klicken oder tippen Sie auf das Cortana-Symbol in der Taskleiste und schließen Sie
das Fenster. Dabei können Sie beobachten, wie die graue Hervorhebung hellblau wird und
danach wieder grau. Wenn Sie auf die Startschaltfläche klicken oder tippen, wird ShellExperienceHost.exe ähnlich hervorgehoben.
→
Anwendungscontainer
Kapitel 7
799
Bei einigen Prozessen mag die hellblaue Hervorhebung überraschend wirken, etwa
bei Explorer.exe, TaskMgr.exe und RuntimeBroker.exe. Es handelt sich dabei nicht um echte
Apps, aber da sie die Windows-Laufzeit-APIs nutzen, werden sie ebenfalls als Vollbildprozesse eingestuft. (Was es mit RuntimeBroker auf sich hat, werden wir uns in Kürze ansehen.)
Blenden Sie in Process Explorer die Spalte Integrity ein und sortieren Sie die Anzeige nach dieser Spalte. Dabei werden Sie feststellen, dass Prozesse wie Calculator.exe und
SearchUI.exe die Integritätsebene AppContainer aufweisen. Explorer und TaskMgr befinden
sich jedoch nicht auf dieser Ebene, was deutlich zeigt, dass es sich bei ihnen nicht um
UWP-Prozesse handelt, sondern dass sie ihren eigenen Regeln folgen.
800
Kapitel 7
Sicherheit
Experiment: Ein Anwendungscontainertoken einsehen
Die Eigenschaften eines Prozesses in einem Anwendungscontainer können Sie sich mit verschiedenen Tools ansehen. Auf der Registerkarte Security von Process Explorer werden die
in dem Token vermerkten Fähigkeiten angezeigt. Für Calculator.exe sieht diese Registerkarte wie folgt aus:
Beachten Sie vor allem die Anwendungscontainer-SID, die als AppContainer in der Spalte Flags angezeigt wird, und eine einzelne Fähigkeit unmittelbar darunter. Die Basis-RIDs
(SECURITY_APP_PACKAGE_BASE_RID bzw. SECURITY_CAPABILITY_BASE_RID) unterscheiden sich,
aber die restlichen acht RIDs sind identisch. Beide SIDs enthalten wie bereits erklärt den
Paketnamen im SHA-2-Format. Dies zeigt, dass es immer eine implizite Fähigkeit gibt, nämlich die Fähigkeit, das Paket selbst zu sein. Die Taschenrechneranwendung braucht also in
Wirklichkeit gar keine Fähigkeit. Im Abschnitt über Fähigkeiten weiter hinten lernen Sie ein
viel anspruchsvolleres Beispiel kennen.
Anwendungscontainer
Kapitel 7
801
Experiment: Attribute von Anwendungscontainertokens einsehen
Ähnliche Informationen können Sie mit dem Sysinternals-Tool AccessChk auch an der Befehlszeile gewinnen. Dabei werden außerdem noch sämtliche Attribute des Tokens angezeigt. Wenn Sie beispielsweise AccessChk mit den Schaltern -p -f und der Prozess-ID für
SearchUI.exe (Cortana) ausführen, ergibt sich Folgendes:
C:\ >accesschk -p -f 3728
Accesschk v6.10 - Reports effective permissions for securable objects
Copyright (C) 2006-2016 Mark Russinovich
Sysinternals - www.sysinternals.com
[7416] SearchUI.exe
RW DESKTOP-DD6KTPM\aione
RW NT AUTHORITY\SYSTEM
RW Package
\S-1-15-2-1861897761-1695161497-2927542615-642690995-327840285-26597451352630312742
Token security:
RW DESKTOP-DD6KTPM\aione
RW NT AUTHORITY\SYSTEM
RW DESKTOP-DD6KTPM\aione-S-1-5-5-0-459087
RW Package
\S-1-15-2-1861897761-1695161497-2927542615-642690995-327840285-26597451352630312742
R BUILTIN\Administrators
Token contents:
User:
DESKTOP-DD6KTPM\aione
AppContainer:
Package
\S-1-15-2-1861897761-1695161497-2927542615-642690995-327840285-26597451352630312742
Groups:
Mandatory Label\Low Mandatory Level INTEGRITY
Everyone
MANDATORY
NT AUTHORITY\Local account and member of Administrators group DENY
...
Security Attributes:
WIN://PKGHOSTID
TOKEN_SECURITY_ATTRIBUTE_TYPE_UINT64
→
802
Kapitel 7
Sicherheit
[0] 1794402976530433
WIN://SYSAPPID
TOKEN_SECURITY_ATTRIBUTE_TYPE_STRING
[0] Microsoft.Windows.Cortana_1.8.3.14986_neutral_neutral_
cw5n1h2txyewy
[1] CortanaUI
[2] Microsoft.Windows.Cortana_cw5n1h2txyewy
WIN://PKG
TOKEN_SECURITY_ATTRIBUTE_TYPE_UINT64
[0] 131073
TSA://ProcUnique
[TOKEN_SECURITY_ATTRIBUTE_NON_INHERITABLE]
[TOKEN_SECURITY_ATTRIBUTE_COMPARE_IGNORE]
TOKEN_SECURITY_ATTRIBUTE_TYPE_UINT64
[0] 204
[1] 24566825
An erster Stelle steht die Pakethost-ID im Hexadezimalformat: 0x6600000000001. Da alle Pakethost-IDs mit 0x66 beginnen, bedeutet dies, dass Cortana die erste verfügbare Host-ID verwendet, nämlich 1. Darauf folgen die Systemanwendungs-IDs, die drei Strings enthalten: den
starken Paketnamen, den Anzeigenamen für die Anwendung und den vereinfachten Paketnamen. Schließlich gibt es noch den Paketanspruch mit dem Hexwert 0x20001. Die steht für den
Ursprung Inbox (2) und die Flags PSM_ACTIVATION_TOKEN_PACKAGED_APPLICATION, was bedeutet,
dass es sich bei Cortana um einen Bestandteil eines AppX-Pakets handelt.
Sicherheitsumgebung von Anwendungscontainern
Eine der größten Nebenwirkungen aufgrund des Vorhandenseins einer Anwendungscon
tainer-SID und der zugehörigen Flags besteht darin, dass der Algorithmus aus dem Abschnitt
»Zugriffsprüfungen« weiter vorn in diesem Kapitel dahin gehend verändert wird, dass er alle
regulären Benutzer- und Gruppen-SIDs in dem Token ignoriert, also praktisch als reine Verweigerungseinträge behandelt. Wenn also beispielsweise der Taschenrechner von Max Mustermann gestartet wird, der zu den Gruppen Benutzer und Jeder gehört, so schlagen trotzdem
alle Zugriffsprüfungen fehl, die den SIDs von Max Mustermann und den Gruppen Benutzer und
Jeder Zugriff gewähren. Die einzigen SIDs, die sich der Algorithmus zur besitzerverwalteten
Zugriffsprüfung ansieht, sind die Anwendungscontainer-SIDs, gefolgt von den Fähigkeits-SIDs,
die anschließend der Algorithmus für die Fähigkeitsprüfung untersucht.
Anwendungscontainertokens aber sorgen nicht nur dafür, dass SIDs für die besitzerverwaltete Zugriffssteuerung als reine Verweigerungs-SIDs behandelt werden, sondern ändern den
Zugriffsprüfungsalgorithmus noch auf eine weitere wichtige Weise: Eine NULL-DACL, bei deren
Vorhandensein gewöhnlich Vollzugriff für alle gestattet wird, weil keine anderweitigen Informationen vorliegen (dies ist etwas anderes als eine leere DACL, bei der der Zugriff aufgrund
ausdrücklicher Zulassungsregeln für alle verweigert wird!), wird ignoriert und als Verweigerung
Anwendungscontainer
Kapitel 7
803
angesehen. Einfacher wird die Sache dadurch, dass ein Anwendungscontainer nur auf solche
sicherungsfähigen Objekte zugreifen kann, die über einen Zulassungseintrag für seine Anwendungscontainer-SID oder eine seiner Fähigkeiten verfügt. Sogar nicht gesicherte Objekte (also
solche mit NULL-DACLs) sind aus dem Spiel.
Bis jetzt haben wir stillschweigend vorausgesetzt, dass jeder UWP-Paketanwendung ein Anwendungscontainertoken entspricht. Das heißt jedoch nicht unbedingt, dass mit einem Anwendungscontainer nur eine einzige ausführbare Datei
verknüpft sein kann. UWP-Pakete können mehre ausführbare Dateien enthalten,
die alle zum selben Anwendungscontainer gehören, z. B. für das Back-End und
das Front-End eines Mikrodienstes. Dadurch können sie sich alle dieselbe SID und
dieselben Fähigkeiten teilen und Daten untereinander austauschen.
Das führt jedoch zu Kompatibilitätsproblemen. Wie kann eine Anwendung ohne Zugriff auf
selbst die grundlegendsten Dateisystem-, Registrierungs- und Objekt-Manager-Ressourcen
funktionieren? Windows berücksichtigt dies und stellt jeweils eine eigene Ausführungsumgebung (ein »Gefängnis«, wenn Sie so wollen) für jeden Anwendungscontainer auf:
QQ Im Namensraum des Objekt-Managers wird unter \Sessions\x\AppContainerNamedObjects
ein privates Unterverzeichnis für benannte Kernelobjekte angelegt und erhält die Stringdarstellung der Anwendungscontainer-SID als Name. Das Objekt dieses Unterverzeichnisses
erhält eine Zugriffssteuerungsliste mit einer Zugriffsmaske, die der SID des Anwendungscontainers Vollzugriff erlaubt. Das steht im Gegensatz zu Desktopanwendungen, die (innerhalb der Sitzung x) alle das Unterverzeichnis \Sessions\x\BaseNamedObjects verwenden.
Die Konsequenzen dieser Vorgehensweise und das Erfordernis, dass im Token jetzt auch
Handles gespeichert werden müssen, sehen wir uns in Kürze genauer an.
QQ Das Token enthält eine LowBox-Nummer. Dabei handelt es sich um einen eindeutigen Bezeichner für die Elemente eines Arrays, das der Kernel in der globalen Variablen g_SessionLowBoxArray speichert. Jedes dieser Elemente verweist auf eine SEP_LOWBOX_NUMBER_ENTRY-Struktur.
Der wichtigste Inhalt dieser Strukturen ist jeweils eine Atomtabelle ausschließlich für den Anwendungscontainer, da der Kernelmodustreiber des Windows-Teilsystems (Win32k.sys) den
Anwendungscontainern keinen Zugriff auf die globale Atomtabelle gewährt.
QQ Das Dateisystem unterhält in %LOCALAPPDATA% das Verzeichnis Packages, das wiederum
Unterverzeichnisse mit den Paketnamen (die Stringversionen der AnwendungscontainerSIDs) aller installierten UWP-Anwendungen enthält. Jedes dieser Anwendungsverzeichnisse wiederum enthält anwendungsspezifische Verzeichnisse wie TempState, RoamingState,
Settings, LocalCache usw. Sie sind jeweils mit einer Zugriffssteuerungsliste versehen, deren
Zugriffsmaske der Anwendungscontainer-SID Vollzugriff erlaubt.
QQ Im Verzeichnis Settings gibt es die Datei Settings.dat. Dabei handelt es sich um eine Datei
für einen Registrierungshive, die als Anwendungshive geladen wird. (Mehr über Anwendungshives erfahren Sie in Kapitel 9 von Band 2.) Der Hive fungiert als lokale Registrierung
für die Anwendung, in der WinRT-APIs die verschiedenen persistenten Status der Anwendung speichern. Auch die Zugriffssteuerungslisten dieser Registrierungseinträge gewähren
der SID des zugehörigen Anwendungscontainers wieder Vollzugriff.
804
Kapitel 7
Sicherheit
Mithilfe dieser vier »Gefängnisse« können Anwendungscontainer ihr Dateisystem, ihre Regis
trierung und ihre Atomtabelle auf sichere Weise lokal speichern, ohne dazu Zugriff auf sensible
Benutzer- und Systembereiche zu benötigen. Was aber ist mit einem möglichen Zugriff – zumindest Lesezugriff – auf kritische Systemdateien (wie Ntdll.dll und Kernel32.dll), Registrierungsschlüssel (diejenigen, die diese Bibliotheken benötigen) oder benannte Objekte (etwa
den ALPC-Port \RPC Control\DNSResolver für DNS-Lookups)? Es wäre nicht sehr sinnvoll, bei
jeder Installation oder Deinstallation einer UWP-Anwendung die Zugriffssteuerungslisten für
ganze Verzeichnisse, Registrierungsschlüssel und Objektnamensräume zu ändern, um mehrere
SIDs hinzuzufügen bzw. zu entfernen.
Zur Lösung dieses Problem gibt es die besondere Gruppen-SID ALL APPLICATION PACKAGES,
die automatisch mit jedem Anwendungscontainertoken verknüpft wird. Viele kritische Systemspeicherorte wie %SystemRoot%\System32 und HKLM\Software\Microsoft\Windows\CurrentVersion enthalten diese SID in ihren DACLs, wobei die Zugriffsmaske gewöhnlich den Zugriff
zum Lesen oder zum Lesen und Ausführen erlaubt. Auch bestimmte Objekte im Namensraum
des Objekt-Managers verfügen über diese SID, z. B. der ALPC-Port DNSResolver im Objekt-Manager-Verzeichnis \RPC Control. Das Gleiche gilt auch für manche COM-Objekte, die das Ausführungsrecht gewähren. Auch wenn es nicht offiziell dokumentiert ist, können Drittanbieterentwickler beim Erstellen von Nicht-UWP-Anwendungen Interaktionen mit UWP-Anwendungen
erlauben, indem sie diese SID für ihre eigenen Ressourcen verwenden.
Da UWP-Anwendungen im Rahmen ihrer WinRT-Bedürfnisse rein technisch in der Lage
sind, fast jede Win32-DLL zu laden (da WinRT auf Win32 aufbaut), und es schwer vorherzusagen ist, was eine einzelne UWP-Anwendung alles benötigt, ist mit den DACLs vieler Systemressourcen leider die SID ALL APPLICATION PACKAGES vorausschauend verknüpft. Dadurch ist es
für UWP-Entwickler unmöglich, zu verhindern, dass von ihrer Anwendung aus beispielsweise
DNS-Lookups erfolgen. Dieser mehr als erforderliche Zugriff hilft auch den Autoren von Exploits, die ihn ausnutzen können, um aus der Sandbox des Anwendungscontainers auszubrechen. Um dieses Risiko einzudämmen, gibt es in neuen Versionen von Windows 10 (beginnend
mit Version 1607, also dem Anniversary Update) die neue Sicherheitsvorkehrung der eingeschränkten Anwendungscontainer.
Wird das Prozessattribut PROC_THREAD_ATTRIBUTE_ALL_APPLICATION_PACKAGES_POLICY beim
Erstellen des Prozesses auf PROCESS_CREATION_ALL_APPLICATION_PACKAGES_OPT_OUT gesetzt (mehr
über Prozessattribute erfahren Sie in Kapitel 3), so wird das Token mit keinerlei Zugriffssteuerungseinträgen verknüpft, in denen die SID ALL APPLICATION PACKAGES angegeben ist. Dadurch wird der Zugriff auf viele Systemressourcen abgeschnitten, die sonst zugänglich wären.
Solche Tokens lassen sich an dem Vorhandensein eines vierten Tokenattributs namens WIN://
NOALLAPPPKG mit einem Integerwert von 1 erkennen.
Das bringt uns jedoch zu unserem alten Problem zurück: Wie kann eine solche Anwendung
auch nur Ntdll.dll laden, die für die Prozessinitialisierung von entscheidender Bedeutung ist?
In Windows 10 Version 1607 wurde die neue Gruppe ALL RESTRICTED APPLICATION PACKAGES
eingeführt, um dieses Problem zu lösen. Unter anderem enthält das Verzeichnis System32 jetzt
diese SID mit Lese- und Ausführungsberechtigungen, da das Laden von DLLs in diesem Verzeichnis für viele Prozesse in Sandboxes unverzichtbar ist. Der ALPC-Port DNSResolver jedoch
hat diese SID nicht, weshalb ein solcher Anwendungscontainer den Zugriff auf DNS verlieren
kann.
Anwendungscontainer
Kapitel 7
805
Experiment: Die Sicherheitsattribute eines
Anwendungscontainers einsehen
In diesem Experiment sehen wir uns die Sicherheitsattribute einiger der im vorherigen Abschnitt beschriebenen Verzeichnisse an.
1.
Starten Sie die Taschenrechneranwendung.
2.
Starten Sie das Sysinternals-Tool WinObj mit erhöhten Rechten und begeben Sie sich
zu dem Objektverzeichnis, das nach der Anwendungscontainer-SID des Taschenrechners benannt ist. (Dieses Verzeichnis haben Sie bereits in einem früheren Experiment
gesehen.)
→
806
Kapitel 7
Sicherheit
3.
Rechtsklicken Sie auf das Verzeichnis, wählen Sie Properties und rufen Sie die Registerkarte Security auf. Wie Sie im folgenden Screenshot sehen, hat die Anwendungscon
tainer-SID des Taschenrechners die Berechtigungen zum Auflisten und zum Hinzufügen
von Objekten und Unterverzeichnissen (sowie weitere, die über einen Bildlauf zu erreichen sind). Das bedeutet, dass die Taschenrechneranwendung in diesem Verzeichnis
Kernelobjekte erstellen kann.
4.
Öffnen Sie den lokalen Ordner des Taschenrechners unter %LOCALAPPDATA%\
Packages\Microsoft.WindowsCalculator_8wekyb3d8bbwe. Rechtsklicken Sie auf das
Unterverzeichnis Settings, wählen Sie Properties und klicken Sie auf die Registerkarte
Security. Dabei können Sie erkennen, dass die Anwendungscontainer-SID des Rechners Vollzugriff auf diesen Ordner hat:
→
Anwendungscontainer
Kapitel 7
807
5.
Öffnen Sie im Explorer das Verzeichnis %SystemRoot% (z. B. C:\Windows), rechtsklicken
Sie auf das Verzeichnis System32, wählen Sie Properties und klicken Sie auf die Registerkarte Security. Hier können Sie erkennen, dass allen Anwendungspaketen und allen
eingeschränkten Anwendungspaketen (bei Windows 10 Version 1607 und höher) Leseund Ausführungsberechtigungen eingeräumt wird.
Die gleichen Informationen können Sie auch mit dem Befehlszeilenwerkzeug AccessChk von
Sysinternals einsehen.
Experiment: Die Atomtabelle des Anwendungscontainers
einsehen
Bei einer Atomtabelle handelt es sich um eine Hashtabelle, in der über Integerwerte zugängliche Strings gespeichert sind. Sie wird von Fenstersystemen in verschiedenen Zusammenhängen zur Identifizierung verwendet, z. B. bei der Fensterklassenregistrierung (RegisterClassEx) und bei benutzerdefinierten Windows-Nachrichten. Die private Atomtabelle
eines Anwendungscontainers können Sie sich mit dem Kerneldebugger ansehen:
1.
Führen Sie die Taschenrechneranwendung aus, öffnen Sie WinDbg und starten Sie eine
lokale Kerneldebuggersitzung.
2.
Suchen Sie den Prozess des Taschenrechners:
lkd> !process 0 1 calculator.exe
PROCESS ffff828cc9ed1080
SessionId: 1 Cid: 4bd8 Peb: d040bbc000 ParentCid: 03a4
DeepFreeze
DirBase: 5fccaa000 ObjectTable: ffff950ad9fa2800 HandleCount: <Data Not
Accessible>
→
808
Kapitel 7
Sicherheit
Image: Calculator.exe
VadRoot ffff828cd2c9b6a0 Vads 168 Clone 0 Private 2938. Modified 3332.
Locked 0.
DeviceMap ffff950aad2cd2f0
Token ffff950adb313060
...
3.
Verwenden Sie den gefundenen Tokenwert in den folgenden Ausdrücken:
lkd> r? @$t1 = @$t0->NumberOfBuckets
lkd> r? @$t0 = (nt!_RTL_ATOM_TABLE*)((nt!_token*)0xffff950adb313060)>LowboxNumberEntry->AtomTable
lkd> .for (r @$t3 = 0; @$t3 < @$t1; r @$t3 = @$t3 + 1) { ?? (wchar_t*)@$t0>Buckets[@$t3]->Name }
wchar_t * 0xffff950a'ac39b78a
"Protocols"
wchar_t * 0xffff950a'ac17b7aa
"Topics"
wchar_t * 0xffff950a'b2fd282a
"TaskbarDPI_Deskband"
wchar_t * 0xffff950a'b3e2b47a
"Static"
wchar_t * 0xffff950a'b3c9458a
"SysTreeView32"
wchar_t * 0xffff950a'ac34143a
"UxSubclassInfo"
wchar_t * 0xffff950a'ac5520fa
"StdShowItem"
wchar_t * 0xffff950a'abc6762a
"SysSetRedraw"
wchar_t * 0xffff950a'b4a5340a
"UIA_WindowVisibilityOverridden"
wchar_t * 0xffff950a'ab2c536a
"True"
...
wchar_t * 0xffff950a'b492c3ea
"tooltips_class"
wchar_t * 0xffff950a'ac23f46a
"Save"
wchar_t * 0xffff950a'ac29568a
"MSDraw"
wchar_t * 0xffff950a'ac54f32a
"StdNewDocument"
→
Anwendungscontainer
Kapitel 7
809
wchar_t * 0xffff950a'b546127a
"{FB2E3E59-B442-4B5B-9128-2319BF8DE3B0}"
wchar_t * 0xffff950a'ac2e6f4a
"Status"
wchar_t * 0xffff950a'ad9426da
"ThemePropScrollBarCtl"
wchar_t * 0xffff950a'b3edf5ba
"Edit"
wchar_t * 0xffff950a'ab02e32a
"System"
wchar_t * 0xffff950a'b3e6c53a
"MDIClient"
wchar_t * 0xffff950a'ac17a6ca
"StdDocumentName"
wchar_t * 0xffff950a'ac6cbeea
"StdExit"
wchar_t * 0xffff950a'b033c70a
"{C56C5799-4BB3-7FAE-7FAD-4DB2F6A53EFF}"
wchar_t * 0xffff950a'ab0360fa
"MicrosoftTabletPenServiceProperty"
wchar_t * 0xffff950a'ac2f8fea
"OLEsystem"
Fähigkeiten von Anwendungscontainern
Wie Sie gesehen haben, verfügen UWP-Anwendungen über stark eingeschränkte Zugriffsrechte. Wie ist es dann beispielsweise Microsoft Edge möglich, das lokale Dateisystem zu
durchsuchen und PDF-Dateien im Dokumentenordner des Benutzers zu öffnen? Wie kann die
Musikanwendung MP3-Dateien aus dem Musikverzeichnis abspielen? Unabhängig davon, ob
die Erlaubnis über Kernelzugriffsprüfungen oder über Broker erfolgt (die Sie im nächsten Abschnitt kennenlernen werden), bilden die Fähigkeits-SIDs den entscheidenden Faktor. Daher
wollen wir uns nun ansehen, woher sie kommen, wie sie erstellt und wie sie verwendet werden.
Als Erstes müssen UWP-Entwickler ein Anwendungsmanifest mit Angaben wie dem Paketnamen, dem Logo, den Ressourcen, den unterstützten Geräten usw. erstellen. Eines der entscheidenden Elemente für die Verwaltung der Fähigkeiten ist die Fähigkeitenliste in diesem
Manifest. Im Manifest von Cortana (%SystemRoot%\SystemApps\Microsoft.Windows.Cortana_
cw5n1h2txywey\AppxManifest.xml) sieht diese Liste wie folgt aus:
<Capabilities>
<wincap:Capability Name="packageContents"/>
<!-- Needed for resolving MRT strings -->
<wincap:Capability Name="cortanaSettings"/>
<wincap:Capability Name="cloudStore"/>
810
Kapitel 7
Sicherheit
<wincap:Capability Name="visualElementsSystem"/>
<wincap:Capability Name="perceptionSystem"/>
<Capability Name="internetClient"/>
<Capability Name="internetClientServer"/>
<Capability Name="privateNetworkClientServer"/>
<uap:Capability Name="enterpriseAuthentication"/>
<uap:Capability Name="musicLibrary"/>
<uap:Capability Name="phoneCall"/>
<uap:Capability Name="picturesLibrary"/>
<uap:Capability Name="sharedUserCertificates"/>
<rescap:Capability Name="locationHistory"/>
<rescap:Capability Name="userDataSystem"/>
<rescap:Capability Name="contactsSystem"/>
<rescap:Capability Name="phoneCallHistorySystem"/>
<rescap:Capability Name="appointmentsSystem"/>
<rescap:Capability Name="chatSystem"/>
<rescap:Capability Name="smsSend"/>
<rescap:Capability Name="emailSystem"/>
<rescap:Capability Name="packageQuery"/>
<rescap:Capability Name="slapiQueryLicenseValue"/>
<rescap:Capability Name="secondaryAuthenticationFactor"/>
<DeviceCapability Name="microphone"/>
<DeviceCapability Name="location"/>
<DeviceCapability Name="wiFiControl"/>
</Capabilities>
Diese Liste enthält verschiedene Arten von Einträgen. Darunter sind die Capability-Einträge,
die die Standardkonstanten für die ursprünglichen, in Windows 8 eingeführten Fähigkeiten
nennen. Die eigentlichen Konstanten beginnen mit SECURITY_CAPABILITY_, also beispielsweise SECURITY_CAPABILITY_INTERNET_CLIENT, die zum Fähigkeits-RID unter APPLICATION PACKAGE
AUTHORITY gehört. Diese Konstante ist mit der SID S-1-15-3-1 verknüpft.
Andere Einträge weisen Präfixe wie uap, rescap und wincap auf. Bei rescap handelt es sich
um eingeschränkte Fähigkeiten, die eine besondere Genehmigung durch Microsoft erfordern,
bevor sie im Store zugelassen werden. Im Fall von Cortana sind das Fähigkeiten wie der Zugriff
auf SMS-Textnachrichten, E-Mails, Kontakte, Standorte und Benutzerdaten. Windows-Fähigkeiten dagegen (wincap) sind für Windows und Systemanwendungen reserviert und können nicht
von Store-Anwendungen genutzt werden. UAP-Fähigkeiten schließlich sind Standardfähigkeiten, die jeder im Store anfordern kann. (Wie bereits erwähnt, ist UAP eine ältere Bezeichnung
für UWP.)
Die Implementierung erfolgt hier anders als bei den zuerst erwähnten Fähigkeiten, die
hartcodierten RIDs zugeordnet sind. Dadurch ist es nicht nötig, eine Liste von Standard-RIDs
zu unterhalten. Stattdessen können die Fähigkeiten vollständig benutzerdefiniert sein und im
laufenden Betrieb aktualisiert werden. Dazu wird einfach der Fähigkeitsstring in Großbuchstaben umgewandelt und ein SHA-2-Hash davon erstellt (ebenso, wie der SHA-2-Hash des
Anwendungscontainer
Kapitel 7
811
Paketnamens als Anwendungscontainer-SID verwendet wird). Auch hier umfassen die SHA-2Hashes wieder 32 Bytes, sodass sich für jede Fähigkeit acht RIDs ergeben, die auf den GrundRID SECURITY_CAPABILITY_BASE_RID (3) folgen.
Des Weiteren gibt es auch einige DeviceCapability-Einträge. Sie geben die Geräteklassen
an, auf die die UWP-Anwendung zugreifen muss, und können entweder ebenfalls Standardstrings verwenden oder direkt den GUID der Klasse enthalten. Für diese Art von Fähigkeiten
wird die SID nicht durch eine der bereits bekannten, sondern durch eine dritte Methode generiert! Dazu wird der GUID ins Binärformat umgewandelt und dann auf vier RIDs abgebildet (da
ein GUID 16 Bytes umfasst). Wurde ein Standardname angegeben, muss dieser zunächst in einen GUID konvertiert werden. Dazu wird im Registrierungsschlüssel HKLM\Software\Microsoft\
Windows\CurrentVersion\DeviceAccess\CapabilityMappings nachgeschlagen, der eine Liste von
Registrierungsschlüsseln für Gerätefähigkeiten und eine Liste von GUIDs für diese Fähigkeiten
enthält.
Eine aktuelle Liste unterstützter Fähigkeiten finden Sie auf https://msdn.microsoft.
com/en-us.windows/uwp/packaging/app-capability-declarations.
Um all diese Fähigkeiten in das Token aufzunehmen, werden die beiden zusätzlichen Regeln
angewendet:
QQ Wie Sie in einem früheren Experiment möglicherweise schon gesehen haben, ist in jedem
Anwendungscontainertoken die Paket-SID in Form einer Fähigkeit enthalten. Damit kann
das Fähigkeitssystem den Zugriff für eine bestimmte Anwendung gezielt durch eine allgemeine Sicherheitsprüfung sperren, anstatt die Paket-SID einzeln abzurufen und zu validieren.
QQ Mithilfe des RIDs SECURITY_CAPABILITY_APP_RID (1024) wird jede Fähigkeit wiederum zu
einer Gruppen-SID gemacht. Sie dient als Unterautorität, die Vorrang vor den regulären
acht Hash-RIDs für die Fähigkeiten hat.
Da die Fähigkeiten im Token angegeben sind, können verschiedene Systemkomponenten sie
lesen, um zu bestimmen, ob eine Operation, die ein Anwendungscontainer durchführt, erlaubt
werden sollte. Die meisten der APIs sind nicht dokumentiert, da Kommunikation und Interoperabilität mit UWP-Anwendung nicht offiziell unterstützt werden und am besten Brokerdiensten, mitgelieferten Treibern und Kernelkomponenten überlassen werden sollten. Beispielsweise
können der Kernel und die Treiber die API RtlCapabilityCheck verwenden, um den Zugriff auf
bestimmte Hardwareschnittstellen oder APIs zu authentifizieren.
Beispielsweise prüft die Energieverwaltung, ob die Fähigkeit ID_CAP_SCREENOFF vorhanden
ist, bevor sie die Anforderung eines Anwendungscontainers, den Bildschirm auszuschalten, genehmigt. Der Bluetooth-Porttreiber hält nach der Fähigkeit bluetoothDiagnostics Ausschau
und der Anwendungsidentitätstreiber prüft, ob eine EDP-Unterstützung in Form der Fähigkeit
enterpriseDataPolicy vorliegt. Im Benutzermodus kann die dokumentierte API CheckTokenCapability verwendet werden, wobei aber nicht der Name der Fähigkeit, sondern ihre SID
angegeben werden muss (den jedoch die nicht dokumentierte Funktion RtlDeriveCapabilitySidFromName abrufen kann). Eine weitere Möglichkeit bietet die nicht dokumentierte API
CapabilityCheck, die einen String akzeptiert.
812
Kapitel 7
Sicherheit
Viele RPC-Dienste nutzen auch die API RpcClientCapabilityCheck. Diese Hilfsfunktion
kümmert sich darum, das Token abzurufen, und benötigt nur den Fähigkeitsstring. Sie wird in
vielen WinRT-fähigen Diensten und Brokern verwendet, die RPCs für die Kommunikation mit
UWP-Clientanwendungen nutzen.
Experiment: Fähigkeiten von Anwendungscontainern einsehen
Um die verschiedenen Arten von Fähigkeiten und ihre Aufnahme in ein Token vorzuführen,
sehen wir sie uns bei einer vielschichtigen Anwendung wie Cortana an. Deren Manifest
kennen Sie bereits und können es daher mit der Benutzeroberfläche vergleichen. Wenn Sie
den Inhalt der Registerkarte Security im Eigenschaftendialogfeld für SearchUI.exe nach der
Spalte Flags sortieren, erhalten Sie Folgendes:
→
Anwendungscontainer
Kapitel 7
813
Cortana hat eine Menge Fähigkeiten erhalten, nämlich alle aus dem Manifest. Einige gehören zu denen, die mit Windows 8 eingeführt wurden und zu Standardfunktionen wie
IsWellKnownSid gehören. Für sie gibt Process Explorer einen Anzeigenamen an. Die anderen
Fähigkeiten werden dagegen nur anhand ihrer SIDs bezeichnet, die – wie bereits erklärt –
entweder für Hashes oder für GUIDs stehen.
Um Angaben zu dem Paket zu erhalten, aus dem der UWP-Prozess erstellt wurde, können Sie das Tool UWPList verwenden, das zusammen mit dem sonstigen Begleitmaterial zu
diesem Buch zum Download bereitsteht. Es zeigt alle Vollbildprozesse auf dem System bzw.
den einzelnen Prozess, dessen ID Sie angeben:
C:\WindowsInternals>UwpList.exe 3728
List UWP Processes - version 1.1 (C)2016 by Pavel Yosifovich
Building capabilities map... done.
Process ID: 3728
-----------------Image name: C:\Windows\SystemApps\Microsoft.Windows.Cortana_cw5n1h2txyewy\
SearchUI.exe
Package name: Microsoft.Windows.Cortana
Publisher: CN=Microsoft Windows, O=Microsoft Corporation, L=Redmond,
S=Washington, C=US
Published ID: cw5n1h2txyewy
Architecture: Neutral
Version: 1.7.0.14393
AppContainer SID: S-1-15-2-1861897761-1695161497-2927542615-642690995327840285-2659745135-2630312742
Lowbox Number: 3
Capabilities: 32
cortanaSettings (S-1-15-3-1024-1216833578-114521899-3977640588-13431805122505059295-473916851-3379430393-3088591068) (ENABLED)
visualElementsSystem (S-1-15-3-1024-3299255270-1847605585-2201808924-7104067093613095291-873286183-3101090833-2655911836) (ENABLED)
perceptionSystem (S-1-15-3-1024-34359262-2669769421-2130994847-30683386393284271446-2009814230-2411358368-814686995) (ENABLED)
internetClient (S-1-15-3-1) (ENABLED)
internetClientServer (S-1-15-3-2) (ENABLED)
privateNetworkClientServer (S-1-15-3-3) (ENABLED)
enterpriseAuthentication (S-1-15-3-8) (ENABLED)
musicLibrary (S-1-15-3-6) (ENABLED)
phoneCall (S-1-15-3-1024-383293015-3350740429-1839969850-1819881064-15694546864198502490-78857879-1413643331) (ENABLED)
→
814
Kapitel 7
Sicherheit
picturesLibrary (S-1-15-3-4) (ENABLED)
sharedUserCertificates (S-1-15-3-9) (ENABLED)
locationHistory (S-1-15-3-1024-3029335854-3332959268-2610968494-19446639221108717379-267808753-1292335239-2860040626) (ENABLED)
userDataSystem (S-1-15-3-1024-3324773698-3647103388-1207114580-21732465724287945184-2279574858-157813651-603457015) (ENABLED)
contactsSystem (S-1-15-3-1024-2897291008-3029319760-3330334796-4656416233782203132-742823505-3649274736-3650177846) (ENABLED)
phoneCallHistorySystem (S-1-15-3-1024-2442212369-1516598453-23309951313469896071-605735848-2536580394-3691267241-2105387825) (ENABLED)
appointmentsSystem (S-1-15-3-1024-2643354558-482754284-283940418-26295591252595130947-547758827-818480453-1102480765) (ENABLED)
chatSystem (S-1-15-3-1024-2210865643-3515987149-1329579022-37618428793142652231-371911945-4180581417-4284864962) (ENABLED)
smsSend (S-1-15-3-1024-128185722-850430189-1529384825-139260854-3294999511660931883-3499805589-3019957964) (ENABLED)
emailSystem (S-1-15-3-1024-2357373614-1717914693-1151184220-28205398343900626439-4045196508-2174624583-3459390060) (ENABLED)
packageQuery (S-1-15-3-1024-1962849891-688487262-3571417821-3628679630802580238-1922556387-206211640-3335523193) (ENABLED)
slapiQueryLicenseValue (S-1-15-3-1024-3578703928-3742718786-7859573-19308449422949799617-2910175080-1780299064-4145191454) (ENABLED)
S-1-15-3-1861897761-1695161497-2927542615-642690995-327840285-26597451352630312742 (ENABLED)
S-1-15-3-787448254-1207972858-3558633622-1059886964 (ENABLED)
S-1-15-3-3215430884-1339816292-89257616-1145831019 (ENABLED)
S-1-15-3-3071617654-1314403908-1117750160-3581451107 (ENABLED)
S-1-15-3-593192589-1214558892-284007604-3553228420 (ENABLED)
S-1-15-3-3870101518-1154309966-1696731070-4111764952 (ENABLED)
S-1-15-3-2105443330-1210154068-4021178019-2481794518 (ENABLED)
S-1-15-3-2345035983-1170044712-735049875-2883010875 (ENABLED)
S-1-15-3-3633849274-1266774400-1199443125-2736873758 (ENABLED)
S-1-15-3-2569730672-1095266119-53537203-1209375796 (ENABLED)
S-1-15-3-2452736844-1257488215-2818397580-3305426111 (ENABLED)
Die Ausgabe zeigt den vollständigen Paketnamen, das ausführbare Verzeichnis, die Anwendungscontainer-SID, Angaben zum Herausgeber, die Version und die Liste der Fähigkeiten.
Des Weiteren ist die LowBox-Nummer angegeben, bei der es sich jedoch lediglich um einen
lokalen Index der Anwendung handelt.
Im Kerneldebugger können Sie all diese Eigenschaften mit dem Befehl !token untersuchen.
Anwendungscontainer
Kapitel 7
815
Einige UWP-Anwendungen werden als vertrauenswürdig bezeichnet. Sie verwenden zwar
ebenso wie andere UWP-Anwendungen die Windows-Laufzeitplattform, können aber nicht in
einem Anwendungscontainer laufen und haben eine Integritätsebene höher als Niedrig. Das
übliche Beispiel hierfür ist die App Systemeinstellungen (%SystemRoot\ImmersiveControlPanel\
SystemSettings.exe), was auch sinnvoll ist, da sie in der Lage sein muss, Änderungen am System
vorzunehmen, die sich von einem Prozess in einem Anwendungscontainer unmöglich durchführen ließen. Wenn Sie sich das Token dieser Anwendung ansehen, können Sie die drei Attribute PKG, SYSAPPID und PKGHOSTID erkennen, die bestätigen, dass es sich tatsächlich um eine
Paketanwendung handelt, auch wenn kein Anwendungscontainertoken vorhanden ist.
Der Objektnamensraum von Anwendungscontainern
Desktopanwendungen können Kernelobjekte anhand ihrer Namen gemeinsam verwenden.
Nehmen wir an, Prozess A ruft CreateEvent(Ex) unter Angabe des Namens MyEvent auf, um
ein Ereignisobjekt zu erstellen. Dabei erhält er ein Handle, mit dem er das Ereignis später bearbeiten kann. Nun kann Prozess B in derselben Sitzung ebenfalls CreateEvent(Ex) oder auch
OpenEvent mit demselben Namen aufrufen. Sofern Prozess B die passenden Berechtigungen hat
(was gewöhnlich der Fall hat, wenn er in derselben Sitzung läuft wie A), erhält er ein weiteres
Handle auf dasselbe Ereignisobjekt zurück. Wenn Prozess A jetzt SetEvent für das Ereignisobjekt aufruft, während B in einem Aufruf von WaitForSingleObject für dessen Ereignishandle
blockiert ist, wird der Wartethread von B freigegeben, da es sich um dasselbe Ereignisobjekt handelt. Diese gemeinsame Nutzung funktioniert, da benannte Objekte im Objekt-Manager-Verzeichnis Sessions\x\BaseNamedObjects erstellt werden (das Sie in Abb. 7–18 in der
Anzeige des Sysinternals-Tools WinObj sehen).
Darüber hinaus können Desktopanwendungen Objekte auch von verschiedenen Sitzungen aus gemeinsam nutzen, indem sie dem Namen Global\ voranstellen. Dadurch wird das
Objekt im \BaseNamedObjects-Verzeichnis unter dem Verzeichnis für Sitzung 0 erstellt (siehe
Abb. 7–18).
816
Kapitel 7
Sicherheit
Abbildung 7–18 Das Verzeichnis des Objekt-Managers für benannte Objekte
Der Stammobjektnamensraum von Prozessen in Anwendungscontainern befindet sich in
\Sessions\x\AppContainerNamedObjects\<Anwendungscontainer-SID>. Da jeder Anwendungscontainer eine eigene SID hat, gibt es für UWP-Anwendungen keine Möglichkeit, um Kernelobjekte gemeinsam zu nutzen. Prozesse in Anwendungscontainern dürfen auch keine benannten
Kernelobjekte im Objektnamensraum von Sitzung 0 erstellen. Abb. 7–19 zeigt das Objekt-Manager-Verzeichnis für die Windows-UWP-App des Taschenrechners.
Wenn UWP-Apps Daten gemeinsam nutzen möchten, können sie das über genau definierte Verträge tun, die von der Windows-Laufzeit verwaltet werden. (Weitere Informationen
darüber entnehmen Sie bitte der MSDN-Dokumentation.)
Eine gemeinsame Nutzung von Kernelobjekten durch Desktop- und UWP-Anwendungen ist möglich und erfolgt oft mithilfe von Brokerdiensten. Wenn eine UWP-Anwendung
beispielsweise vom Dateiauswahl-Broker den Zugriff auf eine Datei im Dokumentenordner
anfordert (und die entsprechende Fähigkeit dazu überprüft wird), erhält sie ein Dateihandle,
das sie direkt für Lese- und Schreibvorgänge einsetzen kann, ohne den Zusatzaufwand für
das Marshalling der Anforderungen in beiden Richtungen in Kauf nehmen zu müssen. Dazu
dupliziert der Broker das Dateihandle in der Handletabelle der UWP-Anwendung. (Mehr
über die Duplizierung von Handles erfahren Sie in Kapitel 8 von Band 2.) Zur weiteren Vereinfachung ermöglicht das ALPC-Teilsystem (das ebenfalls in Kapitel 8 beschrieben wird)
eine solche automatische Übertragung von Handles mithilfe von ALPC-Handleattributen. Die
RPC-Dienste, die ALPC als zugrunde liegendes Protokoll nutzen, können diese Funktionalität
Anwendungscontainer
Kapitel 7
817
in ihren Schnittstellen verwenden. Marshalling-fähige Handles in der IDL-Datei werden automatisch auf diese Weise durch das ALPC-Teilsystem übertragen.
Abbildung 7–19 Das Verzeichnis des Objekt-Managers für die Taschenrechner-Anwendung
Außerhalb der offiziellen RPC-Brokerdienste kann eine Desktopanwendung ein benanntes
(oder sogar ein unbenanntes) Objekt auf die übliche Weise erstellen und dann mit der Funktion
DuplicateHandle manuell ein Handle zu diesem Objekt in den UWP-Prozess injizieren. Das ist
möglich, da Desktopanwendungen gewöhnlich auf mittlerer Integritätsebene ausgeführt werden und es nichts gibt, was sie daran hindern könnte, Handles in UWP-Prozesse zu duplizieren.
Anders herum dagegen geht es nicht.
Gewöhnlich ist keine Kommunikation zwischen einer Desktop- und einer UWP-Anwendung erforderlich, da eine App aus dem Store keine begleitende Desktopanwendung haben und sich daher nicht darauf verlassen kann, dass eine solche Anwendung auf dem Gerät vorhanden ist. Die Fähigkeit, Handles in eine UWP-App zu
injizieren, kann in besonderen Fällen erforderlich sein, etwa bei der Verwendung
einer Desktop-Bridge (Centennial), um eine Desktop- in eine UWP-Anwendung
umzuwandeln und mit einer anderen, bekanntermaßen vorhandenen Desktopanwendung zu kommunizieren.
Handles von Anwendungscontainern
Für typische Win32-Anwendungen garantiert das Windows-Teilsystem, dass sowohl ein sitzungseigenes als auch das globale BaseNamedObjects-Verzeichnis vorhanden ist. Das Verzeichnis AppContainerBaseNamedObjects wird aber leider von der Startanwendung angelegt.
818
Kapitel 7
Sicherheit
Bei der UWP-Anwendung ist dies der vertrauenswürdige Dienst DComLaunch, doch nicht alle
Anwendungscontainer sind unbedingt mit UWP verknüpft, sondern können mithilfe entsprechender Prozesserstellungsattribute auch manuell angelegt werden. (Was für Attribute das
sind, erfahren Sie in Kapitel 3.) In einem solchen Fall ist es möglich, dass eine nicht vertrauenswürdige Anwendung das Objektverzeichnis (und die erforderlichen symbolischen Verknüpfungen darin) erstellt hat. Das wiederum kann dazu führen, dass die Startanwendung in der
Lage ist, Handles von einer Ebene unterhalb der Containeranwendung aus zu schließen. Selbst
wenn keine böse Absicht vorliegt, kann es sein, dass die ursprüngliche Startanwendung beendet wird, ihre Handles aufräumt und dabei das Objektverzeichnis für den Anwendungscontainer zerstört. Um das zu verhindern, kann in einem Anwendungscontainertoken ein Array
aus Handles gespeichert werden, deren Existenz für die gesamte Lebensdauer jeglicher Anwendungen garantiert ist, die das Token nutzen. Diese Handles werden übergeben, wenn das
Token erstellt wird (mit NtCreateLowBoxToken), und als Kernelhandles dupliziert.
Es wird auch eine besondere SEP_CACHED_HANDLES_ENTRY-Struktur verwendet (vergleichbar
mit den Atomtabellen der einzelnen Anwendungscontainer). Sie basiert auf einer Hashtabelle,
die in der Struktur für die Anmeldesitzung des Benutzers gespeichert ist (siehe den Abschnitt
»Anmeldung« weiter hinten in diesem Kapitel). Diese Struktur enthält ein Array aus Kernelhandles, die bei der Erstellung des Anwendungscontainertokens dupliziert wurden. Geschlossen werden diese Handles, wenn das Token zerstört wird (da die Anwendung beendet wird)
oder sich der Benutzer abmeldet (wobei die Anmeldesitzung endet).
Experiment: Im Token gespeicherte Handles einsehen
Um sich die im Token gespeicherten Handles anzusehen, gehen Sie wie folgt vor:
1.
Starten Sie die Taschenrechneranwendung und eine lokale Kerneldebuggersitzung.
2.
Suchen Sie nach dem Prozess des Taschenrechners:
lkd> !process 0 1 calculator.exe
PROCESS ffff828cc9ed1080
SessionId: 1 Cid: 4bd8 Peb: d040bbc000 ParentCid: 03a4
DeepFreeze
DirBase: 5fccaa000 ObjectTable: ffff950ad9fa2800 HandleCount: <Data Not
Accessible>
Image: Calculator.exe
VadRoot ffff828cd2c9b6a0 Vads 168 Clone 0 Private 2938. Modified 3332.
Locked 0.
DeviceMap
ffff950aad2cd2f0
Token
ffff950adb313060
ElapsedTime
1 Day 08:01:47.018
UserTime
00:00:00.015
KernelTime
00:00:00.031
QuotaPoolUsage[PagedPool]
465880
→
Anwendungscontainer
Kapitel 7
819
QuotaPoolUsage[NonPagedPool]
Working Set Sizes (now,min,max)
23288
(7434, 50, 345) (29736KB, 200KB,
1380KB)
3.
PeakWorkingSetSize
11097
VirtualSize
303 Mb
PeakVirtualSize
314 Mb
PageFaultCount
21281
MemoryPriority
BACKGROUND
BasePriority
8
CommitCharge
4925
Job
ffff828cd4914060
Geben Sie das Token mithilfe des Befehls dt aus. (Denken Sie daran, dass Sie die unteren
drei oder vier Bits maskieren müssen, wenn sie nicht null sind.)
lkd> dt nt!_token ffff950adb313060
+0x000 TokenSource
: _TOKEN_SOURCE
+0x010 TokenId
: _LUID
+0x018 AuthenticationId : _LUID
+0x020 ParentTokenId
: _LUID
...
+0x0c8 TokenFlags
: 0x4a00
+0x0cc TokenInUse
: 0x1 ''
+0x0d0 IntegrityLevelIndex : 1
+0x0d4 MandatoryPolicy
: 1
+0x0d8 LogonSession
: 0xffff950a'b4bb35c0 _SEP_LOGON_SESSION_
REFERENCES
+0x0e0 OriginatingLogonSession : _LUID
+0x0e8 SidHash
: _SID_AND_ATTRIBUTES_HASH
+0x1f8 RestrictedSidHash
: _SID_AND_ATTRIBUTES_HASH
+0x308 pSecurityAttributes : 0xffff950a'e4ff57f0 _AUTHZBASEP_SECURITY_
ATTRIBUTES_INFORMATION
+0x310 Package
: 0xffff950a'e00ed6d0 Void
+0x318 Capabilities
: 0xffff950a'e8e8fbc0 _SID_AND_ATTRIBUTES
+0x320 CapabilityCount
: 1
+0x328 CapabilitiesHash : _SID_AND_ATTRIBUTES_HASH
+0x438 LowboxNumberEntry : 0xffff950a'b3fd55d0 _SEP_LOWBOX_NUMBER_ENTRY
+0x440 LowboxHandlesEntry : 0xffff950a'e6ff91d0 _SEP_LOWBOX_HANDLES_ENTRY
+0x448 pClaimAttributes : (null)
...
→
820
Kapitel 7
Sicherheit
4.
Geben Sie das Element LowboxHandlesEntry aus:
lkd> dt nt!_sep_lowbox_handles_entry 0xffff950a'e6ff91d0
+0x000 HashEntry
: _RTL_DYNAMIC_HASH_TABLE_ENTRY
+0x018 ReferenceCount : 0n10
5.
+0x020 PackageSid
: 0xffff950a'e6ff9208 Void
+0x028 HandleCount
: 6
+0x030 Handles
: 0xffff950a'e91d8490 -> 0xffffffff'800023cc Void
Es gibt sechs Handles, deren Werte wir als Nächstes ausgeben:
lkd> dq 0xffff950ae91d8490 L6
ffff950a'e91d8490 ffffffff'800023cc ffffffff'80001e80
ffff950a'e91d84a0 ffffffff'80004214 ffffffff'8000425c
ffff950a'e91d84b0 ffffffff'800028c8 ffffffff'80001834
6.
Wie Sie sehen, handelt es sich durchweg um Kernelhandles, da ihre Werte alle mit
0xffffffff beginnen (64 Bit). Mit dem Befehl !handle können Sie sich jetzt die einzel-
nen Handles ansehen. Die folgende Ausgabe zeigt zwei der sechs zuvor angegebenen
Handles:
lkd> !handle ffffffff'80001e80
PROCESS ffff828cd71b3600
SessionId: 1 Cid: 27c4 Peb: 3fdfb2f000 ParentCid: 2324
DirBase: 80bb85000 ObjectTable: ffff950addabf7c0 HandleCount: <Data Not
Accessible>
Image: windbg.exe
Kernel handle Error reading handle count.
80001e80: Object: ffff950ada206ea0 GrantedAccess: 0000000f (Protected)
(Inherit) (Audit) Entry: ffff950ab5406a00
Object: ffff950ada206ea0 Type: (ffff828cb66b33b0) Directory
ObjectHeader: ffff950ada206e70 (new version)
HandleCount: 1 PointerCount: 32770
Directory Object: ffff950ad9a62950 Name: RPC Control
Hash Address
Type
Name
---- -------
----
----
23
ffff828cb6ce6950 ALPC Port
OLE376512B99BCCA5DE4208534E7732
lkd> !handle ffffffff'800028c8
→
Anwendungscontainer
Kapitel 7
821
PROCESS ffff828cd71b3600
SessionId: 1 Cid: 27c4 Peb: 3fdfb2f000 ParentCid: 2324
DirBase: 80bb85000 ObjectTable: ffff950addabf7c0 HandleCount: <Data Not
Accessible>
Image: windbg.exe
Kernel handle Error reading handle count.
800028c8: Object: ffff950ae7a8fa70 GrantedAccess: 000f0001 (Audit) Entry:
ffff950acc426320
Object: ffff950ae7a8fa70 Type: (ffff828cb66296f0) SymbolicLink
ObjectHeader: ffff950ae7a8fa40 (new version)
HandleCount: 1 PointerCount: 32769
Directory Object: ffff950ad9a62950 Name: Session
Flags: 00000000 ( Local )
Target String is '\Sessions\1\AppContainerNamedObjects
\S-1-15-2-466767348-3739614953-2700836392-1801644223-4227750657-10878335352488631167'
Da die Möglichkeit, benannte Objekte auf einen bestimmten Objektverzeichnis-Namensraum
zu beschränken, eine wertvolle Sicherheitsvorkehrung im Rahmen einer Sandbox für den Zugriff auf benannte Objekte darstellt, enthält das Creators Update von Windows 10 die zusätzliche Tokenfähigkeit der BNO-Isolierung (wobei BNO für BaseNamedObjects steht). Unter
Verwendung der gleichen SEP_CACHE_HANDLES_ENTRY-Struktur wird der Tokenstruktur das neue
Feld BnoIsolationHandlesEntry hinzugefügt, das jedoch den neuen Typ SepCachedHandles
EntryBnoIsolation und nicht SepCachedHandlesEntryLowbox hat. Um diese Einrichtung nutzen
zu können, ist ein besonderes Prozessattribut (siehe Kapitel 3) mit einem Isolationspräfix und
einer Handleliste erforderlich. Dabei wird zwar der gleiche LowBox-Mechanismus eingesetzt wie
zuvor, allerdings wird statt des Objektverzeichnisses für die Anwendungscontainer-SID ein Verzeichnis mit dem Präfix aus dem Attribut verwendet.
Broker
Da Anwendungscontainer fast keine Berechtigungen außer denen haben, die implizit über die
Fähigkeiten gewährt wurden, können sie einige übliche Operationen nicht direkt durchführen,
sondern benötigen dazu Hilfe. (Für diese Operationen gibt es keine Fähigkeiten, da sie zu maschinennah sind, um sie den Benutzern im Store anzuzeigen, und sich nur schwer verwalten
lassen.) Dazu gehören etwa die Auswahl von Dateien mithilfe des üblichen Dialogfelds Datei
öffnen oder das Drucken mit dem entsprechenden Dialogfeld. Für diese und ähnliche Vorgänge
bietet Windows Hilfsprozesse, die als Broker bezeichnet und vom Systembrokerprozess Run
timeBroker.exe verwaltet werden.
822
Kapitel 7
Sicherheit
Ein Anwendungscontainerprozess, der einen dieser Dienste benötigt, teilt dies dem Laufzeit-Broker über einen sicheren ALPC-Kanal mit. Der Laufzeit-Broker sorgt anschließend dafür,
dass der angeforderte Brokerprozess erstellt wird, also z. B. %SystemRoot%\PrintDialog\PrintDialog.exe oder %SystemRoot%\System32\PickerHost.exe.
Experiment: Broker
Die folgenden Schritte zeigen, wie Brokerprozesse gestartet und beendet werden:
1.
Klicken Sie auf Start, geben Sie Fotos ein und wählen Sie die Option Fotos aus, um die
im Lieferumfang von Windows enthaltene Anwendung Fotos zu starten.
2.
Öffnen Sie Process Explorer, schalten Sie die Prozessliste in die Baumansicht und suchen
Sie den Prozess Microsoft.Photos.exe. Platzieren Sie beide Fenster nebeneinander.
3.
Wählen Sie in Fotos eine Bilddatei aus, rechtsklicken Sie darauf oder öffnen Sie das
Menü mit den drei Punkten oben rechts und wählen Sie Drucken. Dadurch wird das
Dialogfeld Drucken geöffnet. In Process Explorer sehen Sie jetzt den neu erstellten
Broker (PrintDialog.exe). Wie Sie sehen, sind all diese Prozesse Kinder desselben
Svchost-Prozesses. (Alle UWP-Prozesse werden von dem darin befindlichen Dienst
DCOMLaunch gestartet.)
4.
Schließen Sie das Dialogfeld Drucken. Der Prozess PrintDialog.exe wird beendet.
Anwendungscontainer
Kapitel 7
823
Anmeldung
Bei der interaktiven Anmeldung (im Gegensatz zur Anmeldung über das Netzwerk) wirken die
folgenden Komponenten zusammen:
Der Anmeldeprozess (Winlogon.exe)
QQ Der Prozess der Anmeldeschnittstelle (LogonUI.exe) und seine Anmeldeinformationsan
bieter
QQ Lsass.exe
QQ Ein oder mehrere Authentifizierungspakete
QQ SAM oder Active Directory
Authentifizierungspakete sind DLLs, die Authentifizierungsprüfungen durchführen. Für die
interaktive Anmeldung an einer Domäne verwendet Windows das Authentifizierungspaket
Kerberos. Für die interaktive Anmeldung am lokalen Computer, für Anmeldungen an vertrauenswürdigen Prä-Windows 2000-Domänen und für Situationen, in denen kein Domänencontroller zugänglich ist, wird dagegen das Paket MSV1_0 eingesetzt.
Winlogon ist ein vertrauenswürdiger Prozess für die Verwaltung sicherheitsrelevanter Benutzervorgänge. Er koordiniert die Anmeldung, startet den ersten Prozess des Benutzers bei
der Abmeldung und kümmert sich um die Abmeldung. Außerdem verwaltet er verschiedene andere sicherheitsrelevante Operationen, darunter den Start von LogonUI zur Eingabe von
Kennwörtern bei der Anmeldung, die Änderung von Kennwörtern und das Sperren und Entsperren der Arbeitsstation. Der Winlogon-Prozess muss dafür sorgen, dass sicherheitsrelevante
Operationen für andere aktive Prozesse nicht sichtbar sind. Beispielsweise garantiert Winlogon,
dass ein nicht vertrauenswürdiger Prozess während dieser Operationen keine Kontrolle über
den Desktop und damit auch keinen Zugriff auf das Kennwort erlangen kann.
Um den Kontonamen und das Kennwort eines Benutzers zu erlangen, stützt sich Winlogon
auf die Anmeldeinformationsanbieter, die auf dem System installiert sind. Bei diesen Anbietern
handelt es sich um COM-Objekte innerhalb von DLLs. Die Standardanbieter sind Authui.dll,
SmartcardCredentialProvider.dll und FaceCredentialProvider.dll, die die Authentifizierung über
ein Kennwort, eine Smartcard-PIN bzw. die Gesichtserkennung ermöglichen. Durch die Installation zusätzlicher Anmeldeinformationsanbieter kann Windows auch weitere Identifizierungsmechanismen nutzen. Beispielsweise kann ein Dritthersteller einen Anbieter hinzufügen, der
den Benutzer anhand eines Fingerabdruckgeräts erkennt und das zugehörige Kennwort dann
aus einer verschlüsselten Datenbank entnimmt. Die vorhandenen Anmeldeinformationsanbieter sind unter HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Authentication\Credential
Providers aufgeführt, wobei jeder Unterschlüssel eine Anbieterklasse anhand ihrer COM-CLSID
bezeichnet. (Die CLSID muss dabei wie jede andere COM-Klasse unter HKCR\CLSID registriert
sein.) Mit dem Werkzeug CPlist.exe aus dem Begleitmaterial zu diesem Buch können Sie sich
die Anmeldeinformationsanbieter mit ihrer CLSID, ihrem Anzeigenamen und der DLL mit ihrer
Implementierung anzeigen lassen.
Um den Adressraum von Winlogon gegen Bugs in Anmeldeinformationsanbietern zu
schützen, die zu einem Absturz des Prozesses führen könnten (und damit zu einem Systemab-
824
Kapitel 7
Sicherheit
sturz, da Winlogon ein kritischer Systemprozess ist), wird zum eigentlichen Laden der Anbieter
und zur Anzeige der Anmeldeoberfläche für die Benutzer ein zweiter Prozess verwendet, nämlich LogonUI.exe. Er wird bei Bedarf gestartet, wenn Winlogon eine Anmeldeoberfläche anzeigen muss, und nach Abschluss dieses Vorgangs wieder beendet. Sollte ein LogonUI-Prozess
aus irgendeinem Grunde abstürzen, kann Winlogon daher ganz einfach einen neuen starten.
Winlogon ist der einzige Prozess, der Anmeldeanforderungen von der Tastatur abfängt,
die als RPC-Nachrichten von Win32k.sys gesendet werden. Er startet sofort die Anwendung
LogonUI, um die Benutzeroberfläche für die Anmeldung anzuzeigen. Nachdem Winlogon den
Benutzernamen und das Kennwort vom Anmeldeinformationsanbieter in Erfahrung gebracht
hat, ruft er Lsass auf, um den Benutzer zu authentifizieren. Wenn das gelingt, aktiviert der
Anmeldeprozess eine Anmeldeshell für den Benutzer. Das Zusammenspiel der verschiedenen
Komponenten sehen Sie in Abb. 7–20.
NetLogonDienst
LSA_Server
Netzwerk
Dienst des
Kerberos-Schlüssel
verteilungscenters
(Andere)
Anmeldeinforma
tionsanbieter-DLL
Active Directory-Server
SAM-Server
Abbildung 7–20 An der Anmeldung beteiligte Komponenten
Es gibt nicht nur die Möglichkeit, weitere Anmeldeinformationsanbieter zu nutzen. LogonUI
kann auch zusätzliche Netzwerkanbieter-DLLs für eine sekundäre Authentifizierung laden. Dadurch können mehrere Netzwerkanbieter zusammenarbeiten, um Identifizierungs- und Authentifizierungsinformationen während der normalen Anmeldung zu erfassen. Dadurch kann ein
Benutzer, der sich an einem Windows-System anmeldet, gleichzeitig auf einem Linux-Server
authentifiziert werden, und anschließend von seinem Rechner aus auf Ressourcen auf diesem
Server zugreifen, ohne sich erneut authentifizieren zu müssen. Dies wird als »einmalige Anmeldung« (Single Sign-On) bezeichnet.
Anmeldung
Kapitel 7
825
Initialisierung durch Winlogon
Während der Systeminitialisierung, noch bevor irgendwelche Benutzeranwendungen aktiviert
werden, führt Winlogon die folgenden Schritte aus, um dafür zu sorgen, dass er die Kontrolle
über die Arbeitsstation hat, wenn das System bereit zur Interaktion mit dem Benutzer ist:
1.
Er erstellt und öffnet eine interaktive Fensterstation (z. B. Sessions\1\Windows\WindowStations\WinSta0 im Namensraum des Objekt-Managers) für die Tastatur, die Maus und den
Monitor. Außerdem legt Winlogon für diese Station einen Sicherheitsdeskriptor mit genau
einem Zugriffssteuerungseintrag an, der nur die System-SID enthält. Dieser besondere Sicherheitsdeskriptor sorgt dafür, dass andere Prozesse nur dann auf die Arbeitsstation zugreifen können, wenn Winlogon dies ausdrücklich erlaubt.
2.
Er erstellt und öffnet einen Anwendungsdesktop (\Sessions\1\Windows\WinSta0\ Default,
auch als »interaktiver Desktop« bezeichnet) und einen Winlogon-Desktop (\Sessions\1\
Windows\WinSta0\Winlogon, »sicherer Desktop«). Die Sicherheit des Winlogon-Desktops
wird so eingestellt, dass nur Winlogon darauf zugreifen kann. Der andere Desktop dagegen ist sowohl für Winlogon als auch für Benutzer zugänglich. Wenn der Winlogon-Desktop aktiv ist, hat daher kein anderer Prozess Zugriff auf irgendwelchen aktiven Code oder
Daten, die mit dem Desktop verknüpft sind. Damit schützt Winlogon die sicherheitsrelevanten Vorgänge im Zusammenhang mit Kennwörtern und mit dem Sperren und Entsperren des Desktops.
3.
Bevor sich irgendjemand am Computer anmeldet, ist nur der Winlogon-Desktop sicher.
Wenn ein Benutzer angemeldet ist, führt ein Sicherheitsaufruf (Secure Attention Sequence,
SAS), also die Betätigung von (Strg) + (Alt) + (Entf) dazu, dass wieder vom Standardzum Winlogon-Desktop umgeschaltet und LogonUI gestartet wird. (Das erklärt auch, warum alle Fenster auf dem interaktiven Desktop zu verschwinden scheinen, wenn Sie die
Tastenkombination (Strg) + (Alt) + (Entf) drücken, und nach dem Schließen des
Windows-Sicherheitsdialogfelds wieder erscheinen.) Der Sicherheitsaufruf führt also immer zu einem von Winlogon gesteuerten sicheren Desktop.
4.
Er richtet eine ALPC-Verbindung mit Lsass ein, die für den Austausch von Informationen
beim Anmelden, beim Abmelden und bei Passwortoperationen verwendet wird. Erstellt
wird sie durch einen Aufruf von LsaRegisterLogonProcess.
5.
Er registriert den Winlogon-RPC-Nachrichtenserver, der auf Nachrichten von Win32k über
Sicherheitsaufrufe, Abmeldungen und das Sperren der Arbeitsstation lauscht. Dadurch
wird verhindert, dass trojanische Pferde bei der Eingabe des Sicherheitsaufrufs Zugriff auf
den Bildschirm gewinnen können.
Der Prozess Wininit führt Schritt 1 und 2 in ähnlicher Weise aus, um älteren interaktiven Diensten in Sitzung 0 zu erlauben, Fenster anzuzeigen. Die weiteren Schritte
jedoch fallen weg, da Sitzung 0 nicht für die Benutzeranmeldung zur Verfügung
steht.
826
Kapitel 7
Sicherheit
Die Implementierung des Sicherheitsaufrufs
Der Sicherheitsaufruf ist deshalb sicher, da keine Anwendung die Tastenkombination
(Strg) + (Alt) + (Entf) abfangen oder Winlogon daran hindern kann, sie zu empfangen.
Win32k.sys reserviert diese Tastenkombination, sodass das Windows-Eingabesystem (das
im Roheingabethread in Win32k implementiert ist) eine RPC-Nachricht an den Nachrichtenserver von Winlogon sendet, sobald es diese Kombination wahrnimmt. Die Ausführung
einer registrierten Tastenkombination wird ausschließlich an den Prozess gesendet, der sie
registriert hat, und nur der registrierende Thread kann diese Registrierung auch wieder
aufheben. Damit ist es trojanischen Pferden nicht möglich, die Registrierung des Sicherheitsaufrufs für Winlogon zu ändern.
Mit der Windows-Funktion SetWindowsHookEx kann eine Anwendung eine Hookprozedur installieren, die bei jeder Betätigung einer Taste noch vor der Verarbeitung von
Tastenkombinationen aufgerufen wird. Dadurch kann der Hook Tastenkombinationen unterdrücken. Allerdings enthält der Windows-Code zur Verarbeitung von Tastenkombinationen einen Sonderfall für (Strg) + (Alt) + (Entf), der Hooks deaktiviert, sodass die
Tastenfolge nicht abgefangen werden kann. Wenn der interaktive Desktop gesperrt ist,
werden überdies nur Tastenkombinationen verarbeitet, die Winlogon gehören.
Sobald der Winlogon-Desktop bei der Initialisierung erstellt ist, wird er zum aktiven
Desktop gemacht. Ist er aktiv, so ist er stets gesperrt. Winlogon entsperrt seinen Desktop nur, um zum Anwendungsdesktop oder dem Bildschirmschonerdesktop umzuschalten.
(Nur der Winlogon-Prozess kann einen Desktop sperren und entsperren.)
Die einzelnen Schritte der Benutzeranmeldung
Die Anmeldung beginnt, wenn ein Benutzer (Strg) + (Alt) + (Entf) drückt. Daraufhin startet
Winlogon die Anwendung LogonUI, die wiederum die Anmeldeinformationsanbieter aufruft,
um den Benutzernamen und das Kennwort abzurufen. Außerdem erstellt Winlogon eine eindeutige Anmelde-SID für den Benutzer und ordnet sie der aktuellen Instanz des Desktops zu
(Tastatur, Bildschirm und Maus). Beim Aufruf von LsaLogonUser übergibt Winlogon diese SID an
Lsass. Wird der Benutzer erfolgreich angemeldet, so wird diese SID in das Anmeldeprozesstoken aufgenommen. Das geschieht, um den Zugriff auf den Desktop abzusichern, denn dadurch
wird verhindert, dass eine Anmeldung am selben Konto, aber auf einem anderen Computer,
auf dem Desktop des ersten Rechners schreibt, weil die SID dieser zweiten Anmeldung nicht im
Desktoptoken der ersten Anmeldung vorhanden ist.
Nach der Eingabe von Benutzername und Kennwort ruft Winlogon die Lsass-Funktion
LsaLookupAuthenticationPackage ab, um ein Handle zu einem Authentifizierungspaket zu gewinnen. Diese Pakete sind in der Registrierung unter HKLM\SYSTEM\CurrentControlSet\Control\
Lsa verzeichnet. Über LsaLogonUser übergibt Winlogon die Anmeldeinformationen an das Authentifizierungspaket. Wenn das Paket den Benutzer authentifiziert hat, setzt Winlogon den
Anmeldeprozess für diesen Benutzer fort. Ist mit keinem der Authentifizierungspakete eine
erfolgreiche Anmeldung möglich, wird der Anmeldevorgang abgebrochen.
Anmeldung
Kapitel 7
827
Für die interaktive Anmeldung mit Benutzername und Kennwort verwendet Windows die
beiden folgenden Standard-Authentifizierungspakete:
QQ MSV1_0 Das Standard-Authentifizierungspaket auf eigenständigen Windows-Systemen
ist MSV1_0 (Msv1_0.dll). Es implementiert das Protokoll LAN Manager 2. Lsass verwendet
MSV1_0 auch auf Computern in einer Domäne, um Prä-Windows 2000-Domänen und
-Computer zu authentifizieren, die keinen Domänencontroller ansprechen können. (Letzteres gilt auch für Computer, die vom Netzwerk getrennt sind.)
QQ Kerberos Das Authentifizierungspaket Kerberos.dll wird auf Computern verwendet, die
Mitglieder von Windows-Domänen sind. Zusammen mit den Kerberos-Diensten, die auf
einem Domänencontroller laufen, unterstützt dieses Paket das Protokoll Kerberos, das auf
RFC 1510 basiert. (Mehr Informationen über den Kerberos-Standard erhalten Sie auf der
Website der Internet Engineering Task Force auf http://www.ietf.org.)
MSV1_0
Das Authentifizierungspaket MSV1_0 nimmt den Benutzernamen und die Hashversion des
Kennworts entgegen und sendet eine Anforderung an den lokalen SAM, um die Kontoinformationen einschließlich des Kennworthashs, der Gruppen des Benutzers und eventueller Kontoeinschränkungen abzurufen. Als Erstes prüft MSV1_0 die Kontoeinschränkungen, z. B. Zeiträume
oder Arten des erlaubten Zugriffs. Wenn sich der Benutzer aufgrund von Einschränkungen in
der SAM-Datenbank nicht anmelden kann, schlägt der Anmeldeaufruf fehl. In diesem Fall gibt
MSV1_0 einen Fehlerstatus an die LSA zurück.
Anschließend vergleicht MSV1_0 den Kennworthash und den Benutzernamen mit den Versionen, die es vom SAM erhalten hat. Bei einer zwischengespeicherten Domänenanmeldung
greift MSV1_0 mithilfe der Lsass-Funktionen zum Speichern und Abrufen von »Geheimnissen«
in der LSA-Datenbank (dem Registrierungshive SECURITY) auf die zwischengespeicherten Informationen zu. Wenn die Angaben übereinstimmen, legt MSV1_0 einen LUID für die Anmeldesitzung an, erstellt die Sitzung durch einen Aufruf von Lsass, wobei es den Bezeichner mit
der Sitzung verknüpft und die erforderlichen Informationen übergibt, um ein Zugriffstoken für
den Benutzer zu generieren. (Wie bereits erwähnt, enthält ein Zugriffstoken die Benutzer-SID,
die Gruppen-SIDs und die gewährten Rechte.)
MSV1_0 speichert nicht den gesamten Kennworthash in der Registrierung zwischen, da eine Person mit physischem Zugang zu dem System sonst leichtes Spiel
hätte, das Domänenkonto des Benutzers zu knacken und Zugriff auf verschlüsselte
Daten und Netzwerkressourcen zu erhalten, für die dieser Benutzer autorisiert ist.
Stattdessen wird nur der halbe Hash gespeichert. Das reicht aus, um das Kennwort
zu überprüfen, aber nicht, um Zugriff auf EFS-Schlüssel zu erhalten, den Benutzer
in der Domäne zu authentifizieren, da dafür der vollständige Hash erforderlich ist.
828
Kapitel 7
Sicherheit
Wenn MSV1_0 eine Authentifizierung über ein Remotesystem vornehmen muss – etwa wenn sich
ein Benutzer an einer vertrauenswürdigen Prä-Windows 2000-Domäne anmeldet –, kommuniziert es über den Netlogon-Dienst mit einer Netlogon-Instanz auf dem Remotesystem. Diese
Instanz gibt die Authentifizierungsergebnisse an das System zurück, auf dem die Anmeldung
stattfindet.
Kerberos
Der grundlegende Ablauf der Kerberos-Authentifizierung ist identisch mit dem von MSV1_0.
Allerdings erfolgen Domänenanmeldungen meistens auf Arbeitsstationen oder Servern, die
Mitglied der Domäne sind, und nicht auf Domänencontrollern. Daher muss das Authentifizierungspaket über den Kerberos-TCP/IP-Port (Port 88) mit dem Kerberos-Dienst auf dem
Domänencontroller kommunizieren. Der Dienst für das Kerberos-Schlüsselverteilungscenter
(Key Distribution Center, KDC; Kdcsvc.dll), der das Kerberos-Protokoll implementiert, wird im
Lsass-Prozess auf Domänencontrollern ausgeführt.
Nach der Überprüfung der Hashes für Benutzername und Kennwort anhand der Benutzerkontoobjekte in Active Directory (mithilfe von Ntdsa.dll auf dem Active Directory-Server)
gibt Kdcsvc die Domänenanmeldeinformationen an Lsass zurück, der wiederum das Ergebnis
der Authentifizierung und die Anmeldeinformationen (bei erfolgreicher Anmeldung) über das
Netzwerk an das System zurückgibt, von dem aus die Anmeldung erfolgt.
Diese Beschreibung der Kerberos-Authentifizierung ist stark vereinfacht, macht
aber die Rollen der einzelnen Komponenten deutlich. Das Authentifizierungsprotokoll Kerberos spielt eine entscheidende Rolle für die verteilte Domänensicherheit in Windows, doch eine ausführliche Beschreibung würde den Rahmen dieses
Buches sprengen.
Nach erfolgter Authentifizierung schaut Lsass in der lokalen Richtliniendatenbank nach, welche
Art des Zugriffs dem Benutzer erlaubt ist, also interaktiver, Netzwerk-, Batch- oder Dienstprozesszugriff. Entspricht der angeforderte Zugriff nicht dem, was zugelassen ist, wird der Anmeldeversuch beendet. Um neu erstellte Anmeldesitzungen zu löschen, räumt Lsass die Daten
strukturen auf und gibt einen Fehler an Winlogon zurück, der wiederum eine entsprechende
Meldung für den Benutzer anzeigt. Ist der angeforderte Zugriff aber erlaubt, fügt Lsass die
entsprechenden zusätzlichen SIDs (z. B. für Jeder, für den interaktiven Zugriff usw.) hinzu, sucht
in der Richtliniendatenbank nach den Rechten, die dem Benutzer für diese SIDs gewährt sind,
und fügt diese Rechte zum Zugriffstoken des Benutzers hinzu.
Nachdem Lsass alle erforderlichen Informationen gesammelt hat, ruft er die Exekutive auf,
die das primäre Zugriffstoken für eine interaktive oder Dienstanmeldung und ein Identitätswechseltoken für eine Netzwerkanmeldung erstellt. Anschließend dupliziert Lsass das Token,
generiert ein Handle für Winlogon und schließt sein eigenes Handle. Bei Bedarf wird die Anmeldeoperation auch überwacht. Wenn der Vorgang bis zu dieser Stelle gediehen ist, gibt Lsass
die Erfolgmeldung, das Handle für das Zugriffstoken, den LUID für die Anmeldesitzung und
ggf. die Profilinformationen, die er vom Authentifizierungspaket erhalten hat, an Winlogon
zurück.
Anmeldung
Kapitel 7
829
Experiment: Aktive Anmeldesitzungen auflisten
Sofern es für den LUID einer Anmeldesitzung mindestens ein Token gibt, sieht Windows
die Sitzung als aktiv an. Mit dem Sysinternals-Tool LogonSessions, das die im Windows
SDK dokumentierte Funktion LsaEnumerateLogonSessions nutzt, können Sie sich die aktiven
Anmeldesitzungen anzeigen lassen:
C:\WINDOWS\system32>logonsessions
LogonSessions v1.4 - Lists logon session information
Copyright (C) 2004-2016 Mark Russinovich
Sysinternals - www.sysinternals.com
[0] Logon session 00000000:000003e7:
User name:
WORKGROUP\ZODIAC$
Auth package: NTLM
Logon type:
(none)
Session:
0
Sid:
S-1-5-18
Logon time:
09-Dec-16 15:22:31
Logon server:
DNS Domain:
UPN:
[1] Logon session 00000000:0000cdce:
User name:
Auth package: NTLM
Logon type:
(none)
Session:
0
Sid:
(none)
Logon time:
09-Dec-16 15:22:31
Logon server:
DNS Domain:
UPN:
[2] Logon session 00000000:000003e4:
User name:
WORKGROUP\ZODIAC$
Auth package: Negotiate
Logon type:
Service
Session:
0
Sid:
S-1-5-20
Logon time:
09-Dec-16 15:22:31
→
830
Kapitel 7
Sicherheit
Logon server:
DNS Domain:
UPN:
[3] Logon session 00000000:00016239:
User name:
Window Manager\DWM-1
Auth package: Negotiate
Logon type:
Interactive
Session:
1
Sid:
S-1-5-90-0-1
Logon time:
09-Dec-16 15:22:32
Logon server:
DNS Domain:
UPN:
[4] Logon session 00000000:00016265:
User name:
Window Manager\DWM-1
Auth package: Negotiate
Logon type:
Interactive
Session:
1
Sid:
S-1-5-90-0-1
Logon time:
09-Dec-16 15:22:32
Logon server:
DNS Domain:
UPN:
[5] Logon session 00000000:000003e5:
User name:
NT AUTHORITY\LOCAL SERVICE
Auth package: Negotiate
Logon type:
Service
Session:
0
Sid:
S-1-5-19
Logon time:
09-Dec-16 15:22:32
Logon server:
DNS Domain:
UPN:
...
[8] Logon session 00000000:0005c203:
User name:
NT VIRTUAL MACHINE\AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D
Auth package: Negotiate
Logon type:
Service
Session:
0
→
Anmeldung
Kapitel 7
831
Sid:
S-1-5-83-1-2895151542-1271406230-163986315-2103441620
Logon time:
09-Dec-16 15:22:35
Logon server:
DNS Domain:
UPN:
[9] Logon session 00000000:0005d524:
User name:
NT VIRTUAL MACHINE\B37F4A3A-21EF-422D-8B37-AB6B0A016ED8
Auth package: Negotiate
Logon type:
Service
Session:
0
Sid:
S-1-5-83-1-3011463738-1110254063-1806382987-3631087882
Logon time:
09-Dec-16 15:22:35
Logon server:
DNS Domain:
...
[12] Logon session 00000000:0429ab2c:
User name:
IIS APPPOOL\DefaultAppPool
Auth package: Negotiate
Logon type:
Service
Session:
0
Sid:
S-1-5-82-3006700770-424185619-1745488364-794895919-4004696415
Logon time:
09-Dec-16 22:33:03
Logon server:
DNS Domain:
UPN:
Zu den Informationen, die über eine Sitzung angegeben werden, gehören die SID und
der Name des betreffenden Benutzers, das Authentifizierungspaket und der Zeitpunkt der
Anmeldung. Das Authentifizierungspaket Negotiate, das in den Anmeldesitzungen 2 und
9 der vorstehenden Ausgabe genannt wird, versucht je nachdem, was für die jeweilige
Anforderung am geeignetsten ist, eine Authentifizierung über Kerberos oder über NTLM
durchzuführen.
Der LUID der Sitzung wird jeweils in der Zeile Logon session angezeigt. Mit dem Hilfsprogramm Handle.exe (ebenfalls von Sysinternals) können Sie die Tokens für eine gegebene
Anmeldesitzung finden. Beispielsweise können Sie die Tokens für Sitzung 8 in der vorstehenden Ausgabe mit dem folgenden Befehl abrufen:
C:\WINDOWS\system32>handle -a 5c203
Nthandle v4.1 - Handle viewer
Copyright (C) 1997-2016 Mark Russinovich
→
832
Kapitel 7
Sicherheit
Sysinternals - www.sysinternals.com
System pid: 4 type: Directory 1274: \Sessions\0\
DosDevices\00000000-0005c203
lsass.exe
pid: 496
type: Token
D7C: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
lsass.exe
pid: 496
type: Token
2350: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
lsass.exe
pid: 496
type: Token
2390: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
svchost.exe
pid: 900
type: Token
804: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
svchost.exe
pid: 1468
type: Token
10EC: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
vmms.exe
pid: 4380
type: Token
A34: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
vmcompute.exe
pid: 6592
type: Token
200: NT VIRTUAL MACHINE\
AC9081B6-1E96-4BC8-8B3B-C609D4F85F7D:5c203
vmwp.exe
pid: 7136
type: WindowStation 168: \Windows\WindowStations\
Service-0x0-5c203$
vmwp.exe
pid: 7136
type: WindowStation 170: \Windows\WindowStations\
Service-0x0-5c203$
Anschließend schaut sich Winlogon den Registrierungswert HKLM\SOFTWARE\Microsoft\Windows
NT\CurrentVersion\Winlogon\Userinit an und erstellt einen Prozess, um das auszuführen, was
dort angegeben ist. (Dieser Stringwert kann die Namen mehrerer EXE-Dateien, getrennt durch
Kommata, enthalten.) Der Standardwert ist Userinit.exe, wodurch das Benutzerprofil geladen
und ein Prozess erstellt wird, der die in HKCU\SOFTWARE\Microsoft\Windows NT\CurrentVersion\
Winlogon\Shell genannte Datei ausführt. Falls es diesen Wert nicht gibt, schaut Userinit.exe in
HKLM\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Winlogon\Shell nach, dessen Standardwert Explorer.exe lautet. Anschließend wird Userinit beendet. Das ist auch der Grund dafür, dass
Sie keinen Elternprozess erkennen können, wenn Sie Explorer.exe in Process Explorer untersuchen. Weitere Informationen über die einzelnen Schritte des Anmeldeprozesses für Benutzer
erhalten Sie in Kapitel 11 von Band 2.
Sichere Authentifizierung
Ein grundlegendes Problem bei der Authentifizierung anhand von Kennwörtern besteht darin,
dass Kennwörter geknackt oder gestohlen und von Angreifern missbraucht werden können.
Windows enthält einen Mechanismus, der erkennen kann, wie sicher die Form der Authentifizierung war, mit der sich ein Benutzer am System angemeldet hat. Dadurch kann der Zugriff
auf bestimmte Objekte bei einer unsicheren Authentifizierung eingeschränkt werden. (Hierbei
Anmeldung
Kapitel 7
833
wird die Authentifizierung per Smartcard als sicherer eingestuft als die Verwendung von Kennwörtern.)
Auf Systemen in einer Domäne kann der Domänenadministrator eine Zuordnung zwischen
einer Objektkennung (einem eindeutigen numerischen String, der für einen bestimmten Objekttyp steht) in einem Zertifikat für die Authentifizierung eines Benutzers (z. B. einer Smartcard
oder einem Hardware-Sicherheitstoken) und einer SID im Zugriffstoken des Benutzers aufstellen. Ein Zugriffssteuerungseintrag in der DACL eines Objekts kann dann eine solche SID als Teil
eines Benutzertokens angeben, um Zugriff auf das Objekt zu erhalten. In technischem Sinne
handelt es sich hierbei um einen Gruppenanspruch: Der Benutzer macht die Mitgliedschaft in
einer bestimmten Gruppe geltend, der bestimmte Zugriffsrechte für bestimmte Objekte eingeräumt sind, wobei der Anspruch in diesem Fall auf dem verwendeten Authentifizierungsmechanismus beruht. Dieses Merkmal ist standardmäßig nicht aktiviert, sondern kann in Domänen
mit zertifikatgestützter Authentifizierung vom Domänenadministrator eingerichtet werden.
Die sichere Authentifizierung baut auf vorhandenen Windows-Sicherheitseinrichtungen auf
und bietet IT-Administratoren sowie allen anderen, die sich um IT-Sicherheit einer Organisation
kümmern, eine sehr große Flexibilität. Die Organisation entscheidet, welche Objektkennungen
(Object Identifiers, OIDs) in die Zertifikate zur Benutzerauthentifizierung aufgenommen werden
und wie die einzelnen OIDs den Active Directory-Universalgruppen (bzw. deren SIDs) zugeordnet werden. Anhand der Gruppenmitgliedschaft eines Benutzers kann erkannt werden, ob bei
der Anmeldung ein Zertifikat verwendet wurde. Für die einzelnen Zertifikate können unterschiedliche Ausgaberichtlinien gelten, was wiederum unterschiedliche Grade an Sicherheit mit
sich bringt, und dies kann berücksichtigt werden, um hochgradig sensible Objekte (wie Dateien
oder auch alle anderen Objekte mit einem Sicherheitsdeskriptor) zu schützen.
Authentifizierungsprotokolle rufen während der zertifikatgestützten Authentifizierung
OIDs von Zertifikaten ab. Diese OIDs müssen SIDs zugeordnet werden, die wiederum bei der
Erweiterung der Gruppenmitgliedschaften verarbeitet und in das Zugriffstoken aufgenommen
werden. Die Zuordnung der OIDs zu den Universalgruppen wird in Active Directory festgelegt.
Nehmen wir beispielsweise an, eine Organisation hat unterschiedliche Zertifikatausgaberichtlinien für Lieferanten, Vollzeitangestellte und das leitende Management, die den Universalgruppen Lieferanten-Benutzer, VZM-Benutzer bzw. LM-Benutzer zugeordnet sind. Die
Benutzerin Abby hat eine Smartcard, deren Zertifikat mit der Richtlinie für das leitende Management ausgegeben wurde. Wenn sie sich mit ihrer Smartcard anmeldet, erhält sie die zusätzliche Mitgliedschaft in der Gruppe LM-Benutzer, was durch eine SID in ihrem Zugriffstoken
angegeben wird. In den Zugriffssteuerungslisten von Objekten können Berechtigungen so
angegeben werden, dass nur Mitglieder von VZM-Benutzer und LM-Benutzer – die anhand
der entsprechenden SIDs in den Zugriffssteuerungseinträgen erkannt werden – Zugriff auf
die Objekte erhalten. Bei der Anmeldung mit der Smartcard kann Abby auf diese Objekte
zugreifen, doch wenn sie sich einfach nur mit ihrem Benutzernamen und Kennwort anmeldet,
sind diese Objekte für sie nicht zugänglich, da ihr Zugriffstoken keine Mitgliedschaft in VZM-
Benutzer oder LM-Benutzer angibt. Ein Benutzer mit einer Smartcard, die mithilfe der Richtlinie für Lieferanten ausgegeben wurde, kann überhaupt nicht auf Objekte zugreifen, deren
Zugriffssteuerungseinträge die Mitgliedschaft in der Gruppe VZM-Benutzer oder LM-Benutzer
erfordern.
834
Kapitel 7
Sicherheit
Das Windows-Biometrieframework
Mit seinem Biometrieframework (WBF) stellt Windows einen Standardmechanismus zur Unterstützung bestimmter Arten von biometrischen Geräten bereit, z. B. von Fingerabdruckscannern.
Wie bei vielen anderen Frameworks dieser Art wurde bei der Entwicklung von WBF darauf
geachtet, die einzelnen Funktionen zur Unterstützung solcher Geräte zu isolieren und den erforderlichen Code zur Implementierung eines neuen Geräts zu minimieren.
Abb. 7–21 zeigt die Hauptkomponenten von WBF. Sofern in der folgenden Aufstellung
nicht anders vermerkt, werden alle diese Komponenten von Windows bereitgestellt:
QQ Windows-Biometriedienst (%SystemRoot%\System32\Wbiosrvc.dll) Dieser Dienst
stellt die Prozessausführungsumgebung bereit, in der ein oder mehrere Biometriedienstanbieter laufen können.
QQ Windows Biometric Driver Interface (WBDI) Dies ist ein Satz von Schnittstellendefinitionen (IRP-Hauptfunktionscodes, DeviceIOControl-Codes usw.), denen Treiber für biometrische Geräte gehorchen müssen, um den Windows-Biometriedienst nutzen zu können.
WBDI-Treiber können mit den normalen Treiberframeworks (UMDF, KMDF und WDM) entwickelt werden, wobei jedoch UMDF empfohlen wird, um den Codeumfang zu verringern
und die Zuverlässigkeit zu erhöhen. WBDI wird in der Dokumentation des Windows Driver
Kit beschrieben.
QQ Windows-Biometrie-API Über diese API können Windows-Komponenten wie Winlog
on und LogonUI auf den Biometriedienst zugreifen. Auch Drittanbieteranwendungen haben Zugang zu der Windows-Biometrie-API und können den Biometriescanner für andere
Zwecke als die Anmeldung an Windows nutzen. Ein Beispiel für eine der Funktionen in
dieser API ist WinBioEnumServiceProviders. Bereitgestellt wird die API in %SystemRoot%\
System32\Winbio.dll.
QQ Fingerabdruck-Dienstanbieter Dieser Anbieter bildet einen Wrapper für die Funktionen eines Adapters für eine bestimmte Art von biometrischer Messung, um dem
Windows-Biometriedienst eine allgemeine, von der Art der Messung unabhängige
Schnittstelle zu präsentieren. In Zukunft können durch zusätzliche Biometrie-Dienstanbieter noch weitere Arten von biometrischen Messungen unterstützt werden, z. B. Retinascans und Stimmanalyse. Der biometrische Dienstanbieter wiederum nutzt die drei
folgenden Benutzermodus-DLLs als Adapter:
•
Sensoradapter Stellt die Datenerfassungsfunktionen des Scanners bereit. Gewöhnlich greift der Sensoradapter mit Windows-E/A-Aufrufen auf die Scannerhardware zu.
Windows enthält einen Sensoradapter, der für einfache Sensoren verwendet werden
kann, für die bereits ein WBDI-Treiber vorhanden ist. Sensoradapter für kompliziertere
Sensoren werden vom Sensorhersteller geschrieben.
•
Engine-Adapter Stellt u. a. die Verarbeitungs- und Vergleichsfunktionen für das Rohdatenformat des Scanners bereit. Dabei können die eigentlichen Verarbeitungs- und
Vergleichsvorgänge in der DLL des Adapters erfolgen, es ist aber auch möglich, dass
die DLL dazu mit einem anderen Modul kommuniziert. Der Engine-Adapter wird immer vom Sensorhersteller geliefert.
Anmeldung
Kapitel 7
835
•
Speicheradapter Stellt Funktionen für eine sichere Speicherung bereit, um Vorlagen
zu speichern und abzurufen, mit denen der Engine-Adapter die gescannten Biometriedaten vergleicht. Windows enthält einen Speicheradapter, der die Windows-Kryptografiedienste und eine reguläre Speicherung in Dateien auf der Festplatte nutzt. Sensorhersteller können eigene Speicheradapter anbieten.
QQ Funktionaler Gerätetreiber für das biometrische Gerät Dieser Treiber macht die obere Seite des WBDI zugänglich. Gewöhnlich nutzt er für den Zugriff auf das biometrische
Gerät die Dienste eines Bustreibers niedrigerer Ebene, z. B. des USB-Treibers. Dieser Treiber
wird stets vom Sensorhersteller geliefert.
Win32-Anwendung
UWP-App
Windows-Biometrie-API (WinBio.dll)
Windows-Biometriedienst
Biometrischer Dienstanbieter
Sensoradapter
Engine-Adapter
Speicheradapter
Windows Biometric Driver Interface
Treiber
Von Microsoft bereitgestellt
Vom Gerätehersteller bereitgestellt
Von Microsoft oder dem
Gerätehersteller bereitgestellt
Abbildung 7–21 Architektur und Komponenten des Windows-Biometrieframeworks
Der typische Ablauf etwa bei der Anmeldung über einen Fingerabdruckscanner sieht so aus:
1.
Nach der Initialisierung erhält der Sensoradapter vom Dienstanbieter eine Anforderung zur
Datenerfassung. Daraufhin sendet der Sensoradapter eine DeviceIOControl-Anforderung
mit dem Steuercode IOCTL_BIOMETRIC_CAPTURE_DATA an den WBDI-Treiber für den Fingerabdruckscanner.
2.
Der WBDI-Treiber versetzt den Scanner in den Erfassungsmodus und stellt die IOCTL_
BIOMETRIC_CAPTURE_DATA-Anforderung in die Warteschlange, bis ein Fingerabdruckscan
erfolgt.
3.
Der Benutzer hält seinen Finger auf den Scanner. Darüber erhält der WBDI-Treiber eine Benachrichtigung, sodass er die rohen Scandaten vom Sensor abruft und in einem Puffer, der
mit der IOCTL_BIOMETRIC_CAPTURE_DATA-Anforderung verknüpft ist, an den Sensortreiber
zurückgibt.
4.
Der Sensoradapter präsentiert die Daten dem Dienstanbieter für Fingerabdrücke, der sie
wiederum an den Engine-Adapter übergibt.
836
Kapitel 7
Sicherheit
5.
Der Engine-Adapter verwandelt die Rohdaten in eine Form, die mit seinem Vorlagenspeicher kompatibel ist.
6.
Mithilfe des Speicheradapters ruft der Dienstanbieter Vorlagen und zugehörige SIDs vom
sicheren Speicher ab. Anschließend ruft er den Engine-Adapter auf, um die einzelnen Vorlagen mit den verarbeiteten Scandaten zu vergleichen. Der Engine-Adapter gibt einen
Status zurück, der besagt, ob eine Übereinstimmung vorliegt oder nicht.
7.
Bei einer Übereinstimmung benachrichtigt der Windows-Biometriedienst über eine Anmeldeinformationsanbieter-DLL Winlogon von der erfolgreichen Anmeldung und übergibt die SID des identifizierten Benutzers. Dies erfolgt über eine ALPC-Nachricht, sodass
der Pfad nicht gefälscht werden kann.
Windows Hello
Das in Windows 10 eingeführte Windows Hello bietet neue Möglichkeiten zur biometrischen
Identifizierung von Benutzern. Mit dieser Technologie können sich Benutzer einfach dadurch
anmelden, dass sie in die Kamera des Geräts blicken oder ihren Finger auflegen.
Zurzeit kann Windows Hello die folgenden drei Körpermerkmale zur biometrischen Identifizierung verwenden:
QQ Fingerabdruck
QQ Gesicht
QQ Iris
Betrachten wir hier zunächst die Sicherheitsaspekte. Wie wahrscheinlich ist es, dass eine andere
Person für Sie gehalten wird? Wie wahrscheinlich ist es, dass Sie nicht als Sie selbst erkannt
werden? Diese Fragen können wie folgt quantifiziert werden:
QQ Falschakzeptanzrate (Einzigartigkeit) Das ist die Wahrscheinlichkeit dafür, dass die
biometrischen Daten eines anderen Benutzers irrtümlich als die Ihren erkannt werden. Bei
den von Microsoft verwendeten Algorithmen liegt diese Wahrscheinlichkeit bei 1:100.000.
QQ Falschrückweisungsrate (Zuverlässigkeit) Das ist die Wahrscheinlichkeit dafür, dass Sie
nicht als Sie selbst erkannt werden (z. B. bei ungünstiger Beleuchtung für die Gesichtsoder Iriserkennung). Bei der Implementierung von Microsoft beträgt diese Wahrscheinlichkeit weniger als 1 %. Sollte es geschehen, kann der Benutzer es noch einmal versuchen
oder eine PIN eingeben.
Eine PIN mag weniger sicher wirken als ein Kennwort (schließlich kann es sich bei der PIN auch
einfach um eine vierstellige Zahl handeln). Allerdings ist eine PIN aus den beiden folgenden
Gründen sicherer:
QQ Die PIN wird nur lokal am Gerät eingegeben und nie über das Netzwerk übertragen. Wenn
jemand die PIN in Erfahrung bringt, kann er sich damit also nicht von einem anderen Gerät
aus anmelden. Kennwörter dagegen werden zum Domänencontroller übertragen. Wenn
jemand ein Kennwort abfängt, kann er sich damit von einem anderen Rechner aus an der
Domäne anmelden.
Anmeldung
Kapitel 7
837
QQ Die PIN wird im TPM gespeichert (Trusted Platform Module), einer Hardware, die auch
beim sicheren Start eine Rolle spielt (siehe Kapitel 11 in Band 2), und ist daher nur sehr
schwer zugänglich. Auf jeden Fall ist physischer Zugriff auf das Gerät erforderlich, was einen Angriff erheblich erschwert.
Windows Hello baut auf dem im vorherigen Abschnitt beschriebenen Windows-Biometrie
framework (WBF) auf. Auf modernen Laptops ist bereits eine Fingerabdruck- und Gesichtserkennung möglich, eine Iriserkennung dagegen gibt es zurzeit nur auf den Telefonen Microsoft
Lumia 950 und 950 XL. (Allerdings ist damit zu rechnen, dass diese Funktion in Zukunft auch
auf vielen anderen Geräten zur Verfügung stehen wird.) Beachten Sie, dass für die Gesichtserkennung sowohl eine Infrarot- als auch eine normale (RGB-) Kamera erforderlich ist. Unterstützt
wird diese Funktion nur auf dem Microsoft Surface Pro 4 und dem Surface Book.
Benutzerkontensteuerung und Virtualisierung
Die Benutzerkontensteuerung (User Access Control, UAC) soll es ermöglichen, dass Benutzer
ihre Arbeit mit Standardbenutzerrechten und nicht mit Administratorrechten ausführen. Ohne
Administratorrechte können sie nicht versehentlich (oder absichtlich) Systemeinstellungen ändern und auch nicht auf sensible Informationen anderer Benutzer auf gemeinsam genutzten
Computern zugreifen. Auch Malware ist unter diesen Umständen normalerweise nicht in der
Lage, Sicherheitseinstellungen zu ändern oder Antivirussoftware auszuschalten. Die Arbeit unter Standardbenutzerrechten kann daher die Auswirkungen von Malware einschränken und
sensible Daten schützen.
Es mussten zunächst einige Probleme mit der Benutzerkontensteuerung gelöst werden, bevor sie für den praktischen Einsatz geeignet war. Erstens beruhte das bisherige Windows-Nutzungsmodell auf Administratorrechten, weshalb Softwareentwickler davon ausgingen, dass ihre
Programme mit diesen Rechten ausgeführt wurden und daher auf beliebige Dateien, Registrierungsschlüssel und Betriebssystemeinstellungen zugreifen und diese ändern konnten. Zweitens
brauchen Benutzer manchmal Administratorrechte, um beispielsweise Software zu installieren,
die Systemzeit zu ändern und Ports in der Firewall zu öffnen.
Bei eingeschalteter Benutzerkontensteuerung laufen die meisten Anwendungen mit Standardbenutzerrechten, auch wenn sich der Benutzer mit einem Konto angemeldet hat, das über
Administratorrechte verfügt. Wenn es nötig ist, können Standardbenutzer jedoch auch Administratorrechte ausüben, beispielsweise für ältere Anwendungen, für die solche Rechte erforderlich sind, oder um Systemeinstellungen zu ändern. Dazu erstellt die Benutzerkontensteuerung
bei der Anmeldung eines Benutzers mit einem Administratorkonto sowohl ein reguläres als
auch ein gefiltertes Administratortoken. Bei allen Prozessen, die in der Sitzung dieses Benutzers
erstellt werden, ist das gefilterte Token in Kraft, sodass Anwendungen, die mit Standardrechten
laufen können, dies auch tun. Durch die Rechteerhöhung der Benutzerkontensteuerung kann
ein als Administrator angemeldeter Benutzer jedoch auch Programme starten oder andere
Funktionen ausführen, die volle Administratorrechte benötigen.
838
Kapitel 7
Sicherheit
Um die Nutzbarkeit der Standardbenutzerumgebung zu erhöhen, erlaubt Windows Standardbenutzern, auch einige Dinge zu tun, die früher Administratoren vorbehalten waren. Beispielsweise gibt es Gruppenrichtlinieneinstellungen, um Standardbenutzern die Installation von
Druckern und Gerätetreibern zu erlauben, die von IT-Administratoren genehmigt wurden.
Wenn Softwareentwickler ihre Tests in einer Umgebung mit Benutzerkontensteuerung
ausführen, ermutigt sie das dazu, Anwendungen zu schreiben, die ohne Administratorrechte
auskommen. Grundsätzlich sollten nicht administrative Programme keine Administratorrechte
benötigen. Bei Programmen, die auf solche Rechte angewiesen sind, handelt es sich gewöhnlich um ältere Anwendungen, die veraltete APIs oder Techniken nutzen und aktualisiert werden
sollten.
Zusammengenommen haben all diese Änderungen dafür gesorgt, dass Benutzer nicht
mehr ständig mit Administratorrechten arbeiten müssen.
Virtualisierung des Dateisystems und der Registrierung
Es gibt zwar durchaus Software, die tatsächlich Administratorrechte benötigt, doch viele Programme legen Benutzerdaten unnötigerweise in globalen Systemspeicherorten ab. Da eine
Anwendung unter verschiedenen Benutzerkonten ausgeführt werden kann, sollte sie benutzerspezifische Daten und Einstellungen im %AppData%-Verzeichnis des Benutzers bzw. in seinem
Registrierungsprofil unter HKEY_CURRENT_USER\Software speichern. Standardbenutzerkonten haben keinen Schreibzugriff auf das Verzeichnis %ProgramFiles% und auf HKEY_LOCAL_MACHINE\
Software, aber da die meisten Windows-Computer Einzelbenutzersysteme sind und die meisten Benutzer vor Einführung der Benutzerkontensteuerung Administratoren waren, funktionieren Anwendungen, die Benutzerdaten und -einstellungen dort ablegten, trotzdem.
Durch die Virtualisierung des Dateisystem- und Registrierungsnamensraums macht
Windows die Ausführung solcher veralteten Anwendungen unter Standardbenutzerkonten
möglich. Wenn eine Anwendung einen globalen Systemspeicherort im Dateisystem oder in der
Registrierung zu ändern versucht und diese Operation fehlschlägt, da der Zugriff verweigert
wird, leitet Windows die Operation zu einem Bereich für den aktuellen Benutzer um. Liest eine
Anwendung von einem globalen Systemspeicherort, schaut Windows erst im Benutzerbereich
nach. Erst wenn dort keine Daten zu finden sind, erlaubt es der Anwendung, in dem globalen
Speicherort zu lesen.
Windows verwendet fast immer diese Form der Virtualisierung. Es gibt nur die folgenden
Ausnahmefälle:
QQ Es handelt sich um eine 64-Bit-Anwendung Da die Virtualisierung eine reine Kompatibilitätstechnologie ist, um auch ältere Anwendungen zu unterstützen, wird sie nur für
32-Bit-Anwendungen durchgeführt. Da 64-Bit-Anwendungen relativ neu sind, müssen ihre
Entwickler die Richtlinien zum Schreiben von Anwendungen beachten, die unter Standardbenutzerrechten laufen können.
QQ Die Anwendung wird bereits mit Administratorrechten ausgeführt In diesem Fall ist
eine Virtualisierung nicht mehr notwendig.
QQ Die Operation stammt von einem Aufrufer im Kernelmodus
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
839
QQ Der Aufrufer hat während der Ausführung der Operation eine andere Identität angenommen Es werden nur Operationen virtualisiert, die von einem als veraltet (legacy)
klassifizierten Prozess ausgehen.
QQ Das ausführbare Abbild für den Prozess verfügt über ein UAC-kompatibles Manifest Das bedeutet, es enthält die Einstellung requestedExecutionLevel (siehe den nächsten
Abschnitt).
QQ Der Administrator hat keinen Schreibzugriff auf die Datei bzw. den Registrierungsschlüssel Die ältere Anwendung wäre auch fehlgeschlagen, wenn sie vor Einführung der
Benutzerkontensteuerung mit Administratorrechten ausgeführt worden wäre.
QQ Dienste werden niemals virtualisiert
Den Virtualisierungsstatus eines Prozesses (der als Flag im Prozesstoken gespeichert wird)
können Sie sich ansehen, indem Sie auf der Seite Details des Task-Managers die Spalte
UAC-Virtualisierung hinzufügen (siehe Abb. 7–22). Bei den meisten Windows-Komponenten – zum Beispiel beim Desktopfenster-Manager (Dwm.exe), dem Client-Server-Laufzeit-Teilsystem (Scrss.exe) und dem Explorer – ist die Virtualisierung ausgeschaltet, da sie
über ein UAC-kompatibles Manifest verfügen oder ohnehin mit Administratorrechten ausgeführt werden. Allerdings ist die Virtualisierung für die 32-Bit-Version von Internet Explorer
(Iexplore.exe) eingeschaltet, da er ActiveX-Steuerelemente und Skripte ausführen kann, bei
denen man davon ausgehen muss, dass sie mit Standardbenutzerrechten nicht richtig funktionieren. Bei Bedarf kann die Virtualisierung auf einem System mithilfe einer lokalen Sicherheitsrichtlinieneinstellung jedoch auch komplett abgeschaltet werden.
Neben der Dateisystem- und Registrierungsvirtualisierung benötigen einige Anwendungen noch zusätzliche Hilfsmaßnahmen, um mit Standardbenutzerrechten laufen zu können.
Stellen Sie sich beispielsweise eine Anwendung vor, die prüft, ob das Konto, unter dem sie ausgeführt wird, zur Administratorengruppe gehört. Ohne Mitgliedschaft in dieser Gruppe läuft
diese Anwendung nicht, auch wenn sie sonst problemlos funktionieren würde. Damit solche
Anwendungen trotzdem ausgeführt werden können, verfügt Windows über eine Reihe von
Kompatibilitätsshims. Die am häufigsten verwendeten Shims, um älteren Anwendungen die
Ausführung unter Standardbenutzerrechten zu ermöglichen, sind in Tabelle 7–15 aufgeführt.
840
Kapitel 7
Sicherheit
Abbildung 7–22 Anzeige des Virtualisierungsstatus im Task-Manager
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
841
Flag
Bedeutung
ElevateCreateProcess
Ändert die Funktion CreateProcess, sodass sie bei ERROR_
ELEVATION_REQUIRED-Fehlern den Anwendungsinformationsdienst aufruft, um eine Erhöhung der Rechte anzufordern.
ForceAdminAccess
Gibt die Mitgliedschaft in der Administratorengruppe vor.
VirtualizeDeleteFile
Gibt die erfolgreiche Löschung von globalen Dateien und
Verzeichnissen vor.
LocalMappedObject
Erzwingt die Aufnahme von globalen Abschnittsobjekten in
den Namensraum des Benutzers.
VirtualizeHKCRLite
Leitet die globale Registrierung von COM-Objekten in einen
Speicherort für den Benutzer um.
VirtualizeRegisterTypeLib
Wandelt computerbezogene typelib-Registrierungen in benutzerbezogene Registrierungen um.
Tabelle 7–15 Kompatibilitätsshims
Dateivirtualisierung
Bei den Dateisystemspeicherorten, die für veraltete Prozesse virtualisiert werden, handelt es
sich um %ProgramFiles%, %ProgramData% und %SystemRoot%, wobei jedoch einige Unterverzeichnisse sowie jegliche Arten von ausführbaren Dateien (.exe, .bat, .scr, .vbs usw.) ausgenommen sind. Wenn ein Programm versucht, sich unter einem Standardbenutzerkonto selbst
zu aktualisieren, schlägt es daher fehl, anstatt private Versionen der ausführbaren Dateien anzulegen, die für Administratoren mit einem globalen Updater nicht sichtbar wären.
Um Dateierweiterungen zu der Ausnahmeliste hinzuzufügen, geben Sie sie im Registrierungsschlüssel HKLM\System\CurrentControlSet\Services\Luafv\Parameters\
ExcludedExtensionsAdd ein und starten den Rechner neu. Verwenden Sie einen Multistringtyp, um mehrere Erweiterungen anzugeben, und lassen Sie den führenden
Punkt bei der Erweiterung weg.
Änderungen, die veraltete Prozesse an virtualisierten Verzeichnissen vornehmen wollen, werden an das virtuelle Stammverzeichnis des Benutzers weitergeleitet, also an %LocalAppData%\
VirtualStore. Die Bezeichnung Local in diesem Pfad deutet darauf hin, dass virtualisierte Dateien nicht zusammen mit dem Rest eines servergespeicherten Profils umziehen.
Der Filtertreiber UAC-Dateivirtualisierung (UAC File Virtualization, %SystemRoot%\
System32\Drivers\Luafv.sys) implementiert die Dateisystemvirtualisierung. Da es sich um
einen Dateisystem-Filtertreiber handelt, sieht er alle Operationen im lokalen Dateisystem,
allerdings wirkt er sich nur auf Operationen aus, die von veralteten Prozessen ausgehen. Wie
Abb. 7–23 zeigt, ändert der Filtertreiber den Zieldateipfad für veraltete Prozesse, die eine
Datei an einem globalen Systemspeicherort erstellen wollen, aber nicht für nicht virtualisierte Prozesse mit Standardbenutzerrechten. Die Standardberechtigungen für das Verzeichnis
842
Kapitel 7
Sicherheit
\Windows verweigern den Zugriff für Anwendungen, die mit UAC-Unterstützung geschrieben wurden. Ältere Prozesse aber verhalten sich so, als hätte die Operation tatsächlich Erfolg,
obwohl die Datei in Wirklichkeit an einem Speicherort erstellt wird, der für den Benutzer voll
zugänglich ist.
Veraltete
Anwendung
UAC-fähige
Anwendung
Schreibt in
\Windows\App.ini
Benutzermodus
Kernelmodus
Schreibt in
\Users\<Benutzer>\
AppData\Local\
VirtualStore\Windows\
App.ini
Schreibt in
\Windows\App.ini
ZUGRIFF
VERWEIGERT
Abbildung 7–23 Funktionsweise des Filtertreibers für die UAC-Dateivirtualisierung
Experiment: Dateivirtualisierung
In diesem Experiment aktivieren und deaktivieren Sie die Virtualisierung an der Befehlszeile
und beobachten die Auswirkungen:
1.
Öffnen Sie eine Eingabeaufforderung ohne erhöhte Rechte (die Benutzerkontensteuerung muss dazu eingeschaltet sein) und aktivieren Sie die Virtualisierung dafür, indem
Sie auf der Registerkarte Details des Task-Managers auf den Prozess rechtsklicken und
UAC-Virtualisierung auswählen.
2.
Begeben Sie sich zum Verzeichnis C:\Windows und schreiben Sie mit dem folgenden
Befehl eine Datei:
echo hello-1 > test.txt
3.
Listen Sie den Verzeichnisinhalt auf. Die Datei wird angezeigt.
dir test.txt
4.
Deaktivieren Sie die Virtualisierung, indem Sie auf der Registerkarte Details des
Task-Managers auf den Prozess rechtsklicken und UAC-Virtualisierung abwählen. Listen
Sie erneut wie in Schritt 3 den Verzeichnisinhalt auf. Die Datei ist verschwunden! Wenn
Sie dagegen das Verzeichnis VirtualStore auflisten, wird sie wieder angezeigt:
dir %LOCALAPPDATA%\VirtualStore\Windows\test.txt
→
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
843
5.
Aktivieren Sie die Virtualisierung für den Prozess wieder.
6.
Um sich einen anspruchsvolleren Fall anzusehen, öffnen Sie eine weitere Eingabeaufforderung, diesmal aber mit erhöhten Rechten. Wiederholen Sie Schritt 2 und 3 mit
dem String hello-2.
7.
Untersuchen Sie an beiden Eingabeaufforderungen den Text innerhalb der Dateien mit
dem folgenden Befehl. Die folgenden Screenshots zeigen die zu erwartende Ausgabe.
type test.txt
→
844
Kapitel 7
Sicherheit
8.
Löschen Sie die Datei test.txt an der Eingabeaufforderung mit erhöhten Rechten:
del test.txt
9.
Wiederholen Sie Schritt 3 in beiden Fenstern. In der Eingabeaufforderung mit erhöhten
Rechten wird die Datei nicht mehr gefunden, während die Standardeingabeaufforderung wieder den alten Inhalt der Datei anzeigt. Das macht den zuvor beschriebenen
Failovermechanismus deutlich: Leseoperationen suchen erst im virtuellen Speicher des
Benutzers, doch wenn die gewünschte Datei dort nicht zu finden ist, erfolgt der Zugriff
auf den Systemspeicherort.
Virtualisierung der Registrierung
Die Virtualisierung der Registrierung unterscheidet sich leicht von der Virtualisierung des
Dateisystems. Zu den virtualisierten Schlüsseln gehören die meisten unter HKEY_LOCAL_MACHINE\
Software, wobei es aber auch zahlreiche Ausnahmen gibt, darunter die folgenden:
QQ HKLM\Software\Microsoft\Windows
QQ HKLM\Software\Microsoft\Windows NT
QQ HKLM\Software\Classes
Nur Schlüssel, die üblicherweise von veralteten Anwendungen bearbeitet werden und die nicht
zu Kompatibilitäts- oder Interoperabilitätsproblemen führen, werden virtualisiert. Windows
leitet Änderungen, die veraltete Anwendungen an virtualisierten Schlüsseln vornehmen, zum
virtuellen Registrierungsstamm für den Benutzer unter HKEY_CURRENT_USER\Software\Classes\
VirtualStore um. Der Schlüssel befindet sich im Hive Classes (%LocalAppData%\Microsoft\
Windows\UsrClass.dat), der wie alle anderen Inhalte virtualisierter Dateien nicht zusammen
mit einem servergespeicherten Benutzerprofil umzieht. Windows unterhält jedoch keine feste
Liste virtualisierter Speicherorte, wie es beim Dateisystem der Fall ist, sondern speichert den
Virtualisierungsstatus eines Schlüssel in Form einer Kombination von Flags (siehe Tabelle 7–16).
Sie können beim Windows-Dienstprogramm Reg.exe die Option flags einsetzen, um den
Virtualisierungsstatus eines Schlüssel abzurufen oder festzulegen. In Abb. 7–24 ist der Schlüssel HKLM\Software vollständig virtualisiert, doch für den Unterschlüssel Windows (und alle seine
Kindschlüssel) ist nur der »Fehlschlag ohne Rückmeldung« aktiviert.
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
845
Flag
Bedeutung
REG_KEY_DONT_VIRTUALIZE
Gibt an, ob die Virtualisierung für den Schlüssel aktiviert ist. Ist
das Flag gesetzt, so ist die Virtualisierung deaktiviert.
REG_KEY_DONT_SILENT_FAIL
Wenn das Flag REG_KEY_DONT_VIRTUALIZE gesetzt (die Virtualisierung also deaktiviert) ist, gibt dieses Flag an, dass eine
veraltete Anwendung, der normalerweise der Zugriff für eine
Operation an dem Schlüssel verweigert würde, nicht die angeforderten Rechte, sondern die maximal zulässigen Rechte
(MAXIMUM_ALLOWED) für den Schlüssel erhält (wodurch jeglicher
Zugriff gewährt wird, der dem Konto erlaubt ist). Wenn dieses
Flag gesetzt ist, wird damit implizit auch die Virtualisierung
ausgeschaltet.
REG_KEY_RECURSE_FLAG
Gibt an, ob die Virtualisierungsflags an die Unterschlüssel des
vorliegenden Schlüssels vererbt werden.
Tabelle 7–16 Virtualisierungsflags für die Registrierung
Abbildung 7–24 Flags für die Virtualisierung der Registrierungsschlüssel Software und Windows
Im Gegensatz zur Dateivirtualisierung, für die ein Filtertreiber verwendet wird, ist die Virtualisierung der Registrierung im Konfigurations-Manager implementiert (siehe Kapitel 9 in Band 2).
Die Funktionsweise ähnelt aber der Dateivirtualisierung: Auch hier wird ein veralteter Prozess,
der einen Unterschlüssel eines virtuellen Schlüssels erstellt, zum virtuellen Registrierungsstamm
des Benutzers umgeleitet, während UAC-kompatiblen Prozessen aufgrund der Standardberechtigungen der Zugriff verweigert wird (siehe Abb. 7–25).
846
Kapitel 7
Sicherheit
Virtualisierter
Prozess
Nicht virtualisierter
Prozess
Schreibt in
HKLM\Software\App
ZUGRIFF
VERWEIGERT
Benutzermodus
Kernelmodus
Schreibt in
HKCU\Software\Classes\
VirtualStore\Machine\
Software\App
Registrierung
Abbildung 7–25 Funktionsweise der Registrierungsvirtualisierung
Rechteerhöhung
Auch wenn Benutzer nur Programme ausführen, die unter Standardbenutzerrechten funktionieren, benötigen sie für einige Operationen trotzdem Administratorrechte, etwa für Installation von
Software, bei der Verzeichnisse und Registrierungsschlüssel in globalen Systemspeicherorten gespeichert oder Dienste und Gerätetreiber eingerichtet werden müssen. Auch für die Bearbeitung
von systemweiten Windows- und Anwendungseinstellungen und die Jugendschutzfunktionen
sind Administratorrechte erforderlich. Es wäre bei den meisten dieser Vorgänge zwar möglich, zu
einem dedizierten Administratorkonto umzuschalten, aber das wäre so unbequem, dass es viele
Benutzer dazu veranlassen könnte, ihre gesamten täglichen Arbeiten unter ihrem Administratorkonto auszuführen, auch wenn für die meisten gar keine Administratorrechte erforderlich sind.
Die Rechteerhöhung durch die Benutzerkontensteuerung ist jedoch nur eine Maßnahme
zur Steigerung der Benutzerfreundlichkeit. Eine Sicherheitsgrenze wird dadurch nicht definiert,
da es keine Richtlinie gibt, die bestimmt, wer oder was die Grenze überschreiten darf und wer
oder was nicht. Benutzerkonten sind Sicherheitsgrenzen, da ein Benutzer nicht auf die Daten
eines anderen zugreifen kann, ohne über dessen Berechtigungen zu verfügen.
Es ist daher nicht garantiert, dass Malware, die unter Standardbenutzerrechten läuft, nicht
in der Lage ist, einen Prozess mit erhöhten Rechten zu missbrauchen, um Administratorrechte
zu gewinnen. In Dialogfeldern zur Rechteerhöhung wird die ausführbare Datei angegeben,
deren Rechte erhöht werden, aber es wird nicht gesagt, was sie damit anstellt.
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
847
Ausführung mit Administratorrechten
Windows schließt eine erweiterte »Ausführen als«-Funktion ein, mit der Standardbenutzer auf
einfache Weise Prozesse mit Administratorrechten starten können. Dazu müssen Anwendungen in der Lage sein, die Operationen zu erkennen, für die das System ihnen Administratorrechte einräumen kann (mehr darüber in Kürze).
Um Benutzer, die Systemadministratoren sind, die Arbeit mit Standardbenutzerrechten
zu ermöglichen, ohne dass sie bei jedem Zugriff auf Administratorrechte Benutzername und
Kennwort eingeben müssen, verwendet Windows den sogenannten Administratorgenehmigungsmodus (Admin Approval Mode, AAM). Dieser Mechanismus erstellt bei der Anmeldung
zwei Identitäten für den Benutzer, nämlich eine mit Standardbenutzer- und eine mit Adminis
tratorrechten. Da jeder Benutzer auf einem Windows-System entweder ein Standardbenutzer
ist oder größtenteils als Standardbenutzer im AAM arbeitet, können Entwickler davon aus
gehen, dass alle Windows-Benutzer Standardbenutzer sind. Das führt dazu, dass mehr Programme geschrieben werden, die auch ohne Virtualisierung und Shims mit Standardbenutzerrechten funktionieren.
Einem Prozess Administratorrechte zu gewähren, wird als Rechteerhöhung oder Rechte
erweiterung bezeichnet. Erfolgt dieser Vorgang für ein Standardbenutzerkonto (oder einen
Benutzer, der zwar zu einer administrativen Gruppe, aber nicht zur Gruppe Administratoren
gehört), so spricht man von einer Über-die-Schulter-Erweiterung (Over the Shoulder, OTS), da
dabei die Anmeldeinformationen eines Mitglieds der Gruppe Administratoren bereitgestellt
werden müssen, was gewöhnlich dadurch geschieht, dass ein entsprechend privilegierter Benutzer seine Anmeldeinformationen sozusagen »über die Schulter« des Standardbenutzers
eingibt. Die Rechteerhöhung für einen AAM-Benutzer dagegen wird als Erweiterung mit Zustimmung (Consent Elevation) bezeichnet, da der Benutzer einfach der Zuweisung von Administratorrechten zustimmen muss.
An Domänen angeschlossene Systeme handhaben den AAM-Zugriff von Remotebenutzern auf andere Weise als eigenständige Systeme (also gewöhnliche Privatcomputer), da sie in
den Berechtigungen für Ressourcen auch administrative Domänengruppen verwenden können. Wenn ein Remotebenutzer auf eine Dateifreigabe auf einem eigenständigen Computer
zugreift, fordert Windows seine Standardbenutzeridentität an. Auf Systemen in Domänen dagegen fordert Windows die administrative Identität des Benutzers an und kann damit seine Mitgliedschaften in allen Domänengruppen berücksichtigen. Wird ein Abbild ausgeführt,
das Administratorrechte anfordert, startet der Anwendungsinformationsdienst (AIS, enthalten
in %SystemRoot%\System32\Appinfo.dll), der innerhalb eines regulären Diensthostprozesses
(SvcHost.exe) läuft, %SystemRoot%\System32\Consent.exe. Dieses Programm fertigt ein Bitmapbild des Bildschirms an, wendet einen Verdunkelungseffekt darauf an, schaltet zum sicheren Desktop um, der nur für das lokale Systemkonto zugänglich ist, verwendet das Bitmapbild
als Hintergrund dafür und zeigt das Dialogfeld zur Rechteerhöhung mit Angaben zu der anfordernden Anwendung an. Durch die Anzeige dieses Dialogfelds in einem separaten Desktop
wird verhindert, dass irgendeine Anwendung, die unter dem Benutzerkonto ausgeführt wird,
das Erscheinungsbild dieses Dialogfelds manipuliert.
Handelt es sich bei dem Abbild um eine (von Microsoft oder einer anderen Stelle) signierte
Windows-Komponente, so wird das Dialogfeld wie in dem linken Dialogfeld von Abb. 7–26 mit
848
Kapitel 7
Sicherheit
einem blauen Streifen am oberen Rand dargestellt. (Die Unterscheidung zwischen Signaturen
von Microsoft und von anderen Stellen wurde mit Windows 10 aufgehoben.) Ist das Abbild nicht
signiert, so wird der Streifen in Gelb angezeigt und darauf hingewiesen, dass der Ursprung des
Abbilds unbekannt ist (siehe rechte Seite von Abb. 7–26). Das Dialogfeld zur Rechteerhöhung
zeigt bei digital signierten Abbildern das Programmsymbol, eine Beschreibung sowie den Herausgeber an und bei nicht signierten nur den Dateinamen und Herausgeber: Unbekannt. Diese
Unterschiede erschweren es Malware, das Erscheinungsbild legitimer Software nachzuahmen.
Über den Link Details anzeigen unten in dem Dialogfeld können Sie die Befehlszeile einsehen,
die beim Start der ausführbaren Datei übergeben wird.
Abbildung 7–26 Dialogfelder zur AAM-Rechteerhöhung für Anwendungen mit und ohne Signatur
Das Dialogfeld für die OTS-Rechteerweiterung aus Abb. 7–27 sieht ähnlich aus, fordert aber
zur Eingabe der Anmeldeinformationen eines Administrators auf und listet alle Konten mit
Administratorrechten auf.
Abbildung 7–27 Dialogfeld zur OTS-Rechteerhöhung
Wenn ein Benutzer die angeforderte Rechteerhöhung ablehnt, gibt Windows einen Fehler
aufgrund einer Zugriffsverweigerung an den Prozess zurück, der den Vorgang ausgelöst hat.
Stimmt der Benutzer dagegen zu, indem er die Anmeldeinformationen eines Administrators
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
849
eingibt oder auf Ja klickt, ruft der Anmeldeinformationsdienst CreateProcessAsUser auf, um
den Prozess mit der entsprechenden Administratoridentität zu starten. Der Anmeldeinformationsdienst ist zwar technisch gesehen der Elternprozess des Prozesses mit erhöhten Rechten,
verwendet aber die neuen Möglichkeiten der API CreateProcessAsUser, um die Elternprozesskennung auf diejenige des Prozesses zu setzen, der den Dienst ursprünglich gestartet hat.
Aus diesem Grunde erscheinen Prozesse mit erhöhten Rechten in den Prozessbäumen von
Programmen wie Process Explorer nicht als Kinder des Hostprozesses, in dem der Anmeldeinformationsdienst ausgeführt wird. Abb. 7–28 zeigt die Vorgänge, die ablaufen, wenn von einem
Standardbenutzerkonto aus ein Prozess mit erhöhten Rechten gestartet wird.
Neuzuweisung der Elternrolle
Explorer
(Standardbenutzer)
Anwendungs
informationsdienst
App.Exe
Consent.exe
(Lokales System)
(Administrator)
Abbildung 7–28 Starten einer administrativen Anwendung als Standardbenutzer
Administratorrechte anfordern
Die Notwendigkeit von Administratorrechten wird vom System und von Anwendungen auf
verschiedene Weisen angezeigt. So kann beispielsweise im Kontextmenü und in den Optionen
einer Verknüpfung der Befehl Als Administrator ausführen angezeigt werden. Dabei wird auch
jeweils das Symbol des blau-goldenen Schildes dargestellt, mit dem alle Schaltflächen und
Menüeinträge gekennzeichnet werden, deren Auswahl eine Rechteerhöhung zur Folge hat.
Wird Als Administrator ausführen ausgewählt, ruft der Explorer die API ShellExecute mit dem
Verb runas aus.
Da fast alle Installationsprogramme Administratorrechte erfordern, enthält der Abbildlader, der den Start einer ausführbaren Datei auslöst, Code zur Erkennung möglicherweise veralteter Installer. Dabei werden einerseits sehr einfache Heuristiken eingesetzt, die die internen
Versionsinformationen abfragen oder prüfen, ob im Dateinamen des Abbilds Wörter wie setup,
install oder update vorkommen, aber auch anspruchsvollere Erkennungsmethoden, bei denen in der ausführbaren Datei nach Bytesequenzen gesucht wird, die für Installationswrapper
von Drittanbietern typisch sind. Des Weiteren ruft der Abbildlader die Anwendungskompatibilitätsbibliothek auf, um zu sehen, ob die betreffende ausführbare Datei Administratorrechte
850
Kapitel 7
Sicherheit
benötigt. Die Bibliothek wiederum schaut in der Anwendungskompatibilitätsdatenbank nach,
ob für die ausführbare Datei das Kompatibilitätsflag RequireAdministrator oder RunAsInvoker
angegeben ist.
Die üblichste Vorgehensweise, mit der ausführbare Dateien Administratorrechte anfordern,
besteht darin, das Tag requestedExecutionLevel in ihr Manifest aufzunehmen. Das Attribut für
die Ausführungsebene in diesem Element kann die drei Werte aus Tabelle 7–17 annehmen.
Ausführungsebene
Bedeutung
Verwendung
Als aufrufende Instanz
Keine Administratorrechte erforderlich; es wird niemals eine
Rechteerhöhung angefordert.
Gewöhnliche Benutzeranwendungen, die keine Administratorrechte benötigen, z. B. der Editor
Die am höchsten verfügbare
[sic!]
Genehmigung für die höchsten
verfügbaren Rechte wird angefordert. Wenn der Benutzer als
Standardbenutzer angemeldet ist,
wird der Prozess als aufrufende
Instanz gestartet. Anderenfalls
erscheint ein AAM-Dialogfeld
zur Rechteerhöhung, sodass der
Prozess mit vollen Administratorrechten laufen kann.
Anwendungen, die ohne volle
Administratorrechte funktionieren, bei denen aber zu erwarten
ist, dass die Benutzer einen Administratorzugriff anfordern, wenn
er leicht erhältlich ist. Diese Ausführungsebene wird beispielsweise vom Registrierungseditor, der
Microsoft Management Console
und der Ereignisanzeige genutzt.
Administrator erforderlich
Es werden stets Administratorrechte angefordert. Für Standardbenutzer wird das OTS-Dialogfeld
zur Rechteerhöhung angezeigt,
anderenfalls das AAM-Dialogfeld.
Anwendungen, die Administra
torrechte benötigen, um zu
funktionieren, z. B. der Editor für
Firewalleinstellungen, der sich
auf die systemweite Sicherheit
auswirkt.
Tabelle 7–17 Angeforderte Ausführungsebenen
Ist in einem Manifest das Element trustInfo vorhanden (wie in der folgenden Ausgabe des Manifests von Eventvwr.exe), wurde die ausführbare Datei mit UAC-Unterstützung geschrieben. In
diesem Element ist außerdem das Element requestedExecutionLevel verschachtelt. Im Attribut
uiAccess setzen die Programme für Eingabehilfen die zuvor erwähnten UIPI-Umgehungsfunktionen ein.
C:\>sigcheck -m c:\Windows\System32\eventvwr.exe
...
<trustInfo xmlns="urn:schemas-microsoft-com:asm.v3">
<security>
<requestedPrivileges>
<requestedExecutionLevel
level="highestAvailable"
uiAccess="false"
/>
</requestedPrivileges>
</security>
</trustInfo>
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
851
<asmv3:application>
<asmv3:windowsSettings xmlns="http://schemas.microsoft.com/SMI/2005/
WindowsSettings">
<autoElevate>true</autoElevate>
</asmv3:windowsSettings>
</asmv3:application>
...
Automatische Rechteerweiterung
In der Standardkonfiguration (wie Sie sie ändern können, erfahren Sie im nächsten Abschnitt)
wird bei den meisten ausführbaren Windows-Dateien und Systemsteuerungsapplets kein Dialogfeld zur Rechteerhöhung angezeigt, selbst wenn sie Administratorrechte benötigen. Das
liegt an der automatischen Rechteerweiterung, die entwickelt wurde, damit Administratoren
bei ihrer Arbeit nicht ständig mit Dialogfeldern zur Rechteerhöhung konfrontiert werden. Die
entsprechenden Programme werden automatisch mit dem vollständigen Administratortoken
des Benutzers ausgeführt.
Für die automatische Rechteerweiterung gelten mehrere Voraussetzungen. Erstens muss
die fragliche ausführbare Datei eine Windows-Datei sein – das heißt, sie muss vom Herausgeber Windows signiert sein. (Also nicht einfach nur von Microsoft. Es mag merkwürdig erscheinen, aber diese beiden Herausgeber sind nicht identisch. Anwendungen mit Windows-Signatur gelten als privilegierter als solche mit Microsoft-Signatur.) Außerdem muss sie sich in
einem der als sicher eingestuften Verzeichnisse befinden: %SystemRoot%\System32 und die
meisten seiner Unterverzeichnisse, %Systemroot%\Ehome sowie einige wenige Verzeichnisse
unter %ProgramFiles% (etwa diejenigen mit Windows Defender und Windows Journal).
Je nach Art der ausführbaren Datei kann es noch weitere Voraussetzungen geben.
EXE-Dateien außer Mmc.exe erhalten eine automatische Rechteerweiterung, wenn dies mit
dem Element autoElevate in ihrem Manifest angefordert wird. Das können Sie auch in dem
Manifest von Eventvwr.exe aus dem vorherigen Abschnitt sehen.
Mmc.exe ist ein Sonderfall. Ob eine automatische Rechteerweiterung erfolgt oder nicht,
hängt davon ab, welches Snap-In es lädt. Gewöhnlich wird Mmc.exe an der Befehlszeile unter
Angabe einer MSC-Datei aufgerufen, die das zu ladende Snap-In angibt. Wird Mmc.exe unter einem geschützten Administratorkonto ausgeführt (also einem Konto mit eingeschränktem Administratortoken), fordert sie Administratorrechte an. Windows vergewissert sich, dass
es sich bei Mmc.exe um eine ausführbare Windows-Datei handelt, und schaut sich dann die
MSC-Datei an. Auch bei ihr muss es sich um eine ausführbare Windows-Datei handeln, und
darüber hinaus muss sie auf der internen Liste von MSCs mit automatischer Rechteerweiterung
stehen (was bei fast allen MSC-Dateien in Windows der Fall ist).
COM-Klassen (Out-of-Process-Server) fordern Administratorrechte mithilfe ihrer Registrierungsschlüssel an. Dazu ist der Unterschlüssel Elevation mit dem DWORD-Wert Enabled erforderlich, der auf 1 gesetzt sein muss. Sowohl die COM-Klasse als auch die ausführbare Datei,
die sie instanziiert, müssen die Anforderungen für ausführbare Windows-Dateien erfüllen. Es
ist jedoch nicht nötig, dass die ausführbare Datei selbst eine automatische Rechteerweiterung
anfordert.
852
Kapitel 7
Sicherheit
Das Verhalten der Benutzerkontensteuerung festlegen
Das Verhalten der Benutzerkontensteuerung lässt sich mit dem Dialogfeld aus Abb. 7–29 ändern, das unter Einstellungen der Benutzerkontensteuerung ändern zur Verfügung steht. In der
Abbildung sehen Sie die Standardeinstellungen.
Abbildung 7–29 Einstellungen zur Benutzerkontensteuerung
Die Bedeutungen der vier möglichen Einstellungen werden in Tabelle 7–18 beschrieben.
Von der dritten Einstellung ist abzuraten, da das Dialogfeld zur Rechteerhöhung dabei auf
dem normalen Desktop des Benutzers und nicht auf dem sicheren Desktop erscheint, sodass
Schadprogramme, die in derselben Sitzung ausgeführt werden, sein Aussehen ändern könnten. Diese Einstellung ist nur für Systeme gedacht, bei denen das Videoteilsystem sehr lange
braucht, um den Desktop abzudunkeln, oder auf denen die übliche Darstellung der Benutzerkontensteuerung aus anderen Gründen nicht geeignet ist.
Benutzerkontensteuerung und Virtualisierung
Kapitel 7
853
Reglerstellung
Ein Administrator, dessen Konto zurzeit nicht mit
Administratorrechten ausgeführt wird, versucht ...
Bemerkungen
... Windows-Einstellungen
zu ändern (z. B. bestimmte
Systemsteuerungs-Applets)
... Software zu installieren,
ein Programm zu starten,
dessen Manifest eine
Rechteerhöhung verlangt,
oder ein Programm
mit »Als Administrator
ausführen« zu starten
Höchste Stellung
(Immer benachrichtigen)
Das Dialogfeld der Benutzerkontensteuerung zur Rechte
erhöhung wird auf dem
sicheren Desktop angezeigt.
Das Dialogfeld der Benutzerkontensteuerung zur Rechte
erhöhung wird auf dem
sicheren Desktop angezeigt.
Dies war das
Verhalten von
Windows Vista.
Zweite Stellung
Die Rechte werden automatisch erhöht, ohne dass ein
Dialogfeld oder eine Benachrichtigung angezeigt wird.
Das Dialogfeld der Benutzerkontensteuerung zur Rechteerhöhung wird auf dem
sicheren Desktop angezeigt.
Standardeinstellung von
Windows
Dritte Stellung
Die Rechte werden automatisch erhöht, ohne dass ein
Dialogfeld oder eine Benachrichtigung angezeigt wird.
Das Dialogfeld der Benutzerkontensteuerung zur
Rechteerhöhung wird auf
dem normalen Desktop des
Benutzers angezeigt.
Nicht empfehlenswert
Unterste Stellung
(Nie benachrichtigen)
Die Benutzerkontensteuerung
ist für Administratoren ausgeschaltet.
Die Benutzerkontensteuerung
ist für Administratoren ausgeschaltet.
Nicht empfehlenswert
Tabelle 7–18 Einstellungen für die Benutzerkontensteuerung
Von der untersten Stellung wird dringend abgeraten, da die Benutzerkontensteuerung dabei für
Administratorkonten ganz abgeschaltet ist. Alle Prozesse, die ein Benutzer mit einem Adminis
tratorkonto ausführt, laufen mit den vollen Administratorrechten und nicht mit einem gefilterten
Administratortoken. Auch die Virtualisierung der Registrierung und des Dateisystems und der
geschützte Modus von Internet Explorer sind für die betreffenden Konten ausgeschaltet. Für
nicht administrative Konten dagegen ist die Virtualisierung nach wie vor in Kraft, und bei ihnen
wird auch ein OTS-Dialogfeld angezeigt, wenn die Benutzer versuchen, Windows-Einstellungen
zu ändern, ein Programm zu starten, das eine Rechteerweiterung benötigt, oder die Option Als
Administrator ausführen zu nutzen.
Die Einstellungen für die Benutzerkontensteuerung werden in vier Werten des Registrierungsschlüssels HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System gespeichert
(siehe Tabelle 7–19). ConsentPromptBehaviorAdmin steuert das Dialogfeld zur Rechteerhöhung für
Administratoren mit gefiltertem Administratortoken, ConsentPromptBehaviorUser das entsprechende Dialogfeld für Benutzer, die keine Administratoren sind.
Reglerstellung
Höchste Stellung
(Immer benachrichtigen)
854
Kapitel 7
ConsentPrompt
BehaviorAdmin
ConsentPrompt
BehaviorUser
2 (zeigt das
AAM-Dialogfeld
zur Rechteerweiterung an)
3 (zeigt das
OTS-Dialogfeld zur
Rechteerweiterung
an)
Sicherheit
EnableLua
PromptOnSecure
Desktop
1 (aktiviert)
1 (aktiviert)
→
ConsentPrompt
BehaviorAdmin
ConsentPrompt
BehaviorUser
EnableLua
PromptOnSecure
Desktop
Zweite Stellung
5 (zeigt das
AAM-Dialogfeld
zur Rechteerweiterung an, außer
bei Änderungen an
Windows-Einstellungen)
3
1
1
Dritte Stellung
5
3
1
0 (deaktiviert; das
Dialogfeld der Benutzerkontensteuerung erscheint
auf dem normalen
Desktop des Benutzers)
Unterste Stellung
(Nie benachrichtigen)
0
3
0 (deaktiviert;
bei Anmeldungen an Administratorkonten
wird kein eingeschränktes Administratortoken
erstellt)
0
Reglerstellung
Tabelle 7–19 Registrierungswerte für die Benutzerkontensteuerung
Schutz gegen Exploits
In diesem Kapitel haben Sie eine Reihe von Technologien gesehen, um die Benutzer zu schützen, das Signieren von ausführbarem Code durchzusetzen und den Zugriff auf Ressourcen
durch Sandboxes einzuschränken. Letzten Endes aber weisen alle Sicherheitssysteme Schwachstellen und alle Programme Bugs auf, während Angreifer immer anspruchsvollere Methoden
einsetzen, um sie auszunutzen. Ein Sicherheitsmodell, bei dem vorausgesetzt wird, dass der
Code vollständig fehlerfrei ist oder dass sämtliche Bugs gefunden und ausgemerzt werden
können, ist zum Scheitern verurteilt. Außerdem bieten viele Sicherheitsfunktionen »Garantien«
zur Codeausführung nur auf Kosten der Leistung oder Kompatibilität, was in manchen Situa
tionen nicht akzeptabel ist.
Ein erfolgversprechenderer Ansatz besteht darin, die gängigsten Techniken von Angreifern
zu ermitteln sowie mithilfe eines eigenen »Red Teams« (das die eigene Software anzugreifen
versucht) neue Techniken aufzuspüren, bevor Angreifer darauf kommen, und Abwehrmaßnahmen dagegen einzurichten. (Das können ganz einfache Abwehrmaßnahmen wie die Verschiebung einiger Daten, aber auch kompliziertere wie CFI-Techniken [Control Flow Integrity] sein.)
Da es in vielschichtigem Code wie etwa dem von Windows Tausende von Schwachstellen geben
kann, es aber nur eine begrenzte Menge von Angriffstechniken gibt, besteht das Ziel darin, die
Ausnutzung ganzer Klassen von Bugs zu erschweren (oder gar unmöglich zu machen), anstatt
zu versuchen, sämtliche Bugs zu finden.
Schutz gegen Exploits
Kapitel 7
855
Abwehrmaßnahmen auf Prozessebene
Anwendungen können eigene Abwehrmaßnahmen gegen Exploits durchführen. So verwendet
beispielsweise Microsoft Edge MemGC als Schutz gegen viele Arten von Speicherbeschädigungsangriffen. In diesem Abschnitt wollen wir uns aber mit den Abwehrmaßnahmen beschäftigen, die das Betriebssystem für alle Anwendungen oder für sich selbst einsetzt. Tabelle 7–20
führt alle Abwehrmaßnahmen der neuesten Version von Windows 10 Creators Update auf und
gibt dabei jeweils die Art der Bugs an, gegen deren Ausnutzung sie schützen, und den Mechanismus zu ihrer Aktivierung.
Maßnahme
Zweck
Aktivierung
ASLR Bottom Up
Randomization
Unterwirft Aufrufe von VirtualAlloc
einer ASLR mit 8-Bit-Entropie einschließlich Stackbasisrandomisierung.
Wird mit dem Prozesserstellungs-
Attributflag PROCESS_CREATION_MITIGATION_POLICY_BOTTOM_UP_ASLR_ALWAYS_ON
eingerichtet.
ASLR Force Relocate Images
Erzwingt ASLR selbst für Binärdateien
ohne das Linkerflag /DYNAMICBASE.
Wird mit dem Prozesserstellungsflag
PROCESS_CREATION_MITIGATION_POLICY_
FORCE_RELOCATE_IMAGES_ALWAYS_ON
eingerichtet.
High Entropy
ASLR (HEASLR)
Sorgt für eine erhebliche Erhöhung der
ASLR-Entropie für 64-Bit-Abbilder. Die
Varianz der Bottom-Up-Randomisierung wird auf bis zu 1 TB heraufgesetzt
(d. h., Bottom-Up-Zuweisungen können irgendwo zwischen 64 KB und 1 TB
im Adressraum beginnen, was eine
Entropie von 24 Bit ergibt).
Muss zur Verlinkungszeit mit
/HIGHENTROPYVA oder mit dem Prozesserstellungs-Attributflag PROCESS_
CREATION_MITIGATION_POLICY_HIGH_
ENTROPY_ASLR_ALWAYS_ON eingerichtet
werden.
ASLR Disallow
Stripped Images
Verhindert in Kombination mit ASLR
Force Relocate Images das Laden jeglicher Bibliotheken ohne Relokalisierung
(verlinkt mit dem Flag /FIXED)
Wird mit SetProcessMitigationPolicy
oder mit dem Prozesserstellungsflag
PROCESS_CREATION_MITIGATION_POLICY_
FORCE_RELOCATE_IMAGES_ALWAYS_ON_REQ_
RELOCS eingerichtet.
DEP: Permanent
Verhindert, dass ein Prozess die Datenausführungsverhinderung (DEP)
für sich selbst ausschaltet. Betrifft nur
32-Bit-Anwendungen (auch WoW64).
Wird mit dem Prozesserstellungsattribut
SetProcessMitigationPolicy oder mit
SetProcessDEPPolicy eingerichtet.
DEP: Disable ATL
Thunk Emulation
Verhindert, dass veralteter ATL-Bibliothekscode ATL-Thunks auf dem Heap
ausführt, selbst wenn ein bekanntes
Kompatibilitätsproblem vorliegt. Betrifft nur 32-Bit-Anwendungen (auch
WoW64).
Wird mit dem Prozesserstellungsattribut
SetProcessMitigationPolicy oder mit
SetProcessDEPPolicy eingerichtet.
SEH Overwrite
Protection
(SEHOP)
Verhindert, das Strukturausnahmehandler durch falsche Versionen überschrieben werden, selbst wenn die Verlinkung nicht mit Safe SEH (/SAFESEH)
erfolgte. Betrifft nur 32-Bit-Anwendungen (auch WoW64).
Kann mit SetProcessDEPPolicy oder mit
dem Prozesserstellungsflag PROCESS_
CREATION_MITIGATION_POLICY_SEHOP_
ENABLE eingerichtet werden.
856
Kapitel 7
Sicherheit
→
Maßnahme
Zweck
Aktivierung
Raise Excep
tion on Invalid
Handle
Hilft dabei, Angriffe durch Handlewiederverwendung (Nutzung eines Han
dles nach dem Schließen) zu erkennen,
bei denen ein Prozess ein Handle verwendet, das nicht mehr das erwartete
ist (z. B. SetEvent für ein Mutex). Dazu
wird der Prozess zum Absturz gebracht,
anstatt einfach einen Fehler zurückzugeben, den der Prozess auch ignorieren
kann.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
STRICT_HANDLE_CHECKS_ALWAYS_ON eingerichtet.
Raise Exception
on Invalid Han
dle Close
Hilft dabei, Angriffe durch Handlewiederverwendung (zweifaches Schließen
eines Handles) zu erkennen, bei denen
ein Prozess ein Handle zu schließen
versucht, das bereits geschlossen war.
Bei dieser Maßnahme wird angeregt,
ein anderes Handle zu verwenden, das
die allgemeine Wirksamkeit dieses Exploits einschränkt.
Nicht dokumentiert; kann auch nur
mithilfe einer nicht dokumentierten API
eingerichtet werden.
Disallow Win32k
System Calls
Deaktiviert den gesamten Zugriff auf
den Kernelmodus-Teilsystemtreiber
Win32, der den Fenster-Manager
(GUI), Graphics Device Interface (GDI)
und DirectX implementiert. Für diese
Komponente sind keine Systemaufrufe
mehr möglich.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
WIN32K_SYSTEM_CALL_DISABLE_ALWAYS_ON
eingerichtet.
Filter Win32k
System Calls
Schränkt den Zugriff auf den Kernelmodus-Teilsystemtreiber Win32k auf
bestimmte APIs ein, sodass nur noch
ein einfacher GUI- und DirectX-Zugriff
möglich ist. Dies schützt gegen viele
mögliche Angriffe, ohne die Verfügbarkeit der GUI/GDI-Dienste vollständig
aufzuheben.
Wird durch ein internes Prozesserstellungs-Attributflag eingerichtet, mit dem
einer von drei möglichen Filtersätzen für
Win32k aktiviert wird. Da die Filtersätze
hartcodiert sind, ist diese Abwehrmaßnahme für den internen Gebrauch durch
Microsoft reserviert.
Disable Exten
sion Points
Hindert Prozesse daran, einen Eingabemethoden-Editor (IME), eine WindowsHook-DLL (SetWindowsHookEx), eine
DLL zur Anwendungsinitialisierung
(Registrierungswert AppInitDlls) oder
einen geschichteten Winsock-Dienstanbieter (LSP) zu laden.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
EXTENSION_POINT_DISABLE_ALWAYS_ON
eingerichtet.
Arbitrary Code
Guard (CFG)
Hindert Prozesse daran, ausführbaren
Code zuzuweisen oder die Berechtigungen von bereits vorhandenem
ausführbarem Code zu ändern, um
ihn schreibbar zu machen. Diese Maßnahme kann so konfiguriert werden,
dass ein bestimmter Thread in einem
Prozess die entsprechende Fähigkeit
anfordern oder ein Remoteprozess
die Maßnahme abschalten kann. Aus
Sicherheitsgründen sind letztere Möglichkeiten jedoch nicht empfehlenswert.
Wird mit SetProcessMitigationPolicy
oder den Prozesserstellungs-Attributflags
PROCESS_CREATION_MITIGATION_POLICY_
PROHIBIT_DYNAMIC_CODE_ALWAYS_ON und
PROCESS_CREATION_MITIGATION_POLICY_
PROHIBIT_DYNAMIC_CODE_ALWAYS_ON_
ALLOW_OPT_OUT eingerichtet.
Schutz gegen Exploits
→
Kapitel 7
857
Maßnahme
Zweck
Aktivierung
Control Flow
Guard (CFG)
Hilft zu verhindern, dass Schwachstellen im Speicher ausgenutzt werden,
um den Steuerungsfluss zu kapern.
Dazu wird das Ziel aller indirekten
CALL- und JMP-Anweisungen mit einer
Liste gültiger, erwarteter Zielfunktionen
verglichen. Diese Maßnahme gehört
zum CFI-Mechanismus (Control Flow
Integrity), der im nächsten Abschnitt
beschrieben wird.
Das Abbild muss mit der Option /
guard:cf kompiliert und verlinkt werden.
Wenn das bei dem Abbild nicht möglich
ist, kann diese Schutzmaßnahme auch
mit dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
CONTROL_FLOW_GUARD_ALWAYS_ON eingerichtet werden. Die Durchsetzung von
CFG ist jedoch nach wie vor für andere
Abbilder wünschenswert, die in den Prozess geladen werden.
CFG Export Suppression
Verstärkt CFG, indem indirekte Aufrufe
der exportierten API-Tabelle des Abbilds unterdrückt werden.
Das Abbild muss mit /guard:
exportsuppress kompiliert werden.
Die Maßnahme kann aber auch durch
SetProcessMitigationPolicy oder
durch das Prozesserstellungs-Attributflag PROCESS_CREATION_MITIGATION_
POLICY_CONTROL_FLOW_GUARD_EXPORT_
SUPPRESSION eingerichtet werden.
CFG Strict Mode
Verhindert, dass im aktuellen Prozess
Abbildbibliotheken geladen werden,
die nicht mit der Option /guard:cf
verlinkt wurden.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY2_
STRICT_CONTROL_FLOW_GUARD_ALWAYS_ON
eingerichtet.
Disable Non System Fonts
Verhindert das Laden von Schriftartdateien, die nach der Installation im
Verzeichnis C:\Windows\Fonts nicht bei
der Anmeldung des Benutzers durch
Winlogon registriert wurden.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
FONT_DISABLE_ALWAYS_ON eingerichtet.
Microsoft-
Signed Binaries
Only
Verhindert, dass im aktuellen Prozess
Abbildbibliotheken geladen werden,
die kein von einer Microsoft-Zertifizierungsstelle signiertes Zertifikat haben.
Wird beim Start mit dem Prozessattributflag PROCESS_CREATION_MITIGATION_
POLICY_BLOCK_NON_MICROSOFT_BINARIES_
ALWAYS_ON festgelegt.
Store-Signed
Binaries Only
Verhindert, dass im aktuellen Prozess
Abbildbibliotheken geladen werden,
die nicht von der Zertifizierungsstelle
des Microsoft Stores signiert sind.
Wird beim Start mit dem Prozessattributflag PROCESS_CREATION_MITIGATION_
POLICY_BLOCK_NON_MICROSOFT_BINARIES_
ALLOW_STORE festgelegt.
No Remote
Images
Verhindert, dass im aktuellen Prozess
Abbildbibliotheken geladen werden,
die einen nicht lokalen Pfad (UNC oder
WebDAV) aufweisen.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
IMAGE_LOAD_NO_REMOTE_ALWAYS_ON eingerichtet.
No Low IL
Images
Verhindert, dass im aktuellen Prozess
Abbildbibliotheken geladen werden,
deren verbindliche Beschriftung nicht
mindestens Medium (0x2000) ist.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
IMAGE_LOAD_NO_LOW_LABEL_ALWAYS_ON
eingerichtet. Kann auch mit dem Ressourcenanspruch IMAGELOAD des Zugriffssteuerungseintrags für die Datei des zu
ladenden Prozesses festgelegt werden.
→
858
Kapitel 7
Sicherheit
Maßnahme
Zweck
Aktivierung
Prefer System32
Images
Ändern des Suchpfads des Loaders,
sodass er unabhängig vom aktuellen
Suchpfad immer in %SystemRoot%\
System32 nach der (durch einen relativen Namen angegebenen) zu ladenden
Abbildbibliothek sucht.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY_
IMAGE_LOAD_PREFER_SYSTEM32_ALWAYS_ON
eingerichtet.
Return Flow
Guard (RFG)
Hilft, weitere Arten von Speicherschwachstellen zu verhindern, die sich
auf den Steuerungsfluss auswirken
können. Dazu wird vor der Ausführung einer RET-Anweisung geprüft, ob
die Funktion von einem ROP-Exploit
(Return-Oriented Programming) aufgerufen wurde, was daran zu erkennen
ist, dass die Ausführung nicht korrekt
begonnen wurde oder dass sie auf einem ungültigen Stack ausgeführt wird.
Diese Maßnahme ist Teil des CFI-Mechanismus (Control Flow Integrity).
Diese Abwehrmaßnahme ist zurzeit noch
nicht verfügbar, da noch an einer stabilen Implementierung gearbeitet wird,
die die Leistung nicht beeinträchtigt. Sie
ist hier der Vollständigkeit halber angegeben.
Restrict Set
Thread Context
Schränkt Änderungen am Kontext des
aktuellen Threads ein.
Zurzeit deaktiviert, bis RFG verfügbar
ist, das diese Abwehrmaßnahme stabiler
machen wird. Diese Maßnahme kann in
zukünftigen Windows-Versionen enthalten sein. Sie ist hier der Vollständigkeit
halber angegeben.
Loader Continuity
Verhindert, dass ein Prozess DLLs dynamisch lädt, die nicht dieselbe Integritätsebene wie der Prozess selbst haben.
Dies wird in Fällen verwendet, in denen
die zuvor genannte Signierrichtlinie
aufgrund von Kompatibilitätsproblemen beim Start nicht aktiviert werden
kann. Diese Maßnahme dient gezielt
zur Abwehr von DLL-Planting-Angriffen.
Wird mit SetProcessMitigationPolicy
oder dem Prozesserstellungs-Attributflag
PROCESS_CREATION_MITIGATION_POLICY2_
LOADER_INTEGRITY_CONTINUITY_ALWAYS_
ON eingerichtet.
Heap Terminate
On Corruption
Deaktiviert den fehlertoleranten Heap
(FTH), sodass bei einer Heapbeschädigung keine Ausnahme ausgelöst wird,
die ein Fortfahren erlaubt, sondern der
Prozess beendet wird. Dadurch wird
verhindert, dass ein Angreifer eine
Heapbeschädigung ausnutzt, um einen
von ihm selbst kontrollierten Ausnahmehandler auszuführen. Dies gilt auch
in Fällen, in denen das Programm die
Heapausnahme ignoriert oder in denen
der Exploit nur manchmal eine Heap
beschädigung verursacht. Dadurch
wird die allgemeine Effektivität und Zu
verlässigkeit des Exploits beschränkt.
Wird mit HeapSetInformation oder dem
Prozesserstellungs-Attributflag PROCESS_
CREATION_MITIGATION_POLICY_HEAP_
TERMINATE_ALWAYS_ON eingerichtet.
Schutz gegen Exploits
→
Kapitel 7
859
Maßnahme
Zweck
Aktivierung
Disable Child
Process Creation
Verhindert das Erstellen von Kindprozessen, indem das Token mit einer
besonderen Einschränkung gekennzeichnet wird, die alle anderen Komponenten davon abhält, einen Prozess anzulegen, während sie die Identität des
Tokens für diesen Prozess annehmen
(z. B. die Prozesserstellung durch WMI
oder eine Kernelkomponente).
Wird mit dem Prozesserstellungs-Attri
butflag PROCESS_CREATION_CHILD_
PROCESS_RESTRICTED eingerichtet und
kann mit PROCESS_CREATION_DESKTOP_
APPX_OVERRIDE überschrieben werden,
um Paketanwendungen (UWP-Anwendungen) zuzulassen.
All Application
Packages Policy
Verhindert, dass eine Anwendung in
einem Anwendungscontainer auf Ressourcen mit der SID ALL APPLICATION
PACKAGES zugreift (siehe den Abschnitt
»Anwendungscontainer« weiter vorn
in diesem Kapitel). Stattdessen muss
die SID ALL RESTRICTED APPLICATION
PACKAGES vorhanden sein. Manchmal
wird diese Maßnahme auch als Less
Privileged App Container (LPAC) bezeichnet.
Wird mit dem Prozesserstellungs-Attributflag PROC_THREAD_ATTRIBUTE_ALL_
APPLICATION_PACKAGES_POLICY eingerichtet.
Tabelle 7–20 Abwehrmaßnahmen auf Prozessebene
Es ist auch möglich, einige dieser Maßnahmen ohne Mitwirkung des Entwicklers anwendungsoder systemweit zu aktivieren. Öffnen Sie dazu den lokalen Gruppenrichtlinien-Editor und
erweitern Sie wie in Abb. 7–30 gezeigt Computerkonfiguration > Administrative Vorlagen >
System > Ausgleichsoptionen (womit die Optionen für die in diesem Abschnitt beschriebenen
Abwehrmaßnahmen gemeint sind, die in der englischen Oberfläche als »mitigations« bezeichnet werden). Geben Sie im Dialogfeld Optionen für den Prozessausgleich den passenden Bitwert
für die zu aktivierenden Abwehrmaßnahmen ein, wobei die einzelnen Maßnahmen mit einer
1 aktiviert und mit einer 0 deaktiviert werden. Bei Eingabe von ? wird die Standardeinstellung
oder der vom Prozess angeforderte Wert verwendet (siehe Abb. 7–30). Die Bitzahlen sind der
Auflistung PROCESS_MITIGATION_POLICY in der Headerdatei Winnt.h entnommen. Die Eingaben
führen dazu, dass der entsprechende Registrierungswert in den IFEO-Schlüssel (Image File Extension Options) für den eingegebenen Abbildnamen geschrieben wird. In der aktuellen Version von Windows 10 Creators Update und den früheren Versionen werden dabei leider viele der
neueren Abwehrmaßnahmen entfernt. Um das zu verhindern, setzen Sie in der Registrierung
den DWORD-Wert MitigrationOptions.
860
Kapitel 7
Sicherheit
Abbildung 7–30 Einstellen der Optionen für Abwehrmaßnahmen auf Prozessebene
Control Flow Integrity
Die Datenausführungsverhinderung (Data Execution Prevention, DEP) und Arbitrary Code
Guard (ACG) machen es für Exploits schwerer, ausführbaren Code auf den Heap oder Stack zu
legen, neuen ausführbaren Code zuzuweisen oder vorhandenen ausführbaren Code zu ändern.
Daher sind für Angreifer reine Speicher/Daten-Techniken interessanter geworden. Dabei werden Teile des Arbeitsspeichers manipuliert, etwa die Rücksprungadresse auf dem Stack oder
indirekte Funktionszeiger im Speicher, um den Steuerungsfluss umzuleiten. Häufig werden
Techniken wie ROP und JOP (Return- bzw. Jump-Oriented Programming) eingesetzt, um in den
normalen Steuerungsfluss des Programms einzugreifen und ihn zu bekannten Speicherorten
von besonderen Codeteilen (»Gadgets«) umzuleiten, die für den Angreifer nutzbar sind.
Da sich solche Codeausschnitte in der Mitte oder am Ende verschiedener Funktionen befinden, erfolgt die Codeumleitung in die Mitte oder an das Ende legitimer Funktionen. Mithilfe
von CGI-Techniken (Control Flow Integrity) können das Betriebssystem und der Compiler die
meisten Arten solcher Exploits erkennen und verhindern. Dabei wird beispielsweise überprüft,
ob das Ziel einer indirekten JMP- oder CALL-Anweisung der Beginn einer echten Funktion ist, ob
eine RET-Anweisung auf einen erwarteten Speicherort zeigt oder ob sie nach dem Eintritt in die
Funktion ausgegeben wurde.
Schutz gegen Exploits
Kapitel 7
861
Ablaufsteuerungsschutz
Der Ablaufsteuerungsschutz (Control Flow Guard, CFG) ist ein Schutzmechanismus gegen
Exploits, der mit Windows 8.1 Update 3 eingeführt wurde und in erweiterter Form auch in
Windows 10 und Windows Server 2016 vorhanden ist, wobei im Verlaufe der Updates weitere Verbesserungen hinzugekommen sind (einschließlich des letzten Creators Updates). Er
war ursprünglich nur für Benutzermoduscode gedacht, doch mit dem Creators Update kam
auch Kernel CFG (KCFG) hinzu. Diese Einrichtung prüft, ob das Ziel eines indirekten CALL- oder
JMP-Aufrufs der Beginn einer bekannten Funktion ist (was das genau bedeutet, erfahren Sie in
Kürze). Ist das nicht der Fall, wird der Prozess einfach beendet. Abb. 7–31 zeigt einen Überblick
über die Funktionsweise von CFG.
Vor einem
indirekten Aufruf
Vom Compiler
generierter Code
Betriebssystemcode
Zieladresse speichern
Validierungsfunktion
aufrufen
Ist das Ziel gültig?
N
Prozess
beenden
J
Aufruf
durchführen
Ausführung
fortsetzen
Abbildung 7–31 Funktionsprinzip des Ablaufsteuerungsschutzes
Für CFG ist die Mitarbeit eines kompatiblen Compilers erforderlich, der vor indirekten Änderungen am Steuerungsfluss einen Aufruf des Validierungscodes hinzufügt. Der Visual C++-Compiler verfügt über die Option /guard:cf, die für Abbilder (oder sogar C/C++-Quelldateien)
gesetzt werden muss, um das Programm mit CFG-Unterstützung zu erstellen. (Diese Option
steht auch in der grafischen Benutzeroberfläche von Visual Studio in der Einstellung C/C++
> Codegenerierung > Ablaufsteuerungsschutz der Projekteigenschaften zur Verfügung.) Dies
muss auch in den Linkereinstellungen festgelegt werden, da zur Unterstützung von CFG beide
Komponenten von Visual Studio zusammenwirken müssen.
EXE- und DLL-Dateien, die mit CFG-Unterstützung kompiliert wurden, zeigen dies im
PE-Header an. Außerdem enthalten sie eine Liste der Funktionen, die gültige Ziele für indirekte
Aufrufe sind. Diese Liste befindet sich im PE-Abschnitt .gfids, der vom Linker normalerweise mit
dem Abschnitt .rdata verschmolzen wird. Sie wird vom Linker erstellt und enthält die relativen
virtuellen Adressen (RVA) aller Funktionen in dem Abbild. Dazu gehören auch solche, die von
dem Code in dem Abbild nicht indirekt aufgerufen werden, da es schließlich keine Möglich-
862
Kapitel 7
Sicherheit
keit gibt, um zu bestimmen, ob externer Code auf legitime Weise die Adresse einer Funktion
herausfinden und versuchen kann, sie aufzurufen. Das gilt insbesondere für exportierte Funktionen, die von Code aufgerufen werden können, nachdem er ihren Zeiger mit GetProcAddress
ermittelt hat.
Allerdings können Programmierer die Technik der sogenannten CFG-Unterdrückung anwenden, die über die Anmerkung DECLSPEC_GUARD_SUPRESS zur Verfügung steht. Sie kennzeichnet eine Funktion der Tabelle der gültigen Funktionen mit einem besonderen Flag, um anzuzeigen, dass der Programmierer es für ausgeschlossen hält, dass die Funktion jemals das Ziel eines
indirekten Aufrufs oder Sprungs wird.
Eine einfache Validierungsfunktion muss nun nur noch das Teil einer CALL- oder JMP-Anweisung mit den Einträgen in der Tabelle gültiger Zielfunktionen vergleichen. Dazu ist ein Algorithmus der Ordnung O(n) erforderlich, bei dem die Anzahl der zu überprüfenden Funktionen
im schlimmsten Fall gleich der Anzahl der Funktionen in der Tabelle ist. Die lineare Durchsuchung eines Arrays bei jeder einzelnen indirekten Änderung des Steuerungsflusses würde das
Programm natürlich in die Knie zwingen. Daher ist eine Unterstützung durch das Betriebssystem erforderlich, um die CFG-Prüfung effizient durchzuführen. Wie Windows das erreicht,
sehen wir uns im nächsten Abschnitt an.
Experiment: Informationen über den Ablaufsteuerungsschutz
Mit dem Visual Studio-Tool DumpBin können Sie sich einige grundlegende Informationen
über den Ablaufsteuerungsschutz anzeigen lassen. Im Folgenden sehen Sie, wie Sie die
Angaben über die Header und die Laderkonfiguration für Smss ausgeben:
c:\> dumpbin /headers /loadconfig c:\windows\system32\smss.exe
Microsoft (R) COFF/PE Dumper Version 14.00.24215.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\windows\system32\smss.exe
PE signature found
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
8664 machine (x64)
6 number of sections
57899A7D time date stamp Sat Jul 16 05:22:53 2016
0 file pointer to symbol table
0 number of symbols
F0 size of optional header
22 characteristics
Executable
Application can handle large (>2GB) addresses
→
Schutz gegen Exploits
Kapitel 7
863
OPTIONAL HEADER VALUES
20B magic # (PE32+)
14.00 linker version
12800 size of code
EC00 size of initialized data
0 size of uninitialized data
1080 entry point (0000000140001080) NtProcessStartupW
1000 base of code
140000000 image base (0000000140000000 to 0000000140024FFF)
1000 section alignment
200 file alignment
10.00 operating system version
10.00 image version
10.00 subsystem version
0 Win32 version
25000 size of image
400 size of headers
270FD checksum
1 subsystem (Native)
4160 DLL characteristics
High Entropy Virtual Addresses
Dynamic base
NX compatible
Control Flow Guard
...
Section contains the following load config:
000000D0 size
0 time date stamp
0.00 Version
0 GlobalFlags Clear
0 GlobalFlags Set
0 Critical Section Default Timeout
0 Decommit Free Block Threshold
0 Decommit Total Free Threshold
0000000000000000 Lock Prefix Table
0 Maximum Allocation Size
0 Virtual Memory Threshold
0 Process Heap Flags
0 Process Affinity Mask
0 CSD Version
0800 Dependent Load Flag
→
864
Kapitel 7
Sicherheit
0000000000000000 Edit List
0000000140020660 Security Cookie
00000001400151C0 Guard CF address of check-function pointer
00000001400151C8 Guard CF address of dispatch-function pointer
00000001400151D0 Guard CF function table
2A Guard CF function count
00010500 Guard Flags
CF Instrumented
FID table present
Long jump target table present
0000 Code Integrity Flags
0000 Code Integrity Catalog
00000000 Code Integrity Catalog Offset
00000000 Code Integrity Reserved
0000000000000000 Guard CF address taken IAT entry table
0 Guard CF address taken IAT entry count
0000000000000000 Guard CF long jump target table
0 Guard CF long jump target count
0000000000000000 Dynamic value relocation table
Guard CF Function Table
Address
-------0000000140001010 _TlgEnableCallback
0000000140001070 SmpSessionComplete
0000000140001080 NtProcessStartupW
0000000140001B30 SmscpLoadSubSystemsForMuSession
0000000140001D10 SmscpExecuteInitialCommand
0000000140002FB0 SmpExecPgm
0000000140003620 SmpStartCsr
00000001400039F0 SmpApiCallback
0000000140004E90 SmpStopCsr
...
Informationen im Zusammenhang mit dem Ablaufsteuerungsschutz sind in der vorstehenden Ausgabe fett markiert und werden in Kürze ausführlicher erläutert. Öffnen Sie zunächst
aber Process Explorer, rechtsklicken Sie auf den Kopf der Spalte Process und wählen Sie
Select Columns. Aktivieren Sie dann auf der Registerkarte Process Image das Kontrollkästchen Control Flow Guard und auf der Registerkarte Process Memory das Kontrollkästchen
Virtual Size. Daraufhin erhalten Sie eine Anzeige wie die folgende:
→
Schutz gegen Exploits
Kapitel 7
865
Wie Sie sehen, wurden die meisten von Microsoft gelieferten Prozesse mit CFG erstellt
(darunter Smss, Csrss, Audiodg, Notepad usw.). Die virtuelle Größe dieser CFG-Prozesse ist
erstaunlich hoch. Denken Sie aber daran, dass die virtuelle Größe den gesamten in dem
Prozess verwendeten Adressraum angibt, unabhängig davon, ob der Speicher zugesichert
oder reserviert ist. Dagegen zeigt die Spalte Private Bytes den privaten zugesicherten Speicher, dessen Umfang nicht einmal in die Nähe der virtuellen Größe kommt (obwohl die
virtuelle Größe auch den nicht privaten Speicher einschließt). Für 64-Bit-Prozesse beträgt
die virtuelle Größe mindestens 2 TB. Den Grund dafür werden Sie in Kürze kennenlernen.
Die CFG-Bitmap
Wie Sie bereits gesehen haben, wäre es nicht praktikabel, das Programm alle paar Anweisungen dazu zu zwingen, eine Liste von Funktionsaufrufen zu durchsuchen. Aus Leistungsgründen
muss statt eines linearen O(n)-Algorithmus ein Algorithmus der Ordnung O(1) verwendet werden, also einer, bei dem das Nachschlagen unabhängig von der Anzahl der Funktionen in der
Tabelle immer gleich lang dauert. Dabei sollte die Nachschlagezeit so kurz wie möglich sein.
Ein guter Kandidat dafür wäre ein Array, das nach den Adressen der Zielfunktionen indiziert
wird und einfach angibt, ob die einzelnen Adressen gültig sind oder nicht (z. B. ein einfacher
BOOL-Typ). Bei 128 TB an möglichen Adressen wäre ein solches Array jedoch selbst 128 TB *
sizeof(BOOL) groß, was für eine Speicherung nicht akzeptabel ist – denn das wäre größer als
der Adressraum! Gibt es eine bessere Möglichkeit?
Zunächst einmal können wir die Tatsache ausnutzen, dass Compiler x64-Funktionscode
in 16-Byte-Grenzen erstellen müssen. Das verringert die Größe des erforderlichen Arrays auf
nur noch 8 TB * sizeof(BOOL). Aber einen kompletten BOOL-Typ zu verwenden (der schlimmstenfalls vier Bytes und bestenfalls ein Byte umfasst), stellt eine ziemliche Verschwendung dar.
Schließlich brauchen wir nur einen Status – gültig oder ungültig –, der nur ein Bit belegt. Da-
866
Kapitel 7
Sicherheit
durch erhalten wir 8 TB/8, also einfach 1 TB. Doch leider gibt es bei der Sache einen Haken: Es
gibt keine Garantie dafür, dass der Compiler alle Funktionen an 16-Byte-Grenzen ausrichtet.
Handgemachter Assemblycode und einzelne Optimierungen können diese Regel verletzen.
Daher müssen wir eine Lösung finden. Eine Möglichkeit besteht darin, einfach ein anderes Bit
zu verwenden, um anzuzeigen, dass die Funktion irgendwo in den nächsten 15 Bytes beginnt
und nicht unmittelbar an der 16-Byte-Grenze. Dabei haben wir die folgenden Möglichkeiten:
QQ {0, 0}
Keine gültige Funktion beginnt innerhalb dieser 16-Byte-Grenze.
QQ {1, 0}
Gültige Funktionen beginnen genau an der 16-Byte-Grenze.
QQ {1, 1}
Gültige Funktionen beginnen irgendwo innerhalb einer 16-Byte-Adresse.
Wenn ein Angreifer versucht, einen Aufruf innerhalb einer Funktion vorzunehmen, die vom Linker als 16-Byte-ausgerichtet gekennzeichnet wurde, ergibt sich der 2-Bit-Status {1, 0}, doch da
die Adresse nicht an den 16-Byte-Grenzen ausgerichtet ist, sind die erforderlichen Bits (die Bits
3 und 4) in der Adresse {1, 1}. Daher kann ein Angreifer nur dann eine willkürliche Anweisung
in den ersten 16 Bytes der Funktion aufrufen, wenn der Linker die Funktion nicht als ausgerichtet erstellt hat (wobei die Bits wie gezeigt {1, 1} wären. Aber selbst in diesem Fall muss die
Anweisung auch noch für den Angreifer von Nutzen sein, ohne die Funktion zum Absturz zu
bringen (gewöhnlich eine Art von Stackpivot oder Gadget, das mit einer ret-Anweisung endet).
Damit können wir nun die folgenden Formeln anwenden, um die Größe der CFG-Bitmap
zu berechnen:
QQ 32-Bit-Anwendung auf x86 oder x64
2 GB / 16 * 2 = 32 MB
QQ 32-Bit-Anwendung mit /LARGEADDRESSAWARE, gestartet im 3-GB-Modus auf
x86 3 GB / 16 * 2 = 48 MB
QQ 64-Bit-Anwendung
128 TB / 16 * 2 = 2 TB
QQ 32-Bit-Anwendung mit /LARGEADDRESSAWARE auf x64 4 GB / 16 * 2 = 64 MB zzgl.
der Größe der 64-Bit-Bitmap, die zum Schutz von 64-Bit-Ntdll.dll- und WoW64-Komponenten benötigt wird, also 2 TB + 64 MB
Es ist jedoch immer noch eine ziemliche Leistungsbremse, bei der Ausführung jedes einzelnen
Prozesses 2 TB zuzuweisen und auszufüllen. Wir haben die Kosten für indirekte Aufrufe zwar
fixiert, aber es ist nicht akzeptabel, dass der Start eines Prozesses so lange dauert. Außerdem
würden 2 TB an zugesichertem Speicher sehr schnell an den Zusicherungsgrenzwert stoßen.
Daher werden noch zwei Tricks angewendet, um Speicher zu sparen und die Leistung zu steigern.
Erstens reserviert der Speicher-Manager nur die Bitmap, wobei er davon ausgeht, dass die
CFG-Validierungsfunktion eine Ausnahme beim Zugriff auf die Bitmap als ein Zeichen für den
Bitstatus {0, 0} deutet. Wenn eine Region 4 KB an Bitstatus enthält, die alle {0, 0} sind, kann
sie reserviert belassen werden. Nur Seiten, auf denen mindestens ein Bit auf {1, X} gesetzt ist,
müssen zugesichert werden.
Wie im Abschnitt über ASLR in Kapitel 5 beschrieben, führt das System die Randomisierung und Relokalisierung von Bibliotheken gewöhnlich nur beim Start durch, um sich wiederholte Relokalisierungen zu ersparen und damit die Leistung zu steigern. Wenn eine Bibliothek,
die ASLR unterstützt, einmal an einer gegebenen Adresse geladen wurde, wird sie daher stets
Schutz gegen Exploits
Kapitel 7
867
an dieser Adresse geladen. Das bedeutet auch, dass die einmal berechneten Bitmapstatus für
die Funktionen in dieser Bibliothek in allen anderen Prozessen, die dieselbe Binärdatei laden,
identisch sind. Daher behandelt der Speicher-Manager die CFG-Bitmap als eine auslagerungsgepufferte, gemeinsam nutzbare Speicherregion, wobei die physischen Seiten, die den gemeinsam genutzten Bits entsprechen, nur einmal im RAM vorhanden sind.
Das verringert den Umfang der zugesicherten Seiten im RAM. Nur Bits, die zu privatem
Speicher gehören, müssen berechnet werden. In regulären Anwendungen ist privater Speicher
normalerweise nicht ausführbar, sondern nur beim »Kopieren beim Schreiben«, wenn jemand
eine Bibliothek gepatcht hat (was jedoch beim Laden von Abbildern nicht passiert). Daher sind
die Kosten beim Laden einer Anwendung, die die gleichen Bibliotheken verwendet wie bereits
gestartete Anwendungen, fast null. Das folgende Experiment veranschaulicht dies.
Experiment: CFG-Bitmap
Öffnen Sie VMMap und markieren Sie einen Notepad-Prozess. Im Abschnitt Sharable sollte
jetzt ein großer reservierter Block angezeigt werden:
Wenn Sie den unteren Bereich der Größe nach sortieren, können Sie sehr schnell den großen Bereich für die CFG-Bitmap finden (siehe Abbildung). Sie können sich auch mit WinDbg
in den Prozess einklinken und den Befehl !address eingeben, um sich die CFG-Bitmap anzeigen zu lassen:
7df5'ff530000 7df6'0118a000 0'01c5a000 MEM_MAPPED MEM_RESERVE
Other [CFG Bitmap]
→
868
Kapitel 7
Sicherheit
7df6'0118a000 7df6'011fb000 0'00071000 MEM_MAPPED MEM_COMMIT PAGE_NOACCESS
Other [CFG Bitmap]
7df6'011fb000 7ff5'df530000 1ff'de335000 MEM_MAPPED MEM_RESERVE
Other [CFG Bitmap]
7ff5'df530000 7ff5'df532000 0'00002000 MEM_MAPPED MEM_COMMIT PAGE_READONLY
Other [CFG Bitmap]
Zwischen den MEM_COMMIT-Regionen, bei denen mindestens ein gültiger Bitstatus gesetzt
sein muss ({1, X}), stehen umfangreiche Regionen, die als MEM_RESERVE gekennzeichnet
sein. Alle (oder zumindest fast alle) Regionen sind im Speicher zugeordnet (MEM_MAPPED), da
sie zu der gemeinsam genutzten Bitmap gehören.
Aufbau der CFG-Bitmap
Bei der Initialisierung des Systems wird die Funktion MiInitializeCfg aufgerufen, um die
CFG-Unterstützung zu initialisieren. Sie erstellt ein oder zwei Abschnittsobjekte (MmCreateSection)
als reservierten Arbeitsspeicher mit der für die jeweilige Plattform geeigneten Größe (siehe die
Berechnung weiter vorn). Auf 32-Bit-Plattformen reicht eine Bitmap aus, doch auf x64 sind zwei
erforderlich, nämlich eine für 64-Bit- und die andere für WoW64-Prozesse (also 32-Bit-Anwendungen). Die Zeiger der Abschnittsobjekte werden in einer Teilstruktur innerhalb der globalen
Variablen MiState gespeichert.
Wenn ein Prozess erstellt wurde, wird der entsprechende Abschnitt auf sichere Weise dem
Adressraum dieses Prozesses zugeordnet. »Auf sichere Weise« bedeutet hier, dass Code, der in
dem Prozess ausgeführt wird, nicht in der Lage ist, die Zuordnung dieses Abschnitts zu ändern
oder seine Schutzeinstellungen zu ändern. (Sonst könnte Schadcode einfach die Zuordnung
des Speichers aufheben, ihn neu zuweisen und alles mit 1-Bits füllen, wodurch der Ablaufsteuerungsschutz aufgehoben würde, oder einfach die Region als schreibbar kennzeichnen, um
beliebige Bits zu ändern.)
Die CFG-Bitmaps für den Benutzermodus werden in folgenden Situationen gefüllt:
QQ Bei der Zuordnung von Abbildern werden die Metadaten über die Ziele von indirekten
Aufrufen von Abbildern extrahiert, die aufgrund der ASLR (siehe Kapitel 5) dynamisch relokalisiert wurden. Verfügt ein Abbild nicht über solche Metadaten – wurde es also nicht
mit CFG kompiliert –, so wird angenommen, dass alle in ihm enthaltenen Adressen indirekt
aufgerufen werden können. Dynamisch relokalisierte Abbilder werden wie bereits erwähnt
in jedem Prozess an derselben Adresse geladen. Daher werden ihre Metadaten dazu herangezogen, den gemeinsam genutzten Abschnitt zu füllen, der für die CFG-Bitmap verwendet wird.
QQ Bei der Zuordnung von Abbildern verlangen Abbilder, die nicht dynamisch relokalisiert
oder nicht an ihrer bevorzugten Basisadresse zugeordnet wurden, besondere Aufmerksamkeit. Bei ihrer Zuordnung werden die entsprechenden Seiten der CFG-Bitmap privat
gemacht und mithilfe der CFG-Metadaten aus dem Abbild gefüllt. Bei Abbildern, deren
CFG-Bits in der gemeinsam genutzten CFG-Bitmap vorhanden sind, wird geprüft, ob alle
Schutz gegen Exploits
Kapitel 7
869
relevanten CFG-Bitmapseiten nach wie vor gemeinsam genutzt werden können. Wenn das
nicht der Fall ist, werden die privaten CFG-Bitmapseiten mithilfe der CFG-Metadaten aus
dem Abbild gefüllt.
QQ Wird virtueller Speicher zugewiesen oder vorab als ausführbar geschützt, werden die entsprechenden Seiten der CFG-Bitmap privat gemacht und standardmäßig ausschließlich mit
Einsen initialisiert. Das ist für Situationen wie die Just-in-Time-Kompilierung erforderlich,
bei der Code im laufenden Betrieb generiert und dann ausgeführt wird (z. B. bei .NET oder
Java).
Verstärkung des CFG-Schutzes
Der Ablaufsteuerungsschutz leistet zwar gute Arbeit, um Exploits zu verhindern, bei denen indirekte Aufrufe oder Sprünge ausgenutzt werden, kann aber auch umgangen werden:
QQ Wenn der Prozess dazu verführt oder eine vorhandene JIT-Engine dazu missbraucht werden kann, ausführbaren Arbeitsspeicher zuzuweisen, dann sind alle zugehörigen Bits auf
{1, 1} gesetzt, was den gesamten Speicher zu einem gültigen Aufrufziel macht.
QQ Wenn das erwartete Aufrufziel bei einer 32-Bit-Anwendung __stdcall ist (Standardaufrufkonvention), der Angreifer es aber in __cdecl (C-Aufrufkonvention) ändern kann, dann
wird der Stack beschädigt, da die C-Aufruffunktion im Gegensatz zur Standardaufruffunktion die Argumente des Aufrufers nicht aufräumt und der Ablaufsteuerungsschutz nicht
zwischen den verschiedenen Aufrufkonventionen unterscheiden kann. Der Stack kann dabei eine vom Angreifer kontrollierte Rücksprungadresse aufweisen, wodurch der Ablaufsteuerungsschutz ausgehebelt wird.
QQ Ähnliches gilt für vom Compiler generierte setjmp/longjmp-Ziele, die sich anders verhalten
als echte indirekte Aufrufe. Auch hier kann CFG nicht zwischen den beiden Vorgängen
unterscheiden.
QQ Bestimmte indirekte Aufrufe lassen sich nicht so leicht schützen, beispielsweise die Importadresstabelle (IAT) oder die Delay-Load-Adresstabelle, die sich gewöhnlich in einem
schreibgeschützten Abschnitt der ausführbaren Datei befindet.
QQ Exportierte Funktionen sind unter Umständen keine wünschenswerten indirekten Funk
tionsaufrufe.
In Windows 10 wurden Verbesserungen am Ablaufsteuerungsschutz vorgenommen, um diese
Probleme zu lösen. Die erste dieser Maßnahmen besteht in der Einführung zweier neuer Flags,
nämlich PAGE_TARGETS_INVALID für die Funktion VirtualAlloc und PAGE_TARGETS_NO_UPDATE für
VirtualProtect. Wenn diese Flags gesetzt sind, können JIT-Engines, die ausführbaren Speicher
zuweisen, nicht alle Bits für ihre Zuweisung sehen, die auf {1, 1} gesetzt wurden. Stattdessen
müssen diese Engines manuell die Funktion SetProcessValidCallTargets aufrufen (die ihrerseits die native Funktion NtSetInformationVirtualMemory aufruft), die es ihnen erlaubt, die tatsächlichen Funktionsstartadressen des von ihnen kompilierten Codes anzugeben. Außerdem
wird diese Funktion mit DECLSPEC_GUARD_SUPPRESS als unterdrückter Aufruf gekennzeichnet, sodass Angreifer keinen indirekten Aufruf oder Sprung nutzen können, um dorthin umzuleiten,
nicht einmal zu ihrem Start. (Da es sich um eine von Natur aus gefährliche Funktion handelt,
870
Kapitel 7
Sicherheit
kann ihr Aufruf mit einem vom Aufrufer kontrollierten Stack oder Registern zu einer Umgehung
des Ablaufsteuerungsschutzes führen.)
Die Verbesserungen am Ablaufsteuerungsschutz ändern auch den Standardablauf, den
Sie zu Anfang dieses Abschnitts gesehen haben. Der Lader implementiert jetzt nicht mehr
eine einfache Funktion nach dem Prinzip »Ziel prüfen, zurückspringen«, sondern »Ziel prüfen,
Ziel aufrufen, Stack prüfen, zurückspringen«. Diese neue Funktion wird an einigen Stellen in
32-Bit-Anwendungen (auch unter WoW64) verwendet. Abb. 7–32 zeigt diesen verbesserten
Ausführungsfluss.
Vor einem
indirekten Aufruf
Vom Compiler
generierter Code
Betriebssystemcode
Zieladresse speichern
Ist das Ziel gültig?
Validierungsfunktion
aufrufen
N
Prozess
beenden
J
Stackzeiger speichern
Aufruf durchführen
Ist der Stackzeiger
derselbe?
N
J
Ausführung
fortsetzen
Abbildung 7–32 Verbesserter Ablaufsteuerungsschutz
Im Rahmen der Verbesserungen wurden auch zusätzliche Tabellen in die ausführbare Datei
aufgenommen, etwa die Address-Taken-IAT-Tabelle und die Longjump-Adresstabelle. Wenn
im Compiler der Longjump- und der IAT-CFG-Schutz aktiviert sind, werden in diesen Tabellen
Zieladressen für die entsprechenden besonderen Arten von indirekten Aufrufen gespeichert.
Die entsprechenden Funktionen stehen dann nicht in der regulären Funktionstabelle und werden daher auch nicht in der Bitmap erwähnt. Code, der versucht, eine dieser Funktionen indirekt anzuspringen oder aufzurufen, wird daher als illegaler Übergang behandelt. Um die
entsprechenden Ziele zu validieren, also z. B. diejenigen der Funktion longjmp, überprüfen die
C-Laufzeit und der Linker manuell die zugehörige Tabelle. Das ist zwar noch unwirtschaftlicher
als die Durchsuchung der Bitmap, aber da diese Tabellen wenn überhaupt, dann nur sehr wenige Funktionen enthalten, ist dieser Mehraufwand tragbar.
Schließlich wurde noch eine Exportunterdrückung eingeführt, die vom Compiler unterstützt und von einer Abwehrmaßnahme auf Prozessebene aktiviert werden muss (siehe den
Schutz gegen Exploits
Kapitel 7
871
Abschnitt »Abwehrmaßnahmen auf Prozessebene« weiter vorn in diesem Kapitel). Wenn diese
Einrichtung eingeschaltet ist, wird der neue Bitstatus {0, 1} verwendet (der in der früheren
Aufstellung nicht definiert war): Er gibt an, dass die Funktion gültig ist, aber einer Exportunterdrückung unterliegt, weshalb sie vom Lader besonders behandelt wird.
Welche Schutzvorkehrungen in einer Binärdatei enthalten sind, können Sie an den Schutzflags
in der IMAGE_LOAD_CONFIGURATION_DIRECTORY-Struktur ablesen, die die bereits vorgestellte Anwendung DumpBin entschlüsseln kann. Eine Übersicht über die Flags finden Sie in Tabelle 7–21.
Flagsymbol
Wert
Beschreibung
IMAGE_GUARD_CF_INSTRUMENTED
0x100
In dem Modul ist die Unterstützung
für den Ablaufsteuerungsschutz vorhanden.
IMAGE_GUARD_CFW_INSTRUMENTED
0x200
Das Modul führt den Ablaufsteuerungsschutz und Schreibintegritätsprüfungen durch.
IMAGE_GUARD_CF_FUNCTION_TABLE_PRESENT
0x400
Das Modul enthält CFG-fähige Funk
tionslisten.
IMAGE_GUARD_SECURITY_COOKIE_UNUSED
0x800
Das Modul nutzt das vom Compilerflag
/GS ausgegebene Sicherheitscookie
nicht.
IMAGE_GUARD_PROTECT_DELAYLOAD_IAT
0x1000
Das Modul unterstützt schreibgeschützte Delay-Load-Importadresstabellen (IAT).
IMAGE_GUARD_DELAYLOAD_IAT_IN_ITS_OWN_
SECTION
0x2000
Die Delay-Load-IAT befindet sich in ihrem eigenen Abschnitt und kann daher
bei Bedarf erneut geschützt werden.
IMAGE_GUARD_CF_EXPORT_SUPPRESSION_INFO_
PRESENT
0x4000
Das Modul enthält unterdrückte
Exportinformationen.
IMAGE_GUARD_CF_ENABLE_EXPORT_SUPPRESSION
0x8000
Das Modul ermöglicht eine Exportunterdrückung.
IMAGE_GUARD_CF_LONGJUMP_TABLE_PRESENT
0x10000
Das Modul enthält Longjump-Zielinformationen.
Tabelle 7–21 Flags für den Ablaufsteuerungsschutz
Zusammenspiel von Lader und Ablaufsteuerungsschutz
Es ist zwar der Speicher-Manager, der die CFG-Bitmap erstellt, doch auch der Benutzermodus-Lader (siehe Kapitel 3) spielt eine Rolle und hat zwei Aufgaben zu erfüllen. Die erste besteht darin, die CFG-Unterstützung dynamisch dann und nur dann zu aktivieren, wenn dieses
Merkmal aktiviert ist. (Es kann beispielsweise sein, dass ein Aufrufer für den Kindprozess einen
Verzicht auf den Ablaufsteuerungsschutz verlangt hat oder der Prozess selbst keine CFG-Unterstützung aufweist.) Dies erfolgt durch die Laderfunktion LdrpCfgProcessLoadConfig, die aufgerufen wird, um den Ablaufsteuerungsschutz für jedes geladene Modul zu initialisieren. Wenn
das CFG-Flag (IMAGE_DLLCHARACTERISTICS_GUARD_CF) in den DllCharacteristics-Modulflags im
optionalen PE-Header oder das Flag IMAGE_GUARD_CF_INSTRUMENTED im Element GuardFlags der
872
Kapitel 7
Sicherheit
IMAGE_LOAD_CONFIG_DIRECTORY-Struktur nicht gesetzt ist oder der Kernel den Ablaufsteuerungs-
schutz für das Modul zwangsweise abgeschaltet hat, tut diese Funktion nichts.
Verwendet das Modul den Ablaufsteuerungsschutz, so besteht die zweite Aufgabe darin,
dass LdrpCfgProcessLoadConfig den Zeiger für die Überprüfungsfunktion für indirekte Aufrufe
vom Abbild abruft (das Element GuardCFCheckFunctionPointer der IMAGE_LOAD_CONFIG_DIRECTORY-
Struktur) und entweder auf LdrpValidateUserCallTarget oder LdrpValidateUserCallTargetES in
Ntdll setzt, je nachdem, ob die Exportunterdrückung aktiviert ist oder nicht. Zuvor vergewissert
sich die Funktion, dass der indirekte Zeiger nicht verändert wurde und auf eine Stelle außerhalb
des Moduls zeigt.
Wurde die Binärdatei mit verbessertem Ablaufsteuerungsschutz kompiliert, so steht darüber hinaus die CFG-Dispatchroutine als zweite Prüfroutine zur Verfügung, um den zuvor
beschriebenen erweiterten Ausführungsfluss zu implementieren. Enthält das Abbild einen
Zeiger auf eine solche Funktion (im Element GuardCFDispatchFunctionPointer in der bereits
erwähnten Struktur), so wird er mit LdrpDispatchUserCallTarget bzw. bei aktivierter Exportunterdrückung mit LdrpDispatchUserCallTargetES initialisiert.
In einigen Fällen kann der Kernel selbst indirekte Sprünge oder Aufrufe für den Benutzermodus durchführen. Wenn das möglich ist, implementiert der Kernel seine
eigene MmValidateUserCallTarget-Routine, die die gleichen Aufgaben ausführt wie
LdrpValidateUserCallTarget.
In Code, der von einem Compiler mit aktiviertem Ablaufsteuerungsschutz generiert wurde,
landen indirekte Aufrufe in der Ntdll-Funktion LdrpValidateCallTarget(ES) oder LdrpDispatch
UserCallTarget(ES), die anhand der Zielverzweigungsadresse den Bitstatuswert für die Funktion prüft:
QQ Ist der Bitstatus {0, 0}, so ist der Aufruf möglicherweise ungültig.
QQ Ist der Bitstatus {1, 0} und die Adresse an 16-Byte-Grenzen ausgerichtet, so ist der Aufruf
gültig. Anderenfalls ist er möglicherweise ungültig.
QQ Ist der Bitstatus {1, 1} und die Adresse nicht an 16-Byte-Grenzen ausgerichtet, so ist der
Aufruf gültig. Anderenfalls ist er möglicherweise ungültig.
QQ Ist der Bitstatus {0, 1}, so ist der Aufruf möglicherweise ungültig.
Bei einem möglicherweise ungültigen Aufruf wird die Funktion RtlpHandleInvalidUserCallTarget ausgeführt, um die angemessene Vorgehensweise zu bestimmen. Als Erstes prüft sie, ob
in dem Prozess unterdrückte Aufrufe erlaubt sind. Diese Kompatibilitätsoption ist zwar ungewöhnlich, kann aber bei eingeschaltetem Application Verifier oder in der Registrierung festgelegt sein. Wenn das der Fall ist, wird geprüft, ob die Adresse unterdrückt wurde, was dann der
Grund dafür wäre, dass sie nicht in die Bitmap eingefügt wurde. (Wie bereits erwähnt, wird dies
durch ein besonderes Flag im Schutzfunktionstabelleneintrag angezeigt.) Wenn ja, wird der
Aufruf zugelassen. Ist die Funktion dagegen überhaupt nicht gültig (also nicht in der Tabelle
vorhanden), dann wird der Aufruf abgebrochen und der Prozess beendet.
Zweitens wird geprüft, ob die Exportunterdrückung aktiviert ist. Wenn ja, wird die Zieladresse mit der Liste unterdrückter Adressen verglichen. Auch diese Unterdrückung wird durch
Schutz gegen Exploits
Kapitel 7
873
ein Flag im Schutzfunktionstabelleneintrag angezeigt. Wenn das der Fall ist, vergewissert sich
der Lader, dass die Zieladresse ein Forwarder-Verweis auf die Exporttabelle einer anderen DLL
ist, was nur bei einem indirekten Aufruf in einem Abbild mit unterdrückten Exporten zulässig
ist. Das geschieht mithilfe eines komplizierten Prüfvorgangs, bei dem sichergestellt wird, dass
sich die Zieladresse in einem anderen Abbild befindet, dass in dessen Abbildladeverzeichnis die
Exportunterdrückung aktiviert wurde und dass die Adresse im Importverzeichnis dieses Abbilds
steht. Wenn alle Überprüfungen bestanden sind, wird der Kernel mit der bereits beschriebenen
Funktion NtSetInformationVirtualMemory aufgerufen, um den Bitstatus in {1, 0} zu ändern.
Schlägt dagegen eine einzige dieser Überprüfungen fehl oder ist die Exportunterdrückung
nicht aktiviert, wird der Prozess abgebrochen.
Bei 32-Bit-Anwendungen erfolgt eine zusätzliche Prüfung, um zu sehen, ob die Datenausführungsverhinderung (DEP) für den Prozess aktiviert ist (siehe Kapitel 5). Wenn nicht, wird der
inkorrekte Aufruf zugelassen, da dann keine Ausführungsgarantien vorhanden sind und es sich
auch um eine ältere Anwendung handeln kann, die aus legitimen Gründen einen Aufruf auf
dem Heap oder Stack vornimmt.
Da aus Platzgründen große Mengen von {0, 0}-Bitstatus nicht zugesichert sind, tritt eine
Ausnahme aufgrund einer Zugriffsverletzung auf, wenn die Überprüfung der CFG-Bitmap auf
einer reservierten Seite landet. Auf x86-Systemen, auf denen die Einrichtung einer Ausnahmebehandlung mit großem Aufwand verbunden ist, wird diese Aufnahme daher nicht vom
Verifizierungscode gehandhabt, sondern auf die übliche Weise weitergeleitet (siehe Kapitel 8
in Band 2). KiUserExceptionDispatcher, der Dispatcherhandler für den Benutzermodus, führt
besondere Prüfungen durch, um in der Validierungsfunktion Ausnahmen aufgrund einer
Zugriffsverletzung in Zusammenhang mit der CFG-Bitmap zu erkennen, und nimmt beim
Ausnahmecode STATUS_IN_PAGE_ERROR die Ausführung automatisch wieder auf. Das macht
den Code in LdrpValidateUserCallTarget(ES) und LdrpDispatchUserCallTarget(ES) einfacher, da diese Funktionen dann keinen Code zur Ausnahmebehandlung enthalten müssen.
Auf x64-Systemen, auf denen Ausnahmehandler einfach in Tabellen registriert werden, wird
stattdessen der Handler LdrpICallHandler mit der gleichen Logik wie zuvor ausgeführt.
Kernel-CFG
Die Binärdaten von Treibern, die in Visual Studio mit der Option /guard:cf kompiliert wurden,
weisen die gleichen Eigenschaften auf wie Benutzermodusabbilder, doch die ersten Versionen
von Windows 10 konnten mit diesen Daten nichts anfangen. Im Gegensatz zur CFG-Bitmap für
den Benutzermodus, die von einer höheren, vertrauenswürdigeren Entität geschützt wird (dem
Kernel), gibt es nichts, was eine Kernel-CFG-Bitmap schützen könnte, falls sie erstellt würde. Ein
Exploit könnte einfach den PTE für die Seite mit den Bits, die er ändern möchte, als schreibbar
kennzeichnen, und dann mit einem indirekten Aufruf oder Sprung fortfahren. Da sich die mögliche Abwehrmaßnahme so leicht umgehen ließ, hätte sich der Aufwand für ihre Einrichtung
nicht gelohnt.
Mit wachsender Anzahl der Benutzer, die VBS-Funktionen aktivieren, lässt sich jedoch wiederum die höhere Sicherheit nutzen, die VTL 1 bietet. Die SLAT-Seitentabelleneinträge bieten
eine zweite Schutzvorkehrung gegen Änderungen am PTE-Seitenschutz. Da SLAT-Einträge als
nur lesbar gekennzeichnet sind, ist die Bitmap in VTL 0 lesbar, doch wenn ein Kernelangreifer
874
Kapitel 7
Sicherheit
versucht, die PTEs zu ändern, um sie als schreibbar zu markieren, kann er das nicht auch mit den
SLAT-Einträgen machen. Daher wird der Vorgang als ungültiger Zugriff auf die KCFG-Bitmap
erkannt, bei dem HyperGuard eingreifen kann (nur aus Telemetriegründen, da die Bits ohnehin
nicht geändert werden können).
KCFG ist fast auf die gleiche Weise implementiert wie der reguläre Ablaufsteuerungsschutz,
allerdings sind die Exportunterdrückung, die Unterstützung, longjmp und die Möglichkeit zur
dynamischen Abfrage von zusätzlichen Bits für die JIT-Kompilierung nicht eingeschaltet, da der
Kerneltreiber nichts davon tun sollte. Gesetzt werden die Bits in der Bitmap stattdessen anhand
der Einträge in der Address-Taken-IAT, falls solche vorhanden sind, und anhand der üblichen
Funktionseinträge in der Wächtertabelle, wenn ein Treiberabbild geladen wird. Für die HAL
und den Kernel werden die Bits beim Start mithilfe von MiInitializeKernelCfg gesetzt. Ist der
Hypervisor nicht aktiviert und keine SLAT-Unterstützung vorhanden, wird nichts davon initialisiert, weshalb Kernel-CFG ausgeschaltet bleibt.
Wie im Benutzermodus wird auch hier ein dynamischer Zeiger im Ladekonfigurationsverzeichnis aktualisiert. Ist Kernel-CFG aktiviert, so verweist dieser Zeiger für die Überprüfungsfunktion auf __guard_check_icall und für die Dispatchfunktion im erweiterten CFG-Modus auf
__guard_dispatch_icall. Darüber hinaus enthält die Variable guard_icall_bitmap die virtuelle
Adresse der Bitmap.
Leider sind die dynamischen Einstellungen der Treiberüberprüfung bei Kernel-CFG nicht
konfigurierbar (mehr über die Treiberüberprüfung erfahren Sie in Kapitel 6), da es dazu erforderlich wäre, dynamische Kernelhooks hinzuzufügen und die Ausführung an Funktionen umzuleiten, die sich nicht unbedingt in der Bitmap befinden. In diesem Fall wird STATUS_VRF_CFG_
ENABLED (0xC000049F) zurückgegeben, und es ist ein Neustart erforderlich (bei dem die Bitmap
mit den Treiberverifizierungshooks erstellt werden kann).
Zusicherungen
Wir haben bereits beschrieben, dass der Ablaufsteuerungsschutz Prozesse beendet und dass
auch andere Abwehrmaßnahmen und Sicherheitseinrichtungen Ausnahmen aufwerfen, um
Prozesse abzubrechen. Es ist jedoch wichtig zu wissen, was genau dabei geschieht.
Wenn eine solche Sicherheitsverletzung auftritt – wenn also beispielsweise der Ablaufsteuerungsschutz einen unzulässigen indirekten Aufruf oder Sprung erkennt –, wäre es nicht angebracht, den Prozess einfach mit dem Standardmechanismus TerminateProcess zu beenden,
denn dabei ist weder ein Absturz garantiert noch werden Telemetriedaten an Microsoft gesendet. Beide Vorgänge sind aber wichtige Hilfsmittel: Sie helfen Administratoren, zu erkennen,
dass möglicherweise ein Exploit aktiv war oder dass es ein Kompatibilitätsproblem gibt, und
erlauben Microsoft, Zero-Day-Exploits in »freier Wildbahn« aufzuspüren. Es gibt jedoch auch
einen Nachteil. Zwar erzielen Ausnahmen das gewünschte Ergebnis, doch es handelt sich bei
ihnen um Callbacks, was die folgenden Konsequenzen haben kann:
QQ Wenn die Abwehrmaßnahmen SAFESEH und SEHOP nicht aktiviert sind, können sich Angreifer darin einklinken und dafür sorgen, dass als Sicherheitsprüfung diejenige verwendet
wird, über die Angreifer überhaupt erst die Kontrolle gegeben wird. Es ist auch möglich,
dass der Angreifer die Ausnahme einfach unter den Tisch fallen lässt.
Schutz gegen Exploits
Kapitel 7
875
QQ Es ist möglich, dass sich legitime Teile der Software durch einen Filter für unbehandelte
Ausnahmen oder einen vektorisierten Ausnahmehandler darin einklinken, was beides dazu
führen kann, dass die Ausnahme versehentlich verschluckt wird.
QQ Auch Drittanbieterprodukte, die ihre eigene Bibliothek in den Prozess injiziert haben, können die Ausnahme abfangen. Dies ist bei vielen Sicherheitswerkzeugen üblich und kann
ebenfalls dazu führen, dass die Ausnahme nicht korrekt an die Windows-Fehlerbericht
erstattung (Windows Error Reporting, WER) ausgeliefert wird.
QQ Ein Prozess kann einen Callback zur Anwendungswiederherstellung bei der Windows-Fehlerberichterstattung registriert haben. Das kann zur Folge haben, dass dem Benutzer eine
unklare Meldung angezeigt wird, weshalb er den Prozess in dem angegriffenen Zustand
neu startet. Das kann zu allem Möglichen führen, von einer rekursiven Absturz/Start-Schleife bis zu einem vollständigen Verschlucken der Ausnahme.
QQ In C++-Produkten kann die Ausnahme von einem äußeren Ausnahmehandler abgefangen
werden, als wäre sie von dem Programm selbst aufgeworfen worden. Auch das kann dazu
führen, dass die Ausnahme verschluckt oder die Ausführung auf unsichere Weise fortgesetzt wird.
Um diese Probleme zu lösen, benötigen wir einen Mechanismus, der Ausnahmen so aufwirft,
dass sie nicht von Komponenten des Prozesses außerhalb des WER-Dienstes abgefangen werden können. Des Weiteren muss garantiert sein, dass der WER-Dienst die Aufnahme auch empfängt. Dazu werden Zusicherungen verwendet.
Unterstützung durch den Compiler und das Betriebssystem
Wenn Bibliotheken, Programme oder Kernelkomponenten von Microsoft auf ungewöhnliche
sicherheitsrelevante Situationen stoßen oder wenn Abwehrmaßnahmen gefährliche Verletzungen des Sicherheitsstatus erkennen, verwenden sie die besondere, von Visual Studio unterstützte systeminterne Funktion __fastfail, die einen Parameter als Eingabe entgegennimmt.
Alternativ können sie die Laufzeitbibliotheksfunktion RtlFailFast2 in Ntdll aufrufen, die ihrerseits die systeminterne Funktion __fastfail nutzt. In manchen Fällen enthält das WDK oder das
SDK Inline-Funktionen, die diese systeminterne Funktion aufrufen, z. B. bei der Verwendung
der LIST_ENTRY-Funktionen InsertTailLists und RemoveEntryList. In anderen Situationen ist es
die Universal CRT (uCRT) selbst, die in ihren Funktionen diese systeminterne Funktion enthält.
Darüber hinaus gibt es auch Fälle, in denen APIs beim Aufruf durch Anwendungen bestimmte
Überprüfungen vornehmen und dann ebenfalls die systeminterne Funktion einsetzen.
Wenn der Compiler diese systeminterne Funktion erkennt, generiert er in jedem Fall Assemblercode, der den Eingabeparameter entgegennimmt, verschiebt ihn in das Register RCX
(x64) oder ECX (x86) und gibt dann den Softwareinterrupt 0x29 aus. (Mehr über Interrupts
erfahren Sie in Kapitel 8 von Band 2.)
In Windows 8 und höher wird dieser Softwareinterrupt in der Interruptdispatchtabelle
(IDT) mit dem Handler KiRaiseSecurityCheckFailure registriert, was Sie sich mit dem Debuggerbefehl !idt 29 selbst ansehen können. Aus Kompatibilitätsgründen führt dies dazu, dass
KiFastFailDispatch mit dem Statuscode STATUS_STACK_BUFFER_OVERRUN (0xC0000409) aufgerufen wird. Diese Funktion führt eine reguläre Ausnahmedisponierung mit KiDispatchExcecption
876
Kapitel 7
Sicherheit
durch, behandelt den Vorfall aber als Ausnahme bei einem zweiten Versuch, weshalb der Debugger und der Prozess nicht benachrichtigt werden.
Dieser Umstand wird erkannt, und es wird wie gewöhnlich eine Fehlermeldung an den
ALPC-Fehlerport von WER gesendet. WER bezeichnet die Ausnahme als nicht fortsetzbar, was
dazu führt, dass der Kernel den Prozess mit dem üblichen Systemaufruf ZwTerminateProcess beendet. Dadurch ist garantiert, dass innerhalb des Prozesses nach dem Auslösen des Interrupts
keine Rückkehr zum Benutzermodus mehr erfolgt, dass WER benachrichtigt und der Prozess
beendet wird. (Überdies ist der Fehlercode der Ausnahmecode.) Beim Erstellen des Ausnahmedatensatzes ist das erste Ausnahmeargument der Eingabeparameter für __fastfail.
Auch Kernelmoduscode kann Ausnahmen aufwerfen, aber in diesem Fall wird KiBug
CheckDispatch aufgerufen, was zu einem besonderen Kernelmoduscrash (»Bugcheck«) mit dem
Code 0x129 führt (KERNEL_SECURITY_CHECK_FAILURE). Das erste Argument ist der Eingabeparameter für __fastfail.
Fehlercodes
Da das Eingabeargument von __fastfail an den Ausnahmedatensatz oder den Absturzbildschirm weitergeleitet wird, kann die Fehlerprüfung erkennen, welcher Teil des Systems oder des
Prozesses nicht korrekt funktioniert oder eine Sicherheitsverletzung erlitten hat. Tabelle 7–22
zeigt die verschiedenen Fehlerbedingungen und ihre Bedeutung.
Code
Bedeutung
Legacy OS Violation (0x0)
Eine ältere Puffersicherheitsprüfung in einer veralteten
Binärdatei ist fehlgeschlagen und wurde in eine Zusicherung
umgewandelt.
V-Table Guard Failure (0x1)
Die Abwehrmaßnahme Virtual Table Guard in Internet
Explorer 10 hat einen beschädigten Zeiger auf eine Tabelle für
virtuelle Funktionen erkannt.
Stack Cookie Check Failure (0x2)
Das mit der Compileroption /GS generierte Stackcookie (auch
Stackcanary genannt) wurde beschädigt.
Corrupt List Entry (0x3)
Eines der Makros für die Bearbeitung von LIST_ENTRY-Strukturen hat eine inkonsistente verknüpfte Liste entdeckt, in der
ein Großeltern- oder Enkeleintrag nicht auf den Eltern- oder
Kindeintrag des zu bearbeitenden Elements zeigt.
Incorrect Stack (0x4)
Eine Benutzer- oder Kernelmodus-API, die häufig von ROP-
Exploits auf einem vom Angreifer kontrollierten Stack verwendet wird, wurde aufgerufen. Der Stack ist daher nicht der
erwartete.
Invalid Argument (0x5)
Eine Benutzermodus-CRT-API (der übliche Fall) oder eine andere sensible Funktion wurde mit einem ungültigen Argument
aufgerufen. Das deutet auf eine Verwendung durch einen
ROP-Exploit oder einen aus anderen Gründen beschädigten
Stack hin.
Stack Cookie Init Failure (0x6)
Die Initialisierung des Stackcookies ist fehlgeschlagen, was auf
Abbildpatching oder eine Beschädigung hindeutet.
→
Schutz gegen Exploits
Kapitel 7
877
Code
Bedeutung
Fatal App Exit (0x7)
Die Anwendung hat die Benutzermodus-API FatalApp#Exit
verwendet, die in eine Zusicherung umgewandelt wurde, um
ihr die damit einhergehenden Vorteile zu gewähren.
Range Check Failure (0x8)
Zusätzliche Validierungsprüfungen in bestimmten festen
Arraypuffern, um festzustellen, ob sich der Index des Array
elements innerhalb der erwarteten Grenzen befindet
Unsafe Registry Access (0x9)
Ein Kernelmodustreiber versucht, von einem Hive aus, der
vom Benutzer gesteuert werden kann (z. B. einem Anwendungs- oder Benutzerprofilhive), auf Registrierungsdaten
zuzugreifen, ohne sich dabei mit dem Flag RTL_QUERY_
REGISTRY_TYPECHECK zu schützen.
CFG Indirect Call Failure (0xA)
Der Ablaufsteuerungsschutz hat eine indirekte CALL- oder
JMP-Anweisung zu einer Zieladresse erkannt, die laut CFG-
Bitmap nicht gültig ist.
CFG Write Check Failure (0xB)
Der Ablaufsteuerungsschutz mit Schreibschutz hat einen ungültigen Schreibvorgang an geschützten Daten erkannt. Diese
Option (/guard:cfw) steht nur bei Tests von Microsoft zur
Verfügung.
Invalid Fiber Switch (0xC)
Die API SwitchToFiber wurde auf eine ungültige Fiber oder
von einem Thread aus angewendet, der nicht in eine Fiber
konvertiert wurde.
Invalid Set of Context (0xD)
Bei dem Versuch, eine Kontextdatensatzstruktur wiederherzustellen (aufgrund einer Ausnahme oder der API SetThreadContext), wurde erkannt, dass der Stackzeiger ungültig ist.
Dies wird nur geprüft, wenn der Ablaufsteuerungsschutz für
den Prozess eingeschaltet ist.
Invalid Reference Count (0xE)
Bei einem Objekt mit Referenzzählung (z. B. OBJECT_HEADER
im Kernelmodus oder ein GDI-Objekt von Win32k.sys) ist der
Referenzzähler unter 0 gefallen oder hat seinen Maximalwert
überschritten und ist damit wieder auf 0 gegangen.
Invalid Jump Buffer (0x12)
Es wurde ein longjmp-Versuch mit einem Sprungpuffer versucht, der eine ungültige Stackadresse oder einen ungültigen
Anweisungszeiger enthält. Dies wird nur geprüft, wenn der
Ablaufsteuerungsschutz für den Prozess eingeschaltet ist.
MRDATA Modified (0x13)
Der änderbare, schreibgeschützte Datenheapabschnitt des
Laders wurde geändert. Dies wird nur geprüft, wenn der Ablaufsteuerungsschutz für den Prozess eingeschaltet ist.
Certification Failure (0x14)
Eine oder mehrere Kryptografiedienst-APIs haben bei der
Analyse eines Zertifikats oder eines ungültigen ASN.1-Streams
ein Problem festgestellt.
Invalid Exception Chain (0x15)
Bei einem mit /SAFESEH oder SEHOP verlinkten Abbild ist ein
ungültiger Ausnahmehandler disponiert worden.
Crypto Library (0x16)
Bei CNG.SYS, KSECDD.SYS oder ihren zugehörigen APIs im
Benutzer ist ein kritischer Fehler aufgetreten.
Invalid Call in DLL Callout (0x17)
Es ist versucht worden, eine gefährliche Funktion im Benachrichtigungscallback des Benutzermodusladers aufzurufen.
Invalid Image Base (0x18)
Der Benutzermodus-Abbildlader hat einen ungültigen Wert
für __ImageBase (IMAGE_DOS_HEADER-Struktur) erkannt.
878
Kapitel 7
Sicherheit
→
Code
Bedeutung
Delay Load Protection Failure (0x19)
Beim verzögerten Laden einer importierten Funktion wurde
erkannt, dass die Delay-Load-IAT beschädigt ist. Dies wird nur
geprüft, wenn der Ablaufsteuerungsschutz für den Prozess
und der Schutz der Delay-Load-IAT eingeschaltet sind.
Unsafe Extension Call (0x1A)
Wird geprüft, wenn bestimmte Kernelmoduserweiterungs-APIs aufgerufen werden und der Status des Aufrufers
nicht korrekt ist.
Deprecated Service Called (0x1B)
Wird geprüft, wenn nicht mehr unterstützte oder nicht dokumentierte Systemaufrufe verwendet werden.
Invalid Buffer Access (0x1C)
Wird von den Laufzeitbibliotheksfunktionen in Ntdll und dem
Kernel geprüft, wenn eine allgemeine Pufferstruktur auf irgendeine Weise beschädigt ist.
Invalid Balanced Tree (0x1D)
Wird von den Laufzeitbibliotheksfunktionen in Ntdll und
dem Kernel geprüft, wenn eine RTL_RB_TREE- oder RTL_AVL-
TABLE-Struktur ungültige Knoten aufweist (wenn zwischen Geschwister- und/oder Elternknoten und den Großelternknoten
Unstimmigkeiten bestehen; ähnlich wie bei den LIST_ENTRYPrüfungen).
Invalid Next Thread (0x1E)
Wird vom Kernelscheduler geprüft, wenn der nächste einzuplanende Thread im KPRCB auf irgendeine Weise ungültig ist.
CFG Call Suppressed (0x1F)
Wird geprüft, wenn der Ablaufsteuerungsschutz einen unterdrückten Aufruf aus Kompatibilitätsgründen zulässt. In dieser
Situation kennzeichnet WER den Fehler als behandelt, sodass
der Kernel den Prozess nicht beendet. Die Telemetriedaten
werden jedoch nach wie vor an Microsoft gesendet.
APCs Disabled (0x20)
Wird vom Kernel geprüft, wenn eine Rückkehr in den Benutzermodus erfolgt und die Kernel-APCs nach wie vor deaktiviert sind.
Invalid Idle State (0x21)
Wird von der Kernel-Energieverwaltung geprüft, wenn die
CPU versucht, einen ungültigen C-Zustand einzunehmen.
MRDATA Protection Failure (0x22)
Wird vom Benutzermoduslader geprüft, wenn der Schutz des
änderbaren, schreibgeschützten Heapabschnitts (Mutable
Read-Only Heap Section) bereits außerhalb des erwarteten
Codepfads aufgehoben wurde.
Unexpected Heap Exception (0x23)
Wird vom Heap-Manager geprüft, wenn der Heap auf eine
Weise beschädigt ist, die auf einen möglichen Exploit hin
deutet.
Invalid Lock State (0x24)
Wird vom Kernel geprüft, wenn bestimmte Sperren nicht den
erwarteten Zustand aufweisen, z. B. wenn eine erworbene
Sperre bereits freigegeben ist.
Invalid Longjmp (0x25)
Wird vom Aufruf von longjmp geprüft, wenn der Ablaufsteuerungsschutz mit Longjump-Schutz für den Prozess eingeschaltet ist, aber die Longjump-Tabelle beschädigt ist oder fehlt.
Invalid Longjmp Target (0x26)
Wie vor; in diesem Fall aber zeigt die Longjump-Tabelle an,
dass die Longjump-Zielfunktion ungültig ist.
Invalid Dispatch Context (0x27)
Wird vom Ausnahmehandler im Kernelmodus geprüft, wenn
eine Ausnahme mit einem falschen CONTEXT-Datensatz disponiert werden soll.
→
Schutz gegen Exploits
Kapitel 7
879
Code
Bedeutung
Invalid Thread (0x28)
Wird vom Scheduler im Kernelmodus geprüft, wenn die
KTHREAD-Struktur bei bestimmten Zeitplanungsoperationen
beschädigt ist.
Invalid System Call Number (0x29)
Ähnelt Deprecated Service Called; hier allerdings kennzeichnet
WER die Ausnahme als behandelt, sodass der Prozess fortgesetzt und die Ausnahme nur für die Telemetrie verwendet
wird.
Invalid File Operation (0x2A)
Wird vom E/A-Manager und bestimmten Dateisystemen als
eine weitere Form von Fehler für die Telemetrie behandelt
(wie beim vorherigen Code).
LPAC Access Denied (0x2B)
Wird von der Zugriffsprüfungsfunktion des SRM verwendet, wenn ein Anwendungscontainer mit niedrigen Rechten
versucht, auf ein Objekt zuzugreifen, für das die SID ALL
RESTRICTED APPLICATION PACKAGES nicht gesetzt ist, und die
Verfolgung solcher Fehler aktiviert ist. Auch hier werden die
Ergebnisse nur für Telemetriedaten verwendet und führen
nicht zum Absturz des Prozesses.
RFG Stack Failure (0x2C)
Wird von RFG (Return Flow Guard) verwendet, allerdings ist
dieses Merkmal zurzeit deaktiviert.
Loader Continuity Failure (0x2D)
Wird von der zuvor gezeigten gleichnamigen Abwehrmaßnahme verwendet, um anzuzeigen, dass ein unerwartetes
Abbild mit einer anderen Signatur oder gar keiner Signatur
geladen wurde.
CFG Export Suppression Failure
(0x2D)
Wird vom Ablaufsteuerungsschutz mit Exportunterdrückung
verwendet, um anzuzeigen, dass ein unterdrückter Export das
Ziel einer indirekten Verzweigung war.
Invalid Control Stack (0x2E)
Wird von RFG (Return Flow Guard) verwendet, allerdings ist
dieses Merkmal zurzeit deaktiviert.
Set Context Denied (0x2F)
Wird von der zuvor gezeigten gleichnamigen Abwehrmaßnahme verwendet, allerdings ist dieses Merkmal zurzeit deaktiviert.
__fastfail-Fehlercodes
Tabelle 7–22
Anwendungsidentifizierung
In Windows wurden Sicherheitsentscheidungen traditionell auf der Grundlage der Identität
des Benutzers (in Form seiner SID und seiner Gruppenmitgliedschaften) gefällt, aber mehr und
mehr Sicherheitskomponenten (AppLocker, Firewall, Antivirus- und Antimalwareprogramme,
Rights Management Services usw.) müssen ihre sicherheitsrelevanten Entscheidungen darauf
gründen, was für Code ausgeführt wird. Früher verwendeten all diese Komponenten jeweils ihre
eigenen Methoden, um Anwendungen zu identifizieren, weshalb das Schreiben von Richtlinien
sehr inkonsistent und übermäßig kompliziert war. Die Anwendungsidentifizierung mithilfe einer AppID soll die Erkennung von Anwendungen durch Sicherheitskomponenten vereinheitlichen, indem sie einen einzigen Satz von APIs und Datenstrukturen für diesen Zweck bereitstellt.
880
Kapitel 7
Sicherheit
Dies ist etwas anderes als die AppID, die von DCOM/COM+-Anwendungen eingesetzt wird und bei der ein GUID für einen Prozess steht, der von mehreren CLSIDs
gemeinsam genutzt wird. Es hat auch nichts mit der UWP-Anwendungs-ID zu tun.
Unmittelbar bevor eine Anwendung startet, wird sie identifiziert. Dazu wird die AppID des
Hauptprogramms generiert. Dazu können beliebige der folgenden Attribute der Anwendung
herangezogen werden:
QQ Felder Mithilfe der Felder in dem Zertifikat zur Codesignierung, das in die Datei eingebettet ist, können verschiedene Kombinationen von Herausgeber-, Produkt- und Dateiname sowie Version verwendet werden. APPID://FQBN ist ein vollständig qualifizierter
Binärdateienname. Dabei handelt es sich um einen String der Form {Herausgeber/Produkt/
Dateiname,Version}. Publisher ist das Feld Subject des X.509-Zertifikats, das zum Signieren
des Codes verwendet wurde, wobei folgende Felder berücksichtigt werden:
•
O
Organisation
•
L
Ort (Locality)
•
S
Bundesstaat, Bundesland, Provinz o. Ä. (State)
•
C
Land (Country)
QQ Dateihash
Für das Hashing können verschiedene Methoden eingesetzt werden, wobei
APPID://SHA256HASH die Standardmethode ist, bei der ein SHA-256-Hash der Datei ange-
legt wird. Zur Abwärtskompatibilität mit SRP und den meisten X.509-Zertifikaten wird jedoch auch SHA-1 unterstützt (APPID://SHA1HASH).
QQ Teilpfad oder vollständiger Pfad zu der Datei APPID://Path gibt einen Pfad an, in dem
optional auch Jokerzeichen (*) vorkommen können.
Mit einer AppID wird auf keinen Fall die Qualität oder Sicherheit einer Anwendung
bestätigt. Sie dient lediglich dazu, die Anwendung zu identifizieren, sodass Administratoren bei sicherheitsrelevanten Entscheidungen auf die Anwendung verweisen können.
Die AppID wird im Prozesszugriffstoken gespeichert, sodass Sicherheitskomponenten Autorisierungsentscheidungen auf der Grundlage einer einzigen, einheitlichen Identifizierung treffen
können. AppLocker verwenden bedingte Zugriffssteuerungseinträge, um anzugeben, ob der
Benutzer ein bestimmtes Programm ausführen darf oder nicht.
Beim Erstellen einer AppID für eine signierte Datei wird das Zertifikat der Datei zwischengespeichert und zu einem vertrauenswürdigen Stammzertifikat zurückverfolgt und überprüft.
Der Zertifikatpfad wird täglich erneut überprüft, um sicherzugehen, dass er nach wie vor gültig
ist. Diese Zwischenspeicherung und Verifizierung wird im Systemereignisprotokoll unter Application und Services Logs\Microsoft\Windows\AppID\Operational aufgezeichnet.
Anwendungsidentifizierung
Kapitel 7
881
AppLocker
In den Enterprise-Editionen von Windows 8.1 und Windows 10 sowie in Windows Server 2012/
R2/2016 gibt es das Feature AppLocker, mit dem Administratoren ein System sperren können,
um die Ausführung nicht autorisierter Programme zu verhindern. In Windows XP wurden die
Richtlinien für Softwareeinschränkung (Software Restriction Policies, SRP) eingeführt, die einen
ersten Schritt in diese Richtung darstellte, aber sich nur schwer verwalten ließ und nicht auf
einzelne Benutzer und Gruppen angewendet werden konnte. (Die SRP-Regeln wirkten sich auf
alle Benutzer aus.) AppLocker ersetzt SRP, kann aber auch parallel dazu verwendet werden,
da die AppLocker-Regeln getrennt von den SRP-Regeln gespeichert werden. Befinden sich in
einem Gruppenrichtlinienobjekt sowohl AppLocker- als auch SRP-Regeln, so werden nur die
AppLocker-Regeln angewendet.
Ein weiteres Merkmal, das AppLocker gegenüber SRP überlegen macht, ist der Überwachungsmodus, in dem ein Administrator eine AppLocker-Richtlinie erstellen und die (im
Systemereignisprotokoll gespeicherten) Ergebnisse untersuchen kann, um festzustellen, ob sich
die Richtlinie wie erwartet verhält, ohne die Einschränkungen tatsächlich anzuwenden. Mit
dem AppLocker-Überwachungsmodus lassen sich auch Anwendungen beobachten, die von
einem oder mehreren Benutzern auf dem System genutzt werden.
Mit AppLocker können Administratoren die Ausführung folgender Arten von Dateien einschränken:
QQ Ausführbare Abbilder (EXE und COM)
QQ Dynamische Programmbibliotheken (DLL und OCX)
QQ Microsoft Software Installer (MSI und MSP) zum Installieren und Deinstallieren
QQ Skripte
QQ Windows PowerShell (PS1)
QQ Batchdateien (BAT und CMD)
QQ VisualBasic Script (VBS)
QQ JavaScript (JS)
Um festzulegen, welche Anwendungen und Skripte von einzelnen Benutzern und Gruppen ausgeführt werden dürfen, verwendet AppLocker einen einfachen regelbasierten Mechanismus mit
einer grafischen Oberfläche, der dem Mechanismus für Firewallregeln sehr stark ähnelt. Dabei
werden bedingte Zugriffssteuerungseinträge und AppID-Attribute verwendet. In AppLocker
gibt es die beiden folgenden Arten von Regeln:
QQ Regeln, die die Ausführung der angegebenen Dateien zulassen und alles andere verweigern
QQ Regeln, die die Ausführung der angegebenen Dateien verweigern und alles andere zulassen. Verweigerungsregeln haben Vorrang vor Zulassungsregeln.
Zu einer Regel kann auch eine Liste von Dateien gehören, die von der Regel ausgenommen
sind. Dadurch können Sie z. B. eine Regel erstellen, nach der alles, was sich in C:\Windows oder
C:\Programme befindet, ausgeführt werden darf, nur RegEdit.exe nicht.
882
Kapitel 7
Sicherheit
AppLocker-Regeln können mit einzelnen Benutzern und Gruppen verknüpft werden. Dadurch können Administratoren Compliance-Anforderungen umsetzen, indem sie festlegen,
welche Benutzer bestimmte Anwendungen ausführen dürfen. Beispielsweise können Sie eine
Regel aufstellen, die den Benutzern in der Sicherheitsgruppe Finanzen die Ausführung von
Finanzanwendungen erlaubt. Dadurch werden alle, die sich nicht in dieser Gruppe befinden,
davon abgehalten, diese Anwendungen zu nutzen (auch Administratoren), während diejenigen, die diese Anwendungen für ihre geschäftlichen Zwecke benötigen, darauf zugreifen können. Eine weitere nützliche Regel wäre beispielsweise eine, die verhindert, dass Benutzer in der
Gruppe Empfang nicht genehmigte Software installieren oder ausführen.
AppLocker-Regeln stützen sich auf bedingte Zugriffssteuerungsregeln und AppID-Attribute. Sie können unter Verwendung der folgenden Kriterien aufgestellt werden:
QQ Felder in dem Zertifikat zur Codesignierung, das in die Datei eingebettet ist, wobei verschiedene Kombinationen von Herausgeber-, Produkt- und Dateiname sowie
Version verwendet werden können Beispielsweise können Sie eine Regel erstellen, die
die Ausführung aller Versionen von Contoso Reader größer als 9.0 zulässt oder allen Mitgliedern der Gruppe Grafik erlaubt, den Installer oder die Anwendung von Contoso für
GraphicsShop auszuführen, sofern es sich um Version 14.* handelt. Der SDDL-String im
folgenden Beispiel verweigert dem Benutzerkonto RestrictedUser (identifiziert anhand der
Benutzer-SID) den Ausführungszugriff auf signierte Programme, die von Contoso herausgegeben wurden:
D:(XD;;FX;;;S-1-5-21-3392373855-1129761602-2459801163-1028;((Exists
APPID://FQBN) && ((APPID://FQBN) >= ({"O=CONTOSO, INCORPORATED, L=REDMOND,
S=CWASHINGTON, C=US\*\*",0}))))
QQ Verzeichnispfad, wobei nur Dateien in einem bestimmten Verzeichnisbaum ausgeführt werden dürfen Hiermit können auch einzelne Dateien bezeichnet werden. Der
folgende SDDL-Beispielstring verweigert dem Benutzerkonto RestrictedUser (identifiziert
anhand seiner SID) den Ausführungszugriff auf die Programme im Verzeichnis C:\Tools:
D:(XD;;FX;;;S-1-5-21-3392373855-1129761602-2459801163-1028;(APPID://PATH
Contains "%OSDRIVE%\TOOLS\*"))
QQ Dateihash Bei der Verwendung eines Hashs lässt sich auch erkennen, ob eine Datei manipuliert wurde, und ihre Ausführung in einem solchen Fall verweigern. Dies kann jedoch
von Nachteil sein, wenn die Dateien häufig geändert werden, da die Hashregel dann ebenso häufig angepasst werden muss. Dateihashes werden vor allem für Skripts verwendet,
da diese nur selten signiert werden. Der folgende SDDL-Beispielstring verweigert dem
Benutzerkonto RestrictedUser (identifiziert anhand seiner SID) den Ausführungszugriff auf
die Programme mit den angegebenen Hashwerten:
D:(XD;;FX;;;S-1-5-21-3392373855-1129761602-2459801163-1028;(APPID://SHA256HASH
Any_of {#7a334d2b99d48448eedd308dfca63b8a3b7b44044496ee2f8e236f5997f1b647,
#2a782f76cb94ece307dc52c338f02edbbfdca83906674e35c682724a8a92a76b}))
AppLocker
Kapitel 7
883
AppLocker-Richtlinien können auf dem lokalen Computer mithilfe des MMC-Snap-Ins Lokale
Sicherheitsrichtlinie (Secpol.msc, siehe Abb. 7–33) oder einem Windows PowerShell-Skript erstellt
werden. Auf Computern in einer Domäne können sie mithilfe einer Gruppenlinie bereitgestellt
werden. AppLocker-Regeln werden an verschiedenen Stellen in der Registrierung gespeichert:
QQ HKLM\Software\Policies\Microsoft\Windows\SrpV2
Dieser Schlüssel wird auch in HKLM\
SOFTWARE\Wow6432Node\Policies\Microsoft\Windows\SrpV2 gespiegelt. Die Regeln werden
im XML-Format gespeichert.
QQ HKLM\SYSTEM\CurrentControlSet\Control\Srp\Gp\Exe Die Regeln werden im SDDL-
Format und als binäre Zugriffssteuerungseinträge gespeichert.
QQ HKEY_CURRENT_USER\Software\Microsoft\Windows\CurrentVersion\Group Policy Objects\
{GUID}Machine\Software\Policies\Microsoft\Windows\SrpV2 Als Teil eines Gruppenrichtlinienobjekts in einer Domäne bereitgestellte AppLocker-Richtlinien werden hier im
XML-Format gespeichert.
Zertifikate für ausgeführte Dateien werden in der Registrierung unter HKLM\SYSTEM\CurrentControlSet\Control\AppID\CertStore gespeichert. AppLocker erstellt von dem Zertifikat in einer
Datei eine Zertifikatkette zurück zu einem vertrauenswürdigen Stammzertifikat (die dann in
HKLM\SYSTEM\CurrentControlSet\Control\AppID\CertChainStore gespeichert wird).
Für skriptgestützte Entwicklung und Tests gibt es die AppLocker-spezifischen Power
Shell-Cmdlets Get-AppLockerFileInformation, Get-AppLockerPolicy, New-AppLockerPolicy, Set-
AppLockerPolicy und Test-AppLockerPolicy, die Sie mit Import-Module AppLocker in die Power
Shell importieren können.
Abbildung 7–33 AppLocker-Konfigurationsseite in der lokalen Sicherheitsrichtlinie
884
Kapitel 7
Sicherheit
Der AppLocker- und der SRP-Dienst befinden sich nebeneinander in derselben Binärdatei
(AppIdSvc.dll), die in einem Diensthostprozess ausgeführt wird. Der Dienst fordert eine Benachrichtigung über Registrierungsänderungen an, um jegliche Änderungen an dem Schlüssel
zu beobachten, die von einem Gruppenrichtlinienobjekt oder von dem AppLocker-Element
im MMC-Snap-In Lokale Sicherheitsrichtlinie vorgenommen werden. Wird eine Änderung erkannt, so löst der AppID-Dienst den Benutzermodustask AppIdPolicyConverter.exe aus, um die
neuen (in XML geschriebenen) Regeln zu lesen und in binäre Zugriffssteuerungseinträge und
SDDL-Strings umzuwandeln, die sowohl für die Anwendungsidentifizierung im Benutzer- und
Kernelmodus als auch für die AppLocker-Komponenten verständlich sind. Diese übersetzten
Regeln speichert der Task im Schlüssel HKLM\SYSTEM\CurrentControlSet\Control\Srp\Gp, der
nur vom System und von Administratoren geschrieben werden kann und für authentifizierte
Benutzer als lesbar, aber nicht schreibbar gekennzeichnet ist. Sowohl die Benutzer- als auch
die Kernelmoduskomponenten der Anwendungsidentifizierung lesen die übersetzten Regeln
direkt in der Registrierung. Der Dienst überwacht auch den Speicher für vertrauenswürdige
Stammzertifikate auf dem lokalen Computer und ruft den Benutzermodustask AppIdCert
StoreCheck.exe auf, um die Zertifikate mindestens einmal täglich und bei jeder Änderung am
Zertifikatspeicher erneut zu überprüfen. Der Kernelmodustreiber für die Anwendungsidentifizierung (%SystemRoot%\System32\Drivers\AppId.sys) wird vom AppID-Dienst mithilfe der
DeviceIoControl-Anforderung APPID_POLICY_CHANGED über Regeländerungen benachrichtigt.
Nachdem AppLocker eingerichtet und der Dienst gestartet wurde, können Administratoren anhand des Systemereignisprotokolls in der Ereignisanzeige verfolgen, welche Anwendungen zugelassen oder verweigert werden (siehe Abb. 7–34).
Abbildung 7–34 Die Ereignisanzeige zeigt, wie AppLocker den Zugriff auf verschiedene Anwen
dungen zulässt oder verweigert. Das Ereignis 8004 zeigt eine Verweigerung,
Ereignis 8002 eine Zulassung.
AppLocker
Kapitel 7
885
Die Implementierungen von Anwendungsidentifizierung, AppLocker und SRP gehen ineinander über. Da die verschiedenen logischen Komponenten nebeneinander in denselben ausführbaren Dateien vorhanden sind, gibt es auch keine strenge Schichtung. Auch die Benennung ist
nicht so einheitlich, wie man es sich gern wünschen würde.
Der AppID-Dienst wird als lokaler Dienst ausgeführt, weshalb er Zugriff auf den Speicher
für vertrauenswürdige Stammzertifikate auf dem System hat. Dadurch kann er auch eine Verifizierung der Zertifikate durchführen. Zuständig ist dieser Dienst für folgende Aufgaben:
QQ Verifizierung der Herausgeberzertifikate
QQ Hinzufügen neuer Zertifikate zum Cache
QQ Erkennen von Änderungen an AppLocker-Regeln und Benachrichtigen des AppID-Treibers
Der AppID-Treiber kümmert sich um den Großteil der AppLocker-Funktionalität und stützt sich
dabei auf die Kommunikation mit dem AppID-Dienst (über DeviceIoControl-Anforderungen).
Sein Geräteobjekt ist mit einer Zugriffssteuerungsliste geschützt und gewährt den Zugriff nur
für NT-DIENST\AppldSvc, LOKALER DIENST und BUILTIN\Administratoren. Daher kann dieser Treiber von Malware nicht gefälscht werden.
Wenn der AppID-Treiber geladen wird, ruft er PsSetCreateProcessNotifyRoutineEx auf, um
einen Prozesserstellungscallback anzufordern. Bei ihrem Aufruf wird der Benachrichtigungsroutine eine PPS_CREATE_NOTIFY_INFO-Struktur übergeben (die den bereits erstellten Prozess
beschreibt). Anschließend erfasst die Routine die AppID-Attribute, die das ausführbare Abbild
identifizieren, und schreibt sie in das Zugriffstoken des Prozesses. Danach ruft sie die nicht
dokumentierte Routine SeSrpAccessCheck auf, die das Prozesstoken und die AppLocker-Regeln
in Form von bedingten Zugriffssteuerungseinträgen untersucht und darüber bestimmt, ob der
Prozess ausgeführt werden darf. Ist die Ausführung des Prozesses nicht erlaubt, schreibt der
Treiber STATUS_ACCESS_DISABLED_BY_POLICY in das Feld Status der PPS_CREATE_NOTIFY_INFOStruktur, was dazu führt, dass die Prozesserstellung abgebrochen wird, und den endgültigen
Beendigungsstatus des Prozesses festlegt.
Für die DLL-Einschränkung sendet der Abbildlader eine DeviceIoControl-Anforderung an
den AppID-Treiber, wenn er eine DLL in einen Prozess lädt. Der Treiber prüft dann wie bei einer
ausführbaren Datei die Identität der DLL anhand der bedingten AppLocker-Zugriffssteuerungseinträge.
Die Durchführung dieser Überprüfungen für jede geladene DLL ist zeitraubend
und kann eine für die Endbenutzer merkliche Verzögerung nach sich ziehen. Daher
sind DLL-Regeln normalerweise deaktiviert und müssen eigens aktiviert werden.
Dies geschieht auf der Registerkarte Erweitert auf der Eigenschaftenseite für App
Locker im Snap-In Lokale Sicherheitsrichtlinie.
Die Skript-Engines und der MSI-Installer wurden geändert, sodass sie beim Öffnen einer Datei
die Benutzermodus-SRP-APIs aufrufen, um zu prüfen, ob die Datei überhaupt geöffnet werden
darf. Diese APIs rufen die AuthZ-APIs auf, um die Zugriffsprüfung anhand der bedingten Zugriffssteuerungseinträge durchzuführen.
886
Kapitel 7
Sicherheit
Richtlinien für Softwareeinschränkung
Windows enthält den Benutzermodusmechanismus der Richtlinien für Softwareeinschränkung
(Software Restriction Policies, SRP), mit dem Administratoren festlegen können, welche Abbilder und Skripte auf ihren Systemen ausgeführt werden können. Der Knoten Richtlinien für
Softwareeinschränkung im Editor für lokale Sicherheitsrichtlinien (siehe Abb. 7–35) dient als
Verwaltungsschnittstelle für die Codeausführungsrichtlinien des Computers. Allerdings können benutzerspezifische Richtlinien auch über Gruppenrichtlinien in der Domäne festgelegt
werden.
Abbildung 7–35 Konfiguration der Richtlinien für Softwareeinschränkung
Unter dem Knoten Richtlinien für Softwareeinschränkung befinden sich verschiedene globale
Richtlinieneinstellungen:
QQ Erzwingen Diese Richtlinie legt fest, ob Einschränkungsrichtlinien auf Bibliotheken
angewendet werden sollen, z. B. auf DLLs, und ob sie nur für Benutzer oder auch für
Administratoren gelten.
QQ Designierte Dateitypen Diese Richtlinie gibt an, in welchem Ausmaß Dateien als ausführbarer Code angesehen werden.
QQ Vertrauenswürdige Herausgeber Diese Richtlinie bestimmt, wer auswählen kann, welchen Zertifikatherausgebern vertraut wird.
Richtlinien für Softwareeinschränkung
Kapitel 7
887
Bei der Konfiguration einer Richtlinie für ein bestimmtes Skript oder Abbild kann ein Administrator angeben, ob das Skript oder Abbild anhand seines Pfades, seines Hashs, seiner Internetzone
(laut Definition in Internet Explorer) oder seines kryptografischen Zertifikats erkannt werden
soll und ob es mit einer Sicherheitsrichtlinie vom Typ Nicht erlaubt oder Nicht eingeschränkt
verknüpft wird.
SRPs werden in den folgenden Komponenten erzwungen, die Dateien als ausführbaren
Code behandeln:
QQ Die Benutzermodusfunktion CreateProcess in Kernel32.dll erzwingt sie für ausführbare Abbilder.
QQ Der Code zum Laden von DLLs in Ntdll erzwingt sie für DLLs.
QQ Die Windows-Eingabeaufforderung (Cmd.exe) erzwingt sie für die Ausführung von Batchdateien.
QQ Windows Scripting Host-Komponenten, die Skripte starten – Cscript.exe für Befehlszeilenskripte, Wscript.exe für Benutzerschnittstellenskripte und Scrobj.dll für Skriptobjekte –,
erzwingen sie für die Skriptausführung.
QQ Der PowerShell-Host (PowerShell.exe) erzwingt sie für die Ausführung von PowerShellSkripten.
Jede dieser Komponenten bestimmt, ob die Einschränkungsrichtlinien aktiviert sind, indem sie
den Registrierungswert TransparentEnabled im Schlüssel HKLM\Software\Policies\Microsoft\
Windows\Safer\CodeIndentifiers liest. Wenn er auf 1 gesetzt ist, sind die Richtlinien in Kraft. Anschließend ermittelt die Komponente, ob auf den auszuführenden Code eine der Regeln zutrifft,
die in einem Unterschlüssel von CodeIdentifiers angegeben sind. Wenn ja, prüft sie, ob die Ausführung nach dieser Regel erlaubt ist. Trifft dagegen keine Regel zu, wird anhand der Standard
richtlinie im Wert DefaultLevel von CodeIdentifiers bestimmt, ob die Ausführung zulässig ist.
Richtlinien für Softwareeinschränkung sind ein wirkungsvolles Werkzeug, um den nicht
autorisierten Zugriff auf Code und Skripte zu verhindern, aber nur dann, wenn sie auch korrekt
angewandt werden. Schon durch kleine Änderungen an einem als unzulässig gekennzeichneten Abbild kann die konkrete Regel dafür umgangen werden. Beispielsweise könnte ein Benutzer ein harmloses Byte eines Prozessabbilds bearbeiten, sodass es von der Hashregel nicht mehr
erkannt wird, oder eine Datei an einen anderen Speicherort kopieren, um der Identifizierung
anhand des Pfads auszuweichen. Wenn die Standardrichtlinie die Ausführung nicht verbietet,
kann das Abbild dann ausgeführt werden.
888
Kapitel 7
Sicherheit
Experiment: Die Erzwingung von Richtlinien für
Softwareeinschränkung beobachten
Die Durchsetzung von SRPs können Sie indirekt beobachten, indem Sie während des Versuchs, ein unzulässiges Abbild auszuführen, auf die Registrierung zugreifen.
1.
Führen Sie Secpol.msc aus, um den Editor für lokale Sicherheitsrichtlinien zu starten,
und öffnen Sie den Knoten Richtlinien für Softwareeinschränkung.
2.
Wenn keine Richtlinien definiert sind, wählen Sie im Kontextmenü Neue Richtlinien für
Softwareeinschränkung erstellen.
3.
Erstellen Sie unter dem Knoten Zusätzliche Regeln eine Pfadregel der Sicherheitsstufe
Nicht erlaubt für %SystemRoot%\System32\Notepad.exe.
4.
Starten Sie Process Monitor und richten Sie einen Pfadfilter für Safer ein.
5.
Öffnen Sie eine Eingabeaufforderung und führen Sie dort den Editor (Notepad) aus.
Bei dem Versuch, den Editor zu starten, erhalten Sie die Meldung, dass Sie das angegebene
Programm nicht ausführen können. In Process Monitor können Sie beobachten, wie die
Eingabeaufforderung (Cmd.exe) die lokalen Einschränkungsrichtlinien auf dem Computer
abfragt.
Kernelpatchschutz
Manche Geräte ändern das Verhalten von Windows auf nicht vorgesehene Weise. Beispielsweise manipulieren sie die Systemaufruftabelle, um Systemaufrufe abzufangen, oder das
Kernelabbild im Arbeitsspeicher, um den Funktionsumfang einzelner interner Funktionen zu
erweitern. Solche Änderungen sind gefährlich und können die Stabilität und Sicherheit des
Systems beeinträchtigen. Außerdem ist es möglich, dass solche Manipulationen in böser Absicht erfolgen, entweder durch schädliche Treiber oder durch Exploits, die Schwachstellen in
Windows-Treibern ausnutzen.
Da es keine Entität mit höheren Rechten gibt als den Kernel selbst, ist es ziemlich knifflig,
Kernelexploits und schädliche Kerneltreiber zu erkennen und abzuwehren. Da sich sowohl die
Erkennungs- und Schutzmechanismen als auch das unerwünschte Verhalten in Ring 0 bewegen, ist es nicht möglich, eine Sicherheitsgrenze im wahren Sinne des Wortes zu ziehen, da das
unerwünschte Verhalten den Erkennungs- und Schutzmechanismus deaktivieren, manipulieren
oder täuschen kann. Allerdings kann ein Mechanismus, der auf unerwünschten Operationen
dieser Art reagiert, selbst unter diesen Umständen noch nützlich sein:
QQ Wenn dieser Mechanismus den Computer mit einem eindeutigen Kernelmodus-Absturzabbild abstürzen lässt, können sowohl Benutzer als auch Administratoren leicht erkennen,
dass im Kernel unerwünschtes Verhalten aufgetreten ist, und entsprechende Maßnahmen
ergreifen. Da die Hersteller legitimer Software die Systeme ihrer Kunden nicht zum Absturz bringen wollen, werden sie eher geneigt sein, nach ordnungsgemäßen Wegen zu
Kernelpatchschutz
Kapitel 7
889
suchen, auf denen sie den Funktionsumfang des Kernels erweitern können (z. B. durch
Verwendung des Filter-Managers für Dateisystemfilter oder durch andere Callbackmechanismen).
QQ Verschleierung (Obfuscation) bildet zwar keine Sicherheitsgrenze, kann es aber für Schadcode zeitraubender oder komplizierter machen, den Erkennungsmechanismus auszuschalten. Die verlängerte Dauer bzw. die höhere Komplexität bewirken, dass das unerwünschte
Verhalten deutlicher als potenziell schädlich erkannt werden kann, und bereiten dem Angreifer einen viel höheren Aufwand. Ein ständiger Wechsel der Verschleierungstechniken
veranlasst Hersteller legitimer Software dazu, ihre veralteten Erweiterungsmechanismen
aufzugeben und stattdessen unterstützte Techniken einzusetzen, bei denen nicht die Gefahr besteht, für Malware gehalten zu werden.
QQ Randomisierung, fehlende Dokumentation der Prüfungen, die der Erkennungs- und
Schutzmechanismus konkret durchführt, und Indeterminismus bei der Auswahl der Zeitpunkte, an denen die Prüfungen stattfinden, machen Exploits unzuverlässig. Angreifer
sind gezwungen, alle möglichen indeterministischen Variablen und Zustandsübergänge
des Mechanismus durch statische Analyse zu berücksichtigen. Dank der Verschleierung
lässt sich eine solche Analyse aber unmöglich erledigen, bevor in dem Mechanismus
der nächste Wechsel der Verschleierungstechnik oder eine Änderung von Merkmalen
erfolgt.
QQ Da Kernelmodus-Absturzabbilder automatisch an Microsoft übertragen werden, erhält
das Unternehmen reale Telemetriedaten über unerwünschten Code. Damit kann es Softwarehersteller erkennen, die nicht unterstützten Code verwenden und damit für Systemabstürze sorgen, die Ausbreitung von Malware verfolgen, Zero-Day-Kernelexploits
aufspüren und Bugs korrigieren, die niemals gemeldet wurden, aber von Angreifern ausgenutzt werden.
PatchGuard
Kurz nach der Veröffentlichung von 64-Bit-Windows für x64 und noch bevor sich ein umfassender Drittanbietermarkt entwickeln konnte, hat Microsoft die Gelegenheit ergriffen, die Stabilität
von 64-Bit-Windows zu wahren. Dazu hat das Unternehmen mithilfe des Kernelpatchschutzes
(Kernel Patch Protection, KPP), auch PatchGuard genannt, die Übermittlung von Telemetriedaten und eine Patcherkennung eingeführt, die Exploits lahmlegen. Als Windows Mobile veröffentlich wurde, das auf einem 32-Bit-ARM-Prozessorkern läuft, wurde dieses Feature auch auf
solche Systeme portiert, und es wird auch auf 64-Bit-ARM-Systemem (AArch64) zur Verfügung
stehen. Da es noch viel zu viele veraltete 32-Bit-Treiber gibt, die nicht unterstützte und gefährliche Hooktechniken verwenden, ist dieser Mechanismus auf den entsprechenden Systemen
jedoch nicht aktiviert, nicht einmal unter Windows 10. Zum Glück geht die Ära der 32-Bit-
Systeme langsam zu Ende. Die Serverversionen von Windows gibt es für die Architektur schon
gar nicht mehr.
Die Bezeichnungen Protection und Guard wecken zwar die Vorstellung, dass dieser Mechanismus das System schützt, allerdings besteht dieser Schutz nur darin, den Computer zum
890
Kapitel 7
Sicherheit
Absturz zu bringen, damit der unerwünschte Code nicht weiter ausgeführt werden kann. Der
Mechanismus verhindert den Angriff nicht und macht ihn auch nicht rückgängig. Sie können
sich den Kernelpatchschutz wie eine mit dem Internet verbundene Überwachungskamera vorstellen, die einen lauten Alarm (Absturz) im Banksafe (Kernel) auslöst, aber nicht als ein Sicherheitsschloss an dem Tresor.
Der Kernelpatchschutz führt eine Vielzahl von verschiedenen Prüfungen durch. Sie alle
zu dokumentieren, wäre nicht nur impraktikabel (aufgrund der Schwierigkeiten der statischen
Analyse), sondern würde auch Angreifern entgegenspielen (da es die erforderliche Recherchezeit für sie verringern würde). Einige dieser Prüfungen sind jedoch von Microsoft dokumentiert.
In Tabelle 7–23 finden Sie einen allgemein gehaltenen Überblick darüber. Wann, wo und wie
der Kernelpatchschutz diese Überprüfungen durchführt und welche Funktionen und Daten
strukturen dabei konkret betroffen sind, können wir hier jedoch nicht zeigen.
Komponente
Legitime Nutzung
Unerwünschte Nutzung
Ausführbarer Code im Kernel,
seine Abhängigkeiten und
Kerntreiber sowie die Importadresstabelle (IAT) dieser
Komponenten
Windows-Standardkomponenten, die für die Verwendung
des Kernels von entscheidender
Bedeutung sind
Die Manipulation des Codes dieser
Komponenten kann ihr Verhalten
ändern, Hintertüren in dem System
einrichten, Daten und unerwünschte Kommunikation verbergen, die
Stabilität des Systems beeinträchtigen und aufgrund von Bugs in dem
Drittanbietercode sogar zusätzliche
Schwachstellen einbringen.
Globale Deskriptortabelle
(GDT)
CPU-Hardwareschutz zur Implementierung von Ringen mit
unterschiedlicher Rechteebene
(Ring 0/Ring 3)
Änderung der Berechtigungen und
der Zuordnung zwischen Code und
Ringebenen, sodass Ring-3-Code
Zugriff auf Ring 0 bekommt
Interruptdeskriptortabelle
(IDT) oder Interruptvektortabelle
Lesen in der Tabelle durch die
CPU zur Auslieferung von Interruptvektoren an die zugehörigen Routinen zur Handhabung
der Interrupts
Abfangen von Tastenbetätigungen,
Netzwerkpaketen, Systemaufrufen,
des Auslagerungsmechanismus,
der Hypervisorkommunikation
usw. Das kann genutzt werden, um
Hintertüren einzurichten und um
schädlichen Code und schädliche
Kommunikation zu verbergen.
Fehlerbehafteter Drittanbietercode
kann zu zusätzlichen Schwachstellen führen.
Systemdienst-Deskriptortabelle (SSDT)
Tabelle mit einem Array aus
Zeigern auf die einzelnen
Systemaufrufhandler
Abfangen der gesamten Benutzermoduskommunikation mit dem
Kernel; die gleichen Probleme wie
oben
Kritische CPU-Register wie
Steuerregister, Vektorbasisadressen-Register und modellspezifische Register
Für Systemaufrufe, Virtualisierung, Aktivieren der CPU-Sicherheitsmerkmale wie SMEP
usw.
Wie vor; des Weiteren können damit wichtige CPU-Sicherheitsmerkmale und der Hypervisorschutz
ausgeschaltet werden.
Verschiedene Funktionszeiger
im Kernel
Wird für indirekte Aufrufe verschiedener interner Einrichtungen genutzt.
Kann zum Einklinken in interne
Kerneloperationen genutzt werden,
was zu Instabilitäten führen kann
und die Möglichkeit zur Einrichtung von Hintertüren gibt.
→
Kernelpatchschutz
Kapitel 7
891
Komponente
Legitime Nutzung
Unerwünschte Nutzung
Verschiedene globale Variablen im Kernel
Konfiguration verschiedener
Teile des Kernels, darunter auch
einzelner Sicherheitsmerkmale
Schadcode kann die Sicherheitsmerkmale ausschalten, z. B. durch
einen Benutzermodusexploit, der
ein willkürliches Überschreiben des
Speichers ermöglicht.
Prozess- und Modulliste
Wird verwendet, um dem Benutzer in Programmen wie dem
Task-Manager, Process Explorer
und dem Windows-Debugger
zu zeigen, welche Prozesse aktiv
und welche Treiber geladen
sind.
Schadcode kann das Vorhandensein einzelner Prozesse oder Treiber
vor dem Benutzer und den meisten
Anwendungen verbergen, darunter
auch vor Sicherheitssoftware.
Kernelstacks
Speichern von Funktionsargumenten, des Aufrufstacks (wohin eine Funktion zurückspringen soll) und von Variablen
Die Verwendung eines nicht standardmäßigen Kernelstacks ist oft
ein Zeichen eines ROP-Exploits (Return-Oriented Programming), bei
dem ein Pivotstack verwendet wird.
Fenster-Manager, Grafik
systemaufrufe, -callbacks usw.
Stellt die GUI-, GDI- und
DirectX-Dienste bereit.
Bietet die schon zuvor beschriebenen Abfangmöglichkeiten, konzentriert sich aber insbesondere auf
den Grafik- und den Fensterverwaltungsstack. Die gleichen Probleme
wie bei anderen Arten von Hooks.
Objekttypen
Definitionen für die verschiedenen Objekte (wie Prozesse
und Dateien), die das System
mithilfe des Objekt-Managers
unterstützt.
Kann als weitere Technik für Hooks
verwendet werden, die keine indirekten Funktionszeiger in den
Datenabschnitten von Binärdateien
angreifen und Code auch nicht
direkt manipulieren. Hierbei bestehen die gleichen Probleme wie bei
den zuvor erwähnten Hooks.
Lokaler APIC
Zum Empfang von Hardware
interrupts auf dem Prozess, von
Timerinterrupts und von Interprozessorinterrupts (IPI)
Kann verwendet werden, um sich
in die Timerausführung, in IPIs
und andere Interrupts einzuklinken. Persistenter Code kann damit
verdeckt auf dem Computer aktiv
bleiben, indem er periodisch ausgeführt wird.
Filter und Drittanbieter-Benachrichtigungscallbacks
Wird von legitimer Drittanbieter-Sicherheitssoftware (und
Windows Defender) genutzt,
um Benachrichtigungen über
Systemaktivitäten zu empfangen, und in manchen Faällen
sogar dazu, bestimmte Aktionen zu blockieren bzw. abzuwehren. Dies ist eine zulässige
Möglichkeit, um viel von dem
zu erreichen, was der Kernelpatchschutz sonst verhindert.
Kann von Schadcode genutzt
werden, um sich in alle filterbaren
Operationen einzuklinken und um
durch periodische Ausführung auf
dem Computer aktiv zu bleiben.
892
Kapitel 7
Sicherheit
→
Komponente
Legitime Nutzung
Unerwünschte Nutzung
Sonderkonfigurationen und
-flags
Verschiedene Datenstrukturen,
Flags und Elemente legitimer
Komponenten, die diesen
Komponenten Sicherheits- und
Abwehrgarantien geben.
Kann von Schadcode genutzt werden, um Abwehrmaßnahmen zu
umgehen und um Garantien und
Erwartungen von Benutzermodusprozessen zu verletzen, z. B. um
den Schutz eines Prozesses aufzuheben.
KPP-Engine
Code im Zusammenhang mit
der Fehlerprüfung des Systems
während einer Verletzung des
Kernelpatchschutzes, mit der
Ausführung der Callbacks für
den Kernelpatchschutz usw.
Durch Manipulation einzelner Teile
des Systems, die vom Kernelpatchschutz verwendet werden, können
unerwünschte Komponenten den
Kernelpatchschutz zum Schweigen
bringen, umgehen oder auf andere
Weise lahmlegen.
Tabelle 7–23 Allgemeine Beschreibung der vom Kernelpatchschutz abgesicherten Elemente
Wenn der Kernelpatchschutz unerwünschten Code entdeckt, bringt er das System mit einem
leicht erkennbaren Code zum Absturz. Dieser Code entspricht dem Bugcheck-Code 0x109, der
für CRITICAL_STRUCTURE_CORRUPTION steht. Das Absturzabbild kann mit dem Windows-Debugger analysiert werden (siehe Kapitel 15 in Band 2). Es enthält einige Informationen über den
beschädigten oder manipulierten Teil des Kernels. Alle weiteren Daten aber sind für Benutzer
nicht verfügbar, sondern werden von den OCA- und WER-Teams von Microsoft (Online Crash
Analysis und Windows Error Reporting) untersucht.
Anstelle der vom Kernelpatchschutz abgelehnten Techniken können Drittanbieterentwickler die folgenden zulässigen Vorgehensweisen einsetzen:
QQ Dateisystem(mini)filter Damit können Sie sich in sämtliche Dateioperationen einklinken, auch in das Laden von Abbilddateien und DLLs, die abgefangen werden können, um
Schadcode im laufenden Betrieb zu entfernen oder das Lesen bekanntermaßen schädlicher
ausführbarer Dateien und DLLs zu verhindern (siehe Kapitel 13 in Band 2).
QQ Filterbenachrichtigungen für die Registrierung Damit können Sie sich in alle Registrierungsoperationen einklinken (siehe Kapitel 9 in Band 2). Sicherheitssoftware kann die
Änderung kritischer Teile der Registrierung blockieren und Schadsoftware anhand von Registrierungszugriffsmustern und bekanntermaßen gefährlichen Registrierungsschlüsseln
auf heuristische Weise erkennen.
QQ Prozessbenachrichtigungen Sicherheitssoftware kann die Ausführung und Beendigung
aller Prozesse und Threads auf dem System sowie das Laden und Entladen von DLLs beobachten. Mit den erweiterten Benachrichtigungen, die für Hersteller von Antivirus- und
anderer Sicherheitssoftware hinzugefügt wurden, kann sie auch das Starten von Prozessen
blockieren (siehe Kapitel 3).
QQ Objekt-Manager-Filterung Sicherheitssoftware kann bestimmte Zugriffsrechte für Prozesse und Threads entfernen, um sich selbst gegen bestimmte Arten von Operationen zu
schützen (siehe Kapitel 8 in Band 2).
Kernelpatchschutz
Kapitel 7
893
QQ LWF und WFP-Filter (NDIS Lightweight Filters/Windows Filtering Platform) Sicherheitssoftware kann alle Socketoperationen (Akzeptieren, Lauschen, Verbinden, Schließen
usw.) und sogar die Pakete selbst abfangen. Mit LWF haben die Hersteller von Sicherheitssoftware Zugriff auf die rohen Ethernet-Framedaten, die von der Netzwerkkarte zum Kabel
fließen.
QQ Ereignisablaufverfolgung für Windows (Event Tracing for Windows, ETW) Mithilfe
von ETW können Benutzermoduskomponenten viele Arten von Operationen mit sicherheitsrelevanten Eigenschaften verarbeiten und dann in beinahe Echtzeit darauf reagieren.
Bei Abschluss eines Geheimhaltungsvertrags mit Microsoft und Teilnahme an verschiedenen Sicherheitsprogrammen sind für Prozesse, die von Antimalware geschützt werden, auch
besondere, sichere ETW-Benachrichtigungen verfügbar. Dadurch erhalten die Hersteller Zugriff auf umfassendere Ablaufverfolgungsdaten. (Mehr über ETW erfahren Sie in Kapitel 8
von Band 2.)
HyperGuard
Auf Systemen mit virtualisierungsgestützter Sicherheit (siehe den Abschnitt »Virtualisierungsgestützte Sicherheit« weiter vorn in diesem Kapitel) wird Schadcode mit Kernelmodusrechten auf VTL 0 ausgeführt, also nicht mehr unbedingt auf derselben Sicherheitsebene wie ein
Erkennungs- und Schutzmechanismus, der auch auf VTL 1 implementiert werden kann. Im
Anniversary Update von Windows 10 (Version 1607) ist ein solcher Mechanismus unter der
Bezeichnung HyperGuard vorhanden. Er unterscheidet sich durch einige bemerkenswerte Eigenschaften von PatchGuard:
QQ Die Namen der Symboldateien und Funktionen, die HyperGuard implementieren, sind für
jeden einsehbar, und der Code ist nicht verschleiert. Eine vollständige statische Analyse ist
möglich. HyperGuard ist eine echte Sicherheitsgrenze und muss daher nicht auf Verschleierungstechniken zurückgreifen.
QQ HyperGuard muss nicht indeterministisch ausgeführt werden, da dies aufgrund der zuvor
genannten Eigenschaft keinen Vorteil mehr bieten würde. Die deterministische Vorgehensweise ermöglicht es HyperGuard sogar, das System genau zu dem Zeitpunkt zum Absturz
zu bringen, an dem das unerwünschte Verhalten auftritt. Dadurch enthalten die Absturzdaten eindeutige und zielführende Informationen für Administratoren und die Analyseteams von Microsoft, z. B. den Kernelstack, der den Code zeigt, von dem das unerwünschte
Verhalten ausgelöst wurde.
QQ Aufgrund der vorstehenden Eigenschaft kann HyperGuard eine breite Palette von Angriffen erkennen, da Schadcode keine Möglichkeit mehr hat, Werte in einem exakt bemessenen Zeitfenster auf ihre korrekte Einstellung zurückzusetzen. Letztere Möglichkeit war eine
ungünstige Nebenwirkung des Indeterminismus von PatchGuard.
HyperGuard dient auch dazu, die Fähigkeiten von PatchGuard auf bestimmte Weise zu erweitern und dessen Fähigkeit zu verbessern, sich vor Angreifern zu verbergen, die es ausschalten
wollen. Wenn HyperGuard Inkonsistenzen wahrnimmt, bringt es das System ebenfalls zum Ab-
894
Kapitel 7
Sicherheit
sturz, allerdings mit dem eigenen Code 0x18C (HYPERGUARD_VIOLATION). Auch hier ist es wiederum nützlich, zumindest grob zu wissen, was HyperGuard schützen kann. Eine entsprechende
Übersicht finden Sie in Tabelle 7–24.
Komponente
Legitime Nutzung
Unerwünschte Nutzung
Ausführbarer Code im Kernel,
seine Abhängigkeiten und
Kerntreiber sowie die Importadresstabelle (IAT) dieser Komponenten
Siehe Tabelle 7–23
Siehe Tabelle 7–23
Globale Deskriptortabelle (GDT)
Siehe Tabelle 7–23
Siehe Tabelle 7–23
Interruptdeskriptortabelle (IDT)
oder Interruptvektortabelle
Siehe Tabelle 7–23
Siehe Tabelle 7–23
Kritische CPU-Register wie
Steuerregister, GDTR, IDTR, Vektorbasisadressen-Register und
modellspezifische Register
Siehe Tabelle 7–23
Siehe Tabelle 7–23
Ausführbarer Code, Callbacks
und Datenregionen im sicheren
Kernel und seinen Abhängigkeiten, einschließlich HyperGuard
selbst
Windows-Standardkomponenten, die für die Verwendung von
VTL 1 und des sicheren Kernels
von entscheidender Bedeutung
sind
Ist Patchcode in diesen Kompo
nenten vorhanden, so muss der
Angreifer irgendeine Form von
Zugriff auf eine Schwachstelle
in VTL 1 haben, entweder durch
die Hardware oder den Hyper
visor. Damit können Device
Guard, HyperGuard und
Credential Guard ausgehebelt
werden.
Von Trustlets verwendete Strukturen und Features
Gemeinsame Nutzung von
Trustlets untereinander, zwischen Trustlets und dem Kernel
oder zwischen Trustlets und
VTL 0
Lässt darauf schließen, dass es in
einem oder mehreren Trustlets
Schwachstellen gibt, mit denen
sich Features wie Credential
Guard oder Shielded Fabric/
vTPM behindern lassen.
Hypervisor-Strukturen und
-Regionen
Wird vom Hypervisor zur Kommunikation mit VTL 1 genutzt.
Lässt darauf schließen, dass
es eine Schwachstelle in einer
VTL-1-Komponente oder dem
Hypervisor selbst gibt, die von
Ring 0 in VTL 0 aus zugänglich
ist.
Kernel-CFG-Bitmap
Wird zur Identifizierung gültiger
Kernelfunktionen verwendet, die
das Ziel indirekter Funktionsaufrufe oder Sprünge sind (siehe
die Beschreibung weiter vorn).
Lässt darauf schließen, dass ein
Angreifer in der Lage war, die
VTL-1-geschützte KCFG-Bitmap
durch einen Hardware- oder
Hypervisor-Exploit zu manipulieren.
Seitenverifizierung
Dient zur Implementierung
der HVCI-Aufgaben für Device
Guard.
Lässt darauf schließen, dass
ein SKCI auf irgendeine Weise
angegriffen wurde. Das kann zu
einer Unterwanderung von Device Guard und zu nicht autorisierten IUM-Trustlets führen.
→
Kernelpatchschutz
Kapitel 7
895
Komponente
Legitime Nutzung
Unerwünschte Nutzung
NULL-Seite
Keine
Lässt darauf schließen, dass ein
Angreifer den Kernel oder den
sicheren Kernel auf irgendeine
Weise dazu gebracht hat, die
virtuelle Seite 0 zuzuweisen.
Dies kann dazu verwendet werden, um NULL-Seiten-Schwachstellen in VTL 0 und VTL 1
auszunutzen.
Tabelle 7–24 Allgemeine Beschreibung der von HyperGuard geschützten Elemente
Auf Systemen mit aktivierter virtualisierungsgestützter Sicherheit gibt es noch eine andere
wichtige Sicherheitseinrichtung, die im Hypervisor selbst implementiert ist, nämlich die Verhinderung der Ausführung nicht privilegierter Anweisungen (Non-Privileged Instruction Execution Prevention, NPIEP). Sie kümmert sich um besondere x64-Anweisungen, die missbraucht
werden können, um die Kernelmodusadressen der GDT, IDT und LDT durchsickern zu lassen
(SGDT, SIDT und SLDT). Bei Verwendung von NPIEP dürfen diese Anweisungen zwar immer
noch ausgeführt werden (aus Kompatibilitätsgründen), geben aber nur eine auf dem Prozessor
eindeutige Zahl zurück und nicht die wahre Kerneladresse der betreffenden Struktur. Dies dient
als Schutz gegen KASLR-Informationslecks (Kernel-ASLR) durch lokale Angriffe.
Wenn PatchGuard und HyperGuard einmal aktiviert sind, gibt es keine Möglichkeit, sie
wieder auszuschalten. Da die Hersteller von Gerätetreibern im Rahmen des Debuggings jedoch Änderungen an einem laufenden System vornehmen können müssen, ist PatchGuard bei
einem Systemstart im Debugmodus mit aktiver Verbindung für das Remotekerneldebugging
nicht aktiviert. Auch HyperGuard wird deaktiviert, wenn der Hypervisor im Debugmodus mit
angeschlossenem Remotedebugger startet.
Zusammenfassung
Windows bietet eine breite Palette von Sicherheitsfunktionen, die die Kernanforderungen
sowohl von staatlichen Stellen als auch von kommerziellen Unternehmen erfüllen. In diesem
Kapitel haben Sie sich einen Überblick über interne Komponenten verschafft, auf denen diese
Sicherheitsfunktionen beruhen. In Kapitel 8 von Band 2 schauen wir uns die einzelnen Mechanismen an, die überall in Windows verstreut sind.
896
Kapitel 7
Sicherheit
Index
! 45
64-Bit-Adressraumlayouts 406
.NET Framework 6
.process 122
A
AAM (Admin Approval Mode) 848
Abbilder
Abbildverschiebung 418
HAL 89
laden siehe Abbildlader
native Abbilder 81
öffnen 151
Randomisierung des Benutzeradressraums
418
Abbildlader
Ablaufsteuerungsschutz 872
Aktivierungskontext 182
API-Sets 194
Binary Planting 179
Datenbank der geladenen Module 183
DLL-Namensauflösung 179
DLL-Namensumleitung 181
DLL-Suchreihenfolge 182
frühe Initialisierung 176
Importanalyse 188
Prozessinitialisierung nach dem Import 190
sicherer DLL-Suchmodus 179
Switchback 191
Überblick 173
untersuchen 175
Abbildverschiebung 418
Ablaufsteuerungsschutz 862
Abbildlader 872
CFG-Bitmap 866
CFG-Unterdrückung 863
Exportunterdrückung 871
Kernel-CFG 874
Überblick 862
untersuchen 863
verstärken 870
Ablaufverfolgung
Prozessstart 167
SuperFetch 543
Abschnittsobjekte 462
Abwehrmaßnahmen 421
Abwehrmaßnahmen gegen Exploits
Abwehrmaßnahmen auf Prozessebene 856
CFG siehe Ablaufsteuerungsschutz
CFI (Control Flow Integrity) 861
Überblick 856
Zusicherungen siehe Zusicherungen
Address Windowing Extensions (AWE) 25, 368
Administratorgenehmigungsmodus 848
Administratorrechte 847
Adressraum
64-Bit-Adressraumlayouts 406
Abbildverschiebung 418
Adressnutzung beobachten 410
ARM-Adressraumlayout 405
Arten von Daten 396
Benutzeradressräume siehe Benutzeradressräume
dynamische Zuweisung 408
Einschränkungen für virtuelle x64-Adressen
408
Grenzwerte für Adressen festlegen 413
ImageBias 418
kanonische Adressen 408
Kontingente 415
Prozesse erstellen 156
PTEs 404
Seitentabelleneinträge 404
Sitzungen 401
x86-Adressraumlayout 397, 401
x86-Sitzungsraum 401
Adressübersetzung
ARM 434
PTEs 426
Schreibbit 428
Seitentabellen 426
TLB 429
Überblick 422
untersuchen 430
x64 433
x86 422
Affinitäts-Manager 382
Affinitätsmasken
erweiterte Affinitätsmasken 311
symmetrisches Multiprocessing 59
Threads 309
Aktivierungskontext 182
897
Anmeldeinformationsanbieter 109
Anmeldung
aktive Anmeldesitzungen untersuchen 830
Benutzerauthentifizierung 828
Gruppenansprüche 834
Kerberos 829
MSV1_0 828
SAS 826
sichere Authentifizierung 833
Überblick 824
WBF 835
Windows-Anmeldeprozess 109
Windows Hello 837
Winlogon-Initialisierung 826
Anspruchsgestützte Zugriffssteuerung 772
Anwendungen siehe auch Prozesse
Anwendungscontainer siehe Anwendungscontainer
AppID 880
AppLocker 881
Desktopanwendungen 115
klassische Anwendungen 115
moderne Apps 115
umfangreiche Adressräume 399
UWP-Apps 794
Anwendungscontainer
Broker 822
Fähigkeiten 810
Handles 818
Lowbox 149
Objektnamensräume 816
Token 801
Überblick 793
UWP-Apps 794
UWP-Prozesse 796
APIs
API-Sets 194
AuthZ 771
COM 5
.NET Framework 6
Überblick 4
Windows-Laufzeit 5
API-Sets 194
AppID 880
AppLocker 881
Arbeitsfactorys 335
Arbeitssätze
Arbeitsspeicher 472
Auslagerung bei Bedarf 472
Balance-Set-Manager 482
Benachrichtigungsereignisse 485
Größe anzeigen 479
Platzierungsrichtlinien 477
Prefetcher 472
ReadyBoot 473
Swapper 482
Systemarbeitssätze 483
898
Index
Überblick 472
verwalten 477
Arbeitsspeicher
Abschnittsobjekte 462
AWE (Address Windowing Extensions) 25, 367
Enklaven 536
Grenzwerte 512
IRQL-Überprüfung 641
Komprimierung 102, 515
Partitionen 523
Poolnachverfolgung 640
Simulation geringer Ressourcen 641
sonstige Prüfungen 642
spezieller Pool 639
Stacks 454
virtueller Arbeitspeicher 23
Windows-Clienteditionen 513
WSRM 248
zusammenführen 526
Architektur
Benutzermodus 53
Kernelmodus 53
Komponenten 69
Überblick 53, 69
VBS 66
ARM
Adressraumlayout 405
Adressübersetzung 433
ASLR 416, 856, 867
Asymmetrisches Multiprocessing 58
Asynchrone E/A 586
Atomtabelle 808
Attribute
Anwendungscontainer 805
konvertieren 145
Trustlets 139
Auflistung 645
Ausführungsbereite Threads 256
Ausführungsschutz 362
Ausgabe
dump 44
ETHREAD 218
Gerätebäume 647
KTHREAD 218
Silokontext 208
Ausgelagerter Pool 370
Ausgleichssatz-Manager, Prioritätserhöhung 277
Auslagerung bei Bedarf 472
Auslagerungsdatei
Größe 452
Reservierung 509
Überblick 442
untersuchen 445
UWP-Auslagerungsdatei 447
virtuelle Auslagerungsdatei 448
Auslassen der durchsuchenden Überprüfung 782
Ausrufezeichen 45
Auswählen
Prozessoren 320
Threads 299, 319
Authentifizierung
aktive Anmeldesitzungen untersuchen 830
Benutzer 827
Kerberos 829
MSV1_0 828
Richtlinien 710
AuthZ 771
Autoboost 286
Automatische Rechteerweiterung 852
AWE (Address Windowing Extensions) 25, 367
B
Balance-Set-Manager, Arbeitssätze 482
Bandbreite reservieren 634
Bäume 645
Bedingte Zugriffssteuerungseinträge 772
Beenden
E/A 619
Prozesse 172
TerminateJobObject 199
Threads 291, 619
Befehle
! 45
~ 225, 233
!address 868
at 8
AuditPol 790
Bang-Befehle 45
!ca 467, 470
!cpuinfo 260
cron 8
!dd 433
dd 432
!devnode 647
!devobj 579, 602
!devstack 598
docker 211
!dq 431
!drvobj 579, 587, 594
dt 45, 87, 120, 203
dump 44
!file 467
!fileobj 585
g 79, 297
!handle 121, 467, 821
!heap 385
!heap -i 389
!heap -s 387
!irp 596, 600, 621
!irpfind 599
!job 201, 298, 333
k 79, 234
!list 186
lm 125
!lookaside 377
!memusage 469
!numa 303
!object 577
!partition 525
!pcr 86, 292
!peb 122, 185
!pfn 508
!pocaps 686
poolmon 372
!poolused 374
!popolicy 688
powercfg /a 681
powercfg /h 680
powercfg /list 687
!prcb 86
!process 121, 201, 219, 293, 595
.process 122
!pte 426, 431, 535
q 48
!ready 256
runas 113
!sd 757
!session 402
!silo 210
!smt 302
start 243
!sysptes 404
!teb 224
!thread 121, 219, 224, 293, 595
!token 734
u 79
!vad 459
ver 2
!verifier 640
!vm 348, 403
!wdfkd.wdfldr 667
winver 2
!wsle 481
Benachrichtigungsereignisse 485
Benutzer
aktive Anmeldesitzungen untersuchen 830
Authentifizierung 827
E/A abbrechen 618
Kerberos 829
mehrere Sitzungen 32
MSV1_0 828
schneller Benutzerwechsel 33, 546
SuperFetch 545
Benutzeradressraum
Abbildrandomisierung 418
Abwehrmaßnahmen 421
EMET 421
Heaprandomisierung 420
IRPs 607
Index
899
Kernel 420
Ladeadresse berechnen 419
Layout 416
Stackrandomisierung 420
Überblick 416
Unterstützung für Randomisierung 421
untersuchen 417
Benutzerkontensteuerung
Administratorgenehmigungsmodus 848
Administratorrechte 847
automatische Rechteerweiterung 852
Dateivirtualisierung 839
Einstellungen 853
Genehmigungserweiterung 848
Rechteerweiterung 848
Registrierungsviertualisierung 839, 845
Überblick 839
Über-die-Schulter-Rechteerweiterung 848
Benutzermodus
Architektur 53
Vergleich mit Kernelmodus 26, 52
Benutzermodusdebugging
Debugging Tools for Windows 43
Threads anzeigen 233
Benutzerstacks 455
Besitzerrechte-SIDs 765
Besonderer Pool 370
Betriebssystem
Modell 52
Multitasking 57
Skalierbarkeit 60
Zusicherungen 876
Binary Planting 179
BNO-Isolierung 822
Broker 822
Buckets 382
Bumps 631, 633
Bustreiber 566
C
CBAC (Claims-Based Access Control) 772
CC (Common Criteria) 699
CFG siehe Ablaufsteuerungsschutz
CFG-Bitmap 866
CFG-Unterdrückung 863
CFI (Control Flow Integrity) 861
Clienteditionen 513
COM 5
Common Criteria (CC) 699
Compiler 876
Component Object Model (COM) 5
Container
Container 211
erstellen 210
Hilfsfunktionen 211
900
Index
Isolierung 205
Kontext 207
Objekte 204
Überblick 204
Überwachung 209
Containerbenachrichtigung 634
Control Flow Integrity (CFI) 861
Copy-on-Write 366
CPU
Aushungern 276
CPU-Rate 330
CPU-Sätze 313
Credential Guard
Authentifizierungsrichtlinien 710
Kennwörter 706
Kerberos-Armoring 710
NTOWF/TGT 707
sichere Kommunikation 708
Überblick 705
UEFI 710
CSR_PROCESS 117, 123
CSR_THREAD 217, 229
D
Dateien
Auslagerungsdatei siehe Auslagerungsdatei
Dateizuordnungsobjekte 22
E/A in zugeordneten Dateien 589
im Speicher zugeordnete Dateien 358
INF-Dateien 658
Katalogdateien 660
Virtualisierung 838
zwischenspeichern 589
Dateiobjekte 582
Dateizuordnungsobjekte 22
Daten
Adressraum 396
laden 541
Datenausführungsverhinderung 362
Datenbanken
Abbildlader 183
Datenbank der geladenen Module 183
Dispatcherdatenbank 255
Datenstrukturen
CSR_PROCESS 117, 123
CSR_THREAD 217, 229
DXGPROCESS 117
EPROCESS 117
ETHREAD 117, 216
KPROCESS 118
KTHREAD 216
PFN 504
!process 121
W32PROCESS 117, 125
Deadline Scheduling 285
Debugging
Benutzermodus 43, 233
DebugActiveProcess 43
DebugBreak 215
Debugging Tools for Windows 43
Heap 389
Kernelmodus 43, 234
nicht beendbare Prozesse 619
Typinformationen untersuchen 45
Deferred Procedure Calls (DPCs)
E/A 563
Stacks 457
DEP (Data Execution Protection) 362
Dependency Walker
exportierte Funktionen 38
HAL-Abbildabhängigkeiten 90
Teilsysteme 70
Designziele 51
Desktopanwendungen 115
Device Guard 712
DFSS (Dynamic Fair Share Scheduling) 326
Dienste
Dienstprozesse 109
Dienststeuerungs-Manager 107
Speicher-Manager 350
Systemdienstdispatcher 79
Trustlets 141
Überblick 8
untersuchen 109
Dienstprozesse 109
Dienststeuerungs-Manager 107
Direct Switch 287
Direkter Kontextwechsel 22
Dispatcher 240
Dispatcherdatenbank 255
Dispatchereignisse 267
Dispatchroutinen
Gerätetreiber 578
IRPs 594
DLLs
analysieren 188
Anmeldeinformationsanbieter 109
DllMain 173
Namensauflösung 179
Namensumleitung 181
Ntdll.dll 78
sicherer DLL-Suchmodus 179
Suchreihenfolge 182
Teilsystem-DLLs 54
Teilsysteme 70
Überblick 8
DPCs (Deferred Procedure Calls)
E/A 563
Stacks 457
DSRM siehe Verzeichnisdienstwiederherstellung
Durchsatz 632
DXGPROCESS 117
Dynamic Fair Share Scheduling (DFSS) 326
Dynamische gleichmäßige Planung 326
Dynamische Prozessoren 333
Dynamische Zugriffssteuerung 770
Dynamische Zuweisung 408
E
E/A
abbrechen 617
asynchron 586
Containerbenachrichtigungen 634
Dateien zwischenspeichern 589
DPCs 563
E/A in zugeordneten Dateien 589
E/A-Manager 556
Einlagerungs-E/A 440
Energietreiber 686
Energieverfügbarkeitsanforderungen 692
Energieverwaltung 679, 689
Energieverwaltungsframework 690
Energiezuordnungen 684
Energiezustände 679
Geräteauflistung 645
Gerätebäume 645
Geräteknoten 648
Gerätestacks 649
INF-Dateien 658
IRPs siehe IRPs
IRQLs 561, 641
Katalogdateien 660
Komponenten 555
Leistungsstatus 691
Parallelität 623
Plug & Play 643
PnP-Unterstützung 644
Prioritätserhöhung 269
Scatter/Gather-E/A 589
schnelle E/A 587
synchron 586
Systemfähigkeiten 686
Threadagnostisch 616
Thread beenden 619
Treiberisntallation 656
Treiberüberprüfung 637, 640
Treiberunterstützung 644, 655
Überblick 555
verarbeiten 558
Vervollständigungsports 622
E/A-Anforderungspakete siehe IRPs
E/A in zugeordneten Dateien 589
E/A-Manager 556
Echtzeitprioritäten 243
Editionen 61
Einfrieren 296
Eingabeaufforderung 15
Index
901
Eingeschränkte Token 743
Einlagerungs-E/A 440
Einstellungen
Adressgrenzwerte 413
Benutzerkontensteuerung 853
EPROCESS 154
PEB 159
EMET (Enhanced Mitigation Experience Toolkit)
421
Energiezuordnungen 684
Enhanced Mitigation Experience Toolkit (EMET)
421
Enklaven 536
EPROCESS 117, 154
Ereignisse
Benachrichtigungsereignisse 485
Dispatchereignisse 267
Erweiterte 64-Bit-Systeme 56
Erweiterte Affinitätsmasken 311
Erweiterte Überwachungsrichtlinie 792
ETHREAD 117, 216
Exekutive 81
Exekutivprozessobjekt 154
Exekutivressourcen 271
Experimente
Abbildlader 175
Ablaufsteuerungsschutz 863
Abschnittsobjekte 463
Adressnutzung 410
Adressübersetzung 430
aktive Anmeldesitzungen 830
Anwendungscontainertoken 801
Arbeitssätze 478
Arbeitsspeicher 345
Atomtabelle 808
ausführungsbereite Threads 256
aushungern der CPU 277
Auslagerungsdatei 443, 452
auslassen der durchsuchenden Überprüfung
782
Benachrichtigungsereignisse 486
Benutzeradressraum 416
Benutzermodusdebugger 233
Broker 822
CFG-Bitmap 868
CPU-Sätze 313
CSR_PROCESS 124
CSR_THREAD 229
Dateiobjekte 583
Dateivirtualisierung 843
Datenausführungsverhinderung 365
Datenbank der geladenen Module 185
Dienste 108
Dienstprozesse 109
Dispatchroutinen 594
DLL-Suchreihenfolge 182
902
Index
DSS 328
Durchsatz 632
Energiefähigkeiten 686
Energieverfügbarkeitsanforderungen 693
Energiezustände 681
Energiezustandszuordnung 685
EPROCESS 119
ETHREAD 218
exportierte Funktionen 38
Fähigkeiten von Anwendungscontainern 813
gefilterte Administratortoken 744
Gerätebäume 647
Geräteknoten 653
Geräteobjekte 576
Gerätetreiber 95
geschützte Prozesse 132, 237
globale Überwachungsrichtlinie 790
Grenzwerte der CPU-Rate 331
Grenzwerte für Adressen festlegen 413
HAL-Abbildabhängigkeiten 90
Heap 384
im Speicher zugeordnete Dateien 359
INF-Dateien 658
Integritätsebenen 724
in Token gespeicherte Handles 819
IRPs 595, 599
Jobs 200
Katalogdateien 660
Kernelmodusdebugger 235
Kernelstacks 456
Kerneltypinformationen 45
KMDF-Treiber 666
KPCR 86
KPRCB 86
KTHREAD 218
Ladeadresse berechnen 419
Leerlaufthreads 292
Lese- und Schreibvorgänge in der PrefetchDatei 475
Liste der freien Seiten 492
Liste geänderter Seiten 494
Look-Aside-Listen 377
Maximale Anzahl an Threads erstellen 455
MMCSS-Prioritätsschub 284
nicht beendbare Prozesse debuggen 619
Nullseitenlisten 493
NUMA-Prozessoren 303
Objektzugriffsüberwachung 787
PEB 122
PFN 490
PFN-Einträge 508
Poolgröße 371
Poollecks 375
Prioritätserhöhungen von GUI-Threads 275
Prioritätserhöhung für Vordergrundthreads
271
Prioritätsschübe und -bumps 633
Privilegien aktivieren 781
Process Explorer 17
Programme auf niedriger Integritätsebene
starten 740
Prozessaffinität 309
Prozessbaum 13
Prozessdatenstrukturen 119
Prozessstart verfolgen 167
PTEs 404
Quantum konfigurieren 265
schnelle E/A 587
Seitenheap 391
Seitenprioritäten 501
Sicherheitsattribute von Anwendungscontainern 806
Sicherheitsdeskriptoren 755
SIDs 722
Silokontext 208
Sitzungen 401
SMT-Prozessoren 302
Speicherkomprimierung 522
Speicherpartitionen 525
Speicher zuweisen 354
SRPs 889
Stacks 600
Standby-Seitenlisten 494
Steuerbereiche 467
Systemdienstdispatcher 79
Taktintervall 258
Taktzyklen pro Quantum 260
Task-Manager 9
TEB 223
Teilsysteme 70
Testbuild 64
Threadpools 338
Threadprioritäten 245
Threads einfrieren 297
Threadstatus 250
Token 732
Treiber 568
Treiberobjekte 579
Trustlets identifizieren 143
UMDF-Treiber 667
Unterstützung für umfangreiche Adressräume
399
UWP-Auslagerungsdatei 448
UWP-Prozesse 799
VADs 458
Vergleich der Leistungsüberwachung im
Kernel- und Benutzermodus 29
Vertrauens-SIDs 760
Virtuelle Auslagerungsdatei 448
Virtuelle Dienstkonten 746
Windows-Editionen 63
Zugriffsmaske 719
Exportunterdrückung 871
F
Fähigkeiten 63
Fehlerbehebung 375
Fehlercodes 877
Fehlertolerante Heaps 394
Fenster 15
Fibers 21
Filter 566
Filtertreiber 566
Firmware 32
Flags 145
Frameworks
Energieverwaltungsframework 690
.NET Framework 6
WBF (Windows Biometric Framework) 835
Freie Seiten
Listen 492
Speicher-Manager 352
Freiwilliger Wechsel 288
FRS siehe Dateireplikationsdienst
FTH (fehlertolerante Heaps) 394
Funktionen
AllocConsole 71
AvTaskIndexYield 285
BaseThreadInit 179, 190
ConvertThreadToFiber 21
CreateFiber 21
CreateFile 37
CreateProcess 113, 144, 149, 176
CreateProcessAsUser 113, 155
CreateProcessInternal 114
CreateProcessInternalW 144, 145, 149, 162,
167
CreateProcessWithLogonW 113
CreateProcessWithTokenW 113
CreateRemoteThread 215
CreateRemoteThreadEx 216, 230
CreateThread 215, 222, 232
Csr 80
DbgUi 80
DebugActiveProcess 43
DebugBreak 215
DeviceIoControl 82
DllMain 173
Etw 81
Ex 82
ExitProcess 172
Exportiert 38
GetQueueCompletionStatus 197
GetSystemTimeAdjustment 259
GetThreadContext 20
GetVersionEx 2
HeapAlloc 379
HeapCreate 379
HeapDestroy 379
HeapFree 379
Index
903
HeapLock 379
HeapReAlloc 379
HeapUnlock 379
HeapWalk 379
Inbv 82
Io 82
IoCompleteRequest 270
Iop 82
Ke 84
KeStartDynamicProcessor 334
KiConvertDynamicHeteroPolicy 324
KiDeferredReadyThread 309, 320
KiDirectSwitchThread 287
KiExitDispatcher 269, 287
KiProcessDeferredReadyList 309
KiRemoveBoostThread 269, 281
KiSearchForNewThreadOnProcessor 320
KiSelecthreadyThreadEx 300
KiSelectNextThread 299
Ldr 79
LdrApplyFileNameRedirection 195
Mi 82
MiZeroInParallel 343
NtCreateProcessEx 116, 134
NtCreateThreadEx 230
NtCreateUserProcess 116
NtCreateWorkerFactory 337
OpenProcess 43
PopInitializeHeteroProcessors 323
Präfixe 98
PsCreateSystemThread 216
PspAllocateProcess 117, 154
PspComputeQuantum 262
PspCreatePicoProcess 116
PspInitializeApiSetMap 195
PspInsertProcess 117, 159
PsTerminateSystemThread 216
QueryInformationJobObject 199
ReadFile 28
ReadProcessMemory 22
ResumeThread 296
Rtl 80
RtlAssert 65
RtlCreateUserProcess 116
RtlGetVersion 62
RtlUserThreadStart 232
RtlVerifyVersionInfo 62
SetInformationJobObject 309
SetPriorityClass 243
SetProcessAffinityMask 309
SetProcessWorkingSetSize 248
SetThreadAffinityMask 309
SetThreadIdealProcessor 313
SetThreadSelectedCpuSets 314
Sichere Systemaufrufe 80
SuspendThread 296
SwitchToFiber 21
904
Index
Systemdienste 81
SystemParametersInfo 199
Teilsystem-DLLs 71
TerminateJobObject 199
TerminateProcess 173
TermsrvGetWindowsDirectoryW 190
TimeBeginPeriod 259
TimeSetEvent 259
TpAllocJobNotification 197
Treiber 565
Überblick 8
UserHandleGrantAccess 199
VerifyVersionInfo 2, 62
VirtualLock 356
WaitForMultipleObjects 288
WaitForSingleObject 288
Wow64GetThreadContext 21
WriteProcessMemory 22
ZwUserGetMessage 234
G
Gefilterte Administratortoken 744
Gemein genutzte PTEs 530
Gemeinsam genutzter Speicher 358
Gemeinsam nutzbare Seiten 352
Geräte
Auflistung 645
Bäume 645
Devnodes 645
Geräteknoten 648
Gerätestacks 649
öffnen 582
Unterstützung 644
Geräteobjekte 574
Gerätetreiber
Benutzeradressraum 607
Bustreiber 566
Dateiobjekte 582
Dispatchroutinen 578, 594
Energieverwaltung 685
Filtertreiber 566
Funktionstreiber 566
Geräteobjekte 574
Geräte öffnen 582
geschichtete Treiber 567, 613
installieren 555, 663
IRPs 603, 613
Klassentreiber 567
KMDF 664
laden 661
Porttreiber 567
Routinen 572
Treiberobjekte 574
Treiberüberprüfung siehe Treiberüberprüfung
Typen 565
Überblick 92, 565
UMDF 565, 664
universelle Windows-Treiber 95
Unterstützung 644, 655
untersuchen 95, 570
WDF siehe WDF
WDK (Windows Driver Kit) 49
WDM 93, 566
Geringe Ressourcen simulieren 641
Gesamter zugesicherter Speicher 356
Geschichtete Treiber
IRPs 613
Überblick 567
Geschützte Prozesse
PPLs 128
Process Explorer 132
Threads 237
Überblick 126
Globale Überwachungsrichtlinie 790
gMSAs siehe Gruppenverwaltete Dienstkonten
Granularität 357
Größe
gesamter zugesicherter Speicher 452
Pools 370
Speicher-Manager 343
umfangreiche Adressräume 399
Große Seiten 344
Gruppen
Ansprüche 834
Claims 834
DFSS 326
dynamische Prozessoren 333
Grenzwerte der CPU-Rate 330
Prozessoren 305
Zeitplanung 324
GUI
Sicherheitseditoren 768
Threads 274
GUIDs 191
besonderer Pool 370
Buckets 382
Debugging 390
fehlertolerante Heaps 394
Größe 370
HeapAlloc 379
HeapCreate 379
HeapDestroy 379
HeapFree 379
HeapLock 379
HeapReAlloc 379
HeapUnlock 379
HeapWalk 379
Lecks 375
Look-Aside-Listen 377
Low-Fragmentation-Heap 381
nicht ausgelagerter Pool 370
NT-Heaps 380
Nutzung 372
poolmon 372
Prozesse 379
Randomisierung 420
Segmentheaps 383
Seitenheap 391
Sicherheit 388
Spezieller Pool 639
Synchronisierung 381
Threadpools 335
Typen 380
Überblick 370, 380
untersuchen 384
Verfolgung 640
Heterogenes Multiprocessing 59
Heterogene Zeitplanung 322
Hierarchien 199
Host 75
Hybridjobs 205
HyperGuard 894
Hypervisor 30
H
I
HAL
IBAC (Identity-Based Access Control) 771
Idealer Knoten 313
Idealer Prozesser 312
Identifizierung
AppID 880
Trustlets 143
Identitäten 140
Identitätsgesstützte Zugriffssteuerung 771
Identitätswechsel 741
ImageBias 418
Immersive Prozesse 115
Im Speicher zugeordnete Dateien 358
INF-Dateien 658
Infrastruktur öffentlicher Schlüssel siehe PKI
Abhängigkeiten von Abbildern 90
Überblick 88
Handles
Anwendungscontainer 818
in Token gespeicherte Handles 819
Hardware
Firmware 32
Kernelunterstützung 88
Hardwareabstraktionsschicht siehe HAL
Hashes 808
Heaps
Affinitäts-Manager 382
ausgelagerter Pool 370
Index
905
Initialisierung
Abbildlader 176, 190
Prozesse erstellen 165
Speicherenklaven 538, 542
Teilsystem 162
Winlogon 826
Integrierte Trustlets 140
Integritätsebenen 724, 740
Interne Synchronisierung 350
Interrupt Request Levels (IRQLs) 561, 641
IoCompletion 623
IRPs 588
Benutzeradressraum 607
Dispatchroutinen 594
geschichtete Treiber 613
IRP-Fluss 597
Stackpositionen 592
Stacks 600
Synchronisierung 610
Überblick 590, 603
untersuchen 595, 599
IRQLs 561, 641
Isolierung 205
J
Jobs
erstellen 199
Grenzwerte 197
Hierarchien 199
Hybridjobs 205
Überblick 23, 196
untersuchen 201
K
Kanonische Adressen 408
Katalogdateien 660
Kennwörter 706
Kerberos
Armoring 710
Authentifizierung 829
Kerne 59
Kernel
Benutzeradressraum 420
Benutzermodusdebugging 43
Debugging 42
Debugging Tools for Windows 43
Hardwareunterstützung 88
Kernel-CFG 874
Kernelmodusdebugging 44
KPCR 85
KPRCB 85
LiveKd 48
Objekte 85
906
Index
Prozesse 118
Prozessstrukturen 157
sicherer Kernel 67
Stacks 456
Symbole 42
Testbuild 64
Threads 234
Typinformationen 45
Überblick 85
Kernelmodus
Architektur 53
Vergleich mit Benutzermodus 26, 52
Kernelpatches
HyperGuard 894
PatchGuard 890
Überblick 889
Kernelprozessorsteuerungsblock (KPRCB) 85
Kernelprozessorsteuerungsregion (KPCR) 85
Klassentreiber 567
Klassifizierung 529
Klassische Anwendungen 115
Kleine Seiten 343
KMDF 664
Knoten
Geräteknoten 648
idealer Knoten 313
Prozessoren 58
Kommunikation 708
Komponenten
Architektur 68
E/A 555
Sicherheit 700
Speicher-Manager 342
SuperFetch 543
Konfiguration
DFSS 327
Quantum 264
Konsolen 75
Konten
auslassen der durchsuchenden Überprüfung 782
Kontorechte 773
Privilegien 773
Superprivilegien 783
Kontext
Abbildlader 182
Aktivierungskontext 182
Direct Switch 287
direkter Kontextwechsel 22
Jobs 207
Kontextwechsel 240, 286
Threads 20
Kontextwechsel 240, 286
Kontingente 415
Kopieren beim Schreiben 366
KPCR 85
KPRCB 85
KPROCESS 118
KTHREAD 216
L
Ladeadresse 419
Laden
Abbilder siehe Abbildlader
Daten 541
Ladeadresse 419
Treiber 661
Layout
64-Bit-Adressraumlayouts 406
ARM-Adressraumlayout 405
Benutzeradressraum 416
x86-Adressraumlayout 397, 401
Lecks 375
Leerlaufprozess 100
Leerlaufthreads 292, 301
Legacy-Standby 683
Leistung
stabil 549
Status 691
SuperFetch 548
Leistungsüberwachung
Kernelmodus und Benutzermodus im
Vergleich 29
Überblick 40
Letzter Prozesser 312
LFH (Low-Fragmentation-Heap) 381
Linux-Teilsysteme 76
Liste geänderter Seiten 494
Listen
Look-Aside-Listen 377
Mindest-TCB-Liste 131
Seitenlisten 493
LiveKd 48
Logischer Prefetcher 473
Lokaler Threadspeicher (TLS) 20
Look-Aside-Listen 377
Look-Aside-Übersetzungspuffer 429
LowBox siehe Anwendungscontainer
Low-Fragmentation-Heap 381
M
Mehrere Sitzungen 32
Mehrprozessorsysteme
Affinitätsmasken 59, 309
Anzahl der Prozessoren pro Gruppe 307
Asymmetrisch 57
CPU-Sätze 313
erweiterte Affinitätsmasken 311
Heterogen 59
idealer Knoten 313
idealer Prozesser 312
letzter Prozessor 312
NUMA-Systeme 302
Prozessoren auswählen 320
Prozessorgruppen 59, 305
Prozessorstatus 308
Skalierbarkeit des Schedulers 308
SMT 301
symmetrisch 57
Überblick 301
MFA siehe Mehrstufige Authentifizierung
Mindest-TCB-Liste 131
Minimale Prozesse 116, 134
MMCSS (Multimedia Class Scheduler Service) 266,
282
Moderne Apps 115
Moderne Prozesse 115
Moderner Standby 683
Module 183
MSAs siehe Verwaltete Dienstkonten
MSV1_0-Authentifizierung 828
Multimedia Class Scheduler Service (MMCSS) 266,
282
Multitasking 57
N
Namensraum 816
Native Abbilder 81
Native Prozesse 116
Nicht ausgelagerter Pool 370
Nicht beendbare Prozesse 619
Ntdll.dll 78
NT-Heaps 380
NTOWF/TGT 707
Nullforderungsseiten 352
Nullseitenlisten 493
NUMA (Non-Uniform Memory Architecture)
Prozessoren 303
Systeme 302
Überblick 461
NX 362
O
Objekte
Abschnittsobjekte 462
DAC 770
Dateiobjekte 582
Dateizuordnungsobjekte 22
Dispatchroutinen 578
EPROCESS 154
Exekutivprozessobjekt 154
Geräteobjekte 574
Index
907
IoCompletion 623
Kernelobjekte 85
Namensräume 816
Objektzugriffsüberwachung 787
Sicherheit 714
Sicherheitsdeskriptoren 751
Überblick 33
virtuelle Dienstkonten 745
Zugriffsprüfung 716
Öffnen
Abbilder 151
Eingabeaufforderung 15
Geräte 582
OneCore 3
OTS-Rechteerweiterung 848
P
PAE (Physical Address Extension) 422
Parallelitätswert 623
Parametervalidierung 145
Partitionen 523
PatchGuard 890
PCB 118
PCR 292
PDE 425
PDPE 425
PDPT 424
PEB 117
einrichten 159
Überblick 117
untersuchen 123
PFN
Auslagerungsdatei 509
Datenstrukturen 504
Einträge 508
Schreibthread für geänderte Seiten 502
Schreibthread für zugeordnete Seiten 502
Seitenlisten 491
Seitenprioritäten 500
Seitenstatus 488
Überblick 487
untersuchen 490
Physische Adresserweiterung (PAE) 422
Pico
Prozesse erstellen 116
Teilsysteme 76
Überblick 134
Planungskategorie 283
Platzierungsricthlinien 477
Plug & Play
Auflistung 645
Bäume 645
Geräteknoten 648
Gerätestacks 649
908
Index
INF-Dateien 658
Katalogdateien 660
Treiber 644
Treiberinstallation 555
Treiberunterstützung 655
Überblick 643
Unterstützung 644
Pools
Größe 371
Nutzung 372
Threads 338
Portierbarkeit 56
Ports
Porttreiber 567
Vervollständigungsports 622
Porttreiber 567
PPL (Protected Processes Light) 128
Präfixe 98
Prefetcher 472
Prioritäten
Bandbreitenreservierung 634
Bumps 631, 633
Durchsatz 632
E/A 627
Echtzeit 243
Prioritätsschübe 631, 633
Prioritätsstufen 240
Prioritätsumkehr 630
Seiten 499
Strategien 628
SuperFetch 546
untersuchen 244
Prioritätserhöhung
anwenden 279
Ausgleichssatz-Manager 276
aushungern der CPU 276
Autoboost 286
Deadline Scheduling 285
Dispatchereignisse 267
E/A 269
entfernen 280
Exekutivressourcen 271
GUI-Threads 274
MMCSS 266, 282
Multimedia 282
Planungskategorie 283
Prioritätsumkehr 276
sperren 269
Spiele 282
Überblick 266
Unwait-Erhöhungen 268
Vordergrundthreads 271
Prioritätsumkehr
E/A-Priorität 630
Prioritätserhöhung 275
Private Seiten 352
Privilegien 773
auslassen der durchsuchenden Überprüfung 782
Superprivilegien 783
Process Explorer 16
Programme siehe Anwendungen
Protected Process Light (PPL) 128
Protokollierung 544
Prototyp-PTEs 438
Prozessbaum 13
Prozesse
Abbilder öffnen 151
Abbildlader 175, 182
Abwehrmaßnahmen auf Prozessebene 856
Adressraum 156
Attribute konvertieren 145
beenden 172
CSR_PROCESS 117, 123
DLL-Suchreihenfolge 182
DXGPROCESS 117
EPROCESS 117, 154
erstellen 113, 144
ETHREAD 117
Exekutivprozessobjekt 154
Flags konvertieren 145
geschützte Prozesse 132, 237
Heap 379
immersive Prozesse 115
initialisieren 165
Kernelprozesse 118
Kernelprozessstruktur 157
Konsolenhost 75
KPROCESS 118
Mindest-TCB-Liste 131
minimale Prozesse 116, 134
moderne Prozesse 115
native Prozesse 116
nicht beendbare Prozesse 619
Parametervalidierung 145
PCB 118
PEB 122, 159
!process 121
Process Explorer 16, 132
Prozessbaum 13
prozessübergreifender Speicherzugriff 352
Reflexion 552
Start verfolgen 167
Task-Manager 9
Teilsystem initialisieren 162
Überblick 8
ursprünglichen Thread ausführen 164
ursprünglicher Thread 160
UWP-Prozesse 796
VADs 458
W32PROCESS 117, 125
Zugriffstoken 784
Prozessoren
Anzahl der Prozessoren pro Gruppe 307
Auswählen 320
idealer Prozesser 312
Knoten 58
KPCR 85
KPRCB 85
letzter Prozessor 312
NUMA 303
PCR 292
Planung 333
SMT 301
Status 308
symmetrisches Multiprocessing 57
zu Gruppen zuweisen 305
Prozessorsteuerregion (PCR) 292
Prozessreflexion 552
Prozessteuerungsblock (PCB) 118
Prozessumgebungsblock (PEB) 117
einrichten 159
Überblick 117
untersuchen 123
Prozess-VADs 458
PSOs siehe Kennworteinstellungsobjekte
PspInsertProcess 117, 159
PTEs (Seitentabelleneinträge)
Adressraum 404
Adressübersetzung 427
Definition 423
gemeinsame PTEs 530
Prototyp-PTEs 438
ungültige PTEs 436
Q
Quantum 289
Konfiguration 265
Länge bestimmen 259
Registrierungswert 263
steuern 261
Taktintervall 258
Taktzyklen 260
Überblick 258
variable Quanten 262
R
Randomisierung des Benutzeradressraums
Abbilder 418
Heap 420
Stacks 420
Unterstützung 421
ReadyBoost 550
ReadyBoot 473
ReadyDrive 551
Index
909
Rechte 773
Rechteerweiterung mit Zustimmung 848
Rechteverwaltung siehe Active Directory-Rechteverwaltungsdienste
Reflexion 552
Registrierung
Sicherheitsschlüssel anzeigen 703
Threads 263
Überblick 36
Virtualisierung 838, 845
Reservierung
Bandbreite 634
PFNs 508
reservierte Seiten 354
Ressourcen
Ressourcenmonitor 40
Simulation geringer Ressourcen 641
Treiberüberprüfung 640
Ressourcenmonitor 40
Richtlinien
Abwehrmaßnahmen auf Prozessebene 856
Authentifizierungsrichtlinien 710
Credential Guard 710
erweiterte Überwachungsrichtlinie 792
globale Überwachungsrichtlinie 790
Softwareeinschränkungsrichtlinien 882, 887
Trustlets 138
Windows-Editionen 63
RODC siehe Schreibgeschützte Domänencontroller
Ruhezustand 546
S
Sandbox 149
SAS 826
Sättigungswerte 241
Scatter/Gather-E/A 589
Scheduler 308
Schlanke Threads 21
Schnelle E/A 587
Schneller Benutzerwechsel 33, 546
Schreibbit 428
Schreibthread für geänderte Seiten 502
Schreibthread für zugeordnete Seiten 502
SDK (Software Development Kit) 48
Secure Attention Sequence 826
Secure-System-Prozess 101
Segmentheaps 383
Seiten
freigeben 533
Speicherzusammenführung 530
Seitencluster 441
Seitenfehler
Auslagerungsdatei 442
Auslagerungsdateien untersuchen 445
Einlagerungs-E/A 440
Größe der Auslagerungsdatei 452
910
Index
Prototyp-PTEs 438
Seitencluster 441
Seitenfehlerkollisionen 440
Überblick 435
ungültige PTEs 436
UWP-Auslagerungsdatei 447
virtuelle Auslagerungsdatei 448
weiche Seitenfehler 437
Zusicherungsgrenzwert 448
Seitenfehlerkollisionen 440
Seitenframenummer siehe PFN
Seitenheap 391
Seitenlisten 491
Seitentabellen 426
Seitentabelleneinträge siehe PTEs
Seitenverzeichniseintrag (PDE) 425
Seitenverzeichnis-Zeigereintrag (PDPE) 425
Seitenverzeichnis-Zeigertabelle (PDPT) 424
Sichere Authentifizierung 833
Sichere Kommunikation 708
Sichere Prozesse
Attribute 139
Dienste 141
identifizieren 143
Identität 140
integriert 140
Richtlinien 138
Systemaufrufe 142
Überblick 69, 137
Sicherer DLL-Suchmodus 179
Sicherer Kernel 67
Sicherheit
Abwehrmaßnahmen 421
AppID 880
AppLocker 881
auslassen der durchsuchenden Überprüfung 782
AuthZ 771
CBAC 772
DAC 770
Dateivirtualisierung 839
Device Guard 712
grafische Sicherheitseditoren 768
Heap 388
Hypervisor 31
IBAC 771
Komponenten 700
Objekte 714
Objektzugriffsprüfung 716
Privilegien 773
Rechte 773
Registrierungsschlüssel 703
Registrierungsviertualisierung 839, 845
Secure-System-Prozess 101
sichere Kommunikation 708
sicherer Kernel 67
sichere Systemaufrufe 80
Sicherheitsdeskriptoren 751, 755
SIDs 720
SRPs 882, 887
Superprivilegien 783
Überblick 34, 697
UIPI 763
VBS 66
Virtualisierung 704, 838
virtuelle Dienstkonten 745
Sicherheitsaufruf 826
Sicherheitseinstufungen
CC 699
TCSEC 697
Sicherheitskennungen siehe SIDs
SIDs
Besitzerrechte-SIDs 765
eingeschränkte Token 743
gefilterte Administratortoken 744
Identitätswechsel 741
Integritätsebenen 724, 740
Token 728
Überblick 720
untersuchen 722
verbindliche Beschriftung 726
Vertrauens-SIDs 760
Silos
Container 211
erstellen 210
Hilfsfunktionen 211
Isolierung 205
Kontext 207
Objekte 204
Überblick 204
Überwachung 209
Siloüberwachung 209
Simulation geringer Ressourcen 641
Single Sign-On siehe Einmalige Anmeldung
Sitzungen
anzeigen 402
mehrere 32
Sitzungs-Manager 102
x86-Sitzungsraum 401
Sitzungs-Manager 102
Skalierbarkeit
Betriebssystem 60
Scheduler 308
SMT 301
Software Development Kit (SDK) 48
Softwareeinschränkungsrichtlinien 882, 887
Software-PTE 437
Speicherkomprimierung 102
Speicherkomprimireung 515
Speicher-Manager
AWE 367
Datenausführungsverhinderung 362
Dienste 350
freie Seiten 352
gemeinsam genutzter Speicher 358
gemeinsam nutzbare Seiten 352
gesamter zugesicherter Speicher 356
Granularität 357
große Seiten 344
im Speicher zugeordnete Dateien 358
interne Synchronisierung 350
kleine Seiten 343
Komponenten 342
kopieren beim Schreiben 366
NX-Seitenschutz 362
prozessübergreifender Speicherzugriff 352
reservierte Seiten 354
Seiten 344
Speicherschutz 360
Speicher untersuchen 346
Speicher verriegeln 356
Speicher zuweisen 352
Überblick 341
verzögerte Auswertung 367
zugesicherte Seiten 352
Zusicherungsgrenzwert 356
Speicherschutz 360
Speicherzusammenführung
Freigabe von zusammengeführten Seiten
533
gemeinsame PTEs 530
Klassifizierung 529
Seiten zusammenführen 530
suchen 528
Überblick 526
untersuchen 534
Sperren
Arbeitsspeicher 356
Prioritätserhöhung 269
Spezieller Pool 639
Spiele 282
SRPs 882, 887
Stabile Leistung 549
Stacks
Benutzeradressraum 420
Benutzerstacks 455
DPC-Stack 457
Gerätestacks 649
IRPs 591, 599
Kernelstacks 456
Plug & Play 649
Randomisierung 420
Überblick 454
Standby
Seitenlisten 494
SuperFetch 545
Starten von Teilsystemen 71
Status
Prozessoren 308
Seiten 487
Threads 248
Index
911
Suche
Abbildlader 178
sicherer DLL-Suchmodus 179
Speicherzusammenführung 527
SuperFetch
Ablaufverfolgung 543
Komponenten 543
Protokollierung 544
Prozessreflexion 552
ReadyBoost 550
ReadyDrive 551
Ruhezustand 546
schneller Benutzerwechsel 546
Seitenprioritäten 546
stabile Leistung 549
Standby 545
Szenarien 545
Überblick 542
Superprivilegien 783
Swapper 482
Symbole
Kerbeldebugging 42
Kerneltypinformationen 45
Symmetrisches Multiprocessing 57
Synchrone E/A 586
Synchronisierung
Arbeitsspeicher 350
Heap 380
interne Synchronisierung 350
IRPs 610
Sysinternals 49
Systemadressraumlayout 401
Systemarbeitssätze 483
Systemaufrufe 142
Systemdienste 81
Systemfähigkeiten 686
System (Prozess) 100
Systemprozesse
Dienstprozesse 109
Dienststeuerungs-Manager 107
Leerlaufprozess 100
Secure System 101
Sitzungs-Manager 102
Speicherkomprimierung 102
System (Prozess) 100
Systemspeicher und komprimierter Speicher
100
Systemthread 100
Überblick 98
Windows-Anmeldeprozess 109
Windows-Initialisierungsprozess 105
System-PTEs
Adressraum 404
Adressübersetzung 427
Definition 423
912
Index
gemeinsame PTEs 530
Prototyp-PTEs 438
ungültige PTEs 436
Systemspeicher und komprimierter Speicher 100
Systemthread 100
T
Taktintervall 258
Taktzyklen 260
Task-Manager 9
TCB
Mindest-TCB-Liste 131
Überblick 218
TCSEC 697
TEB
Überblick 216, 220
untersuchen 224
Teilsysteme
DLLs 70
Initialisierung 162
Konsolenhost 75
Linux 76
native Abbilder 81
Ntdll.dll 78
Pico 76
starten 71
Teilsystem-DLLs 54
Typen 70
Überblick 70
Windows-Teilsystem 72
Terminaldienste 32
Testbuild 64
Threadagnostische E/A 616
Threadinformationsblock (TIB) 223
Threadpools 335
Threads
anhalten 296
Arbeitsfactorys 335
Ausgleichssatz-Manager 276
aushungern der CPU 276
auswählen 299, 319
Autoboost 286
beenden 292, 620
Benutzermodus 233
bereit 256
CSR_THREAD 217, 229
Dateizuordnungsobjekte 22
Deadline Scheduling 285
DFSS 326
Direct Switch 287
direkter Kontextwechsel 22
Dispatcher 240
Dispatcherdatenbank 255
Dispatchereignisse 267
dynamische Prozessoren 333
E/A 269
E/A abbrechen 619
Echtzeit 243
einfrieren 296
erstellen 215, 230, 455
ETHREAD 216
Exekutivressourcen 271
Fibers 21
freiwilliger Wechsel 288
geschützte Prozesse 237
Grenzwerte der CPU-Rate 330
Gruppenplanung 324
GUI-Threads 274
heterogen 322
Kerne 59
Kernelmodusdebugger 235
Kontext 20
Kontextwechsel 240, 286
KTHREAD 216
Leerlaufthreads 292, 301
maximale Anzahl 455
MMCSS 266, 282
Multimedia 282
Parallelität 623
PCR 292
Planungskategorie 283
Prioritäten untersuchen 245
Prioritätserhöhung 266
Prioritätserhöhungen entfernen 280
Prioritätsschübe 279
Prioritätsstufen 240
Prioritätsumkehr 276
Quantum 289
Sättigungswerte 241
sperren 269
Spiele 282
Status 248
Systemthread 100
TEB 223
Threadagnostische E/A 616
Threadpools 335
TIB 223
TLS 20
Überblick 20
UMS-Thread 21
untersuchen 231
Unwait-Erhöhungen 268
ursprünglicher Thread 160, 164
VADs 23
Vordergrundthreads 271
Vorzeitig unterbrechen 289
Zeitplanung 238
Zugriffstoken 22, 784
Threadsteuerungsblock (TCB)
Mindest-TCB-Liste 131
Überblick 218
Threadumgebungsblock (TEB)
Überblick 216, 220
untersuchen 224
TIB 223
TLB 429
TLS 20
Token
Anwendungscontainer 801
BNO-Isolierung 822
gespeicherte Handles 819
SIDs 728
Zugriffstoken 784
Tools
Debugging Tools for Windows 43
Windows 39
Treiber siehe Gerätetreiber
Treiberobjekte 574
Treiberüberprüfung
E/A 638
IRQL-Überprüfung 641
Poolnachverfolgung 640
Simulation geringer Ressourcen 641
sonstige Prüfungen 642
spezieller Pool 639
Überblick 635
Trusted Computer System Evaluation Criteria
(TCSEC) 697
Trustlets
Attribute 139
Dienste 141
identifizieren 143
Identität 140
integriert 140
Richtlinien 138
Systemaufrufe 142
Überblick 69, 137
Typen
Gerätetreiber 564
Heap 380
Kernel 45
Teilsysteme 70
U
UAC (User Account Control) siehe Benutzerkontensteuerung
Über-die-Schulter-Rechteerweiterung 848
Überprüfter Build 64
Überwachung
erweiterte Überwachungsrichtlinie 792
globale Überwachungsrichtlinie 790
Objektzugriffsüberwachung 787
Überblick 784
UEFI 710
UIPI (User Interface Privilege Isolation) 763
UMDF 565, 664, 667
Index
913
Umfangreiche Adressräume 399
Umgebung
Atomtabelle 808
Sicherheitsattribute 806
Überblick 803
Umlauf-VADs 460
UMS-Threads 21
Ungültige PTEs 436
Unicode 37
Universelle Windows-Treiber 95
Untersuchen
Abbildlader 175
Ablaufsteuerungsschutz 863
Abschnittsobjekte 463
Adressübersetzung 430
Adressverwendung 410
aktive Anmeldesitzungen 830
Anwendungscontainer 805
Anwendungscontainertoken 801
Arbeitssätze 478
Arbeitsspeicher 345
Atomtabelle 808
ausführungsbereite Threads 256
aushungern der CPU 277
Auslagerungsdatei 443, 452
Benachrichtigungsereignisse 486
Benutzeradressraum 416, 421
Benutzermodusdebugger 233
Broker 822
CFG-Bitmap 868
CSR_PROCESS 124
CSR_THREAD 229
Dateiobjekte 583
Datenausführungsverhinderung 365
Datenbank der geladenen Module 185
Datenstrukturen 119
DFSS (Dynamic Fair Share Scheduling) 328
Dienste 108
Dienstprozesse 109
Dispatchroutinen 594
DLL-Suchreihenfolge 182
Durchsatz 632
Energiefähigkeiten 686
Energieverfügbarkeitsanforderungen 693
Energiezuordnungen 685
Energiezustände 681
Energiezustandszuordnung 685
EPROCESS 119
ETHREAD 218
exportierte Funktionen 38
Fähigkeiten von Anwendungscontainern 813
gefilterte Administratortoken 744
Geräteknoten 653
Geräteobjekte 576
Gerätetreiber 95
geschützte Prozesse 132, 237
globale Überwachungsrichtlinie 790
914
Index
GUI-Threads 274
HAL-Abbildabhängigkeiten 90
Heap 384
im Speicher zugeordnete Dateien 359
INF-Dateien 658
Integritätsebenen 724
in Token gespeicherte Handles 819
IRPs 595, 599
Jobs 200
Katalogdateien 660
Kernelmodusdebugger 235
Kernelstacks 456
KMDF-Treiber 666
KPCR 86
KPRCB 86
KTHREAD 218
Leerlaufthreads 292
Lese- und Schreibvorgänge in der PrefetchDatei 475
Liste der freien Seiten 492
Liste geänderter Seiten 494
Look-Aside-Listen 377
MMCSS (Multimedia Class Scheduler Service)
284
Nullseitenlisten 493
NUMA-Prozessoren 303
Objektzugriffsüberwachung 787
PEB 122
PFN 490, 508
Pools 337
Prioritäten 244, 501
Prioritätserhöhungen und -bumps 633
Prioritätsschübe und -bumps 633
Privilegien aktivieren 781
Process Explorer 16, 132
Prozessaffinität 309
Prozessbaum 13
PTEs (Seitentabelleneinträge) 404
Registrierungsschlüssel 703
schnelle E/A 587
Seitenheap 391
Sicherheitsattribute von Anwendungscontainern 806
Sicherheitsdeskriptoren 755
SIDs 722
Sitzungen 401, 830
SMT-Prozessoren 302
Speicherkomprimierung 522
Speicherpartitionen 525
Speicherzusammenführung 534
SRPs 889
Stacks 456, 600
Standby-Seitenlisten 494
Steuerbereiche 467
Systemdienstdispatcher 79
Systemfähigkeiten 686
Taktintervall 258
Taktzyklen pro Quantum 260
Task-Manager 9
Teilsysteme 70
Threads 231
Threads einfrieren 297
Threadstatus 250
Token 732
Treiber 568
Treiberobjekte 579
Typinformationen 45
UMDF-Treiber 667
Unterstützung für Randomisierung 421
UWP-Auslagerungsdatei 448
UWP-Prozesse 799
VADs 458
Vertrauens-SIDs 760
Virtualisierung 843
virtuelle Auslagerungsdatei 448
Vordergrundthreads 271
Windows-Funktionen 63
Windows-Tools 39
Zugriffsmaske 719
Unwait-Erhöhungen 268
UPNs siehe Benutzerprinzipalnamen
Ursprünglicher Thread
ausführen 164
erstellen 160
User Interface Privilege Isolation (UIPI) 763
UWP 794
UWP-Auslagerungsdatei 447
V
VADs
Prozess-VADs 458
Überblick 23, 457
Umlauf-VADs 460
Variable Quanten 262
VBS
Architektur 66
Hypervisor 31
Verbindliche Beschriftung 726
Verbundener Standbymodus
Energieverfügbarkeitsanforderungen 692
Energieverwaltung 689
Energieverwaltungsframework 690
Energiezuordnungen 684
Energiezustände 679
Legacy-Standby 683
Leistungsstatus 691
moderner Standby 683
Systemfähigkeiten 686
Treiber 685
Überblick 683
Vererbung 758
Vertrauens-SIDs 760
Vervollständigungsports 622
Verzögerte Auswertung 367
Verzögerte Prozeduraufrufe
E/A 563
Stacks 457
Virtualisierung
Authentifizierungsrichtlinien 710
Dateien 838
Device Guard 712
Kennwörter 706
Kerberos-Armoring 710
NTOWF/TGT 707
Registrierung 838, 845
sichere Kommunikation 708
Überblick 704, 839
UEFI 710
Virtualisierungsgestützte Sicherheit siehe VBS
Virtuelle Adressdeskriptoren siehe VADs
Virtuelle Auslagerungsdatei 448
Virtuelle Dienstkonten 745
Virtueller Arbeitspeicher 23
Virtuelle Vertrauensebenen 66
Vordergrundthreads 271
Vorzeitige Unterbrechung 289
VSM siehe VBS
VTLs (Virtual Trust Levels) 66
W
W32PROCESS 117, 125
WBF (Windows Biometric Framework) 835
WDK (Windows Driver Kit) 49
KMDF 664
Überblick 665
UMDF 565, 664, 667
Weiche Seitenfehler 437
Windows
aktivierte Features 63
aktualisieren 3
Betriebssystemmodell 52
Designziele 51
Editionen 61
interne Mechanismen untersuchen 39
OneCore 3
Portierbarkeit 56
SDK (Software Development Kit) 48
Speichergrenzwerte für Clienteditionen 513
Versionen 1
W32PROCESS 117, 125
WBF (Windows Biometric Framework) 835
WDK (Windows Driver Kit) 49
WDM (Windows Driver Model) 93, 566
Windows-Anmeldeprozess 109
Windows Hello 837
Windows-Initialisierungsprozess 105
Windows-Laufzeit 5
Index
915
Windows-Teilsystem 72
Winlogon-Initialisierung 826
winver 2
WSRM (Windows System Resource Manager)
248
Windows-Anmeldeprozess 109
Windows-Biometrieframework 835
Windows Driver Foundation (WDF)
KMDF 664
Überblick 94, 664
UMDF 565, 664, 667
Windows Driver Kit (WDK) 49
Windows Driver Model (WDM) 93, 566
Windows Hello 837
Windows Identity Foundation siehe WIF
Windows-Initialisierungsprozess 105
Windows-Laufzeit 5
Windows System Resource Manager (WSRM) 248
Winlogon-Initialisierung 826
WSRM (Windows System Resource Manager) 248
X
x64
x86
Adressübersetzung 432
Einschränkungen für virtuelle x64-Adressen
408
Systeme 56
Adressraumlayout 397
Adressübersetzung 422
Sitzungsraum 401
Systemadressraumlayout 401
Z
Zeitplanung
Deadline Scheduling 285
DFSS 326
Dispatcher 240
dynamische Prozessoren 333
freiwilliger Wechsel 288
Grenzwerte der CPU-Rate 330
Gruppen 324
heterogene Threads 322
Kontextwechsel 240
Planungskategorie 283
Quantum 289
916
Index
Scheduler 308
Threads beenden 292
Threads vorzeitig unterbrechen 289
Zugesicherte Seiten 352
ausgelagerter Pool 370
freie Seiten 352
gemeinsam nutzbare Seiten 352
PDE 425
PDPE 425
PDPT 424
Prioritäten 499, 546
reservierte Seiten 354
Schreibthread für geänderte Seiten 502
Schreibthread für zugeordnete Seiten 502
Seitenheap 391
Seitentabellen 426
Speicher-Manager 352
Status 487
SuperFetch 546
Zugriff
bedingte Zugriffssteuerungseinträge 772
Besitzerrechte-SIDs 765
grafische Sicherheitseditoren für Zugriffssteuerungslisten 768
Objektzugriffsüberwachung 787
Vererbung von Zugriffssteuerungslisten 759
Vertrauens-SIDs 760
Zugriff anhand von Zugriffssteuerungslisten
bestimmen 761
Zugriffsmaske 719
Zugriffsprüfung 716
Zugriffssteuerungseinträge 753
Zugriffssteuerungslisten 753
Zugriffssteuerungslisten zuweisen 758
Zugriffstoken 22, 784
Zusicherungen
Betriebssystem 876
Compiler 876
Fehlercodes 877
Überblick 875
Zusicherungsgrenzwert
gesamter zugesicherter Speicher 448
Speicher-Manager 356
Zuweisung
Arbeitsspeicher 352
dynamische Zuweisung 408
Kontingente 415
Prozessoren zu Gruppen 305
Zugriffssteuerungslisten 758
Zwischenspeichern 589