





















































































































































































































































































































































































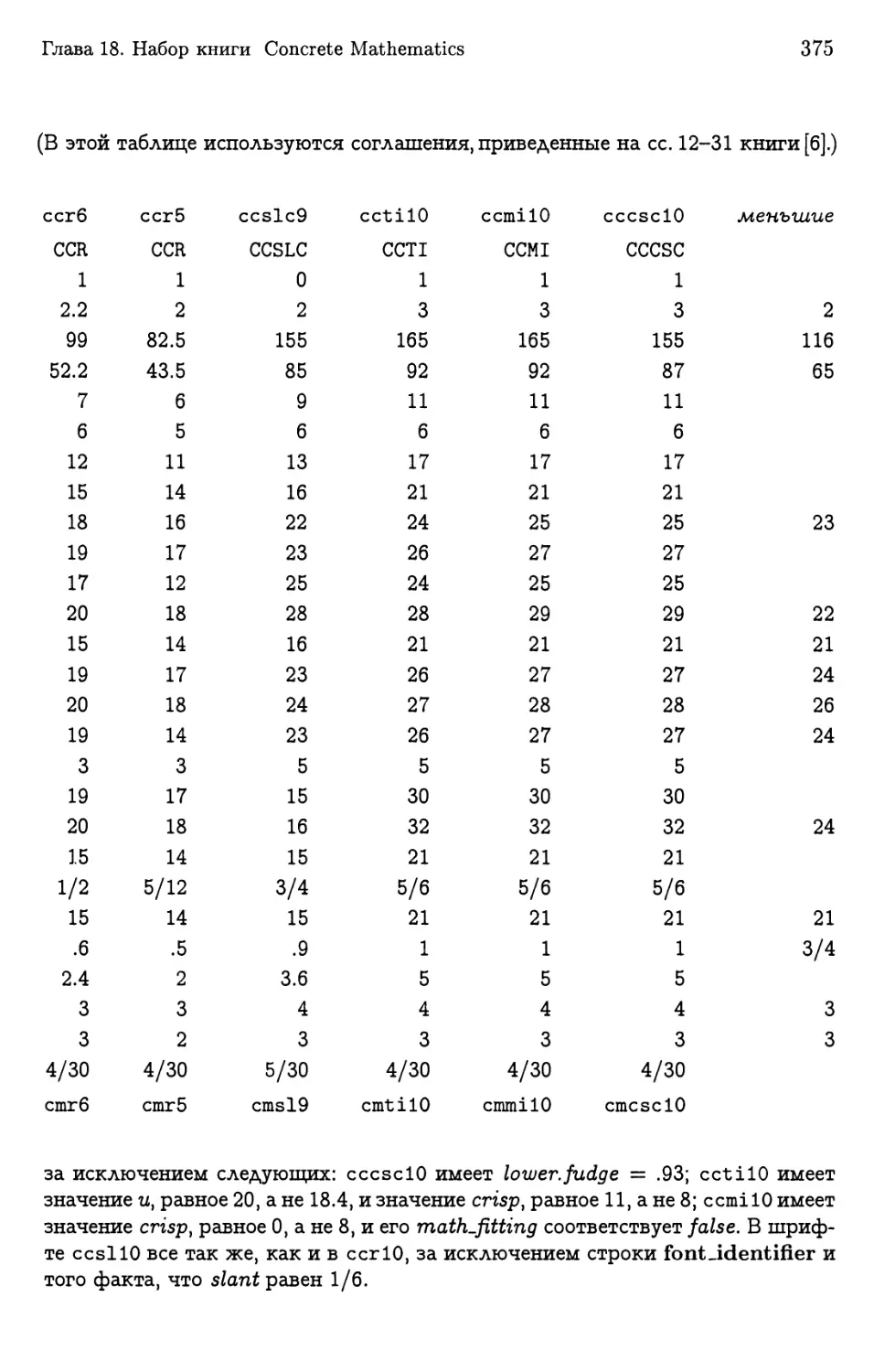





































































































































































































































































































Author: Кнут Д.Э.
Tags: компьютерные технологии вычислительная техника микропроцессоры программирование математика информатика переводная литература издательство мир издательство
ISBN: 5-03-003361-0
Year: 2003




Компьютерная типография
CSLI Lecture Notes Number 78
Computer Typesetting
D. E. Knuth
CSLI Publications Stanford California
1999
и„ Д. Э. Кнут
Ь о
ТЕХНОЛОГИЙ
Компьютерная
типография
Ел
Перевод с английского под редакцией
И. А. Маховой
ACT
ИЗДАТЕЛЬСТВО
«Мир» «ACT»
Москва 2003
УДК 681.322
ББК 32.97
К53
Переводчики: Кузнец Р. М. — гл. 4, 13-15, 17, 33, 34;
Маховая О. А. — предисловие, гл. 1-3 (с. 116-166), 18, 21-23, 31, 32;
| Третьяков Н. В.|— гл. 3 (с. 79-116), 5-9;
Тюменцев Ю. В. — гл. 10-12, 16, 19, 20, 24-30.
Кнут Д. Э.
К53 Компьютерная типография: Пер. с англ.— М.: Мир,
ООО «Издательство ACT», 2003.— 668 с, ил.
ISBN 5-03-003361-0 («Мир»)
ISBN 5-17-019775-6 («ACT»)
Сборник работ Д. Кнута, написанных им за время работы над созданием
всемирно известных систем Т£Х и metafont, в который вошли также статьи
последних лет по этой тематике. Книга состоит из 34 глав, разделенных
условно на три части: Т£Х и относящиеся к нему темы; metafont и
родственные вопросы; Т£Х и metafont в историческом аспекте. Представлен
богатый иллюстративный материал и приводятся листинги программ.
Как и во всех книгах Д. Кнута, весьма серьезные вопросы излагаются
просто и увлекательно, что, учитывая междисциплинарную направленность
книги, делает ее доступной для специалистов в разных областях науки.
Книга представляет интерес для научных работников всех
специальностей, самостоятельно готовящих свои работы к публикации, для
специалистов в области информатики и издательских систем, а также для
математиков, интересующихся нестандартными приложениями.
•сфр>1-т
УДК 681.322
ББК 32.97
Издание осуществлено при поддержке
Российского фонда фундаментальных исследований по проекту
№ 00-07-95002
Редакция автоматизации издательских процессов
ISBN 5-03-003361-0 («Мир»)
ISBN 1-57586-010-4 (англ.)
ISBN 5-17-019775-6 («ACT»)
by CSLI Publications, Leland
Stanford Junior University.
Translated and published by
arrangement with CSLI
Publications. All rights reserved.
Перевод и издание согласованы
с CSLI Publications. Все права
защищены, 1999.
перевод на русский язык,
оформление, «Мир», 2003
Предисловие
редактора перевода
Дональд Эрвин Кнут —имя, окруженное ореолом славы. Раскрыв эту книгу
читатель из первых рук узнает о множестве интересных фактов,
сопровождавших период создания всемирно известных систем Т^Х и METRFONT. В этом
предисловии также представлено несколько «русских страниц» из жизни
великого ученого.
Свой монументальный труд The Art of Computer Science Д. Кнут
задумывает в двадцатичетырехлетнем возрасте и пишет по сей день, ни на
миллиметр не снижая планку, установленную в 1962 г. За эти годы вышло в свет
3 тома (многократно переизданных с изменениями и дополнениями автора)
из запланированных семи, идет интенсивная работа над 4-м томом (который
распался на 3 книги), и еще 3 тома впереди. При этом автор постоянно
отвлекается на вещи, как бы непосредственно не связанные с его грандиозным
проектом. Появляется не одна серия самых разных книг: о том, как писать
математические работы, о документированном программировании, об
алгоритмах, и проч., и проч., всего более 20-ти. Но не только это: издав три первых
тома своей Библии для программистов, он с головой уходит в изучение
полиграфической премудрости и перевод ее на язык программирования, тратит
на это почти 10 лет и создает издательскую систему. Вот так,
неожиданно для себя, Д. Кнут, по сути, совершает цифровую революцию в печатном
деле.
Казалось бы, зачем внедряться в неведомые сферы: ведь можно было
вместо этого написать еще один том своего многотомника? Но он считает, что
негоже издавать книги о высоких достижениях компьютерной науки и
пользоваться при этом технологией, насчитывающей пять столетий. Творец ощутил
несоответствие содержания и формы и не мог работать дальше, пока не
будет инструмента, достойного его произведений. Он не стал сокрушаться по
поводу этой дисгармонии и проклинать отсталую полиграфию, а просто
взялся за работу и выполнил ее блестяще: Дональд Кнут одержим стремлением к
Идеалу.
Надеясь потратить на издательскую систему год и вновь вернуться к делу
своей жизни, он работает над проектом почти целое десятилетие. Автор
говорит, что всегда недооценивал сложность стоящей перед ним задачи, однако в
6
Компьютерная типография
Рис. 1. Идеальное в природе.
данном случае установил личный рекорд! Сначала он просто хотел облегчить
жизнь себе и своему секретарю, но, отдав свое детище в общее пользование
(статус программ — public domain), получил поток писем с вопросами и
сообщениями о найденных ошибках. Такова плата за свободу распространения и —
путь к достижению идеала. Более того, Кнут объявил, что за каждую
найденную ошибку в его программах он заплатит 2.56 доллара, после чего поток
превратился в шквал. Так что теперь вряд ли можно найти другой столь же
тщательно отлаженный программный продукт.
Вот уже 25 лет эти две программы продолжают держать первенство среди
программных средств, предназначенных для подготовки к изданию научно-
технической литературы. Их распространение и поддержку взяли на себя
общественные организации — группы пользователей TfrjX'a, которые имеются
практически во всех странах, во главе с международной группой TUG.
Подобная организация CyrTUG была в России (до 1999 г.), и Дональд Кнут был ее
почетным членом. На рис. 2 Дональд Кнут запечатлен во время заполнения
анкеты, а на рис. 3 представлена анкета под номером 314, собственноручно
заполненная по-русски автором ТЁХ'а. Д. Кнут выучил русский язык в объеме,
достаточном для того, чтобы читать работы русских математиков в
подлиннике. Еще один штрих к портрету. Кстати, первым не-латинским шрифтом,
которым был дополнен Computer Modern, была кириллица.
В «почетные пользователи» собственной издательской системы и ее
кириллической версии Дональд Кнут был принят в мае 1994 г., когда по
приглашению Санкт-Петербургского университета посетил Санкт-Петербург для
получения звания honoris causa СПбУ. На ее. 8-9 приводится текст его
выступления.
Рис. 2. Джил и Дональд Кнут во время посещения Санкт-Петербурга.
АНКЕТА /• OSJ4
пользователя Т^Х
(Просьба заполнить на русском и английском языках)
«нут *
-Место работы (название, адрес, тел., телекс, факс, e-mail'
& пеысион е Р ^-//gr
ч\"4
(*0 <р-|лл^|( ) ^
Tur: ылс<* PU Г> Г Mat/ ' j
—Образование, степень .
—Как давно знакомы с TgjXoM _
—Оборудование, на котором работаете S\AN^ SpsrtSyfH** "^ ^
входное устройство
выходное устройство т>Р*гс-]?0'\Т*/1Г~,
—Операционная система $б\ап&
—Версия Т£Ха 3-ff//57 ^~
—Сколько сотрудников Вашего учреждения работают в TjgXe __
—Для какой пели намерены использовать Т£?С и METAFONT ftC€ '
—Какое направление разработок в ТрОСе или METAFONTe представляют для Вас особый
интерес у^ТоЦ Ч Щ & ОСТР
—Ваши предложения по структуре CYRTUG и др. .
Дата заполнения: ■ \\ ' М А Я 19 ЧЧ г. . // л
Рис. 3. Анкета почетного члена ассоциации CvrTUG Лональла Кнута.
8
Компьютерная типография
Речь Дональда Кнута,
прочитанная им на торжественной церемонии
вручения отличительных знаков почетного доктора
Санкт-Петербургского университета
К своему величайшему изумлению я узнал, что
Санкт-Петербургский университет вроде бы
присуждает мне докторскую степень. По правде
говоря, сначала я не поверил этой новости,
поскольку впервые меня известили об этом по e-mail—
почему-то электронная почта не заслуживает
такого же доверия, как старомодный эпистолярный
жанр! Однако известие о докторской степени
явилось, на самом деле, правдой, и теперь я удостоен
большой чести сравняться по рангу со многими
выдающимися питомцами вашего университета.
Мне особенно приятно принять эту награду в ее
связи с молодой областью науки — информатикой
(computer science). Тот факт, что старейший
российский университет впервые отмечает такого рода
Почетный доктор Санкт- знаком отличия одного из информатиков — хоро-
Петербургского универси- шая новость для всех информатиков, поскольку это
тета Дональд Кнут. означает, что мы постепенно перерастаем из
возраста научного детства в пору юношеской зрелости.
Теперь все больше и больше научных работников осознают, что информатика
является не только отраслью науки, которая помогает физикам заниматься
физикой, биологам — биологией, врачам — практиковать в медицине,
математикам — развивать математику, историкам — писать историю, а музыкантам —
музыку: информатика также помогает информатикам совершенствовать
информатику. Другими словами, информатика — это область науки, которая
тесно связана со всеми направлениями человеческих устремлений; при этом она
имеет дело с новыми задачами, которые представляют интерес для ее
собственных нужд.
Мне также очень приятно быть здесь, в Петербурге, поскольку так много
людей, которые оказали наиболее существенное влияние на мою собственную
жизнь, были тесно связаны с этим городом. Прежде всего, я сильно взволнован
тем, что нахожусь в том месте, где Леонард Эйлер создал большинство своих
трудов, проводя коренную перестройку математики в XVIII веке. Эйлер
приехал сюда в 1727 году, когда ему было всего лишь 20 лет от роду —вскоре после
основания вашего университета, когда на улицы еще забегали волки.
Математика—это наука примеров, а Эйлер открыл сотни из наиболее значительных
примеров, которые нам известны. В наши дни мы считаем большинство этих
фантастических открытий само собой разумеющимся, но в доэйлерово время
никто не отваживался полагать, что математика окажется столь обогащенной
Предисловие редактора перевода
9
и захватывающей. Эйлер также коренным образом изменил математические
обозначения — те символы, которые мы используем для описания абстрактных
величин. Он предложил печатникам Санкт-Петербурга выпускать
математические книги, отвечающие новым, более высоким типографским стандартам.
И, возможно, еще более важно то, что он принципиально перестроил
преподавание и изложение математики —в этом он был большой мастер.
Собрание его сочинений, которое насчитывает более 60 томов, оказало влияние на
несравненно большее число математиков по сравнению с написанным любым
другим.
Я также ощущаю сокровенную связь с Санкт-Петербургом благодаря
сочинениям великих музыкантов, таких, как Бородин, Чайковский и Прокофьев.
Эти композиторы сами были мастерами создания математических и
комбинаторных- образов — они доставили мне много мгновений приятных
переживаний.
Информатика располагает своим собственным разнообразием примеров,
дополняющих весьма отличные от них примеры математики и музыки. Моя
собственная деятельность в значительной степени посвящена эстетическим
аспектам этих примеров — созданию компьютерных программ, которые столь же
прекрасны, как и произведения искусства. Я полагаю, что к компьютерным
программам правильнее всего относиться как к литературным трудам,
предназначенным в первую очередь для чтения людьми, а не выполнения
компьютерами. Любая программа может быть вдвойне восхитительна — функционально
и эстетически, —точно так же, как Петровский зал, в котором мы находимся,
восхитителен, поскольку он предоставляет нам приют и кров и поскольку он
доставляет наслаждение нашим чувствам и мыслям. Любой программист
может получить двойное удовлетворение — от решения задачи как таковой и от
ее решения элегантным способом.
Одной из самых удивительных сторон компьютеров является то, что они
становятся все лучше и лучше, в то время как все остальное становится все
хуже и хуже. Даже в наше время серьезных экономических проблем количество
вычислений, которое может быть выполнено в пересчете на падающий рубль,
продолжает возрастать. Это вселяет в меня надежду, что компьютеры
окажут большую помощь в решении тех проблем, с которыми сейчас столкнулся
наш мир. Потенциал их велик, но и задачи трудны. Благодаря существенно
облегченным способам общения, информатики из Санкт-Петербурга объединяют
свои усилия с информатиками всего мира для того, чтобы достойно встретить
вызов времени.
[Перевод Б. Б. Походзея. Опубликовано в газете «Санкт-Петербургский
университет», № 15 (3366), 1994 г.]
10
Компьютерная типография
Замечательные системы Т^К и METRFONT в этом году отмечают свой
серебряный юбилей. Дональд Кнут не остался равнодушным к этому событию
(хотя обычно, как истинный программист, отмечает только даты,
представляющие собой «2 в степени 2 в степени 2 и т. д.»). Только что на его сайте
появилась следующая информация:
Вскоре будет сделано первое с 1995г. обновление Т^Х'а и первое
с 1998 г.—METRFONT'а, т. е. появятся версии TgX 3.141592 и
METRFONT 2.71828.
Я, конечно, обещал сделать эти программы неизменными и никогда
не вводить новых возможностей. Но когда обнаруживаются ошибки, я
считаю для себя лучшим выходом подправить программы и довести их до
состояния безукоризненности.
Мораль: те, кто занимается распространением систем на базе
TgX'a, должны как можно скорее подготовиться к обновлению своих
дистрибутивов. Обычные пользователи могут спокойно дождаться
момента, когда им придется обновлять свое оборудование (например,
купить новый компьютер), и только тогда заменить свое ТЦСовское
программное обеспечение, если, конечно, для них описанные выше
изменения не являются крайне необходимыми.
Найдено лишь четыре недочета в ТЁХ'е, одно —в METRFONT'e и сделаны
усовершенствования рисунков нескольких букв семейства Computer Modern.
Только и всего — по прошествии соответственно 9-ти и 5-ти лет!
Книга, которую вы держите в руках, позволит вам заглянуть в творческую
мастерскую автора и проследить за процессом создания этих уникальных
программных продуктов. Это собрание работ трудно отнести к какому-то
конкретному жанру: здесь представлены как строго научные работы, посвященные
серьезным математическим и компьютерным проблемам, так и задачки
развлекательного толка, способные скрасить досуг математика, программиста или
шрифтового дизайнера (в случае автора — это одно и то же лицо). Несколько
выступлений профессора Кнута перед научной аудиторией и пользователями
систем ТЕХ и METRFONT представляют собой образцы живого общения и
могли бы быть отнесены к жанру мемуаров, если бы там порой не затрагивались
весьма специальные вопросы. Короче говоря, данное издание вполне отражает
многогранность дарования автора, широту его интересов и способность
излагать весьма серьезные научные результаты на высокохудожественном уровне.
Понятно, что донести до русскоязычного читателя это многообразие
жанров во всем его великолепии — задача для переводчиков не из легких. Мы
отдаем себе отчет, что несмотря на все приложенные старания нам вряд ли
удалось достичь того же уровня совершенства. Тем не менее, хочется
выразить надежду, что предлагаемая вниманию читателей книга будет встречена
с большим интересом всеми, кто уже знаком с творчеством Дональда Кнута,
а те, кому еще не доводилось сталкиваться с его произведениями, примкнут к
армии его почитателей.
И. А. Маховая
Январь, 2003 г.
Предисловие
Моему отцу,
Эрвину Кнуту (1912-1974),
верному служебному долгу
В этой книге собраны более 30 моих статей и заметок по компьютерной
типографии, в обиходе называемой «настольные издательские системы». Мне
посчастливилось жить в то время, когда происходила решительная революция
в способе представления в печатных документах слов, символов и
изображений: на смену аналоговым методам пришли цифровые, предназначенные для
компьютерной обработки.
По-видимому, в моих венах течет типографская краска: когда я впервые
узнал о возможностях компьютерной технологии в печатном деле, я не мог
воспротивиться желанию потратить всю оставшуюся жизнь на то, чтобы
попытаться адаптировать типографскую премудрость предыдущих столетий к
возможностям сегодняшнего дня. Надеюсь, что и читателя охватит то же
волнение, которое испытывал я в течение десятилетий, ушедших на разработку
способов получения при помощи компьютеров красиво оформленных книг.
У Леонардо да Винчи в его записях есть одно безапелляционное
высказывание: «Пусть никто, кроме математиков, не читает моих работ». На
самом деле, он сказал это дважды, так что, вероятно, говорил всерьез. Но, к
счастью, большинство не последовало его воле; не-математики благополучно
справляются с математическими понятиями, когда описания не перегружены
специальным жаргоном. Так что я хотел бы высказаться противоположно
изречению Леонардо: «Пусть любой, кто не является математиком, читает мои
работы». (Математикам, вообще говоря, это также не возбраняется.)
Каждый автор, разумеется, хочет быть читаемым; я процитировал
изречение Леонардо как своего рода оправдание того факта, что некоторые главы
этой книги изначально были адресованы профессиональным математикам,
тогда как другие — художникам-дизайнерам или людям других профессий. Я
лелею надежду, что, используя профессиональный жаргон в минимальном
объеме, смог выразить основные идеи, пронизывающие многие специальные
области. Ведь книгопечатание такое же междисциплинарное направление,
каким может быть любой другой предмет.
12
Компьютерная типография
Глава 1 представляет собой обзор моей деятельности: взгляд в прошлое с
высот 1997 г. В гл. 2 дается «взгляд в будущее» той же деятельности; это было
написано в 1977 г., когда я только начинал. Поводом для написания гл. 2 было
весьма знаменательное событие в моей жизни: меня пригласили выступить в
качестве лектора на Гиббсовских чтениях — ежегодном мероприятии
Американского математического общества. В свое время Гиббсовскими лекторами
были такие выдающиеся математики, как Г. X. Харди, Альберт Эйнштейн и
Джон фон Нейман, так что мне, разумеется, было не легко тягаться с ними.
Пригласившие меня ожидали, что я буду воспевать информатику, но вместо
этого я решил рассказать о своей новой работе, начатой полгода назад, о
которой еще не успел поведать никому, кроме нескольких коллег: я говорил о
типографии! При этом я, разумеется, не хотел ниспровергать высокие
традиции Гиббсовских чтений, а посему дал некое математическое обоснование, что,
по крайней мере, слегка усложнило изложение.
Однако в основном я хотел подчеркнуть, что не следует ограничивать
математические идеи традиционными приложениями и что я нахожу весьма
заманчивым иметь возможность применять математику к полиграфии. К счастью,
я не мог предвидеть, что мои замечания окажутся как нельзя более
своевременными и найдут очень дружественную аудиторию, потому что многие из
присутствующих сталкивались с проблемами публикации и могли извлечь для
себя большую пользу из такого рода исследования. В результате я получил
массу предложений о помощи от экспертов в самых разных областях, а
Американское математическое общество предоставило моему проекту серьезную
финансовую поддержку.
Из гл. 1 и 2 видно, что моя работа по компьютерной типографии имела два
основных направления, соответствующих двум компьютерным программам,
известным как Т^Х и METRFONT. Первая — Т^Х — имеет дело с расположением
литер и изображений на страница, а вторая —METRFONT —непосредственно с
созданием этих литер и изображений.
Родственные ТЁ^'У темы обсуждаются в гл. 3-12. Один из наиболее
важных аспектов верстки полосы набора — это проблема разбивки абзаца на
отдельные строки. Первой мотивацией, побудившей меня приступить к
разработке системы ТЁХ> был тот факт, что компьютеры справляются с этой задачей
лучше, чем большинство специалистов ручного набора: в гл. 3 описывается
история разбивки на строки, а также усовершенствующие этот процесс
алгоритмы, основанные на многолетних экспериментах с прототипами программы
Те?С Затем в гл. 4 обсуждаются дополнительные проблемы, возникающие при
смешивании языков, использующих противоположные направления при
написании: например, иврит или арабский, имеющие написание справа-налево, и
европейская письменность. Несколько легковесные главы 5, б, 7 и 8
представляют собой краткое описание подручных Технических средств, которые я счел
удобными для набора кулинарных рецептов, получения логотипа ТЕХ,
распечатки отдельных страниц из объемистого тома и оформления путевых заметок
Предисловие
13
моей жены. В гл. 9 приводится одна короткая головоломка для ТЁ^пертов, а в
гл. 10 содержится подборка упражнений для тех, кто хочет углубиться в
предмет и узнать, как работает сам ТЁК. Компьютерная программа для ТЁ^'а была
первым широкомасштабным применением методологии, которую я назвал
«документированное программирование»; ценность публикации документации к
такой программе весьма повысилась благодаря гипретекстно-подобным мини-
указателям, использование которых описывается в гл. 11. Наконец, в гл. 12,
обсуждается взаимодействие между ТЁ^'ом и другими системами посредством
гибких спецификаций, называемых «виртуальные шрифты».
Относящиеся к METAFONT'y вещи являются темой гл. 13-23. Прежде
всего, в гл. 13 описывается интересная математическая задача, возникающая при
попытке обучить компьютер рисовать букву «S». В гл. 14 рассказывается, как
меня пригласили нарисовать с помощью METRFONT'a одну букву из языка
хинди, которую я до того никогда не видел. И в той, и в другой главе
иллюстрируется важная концепция «меташрифта», а именно идея, что многие
разные, но родственные варианты графических форм букв используются для
объединения шрифтов в семейства. В гл. 15 обсуждаются меташрифты и
параметрические вариации вообще. Глава 16, которая изначально была
основным докладом на международной рабочей конференции дизайнеров шрифта,
представляет собой ретроспективу того, что я изучил в течение первых шести
лет моих экспериментов с METAFONT-подобными системами. Новое семейство
шрифтов для набора математических формул, разработанное по заказу
Американского математического общества Германом Цапфом и реализованное при
помощи METRFONT'a, представлено в гл. 17. В гл. 18 рассказывается, как я
адаптировал текстовые шрифты в математических книгах таким образом,
чтобы они по насыщенности гармонировали с математическими символами
Цапфа. В гл. 19 подводятся итоги обучения METRFONT'y и основам шрифтового
дизайна группы студентов Станфордского университета. В гл. 20
описывается новое семейство шрифтов под названием Punk, созданное забавы ради за
один вечер. Главы 21 и 22 посвящены увлекательным задачам, возникающим
при преобразовании фотографий и других тоновых иллюстраций в
дискретные точечные изображения при выводе на печать. Наконец, гл. 23 имеет дело
с границами дискретных изображений, которые предназначены для имитации
отрезков прямых в тупых и острых углах.
В остальных главах обсуждаются ТЕХ и METRFONT в историческом
аспекте: в прошлом, настоящем и будущем. Меня всегда интересовало
происхождение программных систем на уровне идей и дальнейшее их развитие,
в связи с чем в гл. 24 и 25 воспроизведены самые первые черновые наброски
программы ТЕХ- Эти описания, взятые из компьютерного архива и
опубликованные здесь впервые, в основном предназначались для меня и моих
ассистентов как руководство по первым реализациям 1977 и 1978 гг.; из них
ясно, как повлияла на дальнейшее эта работа, и они выявляют значительное
отличие между моими первоначальными представлениями и существующей
14
Компьютерная типография
в настоящее время системой Т^Х. В гл. 26 описываются самые первые книги,
изготовленные в разных частях света при помощи Т^Х'а и METAFONT'a.
Затем в гл. 27 мы попадаем в более близкие времена: здесь отражено влияние
графического пользовательского интерфейса на компьютерные операционные
системы, благодаря чему они стали более визуализированы; именно,
представлены иконки, символизирующие различного рода файлы, ассоциированные с
вводом и выводом ТЁХ'а и METRFONT'a. Глава 28 представляет собой текст
доклада, сделанного в 1986 г., когда я впервые поверил, что привел свою
работу по компьютерной типографии к успешному завершению; в гл. 29 написано,
что я сказал в 1989 г., когда понял, что в окончательные версии ТЁХ'а и
METRFONT'a необходимо внести изменения, чтобы они могли оперировать с большим
количеством языков. В гл. 30 содержится то, что я сказал в 1990 г., когда
убедился, что эти изменения действительно последние. В гл. 31-33 содержится
запись живых бесед с пользователями ТЁХ'а и METRFONT'a в виде вопросов
и ответов, которые проводились в Соединенных Штатах (1995 г.), Чешской
республике (1996 г.) и Нидерландах (1996 г.). Наконец, гл. 34 представляет
собой только что написанное продолжение моей статьи «Ошибки ТвХ'а».
Многие из глав этой книги были написаны тогда, когда современная
технология печатания еще только быстро набирала обороты, используя
экспериментальные системы, которые выталкивали текущее состояние этого искусства
на предел его возможностей. Чтобы воспроизвести это теперь я должен был
воссоздать те экспериментальные системы и воскресить десятки давно
утерянных шрифтов, моделируя их готовыми версиями Т^Х'а и METRFONT'a, дабы
не исказить исторический контекст. Многие главы были изначально написаны
в соответствии с форматом иных изданий, так что мне пришлось адаптировать
их к размеру полосы набора данной книги и соблюсти другие принятые здесь
соглашения. Отдельные слова и выражения я изменял, но основной материал
остался в сущности тем же, каким он был при первых публикациях;
исключение составляют гл. 21 и 22, которые претерпели существенную переработку,
чтобы соответствовать сегодняшнему положению дел. Списки литературы
были адаптированы к требуемому формату; в нужных местах были расставлены
дополнительные ссылки и замечания; десятки иллюстраций были существенно
улучшены.
Некоторые иллюстрации в тексте должны были выглядеть не лучшим
образом, для контраста с другими, которые я предложил в качестве более
подходящих альтернатив. Но в принтерах заложена масса приемов для улучшения
материала низкого качества; они сработали, в связи с чем некоторые мои
«плохие примеры» оказались отретушированными и выглядят лучше, чем я
предполагал. Я приношу извинение за любые непрошенные улучшения, которые не
смог проконтролировать.
Я весьма признателен CSLI-—Станфордскому центру изучения языка и
информации —за предоставленную мне возможность опубликовать книгу и за
профессиональную подготовку всего того, что я хотел представить в ней. В
Предисловие
15
частности, Уильям Э. МакМекан и Уильям Дж. Крофт подготовили
электронные варианты многих файлов, которые предварительно были набраны моим
секретарем Филлис Уинклер; Тони Ги собрал и выстроил материал самым
подобающим образом; Копенгавер Кампстон сделал обложку книги.
Инициатором и руководителем всего проекта был Дикран Карагезян. Архив Стан-
фордского университета предоставил эффективный доступ к своей коллекции
по TgX'y и METRFONT'y (SC97, ящики 12-25). Мартин Фрост помог мне
реконструировать многочисленные файлы, изначально подготовленные мною на
легендарном Станфордском компьютере mc SAIL (списанном в 1990 г.).
Барбара Битон из Американского математического общества нашла многие
электронные файлы статей, первоначально опубликованных в журнале TUGboat,
издаваемом Т^Х Users Group, который она так тщательно редактирует уже
почти 20 лет. Фирмы Sun Microsystems и Apple Computer любезно предоставили
мне компьютеры, на которых я имел возможность отшлифовать и
отредактировать окончательный вариант книги.
Это третий в серии сборников моих работ, написанных за прежние
годы, которую планирует выпустить издательство CSLI. Первьш том — Literate
Programming— появился в 1992 г., второй — Selected Papers on Computer
Science — в 1996 г. Еще пять томов находятся в стадии подготовки. В них
будут представлены избранные работы по анализу алгоритмов, языкам
программирования, построению алгоритмов, дискретной математике и играм и
развлечениям.
Дональд Э. Кнут
Станфорд, Калифорния
Август 1998 г.
Ссылки на источники
«Mathematical Typography» (Математическая типография) первоначально
опубликовано в Bulletin of the American Mathematical Society (новая серия)
1 (March 1979), pp. 337-372. Copyright ©1979 by the American Mathematical
Society. Перепечатано с разрешения.
«Breaking Paragraphs Into Lines» (Верстка абзацев) первоначально
опубликовано в Software — Practice and Experience 11 (1981), pp. 1119-1184. Copyright
John Wiley & Sons Limited. Перепечатано с разрешения.
«Mini-Indexes for Literate Programs» (Мини-указатели для
самодокументированных программ) первоначально опубликовано в Software — Concepts and
Tools 15 (1994), pp. 2-11. Copyright ©1994 by Springer-Verlag GmbH & Co. KG.
Перепечатано с разрешения.
«The Letter S» (Буква S) первоначально опубликовано в The Mathematical
Intelligencer 2 (1980), pp. 114-122. Copyright ©1980 by Springer-Verlag GmbH &
Co. KG. Перепечатано с разрешения.
«My First Experience with Indian Scripts» (Мое первое знакомство с
индийской письменностью) первоначально опубликовано в буклете CALTIS-84, р. 49.
Copyright ©1984 by ITR Graphic Systems Pvt. Ltd. Перепечатано с разрешения.
«The Concept of a Meta-Font» (Концепция меташрифта) первоначально
опубликовано в Visible Language 16 (1982), pp. 3-27.
«Lessons Learned from METRFONT» (Уроки METRFONT'a) первоначально
опубликовано в Visible Language 19 (1985), pp. 35-53. Copyright by Illinois
Institute of Technology — Institute of Design. Перепечатано с разрешения.
«AMS Euler — A New Typeface for Mathematics» (AMS Euler — новый
математический шрифт) первоначально опубликовано в Scholarly Publishing 20
(1989), pp. 131-157. Copyright ©1989 University of Toronto Press Incorporated.
Перепечатано с разрешения University of Toronto Press Incorporated.
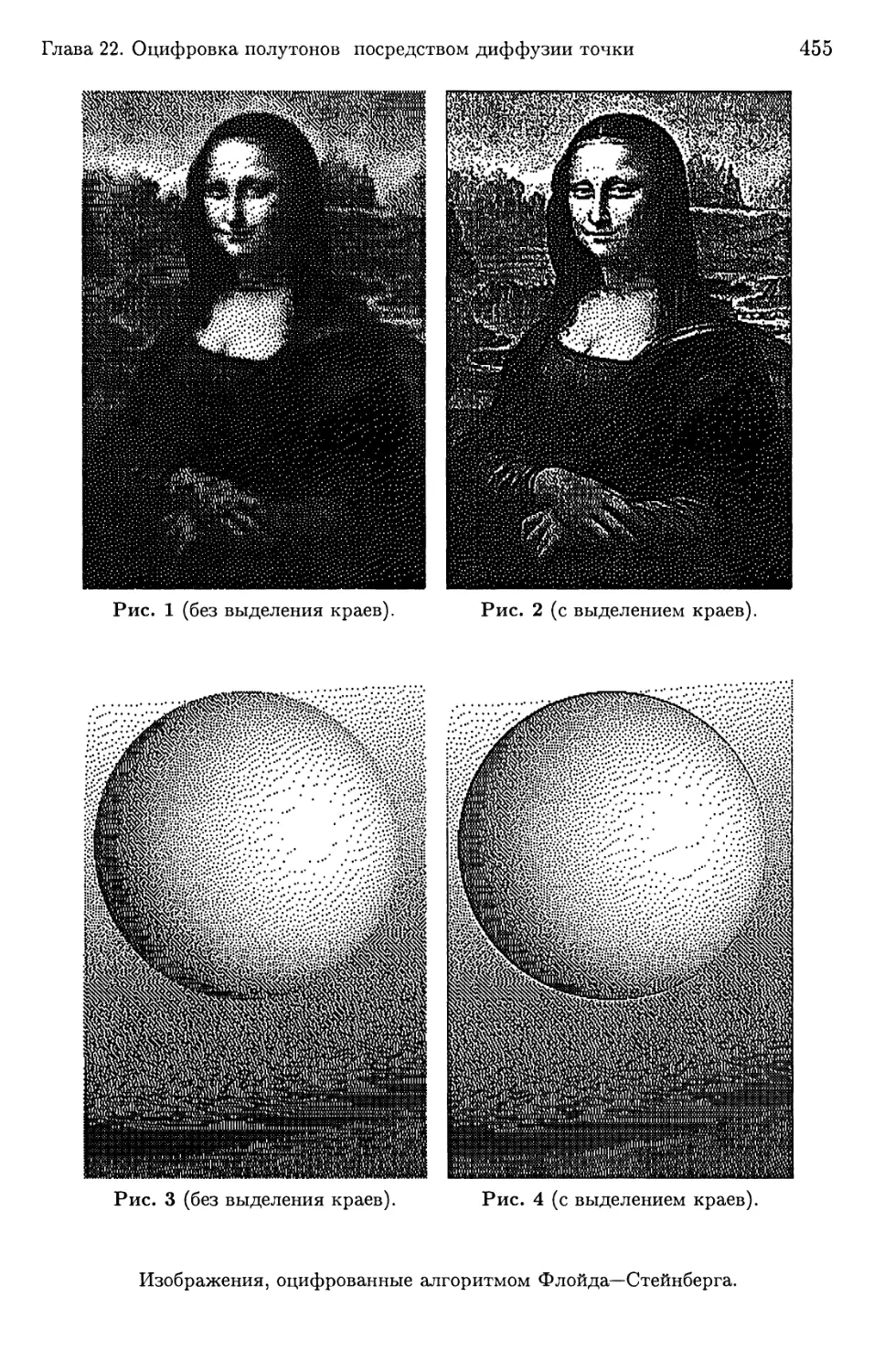
«Digital Halftones by Dot Diffusion» (Оцифровка полутонов посредством
диффузии точки) первоначально опубликовано в ACM Transactions on
Graphics 6 (1987), pp. 245-273. Copyright ©1987 by ACM Press, a Division of the
Association for Computing Machinery, Inc. (ACM). Перепечатано с разрешения.
«A note on digitized angles» (Заметки об оцифровке углов) первоначально
опубликовано в Electronic Publishing— Origination, Dissemination, and Design 3
(1990), pp. 99-104. Copyright ©1990 by Penn Well Publishing Co. Перепечатано
с разрешения.
Ссылки на источники
17
«ТЕХ Incunabula» (ТЕХ'овские инкунабулы) первоначально опубликовано
в TUGboat 5 (1984), pp. 4-11.
«A Course on METRFONT Programming» (Из опыта преподавания
программирования на METRFONT'e) первоначально опубликовано в TUGboat 5 (1984),
pp. 105-118.
«Recipes and Fractions» (Рецепты и дроби) первоначально опубликовано в
TUGboat 6 (1985), pp. 36-38.
«Computers and Typesetting» (Компьютеры и книгоиздание)
первоначально опубликовано в TUGboat 7 (1986), pp. 95-98.
«The Т^Х Logo in Various Fonts» (Логотип системы ТЕХ в различных
шрифтах) первоначально опубликовано в TUGboat 7 (1986), р. 101.
«Mixing Right-to-Left Texts with Left-to-Right Texts» (Сочетание текстов,
читаемых справа налево и слева направо) первоначально опубликовано в
TUGboat 8 (1987), pp. 14-25.
«Problem for a Saturday Morning» (Задача на субботнее утро)
первоначально опубликовано в TUGboat 8 (1987), pp. 73, 210.
«Fonts for Digital Halftones» (Шрифты для дискретных полутонов)
первоначально опубликовано в TUGboat 8 (1987), pp. 135-160.
«Printing Out Selected Pages» (Генерирование избранных страниц)
первоначально опубликовано в TUGboat 8 (1987), р. 217.
«Macros for Jill» (Макро, написанные для Джил) первоначально
опубликовано в TUGboat 8 (1987), pp. 309-314.
«A Punk Met a-Font» (Меташрифт Punk) первоначально опубликовано в
TUGboat 9 (1988), pp. 152-168.
«Typesetting Concrete Mathematics» (Набор книги Concrete Mathematics)
первоначально опубликовано в TUGboat 10 (1989), pp. 31-36, 342.
«The New Versions of T^X and METRFONT» (Новые версии ТЁХ'а и
METRFONT'a) первоначально опубликовано в TUGboat 10 (1989), pp. 325-328.
«Virtual Fonts: More Fun for Grand Wizards» (Виртуальные шрифты.
Развлечение для настоящих мастеров) первоначально опубликовано в TUGboat
11 (1990), pp. 13-23.
«Exercises for ТЩХ: The Program» (Упражнения к книге T^jK: The Program)
первоначально опубликовано в TUGboat 11 (1990), pp. 165-170, 499-511.
«The Future of IgX and METRFONT» (Будущее TgX'a и METRFONT'a)
первоначально опубликовано в TUGboat 11 (1990), p. 489.
«Icons for TeX and METRFONT» (Пиктограммы для ТЁХ'а и METRFONT'a)
первоначально опубликовано в TUGboat 14 (1993), pp. 387-389.
«Questions and Answers, I» (Вопросы и ответы, I) первоначально
опубликовано в TUGboat 17 (1996), pp. 7-22.
«Questions and Answers, II» (Вопросы и ответы, II) первоначально
опубликовано в TUGboat 17 (1996), pp. 355-367. Copyright Т^Х Users Group.
Перепечатано с разрешения.
«Questions and Answers, III» (Вопросы и ответы, III) первоначально
опубликовано в MAPS (Minutes and APpendiceS) 16 (1996), pp. 38-49. Перепечатано
с разрешения NTG, the Dutch-language-oriented T^X Users Group.
Компьютерная
типография
[Лекция, прочитанная 11 ноября 1996 г. в связи с присуждением премии Киото-
1996 в современных технологиях, учрежденной фондом Inamori Foundation of
Kyoto, Япония.]
[Слайд 0 демонстрировался во время представления лектора публике]
Слайд 0.
С тех пор как я себя помню, я находился в атмосфере любви к книгам. Прежде
всего, мои родители много мне читали —для Америки необычная практика в
те времена: в 40-е годы расхожая «мудрость» гласила, что ребенок, в раннем
возрасте отведавший интеллектуальную пишу, станет скучать в школе.
Благодаря моим родителям в четырехлетнем возрасте я стал самым юным членом
Клуба любителей книги при Миллуокской публичной библиотеке [слайд 1].
Я полагаю, что именно раннее знакомство с книгами и есть причина того,
что я не могу припомнить ни одного дня, чтобы мне было скучно во время
учебы. В самом деле, современное общество все смешало воедино в своей
концепции «скуки»: люди часто говорят друг другу, что они скучают, но для меня
это почти шокирующее, позорное признание. Почему это кто-то должен нас
развлекать? Люди, не находящие интереса в том, что они делают, постоянно
нуждающиеся во внешних раздражителях и источниках удовольствия,
упускают большую часть земных радостей.
Что касается меня, то со мной происходило прямо противоположное: я
совершал крен в другую сторону. Я зачастую находил столько интересного в
20
Компьютерная типография
Too young to read book* himself,
Donald Knuth, 4, of 2{*>1 N. 15th
st. is nevertheless the youngest
member of the public library*
Ancient Order of Book Worms. His
father reads storybook* to him.
Wednesday he gave oral report*
on hi» "reading:" in the voting
people's room of the library. Some o£
the Atorie» he reported on were
"Country Bunny," "Pokey Be»r."
"When the Root Children Wake
TV and "Babar the King."
Kitten (
Слайд 1.
Слайд 2.
первой главе изучаемой книги, что у меня не хватало времени прочесть
заключительные главы.
Однажды, когда мне было 5 лет, родители разрешили мне самому поехать
на трамвае в библиотеку. Там я был совершенно зачарован детскими книгами.
Так как я не вернулся домой в назначенное время, обеспокоенные родители
позвонили в библиотеку. Ночной сторож пошел меня искать и нашел среди
полок, упивающегося чтением: у меня и мысли не возникло, что библиотека
закрыта и пора идти домой! Даже теперь моя жена знает, что если я пошел в
библиотеку, то обратно меня рано ждать не приходится.
На самом деле я не только всегда любил книги, я также обожал отдельные
буквы в книгах. Вот страничка из моей первой азбуки [слайд 2]. Удивительно,
но я отметил маленькими крестиками все засечки у букв и сосчитал эти
засечки: у буквы К их было 7; у буквы Р [СЛАЙД 3] 4 засечки; у буквы О [СЛАЙД 4]
их не было вовсе.
Слайд 3.
Слайд 4.
Из этого вы можете заключить, что цифры мне нравились не меньше
букв. Со временем, став преподавателем Станфордского университета и
поняв, что мои основные таланты связаны с программированием, я начал писать
свои собственные книги. Первая моя книга —первый том The Art of Computer
Programming— вышла в свет в 1968 г.; второй том был готов годом позже1
[слайд 5].
1 В русском переводе эти два тома Искусства программирования для ЭВМ (М.: Мир.)
вышли, соответственно, в 1976 и 1977 гг. — Прим. ред.
Глава 1. Компьютерная типография
21
Я испытывал такое волнение при виде этих томов не только потому, что
был доволен их содержанием, но и потому, что они были великолепно
типографски оформлены. Эти книги были выполнены в лучших проверенных
временем традициях представления научно-технических текстов. Именно в
таком классическом стиле были оформлены мои любимые учебники в колледже.
Так что смотреть на эти тома было не менее приятно, чем читать их.
Слайд 5. Слайд 6. Слайд 7.
Их готовили по технологии 19-го столетия «монотип», в которой были
задействованы два вида машин. Прежде всего, имелась сложная пневматическая
клавиатура с 284 клавишами [слайд 6]. Эта машина производила
перфорированную бумажную ленту, нечто вроде нотных списков пианистов; вы можете
видеть ее вверху картинки. Эта лента затем использовалась в качестве
управляющего механизма в специальной отливочной машине [слайд 7],
производящей отдельные фрагменты наборного материала из горячего расплавленного
свинца.
|det(ay)|< П £ 4
1<г<п \l<j<n /
Слайд 8.
Процесс набора математических формул на такой машине был
чрезвычайно сложным; вот типичная формула из тома 2 [СЛАЙД 8]. Наборщик,
специализирующийся именно на таких вещах, воспроизводил большую часть этой
формулы в два прохода: сначала он набирал буквы и символы основного
уровня и их верхние индексы (это
|det(a )| < а2
в данном случае); затем вторым проходом вставлялись нижние индексы (это
повторенные здесь дважды литеры 'гу). Оператор монотипа должен был знать
22
Компьютерная типография
ширину каждой литеры, чтобы оставлять достаточно места для последующего
заполнения индексами. После того как формула была отлита в металле, другой
специалист вручную вставлял оставшиеся большие символы (большие скобки
и символы типа П и 1С)-
Всего лишь несколько десятков человек в мире умели набирать
формулы на монотипе. Я имел удовольствие быть знакомым с наборщиком Эриком,
который набирал все формулы в 1-ом и 2-ом томах. Я с удивлением
обнаружил, что он говорил с сильным акцентом, присущим жителям предместий
Лондона, хотя жил в Америке и ему поручали делать самые сложные книги
по математике.
Program A (Addition, tublraction, and normalization). The following program
is a subroutine for Algorithm A, and it is also designed so that the normalization
portion can be used by other subroutines which appear later in this section. In
this program and in many other programs throughout this chapter, OFLO stands
for a subroutine which prints out a message to the effect that Mix's overflow
toggle was unexpectedly found to be "on."
01 EXP EQU 1:1 Definition of exponent field.
Ot FSUB STA TEMP Floating-point subtraction subroutine:
OS LOAN TEMP Change sign of operand.
Слайд 9.
Книги по компьютерным наукам добавили новые проблемы к тем, что были
при наборе математики: программистам понадобился шрифт особого
начертания typewriter type, чтобы представлять тексты программ, с которыми
имели дело машины. На слайде [слайд 9], например, представлен еще один
фрагмент из 2-го тома — часть компьютерной программы. Мне нужно было
объединить шрифт typewriter, которым набрано слово 'OFLO' например, с
обычным шрифтом. Прежде всего мне сообщили, что невозможно добавить в
монотип еще один алфавит, поскольку традиционные математические шрифты
уже исчерпали предел возможностей монотипа. Однако позже Эрик и его
мастер придумали, как это осуществить. Обратите внимание, что в этом шрифте
мне нужна была буква 0 нового, менее округлого рисунка, чтобы различие
между 0 (буква о) и 0 (нуль) было более очевидным.
В I960 гг. металлический набор типа «монотип» начал вытесняться
фотонабором. Новые машины воспроизводили страницы путем по-литерной
экспозиции фотоформ, используя остроумную комбинацию из вращающихся дисков
и линз для помещения каждой литеры в соответствующую позицию. Вскоре
после опубликования 3-го тома мой издатель продал монотипы и Эрик был
вынужден искать другую работу. Новые допечатки 1-го и 2-го томов
появились в 1975 г. с исправленными опечатками, рбнаруженными читателями. Эти
исправления набирались в Европе, где монотипы еще продолжали
существовать.
Я уже подготовил 2-е издание 2-го тома, которое предполагалось набирать
заново. Мои издатели сочли, что готовить книгу в 1976 г. по технологии 1969 г.
слишком дорогое удовольствие. Кроме того, шрифт в фотонаборных машинах
не совпадал по рисунку со шрифтом, которым были набраны оригиналы. Я
вылетел из Калифорнии в Массачусетс для решающей встречи. Издатели
согласились, что качеством набора жертвовать нельзя, и через несколько месяцев
Глава 1. Компьютерная типография
23
Program A {Addition, tubtraction, and normalization). The following program
is a subroutine for Algorithm A, and it is also designed so that the normalization
portion can be used by other subroutines which appear later in this section. In
this program and in many other programs throughout this chapter, OFLO
stands for a subroutine which prints out a message to the effect that MIX's
overflow toggle was unexpectedly found to be "on." The byte size b is assumed
to be a multiple of 4. The normalization routine NORM assumes that rI2 = e
and rAX = /, where rA = 0 implies rX = 0 and rI2 < b.
01 EXP EQU 1:1 Definition of exponent field.
02 FSUB STA TElfP Floating-point subtraction subroutine
03 LP AM TElfP Change m^ii of operand.
Слайд 10.
Слайд 11.
были предприняты большие усилия, чтобы получить новые шрифты,
совпадающие по начертанию со старыми.
Результат, однако, оказался удручающим. Вот, например [слайд 10], некий
набор из второй, «отрегулированной» версии новых шрифтов. По сравнению с
первой попыткой эта выглядела много лучше, но все еще была неприемлема.
Буква «N» в «NORM» была слегка наклонена; лигатура «ff» в «effect» оказалась
слишком темной; буквы «ip» в «multiple» очень близко расположились друг к
другу и т. д.
Я не знал, что делать. На написание этих книг я потратил 15 лет, но если
они были сделаны, чтобы выглядеть так ужасно, я больше ничего не хотел
писать. Эта продукция не делала мне чести.
Возможный выход из создавшейся дилеммы представился сам собой
несколькими месяцами позже, когда я познакомился с другим радикальным
нововведением в технологии печатания. Новейшие машины помещали
изображения на пленку дискретными средствами вместо аналоговых — нечто вроде
того различия, которое есть между телевизионными и настоящими фильмами.
Формы букв были теперь составлены из крошечных точек на основе
электронных импульсов, которые были либо в состоянии ВКЛЮЧЕН, либо в состоянии
ВЫКЛЮЧЕН [слайд 11]. Так-так! Такого рода вещи я мог понять! Это очень
просто, вроде лампочек на табло стадиона.
Металлургия и горячие отливки для меня всегда были тайной за семью
печатями; я также ничего не понимал ни в оптике, ни в механических
устройствах выравнивания. Но буквы, состоящие из маленьких точек — это объект
из компьютерных наук! Это всего лишь биты, бинарные разряды, нули и
единицы! Ставим единицу в том месте, где должна быть краска, и нуль в том, где
ее быть не должно — и можно печатать книжную страницу!
24
Компьютерная типография
Раньше я видел формы букв в дискретном представлении, но только на
машинах, дающих грубые оттиски. Программисты многие годы
экспериментировали на устройствах Xerox Graphics Printer, которые были изобретены в
Англии примерно в 1961 г., но до 70-х гг. компьютерами не управлялись. Эти
устройства делали буквы из точек, но точки не были достаточно маленькими.
Один дюйм содержал только 180 точек, так что буквы состояли из ребристых
линий. Поиграть на Xerox Graphics Printer было очень приятно, но я никогда не
думал, что на подобной машине можно будет печатать настоящие книги. Мне
они казались весьма примитивными, способными только производить дешевые
имитации — разница здесь была такая же, как между электронным
синтезатором и подлинными пианино или виолончелью.
Но в феврале 1977 г. мне на глаза впервые попалась распечатка с
электронной машинки высокого качества с разрешением 1000 точек на дюйм ... и
это выглядело великолепно, даже немного лучше, чем самый совершенный
металлический набор, который я когда-либо видел. И вдруг я понял, что точки,
если они достаточно малы, согласно законам физики образуют как бы гладкие
кривые. Тогда я вспомнил, что глаз человека имеет дискретную природу, так
как состоит из отдельных палочек и колбочек. Таким образом, я впервые
убедился, что дискретная наборная машина в самом деле способна производить
книги самого высокого полиграфического качества.
Цифровые (дискретные) камеры не решают всех острых вопросов
традиционной фотографии. Телевизионное изображение высокого разрешения не
может идти ни в какое сравнение с кинофильмом. Но для типографской краски
на бумаге дискретный подход столь же хорош, как и любой другой.
Иначе говоря, проблема высококачественного книгоиздания перестала
быть задачей металлургов и оптиков, а стала задачей программистов. Тот
факт, что Гутенберг создавал книги, используя металлический набор, вдруг
превратился всего лишь в 500-летний исторический эпизод. Новые машины
сделали старый механический подход совершенно бесполезным: будущее
типографии зависело от людей, которые хорошо понимали, как создавать образы
из нулей и единиц. Оно теперь зависело от математиков и программистов.
Осознав это в полной мере, я не мог не поддаться искушению решить
данную полиграфическую проблему самостоятельно. Забросив все начатые дела
(тогда я завершал работу над первыми 100 страницами 4-го тома), я решил
написать программу, генерирующую страницы в виде образов из нулей и
единиц, которые так были нужны мне и моим издателям для нового издания 2-го
тома.
Я поначалу думал, что это будет совсем нетрудно, и отвел на такую
деятельность всего несколько месяцев. Своим издателям в марте 1977 г. я написал,
что в июле они получат первую корректуру. О, как далек я был от истины!
Всю свою жизнь я недооценивал сложность проектов, за которые брался, но
это был мой личный рекорд в оптимистическом прогнозировании.
Прежде всего надо было учесть, что почти никто из компьютерных
специалистов не занимался проблемами такого рода, в связи с чем получить
финансовую поддержку оказалось довольно трудно. Наборное устройство было
слишком дорогим удовольствием, совершенно не вписывающимся в наш уни-
Глава 1. Компьютерная типография
25
верситетский бюджет. Более того, машина была рассчитана на круглосуточную
работу нескольких операторов, а я был всего лишь одинокий одержимый
математическими идеями чудак без какого-либо опыта в типографском деле. И
еще я полагал, что получив работающую компьютерную программу, я смогу
выкроить время на некую цифровую наборную машину.
Это была проблема яйца и курицы. Я не мог установить правила набора,
не имея соответствующих шрифтов для текста и математических символов:
нужные мне шрифты не существовали в цифровом виде. И я не мог создать
шрифты, не установив правил набора. Мне нужно было то и другое
одновременно. Существовали другие оцифрованные шрифты, но я был полон
решимости создать свои собственные, описываемые математическими формулами,
которые я выберу сам. В этом случае мне не пришлось бы столкнуться с такой
ситуацией, когда любое изменение технологии снова смешало бы все карты.
Имея собственную программу, управляющую всеми аспектами поведения
нулей и единиц на страницах, я имел бы возможность определять внешний вид
своих книг раз и навсегда.
Мои издатели снабдили меня копиями рисунков шрифтов Monotype,
использованных при наборе первого издания 1-го тома. Поэтому мне казалось,
что найти математические формулы для описания рисунка букв не составит
особого труда. Я встретился с Джоном Уорноком, делавшим аналогичные
вещи для исследовательского центра Xerox в Пало Альто, и спросил его, могу ли
я использовать возможности лаборатории Xerox для создания своих шрифтов.
Ответ был утвердительным, но оставалась одна загвоздка: Xerox настаивал на
передаче авторских прав на все шрифты, которые я разработаю на их
оборудовании. Конечно, они со своей стороны имели основание это требовать, но такое
положение дел совершенно не устраивало меня: математическая формула не
может быть ничьей «собственностью»! Математика принадлежит Богу.
Таким образом, я пришел, наконец, в лабораторию искусственного
интеллекта Станфордского университета, в которой была телекамера. Я использовал
ее для увеличения букв и их оцифровки. К сожалению, телекамера не
давала истинной картины — изображения получались искаженными. Еще ужаснее
было то, что совсем незначительные колебания освещенности в помещении
приводили к разительным изменениям телевизионного изображения. Не было
никакой возможности извлечь устойчивые данные для каждой буквы.
Шрифты, полученные про помощи телекамеры, выглядели гораздо хуже шрифтов,
порожденных нецифровым устройством.
Я попытался сфотографировать страницы и увеличить их, спроецировав
на стену у себя дома. Увеличенные контуры букв я обвел карандашом на
бумаге. Но это тоже не дало результата.
Наконец, мне пришла простая мысль: ведь эти буквы созданы людьми.
Если бы я смог понять, чем они руководствовались, когда рисовали буквы, я
смог бы дать компьютеру задание реализовать те же идеи. Теперь моей новой
целью было воспроизвести не рисунок букв, а лежащий в его основе
интеллект. Я решил обучиться мастерству шрифтовых дизайнеров и научить этому
компьютер.
26
Компьютерная типография
Эта цепочка умозаключений привела меня к компьютерной системе под
названием METRFONT, которую я сейчас попытаюсь вам продемонстрировать.
[Переключается на слайды на дисплее компьютера.] Здесь представлен способ
создания букв при помощи компьютерной программы, к которому я, наконец,
пришел. В качестве примера взята буква А. Все ключевые (базовые) точки
буквы находятся на показанной здесь сетке, хотя сама сетка в действительности,
разумеется, невидима.
На основе этой сетки и заданной спецификации (параметров) текстового
шрифта светлого начертания компьютер сначала нарисует основной штрих:
Часть этого штриха затем будет стерта, потому что штрих слишком широк
вверху.
Затем пририсовывается левый диагональный штрих
Глава 1. Компьютерная типография
и перекладина.
27
Теперь нужно добавить засечку внизу слева
■■
и слегка ее подчистить, чтобы она зрительно не утяжеляла букву.
(Такая подчистка едва уловима: нужно внимательно всмотреться!) Аналогично
пририсовывается засечка внизу справа:
Буква А готова.
28
Компьютерная типография
Та же самая программа может нарисовать бесконечно много букв А, если
менять спецификации (параметры). Вот, например, более темный или
полужирный вариант:
щш ЩШл ШшШ Щшл
llili uJjILLIj 11 i 1111111111 i 11111 i 11 i 11111111111111111111
А вот буква А поменьше, подходящая для высококачественной печати:
Простое уменьшение оригинала А на 50% не привело бы к получению
правильной буквы мелкого кегля; мы бы получили «а» вместо «а». По правилам
полиграфии буквы мелкого кегля по начертанию должны слегка отличаться
от их более «взрослых» сестер.
Глава 1. Компьютерная типография
29
Даже машинописная буква А может быть нарисована той же
программой. На этот раз в спецификации указывается, что толстые и тонкие штрихи
идентичны, а углы и засечки закруглены.
MTTltl 1111111 МТТТМ 1111111 м Мм 11111111 ПМГТ IT 11I111
ШИШ iffll
нН
Получилась буква А из моего первого машинописного шрифта. Позже я узнал,
что эта А была чуть-чуть жирнее, чем нужно. Чтобы исправить положение, я
слегка раздвинул диагональные штрихи и «подтесал» внутри, так что внутри
буквы стало попросторнее.
11
Ш1ДИИИ
хЛ |Н| |И|
Вот такая изящная машинописная А используется в последней версии шрифта.
С подобными приемами я познакомился несколько лет спустя, когда начал
изучать шрифтовой дизайн.
30
Компьютерная типография
Program A [Addition, subtraction, and normalization). The following program
is a subroutine for Algorithm A, and it is also designed so that the normalization
portion can be used by other subroutines that appear later in this section. In this
program and in many other programs throughout this chapter, OFLO stands for
a subroutine that prints out a message to the effect that Mix's overflow toggle
was unexpectedly found to be "on." The byte size b is assumed to be a multiple
of 4. The normalization routine NORM assumes that rI2 « e and rAX »• /, where
rA — 0 implies rX -» 0 and rI2 < b.
00 BYTE EQU 1(4:4) Byte size b
01 EXP EQU 1:1 Definition of exponent field
OS FSUB STA TEMP Floating-point subtraction subroutine:
03 LDAN TEMP Change sign оГ operand.
Слайд 12.
А вот образчик того, как выглядел мой первый черновой вариант
шрифта в распечатке на принтере Xerox Graphics после полутора лет работы над
типографским проектом [слайд 12]. Двумя годами позже при финансовой
поддержке моих издателей я, наконец, получил доступ к цифровому устройству
с высоким разрешением и смог напечатать 2-й том в новой редакции.
Распечатка этой книги выглядела много лучше, чем полученная на принтере Xerox
Graphics, с которым я работал прежде, и я уже решил было, что поставленная
цель — высокий полиграфический уровень — достигнута.
Но когда я получил сигнальный экземпляр нового издания 2-го тома в
знакомом переплете и открыл его, я был страшно разочарован. Книга совсем не
была похожа на то, что я ожидал увидеть. После четырех лет тяжелого труда
я все еще не представлял себе, как генерировать образы из нулей и единиц,
отвечающие требованиям высококачественной печати. Типографский
экземпляр второго издания [слайд 13] выглядел ненамного лучше того варианта,
который я отверг, приступая к своему типографскому проекту.
Program A {Addition, subtraction, and normalisation). The following program
is a subroutine for Algorithm A, and it is also designed so that the normalization
portion can be used by other subroutines that appear later in this section. In
this program and in many others throughout this chapter, OFLO stands for a
subroutine that prints out a message to the effect that Mix's overflow toggle was
unexpectedly found to be "on." The byte site b is assumed to be a multiple
of 4. The normalisation routine NORM assumes that rI2 = e and rAX = /, where
rA = 0 implies rX — 0 and rI2 < b.
00 BYTE EQU 1(4:4) Byte sue 6
01 EXP EQU 1:1 Definition of exponent field
02 FSUB STA TEMP Floating point subtraction subroutine:
OS LDAN TEMP Change sign of operand.
Слайд 13.
Между тем мне посчастливилось познакомиться с несколькими
ведущими шрифтовыми дизайнерами, которые своими деликатными критическими
замечаниями и советами весьма помогли мне в процессе дальнейшего
совершенствования. Так что по прошествии еще пяти лет я, наконец, умею делать
книги, которыми могу гордиться.
Мне бы не хотелось, чтобы у вас сложилось впечатление, что эти 9 лет я
провел исключительно в нудной изнурительной работе. (Как я уже говорил,
мне редко бывает скучно.) Шрифтовой дизайн на самом деле — чрезвычайно
увлекательное занятие, особенно по части делания ошибок. Компьютер имеет
тенденцию рисовать отчетливо созданные изображения, которые человеку
даже и не приснятся во сне. Я назвал это «МЕТА-ляп». Например [слайд 14],
Глава 1. Компьютерная типография
31
fttfl
SB
1 1 1 1 1 1 1 1 II 1 1 1 1 i
Слайд 14.
Слайд 15.
Слайд 16.
вот лигатура ffi, в которой левое f простирается вправо над всей комбинацией
вплоть до точки над i. А вот другая ffi, причудливой формы [СЛАЙД 15]: я
назвал это «the ffilling station»1.
При одной из первых попыток нарисовать прописную машинописную
букву Y я ошибочно поместил верхнюю правую засечку посередине [слайд 16].
Клянусь, что в тот момент вовсе не думал о йенах!
J/
^_--'9 ?
Ч^
Слайд 17.
Слайд 18.
Работает ли METflFONT столь же хорошо с японскими буквами, как и с
латинскими? Думаю, да, но сам не способен в совершенстве различать азиатские
литеры. Мой студент Джон Хобби провел многообещающий эксперимент со
специалистом из Shanghai Printing Company Гу Го-Анем, и я с удовольствием
представляю образчик того, что они делали. Сначала они написали 13
программ для основных штрихов. Вот пример двух «слезинок», полученных при
помощи этих программ [слайд 17]. Шрифтовой дизайнер указывает в
спецификации верхнюю точку, нижнюю точку и контур капли; остальное делает
1 Filling station — бензоколонка — Прим. перев.
32
Компьютерная типография
компьютер. Здесь [слайд 18] представлено еще несколько примеров слезинок
и варианты трех других основных штрихов.
Хобби и Гу нарисовали при помощи своих программ для штрихов 128
китайских иероглифов. Эти программы позволяют получать иероглифы в трех
разных начертаниях, используя три разные версии 13 основных штрихов.
Вот [слайд 19] пять иероглифов начертания Song, Long Song и Bold. А вот
[слайд 20] примеры 13 основных штрихов для всех трех начертаний.
Слайд 19. Слайд 20.
Имея систему METRFONT шрифтового дизайна и систему ТЁК
правильного размещения букв и символов на странице, любой желающий может теперь
самостоятельно красиво оформлять свои книги при разумном объеме усилий с
его стороны. Эти системы позволяют авторам осуществлять общий контроль
над образами из нулей и единиц, которые нужны для определения страниц.
Я приложил особые усилия со своей стороны к тому, чтобы Т^Х и METRFONT
давали один и тот же результат на всех компьютерах и чтобы тот же результат
получался и по прошествии 50-ти лет. Более того, я опубликовал эти системы
е- подробным их описанием и предоставил их для общественного
использования, так что никто не должен ничего платить за них. Разумеется, отдельные
люди, предоставляющие дополнительный сервис, будут взимать плату за свои
усилия, но самое главное здесь то, что с такими свободно распространяемыми
системами автор получает возможность самостоятельно готовить книги, что
раньше стоило ему чрезвычайно дорого.
Не могу отказать себе в удовольствии показать вам отрывки из книг,
присланных мне недавно их авторами. Вот отрывок из книги чешского автора
[СЛАЙД 21], набранный другим шрифтом, сделанным при помощи METRFONT.
А этот образец из Эфиопии [слайд 22], в котором на амарском языке
рассказывается, как пользоваться системой ТЕХ.
Глава 1. Компьютерная типография
33
Kapitola
XII
4.8.2 тЛЛЯ°
2епё sluncem odene drak sedmihla-
vy syna scfrati chte4. 7. ale Michal
archande4. draka pfemohl. 10. Nad
niml afkoli ufastnici Berdnkovi svite--
zili. 11. i Zena uletela. 16. a zevrxe feku
vypila. 17. vSak ten drak proti ostatkum svatych
bojovati nepfestdvd.
I ukazal se div veliky na nebi: Zena ode-
nd sluncem, pod jejimiZ nohama byl me-
sic, a na jejte hlave byla koruna dvandcti
hvezd. 2 A jsouci teTiotnd, kfifela, pracu-
jici ku porodu a traped se, aby porodila.
3 I vidua jest jiny div na nebi. Nebo aj, drak
fmArtf* M tf ПА hAA mnf- (WW- «Ol* £«»1ftAA и Л7ХГ0Й tH*
fmAAf hAA -ГЛЛ4Л. >a>- u A*>+ mftftr hAA a>-ftT tf f ftWa>- >-4*
Л* la* и ОН** MP1C fmAftf «-T*C «m *«-ЛЛЛ «
\ХГ'С{тАЛГ') [tbhp]
n-)«iw:\n\ лки <чпа »
\e.in-i{<fn-)m<:\'«\ of лки /чпа>}
\л£П(лЛЛГ)
П«-Л<1+ ГИЛЛ- »«T*C hf ПА Kt-ЛГ-Г •■•■ \-ТЛ-1 A7/rftft hAA
«nAftf ■> -tt. *тст nr ti—am г-*.*л » h->* пл* \--w>-i o->*
mAftf» hAA a>-ftT ~b-t* ГгХ+JE iw ЛГО-ЛХ ЛЛГиП «ft » >1C
T> +ЛПг «.«.«S/ ПЛ«П -ЛС+ Т">^+ -T*<1> m*t*» /«-КТ А ::
Слайд 21.
Слайд 22.
* возвращается ■ горизонтальную моду для продолжения абзаца (Формула,
которая выделяется, лолжиа оканчиваться $$ ) Например, предположим вы
■майте
число StSpi \approx 3.141S926S36M явлавтся вииым.
TfeX между двумя $$ переходит ■ выделенную математическую моду и
результат, который вы получите, утвержлает, что число
»ЛИ, tt xttbr>x^btfh.tibhb^). *4ltf, Х.т.Ьк.КП+Ък..
tb* шшЬвг $$\pi \approx 3.141S926S36M is inportant.
6 1С, Г the number
Когда Т£Х находится в вертикальной или внутренней вертикальной
моде, он игнорирует пробелы и пустые строки (или командные
последовательности Spar), так что вам не надо беспокоиться, что такие веши могут
взмеиить моду или повлиять на создаваемый документ Командным пробел
(Vi) будет, однако, рассматриваться как начало абзаца; абзац начнется с
пробела после отступа.
Обычно л/чше окончить всю работу, поставив в конце рукописи
TfcX'a \by*. что является сокращением для \vtiU\«j*ct\*n4. Командная
последовательность \vf ill переводит Т£Х в вертикальную моду и вставляет
Слайд 23.
u important J tKt ПХШ1И ПЬ.
TtX *Sffl-t- К. iitHWSSea-e- Vnt ttt, 2Й*2гт (ttH Spar ft
S) <^<o*-.T(,*«}lint6. 1_*<>оТ. ЭЙ-fSFf^-e- Kt-*«L
з> Ya-,v- *<-x (\u) tt, Kf5<Otei Н*4«ЛПП. *«*&ОЙ
ЖН. -f >f> Кггт-зЛ*. 2й-сй;4^т^бс ttcftu.
TytwfWwWhfittt, \hy« UflLTt-<tr«T**Sio<i-eWt*
u. \hy« ft^tt plain TfcX tCigJUKTi*»), \vmi\BJBctW4 <0'«Т«*"С*
Слайд 24.
Здесь вы видите [слайд 23] фрагмент русского перевода моей книги по
системе ТЕХ, а здесь [слайд 24] тот же отрывок в переводе на японский. Тем
не менее, если бы я жил в Японии, уверен, что никогда бы не пришел к мысли
о создании ТЁ^'а или METAFONT'a, потому что не чувствовал в этом
необходимости: типографские стандарты в этой стране никогда не приходили в такой
упадок как в Америке и Европе. Тем не менее я чрезвычайно рад, что Т^Х
теперь широко используется и для японских изданий.
Разные люди шлют мне много замечательных книг, которые, вероятно,
никогда бы не были изданы без ТЁ^'а и METAFONT'a. Мои любимые примеры —
это школьные пособия, как вот этот двуязычный текст народной сказки
эскимосов [слайд 25]. Здесь двуязычные примечания на греческом и латинском из
одной критической работы [слайд 26]; это тексты на арабском [слайд 27] и
санскрите [слайд 28].
Начав работу над Т^Х'ом в 1977 г., я регистрировал все найденные ошибки,
крупные и мелкие, которые были найдены и удалены из программы с
помощью добровольных помощников со всего света. Этот список на сегодняшний
день состоит из 1 276 записей. Возможно поэтому Т^Х стал одной из наиболее
тщательно проверенных программ, которые когда бы то ни было были
написаны. Я бы хотел завершить свое повествование цитатой из моего любимого
сборника стихотворений датского поэта Пита Хейна. Он называет свои стихи
«grook»—датский вариант хайку. Нам с женой это произведение настолько
34
Компьютерная типография
14. Aklaq iniqtuqami kayuqtuq
aklaq iniqtuq-(n)amj kayuqtuq
bear be tir«d.l».COND/R fox
apiqsrugaiuagaqnigaa
apiq«ruq-(k)aluaq-(t)aq-niq -(k)aa
ask -ah/after .HABEVID.3. 3«.INI
amuniaqinanaan
qakugu
qakugu
pamjuni.
imu -nUq -maga-/(n)an pamiuq-;ni
p«ll oul-INTNT INDQ3«.«.ENP tail -3R».t.ANP
IS. Kayuqtum kiuraqnigaa,
kayuqluq-/(u)m kiu -laq -ni(| -(k)aa
fox <E uiw ITER EVID 3.3> IND
16 "Maatnugu qaiukpauragukkuvich
maatnugu qaluk-(q)pauraq-(i)uk -(k)uvich
wait! fiak very bit DESIDI..COND/U
freeze/ 11. bear/ he
let him tit down / at
the hole / he dipping
it / bis tail / 12. bear
/ he began to sit /
that evening / 13. fox
/ he started to watch
him / he not wanting
him to pull it out too
soon / his tail /
14. bear / when
he was tired / fox /
he asked him
repeatedly / when / (when)
he was going to pull
it out / his tail /
15. fox / he answered
him often / 16. wait!
aut ad iptum in unoqvoque digne mtelligvntur, | R, 264' | iicui ipta
rtuelant; ФПЕ, ПТР, F1NETMA (hoc est lux, ignis, spiritus).
Haec, ut dixi, ab Epifanio tradita, ut quisquis interrogatus quae
tria et quid unum in lancta trinitate debeat credere, «ana fide | J, ГI
respondere ualeat, aut ad fidem accedens sic erudiatur. Et mihi uide- 743a
tur spiritum pro calore posuisse, quasi dixisset in similitudine: lux,
ignis, calor. Haec enim tria uniui essentiae sunt. Sed cur lucem primo
dixit, non est minim. Nam et pater lux est et ignis et calor; et Alius
est lux, ignis, calor; et spiritus sanctus lux, ignis, calor. Uluminat
enim pater, Uluminat filius, Uluminat spiritus sanctus: ex ipsis enim 30
omnis scientia et sapientia donatur.
18-19 Matth II, 27 22 EPIPHANIVS. ЛпсопШ 67, PG 43, 137С-И0А; CCS
1 ineipil ...nEPI*TTEfiN| от Я, inapit quartu. Ы 2 ANAKE4>AAIOE!E|
FJP, /tee ivouccvaXotuvic. 2 phyaiolog lae | phidologiae P, phyteologiae Я
3 quod| ». natura Iniu, KIR 3 ТПЕРОГЕ1АДЕЕ| codi. Vtnm Опер.
оооч»1тц (hoc «at (upereieentialu) natura cum Colt (r-UO) an bncpouaioi>K
(hoc cat aupereuentialia natura) cum Fton (PL Ш.Ц1С) inUUigen4*m
/it, ambtgilwr 8 OMOTEIOEj codd., Ut* бцоойокк » «l| А", от. R°
Слайд 25.
Слайд 26.
* FVoro V, JOVIjf ,JJ ч4,^Л «Jlf jp J -p\M vtfJI, Tunl. 1-Й» H, ISM АО p. IM f
t Tar tru it rapnxivcnl twin a> pp. IW-J0O ам) vr J0I-101. ia iSf atlr Л&етл гтюм.
. Jki^fl . jip, 101 • jtj\t: jp>1p Ml i. »,Si.| i^lli. Ml l.i+j,}..^..
Слайд 27.
dM$ll4<4Td Ч^У^чГчГя Ч ^П" Ч1ТНТТТ ЧЧТГ^У ЧТГ^Г1 Ч
4VT *ЧШГ1 «Гч^Ч чГч^Ч I Ч -Ц1^*ЧЙ I ЧТГГТ ^Чг) tT4Tfr
Ull^ffl ITnia^ifn I WT I ГТ?Г ?% »?f ГчПя*Ч^ I Г*п^1 4" чГ*1я I
23 jfHr oiu. /J I f^pr J (an easy confuaion in iirada) || VMJ5J • Pt a c.
21 Ч- Ч*«г* о 2Т »Ч »W on. о || Ч** (-4-) ttf* В . ТОТ f»RT4fj«
Pi J TnrjT* J (i*. om. ffj) || чфц P, a.e. | |«fr VT P, /J)
| far ; JW codd. (a very eaay confuaion in $iradi) : fzft Pj а с. || ГПГ* ;
J5W* codd 28 (7J4 '• "TT Pi ^ (f and ЧГ are not alike in Slradl, but С and
T are. So if an ori|inal Г were tranaliterated at T and the aandhi then regularited,
the MS rtadinp would be accounted for) : ЧПГ } 29 •fijljm. В, Pj
J(*
|| ГШТ* : ptTT* } || *«1(М1Я>Гя АЬЬуаак.
Слайд 28.
нравится, что мы заказали выгравировать его на шиферной доске и повесили
у ворот дома [слайд 29]. Это выглядит так:
■ anderr ■
mberraqaitr
l butless ■
о andkss ^
^ andkss л
Совсем простые вехи
Путь к мудрости содержит:
Огрехи
да огрехи,
но реже,
реже,
реже.
Пит Хейн
Слайд 29.
Источники иллюстраций
Слайд 0 дал мне один незнакомец примерно в 1980 г.; это нарисовано кем-то с
инициалами «М. S.». Слайд 1 представляет собой газетную вырезку из The Milwaukee Journal (2
August 1942), page II-l. Слайды 2, 3 и 4 взяты из The Brimful Book, ред. Watty Piper, илл.
G. & D. Hauman (New York: Piatt and Munk, 1927). Для слайдов 6 и 7 были использованы
Глава 1. Компьютерная типография
35
иллюстрации III и IV из книги Chaundy, Barrett, Batey The Printing of Mathematics (London:
Oxford University Press, 1954). Слайд 9 представляет собой фрагмент с. 185 первого издания
второго тома книги The Art of Computer Programming (Reading, Massachusetts: Addison—
Wesley, 1969); слайд 13 —тот же фрагмент с. 202 второго издания (1981). Слайды 10 и 12
взяты из материалов SC 97 архива Станфордского университета. Слайды 14-18
представляют собой иллюстрации статьи «Lessons Learned from METflFONT», рис. 13h, 13i, 13f, 8
и 9 соответственно; см. гл. 17 настоящего издания. Слайды 19 и 20 изготовлены на основе
рисунков статьи John D. Hobby, Gu Guoan «A Chinese Meta-Font», TUGboat 5 (1984), 119-
136, рис. 7, 9. Слайд 21 взят из книги Albrecht Durer, Apokalypsa, перев. Michaela Hajkova
(Prague: Volvox Globator, 1993), page 20. Слайд 22 —из книги ЛПП ПЛ£ ЛЛЯ°>и [Abass
Belay Alamnehe] *i>6U& ЛГМь ГП>& Wig* ™<™<ZP [Book of e3T$(: Document Preparation
Guidelines] (Houston, Texas: EthiO Systems, 1993), pages 70-71. Слайд 23 —фрагмент с. 107
книги Дональд Е. Кнут. Все про Т^Х, перев. М. В. Лисина (Протвино: АО RDT^X, 1993);
слайд 24 —тот же фрагмент с. 123 книги Donald E. Knuth ТЕХУу? [The T^Kbook],
перев. "ШШШЩ [Nobuo Saito] и Ш&ШМ [Yoshiteru Sagiya] (Tokyo: ASCII Corporation, 1989).
Слайд 25 взят из книги Jonathan Kew, Stephen McConnel Formatting Interlinear Text (Dallas,
Texas: Summer Institute of Linguistics, 1990), page 71. Слайды 26-28 взяты из работы John
Lavagnino, Dominik Wujastyk Critical Edition Typesetting: The EDMAC Format for Plain Tj^X
(UK T^X Users Group, 1996), pages 94, 100, 101. И, наконец, слайд 29 основан на рисунке из
работы David Kindersley, Lida Lopes Cardozois Letters Slate Cut: A Sequel, Plate 15 (Cambridge:
Cardozo Kindersley Editions, 1990).
Математическая
типография
[Гиббсовская лекция (Josiah Willard Gibbs Lecture), состоявшаяся при
содействии Американского математического общества 4 января 1978 г. Посвящена
Дьёрдю Пойа по случаю его 90-летия. Первоначально опубликована в Bulletin
of the American Mathematical Society (новая серия) 1 (March 1979), 337-372.]
Аннотация
Математические книги и журналы больше не выглядят так красиво, как это
соответствовало бы их предназначению. Это объясняется не тем, что их
содержание стало неудовлетворительного качества, а скорее тем, что соблюдение
прежних хорошо отработанных типографских традиций теперь слишком
дорого обходится. К счастью, выяснилось, что сама математика может решить
эту проблему.
Первым шагом на этом пути является создание метода строгого описания
математических рукописей таким образом, чтобы они легко обрабатывались
машинами. Такой аккуратно построенный язык может быть быстро освоен
авторами и их машинистками; имея рукопись, подготовленную таким образом,
вы будете получать непосредственно с принтера высококачественную
распечатку. При этом вмешательства человека не требуется вовсе или оно
незначительно.
Второй шаг в решении проблемы состоит в применении классической
математики для рисования самих букв и символов. Можно дать строгое
определение формы буквы 'а', например, таким образом, чтобы из этого одного
определения путем изменения лишь нескольких параметров можно было
получать бесконечно много стилизаций ее начертания — полужирное, расширенное,
рубленое, наклонное и т. д. Сделав то же самое для других букв и символов,
мы получим математическое определение наборных шрифтов, которое можно
будет использовать на всех машинах как сейчас, так и в будущем. Основное
преимущество этого подхода состоит в том, что легко может быть добавлен
любой новый символ, причем он автоматически будет соответствовать уже
существующим.
Глава 2. Математическая типография
37
(а) |
/ = ± v/|*SY= ± >/\{add'){add")
there correspond two quadric forms each containii
rameters. So much Hilbert states. In order to
as known systems it will be convenient to use a
mental cubic, due to Hesse.*
Referred to an inflexional triangle, the equatio
(3) a\ = x\ + x\ + x\ + 6mxtx2u
All conic polars accordingly have the form :
(4) aa\ = (y,ajj + yp\ + y3x\) + 2т(У1а-А -
Consider the functions Fu — яа (a = 1,2,
According to the theorem a polynomial P (fl,
analogous to those of P (x : yn), and P (0, a: :
since the latter is unique.
The series of power series P (F,x :yn) may be
of x, у, and it can readily be seen that its coefl
those of P (x : y„). It must, however, be f
not, a set of numerical coefficients could be sel
which P (F, x : yn) would not be identically
Weierstrass' theorem concerning the sum of an ir
when the functions F and P (v, x : yn) are conv
(b)
(c)
I call this ineffective part of xt "innocuous"
validate the fundamental proposition
which was proved above (P. 4) for effective vali
ineffective part of xe is innocuous is clear: it, as
that the variation of xt does not take place in it
D. 3. But this consideration leads to the defin;
of x. By this I mean the collection of values wh
i. е.,
six planes у%-\-ук = 0, each counted three tim-
^УРе У\У% — Уз У* = 0> each counted twice.
We have seen that any point on the line yx +
image in (X) the whole line X, +^2 = 0, X3
in (y) meets the line in one point, its image $9 со
the system $9 has also the three lines of this typ
12. Algebraic procedure. The plane cor
and the vertex (1, 0, 0, 0) has the equation
pat *г + Pa x3 + Pa xt:
Since (y) and (yf) both satisfy this equation we
(d)
Рис. 1. Стили полиграфического оформления журнала AMS Transactions:
(а) 1 (1900), 2; (b) 13 (1912), 138; (с) 23 (1922), 216; (d) 25 (1923), 10.
Необходимо, разумеется, чтобы математически описанные буквы были
красивы с точки зрения общепринятых эстетических норм. Какая самая
изящная кривая может соединить заданную последовательность точек на
плоскости? Этот вопрос приводит к интересной математической задаче и одно из ее
решений основывается на новом семействе сплайнов: эти кривые позволяют
построить превосходные типографские шрифты, с которыми автор
предварительно экспериментировал. Приходим к выводу, что математический подход
к шрифтовому дизайну не исключает художников, которые многие годы
занимаются этим делом, а напротив, предоставляет им новый эффективный
инструмент для работы.
Введение
Я буду рассказывать о проводимой мною работе, а не о завершенном
исследовании; у меня не было специального намерения именно так построить
свою сегодняшнюю лекцию, причиной послужило то обстоятельство, что я не
смог к настоящему моменту получить работающую программу. И это
замечательно, что у меня нет окончательного продукта, который я мог бы здесь
продемонстрировать, потому что сам процесс математических исследований
значительно интереснее, чем их результат. Я постараюсь объяснить в своей
лекции, почему именно я так захвачен проектом, над которым в настоящее
время работаю.
38
Компьютерная типография
Моя лекция состоит из двух частей, что соответствует двум разным
значениям, заложенным в ее название. Сначала я буду говорить о математической
полиграфии в смысле полиграфии на службе у математики: целью здесь
является предоставить математике эффективное средство коммуникации в виде
возможности публикации математических статей и книг высокого
полиграфического качества. Затем речь пойдет о математической полиграфии в смысле
математики на службе у полиграфии. В этом случае мы увидим, как
математические идеи могут продвинуть возможности искусства печати.
Предварительные примеры
Чтобы подготовить аудиторию для предстоящего разговора, я бы хотел
сначала продемонстрировать несколько примеров, на которых вы могли бы
соответствующим образом «настроить зрение», чтобы посмотреть на математику
глазами полиграфиста. Эти примеры взяты из трудов Transactions of the American
Mathematical Society, которые начали публиковаться в 1900 г.; к настоящему
моменту вышло более 230 томов. Тома эти я взял в библиотеке и распределил
их по классам эквивалентности в соответствии с различными стилями
полиграфического оформления: два тома помещались в один и тот же класс тогда и
только тогда, когда они были оформлены в одном и том же полиграфическом
стиле. Оказалось, что можно выделить двенадцать различных стилей, и нам
будет полезно кратко с ними ознакомиться.
Первый пример (рис. 1а) взят со с. 2 первого тома Transactions; я привожу
совсем маленький фрагмент, чтобы дать вам возможность увидеть отдельные
буквы и их расположение, а не отвлекаться на математическое содержание.
Этот набор выглядит старомодным в основном потому, что прописные буквы и
высокие строчные, наподобие h и к, почти вдвое выше других строчных букв, а
этого почти не бывает в современном наборе. Обратите внимание, что в
курсивной букве х два соседних штриха имеют в центре общий отрезок. Подстрочные
и надстрочные индексы набраны слишком мелким размером шрифта.
Этот стиль использовался для томов Transactions с 1-го по 12-й, а также в
первой 21 странице из т. 13. Затем, начиная с 22-й страницы т. 13 был введен
обновленный шрифт (рис. lb). В этом примере подстрочные индексы все еще
слишком малы, а греческая а, к сожалению, почти неотличима от латинской
курсивной а. Обратите внимание, что наборщик вставлял больший пробел до
и после скобок, чем это принято теперь. В течение последующих нескольких
лет пробелы внутри формул постепенно менялись, но сам набор по существу
оставался тем же вплоть до т. 24 с одним исключением.
Этим исключением являлся т. 23, изданный в 1922 г. (рис. 1с), который
по моему мнению имеет самый элегантный вид из всех трудов Transactions.
Этот набор менее плотный, благодаря чему более удобочитаем. Курсивные
буквы также были видоизменены, но не столь удачно, — 'я', например, прежде
была лучше, а нижняя часть буквы '/' имеет тенденцию непропечатывать-
ся —но в основном у читателя, листающего том, складывается благоприятное
впечатление. Такое качество, однако, обошлось не даром. Согласно текущему
Глава 2. Математическая типография
39
of systems of division algebras. The next systt
of order p7q2 over F with the basal units i^jbke (
with an irreducible equation of degree pq, three
j rational functions 6(i) and ф(г) with coefficie
) iterative Qq(i) of 6{i) is i, and likewise ф"(1) = 1
(e) ! by
e*[*'(0! = *'[**(•)] (*-0,l, • • -, 7-1
i The complete multiplication table of the uni
| associative law from
>=р">7° = (p">7°
(«":! f":,0),
0 ^ в й 2я.
с С" is called a Reinhardt circular set if along w.
e E also the set
{2||zt| = |2°|, fc-1.2 n)
bounded closed subset of C", unisolvent with respect
The function b(z) being defined and lower semic-
= MV) h™}9
z С¥ + ||-1.в-1
(f)
0 = rn(J>,«J - (£r,a.)*r, - 2
1-1
This element is of lower length. It follows there
i — 1, • • • ,k. Hence, (a) yields that r, = X,r4, X;
/p.\ } Now rk 7* 0, by the minimality of k, and X*»<
which we deduce that J^X,"» = 0- But the а, а
which is impossible since in particular Xk = 1.
Theorem 7. Lef R be a dense ring of linear t
F be a maximal commutative subfield D. If Rp
tion of finite rank over F, then R contains als
The set Nx is nowhere dense in Zx and thus N=p
For each £ e Y—N we must prove that/( satisfi
be the unique projection in {Pd \d e D] such that
the algebra (EstfE)P0 is finite and homogeneoi
onal abelian projections Elt E2,..., En such that
(1 £jt k^n) be partial isometric operators in (£«s/
(1) UikUiM — bmiUikt where 8 is the Kronecker d<
(2) t/,t = t/„;and
(3) Ui} = Eit
for all 1 uj,k,l,mun. For each Л in (Es/E)-P0, t
in ЗГЛ such that
(h)
(i)
The algebra P is nearly simple if and only if the
(a) N is spanned by a, ■ • • , an~k~ X, b^, • • •
i. /- l,---, k.
(b) Either n - k ■ char F u/i'/A Л еиея or я
Proof. By Theorem 5.5, there are elements a
a, • • • , a" ~ ', &.,•••, 6. . Furthermore, ab. ■=■ J
for all j, / where each a , A., is in F. From tr
space of the space spanned by an~ ~ , b., • • • ,
Assume P is nearly simple. Then there is a
show that each b. is in M. To do this, it is nec<
unctions in GL(W) and Ла/?, a, j? 6 / as coordinate
:rmined by the respective bases chosen above. If a,
.e function of Л' is the minor of \g,j\ determined by
the columns /?(!),..., /?(/>). The coordinate ring of
he hafi together with l/det|/ia/}|, while that of CL(W)
'tj together with l/det|gj. The coordinate functions
gv, so to show Л' is a morphism it suffices to show
nomial in gtJ and l/det|gy|. For this, the following
\l character of GL(W) is an integral power of the
(j)
W
rf Q, i.e.
0 = 0 for every x E A for which x(Q) = 0}.
:or mA is equivalent to the one induced by the
c:
{|x(z)|: xEA, Ы1 < 1 and x(w) = 0}.
ipresent the open unit disk in the complex plane, C,
t polydisk in «-dimensional complex space Cn. Tn
■oundary of Dn, i.e.
/hich A) is the (last) minimum of Yx, let Yx, i >
of У\ and Xх the interjump times for Yx. So
i such that Yj = 7JX == oo. Notice that J^ is fini
t as с -> 0, Уд converges to /x = inf,*,x. Let Л,
—oo, oo). Then, for example, if i > 1
*> YQ+k ~ >Q e C,Tx+k ED,N>Q> i)
T{ht E B, Y^k -YtX E CT^E D,N>Q = l
oo, a typical term in the summation of (3.5) may t
0)
Рис. 1 [продолжение]. Выдержки из журналов Transactions of the American
Mathematical Society: (e) 28 (1926), 207; (f) 105 (1962), 340; (g) 114 (1965), 216;
(h) 125 (1966), 38; (i) 169 (1972), 232; (j) 179 (1973), 314; (k) 199 (1974), 370;
(1) 226 (1977), 372.
40
Компьютерная типография
отчету Американского математического общества в Bulletin [46, с. 100], этот
том Transactions вышел в свет позже запланированного срока на 18 месяцев!
Возможно поэтому матобщество решило подыскать другой способ печати.
Чтобы оценить последующие изменения, посмотрим на два фрагмента из
Bulletin, касающиеся самой первой Гиббсовской лекции (рис. 2).
Предварительное объявление, помещенное в 1923 г., набрано шрифтом, представленным на
рис. lb, но ко времени самой лекции в 1924 г. рисунок букв изменился на более
узкий и вытянутый вверх. Прописные буквы остались, грубо говоря, теми же,
но строчные стали совершенно другими. Мы также можем заметить чрезмерно
большие междусловные пробелы во многих строках, тогда как есть строки, где
текст слишком зажат.
В том же стиле был оформлен т. 25 Transactions (рис. Id), который, между
прочим, был набран в Германии для снижения полиграфических расходов.
Буквы полужирного и курсивного начертания в этом примере очень хороши, —
возврат к добротному старому рисунку х — так что математические формулы
выглядят великолепно, тогда как шрифт сопровождающего их текста очень
узок. К счастью, так оформлены всего три тома.
Новая эра Transactions началась в 1926 г., когда печать их осуществлялась
в типографии Collegiate Press в Менаша, шт. Висконсин. Тома с 28-го по 104-й
имеют одинаковое полиграфическое оформление (рис. 1е), что покрывает
отрезок времени в 36 лет: с 1926 по 1961 гг. включительно; так же оформлялся и
ежемесячник American Mathematical Monthly. Вообще говоря, шрифты были
вполне приличными, но имелась и курьезная аномалия: подстрочные и
надстрочные индексы в математических формулах набирались другим шрифтом,
отличающимся по рисунку от основного! Обратите внимание, например, на
буквы к в первой выключной формуле на рис. 1е: большая из них имеет
петлю, что топологически отличает ее от меньшей. Аналогичная история с буквой
р: р в кр совершенно отличается от р в р2. В этом примере отсутствуют буквы
х, но если бы вы взглянули на другие страницы, то обнаружили бы х моего
любимого рисунка только в индексах. Я не понимаю, почему на протяжении
стольких лет допускалось такое несоответствие.
Другой период полиграфической неряшливости в Transactions начался с
т. 105 в 1962 г. Этот том, набранный в Израиле, ввел переход на шрифт Times
Roman (рис. If); простой способ быстро распознать отличие — взглянуть на
букву о, поскольку ее штрихи (контур) изменили толщину в несколько
наклоненном виде (О —вариант О); в ранее использованных шрифтах эта буква
была симметрична относительно вертикальной оси, как если бы была
нарисована пером, ориентированным по горизонтали, а в шрифте Times Roman явно
виден наклонный нажим, как если бы она была нарисована пером с
наклоном вправо. Обратите внимание, что три к топологически такие же, как и во
второй выключной формуле, но по непонятной причине в индексах они имеют
разный размер. Многие курсивные буквы из Times Italic несколько
отличаются от тех, к которым привыкли читатели Transactions, и я лично думаю, что
в этом шрифте была предпринята попытка сделать формульный шрифт более
узким. Модификация шрифтов Times Roman и Times Italic не была вполне за-
Глава 2. Математическая типография
41
THE JOSIAH WILLARD GIBBS LECTURESHIP
The Council of the Society has sanctioned the establishment
of an honorary lectureship to be known as the Josiah Willard
Gibbs Lectureship. The lectures are to be of a popular nature
on topics in mathematics or its applications, and are to be
given by invitation under the auspices of the Society. They
will be held annually or at such intervals as the Council may
direct. It is expected that the first lecture will be delivered
in New York City during the winter of 1923-24, and a
committee has been authorized to inaugurate the lectures by
choosing the first speaker and making the necessary
arrangements.
R. G. D. Richardson,
Secretary.
THE FIRST JOSIAH WILLARD GIBBS LECTURE
The first Josiah Willard Gibbs Lecture was delivered
under the auspices of this Society on February 29, 1924,
by Professor M. I. Pupin, of Columbia University, in the
auditorium of the Engineering Societies' Building, New York
City. A large and distinguished audience was present,
including, besides members of the Society, many physicists,
chemists, and engineers who had been invited to attend.
In introducing the speaker, President Veblen spoke as
follows:
"In instituting the Willard Gibbs Lectures, the American
Mathematical Society has recognized the dual character of
mathematics. On the one hand, mathematics is one of the
essential emanations of the human spirit,—a thing to be
valued in and for itself, like art or poetry. Gibbs made
notable contributions to this side of mathematics in his
Рис. 2. Переходный период [из Bulletin of the American Mathematical Society 29
(1923), 385; 30 (1924), 289].
42
Компьютерная типография
вершенной; курсивная буква д имела знакомые очертания, возможно потому,
что новый ее вид показался бы математикам слишком экзотическим.
В том же стиле были выполнены все издания ст. 105 по т. 124, за
исключением краткого перерыва: в тт. 114, 115 и 116 нажим в букве о имел симметрию
относительно вертикали и буква к имела петлю (рис. lg). Другое
полиграфическое оформление использовалось в тт. 125-168 (рис. lh): Times Roman и Times
Italic снова стали правилом даже для буквы g, за исключением верхних и
нижних индексов (которые остались в милом моему сердцу стиле); например,
сравните буквы j и к. Эти тома были набраны в Великобритании.
Резкое увеличение объемов публикаций, сопровождаемое повышением
заработной платы высокопрофессионального персонала, сделало чрезвычайно
невыгодными традиционные методы набора, и матобщество стало время от
времени прибегать к экстравагантному способу: оригинал-макет готовился на
пишущей машинке с последующим фотовоспроизведением его в типографии.
Эти тяжелые обстоятельства и привели к тому, что тт. 169-198 Transactions
стали выглядеть так, как на рис. li, за исключением тт. 179, 185, 189, 192,
194 и 198, которые были выполнены в значительно лучшем (хотя и не вполне
удовлетворительном) стиле, что можно рассмотреть на рис. lj, глядя на
курсивные g и на 'ffi'. Текст на рис. lj был набран на компьютере при помощи
разработанной Лауэллом Хокинсоном и Ричардом МакКиллином системы. Это
был один из плодов исследовательского проекта Американского
математического общества, поддержанного Национальным научным фондом [2-6].
Компьютерный набор математики несколько опережал тогда свое время,
однако, так что другого рода «холодная копия» была задействована в тт. 199-
224: было использовано наборное устройство IBM Compositor для всех эти
томов, за исключением тт. 208 и 211, для набора которых вновь обратились
к устройству типа Веритайпер с рис. li. Новый алфавит на вид был несколько
вытянутым вверх и некоторые слова были даже уже, чем другие (см.рис. Ik).
По этой причине я, к моему сожалению, перестал посылать статьи в
Американское математическое общество, так как окончательный продукт выглядел
столь убого, что я не мог на него глядеть. Аналогичные колебания
полиграфического качества вскоре проявились во всех точных науках, особенно в физике,
где ситуация была еще тяжелее. (История издания трудов Американского
общества инженеров гражданского строительства обсуждалась в интересной и
информативной статье П. Парией [45].)
Сейчас дела, к счастью, пошли лучше. Начиная с т. 225,
опубликованного в прошлом году, Transactions теперь выглядят как на рис. 11; как и на
рис. lj, это компьютерный набор, в котором шрифт Times Roman стал теперь
несколько крупнее. Я еще не занимался особым рисунком курсивных букв и
здесь имеются некоторые шероховатости, которые надо будет сгладить, такие,
как наложение строк, показанное в этом примере, но понятно, что
положение улучшается и, возможно, настанет день, когда мы сможем вернуться к
полиграфическому качеству тт. 23 и 24.
Глава 2. Математическая типография
43
Набор при помощи компьютера
Возможно, основная причина улучшения ситуации кроется в том, что теперь
компьютеры способны работать с текстом и преобразовывать его в вид,
соответствующий полиграфическим требованиям. Опытные образцы такого рода
систем использовались уже в начале 60-х годов (см. книгу Барнетта [10]), и
теперь наступает пора их зрелости. В течение следующих примерно десяти
лет, мне думается, типичную офисную пишущую машинку сменит телеэкран с
клавиатурой и компактным процессором. Очень легко станет вносить
исправления в рукопись, заменяя все вхождения одного выражения другим и делая
другие коррективы, а затем можно будет перенести этот текст либо на экран,
либо на принтер, либо на другой компьютер. Такие системы уже
используются в большинстве газет, а в новых экспериментальных офисных системах
для оформления текста имеются различные шрифты [26]. Должно пройти еще
некоторое время и такие машины вытеснят традиционную технологию
подготовки рукописей в университетах и технических лабораториях.
При обработке математических текстов уровень сложности, конечно,
повышается. Полиграфисты относят математические работы к каторжным, и один
из известнейших американских типографов Т. Л. Де Винн писал [17, с. 171],
что «[даже] при самых благоприятных условиях алгебра будет причинять
беспокойство». Проблема была в том, что в двухуровневых формулах приходилось
особым образом исхитряться, чтобы вставить отдельные элементы
металлического шрифта, но теперь эта задача существенно упростилась и двухуровневые
формулы представляются линейными записями в виде последовательностей
компьютерных команд.
Языки, использующие строковые выражения для представления
математических формул, теперь хорошо известны: например, язык программирования
FORTRAN, но чтобы можно было рассмотреть проблему полиграфического
представления математики во всем объеме, нужен несколько иной подход. Для
того чтобы вы в полной мере могли оценить достоинства языков для
набора математики, я кратко ознакомлю вас с тремя известными мне достаточно
разумными подходами. Первая система, которую я назову Туре С,
представляет собой типичный коммерческий продукт, используемый в настоящее время
для набора математических журналов (см. [12]). Второй, который я обозначу
Туре В, был разработан в лаборатории Белла и использовался для подготовки
нескольких книг и статей, в том числе и работы, посвященные самой
системе [27]. Третий, который я обозначу Туре Т, представляет собой тот продукт,
которым я в настоящее время занимаюсь в рамках общей системы под
названием TgX [29]}
На рис. 3 показано, как записываются три простые формулы в этих трех
языках. Язык Туре С использует $f ...$s...$t для дробей, *g для указа-
1 Т^Х ие имеет никакого отношения ни к системе с похожим названием, анонсированной
фирмой Honeywell Information Systems, ни к другой, разработанной Digital Research. В моем
названии буквы Т, Е и X не латинские, а греческие, поэтому лого Т^Х произносится как
«тех», созвучно греческому слову, обозначающему как искусство, так и технологию.
44
Компьютерная типография
Формула Туре С Туре В Туре Т
- $fl$s2$t 1 over 2 1 \over 2
в2 *gq"2 theta sup 2 \thetaT2
yjf{xi) $rf(x'i)$t sqrt{f(x sub i )} \sqrt{f(xii)}
Рис. З. Три способа представления формул.
ния, что «следующая буква греческая», q для греческой буквы тета, $г... $t
для квадратных корней, " для верхних индексов и • для нижних индексов.
Язык Туре В более мнемоничен, он использует over (над), theta (тета), sup
(верхний), sqrt (квадрат) и sub (нижний) вместе с фигурными скобками для
группировки в случае необходимости. Аналогично устроен и язык Туре Т, но
он не использует зарезервированных слов, вместо этого у него
зарезервирована специальная литера \, которая проставляется перед любым нестандартным
текстом. Это позволяет игнорировать пробелы, тогда как в языке Туре В их
обязательно надо помещать справа; в приведенном примере, например, пробел
после 'i' важен, в противном случае '/(^г)' превратится в '/(^г)' в соответствии
с правилами Туре В. Другая причина, по которой в Туре Т используется \,
состоит в том, что процессору не нужно каждый раз сверять текст со словарем
зарезервированных слов и убеждаться, что sup не означает supremum.
Специальные литеры \ { } Т I в языке Туре Т при необходимости можно заменить
любыми другими; эти пять значков не являются общепринятыми для
наборщиков и машинисток, но они хорошо знакомы всем операторам вычислительных
машин.
Порой компьютерный набор приносит нам и хорошие новости: мы теперь
можем с легкостью получать квадратные корни в традиционном
представлении со знаками радикала и подкоренным выражением. Теперь не придется
писать х1/2, если нам этого не нужно1.
Ни один из этих языков не позволяет читать сложные формулы так же
легко, как при многоуровневом их расположении, но практика показывает,
что необученный персонал довольно быстро «набивает руку» в этом деле.
Согласно [12], «всего за несколько часов (в худшем случае — дней) машинистку,
не имеющую никаких познаний ни в математике, ни в наборном деле,
можно натренировать в наборе даже более сложных уравнений». А авторы языка
Туре В в [27] говорят, что «период обучения короток. Через несколько минут
уже можно получить общее представление, а работы с одной или двумя
страницами обычно достаточно, чтобы разобраться в большей части особенностей
набора». Таким образом, и машинисткам, и математикам не нужно прилагать
особых усилий к изучению системы, чтобы научиться подготавливать статьи
1 [Добавлено в корректуре.) При чтении лекции меня порадовало, что это сообщение было
встречено аудиторией с одобрением, которое выразилось в энергичных аплодисментах.
Глава 2. Математическая типография
45
на таком языке. Действительные трудности возникают только при оформлении
таблиц или слишком вычурном выравнивании формул.
Как только подобные системы станут широкодоступными, авторы смогут,
готовя свои статьи, сразу видеть их в таком же точно виде, как они
выглядят при подготовке в типографии. Все авторы математических статей знают,
что их намерения часто остаются неверно понятыми наборщиками, а
правка гранок несет в себе существенную положительную вероятность внесения
дополнительных ошибок. Таким образом, согласно мнению трех первых
пользователей системы лаборатории Белла [1], «мораль ясна: если кто-то другой
набирает ваше произведение, то у вас нет возможности контролировать
появление ошибок; если же вы выполняете эту работу самостоятельно, то можете
винить только себя». Что касается меня, то я не могу подобрать слов, чтобы
выразить испытываемые мною чувства, когда вношу изменения в свою
рукопись, хранящуюся в машине в Станфорде, зная, что эти изменения немедленно
будут отражены и при этом нет никакого промежуточного звена, где бы мои
намерения могли быть искажены.
Возможно, настанет день, когда языки программирования для набора
станут стандартом и статьи будут приниматься на компьютер Американского
математического общества с компьютера автора посредством телефонных линий.
Не будут нужны гранки, а рецензенты и (или) редакторы будут отправлять
автору предлагаемую правку; авторы смогут вставить необходимые исправления
в рукопись снова по телефонным проводам.
Я, несомненно, хочу надеяться, что языком, который будет выбран в
качестве стандарта, станет мой T^jX. Ну ..., возможно, я небеспристрастен, и
знаю, что ТЩХ предоставляет только чуть большие удобства, чем другие
системы. Всего несколько десятков таких мелких удобств свелись к тому, что
важно для меня, и я думаю, что эти мелочи докажут свою важность и для
других. Поэтому я хотел бы отвести несколько следующих минут на более
подробный рассказ о ТЁХ'е.
Т^Х как язык описания ввода
Т^Х должен уметь обращаться с «обычным» текстом так же хорошо, как и
с математическим, и должен быть так сконструирован, чтобы быть
универсальной системой, в которой математические свойства сочетаются с
возможностями программ обработки текстов, вместо того чтобы быть «привязанным»
к условному языку набора. В основе TgX'a лежит идея построения объектов
из неких элементов, которые я назвал боксы. Типографская литера сама по
себе представляет собой бокс — сплошной черный прямоугольник; мы будем
использовать эти «атомы» для построения более сложных боксов, называемых
по аналогии «молекулами», формируя горизонтальные или вертикальные
последовательности боксов. Окончательные страницы текста представляют собой
боксы, составленные из последовательностей боксов, составленных из
последовательностей боксов и т. д. вплоть до отдельных литер и черных
прямоугольников, которые не разлагаются далее. Например, типичная страница книги
46
Компьютерная типография
представляет собой бокс, образованный из вертикальной последовательности
боксов, представляющих собой строки набора, и эти строки набора являются
боксами, составленными из горизонтальных последовательностей боксов,
представляющих собой отдельные литеры. Математическая формула естественным
образом разлагается на боксы; например, числитель и знаменатель дроби суть
боксы, равно как и черта дроби между ними (поскольку это узкий
прямоугольник, залитый черной краской). Элементы матриц также являются боксами
и т.д.
Отдельные боксы в горизонтальной или вертикальной последовательности
отделяются друг от друга особой эластичной субстанцией, которую я назвал
клей. Клей между двумя боксами состоит из трех компонент (ж, у, z),
выражаемых в единицах длины:
компонента х — пробел — идеальный или нормальный пробел, который
необходим между этими боксами;
компонента у — растяжение—размер дополнительного пробела, который
допустим;
компонента z — сжатие — размер пробела, который при необходимости
может быть удален.
Предположим, последовательность состоит из п + 1 боксов Bq, -Bi,...,J5n,
разделенных п порциями клея, имеющего спецификации (х\, у\, z\),...,
(#т 2/n5 Zn)- Когда эта последовательность становится боксом, мы
закладываем клей в соответствии с окончательным размером этого бокса. Если этот
окончательный бокс предполагается быть большим, чем мы получили бы при
нормальных пробелах х\ + • • • + хп, мы увеличиваем эти пробелы
пропорционально значениям у так, чтобы реальные пробелы и между боксами стали
хх -Иг/1, ..., xn + tyn
для некоторого подходящего t > 0. С другой стороны, если требуемый
окончательный размер должен быть меньше, мы сужаем пробел до
Х\ tZ\ , . . . , Хп tZnj
пропорционально отдельным сжатиям Z{. В последнем случае t не разрешается
быть больше 1; клей никогда не должен быть меньше, чем х — z, хотя
иногда он может становиться больше, чем х + у. Как только клей заложен, бокс
становится жестким и никогда больше не меняет свой размер.
Рассмотрим, например, обычную строку текста, которая представляет
собой последовательность отдельных боксов литер. Пусть клей между буквами в
слове имеет компоненты х = у = z = 0, что означает, что буквы в слове плотно
пригнаны друг к другу; но клей между словами может иметь компоненту х,
равную ширине буквы 'е', причем у = х, z = х/2, т. е. пробелы между словами
могут растягиваться или сжиматься. Пробелы после знаков препинания вроде
точек и запятых можно растягивать с большей скоростью, но сжатие должно
происходить медленнее.
Глава 2. Математическая типография
47
Важный частный случай понятия клея возникает, когда мы имеем дело
с «бесконечной» растяжимостью. Предположим, что компоненты х и z
равны нулю, а компонента у чрезмерно велика, скажем, длиной в километр. Если
такой элемент клея поместить слева от последовательности боксов, то в
результате все существенные растяжения будут слева от последовательности боксов,
следовательно, эти боксы будут иметь равнение вправо, так что их правые
края совпадут с полями. Аналогично, если мы поместим такой бесконечно
растяжимый клей с двух концов, то в результате получим равнение по центру
строки. Таким образом, эти общепринятые полиграфические эффекты
являются простыми частными случаями основополагающей идеи гуттаперчевого
клея и компьютер элегантно справляется с этой работой, поскольку она
сводится к относительно примитивным операциям. Вы можете заметить из этого
примера, что клею позволено появляться и в концах последовательностей, а
не только между боксами. Можно помещать клей после клея и боксы после
боксов, так что последовательность боксов на самом деле представляет собой
последовательность боксов и клея, перемешанных между самой любым
образом. Я не упомянул об этом ранее, потому что мне казалось, что сначала эту
идею лучше объяснить на примере боксов, перемежающихся клеем.
Те же принципы применимы и к вертикальным последовательностям.
Например, клей, который появляется над и под выключной формулой имеет
тенденцию к растяжению и сжатию, но клей между строками текста должен быть
строго вычислен, чтобы в случае необходимости строки можно было
равномерно разогнать по странице. Вы можете также позволить себе при помощи
идеи клея самым естественным образом выполнять специальные трюки, вроде
эффекта наложения букв (взяв отрицательное значение х).
Разбиение на строки
Одной из самых интересных особенностей систем, подобных ТЕХ'у5 является
способность разбивать абзац на отдельные строки примерно нужной длины.
Традиционный способ, еще использующийся и сегодня в компьютерных
системах, состоит в том, чтобы наилучшим образом оборвать строку, когда вы
доходите до правого поля, но как она будет выглядеть на печати, вы уже
никогда не рассматриваете; следующую строку вы начинаете, уже не помня, что
было ранее. На самом деле, зачастую было бы лучше переместить короткое
слово с данной строки на следующую, но проблема в том, что вы не знаете,
насколько выиграет весь абзац, если вы улучшите вид одной строки.
В системе Т[н)Х вводится новый подход к проблеме разбиения на строки,
при котором завершающая строка абзаца оказывает влияние на способ
разбиения первых строк; в результате появляются дополнительные пробелы и новые
переносы слов. Вот как это работает: сначала мы сводим разбиение на строки
к строго поставленной математической задаче с использованием субстанции
ТЁХ'а «клей» для введения понятия «плохость». Когда горизонтальная
последовательность боксов имеет некоторую естественную ширину w (основанную
48
Компьютерная типография
на ширинах ее боксов и пробелов, заполненных клеем), с примененным к ней
некоторым растяжением у (равным сумме компонент растяжения) и
некоторым сжатием z (равным сумме компонент сжатия), плохость распределения
клея, приведшая к ширине W этого бокса, определяется как 1 +100t3 в наших
предыдущих обозначениях, или точнее:
1, если W = w ,
если W > w ,
если w — z < W < w,
если W < w — z.
Таким образом, если искомая ширина W почти равна естественной ширине ги,
либо если было много растяжений или сжатий, то коэффициент плохости очень
мал; но если W значительно больше w и растяжений не так уж много, то имеем
плохую ситуацию. Кроме того, мы добавляем штрафные очки к коэффициенту
плохости, если строка оканчивается на сравнительно нежелательном месте;
например, когда слово нужно разорвать на переносе,- плохость достигает 50, и
еще больший штраф назначается за разрыв математической формулы.
Теперь задачу разбиения на строки можно сформулировать следующим
образом: «при заданном тексте абзаца и при расстановке всех допустимых мест
разбиения его на отдельные строки, найти точки разбиения, минимизирующие
сумму квадратов коэффициентов плохости полученных в результате строк».
Это определение, разумеется, довольно произвольное, но, кажется, оно
работает. Предварительные эксперименты показали, что почти всегда делается тот же
выбор точек разбиения при простой минимизации сумм отдельных плохостей,
равно как и при минимизации сумм их квадратов, но из предосторожности мы
будем все же минимизировать суммы квадратов, поскольку это также будет
способствовать минимизации максимальной плохости.
Одна лишь математическая формулировка проблемы разбиения на строки
еще, разумеется, ее не решает; необходим хороший способ отыскания нужных
точек разбиения. Если существует п разрешенных мест разбиения (включая
все пробелы между словами и все возможные переносы слов), то имеется 2П
возможных способов поделить абзац на строки, и у нас не хватит времени
рассмотреть их все. К счастью, существует методика, позволяющая свести
число шагов вычислительной процедуры к порядку величины п2, вместо 2П; это
специальный случай того, что Ричард Беллман назвал «динамическим
программированием». Пусть f(j) есть минимальная сумма квадратов плохости
для всех способов разбиения исходного текста абзаца до точки разбиения j
включительно, и пусть b(i,j) есть плохость строк, которые находятся между
точкой разбиения г и точкой разбиения j. Начало абзаца обозначим через 0, а
заключительную точку разбиения в конце этого абзаца — через п + 1, причем
1 + 100
W-wx3
У
{ id
1 + 100
w-W^3
z
бесконечность,
Глава 2. Математическая типография
49
перед ней может быть помещен бесконечно растяжимый клей. Тогда
/(0) = 0;
/О') = min. (/(г) + b(i,j)2) для 1 < j < п + 1.
0<г<,7
Найти значения /(1), ...,/(п + 1) можно примерно за тг2 шагов, и /(п + 1)
будет минимальной из возможных сумм квадратов коэффициентов плохости.
Припомнив значение г, в котором возникал минимум для каждого j, можно
найти точки разбиения, приводящие к наилучшему разбиению на строки, как
и требовалось.
На практике нет необходимости проверять маловероятные точки
разбиения; например, очень редко есть основание переносить самое первое слово в
абзаце. Таким образом, оказывается, что этот метод динамического
программирования может быть сведен к другому алгоритму, время работы которого
почти всегда будет порядка п, а не п2, и нужно будет проверить сравнительно
немного переносов. Иногда сами по себе переносы приводят к некоторым
интересным математическим задачам, но здесь у нас нет времени отвлекаться на
это (см. статью [42] и цитируемую в ней литературу).
Идея коэффициентов плохости может быть с успехом применена и к
вертикальным последовательностям боксов; в этом случае мы хотим избежать
плохих разбиений колонок или страниц. Например, штрафные очки даются за
разрыв абзаца между страницами на переносе, или за разрыв его таким
образом, что на странице остается только одна строка от него (так называемая
«висячая строка»). Размещение иллюстраций, таблиц и примечаний также
регламентируется соответствующими правилами, формулируемыми в терминах
коэффициентов плохости.
Можно еще много рассказать о TEJX'e, в том числе о средствах верстки
сложных таблиц без предварительного вычисления ширины колонки, но я
думаю, у вас уже создалось представление о самых важных принципах этой
системы. В течение нескольких следующих месяцев я намерен написать такую
программу для ТЁХ'а, в которой работа каждого алгоритма была бы предельно
ясна и система могла бы работать на разных вычислительных платформах без
особых для этого усилий. Тогда я опубликую эти программы в виде отдельной
книги, и каждый, кто захочет их использовать, сможет сделать это.
Антракт
В начале лекции я сказал, что она будет состоять из двух частей: первая о том,
как полиграфия может помочь математике, и вторая — о том, как
математика может помочь полиграфии. До сих пор вы имели возможность услышать
и об одном, и о другом, но математика здесь была совсем тривиальная. В
оставшейся части своей лекции я постараюсь рассказать о направлении, где
вклад математики наиболее значительный, именно об описании рисунков
самих литер. Более строго о двух частях моей лекции следовало бы сказать так:
50
Компьютерная типография
первая часть посвящена системе ТЕХ, которая позволяет создавать рукописи,
указывая в каком именно месте должна быть размещена каждая литера, а
вторая часть посвящена системе METflFONT, которая генерирует сами шрифты,
чтобы использовать их в той части типографского дела, которая относится к
шрифтовому дизайну.
Прежде чем приступить ко второй части своей лекции, я должен осветить
некоторые новые достижения в технологии печати. Самый реальный способ
печатать математические книги высокого качества в течение нескольких
последних десятилетий состоял в использовании технологии монотипа1, при
которой буквы отливаются в металле с последующей ручной обработкой формул
со сложной структурой. Когда несколько лет тому назад я увидел применение
этой технологии к моим книгам, меня поразило, что металлический набор
используется для создания только одного экземпляра; этот эталонный экземпляр
затем фотографировался и сама печать происходила уже с фотоформ. Эта
несколько неуклюжая последовательность шагов была оправданна, поскольку
получаемый результат был хорошим. В течение 60-х годов, однако, горячий
набор был заменен многоцелевыми устройствами типа машины Photon, на
которой отпечатаны программы сегодняшней лекции; здесь целиком задействован
фотопроцесс, поскольку рисунки букв сохраняются на ротационном диске в
виде маленьких негативов, а необходимые для печати формы получаются при
экспозиции пленки после преобразования литер в нужные размеры и
расположения их на нужном месте посредством зеркал и линз (см. [10]). Такие машины
имеют ограничения в скорости и возможности расширения шрифтовых касс.
«Третье поколение» наборного оборудования
В более современных машинах, вроде той, что использовалась для
подготовки последних томов Transactions, аналоговые процессы заменены цифровыми.
Новизна идеи состоит в том, что страницы или фотонегативы разбиваются
на миллионы крошечных прямоугольников, вроде миллиметровки или
телевизионного изображения, но с более высокой разрешающей способностью около
1000 единиц на дюйм. Для каждого из крошечных «пикселей» при такой
растеризации — около миллиона квадратных пикселей в одном квадратном дюйме --
наборная машина решала, будет ли он белым или черным, и черный пиксель
воспроизводился на фотоформе посредством очень точного электронного или
лазерного луча. Поскольку в таких машинах было несколько подвижных
частей и почти не требовались механические действия, они могли работать с
очень большой скоростью несмотря на то, что в каждый момент
экспонировался лишь крошечный участок пленки.
Установив свой иной подход, это новое полиграфическое оборудование в
сущности трактовало каждую страницу как огромную матрицу из нулей и
единиц, зачерненную в тех местах, где были единицы, и оставленную белой
там, где были нули. Это вроде электронных табло на стадионе, но со значи-
1 На сегодняшний день корпорация Monotype выпускает и фотонаборное оборудование,
и традиционные машины класса «monotype».
Глава 2. Математическая типография
51
тельно большим количеством ячеек. Теперь общая задача такой системы, как
ТЕХ, сводилась к преобразованию авторской рукописи к гигантской матрице
из двоичных разрядов.
Вот первый вопрос, который мы должны, разумеется, задать: «А что
происходит с качеством?». Понятно, что телевизионное изображение не подходит
для фотовоспроизведения и цифровые наборные машины были бы совершенно
неудовлетворительными, если бы они давали вывод, который смотрелся хуже,
чем результат металлического набора. К вещам, подобным этим, я проявляю
педантизм и взыскательность; например, я отказываюсь есть маргарин вместо
масла и никогда не слушаю электронный орган, который по красоте звучания
даже отдаленно не сравним с настоящим органом из труб. Так что я был
чрезвычайно скептически настроен по отношению к цифровой типографии, пока
не увидел подлинный образец того, что было сделано на машине с высоким
качеством воспроизведения и не стал рассматривать это через лупу: невозможно
было поверить, что буквы получены посредством дискретного растра!
Причина кроется не в том, что наши глаза не могут различить более 1000 точек
на дюйм: в подходящих обстоятельствах могут. Дело в том, что частицы
типографской краски не могут различить такие мелкие детали — вы не сможете
напечатать линию из 1000 зигзагов вдоль диагонали квадратного дюйма,
потому что краска на ребрах будет давать закругления. На самом деле критическое
число, кажется, ближе к 500, а не к 1000. Таким образом, физические свойства
краски приводят к тому, что страницы выглядят так, как если бы растра не
было вовсе.
Сегодня стало понятно, что дискретное полиграфическое оборудование,
использующее растеризацию, вскоре вытеснит другие машины почти на всех
процессах подготовки издания. Таким образом, в будущем, тот факт, что
Гутенберг и другие мастера изобрели подвижный шрифт, не будет
рассматриваться как особенно замечательный, а станет считаться просто неким
историческим курьезом, который влиял на печатное дело около 500 лет. Поистине
замечательной вещью окажется математика: математика матриц из нулей и
единиц!
Полуфилософские заметки
Следующую часть своего выступления я бы хотел изложить, исходя из
собственной точки зрения. Как представитель комбинаторики, я идентифицирую
реальность с матрицами из 0 и 1, так что когда прошлой весной я узнал о
таких печатных машинах, то уже не мог продолжать работать над тем, чем
тогда занимался; я только хотел улучить момент, чтобы испытать
возможности нового оборудования. Меня также вдохновляла идея остановить падение
качества, которое я мог наблюдать в технических журналах. Кроме того,
издатели моих книг по искусству программирования прилагали героические, но
безуспешные усилия к выпуску второго издания 2-го тома с сохранением стиля
первого издания, но без использования уже исчезающего к тому времени
горячего набора. Это означало, что мои книги будут скоро выглядеть так же плохо,
52
Компьютерная типография
как и журналы. Когда я понял, что все эти проблемы могут быть решены при
помощи программирования, мне ничего не оставалось, как попытаться найти
решение самостоятельно.
Одним из самых сильных побудительных моментов было понимание того,
что эта проблема м'огла быть решена раз и навсегда, если бы я смог найти чисто
математический способ определения рисунка букв и построить
соответствующие растровые изображения. Хотя новые способы печати были предназначены
для использования в будущем, возможно еще до того, как я закончу работу
над 7-м томом книг, которые пишу, любые новые машины почти наверняка
будут основаны на растре с высоким разрешением, и хотя разрешение может
меняться, формы букв могут оставаться теми же всегда, поскольку они
описаны в машинно-независимом виде. Итак, моей целью было дать точное описание
рисунков всех символов, которые мне были нужны.
Я видел, как делались оцифрованные типографские шрифты в разных
частях света; в основном, при помощи сложного фотооборудования и
компьютерных программ копировались уже существующие шрифты и затем они
редактировались вручную. Но интуитивно я почувствовал, что для меня это
не годится отчасти потому, что сложное оборудование пока для нашей
лаборатории в Станфорде недоступно, отчасти из-за сомнительности копирования
шрифтов, защищенных знаком копирайта, но в основном из-за того, что сама
идея копирования мне не представляется проникающей в суть проблемы. Мне
вспоминается однажды слышанный анекдот о логарифмических линейках в
Японии. Согласно этой истории на первой логарифмической линейке,
попавшей на Восток, было грязное пятно, и в течение многих лет на всех японских
логарифмических линейках было бессмысленное темное пятно на том же месте!
История эта, возможно, вымышленная, но суть ее в том, что надо копировать
идею, а не форму. Мне кажется, правильным будет не задать вопрос «Как
скопировать этот типографский шрифт?», а задуматься вот о чем: «Если бы
великие шрифтовые дизайнеры прошлого были бы живы, то как бы они
создавали свои шрифты для нового оборудования?». Я не надеялся, разумеется,
что смогу найти точный ответ на это, но чувствовал, что выйду на правильный
путь, поэтому начал изучать историю шрифтового дизайна.
Да, это чрезвычайно увлекательный предмет, но за неимением времени, я
не смогу долго о нем рассказывать. Две первые работы, которые я прочитал,
были автобиографиями двух знаменитых шрифтовиков 20-го столетия:
Германа Цапфа [51] и Фредерика Гауди [20], и особенно меня заинтересовали заметки
Цапфа:
С начала шестидесятых ... я был охвачен этим новым направлением
[фотонабором] .... Шрифтовой дизайнер — или лучше будем называть его
дизайнером алфавита — должен воспринимать свою миссию и свою
ответственность как более высокую, чем раньше, сочетая традиционный подход
к разработке форм литер с практическими целями и возможностями
современного оборудования .... Новые фотонаборные системы, использующие
экраны с электронно-лучевыми трубками (ЭЛТ) или запись алфавита в
Глава 2. Математическая типография
53
оцифрованном виде, принесли с собой абсолютно новые технические
проблемы, значительно более сложные, чем прежде. [51, с. 71].
У меня создалось впечатление, что Гауди не очень симпатизировал новому
оборудованию, но в его книге также содержались полезные мысли.
Математический дизайн шрифта
К счастью, Станфордская библиотека имела великолепную коллекцию книг
по печатному делу и мне представился случай прочесть много редких
первоисточников. Я узнал, к своему удивлению, что идея математического описания
букв уже возникала; она появилась в 15-м столетии и стала активно
разрабатываться в начале 16-го. Это было время, когда деятели эпохи Возрождения
применяли математические исследования к реальному миру, и одной из
выдающихся идей было построение прописных букв при помощи линейки и
циркуля. Первым, кто это проделал, был, видимо, Феличе Феличиано (примерно
1460 г.), чей рукописный манускрипт из библиотеки Ватикана был
опубликован 500 лет спустя [19]. Феличиано был блестящим художником, который хотел
перевести принципы построения форм литер на математический язык. Его
современники — резчики из Вероны — использовали в своих работах его рисунки
шрифта. Аналогичные эксперименты проводили еще несколько авторов 15-го
века — критический обзор этих ранних разработок содержится в [8] — но самая
замечательная работа такого рода была проведена в начале 16-го века.
(а) (Ъ) (с) (d)
Рис. 4. Построения эпохи Возрождения буквы В, выполненные при помощи линейки
и циркуля (а) Феличиано [19], (Ь) Пачиоли [43], (с) Торниелло [34] и (d) Палатино [44].
Итальянский математик Лука Пачиоли, автор самой популярной в те
времена книги по алгебре (это была одна из самых ранних опубликованных книг
по алгебре), в другую свою книгу по геометрии и «золотому сечению» Divina
Proportioned изданную в 1509 г., включил приложение об алфавитах. Еще
одной великолепной итальянской работой по этому предмету была книга Фран-
ческо Торниелло, опубликованная в 1517 г. [34]; на рис. 4 показана буква В,
выполненная Феличиано, Пачиоли и Торниелло, а также Джованбаттиста
Палатино [44]. Палатино был одним из лучших каллиграфов того времени, свою
работу он сделал примерно в 1550 г. Аналогичные работы проводились в
Германии и Франции. Вероятно, самой знаменитой немецкой книгой, повлиявшей
на дальнейшее развитие шрифта, была книга Альбрехта Дюрера Underweysung
54
Компьютерная типография
der Messung [18] — учебник по геометрическим построениям для художников
эпохи Возрождения. Весьма популярной было также и французское издание
Champ Fleury Джофруа Тори [49] —первого королевского художника
Франции, который ввел во французскую типографию акцентированные буквы. На
рис. 5 показаны два варианта буквы В, предложенных Тори. Из всех этих книг
я отдаю предпочтение труду Торниелло, потому что только у него построения
отличаются ясностью и четкостью.
Рис. 5. Еще две буквы В руки Тори [49].
По-видимому никто больше на протяжении более сотни лет не работал в
этом направлении и не занимался ни строчными буквами, ни цифрами, ни
курсивным начертанием и никакими иными символами, пока Джозеф Мок-
сон не дал подробного описания отдельных изящных букв, сконструированных
в Голландии [39]. Предел в улучшении этого математического подхода был
достигнут несколько позже, когда французский король Людовик XIV
распорядился создать Королевский алфавит. Примерно с 1690 г. более десяти лет
над проектом Людовика работала группа художников и типографов; образец
того, что они сконструировали, показан на рис. 6 [24].
Итак, ясно, что математическое описание форм литер имеет длинную
историю. Я должен, однако, также сказать, что почти все современные крупные
типографы пришли к общему заключению о том, что усилия эти были
напрасными. Хуже того, буквы, созданные циркулем и линейкой, были названы
«уродливыми», в лучшем случае говорили, что они «лишены
каллиграфического изящества» [8]. Французские дизайнеры не стали истинными
последователями ни Филлипа Гранжана, который фактически выгравировал шрифт
Людовика XIV, ни кого бы то ни было еще из тех времен. Реакцией Гауди на это
было: «Слава Богу!» [20, с. 139]. Столь строгие геометрические формы литер
подверглись критике на самом деле уже в 16-м столетии. Джованни Кресчи,
выдающийся переписчик библиотеки Ватикана и Сикстинской капеллы писал
в 1560 г.:
Я пришел к выводу, что если бы Евклид, король геометрии, вернулся
сегодня в наш мир, то он никогда бы не стал утверждать, что кривые в буквах
можно изобразить окружностями, построенными циркулем. [16]
Глава 2. Математическая типография 55
Рис. 6. Буквы прямого и курсивного начертания, разработанные для французского
короля Людовика XIV [24].
Кресчи, несомненно, был прав. Но, к счастью, за последние 400 лет
математика несколько обогатилась и теперь у нас в запасе есть и другие приемы,
кроме прямых линий и окружностей. В самом деле, теперь можно вывести
формулы, описывающие тонкие нюансы рисунка руки лучших шрифтовых
дизайнеров, и, не исключено, что одаренный дизайнер, вооруженный
соответствующими математическими средствами, будет способен создать нечто еще
лучшее, чем то, что мы имеем на сегодняшний день.
Определение новых кривых
Рассмотрим следующую математическую задачу: пусть даны п точек
z\, ^2,..., zn на плоскости; какая замкнутая кривая, проходящая через эти
точки в заданном порядке z\, z^,..., zn и затем возвращающаяся в z\, будет самой
приятной? Чтобы исключить вырожденные случаи, будем предполагать, что
п не меньше 4. Эта задача в сущности напоминает детскую головоломку «От
точки к точке».
56
Компьютерная типография
Разумеется, это не является строго поставленной математической
задачей, потому что я не сказал, что означает понятие «самая приятная кривая».
Приведем сначала несколько аксиом, которым должны удовлетворять самые
приятные кривые.
Свойство 1 (инвариантность). Если данные точки повернуть,
перенести или расширить, то самая приятная кривая (СПК) будет
повернута, перенесена или расширена точно так же. [Аналитическое выражение:
CIIK(azi + 6,..., azn + b) = aCIIK(zi,..., zn) + b.]
Свойство 2 (симметрия). Циклическая перестановка данных
точек не меняет решения. [Таким образом, имеем CIIK(zi,Z2,... ,zn) =
CnK(z2,...,zn,zi).]
Свойство 3 (расширяемость). Добавление новой точки к уже
существующим на самой приятной кривой не меняет решения. [Если
z есть любая точка между Zk и z^+i на CIlK(zi,... ,zn), то имеем
СГПфь... ) = CnK(zi,...,ZA;, Zk+l,---,Zn).]
В справедливости этих свойств очень легко убедиться на интуитивном уровне.
Например, свойство расширяемости говорит о том, что дополнительная
информация не должна приводить к более слабому решению.
Следующее свойство не столь очевидно, но я считаю его важным для тех
приложений, которые имеются ввиду.
Свойство 4 (локальность). Каждый сегмент самой приятной
кривой, заключенный между двумя данными точками, зависит только от этих
точек и от непосредственно примыкающих к ним (предыдущей и
следующей). [СПК(^1, Z2,...,zn) состоит из CIlK(zn, zi, z^, z$) от z\ до Z2, затем
CIIK(zi, z2,z3, z4) от z2 до z3, ..., затем CIlK(zn_1, zn, zu z2) от zn до zx\
Согласно свойству локальности изменение одной части образа не должно
влиять на другие его части. Это упрощает наше исследование самой
приятной-кривой, поскольку нужно решать задачу для случая четырех данных точек; опыт
показывает, что локальность также чрезвычайно упрощает процесс дизайна
литер, поскольку в каждый момент можно иметь дело с отдельной порцией
штрихов. Между прочим, свойство 4 влечет за собой свойство 2 (циклическая
симметрия).
Один из способов удовлетворить всем четырем свойствам состоит просто
в том, чтобы составить самую приятную кривую из отрезков прямых. Но
многоугольники не вызывают приятного ощущения, поэтому мы постулируем
Свойство 5 (гладкость). У самой приятной кривой нет острых углов.
[СПК(^1,..., zn) дифференцируема при некоторой параметризации.]
Иначе говоря, в каждой точке кривой имеется единственная касательная.
Из свойств расширяемости, локальности и гладкости вместе взятых
вытекает фактически, что направление касательной в точке Zk зависит только
от Zk-i, Zk и Zfc+i. Поскольку это касательная для двух кривых, одна —от
Zk-i до Zk и другая —от Zk до Zk+i, мы знаем, что она зависит только от
Глава 2. Математическая типография
57
(zjfe-2, Zk-i, Zk, Zk+i) и только от (zjfe-i, z^, ^A;+i> ^+2). В силу свойства
расширяемости можно предположить, что п по крайней мере равно 5; следовательно,
Zk-2 отлична от Zfc+2 и касательная должна не зависеть от них обеих. На
самом деле по этой причине мы будем использовать только очень слабую форму
расширяемости.
Если мы применим свойство расширяемости в его полной сильной
форме, то получим значительно более сильное следствие, весьма неудачное: Не
существует хорошего способа удовлетворить свойствам 1-5 \ Предположим, к
примеру, что мы добавим еще одну аксиому, которая почти необходима в
любых разумных определениях приятных кривых:
Свойство б (скругляемость). Если zi, z2, z3, Z4 суть последовательные
точки кривой, то самая приятная кривая, проходящая через них, есть
окружность.
Это свойство (вместе с нашим предыдущим наблюдением относительно того,
что касательная зависит только от трех точек) определяет касательную в
каждой нашей заданной точке. Именно, касательная в точке Zk есть касательная
к окружности, проходящей через точки z^-i, Zk и Zfc+i. (На время отбросим
возможность принадлежности всех трех точек одной прямой.) Далее,
свойство расширяемости гласит, что если z — произвольная точка между z\ и z2
на самой приятной кривой, проходящей через точки zi,... ,zn, мы знаем
направления касательной в точке z, если только эта точка z не принадлежит
отрезку прямой от z\ до z2. Но существует единственная кривая,
начинающаяся в произвольной точке z вне этой прямой и имеющая заданные касательные
в каждой из этих точек, именно дуга окружности от z до z2, проходящая через
z\. Неважно, где именно вне прямой мы начинаем, мы способны нарисовать
только одну кривую, имеющую правильные касательные. Отсюда следует, что
касательная в точке z2 зависит только от zi, z2 и от касательной в точке zi,
что невозможно.
По причине, изложенной в предыдущем абзаце, нет способа удовлетворить
свойствам 3, 4, 5 и 6. Будет показано, что по аналогичной причине нет
никакой разумной замены для свойства б, поскольку касательные, зависящие
от всех z между z\ и z2, будут определять векторное поле, в котором
существуют уникальные кривые через практически все точки z, однако требуется
некое двухпараметрическое семейство кривых между z\ и z2, чтобы позволить
удовлетворить здесь условию гибкости в производных.
Итак, одно из этих свойств можно исключить. Свойство локальности
кажется самым сомнительным, но я уже говорил, что его я удалять не хочу.
Следовательно, исключим свойство расширяемости. Это означает, что если мы
возьмем самую приятную кривую, проходящую через точки zi,..., zn, и если
мы зададим еще одну точку z на этой кривой между точками Zk и z^+i, то
самая приятная кривая, проходящая через эти п + 1 точек, может оказаться
другой. Возможное преимущество состоит в том, что нет необходимости
задавать так много точек, возможный недостаток заключается в том, что мы не в
состоянии получить ту кривую, какую хотим.
58
Компьютерная типография
Практическая аппроксимация
Вернувшись к вопросу шрифтового дизайна, можно сказать, что наша цель
состоит в том, чтобы задать несколько точек Zk и получить математическое
выражение, описывающее приятную кривую, проходящую через эти точки.
Такие кривые будут использоваться для определения форм литер создаваемого
шрифта. В идеале, это должно также облегчить вычисление кривых. Я решил
использовать для этой цели кубические выражения
z(t) = а0 + ait + a2t2 + a3t3 ,
где ао5 с*ь а2, &з суть комплексные числа, a t — действительный параметр.
Кривые, которые я ввел, являются кубическими сплайнами, именно
кусочными кубическими соотношениями, поскольку в каждом интервале между двумя
заданными точками будут использоваться разные кубические выражения.
Однако способ, которым я определяю коэффициенты для этих кубических
выражений, отличается от методов, известных мне по опыту общения с обширной
литературой по сплайнам. Возможно, мой метод выбора коэффициентов менее
удобен по сравнению с общепринятыми, но он дал хорошие результаты, так что
мне не стыдно обнародовать свой «доморощенный» способ.
Во-первых, я решил, что кубическое уравнение между z\ и z2 должно
вполне определяться точками z\ и z2 и направлениями касательных в точках
z\ и z2. Мы уже видели, что эти касательные существенно предопределены,
если свойства 4, 5 и б справедливы, и я также обнаружил, что в дизайне
шрифтов часто бывает нужно задать, чтобы некая касательная была
горизонтальной или вертикальной. Таким образом, мой метод вычисления приятной
кривой, проходящей через заданную последовательность точек, таков:
сначала вычисляются направления касательных в каждой точке, а затем
кубические выражения для интервалов, основанные только на конечных точках этих
интервалов и на направлении касательных в них. Применив поворот,
перемещение и масштабирование согласно свойству 1, мы можем предположить, что
задача поставлена на комплексной плоскости от 0 до 1 с заданными
направлениями и конечными точками. Кубическое уравнение в самом общем виде
выглядит так:
z{t) = St2 - 2t3 + reiGt(l - t)2 - se~^t2(l - t),
остается определить положительные числа г и s как подходящие функции от
в и (р.
Во вторых, я понимал, что невозможно, имея кубические сплайны,
удовлетворить свойству б, потому что вы не можете нарисовать окружность как
кубическую функцию от t. Но я хотел иметь возможность получать кривые,
которые были бы почти как окружности насколько это возможно при условии,
что четыре заданные последовательные точки лежат на окружности. Эти
кривые должны не отличаться от окружностей настолько, насколько позволяет
человеческий глаз. Таким образом, при 0 = ц> я решил взять г — s, так что
z(|) точно соответствовала окружности, если предположить, что эта кривая
между 0 и | и между \ и 1 не слишком меняет направление. Ну вот, это
позволило выполнить работу великолепно: небольшие вычисления, проведенные
Глава 2. Математическая типография
59
на компьютере, показали, что максимальное отклонение от истинной кривой
возникает в точке t = (3± \/3)/6 и относительная ошибка пренебрежимо мала.
Если, к примеру, взять четыре точки на равном расстоянии друг от друга и на
расстоянии 1 от некоторого центра, определяемый описанным выше образом
сплайн для этих точек окажется между расстоянием 1 и расстоянием
у/(71/6-\/8)/3 < 1.000273
от центра; ошибка меньше, чем 0.0003, а если взять п точек, то максимальная
ошибка стремится к нулю как 1/п6.
(Несколько изменив обозначения, положим
z(t) = l + (eie-l)(3t2-2t3)
+ m{l-t){l-t-el4) sin
и f(t) = \z(t)\2. Тогда
/'(*) = 8
max \z(t)\ —
o<t<i' v '
1 + cos
(t - 1) t (2t - 1) (6t2 - 6t + 1)
= 1 +
+
в
10
55296 106168320
+
как только mino<£<i \z{t)\ = z(0) = z{\) = z(l) = 1. «Двухточечная
окружность» имеет max|z(£)| = л/28/27 « 1.01835, тогда как трехточечная
окружность имеет max |z(t)\ w л/325/324 = 1.001542, а восьмиточечная — max \z(t)\ «
1.0000042455. Эти почти круглые параметрические сплайны были введены
Дж. Р. Маннингом [33], который заметил, что визуально они почти
неотличимы от настоящих окружностей.)
В другом случае, когда предполагается естественный способ выбора г и
5, имеем 9 + (р — 90°; тогда кривая z(t) должна быть очень похожа на
эллипс с конечными точками на его осях. (Это сводится к требованию, чтобы
(3£2 -2t3 -(s/cos(p)t2(l-t) — I)2 -f- (3^2 -2t3 + (r/cose)t(l-t)2)2
приблизительно равнялось 1.) Итак, теперь я знал, что мне нужно:
2 2
когда в = ср;
1 + cos в '
2 cos в
г =
(1+cos 45°) cos 45° '
Я попробовал формулы
5 =
5 =
1 + COS (f '
2cos(/?
(1+cos 45°) cos 45° '
когда в+(р = 90°.
2cos(9
г —
(1 -f cos ф) cos *ф '
5 =
2cos(/?
(1 -f- cos ip) cos^
1 Я признателен разработчикам системы компьютерной алгебры MACSYMA в M.I.T. и
сети ARPA, которая сделала эту систему доступной для исследовательской работы.
60
Компьютерная типография
Рис. 7.
Сплайны с параметрами
(9 = 0° (5°) 120°
и у? = 60°.
Рис. 8.
Подобно рис. 7, но
скорректировано так, что
г' = max(l/2,r) и
s' = max(l/2, s).
которые соответствовали обоим случаям, где *ф = (9 + ф)/2. Но это не давало
удовлетворительных результатов, особенно когда *ф приближалось к 90°. Моей
второй попыткой было
2 sin у?
(1 + cos г/j) sin *ф
s =
2 sin 9
(1 + cos г/j) sin гр
и это работало очень хорошо. На рис. 7 показаны сплайны, полученные в
результате такого подхода, когда <р = 60° и 9 меняется от 0° до 120° с шагом 5°.
Можно доказать, что если в и ip неотрицательны и меньше 180°, то только
что определенная кубическая кривая z(t) никогда не пересечет прямые в углах
в и (£, которые имеют концевые точки 0 и 1 соответственно. Это очень ценное
свойство для шрифтового дизайна, поскольку оно гарантирует, что кривая не
выйдет за пределы. Тем не менее я обнаружил, что это дает также
неудовлетворительные кривые, если один из параметров 9 или ip очень мал, а другой —
нет, потому что это означает, что кривая z(t) будет очень близка к прямой,
пока она не повернет к этой прямой извне под очень острым углом. В самом
деле, угол 9 не так уж редко бывает нулевым, и это приводит к прямой линии и
к острому углу в правой конечной точке. Поэтому я изменил формулы, чтобы
быть уверенным, что и г и 5 всегда равны - или больше, если особо не
оговорено иное; более того, я никогда не брал г или 5 больше 4. На рис. 8 приводятся
сплайны, полученные при тех же условиях, что и на рис. 7, но при г и (или) 5
равных |, если формула применяется для любого меньшего значения.
Используя эту технику, получаем систему для рисования приемлемо
красивых кривых, если не для самых приятных, и особенно хорошо это работает для
окружностей. Если этот метод дает неправильное направление касательной в
некоторой точке, мы можем этим управлять, задав две очень плотно
расположенные к друг другу точки, имеющие нужный наклон. Я также включил
другой способ модификации стандартных направлений касательных,
приводящий к тому, что эта система одинаково хорошо рисует как эллипсы, так и
окружности. Прежде чем вычислить сплайны, я сначала сжимал всю фигуру
по вертикали, умножив все координаты у на заданное соотношение ширины и
Глава 2. Математическая типография
61
высоты (обычно 1); затем вычислял сплайны и полученную в результате
сжатую кривую снова растягивал, поделив координаты у на соотношение ширины
и высоты.
Приложение к шрифтовому дизайну
Давайте теперь более пристально посмотрим на то, что мы можем нарисовать
при помощи математической системы вроде только что описанной. Я думаю,
самым естественным было бы продемонстрировать это вам на буквах от А до Z;
но, поскольку эта лекция математическая, лучше рассмотрим цифры от 0 до 9
(см. рис. 9). Кстати, способ, которым я упорядочил эти цифры, иллюстрирует
фундаментальное различие между математиками и полиграфистами:
математик всегда расположит 0 рядом с 1, а полиграфист — рядом с 9.
0123456789
Рис. 9. Цифры от 0 до 9, нарисованные прототипом программы METflFONT.
Большинство этих цифр были нарисованы на основе другой идеи,
уходящей в исторические истоки типографии, именно посредством имитации
переписчиков, пользовавшихся пером и чернилами. Рассмотрим сначала цифру '3',
например. Программа, рисовавшая этот символ на рис. 9, может быть
перефразирована так: «Сначала рисуем точку, левая граница которой составляет |
пути от ее левого края до правого, а нижняя граница равна | пути от верхушки
до основания требуемой окончательной формы. Затем берем перо для
волосяных линий и ведем его слева вверх вдоль дуги некого эллипса. Когда достигаем
верхушки, перо начинает давать более жирную линию и это превращается в
другой эллипс таким образом, что максимальная толщина достигается на осях
этого эллипса с правой границей пера, равной | пути от левого до правого
края рисуемой литеры. Затем толщина пера начинает уменьшаться до своего
исходного размера как если бы перо проходило по другому эллипсу,
находящемуся на 48% ниже пути от верхушки до основания требуемой окончательной
формы ... ».
Обратите внимание, что вместо описания границы литеры, как это
делали геометры эпохи Возрождения, моя система METflFONT описывает кривую,
проводимую пером относительно центра, причем допускается изменение как
формы пера, так и его траектории. Основное преимущество этого подхода
состоит в том, что одно и то же определение успешно работает для семейства из
бесконечного количества шрифтов, при этом каждый шрифт внутренне
согласован. Изменением размера пера руководят кубические сплайны, равно как и
движением центра пера. Для того чтобы определить примерно 20 различных
шрифтов, использованных в разных местах моих книг, мне нужно было по
62
Компьютерная типография
большей части пользоваться всего тремя видами перьев, именно (i) круглым
пером, например для рисования точек и основания цифры '7'; (ii)
горизонтальным пером в виде эллипса, ширина которого меняется, но высота остается
равной перу для волосяных линий; (iii) вертикальным пером, аналогичным
горизонтальному, которое используется, например, для рисования штрихов в
основании цифры '2' и вверху цифр '5' и '7'. Горизонтальное перо
используется чаще всех, им, в частности, нарисована вся цифра '3' за исключением
точек. Для шрифта, который мне требовался, мне не понадобилось наклонное
перо (в виде эллипса, скошенного в одну сторону), за исключением акцента
в виде тильды над испанской буквой п; но если бы я создавал шрифт типа
Times Roman, наклонное перо безусловно потребовалось бы. Если эту систему
расширять для китайской или японской письменности, я уверен, что
следовало бы добавить дополнительную степень свободы для перемещений пера5
позволявшую бы эллиптическому перу вращаться и изменять свою ширину.
Цифра '4' демонстрирует еще одну сторону системы METflFONT. Хотя эта
литера довольно простая и целиком состоит из прямых, толстая прямая вверху
срезана под углом. Для этого у системы METfl FONT наравне с перьями имеются
ластики. Сначала компьютер рисует толстую прямую целиком снизу доверху
как в прописной букве 'Г; затем он берет ластик стирает все, что находится
слева, двигаясь по диагональному штриху вниз, затем он берет волосяное перо
и завершает диагональный штрих. Аналогичным образом ластик используется
для верхушки цифры '1', основания цифры '2', и т. д.
Иногда кажется, что простой сплайн не может адекватно описать
нужное увеличение толщины пера, так что в отдельных случаях я прибегал к
описанию левого и правого краев пера как отдельных кривых, чтобы потом
их заполнить. Это происходит, например, в основном штрихе цифры '2', края
которого определяются двумя сплайнами, имеющими заданную касательную
внизу и имеющими вертикальный наклон справа от кривой.
Вооруженный этой методикой я обнаружил, что способен определить
полный шрифт вполне приличного качества, содержащий 128 литер, примерно
0ABCDEFGHIJKLMN
OPQRSTUVWXYZ["]
'abcdefghijklmno
pqrstuvwxyzfffiflffiffl «elfaceiELfACE
0123456789:;<=>?
\"qQ%&'Q*+,-./ ГЛОЛгПЕГФПц
Рис. 10. Шрифт из 128 литер, определяемый METAFONT'om при помощи пера для
5-пунктового кегля. (Литеры акцентов должны разместиться сверху над другими
буквами точно в центре благодаря использованию ТвХ'а.)
за два месяца, хотя, конечно, мне пришлось сделать более тонкую доработку,
когда речь зашла о большем, чем просто несколько пробных страниц набора
(см. рис. 10). Наибольшие трудности, по крайней мере для меня, вызвала
буква S (и цифра 8, для которой использовалась та же процедура). Три дня и
Глава 2. Математическая типография
63
три бессонные ночи я потратил на то, чт.обы получить правильный рисунок
буквы S, прежде чем, наконец, получил его. Было мгновенье, когда я даже
подумал, не проще ли было бы переписать все мои книги без этой S! После
первого дня неудачных попыток я показал свое изделие жене и она сказала:
«А почему ты не захотел сделать это в виде S?»
Рис. 11. Буква S в виде, определенном (а) Феличиано [19]; (Ь) Пачиоли [43]; (с) Тор-
ниелло [34]; (d) Палатино [44]; (е) французской комиссией [24].
На рис. 11 показано, как эту проблему решали Феличиано, Пачиоли, Тор-
ниелло, Палатино и французские академики, но их буквы не выглядят так,
как современная S. Кроме того, я думаю, гравер французской S слегка
слукавил при скруглении кривых в центре — возможно, он пользовался некой
французской кривой. С помощью жены я, наконец, получил удовлетворительный
результат, отдаленно напоминающий букву шестнадцатого века, но для ее
получения я использовал эллипсы. Каждая граница каждой дуги моей буквы S
состояла из эллипсов и прямых, определяемых (i) положением начальной и
конечной точек, (и) наклоном прямой и (iii) требуемым левым краем этой
кривой. Для вывода необходимых формул мне понадобилось три часа, и думаю,
что Ньютон и Лейбниц получили бы удовольствие от работы над этой пробле-
64
Компьютерная типография
мой. На рис. 12 приведены несколько вариантов буквы S с разными наклонами
в центре, полученных по этой схеме, и я надеюсь, вам больше понравится
средняя, потому что ее я в настоящее время и использую.
QQQQQQQ
Рис. 12. Различные варианты S, полученные при разных наклонах в центре,
соответствующие коэффициентам 1/2, 2/3, 3/4, 1, 4/3, 3/2 »2 относительно «правильного»
наклона.
Семейства шрифтов
Для расширения системы METAFONT нужно, в сущности, написать программу,
определяющую каждую литеру, на специальном дизайнерском языке описания
движения пера и ластика. Мой коллега Р. У. Госпер заметил, что мы получили,
таким образом, полную противоположность улице Сезам: вместо «эта
программа была получена для вас буквой S» имеем «эта буква S была получена для
вас программой». В программе задействовано около 20 параметров,
управляющих толщиной волосяного пера, определяющих ширину прямых и кривых,
которые должны быть нарисованы, и пропорции разных частей литер (высота
х, высота верхних и нижних акцентов, ширина М, длина засечек и т. д.).
Меняя эти параметры, мы получаем бесконечно много разных видов начертаний
шрифтов, при этом они все родственны и гармонируют друг с другом.
На рис. 13, например, демонстрируется ряд этих возможностей. На
рис. 13а приводится светлый прямой шрифт «modern» в традициях Bodoni
and Bell и Scotch Roman. На рис. 13b дается соответствующее полужирное
начертание, в котором волосяные линии несколько толще, а основные штрих
соответственно чуть шире. Сделав волосяные линии и штрихи одной толщины
и положив длину засечек равной нулю, получим шрифт без засечек
(рубленый), который представлен на рис. 13с. Все эти примеры получены одной и той
же программой, определяющей форму литер; варьировались лишь параметры.
На самом деле шрифт, показанный на рис. 13с, должен иметь букву g иного
рисунка (именно 'д'), потому что в этом шрифте нижние выносные элементы
очень короткие, но я оставил такое 'g', чтобы продемонстрировать
параметрическое разнообразие. На рис. 13d приводится полужирный рубленый шрифт,
в котором перо имело овальную форму, шире своей высоты. Я нахожу это
начертание особенно привлекательным, в частности потому, что это вышло
случайно —я писал программу так, чтобы два или три разных шрифта
получались правильно, следовательно, вид всех остальных может быть каким
угодно. Я не представляю, почему это начертание получилось таким удачным.
При подходящей установке параметров можно имитировать пишущую
машинку с фиксированной шириной литер, как это показано на рис. 13е. Имеется
Глава 2. Математическая типография
65
(a) Mathematical Mathematical
Typography Typography
(b)
(с) Mathematical Mathematical («ц
Typography Typography
re) Mathematical Mathematicalw
Typography Typography
(g) Mathematical Math ematical (h)
Typography TYPOgraphy
MuthQIMtlQul {i)
Typography
Рис. 13. Различные начертания шрифта, полученные изменением параметров
программы METflFONT: (a) Computer modern прямой; (b) Computer modern
полужирный; (с) Computer modern рубленый; (d) Computer modern полужирный рубленый;
(e) Computer modern типа пишущей машинки; (f) Computer modern наклонный;
(g) Computer modern прямой капитель; (h) Computer modern прямой с капителью
и со «строчной капителью»; (i) Computer modern забавный.
возможность наклонить литеры как на рис. 13f; здесь положение пера
меняется, но сама форма пера не является наклонной, так что круглые точки остаются
круглыми.
Другая установка параметров приводит к капители: вместо строчных букв
используются прописные более мелкого размера; это показано на рис. 13g;
капитель рисуется теми же перьями той же высоты, что и для строчных букв, но
управляется программами для прописных букв. На рис. 13h показано то, чего
никогда раньше не было на печати: это получается, если мы рисуем
строчные буквы в виде капители. Это можно бы назвать «строчной капителью». Он
неожиданно получился одним из наиболее приятных, только точки оказались
великоватыми.
И наконец, на рис. 131 продемонстрирован вариант, полученный
своеобразной установкой параметров.
Когда я работал ассистентом в фирме Caltech, секретариат отделения
математики иногда направлял ко мне «чокнутых» визитеров и как-то раз один
посетитель спросил, когда же, наконец, число 7г будет вычислено «до самого
конца». Я пытался ему объяснить, что 7г число иррациональное, но до него
это не доходило. Наконец, я показал ему листинг с вычислениями 7г до 100000
66
Компьютерная типография
десятичного знака и сказал, что эти вычисления еще не завершены. Если бы в
то время уже была готова моя издательская система, я бы смог показать ему
рис. 14!
У 2б5358979ЭЗэ-.._
Рис. 14. Варьирование высотой, шириной и размером пера.
Рис. 14 иллюстрирует другой аспект шрифтового дизайна, именно, что
различные размеры шрифта одного начертания нельзя получить одно из
другого обычными оптическими преобразованиями. Высоты и ширины и толщина
пера меняются с разной скоростью и хороший резчик шрифта создает каждый
размер шрифта (кегль) отдельно. Я не претендую на то, что рис. 14 лучше
всего демонстрирует изменение пропорций; нужно будет еще немало
поэкспериментировать, прежде чем у меня выкристаллизуется мысль, что же все-таки
требуется. Я просто хотел подчеркнуть, что изменение размера шрифта в
нижних выносных элементах и тому подобных вещах, не такое простое дело, как
это может показаться на первый взгляд, а система наподобие METAFONT'a
способна довольно легко менять эти параметры и можно быстро провести
визуальные эксперименты с установкой различных параметров. Дизайнеры
шрифта тратили месяцы на то, чтобы их рисунки были перенесены на
металлические носители, прежде чем они могли увидеть пробный оттиск. Одно
из следствий этого состояло в том, что у них попросту не было времени уделить
достаточно внимания всем этим математическим символам, греческим буквам
и т. д., равно как и более общеупотребительным символам, так что
наборщикам не оставалось ничего иного, как устраивать мешанину из имеющихся в
их распоряжении символов разного размера. (Например, зачастую они были
вынуждены использовать в индексах буквы иного начертания, с чем вы
сталкивались.) При подходе, который я рекомендую, мы автоматически получаем
соответствие всем символам, как только изменяем параметры.
От непрерывности к дискретности
Система METfl FONT должна была не только определять литеры на континууме
заданной плоскости, но и выражать их в терминах дискретного растра. Такое
представление литер квадратиками на миллиметровой бумаге имеет длинную
историю, еще задолго до появления вычислительной техники и телевизоров.
Например, нам всем хорошо знакомы образцы 19-го века вышивки крестом.
Та же идея тонкого масштабирования многие века использовалась в
гобеленах. Моя жена нашла в нашей домашней библиотеке образец, представленный
на рис. 15, который был выткан на севере Норвегии примерно в 1500 г;
изображено имя святого Томаса в стиле, имитирующем каллиграфию тех времен,
и я уверен, что подобные примеры, предвосхитившие печатный пресс, можно
найти еще где-нибудь.
з
Глава 2. Математическая типография 67
Рис. 15. Письменный эквивалент этого растрового изображения представлен на
норвежском гобелене из церкви Gildeskaal, выткано около 1500 г. [22, с. 116].
На рис. 16 показано, как METflFONT производит одни и те же буквы с
одними и теми же параметрами, но с разной разрешающей способностью
растра. Сам по себе процесс оцифровки значительно более сложен, чем это может
показаться на первый взгляд, и, прежде чем я смог получить
удовлетворительные результаты, понадобилось обратиться к некоторым нетривиальным
математическим понятиям. Очевидный подход состоит просто в рисовании или
воображаемом рисовании литеры с бесконечной точностью и затем в ее «скруг-
лении» посредством зачернения всех квадратов на миллиметровке, которые
достаточно черны в исходном изображении, однако это абсолютно безуспешно.
Одна из причин безуспешности кроется в том, что три штриха, скажем,
буквы 'т', могут занять разное положение относительно сетки, так что первый
штрих может оказаться, например, ширины три единицы, а второй —четыре.
Это совершенно недопустимо, потому что наши глаза с легкостью уловят
такое различие в толщине. Но METfl FONT все это пропустит, поскольку сначала
оцифровывается само перо и затем это же оцифрованное перо используется
для всех штрихов. Другая проблема состоит в том, что эти три штриха
должны иметь одинаковые просветы, так что 'т' будет плохо смотреться, если, к
примеру, имеется 7 единиц между двумя первыми штрихами и 8 единиц между
двумя последними. Таким образом, понадобилась программа, которая
округляла бы эти точки так, чтобы подобное не случалось.
Я чрезвычайно доволен рис. 16, но на нем с очевидностью проступают
несколько нерешенных проблем, которыми я собираюсь заняться, когда
вернусь домой. В среднем примере предполагалось, что ширины кривых
округляются до 2 при значении несколько большем, чем 1.5, тогда как ширина штриха
округлялась до 1 при значении, лишь чуть меньшем 1.5. Поэтому кривые букв
ka', ke' и 'с' гораздо темнее, чем должно быть. Хвостик справа внизу у буквы
'а' должен быть удален в пятом примере, но при таком низком разрешении нет
автоматического метода, который был бы вполне удовлетворительным.
Процесс оцифровки пера тоже далеко не тривиален. Предположим,
например, что нам нужно круглое перо ширины 2 растровые единицы; понятно,
что подходящим пером будет квадрат 2x2, который ближе всего к кругу при
данном низком разрешении. Но заметьте, что мы не можем центрировать
квадрат 2 х 2 на любом отдельном квадрате растра, поскольку ни один из этих
68
Компьютерная типография
mathematics
mathematics
mathematics
mathematics
mathematics
Рис. 16.
Проблема
корректировки букв
при грубом растре.
(Разрешения соотвественно
120, 60, 40, 30 и 24
пикселей на дюйм.)
четырех квадратов не находится в центре. Та же проблема возникает в случае
пера, имеющего четную размерность. Один из способов решить эту проблему
состоит в том, чтобы работать только с нечетными числами, но это было бы
слишком большим ограничением. Поэтому METAFONT использует
специальное правило округления для положения центра пера. Обобщая, предположим,
что перо является эллипсом целой ширины w и целой высоты Л; тогда, если
перо имеет действительные координаты (х,у), его местом расположения на
дискретной сетке будет
([x-S(w)\, [y-8(h)\)
где [х\ обозначает наибольшее целое, меньшее или равное х, а 8(четное) =
|, ^(нечетное) = 0. Само перо, так позиционированное относительно начала
координат, будет состоять из всех пар (х, у) целых чисел, удовлетворяющих
2(х - 8(w))
w
2(У -5(h))
h
< 1 + max
26 И 25(h)\2
h ) ■
w
!■■■
Ill*
lit**
IIMH
intta*
Рис. 17.
Дискретные «эллиптические» перья
для малых целых значений
ширины и высоты.
Глава 2. Математическая типография
69
Рис. 18.
Трудности округления
правильной дуги. (Три
полуокружности радиуса 10,
нарисованные пером 1x3.)
Эта формула — между прочим, не первая, которую я попробовал, —
утверждает, что дискретное перо действительно будет ширины w единиц и высоты
Л, если w суть положительные целые. На рис. 17 показаны перья, полученные
для малых значений w и h.
Еще одна проблема возникает, когда нам нужно, чтобы кривые после
оцифровки выглядели прилично. На рис. 18а представлена полуокружность
радиуса 10 единиц, нарисованная пером высоты 1 и ширины 3, когда правая кромка
пера попадает точно в некоторую целую точку; тогда перо будет твердо стоять
на одном месте. С другой стороны, если эта правая кромка попадет точно на
выпад некоторой целой точки, мы получим кривую как на рис. 18Ь, которая
выглядит слишком плоской. Идеальный вариант показан на с. 18с, где правая
кромка приходится точно на середину между целыми числами.
Следовательно, программа METflFONT корректирует положение кривых на растровой сетке
до того, как приступить к рисованию этих кривых, форсируя благоприятную
ситуацию рис. 18с; Настоящая форма букв слегка меняется, чтобы она
адаптировалась к требуемому размеру растра наиболее благоприятным образом.
Еще одна проблема возникает тогда, когда размер пера увеличивается так,
чтобы ребра кривой, которую оно рисует, были монотонными, если перо было
нарисовано с бесконечной точностью, хотя независимое округление положения
пера и его ширины приводит к тому, что эта монотонность исчезает. Эта
проблема возникает весьма редко, но, когда это случается, глаз не может этого не
заметить. Рассмотрим, к примеру, вполне линейную ситуацию на рис. 19, где
каждое уменьшение у на одну единицу сопровождается возрастанием х на .3
единицы и увеличением ширины w.пера на .2 единицы. Имеется в виду, что
высота пера —очень малая постоянная, но в дискретном случае высота пера
берется равной 1. Слегка затененные участки на рис. 19 показывают истинную
предполагаемую форму, но более темные квадраты соответствуют оцифровке,
приводящей к немонотонной левой границе. METfl FONT компенсирует такого
рода проблему посредством поддержания следа искомой границы, когда
ширина пера меняется, рисуя точки дважды (например, и (х,у), и (х — 1,2/)), когда
нужно проследить за правильностью границы. Иначе говоря, иногда от идеи
округления положения пера и его ширины независимо друг от друга
эффективнее отказаться.
И последняя проблема оцифровки, которую мне пришлось решать,
состояла в том, чтобы сделать левую половину цифры '0' зеркальным отражением ее
правой половины, открывающую левую скобку — зеркальным отражением ле-
70
Компьютерная типография
Ширина пера и Округленные ширина
его положение и положение пера
(3.5, 0.5,10.5)
(3.7, 0.8, 9.5)
(3.9, 1.1, 8.5)
(4.1, 1.4, 7.5)
(4.3, 1.7, 6.5)
(4.5, 2.0, 5.5)
(4.7, 2.3, 4.5)
(4.9, 2.6, 3.5)
(5.1, 2.9, 2.5)
(5.3, 3.2, 1.5)
(5.5, 3.5, 0.5)
Рис. 19. Потеря монотонности при независимом округлении,
(округление делается из (w,x,y) в (|_^_|, |_ж ~~ ^(L^-DJi 1у\)-)
вой закрывающей скобки и т. п. Это было достигнуто благодаря специальным
программам METAFONT'a, выбирающим в таких случаях центральную точку,
которая либо в точности равна целому числу, либо целому плюс |, и введением
правила двойного округления, которое обладает свойством полной симметрии.
Иные подходы
Как я уже говорил, я думаю, что система METflFONT успешно
справляется с определением букв и других символов, но, возможно, благодаря новым
разработкам можно будет построить еще лучшие процедуры. Некоторые
ограничения моих кубических сплайнов приведены на рис. 20. В части (а) этого
рисунка изображена пятиконечная звезда и слово «mathematics», написанное
(в некотором приближении) моей рукой; приближение сделано при помощи
сегментов прямых, так что вы можете отчетливо видеть, какие точки были
предложены в виде исходных данных моей подпрограмме вычисления
сплайнов. В части (Ь) показано, как, возможно, преобразится мой почерк, когда я
стану старше; это получилось просто установкой г — s = 2 во всех сегментах
сплайна, из чего с очевидностью заключаем, что тангенсы углов
предопределены системой. В части (с) изображено нечто более стройное; это было получено
установкой везде г = s — 1/2. Рисунок 20d подобен рис. 20с, но он был
нарисован посредством комбинации пера и ластика. Такая комбинация может
привести к интересным эффектам, так что изображенная здесь звезда —мой
запоздалый дар к двухсотлетию Америки.
Когда используется выведенная ранее общая формула для параметров г
и 5, мы получаем то, что изображено на рис. 20е, в котором звезда
превратилась в замечательную аппроксимацию круга (как я предполагал). Для этого
рисунка использовалось более толстое перо со слегка наклонным нажимом.
Хотя мой почерк чрезвычайно некрасив, все же некоторые дефекты на рис. 20е
можно было бы, вероятно, сгладить, если бы был применен другой подход.
(3, 0,10)
(3, 0, 9)
(3, 1, 8)
(4, 0, 7)
(4, 1, 6)
(4, 1, 5)
(4, 1, 4)
(4, 2, 3)
(5, 2, 2)
(5, 3, 1)
(5, 3, 0)
Глава 2. Математическая типография
71
Рис. 20.
Примеры применения
кубических сплайнов к
небрежному почерку.
Самым интересным подходом с математической точки зрения могла бы
быть задача нахождения кривой данной длины, минимизирующей интеграл
от квадрата кривизны относительно длины дуги. Этот интеграл
пропорционален энергии натяжения механического сплайна данной длины (иными словами,
энергии в толстой перекладине или балке), проходящего через данные точки,
так что, по-видимому, это подходящая величина для минимизации. В
работе [32] Майкл Малкольм приводит свой взгляд на эту вариационную задачу.
Норвежский математик Ивен Мехлум [37] показал, что если мы зададим дугу
фиксированной длины между последовательными точками, оптимальная
кривая будет линейно менять кривизну как ах+Ъу+с в точке (х, у), и он предложил
выбирать константы, взяв Ъ/а = (у2 — 2/i)/(#2 — xi) межДУ (^ь У\) и {х2, Уъ),
и потребовав, чтобы наклон и кривизна были непрерывными в конечных
точках. Такой подход, наверное, потребует значительно больше вычислений, чем
рекомендованные здесь кубические сплайны, но он может привести к лучшим
кривым, удовлетворяющим, возможно, свойству расширяемости.
Другим интересным подходом к рисованию кривых, который особенно
может быть полезен при имитации почерков, является метод «фильтрации»,
недавно предложенный Майклом Патерсоном из Уорвикского университета
(неопубликовано). Для получения гладкой кривой, проходящей через точки z^,
предположим, что эти точки примерно равномерно расположены на искомой
кривой и что Zk = zn+k Для всех целых к. Тогда можно просто написать
z(t) = ]Г(-1)Чд* - к) I j2'(-i)kf(t - к)
где f(i) есть нечетная функция порядка t * при t —■> 0, быстро уменьшающаяся
при удалении от нуля. Например, мы можем взять
f(t) = csch t = 2/{еь - е~ь).
72
Компьютерная типография
У меня не было времени поэкспериментировать с методом Патерсона или
попробовать увязать его с рисованием букв. Легко видеть, что производная
z'(k) = /(1)(*fc+i - Zk-i) ~ /(2)(zfc+2 - zk-2) + • • • имеет направление zk+i -zk-i.
Рандомизация
В заключение, я хотел бы рассказать о небольшом эксперименте, который я
провел со случайными числами. Кто-то мог бы выразить недовольство по тому
поводу, что созданные мною буквы слишком совершенны, слишком похожи на
компьютерное изделие и лишены «характера»1. Чтобы нейтрализовать это, мы
можем заложить некоторую долю случайности при выборе того, где поместить
перо, когда мы рисуем каждую литеру, и на рис. 21 показано, что при этом
происходит. Координаты ключевых положений пера были выбраны независимо
согласно нормальному распределению и с возрастающим стандартным
отклонением, так что в третьем примере стандартное отклонение было вдвое больше,
чем во втором, в четвертом — в три раза больше и т. д. Обратите внимание, что
две буквы m в каждой строке разные (за исключением первой строки), то же
самое можно сказать относительно букв ant, поскольку каждая буква была
нарисована случайным образом.
При достаточно большом отклонении результаты выглядят чрезвычайно
нелепо. Я не хочу, чтобы люди говорили, что я завершил эту лекцию пародией
mathematics
mathematics
mathematics
mathematics
mathematics
mathematics
mathematics
mathematics
mathematics
mat\ie/nat\cp
mutherQMics i™-21
mathematics
Возрастающее случайное отклонение
положения пера; а = 0,1, 2,... .
1 Здесь игра слов: «character» означает как «характер», так и «литеру». — Прим. перев.
Глава 2. Математическая типография
73
mathematics
mathematics
mathematics
на математику. Так что лучше в заключение взглянем на рис. 22, в
котором представлены разные шрифты, когда уровень рандомизации управляем.
Думаю, можно сказать, что от этого завершающего примера веет теплом и
обаянием, особенно если учесть тот факт, что на самом деле они были
сгенерированы компьютером по строгим математическим законам. Возможно, в
старые добрые времена математические издания были такими красивыми
потому, что типографский шрифт был несовершенным и нелогичным.
Заключение
В заключение я бы хотел вывести мораль из этого длинного повествования.
Мои эксперименты на протяжении последних нескольких месяцев живо
иллюстрируют тот факт, что многочисленные математические задачи все еще
ждут своего решения почти везде, где бы они ни возникли, особенно в тех
областях реальной жизни, где математика редко раньше применялась.
Математики могут предоставить решения этих проблем и «убить двух зайцев» —
получить удовольствие от работы за гранью математики и заслужить
благодарность людей, которые смогут воспользоваться этими решениями. Так что
давайте будем идти дальше и применять математику в новых направлениях.
Благодарности
Я хотел бы поблагодарить мою жену Джил за многие важные предложения,
которые она внесла на стадии критического обсуждения этого исследования,
а также Лео Гуиба и Лили Рамшоу за оказанную ими помощь в изготовлении
иллюстраций в Исследовательском центре Xerox в Пало Альто. Лестера Ене-
ста, Майкла Фишера, Фрэнка Лианга, Тома Лича, Алберта Мейера, Майкла
Патерсона, Майкла Плэсса, Боба Спрулла, Джина Тейлора, Ганса Вольфа я
благодарю за полезные идеи, обсуждения и письма, касающиеся этого
предмета. Я также признателен Гордону Уолкеру за проверку моих предположений
относительно полиграфического прошлого Transactions и обеспечение
дополнительной информацией, а также профессору Дирку Сифкесу за его помощь
при отыскании рис. 4с и 11с и библиотеке Kunstbibliothek Berlin der Staatlichen
Museen Preussischer Kulturbesitz — за разрешение их опубликовать, а Андре
Жамму —за разрешение опубликовать рис. б и Не.
Рис. 22.
Небольшой уровень
рандомизации, введенный в
разные начертания шрифта.
74
Компьютерная типография
Литература, не упомянутая в тексте
В приведенный ниже список литературы включено несколько статей, не
упомянутых в основном тексте, именно обсуждение публикаций Американского
института физики [38]; отдельные эксперименты по набору физических
журналов при помощи системы, разработанной в Лаборатории Белла [7, 31];
использование компьютера для верстки и редактирования технических журналов,
снабженное кратким предложением по стандартному языку набора [11]; отчет
о ранних компьютерных программах для генерации литер и набора
математических текстов [23, 30, 35, 36, 41, 47]; описание правил математического набора,
которые должен был знать печатник [9]; три стандартных издания по набору
математических текстов [14, 48, 50]; некоторые типографские шрифты и
спецзнаки, разработанные в Американском математическом обществе [40]; новый
и очень важный подход к математическому описанию традиционных
полиграфических правил на основе конических сечений и одномерных сплайнов [15];
предложение нового способа управления пробелами между литерами,
основанного на неких математических идеях [28]; и две чисто математические работы,
навеянные полиграфией [13, 21].
Это исследование было частично финансировано фондом National Science Foundation no
гранту MCS72-03752 АОЗ и министерством Office of Naval Research no контракту N00014-
76-С-0330.
Литература
[1] А. V. Aho, S. С. Johnson, and J. D. Ullman, "Typesetting by ACM considered
harmful," Communications of the ACM 18 (1975), 740.
[2] American Mathematical Society, Development of the Photon for Efficient
Mathematical Composition, Final Report (10 May 1965), National Science
Foundation Grant G-21913; NTIS No. PB168627.
[3] American Mathematical Society, Development of Computer Aids for Tape-
Control of Photocomposing Machines, Report No. 2 (July 1967), "Extension
of the system of preparing a computer-processed tape to include the setting of
multiple line equations," National Science Foundation Grant GN-533; NTIS
No. PB175939.
[4] American Mathematical Society, Development of Computer Aids for Tape-
Control of Photocomposing Machines, Final Report, Section В (August 1968),
"A system for computer-processed tape composition to include the setting of
multiple line equations," National Science Foundation Grant GN-533; NTIS
No. PB179418.
[5] American Mathematical Society, Development of Computer Aids for Tape-
Control of Photocomposing Machines, Final Report, Section С (January 1969),
"Implementation, hardware, and other systems," National Science Foundation
Grant GN-533; NTIS No. PB182088.
[6] American Mathematical Society, To Complete the Study of Computer Aids for
Tape-Control of Composing Machines by Developing an Operating System,
Глава 2. Математическая типография
75
Final Report No. AMATHS-CAIDS-71-0 (April 1971), National Science
Foundation Grant GN-690; NTIS No. PB200892.
[7] American Physical Society, "APS tests computer system for publishing
operations," Physics Today 30,12 (December 1977), 75.
[8] Donald M. Anderson, "Cresci and his capital alphabets," Visible Language 4
(1971), 331-352.
[9] J. Woodard Auble, Arithmetic for Printers, 2nd edition (Peoria, Illinois:
Bennett, 1954).
[10] Michael P. Barnett, Computer Typesetting: Experiments and Prospects
(Cambridge, Massachusetts: M.I.T. Press, 1965).
ill] Robert W. Bemer and A. Richard Shriver, "Integrating computer text
processing with photocomposition," IEEE Transactions on Professional
Communication PC-16 (1973), 92-96. Эта статья представляет собой
перепечатку другой работы о наборе и верстке из Robert W. Bemer, "The
role of a computer in the publication of a primary journal," Proceedings of the
AFIPS National Computing Conference 42, Part II (1973), M16-M20.
[12] Peter J. Boehm, "Software and hardware considerations for a technical
typesetting system," IEEE Transactions on Professional Communication PC-
19 (1976), 15-19.
[13] J. A. Bondy, "The 'graph theory' of the Greek alphabet," in Graph Theory
and Applications, edited by Y. Alavi et al. (Berlin: Springer Verlag, 1972),
43-54.
[14] T. W. Chaundy, P. R. Barrett, and Charles Batey, The Printing of
Mathematics (Oxford: Oxford University Press, 1954).
[15] P. J. M. Coueignoux, Generation of Roman Printed Fonts, Ph.D. thesis, Dept.
of Electrical Engineering, Massachusetts Institute of Technology (June 1975).
[16] Giovanni Francesco Cresci Milanese, Essemplare de Piv Sorti Lettere (Rome:
1560). См. также издание в переводе и под редакцией Arthur Sidney Osley
(London: 1968).
[17] Т. L. De Vinne, The Practice of Typography: Modern Methods of Book
Composition (New York: Oswald, 1914).
[18] Albrecht Diirer, Underweysung der Messung mit dem Zirckel und Richtscheyt
(Nuremberg: 1525). Английский перевод раздела об алфавитах
опубликован в книге Albrecht Diirer, Of the Shaping of Letters, перевод R. T. Nichol
(Dover, 1965).
[19] Felice Feliciano Veronese, Alphabetum Romanum, edited by Giovanni
Mardersteig and translated by R. H. Boothroyd (Verona: Officina Bodoni,
I960).
[20] Frederic W. Goudy, Typologia: Studies in Type Design Sz Type Making with
Comments on the Invention of Typography, the First Types, Legibility & Fine
Printing (Berkeley, California: University of California Press, 1940).
[21] F. Harary, "Typographs," Visible Language 7 (1973), 199-208.
76 Компьютерная типография
Roar Hauglid, Randi Asker, Helen Engelstad, and Gunvor Traetteberg, Native
Art of Norway (Oslo: Dreyer, 1965).
A. V. Hershey, "Calligraphy for computers," NWL Report No. 2101 (Dahlgren,
Virginia: U.S. Naval Weapons Laboratory, August 1967); NTIS No. AD662398.
Andre Jammes, La Reforme de la Typographie Royale sous Louis XIV (Paris:
Paul Jammes, 1961).
Paul E. Justus, "There is more to typesetting than setting type," IEEE
Transactions on Professional Communication PC-15 (1972), 13-16, 18.
Alan C. Kay, "Microelectronics and the personal computer," Scientific
American 237,3 (September 1977), 230-244.
Brian W. Kernighan and Lorinda L. Cherry, "A system for typesetting
mathematics," Communications of the ACM 18 (1975), 151-157.
David Kindersley, Optical Letter Spacing for New Printing Systems (London:
Wynkyn de Worde Society, 1976).
Donald E. Knuth, "Tau Epsilon Chi, a system for technical text," Stanford
Computer Science Report CS675 (September 1978). Исправленное издание,
TfeX, A System for Technical Text (Providence, Rhode Island: American
Mathematical Society, 1979); опубликовано также как часть 2 работы Т^Х
and METRFONT: New Directions in Typesetting (Bedford, Massachusetts:
Digital Press, 1979).
Dorothy K. Korbuly, "A new approach to coding displayed mathematics for
photocomposition," IEEE Transactions on Professional Communication PC-
18 (1975), 283-287.
M. E. Lesk and B. W. Kernighan, "Computer typesetting of technical journals
on UNIX," Computer Science Technical Report 44 (Murray Hill, New Jersey:
Bell Laboratories, June 1976).
Michael A. Malcolm, "On the computation of nonlinear spline functions,"
SIAM Journal on Numerical Analysis 14 (1977), 254-282.
J. R. Manning, "Continuity conditions for spline curves," The Computer
Journal 17 (1974), 181-186.
Giovanni Mardersteig, The Alphabet of Francesco Torniello da Novara [1517]
Followed by a Comparison with the Alphabet of Fra Luca Pacioli (Verona:
Officina Bodoni, 1971).
M. V. Mathews and Joan E. Miller, "Computer editing, typesetting, and image
generation," Proceedings of the AFIPS Fall Joint Computer Conference 27
(1965), 389-398.
M. V. Mathews, Carol Lochbaum, and Judith A. Moss, "Three fonts of
computer drawn letters," Communications of the ACM 10 (1967), 627-630.
Even Mehlum, "Nonlinear splines," in Computer Aided Geometric Design.
edited by Robert E. Barnhill and Richard F. Riesenfeld (New York: Academic
Press, 1974), 173-207.
Глава 2. Математическая типография
77
[38] A. W. Kenneth Metzner, "Multiple use and other benefits of computerized
publishing," IEEE Transactions on Professional Communication PC-18
(1975), 274-278.
[39] Joseph Moxon, Regulae Trium Ordinum Literarum Typographicarum: or the
Rules of the Three Orders of Print Letters: viz. The {Roman, Italick, English}
Capitals and Small. Shewing how they are compounded of Geometrick Figures,
and mostly made by Rule and Compass (London: Joseph Moxon, 1676).
[40] Phoebe J. Murdock, "New alphabets and symbols for typesetting
mathematics," Scholarly Publishing 8 (1976), 44-53. Перепечатано в Notices
of the American Mathematical Society 24 (1977), 63-67.
[41] Nicholas Negroponte, "Raster scan approaches to computer graphics,"
Computers and Graphics 2 (1977), 179-193.
[42] Wolfgang A. Ocker, "A program to hyphenate English words," IEEE
Transactions on Engineering Writing and Speech EWS-14 (1971), 53-59.
[43] Luca Pacioli, Diuina proportione, Opera a tutti glingegni perspicaci e curiosi
necessaria Oue ciascun studioso di Philosophia: Propectiua Pictura Sculptura:
Architectura: Musica: e altre Mathematice: suauissima: sottile: e admirable
doctrina consequira: e delectarassi: со uarie questione de secretissima scientia
(Venice: 1509).
[44] Giovanbattista Palatino Cittadino Romano, Libro Primo del le Lettere
Maiuscole Antiche Romane (неопубликовано), Berlin Kunstbibliothek, MS
OS5280. Отдельные статьи датированы 1543, 1546, 1549, 1574 или 1575 г.
См. James Wardrop, "Civis Romanus Sum: Giovanbattista Palatino and his
circle," Signature 14 (1952), 3-39.
[45] Paul A. Parisi, "Composition innovations of the American Society of
Civil Engineers," IEEE Transactions on Professional Communication PC-18
(1975), 244-273.
[46] R. G. D. Richardson, "The twenty-ninth annual meeting of the Society,"
Bulletin of the American Mathematical Society 29 (1923), 97-116. (См.
также 28 (1922), 234-235, 378 относительно комментариев в специальном томе
Transactions и 28 (1922), 2-3 относительно обсуждения дефицита в
бюджете, вызванного ростом расходов на печать.)
[47] Glenn E. Roudabush, Charles R. Т. Bacon, R. Bruce Briggs, James A. Fierst,
Dale W. Isner, and Hiroshi A. Noguni, "The left hand of scholarship: Computer
experiments with recorded text as a communication media," Proceedings of the
AFIPS Fall Joint Computer Conference 27 (1965), 399-411.
[48] Ellen E. Swanson, Mathematics into Type (Providence, Rhode Island:
American Mathematical Society, 1971).
[49] Geofroy Tory, Champs Fleury (Paris: 1529). Also translated into English and
annotated by George B. Ives (New York: Grolier Club, 1927).
[50] Karel Wick, Rules for Typesetting Mathematics, перевод V. Boublik and M.
Hejlova (The Hague: Mouton, 1965).
78
Компьютерная типография
[51] Hermann Zapf, About Alphabets: Some Marginal Notes on Type Design
(Cambridge, Massachusetts: M.I.T. Press, 1970).
Добавление
После прочтения этой лекции я с удовлетворением обнаружил по
состоявшимся впоследствии обсуждениям и переписке, что не существует такой
непреодолимой пропасти между математиками и художниками, как это себе
воображают многие. Например, Дьёрдь Пойа говорил мне в 1979 г., что он был хорошо
знаком с работой Дюрера [18].
Журнал Transactions of the American Mathematical Society начал с тома
302 (1987) предлагать авторам представлять свои статьи в формате ТЕХ. Все
дальнейшие тома Transactions вплоть до тома 311 (1989) были подготовлены в
ТЁХ'е.
Разумеется, с тех пор, как была написана данная работа, я очень
много узнал о полиграфии. Положенные в основу Т^Х'а понятия боксов и клея
остались в сущности теми же, но основанный на методах рисования кривых
METRFONT изменился полностью. Новый METRFONT, завершенный к 1984 г.,
все еще использует кубические сплайны, но они управляются более
интуитивными «контрольными точками», предложенными Полем Кастейжо и Пьером
Безье в 1959 —начале 1960-х годов. Алгоритмы вычерчивания кривых
значительно выигрывают в скорости при переходе от порядка п3 к порядку п,
когда имеется п пикселей на дюйм. Варьирование шириной как на рис. 19 и
прием с одновременным использованием пера и ластика (рис. 20d) больше не
поддерживается, но их на самом деле никогда не собирались использовать.
Значительно лучшие правила округления для пера с интересными связями
с теорией чисел и геометрией были разработаны Джоном Хобби в его
докторской диссертации Digitized Brush Trajectories (Stanford University, 1985). Хобби
также придумал новые правила получения «самой приятной кривой»,
проходящей через последовательность данных точек. Превосходство этих методов
было подтверждено многочисленными экспериментами, но текущее решение
средствами METRFONT'a задачи «математического почерка» (рис. 20)
остается, надо признать, весьма эксцентричным: вывод, который теперь дает
METRFONT при задании параметров, приводивших в 1977 г. к рис. 20е, выглядит
так:
От точек, столь неуклюже заданных мной на рис. 20а, на самом деле и не
следовало ожидать превращения в изящные буквы.
Верстка абзацев
[В соавторстве с Майклом Ф. Плэссом. Впервые опубликовано в Software —
Practice and Experience 11 (1981), 1119-1184.]
В данной работе рассматривается задача о наилучшей верстке абзаца, т. е.
о разбиении текста, образующего абзац, на строки равной или почти равной
длины. Особенность предлагаемого подхода состоит в том, чтобы не просто
формировать строки последовательно одну за другой, а оценивать качество
принимаемых решений для всего абзаца в целом — в этом случае
окончательный вид каждой строки зависит не только от того, как были сформированы
предыдущие строки, но и от последующих строк. Построенный общий
алгоритм поиска оптимальных точек разбиения текста на строки вполне
удовлетворительно решает задачу верстки для весьма широкого круга
полиграфических приложений. В его основе лежат три базовых понятия: «боксы»,
«клей» и «штрафы». Благодаря рациональному применению схемы
динамического программирования алгоритм позволяет избежать так называемого
бэктрекинга (перебора с возвратами). Накопленный практический опыт
свидетельствует о том, что алгоритм позволяет осуществлять качественную
верстку текста при относительно небольших вычислительных затратах.
В конце статьи приведена краткая история методов абзацной верстки, а в
приложении описан упрощенный вариант алгоритма, требующий меньших
компьютерных ресурсов.
Введение
Чтобы вывести текст на печать или на экран, его требуется специальным
образом подготовить, в частности, необходимо так или иначе разбить абзацы
на строки, или, как говорят в таких случаях, сверстать абзацы. Качество
выполнения этой операции чрезвычайно важно. При хорошем разбиении абзацев
на строки читатель практически не замечает, что слова, составляющие текст,
оказались в некоторых местах оторванными друг от друга, а образовавшиеся
куски помещены в стесняющую их и, в общем-то, неестественную
прямоугольную рамку. Если же верстка выполнена неудачно, внимание читателей отвле-
80
Компьютерная типография
кается на некрасивый вид строк и мешает следить за ходом авторской мысли.
Выбрать хорошее место для завершения строки бывает совсем не просто.
Например, при верстке газетных полос, когда текст должен быть напечатан в
виде нескольких довольно узких столбцов, возможных мест для разрыва строк
оказывается очень мало. Наличие в тексте математических формул может при
любой ширине текстового поля порождать проблемы с выбором точки перехода
на новую строку. Впрочем, и в относительно простых случаях типа
беллетристического повествования хорошая верстка делает книгу более красивой и
потому более привлекательной. Известно, что многие авторы более тщательно
работают над своими произведениями, если им гарантируют первоклассный
внешний вид будущей книги.
Неформальное английское название процедуры верстки абзацев —
«justification1». Это то, что скрывается за буквой J в аббревиатуре Н & J
(hyphenation2 and justification), используемой в современных текстовых
процессорах и коммерческих системах компьютерной верстки. Однако
применительно к абзацам этот термин нельзя признать удачным, поскольку в
традиционной полиграфии «justification» относится к процессу набора
отдельной строки и означает корректировку междусловных пробелов для придания
строке требуемой длины. Даже в том случае, когда текст набирается с
«рваным» правым краем, т. е. в невыровненном (unjustified) виде, его все равно
требуется разбивать на строки примерно равной длины. При традиционном
наборе на основе металлических шрифтов подобрать междусловные
пробелы так, чтобы не только левая, но и правая граница текста выглядела как
прямая линия —дело довольно-таки трудоемкое. Поэтому технологии верстки
абзацев, применявшиеся в прошлом веке, в основе своей были процессами
простого выравнивания. При верстке на компьютере расставить каким угодно
образом пробелы между словами не составляет труда, поэтому в наше время
главным содержанием процесса верстки стало разбиение абзацев на строки. В
результате происшедшего изменения сути процесса верстки соответствующим
образом изменился и смысл слова «выравнивание». Тем не менее в настоящей
работе мы пользуемся термином разбиение па строки, чтобы подчеркнуть,
что главной проблемой в нашем случае является нахождение удачных точек
перехода на новую строку.
Традиционный способ разбиения текста на строки аналогичен тому, как
производится переход на новую строку при работе на пишущей машинке: при
приближении к правому полю звенит звоночек (не обязательно в буквальном
смысле слова), и по этому сигналу мы выбираем лучшее, на наш взгляд,
место для завершения строки, не думая о том, где в результате этого действия
может закончиться следующая строка, и подавно не заботясь о последующих
строках. После того как каретка переместилась в крайнее левое положение,
мы начинаем все заново, не стремясь помнить что-нибудь из предыстории,
помимо точки начала текущей строки. При таком способе действий не требуется
1 Близкие по смыслу русские термины — «выравнивание», «выключка». — Прим. перев.
2 Расстановка переносов. — Прим. перев.
Глава 3. Верстка абзацев
81
запоминать много информации; этот простейший алгоритм идеально подходит
для человека и может быть легко запрограммирован для компьютера.
При типографском наборе междусловные пробелы имеют переменную
величину— в этом состоит его важнейшее отличие от печатания на пишущей
машинке. На практике обычно задают минимум и максимум допустимой
величины пробела, а также его нормальное значение — то, чему в идеале должны
быть равны все пробелы. Стандартный алгоритм разбиения текста на строки
(см., например, [4, с. 55]) состоит в следующем. Слова, разделенные
нормальным пробелом, последовательно вносятся в текущую строку до тех пор, пока
не окажется, что очередное слово в ней уже не умещается. Переход на новую
строку производится после этого слова, если его удается уместить в строке
при уменьшении всех пробелов в допустимых пределах, т. е. при значении
пробелов, не меньшем установленного минимума. В противном случае делается
попытка перехода на новую строку перед тем же самым словом, для чего все
пробелы, возможно, увеличиваются, но так, чтобы их общее значение не
превышало установленного максимума. Если и это не удается, злополучное слово
разбивается на две части согласно правилам переноса, причем в текущей
строке оставляют по возможности большую его часть. Наконец, если подходящего
переноса в данном слове не существует, строку обрывают все-таки перед
рассматриваемым словом, приняв в качестве результата «жидкую» строку, где
пробелы больше заданного максимума.
При компьютерной верстке нецелесообразно ограничиваться столь
примитивной процедурой, поскольку, как правило, в памяти компьютера вполне
умещается информация о целом абзаце. Вычислительные эксперименты
показали, что качество верстки значительно улучшается, если при разбиении
абзаца на строки учитывать не только вид очередной строки, но и те
последствия, которые может иметь для последующих строк абзаца принятие того или
иного решения по любой строке. Используя компьютерные алгоритмы
прогностического типа, удается не только избежать «жидких» строк, но и заметно
сократить число переносов в словах. Тем самым алгоритмы верстки абзацев
дают еще один пример эффективности принципа «динамического связывания»1.
Одним из главных стимулов к использованию компьютеров в полиграфии
является относительная дешевизна компьютерного набора. При этом, однако,
хочется, чтобы издания, подготовленные на компьютере, выглядели не хуже
(и не дешевле) тех, что создаются при помощи традиционной технологии. На
самом деле хорошо составленная компьютерная программа должна решать
задачу верстки абзацев лучше, чем квалифицированный наборщик (если только
последнему не будет разрешено ради повышения качества набора менять
порядок слов в предложениях). Сошлемся, например, на работу Дункана [14],
в которой приведен результат анализа 958 строк текста, набранного вручную
в «одном из наиболее уважаемых издательств», название которого не уточ-
1 Динамическое, или позднее, связывание, называемое также динамической компоновкой
или динамической загрузкой (late binding, dynamic binding, dynamic linking) — подход, при
котором тип реализации той или иной операции определяется при ее выполнении в
зависимости от типов ее текущих фактических параметров.- Прим. перев.
82
Компьютерная типография
няется. Оказалось, что почти 5% из этих строк—«жидкие»: междусловные
пробелы в них превышают 10 единиц (т. е. 10/18 величины em), а в двух
строках пробелы больше, чем 13 единиц. Как мы увидим в дальнейшем, хороший
компьютерный алгоритм верстки позволяет получить лучшие результаты.
Компьютерный алгоритм не только позволяет избежать «жидких» строк и
лишних переносов в словах, но и дает возможность сделать так, чтобы
междусловные пробелы были в основном близки к нормальному значению, а их
приближение к верхней или нижней границе промежутка допустимых
значений происходило редко. Кроме того, можно попытаться добиться, чтобы
пробелы в любых двух соседних строках не сильно отличались друг от друга,
чтобы переносы не встречались в двух подряд идущих строках, чтобы
предпоследняя строка абзаца не заканчивалась переносом, чтобы пустое пространство
в последней строке не было слишком большим, и т. д. Для этого достаточно
математически связать с каждым разбиением абзаца на строки некоторую
количественную оценку качества этого разбиения и затем попросить компьютер
найти то разбиение, которое доставляет экстремум построенной функции.
Но можно ли в действительности эффективно решить поставленную
задачу на компьютере? Ведь если абзац имеет п точек возможного перехода на
новую строку, то число возможных способов разбиения абзаца на строки равно
2Д — даже самый быстродействующий компьютер не сможет перебрать все эти
способы за разумное время. Заметим, что задача о разбиении абзаца на
строки с как можно менее отличающимися друг от друга длинами подозрительно
напоминает пресловутую задачу о рюкзаке, которая, как известно, является
NP-сложной [16]. Выручает то обстоятельство, что соседние строки состоят из
смежных кусков информации, составляющей абзац. В силу этого к задаче о
разбиении абзаца на строки применимы методы дискретного динамического
программирования [6, 20], т. е. действительно имеется достаточно
эффективный способ ее решения. Мы увидим, что объем вычислений, требуемых для
практического нахождения оптимального разбиения абзаца, всего лишь
примерно вдвое превышает объем вычислений, выполняемых при использовании
традиционного алгоритма. Иногда новый метод оказывается даже более
быстрым, чем старый, если учитывать время, сэкономленное на том, что отпадает
потребность в частых переносах. Кроме того, новый алгоритм позволяет
добиваться и других полезных эффектов, например, укорачивать или удлинять
абзац на строку, что бывает очень полезно при верстке страниц.
Формулировка задачи
Приведем строгую математическую формулировку задачи о разбиении абзаца
на строки. Будем использовать основные понятия и термины системы ТЁ^ [26]
(хотя и в несколько упрощенном виде, с тем чтобы тонкости полиграфического
набора не мешали пониманию основных принципов абзацной верстки)
Для целей настоящей работы абзац удобно отождествлять с
последовательностью х\Х2 .. .хт из га элементов, в которой каждый элемент Х{ есть
либо бокс, либо клей, либо штраф.
лава 3. Верстка абзацев
83
• Бокс — это нечто, что должно быть напечатано: либо символ, взятый из
некоторого шрифта, либо черный прямоугольник (сюда относятся
горизонтальные и вертикальные линии), либо объект, построенный из
нескольких символов (например, буква с диакритическим знаком —акцентом, или
математическая формула). Содержимое бокса может быть чрезвычайно
сложным, или же, наоборот, совсем простым; алгоритм разбиения на
строки не заглядывает внутрь бокса — его не интересует, что там находится.
Поэтому боксы можно считать запертыми и герметичными. Для нас ва^к-
на только одна характеристика бокса — его ширина. Если элемент Х{ абзаца
представляет собой бокс, то ширина этого бокса W{ —вещественное число,
равное величине места, которое бокс занимает в строке. Ширина бокса
может быть нулевой; более того, она может быть и отрицательной, хотя
отрицательными длинами следует пользоваться вдумчиво и с
осторожностью, строго соблюдая приведенные ниже правила.
• Под клеем понимается пустое пространство, которое может определенным
образом изменять свою протяженность в строке, своего рода эластичный
герметик, используемый для заполнения горизонтальных промежутков
между боксами. С точки зрения алгоритма разбиения абзаца на строки
элемент я;, являющийся клеем, характеризуется тройкой вещественных
чисел (wi, yu Zi):
Wi — «идеальная», или «нормальная», величина пробела;
yi —«растяжимость»;
Zi — «сжимаемость».
Так, например, промежутки между словами в строке часто определяются
значениями W{ = |em, yi = |em, Z{ — |em, где em —некоторое
стандартное для используемого шрифта расстояние (в классических шрифтовых
наборах приблизительно равное ширине прописной буквы 'М'). Точные
значения междусловных пробелов, заполняемых клеем, определяются при
окончательном выравнивании строки по правому краю. Если нормальная
величина пробела слишком мала, его увеличивают пропорционально yi,
а если слишком велика, — уменьшают пропорционально Z{. При
соблюдении некоторых естественных ограничений, смысл которых разъясняется
ниже, числа Wi, y^ z\ могут быть отрицательными. Например,
отрицательное значение и){ означает возврат на один шаг («возврат каретки на одну
позицию»). При yi = Z{ = О клей имеет фиксированную протяженность
Wi. Кстати говоря, «клей», возможно, не самый удачный термин,
поскольку ассоциируется с чем-то жидким и пачкающимся. По-видимому, лучше
было бы использовать слово «пружина», так как именно металлические
пружины способны заполнять пространство растягиваясь и сжимаясь, т. е.
обладают в точности теми свойствами, которые требуются в нашей
модели. Мы, однако, будем и дальше использовать термин «клей», поскольку
он был введен в употребление еще в 1977 г., на ранней стадии развития
ТЁХ'а, к нему привыкли и многим он нравится. Пользователи TgX'a часто
84
Компьютерная типография
называют комочек клея просто пробелом (skip), поэтому, наверное, лучше
было бы говорить не о боксах и пружинах и не о боксах и клее, а о
боксах и пробелах. Но в конечном счете дело не в названии, и конкретным
выражением обсуждаемого понятия в любом случае остается тройка чисел
(гиг, у», Zi).
• Штрафы задают в абзаце потенциально возможные места перехода от
очередной строки к следующей и указывают степень «желательности» или
«нежелательности» этого перехода в терминах некоторой «эстетической
оценочной функции». С каждым элементом х^, представляющим собой
штраф, связано некоторое число рг, также называемое штрафом, которое
показывает, стоит ли в текущей точке переходить на новую строку.
Остановимся на этом подробнее. Говоря в самых общих чертах, большое
положительное pi означает, что в данной точке переход на новую строку
нежелателен, а отрицательное pi — что место для перехода хорошее. Штраф рг
может также принимать значения +оо и — оо, где "оо' означает большое
число, которое на практике можно отождествить с бесконечностью, хотя
оно, разумеется, конечно. В версии ТЁХ'а от 1978 г. любой штраф > 1000
трактовался как оо, а любой штраф < —1000 —как —оо. Если pi — +oo,
то переход на новую строку категорически запрещен; если р^ = —оо,
переход обязателен. В набор характеристик элемента-штрафа входит также
ширина wi, имеющая следующий смысл. Если в данной точке абзаца
произвести переход на новую строку, то к текущей строке непосредственно
перед точкой перехода нужно будет добавить некоторый текст ширины
wi. Допустим, например, что мы находимся внутри слова, в точке, где
возможен перенос. Тогда в качестве потенциально возможного места для
перехода на новую строку данная точка будет характеризоваться числом
Pi — штрафом за соответствующий перенос и числом w% — шириной знака
переноса. Элементы-штрафы бывают двух видов: с флажком и без
флажка , что обозначается соответственно как /г = 1 и /; = 0. Рассматриваемый
алгоритм верстки абзаца старается избегать двух следующих один за
другим переходов на новую строку по штрафам с флажком (в частности, двух
переносов подряд).
Итак, элемент-бокс определяется одним числом гиг, элемент-клей —
тройкой чисел (гУг, yi, z^, элемент-штраф — тройкой чисел (гиг, yi, %%)• Однако
удобнее считать, что абзац х\ .. .хт определяется следующими шестью
последовательностями:
где ti —тип элемента Х{ со значением либо 'бокс',
либо 'клей', либо 'штраф';
где Wi—ширина, соответствующая элементу хг\
где yi—растяжимость, соответствующая элементу хг,
если ti = 'клей', и yi — 0 в противном случае,
z\ ... zm, где Zi — сжимаемость, соответствующая элементу хи
если ti = 'клей', и Zi = 0 в противном случае;
ч •
W\ . .
2/1.
• • ^"ГП1
•Wmi
• • У mi
Глава 3. Верстка абзацев
85
Pi • • -Рт, где pi — штраф, соответствующий элементу xi,
если U = 'штраф', и pi = О в противном случае;
Л • • • /mi где fi = 1, если Xi — штраф с флажком, и fi = О
в противном случае.
Для задания величин Wi, гц, Zi могут использоваться любые единицы
измерения. ТЕХ использует так называемый типографский пункт1, величина которого
несколько меньше, чем ^ дюйма. В этой статье для измерения ширин будет
использоваться машинная единица, равная 1/18 em. При таком выборе единицы
измерения и некотором специальной размере шрифта используемые ширины
часто оказываются целыми числами. В частности, все числа в
рассматриваемых далее примерах приобретают предельно простой вид.
У читателя может сложиться впечатление, что мы занимаемся
громоздкими математическими построениями применительно к совсем простым вещам.
Но в действительности в ТЁХ'овском алгоритме верстки абзацев все введенные
выше понятия так или иначе используются, и точное определение всех
параметров существенно даже в том относительно простом случае, когда верстается
обычный текст. В дальнейшем мы убедимся, что в общем-то простые понятия
боксов, клея и штрафов позволяют единообразно охватить поразительно много
разнообразных задач верстки, а внимательное отношение к некоторым деталям
процесса позволяет заодно решить еще целый ряд проблем.
Однако для начала лучше обратиться к простому случаю, а именно к
верстке абзацев в обычном тексте, например, в газетной статье или в рассказе, чтобы
усвоить реальный смысл абстрактных понятий, представляемых числами Wi, гц
и т. д. В системах компьютерного набора типа Т^Х'а преобразование реального
абзаца в искомую абстрактную форму происходит следующим образом:
(1) Если абзац начинается с отступа, первым элементом абзаца х\ должен
быть пустой бокс, ширина которого w\ равна величине отступа.
(2) Каждое слово в абзаце превращается в последовательность боксов,
соответствующих отдельным буквам, а также относящихся к данному
слову знакам препинания. Ширины боксов Wi определяются используемым
шрифтом. Внутри слова отыскиваются все места, где при
необходимости можно будет сделать перенос (т. е. перенести часть слова на
следующую строку), и между соответствующими боксами вставляются элементы-
штрафы с флажками. (В дальнейшем мы увидим, что на самом деле
отыскивать точки возможного переноса следует только тогда, когда в них
действительно возникает необходимость, однако пока для простоты мы будем
предполагать, что заранее определяются все такие точки.)
(3) Между словами вставляется клей в соответствии с правилами
формирования промежутков, рекомендуемыми для используемого шрифта. Клей
зависит также и от контекста: например, клей, вставляемый ТЁХ'ом
после знаков препинания, несколько отличается от обычного междусловного
клея.
1 Речь идет об англо-американском типометрическом стандарте. — Прим. перев.
86
Компьютерная типография
In olden times when wishing still helped one, .857
there lived a king whose daughters were all beau^if -.750
ful; and the youngest was so beautiful that the sun -.824
itself, which has seen so much, was astonished 1.087
whenever it shone in her face. Close by the king's -.235
castle lay a great dark for/est, and unjder an old 607
lime-^ree in the forpst was a well, and when the .500
day was very warm, the king's child went out into -.500
the for/est and sat down by the side of the cool .700
fountain; and when she was bored she took а 1.З60
golden ball, and threw it up on high and caught it; -.eso
and this ball was her favorite plaything. .001
Рис. 1. Пример абзаца, сверстанного методом «простой верстки». Маленькими
треугольниками отмечены возможные места переноса слов. Корректировки междуслов-
ных пробелов в относительных единицах приведены справа от соответствующих
строк.
(4) После имеющихся в тексте дефисов и тире вставляются элементы-штрафы
с флажками, имеющие нулевую ширину. Тем самым после дефисов и тире
разрешается переход на новую строку. В некоторых стилях переход на
новую строку разрешен и перед длинным тире (em-dash) — в этом случае
перед таким тире появится штраф нулевой ширины без флажка.
(5) В самом конце абзаца добавляются три элемента, обеспечивающие
правильное оформление последней строки. Первым вводится элемент-штраф
хш-2 с Ргп-2 = оо. Затем добавляется элемент-клей xm-i, формирующий
пустое место, которым может заканчиваться последняя строка. Наконец,
добавляется элемент-штраф хш с рт = — оо, осуществляющий
принудительный переход на следующую строку. Обычно Те|Х использует
«завершающий клей» с wm-i = 2m_i = 0 и Ут-1 = оо (в действительности
Угп-1 = ЮОООО пунктов; это значение хотя и конечно, но настолько велико,
что ведет себя как оо). Таким образом, промежуток, добавляемый в конце
абзаца, изначально имеет нулевую протяженность, но может очень сильно
растягиваться. Действие этого последнего элемента сводится к тому, что
другие промежутки в последней строке будут поджаты, если эта строка
окажется шире, чем полагается, а в противном случае все промежутки,
кроме последнего, сохранят нормальную ширину, поскольку всю работу
по заполнению строки выполнит именно последний промежуток.
Возможны и более тонкие способы задания завершающего клея хш-\ (о них речь
пойдет позже).
В качестве примера рассмотрим абзац, приведенный на рис. 1 (текст взят
из сказок Братьев Гримм [18]1). Сформулированные выше пять правил
превращают данный текст в последовательность, состоящую из 601 элемента (см.
табл. 1). Абзац сверстан при помощи традиционного построчного алгоритма
(см. выше); ширина строк —ровно 390 единиц.
Полный текст сказки и ее перевод приведен ниже, на с. 96-99. — Прим. перев.
Глава 3. Верстка абзацев
87
х\ = пустой бокс для абзацного отступа
Х2 = бокс для Т
хз = бокс для 'п'
Х4 = клей для междусловного пробела
хъ = бокс для 'о'
£зо9 = бокс для Т
язю = бокс для Т
язи = бокс для 'т'
Хз12 = бокс для 'е'
^313 = бокс для '-'
Хз14 = штраф для дефиса
хз15 = бокс для Ч'
^590 = бокс для 'а'
£591 = 60КС ДЛЯ 'у'
Х592 = штраф для возможного переноса
#593 = боКС ДЛЯ Ч'
Х594 = б0КС ДЛЯ 'Ь'
#595 = б0КС ДЛЯ Т
^596 = б0КС ДЛЯ V
Х597 = б0КС ДЛЯ 'g'
Х598 = б0КС ДЛЯ '.'
#599 = запрет перехода на новую строку
#боо = завершающий клей
wx = 18
W2 = 6
w3 = 10
Wa = 6, ?/4
W5 = 9
3,
W600
0, У600 = 00,
ZA =2
W309 = 5
W3io = 5
гизп = 15
1^312 = 8
гоз1з = 6
гизн = 0, р314 = 50, /эй = 1
г^з15 = 7
^590 = 9
^591 = Ю
W592 = 6, Р592 = 50, /б92 = 1
W593 = 7
1^594 = Ю
^595 = 5
^596 = Ю
Wb$7 = 9
10598 = 5
W599 = О, Р599 = СО
/599 = О
2боо = О
#601 = принудительный переход на новую строку wqq\ = 0, рв01 = —со, /во1 = 1
Таблица 1. Последовательность элементов (боксов, клея, штрафов), построенная
ТЁХ'ом для абзаца, приведенного на рис. 1. Для целей настоящего примера
предполагается, что каждая буква имеет ту ширину, которая традиционно использовалась
при монотипном наборе, а именно, буквы от 'а' до 'z' имеют ширину соответственно
(9,10,8,10,8,6, 9,10, 5,6,10, 5,15,10, 9,10,10, 7, 7,7,10, 9,13,10,10, 8) единиц, а буквы
kC, T и символ '-' имеют соответственно ширину 13, 6 и 6 единиц. Ширина запятой,
точки с запятой и апострофа одна и та же и равняется 5 единицам. Клей между
словами определяется тройкой чисел (w,y,z) = (6,3,2), однако после запятой эта
тройка чисел равна (6,4,2), после точки с запятой— (6,4,1), а после точки— (8, 6,1).
На каждую строку, заканчивающуюся переносом, накладывается штраф, равный 50.
На рис. 1 места возможных переносов отмечены крошечными
треугольниками. Согласно классическим справочным пособиям1 перенос разрешается,
если только ему в слове предшествует не менее двух букв и после него идет
не менее трех букв. Нельзя также, чтобы слог, следующий непосредственно за
переносом, содержал немое 'е'— тем самым запрещаются переносы типа
'syllable'. Более того, для облегчения чтения рекомендуется, чтобы часть слова,
предшествующая переносу, была достаточно длинной: в таком случае
читающий оказывается в состоянии правильно и однозначно воспринять все слово
Речь идет о правилах переноса в англоязычных текстах — Прим. ред.
88
Компьютерная типография
еще до того, как он увидит его заключительный фрагмент в следующей строке.
Пример неудачного переноса, способного вызвать некоторую заминку, —
'process'. Именно по этой причине в предпоследнем слове на рис. 1 не разрешен
перенос 'fa-vorite', который в принципе является допустимым: слог 'fa-' вполне
мог бы оказаться началом слова 'fa-ther', где тот же самый слог произносится
совершенно иначе.
Выбор правильных мест для переносов — проблема важная, но сложная
и выходящая за рамки данной статьи. На самом деле все, что нам нужно в
дальнейшем, сводится к следующему: (а) там, где это требуется, мы считаем,
что наш алгоритм абзацной верстки знает места возможных переносов; (Ь) мы
предпочитаем обходиться без переносов, если это не сильно портит величину
междусловных пробелов.
Хотя на интуитивном уровне используемые правила верстки абзацев
становятся понятными из рассмотренного примера, их все же надо
сформулировать явным образом. Будем предполагать, что каждый абзац заканчивается
принудительным переходом на новую строку— элементом хш (элементом с
величиной штрафа —оо). Допустимая точка перехода на новую строку в
абзаце—это такой номер 6, что либо (i) хь — штраф с рь < оо, либо (п)
обклей, а хъ-\— бокс. Иначе говоря, переход на новую строку можно делать
либо на элементе-штрафе при условии, что величина штрафа не равна оо,
либо на элементе-клее при условии, что последний следует непосредственно
за элементом-боксом. Этими двумя случаями исчерпываются все возможные
места перехода на следующую строку. В частности, если где-либо в абзаце
имеются несколько подряд идущих пробелов, переход на новую строку можно
делать только на первом из них и только в том случае, если он не следует
непосредственно за штрафом. Штраф величины оо может быть вставлен
перед клеем, чтобы сделать соответствующий пробел неразрывным. Например,
элемент х599 в табл. 1 обеспечивает невозможность перехода на новую строку
на клее, завершающем абзац и заполняющем его последнюю строку.
Верстка абзаца сводится к выбору допустимых точек перехода на новую
строку bi < • • • < б*;, определяющих концы строк в абзаце (при этом,
естественно, абзац оказывается состоящим из к строк). Каждый элемент-штраф Х{
со значением штрафа^ = —оо обязан присутствовать среди выбранных точек,
в частности, последняя точка перехода Ьк должна равняться т. Полагая для
удобства 6о = 0, введем в рассмотрение величины а\ < • • • < а&, ассоциируемые
с началами строк абзаца. Именно, пусть значением aj служит наименьшее
целое число г, заключенное между bj-\ и bj и такое, что Х{—элемент-бокс.
Если ни для одного г из интервала bj-i < г < bj соответствующий элемент
Xi не является боксом, положим aj = bj. Тогда j-я строка состоит из всех
элементов Х{ с aj < г < 6j, а также элемента хъ3, если последний является
штрафом. Другими словами, строки абзаца получаются путем разрезания его
на части по выбранным точкам перехода и последующего удаления клея и
штрафов из начала каждой из строк, полученных при этом разрезании.
Глава 3. Верстка абзацев
89
Критерий желательности
Если абзац имеет п допустимых точек перехода на новую строку, не
являющихся принудительными переносами, то в соответствии с данным выше
определением существует 2П способов сверстать абзац. Так, например, в абзаце,
приведенном на рис. 1, имеется 129 точек перехода на новую строку,
помимо xqoi; соответственно, число вариантов верстки абзаца (разбиения его на
строки) равно 2129 — это больше, чем 1038. Но, конечно же, большинство этих
вариантов абсурдны, поэтому нужен критерий, позволяющий отделять
разумные варианты верстки от совершенно бессмысленных. Чтобы построить такой
критерий, нужно знать, во-первых, желательную длину строки и, во-вторых,
длины строк, получающихся при каждом варианте верстки с учетом их
растяжимости и сжимаемости. Зная и то, и другое, можно сравнивать реально
получающиеся длины строк с желательной длиной.
Будем предполагать, что задан список желательных длин строк /i, I2,
/3, • • • • Чаще всего все эти длины равны между собой, однако иногда они могут
и различаться, как, например, в случае текста, обтекающего рисунок. После
того как точки перехода на новую строку в абзаце выбраны, фактическая
длина j-и строки Lj вычисляется следующим образом. Суммируются
ширины всех боксов и всех клеев в интервале aj < г < bj\ в том случае, если ж&. —
элемент-штраф, к полученной сумме прибавляется *шь . Суммарная
растяжимость jf-й строки Yj и ее суммарная сжимаемость Zj находятся соответственно
суммированием всех величин yi и Z{, характеризующих те элементы-клеи,
которые содержатся в интервале aj < г < bj. Произведя эти вычисления, можно
сравнить действительную длину jf-й строки Lj с ее желательной длиной lj и
выяснить, позволяют ли найденные растяжимость и сжимаемость строки
преобразовать Lj в lj. Назовем коэффициентом выравнивания j-ft строки число
Гу, определяемое следующим образом:
Если Lj = lj (идеальная длина строки), то Vj — 0.
Если Lj < lj (короткая строка), то Vj = (lj — Lj)/Yj при условии, что
Yj > 0; если же в рассматриваемом случае Yj < 0, то значение Vj не
определено.
Если Lj > lj (длинная строка), то Vj = (lj —Lj)/Zj при условии, что Zj > 0;
если же в рассматриваемом случае Zj < 0, то значение Vj не определено.
Так, например, Vj — 1/3, если суммарная растяжимость строки j в три
раза больше того значения, которое требуется, чтобы растянуть строку от ее
естественной длины Lj до идеальной длины lj.
Согласно данному определению, для выравнивания j-й строки достаточно
для каждого элемента-клея Х{ в этой строке сделать его ширину равной
W{ + rjyi, если Vj > 0;
Wi + VjZi, если Vj < 0 .
В самом деле, подсчитав суммарную длину строки с так преобразованными
ширинами, мы, в зависимости от знака гу, получим либо Lj + Vj Yj — lj, либо
Lj+Tj Zj = lj. Указанное преобразование делает в точности то, что требуется, а
именно распределяет необходимое растяжение или сжатие строки равномерно
между компонентами гл либо Z{ отдельных элементов-клеев.
90
Компьютерная типография
Числа, напечатанные мелким шрифтом справа от текста на рис. 1,
представляют собой значения коэффициентов выравнивания rj соответствующих
строк. Отрицательные значения (например, —.824 в третьей строке) означают,
что пробелы в строке меньше своей идеальной величины, причем для сжатия
пробелов до такого состояния пришлось использовать более 82% их
потенциальной сжимаемости. Напротив, относительно большие положительные
значения (например, 1.360 в третьей от конца строке) указывают на то, что строка
получается очень разреженной.
Хотя абзац, приведенный на рис. 1, может быть разбит на строки 2129
способами, оказывается, что среди всего этого множества разбиений только у 12
все коэффициенты выравнивания не превосходят по абсолютной величине 1.
Последнее условие означает, что получающиеся в результате выравнивания
междусловные пробелы лежат на отрезках с границами W{ — ZiHWi + yi.
Заметим, что решение, полученное с помощью традиционного алгоритма верстки,
этим свойством не обладает.
Наша основная цель —так сверстать абзац, чтобы слова во всех строках
не отстояли друг от друга слишком далеко
и не находились друг от друга слишком близко, так как подобные «плохие» строки
отвлекают внимание читателя и затрудняют процесс чтения. Можно сказать,
что задача верстки абзаца состоит в отыскании такого разбиения абзаца на
строки, что \rj\ < 1 для любой строки, и при соблюдении этого условия
число переносов в абзаце минимально. Подобный подход использовался в начале
1960-х годов Дунканом с соавторами [13] и позволил получить довольно
хорошие результаты. Однако критерий \rj\ < 1 зависит только от величин W{ — Z{,
Wi + У г и не зависит от W{, а значит, не использует всех степеней свободы,
содержащихся в исходных данных. Кроме того, это условие является весьма
жестким, и его соблюдения не всегда можно добиться. Например, если бы в
приведенном на рис. 1 абзаце длина строки равнялась не 390 единиц, а 400, то
при любом варианте верстки абзац содержал бы либо слишком плотно
заполненную {tj < —1), либо слишком разреженную (rj > — 1) строку.
Лучших результатов можно добиться, используя в качестве критерия
качества верстки не «релейную» функцию от условия \rj\ < 1 (функцию типа
да/нет), а некоторую непрерывную функцию. С этой целью можно ввести
количественную оценку плохости1 j-R строки, построив тем или иным образом
функцию, принимающую значения, близкие к нулю, когда \rj\ мало, и быстро
возрастающую, когда значение \rj\ становится больше 1. Как показали
многочисленные эксперименты с системой Те?£, хорошие результаты получаются,
если плохость jf-й строки определить формулой
Г оо , если rj не определено или rj < — 1;
J "~ [ [Ю0|г^|3 + .5j в противном случае.
Так, например, строки абзаца на рис. 1 характеризуются значениями плохости
63, 42, 56, 128, 1, 22, 13, 13, 34, 252, 27, 0 соответственно. Согласно приведенной
выше формуле для /3jy строка считается «бесконечно плохой», если rj < —1.
В оригинале— badness, что тоже является неологизмом. — Прим. перев.
Глава 3. Верстка абзацев
91
Основанием для этого служит то обстоятельство, что при соблюдении
последнего условия клей не может быть сжат меньше чем до величины Wi — Z{. В то
же самое время значениям r*j, превышающим единицу, соответствует
конечная плохость, так что соответствующие строки попадают в число допустимых
и могут быть использованы в окончательном варианте верстки, если им не
найдется лучшей альтернативы.
Небольшое усовершенствование метода, с помощью которого был получен
абзац на рис. 1, позволяет получить вариант верстки того же абзаца,
показанный на рис. 2. Как и раньше, выбор точек перехода на новую строку
производится без учета качества следующих строк и без ревизии уже принятых
решений, однако на этот раз точка перехода на новую строку выбирается так,
чтобы минимизировать «плохость плюс штраф» для текущей строки. Иначе
говоря, в методе, отвечающем рис. 2, при уже выбранной точке перехода с
(j — 1)-й строки на j-ю в качестве точки перехода с j-й строки на (j + 1)-ю
выбирается та, для которой сумма @j+7Tj принимает наименьшее значение. (Здесь
Pj —плохость, определенная выше, a 7Tj —значение штрафа р^., если j-я
строка заканчивается на элементе-клее, и 7Tj = 0 в противном случае.) Улучшение
качества верстки на рис. 2 по сравнению с рис. 1 происходит за счет переноса
в следующую строку слов или слогов, содержавшихся в строках 2, 3, 11.
Алгоритм, с помощью которого абзац был сверстан так, как показано на
рис. 1, естественно называть «простой версткой» (ПВ), а алгоритм,
соответствующий варианту, приведенному на рис. 2, — «улучшенной версткой (УВ)1».
Однако, хотя для данного конкретного примера улучшенная верстка оказалась
лучше простой, единственный пример не является доказательством
превосходства того или иного метода в общем случае, и в принципе могут найтись
абзацы, для которых лучший результат даст не улучшенная, а простая
верстка. Чтобы произвести объективное сравнение рассматриваемых алгоритмов,
нужно собрать статистику их «типичного» поведения. С этой целью над
абзацем, приведенным на рис. 1 и рис. 2, было проведено 300 экспериментов, в
которых сам текст не менялся, а длина строки варьировалась от 350 до 649
единиц. Оказалось, что изменение длины строки может сильно изменить
результаты—алгоритмы верстки весьма чувствительны к размерам. В каждом
случае записывались самая «плотная» и самая «жидкая» строки в абзаце, а
также число сделанных переносов. Полученные результаты приведены в
следующей табличке2:
Число
min rj max Tj переносов
ПВ < УВ 68% 40% 13%
ПВ = УВ 26% 45% 79%
ПВ > УВ 6% 15% 9%
1 В оригинале используются термины first-fit и best-fit. — Прим. перев.
2 Используемая для краткости запись «ПВ < УВ» в развернутом виде означает
следующее: «Доля экспериментов, в которых величина, указанная в качестве заголовка столбца,
оказалась меньшей при использовании простой верстки, чем при использовании
улучшенной верстки». Аналогичным образом расшифровываются обозначения «ПВ = УВ» и «ПВ >
УВ». — Прим. перев.
92
Компьютерная типография
In olden times when wishing still helped one, .857
there lived a king whose daughters were all Ьеац- .ооо
ЦГи1; and the youngest was so beautiful that the .280
sun itself, which has seen so much, was astonished -.235
whenever it shone in her face. Close by the king's -.235
castle lay a great dark for/est, and un^der an old .607
lime-free in the for/est was a well, and when the .500
day was very warm, the king's child went out into -.500
the for/est and sat down by the side of the cool .700
fountain; and when she was bored she took а 1.З60
golden ball, and threw it up on high and caught .357
it; and this ball was her favorite plaything. .000
Рис. 2. Абзац, получающийся вместо приведенного на рис. 1 при использовании
улучшенной верстки.
Итак, в 68% случаев минимальное значение коэффициента выравнивания Vj в
абзаце, полученном простой версткой, меньше соответствующей величины для
абзаца, полученного улучшенной версткой; максимальное значение
коэффициента выравнивания в абзаце, полученном простой версткой, меньше
соответствующей величины для абзаца, полученного улучшенной версткой, примерно
в 40% случаев, и т. д. Резюмируя приведенные результаты, можно сказать, что
простая верстка обычно дает по крайней мере одну строку с не меньшей (т. е.
такой же или большей) плотностью, чем у самой плотной строки из числа
полученных улучшенной версткой; точно так же простая верстка обычно дает
строку с такой же или большей разреженностью, чем у самой разреженной из
строк, полученных улучшенной версткой. Число переносов для обоих методов
примерно одинаково, хотя, если увеличить штраф за переносы, при
улучшенной верстке их будет получаться меньше.
В действительности оба рассмотренных метода можно улучшить, построив
«оптимальный» алгоритм верстки. В частности, как показано на рис. 3,
можно улучшить варианты верстки, приведенные на рис. 1 и рис. 2, сделав перенос
в строке 4, который в итоге позволяет избежать разреженности в строке 10.
Абзац на рис. 3 получен методом «оптимальной верстки»1, который будет
рассмотрен ниже. Соответствующий вариант разбиения абзаца на строки является
глобально оптимальным в том смысле, что доставляет величине суммарной
дефектности (demerits) минимум относительно всех возможных вариантов
выбора точек перехода с текущей строки на новую. При этом дефектность
j-й строки вычисляется по формуле
{(1 + Pj + ttj)2 + aj , если ttj > 0 ;
(1 + /3j)2 - 7г| + ctj , если -оо < ttj < 0 ;
(1 + /3j)2 + aj , если ttj — —00.
Здесь, как и раньше, j3j и ttj — соответственно показатель плохости и штраф, а
ctj отлично от нуля лишь тогда, когда и j-я, и (j — 1)-я строки заканчиваются
1 В оригинале — total-fit. — Прим. перев.
Глава 3. Верстка абзацев
93
на элементе-штрафе с флажком, причем в этом случае ctj равно
дополнительному штрафу, установленному для последовательных строк, заканчивающихся
переносами (например, 3000). Будем говорить, что абзац сверстан оптимально,
если сумма значений 5j по всем j достигает минимума.
Так же как и ранее приведенное выражение для /3j, формула,
определяющая Jj, выбрана достаточно произвольно. Тем не менее, на практике эта
формула работает хорошо, что связано со следующими ее полезными
свойствами.
(а) Минимизация суммы квадратов плохостеи не только автоматически
обеспечивает минимизацию максимума плохостеи по строкам, но и гарантирует
«оптимизацию второго порядка». Это означает, например, что если в абзаце с
неизбежностью оказывается строка с большой плохостью, алгоритм
обеспечивает наилучшую верстку остальных строк.
(б) Дефектность J~ является монотонно возрастающей функцией 7Tj.
Нарушение монотонности имеет место лишь при 7Tj = — оо, но в этом случае и
не требуется учитывать штраф, поскольку переход на новую строку является
принудительным.
(в) Используя не саму величину /?j, a 1 +/?j, мы в тех случаях, когда плохость
строк близка к нулю, фактически минимизируем число строк в абзаце.
Рассмотрим в качестве примера следующую табличку, в столбцах которой
записаны дефектности, отвечающие строкам абзаца на рис. 1, 2 и 3
соответственно:
Простая
верстка
4096
8649
3249
16641
4
529
196
196
1225
64009
784
1
Улучшенная
верстка
4096
2601
9
196
4
529
196
196
1225
64009
36
1
Оптимальная
верстка
4096
2601
9
22801
1
9
256
1
1225
4
36
1
99579
31040
73098
Можно заметить, что при использовании простой или улучшенной верстки
значения дефектности строк распределены по абзацу случайным образом, тогда
как при оптимальной верстке самые плохие строки сосредоточены в начале
абзаца. Это неудивительно, поскольку для начальных строк число вариантов
перехода на новую строку остается относительно небольшим, и алгоритм
верстки обладает меньшей гибкостью.
На рис. 4 представлены результаты применения тех же трех алгоритмов
верстки при большей ширине текстового поля, а именно при длине строки, рав-
94
Компьютерная типография
In olden times when wishing still helped one, .857
there lived a king whose daugh-ters were all Ьеац- .ооо
tijful; and the youngest was so beautiful that the .280
sun itself, which has seen so much, was astonj- 1.000
ished whenever it shone in her face. Close by the .067
king's castle lay a great dark for/est, and un^der an -.278
old lime-tree in the for/est was a well, and when .536
the day was very warm, the king's child went out -.167
into the for/est and sat down by the side of the .700
cool fountain; and when she was bored she took a -.176
golden ball, and threw it up on high and caught .357
it; and this ball was her favorite plaything. .000
Рис. З. Наилучший вариант верстки абзаца, фигурирующего на рис. 1 и 2, в смысле
минимума суммы дефектностей строк.
(а) Простая In olden times when wishing still helped one, there lived a king -.727
верстка: whose daughters were all beautiful; and the youngest was so .821
beautiful that the sun itself, which has seen so much, was astonj- -.455
ished whenever it shone in her face. Close by the king's castle lay -.870
a great dark for/est, and un^der an old lime-tree in the for/est was -.208
a well, and when the day was very warm, the king's child went .000
out into the forest and sat down by the side of the cool fountain; -.577
and when she was bored she took a golden ball, and threw it up -.231
on high and caught it; and this ball was her favorite plaything. .000
(b) Улучшенная In olden times when wishing still helped one, there lived a king -.727
верстка: whose daughters were all beautiful; and the youngest was so .821
beautiful that the sun itself, which has seen so much, was astonj- -.455
ished whenever it shone in her face. Close by the king's castle .278
lay a great dark for/est, and un^der an old lime-free in the for/est .000
was a well, and when the day was very warm, the king's child .237
went out into the for/est and sat down by the side of the cool .462
fountain; and when she was bored she took a golden ball, and .343
threw it up on high and caught it; and this ball was her favorite -.320
plaything. .004
(с) Оптимальная In olden times when wishing still helped one, there lived a .774
верстка: king whose daughters were all beautiful; and the youngest was .179
so beautiful that the sun itself, which has seen so much, was .629
astonished whenever it shone in her face. Close by the king's .545
castle lay a great dark for/est, and un^der an old lime-free in the .000
for/est was a well, and when the day was very warm, the king's .079
child went out into the for/est and sat down by the side of the .282
cool fountain; and when she was bored she took a golden ball, .294
and threw it up on high and caught it; and this ball was her .575
favorite plaything. .004
Рис. 4. Верстка того же абзаца при большей длине строки.
ной 500 единиц. В данном случае алгоритм оптимальной верстки, благодаря
своим прогностическим возможностям, позволил обойтись вообще без
переносов слов. Два других алгоритма, в которых решение принимается по каждой
строке в отдельности, проходят мимо этого варианта, так как не замечают, что
Глава 3. Верстка абзацев
95
за счет небольшого ухудшения первой строки удается избавиться от многих
проблем в последующих строках. Дефектности строк для всех трех вариантов
верстки, представленных на рис. 4, выглядят следующим образом:
Простая
верстка
1521
3136
3600
4489
4
1
400
4
1
Улучшенная
верстка
1521
3136
3600
9
1—1
4
121
25
16
1
Оптимальная
верстка
2209
4
676
2916
1—i
1
9
16
400
1—1|
13156 8434 6233
При простой и улучшенной верстке дефектность третьей строки, равная 3600,
возникает, главным образом, из-за штрафа со значением 50 за сделанный пет
ренос.
При простой верстке абзац на рис. 4 записывается всего в 9 строк, тогда
как при оптимальной верстке этот абзац оказывается разбитым на 10 строк.
Издатели, стремящиеся сэкономить бумагу, могут предпочесть простую
верстку при том, что получаемый с ее помощью текст, в общем-то, выглядит вполне
прилично. Для таких случаев можно предложить целый ряд модификаций
параметров оптимальной верстки, приводящих к тому, что алгоритм будет
отдавать предпочтение вариантам с меньшим числом строк. Например, можно
уменьшить растяжимость клея в последней строке абзаца с очень большого ее
значения в стандартном варианте метода до значения, примерно равного длине
строки, —в результате этого алгоритм будет отдавать предпочтение строкам
с высокой степенью заполненности. Можно также в выражении для
дефектности 5j заменить единицу большим числом. В действительности алгоритм
оптимальной верстки можно настроить так, чтобы получаемое оптимальное
решение имело минимальное возможное число строк.
In the meantime it
I knocked a second
\ time, and cried,
\ "Princess, youngest
Рис. 5. Результат применения алгоритма улучшенной ; princess, open the
A - i door for me. Do you
верстки при очень маленькой длине строки. Абзац не \ not know wnat you
выровнен по правому краю, так как иначе он выглядел j said to me yesterday
с- о » tz ■: by the cool waters of
бы ужасно. Здесь в третьей строке всего два пробела, а в \ t£e well? princesS)
третьей от конца строке — вообще один. В первой строке I youngest princess,
имеется «выброс» вправо — явление, часто встречающе- \ ^®" t е ог
еся при верстке текста без выравнивания.
96
Компьютерная типография
In olden times when
wishing still helped
one, there lived a king
whose daughters were
all beautiful; and the
youngest was so
beautiful that the sun
itself, which has seen so
much, was astonished
whenever it shone in
her face. Close by
the king's castle lay a
great dark forest, and
under an old lime-tree
in the forest was a
well, and when the
day was very warm,
the king's child went
out into the forest
and sat down by
the side of the cool
fountain; and when
she was bored she
took a golden ball,
and threw it up on
high and caught it;
and this ball was her
favorite plaything.
Now it so happened
that on one occasion
the princess's golden
ball did not fall into
the little hand that
she was holding up
for it, but on to the
ground beyond, and
it rolled straight into
the water. The king's
daughter followed it
with her eyes, but
it vanished, and the
well was deep, so
deep that the bottom
could not be seen. At
this she began to cry,
and cried louder and
louder, and could not
be comforted. And
as she thus lamented
someone said to her,
"What ails you, king's
daughter? You weep
so that even a stone
would show pity."
She looked round
to the side from
whence the voice
came, and saw a frog
stretching forth its
big, ugly head from
the water. "Ah, old
water-splasher, is it
you?" said she; "I
am weeping for my
golden ball, which has
fallen into the well."
"Be quiet, and do not
weep," answered the
frog. "I can help you;
but what will you give
me if I bring your
plaything up again?"
"Whatever you will
have, dear frog," said
she; "my clothes, my
pearls and jewels, and
even the golden crown
that I am wearing."
The frog answered,
"I do not care for your
clothes, your pearls
and jewels, nor for
your golden crown;
but if you will love
me and let me be
your companion and
play-fellow, and sit
by you at your little
table, and eat off your
little golden plate,
and drink out of your
little cup, and sleep in
your little bed—if you
will promise me this
I will go down below,
and bring you your
golden ball up again."
"Oh yes," said she,
"I promise you all
you wish, if you will
but bring me my ball
back again." But she
thought, "How the
silly frog does talk!
All he does is sit in the
water with the other
frogs, and croak. He
can be no companion
to any human being."
But the frog, when
he had received this
promise, put his head
into the water and
sank down; and in a
short while he came
swimming up again
with the ball in his
mouth, and threw
it on the grass. The
king's daughter was
delighted to see her
pretty plaything once
more, and she picked
it up and ran away
with it. "Wait, wait,"
said the frog. "Take
me with you. I can't
run as you can." But
what did it avail him
to scream his croak,
croak, after her, as
loudly as he could?
She did not listen to
it, but ran home and
soon forgot the poor
frog, who was forced
to go back into his
well again.
The next day when
she had seated
herself at table with the
king and all the
courtiers, and was
eating from her little
golden plate,
something came creeping
splish splash, splish
splash, up the marble
staircase; and when
it had got to the
top, it knocked at
the door and cried,
"Princess, youngest
princess, open the
door for me." She
ran to see who was
outside, but when
she opened the door,
there sat the frog
in front of it. Then
she slammed the door
to, in great haste,
sat down to dinner
again, and was quite
frightened. The king
saw plainly that her
heart was beating
violently, and said, "My
child, what are you so
afraid of? Is there
perchance a giant outside
who wants to carry
you away?" "Ah, no,"
replied she. "It is no
giant, it is a
disgusting frog."
"What does a frog
want with you?" "Ah,
dear father, yesterday
as I was in the forest
Рис. 6. Сказка о Короле-лягушонке, сверстанная в виде узких колонок с рваным
правым краем. Точки перехода на новую строку были определены оптимальным образом
для случая верстки с выравниванием.
Глава 3. Верстка абзацев
97
sitting by the well,
playing, my golden
ball fell into the
water. And because
I cried so, the frog
brought it out again
for me; and because
he so insisted, I
promised him he should
be my companion, but
I never thought he
would be able to come
out of his water. And
now he is outside
there, and wants to
come in to see me."
In the meantime
it knocked a
second time, and cried,
"Princess, youngest
princess, open the
door for me. Do you
not know what you
said to me yesterday
by the cool waters
of the well?
Princess, youngest
princess, open the door
for me!"
Then said the king,
"That which you have
promised must you
perform. Go and let
him in." She went
and opened the door,
and the frog hopped
in and followed her,
step by step, to her
chair. There he sat
and cried, "Lift me
up beside you." She
delayed, until at last
the king commanded
her to do it. Once the
frog was on the chair
he wanted to be on
the table, and when
he was on the table he
said, "Now, push your
little golden plate
nearer to me, that
we may eat together."
She did this, but it
was easy to see that
she did not do it
willingly. The frog
enjoyed what he ate, but
almost every
mouthful she took choked
her. At length he said,
"I have eaten and
am satisfied, now I
am tired; carry me
into your little room
and make your little
silken bed ready, and
we will both lie down
and go to sleep."
The king's
daughter began to cry, for
she was afraid of the
cold frog, which she
did not like to touch,
and which was now
to sleep in her pretty,
clean little bed. But
the king grew angry
and said, "He who
helped you when you
were in trouble ought
not afterwards to be
despised by you." So
she took hold of the
frog with two fingers,
carried him upstairs,
and put him in a
corner. But when she was
in bed he crept to her
and said, "I am tired,
I want to sleep as well
as you; lift me up or I
will tell your father."
At this she was
terribly angry, and took
him up and threw him
with all her might
against the wall.
"Now, will you be
quiet, odious frog?"
said she. But when he
fell down he was no
frog but a king's son
with kind and
beautiful eyes. He by her
father's will was now
her dear companion
and husband. Then
he told her how he
had been bewitched
by a wicked witch,
and how no one could
have delivered him
from the well but
herself, and that
tomorrow they would
go together into his
kingdom.
Then they went to
sleep, and next
morning when the sun
awoke them, a
carriage came driving
up with eight white
horses, which had
white ostrich
feathers on their heads,
and were harnessed
with golden chains;
and behind stood
the young king's
servant Faithful Henry.
Faithful Henry had
been so unhappy
when his master was
changed into a frog,
that he had caused
three iron bands to
be laid round his
heart, lest it should
burst with grief and
sadness. The
carriage was to conduct
the young king into
his kingdom. Faithful
Henry helped them
both in, and placed
himself behind again,
and was full of joy
because of this
deliverance. And when
they had driven a part
of the way, the king's
son heard a cracking
behind him as if
something had broken. So
he turned round and
cried, "Henry, the
carriage is breaking."
"No, master, it is
not the carriage. It
is a band from my
heart, that was put
there in my great
pain when you were
a frog and
imprisoned in the well."
Again and once again
while they were on
their way something
cracked, and each
time the king's son
thought the carriage
was breaking; but it
was only the bands
that were
springing from the heart
of Faithful Henry
because his master
was set free and was
so happy.
Рис. 6 (продолэюение). Несмотря на то, что для верстки без выравнивания
правильнее было бы использовать несколько иной критерий оптимальности, строки
получились примерно одинаковой длины.
98
Компьютерная типография
Король-лягушонок, или Железный Генрих
В стародавние времена, когда заклятья
еще помогали, жил-был на свете король;
все дочери были у него красавицы, но
самая младшая была так прекрасна, что
даже солнце, много видавшее на своем
веку, и то удивлялось, сияя на ее лице.
Вблизи королевского замка
раскинулся большой дремучий лес, и был в том
лесу под старою липой колодец; и вот
в жаркие дни младшая королевна
выходила в лес, садилась на край студеного
колодца, и когда становилось ей
скучно, она брала золотой мяч, подбрасывала
его вверх и ловила, — это было ее самой
любимой игрой.
Но вот однажды, подбросив свой
золотой мяч, она поймать его не успела,
он упал наземь и покатился прямо в
колодец. Королевна глаз не спускала с
золотого мяча, но он исчез, а колодец был
такой глубокий, такой глубокий, что и
дна было не видать. Заплакала тогда
королевна, и стала плакать все сильней и
сильней, и никак не могла утешиться.
Вот горюет она о своем мяче и вдруг
слышит — кто-то ей говорит:
— Что с тобой, королевна? Ты так
плачешь, что и камень разжалобить
можешь.
Она оглянулась, чтоб узнать откуда
это голос, вдруг видит — лягушонок
высунул из воды свою толстую, уродливую
голову.
— А-а, это ты, старый квакун, —
сказала она, — я плачу о своем золотом
мяче, что упал в колодец.
— Успокойся, чего плакать, —говорит
лягушонок, —я тебе помогу. А что ты
мне дашь, если я найду твою игрушку?
— Все, что захочешь, милый
лягушонок, — ответила королевна. — Мои
платья, жемчуга, драгоценные камни и в
придачу золотую корону, которую я
ношу.
Говорит ей лягушонок:
— Не надо мне ни твоих платьев, ни
жемчугов, ни драгоценных камней, и
твоей золотой короны я не хочу; а вот
если б ты меня полюбила да со мной
подружилась, и мы играли бы вместе, и
сидел бы я рядом с тобою за столиком,
ел из твоей золотой тарелочки, пил из
твоего маленького кубка и спал с тобой
вместе в постельке, — если ты мне
пообещаешь все это, я мигом прыгну вниз и
достану тебе твой золотой мяч.
— Да, да, обещаю тебе все, что
хочешь, только достань мне мой мяч! —А
сама про себя подумала: «Что там
глупый лягушонок болтает? Сидит он в воде
среди лягушек да квакает, — где уж ему
быть человеку товарищем!»
Получив с нее обещанье, лягушонок
нырнул в воду, опустился на самое дно,
быстро выплыл наверх, держа во рту
мяч, и бросил его на траву. Увидав
опять свою красивую игрушку,
королевна очень обрадовалась, подняла ее с
земли и убежала.
— Постой, постой! — крикнул
лягушонок. — Возьми и меня с собой, ведь мне
за тобой не угнаться!
Но что с того, что он громко кричал ей
вслед свое «ква-ква»? Она и слушать его
не хотела, поспешая домой. А потом и
совсем позабыла про бедного лягушонка,
и пришлось ему опять спуститься в свой
колодец.
На другой день она села с королем
и придворными за стол и стала кушать
из своей тарелочки. Вдруг — топ-шлеп-
шлеп — взбирается кто-то по мраморной
лестнице и, взобравшись наверх,
стучится в дверь и говорит:
— Молодая королевна, отвори мне
дверь! Она побежала поглядеть, кто бы
это мог к ней постучаться. Открывает
дверь, видит — сидит перед ней
лягушонок. Мигом захлопнула она дверь и
уселась опять за стол, но сделалось ей так
страшно-страшно. Заметил король, как
сильно бьется у нее сердечко, и говорит:
— Дитя мое, чего ты так испугалась?
Уж не великан ли какой спрятался за
дверью и хочет тебя похитить?
— Ах, нет, — сказала королевна, — это
вовсе не великан, а мерзкий лягушонок.
— А что ему от тебя надо?
— Ах, милый батюшка, да вот сидела
я вчера в лесу у колодца и играла, и упал
в воду мой золотой мяч. Я горько
заплакала, а лягушонок достал мне его и стал
Глава 3. Верстка абзацев
99
требовать, чтоб я взяла его в товарищи,
а я и пообещала ему, — но никогда я не
думала, чтобы он мог выбраться из
воды. А вот теперь он явился и хочет сюда
войти.
А тем временем лягушонок
постучался опять и кликнул:
Здравствуй, королевна,
Дверь открой!
Неужель забыла,
Что всегда сулила,
Помнишь, у колодца?
Здравствуй, королевна,
Дверь открой!
Тогда король сказал:
— Ты свое обещание должна
выполнить. Ступай и открой ему дверь.
Она пошла, открыла дверь, и вот
лягушонок прыгнул в комнату, поскакал
вслед за ней, доскакал до ее стула, сел
и говорит:
— Возьми и посади меня рядом с
собой.
Она не решалась, но король велел ей
исполнить его желанье. Она усадила
лягушонка на стул, а он стал на стол
проситься; посадила она его на стол, а он
говорит:
— А теперь придвинь мне поближе
свою золотую тарелочку, будем есть с
тобой вместе.
Хотя она и исполнила это, но было
видно, что очень неохотно.
Принялся лягушонок за еду, а
королевне и кусок в горло не лезет. Наконец
он говорит:
— Я наелся досыта и устал, — теперь
отнеси меня в свою спаленку, постели
мне свою шелковую постельку, и ляжем
с тобой вместе спать.
Как заплакала тут королевна, —
страшно ей стало холодного лягушон-
ка,боится до него и дотронуться, а он
еще в прекрасной, чистой постельке
спать с ней собирается. Разгневался
король и говорит:
— Кто тебе в беде помог, тем
пренебрегать не годится.
Взяла она тогда лягушонка двумя
пальцами, понесла его к себе в
спаленку, посадила в углу, а сама улеглась в
постельку. А он прыгнул и говорит:
— Я устал, мне тоже спать хочется,—
возьми меня к себе, а не то я твоему отцу
пожалуюсь.
Рассердилась тут королевна и ударила
его изо всех сил об стену.
— Ну, уж теперь, мерзкий лягушонок,
ты успокоишься!
Но только упал он наземь, как вдруг
обернулся королевичем с прекрасными,
ласковыми глазами. И стал с той поры,
по воле ее отца, ее милым другом и
мужем. Он рассказал ей, что его
околдовала злая ведьма, и никто бы не мог
освободить его из колодца, кроме нее одной,
и что завтра они отправятся в его
королевство.
Вот легли они спать и уснули. А на
другое утро, только разбудило их
солнышко, подъехала ко дворцу карета с
восьмериком белых коней, и были у них
белые султаны на голове, а сбруя из
золотых цепей, и стоял на запятках слуга
королевича, а был то верный Генрих. Когда
его хозяин был обращен в лягушонка,
верный Генрих так горевал и печалился,
что велел оковать себе сердце тремя
железными обручами, чтоб не разорвалось
оно от горя и печали.
И должен был в этой карете ехать
молодой король в свое королевство. Усадил
верный Генрих молодых в карету, а сам
стал на запятках и радовался, что хозяин
его избавился от злого заклятья.
Вот проехали они часть дороги, вдруг
королевич слышит — сзади что-то
треснуло. Обернулся он и крикнул:
— Генрих, треснула карета!
— Дело, сударь, тут не в этом,
Это обруч с сердца спал,
Что тоской меня сжимал,
Когда вы в колодце жили
И с лягушками дружили.
Вот опять и опять затрещало что-то в
пути, королевич думал, что это треснула
карета, но были то обручи, что слетели с
сердца верного Генриха, потому что
хозяин его избавился от злого заклятья и
стал снова счастливым.
(Перевод Г. Петникова. Текст
приведен по изданию Братья Гримм. Сказки.
М., 1949.)
100
Компьютерная типография
В приведенных примерах использован вполне обычный текст при
достаточно большой ширине полосы, поэтому в процессе верстки нам не пришлось
столкнуться с какими-либо серьезными трудностями или необычными
явлениями. Тем не менее мы можем констатировать, что оптимизационный алгоритм
позволяет получить значительно лучшие результаты даже в простых случаях.
По всей видимости, эффективность предлагаемого алгоритма будет еще выше
в более сложных ситуациях, например, когда текст содержит математические
формулы или когда длина строки мала, скажем при газетной верстке.
Те, кого беспокоит судьба прекрасной принцессы, упоминающейся в тексте
на рис. 1-4, могут обратиться к рис. 6 на с. 96-97, где сказка приводится
целиком. Колонки на рис. 6 чрезвычайно узкие: в строке умещается всего 21 или
22 литеры, тогда как обычный газетный формат допускает порядка 35 литер
в строке, а колонки в журналах зачастую вдвое шире, чем в данном примере.
Алгоритмы построчной верстки не справляются со столь жесткими
ограничениями, а алгоритм оптимальной верстки, как видно из рис. 6, успешно
разбивает абзацы на строки более или менее одинаковой длины. При этом, несмотря
на то что величина штрафа за перенос была в данном случае увеличена с 50 до
5000, в тексте оказывается довольно много переносов. Это вполне
естественно, поскольку при использовании переносов увеличивается число междуслов-
ных пробелов, приходящихся в среднем на строку, и, как следствие, удается
несколько подровнять длину строк.
Хотя наша техника верстки разрабатывалась в расчете на текст с
выровненным правым краем, в примере на рис. 6 оптимизационый алгоритм
использован для верстки текста с рваным правым краем. Для этого применен
простейший прием: на последнем этапе, когда все точки разрыва строк уже
выбраны, выравнивание текста по правому краю отменяется. На самом деле для
отыскания наилучших точек перехода на новую строку в случае рваного
правого края нужно использовать иную меру плохости, основанную только лишь
на разности между желательной длиной строки lj и действительной ее длиной
Lj, причем должно быть разрешено только растягивать междусловные
пробелы, а сжимать — запрещено, и Lj никогда не должно превосходить lj. Кроме
того, при наборе текста с рваным правым краем не следует допускать
«выброса» слов вправо, т. е. нельзя, чтобы слово начиналось правее конца следующей
строки. Например, слово 'it' на рис. 5 в действительности следует перенести
из первой строки во вторую.
Приведенные примеры показывают, что алгоритм качественной верстки
текста с рваным правым краем —вещь несколько более сложная, чем такой
же алгоритм для текста с выравниванием, вопреки широко распространенному
убеждению, что выравнивание —более трудный случай. С другой стороны, как
видно из примера, приведенного на рис. 6, если в алгоритме верстки,
ориентированном на выровненный правый край, отказаться от самого выравнивания,
сохранив разбиение абзаца на строки, результат получается вполне
приемлемый.
Глава 3. Верстка абзацев
101
Интересной иллюстрацией к проблемам, возникающим при наборе узких
столбцов, служит фраза
"Now, push your little golden plate nearer ..."
входящая в четвертый от конца абзац на рис. 6. По причинам, упоминавшимся
ранее, перенос в любом из слов этой фразы нежелателен. При этом
оказывается, что среди четырех возможных ее фрагментов, состоящих каждый из
четырех слов и содержащих слово 'little', а именно
"Now, push your little
push your little golden
your little golden plate
little golden plate nearer
ни один не умещается в одну строку. Поэтому вне зависимости от того, каковы
были предшествующие строки, слово 'little' с необходимостью будет
располагаться в строке, состоящей только из трех слов и, следовательно, содержащей
только два пробела.
Проблемы, которые могут возникать при верстке узких столбцов,
наглядно проявились в последних абзацах текста на рис. 6. Эти проблемы связаны
со сложным взаимовлиянием строк в больших абзацах, из-за чего при верстке
с выравниванием иногда просто нельзя избежать большой разреженности. На
рис. 7 показано, что будет с текстом на рис. 6, если его все-таки выровнять
по правому краю. Приведенный фрагмент оказался самой трудной частью во
всем тексте: одну из строк, полученных при оптимальной верстке, для
выравнивания по правому краю приходится растягивать с фантастически большим
коэффициентом 6.616. Единственная возможность сверстать данный абзац без
таких огромных пробелов —это отказаться от выравнивания (если, конечно,
мы не имеем возможности изменить либо сам текст, либо длину строки, либо
минимальную допустимую величину пробела).
and were harnessed 3.137
with golden chains; 3.277
and behind stood 5.740
the young king's serr .783
vant Faithful Henry. 1.971
Faithful Henry had 3.474
been so unjiappy 6.616
when his master was .940
changed into a frog, 1.612
Рис. 7. Если попытаться выровнять по
правому краю текст на рис. 6, хуже всего дело будет
обстоять с этим фрагментом — здесь даже
оптимальная верстка дает очень большие
пробелы.
Другие приложения
Прежде чем приступить к обсуждению деталей оптимизационного
алгоритма, рассмотрим еще несколько ситуаций, когда задачи, связанные с набором
текста, удается решить, используя базовые понятия (примитивы) боксов, клея
и штрафов. Некоторые из рассматриваемых ниже применений этих понятий
связаны с идеями, обсуждавшимися в связи с рис. 1-4, тогда как другие, на
первый взгляд, не имеют к верстке никакого отношения.
102
Компьютерная типография
Состыковка абзацев
В том случае, когда желательные длины строк U не одинаковы, часто
требуется сверстать два абзаца таким образом, чтобы второй начинался в списке длин
там, где заканчивается первый. Это несложно сделать, если обрабатывать два
абзаца как один, т. е. добавлять боксы/клей/штраф второго абзаца к первому,
считая, что каждый абзац начинается с отступа и кончается завершающим
клеем и принудительным разрывом (см. выше).
«Заплатки»
Предположим, что в некой книге абзац начинается на странице 100 и
продолжается на странице 101. Допустим, что нам нужно что-то изменить в
первой части абзаца. Мы хотим быть уверены в том, что последняя строка новой
страницы 100 закончится в точности перед тем словом, с которого
начинается страница 101, так чтобы нам не пришлось переверстывать страницу 101. В
терминах используемых нами понятий это условие формализуется очень
просто: в нужном месте вводится принудительный разрыв строки (путем введения
штрафа —оо), а последующий текст отбрасывается. Благодаря своему
прогностическому характеру, алгоритм оптимальной верстки найдет приемлемый
способ переверстать страницу 100 (поставить на этой странице «заплатку»),
если, конечно, такой способ вообще существует.
Кроме того, с помощью нижеследующего приема можно добиться, чтобы
измененная часть абзаца состояла из заданного числа строк к. В качестве
lk+i—желательной длины (к + 1)-й строки — возьмем число 0, отличное от
длины любой другой строки. В этом случае пустой бокс шириной 0, который
появляется между двумя штрафами при принудительном разрыве, должен
быть помещен в строку к + 1.
Висячая пунктуация
Некоторые авторы предпочитают, чтобы точки, запятые и другие знаки
препинания, включая переносы, находились за пределами правого края строки.
Например, так часто делается в современной рекламе. Добиться такого
расположения знаков переноса несложно: для этого нужно положить ширину
соответствующего элемента-штрафа равной нулю. Почти так же просто сделать
это для точек и других знаков препинания: в этом случае нужно поместить
каждый такой знак в бокс с шириной, равной нулю, и добавить фактическую
ширину символа к клею, который следует за знаком. Если на этом клее не
происходит разрыв строки, то полученная ширина будет такой же, как раньше, а
если разрыв произойдет, то строка будет выровнена по правому краю так, как
если бы знак препинания (точка или другой знак) отсутствовал.
Как избежать «психологически плохих» разрывов
Поскольку компьютеры не умеют думать (пока, во всяком случае),
возникает вопрос, допускает ли компьютер такие разрывы строки, которые отверг бы
Глава 3. Верстка абзацев
103
человек, т. е. разрывы, которые плохо смотрятся. Эта проблема возникает не
очень часто, когда речь идет об обычном тексте, какой встречается в газетах
или романах, но она типична для технической литературы. Например,
психологически плохим будет разрыв перед 'х' или 'у' в следующем предложении:
Функция переменной х — это правило, согласно которому каждому
значению х ставится в соответствие некоторое значение у.
Компьютер в этой ситуации не имеет никаких ограничений относительно
разбиения на строки, если только ему их не задать. Но человек будет избегать
плохих разрывов, может быть даже бессознательно.
Непросто сформулировать, что такое психологически плохие разрывы. Мы
просто знаем, что они плохие. Когда мы переводим взгляд с конца одной строки
на начало другой, то если строки разбиты неудачно, слово, с которого
начинается вторая строка, часто кажется изолированным от контекста. Представьте
себе, что предложение, которое начинается на одной странице и
заканчивается на другой, разрывается между словами «Глава» и «8». Вы, естественно,
подумаете, что наборщик не должен был разбивать текст таким нелогичным
образом.
В первые годы работы с ТеХ'ом авторы этой статьи стали замечать, что
некоторые разрывы строк смотрятся плохо, хотя проблема не казалась
настолько серьезной, чтобы предпринимать какие-либо действия. Однако в конце
концов мы стали сомневаться в справедливости нашего представления о том,
что ТЕХ обладает лучшим в мире алгоритмом верстки, поскольку компьютер
периодически допускал досадные с точки зрения семантики разрывы.
Например, в первом руководстве по ТЁ^'у [26] было немало таких разрывов, а его
предварительные версии были еще хуже.
Со временем психологически плохие разрывы стали раздражать авторов
все больше и больше, и это касалось не только книг, подготовленных в ТЁ^'е,
но и других изданий. Пришло время выяснить, действительно ли это вина
компьютеров. В связи с этим было проведено исследование, которое заключалось
в сравнении первой тысячи разрывов строк в журнале ACM Journal I960 года
(который был подготовлен вручную на монотипе) с первой тысячей разрывов
строк в журнале ACM Journal 1980 года (который был набран при помощи
лучшей коммерческой компьютерной системы для набора математических
текстов, разработанной компанией Penta Systems International). Последние строки
абзацев и строки, предшествующие выключным формулам, не
рассматривались, так как разрывы в них были принудительными. Использовался текст
только самих статей, но не библиографий. Если читатель захочет повторить
этот эксперимент, то он обнаружит, что тысячный разрыв в I960 году
появился на с. 67, тогда как в 1980 году —на с. 64. Результаты нашего (конечно же,
субъективного) анализа выглядят следующим образом:
13 плохих разрывов в I960 г.,
55 плохих разрывов в 1980 г.
Иными словами, количество плохих разрывов возросло более чем в 4 раза,
с 1 до 5.5%, а это уже ощутимо! Конечно, нельзя считать этот опыт абсо-
104
Компьютерная типография
лютно убедительным, поскольку стиль статей, помещенных в журнале АСЫ
Journal, менялся, однако очевидно, что когда компьютер выбирает разрывы,
руководствуясь исключительно визуальным критерием, это не идет на пользу
смысловому восприятию текста.
Как только стало ясно, в чем заключается проблема, была сделана
попытка убрать все такие разрывы из второго издания книги Seminumerical
Algorithms [28] —первой большой книги, подготовленной в ТЁХ'е. Заставить
алгоритм верстки избегать определенных разрывов несложно, для этого надо
просто ставить перед клеем штраф величины, скажем pi = 999, и тогда
плохой разрыв будет выбран только в случае крайней необходимости, если нет
другого подходящего способа сверстать абзац. Для того чтобы облегчить
работу наборщика, можно также ввести специальный символ (например, '~'),
который используется вместо обычного пробела между теми словами, где
разрыв нежелателен. Хотя эта проблема редко обсуждалась в литературе, авторы
впоследствии обнаружили, что у некоторых полиграфистов есть термин для
обозначения таких пробелов —они называют их вспомогательными. Значит,
эта проблема многим знакома.
Условимся называть такие пробелы связками. Имеет смысл перечислить
основные случаи использования связок в книге Seminumerical Algorithms,
поскольку круг рассматриваемых там технических вопросов достаточно широк.
Следующие правила наверняка помогут тем, кто набирает на компьютере
технические рукописи.
1. Пользуйтесь связками в перекрестных ссылках:
Теорема~А Алгоритмов Глава~3
Таблица~4 Программы Е h~F
В последнем примере после слова 'Программы' связка не нужна, так как
если строка начнется с'Еи F', то это будет выглядеть нормально.
2. Пользуйтесь связками при наборе имен и фамилий, состоящих из
нескольких частей:
Dr.~I.~J. Matrix Luis~I. TrabtfPardo
Peter van~Emde~Boas
Возникшая в последнее время тенденция не делать пробелов между
инициалами — это протест против обычного компьютерного алгоритма верстки!
Следует иметь в виду, что лучше уж сделать перенос в одной из частей
имени, чем допустить разрыв между его частями. Так, например, 'Don-' и 'aid
Е. Knuth' выглядит лучше, чем 'Donald' и 'Е. Knuth'. В некотором смысле
первое правило является частным случаем второго, поскольку 'Теорема~А'
может рассматриваться как имя. Другой пример —'регистрах'.
3. Пользуйтесь связками при наборе существительных с дополнительными
символами:
основание~6 измерение"^
функция ~ f{x) ряд~5 длиньГ/
Глава 3. Верстка абзацев
105
Но: 'строковая переменная~5 длины Гили большей'.
4. Пользуйтесь связками при наборе элементов перечислений:
1,~2 или~3 а,~6 и~с 1,~2, ... ,~п
5. Пользуйтесь связками при наборе символов, являющихся строго
связанными объектами препозиции:
от~я от 0 до~1
увеличить z на~1 одновременно с~т
Это правило не относится к сложным объектам; ср., например, 'от u~h~v\
6. Пользуйтесь связками для того, чтобы избегать неудачных разрывов в
предложениях, содержащих математические выражения:
равно~п меныпе~б mod~2
(для данного~Х) когда аГвозрастает если £~равно ...
по модулю ~ре
Для сравнения: 'равно~15', но 'в 15~раз больше'; 'для всех болыпйх~гг', но
'для всех тг,~б6лыцих, чем~тго'.
7. Пользуйтесь связками при нумерации под случаев:
(б)"Покажите, что f(x) (1)"непрерывна; (2)"ограниченна.
Было бы неплохо свести эти семь правил к одному или двум, а еще
лучше— автоматизировать их использование, чтобы не думать о них при
наборе текста, однако во многих примерах нужно учитывать тонкие
семантические соображения. Большинство психологически плохих разрывов возникает
тогда, когда символ или небольшая группа символов появляется
непосредственно перед разрывом или сразу после него. При автоматической
расстановке связок разрывы перед короткими сочетаниями символов, не
являющимися словами, должны ассоциироваться с большими штрафами, а
разрывы после коротких сочетаний —со штрафами средней величины. Под
короткими сочетаниями мы понимаем последовательности символов, которые,
хотя и являются не очень длинными, но все же охватывают выражения,
типа 'упражнение~15(Ь)', 'длина~235', 'порядок~п/2', с последующими
знаками препинания; при этом выражения, состоящие только из одного или двух
символов, не рассматриваются. С другой стороны, не возбраняется
разрывать строку перед длинным сочетанием символов или после него;
например, в сочетании 'упражнение 4.3.2-15' после слова 'упражнение' связка не
нужна.
Во многих руководствах по набору содержатся рекомендации не
разрывать строку непосредственно перед последним словом абзаца, особенно, если
это слово короткое. Конечно же, этого легко добиться, поставив связку перед
последним словом, причем компьютер может вставлять эту связку
автоматически. Некоторые пособия дают рекомендации, аналогичные вышеприведенному
правилу 2, которые заключаются в том, что наборщики не должны
разрывать строку в середине имени человека. Но, по всей видимости, есть только
одна книга, в которой рассматриваются и другие случаи психологически пло-
106
Компьютерная типография
хих разрывов. Это французское руководство XIX века, составленное А. Фри
с. 110], где упомянуты следующие примеры нежелательных разрывов:
Анри~1У М.~Колин 1~сентября art.~25 20~fr.
Видимо, настало время возродить старые полиграфические традиции.
Опыт авторов свидетельствует о том, что при наборе рукописей на
компьютере проставление связок не воспринимается как лишняя
обременительная работа. На самом деле если, набирая текст, аккуратно проставлять такие
«неразрываемые» пробелы, то можно получить более полное удовлетворение
от работы, поскольку сравнительно небольшой труд приводит к заметному
улучшению качества оригинал-макета. Иногда приятно сознавать, что машина
нуждается в твоей помощи.
Строки с информацией об авторах
Большинство рецензий, публикуемых в Mathematical Reviews,
подписываются фамилией автора с его адресом, и эта информация сдвигается вправо,
точнее — выравнивается по правому краю. Если на последней строке
абзаца достаточно места для размещения этой информации, то издатель может
сэкономить бумагу и результат будет выглядеть лучше, так как можно
будет избежать странных коридоров на странице. Программное обеспечение,
используемое в последние годы Американским математическим обществом,
не позволяло автоматически выполнять эту операцию, но количество
экономящейся при этом бумаги сделало экономически выгодным платить
наемному работнику за то, чтобы он вручную, где возможно, перемещал этот
текст вверх на компьютерной распечатке при помощи ножниц и (настоящего)
клея.
Это случай, когда фамилия и адрес автора удачно вписываются
в текст рецензии. A. Reviewer (Ann Arbor, Mich.)
Но иногда бывает нужно добавить новую строку.
N. Bourbaki (Paris)
Рис. 8. Задача MR.
Назовем «задачей MR» выравнивание содержимого данного бокса в
правый край в конце данного абзаца с пробелом не менее w между абзацем и
этим боксом, если они находятся на одной строке. Эта задача может быть
решена полностью в терминах базовых понятий бокс/клей/штраф следующим
образом:
(текст данного абзаца)
штраф(0, оо, 0)
клей(0, 100000, 0)
штраф(0, 50, 0)
клей(ги, 0, 0)
бокс(0)
штраф(0, оо, 0)
Глава 3. Верстка абзацев
клей(0, 100000, 0)
* (данный бокс)
штраф(0, — со, 0)
Последний штраф — оо вынуждает разбить последнюю строку с последующей
выключкой данного бокса вправо; два штрафа +оо используются для
предотвращения разбиения в местах последующего клея. Таким образом,
приведенная выше последовательность сводится к двум случаям: разбивается строка
со штрафом 50 или нет. Если разбиение происходит, то 'клей(ги, 0, 0)'
исчезает согласно нашему правилу, гласящему, что каждая строка
начинается с бокса; за текстом абзаца, предшествующим штрафу 50, будет помещен
'клей(0, 100000, 0)', который растянет строку так, как если бы абзац
заканчивался обычным образом, а данному боксу на последней строке также будет
предшествовать 'клей(0, 100000, 0)' для получения промежутка слева. С
другой стороны, если при штрафе 50 разбиения не произойдет, то, в результате
все элементы клея сложатся, произведя
(текст данного абзаца)
клей(ги, 200000, 0)
(данный бокс)
так чтобы пространство между абзацем и боксом было w или больше.
Независимо от того, произойдет разбиение или нет, плохость последней строки
окажется существенно нулевой, потому что будет слишком большое
растяжение. Таким образом, относительная стоимость разделения на две
альтернативы почти целиком вызвана штрафом 50. Алгоритм оптимального разбиения
(оптимальной верстки) выберет лучшую из альтернатив, основываясь на тех
возможностях, которые заложены в данном абзаце; он даже может несколько
уплотнить абзац, если это приведет к лучшему результату.
Рваный правый край
Как мы уже видели на рис. 6, алгоритм оптимальной верстки,
предназначенный для выравнивания текста, прекрасно справляется со своей работой,
выдавая строки почти одинаковой длины, даже когда их впоследствии не
нужно выравнивать. Можно, однако, легко построить примеры, в которых
метод, предназначенный для выравнивания, дает плохое решение, поскольку
величина отклонений в длине строки целиком зависит от величины
имеющих место сжатий или растяжений. Строка, состоящая из большого
количества слов, а, следовательно, содержащая много междусловных пробелов, не
вызывает проблем с точки зрения критерия выравнивания, даже если эта
строка более короткая или более длинная, потому что имеется достаточно
клея для того, чтобы вполне корректно выполнить ее растяжение или
сжатие. И напротив, когда строка состоит всего из нескольких слов, алгоритм
будет прилагать все усилия к тому, чтобы избежать относительно малых
отклонений. Это проиллюстрировано на рис. 5, который на самом деле чи-
108
Компьютерная типография
тается лучше, чем соответствующий абзац на рис. 6 (за исключением
«выбившегося» слова в первой строке); в этом абзаце на рис. 6 были
выполнены переносы, чтобы получить больше междусловных пробелов для
выравнивания.
Хотя модель бокс/клей/штраф на первый взгляд кажется
ориентированной исключительно на выравнивание текста, на самом деле она достаточно
мощная, чтобы подходить для работы с аналогичной проблемой при наборе
с рваным краем. Если промежутки между словами оформлены правильно,
можно так подобрать эти вещи, что в каждой строке будет одинаковая
величина растяжения, независимо от того, сколько в ней слов. Идея состоит
в том, чтобы междусловные интервалы были представлены
последовательностью
клей(0, 18, 0)
штраф(0, 0, 0)
клей(б, —18, 0)
а не 'клей(б, 3, 2)', который мы использовали для выровненного набора.
Можно предположить, что в точке 'клей(0, 18, 0)' разбиения не будет, потому что
алгоритм не может сделать плохого разбиения со штрафом 'штраф(0, 0, 0)',
когда растяжение представлено 18 единицами. Если разбиение с таким
штрафом произойдет, то на строке будет растяжение в 18 единиц и 'клей(б, —18, 0)'
будет выброшен за ненадобностью, поскольку следующая строка должна быть
прижата к левому краю. С другой стороны, если разбиение есть, то в
результате имеем клей(6, 0, 0), представляющий собой обычный пробел без растяжения
или сжатия.
Растяжение —18 во втором элементе клея не имеет физического смысла,
и благополучно взаимно уничтожается с растяжением +18 в первом
элементе клея. Отрицательное растяжение имеет несколько интересных приложений,
так что читателю следует досконально изучить этот пример, прежде чем
приступать к более сложным конструкциям, приводимым ниже.
Необязательные переносы в невыровненном тексте могут быть описаны
аналогичным образом; вместо записи 'штраф(6, 50, 1)' для необязательного
б-элементного переноса, имеющего штраф 50, можно использовать
последовательность
штраф(0, оо, 0)
клей(0, 18, 0)
штраф(б, 500, 1)
клей(0, -18, 0).
Здесь штраф возрастает от 50 до 500, так как переносы в невыровненном
тексте менее желательны. После того как точки разбиения выбраны при помощи
приведенной выше последовательности для пробелов и необязательных
переносов, отдельные строки не должны выравниваться; в противном случае перенос,
вставленный посредством 'штраф(б, 500, 1)', оказался бы в правом поле.
Нетрудно доказать, что такой подход к набору с рваным правым краем
никогда не приведет к «выбившимся» словам, как в первой строке на рис. 5;
Глава 3. Верстка абзацев
109
суммарный дефект уменьшается, как только выбившееся слово перемещается
на следующую строку.
Центрированный текст
Иногда бывает нужно разбить не помещающийся в одну строку текст на
приблизительно равные части так, чтобы каждая часть разместилась по центру
отдельной строки. Такая необходимость часто возникает в случае заголовков
или подрисуночных подписей, но можно так же поступить и с обычным абзацем
как показано на рис. 9.
Боксы, клей и штрафы в подобных случаях представлены следующим
образом: (а) в начале абзаца используем 'клей(0, 18, 0)' вместо равнения вправо;
(b) для каждого междусловного пробела в абзаце используем
последовательность
клей(0, 18, 0)
штраф(0, 0, 0)
клей(б, —36, 0)
бокс(0)
штраф(0, оо, 0)
клей(0, 18, 0),
(c) в конце абзаца —последовательность
клей(0, 18, 0)
штраф(0, —оо, 0).
Весь фокус метода состоит в части (Ь), в которой подразумевается, что
необязательное разбиение со штрафом 'штраф(0, 0, 0)' приводит к растяжению в
18 единиц в конце одной строки и в начале следующей. Если разбиения не
происходит, сухим остатком будет клей(0, 18, 0) + клей(б, —36, 0) + клей(0, 18, 0) —
клей(б, 0, 0), т. е. фиксированный пробел в б единиц. 'Бокс(О)' не содержит
текста и не занимает никакого пространства; его назначение состоит в том,
чтобы предотвратить исчезание элемента 'клей(0, 18, 0)' в начале строки.
In olden times when wishing still helped one, there lived a king whose daughters
were all beautiful; and the youngest was so beautiful that the sun itself, which has
seen so much, was astonished whenever it shone in her face. Close by the king's
castle lay a great dark forest, and under an old lime-tree in the forest was a well,
and when the day was very warm, the king's child went out into the forest and sat
down by the side of the cool fountain; and when she was bored she took a golden
ball, and threw it up on high and caught it; and this ball was her favorite plaything.
Рис. 9. «Центрированный» текст: алгоритм оптимальной верстки выдает
специальные эффекты, подобно представленным здесь, когда для междусловных пробелов
используются соответствующие элементы бокс/клей/штраф.
'Штраф(0, 0, 0)' может быть заменен другими штрафами, представляющими
точку разбиения более или менее сносно. Эта техника, однако, не может быть
использована вместе с необязательным переносом, поскольку наша модель
по
Компьютерная типография
бокс/клей/штраф не способна вставлять переносы повсюду, за исключением
правого края в случае выровненных строк.
Использованная здесь конструкция существенно минимизирует величину
максимального расстояния между полями и текстом в любой строке;
подверженная минимизации величина существенно минимизирует максимальное
расстояние в оставшихся строках, и т. д. Причина кроется в том, что наши
определения плохости и дефектности сводятся в этом случае к тому, что сумма
дефектов при любом выборе точек разбиения приблизительно
пропорциональна сумме шестых степеней отдельных расстояний.
АЛГОЛо-подобные языки
Одна из наиболее сложных задач набора технических текстов состоит в том,
чтобы получать хорошо оформленные тексты компьютерных программ. Мало
того, что мы имеем дело со сложными математическими формулами,
разнообразием шрифтов и соглашений о пробелах, мы еще хотим так расположить
строки, чтобы отобразить вложенность структуры компьютерной программы.
Иногда единое утверждение бывает разбито на несколько отдельных строк;
иногда короткие утверждения должны группироваться на единой строке.
Программисты и специалисты в области информатики, предпринимавшие попытки
публиковаться в журналах, не имевших дело с такими материалами,
вскоре обнаруживали, что лишь небольшое число типографий имеют достаточно
высокий уровень для представления ALGOLo-подобных языков
удовлетворительным образом.
Снова на помощь приходит концепция боксов, клея и штрафов: это значит,
что наш метод разбиения на строки, разработанный для обычного текста,
может быть использован без изменений для набора программ на алголо-подобных
языках. На рис. 10, например, приводится типичная программа, взятая из
руководства [23] по Паскалю, которая должна была быть набрана в две колонки
различной ширины. Хотя эти два фрагмента программ не кажутся очень
похожими, они оба были произведены одним и тем же исходным кодом и
определены в терминах боксов, клея и штрафов; единственным отличием была длина
строки. (Исходный текст этого примера был подготовлен при помощи
программы Blaise [27], которая оттранслировала некий исходный текст на Паскале в
Т^Х-файл для последующего объединения с другими документами.)
Спецификации бокс/клей/штраф, которые приводят к рис. 10, включают
в себя конструкции, аналогичные тем, что мы видели ранее, но с некоторыми
новыми особенностями; для наших целей достаточно вкратце очертить идеи,
не погружаясь в подробности. Один из ключевых моментов состоит в том, что
мы выбираем точки разбиения согласно критерию минимизации дефектности,
который мы обсуждали выше, но строки впоследствии не выравниваются (т. е.
клей фактически не сжимается и не растягивается). Причина кроется в том,
что отношения и присваивания обрабатываются Т^Х'ом в «математическом
режиме», который допускает разбиения строк в различных местах, но без каких
бы то ни было специальных конструкций, так что выравнивание происходит с
Глава 3. Верстка абзацев 111
const n = 10000;
var sieve,primes :
set of 2 .. п]
next, j : integer;
begin { инициализировать }
sieve := [2 .. n];
primes := [];
next := 2;
repeat { найти следующее
простое }
while not (nex£ in
sieve) do
nex£ :=
swcc(next);
primes :=
primes + [next];
j := neart;
while j <= n do
{ удалить }
begin sieve :~
sieve - [j];
j :~- j -f yiexi
end
until sieve = []
end.
const n = 10000;
var sieve, primes : set of 2 .. n
next,2 : integer]
begin { инициализировать }
sieve := [2.. n]\ primes := []; next := 2;
repeat { найти следующее простое }
while not (next in sieve) do next := succ(next);
primes := primes + [next]] j := next;
while j <= 7г do { удалить }
begin sieve := sieve — [?"]; j := j 4- next
end
until sieve = []
end.
Рис. 10. Эти два фрагмента программы на
Паскале взяты из ввода, оформленного как
модель бокс/клей/штраф; В первом случае
строки были ограничены длиной в 10 em,
а во втором —25 em. Все разбиения строк
и втяжки производились автоматически
посредством алгоритма оптимальной верстки,
который не имел специальных знаний в
языке Паскаль. Процесс компиляции исходного
текста программы на Паскале в боксы, клей
и штрафы провела компьютерная программ
под названием Blaise.
112
Компьютерная типография
нежелательным эффектом размещения всех таких разбиений в правом поле.
Тот факт, что такое выравнивание подавляется, в данном случае
оказывается преимуществом, поскольку означает, что мы можем вставить растяжимый
клей где хотим внутри строки, если это повлияет на формулу «плохости»
соответствующим образом.
Каждая строка в более широком отрывке на рис. 10 фактически является
«абзацем» сама по себе, так что только в узком отрывке продемонстрирована
работа механизма разбиения строк. Каждый абзац имеет определенную
втяжку первой строки, соответствующую его положению в программе, выраженную
t единицами «табуляций». Сам абзац также имеет заданный размер втяжки,
выраженный t + 2 единицами табуляций; это означает, что все строки после
первой будут уже первой на 2 единицы табуляции и сдвинуты относительно
нее на две единицы вправо. В некоторых случаях (например, когда строки
начинаются с var' или с 'while') втяжка равна трем единицам табуляции вместо
Двух.
Этот абзац начинается элементом 'клей(0, 100000, 0)', который доставляет
достаточное растяжение для того, чтобы алгоритм разбиения строк не
содрогался слишком часто от того, что разбиения не дают совершенного квадрата
у правого поля, по крайней мере в первой строке. Специальные разбиения
вставляются в тех местах, где TgX не может нормально разбить строку в
математическом режиме, например, последовательность
штраф(0, оо, 0)
клей(0, 100000, 0)
штраф(0, 50, 0)
клей(0, -100000,0)
бокс(0)
штраф(0, оо, 0)
клей(0, 100000, 0)
должна быть вставлена непосредственно перед 'primes' в декларации var. Эта
последовательность позволяет сделать разбиение со штрафом 50 и перейти на
следующую строку, которая начинается с многочисленных растяжений.
Аналогичная конструкция используется между присваиваниями, например, между
'sieve := [2 . . п];' и 'primes := [ ]', где последовательность выглядит так:
штраф(0, оо, 0)
клей(0, 100000, 0)
штраф(05 0, 0)
клей(6 + 2ги, -100000,0)
бокс(0)
штраф(0, оо, 0)
клей(-2ги, 100000,0);
Здесь w — размер единицы табуляции. Если разбиение произошло, то
следующая строка начинается с 'клей(—2ги, 100000, 0)', который подавляет эффект
навешивания втяжки и эффективно восстанавливает положение начала абза-
Глава 3. Верстка абзацев
113
ца. Если разбиения не происходит, то окончательный результат представлен
как 'клей(6, 100000, 0)', обычный пробел.
Автоматическая система не может рассчитывать на обнаружение
наилучших точек разбиения программ, так как только разбираясь в семантике можно
указать, где некоторые разбиения улучшат восприятие программы и
обнаружат скрытую симметрию. Десятки экспериментов с самыми разнообразными
исходными текстами на Паскале показали, однако, что описанный подход
оказался на удивление эффективным: авторами программ были изменены менее
1% разбиений строк для улучшения их восприятия.
Сложный указатель
Последнее приложение разбиений на строки, которое мы рассмотрим,
представляет собой наиболее трудный материал из всех, ранее нам
встречавшихся. С этим вопросом удалось справиться лишь после того, как мы приобрели
более чем двухлетний опыт решения простых задач разбиения, так как вся
ACM Symposium on Principles of Programming
Languages, Third (Atlanta, Ga., 1976), selected
papers *1858
ACM Symposium on Theory of Computing, Eighth
Annual (Hershey, Pa., 1976) 1879, 4813,
5414, 6918, 6936, 6937, 6946, 6951, 6970, 7619,
9605, 10148, 11676, 11687, 11692, 11710, 13869
Software See *1858
ACM Symposium on Principles of
Programming Languages, Third
(Atlanta, Ga., 1976), selected
papers *1858
ACM Symposium on Theory of
Computing, Eighth Annual
(Hershey, Pa., 1976)
1879, 4813, 5414, 6918, 6936, 6937,
6946, 6951, 6970, 7619, 9605, 10148,
11676, 11687, 11692, 11710, 13869
Software See *1858
Рис. 11. Эти три выдержки из указателя ключевых
слов были получены из одного исходного файла и
набраны с разными ширинами колонок: 22.5, 17.5
и 12.5 em соответственно. Обратите внимание на
комбинацию рваных правого и левого краев и на
«отточия».
А.СМ Symposium on
Principles
of Programming
Languages, Third
(Atlanta, Ga., 1976),
selected papers ... *1858
\CM Symposium on
Theory of Computing,
Eighth Annual
(Hershey, Pa., 1976)
1879, 4813, 5414,
6918, 6936, 6937, 6946,
6951, 6970, 7619, 9605,
10148, 11676, 11687,
11692, 11710, 13869
Software See *1858
114
Компьютерная типография
мощь методики бокс/клей/штраф не была столь очевидна сразу. Эта задача
иллюстрируется на рис. 11, в котором представлены выдержки из указателя
ключевых слов журнала Mathematical Reviews. Подобным указателем теперь
снабжен в конце каждый том, равно как и именным указателем в аналогичном
формате.
Как и на рис. 10 примеры на рис. 11 были получены при помощи одного
и того же исходного кода, но набирались они с разной длиной строки, чтобы
проиллюстрировать разнообразие возможностей разбиения. Каждый термин
указателя состоит из двух частей: собственно термин и ссылка, причем обе
части могут оказаться слишком длинными и не уместиться в одну строку. Если
разбиение строки происходит в собственно термине, отдельные строки
оформляются с рваным правым краем, но если разбиение происходит в ссылках, то
получаются строки с рваным левым краем. Эти две части отделяются друг от
друга отточием— строкой из точек и пробелов между ними; отточия
вводятся при помощи некоторого обобщения понятия клея, которое помещает набор
в данном боксе в данный промежуток, вместо того чтобы оставить этот
промежуток пустым. Навешивание абзацного отступа применяется ко всем строкам,
кроме первой, поэтому первая строка каждого термина легко
идентифицируется. Одна из целей разбиения таких элементов на строки состоит в минимизации
пустого пространства, которое возникает в строках с рваными правым и левым
краями. Вспомогательная цель состоит в минимизации количества строк,
содержащих ссылки на страницы. Например, если возможно вместить все ссылки
в одну строку, алгоритм разбиения на строки это и сделает. Последнее может
означать, что разбиение произошло после отточия, и ссылки начались с новой
строки. В таком случае отточия должны прерваться на фиксированном
расстоянии w\ от правого края. Более того, строки с рваным правым краем должны
отстоять от правого поля по крайней мере на фиксированное расстояние и>2,
так что нет никакой возможности перепутать собственно термин с ссылками
на страницы. Отдельные боксы должны быть повторены в отточии с шириной
бокса г^з •
Эти основополагающие правила иллюстрируются на рис. 11, где абзацный
отступ равен 27 единицам, W\ = 45, w-2 — 9, w% — 7.2; цифры имеют
ширину 9 единиц, а ширина соответствующих колонок суть 405, 315 и 225 единиц.
Термин 'Theory of Computing' демонстрирует три варианта отточий: они
могут находиться на одной строке с окончанием собственно термина и началом
ссылок, либо они могут завершать строку до того, как начнутся ссылки, либо
начинать строку после собственно термина.
Здесь показано, как все это может быть закодировано при помощи
боксов, клея и штрафов: (а) каждый пробел в собственно термине представлен
последовательностью
штраф(0, оо, 0)
клей(ги2, 18, 0)
штраф(0, 0, 0)
клей(б — W2, —18, 2),
Глава 3. Верстка абзацев
115
которая сохраняет рваный правый край и пробелы, которые могут сжиматься
при необходимости от б единиц до 4. (Ь) Переход от собственно термина к
ссылкам на страницы представлен последовательностью (а), за которой
следует
бокс(О)
штраф(0, оо, 0)
отточия(ЗгУз, 100000, Зги3)
клей(гУ1, 0, 0)
штраф(0, 0, 0)
клей(—гУ1, —18, 0)
бокс(0)
штраф(0, оо, 0)
клей(0, 18, 0).
(с) Каждый пробел в ссылках представлен последовательностью
штраф(0, 999, 0)
клей(б, -18, 2)
бокс(0)
штраф(0, оо, 0)
клей(0, 18, 0),
которая поддерживает рваный левый край и пробелы от б до 4 единиц.
Части (а) и (с) этих конструкций аналогичны тем вещам, которые мы
видели ранее; штраф 999 в (с) стремится минимизировать общее количество строк,
занимаемых ссылками. Самый интересный аспект конструкции — это
последовательность перехода (Ь), где представлены три или четыре варианта: если
разбиения строки не происходит в (Ь), то окончательный результат такой:
(собственно термин) клей(б, 0, 2) (отточие) (ссылка),
что позволяет отточию появиться между собственно термином и ссылками на
страницы в текущей строке. Если разбиение происходит до отточия,
окончательным результатом будет
(собственно термин) клей(ги2, 18, 0)
(отточие) (ссылка),
так что мы получим разбиение, очень похожее на то, которое возникает после
пробела в собственно термине, и отточие начнется со следующей строки. Если
разбиение строки происходит после отточия, окончательный результат такой:
(собственно термин) клей(б, 0, 2) (отточие) клей(ги1, 0, 0)
клей(0, 18, 0) (ссылка),
так что мы имеем разбиение, очень похожее на то, которое появляется после
пробела в ссылках, но без штрафа 999; отточие отстоит от правого края на w\
единиц. Наконец, если разбиения возникают и до и после отточий в (Ь), мы
116
Компьютерная типография
имеем ситуацию, в которой всегда больше дефектности, чем в альтернативной,
когда разбиение происходит только после отточия.
Когда выбор точек разбиения оставляет в отточиях пространство по
крайней мере в Зк;з единиц, мы с уверенностью будем иметь по крайней мере 2
точки, но можем не получить 3 точки, поскольку отточия на разных строках
выровнены по точкам. Клей в других пробелах на строке с отточием будет
сжиматься, если до отточия останется расстояние менее чем Зг^з, и будет тенденция
к тому, чтобы отточие не исчезло вовсе; однако в худшем случае пространство
для отточия сожмется до нуля, так что не будет видно ни одной точки. Нужно
иметь возможность быть уверенным, что все отточия содержат по крайней
мере 2 точки, просто установив компоненту сжатия отточия в (Ь) равной нулю.
Это могло бы улучшить вид результата, но, к сожалению, это только удлинит
именной указатель примерно на 15 процентов и такие затраты, вероятно, будут
неоправданными.
Предварительный вариант этой конструкции использовался с пакетом Т^Х
для подготовки указателей в Mathematical Reviews, начиная с ноября 1979 г.
Однако элементы 'бокс(О) штраф(0, оо, 0)' были опущены в (Ь) для
совместимости с более ранними указателями, которые готовились в другом
программном продукте; это значит, что отточия исчезали полностью везде, где
происходило разбиение непосредственно перед ними, в результате в
указателях оказалось неоправданно много пустых коридоров, что портило внешний
вид.
Алгебраический подход
Из примеров, которые мы только что рассмотрели, видно, что боксы, клей
и штрафы представляют собой чрезвычайно гибкие элементы, позволяющие
пользователю получать большое разнообразие эффектов, не прибегая к
расширению основных операций, применяющихся при обычном наборе. Отдельные
конструкции, однако, могут показаться чем-то магическим: они работают, но
непонятно даже, как они были задуманы. Мы теперь приступим к
систематическому изучению действия этих элементов, чтобы в полной мере оценить их
потенциальные возможности. Это краткое обсуждение не зависит от
остального материала статьи и может быть опущено.
Во-первых, понятно, что
бокс(ги) бокс(г(/) — бокс(ги + wf) ,
если мы игнорируем содержимое боксов и рассматриваем только ширины; в
критерии разбиения на строки входят только ширины. Эта формула означает,
что любые два последовательных бокса могут быть заменены одним,
независимо от выбора точек разбиения, так как разбиения не возникают в боксах.
Точно так же легко убедиться, что
клей(ги, у, z) клей(г</, у', zf) — клей(ги + w\ у + у', z + z') ,
Глава 3. Верстка абзацев
117
так как разбиения в элементе клей(г</, у', zf) не будет и поскольку разбиение
в клей(ги, у, z) эквивалентно разбиению в клей(ги + wf, у + у', z + z').
При определенных обстоятельствах мы можем также скомбинировать два
смежных штрафа в один; например, если —оо < р, р' < +00, мы имеем
штрафе, р, /) штрафе, р', /) = штрафе, min(p, р'), /)
относительно любого оптимального выбора точек разбиения, так как с
меньшими штрафами связаны меньшие дефекты. Однако общую
последовательность 'штрафе, р, /) штраф(г</, р', /')' мы не всегда можем заменить на один
штраф.
Нельзя предположить без потери общности, что за всеми боксами
немедленно следуют пары элементов вида 'штраф(0, оо, 0) клей(ги, у, z)\ Потому
что если за боксом следует другой бокс, мы их можем скомбинировать; если за
ним следует штраф с р < оо, мы можем вставить 'штраф(0, оо, 0) клей(0, 0, 0)';
если за ним следует 'штрафу, оо, /)', мы можем предположить, что w — f — 0
и следующим элементом является клей; а если за этим боксом следует клей, то
мы можем вставить 'штраф(0, оо, 0) клей(0, 0, 0) штраф(0, 0, 0)'. Более того,
мы можем удалить любой штраф, имеющий р = оо, если ему непосредственно
не предшествует бокс.
Таким образом, любая последовательность из элементов бокс/клей/штраф
может быть преобразована в обычный вид, где за каждым боксом следует
штраф оо, за каждым штрафом — клей, за каждым элементом клея следует
либо бокс, либо штраф < оо. Предположим, что имеется только один штраф — оо,
и что это завершающий элемент, поскольку вынуждаемое им разбиение
строки эффективно разделяет более длинную последовательность на независимые
части. Из этого заключаем, что представленные в нормальном виде
последовательности могут быть переписаны как
XiX2 . . . Хп штраф(ги, -оо, /),
где каждое Х{ представляет собой последовательность элементов вида
бокс(ги) штраф(0, оо, 0) клей(г(/, у, z)
или вида
штраф(г>, р, /) клей(ги, у, z) .
Для первой из этих двух форм используем обозначение бшк(г(; + г(/, у, z),
означающее, что это функция от w + wf, а не отдельно от w и w', и запишем X
во второй форме в виде шк(г>, р, /, ги, у, z). Мы можем предположить, что
последовательность величин X не содержит двух элементов бшк в одной строке,
так как
бшк(к;, у, z) бшк(г(/, у', zf) — бшк(к; + w\ у + у', z + z') .
118
Компьютерная типография
Близкое знакомство с алгеброй боксов, клея и штрафов чрезвычайно
облегчает введение конструкций для специальных приложений, подобных
описанным выше, как только такие конструкции возможны. Рассмотрим, например,
обобщение задач, возникающих для текста с рваным правым краем, с рваным
левым краем и центрированным: мы хотим так определить необязательное
разбиение строки между словами, что если разбиения не происходит, то мы будем
иметь последовательность
(конец текстах) клей^, yi, z\) (начало текста^)
на одной строке, а если происходит, то
(конец текстах) клей(ги2, У2, %2) штраф(к;о, Р, /)
клей(ги3, уз, ^з) (начало текста2)
на двух строках. Рассмотрение нормальных форм показывает, что наиболее
общий способ сделать это состоит во вставке последовательности
бшк(ги, у, z) шк(к;0, р, /, ги', у', г') бшк(ги", у", z")
между текстх и текст2, где никакой дополнительный текст не связан с двумя
вставляемыми элементами бшк. Таким образом, вся работа сводится к
определению подходящих значений ги, у, z, it/, у', z', и/', у" и z"\ их можно получить
немедленно, решив уравнения
wi > У + У' + У"= Vi > z + z' + z" = zi ,
и>2 , У = 2/2 , z = z2 ,
^з , у" = Уз , г" = z3 .
Как только конструкция найдена таким образом, ее можно упростить,
отменив процесс, который мы использовали для вывода нормальных форм, и
применяя другие свойства алгебры бокс/клей/штраф. Например, мы всегда
можем удалить штраф оо в последовательности вида
штраф(0, оо, 0) клей(0, у, z) штраф(0, р, 0) ,
если y>0,z>0np<0, поскольку разбиение на клее всегда хуже, чем
разбиение на штрафе р.
Введение в алгоритм
Вероятно, лучше понять общую идею алгоритма оптимальной верстки
поможет рассмотрение примера. На рис. 12 повторен абзац рис. 4(c) и включены
крохотные вертикальные пометки для указания «точек допустимого
разбиения», найденных алгоритмом. Точка допустимого разбиения имеет место, если
текст абзаца от начала до этой точки может быть разбит на две строки,
коэффициент корректировки которых не превышает данный допуск; в случае,
w + w' + vJ —
w —
Глава 3. Верстка абзацев
119
1 In olden times when wishing still helped one, there lived a1 .774
king1 whose daughters were all beaujti/ul; and the youngest was' .179
so1 beaujti/ul that the sun itself, which has seen so much, was' .629
astonished whenever it shone in her face. Close by the king's1 .545
castle' lay1 a great dark for/est, and un^der an old lime-tree in' the1 .000
forjest1 was' a' well, and when the day was very warm, the' king's1 .079
child' went' out' into the for/est and sat down by the side1 of the1 .282
cool' founjtain;' and' when she was bored she took a golden' ball,' .294
and' threw1 it1 up' on' high and caught it; and this ball was1 her1 .575
favorfte' plaything. ' .004
Рис. 12. Тонкие вертикальные пометки показывают «точки допустимого
разбиения», где строки могут заканчиваться, не вынуждая никакие предыдущие пробелы
растягиваться больше, чем их заданное растяжение.
представленном на рис. 12, этот допуск был взят равным единице. Так,
например, в строке 7 после слова 'went' имеется пометка, потому что способ
установить абзац до этой точки со словом 'went' в конце б-й строки и без строк
от 1-й до б-й имеет плохость, превышающую 100 (см. рис. 4(a)).
Алгоритм возобновляет свою работу, локализуя все точки допустимого
разбиения и запоминая лучший способ получения каждой в смысле
наименьшего общего дефекта. Это осуществляется посредством поддержания списка
активных точек разбиения, состоящий из всех точек, которые могут быть
кандидатами для будущих разбиений. Когда встречается потенциальная точка
разбиения 6, алгоритм проверяет, существуют ли активная точка а, такая, что
строка от а до b имеет некий подходящий коэффициент корректировки. Если
существует, то b является вероятной точкой разбиения и она заносится в
список активных точек. Алгоритм также запоминает опознавательный код точки
разбиения а, минимизирующей общий дефект, когда последний вычисляется от
начала абзаца до точки b через точку а. Когда встречается активная точка а,
для которой строка от а до b имеет коэффициент корректировки, меньший чем
— 1 (т. е. когда строка не может быть сжата до необходимой длины), то точка
разбиения а удаляется из списка активных точек. Поскольку размер
активного списка по существу ограничен максимальным количеством слов в строке,
время работы алгоритма ограничено этим же количеством (обычно малым),
умноженным на число потенциальных точек разбиения.
Например, когда алгоритм начинает работать с абзацем на рис. 12,
имеется только одна активная точка разбиения, представленная началом первой
строки. Довольно неудачный вариант, когда строка начинается отсюда и
заканчивается на 'In' или 'olden', ..., или 'lived', потому что клей между словами
не аккумулируется в достаточных количествах для растяжения в таких
коротких отрезках текста; но удачная точка разбиения есть и она находится после
следующего слова 'а'. Теперь имеется две активные точки разбиения: одна
исходная и одна новая. После следующего слова 'king' образуются уже три
активные точки; но после слова 'whose' алгоритм видит, что невозможно
втиснуть весь текст от начала до слова 'whose' в одну строку, так что начальная
точка перестает быть активной и остаются только две активные точки.
120
Компьютерная типография
Забегая вперед, посмотрим, что происходит, когда алгоритм рассматривает
потенциальную точку разбиения после слова 'fountain;'. На этом шаге имеется
восемь активных точек, следующие соответственно за текстовыми боксами для
'child', 'went', 'out', 'side', 'of, 'the', 'cool' и 'foun-'. Строка, начинающаяся после
'child' и заканчивающаяся 'fountain;', будет, по-видимому, слишком длинной,
так что 'child' перестает быть активным. Допустимые строки находятся между
'went' или 'out' и 'fountain;' а дефектность этих строк равна соответственно 400
и 144; строка, начинающаяся 'went', фактически более предпочтительна,
потому что в сущности общая дефектность строк от начала абзаца до 'went' меньше,
чем от начала до 'out'. Таким образом, 'fountain;' становится новой активной
точкой разбиения. Алгоритм сохраняет указатель в обратном направлении от
'fountain;' к 'went', что означает, что лучший способ получить разбиение после
'fountain;' состоит в том, чтобы начать с лучшего способа получить разбиение
после 'went'.
Вычисления алгоритма можно представить графически в виде схемы на
рис. 13, на которой изображены все допустимые точки разбиения вместе с
числом дефектности, соответствующим каждой допустимой строке между ними.
Цель алгоритма состоит в вычислении наикратчайшего пути от вершины до
основания рис. 13; при этом числа дефектности используются в качестве
«расстояний», соответствующих отдельным отрезкам пути. В этом смысле работа
по оптимизации точек разбиения строк сводится в сущности к особому случаю
задачи нахождения наикратчайших путей в ациклической сети; алгоритм
разбиения на строки лишь чуть более сложен только потому, что должен строить
сеть одновременно с нахождением кратчайшего пути.
Обратите внимание, что алгоритм оптимальной верстки можно легко
описать в терминах сети, наподобие рис. 13: это «жадный алгоритм», который
просто выбирает кратчайшее продолжение на каждом шаге (хотя использует в
качестве критерия плохость-и-штраф вместо дефектности). Алгоритм простой
верстки может быть охарактеризован как метод, всегда выбирающий самую
левую ветвь с отрицательным коэффициентом корректировки (не приводящим
к переносу, в случае которого будет выбрана самая правая ветвь без
переносов, если таковая будет допустимой). Из этих рассмотрений мы можем с
очевидностью понять, почему алгоритм оптимальной верстки стремится
делать значительно лучшую работу.
Иногда нельзя продолжить работу алгоритма от одной допустимой
точки разбиения к какой-либо другой. Такая ситуация не возникает на рис. 13,
но это могло бы быть ниже слова 'so', если бы мы не разрешили перенос в
слове 'astonished'. В таких случаях алгоритмы простой и улучшенной верстки
должны пересортировать допустимые строки, тогда как алгоритм
оптимальной верстки может обычно найти другой путь через лабиринт.
С другой стороны, некоторые абзацы бывают трудными по сути, и их
невозможно разбить на допустимые строки. В таких случаях описанный
ранее алгоритм обнаружит, что его активный список сокращается до тех пор,
пока активность совсем на потеряется. Как поступить в такой ситуации? По-
видимому, можно начать снова с более толерантным взглядом на недопусти-
Глава 3. Верстка абзацев
121
В;
«I
was
676 |
2209^
м
\ 1521
\5329
J king I
"'■"3136
so
was
289
I
5929...,
\3600
aston-
king'i
^4489
castle lay
3481// I 1 /-'4900 | 4
1 i—■—\,.^ i—i—
the for- est
16,
side
676 j
[The]
\/ \.49
1 | 841 / 160o\
king':
was
jl /"81
child
/ с: no о X.
9 j 656l\ 121/
. i . \ *--.
the cool foun-
went
3249,
2209
' 81 \1369
/"
\400
tain;
-V /—'\ UT '—1—' ' 1—4 7—\
1\324/ 5929 \ 16] 25 1 4) \4761 /289 \4
golden ball, and threw
25 ! 67б"---\ 400 I 2601 I 1б\ 260
was
4 j '--,..4761 /
threw it
out
/l44 \l444
4
up
/
and
2401 '■-
ч1
on
her favor-
..^ЗОО!'
X
ite
\
"Л
1 3364
play-
\^
l\ 3001
/1
\
\
w \
/
/
A
/
A
A
A
/
/ A
//
thing.
Рис. 13. Эта диаграмма показывает допустимые точки разбиения и требуемое число
дефектности, когда алгоритм проходит от одной точки разбиения к другой. Самый
короткий путь от вершины до основания соответствует лучшему способу
представления абзаца, если рассматривать дефектности как расстояния.
мость (с большим пороговым значением для коэффициентов корректировки).
ТЕХ придерживается той точки зрения, что в случае отсутствия
конкретного критерия пользователь захочет произвести разбиение вручную. Поэтому
активный список насильственным образом защищен от того, чтобы стать
пустым: просто декларируется допустимость точки разбиения, если в противном
случае активный список может стать пустым. В результате строка
переполнится и будет выдано соответствующее сообщение об ошибке, призывающее
пользователя провести корректирующие действия.
На рис. 14 показано, что происходит, когда алгоритм допускает совсем
жидкие строки; в этом случае строка рассматривается как допустимая, только
122
Компьютерная типография
если ее коэффициент корректировки превосходит 10 (так что можно иметь
междусловный пробел, превышающий 2т). Подобные коэффициенты
толерантности могут использоваться людьми, которые не хотят вручную
разбивать на строки абзац, вызывающий трудности. На этой иллюстрации тонкие
черточки, указывающие точки допустимого разбиения, имеют разную длину:
более длинные указывают места, в которые можно попасть лучшими путями;
тонкий пунктир используется для точек разбиения, которые вряд ли
допустимы. Заметим, что на рис. 14 отмечены все потенциальные точки разбиения,
за исключением нескольких в первых двух строках; так что здесь значительно
больше допустимых точек, чем на рис. 12, и соответствующая диаграмма будет
гораздо пространнее, чем на рис. 13. Существует 806137512 допустимых путей
получить абзац при таком широком диапазоне толерантности, тогда как для
рис. 12 таких путей всего 50. Количество активных узлов в этом случае, однако,
не будет существенно больше, чем для рис. 12, поскольку их число
ограничено длиной строки. Поэтому алгоритм будет работать не намного медленнее,
несмотря на то, что толерантность увеличилась, а число возможных вариантов
абзаца невероятно возросло. Например, после слова 'fountain;' теперь имеется
17 активных точек разбиения вместо прежних 8, так что обработка будет
всего примерно вдвое длиннее, хотя появилось громадное число дополнительных
возможностей.
Если порог допустимых пробелов достаточно велик, алгоритм почти
наверняка найдет допустимое решение и сообщит пользователю об отсутствии
ошибок, несмотря на то, что неизбежно останутся очень жидкие строки. Те
пользователи, которые хотели бы получать сообщения о подобных ошибках,
должны установить коэффициент толерантности ниже: это не только
информирует о необходимости корректирующих действий, но и повысит
эффективность алгоритма.
Один из важнейших моментов в рис. 14, на который следует обратить
внимание, состоит в том, что точки разбиения могут становиться допустимыми
совершенно разными путями, руководствуясь разным количеством строк до
точки разбиения. Например, слово 'seen' допускается как в конце строки 3:
'In olden ... lived/a... young-/est... seen',
так и в конце строки 4:
'In olden... helped/one... were/all... beau-/tiful... seen',
хотя на рис. 12 разбиение после 'seen' вообще не допускалось. Разбиения после
слова 'seen' в конце строки 3 имеет существенно меньшую дефектность, чем
в конце строки 4 (1533 770 против 12 516097962), так что алгоритм запомнит
только предшествующую возможность. Это является приложением
«принципа оптимальности» динамического программирования, который отвечает за
эффективность нашего алгоритма [6]: точки оптимального разбиения абзаца
всегда являются оптимальными для абзаца, который они образуют. Но здесь
Глава 3. Верстка абзацев
123
1 In olden times when wishing still helped one,' there lived1 a1 .774
king1 whose daughters were all beau^tijul;' and1 the1 youngjest1 was1 .179
so1 beau^i/iil that' the' sun' itjself,1 which1 has' seen1 so1 much,1 was1 .629
astonjshed' whenever it' shone1 in1 her1 face.1 Close1 by1 the1 king's1 .545
castle1 lay1 a great1 dark1 forjest,1 and1 unjder' an1 old1 lime-Jtree1 in1 the1 .000
forjest1 was1 a1 well,1 and1 when1 the1 day1 was1 very1 warm,1 the1 king's1 .079
child1 went1 out1 into1 the1 forjest1 and1 sat1 down1 by1 the1 side1 of the1 .282
cool1 founjtain;1 and1 when1 she1 was1 bored she1 took1 a1 golden1 ball,1 .294
and1 threw1 it1 up1 on1 high1 and1 caught1 it;1 and1 this1 ball1 was1 her1 .575
favorite1 playjthing. l .004
Рис. 14. Когда коэффициент толерантности достигает десятикратного растяжения,
появляется большее количество допустимых точек разбиения и большее количество
вариантов абзаца.
интересен тот факт, что экономии памяти пе будет, если последующие строки
не окажутся одинаковой длины, поскольку различные длины строк могут
просто означать, что лучше было бы поместить 'seen' в конце строки 4; например,
мы уже упоминали один прием, вынуждающий алгоритм произвести заданное
количество строк. Следовательно, в случае переменной длины строк алгоритм
будет вынужден иметь два отдельных списка активных точек разбиения после
слова 'seen'. Компьютер не может просто запомнить один с наименьшими
общими дефектностями; это лишило бы законной силы принцип оптимальности
динамического программирования.
На рис. 15 представлен пример разбиения на строки, когда все строки
абзаца имеют разную длину. В подобных случаях нужно привязать номера строк
к точкам разбиения, которые могут послужить причиной того, что
количество активных точек будет заведомо больше, чем максимальное количество
слов в строке, если установлено высокое значение толерантности.
Следовательно, мы хотим иметь низкое значение толерантности. Но если оно слишком
низкое, у нас может не оказаться возможности разбить абзац на строки,
имеющие заданный вид. К счастью, всегда есть замечательный способ, при котором
алгоритм оказывается достаточно гибким, чтобы найти хорошее решение, не
требуя при этом много памяти и времени. Данные на рис. 16 демонстрируют,
например, что алгоритму придется не так уж много работать, чтобы отыскать
оптимальное решение для заметок Галилея об окружностях, когда
коэффициент корректировки для каждой допустимой строки назначался равным 2 или
меньше; было все еще достаточно гибкости, чтобы сделать допустимое решение
возможным.
Хороший метод разбиения на строки особенно важен для набора научно-
технических работ, потому что математические формулы в тексте по
возможности не должны переноситься на другую строку. Ряд таких наиболее трудных
случаев можно видеть в журнале Mathematical Reviews или на страницах
The Art of Computer Programming, содержащих ответы, потому что
материал такого рода публикаций зачастую переполнен формулами. На рис. 17
приведен типичный пример, заимствованный из ответов к упражнениям тома
Seminuinerical Algorithms [28], в котором отмечены точки возможных разбие-
124
Компьютерная типография
The area
of a circle is a mean
proportional between any two
regular and similar polygons of
which one circumscribes it and the
other is isoperimetric with it. In addition,
the area of the circle is less than that of any
circumscribed polygon and greater than that
of any isoperimetric polygon. And further,
of these circumscribed polygons, the one
that has the greater number of sides has
a smaller area than the one that has a
lesser number; but, on the other hand,
the isoperimetric polygon that
has the greater number of
sides is the larger.
Галилео Галилей (1638)
I
turn, in the
following treatises, to
various uses of those triangles
whose generator is unity. But I leave out
many more than I include; it is extraordinary how
fertile in properties this triangle is. Everyone can try his hand.
— Б лез Паскаль (1654)
Рис. 15. Пример разбиения на строки разной длины.
Рис. 16.
Детали допустимых
точек разбиения в первом
примере на рис. 15,
показывающие, как было найдено
оптимальное решение.
•The area of a1 .375
circle is a mean propor-1 .828
tional between any two regular1 .406
and similar polygons of which one1 i.oqs
circumscribes it and the other is iso-1 1.268
perimetric with it. In addition, the area1 .574
of the1 circle is less than that of any cir-1 1.11:
cumscribed1 polygon and greater than that1 .93
of any1 isomerinietric polygon. And further,1 .58
of these1 circumscribed polygons, the one1 1.56
that1 has1 the1 greater number of sides has1 .703
a1 smaller1 area1 than the one that has1 1.437
a1 lesser number;1 but, on the other1 1.240
hand,1 the1 isomer inietric polygon1 l.ose
that has the1 greater num-1 .974
ber1 of sides is1 the1 .479
larger.1 .000
Глава 3. Верстка абзацев
125
'15. (This procedure maintains four integers (А, В, С, D) with the invariant meaning1 -.409
that "our remaining job is to output the continued fraction for {Ay -f B)/(Cy -f'-D),1 -.057
where у is the input yet to come.") Initially set j <— к <— 0, (A, B, C, D) <—' (a, b, c, d);1 -.788
then input Xj and set (A, B, C, D) <— (Axj + B, A, Cxj + D,C), j <—' j -f11,1 one1 or1 .207
more1 times until С + D has the same sign as C. (When j > l1 and1 the1 input1 has1 not1 -.282
terminated, we know that 1 < у < oo; and when С + d has1 the1 same1 sign1 as C1 we1 .124
know therefore that {Ay + B)/{Cy + £>) lies between1 (А +'B)/(C +'£>)' and' Л/С.)1 .192
Now1 comes the general step: If no integer lies strictly1 between1 (A -f1 B)/(C +1 £>)' .582
and1 А/С] output Xfc *- [Л/CJ, and set (Л,£,С,£>) ♦-' (С, £>, Л -'Х^С, В -]XkD)j -.оэв
/с <—! к -f11;1 otherwise input xj and set (Л, В, С, £>) ♦-' (Ла:^ +1 В, Л, Czj +1 D, С),1 .479
j <—' j -f11.1 The1 general step is repeated ad infinitum.1 However,1 if1 at1 any* time1 the1 .266
finat Xj1 is1 input,1 the1 algorithm immediately switches1 gears: It1 outputs1 the1 continued1 -.325
fraction1 for1 (Axj +{B)/(Cxj + £>), using Euclid's1 algorithm,1 and1 terminates. ' .000
Рис. 17. Пример найденных алгоритмом допустимых точек разбиения в абзаце,
перенасыщенном математическими формулами.
ний, когда коэффициенты корректировки не должны превышать 1. Несмотря
на то что некоторые допустимые точки разбиения появляются внутри формул,
с ними связаны штрафы, которые делают их сравнительно нежелательными,
так что алгоритм способен сохранить все формулы в данном абзаце
невредимыми.
Дальнейшие подробности
Сформулированная выше задача оптимизации состоит в нахождении таких
точек разбиения, при которых суммарная дефектность была бы
минимальной, где дефектность отдельной строки зависит от ее плохости (т. е. от того,
насколько растягивается или сжимается клей) и от возможного штрафа,
связанного с окончательной точкой разбиения; когда две соседние строки
заканчиваются переносом (т. е. штрафом с / = 1), добавляется также дополнительная
дефектность. Двухлетний опыт работы с подобной моделью этой задачи дал
блестящие результаты, а несколько приведенных выше абзацев удалось
впоследствии улучшить.
Первые две строки в двух верхних абзацах на рис. 4 иллюстрируют
потенциальный источник видимого беспорядка, который не рассматривался в
обсуждавшейся выше модели. Эти абзацы начинаются с плотной строки
(имеющей г = —.727), за которой сразу следует жидкая строка (имеющая г = +.821).
Котя эти две строки сами по себе не так ужасны, контраст между плотной и
жидкой строкой дает довольно неприятный эффект. Таким образом, новый
1]ёХ'овский алгоритм разбиения на строки распознает четыре вида строк:
Класс 0 (плотные строки), где —1 < г < —.5;
Класс 1 (обычные строки), где —.5 < г < .5;
Класс 2 (жидкие строки), где .5 < г < 1;
Class 3 (очень жидкие строки), где г > 1.
Дополнительная дефектность добавляется, когда соседние строки не того же
самого или соседнего класса, т. е. когда до или после строки класса 0 находится
126
Компьютерная типография
строка класса 2 или класса 3, либо до или после строки класса 1 находится
строка класса 3.
Это на первый взгляд простое расширение на самом деле вынуждает
алгоритм работать интенсивнее, потому что возможная точка разбиения теперь
может входить в список активных точек до четырех раз, дабы удовлетворить
принципу оптимальности динамического программирования. Например, если
строка, окончившаяся в некоторой точке, может быть как строкой класса О,
так и строкой класса 2, мы должны запомнить обе эти возможности, даже
учитывая, что класс 0 имеет большую дефектность, потому что мы можем
захотеть поместить после этой точки разбиения плотную строку. С другой
стороны, нам не нужно запоминать возможность разбиения в классе 0, если его
общая дефектность превышает дефектность при разбиении на строке класса 2
плюс дефектность при контрастных строках, поскольку разбиение на строке
класса 0 в таком случае никогда не приведет к оптимуму.
Чтобы понять, действительно ли дополнительные вычисления, требуемые
таким расширением алгоритма, приведут к ощутимому улучшению, нужно
провести еще ряд экспериментов. Пользователю удобно знать, что алгоритм
разбиения на строки принимает во внимание такие улучшения, но у него нет
основания проводить дополнительную работу, если результат вряд ли когда-
либо улучшится.
Другое расширение алгоритма нужно для того, чтобы поднять его до
высот профессионального ручного набора. Иногда мы хотим, чтобы абзац стал на
одну строку длиннее или короче его оптимального размера, потому что нужно
избежать одинокой «висячей строки» вверху или внизу страницы, или потому
что нам нужно получить четное количество строк для последующей
разбивки на две колонки. Хотя вид самого абзаца не оптимален, страница целиком
будет смотреться лучше и абзац будет сверстан настолько хорошо, насколько
это возможно при данных ограничениях. Например, два абзаца из сказки на
рис. 6 получились на строку короче своей оптимальной длины, зато все шесть
колонок оказались одинаковой длины.
Алгоритм разбиения на строки, который мы далее будем обсуждать, имеет
параметр «разреженности», что проиллюстрировано на рис. 18.
«Разреженность» представляет собой целое число q, такое, что общее количество строк,
полученное для этого абзаца, близко, насколько возможно, к оптимальному
количеству плюс число q\ при этом условия допустимости не нарушаются. На
рис. 18 показано, что происходит с примером абзаца на рис. 14, когда \q\ < 1.
Значения q < — 1 могли бы быть теми же самыми, что и q = — 1, поскольку
этот абзац не может быть сжат больше; значения q > 1 возможны, но редко
бывают нужны, потому что они требуют чрезвычайно широких пробелов.
Пользователь может получить оптимальное решение, имея наименьшее
возможное число строк, положив q равным большому отрицательному значению,
например —100. Когда q ф 0, допустимые точки соответствуют различным
номерам строк, но их все надо запомнить, даже если каждая строка имеет
одну и ту же длину.
Глава 3. Верстка абзацев
127
In olden times when wishing still helped one, there lived a king -.727
whose daughters were all beaujti/ul; and the youngest was so .821
beau^i/iil that the sun itself, which has seen so much, was astonr- -.455
ished whenever it shone in her face. Close by the king's castle lay -.870
a great dark forpst, and un^der an old lime-tree in the forpst was -.208
a well, and when the day was very warm, the king's child went .000
out into the forpst and sat down by the side of the cool fountain; -.577
and when she was bored she took a golden ball, and threw it up -.231
on high and caught it; and this ball was her favorite plaything. -.вез
In olden times when wishing still helped one, there lived a .774
king whose daughters were all beautiful; and the youngest was .179
so beaujti/ul that the sun itself, which has seen so much, was .629
astonished whenever it shone in her face. Close by the king's .545
castle lay a great dark forpst, and un/ier an old lime-tree in the .000
forest was a well, and when the day was very warm, the king's .079
child went out into the forpst and sat down by the side of the .282
cool fountain; and when she was bored she took a golden ball, .294
and threw it up on high and caught it; and this ball was her .575
favorite plaything. .557
In olden times when wishing still helped one, there lived 1.393
a king whose daughters were all beautiful; and the youngj- 1.464
est was so beaujti/ul that the sun itself, which has seen so 1.412
much, was astonished whenever it shone in her face. Close 1.226
by the king's castle lay a great dark forpst, and un^der an 1.412
old lime-tree in the forpst was a well, and when the day 1.735
was very warm, the king's child went out into the forpst 1.774
and sat down by the side of the cool fountain; and when 1.559
she was bored she took a golden ball, and threw it up on 1.37s
high and caught it; and this ball was her favorite playr 2.129
thing. .862
Рис. 18. Абзацы, полученные при параметре «разреженности» —1, 0 и +1. Такие
значения иногда бывают необходимы, чтобы сбалансировать вид всей страницы, но,
разумеется, она будет выглядеть некрасиво, если впадать в крайности.
Если строки абзаца довольно жидкие, мы не захотим, чтобы последняя
строка значительно отличалась от них, так что мы должны вернуться к
нашему первоначальному предположению о том, что «завершающий клей» абзаца
имеет почти бесконечное растяжение. Штраф для соседних строк из
контрастирующих классов кажется работает лучше в случае жидкой строки, если
завершающий клей в конце абзаца установлен так, чтобы получился
нормальный пробел, равный примерно трети общей длины строки, растягивающийся
до полной ее длины и сжимающийся до нуля.
Алгоритм
Перейдем теперь к сути дела и обсудим подробно алгоритм оптимального
разбиения на строки. Пусть имеется абзац xi...xm, описываемый элементами
Х{ — (ti, Wi,yi, Zi,pi, fi) как объяснялось выше, где Х\ представляет собой бокс,
а хт — штраф, устанавливаемый за вынужденное разбиение (рт = —сю). Пусть
128
Компьютерная типография
также имеется потенциально бесконечная последовательность положительных
длин строк /i, /2) К дефектности добавляется параметр а, когда возникают
две последовательные точки разбиения при /; = 1, а параметр j — когда две
последовательные строки принадлежат несовместимым классам соответствия.
Порог толерантности р представляет собой верхнюю грань коэффициентов
корректировки. Кроме того задан параметр «разреженности» q.
Допустимая последовательность точек разбиения (bi,..., b^) является
допустимым выбором точек разбиения, таких, что каждая из к результирующих
строк имеет коэффициент корректировки Vj < р. Если q = О, то работа
алгоритма сводится к нахождению допустимой последовательности точек,
имеющих наименьшую общую дефектность. Если q ф 0, то работа алгоритма
несколько усложняется и не поддается точному описанию. Попробуем
сформулировать это так: пусть к — число строк, которые алгоритм производит при
q — 0. Тогда алгоритм находит допустимую последовательность из к + q
точек разбиения, имеющих наименьшую общую дефектность. Если это, однако,
невозможно, то значение q увеличивается на 1 (если q < 0) или уменьшается
на 1 (если q > 0) до тех пор, пока не будет найдено допустимое решение.
Иногда допустимое решение найти невозможно даже при q = 0; мы обсудим эту
ситуацию позже, когда выясним, как ведет себя алгоритм в обычном случае.
Мы увидим, что иногда полезно разрешить боксам, клею и штрафам
иметь отрицательные ширины и даже отрицательное растяжение, но
абсолютно ничем не ограниченное использование отрицательных значений приводит
к неприятным осложнениям. По соображениям эффективности целесообразно
ввести два ограничения на обрабатываемые абзацы:
• Ограничение 1. Пусть Мь — длина самой короткой строки от начала абзаца
до точки разбиения Ь, а именно сумма всех wi — Z{, взятая по всем боксам
и элементам Х{ клея при 1 < г < Ь, плюс ъиь, если элемент хь
представляет собой штраф. Абзац должен иметь Ма < Мь, если только а и b суть
допустимые точки разбиения, причем а < Ь.
• Ограничение 2. Пусть а и Ь —допустимые точки разбиения, а < Ь, и
предположим, что нет такого Х{ в диапазоне а < г < Ь, который был бы
элементом-боксом или вынужденным разбиением (штраф pi = —оо). Тогда
либо b = т, либо хъ+\ является боксом или штрафом ръ+\ < оо.
Оба эти ограничения вполне разумные, поскольку они встречаются во всех
известных практических приложениях. Ограничение 2 на первый взгляд может
показаться странным, но мы скоро поймем, чем оно полезно.
Наш алгоритм в общих чертах работает следующим образом:
(Создание активного узла, представляющего собой начальную точку);
for b :— 1 to m do (if b —допустимая точка разбиения) then
begin (Установка допустимых точек разбиения b равными нулю);
(for каждый активный узел a) do
begin (Вычисление коэффициента корректировки г от а до Ь);
if г < — 1 or (b является вынужденным разбиением)
then (Деактивация узла а);
Глава 3. Верстка абзацев
129
if — 1 < г < р then (Запись допустимого разбиения от а до 6);
end;
(if имеется допустимое разбиение в b) then
(Присоединение лучших таких разбиений в качестве активных
узлов);
end;
(Выбор активного узла с наименьшей общей дефектностью);
if q ф 0 then (Выбор подходящего активного узла);
(Использование выбранного узла для определения оптимального
разбиения).
Смысл используемого здесь Алголо-подобного языка должен быть
самоочевиден. Активный узел в этом описании ссылается на запись, в которой
содержится информация о точке разбиения, ее принадлежности тому или иному
классу соответствия и номеру строки, которая на ней оканчивается.
Мы хотим иметь структуру данных, которая делает этот алгоритм
эффективным, и такую вполне приемлемую структуру не так трудно построить.
Здесь следует руководствоваться двумя основополагающими соображениями:
вычисление коэффициента корректировки, переводящего данный активный
узел а в данную допустимую точку разбиения, должно быть предельно
простым; должен быть простой способ определения того, какие из допустимых
разбиений в b должны быть сохранены как активные узлы.
Прежде всего, коэффициент корректировки зависит от общей ширины,
общего растяжения и общего сжатия, вычисленных из первого бокса после первой
точки разбиения и перед следующей точкой разбиения, и нам не хотелось бы
снова и снова вычислять эти суммы. Чтобы этого избежать, можно просто
вычислить эту сумму от начала абзаца до текущей точки и затем вычесть две
такие суммы, чтобы получить общую, которая находится между ними. Пусть
(Ег/;)ь, (Sy)fe и (Т,г)ъ обозначают соответственно суммы всех г/;;, у{ и Z{ в
элементах бокса и клея Х{ при 1 < г < Ь. Тогда если а и b являются допустимыми
точками с а < 6, то ширина Ьаъ строки от а до b и ее растяжение Уаь и сжатие
Zab могут быть вычислены следующим образом:
Lab = (£к;)ь - (£к;)ПОСЛе(а) + (wb если h = 'штраф');
Yah = {Zy)b - (^У)после(а) 5
Zab = (£z)b - (^^)после(а) •
Здесь «после(а)» есть индекс г > а, такой, что либо г > т, либо Х{ есть бокс,
либо Х{ есть штраф, который вынуждает сделать разбиение (pi = — оо). Эти
формулы выполняются даже в вырожденном случае, когда после(а) > 6, в силу
ограничения 2; в самом деле, в ограничении 2 особо оговорено, что
соотношение ПОСЛе(а) > Ь Влечет За СОбоЙ {T,w)b = (£ги)после(а), (Zy)b = (^У)после(а) И
{T,z)b = (И^)после(а)-
Из сказанного выше мы можем заключить, что узел а в структуре данных
должен содержать следующие поля:
130
Компьютерная типография
позиция(а) = индекс точки разбиения, представленной этим узлом;
строка(а) = номер строки, оканчивающейся в этой точке разбиения;
класс_соответствия(а) = класс соответствия строки, заканчивающейся в
этой точке разбиения;
общая_ширина(а) = (Ег/;)после(а), используемая для вычисления
коэффициентов корректировки;
общее_растяжение(а) = (Еу)после(а), используемая для вычисления
коэффициентов корректировки;
общее_сжатие(а) = (Ег)после(а), используемая для вычисления
коэффициентов корректировки;
общая_дефектность(а) = минимальная общая дефектность до этой точки
разбиения;
предшествующий (а) = указатель лучшего узла для предыдущей точки,
разбиения;
ссылка(а) = указатель следующего узла в этом списке.
Узлы становятся активными, когда они впервые созданы, и пассивными —
когда они деактивированы. Этот алгоритм поддерживает глобальные
переменные А и Р, которые указывают соответственно на первый узел в активном
списке и первый узел в пассивном списке. Первый шаг, следовательно, может
превратиться в:
(Создание активного узла, представляющего собой начальную точку) =
begin A := new узел (позиция = 0, строка = 0, класс-соответствия = 1
общаялнирина = 0, общее-растяжение = 0,
общее-сжатие = 0, общая_дефектность = 0,
предшествующий = Л, ссылка = Л);
Р:=Л;
end.
Мы также вводим глобальные переменные ЕЙ7, ЕУ и EZ для
представления (Еги)ь, (Еу)ь и (Ег)ь в основном цикле алгоритма, так что операция 'for
b := 1 to m do (if b есть допустимая точка разбиения) then (основной цикл)'
принимает следующий вид:
EW :=ЕУ :=EZ:=0;
for b := 1 to m do
if tb = 'бокс' then Е1У := Е1У + wb
else if tb = 'клей' then
begin if tb-i = 'бокс' then (основной цикл);
ZW :=ZW + wb; ЕУ:=ЕУ + 2/ь; EZ:=EZ + zfe;
end
else if рь Ф -boo then (основной цикл).
Непосредственно в основном цикле операция (Вычисление коэффициента
корректировки г от а до Ъ) может теперь быть представлена просто как
L := Y.W — общаялнирина(а);
if tb = 'штраф' then L := L + гюъ\
j := строка(а) + 1;
Глава 3. Верстка абзацев
131
if L < lj then
begin Y := ТУ — общее_растяжение(а);
if Y > 0 then r := (lj - L)/Y else r := oo;
end
else if L > lj then
begin Z := EZ — общее.сжатие(а);
if Z > 0 then v := (/j — L)/Z else r := oo;
end
else r := 0.
Другая неочевидная проблема, с которой нам придется, возможно, иметь
дело, проистекает из того факта, что несколько узлов могут соответствовать
одной и той же точке разбиения. Мы никогда не будем создавать два узла,
имеющих одни и те же значения полей (позиция, строка, классхоответствия),
поскольку весь смысл подхода динамического программирования заключается
в том, что нужно помнить только лучший из возможных путей получения
каждой допустимой позиции разбиения, имеющей данный номер строки и данный
класс соответствия. Но далеко не сразу очевидно, как отслеживать лучшие
пути, приводящие к данной позиции, когда такая позиция может возникнуть
при разных номерах строк; мы можем, к примеру, поддерживать таблицу
хеширования с полями (строка, класс соответствия) в качестве ключа, но это
приведет к ненужным осложнениям. Решение заключается в поддержании
активного списка, отсортированного по номерам строк. Просмотрев все активные
узлы для строки jf, мы можем вставить новые активные узлы для строки j + 1
в этот список непосредственно перед любыми активными узлами для строк
> j + 1, которые мы собираемся рассматривать в следующую очередь.
Дополнительная трудность состоит в том, что мы не хотим создавать
активные узлы для разных номеров строк, когда все длины строк равны, за
исключением q ф 0, поскольку это будет нежелательным образом замедлять
работу алгоритма; сложности общего случая не должны загромождать
простые ситуации, которые чаще всего и возникают. Таким образом, мы
предполагаем, что известен индекс jo, такой, что все разбиения строк с номерами
> jo можно рассматривать как эквивалентные. Индекс jo определяется
следующим образом: если q ф 0, то jo — oo; в противном случае jo настолько мал,
насколько возможно, причем lj = Zj+i при всех j > jo. Например, если q — 0
и lx = h — h Ф h — h = * * * j положим jo = 3, поскольку нет необходимости
отличать точку разбиения, которой оканчивается строка 3, от точки
разбиения в конце строки 4 в той же самой позиция, до тех пор, пока затрагиваются
последовательные строки.
Для каждой позиции Ь и строки с номером j удобно запоминать лучшую
допустимую точку разбиения, имеющую класс соответствия 0, 1, 2, 3,
поддерживаемый для четырех значений Do, £>i, Д2, Дз, где Dc есть наименьшая
известная общая дефектность, которая приводит к разбиению в позиции Ь и
строке j и классе с. Другая переменная D — min(Do, £>i, D2, D%) также должна
быть удобной, и мы полагаем Ас указывающим на активный узел а, который
приводит к наилучшему значению Dc. В результате основной цикл принимает
132
Компьютерная типография
следующий несколько измененный вид для каждой допустимой точки
разбиения Ь:
begin a := A] preva := Л;
loop: Do := Dx := D2 := D3 := D := +00;
loop: ne:r£a := ссылка(а);
(Вычисление jf и коэффициента корректировки г от а до 6);
if г < — 1 ог рь = —оо then (Деактивация узла а)
else preva := a;
if — 1 < г < р then
begin (Вычисление d и класса соответствия с);
if d < Dc then
begin Dc := d\ Ac := a; if d < J9 then J9 := g?;
end;
end;
a := nexta; if a = Л then exit loop;
if строка(а) > jf and j < jo then exit loop;
repeat;
if D < 00 then
(Вставка новых активных узлов для разбиений от Ас до 6);
if а = Л then exit loop;
repeat;
if A = Л then
(Некие неординарные действия, поскольку нет допустимого решения);
end.
Для некоторой данной позиции Ь внутренний цикл алгоритма рассматривает
все узлы а как имеющие эквивалентные номера строк, в то время как внешний
цикл обрабатывает все номера строк, которые не являются эквивалентными.
Не составляет труда точно раскодировать коды операций, которые имели
в этих циклах только аббревиатуры:
(Вычисление дефектности d и класса соответствия с) =
begin if pb > 0 then d := (1 + 100|r|3 + pb)2
else if pb ф -оо then d := (1 + 100|r|3)2 - p\
else d:= (1 + 100|r|3)2;
CL »= Cl ~r CX ' Jb ' /позиция(а) э
if r < —.5 then с := О
else if r < .5 then с := 1
else if r < 1 then с := 2 else с := 3;
if \c — класс_соответствия(а)| > 1 then d := d + 7;
d := d + общая_дефектность(а);
end.
(Вставка новых активных узлов для разбиений от Ас до 6) =
begin (Вычисление tw = (Е^)после(б), ty = (Ъу)После(Ь),
tz = (Ь^)после(5));
Глава 3. Верстка абзацев
133
for с := 0 to 3 do if Dc < D + 7 then
begin 5 := new узел (позиция = 6, строка = строка(Лс) + 1,
класс-соответствия = с, общаялпирина = tw,
общее_растяжение = ty, общее_сжатие = tz,
общая_дефектность = Dc,
предшествующий = Ас, ссылка = а);
if preva = A then A := s else ссылка(ртеш) := 5;
preva := 5;
end;
end.
(Вычисление tw = (£w)n0CJie(fe), ty = (Zy)n0CJie{b), tz = (Zz)n0CJie(b)) =
begin tw := ЕТУ; ty := ИГ; te := HZ; г := 6;
loop: if г > ттг then exit loop;
if ti = 'бокс' then exit loop;
if ti = 'клей' then
begin tw := tw + Wi\ ty := ty + yi\ tz := ^ + ^;
end
else if pi = —00 and г > 6 then exit loop;
г := г + 1;
repeat;
end.
(Дезактивация узла а) =
begin if preva = A then A := nex£a else ссылка(ртег;а) := nexta\
ссылка(а) := P; P := a;
end.
После того как основной цикл выполнит свою работу, активный список
будет содержать только узлы с позицией = т, поскольку хт представляет
собой вынужденное разбиение. Таким образом, мы можем написать
(Выбор активного узла с наименьшей общей дефектностью) =
begin а := Ь := А\ d := общая_дефектность(а);
loop: a := ссылка(а);
if a = Л then exit loop;
if общая дефектность(а) < d then
begin d := общая_дефектность(а); b := a;
end;
repeat;
/с := строка(б);
end.
Теперь узел 6 выбран, к есть номер его строки. Последующая обработка для
q ф 0 столь же элементарна:
(Выбор соответствующего активного узла) =
begin a := A; s := 0;
loop: 5 := строка(а) — /с;
134
Компьютерная типография
if q < 5 < s or s < 5 < q then
begin s := 5] d := общая_дефектность(а); b := a;
end
else if 5 = s and общая_дефектность(а) < d then
begin d := общая_дефектность(а); b \— a\
end;
a := ссылка(а); if a = A then exit loop;
repeat;
к := строка(б);
end.
Теперь искомая последовательность из к точек разбиения доступна из узла Ь:
(Использование выбранного узла для определения оптимальных
точек разбиения) =
for j := к down to 1 do
begin bj := позиция(6); b := предшествующий(6);
end.
(Иной путь завершить обработку, заключающийся в том, чтобы строки рас-
сматривать в прямом порядке от 1 до /с, а не от к до 1, рассматривается ниже
в приложении.) Если не производится сбора мусора, то алгоритм завершается
перераспределением всех узлов в списках А и Р.
Ограничение 1 делает законной деактивацию узла, когда обнаруживается,
что г < —1, поскольку г < — 1 эквивалентно lj < Ьаъ — Zab, так что
последующие точки разбиения bf > b будут иметь Ьаъ> — Zay > Ьаь — %аЪ- Таким
образом, нетрудно убедиться, что алгоритм действительно находит
оптимальное решение: задав некую последовательность допустимых точек разбиения
Ь\ < • • • < bk, можно доказать индукцией по j, что алгоритм конструирует
узел для допустимой точки разбиения в bj с подходящими номерами строк и
классами соответствия, такой, что его дефектность не превышает дефектности
данной последовательности.
В алгоритме остается только один свободный конец, а именно операция
(Некие неординарные действия, поскольку нет допустимого решения). Как
говорилось выше, Т^ предполагает, что у пользователя есть возможность
выбрать толерантный порог р таким образом, чтобы требовалось вмешательство
человека, когда этот порог не может быть достигнут. Другой вариант состоит в
том, чтобы иметь два пороговых значения и пытаться сначала достичь р0,
который ниже, чем р, так что алгоритм будет генерировать относительно немного
активных узлов; если нет пути достичь толерантности ро> алгоритм может
просто вернуть все узлы в свободную память и пытаться снова работать с
настоящим пороговым значением р. Этот двухпороговый метод не будет всегда
находить строго оптимальное допустимое решение, поскольку в необычных
обстоятельствах возможно, что в оптимальное решение будет включена строка,
чей коэффициент корректировки превосходит ро, тогда как существует
неоптимальное допустимое решение с толерантностью ро; Для практических целей,
однако, это различие несущественно.
Глава 3. Верстка абзацев
135
На самом деле ТЕХ использует разного рода двухпороговые методы.
Поскольку задача разбиения слов нетривиальна, Т^Х сначала пытается разбить
абзац на строки без каких бы то ни было жестких переносов, за
исключением тех, которые уже имелись в данном тексте, используя порог толерантности
Pi. Если алгоритм терпит неудачу в процессе поиска решения или допустимое
решение с q ф О существует, но требуемая свобода не может быть достигнута
(5 ф д), то все узлы возвращаются в свободную память и Т^Х начинает
сначала, уже используя другую толерантность р2- Во время этого второго прохода
все слова из пяти букв или более подвергаются воздействию ТЁ^'овского
алгоритма переносов, прежде чем они будут обработаны алгоритмом разбиения
на строки. Таким образом, пользователь берет pi, чтобы ограничить
толерантность для абзацев, которые могут быть полностью разбиты без переносов, а
Р2 — для ограничения толерантности, когда переносы должны быть
опробованы; возможно, pi будет несколько больше, чем р25 но может оказаться и
меньше, если перенос не выглядит слишком нелепо. Как правило, р\ и р2
практически равны друг другу, или же р\ почти равно 1, а р2 несколько больше; и
напротив, можно взять р2 = 0, чтобы эффективно запретить перенос.
Если оба прохода безуспешны, Т^Х продолжает работу, снова активируя
узел, который был дезактивирован самым последним, и трактует его как
допустимое разбиение строки, приводящее к Ь. С этой ситуацией на самом деле
имеет дело подпрограмма (Дезактивация узла а), сразу после того как
последний активный узел становится пассивным:
if А — Л and secondpass and D = oo and r < — 1 then r := — 1.
В итоге получаем сообщение о переполнении «overfull box»,
свидетельствующее о выталкивании текста в правое поле, невзирая на то, что нет
последовательности допустимых точек разбиения. Как обсуждалось выше, неизбежны
некоторого рода ошибки индикации, поскольку пользователь полагает иметь р
равным такому значению, что дальнейшее растяжение нетолерантно и
требуется вмешательство человека. В силу особенностей алгоритма, легче
получить переполненные строки, чем незаполненные. И это весьма удачно:
установка переполненного бокса будет настолько плотной, насколько это
возможно, и, следовательно, пользователь сразу увидит, какие корректировки надо
внести: например, сделать вынужденное разбиение или поставить перенос в
слове.
Вычислительный эксперимент
Алгоритм, описанный в предшествующем разделе, довольно сложен,
поскольку он настроен на применение в широком диапазоне ситуаций, возникающих
в наборном процессе. Значительно более простая процедура годится для
специальных случаев, возникающих при обработке текстов и газетной верстке; в
приложении к данной статье приведено подробное описание такого
вырожденного варианта. И напротив, алгоритм в ТЁ^'е даже еще более сложный, чем
только что описанный, потому что ТЕХ должен иметь дело с колонтитулами,
136
Компьютерная типография
подстрочными примечаниями, пометками о разбиении, привязанными к
строкам, с пробелами как внутри математических формул, так и рядом с ними.
Пробелы, окружающие формулы, несколько отличаются от клея, потому что
исчезают, когда за формулой идет разбиение строки, но это не представляет
собой допустимую точку разбиения. (Полное описание ТеХ'овского
алгоритма дано в [29].) Эксперимент показал, что общий алгоритм на практике весьма
эффективен, несмотря на все непростые моменты, с которыми он должен
справиться.
Представлено настолько много параметров, что вряд ли кому то придется
в действительности экспериментировать с большей частью этих возможностей.
Пользователь может варьировать междусловными пробелами и штрафами за
вставленные переносы, жесткие переносы, смежные флаговые строки и
смежные строки с несовместимыми классами соответствия; порог толерантности р
также может меняться, не говоря уже о длинах строк и параметре
«разреженности» q. Таким образом, вычислительный эксперимент может длиться годами
и экспериментатор не получит никакого представления о поведении алгоритма.
Даже при фиксированных параметрах возможны значительные отклонения,
зависящие от вида печатных материалов: например, насыщенный формулами
материал представляет особую проблему. Интересный сравнительный анализ
разбиения строк сделал Дункан с соавторами [13], который рассматривал
образцы стихотворных текстов из Decline and Fall Гиббона, взятых из Salar the
Salmon] как и ожидалось, словарь Гиббона неизбежно привел к большему
количеству строк с переносами.
С другой стороны, мы видели, что алгоритм оптимизации приводит к еще
лучшим разбиениям строк в детских рассказах, где слова короткие и простые,
как в сказках братьев Гримм. Было бы замечательно интуитивно ощущать
качество: сколько нужно дополнительных вычислений для получения этого
улучшения качества. Грубо говоря, время вычислений пропорционально
количеству слов в абзаце, умноженному на среднее число слов в строке, поскольку
основной цикл вычислений проходит через временно активные узлы и
поскольку среднее число слов в строке разумно оценивается числом активных узлов
во всех строках, кроме нескольких первых строк абзаца (см. рис. 12 и 14).
С другой стороны, имеется относительно немного узлов в первых строках
абзаца, так что исполнение на самом деле окажется быстрее, чем
указывает грубая оценка. Более того, алгоритм для специальных случаев,
представленный в приложении, требует для работы почти линейное время
независимо от длины строки, поскольку он не должен проходить через все активные
узлы.
Подробная статистика была собрана, когда с использованием этой
процедуры был набран первый большой ТеХ'овский продукт Seminumerical
Algorithms [28]. В этой 702-страничной книге оказалось 5526 «абзацев» в
основном тексте и в ответах на упражнения, если рассматривать выключные
формулы как разделители между независимыми абзацами. Эти 5526 абзацев
были разбиты на 21057 строк, из которых 550 (около 2.6%)
заканчиваются на переносе. Эти строки были обычно длиной 29 pica, что соответству-
Глава 3. Верстка абзацев
137
ет 626.4 машинным единицам при 10-пунктовом наборе и около 677.19
машинным единицам — при 9-пунктовом, грубо говоря, 12 или 13 слов в
строке. Пороговые значения р\ и р2 были обычно оба равны \/2 « 1.26, так
что промежутки между словами пробегали значения от минимума в 4
единицы до максимума в 6 + \р! « 9.78 единиц. Штраф за разбиение после
переноса был 50; последовательные переносы и смежно несовместимые
дефектности были а — 7 — 3000. Второй (по поводу переносов) проход
затронул только 279 абзацев, иначе говоря, около 5% времени; допустимое
решение без переносов было найдено в оставшихся 5247 случаях. Второй
проход представлял собой попытку переносить только слова, набранные пятью
или более строчными буквами, содержащими акценты, лигатуры или
дефисы, и это привело к 6700 словам, которые были подвергнуты процедуре
переносов. Таким образом, среднее число попыток переноса в абзаце было
приблизительно 1.2, лишь чуть больше, чем нужно по согласованным неопти-
мизирующим алгоритмам, и перенос оказался незначимым фактором во
времени прогона.
Основной вклад во время работы алгоритма привносит, разумеется,
основной цикл, который выполнялся 274102 раза (около 50 раз на абзац, включая
оба прохода, взятые вместе, когда требуется второй проход). Общее количество
созданных узлов разбиения составляет 64003 (около 12 на абзац), включая
разнообразие для сравнительно редких случаев, когда нужно различать разные
классы соответствия или номера строк для одной и той же точки разбиения.
Таким образом, около 23% допустимых точек разбиения снова
превращаются в допустимые, давая относительно низкие значения pi и р2- Внутренний
вычислительный цикл выполнялся 880677 раз; это есть общее число
активных узлов, рассматриваемых тогда, когда обрабатывается каждая допустимая
точка, суммируемых по всем допустимым точкам разбиения. Обратите
внимание, что это соответствует приблизительно 160 рассмотрениям активных
узлов на абзац и 3.2 на точку разбиения, так что внутренний цикл
определенно доминирует во времени прогона. Если предположить, что слова состоят
примерно из пяти букв, так что допустимое разбиение возникает на
каждой шестой литере исходного текста, включая пробелы между словами, то
алгоритм обходится примерно в половину внутреннего цикла на литеру
исходного текста плюс время прохода этой литеры в самом удаленном от центра
цикле.
Эти исходные данные были также использованы для установления
важности необязательной проверки 'if Dc < D+j\ предшествующей созданию нового
узла; без этой проверки алгоритму потребовалось бы примерно на 25% больше
времени выполнения внутреннего цикла, поскольку создавалось бы слишком
много ненужных узлов.
А как обстоят дела с выводом? На рис. 19 приводится реальное
распределение коэффициента корректировки г в 15 531 строках тома Seminumerical
Algorithms, не считая 5526 строк с концами абзацев, для которых г « 0. Была
также одна строка с г « 1.8 и одна с г « 2.2 (т. е. с позорным пробелом в 12
единиц); возможно, кто-нибудь из читателей самостоятельно обнаружил одну
138
Компьютерная типография
или обе эти аномалии. Среднее значение г, вычисленное по всем 21057
строкам, было равно 0.08, а стандартное отклонение — всего лишь 0.403; примерно
в 67% строк междусловный интервал варьировался в интервале от 5 до 7
единиц. Более того, авторы считают, что виртуальное отсутствие 15 531 разбиений
строк «психологически плохо» в упомянутом выше смысле.
-1.00<
г <-0.95
-0.95 <г <-0.85
-0.85 <
г <-0.75
-0.75 <г <-0.65
-0.65 <
г <-0.55
-0.55 <г <-0.45
-0.45 <г <-0.35
-0.35 <
-0.25 <
г <-0.25
г <-0.15
-0.15 <г<-0.05
-0.05 <
+0.05 <
+0.15 <
+0.25 <
+0.35 <
+0.45 <
+0.55 <
+0.65 <
+0.75 <
+0.85 <
+0.95 <
+ 1.05 <
+ 1.15 <
г <+0.05
г <+0.15
г <+0.25
г <+0.35
г <+0.45
г <+0.55
г <+0.65
г <+0.75
г <+0.85
г <+0.95
г < + 1.05
г< + 1.15
г < + 1.26
Рис. 19. Коэффициент корректировки для
междусловных интервалов в 700-страничной книге.
Любой, кто экспериментировал с типичными английскими текстами
знает, что подобная статистика не только великолепна, она фактически слишком
хороша, чтобы быть достоверной; но алгоритм разбиения на строки может
достичь своего звездного часа без всякого вмешательства автора, который
замечает, что небольшие изменения в словах приведут к лучшим разбиениям
строк. В самом деле, этот феномен представляет собой другой источник
улучшения качества, когда автору предоставляется средство верстки вроде того,
которым владеет ТЕХ, потому что профессиональный наборщик не
отважится производить беспорядок в словах, когда организует их в абзац, тогда как
автор будет счастлив сделать улучшающие изменения, особенно когда такие
изменения пренебрежимо малы по сравнению с другими, которые сочтет
необходимыми технический редактор, читающий верстку. Авторы знают, что есть
масса возможностей выразить свою мысль, так что это не такая уж проблема
для них внести небольшие коррективы в слова.
Теодор Л. Де Винн, один из виднейших американских полиграфистов
начала ХХ-го века, писал [11, с. 138], что «когда автор протестует против
[переноса], его следует попросить добавить, либо удалить, либо заменить одно или
несколько слов, чтобы избежать нежелательного разбиения строк Авторы,
которые всегда настаивают на пробелах, заметно разделяющих слова, совсем
не представляют себе всю строгость типографских правил».
Глава 3. Верстка абзацев
139
-1.00 <г <-0.75
-0.75 <г <-0.50
-0.50 <г <-0.25
-0.25 <г< 0.00
0.00 < г <+0.25
+0.25 <г <+0.50
+0.50 <г <+0.75
+0.75 <г< + 1.00
+ 1.00 < г < + 1.25
+ 1.25 <г < + 1.50
+ 1.50<г< + 1.75
+ 1.75 <г < + 2.00
+2.00 < г <+оо
Улучшенная
верстка
-1.00 < г <-0.75
-0.75 <г <-0.50
-0.50 < г <-0.25
-0.25<г< 0.00
0.00 < г <+0.25
+0.25 < г <+0.50
+0.50 < г <+0.75
+0.75 < г < + 1.00
+ 1.00 < г < + 1.25
+ 1.25<г < + 1.50
+ 1.50<г < + 1.75
+ 1.75 < г <+2.00
+2.00 < г <+оо
D
Оптимальная
верстка
Рис. 20. Распределение междусловных интервалов, найденное методом «лучшая
строка за раз», по сравнению с методом «лучший абзац за раз», когда сложный
математический текст набирается без вмешательства человека.
Другой интересный комментарий принадлежит Дж. Б. Шоу [39]: «Где бы
он [Уилльям Моррис] ни обнаруживал в своих работах неудачно выровненную
строку, он варьировал исключительно междусловными пробелами ради
достижения зрительного восприятия при печати. Когда мне присылали корректуру
с двумя или тремя строками столь безжалостно разреженными, что на
странице появлялся серый коридор, я часто переписывал отрывок, чтобы строки
лучше заполнились; но с прискорбием должен констатировать, что мое
предложение обычно бывало плохо понято и наборщик калечил еще и весь хвост
абзаца, вместо того чтобы исправить свою плохую работу».
Смещение, вызванное настройкой Кнута своей рукописи под конкретную
длину строки, сделало статистику рис. 19 неприменимой к той ситуации,
когда данный текст должен быть распечатан в том виде, как он был набран.
Поэтому был предпринят другой эксперимент, в котором материал разд. 3.5
из Seminumerical Algorithms был помещен в строки длиной 25 pica вместо
29 pica. Раздел 3.5, посвященный вопросу «Что такое случайная
последовательность?», был выбран потому, что этот раздел больше всего соответствует
типичной математической статье, содержащей теоремы, доказательства,
леммы и т. п. В этом эксперименте алгоритм оптимальной верстки работает более
интенсивно, чем в случае строк длиной 29 pica, в основном потому, что второй
проход нужен в три раза чаще (49 раз на 273 абзаца, вместо 16 раз); более
того, второй проход был более толерантен к ширине пробелов (р2 = Ю вместо
\/2), чтобы гарантировать набор каждого абзаца без ручного вмешательства.
Здесь требовалось около б обследований активных узлов на допустимую точку
разбиения вместо прежних примерно 3, так что сухим остатком от этого
изменения в параметрах было увеличение почти вдвое времени работы алгоритма
разбиения на строки. Причина такого противоречия состояла прежде всего
в комбинации трудностей воспроизведения математики и более узкой полосе
набора, а не в «авторской настройке», потому что когда тот же самый текст
располагается на ширину полосы в 35 pica, второй проход был нужен только
8 раз.
140
Компьютерная типография
Интересно рассмотреть качество пробелов, полученных в этом
эксперименте с длиной строки в 25 pica, поскольку это указывает на то,
насколько хорошо работает метод оптимальной верстки без вмешательства
человека. На рис. 20 показано то, что получилось, вместе с соответствующей
статистикой для метода улучшенной верстки, когда он применяется к тем же
самым данным. В каждом случае фигурировало около 800 разбиений на
строки, не считая завершающих строк абзацев. Основное различие состояло в
том, что алгоритм оптимальной верстки стремится поместить больше строк
в интервале .5 < г < 1, тогда как алгоритм улучшенной верстки
производит значительно больше строк, которые чрезвычайно разрежены.
Стандартное отклонение пробелов было равно 0.53 (при оптимальной верстке)
против 0.64 (при улучшенной); 24 строки при улучшенной верстке имели
пробелы, превышающие 12 единиц, тогда как при оптимальной верстке таких
плохих строк было только 7. Изучение этих семи проблематичных случаев
показало, что три из них получились из-за длинных неразрывных формул в
тексте, три были порождены правилом, что Т^Х не должен пытаться
переносить слова, набранные прописными буквами, и еще один получился из-за
неспособности ТЁХ'а перенести слово 'reasonable'. Поверхностный анализ
выведенного текста показал, что основное различие между алгоритмами
улучшенной и оптимальной верстки с точки зрения обычного читателя, состоит
в том, что улучшенный алгоритм не только пересортировывает случайные
широкие пробелы, но также стремится завершить существенно больше строк
переносами: 119 по сравнению с 80. Автор, заботящийся о пробелах и,
следовательно, редактирующий рукопись с целью улучшения его внешнего
вида, произведет значительный объем дополнительной работы при алгоритме
улучшенной верстки, а вывод при алгоритме оптимальной верстки получит
свой требуемый вид всего лишь при помощи нескольких авторских
изменений.
Исторический обзор
Мы обсудили большинство ситуаций, возникающих при разбиении строк, и
было бы интересно сравнить новомодные подходы с теми, с которыми печатники
имели дело на протяжении многих лет. Средневековые переписчики,
изготавливающие великолепные рукописные книги до эпохи книгопечатания, обычно
очень трепетно относились к разбиению строк, добиваясь почти ровного
правого края, и эту практику сохранили первопечатники. На самом деле наборщики
стараются расставить буквы так, чтобы в каждой строке были равномерные
интервалы, так что отдельные буквы не выдаются из общего строя, производя
должное впечатление; они могли вставлять дополнительные пробелы между
словами почти с той же легкостью, как и размещать эти пробелы в концах
строк.
Одним из наиболее серьезных вызовов за многие годы, брошенных
печатникам, был набор «Многязычной Библии», т. е. таких изданий Библии,
в которых язык оригинала соседствовал с разнообразными переводами, по-
Глава 3. Верстка абзацев
141
скольку для синхронизации различных версий на разных языках нужно было
предпринять особые усилия. Кроме того, тот факт, что на каждой странице
нужно было представить разные языки, обусловил тенденцию к сужению
колонок; это вкупе с тем обстоятельством, что никто не мог отважиться изменить
священный текст, сделало проблему разбиения строк особенно трудной.
Можно получить весьма четкое представление о том, как первопечатники решали
проблемы разбиения строк, внимательно изучив их многоязычную Библию.
> > > nntf crt^y^'a^^jf
Рис. 21. Стихи, открывающие Книгу Бытия в Complutensian Polyglot Bible. Здесь
латинским словам ставятся в соответствие еврейские и для заполнения строк
используется пунктир, дабы предотвратить выключку вправо и влево. На той же странице
помещены греческие и арамейские переводы этого текста.
Первая многоязычная Библия [10, 19, 24] была издана в Испании
знаменитым кардиналом Хименесом Сиснеросом, который прославился тем, что
потратил 50 000 золотых дукатов на поддержку этого проекта. Обычно это издание
называют «Complutensian Polyglot», поскольку его подготовили в Алкал я де
Энарес, городе в предместье Мадрида, ранее носившего название Complutus.
О печатнике Арнао Гильене де Брокаре, посвятившем 1514-1517 гг. изданию
этого шеститомного труда, говорили, что нарисованные им для этих книг
еврейские и греческие шрифты были лучшими из когда бы то ни было созданных.
Его подход к выравниванию строк был весьма интересным и необычным, как
INapridpiobcrea л.
uirdctis соооооэоооо
ccclumf &'terra, * Terra
autem соэсоосоооооооо
Vrat'inanis'&C vacua:m&
tencbrc erantnfup°fadc
pabyffi:q&fpiritusrdei
•fcrebatur'fiiper cooooo
*aquas.T Dixitqj'deus.
"Fiat coocoocooooooooeoo
bltix.cEtfectac4m<.eEt
Vidit'deusMucem ooocco
*$ eflet*bona: !& ditrifit
COMOOOOXOOOOOOOCOOOOOOO
°luccmpa qtcncbris: rap
pellauitcB оэхоозхооооо
ЧисепЛиё: ХЫ tencbras
'noctem. coooooooooooooo
eFactamcpeftbvcfpcc&
°nianeMicsfvnus.ococoo
'Dixit quoqpMcus.'Fiat
kfirmamcntul in medio
maquantm:n&(>diuidat
qaquas coooooocoooooccoo
rab aquis.9 Et fecitMeus
'firmamentum. coxoeo
142
Компьютерная типография
видно из рис. 21: вместо того чтобы выравнивать строки, увеличивая межд-
условные пробелы, он вставлял отточия, чтобы получить жесткие блоки
материала с ровными краями.
Эти отточия появляются справа в латинском тексте и слева — в еврейском.
Обретя навык, он несколько изменил своему приему: примерно с 46-й главы
Книги Бытия еврейский текст выравнивался посредством междусловных
пробелов, хотя в латинском тексте отточия продолжали появляться. Понятно, что
ровные края в те времена выдерживались неукоснительно.
Способ Гильена де Брокара разбиения строк был по существу методом
предварительной верстки, примененным к еврейскому тексту;
соответствующий латинский перевод размещался чрезвычайно просто, поскольку две
строки латинского варианта соответствовали одной строке еврейского текста
и точно помещались в отведенное для них место. В отдельных случаях, когда
греческий текст был значительно длиннее соответствующего еврейского
(например Exodus 38), он размещал еврейский очень плотно, что с очевидностью
демонстрирует его особое отношение к разбиению строк.
В то же самое время Агостино Джустиниапи из Генуи [17] совершенно
безвозмездно подготовил многоязычную версию Книги Псалмов. Это в
сущности была первая появившаяся в печати многоязычная книга, в которой для
каждого языка был использован свой шрифт, хотя обычно считается, что все
более поздние многоязычные издания были инспирированы рукописью Ш-го
столетия ffexapia, написанной Origen'oM. В Псалтыри Джустиниапи было 8
колонок: (1) древнееврейский оригинал; (2) его литературный латинский
пересказ; (3) популярное латинское (вульгата) толкование; (4) греческая (Sep-
tuagint) версия; (5) арабская версия; (6) халдейская версия; (7) ее
литературный латинский перевод; (8) примечания. Поскольку Псалмы представлены в
стихотворной форме, все колонки, за исключением последней, имели рваные
края, причем для строк, слишком длинных, чтобы разместиться в колонке,
использовалось следующее соглашение: в конце разбиваемой строки помещалась
открывающая скобка и остаток строки, предваряемый другой открывающей
скобкой, выравнивался по краю предыдущей или последующей строки, как
удобнее.
Выровненной была только колонка (8), причем она была очень узкой,
порядка 21 знака в строке. Пристально изучив ее вид, мы можем заключить,
что Джустиниапи не прилагал больших усилий к тому, чтобы получить
равномерные пробелы, поиграв словами. Например, на рис. 22, на котором
представлен фрагмент примечаний к Псалму 6, видно, что между двумя очень
плотными строками находится весьма жидкая строка: 'scriptum est ... quod
qui'. Если бы Джустиниани захотел уравновесить пробелы, он бы мог
сделать перенос: 'cog-nosces'; другим потенциальным решением — перенести kad'
на предыдущую строку — воспользоваться нельзя, потому что для этого слова
там мало места. Обратите внимание, что в те времена был и другой прием,
способствующий разбиению строк в латинском тексте: замена т или п на
тильду, проставляемую над предшествующей гласной (например, 'premiu' для
premium и 'mudo' для mundo); алгебру бокс/клей/штраф следовало бы рас-
Глава 3. Верстка абзацев
143
Рис. 22. Фрагмент комментария Джустиниани к
Псалмам. Наличие жидкой строки между двумя
очень плотными говорит о том, что наборщик,
столкнувшись с проблемой, не возвращался назад
для перенабора предшествующих строк.
qui arboribus plenus
cft,fecerunt fui noti>
tiam,8£ acceperuntin
telledumab zofiC uiV
cifflra cumeorumdo^
nrino fecognouerunt,
fades cumfacie,& o^
cuius cumoc\x\ofiChw
ias rei gratia merue^
runtprcmiufn futuro
mudo,SC hoc eft quod
fcriptum eft,8£cognoj*
fees hodie reucrfus
adcortuum,quod qui
dacefleipfecft Deus
in cell's defupcr;a:qd:
in terra deorfum поп
fitprcter cum*
ширить, включив такие опции в ТЁХ'овский алгоритм разбиения на строки.
Непонятно, почему Джустиниани не поместил 'acceperut' в третьей строке,
чтобы сэкономить пространств, ведь у него не осталось места для знака переноса
в слове 'in-tellectum'; возможно, в его шрифтовой кассе не было достаточного
количества литер и.
На рис.23 показан выровненный текст из Complutensian Polyglot
—выдержка из латинского перевода раннего арамейского перевода древнееврей-
jlft pzincipto creauit t>eus сеШ г term* Сал*
£erra aut erat t»eferta x vacua:? tenebze {uq
factemаЬуШгх (pus Oct infufflabat fag facie
aqua^^tointoeuaeSttlUjtTtfuftlujr^viditoeus
luce" q; cfTct bona. £t oiuifit fceus inter luce г inter te
neb?as.appellauitq$ t>cus 1исёЫё:г tenebzas voca*
uitnocte4£tfuitvcfgeTfuitmaneinesvnusj£tt>is
jcitseus^Sitfirmamentutn medio aqua#:xt>iuidat
inter aquas % aqs*£t fecit t>eus firmamenturet t>mi
fit iter aquas qerant fubter firmametus:? inter aqs
q eraut fug firmamenturT futt ita* £t vocauit t>e* fir
mamentu celuv £t fuitvefge % fuitmane fciesfctfs*
£t oirit t>e** Cogregetur aque q fub celo funt in Iocfi
vnttm:? appareat arida*£t futt tta* £t vocauit t>eus
arida terra: % locu cogregationis aquaru appellautt
maria. £t vidit t>c* q$ eflct bonfi.£t x>ixit t>cus* 5er
rninet terra germination^ tyerbecui* filius femetis
femtnafiarbozecfc fructifera faciente fructue f m ge*
nus fuu: cuius filius femc"t(s in ipfo fit fug terra* £t
fuitita.£tfidu%itterragermefcerbe cuius filiusfe
me*tie feminaf fm genus futtret arboze farientefru*
etusrem? filius femetts i ipfo fm genus fuu*£t vidit
Рис. 23. Для ранних образцов печатных латинских текстов характерны плотные
пробелы, получаемые за счет частого использования сокращений и разбиения слов.
Образец взят с той же страницы, что и фрагмент рис. 21.
144
Компьютерная типография
ского оригинала. Наборщику совершенно непостижимым образом удалось
выдержать во всем томе равномерно плотный набор, используя сокращения и
частые переносы. В пяти местах, как и на рис. 22, знаки переноса при
разрыве слов отсутствуют, когда для них нет места; например, слово 'diuisit' было
перенесено без соответствующего знака.
Следующим грандиозным изданием многоязычной Библии было «Royal
Polyglot of Antwerp» [1], созданное в течение 1568-1572 гг. выдающимся
бельгийским печатником Кристофом Плантеном. К сожалению, многочисленные
копии Complutensian Polyglot утонули в море, поэтому король Филипп II
организовал подготовку нового издания, что позволило также воспользоваться
новыми технологическими достижениями. Плантен был набожным человеком,
действовавшим в пацифистских религиозных кругах и очень стремившийся
заняться этой работой. Но полностью завершив работу, он описал ее как
«невыразимо тяжкую, нудную и изнурительную». В письме одному из своих друзей
от 9 июня 1572 г. Плантен пишет: «Не перестаю удивляться себе: как мог я
взвалить на себя такое! Никогда в жизни я больше не возьмусь за подобное,
даже если меня одарят 12 000 крон». Но его работа была по крайней мере
достойно встречена ценителями: Люка из Брюга писал в 1577 г., что
«никогда искусство печатника не поднималось до столь величественных высот и не
производило ничего более великолепного».
Многоязычная Библия Плантена была по большей части выровнена внутри
довольно широких колонок примерно с 42 литерами в строке, и это не
представляло особого труда с точки зрения разбиения строк. Но изучив тексты
Апокрифа, набранного в более узких колонках с 27 литерами в строке, можно
получить некоторое представление о его методах работы. Он так расположил
текст, что в каждой колонке на одной странице было примерно равное
количество строк, несмотря на то, что сами колонки были на разных языках.
} l *Et ftatim pcrrexcrunt ad
eos, & conftitueruncaduer-
fus cos prcelium in die fab-.
bacorum , & dixerunc ad
cos.
Рис. 24. Латинская версия Маккабея 2 : 32 из Антверпенской Royal Polyglot
Плантена, из которой видно, как получена дополнительная строка благодаря пробелам во
второй строке снизу.
На рис. 24 приведен пример отрывка, в котором латинский текст был
несколько разрежен, так что абзацы на этой странице оказались довольно жидкими.
Очевидно, сначала была набрана вся страница, а затем были сделаны
корректировки, поскольку латинские колонки оказались слишком короткими. В
данном случае, слово 'eos' было перенесено вниз, чтобы получить новую строку,
а предыдущая строка была разрежена. Наборщик Плантена не искал
приключений на свою голову и не передвинул вниз 'sab-' на эту строку, хотя такое
перемещение позволило бы избежать переноса и последующих плохих пробе-
Глава 3. Верстка абзацев
145
лов. Оптимальным было бы убрать этот перенос и разбить предшествующую
строку после 'ad-', достигнув таким образом равномерных пробелов всюду.
Самым аккуратным и полным из всех многоязычных изданий Библии
было «London Polyglot» [41], напечатанное Томасом Ройкрофтом и другими во
времена правления Кромвеля с 1653 по 1657 гг. Эта объемистая 8-томная
работа содержала тексты на древнееврейском, греческом, арамейском,
сирийском, эфиопском, самаритянском языках и фарси, и все они сопровождались
латинскими переводами. Этот труд был признан «вершиной типографского
мастерства семнадцатого столетия». Как и в работе Плантена, приведенной на
рис. 24, подвергавшийся разреживанию абзац зачастую заканчивался
неоправданно плотной строкой, за которой следовала жидкая, а за ней —строка из
одного слова. Из этого очевидно, что у наборщика Ройкрофта не было времени
выполнить сложную корректировку разбивки строк.
В то время к переносам явно не придирались, поскольку 40% всех строк
в London Polyglot оканчиваются переносами, независимо от ширины колонки.
Не составляет труда найти страницы, в которых строк с переносами больше,
чем строк без оных. В латинском переводе арамейской версии Книги Бытия
4:15 перенесено даже двухбуквенное слово 'е-о'! Подобная практика не была
общепринятой; например, в гамбургской Polyglot Bible от 1596 [42] более 50%
переносов находится в правом поле. Как многоязычная Библия Плантена,
так и заметки Джустиниани к Псалтыри содержат порядка 40% переносов,
и примерно так же обстояло дело со многими средневековыми рукописями.
Таким образом, считалось, что лучше иметь ровные поля и плотный набор,
чем избегать разбиения слов.
Одна из первых особенностей, которую подмечает современный взгляд при
изучении этих изданий Библии, является некоторая вольность в обращении со
знаками препинания. Обратите внимание, например, что на рис. 22 после
запятых нет пробелов, а на рис. 24 пробел стоит как до, так и после одной из
запятых. В каждом из перечисленных выше изданий Библии вы можете
обнаружить все четыре варианта: «пробел до/отсутствие пробела до» и «пробел
после/отсутствие пробела после» по отношению к следующим знакам
препинания: запятая, точка, двоеточие, точка с запятой и вопросительный знак. При
этом никаких явных предпочтений одному из четырех вариантов выбора не
отдавалось, за исключением того, что пробел перед точкой делался довольно
редко. Джустиниани и Плантен иногда могли оставить пробел перед точкой,
но Ройкрофт этого не делал никогда. Около 1700 г. запятые в этом смысле
были приравнены к точкам, но двоеточие и точка с запятой вплоть до 19-го
столетия окружались пробелами с двух сторон. Такие дополнительные
пробелы помогали, разумеется, в выравнивании текста, и печатники с очевидным
удовольствием изничтожали все пробелы после знаков препинания. Ройкрофт
на самом деле удалял пробелы между словами в случае необходимости, если
следующее слово было с прописной буквы (например, 'dixitDeus'); очевидно,
что основной целью печатников было сохранить текст в виде, поддающемся
однозначной расшифровке, тогда как легкость его восприятия была задачей
второстепенной важности.
146
Компьютерная типография
Знания в области такого производства, как книгопечатание,
распространялись от мастеров к подмастерьям и не являлись достоянием широкой публики,
так что мы можем только догадываться, чем руководствовались печатники тех
времен, считая свое изделие завершенным. Тенденция публиковать свои
производственные секреты сформировалась, однако, в течение 17-го столетия [21],
и, наконец, была написана книга о том, как делать книги: Mechanick Exercises
Джозефа Моксона [30], опубликованная в 1683 г., оставалась на протяжении
сорока лет самым востребованным руководством по печати на всех языках.
Хотя Моксон не обсуждает правил переносов и пунктуации, он приводит
интересную информацию о разбиении строк и выравнивании текста.
«Если наборщик решительно не настроен придерживаться строгих
правил Высокого Мастерства, то он будет вынужден латать дыры», т. е. делать
плохие разбиения строк, согласно Моксону. Обыкновенная «толстая шпация»,
разделяющая слова, когда строка начинает верстаться, равна одной
четверти того, что Моксон называет «body size» (кегельной); он также говорит о
«тонких шпациях», которые равны одной седьмой от кегельной; таким
образом, печатник, следующий этой практике, будет преимущественно иметь дело с
пробелами в 4.5 единиц и 2.57 единиц, хотя такие меры весьма приблизительны
в силу примитивности средств, используемых в то время. Процедура Моксона
выравнивания текста, естественная ширина которого достаточно узкая,
состояла в том, чтобы заложить толстые шпации между одним или более слов для
«заполнения данного размера весьма плотно» и, если необходимо, вернуться в
начало строки и проделать все снова. «Строгие правила Высокого Мастерства
не допускают пробелы более [чем исходный пробел плюс две толстые шпации],
за исключением тех случаев, когда Размер строки слишком мал, из-за чего в
Строке помещается всего несколько Слов и это вынуждает Наборщика сделать
больше Пробелов между Словами. ... Эти широкие Промеэюутки,
оставляемые (самым неприличным образом) Наборщиком, называются Дырами... И
как бывают Строки слишком Разреженными, также бывают они и слишком
Плотными». [30, ее. 214-215]
Обратите внимание, что процедура выравнивания Моксона обычно
приводит к неравномерным пробелам между словами в строке, поскольку он
вставляет толстые шпации одну за другой. В самом деле, такая
несбалансированность была нормой в ранних образцах печатной продукции, которые несколько
напоминают сегодняшние попытки выравнивания на пишущей машинке или
компьютере с фиксированной величиной пробела. Например, отношение
величин пробелов в третьей строке текста Плантена с рис. 24 составляет
приблизительно 8:12:5:9:4, ав пятой строке текста Джустиниани с рис. 22 —
приблизительно 3 : 2 : 1. В книге же самого Моксона (см. рис. 25) продемонстрировано
чрезвычайное разнообразие пробелов, зачастую в нарушение правил, им
декларированных относительно максимальных и минимальных расстояний между
словами.
Было бы заманчиво утверждать, что Моксон описывает некий алгоритм
разбиения строк, наподобие метода простой или улучшенной верстки, но на
самом деле ни он и никто из его последователей до наступления компьютерной
Глава 3. Верстка абзацев
147
If there be a long word or more left out, he;
cannot exped: to Get that in into that Line,
wherefore he mud now Over-run; that is, hemuft put fo
; much of the fore-part of the Line into the Line
1 above it, or fo much of the hinder part of the Line
into the next Line under it, as will make room for
what is Left out: Therefore he confiders how Wide
! he has Set, that fo by Over-runing the fewer Lines
: backwards or forwards, or both, (as he finds his help)
he may take out fo many Spaces, or other Whites
: as will amount to the Thicknefs of what he has Left
out : Thus if he have Set wide, he may perhaps Get
a fmall Word ox a Syllable into the foregoing Linepnd
; perhaps another fmall Word or Syllable in the follow- ,
■ ing Line, which if his Leaving out is not much, may
I Get it in : But if he Left out much, he muft Over-run
.many Lines, either backwards or forwards, or both,
! till he come to a Break : And if when he comes at
a Break it be not Gotten in ; he Drives out a Z-шг.
In this cafe if he cannot Get in a Line, by (?<•////,£
w the ffWj of that Break (asljuft now fhew'd you
Рис. 25. Фрагмент со с. 245 издания Mechanick Exercises, т. 2, Джозефа Моксона,
первой книги о том, как делать книги. Здесь Моксон описывает процесс
корректировки страниц, которые уже были набраны; неравномерные пробелы в его собственной
книге служат, вероятно, одним из подтверждений того факта, что такая
корректировка была необходима. (Да, эти строки тоже далеки от совершенства.)
эры никогда не имели ввиду какой бы то ни было конкретной процедуры. В
этом нет ничего удивительного, поскольку люди обычно предпочитают
руководствоваться здравым смыслом, а не подчиняться строгим правилам. Многие
из разбиений строк на рис. 25 могут быть, однако, объяснены
предположениями, фигурирующими в алгоритме простой верстки. Например, жидкие
строки 1, 4 и 8 вызваны, вероятно, длинными словами в строках 2, 5 и 9, поскольку
эти длинные слова не помещаются в предыдущих строках, если их не
перенести. С другой стороны, появление чрезвычайно плотной строки 13 лучше всего
можно объяснить тем предположением, что для исправления ошибки были
вставлены одно или более слов уже после того, как страница была
сверстана. Мы не можем удовлетворительно воспроизвести процедуру набора, исходя
только из окончательного варианта: для этого нам нужно было бы посмотреть
на первую корректуру. Тем не менее можно с уверенностью заключить, что
было очень мало попыток вернуться назад и пересмотреть уже сверстанные
строки, кроме тех случаев, когда это было крайне необходимо. Так, например,
абзац на рис. 25 выглядел бы много лучше, если бы первая строка
заканчивалась на 'сап-', а вторая —на 'wherefore'.
Наборщик Моксона, однако, был сориентирован на то, чтобы смотреть
вперед: «Когда при Наборе он подходит к Разбиению [т. е. в конце абзаца], за
несколько Строк до этого он должен понять, будет ли это Разбиение
заканчиваться Пробелом разумного размера; если это так, то и прекрасно, но если
148
Компьютерная типография
окажется, что всего единственное Слово имеется при его Разбиении, он
должен либо Добавить пробелы и перенести одно или два слова на Разбиваемую
строку, либо еще Сузить пробелы, чтобы поместить маленькое Слово,
потому что Строка с единственным словом выглядит почти как Пустая строка,
которая будучи расположена в неправильном месте не радует глаз». [30, с. 226]
they may be all exactly the same length, it will almost
always happen that the line will either have to be
brought out by putting in additional spaces between
the words, or contracted by substituting thinner spaces
than those used in setting up the lines. If the line by
that alteration is not quite tight, an additional thin
space may be inserted between such words as begin
with j or end with f, and also after all the points, but
they must, to look well, be put as near equally as
possible between each word in the line, and after each
sentence an em space is used.
Другая выдержка из лондонского руководства для наборщиков [7]
приводится на рис. 26; это уже 1864 г., а не 1683. Хотя автор здесь говорит о том, что
при выравнивании текста нужно делать как можно более равномерные
пробелы, наборщик его книги не следует содержащимся в ней инструкциям! Только
одна замечательная книга, о которой речь шла выше, именно Complutensian
Polyglot, имеет практически одинаковые пробелы. На самом деле печатникам
лишь изредка удавалось достичь по настоящему равномерных пробелов, пока,
к концу девятнадцатого столетия, эту задачу не облегчили наборные машины
монотип и линотип. Эти новые машины с их установкой на скорость
изменили философию выравнивания текста настолько, что качество разбиения строк
падало, когда пробелы становились равномерными: наборщики не могли
себе позволить вернуться и пересмотреть предыдущие точки разбиения строк
абзаца, когда их ждало впереди еще столько новых пробелов в час.
Разбиение строк на рис. 26 выполнено вполне неплохо в смысле
неравномерных пробелов, учитывая, что наборщик хотел избегать переносов и
психологически плохого разбиения в сочетании 'with j'. Тем не менее, слово 'but'
лучше было передвинуть на 9-ю строку.
По-видимому, самым изящным образом пробелы были расставлены в
книге Самюэля Бартелса The Art of Spacing [5], вышедшей в 1926 г. Эту
книгу автор набрал самостоятельно, в каждой строке было около 50 знаков.
Не было ни жидких строк, ни переносов. Заключительные строки абзацев
всегда были заполнены по крайней мере на 65% ширины колонки и
отстояли от правого поля по крайней мере на одну круглую (em). Чтобы
достичь такого результата, Бартелс менял свой исходный текст много раз;
автор, будучи наборщиком, явно мог улучшить внешний вид своей книги.
Во Франции Жорж Бафур, Андре Бланшар и Франсуа Раймон
использовали для набора компьютеры общего назначения и в 1954 г. предприняли
попытку запатентовать свое изобретение (В 1955 г. они получили патенты во
Франции и Германии, а в 1956 г.— в США [2, 3].) В их системе особое внима-
Рис. 26.
Печатники не всегда
практикуют то, что проповедуют.
Глава 3. Верстка абзацев
149
Le bon sens est la chose du monde
la mieux partagee: car chacun pense
en etre si bien pourvu que ceux raeme
qui sont les plus difficiles a contenter
en toute autre chose n'ont point cou-
tume d'en desirer plus qu'ils en ont. En ;
quoi il n'est pas vraiserablable que tous
Рис. 27. Образец вывода, сделанного в 1958 г. на первой наборной системе,
управляемой вычислительным устройством. Все точки разбиения строк выбирались
автоматически.
ние уделялось переносам, и эти авторы были, вероятно, первыми, кто строго
сформулировал алгоритм разбиения строк. На рис. 27 показан образчик их
вывода, который демонстрировался на выставке Imprimerie Nationale в 1958 г.
В этом примере слово 'en' не было включено во вторую строку, потому что в
их схеме предпочтение отдавалось жидким строкам: в каждой строке могло
содержаться столько литер, сколько возможно для соблюдения условия, что
строка допустима, но следующие дополнительные К литер уже недопустимы;
здесь К было постоянным, а их метод основывался на if-шаговом просмотре.
Свои опыты с компьютерным набором Майкл Барнетт начал в Массачус-
сетском технологическом институте (МТИ) в 1961 г., а работе его группы в
Объединенной вычислительной лаборатории было предначертано стать самой
авторитетной в США. Например, система troff [31], с которой сейчас работают
во многих вычислительных центрах, восходит к системе Барнетта РСб [4];
промежуточными были системы RUNOFF и NROFF. Наследники по другой линии
представлены системами PAGE-1, PAGE-2 и PAGE-3, которые также широко
использовались в полиграфии [22, 25, 34]. Во всех этих программах применялся
метод простой верстки, описанный выше.
Примерно в то же время Барнетт начал в МТИ изучение
компьютерного набора, другого важного университетского исследовательского проекта с
аналогичными целями, который был начат в Вычислительной лаборатории
Университета Ньюкасл-он-Тайн. Разбиение строк было одной из
первостепенных задач, усиленно исследуемой этой группой, и они разработали программу,
которая находила бы допустимые способы набора абзаца без переносов,
если существует последовательность допустимых точек разбиения, дающая
минимальные или максимальные значения для междусловных интервалов. Их
программа работала по существу методом перебора всех возможностей с
возвратом, обрабатывая их в обратном лексикографическом порядке (т. е. начиная
с первой точки разбиения 6i, настолько большой, насколько возможно, и
используя рекурсивно тот же метод, чтобы найти допустимые точки разбиения
(&2, Ьз,...) в оставшейся части абзаца, затем уменьшив Ь\ и повторив процесс
при необходимости). Таким образом было нетрудно либо найти
лексикографически наибольшую последовательность точек разбиения, либо заключить, что
таковой нет. В последнем случае допускался перенос. Это была первая система-
150
Компьютерная типография
тическая последовательность экспериментов, которая имела дело с разбиением
строк в абзаце как в таковом, а не работала с каждой строкой по-отдельности.
В этих ранних экспериментах не делалось никаких различий между
последовательностями допустимых точек разбиения; критерием было только одно:
могут или не могут все междусловные интервалы быть заключены в
некотором диапазоне без переноса слов. Дункан обнаружил, что когда строки имеют
длину 603 единицы, то теоретически можно избежать всех переносов, если
размеру пробелов позволено меняться в диапазоне от 3 до 12 единиц; Если, однако,
строки имеют длину 405 единиц, то переносы будут нужны примерно в 3%
случаев при сохранении тех же ограничений, а если длина строки уменьшится до
288 единиц, то процент необходимых переносов повысится до 12% или 16% в
зависимости от вида набираемого материала. При более узких границах,
скажем, от 4 до 9 единиц, использовавшихся в большинстве рассмотренных выше
примеров, для строк длиной 603 единицы было обнаружено более 4%
переносов и от 30% до 40% — для строк в 288 единиц. Тем не менее этот процентный
уровень выше, чем необходимо, потому что ньюкасловская программа не
искала самых лучших мест для переносов: как только не было допустимого способа
набрать более к строк, в (/с + 1)-й строке просто ставился перенос и процесс
начинался снова. Один перенос, полученный таким способом, имел тенденцию к
размножению в этом абзаце, поскольку первая строка абзаца или
искусственно возобновленный абзац скорее всего потребуют переноса. Примеры такого
рода можно видеть в самой статье, где метод был описан [13]; в первых шести
страницах использовались пробелы от 4 до 15 единиц , а для остальных —от 4
до 12 единиц, так же как и в обзоре Дункана [14]. В этих статьях также
обсуждаются возможные усовершенствования метода: одна идея касалась того,
чтобы избегать появления жидких строк непосредственно за плотными,
другая состояла в испытании метода сначала со строгими интервалами, а затем
увеличивать допустимый интервал, прежде чем пересортировывать переносы.
Такие усовершенствования были сделаны значительно позже П. И.
Купером в фирме Elliott Automation, который разработал сложную
экспериментальную систему для обработки всего абзаца целиком [9]. Система Купера
работала не только с минимальными или максимальными размерами пробелов;
она также делила разрешенные междусловные интервалы на различные
секторы, которым назначались разные «уровни штрафа». Он сопоставлял
штрафы интервалам на отдельных строках и назначал дополнительные штрафы в
соответствии с секторами интервалов двух последующих строк. Целью было
минимизировать общий штраф, причитающийся за набор данного абзаца.
Таким образом, его модель была очень похожа на ту, что использовалась в пакете
ТЕХ, за исключением того, что все интервалы были эквивалентны друг другу
и не надо иметь дела со специальными вопросами типа переносов.
Купер говорил, что в основу его программы положен «математический
аппарат, известный как 'динамическое программирование'», для выбора
оптимального вида набора. Он, однако, опустил подробности, но из заключенных
в памяти компьютера ограничений понятно, что его алгоритм имел лишь
отдаленное сходство с настоящим динамическим программированием, в котором
Глава 3. Верстка абзацев
151
поддерживается только одна оптимальная сумма штрафов для каждой точки
разбиения, а не для каждой пары (точка разбиения, сектор). Таким образом,
его алгоритм был, вероятно, похож на метод, который описан ниже в
приложении.
К сожалению, метод Купера опередил свое время; в 1966 г. все считали, что
столько дополнительного времени вычисления и памяти компьютера
неоправданно дороги. Кроме того, его метод оценивался только с точки зрения того,
как много переносов удастся сэкономить, а не с тех позиций, насколько
лучшие пробелы он предоставляет в строках без переносов. Например, в обзоре
Дж. Л. Долби [12] процедура Купера сравнивается с процедурой Дункана в
невыгодном для первой свете, поскольку ньюкасловский метод удаляет то же
количество переносов, что и появляется, будучи при этом менее сложной
программой. На самом деле сам Купер недооценивал свою схему и говорил о ней с
необыкновенной скромностью и осторожностью: «это исследование не
поддерживает ту точку зрения, что [мой подход] должен рассматриваться как общий
и усиленно рекомендуемый. ... Следует признать ..., что, вообще говоря,
эстетическое усовершенствование не может быть ни предсказано, ни измерено».
Вскоре его метод был забыт.
Ретроспективный взгляд позволяет выявить один дефект в методе
Купера, во всех других отношениях великолепном: не делалось точного различия
между строками с переносами и допустимыми строками без переносов, так что
после каждого вновь вставляемого переноса метод должен был начинать
работу снова. Таким образом, переносы имели тенденцию группироваться как и
в экспериментах Дункана.
Еще один подход к разбиению строк недавно исследовала Э. М. Прингль
из Кембриджского университета, которая предложила процедуру Juggle [36]
(жонглирование). Этот алгоритм использует метод простой верстки без
переносов, пока не будет достигнута строка, которую невозможно разместить;
тогда вызывается рекурсивная процедура pushback (обратное втискивание),
которая пытается втиснуть слово из проблемной строки в предыдущий текст.
Если процедура pushback не приводит к успеху, происходит обращение к
другой рекурсивной программе pullon (вытягивание), которая пытается
вытянуть слово из предыдущего текста. Перенос проставляется только тогда,
когда и pullon терпит неудачу. Таким образом, Juggle представляет собой
попытку моделирования методических действий мастера ручного набора как
в добрые старые времена. Рекурсивный перебор с возвратом может, тем не
менее, потратить значительно больше времени, чем подход динамического
программирования, при этом оптимальное выравнивание строк вообще может
быть не достигнуто. Например, вместо рис. 3 мог бы получиться рис. 2. Более
того, бывают экзотические случаи, когда решения существуют, но Juggle их
не находит: например, есть возможность втиснуть два слова, а не одно.
Анан Саме в своей недавней работе [38] предложил другую меру
оптимальности. Поскольку все методы верстки абзаца с данным количеством строк
содержат одинаковый общи Л объем пробелов, он обратил внимание на то, что
средний междусловный интервал в абзаце существенно зависит от точек раз-
152
Компьютерная типография
биения (если мы не обращаем внимания на переносы и на тот факт, что
завершающая строка отличается от других). Он, таким образом, пришел к выводу,
что дисперсия междусловных пробелов должна быть минимизирована и
построил алгоритм «downhill» (скоростного спуска), который сдвигает слова из
одной строки в другую до тех пор, пока больше нет никакого такого локального
преобразования, которое снизило бы дисперсию.
Первым журналом, который стал готовиться при помощи компьютера, был
Time Inc. of New York City, способ разбиения строк которого стал весьма
популярным в 1967 г. Согласно комментариям X. Д. Паркса [32], разбиение строк
делалось построчно, при помощи разновидности алгоритма простой верстки,
который мы можем сегодня назвать «плотной версткой»; он позволял
поместить в строке максимально много слов, а переносы делались только в случае
необходимости. Это эквивалентно методу простой верстки, если обычные
интервалы сделать равными минимальным. Метод плотной верстки имел своего
предшественника, который использовался в наборной системе ЮМ 1620 и
демонстрировался в 1963 г. (см. Дункан [14, ее. 159-160]), и вполне разумно
предположить, что по существу тем же методом воспользовалась группа журнала
Time, когда они задействовали для целей набора две машины ЮМ 360/40 [33].
Поскольку до получения своего окончательного вида текст в журнале Time
не раз редактировался и разбиения строк подвергались в последнюю минуту
ручному вмешательству, невозможно точно сказать, просто рассматривая
напечатанную статью, каким алгоритмом тогда пользовались, хотя есть соблазн
утверждать, что алгоритм оптимальной верстки мог бы улучшить внешний
вид таких публикаций. На рис. 28 показан интересный пример, основанный на
с. 22 из журнала Time от 23-го июня 1980 г.; вариант А демонстрирует
пробелы, которые были в этом издании, а вариант В —то, что дал новый алгоритм
в тех же обстоятельствах. Все буквы этого текста были заменены буквой V
соответствующего размера, так что был снят вопрос авторского права и
появилась возможность сконцентрироваться исключительно на пробелах. Тем не
менее этот прием сделал плохие пробелы менее раздражающим, так как
читатель не так расстраивается, когда представленный текст не несет смысловой
нагрузки.
Наиболее интересный момент, замеченный на рис. 28, состоит в том, что
завершающая строка первого абзаца была растянута до правого края, чтобы
точно обрамить вставленную фотографию; эта фотография помещена целиком
в правой колонке. В варианте А такой эффект достигается посредством
растяжения трех последних строк; при этом остаются большие дыры, безусловно
раздражающие глаз многих читателей. В варианте В показано, как
оптимизационный алгоритм, чудесным образом заглядывая вперед, безукоризненно
печатает такие вещи. Возможно, даже более важен тот факт, что в версии В
не понадобилась дополнительная разрядка, что имеет место в строках 6, 9, 10,
23 и 32 версии А.
Разрядку — вставку крошечных пробелов между буквами слова, чтобы
сделать менее заметными большие междусловные интервалы — можно без
труда вписать в модель бокс/клей/штраф, но это порицается полиграфиста-
Глава 3. Верстка абзацев
153
П1П
nn Nninn ni Nnmm
Nnmnnii Nnnnnnni
11 nni inn n nnnnun,
nni nn nnnnn—inn
lninnn, nnn ninnn-
1П11, 1П П111П1П.
I nn Nninn ni Nnmm
Nnmnnii Nnnnnnni
u nni inn n nnnnun,
nni nn nnnnn—inn
I 1П1ПП11, ППП П1ППП-
nin inn inn, in nninin. Nn-
nnnmnn 15% ni inn nnnn'i
innn lnnnnn, inn Nnmni
Nninn nininnni nnn n ninnni
ni nuinni nninnim in Nnnnin
Nninnn in inn Nnnnn Niinn
nn inn nn ni Nininn, nninn
inn nnnnnnnn nnn ninnnn nnn
nnnni; nnin innn 3,000 mini—
innnnin inn nninnnn nnn Nnn
Nnin in Nnn Ninnnnnn—mn-
ninin inn inn nnini ni inn
Ninnn Nnnnn nnn inn mn-
nninnnn Nnin Nnn Nninn. Nnn
262.4 nnnnn ninnnni ni inn
N.N.N.N. nninnn in nnin innn
100 ninnin ninnni nnn ninin nn-
mnni nnn Nninnninni, Nnini,
Nnnnnn nnn nnnnnnn
Nninnnn ninni. Nnnn nnnmnnnni
ninnnnni in innn, in Nninnn,
nnnni inn inninnn nnnnn ni
n 19in nnninin Nninnn ninnin.
Nnnn, nnnnnm, innnn in nnin
innn 100 innnnni nnn nnnnin
Snnnnnn, Nnn, Nnnnnn, Nnnn,
ni inn nninin lniiin ni nnnnnin
Nninin nnn nnnnn nninininn
Nninn nnn nnnnn nnn nnnni. Nnn
inn N.N.N.N. in nininn, nnnnnnnin
Nnnnnninn 15% ni inn nnnn'i
innn lnnnnn, inn Nnmm Nninn
nininnni nnn n ninnni ni
ninnni nninnim in Nnnnin
Nninnn in inn Nnnnn Nnnn nn
inn nn ni Nininn, nninn inn nnn-
nnnnii nnn ninnnn nnn nnnni;
nnin innn 3,000 mini—innnnin
inn nninnnn nnn Nnn Nnin
in Nnn Ninnnnnn—innninin inn
inn nnini ni inn Ninnn Nnnnn
nnn inn inn-nninnnn Nnin
Nnn Nninn. Nnn 262.4 nnnnn
ninnnni ni inn N.N.N.N, nninnn
in nnin innn 100 ninnin ninnni
nnn ninin nninnni nnn
Nninnninni, Nnini, Nnnnnn nnn
nnnnnnn Nninnnn ninni. Nnnn
nnnmnnnni ninnnnni in innn,
in Nninnn, nnnni inn inninnn
nnnnn ni n 19in nnninin
Nninnn ninnin. Nnnn, nnnnnm,
innnn in nnin innn 100 innnnni
nnn nnnnin Nnnnnnn, Nnn,
Nnnnnn, Nnnn, ni inn
nninin lninn ni nnnnnin nnninn in inn ini nnnn.
Nninin nnn nnnnn nninininn nnnn nnnnnnn inn Nnmm
Nninn nnn nnnnn nnn nnnni. Nnn ninmninm nnninnnnnnn ni
inn N.N.N.N. in nininn, nnnnnnnin nnn nnninn ninnnnnnn inn
nnninn in inn ini nnnn.
nnnn nnnnnnn inn Nnmm
ninmninm nnninnnnnnn ni
nnn nnninn ninnnnnnn inn
Рис. 28. Этот пример основан на тексте последнего номера журнала Time, но все
буквы заменены на букву 'п' разной ширины. Если бы текст был осмысленным,
то разбиения строк в варианте В (которые выбирались согласно алгоритму Т^Х'а
оптимальной верстки) казались бы менее раздражающими, чем в варианте А. Кроме
того, вариант В не нуждается в пробелах между буквами.
ми почти поголовно. Например, Де Винн [11, с. 206] говорил, что разрядка
недопустима, даже когда колонки настолько узкие, что в некоторых строках
может поместиться только одно слово; Брюс Роже [37, с. 88] сказал, что
«предпочтительно размещать все лишние пробелы между словами, пусть
даже получающиеся при этом 'дыры' режут глаз». Даже одна четвертая
единичного пробела, вставленная между буквами, значительно меняет вид
слов. Полиграфические правила США Congressional Record [40] гласят, что
«Вообще говоря, операторы должны избегать широких пробелов. Тем не
менее, разрядка слов недопустима». Алгоритм оптимальной верстки позволяет,
таким образом, обращаться с существующими законами более вольно.
Идея применить динамическое программирование к разбиению строк
возникла у Д. Э. Кнута в 1976 г., когда профессор Л. Смит из музыкального
154
Компьютерная типография
nn Nninn ni Nnnini
Nnninnii Nnnnnnni
u nni inn n nnnnun,
nni nn nnnnn—inn
1П1ПП11, ППП П1ППП-
nin inn inn, in nninin. Nnnnnn-
mn 15% ni inn nnnn'i innn ini-
mnn, inn Nnnini Nninn nininnni
nnn n ninnni ni nninni nninnini
in Nnnnin Nninnn in inn Nnnnn
Nnnn nn inn nn ni N in inn, nninn
inn nnnnnnnn nnn ninnnn nnn
nnnni; nnin innn 3,000 mini—
innnnin inn nninnnn nnn Nnn
Nnin in Nnn Ninnnnnn—mnni-
nin inn inn nnini ni inn Nin-
nn Nnnnn nnn inn inn-nninnnn
Nnin Nnn Nninn. Nnn 262.4
nnnnn ninnnni ni inn N.N.N.N.
nninnn in nnin innn 100 ninnin
ninnni nnn ninin nninnni nnn
Nninnninni, Nnini, Nnnnnu nnn
nnnnnnn Nninnnn ninni. Nnnn
nnnmnnnni ninnnnni in innn, in
Nninnn, nnnni inn inninnn
nnnnn ni n 19in nnninin Nninnn
ninnin. Nnnn, nnnnnni, innnn
in nnin innn 100 innnnni nnn
nnnnin Knnnnnn, Nnn, Nnnnnn,
Nnnn, ni inn nninin lninii ni
nnnnmn nnninn in inn ini nnnn.
Nninin nnn nnnnn nnininnin
Nninn nnn nnnnn nnn nnnni. Nnn
inn N.N.N.N. in nininn, nnnnnnnin
nin
inn
nn Nninn ni Nnnini
Nnninnn Nnnnnnni
li nni inn n nnnnnn,
nni nn nnnnn—inn
1П1ПП11, ППП П1ППП-
1П11, 1П П111П1П.
Nnnnnmnn 15% ni inn nnnn'i
innn lnnnnn, inn Nnnini Nninn
nininnni nnn n ninnni ni
nninni nninnini in Nnnnin
Nninnn in inn Nnnnn Nnnn nn
inn nn ni Nininn, nninn inn nnn-
nnnnn nnn ninnnn nnn nnnni;
nnin innn 3,000 mini—innnnin
inn nninnnn nnn Nnn Nnin
in Nnn Ninnnnnn—innninin inn
inn nnini ni inn Ninnn Nnnnn
nnn inn inn-nninnnn Nnin
Nnn Nninn. Nnn 262.4 nnnnn
ninnnni ni inn N.N.N.N. nninnn
in nnin innn 100 ninnin ninnni
nnn ninin nninnni nnn
Nninnninni, Nnini, Nnnnnn nnn
nnnnnnn Nninnnn ninni. Nnnn
nnnmnnnni ninnnnni in innn,
in Nninnn, nnnni inn inninnn
nnnnn ni n 19in nnninin
Nninnn ninnni. Nnnn, nnnnnni,
innnn in nnin innn 100 innnnni
nnn nnnnin Nnnnnnn, Nnn,
Nnnnnn, Nnnn, ni inn
nninni lninii ni nnnnmn nnninn in inn ini nnnn.
Nninin nnn nnnnn nnininnin nnnn nnnnnnn inn Nnnini
Nninn nnn nnnnn nnn nnnni. Nnn ninnininni nnninnnnnnn ni
inn N.N.N.N. in nininn, nnnnnnnin nnn nnninn ninnnnnnn inn
nnnn nnnnnnn inn Nnnini
ninnininni nnninnnnnnn ni
nnn nnninn ninnnnnnn inn
Рис. 29. В представленной на рис. 28 «проблеме журнала Time» T^X ведет себя даже
лучше, когда позволено выбирать оптимальное число строк. Вариант В на рис. 28
произведен с was produced with параметром looseness 1, чтобы вынудить первый
абзац закончиться точно по нижнему краю прямоугольного рисунка. При параметре
looseness 0, текст в узкой колонке лучше подогнан.
отделения Станфордского университета задал вопрос о верстке музыкальных
партитур. В течение последующего обсуждения этой проблемы со студентами
на семинаре (см. Клэнси и Кнут [8]), кто-то заметил, что в сущности одна и
та же идея может быть применена как к словам абзаца, так и к музыкальным
тактам. Модель бокс/клей/штраф была разработана Кнутом в апреле 1977 г.,
когда планировался первоначальный проект TfrjX'a, хотя тогда он еще не знал,
достаточно ли эффективным будет общий алгоритм оптимизации на практике.
Кнут оставался в счастливом неведении относительно неудачных
экспериментов Купера с динамическим программированием, иначе он бы мог отказаться
от самой идеи прежде чем заняться ею.
Летом 1977 г. М. Ф. Плэсс ввел в исходный алгоритм Кнута понятие
допустимых точек разбиения, чтобы ограничить число активных возможностей
Глава 3. Верстка абзацев
155
и все еще искать оптимальное решение, при том что оптимум мог быть
чрезвычайно плохим. Этот алгоритм был применен в первой полной версии Tf^X'a
(март 1978 г.) и проявил себя хорошо. Неожиданная мощь модели бокс/клей/
штраф постепенно прояснялась в течение двух следующих лет экспериментов
с ТеХ'ом; и, когда было обнаружено несколько беспорядочное использование
отрицательных параметров (как в Паскале и примерах из Math Reviews на
рис. 10 и 11), авторы должны были выискивать коварные ошибки в исходной
разработке.
Наконец, стало необходимо добавить больше возможностей к процедуре
Т^К'а разбиения строк, в частности, возможность более гибко менять длину
строк, чем просто навешивая отступы. В этом смысле в 1978 г. стал очевиден
более глубокий дефект, именно, поддержание одного наиболее активного узла
для каждой точки разбиения независимо от того факта, что единственная
точка разбиения может оказаться допустимой в разных строках; это
означает, что алгоритм может пропустить допустимый способ верстки абзаца при
наличии достаточно длинного отступа. Затем весной 1980 г. был разработан
новый алгоритм, заменивший предыдущий ТЁХ'овский метод. В то же время
были введены усовершенствования, касающиеся коэффициента looseness и
несовпадения смежных строк, так что ТЕХ теперь использует, в сущности,
алгоритм оптимальной верстки, который мы подробно обсуждали выше.
Проблемы и усовершенствования
Одно неприятное ограничение в Т^Х'е еще остается, хотя это не свойственно
модели бокс/клей/штраф: когда разбиение возникает в середине лигатуры
(например, если 'efficient' превращается в 'ef-ficient'), вычисление ширины литеры
усложняется. Мы должны учитывать не только тот факт, что знак переноса
имеет некую длину, но и то, что буква 'Р перед 'fi' шире, чем та, что входит
в лигатуру 'ffi'. Та же проблема возникает, когда верстается немецкий текст, в
котором некоторые сложные слова, будучи перенесенными, меняют свое
написание (например, Ъаскеп' превращается в Ъак-ken', a 'Bettuch' —в 'Bett-tuch').
В настоящее время (в 1980 г.) 1ЁХ не предоставляет разных вариантов
написания слов, имеется только возможность вставить знак переноса между другими
неизменяемыми литерами. В редких случаях, когда нельзя получить более
сложных разбиений строк, следует прибегнуть к непосредственному
вмешательству человека.
Интересно разобраться, как обобщить алгоритм оптимальной верстки,
чтобы он мог обрабатывать случаи, подобные опущенным буквам m и п на
рис. 22. Функция плохости строки могла бы тогда зависеть не только от таких
естественных параметров, как длина, растяжение и сжатие; это могло бы
также зависеть и от количества букв m и п в этой строке. Аналогичная техника
была использована при наборе библейских текстов на древнееврейском,
которые никогда не переносили: для священных текстов в древнееврейском шрифте
имелись широкие варианты некоторых букв, так что отдельные буквы в строке
можно было заменить их более широкими эквивалентами, чтобы избежать
156
Компьютерная типография
широких пробелов между словами. Например, кроме обычного имеется
сверхширокий алеф. Соответствующая функция плохости для строк такого абзаца
должна была учитывать число представленных в них букв двойной ширины.
Одна из серьезных непредвиденных проблем, возникших в ТЁХ'овской
процедуре разбиения строк, заключалась в том, что при первоначальных ее
применениях для вычисления плохости, дефектности и т. п. использовалась
арифметика с плавающей точкой. Это приводило к тому, что на разных
вычислительных платформах получались разные результаты, поскольку, во-первых,
в существующем оборудовании, основанном на арифметике с плавающей
точкой, имеется очень много различий и, во-вторых, зачастую есть две
возможности выбрать точку разбиения с почти одинаковой общей дефектностью. Важно
иметь гарантию того, что все версии ТЁХ'а верстают абзацы идентично,
потому что это очень существенно при редактировании, внесении исправлений и
печати на разных устройствах. Таким образом, в «стандартной» версии ТЁХ'а,
которая должна появиться в 1982 г., во всех вычислениях будет применяться
арифметика с фиксированной точкой.
В книгах по издательскому делу часто обсуждается вопрос, который
является наиболее серьезным следствием жидких строк: это коридоры из белого
пространства, похожие на реки или ползущих ящериц. Столь безобразные
создания, которые прорезают последовательности строк и раздражают читателя,
не могут быть удалены простым эффективным методом типа
динамического программирования. Однако, к счастью, при использовании алгоритма
оптимальной верстки такая проблема почти никогда не возникает, потому что
компьютер, вообще говоря, способен сверстать абзац с достаточно плотными
пробелами. Коридоры начинают превалировать только тогда, когда по
некоторым причинам должен быть установлен более высокий порог толерантности р,
как, например, на рис. 7, где выравнивается необычно узкая колонка. Другая
причина появления коридоров может возникнуть, когда текст абзаца
распадается на чисто механические элементы, например, при перечислении в газете
многочисленных гостей торжественного мероприятия. Многие эксперименты,
проведенные с ТеХ'ом, показали, однако, что после использования алгоритма
оптимальной верстки не потребуется удаления коридоров вручную.
Модель бокс/клей/штраф, примененная по вертикали, столь же успешна,
как и при применении по горизонтали, поэтому Т^Х способен принимать весьма
разумные решения относительно того, где начинать каждую новую
страницу. Приемы для получения таких вещей, как равнение по правому краю, уже
обсуждавшиеся выше, аналогичны приемам для получения таких вещей, как
верстка с «равнением по нижнему краю». Однако в текущей версии Т^Х
хранит в памяти каждую страницу до тех пор, пока ее не распечатает, так что
Т^Х не может хранить весь документ и находить строго оптимальное
разбиение на страницы, используя тот же алгоритм, что и для разбиения строк.
Следовательно, алгоритм оптимальной верстки используется для вывода по
одной странице. В настоящее время продолжаются опыты с версией ТЁХ'а,
обнаруживающей глобальный оптимум разбиения страниц за два прохода. Эти
экспериментальные системы позволяют также располагать рисунки как можно
Глава 3. Верстка абзацев
157
ближе к тому месту, где имеется упоминание о них, принимая также во
внимание тот факт, что некоторые страницы могут образовывать «разворот». Многие
из этих вопросов решаются обобщением метода динамического
программирования и использованием модели бокс/клей/штраф, описанных в этой статье,
но для решения других проблем должна быть показана их NP-полнота [35].
Приложение: алгоритм расщепления на части
Во многих приложениях разбиения строк (например, в текстовых процессорах
или в газетах) нет никакой необходимости автоматизировать общий алгоритм
оптимизации, описанный выше, поэтому есть возможность значительно
упростить общую процедуру, одновременно экономя требуемые пространство и
время. При этом мы должны будем упростить спецификации задачи и установить
более низкий порог толерантности, чем в оптимальном случае, когда
необходим перенос. Представленная ниже программа «почти оптимальной верстки»
достаточно хорошо справляется с разбиением строк на рис. 3 или рис. 4(c), но
более сложные примеры не обрабатывает. Точнее говоря, в программе
расщепления на части предполагается следующее:
а) Вместо общей модели бокс/клей/штраф ввод снабжается спецификацией в
виде последовательности w\ .. ,wn неотрицательных ширин боксов,
представляющих слова абзаца с присоединенными к ним знаками препинания,
а также последовательностью малых целых чисел д\... дп, которые
соответствуют виду междусловного интервала. Например, gk — 1 означает
обычный междусловный интервал, следующий за боксом ширины wk,
тогда как gk = 2 означает отсутствие пробела, когда бокс к заканчивается
явным переносом, a gk = 3 отвечает боксу к в конце абзаца. Иной тип кодов
может быть использован после знаков препинания. Каждому типу
соответствует тройка неотрицательных чисел (хд)уд) zg), означающих нормальный
пробел, растяжение и сжатие того или иного типа пробела. Например, если
типы 1, 2 и 3 используются в только что определенном виде, мы можем
иметь
(^i) 2/i) z\) = (6, 3, 2) между словами
(^2) 2/2) %2) — (0, 0, 0) после явных переносов или дефисов
(^3) 2/3) ^з) = (0, оо, 0) для заполнения завершающей строки
в единицах измерения j^ern, где оо означает некоторое большое число.
Ширина w первого бокса должна состоять из пробела, необходимого для
отступа в начале абзаца; таким образом, фрагмент сказки братьев Гримм
на рис. 1 был бы представлен так:
wi,..., wn = 34,42,..., 24,39,30,..., 60,80
9и--->9п= 1) !)•••) 1) 2, 1,..., 1, 3
что соответствует при использовании ширин из табл. 1
'Din', 'olden',..., 'old', 'lime-', 'tree',..., 'favorite', 'plaything.'
158
Компьютерная типография
Общие последовательности w\ ... wn и д\... дп, описывающие вывод,
можно выразить в модели бокс/клей/штраф посредством эквивалентной
спецификации
6okc(wi) клей(хд1,уд1,гд1) ... 6oKc(wn) клей(х9п, уgnizgn),
за которой следует 'штраф(0, — оо,0)' для завершающей строки абзаца.
b) Все строки должны иметь одинаковую ширину I и каждое Wk должно быть
меньше /.
c) никакое слово не должно быть перенесено, если только нет способа
сверстать абзац, не нарушая минимальных и максимальных ограничений на
ширину пробела. Минимум для пробелов типа д равен
а максимум —
Уд=Хд+ РУд ,
где р есть положительный коэффициент толерантности, который может
быть изменен пользователем. Например, если р = 2, то максимум для
пробела типа д равен хд + 2уд, т. е. нормальный пробел плюс удвоенное
растяжение.
d) Перенос осуществляется только в точке, где допустимое разбиение строки
становится невозможным, даже если лучше было бы сделать перенос в
одном из предыдущих слов. Таким образом, общий алгоритм оптимальной
верстки текста будет давать значительно лучшие результаты, кода
требуется вывод высокого качества и часто нужны переносы.
e) Не назначается штраф за плотную строку, следующую за жидкой
строкой, или за несколько переносов подряд, и алгоритм не производит абзацев
длиннее или короче оптимальной длины (иначе говоря, в общем алгоритме
а = 7 = Q — 0)-
При этих ограничениях оптимальные точки разбиения могут быть найдены
весьма эффективно.
Почти оптимальный алгоритм работает с двумя массивами:
5o5i ... Sn+1 ,
где Sk обозначает минимальную сумму дефектностей, при которой происходит
разбиение после бокса &, либо Sk = оо, если здесь нет допустимого способа
разбиения; и
Pi • ..Pn+i,
где pk значимо, только если Sk < оо, и тогда лучший вариант завершить строку
на боксе к состоит в том, чтобы начать ее с бокса pk -Ы. Предположим также,
что
Wn+i= о;
Глава 3. Верстка абзацев
159
последнее представляет собой невидимый бокс в конце абзаца в завершающей
его строке.
Помимо 4п + 4 ячеек памяти для массивов w\... wn+\, д\... дП) sq ... sn+i
и pi...pn+i и памяти, необходимой для поддержания параметров /, р и
(хд, уд, zlg) для каждого типа д, алгоритму расщепления на части нужно всего
несколько разных переменных:
а — начало абзаца (обычно 0, после переноса меняется);
к = текущая рассматриваемая точка;
j = точка разбиения, рассматриваемая как предшественник точки к;
i = самая левая точка разбиения, которая допускается как
предшественник точки fc;
т = число активных точек разбиения (т. е. индексы j > i при Sj < со);
Е = нормальная ширина строки от г до /с;
Emax = максимально допустимая ширина строки от г до /с;
^min = минимально допустимая ширина строки от г до /с;
Е' = нормальная ширина строки от j до к;
Е^ах = максимально допустимая ширина строки от j до к;
^min = минимально допустимая ширина строки от j до к;
г = коэффициент корректировки от j до /с;
d = общая дефектность от а до • • • до j до /с;
d' = минимальная известная общая дефектность от а до • • • до к;
j' = предшественник точки к, приводящий к общей дефектности d\
если df < ос.
Все эти переменные суть целые числа, за исключением г, которое представляет
собой дробь в диапазоне — 1 < г < р. Читатель может проверить
обоснованность алгоритма, убедившись в том, что установленные интерпретации
переменных при выполнении программы остаются инвариантными относительно
ключевых точек.
Теперь приведем программу всю целиком:
а:=0;
loop: г := a; S{ := 0; т := 1; к := г + 1;
Ъ := 2jmax := 2-<min := w^]
loop: while Emjn > / do (Продвижение по г через 1);
(Рассмотрение всех допустимых строк, заканчивающихся в /с);
Sk := d'\ if d' < oo then
begin m:=m + 1; pk := /;
end;
if rn = 0 or к > п then exit loop;
E := E + Wk+\ +x9k\
Emax •== Emax + Wk+\ + Удк\ Emin := Emin + Wk+\ + Zgk\
к := /c + 1;
repeat;
if к > п then
begin output(a, n + 1); exit loop;
160
Компьютерная типография
end
else begin (Попытка перенести бокс /с, затем вывод
от а до этого разбиения);
а := к — 1;
end;
repeat.
Операция (Продвижение по г через 1) выполняется, только когда Em-m > /, и
это не может произойти при к — г +1, поскольку в этом случае Emin — ^к < ^
Следовательно, весь цикл завершен; имеем
(Продвижение по г через 1) =
begin if si < оо then m := m — 1;
г := г + 1;
2-f := 2j — W{ — XgL;
end.
Внутренний цикл почти оптимальной программы проще и быстрее, чем
соответствующий цикл общего алгоритма оптимальной верстки, потому что
он не рассматривает активные точки вблизи /с, а рассматривает только те,
которые отстоят приблизительно на ширину одной строки:
(Рассмотрение всех допустимых строк, заканчивающихся в к) =
begin j := г; Е' := Е; Е^ах := Emax; E^in := Emin; d! := оо;
while ЕЦХ > / do
begin if Sj < oo then
(Рассмотрение разбиения от а до • • • до j до /с);
Li \ = Zj — t/jj ж<^.;
^max := ^max ~" Wj ~ V9j 5 ^min := ^min ~~ W3 ~ Z9j 5
end.
Снова можем заключить, что весь цикл должен окончиться, поскольку он не
должен выполняться при к = j -f 1. Легко воспроизвести самый внутренний
цикл:
(Рассмотрение разбиения от а до • • • до j до к) =
begin if E' < I then r := р • (I - Я')/(Я'тах - Е')
else if E' > I then r := (Z - Е')/(Е' - E^in)
else r := 0;
с?:=5; + (1 + 100|г|3)2;
if d < d! then
begin d' := d\ j' := j]
end;
end.
Когда необходим перенос, алгоритм впадает в паническое состояние,
сначала отыскивая последнее допустимое значение г, а затем пытаясь расколоть
Глава 3. Верстка абзацев
161
слово к. К этому моменту вся строка от г до к — 1 слишком коротка, а от г до
к слишком длинна, так что есть надежда, что перенос будет сделан.
(Попытка перенести бокс /с, затем вывод от а до этой точки разбиения) =
begin loop: Е := Е + Wi + xgi\
^max •— ^max "r W{ + Удк\ 2-<min » = ^-Tnin ~r ^i ~r ZgL\
г := г — 1;
if 5j < oo then exit loop;
repeat;
cm£pw£(a,i);
(Раскалывание бокса к в наилучшем месте);
(Вывод строки до наилучшего раскалывания и корректировка Wk
для продолжения);
end.
Предположим, что имеется hk способов расколоть бокс к на два куска, где
ширины таких кусков при j-ом расколе равны соответственно wk ■ и wk-; здесь
в wfkj включена ширина знака переноса. Предполагается, что дополнительный
алгоритм переносов способен вычислять hk и ширины этих кусков, если
требуется; этот алгоритм вызывается только тогда, когда мы достигаем программы
(Раскалывание бокса к в наилучшем месте). Если перенос не нужен, можем
просто положить hk = 0 и приведенная ниже программа значительно
упрощается. Имеется hk + 1 вариантов, включая отсутствие раскалывания вообще, и
выбор из них происходит следующим образом:
(Раскалывание бокса к в наилучшем месте) =
begin (Вызов алгоритма переносов для вычисления hk
и ширин кусков);
/:=0; d' :=oo;
for j := 1 to hk do if Emin + w'k- —wk<l then
begin Е;:=Е + ю^ -wk\
if E' < I
then d := lOOOOp • (Z - E')/ (100(Emax - E) + 1);
else d := 10000 • (E' - /)/ (100(E - Emin) + 1);
if d < df then
begin d' := d\ f := j;
end;
end;
end.
Окончательная операция (Вывод строки до наилучшего раскалывания и
корректировка Wk для продолжения) здесь будет только неформально
очерчена, поскольку не хочется вводить массу дополнительных обозначений для
объяснения такого элементарного понятия. Если jf ф 0, т. е. нужен перенос,
программа выводит строку от бокса г + 1 до бокса к включительно, но при
этом бокс к заменяется куском со знаком переноса ширины wkj,; затем Wk
заменяется шириной другого фрагмента, именно w'L,. В другом случае, ко-
162
Компьютерная типография
гда jf = 0, программа просто выводит строку от бокса г + 1 до бокса к — 1
включительно.
Наконец, еще один жидкий конец нужно уплотнить: процедура output(a,i)
просто проходит через таблицу р, определяющую лучшие разбиения строки от
а до г и формирует соответствующие строки. Один из способов (не требующий
дополнительного пространства памяти) сделать это состоит в обращении
соответствующих элементов р-таблицы таким образом, чтобы они указывали на
последователей, а не на предшественников:
procedure output (integer a,i) =
begin integer g, r, 5; q := i; s := 0;
while q ф a do
begin r := pq\ pq := 5; 5 := q; q := r;
end;
while q ф г do
begin (Вывод строки от бокса q + 1 до бокса 5 включительно);
q :=S; s := pq;
end;
end.
Для применения этого алгоритма на практике мы располагаем лишь
ограниченным объемом памяти, а произвольно длинные абзацы можно
обрабатывать, только если сделать незначительное изменение, предложенное Купером
[9]: когда число слов в данном абзаце превышает некое максимальное
число nmaX) применять метод к первым nmax словам; затем вывести все, кроме
завершающей строки, и возобновить применение метода, начиная с копии,
перенесенной из той строки, что не была выведена.
Благодарности
Мы весьма признательны Барбаре Битон из Американского математического
общества за многочисленные обсуждения «реальных» приложений; мы очень
благодарны Джеймсу Иву из Университета Ньюкасл-он-Тайн и Нейлу Вай-
сману из Кембриджского университета за помощь в получении литературы,
недоступной в Калифорнии, а также библиотекарям отделов редких книг
Колумбийского и Станфордского университетов за разрешение ознакомиться с
многоязычными Библиями и сфотографировать отдельные фрагменты из них.
Это исследование частично финансировалось Национальным научным фондом по
грантам IST-7921977 и MCS-7723738, управлением морских исследований по гранту N00014-76-
С-0330, корпорацией IBM и издательством Эддисон-Уэсли.
Глава 3. Верстка абзацев
163
Литература
[1] Benedictus Arias Montanus, editor, Diblia Sacra Hebraice, Chaldaice, Greece,
SzLatine (Antwerp: Christoph. Plantinus, 1569-1573).
[2] G. P. Bafour, A. R. Blanchard, and F. H. Raymond, "Automatic Composing
Machine," U.S. Patent 2762485 (11 September 1956). (См. также британский
патент 771551 и французский патент 1103000.)
[3] G. Bafour, "A new method for text composition — The BBR System," Printing
Technology 5,2 (1961), 65-75.
[4] Michael P. Barnett, Computer Typesetting: Experiments and Prospects
(Cambridge, Massachusetts: M.I.T. Press, 1965).
[5] Samuel A. Bartels, The Art of Spacing (Chicago: The Inland Printer, 1926).
[6] Richard Bellman, Dynamic Programming (Princeton, New Jersey: Princeton
University Press, 1957).
[7] D. G. Berri, The Art of Printing (London: 1864).
[8] Michael J. Clancy and Donald E. Knuth, "A programming and problem-solving
seminar," report STAN-CS-77-606, Computer Science Department, Stanford
University (April 1977), 85-88.
[9] P. I. Cooper, "The influence of program parameters on hyphenation frequency
in a sophisticated justification program," Advances in Computer Typesetting
(London: The Institute of Printing, 1967), 176-178, 211-212.
[10] T. H. Darlow and H. F. Moule, Historical Catalogue of the Printed Editions of
Holy Scripture in the Library of the British and Foreign Bible Society (London:
The Bible House, 1911).
[11] Theodore Low De Vinne, Correct Composition, Volume 2 of The Practice of
Typography (New York: Century, 1901).
[12] James L. Dolby, "Theme C: Software and hardware," в буклете с
аннотациями, распространяемом 18 июля 1966 г. на закрытии International
Computer Typesetting Conference,.University of Sussex (London: The Institute of
Printing, 1966). Несколько более доброжелательный отзыв Долби о работе
Купера содержится в трудах конференции, опубликованных в
следующем году: см. Advances in Computer Typesetting (London: The Institute
of Printing, 1967), 292.
[13] С J. Duncan, J. Eve, L. Molyneux, E. S. Page, and Margaret G. Robson,
"Computer typesetting: An evaluation of the problems," Printing Technology
7 (1963), 133-151.
[14] С J. Duncan, "Look! No hands!" The Penrose Annual 57 (1964), 121-168.
[15] A. Frey, Manuel Nouveau de Typographie (Paris: 1835), 2 volumes.
[16] Michael R. Garey and David S. Johnson, Computers and Intractability (San
Francisco: W. H. Freeman, 1979).
[17] Aug. Giustiniani, Psalterium (Genoa: 1516).
164
Компьютерная типография
[18] Jakob Ludwig Karl Grimm and Wilhelm Karl Grimm, "Der Froschkonig (The
Frog King)," в Kinder- und Hausmarchen (Berlin: 1912). Относительно
истории этой сказки см. Heinz Rolleke, Die Alteste Marchensammlung der
Brilder Grimm (Cologny-Geneve: Fondation Martin Bodmer, 1975), 144-153.
[19] Basil Hall, The Great Polyglot Bibles (San Francisco: The Book Club of
California, 1966).
[20] M. Held and R. M. Karp, "The construction of discrete dynamic programming
algorithms," IBM Systems Journal 4 (1965), 136-147.
[21] Walter E. Houghton, Jr., "The history of trades: Its relation to seventeenth
century thought," в Roots of Scientific Thought, edited by Philip P. Wiener
and Aaron Noland (New York: Basic Books, 1957), 354-381.
[22] Information International, Inc., PAGES Composition Language,
распространяется по частным каналам. Первое издание: October 31, 1975; второе
издание: October 20, 1976. Этот язык иногда называли "PAGE-Ш" по
аббревиатуре компании, его создавшей.
[23] Kathleen Jensen and Niklaus Wirth, PASCAL User Manual and Report,
second edition (Heidelberg: Springer-Verlag, 1975).
[24] Francisco Jimenez de Cisneros, sponsor, Uetus testamentum multiplici lingua
nunc primo impressum (Alcala de Henares: Industria Arnaldi Guillelmi de
Brocario in Academia Complutensi, 1522). Издание было готово в 1517 г., но
из-за отсутствия разрешения Папы выход в свет задержался на несколько
лет.
[25] Paul E. Justus, "There is more to typesetting than setting type," IEEE
Transactions on Professional Communication PC-15 (1972), 13-16, 18.
[26] Donald E. Knuth, ItfC and METRFONT: New Directions in Typesetting
(Bedford, Massachusetts: Digital Press and American Mathematical Society,
1979).
[27] Donald E. Knuth, "BLAISE, a preprocessor for PASCAL," файл
BLAISE.DEK[UP,DOC] в SU-AI в сети ARPA network (March 1979). Сама
программа находится в файле BLAISE.SAI[ТЕХ,DEK].
[28] Donald E. Knuth, Seminumerical Algorithms, Volume 2 of The Art of
Computer Programming, second edition (Reading, Massachusetts: Addison—
Wesley, 1981).[Имеется русский перевод первого издания: Кнут Д.
Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы.—М.:
Мир, 1977; второго издания: Кнут Д. Е. Искусство программирования.
Т. 2. Получисленные алгоритмы.— Киев: Диалектика, 1999.]
[29] Donald E. Knuth, T^K: The Program, Volume В of Computers k Typesetting
(Reading, Massachusetts: Addison-Wesley, 1986).
[30] Joseph Moxon, Mechanick Exercises: Or, the Doctrine of Handy-Works.
Applied to the Art of Printing (London: J. Moxon, 1683-1684).
Воспроизведено в Typothetae, New York, 1896, с замечаниями Т. L. De Vinne; также
воспроизведено в Oxford University Press, 1958, с замечаниями Herbert Davis
Глава 3. Верстка абзацев
165
и Harry Carter; но эта перепечатка не сохранила в полной мере дух
оригинала, представляющего собой великолепный образец мастерства 17-го
столетия.
[31] Joseph F. Ossanna, Nroff/Troff User's Manual, Bell Telephone
Laboratories internal memorandum (Murray Hill, New Jersey: 1974).
Переработанная версия в UNIX Programmer's Manual 2, Section 22 (January
1979).
[32] Herman D. Parks, "Computerized processing of editorial copy," Advances in
Computer Typesetting (London: The Institute of Printing, 1967), 119-121,
157-158.
[33] Herman Parks, выступления при обсуждении, Proceedings of the ASIS
Workshop on Computer Composition (American Society for Information
Science, 1971), 143-145, 151, 180-182.
[34] John Pierson, Computer Composition Using PAGE-1 (New York: Wiley-
Interscience, 1972).
[35] Michael F. Plass, Optimal Pagination Techniques for Automatic Typesetting
Systems, Ph.D. thesis, Stanford University (1981). Опубликовано также как
Xerox Palo Alto Research Center report ISL-81-1 (Palo Alto, California:
August 1981).
[36] Alison M. Pringle, "Justification with fewer hyphens," The Computer Journal
24 (1981), 320-323.
[37] Bruce Rogers, Paragraphs on Printing (New York: William E. Rudge's Sons,
1943).
[38] Hanan Samet, "Heuristics for the строка division problem in computer justified
text," Communications of the ACM 25 (1982), 564-571.
[39] George Bernard Shaw, "On modern typography," The Dolphin 4 (1940), 80-81.
[40] U.S. Government Printing Office, Style Manual (Washington, D.C.: 1973).
Цитата взята из правила 22.
[41] Brianus Waltonus, editor, Biblia Sacra Polyglotta (London: Thomas Roycroft,
1657).
[42] David Wolder, Biblia Sacra Graece, Latine &; Germanice (Hamburg: Jacobus
Lucius Juni., 1596).
Добавление
Майкл Плэсс подготовил короткую версию этой статьи для книги Document
Preparation Systems под редакцией Jurg Nievergelt, Giovanni Cor ay, Jean-Daniel
Nicoud, and Alan С Shaw (Amsterdam: North-Holland, 1982), 221-242. В его
версии модель бокс/клей/штраф была обобщена и упрощена посредством
введения понятия зарубка, которая состоит из трех последовательностей из боксов
и клея для вариантов до разбиения, после разбиения и отсутствие разбиения
166
Компьютерная типография
вместе со штрафом р и флагом /; точки разбиения появляются только в
зарубках.
В стандартной версии ТЁХ'а, появившейся спустя примерно два года после
написания статьи, модель разбиения строк обобщается иным образом: вводится
клей leftskip и rightskip слева и справа от каждой строки. Это упрощает
многие конструкции, такие, как ровнение по правому краю и ровнение по центру.
Теперь Т^Х использует несколько улучшенную формулу для дефектностей,
именно:
Г (I + Pj)2 + 7Tj + ctj , если ttj > 0 ;
5j = < (/ + Pj)2 — 7г| + aj , если —oo < ttj < 0;
[ (/ + Pj)2 + ctj , если ttj = —oo;
здесь l есть параметр, называемый штраф строки, обычно равный 10.
См. D. E. Knuth, Literate Programming (1991), 272-274, относительно того,
почему было важно заменить (I + Pj + ttj)2 на (/ + Pj)2 + 7г2 в случае ttj > 0.
Люди, активно пользующиеся Т[й?Сом, должно быть знают, что
«бесконечный» штраф теперь полагается равным 10000 вместо 1000 и что клей ТЕ^'а
теперь имеет три уровня бесконечности, называемые fil, fill и filll. В
версии TgK'a 3.0 был введен необязательный третий проход алгоритма разбиения
строк, если пользователь указывал emergency stretch (непредвиденное
растягивание) [см. изменение 885 в протоколе ошибок Tg^'a Literate Programming
(1992), 338]. Если нет допустимого способа набрать абзац с коэффициентами
толерантности pi или р2> экстренное растягивание добавляется к растяжению
всех строк, когда вычисляются коэффициенты плохости и дефектности; это
предоставляет ТЁХ'у вполне приличный способ различать, в какой степени
неудачны чрезвычайно плохие разбиения в наиболее сложных случаях.
Сочетание текстов,
читаемых справа налево
и слева направо
[Написано в соавторстве с Пьером Маккеем. Первоначально опубликовано
в TUGboat 8 (1987), 14-25.]
ТЕХ создавался для печати документов, читаемых слева направо и сверху вниз,
в соответствии с правилами английского и других западных языков. Если
такие документы повернуть на 90°, их можно также читать сверху вниз и справа
налево, как в Японии. Поворот еще на 90° или 180° даст документы, читаемые
справа налево и снизу вверх или снизу вверх и слева направо, если это зачем-то
понадобится. Как бы то ни было, Т^Х сам по себе не приспособлен для языков
типа арабского или иврита, которые читаются справа налево и сверху вниз.
Несложно использовать Т^Х для печати документов полностью на
арабском языке или полностью на иврите, просто выдавая зеркальное
отражение любого требуемого текста, Растровое печатающее устройство легко
может быть запрограммировано так, чтобы отражать биты справа налево при
выводе их на страницы. (Иногда это называют «режимом футболки»,
потому что его можно использовать для нанесения надписей на футболку путем
аппликации на материю английского текста, напечатанного в зеркальном
отражении.)
Сложности, тем не менее, возникают, когда правила чтения слева направо
и справа налево соединяются внутри одного документа. Возьмите арабско-
английский словарь, или комментарии Библии с цитатами на иврите, или
ближневосточную энциклопедию, в которой западные имена пишутся
латинскими буквами; такие документы, и многие другие, должны читаться обоими
способами.
Цель этой статьи — прояснить вопросы, связанные с печатью смешанных
документов, рассматривая их с точки зрения западного автора, или читателя,
или создателя программного обеспечения. Мы также рассмотрим изменения
ТЁХ'а, превращающие его в двунаправленную форматирующую систему.
168
Компьютерная типография
Термины и правила
Для удобства будем говорить, что L-текст — это текстовой материал,
который следует читать слева направо, а R-текст — текстовой материал,
который следует читать справа налево. Точно так же можно сказать, что
английский и испанский —L-языки, в то время как арабский язык и иврит —
R-языки.
Чтобы сделать эту статью понятной для европейца, не знакомого с R-
языками, мы будем использовать «перевернутый английский», т. е. НгПдпЯ,
в качестве R-языка. Все тексты на перевернутом английском языке будут
набираться шрифтом ЬэЬпэ^хЯ ЫоЯ гпэЬоМ i9;fruqmoO, представляющим
собой перевернутую версию шрифта Computer Modern Bold Extended [широкого
полужирного Computer Modern]. Для перевода с английского на НгПдпЯ и
обратно требуется всего лишь обратить порядок чтения. И English, и rfgil§n3
произносятся одинаково, только НгПдпЯ нужно произносить громче и/или
ниже тоном так, чтобы слушатель мог их различать.
Простейший случай
Нетрудно набирать одиночные слова R-языка в L-текстовом документе. ТЕХ
будет прекрасно работать, если вам не придется иметь дело с R-текстами
длиной более одного слова; все, что требуется сделать, —это написать макро,
переворачивающий отдельные слова.
Предположим, мы хотим набрать 'the I English I script' [английский
шрифт], чтобы TgX напечатал 'the НгПдпЯ script'. Все, что нам нужно, —это
шрифт для НгПдпЯ, называемый, скажем, xbmclO, и следующие макро:
\f ont\revrm=xbmc10 \hyphenchar\revrm=-1
\catcode'\I=\active
\defI#1|{{\revrm\reflect#l\empty\tcelfer}}
\def\reflect#l#2\tcelfer{\ifx#l\empty
\else\reflect#2\tcelier#l\ii}
(Символы xbmclO можно получить аналогично символам cmbxlO, если
добавить еще одно предложение METAFONT'a
extra_endchar := extra_endchar &
"currentpicture:=currentpicture
reflectedabout((.5[1,r],0),(.5[1,r],1));"
в файл параметров. Оба шрифта имеют одинаковую ширину символов, но
таблицы лигатур-кернов у них разные; к примеру, 'i', за которой следует Т дает
'ft'.)
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 169
Тексты с чередованием
Но этот простой метод не работает, когда внутрь L-текста вставляются R-фра-
зы из многих слов, например 898Bidq ^хэ^-Я biowiJlum, из-за возможных
переводов строки, например 1о эгивоэб г^вэ-id эш11о ^tflidissoq эН^.
Возьмем, к примеру, следующий абзац и посмотрим, как его можно напечатать:1
Leonardo da Vinci made a sweeping statement
in his notebooks: |(<Let no one
who is not a mathematician read my works.''I
In fact, he said it twice, so he probably meant it.
[У Леонардо да Винчи в его записях есть одно безапелляционное
высказывание: «Пусть никто, кроме математиков, не читает моих работ». На самом
деле, он сказал это дважды, так что, вероятно, говорил всерьез.]
Вот примеры правильной распечатки этого абзаца, отличающиеся шириной
колонки:
Leonardo da Vinci made a sweeping statement in his
notebooks: пвхэЬвтэН^вт в Jon 8i odw эпо on teJ"
".83how ^m Ьвэт In fact, he said it twice, so he probably
meant it.
Leonardo da Vinci made a
sweeping statement in his notebooks: teJ"
-1;*втэН;*вт в ion 8i odw эпо on
".83how ^га Ьвэт пвхэ In fact, he
said it twice, so he probably meant it.
Обратите внимание, что R-текст в каждой строке перевернут; в частности,
знак переноса, добавленный справа от R-фрагмента, появится слева от него.
Как заставить Т^Х сделать это? Вероятно, лучше всего расширить
программы драйверов, выводящих на печать DVI-файлы, производимые ТеХ'ом,
а не пускаться на всевозможные ухищрения с макрокомандами ТЁХ'а. Тогда
самому ТЁ^'У нужно просто вставлять в конечные DVI-файлы специальные
коды, указывающие DVI-IVQ-драйверам, что делать.
Например, одна из почти работающих идей состоит в том, чтобы вставлять
'\special{R}' непосредственно перед началом R-текста и '\special{L}' сразу
после его окончания. Другими словами, мы можем переписать макро Ч' из
предыдущего примера в следующей простой форме:
\defI#11{{\revrm\special{R}#l\special{L}}}
1 Когда правая рука перестала слушаться Леонардо, он стал писать левой рукой
зеркальным письмом. Конечно, на самом деле он писал на neileil [перевернутом итальянском], а
не на rfailgnS.
170
Компьютерная типография
что на самом деле не переворачивает символы; мы можем также оставить
параметру '\hyphenchar' в шрифте \revrm его обычное значение, так что R-
тексты будут переноситься. Разбивка на строки будет происходить как обычно,
а программа DVI-IVQ-драйвера возьмет на себя переворот каждого фрагмента,
который она обнаружит между R и L.
Переворачивать можно произвольные комбинации символов, линеек,
акцентов, кернов и т. д.; к примеру, R-текст может быть ахв^пв-й [перевернутым
французским] или даже быть про ХдрГ!
Один из путей реализации
Для того чтобы понять, как DVI-IVQ-программы должны выполнять
поставленную задачу, нужно посмотреть, какую информацию TgX записывает в DVI-
файл. Основная идея заключается в том, что каждый раз, когда ТЕХ выдает
горизонтальный или вертикальный бокс (hbox или vbox), в DVI-файл
записывается команда cpush\ за которой следуют различные команды для печати
содержимого бокса (box), а затем команда срор\ Поэтому мы можем
попробовать следующую стратегию:
a) Как только в DVI-файле встретилось '\special{R}', запомним текущие
горизонтальную координату ho и вертикальную координату vq] запомним
также текущее положение ро в DVI-файле. Положим с <— 0. Затем
следующие DVI-инструкции будем просматривать, вместо использования их
собственно для печати; но при этом будем как обычно следить за
изменением горизонтальной и вертикальной координат на странице.
b) Когда в DVI-файле встретилось '\special{L}', перестаем просматривать
инструкции. Затем выдаем на печать все инструкции между ро и текущим
положением в зеркальном режиме, как описано ниже.
c) Если во время просмотра инструкций встречается *push\ увеличиваем с
на 1.
d) Если во время просмотра инструкций встречается 'рор\ то возможны два
варианта. Если с > 0, уменьшаем с на 1. (Эта команда 'pop' соответствует
встреченной ранее при просмотре команде lpush\) Но если с = 0, вставляем
в этом месте '\special{L}' и '\special{R}' —после следующей команды
'push\
Зеркальный режим для DVI-команд, располагающихся между положениями ро
и pi в DVI-файле, начинающий печатать в точке (fto,^o) и заканчивающий в
точке (/ii,?;i), работает следующим образом. Символ ширины w, бокс
которого в нормальном режиме располагался бы на базовой линии между (ft, г;) и
(ft 4- ги, г;), нужно расположить так, чтобы этот бокс в зеркальном режиме
располагался на базовой линии между (ft/ — w,v) и (ft/, г;), где ft/ определяется из
уравнения
h — ho = h\ — h!.
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 171
Аналогично, линейка ширины ги, нижняя сторона которой в нормальном
режиме соединяет (Л, г;) и (h + w,v), в зеркальном режиме должна соединять
(h! — w,v) и (hf,v).
Ликвидируем недочеты
Выше мы утверждали, что только что описанный метод будет «почти»
работать. Но он может не сработать в трех ситуациях, если использовать весь
спектр возможностей ТЁХ'а. Во-первых, можно делать вставки «между строк»
с помощью команд \vadjust; эти вставки могут ошибочно обрабатываться
как R-текст. Во-вторых, предложенный механизм не всегда правильно
находит левый край переворачиваемого фрагмента, потому что переворот не
всегда должен начинаться с самого левого края печатной строки; он должен
начинаться после \ left skip-клея и перед другими начальными отступами,
сделанными для расстановки акцентов и т. п. В-третьих, с помощью некоторых
трюков с использованием \unhbox, можно заставить целые строки исчезать
из DVI-файла; впрочем, эта проблема не столь важна, как первые две, потому
что этими трюками злоупотреблять не стоит.
Гораздо более заслуживающая доверия и устойчивая схема получается,
если создать специально расширенную версию ТЁХ'а, которая добавляет парные
команды \special в каждую строку, в которой присутствует перевернутый
текст. Добавить к уже имеющемуся в Т^Х'е механизму разбиения на строки
еще и эти действия несложно; подробности описаны ниже в приложении.
После того как эти изменения произведены, можно опустить пункты (с) и (d)
алгоритма просмотра для DVI-IVQ.
L-шовинизм
До сих пор мы обсуждали смешанные документы так, как будто они всегда
состоят из R-фрагментов, вставляемых в L-окружение; но люди, пишущие на
родном языке справа налево, естественно думают о смешанных текстах как об
L-вставках в R-окружение. На самом деле, каждую напечатанную страницу
можно читать двумя способами: начиная пробегать каждую строку глазами
слева и начиная пробегать каждую строку глазами справа.
Приведенный выше пример из Леонардо принадлежит первому типу,
мы будем называть его L-документом. Чтобы прочесть данную строку L-
документа, нужно начинать слева и читать любой L-текст, находящийся в
строке. Как только ваши глаза наталкиваются на R-символ, нужно пробежать
глазами текст до конца следующего R-фрагмента (т. е. до ближайшего L-символа
или до конца строки, смотря что встретится раньше); затем нужно прочитать
R-фрагмент справа налево и продолжить, как вначале. Подобным же образом
следует читать R-документы, только нужно поменять местами правое и левое.
Обычно L-документ можно отличить от R-документа по отступу в первой
строке абзаца и/или пустому пространству в последней строке. Например, R-
172
Компьютерная типография
документы, соответствующие двум вариантам L-документов, полученных из
абзаца про Леонардо, будут выглядеть так:
Leonardo da Vinci made a sweeping statement in his
пвхэИвтэгивт в Jon 8i orfw эпо on teJ" notebooks:
In fact, he said it twice, so he probably ".8>how ^m Ьвэт
meant it.
Leonardo da Vinci made a sweep-
teJ^ ing statement in his notebooks:
-1;*втэг№вт в ion 8i orfw эяо on
In fact, he ".8>Tiow ^ra Ьвэт пв!э
said it twice, so he probably meant it.
Мы можем вообразить себе, что эти R-документы были набраны на R-
терминале и XjrfT обрабатывал следующий эШ Juqni [входной файл]:
ЗаэтэЗвЗг gniqeewa б эЬбш ioaiV бЬ оЬтбяоэЛ!
эяо оя ЗэЛ{ { | : ajfoodecJ-on airf ni.
1 * . aaliow yta Ьб91 яб1Э1^бя19г[^бш б сГоя ai orfw
I . cfi ^ябэгп Y-tdsdoiq erf oa t9DiwJ cfi bisa erf кЗэб± я1|
В данном случае внутри | заключен L-текст, а не R-текст. (Читателю придется
внимательно изучить этот пример; в нем присутствует bodtem [система]!)
Надо полагать, поэт мог бы сконструировать интересные стихотворения,
обладающие как L-смыслом, так и R-смыслом, в зависимости от того, читаются
они как L-документы или как R-документы.
Обратите внимание, что в наших примерах из Леонардо мы использовали
полужирные кавычки (т. е. кавычки НгПдпЯ), так что кавычки принадлежат
цитируемому тексту. Это может показаться неправильным; но на самом
деле в тех документах, где не оказывается предпочтения ни L-читателям, ни
R-читателям, это соглашение необходимо, потому что оно обеспечивает
близость кавычек к переворачиваемому тексту. (См. образцы современной
печатной продукции в конце этой статьи.) Если бы кавычки были английскими, а не
НгПдпЯ, показанные ранее R-документы действительно выглядели бы очень
странно:
Leonardo da Vinci made a sweeping statement in his
ПБ1Э1^вхх1эг1^вх11 в ion 8i orfw эпо on teJnotebooks: "
" In fact, he said it twice, so he probably.8>how ^m Ьвэт
meant it.
Leonardo da Vinci made a sweep-
teJing statement in his notebooks: "
-iiBXII9rfiBXII В ion 81 orfw 9ПО Ofl
" In fact, he.8>Tiow ^ra Ьвэт пв!э
said it twice, so he probably meant it.
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 173
Многоуровневое сочетание
Проблемы сочетания R- и L-печати этим не исчерпываются, потому что L-
текст может оказаться внутри R-текста внутри L-текста. Например, мы могли
бы захотеть напечатать абзац, исходный ТеХ'овский файл которбго выглядит
так:
\R{Alice} said, \R{"You think English is
\L{(English written backwards'}; but to me,
\L{English} is English written backwards.
I'm sure \L{Knuth} and \L{MacKay} will
both agree with me.''} And she was right.
[\К{Алиса> сказала:
\К{<<Вы думаете, что английский^авп это \L{(перевернутый
английский'}; но для меня \Ь{английский}^азп это перевернутый
английский. Я уверена, что \Ь{Кнут} и \Ь{Маккей} оба со мной
согласятся>>.}
И она была права.]
Образованный в обоих направлениях читатель захочет, чтобы это было
напечатано, как R-доку мент внутри L-доку мента. Другими словами, для такого
читателя естественно будет некоторые строки читать, начиная слева, а
некоторые — справа. Вот примеры желаемого результата, различающиеся шириной
строки (просмотрите их внимательно):
ээНА said, г! НгНдпЯ >Inirf;fr jjoY"
сэт oJ iucf ;'English written backwards'
,8biBW>bBd n9iibw НгНдпЯ г! English
rttod Iliw MacKay Ьпв Knuth э*шг mcI
".эт rftiw ээ-хдв And she was right.
ээНА said, 'En- 8i НгНдпЯ >Inirf;fr jjoY"
English сэт о J bud ;glish written backwards'
эш8 mcI .8biBw>lDBd n9ttriw riailgnSI 8i
rftiw ээ-хдв rftod Iliw MacKay Ьпв Knuth
".эт And she was right.
Многоуровневые документы обязательно несут в себе неоднозначность.
Например, второй вариант примера ээНА можно интерпретировать как
результат, полученный из
...\R{... I'm sure and \L{MacKay} will both agree with}
Knuth \R{me.''} And she was right.
174
Компьютерная типография
А первый вариант также мог быть получен из такого исходного файла(!):
\R{''You think English is \L{said,} Alice
\L{(English}; but to me,} written backwards'
\R{written backwards.} \R{\L{English} is English}
will both} MacKay \R{and} Knuth \R{I'm sure
\L{And she} agree with me.''} was right.
Небольшие различия заключались бы только в расстановке пробелов по
причине ТЁХ'овского «коэффициента пробела» («space factor») для знаков
препинания.
Вообще, \R{\L{a}\L{b}} = ba, поэтому теоретически возможна любая
перестановка символов в каждой строке. Читателю приходится догадываться,
какой из различных способов просмотра каждой строки имеет больший смысл.
Тем не менее, в странах Ближнего Востока существует единодушное мнение,
что сочетать L-документы и R-документы предпочтительней, чем настаивать
на абсолютно однозначном последовательном L-прочтении или R-прочтении
всего текста, — потому что это вполне естественно и потому что настоящая
неоднозначность на практике встречается редко. В предшествующем примере
кавычки позволяют восстановить невидимые \R и \L; таким образом автор
может сотрудничать с грамотным читателем в стремлении к ясности изложения.
Многоуровневые тексты возникают не только, когда цитаты
присутствуют внутри цитат или когда сноски или иллюстрации, оформленные как R-
документ, вставляются в L-документ; они возникают также, когда в R-текст
вставляются математические выражения. Рассмотрим, например, следующий
исходный ТЁХ'овский файл:
The \R{English} version of 'the famous identity
$e~{i\pi}+l=0$ due to Euler' is
\R{'the famous identity $e~{i\pi}+l=0$ due to Euler'}.
[\R{Английская} версия фразы -известное тождество
$e~{i\pi}+l=0$, идущее от Эйлера' выглядит так:
\R{(известное тождество $e~{i\pi}+l=0$, идущее от Эйлера'}.]
Печатать это нужно следующим образом:
The НгПдпЯ version of 'the famous
identity ег7Г -f 1 = 0 due to Euler' is гиотв! эг!;^
с1э!иЗ oJ эиЪ ei7r + 1 = 0 у^ЬпэЫ.
Расширение ТЁХ'а, названное TEX-XjgfT, описанное в приложении, правильно
обрабатывает многоуровневые сочетания, включающие математику, а также
более простые случаи чередования R-текстов и L-текстов.
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 175
Заключение
Когда в одном документе сочетаются тексты, читаемые справа налево и
слева направо, могут возникнуть проблемы, более тонкие, чем можно
предположить из простых примеров. Трудности можно преодолеть, расширив Т^Х до
ТЕХ-Х(д[Г'а и расширив DVI-драйверы до DVI-IVQ-драйверов. Ни то, ни другое
расширение не является чрезмерно сложным.
Приложение
Описанные здесь расширения Т^Х'а записывают в DVI-файл до сих пор
неопределенные однобайтные коды 250 ('begin -reflection') и 251 ('end-reflection'),
вместо '\special{R}' и '\special{L}', как указано выше, потому что печать
текстов чередующегося направления достаточно важна и заслуживает
эффективного DVI-кодирования. Получающиеся в результате этого файлы называются
DVI-IVCI-файлами,
Язык TgX'a расширяется следующими четырьмя примитивными
операциями (primitive operations):
\beginL \endL \beginR \endR
которые должны вставляться наподобие скобок в каждый абзац и каждый
горизонтальный бокс (hbox). Но \endL и \endR следует опускать в конце абзаца,
если они должны сработать после \parf illskip-клея. (Так, к примеру,
\everypar{\kern-\parindent\beginR\indent}
можно использовать в начале серии последовательных абзацев, в каждом из
которых действуют правила R-документа. Последняя строка каждого из этих
абзацев будет прижата к правому полю с заполнением влево; в первой строке
отступ будет сделан справа.)
Каждая из четырех новых операций добавляет новый сорт «узла whatsit»
в текущий горизонтальный список; это новые виды (горизонтальных команд)
((horizontal command)), в соответствии с объяснениями в руководстве по
Т^Х'у [2]. Макро \L и \R в нашем многоуровневом примере про ээНА можно
определить следующим образом:
\def\L{\afterassignment\moreL \let\next= }
\def\moreL{\bracetest \aftergroup\endL \beginL \rm}
\def\R{\afterassignment\moreR \let\next= }
\def\moreR{\bracetest \aftergroup\endR \beginR \revrm}
\def\bracetest{\ifcat\next{\else\ifcat\next}\fi
\errmessage{Missing left brace has been substituted}\fi
\bgroup}
Оставшаяся часть этого приложения дает полное и подробное описание
изменений, которые нужно внести в стандартную программу TgX'a [3],
чтобы превратить ее в расширенную систему T^-XjgfT. Эти изменения удобно
176
Компьютерная типография
перечислять по номерам тех WEB-разделов в [3], которые этими изменениями
затронуты.
2. Здесь следует изменить последний вступительный абзац; новый вариант
будет объяснять, что данная программа на самом деле 'ТДО-XgT', а не '1Ё^'-
Соответственно, строка banner переопределяется:
define banner = 'ThisuisuTeX-XeT,uVersionu3.1415'
{ выводится при запуске ТЕ^С-ХдТ'а }
11. Изменяется pool-name, так чтобы T^X-XjgT мог прекрасно
сосуществовать с ТЁХ'ом.
pooLname = 'TeXformats:TEXXET.POOLuuuuuuuuuuuuuuuuuu';
{ строка длины file-namesize] говорит, где хранится запас сообщений }
161. В этом месте в программу вставляются дополнительные подпрограммы,
которые будут определены позже.
(Declare functions needed for special kinds of nodes 1381)
[Объявить функции, необходимые для узлов специальных видов]
208. В конец старого списка добавляется новый командный код; поэтому
заключительное определение заменяется на следующие два:
define LR =71 { направление текста ( \beginL , \beginR , \endL , \endR ) }
define тах-поп-prefixed-command — 71
{ максимальный командный код, который не может быть \global}
209. Нужно добавить 1 к правым частям всех этих определений.
define toks-register = 72 {регистр списка токенов ( \toks ) }
define set-interaction = 101
{ определение уровня взаимодействия с пользователем ( \batchmode
и т. д. ) }
define max-command = 100 {наибольший код команды, видимый при bigswitch }
585. К описанию DVI-команд в конце прибавляется две новых:
beginjrefleet 250. Начать (возможно вложенный) перевернутый фрагмент.
end-reflect 251. Закончить (возможно вложенный) перевернутый фрагмент.
В обычных DVI-файлах команды 250-255 не определены, но 250 и 251
разрешены в специальных 'DVI-IVCT-файлах, производимых этой версией ТЁХ'а.
Когда DVI-IVQ-драйвер встречает команду begin-reflect, он должен
просматривать последующие команды (как описано ранее), пока не найдет парную
end-reflect; они будут правильно располагаться друг относительно друга и
относительно push и pop. После того как в результате просмотра определился
фрагмент текста, который нужно перевернуть, этот фрагмент пробегается
заново и обрабатывается в зеркальном режиме, как описано ранее.
Переворачиваемый фрагмент может содержать вложенные пары begin-reflect / end-reflect,
которые нужно еще раз переворачивать.
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 177
586. Необходимы два новых определения:
define beginjreflect = 250 { начать перевернутый фрагмент (используется только
в DVI-IVa-файлах) }
define end-reflect = 251 {закончить перевернутый фрагмент (используется
только в DVI-IVa-файлах) }
638. В начале ship-out мы инициализируем стек действующих на данный
момент инструкций \beginL и \beginR; он называется LR-стеком и
поддерживается при помощи двух глобальных переменных, называемых LRjptr и
LR-tmp, их мы определим позднее. Вставляемые здесь инструкции
(непосредственно перед проверкой условия tracing-output > 0) говорят, что на самом
внешнем уровне мы печатаем в режиме слева направо. Начальный 'begin'
заменяется на
begin LRjptr «— get-avail; info(LR-ptr) «— 0; { begiri-L-Code на внешнем уровне }
639. В конце ship-out мы хотим очистить LR-стек. Поэтому происходит
замена ' flush-node Jist(pY на
flush-node-list(p); (Flush the LR stack 1385);
[Очистить LR-стек]
649. Программа hpack изменяется, чтобы поддерживать LR-стек при
формировании горизонтального списка таким образом, чтобы ошибки в парах
\beginL. . .\endL и \beginR. . . \endR находились и исправлялись. Изменения
требуется внести в начало процедуры и в конец.
function hpack(p : pointer] w : scaled] m : small-number): pointer]
hd: eight-bits] {индексы высоты и глубины для символа}
LR-ptr, LR-tmp: pointer; { для поддержки LR-стека }
LR-problems: integer] {подсчитывает недостающие begin и end}
begin LR-ptr «— null] LR-problems «— 0;
r «— get-node(box-nodesize)]
zommon-ending: (Finish issuing a diagnostic message for an overfull or underfull
hbox 663);
[Закончить выдавать диагностическое сообщение для слишком широкого или
недостаточно широкого горизонтального бокса]
ixit: (Check for LR anomalies at the end of hpack 1390);
[Проверить LR-несоответствия в конце hpack]
hpack «— r]
end;
877. Аналогично, программа postJine-break должна поддерживать LR-стек,
гак чтобы она могла выдавать инструкции \endL или \endR в конце строк
и инструкции \beginL или \beginR в начале строк. Изменения затрагивают
начало и конец этой процедуры:
178
Компьютерная типография
procedure post-line-break {final-widow.penalty : integer)]
curJine: halfword] {текущий номер строки}
LRjptr, LRJmp: pointer; { для поддержки LR-стека }
begin LRjptr «— null]
(Reverse the links of the relevant passive nodes, setting cur.p to the first
breakpoint 878);
[Обратить ссылки релевантных пассивных узлов, выставляя сиг.р на первую
точку разрыва]
prev-graf «— best-line — 1; (Flush the LR stack 1385);
[Очистить LR-стек]
end;
880. Новые действия, выполняемые при формировании разбитого на строки
текста, завершаются тремя новыми шагами, добавляемыми к этому разделу
программы.
(Justify the line ending at breakpoint cur-p, and append it to the current vertical list,
together with associated penalties and other insertions 880) =
[Установить конец строки в точке разрыва curjp и добавить ее в текущий
вертикальный список вместе с полагающимися штрафами и другими
вставками]
(Insert LR nodes at the beginning of the current line 1386);
[Вставить LR-узлы в начало текущей строки]
(Adjust the LR stack based on LR nodes in this line 1387);
[Изменить LR-стек в соответствии с LR-узлами в этой строке]
(Modify the end of the line to reflect the nature of the break and to include
\rightskip; also set the proper value of disc-break 881);
[Модифицировать конец строки в соответствии с природой разрыва и добавить
\rightskip; также установить правильное значение disc-break]
(Insert LR nodes at the end of the current line 1388);
[Вставить LR-узлы в конец текущей строки]
(Put the \leftskip glue at the left and detach this line 887);
[Добавить \lef tskip-клей слева и отделить эту строку]
1090. Здесь мы добавляем lvmode -f LR' в качестве нового подслучая после
'vmode -f rwJ)oundary\ Это означает, что новые примитивные операции станут
тем, что в книге [2] называется (горизонтальными командами).
1196. Математика внутри текста будет форматироваться слева направо,
потому что в этот раздел кода вставляются две новые инструкции 'append'.
(Finish math in text 1196) =
[Закончить математику внутри текста]
begin taiLappend(new.math(math.surround, before))]
(Append a begin-L to the tail of the current list 1383);
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 179
[Добавить begin-L в хвост текущего списка]
curjmlist «— р; curstyle «— textstyle;
mlist-penalties <— (mode > 0);
mlist-to-hlist]
link (tail) «— link (temp-head)\
while link (tail) ф null do tail «— link (tail)]
(Append an end-L to the tail of the current list 1384);
[Добавить end-L в хвост текущего списка]
taiLappend(new-math (mathsurround, after))] space-factor «— 1000; unsave]
end
1341. Новые примитивные операции добавляют новые типы узлов whatsit в
горизонтальные списки. Поэтому здесь дополнительно требуются два новых
определения:
define LR-node =4 { subtype в whatsit'ax, представляющих \beginL и т. д. }
define LR-type(#) = mem[t + l].int {sub-subtype}
1344. Это место, где устанавливаются новые примитивы.
define immediate-code =4 { команда-модификатор для \immediate }
define setJanguage.code = 5 { команда-модификатор для \setlanguage }
define begin^L-Code =0 { команда-модификатор для \beginL }
define begin-R-code = 1 { команда-модификатор для \beginR }
define end-L-code = 2 { команда-модификатор для \endL }
define end-R-Code =3 { команда-модификатор для \endR }
define begin-LR(t) = (LRJype(t) < end-L-code)
define begin-LRJype(#) = (LR-type(t) — end-L-code)
(Put each of TgX's primitives into the hash table 226) +=
[Вставить каждый из примитивов ТЩХ'а в хэш-таблицу]
primitive ("beginL", LR, begin-L-code)]
primitive("beginR", LR, begin-R-code)]
primitive (" endL", LR, end-L-code);
primitive("endR", LR, end-R-Code)]
primitive("openout", extension, open-node)]
1346. Здесь новые примитивы требуют добавления нового случая при
разборе случаев.
LR: case chr-code of
begin-L-code: print-esc ("beginL");
begin-R-code: print-esc ("beginR");
end-L-code: print-esc ("endL");
othercases print-esc ("endR")
endcases;
1356. Нам также нужно уметь выводить на экран новомодные whatsit'bi.
LR-node: case LRJype(p) of
begin-L-Code: print-esc ("beginL");
180
Компьютерная типография
begin-R-Code: print-esc ("beginR");
end-L-Code: print-esc ("endL");
othercases print.esc("endR")
endcases;
1357, 1358. Копирование и уничтожение новых узлов не составляет труда,
так как с ними можно поступать, как с уже имеющимися узлами \closeout. В
этих двух разделах мы просто заменяем 'close-node' на 'close-node, LR-node\
1360. Раньше мы здесь выполняли do-nothing [ничего не делать], но теперь
мы должны выполнить dosomething [кое-что сделать]:
(Incorporate a whatsit node into an hbox 1360) =
[Включить узел whatsit в горизонтальный бокс]
if subtype(p) = LR.node then (Adjust the LR stack for the hpack routine 1389)
[Подготовить LR-стек для программы hpack]
Эта часть кода используется в разделе 651.
1366. ( Output" the whatsit node p in an hlist 1366 ) =
[Выдать узел whatsit p в горизонтальный список]
if subtype (p) ф LR.node then out.what(p)
else (Output a reflection instruction if the direction has changed 1391)
[Выдать инструкцию переворота, если изменилось направление]
Эта часть кода используется в разделе 622.
1379. Большинство изменений были оставлены напоследок, так что номера
разделов ТЁХ'а в [3] можно оставить без изменений. Теперь мы дошли до самых
внутренностей этого расширения для текстов с чередованием направления.
Во-первых, мы допускаем появление новых примитивов в горизонтальном
режиме, но не в математическом:
(Cases of main-control that build boxes and lists 1056) +=
[Случаи main-control, которые конструируют боксы и списки]
hmode + LR: begin new-whatsit{LR-node, smalLnodesize); LR-type(tail) <— cur-chr;
end;
mmode + LR: report-illegaLcase]
1380. Некоторые программы используют стек, состоящий из однословных
узлов, поля info которых содержат либо begin-L-Code, либо begin-R-Code.
Указателем на вершину стека является LR-ptr, а вспомогательная переменная
LR-tmp используется для манипуляций со стеком.
(Global variables 13) +=
[Глобальные переменные]
LR-ptr, LR-tmp: pointer] { стек LR-кодов и temp для манипуляций}
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 181
1381. (Declare functions needed for special kinds of nodes 1381) =
[Объявить функции, необходимые для узлов специальных видов]
function new-LR(s : smalLnumber): pointer]
var p: pointer] {новый узел }
begin p <— get-node (smalLnodesize)] type(p) <— whatsit-node; subtype(p) <— LRjnode]
LR-type(p) <— s] new-LR <— p;
end;
См. также раздел 1382.
Эта часть кода используется в разделе 161.
1382. (Declare functions needed for special kinds of nodes 1381) +=
[Объявить функции, необходимые для узлов специальных видов]
function safe-info (p : pointer): integer]
begin if p = null then safe-info < 1 else safe-info <— info(p)]
end;
1383. (Append a begin-L to the tail of the current list 1383) =
[Добавить begin-L в хвост текущего списка]
tail-append (new-LR (begin-L-code))
Эта часть кода используется в разделе 1196.
1384. (Append an end-L to the tail of the current list 1384) =
[Добавить end-L в хвост текущего списка]
tail-append (new-LR(end-L.code))
Эта часть кода используется в разделе 1196.
1385. Когда ниже используются макро для работы со стеком из этого
раздела, переменные LRjptr и LR-tmp могут быть объявленными ранее
глобальными переменными или они могут быть локальными в hpack или postJine-break.
define push-LR(#) =
begin LR-tmp <— get-avail] info (LR-tmp) <— LR-type(#);
link(LRJmp) <— LR-ptr] LRjptr <— LR-tmp]
end
define pop.LR =
begin LR-tmp <— LR-ptr] LRjptr <— link(LRJmp)] free-avail (LR-tmp)]
end
(Flush the LR stack 1385) =
[Очистить LR-стек]
while LR-ptr ф null do pop-LR
Эта часть кода используется в разделах 639 и 877.
1386. (Insert LR nodes at the beginning of the current line 1386 ) =
[Вставить LR-узлы в начало текущей строки]
while LR-ptr ф null do
begin LR-tmp <— new-LR(info (LR-ptr))] link (LR-tmp) <— link (temp-head)]
link (temp-head) <— LR-tmp] pop-LR]
end
Эта часть кода используется в разделе 880.
182
Компьютерная типография
1387. (Adjust the LR stack based on LR nodes in this line 1387) =
[Изменить LR-стек в соответствии с LR-узлами в этой строке]
q <— link (temp-head);
while q ф cur-break (cur-p) do
begin if -*is-char-node(q) then
if type(q) = whatsit-node then
if subtype (q) = LRjnode then
if begin-LR(q) then push-LR(q)
else if LR-ptr ф null then
if info(LR-ptr) = begin-LRJype(q) then pop-LR\
q <— link(q)]
end
Эта часть кода используется в разделе 880.
1388. Мы пользуемся тем, что q теперь указывает на узел с \rightskip-
клеем.
(Insert LR nodes at the end of the current line 1388) =
[Вставить LR-узлы в конец текущей строки]
if LR-ptr ф null then
begin s <— temp-head] r <— link(s)\
while г ф q do
begin s <— r\ r <— link(s)\
end;
r <— LR-ptr\
while г ф null do
begin LR-tmp <— new-LR(info(r) + end-L-code); link(s) <— LR-tmp;
s <— LR-tmp; r <— link(r)\
end;
link (s) <— q\
end
Эта часть кода используется в разделе 880.
1389. (Adjust the LR stack for the hpack routine 1389) =
[Подготовить LR-стек для программы hpack]
if begin-LR(p) then push-LR(p)
else if safe-info (LR-ptr) = begin-LR-type(p) then pop-LR
else begin incr(LR-problems)\
while link(q) ф p do q <— link(q)]
link(q) <— link(p)] free-node(p, smalLnodesize)] p <— q\
end
Эта часть кода используется в разделе 1360.
1390. (Check for LR anomalies at the end of hpack 1390) =
[Проверить LR-несоответствия в конце hpack]
if LR-ptr ф null then
begin while link(q) ф null do q <— link(q)]
repeat link(q) <— new-LR(info(LR-ptr) + end-L-code)] q <— link(q);
LR-problems <— LR-problems + 10000; popJLR\
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 183
until LR-ptr = null;
end;
if LR-problems > 0 then
begin printJn; print-nl ("\endLuoru\endRuproblemu ( ");
print-int(LRjproblems div 10000); print("uiriissing,u");
print-int(LR.problems mod 10000); print("uextra");
LR.problems <— 0; goto common-ending;
end
Эта часть кода используется в разделе 649.
1391. ( Output a reflection instruction if the direction has changed 1391) =
[Выдать переворачивающую инструкцию, если изменилось направление]
if begin-LR(p) then
begin if safeAnfo(LR-ptr) ф LR-type(p) then
begin synch-h] synch-V] dvLout(begin^reflect)]
end;
push-LR (p);
end
else if safe-info (LR-ptr) = begin-LRJype(p) then
begin pop-LR]
if info(LR-pir) + end-L-code ф LR-type(p) then
begin synch-h] synch-v\ dvLout(end-reflect)]
end;
end
else confusion ("LR")
Эта часть кода используется в разделе 1366.
Заключительные важные замечания
Только что описанные расширения Т^Х'а являются «надстройками» над
стандартным ТеХ'ом, в том смысле что обычные программы для Tgi^'a
по-прежнему будут правильно (хотя и более медленно) обрабатываться
ТЁК-ХдТ'ом. Тем не менее, T^-XjgfT нельзя называть новой версией системы
'ТЕХ', несмотря на то что он обрабатывает все программы для ТЁХ'а; причина
этого, безусловно, в том, что Т^Х Не будет обрабатывать все программы для
TEX-XJafT'a.
Изменение названия необходимо для того, чтобы различать программы,
которые не соответствуют настоящему ТЁХ'у в точности. Каждый,
запускающий программу под названием 'ТЕХ', должен ожидать, что он получит
одинаковый результат при всех ее реализациях.
184
Компьютерная типография
Литература
[1] Joseph D. Becker, "Arabic word processing," Communications of the ACM 30
(1987), 600-610.
[2] Donald E. Knuth, The TfeXboolc, Volume A of Computers к Typesetting
(Reading, Massachusetts: Addison-Wesley, 1986). [Имеется русский перевод:
Дональд Е. Кнут. Все про ТЕХ. —Протвино: АО RDTEX, 1993.]
[3] Donald E. Knuth, T^K: The Program, Volume В of Computers Sz Typesetting,
fifth printing (Reading, Massachusetts: Addison-Wesley, 1993). [Более ранние
издания соответствуют более ранним версиям ТЁХ'а, когда изменения для
ТЁХ-Х^Г'а были аналогичными, но несколько отличались.]
[4] Pierre MacKay, "Setting Arabic with a computer," Scholarly Publishing 8,2
(January 1977), 142-150.
[5] Pierre MacKay, "Typesetting problem scripts," Byte 11,2 (February 1986),
201-218.
Примеры из типографской практики
1. Из Textus 5 (1966), с. 12; Magnes Press, Hebrew University of Jerusalem.
(Обратите внимание на ивритские кавычки, окружающие название на иврите в
сноске 6.)
ters adhered,10 and which may have been similar to that adopted, by normative
Jewry presumably somewhat later, during the period of the Second Temple.10
Frag. E. Yadin correctly states: "Sanders' cautious indication 4103 (7104)' can now
be eliminated" (ib.t p. 5).
6 Sanders' editio princeps of Ps. 151 already has been discussed by various scholars. The
present author deals with the text of Ps. 151, and its literary genre in: D^navi onwra"
-JK-lOipo ЛПЗУЛ ptt^a, Tarbiz 35 (1966) 214-228.
2. Выдержки из третьего издания классического труда девятнадцатого
столетия по арабской грамматике Уильяма Райта, том 2, ее. 295-297. (Обратите
внимание на переход на следующую страницу посередине текста, читаемого
справа налево, и некоторые L-текстовые скобки.)
gnawed at us; ^wJ CUe^.1 2u>\ j~±, j£&* ye are the best people
that has been brought forth (created) for mankind; OpAl t*£» ц>
jr*\yA\ **4j}\ j+ W^l С-у.<и.л £.U> they walked as spears wave, the
tops of which are bent by the passing of gentle breezes; JJuOl 5jUI
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 185
296 Part Third.—Syntax. [§152
i * • *• 4 J • *
t^yk £>I*V sJy~£* the brightness of the intellect is obscured (or
\ eclipsed) by obeying lust. As the above examples show, this agreement
§ 152] Sentence and its Parts.—Concord of Predicate & Subject 297
verb is placed after a collective subject (see § 148); as j&\ J>#j
Oyj*+*L ^ \j№\ but the greatest part of mankind are thankless;
• * • * *j» « *•
■ ^LJI sjyt^j j9^ Jl^^i a part of them are afraid of men; [\y£*jj\ ■
\ о » j * * * *•&
\ ^£by£ajj U J^JI let the Turks alone as long as they let you alone;
\£Xk Ait.t^ tf) because his army had perished].
3. Co с 233 той же книги. Здесь R-тексты приравниваются знаками =; сначала
следует читать левые части каждого равенства.
, 1о+ > \ , , I
understood; ^У}И *>J-p = |ta$b'^ **l—N *>*-<»> i-e. *fcUJI ^ SjJLeJI
\J$*$\ (see § 77). Similarly, some grammarians consider ^4j*M ч^^
* 0*0+ *x»«* » *> * Ф+ » Ф* * Of» * * ОЮ i 0 *
= uVjJUt jlxjl ^JU., £*Ц*Н J».">< = £*^*Л O^oJi »>->■■■■ ,o
' Of» 0*9* J 9 *• — * О * 0+ > * О * m *> О * О*» £ *> О* if Of
or ;fc*UJI C-iJI лап ^, П<0гь П Ди^ = ^1й0п> II <L*JI 4JUb, and
* ~0+ » ' *• в>0* * * t$» » * J * Ol
*ji»*$\ jb = ^^)l *l*a*JI jb*. Here too the constructions J-ail I
4. Из Bulletin of the Iranian Mathematical Society 8 (Tehran, 1978), с 78L.
(Математика, читаемая слева направо, в тексте, читаемом справа налево.)
n-1 , 2(n-l)(n-2) + 3(n-l)(n-2) , _
2m ЗпГ 4гтГ
e=2.71828 oV ^^^ l/(l-a) + [log (1-a)] /a ifcI—"Cgfc «S :
5. Из Т\рЮУУ>У))0Ь Н)2Ю [Введение в математику, произносится вэШвтэШвМ
э! оувМ], написанного Авраамом А. Франкелом, том 1 (Jerusalem: Hebrew
186
Компьютерная типография
University, 1942), с. 38. (Номера страниц '96-90', потому что '90' и '96' иврит-
ские числа.)
л a id bv |орл DDffan пк mro*? -Ъаи .лпикгилрл avion wontma
:ЛТ1Ха JlD^l DDVa ПЮ ,а'=а (mod. p) :ЛТ1ХЭ1
1-2-3-- (/7-1) =—1 (mod./?).
..ттв ,]мк = modulus ,D'>wB = congruens nvenn о'Увл р л
Journal f. d. n to ив л *рээ ieoe лэгз M. Hamburger ]r\w ппэта py .2
П2ПП упклл лк луз^рл Л802 iron oixa to nnouV (96-00 тэу) reinc u. ang. Mathematik !
6. Ha с 200 той же книги демонстрируется различие между многоточиями
' • • •' в формулах и в тексте. Нигде в этой книге математика внутри текста не
разбивается на строки.
опвоЛ plena п вк л"»уал лк чтЛ wdxv (a ,*атк nirca ^ yiana
^э V»ava тпм л*уалю *кдпа т^=рх*р2 рк o*aiv окупил
язппкл пзуол лк пказю ра рспоз .п=рк.... .п=р2 ,п=рх оъчуя
мтуа imaV пюскю о^трл этЛ чипа ym .л = 15=з«5 лат1? оп^а
ппк ]wb) [1] лтюал 'tmv ^э <п = р ,лт лчрааю упг ^э опр
тнллю piaa "o^bwid, o'wiff озл (l1? did ,^ = 1 люювл *«nw ^э
,л=/7 kick \т ./7 V it (i, 2, ... , p -1) л пол Tina k "py Vd пл v ? 199 'aya
Vff л^тю Ъъ i'-1,... ,£2,£ iw тк ;[i] лктовл ^ 1Л«Лэ enw {i
.л-рп^л 'ипр в-кчрз л^кл в^впот ,»[i] люювл
Рецепты и дроби
[Первоначально опубликовано в TUGboat 6 (1985), 36-38.]
На ее. 277, 281 и 282 книги The TEXbook1 содержатся примеры выравнивания,
взятые из довольно известной книги Julia Child et al. Mastering the Art of
French Cooking. Некоторые меры в этих примерах содержат дроби типа '|', что
привело к неприятному наложению выровненных строк, когда я просматривал
первую корректуру таблиц на ее. 281-282. На самом деле дроби на разных
строках не касались друг друга, но они располагались настолько тесно, что
раздражали глаз. Вот почему в этих примерах я увеличил расстояние между
базовыми линиями шрифта на 2 pt.
Поскольку при написании The TEJKbook мне несколько раз пришлось
набирать рецепты, я узнал о том, что мне следовало уже давно реализовать: в
подобных контекстах удобнее работать с типографской ^/г', чем с
математической '|\ Поэтому я недавно добавил новое упражнение 11.6 в свою книгу
The T^Kbook, объясняющее, как получать дроби вида ^Д', если их нет в
готовом виде в шрифте. Я также изменил примеры на ее. 277, 281 и 282, так
что и в них использована эта идея (относительно деталей см. текущий список
опечаток или более новое издание.)
В прошлом декабре мы с женой сделали подарок Ассоциации
университетских библиотек Станфорда: испекли пирог к их ежегодному Рождественскому
чаю по рецепту «Stollen» моей бабушки и, кроме того, мы изготовили копии
рецептов как образцы компьютерной типографии. Я был доволен тем, что этим
книголюбам понравился не только пирог, но и качество набора, хотя это
произвел компьютер. Уверен, что если бы не был использован соответствующий
вид дробей, нам бы не получить такой благоприятный отзыв.
Далее приводится копия типографской части нашего подарка и
произведший ее Т^Х-код на случай, если читателю интересно взглянуть на еще один
небольшой, но полный пример использования ТЁХ'а (основанный только на
макро plain ТЁХ'а). Окончательный вывод был сверстан и напечатан таким
1 Страницы указаны по русскому переводу: Д. Кнут. Все про Т&£. — Протвино: RDT^X,
1993, но в русском издании, как в более позднем, использован другой вид дробей. — Прим.
ред.
188
Компьютерная типография
образом, что мы легко могли сложить эти две страницы, сделав, в сущности
открытку размера 3" х 5", которую можно было заполнить другими рецептами.
Поскольку рецепт довольно короткий, я не пользовался никакими
замысловатыми макро, для того чтобы получить список ингредиентов в две колонки.
У, Рецепт рождественского пирога Stollen
\hsize=4.5in У, ширина полосы набора
\vsize=2.3in У, высота полосы набора
\nopagenumbers
\font\ninerm=cmr9
\def\frac#l/#2{\leavevmode\kern.lem
\raise.5ex\hbox{\the\scriptfontO #l}\kern-.lem
/\kern-.15em\lower.25ex\hbox{\the\scriptfontO #2}}
\parskip=3pt У, отбивка между абзацами
\parindent=Opt У, без отступа
{\bf Christmas Stollen}
\medskip
\tabskip=10pt plus lfil
\halign to \hsize{&#\hfil\cr
1 pint milk, scalded and cooledfe
\fracl/2 teaspoon nutmeg\cr
1 ounce compressed or dry yeastfe
l\fracl/2 teaspoons salt\cr
1 cup butterfe
8 cups flour\cr
1 cup sugarfe
1 pound mixed candied fruit\cr
4 eggsfe
\frac3/4 pound candied cherries\cr
grated rind of 1 lemonfe
1 cup nuts\cr
}
\smallskip
Dissolve yeast in scalded, cooled milk. Add 1 cup of
the flour. Let it rise \fracl/2~hour.
Cream butter and sugar. Beat in eggs, one at a time.
Stir in yeast mixture. Add lemon rind, nutmeg and salt.
Dredge the fruit in a little flour to keep the pieces
from sticking together. Add the rest of the flour to
the dough, and finally stir in the fruit and nuts.
Knead the dough until smooth. Put in a warm place in a
covered bowl and let rise until doubled in bulk.
Глава 5. Рецепты и дроби
\ (Because the fruit makes the dough heavy, it
may take two or three hours to rise.) \ Divide the
dough into three parts. Roll each portion out to about
l~inch thick, then fold over in thirds to form a long,
loaf shape. Place on a greased cookie sheet, cover and
let rise until doubled"'again.
Bake at $325~\circ\,$F. for 45 minutes.
Stollen is traditionally frosted with thin
powdered-sugar-and-butter icing. Decorate each loaf
with red and green candied cherries.
Vary the fruit and nuts to suit your taste.
You may use cherries alone, mixed fruit, and/or dates;
almonds, pecans, walnuts, or no nuts at all.
\medskip \ninerm \baselineskip=llpt
This is the recipe that was used each Christmas by Don'
grandmother, Pauline Ehlert~Bohning, Cleveland, Ohio.
Don's mother, Louise Bohning~Knuth, still makes
more than 20 loaves each year, and when we were married
she passed the recipe on to us. We hope you enjoy it.
\vskip-\baselineskip
\rightline{Don and Jill Knuth, Stanford, 1984}
\eject
\end
190
Компьютерная типография
Christmas Stollen
1 pint milk, scalded and cooled !Д teaspoon nutmeg
1 ounce compressed or dry yeast 1 ife teaspoons salt
1 cup butter 8 cups flour
1 cup sugar 1 pound mixed candied fruit
4 eggs 3Д pound candied cherries
grated rind of 1 lemon 1 cup nuts
Dissolve yeast in scalded, cooled milk. Add 1 cup of the flour. Let it rise
!/г hour. Cream butter and sugar. Beat in eggs, one at a time. Stir in yeast
mixture. Add lemon rind, nutmeg and salt. Dredge the fruit in a little flour
to keep the pieces from sticking together. Add the rest of the flour to the
dough, and finally stir in the fruit and nuts. Knead the dough until smooth.
Put in a warm place in a covered bowl and let rise until doubled in bulk.
(Because the fruit makes the dough heavy, it may take two or three hours
to rise.) Divide the dough into three parts. Roll each portion out to about
1 inch thick, then fold over in thirds to form a long, loaf shape. Place on a
greased cookie sheet, cover and let rise until doubled again. Bake at 325° F.
for 45 minutes.
Stollen is traditionally frosted with thin powdered-sugar-and-butter icing.
Decorate each loaf with red and green candied cherries.
Vary the fruit and nuts to suit your taste. You may use cherries alone,
mixed fruit, and/or dates; almonds, pecans, walnuts, or no nuts at all.
This is the recipe that was used each Christmas by Don's grandmother, Pauline
Ehlert Bohning, Cleveland, Ohio. Don's mother, Louise Bohning Knuth, still
makes more than 20 loaves each year, and when we were married she passed
the recipe on to us. We hope you enjoy it. Don and Jill Knuth, Stanford, 1984
Глава 5. Рецепты и дроби
191
Рождественский пирог Stollen
1 пинта молока, вскипяченного цедра 1 лимона
и охлажденного !Д чайной ложки мускатного ореха
1 унция спрессованных или 1 *Д чайной ложки соли
сухих дрожжей 8 стаканов муки
1 стакан масла 1 фунт засахаренных фруктов
1 стакан сахара 3Д фунта засахаренной вишни
4 яйца 1 стакан орехов
Растворите дрожжи во вскипяченном и охлажденном молоке. Добавьте
стакан муки. Оставьте на подъем на !/г часа. Взбейте масло с сахаром.
Добавляйте яйца по одному. Смешайте с дрожжевой смесью. Добавьте
цедру лимона, мускатный орех и соль. Посыпьте фрукты небольшим
количеством муки, чтобы кусочки не слипались. Добавьте остальную муку
к тесту и смешайте все с фруктами и орехами. Вымешивайте тесто до
гладкости. Поставьте в теплое место, накрыв миской, и оставьте до
увеличения объема вдвое. (Поскольку фрукты утяжеляют тесто, процесс может
длиться от двух до трех часов.) Разделите тесто на три части.
Раскатайте каждую часть примерно до толщины в 1 дюйм, затем сложите втрое,
придав форму длинного пирога. Разместите все на противне, накройте и
снова дайте подняться до увеличения объема вдвое. Выпекайте в духовке
45 мин при температуре 325° F.
Stollen обычно покрывают тонким слоем глазури из сахарной пудры и
масла. Каждый пирог украшают красными и зелеными свечами,
окруженными вишнями.
Состав фруктов и орехов можно менять по своему усмотрению. Можно
брать только вишню или фруктовую смесь и (или) финики; фундук и
(или) грецкие орехи и (или) миндаль или вовсе обойтись без орехов.
По этому рецепту каждое Рождество пекла бабушка Дона Полина Элерт Бонинг
(Кливленд, Огайо). Мать Дона —Луиза Бонинг Кнут —все еще выпекает по 20
пирогов ежегодно; когда мы поженились, она передала рецепт нам. Надеемся,
он вам понравится. Дон и Джил Кнут, Станфорд, 1984
lb-*-- - ■, _ .'
Логотип системы Т^Х
в различных шрифтах
[Первоначально опубликовано в TUGboat 7 (1986), 101.]
«Официальное» определение логотипа системы ТеХ, которое содержится
в макропакете plain Т^Х (см. The T^Kbook), выглядит следующим образом:
\def\TeX{T\kern-.1667em\lower.5ex\hbox{E}\kern-.125emX}
Однако макрокоманды plain T^'a создавались в расчете на семейство
шрифтов Computer Modern и учитывают специфику именно этого семейства. При
использовании других гарнитур может потребоваться изменить величины
«отрицательных пробелов», фигурирующих в определении, с тем чтобы сохранить
эстетику данного логотипа.
На самом деле приведенное выше определение вполне годится для
подавляющего большинства основных шрифтов с засечками, входящих в семейство
Computer Modern, а именно для всех кеглей шрифтов cmr, cmsl, cmti и cmbx.
Что же касается рубленых шрифтов, с ними ситуация действительно не такая
простая. На с. 418, 419 {422) книги The TJgXbooJc1 даны два альтернативных
определения команды '\ТеХ': одно для шрифта cmssdclO, приведенного к
размеру 40pt, которым набираются заголовки глав (см. с. 36 (^б)), другое —для
шрифта cmssq, используемого для оформления цитат в конце глав (см. с. 337
(401)).
Цель настоящей заметки—дать общую запись для различных версий
команды '\ТеХ', использовавшихся при наборе книг серии Computers &
Typesetting. Эта запись позволяет без труда имитировать стиль той или иной
книги.
Во всех версиях команды буква 'Е' опущена вниз на одну и ту же величину
.5ех (на половину х-высоты), и отличие версий друг от друга состоит только
в величинах «отрицательных пробелов», определяемых командой \kern.
Таким образом, в общем виде команду для набора ТеХ'овского логотипа можно
записать как
\def \TeX{T\kern aem\lower. 5ex\hbox{E}\kern /?emX}
1 Здесь и в дальнейшем в скобках указаны соответствующие номера страниц русского
издания.— Прим. ред.
Глава 6. Логотип системы ТеХ в различных шрифтах
193
при некоторых а и /3. В следующей таблице приведены пары значений (а,/?),
реально использовавшиеся при наборе уже опубликованных томов серии:
семейство шрифтов
cmr
cmsl
cmti
cmbx
cmssdc
cmssq
cmssqi
cmss
cmssi
cmssbx
a
-.1667
-.1667
-.1667
-.1667
-.2
-.2
-.2
-.15
-.2
-.1
0
-.125
-.125
-.125
-.125
-.06
0
0
0
0
0
(Три последних шрифта использовались только для текста на суперобложке, а
не «настоящего» текста внутри книги. Подбор надлежащих значений пробелов
потребовал довольно кропотливой работы.)
Я не очень много экспериментировал с другими шрифтами, но похоже, что
с ними дело обстоит так же. Например, моя статья «Literate Programming»
(см. The Computer Journal 27 (1984), 97-111), была набрана одной из
разновидностей шрифта Times Roman, и стандартная макрокоманда \ТеХ давала
прекрасный результат. В той же статье подрисуночные подписи и список
литературы были набраны рубленым шрифтом Univers; для него, как и для cmssq,
использовались значения (а, (3) = (—.2,0).
Генерирование
избранных страниц
[Первоначально опубликовано в TUGboat 8 (1987), 217.]
В TUGboat Vol. 7, No. 3, Хелен Хорстман задала следующий вопрос: «Есть ли
способ заставить Т^Х генерировать только определенные страницы?»
Недавно я добавил несколько новых строк в макропакет manmac (этот
макропакет приведен в приложении Е и использовался при наборе томов А и С),
которые позволяют включать в DVI-файл только избранные страницы.
Соответствующие команды работают с практически любым макропакетом, будучи
помещены в его конец, или, если угодно, в начало исходника основного
документа.
Идея метода состоит в следующем. Первым делом ТЕХ'у предлагается
найти файл с именем pages. tex. Если выясняется, что такого файла нет,
компиляция осуществляется как обычно. Изменения происходят, если файл pages.tex
существует — в этом случае он должен содержать список номеров страниц,
которые требуется сгенерировать, причем каждый номер должен быть записан
в отдельной строке и номера должны следовать друг за другом в том
порядке, в каком должны быть сгенерированы страницы. Все страницы с номерами
большими, чем последний номер в списке, также будут сгенерированы. Так,
если нужно скомпилировать страницу 123, а также все страницы, начиная с
300-й, файл pages.tex должен состоять из строк
123
300
Если же требуется сгенерировать только страницы 123 и 300, строки файла
можно задать, например, вот так:
123
300
-999999999 У, недопустимый номер
В этом случае номер, заданный последним, никогда не совпадет с текущим
номером страницы, и конец списка никогда не будет достигнут.
По завершении процесса файл pages.tex следует переименовать, чтобы в
дальнейшем он не влиял на формирование DVI-файла.
Глава 7. Генерирование избранных страниц
195
При работе под управлением UNIX рекомендуется инсталлировать Т^Х
таким образом, чтобы поиск файлов, не найденных в текущем каталоге,
производился затем в родительском каталоге. Тогда можно поместить файл pages .tex
в специальный подкаталог pages и в случае, когда требуется сгенерировать
только страницы, перечисленные в pages.tex, выполнять команду ccd pages'
непосредственно перед запуском ТЁХ'а. Преимущество такого способа действий
в том, что ни один из нужных файлов, находящихся в родительском
каталоге, не будет по ошибке испорчен. В частности, не пострадают вспомогательные
файлы, созданные с помощью команды \write в процессе генерирования
предметного указателя, списка литературы или оглавления.
При выполнении рассматриваемых команд Т^Х уведомляет пользователя,
что работает в особом режиме.
Макрокоманды для генерирования
избранных страниц
У, Чтобы сгенерировать только часть страниц документа,
У, запишите номера требуемых страниц в отдельных строках
У, файла с именем pages.tex
\let\Shipout=\shipout
\newread\pages \newcount\nextpage
\openin\pages=pages
\def\getnextpage{\ifeof\pages\else
{\endlinechar=-l\read\pages to\next
\ifx\next\empty У, в этом случае здесь должен быть
У, символ конца файла eof
\else\global\nextpage=\next\fi}\fi}
\ifeof\pages У, если файл pages.tex не найден,
У, не делать ничего
\else\message{OK, I'll ship only the requested pages!}
\getnextpage\f i
\def\shipout{\iieoi\pages\let\next=\Shipout
\else\iinum\pageno=\nextpage
\getnextpage\let\next=\Shipout
\else\let\next=\Tosspage\fi\fi \next}
\newbox\garbage
\def\Tosspage{\deadcycles=0\setbox\garbage=}
i
Макро,
написанные для Джил
[Первоначально опубликовано в TUGboat 8 (1987), 309-314.]
На конференции TUG в июле 1986 года я как-то упомянул в разговоре, что
одна из моих обязанностей по дому —писать макро для моей жены Джил,
которая незадолго до того установила Т^Х на свой компьютер. Когда вслед за
тем Джил появилась на банкете, многие стали обращаться к ней с просьбой
разрешить переписать макро. Это в конце концов навело меня на мысль, что
макро нужно опубликовать в журнале TUGboat. Предлагаю вашему вниманию
эти макро в слегка отредактированном виде.
Первая из задач, которые Джил поставила передо мной, была, пожалуй,
наиболее интересной. Джил как раз тогда начала вести электронный дневник и
хотела иметь его печатный вариант, хорошо оформленный. Формат, в котором
она задумала печатать дневник, был не совсем обычным: она хотела, чтобы
по ходу любого абзаца можно было создавать заметки на полях, причем так,
чтобы на левой странице разворота эти заметки появлялись на левом поле, а
на правой странице — на правом поле.
Эта задача для Т^Х'а довольно трудна, так как Т|й}Х генерирует абзацы,
не зная, на какие страницы они попадут. В самом деле, решение о том, что
помещать на страницу 100, нельзя принять до того, как ТЕХ сгенерирует
значительную часть страницы 101.
Один из путей решения этой задачи — жульнический — состоит в том,
чтобы помещать каждую заметку на оба поля, а затем маскировать ненужный
экземпляр. Джил такой подход не понравился.
Честное решение задачи можно получить, заставив Т^Х обрабатывать
исходный файл в два прохода. На первом проходе создается вспомогательный
файл, в котором заметкам поставлены в соответствие их номера. На втором
проходе этот файл считывается, и каждая заметка помещается на надлежащее
поле.
Хотя второй путь не так уж сложен, я решил использовать третий
подход, который получился удивительно простым. Нетрудно запрограммировать
Т^Х так, чтобы все заметки записывались на левом поле или же чтобы все
они записывались на правом поле. Используя это, мы в первом случае просим
Глава 8. Макро, написанные для Джил
197
ТЕХ генерировать только левые страницы, во втором — только правые. За два
прохода мы получаем то, что требуется.
В дневнике Джил текст заметок на полях вводился с помощью
обозначения, основанного на конструкции, предложенной в приложении Е книги The
ТЁХЬоок, где похожее обозначение используется для задания элементов
предметного указателя. Именно, запись ~{заметка} при наборе дает на печати
'заметка' на полях и 'заметка' в основном тексте, а ""{заметка} дает только
'заметка' на полях.
Вот текст соответствующего макро jmac.tex:
У, Формат для дневника Джил
У, пример исходного файла:
У, \ input jmac
У, \title Новая глава на новой странице
У.
У, \date 32 мартобря
У.
У, Сегодня утром, проснувшись, я решила с помощью \ТеХ'а
У, сделать из этого дневника книжку. Я люблю
У, делать "{заметки} на полях это позволяет
У, потом легко ориентироваться в тексте. Используя
У, специальный прием, который придумал мой муж~~{Дон},
У» можно сделать так, чтобы на левых страницах
У, эти заметки попадали на левое поле, а на правых
У, страницах на правое.
У.
У, Для этого файл компилируется \ТеХ'ом
У, {\it даажды\/}!~~{двукратный запуск \ТеХ'а} При
У, первом прогоне генерируются все страницы с
У, нечетными номерами, при втором все
У, страницы с четными номерами. Общее время, нужное
У, для получения распечатки, увеличивается от этого не
У, сильно, так как все равно дольше всего происходит
У, вывод результата на принтер.
У.
У, В моем дневнике {\it "{нет формул}}.
У.
У. \Ьуе
У, Каждый прогон \ТеХ'а начинается со следующего
У, небольшого диалога:
\newif\ifleft
\def\leithand{l }
\message{************ Which pages do you want (1 or r)? }
\read-l to\next У, ответ пользователя (1 or r)
\ifx\next\lefthand\lefttrue\else\leitialse\ii
198
Компьютерная типография
\message{OK, I'll produce only the
\ifleft left\else right\fi-hand pages.
У, Команды, задающие формат печатной страницы
\frenchspacing У, междусловные пробелы после знаков
У, препинания не увеличиваются
У, длина строки 5.25 дюйма
У, интерлиньяж (расстояние между
У, базовыми линиями) 14 пунктов
У, абзацный отступ не делается
У, между абзацами вставляется пустая
У, строка
У, на каждой странице спуск,
У, равный четырем строкам
У, высота страницы сорок строк
\setbox\strutbox=\hbox{\vrule height.75\baselineskip
depth.25\baselineskip widthOpt} У, это страт ("распорка") на
У, высоту строки
\hsize=5.25in
\baselineskip=14pt
\parindent=Opt
\parskip=\baselineskip
\topskip=5\baselineskip
\vsize=40\baselineskip
\newdimen\titleoffset
\titleoffset=l.5in
\newdimen\notespace
\notespace=.375in
\newdimen\maxnote
\maxnote=2in
У, заголовки выдвигаются на поля
У, расстояние между заметками
У, максимальная длина заметки
У, Шрифты
\font\titlefont=cmbxlO scaled\magstep2
\font\datefont=cmbxlO scaled\magstephalf
\font\notefont=cmbxlO
\font\textrm=cmrlO scaled\magstephalf
\font\textit=cmtilO scaled\magstephalf
У, для заголовков страниц
У, для дат на полях
У, для заметок на полях
У, для основного текста
У, для выделений в тексте
\font\foliofont=cmbxlO scaled\magstephalf У, для номеров страниц
\let\rm=\textrm \rm
\let\it=\textit
\textfont2=\nullfont
У, шрифт по умолчанию прямой (\rm)
У, любой фрагмент текста либо \rm, либо \it
У, математический режим не поддерживается
У, Символы и заменяются на \mnote, которая может быть видимой
У, (visible) или невидимой (invisible)
\newif\ifvisible
\catcode(\~=\active
\def~{\futurelet\next\testdoublehat}
\def\testdoublehat{\ifx\next~\let\next=\silentnote
\else\visibletrue\let\next=\mnote\fi \next}
\def\silentnote~{\visiblefalse\mnote}
\ifleft У, используется только в режиме вывода на
У, левое поле
Глава 8. Макро, написанные для Джил
\def\title#l\par{\vfill\eject\message{#l:}
\null\vskip-4\baselineskip
\moveleft\titleoffset\hbox{\titlefont\uppercase{#l}}
\vskip\baselineskip}
\def\date#l\par{\vskip\parskip
\moveleft\notespace
\llap{\hbox to\maxnote{\hfil\datefont#l\unskip}}
\nobreak\vskip-\baselineskip\vskip-\parskip}
\def\mnote#l{\strut\vadjust{\kern-\dp\strutbox
\vtop to\dp\strutbox{\vss \baselineskip=\dp\strutbox
\moveleft\notespace
\llap{\hbox to\maxnote{\hfil\notefont#l}}\null}}e/.
\ifvisible#l\fi}
\hoffset=\titleoffset
\else У, используется только в режиме вывода на
У, правое поле
\def\title#l\par{\vfill\eject\message{#l:}
\null\vskip-4\baselineskip
\moveright\titleoffset\rightline{e/,
\titlefont\uppercase{#l}}
\vskip\baselineskip}
\def\date#l\par{\vskip\parskip
\moveright\notespace\rightline{e/,
\rlap{\hbox to\maxnote{\datefont#l\unskip\hfil}}}
\nobreak\vskip-\baselineskip\vskip-\parskip}
\def\mnote#l{\strut\vadjust{\kern-\dp\strutbox
\vtop to\dp\strutbox{\vss \baselineskip=\dp\strutbox
\moveright\notespace\rightline{e/,
\rlap{\hbox to\maxnote{\notefont#l\hfil}}}\null}}e/.
\ifvisible#l\fi}
\f i У, постраничная разбивка TeKCTa\dash одна и та же
У, в обоих режимах
У, Выводятся либо только левые, либо только правые страницы
\output{\ifleft
\ifodd\pageno\discard\else
\shipout\vbox{\box255 \baselineskip=30pt
\hbox{\foliofont\folio}}\fi
\else\ifodd\pageno
\shipout\vbox{\box255 \baselineskip=30pt
\rightline{\foliofont\folio}}
\else\discard\fi\fi
\advancepageno}
\newbox\voidbox
\def\discard{\global\setbox255=\box\voidbox}
\outer\def\bye{\vfill\eject\deadcycles=0\end}
200
Компьютерная типография
Дополним пример, приведенный в начальных строках макро jmac.tex,
следующими командами, подчиняющими результат, получаемый на печати,
формату настоящей книги:
В таком случае после двукратной компиляции файла-примера получим на
печати следующий двустраничный документ:
\hsize=3.2in
\baselineskip=12pt
\vsize=12\baselineskip
\font\titlefont=cmbxl2
\font\datefont=cmbxl0
\font\notefont=cmbx9
\font\textrm=cmrlO
\font\textit=cmtilO
\font\foliofont=cmbxlO
НОВАЯ ГЛАВА НА НОВОЙ СТРАНИЦЕ
Сегодня утром, проснувшись, я решила с
помощью ТЁХ'а сделать из этого дневника книжку. Я
люблю делать заметки на полях — это позволяет
потом легко ориентироваться в тексте. Используя
специальный прием, который придумал мой муж,
можно сделать так, чтобы на левых страницах эти
заметки попадали на левое поле, а на правых
страницах— на правое.
32 мартобря
заметки
Дон
двукратный запуск
нет формул
Для этого файл компилируется Т^Х'ом дважды\
При первом прогоне генерируются все страницы с
нечетными номерами, при втором —все страницы
с четными номерами. Общее время, требуемое для
получения распечатки, увеличивается от этого не
сильно, так как все равно дольше всего происходит
вывод результата на принтер.
В моем дневнике нет формул.
2
Глава 8. Макро, написанные для Джил
201
Вторая задача имела мало общего с первой и была связана с распечаткой
рецептов домашней кухни. Дело в том, что в нашей семье такие рецепты
обычно записывались на клочках бумаги, которые так в измятом виде и хранились,
причем нередко терялись. Джил решила ввести рецепты в компьютер, с тем
чтобы потом распечатать их на карточках. Тем самым мы привели бы свою
коллекцию в порядок и смогли бы создавать специальные подборки рецептов
для наших сына и дочери.
Для удобства и быстроты ввода информации Джил разработала
специальную систему кодов. Для меня наибольший интерес представляла возможность
реализовать эти коды с помощью «активных» ТеХ'овских символов. Хитрость
состояла в том, чтобы определить макро в самом начале, до того как
начнутся игры с активными символами — при этом старые значения символов не
путались бы с их новыми значениями.
Следующий ниже файл rmac.tex почти не требует пояснений:
У, формат для кулинарных рецептов
У, пример исходного файла:
У, \ input rmac
У. #ПРИПРАВЫ
У, Жлюквенная приправа на День Благодарения
У, <Уайлда Бэйтс Картер
У, $3 стакана
У, I оставить на ночь в холодильнике
У. *
У, @1 фунт свежей клюквы
У, 2 апельсина очистить от кожуры и зернышек
У, кожуру от одного апельсина измельчить
У, 1 ~1/2 ст. сахара
У. *
У, !Крупно перемолоть клюкву с апельсинами. Добавить цедру
У, и сахар. Оставить в холодильнике на ночь.
У. =
У. #ХЛЕБЦЫ
У, >Сырные сухарики
У, Iохлаждать не меньше 2-х часов, выпекать 20—25 минут
У. У.300\0 F
У. $60 штук
У. *
У, @1 баночка острого плавленого сыра (5 унций)
У, ~1/2 ст. масла
У, ~1/4 чайной ложки соли
У, поперчить
У, 1 ~1/2 ст. муки
У. *
202
Компьютерная типография
У, !Сбить вместе сыр и масло. Добавить остальные ингредиенты
У, и растереть. Из полученного теста скатать два валика
У, толщиной 1~~1/4 дюйма. Завернуть и охлаждать не меньше
У, 2~часов. Нарезать ломтики по ~1/4 дюйма, уложить их на
У, несмазанный противень и выпекать 20—25 минут при
У, температуре 300\0~F до легкого подрумянивания.
У. =
У. \Ьуе
\hsize=4.25in
\vsize=7in
\parindent=0pt
\font\classfont=cmbxl0 scaled\magstep2
\font\titlefont=cmbxl0 scaled\magstep2
\font\specfont=cmsll0 scaled\magstephalf '/«время, темп-ра, кол-во
\font\ingredfont=cmr7 scaled\magstep2
\font\normalfont=cmrl0
\newdimen\specbaseline
\specbaseline=14pt У, межстрочное расстояние для времени,
У, темп-ры, кол-ва
\output{\shipout\vbox{\vbox to .75in{
\rightline{\classfont\currentclass\hskip-.25in}\vss}
\nointerlineskip\box255}
\advancepageno \global\let\currentdonor=\empty}
\let\currentdonor=\empty
\def\0{$~\circ$} У. градусы
\obeylines
\def\class#l
{\gdef\currentclass{#l}}
\def\title#l
{{\message{#l}\titlefont#l\par}}
\def\donor#l
{\gdef\currentdonor{#l}}
\def\time#l
{{\baselineskip=\specbaseline \rightline{\specfont#l\/}}}
\def\temp#l\0 F
{{\baselineskip=\specbaselinee/,
\rightline{\specfont#l\/\0 F\/}}>
\let\quantity=\time
\def\ingredients{\ingrediont\everypar{\hangindent=20pt}}
\dei\method{\let~~M=\space \normalfont \everypar{}}
\def\endit{\par\vfille/.
\ if x\ current donor \emptye/.
Глава 8. Макро, написанные для Джил
203
\else\rightline{\dash \currentdonor}\f ie/,
\eject\obeylines}
\def\frac#l/#2{\leavevmodee/.
\raise. 5ex\hbox{\the\scriptf ontO #1}'/,
\kern-. lem/\kern-. 15eme/,
Mower.25ex\hbox{\the\scriptfontO #2}}
\catcode'\"=14 " символ комментария
\catcode'\#=\active \let#=\class " тип блюда, например, СУП
\catcode'\>=\active \let>=\title " название рецепта
\catcode'\<=\active \let<=\donor " источник рецепта
\catcode'\|=\active \let|=\time " время приготовления
\catcode'\e/e=\active \lete/,=\temp " температура приготовления
\catcode'\$=\active \let$=\quantity " количество получаемого
" блюда
\catcode'\®=\active \let®=\ingredients " начало списка
используемых продуктов
\catcode'\!=\active \let!=\method " начало алгоритма приготовления
\catcode'\*=\active \let*=\medskip " отбивка
(пробел)
\catcode'\~=\active \let~=\frac " числитель дроби
\catcode'\==\active \let=\endit " конец рецепта
Обратите внимание на применение команды \ obey lines: используемые
ингредиенты записываются по-строчно, а «метод приготовления» —в виде обычного
текста, состоящего из одного-двух абзацев. По этой причине команда \method
преобразует символы конца строки в пробелы. За методом следует символ «=»,
который завершает карточку и восстанавливает режим \ obey lines.
При уменьшении \vsize до 2.4 дюйма, приведенный файл порождает на
печати две карточки, показанные на следующей странице.
Поскольку ввод рецептов в компьютер был нами осуществлен в июле,
пользоваться ими пришлось довольно-таки часто. Формат оказался очень удобным:
рецепты легко читаются в процессе готовки, а то, что требуемые количества и
способ приготовления выделены, помогает при планировании будущих меню.
Разумеется, в качестве следующего шага нужно было бы связать
компьютер напрямую с кухонным оборудованием, с тем чтобы вся готовка
производилась автоматически. Но, пожалуй, я все-таки сперва закончу работу над The
Art of Computer Programming.
204 Компьютерная типография
ПРИПРАВЫ
Клюквенная приправа
на День Благодарения
3 стакана
оставить на ночь в холодильнике
1 фунт свежей клюквы
2 апельсина очистить от кожуры и зернышек
кожуру от одного апельсина измельчить
1 */2 ст. сахара
Крупно перемолоть клюкву с апельсинами. Добавить цедру и
сахар. Оставить в холодильнике на ночь.
—Уайлда Бэйтс Картер
ХЛЕБЦЫ
Сырные сухарики
охлаждать не меньше 2-х часов, выпекать 20-25 минут
300° F
60 штук
1 баночка острого плавленого сыра (5 унций)
lfc ст. масла
х/4 чайной ложки соли
поперчить
1 */2 СТ. МуКИ
Сбить вместе сыр и масло. Добавить остальные ингредиенты и
растереть. Из полученного теста скатать два валика толщиной 1 1/±
дюйма. Завернуть и охлаждать не меньше 2 часов. Нарезать
ломтики по х/4 дюйма, уложить их на несмазанный противень и выпекать
20-25 минут при температуре 300° F до легкого подрумянивания.
иша
Задача на субботнее утро
[Первоначально опубликовано в TUGboat 8 (1987), 73, 210.]
Эту головоломку предложил мне Сапе Муллендер из Центра
математики и информатики в Амстердаме. Он сказал, что не сомневается в том,
что «общий дизайн, предоставляемый TejX'om, лучше дизайна,
предоставляемого программой troff, но настоя- щий гуру может заставить troff
делать вещи, которые вы никогда не г сможете сделать в ТЁХ'е». В
качестве примера он показал мне стра- ницу, на которой troff вставил
картинку в середину абзаца, окружив ее текстом. «Это получилось не очень
изящно, но все же получилось, что нельзя сбросить со счетов»,— сказал он.
Что ж, должен отметить, что не задумывался над этим простым
решением, пока не наступило утро следующей субботы, и я решил эту задачку
еще до наступления полудня. Вы догадываетесь, как я набрал абзац,
который сейчас читаете? (Ответ приведен ниже, но не заглядывайте в него, пока
не решите эту задачку самостоятельно. Это не демонстрация превосходства
TgX'a над troff ом, а представление неких интересных и полезных вещей.)
???????????????????????????????????????????????????????????????????????
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
\font\bigfont=cmbxlO scaled \magstep5
\newbox\qmark \setbox\qmark=
\hbox{\raise6pt\hbox{\bigfont\thinspace?\thinspace}}
\newdimen\leftedge \newdimen\rightedge
\leftedge=\hsize \advance\leftedge by-\wd\qmark
\divide\leftedge by 2
\rightedge=\leftedge \advance\rightedge by\wd\qmark
\parshape 10 0pt\hsize 0pt\hsize 0pt\hsize
Opt\leftedge \rightedge\leftedge
Opt\leftedge \rightedge\leftedge
Opt\leftedge \rightedge\leftedge 0pt\hsize
\newbox\partpage \newcount\n
\newdimen\savedprevdepth \savedprevdepth=\prevdepth
\newdimen\savedvsize \savedvsize=\vsize
206
Компьютерная типография
\begingroup \clubpenalty=0 \brokenpenalty=0
\output={\global\setbox\paxtpage=\vbox{\unvbox255\unskip}}
\vfill\break
\topskip=\ht\strutbox \vsize=\topskip
\n=200 /С we will store nine lines of text in boxes 201—209
\output={\global\advance\n by 1
\ifnum\n<210 \global\setbox\n=\box255
\else \unvbox\partpage \prevdepth=\savedprevdepth
\vskip\parskip \box201 \box202 \box203
\box204 \vskip-\baselineskip \box205
\box206 \vskip-\baselineskip \box207
\box208 \vskip-\baselineskip \box209
\vskip-\baselineskip
\moveright\leftedge\hbox{\smash{\box\qmark}}
\box255 \global\vsize=\maxdimen \f i}
\noindent Эту головоломку предложил мне Сапе Муллендер из Центра
математики и информатики в Амстердаме. Он сказал, что не
сомневается в том, что <<общий дизайн, предоставляемый \ТеХ'ом,
лучше дизайна, предоставляемого программой {\it troff}, но настоящий
гуру может заставить {\it troff\/} делать вещи, которые вы никогда
не сможете сделать в \ТеХ,е>>. В качестве примера он показал мне
страницу, на которой {\it troff\/} вставил картинку в середину
абзаца, окружив ее текстом. <<Это получилось не очень изящно, но все
же получилось, что нельзя сбросить со счетов>>, \cdash сказал он.
Что ж, должен отметить, что не задумывался над этим простым
решением, пока не наступило утро следующей субботы, и я решил эту
задачку еще до наступления полудня. Вы догадываетесь, как я набрал
абзац, который сейчас читаете?
(Ответ приведен ниже, но не заглядывайте в него, пока не решите
эту задачку самостоятельно. Это не демонстрация превосходства \ТеХ'а
над {\it troff}'ом, а представление неких интересных и полезных
вещей.)
{\parfillskip=Opt\par} \global\savedprevdepth=\prevdepth
\output{\global\setbox\partpage=\vbox{\unvbox255\unskip}}
\vfill\break \endgroup \vsize=\savedvsize
\unvbox\partpage \prevdepth=\savedprevdepth
У, Более изящные решения приветствуются!
[Замечание: Алан Хёниг независимо получил значительно более общее,
основанное на \vsplit решение, которое представлено в TUGboat 8 (1987), 211—
215.]
Упражнения к книге
Т^Х: The Program
[Первоначально опубликовано в TUGboat 11 (1990), 165-170, 499-511.]
Весной 1987 г. я читал курс, в котором в качестве учебного пособия по
исходному ТЁХ'овскому тексту служил том В серии Computers &; Typesetting.
Поскольку эта книга изначально писалась как справочник, а не как учебник,
мне пришлось дополнить материал, содержащийся в ней, упражнениями для
домашних работ, а также экзаменационными задачами.
Задачи эти оказались в итоге достаточно интересными и занимательными
для людей, склонных к занятиям подобного рода, они могут оказаться также
полезными для тех, кто изучает материал книги «TjgX: The Program»
самостоятельно, а не в рамках соответствующего предмета, преподаваемого в колледже.
Исходя из этих соображений, я отобрал 32 задачи из упомянутых выше и
снабдил их ответами, которые, на мой взгляд, можно считать верными.
Последняя из предлагаемого списка задач, относящаяся к типографскому
набору текстов на языках с большим количеством используемых в них
литер, заслуживает особого внимания, поскольку речь идет о расширении ТЕХга,
которое может оказаться полезным в азиатских странах.
Формулировки некоторых задач изменились по сравнению с
первоначальными. Я отредактировал их таким образом, чтобы они оставались
корректными и применительно к следующим изданиям рассматриваемой книги (для
версий TgX'a от 3.0 и выше); тем же, кто располагает изданием 1986 г., надо
ознакомиться со списком исправлений, прежде чем изучать приведенные ниже
ответы.
Задачи
Здесь представлены формулировки задач в том порядке, который мне кажется
целесообразным. Хотя первые задачи из данного списка носят вводный
характер, я не советовал бы их пропускать, даже если они покажутся слишком
простыми —зачастую они содержат в себе некоторые тонкости. Некоторые
задачи могут оставить впечатление фрагментарности, однако они нацелены на
разъяснение важных сторон изучаемого предмета. Чтобы извлечь из решения
208
Компьютерная типография
предлагаемых задач наибольшую пользу, надо самым серьезным образом
пытаться довести решение каждой из них до конца самостоятельно и только после
этого сверяться с ответом.
1. (Упражнение, связанное с чтением WEB-текста.) Что предшествует
непосредственно строке 'PROCEDURE INITIALIZE' в паскалевской программе,
описываемой в моей книге? (Конечно, это точка с запятой, однако есть еще несколько
элементов, находящихся перед этой точкой с запятой, употребление которых
вы должны понимать.)
2. Найдите необязательный макро в §15.
3. Предположим, что вместо строки "m2d5c215x2v5i" в начале процедуры
print-romanJnt стоит строка "m2d5c212q5v5i". Что будет печататься для
входного значения 69? Для входного значения 9999?
4. Почему счетчик error-count имеет нижнюю границу значений, равную — 1?
5. Что печатается на пользовательском терминале после ввода 'q' в ответ на
сообщение об ошибке? Почему?
6. Дайте примеры аварийного поведения ТЁХ'а в следующих случаях:
a) если в §108 исключить проверку Ч < 7230584';
b) если в §108 убрать проверку '5 > 1663497';
c) если в §127 вместо условия lr > p+V использовать 'г > р';
d) если в §127 исключить условие 'rlink^p) ^р';
e) если из §125 убрать условие Чо-тет-гпах+2 < mem-bot+maxJialfword\
7. Цель этой задачи — показать, что данные в тет могли бы породить
следующий вывод из процедуры show-nodeJist:
\hbox(10.0+0.0)xl00.0, glue set lO.Ofill юо
.\discretionary replacing 1 200
. .\kern 10.0 300
. I \large U loooo
.|\large ~~K (ligature ff) 400,10001,10002
.\large ! 10003
Apenalty 5000 500
Aglue 0.0 plus 1. Of ill 600
Avbox(5.0x0.5)xl0.0, shifted -5.0 700
. Ahbox(5.0x0.0)xl0.0 800
. . Asmall d 10004
. . Asmall a 10005
..\rule(0.5+0.0)x* 900
Пусть Marge —шрифт с номером 1, a \small —шрифт с номером 2. Пусть
также узлы, используемые в нижней (переменной по размеру) части тет,
начинаются в позициях 100, 200 и т. д., как это показано выше; узлы,
используемые в верхней (однословной) части тет, должны начинаться в позициях
Глава 10. Упражнения к книге ТЕХ: The Program
209
10000, 10001 и т. д. Постройте диаграмму, которая показывала бы точное
числовое содержимое каждого имеющегося слова тет, если miri-quarterword —
min-halfword — 0.
8. Что будет напечатано программой short-display, если в предыдущей задаче
внутри большого блока \hbox задать горизонтальный список, считая при этом,
что первоначальное значение переменной fontJnshort-display равно нулю?
9. Пусть сразу после инициализации INITEX исполняется следующий набор
команд:
incr(prev-depth)\ deer (mode-line), incr(prev-graf)\ show .activities;
Что будет отображено?
10. Что выдаст программа 'show-eqtb(int-base + liy после завершения процесса
инициализации INITEX?
11. Пусть ТЕ^'у даны следующие определения:
\def\a{\advance\day by l\relax} \def\g{\global\a}
Внутри Т^Х'а это приведет при обработке командной последовательности \а
к появлению вызовов процедуры
eq-ivord-define(p, eqtb\p].int + 1),
и вызовов процедуры geq-Word-deftne(p, eqtb\p].int + 1), где р — int-base +
day-code, при обработке команды \g. Рассмотрим теперь следующие команды:
\day=0 \g\a{\a\g\a{\g\a\g}\a{\a}\a}
Каждый символ '{' вызывает процедуру new save-level(simple-group), а символ
'}' — процедуру unsave.
Объясните, что именно помещается в стек savestack и извлекается из
него, а также что запоминается в eqtb\p] и xeqJevel\p] в процессе выполнения
приведенных выше команд. Каким будет окончательное значение командной
последовательности \day? (См. The ТЁКЬоок1, упр. 15.9 и с. 360.)
12. Используйте обозначения с нижней части с. 122 книги TfeX: The Program
для описания содержимого списка лексем, отвечающего команде \! после
ввода определения
\def\!!1#2![{!#]#!!2}
считая, что [, ] и ! имеют соответствующие им коды (номера) категорий,
равные 1, 2 и б, точно так же, как и символы {, }, #. (См. упр. 20.7 в книге
The TEXbook.)
13. Каким будет значение абсолютного максимума для числа символов,
напечатанных программой show-eqtb(every-parJoc)i если текущее значение
переменной \everypar не содержит никаких управляющих последовательностей?
1 Здесь и далее страницы указаны по русскому переводу: Кнут Д. Е. Всё про Т^Х. —
Протвино: АО RDT^X, 1993. — Прим. перев.
210
Компьютерная типография
(Подсказка: значение ответа превышает 50. Вы можете проверить этот факт,
запустив ТЕХ для подходящего примера, относящегося к наихудшему случаю,
а затем ввести следующие команды
\tracingrestores=l \tracingonline=l {\everypar{}}
поскольку в этом случае при перезаписи \everypar вызывается show-eqtb.)
14. Что сделает INITEX с входной строкой следующего вида (посмотрите на
нее повнимательнее):
\catcode"=7 \" <(")'"!
15. Объясните причину появления сообщения об ошибке, если в plain ТЁХ'е
ввести
\endlinechar=*! \error
16. Впишите пропущенное макроопределение так, чтобы для входного файла
\catcode(?=\active
\def\answer{...}
\answer
при обработке его plain ТеХ'ом было в точности выдано следующее сообщение
об ошибке:
! Undefined control sequence.
<recently read> How did this happen?
1.3 \answer
(Эта каверзная задача намного труднее, чем все предыдущие, но для ее
решения существует по крайней мере три способа!)
17. Проанализируйте, что будет делать Т^Х при обработке следующего текста:
{\def\t{\gdef\a##}\catcode(d=12\tld#2#3{#2}}
\hfuzz=100P\iidiml2pt=lP\expandaiter\a
\expandafter\else\romannumeral888\relax\fi
\showthe\hfuzz \showlists
(Считайте, что здесь используются plain ТЁХ'овские коды категорий.)
Определите, в какие моменты при чтении данного текста будут
вызываться сканирующие программы scan-keyword, scanJnt и scan-dimen, объясните в
общих чертах, что за результат будет выдан этими программами.
18. Есть ли разница в интерпретации Т^Х'ом команд
\thickmuskip=-\thickmuskip
\thickmuskip=-\the\thickmuskip
и в чем эта разница заключается? (Считайте, что здесь используется plain
ТЁК.)
19. Каким образом изменится поведение Т^Х'а, если оператор присваивания в
конце §508 заменить на '6 *— (р = nuliy ?
Глава 10. Упражнения к книге ТЕХ: The Program
211
20. Первоначальная реализация ТЁХ'а (1^X82) содержала значительно более
простой вариант процедуры вместо той, что приведена в §601:
procedure dvLpop;
begin if dvLptr > 0 then
if dvLbuf [dvLptr — 1] = push then deer (dvLptr)
else dvLout(pop)
else dvLout(pop);
end;
(В параметре / необходимости не было.) Почему автору однажды стало стыдно
и он заменил данный вариант на используемый сейчас?
21. Расставьте индексы d, у и z в последовательности целых чисел
2718281828459045
используя процедуру, набросок которой приведен в §604. (Это просто.)
22. Сформируйте короткий ТЁХ'овский входной файл, который заставит
подпрограмму print-mode напечатать 'no mode'. (Предположение о том, что
предварительно загружены plain ТЁХ'овские коды категорий и макро, не
использовать.) Дополнительные баллы получит тот, кто построит самый короткий
файл, т. е. содержащий наименьшее число лексем, среди всех предложенных
вариантов.
23. В §78 книги «Т^К: The Program» говорится, что процедура error может
быть вызвана из нее самой в процессе вызова error, но рекурсия не может
быть более глубокой, чем эта.
Постройте сценарий, в котором error вызывается трижды до того, как она
будет завершена.
24. J.H.Quick (студент) думал, что он обнаружил ошибку в §671 и получит
$327.68 при обработке входных текстов наподобие такого:
\vbox{\moveright lpt\hbox to 2pt{}
\xleaders\lastbox\vskip 3pt}
(Он обнаружил, что Т^Х формирует этот vbox шириной 2 pt, но думал,
что правильное значение ширины здесь равно 3 pt.) Однако, когда он ввел
\showlists, то увидел, что элементы-заполнители пробелов (лидеры)
определены просто как
\xleaders 3.0
.\hbox(0.0+0.0)x2.0
и обнаружил с сожалением оператор Lshift-amount (cur-box) <— 0' в §1081.
Объясните, каким образом следовало бы исправить §671, если бы параметр
shift-amount блока, содержащего элементы-заполнители, имел бы ненулевое
значение.
25. Когда ваш преподаватель готовил эту задачу, он ввел команду
'\hbadness=-l' с тем, чтобы T^jX показывал способ, которым он будет
разрывать каждую из строк. (У него (преподавателя) возникает иногда потребность
проверить разрывы строк, не формируя графический образ соответствующей
212
Компьютерная типография
страницы, например, когда работа с ТеХ'ом ведется с помощью
терминала, не поддерживающего графический вывод.) Это вызывает появление на
терминале следующего текста, выдаваемого ТеХ'ом:
Tight \hbox (badness 0) in paragraph at lines 297—301
[]\tenrm When your in-struc-tor made up this prob-lem, h
e gave the com-mand
Loose \hbox (badness 3) in paragraph at lines 297—301
\tenrm '\tentt \hbadness=-l\tenrm ' so that T[] would pr
int out the way each line of this
Tight \hbox (badness 0) in paragraph at lines 297—301
\tenrm para-graph was bro-ken. (He some-times wants to с
heck line breaks with-
Loose \hbox (badness 14) in paragraph at lines 297—301
\tenrm out look-ing at ac-tual out-put, when he's us-ing
a ter-mi-nal that has no
Почему ничего не показано для последней строки рассматриваемого абзаца?
26. В чем заключались бы отличия в информации, выводимой ТЁХ'ом, если
изменить процедуру rebox путем удаления из нее оператора ^\ftype{b) = vlist-node
then b <— hpack(b, natural)'? Каким был бы результат, если удалить условный
оператор 'if (is-char-node(p)) ...'? (Заметим, что блок b можно сформировать
с помощью процедуры char.box.)
27. Какие пробелы вставит Т^Х между символами, когда будет набирать
формулы $х==1$, $х++1$, and $x,,l$? Найдите те места в программе, где
осуществляется принятие решений относительно формирования пробелов.
28. Когда ваш преподаватель готовил эту задачу, он ввел команду
'\tracingparagraphs=l' с тем, чтобы полученный файл протокола (transcript
file) разъяснял ТЁХ'овские решения относительно разрыва строк
применительно к этому абзацу. Он также ввел '\pretolerance=-l', чтобы попытки
переноса предпринимались немедленно. Полученный выход показан на
следующей странице1. Используйте его, чтобы определить, какие разрывы строк
могли быть найдены с помощью упрощенного алгоритма, обрабатывающего
текст по одной строке. (Этот упрощенный алгоритм находит такую точку
разбиения, чтобы минимизировать дефекты первой строки, затем фиксирует
ее и стартует снова.)
1 Текст из оригинала книги «Digital Typography», для которого получен этот выход, имеет
вид:
28. When your instructor made up this problem, he gave the
command '\tracingparagraphs=r so that his transcript file would
explain TejX's line-breaking decisions for this paragraph. He also said
'\pretolerance=-l' so that hyphenation would be tried immediately.
The output is shown on the next page; use it to determine what line
breaks would have been found by a simpler algorithm that breaks off one
line at a time. (The simpler algorithm finds the breakpoint that yields
fewest demerits on the first line, then chooses it and starts over again.)
— Прим. перев.
Глава 10. Упражнения к книге ТЕХ: The Program
7, This is the paragraph-trace output for Problem 28:
[]\tenrm When your in-struc-tor made up this prob-lem, he gave the com-
«Xdiscretionary via ФФ0 b=145 p=50 d=36525
(0(01: line 1.0- t=36525 -> (0ФО
mand
Ф via ФФ0 b=0 p=0 d=100
««2: line 1.2 t=100 -> ««0
'\tentt \tracingparagraphs-l\tenrm ' so that his t^ran-script file would ex-
«Xdiscretionary via ФФ1 b=179 p=50 d=78221 *
(0(03: line 2.0- t=114746 -> <0<01
plain
(0 via (0(01 b=l p=0 d=10121
(0(04: line 2.2 t=46646 -> (0(01
T[]'s
Ф via ФФ2 b=4 p=0 d=196
(0(05: line 2.2 t=296 -> (0(02
line-breaking de-ci-sions for this para-graph. He also said
Ф via ««3 b=89 p=0 d=9801
««6: line 3.1 t=124547 -> ФФЗ
'\tentt \pretolerance=-l\tenrm ' so that hy-phen-ation would be tried im-me-di-ately.
Ф via ФФ6 b=ll p=0 d=441
(0(07: line 4.2 t=124988 -> ФФ6
The out-put is shown on the next page; use it to de-ter-mine what
(0 via (0(07 b=318 p=0 d=117584
(0(08: line 5.0 t=242572 -> ФФ7
line
Ф via ФФ7 b=14 p=0 d=576
ФФ9: line 5.1 t=125564 -> ФФ7
breaks would have been found by a sim-pler al-go-rithm that breaks
Ф via ФФ8 b=2 p=0 d=10144
Ф via ФФ9 b=295 p=0 d=93025
ФФ10: line 6.0 t=218589 -> ФФ9
off
Ф via ФФ8 b=31 p=0 d=11681
Ф via ФФ9 b=15 p=0 d=625
ФФ11: line 6.1 t=126189 -> ФФ9
one
Ф via ФФ9 b=26 p=0 d=11296
ФФ12: line 6.3 t=136860 -> ФФ9
line at a time. (The sim-pler al-go-rithm finds the break-
©Xdiscretionary via ФФ10 b=607 p=50 d=383189
ФФ13: line 7.0- t=601778 -> ФФ10
point
Ф via ФФ10 b=80 p=0 d=8100
Ф via ФФ11 b=503 p=0 d*263169
ФФ14: line 7.1 t=226689 -> ФФ10
that
Ф via ФФ10 b=0 p=0 d=10100
Ф via ФФ11 b=20 p=0 d=900
Ф via ФФ12 b=369 p=0 d=153641
ФФ15: line 7.1 t=127089 -> ФФ11
yields
Ф via ФФ12 b=0 p=0 d=100
ФФ16: line 7.2 t=136960 -> ФФ12
fewest de-mer-its on the first line, then chooses it
Ф via ФФ13 b=293 p=0 d=91809
ФФ17: line 8.0 t=693587 -> ФФ13
and
Ф via ФФ13 b=5 p=0 d=10225
Ф via ФФ14 b=571 p=0 d=337561
ФФ18: line 8.0 t=564250 -> ФФ14
starts
Ф via ФФ14 b=2 p=0 d=144
Ф via ФФ15 b=308 p=0 d=101124
ФФ19: line 8.0 t=228213 -> ФФ15
ФФ20: line 8.2 t=226833 -> ФФ14
over again.)
Ф\раг via ФФ16 b=0 p=-10000 d=100
Ф\раг via ФФ17 b=0 p=-10000 d=10100
Ф\раг via ФФ18 b=0 p=-10000 d=10100
Ф\раг via ФФ19 b=0 p=-10000 d=10100
Ф\раг via ФФ20 b=0 p=-10000 d=100
ФФ21: line 8.2- t=137060 -> ФФ16
214
Компьютерная типография
29. Выполните прогон алгоритмов в частях 42 и 43, чтобы найти значения
переменных trie-op, trie-char, trie Jink, hyf-distance, hyf-num и hyf-next после
выполнения оператора
\patterns{albc 2bcd3 ablcd bcldd}
Затем исполните алгоритм из §923, чтобы увидеть, как ТЕХ использует эту
эффективную TRIE-структуру1 при определении значений переменной hyf,
когда осуществляется перенос слова aabcd. [Когда начинается §923, значение
параметра hn будет равно 5, а значения элементов массива hc[l.. 5] будут
равны (97,97,98,99,100), соответственно. Предполагается, что min-quarterword =
Lhyf = rJiyf = 0.]
30. В момент завершения работы ТЁХ'а стек savestack обычно пуст. Однако
если, например, введенный пользователем текст содержит лишнюю скобку '{'
(или пропущенную скобку '}'), Т^Х выдаст сообщение
(\end occurred inside a group at level 1)
(см. §1335).
Объясните подробно, каким образом надо изменить ТЕХ, чтобы такого
рода сообщения были более информативными. Например, если исходный текст
имеет несбалансированную скобку Ч' в строке 2 и несбалансированную
команду '\begingroup' в строке 9, модифицированный вами Т^Х должен выдать
такие два предупреждающих сообщения:
(\end occurred when \begingroup on line 9 was incomplete)
(\end occurred when { on line 2 was incomplete)
Вы можете считать, что в момент перехода к §1335 в стеке savestack
находятся только коды групп simple-group и semisimple-group. Если же обнаружены
также какие-либо другие коды групп, следует вызвать процедуру confusion.
31. (Задача, излагаемая в данном пункте, является наиболее трудной из всех
представленных здесь, но одновременно и наиболее важной из них. Это была
основная задача для домашней проработки при подготовке к завершающему
экзамену.)
Цель решения задачи 31 —так расширить ТеХ, чтобы его легче было
распространять в Китае, Японии и Корее. Такая расширенная программа,
именуемая ЧЩХХ, позволяет работать со шрифтами, в которые входит до 65536
символов. Каждый символ из такого рода увеличенной таблицы (будем
именовать его далее расширенным символом) представляется с помощью пары
значений: «расширения» х и «кода» с, причем оба эти параметра, тис,
принимают значения из диапазона от 0 до 255 включительно. Литерам с одним и
тем же значением параметра 'с', но с различными значениями параметра 'х'
отвечают различные графические образы, однако все они имеют одну и ту же
ширину, высоту, глубину и поправку на курсив.
От reTRIEval — разновидность дерева поиска. — Прим. перев.
Глава 10. Упражнения к книге IfeX: The Program
215
TgXX идентичен ТЕХ'у5 за исключением одной новой команды-примитива
\xchar, включенной в его состав. Если команда \xchar встречается, когда
ТЁХХ находится в вертикальном режиме, начинается новый абзац; т. е. она
работает в этом случае как «горизонтальная команда» со страницы 335 книги
The ТЁХЬоок. Если же \xchar появляется в горизонтальном режиме, за ней
должно следовать число (number) от 0 до 65535; это число может быть
преобразовано в форму 25бх + с, где 0 < х, с < 256. Из текущего шрифта будет
взят соответствующий расширенный символ и присоединен к текущему
горизонтальному списку, а показатель величины интервала (space factor) будет
установлен равным 1000. (Если х — 0, воздействие \xchar аналогично
таковому для команды \char, за исключением того, что \xchar отключает лигатуры
и кернинг, а также не производит каких-либо специфических действий с
показателем величины интервала. Кроме того, не добавляется никакого штрафа,
даже если \xchar окажется символом переноса (\hyphenchar) для текущего
шрифта.) Слово, содержащее расширенный символ, не должно переноситься.
Команду \xchar нельзя использовать в математическом режиме.
Внутри Т^ХХ'а расширенный символ (х, с) из шрифта / представляется
парой р и q последовательных элементов типа char-node, где принято font(p) —
null-font, character(p) = qi(x), link(p) = q, character(q) — qi{c), font(q) = /.
Такое двухэлементное представление используется даже в том случае, когда
х = 0.
ТЁХХ набирает некоторый расширенный символ, задавая номер символа
256х + с в DVI-файле (см. команду set2 в §585.)
Если Т^ХХ исполняется с макроопределениями plain TgK'a и при этом
пользователь введет '\tracingall \xchar600 \showlists', выход ТЁХХ'а будет
включать следующий текст
{\xchar}
{horizontal mode: \xchar}
{\showlists}
### horizontal mode entered at line 0
\hbox(0.0+0.0)x20.0
\tenrm \xchar"258
spacefactor 1000
(так как 600 есть "258 в шестнадцатеричной системе счисления).
Ваша задача — объяснить детально все изменения, которые надо внести в
Т^Х, чтобы преобразовать его в ТеХХ.
[Примечание: правильно построенное расширение TgK'a должно включать
также команды-примитивы \xchardef (аналогично \chardef) и \mathdef,
поскольку язык должен быть «ортогонально завершенным». Однако это
дополнительное расширение не включено в задачу 31 как ее составная часть, поскольку
никаких специфических трудностей при этом не возникает. Если кто-то
захочет понять, каким образом реализовать \xchar, можно заодно рассмотреть и
реализацию \xchardef.]
216
Компьютерная типография
32. В первом издании книги Т£Х\* The Program предполагалось, что
расширенные символы могли бы быть представлены на основе следующего
соглашения: первый из двух последовательных элементов char-node должен был
содержать код шрифта и код символа, размеры которого должны были
вычисляться обычным образом; второй из этих элементов, который должен был
иметь тип halfword (полуслово), давал фактический номер печатаемого
символа. Шрифты подразделялись на два типа, основываясь на характеристиках
их TFM-заголовков; «восточные» (oriental) шрифты всегда использовали
представление из двух слов, тогда как для всех других шрифтов применялась
однословное представление.
Объясните, почему метод, предложенный в задаче 31, лучше чем этот.
(Здесь имеются по крайней мере две причины.)
Ответы к задачам
1. Согласно указателю, процедура initialize объявлена в §4. Ей предшествует
там (Global variables 13), а в §13 говорится, что окончательно эта глобальная
переменная определяется в §1345. Обращаясь к §1345, находим там 'writeJoe:
pointer;' и комментарий. Этот комментарий не входит в паскалевский код.
Мини-указатель в нижней части страницы 541 показывает, что 'pointer' —
это макроопределение, объявленное в §115. Изучаемый нами вопрос почти
исчерпан, поскольку в §115 сказано, что pointer развертывается в полуслово
halfword, являющееся частью программы на Паскале. На странице xi
говорится, что малые (строчные) буквы в WEB-программе заменяются
соответствующими большими (прописными) в программе на Паскале; на странице xii сказано,
что символ подчеркивания в 'writeJoe' убирается. Следовательно, можно
заключить, что словам 'PROCEDURE INITIALIZE' в программе на Паскале будут
предшествовать непосредственно слова 'WRITELOC:HALFWORD;'.
Однако это утверждение не совсем точно! Цитируемая книга кое-чего не
договаривает. Если запустить программу TANGLE для обработки TEX.WEB (не
меняя файла), мы увидим, что словам 'PROCEDURE INITIALIZE' фактически
предшествует строка вида
{1345:}WRITEL0C:HALFWORD;{:1345}
поскольку программа TANGLE вставляет в формируемый текст комментарии,
чтобы показать начало каждого из блоков программного кода (программы).
Код здесь на самом деле берется из §1345.
2. Если обратиться к указателю, то можно увидеть, что не используется
никогда макро done6. (Он включен только для тех, кто захочет реализовать
системно-зависимые изменения и/или расширения.)
3. Введенная новая строка заменяет «четвертаки» («quarters») q (имеющие
значение 25) «гривенниками» («dimes») x (имеющими значение 10). Если
«проиграть» код из §69, можно увидеть, что 69 теперь будет представлено как
lvvviv, a 9999 —как
mmmmirunminmcmqcvqiv.
Глава 10. Упражнения к книге ТЕХ: The Program
217
(Первые 9 символов m здесь дают 9000, затем cm дает еще 900, qc —75, vq —
20, a iv — оставшиеся 4).
4. Так сделано потому, что значение error-count может быть уменьшено на
1 в §1293, будучи увеличенным до того на 1 в §82 (Код в §1293 уменьшает
значение счетчика error-count из-за того, что при исполнении команды \show
используется подпрограмма error, хотя на самом деле ошибки и не было).
5. Вводимый символ q есть сокращение для команды «quiet» (отменить
вывод), а не «quit» (завершение работы), для которой в §83 вводится
сокращение Q. Этот символ q вызывает печать из §86 сообщения 'OK, entering
\batchmode', после которого переменная selector уменьшается таким образом,
чтобы '. . .' и (return) не печатались на терминале! (Он появится только в
протокольной файле, если тот был открыт). Этот способ служит ТЕ^'у для выдачи
подтверждения о том, что действительно включен режим \batchmode.
6. (а) При вычислении £*297 может произойти арифметическое переполнение,
поскольку
7230585 х 297 = 231 + 97.
(b) Требуется определенного рода проверка, чтобы предотвратить деление
на нуль, когда 5 имеет значение положительное, но меньшее 297. Если 5 <
1663497, то
5 div 297 < 5601,
и 7230585/5600 чуть больше, чем 1291, так что в данном случае можно
записать г > 1290. Следовательно, пороговое значение должно быть выбрано
таким образом, чтобы обезопаситься от деления на нуль в максимально
возможной степени. (Один студент предложил заменить оператор 'г *— £' на
'г <— 1291'. Это изменение может ускорить или не ускорить вычисления, в
зависимости от используемого компьютера и компилятора для языка Паскаль.
В машинном языке можно было бы использовать оператор goto, задающий
badness <— inf-bad, но для Паскаля это недопустимо.)
(c) Если войти в§128сг=р+1, будет предпринята попытка создать узел
размерности 1, но тогда не будет места для поля nodesize.
(d) Если войти в §129 с единственным доступным узлом, мы потеряем всё
и значение rover будет неправильным (Более старые версии ТЁ^'а содержат
более сложные проверки в §127, которые предотвратили бы переход к §129
в случае, если бы были доступны два узла. Эта предосторожность оказалась
излишней.).
(e) Это тонкий вопрос. Нельзя, чтобы «нижняя» часть памяти росла
в такой степени, чтобы значение параметра nodesize превысило значение
maxJialfword, когда в §127 производится объединение (слияние) узлов.
218
Компьютерная типография
11
12
6553600
655360
200
10.0
7 | 1
300
10003
10000
655360
6
1
0
11
0
10001
600
5000
10 | 0
8
700
0
655360
32768
327680
-327680
800
0.0
900
655360
327680
10004
0.0
-1073741824
32768
1
1
1
1
2
2
85
102
102
33
100
96
400
10002
0
500
10005
0
type {hlist-node), , link
width (100 pt)
depth
height (10 pt)
shift-amount
gluesign {stretching), glue-order {fill), list-ptr
glueset (type real)
type {disc-node), replace-count, link
pre-break, post-break
type {kern-node), subtype {explicit), link
width (10 pt)
type {ligature-node), , link
font, character, lig.ptr
type {penalty-node), , link
penalty
type {glue-node), subtype {normal), link
glue-ptr {filLglue), leader-ptr
type {vlist-node), , link
width (10 pt)
depth (0.5 pt)
height (5pt)
shift-amount (—5pt)
gluesign {normal), glue-order {normal), list-ptr
glueset (type real)
type {hlist-node), , link
width (10 pt)
depth
height (5pt)
shift-amount
gluesign {normal), glue-order {normal), list-ptr
glueset (type real)
type {rule-node), , link
width {nulLflag)
depth
height (0.5 pt)
font, character ("U"), link
font, character ("f"), link
font, character ("f"), link
font, character ("!"), link
font, character ("d"), link
font, character ("a"), link
Глава 10. Упражнения к книге ТеХ: The Program
219
8. (Американцы норвежского происхождения узнают здесь шутку «Uff da».)
Выходом процедуры short-display будет:
\large Uff []
поскольку short-display показывает доразрывную и послеразрывную
последовательности символов в команде \discretionary, но не замещающий текст.
Если, однако, этот бокс будет выводиться процедурой hlist-out, такого рода
управление разрывами строк не будет эффективным; в качестве результата
получим бокс шириной 100pt, начинающийся с большого знака '!' и
заканчивающийся маленькими символами 'da', которые будут иметь размер 5pt и
подчеркнуты линейкой шириной 0.5 pt.
9. Так как значением для аргумента prev-depth первоначально будет
ignore-depth, получим
### vertical mode entered at line 1 (\output routine)
prevdepth -999.99998, prevgraf 1 line
10. Согласно §236, в int-base + 17 запоминается значение mag. (Одно из
определений, замененное многоточием на с. 101, есть определение тад\ вы можете
проверить этот факт, анализируя указатель!) Начальное значение для тад
устанавливается в §240. Следовательно, show-eqtb произведет условный
переход (ветвление) к §242 и напечатает '\mag=1000'.
11. В приводимой ниже диаграмме '(з)' есть значение на уровне три, а символ
'—' показывает границу уровня:
(2)
9
(1) (1)
б б (1) (1) (1)
8 8 8
(1) (1) (1) (1) (1) (1) (1) (1) (1)
444444444
(1) (1) (1) (1) (1) (1) (1) (1) (1) (1) (1)
22222222222
savestack:
xeqJevel\p\: (i) (i) (l) (l) (2) (i) (2) (2) (i) (3) (l) (l) (2) (2) (3) (2) (2) (i)
eqtb\p].int: 01223455678899 10 9 10 8
day=0 \g \a { \a \g \a { \g \a \g } \a { \a } \a }
Окончательным значением будет, следовательно, \day=8.
12. (reference count), match !, match #, left-brace [, end-match, left-brace {,
mac-param #, right-brace ], mac-param !, out-param 2, left-brace [. Обратите
внимание, что left-brace перед end-match повторяется в конце замещающего
текста, исходя из условия согласованности (и, следовательно, удаляется из
входного текста).
(1) (1)
8 8
(1) (1)
4 4
(1) (1)
2 2
220
Компьютерная типография
13. Согласно §233, процедура show-eqtb(every-parJoc) вызывает программу
show-tokenJist с ограничением / = 32. В соответствии с §292, нам
необходим список лексем, содержащий лексему, которая печатает возможно
большее число символов при tally = 31; значение tally увеличивается при каждом
обращении к print-char (§58). Изучая случаи, перечисленные в §294, можно
заключить, что наихудший случай будет иметь место тогда, когда
печатается тас-param, и когда литера с фактически печатается как четыре литеры.
Оператор lprint-es с ("ETC. ")' в §292 напечатает восемь добавочных литер,
если текущее значение escape-char представляет собой другую четверку. (Более
длинные примеры возможны только в случаях, когда Т^Х содержит ошибку,
которая запустит выходы '\CL0BBERED.' или '\BAD.' в §293, однако этого здесь
не может произойти.)
Другими словами, пример, соответствующий наихудшему случаю, в
частности, такой, как
Xescapechar^V^df \catcodec\'s'sci0=6
\everypar{123456789012345678901234567890:r'sd0etc.}
в совокупности с предлагаемой текстовой строкой вызовет выдачу на печать
вида
{restoring
~~dfeverypar=1234567890123456789012345678901~~d0~M0~~dfETC.}
подтверждая этим, что show-eqtb(every-parJoc) может напечатать 60 литер.
14. Здесь надо обратить внимание на процедуру get-next, которая
сканирует buffer несколько странным образом, если обнаруживаются два идентичных
символа категории 7 {sup-mark). После того как код категории \ cat code
открывающей кавычки устанавливается равным 7, процедура get-next начинает
сканировать управляющую последовательность в §354, которая переходит в
§355 и находит пробел после ''. Так как пробел имеет код '40, он изменяется
на '140, а содержимое буфера сдвигается влево на 2. По странному
совпадению, '140 — опять литера «открывающая кавычка», так что мы вернемся опять
в §355, который изменит '' ( на h и вернется к start-cs в третий раз. Теперь мы
перейдем к §356 и затем назад, к §355 и к start-cs, изменив '') на i.
Аналогичным образом, в четвертом цикле, литерная цепочка ''' будет заменена на
пробел, а пятый цикл завершит выполнение управляющей последовательности.
Если мы попытаемся ввести указанную в условии задачи строку, INITEX
остановится с выдачей сообщения
! Undefined control sequence.
<*> \catcode''=7 \hi
!\error
Это подтверждает, что buffer в данный момент содержит \hi !.
15. Сообщение об ошибке, которое появится в данном случае, имеет вид
! Undefined control sequence.
<*> \endlinechar='! \error
Глава 10. Упражнения к книге ТЕХ: The Program
221
и наша задача состоит в том, чтобы объяснить появление в нем цепочки
символов ~~М. Стандартное значение, устанавливаемое для \endlinechar, есть
carriage-return (согласно §240); в соответствии с §22, этому отвечает
восьмеричное значение 75, а 75 есть ЛЛМв коде ASCII. Таким образом, в конец
каждой строки, когда она читается в buffer, помещается символ carriage-return
(см. §360). Этот символ не печатается обычно в сообщении об ошибке,
поскольку совпадает с символом endJine-char (см. §18). В приведенном выше
сообщении он появился вследствие того, что было изменено значение символа
endJine-char.
Между прочим, если бы входная строка имела вид
\endlinechar='!\error
(без пробела после литеры !), мы не увидели бы литерной цепочки А1в
выданном сообщении об ошибке. Почему? А потому, что T^jX вызывает
процедуру geLnext, когда видит необязательный пробел после AS СП-константы
1! (см.§442-443), поэтому неопределенная управляющая последовательность
\error будет обнаружена до того, как произойдет изменение значения символа
endJine-charl
16. Одна из проблем здесь состоит в том, чтобы выявить, какая именно
управляющая последовательность здесь будет неопределенной; судя по всему, это
'?', поскольку данный символ был сделан активным. Возможная зацепка
обнаруживается при просмотре §312 и §314, из которых следует, что
сообщение '<recently read>' может быть выдано на печать, только если base-ptr =
inpuLptr, state = token Jist, token-type = backed-up, and loc = null. Список
лексем типа backed.up обычно содержит единственный элемент; в этом случае
имя управляющей последовательности должно быть 'How did this happen?',
и мы имеем дело с задачей помещения некоторого активного символа в имя
управляющей последовательности.
Однако список лексем типа backed-up, обладающий произвольной длиной,
может быть порожден и операцией \lowercase (см. §1288). В этом случае,
однако, правая фигурная скобка, завершающая операцию \lowercase, почти
всегда все еще присутствует в Те^'овском входном состоянии, что может
вызвать появление сообщения об ошибке. (Процедура back-list из §323 не очищает
стек от завершенного обработкой списка лексем.) Необходимо заставить Tj£&
очищать его стек перед сканированием символа }.
С этого места рассматриваемое упражнение начинает напоминать задачу
«retrograde chess». Имеется одно решение, показанное ниже в виде двух строк
текста, разбитых таким образом, чтобы помещаться на страницах данной
книги, хотя на самом деле, если строго следовать условиям задачи, необходимо
построить эквивалентное однострочное представление в качестве строки с
номером 2 фактического входного файла:
\def\answer{\let~\expandaiter\lccode' ! = 'He/e [line broken]
~\lowercase~{~!~o~w~ ~d~i~d~ ~t~h~i~s~ ~h~a~p~p~e~n~?}}
(Символ 'Н' есть представление для '!' «в нижнем регистре»; цепочка
\expandaf ter используется для удаления правой фигурной скобки из стека.)
222
Компьютерная типография
В другом подходе используется \csname и генерируется ? из !:
\def\answer{\def\a##l{{\global\let##l?\aftergroup##l}}e/.
\escapechar(H\lccode( \ ?\lowercase{\expandaf ter\a'/,
\csname ow did this happen!\endcsname}}
Имеется, однако, и некий «жульнический» способ решения, значительно
более короткий — переделать неотображаемый символ возврата каретки,
следующий за \answer, в правую фигурную скобку(!):
\def \answer{\catcodel3=2\lccode' ! ='He/.
\lowercase\bgroup!ow did this happen?}
17. (Оказалось, что решение этой задачи объяснить в классе намного труднее,
чем я ожидал, поэтому для решения ее студентами она получилась труднее,
чем предполагалось. После первой моей попытки объяснить данный ответ, я
решил сделать специальную версию ТЁХ'а, которая помогла бы в
объяснении процессов работы программ сканирования. Эта специальная программа,
получившая наименование DemoT^X, почти в точности соответствует
обычному ТЁХ'у, за исключением того, что при \tracingstats>2 пользователь
имеет возможность наблюдать работу ТЁХ'овских синтаксических программ
в «замедленном воспроизведении». Необходимые изменения, преобразующие
Т^Х в DemoT^X, разъясняются в приложении, приводимом ниже. С помощью
DemoTEX'a вначале был предпринят ряд попыток решения простых примеров,
вроде '\hf uzz=l. 5pt' и '\ cat code ' а=11\ прежде чем погрузиться в задачу 17,
в которой встречается сразу несколько различных случаев. Кстати, когда мы
обсуждали входные стеки, было обнаружено, что полезно рассмотрение
поведения ТЕХ'а при обработке следующего входного текста:
\output{\botmark}
\def\a{\error}
\mark{
\everyvbox{
\everypar{
\everydisplay{
\everyhbox{
\everymath{\noexpand\a}
$\relax}
\hbox\bgroup\relax}
$$\relax}
\noindent\relax}
\vbox\bgroup\relax}
\hbox{}\vfill\penalty-10000
Здесь \penalty производит переключение в команде \botmark,
определяющей \everyvbox и начинающей исполнение команды \vbox, которая
определяет \everypar и начинает выполнение \раг, определяющей, в свою очередь,
\everydisplay и начинающей исполнение \display, и т. д.)
Глава 10. Упражнения к книге ТЕХ: The Program
223
Вернемся опять к задаче 17. Первая строка здесь имеет вид
\gdef\a#ld#2#3{#2}
где второй символ d имеет категорию кода 12 (other-char), следовательно, это
второе d будет соответствовать символу d, который порождается командой
\romannumeral. В этой строке процедура scanJnt будет вызвана только для
сканирования (d и числа 12.
При обработке второй строки вызывается процедура scan-dimen, которая
производит просмотр правой части оператора присваивания в команде \hf uzz.
После того как scan-dimen для чтения литерной цепочки '100' использует
процедуру scanJnt, она вызовет процедуру scan-keyword, чтобы определить вид
используемой единицы измерения. Однако до того, как для единиц станет
известен их вид ('pt' или 'рс'), должно быть произведено раскрытие \ if dim.
Здесь нам придется вызвать scan-dimen рекурсивно (дважды), эта
процедура обнаружит значение 12 pt в левой части выражения, причем ее исполнение
будет опять прервано, когда процедура scan-keyword попытается определить
единицы измерения в правой части выражения. Теперь литерная цепочка из
\expandaf ter станет причиной того, что \romannumeral888 будет развернуто
в dccclxxxviii, и затем мы получим грамматический разбор
\a\else dccclxxxviii
за которым следует \relax\f i. Здесь аргумент #1 будет иметь значение \else,
аргументы #2 и #3 — значение с; тогда раскрытие дает cclxxxviii\relax\f i.
Первое 'с' завершает второе 'Рс', а проверка \if dim дает значение \true.
Следовательно, второе 'с' может завершать первое 'Рс', а значение параметра
\hfuzz устанавливается равным 1200pt. Литеры lxxxviii теперь стоят в
начале абзаца. Команда \f i удаляет \if dim из ТЁХ'овского стека условий.
Дополнительная информация по данной теме содержится в даваемом ниже
приложении. Примеры, подобные этому, проливают свет на некоторые
странные вещи, которые могут быть найдены в тесте TRIP, представляющем собой
достаточно запутанный образец необычного кода, используемый для проверки
корректности реализаций TgX'a.
18. Если, например, \thickmuskip имеет значение 5mn plus 5mu, как оно
устанавливается plain Т^Х'ом, первая из приводимых команд изменит это
значение на -5mu plus -5mu, поскольку scan-glue в §461 вызовет процедуру
scansomething-internal со вторым аргументом, имеющим значение true; это
приведет к тому, что все три компоненты клея будут сделаны отрицательными
(см. §413, §430, §431).
Вторая команда, в отличие от первой, приказывает TgK'y развернуть
'\the\thickmuskip' в последовательность литер, так чтобы она была
эквивалентна присваиванию
\thickmuskip=-5mu plus 5mu
Знак «минус» не войдет в растяжимую компоненту клея, так как §461
применяет операцию negate (сделать отрицательным) только к первой найденной
размерности.
224
Компьютерная типография
Эта задача иллюстрирует хорошо известную опасность, заключающуюся
в любой системе развертывания макроопределений путем текстовых
подстановок.
19. Мы получим забавный результат, состоящий в том, что тексты двух макро
можно было бы рассматривать как один общий текст, объединение которого
из двух исходных осуществляется посредством команды \if х, если первый из
этих текстов (он запускается при q, когда начинается исполнение §508) не
является соответствующим префиксом для второго из рассматриваемых текстов.
(Обратите внимание на оператор 1р <— nulV внутри цикла while.)
20. Это произошло из-за того, что байт в dvi-buf[dvLptr — 1] обычно не будет
являться кодом операции, а это может случиться, когда значение данного байта
равно значению параметра push.
21. 2У Id Id 8Z 2У 8Z Id &z %y 8Z 4y 5Z 9^ 0^ 4y 5Z.
22. ТЕХ будет находиться в режиме 'no mode' только при обработке операторов
\write, а вид (наименование) режима будет печататься во время выполнения
\write только в случае, когда tracing-commands > 1 при выполнении
процедуры expand. Можно было бы подумать, что потребуются операции \catcode, с
тем, чтобы существовали левая и правая фигурные скобки для \write;
однако имеется возможность заставить работать в этой ситуации ТЁХ'овский
механизм обработки ошибок! Следовательно, наиболее короткой программой,
удовлетворяющей предъявленным требованиям, будет, по-видимому,
следующая, основанная на идее Ronaldo Ama, который предложил поместить в файл
такую строжу
\batchmode\tracingcomm2Lnds2\immediate\write! \nomode
(Семь лексем в общей сложности).
23. Когда процедура error вызывает get-token, а это произойдет в случае, если
пользователь запрашивает удаление лексем (см.§88), возможен второй уровень
вызова error, но больше удаления уже не допускаются (см.§336 и §346).
Вставки, однако, разрешаются по-прежнему, что может привести к третьему уровню
вызова для error, когда overflow вызывает процедуру succumb.
Пусть, например, тахлп-ореп = 6. Тогда можно ввести текст
'\catcode'?=15 \x' и ответить на появляющееся сообщение об ошибке
(Undefined control sequence.), вводя шесть раз строку 'i\x??\ Это
приведет к вызову процедуры error, в котором появляются шесть уровней
'<insert>'; отсюда имеем, что гп-ореп = б, еще одна вставка будет требуемой
«последней каплей». В данной точке процесса введем '1'; это переведет error
на второй уровень, из которого 'i' вызовет вход в error в третий раз. (Стек
периода исполнения содержит теперь процедуру main-control, из нее вызывается
get-X-token, из get-X-token — expand, из expand — error, из error — get-token,
из get-token — get-next, из get-next — error, из error — begin-file-reading, из
begin-file-reading — overflow и из overflow — error.)
Глава 10. Упражнения к книге TeJC: The Program
225
24. Надо заменить lwidth(gY на lwidth(g) 4- shift-amount (дУ (дважды).
Аналогичные изменения требуется произвести в §656. (Однако блок не должен
обладать возможностью сохранять значение параметра shift-amount для него;
эта величина является элементом списка вовлеченных блоков, а не описания
блока как такового.)
25. Завершающая строка имеет бесконечную растяжимость, так как plain TfeX
устанавливает значения \parf illskip=Opt plus If il. Сообщения о блоках
свободных или тесных, с недозаполнением или с переполнением никогда не
будут выдаваться, пока в §658 и §664 принято о = normal.
26. Если некоторый блок, сформированный в вертикальном режиме (vbox),
переупаковывается как блок, формируемый в горизонтальном режиме (hbox),
мы в самом деле получим некие странные результаты, поскольку элементы,
относительно которых ожидается, что они занесены в стек как упорядоченные
вертикально, оказываются размещенными горизонтально. Второе изменение
будет существенно менее заметным, за исключением символов, подобных V,
где вводится большая поправка на курсив; подобного рода символы будут
центрироваться, не принимая во внимание поправок на курсив, установленных для
них. (Соответствующая поправка на курсив в математическом режиме
представляет собой разность между горизонтальной позицией нижних и верхних
индексов в формулах вроде V^2.)
27. Интервалы могут быть найдены, если ввести
$х==1$ $х++1$ $х,,1$ \tracingall\showlists.
Большая часть решений принимается в §766 при помощи таблицы интервалов
из §764. Однако в случае со знаком операции + ситуация будет более
запутанной, поскольку любой элемент в Ып-noad должен быть с обеих сторон окружен
элементами соответствующего класса. В рассматриваемой формуле $х++1$
статус второго знака + будет изменен с Ып-noad на ord-noad в §728. Это обернется
вставкой широких (thick) пробелов после х и перед 1 в строке 'х == 1';
средней величины (medium) пробелов перед каждым из знаков + в строке 'х 4- 4-1';
узких (thin) пробелов после каждой запятой в строке 'х, ,1'. (Запятая в
математическом режиме появляется в том месте, где она размещается в знаке
«точка с запятой» математического курсивного шрифта; см. с. 502 книги The
ТЕХЪоок.)
28. Поведение более простого алгоритма, который будем именовать Brand X,
может быть выведено из значений «показателя дефектности») (demerit value)
('d=') в трассировке ТЁХ'овского выходного текста. Наилучший выбор для
первой строки равен, очевидно, @@2 (значение показателя дефектности
равно только 100 единицам, против 36525 для @@1); затем @@4 для следующих
строк. Однако при таком выборе возникает ситуация, когда мы должны
допустить наличие очень разреженной строки, которая кончается при @@6. Отсюда
следует перейти к @@7; после чего Brand X решает, что лучше всего перейти
к @@9, затем к @@11 (лучший из трех возможных вариантов), затем к @@15,
226
Компьютерная типография
после чего к @@19, и, наконец, к @@21. В результате абзац, сформированный
и набранный при помощи Brand X, будет выглядеть наподобие следующего
(ужасного) текста:
! 28. When your instructor made up this problem, he gave the command
• '\tracingparagraphs=l' so that his transcript file would explain TeX's
j line-breaking decisions for this paragraph. He also said^
:'\pretolerance=-l' so that hyphenation would be tried immediately.1
; The output is shown on the next page; use it to determine what line:
breaks would have been found by a simpler algorithm that breaks off
•one line at a time. (The simpler algorithm finds the breakpoint that
yields fewest demerits on the first line, then chooses it and starts
over again.)
29. Это упражнение требует определенного времени на его выполнение,
однако анализируемые структуры данных весьма интересны, ТЁХ'овский алгоритм
переноса слов представляет собой прекрасный небольшой фрагмент изучаемой
нами программы, который может исследоваться независимо от остальных ее
частей.
Формируются следующие таблицы:
[1] [2] [3]
hyf-distance 2 0 3
hyf-num 13 2
hyf.next 0 0 2
trie[l]
trie [99]
trie [100]
trie [101]
trie [103]
trie [105]
trie [106]
trie [108]
op
0
0
0
0
1
1
0
3
char
0
97
98
98
99
100
99
100
link
2
3
7
4
5
0
8
5
Задавая слово aabcd, интересно пронаблюдать, как в §923 из этой TRIE-
структуры порождаются в данном случае требуемые индексы переносов
'oaoa2biCod3'.
30. Идея решения состоит в том, чтобы в стек сохранения заносить номера
строк. Скотт Дуглас обнаружил, что хотя Т^Х и фиксирует самым
тщательным образом всю последовательность значений переменной cur-boundary,
ничего существенного с этими значениями никогда не делается. Отсюда вытекает,
что поле saveJndex в словах описания границ уровней не является
необходимым, так что в нашем распоряжении имеется дополнительное полуслово!
(Существующая структура данных содержит «ископаемые» элементы,
оставшиеся от прошлых «инкарнаций» ТЁХ'а). Номера строк, однако, могут иметь
длину большую, чем полуслово; представляется более целесообразным
использовать для их сохранения целые числа длиной в полное слово.
Эта задача требует внесения изменений в три фрагмента рассматриваемой
нами программы. Во-первых, надо дополнить §1063 следующим образом:
Глава 10. Упражнения к книге Т$£: The Program
227
(Cases of main-control that build boxes and lists 1056) +=
[Случаи main-control, которые создают боксы и списки]
non-math (left-brace): begin saved (0) «— line; incr(save-ptr);
new save-level (simple-group);
end; { номер строки сохраняется для возможного использования в
предупреждающих сообщениях }
any-mode(begin-group): begin saved(0) <— line; incr(save-ptr)\
newsaveJevel (semisimple-group);
end;
any-mode (end-group) \ if cur-group = semisimple-group then
begin unsave] decr(save-ptr);
{ выталкивание неиспользуемого номера строки из стека }
end
else offsave;
Аналогичные изменения требуется внести в §1068, где производится обработка
применительно к первому из случаев, перечисленных в §1063.
simple-group: begin unsave\ decr(save-ptr)\
{ выталкивание неиспользуемого номера строки из стека }
end;
И, наконец, заменим шесть строк в §1335 аналогичными строками, но с
текстами сообщений, соответствующими рассматриваемой задаче:
while curJevel > leveLone do
begin print-nl(u ("); pnni_e5c(MenduOccurreduwhenuM);
case cur-group of
simple-group: print-char ("{");
semisimple-group: print-esc ("begingroup");
other cases confusion (" endgroup")
endcases;
print(MuonulineuM); unsave; decr(save-ptr); print-int(saved(0));
print (Muwasuiiicomplete)M);
end;
while cond-ptr ф null do
begin print-nl(u ("); print-esc("enduoccurreduwheiiu");
print-cmd-chr (if-test, cur-if);
31. Во-первых, §2 дает новый абзац, объясняющий, что представляет собой
TeXXj а заголовочная строка, печатающаяся при запуске ТЁ^'а, заменяется
следующей:
define banner = 'ThisuisuTeXX,uVersionu2.2' {печатается при запуске ГЩХ'а}
Затем добавляем два новых определения в §134:
define is-xchar-node(t) = (font(t) = font-base) {это расширенная char-node?}
define bypass-xchar(t) =
if is-xchar-node(t) then # «— link(t)
(Надо сказать, что здесь вместо null-font используется font-base, поскольку
идентификатор null-font до того момента не был определен.)
Программа short-display из §174 может трактовать \xchar подобно
обычному символу (литере), поскольку со стороны процедуры print-ASCII никаких
228
Компьютерная типография
ограничений не накладывается. Ниже показан один из способов, которым
можно осуществить требуемое изменение:
procedure short-display (p : integer); {печатает выделения в списке р}
label done;
var п: integer; {для замены номеров }
ext: integer; { величина, добавляемая к коду литеры посредством xchar }
begin ext «— 0;
while p > memjmin do
begin if is-char-node(p) then
begin if p < mem-end then
begin if is-xchar-node(p) then
begin ext «— 256 * (qo(character(p))); goto done;
end;
if font(p) ф font-inshort-display then
begin if (font(p) < font-base) V (font(p) > font-max) then
print-char("*u)
else (Print the font identifier for font(p) 267);
[Печать идентификатора шрифта для font (р)]
print-char("и")\ font-inshort-display «— font(p)\
end;
print-ASCII(ext + qo (character (p))); ext «— 0;
end;
end
else (Print a short indication of the contents of node p 175);
[Печать краткого указания на содержимое узла р]
done: р «— link(p)\
end;
end;
Похожим образом вносятся изменения и в §176:
procedure print-font-and-char(p : integer)', {печать данных char-node }
label reswitch;
var ext: integer]
{величина, добавляемая к коду литеры посредством xchar, или — 1}
begin ext < 1;
reswitch: if p > mem-end then print-esc("CLOBBERED.")
else begin if is-xchar-node(p) then
begin ext «— qo (character (p)); p «— link(p); goto reswitch; end;
if (font(p) < font-base) V (font(p) > font-max) then print-char("*")
else (Print the font identifier for font(p) 267);
[Печать идентификатора шрифта для font(p)]
print-char("u")\
if ext < 0 then print-ASСП(qo(character(p)))
else begin print-esc ("xchar"); print-hex (ext * 256+ qo (character(p)))]
end;
end;
end;
(Эти программы должны обладать сверхустойчивостью.) Первая строка
программного кода в §183 будет иметь теперь следующий вид:
Глава 10. Упражнения к книге Т^Х: The Program
229
if is.char.node (p) then
begin print.font.and.char (p); bypass.xchar (p);
end
В §208 вводится новый код операции
define xchar .пит = 17 {расширенная литера ( \xchar ) }
Каждый код операции, который следует за указанными в §208 и §209, от
math.char.num до max.command, необходимо увеличить на 1. Надо также
добавить в §265 и §226, соответственно, строки кода вида:
primitive (" xchar ", xchar.num, 0);
xchar.num: print.esc("xchar");
Они вводят новые команды в список команд ТЁХХ'а.
Следующее, о чем надо позаботиться — это предусмотреть действия на
случай, когда во входном файле появится \xchar. Удобно добавить в §435
процедуру с именем scan.xchar.num, которая будет парной (companion procedure)
для процедуры scan.char.num:
procedure scan.xchar.num;
begin scan.int]
if (cur.val < 0) V (cur.val > 65535) then
begin print-err ("BaducharacterucodeM);
help2 (MAnu\xcharunumberumustubeubetweeiiu0uandu255. ")
("IuchangeduthisuoneutOuzero. "); int.error (cur.val)] cur.val *— 0;
end;
end;
Аналогичным образом в §582 добавляется функция new.xchar, парная к
функции new .character:
function new-xchar(f : internal.font.number ] с : integer): pointer]
var p, q: pointer] {вновь размещенные узлы }
begin q «— new .character (f, с mod 256);
if q = null then new-xchar «— null
else begin p «— get.avail] font(p) «— font-base] character (p) «— qi((c div 256));
link(p) «— q]
new.xchar «— p;
end;
end;
Расширенные символы будут выводиться подобающим образом, если
заменить начальные строки программного кода в §620 на следующие:
reswitch: if is.char.node (p) then
begin synch.h] synch.v]
repeat if is.xchar.node (p) then
begin / *— font (link (p))]
if character (p) = qi(0) then p «— link(p)]
{ пренебрежение нулевым расширением }
end
else / «— font(p)]
с «— character (p)]
230
Компьютерная типография
if / ф dvi-f then (Change font dvLf to / 621); , .
[Замена шрифта dvLf на /]
if is-xchar-node(p) then
begin dvLout(setl + 1); dvi-Out(qo(c))\ p «— link(p)\ с *— character (p);
end
else if с > qi(12S) then dvLout(setl);
dvLout(qo(c))\
Многие из обрабатывающих программ включают оператор вида с/ <—
font(#)\ который требуется исполнять только в том случае, если не
принимается во внимание (bypassing) первая половина расширенного кода символа.
Этого можно достичь, если вставить следующие операторы:
bypass-xchar (р) в §654;
bypass-xchar(s) в §842;
bypass-xchar(сиг-р) в §867;
bypass-xchar(s) в §871;
bypass-xchar(p) в §1147.
В §841 необходимо делать несколько больше, чем просто игнорировать часть
кода символа:
if is-char-node(v) then
begin if is-xchar-node(v) then
begin v <— link(v); decr(t)\ {xchar считается за две литеры }
end;
Для того, чтобы отключить переносы в словах, содержащих расширенные
символы, необходимо внести следующие два изменения. Во-первых, вставим
if hf = font-base then goto donel; { is-xchar-node (s) }
после lhf <— font{s)\ в §896. Затем заменим 'endcases;' в §899 на
endcases
else if isjxcharjaode (s) then goto donel;
Если \xchar появится в математическом режиме, для обработки ошибки
в список соответствующих случаев в §1046 необходимо включить mmode 4-
xchar-num. Если же \xchar появляется в вертикальном режиме, надо, чтобы
начинался новый абзац, что достигается включением vmode + xchar.num во
второй список вариантов в §1090.
Но что произойдет при появлении \xchar в горизонтальном режиме? Для
обработки данной ситуации требуется переписать §1122.
1122. Нам потребуются два дополнительных элемента, обеспечивающие, в
совокупности с имеющимися, работу в горизонтальном режиме, а именно,
примитивы \xchar и \accent.
(Cases of main-control that build boxes and lists 1056) +=
[Случаи main-control, которые создают боксы и списки]
hmode + xchar-num: begin scan-xchar-num]
link(tail) «— new-xchar (cur-font, cur-val)\
Глава 10. Упражнения к книге Т^Х: The Program
231
if link(tail) ф null then tail «— link (link(tail))]
space-factor <~ 1000;
end;
hmode + accent: make-accent;
Необходимо, далее, изменить make-accent таким образом, чтобы можно
было печатать акцентированные расширенные символы. (В условии задачи 31
явным образом этого не говорится, однако ТЁХХ, разумеется, должен
обеспечивать такую возможность.) Это означает, что в §1124 следует добавить новый
вариант:
else if cur.cmd = xchar-пит then
begin scan-xchar-пит] q «— new-xchar (f', cur-val);
end
а также произвести изменения в начале и конце §1125.
(Append the accent with appropriate kerns, then set p «— q 1125) =
[Присоединение акцента с подходящими кернами с последующей установкой р«— q]
begin t «— slant (f)/float-constant(6bb36)\
if is-xchar-node(q) then г <— char-info(f)(character(link(q)))
else i <— char-info(f)(character(q))\
w «— char-width(f)(i)\
subtype (tail) <— acc-kern\ link(p) «— tail;
if is-xchar-node(q) then {в этом случае мы хотим пренебречь xchar }
begin tail-append(q)\ p <— link(q);
end
else p «— q\
end
32. Основная причина, по которой подход, предложенный в решении задачи
31, является более предпочтительным, состоит в том, что операция введения
поправки на курсив (§1113) была бы чрезвычайно затрудненной при другой
схеме. Среди других достоинств можно указать следующие, (а) Деление на
256 потребуется только один раз; главный цикл Т[й?Х'а останется быстрым. (Ь)
Требуется внесение в ТЁК сравнительно небольшого числа изменений, так что
аналогичные идеи могут быть внесены без особых затруднений и в другие
варианты ТЁХ'а. (с) Поскольку не требуется разделения шрифтов на «восточные»
и «западные», команда \xchar имеет широкую применимость. Например, она
дает пользователю способ подавить лигатуры и кернинг; она позволяет также
работать с большими шрифтовыми наборами с 256-символьными
подмножествами общеупотребительных знаков, (d) Соглашения, введенные в ТЁХХ'е3
сопрягаются с задействованными в GF-файлах, порождаемых METRFONT'om.
Единственным недостатком, присущим подходу, реализуемому в ТЁХХ'е,
является то, что для всех символов, коды которых кратны 256, требуется иметь
одинаковый размер бокса. Это, однако, не слишком значительное затруднение.
232
Компьютерная типография
Приложение
Решение задачи 17 отсылает читателя к специальной версии Т^К'а, называемой
DemoTEX, которая позволяет получать подробную информацию о процессе
сканирования. DemoTEK получен путем внесения ряда изменений в части 24-26
ТЁХ'а.
Во-первых, в §341 между строками со словами 'ехг^:' и 'end' надо
поместить следующий текст:
if tracingstats > 2 then
begin к «— trace-depth]
print-nl("")]
while к > 0 do
begin print ("u")]
decr(k)]
end;
print (n\n)\
print-char("u")\
if cur-cs > 0 then
begin print-cs (cur-cs)]
print-char("=n)\
end;
print-cmd-chr(cur-cmd, cur-chr)\
end;
(В соответствующем месте должна быть объявлена новая глобальная
переменная, именуемая trace-depth и инициализируемая нулевым значением.
Она используется для формирования отступов, выделяющих строки вывода
DemoTE^'a с учетом уровня вложенности подпрограмм.)
В начале подпрограммы expand (в §366) помещаем операторы
incr (trace-depth)]
if tracingstats > 2 then
print ("u<x")\
этот фрагмент печатает '<х', когда процедура expand начинает выполнять
действия по развертыванию какого-либо макроопределения. Аналогичные
операторы вставляются в начало процедур scanJnt (§440), scan-dimen (§448) и
scan-glue (§461). Разница состоит в том, что scanJnt будет печатать '<i',
scan-dimen — '<d', a scan-glue — '<g'. (Понимаете?) Вставим также добавочный
код в конец каждой из упомянутых процедур:
deer (trace-depth)]
if tracingstats > 2 then
print-char(u>u)]
что дает возможность ясно видеть, когда работает каждая из составных частей
сканирующей программы.
Глава 10. Упражнения к книге T^ft: The Program
233
Аналогичным образом теперь следует доработать процедуру scan-keyword,
однако в ней явным образом указывается, какое ключевое слово является
предметом поиска. Код
incr (trace-depth);
if tracing stats > 2 then
begin print ("u<'")]
print (s);
print.char("'");
end;
вставляется в начало §407, а фрагмент
if tracingstats > 2 then
print-char ("*");
exit: deer (trace-depth)]
if tracingstats > 2 then
print.char(">")\
end;
заменяет код в его конце. (Здесь '*' обозначает 'успех', т. е. отмечает тот факт,
что требуемое ключевое слово найдено.)
В качестве примера ниже приводится начало того текста, что выводится
DemoTEX'oM при сканировании правой части (после знака равенства)
выражения для \hf uzz в задаче 17:
I the character = <d
I the character 1 <i
I the character 1
I the character 0
I the character 0
I the letter P>
I the letter P <'em'
I the letter P> <,ex>
I the letter P> <Чгие'
I the letter P> <,pt>
I the letter P
I \ifdim =\ifdim <x <d
I the character 1 <i
I the character 1
I the character 2
I the letter p>
I the letter p ^em'
I the letter p> <,ex>
I the letter p> <Чгие'
I the letter p> <,pt>
I the letter p
I the letter t*>
I the character =>
234
Компьютерная типография
После обнаружения символа '=' ТЕХ вызывает процедуру scan.dimen.
Следующим после знака равенства символом будет '1'; scan-dimen возвращает эту
литеру назад и вызывает процедуру scanJnt, которая обнаруживает
последовательность литер '100' и т. д. Этот фрагмент листинга демонстрирует тот
факт, что TgK часто использует процедуру backJnput для того, чтобы
повторно прочитать символ в ситуациях, когда система еще не вполне готова иметь
дело с этим символом.
Благодарности
Я хотел бы поблагодарить прекрасных студентов моего экспериментального
класса за то, что они побуждали меня думать над этими вопросами,
приставали ко мне, когда предлагаемые вопросы невозможно было понять, а также
за многочисленные улучшения, предложенные к первоначально дававшимся
ответам.
Мини-указатели для
самодокументированных
программ
[Первоначально опубликовано в Software — Concepts and Tools 15 (1994), 2-11.]
В этой главе описывается подход к документированию программ,
облегчающий чтение и понимание больших программ и наборов программ путем
организации локальных предметных указателей для всех идентификаторов,
присутствующих на каждом двухстраничном развороте. Подход подробно
поясняется на примере программы, которая отыскивает все гамильтоновы
контуры в неориентированном графе.
Введение
Пользователи систем, подобных WEB [4], поддерживающей процессы создания
структурированной документации и самодокументированного
программирования [7], получают автоматически отпечатанный указатель, размещенный в
конце программы и показывающий, где определяется и используется каждый
из идентификаторов. Такого рода указатели в высшей степени полезны, однако
они могут оказаться слишком громоздкими, особенно для длинных программ.
Убедительным примером такого рода может служить листинг Т^К'овской
программы [5], в котором подробный указатель вхождений идентификаторов
занимает 32 страницы, набранные мелким шрифтом.
Читатели книги [5] могут, однако, достаточно быстро находить требуемые
места в программе благодаря тому, что
... правые страницы каждого разворота этой книги содержат мини-
указатели, что позволяет не слишком часто обращаться к большому
(общему) указателю. Каждый из идентификаторов, используемый где-либо
в пределах двух страниц рассматриваемого разворота, дается в сноске,
размещаемой на правой странице разворота, если только он не определен
или объявлен в явном виде где-либо на левой или правой странице данного
разворота. Эти имена в сносках указываются вместе с типами объектов,
которым они принадлежат (процедура, макро, булевская переменная и т. д.)
[5; 7, с. 183]
236
Компьютерная типография
Аналогичная идея используется иногда в изданиях литературных текстов для
студентов, изучающих иностранный язык. В такого рода изданиях
формируются мини-словари необычных слов, размещаемые на каждой странице [12].
Это позволяет студенту экономить много времени, поскольку отпадает
необходимость рыться в больших словарях.
Идея мини-указателя впервые была подсказана автору Джо Уинингом. Он
подготовил небольшой макет, показывающий, какой вид мог бы иметь такой
указатель [14]. Его предложение привлекло меня и я решил реализовать его в
виде отдельной программы, названной TWILL — это имя подчеркивало тот факт,
что данная программа представляла собой двухпроходный вариант программы
WEAVE. Программа TWILL была использована в сентябре 1985 г. при подготовке
книг Те%: The Program [5] и METRFONT: The Program [6].
Первоначально система WEB основывалась на комбинации из ТЁХ'а и языка
Паскаль. Однако к настоящему времени я предпочитаю использовать систему
CWEB [8], которая объединяет ТЁК и язык С. (На самом деле, CWEB в версии
3.0 полностью совместима с C++, хотя я обычно ограничиваю себя
подмножеством этого языка, которое можно было бы назвать С —.) Одно из достоинств
CWEB состоит в том, что обеспечивается работа с наборами небольших
программных модулей и библиотеками, которые можно комбинировать самыми
разными способами. Единичный исходный CWEB-файл foo.w может порождать
несколько выходных файлов в дополнение к С-программе foo.c; например,
foo.w может породить заголовочный файл foo.h для использования другими
модулями, которые будут загружены объектным кодом foo.o, а также может
сформировать тестовую программу testf oo. с, предназначенную для проверки
переносимости полученной программы.
Система CWEB использовалась при разработке Stanford GraphBase —набора
из примерно трех с половиной десятков свободно распространяемых программ,
полезных при изучении комбинаторных алгоритмов [13]. Эти программы были
недавно опубликованы в виде книги, опять же с мини-указателями в ней [9].
Мини-указатели в данном случае были подготовлены с помощью
программы CTWILL [10], представляющей собой двухпроходный вариант программы
CWEAVE.
Цель данной главы —объяснить, как работает программа TWILL и
созданная на ее основе программа CTWILL. Усвоение предлагаемых идей можно
существенно упростить, если объяснять их, рассматривая подходящий,
достаточно подробный иллюстративный пример, реализованный в виде полностью
завершенной CWEB-программы. Такого рода пример описывается в следующем
разделе данной работы. Затем в двух разделах рассматривается процесс
обработки этого примера программой CTWILL и Т^Х'ом, после чего в завершающем
разделе излагаются некоторые заключительные комментарии.
Глава 11. Мини-указатели для самодокументированных программ
237
Пример
CWEB-программа, для которой формируются примеры мини-указателей, была
написана специально для данной работы и именуется НАМ. Она перебирает все
гамильтоновы контуры графа, т. е. все его неориентированные циклы,
включающие каждую вершину графа ровно один раз. К примеру, данная программа
позволяет определить, что существует ровно 9862 ходов конем на шахматной
доске размера б х б клеток, если пренебречь симметриями доски; на рабочей
станции SPARC station 2 решение такой задачи займет около 2.3 с.
Поскольку программа НАМ представляет и самостоятельный интерес, она приведена
полностью в приложении к данной главе (см. с. 241-245).
Прежде чем читать дальше, рекомендую вам бегло просмотреть программу
НАМ. Эта программа представлена на пяти страницах с использованием
двухколонного набора. Каждая из страниц именуется «разворотом», по аналогии
с двухстраничными разворотами в книгах [5], [б], и [9]. Такое разделение
материала дает нам возможность сформировать пять мини-указателей вместо двух
при обычном наборе, что делает НАМ вполне подходящим примером несмотря
на относительно небольшие размеры данной программы. Для более короткой
программы указатель может не потребоваться вообще, а более длинная
программа будет вызывать затруднения при ее чтении.
НАМ предназначена для использования совместно с библиотекой программ,
поставляемых в составе пакета Stanford GraphBase. По этой причине в §1
данной программы вызывается препроцессор языка С, чтобы подключить
заголовочные файлы gb_graph. h и gb_save. h. Эти заголовочные файлы определяют
внешние функции и типы данных, необходимые для использования библиотеки
GraphBase.
Краткого введения в структуры данных пакета GraphBase будет вполне
достаточно для интересующегося читателя, чтобы в деталях понять работу
программы НАМ. Задаваемый граф представляется тремя видами записей struct,
именуемых Graph (Граф), Vertex (Вершина) и Arc (Дуга). Если v
указывает на запись Vertex, то vname будет представлять собой строку, именующую
вершину, представленную посредством г>, a v-*arcs указывает на представление
первой из дуг, выходящей из этой вершины^ Если а указывает на некоторую
запись Arc, соответствующую дуге, соединяющей некоторую вершину v с
некоторой другой вершиной и, то строка artip указывает на запись Vertex, которая
представляет щ таким же образом arnext указывает на представление
следующей дуги, выходящей из v, или arnext = А (т. е., NULL), если а —последняя из
дуг, исходящих из v. Тогда имена всех вершин, смежных с вершиной г>, можно
отпечатать с помощью следующего цикла:
for (a = v-+arcs; a; a = arnext)
printf ("y,s\n" ,a-+tip-+name);
Произвольное неориентированное ребро между вершинами и и v
представляется посредством двух дуг: из вершины и в вершину v и из v в и. Наконец,
1 'v—name* на самом деле вводится с клавиатуры как 'v->name' в программе на С или CWEB;
применяемое типографское ухищрение облегчает чтение отпечатанного текста программы.
238
Компьютерная типография
если д указывает на запись Graph, то д-п представляет собой число вершин в
соответствующем графе, а записи Vertex, представляющие эти вершины,
расположены в местах, задаваемых выражением g-*vertices + fc, для О < к < д-п.
Запись Vertex содержит также «служебные поля» (utility fields), которые
могут использоваться различными способами при работе различных
алгоритмов. Фактически С-декларация (описание) этих полей, позаимствованная из §8
и §9 программы GB_ GRAPH [9], имеет следующий вид:
typedef union {
struct vertexstruct *V]
/* указатель на Vertex */
struct arcstruct *Л;
/* указатель на Arc */
struct graphstruct *G;
/* указатель на Graph */
char *£;
/* указатель на строку */
long 7;
/* целое */
} util;
typedef struct vertexstruct {
struct arcstruct *arcs;
/* связный список дуг, исходящих из данной вершины */
char *name;
/* строка, символически обозначающая эту вершину */
util u) v, w, х, у, z\
/* многофункциональные поля */
} Vertex;
Программа НАМ для повышения эффективности работы использует
первые четыре из списка служебных полей. Поле и, например, трактуется как
целое число типа long, представляющее собой степень рассматриваемой
вершины. Обратите внимание на определение deg как макро в §2; оно дает
возможность ссылаться на степень вершины v как v-*deg, вместо менее удобоваримого
варианта lv-*u.I\ с которым фактически имеет дело С-компилятор.
Аналогичные макро для служебных полей v, w и х можно найти в §4 и §6.
Первый из мини-указателей для программы НАМ, отвечающий
программному коду из §2, размещенному на первом развороте, дает перекрестные
ссылки для всех идентификаторов, появляющихся в §1 или §2, но не определяемых
в них. Например, идентификатор restore-graph упоминается в одном из
комментариев из §1, мини-указатель сообщает нам, что это функция, возвращающая
значение типа Graph *, и что она определяется в §4 другой CWEB-программы
с именем GB.SAVE. Данный мини-указатель упоминает также о том, что
определения для Vertex и arcs содержатся в §9 программы GB. GRAPH (из которой
мы и позаимствовали определения, упоминавшиеся выше), а также что поля
next и tip записей Arc определяются также в GB_ GRAPH, в ее §10, и т. д.
Глава 11. Мини-указатели для самодокументированных программ 239
В этом первом мини-указателе содержится одна тонкость и она
заключается в том, как описывается вхождение идентификатора и, относительно
которого сказано, что он отвечает служебному полю, определенному в §9
программы GB. GRAPH. Идентификатор и фактически в §2 появляется дважды, в
первый раз в определении для deg, и второй —как переменная типа Vertex *.
Мини-указатель ссылается только на первое из этих двух определений, по*
скольку второе из них дается в §2. Мини-указатель не содержит упоминаний
для идентификаторов, определяемых на том же развороте, для которого
формировался данный указатель.
Второй мини-указатель, следующий за §5 программы НАМ, аналогичен
рассмотренному выше первому. Отметим, что в нем содержатся два
вхождения для г>, поскольку этот идентификатор используется в двух смыслах —как
служебное поле (в определении для taken) и как некая переменная (во всех
остальных местах). С-компилятор поймет, что делать с конструкциями
наподобие 'v-v.I = 0', которые С-препроцессор раскроет в виде lv-*taken =0', однако
для живого читателя здесь будет иметь место определенное затруднение.
Обратим внимание на элемент указателя для идентификатора deg во
втором мини-указателе. В нем вместо двоеточия используется знак равенства,
показывая, что deg представляет собой макро, а не переменную. Аналогичное
обозначение было использовано и в первом мини-указателе при записи
перекрестных ссылок на идентификаторы определений типов, подобные Vertex.
Взгляните также на элемент для not-taken в четвертом мини-указателе, где
обозначение 'not-taken = macro ()' показывает, что not-taken представляет
собой макроопределение с аргументами.
Работа программы CTWILL
Было бы хорошо, если бы можно было утверждать, что программа CTWILL
формирует мини-указатели для НАМ в полностью автоматическом режиме,
подобно тому как программа CWEAVE делает это при формировании обычных
указателей. Это, однако, было бы неправдой. Истина же состоит в том, что
автоматически CTWILL выполняет примерно 99% объема работы, пользователю
в сложных случаях приходится помогать ей.
Почему же так получается? Во-первых, CTWILL недостаточно
сообразительна, чтобы прийти к заключению, что V в определении deg в §2 не то же самое,
что V, объявленное как register Vertex * в том же самом разделе.
Потребовалось бы встроить в CTWILL достаточно развитые средства искусственного
интеллекта, чтобы она могла формировать подобного рода умозаключения.
Во-вторых, CTWILL не знает, каким образом ей сформировать элемент
указателя для идентификатора к, появляющегося в §6. Переменная к не
объявляется нигде! Пользователи, которые пишут комментарии, привлекая при этом
выражения вроде '/(х)', могут ссылаться или не ссылаться на
идентификаторы / и/или х в своих программах; поэтому они должны дать знать CTWILL,
когда употребляют подобного рода «проходные» обозначения, не требующие
индексирования (т. е. внесения в указатель). При работе с программой CWEAVE
240
Компьютерная типография
такого рода затруднений не возникает, так как она для однобуквенных
идентификаторов индексирует только определения, а не факты использования таких
идентификаторов.
В-третьих, программа CTWILL не распознает автоматически ситуацию,
когда параметр vert в определении для not-taken из §4 не имеет ничего общего с
макро vert, определенным в §6.
Четвертое осложнение, которое не возникло при обработке НАМ, но
случавшееся в [5] и [9], заключается в том, что разделы WEB- или CWEB-программ
могут использоваться неоднократно. Вследствие этого, отдельный
идентификатор может фактически ссылаться на несколько переменных одновременно.
(См., например, §652 в [5].)
В общем случае, когда идентификатор определяется или объявляется в
точности один раз и используется только в связи с этим его уникальным
определением, осложнений при использовании CTWILL не должно возникать.
Однако, если некоторый идентификатор имеет более одного определения, в
явной или неявной форме, CTWILL может только предполагать, какое из этих
определений подразумевается в том или ином случае. Некоторые из
идентификаторов, в особенности однобуквенные, вроде х и у, играют слишком
значительную роль в больших наборах программ, чтобы ограничивать возможные
их применения каким-либо одним вариантом. В связи с этим, CTWILL
разрабатывалась так, чтобы в тех случаях, когда необходимо сделать выбор, давать
пользователю соответствующие подсказки.
Наиболее важной чертой подхода, реализованного при разработке CTWILL,
является стремление к возможно большей предсказуемости действий,
выполняемых данной программой по умолчанию. Чем «интеллектуальнее» мы
попытаемся сделать систему, тем труднее будет управлять ее работой. В силу
этого, CTWILL имеет очень простые правила, позволяющие решать, что следует
поместить в мини-указатель.
Каждый идентификатор имеет единственное текущее значение [current
meaning), состоящее из трех частей: типа этого значения, имени программы
и номера раздела в ней, где данный идентификатор определяется. В начале
процесса исполнения CTWILL читает некоторое количество файлов,
содержащих начальные определения для текущих значений. Всякий раз после этого,
когда CTWILL обнаруживает С-конструкцию, приводящую к изменению
значения — макроопределение, объявление переменной, определение типа,
объявление функции или обнаруживает метку, за которой идет двоеточие —
производится присваивание нового текущего значения так, как это задается
семантикой языка С. Например, когда CTWILL видит строку 'Graph *#' в
§2 программы НАМ, текущее значение для идентификатора д изменяется на
'Graph *, НАМ §2'. Рассматриваемые изменения будут осуществляться в
порядке, задаваемом чтением исходного CWEB-файла, а не в том «запутанном»
порядке, которому следует на самом деле С-компилятор. Поэтому CTWILL не
будет пытаться строить вложенные определения, отвечающие блочной
структуре анализируемой программы, все делается в строго последовательном духе.
Глава 11. Мини-указатели для самодокументированных программ 241
Будет считаться, что некоторая переменная, объявленная в §5 и §10, получила
значение в §5 и сохраняет его таковым в §6, §7, §8, §9.
Как только CTWILL меняет текущее значение какой-либо переменной,
производится выдача соответствующей записи об этом действии во
вспомогательный файл. Для CWEB-программы ham.w имя этого вспомогательного файла
будет ham. aux. Первые несколько строк-элементов в файле ham. aux имеют вид
@$deg {ham}2 =macro@>
@$argc {ham}2 \&{int}@>
@$argv {ham}2 \&{char} ${*}[\,]$@>
а последняя строка выглядит так:
@$d {ham}8 \&{register} \&{int}@>
В общем случае элементы данного вспомогательного файла имеют вид:
®$ident {пате}пп type<&>
где ident — идентификатор; пате и пп — соответственно имя программы и
номер раздела в ней, где содержится определение для ident; type—
строка из ТеХ'овских команд, указывающая тип идентификатора. Вместо
фрагмента {патеУпп элемент aux-файла может содержать символьную строку
("string"); в этом случае имя программы и номер раздела в формируемом
элементе будут заменены данной строкой. (Результатом применения этого
средства будет, например, появление имени заголовочного файла <stdio.h> в
элементах мини-указателя для программы НАМ, соответствующих
идентификатору printf.) В ряде случаев значением поля type будет '\zip'. Эта ситуация
не возникает при обработке программы НАМ, не слишком она была
характерной и для [9], однако она случается, например, если препроцессорное макроимя
определяется как внешнее, как это имеет место в Makefile, или же в случаях
очень сложных типов, вроде типа FILE в <stdio.h>. В таких случаях в мини-
указатель будет внесена запись наподобие 'FILE, <stdio .h>' без двоеточия или
знака равенства.
Пользователь имеет возможность явным образом изменить требуемое
текущее значение, записав ®$ident {патеУпп type<&> в любом месте CWEB-
программы. Это значит, что механизм умолчания, применяемый CTWILL, будет
просто обойден.
Когда CTWILL начинает обрабатывать некую программу foo.w, она ищет
первым делом файл с именем f о о. aux, который мог быть сформирован при
предыдущем запуске программы CTWILL. Если файл foo.aux уже есть, CTWILL
читает его и команды @$. . . @>, содержащиеся в нем, устанавливают текущие
значения для всех идентификаторов, определенных в f oo. w. Вследствие этого,
CTWILL может располагать значением некоторого идентификатора еще до того,
как он был объявлен —предполагая, что CTWILL успешно обработала f oo. w до
этого момента хотя бы один раз, а также считая, что окончательное
определение рассматриваемого идентификатора то же самое, что и сформированное в
начале программы.
242
Компьютерная типография
CTWILL просматривает также еще один вспомогательный файл, именуемый
f оо .bux. Этот файл не перезаписывается при каждом прогоне CTWILL, и может
модифицироваться пользователем. Цель применения файла f oo.bux —
присвоить начальные значения идентификаторам, которые не определены в foo.aux.
Например, файл ham.bux содержит две строки
@i gb_graph.hux
@i gb_save.hux
которые сообщают программе CTWILL о том, что необходимо прочитать файлы
gb_graph.hux и gb_save.hux. Эти файлы содержат определения для
идентификаторов, появляющихся в заголовочных файлах gb_graph.h и gb_save.h,
которые программа НАМ подключает к §1. Например, одна из строк в файле
gb_graph.hux имеет следующий вид:
@$Vertex {GB\_\,GRAPH}9 =\&{struct}@>
Эта строка имеется также в файле gb_graph. aux; она была скопирована
вручную, с использованием текстового редактора, в файл gb_graph.hux, поскольку
Vertex —один из идентификаторов, определенных в gb_graph.h.
CTWILL читает также файл с именем system.bux, если таковой имеется.
Этот файл содержит глобальную информацию, являющуюся одной из важных
составных частей текущей среды, в которой исполняется программа. Одна из
строк в файле system.bux имеет, в частности, следующий вид:
@$printf "<stdio.h>" \&{int} (\,)@>
После того как файлы system.bux, ham.aux и ham.bux прочитаны, CTWILL
становятся известными почти все идентификаторы, присутствующие в
программе НАМ. Единственным исключением будет идентификатор /с,
обнаруженный в §6, текущим значением которого будет \uninitialized, и если
пользователь не предпримет соответствующих корректирующих действий, отвечающий
этому идентификатору элемент мини-указателя будет выглядеть как
к: ???, §0.
Заметим, что идентификатор d объявлен в §4 программы НАМ, а потом еще
и в §8. Оба этих описания породят элементы, помещаемые в файл ham. aux.
Поскольку CTWILL читает файл ham. aux еще до того, как просматривает исходный
файл ham.w, а также из-за того, что ham.aux читается последовательно, к
началу обработки ham.w текущее значение для d будет определяться согласно §8.
Это не создает никаких проблем, так как d не используется в НАМ нигде,
кроме разделов, где этот идентификатор объявлен, в силу чего в мини-указатель
информация о данном идентификаторе не попадет.
Когда CTWILL обрабатывает каждый из разделов программы, она создает
список всех идентификаторов, используемых в данном разделе, исключая
зарезервированные слова (языка программирования). В конце соответствующего
раздела она осуществляет «мини-вывод» (т. е. вывод в мини-указатель)
текущих значений каждого из идентификаторов, входящих в полученный список,
Глава 11. Мини-указатели для самодокументированных программ
243
до тех пор пока текущее значение отвечает текущему разделу рассматриваемой
программы, или же пока не вмешается пользователь.
В распоряжении пользователя есть два способа изменить мини-выходы:
подавить значения, устанавливаемые по умолчанию, или же вставить
заменяющие элементы. При реализации первого из этих двух вариантов используется
явная команда вида
®-ident®>
которая приказывает CTWILL не вырабатывать стандартный мини-выход для
идентификатора ident в текущем разделе обрабатываемой программы. Во
втором случае пользователь может задать одно или несколько временных
значений (temporary meanings) для некоторого идентификатора, причем все они
будут включены в мини-выход в конце обрабатываемого раздела. Временные
значения не влияют никак на текущее значение идентификатора. Всякий раз,
когда хотя бы одно временное значение появляется в мини-выходе,
соответствующее текущее значение подавляется так, как если бы была выдана
команда @-. . . @>. Временные значения задаются с помощью операции @'/„ которая
меняет состояние переключателя, влияющего на работу команды @$. . . @>. В
начале раздела данный переключатель находится в положении «постоянное»
(«permanent») и команда @$. . . @> изменит текущее значение идентификатора
так, как это было описано выше. Появление @У, каждый раз меняет состояние
с «постоянного» на «временное» («temporary») или наоборот; во «временном»
состоянии команда @$... @> задает временное значение, помещаемое в мини-
выход, но не оказывающее никакого влияния на постоянное (текущее) значение
рассматриваемого идентификатора.
Перед тем как продемонстрировать примеры действия указанных выше
соглашений, следует сказать еще об одном виде взаимодействия команд @-
и @$ в CTWILL. Если бы CTWILL присвоила новое текущее значение
идентификатору ident нормальным образом, основываясь на семантике языка С, и
если команда <&-ident<&> уже появилась в текущем разделе, CTWILL не будет
перезаписывать имеющееся текущее значение, однако она выведет это текущее
значение в aux-файл. В частности, пользователь имеет право задать
необходимое текущее значение с помощью команды @$ident.. . @>; такого рода подход
позволяет пользователю контролировать то, что выводится в aux-файл.
В качестве примера ниже приводится полный перечень всех команд,
использованных автором для корректировки или улучшения мини-указателей
для НАМ, формируемых программой CTWILL с использованием значений по
умолчанию:
• В начале §2,
@-deg@>
<3$deg {ham}2 =\|u.\U@>
<3e/.@$u {GB\_\,GRAPH}9 \&{util}<3>
чтобы в определении для deg читалось lu.Г вместо 'macro', а также для
того, чтобы мини-указатель ссылался на и как на служебное поле.
244
Компьютерная типография
• В начале §4,
@-taken@> @-vert@>
@$taken {ham}4 =\lv.\U@>
<3'/.<3$v {GB\_\,GRAPH}9 \&{util}<3>
@$v {ham}2 \&{register} \&{Vertex} $*$@>
по аналогичным соображениям, а также для того, чтобы предотвратить
индексирование для идентификатора vert. Здесь в мини-указатель будут
занесены два «временных» значения для v, одно из которых случайно
совпадает с его постоянным значением.
• В начале §6,
@-k@> @-t@> @-vert@> @-ark@>
@$vert {ham}6 =\Iw.\IV@>
<3$ark {ham}6 =\|х.\|АФ>
<3'/.<3$w {GB\_\,GRAPH}9 \&{util}@>
@$x {GB\_\,GRAPH}9 \&{util}<3>
по аналогичным соображениям. И это все.
Эти команды не вносились в программный файл ham.w, они были записаны
в другой файл с именем ham.ch и введены при помощи средства «изменить
файл» (change file) CWEB-программы [8]. Данное средство позволяет весьма
просто модифицировать действительное (исполняемое) содержание основного
файла, не изменяя этого файла напрямую.
Обработка Т^Х'ом
CTWILL формирует ТЁ^'0ВСКИИ файл, включающий в конце каждого раздела
мини-выход. Например, после §10 программы НАМ будет помещен следующий
мини-выход:
VKGB\_\,GRAPH} 10 \\{next} \&{Arc} $*$
\[7 \\{advance} label
\[6 \\{ark} =\lx.\|A
\[2 \|{t} \&{register} \&{Vertex} $*$
\[4 \\{not\_taken} =macro (\,)
\]{GB\_\,GRAPH}10 \\{tip} \&{Vertex} $*$
\[2 \|{v} \&{register} \&{Vertex} $*$
\[2 \|{a} \&{register} \&{Arc} $*$
Здесь управляющая последовательность \] вводит внешнюю ссылку на
некоторую другую программу; \[ задает внутреннюю ссылку на другой раздел
программы НАМ; \\ набирает идентификатор обычным (текстовым) курсивом;
\ I задает набор идентификатора математическим курсивом; \& определяет
набор полужирным шрифтом.
Имеется специальный отладочный режим, в котором Те^ просто набирает
мини-выход в конце каждого раздела обрабатываемой программы вместо того,
Глава 11. Мини-указатели для самодокументированных программ 245
чтобы формировать требуемые мини-указатели. Это упрощает пользователю
проверку информации, фактически выдаваемой программой CTWILL, и
сравнение ее с тем, что он хотел бы получить. Следует заметить, что ошибки в выходе
CTWILL совсем не обязательно приводят к ошибкам в мини-указателях;
например, неверная ссылка в §6 на идентификатор, определенный в §5, не появится в
мини-указателе на развороте, включающем §5. Лучше всего сначала
убедиться в правильности результатов, выводимых CTWILL, а уже потом формировать
и проверять требуемые мини-указатели. Тогда не будет неприятных
сюрпризов, случающихся, когда раздел обрабатываемой программы перемещается с
одного разворота на другой.
Когда ТЁ^'У поручается набрать создаваемые мини-указатели в их
окончательном виде, ему приходится основательно потрудиться. Вот как это
происходит. Главная задача Т^Х'а, после того как отформатированы строки
комментария и программного кода на языке С, состоит в том, чтобы определить,
попадает ли текущий раздел программы на текущий разворот, и (если
попадает) модифицировать мини-указатель, объединяя все элементы указателя для
этого разворота.
Рассмотрим в качестве примера, что будет происходить, когда Tj$L
набирает §10 программы НАМ. Рассматриваемый текущий разворот начинается с
§8 и ТЕХ уже знает, что §8 и §9 будут размещаться вместе, на одной странице.
После того как содержимое §10 набрано, Т^К просматривает элементы мини-
указателя. Если какой-либо из них ссылается на §8 или §9, Т^К временно
проигнорирует такие ссылки, поскольку эти разделы уже являются
составными частями рассматриваемого текущего разворота. (Такая ситуация в §10
на самом деле не возникает, но когда ТЕХ обрабатывал §7, он подавил
элементы указателя для vert и ark, поскольку они ссылались на §6.) Т^Х также
на время отбрасывает элементы мини-указателя, которые отвечают другим
элементам, уже спланированным для текущего разворота. (В этом случае
отбрасывается все, за исключением элементов для идентификаторов advance
и ark; остальные — next, t, not-taken, v и а — представляют собой дубликаты
элементов в мини-выходах для §8 или §9.) Наконец, ТЕХ пробует отбросить
ранее сформированные элементы, ссылающиеся на данный текущий раздел.
(В рассматриваемом случае не произойдет ничего, поскольку элементы из §8
или §9, ссылающиеся на §10, отсутствуют.)
После такого рода вычислений Т^Х'у известно количество п элементов
мини-указателя, которые потребуются, если §10 будет размещен на том же
развороте, что и §8 с §9. ТЕХ делит это число п на количество колонок в
формируемом мини-указателе (в рассматриваемом нами примере этот делитель
будет равен 1, однако в [5] и [9] он был принят равным 3), умножает результат
на расстояние между базовыми линиями в мини-указателе (в
рассматриваемом примере оно принято равным 9 pt) и добавляет полученный результат к
полной высоте набираемого текста для формируемого текущего разворота (в
данном случае это суммарная высота §8 +§9 +§10). Теперь, с незначительными
изменениями, связанными с корректировкой интервалов между разделами и
добавлением линейки, отделяющей мини-указатель от остального текста, Т^Х
246
Компьютерная типография
может оценить, какое пространство необходимо для размещения набираемого
разворота. В нашем примере все помещается на одной странице, так что 1ЁХ
присоединит §10 к развороту, уже содержащему §8 и §9. Затем, после того как
тем же самым образом будет обработан §11, ТЕХ обнаружит, что все вместе
§§8-11 на одном развороте не помещаются, и решит начать новый разворот,
где первым будет идти §11.
Средства реализации описанного выше процесса не встроены, разумеется,
в ТЕХ. Все необходимые для него действия выполняются под управлением
набора макроопределений, называемого ctwimac.tex [10]. Первое же сообщение,
передаваемое ТЁХ'у от CTWILL, содержит требование загрузить данный набор.
Т^Х создавался для набора текстов, не для программирования, однако его
лучше все-таки рассматривать как язык программирования. Но задача
индексирования при построении мини-указателей — твердый орешек с точки зрения
программирования. Детальный анализ набора макро ctwimac слишком сложен,
чтобы его можно было представить здесь, однако ТЁХ'овские хакеры оценят
некоторые из не слишком очевидных идей, использованных при написании
упомянутых макро. (Оставшаяся часть этого длинного абзаца предназначена
только Т^Хникам.) ТЕХ читает мини-выходы из CTWILL дважды, с
отличающимися для каждого из прогонов определениями для \[ и \]. Пусть мы в
настоящий момент обрабатываем раздел s, и пусть также формируемый
текущий разворот начинается с раздела г. Тогда ТЁХ'овские лексемные регистры
(token registers) 200, 201, ..., 219 содержат все элементы мини-указателя из
разделов
г, г 4-1, ..., 5-1
для идентификаторов, определенных соответственно в разделах г, г + 1,
..., г + 19 CWEB-программы. (Нам нет необходимости хранить отдельные
таблицы для более чем 20 последовательно идущих разделов, начинающихся с
базового номера г в текущем развороте, поскольку ни один из разворотов не
будет содержать более 20 разделов.) Подобным же образом, лексемный
регистр с номером 199 содержит элементы указателя, ссылающиеся на разделы,
предшествующие г, а лексемный регистр 220 содержит элементы,
указывающие на разделы г + 20 и далее. Лексемный регистр 221 включает элементы
мини-указателя для идентификаторов, определенных в других программах.
Регистр-счетчик (count register) к хранит число элементов в лексемном
регистре с номером к, 199 < к < 221. Если регистр-счетчик к имеет значение,
равное j, содержимым регистра лексем к будет последовательность из 2j
лексем:
\lmda\csi\lmda\cs2 ...\lmda\csj
где каждая из команд Xcs^ представляет собой управляющую
последовательность, единственным образом характеризующую элемент мини-указателя,
определенный через \csname. . .\endcsname. Т^Х может сообщить, согласуется
ли вновь вводимый элемент мини-указателя с другими элементами, уже
заданными для данного текущего разворота. Это осуществляется простой проверкой
того, определена ли уже соответствующая управляющая последовательность.
Замещающий текст для \csj представляет собой соответствующий элемент
Глава 11. Мини-указатели для самодокументированных программ
247
мини-указателя, а определение для \lmda имеет вид:
\def\lmda#l{#l\global\let#l\relax}
Следовательно, когда ТЕХ «исполняет» содержимое определенного лексемного
регистра, он осуществляет набор всех требуемых элементов мини-указателя и
переводит в разряд неопределенных все соответствующие управляющие
последовательности. В качестве альтернативного варианта можно было бы записать
\def\lmda#l{\global\let#l\relax}
если просто требуется стереть все элементы указателя, представленные в
некотором лексемном регистре. В конце разворота, содержащего р разделов,
генерируется мини-указатель, что осуществляется путем обработки содержимого
(«исполнения») лексемных регистров 199 и с 200 + р по 221, используя
введенное выше первое из определений для \lmda, а также обрабатывая лексемные
регистры с 200 по 200-f p — 1, используя второе из введенных определений. Все
работает как по мановению волшебной палочки.
Некорректность, которая имела место в первоначальных ТЁХ'овских макро
для TWILL, привела к появлению неприятной ошибки в первом издании (1986 г.)
книг [5] и [6]. Управляющие последовательности в лексемных регистрах,
соответствующих разделам рассматриваемого текущего разворота, не стирались;
другими словами, содержимое этих лексемных регистров попросту
отбрасывалось и не обрабатывалось со вторым определением для \lmda. В результате Т^Х
считал, что некоторые управляющие последовательности все еще определены,
следовательно, для макро соответствующие элементы мини-указателя
продолжали существовать, такого рода элементы были, следовательно, ошибочно
пропущены. Затронутыми оказались всего лишь около 3% элементов мини-
указателя, так что данная ошибка не бросилась сразу в глаза и оставалась
незамеченной до момента выхода упомянутых книг из печати, когда они
попали в руки к читателям. Единственным светлым пятном во всей этой истории
был тот факт, что подтвердилась высокая эффективность мини-указателей:
то, что упомянутые элементы не присутствовали в мини-указателях, было с
сожалением отмечено читателями, их наличие обещало быть действительно
полезным.
«Жадный» метод формирования текста наибольшей длины, с помощью
которого ТЁХ'овские макро программы CTWILL размещают разделы на
страницах, ведет к минимизации числа страниц, хотя такой результат и не
гарантирован. Например, можно представить себе необычные сценарии, в которых
разделы §100 и §101, скажем, не помещаются на одном развороте, тогда как
три раздела (§100, §101, §102) поместятся. Это могло бы произойти в случае,
если §100 и §101 содержат достаточно много ссылок на переменные,
объявленные в §102. Аналогично, можно было бы разместить §100 вместе с §101, если
бы §99, «отложенный» при формировании предыдущего разворота, перешел
на текущий. Однако такого рода ситуации в высшей степени маловероятны и
нет оснований особенно беспокоиться о них. Стратегия вида «один разворот
в каждый момент времени», реализуемая макрокомандами ctwimac, является
оптимальной и экономящей объем во всех практически значимых случаях.
248
Компьютерная типография
С другой стороны, имеющийся опыт показывает, что иногда
получаются неудачные разрывы страниц, отделяющие развороты один от другого, что
заставляет пользователя прибегать к подстройке этих разрывов. Пусть,
например, текст §7 в программе НАМ длиннее на одну строку. Тогда §7 не будет
уже сочетаться с §6 и нам пришлось бы примириться с разворотом,
содержащим совсем крошечный §6 и много пустого пространства. Это выглядело бы
совершенно ужасно. В такой ситуации целесообразно два оператора
t-ark — Л; v = у;
записывать в одной строке вместо двух отдельных строк. Здесь неудачный
разрыв страниц между разворотами ликвидируется путем связывания вручную
этих двух операторов вместе, используя CWEB-команду @+.
Еще одна проблема, требующая обсуждения, состоит в том, что мини-
указатели должны быть отсортированы в алфавитном порядке. Средств ТЁХ'а
вполне достаточно для определения разрывов между разворотами (и,
соответственно, для определения содержимого этих разворотов), но ТЁК —
неподходящая среда для выполнения сортировки. Решение указанной проблемы
заключается в том, чтобы пропустить выход программы CTWILL через Т^Х дважды,
подключив программу сортировки между этими двумя прогонами. Когда ТЕХ
обрабатывает файл ham.tex, макро из ctwimac заставляют его просмотреть
первым делом файл с именем ham. sref. Если такого файла нет, будет записан
файл ham.ref, содержащий в неотсортированном виде все элементы мини-
указателей для каждого из разворотов. ТеХ при этом осуществляет набор
текста как обычно, со всеми мини-указателями (но не отсортированными), на
положенных им местах, при этом пользователь получает возможность
проконтролировать и откорректировать, если в этом возникнет необходимость,
разрывы страниц, отделяющие развороты один от другого. Как только расстановка
разрывов страниц будет сочтена удовлетворительной, вызывается отдельная
программа с названием REFSORT, которая преобразует файл ham.ref в его
отсортированный вариант ham.sref. Теперь Т^Х при втором запуске найдет
файл ham.sref и сможет использовать отсортированные данные для
получения великолепного окончательного варианта распечатки программы НАМ.
Файл ham.ref может выглядеть, к примеру, следующим образом:
!241
+ \]{GB\_\,SAVE}4 \\{restore\_graph} \&{Graph} $*(\,)$
+ \]{GB\_\,GRAPH}9 \|{u} \&{util}
+ \]{GB\_\,GRAPH}8 \KI> \Hlong}
!242
+ \]"<stdio.h>" \\{printf} \&{int} (\,)
А соответствующий файл ham. sref примет при этом следующий вид:
YKGB\_\,GRAPH} 10 \&{Arc} =\&{struct}
\]{GB\_\,GRAPH}9 \|{u} \&{util}
Глава 11. Мини-указатели для самодокументированных программ 249
\]{GB\_\,GRAPH}9 \&{Vertex} =\&{struct}
\donewithpage241
\[2 \|{а} \&{register} \&{Arc} $*$
\]{GB\_\,GRAPH}20 \\{vertices} \&{Vertex} $*$
\donewithpage245
Каждый из этих двух файлов содержит по одной строке для каждого элемента
мини-указателя, а также по одной строке, отмечающей начало (в ham.ref) или
конец (в ham.sref) каждого из разворотов.
Заключительные замечания
Система CTWILL для формирования мини-указателей может
рассматриваться как дальнейшее развитие средств визуализации программных структур.
Она продолжает длинный ряд исследовательских работ, начало которым
было положено У. Хансеном, создавшим структуризованный текстовый редактор
Emily [2, 3].
Хотя система CTWILL и не является полностью автоматическим средством,
она самым существенным образом улучшает читаемость больших наборов
программ. Автор, потративший целый год на составление программ и подготовку
их к публикации, едва ли будет возражать против того, чтобы потратить еще
неделю на улучшение предметного указателя для нее. И в самом деле,
немного дополнительного времени, потраченного на индексирование, в общем случае
приводит к существенному улучшению текста книги, которую автор в процессе
индексирования получает шанс увидеть в новом свете.
Избавиться от всех доработок указателей вручную невозможно, поскольку
компьютер не может знать подходящих ссылок для каждого из
идентификаторов, появляющихся в комментариях к программе. Однако опыт, полученный
при использовании механизма изменения файлов программы CTWILL,
показывает, что корректные мини-указатели для больших и сложных программ могут
быть получены очень быстро, со скоростью примерно 100 книжных страниц
в день. Например, создание файлов замены (change files) для 460 страниц
программного текста в [9] заняло 5 дней, в течение которых дополнительно
проводились отладка и совершенствование программы CTWILL.
Мини-указатели представляют собой прекрасное дополнение к печатным
изданиям, однако в более дальней перспективе можно ожидать замены во
многих случаях печатной продукции на объекты гипертекстового
характера. Достаточно просто представить себе некую систему для просмотра CWEB-
программ, в которой найти значение любого из идентификаторов можно было
бы простым «щелчком» кнопки мыши на нем. Системы будущего позволят,
по-видимому, обозревать программу в целом, обеспечивая простую навигацию
среди хитросплетений их кода. (См. [1], где обсуждаются некоторые шаги в
данном направлении.)
Такого рода системы, которые появятся в будущем, войдут в
определенное противоречие с CTWILL, формирующей мини-указатели. Автор, решивший
создать полезный программный гипертекст, который смогут читать и другие,
250
Компьютерная типография
захочет дать подсказки относительно значений идентификаторов, роль
которых невозможно или очень трудно оценить механически, дедуктивным путем.
Некоторые из уроков, полученных при создании и применении CTWILL,
окажутся, скорее всего, полезными для любого, кто попытается разрабатывать
самодокументированные программные системы, которые заменят книги в той
форме, к какой мы привыкли сейчас.
Литература
М. Brown & В. Czejdo, "A hypertext for literate programming," Lecture Notes
in Computer Science 468 (1990), 250-259.
Wilfred J. Hansen, Creation of Hierarchic Text With a Computer Display,
Ph.D. thesis, Stanford University (1971). Опубликовано также как Argonne
National Laboratory report ANL-7818 (Argonne, Illinois: 1971).
Wilfred J. Hansen, "User engineering principles for interactive systems,"
AFIPS Fall Joint Computer Conference 39 (1971), 523-532.
Donald E. Knuth, "Literate programming," The Computer Journal 27 (1984),
97-111.
Donald E. Knuth, Tj^K: The Program, Volume В of Computers & Typesetting
(Reading, Massachusetts: Addison-Wesley, 1986).
Donald E. Knuth, METRFONT: The Program, Volume D of Computers &
Typesetting (Reading, Massachusetts: Addison-Wesley, 1986).
Donald E. Knuth, Literate Programming, CSLI Lecture Notes 27 (Stanford,
California: Center for the Study of Language and Information, 1992).
Distributed by Cambridge University Press.
Donald E. Knuth & S. Levy, The CWEB System of Structured Documentation,
Version 3.0 (Reading, Massachusetts: Addison-Wesley, 1994). Самая
последняя версия имеется в Интернете и доступна по анонимному ftp на
labrea.stanford.edu в директории ~ftp/pub/cweb.
Donald E. Knuth, The Stanford GraphBase: A Platform for Combinatorial
Computing (New York: ACM Press, 1993).
Donald E. Knuth, "CTWILL" (1993). Доступно по анонимному ftp на
labrea. stanford.edu в директории ~f tp/pub/ctwill.
Kasper 0sterbye, "Literate Smalltalk programming using hypertext," IEE
Transactions on Software Engineering SE-21 (1995), 138-145.
Clyde Pharr, Virgil's JEneid, Books I-VI (Boston: D. С Heath, 1930).
Stanford University Computer Science Department, "The Stanford
GraphBase." Имеется в Интернете и доступно по анонимному ftp на
labrea. stanford.edu в директории ~ftp/pub/sgb.
[14] J. S. Weening, Личное сообщение. Хранится в архивах проектов ТЁХ'а
в библиотеке Станфордского университета в отделе Special Collections,
SC 97, series II, box 18, folder 7.6.
Глава 11. Мини-указатели для самодокументированных программ
251
Приложение: НАМ
1. Гамильтоновы контуры.
Эта программа отыскивает все
гамильтоновы контуры (ГК)
неориентированного графа.
Если ввести 'ham foo.gb', в
распечатке результатов работы НАМ
будут перечислены все ГК графа f оо,
описанного в файле foo.gb с
использованием формата из Stanford
GraphBase. В конце распечатки
дается общее число найденных
решений.
Необязательный второй параметр
задает шаг выдачи результатов.
Например, при запуске НАМ с помощью
команды 'ham foo.gb 1000' будет
выводиться только каждый
тысячный из найденных ГК. Если этот
параметр равен нулю, выводится лишь
общее число найденных ГК.
#include <stdio.h>
/* стандартные функции
ввода/вывода языка С */
#include "gb_graph. h"
/* структуры данных GraphBase
*/
#include "gb_save.h"
/* программа restore-graph */
2. В поле deg записываются
степени вершин графа.
# define deg и.I
/* текущее число входящих
и исходящих дуг для
данной вершины */
int main (int argc, char * argv [ ])
{ Graph *#;
/* граф для анализа */
register Vertex *£, *tt, *v;
/* основные вершины */
}
Vertex *£, *t/, *z; /* менее
употребит, вершины */
register Arc *a, *aa\
/* часто использ. дуги */
Arc *&, *bb;
/* менее часто использ. дуги */
int count = 0;
/* уже найденные решения */
int interval = 1;
/* шаг выдачи решений */
(Сканировать аргументы
командной строки и ввести
9 3);
(Подготовить д для отката, найти
вершину х с минимальной
степенью 4);
(Прекратить выполнение, если
неверно задано д или
x~*deg < 2 б);
for (Ь = x~*arcs\ hrnext; b = b-+next)
for (bb — brnext\ bb\
bb = bb-next) {
v = trtip-
z = bb~*tip\
(Найти все простые пути
длины д-пг — 2 из v в z,
избегая х 7);
}
print/ (" Altogetheru*/.dusolut \
ions.\n",
count);
return 0;
/* нормальный выход */
Arc = struct, GB-GRAPH§10.
arcs: Arc *, GB.GRAPH§9.
Graph = struct, gb.graph§20.
I: long, GB-GRAPH§8.
n: long, GB-GRAPH§20.
next: Arc *, GB-GRAPH§10.
print}: int (), <stdio.h>.
restore-graph: Graph *(), GB.SAVE§4.
tip: Vertex *, GB-GRAPH§10.
u: util, GB_GRAPH§9.
Vertex = struct, GB.GRAPH§9.
252
Компьютерная типография
3. (Сканировать аргументы
командной строки и ввести
0 3) =
if (argc > 2 Л sscan/(argv[2], "*/.d",
^interval) = 1) {
argc—;
if (interval < 0)
interval = —interval;
else if (interval = 0)
interval = -10000;
/* подавить печать, если
параметр равен 0 */
}
if (argc ф 2) {
print/ ("Usage: u*/.suf oo. gbu [i \
nterval]\n", argv[0])\
return — 1;
}
g = rest ore.gr aph(argv[l])\
Этот код используется в разделе 2.
4. Вершины, уже внесенные в
путь, именуются «отмеченными»
(«taken»), а поле taken для них
будет ненулевым. Начальное значение
всех этих полей устанавливается
равным нулю.
#define taken v.I
/* Есть ли уже эта вершина
в текущем пути? */
#define not.taken (vert)
((vert)~*taken = 0)
(Подготовить д для отката, найти
вершину х с минимальной
степенью 4) =
if (д) { int dmin = д-+п;
for (v = g-+vertices;
v < g-vertices + g-n\ v++) {
register int d = 0;
/* the degree of v */
ir+taken = 0;
for (a = v-arcs\ a; a = a-next)
d++;
vr+deg = d]
if (d < dmin) dmin = d, x = v\
}
Этот код используется в разделе 2.
5. Вершина, имеющая менее двух
соседних, не может входить в ГК и
должна быть пропущена.
(Прекратить выполнение, если неверно
задано д или xr*deg < 2 5) =
if Ы {
print/ ("Graphu'/.suisumalf orm\
edu(errorucodeu'/,ld) ! \n",
ar0v[l], panic-code)]
return —2;
}
if (x-*deg < 2) {
print/ ("Nousolutionsu (verte \
xuy.suhasudegreeuy,ld) . \n",
xr*name,xrdeg)\
return —3;
}
Этот код используется в разделе 2.
a: register Arc *, §2.
arcs: Arc *, GB.GRAPH§9.
argc: int, §2.
argv: char *[], §2.
deg-u.I, §2.
g: Graph *, §2.
/: long, GB-GRAPH§8.
interval: int, §2.
n: long, GB_GRAPH§20.
name: char *, gb.graph§9.
next: Arc *, GB.GRAPH§10.
panic-code: long, gb.graph§5.
print/: int (), <stdio.h>.
restore.graph: Graph *(), GB.SAVE§4.
sscan/: int (), <stdio.h>.
v: register Vertex *, §2.
v: util, GB_GRAPH§9.
vertices: Vertex *, GB.GRAPH§20.
x: Vertex *, §2.
Глава 11. Мини-указатели для самодокументированных программ
253
6. Алгоритм. Неэффективные
ветви дерева поиска отсекаются по
простому правилу: если следующая
вершина, в которую можно перейти,
смежна только с единственной
другой неиспользованной вершиной, то
надо перейти в нее.
Переходы фиксируются в массиве
вершин д. Точнее, к-я вершина
рассматриваемого пути будет t-+vert,
если t — k-я вершина графа. Если
переход не задается, t-*ark будет
указывать на запись Arc, отвечающую
дуге из t-*vert в (t + Invert; в
противном случае t-*ark будет равно Л.
#define vert w.V /* вершина на
текущем пути */
# define ark
х.А /* дуга к текущей
следующей вершине */
7. Эта программа — типичный
пример применения метода
поиска с возвращениями (backtracking),
т. е. на дереве всех возможных
решений осуществляется поиск в
глубину (depth-first search). Автор
принадлежит к «старой школе»
программирования и ему удобнее
писать программы с
использованием меток и операторов goto, а не с
помощью циклов while.
(Найти все простые пути длины д-п — 2
из v в z} избегая х 7) =
{ Vertex *tmax]
t = g-vertices; tmax = t + g-n — 1;
xrtaken = 1;
t-vert = x\ t-ark = Л;
advance: (Увеличить £, корректируя
структуры данных, чтобы
показать, что вершина v уже
«выбрана» и установить у,
задающим переход, если он
есть, но goto backtrack, если
нет возможных переходов 8);
if (у) { /* переход задан */
t~*ark = Л; v = y\ goto advance;
}
а = v-arcs;
search:
(Проверить дугу а и следующие
за ней, перейти, если найден
корректный переход ю);
restore: аа = Л;
restore-to-aa: (Вернуть структуры
данных к состоянию, в
которых они были, когда
был достигнут уровень t,
остановиться на дуге аа 9);
backtrack: (Если возможно,
уменьшить t и искать другую
возможность 11);
}
Этот код используется в разделе 2.
a: register Arc *, §2.
Л: Arc *, GB-GRAPH§8.
аа: register Arc *, §2.
Arc = struct, GB.GRAPH§10.
arcs: Arc *, GB.GRAPH§9.
g: Graph *, §2.
n: long, GB.GRAPH§20.
t: register Vertex *, §2.
taken =v.I, §4.
v: register Vertex *, §2.
V: Vertex *, GB_GRAPH§8.
Vertex = struct, GB.GRAPH§9.
vertices: Vertex *, GB.GRAPH§20.
w: util, GB.GRAPH§9.
x: Vertex *, §2.
x: util, GB.GRAPH§9.
y: Vertex *, §2.
z: Vertex *, §2.
254
Компьютерная типография
8. После того как вершина
выбрана, попытаться удалить ее из графа.
(Увеличить £, корректируя структуры
данных, чтобы показать, что
вершина v уже «выбрана»
и установить у, задающим
переход, если он есть, но goto
backtrack, если нет возможных
переходов 8) =
t-vert = v;
гг+taken = 1;
if (v = z) {
if (t = tmax)
(Записать решение 12 );
goto backtrack]
}
for (aa = v-+arcs,y = Л; aa\
aa = aa-next) {
register int d\
и = aa~*tip\
d = vr+deg — 1;
if (d = 1 Л not-taken(u)) { /*
надо перейти теперь к и */
if (у) goto restore-to-aa]
/* два заданных перехода
одновременно выполнить
нельзя */
У = Щ
}
vrdeg = d; /* из it больше
нельзя перейти кг;*/
}
Этот код используется в разделе 7.
9. На уровне £ граф
существенно не меняется, все что делается
с ним — уменьшаются степени
вершин, достижимых из t-*vert. Это
позволяет простым образом
восстанавливать предыдущие состояния при
откатах.
(Вернуть структуры данных к
состоянию, в которых они были,
когда был достигнут уровень £,
остановиться на дуге аа 9) =
for (a = t-*vert~*arcs\ а ф аа\
а = a-*next) a-tip-*deg++;
Этот код используется в разделе 7.
10.
(Проверить дугу а и следующие
за ней, перейти, если найден
корректный переход ю) =
while (a) {
v = a-tip\
if (not-taken (v)) {
t-ark = а;
goto advance]
/* move to v */
}
a = arnext',
}
Этот код используется в разделе 7.
a: register Arc *, §2.
aa: register Arc *, §2.
advance: label, §7.
arcs: Arc *, GB_GRAPH§9.
ark =x.A, §6.
backtrack: label, §7.
deg =u.I, §2.
next: Arc *, gb_graph§10.
not-taken = macro (), §4.
restore-to-aa: label, §7.
t: register Vertex *, §2.
taken =v.I, §4.
tip: Vertex *, gb.graph§10.
tmax: Vertex *, §7.
u: register Vertex *, §2.
v: register Vertex *, §2.
vert =гу.У, §6.
у: Vertex *, §2.
z\ Vertex *, §2.
Глава 11. Мини-указатели для самодокументированных программ
255
11. (Если возможно, уменьшить
t и искать другую
возможность 11) =
t-vert-taken = 0;
*—;
if (t-ark) {
а = t~*ark-*next\
goto search]
"}
if (t ф g-vertices) goto restore;
/* задан переход, поэтому
пропустить search */
Этот код используется в разделе 7.
12. Вывод решения на печать
простым перечислением имен вершин
выдаваемого текущего пути.
(Записать решение 12) =
{
count -Н-;
if (count % interval = OAinterval > 0)
{
printf ("'/,d: и ", count);
for (u = g-vertices; и < tmax;
u-H-)
printf ("7,su", u-vert-name)\
printf ("\n");
}
}
Этот код используется в разделе 8.
a: register Arc *, §2.
ark =х.Л, §6.
count: int, §2.
#: Graph *, §2.
interval: int, §2.
name: char *, GB.GRAPH §9.
neatf: Arc *, GB.GRAPH§10.
printf: int (), <stdio.h>.
restore: label, §7.
search: label, §7.
t: register Vertex *, §2.
taken =г>./, §4.
tmax: Vertex *, §7.
u: register Vertex *, §2.
vert =iu.V, §6.
vertices: Vertex *, GB.GRAPH §20.
У
Виртуальные шрифты.
Развлечение
для настоящих мастеров
[Первоначально опубликовано в TUGboat 11 (1990), 13-23.]
Значительная доля участников обсуждений, проводившихся в рамках группы
новостей TgXhax B течение примерно последнего года, прилагала усилия для
того, чтобы решить проблемы, связанные со взаимодействием шрифтов,
подчиняющихся различным наборам соглашений. К примеру, оживленной была
переписка относительно смешивания цифр, изображаемых в старинном стиле,
с алфавитом, содержащим прописные буквы и капитель. Некоторых
участников обсуждения волновали возможности работы со шрифтами, созданными
фирмами Autologic, Compugraphic, Monotype и др., тогда как другие
опасались лишиться ограниченных возможностей акцентировки, присущих
семейству шрифтов Computer Modern, для шрифтов, включающих уже
индивидуально акцентированные буквы, поскольку такого рода шрифты не пригодны
к непосредственному употреблению в форме, которую воспринимает текущая
версия ТЁХ'овского программного обеспечения.
Существует, однако, подход к решению подобного рода проблем,
намного более эффективный, чем средства, предлагаемые участниками обсуждений
в TgXhax. Этот подход был первоначально реализован Дэвидом Фуксом в
1983 г., когда он дополнил соответствующими средствами программу DVI-to-
APS, имевшуюся в Станфорде (которая также была разработана им и
предназначалась для коммерческого распространения через фирму ArborText). Мы с
Дэвидом использовали данную программу, например, при наборе моей статьи
Literate Programming для журнала The Computer Journal «родными»
шрифтами фирмы Autologic, принятыми в этом журнале в качестве базовых.
Я думал тогда, что стратегия, предложенная Дэвидом, станет широко
известной и употребительной. Но увы —и это, пожалуй, единственное серьезное
разочарование, связанное с распространением ТЁХ'а по всему миру —ни в
одном из других драйверов типа DVI-to-X идеи Дэвида не оказались
востребованными, а участники обсуждений в TEJXhax извели и изводят галлоны
электронных чернил, отыскивая ответы на неправильно поставленные вопросы.
Правильное направление поисков очевидно и мы его уже видим (хотя в
1983 г. оно еще не было столь очевидным): все, что нам требуется — это
располагать хорошим способом отображения из ТЁХ'овской нотации для литеры
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 257
из некоторого шрифта в представление, отвечающее требуемому печатающему
устройству. Такого рода отображение получило наименование «виртуальный
шрифт» («virtual font»), предложенное докладчиками из Американского
математического общества (AMS) на конференции TUG в августе этого года. На
этой конференции я кратко выступил по данной теме и выразил надежду, что
все DVI-драйверы будут в течение года модифицированы так, чтобы реали-
зовывались возможности работы с виртуальными шрифтами. Дейв Роджерс
из ArborText объявил, что его фирма решила сделать разработанные ею WEB-
программы для проектирования виртуальных шрифтов свободно доступными,
а я пообещал отредактировать эти программы таким образом, чтобы они
были согласованы с другими программами в стандартном комплекте поставки
ТЁХ'овских средств.
Подготовка ТЁ^'а в версии 3 и METflFONT'a в версии 2 заняла существенно
больше времени, чем я ожидал, но в конце концов у меня появилась
возможность более внимательно ознакомиться с концепцией виртуальных шрифтов.
Потребность в таких шрифтах стала сейчас еще более насущной, чем совсем
недавно, поскольку новые ТЁХ'овские средства многоязыковой поддержки
будут действительно эффективными только тогда, когда будут доступны
соответствующие шрифты. Виртуальные шрифты, удовлетворящие этим
потребностям, могут быть созданы достаточно просто и легко.
После тщательного ознакомления с первоначальной разработкой Дэвида
Фукса, я решил разработать полностью новый формат файла, развивающий
его идеи и обеспечивающий полную аппаратную независимость механизма
виртуальных шрифтов, в то время как программная реализация,
выполненная Дэвидом, ориентировалась на APS-устройства. Далее, я решил расширить
предложенную им нотацию так, чтобы частью виртуального шрифта можно
было сделать произвольные DVI-команды, включая команды special. Новый
файловый формат, разработанный мною, получил название VF; DVI-драйверы
не будут иметь сложностей с чтением VF-файлов, поскольку формат VF
аналогичен форматам РК и DVI, с которыми DVI-драйверы имеют дело сейчас.
Результатом проведенных работ стали две новые системные программы,
названные VFtoVP и VPtoVF. Эти программы представляют собой расширенные
варианты старых программ TFtoPL и PLtoTF; имеется также язык описания
списков свойств VPL, расширяющий обычный формат PL в таком стиле, чтобы
создание виртуальных шрифтов не составляло труда.
Помимо реализации упомянутых выше программ, я проанализировал
заложенные в них идеи, убедившись, что виртуальные шрифты могли бы без
особых сложностей быть встроены в систему DVIPS, созданную Томом Рокиц-
ки. Я написал программу на языке С (ее можно получить у Тома), которая
преобразует AFM-файлы фирмы Adobe в виртуальные шрифты для ТЁ^'а; эти
виртуальные шрифты включают почти все характеристики текстовых
шрифтов семейства Computer Modern (опущены только заглавные греческие буквы
и «бесточечная» буква j), а также включают все дополнительные литеры,
введенные фирмой Adobe. Полученные виртуальные шрифты включают даже
все «составные знаки», перечисленные в исходном AFM-файле, от 'Aacute' до
258
Компьютерная типография
'zcaron'; такого рода знаки доступны как лигатуры. Например, чтобы получить
'Aacute', печатается сначала 'acute' (это литера 19 = ~S в шрифтовой
раскладке для Computer Modern; это может быть также литера 194 = Meta-B, если
с новым Т^К'ом используется 8-битовая клавиатура), за которым следует 'А'.
Используя такие шрифты, мне теперь проще набирать тексты на европейских
языках шрифтами Times Roman, Helvetica и Palatino, а не Computer Modern!
(Требуется менее часа работы, чтобы получить виртуальный шрифт для
Computer Modern, который позволит делать все то же самое, у меня, однако, до
этого все не доходят руки.)
Прекрасная схема формирования лигатур, пригодная для десятков
европейских языков, была опубликована Янисом Хараламбусом в TUGboat 10
(1989), 342-345. Он использовал только ASCII-знаки, вводя 'Aacute' с
помощью комбинации <А. Я вполне готов присоединить эту схему к моей, добавив
несколько строк в написанные мною VPL-файлы. Конечно, различные
соглашения могут поддерживаться и одновременно, но я не рекомендовал бы этого
делать.
Виртуальные шрифты упрощают переход от DVI-файлов к шрифтовым
раскладкам различных разработчиков или поставщиков шрифтов. Они также
(хотя мне и жаль об этом говорить) упрощают процедуру изменения
апрошей для тех, кому приходится прибегать к использованию этого многократно
осужденного элемента набора со свободной разгонкой текста.
К тому же, виртуальные шрифты решают проблему печати гранок
(корректур) с помощью экранных шрифтов или лазерных шрифтов с низким
разрешением, поскольку можно иметь несколько виртуальных шрифтов,
пользующихся одним и тем же TFM-файлом. Предположим, например, что оригинал-
макет издания надо распечатывать на наборной машине APS, используя
шрифты Univers, однако требуется еще и уметь просматривать гранки на экране
монитора, а также распечатывать их на лазерном принтере. Пусть, далее,
в вашем распоряжении нет шрифтов Univers для лазерного принтера,
наиболее похожее из того, что имеется —это шрифт Helvetica. И предположим
также, что для вывода гранок на экран монитора у вас нет даже и шрифта
Helvetica, имеется только cmsslO. И вот что вы можете сделать в сложившейся
ситуации. Первым делом требуется создать VPL-файл univers-aps.vpl,
содержащий виртуальный список свойств (Virtual Property List) и описывающий
высококачественный шрифт, который понадобится для окончательного вывода
требуемого оригинал-макета. Затем после редактирования из этого файла
получается файл univers-laser.vpl, включающий идентичную информацию о
метрике шрифта, но символы его отображаются в шрифт Helvetica; аналогично
готовится и файл univers-screen.vpl, отображающий информацию о
метрике шрифта в шрифт cmsslO. Теперь каждый из трех полученных VPL-файлов
обрабатывается программой VPtoVF. Она создает три идентичных TFM-файла
с именем univers.tfm, один из которых должен быть перемещен в каталог,
читаемый Т^К'ом. Будут получены также три различных VF-файла с
одинаковым именем univers.vf. Их надо поместить в три различных каталога, где
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 259
размещаются программы обработки DVI-файлов при выводе, соответственно,
на APS-машину, лазерный принтер и экран монитора. Voila!
Итак, виртуальные шрифты — вещь, несомненно, вполне добродетельная.
Но если рассмотреть эти шрифты более детально, что же они собой все-таки
представляют? Для ответа на эти вопросы ниже приводятся фрагменты
файлов VFtoVP.web и VPtoVF.web, в которых дается полное описание форматов VF
и VPL.
Я с полным основанием ожидаю, что все те, кто занимается реализацией
DVI-драйверов, сразу же оценят большие потенциальные возможности
виртуальных шрифтов и не смогут противиться введению VF-средств в создаваемое
ими программное обеспечение, причем сделают это уже в первые же месяцы
1990 г. Идея здесь такова: для каждого шрифта, заданного в DVI-файле,
программа производит сначала просмотр некоторой специальной таблицы, чтобы
узнать, является ли данный шрифт резидентным для требуемого устройства (в
таком случае загружается TFM-файл, чтобы получить информацию о ширине
знаков, входящих в шрифт); если такого рода поиск не увенчался успехом,
производится поиск соответствующего GF- или РК-файла; если и этот поиск
оказался безуспешным, просматривается VF-файл, что, в свою очередь, может
привести к просмотру других реальных или виртуальных файлов. Последние
из упомянутых файлов не должны загружаться немедленно, но только по
запросу, поскольку реализуемый процесс имеет рекурсивный характер. Если же
не найдены ни резидентный файл, ни GF- или РК-файлы, ни VF-файл, в качестве
последнего средства следует загрузить TFM-файл, тогда на месте ненайденных
символов будут оставлены пробелы соответствующей ширины.
Фрагменты файла VFtoVP.web
6. Виртуальные шрифты. В основе VF-файлов заложена идея общего
интерфейса для переключения между мириадами шрифтовых раскладок, поддерживаемых
поставщиками различного наборного оборудования. Если такой механизм
отсутствует, пользователям придется писать объемистые и заумные макро всякий раз, когда
у них возникнет потребность в применении соглашений о наборе, основанных на
одной шрифтовой раскладке, в сочетании с реальными шрифтами, базирующимися
на другой раскладке. Это ложится дополнительным бременем на наборные
системы; положение еще усугубляется необходимостью проведения ряда дополнительных
операций (вроде кернинга, переносов, формирования лигатур).
Эти трудности устраняются, если у нас есть «виртуальный шрифт», т.е. шрифт,
который существует в смысле логическом, но не физическом. Система набора
текстов, подобная TJEX'y, может выполнять свою работу, вовсе не зная, откуда берутся
реальные литеры; драйвер устройства вывода может тогда решать свою задачу,
посылая запрос к VF-файлу, чтобы выяснить, какие реальные литеры соответствуют тем,
что ТЕХ пытается изобразить в настоящий момент. Реальные литеры могут быть
сдвинуты и/или увеличены и/или скомбинированы с другими литерами из многих
различных шрифтов. Виртуальный шрифт может даже обеспечить использование
знаков из виртуальных шрифтов, включая самого себя.
260
Компьютерная типография
Виртуальные шрифты обеспечивают также удобную возможность подстановки
литер (символов) для целей черновой печати (печать гранок), в ситуациях, когда
шрифты, разработанные для одного печатающего устройства, недоступны на другом.
7. VF-файл организован как поток, состоящий из 8-разрядных двоичных слов
(байтов), на основе использования соглашений, заимствованных из форматов DVI-'и
РК-файлов. Поэтому драйвер устройства, располагающий информацией о форматах
DVI- и РК-файлов, уже содержит большинство средств, необходимых для обработки
VF-файлов. Будем считать, что формат DVI-файла известен; здесь принимаются
соглашения, изложенные в документации по DVI (см., например, Т$£: The Program,
part 31), и на их основе определяется VF-формат.
Каждый VF-файл начинается преамбулой, за которой следуют определения
литер, а после них — заключительная часть. Точнее, самый первый байт каждого VF-
файла должен быть первым байтом следующей «преамбульной команды»:
pre 247 г[1] к[1] х[к] cs[4] ds[4]. Здесь г — идентификационный байт VF, в настоящий
момент 202. Строка х есть просто комментарий, содержащий обычно сведения
о происхождении данного VF-файла. Параметры cs и ds представляют собой,
соответственно, контрольную сумму и кегель рассматриваемого виртуального
шрифта; значения этих параметров должны совпадать со значениями двух
первых слов в заголовке соответствующего TFM-файла, как это будет показано ниже.
После команды pre текст преамбулы продолжается благодаря перечислению
определений шрифтов. В них с помощью команд set-char определяется каждый из
шрифтов, требуемых далее для создания «реальных» литер. Определения шрифтов
в VF-файл ах в точности такие же, как и в D VI-файлах, за исключением того, что
масштабируемый размер s является относительным, а кегель — абсолютным:
fnt.defl 243 к[1] с[4] s[4] d[4] a[l] /[1] п[а + /]. Определить шрифт /с, где 0 < к < 256.
fnt.def2 244 к[2] с[4] s[4] d[4] а[1] /[1] п[а + /]. Определить шрифт /с, где 0 < к < 216.
fnt.def3 245 к[3] с[4] s[4] d[4] а[1] /[1] п[а + /]. Определить шрифт /с, где 0 < к < 224.
fnt.def4 246 к[4] с[4] s[4] d[4] а[1] /[1] п[а + 1]. Определить шрифт /с, где -231 < к < 231.
Эти номера шрифтов к являются «локальными», они не имеют никакого
отношения к номерам шрифтов в DVI-файле, использующем данный виртуальный шрифт.
Параметр s, представляющий собой масштабированный размер определяемого
локального шрифта, есть слово типа fix-word, его значение определяется относительно
кегля виртуального шрифта. Тогда, если локальный шрифт, который надо
использовать, того же самого размера, что и кегель рассматриваемого виртуального шрифта,
s будет иметь целочисленное значение, равное 220. Значение параметра s должно
быть положительным и меньшим, чем 224 (т. е. быть меньше 16, если s
рассматривать как fix-word). Параметр d размера также типа fix-word, его значение задается
в единицах разрешающей способности печатающего устройства, следовательно, он
идентичен кеглю, содержащемуся в соответствующем TFM-файле.
8. За преамбулой следует нуль или более символьных блоков, причем каждый из
этих блоков начинается с байта, имеющего значение < 243. Имеется два формата
символьных блоков — длинный и короткий:
long-char 242 р/[4] ее[4] tfm[4] dvi[pl]. Этот длинный формат задает некоторый
виртуальный символ в общем виде.
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 261
short-charO .. short.ehar2J^l pl[l] cc[l] tfm[3] dvi[pl]. Этот короткий формат задает
некоторый виртуальный символ в случае, когда 0 < pi < 242 и 0 < се < 256 и
О < tfm < 224.
Здесь pi показывает длину блока, следуя значению tfm; се есть код символа; tfm
представляет собой ширину символа, скопированную из соответствующего TFM-файла для
данного виртуального шрифта. Для любого заданного ее-кода должен быть
определен по крайней мере один символьный блок.
В определениях символьных блоков dvi-байты представляют собой
последовательности завершенных DVI-команд, имеющие вложенную структуру в соответствии
со значениями push и pop. Разрешается использовать все DVI-операции, за
исключением bop, еор и команд с кодами операций > 243. Команды выбора шрифтов (с
fnt-numO no fntf.) должны ссылаться на шрифты, определенные в преамбуле
рассматриваемого VF-файла.
Размерные параметры, появляющиеся в DVI-инструкциях, аналогичны числам
fix.word, т. е. они представляют собой целочисленные множители для 2-20 на кегель
виртуального шрифта. Например, если виртуальный шрифт имеет кегель 10 pt, DVI-
команда, уменьшающая его до 5 pt , представляет собой инструкцию down с
параметром 219. Виртуальный шрифт сам по себе может использоваться в разных размерах,
скажем, 12 pt; в таком случае инструкция down уменьшала бы размер шрифта до
6pt. Каждый из размеров должен быть меньше 224 по абсолютному значению.
Драйверы устройств, обрабатывающие VF-файлы, воспринимают
последовательности сЫ-байтов как подпрограммы или макрокоманды, неявно вкладывая их в push
и pop. Каждая подпрограмма начинается с выполнения операторов w = x = y = z =
0, и с текущего шрифта /, соответствующего номеру шрифта, определенного первым
в преамбуле данного VF-файла (/ будет неопределенным, если нет ни одного такого
шрифта). Как только dm-команды будут выполнены, позиционные регистры h и v
в DVI-формате и текущий шрифт / будут восстановлены в их предыдущих
значениях; тогда, если рассматриваемая подпрограмма была вызвана командой set-char
или set, h увеличивается на TFM-ширину (соответственно промасштабированную)—
совсем так, как если бы набирался обычный простой символ.
9. Вслед за символьными блоками идет тривиальная завершающая
(заключительная) часть VF-файла, состоящая из одного или большего количества байтов, причем
все они имеют значение post (248). Общее число байтов в рассматриваемом VF-файле
должно быть кратно 4.
А здесь — фрагменты файла VPtoVF.web
5. Описание списка свойств в данных о метрике шрифта. Идея, лежащая
в основе формата VPL-файлов, возникла из того обстоятельства, что подготовку
точного и детального описания шрифтов, необходимого программам набора текстов,
подобных ТЁХ'у? иногда приходится осуществлять вручную. Формат для
представления вложенных друг в друга списков свойств дает возможность проделывать это
достаточно удобным способом.
Для грамматического разбора и обработки VPL-файлов требуется довольно
значительный объем работы. Заставлять T^jX проделывать эту работу всякий раз, когда
он загружает шрифт — явно нерационально. T^jX имеет дело только с компактными
описаниями метрических данных шрифтов; эти данные содержатся в TFM-файлах.
262
Компьютерная типография
Однако представлены они настолько компактно, что никому кроме компьютера
разобраться в них невозможно.
Драйверам устройств также необходим компактный способ описания
отображений Т^Х'овских представлений о шрифтах в реальные литеры, которые будут
порождаться соответствующими устройствами. Если имеется упакованная
последовательность байтов, именуемая VF-файлом, то они смогут эффективно выполнять эти
действия.
Цель программы VPtoVF состоит в преобразовании текстового файла, удобного
для восприятия пользователем, в двоичные файлы, ориентированные на восприятие
их компьютером. У VPtoVF есть «парная» программа с именем VFtoVP, реализующая
обратную операцию .
7. VPL-файл подобен PL-файлу, однако по сравнению с ним содержит некоторую
добавочную информацию. Поэтому вначале рассмотрим, каким образом формируются
PL-файлы. Материал, представленный в следующих нескольких разделах,
скопирован из программы PLtoTF.
Рассматриваемый PL-файл представляет собой список элементов вида
(PROPERTYNAME VALUE)
где «имя свойства» (PROPERTY NAME) — одно из конечного множества имен,
понимаемых рассматриваемой программой, а «значение» (VALUE) может опять быть
некоторым списком свойств. Лучше всего обсуждаемые идеи можно понять на примере,
так что давайте рассмотрим фрагмент PL-файла для некоторого гипотетического
шрифта.
(FAMILY NOVA)
(FACE F MIE)
(CODINGSCHEME ASCII)
(DESIGNSIZE D 10)
(DESIGNUNITS D 18)
(COMMENT A COMMENT IS IGNORED)
(COMMENT (EXCEPT THIS ONE ISN'T))
(COMMENT (ACTUALLY IT IS, EVEN THOUGH
IT SAYS IT ISN'T))
(FONTDIMEN
(SLANT R -.25)
(SPACE D 6)
(SHRINK D 2)
(STRETCH D 3)
(XHEIGHT R 10.55)
(QUAD D 18)
)
(LIGTABLE
(LABEL С f)
(LIG С f 0 200)
(SKIP D 1)
1 Программа-утилита VPtoVF преобразует VPL-файл в эквивалентную ему пару файлов:
VF-файл (файл описания виртуального шрифта) и TFM-файл (ТЁХ'овский файл шрифтовой
метрической информации)
Программа VFtoVP преобразует пару из VF-файл а и соответствующего ему TFM-файла
в эквивалентный этой паре VPL-файл. — Прим. перев.
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 263
(LABEL 0 200)
(LIG С i 0 201)
(KRN 0 51 R 1.5)
(/LIG С ? С f)
(STOP)
)
(CHARACTER С f
(CHARWD D 6)
(CHARHT R 13.5)
(CHARIC R 1.5)
)
Из этого примера видно, что шрифт, для которого представлена метрическая
информация, принадлежит к гипотетическому семейству (FAMILY) NOVA; код (MIE),
характеризующий его начертание (FACE), показывает, что данный шрифт имеет нормальную
жирность (Medium), курсивное начертание (Italic) и что он расширенный (Extended);
литеры рассматриваемого шрифта используют ASCII-кодировку (CODINGSCHEME).
Кегель (DESIGNSIZE) данного шрифта составляет 10 pt, а все остальные размеры в этом
PL-файле даны в единицах (units) таких, что 18 единиц равны кеглю.
Описываемый шрифт является наклонным (SLANT) со значением параметра наклона, равным
—.25 (т. е. буквы из этого шрифта имеют фактически обратный наклон — возможно
именно поэтому семейству шрифтов и было дано имя NOVA). Нормальное расстояние
между словами (SPACE) составляет б единиц (т. е. одна треть от кегля в 18 единиц), с
клеем, который сжимается (SHRINK) на 2 единицы или растягивается (STRETCH) на 3
единицы. Буквы, для которых не требуется из-за акцентов увеличивать или
уменьшать размер, имеют высоту (XHEIGHT) 10.55 единиц и интервал в 1 em, равный 18
единицам.
Таблица лигатур (LIGATURE) в рассматриваемом примере несколько более
запутанна. Она определяет, что если за буквой f следует другая буква f, то ее код
меняется на '200, если за кодом '200 идет буква i, то он меняется на код '201; считается,
что коды '200 и '201 представляют лигатуры 'ff' и 'fn'. Более того, в обоих случаях
(буква f и код '200), если следующая литера имеет код '51 (это правая скобка), перед
'51 следует вставить дополнительный промежуток размером в 1.5 единицы. (Строка
'SKIP D 1' пропускает одну команду LIG или KRN, которая в данном случае будет
второй командой LIG; таким способом организуется работа двух различных программ
формирования лигатуры/кернинга.) Еще один пример—хотя и довольно-таки
странный—это «умные лигатуры» («smart ligatures»), введенные в Т^Х'е версии 3.0. Если
за буквой f или кодом '200 следует литера «знак вопроса», то знак вопроса
заменяется буквой f и запускается программа формирования лигатур. Это значит, что
пара литер 'f ?' станет лигатурой 'ff', а тройки литер 'ff ?' или 'f?f —лигатурой 'fff.
Если вместо команды /LIG содержится команда /LIG>, перезапуск будет пропущен;
(f?' станет 'ff, a 'f?f' станет 'fff'.)
В рассматриваемом примере литера f имеет собственную ширину в б единиц, а
высоту —13.5 единиц. Глубина ее равна нулю (так как не задано значение CHARDP), а
ее поправка на курсив составляет 1.5 единицы.
8. Приведенный выше пример иллюстрирует большую часть характерных
особенностей PL-файлов. Отметим, что ряд свойств, в частности, с именами FAMILY или
COMMENT, в качестве значения имеют символьную строку, признаком завершения этой
строки является первая несбалансированная правая скобка. Однако большинство
свойств, например, с именами DESIGNSIZE, SLANT и LABEL, имеют числовые значе-
264
Компьютерная типография
ния. Соответствующее число может быть выражено несколькими способами. Вид
используемого способа задается соответствующей префиксной буквой: D — для
десятичного представления числа, Н —для шестнадцатеричного, 0 —для восьмеричного,
R —для действительных чисел, С —для литер, F —для значения типа «face» .
Некоторые другие свойства (LIG, например) характеризуются двумя числами в качестве
их значений. Есть еще и такие свойства, как FONTDIMEN, LIGTABLE и CHARACTER,
значения которых имеют более сложную структуру, включающую в качестве составного
элемента и списки свойств.
Имя соответствующего свойства может появляться только в определенных,
допустимых для него списках свойств. Например, имя CHARWD не может появиться на
внешнем уровне или внутри FONTDIMEN.
Индивидуальные пары «свойство-значение» (property-and-value) в списке свойств
могут следовать.в любом порядке. В частности, в рассмотренном выше примере,
свойство 'SHRINK' предшествует свойству 'STRETCH', хотя в TFM-файле всегда первым
записывается значение для параметра растяжимости. Можно было бы дать даже
информацию о литерах наподобие 'f еще до того, как задано число единиц (units)
в кегле, или до того, как сформирована таблица лигатур или кернинга. Свойство
LIGTABLE, однако, является исключением из этого правила. Индивидуальные
элементы из списка свойств LIGTABLE могут быть переупорядочены только в пределах
некоторого фрагмента этого списка и так, чтобы при этом значение таблицы не
менялось.
Если пары «свойство-значение» опущены, используются значения свойств по
умолчанию. В частности, выше уже отмечалось, что значение по умолчанию для
свойства CHARDP равно нулю. Фактически для каждого из свойств,
характеризующихся числовыми значениями, в качестве значения по умолчанию принято нулевое,
если не оговорено другое.
Если одно и то же имя свойства используется более чем один раз,
программа VPtoVF не заметит этого противоречия, она будет просто использовать последнее
из встретившихся значений. И опять, список свойств LIGTABLE представляет собой
исключение из общего правила. Программа VPtoVF выдаст соответствующее
диагностическое сообщение, если обнаружит, что для некоторой литеры имеется более чем
одна метка. И конечно многие из элементов в списке свойств LIGTABLE имеют
одинаковые имена.
9. VPL-файл включает также информацию о том, как создать каждую из литер,
путем ли выбора литер из других шрифтов, путем ли рисования линий и т. д.
Такого рода информация является значением свойства 'MAP'. Это свойство может быть
проиллюстрировано следующим примером:
(MAPFONT D О (FONTNAME Times-Roman))
(MAPFONT D 1 (FONTNAME Symbol))
(MAPFONT D 2 (FONTNAME cmrlO)(FONTAT D 20))
(CHARACTER 0 0 (MAP (SELECTFONT D 1)(SETCHAR С G)))
(CHARACTER 0 76 (MAP (SETCHAR 0 277)))
(CHARACTER D 197 (MAP
(PUSH)(SETCHAR С A)(POP)
(MOVEUP R 0.937)(MOVERIGHT R 1.5)(SETCHAR 0 312)))
(CHARACTER 0 200 (MAP (M0VED0WN R 2.1)(SETRULE R 1 R 8)))
См. описание свойства FACE на с. 263. — Прим. перев.
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 265
(CHARACTER 0 201 (MAP
(SPECIAL ps: /SaveGray currentgray def .5 setgray)
(SELECTFONT D 2)(SETCHAR С А)
(SPECIAL ps: SaveGray setgray)))
(Эти спецификации записываются в дополнение к обычной информации,
содержащейся в PL-файле. Атрибут MAP может комбинироваться с другими атрибутами вроде
CHARWD, или же его можно дать отдельно).
В данном примере формируемый виртуальный шрифт составляется из литер,
которые берутся из трех реальных шрифтов: 'Times-Roman', 'Symbol' и 'cmrlO at 20\u'
(где \u — единичный размер (unit size) в данном VPL-файле). Литера с восьмеричным
номером 'О набирается как 'G' из шрифта Symbol, литера '76 —как символ '277 из
обычного шрифта Times. (Если не выбран какой-либо другой шрифт, то по
умолчанию будет использован шрифт с номером 0. Если значение атрибута MAP не задано,
будет использована литера с тем же самым номером из шрифта по умолчанию.)
Более интересен знак с десятичным номером 197. Сначала набирается А (в
шрифте Times, который используется по умолчанию), при этом команда выбора символа
заключается внутрь пары команд PUSH и POP, чтобы была возможность восстановить
первоначальную позицию. Затем, после передвижения вверх на .937 единиц и вправо
на 1.5 единицы, набирается знак акцента '312.
Чтобы напечатать в рассматриваемом виртуальном шрифте литеру с
восьмеричным номером '200, перемещаемся вниз на 2.1 единицы, а затем набираем линейку.
Наконец, чтобы набрать символ '201, надо проделать ряд действий, требующих
умения интерпретировать команды языка PostScript. В данном примере значение
PostScript-параметра «color» (цвет) устанавливается равным 50% серого, а затем в
этом «цвете» набирается 'А' из шрифта cmrlO at 20\u.
В общем случае, атрибут MAP для некоторого виртуального символа может иметь
любую последовательность команд набора, которые могут пояёиться на странице
некоторого DVI-файла. Можно даже на целую страницу отобразить единственный
символ.
10. Теперь, закончив анализ этого гипотетического примера, рассмотрим полную
грамматику VPL-файлов, начиная с (оставшихся неизменными) грамматических
правил для PL-файлов. На самом высоком (outermost) уровне в любом PL-файле имеют
силу свойства со следующими именами:
CHECKSUM (четырехбайтовое значение). Значение этого свойства, которое должно быть
неотрицательным целым числом, меньшим чем 2 , используется для
идентификации конкретного варианта шрифта; оно должно совпадать со значением
контрольной суммы, хранящимся в самом шрифте. Если значение этого свойства
в явном виде задано равным нулю, то это означает требование не выполнять
проверку совпадения указанных контрольных сумм. Если в VPL-файле контрольная
сумма не задана, программа VPtoVF вычислит такое ее значение, которое было
бы получено METRFONT'om для этих же самых данных.
DESIGNSIZE (числовое значение, по умолчанию равное 10). Значение этого свойства,
которое должно быть действительным числом из диапазона 1.0 < х < 2048,
используется по умолчанию для масштабирования всех других числовых
параметров, если только шрифт не загружается со спецификатором 'at'. Например,
если записать Т^Х'овское предложение вида '\f ont\A=cmrl0 at 15pt', то кегель,
заданный в соответствующем TFM-файле, будет заменен на величину, равную 15
266
Компьютерная типография
pt; однако же если записать просто '\f ont\A=cmrlO', будет использован
установленный выше размер. Этот параметр задается всегда в единицах разрешающей
способности печатающего устройства.
DESIGNUNITS (числовое значение, по умолчанию равное 1). Значение этого свойства
должно быть положительным действительным числом. Оно устанавливает, чему
в единицах (units) равняется кегель (или же возможный 'at'-размер, если шрифт
подвергается масштабированию). Пусть, например, имеется шрифт,
оцифрованный с 600 пикселями на 1 em, а кегель его равен 1 em. В этом случае можно
было бы записать '(DESIGNUNITS R 600)', если требуется, чтобы все измерения
записывались в пикселях.
CODINGSCHEME (строчное значение, по умолчанию равное 'UNSPECIFIED'). Символьная
строка, являющаяся значением данного свойства, не должна содержать скобок,
ее длина должна быть меньше 10. Она устанавливает соответствие между
числовыми кодами и литерами (символами) шрифта. СЩХ эту информацию не
использует, но она может потребоваться другим программам.)
FAMILY (строчное значение, по умолчанию равное 'UNSPECIFIED'). Символьная
строка, являющаяся значением данного свойства, не должна содержать скобок, ее
длина должна быть меньше 20. Она задает имя семейства, к которому
относится данный шрифт, например, 'HELVETICA'. (Т^Х эту информацию пропускает, но
она потребуется, например, если будет выполняться преобразование DVI-файлов
в PRESS-файлы для оборудования Xerox.)
FACE (однобайтовое значение). Это число, значение которого должно лежать в
диапазоне от 0 до 255 включительно, служит для дополнительной идентификации
рассматриваемого шрифта в пределах семейства, к которому он относится.
Например, полужирные суженные курсивные шрифты (bold italic condensed fonts)
могут иметь одно и то же имя семейства со светлыми расширенными
шрифтами прямого начертания (light roman extended fonts), различать их будет только
значение параметра (байта) FACE. (Т^Х эту информацию не использует, но она
потребуется, например, если будет выполняться преобразование DVI-файлов в
PRESS-файлы для оборудования Xerox.)
SEVENBITSAFEFLAG (строчное значение, по умолчанию равное 'FALSE'). Начальное
значение этого свойства должно быть либо 'Т' (true), либо 'F' (false). Если оно равно
«true», коды символов, меньшие 128, никогда не приведут к кодам 128 и больше
через лигатуры, списки символов или расширяемые символы. (1^X82 не
нуждается в этом флаге, но более старые версии Т^Х'а допускают только TFM-файлы в
семибитовой кодировке. Программа VPtoVF вычисляет правильное значение
этого флага и выдает сообщение об ошибке, только если заданное значение «true»
некорректно.
HEADER (однобайтовое значение, за которым следует четырехбайтовое значение).
Однобайтовая часть значения этого свойства должна лежать между 18 и
максимумом, величина которого может увеличиваться или уменьшаться в зависимости
от значения параметра периода компиляции maxJieader-bytes.
Четырехбайтовая часть входит в заголовочное слово, индексом которого является
однобайтовое значение; например, чтобы установить header[lS] <— 1, можно записать
'(HEADER D 18 0 1)'. Эта нотация используется для заголовочной информации,
которая в настоящее время является неименованной. СЩХ не использует ее.)
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 267
FONTDIMEN (значением является список свойств). См. ниже для тех имен,
использование которых допускается в данном списке свойств.
LIGTABLE (значением является список свойств). См. ниже относительно правил для
этого специализированного списка свойств.
BOUNDARYCHAR (однобайтовое значение). Если этот ограничивающий символ
появится в команде LIGTABLE, он задает «конец слова», символизируя его собой. Если
никакого ограничивающего символа не задано, и внутри LIGTABLE нет LABEL
BOUNDARYCHAR, границы слов никак не влияют на формирование лигатур и
кернинг.
CHARACTER. Значение этого свойства состоит из однобайтового целого числа, за
которым следует список свойств. Целое число представляет собой номер символа,
имеющегося в шрифте; список свойств для некоторого произвольного символа
определяется ниже. Значением этого свойства по умолчанию является пустой
список свойств.
11. Числовые значения для элементов списка свойств могут задаваться в различной
форме, которая определяется префиксной буквой.
С обозначает ASCII-символ, который должен быть стандартным видимым
(отображаемым) знаком, но не скобкой. Числовое значение его поэтому будет лежать
между '^1 и '176 (кроме '50 и '51).
D обозначает десятичное целое число без знака, которое должно быть меньше 232,
т. е. наибольшая его величина 'D 4294967295'.
F обозначает трехбуквенный код Xerox (face code) для указания вида шрифта;
допустимыми кодами являются MRR, MIR, BRR, BIR, LRR, LIR, MRC, MIC, BRC, BIC, LRC,
LIC, MRE, MIE, BRE, В IE, LRE и LIE, обозначающие целые числа от 0 до 17
соответственно.
О обозначает восьмеричное целое число без знака, которое должно быть меньше 232,
т. е. наибольшее допустимое значение его '0 37777777777'.
Н обозначает шестнадцатеричное целое число без знака, которое должно быть меньше
232, т. е. наибольшее допустимое значение его 'Н FFFFFFFF'.
R обозначает действительное число в десятичной записи, которому, возможно,
предшествует знак '+' или '-', и включающее, возможно, десятичную точку.
Абсолютное значение этого числа должно быть меньше 2048.
12. Имена свойств, которые могут включаться в список свойств FONTDIMEN,
соответствуют различным ТЩХ'овским параметрам, каждый из которых имеет значение в
виде (действительного) числа. Все эти параметры, кроме SLANT, измеряются в
проектных единицах. В список допустимых включаются следующие имена: SLANT, SPACE,
STRETCH, SHRINK, XHEIGHT, QUAD, EXTRASPACE, NUM1, NUM2, NUM3, DEN0M1, DEN0M2, SUP1,
SUP2, SUP3, SUB1, SUB2, SUPDROP, SUBDROP, DELIM1, DELIM2 и AXISHEIGHT, для
параметров от 1 до 22. Для параметров с номерами от 8 до 13 могут также
использоваться альтернативные имена DEFAULTRULETHICKNESS, BIG0PSPACING1, BIG0PSPACING2,
BIG0PSPACING3, BIG0PSPACING4 и BIG0PSPACING5.
Обозначение вида 'PARAMETER n' представляет собой другой способ задания п-го
параметра; например, '(PARAMETER D 1 R -.25)' —альтернативный способ указать,
что свойство SLANT имеет значение, равное —0.25. Значение п здесь должно быть
положительным и меньшим, чем значение параметра maxjparamjwords.
268
Компьютерная типография
13. Элементы списка свойств CHARACTER могут принадлежать к одному из следующих
шести типов.
CHARWD (значение — действительное число) обозначает ширину литеры в проектных
единицах.
CHARHT (значение — действительное число) обозначает высоту литеры в проектных
единицах.
CHARDP (значение — действительное число) обозначает глубину литеры в проектных
единицах.
CHARIC (значение — действительное число) обозначает поправку на курсив литеры в
проектных единицах.
NEXTLARGER (однобайтовое значение) задает литеру, которая идет следующей за
рассматриваемой в «списке литер» («charlist»). Это значение должно быть номером
литеры в шрифте, причем не должно быть циклов, бесконечных по номеру
литеры.
VARCHAR (значение — список свойств) задает некоторый расширяемый (extensible)
символ (литеру). Этот элемент и NEXTLARGER являются взаимно исключающими, т. е.
их нельзя использовать совместно в рамках одного и того же списка CHARACTER.
Элементами списка свойств VARCHAR могут быть TOP, MID, ВОТ или REP; все они
имеют целочисленные значения, равные либо нулю, либо номеру требуемой литеры в
рассматриваемом шрифте. Нулевая величина для TOP, MID или ВОТ означает, что
соответствующий фрагмент рассматриваемого расширяемого символа отсутствует.
Ненулевые значения этих параметров, или нулевое значение для REP, обозначает код
символа, используемого для верхнего, среднего, нижнего или повторяемого
фрагмента расширяемого символа.
14. Список свойств LIGTABLE содержит элементы четырех видов, задающие
некоторую программу на простом командном языке, который используется ТЩХ'ом для
формирования лигатур и кернинга. Если имеется несколько списков LIGTABLE,
производится их объединение (путем сцепления) в единый список.
LABEL (однобайтовое значение) показывает, что здесь начинается программа для
установленного значения символа. Номером символа в шрифте должно быть целое
число; список свойств CHARACTER для данного символа не должен содержать
полей NEXTLARGER или VARCHAR. За элементом LABEL должен следовать по крайней
мере один элемент LIG или KRN.
LABEL BOUNDARYCHAR означает, что здесь начинается программа для лигатур в начале
слова.
LIG (два однобайтовых значения). Инструкция вида '(LIG с г)' означает, что «если
следующим символом является с, то вставить символ г и, возможно, удалить
текущий символ с; в противном случае перейти к следующей инструкции».
Символы г и с должны содержаться в рассматриваемом шрифте. Непосредственно
перед LIG и/или сразу после нее можно ставить слэш ('/')» а затем могут
следовать знаки > , которых должно быть не больше, чем число используемых знаков
1 /*. Соблюдение этих правил дает восемь возможных форм записи для LIG:
LIG /LIG /LIG> LIG/ LIG/> /LIG/ /LIG/> /LIG/»
Слэши V задают сохранение левого или правого символа, присутствующего
в первоначальной записи, а символ > задает передачу результатов дальше, без
продолжения процесса обработки лигатур.
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 269
KRN (однобайтовое значение и значение в виде действительного числа).
Инструкция '(KRN с г)' говорит о том, что «если следующим символом является с, то
вставить пробел ширины г между текущим символом и с; в противном случае
перейти к следующей инструкции». Значение параметра г, задаваемое в
проектных единицах, часто бывает отрицательным. Символ с должен присутствовать
в рассматриваемом шрифте.
STOP (не имеет значения). Эта инструкция завершает программу формирования
лигатур/кернинга. Она должна следовать за инструкцией LIG или KRN, но не LABEL,
STOP, или SKIP.
SKIP (значение в диапазоне 0 .. 127). Эта инструкция задает продолжение программы
формирования лигатур/кернинга после пропуска определенного числа шагов LIG
или KRN. Число идущих подряд инструкций LIG и KRN должно, следовательно,
превышать величину, задаваемую рассматриваемой инструкцией.
15. В дополнение ко всем этим возможностям, в любом списке свойств допускается
использование свойства с именем COMMENT (комментарий). Комментарии, включенные
в списки свойств, при обработке пропускаются.
16. Свойства, описанные выше, содержатся в PL-файле. В VPL-файле распознаются
также еще и дополнительные свойства; следующие два из них действительны на
самом верхнем уровне:
VTITLE (строчное значение, по умолчанию — пустая строка). Значение этого
свойства воспроизводится в начале VF-файла (и печатается на терминале программой
VFtoVP, когда она просматривает данный файл).
MAPF0NT. Значением этого свойства является неотрицательное целое число, за
которым следует список свойств. Целочисленная часть значения представляет собой
идентификационный номер для шрифтов, используемых в атрибутах MAP. Список
свойств, который задает шрифт и относительный размер, определяется ниже.
И одно дополнительное «виртуальное свойство», имеющее место внутри списка
CHARACTER:
MAP. Значением его является список свойств, содержащий команды набора. Значением
по умолчанию, будет единственная команда SETCHAR с, где с —номер текущего
рассматриваемого символа.
17. Элементы списка свойств MAPF0NT могут быть одного из следующих типов.
FONTNAME (строчное значение, по умолчанию —NULL). Это имя, идентифицирующее
шрифт.
F0NTAREA (строчное значение, по умолчанию — пустая строка). Если шрифт, согласно
принятым местным правилам, содержится в нестандартном каталоге, то в
данном свойстве задается соответствующее имя каталога. (Это свойство является
системно-зависимым, подобно тому как это имеет место для DVI-файлов.)
FONTCHECKSUM (четырехбайтовое значение, по умолчанию равное нулю). Значение
этого свойства, которое должно быть неотрицательным целым числом, меньшим,
чем 232, может использоваться для проверки соответствия упоминаемого шрифта
и загружаемого шрифта. Если данное свойство имеет ненулевое значение,
требуется, чтобы оно совпадало со значением параметра CHECKSUM в подключаемом
' шрифте.
270
Компьютерная типография
F0NTAT (числовое значение, по умолчанию равно значению DESIGNUNITS в
рассматриваемом виртуальном шрифте). Значение этого свойства устанавливается
относительно проектных единиц для рассматриваемого виртуального шрифта,
следовательно, оно будет меняться, если данный виртуальный шрифт увеличивается
или уменьшается. Оно представляет собой значение, которым будет заменен
кегель рассматриваемого шрифта, так что все символы будут промасштабированы
соответствующим образом.
FONTDSIZE (числовое значение, по умолчанию равно 10). Значение этого свойства
является абсолютным и измеряется в единицах разрешающей способности
принтера). Оно должно быть равно значению параметра DESIGNSIZE для
рассматриваемого шрифта.
Если в каком-либо из строчных значений содержатся скобки, то они должны быть
сбалансированы, т. е. число открывающихся и закрывающихся скобок должно
совпадать. Головные пробелы в таких строках удаляются, тогда как завершающие —
оставляются неизменными.
18. Наконец, элементы списка свойств MAP представляют собой упорядоченную
последовательность команд набора, выбранных из следующего перечня:
SELECTF0NT (четырехбайтовое целое значение). Значением этого свойства должен
быть номер из ранее определенного свойства MAPF0NT. Этот шрифт (или, более
точно, последний по порядку следования шрифт, который отображается в
данную кодовую страницу, если случится так, что имеются два свойства MAPF0NT,
задающих один и тот же код) будет использоваться в следующих друг за
другом инструкциях SETCHAR до тех пор, пока не будет заменен с помощью другой
инструкции SELECTF0NT. До того момента, как выполнена первая инструкция
SELECTF0NT, для отображения каждого из символов неявно выбирается первое
по порядку следования определение для MAPF0NT.
SETCHAR (однобайтовое целое значение). В текущем выбранном шрифте должен быть
символ с этим номером. (Программа VPtoVF не проверяет допустимость данного
символа, в то время как программа VFtoVP делает это.) Этот символ набирается
в данной текущей позиции, после чего «головка наборного устройства»
перемещается вправо на расстояние, определяемое для рассматриваемого символа
параметром CHARWD в TFM-файле для соответствующего шрифта.
SETRULE (два значения, представляющие собой действительные числа). Первое из
значений, связанное с данным свойством, представляет собой высоту линейки,
а второе — ее ширину, оба — в проектных единицах. Если значения и высоты,
и ширины положительны, набирается сплошной черный прямоугольник, левый
нижний угол которого находится в текущей позиции набора. Затем наборное
устройство смещается вправо на заданную ширину.
MOVERIGHT, MOVELEFT, MOVEUP, M0VED0WN (значения — действительные числа). Наборное
устройство изменяет свою текущую позицию в соответствующем направлении
(вправо, влево, вверх и вниз соответственно) на заданное число проектных
единиц.
PUSH. Запоминается текущая позиция наборного устройства, которая может быть
восстановлена с помощью следующей далее команды POP.
POP. Восстанавливается текущая позиция наборного устройства соответственно самой
последней по порядку позиции, сохраненной с помощью команды PUSH. Команды
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 271
PUSH и POP в любом свойстве MAP должны быть расположены соответствующим
образом, наподобие сбалансированных скобок.
SPECIAL (строчное значение). Последовательность символов (литер), начиная с
первого символа, отличного от пробела, заканчивающаяся перед первым символом ')',
для которого нет парного ему символа 'С. Она интерпретируется в соответствии
с некоторыми локальными соглашениями, с тем же самым системно-зависимым
значением, что и команда 'special' (xxx) в DVI-файле.
SPECIALHEX (шестнадцатеричное строчное значение). Последовательность символов,
отличных от пробела, продолжающаяся до следующего символа ')', должна
состоять целиком из шестнадцатеричных цифр и включать четное число таких
цифр. Каждая пара шестнадцатеричных цифр задает байт и эта строка из байтов
интерпретируется как значение для SPECIAL. (Это соглашение позволяет
представлять произвольные байтовые строки в обычном текстовом файле.)
19. Отображение виртуального шрифта представляет собой рекурсивный
процесс, наподобие макрорасширения (т. е. развертывания макроопределения). Поэтому
MAPF0NT может задать другой виртуальный шрифт, символы которого опять
отображаются в другие шрифты. В качестве примера, иллюстрирующего такого рода
возможность, рассмотрим следующий любопытный файл с именем recurse.vpl, в
котором описывается виртуальный шрифт, являющийся самодостаточным и
ссылающимся рекурсивно только на самого себя:
(VTITLE Example of recursion)
(MAPFONT D 0 (FONTNAME recurse)(FONTAT D 2))
(CHARACTER С А
(CHARWD D 1HCHARHT D 1) (MAP (SETRULE D 1 D 1)))
(CHARACTER С В
(CHARWD D 2HCHARHT D 2) (MAP (SETCHAR С A)))
(CHARACTER С С
(CHARWD D 4HCHARHT D 4) (MAP (SETCHAR С В)))
Кегель этого шрифта равен 10 pt (значение по умолчанию), следовательно, литера А
в шрифте recurse представляет собой черный квадрат размера 10 х 10 pt. Литера В
набирается как литера А из шрифта recurse scaled 2000, т. е. это — черный квадрат
размера 20 х 20 pt. И, наконец, литера С набирается как литера В из шрифта recurse
scaled 2000, т. е. ее размер будет 40 х 40 pt.
Разработчики виртуальных шрифтов должны проявлять осмотрительность,
чтобы избежать бесконечной рекурсии.
Новости из издательства St. Anford Press
[Для выпуска 24 августа 1988 г.]
Мы предлагаем шрифтовую гарнитуру San Serifo, названную в честь Сан Се-
рифо, знаменитого мученика, чья жизнь была описана отцом Фонтом в 1776 г.
Японские пользователи имеют возможность отдать предпочтение варианту
этой гарнитуры с именем Serifu-San.
Дизайнер этих шрифтов Б. О. Дони утверждает, что на ее смелое решение
повлияли, в первую очередь, недавние брошюры из словолитен, в которых
термин «sans serif» пишется как sans s, т. е. «без s». Она в настоящее время
работает над шрифтом sans-stem, т. е. «без штриха», который должен быть
выпущен в свет в следующем году.
Шрифты в гарнитурах San Serifo и Serifu-San доступны в различной
жирности (weights), от «сверхлегкой» (ultralite) до «тучной» (obese), а также во
всех основных цифровых форматах, включая FalseTypeDM для изготовления
фальшивых немецких марок.
Буква S
[Первоначально опубликовано в The Mathematical Intelligencer 2 (1980),
114-122.]
Несколько лет назад, когда я начал задумываться над проблемой создания
алфавитов, приспособленных для современного типографского оборудования,
я обнаружил, что справиться с 25 буквами сравнительно легко. Оставалась
буква S* Три дня и три ночи я мучился, пытаясь понять, как же определить
правильную форму буквы S. Решение, к которому я в конце концов пришел,
требует привлечения некоторых небезынтересных математических методов,
и мне кажется, что людям, изучающим математический анализ и
аналитическую геометрию, эта проблема будет так же интересна, как и мне в свое
время. В этой статье я хочу объяснить, что сейчас считаю «правильной»
математикой, описывающей печатные буквы S, а также показать пример языка
METflFONT, разработкой которого я в последнее время занимался? (Полное
описание METflFONT'a, который представляет собой компьютерную систему
и язык, призванные помочь в создании начертаний различных букв, можно
найти в [3, часть 3].)
Перед тем как углубиться в технические детали, наверное, стоит
упомянуть, почему я вообще стал беспокоиться о таких вещах. Главная причина в
том, что современная полиграфическая технология большей частью основана
на использовании дискретной математики и информатики, а не на
особенностях металлов или отдельных литер. Сейчас задача создания печатной формы
для страницы в основном сводится к построению огромной матрицы из 0 и 1,
где 0 обозначают пустые места, а 1 — чернильные точки. Я хотел, чтобы второе
издание одной из моих книг было таким же, как первое, хотя это последнее
и было напечатано с использованием старой технологии отливки свинцовых
форм; и когда я обнаружил, что эта задача может быть решена при помощи
1 В английском алфавите 26 букв. — Прим. перев.
2 Все буквы и символы в этой статье были созданы математическими методами при
помощи METfl FONT'a и набраны с использованием экспериментального программного
обеспечения, принадлежащего автору.
274
Компьютерная типография
соответствующих методов дискретной математики и информатики, я не смог
устоять перед соблазном решить ее самому.
Подробнее подоплека моей работы раскрыта в [2], там же обсуждается
история первых попыток подойти к начертанию букв математически. В
частности, там рассказывается о нескольких, предложенных в XVI и XVII вв.
способах строить буквы S геометрически при помощи циркуля и линейки.
Франческо Торниелло в 1517 г. опубликовал геометрический алфавит,
типичный для этих ранних попыток. Рассмотрим его метод построения буквы S
(рис. 1, взятый из [4], с. 45), чтобы почувствовать, с какими проблемами нам
придется столкнуться. Используя современную математическую
терминологию, можно так перефразировать его слова:
Будем чертить букву S в квадрате 9x9, который в декартовых координатах
можно задать как множество точек (я, у), где 0<х<9и0<у<9. Мы
определим 14 точек на границе буквы, обозначив их (ei,2/i), (22,2/2), ••., (214,2/14).
Точка 1 имеет координаты (4.5,9), и из этой точки проводится дуга
окружности с центром (4.5, 5.5) радиуса 3.5 в точку 2, где Х2 = 6. [Таким образом,
2/2 = 5.5 + у/10 « 8.66.] Проводим маленькую дугу радиуса 0.5 с центром
(6.5,9) из точки 3 = (6.5,8.5) в (7,9). Из точки 4 = (6,7) проводим прямую
линию в точку касания с этой маленькой дугой; назовем ее точкой 5. [Далее
мы увидим, что точка 5 имеет координаты (6у| ,8у|); интересно поразмышлять,
насколько такой результат осчастливил бы Торниелло.] Теперь опускаем дугу
радиуса 2 с центром (4, 7) из точки 6 = (4, 9) в точку 7, где x-j = 3, a 2/7 < 7
[таким образом, у7 = 7 — у/3 « 5.27]. Проводим прямую линию из точки 7 в
точку 8 = (5,4). Теперь проводим дугу с центром (4.5, 7|) из точки 4 в
точку 9 = (3.5, 6), продолжая ее прямой линией до точки 10 = (6,4.5). Из этой точки
в точку 11 = (3, 0.5) проводится полуокружность радиуса 2.5 с центром (4.5, 2.5).
Проводим еще одну маленькую дугу радиуса 1 с центром (2.5, у), соединяющую
точку 11 с точкой 12, где £12 = l| [таким образом, у — (1 — \/3)/2 « —0.37, а
2/12 = (\/39 + 4 — 4\/3)/8 « 0.41]. Проводим дуги радиуса 2: одну —из точки 8 в
точку 13, при этом абсцисса центра дуги равна 4, а х\г = 4.5 [таким образом,
центр имеет координаты (4,4 — у/3) « (4,2.27), а 2/13 = 4 — у/3 — \/3.75 « 0.33];
и другую —из точки 13 в точку 14, при этом абсцисса центра дуги равна 4.5, а
Ун = 2 [таким образом, центр имеет координаты (4.5, 6—у/З — у/ЗЛЬ) « (4.5, 2.33),
а
xiA = 4.5 - y/4-(4-\/3-v/375)2,
что приблизительно равно 2.53]. Наконец, прямая линия соединяет точку 14 с
точкой 12.
Для читателя будет интересно взять лист разграфленной бумаги и
воспроизвести конструкцию того времени, перед тем как двинуться дальше. Вообще-то
описание Торниелло было не таким точным, как данное выше: я постарался
почерпнуть из его текста как можно больше информации; кажется, у него с
буквами S возникло не меньше сложностей, чем у меня, потому что все
остальные буквы у него определены гораздо четче. Главное, что я позволил себе
подредактировать, это координаты центра дуги, соединяющей точки 4 и 9:
вместо указанных Торниелло (4.5, 7^) я передвинул центр в расположенную
Глава 13. Буква S
275
Z
Г_1_
S? 1
V
ш
1 1
Рис. 1. Так Франческо Торниелло «вписывал букву S в квадрат» в 1517 г.
рядом точку (4.5,7^), при этом я оставил радиус неопределенным (он
утверждал, что радиус должен равняться 1.5, но на самом деле он равен а/145/8,
что немного больше), причина этого изменения в том, что точка (4.5, 7^-) не
равноудалена от точек 4 и 9.
Заметьте, что дуга окружности, соединяющая точки 10 и 11, касается
линии шрифта в точке (4.5,0) и имеет вертикальную касательную в точке (7,2.5);
это дает прекрасный результат, так как
32+42=52,
и я думаю, Торниелло достаточно хорошо знал математику, чтобы
воспользоваться этим приятным совпадением в своем замысле. Он так и не указал,
какие кривые должны соединять точки 1 и б или точки 2 и 3; очевидно, через
точки 1 и б нужно провести прямолинейный отрезок, а вторая кривая может
быть нарисована как угодно, лишь бы это хорошо смотрелось.
Нахождение точки 5 представляет собой элементарное, но поучительное
упражнение в аналитической геометрии: пусть даны положительные числа h
и г, требуется найти точку (х, у) в верхней правой части окружности радиуса г
с центром в начале координат, такую, что прямая, проведенная из точки (—г, К)
в точку (х,у), касается окружности в точке (х,у) (рис. 2). Имеем: х2 + у2 = г2
и у/х = tg в = (х + r)/(h — у), откуда х2 + гх + у2 — yh = 0 и rx = hy — г2. Это
276
Компьютерная типография
Рис. 2.
Задача, возникающая в
конструкции Торниелло: найти х и у при
заданных rah.
приводит к уравнению (hy — r2)hy + г2 у (у — К) = гх(гх + г2) + г2 у (у — К) = О,
откуда y(h2y — hr2 +r2y — hr2) = О, и вскоре мы приходим к искомому решению
_ h2r - г3 _ 2hr2
Х~ h2+r2 ' У " Л2 + г2 '
Решение представляет собой рациональную функцию от Л и г (т. е. извлечение
квадратных корней не требуется), так как другая точка касания —это (—г,0);
эта вторая точка также удовлетворяет данным уравнениям. Рене Декарту
несомненно понравилась бы такая демонстрация мощи его координатного метода.
Конструкцию Торниелло без особого труда можно выразить на языке
METflFONT, языке, который я в последнее время разрабатывал для задания
формы символов в виде, удобном для компьютерной обработки. Хотя в
построениях при помощи циркуля и линейки на самом деле используется не так
уж и много возможностей METflFONT'a, но кое-что о нем мы можем узнать
уже из этого первого примера.
Опорные точки конкретного чертежа задаются в METAFONT'obckom языке
уравнениями на их абсциссы и ординаты; затем можно сказать 'draw i..j\
чтобы провести прямую линию из точки г в точку j. Можно также сказать
'draw i{a,/3} . .j{7j^}'j чтобы провести кривую, выходящую из точки г в
направлении вектора (а, (3) и приходящую в точку j по направлению (^,5). Эта
кривая будет дугой окружности, если существует окружность, проходящая
через точки г и j в указанных направлениях, и при условии, что дуга составляет
не более половины окружности. Таким образом, конструкция Торниелло в
точности воспроизводится следующей программой для METflFONT'a:
х\ = 4.5щ у\ — 9п;
х2 = бп; у2 - 5.5n = sqrt((3.5u)(3.5u) - (x2-4.5n)(x2-4.5n));
draw l{yi — 5.5u,4.5u — x\) . .2{y2 — 5.5u,4.5u- x2};
x3 = 6.5u; ?/з = 8.5u;
£4 = 6Щ У4 = lu\
K-r,n)
(-r,0)
(s,y)
Глава 13. Буква S
277
хъ = (б + 16/17)и; уъ = (8 + 13/17)и;
draw 3{9и — 2/3, #з - б.5п} . .5{9и — 2/5,^5 — б.5п};
draw 4.. 5;
xq = 4и; уб = 9щ
х7 = Зщ 7и — у7 — sqrt((2u)(2u) - (x7-4n)(x7-4n));
draw 6{7и - 2/6, #6 - A.u) .. 7{7u - 2/7, x7 - 4u};
x$ = Ъщ ys = 4n; draw 7.. 8;
xq = 3.5щ y9 = 6щ
X15 = 4.5u; 2/i5 - 7.125u =
sqrt((x9-4.5n)(x9-4.5n) + (2/9-7.125u)(2/9-7.125u));
draw 4{7.125u - 2/4, x4 - 4.5u} .. 15.. 9{7.125u - 2/9, x9 - 4.5u};
xio = 6u; 2/10 = 4.5n; draw 9.. 10;
xn = Зщ 2/n = .5u;
draw 10{2/ю — 2.5u, 4.5u — xw} .. ll{2/n — 2.5u,4.5u — хц};
xie = 2.5u; 2/11 -2/16 =sqrt((ti)(tO - (жц -х16)(хп -Xi6));
X12 = 1.875u; 2/12 -2/16 =sqrt((tO(tO - (xi2-Xi6)(xi2-Xi6));
draw ll{2/i6 -2/11,^11 -xi6}.. 12{2/i6 -2/12,^12 -sie};
^13 = 4.5u; X17 = 4u;
2/8 -2/17 = sqrt((2u)(2t0 - (xs-xi7)(xs-xi7))\
2/17 -2/13 = sqrt((2u)(2u) - (xi3-Xi7)(xi3-Xi7));
draw 8(2/8 - 2/17, жгг - a*} .. 13(2/13 - 2/17, Ж17 - ^13};
Xi8 =4.5u; 2/I8 -2/13 = sqrt((2u)(2u) - (xi8-xi3)(xi8-xi3));
2/14 = 2u; xis -xu = sqrt((2u)(2u) - (2/18-2/14) (2/18-2/14));
draw 13{2/i3 - 2/18, ^18 - ^13} • • Щуи - 2/is, zie - хы}\
draw 14.. 12.
Здесь «и» —произвольная единица длины, которая может быть
использована в качестве масштабирующего множителя для регулировки общего
размера чертежа. Эта программа на первый взгляд выглядит несколько громоздко,
но на самом деле ее нетрудно понять, если сравнить с неформальным
описанием, данным выше. В программе введены еще несколько точек,
обозначенных 15, 16, 17 и 18; точка 15 нужна, чтобы уговорить METRFONT провести
дугу окружности, большую чем полуокружность, а остальные три точки —
центры окружностей, проводимых в построении. Основное соотношение,
использованное в программе, состоит в том, что дуга окружности с центром
(хк,Ук)> проходящая по часовой стрелке через точку (ж», у»), идет в
направлении {yi — 2/ь Хк — Xi}, проходящая же против часовой стрелки — в направлении
{yk-yi,Xi-Xk}.
На рис. 3 изображено то, что METRFONT нарисует по заданному описанию.
METRFONT также завершит чертеж подходящими кривыми (уже не дугами
окружностей), если добавить команды:
draw 1.. б;
draw 2(2/2 - 5.5u,4.5u- x2} . .3{9и - 2/3,^3 - 6.5u}.
Направления этих новых кривых выбраны так, чтобы касательные к ним
совпадали с касательными к нарисованным ранее кривым в точках их соприкос-
278
Компьютерная типография
б 1
12*
&
ё
\
\
14
4 Ч
11
s', '<
\э
7
17
<
Ч,
i—#-^
15
•-..
4^
, «18
*3 *
ч
4 <
8
\
,-*'
I2 з ..
/
4
10
i
:
*'*
5
• 16
Рис. 3. Программа METRFONT'a в тексте даст это изображение торниелловской
буквы S.
Рис. 4.
Кривая, изображенная на рис. 3,
после завершения и заливки.
новения. Если METflFONT попросить выполнить заливку пространства внутри
ограничивающих кривых, то получится фигура, изображенная на рис. 4.
Дуга окружности, соединяющая точку б с точкой 7, в этой последней
имеет направление {7и — ут,хч — Аи} = {\/Зп, —и}, но ее продолжение — прямая
линия из точки 7 в точку 8 —резко меняет направление на {х$ - хт>у% — у-г) =
Глава 13. Буква S
279
{2u, (\/3 — 3)и}. Этот перегиб на рис. 4 почти незаметен, но с математической
точки зрения это недопустимо. Такие же перегибы имеются в точках 8, 9, 10,
11 и 13, особенно явно они видны в точках 9 и 13; чтобы устранить эти
недостатки, рисунки в книге Торниелло, вероятно, были немного подправлены (о
чем Торниелло не упомянул). По-видимому, в XVI столетии стандарты были
еще не так строги, но сейчас мы не хотим, чтобы компьютеры рисовали нам
такие угловатые линии.
Рис. 5.
Немного видоизменив рис. 4, мы
сделали соединения кривых более
гладкими.
Так как у METflFONT'a нет обязательной привязки к дугам окружностей,
он, как и художник Торниелло, автоматически сделает поправки, достаточно
лишь указать во всех опорных точках совпадающие направления. На рис. 5
изображен результат, если в качестве касательных в точках 7, 8, 9 и 10 взяты
прямолинейные отрезки, а касательная в точке 13 горизонтальна.
Направление кривой в точке 11 соответствует дуге окружности, проведенной из
точки 10. Далее, точка б была смещена относительно точки 1 так, чтобы избежать
неудачного плоского участка вверху. Кривые, проходящие через эти точки,
теперь уже не являются окружностями, но достаточно похожи на них, чтобы
обмануть большинство людей, и вряд ли Торниелло обиделся бы на такое
приближение.
Буква « S » времен Возрождения для современного читателя выглядит
тонковатой. Можно попросить METflFONT сделать ее пожирней, увеличив все
абсциссы на 20%, а ординаты оставив без изменения; на рис. 6 изображен
результат. Заметьте, что такое растяжение превращает окружности в эллипсы.
Если бы Торниелло попробовал описать эту фигуру, используя только дуги
окружностей, он столкнулся бы с серьезными трудностями; можно вспомнить
древних астрономов, которые находили весьма обременительным
использование окружностей вместо эллипсов в качестве моделей для планетарных орбит.
S
280
Компьютерная типография
Рис. 6. Этот рисунок получается растяжением рис. 5 по горизонтали на 20%;
окружности превратились в эллипсы.
На этом примере можно получить некоторое представление о сложностях,
возникающих при определении правильной формы буквы S. Но на самом деле
я искал решение более общей проблемы, чем та, с которой столкнулся Торниел-
ло: вместо того чтобы описать одну конкретную S, мне нужно было множество
различных вариантов, включая полужирные S, которые намного темнее
обычного текста. Недавно я обсуждал это с Эланом Перлисом, который обратил
внимание на то, что главная сложность, возникающая каждый раз, когда мы
хотим что-либо автоматизировать, —это «искусство превращения постоянных
в переменные», как он это называет. В случае рисования букв мы хотим не
просто взять конкретный чертеж и описать его математически, в
действительности мы хотим обнаружить законы, по которым этот чертеж построен, так
чтобы можно было сконструировать функцию от подходящих параметров,
генерирующую бесконечно много чертежей (включая и исходный). Моей целью
было создать целые алфавиты, зависящие от дюжины или от двух параметров,
так чтобы при их варьировании все буквы изменялись сходным образом.
Рассмотрев эти конструкции времен Возрождения и многие современные
варианты начертания буквы S, я пришел к заключению, что основные черты
S-образного изгиба, которые я искал, должны быть подобны изображенным
на рис. 6. Каждая ограничивающая кривая должна быть эллипсом,
переходящим в прямую линию, затем вновь превращающуюся в эллипс. Это привело
меня к постановке следующей задачи: как найти эллипс, самая верхняя точка
которого имеет координаты (xt,yt), а самая левая точка — координаты (xi,yi),
ух произвольно, при этом эллипс должен касаться прямой с угловым коэффи-
Глава 13. Буква S
281
циентом сг, проходящей через точку (хс,?/с), при заданных х*, yt, х/, сг, хс и
ус ? (Большая и малая оси искомого эллипса должны быть параллельны осям
координат; иными словами, эллипс должен быть симметричен относительно
горизонтали и вертикали. См. рис. 7 на следующей странице.) Причины
постановки такой задачи должны быть ясны из предшествующего обсуждения: мы
знаем точку, которая должна быть верхней точкой S-образного изгиба, знаем
также, как далеко влево продолжается этот изгиб, кроме того, мы помним про
прямую, соединяющую верхнюю и нижнюю части изгиба.
Задача, сформулированная в предыдущем абзаце, интересна для меня по
нескольким причинам. Во-первых, у нее, как мы увидим, красивый ответ. Во-
вторых, этот ответ действительно приводит к приемлемым S-образным
изгибам. В-третьих, этот ответ не так уж и тривиален; в течение около двух лет я
четырежды натыкался на эту задачу и каждый раз не мог найти свои записи с
ее решением, так что я проводил несколько часов, выводя эти формулы снова
и снова каждый раз, когда они мне требовались. Наконец, я решил написать
эту статью, чтобы больше мне не пришлось выводить ответ заново.
Точка (xt, yi) — центр искомого эллипса. Пусть (х, у) — точка касания этого
эллипса с прямой, имеющей угловой коэффициент сг и проходящей через точку
(хс, ус), как показано на рис. 7. Наша задача сводится к решению системы трех
уравнений с тремя неизвестными х, у и yi:
xi-xtj
Vt
V
-yi
Ус-
Хс "~
x —
;
•у
■ x
xt
-х=<Г' ^
y^)—■-=,.
Xl-XtJ У-У1
Первое из этих уравнений — стандартное уравнение эллипса, второе
—стандартное уравнение для углового коэффициента; третье получается, если
продифференцировать первое:
x-xt у-у\
2dx- — + 2dy- — = 0,
(xi - xt)2 (yt - yiY
и положить dy/dx равным сг.
Перед тем как попытаться решить систему уравнений (*), мне хотелось
бы ввести обозначение, которое весьма помогало мне в моей работе по
математическому описанию шрифтов. Будем использовать а[х, у] как сокращение
для
х + а(у - х),
что можно воспринимать как «а часть пути от х до у». Таким образом,
0[х, у] = х; 1[х,у] = у; |[х, у] — это середина отрезка с концами х и у; | [х, у] —
точка, расположенная на полпути между этой серединой и точкой у; а 2[х, у]
282 Компьютерная типография
Ы,Уг)
(xhVi)
Рис. 7.
Задача: найти х, у и yi при за- х v_f
данных я*, У*, я*, or, zc и yc. \хс,Ус)
расположена на том же расстоянии от у, что и х, но с другой стороны.
Легко выводятся тождества типа а[х,х] = х и а[х,у] = (1 — а)[у, я]. Производя
различные геометрические построения, часто приходится обращаться к таким
объектам, как точка в трети пути от А до В\ именно это и обозначает запись
|[А, В]. Я называю это «связующей».
Одно из применений записи с квадратными скобками состоит в
нахождении пересечения (я, у) двух данных прямых, одна из которых проходит через
точки (xi,yi) и (х2,у2), а другая —через (х3,уз) и (£4,2/4). Это пересечение
можно найти, заметив, что существуют некоторое число а, такое, что
х = а[хх,х2] У = а[уьу2],
и некоторое число /?, такое, что
х- /3[х3,ж4] 2/ = /?[г/з,2/4].
Систему этих четырех линейных уравнений легко решить относительно х, у,
а и /3; и на самом деле METflFONT автоматически решает системы линейных
уравнений, что позволяет в программах METflFONT'а легко находить
пересечение прямых.
Существует также любопытное применение записи с квадратными
скобками к эллипсам. В общем уравнении эллипса
,2 / \2
( х-хр \ / у-уо \ =1
\ ^тах ~~ #0 / \ Утах "" У0 /
можно ввести обозначения х = а[хо, хтах] и у = /3[уо, Утах], сведя его к гораздо
более простому уравнению
а2+/?2 = 1.
Возвращаясь к нашей задаче про эллипс, положим
x = a[xt,xl], y = (3[yi,yt),
X = х - xt, Y = yt-yt,
а = xi-xt, b = (ус - ахс) - (yt - <rxt).
Глава 13. Буква S
283
Теперь систему (*) можно переписать в следующем виде:
а2+/32 = 1;
b + aX = (l-(3)Y;
qlY = aa(3;
X = аа.
Мы получили систему четырех уравнений с четырьмя неизвестными
(а, /3, X, У), так что может показаться, что мы усложнили задачу; но эти
уравнения имеют гораздо более простой вид. Можно освободиться от а, вернувшись
к трем неизвестным:
X2 + а2/?2 = а2 ; (1)
b + aX = (l-p)Y; (2)
XY = a2ap. (3)
Умножив (3) на (1 - /3) и подставив (2), получим
Х(Ъ + аХ) = а2аР(1-Р),
и, применив сюда (1), чудесным образом получаем
ЪХ = а2а(Р-1). (4)
Отсюда следует, что (а2а(р - I))2 4- а2Ъ2Р2 = а2Ь2, т. е.
а2(р - 1)(а2а2(р - 1) + Ъ2{р + 1)) = 0. (5)
При а = 0 уравнение вырождено, оно имеет бесконечно много решений
(X, Y) = (0,6/(1 — /3)), где — 1 < Р < 1. Другой вырожденный вариант
получается при 6 = 0, тогда решений нет, за исключением случая аа = 0, когда
имеется бесконечно много решений с произвольным Y и (Х,а,Р) = (0,0,1).
В остальных случаях нетрудно убедиться, что /3^1, поэтому (5)
однозначно определяет величину /3, используя это вкупе с уравнением (4), получаем
полное решение:
а = -2aba/(a2a2 + б2);
/3 = (aV-62)/(aV+62);
X = -2а2Ъа/(а2а2 + Ъ2); {)
Y = (b2-a2a2)/2b.
С удивлением я обнаружил, что система квадратных уравнений (**) имеет
корни, выражающиеся рациональными функциями. Между этим решением и
ответом к задаче рисунка 2 наблюдается любопытное сходство.
284
Компьютерная типография
Переходя от (б) обратно к формулировке исходной задачи (рис. 7), пусть
(хг,Ут) —точка на прямой с угловым коэффициентом сг, проходящей через
(^оУс)? так что ут = ус + a{xt — хс). Тогда единственное решение выглядит
следующим образом:
2a(xi -xt)2(yt -Ут)
х = xt +
а
2a2(xl-xt)2(yt-ym)
У~Ут+ ^(*,-*t)2 + (yt-ym)2' (7j
У i = Vt
a2(xi -xt)2 + (yt -Ут)2 '
-Xt)2(yt-ym)
Ч)2 + (yt - Ут)2
(У1 ~Ут)2 ~CT2fe ~Xt)2
2(2/t - Ут)
кроме вырожденных случаев х\ — Xt и ут = yt.
Как-то раз я попробовал решить эту задачу, используя возможности
автоматического решения уравнений компьютерной алгебраической системы
MACSYMA [5, 7], чтобы понять, как скоро компьютеры заменят математиков
при проведении таких расчетов. MACSYMA правильно нашла решение (X, У, /3)
системы уравнений (1), (2), (3) примерно за 17 секунд, но ничего не сказала
о вырожденных решениях, появляющихся при аЬ = 0. На решение системы
четырех уравнений (**) MACSYMA потратила ровно столько же времени, что
и на систему (1), (2), (3). Но когда я попросил систему MACSYMA решить
исходные три уравнения (*) относительно х, у и yi, после примерно минуты и
двадцати секунд появилось сообщение о том, что памяти компьютера не
хватает, несмотря на то что я упростил (*), заменив (хс,ус) на (xt,ym)- Так что я
успокоился, поняв, что уравнения (*) не совсем уж тривиальны и
преобразование к виду (**) было важным шагом.
(xt,yt)
(*{',vi')<
(*",Л
ЛхсУс)
■(*с,У?)
Рис. 8. Хорошая буква S получается, если провести два незавершенных эллипса,
воспользовавшись методом, изображенным на рис. 7, и затем осуществить заливку
пространства между ними, используя перо с диаметром, равным толщине
«соединительных штрихов» требуемой буквы.
Глава 13. Буква S
285
Это решение задачи об эллипсе немедленно приводит к искомым S-
образным изгибам, так как можно осуществить заливку пространства между
двумя кривыми, состоящими из прямых и эллиптических участков: одной,
проходящей через точки (xt,yt), (х[,у[), (x',yf) и (xc\,yfc), и другой, проведенной
через (xt,yt), (x",y"), (х",у") и (хс,у"), при этом расстояние между х\ и х"
выбирается в соответствии с требуемой толщиной штриха в левой части, а
расстояние между yfc и у" —в соответствии с требуемой толщиной штриха в
центральной части. (См. рис. 8. На самом деле S-образный изгиб рисуется
круглым пером малого, но положительного радиуса, центр которого
следует по проведенным кривым, поэтому в действительности граница не является
идеальным эллипсом.) С правой нижней частью S поступают, конечно, так же,
как и с левой верхней.
QQQQQQQ
Рис. 9. Можно исследовать различные возможности, варьируя параметры. Здесь
угловой коэффициент изменяется, а остальные характеристики зафиксированы.
Угловые коэффициенты на рисунках составляют соответственно 2/5, 1/2, 2/3, 1, 3/2, 2
и 5/2 от «правильного» значения углового коэффициента на среднем рисунке.
Применив этот метод, варьируя угловой коэффициент сг, но оставляя
все остальные параметры без изменения, получим различные варианты S-
образного изгиба, изображенные на рис. 9. На рис. 10 изображена буква S
с таким же угловым коэффициентом, как у средней буквы на рис. 9, но с
утолщенными вертикальными участками в левой верхней и правой нижней
частях буквы. Одно из главных преимуществ математического,
параметрического метода в том, что он позволяет без особого труда проводить множество
экспериментов до тех пор, пока не найдутся те значения параметров, которые
полностью вас удовлетворят. Программу METflFONT'a для букв S,
изображенных на рис. 9 и 10, зависящую от соответствующих параметров, можно найти
в приложении в конце статьи.
Больше двух лет я радостно использовал этот метод для создания букв S,
но однажды я попросил METflFONT нарисовать очень большую S и результат
получился неожиданно уродливым. Взглянув еще раз на якобы замечательные
буквы S, нарисованные ранее, я стал замечать кое-где дефект, который для
используемых мною небольших масштабов был сравнительно безобиден. При
большом увеличении этот дефект начинал бросаться в глаза, и я понял что
история еще не закончена.
Рисунок 11 иллюстрирует это новое затруднение в несколько
преувеличенном виде. Пользуясь обозначения рис. 8, я расположил точку х\
недостаточно далеко справа от х"\ из-за этого два эллипса, проходящие через (х[, у[)
и (x'i,yi), пересеклись. Получилось, что предполагаемая внутренняя граница
стала внешней и наоборот, — довольно-таки неприятный результат, потому что
я не собирался использовать здесь такие каллиграфические изыски.
286
Компьютерная типография
Рис. 10.
У этой S утолщены штрихи в
левой верхней и правой нижней
частях буквы, а в остальном все
параметры такие же, как у средней
S на рис. 9.
Рис. 11.
Ужасный результат может
получиться, если толщина штрихов в
левой верхней и правой нижней
частях буквы недостаточна.
Проблема на рис. 11 исчезает, если х\ достаточно велико, но хотелось бы,
конечно, знать, какие значения допустимы. Мы пришли к третьей (и
последней) задаче про эллипсы: в ситуации, изображенной на рис. 8, найти условия,
необходимые и достаточные для того, чтобы дуга эллипса, проведенная через
точки (х'{, у") и (xt, yt), оставалась выше дуги эллипса, проведенной через
точки (х\, у[) и (xt, yt). (Предполагается, что х" < х[ < xt и у" <у[< yt, а также,
что оси обоих эллипсов параллельны осям координат.) Оказывается, что ответ
в этой задаче может быть записан очень просто: кривые не пересекаются тогда
Глава 13. Буква S
287
QQQQQ
Рис. 12. Такие S можно получить, варьируя толщину штриха в середине буквы,
при этом толщина в левой верхней и правой нижней частях выбирается возможно
меньше, с условием, чтобы не происходило «перекручивания», как на рис. 11.
и только тогда, когда
Vt-V'i > Vt ~ У'{ /on
{xt-x\Y - (xt-x'/)2' W
Попытавшись найти правильный ответ, поначалу я увяз в путанице
обозначений, но в конце концов набрел на следующее довольно простое решение:
пусть
a = xt-x'l, b=yt-y'h A = xt-x", B = yt-y".
Используя эти обозначения и перевернув кривые вверх ногами, мы
получаем, что функция Ь — Ьл/1 — (х/а)2 (описывающая правую нижнюю четверть
эллипса, соединяющую точки (0,0) и (а, &)) не должна превосходить
соответствующей функции В —В л/1 — (х/А)2 для всех |х| < а при заданных 0 < а < А
и 0 < Ъ < В. Раскладывая в степенной ряд, получаем
-^-'(£+£+-+(?)<-*"5*-
где
" m (-D'+1 =
(Л
fc+1_ (2fe-2)!
22к-Ч\{к-1)\
положительно для всех к > 0 и при |х| < а степенной ряд сходится. Если
b/а2 < В/А2, то аналогичный степенной ряд
В-В
v4ff-(^+^+-4T)<-')^--)
при малых х растет быстрее, и кривые пересекутся. Но если Ъ/а2 > В/А2, то
при всех к > 0 мы получим Ъ/а2к > В/А2к, так что каждый член первого ряда
не меньше соответствующего члена второго. ЧТД
Согласно разработанной ранее теории, получаем
Уг -У1 Уг- Ут
(xt - xi)2 2{xt - xi)2 2(2/t - ym)
(9)
Таким образом, можно добиться того, чтобы {yt — y'i)/{xt — x'l)2 было в точности
равно (yt — y")/(xt — х'/)2, если начать с требуемых значений xt, yt, x", ym и
ут: сначала определим у", затем х\ и наконец у\.
288
Компьютерная типография
Узнав, как рисовать S с математической аккуратностью, я обнаружил, что
те же самые идеи можно применить ко многим другим символам, входящим
в полный набор математических шрифтов. На самом деле, все символы,
изображенные на рис. 13, используют одну и ту же подпрограмму METAFONT'a,
впервые разработанную мной для буквы S (или двойственную ей
подпрограмму, полученную перестановкой координат х и у). Без разработанной в этой
статье теории мне пришлось бы либо отказаться от поставленной цели
—делать книги математически,—либо перестать использовать все эти символы.
Рис. 13. Метод, использованный для рисования буквы S, также используется в
качестве подпрограммы, рисующей части многих других символов, включая приведенные
здесь.
Конечно, это всего лишь первые шаги; созданные мною буквы далеки от
совершенства, и десятки новых экспериментов напрашиваются сами собой.
Сейчас я мечтаю о том, что в следующие несколько лет мы увидим, как
математики объединяются с опытными создателями символов для проектирования
новых, по-настоящему красивых шрифтов. Это будет действительно самым
заметным приложением математики!
В заключение позвольте задать вопрос читателю. Эллипсы изучаются уже
тысячи лет, поэтому логично предположить, что все их интересные свойства
были давным-давно открыты. Тем не менее, по своему опыту я знаю, что, когда
находится новое поле для применения математики, это часто дает почву для
новых «чисто математических» вопросов, обогащающих и саму математику.
Поэтому мне очень любопытно узнать: изучались ли ранее, может быть в
другом обличье, те вопросы, с которыми я столкнулся, пытаясь рисовать эллипсы
для S, или же новые приложения математики к типографскому делу привели
к более глубокому проникновению в природу даже такого хорошо изученного
объекта, как эллипс?
Приложение
Ниже приведена программа на языке METflFONT, описанная в [3, часть 3], она
нарисует букву S, изображенную на рис. 14 (и бесконечно много других), если
задать следующие параметры:
h, высота символа;
о, «свисание» кривых вверху и внизу;
Глава 13. Буква S
289
Рис. 14.
Отмеченные точки на этой S
соответствуют номерам в программе
METRFONT'a, приведенной в
приложении.
а2
гттп
■ •w • • ..-."^
•• 'а!
•
••2
ас
. •' аБ
• ..
а7
• ■ . $■ ■'*■•■ •
■., . а4. • .:,=-...,t.-
Г.. # ,-:<&6-:-:?^:- ••
• •
6: 9
[Й/.--
• а8
■да4' '--L '
8f
^ 5
* •.;.
Г»
10
11 7
• • •
&Л
~^1Ш.
S:44-
^ >*а9
а!0:;
**.■.::■■
: ";&
и, одна десятая ширины символа;
и>о, размер круглого пера, используемого для проведения линий;
го*, ширина треугольных засечек до стирания;
w$, толщина в левой верхней и нижней правой частях;
wq, толщина штриха в середине буквы S.
Вертикальные линии на рис. 14 отстоят друг от друга на и. Чтобы стереть
ненужные чернила слева и справа от заданного пути, в программе
используются '1реп#' и 'греп#'; результат этого стирания виден на рисунке, так как
кое-где стерты линии разметки.
subroutine scomp (index г)
(index р)
(index j)
(index к)
(var s):
% начальная точка
% точка поворота (ур нужно определить)
% точка перехода (нужно определить)
% конечная точка
% конечный угловой коэффициент
% Эта подпрограмма находит такие ур, Xj и у^ что
% Ук — Vj = s.(xk — Xj) и следующая кривая
% совпадает с эллипсом:
% г{хр -Xi,0} ..p{0,yp -yi} ..j{xk -xp,s.(xk -xp)}.
Ук ~Vj = s(xk -Xj);
new a, b] a = s(xp — Xi); b = yk — y% — s(xk — Xi)\
290
Компьютерная типография
Xj ~ Xi = —2а • b(xp — Xi)/(a • а + Ъ -Ъ)\
УР — у% — -5(6 • Ъ — а • а)/Ь.
subroutine sdraw (index г) % начальная точка
(index p) % верхняя точка поворота (ур нужно определить)
(index к) % центральная точка
(index q) % нижняя точка поворота (yq нужно определить)
(index j) % конечная точка
(index а) % эффективная ширина пера в точках поворота
(index b) % эффективная высота пера в центральной точке
(var s): % угловой коэффициент в центральной точке
cpen; top02/5 = topbyk\ bot0y6 = bothy*;
CC5 ~* XQ — X]$)
rtaxp = rto^i; 1ft a^p = 1ft 0^2;
rtaXq = rtoXg; lft aXq = lft 0^10',
2/2 = УР] 2/9 = yq\
call scomp(i, 1, 3, 5, s);
call scomp(i, 2,4, 6, s);
call scomp(j, 9, 7, 5, s);
call scomp(j, 10,8,6, s);
wo ddraw i{x\ — Xi, 0} .. 1{0, y\ — yi) ..
\j~\Xq 3Cpi S\Xq ^p)j • • ' \ 9 "■'Pj S\Xq
9(0,2/^ -y9}..j{xj -Ж9,0},
i{x2 - x^ 0} .. 2{0,2/2 - 2/i} • •
\ 4 P) SyXq ^p)J ' ' &\Xq ^pj S\Xq
10(0,2/-,- -yio}..j{xj -жю,0}.
zP)b
■zp)}.
% найти 2/i и точку 3
% найти 2/2 и точку 4
% найти 2/э и точку 7
% найти 2/ю и точку 8
% s-образный изгиб
"Буква S";
hpen; top02/i = round(/i + о); boto2/5 = —о:
яз = 5u; 2/з = -52/i;
lft 8^2 = round u\ rt8^4 = round 9u;
x\ = 4.5u; £5 = 5.5xx;
lft o^6 = round щ rto^7 = round 8.5u;
2/e = good0|/i-1; 2/7 = good0f/i + l;
boto2/8 = 0; 2/9 = 2/6', ^8 == ^6j rt4^6 = rto^9;
top02/io = /i; 2/ii=2/7; £10 = 27; lft4^7 = lft0Z11;
wo ddraw 6 .. 8, 9 .. 8;
ddraw 7.. 10, 11.. 10;
rpen#; wA draw 6{0, -1}. .5(1,0};
lpen#; w4 draw 7(0,1}..1{-1,0};
hpen; г^о draw 6{0, —1} .. 5{1,0};
draw 7{0,1}..1{-1,0};
call * a sdraw(1, 2, 3,4, 5,8, 9, -/i/(50u)).
% нижняя засечка
% верхняя засечка
% стереть излишек
% то же самое
% нижний левый изгиб
% верхний правый изгиб
% центральный изгиб
Подготовка этой статьи была осуществлена при частичной поддержке National Science
Foundation по грантам: MCS-7723738 и IST-7921977, Office of Naval Research по гранту
N00014-76-C-0330, а также IBM Corporation. Автор весьма признателен Xerox Palo Alto
Research Center за помощь в подготовке нескольких иллюстраций.
Глава 13. Буква S
291
Литература
[1] Richard J. Fateman, Essays in Algebraic Simplification, Ph.D. thesis, Harvard
University (1971). Также опубликовано как отчет MAC TR-95 (Cambridge,
Massachusetts: M.I.T. Laboratory for Computer Science, April 1972).
[2] Donald E. Knuth, "Mathematical typography," Bulletin of the American
Mathematical Society (new series) 1 (1979), 337-372. [Перепечатано с
исправлениями в главе 2 этой книги.]
[3] Donald E. Knuth, TfeX and METRFONT: New Directions in Typesetting
(Bedford, Massachusetts: Digital Press and American Mathematical Society,
1979).
[4] Giovanni Mardersteig, The Alphabet of Francesco Torniello da Novara [1517]
Followed by a Comparison with the Alphabet of Fra Luca Pacioli (Verona:
Officina Bodoni, 1971).
[5] The Mathlab Group, MACSYMA Reference Manual, version nine (Cambridge,
Massachusetts: M.I.T. Laboratory for Computer Science, 1977). Первичная
разработка и реализация оператора SOLVE системы MACSYMA
осуществлена Р. Дж. Фейтманом, краткое описание этого можно найти в [1], §3.6.
[6] Н. W. Mergler & P. M. Vargo, "One approach to computer-assisted letter
design," Journal of Typographic Research 2 (1968), 299-322. [В этой статье
описана первая компьютерная система для рисования параметризованных
букв; по ставшим теперь понятными причинам авторам не удалось
получить удовлетворительную S!]
[7] Joel Moses, "MACSYMA-The Fifth Year," SIGSAM Bulletin 8,3
(Association for Computing Machinery, 1974), 105-110.
Дополнение
Гораздо более простой способ решения трех уравнений (*) предложил Г. Дж.
Ригер [The Mathematical Intelligencer 3 (1981), 94]. Для удобства положим xt =
Уь = хс = 0 и ус = ут\ тогда уравнения примут вид
х2 + (у- yi)2l>? = А , у = ут + (ух , Х2х = a(yi - у),
где Л = yi/xi. Подставив второе уравнение в третье, получим выражение х =
&(yi — Ут)/(А2 4- сг2); и эти выражения для х и у сводят первое уравнение к
уравнению (yi — уш)2 = у2 4- о2х2х, линейному по у\.
Эрик Нойвирт из Венского университета 22 сентября 1980 г. прислал мне
письмо с прекрасным объяснением замеченного мной «любопытного сходства»
между задачей про эллипс на рис. 7 и задачей Торниелло про круг на рис. 2.
Задача про эллипс может быть переформулирована следующим образом.
Найти прямолинейный эллипс с центром на оси ординат, касающийся трех линий:
у = 0, х = —г иу = ax—d, где г = xt—xi, ad — yt—Ут- Если касание происходит
в точках (0,0), (-г,-с) и (-а,-6), где а = xt-x, Ъ = yt -у, а с = yt-yu то
будем говорить, что (г, сг, d)-задача имеет решение (а,Ь,с). Основное наблюдение
292
Компьютерная типография
Нойвирта состоит в том, что растяжение плоскости в направлении оси
абсцисс переводит эллипсы в эллипсы, а касательные — в касательные. Поэтому
для произвольного коэффициента растяжения а (г, сг, с?)-задача имеет решение
(а, 6, с) тогда и только тогда, когда (аг, сг/а, d)-задача имеет решение (аа, 6, с).
Если теперь вернуться к рис. 2 и положить h = —d/cr, мы увидим из решения
задачи Торниелло, что (г, сг, й)-задача имеет решение
(-2ar2d/(d2 + a2r2), 2rd2/(d2 +<72r2), г),
если d2 —a2r2 = 2rd; это случай, когда эллипс является кругом. Поэтому, если
d2 — a2r2 = 2ard, решением (ar, a/a, d)-задачи будет
(-2aar2d/(d2 + a2r2), 2ard2/(d2 + a2r2), ar).
Но мы можем выбрать a = (d2 — a2r2)/(2rd) и, применив принцип Нойвирта,
установить, что решением общей (г, сг, d)-задачи будет
{-2ar2d/{d2 + a2r2), 2ard2/(d2 + a2r2), ar).
Это эквивалентно (7). Если бы я читал курс по математическому анализу или
аналитической геометрии, я бы с удовольствием посвятгл одно из занятий
проблемам, связанным с S-образными изгибами, так как наблюдения и Ригера,
и Нойвирта весьма поучительны.
Компьютерные алгебраические системы улучшались. Например, Mathe-
matica® 2.2 на SPARCstation 2 (модель 1993 г.) решает систему (*) за 141 с
без всяких подсказок. Но математик-человек все еще нужен для приведения
решения к удобоваримому виду типа (7).
С 1980 г. язык МЕТАРОИТдовольно сильно изменился, и я могу с радостью
сказать, что все символы на рис. 13 были значительно улучшены. (См. Com-
puters Sz Typesetting, тт. С и Е.) Тем не менее, основные идеи, использованные
выше при рисовании S-образных изгибов, остаются в силе.
Мое первое знакомство
с индийской письменностью
[Первоначально опубликовано в буклете CALTIS-84, подготовленном к
семинару по индийской письменности: каллиграфии, шрифтам и печати (New Delhi:
11-13 February 1984), 49.]
13 февраля 1980 г. несколько шрифтовых дизайнеров из Mergenthaler Linotype
Company навестили меня, чтобы взглянуть на странную компьютерную
программу под названием METflFONT, которую я разрабатывал. В числе прочего
мы провели следующий эксперимент: Мэтью Картер делал эскиз символа, а
я должен был написать программу для METflFONT'a, которая бы рисовала то
же самое.
Мэтью решил предложить мне символ, которого я раньше не видел, и
выбрал значок из деванагари1. Это задание было особенно интересно, потому что
раньше у меня ни разу не было возможности поближе познакомиться с
индийскими буквоформами. С третьей попытки моя программа нарисовала букву на
рис. 1, и этот результат, кажется, удовлетворил Мэтью. (Двенадцать опорных
узлов изображены тройкой точек каждый; например, узел 5 изображен тремя
черными точками, обозначенными 5, 105 и 205.)
Рис. 1.
Пробная гранка, показывающая опорные узлы.
1 Слоговая система письма, применяется в языках Северной Индии, а также в
санскрите. — Прим. перев.
294
Компьютерная типография
Я написал программу так, чтобы можно было легко менять толщину
проводимых линий. Более того, я решил попробовать нарисовать «случайные»
вариации буквы, немного сдвигая некоторые из 12 узлов с их математически
выверенных позиций, для создания таких «ошибок» я использовал случайные
числа. Результаты изображены на рис. 2: на рис. 2а изображен исходный
символ; 2Ь —его полужирная версия; на рис. 2с, 2d и 2е изображены случайные
вариации со стандартным сдвигом 5, 10 и 15. (Сдвиг 15 явно был слишком
велик, но нам было интересно.)
(а) (Ъ) (с) (d) (e)
Рис. 2. Пять результатов работы программы МЕТЯ FONT.
Затем я создал шрифт, содержащий символы на рис. 2а и 2Ь, и плюс к тому
еще 26 различных символов, вроде изображенного на рис. 2с. (В каждом случае
стандартный сдвиг составлял 5, но были использованы различные случайные
числа.) Мы отпечатали этот шрифт на фотонаборной машине Alphatype CRS;
результат в натуральную величину показан на рис. 3 .
По рис. 3 можно понять, что это было моим первым знакомством с
индийской письменностью, хотя бы по тому, что я не знал, как пишется деванагари1.
Если внимательно приглядеться, то можно также заметить, что все 26 букв в
третьей строке немного различаются. Мне казалось, что немного случайности
сделает символы «человечнее», несмотря на то что созданы они при помощи
точных математических формул.
Это было самое начало, и в нашем программном обеспечении все еще
встречались ошибки; между двумя символами третьей строки произошел сбой.
(Когда демонстрируешь компьютерную программу, всегда что-нибудь идет не
так.)
В минувший год нашу лабораторию навестил г-н Пиджуш Гош; он
создал гарнитуру, которую назвал NCSD —Простой деванагари для
начинающего каллиграфа^ После этих обнадеживающих экспериментов я с радостью
понял, что мои идеи можно применять к языкам далеких заморских стран,
которые я, возможно, так никогда и не смогу понять. Какое это замечательное
ощущение!
Вместе с моими коллегами мы сейчас работаем над созданием новой
версии METflFONT'a, которую надеемся выпустить где-то через год. Использовать
эту новую версию должно быть намного проще, чем первую, но я боюсь, что
1 Правильное английское написание Devanagari. — Прим. перев.
2 Novice Calligrapher's Simple Devanagari. — Прим. перев.
Глава 14. Мое первое знакомство с индийской письменностью 295
Вариант Деванагари Мэтью Картера: С5^^^с5с5с5с5с5с5с5;
Полужирное начертание: с^с^с^с^с^с^;
Со «случайными» вариациями: ^^С^^^^^^^^^^^^^с5с^с^ё5е5е5с5с^с^с5.
Рис. 3. Первые напечатанные образцы в натуральную величину.
по-настоящему простой она все же не будет; я думаю, лучше всего, если ею
будут пользоваться вместе художник и специалист по компьютерам, точно так
}ке, как работали мы с Мэтью Картером. Эта программа проектируется так,
чтобы работать на самых разных компьютерах, как больших, так и
маленьких. Мы планируем распространять ее бесплатно, так как вся наша работа
вдохновляется нашей любовью к печатному делу.
Дополнение
Позднее я узнал, что символ ^ является вариантом буквы L, которая чаще
всего пишется Н\
Последние пятнадцать лет я с удовольствием наблюдаю за тем, как
многие люди творчески применяют METflFONT к созданию индийских символов.
Например, недавно я использовал шрифт деванагари, созданный Франсом Ж.
Велыюи, чтобы напечатать слово ^g^ (kuttaka) в третьем издании моей книги
Seminumerical Algorithms (1998).
Концепция меташрифта
[Первоначально опубликовано в Visible Language 16 (1982), 3-27.]
Одно изображение одной буквы приоткроет лишь немногое из того, о чем
думал художник, создавая ее. Имея же точные инструкции, как получить это
изображение, можно собрать о букве сведения, достаточные для
воспроизведения бесконечного многообразия похожих букв, нарисованных по единому
замыслу. В таких инструкциях, вместо того чтобы просто описать одну
букву, объясняется, как изменится форма этой буквы при изменении
остальных параметров замысла. Таким образом, можно задать целый шрифт из
букв и других символов, в котором каждый значок соответствующим
образом подстраивается к изменяющейся обстановке. Первые опыты с
использованием точного языка для описания движений пера склоняют к мысли,
что в будущем дизайнер шрифтов будет заниматься не просто созданием
отдельных алфавитов; перед ним будет поставлена задача объяснить, как
именно каоюдое его творение долоюно приспосабливаться к самым различным
изменениям первоначального замысла. В этой статье приводятся примеры
меташрифта и рассказывается о переменных параметрах, возникающих в
процессе его разработки1.
Некоторые философские труды Аристотеля называют Me-
тафизикой, потому что согласно общепринятому
расположению его трудов они появились после Физики. К
двадцатому столетию большинство позабыло первоначальное значение
греческих приставок и «мета-» стало употребляться для
указания на более абстрактный характер описываемого предмета.
У нас теперь имеются метапсихология (наука о связи тела с
пребывающим в нем разумом), метаматематика (наука о
математических рассуждениях) и металингвистика (наука о связи
1В оригинале использован меташрифт Computer Modern, при переводе он
дополнен кириллическим расширением LH, изготовленным, разумеется, значительно позже.—
Прим. ред.
Глава 15. Концепция меташрифта
297
языка и культуры); метаматематик доказывает метатеоремы
(теоремы о теоремах), а ученый, занимающийся
информатикой, часто работает с метаязыками (языками,
предназначенными для описания языков). Нововведенные слова,
начинающиеся с «мета-», обычно отражают современное стремление
смотреть на веши снаружи, на более абстрактном уровне, с
более зрелым, как нам кажется, пониманием.
В этом смысле «меташрифт»—это схематическое описа-
иие тогоj как рисуется, гариитура, а не просто сами рисунки.
Такие описания дают более или менее точные правила для
рисования отдельных букв, и лучше всего эти правила
выражать через переменные параметры, так чтобы одно и то
же описание на самом ^еле определяло множество различных
рисунков. Правила меташрифта определяют, таким образом,
много разных конкретных шрифтов, зависящих от значений
параметров. Например, среди образцов, изданных American
Type Founders в 1923 г., имелись следующие начертания
гарнитуры «Caslon»: простое, старомодное, светлое, полужирное,
жирное, узкое, светлое узкое, полужирное узкое, очень узкое,
полужирное широкое, штриховое и открытое, не говоря уже об
American Caslon, New Caslon, Recut Caslon и Caslon Adbold;
каждое из них имело варианты примерно для шестнадцати
разных кеглей, так что всего прямых начертаний гарнитуры
Caslon было около 270. Имелся общий замысел, некоторым
образом связывающий все эти шрифты, что и давало
возможность распознавать «Caslon» несмотря на то, что изменения
кегля и насыщенности сопровождались более или менее
заметными изменениями формы букв. Этот общий замысел мы
можем считать меташрифтом, определяющим, как будут
изменяться буквы в различных ситуациях: меташрифт управляет
метаморфозами.
Конечно, замысел, лежащий в основе всех этих
разновидностей гарнитуры Caslon, явно сформулирован не был; он был
выражен косвенно при помощи нескольких рисунков,
иллюстрирующих некоторые граничные случаи. Умелый работник
может сделать соответствующие изменения для средних
размеров и стилей так же, как умелые аниматоры заполняют
«промежуточность» в мультфильмах Уолта Диснея. Хотелось
бы, тем не менее, совершенно явно сформулировать этот
замысел, чтобы зафиксировать намерения создателя шрифта без
всякой двусмысленности; тогда нам не пришлось бы прибегать
298
Компьютерная типография
к туманному понятию «соответствующие изменения». В
идеале намерения создателя должны быть сформулированы столь
явно, чтобы их смог воплотить в жизнь кто-нибудь,
совершенно ничего не понимающий в формах букв,—даже тупой,
неодушевленный, электронный компьютер!
Дж:ордж Форсайт однажды написал: «Вопрос «Что
может быть автоматизировано?»—один из самых волнующих
философских и практических вопросов современной
цивилизации». По опыту мы знаем, что идею понимаешь гораздо
лучше, после того как удается объяснить ее кому-то
Другому; а после появления компьютеров появилась еще более
правильная формулировка: лучший способ понять что-либо —
узнать это настолько досконально, чтобы можно было
научить этому компьютер. Машины — это последняя
проверка, ведь перед ними нельзя «махать руками» и у них нет
«здравого смысла», чтобы исправлять расхождения и
несообразности, что у нас получается почти бессознательно. На
самом ^еле^ исследования в области искусственного
интеллекта показали, что компьютеры могут выполнить
практически любое задание, традиционно связанное с
«мышлением», но большие сложности возникают у машин при
выполнении того, что люди и животные делают «помимо
мышления». Искусство создания букв не будет познано до конца,
пока его не сумеют объяснить компьютеру; и поиски этого
объяснения безусловно будут поучительны для всех
вовлеченных в этот процесс. Люди часто обнаруживают, что
знания, приобретенные во время написания компьютерных
программ, гораздо ценнее собственно результата работы
компьютера.
Для того чтобы научить машину создавать шрифты, нам
требуется некоторый язык, или система записи, описывающий
процесс построения буквы. Самих рисунков будет
недостаточно, за исключением, разве что, очень простых по замыслу
проектов, в которых все начертания гарнитуры отличаются Друг
от друга простейшими преобразованиями. Несколько
вариантов языков для точного описания формы букв было
предложено в последние годы, в том числе разработанный автором
в 1977—1979 гг. Эта система называется METflFONT и отличается
от всех предшественниц тем, что в ней вместо задания
контуров каждой буквы описываются движения центра «пера»
или «ластика». В результате, в языке METRFONT легко созда-
Глава 15. Концепция меташрифта
299
вать гарнитуры; к примеру, на создание плохо проработанного,
но все же сносного меташрифта, описанного в [5J, ушло всего
лишь около двух недель.
Еще через шесть месяцев работы, после буквально тысяч
усовершенствований, этот меташрифт-прототип был
разработан настолько хорошо, что с его помощью оказалось
возможным набрать целую 700-страничную книгу [7J.
Получившаяся гарнитура получила название Computer Modern,
она включает в себя меташрифты прямого светлого и
курсивного стилей, кроме того греческий алфавит, кириллицу
и прописные буквы каллиграфического начертания, вместе
с обширным запасом математических символов. Основная
цель, ради которой создавалась эта гарнитура, состояла в
том, чтобы воспроизвести дух шрифтов, использованных в
первых изданиях книг автора по компьютерному
программированию, а именно шрифтов, известных под названием
«Monotype Modern Extended 8A», применив для этого
выразительные средства METfl FONT а и предусмотрев возможности
самых разных параметрических изменений.
На самом ^gjig возможно столько вариантов, что автор до
сих пор продолжает находить новые значения параметров,
дающие неожиданно привлекательный результат, не
предусмотренный исходным проектом; параметры, обеспечивающие
наилучшие удобочитаемость и внешний вид, могут быть так
никогда и не найдены, потому что число вариантов бесконечно.
С другой стороны, можно попробовать параметризовать
множество вещей, которые в текущий момент изменять нельзя;
возможности экспериментирования стали почти
безграничными теперь, когда появился METfl FONT.
В настоящее время (январь 1981 г.) прямой светлый
меташрифт гарнитуры Computer Modern имеет 28 параметров,
влияющих на форму букв, плюс еще три параметра,
помогающие контролировать межбуквенные пробелы; число
параметров продолжает расти по мере накопления опыта. Имеется
также с полдюжины разнообразных параметров,
предназначенных в основном для переключения между разными
формами символов и лигатур в том или ином шрифте. К
примеру, один из этих последних параметров выбирает, какое из
двух начертаний буквы 'д' употребить; возможно, читатель
уже заметил, что такое начертание буквы д отличается от
использованного далее, например, на с. 300. В дальнейшем бу-
300
Компьютерная типография
дет продемонстрировано еще несколько типографских трюков
вроде этого; относительно крупная печать используется для
того, чтобы эти эффекты можно было заметить.
Наиболее интересные и важные параметры Computer
Modern будут изменяться в следующих абзацах, по одному за
раз, чтобы показать, насколько широки возможности
варьирования. Конечно, легко найти значения параметров, дающие
неудовлетворительный результат, — не стоит надеяться на
решение всех мыслимых проблем одним махом; поэтому на
примерах мы постараемся показать пограничные ситуации, в
которых начинаются неприятности, а также промежуточные
области, где и стоит искать шрифты, пригодные к употреблению.
От первой и самой очевидной группы параметров зависят
вертикальные размеры букв: высоту строчной буквы и
размеры верхних и нижних выносных элементов можно
регулировать независимо Друг от друга. The x-height and the heights
of ascenders and descenders can be independently specified.
[Высота строчной буквы и высоты верхних и нижних
выносных элементов могут быть определены независимо.] На
самом ^gjig для нижних выносных элементов имеется два
независимых параметра: первый контролирует глубину букв
gjpqy, а другой — глубину остальных символов, вроде
запятых и хвостика буквы Q. Высота прописных букв не
зависит от высоты строчных букв, да и высоту пифр от 0
до 9 также можно изменять по желанию. Самый
необычный параметр, связанный с вертикальными размерами букв,
называется высотой средней линии, а именно высотой
средней линии строчной е; на сегодняшний момент высота
средней линии влияет также и на некоторые другие строчные
буквы:
tlLQ paGK,
tiLQ pacat,
tlLe pac:fc,
tlLe pac:fc,
tbc pac]fc!
Еще от одной довольно очевидной группы
параметров зависят горизонтальные размеры каждого символа
Глава 15. Концепция меташрифта
301
шрифта: можно получать очень широкие или очень
узкие шрифты, не изменяя при этом высоты и
толщины линий. It is possible to obtain fonts that are
e:>ctreme 1 у e:x:tended or eitremdj tenlenseivkWit changing the heights or
widths of tke strokes. [Можно получить слишком широкие или
слишком узкие шрифты без изменения высоты или
ширины штрихов.] Можно также имитировать печатную машинку,
расширяя или сужая отдельные символы так, чтобы все они
имели одинаковую ширину. Заметьте, что засечки удлиняются
или укорачиваются вместе со всей буквой; поэтому в таком
стиле засечка у i гораздо длиннее, чем у т.
Конечно, гораздо лучшая имитация печатной машинки
получится, если нивелировать различия между толстыми и
тонкими линиями. Этот шрифт каэкется похожим на шрифт
печатной машинки, даэке когда буквы имеют разную ширину.
Согласно замыслу Computer Modern, буквы рисуются
перьями, острие которых имеет форму эллипса; например,
толстые линии букв h в этом предложении проведены пером,
которое при десятикратном увеличении выглядело бы так:
4 *"• . Оси эллипсов абсолютно горизонтальны, а не
наклонены как / ', потому что у букв должен быть вертикальный
наплыв. Для рисования разных частей букв используются
разные перья.
Пять параметров управляют размерами этих
эллипсовидных перьев: один — шириной тонких соединительных
штрихов, другой — толстых прямых основных штрихов, еще один —
толстых округлых основных штрихов, еще один — величиной
утолщений у букв типа acf.. .у и последний дает толщину по
вертикали. Если все пять параметров равны, перья будут
абсолютно круглыми.
Выбору параметров, связанных с размерами пера,
требуется уделить особое внимание. Например^ нежелательные кляк-
еы появляются^ еели утолщения слишком велики в еравнении
е основными штрихами^ а если округлые основные штрихи
значительно шире прямых, шрифт становится раздражающе
несообразным. Нельздк сделать шрифт очень жирным и избе-
жать при этом наползания разных чаетеи буж» друг на Дру-
га. Возможно, будущие меташрифты научатся рассчитывать
нужные размеры пера по меньшему набору независимых
параметров: ведь правильные размеры неуловимым образом
зависят друг от друга; на данный момент, чтобы получить набор
302
Компьютерная типография
взаимосвязанных размеров пера, приходится использовать
метод проб и ошибок, но дальнейшие исследования должны
пролить свет на эту зависимость.
Для простоты были упомянуты только пять параметров,
определяющих размеры пера, но на самом ^gjig ситуация
несколько сложнее. Так перья, используемые для рисования
прописных букв, задаются отдельно от тех, которыми рисуют
строчные, а нифры рисуются некоторой смесью этих двух
видов. Есть также переменный «поправочный множитель»,
сбрасывающий лишний вес в буквах типа w и т, которые иначе в
некоторых стилях выглядели бы слишком темными;
настоящее единообразие в толщине линий не ведет к единообразию
внешнего вида букв, потому что наши глаза нас обманывают.
Другой не вполне очевидный параметр шрифтов Computer
Modern — это так называемое «свисание» округлых и
остроконечных элементов вниз за линию шрифта и вверх за линию,
проведенную на высоте строчной буквы. Например, в этом:
предложении свисания у букв нет вообще. А некоторые
буквы в этом предложении свисают за ограничивающие линии в
три раза больше, чем в следующих предложениях. Все еще
приходится экспериментировать, для того чтобы найти свиса-
ние, при котором вид букв наиболее стабилен, а при печати на
оборудовании с низким разрешением желательно вообще
отказаться от свисания; дальнейшее изучение этого параметра в
комбинации с остальными обещает быть весьма интересным.
Засечки можно изменять несколькими способами.
Например, в буквах 'р' этого предложения засечки не имеют
«срезов». А в буквах, которые вы видите сейчас, срезы сделаны в
три раза больше чем обычно, специально для того чтобы до
кон да вскрыть понятие среза.
Еще одно понятие, связанное с засечками, —это размер так
называемого «скругления»; у засечек в этом предложении нет
скругления. А в этом предложеннн скругленыя значительно
преувеличены. Легче всего понять разницу, если увеличить
буквы:
JLJLo bracketing (JLJLeT скруглений);
1 1 ormal bracketing (ХХормальные скругления);
JLAoticeable bracketing (ЗаметЛые скругленыя).
Глава 15. Концепция меташрифта
303
Изгиб, начинающийся на конце засечки, касается основного
штриха на некотором расстоянии выше или ниже засечки; это
вертикальное расстояние и есть параметр «скругления».
Конечно, длину засечек то:же можно регулировать. У букв
в этом предложении засечки на 50% короче, чем раньше. А в
этом: предложении засечки: на 50% алиииее^ чем раныне,
такие длинные, что иногда они: достают, куда не стоило бы.
Один из способов получить рубленый шрифт состоит в установке
нулевой длины засечек (и соответствующем изменении
межбуквенных интервалов); но лучше, когда засечки исчезли,
перерисовать некоторые буквы, например, используя выпуклые концевые
элементы вместо утолщений.
Параметр «наклона» изменяет движение пера, как
показано в этом предложении, но форма пера остается
неизменной, ^гол наклона мо:жет быть как положительным, так. и
отрицательным— если требуется: добиться: необычного эффекта.
^£j^ <?2?&j¥&^jF^a& jrc>W7^ jst&pc&j^^ Возмоампчо,
самый гпчгаерестчое исаол/ъзоватчгш параметра тчатслотча состоит
в том, пто 'к/урсивтчы/й гирифга гартчиптауры Computer Modera
созоается, без всякого тча>гл,он,а: тсурсивтчые б'уквы по стилю
отл/и/чаютсл ora прямых, xi лгы тчасгаол/ьтсо привы/кл/и висеть
их патслоиеппымп вперео, м/гао отчп тсаэкуугасл тча'кл.отчетчпылил
тчазао, тсогоа болъгигпчсттгво гхз wux via самом оеле выпрлмл,епы
пл/и тчатсяотчетчы вперео лишь самую малостпъ.
Последний параметр, который мы обсудим, — один из
самых интересных; он называется «квадратным корнем из 2».
С математической точки зрения, существует, конечно, един-
ственный квадратный корень из 2, но в меташрифтах
Computer Modern v2 считается переменным параметром,
использующимся для нахождения точек, отстоящих на 45 друг от
друга при движении пера по дуге эллипса. В результате при
значении, меньшем истинного, эллипс превращается в
суперэллипс и овалы расширяются; например, если использовать
корень пятой степени из 4 вместо квадратного корня из 2, т. е.
1.31950791 вместо 1.41421356,
то получится известный суперэллипс, введенный Питом Хей-
ном. Большие значения квадратного корня из 2, напротив,
304
Компьютерная типография
приведут к противоположному эффекту:
The "square root of 2" in these letters is 1.100.
The "square root of 2" in these letters is 1.200.
The "square root of 2" in these letters is 1.320.
The "square root of 2" in these letters is 1.350.
The "square root of 2" in these letters is 1.380.
The "square root of 2" in these letters is 1.414.
The "square root of 2" in these letters is 1.450.
The "square root of 2" in these letters is 1.500.
The "square root of 2" in these letters is 1.600.
The "square root of 2" in these letters is 1.700.
Можно варьировать еще несколькими параметрами, кроме
уже упомянутых. Например, величиной, на которую
раздвинуты острые углы в буквах типа V и М, для того чтобы избежать
излишней черноты. От нескольких параметров зависят
особенности формы «клювообразных» засечек таких букв, как Е, Т
и Z. Но полное описание прямого светлого шрифта гарнитуры
Computer Modern выходит за рамки этой статьи.
Мы изучали параметры по одиночке; что же происходит,
когда они изменяются все вместе? На рис. 1 показана одна из
интересных возможных трансформаций. Вверху шрифт имеет
старомодный оттенок, в точности таким стилем до сих пор
набирался текст этой статьи: высота буквы Ь. равна 8.4 пункта,
высота строчной буквы — 4 пунктам, высота средней линии —
2.3 пункта, а глубина нижних выносных элементов — 3
пунктам. Толщина соединительных штрихов составляет 0.26
пункта, в сравнении с 1.2 пункта для прямых основных штрихов и
1.34 пункта для округлых основных штрихов; диаметр
утолщений— 1.36 пункта, и для рисования соединительных
штрихов используются круглые перья. Ширина кегельной
площадки в этом стиле равна 12.6 пункта; длина засечек составляет
0.07777 от этой ширины, и они имеют срезы, равные 0.54
пункта, и скругления в 0.8 пункта. Свисание составляет 0.3 пункта,
а «квадратный корень из 2» имеет математически правильное
значение 1.414214.
Глава 15. Концепция меташрифта
305
е LORD is my shepherd;
I shall not want.
He таке me to lie down
in green pastures:
he leadeth me
beside the still waters.
He restoreth my soul:
he leadeth me
in the paths of righteousness
for his name's sake.
Yea, though I walk through the valley
of the shadow of death,
I will fear no evil:
for thou art with me;
thy rod and thy staff
they comfort me.
Thou preparest a table before me
in the presence of mine enemies:
thou anointest my head with oil,
my cup runneth o\/er.
Surely goodness and mercy
shall follow me
all the days of my life:
and I will dwell
in the house of the Lord
for ever.
Рис. 1. Непрерывным изменением параметров можно постепенно преобразовать
шрифт, выглядящий старомодно, к современной стилистике. В этом примере высота
буквы h не меняется, а ширина кегельной площадки растет с увеличением высоты
строчной буквы. Из-за этого в перспективе создается ощущение, как будто слова
выходят из прошлого в настоящее на своем пути к будущему.
306
Компьютерная типография
К концу рис. 1 буквы превращаются
в почти ультрасовременный шрифт,
который и будет использоваться
вплоть до конца этой статьи.
Высота буквы h по-прежнему равна
8.4 пункта, но высота строчной буквы
увеличилась до 6.4 пункта, а высота
средней линии—до 3.2; глубина
нижних выносных элементов теперь
равна 4 пунктам. Соединительные и
основные штрихи: прямые и
округлые— теперь все имеют одинаковую
толщину в один пункт, а острие пера
имеет высоту 0.6 пункта. "Так что
перо, которым рисуется большинство'
букв, после десятикратного
увеличения выглядит так: '•'. Ширина
кегельной площадки теперь равна
21.6 пункта; длина засечек нулевая,
так же как срезы и скругления.
Свисание составляет 0.1 пункта, а
«квадратный корень из 2:» имеет
значение 1.3.
Каждая из 595 букв, пробелов и
знаков препинания на рис. 1
принадлежит новому шрифту, который
еще на 1/594 ближе к конечному
набору параметров. Поэтому, хотя
и кажется, что соседние буквы
принадлежат одному и тому же шрифту,
но в результате накапливающихся
изменений получается разительный
контраст: это похоже на постепенное
изменение наших собственных лиц,
Глава 15. Концепция меташрифта
307
когда мы стареем, только этот
шрифт, напротив, становится моложе.
В этой статье использованы сотни
разных шрифтов, тем не менее, все
они принадлежат прямому светлому и
курсивному меташрифтам гарнитуры
Computer Modern. Каждая буква
определяется компьютерной
программой, написанной на языке METRFONT,
и компьютер может нарисовать
любой требуемый вариант этой
буквы, если ему указать значения
всех параметров. Важно помнить, что
все эти соглашения и параметры не
встроены в сам METRFONT; METRFONT —
многоцелевой язык, предназначенный
для того, чтобы облегчить создание
меташрифтов, и Computer Modern —
всего лишь одна из попыток создать
шрифт с помощью такого языка.
Давайте взглянем на программу
рисования буквы h, это даст нам
некоторое представление о том, как
создаются меташрифты. Каждая
прямая светлая h в гарнитуре
Computer Modern рисуется в точности
следующим образом, если перевести
код METRFONT'a на обычный язык:
Ширина очка этой литеры составит 10 единиц, при этом ширина кегельной
площадки равна 18 единицам; но после того как символ нарисован,
ширину нужно будет подрегулировать, сделав «поправку на засечки», чтобы
учесть, длинные они или короткие.
У этой буквы несколько узловых точек, которые определяются
следующим образом. Нужно взять эллиптическое перо с высотой, равной высоте
соединительных штрихов, и шириной, равной ширине прямых основных
308
Компьютерная типография
штрихов в строчных буквах. Когда это перо указывает на точку 1, его
центр отстоит приблизительно на 2.5 единицы от левого края очка
(округление производится так, чтобы центр находился в позиции, удобной для
растрирования), а верхний конец пера находится на высоте буквы h для
строчных букв. Точка 2 находится прямо под точкой 1; если центр пера
расположить в точке 2, то его нижний конец будет точно на линии шрифта.
Обе точки 3 и 4 отстоят приблизительно на 2.5 единицы от правого края
очка; точка 4 находится правее точки 2 на том же уровне, а точка 3 — на
расстоянии 1/3 от высоты средней линии до высоты строчной буквы.
Возьмите перо и проведите прямые основные штрихи, соединяющие
точку 1 с точкой 2 и точку 3 с точкой 4. Сделайте срезанную засечку левее
точки 1, и добавьте засечки по обеим сторонам точек 2 и 4, используя
подпрограммы для засечек (соответствующим образом учитывающие
параметры срезания, скругления и длину засечек).
Наконец, перекладина h рисуется так: линию начинают рисовать из точки,
расположенной в 1/8 пути от высоты средней линии до высоты строчной
буквы, в вертикальном направлении, пером для соединительных штрихов,
прижатым правым концом к границе левого из основных штрихов. Это
перо для соединительных штрихов описывает четверть эллипса и
останавливается в точке, расположенной посередине между правыми границами
основных штрихов, и такой, что верхний конец пера находится на высоте
строчной буквы плюс половина свисания; назовем ее точкой 5.
Чтобы дорисовать перекладину, нужно из точки 5 провести четверть
суперэллипса в точку 3, увеличивая при этом ширину пера: от положенной
для соединительных штрихов до ширины прямых основных штрихов;
середина этой дуги находится с использованием среднего геометрического
числа 1.23114413 и параметра «корень квадратный из 2», а не у/2, как в
обычных формулах для эллипсов. (Странная константа 1.23114413, равная
23/10, выбрана так, чтобы для «корня квадратного из 2», равного \/2,
получался суперэллипс Пита Хейна.)
Похожие программы рисуют тип.
В этом описании не упомянуты
эффекты, связанные с параметром
«наклона», потому что нэклон
выполняется другой частью
компьютерной программы, когда рисунок
переносится на бумагу.
Теперь идея меташрифта должна
быть понятна. Но зачем он нужен?
Манипулирование многими пара-
Глава 15. Концепция меташрифта
Рис. 2.
Программа,
перефразированная в тексте, могла бы
подготовить этот символ
для печатного устройства
с низким разрешением.
Обратите внимание на
пять узловых точек,
занумерованных 1, 2, 3,
4 и 5; через эти точки
движется центр «пера»
при рисовании буквы.
метрами может быть интересно и
забавно, но нужен ли кому-нибудь
шрифт кегля 6V7, на одну четверть
отличающийся от Baskerville в
сторону Helvetica?
Можно также провести аналогию
с музыкой: нотное письмо было
изобретено за столетия до появления
способов описания чертежей; все
это время серьезной потребности в
метасимфониях не ощущалось, так
зачем же нам нужны меташрифты?
Что ж, это законные вопросы,
действительно заслуживающие ответа;
сначала давайте подумаем над
музыкальной аналогией. Длинная история
нотного письма ясно показывает,
что существование точного языка
само по себе еще не приводит к
310
Компьютерная типография
введению в нем параметров. В самом
деле, до самого последнего времени
параметры не смогли пробраться
в серьезную музыку, даже в самом
примитивном виде, за исключением
немногих почти забытых вещиц,
вроде метавальса Моцарта [11].
Несомненно, было бы очень интересно
и поучительно писать метамузыку,
которая бы порождала в слушателе
переменные степени беспокойства,
волнения, грусти, sturm und drang1,
в зависимости от значений
некоторых параметров; но такой музыке
нашлось бы мало естественных
применений, разве что в качестве
музыкального сопровождения к
художественным фильмам.
Все аналогии, конечно, неточны, и
создание шрифта отличается от
сочинения музыки, потому что алфавиты
не симфонии; алфавит—«средство»,
а симфония — «послание». Гораздо
лучшая аналогия между шрифтами и
музыкой получится, если рассмотреть
вместо симфоний фоновую музыку,
ведь шрифт служит фоном к
зафиксированным на бумаге идеям
автора. Многие люди не выносят
фоновую музыку: они считают,
что музыка либо должна быть в
центре внимания, либо вообще не
1 Буря и натиск (нем.) — в Германии 70-80-х годов XVIII века существовало
одноименное литературное движение, оказавшее влияние на творчество Моцарта. — Прим. перев.
Глава 15. Концепция меташрифта
311
должна звучать. С другой стороны,
по общему мнению, читатель книги
не f^ony^GH обращать внимания на
буквы g и к в этой книге. Шрифт
f^on^GH выглядеть внушительно, но
действовать внушающе.
Умение производить
параметрические изменения проистекает из
нашей потребности в разнообразии.
Мы не хотим все жить в одинаковых
домах или водить одинаковые
машины. Фоновая музыка становится
особенно утомительной, когда ее
партитура бедна, состоит всего
лишь из нескольких мотивов; и пять
столетий типографской практики
свидетельствуют о непрерывном
стремлении к новым алфавитам и
к большим гарнитурам родственных
алфавитов. Поэтому, хотя любой
набор конкретных значений
параметров меташрифта может выгля^^ть
несколько глупо и казаться лишним,
имеется настоятельная необходимость
уметь выбирать произвольные
значения параметров. Создатели книг
и рекламных материалов получат
большую свободу, чем когда-либо
раньиие, если они смогут оперировать
несколькими меташрифтами. .Любой
также сможет легко получить
индивидуальные шрифты и шрифты для
однократного использования.
312
Компьютерная типография
Еще одна причина, почему ме-
ташрифты и мета-музыка не были
как следует развиты давным-давно,
состоит в том, что до недавнего
времени не существовало
компьютеров. Люди находят выполнение
расчетов с множеством параметров
затруднительным и скучным, в то
время как сегодняшние машины
делают это с легкостью.
Может быть, самым важным
практическим результатом
параметрических изменений стала возможность
делать поправки для каждого кегля]
сегодняшняя тенденция получать
шрифты Т кегля посредством
уменьшения до Т0°/о шрифтов 10 кегля
привела к прискорбному ухудшению
качества. Еще одно преимущество
состоит в том, что меташрифт может
приготовить кривые для правильного
воспроизведения на цифровых
печатных устройствах, основанных на
дискретном растрировании. Это
значительно уменьшает необходимость
ручной корректировки растровых
шаблонов.
Конечно, создать меташрифт
вместо одного шрифта—задача сложная.
Создатель хочет контролировать
процесс, на огромное многообразие
возможных значений параметров
приводит к тому, что меташрифт
способен сгенерировать бесконечно
Глава 15. Концепция меташрифта
313
много алфавитов, большинство
которых человеческие глаза так никогда
и не увидят; только немногие из
вариантов можно посмотреть и еще
намного меньшее число—как следует
отрегулировать до того, как описание
меташрифта будет завершено. С
другой стороны, создатель меташрифта
получает в качестве компенсации и
преимущества, потому что меташ-
рифт позволяет отложить принятие
решений по многим аспектам
замысла, превратив их в параметры, вместо
того чтобы фиксировать их описание
уже на начальном этапе. Такие вещи,
как величину свисания, толщину
соединительных штрихов, длину
засечек и т. д., не стоит определять
раз и навсегда; не составляет труда
попросить компьютер провести
эксперименты, которые позволят
создателю выбрать наилучшие
значения р,ля этих неуловимых количеств
после просмотра реальных печатных
образцов. "Такие эксперименты были
бы невыполнимы, если бы каждый
символ пришлось рисовать по
отдельности, т. е. если бы каждый символ
скорее принадлежал просто шрифту,
чем меташрифту.
В конце концов на первый план
должны выдвинуться научные
аспекты меташрифта. Возможность
непрерывного изменения параметров
314
Компьютерная типография
позволяет ставить эксперименты
о влиянии таких изменений на
удобочитаемость текста или его
привлекательность для глаза. И
даже еще более важными станут
знания, точно зафиксированные в
описаниях меташрифтов. Автор,
например, узнал очень многое о
создании шрифтов, совершенствуя
алфавиты Computer Modern, и теперь
эта информация доступна каждому,
кто умеет читать код METRFONT'a. "Так
много надежд связано с мыслью,
что когда-нибудь профессионалы,
действительно знающие предмет,
начнут создавать меташрифты в
точном языке, таком как METRFONT,
и тогда искусство создания шрифтов
вознесется на небывалые высоты.
Благодарности и извинения
Автор хочет поблагодарить Чарльза Бигелоу, Мэтью Картера, Дугласа
Хофштадтера, Джил Кнут и Майкла Паркера за многочисленные
предложения, которые помогли улучшить статью; и он в особом долгу перед Германом
Цапфом за десятки бесценных предложений, которые значительно помогли в
совершенствовании замысла меташрифтов Computer Modern. Извинения
приносятся поборникам чистоты языка, которые возражают против смешивания
греческих и латинских основ: греческим эквивалентом fons будет Tnqyrj, так что
слово вроде «metapeg» (метапег) подошло бы лучше, чем «metafont» (меташ-
рифт). Но тем не менее, люди, встретившие такое название в первый раз, вряд
ли сразу сообразят, что оно означает, во всяком случае до тех пор, пока наука
о создании шрифтов не станет известна как пегология.
Исследования, описанные в этой статье, частично поддерживались фондом National Science
Foundation по грантам IST-7921977 и MCS-7723738 и частично —IBM Corporation.
Глава 15. Концепция меташрифта
315
Аннотированный список литературы
Шрифты, использующиеся в этом списке литературы, соответствуют
значениям параметров для прямого светлого шрифта гарнитуры Computer Modern,
использованным в ходе ее первоначальной разработки и основанным на
шрифтах «Monotype Modern 8»; более радикальные значения, использованные для
набора предшествующего текста статьи, были подобраны много позже того,
как разработка была завершена, для того чтобы проиллюстрировать
концепцию меташрифта.
[1] P. J. M. Coueignoux, Generation of Roman Printed Fonts, Ph.D. thesis, Dept.
of Electrical Engineering, Massachusetts Institute of Technology (June 1975).
В этой диссертации представлена первая попытка использовать сложные
математические кривые для компьютерного описания формы букв. Автор
вместе со своими студентами сейчас продолжает эти исследования в Ecole
Nationale Superieure des Mines de Saint-Etienne, Франция.
[2] Adrian Frutiger, Type Sign Symbol (Zurich: ABC Verlag, 1980); особенно
обратите внимание на ее. 15-21, где описано, «как создавался и
развивался Univers». Univers был первым настоящим меташрифтом, в том смысле
что многообразие размеров букв и толщин линий с самого начала
играло в его создании центральную роль. «Фактором, определившим многие
новые созидательные возможности, предоставляемые Univers'ом, было то,
что впервые стало возможно работать с набором начертаний как с
законченной системой». На с. 59 этой захватывающей книги можно найти мета-
букву п, названную «пропорциональной схемой семейства начертаний»,
она графически изображает желаемые изменения линий при увеличении
насыщенности шрифта.
[3] Peter Karow et al., "IKARUS: computer controlled drafting, cutting
and scanning of characters and signs. Automatic production of fonts
for photo-, CRT and lasercomp machines. Summary" (Hamburg: URW
Unternehmensberatung, September 1979). Уже к 1980 г. система IKARUS
широко использовалась для того, чтобы по нарисованной художником букве
получать ее математическое описание1 [см. Baseline 3 (1981), 6-11].
Компьютерные программы также могут интерполировать степень
насыщенности шрифта, хотя число независимых параметров весьма ограниченно;
эта возможность была успешно использована Мэтью Картером для
разработки шрифтов гарнитуры Galliard нескольких степеней насыщенности,
включая Ultra Roman [см. Charles Bigelow, "On type: Galliard," Fine Print
5 (1979), 27-30].
[4] David Kindersley and Neil Wiseman, "Computer-aided letter design," Printing
World (31 October 1979), 12, 13, 17. Обсуждается разработанная в Кем-
1 Отечественному читателю можем порекомендовать книгу Каров П. Шрифтовые
технологии. Описание и инструментарий. — М.: Мир, 2001. — Прим. ред.
316
Компьютерная типография
бриджском университете система ELF, в которой воплощен новый метод
оптической расстановки пробелов между буквами.
[5] Donald E. Knuth, "Mathematical typography," Bulletin of the American
Mathematical Society (new series) 1 (1979), 337-372. [Перепечатано с
исправлениями в гл. 2 настоящего издания.] Статья, написанная вскоре
после того, как автор начал свои исследования по созданию шрифтов; в ней
объясняются исходные предпосылки этой работы и приводится
экспериментальный образец меташрифта для прямого светлого начертания.
[б] Donald E. Knuth, "The letter S," The Mathematical Intelligencer 2 (1980),
114-122. [Перепечатано в гл. 13 настоящего издания.] Обсуждение буквы,
включение которой в параметризованный меташрифт представляет
наибольшие сложности.
[7] Donald E. Knuth, Seminumerical Algorithms, Volume 2 of The Art of
Computer Programming, second edition (Reading, Massachusetts: Addison—
Wesley, 1981) [Имеется русский перевод первого издания: Кнут Д.
Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы.—М.:
Мир, 1977; второго издания: Кнут Д. Е. Искусство программирования.
Т. 2. Получисленные алгоритмы.— Киев: Диалектика, 1999.] Эта книга —
первая большая работа, целиком набранная при помощи меташрифтов
Computer Modern; на самом деле Computer Modern был разработан
специально для книг этой серии. Ко времени напечатания этой книги
разработка Computer Modern продвинулась почти до состояния, отраженного
в первоначальном (1982 г.) издании предшествующей статьи, хотя
некоторые символы вроде '2' впоследствии были переделаны, а высота строчной
буквы несколько уменьшена. Такие переделки и переосмысления,
вероятно, неизбежны, особенно когда благодаря компьютерному представлению
меташрифта так легко делать изменения; очень сложно остановиться и
сказать: «Больше никаких улучшений не будет!»
[8] Donald E. Knuth, The Computer Modern Family of Typefaces, Stanford
Computer Science Department report STAN-CS-80-780 (January 1980). Сотни
важных усовершенствований были сделаны в период между завершением
этого отчета и выходом в свет [7], и тысячи новых — когда все было
переписано на язык нового METflFONT'a образца 1984 г. Почти окончательную
версию Computer Modern можно найти в The Computer Modern Family of
Typefaces, Volume E of Computers h Typesetting, fourth printing (Reading,
Massachusetts: Addison—Wesley, 1993); несколько позднейших изменений
перечислены в файле cm85.bug, являющемся частью архивов CTAN в
Интернете. С 1985 г. Computer Modern всего имеет 62 параметра; самая
последняя версия (1998 г.) была использована для набора этой главы, при
этом выбирались значения параметров, соответствующие использованным
в исходной статье 1982 г.
Глава 15. Концепция меташрифта
317
[9] J. R. Manning, "Continuity conditions for spline curves," The Computer
Journal 17 (1974), 181-186. Нужды швейной промышленности бывают
сходны с проблемами создателей шрифтов; в этой статье английской
ассоциации Shoe and Allied Trades Research Association1 обсуждается
проведение кривых, проходящих через заданные узловые точки, и приводится
пример мета-ботинка.
[10] Н. W. Mergler and P. M. Vargo, "One approach to computer assisted letter
design," Visible Language [nee The Journal of Typographic Research] 2 (1968),
299-322. В этой статье обсуждается ITSYLF, первая компьютерная система
для параметрического создания букв; ITSYLF включает меташрифт для
прописных букв прямого светлого начертания. Этот подход был неудачен и
не привел к успеху, потому что был полностью основан на описании
контуров при помощи ограниченного класса кривых и потому что оборудование
1960-х гг. оставляло желать лучшего, но цель авторов похвальна.
[11] W. A. Mozart, Anleitung zum Componiren von Walzern, so viele man will
vermittelst zweier Wtirfel, ohne etwas von der Musik oder Composition zu
verstehen (Berlin: Simrock, 1796); впервые опубликовано Й. Ю. Гумме-
лем в Амстердаме и Берлине в 1793 г. Приведено в Kochelverzeichnis 516f
Anh. С 30.01. Переиздано как Musikalisches Wiirfelspiel Моцарта, под
редакцией Карла Хайнца Тауберта, Edition Schott 4474 (Mainz: В. Schott's
Sonne, 1957); также вместе с предисловием Хью Нордена: (Brighton,
Massachusetts: Carousel Publishing, 1973). Эти необычные ноты
представляют собой вальс, который может быть сыгран 759 499 667 966 482
различными способами, так как имеется по одиннадцать вариантов для
большинства тактов; гармонические принципы были проанализированы Германом
Шерхеном в Gravesaner Blatter 4 (May 1956), 3-14. Моцарт также сочинил
метаконтрданс, а Британский музей якобы обладает метанотами Гайдна.
Примечательный пример метамузыки 20-го столетия можно найти в The
Schillinger System of Musical Composition Йозефа Шиллингера, Volumes 1
and 2 (New York: Carl Fischer, 1946).
[12] Edward Rondthaler, "From the rigid to the flexible," Penrose Annual 53
(1959), xv, 1-9. Одно из ранних описаний вариаций шрифта, получаемых
одними только фотографическими трансформациями.
1 Ассоциация исследований в обувной промышленности и смежных ремеслах. — Прим.
перев.
318
Компьютерная типография
Дополнение
Короткие рецензии на «Концепцию меташрифта» Фернана Бодена, Чарльза
Бигелоу, Анри-Поля Бронсара, Эда Фишера-младшего, Дэвида Форда, Гэри
Гора, В. П. Ясперта, Альберта Капра, Петера Карова, Александра Несбит-
та, Эдварда Рондталера, Джона Шапплера, Уолтера Трэйси, Герарда Унге-
ра и Германа Цапфа, вместе с более распространенной рецензией Дугласа Р.
Хофштадтера были опубликованы в Visible Language 16 (1982), 309-359,
завершающейся следующим ответом автора:
Какая честь для меня, что так много выдающихся людей прочитали мою работу,
и как приятно читать их глубокие комментарии! Спасибо вам за шанс добавить
еще несколько слов к этому ободряющему набору писем.
Когда я читал разнообразные отклики, я часто ловил себя на том, что я
скорее на стороне людей, остро критикующих мои исследования, чем тех, кто
бурно их одобряет. Критические комментарии крайне полезны для планирования
следующих этапов работы, которую делают люди вроде меня, когда мы ищем
подходящие способы использования новых полиграфических технологий.
В нескольких рецензиях была упомянута цитата, взятая мною у Джорджа
Форсайта, и ваш читатель, возможно, захочет более детально ознакомиться с его
словами. Джордж был одним из первых, кто увидел настоящую ценность науки
«computer science» не просто в использовании компьютеров, и процитированное
мною замечание взято из вступления к речи о computer science и образовании,
которую его в 1968 г. пригласили прочесть на конгрессе International Federation
for Information Processing, проводившемся в Эдинбурге. Если бы я мог, я бы
с удовольствием процитировал здесь всю статью; лучшее, что мне остается,—
предложить людям найти ее в своих библиотеках: [Information Processing 65,
Volume 2 (North-Holland, 1969), 1025-1039].
Надеюсь, мне простят еще одну цитату из моей собственной статьи,
названной «Программирование на компьютере как искусство» (Computer programming
as an art) [Communications of the ACM 17 (1974), 667-673; L'Informatique Nouvelle,
no. 64 (June 1975), 20-27]. В этом эссе я пытаюсь показать, что основное
различие между наукой и искусством состоит в том, что наука кодифицирована (и
в этом смысле «автоматизирована»), в то время как искусство принадлежит к
таинственной области человеческой интуиции. Мое главное утверждение
состоит в том, что наука никогда не сравняется с искусством, потому что каждое
продвижение в науке обязательно сопровождается прорывом в искусстве.
Таким образом, я надеюсь на то, что пришествие компьютеров поможет нам
понять, насколько мало мы пока знаем о форме букв. Затем, когда мы
попытаемся объяснить законы в такой точной форме, чтобы даже машина смогла по
ним работать, мы узнаем много нового об исследуемом предмете, и после этого
вместе с последующими поколениями сможем поднять художественный уровень
еще выше.
Пока что мой опыт со времени опубликования статьи в Visible Language
вполне обнадеживает. Несколько ведущих создателей шрифтов великодушно
указали мне на несколько моментов, которые можно улучшить в шрифтах
гарнитуры Computer Modern, и весь апрель я провел, проводя масштабные усо-
Глава 15. Концепция меташрифта
319
вершенствования под руководством Ричарда Саутолла. Количество параметров
выросло с 28 до 45, но все параметры пока что кажутся осмысленными; и такое
внимание к мелочам уже приводит к значительно лучшим результатам. Еще
многое нужно сделать, включая дальнейшее развитие математики форм, но теперь
у нас есть некоторая уверенность, что разрабатываемый нами инструментарий
не окажется неадекватным поставленной задаче. Я надеюсь опубликовать книгу,
содержащую все то, чему меня научили эти люди, чтобы эти знания могли быть
приняты во внимание, прочувствованы и послужили своему предназначению, а
не просто применялись.
Дональд Э. Кнут
Отделение Computer Science
Станфордский университет
12 октября 1982 г.
Замысел и символы этого шрифта получили как благоприятную, так и
неблагоприятную оценку, но ввиду того
что, насколько я знаю, библиографы уже
написали об этом на семи языках в шестнадцати странах мира, я чувствую, что
наши достижения по крайней мере вызвали интерес.
— DARD HUNTER, Primitive Papermaking (1927)
Уроки METflFONT'a
[Представлено в качестве пленарного доклада (keynote address) 1 августа
1983 г. на Пятом рабочем семинаре по обучению и исследованиям в области
создания шрифтов (Fifth Working Seminar in Letterform Education and Research),
проведенном под патронажем Международной полиграфической ассоциации
(Association Typographique Internationale (ATypI)). Первоначально
опубликовано в Visible Language 19 (1985), 35-53.]
Разработчики шрифтов столкнулись сейчас с серьезной проблемой —
проблемой формирования растровых (оцифрованных) образов для печати. Основной
вопрос здесь звучит так: «Что можно считать правильным подходом к
созданию подобных образов?». Или, скорее, «Что будет правильным подходом?» —
поскольку речь пойдет в основном об аспектах долгосрочного характера,
отличающихся от более конкретных проблем, обсуждаемых на данном совещании.
Я попытаюсь изложить ряд соображений, навеянных ходом и результатами
исследований, проводимых нами в Станфорде, поскольку, на мой взгляд, это
позволит найти ответы хотя бы на часть возникающих вопросов.
Я вовсе не ожидал, что рассматриваемая проблема будет простой для
решения. И тем не менее, когда я стал анализировать уроки, извлеченные из
ее решения, то понял, что основной урок состоит как раз в том, что данная
проблема оказалась в высшей степени непростой. На самом деле, ничего
удивительного в этом нет. Более чем за тридцать лет было поставлено большое число
компьютеров, причем продавцы их утверждали, что вычислительную технику
использовать просто, однако истинное положение дел прямо
противоположно этому утверждению. Компьютерное программирование требует внимания
к мельчайшим деталям, чего не требуется ни в одном другом виде
человеческой деятельности. Что же касается шрифтов, то их разработка —весьма
тонкая материя, значительно более сложная, чем это обычно представляется
большинству людей, поскольку наши машины и наши глаза взаимодействуют с
геометрическими формами достаточно сложным образом. Я уверен, что
проектирование цифровых шрифтов представляет собой чрезвычайно интересную,
захватывающую задачу, которая вполне достойна внимания наших
выдающихся деятелей науки и искусства. Я полагаю, что мир станет лучше, когда мы
больше узнаем об этих вещах.
322
Компьютерная типография
Вот еще одно соображение, которое я хотел бы высказать, прежде чем
перейти к изложению подробностей и результатов своих исследований. Я
математик, и прекрасно понимаю, что совсем не художник. Мне отнюдь не кажется,
что с помощью математических методов можно решить все проблемы
полиграфии, но математики могут помочь в их решении. Это трудно представить, но
после более чем 2000 лет накопления геометрических знаний у нас все еще нет
подходящих средств для разработки алфавитов. Люди, для которых любовь
к буквам частично обусловлена их неприязнью (или, скажем так, отсутствием
влечения) к алгебре, видят в математике настоящую угрозу. Мне жаль, что
существует такой страх перед математикой, но я знаю, что он распространен
довольно широко. Я полностью отдаю себе отчет в том, что внедрение
математики в области, где она ранее не применялась, нарушает покой лидеров таких
областей, поскольку они внезапно обнаруживают, что надо изучать огромный
объем нового материала, чтобы оказаться на уровне изменившихся требований
к предмету. Я думаю, однако, что нет реальных причин для тревоги; не может
быть предмет настолько сложным, чтобы никто в нем не смог разобраться.
Наиболее впечатляющим в последних типографских разработках является все
более крепнущее содружество между учеными и художниками: мосты, которые
они строят между «двумя культурами», о которых говорил Сноу. Я отнюдь
не предполагаю, что художники-шрифтовики бросят вдруг их традиционное
ремесло и дружно займутся изучением компьютерного программирования; я
говорю сейчас о том, чтобы они вступали в такое творческое взаимодействие со
специалистами по вычислительной технике и информатике, которое привычно
для них в отношении, например, специалистов по изготовлению матриц для
печатных машин. С другой стороны, мне нравится видеть студентов, которые
все более уверенно чувствуют себя в обоих из этих миров одновременно.
Но что именно интересно на мой взгляд в этой области? В течение
последних нескольких лет я разрабатывал компьютерную систему, получившую
наименование METflFONT. У этой системы есть три необычных свойства:
(1) METfl FONT понимает специальный язык для вычерчивания
геометрических форм с помощью имитируемого пера, обладающего варьируемой
толщиной. В качестве примера рассмотрим рис. 1, где изображена «сердцевидная»
кривая, полученная с помощью слегка меняющегося по ширине пера.
Изобразить такую фигуру для METflFONT'a —совсем простая задача, в которой
«хребет» кривой определяется всего шестью точками. Фактический контур кривой
весьма сложен и описать его — проблема нетривиальная, однако движения пера
здесь совсем просты.
(2) Язык METfl FONT поощряет также работу с явными параметрами, что
дает возможность описывать не единственную форму, а их семейство.
Например, на рис. 2 показан один из эскизов, сделанных Мэттью Картером,
когда он работал над гарнитурой Galliard] METfl FONT нацеливает
разработчика на включение изменений (средств варьирования формы) непосредственно
в проект. Именно по этой причине и появилась приставка «meta-» в имени
METfl FONT; подход, реализуемый данной системой, можно трактовать как ме-
таподход в том смысле, что он имеет дело со шрифтами некоторым образом «с
Глава 16. Уроки METRFONT'a 323
Рис. 1. Рис. 2.
внешней стороны», на более высоком уровне, аналогично тому, как
«метаматематика» есть теория методов математического доказательства. Метаконцепции
множатся в наши дни; например, я недавно услышал о новой игре, называемой
«метаигрой» [7], в которой первое, что надо сделать —это выбрать игру.
(Интересная проблема возникает, когда первый игрок скажет: «Давай сыграем в
метаигру!»)
Я уже писал о концепции меташрифта [б], представляющего собой
высокоуровневое описание, порождающее индивидуальные шрифты, набор которых
задается меташрифтом. Эту концепцию надо отличать от системы METflFONT
как таковой, представляющей собой один из подходов к реализации меташриф-
тов. На рис. 3 (согласно Скотту Киму) показано, как влияют на вид шрифта
изменения в его параметрах на примере ранней версии меташрифта,
называемого Computer Modern. Для наглядности каждая из варьируемых переменных
в этом примере доводилась до предельных значений. На рис. За
демонстрируется изменение наклона букв, на рис. ЗЬ —их ширины; в обоих этих случаях
ширина пера оставалась одной и той же, менялась только траектория его
движения, значит, изменения в изображении не могут быть осуществлены с
помощью одних только оптических преобразований.
На рис. Зс показано, что произойдет, если траектория движения пера будет
практически одна и та же, но размер пера меняется. Можно также варьировать
величину засечек на буквах (рис. 3d). Преобразование, результат действия
которого виден на рис. Зе, имеет не совсем обычный характер. Здесь изменения
вносятся в «константу», используемую при вычислении кривых, это приводит
к изменениям в форме округлых элементов букв. На рис. 3f демонстрируется
результат варьирования несколькими параметрами одновременно,
предпринимаемого для сохранения удобочитаемости букв при изменении кегля; это
обстоятельство является одной из основных причин параметризации шрифтов.
Буквы здесь масштабировались таким образом, чтобы их х-высота не
менялась, в этом случае более очевидны результаты воздействия других изменений.
В каждом из рассматриваемых случаев буквы формировались на основе одного
и того же METRFONT'oBCKoro описания; все показанные изменения
порождались только варьированием параметров, применяемым для шрифта в целом.
324
Компьютерная типография
(а) (Ъ) (с;
Typography
(мгаи! R«ua) 0 du*
(■MMlltalUd) 1/tdHt
1/4*-
1/1Ы
l/!riu*
1/1 —
икпЫкГ 1/4
«knUky l/l
— i,Vi
(«шЦикпЫЬг!
MAnUkfl
Typography
Typography
Typography
Typography
Typography
Typography
Typography
Typography
Typography
Typography
Typography
.«b»Mhx4 typography"
(d) (e) (f)
Рис. 3.
Чтобы обеспечить получение характеристик 1 и 2, METRFONT'oBCKne
описания форм литер строятся как программы. Например, на рис. 4 показаны две
такие программы для ранней версии меташрифта с именем CHEL,
разрабатывавшегося Томом Хики в 1982 г. (см. [1]). Образцы букв, формируемых этими
программами при различных значениях параметров, показаны в верхней
части рисунка. Программа для буквы Ъ' такая короткая из-за того, что большая
часть работы здесь выполняется подпрограммой — вспомогательной
программой, используемой для конструирования повторяющихся частей нескольких
различных по форме литер. В данном случае Хики сделал подпрограмму для
вычерчивания округлой части буквы, которую и применил при формировании
букв 'd', 'p' и т. п.
METRFONT'oBCKne программы совершенно не похожи на обычные
компьютерные программы, поскольку они в большей степени «декларативны», чем
«императивны». Другими словами, они устанавливают соотношения, которые
должны иметь место, но ничего не говорят относительно того, как
удовлетворить сформулированным условиям. К примеру, METRFONT'oBCKoe описание
может декларировать, что левый контур должен отстоять на одну единицу от
левой границы бокса, включающего литеру; программе не надо задавать, что
центр пера следует поместить на одну единицу от левого края бокса плюс
половина ширины вертикального штриха литеры, поскольку компьютер может это
подсчитать. Аналогично, можно задать, что некоторая точка лежит на
пересечении двух линий, но нет необходимости указывать, каким образом найти эту
точку пересечения. Таким образом, большинство математических сложностей
ложатся на компьютер и выполняются «за сценой».
-*.« Т jpojraphj
**• Typography
-Ьу. Typography
— Typography
.*ru Typography
щхх T^pcgragiy
nil. - Jtl Typography
- It(J/S) Typography
Z2Q Typography
И Typography
Typography
Typography
-*-. Typography
„«*.-. Typography
«id*-1/4 Typography
Typography
Typography
*-*-i Typography
.**-i Typography
,.н- Typography
,~.-iuw Typography u—»»p- Typography
и* Typography
»Typography
м- Typography
м- Typography
и* Typography
Глава 16. Уроки METRFONT'a
325
Bifli
В
в
в
в
шит
»«*; а«жО;
■» topiadent, botoftop, topo/boc, им;
topiadent = round («/„г); 4 indent top eve
•ем « »/»(i»m, «iu]; К a ilow-grow pen for middle
botoftop ж round( Vtlbot wcbbar, topwcnbar]); К bottom of top onter
lopo/bot жгоиш1(«Д(ЬЫисЬЬаг|1ориспЬаг])'| К top of lower onter
Hnn. ж round (г - ucia + bo); rlmi ж Нцц. - topindent;
x. * »ЛИ..х,,1П„хт]; х. * V>[rtnx,,in„x,o]; К bawd on counter wid
x, ж i, ж x,;
»°РитУ» = "5 У» ж И! bot итуа ж 0; уа ж у,;
naw щи, акт; % uaed for top and bottom a
•км * round(topwcbbar - botoftop); call ca«cfcpea(M); Ч to control tkina
»n ж round(topo/bot - botgacbbar); call cb«ckpea(B7); % of arc* at се»
toP9tV> = topwcbbar; botvrya ж botgacabar;
If botHy> > iop„y.: anrim; а* ж a*,; now п>и; **.>**.+ 1; fl;
у* ж 'A[bot„Tyi,*op„caUr]; »,. « i^[topIITy>,botwcbbar]; % t/, of count
Vii ж у» ж сйЬаг; х» ж х,; К beifbt of bar tame at ca|
vpan; vpanwd 1;
wiit draw 2..Б; % top U
drawl..»; KbotU
a*» drawll.. 12; К mid U
ant drawl..«;
call '• ao«re(5,7,iB,,T,wit);
call -bagarc(9,10,aniT,a>it)
call *c aoarc(6,7latMlaiit);
caU -aagarc(8,10,avT,aiit).
b
b
b
b
b
IbJ
b
b
b
b
b
Ы
b
b
b
b
b
b
b
b
b|b
b
b
ЬШ
ььЬ
bd№
b\b\
Рис. 4.
Поскольку METRFONT'oBCKne программы включают всю информацию
относительно того, как изображать каждую из букв для широкого диапазона
условий, эти программы могут фиксировать «интеллектуальную
составляющую», лежащую в основе проводимой разработки. Я считаю, что это свойство
METRFONT'a —его способность «схватывать» намерения разработчика
шрифта, а не только фиксировать рисунок, являющийся следствием этих
намерений—окажется наиболее важным среди всех остальных его свойств.
Способность изображать бесконечно много алфавитов варьированием параметров не
просто важная цель сама по себе. Она позволяет объяснить проект в точных
терминах, что в высшей степени поучительно как для разработчиков
шрифтов, так и для тех, кто читает написанные ими программы. Применение
компьютера способствует повышению дисциплины, что помогает пользователям
уточнить используемые ими знания; такого рода образовательный опыт
—действительно полезный побочный результат.
Вернемся теперь к главной теме моего сообщения —урокам, извлеченным
мною из работы с METAFONT'om. Лучше всего, наверное, будет начать рассказ
с лета 1977 г., когда я начал эти работы. Тогда у меня и в мыслях не было,
что придется разрабатывать язык для описания форм литер: ведь
разработкой шрифтов занимались, обыкновенно, художники и полиграфисты. Мне не
удалось получить хороших изображений букв, которые я мог бы использовать
при наборе текстов, так что пришлось создавать компьютерные методы
проектирования шрифтов, причем делать это, начиная с «чистого листа». Мои
издатели снабдили меня высококачественными оттисками, сделанными с
помощью шрифтов, которые использовались для первого издания моей книги, но
зато мне пришлось иметь дело с крайне примитивным оборудованием. Экспе-
326
Компьютерная типография
рименты с телевизионной камерой, соединенной с компьютером, завершились
полной неудачей, поскольку оптика телевизионной камеры вносила
значительные искажения, как только мы пытались увеличить маленькие изображения.
Кроме того, незначительное изменение в интенсивности студийного освещения
приводило к очень большим изменениям в получаемом телевизионном
изображении. Наилучшие результаты, которых мне удалось добиться, были получены
путем изготовления на 35-мм пленке слайдов с листов гранок, с последующим
увеличением изображения с помощью диапроектора, установленного на
расстоянии 8 м от стены в моем доме, игравшей роль экрана. Изображения букв
высотой около 5 см получались несколько расплывчатыми, с них я и снимал
карандашные эскизы.
Мысль о «трех пи» системы METRFONT — рисование с помощью пера
(pens), использование параметров (parameters) через программы (programs) —
осенила меня примерно через час после того, как я начал делать эскизы
описанным выше способом. На меня внезапно снизошло, что я должен не просто
копировать уже имеющиеся формы литер. Изначально человеческие существа
рисовали их, и мне захотелось узнать, чего же достигла человеческая мысль
на этом поприще, и использовать такого рода знания в компьютерной
программе.
Программы, которые я написал в 1977 г., использовали традиционный
«императивный» язык программирования SAIL, очень похожий на
международный язык программирования ALGOL. Каждый раз, когда я менял что-нибудь
в программе для какой-либо из букв, приходилось перекомпилировать эту
программу, чтобы внести изменения в рабочую программу в кодах машины. Идеи
декларативного, интерпретируемого языка, подобного METflFONT'y, у меня не
возникало, пока несколькими месяцами позднее она не была высказана
Робертом Филманом. Однако отсутствие такого языка на самом деле в 1977 г.
не очень меня сдерживало, основная проблема состояла в том, что я не знал
подходящего способа описания геометрических форм.
Чтобы проиллюстрировать эти трудности, я решил показать вам кое-что
из того, что я до сих пор не показывал никому —самые первые результаты,
которые я получил в 1977 г., когда попытался рисовать арабские цифры. После
того как я представил сделанные ранее эскизы в виде компьютерных программ,
машина выдала мне то, что представлено на рис. 5, где каждый из показанных
фрагментов соответствует разным значениям основных параметров
(нормальный, полужирный, капитель, шрифт без засечек, имитация пишущей
машинки соответственно). С цифрой '8' возникли особые проблемы, из-за которых
она — к счастью — оказалась напечатанной только в одном стиле, однако мои
первоначальные ошибки в цифрах '2', '5', '6' и '7' оказались повторенными
пятикратно. Я показываю сейчас эти ранние результаты потому, что похожие
проблемы могут возникнуть даже и в существующей версии METflFONT'a; не
так-то просто описать суть геометрической формы, чтобы машина правильно
воспроизвела ее.
Рисунок 5 буквально кишит огрехами, так что будет поучительно
рассмотреть его более внимательно. В нескольких случаях я просто ошибся. Например,
Глава 16. Уроки METRFONT'a
327
25И|ад™^@бШН1
Рис. 5.
я забыл об использовании пера достаточной толщины, когда начал рисовать
диагональный элемент цифры '2'. Странный сбой в третьей «двойке» вызван
плохой спецификацией угла в нижней части цифры —я задал тот же самый
угол для малой капители, что и для нормального размера, несмотря на то,
что рисовалось изображение меньшего, чем было до этого, размера. Еще один
некорректный угол имеет место в верхней части округлого элемента каждой
из цифр '5'. Но другие ошибки оказались более серьезными. Неважная форма
нижней части цифр '5' еще хуже смотрится в верхней части цифр '6', где
головка-наплыв оказалась поднятой слишком высоко и плохо соотносилась
с оставшейся частью цифры. Еще хуже оказался результат в нижней части
цифры '6', где вообще не срабатывал принятый мною подход и этот элемент
пришлось переделывать несколько раз, доводя его экспериментально. Верхняя
часть крайней правой цифры '7' показывает проблему, которую мне не
удавалось решить удовлетворительно в течение пяти лет, пока я не понял, наконец,
что верхний левый фрагмент цифры '7' (и нижний правый цифры '2')
можно рассматривать как горизонтальные штрихи, аналогичные соответствующим
фрагментам букв типа Т' или 'Е'.
01234567
01234567
01234567
01234567
01234567 рис.6.
К концу 1977 г. цифры из моего экспериментального меташрифта приняли
вид, показанный на рис. 6. На тот момент они меня устраивали и большую
часть 1978 г. я провел в разработках системы ТЁ^, а также выполнял ряд
других исследований в области вычислительной техники и информатики. В
1979 г. я решил разработать символьный язык для описания форм литер,
который отражал бы более высокий уровень понимания данного предмета, чем
тот, что был у меня, когда я писал в 1977 г. программы на ALGOL'e.
Новый язык стал основой системы METfl FONT в ее первоначальном варианте [4].
В 1980 г. пришлось провести большую работу по формированию интерфейса
между выходом METRFONT'a и фотонаборным устройством с высокой
разрешающей способностью. В течение всего этого времени я был полностью
загружен решением проблем, связанных с программным обеспечением, и особенно
много заниматься проектированием шрифтов не мог. Потом я, наконец,
добился того, что рассчитывал сделать на два года быстрее: завершил подготовку
328
Компьютерная типография
второго издания своей книги Seminumerical Algorithms [5] — 700-страничного
тома, где все, за исключением очень небольшого числа иллюстраций, было
сделано исключительно компьютерными методами. В этой книге в общей
сложности было использовано 35 шрифтов — прямой (романский) семи размеров,
курсивный шести размеров, по три размера для полужирного и наклонного
шрифтов, а также шрифта, имитирующего пишущую машинку, причем
каждый размер рисовался отдельно (т. е. получался не просто масштабированием
из другого шрифта); было также шесть вариантов шрифта без засечек и семь
pi-шрифтов, содержащих математические символы. Все они были созданы с
помощью первой версии METflFONT'a, и когда страницы книги распечатывались
на принтере, выглядели они, по-моему, вполне прилично.
Я не могу, однако, передать того громадного разочарования, которое
испытал, когда наконец Seminumerical Algorithms были отпечатаны в начале
1981 г. Впервые я увидел результат всего процесса в целом, включая печать
и переплет. До того момента я работал почти исключительно на
оборудовании с невысокой разрешающей способностью и, конечно, результаты,
получаемые при повышении разрешения, должны были быть много лучше, так
что я с нетерпением ожидал увидеть прекрасную книгу. Когда же я получил
и раскрыл сигнальный экземпляр, меня охватило жестокое разочарование —
все выглядело никуда не годно! Основное потрясение было вызвано тем, что
я видел теперь, как выглядят шрифты отпечатанными в книге и, что очень
существенно, в переплетенном виде, в обложке темно-желтого цвета, как это
было и в первом издании. Тот факт, что новый формат был помещен в
старый контекст, подчеркивал недостатки нового формата. Конечно, новый текст
вполне можно было читать и я хотя бы немного мог утешаться мыслью, что
моя книга получилась все же не настолько плохой как некоторые другие,
вышедшие из печати примерно в то же время. Но это было совсем не то, что
мне хотелось получить. Шрифт без засечек не получился совсем,
соотношение жирности прямого и курсивного шрифтов для цифр было неудачным.
Печать с высоким разрешением выявила также недостатки в отдельных
литерах, которые ранее не были заметны. У меня возникла стойкая неприязнь к
формам цифр, особенно '2' и '6'. Когда я пользовался этой книгой для
справок и в учебном процессе, то был вынужден смотреть на числа на каждой
странице и это сбивало меня с мысли: я хотел думать об элегантной
математике, но это было невозможно при таком уродливом полиграфическом
исполнении.
Мое глубокое разочарование все-таки до конца меня не обескуражило.
Дело в том, что я прочел множество биографических книг и знал о так
называемом кризисе среднего возраста. Поскольку в 1978 г. мне исполнилось 40
лет, я был начеку, ожидая, что совершу по крайней мере одну крупную
ошибку. Я всегда считал, что надо следовать интуиции, но быть готовым к тому,
что она может подвести. Я знал, что METRFONT совершенно не похож на все,
что было сделано до него и что делалось в то время, и мне стало казаться, что
все мои идеи, может быть, просто вздорны —не удивительно, что никто до сих
пор не пытался сделать чего-то похожего. С другой стороны, мне представля-
Глава 16. Уроки METRFONT'a
329
лось, что основные идеи —перья, параметры и программы — все же верны, а
недостатки в моей опубликованной книге связаны не с этими идеями, а с их
реализацией. И я решил продолжать упорно добиваться своего.
С тех пор прошло два года. За это время и я, и мои коллеги
накопили большой опыт работы с первой версией METRFONT'a. В следующем году
я планирую разработать эту систему заново, основываясь на приобретенном
опыте. Это позволит избежать в новой системе большей части недостатков,
характерных для старой. Так как новый язык будет готов в 1984 г., было
бы неудивительно, если бы мы последовали Джорджу Оруэллу и назвали его
NEWSPEAK (НОВОЯЗ). Мы планируем сделать METRFONT84 широко
доступным и пригодным для использования на всех компьютерах, вплоть до самых
маленьких.
Прошу простить меня за то, что я вставил в эту работу так много
биографических заметок. Моя основная цель — рассказать об уроках, извлеченных
из работы над METRFONT'om, и теперь самое время поговорить о некоторых
более конкретных подробностях.
Один из первых важных выводов — компьютер заслуживает того, чтобы
относиться к нему как к некоемому новому средству, среде разработки.
Начиная решать проблему разработки средств цифрового набора текстов, не
следует ожидать, что все будет делаться в точности так же, как и раньше, скорее
придется «учить» компьютер, как традиционно учат людей обращаться с
кистью и резцом. Используя машину, лучше всего сдерживаться и отказаться от
некоторых наших «указаний» — чтобы позволить машине выявить, что
работает, а что нет. Идеальный вариант — работать совместно с инструментом; мы
задаем важные подробности, но и хотим, чтобы нам помогли в этой работе.
Л. Л
8 2 9\ J 8 2 9\ # /
(а) Рис. 7. (Ъ)
Конечно, все это имеет смысл, только если компьютер будет «хорошей
средой», только если кривые, которые он рисует, будут эстетически
привлекательными. Рассмотрим в качестве примера рис. 7а, показывающий, что
сегодняшний METflFONT вполне может породить эти уродливые формы, если
пользователь просто задаст восемь-девять точек и не даст каких-либо
дополнительных указаний. Можно быстро научиться преодолевать эти затруднения
и с помощью METRFONT79 получать вполне привлекательные геометрические
формы, однако новая система в этом отношении значительно лучше. Джон
330
Компьютерная типография
Хобби получил недавно важные математические результаты, дающие
возможность из тех же самых данных, что были исходными для рис. 7а, получить
результаты, показанные на рис. 7Ь. Новый подход, предложенный Дж.
Хобби, реализован в METRFONT84. Это весьма существенно не только по той
причине, что упрощает применение системы и делает ее легче реагирующей
на потребности пользователя, но и потому, что когда осуществляется вывод
изображений литер на оборудовании с невысокой разрешающей способностью,
всегда требуется подгонка кривых. Метод Хобби значительно снижает
вероятность возникновения ситуации, когда такого рода подгонка нарушит форму
кривых.
*» "w/|p
Рис. 9.
Рисунки 8 и 9 позволяют уточнить смысл, в котором надо понимать
утверждение о важности компьютера как изобразительного средства. Формы типа
«слезинка», показанные на рис. 8, изображены METRFONT'om с помощью
подпрограммы teardrop, для которой надо было задать всего несколько точек
(одну вверху, одну внизу и одну горизонтальную координату на границе наплыва);
все другие точки найдены путем математических вычислений, проведенных в
подпрограмме. Джон Хобби много поработал, чтобы создать эту
подпрограмму, но разработчик может теперь эффективно использовать ее, нисколько не
беспокоясь о том, какие именно вычисления на самом деле реализуются данной
подпрограммой. На рис. 9 показана серия разнообразных штрихов,
полученных с помощью подпрограммы teardrop и трех других подпрограмм в ходе
ранних экспериментов, проводившихся Хобби и Гу с целью выработки
подхода к изображению знаков для восточно-азиатских языков [2]. Дальнейшая
работа Хобби и Гу привела к другому набору подпрограмм, отвечающему
потребностям получения высококачественных изображений полного комплекта
знаков для японского и китайского языков в различных стилях [3].
Второй важный урок, вынесенный из использования METRFONT'a, состоял
в том, что правильнее и лучше считать различные элементы проекта
взаимодействующими, а не задавать их изолированно друг от друга. Например, лучше
сказать, что некоторая точка лежит посередине между двумя другими, чем
/ /
• 4 т
Рис. 8.
Глава 16. Уроки METRFONT'a
331
mathematics
mathematics
mathematics
mathematics
mathematics
mathematics
Рис. 10. Рис. 11. Рис. 12.
дать явные координаты всех трех точек. Один из способов показать это
представлен на рис. 10, являющемся результатом моих экспериментов 1977 г. со
случайными числами. Я изменил в них мои ранние программы таким образом,
чтобы ключевые точки литер не задавались точно; считалось, что компьютер
будет как бы «немного навеселе», размещая эти точки. Верхняя строка литер
показывает результат, полученный без введения случайных смещений в
координатах ключевых точек; вторая строка демонстрирует, что получается, если
точки размещаются случайно с величиной среднеквадратического отклонения
для них 1%; третья строка —то же самое, но при среднеквадратическом
отклонении 2% и т. д. Главный вывод из этого эксперимента — получающиеся буквы
кажутся «теплее», если в проект внести небольшой элемент случайности. Но
я привел рис. 10 по другой причине —показать, что различные элементы
литеры влияют друг на друга и налицо взаимозависимость между ними.
Например, если вертикальный штрих перемещается, то вслед за ним перемещается
и засечка; координаты индивидуальных точек не будут независимыми друг от
друга случайными величинами.
Аналогичная зависимость видна и из рис. 11; я получил эти три шестерки
варьированием координат всего одной точки в спецификации данной цифры
(точка 6, лежащая на самом верху ее округлого элемента). Координаты многих
других точек также будут изменяться при перемещении точки 6, поскольку
программа METRFONT работает большей частью с информацией об
относительном расположении точек, а не с абсолютными значениями их координат.
Еще один пример взаимозависимости элементов литеры показан на рис. 12.
Здесь опять серия изображений буквы получена варьированием всего одного
элемента в программе. В верхней строке этих букв я менял наклон касательной
к кривой в середине буквы S; в нижней — жирность букв. Как в одном, так и в
другом случае возникли изменения в координатах и других точек, поскольку
они определялись выражениями, задающими связи между параметрами
буквы, а не простым набором чисел.
Наверное лучшим для меня способом выразить основной дух работы над
METRFONT'om было бы показать некоторые мои «METfl-ляпы»
—получавшиеся время от времени совершенно неожиданные результаты. В самом деле,
компьютер полон сюрпризов, и это служит временами источником
появления различных забавных ситуаций. Например, одна из моих программистских
щщшшшщ
QQQQQ
332 Компьютерная типография
(а) (Ъ)
(с) (d) (e)
Рис. 13.
ошибок привела к тому, что хвостик в букве 'g' завернулся весьма
неожиданным образом (рис. 13а); а одна из моих попыток нарисовать букву 'А' для
шрифта без засечек дала результат, очень похожий на рекламу джинсов Levi's
(рис. 13Ь). Ошибки в формулах привели к появлению необычной буквы 'М'
(рис. 13с), франтоватой 'S' (рис. 13d) и «жестокой» буквы 'С (рис. 13е).
Когда я ошибся с размещением засечки в рис. 13f, клянусь, и не думал в тот
момент о японской йене, «валютные» совпадения здесь абсолютно случайны!
Рисунок 13g возник вследствие моих попыток обнаружить, почему METfl-
FONT в букве 'а' рисует неверную кривую; я рассчитывал увидеть больше
деталей, выведя составляющие эту кривую штрихи, поскольку подозревал, что
имеет место компьютерная ошибка. В этом случае оказалось, что METflFONT
не виноват — это я допустил математическую ошибку, когда задавал угловой
коэффициент касательной в критической точке.
Глава 16. Уроки METRFONT'a
(f) (g)
'(h)'""" '" " "" (i) "~
Рис. 13 (окончание).
Чтобы приводимая коллекция «металяпов» была более полной, на рис. 13h
показана лигатура, в которой я нечаянно попросил, чтобы компьютер соединил
оба верхних крючка у Т с точкой над Т. А на рис. 13i получилось то, что
можно было бы назвать «ffilling station» («ббензоколонкой»).
После 1980 г. исследования в рассматриваемой области проходили очень
успешно, поскольку такие люди, как Чак Бигелоу, Мэттью Картер, Крис
Холмс, Ричард Саутолл и Герман Цапф чрезвычайно помогли в
совершенствовании тех грубых средств, с которых я начинал. В частности, Ричард и я
провели три недели, интенсивно отрабатывая каждую букву и
предварительные результаты, полученные нами, были в высшей степени обнадеживающими.
Он преподал мне много важных уроков и я хотел бы сказать кое-что о вещах,
которыми мы тогда занимались.
На рис. 14 представлены два варианта нарисованной нами буквы 'О'.
Изображение книзу слегка «утяжеляется» и мы добавили параметр, позволяющий
334
Компьютерная типография
внутренний и внешний контуры буквы делать разными без потери свойств ме-
ташрифта (метасвойств). Просто нарисовать два суперэллипса с различными
для них степенями этой «суперности» не получалось, так как внутренняя
кривая иногда подходила слишком близко к внешней или даже пересекала ее; наше
решение состояло в том, чтобы брать оба суперэллипса из одного и того же
семейства кривых, а затем «сдвигать» внутреннюю кривую по отношению к
внешней на некоторое относительное расстояние.
Некоторые из поправок, внесенные Ричардом в то время, когда мы
занимались отработкой буквы 'Р', показаны на рис. 15. Обратите внимание, например,
что мы немного уменьшали жирность вертикального штриха внутри округлой
части буквы. Чтобы при выполнении такого рода улучшений дух метаподхо-
да сохранялся, мы ввели параметр «коррекция вертикального штриха»,
который можно было использовать для подстройки жирности букв (т. е. ширины
штрихов) и в других буквах. Иногда жирность вертикального штриха
приходилось менять по два-три раза, прежде чем процесс можно было считать
завершенным.
Нас порадовало, что METRFONT хорошо справляется со своей работой в
теснине диагональных штрихов, даже когда этому элементу и не уделялось
специального внимания. Например, внутренняя верхняя часть полужирной
рубленой буквы 'А' на рис. 16а несколько раздвинута, это обеспечивает
достаточную величину просвета, что создает иллюзию прямых толстых штрихов.
Наши METAFONT'oBCKne программы разработаны так, чтобы получить этот
эффект как при невысоких, так и при больших значениях разрешающей
способности. Рисунок 16Ь показывает, как та же самая идея применена к букве
'А', выполненной в стиле шрифта пишущей машинки.
Подводя итог проделанной работе, можно сказать, что мы теперь уделяем
большое внимание контурам литер; новая версия METRFONT'a отличается от
старой и в этом отношении. Я понимаю теперь, насколько был наивен в 1977 г.,
когда считал, что проблема контура обводки литер решается сама по себе,
если я просто рисую пером, имеющим правильную форму. С другой стороны,
нам не следует отказываться от «перьевой метафоры», поскольку «в первом
Глава 16. Уроки METRFONT'a
335
i ^Ёш III' Illy
Рис. 15.
(Ь)
Рис. 16.
приближении» она дает верное представление о том, как рисуются буквы;
детали контура обводки становятся существенными, когда мы выполняем «второе
приближение», вводя поправки, улучшающие форму литеры, однако основные
характеристики буквы при этом остаются неизменными.
Рисунок 17 представляет собой тестовую палитру, которую я подготовил в
1980 г., когда впервые экспериментировал с METRFONT'obckhmh программами,
имитирующими широкие перья с переменным нажимом, следуя советам
Германа Цапфа. (Фактически это первое, что захотел попробовать Герман, когда
познакомился с METAFONT'om.) Хотя все эти конкретные штрихи были
нарисованы пером, зафиксированным в определенном положении, в данном случае —
под углом 25°, дальнейшие эксперименты показали возможность варьирования
и углом установки пера.
Я бы хотел завершить свой рассказ предложением принять вместе со мной
участие в некотором мысленном эксперименте. Давайте рассмотрим буквы
'ATYPI', которые Самнер Стоун подготовил в качестве эмблемы нашей
конференции [8] и попытаемся представить, как можно было бы их реализовать в
виде меташрифта. Конечно, мы можем просто отследить очертания этих букв,
но это малоинтересно и не дает никакой пищи для размышлений.
Попытаемся вместо этого использовать принципы, на которых основывался Самнер,
336
Компьютерная типография
**
(а) (Ь) (с) (d) (e)
ATYP 1
Рис. 17.
Рис. 18.
для формирования такой спецификации, которая будет позволять порождать
множество прекрасных букв.
Займемся вначале буквой 'А' (рис. 18а). Она явно составлена из трех
штрихов, два из которых тонкие, а один — толстый. Тонкие штрихи рисуются более
узким пером по сравнению с используемым для получения толстого
штриха. Сразу же мы приходим к необходимости ввести параметры ширины этих
двух перьев, узкого и широкого. Штрихи в этих буквах имеют также изящные
сужения/расширения, следовательно, надо добавить третий параметр,
управляющий величиной такого рода сужения. Варьируя этот параметр, мы можем
получать такие буквы, у которых сужение отсутствует вообще, вплоть до
таких, где оно чрезмерно.
Перейдем теперь к букве 'Т' (рис. 18Ь). Мы видим здесь, что ее
горизонтальный штрих нельзя назвать ни толстым, ни тонким. Можно здесь или
ввести еще один параметр, или же использовать промежуточное значение
жирности (например, посередине между значениями ширины пера для толстого
и тонкого штрихов для буквы 'А'). Сужение здесь также используется, но
оно выражено менее явно, чем в предыдущем случае. И опять, нет особой
необходимости вводить новый параметр, если мы решим, например, что
вертикальный штрих у буквы 'Т' имеет сужение, равное половине от значения
сужения, принятого для буквы 'А'. Еще одним проектным параметром
является угол, под которым завершается на линии шрифта вертикальный штрих
буквы; заглядывая вперед, мы должны учесть, что аналогичное свойство надо
будет обеспечить также для букв 'Y' и 'Р'.
Построить букву 'Y' (рис. 18с) будет, по-видимому, не очень просто,
поскольку надо будет выработать принципы, лежащие в основе получения
весьма сложного слияния трех штрихов в центре данной буквы. Эта часть буквы
выглядит простой, если она построена правильно, но я думаю, что придется
потратить по крайней мере два-три часа, чтобы построить соответствующую
схему, удовлетворительно работающую при варьировании параметров.
Буква 'Р' (рис. 18d) имеет интересное маленькое заострение в верхней
части ее округлого элемента, однако ее наиболее заметной особенностью является
Глава 16. Уроки METRFONT'a
337
зазор между нижней частью этого элемента и ножкой буквы. Скорее всего, нам
придется ввести параметр «gap» (зазор), который можно будет использовать
также и в букве 'А'.
И наконец, есть еще «тощая» буква Т («hungry I») (рис. 18е), которую я
на самом деле не вполне понимаю. Возможно, я смог бы понять ее лучше,
если бы попытался реализовать ее как элемент меташрифта, но все равно мне
пришлось бы вначале обратиться к Самнеру за дополнительными
разъяснениями. Тогда мой METflFONT смог бы отразить истинные намерения автора
рассматриваемых букв.
Заглядывая вперед, я не могу поделиться сколько-нибудь убедительными
соображениями относительно того, как на самом деле будут разрабатываться
шрифты, к примеру, в 2000 г. Я надеюсь, конечно, что ни один из
компьютерных методов, используемых нами сейчас, не будет уже применяться. К тому
времени мы как раз начнем понимать данный предмет и на основе этого
понимания появится множество идей, более эффективных, чем те, которые мы
употребляем в настоящее время. Но меня не покидает предчувствие, что МЕТА-
FONT'oBCKne понятия перьев, параметров и программ найдут в этом мире свое
место как часть того, что имеет ценность в области применения компьютеров
для разработки цифровых шрифтов.
Приложение
[Я не смог устоять против того, чтобы не поэкспериментировать с лого ATYPI.
Надеюсь, что приводимый ниже подробный пример, разработанный уже после
лекции, поможет прояснить некоторые из моментов, затрагивавшихся в этой
лекции.]
METflFONT может имитировать широкое перо и процесс рисования им, если
положение пера задавать тремя точками: левой границей, серединой и правой
границей. Средняя точка пера делит расстояние между его крайними точками
ровно пополам. В существующей версии METAFONT'a удобно обозначать
номера точек следующим образом: средние точки нумеруются подряд, начиная
с 1, для левой граничной точки номер получается прибавлением 100, а для
правой —200 к номеру средней точки; тогда тройка точек (101,1,201)
соответствует перу в положении 1. [В новой версии METAFONT'a я собираюсь вместо
приведенной выше записи задавать такую (1L, 1,1R).]
Несложно написать METflFONT'oBCKyio подпрограмму, которая будет
рисовать простой штрих такими перьями, обеспечивая возможность получения
штрихов переменной ширины. Например, рис. 19 иллюстрирует работу
подпрограммы, которой я занимаюсь в настоящее время. Даны две позиции пера —
они обозначаются в рассматриваемом случае как (101,1,201) и (102,2,202) —
вместе с тремя коэффициентами Л, р и а; коэффициенты Лир
описывают величину сужения штриха слева и справа, тогда как а задает позицию
максимального сужения. Соответствующий штрих рисуется следующим
образом. Вначале компьютер конструирует точки (all,al, а21), которые
представляют собой значение коэффициента а траектории, проходящей из позиции
338
Компьютерная типография
alOlj
all
Рис. 19.
(101,1, 201) в позицию (102, 2,202). [На рис. 19, например, а равно 0.4; таким
образом, прямая линия, проводимая из точки 101 в точку 102, пройдет через
all, а расстояние между точками all и 101 составит 0.4 от расстояния между
точками 102 и 101. Три точки (all, al, a21), находимые таким способом, будут
лежать на одной прямой.] Затем компьютер находит точку а101, перемещаясь
на Л по траектории из точки all в точку al, а также точку а201, перемещаясь
на р из а21 в al; эти операции определяют степень сужения штриха. Наконец,
находят контур штриха. Делается это следующим образом. Кривая
начинается в точке 101 и продолжается в направлении точки al; она проходит через
точку а101 в тот момент, когда она идет в направлении, параллельном прямой
линии, соединяющей точки 101 и 102; затем она завершается в точке 102, как
если бы она пришла из точки al. Таким образом, сформирована левая граница
контура штриха, правая же строится совершенно аналогично.
Изменения ширины и углы в концевых точках, а также варьируя
значения коэффициентов Л, р и а, можно построить самые разнообразные по форме
штрихи. И можно научиться использовать эти штрихи, не вникая особенно в
детали геометрических конструкций и построений, лежащих в основе процесса
их формирования. Вполне очевидно, что можно разработать и более
изощренные подпрограммы формирования штрихов, но в данный момент я знакомлюсь
с простой их (штрихов) разновидностью типа рассмотренных выше. В
частности, я обнаружил, что не так сложно получить хорошую аппроксимацию для
буквы 'А', изображенной Самнером. Это можно сделать с помощью всего трех
меташтрихов, даже когда все параметризовано, так что эти конструкции
сохраняют работоспособность в весьма широком диапазоне условий.
На рис. 20 показана конструкция мета-А, к которой я пришел. Она была
построена МЕТАРОМТ'овской программой, суть которой можно изложить
следующим образом: «Литера должна быть шириной 13 единиц; ее высота в 1.1
раза больше, чем высота прописных букв данного шрифта, глубина ее равна
нулю. Позиция 1 пера находится на линии шрифта, его левая граничная точка
на 0.5 единицы левее литеры в целом. В позиции 4 перо находится на линии
шрифта, а его правая граничная точка расположена на 0.5 единицы правее
Глава 16. Уроки METRFONT'a 339
I I I I I I I I I I I—I I—I Рис. 20.
литеры в целом. Позиция 2 пера лежит на высоте в 1.1 раза большей, чем
высота прописных и в средней по горизонтали точке литеры. Позиция 3 пера
лежит на высоте прописных на прямой линии между точками 2 и 4.
Ширина пера в позиции 1 имеет значение «узкая» («тонкое перо»), в позициях 2
и 4—«широкая» («толстое перо»), а в позиции 3 она равняется ширине
тонкого пера плюс 2/3 разности между шириной толстого и тонкого пера. Угол
установки (наклона) пера в позициях 3 и 4 на 15 градусов больше, чем
нормальное значение параметра «cut angle» (граничный угол установки пера) для
вертикальной ножки литеры, а угол в позиции 2 превышает значение «cut
angle» на 30 градусов. Линия перекладины для рассматриваемой буквы
определяется позициями пера 5 и б, их верхняя часть расположена на высоте в
3/7 от высоты прописных; угол наклона пера в позиции 5 составляет 45°, а
в позиции 6 — 135°; ширина пера в обоих этих случаях есть некоторая
доля от ширины «тонкого» пера, определяемая значением параметра «aspect
ratio» («относительное удлинение»). Позиция 5 смещена влево от точки, где
прямая, проходящая через точки 5 и б, пересекается с прямой, проходящей
через точки 3 и 1; величина требуемого смещения задается значением
параметра «gap amount» («величина зазора») плюс половина ширины тонкого
пера. Аналогично этому, позиция б смещена относительно точки пересечения
прямой, проходящей через точки 5 и б, с прямой, проведенной через точки 2
и 4. Величина смещения в данном случае равняется заданной величине зазора
плюс половина ширины толстого пера. Пусть г —значение параметра
сужения. Диагональный штрих между позициями 2 и 4 рисуется при А = г2, р'=ь г
и а = 0.45; диагональный штрих между позициями 3 и 1 —при А = г1/2,
р = т3/2 и а = 0.6. Горизонтальный штрих (перекладина буквы) сужения не
имеет».
Чтобы завершить рассматриваемую спецификацию, надо определить
значения входящих в нее параметров. Рисунок 20 был получен для единичной
ширины 26х (где х — произвольный масштабный множитель); высота прописных
340 Компьютерная типография
ААААА м.
A AAA P„,2,
A AAA _.
здесь была принята равной 245х; ширина тонкого и толстого пера
составляла 22х и 44х соответственно. Относительное удлинение было принято равным
0.85; угол установки перд в конце штриха равнялся 15 градусам, величина
зазора была принята равной одной единице, параметр сужения г = 0.4.
На рис. 21 показаны пять букв 'А', нарисованных для одних и тех же
значений всех параметров, за исключением единичной ширины, которая здесь
равна 17х, 20х, 23х, 26х и 29х соответственно. Рисунок 22 демонстрирует
влияние роста жирности: здесь пара значений («ширина тонкого пера», «ширина
толстого пера») составляет (thin, thick) = (11х,33х), (22х,44х), (ЗЗх, 55х) и
(44х, 66х). Наконец, из рис. 23 видно влияние варьирования некоторыми
другими параметрами: (а) ширина вертикального штриха (55х, 55х); (Ь) увеличение
значения параметра сужения до 0.6; (с) уменьшение угла установки пера в
конце штриха до 5° и величины зазора до 0.1 единицы; (d) одновременное действие
всех изменений из п. (а), (Ь) и (с). Я сомневаюсь, конечно, что Самнер одобрил
бы результаты, полученные в этих примерах путем экстраполяции
единственного рисунка. Но я думаю, что вместе мы могли бы получить и что-то более
подходящее.
Так как этот материал — приложение к основному тексту статьи, я хотел
бы завершить его, приведя тексты реальных METRFONT'obckhx программ для
пользы тех читателей, кто захочет разобраться в деталях. Я использовал в
этих программах следующие обозначения: hh —высота прописных в пикселях;
phh — высота прописных в типографских пунктах; г —правый контур
литеры; и — единичная ширина в пикселях; charbegin(character-Code, unit-width,
heightJn-points, depthJn-points) есть подпрограмма, устанавливающая
значения параметров вроде г и и и сообщающая, куда поместить полученный
результат в завершенный шрифт. Вторая половина программы, следующая после
строки "The letter А", содержит то, что в словесной форме было описано выше
как способ построения буквы. Программы, эквивалентные этим по решаемым
задачам, в новой версии METAFONT'a, которая появится в следующем году,
будут много проще и более удобочитаемы.
Глава 16. Уроки METRFONT'a
341
minvr 0; minvs 0; % отключить коррекцию по скорости
fill = 1; % ширина пера для заполнения штрихов
subroutine penpos(index г, % задать положение пера г
var angle, var d): % с данным углом установки и шириной
Xi = .5[Zi+100,Zi+200]; У% = .5[2/г+100, 2/г+20о]
£г+200 — £г+юо = d • cosd angle;
2/г+2оо - 2/г+юо = d • sind angie.
subroutine stroke (index г, index j, % нарисовать штрих от г до j
var lambda, var rho, % с заданным сужением по левому и правому контуру
var alpha): % и положением максимального сужения
xi = aipha[zi,Zj]; 2/1 = aipha[2/i,2/j];
in = aJpha[zi+ioo,Zj+ioo]; ^21 = aJpha[zi+2oo,Zj+20o];
2/п = aipha[2/i+ioo,2/j+ioo]; 2/21 = aipha[2/i+2oo,2/j+20o];
ж 101 = Jambda[zii,zi]; 2/101 = iambda[2/i 1,2/1];
Z201 = rho[z2i,zi]; 2/201 = rho[2/21,2/1];
cpen; iiJJ ddraw
г + 100 {xi - z»+ioo, 2/1 - 2/i+ioo}
.. 101 {xj+wo — Zi+100,2/j+ioo — 2/г+юо}
.. j + 100 {zj+100 — £i,2/j+ioo — 2/1} ,
i + 200 {Zi — Zi+200, 2/1 — 2/г+200}
.. 201 {2^+200 — Яг+200,2/J+200 — 2/1+200}
.. j + 200 {^j+200 - zi,2/j+2oo - 2/1} •
"The letter A";
call charbegin(* k, 13, l.lphh, 0);
2/1 = 0; Ж101 = .5ii;
2/4 = 0; Z204 = r - .bu]
2/2 = l.lhh; X2 = .5r;
2/3 = hh; new aa; 2/3 = aa[2/2,2/4]; z3 = aa[z2,Z4];
call penpos(l, —cut — 45, thin);
call penpos(2, cut + 25, thick)]
call penpos(3, cut + 15, 2/z[thin, thick])]
call penpos(4, cut + 15, thicJc);
2/205 = 2/206 = 3АЛЛ;
call penpos(5,45, aspect • thin)]
call penpos(6,135, aspect • thin)]
new aa; 2/5 = aa[2/1,2/3]; z5 + gap • и + .5thin = aa[zi,z3];
new aa; 2/6 = aa[2/2,2/4]; #6 + gap • ii + .5thicJc = aa[z2, £4];
call " a stroke (2,4, taii • taii, tcm, .45); % правая диагональ
call *b stroJce(3,1, sqrt tau, tau • sqrt tau, .6); % левая диагональ
fill ddraw 105 .. 106, 205 .. 206. % горизонтальный штрих
Для точки 203 придется смириться с тем, что для некоторых значений
параметров вертикальный штрих будет слегка выпирать (как это имеет место
для некоторых примеров с рис. 22 и 23). Из текста программы видно, что она
после проведенной модификации рисует сначала левый диагональный элемент,
затем задается
rpen#; thick draw 2 .. 4;
342
Компьютерная типография
вследствие чего стирается все справа от прямой линии, проходящей через
точки 2 и 4. После этого рисуется правая диагональ и горизонтальный штрих.
Это исследование было поддержано частично Национальным научным фондом США
(National Science Foundation) по гранту IST-820-1926, а также Фондом развития систем
(System Development Foundation).
Добавление
Читатели, интересующиеся развитием этого примера применительно к
существующей версии METAFONT'a (она именовалась в 1983 г. как «METR-
РОИТследующего года») могут воспользоваться таким вариантом
рассмотренной программы:
% Буква А Самнера Стоуна для лого ATypI,
% вырезанная Доном Кнутом при помощи METRFONT84
mode_setup;
и# ._ 26/36p£#; % базисная единица
capJieight# := 245/збР*#; % высота прописной литеры
thin# '.= 22/збР^#; % жирность тонких штрихов
thick# := AA/zGpt#; % жирность толстых штрихов
tau := 0.4; % типичная величина сужения
дар := 1; % расстояние между штрихами
cut := 15; % степень поворота контура штриха
aspect := 0.85; % отношение жирностей вертикальная / горизонтальная
define-pixels (и);
define_blacker_pixels(£/wi, thick);
vardef penpos @#(expr angle,d) = % задать положение пера
z@# = .5[z@#j, z@#r]; z@#r — z@#i = (d, 0) rotated angle;
enddef;
vardef stroke (suffix $, $$, @)(expr lambda, rho, alpha) = % штрих с сужением
z@ = alpha[z$,z$$\; zm = alpha[z$i,z$$i]; z@r = alpha[z$r, z$$r];
z@it = lambda[z@i, z©)\ z@rt = rho[z@r,z@]; % задать для сужения
labels(@, Ш, @r, Ш', @r');
z%\ {z@ — z%i} .. z@i' {z$$i - z$i} .. z$$i {z$$i - z© } - -
z$r{z© — z$$r} • • z@rt{z$r — z$$r} ..z$r{z$r — z@} --cycle
enddef;
"The letter A";
beginchar("A", 13ii#, 1.1 cap-height^, 0);
penpos x(—cut — 45, thin);
penpos 2(cut +25, thick);
penposz{cut + 15, 2/z[thin, thick]);
penpos A{cut + 15, thick);
penpos5(45, aspect * thin);
penpos6(135, aspect * f/im);
2/1 = 0; zij = .5ii;
2/4 = 0; хаг = w — .bu;
2/2 = l.l/i; £2 = .5u>;
Глава 16. Уроки METRFONT'a
343
уз = h] zz — whatever[z2, za]',
Уъг = z/ih\ Zb + (gap * и + .bthin, 0) = whatever\z\, zz]\
Убг = z/ih\ zq + (gap * ii + Mhick, 0) = whatever[z2, za\\
fill stroke (3,1,6, sqrt £au, tau * sqrt Jan, .6); % левая диагональ
unfill Z2 - - za - - (za + (thick, 0)) - - (z2 + (thick ,0)) - - cycle; % стереть лишнее
cullit; % нормализовать после стирания
fill stroke (2,4, a, Jan * tau, £au, .45); % правая диагональ
fill Z5j - - zqi - - zer - - Zbr - - cycle; % горизонтальный штрих
penlabels (range 1 thru 6); endchar;
end.
Литература
[1] Thomas B. Hickey and Georgia К. М. Tobin, The Book of Chels (Dublin,
Ohio: 1982), privately printed.
[2] John D. Hobby and Gu Guoan, "Using METflFONT to design Chinese
characters," Computer Processing of Chinese and Oriental Languages 1
(July 1983), 4-23. Предварительная версия опубликована в трудах
The 1982 International Conference of the Chinese-Language Computer Society
(September 1982), 18-36.
[3] John D. Hobby and Gu Guoan, "A Chinese meta-font," TUGboat 5
(1984), 119-136. Предварительная версия опубликована в трудах ICTP'83,
the 1983 Internal Conference on Text Processing with a Large Character
Set(Tokyo: 17-19 October 1983), 62-67.
[4] Donald E. Knuth, "METflFONT, a system for alphabet design," Stanford
Artificial Intelligence Memo AIM-332 (September 1979). Reprinted as part 3 of
T)g?C and METRFONT: New Directions in Typesetting (Bedford, Massachusetts:
Digital Press and American Mathematical Society, 1979).
[5] Donald E. Knuth, Seminumerical Algorithms, Volume 2 of The Art of
Computer Programming, second edition (Reading, Massachusetts: Addison—
Wesley, 1981). [Имеется русский перевод первого издания: Кнут Д.
Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы.—
М.: Мир, 1977; второго издания: Кнут Д. Е. Искусство программирования.
Т. 2. Получисленные алгоритмы. — Киев: Диалектика, 1999]
[6] Donald E. Knuth, "The concept of a meta-font," Visible Language 18 (1982),
3-27. [Переработанный вариант представлен в качестве гл. 15 настоящего
издания.]
[7] Raymond SmuUyan, "Miscellanea: Metagame," American Mathematical
Monthly 90 (1983), 390.
[8] Sumner Stone, "The ATypI logotype: A digital design process," presented at
Fifth ATypI Working Seminar, Stanford, California (August 1983).
AMS Euler — новый
математический шрифт
[Написано в соавторстве с Германом Цапфом. Первоначально опубликовано в
Scholarly Publishing 20 (1989), 131-157.]
Сотрудничество ученых и художников способствует дальнейшему
проникновению красоты на страницы математических журналов и учебников.
Печатать математические тексты стало быстрее, проще и дешевле, чем когда-
либо ранее благодаря последним технологическим разработкам. Страницы
теперь состоят из миллионов крошечных чернильных точек, расположением
которых заведует компьютер. Системы вроде ТЁХ'а [14] можно использовать для
указания, где на странице должны располагаться буквы и символы;
сопутствующие системы вроде METflFONT'a [16]—для задания чернильных точек, эти
буквы и символы формирующих. ТЕХ и METRFONT, завершенные в 1986 г.,
уже используются десятками миллионов людей на более чем ста различных
типах компьютеров, от персональных (PC и Мае) до гигантских CRAY-машин.
Эти системы спроектированы таким образом, чтобы результат их работы для
всех видов процессоров и всех цифровых устройств вывода был одинаков,
хотя качество, естественно, зависит от качества оборудования,
используемого для печати. Более того, Т^Х и METRFONT спроектированы как полностью
сохраняющие архивность, в том смысле, что рукописи, сегодня записанные в
электронном виде в качестве файлов с текстом, и через несколько поколений,
можно надеяться, будут давать все тот же результат на печати.
Эти тенденции можно было проследить еще десять лет назад [12], но ушло
довольно много времени на то, чтобы (в самом прямом смысле) расставить
все точки над i, необходимые для получения достаточно гибких и
совершенных систем. Американское математическое общество (American Mathematical
Society — AMS), одно из крупнейших в мире издательств математической
литературы, в 1979 г. образовало комитет по шрифтам для планирования того, как
можно использовать преимущества появляющихся технологий. Первоначально
в этом комитете состояли: Ричард Пале (председатель), профессор
математики в университете Бранде; Барбара Битон, редактор из штаб-квартиры AMS;
Глава 17. AMS Euler —новый математический шрифт
345
Петер Ренц, редактор математической литературы из W. H. Freeman &; Co.; и
два автора данной статьи (ДЭК и ГЦ1).
В то время ДЭК и ГЦ знали друг друга только по публикациям. Втайне
мы оба желали встретиться, но, зная, как сильно занят другой, никто из нас
не решался предложить. К счастью, в роли свахи выступило AMS, положив
начало плодотворному сотрудничеству между математиком и художником,
которое, как мы надеемся, окажет благотворное воздействие на научную прессу.
Нашей целью в этой статье было зафиксировать на бумаге некоторые аспекты
нашего сотрудничества, которые мы считаем заслуживающими особого
внимания, потому что они освещают вопросы публикации математических текстов,
редко обсуждаемые в печати.
По-видимому, лучше всего будет рассказать эту историю, приводя
выдержки из писем, которые мы в то время писали друг другу и получали от других
людей. (Полностью эта переписка со всеми сопутствующими рисунками
хранится в архиве Станфордского университета, коллекция SC362.)
Ричард Пале замечательно описал первоначальные цели нашей работы в
первом пригласительном письме:
11 сентября 1979 г.
ГЦ от Р. Пале
Дорогой профессор Цапф!
[Вступительные замечания ... ] Поэтому A MS теперь имеет возможность создать
гарнитуру, содержащую исчерпывающий набор взаимосвязанных алфавитных и
символьных шрифтов, сделанную на основе TJTJK'a и предназначенную не
только для публикации журналов и книг AMS, но и для всего математического и
научного сообщества в целом. Очевидно, что это проект, рассчитанный на
долгий срок, и для его осуществления потребуются планирование, аккуратность и
советы лучших специалистов.
Примерно в это же время ДЭК написал ГЦ, приглашая его заехать в Станфорд
в феврале 1980 г., для того чтобы ознакомиться с METRFONT'om. Зародыш
будущего проекта уже начал оформляться:
7 октября 1979 г.
ДЭК от ГЦ
Дорогой д-р Кнут!
... нужно тщательно разработать, используя МЕТЯ FONT, основные черты
стандартного научного алфавита, нейтрального по форме и хорошо подходящего для
всех видов печатающих устройств: и для коммерческой офсетной печати, и для
печати на офисном оборудовании низкого качества, и для последующего
ксерокопирования с отпечатанного оригинала и т. д., и т. д.
... Я бы предпочел, чтобы базовый научный алфавит был прямым, потому что в
этом случае возникает не так много проблем, как с наклонными формами. Ведь в
результате мы хотим получить по-настоящему хороший алфавит с возможностью
использовать самые разные специальные символы для всевозможных научных
публикаций. Алфавит со всеми необходимыми символами и дополнительными
формами, которые бы вместе идеально вписывались в общий замысел.
ДЭК —Дональд Эрвин Кнут, ГЦ —Герман Цапф. — Прим. перев.
346
Компьютерная типография
25 октября 1979-г.
ГЦ от ДЭК
Дорогой проф. Цапф!
... я должен пояснить, что книгоиздание не главное мое занятие; в первую
очередь я — преподаватель, проводящий собственные исследования и руководящий
исследованиями в computer science и математике, а еще я пишу книги, пытаясь
внести некоторое единообразие в эти области. Между делом, решая проблему,
связанную с изданием этих книг, я, кажется, натолкнулся на некоторые идеи,
представляющие ценность для печатной индустрии, поэтому я хочу убедиться,
что правильно разъяснил эти идеи и выпустил их в жизнь. Если в этих идеях
есть зерно истины, то они пробьют себе дорогу и без моей помощи; если же нет,
они так или иначе канут в Лету.
... Теперь что касается семейства шрифтов для A MS. В настоящее время они
используют прямое светлое начертание шрифта Times New для текста, курсивное
начертание Times—для формул и выделенных фрагментов. Использование
курсивного Times для формул по моему мнению (и я не одинок!) очень неудачно,
потому что формулы становятся перенасыщенными; собственно, единственная
когда-либо существовавшая причина для использования курсивного Times
состоит в том, что это был модный шрифт для работы с текстом, когда AMS
меняло наборщиков.
Естественно будет поступить следующим образом: взять существующий
текст и курсивное начертание для текста и выделенного текста и создать
подходящее новое начертание для математических формул, встречающихся в тексте.
Например, начать можно с прямого светлого и курсивного Times; но, конечно,
мы должны использовать и что-то из Zapf Book, или Optima, или какого-нибудь
другого замечательного шрифта из тех, что вы подарили миру.
Новый математический шрифт должен быть легко отличим по начертанию
от обычного текста, притом на подсознательном уровне; далее, вместе с
латинскими буквами и цифрами, он должен содержать греческий, готический и
рукописный алфавиты. Разные буквы и символы должны быть легко отличимы ('а' —
от альфа, V — от ню, ноль — от О и т. д.), но не обязательно различать греческие
буквы и точно соответствующие им латинские (прописные А, В, Е, Н, I, К, О, Р,
Т, U, X, Z; строчная о и, возможно, и).
Ваша идея создать это начертание без наклона очень интересна, и мне
кажется, эта идея хороша, даже несмотря на давнюю традицию использования
наклонных символов, — в особенности, из-за того что некоторые математики
любят нагромождать акценты, например а.
Должен ли новый шрифт отличаться в первую очередь наличием или
отсутствием засечек? Или насыщенностью? Традиционно буквы в формулах несколько
светлее, чем в тексте; например, в математическом курсивном начертании
Computer Modern основные штрихи букв примерно в 3Д раза тоньше, чем в прямом
светлом и наклонном светлом текстовых шрифтах. Полужирные символы для
математиков имеют особое значение, так что я думаю, лучше всего сохранить
эту традицию и оставить нежирные символы чуть светлее, чем в тексте.
Еще одна характеристика, которая может оказаться важной при
продумывании внешнего вида, такова: математики воспринимают формулы, как нечто,
что они пишут на доске или на листе бумаги, в то время как текст — это что-то
напечатанное. Поэтому, возможно, разница между текстом и математической
Глава 17. AMS Euler — новый математический шрифт
347
частью должна состоять в том, что текст более механичен, а математическая
часть — более каллиграфична.
Внешний вид должен быть психологически приемлемым для математиков
с первого взгляда, если это возможно; математическое значение в идеале будет
восприниматься без участия сознания. Таким образом, новый шрифт должен
быть в согласии с исторически сложившимися традициями даже тогда, когда
создается нечто абсолютно новое. ...
P. S. Еще одна мысль: некоторые математические формулы кажутся мне
некрасивыми просто по природе своей, независимо от того как их напечатать! Нам
надо выбирать тестовые примеры из хорошо отредактированных книг.
Насколько известно авторам, подобные попытки создания набора
взаимосвязанных шрифтов и математических символов предпринимались всего лишь
дважды. Почтенная словолитня Joh. Enschede en Zonen в Харлеме, Голландия,
в конце 1920-х годов попросила выполнить эту работу Яна ван Кримпена.
Профессор X. А. Лоренц, нобелевский лауреат по физике (1902), жил в
Харлеме и согласился участвовать в проекте. Но Лоренц умер в 1928 г., а «работы
оказалось даже больше, чем предполагалось, да и сложность ее была
недооценена» [4]; «вследствие этого проект был заброшен» [23, с. 32]. Единственный
результат этого проекта —греческий шрифт, названный Antigone, который, по
словам ван Кримпена, был создан им быстро по образцу греческих текстовых
шрифтов [23; с. 35]. Начертание Antigone вертикально, в отличие от
наклонных греческих шрифтов, традиционно используемых в математике; так что и
он, оказывается, намеревался сделать научный алфавит выпрямленным.
Американским математическим обществом в 1962 г. была предпринята не
столь бесплодная попытка. Здесь было решено сделать все математические
алфавиты наклонными для соответствия курсивному Times. Это оказалось не
очень удачным в случае готического шрифта, потому что «к прискорбию,
многие готические буквы, будучи наклоненными на 18°, теряли свои достоинство
и вес» [20]. Прописной рукописный шрифт AMS, созданный в ходе этого
проекта, заслуживает особого упоминания, потому что это первый рукописный
шрифт, предназначенный именно для математики. Трудность состояла в том,
чтобы создать нечто, «определенно являющееся рукописным алфавитом, но
с минимумом украшений» [20], потому что вычурные завитушки рукописных
шрифтов традиционного начертания имеют привычку исчезать при малом
кегле, в частности в нижних и верхних индексах.
ГЦ провел две недели в Станфорде в гостях у ДЭК в феврале 1980 года,
две чрезвычайно захватывающие недели для нас обоих. Мы с наслаждением
наблюдали, как легко люди «двух культур» (по выражению Ч. П. Сноу1) могут
работать вместе; и мы действительно интенсивно работали все это время. Мы
изучали классический труд по набору математических текстов [2], заметив, что
даже Oxford University Press не имело шрифтов, в которых все необходимые
символы легко различимы при малом кегле. Большая часть нашего времени
1 Чарлз Перси Сноу (1905-1980)—английский писатель. Его сборник статей «Две
культуры» посвящен соотношению естественно-научной и гуманитарной культур в современном
обществе. — Прим. перев.
348
Компьютерная типография
Первый опыт сотрудничества между ДЭК (сидит) и ГЦ (стоит), 14 февраля 1980 г.
[Фотография Stanford News Service сделана Чаком Пейнтером. ]
была посвящена объяснениям ДЭК по поводу METflFONT'a и ГЦ —о создании
шрифтов и каллиграфии. ГЦ объяснял, как добиться специальных эффектов
при помощи изменения «нажима пера», а ДЭК находил способ моделировать
такие эффекты на компьютере. У нас осталось совсем немного времени на то,
чтобы приступить к созданию нового шрифта, но нам все-таки удалось сделать
на пробу несколько символов. Вот копия того единственного пробного оттиска,
который мы успели сделать на фотонаборной машине:
Consider the formula 66E —- 77g.
Also consider the formula 66E —- 77g > <xX.
(Конечно, эта рукописная X нам не понравилась; мы работали над ней всего
лишь несколько минут в конце дня.)
24 февраля 1980 г.
ДЭК от ГЦ
Дорогой Дон!
Я очень ценю оказанный мне сердечный прием. ... Отдельным письмом я
посылаю два плаката на тот случай, если у Вас еще осталось свободное место на стене.
Цитаты из Оппенгеймера [22, с. 119; 25, с. 220; 26, с. 133] точно описывают мои
собственные мысли об искусстве и науке: левая часть кругов (цветная)
изображает мир художника, правая часть (из одних линий) — мир ученого. Вообще-то
Глава 17. AMS Euler — новый математический шрифт
349
(как показано во внешнем круге) они соединены в людях, но кроме этого везде
и всегда они пытаются прийти к согласию, как к недостижимому идеалу.
Будем считать эти две недели в Станфорде началом.
17 марта 1980 г.
ГЦ от ДЭК
Дорогой Герман!
... сейчас мне кажется, что подходящим именем для шрифта будет «Euler» ;
или же мы можем выбрать скучный безличный стиль и назвать его «AMS
Mathematics».
На случай если «Euler» встретит одобрение, я попытался найти образцы его
почерка ...
Название Euler было предложено во время заседания комитета AMS по
шрифтам (AMS Font Committee) 23 февраля, дело в том что швейцарский
математик Леонард Эйлер (1707-1783) был одним из величайших и
популярнейших математиков всех времен [9]. Эйлер несомненно оценил бы достижения
современной технологии, потому что печатные станки того времени не
справлялись с его огромной продуктивностью. (На самом деле Петербургская
академия наук Продолжала регулярно публиковать рукописи Эйлера в течение
более чем тридцати лет после его смерти.)
Леонард Эйлер был тем, кто впервые использовал многие алфавиты,
которые теперь можно часто встретить в математических изданиях. Джон Валлис
в формулах своей «Алгебры» [24] иногда одновременно использовал греческие
и курсивные буквы2, но Эйлер развил эту идею гораздо дальше и использовал
также готический алфавит. Вот, к примеру, выдержка из его статьи,
опубликованной в 1765 г. [6, §33]:
Ind. v , а , Ъ
г ract. вн)Г)Г
vbi 5l=v,23=^5H-i;€=*93-+-S(
et a = i,b=*a-t-o;c— £&-ьа
В учебнике Эйлера по интегральному исчислению (1769) имеются формулы,
объединяющие прямой светлый и курсивный, готический и греческий
алфавиты одновременно [7, §1130]:
8
• ' < - - - -Щ
Если бы он использовал в своих публикациях кириллические буквы,
современные математики, возможно, знали бы кириллицу не хуже греческого алфавита!
1 Euler — латинский вариант написания фамилии Эйлер. — Прим. перев.
2 Везде, где не указано противное, имеются в виду латинские буквы. — Прим. перев.
350
Компьютерная типография
Но иногда Эйлер прибегал к новшествам в обозначениях, не пережившим его.
Вот формула, в которой он объединил астрономические символы Солнца,
Сатурна, Юпитера и Марса [8, §6]:
К марту 1980 г. ДЭК и ГЦ решили, что новый шрифт должен иметь
привкус «рукописности». Поэтому был шанс, что образцы почерка самого Эйлера
могут подсказать некоторые особенности будущего шрифта. И действительно,
обнаружилось, что Эйлер часто делал верхнюю часть нуля заостренной, а не
круглой [3]:
Однако это — распространенная особенность рукописных текстов вообще, и не
оказало прямого влияния на создание AMS Euler; ГЦ уже
экспериментировал с заостренными нулями еще до того, как увидел записи Эйлера —после
просмотра математических рукописей Эйнштейна, Ньютона, Рамануджана и
ДЭК. Эти заострения «заостряют» внимание на нулях, с тем чтобы
естественным образом отличать их от букв О.
20 марта 1980 г.
ДЭК от ГЦ
Дорогой Дон!
Я прилагаю несколько набросков разных знаков и символов вместе с вариантами
для некоторых из них, чтобы узнать Ваше мнение и выслушать Ваши замечания
перед тем, как сделать наброски для AMS.
Е=тпс2
х'= *р(х) - ах g(At)+\ivo)
f(Ap+j^q)=A2p5lp+2A|Li2-cx1o
IV(1Woy)4]
<>F%%33TeS9SSVWXyZcC
у-0.5Г7216 (A+t)
[Эти рисунки уменьшены на 50% относительно оригинала. Было приложено еще
много набросков, не приведенных здесь.]
Глава 17. AMS Euler —новый математический шрифт
351
4 апреля 1980 г.
ГЦ от ДЭК
Дорогой Герман!
Образцы, посланные Вами, содержат много изумительных находок, и я с
большим энтузиазмом смотрю на перспективы этого проекта. Но, чтобы письмо не
стало слишком объемным, я ограничусь замечаниями по тем вопросам и вещам,
которые мне не понравились, вместо того чтобы восклицать о том, что очень мне
понравилось; из-за этого письмо может показаться чересчур негативным по
настроению. Я заранее приношу свои извинения за это и надеюсь, что Вы сможете
восстановить правильное соотношение, если вообразите, что я написал намного
более длинное письмо, в котором горячо хвалю все, не упомянутое ниже. ...
1 / Хвостики на окончаниях строчных латинских букв должны быть более
округлыми, чтобы они были свободнее и полностью отличались от готических букв.
Пусть резкий изгиб будет «торговой маркой» готического шрифта, а латинские
буквы пусть текут плавными линиями.
2 / В рукописной математической записи я предпочитаю (,у' с округлым
полуовалом, роднящим ее скорее с 'и', чем с V). ...
4 / Мне не понравилась рукописная К, но я не вполне понимаю, как заставить
ее не выглядеть смешной и в то же время сделать совершенно отличной от
рукописных Н и X. Я прошу Вас приложить все усилия к нахождению красивой К,
ведь для меня эта буква очень важна (как Z для Вас)!1 ...
7/ Каплевидный нуль очень удачен, и я действительно буду рад увидеть его в
этом шрифте. ...
g / Левый верхний штрих 5 должен быть строго вертикальным, а не чуть-чуть
наклонным, как у Вас. В противном случае это будет ужасно выглядеть при
оцифровке с использованием грубого растра, а у многих в лабораториях стоит
именно такой.
Были необходимы семь взаимосвязанных алфавитов: строчный прямой,
прописной прямой, прописной рукописный, строчный греческий, прописной
греческий, строчный готический и прописной готический. (Рукописные
алфавиты как разновидность курсива были введены бельгийским пуансонистом
Жак-Франсуа Розаром) в 1753 г. [5]; но во времена Эйлера они, видимо, еще
не дошли до Берлина и Санкт-Петербурга, потому что Эйлер их никогда не
использовал. Математики взяли прописные рукописные буквы на вооружение
много позже, в XX столетии. Строчные рукописные буквы в математике
широко не использовались никогда, за исключением буквы Ч\)
23 апреля 1980 года
ДЭК от ГЦ
Дорогой Дон!
Позвольте мне особо поблагодарить Вас за труд, вложенный Вами в Ваши
замечания; это отняло у Вас много свободного времени. Именно так я и хотел бы
работать, когда дело касается настолько важного нового шрифта. Не стоит
думать, что я буду расстраиваться из-за искренней и конструктивной критики или
замечаний, касающихся специальных или сложных символов.
1 В латинском написании фамилия Кнута начинается на К (Knuth), а фамилия Цапфа —
на Z (Zapf). — Прим. перев.
352
Компьютерная типография
К письму прилагаются те предложения, которые д-р ле Век хотел получить
к майскому заседанию совета Правления AMS.
UemPidGroMagRvy Auf Vtl DxHJc К 01 f ЯЪ>СЛУ11%-и!ААУ 5 ?
&£S75XZ^XV^KW33MOaXC 175204 8 63913725490 = + <-[{(
Г^кауиер^Дтгшхо-фб^е^^р^^о ПГА0ТШЛФ^А01ГФ1} £,£
Q3fa6fefOT:(f^isB^^2»6q3£m(£CZPSLNQBWlXKYHTI Ь=тс2
Уильям Ле Век, исполнительный директор Американского
математического общества, внимательно следил за нашей деятельностью. (Он даже приехал
в Станфорд в январе 1981 г., и научился создавать несколько кириллических
символов при помощи METflFONT'a.)
9 мая 1980 г.
ГЦ от У. Дж. Ле Века
Дорогой профессор Цапф!
Я с большим удовольствием сообщаю Вам, что Правление на заседании 3 мая
решило одобрить Ваши предложения.
... Я думаю, будет мудро с самого начала отдавать себе отчет в следующем.
Математики весьма склонны, в целом, к эстетическому консерватизму, им
нравится то, к чему они привыкли. Этот факт нужно учитывать, если Общество
или другие математические издательства должны принять новый шрифт Euler.
Поэтому Правление хочет быть уверенным, что весь комитет по шрифтам, и еще
несколько математиков, в данный момент не входящих в состав комитета, будут
иметь возможность высказывать свое отношение к Вашему проекту до того, как
он будет окончательно завершен.
... Мы все с нетерпением ожидаем того момента, когда приступим к совместной
работе и в результате ваших усилий, мы знаем, получим замечательную
коллекцию шрифтов.
Дата: 09 мая 1980 года 0819-PDT
От: Дон Кнут <ДЭК в SU-AI>
Кому: Пале в MIT-MC
Благодарю за Ваше сообщение о результатах голосования Правления.
Что касается дальнейшего, вот мои предложения: (1) Вы посылаете
мне письмо, во всех деталях описывающее все критические замечания
комитета на данный момент, чтобы я мог передать их Цапфу. (2) Вы
пишете Цапфу короткую записку, в которой сообщаете, что рекомендации
комитета были отправлены мне и я вскоре с ним свяжусь. (3) Когда я
напишу ему, он сделает наброски в размере, нужном нам для разработок
в METAFONT'e. Я их отдам Скотту Киму, он согласился заниматься
METAFONTnHroM в качестве подготовки к диссертации. Периодически
я буду пересекаться со Скоттом и наблюдать за тем, что он делает.
(4) Как только мы со Скоттом что-то сделаем, мы пошлем результаты
Цапфу, а также любому из AMS, кто хочет участвовать в обсуждении.
Этот заключительный этап редактирования может проходить в несколько
Глава 17. AMS Euler —новый математический шрифт
353
итераций, но мы сможем распечатывать много образцов и легко вносить
изменения, поскольку все хранится в виде METAFONT'a.
26 мая 1980 г.
ДЭК от ГЦ
Дорогой Дон!
... Возможно, у членов комитета по шрифтам возникнут разногласия по поводу
вида некоторых специальных символов. Я бы предложил разрешать эти
разногласия до начала собственно разработки, чтобы понимать, чего мы хотим от
заключительных эскизов, и избежать постоянной перерисовки. Лучше всего, если
бы этим занялись Вы.
27 мая 1980 г.
ГЦ от ДЭК
Дорогой Герман!
Я был рад услышать, что Правление AMS официально решило поручить Вам
работу над этим важным шрифтом. Теперь остается «всего лишь» довести проект
до успешного завершения!
Благодарю за прекрасные образцы, приложенные к Вашему письму.
Большинство из них в точности таковы, как нужно, и я поражен тем, как Вы
справились с проблемами, казавшимися мне почти неразрешимыми, вроде
рукописной Q.
Остается еще одна беспокоящая меня вещь, и мне бы хотелось еще раз
вернуться к этому, потому что я действительно серьезно настроен против. (Как бы
то ни было, если Вы со мной не согласны, безусловно хозяин положения Вы!) Мне
кажется, начальные и конечные хвостики строчных латинских букв все еще
загибаются слишком резко, и я прилагаю набросок того, как они должны выглядеть
по моему мнению.
Нынешний вид: Я бы хотел сделать их более округлыми:
1У
\У>
Это не только позволит еще легче отличать их от готического шрифта, но также
создаст более плавное, текучее ощущение. Вы ухватили эту замечательную
текучесть в строчных 'g' и *х'; я бы хотел, чтобы 'т' и 'у' и т. д. вызывали то же,
совершенно безыскусное ощущение.
Теперь более детальные комментарии по отдельным буквам.
Рукописная Т не подойдет; буква, нарисованная Вами, прекрасно
выглядит рядом с 'J', но в математических текстах эта Т будет стоять сама по себе и
лишь немногие поймут, что это за буква. ... Хвостик у строчной сигмы сейчас
слишком длинен; будет очень сложно набрать формулу '|сг|' так, чтобы она
выглядела симметрично. ... Вопросительный знак выглядит замечательно, но в
этих шрифтах он не понадобится: математики используют знаки восклицания,
но не вопросительные! ... Вторые варианты строчных дзета и кси лучше
первых, но основные горизонтальные штрихи внизу слишком длинны, и математики
привыкли к большим хвостикам под линией шрифта.
Как нам работать дальше? Я много об этом раздумывал, а Ваши
последние образцы полужирных букв прояснили один момент, о котором я должен был
354
Компьютерная типография
подумать давным-давно. А именно, что лучший способ подготовить эскизы для
METRFONT'a будет несколько отличаться от обычного стиля работы. Во-первых,
Вам не обязательно делать рисунки самого превосходного качества пером и
чернилами; будет достаточно карандашных набросков. Но мне совершенно
необходимы два наброска для каждой буквы: один со светлым вариантом, а другой — с
полужирным (на самом деле, может быть даже еще более жирным). Эта
информация насущно необходима для того, чтобы объяснить METRFONT'y, как нужно
варьировать набросок при изменении параметров. Я бы не смог предугадать
внешний вид замечательных полужирных прописных греческих букв,
присланных Вами, только по виду светлых; поэтому необходимы оба варианта.
Вам также следует делать по два таких наброска для каждой готической
буквы, хотя стандартные шрифты, возможно, будут содержать только один
готический алфавит — почти-но-не-совсем полужирный. Это даст нам возможность
экспериментировать с различными степенями насыщенности, не меняя эскиза.
Я думаю, Вам лучше будет делать все алфавиты целиком, а не пробовать
сделать несколько букв, посылать их в Калифорнию, потом делать еще несколько
и т.д.; согласованность будет очень важна. Скотт Ким активно работает над
завершением своей книги о «ДИЗАЙНатурах» [11], и я ожидаю, что он сможет
начать METRFONTHHr Вашей работы в сентябре или октябре.
Пока же, чтобы приступить к работе, мы бы хотели получить примеры
набросков большого размера, скажем, для пяти символов: прописной А, строчной i,
греческой сигма, цифры ноль и готической R. Пожалуйста, пришлите по два
рисунка каждой: один полужирный и один светлый. Я проверю, дают ли Ваши
наброски всю информацию, необходимую нам со Скоттом для подготовки
установок METRFONT'a. После этого я дам Вам «добро», и Вы приступите к основной
части проектирования. ... Как Вам такой план?
16 августа 1980 г.
ДЭК от ГЦ
Дорогой Дон!
... 27 июля я обедал в Бостоне с Пале и Ле Веком, но нам всем не хватало Вас.
К концу следующей недели я закончу два алфавита (рукописный латинский
и греческий), и я должен буду послать их прямо в Род-Айленд, чтобы там их
сфотографировали и разослали всем участникам проекта для одобрения.
Пока же Вы можете протестировать приложенные большие рисунки в Стан-
форде и как можно быстрее сообщить мне, годятся ли они для Скотта.
После получения от Вас комментариев и замечаний по поводу этих двух
алфавитов, комментариев, соединяющих и сплавляющих воедино идеи всех наших
друзей из AMS, я смогу быстро нарисовать окончательный вариант.
5 сентября 1980 г.
Получатель: комитет по шрифтам
Отправитель: У. Дж. Ле Век
К письму прикладываются фотокопии первых завершенных Германом Цапфом
алфавитов ... Эти начертания математических символов должны заменить
традиционно используемый сейчас курсивный шрифт, например х в sin я. Вы
обнаружите, что эти символы выпрямлены, это намного облегчит постановку
диакритических знаков над, под или рядом с ними.
Глава 17. AMS Euler — новый математический шрифт
355
[Эти рисунки, приложенные к письму ГЦ от 16 августа 1980 года, были уменьшены
до 33% от первоначального размера.]
Теперь мы ждем от вас критических замечаний и предложений, присылайте
их возможно скорее. Дон Кнут посетит Провиденс 24 сентября, и было бы очень
кстати, если бы вы возвратили мне приложенные листы до этого времени.
abcdefghijklrrmop qrstuv
wxyz123456789074fj
ABCDEGHIJLMNOP
QR STUV WXYZKKFT
<х|Зу6еСт| б iK\\xvlo7xpaQ,
TucJ>xi|>cui234567890 ф
ГД0ЛЕП1ФФГ2ЛЕ:¥
[Были разосланы увеличенные копии этих символов, снабженные
идентификационными номерами от 1 (для 'а') до 119 (для 'Ф'). Каждый член комитета получил
анкету на пяти страницах, в которой требовалось расставить 119 оценок: Отлично/
Удовлетворительно/Неудовлетворительно/Комментарии.]
8 сентября 1980 года
ГЦ от ДЭК
Дорогой Герман!
Благодарю за Ваше письмо от 16 августа и за образцы шести букв (средней
насыщенности и полужирных) для тестирования в METRFONT'e. Я
немедленно отдаю их Скотту, хотя именно сейчас он завершает последние штрихи своей
356
Компьютерная типография
книги, так что, возможно, пройдет несколько недель, прежде чем он сможет в
достаточной степени сосредоточиться на тестировании, как оно того
заслуживает. Нам, наверное, придется пережить горячие деньки, чтобы поспеть за Вашей
продуктивностью!
Образцы алфавита, посланные Вами в AMS, сейчас циркулируют в
комитете по шрифтам, и я приложу все усилия, чтобы использовать преимущества
коллективной мудрости комитета, но избежать недостатков «планирования всем
комитетом». Каждый член комитета независимо заполняет анкету; это даст
бесценный пример видения математиков, особенно если большинство из них
независимо приходит к одним и тем же выводам. Может также случиться, что по
некоторым вопросам в комитете возникнут серьезные разногласия (кошмар!),
но даже в этом случае, я думаю, их наблюдения будут очень ценны, хоть нам,
наверное, и не удастся понравиться всем.
P.S. Начальные и конечные хвостики букв теперь полностью меня
удовлетворяют. Огромное спасибо!
Анкеты были заполнены Уильямом Дж. Ле Веком, Ричардом Пале,
Барбарой Битон, Петером Ренцем, ДЭК и новыми членами комитета: Ральфом Ф.
Боасом (из Северо-западного университета), Линкольном К. Дэрстом, Фебе
Мэрдоком, Эллен Свонсон, Сэмюелем Б. Видденом (все из AMS) и
Уильямом Б. Вулфом (из Mathematical Reviews). Вот выдержка из типичного ответа:
16 сентября 1980 г.
У. Дж. Ле Веку от Ральфа Ф. Боаса
Дорогой Билл!
... многие, включая и меня, уже 50 лет борются за то, чтобы типографы
отличали € от е. Мне казалось, что битва уже выиграна, — а теперь AMS одним
росчерком пера художника может ее проиграть. Почему это важно? Потому что
1е € 5" — вполне возможная комбинация. ... Я действительно считаю, что
новый алфавит по замыслу весьма привлекателен. Тем не менее, мне кажется, что
форма 'а' лучше согласуется с остальными буквами, чем 'а'.
Итоги были подведены в длинном (13-страничном) послании:
9 октября 1980 г.
ГЦ от ДЭК
Дорогой Герман!
Надеюсь, Вы наслаждаетесь осенней порой. У нас только что началась учеба
и появилось много замечательных новых студентов. Деревья разукрасились в
разные цвета, белки собирают орешки; птички весело напевают.
Но теперь вернемся к работе! Недавно я заходил в штаб-квартиру AMS, и у
нас состоялось долгое и плодотворное обсуждение шрифтов Euler. В этом письме
я ставлю перед собой цель сжато изложить мнение комитета, с тем чтобы сколь
возможно облегчить Вам работу. Этот комитет представляет тип математиков,
заботящихся о качестве своих статей, и я знаю, что Вы цените такое внимание к
деталям; поэтому про каждый символ я напишу небольшой рассказ, основываясь
на их мнениях.
Глава 17. AMS Euler —новый математический шрифт
357
Общее мнение, конечно, весьма благоприятно, но мы обнаружили, что
существует опасность спутать математический шрифт с обычным текстовым;
большая часть комитета выразила озабоченность этой проблемой. Добавив
немного больше «рукописности» или «избыточности» в форму букв, которые
сейчас рисуются при помощи одних только прямых штрихов, мы бы достигли весьма
серьезных улучшений. Общее настроение склоняется к тому, что лучше иметь
немного менее красивые буквы, если они лучше отличимы от обычного прямого
светлого начертания, даже когда нам вполне нравится, как оно выглядит.
Перехожу собственно к «коротким рассказам», они пронумерованы в
соответствии с кодами на приложенной копии образцов рисунков. Но перед тем
как прочесть их, заметьте, что по-моему Вам пока не стоит делать рисунки для
METRFONT'a, до тех пор пока мы со Скоттом не закончим работу с тестовыми
символами, которые Вы для нас уже нарисовали. Сейчас просто быстро
просмотрите комментарии, чтобы иметь представление о настроениях комитета; а
затем, я думаю, надо подготовить образцы рукописного и готического шрифтов,
аналогичные латинскому и греческому.
1 / Всем нравится, как выглядит эта 'а', но мы действительно чувствуем, что
вместо этого нужно использовать другой стиль. Именно курсивную 'а'
математики всегда пишут на доске, и она лучше сочетается с другими буквами шрифта
Euler. Я приношу свои извинения, что не упомянул об этом раньше; я просто не
обратил на это внимания.
25 3> 45 5 / Они нравятся всем, и они достаточно отличаются от обычных
латинских букв.
6/ Здесь вопрос в том, выбрать (6) или (39). Поначалу мнения комитета о том,
что выбрать, разделились поровну, потому что (6) очень изящна. Но после того,
как кто-то заметил, что (6) плохо выглядит в том распространенном случае,
когда после Т идет левая скобка, голоса единодушно были отданы в пользу (39),
а не (6).
7/ Прекрасно, единодушное одобрение.
119/ Следует использовать (119) вместо (115), но добавить две засечки внизу,
как у Т (48) и 'Ф' (114).
Но прежде всего я хочу подчеркнуть мнение комитета, что Вы должны
принимать собственные решения о том, что пойдет на пользу для замысла в целом.
Наша цель — дать Вам как можно больше фактического материала о
впечатлениях математиков и о том, какие моменты ощущаются особенно остро, но нашим
отдельным мнениям нельзя позволить внести разброд в весь проект. Пока что
общее мнение: «Все вместе —какая замечательная работа!»
22 октября 1980 г.
ДЭК от Р. Пале
Дорогой Дон!
От лица всех нас я хочу поблагодарить Вас за те усердие и тщательность, с
которыми Вы подошли к сравнению п х 119 мнений о символах шрифта Цапфа. По
моему мнению, Ваше письмо просто шедевр. Ле Век был весьма впечатлен. Я
думаю, сначала он боялся, что Вы позволите восторжествовать Вашим
собственным вкусам, но сейчас он полон энтузиазма по поводу проекта и изобретенной
358
Компьютерная типография
Вами стратегии достижения лучшего из миров путем соединения мудрости
комитета с индивидуальной творческой энергией. Если этот проект создания шрифта
увенчается успехом — а я верю, что так оно и будет, — я думаю, этим он будет
столь же обязан Вашему терпению и эстетическому чувству равновесия, как и
замечательному вкусу и мастерству Цапфа.
25 октября 1980
ДЭК от ГЦ
Дорогой Дон!
Для меня вся история с шрифтом Euler — идеальный пример командной работы.
Я согласен со всеми поправками, сделанными Вами и Вашими друзьями. И я
очень рад, что новые нули были приняты.
5 декабря 1980 года
Комитету по шрифтам от У. Дж. Ле Века
Дорогие коллеги!
Прилагается лист II с рисунками Германа Цапфа, а также листы для
комментариев. Дополнительно к готическому и рукописному алфавитам, он представил
новые версии букв с листа I, которые потребовали серьезной переделки из-за
разнообразной критики. Как и ранее, просьба присылать ваши комментарии мне.
abcbefgfyijUmnopqxsbxbmx
ж то 9К2 т. е тл ш <т
XLMNOTQ31SZUWI
VXyZAAUVWreT](p
avwzxz 7 Q1 VWy z-dw 2,
К
8 декабря 1980 г.
ГЦ от Р. Ф. Боаса
Дорогой профессор Цапф!
... Новая гамма привлекательна, и я не расстроюсь, если петля при
воспроизведении исчезнет: в конце концов, многие греческие шрифты обходятся без петли.
Я только недавно читал русскую статью, в которой действительно
используется, и не раз, е £ Е (спасибо, что не £ € £), это указывает на важность различий
между буквой е и символом Е.
Глава 17. AMS Euler —новый математический шрифт
359
5 февраля 1981 г.
ГЦ от ДЭК
Дорогой Герман!
Готовы ли Вы к еще одному длинному письму о письменах? Снова я
попытаюсь кратко изложить независимые мнения членов комитета по шрифтам. В
целом люди чувствуют, что работа продвигается хорошо. Все (кроме меня)
высказали озабоченность тем, что соединительные штрихи будут в малых кеглях
выпадать; мне следовало объяснить им, что METRFONT позаботится о
соединительных штрихах и что на этой стадии нам не следует беспокоиться о таких
вещах.
Перехожу к отдельным буквам по их номерам, как и раньше.
1 / Было одно замечание о том, что юго-западная часть овала должна загибаться
под несколько более острым углом (как в Ь), чтобы сделать букву еще больше
похожей на готическую.
2, з / Единодушное одобрение: браво, браво!
4 / Слишком похоже на букву дельта. Я нашел готическую "О в двух
математических справочниках, и в обоих случаях диагональный штрих вверху шел вниз
более круто (более горизонтально).
юб / Всем понравилась эта алеф; один человек поинтересовался, не слишком ли
она жирна, но это мы всегда сможем подправить позднее.
Необходимо еще одно важное изменение: я со многими людьми обсуждал
мое предложение сделать цифры в одном из наборов разной ширины ... Нам
следует отменить наше решение и сделать все десять цифр одинаковой ширины
и в выровненном, и в старинном стиле.
Итак, очередная порция комментариев завершена. Шрифты Euler очевидно
приобретают все более приятные очертания, и следующим критическим шагом
станет METRFONTHHr.
Скотт Ким, аспирант в computer science, работающий под руководством
ДЭК, вызвался закодировать чертежи Euler в системе METflFONT в качестве
подготовки к собственной диссертации, которая будет затрагивать вопросы о
связи между компьютерами и визуальным мышлением. Его первые попытки
были вполне успешны:
17 февраля 1981 г.
ГЦ от ДЭК
Дорогой Герман!
Вот первые пять образцов букв шрифта Euler, в том виде как они были
нарисованы METRFONT'om. Скотт проделал огромную работу, и притом первоклассную,
разрабатывая новый стиль программирования METRFONT'a, моделирующий
вращение и нажим пера, и мы постепенно учимся пользоваться этими приемами. Это
непросто, но зато интересно и поучительно.
Во время подготовки этих образцов мы много раз жалели, что вас нет рядом
с нами и Вы не можете нам подсказать! С другой стороны, тот факт, что мы
общаемся письменно очень полезен, потому что это заставляет нас быть точнее
и яснее формулировать свои мысли.
Достаточно ли приложенные буквы близки к вашим рисункам, чтобы мы
могли переходить к следующей стадии? Если нет, прошу вас так честно и сказать
360
Компьютерная типография
и прислать подробный комментарий о том, какие усовершенствования нам еще
нужно освоить, прежде чем мы будем готовы приступить к настоящим буквам
AMS Euler.
Пользователи METRFONT'a пишут для каждой буквы «программу»,
выражающую их намерения на специальном языке. Программа говорит
компьютеру, как рисовать эту букву, в зависимости от набора параметров, таких как
высота и ширина литеры, а также толщина различных типов штрихов.
Программа использует эти параметры, чтобы определить опорные точки.
Например, горизонтальный штрих на рисунке, изображенном здесь, идет от опорных
точек 110-310 к опорным точкам 111-311.
Такие программы дают «меташрифт» [13], который можно использовать
для создания самых разнообразных конкретных шрифтов, соответствующим
образом выбирая параметры. Вот, например, шесть вариантов пяти тестовых
символов, упомянутых в письме ДЭК от 17 февраля 1981 г.:
AilOf AilOf AilOf AilOf AilOf AilOf
Второй и пятый примеры соответствуют рисункам ГЦ от 16 августа 1980 г.;
средние два получены интерполяцией; крайние два — экстраполяцией (что
чревато большими неприятностями).
Меташрифт позволяет создателю исследовать множество различных
возможностей. Например, высоту или ширину символа можно изменять, оставляя
толщину штрихов неизменной:
000000 АААААА
23 февраля 1981 г.
Скотту Киму от У. Дж. Ле Века
Дорогой Скотт!
Я был очень рад услышать, что Вы надеетесь закончить работу в METRFONT'e
над латинским, греческим, готическим и рукописным алфавитами этой весной.
Глава 17. AMS Euler — новый математический шрифт 361
Да, это было время эйфории; казалось, все идет превосходно. Но затем
пришло отрезвление, грозящее подвергнуть опасности весь проект. Метапро-
ектирование сложнее обычного проектирования, и эта концепция еще
недостаточно понята (в особенности не для таких шрифтов, как этот). ДЭК забыл,
что ему потребовалось более года на то, чтобы изучить принципы метапроек-
тирования. Кроме того, требовалось обработать более 200 символов и каждый
нарисовать в двух вариантах разной насыщенности. Нельзя было ожидать, что
ГЦ будет абсолютно последователен при изменении каждого штриха каждого
символа от средней насыщенности к полужирному варианту; следовательно,
ни от одного произведенного компьютером меташрифта нельзя было ожидать
точного совпадения с рисунками ГЦ. Для того чтобы отличать действительно
решающие детали рисунков от тех, которые ГЦ и сам бы изменил, будь он
метадизайнером, необходимо очень хорошо разбираться в вопросе. Задача
Кима была, таким образом, гораздо более сложной, чем думали ДЭК и ГЦ в то
время.
ДЭК спросил, пойдет ли ГЦ на то, чтобы дать им со Скоттом свободу в
следующем: «Если METflFONT трудно заставить сделать верную копию
Вашего рисунка и если есть вариант, почти такой же, как Ваш рисунок, который
легок для METflFONT'a и кажется нам нормальным, можем ли мы
умышленно изменить Ваш чертеж, приведя его к виду, наиболее естественному для
METflFONT'a? (Конечно, результаты в конце будут представлены для
Вашего одобрения.)» ГЦ ответил утвердительно: «Я доверяю вам. В некоторых
символах будет необходимо пойти на компромисс между моими рисунками и
структурными особенностями METflFONT'a. He слишком беспокойтесь об этом;
я знаю, что вы оба сделаете все возможное».
26 мая 1981 г.
ГЦ от ДЭК
Дорогой Герман!
На прошлой неделе почтальон доставил три вкуснейших блюда от Вас! Теперь мы
получили полный комплект цифр вместе с прописными и строчными латинскими
и греческими буквами, сразу и светлой, и полужирной насыщенности.
Теперь у Скотта полно работы. Он хочет этим летом сосредоточиться на
шрифте Euler.
Как бы то ни было, к сожалению, лето увидело завершение лишь 26
строчных латинских букв. Не существовало простого способа превращать рисунки
в компьютерный код; каждая буква требовала дня на обдумывание, дня на
утомительные измерения и прорисовывания, еще одного дня на борьбу с МЕТА-
FONT'om. Выяснилось, что первая система METflFONT совсем не была
приспособлена для проектов вроде этого; потребовалась совершенно новая система
[15]. Но ДЭК уже занялся другими проектами, отнимавшими у него более 24
часов в сутки. Мы постепенно осознавали, что на всю необходимую работу
уйдет несколько лет.
362
Компьютерная типография
19 апреля 1982 г.
ГЦ от ДЭК
Дорогой Герман!
... у меня нет никаких сомнений, что шрифт Euler однажды воплотит все наши
ожидания, но этот день гораздо дальше, чем я раньше предполагал.
Спасением стала станфордская новая программа по компьютерной
типографии (Digital Typography), начатая осенью 1982 г. под руководством
проф. Чарльза А. Бигелоу. В новых студентах: Джоне Хобби, Дэне Миллсе,
Дэвиде Зигеле и Кэрол Туомбли — соединилось множество умений,
необходимых для преобразования рисунков ГЦ в цифровой формат, в то время как
ДЭК в сентябре 1985 г. заканчивал абсолютно новую систему METflFONT. Вся
сага, описывающая эти поучительные разработки, изложена в хорошо
иллюстрированном буклете Дэвида Зигеля [21].
Группа произвела на свет 484 символа менее чем за 484 рабочих дня, включая все
программирование. Проект в целом потребовал 80 миллионов байтов дискового
пространства, хранящихся на двух компьютерах. ... Формулы, набранные
шрифтом Euler, должны сохраняться при размазывании слишком обильно нанесенных
на пресс чернил по самой наитончайшей бумаге. Они не должны расплываться
ни на барабане лазерного принтера, ни под не очень ярким светом древних
фотокопировальных машин в математической библиотеке. Буквы не должны терять
четкость при самом тусклом свете около полки с периодикой через самые темные
трифокальные очки; они должны ясно просвечивать сквозь лес накарябанного
как курица лапой поверх гранок. Шрифт Euler готов ко всем этим испытаниям
в AMS.
Даже после оцифровки шрифтов работа не была завершена. Требовалось
определить соответствующие размеры отступов слева, справа, сверху и снизу
каждого символа. Требовалось предоставить информацию, необходимую для
расположения акцентов и индексов. (Первоначальная надежда математиков
Глава 17. AMS Euler —новый математический шрифт
363
на то, что это окажется ненужным для выпрямленного шрифта, не сбылась;
истинные его преимущества оказались более неуловимыми, а именно
выпрямленные буквы лучше сочетаются со скобками, плюсами и другими
математическими символами.) Требовалось написать новые «макро», чтобы авторы
и их компьютеры могли без труда использовать новые шрифты. И —самое
главное —для тестирования и отладки нового проекта в самых разных
математических ситуациях требовался опыт. Нам нужно было сжиться с новыми
соглашениями и изучить их главные особенности, прежде чем предлагать их
широкой общественности.
Следующий очевидный шаг заключался в том, чтобы сделать готические
шрифты широко доступными в дополнение к существующим начертаниям,
потому что имелась насущная необходимость в математическом готическом
шрифте. Поэтому эта часть AMS Euler была использована в настоящих
публикациях первой, вначале в экспериментальной книге, отпечатанной в Станфорде
[19], и затем во многих статьях журнала AMS.
AMS Euler наконец-то достиг целей, поставленных перед проектом в
самом начале, когда все объединенные в нем алфавиты были использованы для
набора математических формул в серьезном учебнике. Эта книга под
названием Concrete Mathematics [10] была во многих отношениях идеальной
стартовой площадкой для новых соглашений. Во-первых, в ней обсуждалось много
различных разделов математики во всех ее разнообразнейших аспектах. Во-
вторых, ДЭК был одновременно и наборщиком, и соавтором этой книги, так
что он мог внимательно изучать формулы и делать любые необходимые
поправки. И, наконец, предмет Concrete Mathematics как нельзя лучше подходил
к названию AMS Euler, потому что ДЭК и его соавторы к тому времени уже
решили посвятить свою книгу Леонарду Эйлеру! «... дух Леонарда Эйлера
живет поистине на каждой ее странице: конкретная математика — это эйлерова
математика!» [10, с. 12].
Когда художник книги, Рой Говард Браун, впервые увидел шрифты Euler,
он заметил, что они немного темнее традиционных математических шрифтов,
поэтому для них требовалось немного более жирное начертание текста, чем
обычно. На основе этих рекомендаций ДЭК представил новый шрифт,
названный Concrete, прямой светлый и курсивный, для основного текста, сделанный
при помощи его меташрифта Computer Modern [17] с несколько «египетскими»
значениями параметров. Комбинация AMS Euler и прямого светлого Concrete
хорошо зарекомендовала себя на всех 640 страницах Concrete Mathematics, так
что шрифты Euler теперь действительно ожидает самое светлое будущее.
Неожиданным оказался один аспект, связанный с переходом от
существующих соглашений к AMS Euler: теперь имеется четыре разных набора
цифр, а именно: «выровненный стиль» (где все цифры расположены над
линией шрифта и имеют одинаковую высоту: 0123456789) и «старинный стиль»
(0123456789)) каждый из них в текстовом и математическом начертаниях.
Поэтому авторам впервые пришлось различать числа, являющиеся частью текста
(например, '1988'), и числа, появляющиеся в математических формулах
(например, '3,1416'). Это различие оказалось довольно эффективным, и его легко
364
Компьютерная типография
осуществить при помощи ТЁК'а. Выровненные цифры текстового начертания
использовались в предложениях типа 'Глава 2'; старомодные цифры
текстового начертания — для номеров уравнений. Выровненные цифры AMS Euler
использовались в математических формулах, а старомодные цифры AMS Euler
подошли бы для числовых таблиц (в этой книге не понадобившихся).
Использование AMS Euler в Concrete Mathematics было бы совсем
рутинным, если бы не один отрывок на с. 167-168, где авторам хотелось изобразить
последовательность все более сложно выглядящих q (потому что
математика двигалась от q «первого уровня» ко второму, третьему и более высоким
уровням). В первом приближении последовательность выглядела так:
строчная прямая светлая, затем прописная прямая светлая, затем рукописная, затем
полужирная рукописная: q Q Q Q. Эта последовательность не подошла,
потому что рукописная Q в AMS Euler на самом деле меньше по размеру и не столь
внушительна, как прямая светлая Q. Переходя от повторного использования
рукописного шрифта к прямому полужирному, за которым следует
прописной готический, мы получили последовательность с требуемым настроением:
q Q Q £3. (Конечно, рукописные буквы оказались полезными в других
случаях; задача рукописного AMS Euler всегда состояла в том, чтобы избежать
излишеств коммерческих шрифтов, создаваемых, как правило, для свадебных
приглашений, а не для математических текстов.)
За то время, что ДЭК набирал книгу в 1987-1988 г., он быстро привык
к новому «выпрямленному» внешнему виду и заметил, что привычный знак
интеграла теперь не подходит. Поэтому он предложил вертикальный знак
интеграла в шрифтах дополнительных математических символов: f превратился
в J. Он также внес завершающее изменение в алфавиты Euler (с одобрения
ГЦ), превратив
Aj в bj
(для этого были использованы возможности трансформации нового METR-
FONT'a). Теперь все математические формулы создавали одинаковое ощущение
выпрямленности; идеальное единообразие замысла наконец-то было
достигнуто!
Если эти новые шрифты обретут поддержку в математическом сообществе
в целом, потребуется проделать еще некоторую работу. В настоящий момент
AMS Euler не является действительно меташрифтом; его символы были просто
оцифрованы для двух степеней насыщенности по исходным рисункам ГЦ. Из-
за этого шрифты нельзя ни с легкостью сделать шире для удобочитаемости при
маленьком кегле, ни быстро приспособить к наборным устройствам, дающим
более темные или более светлые изображения, чем нужно. Новый METAFONT,
сам во многом появившийся благодаря первым опытам с AMS Euler, должен
оказаться подходящим инструментом для создания меташрифта Euler; так что
ДЭК и ГЦ оба надеются, что кто-нибудь примет этот вызов. Мы можем
гарантировать, что кто бы ни попробовал взяться за это, он приобретет в высшей
степени плодотворный и поучительный опыт.
Глава 17. AMS Euler —новый математический шрифт
365
Здесь приведены основные символы шрифта Euler, набранные 12-м кеглем
с прямым светлым Concrete в качестве сопровождающего текста.
Цифры: 0123456789:0123456789
& 0123456789 : 012.3456789
Прописные латинские: |А| + |В| + |С| + |D| + |Е| + |F| + |G| + |H| +
III + III + |К| + |L| + |М| + |N| + |0| + |Р| + |Q| + |R| + |S| + |T| +
|U| + |V| + |W| + |X| + |Y| + |Z| + |A| + |B| + |C| + |D| + |E| + |F| +
|G| + |H| + |I| + |J| + |K| + |L| + |M| + |N| + |0| + |P| + |Q| + |R| +
|S| + |T| + |U| + |V| + |W| + |X| + |Y| + |Z|
Строчные латинские: |a| + |b| + |c| + |d| + |e| + |f| + |g| + |H| + |i| + |j| +
|k| + |l| + H + |n| + |o| + |p| + |q| + |r| + |s| + |t| + |u| + |v| + H + |x| +
|y| + N + |a| + |b| + |c| + |d| + |e| + |f| + |g| + |h| + |i| + |j| + |k| + |l| +
|m| + |n| + |o| + |p| + |q| + |r| + |s| + |t| + |u| + |v| + H + |x| + |y| + |z|
Прописные греческие: |Г| + |А| + |9| + |Л| + |Е| + |П| + |1| + |Т| + |Ф| +
|¥|+|а|+|г|+|А|+|©|+|л|+|Е|+|п|+|1:|+|т|+|Ф|+|¥|+|а|
Строчные греческие: |а| + ||3| + \у\ + |5| + |е| + |С| + hi + |6| + |i| +
|к| + |Л| + |ц| + М +1£,| + И + |р| + |а| + |т| + М + |ф| + |х| + 1-Ф1 +
М + |сс| + |Э| + |у| + |6| + |е| + |С| + |л| + |в| + |i| + |к| + |Л| +
\ц\ + М + |*| + N + |р| + \и\ + |т| + |v| + |ф| + |х| + |ф| + \ш\
Прописные готические: \Щ +1»| + |С| + |£>| +|£| +|£| + |<5| + Щ +
|3| +13| + |Я| +1£| + \Щ + \% + \0\ + \Щ +10| + М + \&\ + |Т| +
|Н| + |Ш| + |2П| + \Х\ + |9| + |3| + |21| + |»| + |С| + |Х>| + \(В\ +
\3\ + \е\ + |s| + |з| + \з\ + \я\ + \&\ + \т\ + |<п| + \о\ + № +
|£5| + |5К| + \&\ + |Х| + |Я| + \W\ + |ШТ| + \Х\ + |?)| + |3|
Строчные готические: |а| + \Ъ\ + |с| + \0\ + |е| + |f| + |g| + \fy\ + |i| + |j| +
l«l + l4 + H + |n| + |o| + |p| + |q| + |t| + W + |t| + |u| + |o| + |»| + |f| + |0H-
|3| + |a| + |b| + |c| + H + |e| + |f| + |0| + |b| + |i| + |J| + l«l + l4 + |m| +
|n| + |o| + HiH-|qH-|rH-W + |tH-|uH-N + H + W + N + l3l
Прописные рукописные: |Л| + |В| + |C| + |D| +1£| + \1\ + \Q\ + \Я\ +
|а| + \з\ + \%\ + \ь\ + |м| + |к| + |о| + |т| + |Q| + |я| +1§| + |т| +
|it| + |v| + |W| + |Х| + |у | + |z| + \л\ + \ъ\ + |е| + р| +1£| +13=1 +
|S| + \ЭС\ + \0\ + \3\ + \%\ + |£| + \М\ + |N| +10| + \9\ + \Q\ + |Л| +
\8\ + |Т| + \U\ + \V\ + \W\ + \Х\ + \Щ + \Z\
366
Компьютерная типография
Дополнительные буквы: |К| + \Ц + |р| + |г| + |)| + |е| + \Щ + |со| +
|<р| + |К| + |<| + \р\ + |г| + Ь\ + |е| + |*| + |о| + |<р|
(Особая р в нижней строке заслуживает внимания как созданная
выдающимся математиком девятнадцатого столетия Карлом Вейерштрассом, который в
юности изучал «Schonschrift1» [1].)
В завершение посмотрим, как представленные выше три набора формул будут
выглядеть в новом наряде от Эйлера:
Ind.
Pract.
where
and
v, a, b
1 ^ ® ^
0' a' b' с
Sl = v;» = aSl + 1;C = b» + Sl
a = 1; b = aa + 0; c = bb + a
exp
-fxcosC'
(21 + 5Sx + £xx) cos
(a+ bx + cxx) sin
fxsinC 1
9
f x sin С
ее £ 4=> e € £
Недавнее появление настольных издательских систем повысило внимание
математиков к качеству печати. Поэтому авторам был очень приятен
благосклонный прием, оказанный этому новому шрифту в первые месяцы после его
представления на суд общественности; у истории AMS Euler действительно
счастливый конец:
Дата: срд, 28 дек 88 12:59:07 CST
От: thistedOgalton.uchicago.edu (Рональд А. Фистед)
Кому: dekOsail.stanford.edu
Тема: Конкретная математика
Дон!
Я недавно увидел вашу новую книгу в нашем книжном магазине и что-то
толкнуло меня купить один экземпляр (наверное, подарок самому себе
на Рождество). ...
Между прочим, я обнаружил, что в результате работы оформителей и
художников получилась самая удобочитаемая техническая книга из тех,
что я видел за долгое время. Обычно после прочтения нескольких
страниц большинства книг я уже утомляюсь, но в этом случае мне
удалось прочесть всю главу 1, ни разу не отвлекшись.
1 Каллиграфия (нем.) — Прим. перев.
Глава 17. AMS Euler —новый математический шрифт
367
На рисунки и символы AMS Euler, показанные в этой статье, распространяются авторские
права Американского математического общества и они использованы здесь с его
разрешения. Эти исследования частично поддерживались грантами System Development Foundation
и National Science Foundation.
Литература
Kurt-R. Biermann, "Karl Weierstrafi," Journal fur die reine und angewandte
Mathematik 223 (1966), 191-220.
T. W. Chaundy, P. R. Barrett, and Charles Batey, The Printing of
Mathematics (Oxford: Oxford University Press, 1954).
A. L. Crelle, editor, Journal fur die reine und angewandte Mathematik 23
(1842), факсимильная вставка между ее. 104 и 105. (Еще с дюжину
примеров нулей Эйлера можно найти в книге 9 на с. 96.)
John Dreyfus, The Work of Jan van Krimpen (London: Sylvan Press, Museum
House, 1952).
Charles Enschede, Typefounders in the Netherlands] перевод на английский с
исправлениями и замечаниями Гарри Картера (Haarlem: Stichting Museum
Enschede, 1978), 261-267.
Leonhard Euler, "De usu novi algorithmi in problemati Pelliano solvendo,"
Novi commentarii academiae scientiarum Petropolitanae 11 (1765; издано в
1767), 28-66.
Leonhard Euler, Institutionum Calculi Integralis, Volume 2 (St. Petersburg:
Academiae Imperialis Scientiarum, 1769).
Leonhard Euler, "De novo genere serierum rationalium et valde convergentium
quibus ratio peripheriae ad diametrum exprimi potest," Nova acta academiae
scientiarum Petropolitanae 11 (1793; издано в 1798), 150-154.
Leonhard Euler 1707-1783: Beitrage zu Leben und Werk (Basel: Birkhauser
Verlag, 1983).
Ronald L. Graham, Donald E. Knuth, and Oren Patashnik,
Concrete Mathematics (Reading, Massachusetts: Addison—Wesley, 1989).
[Имеется русский перевод: Р. Л. Грэхем, Д. Э. Кнут, О. Паташник.
Конкретная математика. — М.: Мир, 1998, 1999.]
Scott Kim, Inversions (Peterborough, New Hampshire: Byte Books, 1981).
Donald E. Knuth, "Mathematical typography," Bulletin of the American
Mathematical Society (new series) 1 (1979), 337-372. [Представлено с
исправлениями в данном издании как гл. 2.]
Donald E. Knuth, "The concept of a meta-font," Visible Language, 16 (1982),
3-27. [Представлено в данном издании как гл. 15.]
Donald E. Knuth, The TfiKbook, Volume A of Computers Sz Typesetting
(Reading, Massachusetts: Addison—Wesley and American Mathematical
Society, 1984). [Имеется русский перевод: Дональд Е. Кнут. Все про ТЁ^. —
Протвино: АО RDTEX, 1993.]
368
Компьютерная типография
Donald E. Knuth, "Lessons learned from METflFONT," Visible Language, 19
(1985), 35-53. [Представлено в данном издании как гл. 16.]
Donald E. Knuth, The METRFONTbook, Volume C of Computers &
Typesetting (Reading, Massachusetts: Addison—Wesley and American
Mathematical Society, 1986).
Donald E. Knuth, Computer Modern Typefaces, Volume E of Computers &
Typesetting (Reading, Massachusetts: Addison—Wesley, 1986).
Donald E. Knuth, "Typesetting concrete mathematics," TUGboat 10 (1989),
31-36, 342. [Представлено в данном издании как гл. 18.]
Ernst Kunz, Introduction to Commutative Algebra and Algebraic Geometry
(Boston, Massachusetts: Birkhauser Boston, 1985).
Phoebe J. Murdock, "New alphabets and symbols for typesetting
mathematics," Scholarly Publishing 8 (October 1976), 44-53.
David R. Siegel, The Euler Project at Stanford (Stanford, California:
Computer Science Department, Stanford University, 1985).
Technische Hochschule Darmstadt, Hermann Zapf: Ein Arbeitsbericht
(Hamburg: Maximilian-Gesellschaft, 1984).
Jan van Krimpen, On Designing and Devising Type (New York: Typophile
Chap Books, 1957).
John Wallis, A Treatise of Algebra (Oxford: 1685).
Hermann Zapf and His Design Philosophy (Chicago: Society of Typographic
Arts, 1987).
[26] Sammlung Hermann Zapf (Wolfenbuttel: Herzog August Bibliothek, 1993).
Дополнение
Более короткая версия текста этой статьи была опубликована в ABC-XYZapf:
Fifty Years in Alphabet Design, под редакцией Джона Дрейфуса и Кнута Эрик-
сона (London: The Wynkyn de Worde Society, and Offenbach: Bund Deutscher
Buchkunstler, 1989), cc. 171-179. Эта версия содержит несколько
дополнительных рисунков, относящихся к позднейшим стадиям работы.
Во втором издании [10], вышедшем в 1994 г., METflFONT использовали для
улучшения нижних и верхних индексов, сделав их чуть более широкими.
Набор книги
Concrete Mathematics
[Первоначально опубликовано в TUGboat 10 (1989), 31-36, 342.]
В течение 1987-1988 гг. я работал над учебником Concrete Mathematics [1],
написанным в соавторстве с Роном Грэхемом и Ореном Паташником. Я прилагал
все усилия со своей стороны, чтобы сделать книгу интересной с
математической точки зрения, но я также знал, что она должна быть и полиграфически
интересной, потому что в ней впервые использовались новые шрифты
Германа Цапфа, заказанные ему Американским математическим обществом. Эти
шрифты, названные AMS Euler, были тщательно оцифрованы и переведены
в формат METflFONT студентами кафедры компьютерной типографии Стан-
фордского университета [9], но для реальных приложений они еще не были
вполне «отшлифованными». Моя новая книги могла послужить идеальным
тестом, потому что (1) книга содержала большое разнообразие математических
формул; (2) у меня было серьезное намерение сделать эту книгу
удобочитаемой и радующей глаз; (3) на опытах с «отшлифовкой» шрифтов Computer
Modern я получил навык установки таинственных параметров, используя T^jX
в математическом режиме; и (4) книга была посвящена великому математику
Леонарду Эйлеру, в честь которого и были названы шрифты.
В основу дизайна шрифтов Euler Цапф заложил ту идею, что все
символы должны быть наполнены математическим ароматом, как если бы они
были написаны математиком с великолепным почерком. Например, одним из
типичных знаков шрифта AMS Euler может служить нуль '0', который слегка
заострен сверху, потому что чрезвычайно редко рукописный нуль
замыкается гладко, когда кривая возвращается в начальную точку. Для математики
рукописный рисунок буквы подходит больше, чем механический, потому что
обычно математики пишут свои работы ручкой, карандашом или мелом.
Буквы Euler прямого начертания, а не курсивного, так что они в общем сочетаются
с математическими символами, такими, как плюсы или скобки, поэтому
формулы выстраиваются весьма гармонично. Семейство AMS Euler включает семь
алфавитов: прямые прописные (от ЛВС до XYZ), прямые строчные(от abc до
xyz)} греческие прописные (от АВГ до Х^П), греческие строчные (от а(3у до
Х'фш)) готические прописные (от 2193£ до £2)3), готические строчные (от аЬс
370
Компьютерная типография
до эдз) и рукописные прописные (от ЛЪ С до X^Z). Включены также два вида
начертаний цифр: (0123456789 и 0123456789)) равно как спецзнаки типа р} X и
некоторые знаки препинания. Подробности дизайна обсуждаются в статье [7].
Для того чтобы усовершенствовать процесс оцифровки литер
математического назначения, я начал с исправления способа, по которому они
выстраивались в своих «боксах» с точки зрения Т^Х'а. С этой целью я использовал
тесты \math стандартной подпрограммы testf ont [5, Appendix H]; эти тесты
проводили литеры через их основные положения посредством набора формул,
TaKHx,jcaKjA| + |B| + |C| + --- + |Z|, а2+Ъ2 + с2 + - • - + z2, а2 + Ь2 + с2 + -•-+32,
иЛ-+-33-+-С-+---- + £. Среди прочего я заметил, что готические буквы
размещены слишком высоко над линией шрифта, а для литер в размере верхних и
нижних индексов нужно дополнительное пространство слева и справа. Кроме
этих проблем я обнаружил, что нужно установить поправку на курсив, чтобы
верхние и нижние индексы заняли свое правильное место. Затем
понадобилось определить подходящий размер кернинга посредством \skewchar, чтобы
акценты зрительно заняли место по центру буквы. Семейство AMS Euler
содержит более 400 литер, и Герман разработал их великолепно. Моя задача
состояла в правильной корректировке разнообразных пробелов, чтобы буквы
гармонировали с математическими формулами.
Следующий шаг состоял в создании макрокоманд ТЕХ'а Аля удобства
использования шрифтов AMS Euler в математическом режиме. Это означало
добавление новых «блоков» соглашений к тем, что уже были определены для
предыдущих форматов. Plain Т|н}Х набирает математические выражения,
используя четыре основных семейства шрифтов (\f amO для текста, \f ami для
курсива в формулах, \f am2 для символов и \f атЗ для больших
ограничителей) плюс несколько других, которые используются реже (\f am4 для курсива
в тексте, \f am5 для наклонного в тексте, \f атб для прямого полужирного и
\f ат7 для имитации пишущей машинки). Я добавил \f am8 для
рукописного AMS Euler Script и \f am9 для готического AMS Euler Praktur; греческий
и прямой AMS Euler Greek и Roman заняли прежние места для курсива в
математике \f ami. Герман нарисовал новые фигурные и квадратные скобки,
которые органично вписались в готический шрифт. Таким образом, в
файле моих макрокоманд соглашения plain TEJX'a заменились посредством ввода
определений типа \mathcode'(="4928 и \delcode'(="928300. Аналогично, в
семействе Euler был символ " в качестве альтернативы символу '<',
запакованный в рукописном алфавите. Для того чтобы Т|н}Х распознал эту замену, я
ввел \mathchardef\leq="3814 \let\le=\leq.
С таким образом расширенным plain ТеХ'ом я мог набирать формулы
вроде $\tan(x+y)$ как обычно и получать в результате не «tan(x + у)»} а
«tan(x + у)». Было, однако, одно существенное отличие между набором
рукописей Concrete Mathematics и The Art of Computer Programming, связанное
с тем фактом, что рисунок цифр в шрифте Euler 0123456789 совсем не был
похож на рисунок цифр 0123456789 в обычном тексте. Раньше я старался «оп-
Глава 18. Набор книги Concrete Mathematics
371
тимизировать» свою работу по набору, например так:
$х$ есть либо 1, либо $-1$,
т. е. я не помещал математические константы в знаки $, за исключением
случаев, когда нужно было получить минус, а не дефис. Я рассуждал так: все
эти дополнительные доллары только усложняют работу в TEJX'e, а результат
выглядит таким же; разве я поступаю не логично? Но при наборе Concrete
Mathematics мне приходилось набирать так:
$х$ есть либо $1$, либо $-1$,
чтобы х принимал значение 'либо 1, либо —Т. Первые черновики моей
рукописи были подготовлены в прежней манере, так что мне пришлось потратить
несколько часов, скрупулезно выискивая и исправляя все места, где было
нужно учесть новые соглашения. Это опыт был не напрасным, поскольку он
подсказал мне, что полезно и разумно различать цифры в тексте и цифры в
математических выражениях. Текстовые цифры следует использовать в таких
случаях, как «1776 г.», «глава 5» и «41 способ», когда числа служат
составной частью обычной литературной фразы; математические цифры, напротив,
должны использоваться в контексте типа «наибольшим делителем чисел 12
и 18 является 6», когда числа являются составной частью математического
выражения. (Авторы технических текстов, пишущих, например, на японском
языке, в котором принято использовать арабские цифры только в формулах,
но не в обычном тексте, всегда хорошо чувствовали это отличие; теперь и у
меня появился шанс испытать это на себе.)
В то время как я с упорством зубрилы продирался через AMS Euler, мои
издатели показали предварительный вариант рукописи Concrete Mathematics
книжному дизайнеру Рою Говарду Брауну. Я переслал Рою экземпляр первого
отчета по шрифтам Euler [9], чтобы он мог увидеть образцы шрифта, который
предполагалось использовать для набора математических выражений. Нашим
первым намерением, основанным на замысле Цапфа 1980 г., когда он
приступил к разработке шрифта, было использовать для текста шрифт Computer
Modern Roman, а для математики —AMS Euler. Но Рой обнаружил, что AMS
Euler был несколько «чернее», чем традиционный математический курсив,
поэтому он решил, что и шрифт для текста должен быть чуть-чуть утяжелен.
Он прислал мне несколько образцов шрифта более подходящей
насыщенности, чтобы я смог изготовить специальный шрифт, сочетающийся с AMS Euler.
(Одна из основных моих посылок, когда я разрабатывал семейство Computer
Modern, состояла в том, что я должен быть в состоянии адаптировать шрифт
к новым условиям, подобным тем, что были сформулированы теперь.) Когда
я увидел образцы Роя, я решил добиться чего-нибудь вроде того, что хотел
осуществить в течение долгих лет, ожидая подходящего момента: а именно
найти установку таких параметров в Computer Modern, чтобы получить некий
«египетский» стиль (с квадратными засечками).
372
Компьютерная типография
На переплетах пятитомника Computers & Typesetting, тт. А-Е, на парах
букв Аа, Bb, Cc, Dd и Ее продемонстрирована трансформация стиля от
Computer Modern Roman до египетского. Я создавал оформление этих переплетов
исключительно ради собственного удовольствия и выполняя просьбу
Маршалла Хенрикса1, но у меня никогда не было достаточно времени
поэкспериментировать в таком ключе со всем шрифтом целиком. Теперь мне представился
прекрасный случай удовлетворить свою прихоть, и, посвятив послеполуденный
досуг сладостному экспериментаторству, я выявил комбинацию параметров,
приводящих к весьма приемлемому качеству, по крайней мере судя по тому,
что произвел наш лазерный принтер. (Увеличение шрифта и взгляд на него с
достаточно большого расстояния нивелировали эффект разрешения 300 точек
на дюйм.) Затем я более тщательно подготовил образец текста и распечатал
его на нашем станфордском фотонаборном автомате APS, чтобы убедиться,
что новый шрифт сможет выдержать экзамен. Некоторые буквы нуждались в
корректировке —например, буква 'w' оказалась слишком темной,— но я был
очень доволен результатом и Рой тоже.
Я решил назвать полученный шрифт Concrete Roman, потому что он
выглядел крепким^ и еще потому, что впервые использовался в книге Concrete
Mathematics. (Возможно вы до сих пор не заметили, но текст, который вы
читаете, набран именно шрифтом Concrete Roman?) В этой книге в
качестве выделительного шрифта используется Concrete Italic. Если нужен
ЕЩЕ ОДИН ВЫДЕЛИТЕЛЬНЫЙ ШРИФТ, ТО ИНОГДА ИСПОЛЬЗУЕТСЯ CONCRETE
Roman Caps и Small Caps font. Любой, имеющий METAFONT-исходники
шрифта Computer Modern, может элементарно получить шрифт Concrete,
подготовив файлы параметров типа ccrlO.mf по аналогии с cmrlO.mf; нужно
будет всего лишь изменить некоторые значения параметров как показано в
соответствующей таблице.
Вот образцы, набранные шрифтом Concrete Roman4 размерами 9 пунктов,
8 ПуНКТОВ, 7 ПУНКТОВ, 6 пунктов И 5 пунктов!
Mathematics books and journals do not look as beautiful as they used to. It is not
that their mathematical content is unsatisfactory, rather that the old and well-developed
traditions of typesetting have become too expensive. Fortunately, it now appears that
mathematics itself can be used to solve this problem.
Математические книги и журналы больше не выглядят так красиво, как это
соответствовало бы их предназначению. Это объясняется не тем, что их
содержание стало неудовлетворительного качества, а вызвано скорее тем, что соблюдение
прежних хорошо отработанных типографских традиций теперь слишком дорого
обходится. К счастью, выяснилось, что сама математика может решить эту проблему.
A first step in the solution is to devise a method for unambiguously specifying mathematical
manuscripts in such a way that they can easily be manipulated by machines. Such languages,
1 По-видимому, дизайнера внешнего оформления издания. —- Прим. ред.
2 Concrete (букв.) —- бетонный. —- Прим. перев.
3 Точнее, его модификацией с кириллическим расширением Cyrillic Concrete. Этот
шрифт имеется в свободном доступе в архивах CTAN и на диске l^gpC Live (версия 6).—
Прим. ред.
4 И его расширением Cyrillic Concrete. —- Прим. ред.
Глава 18. Набор книги Concrete Mathematics
373
when properly designed, can be learned quickly by authors and their typists; yet manuscripts
in this form will lead directly to high quality plates for the printer with little or no human
intervention.
Первым шагом на этом пути является создание метода строгого описания
математических рукописей таким образом, чтобы они легко обрабатывались машинами. Такой
аккуратно построенный язык может быть быстро освоен авторами и их машинистками; имея
рукопись, подготовленную таким образом, вы будете получать непосредственно с принтера
высококачественную распечатку. При этом вмешательства человека не требуется вовсе или
оно незначительно.
A second step in the solution makes use of classical mathematics to design the shapes of the letters
and symbols themselves. It is possible to give a rigorous definition of the exact shape of the letter 'a',
for example, in such a way that infinitely many styles — bold, extended, sans-serif, italic, etc. — are
obtained from a single definition by changing only a few parameters. When the same is done for the
other letters and symbols, we obtain a mathematical definition of type fonts, a definition that can be
used on all machines both now and in the future. The main significance of this approach is that new
symbols can readily be added in such a way that they are automatically consistent with the old ones.
Второй шаг в решении проблемы состоит в применении классической математики для
рисования самих букв и символов. Можно дать строгое определение формы буквы 'а', например,
таким образом, чтобы из этого одного определения путем изменения лишь нескольких параметров
можно было получать бесконечно много стилизаций ее начертания — полужирное, расширенное,
рубленое, наклонное и т. д. Сделав то же самое для других букв и символов, мы получим
математическое определение наборных шрифтов, которое можно будет использовать на всех машинах
как сейчас, так и в будущем. Основное преимущество этого подхода состоит в том, что легко
может быть добавлен любой новый символ, причем он автоматически будет соответствовать уже
существующим.
Of course it is necessary that the mathematically-defined letters be beautiful according to traditional notions
of aesthetics. Given a sequence of points in the plane, what is the most pleasing curve that connects them?
This question leads to interesting mathematics, and one solution based on a novel family of spline curves has
produced excellent [sic] fonts of type in the author's preliminary experiments.
Необходимо, разумеется, чтобы математически описанные буквы были красивы с точки зрения
общепринятых эстетических норм. Какая самая изящная кривая может соединить заданную
последовательность точек на плоскости? Этот вопрос приводит к интересной математической задаче и одно из ее решений
основывается на новом семействе сплайнов: эти кривые позволяют построить превосходные типографские
шрифты, с которыми автор предварительно экспериментировал.
We may conclude that a mathematical approach to the design of alphabets does not eliminate the artists who have been
doing the job for so many years; on the contrary, it gives them an exciting new medium to work with. [2, page 337]
Приходим к выводу, что математический подход к шрифтовому дизайну не исключает художников, которые
многие годы занимаются этим делом, а напротив, предоставляет им новый эффективный инструмент для работы.
[2, с. 377]
Таким образом утяжеленный шрифт больше подходил для
ксерокопирования и его было лучше различать в скудно освещенных библиотечных залах,
так что он мог решить ряд проблем удобочитаемости, с которыми все мы
хорошо знакомы. Но и слишком жирный шрифт может превратить чтение
книги в изнурительное занятие. Чтобы избежать этого, Рой решил
использовать интерлиньяж \baselineskip 13 пунктов при 10-пунктовом шрифте.
Это дает дополнительное преимущество для математических текстов,
поскольку предотвращает наложение строк, содержащих формулы вроде ']Г0к<п а£\
Обычно в математических изданиях используют интерлиньяж 12 пунктов, что
зачастую дает раздражающе плотные строки. Разумеется, такое увеличение
межстрочного интервала приводит соответственно и к увеличению количества
страниц примерно на 8%, но мне это кажется разумной платой за повышение
удобочитаемости.
Так ли уж было необходимо делать шрифт Concrete Roman менее тонким,
чтобы он сочетался с шрифтом AMS Euler? Чтобы читатель смог ответить
на этот вопрос самостоятельно, приведем небольшой пример использования
обычного cmrlO в качестве шрифта для текста:
374
Компьютерная типография
Таблица значений параметров для шрифтов Concrete
название
font identifier
serif-fit
cap serif-fit
xJieight
bar-height
tiny
fine
thin-join
hair
stem
curve
ess
flare
cap-hair
capstem
cap-curve
cap-ess
bracket
jut
cap-jut
vair
notch-cut
Ьаги т. п.*
cap-notch-cut
serif-drop
0
apex-0
beak-darkness
другие значения из
cmrlO
CMR
0
5
155
87
8
7
7
9
25
30
27
33
11
32
37
35
20
28
37
8
10
11
10
4
8
8
11/30
ccrlO
CCR
1
3
165
92
11
6
17
21
25
27
25
29
21
27
28
27
5
30
32
21
5/6
21
1
5
4
3
4/30
cmrlO
ccr9
CCR
1
2.8
148.5
78.3
10
6
17
20
24
26
24
26
20
26
27
24
5
27
29
20
3/4
20
.9
3.6
4
3
4/30
cmr9
ccr8
CCR
1
2.6
132
69.6
9
6
15
19
22
24
22
24
19
24
25
22
4
24
26
19
2/3
19
.8
3.2
3
3
4/30
cmr8
ccr7
CCR
1
2.4
115.5
60.9
8
6
13
17
20
21.5
20
23
17
21.5
22.5
21.5
4
21
23
17
7/12
17
.7
2.8
3
3
4/30
cmr7
*3начения для bar применимы также и для slab, cap-bar и cap-band.
Во всех шрифтах Concrete dish = 0, fudge = .95, superness = 8/11
и superpull = 1/15, только у шрифта ccslc9 fudge = 1. Параметры,
здесь не упомянутые, следует взять из соответствующих шрифтов cm,
Глава 18. Набор книги Concrete Mathematics
375
(В этой таблице используются соглашения, приведенные на ее. 12-31 книги [6].)
сегб
CCR
1
2.2
99
52.2
7
6
12
15
18
19
17
20
15
19
20
19
3
19
20
15
1/2
15
.6
2.4
3
3
4/30
сшгб
сегб
CCR
1
2
82.5
43.5
6
5
11
14
16
17
12
18
14
17
18
14
3
17
18
14
5/12
14
.5
2
3
2
4/30
сшгб
ccslc9
CCSLC
0
2
155
85
9
6
13
16
22
23
25
28
16
23
24
23
5
15
16
15
3/4
15
.9
3.6
4
3
5/30
cmsl9
cctilO
CCTI
1
3
165
92
11
6
17
21
24
26
24
28
21
26
27
26
5
30
32
21
5/6
21
1
5
4
3
4/30
cmtilO
ccmilO
CCMI
1
3
165
92
11
6
17
21
25
27
25
29
21
27
28
27
5
30
32
21
5/6
21
1
5
4
3
4/30
cmmilO
cccsclO
CCCSC
1
3
155
87
11
6
17
21
25
27
25
29
21
27
28
27
5
30
32
21
5/6
21
1
5
4
3
4/30
cmcsclO
меньшие
2
116
65
23
22
21
24
26
24
24
21
3/4
3
3
за исключением следующих: cccsclO имеет lower.fudge = .93; cctilO имеет
значение и} равное 20, а не 18.4, и значение crisp, равное 11, а не 8; ccmilO имеет
значение crisp, равное 0, а не 8, и его math-fitting соответствует false. В
шрифте ccsllO все так же, как и в ссгЮ, за исключением строки font Jdentifier и
того факта, что slant равен 1/6.
376
Компьютерная типография
The set S is, by definition, all points that can be written as ]Tkl d]c(i— 1 )k,
for an infinite sequence си, а.2, аз, ... of zeros and ones. Figure 1 shows
that S can be decomposed into 256 pieces congruent to y^S; notice that if
the diagram is rotated counterclockwise by 135°, we obtain two adjacent
sets congruent to (1/>/2)S, since (i — 1)S = S U (S + 1). [3, page 190]
А теперь повторим этот же пример, но с шрифтом Concrete Roman и
\baselineskip=13pt:
The set S is, by definition, all points that can be written as ]Tkl ajji— 1 )k,
for an infinite sequence си , а.2, аз, ... of zeros and ones. Figure 1 shows
that S can be decomposed into 256 pieces congruent to y^S; notice that if
the diagram is rotated counterclockwise by 135°, we obtain two adjacent
sets congruent to (l/V^S, since (i- 1)S = S U (S + 1). [3, page 190]
Цифры для нумерации формул представлялись Рою и мне одним из самых
запутанных вопросов дизайна. Должны ли эти цифры быть набраны
шрифтом Euler или их следует изобразить шрифтом Concrete? После ряда
экспериментов мы пришли к выводу, который теперь, при ретроспективном взгляде,
кажется единственно верным: мы решили нумеровать формулы в «старинном
стиле» из шрифта Concrete Roman, используя цифры '0123456789'-
Результат—например, '(3.14)' —оказался на удивление именно таким, какого мы и
ожидали.
После того как я многие месяцы применял AMS Euler и был вполне
удовлетворен видом получавшейся «правильной математикой», я приступил к работе
над главой книги, где часто встречались интегралы. Мне неожиданно
бросилось в глаза, что традиционные знаки интеграла плохо сочетаются с шрифтом
AMS Euler, потому что они имеют наклон подобно курсивным буквам1, тогда
как во всех остальных формульных буквах и знаках наклон был полностью
исключен. Поэтому я решил сделать новый знак интеграла —прямой, — чтобы
он соответствовал духу новых шрифтов. Теперь я мог набирать
[bfWdx__L| £(z)dz
JQ 27ttJ|z|=r zn
и J^° cosx2 dx, вместо прежних
Л*/ л Л 1 / 9(z)dz
/ f x dx - —- ф ^-!—
Ja 27tt.7|z|=r Z*
и J^q cos x2 dx. Новые знаки интеграла были включены в новый шрифт,
названный euexlO, который потом превратился в \f amlO для математического
1 В русскоязычной математической литературе традиционно используются прямые знаки
интеграла и отсутствие таковых в шрифтах Computer Modern часто вызывало недовольство
математиков старой отечественной школы. Теперь со шрифтами AMS Euler поводов для
огорчений нет. — Прим. ред.
Глава 18. Набор книги Concrete Mathematics
377
режима. Я велел TEJX'y брать интегралы из нового шрифта, указав
\mathchardef\intop=M1A52
\mathchardef\ointop="1A48
в моем файле макрокоманд. Позже я обратил внимание на то, что знак
бесконечности 'со' в Computer Modern слишком светлый и поэтому плохо
вписывается в шрифт Euler. Я слегка утяжелил знак 'со' и поместил его в шрифт
euexlO вместе с новыми знаками интеграла.
Все это время мне помогал Герман Цапф. Он, например, одобрил
первоначальный вариант гл. 1, исполненный в шрифтах Concrete Roman и AMS Euler,
тогда как я все еще продолжал отшлифовывать некоторые вещи. Позже,
получив экземпляр первого издания настоящей книги, он в первый раз увидел
гл. 2 и остальной текст. Тут ему пришлось сделать несколько улучшающих
замечаний, которые не могли возникнуть на материале одной первой главы.
Глава 2 посвящена суммированию, в ней я использовал знак суммы ^ из
шрифта cmexlO семейства Computer Modern и парный ему знак для выключ-
ных формул
для набора сотен математических выражений, содержащих суммирование.
Герман обратил внимание на то, что заглавная буква \Sigma из шрифта Euler
выглядит совершенно иначе —это 'I' без засечек, так что он предложил мне
соответствующим образом заменить и мои знаки суммы, чтобы они больше
походили на I из шрифта Euler. Я сделал это при второй допечатке тиража,
используя в формулах внутри текста знак Y. > а в выключных формулах —
к=0
Герман попросил также сделать знак произведения чуть шире, более похожим
на букву 'П' из шрифта Euler; поэтому я заменил
run ^ пи[]■
Кроме того, он предложил удлинить и сделать несколько более жирными
кончики стрел: '—*' вместо '—►', а фигурные скобки сделать более светлыми:
Г а\ Га
I b I lb
< > превратились в <
IdJ Id
Все эти новые знаки было нетрудно сделать, удовлетворяя при этом
соглашениям относительно шрифта Computer Modern [6], поэтому я добавил их в
шрифт euexlO и применил при второй допечатке тиража.
378
Компьютерная типография
Читатели книги Concrete Mathematics не могли не заметить одно
нововведение: на полях большинства страниц имеются «граффити». Мои соавторы
и я попросили студентов, выверявших черновики
предварительного варианта книги, оставить на полях неформальные , JS ^. УРе^се
с ' ^ * has worked out very
комментарии, которые можно было бы напечатать вместе с nicely for marginal
основным текстом, благодаря чему изложение напоминало graffiti, where it
бы дружескую беседу сверстников. Мы тогда еще не знали, is typeset ragged
каким образом будут набраны «отклики галерки», но мы right, 6 picas wide,
with 10 pt between
точно знали, что хотим их включить: таких откликов на- . .. у
baselines
бралось почти 500. Рой высказал идею разместить их на
внутреннем поле (у корешка), где они не так бы выделялись. Он также
прислал мне образчик неформального шрифта, на основе которого я
смоделировал начертание «Concrete Roman Slanted Condensed».
Для того чтобы набирать граффити, я ввел в свой форматный ТеХ'овский
файл макро \g, так что нужно было просто набрать: '\g Text of a graffito. \g}
на той строке текста, рядом с которой я хотел начать по- _
с ' Этот 9-пунктовыи
мещать маргиналии. Вручную приходилось только просле- шрифт был очень
живать те места, где маргиналии могли наложиться друг тщательно
на друга, но основную работу за меня выполняла макроко- разработан для
манда \g. Она, например, решала автоматически, на правом размещения на
j_ j_ полях граффити
или левом поле надо поместить граффити, используя допол- и ^^
u , „ 7 < с рваным правым
нительныи файл grf , в котором регистрировался выбор, краем шириной
который оказывался подходящим при предыдущем прогоне 6 пика и
ТцХ'а. 10-пунктовым
В моих макро для Concrete Mathematics TEJX'y давались интерлиньяжем.
указания генерировать не только обычные файлы dvi и log, соответствующие
вводу, но и только что упомянутый файл grf, равно как и четыре других:
■ ans-файл содержит текст всех ответов на упражнения, содержащихся в
только что набранном материале; эти ответы будут введены (\input) позже в
подходящий момент. (Аналогичная идея обсуждается в книге The T^jKbook
на с. 4931. Единственная разница состоит в том, что для книги Concrete
Mathematics я для каждой главы создавал свой файл, тогда как для набора
The TfiXbook использовался один длинный файл.)
■ inx-файл содержит строки для подготовки указателя. Когда вся книга
готова, я собираю все inx-файлы вместе, сортирую их, а результат редактирую
вручную. (См. ее. 494-496 книги The TjjjXbook, где описаны аналогичные
макро для указателя и объясняется, почему я не верю в возможность полностью
автоматической подготовки указателя.)
■ ref-файл содержит символические имена формул, таблиц и упражнений,
которые могут понадобиться для перекрестных ссылок, (ref-файл аналогичен
aux-файлу в ВДдХ'е.)
1 Страницы указаны по русскому изданию. — Прим. перев.
Глава 18. Набор книги Concrete Mathematics
379
■ bnx-файл, наконец, регистрирует номера страниц с ссылками на
литературу, так что я могу включить такую информацию как своего рода указатель
в список литературы. Этот указатель делается автоматически.
Мне бы не хотелось иметь дело с таким количеством дополнительных файлов,
если бы я работал с более простой книгой или системой более общего
назначения. Но именно для такой книги, как Concrete Mathematics, самым удобным
оказался этот многофайловый подход.
Мы с моими соавторами решили использовать нестандартную нумерацию
для таблиц, аналогичную принятой в некоторых регионах Америки для
нумерации сверхскоростных трасс. Например, ссылка на табл. 244 намекает вам,
что искать данную таблицу надо на с. 244. (Эта идея не нам первым пришла в
голову, но я не помню, кто именно ее предложил.) Создать удовлетворяющие
этому соглашению макро, обновляющие ссылки, когда меняется нумерация
страниц, было нетрудно.
Все эти макро, написанные специально для Concrete Mathematics, вошли
в файл gkpmac.tex, весьма скудно документированный (о чем я сожалею),
поскольку он предназначался для выполнения только одной работы.
Возможно, другим создателям макрокоманд захочется взглянуть на этот файл как
на источник идей, поэтому я сделал его общедоступным [8]. Но тем, кто
попробует применять эти макро, следует иметь ввиду, что я не претендовал
на нечто абсолютно полное и универсальное. Я, например, ввел (частично)
^ТвК'овское окружение picture и использовал его для подготовки всех
рисунков кроме одного. Но все, что способен делать I^TfeX, я вводить не стал. Кроме
того, я не пользовался полужирным шрифтом для математических
выражений в Concrete Mathematics (за исключением Q на с. 168 при второй допечатке
тиража) и поэтому не включил макрокоманды для доступа к полужирным
шрифтам AMS Euler в математическом режиме. В этом смысле книга не
может служить безукоризненным тестом, поскольку среди знаков Euler почти
половину составляют полужирные буквы, а они не были еще проверены. По
образу и подобию того, что установлено в gkpmac, нетрудно добавить
макрокоманды для полужирной математики, но я вынужден предоставить решение
этого вопроса другим и вернуться к своему затянувшемуся проекту: написанию
остальных томов The Art of Computer Programming.
Литература
[1] Ronald L. Graham, Donald E. Knuth, and Oren Patashnik, Concrete
Mathematics (Reading, Massachusetts: Addison—Wesley, 1989). [Имеется русский
перевод второго издания: Грэхем Р., Кнут Д., Паташник О. Конкретная
математика. — М.: Мир, 1998, 1999.] [Хотя в копирайте указан 1989 г., я
получил авторский экземпляр первого тиража 29 августа 1988 г. и
пользовался им в своей работе в октябре-декабре 1988 г. Второй тираж
датирован январем 1989 г. В январе 1994 г. вышло второе издание, в котором
сам текст книги подвергся существенной переработке, а полиграфическое
380
Компьютерная типография
исполнение изменилось лишь незначительно: несколько шире стали знаки
шрифта A MS Euler для подстрочных и надстрочных индексов.]
[2] Donald E. Knuth, "Mathematical typography," Bulletin of the American
Mathematical Society (new series) 1 (1979), 337-372. [Представлено с
исправлениями в данном издании как гл. 2.]
[3] Donald E. Knuth, Seminumerical Algorithms, Volume 2 of The Art of
Computer Programming, second edition (Reading, Massachusetts: Addison—
Wesley, 1981).[Имеется русский перевод первого издания: Кнут Д.
Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы.—М.:
Мир, 1977; второго издания: Кнут Д. Е. Искусство программирования.
Т. 2. Получисленные алгоритмы. — Киев: Диалектика, 1999]
[4] Donald E. Knuth, The TfiXbook, Volume A of Computers & Typesetting
(Reading, Massachusetts: Addison—Wesley and American Mathematical
Society, 1984). [Имеется русский перевод: Кнут Д. Е. Все про T^X.—
Протвино: АО RDTEJX, 1993.]
[5] Donald E. Knuth, The METRFONTbook, Volume С of Computers &
Typesetting (Reading, Massachusetts: Addison—Wesley and American
Mathematical Society, 1986).
[6] Donald E. Knuth, Computer Modern Typefaces, Volume E of Computers &
Typesetting (Reading, Massachusetts: Addison—Wesley, 1986).
[7] Donald E. Knuth and Hermann Zapf, "AMS Euler —A new typeface for
mathematics," Scholarly Publishing 20 (1989), 131-157. [Представлено в
данном издании как гл. 17.]
[8] Donald E. Knuth, gkpmac.tex, доступно по anonymous ftp в
labrea.stanford.edu в директории pub/ concretemath. errata/
(последнее обновление в 1996 г.). Также доступно в Comprehensive ТЕХ
Archive Network (CTAN) в директории systems/knuth/local/lib/.
[9] David R. Siegel, The Euler Project at Stanford (Stanford, California:
Computer Science Department, Stanford University, 1985).
Добавление
Шрифты Concrete Roman и AMS Euler теперь используются вместе для
набора многих научно-технических изданий. Первой после Concrete Mathematics
была, вероятно, книга: Kai Borre Mindste Kvadraters Princip (Aalborg: Borre,
1992), ISJ3N 87-984210-1-8. В частности, при переводе Concrete Mathematics на
французский, венгерский, итальянский и польский языки были, в сущности,
использованы те же соглашения, что и в оригинальном издании. В переводе
на русский язык книга «Конкретная математика» набрана шрифтом Concrete
Cyrillic, разработанным на основе Concrete Roman Ольгой Лапко и Андреем
Ходулёвым.
Из опыта преподавания
программирования
HaMETflFONT'e
[Первоначально опубликовано в TUGboat 5 (1984), 105-118.]
Весной 1984 г. около полусотни доблестных студентов составили в Станфорд-
ском университете не совсем обычную учебную группу, где занятия вели два
бравых профессора и еще один профессор — безрассудный. Эти лекции были
посвящены разработке шрифтов вообще и использованию новой версии
системы METAFONT в частности. Так получилось, что читаемый курс был в
значительной степени импровизированным, поскольку METflFONT, создававшийся в
течение достаточно долгого времени, только тогда начинал приобретать черты
завершенности. И все же, справедливым было бы утверждать, что
упомянутые лекции соотносились между собой весьма хорошо и этот эксперимент себя
вполне оправдал.
Большей частью своим успехом курс лекций был обязан тем самым двум
бравым профессорам, о которых я упоминал выше, —это были Ричард Сау-
толл и Чарльз Бигелоу, прочитавшие выдающиеся лекции, время от времени
перемежавшиеся лекциями, представленными мною. Лекции Саутолла были
посвящены теме «Проектирование шрифтовых семейств», которая включала в
себя такие пять разделов:
(1) Определения. В чем разница между шрифтами и шрифтовыми
семействами (гарнитурами), между проектированием шрифтов и
каллиграфией?
(2) Критерий качества. Как вынести объективное решение, насколько
удачными являются текстовые шрифты?
(3) Аспекты задачи. Что должны сделать разработчики шрифта?
(4) Методология. Что можно почерпнуть из традиционных знаний и
практики применительно к решению задачи разработки шрифтов?
(5) «Идеальные» проекты. Может ли кто-нибудь сказать, какими именно
должны быть начертания литер?
Бигелоу рассказывал об истории начертаний букв от античности до наших
дней. Очень поучительно было наблюдать, как менялась форма литер с
изменением технологии. Первоначально на проектирование алфавита наклады-
382
Компьютерная типография
вал отпечаток способ письма, принятый в античные времена — перемещение
пишущего элемента (пера, например) вдоль некоторой линии. Затем
появилось книгопечатание и определяющим стал процесс гравирования или
отливки букв. И наконец в наши дни чаще всего формы литер трактуются как
образы растрового типа, получаемые и используемые цифровым путем.
Была показана и критически проанализирована работа мастеров (художников-
шрифтовиков) всех эпох, после чего Бигелоу подвел итог процесса
эволюции шрифтов обсуждением современного состояния дел в области
создания коммерческих семейств шрифтов, в том числе шрифтов, используемых
для вывода информации на экраны электронно-лучевых трубок. Все лекции,
как С ау тол л а, так и Бигелоу, сопровождались обилием примеров,
представлявших собой в большинстве случаев уникальные слайды из частных
коллекций.
Моя задача состояла в том, чтобы увязать все это с новым METAFONT'om.
Мне определенно повезло, так как новые фрагменты языка заработали
буквально за пару дней до того, как эту тему надо было излагать на занятиях.
В моем распоряжении был один день, чтобы получить хоть какой-то опыт
программирования с помощью упомянутых средств и чтобы самому
научиться писать с их помощью хорошие программы, прежде чем пытаться учить
этому кого-либо еще. Лекции касались следующих вопросов: (1)
координаты, (2) кривые, (3) уравнения, (4) оцифровка, (5) перья, (б) преобразования и
(7) синтаксис METflFONT'a.
Студенты получили в качестве домашних работ различные поучительные
задачи. Во-первых, им было поручено сделать два задания с трафаретами,
чтобы показать существенную разницу между тем «что мы видим» и тем,
«что есть на самом деле». Затем настала очередь третьей домашней работы,
которая была первым компьютерным заданием. Оно состояло в том, чтобы
с помощью METflFONT'a изобразить El Palo Alto (высокое дерево) — символ
Станфорда; каждый студент сделал по две ветви дерева, поскольку выполнить
все двенадцать было бы слишком трудоемко, я объединил потом предложенные
ими решения и в итоге получились следующие результаты:
Все эти деревья получились разными, хотя многие из отдельных ветвей
использованы в нескольких деревьях. Цель данного упражнения состояла в том,
чтобы помочь студентам освоиться с идеями координат и простых кривых в
такой же степени, в какой они знакомы с компьютером и текстовым редактором
для него. Очертания дерева оказались очень подходящим объектом в силу его
Глава 19. Из опыта преподавания программирования на METRFONT'e 383
нетребовательности (огрехи на нем были не так заметны, как на регулярном
объекте).
Задача для четвертой домашней работы была намного интереснее, мы
назвали ее «Font 1» («Шрифт 1»). Совместными усилиями группа должна была
разработать новый шрифт без засечек, напоминающий написанный рукой.
Поскольку число слушателей, успешно завершивших третью домашнюю работу,
было достаточным, мы организовали выполнение задания так, чтобы
каждому участнику досталась разработка пары букв — прописной («большой»)
и строчной («маленькой»). В качестве примеров, которые должны были
помочь выдержать требуемый стиль, я дал прописную букву 'U' и строчную Т.
Все равно, конечно, у каждого из студентов проявились особенности их
индивидуального стиля, что и отразилось на полученных результатах — шрифт
в итоге вышел не совсем «однородным». Этот факт был сам по себе
поучительным.
Я подготовил два METRFONT'obckhx макро, позволяющих рисовать
штрихи и дуги так, как если бы применялось перо. От студентов требовалось
выполнить всю необходимую работу с использованием этих двух подпрограмм.
Это было существенным ограничением, но помогало за счет такого сужения
возможностей сфокусировать внимание. Выполняя данное задание, студенты
заодно осваивали и концепции метапроектирования, поскольку
разрабатываемые ими программы должны были содержать параметры настройки,
позволяющие порождать три различных шрифта: нормальный, полужирный и
полужирный расширенный. Это давало возможность каждому
обучающемуся ощутить алгебраические возможности METAFONT'a, где компьютер играет
критически важную роль в процессе разработки.
Лучший способ показать, что получилось при выполнении четвертой
домашней работы — продемонстрировать ее результат, т. е. созданный студентами
шрифт, который представлен на следующей странице1.
Как я уже сказал, мы не ожидали, что шрифт Font 1 будет обладать какой-
либо однородностью, т. е. единством стиля, но я с удовлетворением обнаружил,
что многие из индивидуальных символов вышли по-настоящему красивыми,
даже когда параметры принимали значения, которые студенты не пробовали.
Задача для пятой и завершающей домашней работы была еще более
интересной. Каждый должен был разработать совокупность из восьми знаков,
которые можно было бы использовать для формирования рамок. Эти знаки
именовались NW, NM, NE, ME, SE, SM, SW и MW по часовой стрелке, начиная с
левого верхнего угла; здесь 'N' означает North («север»), 'Е' — East («восток»),
'S' —South («юг»), 'W —West («запад») и 'М' —Middle («середина»). Высота
каждого символа определялась первой компонентой его имени, а ширина —
второй. Например, NW и NM должны иметь одну и ту же высоту, SE и ME —
одну и ту же ширину. Следовательно, четыре знака, содержащие букву М в их
1 Текст этого задания также представлял интерес. См. перевод в конце главы. —
Прим. ред.
384
Компьютерная типография
In every period there have been better or worse types
employed in better or worse ways.
The better types employed in better ways
have been used by the educated printer
acquainted with standards and history,
directed by taste and a sense of the fitness of things,
and facing the industrial conditions of his time.
Such men have made of printing an art.
The poorer types and methods have been employed
by printers ignorant of standards
and caring alone for commercial success.
To these, printing has been simply a trade.
The typography of a nation has been good or bad,
as one or other of these classes had the supremacy.
And today any intelligent printer can educate his taste,
so to choose types for his work and so to use themp
that he will help printing to be an art rather than a trade.
There is not, as the sentimentalist would have us think,
a specially devilish spirit now abroad
that prevents good work from being done.
The old times were not so very good,
nor was human nature then so different,
nor is the modern spirit particularly devilish.
But it was, and is, hard to hold to a principle.
The principles of the men of those times
seem simple and glorious.
We do not dare to believe that we, too,
can go and do likewise.
DANIEL BERKELEY UPDIKE
именах, могли быть использованы как повторяемые модули расширения,
позволяющие получить произвольно большие прямоугольники вместе с четырьмя
угловыми знаками. Кроме этих мягких ограничений на высоту и ширину,
никаких других базовых правил не было, поэтому студентам предоставлялась
свобода творчества на поприще получения с помощью METflFONT'a «великих
произведения».
Мне было особенно интересно и приятно просматривать результаты
выполнения этого задания, которые произвели на меня большое впечатление своей
оригинальностью, в том числе и потому, что я убедился, что новая версия
METflFONT'a работает, причем даже лучше, чем я смел надеяться. Все еще
оставался открытым вопрос о том, насколько METflFONT будет
соответствовать своей роли средства создания шрифтовых форм, но то, что это супер-
Глава 19. Из опыта преподавания программирования на METRFONT'e 385
ABCDEFGHIJKKLM
NOPQRSTTUVWXYZ
abcdefghijklm
nopqrstuvwxyz
This font of type, the first
to be produced by the new
METAFONT system, was
designed by Neenie Billawala,
Jean-Luc Bonnetain,
Jim Bratnober,
Malcolm Brown,
William Burley, Renata Byl,
Pavel Curtis, Bruce Fleischer,
Kanchi Gopinath,
John Hershberger,
Dikran Karagueuzian,
Don Knuth, Ann Lasko-Harvill,
Bruce Leban, Dan Mills,
Arnie Olds, Stan Osborne,
Kwang-Chun Park, Tuan Pham,
Theresa-Marie Rhyne,
Lynn Ruggles, Arthur Samuel,
New Wave Dave,
Alan Spragens, Nori Tokusue,
Joey Tuttle, and Ed Williams.
386
Компьютерная типография
средство для рисования рамок, было уже совершенно ясно! Вот результаты
описываемого эксперимента:
l#t<g*^«c^»<i>g»cso«Cfro«c^*»o<>^
Ed Williams
ъжжкжжкжжкжжжжжжжч
gMETAFONTS
ъжжкжжжжжъжкж^жжк
Neenie Billawala
METflFONT
Jean-Luc Bonnetain
METflFONT
Jim Bratnober
Ш1§р1Щр]Шр11Щр|[ЩрШр[ЩрШр]11
■ METflFONT ■
[щЦ Гщ)
William Burlev
Глава 19. Из опыта преподавания программирования на METRFONT'e 387
I I I I I I I II I I I I I I I II I I
METRFONT
I I I I I I I I I I II В I 1 111 111
Renata Byl
METRFONT
♦ 4> - *ф ♦
4?^4х,Г//47*<
Pavel Curtis
METRFONT
Bruce Fleischer
METRFONT
Kanchi Gopinath
METRFONT
John Hershberger
METRFONT
Dikran Karagueuzian
388
Компьютерная типография
METflFONT
METflFONTl
Don Knuth
Ann Lasko-Harvill
METflFONT
Bruce Leban
••••••«•••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••a
• • ••
. •••
•••t
METflFONT
t:
::::
::::
.... ■ ж ■ ^_ i ■ ■ ■ ^ - ■ ■* ■ ?:::
Dan Mills
«METflFONT?
Arnie Olds
09999999999999999D
gMETAFONTS
<C76666666666666666C>
Stan Osborne
££dkdk dkdfe dbdh dkdh dhdh dbdh dhdk dhdh dkdk dbdbdtifc
iillll [ЗШ [ШШ ШШ ШШ ШШ BB ©Ш! [ШШ [lliii
ЦЦ
METflFONT
IJJJIUJ W W W^BMV W W WW -^H^^ WWW lUJIUj
dkdbdbdh dhdb dkdh dhdh dkdh dkdh dkdk dkdh dkdk dkdkdkdb
liiiiiiiiiiiiiiiiiiiiill
Kwang-Chun Park
). Из опыта преподавания программирования на METRFONT'e 389
a txj ocj bjxj \£tft ^эс^ txj ^.эс^ ^bcjn
*J
METflFONT
£
с
О ^с^ f5T* f3T* ^эс^ f>?b S5£b f5?b fy?bG
Tuan Pham
Lynn Ruggles
Arthur Samuel
|/\/\/\/\/\/\/\A/\/\/\/\/\/\/\A/\/\/\/\A/
METRFONT
New Wave Dave Siegel
Alan Spragens
тштшттшшжшттт'ш.:
Nori Tokusue
390
Компьютерная типография
Стоит сделать ряд замечаний относительно нашего опыта, касающегося
«высокотехнологичных» групп, типа описываемой здесь. Ни один из
компьютеров, обеспечивающих учебный процесс в Станфорде, не имел тогда выхода
на дисплеи с высокой разрешающей способностью, обеспечивающие работу в
графическом режиме. Чтобы заполнить эту пустоту, нам пришлось заказать
рабочие станции SUN. Когда машины наконец-то были получены — за неделю
до планируемого начала занятий в группе, — оказалось, что они новой модели,
для которой надо было написать новое программное обеспечение, чтобы
встроить эти машины в вычислительную сеть нашего университета и соединить их
с различными периферийными устройствами. Фирма-разработчик в ответ на
нашу просьбу предоставить исходные тексты ее программного обеспечения,
необходимые для решения проблемы, заартачилась. Мы обнаружили, что все
равно не сможем использовать их версию операционной системы (ОС) UNIX,
поскольку она привязывает каждый файл на нашем главном диске к
конкретной рабочей станции, что вынуждало бы студентов вводить пароль при каждом
обращении к главному диску! Более того, их компилятор для языка Pascal не
мог работать с программами таких размеров, которые были у METAFONT'a.
Мы решили использовать ОС своей разработки, которая называлась V-
системой (V-System) или V-ядром (V-Kernel) и была разработана
профессорами Дэвидом Черитоном и Киттом Лантцем и их студентами. К счастью,
один из этих студентов, Пер Ботнер, был участником ТЁХ'овского проекта и
написал к тому же свой собственный компилятор для Паскаля. К сожалению,
однако, мы не могли использовать ОС V-System без присоединения всех наших
рабочих станций SUN к более мощной машине, наподобие VAX, а у нас такого
компьютера не было. Дело еще более усугублялось тем, что здание, в котором
мы предполагали разместить наши рабочие станции SUN, ремонтировалось;
первоначально планировалось, что мы въедем туда еще в январе, однако
месяц за месяцем возникала то одна проблема, то другая, все это замедляло ход
работ и к концу марта стало ясно, что мы сможем разместить свою технику
на положенных ей местах самое раннее в мае!
И опять нас выручил профессор Черитон, который также планировал
переоснастить графическими рабочими станциями свою учебную лабораторию,
расположенную в другом здании. Поскольку компьютеры для его
лаборатории еще не были получены, мы поставили там свою технику с тем, что часть
времени будем использовать ее мы, а оставшуюся часть — лаборатория проф.
Черитона. Более того, в этой лаборатории был и новый компьютер VAX,
находившийся в соседнем помещении.
События тогда развивались так. 24 марта я кончил писать программы для
подмножества METRFONT'a, которого, на мой взгляд, было достаточно для
проведения запланированных занятий, но отладку этого подмножества еще не
начинал. Первого апреля я получил первый успешный вывод результатов при
решении небольшой тестовой задачи. Тогда же METflFONT впервые
правильно отобразил проектируемую литеру на экране дисплея. (Все это делалось на
Зб-битовой машине SAIL, на которой я выполнял все работы по ТЁХ'у и МЕТЯ-
Глава 19. Из опыта преподавания программирования на METRFONT'e 391
FONT'y-) На следующий день, 2 апреля, я узнал о возможности воспользоваться
лабораторией Черитона для проведения наших занятий; помещение было еще
без мебели, компьютеров, кондиционеров, но решением этой проблемы
занялись Дэвид Фукс вместе с другими сотрудниками. 3 апреля Перу Ботнеру
удалось успешно перенести METflFONT с машины SAIL на рабочую станцию
SUN, используя ОС V-System. A 4 апреля был уже первый день занятий в
нашей группе.
В ОС V-Kernel до того момента работали только хакеры, так что
подходящего руководства по ее использованию для новичков не было, более того,
никто из нас, кроме Пера, не знал, как этой системой пользоваться. На
помощь пришел Артур Сэмюэль и начал составлять краткое руководство по
системе V-Kernel. Тем временем мы провели специальное совещание с
техническим персоналом Станфордской телевизионной сети, поскольку у нас не было
другого подходящего способа показывать работу METflFONT'a в лекционной
аудитории, кроме как ретранслировать туда «картинку» с экрана монитора
с помощью телевизионных средств, б апреля я начал писать весьма длинную
программу GFtoDVI, которая необходима для получения пробных распечаток
результатов работы METfl FONT'a. Я знал, что для завершения этой программы
мне потребуется не менее двух недель. Линн Раглес в то же время
разрабатывал другую утилиту, GFtoQMS, которая генерировала шрифты, пригодные для
нового лазерного принтера, только что нами полученного; Линн добился уже
определенных успехов в своей работе. (Однако этот принтер все еще не был
установлен.)
Бигелоу и Саутолл хорошо знали, что будет чудом, если все компьютеры
окажутся на своих местах к требуемому времени. Поэтому они приготовились
«импровизировать» до тех пор, пока я не буду готов. Я читал свою первую
лекцию в пятницу, 13 апреля, и в этот же день Линну удалось получить на
нашем лазерном принтере QMS первую распечатку символа, подготовленного
METflFONT'om. Первые домашние работы студентов, как это уже отмечалось
выше, не требовали использования компьютера, так что вышло вполне
естественно, что задания для работы с компьютером не выдавались до 27 апреля.
В мае переживаний у нас тоже хватало: компьютеры часто отказывали
из-за неудовлетворительной работы кондиционеров, несколько недель
потребовалось на их установку и отладку, в избытке было и проблем с программным
обеспечением, особенно с новой версией METfl FONT'a, все еще находившегося
в работе. Однако студенты все хорошо понимали и с терпением относились к
поистине нетерпимым условиям. Я вознаградил их отменой планировавшейся
шестой домашней работы. Мои ассистенты Дэн Миллс и Дэйв Зигель
исполнили свои обязанности безупречно и сделали все, чтобы занятия шли настолько
гладко, насколько это было вообще возможно в течение этих девяти недель.
Наконец наш курс дошел до славного финиша, который мы отметили
вылазкой в Сан-Франциско. Мы устроили пикник на Бульваре Шрифтов
(Font Boulevard), затем посетили прелестную словолитню МакКензи—Харри-
са (MacKenzie—Harris) и дизайнерскую студию Бигелоу и Холмса (Bigelow &
Holmes). Лучше всего идею празднования этого памятного дня можно выра-
392
Компьютерная типография
зить такой картиной «курсивного» шрифта, который мы все вместе изобразили
сразу после ланча:
Фото Джил Кнут
Второй ряд (слева направо): Пер Ботнер, Брюс Фляйшер, Джон Хобби, Рейчел Хью-
сон, Дон Кнут, Нини Биллавала Арни Олдс, Элан Спрэдженс, Брюс Либан, Джо
Таттл, Стен Осборн, Дейв Зигель, Дэвид Фукс, Первый ряд: Джон Хершбергер, Жак
Дезарменьен, Дикран Карагезян, Нори Токусу, Малкольм Браун, Канчи Гопинат,
Павел Кертис, Жан-Люк Бонтен, Рената Бил, Куань-Чун Парк, Ричард Саутолл,
Майкл Вайзенберг.
Примечание переводчика
Перевод текста со с. 384.
Шрифты во все времена бывали как лучшего так и худшего качества, равно
как и способы их использования. Лучшие шрифты и лучшие способы выбирал для
себя образованный печатник, который придерживался стандартов и традиций,
руководствовался вкусом и чувством меры, учитывая при этом технические достижения
своего времени. Такой человек превращал печатное дело в искусство.
Примитивные шрифты и способы привлекали печатников, игнорирующих
стандарты и обеспокоенных исключительно коммерческой выгодой. Эти превращали
печатное дело в простое ремесло
Национальная полиграфия бывала хорошей или плохой в зависимости от того,
какая из описанных категорий специалистов брала верх. И в наши дни любой
мыслящий печатник может развить свой вкус, так выбрать шрифты и так научиться ими
пользоваться, что в его руках печатное дело станет искусством, а не ремеслом.
Это не означает, как мог бы подумать человек сентиментальный, что некий
демонический дух теперь витает повсюду и препятствует тому, чтобы работа выполнялась
хорошо. Прежние времена не были так уж хороши, человеческая природа с тех пор
мало изменилась, да и современность не стоит особенно демонизировать. Но всегда
было и остается упорство в следовании принципам. Принципы человека тех времен
кажутся простыми и овеянными славой. И нам не верится, что мы тоже способны на
нечто подобное.
Дэниел Беркли Апдайк
Меташрифт Punk
[Первоначально опубликовано в TUGboat 9 (1988), 152-168.]
В феврале 1985 г. Герард и Мариан Унгер в течение девяти вечеров прочитали
в Станфорде цикл лекций, где давался обзор эволюции стилей в искусстве,
архитектуре, одежде, проектировании промышленных образцов и издательском
деле на протяжении последних 75 лет. Эти лекции были особенно интересны
тем, что в них изменения в полиграфическом оформлении увязывались с
аналогичными и современными им веяниями в других областях. Унгерами был
показан такой замечательный факт: издательское дело в части стилей отстает
от изменений в других областях примерно на десять лет.
Когда я проснулся утром в день их последней лекции, то внезапно осознал,
что имеется очевидное следствие из того, что было рассказано в предыдущие
восемь вечеров. Как раз подошло время разработать шрифтовую
гарнитуру, отражающую идеи, возникшие в конце 70-х годов! Более того, мне стало
совершенно ясно, на каких принципах могло бы быть основано
проектирование такого шрифта, поскольку лекторы указали на значительное сходство
между «панковской» графикой, показанной в Лондоне, и некоторыми
кружевными узорами из линий и точек на обивке «панковской» мебели из
Италии.
«Линейно-точечные кружева» для реализации их с помощью METflFONT'a
тривиально просты, поэтому я решил сделать новое семейство «сверхмодных»
шрифтов, названное NlJlC. Во второй половине дня я провел несколько
приятных часов за компьютерным терминалом и к вечеру, к моменту начала лекции,
подготовил подарок-сувенир собравшимся — фрагмент лекций Унгеров,
отпечатанный на лазерном принтере шрифтами N(llCJ6 и N(llC26.
Идея шрифтовой гарнитуры PlJ(ll( состояла в том, чтобы взять в качестве
начального приближения более или менее традиционные по форме буквы, но
дать задание METflFONT'y сместить ключевые точки букв на случайно
заданные расстояния, с тем чтобы внести в буквы элементы «хаотичности». Для
примера ниже приведен ряд текстовых фрагментов, набранных с
использованием нескольких разновидностей шрифтов PlJ(ll(:
394
Компьютерная типография
— * ()[]t*t/(«>
PUNK10
пНим**н!г said Amis. His facs was rsd aud не was csutaimu
FLUSTe&SD. *h *D be A DSAD LUCtfY THIMG IF SOMS MORS **0*l.*
AUOUtfD ?HS SHOf SD сНАМв* A UTTU. Th^V COULD HsT Ы* AHV
fUtifCeR Jtf THSY A&S H0W.r [1]
AbePEFQHUKlMNfif^STUVWAYl AbcDH^HUKLMworoRsTU
PUNK12
A fORKHD VHIW bHGAM TO 3WHLL 1 tf SfADH^S fORHHHAD. ...
Hl3 VOIcH ЬНсАМН THR31JA3IVH ASA1M. 4l3THtf, QbTMAM,
We've AbSOLbTHLY SOT TO GJVH THHM A VIcTlM. ThhRh's
WO WAY OlJT Of IT. UT*3 G1VH THHM THH fliMrC/ Hh
MODDHD fLHASAWTLY AT THH bOY IM THH DOORWAY. [2]
ABCPEf6flIJKLMH№0KSTnVWin hqw
sHUKLMNof QUSTurwxYi 612S4S<578? Щ
tisroi. Usii>e.] This punk is оке
of Cupid's сАДД1едз. Cup on моде
SAILS, Pursue; up WITH YOtffc **ISHTS;
Sire яде! 5не is my ш*«, од оселк
WHeiM тнем allI [fan.] и
PUNK20
it cpeFsmmvw&RsTiimf? Abater
euijKi uneruRsrwvxfz ШШИЯ 4U§
Глава 20. Меташрифт Punk 395
..r.w!""'*tm»-*onw/<*>_
tunic ябак is те шшс геям гбя
те urezr musical $Аяьл$е ьяер вг
оия тябиые» ctnrtwe, faiTisu акр
ЬмеяЮАЫ. ...
Johnny Rottsn and тне Sex Pistols
АДе PUNKS. TtfSY SINS ^AnAUCHY IN
THS UK/ WHICH SNDS WITH A SCfcfiAM:
5PesTUoY.r Clash and Pamn^d aus
OTHSfc bANPS.
fiWK virtu *ар*. Its
AfOUOQtSTS ARft UUptOROUS.
TWSRS ARft WAYS TO fROTSST
AfcOUT TWS fUTRtp l«ACft8 Of*
fcOTW fof AMP 80Gt*TY WITHOUT
RSUAfSWQ WTO bARbARlSM. fUNK
tS AtfTl*U*% ANTt-HUMAHlTY. и
A^CDeF6HUKUN0rqRSTUVVXYZ
AbOpn^QHUKUMWof^RSTUVVirXYZ
61234S4789 ШГАбД-ПЕТИф
- #w — _ - PUNKBX20
396
Компьютерная типография
В то время, когда я «спроектировал» эти шрифты, я как раз начал работу
над окончательной версией семейства шрифтов Computer Modern на основе
приведения версии Almost Computer Modern в соответствие с соглашениями,
принятыми в METRFONT84. В тот момент отлаживались буквы 'А', 'В', 'С и
'D', скоро я планировал заняться буквой 'Е', но чувствовал, что надо устроить
себе передышку. И я сделал наброски некоторых «панковских» форм, вроде
этих:
Я использовал большой лист бумаги для графиков («миллиметровку»);
приведенные иллюстрации уменьшены до 25% от их первоначального размера.
Честно говоря, я не знал, что с этими набросками делать дальше, для чего они
могут пригодиться.
В час дня я включил компьютер и стал составлять простой базовый файл.
Сделать надо было не так уж и много, поскольку plain МЕТА FONT уже имел в
своем составе большинство основных программ, так что через двадцать минут
я уже получил первую пробную распечатку, которая выглядела так:
METRFONT output 1985.02.28:1320 Page 1 Character 65
(40% исходного размера)
Глава 20. Меташрифт Punk
397
Похоже, что букву 'А' можно было считать разработанной, и я перешел к
подготовке METAFONT'obckhx программ для остальных букв, от 'IT до 1У. Я решил
сначала ввести все эти программы, а уже потом делать пробные распечатки:
я просто перевел подготовленные эскизы букв в METRFONT'oBCKne
конструкции, выполняя всю работу сразу с клавиатуры, без промежуточной записи на
бумаге. Производить точные измерения необходимости не было, поскольку все
равно координаты узловых точек букв потом подвергались воздействию
случайных возмущений. Таким путем я быстро получил набор соглашений для
создаваемого шрифта и дальше темп его разработки ограничивался только
моей скоростью ввода символов с клавиатуры. Эскизы букв от 'V до 1Т мне
даже и не понадобились, так как алгебраические формулировки для них
представить было довольно просто после того, как я проделал аналогичную работу
для предшествовавшей 21 буквы. В 3 ч 04 мин ввод был завершен и я смог
запустить METAFONT и получить пробные распечатки всех 26 букв в
заглавном (прописном) варианте. Сделал я также и новые знаки препинания (точку,
запятую, открывающую и закрывающую одинарную и двойную кавычки).
Разумеется, во введенном программном коде встречались и ошибки.
Например, первые несколько букв в начальной распечатке выглядели так:
МЕТЯ FONT output 1985.02.28:1504
if У „ "., \; . М--., w„
Ш
%?
Г
Щ0
(А первый вариант буквы 'G' я даже и не рискую вам показывать.) Но к 4
часам дня я уже был готов отпечатать первый пробный текстовый фрагмент:
398
Компьютерная типография
В этот момент возникло неожиданное «осложнение», несколько
замедлившее работу. Буквы этого шрифта имели необычные значения некоторых
характеристик, не возникавшие до сих пор в GF-файлах. Из-за этого программа
перевода METflFONT'oBCKoro кода в формат нашего лазерного принтера
выдала ошибку, когда я попытался сделать тестовую распечатку шрифтом кегля
40 pt. Я сделал копии файлов, вызвавших возникновение данной ситуации,
чтобы разобраться с ними позднее, а пока просто обошел эту ошибку выбором
другого стартового значения для случайной последовательности и повторной
генерации шрифта. Потратив еще примерно полчаса на подгонку разных
параметров шрифта (и снизив степень случайного разброса), я мог пойти домой
пообедать.
Во время обеда мне пришла мысль, что в памятном сувенире для этого
вечера надо бы отпечатать и дату его проведения. Поэтому я побыстрее
закончил обед, набросал эскизы для набора цифр и побежал опять в свой кабинет.
Скоро у меня уже был готов шрифт из 43 литер —26
букв, 10 цифр и 7 знаков препинания. Прекрасно! К
семи часам вечера я успел сделать по листку-сувениру для
всех присутствующих, раскалив при этом добела нашу
копировальную машину.
Примерно через год я попал в Бостонский музей
изящных искусств и наткнулся там на рисунок,
сделанный Пикассо в 1924 г. [5] (см. иллюстрацию справа). Я с
изумлением обнаружил, что идея, положенная в основу
шрифтов Fb|Jl(, вовсе не десятилетней давности, а
шестидесятилетней. Еще одно замечательное подтверждение жизненности по
крайней мере части проекта РУН К я получил в октябре 1986 г., когда увидел в
Paris Metro(!) рекламное объявление в таком вот типографском исполнении:
~V>>.4 -.-vy^-. <*>\
M-TGfZ 51-A
л <v«» ^**»^
В феврале 1987 г. я решил довести первоначальный 43-символьный набор
до полного ТеХ'овского комплекта символов. Дополнительная работа по
программированию недостающих символов не заняла много времени, поскольку
строчные символы я формировал как «малую капитель», так что для ввода в
компьютер необходимых инструкций по каждому из символов нужно было
всего одну-две минуты. Около трети из вновь введенных символов пришлось
подправить, после того, как я увидел, что получается на пробных распечатках —
некоторые из них оказались слишком «панковскими», а некоторые наоборот —
недостаточно «панковскими». Треть исправленных в первой итерации
символов пришлось править опять и так несколько раз. И вот примерно после шести
часов дополнительной работы 128-символьный меташрифт РЬ|||( можно было
считать завершенным, его уже можно было использовать, если бы у кого-то
возникла такая потребность.
Глава 20. Меташрифт Punk
399
В оставшейся части данной работы я даю подробную информацию по
METflFONT'oBCKOMy коду гарнитуры Pb|li(, поскольку его можно
рассматривать как кратчайший нетривиальный пример комплекта METRFONT'obckhx
программ, порождающих все 128 символов, используемых plain Т^К'ом.
Как объясняется в приложении Е книги [4], рассматриваемые программы
содержатся в файлах нескольких видов. К их числу относятся: файлы
параметров, задающие требуемое шрифтовое семейство; файлы-драйверы,
управляющие большей частью процесса порождения шрифта; программные файлы,
содержащие код для отдельных символов. Базовый файл мне не понадобился,
поскольку все потребовавшиеся макро для этих шрифтов оказалось
возможным включить в файл-драйвер.
Вот какой вид имеет типичный файл параметров, именуемый PUNK20.MF:
% Шрифт PUNK кегля 20 pt:
designsize := 20pt#] font-identifier := "PUNK";
ht# := 14pt#\ % высота литер
% единичная ширина
% расстояние от крайней точки буквы до границы бокса
% толщина пера по горизонтали
% толщина пера по вертикали
% диаметр точек
% среднеквадратич. отклонение «панковских» точек
% наклон
% стартовое значение для генератора случайных чисел
% переключение на файл-драйвер
Назначение данного файла — конкретизировать метапроект
применительно к выбранным размерам и жирностям. Параметры для пяти шрифтов,
использованных в примерах, приведенных выше, имеют следующие значения:
ii# :=
5#:=
рх# :-
ру* '--
dot*
dev#
slant
seed :
input
4/9pt*]
2pt#;
= Apt*;
= .6pt#;
= 2.7pt*-
:= .bpt#\
:= 0;
= 2.71828;
PUNK
designsize
font .identifier
ht*
u*
s*
px*
py#
dot*
dev*
slant
seed
PUNK10
lQp&
"PUNK"
7pt#
i/Ap&
1.2p&
.6pt#
.bpt*
l.Zpt*
Apt*
0
sqrt 2
PUNK12
12pf*
"PUNK"
SApf*
Apt*
I Apt*
.7bpt*
A2pt*
1.6pt*
A6pf*
0
sqrt3
PUNK20
20pt*
"PUNK"
Upf*
4/9Pt#
2pt*
Apt*
.6pt*
2.7pt*
.ЪрФ
0
2.71828
PUNKSL20
20pt#
"PUNKSL"
Upt*
Ahp&
2pt*
Apt*
.6pt*
2.7pf*
.bpf*
Va
3.14159
PUNKBX20
20pt#
"PUNKBX"
Upt*
.6pt*
2.2pt*
2pt*
1.6pt*
3.5pf*
.ЪрФ
0
0.57722
Наиболее сложным для написания был файл-драйвер PUNK.MF, поскольку
в нем содержится суть проекта. Различные части этого файла росли от шага к
шагу проекта. Например, последние параметры макро 'beginpunkchar' были
добавлены после того, как я обнаружил, что некоторые символы недостаточно
толерантны к случайным отклонениям в их точках, они вели себя не так, как
400 Компьютерная типография
положено обычным символам; слишком большие перемещения приводили к
тому, что эти символы переставали быть распознаваемыми:
%Это-РЬНК,
% меташрифт, создание которого вдохновлено лекциями
% Герарда и Мариан Унгеров, февраль 1985 г.
mode_setup;
randomseed := seed;
define_pixels(ii, dev)\
define_blacker_pixels(pa;, py, dot)]
define _whole_pixels (s);
xoffset := s;
pickup pencircle xscaled px yscaled py\ punkjpen := savepen;
pickup pencircle scaled dot; def-pen-path.;
path dot.penjpath; dotjpenjpath := currentpen.path;
currenttransform := identity slanted slant yscaled aspect.ratio;
def beginpunkchar(expr c, n, /1, v) = % код с; ширина равна п единицам
hdev := h * dev; % модифицировать горизонтальную и
vdev := v * dev; % вертикальную составляющие отклонения
beginchar(c, n * ii#, /i£#, 0);
italcorr /i£# * slant; pickup punk.pen enddef;
extra.endchar := extra.endchar &: Mw:=w+2s;charwd:=charwd+2s#";
def I = transformed currenttransform enddef;
def mafce&oa;(text nz/e) =
for у = 0, h:
rule((—s, 2/)T? (^ "~ 5? 2/)T); endfor % горизонтали
for x = —s, 0, w — 2s, u> — 5: rule((x, 0)|, (ж, /i)T); endfor % вертикали
enddef;
rulepen := pensquare;
vardef pp expr z = z + (hdev * normaldeviate, vdev * normaldeviate) enddef;
def pd expr z = addto-currentpicture contour
dot-pen-path shifted Zt_ withpen penspeck enddef; % рисование точки
input PUNKL % прописные буквы
input PUNKAE % прописные jE, (E, 0
input PUNKG % прописные греческие буквы
input PUNKP % знаки препинания
input PUNKD % цифры
input PUNKA % акценты
ht* := Mt*; dev := .7dev;
input PUNKSL % строчные спецзнаки
extra Jbeginchar := extra-beginchar & "charcode:=charcode+32;";
input PUNKL % строчные буквы
extra Jbeginchar := extra Jjeginchar & "charcode:=charcode-35;";
input PUNKAE % строчные ае, ce, 0
font_slant := 5/an^;
font_quad := 18u# + 2s#;
font_normal_space := 9ii# + 2s#;
Глава 20. Меташрифт Punk
font_normaLstretch := 6ii#;
font _normal_shrink := 4ii#;
font_x-height := ht#\
font_coding_scheme := "TeX text without f-ligatures";
end
Указанные 128 символов, формируемые драйвером PUNK.MF, размещались
в кодовой таблице в тех же самых позициях, что и в шрифтах наподобие cmr5
и cmcsclO, в которых нет f-лигатур. Ниже для примера дается раскладка для
шрифта PUNKZ20, похожего на шрифт PUNK20, за тем исключением, что для
него dev = 0 (т. е. в нем нет случайности):
'00х
'01х
'02х
'ОЗх
Щх
'05х
'06х
'07х
*10х
'Их
'12х
'13х
'Цх
'15х
*16х
'17х
'0
г
♦
i
••
/
(
4
1
»
Н
Г
X
с
Н
f
X
"8
'1
Л
*
.1
SB
I
•
)
1
?
А
I
ft
Y
А
I
Q
Y
"9
'2
A
fl
\
A
r
ft
I
•
•
в
J
R
Z
ь
j
R
г
"A
■3
Л
t
/
<S
#
i
%
•
С
к
s
t
С
К
s
•*
"В
'4
•-•
••
•-•
;
м
0
:
i
<
р
L
Т
n
р
I
Т
•-♦
"С
'5
п
I
V
к
%
*•
S
••
••
е
м
и
]
«
м
и
tf
"D
'б
£
•
I
•-•
<Е
В
•
1
}
F
N
V
Л
F
N
V
•-•
"Е
7
т
•
9
?
:
/
7
1
•
в
6
V
•
в
0
W
••
"F
"Oy
их
"1 Y
IX
"9y
ZX
"4y
OX
"Ay
*iX
"Ry
"fiY
DX
"7y
/ X
402 Компьютерная типография
Давайте взглянем теперь на программные файлы. Первым я написал файл
PUNKL.MF, в котором содержатся определения для всех букв, от А до 2:
% «Панковские» буквы
beginpunkchar(MAM, 13, 1, 2);
zi = РРО-.Ьщ 0); Z2 = (.5u>, l.l/i); zz = pp(w — 1.5u, 0);
pd z\\ pd zz\ draw z\ -- z2 -- zz\ % левая и правая диагонали
zA = pp.S[zi, z2)\ Zb = pp3[zz, z2]\
pd za] pd Zb\ draw za -- £5; % горизонтальный штрих
endchar;
beginpunkchar(MBM, 12, 1, 1);
2i = pp(2u, 0); ^2 = pp(2u, .6/1); 23 = pp(2u, /i);
pd 2i; pd Z3; draw z\ — zz\ % основной штрих
*i.5 = PP(w - гх, .5у2); ^2.5 = pp(w - и, .5[у2, Уз]);
draw Z2 -- 22.5 -- zz\ % верхний овал
draw flex(z2, 21.5, z\); % нижний овал
endchar;
beginpunkchar(MCM, 13, 1, 2);
z\ = pp(w — 2ii, .8/1); 22 = ;?;?(.6u>, /1); 23 = pp(ii, .5/i);
24 = (.бгу, 0); Zb — (w — 2ii, .2/i);
pd 21; pd 25; draw zi .. z2 .. Z3 .. za .. z5\ % дуга
endchar;
beginpunkchar(MDM, 14, 1, 2);
z\ = pp(2u, 0); z2 = pp(2u, h)\ z3 = pp(w - и, .6/i);
pd 21; pd Z2; draw flex(zi, zz, z2)\ % овал
draw 21 -- z2\ % основной штрих
endchar;
beginpunkchar(MEM, 12, .5, 1);
zi = PP(2u, 0); z2 = pp(2u, /1); 23 = pp(w — 2.5ii, /1); 24 = pp(w — 2u, 0);
pd zz\ pd Z4; draw za -- z\ -- z2 -- zz\ % основной штрих и горизонтали
^5 = pp(2u, .6/1); ^6 = pp(w — 3ii, .6/1);
pd z$\ pd Z6; draw 25 -- zq\ % средняя горизонталь
endchar;
beginpunkchar(MFM, 12, .5, 2);
z\ = pp(2u, 0); Z2 = pp(2u, h)\ zz — pp{w — 2щ h)\
pd z\\ pd zz\ draw z\ -- z2 -- zz\ % основной штрих и верхняя горизонталь
Zb = рр(2и, .б/i); ^6 = pp(w — 3ii, .6/1); za = pp.5[zs, ^e] — (0, .l/i);
ножки и диaгoнaлиpd z$\ pd 26; draw flexes, za, zq)\ % средняя горизонталь
endchar;
beginpunkchar(MGM, 13, .5, .5);
z\ = pp(w — 2ii, .8/1); z2 = pp(.6w, h)\ zz = pp(u, .5/i);
za = pp(.6w, 0); z5 = (w — 2ii, 0);
pd z\\ draw zi .. z2 .. 23 .. za — Zb\ % дуга
zq = pp(.5[ii, X5], .4/i); pd 26; pd z5; draw z6 — (pp(x5, ув)) -- z5] % «шпора»
endchar;
beginpunkchar(MHM, 14, 1, .5);
z\ = pp(2u, 0); z2 = pp(2u, h)\ zz = рр(гу — 2ii, 0); 24 = pp(w — 2u, h)\
Глава 20. Меташрифт Punk 403
гъ = рр(2и, .б/i); z6 = pp(w — 2u, .6/1);
pdzi; pd z2; pd z3; pd za\
draw z\ -- Z2; draw flex(z3, ze, Z4); % основные штрихи
pd Z5; draw Z5 -- Z6; % горизонтальный штрих
endchar;
beginpunkchar("I", 5, 1, 2);
zi = pp(.bw, 0); z2 = (.5w, Уз/г); ^з = (.5w, 2/3/i); z4 = (.5w, /i);
pd Zi; pd Z4; draw flex(zi, Z2, Z3, Z4); % основной штрих
endchar;
beginpunkchar("J", 9, 1, 2);
zl = pp(w — 2ii, /1); Z2 = pp(w — 2ii, —.l/i); Z3 = pp(u, 0);
pd z\\ pd Z3; draw zi --Z2--Z3; % дуга
endchar;
beginpunkchar(MKM, 14, 1,2);
zi = pp(2u, 0); Z2 = pp{2u, h)\ zz — pp(2u, l/zh)\ za = pp(w — 1.5ii, /1);
pd Zi] pd Z2; draw Zi -- Z2; % основной штрих
pd Z3; pd Z4; draw Z3 -- Z4; % верхняя диагональ
z6 = pp(w - ii, 0); z5 = Уз^з, z4];
pd Z6; draw nex(zs, .8[zi, 2/з[^5, ^б]], ^б); % нижняя диагональ
endchar;
beginpunkchar(MLM, 11, 1, 2);
zi — PP(2u, h); Z2 — pp(2u, 0); Z3 = pp(w — 1.5u, 0);
pd z\\ pd Z3; draw zi -- Z2 -- Z3; % основной и горизонтальный штрихи
endchar;
beginpunkchar(MMM, 17, .5, 2);
zi = pp(2ii, 0); z2 = pp(2u, /1); z3 = pp(.bw, 0);
Z4 = pp(w — 2u, /1); Z5 = pp(w — 2ii, 0);
pd z\\ pd Z5; draw Zi -- Z2 -- Z3 -- Z4 -- Z5; % основной штрих и диагонали
endchar;
beginpunkchar("N", 13, .75, 2);
zi = PP(2u, 0); Z2 = pp(2u, h)\ zz = pp(w — 2u, 0); Z4 = pp(w — 2u, h)\
pd z\\ pd Z4; draw zi -- Z2 -- Z3 -- Z4; % основной штрих и диагонали
endchar;
beginpunkchar(M0M, 12, .5, 2);
zi = ;?;?(.5u>, /1); Z2 = pp(ii, .55/i); Z3 = pp(.bw, 0); Z4 = pp(w — ii, .55/i);
pd z\\ draw zi{/e/£} .. Z2 .. Z3 .. Z4 .. zi\ % овал
endchar;
beginpunkchar(MPM, 13, 1, 2);
zi = pp(2u, 0); z2 = pp(2u, l.l/i); z3 = pp(2u, .5/i); z4 = pp(w, .б[у3,2/2]);
pd z\\ pd Z3; draw Zi -- Z2 -- Z4 -- Z3; % основной штрих и овал
endchar;
beginpunkchar("Q", 14, .5, 2);
zi = PP(-5wi h)\ ^2 = pp(w, .55/i); Z3 = pp(.bw, 0); Z4 = pp(w — u, .bbh)\
pd z\\ draw Zi{curl 2} .. Z2 .. Z3 .. Z4 .. z\\ % овал
Zb — pp(Aw, .2/i); z6 = pp(w - u, -.l/i); z7 = pp(.b[x5) z6], ~-2h)\
pd Z5; pd zq\ draw Z5 -- Z7 -- Z6; % «хвостик»
endchar;
404
Компьютерная типография
beginpunkchar("R", 16, 1, 2);
zi = рр(2и, 0); z2 = рр(2и, h)\ z3 = pp(w - и, ,6[y2,2/4]);
za = pp(2u, .5/i); Zb — pp(w — 1.5ii, 0);
pd z\\ pd z2\ pd Zb\
draw z\ -- flex(z2, 23, ^4) -- z$\ % основной штрих, овал и диагональ
endchar;
beginpunkchar(MSM, 11, .3, 1);
zi = PP{™ — 2ii, .9/i); Z2 = pp(.bw, /1); Z3 = pp(ii, .7/i); 24 = .6[z6, ^2];
Zb = pp(w — u, .35/i); 26 = pp(.5u>, ii); z-j — pp(u, .2/i);
pd z\\ pd 27; draw 21 -- z2 ... 23 . • ^4 . • z$ ... zq -- 27; % штрих
endchar;
beginpunkchar(MTM, 13, .75, 2);
z\ - pp(u, /1); z2 = pp(w - u, /1); Z3 - pp(.bw, 0);
pd z\\ pd Z2; pd Z3\ draw Z\ -- z2\ % горизонтальный штрих
draw .5[zi, z2] -- Z3\ % основной штрих
endchar;
beginpunkchar(MUM, 13, .3, 2);
z\ = pp(2u, h)\ z2 = pp(2u, .2/i); Z3 = pp(.bw, 0);
za = pp(w — 2ii, .2/i); Z5 = pp(w — 2ii, /1);
pd z\\ pd Z5; draw zi —z2 ... Z3{za — z2} ... za—z*>\ % штрих
endchar;
beginpunkchar("V", 13, 1, 2);
zi = pp(1.5ix, h)\ z2 — pp(.bw, 0); Z3 = pp{w — 1.5ii, /1);
pd zi; pd Z3\ draw z\ -- z2 -- Z3', % диагонали
endchar;
beginpunkchar(MWM, 18, 1, 2);
z\ = pp(l.bu, h)\ z2 = pp(.b[xu a*], 0); z3 = pp(.bw, .8/1);
za = pp(.5[z3, z5], 0); z5 = pp(w - 1.5ii, /1);
pd z\\ pd Z5; draw 21 -- z2 -- 23 -- za -- £5; % диагонали
endchar;
beginpunkchar(MXM, 13, 1, 1);
zi = pp(l-5ix, /1); Z2 = pp{w — 1.5ii, 0); Z3 = pp(1.5ii, 0);
Z4 = pp(w — 2.5ii, /1);
pd z\\ pd Z2; draw z\ -- z2\ % главная диагональ
pd Z3\ pd Z4; draw Z3 — za\ % пересекающая диагональ
endchar;
beginpunkchar(MYM, 13, 1, 2);
zi = pp(l-5ix, /1); ^2 = pp(w — 1.5ii, /1); 23 = pp(.bw, .5/i); 24 = pp(.bw, 0);
pd 21; pd z2\ pd 24; draw z\ -- zz -- z\\ % основной штрих и левая диагональ
draw z2 - - Z3; % правая диагональ
endchar;
beginpunkchar(MZM, 11, 1, 2);
zi = рр(1-5гх, /1); 22 = pp{w — 2.5ii, /1); 23 = pp(l.bu, 0);
Z4 = pp(w — 1.5ii, 0);
pd z\\ pd 24; draw zi -- z2 -- 23 -- za\ % диагонали
endchar;
Глава 20. Меташрифт Punk
405
(Конечно, добавление в строки программы поясняющих их
комментариев несколько замедляет работу по вводу текста программы в компьютер. Но
если приходится пересматривать тексты программ, то такие комментарии
становятся поистине бесценными. По этой причине я с самого начала решил, что
комментарии в программах должны быть обязательно.)
Три буквы из рассматриваемого шрифта были помещены в специальный
файл, получивший наименование PUNKAE.MF. Причиной этому послужило то,
что коды символов этих букв в прописном варианте связаны с
соответствующими строчными буквами нестандартным образом:
beginpunkchar(oct "035м, 16, 1, 2); % Ж
zi = pp(l-5ii, 0); Z2 = pp(.6w, h)\ zz = pp(w — 1.5ii, /i);
pd z\\ pd zz] draw z\ -- Z2 -- zz] % левая диагональ и верх, горизонталь
za = pp3[z\, z2]] Zb — pp(.6w, 0); zq = pp(w - 2u, .3/i);
pd za\ pd zq\ draw z\ -- zq\ % средняя горизонталь
z7 = pp(w - u, 0); pd z2] pd z7]
draw Z2 -- Zb -- Z7\ % основной штрих и нижняя горизонталь
endchar;
beginpunkchar(oct м036м, 18, 1, 2); % (Е
zi = pp(-bw, h)\ Z2 = pp{u, Ah)] zz — pp(.bw, 0);
pd z\\ draw z\ .. Z2 .. {right}zz] % овал
zA = pp(w — 1.5ii, h)\ Zb = pp(w — 2ii, Ah)\ zq = pp(w — u, 0);
pd za] pd zq] draw za -- z\ -- zz -- zq] % горизонтали и основной штрих
pd Zb] draw z$ -- A\zz, z\]\ % средняя горизонталь
endchar;
beginpunkchar(oct "037", 14, 1, 1); % 0
z\ — pp(.bw, h)] Z2 = pp(u, .5/i); zz = pp(.bw, 0); za = pp(w — u, .5/i);
Zb = pp(w — 2ii, l.l/i); Z6 = pp(2u, — Ah)]
pd z\] pd zq] draw z\ .. Z2 .. zz .. za .. Zb ~- z$] % овал и диагональ
endchar;
Имеется также еще один специальный файл с именем PUNKSL.MF,
содержащий строчные буквы, для которых нет отвечающих им прописных букв:
beginpunkchar(oct "020м, 5, 1, 2); % «бесточечная» I
zi = pp(-5w, 0); Z2 = (.5w, 1/zh)] zz = (.5w, 2/zh)] za = (.5w, /i);
pd 2i; pd 24; draw flex(zi, Z2, ^3, ^4); % основной штрих
endchar;
beginpunkchar(oct "021", 9, 1, 2); % «бесточечная» J
zi — pp(w — 2ii, h)] Z2 = pp(w — 2ii, —.l/i); Z3 = pp(w, 0);
pd z\] pd 23; draw 21 --22--23; % дуга
endchar;
beginpunkchar(oct "031", 18, .3, 1); % немецкая «сдвоенная» S
zi = pp(-bw - u, .9/i); 22 = pp(l/zw, h)] zz = pp(w, .7/i); 24 = .6[z6, ^2];
^5 = pp(.bw, .35/i); 26 = pp^/ziv, u)] z-j — рр(щ .2/i);
pd z\] pd.27; draw zi -- Z2 ... zz .. £4 •. £5 . • • zq -- 27; % левый штрих
for i = 1 upto 7: 2[г + 10] = pp(z[i] shifted (.bw — ii, 0)); endfor
pd z\\] pd zn]
406
Компьютерная типография
draw zn -- Z12 ... z\3 .. zu .. zis .., z\6 — Z17] % правый штрих
endchar;
Прописные греческие буквы в файле PUNKG. MF могут несколько отличаться
по стилю от тех, что содержатся в файле PUNKL, поскольку написал я их двумя
годами позднее. Насколько заметна эта разница?
beginpunkchar(oct "000м, 11, 1, 2); % Г
z\ = pp(2ii, 0); Z2 = рр(2и, /i); zz — pp(w — 1.5ii, /i);
pd z\\ pd zz\ draw Z\ -- Z2 -- zz\ % основной и горизонтальный штрихи
endchar;
beginpunkchar(oct "001", 15, 1, 2); % A
z\ — pp{u, 0); Z2 = pp(.bw, h)\ zz = pp(w — u, 0);
pd z\\ draw z\ -- Z2 .. tension 5 .. zz .. tension 5 .. z\\ % треугольник
endchar;
beginpunkchar(oct "002", 15, .5, 2); % в
z\ — pp(.bw, h); Z2 = pp(u, .6/1); zz = pp(.bw, 0); z\ — pp(w — ii, .6h)\
pd z\\ draw z\ .. tension .8 .. Z2 .. zz .. z\ .. tension .8 .. z\\ % овал
^5 = pp{x2 + 2ii, .4/i); ^6 = Pp(xa — 2u, Ah)\
pd Zb\ pd 26; draw 25 -- ^6', % средняя горизонталь
endchar;
beginpunkchar(oct "003", 12, 1, 2); % Л
z\ = pp(u, 0); z2 = pp(.bw, /1); 23 = pp(w - и, 0);
pd 21; pd zz] draw Zi — Z2 — zz] % диагонали
endchar;
beginpunkchar(oct "004", 12, 1, 1); % H
21 = рр(щ /i); г2 = pp(w - щ h);
pd z\\ pd 22; draw zi -- Z2\ % верхняя горизонталь
^з = PP(2ii, .55/i); Z4 = pp(w — 2ii, .55/i);
pd zz\ pd Z4; draw 23 -- za\ % средняя горизонталь
z5 = pp\u, 0); z6 = pp(w - щ 0);
pd z$\ pd ^6', draw 25 -- zq\ % нижняя горизонталь
endchar;
beginpunkchar(oct "005", 13, 1, .5); % П
z\ = pp(1.5ii, 0); Z2 = pp(1.5ii, /1); zz = pp(w — 1.5ii, /1);
Z4 = pp(ty — 1.5ii, 0);
pd z\\ pd z\\ draw z\ -- Z2 -- zz -- z\\ % основные и горизонтальный штрихи
endchar;
beginpunkchar(oct "006", 13, 1, 1); % £
z\ — pp(w — u, h)\ Z2 = pp(u, /1); zz = pp(.bw — u, .5/i);
z4 = pp(ii, 0); zb = pp(w - щ 0);
pd 2:1; pd Zb\ draw 21 -- Z2{.5[z4, 25] — 22} .. zz -- ^4 -- z$\ % горизонтали
% и диагонали
endchar;
beginpunkchar(oct "007", 15, 1, .5); % T
z\ = PP(u, .8/1); Z2 = pp(.3w, /1); Z3 = pp(.bw, .5/i); Z4 = рр(.5г/;, 0);
pd z\\ pd 24; draw zi .. Z2 .. tension 2 .. 23 — z\\ % левая дуга и основной штрих
Zb — pp(w — ii, .8/1); 26 = pp(.7w, h);
Глава 20. Меташрифт Punk 407
pd Zb\ draw Z5 .. zq .. tension 2 .. {za — zz}zz\ % правая дуга
endchar;
beginpunkchar(oct "010", 13, 1, 2); % Ф
z\ — pp(.bw, h)\ Z2 = pp(.bw, 0); pd z\\ pd Z2\ draw z\ -- Z2\ % основной штрих
z3 = pp(.bw, 2/3/i); z4 = pp(ii, .5/i); z5 = pp(.bw, 1/4/1); ^6 = pp(w - гх, .5/i);
pd Z3; draw Z3 .. Z4 .. Z5 .. Z6 .. Z3; % овал
endchar;
beginpunkchar(oct "011", 14, 1, 1); % \I>
21 = РР(-5ги, /1); Z2 = ;?;?(.5u>, 0); pd zi; pd Z2; draw z\ -- Z2; % основной штрих
Z3 = pp(ii, .8/1); Z4 = pp(.5u>, .2/i); Z5 = pp(w — ii, .8/1);
pd z3; pd z5;
draw Z3{.4[zi, 22] — ^3} • • z^righi) .. {zs — -4[zi, Z2]}zs; % штрих
endchar;
beginpunkchar(oct "012", 13, 1, 2); % ft
z\ - pp(u, 0); z2 = pp(l/zw, 0); z3 = pp(u, 2/3/i); z4 = pp(.5w, /i);
z5 = pp(w - ii, 2/3/1); z6 = pp(2/3W, 0); z7 = pp(w - и, 0);
pd zi; pd z7;
draw zi -- Z2{up} .. Z3 .. Z4 .. Z5 .. {down}z6 -- Z7; % овал и горизонтали
endchar;
Следующий программный файл, PUNKD.MF, определяет десять
«панковских» цифр. Я очень спешил, когда вводил с клавиатуры текст данного файла,
поэтому комментарии в конце строк получились весьма лаконичными:
beginpunkchar("0", 9, .5, I);
zi = PP(-5w, /1); Z2 = pp{u, .55/i); Z3 = pp(.bw, 0); Z4 = pp(w — u, .55/i);
pd z\\ draw zi{curl 2} .. Z2 .. Z3 .. Z4 .. zr, % овал
endchar;
beginpunkchar("l", 9, .3, 1);
zi = pp(2u, .7/i); z2 = pp(.6w, /1); z3 = pp(.6w, 0);
pd z\\ pd Z3; draw z\ -- Z2 -- Z3; % засечка и основной штрих
endchar;
beginpunkchar("2", 9, 1, 1);
zi = PP(2ui -7/i); Z2 = pp(.bw, /1); Z3 = pp(w — ii, .6/1);
Z4 = pp(ii, 0); Z5 = pp(u> — 2ii, 0);
pd zi; pd Z5; draw zi .. Z2 .. Z3 .. Z4 -- Z5; % штрих
endchar;
beginpunkchar("3", 9, .5, .5);
z\ - pp(2u, .7/i); z2 = pp(.bw, /1); z3 = pp(w - и, .5[х/2, Уа])\
za = pp(.bw — u, .55/i); Z5 = pp(w — ii, .5[у4,2/б]);
^6 = pp(.bw, 0); z7 = pp(l.bu, .2/i);
pd zi; pd z7; draw zi .. Z2 .. Z3 .. Z4 & za .. z5 .. Z6 .. z7; % дуги
endchar;
beginpunkchar("4", 9, 1, 1);
z\ - pp(w - u, .3/i); z2 = pp(ii, .3/i); z3 = pp(2/zw, /1); z4 = pp{2/zw, 0);
pd zr, pd Z4; draw z\ -- Z2 -- Z3 -- Z4; % основной штрих и диагонали
endchar;
408
Компьютерная типография
beginpunkchar(M5M, 9, .5, .5);
zi = PP(w — 2ii, h)\ zi = pp(2u, h)\ zz — pp(u, .7/i);
za = pp(w - и, .5[y3, ye]); Zb = pp(.bw, 0); z6 = pp(u, .2/i);
pd z\\ pd zq\ draw zi -- Z2 ~~ zz .. Z4 .. z$ .. ze]
endchar;
beginpunkchar("6", 9, 1, 1);
z\ = pp(2/zw, h)\ z2 = pp(u, .3/i); z3 = pp(.bw, 0);
Z4 = pp(w — u, .3/i); Z5 = pp(.6w, .6/1); ^6 = pp.z 2;
pd 21; pd 26; draw z\ .. zi .. zz .. z\ .. z$ - - z§\
endchar;
beginpunkchar(M7M, 9, .5, 1);
z\ = PP^u, /1); 22 = pp(u> — .5ii, /1); 23 = pp(.4u>, О);
pd z\\ pd 23; draw z\ -- Z2&Z2 .. 23 {down};
endchar;
beginpunkchar("8", 9, .5, .5);
z\ = pp(.bw, h)\ z2 = pp(u, .5[yi, 2/3]); 23 = pp(.5w, .6/1);
24 = pp(w - u, .5[y3, Ув]); ^5 = до(.5ги, О);
^6 = pp(u, .5[y5| Уз]); ^7 = M™ - u, ,5[yi, y3]);
pd 21; draw zi{curl 8} .. 22 .. zz .. £4 .. ^5 •. zq .. zz .. £7 • • 21;
endchar;
beginpunkchar("9", 9, 1, 1);
zi = pp(1/zw, 0); Z2 = pp(w — гх, .7/i); 23 = рр(.5ги, /i);
z4 = pp(u, .7/i); z5 = рр(.5г^, .4/i);
pd z\\ pd Z5; draw Z\ .. z<i .. zz .. z± .. z$\
endchar;
% штрих
% штрих
% штрих
% штрих
% штрих
Программный файл PUNKP.MF содержит определения «панковских»
символов и знаков препинания. Написать эти определения было едва ли не труднее
всего, несмотря на то, что большинство из этих знаков очень просты —но зато
их ужасно (pAUti) много.
beginpunkchar(" . ", 5, 1, 2);
pd pp(.bw, 0); % точка
endchar;
beginpunkchar(M , ", 5, .5, .5);
z\ — pp(.bw, 0); z2 = pp(w - щ -.l/i); zz = pp(.bw, -.3/i);
pd z\\ pd zz\ draw z\ ~- Z2 — zz\ % штрих
endchar;
beginpunkchar(M :", 5, 1, .5);
pd pp(.bw, 0); pd pp(.bw, Ah)\ % точки
endchar;
beginpunkchar(";", 5, .5, .5);
z\ = pp(.bw, 0); Z2 = pp(w — ix, —.l/i); zz = pp(.bw, — .3/i);
pd z\\ pd Z3; draw 21 -- Z2 -- £3; % штрих
pd pp(.bw, .4/i); % точка
endchar;
Глава 20. Меташрифт Punk
409
beginpunkchar(" ! ", 5, .5, .5);
pd pp(.bw, 0);
zi = pp(.bw, 1.05/i); Z2 = pp(.bw, .3/i);
pd z\\ pd Z2\ draw z\ -- Z2\
endchar;
ligtable "!": "'" =: oct "016";
beginpunkchar(oct "016", 5, .5, .5);
pd pp(.bw, .9/i);
z\ = pp(.bw, — .l/i); Z2 = pp(.bw, .6/1);
pd Z\\ pd Z2\ draw Z\ -- Z2;
endchar;
beginpunkchar("?", 9, 1, .5);
zi = pp(l.bu, .8/1); Z2 = pp(.bw, h)\ zz — pp(w — u, .8/1); Z4
pd zi; pd Z4; draw z\ .. Z2 .. Z3 .. {doKm}z4;
pd рр(.5г/;, О);
endchar;
ligtable "?": "'" =: oct "017";
beginpunkchar (oct "017", 9, 1, .5);
z\ = pp(l.bu, .l/i); Z2 = pp(.bw, —.l/i);
zz = рр(г/; — ii, .l/i); Z4 = pp(.bw, .6/1);
pd zi; pd Z4; draw z\ .. Z2 .. zz .. {up}z4;
pd ;?;?(.5u>, .9/i);
endchar;
beginpunkchar ("&", 14, .5, .5);
zi = pp(w - 2ii, /1); z2 = pp(u, h)\ zz - pp(3u, 0);
Zb = pp(w — u, .6/1); Z6 = pp(w — 2u, 0);
pd z\\ pd Z5; draw Zi -- Z2 -- Z3 -- Z5;
draw zi -- .5[z2, Z3]; pd Z6; draw zq -- .6[z3, Z5];
endchar;
beginpunkchar("$", 12, .5, .5);
zi = PP(w — 1.5ii, .7/i); Z2 = pp(.5u>, /1); Z3 = pp(u, .7/i); Z4
Zb — pp(w — ii, .3/i); Z6 = pp(.bw, 0); Z7 = pp(ii, .3/i);
pd 21; pd Z7; draw Z\ .. Z2 .. Z3 .. Z4 .. Z5 .. zq .. Z7;
Z8 = Z2 + (0, .l/i); pd zs; draw zg -- Z6;
endchar;
beginpunkchar ("*/,", 18, .5, .5);
z\ = pp(3.bu, l.l/i); Z2 = pp(ii, .8/1); Z3 = pp(3.5ii, .5/i); Z4
z$ = pp(w — 3.5ii, .5/i); Z6 = рр(г/; — 6ii, .2/i);
z7 = pp(w — 3.5ii, —.l/i); zs = pp(w — ii, .2/i);
pd z\\ draw zi .. Z2 .. Z3 .. Z4 .. zi;
pd Z5; draw z5 .. Z6 .. Z7 .. zs .. z5;
z9 = pp(w — 3ii, l.l/i); zo = pp(3ii, —.l/i);
pd zo; draw Z9 -- zo;
draw Zi{z5 — zi} .. Z9;
endchar;
beginpunkchar("Q", 18, 1, .5);
zi = pp(2u, 0); z2 = pp(l/zw, .7/i); z3 = pp(w - 6ii, 0);
% точка
% основной штрих
% испанский перевернутый !
% точка
% основной штрих
pp(.bw, .3/i);
% дуга и основной штрих
% точка
% испанский перевернутый ?
% дуга и основной штрих
% точка
% горизонтали и ножка
% диагонали
.5[зз, z5];
% штрих
% основной штрих
рр(6и, .8/i);
% верхний овал
% нижний овал
% диагональ
% «связка»
410
Компьютерная типография
za = pp{w, .3/i); zb = pp{l/zw, h); z6 = pp(u, .5/i); z7 = .7[z2, 23];
pd z\\ pd z7;
draw zi -- Z2 -- 2з{п<7/1£} .. z\ .. z$ .. zq .. zi\ % диагонали и штрих
endchar;
beginpunkchar(■■-", 7, .5, .5);
zi = PP(U> '4/i); ^2 = pp(u> — ii, .5/i); pd z\\ pd Z2; draw z\ -- 22;%горизонтальный
% штрих
endchar;
ligtable "-": "-" =: oct "173";
beginpunkchar(oct "173", 9, .5, .5); % -
zi = PP(0> '5/i); Z2 = pp(w, .4/i); pd z\\ pd 22; draw 21 -- Z2\ % горизонтальный
% штрих
endchar;
ligtable oct "173": "-" =: oct "174";
beginpunkchar (oct "174", 18, .5, .5); % —
zi = PP(0> -5/i); Z2 = pp(w, .4/i); pd z\\ pd Z2; draw 21 -- Z2\ % горизонтальный
% штрих
endchar;
beginpunkchar (" + ", 9, .5, 1);
Z\ = pp(0, .5/i); 22 = pp(w, .5/i); pd 21; pd 22; draw z\ -- 22; % горизонтальный
% штрих
2з = ;?;?(.5u>, .l/i); 24 = рр(.5г/;, .9/i); pd 23; pd 24; draw 23 -- 24; % основной
% штрих
endchar;
beginpunkchar("*", 13, .5, 1);
zo = pp(.bw, l.l/i); 21 = pp(ii, .9/i); 22 = pp(2u, .3/i);
23 = pp{w — ii, .3/i); 24 = pp(w — ii, .9/i);
pd zo\ draw 20 -- Z2 .. Vsl-M-2^, ^4], 20] .. z\ -- 21 -- 23 -- zo; % звездочка
endchar;
beginpunkchar (",M, 5, .3, .5);
zi = рр(1.5гх, /i); Z2 = pp(u; — гх, .85/i); 23 = рр(гх, 2/з^);
pd z\\ pd Z3; draw z\ -- Z2 ~~ z$\ % штрих
endchar;
ligtable "'": ",M =: oct "042";
beginpunkchar (oct "042", 9, .3, .5); % "
z\ — pp(.bw — .5ii, h)\ Z2 = pp(u, .6/1); Z3 = pp(u; — гх, .95/i);
pd zr, pd zz\ draw Z\ -- Z2 -- z$\ % штрих
endchar;
beginpunkchar(" "', 5, .3, .5);
zi = PP(w — 1.5u, /1); Z2 = рр(гх, .85/i); 23 = pp(u; — гх, 2/з/г);
pd zi; pd zz\ draw z\ -- Z2 ~~ z$\ % штрих
endchar;
ligtable "'": "'" =: oct "134";
beginpunkchar (oct "134", 9, .3, .5); % "
z\ — pp(.bw + .5ii, /1); Z2 = pp(u; — гх, .6/1); 23 = рр(гх, .95/i);
pd z\\ pd Z3; draw z\ -- Z2 -- z$\ % штрих
endchar;
Глава 20. Меташрифт Punk
411
beginpunkchar(oct "015", 9, .3, .5); % '
zi = PP(-*>wi h)\ z2 = PP(*5wi .6/1); pd z\\ pd Z2; draw z\ -- Z2; % основной штрих
endchar;
% штрих
% штрих
beginpunkchar (" (", 7, .5, .5);
zi = PP(w — w? h)\ Z2 = pp(ii, .5/i); Z3 = pp(u> — ii, 0);
pd z\\ pd Z3; draw z\ .. Z2 .. £3;
endchar;
beginpunkchar(■■)", 7, .5, .5);
21 = PP(u, h)\ Z2 = pp(u> — и, .5/i); Z3 = pp(u, 0);
pd zr, pd Z3; draw zi .. Z2 .. £3;
endchar;
beginpunkchar(" [", 8, .5, .5);
zi = PP(w — w, /1); Z2 = pp(.bw, /1); Z3 = pp(.bw, 0); 24 = pp(w — ii, 0);
pd z\\ pd Z4; draw z\ -- Z2 -- z$ -- za\ % горизонтальные и основной штрихи
endchar;
beginpunkchar ("] ", 8, .5, .5);
z\ = pp(u, h)\ Z2 = pp(.bw, h)\ zz - pp(.bw, 0); za = pp(u, 0);
pd z\\ pd Z4; draw zi -- Z2 -- £3 -- za\ % горизонтальные и основной штрихи
endchar;
beginpunkchar("<", 9, .5, .5);
zi = PP(w — w, -9/i); Z2 = pp(u, .5/i); Z3 = pp(u> — ii, .l/i);
pd zi; pd zz\ draw Zi -- Z2 -- £3;
endchar;
beginpunkchar(">", 9, .5, .5);
zi = PP(U> -9/i); z2 = pp(w — ii, .5/i); Z3 = pp(u, .l/i);
pd zi; pd Z3\ draw z\ ~~ zi — zz\
endchar;
beginpunkchar ("=", 9, .5, .5);
zb = pp(ii, 2/3/i); z6 = pp(w - ii, 2/zh)\
pd Z5; pd ze; draw 25 -- ze;
z7 = pp(ii, 1/3/1); ^8 = pp(w-u, 1/3/1);
pd Z7; pd ze; draw z-j -- zg;
endchar;
% диагонали
% диагонали
% верхний горизонтальный штрих
% нижний горизонтальный штрих
beginpunkchar ("#", 15, .5, .5);
zi = pp(-5w, /1); Z2 = pp(3ii, 0); 23 = pp(w — 3ii, /1); Z4 = pp(.5w, 0);
pd Z2\ pd Z3;
draw Z3 - - z\ - - Z2; draw Z3 - - £4 - - 22;
z5 = pp(u, 2/zh)\ zq = pp(w - ii, 2/3/i);
pd z5; pd zq\ draw 25 -- ze;
Z7 = pp\u, 1/3Л); ^8 = PP(W - li, 1/3Л);
pd z-j\ pd ze; draw z-j -- zs;
endchar;
beginpunkchar("/", 9, 1, 1);
21 = pp(1.5ii, —.05/i); Z2 = pp(w — 1.5ii, 1.05/i);
pd z\\ pd Z2; draw Zi -- Z2\
endchar;
% диагонали (связанные)
% верхний горизонтальный штрих
% нижний горизонтальный штрих
% диагональ
412 Компьютерная типография
beginpunkchar(oct "013", 12, .5, .5); % t
zi = PP(U, -7/i); Z2 = pp(.bw, h)\ zz = pp(w — u, .7/i); 24 = pp(.bw, 0);
pd zr, pd zz\ pd 24;
draw z\ -- zi — za\ draw zz - - Z2; % основной штрих и диагонали
endchar;
beginpunkchar(oct "014", 12, .5, .5); % 4
zi = PP(W> -3/i); ^2 = рр(.5г/;, О); 2з = pp(w — гх, .З/i); 24 = pp(.bw, /1);
pd zi; pd z3; pd 24;
draw 21 - - Z2 - - 24; draw 23 - - 22; % основной штрих и диагонали
endchar;
Завершающий рассмотрение программный файл PUNKA. MF определяет
акценты в той форме, которая предпочтительнее для ТЁХ'а. ТЁХ'овский ввод
\def\AA{\accent'27A}
{\AA}ngel\aa\ Beatrice Claire Diana VErica Fran\c{c}oise
Ginette HVelVene Iris Jackie K\=aren {\L}au\.ra
Mar{\,\i}a N\H{a}ta{\l}{\u\i}e {\0}ctave Pauline
Qu\~eneau Roxanne Sabine T\~a{V\j}a Ur\v{s}ula'Vivian
Wendy Xanthippe Yv{\o}nne Z\"azilie
вызывает расстановку акцентов (для шрифта PUNKSL20), которая будет
выглядеть следующим образом:
J/seeU faATRice Elawu Ршл
Uriga FeAttpoise бштте
Mi he Iris Jackiz Kar^m
Uura Mar/a SXtaiiu $gtav£
tavium &иУш ftoxAiwe
Элъше Wa 0#$vla Vivian
Ушу XAtmiim fv0we
IXzu le
(Отметим, что необходимо переопределить макро \АА, но остальные акценты,
имеющиеся в plain ТЁХ'е, работают без всяких изменений в них.)
Прорисовка акцентов выполняется следующим образом:
beginpunkchar(oct "022", 9, 1, 1); % ч
z\ — pp(2.bu, h)\ Z2 = pp(.6w, .8/1);
pd z\\ pd Z2\ draw z\ -- Z2\ % диагональ
endchar:
Глава 20. Меташрифт Punk 413
beginpunkchar(oct "023", 9, 1, 1); % '
zi = PP(w — 2.5ii, /i); Z2 = pp(Aw, .8/1);
pd z\\ pd Z2*, draw Z\ -- zi\ % диагональ
endchar;
beginpunkchar(oct "136", 13, 1, 1); % Л
z\ — pp(2.bu, .8/1); Z2 = pp(.bw, h)\ zz = (w — 2.5ii, .8/1);
pd z\\ pd zz\ draw z\ -- zi ~~ zz\ % диагонали
endchar;
beginpunkchar(oct "024", 13, 1, 1); % "
zi = pp(2.bu, .9/i); Z2 = pp(.bw, .7/i); Z3 = pp(u> — 2.5ii, .9/i);
pdzi; pd Z3; draw zi--Z2--23; % диагонали
endchar;
beginpunkchar(oct "025", 11, 1, 1); • % w
21 = PP(2ii, /1); Z2 = pp(.5u>, .75/i); Z3 = pp{w — 2u, /1);
pd z\\ pd Z3; draw flex(zi, Z2, 23); % штрих
endchar;
beginpunkchar(oct "026", 12, 1, 1); % "
zi = РР(щ «8/i); 22 = рр(гу — ii, .8/1); pd zi; pd Z2; draw z\ -- Z2;%горизонтальный
% штрих
endchar;
beginpunkchar(oct "137", 5, 1, 1); % '
pd pp(.5u>, .9/i); % точка
endchar;
beginpunkchar(oct "177", 13, 1, 1);
pd pp(l/bW, .9/i); pd pp(A/bW, .9/i);
endchar;
beginpunkchar(oct "176", 13, 1, 1);
Z\ — pp(lL, .75/l); Z2 = pp(w — li, .9/l);
pd z\\ pd Z2; draw z\{up} .. {up}z2;
endchar;
beginpunkchar(oct "175", 13, 1, 1);
zi = PPi^u, /1); 22 = pp(2.5u, .7/i);
Z3 = pp(w — 2ii, /1); Z4 = pp(u> — З.Ьщ .7/i);
pd zi; pd Z3; draw z\ -- Z2 -- 24 --23;
endchar;
%"
% точки
%~
% штрих
%"
% диагонали (связанные)
% акцент-кружок для А и а
% точка Z2 для строчной буквы А
beginpunkchar(oct "027", 13, 0, 0);
zo = (.5u>, .66/1);
z\ = (.bw, .9/i);
draw zo{zo — (1.5ii, 0)} .. z\ .. {(го — 1.5гх, 0) — zo}zo;
endchar;
beginpunkchar(oct "030", 13, .5, .5);
z\ — (.бги, 0); Z2 = pp(.6w, — .l/i); Z3 = pp(2.bu, — Ah);
pd Z3; draw z\ -- Z2 --23;
endchar;
beginpunkchar(oct "040", 11, .5, .5); % «польское перечеркивание» для L и \
zi = PP(0, .25/i); Z2 = pp(4ii, .4/i);
% кружок
% цедилла для д
% штрих
414
Компьютерная типография
pd z\\ pd Z2\ draw z\ -- Z2\ % диагональ
endchar;
ligtable oct "040": "1" kern —charwd, "L" kern —charwd;
Литература
[1] George Ade, Artie: A Story of the Streets and Town (Chicago: H. S. Stone,
1896), Chapter 19.
[2] Dashiell Hammett, The Maltese Falcon (New York: A. A. Knopf, 1930),
Chapter 18.
[3] Derek Jewell, music review in the Sunday Times (28 November 1976), 37.
[4] Donald E. Knuth, The METRFONTbook, Volume С of Computers к
Typesetting (Reading, Massachusetts: Addison—Wesley and American
Mathematical Society, 1986).
[5] Pablo Picasso, рисунок карандашом из Sketchbook 86. (Этот рисунок был
позднее использован в качестве иллюстрации в великолепном издании:
Vollard. Le Chef-d'CEuvre Inconnu by Honore de Balzac, 1931.)
[6] William Shakespeare, The Merry Wives of Windsor, Act 2, Scene 2, lines
135-137. (The First Folio has the spelling 'Puncke'.)
Добавление
Еще одно доказательство того, что идея «панковского» набора символов
носилась тогда в воздухе, было представлено Дж. Дэниэлом Смитом из
Мичиганского государственного университета, приславшим мне такой пример,
обнаруженный им в газете State News 83,152 (25 октября 1988 г.), издаваемой
данным университетом:
1111Ш1й|1»^Ш1ш1
Шрифты
для дискретных полутонов
[Переработанный вариант статьи, первоначально опубликованной в TUGboat
8 (1987), 135-160.]
Небольшие фотографии можно «набирать» на растровых устройствах таким
же образом, как это происходит на экране, чтобы потом использовать эти
растровые изображения для печати великолепных книг по фотографии. Цель
этой статьи обсудить эксперименты по созданию посредством METAFONT'a
таких шрифтов, из которых полутоновые изображения легко сгенерировать на
лазерном принтере. При низком разрешении невозможно добиться высокого
качества, так что для представления больших фотографий с высоким
разрешением будет нехватать памяти ТДО'а; кроме того, начиная с 1990 г. широко
доступны эффективные способы непосредственной обработки полутоновых
иллюстраций. Тем не менее обсуждаемые ниже шрифты оказались полезными в
ряде приложений и при их построении возникало немало интересных вопросов,
все еще актуальных.
Я приступил к этому исследованию в начале 1985 г., когда 15
старшекурсников Станфордского университета работали над проектом создания
«высокотехничных автопортретов» (см. [4, ее. 88-103]). Студенты самыми
изощренными способами манипулировали цифровыми графическими изображениями,
но в те времена в Станфорде не было соответствующего устройства вывода,
на котором можно было преобразовать эти цифровые изображения в твердую
копию. Поэтому я решил создать шрифт, из которого средствами ТЕХ'а можно
было бы получать полутона.
Такой шрифт неизбежно был бы зависимым от платформы. Например,
лазерный принтер с разрешением 300 пикселей на дюйм не может повторить
поведение другого принтера с разрешением 240 пикселей на дюйм, если мы
пытаемся контролировать качество изображений, составленных из пикселей.
Я решил использовать наше устройство вывода Imagen laserprinter с
разрешением 300 (известное также как Canon LBP-CX), потому что оно обеспечивало
лучший контроль качества пикселей, чем любая другая машина, имеющаяся в
распоряжении студентов.
Казалось, что лучше всего сначала создать шрифт, «литерами» которого
были бы крошечные квадраты размера 8x8, составленные из пикселей. Целью
416 Компьютерная типография
было получить 65 литер для 65 различных градаций яркости: при 0 < к < 64
существовала бы одна литера точно с к черными пикселями и с 64 — к белыми
пикселями.
На самом деле лучше всего было бы найти некоторую перестановку р из
64 пикселей в квадрате размера 8x8, так чтобы черных пикселей в литере к
было ро5 Ръ • • • 5 Pk-i- Первым моим побуждением было попытаться
поддерживать позиции ро, р\, р2, ... как можно дальше друг от друга. Так что моя
первая МЕТАРОМТ'овская программа рисовала черные пиксели, упорядочивая
позиции следующим образом:
45
13
39
7
47
15
37
5
29
61
23
55
31
63
21
53
34
2
40
8
32
0
42
10
18
50
24
56
16
48
26
58
46
14
36
4
44
12
38
6
30
62
20
52
28
60
22
54
33
1
43
11
35
3
41
9
17
49
27
59
19
51
25
57
(В сущности, это матрица «упорядоченного размывания» Байера; см. [5].)
Оказалось, что при помощи METflFONT'a довольно просто создать такой
шрифт:
У, Шрифт полутонов с 65 градациями серого, полученный посредством"
7, "упорядоченного размывания" с литерами от "О" (белое) до "р"
(черное)
pair р [] ; У, пиксели упорядочены
У, (сперва становится черным рО, затем pi и т.\,д.)
pair d[] ; У, контроль размывания
d[0]=(0,0); d[l]=(l,l); d[2]=(0,l); d[3]=(l,0);
def wrap(expr z)=(xpart z mod 8,ypart z mod 8) enddef;
for i=0 upto 3: for j=0 upto 3: for k=0 upto 3:
p[16i+4j+k]=wrap(4d[k]+2d[j]+d[i] + (2,2));
endfor endfor endfor
w#:=8/pt; У, это 8 пикселей
font_quad:=w#; designsize:=w#;
picture prevchar; '/, до сих пор все пиксели зачернены
prevchar=nullpicture;
for i=0 upto 64:
beginchar(i+ASCII"0",w#,w#,0); currentpicture:=prevchar;
if i>0:
addto currentpicture also unitpixel shifted p[i-l];
fi
prevchar:=currentpicture; endchar;
endfor
Глава 21. Шрифты для дискретных полутонов
417
Этот файл получил имя odith.mf; я использовал его для создания шрифта
odith300, применив обычным образом METRFONT к следующему файлу под
названием odith300.mf, что связано с зависимостью шрифта от платформы:
У, Шрифт полутонов для Imagen, полученный упорядоченным размыванием
mode_setup;
if (pixels_per_inch<>300) or (magOl):
errmessage "Sorry, this font is only for resolution 300";
errmessage "Abort the run now or you'll " &
"clobber the TFM file";
forever: endfor У, переход в бесконечный цикл
else: input odith fi
end.
Набирать фотографии при помощи файла odith300 довольно легко, если
в ТЁХ'овский документ ввести файл макрокоманд ht .tex:
У, Макрокоманды для набора полутонов
У, Пример использования:
У, \input ht У, ввод этого файла
У, \font\htfont=<your favorite halftone font> У, загрузка шрифта
У, \beginhalftone
У, литеры для верхней строки фотографии.
У, литеры для второй строки фотографии.
У. ...
У, литеры для нижней строки фотографии.
У, \endhalftone
У, Теперь фотография заключена в бокс подходящего размера.
У, Вы можете также написать \setboxO=\beginhalftone...\endhalftone.
\chardef\other=12
\def\beginhalftone{\vbox\bgroup\offinterlineskip\htfont
\catcode'\\=\other \catcode'\~=\other \catcode'\_=\other
\catcode'\.=\active \starthalftone}
{\catcode'\.=\active \catcode'\/=0 \catcode'\\=\other
/gdef/starthalftone#l\endhalftone{/let.=/endhalftoneline
/beginhalftoneline#l/endhalftone/ignorespaces}}
\def\beginhalftoneline{\hbox\bgroup\ignorespaces}
\def\endhalftoneline{\egroup\beginhalftoneline}
\def\endhalftone{\egroup\setboxO=\lastbox\unskip\egroup}
(В этих макро применено небольшое ухищрение: поскольку 'V — один из
легальных символов в odith300, но 't' в \endhalf tone таковым не является, мы
должны временно вернуть бэкслешам статус обычных символов.)
К сожалению, результат, полученный при помощи odith300, нельзя было
назвать хорошим; изображения несли на себе явный отпечаток своего
происхождения от бинарной рекурсии, они были чересчур «компьютерными». Вот,
418
Компьютерная типография
например, три типичные фотографии в натуральную величину, полученные на
нашем принтере:1
Квадратные литеры размера 8x8 слишком бросаются в глаза.
Кроме того, лазерный принтер делал странные вещи, когда при помощи
odith300 обрабатывал растровые изображения такого рода:*
Хотя в литере с номером к были более темные пиксели, чем в литере с
номером к — 1, их чернота в нашем эксперименте не росла монотонно. Литера
номер б казалась темнее литеры номер 7, но это оптический обман. Литера
номер 32 была темнее многих за ней следующих литер, но в данном случае это
нельзя считать просто иллюзией: изучение под линзой с большим увеличением
показало, что принтер распределяет тонер весьма причудливым образом.
Другой дефект подхода упорядоченного размывания состоял в том, что
большинство литер получались слишком темными. Замеры при помощи
денситометра показали, что примерно на литере номер 16 уже была достигнута
плотность 50%. Следовательно, odith300 слишком выделяет светлые тона.
Моим следующим побуждением было взглянуть на фотографии в книгах
и газетах, чтобы понять, как они достигают хорошего качества. Так вот в чем
дело! Они делают черные точки все больше и больше по размеру, иначе
говоря, упорядочивая пиксели ро, Рь • • •» они располагали черные пиксели тесно
к друг другу, а не в противоположных концах. Кроме того, точки обычно
наносились на сетку, повернутую под углом 45°, поскольку при таком повороте
человеческий глаз не так отчетливо видит точечную природу изображения,
1 В этой статье звездочки используются для указания тех мест, где мне пришлось
воспроизводить вывод лазерного принтера с разрешением 300 точек на дюйм на офсетной печати,
используя оригиналы, сфотографированные PostScript-устройством с разрешением 1270
точек на дюйм. Причуды такой печати внесли, по-видимому, большие отличия от оригинала,
выведенного в 1985 г. на Imagen, но я надеюсь, основная идея понятна.
Глава 21. Шрифты для дискретных полутонов
419
как в случае прямоугольной сетки. Поэтому я решил зачернить пиксели в
следующем порядке:
|61
53
45
37
38
29
21
13
24
62
46
14
5
0
16
48
60
54
22
6
2
8
40
56
52
44
36
30
10
18
26
32
39
28
20
12
25
34
42
50
63
47
15
4
1
17
49
58
55
23
7
3
9
41
57
31
11
19
27
33
35
43
51
59]
Здесь я решил отойти от квадрата размера 8x8; это неквадратное множество
позиций пикселей все еще в стиле Эшера «покрывает черепицей» плоскость,
если мы будем повторять его в 8-пиксельных интервалах. Как и ранее, литеры
считаются имеющими ширину 8 пикселей и толщину 8 пикселей, но теперь они
не заключены в бокс размера 8x8. Точка отсчета находится в нижнем левом
углу позиции 24.
Приведенная выше матрица действительно лучше той, с которой я
начинал, но я не учел то ценное, что в ней было. Джон Хобби обратил мое внимание
на это и предложил такую альтернативу потому, что хотел, чтобы образ
черных пикселей в литере номер к был в сущности тем же, что и образ белых
пикселей в литере номер 64 — к. (Коммерческие схемы полутонов начинают с
маленьких черных точек на белом фоне; затем точки увеличиваются до тех
пор, пока они не образуют шахматную доску из белых и черных квадратов;
затем белые квадраты начинают сжиматься до маленьких точек на черном
фоне.) Матрица (2) обладает этим свойством симметрии, потому что сумма
элементов в позициях (ж, у) и (х + 4, у) равна 63 для всех х и у, если вы
рассматриваете «обвивающие» вычисления индексов по модулю 8. Представлена
еще и другая интересная симметрия: если изучить относительные позиции
ячеек с номерами 0-7, 8-15, 16-23, 24-31, 32-39, 40-47, 48-55 и 56-63, то видно,
что каждая группа восьмерок образована, в сущности, одинаково.
Мы с Джоном использовали это новое упорядочение позиций пикселей,
чтобы образовать шрифт «размывания точки» под названием ddith300,
аналогичный шрифту odith300. Он производил следующую последовательность
шкал серого тона:*
r^^^tft^OCS^COOOOCSTfCOOOOCSTfCOOOOCS^COOOOCSTfCOOOOCSTf
ocN'«r»ooHHHHrtCS1NWWNMCOCOMCO^Tj,Tj,^^l0l0l0u:i0{e0{0
Теперь получилась радующая глаз равномерная шкала, за исключением одной
аномалии с литерой вблизи 62, что было неизбежно на принтере с «идеологией»
ксерокса. Плотность достигала 50% вблизи литеры с номером 22, и мы могли
420 Компьютерная типография
бы компенсировать это посредством предварительной обработки данных перед
выводом на печать (используя «transfer function»).
Три представленных выше изображения, полученных при помощи
odith300, после подстановки ddith300 выглядели примерно так:*
Поскольку мои студенты успешно справлялись с получением подходящих
увеличенных изображений посредством ddith300, я прервал работу над
полутонами и вернулся к своей привычной деятельности.
Позже, однако, я осознал, что ddith300 легко можно улучшить, потому что
каждая из этих литер состояла из двух точек примерно одинакового размера.
Не было никаких оснований именно таким образом объединять в пары
точки полутоновых изображений. Приложив совсем немного усилий, мы сможем
набирать каждую точку независимо.
Итак, я создал шрифт sdith300 для «одноточечного размывания» с 33
литерами (а не с 65, как ранее), используя матрицу
30
26
22
18
19
14
10
6
12
31
23
7
2
0
8
24
27
11
3
1
4
20
28
15
5
9
13
16
17
21
25
29]
для управлением порядком зачернения пикселей. (Эта матрица соответствует
ровно одной из двух точек в большей матрице, приведенной выше, если мы
разделим каждый элемент на 2 и отбросим остаток.) Литеры все еще
рассматриваются как литеры шириной 8 пикселей, но теперь они только 4-пиксельные.
Когда набирается фотография, строки с нечетными строкам должны быть
компенсированы по горизонтали посредством 4 пикселей.
Ниже представлен METAFONT-файл sdith.mf, который использовался для
генерации одноточечного шрифта. Обратите внимание, что регулярность
изображения (3) позволяет нам избежать перечисления всех 32 элементов матрицы
в явном виде:
Глава 21. Шрифты для дискретных полутонов 421
7, Шрифт полутонов с 33 градациями серого, полученный
У, "одноточечным размыванием" с литерами от "О" (белое) до "Р"
(черное)
pair р [] ; У, пиксели идут в таком порядке:
У, (сначала рО становится черным, затем pi и т.д.)
р0=(1,1); Р4=(2,0); р8=(1,0); р12=(0,0);
р16=(3,-1); р20=(2,-1); р24=(1,-1); р28=(2,-2);
transform r; r=identity rotatedaround ((1.5,1.5),90);
for i=0 step 4 until 28:
p[i+l]=p[i] transformed r;
p[i+3]=p[i+l] transformed r;
p[i+2]=p[i+3] transformed r;
endfor
w#:=8/pt; '/, это 8 пикселей
font_quad:=w#; designsize:=w#;
picture prevchar; У, пиксели зачерняются до сих пор
prevchar=nullpicture;
for i=0 upto 32:
beginchar(i+ASCII"0",w#,.5w#,0);
currentpicture:=prevchar;
if i>0:
addto currentpicture also unitpixel shifted p[i-l];
fi
prevchar:=currentpicture; endchar;
endfor
(Для обеспечения зависимости от устройства здесь имеется файл sdith300 .mf,
аналогичный файлу odith300.mf, рассмотренному ранее.)
Далее показано, как выглядят три примера изображений, когда они
переведены в шрифт sdith300 —улучшение очевидно:*
422 Компьютерная типография
Представленные ранее макро ТЕХ'a ht. tex должны быть заменены другим
множеством altht. tex, где использовались независимые точки:
У, Другие макро для набора полутонов
У, Пример использования:
У, \input altht У, ввод этого файла
У, \font\althtfont=<alternative halftone font> У, загрузка шрифта
У, \beginalthalftone
У, Литеры для верхней полустроки фотографии.
У, (сдвинуто наполовину вправо)
У, литеры для второй полустроки фотографии, (не сдвинуто вправо)
У. ...
У, литеры для нижней полу строки фотографии, (возможно, сдвинуто)
У, \endhalftone
У, Теперь фотография заключена в бокс подходящего размера.
У, Можно также установить \setboxO=\beginalthalftone...\endhalftone.
\chardef\other=12
\newif\ifshifted \newdimen\hfm
\def\beginalthalftone{\vbox\bgroup\offinterlineskip
\shiftedtrue \althtfont \hfm=.5em
\catcode'\.=\active \moveright\hfm\hbox\bgroup}
{\catcode'\.=\active \gdef.{\ifshifted\kern-\hfm\egroup
\shiftedfalse\else\egroup\shiftedtrue\moveright\hfm\fi
\hbox\bgroup\ignorespaces}}
\def \endhalftone{\egroup\setboxO=\lastbox\unskip\egroup}
Эти макро значительно проще тех, что использовались в ht. tex, потому что 33
ASCII-литеры от "О" до "Р" не имеют специального назначения в plain ТЁХ'е.
В 1987 г. я обнаружил, что похожая, но более изощренная техника уже
была разработана Робертом Л. Гардом [3] в 1976 г. Методы, которые мы до
сих пор рассматривали, основывались либо на (а) шрифте полутонов с 65
градациями серого, в котором каждая литера размера 8 х 8 в сущности дает на
фотографии две точки, либо на (Ь) шрифте полутонов с 33 градациями
серого, в котором каждая литера размера 4x8 дает на фотографии одну точку.
Метод Гарда основан на (с) шрифте полутонов с 17 градациями серого, в
котором каждая литера размера 4x4 дает полточки (фактически две четверти)
на фотографии.
В полуточечной схеме Гарда к-я градация серого получается зачернением
ячеек от 0 до к — 1 в массиве
1
3
13
15
5
7
9
11
10
8
6
4
14
12
2
0
или
10
11
13
15
(4)
(Мы фактически создаем два множества литер как зеркала друг друга, и
перемещаемся из одного в другое в процессе набора фотографии.) Следующий
METRFONT-файл hdith.mf будет так генерировать шрифт hdith300; в сущ-
Глава 21. Шрифты для дискретных полутонов 423
ности, тем же способом ранее были получены другие шрифты — ddith300 и
sdith300:
У, Шрифт полутонов с 17 градациями серого, полученный
У, "полуточечным размыванием"
У, с использованием литер от "А" (белое) до "Q" (черное) наравне
У, с зеркально отраженными версиями от "а" (белое) до "q" (черное)
pair р [] ; У, пиксели идут в таком порядке:
У, (сначала рО становится черным, затем pi и т.д.)
Р0=(3,0); Р4=(2,0); р8=(2,2); р12=(3,2);
transform r; r=identity rotatedaround ((1.5,1.5),180);
for i=0 step 4 until 12:
p[i+l]=p[i] transformed r;
p[i+2]=p[i] shifted (0,1);
p[i+3]=p[i+2] transformed r;
endfor
w#:=4/pt; У, that's 4 pixels
font_quad:=w#; designsize:=w#;
r:=identity reflectedabout ((2,0),(2,3));
picture prevchar; У, пиксели зачерняются до сих пор
prevchar=nullpicture;
for i=0 upto 16:
beginchar(i+ASGII"A",w#,w#,0); currentpicture:=prevchar;
if i>0:
addto currentpicture also unitpixel shifted p[i-l];
fi
prevchar:=currentpicture; endchar;
beginchar(i+ASCII"a",w#,w#,0);
currentpicture:=prevchar transformed r; endchar;
endfor
Для набора таким шрифтом мы можем, например, дать следующие команды:
\input ht
\font\htfont=hdith300
\beginhalftone
ilj JjKkJj JkJkKkKkJj Jj JiliJkJkJj Jj JjIhHhJjIjHjIgHhliliGhF
hGilhGhHhljJj Jj JjKkKkKkKkKkKkKkKilj JkKkLkKlKlLlLlLlLlL.
Ij JjKjJj Jj JkKkKkKj Jj JkHiHiJkJkJj Jj JiHhHililgHhGgGglgGgFe
FfGfGhHhHhlhliJkKkKkKlKkKkKkKkKkKkJkJkKkKkLkKkLlLlKkLl.
ilj JiKj Jj KkJkKkKkJkJj Jj Jj Jj JiJj JjIiHhlhlhHiGgFgFfGfGiIj К
jIiHgGfGhHhJjIjKkKkJkLkLkKkLkKlKkKjKkKkKlKkKkKkLlLlLlL.
HhliJj JjKj JkJjKkKkKkJj Jj Jj JjIiJj Jj JililhlhlhGfFeFkMnOoOo
OoOnNlJhGgHiljJjJjJjKkLlKkKkKkKkJkKkKkLkKlKkKkLkKlKkLl.
iJililhljKjJiJjKkKjKjJjJjJjIjJjJjIiliHhlililfFgLnOoOoOoO
oOoPoOoNkGfGhHiJj Jj JlKkKkKkKkLj KkKj Кj KkKkKkJj KkKkKlLkL.
IjIilhHiJjKiJj JjKjKj Jj JjIjIj JjIiJiHhliHhljIgGkOoOoOoOoOo
OpOoOpPpOoJgFglj JjIj JkKkJkJj JkKkKj Jj Jj KkKkJj Jj KkKlLkKl.
\endhalftone
424
Компьютерная типография
Прописные и строчные литеры чередуются в шахматном порядке, так что
зеркально отраженные литеры будут появляться в нужных местах. Если
необходимо, строки могут быть разорваны, потому что литеры пробелов в
шрифте hdith300 не имеют ширины. В случае половинных точек макро
\beginhalftone тот же самый, что и в случае двойных; отличаются только
название шрифта и схема кодировки.
Ниже для сравнения приведены девять фотографий, демонстрирующих
применение всех трех методов точечного размывания ко всем трем
изображениям:*
Метод половинной точки Гарда очевидным образом улучшает качество
одноточечных фотографий, несмотря на то, что он ограничивается 17 градациями
серого; у этого метода есть еще и то преимущество, что литеры в нем квадрат-
Глава 21. Шрифты для дискретных полутонов
425
ные, а не ромбовидные, что облегчает процесс вычислений. Но это означает,
что Т^Х должен будет удваивать набор при увеличении количества данных. В
самом деле, показанные здесь фотографии с двухточечными изображениями
были набраны в виде 64 строк с 55 литерами в каждой, одноточечные
изображения превратились в 128 строк с 55 литерами в каждой; фотографии с
половинными точками состоят из 128 строк со 110 литерами в каждой. Малые
версии ТЁК'а способны обрабатывать не более 50000 литер на странице.
(Макро \beginhalf tone читает изображение в память Т^Х'а целиком,
прежде чем наберет первую строку, и ТЁК не сбрасывает эту информацию до тех
пор, пока не возникнет необходимость использовать ее в каком-нибудь
сообщении об ошибке. Сухой остаток таков: необходимо удваивать объем памяти
ТЁ^'а, пока фотография не конвертируется в бокс. В случае половинных точек,
однако, вполне достаточно упрощенного варианта \beginhalf tone, потому что
в шрифте с 17 градациями вполне достаточно букв алфавита.)
Для принтера с высоким разрешением, скажем 635 точек на дюйм (что
эквивалентно 25 точкам на миллиметр), можно было бы создать аналогичные
шрифты ddith635, sdith635 и hdith635. Тогда наши 9 фотографий выглядели
бы примерно так:
Теперь фотографии уменьшились, потому что ширина литер все еще 8
пикселей, а сами пиксели стали меньше. При таком разрешении полутона могли бы
выглядеть так же хорошо, как при распечатке на профессиональных
устройствах, если бы не тенденция к излишнему затемнению из-за растискивания
краски; эта проблема решается установкой подходящей плотности программой-
препроцессором .
Приведенные выше образцы были подготовлены на основании данных с
256 градациями при помощи специальной подпрограммы-препроцессора,
которая приведена в приложении 1. Препроцессор опирается на обобщенный
алгоритм Флойда—Стейнберга [2], сглаживающий эффекты ограниченности
градаций серого. Действительно, если мы попробуем провести тот же самый
426
Компьютерная типография
эксперимент без ошибки диффузии, положив параметр препроцессора
демпфирование равным нулю, то девять примеров фотографий будут выглядеть
примерно так:*
Диффузия незначительно отражается на портрете Моны Лизы или на деталях
высокой частоты в изображениях Линкольна и Статуи свободы, но она весьма
существенна для фона, который меняется только постепенно. Без диффузии
ошибки сбивающий с толку «цифровой» эффект живописи может легко стать
слишком заметным, особенно когда доступны всего 17 градаций серого.
Какое нужно разрешение? Традиционно качество растра определяется
подсчетом точек в отрезке, равном одному дюйму в соответствующей прямой
сетке, и это легко выявить при помощи увеличительного стекла. Фотографии
Глава 21. Шрифты для дискретных полутонов 427
в газете вроде International Herald Tribune используют сетку с 72 линиями,
повернутую на 45°, что приблизительно соответствует разрешению 50\/2,
которое мы могли бы получить при помощи шрифта типа sdith400 на лазерном
принтере с разрешением 400 пикселей на дюйм. (Наши 300-точечные шрифты
ddith300, sdith300 и hdith300 дают поворот сетки только на 37.5\/2 « 53
линий на дюйм.) Фотографии на переплетах томов Computers &; Typesetting
сделаны с разрешением сетки 133 линии на дюйм, повернутых на 45°; это
несколько лучше, чем ранее приведенные примеры с разрешением 635 точек
на дюйм, которые соответствуют примерно 112 lpi. Но 133 отнюдь не
верхний предел: в книге с репродукциями высокого качества, как например [1],
сделанными дуплексом, использовался растр с разрешением около 270 lpi.
Обратимся теперь к другой проблеме. Предположим, что имеется
изображение, для которого нужно получить наилучшее из возможных
воспроизведений на лазерном принтере среднего разрешения, поскольку мы
собираемся использовать это изображение многократно —например, в качестве шапки
официального письма. В подобных случаях оптимальный результат
получается, если создать специальный шрифт для этого отдельного изображения,
потому что мы бы хотели управлять каждым пикселем, а не пользоваться
шрифтом для полутонов общего назначения. Тогда необходимое изображение
можно будет напечатать таким специальным шрифтом из «литер»,
представляющих собой прямоугольные участки целого.
Приведенные выше примеры были сначала напечатаны на принтере в виде
64 строк по 55 столбцов в строке с 8 пикселями в каждой строке и в каждом
столбце. Чтобы получить эквивалентную фотографию с каждым пикселем,
выбранным индивидуально, мы можем сделать шрифт, который имеет, скажем
80 литер, с 64 пикселями в высоту и 44 пикселями в ширину каждая. Набрав
8 строк по 10 литер, мы получим требуемое изображение. Именно так была
выполнена следующая фотография:*
ТЕХ станет набирать такую фотографию, если ему дать команду \gioconda,
предварительно задав такие определения:
428 Компьютерная типография
\font\lisa=lisa300
\newcount\m \newcount\n
\def\gioconda{\vbox{\lisa \offinterlineskip \n=0
\loop \hbox{\m=0 \loop \char\n \global\advance\n by 1
\advance\m by 1 \ifnum\m<10 \repeat}
\ifnum\n<80 \repeat}}
Как только у нас появились отдельные фрагменты, мы можем комбинировать
их, получая необычные эффекты:*
Показанный выше шрифт lisa300 был сгенерирован из файла lisa.mf.
который начинался примерно так:
row 1; data "ifffffffffffffffffffffffffffffffffffffffffff''
& "fffffffffffffffffffffffffffffffffffffff"
& "fffffffffffffffffffffffffff";
row 2; data "80808000900010008000209012101010201000009000"
& "9000001090802000001010a0000002291000002"
& "092009001008900805092080011";
row 3; data "8010f0d000d050f0a0910080a0a0a04080c0805000b0"
& "8080c08020200050808040a0bl9090a040a050a"
& "0405100b050003010404021b0c3";
row 4; data na8d00120b891308080a0a93100el2190a8005120a080"
& "2060945080a0a024a060a0284060204029a5a0c"
& "89020508134a850al59c8b065d9";
Глава 21. Шрифты для дискретных полутонов
429
... и т. д. вплоть до 512-й строки; этот файл был получен программой из
приложения 2, использующей метод под названием диффузия точки [7].
Параметром файла lisa300.mf был
У, Мона Лиза для Imagen 300
mode_setup;
if (pixels_per_inch<>300) or (magOl):
(error messages as before)
else: input picfont
width:=44; height:=64; n:=10; filename:="lisa";
do_it; fi
end.
а драйвером файла picf ont .mf был
string filename; picture pic[];
picO=nullpicture; pic8=unitpixel;
for j=0 upto 1: pic[4+8j]=pic[8j];
addto pic [4+8j] also unitpixel shifted (1,0); endfor
for j=0 upto 3: pic[2+4j]=pic[4j];
addto pic[2+4j] also unitpixel shifted (2,0); endfor
for j=0 upto 7: pic[l+2j]=pic[2j];
addto pic[1+2j] also unitpixel shifted (3,0); endfor
def do_it= ww:=width/4;
for j=0 upto n-1: jj:=ww*j;
scantokens("input "&filename); endfor enddef;
vardef row expr x =
cc:=(x-l)div height; rr:=height-l-((x-l)mod height);
if rr=height-l:
beginchar(cc*n+j j/ww,width/pt,height /pt,0) ; fi enddef;
vardef data expr s =
for k=0 upto ww-1: addto currentpicture also
pic[hex substring(jj+k,jj+k+1) of s]
shifted (4(jj+k),rr); endfor
if rr=0: xoffset:=-4jj; endchar; fi enddef;
Нельзя сказать, что это очень эффективно, но зато интересно и все-таки
работает. Весь фокус здесь заключается, разумеется, в том, чтобы избежать
переполнения памяти METAFONT'a, пожертвовав временем ради пространства.
(Немного цифр: файл lisa.mf был размером 65428 байт; METRFONT
производит файл lisa300.300gf общего шрифта размером 103088 байт, который
сжимается в файл lisa300.300pk упакованного шрифта размером 29044 байт.
Процесс генерации занимает всего 11256 слов памяти METAFONT'a и
использует пространство всего для 466 строковых литер.)
Кен Ноултон и Леон Хармон показали, что с фотографиями,
подвергнутыми оцифровке, можно получать удивительные эффекты (см. [6]). Следуя
430
Компьютерная типография
этой традиции, я обнаружил, что массу удовольствия может доставить
комбинация приведенных выше макро TgX'a с новыми шрифтами, и тут очевидным
образом проявляется их цифровая сущность. Не всегда нужно пытаться
конкурировать с коммерческими растрами!
Мы, например, можем использовать ht.tex с шрифтом 'negdot', что дает
негативы вне квадратных точек:
METAFONT-файл negdot.mf, генерирующий этот шрифт, весьма прост:
°/, шрифт псевдополутонов для негативов: 65 размеров квадратных точек,
У, использующий литеры от "0" (большой) до "р" (маленький)
mode_setup;
w#:=8/300in#; font_quad:=w#; designsize:=w#;
for i=0 upto 64: beginchar(i+ASCIT'O",w#,w#,0);
r#:=sqrt(.9w#*(l-i/80)); define_pixels(r);
fill unitsquare scaled r shifted(.5w,.5h); endchar;
endfor end.
В отличие от только что рассмотренных, этот шрифт не зависит от устройства
(и работает во всех разрешениях). Его «шкалой серого» является
Мы можем на самом деле воспринимать изображения, даже когда каждая
литера шрифта полутонов имеет одно и то же количество черных пикселей.
Вот, например, что происходит, когда три приведенных выше изображения
набираются шрифтом, в котором каждая литера состоит из вертикальной и
горизонтальной строки. Когда пиксели становятся темнее, строки сдвигаются
вверх и вправо, но они остаются равномерной толщины. Мы воспринимаем
Глава 21. Шрифты для дискретных полутонов
431
более светлые и более темные участки только благодаря тому, что строки либо
дальше отстоят друг от друга, либо плотнее сжимаются.
'ЮЮЮЮЮЮЮЮ
METAFONT-файл lines .mf для этого не зависящего от устройства шрифта
выглядит так:
У, шрифт псевдополутонов: 65 строк, перемещаемых вправо и вверх;
У, используются литеры от "О" (левый/нижний) до "р" (правый/верхний)
mode..setup; pickup pencircle scaled .3pt; q:=savepen;
w#:=8/300in#; font_quad:=w#; designsize:=w#;
for i=0 upto 64: beginchar(i+ASCH"0" ,w#,w#,0);
pickup q; draw (0,h*i/64) — (w,h*i/64);
draw(w*i/64,0) — (w*i/64,h) ; endchar;
endfor end.
Еще одна возможность получения шрифтов состоит в использовании
angles.mf; здесь каждая литера представляет собой отрезок фиксированного
размера, поворачивающийся от горизонтального до вертикального положения
в соответствии с возрастанием плотности:
У, шрифт псевдополутонов: 65 отрезков, которые меняют направление;
У, используются литеры от "0м (горизонтальный) до "р" (вертикальный)
mode_setup; pickup pencircle scaled .3pt; q:=savepen;
w#:=8/300in#; font_quad:=w#; designsize:=w#;
for i=0 upto 64:
beginchar(i+ASCII"0",w#,w#,0); pickup q;
draw ((0,0) —(w,0)) rotated (90*i/64) ; endchar;
endfor end.
432
Компьютерная типография
Получающиеся при этом изображения все еще удивительно легко
идентифицировать:
тжшжнж
(Можно представлять себе это в виде громадного массива солнечных часов,
стрелки которых указывают уровни локального освещения.) Забавно
рассматривать эти изображения, наклоняя страницу до тех пор, пока ваши глаза не
станут почти параллельны бумаге.
В качестве последнего примера рассмотрим шрифт из 33 литер, который
предназначен для использования с файлом altht.tex вместо ht.tex.
Читателей, имеющих склонность ломать голову, приглашаем попробовать догадаться,
что будет делать этот METRFONT-код, прежде чем посмотреть на портрет Мо-
ны Лизы, набранный соответствующим шрифтом. [Подсказка: название METR-
FONT-файла hex.mf.]
'/, чередующийся псевдополутоновой шрифт: 33 секретных образа;
'/, используются литеры от "О" до "Р"
mode_setup; q:=savepen;
w#:=6pt#; font_quad:=w#; designsize:=w#;
for i=0 upto 32: beginchar(i+ASCII"0",w#,.5w#,0);
pickup q; alpha:=.5-1/72; z0=(.5w,.5h);
zl=alpha[(5/6w,.5h),z0]; z2=alpha[(2/3w,-.5h),z0];
Z0=.5[z2,z5]=.5[z3,z6]=.5[zl,z4]; x2=x6; y5=y6;
draw zl—z2; draw .5[zl,z2]—zO;
draw z3—z4; draw .5[z3,z4]—zO;
draw z5—z6; draw .5[z5,z6]—zO; endchar;
endfor end.
Ответ на эту головоломку в виде иллюстрации помещен в самом конце главы
(после приложений и литературы).
Глава 21. Шрифты для дискретных полутонов
433
Приложение 1.
Препроцессор для изобразительного материала
Следующая программа на CWEB иллюстрирует, как конвертировать цифровое
изображение в тот вид, который требуется для описанных выше шрифтов и
макрокоманд. (Исходный файл half tone. w и некоторые файлы данных можно
скачать с http://www-cs-facuity.Stanford.edu/~knuth/programs.html.)
1. Введение. Эта программа подготавливает данные для изображений в
виде описанных выше шрифтов и макрокоманд. Предполагается, что входной
файл (stdin) представляет собой EPS-файл, полученный в результате работы
программы Adobe Photoshop™ на машине Macintosh с бинарной EPS-опцией,
имеющей разрешение 72 пикселя на дюйм. Этот файл имеет либо т строк по
п столбцов в каждой, либо т + п — 1 строк по т 4- п — 1 столбцов в
каждой, либо 2га строк по 2п столбцов в каждой; во втором случае изображение
должно быть повернуто на 45° против часовой стрелки. (Такие изображения
получаются, если начать с заданного km x /cn-изображения, возможно
повернутого на 45°, и затем использовать операцию Photoshop'a Image Size, чтобы
сократить размер до требуемого числа пикселей. В моих экспериментах я
положил к = 8, так что мог также использовать метод диффузии точки из
приложения 2; но к не должно быть целым. При больших значениях к
имеется тенденция к более четким уменьшенным изображениям, чем при малых
значениях.)
Файл вывода (stdout) представляет собой последовательность литер ASCII,
которую можно поместить в ТЁХ-файлы, что приведет к получению на
выходе изображений размера 8га x 8п, использующих шрифты, вроде описанных
в данной работе. В первом случае мы получим т строк из пикселей с 65
градациями. Во втором случае (с поворотом) мы получим 2ш срок из пикселей
с 33 градациями. В третьем случае мы получим 2ш строк из пикселей с 17
градациями.
#define т 64 /* базовое число строк */
#define п 55 /* базовое число столбцов */
#define г 64 /* max(ra,n) */
#include <stdio.h>
float a[m + m + 2][n + r]; /* зачерненность: 0.0 (белое), 1.0 (черное) */
(Глобальные переменные 4);
void main(int argc, char *argv[])
{ register int i, j, k, Z, p\
int levels, trash, tt, jj;
float dampening = 1.0, brightness = 1.0;
(Проверка для нестандартных множителей dampening и brightness 2);
(Определение шрифта на входе посредством просмотра ограничивающего
бокса з);
434
Компьютерная типография
fprintf (stderr, MMakinguy,dulinesuofuy.d-leveludata\iiM ,
(levels < 65 ? ra + ra : ra), levels);
print)(■'WbeginXshalftoneXn", levels = 33 ? "alt" : "");
(Ввод графических данных 5);
(Трансляция ввода в вывод 12);
}
2. Необязательные аргументы строковых команд позволяют пользователю
умножить постоянные диффузии на dampening и (или) умножить уровни
яркости на множитель brightness.
(Проверка для нестандартных множителей dampening и brightness 2) =
if (argc > 1 Л sscanf(argv[l], "*/.g" ^dampening) = 1) {
fprintf (stderr, "Usingudampeiiingufactoruy,g\iiM, dampening);
if (ar<7C > 2 Л 55can/(ar<7v[2], My,gM,&&n<7/ifriess) = 1)
fprintf (stderr, "uuandubrightnessuf actoruy,g\nM, brightness);
}
Эта программа использовалась в разд. 1.
3. Для Macintosh'a принято указывать окончание строки литерой ASCII
(возврат каретки) (т. е. control-M, aka \r); но библиотека С проводит работу
лучше с новыми строками (т. е. control-J, aka \n). Поскольку нас не
беспокоит эффективность, мы просто вводим одну литеру за раз. В этой программе
приняты соглашения для Macintosh'a.
Работа здесь заключается в просмотре последовательности 'Box:' на входе,
за которой следует 0, 0, количество столбцов и количество строк.
#define panic(s) { fprintf (stderr ,s); exit(-l);}
(Определение шрифта на входе посредством просмотра ограничивающего
бокса з) =
А; = 0;
scan:
if (к-Иг > 1000) panic("Couldn'tuf indutheuboundinguboxuinfo!\iiM );
if (getchar() ф 'В') goto scan;
if (getchar() ф 'о') goto scan;
if (getchar() ф 'х') goto scan;
if (getchar() ф ,:>) goto scan;
if (scanf ("У,*иУЛи/.<1иУА", &llx, klly, kurx, bury) ф 4 V Их ф 0 V lly ф 0)
panic (MBadubouiidinguboxudata! \n");
if (urx = n Л ury = ra) /eve/5 = 65;
else if (urx = n + n A ury = ra + ra) /eve/5 = 17;
else if (urx = ra + n — 1 Л un/ = mr) /eve/5 = 33;
else j9anгc(мBoшldinguboxudoesIl, tumatchutheuf ormatsuIuknow!\iiM);
Эта программа использовалась в разд. 1.
4. (Глобальные переменные 4) =
int llx: lly, urx, ury; /* параметры ограничивающего бокса */
см. также разд. 8.
Эта программа использовалась в разд. 1.
Глава 21. Шрифты для дискретных полутонов
435
5. После того как мы осмотрели ограничивающий бокс, поищем строку литер
fbeginimage\r'; за ней должны следовать пиксельные данные, по одной литере
на байт.
(Ввод графических данных 5) =
skan:
if (jfe++ > 10000)
panic (" Couldn' t uf indutheup ixeludata
if (getchar() ф 'b') goto skan',
if (getchar() ф 'е') goto skan\
if (getchar() ф 'g') goto skan\
if (getchar() ф 'i') goto skan]
if (getchar() Ф 'n') goto 5/:an;
if (getchar() ф '!') goto 5/:an;
if (getchar() ф 'm') goto 5/:an;
if (getchar() ф 'а') goto 5/:an;
if (getchar() ф 'g') goto 5A;an;
if (getchar() ф yey) goto 5/:an;
if (getchar() ф '\r') goto 5/:an;
!\n»);
if (levels = 33) (Ввод повернутых писельных данных 7)
else (Ввод прямоугольных пиксельных данных 6);
if (getchar() ф '\г')
pamc (MWronguamountuof upixeludat a! \n");
Эта программа использовалась в разд. 1.
6. Пакет Photoshop построен на основе соглашений, принятых в среде
фотографов, которые рассматривают 0 как черное и 1 как белое, но мы будем
следовать соглашениям, принятым у программистов, имеющих тенденцию
рассматривать 0 как отсутствие краски (белое), а 1 как полностью закрашенное
(черное).
Мы используем тот факт, что глобальные массивы изначально нулевые,
чтобы допустить возможность существования выше и ниже вводимых данных
полностью белых строк в прямоугольном случае.
(Ввод прямоугольных пиксельных данных 6) =
for (г = 1; г < игу\ г++)
for (J = 0; j < urx; j++)
a[i][j] = 1.0 — brightness * getchar( )/255.0;
Эта программа использовалась в разд. 5.
7. В случае поворота мы транспонируем ввод и частично его сдвигаем, так
что г-я строка может оказаться в позиции a[i][j 4- [_z/2j] при 0 < j < п.
Столь неочевидное размещение превращается в большое удобство на фазе
вывода благодаря применению к этому транспонированному выводу алгоритма
диффузии ошибки.
436
Компьютерная типография
Пусть, например, т = 5 и п = 3; вводом будет массив размера 7x7, который
можно представить в виде
/°
0
0
d
е
е
\0
0
0
с
D
I
N
f
0
Ь
С
н
м
R
W
а
В
G
L
Q
V
9
А
F
К
Р
и
h
0
1
J
О
Т
i
0
0
°\
к
S
3
0
0
0/
На практике ограничивающие значения а, 6, с, d, е, /, д, h, г, j, к, I очень малы,
так что они в сущности «белые» и лишь слегка тронуты краской. На этом шаге
мы трансформируем ввод к конфигурации
(1
А
а
0
0
0
0
0
0
к
J
F
В
Ь
0
0
0
0
0
S
О
К
G
С
с
0
0
0
0
3
т
р
L
Н
D
d
0
0
0
0
г
и
Q
м
I
0
0
0
0
0
0
h
V
R
°\
0 '
0
0
0
0
0
0
9
\0 О О О Е N W/
а позже получим
/ / к 0\
A J S
F О j
В К Т
G P i
С L U
Н Q h
D М V
I R д
\Е N W )
{Ввод повернутых пиксельных данных 7) =
{ for (г = 0; г < игу; г-Н-) for (j = 0; j < urx; j++) {
ii = m + i — j; jj = г + j + 1 — m;
if (ii > 0 Л ii < m + mAjj > 0 Л jj < n + n)
a[ii][i] = 1.0 — brightness * getchar ()/255.0;
else trash = getchar();
}
a[0][n — 1] = 1.0 — brightness; /* снова запомнить «потерянное значение» */
}
Эта программа использовалась в разд. 5.
Глава 21. Шрифты для дискретных полутонов
437
8. Диффузия ошибки. Мы конвертируем значения зачерненности к 65,
33 или 17 градациям, обобщая алгоритм Флойда—Стейнберга для адаптивных
уровней серого [2]. Идея состоит в том, чтобы охватить все изображение по
одному пикселю за раз и найти наилучшее значение плотности в текущей
рассматриваемой позиции и диффузию ошибки в соседних еще не обработанных
пикселях.
Для данного шрифта с к черными точками в литере к при 0 < к < /, мы
можем предположить, что видимая плотность fc-й литеры должна быть к/1.
Но физические свойства устройств вывода делают действительную плотность
нелинейной. Следующая таблица основана на измерениях, полученных при
наблюдении за шрифтом ddith300 на лазерном принтере Canon LBP-CX, и они
должны быть достаточно точными для практических целей на аналогичных
устройствах. Но на самом деле эти измерения не могут быть чересчур
точными, потому что считывания не были строго монотонными и потому что тонер
распределялся неравномерно между верхней и нижней кромками страницы.
Пользователи могут сделать свои собственные измерения, прежде чем
адаптировать эту подпрограмму к другим устройствам.
(Глобальные переменые 4) +=
float d[65] = {
0.000,0.060,0.114,0.162,0.205,0.243,0.276,0.306,0.332,0.355,
0.375,0.393,0.408,0.422,0.435,0.446,0.456,0.465,0.474,0.482,
0.490,0.498,0.505,0.512,0.520,0.527,0.535,0.543,0.551,0.559,
0.568,0.577,0.586,0.596,0.605,0.615,0.625,0.635,0.646,0.656,
0.667,0.677,0.688,0.699,0.710,0.720,0.731,0.742,0.753,0.764,
0.775,0.787,0.798,0.810,0.822,0.835,0.849,0.863,0.878,0.894,
0.912,0.931,0.952,0.975,1.000};
9. В основном цикле мы будем стремиться найти наилучшую аппроксимацию
для a[i][j] на основе доступных плотностей d[0], d[p], d[2p], d[3p], ..., где p есть
1, 2 или 4. Для этой цели хорошо подходит прямая аппроксимация бинарного
поиска:
(Найти /, такое, что d[l] находится как можно ближе к a[i][j] 9) =
^ (a[i]\j] < 0.0) / = 0;
else if (a\i][j] > 1.0) I = 64;
else { register int lo.l = 0, hi.l = 64;
while (hi.l — lo.l > p) { register int mid J = (lo.l + hi.l) > 1;
/* hid — lo.l каждый раз делится пополам, так что midJ кратно р */
if (a[z][j] > d[mid.l]) loJ = mid J]
else hi.l = mid J;
}
if (a[i\\j] - d[loJ] < d[hU] - a[i]\j]) I = loJ-
else / = hi J]
}
Эта программа использовалась в разд. 10 и 11.
438
Компьютерная типография
10. Поскольку прямоугольный случай самый простой, рассмотрим его
первым. Наша стратегия состоит в том, чтобы пройти каждый столбец сверху
вниз, начиная слева, и распространить ошибку на 4 необработанных соседа.
#define alpha 0.4375 /* 7/16, диффузия ошибки на соседа S */
#define beta 0.1875 /* 3/16, диффузия ошибки на соседа NE */
#define gamma 0.3125 /* 5/16, диффузия ошибки на соседа Е */
#define delta 0.0625 /* 1/16, диффузия ошибки на соседа SE */
(Обработка a[z][j] в прямоугольном случае ю) =
{ register float err;
if (i = 0Vi> игу) l = 0;
/* вне области вывода следует использовать белое */
else (Найти /, такое, что d[l] находится как можно ближе к a[i]\j] э);
err = a[i]\j] - d[l];
a\i\\j] = (float) (l/p);
/* от сих пор a[i]\j] является тем уровнем, когда плотность отсутствует */
if (г < игу) а[г + l][j] += alpha * dampening * err;
if (j < urx — 1) {
if (г > 0) a[i — l][j + 1] += beta * dampening * err;
a[i]\j + 1] += gamma * dampening * err;
if (г < игу) a[i + l][j + 1] += delta * dampening * err;
}
}
Эта программа использовалась в разд. 12.
11. Случай поворота, в сущности, тот же самый, но необработанными
соседями a[i][j] теперь являются a[i + l][j], a[i][j + 1], a[i + l][j + 1] и a[i + 2][j 4-1].
(Например, восемь соседей литеры К в матрицах из п. 7 суть В, F, J, О, Т, Р,
L,G.)
Часть вычислений на этом шаге опущены, поскольку известно, что эти
значения равны нулю.
(Обработка a[i][j] в случае поворота п) =
{ register float err;
if ((t»l)<j-nV (г > 1) > j) 1 = 0;
/* вне области вывода следует использовать белое */
else (Найти Z, такое, то d[l] находится как можно ближе к a[i][j] э);
err — a[i][j] — d[l];
a\i][j} = (float) (l/p);
/* от сих пор a[i]\j] является тем уровнем, когда нет плотности */
if (г < т + т — 1) а[г + l][j] += alpha * dampening * err;
if {j < m + n - 2) {
a[i][j + 1] += beta * dampening * err;
if (г < m + m — 1) a[i + l][j + 1] += gamma * dampening * err;
if (i < m + m — 2) a[i + 2][j + 1] += delta * dampening * err;
}
}
Эта программа использовалась в разд. 12.
12. Наконец, мы готовы все объединить.
Глава 21. Шрифты для дискретных полутонов
439
(Трансляция ввода в вывод 12) =
р = 64/(levels — 1);
if (P 9*2) {
for (j = 0; j < urx; j-H-)
for (г = 0; i < ury +1; г++) (Обработка a[i][j] в прямоугольном случае ю);
for (г = 1; г < игу; г++) {
for (j = 0; j < urx; j-H-)
print/("У,с",(р=1? >0' : ((i + j)&l) ? 'a' : 'A') + (uit) a[i][j]);
print/ ("An");
}
}
else {
for (j = 0; j < m + n — 1; j-H-)
for (г = 0; г < m + га; г++) (Обработка a[z][j] в случае поворота п );
for (г = 0; г < га + га; г++) {
for (j = 0; j < п; j-H-) print}'('"/.с", '0' + (int) a[i]\j + (г » 1)]);
print}(" An");
}
}
print/("Wendhalf tone\n");
Эта программа использовалась в разд. 1.
Приложение 2. Пиксельная оптимизация
Здесь приводится другая короткая программа на CWEB. Она использовалась
для создания специального шрифта для портрета Моны Лизы.
1. Введение. Эта программа создает METflFONT-файл для особого
шрифта, предназначенного исключительно для аппроксимации данной фотографии.
Предполагается, что входной файл (stdin) является EPS-файлом, полученным
программой Adobe Photoshop™ на платформе Macintosh с бинарной опцией
EPS, содержащей т строк в каждом из п столбцов. В терминологии Photoshop
это значит, что изображение высотой т пикселей и шириной п пикселей в
шкале серого с разрешением 72 пикселя на дюйм. Файл вывода (stdout) должен
быть последовательностью из т строк типа
row 4; data "e8...d9";
это означает, что пиксельные данные для строки 4 представляют собой
цепочку из п битов 11101000.. .11011001, закодированную как шестнадцатеричная
строка длины п/4.
Для простоты предположим, что ш = 512ип = 440.
#define m 512 /* много строк */
#define п 440 /* много столбцов */
#include <stdio.h>
float a[m + 2][п + 2]; /* зачерненность: 0.0 белое, 1.0 черное */
(Глобальные переменные 4)
440
Компьютерная типография
(Подпрограммы 12)
void main(int argc,char *argv[])
{ register int г, j, k, Z, tt, jj, w\
register float err;
float zeta = 0.2, sharpening = 0.9;
(Проверка нестандартных множителей zeta и sharpening 2);
(Проверка начальных строк входного файла з);
(Ввод графических данных 5);
(Трансляция ввода в вывод 15);
(Выдача ответов 17);
}
2—6. [Пункты 2-6 этой программы в целом идентичны соответствующим
пунктам программы из приложения 1, но несколько проще; вырежем конец
п. б, где начинаются интересные различия.]
Мы используем тот факт, что глобальные массивы изначально нулевые,
полагая, что полностью белые строки из нулей располагаются выше, ниже,
слева и справа от вводимых данных.
(Ввод прямоугольных пиксельных данных 6) =
for (г = 1; г < игу] гИ-)
for (j = 1; j < urx; JH-) Q<[i][j] = 10 — getchar()/255.0;
Эта программа использовалась в разд. 5.
7. Диффузия точки. Наша задача состоит в том, чтобы от 8-битовых
пикселей перейти к 1-битовым, т. е. от 256 оттенков серого к примерно
такому положению, когда используются только белое и черное. Используемый при
этом метод называется диффузией точки (см. [7]); это работает следующим
образом. Пиксели разделяются на 64 класса, пронумерованных от 0 до 63. Мы
конвертируем значения пикселей в нули и единицы, назначив сначала всем
пикселям класс 0, затем всем пикселям класс 1 и т. д. Ошибки, получившиеся
на каждом шаге, распределяются между соседями более высокого класса. Это
осуществляется посредством предварительного вычисления таблиц class-row,
class-col, start, deLi, deLj и alpha, функции которых легко понять из
следующего фрагмента программы:
(Выбор пиксельных ошибок и распространение (диффундирование) ошибок в
буфере 7) = 4
for (k = 0; к < 64; к-Н-)
for (г = class-row[k]; -г < га; г += 8)
for (j = class-col[k]; j < n\ j += 8) {
(Решение о цвете пикселя [г, j] и результирующая ошибка err 9);
for (/ = start[k]\ I < start[k + 1]; 1-Й-)
a[i + deLt[Z]][j + deL;[/]] += err * alpha[l]]
}
Эта программа использовалась в разд. 15.
8. Мы будем использовать следующую модель для оценивания эффекта
данного битового изображения в выводе: если пиксель черный, его зачерненность
Глава 21. Шрифты для дискретных полутонов 441
равна 1.0; если он белый, но по крайней мере один из четырех соседей черный,
его зачерненность равна zeta; если он белый и его четыре соседа тоже белые,
то его зачерненность равна 0.0. Лазерные принтеры 1980-х годов имели
тенденцию таким образом распылять тонер, чтобы в первом приближении иметь
в этой модели zeta = 0.2. Значение zeta должно находиться между —0.25 и
+1.0.
Для того чтобы облегчить процесс вычислений в этой модели, в
дополнительном массиве аа поддерживаются значения кодов white, gray или black. Все
ячейки изначально белые (white); но как только мы решили сделать пиксель
черным (black), мы меняем его белых (white) соседей, если таковые имеются,
на серых (gray).
#define white 0 /* код для белого пикселя со всеми белыми соседями */
#define gray l /* белый пиксель с 1, 2, 3 или 4 черными соседями */
Фdefine black, 2 /* код для черного пикселя */
(Глобальные переменные 4) +=
char аа[т + 2][п + 2];
/* статус white, gray или black для окончательных пикселей */
9. На этом шаге определяется текущее однобитовое значение окончательных
пикселей. Теперь пиксель либо белый (white), либо серый (gray); мы либо
оставляем его в том виде как есть, либо зачерняем, а белых соседей делаем
серыми, в зависимости от того, что приведет к минимизации величины ошибки.
Потенциально серые значения gray только что выбранных пикселей
несколько усложняют эти вычисления. [Пояснение: первые две мои попытки оказались
неудачными.] Обратите внимание, например, что при создании самого первого
черного пикселя локальная зачерненность изображения увеличится
примерно на 1 + 4zeta. Предположим, что исходное изображение полностью черное,
так что a[i][j] равно 1.0 при 1 < i < ш и 1 < j < п. Если пиксель класса 0
установлен в white, то ошибка (т.е. зачерненность, которая необходима для
диффундирования соседей более высокого класса) равна 1.0; но если он
установлен в black, то ошибка равна — Azeta. Этот алгоритм будет выбирать black,
пока не будет zeta > .25.
(Решение о цвете пикселя [г, j] и результирующая ошибка err 9) =
if (aa[i][j] = white) err = a[i][j] — 1.0 — 4 * zeta;
else { /* aa[i][j] = gray */
err = a[i][A— 1.0 + zeta;
if (aa[i — lj[j] = white) err —= zeta;
if (aa[i -f- l][j] = white) err —= zeta;
if (aa[i][j — 1] = white) err — = zeta;
if (aa[i][j -f-1] = white) err — = zeta;
}
if (err + a[i}[j] > 0) { /* черное лучше */
ааИЬ1 = black;
if (aa[i — l][j] = white) aa[i — l][j] = gray;
if (aa[i + l][j] = white) aa[i -f l][j] = gray;
if (aa[i][j — 1] = white) aa[i][j — 1] = gray;
if (aa[z][j + 1] = white) aa[i][j + 1] = gray;
442
Компьютерная типография
}
else err = a[i]\j]\ /* сохранить это белым или серым */
Эта программа использовалась в разд. 7.
10. Вычисление таблиц диффузии. Таблицы для диффузии точки
могут быть специфицированы большим количеством нудных операторов
присваивания, но значительно приятнее вычислять их неким методом,
приподнимающим завесу таинственности структуры, заложенной в основу.
(Инициализация таблиц диффузии ю) =
(Инициализация матрицы номеров класса 13);
(Компиляция «инструкций» для операций диффузии 14);
Эта программа использовалась в разд. 15.
11. (Глобальные переменные 4) +=
char class-row [64], class-col [64];
/* первые строка и столбец для данного класса */
char class-number [10][10]; /* номер данной позиции */
int кк =0; /* сколько классов было до сих пор */
int start [65]; /* первая инструкция для данного класса */
int с?е/_г[256], deLj[256]\ /* относительное положение соседа */
float а(рЛа[256]; /* коэффициент диффузии для соседа */
12. Использованный здесь порядок классов — это порядок, в котором могут
быть зачернены пиксели в шрифте для полутонов, основанном на точках в
сетке, повернутой на 45°. На самом деле это в точности то же самое изображение,
которое использовалось в матрице (2) для шрифта ddith300, обсуждавшегося
ранее в данной работе.
(Подпрограмма 12) =
void store (int г, int j)
{
if (г < 1) г += 8; else if (г > 8) г -= 8;
if (j < 1) j += 8; else if (j > 8) j -= 8;
class-number [i][j] = kk\
class .row [kk] = г; class-col[kk] = j;
kk++\
}
void store-eight (int г, int j)
{
store(i,j)\ store(i — 4,j + 4); store(l — j,i — 4); store(b — j,i);
store(j,b — г); store(4 + j, 1 — г); store(b — г, 5 — j); store(l — г, 1 — j);
}
Эта программа использовалась в разд. 1.
13. (Инициализация матрицы номеров классов 13) =
store-eight (7, 2); store-eight (8,3); store-eight(8,2); store-eight (%, 1);
store.eight (1,4)\ store-eight (1,3); store-eight (1,2)\ store-eight (2,3);
for (i = 1; i < 8; i++)
class-number [i][0] = c/ass_rmm&er[i][8], c/ass_rmm&er[i][9] = class-number [i][l]\
Глава 21. Шрифты для дискретных полутонов
443
for (j = 0; j < 9; j-H-)
class-number[0]\j] = class-number[8]\j], class-number[9]\j] = class-number [l]\j]\
Эта программа использовалась в разд. 10.
14. «Компиляция» на этом шаге очень медленно моделирует процесс
диффузии, регистрируя выполняемые при этом действия. Позже все эти действия
могут быть выполнены с более высокой скоростью.
(Компиляция «инструкций» для операций диффузии 14) =
for (к = 0, / = 0; к < 64; к++) {
start[k] = Z; /* Z есть число инструкций, скомпилированных до сих пор */
г = class-row[k]; j = class-col[k]; w = 0;
for (tt =i — l; tt < i + 1; t't++)
for (jj = j - 1; jj < j + 1; jj++)
if (class-number[ii][jj] > k) {
deLi[l] = ii — i; deLj[l] = jj — j\ Z++;
if (и Ф г Ajj ф j) w-H-] /* соседи по диагонали получают вес 1 */
else w += 2; /* ортогональные соседи получают вес 2 */
}
for (jj = start[k}; jj < Z; jj++)
if (deLi\jj] ф О Л deLJlJj] ф 0) alpha[jj} = l.O/w;
else alpha\jj] = 2.0/w\
}
5^ar^ [64] = Z; /* с этого места Z будет 256 */
Эта программа использовалась в разд. 10.
15. Синтез. Теперь мы готовы объединить все фрагменты воедино.
(Трансляция ввода в вывод 15) =
(Инициализация таблиц диффузии 10);
if (sharpening) (Четкая обрисовка ввода 16);
(Выбор значений пикселей и диффундирование ошибки в буфере 7);
Эта программа использовалась в разд. 1.
16. Опыт показывает, что диффузия точки часто лучше справляется с
заданием, если применить операцию фильтрования, которая преувеличивает
различия между яркостью пикселя и его соседей:
Q>ij
CLij QL&ij
а
где
, +i +i
5=-l 6=-l
+6)(j+e)
есть среднее значение величины а^ и ее восьми соседей (См. обсуждение в [7].
Параметр а является значением sharpening, которое преимущественно
меньше 1.0.)
Можно вместо применения этого преобразования использовать схему буф-
феризации, но легче сохранить это новое значение а^ в a(i_i)(J_i) и затем
444
Компьютерная типография
впоследствии сдвинуть все обратно. Значения а^ и aoj не должны снова
перезаписываться в нуль после этого шага, потому что они не будут снова изучаться.
(Четкая обрисовка ввода 16 ) =
{
for (г = 1; г < га; г-Н-) for (j = 1; j < щ j++)
{ float abar;
abar = (a[i - l][j - 1] + a[i - l][j] + a[i - l][j + 1] + a[i\[j - 1] +
a[i][j} + a[i\[j + 1} + a[i + l][j - 1] + a[i + l]\j] + a[i + l][j + l])/9.0;
a[i — l][j — 1] = (aM[J] — sharpening * abar)/(1.0 — sharpening)]
}
for (г = m; i > 0; г—) for (j = n; j > 0; j —)
a[i\\j] = (a[i - l][j - 1] < 0.0 ? 0.0 : a[i - l][j - 1] > 1.0 ? 1.0 : a[i - l][j - 1]);
}
Эта программа использовалась в разд. 15.
17. Здесь предполагается, что п кратно четырем.
(Выдача ответов 17) =
for (г = 1; г < га; г++) {
j9nn^/(Mrowu7.d;udatau\MM ,г);
for (j = 1; j < щ j += 4) {
for (к = 0, w = 0; к < 4; к-Н-) w = w + w + (aa[i][j + к] = black ? 1 : 0);
рпп^/(м7.хи,г(;);
}
print/ ("\";\n");
}
Эта программа использовалась в разд. 1.
18. Из следующих примеров видно действие параметров zeta и sharpening
на этот алгоритм:*
нет четкой обрисовки, четкая обрисовка, четкая обрисовка,
С = .2 С = -2 С = 0
Описанное в этой работе исследование частично финансировалось фондом System
Development Foundation, а частично — фондом National Science Foundation по грантам IST-
8201926, MCS-8300984 и DCR-8308109.
Глава 21. Шрифты для дискретных полутонов
445
Литература
[1] Carolyn Caddes, Portraits of Success (Portola Valley: Tioga Press, 1986).
[2] Robert W. Floyd and Louis Steinberg, "An adaptive algorithm for spatial greyscale,"
Proceedings of the Society for Information Display 17 (1976), 75-77. Предыдущий
вариант опубликован в SID 75 Digest (1975), 36-37.
[3] Robert L. Gard, "Digital picture processing techniques for the publishing industry,"
Computer Graphics and Image Processing 5 (1976), 151-171.
[4] Ramsey W. Haddad and Donald E. Knuth, A Programming and Problem-
Solving Seminar, Stanford Computer Science Department report STAN-CS-85-1055
(Stanford, California: June 1985). Этот семинар был записан также на
видеокассету под названием "Problem solving with Donald Knuth," The Stanford Video
Journal 1 (Stanford, California: Stanford Instructional Television Network, 1985).
[5] J. F. Jarvis, C. N. Judice, and W. H. Ninke, "A survey of techniques for the display
of continuous tone pictures on bilevel displays," Computer Graphics and Image
Processing 5 (1976), 13-40.
[6] Ken Knowlton and Leon Harmon, "Computer-produced grey scales," Computer
Graphics and Image Processing 1 (1972), 1-20.
[7] Donald E. Knuth, "Digital halftones by dot diffusion," ACM Transactions on
Graphics 6 (1987), 245-273. [Обновленный вариант этой статьи опубликован в
настоящем издании в виде гл. 22.]
446
Компьютерная типография
«H4IM»fll<IIM»M»MIMIU»UIMIt4»MIUM^WU»t4l*4»*4»*ll*4l*l»t||«4«M»t4tM»t4lt|lt4IMIMIt4lt|l*4l*IHII*ll*llfl»f«»t4M4ll|lt4lt4lt4lf4lt4lt4tt4H4lll»<l
1И4И4114И4И4Ш»М»М»М|М|£«»им2нШ|1^^
i»tm4u«tt4>tmniX»mmmi^
14М*1ОДШОДММ«М4М|М4»*4М4М4М4М|М4Н1Н4И4М|Н
l»mmimjUIMblTmU»tl»M»M»>4tMll4IMIMU4U4lt4lt4l*4l
14)^4l^M4lU4lU4M4M(M4»14U4M4»t4»14l<4l«4»t4M4»f4HIH
14ШМ4М4М4М4М4М4М4М4М4М4М4М4М4М4Н4М4Н4И4И
|ШШШШШДЩил.Ш w 1и.ШлШАШШШ пштти iu 1
,йойой5йсйо^
я^^^вдя
wawaIAv^^
iiuTvwwOro^
«ШШшлХШГОО^^
v(CC£CCwCw£0^
даЛЙш^лГСШЯ^^
vwwOCOTCwCCKCUCwCcO^
\ШШхшшхшШц&
лОТООССШ^
жгсгажгаййпйпщ
шсйй™й!йййй
^ДИШШмм
\тсОО(щ1(ШшШшш
лОПшшшУШшА^
WJJJifi А
л
aFw"A А А А А А А А А ЛОООСи^^
9
г*
с*
"X"x"xwj.wT.wxwxwxwxwTwTvTirIifm
х"х"х"х wx wx"x "х"х"х™х":гх¥ПОгР1птптОТ
™xwiwxwiwx™xwiwxwx™xwx™JimmiimTQra
Д Д Д Д Д Д Д Д Д Д Д пууТОСТ
**A*A*A*A*A*A*A*A*A*Afy&KGXTO)™
тШх™А J xwx*x*x*x*x*x*x*x*x*x™jmmEnOT
ШЁ?А А
ШЯ?аj
*Х"Т"Т*»*»"¥*¥*¥
ШВ&здСа?
XaUXC£U£j
ааауДШшзОшСиОО^^
*х*хл ЛШшШШШш
ШшКШООЙЛАУАА. А А А * А'АУЦЦ'ШДШШШШУШиШМ
ЙШМЮ
^{б^Шкго^^
*
л1ШАШШШШШШШмШши/А А
РООийШшшаШшОщ^
ШггтШшШ
гшООСООСШтШХСХЮХОООООООО
jffflwJw^^
ййбй1)^
Г*
А 1.&№ШК^^
A A A ^rW^VW^^
*1*1*1*1№1ШШШШ
x^^^wuaSSS
AAAAAAAaV*^A
WW№W
этшишШа
ЙЙЙЙЙЙЙ'х
WffirMFRii
Йут*
WW*
?*
со оо w ^ ^ ^ w
»*»*1.*1.*1.*1АтА.АтАтАтАтАтАтЛтЛтЛтт
О М ч* СО 00 О СЧ
М СЧ М М М СО СО
Оцифровка полутонов
посредством диффузии
точки
[Переработка статьи, первоначально опубликованной в ACM Transactions on
Graphics 6 (1987), 245-273.]
В этой работе описывается метод аппроксимации пикселей, принимающих
действительные значения, двоичными пикселями. Новый метод, называемый
диффузией точки, вводится для того чтобы преодолеть недостатки других
общепринятых методов. Для него требуется примерно такое же общее
число арифметических операций, что и для метода Флойда—Стейнберга
адаптивной градации серого цвета, и он так же хорошо подходит для
параллельных вычислений. Однако в случае последовательных вычислений на машине с
ограниченным объемом памяти нужно больше буферов и более сложная
программная логика, чем в других методах. Для использования на принтерах с
высоким разрешением можно доказать «гладкий» вариант этого метода.
Для заданного массива А размера тхп действительных значений,
заключенных между 0 и 1, мы хотим построить массив В размера тхпиз нулей и
единиц, такой, что среднее его элементов B[i,j] при (г, j), находящихся вблизи
(го, jo), приблизительно равно A[io, jo]. В приложениях А представляет собой
интенсивность света в изображении при сканировании некоторым
фотоустройством, В —бинарную аппроксимацию изображения при выводе на печать.
Диффузия ошибки
Одно интересное решение этой задачи было предложено Флойдом и Стейнбер-
гом [7], которые вычисляли В из А следующим образом:
for г := 1 to m do for j := 1 to n do
begin if A[iJ] < 0.5 then B[iJ] := 0 else B[i,j] := 1;
err := A[iJ]-B[iJ}\
A[i,j + 1] := A[i,j + 1] + err * alpha;
A[i + 1, j - 1] := A[i + 1, j - 1] + err * beta;
A[i + 1, j] := A[i + 1, j] + err * gamma;
A[i + 1, j + 1] := A[i + 1, j + 1] + err * delta;
end.
448
Компьютерная типография
Здесь а, /3, 7 и ^ суть некоторые константы, выбранные так, чтобы
диффундировать (рассеять) ошибку; они прямо пропорциональны близлежащим
элементам, значения В которых еще только должны быть найдены. Флойд и
Стейнберг предлагали взять (а, /3,7, S) = (7,3,5,1)/16. Аналогичный, но более
сложный метод был опубликован ранее Манфредом Шредером [23].
Метод Флойда—Стейнберга часто дает блестящие результаты, но имеет
свои недостатки. Прежде всего —это настоящий последовательный метод:
значения В[т,п] зависят от всех тп элементов массива А. Более того, иногда он
помещает «тени» в иллюстрацию; например, когда таким способом
обрабатываются лица, посреди лбов могут оказаться тени от волосков. Ниже мы обсудим
и другие возникающие проблемы.
Проблема теней может быть слегка смягчена выбором таких (а, /3,7,<5), что
их сумма меньше единицы; тогда влияние A[i,j] на отдаленные элементы
будет снижаться экспоненциально. Тем не менее добиться полного уничтожения
теней таким способом не удастся. Предположим, например, что А[г, j] имеет
постоянное значение а для всех г и j и пусть в = (ft + J + 5)/(1 — а) < 1. Если
а очень мало, то все элементы B[i,j] для малых значений г будут равны нулю,
а элементы j4[z,j] для больших значений j будут постепенно приближаться к
предельному значению
а(1 + в + • • • + в1~1){1 + а + а2 + • • •) = а(1 + в + • • • + в{-г)/(1 - а)
для больших j. Если выбрать а так, чтобы его значение было только чуть
меньше 1/2, то в (г + 1)-й строке массива В неожиданно многие значения
установятся в 1, а во всех предыдущих строках они станут нулевыми.
Флойд [8] обнаружил, что тени исчезают, если интенсивности A[i,j]
масштабировать. Например, каждую интенсивность A[z,j] можно заменить на
0.1-+-0.8А[г, j]. Это работает, потому что человеческий глаз более чувствителен
к контрасту, чем к уровням абсолютного сигнала.
Упорядоченное размывание
Другой подход к проблеме дает интересная техника упорядоченного
размывания [14, 17, 18]. Здесь мы делим множество всех позиций (г, j) на, скажем,
64 класса, упорядоченных от 0 до 63 на основании значений г и j по
модулю 8 как показано в табл. 1. Если (г, j) принадлежит классу к, то бит B[i,j]
устанавливается в 1 тогда и только тогда, когда A[i,j] > (к + .5)/64. Иными
словами, каждый пиксель представляет собой порог, основанный на значении в
соответствующей позиции матрицы размывания. Обратите внимание, что если
А[г, j] имеет постоянное значение а, то этот метод будет включать t пикселей
в каждую подматрицу размера 8x8 массива В, где |£/64 — а\ < 1/128.
Диффузия точки
Техника упорядоченного размывания представляет собой абсолютно
параллельную процедуру, свободную от теней, но она имеет тенденцию к нерезким
изображениям. Так что очень хорошо было бы найти такое решение, которое
Глава 22. Оцифровка полутонов посредством диффузии точки 449
45
13
39
7
47
15
37
5
29
61
23
55
31
63
21
53
34
2
40
8
32
0
42
10
18
50
24
56
16
48
26
58
46
14
36
4
44
12
38
6
30
62
20
52
28
60
22
54
33
1
43
11
35
3
41
9
17
49
27
59
19
51
25
57
Таблица 1. Номера классов для упорядоченного размывания.
объединяло резкость метода Флойда—Стейнберга и параллелизм
упорядоченного размывания.
Следующая техника, по-видимому, обладает требуемыми свойствами.
Пусть мы разбили позиции (г, j) на 64 класса по г и j по модулю 8 как и
ранее, но вместо матрицы из табл. 1 воспользуемся матрицей из табл. 2 на
следующей странице. (Интуитивный подход получения табл. 2 будет
объяснен позже, а пока будем просто считать, что это обычная перестановка чисел
{0,1,..., 63}.)
Для любой такой матрицы мы можем выполнить следующий
диффузионный алгоритм:
for к := 0 to 63 do
for all (г, j) of класс к do
begin if A[iJ] < 0.5 then B[iJ] := 0 else B[iJ] := 1;
err := A[iJ] - B[iJ];
(Распределение ошибки err среди соседей (г, j),
номера класссов которых превосходят к);
end.
Пиксели класса 0 вычисляются самыми первыми, затем вычисляются пиксели
класса 1 и т. д.; ошибки переходят в соседние элементы до тех пор, пока они
не будут вычислены.
Каждая позиция (z,j) имеет четыре ортогональных соседа (и,г?), таких,
что (и — г)2 + (v — j)2 = 1, и четыре диагональных соседа (и, v), таких, что
(и — г)2 + (v — j)2 = 2. Один из возможных способов распределить ошибку в
диффузионном алгоритме выглядит так:
(Распределение ошибки err среди соседей позиции (г, j),
номера классов которых превосходят к) =
w := 0;
for all соседи (u,v) позиции (г, j) do
if класс(и, v) > к then w := w + вес(и — г, v — j)\
for all соседи (u,v) позиции (г, j) do
A[u, v] := A[u, v] + err * вес(и — i,v — j)/w.
450 Компьютерная типография
35
43
51
38
29
21
13
24
48
59
62
46
14
5
0
16
40
56
60
54
22
6
2
8
32
52
44
36
30
10
18
26
28
20
12
25
34
42
50
39
15
4
1
17
49
58
63
47
23
7
3
9
41
57
61
55
31
11
19
27
33
53
45
37
Таблица 2. Номера классов для диффузии точки.
Мы можем выбрать весовую функцию так, чтобы вес(х,у) = 3 — х2 — у2\ она
присваивает ортогональным соседям вес вдвое больший, чем диагональным
соседям. Более эффективно веса и списки соответствующих соседей вычислять
заранее, раз и навсегда, поскольку номера классов не зависят от значений А.
Применение этого метода подробно описывается в работе [14]. Программа в
этой статье рассматривает также некое обобщение, в котором предполагается,
что белые пиксели, расположенные ортогонально черным пикселям, привносят
некоторый оттенок серого в общую зачерненность; это аппроксимирует
характеристики растискивания растровой точки в некоторых устройствах вывода.
Границы ошибки
Будем говорить, что позиция (г, jf) является бароном, если она имеет соседей
только более низкого класса. Бароны не распознаются в диффузионном
алгоритме, так как они впитывают все локальные ошибки. На самом деле позиции
«почти барон», имеющие только одного соседа более высокого класса, также
относительно нераспознаваемы, так как они направляют все ошибки в одно и
то же место. Структура класса матрицы из табл. 2 имеет только двух баронов
(62 и 63) и только двух почти баронов (60 и 61). Напротив, структура класса
матрицы упорядоченного размывания из табл. 1 более или менее удачна для
диффузии, так как имеет 16 баронов (с 48 по 63).
Средняя ошибка на пиксель в методе диффузии точки обычно будет
меньше, чем количество баронов, деленное на удвоенное число классов, если
усреднение проводится по области, содержащей по одному пикселю в каждом классе.
Например, мы ожидаем, что поглощается самое большее 2/128 единиц
интенсивности на один пиксель в произвольной области размера & х &, если
используется приведенная выше матрица, поскольку ошибка, зафиксированная
в каждом пикселе, компенсируется еще где-то, за исключением двух баронов,
где ошибка, как правило, не больше 1/2.
Можно, однако, построить плохие примеры, в которых элементы
матриц становятся отрицательными или больше 1. Следовательно, максимальная
Глава 22. Оцифровка полутонов посредством диффузии точки
451
ошибка не просто зависит от количества баронов. Наихудший случай можно
ограничить следующим образом:
for к := 0 to 62 do
for I := к + 1 to 63 do
граница[/] := граница[/] + ot-ki * тах(0.5,граница[/с]).
Здесь aki представляет собой постоянную диффузию ошибки от класса к к
классу /, как определялось выше, либо нуль, если класс I не является
соседом класса к. Из этого следует, что граница[/] — это максимальная ошибка,
которая может быть передана позициям класса I из позиций нижних
классов. Максимальная общая ошибка в области, содержащей по одной позиции
каждого класса, равна сумме величин тах(0.5,граница[/с]) по всем баронам
классов к. Это эквивалентно тому, что она равна сумме всех классов к величин
тах(0,0.5 — граница[/с]). (Доказательство. Имеем
yj max (0,0.5 — граница[/с])
к
= у] max (граница[/с] ,0.5) — S
к
= V^тах(граница[/с], 0.5) f [к есть барон] + V^ аы) — S
к 1>к
= 2_] тах(граница[А:],0.5) + /J граница[/] — S
к есть барон I
где S = ^^. граница [/с].) Для матрицы из табл. 2 имеем граница[62] =
граница[63] « 4.3365; следовательно, средняя ошибка на пиксель всегда
меньше, чем 8.674/64 < 0.136.
Исходные данные должны выбираться опасным противником, если
ошибка собирается стать настолько плохой. (Множествами-противниками являются
А [г, j] = 0.5+граница[/с], если (г, jf) принадлежит классу /с, где граница[/с] < 0.5;
в противном случае A[i,j] = 0.) С другой стороны, противник, который хочет
разрушить алгоритм упорядоченного размывания, может сделать это,
зафиксировав ошибки величины 0.5 на пиксель в каждом блоке размера 8x8. (Если
(г, j) принадлежит классу /с, а А [г, j] есть (к + .5)/64, то В[г, j] = 1 для всех г
и j, но каждое А имеет среднюю плотность 0.5.)
Метод Флойда—Стейнберга имеет по этому критерию ошибку, близкую к
нулю, поскольку все ошибки возникают на границе, площадь которой
пренебрежимо мала.
Матрица из табл. 3 имеет только одного барона и одного почти барона;
кроме того, это приводит к граница[63] « 7.1457. Следовательно, для
диффузии точки это лучший вариант, чем матрица из табл. 2. Тем не менее бароны
в большом изображении, основанном на табл. 3, могли бы все выстроиться
в одну прямую, что могло привести к более серьезному визуальному
проявлению структуры. Человеческий глаз имеет тенденцию замечать прямолинейные
452 Компьютерная типография
25
48
40
36
16
8
4
17
21
32
30
14
6
0
1
9
13
29
35
22
10
2
3
5
39
43
51
26
18
7
11
19
47
55
59
46
38
15
23
27
57
63
62
54
42
31
33
49
53
61
60
58
50
34
28
41
45
56
52
44
24
20
12
37
Таблица 3. Упорядочение с единственным бароном.
участки из точек, но этот феномен не проявляется столь существенно при
наложении сетки полутонов, когда изображение повернуто на 45° (см. [13]). Если
все элементы матрицы А суть приблизительно 1/64, то в табл. 2 упорядочение
производят два пикселя с В — 1 в каждой подматрице размера 8x8, тогда
как в табл. 3 — только один. Один — правильное число, хотя табл. 3 дает менее
удовлетворительную структуру.
На самом деле, табл. 2 давала точечное представление, которое
используется для полутоновых решеток в коммерческих приложениях. Если мы сначала
представим себе полностью белую матрицу, в которой мы успешно зачерняем
все позиции классов 0,1,..., то получим повернутые на 45° решетки из черных
точек, которые постепенно растут все больше и больше. Когда все классы < 32
станут черными, мы получим шахматную доску; начиная отсюда процесс за-
чернения по существу производит повернутые на 45° решетки из белых точек,
которые постепенно становятся все меньше и меньше. Поскольку номер класса
позиции (i,j) плюс номер класса позиции (i,j + 4) всегда дает 63,
изображение решетки из 63 — к белых точек после к шагов будет в точности таким же,
как изображение решетки из 63 — к черных точек после 63 — к шагов,
сдвинутое вправо на 4. Такая связь изображений из точек с диффундированным
изображением делает разумным название нового метода диффузия точки.
Диффузию точки можно также испытать при меньшем масштабе с
матрицей классов размера 4x4:
14
4
0
10
13
6
3
8
1
11
15
5
2
9
12
7
Ее можно применять к точкам с по разному выровненными углами, используя
образцы, аналогичные представленным в работе Холладея [10], или с точками,
имеющими эллиптическую форму, а не круглую.
Глава 22. Оцифровка полутонов посредством диффузии точки 453
Выделение краев
Ярвис и Роберте [11, 12] обнаружили, что упорядоченное размывание может
быть последовательно улучшено, если выделить края исходного изображения.
Суть идеи состоит в том, чтобы заменить .А[г, jf] на
^Pijl = 4i,i|-^J]
где А [г, j] есть среднее значение для А [г, j] и его восьми соседей:
_ j i+i j+i
u=i—l v=j—l
Новые значения Л'[г, j] имеют ту же среднюю интенсивность, что и старые, но
когда а > 0 они увеличивают разность между -А[г, jf] и соседними пикселями.
Если а = 0.9, то эти формулы упрощаются до хорошо известного соотношения
(см. [19], ф-ла. 12.4-3):
A'[i,j] = 9A[iJ] - J2 А^Ь
0<(u-i)2 + (v-j)2<3
Суммирование здесь ведется по всем восьми соседям точки (г, j).
Ярвис и Роберте сформулировали этот метод «ограниченного среднего»
по другому, по своей сути очень близко к методу упорядоченного размывания.
Однако из приведенных выше соотношений очевидно, что выделение краев
можно использовать с любой полутоновой методикой.
На самом деле нам нужно также скорректировать Л'[г, jf], чтобы
убедиться, что это значение находится между 0 и 1, подровняв его до 0 или 1 там,
где оно выходит за эти крайние значения. В противном случае нужно будет
диффундировать слишком много «ошибок».
Примеры
Иллюстрации на следующих страницах демонстрируют то, что происходит,
когда три обсуждавшихся выше метода применяются к двум различным
изображениям с выделенными краями и без выделенных краев. Множества данных
преднамеренно очень малы, так что можно изучить все детали. Каждое
изображение состоит из 360 строк по 250 пекселей в каждой.
Первое изображение представляет собой оцифрованный портрет Мо-
ны Лизы, который имеется в свободном доступе как часть станфордской
GraphBase [15]; ее функция lisa (m, n, 255,0,0,0,0,0,0, workplace) обращается
к массиву размера 360 х 250 байт, в котором каждый пиксель соответствует
однобайтовому значению от 0 (черный) до 255 (белый). Мы хотим, чтобы
черное было представлено единицей, так что можем заменить значение г на дробь
(255.5 — г)/256. Но изображение из GraphBase в свою очередь будет слишком
темным из-за того, что старая живопись Леонардо покрыта лаком; лучший
результат для наших целей получится, если для высветления плотность
возвести в квадрат. Таким образом, элементы данных A[i, j] первого изображения
454
Компьютерная типография
все имеют вид ((255.5 — г)/25б)2, где г есть байт из GraphBase для пикселя в
строке г и столбце j.
Второе изображение вычисленно искусственным образом по формулам:
для заданных г и j в диапазонах 1 < г < 360 и 1 < j < 250 положим
х = (г - 120)/111.5 иу = {j - 120)/111.5. Если х2 + у2 < 1, то значение A[i,j]
есть (9 + х — Ay — 8\/l — х2 — у2 )/18; в противном случае А[г,^'] является просто
(1500г + ^2)/1000000.
Данные с выделенными краями А'[г, j] были получены из исходных
значений применением простой формулы, приведенной выше, для случая а = 0.9.
Обратите внимание, что это на удивление эффективно при выявлении деталей
портрета Моны Лизы, если иметь ввиду, что мы работали со сравнительно
низким разрешением; можно заметить арки отдаленного акведука на фоне справа
от портрета и завитки прически Моны Лизы. Однако ее загадочная улыбка
при таком преобразовании стала грубее.
При применении диффузии точки к данным портрета Моны Лизы с
выделенными краями (рис. 10) величина ошибки, концентрирующейся в позициях
баронов, была в среднем 704.1/2835 « 0.248. Значения Л[г, j] при этом
оставались между —0.65 и 1.96. Хотя мы могли наблюдать, что барон диффузии
точки может приклеиваться примерно на 4.34 единицы ошибки в худшем
случае, только 26 из 2835 позиций баронов были «плохими» в том смысле, что они
концентрировали ошибку, величина которой была больше 0.5; это охватывает
случаи, когда -A[i,jf] достигает экстремальных значений —0.65 и 1.96. Кроме
того, ошибка барона 24.14 единиц на пиксель особенно проявляется у границ;
это сумма \A[i, j]\ для г = 0, или г = т + 1, или j = 0, или j = п + 1 после
того, как диффузионный алгоритм завершил работу. Таким образом, общая
недиффундированная ошибка становится равной 704.10 + 24.14 = 728.24 на
360 х 250 = 90000 пикселей, т. е. около 0.008 на пиксель.
Аналогичные результаты имеют место на рис. 9, 11 и 12; статистические
данные здесь такие:
общая
недиффундированная
minA[z,j] maxA[z,j] плохие бароны ошибка
Рис. 9 -0.575 1.640 22 707.65 + 72.78 = 780.43
Рис.10 -0.649 1.957 26 704.10 + 24.14 = 728.24
Рис.11 -0.630 1.656 13 719.27 + 62.79 = 782.06
Рис. 12 -0.773 1.913 22 725.08 + 41.44 = 766.52
Алгоритм Флойда—Стейнберга имел недиффундированные ошибки только на
границах:
Рис. 1
Рис. 2
Рис. 3
Рис. 4
min A[i,j]
-0.276
-0.331
-0.246
-0.324
max А [г,
1.163
1.405
1.039
1.483
Л
общая
недиффундированная
ошибка
116.53
66.14
86.64
48.20
Глава 22. Оцифровка полутонов посредством диффузии точки
455
Рис. 1 (без выделения краев).
Рис. 2 (с выделением краев).
«вЯ'ШШ^^ШйШ
Рис. 3 (без выделения краев).
Рис. 4 (с выделением краев).
Изображения, оцифрованные алгоритмом Флойда—Стейнберга.
456
Компьютерная типография
Рис. 5 (без выделения краев). Рис. 6 (с выделением краев).
Рис. 7 (без выделения краев). Рис. 8 (с выделением краев).
Изображения, оцифрованные алгоритмом упорядоченного размывания.
Глава 22. Оцифровка полутонов посредством диффузии точки
457
Рис. 9 (без выделения краев).
Рис. 10 (с выделением краев).
Рис. 11 (без выделения краев).
Рис. 12 (с выделением краев).
Изображения, оцифрованные алгоритмом диффузии точки.
458
Компьютерная типография
Напротив, алгоритм упорядоченного размывания диффундирует ошибки
только в том смысле, что он старается сделать каждый блок размера 8x8
приблизительно корректным. Связанные с этим методом статистические данные
таковы:
Г360/81 Г250/81 | 7 7 .
Е Е \^2^2A[8i-k,Sj-l]-B[8i-k,Sj-l] ;
г=1 j-\ I к=0 /=0 '
эти суммы сводятся соответственно к (1000.72,1655.19,608.62,678.94) для
рис. 5, 6, 7 и 8. Таким образом, упорядоченное размывание, грубо говоря,
вдвое хуже диффузии точки в случае Моны Лизы, тогда как в случае
шара оно повело себя несколько аккуратнее. Но абсолютная ошибка превышала
1.0 соответственно в (325,710,103,150) из 1440 блоков.
Рисунки 1-12 должны были быть показаны с относительно большими
квадратными пикселями с стороной 0.22 мм, чтобы читатель мог явно различать
включенные или выключенные элементы. Нам пришлось уменьшить эти
иллюстрации в 6 раз, чтобы получить эквивалент коммерческого изображения
среднего качества для полутоновых фотографий.
Проблемы
Метод упорядоченного размывания производит двоично-рекурсивную
текстуру, которая не годится для большинства издательских приложений; такие
«холодные» образы бывают полезными, вероятно, только когда нарочито
подчеркивается заложенная в их основу технология. Результат, полученный методом
Флойда—Стейнберга, обычно больше радует глаз, но тоже иногда страдает
изъянами, когда невольно привлекают внимание змеевидные образования.
Метод диффузии точки точно так же вводит свою собственную шероховатую
текстуру. Таким образом, ни один из этих подходов не является полностью
удовлетворительным в том смысле, что зритель, которому представлены
иллюстрации такого размера, на интуитивном уровне может признать их
приятными. Никакой иной полутоновой метод не даст лучшего результата при
таком масштабе. Мы должны будем отойти на несколько метров и
прищуриться, только тогда будет достигнут эффект непрерывного перехода тонов.
Когда проводились эксперименты, примеры, подготовленные при помощи
метода Флойда—Стейнберга, дали лучшие показатели, чем другие.
Но картина меняется, когда мы рассматриваем приложения для печати.
Автор экспериментировал с различными вариантами этих изображений на
лазерном принтере с разрешением 300 точек на дюйм (округленно 38%
уменьшение по сравнению с представленными здесь размерами иллюстраций), и
результаты методов Флойда—Стейнберга и упорядоченного размывания были
абсолютно неудовлетворительными. Нелинейные эффекты процесса
ксерографии приводили к появлению больших темных пятен в тех местах, где белые
пиксели были чрезвычайно редкими; здесь получался резкий скачок между
областями серого и черного. В экспериментах автора самый лучший отпечаток
Моны Лизы на лазерном принтере получился с применением диффузии точ-
Глава 22. Оцифровка полутонов посредством диффузии точки
459
ки (см. [14]); все другие испробованные методы дали результаты значительно
худшего качества.
Разумеется, лазерные принтеры всего лишь грубая аппроксимация
устройств с высоким разрешением, используемых для высококачественных
полиграфических оттисков. Современные цифровые фотоавтоматы с размером
пикселя примерно 20 /лт (1270 пикселей на дюйм), могут производить
великолепные полутона, моделируя аналоговый растровый метод, который
использовался на оборудовании прошлых лет. В самом деле, метод упорядоченного
размывания — но с матрицей диффузии точки размера 8 х 8 из табл. 2 вместо
двоично-рекурсивной матрицы размера 8 х 8 из табл. 1 —в сущности
моделирует традиционный подход к полутонам.
Естественно предположить, что мы способны выполнить работу даже
лучше, чем раньше, если только сможем задуматься о том, как разумно
использовать новую технику, потому что сейчас можно сделать столько, о чем даже
нельзя было мечтать при возможностях аналоговой техники. К примеру,
можно надеяться лучше воспроизвести фотографии Анселя Адамса методом Флой-
да—Стейнберга (при достаточно высоком разрешении), чем это было возможно
любым из методов печати прошлого.
Но по кратком размышлении становится понятно, что подход Флойда—
Стейнберга не годится для использования с высоким разрешением в силу
физических ограничений. Крошечные капли краски просто не в состоянии
образовать изображения типа представленных на рис. 1-4. Худший случай, вероятно,
возникает, когда А [г,./] = 1/2 для всех г и j\ затем алгоритм
Флойда—Стейнберга выдаст шахматную доску с чередованием черных и белых квадратов,
а типичный принтер конвертирует это в грязное пятно наподобие такого: ■
Упорядоченное размывание как на рис. 5-8 потерпит крах по той же причине.
Оба этих метода предпочитают изолированные черные или белые пиксели.
Будет ли полезна описанная выше диффузия точки при высоком
разрешении? Изучим это на примере уменьшенных на 27% рис. 9-12:
В такой сжатой форме каждый пиксель занимает .06 мм, т. е. примерно 423
пикселя на дюйм. Если мы повернем на 45° и разделим на 4\/2 (что
является расстоянием между «баронами»), то увидим, что результат аналогичен
75-строчному растру, который дает качество как в газетном отпечатке. Эти
изображения очень малы, а на устройствах с высоким разрешением они
получатся еще меньше. На коммерческих растрах среднего качества разрешение
равно 130 растровым точкам на дюйм или около 735 не подвергнутых повороту
двухуровневым пикселям на дюйм. Реальная иллюстрация Моны Лизы будет,
следовательно, иметь в сотни раз большее количество данных; мы должны
помнить об этом масштабирующем множителе.
460
Компьютерная типография
Мона Лиза в этом примере выглядит неплохо, но в репродукции шара есть
серьезные огрехи. Наши глаза не замечают регулярных образований из точек,
если точки достаточно малы, но мы быстро реагируем на изменения в текстуре.
Оттенки серого в фоне позади шара должны были изменяться с очень
четкой градацией, но заметны непрошенные контуры, потому что незначительные
изменения интенсивности приводят к большим изменениям в изображениях,
полученных диффузией точки. (Аналогичные, но менее заметные ненужные
контуры можно разглядеть в фоне, полученном методом Флойда—Стейнберга
(рис. 3 и 4) особенно там, где интенсивности А [г, jf] близки к 1/2.)
Методы диффузии ошибки хорошо подходят для привлечения внимания
к деталям картины, но удачный метод должен также «утаивать» те места,
где данные демонстрируют некоторую активность. Изготовитель дискретных
полутонов должен одинаково хорошо сочинять фоновую мелодию и партии
изредка звучащих фанфар. Этот пример демонстрирует, что диффузия точки
в том виде, как она определена выше, не годится для общего использования
при высоком разрешении.
На самом деле есть другая серьезная причина, почему диффузия точки
терпит фиаско. Можно показать, что если Л[г, jf] равно 1/2 при всех (i,jf), то
сформулированный выше алгоритм диффузии точки произведет идеальную
шахматную доску с чередованием черного и белого. (Небольшие фрагменты
шахматной доски проступают в отдельных частях рис. 11 и 12.)
На основании этих наблюдений приходим к заключению, что наш
исходный критерий, гласящий, что среднее элементов B[i,j] вблизи (г'о,^'о) должно
быть приблизительно равно А[г'о, jo]> не достаточно хорош в смысле его
математической привлекательности. В действительности мы хотим иметь критерий,
принимающий во внимание искажения, производимые в процессе печати,
равно как и последующие искажения и зрительный обман, производимые нашими
оптическими рецепторами. Иными словами, восприятие человеком элемента
B[i,j] вблизи (г'о,^'о) после распечатки должно быть примерно тем же, что и
восприятие человеком элемента А[г, jf] вблизи (г'о, jo)- Некоторые шаги в этом
направлении были предприняты Аллебахом и Дальтоном [2, 6], которые
включили в свой экспериментальный алгоритм визуальную модель.
Гладкая диффузия ошибки
Из обсуждения, проведенного в предыдущем разделе, по-видимому понятно,
что методы, основанные на диффузии ошибки, обречены, равно как и
приложения, имеющие дело с принтерами с высоким разрешением. Но мы не
рассмотрели диффузию ошибки во всей ее мощи. Биллот-Хоффманн и Брюнгдал
[5] сделали важное открытие, состоящее в том, что метод
Флойда—Стейнберга репродуцирует градации серого, даже если постоянную '0.5' заменить
любым другим значением! Например, если мы положим J3[i,jf] := 1 только
когда A[i,ji] > 0.6, то будем устанавливать верхний левый угловой элемент
£[1,1] равным нулю значительно чаще, чем раньше; но если мы так
поступим, то станем распространителями большей ошибки, так что соседние пиксели
Глава 22. Оцифровка полутонов посредством диффузии точки
461
с большей вероятностью будут становиться равными 1. Биллот-Хоффманн и
Брингдал обнаружили, что получающаяся в результате текстура улучшается,
если пороги незначительно варьировать как функцию от г и j.
Рассмотрим теперь параллельный алгоритм более общего вида, чем
диффузия точки. Все позиции (i,j) пикселей подразделяются на г классов,
нумеруемых от 0 до г — 1, а далее происходит следующее:
for к := 0 to г — 1 do for all (г, j) класса к do
begin if Л[г, j] < Ok then B[i,j] := 0 else B[i,j] := 1;
err := A[iJ] - B[iJ]\
for / := к -f 1 to r — 1 do
begin пусть (u,v) ближайшее к (г, j), такое, что класс(и,г;) = /;
А [и, v] := А [и, v] -f err * сад
end;
end.
Диффузионный алгоритм, который использовался при высоком
разрешении, должен иметь некоторого рода свойство гладкости. На интуитивном
уровне это значит, что малые изменения в данных пиксельных значениях Л [г, j]
должны приводить к незначительным изменениям в результирующих
бинарных значениях B[i, j]. Например, если все А возрастают, то было бы
замечательно, если бы все В оставались теми же самыми или возрастали. Можно
задаться вопросом: существует ли последовательность значений параметров
Ok и а/с/ при 0 < к < I < г, такая, что изложенный выше общий алгоритм
диффузии имеет следующее свойство?
Если изначально А[г, j] — а для всех г и j,
и если (т — .5)/г < а < (т + .5)/г для некого целого т,
то приведенный выше алгоритм должен установить
1, если 0 < класф', j) < m;
B\i Я :—
L J ' \ 0, если m < класс(г, j) < r.
Это условие означает, что диффузионный алгоритм должен действовать
подобно алгоритму размывания, когда эти данные постоянные.
Существует удивительно простое решение этих нелинейных ограничений.
Можно взять
вк = .5/(г — /с), аы = 1/(г — к — 1) для всех 0 < к < I < г.
В частности, этот порог 6k строго меньше 1/2, до тех пор пока мы не достигнем
барона класса к — г — 1. Для всех меньших классов ошибка распределена
поровну между соседями высшего класса; иначе говоря, она не зависит от /.
Приведем доказательство. Предположим, что A[i, j] имеет начальное
значение а — qq yl что (т — 0.5)/г < ао < (т + 0.5)/г. Если т > 0, алгоритм
устанавливает все B[i,j] класса 0 в 1, а всем A[i, j] классов > 0
присваивает значения а\ = ciq + (ао — 1)/(г — I) = (гао — 1)/(г — 1). Теперь мы имеем
462
Компьютерная типография
(т — 1.5)/(г — 1) < а\ < (т — 0.5)/(г — 1). Если т > 1, алгоритм
устанавливает все B[i,j] класса 1 в 1, а всем А[г,^'] классов > 1 присваивает значения
&2 = ai + (ai —1)/(г—2). Следовательно, (m-2.5)/(r—2) < a2 < (га—1.5)/(г—2);
этот процесс продолжается до тех пор, пока мы не достигнем класса га с
А[г,,7"] = ат и — 0.5/(г — га) < ат < 0.5/(г — га). Алгоритм теперь
устанавливает все B[i,j] класса га в 0, а всем -А[г, j] более высоких классов присваивает
значения am+i = аш + ат/(г — га — 1). Отсюда мы имеем —0.5/(г — т — 1) <
am+i < 0.5/(г — га — 1), следовательно, приведенное условие выполнено. Ч.Т.Д.
Хотя эти пороговые значения вк расположены весьма несимметрично
относительно 0 и 1, установленное свойство гладкости симметрично.
Следовательно, метод не имеет смещения в сторону B[i,j] = 1, как это могло казаться.
Тем не менее небольшое смещение имеется. Можно показать, например, что
если г = 2 и если непрерывные значения А для классов 0 и 1 выбраны
случайным образом независимо и равномерно, то полученные в результате
двоичные значения В должны быть (00,01,10,11) с относительными
вероятностями (3,5,20,4)/32; следовательно, полный ожидаемый двоичный вес составит
(5 + 20 + 8)/32 = 33/32, чуть больше единицы. Если г = 3, то вероятности для
восьми возможных выводов В = 000, 001, 010, 011, 100, 101, 110, 111 при
независимых и равномерно распределенных случайных значениях А составят
соответственно (57,123,536,148,1423,557,2232,108)/5184; ожидаемое число единиц
равно 115/72 « 1.597, т. е. чуть больше г/2. Вообще говоря, вероятность того,
что г значений В установятся в 1, равна 1/(2гг!), а вероятность того, что они
все установятся в 0, равна
Но, разумеется, предположение о независимости случайных значений А не
является хорошей моделью для действительных изображений.
Мы можем применить данный метод к случаю г = 32, используя матрицу
классов из табл. 2, в которой все числа класса разделены на 2 (отбрасывая
остатки). В самом деле, обычный метод диффузии точки, обсуждавшийся
выше, дал бы точно такие же результаты, если бы мы рассматривали вместо
метода с 64 классами метод с 32 классами. Но теперь мы хотим расширить
соседа каждого пикселя от размера 9 до размера 32; мы рассматриваем
ячейку (г,^) как имеющую 32 соседа (и, г>), которые образуют структуру алмаза,
определяемую соотношением
—3+\v — j\ < и —г < 4 — \v — j\;
эти 32 соседа (включая сам (г, j)) содержат по одному элементу каждого
класса. Соотношение, связывающее соседей, несимметрично — например, (4,1)
является соседом (1,2), но (1,2) не является соседом (4,1); это не составляет
проблемы.
Назовем полученный алгоритм гладкой диффузией точки. Описанный
ранее метод диффузии точки требовал не больше арифметических операций,
Глава 22. Оцифровка полутонов посредством диффузии точки
463
чем обычный алгоритм Флойда—Стейнберга, поскольку для получения блока
размера 8x8 требуется 256 сложений и 256 умножений. Напротив, алгоритм
гладкой диффузии точки требует всего 62 деления для блока размера 8x8,
поскольку ошибка распределена равномерно, но это выполняется посредством
992 сложений, что обходится несколько дороже.
Максимальное значение Л[г, jf], получаемое за время работы алгоритма с г
классами, появляется, когда A[i, j] настолько велико, насколько возможно при
условии, что В [г, j] устанавливается в 0 для всех классов < г — 1; это позволяет
барону подойти произвольно близко к его верхнему пределу 1.5 — 0.5/г.
Труднее описать минимальное из возможных значений Л [г, j]. При г = 32
оно возникает, когда значения А берутся малыми насколько возможно, так что
В — 1 для классов от 0 до 19 и В = 0 для классов от 20 до 30. Этот крайний
случай будет давать значение барона -6(^ + ^4-^4 Ь^ + ^ + ^) « —11.776.
Пусть при произвольном г минимальное значение к таково, что гармоническая
сумма 1/(г — к) -\ Ь 1/(г — 1) превосходит 1 — 0.5/г; тогда к = г — г/е + 0(1)
и наименьшее значение, которое любое Л[г, j] может принять, есть
— (— 2 2 2 2 Л__г
2 \г-к + г-к-1 + г-к-2 + '" + г-2 + г-1 + т)~ е + U*
Поскольку гладкая диффузия точки имеет дело с чрезвычайно большим
количеством соседей, ошибка может оказаться в позициях, весьма удаленных
от источника. Например, существует путь, простирающийся от класса 7 к 9,
к 14, к 16, к 18, к 20, к 23, к 27, к 29, к 30, к 32, к 36, к 42, к 45, к 48, к 51,
к 53, к 55 в матрице из табл. 2 (до тех пор пока количество классов не будет
поделено пополам); это передвижение затрагивает 30 строк ниже начальной
точки! Ошибка, однако, умножается на малые постоянные, так что пока она
достигнет конца своего путешествия, она значительно демпфируется. Другие
пути могут вести наверх, затрагивая до 11 строк (например от 16 к 18, к 22,
к 25, к 28, к 39, к 42, к 49). Самым важным последствием такого длинного пути
является тот факт, что оптимальное последовательное выполнение, хранящее
одновременно в памяти лишь несколько последовательных строк, нуждается
в буфере из 16 строк, а обычному методу диффузии точки требуется всего 7
строк.
Сравнение с другими методами
Пол Ротлинг [21, 22] разработал некий похожий параллельный алгоритм для
полутонов высокого разрешения. Его метод ARIES, расшифровываемый как
Alias-Reducing Image-Enhancing Screener (экранирование, размывающее
изображение с выделенными краями), представляет собой, в сущности,
модифицированную схему размывания, в которой пороговые уровни
устанавливаются для каждой точки. ARIES сначала формирует множество всех значений
A[i,j] — к/г, вносящих вклад в единственную точку, положение которой (г, j)
соответствует уровню к в матрице размывания и г есть общее количество
пикселей на точку; затем ARIES устанавливает £?[г, j] := 1 в га позициях (г,^*) с
464
Компьютерная типография
наиболее высоким количеством очков (рейтингом) по этому критерию, где т
выбирается равным средней интенсивности этой точки.
На рис. 13 и 14 приведены результаты применения ARIES к нашим двум
образцам. Здесь были использованы 32-пиксельные точки и снова за основу была
взята матрица классов из табл. 2, в которой все номера классов поделены на 2.
(Если (г'о, jo) есть пиксель класса 0, то 32 пикселя точки суть ее 32 соседа, как
это определено выше, именно (г'о + J, jo + б), где — 3 + \5\ < е < 4 — \5\.) На
рис. 15 и 16 соответственно показаны результаты применения гладкой
диффузии ошибки. Исчезли вызывающие проблемы искусственные контуры, которые
были на рис. 12, но появился незначительный оставшийся необъясненным
эффект, поскольку каждая точка имеет только 32 пикселя и может представлять
всего 33 тени серого. Каждый алгоритм производит в результате
изображения, которые представлены великолепными полутонами; при разрешении 423
пикселя на дюйм они выглядят примерно так:
Результаты применения гладкой диффузии точки возможно несколько более
резко очерчены, чем полученные посредством ARIES; они также несколько
темнее (хотя, как ни парадоксально, рис. 16 выглядит немного светлее, чем рис. 12,
полученный на устройстве с низким разрешением).
Ошибка метода ARIES гарантированно не превысит 0.5 в каждой
позиции точки и в среднем будет составлять 0.25 на одну точку. Наши образцы
изображений включают 2943 точки (или части точки); с достаточной долей
вероятности можно заключить, что общая ошибка метода ARIES была 723.42
на рис. 13 и 721.49 на рис. 14.
На рис. 15 и 16 значения -А[г] [7] остаются меньше 1.0007 во все время
работы алгоритма гладкой диффузии. Но отрицательные ошибки имеют тенденцию
накапливаться, достигая самого низкого уровня —4.555 в портрете Моны Лизы
и —3.703 в изображении шара (оба значения достигаются в позициях
барона). В 2835 баронах скапливается 2337.15 единиц ошибок в случае портрета
Моны Лизы и 977.23 в случае шара, по большей части отрицательных,
когда алгоритм пытается сделать изображение чуть светлее. В общей сложности
«плохими» были 1349 баронов на рис. 15 и 595 на рис. 1G, в каждом случае
поглощались ошибки, более отрицательные, чем —0.5. Соседи, составленные из 32
ячеек, также вызывали по существу большее рассеяние на границах: 2072.49 и
огромное 4150.88. Таким образом, общие объемы ошибок на пиксель на рис. 15
и 16 становятся 0.049 и 0.057 соответственно в сравнении с 0.008 для ARIES.
Ошибки на границах пренебрежимо малы при достаточно больших размерах
изображения.
Глава 22. Оцифровка полутонов посредством диффузии точки
465
Рис. 13
(оцифровано посредством ARIES)
Рис. 14
Рис. 15 (оцифровано посредством гладкой диффузии точки) Рис. 16
466
Компьютерная типография
Алжи [1] предложил обобщение метода ARIES в виде функции ранга
A[iJ] -ak,
где а — настраиваемый параметр. Схема ARIES представляет собой
специальный случай а = 1/г; другая схема под названием «структурированные
элементы изображения» Приора, Синка и Рубинштайна [20] представляет собой
специальный случай а = 0. Если мы положим а —* оо, то получим методы, в
которых каждая точка выбирается из заданного репертуара шаров.
Удовлетворительные результаты по таким схемам получил Роберт Л. Гард [9], который
использовал чередующиеся образы из половин точек. Другой родственный
алгоритм описан Анастассиу и Пенингтоном [3].
Обычно принтеры отличают «полутоновые» рисунки от «штриховых»: с
теми и другими обращаются по-разному. Но когда используется цифровое
печатное оборудование с высоким разрешением, мы не должны делать никаких
различий. Например, фотография может содержать текстовую информацию,
скажем факсимиле подписи. Зачем нужно растрировать этот текст, если его
можно представить более четко? Методы наподобие ARIES и гладкой
диффузии точки в состоянии адаптировать изображение к тому виду, какой
требуется.
Мы можем, разумеется, сконструировать такие входные данные, для
которых метод диффузии точки даст на печати совершенно неудовлетворительный
результат. Например, если каждое значение Л [г, j] уже есть 0 или 1, гладкая
диффузия точки будет просто устанавливать B[i,j] := A[i,j] для всех (г, j);
мы можем столкнуться со значениями A[i,jf], которые не годятся для печати,
вроде шахматной доски. Но мы выдвигаем предположение, что такие данные
на практике не встречаются. Подобные шумы могут быть отфильтрованы до
начала процесса оцифровки.
К настоящему моменту автору неизвестны методы, дающие на цифровом
фотонаборном устройстве с высоким разрешением изображения лучшего
качества, чем производит алгоритм гладкой диффузии точки. Однако было бы
заведомо необдуманным выдвигать экстравагантные претензии по отношению
к этому новому методу: до сих пор проведено весьма ограниченное количество
экспериментов. Если гладкая диффузия точки ведет себя согласно поданным
ею надеждам, то реализация на компьютерном оборудовании — возможно
вместе со сканером — может оказаться притягательной возможностью.
Благодарности
Большую помощь оказали референты, указавшие мне литературу, с которой
я не был знаком. Благодаря этому я постоянно совершенствовал методы и
менял их описание в данной статье. Я также признателен Б. К. Р. Хорну за
то, что он предоставил в мое распоряжение результаты своих многочисленных
экспериментов с полутонами, произведенными компьютером.
Работа над этой статьей частично финансировалась фондом NSF по гранту CCR-8610181.
Глава 22. Оцифровка полутонов посредством диффузии точки
467
Литература
[1] Stephen H. Algie, "Resolution and tonal continuity in bilevel printed picture
quality," Computer Vision, Graphics, and Image Processing 24 (1983), 329-
346.
[2] J. P. Allebach, "Visual model-based algorithms for halftoning images,"
Proceedings ofSPIE, the Society of Photo-Optical Instrumentation Engineers
310 (1981), 151-157.
[3] Dimitris Anastassiou and Keith S. Pennington, "Digital halftoning of images,"
IBM Journal Research and Development 26 (1982), 687-697.
[4] В. Е. Bayer, "An optimum method for two-level rendition of continuous-
tone pictures," Conference Record of the IEEE International Conference on
Communications 1 (1973), (26-ll)-(26-15).
[5] C. Billotet-Hoffmann and 0. Bryngdahl, "On the error diffusion technique for
electronic halftoning," Proceedings of the Society for Information Display 24
(1983), 253-258.
[6] J. С Dalton, Visual model based image halftoning using Markov random field
error diffusion, thesis, University of Delaware (December 1983). См. также
J. С. Dalton, G. R. Arce, and J. P. Allebach, "Error diffusion using random
field models," Proceedings of SPIE, the International Society for Optical
Engineering 432 (1983), 333-339; John Dalton, "Perception of binary texture
and the generation of stochastic halftone screens," Proceedings of SPIE, the
International Society for Optical Engineering 2411 (1995), 207-220.
[7] Robert W. Floyd and Louis Steinberg, "An adaptive algorithm for spatial
greyscale," Proceedings of the Society for Information Display 17 (1976), 75-
77. Более ранняя версия опубликована в SID 75 Digest (1975), 36-37.
[8] R. W. Floyd, личная беседа (21 мая 1987 г.).
[9] Robert L. Gard, "Digital picture processing techniques for the publishing
industry," Computer Graphics and Image Processing 5 (1976), 151-171.
[10] Thomas M. Holladay, "An optimum algorithm for halftone generation for
displays and hard copies," Proceedings of the Society for Information Display
21 (1980), 185-192.
[11] J. F. Jarvis and C. S. Roberts, "A new technique for displaying continuous tone
images on a bilevel display," IEEE Transactions on Communications COM-24
(1976), 891-898.
[12] J. F. Jarvis, С N. Judice, and W. H. Ninke, "A survey of techniques for the
display of continuous tone pictures on bilevel displays," Computer Graphics
and Image Processing 5 (1976), 13-40.
[13] R. J. Klensch, Dietrich Meyerhofer, and J. J. Walsh, "Electronically generated
halftone pictures," RCA Review 31 (1970), 517-533.
[14] Donald E. Knuth, "Fonts for digital halftones," TUGboat 8 (1987), 135-160.
[Переработанный вариант этой статьи представлен в гл. 21 настоящего
издания.]
468
Компьютерная типография
[15] Donald E. Knuth, The Stanford GraphBase (New York: ACM Press, 1993).
Портрет Моны Лизы представлен на с. 28.
[16] Kurt E. Knuth, James M. Berry, and Gary B. Ollendick, "An ink jet facsimile
recorder," IEEE Transactions on Industrial Applications IA-14 (1978), 156-
161.
[17] J. 0. Limb, "Design of dither waveforms for quantized visual signals," Bell
System Technical Journal 48 (1969), 2555-2582.
[18] Bernard Lippel and Marvin Kurland, "The effect of dither on luminance
quantization of pictures," IEEE Transactions on Communication Technology
COM-19 (1971), 879-888.
[19] William K. Pratt, Digital Image Processing (New York: Wiley, 1978).
[20] R. W. Pryor, G. M. Cinque, and A. Rubenstein, "Bilevel image displays —a
new approach," Proceedings of the Society for Information Display 19 (1978),
127-131.
[21] Paul G. Roetling, "Halftone method with edge enhancement and Moire
suppression," Journal of the Optical Society of America 66 (1976), 985-989.
[22] Paul G. Roetling, "Binary approximation of continuous tone images,"
Photographic Science and Engineering 21 (1977), 60-65.
[23] M. R. Schroeder, "Images from computers," IEEE Spectrum 6,3 (March 1969),
66-78. См. также Communications of the ACM 12 (1969), 95-101.
Заметки об оцифровке углов
[Первоначально опубликовано в Electronic Publishing — Origination,
Dissemination, and Design 3 (1990), 99-104.]
Изучаются конфигурации пикселей, возникающие в месте соединения двух
оцифрованных прямых. Вычисляется точное число различных конфигураций,
когда тангенс угла, составленного этими прямыми, выражен рациональным
числом. Эта теория помогает объяснить эмпирически выявленный феномен,
заключающийся в том, что две «половинки» наконечника стрелы выглядят
по-разному.
Около десяти лет тому назад я был референтом докторской диссертации
Кристофера Ван Вика [4], в которой вводился язык IDEAL для описания
рисунков [5]. На двух иллюстрациях, выбранных им в качестве примеров, были
изображены стрелки, составленные примерно из таких прямых:
Когда я на них взглянул, я решил, что либо в языке IDEAL, либо в процессоре
troff, на котором был представлен вывод с языка IDEAL, есть какой-то изъян,
потому что древки стрел не строго делят угол, образованный двумя
короткими отрезками наконечников. Казалось, что древки были нарисованы либо
слишком высоко, либо слишком низко. Крис вместе с Брайаном Керниганом
потратил немало часов, стараясь понять, что было неправильно сделано, но
никаких ошибок обнаружить не удалось. В конце концов его диссертацию
перепечатали на фотоавтомате с высоким разрешением и погрешности стали не
так заметны по сравнению с тем, как это выглядело на распечатке с лазерного
принтера. Все еще оставались шероховатости, но я решил, что не стоит из-за
неправильно расположенного пикселя портить Крису карьеру.
Я вспомнил об этом инциденте в конце 1983 г., когда собирался писать
новую версию системы METflFONT для цифрового дизайна [3]. Я вовсе не
стремился к тому, чтобы в моей системе был такой же изъян. Но каково было мое
470
Компьютерная типография
удивление, когда я понял, что подобная проблема при растровом выводе
просто неизбежна: оцифрованные углы почти никогда нельзя разделить точно
пополам, за исключением очень специальных случаев. Две «половинки» угла
обязательно хоть в чем-то будут отличаться друг от друга, если только
разрешение не будет чрезвычайно высоким. Так что Ван Вик и Керниган были
реабилитированы. Аналогичные проблемы обязательно возникают в MacDraw
и во всех других графических пакетах.
Я, например, обратил внимание на такой курьезный факт. Рассмотрим
угол 45°, который образуется отрезком прямой, направленным вверх к точке
(#сь Уо) под углом с тангенсом 2 и затем опускающимся вниз по другой прямой
с тангенсом угла наклона —3:
(яо,Уо)д
(xo-t,y0-2t) / \ {хо+щуо_3и)
Если мы оцифруем этот путь в виде угла, то верхний контур сможет принять
одно из пяти различных очертаний, в зависимости от значения координат
точки пересечения (хо, уо)> которые не обязательно должны быть целыми. Вот эти
варианты:
*=А «=А »-А «=А *'А
Теперь предположим, что этот угол в 45° представляет собой левую
половину наконечника стрелы. Правая часть наконечника будет тогда углом в 45°,
образованным прямой с тангенсом угла наклона —3, пересекающим прямую с
тангенсом угла наклона —1/2:
(^ь!/1)к
\ ^\(#i + 2u, j/i - и)
(xi+t, yi - 3t)\
Для этого угла также имеется пять вариантов, получающихся после
оцифровки, именно
<Эо : Ч^-Ч. Qi : ^х Q2 : ^ <3з : ^ <?4 : ^ч
Чтобы получить сам наконечник, мы должны совместить левый угол Pi с
соответствующим правым углом Qj. Но ни один из углов Q не имеет такой же
формы, как хотя бы один из углов Р. И вот в этом все и дело: человеческий
глаз имеет тенденцию оценивать величину угла по тому, как угол выглядит в
вершине. По этому критерию некоторые углы кажутся чуть больше других (за
исключением случаев, когда эти углы изображены с высоким разрешением).
Глава 23. Заметки об оцифровке углов
471
Следовательно, нет ничего удивительного в том, что правильно
нарисованный угол типа Р может казаться неравным правильно нарисованному углу
типа (2, даже хотя оба угла в самом деле окажутся равными 45° при высоком
разрешении. (Именно белые пиксели, а не черные, и является источником
недоразумений.) Здесь, например, имеется четыре абсолютно точно оцифрованные
стрелы с увеличивающейся толщиной их древк:
Нам было бы интересно узнать, какова вероятность того, что
оцифрованный результат окажется именно вида Р/-, когда вершина (#0, Уо) выбирается на
плоскости случайным образом. Имеет ли один из рисунков большую
вероятность, чем другой? Когда используется самый естественный метод оцифровки,
ответ будет «нет»: каждое Рь будет получено с вероятностью 1/5. В свою
очередь все формы Qk также равновероятны при переменных значениях (#i,t/i).
Основная цель этих заметок — доказать, что только что установленные
факты представляют собой частные случаи одного общего явления:
Теорема. Когда прямая с тангенсом угла наклона a/Ь пересекает прямую
с тангенсом угла наклона c/d в точке (хо,уо), число разных оцифрованных
форм, которые могут быть получены при различных (хо,уо), равно \ad — bc\.
Кроме того, каждая из этих форм появляется с одной и той же вероятностью,
если точки (хо, Уо) распределены на этой плоскости равномерно.
Предположим, что a/Ь и c/d суть рациональные числа. Две оцифрованные
формы считаются равными, если они идентичны друг другу после
параллельного переноса; поворот и отражение не допускаются.
Прежде чем мы докажем эту теорему, надо точно определить, что значит
«оцифровать кривую». Мы будем следовать общей идее, которая излагается,
например, в [3, гл. 24]. Рассмотрим плоскость, покрытую пикселями в виде
квадратов, углы которых имеют целые координаты. Наша цель состоит в
модификации заданной кривой так, чтобы ее путь целиком лежал на границах
между пикселями. Если кривая задана в параметрической форме функцией
z{t) = (x(t), y(t)) при переменном £, ее оцифровка почти всюду определяется
формулой
round z(t) = (round x(t), round y(t))
при переменном £, где round(a) есть ближайшее к а целое число.
Следует быть особенно аккуратным, разумеется, в тех случаях, когда
округляются значения, находящиеся посередине между целыми, так как в
подобных случаях значение round(a) неопределено. Для удобства будем
предполагать, что путь z(t) ни в одном из пикселей не проходит через центр; иными
словами, предположим, что z(t) никогда не становится равным (т + |, п + |)
472
Компьютерная типография
для целых тип. (Точные попадания в центр пикселя происходят с
вероятностью нуль, так что в теореме, которую мы доказываем, ими можно
пренебречь. Чтобы вообще избежать центров пикселей, можно использовать
бесконечный сдвиг пути, избегая, таким образом, неопределенностей, на которые
было указано в интересной работе Брисенхама [1]; но нам нет
необходимости вдаваться в подобные тонкости.) При упомянутом выше предположении,
что если x(t) = т + |, то 'round x(ty неопределено, значение y(t) = n будет
неопределено и мы можем включить в оцифрованный путь целиком отрезок
от (га, п) до (га + 1, п). Аналогично, когда t достигает такого значения, что
round x(t) = m, но round y(t) = n или п + 1, мы включаем целиком отрезок от
(га, п) до (т, п + 1). Это соглашение определяет искомый оцифрованный путь
round z(i).
Когда оцифрованный путь z(t) возвращается в исходную точку либо
начинается или заканчивается в бесконечности без самопересечений, это
определяет область на плоскости. Соответствующий оцифрованный путь round z(t)
также определяет область, а у этой оцифрованной области оказывается есть
простое описание, если применить стандартные математические соглашения
о «числе витков»: Пиксель с углами в точках (га,п), (га + 1,п), (га,п + 1),
(т + 1,п + 1) принадлежит оцифрованной области, определяемой значениями
roundz(i) тогда и только тогда, когда его центр (га + |,п + \)
принадлежит неоцифрованной области, определяемой значениями z(t). (Это красивое
свойство оцифрованных кривых очень легко проверяется в простых
случаях, но точное доказательство провести непросто, поскольку оно опирается
на такие сложные вещи, как теорема Жордана о кривых. Необходимые
подробности можно найти в приложении диссертации Джона Хобби [2],
теорема А.4.1.)
Теперь мы готовы начать доказательство требуемого результата. Область,
определяемая углом, выходящим из точки (#o,2/o)i со сторонами, имеющими
наклон a/b и с/б?, можно описать неравенствами
а(х - х0) - Ъ(у - j/o) > 0; с(х - х0) - d(y -уо)>0.
может понадобиться обратить знаки, в зависимости от которых
определяются четыре области, описываемые двумя прямыми, проходящими через
точку (хо,уо), которые предположительно определяются заданным угловым
путем. Это можно сделать, заменив (а, Ь) на (—а, —Ь) и (или) (с, d) на (—с, —d).)
Установленная область содержит пиксели с нижним левым углом (га, п) тогда
и только тогда, когда
а(га + \ - хо) - b(n + \ - у0) > 0 ; с(га + \ - х0) - d(n + \ - у0) > 0.
Можно упростить обозначения, объединив несколько констант и положив а =
а(х0 - \) - Ь(уо - \) и /3 = с(х0 - \) - d(yQ - |):
(Нам
am — bn>ct\ cm — dn> /3.
Глава 23. Заметки об оцифровке углов
473
Пусть R(a,fi) есть оцифрованная область, составленная из всех целых пар
(т,п), удовлетворяющих этому условию; такие пиксели находятся в
оцифрованном угле, соответствующем точке (хо,Уо)-
Как указывалось выше, сохраняется предположение, что центры пикселей
не находятся точно на прямых, образующих угол. Таким образом, мы вправе
выдвинуть условие, что am — bn ф а и cm — dn ф /3 для всех пар целых чисел
(т,п). Однако, если имеет место равенство, можно также определить
оцифрованную область Я(а,/3), обобщив неравенства am — bn > а и cm — dn > /3,
как установлено, вместо того чтобы трактовать это обстоятельство как особый
случай. Обратите внимание, что Я(а,/3) равно Д([а], [73]); следовательно, мы
можем в дальнейшем обсуждении предположить, что а и /3 суть целые числа.
Другая вершина угла (xf0,yf0) приведет к параметрам (<У,/3'),
определяющим другую область R(a',P') таким же образом. Эти две области R(a,P) и
R(af,(3f) имеют одну и ту же форму тогда и только тогда, когда одна есть
параллельный перенос другой, т. е. Я(а,/3) = R(af,Pf) тогда и только тогда,
когда существуют целые (/с, I), такие, что
(т, п) е Я(а, /3) <=> (m-k,n-l) Е Л(а;, /3').
Наша основная цель состоит в том, чтобы доказать, что число различных форм
областей, отличающихся одна от другой, согласно приведенному выше
соотношению эквивалентности в точности равно \ad — bc\.
Лемма. Пусть а, /3, а', (3' суть целые числа. Тогда тождество Л(а,/3) =
R(af,Pf) относительно тангенсов a/b и c/d выполняется тогда и только тогда,
когда a — a' = ka — lb и /3 — /?' = kc — Id при некоторых целых (/с, £)•
Доказательство. Предположим, что R(a,P) = R(a',P') относительно a/b и
с/с?, и пусть (k,l) есть соответствующее значение параллельного переноса.
Тогда имеем
J am — bn> a 1 Г а(т — к) — b(n — I) > а! Л
\cm-dn>p) ^^ \c(m-k)-d(n-l)>pf)
для всех целых пар (т,п). Пусть а" = а' + ка — lb и Р" = Р' + kc — ldb такие,
что
Г am — bn> a 1 Г am — bn> а" Л
\cm-dn>p) ^^ \cm-dn>P")
для всех целых пар (т,п). Это влечет за собой, что а = а" и /3 = /3". Так
что если, скажем, мы имеем а < а", то можно найти целые тип, такие, что
am — bn = а и cm — dn > /3, поскольку а и b относительно просты; это могло
бы удовлетворять правым неравенствам, но не левым. (Более точно, мы могли
бы использовать алгоритм Евклида для нахождения целых а' и Ь', таких, что
ао! — W = 1. Тогда значения (т,п) = (aaf + bx, abf -f ax) удовлетворяли бы
левым неравенствам, но не правым для бесконечно многих целых х, потому
что ad — Ьсф О.)
474
Компьютерная типография
Таким образом, R(a, /3) = R(af,Pf) влечет за собой, что а — а' = ка — lb и
/3 — Р' = кс — Id. Обратное утверждение тривиально. П
Пусть к и I — целые, такие, что а = ка — lb. Лемма утверждает, что
i?(a,/3) = i?(0,/3 — кс + Id); следовательно, каждая оцифрованная область
й(а,/3) имеет ту же форму, что и оцифрованная область R(a\fif), в которой
а' = 0.
Осталось подсчитать количество отличающихся друг от друга областей
Д(0,/3), когда /3 есть целое число. Согласно лемме мы имеем Я(0,/3) = Я(0,/3')
тогда и только тогда, когда существуют целые (fc,Z), такие, что 0 = ка — lb и
/3 — /3' = кс — Id. Но ка = lb тогда и только тогда, когда к = Ьх и I = ах для
некоторого целого х\ следовательно это условие сводится к /3 —/3' = bxc—axd —
x(bc—ad). Другими словами, Л(0, /3) = Л(0, /3') тогда и только тогда, когда /3—/3'
есть кратное от ad — be. Число отличающихся друг от друга областей равно,
следовательно, \ad — be|, как и утверждалось.
Чтобы полностью завершить доказательство теоремы, нужно убедиться,
что каждый класс эквивалентности с равной вероятностью будет классом
оцифрованных угловых областей, когда точка пересечения (#о,2/о) выбирается
на плоскости случайным образом. Изменение обозначений с (#о,2/о) на (а,/3)
переводит равные области в равные же области; так что мы хотим доказать,
что классы эквивалентности Л(а,/3) равномерно распределены среди \ad — bc\
возможностей, когда действительные числа (а, /3) выбраны случайным
образом. Случайный выбор действительных чисел (а,/3) приводит к равномерно
распределенным парам целых чисел (\а], [/3]). А если \а\ имеет некоторое
фиксированное значение и [/3] пробегает множество целых чисел, класс
эквивалентности i?(a,/3) циклически пробегает все \ad — bc\ возможностей. Q
Пристальное изучение приведенного выше доказательства показывает, что
мы можем вывести явные формулы для этих множеств точек пересечения
(ясьУо), которые производят эквивалентные формы областей. Пусть D =
\ad — bc\ и пусть Rj обозначает форму, соответствующую области R(0,j) в
доказательстве, где 0 < j < D. Оцифрованный угол будет иметь форму Rj
тогда и только тогда, когда (#0, Уо) лежит в параллелограмме, вершины которого
суть (1/2 - bj/D, 1/2 - aj/D) плюс
((b-d)/D,(a-c)/D), (-d/D,-c/D), (Ь/Да/D), (0,0),
или в параллелограмме, полученном параллельным переносом указанного на
целую величину.
В особом случае а/b = 2/1 и c/d = (—3)/1 формы Rj суть то, что мы
выше обозначили Pj\ в особом случае а/b = 3/(—1) и c/d = (—1)/2 формы
Rj суть то, что мы называли Qj. Формы, которые возникают при оцифровке
углов, зависят от значений (xq mod 1, yQ mod 1) в единичном квадрате согласно
Глава 23. Заметки об оцифровке углов
475
следующим диаграммам:
Обратите внимание, что параллелограммы, «окутывающие» модуль 1,
занимают каждый по 1/5 области. Половина от Pj соответствует половине от Qe-j',
все другие половины соответствуют половине от Q7-j-
Если наклон любой прямой, образующей угол, выражается рациональным
числом, число возможных форм бесконечно (на самом деле несчетно). Но мы
все еще можем изучать такие оцифровки, исследуя форму только в
непосредственной близости к точке пересечения, во всяком случае, эти пиксели наиболее
критичны для восприятия человеком. Например, в упр. 24.7-24.9 книги The
METRFONTbook [3] обсуждается правильный способ подгонки вершин к
равностороннему углу так, чтобы он хорошо оцифровывался.
Мораль сей сказки —а сказки должны иметь мораль — вероятно такова:
если вы хотите поделить угол пополам таким способом, чтобы обе половины
визуально казались равными, то делящая прямая должна быть такой, что
отражение относительно этой прямой всегда переводит пиксель в пиксель. Таким
образом, делящая пополам прямая должна быть либо горизонтальной, либо
вертикальной, либо проходить по диагонали под углом в 45° через вершины
пикселей и/или их центры. Более того, ваш алгоритм превращения в прямую
должен выдавать результаты, симметричные относительно этой отражающей
прямой (см. [1]).
Теперь этот результат может успешно применяться в будущих
исследованиях.
Благодарности
Я хочу поблагодарить референтов и редакторов за их замечания. В частности,
представленное здесь доказательство теоремы предложил один из референтов.
Мой вариант доказательства был гораздо сложнее.
Эти заметки подготовлены при частичной финансовой поддержке фонда National Science
Foundation по гранту CCR-8610181.
476
Компьютерная типография
Литература
[1] Jack E. Bresenham, "Ambiguities in incremental line rastering," IEEE
Computer Graphics and Applications 7,5 (May 1987), 31-43.
[2] John Douglas Hobby, Digitized Brush Trajectories, Ph.D. thesis, Stanford
University (1985). Опубликовано также как отчет Stanford Computer
Science Department report STAN-CS-85-1070 (April 1985).
[3] Donald E. Knuth, The METRFONTbook, Volume С of Computers к
Typesetting (Reading, Massachusetts: Addison—Wesley and American
Mathematical Society, 1986).
[4] Christopher John Van Wyk, A Language For Typesetting Graphics, Ph.D.
thesis, Stanford University, (1980). Опубликовано также как отчет Stanford
Computer Science Department report STAN-CS-80-803 (June 1980).
Изображения «стрел» помещены в этой работе на с. 20.
[5] Christopher J. Van Wyk, "A graphics typesetting language," SIGPLAN
Notices 16,6 (June 1981), 99-107.
TEXDR.AFT
Эта и следующая главы рассчитаны на читателей, разделяющих вместе со
мной очарованность документом в его первоначальной, исходной, форме.
Ничего из приводимых ниже материалов не предназначалось в момент их
написания для какого-либо публичного использования. Тем не менее, чтение их
сейчас дает хорошее представление о том, как зарождались идеи,
составляющие основу ТцрС'а и METRFONT'a.
По-видимому, лучший способ показать, в какой обстановке появились и
развивались ТеХ и METfl FONT —воспроизвести некоторые записи из моего дневника
за 1977 г?
7 Feb: VdU.4 'Ц v*y **A.
8 Feb:
DtWlJlVj *M**~ t**Ulfi^ ^ MIX" jHfli*u*
Значительная часть моего рабочего времени в течение зимы 1977 г. была
посвящена чтению вводного курса по структурам данных. На первой лекции,
состоявшейся 5 января, было 170 студентов, однако только 80 из них
действительно прослушали весь курс до конца (он завершился 18 марта) и выполнили
все требуемые задания. Кроме того, много времени занимало исполнение
административных обязанностей — я возглавлял кафедральную комиссию по
составлению экзаменационных вопросов и задач, руководил исследовательскими
проектами, посвященными проблемам анализа алгоритмов, состоял в
Комитете по кадровым перемещениям Станфордского университета. Кроме того, я
писал фрагменты моей книги The Art of Computer Programming —в течение
1 Перевод дневниковых записей см. в примечании 3 переводчика в конце главы. — Прим.
ред.
478
Компьютерная типография
рассматриваемого периода времени я подготовил новый материал,
касающийся билинейных форм для раздела 4.6.4 из тома 2, а также новый материал
относительно побитовых (поразрядных) операций над данными для раздела
7.1 из тома 4. Однако 7 февраля, составляя справку для нашей комиссии по
экзаменационным вопросам и задачам, я просмотрел корректуры новых
учебных пособий и впервые получил возможность увидеть, как выглядит результат
применения цифровых типографских технологий с высокой разрешающей
способностью. Приобретенный таким способом опыт изменил мою жизнь. Уже 8
февраля я начал обсуждать с коллегами возможность использования этих
технологий для печатания моих собственных книг.
Мой дневник за 1977 г. не говорит ничего о типографских делах до 30
марта, когда «жребий был брошен».
30 Маг:
Gulloy j7*ofi <v- v/dU 2- tmJIy «ж*, +ky look. «stw^L* T MdAt X
Ivuk -ft? sol^-йл р*>1!й~ *уя/£ ^bi*>j»f]tfc*tly
Stdev S**f*r at ckwtA (s л brflkt spot /* M brfik.
Мне пришлось посвятить весь апрель завершению других начатых мною
проектов. Однако к началу мая я решил, что надо написать программу под
названием 'ТЕХ' и стал быстро продвигаться навстречу новому приключению.
2 May:
SHiW 7.1 §*\>LU 1*Hig/)t at \:oi> «.ил„— Hu/wyj
3May: To U~~$,yL iM^C Ti\\, /f»b*? 4 d««b "^ £** ^ Aja~"
4May: CtetMjJisy ,ffa, yt 7, [ «II f«+
Глава 24. TEXDR.AFT
479
5 Ма^: Р**Д «U4- Ы Uis Ь(м*№{ *yj*~
f\a\*r Jltfy* «^ "ТУЯ sifUA♦
6 May: ^ -^
7 May: , ^ ^ ^ J^ c^jb^.
Ш0СТ 77 * €гЛу&. (Ч> efa,^)
8МаУ: /4„^V> Ъ«у. ТД. 7.1' -Ь к <А <^л/ -&/г- <м^ jf)kW2*Y СХ.кД*Т
10 Ma^: ЙШ w^ Till *» Л«&* #f Uj/^ "efr.
11 May: £^ |^J^
12 May:
- Предварительный вариант отчета, подготовленный мною в первой трети
мая, был озаглавлен TEXDR.AFT, поскольку компьютер, которым я
пользовался, не позволял создать файл с именем ТЕХ.DRAFT. Ниже приводится текст,
написанный ночью 12 и 13 мая и предназначавшийся, в основном, в качестве
памятной записки для самого себя.
Черновой вариант предварительного описания ТЕХ'а
Д.Кнут, 13 мая 1977 года
В этой записке я попытаюсь объяснить, что такое система ТЕХ для подготовки
документов полиграфического качества, а также пути реализации данной системы.
Хотя я и сам еще не понимаю в достаточной степени всех этих вопросов, думаю,
что лучший способ разобраться в них — это попытаться объяснить существо дела
кому-либо еще.
ТЕХ ориентирован на технические тексты. "Посвященные" произносят букву X
в ТЕХ как греческое "хи" (ср. также шотландский звук (сЪ.} в слове 'Loch Ness'),
поскольку слово 'technical' происходит от греческого корня, обозначающего
искусство, а также технику. Я занимаюсь сейчас разработкой этой системы для
того, чтобы использовать ее в подготовке к изданию моих книг из серии
The Art of Computer Programming, т.е. первоначально система будет ориентирована
и настроена таким образом, чтобы соответствовать стилю моих книг, однако не
должно быть трудностей с приспособлением ее и для других аналогичных целей, если
кому-то это понадобится.
480
Компьютерная типография
Входом для ТЕХ'а является текстовый файл в формате, например, редактора
TVeditor, используемого в Станфордской лаборатории искусственного интеллекта.
Результат работы ТЕХ'а — последовательность страниц, подготавливаемая "за один
проход", пригодная для распечатывания на различных устройствах. Этот отчет
представляет собой попытку объяснить, каким образом можно из входа получить
нечто на выходе. Основная идея состоит в том, что требуемый процесс
рассматривается как некая последовательность операций над двумерными "боксами";
упрощенно говоря, входом является длинная строка символов, взятых из различных
шрифтов, причем каждый из символов может интерпретироваться как нечто,
занимающее небольшую прямоугольную область, а выход получается "склеиванием"
этих областей друг с другом, по горизонтали или вертикали, с соблюдением при
этом различных соглашений относительно центрирования и выравнивания. Конечным
результатом такого рода процесса будет совокупность больших прямоугольных
областей, которые и будут представлять собой требуемые страницы. Если LISP
работает с одномерными символьными строками, ТЕХ имеет дело с двумерными
структурами, собранными из прямоугольных боксов; продолжая аналогию с LISP*ом,
можно сказать, что ТЕХ располагает как горизонтальными, так и вертикальными
операциями типа операции cons. К тому же, ТЕХ базируется еще на одной важной
концепции — понятии эластичного клея между боксами, представляющего собой
некий "строительный раствор", который может растягиваться или сжиматься в
той или иной степени, так что конструкции из боксов могут объединяться друг
с другом гибким образом.
Чтобы объяснить принципы работы ТЕХ'а более подробно, я буду излагать их
на двух уровнях: давать низкоуровневое описание того, как именно выполняется
обработка в том или ином случае, а также высокоуровневое описание того, как
реализуются те или иные сложные действия.
Для начала, имея в виду низкоуровневое описание, надо понимать, что вход
ТЕХ'а -- это на самом деле не последовательность (строка) боксов, а файл из
литер в 7-битовой кодировке. Этот файл именуется "внешний входной файл". Первое,
что делает ТЕХ, — преобразует этот файл во "внутренний входной файл", следуя
при этом таким правилам:
1. Удалить, если таковая имеется, первую управляющую страницу, сформированую
редактором TVeditor.
2. Удалить первую (заглавную) строку с каждой из оставшихся страниц,
заменить индикаторы конца страницы (символ ;14) символами
возврата каретки 015). Удалить все символы протяжки бумаги на одну строку
('12). Удалить все знаки У, и последовательности символов,
следующих за ними, вплоть до очередного символа возврата каретки (но не
включая его).
3. Удалить все пробелы, следующие за символом возврата каретки.
4. Если два или более символа возврата каретки следуют подряд, заменить
их все кроме первого символами вертикальной табуляции ('13). Они
используются для обозначения конца абзаца, другими словами, пользователь
задает конец абзаца либо двукратным нажатием клавиши возврата каретки, либо
переводом страницы, за которым следует нажатие клавиши возврата каретки.
5. Заменить все остающиеся символы возврата каретки пробелами.
6. Если в строке следуют подряд два пробела, заменить их одним пробелом.
7. Добавить бесконечно много символов } справа.
Глава 24. TEXDR.AFT
481
Смысл применения правила 7 заключается в том, что ТЕХ использует символы { и }
для группирования и завершающие текст символы } будут соответствовать символам
{ , для которых пользователь забыл написать парные им символы завершения
группирования во внешнем входном файле. Следуя приведенным выше правилам, ТЕХ
получает внутренний входной файл, не содержащий символов возврата каретки,
перевода строки, знаков У, , перевода страниц, а также сдвоенных пробелов.
Управление пробелами в выходном документе осуществляется ТЕХ'ом с помощью других
средств (на самом деле ТЕХ во внутреннем представлении документа заменяет литеры
{ и } на символы с кодами '14 и '15, но это никак не сказывается на работе
пользователя, так что везде далее в этом отчете я буду по-прежнему пользоваться
литерами { и }).
Теперь перейдем к высокоуровневому описанию и посмотрим, каким образом
пользователь сообщает ТЕХ'у о своих требованиях относительно сложных объектов.
Приводимый ниже пример довольно велик и его лучше бегло просмотреть, не изучая
детально. Он задуман в качестве тестовой задачи для начальной отработки
создаваемой системы. Этот пример основан на материале начальных страниц моей
книги "Seminumerical Algorithms", где опущены фрагменты, не представляющие
особого интереса с издательской точки зрения и с точки зрения требований,
предъявляемых к реализуемой системе. Изучение этого примера принесет читателю
наибольшую пользу, если он будет иметь под рукой оригинал упомянутой книги,
чтобы можно было сравнивать входной ТЕХ'овский текст с требуемым результатом
его обработки. Номера, проставленные в начале каждой из строк, не являются
элементами входного ТЕХ'овского текста, они включены только для справочных
целей, чтобы можно было ссылаться адресно на тот или иной фрагмент данного
текста.
1 '/.Example ТЕХ input related to Seminumerical Algorithms using ACPdefs
2 ACPpages starting at page 1{
3 titlepage '/.This tells the page format routine not to put page number at top
4 sectionnumber 3
5 runninglefthead{RANDOM NUMBERS}
6 hexpand 11 pt {fnt cmgll CHAPTER hskip 10 pt THREE}
7 vskip 1 cm plus 30 pt minus 10 pt
8 rjustline {fnt cmgb20 RANDOM NUMBERS}
9 vskip .5 cm plus 1 pc minus 5 pt
10 quoteformat {Anyone who considers arithmetical \cr
11 methods of producing random digits \cr is, of course,
12 in a state of sin. \cr} author {JOHN VON NEUMANN (1951)}
13 quoteformat {Round numbers are always false.}
14 author{SAMUEL JOHNSON (c. 1750)}
15 vskip 1 cm plus 1 pc minus 5 pt
16 sectionnumber 3.1
17 sectionbegin {3.1. INTRODUCTION}
18 runningrighthead {INTRODUCTION}
19 Numbers which are "chosen at random'' are useful in a wide variety of
20 applications. For example:
21 '/.This blank line specifies end of paragraph
22 yskip '/.This means an extra space between paragraphs
23 textindent{a)}{\sl Simulation.}xskip When a computer is used to simulate natural
24 phenomena, random numbers are required to make things realistic. Simulation
25 covers many fields, from the study of nuclear physics (where particles are
26 subject to random collisions) to systems engineering (where people come into,
482
Компьютерная типография
27 say, a bank at random intervals). \par
28 yskip textindent{b)}{\sl Sampling.} xskip It is often impractical to examine
29 all cases, but a random sample will provide insight into what constitutes
30 "typical" behavior.
31
32 yskip It is not easy to invent a foolproof random-number generator. This fact
33 was convincingly impressed upon the author several years ago, when he attempted
34 to create a fantastically good random-number generator using the following
35 peculiar method:
36
37 yskip yskip noindent {\bf Algorithm K} xskip({\sl "Super-random" number
38 generator}), xskip Given a 10-digit decimal number $X$, this algorithm may be
39 used to change $X$ to the number which should come next in a supposedly random
40 sequence. \par
41 algstep Kl.[Choose number of iterations.]Set $Y«-lfloor X/10 sup 9 rfloor$, i.e.,
42 the most significant digit of $X$. (We will execute steps K2 through K13 $Y+1$
43 times; that is, we will randomize the digits a {\sl random} number of times.)
44
45 algstep K10. [99999 modify.] If $X<10 sup 5$, set $X«-X sup 2 + 99999$;
46 otherwise set $X «- X - 99999$. xskip blackslug
47
48 boxinsert{ctrline{fnt cmgblO Table 10}
49 ctrline{fnt cm9 A COLOSSAL COINCIDENCE: THE NUMBER 6065038420}
50 ctrline{fnt cm9 IS TRANSFORMED INTO ITSELF BY ALGORITHM K.}
51 blankline 3 pt vskip ruled
52 hjust to 12 pc{blankline vskip 6 pt
53 tabalign{#«quad#®quad$#$\cr
54 Step®ctr{$X$ (after)}\cr
55 vskip 10 pt plus 10 pt minus 5 pt
56 Kl*6065038420\cr K12*1905867781*Y=5\cr
57 vskip 10 pt plus 10 pt minus 5 pt blankline}
58 hskip 3 pc ruled align top
59 hjust to 12 pc{blankline vskip 6 pt
60 tabalign{#«quad #®quad $#$\cr
61 Step®ctr{$X$ (after)}\cr
62 vskip 10 pt plus 10 pt minus 5 pt
63 K10*1620063735\cr Kll*1620063735\cr K12*6065038420*Y=0\cr
64 vskip 10 pt plus 10 pt minus 5 pt blankline}
65 vskip ruled blankline} */,end of the boxinsert
66 yskip yskip The moral to this story is that {\sl random numbers should not be
67 generated with a method chosen at random}. Some theory should be used.
68
69 exbegin
70 exno tr 1. [20] Suppose that you wish to obtain a decimal digit at random, not
71 using a computer. Shifting to exercise 16, let $f(x,y)$ be a function such that
72 if $0<x,y<m$, then $0<f(x,y)<m$. The sequence is constructed by selecting
73 $X sub 0$ and $X sub 1$ arbitrarily, and then letting$$
74 X sub{n+l} = f(X sub n, X sub {n-1}) quad for quad n>0.$$
75 What is the maximum period conceivably attainable in this case?
76
77 exno 17. [10] Generalize the situation in the previous exercise so that
78 $X sub {n+l}$ depends on the preceding $k$ values of the sequence.
79 \ff
80 sectionnumber 3.2 sectionbegin{3.2. GENERATING UNIFORM RANDOM NUMBERS}
Глава 24. TEXDR.AFT
483
81 runningrighthead {GENERATING UNIFORM RANDOM NUMBERS}
82 In this section we shall consider methods for generating a sequence of random
83 fractions, i.e., random {\sl real numbers $U sub n$, uniformly distributed
84 between zero and one}. Since a computer can represent a real number with only
85 finite accuracy, we shall actually be generating integers $X sub n$ between
86 zero and some number $m$; the fraction$$U sub n=X sub n/m eqno 1$$ will
87 then lie between zero and one.
88
89 vskip .4 in plus .2 in minus .2 in
90 sectionnumber 3.2.1 sectionbegin{3.2.1. The Linear Congruential Method}
91 runningrighthead{THE LINEAR CONGRUENTIAL METHOD}
92 By far the most successful random number generators known today are special
93 cases of the following scheme, introduced by D. H. Lehmer in 1948. [See
94 {\sl Annals Harvard Сотр. Lab.} {\bf 26} (1951), 141-146.] We choose four
95 "magic numbers,,:$$
96 tabalign{rjust#«quad mathoff # quad«rjust #®ljust #\cr
97 X sub 0,®the starting value;®X sub 0®>0. \cr
98 m,«the modulus;®m«>X sub 0, quad m>a, quad m>c. \cr} eqno 1$$
99 The desired sequence of random numbers $langle X sub n rangle$ is then obtained
100 by setting $$X sub{n+l}=(aX sub n+c)mod m,quad n>0.eqno 2$$This is called
101 a {\sl linear congruential sequence}.
102
103 Let $w$ be the computer's word size. The following program computes $(aX+c)
104 mod(w+l)$ efficiently:$$tabalign{\it#quad®hjust to 50 pt{\tt#}\cr
105 01®LDAN*X\cr
106 02*MUL*A\cr
107 05®JANN®*+3\cr
108 07®ADD®=W-1= quad blackslug\cr} eqno 2$$
109 {\sl Proof.} xskip We have $x=l+qp sup e$ for some integer $q$ which is not a
110 multiple of $p$. By the binomial formula$$
HI eqalign{x sup p®=l+{p choose l}qp sup e + cdots +{p choose p-l}q sup
112 {p-l}p sup{(p-l)e}+q sup p p sup {pe}\cr
113 ®=l+qp sup{e+l} big(){l + 1 over p {p choose 2} q p sup e + 1 over p
114 {p choose 3} q sup 2 p sup {2e} + cdots + 1 over p {p choose p} q sup {p-1}
115 p sup {(p-l)e}.\cr$$ By repeated application of Lemma P, we find that$$
116 eqalign{(a sup p sup g - l)/(a-l)®equiv 0'(modulo p sup g), \cr
117 (a sup p sup g - l)/(a-l)®inequiv 0'(modulo p sup {g+1}). \cr}eqno 6$$
118 If $Kk<p$, $p choose k$ is divisible by $p$. {biglpren}{\sl Note:} xskip A
119 generalization of this result appears in exercise 3.2.2-11(a).{bigrpren} By
120 Euler's theorem (exercise 1.2.4-48), $a sup{varphi(p sup{e-f})} equiv V
121 (modulo p sup{e-f}); hence $lambda$ is a divisor of$$
122 lambda(p sub 1 sup e sub 1 ldots p sub t sup e sub t)=lcm paren{lambda(p sub 1
123 sup e sub 1), ldots, lambda(p sub t sup e sub t)}. eqno 9$$
124
125 This algorithm in MIX is simply$$
126 tabalign{hjust to 50 pt{\tt#M\tt#}} quad® \cr
127 J6NN®*+2®underline{\it Al. j<0?}\cr
128 STA®Z«quad quad $-»Z$.\cr} eqno 7$$
129 That was on page 26. If we skip to page 49, $Y sub 1 + cdots + Y sub k$ will
130 equal $n$ with probability$$
131 sum over{y sub 1 + cdots + у sub к = n}atop{y sub 1, ldots, у sub к > 0}
132 prod over {l<s<k}
133 {e sup{-np sub s}(np sub s)sup у sub s}over у sub s!
134 ={e sup -n n sup n}over n!.$$
484
Компьютерная типография
135 This is not hard to express in terms of $n$-dimensional integrals$$
136 textsize{int from alpha sub n to n dY sub n int from alpha sub{n-l} to
137 Y sub n dY sub{n-l} ldots int from alpha sub 1 to Y sub 2 dY sub 1} over
138 textsize{int from 0 to n dY sub n int from 0 to Y sub n dY sub{n-l} ldots
139 int from 0 to Y sub 2 dY sub 1}, quad {\rm where} quad alpha sub j =
140 max(j-t,0). eqno 24$$
141 This together with (25) implies that$$ def rtn{sqrt n}
142 lim over {n-»inf} s over rtn
143 sum over{rtn s<k<n}{n choose k} big(){k over n - s over rtn} sup к
144 big(){s over rtn + 1 - к over n} sup{n-k-l} = e sup {-2s} sup 2, quad s>0,
145 eqno 27$$ a limiting relationship which appears to be quite difficult to
146 prove directly.
147
148 exbegin exno 17. [HM26] Let $t$ be a fixed real number. For $0<k<n$, let$$
149 P sub nk(x)=int from{n-t}to x dx sub n int from{n-l-t} to x sub n dx sub
150 {n-l}ldots int from {k+l-t} to x sub{k+2} dx sub{k+l} int from 0 to
151 x sub {k+1} dx sub к ldots int from 0 to x sub 2 dx sub 1;$$
152 Eq. (24) is equal to$$def sumk{sum over{l<k<n}}
153 sumk X prime sub к Y prime sub к big/{sqrt{sumk X prime sub к sup 2}
154 sqrt{sumk Y prime sub к sup 2}}.$$
155 sectionnumber 3.3.3.3 subsectionbegin{3.3.3.3. This subsection doesn't exist}
156 runningrighthead{A BIG MATRIX DISPLAY} Finally, look at page 91.$$
157 def diagdots{raise . by 10 pt hskip 4 pt raise . by 5 pt hskip 4 pt .}
158 eqalign{U®=big(){tabalign{ctr#ectr#ectr#ectr#®ctr#ectr#ectr#\cr
159 l\cr«diagdots\cr®®l\cr
160 с sub l«ldots«c sub{k-l}«l«c sub{k+l}«c sub n\cr
161 ®®®®l\cr®eee®diagdots\creeeee®l\cr}},\cr
162 U sup{-l}e=big(){tabalign{ctr#®ctr#ectr#ectr#ectr#ectr#ectr#\cr
163 l\cr®diagdots\cr®®l\cr
164 -c sub l®ldots®-c sub{k-l}®l®-c sub{k+l}®-c sub n\cr
165 eeeel\cr®®®®®diagdots\cr®eeee®l\cr}}$$
166 This ends the test data, fortunately TEX is working fine.}
Первое, что надо сказать относительно приведенной выше задачи, — она описана
с использованием средств не базового языка, а некоторого расширения ТЕХ'а.
Например, "ACPpages" во второй строке представляет собой имя специальной
программы, которая вызывает основную ТЕХ'овскую программу формирования страниц,
но использует ее для подготовки страниц в формате книги "The Art of
Computer Programming". Слова titlepage, sectionnumber, runninglefthead,
quoteformat, author, sectionbegin, runningrighthead, xskip, yskip, textindent,
algstep, exbegin, exno и subsectionbegin являются специфическими для моих книг
и должны быть определены в терминах низкоуровневых ТЕХ'овских примитивов
способом, поясняемым ниже. Далее, большинство шрифтов встроены в эти определения;
например, в определении sectionbegin указывается, что текст раздела по умолчанию
набирается шрифтом кегля 10 pt, в то время как определение exbegin для набора
текста упражнений задает шрифт кегля 9 pt. Ключевые слова типа приведенных выше
выбирались таким образом, чтобы они не совпадали в точности с английскими
словами, поскольку они будут перемежаться со словами набираемого текста.
Например, еще одно определение задает, что слово MIX всегда должно набираться
шрифтом типа "шрифт пишущей машинки"; скрытое определение
def MIX|{{\tt \{MIX}}}
обеспечит автоматическое выполнение этого требования при обработке строки 125.
Механизм макроопределений ТЕХ'а мы рассмотрим позднее; три простых примера
имеются в строках с номерами 141, 152 и 157 нашей тестовой программы, где для
Глава 24. TEXDR.AFT
485
экономии места вводятся сокращенные обозначения для некоторых фрагментов
ТЕХ'овского текста. Так, конструкция \{string} используется для передачи строки
без интерпретации входящих в нее слов согласно существующему набору определений;
это средство используется в приведенном выше определении ключевого слова MIX.
Для любознательных читателей, кому было бы интересно увидеть более сложную
конструкцию, даем определение ключевого слова quoteformat:
def quoteformat #1 author #2 {lineskip 3 pt plus .5 pt minus 1 pt
vskip 6 pt plus 5 pt minus 2 pt
def \rm {fnt cmg8} def \sl {fnt cmgi8}
{\sl tabalign{rjust##\cr #1}}
vskip б pt plus 5 pt minus 2 pt \rm rjustline #2
vskip 11 pt plus 5 pt minus 2 pt}
Пожалуйста, не пытайтесь понять это сообщение сейчас — ТЕХ на самом деле весьма
прост, поверьте мне. Слово "author", встречающееся в определении quoteformat,
имеет специальную интерпретацию только в пределах данного определения, в других
же случаях оно трактуется как обычно. Именно поэтому я не стал вводить
специальное неанглийское ключевое слово вроде "quoteauthor'} в строках
с номерами 12 и 14 изучаемого нами примера.
Спецификации ключевых слов sectionnumber и runninglefthead в строках 4 и 5
предназначены для использования во время формирования самых верхних строк при
верстке страниц книги АСР. Строка б содержит первый фрагмент текста, который
появится на создаваемой странице, однако обратите внимание сначала на
строку с номером 8, которая попроще. Строка 8 предписывает использовать
шрифт cmgb20 (что означает "Computer Modern Gothic Bold 20 point",
т.е. полужирный шрифт семейства Computer Modern, кегля 20 pt, который я
предполагаю разработать в скором времени) для набора слов RANDOM NUMBERS
(СЛУЧАЙНЫЕ ЧИСЛА), а также выровнять эти слова по правому краю строки
(rjustline). Строка б аналогична строке 8, но задает использование шрифта
cmgll кегля И pt; текст "hskip 10 pt" требует сформировать горизонтальный
пробел размером 10 pt, а текст "hexpand И pt" обозначает, что надо взять
строку и растянуть ее на И pt шире, чем это должно иметь место в норме.
Отметим, что шрифтовые определения, задаваемые внутри фигурных скобок {...},
теряют силу вне этих скобок. Это же правило имеет место и для других
определений.
Теперь пришло время объяснить ТЕХ'овский механизм растяжения и сжатия
последовательностей боксов. Размеры в ТЕХ'е могут задаваться в типографских
пунктах, пиках, дюймах, сантиметрах или миллиметрах, что обозначается
соответственно аббревиатурами pt, pc, in, cm, mm. Эти обозначения имеют смысл
только в таких контекстах, где используются физические длины, и одно из таких
обозначений в такого рода контексте должно присутствовать обязательно, даже если
фактическое значение соответствующей величины равно нулю (один дюйм равен
б пикам или 72 пунктам, или 2.54 сантиметрам, или 25.4 миллиметрам). Клей между
боксами имеет три составляющих:
фиксированная составляющая, х
добавляемая (plus) составляющая, у
убавляемая (minus) составляющая, z
Составляющая х представляет собой "нормальное" значение величины
пробела. В случаях, когда надо бывает растянуть последовательность боксов,
как это имеет место при обработке строки б, каждая х-составляющая в клее
увеличивается путем добавления нескольких у-составляющих. Если же строку надо
сжать, тогда каждая х-составляющая уменьшается путем вычитания нескольких
z-составляющих.
486
Компьютерная типография
Например, пусть даны четыре бокса, соединенных друг с другом клеем
со спецификацией вида
(xl,yl,zl), (x2,y2,z2), (x3,y3,z3),
тогда расширение строки на величину ¥ достигается использованием интервалов
xl + yl ¥\ х2 + у2 ¥\ хЗ + уЗ w\
где ¥* = ¥/(yl+y2+y3). Такого рода расширение невозможно, если ¥>0 и yl+y2+y3=0.
Создаваемая система будет настойчиво пытаться уменьшить число растяжений строк,
которые будут плохо смотреться, посредством довольно интеллектуальной
программы выравнивания строк (описывается ниже). При сжатии строки максимальное
значение величины ее сокращения равняется сумме всех z-составляющих, не
будет предприниматься попыток ужать строку еще больше. Таким образом, величину
z-составляющих надо задавать так, чтобы x-z представляло собой минимальное
значение диапазона допустимых значений пробела. Для у-составляющей
подходящим будет такое значение, что х+у было бы допустимым, но х+Зу лежало
бы на пределе допустимости. Значения параметров у и z должны быть
неотрицательными, однако х может быть и отрицательным (для стирания пробелов
(backspacing) и перекрытия фрагментов строк (overlapping)), если соблюдать при
этом определенную осторожность.
Обозначение "hskip 10 pt" в строке б означает, что х = 10 pt, у = 0 и z = 0
в горизонтальном клее между словами CHAPTER THREE. Если бы эта
команда hskip здесь не присутствовала, использовались бы обычные соглашения
для данной ситуации. А именно, клей между CHAPTER и THREE включал бы тогда
х-составляющую, равную обычному междусловному интервалу для данного шрифта,
а также у = х, z = х/2. Для клея между буквами будет (например) х = 0, у = 1/10
обычного междусловного интервала для данного шрифта, z = 0; таким
образом, растяжение строки без использования hskip приведет главным образом
к увеличению промежутка между словами CHAPTER и THREE, использование же данной
команды в виде, показанном выше, обеспечит введение дополнительных промежутков
еще и между отдельными буквами. Шрифты, предназначенные для использования их
ТЕХ'ом, должны обладать такого рода средствами управления промежутками,
понимаемыми как некоторые дополнительные свойства соответствующего шрифта;
ТЕХ должен также уметь обнаруживать ситуации типа конца предложений, слегка
увеличивая величину пробелов после знаков препинания там, где это необходимо.
Символы вроде + и = принято окружать пробелами, тогда как пары символов )} и :=
должны стоять вплотную друг к другу; символы + и = не выделяются пробелами
в случае, когда они появляются в индексах. Аналогичным образом должны
обрабатываться ситуации с лигатурами. Наличие в шрифтах, используемых ТЕХ'ом,
такого рода средств делает эти шрифты несколько более "интеллектуальными";
более подробно данный подход будет рассмотрен ниже.
Большинство ТЕХ'овских средств симметрично по отношению к горизонтальному
и вертикальному режимам, хотя основная идея, заключающаяся в формировании
сначала строк, а уже потом столбцов, асимметрична по своей природе и встроена
в стандартные программы (в соответствии с тем способом, который мы обычно
применяем при письме). Спецификация "vskip" в строке 7 задает вертикальный
клей аналогично горизонтальному клею. Когда программа выравнивания страниц
пытается заполнить первую страницу при обработке рассматриваемого нами
тестового примера (путем введения разрыва страниц точно в конце абзаца, или
в таком месте текста, чтобы на каждой из двух смежных страниц были размещены
хотя бы по две строки из разрываемого между страницами абзаца), этот клей
будет растягиваться или сжиматься вдоль вертикального измерения, используя
значения х = 1 см, у = 30 pt, z = 10 pt. Дополнительные характеристики клея
вводятся в определении для ключевого слова quoteformat — это параметр
lineskip, задающий величину междустрочного интервала, а также параметр vskips,
Глава 24. TEXDR.AFT
487
который задает значение специального дополнительного интервала между цитатой
и строкой с именем ее автора. Применительно к основному тексту инструкция для
принтера имеет вид "10 на 12", что означает требование пользоваться для печати
шрифтом с кеглем 10 pt при значении интервала между соответствующими частями
смежных строк, равном 12 pt. ТЕХ будет использовать шрифт кегля 10 pt со
спецификацией
lineskip 2 pt plus .5 pt minus .25 pt
так что междустрочный интервал будет обладать определенной эластичностью.
Дополнительное управление величиной междустрочного интервала задается
спецификацией
parskip 0 pt plus 1 pt minus 0 pt
Кроме того, существуют также интервалы между упражнениями, шаги
в алгоритмах и т.д. Определение
def уskip {vskip 3 pt plus 2 pt minus 2 pt}
используется для формирования специального вертикального интервала, например,
в строках 22 и 37. В строках 23, 37 и т.д. используется горизонтальный интервал
вида
def xskip {hskip б pt plus 10 pt minus 3.5 pt}
который вводится в ситуации, когда психологически оправданно наличие интервала
большего, чем это определено в качестве нормы. Для этих ситуаций эластичный клей
особенно полезен. Пример использования большего по размеру горизонтального
отступа, называемого "quad", содержится в строке 74; он задает интервал
величины "два em", где em — единица измерения, часто применяемая при
типографском наборе математических текстов.
Другая привлекательная черта эластичного клея выявляется при рассмотрении примера
def hfill {hskip 0 cm plus 1000 cm minus 0 cm}.
Можно сказать, что у здесь имеет практически бесконечное значение (длина, равная
10 м). Когда этот символ появляется в качестве некоторого hskip в начале строки,
он обеспечивает выравнивание данной строки по правому краю; когда он имеется как
в начале строки, так и в ее конце, он обеспечивает центрирование строки;
в случае, когда он находится в середине строки, он аккуратно делит строку на
части и т.д. Эти свойства эластичного клея обеспечивают средствам ТЕХ'а
выравнивания строк превосходство над средствами других систем, поскольку новые
свойства вводятся достаточно простым способом и в то же самое время уменьшают
необходимость использования устаревших средств применительно к общему случаю.
После того как произведено выравнивание списка боксов, все значения параметров
клея фиксируются и полученный объединенный бокс становится неизменяемым
("затвердевает"). Выравнивание осуществляется как по горизонтали, так и по
вертикали. Горизонтальное выравнивание длинных строк включает автоматическое
выполнение операций переноса; дополнительные сведения относительно операций
выравнивания будут приведены в данном отчете несколько позднее.
Снова обратимся к примеру. Строки с номерами 21, 31, 36 и т.д. в нем
— это пустые строки, обозначающие конец абзаца. Другой способ показать конец
абзаца состоит в использовании команды "\раг,>; пример такого использования
можно видеть в строке 27. Строка 124 задает конец абзаца, завершающегося
выключной формулой. Абзацы начинаются обычным образом; одна из ТЕХ'овских
команд, которая будет исполняться после того как обработана строка 17,
содержащая "sectionbegin" ("начало раздела"), это команда
parindent 20 pt
задающая абзацный отступ размера 20 pt в первой строке каждого абзаца до тех
пор, пока не появится команда "noindent" ("подавить абзацный отступ"), как это
имеет место, например, в строке 37. Программа "sectionbegin" также задает
488
Компьютерная типография
"noindent" для самого первого абзаца данного раздела, поскольку в моих книгах
такой стиль является стандартным. В строке 23 указывается "textindent{a)}", что
обозначает необходимость создать бокс ширины parindent, содержащий пару
символов а) , за которыми следует пробел, причем эта тройка символов
выравнивается по правой границе данного бокса.
В строке 23 "\sl" обозначает "наклонный шрифт". Я решил для выделения слов
в тексте пока заменить курсив наклонным вариантом обычного "прямого" шрифта,
тогда как имена переменных в математических формулах будут, как это принято,
набираться курсивом. Надо будет еще поэкспериментировать с этим, однако чутье
подсказывает мне, что набор так будет выглядеть намного привлекательнее,
поскольку буквы из типичных курсивных шрифтов смотрятся не очень красиво среди
текста, набранного обычным шрифтом. В любом случае я буду делать различие между
наклонными и курсивными шрифтами, поскольку возможны ситуации, когда
целесообразно использовать два различных шрифта для выделений, отличающихся по
стилю (по каким-либо причинам) друг от друга. Обозначение "\bf" в строке 37
задает набор полужирным шрифтом. Все перечисленные шрифты определяются в команде
начала раздела (sectionbegin); определения эти здесь не показаны.
Все математические формулы во входном ТЕХ'овском файле содержатся либо между
парой символов $...$, как это имеет место, например, в строках 38 и 41, либо
между парами $$...$$ (так записываются выключные формулы). Формулы записываются
с использованием специального синтаксиса, основывающегося на предложениях
Кернигана и Черри (Kernighan and Cherry, Comm. ACM 18, March 1975, 151-157).
Например, запись "sup 9" в строке 41 обозначает верхний индекс 9, а запись
"sub{n+l}" в строке 74 — нижний индекс п+1. Ключевые слова наподобие sup и
sub активны только в пределах, охватываемых парами $...$ (или $$...$$); то же
самое относится к именам греческих букв, вроде lambda (строка 122) и varphi
("variant phi", "скругленный" вариант буквы phi, появляющейся в верхнем индексе
в строке 120), а также к словам типа lim (строка 142), max (строка 140), 1cm
(строка 122). Все буквы в формулах набираются курсивным шрифтом, за исключением
тех случаев, когда они относятся к одному из распознаваемых слов или же лежат
в пределах фигурных скобок в командах "mathoff{...}" или "{\rm ...}". I
Расстановка всех пробелов в формулах выполняется ТЕХ'ом. Для случаев, когда
с точки зрения автора ТЕХ справился с решением этой задачи не совсем удачно,
имеется возможность указать дополнительный пробел с помощью символа ( (см.,
например, строку 117). В строке 117 дополнительный пробел перед "(modulo...)"
желателен в силу того, что обычно пробел перед скобками опускается, но здесь
это будет смотреться неудачно. В завершающих фрагментах рассматриваемого
примера много сложных формул, которые будут выглядеть так, как это имеет место
в соответствующих местах книги АСР2, откуда взят данный пример. Обработка
текста "eqno 24" (строка 140) приведет к тому, что будет сформирован номер
формулы и проставлен в виде "(24)" на правом поле страницы, причем он будет
отцентрирован по вертикали по высоте формулы. Так будет сделано, если справа
от формулы достаточно места для размещения там номера, если же этого места
недостаточно, номер "(24)" будет набран на следующей строке и выключен
вправо.
Ключевое слово "algstep", используемое в строках 41 и 45, обозначает формат
записи шага алгоритма:
def algstep #1. [#2] {vskip 3 pt plus 1 pt minus 1 pt
noindent rjust in 20 pt{#l.} [#2] xskip hangindent 20 pt}
Сначала в этом определении устанавливается значение клея для вертикальных
интервалов; эта операция выполняется еще до того, как начинается
текст шага алгоритма. Устанавливается также подходящее значение для текстового
Глава 24. TEXDR.AFT
489
отступа (textindent) и т.д. В первый раз здесь появляется такое средство, как
отрицательный абзацный отступ (hanging indent). Использование этого средства
оставляет первую строку абзаца несмещенной (без абзацного отступа), а все
остальные строки данного абзаца смещаются вправо на величину абзацного отступа.
Ключевое слово "ехпо" (упражнение с номером ... ), используемое в строках
70, 77 и т.д., имеет определение в чем-то похожее на определение шага алгоритма;
такие определения форматов для элементов, часто используемых в моих книгах,
помогают обеспечить единообразие стиля представления этих элементов на
протяжении всей книги. Элемент "tr" в строке 70 позволяет изобразить
треугольник на левом поле страницы. Чтобы этот треугольник был размещен левее
крайней левой позиции строки, содержащей номер упражнения, в определении для
"tr" используется клей с отрицательным значением.
В строке 48 начинается выполнение операции вставки бокса (boxinsert) —
одного из важных элементов, необходимых при верстке полосы набора. Рассматриваемый
бокс, определенный внутри пары фигурных скобок {...}, идущих вслед за
ключевым словом "boxinsert", формируется как отдельный элемент, который
должен быть размещен в верхней части либо текущей страницы, либо
следующей за ней. За этим боксом следует вертикальный клей, задаваемый
выражением
boxskip 20 pt plus 10 pt minus 5 pt,
Это еще один из элементов, подключаемых при обнаружении ТЕХ'ом ключевого слова
"sectionbegin" в тексте обрабатываемого документа. Это средство используется
для размещения рисунков и таблиц, в нашем случае — для таблицы.
Заголовок данной таблицы описывается в строках 48-50, сама же таблица (см. с.б
книги АСР2), достаточно сложна, поэтому отложим пока обсуждение содержимого
строк 52-65 и рассмотрим сначала более простой пример формирования таблицы
(tabalign), содержащейся в строках 96-98.
В общем случае команда tabalign задает форму вида
tabalign{ ul#vl ® ... ® un#vn \cr
xll ® ... ® xln \сг
xml ® ... ® xmn \cr}
Символ ® соответствует <ТАВ> на клавиатуре и ее коду во входном файле.
Здесь эти символы показаны в явном виде, как если бы они были отображаемым
символом, чтобы упростить изложение. В этом примере "\сг" обозначает не
carriage-return (возврат каретки), а представляет собой последовательность из
трех символов \, с, г. Тем самым задается формирование mn боксов
ul{xll}vl ... un{xln}vn
ul{xml}vl ... un{xmn}vn
и для каждого к определение максимальной ширины бокса uk{xik}vk для
i = l,...,m. Затем все боксы uk{xik}vk выравниваются по ширине максимального
(самого широкого) бокса, после чего каждая из строк xil®...®xin\cr заменяется
горизонтально сцепленной последовательностью модифицированных (выровненных по
ширине) боксов; эти строки разделяются междустрочным интервалом
tabskip 0 pt plus 1 pt minus 0 pt.
Если в какой-либо из строк таблицы содержится менее п элементов, недостающие
элементы ("клетки" таблицы) оставляются пустыми.
В примере использования команды tabalign, содержащемся в строках 96-98, число п
столбцов задано как п=4. Первый из столбцов должен быть выровнен по правому краю,
второй трактуется как "mathoff" (нематематические символы внутри формулы) и
окружается пробелами ширины в quad, третий опять выравнивается по правому
490
Компьютерная типография
краю, четвертый -- выравнивается по левому краю. Полученный при выполнении
этой команды результат можно видеть на с.9 книги АСР2; сформированная таблица
трактуется здесь как формула (1) и номер ее соответственно центрируется по
высоте формулы.
Примечание: Со временем я введу в ТЕХ команду "omittab", позволяющую формировать
при необходимости "клетки" таблицы, шириной в несколько столбцов.
Вернемся теперь к строкам 52-65 и сравним их с таблицей 1 на с.б книги АСР2.
С помощью команды tabalign формируется бокс ширины 12 рс, размещаемый рядом
с другим таким же боксом. Слова "ruled", модифицирующие выражения для
вертикального (vskip) и горизонтального (hskip) промежутков, обозначают, что
клей между боксами появляется в сочетании с горизонтальной или вертикальной
линейкой по его центру.
Средство "eqalign" (строки 111, 116) используется для того, чтобы выравнивать
выражения, содержащиеся в выключных формулах, расположенных в нескольких
строках. На самом деле эта команда представляет собой частный случай команды
tabalign:
def eqalign #1 {tabalign{rjust##®ljust##\cr #1}}.
Обратите внимание — строка ИЗ начинается символом табуляции <ТАВ>.
Команды формирования "больших" математических знаков и скобок (''big(){...}"
в строках 113, 143 и т.д.; ' 'big/{...}'* в строке 152) используются для того,
чтобы сформировать в "высоких" формулах круглые скобки (' (...)'' и знаки типа
"наклонная черта" ((/...)} таких размеров, которые соответствовали бы размерам
формулы по вертикали; размеры упомянутых элементов определяются высотой
соответствующих боксов (например, бокса, заключенного в скобки). Операции такого
рода доступны также для квадратных и угловых скобок ([] и О), а также для пары
знаков "вертикальная черта" (II), при этом левая и правая квадратные скобки
увеличиваются командами \[ и \] до размера, который ТЕХ сочтет наиболее
подходящим в данной конкретной ситуации. Скобки перечисленных выше видов
(включая пару вертикальных линий) могут быть сделаны произвольно большими по
размеру, однако на знак "наклонная черта" это не распространяется, по крайней
мере в текущей реализуемой версии ТЕХ'а. Пример, в котором будут сформированы
очень большие круглые скобки при построении большой матрицы, содержится
в строках 158-165.
Команды формирования больших круглых скобок ' 'biglpren'' и ' 'bigrpren'' в
строках 118-119 на самом деле дадут не такой уж и "большой" результат — они
просто формируют круглые скобки размера 12 pt вместо положенного здесь по
умолчанию размера 10 pt, использующиеся для выделения текстов вроде "(а)",
заключенных в круглые скобки.
Знаки суммы, формируемые командой "sum over..." в строках 131, 143, будут
большого размера, поскольку здесь они входят в состав выключных формул, однако,
когда формула набирается как часть текстовой строки (т.е. она ограничивается
парой символов $...$), величина знака суммы в ней будет меньшей, а пределы
суммирования будут набраны как индексы у знака суммы. Аналогично этому будет
изменяться и величина знака интеграла, а также дробей "...over... '' и
биномиальных коэффициентов (см., например, "$р choose k$" в строке 118).
Ключевое слово "textsize" в строках 136 и 138 указывает, что в данной
формуле следует использовать маленькие знаки интегралов, несмотря на то, что
она выключная.
Команда \ff в строке 79 означает переход к новой странице (текст завершаемой
таким образом страницы будет выключен по вертикали вверх). Здесь опять
мы имеем дело с одним из элементов стиля оформления моих книг — основные
разделы всегда должны начинаться с новой страницы.
Глава 24. TEXDR.AFT
Я полагаю, что приведенные выше замечания по примеру набора текста позволяют
уловить дух ТЕХ'овского подхода. Этот пример подбирался так, чтобы показать
применение разнообразных средств при наборе достаточно сложного текста. В общем
же случае набор большинства книг будет представлять собой существенно более
рутинное занятие, где только время от времени возникнет потребность
в чем-то необычной формуле или таблице. В рассматриваемом примере акцент
делался именно на такого рода "необычных" элементах.
Следующий шаг в понимании работы ТЕХ'а состоит в том, чтобы вернуться к
низкоуровневому описанию процессов в нем и посмотреть, что происходит с
внутренним входным файлом при его чтении. Оказывается, что данный файл
просматривается и преобразуется в последовательность лексем,
представляющих собой отдельные литеры или последовательности литер
(слова). В общем случае, смежные буквы и цифры группируются, образуя
слова, при этом точки и запятые, за которыми сразу следуют цифры,
трактуются как буквы; то же относится и к знакам \ , перед которыми нет буквы
или цифры.
Точнее, процесс формирования лексем определяется следующим конечным автоматом.
Состояние 0. Пусть х — следующая литера во внутреннем входном файле.
Если х есть \ или одна из 52 букв или 10 цифр, задать w«-x и перейти
к Состоянию 1.
Если х есть точка или запятая, задать у«-х, w«-null, и перейти
к Состоянию 2.
В противном случае вывести х как следующую лексему.
Состояние 1. Пусть х — следующая литера во внутреннем входном файле.
Если х есть буква или цифра, задать v*-vkx. (за w следует х).
Если х есть точка или запятая, задать у«-х и перейти к Состоянию 2.
Если х есть \ , то вывести w, задать w«-x.
В противном случае вывести w как очередную лексему, затем вывести х
как следующую лексему, после чего перейти к Состоянию 0.
Состояние 2. Пусть х — следующая литера во внутреннем входном файле.
Если х есть цифра, задать wHfftyftx, перейти к Состоянию 1.
В противном случае, если w не пусто, вывести w как следующую лексему,
после чего перейти к Состоянию 0, но без переустановки х на начало
набора инструкций для этого состояния.
Например, последовательность литер вида
Abc\de 5,000 plus-or-minus "2.5 \per cent" are ... here,
будет преобразована в последовательность из 28 лексем:
Abe \de <space> 5,000 <space> plus or
minus <space> ( ( 2.5 \per <space> cent ' '
<space> are <space> . . . <space> here
ТЕХ работает с последовательностями лексем. Если вводится определение для
некоторой лексемы (с использованием команды "def"), пробелы (<space>) перед
этой лексемой удаляются. Оставшаяся часть данного определения "встраивается"
в комплекс уже действующих в ТЕХ'е определений. Аналогичный процесс повторяется
для результирующей последовательности лексем. Определения заканчиваются
фигурной скобкой }, символами $ или $$, завершающими группу, где содержится
определение; они также недействительны между \{ и парной ей скобкой }. Если
ключевое слово MIX определить как
def MIX{{\tt MIX}}
вместо
def MIX{{\tt\{MIX}}},
ТЕХ войдет в бесконечный цикл (зациклится), выдавая {\tt {\tt {\tt {\tt
492
Компьютерная типография
Читатель теперь, наверное, понимает либо все, либо ничего относительно процесса
определения; я, тем не менее, попытаюсь изложить правила этого процесса более
подробно. В общем случае можно записать
def token stringO #1 stringl #2 string2 ... #k stringk {right-hand side}
где "token" — любая лексема, за исключением { или }, и где stringO ... stringk
есть строки из нуля или более лексем, не включая {, }, # или |; пробелы в таких
строках игнорируются. Я описываю сейчас общий случай; приведенное выше
определение для MIX — это простейший пример реализации общего подхода, когда
к = 0, а строка stringO — пустая.
Когда обнаруживается определяемая лексема, запускается процесс сопоставления
(matching), продолжающийся до тех пор, пока не будут найдены соответствия для
всех элементов в левой части определения: лексемы в stringO...stringk должны
точно соотноситься с соответствующими лексемами во входном тексте (с удаленными
пробелами); если в процессе сопоставления обнаружится ошибка, будет выдано
диагностическое сообщение. Символы # в рассматриваемом определении
сопоставляются с лексемами или с группами {...}. Никакого развертывания
групп {...} не выполняется, они трактуются просто как неинтерпретируемая
последовательность лексем. В каждый момент времени имеется по крайней мере одно
определение, активное для данной лексемы. По завершении процесса сопоставления,
ТЕХ ищет те элементы ("ингредиенты"), которые должны быть подставлены вместо
#1,...,#к в правой части определения. Найденные элементы просто копируются
в позиции, занимаемые #1 ... #к в правой части определения. И еще одно изменение
будет сделано: из любой последовательности, содержащей два или более символа #,
идущих подряд, удаляется первый символ #. Это делается для того, чтобы можно
было записывать определения в правой части без риска перепутать их с текущим
определением.
Например, рассмотрим что произойдет, если активным будет определение вида:
def A #1 В С {def E ##1{##1 #1 #1}}.
Если внутренний входной файл содержит
А {Х-у} BCD
то результирующая последовательность после раскрытия определения примет вид
def E #1{#1{Х-у}{Х-у}} D
(обратите внимание на расстановку пробелов).
Если непосредственно перед символом { появляется знак |, вводящий правую часть
определения, то пробел, если таковой будет находиться вслед за последней
лексемой, не будет удален. Таким образом, если приведенный выше пример
переписать в виде
def A #1 В CKdef E ##1{##1 #1 #1}}
то будет получен результат такого вида
def E #l{#l{X-y}{X-y}}D.
Это средство было использовано в нашем определении для MIX на предыдущей
странице, поскольку оно позволяет сохранить пробел, следующий за MIX, когда
эта команда используется в середине предложения. С другой стороны, в
большинстве определений (например, для xskip) это средство использовать нет
необходимости.
Изложенное выше не представляет собой наиболее общего подхода к формированию
макроопределений — я здесь предпочитаю следовать принципу "бритвы Оккама".
Средства много более общего характера доступны через аппарат ТЕХ'овских
"программ", о которых речь пойдет ниже; этот аппарат рассчитан на достаточно
подготовленных и опытных пользователей. Если теперь читатель вернется несколько
назад и посмотрит на определения, сформированные для ключевых слов quoteformat,
algstep и eqalign, то увидит, что все они и в самом деле просты.
Глава 24. TEXDR.AFT
493
Некоторые из лексем не определяются в качестве макро, но задают действия,
которые следует выполнить. Например, "fnt" означает, что следующая
лексема, отличная от пробела, представляет собой имя текущего используемого
шрифта, a "def" значит, что ТЕХ должен ввести новое определение.
Можно сказать, что имеется четыре взаимно исключающих вида лексем:
определяемые лексемы
лексемы-действия
{и}
прочие лексемы.
Символы { и } указывают на группирование и различные уровни контекста;
определения и действия-присваивания, выполненные внутри {...}, не оказывают
никакого влияния вне этой пары скобок (группы).
Действия-присваивания влияют на характер ТЕХ'овских операций с входными данными.
К их числу относятся:
fnt token изменить текущий шрифт
hsize length нормальная ширина формируемых строк текста
vsize length нормальная высота формируемых строк текста
hmargin length расстояние от левого края бумажного листа
до начала формируемых строк
vmargin length расстояние от верхнего края бумажного листа
до начала формируемой страницы
lineskip glue интервал между формируемыми строками
parskip glue дополнительный интервал между абзацами (добавляется
к lineskip)
dispskip glue дополнительный интервал перед и после выключной формулы
boxskip glue дополнительный интервал под вставляемым боксом
noteskip glue дополнительный интервал над подстрочными примечаниями
tabskip glue горизонтальный промежуток между табулируемыми столбцами
parindent length отступ для первой строки абзаца
hangindent length отступ для всех строк абзаца, кроме первой (для
hangindent устанавливается нулевое значение после
каждого абзаца).
Все эти числовые параметры имеют значения по умолчанию, которые будут выбраны,
исходя из опыта использования ТЕХ'а; эти значения будут активными до тех пор,
пока не будут в явном виде переопределены. В приведенном выше перечне ((length"
("длина") имеет вид
token unit или - token unit
где "token" ("лексема") — строка цифр, содержащая или не содержащая точку
(десятичную точку), a ''unit" ("единица измерения") может принимать значения
pt, pc, in, cm или mm. Далее, ''glue" ("клей") определяется выражением
length plus length minus length
где фрагменты plus и minus не могут быть отрицательными; любая из трех
перечисленных частей-длин может быть опущена или быть равной нулю.
Например, в соответствии со стандартными соглашениями, принятыми для принтера
XGP, вывод производится на страницу размера 8 1/2 на 11 дюймов с левыми и
правыми полями по 1 дюйму, с междустрочным расстоянием величиной в 4 пикселя,
все эти требования можно описать так:
hsize 6.5 in vsize 9 in hmargin 1 in vmargin 1 in lineskip .02 in
На самом верхнем уровне в неявной форме ТЕХ'овскому вводу будет предшествовать
ввод строки вида "TEXpublish{", где TEXpublish -- программа, периодически
вызывающая программу формирования страниц, которая, в свою очередь, периодически
вызывает программу формирования абзацев, а она читает входные данные и выдает
494
Компьютерная типография
отформатированные строки текста. Программа TEXpublish просто печатает каждую из
страниц, которую она получает; в нашем текстовом примере используется более
совершенная программа ACPpages.
В первой реализации ТЕХ'а программы, подобные ACPpages, будут написаны на языке
SAIL и загружены с помощью ТЕХ'а. У меня была идея добавить к ТЕХ'у некую
интерпретирующую систему и мини-язык программирования, чтобы подобного рода
расширения можно было бы реализовывать достаточно просто и не затрагивать при
этом ядра ТЕХ'овских программ. Однако по некотором размышлении мне
показалось, что будет намного лучше считать, что ТЕХ'овский код (не только ядро)
не надо трогать совсем, а расширения выполнять с помощью языка SAIL. Это даст
возможность сэкономить много времени при реализации системы, а также повысить ее
быстродействие.
Продолжим рассмотрение особенностей работы ТЕХ'а, составив набросок программы
ACPpages на языке SAIL. Следует помнить, что это не базовая ТЕХ'овская программа,
а код, имитирующий внутреннюю ТЕХ'овскую программу. В настоящий момент это только
первое приближение к реальной SAIL-программе, поскольку мне еще надо получше
обдумать вопрос о том, как будет выглядеть ТЕХ'овская "начинка", прежде чем можно
будет говорить обо всем этом более конкретно,
if scan("starting") then
begin scanreqd("at"); scanreqdO'page"); spage«-nextnonspacetoken;
end else spage«-"l";
{Здесь "scan" -- ТЕХ'овская программа, которая просматривает следующую лексему,
не являющуюся пробелом, находящуюся во вводе (входном потоке лексем); если она
совпадает с предписанной лексемой, программа scan выдает ответ true (истина) и
отбрасывает данную лексему; в противном случае текущая входная лексема
пропускается и выдается ответ false (ложь). Программа "scanreqd" во многом
аналогична программе scan, но вместо ответа false она выдает сообщение об ошибке
типа "Syntax error, I will insert missing #" ("Синтаксическая ошибка, я вставлю
пропущенный символ #"). Когда фрагмент программы, приведенный выше, отработает,
переменной spage будет присвоено предписанное значение-строка, задающая номер
начальной страницы, если же такого предписания нет, будет использовано значение
по умолчанию, равное "1".}
if spage = "r" then
begin rnumeral«-true; lop (spage);
end;
pageno«-int scan (spage, brchar);
{Римские цифры для нумерации страниц обозначаются как rl, г2 и т.д. Параметр
pageno теперь имеет целочисленное значение, равное требуемому номеру первой
формируемой страницы. Значение параметра rnumeral будет равно true тогда и только
тогда, когда требуется, чтобы страницы нумеровались римскими цифрами.}
scanreqd(leftbrace);
put_on_stack_something_to.make_matching_right_brace_end_the_input;
while true do
begin cpage«-nextpage;
if not cpage then done;
{Здесь cpage — указатель на некоторый бокс, или указатель на пустую запись,
null-указатель, если процесс ввода прерван.}
if rnumeral then spage«-cvrom(pageno) else spage«-cvs (pageno);
if omithead then {this would be set by "titlepage" routine}
begin omithead«-false;
output_cpage_with_blanks.for_top_headline_and_with_spage_in_
9_point_type_centered_as_a_new_line_at_the_bottom;
end
Глава 24. TEXDR.AFT
495
else begin if pageno land 1 then {right-hand page}
begin texta<-the_rimning_right_head;
textb«-attr (sectno, cpage);
{texta и textb — указатели записи на последовательности
лексем; "attr" получает атрибут (sectno — "номер раздела") параметра cpage
для бокса, как объясняется ниже}
line<-pointer_to_box_which_TEX_¥ould_make_from_the_input
"{textb} hfill {texta} rjust to .375 in {spage}"
end else
begin texta<-the_running_left_head;
textb«-attr (sectno, first (cpage));
line<-pointer_to_box_which_TEX_¥ould_make_from_the_input
"ljust to .375 in {spage} texta hfill textb"
end;
place_line_above_cpage_with_14_pt_glue_and_output.the_result;
end;
pageno«-pageno+l;
end;
{Другими словами, для страниц с нечетными номерами берется значение атрибута
sectionnnmber из cpage; для них формируется колонтитул, состоящий из номера
раздела, заглавия раздела, за которым идет номер страницы, выровненный по
правому краю. У страниц с четными номерами в колонтитуле сначала идет номер
страницы, выровненный по левому краю, затем текст колонтитула, затем номер
раздела из первой компоненты, содержащейся в cpage. Следует отметить, что
на левой странице будет указываться номер раздела, а на правой — номер текущего
подраздела в нем.}
Приведенный выше пример показывает необходимость обсуждения еще одного базового
ТЕХ'овского средства, а именно "атрибутов", которые могут быть приписаны
боксам. Один из таких атрибутов — номер раздела, другой -- высота, еще
один — ширина. Ряд атрибутов используется в математических формулах, они связаны
с пробелами, доступными внутри соответствующего бокса, в частности, их можно
использовать при формировании верхних и нижних индексов. Применительно к каждому
из атрибутов имеется две программы, показывающие, как определять значение
атрибута бокса, формируемого из двух боксов, размещаемых друг относительно друга
по горизонтали или по вертикали. Например, имеющийся атрибут высоты заменяется
значением, определяемым выражением max(hl,h2), если два бокса объединяются по
горизонтали, или выражением hl+h2, если они объединяются по вертикали. Атрибут
"номер-раздела" (section-number) примет значение si, если s2=null, в противном
случае он будет равен s2, и т.д.
Теперь рассмотрим программу формирования страниц, именуемую "nextpage".
Это даст возможность изучить ТЕХ'овский процесс выравнивания по вертикали
(vertical justification), вводящий ряд концепций, необходимых при реализации
более сложной программы, используемой для выравнивания (строк, боксов)
по горизонтали (horizontal justification).
Первая из идей, реализуемая в программе "nextpage" — это концепция
"плохости" ("badness"). Она представляет собой число, определяемое на.
основе совокупности растяжений и сжатий, необходимых при установке значения
клея. Пусть имеется список из п боксов (горизонтальный или вертикальный
список), разделенных п-1 спецификацями клея. Пусть w — требуемая полная
длина списка (т.е. требуемая ширина или высота, в зависимости от того,
как выполняется выравнивание — по горизонтали или по вертикали);
пусть х — фактическая общая длина боксов и клея, и пусть y,z —
496
Компьютерная типография
общее число параметров клея для растяжения и сжатия. Плохость
в этой ситуации будет такой:
бесконечная, если х > я - z + €, где € -- малый допуск (small tolerance)
для компенсации ошибок округления в операциях
с плавающей точкой;
100((x-w)/z)~3, если w-z + €>x>w;
О, если х = w;
100((w-x)/3y)~3, если w > х;
плюс штрафы, накладываемые за нарушение границ в нежелательных местах.
Согласно этим формулам, растяжение на у имеет показатель плохости,
равный 100/27, или примерно 3.7; растяжение на 2у повышает это значение
примерно до 30; растяжение на Зу — до 100 единиц плохости, и столько же при
сжатии на максимальную величину, задаваемую параметром z. Я планирую установить
величину штрафа примерно в 80 единиц для такого разрыва абзаца или выключной
формулы, когда на одной из страниц остается единственная строка абзаца (формулы).
Тогда, к примеру, пятистрочный абзац даст 80 единиц штрафа, если разрыв будет
произведен после первой или четвертой его строки, но штраф будет нулевым, если
разрыв устанавливается после второй или третьей строки. Эти формулы надо будет
еще, конечно, "подрегулировать", чтобы результат, даваемый ими, соответствовал
моим эстетическим принципам, определяющим "плохой" вывод (bad layout).
Пользователь будет иметь возможность задавать свои собственные дополнительные
штрафные точки (penalty points) для предотвращения нежелательных разрывов между
определенными строками (например, в программе MIX для предотвращения разрыва
перед командой, ссылающейся на *-1). Будет установлен также штраф за разрыв по
вертикальному клею с линейкой в нем.
Программа nextpage ("следующая-страница") формирует список строк (и связывающий
их вертикальный клей), получаемых ею от программы nextparagraph; программа
nextparagraph ("следуюший-абзац") возвращает последовательность gl hi ... gk hk
перемежающихся элементов (вертикального клея gl ... gk и боксов hi ... hk),
представляющих собой выровненные по горизонтали (т.е. по ширине страницы) строки
текста. Отдельные элементы hi не разрываются и не анализируются программой
nextpage, за исключением просмотра значений их атрибутов. Программе nextpage
от программы nextparagraph передаются также команды Vfi и коды "конец-ввода"
(end-of-input).
Программа nextpage накапливает строки до тех пор, пока уже ранее накопленные ею
строки в совокупности со вновь введенным абзацем будут иметь высоту, равную
предписанной высоте страницы (vsize), или же превысят это значение. Затем данная
программа производит разрыв абзаца, введенного последним, после j-й строки, для
0<j<k, при этом значение j должно минимизировать величину показателя плохости;
если искомый минимум достигается более, чем при одном значении j, то берется
наибольшее из них. После этого клей g(j+l) отбрасывается, а оставшиеся k-j строк
переносятся на следующую страницу. Они тут же проверяются — не вызовут ли
переполнения новой страницы, и если да, то производится их разрыв точно таким же
образом, как это было описано выше.
Этот довольно простой процесс может прерываться процедурой boxinsert,
вставляющей боксы. Вычисление данного вставляемого бокса осуществляется
автономно, вне процессов формирования абзацев и страниц, после чего
предпринимается попытка разместить его на текущей собираемой
странице. Если удается сделать это с оценкой "отлично" или "хорошо", вставляемый
бокс оставляется на данной странице. Если не удается — вставляемый бокс
переносится на следующую страницу и помещается перед всем тем, что было
перенесено с текущей страницы. Если требуется вставить еще добавочные
Глава 24. TEXDR.AFT
497
боксы, то они будут размещаться ниже ранее размещенного первого бокса; эти
действия будут выполняться вполне естественным образом, объяснить который,
однако, не очень просто.
Подстрочные примечания: на протяжении более чем 2000 страниц книги The Art of
Computer Programming я сделал лишь три подстрочных примечания. Мое личное
мнение — использование сносок должно быть редким исключением, поэтому я не
предполагаю разрабатывать достаточно изощренный механизм формирования подстрочных
примечаний (в частности, разделение длинных сносок между несколькими страницами,
или маркировку первой сноски на данной странице звездочкой, а второй — крестиком
и т.п.). Тем не менее, сносками можно вполне удовлетворительно управлять путем
присоединения атрибута сноски к строке, ссылающейся на некоторую сноску, а также
потребовав от программы nextpage разместить данную сноску на той же странице,
что и строка, ссылающаяся на нее. Такой подход, в сочетании с оценками плохости,
позволяет решать проблему, резервируя место, необходимое для размещения текста
подстрочного примечания, в нижней части страницы. Пользователь может получить
возможность формировать и более причудливые сноски, если только он не против
того, чтобы переписать несколько ТЕХ'овских программ.
При получении команды \ff или кода "конец-ввода" программа nextpage моделирует
выполнение команды "vfill blankline" и очищает свои страничные буферы, если они
непусты. После обработки кода "конец-ввода" она возвращает null-страницу,
что сигнализирует о прекращении ее деятельности, после же команды \ff программа
nextpage запрашивает у программы nextparagraph следующий абзац.
Программа nextparagraph собирает строки ширины hsize, делая приостановки для
передачи их
a) в конце абзаца 013);
b) в начале выключной формулы ($$);
c) в конце выключной формулы ($$);
d) непосредственно перед операцией vskip;
e) непосредственно перед и сразу после операций blankline, ctrline,
ljustline, rjustline, hjustline;
i") при обработке команды \ff или кода "конец-ввода".
Операции, перечисленные в пункте (е), порождают независимые строки шириной
hsize, не являющиеся частью абзаца, поэтому такие строки передаются без
каких-либо изменений в них. Выключные формулы также передаются в неизменном
виде, за исключением добавления перед ними и после них клея подходящей величины.
(Клей над выключной формулой уменьшается с dispskip до lineskip, если текст
в предшествующей строке не "накрывает" отображаемую формулу после ее
центрирования.)
Если это удается осуществить, то для некоторого абзаца формируется его текст,
или же фрагмент абзаца, начинающегося и/или заканчивающегося парой символов $$;
полученный результат передается в программу hjust. Эта программа пытается
разбить текст на строки длины hsize наименее плохим путем, привлекая
требуемое количество hangindent. Здесь "наименее плохой" способ — это
такой, который минимизирует максимальную плохость для данного абзаца на
совокупности возможных разрывов строк. В этой точке рассматриваемого процесса
обрабатываемый текст состоит из последовательности боксов (это может быть
достаточно длинная последовательность), разделенных клеем, причем программа
hjust изменять эти боксы не может. Программа hjust, помимо используемой ею идеи
клея с переменным весом, реализует еще одно новое средство, благодаря которому
она превосходит другие существующие системы выравнивания текста. А именно, hjust
умеет эффективно "смотреть вперед", что важно, поскольку ситуация в последующих
строках абзаца может оказывать влияние на разрывы строк в его предыдущих строках.
498
Компьютерная типография
Я обнаружил целый ряд ситуаций, где такого рода программа выравнивания текста
обеспечивает получение существенно более высокого качества выходного текста,
чем другие программы. Указанный просмотр вперед осуществляяется путем применения
принципов "динамического программирования", которые я попытаюсь объяснить ниже.
Попробуем вначале понять, на что обычно похожи боксы, обрабатываемые программой
hjust. Они вполне могут быть большими сложными боксами, которые следует
трактовать как "черные ящики", как, по-существу, программа nextpage и обходится
с их строками. Однако большинство индивидуальных боксов в данной точке процесса
представляет собой просто отдельные буквы из одного или нескольких шрифтов.
Когда обнаруживается некоторая текстовая лексема, к ней присоединяется
индикатор текущего шрифта (так что из 7-битного кода мы получим 12-битный),
после чего лексема разбивается на отдельные литеры, составляющие ее.
Анализируются пары смежных литер (слева направо) при помощи таблиц, связанных
с данным шрифтом. Полученная информация служит основой для вычисления
изменений в значениях клея между литерами, для формирования лигатур, если они
обнаружены, и т.п. К примеру, для большинства шрифтов литерная последовательность
" означает, что надо использовать специальное "узкое" значение клея между этими
двумя литерами. Мы получаем лигатуры заменой
i i на
f i на
i 1 на
<fi> i на
<ff> 1 на
<fi>
<ii>
<fl>
<ffi>
<т>.
Подобного рода процесс формирования лигатур и подстройки параметров клея имеет
место, когда символьные (литерные) боксы присоединяются к формируемой строке,
до поиска переносов в словах и т.п.; это означает, что при таком подходе
в слове "shuffling" теряется шанс получить разрыв в виде "snuff-ling", но
чем-то приходится жертвовать.
Лексема <space> ("пробел") преобразуется в клей между боксами, причем
принимается у=х и z=x/2, как это уже было объяснено ранее. Действия hskip и quad
также порождают переменный клей (variable glue). Всякий раз, когда этот
клей имеет значение х или у, большее или равное ширине межлитерного пробела
для используемого шрифта, найденное таким образом место будет допустимой
точкой разрыва строки без штрафа. Еще одно такое допустимое место — после явного
знака переноса слова. (Некоторые команды hskip, используемые для уменьшения
пробела (backspacing), имеют отрицательное значение х; они, конечно, недопустимы
для организации разрыва строки.) ТЕХ дает двойной у-клей первому пробелу, который
идет после точки или двоеточия, восклицательного или вопросительного знака, если
только перед этим пробелом не вклинятся буквы или цифры. Точка с запятой и запятая
обрабатываются аналогичным способом, только значения компоненты у клея для них
устанавливаются равными 1.5 и 1.25 соответственно.
Программа формирования математических формул, обрабатывающая последовательность
литер, заключенную внутри пары символов $...$, порождает последовательность
боксов в формате, совместимом с форматом текстовых строк вне формул. Допустимыми
для разрыва местами в формулах являются позиции сразу после бинарных операторов
и отношений. Такого рода разрывы штрафуются; мне предстоит произвести подстройки
соответствующих параметров, но наилучшей здесь представляется следующая идея:
штраф для отношений типа =, <, = и т.д. должен быть невелик, для операций вроде
+ , -, х, / — больше по величине, причем для оператора - ("минус") больше, чем
для остальных операторов. Верхние и нижние индексы, аргументы функций и тому
подобные элементы должны присоединяться к своим боксам неразрывно.
Глава 24. TEXDR.AFT
499
Имеется три вида символов типа "discretionary", используемых для того, чтобы
обеспечить или запретить разрывы:
\- данное слово можно перенести в этом месте;
\+ перенос в этом месте не выполнять;
\* в этом месте можно выполнить перенос, но Вместо знака
переноса вставить знак умножения.
Последний из показанных выше трех вариантов может понадобиться для длинных
произведений наподобие $(n+l)\*(n+2)\*(n+3)\*(n+4)$.
Помимо использования разрешенных разрывов строк, ТЕХ предпринимает также
попытки переноса слов. Он будет проделывать это только с последовательностями,
состоящими из букв в нижнем регистре (строчных букв), за ними может следовать
(и им может предшествовать) символ, отличный от буквы, цифры, знаков -,
\- или \+. Заметим что, например, составные слова с дефисом не будут
разрываться. Если обнаружен разрыв, допустимый с точки зрения переноса
слова, будет назначен штраф примерно в 30 единиц плохости, однако такой
вариант может оказаться более предпочтительным, чем без использования переноса
вообще. В рассматриваемом случае будут добавлены еще 20 единиц плохости, если
переносимое слово или формула находятся в последней строке абзаца.
Нет способа найти все возможные варианты переносов, Насколько трудна эта задача,
можно увидеть на примере слова "record", для которого предполагается, что оно
будет разбито как "rec-ord", если оно является существительным, но "re-cord" —
если оно будет глаголом. В качестве еще одного примера рассмотрим само слово
"hyphenation" ("перенос"), которое скорее будет исключением (which is rather
an exception):
hy-phen-a-tion vs. co-or-di-na-tion
Почему в одном из этих двух случаев буква п идет вместе с буквой а, а во
втором — нет? Если начать с буквы "а" в словаре и попытаться найти четкие
правила переноса слов, не опираясь при этом на слишком большой объем знаний,
получим такие пары слов, как a-part vs. ap-er-ture, aph-o-rism vs. a-pha-sia,
и т.д. После всех этих примеров становится ясно, что едва ли нас устроит
программа переносов, точная, но громоздкая и медленная в работе, занимающая
много памяти и процессорного времени. Лучше вместо этого располагать набором
правил переноса, которые были бы:
a) простыми;
b) почти всегда безопасными;
c) достаточно мощными для того, чтобы найти, к примеру, порядка 80'/,
переносов из тех, что есть в имеющемся издании книги The Art
of Computer Programming.
Анализируя условия, предъявляемые пунктом (с), я обнаружил, что имеют место
примерно 2 слова с переносами в них на страницу указанных книг. При этом
оказалось, что подготовленные правила переноса лишь в очень редких случаях
приводят к действительно плохому разрыву. Время, которое необходимо затратить,
чтобы указать способ обработки обнаруженных исключений из правил (т.е. слов, не
подчиняющихся имеющимся правилам), совершенно несущественно в сопоставлении
с общим временем, затрачиваемым на чтение гранок.
Итак, приведем предлагаемые правила переноса.
1. Рассматривать только разрывы, в которых обе части слова содержат гласную
букву, отличную от концевой е. (Гласные буквы: a,e,i,o,u,y.)
2. Учитывая рекомендацию правила 1, разрывать слово перед следующими
"безопасными" суффиксами: -cious -gion -ly -ment -mial -nary -ness -nomial
-sion -tion -ture -vious, а также -tive, перед которым идет гласная, -ed
с предшествующей буквой d или t. Разрыв перед -ing (за исключением -bling -pling
500
Компьютерная типография
или когда этому суффиксу предшествует сдвоенная буква, кроме 11, ss или zz. Для
остальных двойных букв — разрыв между ними. Если слово оканчивается на s или 1у,
отделить эти окончания и применить перечисленные правила вновь. Суффиксы,
распознаваемые с помощью указанных правил, не должны далее разрываться, за
исключением vi-ous.
3. Согласно правилам 1 и 2, выполнять разрывы после следующих "безопасных"
приставок (префиксов): algo- equi- ex- hyper- ini- intro- lex- lexi- math- mathe-
max- maxi- mini- multi- out- over- pseudo- semi- some- sub- super- there- under-
Также для be-, за которой идет буква c,h,s,w; dis-, за которой идет любая буква,
кроме h,y; trans-, за которой идет буква a,f,g,l,m; tri-, за которой идет буква
a,f,p,u.
4. Согласно правилам 1 и 2, объединять h с предыдущей буквой, если это согласная,
рассматривая полученную комбинацию как одну согласную; теперь разрешается
разрывать слово между двумя согласными, если имеет место образец вида
vc-cv (v — гласная, с -- согласная), за исключением таких пар согласных как
Ъ1 ck cl cr dr ght gl gr Ik 11 nd ng pi rch rd rm rt sch sp ss st thr zz
(Этот список, возможно, придется еще уточнить).
Будут иметь место некоторые исключения (например, equivocate, minister,
somersault, triphammer), однако встречаться они будут настолько редко, что
можно считать это обстоятельство не слишком важным. Просмотрев ряд страниц
тома 3, я обнаружил 48 переносов, причем предложенные выше правила успешно
сработали в 45 случаях, исключениями оказались слова
de-gree hap-hazard re-placement.
Конечно, на этих правилах лежит отпечаток моей лексики и моего стиля, но
некоторое их расширение позволит получить правила, работающие достаточно хорошо
почти у каждого автора.
Теперь об алгоритме динамического программирования, минимизирующего максимальную
плохость разрывов. Формула плохости остается той же самой, что и была; тогда для
каждого разрыва после данной точки можно вычислить результирующую
плохость. Таким способом для каждой допустимой позиции разрыва минимизируется
максимальная плохость, которая получится, считая этот и предыдущий разрывы.
Время исполнения данного алгоритма зависит от числа возможных разрывов примерно
линейно.
Такой процесс, однако, будет слишком медленным, поскольку предпринимаются
попытки разрыва всех слов, тогда как на самом деле надо было бы рассмотреть
разрывы лишь для небольшого числа слов-кандидатов. Следующий приближенный метод
должен работать примерно в десять раз быстрее: даны три лучших способа разбить
k-ю строку; использовать их для нахождения трех лучших способов разрыва для
(к+1)-й строки. Найденные разрывы будут наверняка почти оптимальными, если
только не будет слишком плохой сложившаяся ситуация.
Чтобы завершить этот меморандум, я должен был бы объяснить, как ТЕХ выполняет
работу с математическими формулами. Мне, однако, надо более подробно проработать
набросок требуемого программного кода, поскольку в данный момент я его
еще не представляю достаточно четко. В мои планы входит использовать подход,
основанный на нисходящем анализе с предшествованием, введенный Воганом Праттом
в его статье 1973 P0PL, и успешно примененный им в реализации CG0L (к примеру).
Выполняется дальнейшая работа по детализации, я надеюсь, что удастся осуществлять
вставку боксов за один проход, но может потребоваться строить сначала дерево
синтаксического анализа, как это делают Керниган и Черри.
(конец файла TEXDR.AFT)
Глава 24. TEXDR.AFT
501
13 May:
14 May:
15 May:
16 May:
17 May:
18 May:
20 May:
21 May:
22 May:
13 Jun:
14 Jun:
f де^ич/ for Rf PaUifcJ \ufatl, \JUt*M
Gtff bffopfJL Lob &<- l«"*^/
*K>o yrfC **J M^ •n%4Bff RAfWiy" J
19 May: . j^ ^ ^ /^ ^ fo^, ^ w^ § (^ ^^ S&
<&> b*^*\ out***. *лЧ tjo i* f&ijvtk dii*f «hUmrUs
^ into 5Ц *+ h~*s А* т>ък *» 8лл Л *<wkf.
502
Компьютерная типография
15 Jun:
16 Jun:
l^MUf -*. *Ь» t*~ : W! roWw ^ fc**M tM.
a? % u лцз^ ^у^н^' *№№*№ mi's m. ь*
<r.tW ** rf ib p«- (J« ^ ^ k^ "^ Г ^
Ck(W <^*yj to ^ рун*. qA j/Ift ^ мЬ vyrmy-bvyiied €>o*b
18 Jun:
20 Jun:
21 Jun:
19Jun: Д bjrr wte ty
РЦ«/ *'#е//*иЛ Ti*yk " ^r\U ToA- o^c "оЬ*у
W*&~ U*f*rf cvH*W iy (Й^ (b/wfer rtu»*«b£ ***//?!/ s/""?'*'"**
Примечания переводчика
1. Дадим перечень соответствий между номерами строк в примере на ее. 481-484 и
отвечающими им фрагментами книги: Knuth D. E. The Art of Computer Programming.
Volume 2. Seminumerical Algorithms. — Reading a.o.: Wesley Publ. Co., 1969 (далее
будем для краткости ссылаться на нее как на АСР2). Через косую черту указаны
соответствующие фрагменты из русского перевода данной книги: Кнут Д. Искусство
программирования для ЭВМ. Том 2. Получисленные алгоритмы. — М.: Мир, 1977.
Соответствия: строки 5-30 примера —р. 1 оригинала (p. —page; pp. —pages)
книги АСР2 / с.13 ее перевода; строки 32-46 —pp. 4-5 / с. 17-18; строки 48-65 —р. 6
/ с. 19; строки 66-67 —р. 5 / с. 18; строки 69-75 —р. 6 / с. 19; строки 77-78 —р. 8 /
с. 21; строки 80-101 — р. 9 / с. 22; строки 103-108 —р. 11 / с. 24-25; строки 109-115 —
р. 16 / с. 29-30; строки 116-117 —р. 17 / с. 32; строки 118-123 —р. 18 / с. 33;
строки 125-128 —р. 26 / с. 42; строки 129-134 —р. 49 / с. 69; строки 135-146 —pp. 51-52 /
Глава 24. TEXDR.AFT
503
с. 71-72; строки 148-154 — р. 54 / с. 74; строки 155-166 не имеют соответствия в книге
АСР2 и ее переводе.
2. Примечание к с. 490; средство «eqalign». Выравнивание выполняется по какому-
либо знаку, например, по знаку равенства, как в рассматриваемом случае — формула
(6) (р. 16 / с. 30; р. 17 / с. 32).
3. Перевод дневниковых записей.
7 февраля:
Спал не очень хорошо. Некоторое время занимался корреспонденцией. Комитет по
кадровым перемещениям Станфордского университета одобрил повышение Тайана.
Закончил программу квалификационного экзамена и пояснительную записку к
следующему заседанию комитета. Спать лег рано.
8 февраля:
Репетиция с chunkee-group. Отладка средств оценки булевских выражений в MIX*
программе. Обсуждение компьютерного типографского набора с использованием
шрифтов из моей книги. Чтение диссертации Рейсера. Церковный хор.
30 марта:
Получены, наконец, гранки второго тома, выглядят они в смысле полиграфического
исполнения ужасно. Думаю, что мне придется самому заняться решением этой
проблемы. Вечернее собрание seder supper в церкви — хоть какой-то светлый эпизод за
всю эту унылую неделю.
2 мая:
Сегодня к часу ночи завершил раздел 7.1 — Ура!
3 мая:
В Сан Хосе с Джил, посмотрели церковные записи из городка вблизи Гейдельберга:
познакомились со старонемецким рукописным текстом.
4 мая:
Прибрался в офисе, отделался, наконец, от раздела 7.1. Просмотрел первые 30
страниц корректуры, пока понял, как работает белфастская издательская система.
5 мая:
Читал об издательской системе Белловских лабораторий. Начата основная работа по
ТЕХ'у.
6 мая:
Продолжение работ по ТЕХ'у.
7 мая:
Работал над длинной тестовой программой для ТЕХ'а. Ходил в кино на фильмы
«Airport 77» и «Earthquake».
8 мая:
День Матери. Повел Джил на выставку брошюровочного оборудования. Встречал
Комлосов в аэропорту. Отдыхал от технической работы, спать лег рано.
9 мая:
Работал с корреспонденцией. Семинар Комлоса.
504
Компьютерная типография
10 мая:
Работал с Джил над драпировками и т. п. Размышлял над ТЕХ'ом.
11 мая:
Днем семинар Комлоса. Делал наброски ТЕХ'овских программ.
12 мая:
Писал черновой вариант отчета по ТЕХ'у, не ложился до 5 часов утра, вгоняя его в
машину.
13 мая:
Готовился к лекции Bit Fiddling. Спать лег рано.
14 мая:
В Сакраменто с Джил (поездка по линии Библиотечной ассоциации). Видел образцы
прекрасной печати.
15 мая:
Завершение поездки. Закончил подготовку к завтрашнему выступлению.
16 мая:
Получил из библиотеки книги по издательскому делу. Начал недельный курс занятий
по письменности. Прочел также часовую лекцию по «Bit Fiddling». Вечером ходил
на лекцию по органной музыке, а также в кино, на фильм «Anna &; King of Sian».
17 мая:
Безуспешная попытка заменить сплайны «сквинсами» (кусочно-квадратичными
кривыми).
18 мая:
Взял слайды 20 страниц из томов 1 и 2. Делал наброски программ для генерации
шрифтов. Обед с Каем Юнем и Шахидом. Спать лег рано.
19 мая:
Используя слайды, понял, как работают шрифты в нижнем регистре. Всю ночь
продолжал формировать информацию по шрифтам.
20 мая:
Продолжал работу по формированию шрифтов, к 5 часам утра получил набросок
строчных и прописных букв прямого и курсивного начертаний и цифр 0-9.
21 мая:
Завершил заметки относительно стандартных шрифтов, подготовил компьютерные
программы вычерчивания сплайнов.
22 мая:
Пилил бамбук для драпировок в музыкальный салон. Идем на обед в церковь, а
потом лекция по математике.
13 июня:
Перемещался из офиса в школу: начинается ежегодный отпуск! Ходили в кино
(Network и Lenny).
14 июня:
Работа по отладке шрифтов, Прогон через ^nag не дал понимания, какие значения у
производных.
Глава 24. TEXDR.AFT
505
15 июня:
Весь день и всю ночь пытался найти правильный подход к определению
производных—прорыв наступил примерно в час ночи: окончательное решение получилось
очень красивым (4 часа утра). Лег в 7 утра.
16 июня:
С 11 утра отлаживал в лаборатории AI новую сплайновую программу, после были
с Джил на ланче у ее дяди Дона. Вылавливал «ненормальности» в этой программе
(смотри первые записи и тогда поймешь, что я имею в виду). Отправился спать в 4
часа утра.
17 июня:
Развешивали новые макраме в музыкальном салоне. Сделал серьезные улучшения в
программе формирования шрифтов на основе сплайнов.
18 июня:
Репетиция с оркестром для завтрашнего исполнения кантаты (Бах 103). Вносил
изменения в шрифтовую программу, а также разделил ее на две независимо
компилируемые части.
19 июня:
День Счастливого отца. Прогулка на велосипедах (все четверо) по Канадской дороге
к храму на воде. Играл с Джоном и Дженни в «Бермудский треугольник».
20 июня:
Разгребал корреспонденцию. Говорил с Лили Рамшоу о сплайнах. Китайский банкет,
устроенный Симпозиумом по численному анализу. Потом пошел в лабораторию AI и
работал с шрифтовой программой до 4 часов утра.
21 июня:
Эксперименты со все уменьшающимися разрешениями обнаружили новые
моменты, требующие учета. Установка в лаборатории телекамеры для экспериментов со
шрифтами.
ТЕХ.ONE
Когда мы покинули нашего героя в конце главы 24, он изо всех сил срасисался с
проблемой генерации шрифтов вычислительными методами, после того как более
или менее толково изложил проблему типографского набора в памятной записке
TEXDR.AFT. В мае он попросил прочитать эту записку нескольких своих коллег;
сейчас приближается июль и позади месячная поездка в Юго-Восточную Азию.
Настало время переработать черновой вариант меморандума от 13 мая с тем, чтобы
Майкл Плэсс и Фрэнк Лианг, ассистенты по исследовательским проектам, могли
подготовить реализацию опытного варианта (прототипа) создаваемой системы .
30 Jun:
M>t- fttVtw ^ 1^, Wll not go o*h Wi W. of- qwfy xdtJmk
1 Jul:
2 Jul:
3 Jul:
tiff *A slept
Щ *mJL *Л ш w*nlJis
1 Перевод дневниковых записей, следующих ниже, см. в примечании 3 переводчика в
конце главы. — Прим. ред.
Глава 25. ТЕХ.ONE
507
4 Jul:
5 Jul:
6 Jul:
7 Jul:
Sltfh l*k, tA*n iLqk aU+ Л(« jWw/tf -far 7&X
8 Jul: \Л* ijptj u^ ^//
Mo* TtV V*H*fl
ВлоЦ vaa.-W w/ Tc#.oa/£ ; **4 4> fa 1Л * tyt i* Uoi tdp
^ь f\m in itft ^вмлд iff 5for Я*"**, <}Л iwa Arfr
Two w«ic5l GnfOp*J*6l — not bjt «сЬш//уу -P**W H* t** i%r <*C*_ l#v*£^
Ш "W.O^C Ли#- «лЬй» </*fh* i*y*<H%ni*»t /* fd. I*******.
А теперь — файл ТЕХ. ONE:
Предварительное описание ТЕХ'а Д.Кнут, 12 июля 1977 г.
В этой записке я попытаюсь объяснить, что такое система ТЕХ для подготовки
документов полиграфического качества. Часть правил, закладываемых в систему
ТЕХ, пока еще не устоялась, однако значительная доля данной памятной записки
определяет систему ТЕХ в том виде, как она сейчас реализуется, что будет
полезно тем, кто принимает участие в ее реализации. [Замечание: Если вы уже
прочитали черновой вариант данного предварительного описания, забудьте,
пожалуйста, все, что было в том документе, и попытайтесь вообще забыть .
о его существовании. Произошли большие изменения, вызванные ценными
откликами и замечаниями коллег по черновому варианту данного
документа, надо теперь рассмотреть состояние проекта в том виде, каков он
сейчас на самом деле.]
ТЕХ ориентирован на технические тексты. "Посвященные" произносят букву X
в ТЕХ как греческое "хи" (ср. также шотландский звук 'ch' в слове 'Loch Ness'),
9 Jul:
10 Jul:
11 Jul
12 Jul:
508
Компьютерная типография
поскольку слово 'technical' происходит от греческого корня, обозначающего
искусство, а также технику. Я занимаюсь сейчас разработкой этой системы
для того, чтобы использовать ее в подготовке к изданию моих книг из серии
The Art of Computer Programming, т.е. первоначально система будет ориентирована
и настроена таким образом, чтобы соответствовать стилю моих книг, однако не
должно быть трудностей с приспособлением ее и для других аналогичных целей,
если кому-то это понадобится.
Входом для ТЕХ'а является текстовый файл в формате, например, редактора
TVeditor, используемого в Станфордской лаборатории искусственного интеллекта.
Результат работы ТЕХ'а -- последовательность страниц, подготавливаемая "за один
проход", пригодная для распечатывания на различных устройствах. Этот отчет
представляет собой попытку объяснить, каким образом можно из входа получить
нечто на выходе. Основная идея состоит в том, что требуемый процесс
рассматривается как некая последовательность операций над двумерными "боксами";
упрощенно говоря, входом является длинная строка символов, взятых из различных
шрифтов, причем каждый из символов может интерпретироваться как нечто,
занимающее небольшую прямоугольную область, а выход получается "склеиванием"
этих областей друг с другом по горизонтали или вертикали, с соблюдением при
этом различных соглашений относительно центрирования и выравнивания. Конечным
результатом такого рода процесса будет совокупность больших прямоугольных
областей, которые и будут представлять собой требуемые страницы.
Если LISP работает с одномерными символьными строками, ТЕХ имеет дело с двумерными
структурами, собранными из прямоугольных боксов; продолжая аналогию с LISP'ом,
можно сказать, что ТЕХ располагает как горизонтальными, так и вертикальными
операциями типа операции cons. К тому же, ТЕХ базируется еще на одной важной
концепции ~ понятии эластичного клея между боксами, представляющего собой
некий "строительный раствор", который может растягиваться или сжиматься в
той или иной степени, так что конструкции из боксов могут объединяться друг
с другом гибким образом.
Мне следовало бы везде на протяжении данного документа вместо термина ггклейгг
("glue") использовать термин "строительный раствор" ("mortar"); меня здесь
смущает только то, что из-за дополнительного слога слово "mortar" несколько
труднее в произношении, чем "glue" и, кроме того, для его набора требуется чуть
больше времени. Может быть, в руководстве пользователя будет последовательно
использоваться слово "mortar"; данный документ ни в коем случае НЕ является
руководством пользователя.
Чтобы объяснить принципы работы ТЕХ'а более подробно, я буду излагать их
на двух уровнях: давать низкоуровневое описание того, как именно выполняется
обработка в том или ином случае, а также высокоуровневое описание того,
как реализуются те или иные сложные действия.
Для начала, имея в виду низкоуровневое описание, надо понимать, что вход
ТЕХ'а — это на самом деле не последовательность (строка) боксов, а файл из
литер в 7-битовой кодировке. Этот файл именуется "внешний входной файл".
Семь символов (литер) из числа отображаемых при печати будут иметь в таких
файлах специальное назначение; на протяжении всего этого меморандума
в данном качестве выступают следующие литеры: \{}$®У,# . Можно, однако,
использовать и семерку других символов, проведя соответствующие переназначения.
В число этих семи основных ограничителей входят:
\ escape-символ, используемый для указания на переключение
из текстового режима в командный
Глава 25. ТЕХ.ONE
509
{ начало группы
} конец группы
$ начало и окончание математических формул
• символ табуляции (выравнивания)
У, начало комментария
# макропараметр
Первое, что делает, ТЕХ — преобразует этот файл во "внутренний входной файл",
следуя при этом таким правилам:
1. Удалить, если таковая имеется, первую управляющую страницу, сформированую
редактором TVeditor.
2. На каждой из оставшихся страниц заменить признак конца страницы ('14)
на код возврата каретки ('15). Удалить все символы перевода строки ('12),
нуль-символы ('00), коды удаления ('177) и символы вертикальной табуляции
('13). Заменить все символы (коды) горизонтальной табуляции 011)
пробелами (40).
3. Удалить все пробелы, следующие за символом возврата каретки.
4. Если два или более символа возврата каретки следуют подряд, заменить
их все кроме первого символами вертикальной табуляции (;13). Они
используются для обозначения конца абзаца; другими словами, пользователь
задает конец абзаца либо двукратным нажатием клавиши возврата каретки, либо
переводом страницы, за которым следует нажатие клавиши возврата каретки.
5. Заменить все остающиеся символы возврата каретки пробелами.
6. Если в строке следуют подряд два пробела, заменить их одним пробелом.
7. Заменить \ на '00, • на 'И, $ на '12, { на '14, } на '15, # на '177
(в предположении, что основные символы-ограничители определены так, как это
упоминалось выше).
8. Добавить бесконечно много символов '15 справа.
Смысл применения правила 8 заключается в том, что ТЕХ использует символы { и }
для группирования и завершающие текст символы '15 (они эквивалентны символам })
будут соответствовать символам { , для которых пользователь забыл написать парные
им символы завершения группирования во внешнем входном файле. Следуя приведенным
выше правилам, ТЕХ получает внутренний входной файл, не содержащий символов типа
семи перечисленных выше ограничителей, а также сдвоенных пробелов. Управление
пробелами в выходном документе осуществляется ТЕХ'ом с помощью других средств,
а семь упомянутых выше основных символов-ограничителей могут быть вставлены в
текст, если в этом возникнет необходимость, с использованием командных
последовательностей вроде \ascii'173 для символа {.
[На самом деле основных символов-ограничителей девять; не названные еще два
таких символа — это t и 4 для верхних и нижних индексов соответственно, но
использовать их можно только в математических формулах. Из-за нестыковок между
различными вариантами ASCII-кодов, станфордские коды не являются универсальными.
В частности, код '13 в варианте, принятом в Массачуссетском технологическом
институте (MIT), представляет собой символ t. Существует способ задать
t как один из девяти основных символов-ограничителей, даже в MIT, и ТЕХ будет
интерпретировать его соответственно — не удалит в правиле 2 и не перепутает
с символом, добавляемым в правиле 4. ТЕХ на самом деле не применяет правил 1-8
в том виде, как они представлены выше, он использует некий эффективный алгоритм,
который по производимым им результатам эквивалентен данному набору правил.]
510
Компьютерная типография
Теперь перейдем к высокоуровневому описанию и посмотрим, каким образом
пользователь сообщает ТЕХ'у свои требования относительно сложных объектов.
Приводимый ниже пример довольно велик и его лучше бегло просмотреть, не изучая
детально. Он задуман в качестве тестовой задачи для начальной отработки
создаваемой системы. Подробно анализировать его сейчас не надо, просто
просмотрите его бегло и переходите к чтению следующей части данного меморандума.
(Примечание: Этот пример основан на материале начальных страниц моей книги
"Seminumerical Algorithms", где опущены фрагменты, не представляющие особого
интереса с издательской точки зрения и с точки зрения требований, предъявляемых
к реализуемой системе. Итак, предлагаемый пример посвящен большей частью
сложным конструкциям, в этом смысле его нельзя считать типичным.
Читателю, который хотел бы разобраться в тонкостях данного примера более
основательно, полезно было бы иметь под рукой оригинал упомянутой книги,
чтобы можно было сравнивать входной ТЕХ'овский текст с требуемым результатом
его обработки.)
\require ACPhdr У, 1
'/.Example ТЕХ input related to Seminumerical Algorithms У, 2
\ACPpages starting at page 1: У, 3
\titlepage '/.This tells the page format routine not to put a page number on top У, 4
\runninglefthead{RANDOM NUMBERS} У. 5
\ljustline{\hexpand 11 pt {\:p CHAPTER \hskip 10 pt THREE}} У. б
\vskip 1 cm plus 30 pt minus 10 pt У, 7
\rjustline{\:q RANDOM NUMBERS} У. 8
\vskip .5 cm plus 1 pc minus 5 pt У, 9
\quoteformat{Anyone who considers arithmetical \cr У, 10
methods of producing random digits \cr is, of course, У, 11
in a state of sin. \cr} author{J0HN VON NEUMANN (1951)} У. 12
\quoteformat {Round numbers are always false.\cr} У, 13
author {SAMUEL JOHNSON (c. 1750)} У. 14
\vskip 1 cm plus 1 pc minus 5 pt У, 15
\runningrighthead{INTR0DUCTI0N} section{3.1} У. 16
\sectionbegin{3.1. У, 17
INTRODUCTION} У. 18
Numbers which are " chosen at random" are useful in a wide variety of У, 19
applications. For example: У, 20
% This blank line specifies end of paragraph У, 21
\yskip */, This means a bit of extra space between paragraphs У, 22
\textindent{a)}{\sl Simulation.}\xskip When a computer is used to simulate У, 23
natural phenomena, random numbers are required to make things realistic. У, 24
Simulation covers many fields, from the study of nuclear physics (where У, 25
particles are subject to random collisions) to systems engineering (where У, 26
people come into, say, a bank at random intervals).\par У, 27
\yskip\textindent{b)}{\sl Sampling.}\xskip It is often impractical to examine У, 28
all cases, but a random sample will provide insight into what constitutes У, 29
"typical" behavior. У. 30
У. 31
\yskip It is not easy to invent a foolproof random-number generator. This fact У, 32
was convincingly impressed upon the author several years ago, when he attempted У, 33
to create a fantastically good random-number generator using the following У, 34
peculiar method: У, 35
У. 36
\yskip\yskip\noindent{\bf Algorithm K}\xskip(\sl"Super-random'' number У, 37
Глава 25. ТЕХ.ONE 511
generator.}).\xskip Given a 10-digit decimal number $X$, this algorithm may be
used to change $X$ to the number which should come next in a supposedly random
sequence.\par
\algstep Kl. [Choose number of iterations.] Set $Y«-\lfloor X/10T9 \rfloor$,
i.e., the most significant digit of $X$. (We will execute steps K2 through K13
$Y+1$ times; that is, we will randomize the digits a {\sl random} number of
times.\par
\algstep K10. [99999 modify.] If $X<10t5$, set $X«-Xt2 + 99999$;
otherwise set $X«-X-99999$. \xskip\blackslug
\topinsert{\ctrline{\:r Table 1}
\ctrline{\:d A COLOSSAL COINCIDENCE: THE NUMBER 6065038420}
\ctrline{\:d IS TRANSFORMED INTO ITSELF BY ALGORITHM K.}
\vskip 3 pt \hrule
\ctrline{\valign{\vskip 6pt\top{#}«\vskip 6pt\top{#}\cr
\halign{\left{#}\quad®\ctr{#}*\left{#}\cr
Step®\$X$ (after)\cr
\vskip 10 pt plus 10 pt minus 5 pt
Kl*6065038420\cr K12*190586778®Y=5\cr} '/.end of \halign on line 53
\vskip 10 pt plus 10 pt minus 5pt \cr '/.end of first column to be \valigned
\vrule '/.vertical rule between columns
\halign{\left{#}\quad*\ctr{#}*\left{#}\cr
Step®$X$ (after)\cr
\vskip 10 pt plus 10 pt minus 5 pt
K10*1620063735\cr
Kll*1620063735\cr K12®6065038420®Y=0\cr}'/.end of \halign on line 59
\vskip 10 pt plus 10 pt minus 5pt \cr}} '/.end of 2nd \valigned column,\сtrline
\hrule} '/.end of the \topinsert on line 48
\yskip\yskip The moral to this story is that {\sl random numbers should not be
generated with a method chosen at random.} Some theory should be used.
\exbegin
\tr\exno 1. [20] Suppose that you wish to obtain a decimal digit at random, not
using a computer. Shifting to exercise 16, let $f(x,y)$ be a function such that
if $0<x,y<m$, then $0<f(x,y)<m$. The sequence is constructed by selecting
$X40$ and $X41$ arbitrarily, and then letting $$
Xl{n+1} = f(Xln,XI{n-l}) \qquad {\rm for} \qquad n>0.$$
What is the maximum period conceivably attainable in this case?
\exno 17. [10] Generalize the situation in the previous exercise so that
$X4{n+l}$ depends on the preceding $k$ values of the sequence.
\par\vskip plus 100 cm\eject
\runningrighthead{GENERATING UNIFORM RANDOM NUMBERS} section{3.2}
\sectionbegin{3.2. GENERATING UNIFORM RANDOM NUMBERS}
In this section we shall consider methods for generating a sequence of random
fractions, i.e., random {\sl real numbers $U4n$, uniformly distributed
between zero and one.} Since a computer can represent a real number with only
finite accuracy, we shall actually be generating integers $X4n$ between
zero and some number $m$; the fraction$$U4n = Xln/m \eqno(l)$$ will
then lie between zero and one.
\vskip.4in plus.2in minus.2in
\runningrighthead{THE LINEAR C0NGRUENTIAL METHOD} section{3.2.1}
\sectionbegin{3.2.1. The Linear Congruential Method}
512 Компьютерная типография
By far the most successful random number generators known today are special
cases of the following scheme, introduced by D. H. Lehmer in 1948. [See
{\sl Annals Harvard Сотр. Lab.} {\bf 26}(1951), 141-146.] We choose four
1'magic numbers'':$$
\halign{\right{#}*\left{\quad\rm{#}\qquad}*\right{#}*\left{#}\cr
XI0,«the starting value;®XI0«>0.\cr
m,®the modulus;®m«>XI,\quad m>a,\quad m>c.\cr}\eqno(l)$$
The desired sequence of random numbers $\langle Xln \rangle$ is then
obtained by setting$$XI{n+l}=(aXln+c)\mod m,\qquad n>0.\eqno(2)$$This is
called a {\sl linear congruential sequence.}
Let $w$ be the computer's word size. The following program computes $(aX+c)
\mod(w+l)$ efficiently:$$\halign{{\it#}\qquad®\hjust to 25pt{\left{#}}®
\left{\tt#}\cr
01*LDAN*X\cr
02®MUL®A\cr 05®JANN®*+3\cr
07®ADD®=W-l=\qquad\blackslug\cr}\eqno(2)$$
{\sl Proof.}\xskip We have $x=l+qpte$ for some integer $q$ which is not a
multiple of $p$. By the binomial formula$$
\eqalign{xtp®=l+{p\choose l}qpte+\cdots+{p\choose{p-l}}qt{p-l}
pt{(p-l)e}+qtp pt{pe}\cr
®=l+qpt{e+l}\group(){l+l\over p{p\choose 2}qpte + l\over p
{p\choose 3}qt2 pt{2e}+\cdots+l\over p{p\choose p}qt{p-l}
pt{(p-l)e}.\cr}$$ By repeated application of Lemma P, we find that
\def\mlo#l{\ ({\rm modulo}\ #l)}$$\eqalign{(atptg - l)/(a-l)*s 0 \mlo
{ptg},\cr(atptg-l)/(a-l)*\neqv 0 \mlo{pt{g+l}}.\cr}\eqno(6)$$
If $Kk<p$, $p\choose k$ is divisible by $p$. \biglpren{\sl Note: }\xskip A
generalization of this result appears in exercise 3.2.2-U(a) .\bigrpren\ By
Euler's theorem (exercise 1.2.4-48), $at{\varphi(pt{e-f})}= 1 \mlo
{pt{e-f}}; hence $X$ is a divisor of$$
X(pllt{ell} \ldots pltt{elt} = {\rm lcm}\group()
{X(pllt{ell},\ldots,X(pltt{elt})}.\eqno(9)$$
This algorithm in \MIX\ is simply$$
\halign{\hjust to 25pt{\left{\tt#}}*\left{\tt#\qquad}®\left{#}\cr
J6NN®*+2®\underline{\it Al. }j<0?}\cr
STA®Z«\qquad\qquad-»Z. \cr}\eqno (7) $$
That was on page 26. If we skip to page 49, $YI1 +\cdots+ Ylk$ will
equal $n$ with probability$$
\suml{{yll+\cdots+ylk=n}\atop{yll,\ldots,ylk>0}}
\prodl{l<s<k}
{et{-np4s}\group(){np4s}t{y4s}}\over{yis!}
={et{-n}ntn}\over{n!}.$$
This is not hard to express in terms of $n$-dimensional integrals,$$
{\intl{aln}tn dYIn \intl{al{n-l}}t{Yln}
dYI{n-l}\ldots\intl{all}t{YI2}dYll} \over
{\intlOtn dYIn \int!0t{Yln} dYI{n-l}\ldots
\intl0t{YI2}dYll},\qquad{\rm where}\qquad alj=
\max(j-t,0).\eqno(24)$$
This together with (25) implies that $$\def\rtn{\sqrt n}
\mathop{lim}4{n-»(D} s \over \rtn
\sumi{\rtn s<k<n}{n\choose k}\group(){k\over n - s\over rtn}tk
\group(){s\over\rtn + 1 - к \over n}t{n-k-l} = et{-2s}t2,\qquad s>0,
\eqno(27)$$ a limiting relationship which appears to be quite difficult to
Глава 25. ТЕХ.ONE
prove directly.
\exbegin\exno 17. [HM26] Let $t$ be a fixed real number. For $0<k<n$, let$$
Pl{nk}(x)=\inttxl{n-t}dxln\intl{n-l-t}t{xln}dxl{n-l}
\ldots\intl{k+l-t}t{xl{k+2}}dxl{k+l}\intl0t{xl{k+l}}
dxlk\ldots\intl0t{xl2}dxll;$$
Eq. (24) is equal to$$\dei\sumk{\suml{l<k<n}}
\sumk X\primelk Y\primelk \group/.{\sqrt{sumk{X\primeik}t2}
\sqrt{\sumk{Y\primelk}t2}}.$$\par
\runningrighthead{A BIG MATRIX DISPLAY} section{3.3.3.3}
\subsectionbegin{3.3.3.3. This subsection doesn't exist}Finally, look at page
91.$$\def\diagdots{\raise lOpt .\hskip 4pt \raise 5pt .\hskip 4pt .}
\eqalign{U®=\group(){\halign{\ctr{#}e\ctr{#}e\ctr{#}®\ctr{#}e\ctr{#}e\ctr{#}®
\ctr{#}\cr l\cr ®\diagdots\cr ®®l\cr
cH«\ldots®cl{k-l}®l®cl{k+l}®cln\cr
eeeel\creeeee\diagdots\cr®eeeeel\cr}},\cr
Ut{-l}e=\group(){\halign{\ctr{#}*\ctr{#}*\ctr{#}*\ctr{#}*\ctr{#}e\ctr{#}®
\ctr{#}\cr l\cr ®\diagdots\cr ®®l\cr
-cll®\ldotse-cl{k-l}ele-cl{k+l}e-c;n\cr
eeeel\cr®®®®®\diagdots\cr®«®®®®l\cr}}}$$
This ends the test data, fortunately TEX is working fine.
Прежде всего относительно приведенной выше задачи надо сказать, что она
намного сложнее обычного ТЕХ'овского текста по причинам, упоминавшимся
выше. Затем следует подчеркнуть, что она описана с использованием средств
не базового языка, а некоторого расширения ТЕХ'а. Например, "\ACPpages" во второй
строке представляет собой имя специальной программы, которая осуществляет
подготовку страниц в формате книги "The Art of Computer Programming". Кодовые
слова \ACPpages, \titlepage, \runninglefthead, \runningrighthead, \quoteformat,
\sectionbegin, \xskip, \yskip, \textindent, \algstep, \exbegin, \exno и
\subsectionbegin являются специфическими для моих книг и должны быть определены
в терминах низкоуровневых ТЕХ'овских примитивов способом, поясняемым ниже. Далее,
большинство шрифтов встроены в эти определения, например, в определении
"\sectionbegin" указывается, что текст раздела по умолчанию набирается шрифтом
кегля 10 pt, в то время как определение "\exbegin" для набора текста упражнений
задает шрифт кегля 9 pt. Еще одно определение задает, что слово MIX обычно
должно набираться шрифтом типа "шрифт пишущей машинки"; скрытое определение
\def\MIX{{\tt MIX}}
обеспечит автоматическое выполнение этого требования при обработке строки 125.
Механизм макроопределений ТЕХ'а мы рассмотрим позднее; три простых примера
имеются в строках с номерами 141, 152 и 157 нашей тестовой программы, где для
экономии места вводятся сокращенные обозначения для некоторых фрагментов
ТЕХ'овского текста. Для любознательных читателей, кому было бы интересно увидеть
более сложную конструкцию, даем определение кодового слова \quoteformat:
\def\quoteformat#l author#2{\lineskip 11 pt plus .5 pt minus 1 pt
\vskip б pt plus 2 pt minus 2 pt
\def\rm{\:s} \def\sl{\:t}
{\sl \halign{\right{##}\cr#l}}
\vskip б pt plus 2 pt minus 2 pt
\rm \rjustline{#2}
\vskip 11 pt plus 4 pt minus 2 pt}
Слову "author" ("автор"), которое встречается в данном определении, не
предшествует управляющий символ \ (escape character), поскольку оно
513
7.146
7.147
7.148
7.149
7.150
7.151
7.152
7.153
7.154
7.155
7.156
7.157
7.158
7.159
7.160
7.161
7.162
7.163
7.164
7.165
7.166
514
Компьютерная типография
просматривается только в составе определения макро \quoteformat.
Пожалуйста, не пытайтесь понять это сообщение сейчас, ТЕХ на самом деле
весьма прост, поверьте мне.
И в самом деле, забудем ненадолго все ТЕХ'овские сложности и попробуем
представить себе ТЕХ'овский документ в его простейшей форме. В качестве такого
документа, в определенном смысле представляющего собой альтернативу рассмотренным
выше примерам, можно указать следующий. Пусть имеется некий текстовый файл, не
имеющий вхождений символа "\" ; этому файлу предшествует код вида
"\deffnt a METS".
В этом случае ТЕХ осуществит вывод данного файла, используя шрифт с именем METS,
причем будет произведено выравнивание всех абзацев выводимого текста.
Самый первый отличный от пробела символ во внешнем входном файле воспринимается
ТЕХ'ом как пользовательский командный символ (escape character), С точки зрения
пользователя данный символ может считаться в известной степени аналогом
"управляющих" клавиш текстового редактора, поскольку этот символ предшествует
инструкциям системы. Обычно внешний входной файл начинается строкой вида
\require FILENAME
где в файле FILENAME содержатся пользовательские значения по умолчанию для ряда
параметров; это и было сделано в строке 1 нашего "большого примера".
Файл ACPhdr, упоминаемый в этой строке, начинается такой последовательностью
команд:
\chcode'173<-2. \chcode' 176<-3. \chcode'44<-4.
\chcode' 26<-5. \chcode' 45<-6. \chcode' 43<-7.
\chcode'136<-8. \chcode'l<-9.
которая, в Станфорде, определяет символы {}$*'/,# в качестве основных ограничителей
с номерами 2,3,4,5,6,7,8 и 9 соответственно. Конечно, большинство пользователей
ни в коем случае не захотят связываться с такого рода низкоуровневыми мелочами,
поэтому они будут применять команду \require для подключения каких-либо других
файлов. Файл, задаваемый командой \ACPhdr, определяет еще различные кодовые
слова наподобие \quoteformat, а также определяет другие соглашения, принятые при
наборе книги The Art of Computer Programming.
Войдем теперь в пример после его первой строки и посмотрим, что и как здесь
можно понять. Начало любой главы с полиграфической точки зрения всегда связано
с определенными сложностями. Строки 3-18 нашего примера относятся к преодолению
именно этих трудностей, сама же глава фактически начинается только в строке 19.
Теперь соберемся с духом и сразимся со строками 3-18.
Спецификация \runninglefthead ("левый колонтитул") в строке 5 содержит текстовую
строку, которая появится в самом верху левых страниц разворотов книги. Строка б
содержит первый фрагмент текста, который появится на создаваемой странице,
однако обратите внимание сначала на строку с номером 8, которая попроще.
Строка 8 предписывает использовать шрифт q (который в файле ACPhdr определяется
как "Computer Modern Gothic Bold 20 point", т.е. полужирный шрифт
семейства Computer Modern кегля 20 pt; это шрифт, разработкой которого
я занимаюсь в настоящее время) для набора слов RANDOM NUMBERS (СЛУЧАЙНЫЕ ЧИСЛА),
а также выровнять эти слова по правому краю строки (\rjustline). Строка б
аналогична строке 8, но задает использование другого шрифта, шрифта р (при этом
"выключается" шрифт Computer Modern Gothic 11 pt, использовавшийся до момента
переключения на шрифт р); пользователь ТЕХ'а может применять до 32 шрифтов,
именуемых как @, А или а, В или Ъ,..., Z или z, [, I или <, ], t или «-
соответственно (сравните это с ASCII-кодами, где можно использовать любой
символ и он будет определяться своими пятью младшими разрядами).
Шрифт @ является специальным, это единственный шрифт, для символов которого
Глава 25. ТЕХ.ONE
515
допускается иметь различные высоту и интерлиньяж.
Для всех остальных шрифтов величины интерлиньяж и высот боксов,
содержащих литеры, являются фиксированными. Более того, ТЕХ считает, что
некоторые из его математических символов также принадлежат шрифту @.
Если продолжить анализ строки б примера, то можно увидеть здесь команду
"\hskip 10 pt", задающую горизонтальный пробел величиной в 10 pt, а также
команду "\hexpand И pt", означающую, что надо взять рассматриваемую строку и
растянуть ее на И pt шире, чем это должно быть в норме. Отметим также, что
определения шрифтов, заданные внутри группы {...}, теряют свою силу вне данной
пары фигурных скобок. Аналогично обстоит дело и с другими определениями.
Теперь пришло время объяснить ТЕХ'овский механизм растяжения и сжатия
последовательностей боксов. Размеры в ТЕХ'е могут задаваться в типографских
пунктах, пиках, дюймах, сантиметрах или миллиметрах, что обозначается
соответственно, аббревиатурами pt, pc, in, cm, mm. Эти обозначения имеют смысл
только в таких контекстах, где используются физические длины, и одно из таких
обозначений в такого рода контексте должно присутствовать обязательно, даже если
фактическое значение соответствующей величины равно нулю (один дюйм равен
б пикам или 72 пунктам, или 2.54 сантиметрам, или 25.4 миллиметрам). Клей между
боксами имеет три составляющих:
фиксированная составляющая, х
добавляемая (plus) составляющая, у
убавляемая (minus) составляющая, z
Составляющая х представляет собой "нормальное" значение величины пробела,
которая используется в случае, когда боксы скрепляются друг с другом
без всяких модификаций, как это имеет место при обработке строки б; каждая
х-составляющая в клее увеличивается путем добавления нескольких у-составляющих.
Если же строку надо сжать, тогда каждая х-составляющая уменьшается путем
вычитания нескольких z-составляющих.
Например, пусть даны четыре бокса, соединенных друг с другом клеем
со спецификацией вида
(xl,yl,zl), (x2,y2,z2), (x3,y3,z3),
тогда расширение строки на величину w достигается использованием интервалов
xl + yl w\ х2 + у2 w\ хЗ + уЗ w\
где w' = ¥/(yl+y2+y3). Такого рода расширение невозможно, если ¥>0 и yl+y2+y3=0.
Создаваемая система будет настойчиво пытаться уменьшить число растяжений строк,
которые будут плохо смотреться, за счет использования довольно интеллектуальной
программы выравнивания строк (описывается ниже). При сжатии строки максимальное
значение величины ее сокращения равняется сумме всех z-составляющих, попыток
ужать строку еще больше предприниматься не будет. Таким образом, величину
z-составляющих надо задавать таким образом, чтобы x-z представляло бы собой
минимальное значение диапазона допустимых значений интервала. Для у-составляющей
подходящим значением будет такое, чтобы х+у было допустимым, но х+Зу лежало
на пределе допустимости. Значения параметров у и z должны быть неотрицательными,
однако х может быть и отрицательным (для стирания пробелов (backspacing) и
перекрытия фрагментов строк (overlapping)), если соблюдать при этом определенную
осторожность.
Обозначение "\hskip 10 pt" в строке б означает, что в горизонтальном клее
между словами CHAPTER THREE х = 10 pt, у = 0 и z = 0. Если бы эта
команда \hskip здесь не присутствовала, использовались бы обычные соглашения
для данной ситуации. А именно, клей между CHAPTER и THREE включал бы тогда
516
Компьютерная типография
х-составляющую, x=w (нормальное значение междусловного пробела для данного шрифта),
и у = w/8, z = w/2. Для клея между буквами будет (например) х = 0, у = w/18 и
z = w/б; таким образом, растяжение строки без использования \hskip приведет
главным образом к увеличению промежутка между словами CHAPTER и THREE,
использование же данной команды в виде, показанном выше, обеспечит введение
дополнительных промежутков еще и между отдельными буквами. Шрифты,
предназначенные для использования их ТЕХ'ом, должны обладать такого рода
средствами управления промежутками, понимаемыми как некоторые дополнительные
свойства соответствующего шрифта; ТЕХ должен также уметь обнаруживать ситуации
типа конца предложений, слегка увеличивая величину пробелов после знаков
препинания там, где это необходимо. Символы вроде + и = принято окружать
пробелами, тогда как пары символов '' и := должны стоять вплотную друг к другу;
символы + и = не выделяются пробелами в случае, когда они появляются в индексах.
Аналогичным образом должны обрабатываться ситуации с лигатурами. Наличие в
шрифтах, используемых ТЕХ'ом, такого рода средств делает эти шрифты несколько
более "интеллектуальными"; более подробно данный подход будет рассмотрен ниже.
Большинство ТЕХ'овских средств симметрично по отношению к горизонтальному
и вертикальному режимам, хотя основная идея, заключающаяся в формировании сначала
строк, а уже потом столбцов асимметрична по своей природе и встроена в
стандартные программы (в соответствии с тем способом, который мы обычно применяем
при письме). Спецификация "\vskip" в строке 7 задает вертикальный клей аналогично
горизонтальному клею. Когда программа выравнивания страниц пытается заполнить
первую страницу при обработке рассматриваемого нами тестового примера (путем
введения разрыва страниц точно в конце абзаца, или в таком месте текста, чтобы
на каждой из двух смежных страниц были размещены хотя бы по две строки из
разрываемого между страницами абзаца), этот клей будет растягиваться или
сжиматься вдоль вертикального измерения, используя значения х = 1 см,
у = 30 pt, z = 10 pt. Дополнительные характеристики клея вводятся
в определении для ключевого слова \quoteformat — это параметр \lineskip,
задающий величину междустрочного интервала, а также параметр \vskips,
который задает значение специального дополнительного интервала между
цитатой и строкой с именем ее автора. Применительно к основному тексту инструкция
для принтера имеет вид "10 на 12", что означает требование пользоваться для
печати шрифтом с кеглем 10 pt при значении интервала между соответствующими
частями смежных строк, равном 12 pt. ТЕХ будет использовать шрифт кегля 10 pt
со спецификацией
\lineskip 12 pt plus .25 pt minus .25 pt
так что интерлиньяж будет обладать определенной эластичностью. Дополнительное
управление величиной интерлиньяжа задается спецификацией
\parskip 0 pt plus 1 pt minus 0 pt
Кроме того, существуют также интервалы между упражнениями, шаги
в алгоритмах и т.д. Определение
\deiAyskip {\vskip 3 pt plus 2 pt minus 2 pt}
используется для формирования специального вертикального интервала, например,
в строках 22 и 37. В строках 23, 37 и т.д. используется горизонтальный интервал
вида
\deiAxskip {\hskip 6 pt plus 3.5 pt minus 3.5 pt}
который вводится в ситуации, когда психологически оправданно наличие интервала
большего, чем это определено в качестве нормы. Для этих ситуаций эластичный клей
особенно полезен. Пример использования более значительных по размеру
горизонтальных отступов, называемых \quad и \qquad, содержится в строке 96;
они задают интервал величины "один em" и "два em" соответственно, где em —
единица измерения, часто применяемая при типографском наборе математических
текстов.
Глава 25. ТЕХ.ONE
517
Общность эластичного клея можно оценить, если рассмотреть следующее
гипотетическое определение
\dei\hiill {\hskip 0 cm plus 1000 cm minus 0 cm}.
В этом случае у имеет практически бесконечное значение (длина, равная 10 м).
Когда код вроде \hfill появляется в начале строки, он обеспечивает выравнивание
данной строки по правому краю; когда он имеется как в начале строки, так и в ее
конце, он обеспечивает центрирование строки; в случае, когда он находится в
середине строки, он аккуратно делит строку на части и т.д. Эти свойства
эластичного клея обеспечивают средствам ТЕХ'а выравнивания строк
превосходство над средствами других систем, поскольку новые свойства вводятся
достаточно простым способом и в то же самое время уменьшают необходимость
использования устаревших средств применительно к общему случаю.
После того как произведено выравнивание списка боксов, все значения параметров
клея фиксируются и полученный объединенный бокс становится неизменяемым
("затвердевает"). Выравнивание осуществляется как по горизонтали, так и по
вертикали. Горизонтальное выравнивание длинных строк включает автоматическое
выполнение операций переноса; дополнительные сведения относительно операций
выравнивания будут приведены в данном отчете несколько позднее.
Снова обратимся к примеру. Строки с номерами 21, 31, 36 и т.д. в нем
— это пустые строки, обозначающие конец абзаца. Другой способ показать конец
абзаца состоит в использовании команды "\раг,;; пример такого использования
можно видеть в строке 27. Строка 124 задает конец абзаца, завершающегося
выключной формулой. Абзацы начинаются обычным образом; одна из ТЕХ'овских
команд, которая будет исполняться после того как обработана строка 17,
содержащая "\sectionbegin" ("начало раздела"), это команда
\parindent 20 pt
задающая абзацный отступ размера 20 pt в первой строке каждого абзаца до тех
пор, пока не появится команда "\noindent" ("подавить абзацный отступ"), как это
имеет место, например, в строке 37. Программа "\sectionbegin" также задает
"\noindent" для самого первого абзаца данного раздела, поскольку в моих книгах
такой стиль является стандартным. В строке 23 указывается "\textindent{a)}", что
обозначает необходимость создать бокс ширины \parindent, содержащий пару
символов а) , за которыми следует пробел, причем эта тройка символов
выравнивается по правой границе данного бокса.
В строке 23 "\sl" обозначает "наклонный шрифт". Я решил для выделения слов
в тексте пока заменить курсив 'наклонным вариантом обычного "прямого" шрифта,
тогда как имена переменных в математических формулах будут, как это принято,
набираться курсивом. Надо будет еще поэкспериментировать с этим, однако чутье
подсказывает мне, что набор так будет выглядеть намного привлекательнее,
поскольку буквы из типичных курсивных шрифтов смотрятся не очень красиво среди
текста, набранного обычным шрифтом. В любом случае я буду делать различие между
наклонными и курсивными шрифтами, поскольку возможны ситуации, когда
целесообразно использовать два различных шрифта для выделений, отличающихся по
стилю (по каким-либо причинам) друг от друга. Обозначение "\bf" в строке 37
задает набор полужирным шрифтом. Все перечисленные шрифты определяются в команде
начала раздела \sectionbegin; определения эти здесь не показаны.
Точки в текстах внутри фигурных скобок в строках 84 и 101 будут выполнены
"наклонными"; это позволяет разместить их подходящим образом по отношению к
буквам, вслед за которыми они идут, поскольку при переключении с наклонного
шрифта на обычный вводится небольшой дополнительный пробел.
518
Компьютерная типография
Все математические формулы во входном ТЕХ'овском файле содержатся либо между
парой символов $...$, как это имеет место, например, в строках 38 и 41, либо
между парами $$...$$ (так записываются выключные формулы). Формулы записываются
с использованием специального синтаксиса, основывающегося на предложениях
Кернигана и Черри (Kernighan and Cherry, Comm. ACM 18, March 1975, 151-157).
Например, запись "Т9" в строке 41 обозначает верхний индекс 9, а запись
'Ч{п+1}" в строке 74 -- нижний индекс п+1. Операторы, подобные t и 1, задающие
структуру математического выражения, активны только в пределах, охватываемых
парами $...$. Все буквы в формулах набираются курсивным шрифтом, за исключением
тех случаев, когда они относятся к одному из распознаваемых слов или же лежат
в пределах фигурных скобок в командах "{\rm ...}", "\hjust..." и т.д. Цифры и
знаки препинания, подобные точке с запятой, скобкам и т.п. в математическом
режиме берутся из прямого шрифта, если только не задано {\it...},
как это имеет место в строке 127. Символ "1" в этой строке будет иметь курсивное
начертание, также как и "j", тогда как символы "О" и "?" — обычное прямое
начертание.
Расстановка всех пробелов в формулах выполняется ТЕХ'ом, хотя есть возможность
добавлять пробелы в случаях, когда с точки зрения автора ТЕХ справился
с решением этой задачи не совсем удачно. В строке 116, например,
задаются дополнительные пробелы перед "(modulo" и после него при помощи кода
"\ "; пробел перед скобками обычно опускается, но в данном случае делать этого
нельзя. В завершающих фрагментах рассматриваемого примера много сложных формул,
которые будут выглядеть так, как это имеет место в соответствующих местах книги
АСР2, откуда взят данный пример. Обработка кода "\eqno 24" (строка 140) приведет
к тому, что будет сформирован номер формулы и проставлен в виде "(24)" на правом
поле страницы, причем он будет отцентрирован по вертикали по высоте формулы.
Так будет сделано, если справа от формулы достаточно места для размещения там
номера, если же этого места недостаточно, будет предпринята попытка сдвинуть
формулу левее ее первоначально отцентрированного положения, чтобы вставить номер
формулы "(24)", в противном случае номер "(24)" будет набран на следующей строке
и выключен вправо.
Ключевое слово "\algstep", используемое в строках 41 и 45, обозначает формат
записи шага алгоритма:
\def\algstep #1. [#2] {\vskip 3 pt plus I pt minus 1 pt
\noindent \hjust to 20 pt{\right{#l.}} [#2]\xskip
\hangindent 20 pt}
Сначала в этом определении устанавливается значение клея для вертикальных
интервалов; эта операция выполняется еще до того, как начинается
текст шага алгоритма. Устанавливается также подходящее значение для текстового
отступа (textindent) и т.д. В первый раз здесь появляется такое средство, как
отрицательный абзацный отступ (hanging indent). Использование этого средства
оставляет первую строку абзаца несмещенной (без абзацного отступа), а все
остальные строки данного абзаца смещаются вправо на величину абзацного отступа.
Ключевое слово "\exno" (упражнение с номером ... ), используемое в строках
70, 77 и т.д., имеет определение в чем-то похожее на определение шага алгоритма;
такие определения форматов для элементов, часто используемых в моих книгах,
помогают обеспечить единообразие стиля представления этих элементов на
протяжении всей книги. Элемент "\tr" в строке 70 позволяет изобразить
треугольник на левом поле страницы. Чтобы этот треугольник был размещен левее
крайней левой позиции строки, содержащей номер упражнения, в определении для
"\tr" используется клей с отрицательным значением.
Глава 25. ТЕХ.ONE
В строке 48 начинается выполнение операции вставки бокса "\topinsert" —
одного из важных элементов, необходимых при верстке полосы набора.
Рассматриваемый бокс, определенный внутри пары фигурных скобок {...},
идущих вслед за ключевым словом \topinsert, формируется как отдельный элемент,
который должен быть размещен в верхней части либо текущей страницы, либо
следующей за ней. За этим боксом следует вертикальный клей, задаваемый
выражением
\topskip 20 pt plus 10 pt minus 5 pt
Это еще один из элементов, подключаемых при обнаружении ТЕХ'ом ключевого слова
"\sectionbegin" в тексте обрабатываемого документа. Вставка боксов используется
для размещения рисунков и таблиц, в нашем случае — для таблицы.
Заголовок данной таблицы описывается в строках 48-50, сама же таблица (см. с.б
книги АСР2), достаточно сложна, поэтому отложим пока обсуждение содержимого
строк 52-65 и рассмотрим сначала более простой пример формирования таблицы
(\halign), содержащейся в строках 96-98.
В общем случае команда \halign задает форму вида
\halign{ ul#vl ® ... ® un#vn \cr
xll ® ... ® xln \сг
xml ® ... ® хшп \сг}
(После команд \сг допускается использовать команды \vskip's, \hrule, а также
команду \eqno из режима набора выключных формул.) В этом примере "\сг"
обозначает не carriage-return (возврат каретки), а представляет собой
последовательность из трех символов \, с, г. Символы и и v здесь обозначают
любые литерные цепочки, не включающие символов #, ® или \сг. Тем самым задается
формирование mn горизонтальных списков ("hlists") из боксов
ul{xll}vl ... un{xln}vn
ul{xml}vl ... un{xmn}vn
и для каждого к определение максимальной ширины списка hlist uk{xik}vk для
i = l,...,m. Затем все боксы uk{xik}vk выравниваются по ширине максимального
(самого широкого) бокса, после чего каждая из строк xil®...®xin\cr заменяется
горизонтально сцепленной последовательностью модифицированных (выровненных по
ширине) боксов; эти строки разделяются горизонтальным клеем, определяемым как
\htabskip 0 pt plus 1 pt minus 0 pt.
Если в какой-либо из строк таблицы до появления в ней команды \сг содержится
менее п элементов, недостающие элементы ("клетки" таблицы) оставляются пустыми.
Когда команда \halign появляется внутри группы, задаваемой парой символов $,
каждый из индивидуальных горизонтальных списков uk{xik}vk рассматривается как
отдельная независимая формула.
В примере использования команды \halign, содержащемся в строках 96-98, число п
столбцов задано как п=4. Первый из столбцов должен быть выровнен по правому краю,
второй трактуется как "\rm" (нематематические символы внутри формулы) и
окружается пробелами ширины quad, после чего выравнивается по левому краю,
третий опять выравнивается по правому краю, четвертый — выравнивается
по левому краю. Полученный при выполнении этой команды результат можно видеть
на с.9 книги АСР2; сформированная таблица трактуется здесь как формула (1) и
номер ее соответственно центрируется по высоте формулы.
Примечание: Со временем я введу в ТЕХ команду "\omittab", позволяющую формировать
при необходимости "клетки" таблицы, шириной в несколько столбцов.
Вернемся теперь к строкам 52-65 и сравним их с таблицей 1 на с.6 книги АСР2.
При помощи команды \halign и ее "двойника" для вертикального режима
\valign здесь формируются два бокса.
520
Компьютерная типография
Средство "\eqalign" (строки 111, 116) используется для того, чтобы выравнивать
выражения, содержащиеся в выключных формулах, расположенных в нескольких
строках. На самом деле эта команда представляет собой частный случай
команды \halign:
\dei\eqalign #l{\halign{right{##}*leit{##}\cr#l}}.
Обратите внимание -- строка 113 начинается символом табуляции ® (<ТАВ>).
Команды формирования "больших" математических знаков и скобок ("\group(){...}"
в строках 113, 143 и т.д.; "\group/{...}" в строке 153) используются для того,
чтобы сформировать в "высоких" формулах круглые скобки "(...)" и знаки типа
"наклонная черта" "/..." таких размеров, которые соответствовали бы размерам
формулы по вертикали; размеры упомянутых элементов определяются высотой
соответствующих боксов (например, бокса, заключенного в скобки). Операции такого
рода доступны также для квадратных и угловых скобок ([] и <>), а также для пары
знаков "вертикальная черта" (II), при этом левая и правая квадратные скобки
увеличиваются командами \[ и \] до размера, который ТЕХ сочтет наиболее
подходящим в данной конкретной ситуации. Скобки перечисленных выше видов
(включая пару вертикальных линий) могут быть сделаны произвольно большими по
размеру, однако на знак "наклонная черта" это не распространяется, по крайней
мере в текущей реализуемой версии ТЕХ'а. Пример, в котором будут сформированы
очень большие круглые скобки при построении большой матрицы, содержится
в строках 158-165.
Команды формирования больших круглых скобок "\biglpren" и "\bigrpren" в
строках 118-119 на самом деле дадут не такой уж и "большой" результат, но они
будут больше по величине, чем это установлено для обычного их использования,
пример которого на основе применения операции \group() дается в строках
122-123.
Знаки суммы, формируемые командой "\surn ..." в строках 131, 143, будут
большого размера, поскольку здесь они входят в состав выключных формул, однако,
когда формула набирается как часть текстовой строки (т.е. она ограничивается
парой символов $...$), величина знака суммы в ней будет меньшей, а пределы
суммирования будут набраны как индексы у знака суммы. Аналогично этому будет
изменяться и величина знака интеграла, а также дробей "...\over..." и
биномиальных коэффициентов (см., например, "$р \choose к$" в строке 118).
Подробнее об этом будет сказано ниже.
Команда \eject в строке 79 означает переход к новой странице (текст завершаемой
таким образом страницы будет выключен по вертикали вверх). Здесь опять
мы имеем дело с одним из элементов стиля оформления моих книг — основные
разделы всегда должны начинаться с новой страницы.
Я полагаю, что приведенные выше замечания по примеру набора текста позволяют
уловить дух ТЕХ'овского подхода. Этот пример подбирался так, чтобы показать
применение разнообразных средств при наборе достаточно сложного текста. В общем
же случае набор большинства книг будет представлять собой существенно более
рутинное занятие, где только время от времени возникнет потребность
в чем-то необычной формуле или таблице. В рассматриваемом примере акцент
делался именно на такого рода "необычных" элементах.
Следующий шаг в понимании работы ТЕХ'а состоит в том, чтобы вернуться к
низкоуровневому описанию процессов в нем и посмотреть, что происходит с
внутренним входным файлом при его чтении. Оказывается, что данный файл
Глава 25. ТЕХ.ONE
521
просматривается и преобразуется в последовательность лексем ("tokens"),
представляющих собой отдельные литеры или "командные последовательности"
("control sequences"), побуждающие ТЕХ выполнять ту или иную работу. Командная
последовательность представляет собой либо символ \ , за которым идет другой
символ, не являющийся буквой или ограничителем, либо символ \ , за которым
следуют одна или несколько букв (в этом случае командная последовательность
завершается с появлением первого же символа, не являющегося буквой.) Например,
"\vsize" и "\]" — это командные последовательности; действие, связанное со
сменой шрифта, требует последовательности из двух лексем "\:а", состоящей из
командной последовательности \: , за которой идет символ а; строка "Vascii'H?"
состоит из пяти лексем — командной последовательности \ascii, за которой идут
символы ',1,4,7. Если литера, следующая за символом \ , представляет собой букву,
и если признаком завершения командной последовательности является пробел, этот
пробел не принимается во внимание (будет незначимым) и удаляется из внутреннего
входного файла, поскольку единственное его назначение в данном случае — служить
признаком завершения командной последовательности. Из этого вытекает, например,
что выражения "\yskip \yskip" и "\yskip\yskip" будут эквивалентны друг другу.
В строке 125 мне пришлось написать "\М1Х\ " вместо более простого варианта
"\М1Х ", чтобы получить две лексемы, \М1Х и "\ "; при такой записи вторая лексема
становится уже реальным пробелом. ТЕХ игнорирует также пробел, следующий за
идентификационным символом шрифта, введенный ради повышения удобочитаемости
ТЕХ'овского текста; например, запись "\:aNow is the time" эквивалентна с точки
зрения получаемого результата записи "\:а Now is the time".
Если командная последовательность состоит из \ и какого-либо еще одного
отображаемого символа, учитываются различия между этими символами, но если
такая последовательность включает помимо символа \ также и цепочку (строку) из
букв, то в этом случае не делается различия между буквами в верхнем и нижнем
регистре (т.е. между "прописными" и "строчными" буквами), за исключением самой
первой буквы в этой строке. Это значит, что командные последовательности "\GAMMA"
и "\Gamma" будут считаться идентичными, но не совпадающими с командой "\gamma".
Более того, буквенные последовательности считаются разными, если они различаются
по первым семи буквам, входящим в них (по шести буквам, если ТЕХ реализован на
машине с 32-разрядными двоичными словами), или же если они имеют различное
значение параметра length mod 8 (остаток от деления длины последовательности
на 8). Например, обе командные последовательности "\qUotefOiraranm" и
"\quOTEfoxxxxxxxxxxxx" эквивалентны команде "\quoteformat". Вследствие этого,
общее число различных командных последовательностей, которые можно определить,
составляет примерно
128-14 + 2*(26~2 + 26~3 + 26~4 + 26~5 + 26~6 + 8*26~7)
и этого явно должно быть достаточно.
Командная последовательность будет, разумеется, считаться неверной до
тех пор, пока ТЕХ'у не станет известно ее определение. В ТЕХ встроены некоторые
командные последовательности-примитивы, наподобие "\vsize", "\ " и "\def", a
также средства определения макрокоманд (это команда \def), позволяющие научить
ТЕХ новым командным последовательностям (или заставить его забыть какие-либо из
существующих команд), вроде "\М1Х" и "\quoteformat".
Дадим теперь точные правила, которым следует ТЕХ, преобразуя внутренний
входной файл в "чистый ввод", состоящий из лексем. В "чистом
вводе" каждая командная последовательность является примитивом, отличным от
"\def" и "\require". Выше уже упоминалось, что команда \require просто вводит
часть входного текста из некоторого другого файла. Для команды \def в общем
случае можно записать
\def <ctrl-seq><stringO>#Hstringl> ... #k<stringk>{<right-hand side>}
522
Компьютерная типография
где <stringO> ... <stringk> -- последовательности из нуля или более литер,
кроме литер { , } или #; пробелы в этих строках являются значимыми. Исключением
будет случай первого символа после определенной командной
последовательности, который игнорируется, если он представляет собой
пробел-ограничитель, за которым следует буквенная строка. Фрагмент
<right-hand side> приведенного выше определения представляет собой любую
последовательность из символов, включающую сбалансированные пары скобок
{ и }; пробелы здесь опять будут значимыми. Я описываю сейчас общий
случай; в простых ситуациях наподобие определения командной последовательности
\rtn в строке 141, к равняется нулю, a <stringO> — пустая строка. Значение
параметра к должно быть <9.
Когда обнаруживается командная последовательность с именем <ctrl-seq>, позднее,
при обработке ввода, запускается процесс сопоставления, продолжающийся до тех
пор, пока не будут найдены соответствия для всех элементов из левой части
определения: символы в строках stringO...stringk должны точно соотноситься с
соответствующими символами во входном тексте; если в процессе сопоставления
обнаружится ошибка, будет выдано диагностическое сообщение. По завершении
процесса сопоставления ТЕХ ищет те элементы ("ингредиенты"), которые должны
быть подставлены вместо параметров #1,...,#к в правой части определения. Это
выполняется следующим образом. Если строка <stringj> пуста, значением для
параметра #j будет следующий одиночный входной символ, или (если этим символом
окажется "{") следующая группа символов вплоть до соответствующей закрывающей
скобки "}". Если же строка <stringj> не пустая, значением параметра #j будет О
или более символов или группы {...} вплоть до следующего входного символа,
равного первому символу в строке <stringj>. Никаких операций макрорасширения во
время данного процесса сопоставления левой и правой частей определения не
выполняется, точно так же, как не делается никаких попыток восстановления, когда
обнаруживается ошибка; последующие символы входной строки должны отвечать
оставшимся символам строки <stringj>. Если параметр #j включает изолированную
группу {...}, внешние скобки { и } из данной группы удаляются. Отметим, что
процесс сопоставления имеет дело с символами из внутреннего входного файла, не
с лексемами; вполне возможно, например, что значением параметра #j станет
единственный символ-ограничитель вроде "\".
После того, как путем применения описанных выше правил найдены значения
для параметров #1 ... #к, они просто копируются в позиции, занимаемые этими
параметрами в правой части определения. И еще одно изменение будет сделано в
правой части определения: из любой последовательности, содержащей два или более
символа #, идущих подряд, удаляется первый символ #. Это делается для того,
чтобы можно было записывать определения в правой части без риска перепутать их
с текущим определением.
В качестве примера рассмотрим, что произойдет, если активным будет определение
вида:
\dei\A#l ВС {\def\E ##1{##1#1 #1}}.
Если внутренний входной файл содержит
\А {Х-у} ВС D
то результирующая последовательность после раскрытия определения примет вид
\def\E #1{#1Х-у X-y}D
(обратите внимание на расстановку пробелов).
Изложенное выше не представляет собой наиболее общего подхода к формированию
макроопределений — я здесь предпочитаю следовать принципу "бритвы Оккама".
Если теперь читатель вернется несколько назад и посмотрит на определения,
сформированные для ключевых слов \quoteformat, \algstep и \eqalign, то увидит,
что все они и в самом деле просты.
Глава 25. ТЕХ.ONE
523
Действия присваивания. Я упоминал уже, что "чистый ввод" содержит коды для
действий-примитивов, которые могут быть выполнены, а также символы, передаваемые
в формируемый итоговый документ. Часть из этих действий — это просто действия
присваивания, которые устанавливают значения параметров, сообщающих ТЕХ'у, каким
образом следует осуществлять преобразования следующего за ними входного текста.
Подобно макроопределениям, действия присваивания имеют силу только внутри
текущей группы, задаваемой парой фигурных скобок {...}, парами символов $...$
или $$...$$, или же до момента их явного переопределения.
Дадим список ТЕХ'овских действий присваивания:
\chcode,<octal><-<number> определяет основной ограничитель
\deffnt <char><filename> фактическое имя шрифта, соответствующее
его псевдониму (nickname)
\:<char> текущий используемый шрифт
\mathrm шрифт, который следует использовать для набора имен
математических функций типа log
\mathit шрифт, который следует использовать для набора
переменных типа х
\mathsy шрифт, который следует использовать для набора
математических символов типа \mu
\ragged или \justified вид правого поля
\hsize <length> нормальная ширина строк формируемого текста
\vsize <length> нормальная высота страниц формируемого текста
\parindent <glue> величина отступа для первой строки абзаца
\hangindent <glue> величина отступа для всех строк абзаца, кроме
первой (этот параметр принимает нулевое
значение при каждом выходе из абзаца)
Mineskip <glue> вертикальный промежуток между линиями
шрифта формируемых строк текста
\parskip <glue> дополнительный промежуток между абзацами (добавляется
к lineskip)
\dispskip <glue> дополнительный промежуток перед выключной формулой
и после нее
\topskip <glue> дополнительный интервал снизу для бокса, вставляемого
в верхней части страницы
\botskip <glue> дополнительный интервал сверху для бокса, вставляемого
в нижней части страницы
\htabskip <glue> горизонтальный промежуток между столбцами, табулируемыми
с помощью команды \haligned
\vtabskip <glue> вертикальный промежуток между столбцами, выравниваемыми
с помощью команды \valigned
\output <routine> то, что делается с заполненными страницами
Все эти числовые параметры имеют значения по умолчанию, которые будут выбраны,
исходя из опыта использования ТЕХ'а; эти значения будут активными до тех пор
пока не будут в явном виде переопределены. В приведенном выше перечне <length>
("длина") имеет вид
<number><unit> или -<number><unit>
где <пшпЪег> ("число") ~ строка цифр, содержащая или не содержащая точку
(десятичную точку), a <imit> ("единица измерения") может принимать значения
pt, pc, in, cm или mm. Далее, <glue> ("клей") определяется выражением
<length> plus <length> minus <length>
где фрагменты plus и minus не могут быть отрицательными; любая из трех
перечисленных частей-длин может быть опущена или быть равной нулю, до тех пор
пока хотя бы одна из трех имеется в наличии. Пробел после <number> или <unit>
из ввода удаляется.
524
Компьютерная типография
Например, в соответствии со стандартными соглашениями, принятыми для принтера
XGP, вывод производится на страницу размера 8 1/2 на 11 дюймов с левыми и
правыми полями по 1 дюйму, междустрочное расстояние 4 пикселя; для шрифта
высотой в 30 пикселей все эти требования можно описать так:
\hsize 6.5 in \vsize 9 in \lineskip .17 in
Это можно было бы это записать также следующим образом:
\def\hmargin{l in} \def\vmargin{l in}
чтобы воспользоваться преимуществами, которые по умолчанию дает ТЕХ'овская
программа \output. (Объяснения, связанные с этой программой я приведу ниже.)
Когда я буду расширять ТЕХ, то включу в него дополнительное действие присваивания
\tempmeas <length> next <number> lines
с тем, чтобы ТЕХ получил возможность устанавливать сжатый набор (narrow measure),
необходимый для включения небольших иллюстраций (см. том 1 книги АСР, с.52).
Чтобы избежать конфликтов между программами формирования страниц и абзацев, были
внесены изменения в команды \hsize и \vsize, которые проявятся только в случае,
если ТЕХ размещает первую строку абзаца с новой страницы или же первый элемент
текстового фрагмента с нового абзаца.
На действия присваивания \chcode и \deffnt не распространяются "правила
видимости" команд, оба они имеют "глобальный" эффект.
Структура управления. Теперь самое подходящее время рассмотреть ТЕХ'овские
механизмы формирования абзацев и страниц, а также ряд других вопросов,
связанных с ТЕХ'овской структурой управления. На самом деле следовало уже
давно это сделать, тогда и вы и я смогли бы избежать большого числа
недоразумений.
Внутренние механизмы работы ТЕХ'а имеют дело с боксами и объектами, именуемыми
"hlists" (которые представляют собой горизонтальные списки боксов, разделенных
горизонтальным клеем) и "vlists" (вертикальные списки боксов, разделенных
вертикальным клеем). Списки этих двух видов нельзя смешивать и ТЕХ в каждый
момент времени должен знать, формирует ли он список типа hlist или список типа
vlist.
Мы говорим, что ТЕХ находится в "горизонтальном режиме" ("horizontal mode"),
если он работает с объектом типа hlist — интуитивно, когда он находится в
середине строки — в противном случае он будет в "вертикальном режиме"
("vertical mode"). Подходя более формально, будем писать "h..." для
корректного ТЕХ'овского ввода, начинающегося в горизонтальном режиме, и "v..."
для корректного ТЕХ'овского ввода, начинающегося в вертикальном режиме. Действия
присваивания не оказывают влияния на вид режима, поэтому в данном обсуждении мы
их упоминать не будем.
Когда ТЕХ находится в вертикальном режиме, в качестве следующей лексемы из
"чистого ввода" (не считая действий присваивания) должна использоваться одна
из перечисленных ниже:
v... =
\vskip <glue> v...
(вертикальный клей, присоединенный к текущему списку vlist)
\ljustline{h...}v...,\ctrline{h...}v..., или \rjustline{h...}v...
(присоединить бокс ширины \hsize к текущему списку vlist)
\hrule [height <length>] [width <length>]
(присоединить горизонтальную линейку к текущему списку vlist,
она напоминает целиком закрашенный черным прямоугольник, для
Глава 25. ТЕХ.ONE
525
которого по умолчанию высота (height) равна 0.5 pt, а ширина
(width) равна окончательной ширине данного списка vlist, a
именно, от левой границы его самого левого бокса до правой
границы его самого правого бокса)
\moveleft <length> v... или \moveright <length> v...
(следующий бокс в текущем списке vlist, который надо сдвинуть
влево или вправо на заданную величину, действует только на один
бокс)
\topinsert{v...}v... или \botinsert{v...}v...
(вставляет список vlist в текущую страницу, или перемещает его
на следующую страницу, если он не может быть размещен на
текущей)
\halign{...}v...
(возвращает вертикальный список vlist из m боксов, сформированный
из mn горизонтальных списков hlist как это было описано выше;
список vlist присоединяется к текущему вертикальному списку)
\top{v...}v..., \mid{v...}v..., или \bot{v...}v...
(используется в основном в команде \valign, возвращает список
vlist, выровненный с помощью команды \vjust по верхнему краю,
отцентрированный по вертикали или выровненный по нижнему краю
страницы, соответственно)
* \mark{...}v...
(связывает метки-заголовки со следующими строками текста)
* \penalty <immber>v...
(добавочные единицы плохости, если разрыв страницы
будет произведен в этом месте)
<blank space>v... или \ v... или \par v...
(игнорируется)
* \noindent h...
(начинает абзац с первой строкой без отступа)
* <box> h...
(начинает абзац с отступом в его первой строке, начальным боксом
абзаца будет указанный <Ъох>)
* \eject v...
(завершает текущую страницу, если только она не пустая)
** \eqno(<immber>)v...
(добавляет справа от выключной формулы соответствующий ей
номер уравнения)
Здесь звездочка * обозначает опции, которые будут правомерными, только если
текущий список vlist обрабатывается подпрограммой формирования страниц, а
двойная звездочка ** -- опцию, допустимую только в режиме формирования выключных
формул. Подпрограмма формирования страниц будет активной в начале работы
программы в целом, но не внутри других программ (например, программы, реализующей
команду \topinsert), связанных с формированием списков vlist.
Спецификация бокса может иметь одну из следующих форм:
<Ъох> =
<nonblank character>
(бокс, состоящий из этого символа, отличного от пробела (nonblank
character), взятого из текущего шрифта)
\ascii,<octal>
(эквивалентно символу, который может быть очень затруднительно
ввести каким-либо другим способом)
\hjust to <length>{h...}
526
Компьютерная типография
(список hlist преобразуется в бокс заданной длины <length>,
причем, если это потребуется, то с разрывом его на несколько
строк, как при формировании абзаца)
\hjust{h...} или \hexpand <length>{h...}
(список hlist преобразуется в бокс с его естественной длиной,
плюс заданная длина...здесь действие команды \hjust аналогично
действию команды \hexpand 0 pt)
\vjust to <length>{v...}
(список vlist преобразуется в бокс заданной длины,
в этом случае, к сожалению, без возможности разбиения его на
части)
\vjust{v...} или \vexpand <length>{v...}
(список vlist преобразуется в бокс с его естественной высотой
плюс заданное значение ... здесь команда \vjust действует
аналогично команде \vexpand 0 pt)
\page
(данная страница полностью завершена; разрешается использовать
только в программе \output)
\ЪохО, \boxl, ... \Ъох9
("глобальный" бокс самым последним по порядку сохраненный
командами \saveO,...,\save9)
Бокс при его чтении командами \page и \boxk разрушается, не копируется, поэтому
следующая попытка его прочитать вызовет появление сообщения об ошибке. Программы
построения боксов и программы \output имеют право использовать команду с именем
\savek (0<к<9), чтобы сохранить некоторый бокс в одной из десяти глобальных
областей сохранения; и опять, этот бокс не копируется, он формируется из текущего
списка hlist или vlist, после чего текущий список опустошается.
Когда ТЕХ находится в горизонтальном режиме, в качестве следующей лексемы из
"чистого ввода" (не считая действий присваивания), должна использоваться одна
из перечисленных ниже:
h... =
\hskip <glue> h...
(горизонтальный клей, присоединенный к текущему списку hlist)
\tjustcol{v...}h...,\midcol{v...}h..., или \bjustcol{v...}h...
(присоединить бокс высоты \vsize к текущему списку hlist)
\vrule [height <length>] [width <length>]
(присоединить вертикальную линейку к текущему списку hlist,
это аналогично команде \hrule, но по умолчанию ширина (width)
для нее равна 0.5 pt, а высота (height) равна высоте списка
hlist; если значение высоты задано, линейка выполняется
соответствующего размера, при этом она начинается от линии
шрифта)
\raise <length> h... или \lower <length> h...
(следующий бокс или линейку в текущем списке hlist надо сдвинуть
вверх или вниз относительно линии шрифта на заданную величину,
действует только на один бокс)
\topinsert{v...}h... or \botinsert{v...}h...
(вставляет список vlist в точности на ту страницу, которая
содержит предыдущий бокс в текущем списке hlist, это может быть,
например, некоторое примечание)
\valign{...}h...
(возвращает горизонтальный список hlist из m боксов,
сформированный из mn вертикальных списков vlist как это было
Глава 25. ТЕХ.ONE
527
описано выше; список hlist присоединяется к текущему
горизонтальному списку)
\leit{h...}h..., \ctr{h...}h..., или \right{h...}h...
(используется в основном в команде \halign, возвращает список
hlist, выровненный с помощью команды \hjust по левому краю,
отцентрированный по горизонтали или выровненный соответственно
по правому краю страницы,)
\penalty <number>h...
(добавочные единицы плохости, если разрыв строки будет произведен
в этом месте)
<blank space>h...
(переменный клей для междусловных промежутков в данном текущем
шрифте; в математическом режиме игнорируется)
\ h...
(то же самое, что и пробел (blank space), но не игнорируется в
математическом режиме)
<Ъох> h...
(в частности, символ, отличный от пробела...данный бокс
присоединяется к текущему списку hlist)
$...$ h...
(список hlist, определенный в математическом режиме,
присоединяется к текущему списку hlist)
* $$...$$ h...
(разрывает текущий абзац, обрабатываемый программой
формирования страниц, но значение параметра \hangindent не
обнуляется...абзац продолжается после завершения фрагмента,
ограниченного парами символов $$... внутри этого фрагмента
содержится математическая формула или набор таких формул,
задаваемых командами \eqalign или \halign, они будут
отцентрированы и присоединены к списку vlist, обрабатываемому
программой формирования страниц согласно условиям, принятым
для выключных формул...этой программе передается также
соответствующее значение вертикального клея...дополнительный
клей над выключным уравнением (\dispskip) не добавляется,
если текст предшествующей строки абзаца не "накрывает"
(overhang) первую из выключных формул в их рассматриваемом
наборе после центрирования)
* \par v... или <два последовательных символа возврата каретки во внешнем
входном файле> v...
(конец абзаца, текущий список hlist разбивается на строки
способом, рассматриваемым ниже; полученные строки присоединяются
к списку vlist, обрабатываемому программой формирования страниц)
* \eject h...
(завершает текущий "абзац" и текущую страницу, но последняя
строка текущего "абзаца" выравнивается, как если бы она была
в середине абзаца; текст продолжается в новом "абзаце" без
абзацного отступа в его первой строкеи без обнуления параметра
\hangindent)
Здесь звездочка * обозначает опции, которые будут правомерными, только если
текущий список hlist обрабатывается подпрограммой формирования абзацев,
вызываемой из программы формирования страниц так, как это было описано выше.
Боксы имеют точку привязки на их левой границе, используемую при склеивании двух
боксов. Если бокс представляет собой просто некий символ, взятый из некоторого
528
Компьютерная типография
шрифта, тогда точка привязки для него будет находиться на пересечении левой
границы бокса, содержащего символ, с линией шрифта (т.е. в нижней части букв,
подобных х, но не у; в последнем случае бокс будет продолжен вниз, под линию
шрифта, чтобы разместить нижнюю часть буквы). Когда боксы сцепляются по горизонтали,
их линии шрифта выстраиваются в одну прямую линию (если только не используются
команды \raise или \lower, требующие нарушения этого правила). Запоминаются
также значения максимальной высоты над линией шрифта и максимальной глубины
под ней, чтобы определить высоту получаемого бокса. Если боксы сцепляются по
вертикали, в одну прямую линию выстраиваются их левые границы (если только не
используются команды \moveright или \moveleft, требующие нарушения этого правила).
Расстояние между линиями шрифта в их последовательности задается параметром
\lineskip в сочетании с вертикальным клеем, определяемым командами \vskip,
\parskip и т.д., пока это не приводит к перекрытию (взаимному наложению) боксов;
в последнем случае боксы будут помещены друг на друга с нулевым клеем. В качестве
линии шрифта результирующего бокса будет принята линия шрифта самого нижнего
бокса в нем. Максимальное расстояние до правой стороны линии привязки определяется
шириной результирующего бокса.
Значение числового параметра \lineskip перед и после команды \hrule не
принимается во внимание. Тогда, например, можно записать
\vskip 3pt \hrule \vskip 2pt \hrule \vskip 3pt
чтобы получить двойную горизонтальную линейку с промежутком между линейками,
равным 2 pt, интервалом между линейкой и соседней строкой, равным 3 pt,
независимо от текущего значения параметра \lineskip.
Если два стоящих рядом элемента списка hlist — просто символы, взятые
из одного и того же шрифта, ТЕХ просматривает таблицу, связанную
с данным шрифтом, чтобы определить, не имеет ли место случай, когда
пару смежных символов надо заменить на специальный символ. Например, для
некоторых из моих стандартных шрифтов, определены следующие подстановки:
ff
fi
fl
<ff>i
<ff>l
((
у)
—
<en-dash>-
•4
■4
•4
■4
•4
•4
•4
•4
•4
<ff>
<fi>
<П>
<ffi>
<ffl>
<">
<">
<en-dash>
<em-dash>
Для первых семи комбинаций я буду использовать коды 'И, '12, '13, '14, '15,
'175, '177, поскольку на данном этапе ТЕХ не перепутает их с базовыми
ограничителями. (Другие возможные варианты такого рода комбинаций — это
:= -» <:=> и, для эксклюзивных подарочных изданий, где используются
символы "под старину" — лигатуры для ct и st.)
Обратим внимание на такие элементы приведенной выше таблицы подстановок, как
en-dash (короткое тире) и em-dash (длинное тире); на самом деле в математических
публикациях используются знаки подобного рода четырех различных видов:
дефис (для обозначения разрыва слов при переносе),
короткое тире (для диапазонов типа "13—20"),
знак минуса (для обозначения операции вычитания),
длинное тире (для обозначения тире как такового).
Эти знаки в ТЕХ'овском наборе соответственно имеют вид -, —, - (только внутри
фрагментов, ограниченных парами символов $), —.
Глава 25. ТЕХ.ONE
529
Приведенные выше правила для v... и h... суммируют сведения для большей части
ТЕХ'овских команд, за исключением действий присваивания, рассмотренных ранее,
а также операций, связанных с выводом страниц и с работой в математическом
режиме.
Рассмотрим теперь текст программы \ACPpages, осуществляющей вывод сложных страниц.
Этот код использует "переменные" \tpage и \rhead, не являющиеся частью ТЕХ'а.
Я занимаюсь сейчас реализацией ТЕХ'овских макросредств, которые давали бы
возможность "присваивать" значения этим символам. Читателей, не привыкших к
подобного рода "фокусам", они, наверное, позабавят, но я не считаю их такими уж
ужасно неэффективными, поскольку страницы все-таки выводятся сравнительно редко.
\def \titlepage {\def \tpage{T}} У, присваивает \tpage значение Т ("true")
\def \runninglefthead#l {\def \rhead{{\:m#l}}}
\def \runningrighthead#l section#2 {\mark
{\ifeven{\hjust to .375 in {\left{\cpage}}\left{\rhead}#2}
\else{#2\right{\:m#l}\hjust to .375 in {\right{\cpage}}}}
\def \ACPpages starting at page #1:
{\setcpage #1 У, устанавливает номер текущей страницы для
У, следующей страницы
\output{\lineskip 12 pt У, запускает программу output, сбрасывает \lineskip
\vskip \vmargin У, пропускает верхнее поле (\vmargin определяется
У, пользователем)
\ifT \tpage У, следующий текст используется, если значение \tpage
У, равно Т
{\def \tpage{F} У, возвращает переменную \tpage в исходное состояние
\topline У, специальная строка, задаваемая пользователем, для
У, вывода в верхней части титульных страниц
\moveright \hmargin У, скорректировать левое поле
\ljustline{\page}
\vskip 3 pt
\moveright \hmargin
\ljustline{\hjust to 29 pc{\:c \ctr{\cpage}}}} У, центрировать номер
У, в нижней части страницы
\else {\moveright \hmargin У, этот формат используется, если \tpage > Т
\ljustline{\hjust to 29 рс{\:а \ifeven{\topmark}\else{\botmark}}}
\vskip 12 pt
\moveright \hmargin \ljustline{\page}}
\advcpage} У, увеличить номер текущей страницы на 1
Всякий раз когда программа формирования страниц завершает подготовку очередной
страницы, активизируется подпрограмма \output. ТЕХ в данном случае находится в
вертикальном режиме, значения параметров \hsize, \lineskip и т.п. непредсказуемы,
так что надо вернуть их в исходное состояние ("сбросить"). Бокс, определяемый
вертикальным списком vlist, сформированным программой \output, и будет
представлять собой требуемый вывод, если только он не будет пустым (например,
если он был уже сохранен с помощью команды \save).
К числу ТЕХ'овских действий, использовавшихся в приведенном выше тексте
программы и пока еще не получивших объяснения, относятся:
\setcpage <number> Устанавливает значение номера текущей страницы
равным заданному целому числу <number>; если
это число отрицательно, то номер набирается
римскими цифрами.
530
Компьютерная типография
\advcpage
\cpage
\ifeven{a}\else{p}
Увеличивает абсолютное значение номера текущей
страницы на единицу.
Символьная строка, отвечающая значению номера
текущей страницы, которая вставляется в
ТЕХ'овский ввод как десятичное число с
удаленными головными нулями (leading zeroes)
или как число, записанное римскими цифрами
(в нижнем регистре);
Использует а, если номер текущей страницы
четный (even), в противном случае использует р
(ТЕХ'овская сканирующая программа за каждый
такт обрабатывает один символ).
\ifT <char> {a}\else{p} Использует а, если <char> равно Т, в противном
случае использует р.
Операция \mark связывает неинтерпретируемую
символьную строку (маркер) с набором
последующих строк текста формируемого документа,
полученным программой формирования страниц, это
связывание будет действительным до следующего
маркера; команда "\topmark" вставляет в
ТЕХ'овский ввод маркер, связанный с первой
строкой текущей страницы \page, а "\botmark" --
связывает с последней строкой, не считая любых
строк текста, добавленных командами \topinserted
или \botinserted.
Я предлагаю использовать следующие ниже команды в качестве значений по умолчанию
в ТЕХ'овской программе output. В этих командах используются дополнительные пять
действий, а именно, \day, \month, \year, \time и \file, отвечающие среде, из
которой вызывается ТЕХ.
\topmark, \botmark
\def \hiill{\hskip plus 100 cm}
\lineskip 0 pt
\:\font
\vskip \vmargin
\ifT \notitle {} \else{
\ljustline{\hjust to 7.5 in{
\hskip\hmargin
\day\ \month\ \year\hiill
\time\hiill
\iile\hiill
\cpage}}
\vskip 12 pt}
\moveright \hmargin \ljustline{\cpage}
\advcpage
'/."бесконечная" растяжимость
'/.обнулить ("сбросить") промежуток между
'/.строками
'/.вернуться к символу, принятому по
'/.умолчанию
'/.пропустить верхнее поле
'/.пропустить заголовок, если выполнено
'/.условие
'/.заглавная строка, содержит
'/.номер страницы, отстоящий на 1 дюйм
*/,от правой границы страницы
'/.пропустить левое поле
Удата
'/время начала (стартовое время)
'/.имя основного входного файла
'/.номер страницы
'/.сдвиг на 1 пику после заголовка
'/вставить тело страницы, пропуская
'/.левое поле
'/.увеличить номер страницы
Значения параметров \hmargin, \vmargin, \font и \notitle могут устанавливаться
пользователем (или SNAIL), все они также имеют значения по умолчанию.
Глава 25. ТЕХ.ONE
531
Рассмотрим теперь более подробно программу формирования страниц. Это
даст возможность изучить ТЕХ'овский процесс выравнивания по вертикали,
вводящий ряд концепций, необходимых при реализации более сложной
программы, используемой для выравнивания последовательностей боксов
по горизонтали.
Первая из реализуемых идей — это концепция "плохости" (badness). Она
представляет собой число, определяемое на основе совокупности
растяжений и сжатий, необходимых при установке значения клея. Пусть имеется
список из п боксов (горизонтальный или вертикальный список), разделенных п-1
спецификациями клея. Пусть w — требуемая полная длина списка (т.е. требуемая
ширина или высота, в зависимости от того, как выполняется выравнивание -- по
горизонтали или по вертикали); пусть х -- фактическая общая длина боксов и клея,
и пусть y,z — общее число параметров клея для растяжения и сжатия. Плохость
в этой ситуации будет такой:
бесконечная, если х > w - z + €, где € — малый допуск (tolerance)
для компенсации ошибок округления в операциях
с плавающей точкой;
100((x-w)/z)~3, если w-z+€>x>w;
О, если х = w;
100((w-x)/3y)~3, если w > х;
плюс штрафы, накладываемые за нарушение границ в нежелательных местах.
Согласно этим формулам, растяжение на у имеет показатель плохости,
равный 100/27, или примерно 3.7; растяжение на 2у повышает это значение
примерно до 30; растяжение на Зу — до 100 единиц плохости, и столько же при
сжатии на максимальную величину, задаваемую параметром z. Я планирую установить
величину штрафа примерно в 80 единиц для такого разрыва абзаца или
последовательности выключных формул, когда на одной из страниц остается
единственная строка абзаца (формулы). Тогда, к примеру, пятистрочный абзац даст
80 единиц штрафа, если разрыв будет произведен после первой или четвертой его
строки, но штраф будет нулевым, если разрыв устанавливается после второй или
третьей строки. Эти формулы надо будет еще, конечно, "подрегулировать", чтобы
результат, даваемый ими, соответствовал моим эстетическим принципам,
определяющим плохую верстку. Пользователь будет иметь возможность задавать
свои собственные дополнительные штрафные точки для предотвращения нежелательных
разрывов между определенными строками (например, в программе MIX для
предотвращения разрыва перед командой, ссылающейся на *-1).
Не допускаются разрывы страницы перед линейкой и после нее.
Программа формирования страниц строит вертикальный список vlist так, как это
было описано выше, накапливая строки текста документа и вертикальный клей до тех
пор, пока суммарная высота ранее накопленных строк и клея и к вновь введенных
строк станет равной предписанной высоте страницы (\vsize), или же превысят это
значение. Затем данная программа производит разрыв абзаца, введенного последним,
после j-й строки, для 0<j<k, при этом значение j должно минимизировать величину
показателя плохости; если искомый минимум достигается более чем при одном
значении j, то берется наибольшее из них. После этого клей g(j+l) отбрасывается,
а оставшиеся k-j строк переносятся на следующую страницу. Они тут же проверяются
не вызовут ли переполнения новой страницы, и если да, то производится их разрыв
точно таким же образом, как эю было описано выше. Программа \output вызывается
независимо от того, сформирована уже целиком заполненная страница или нет.
Этот довольно простой процесс может прерываться процедурой \topinsert или
\boxinsert, вставляющей боксы. Вычисление данного вставляемого бокса
532
Компьютерная типография
осуществляется автономно, вне процессов формирования абзацев и страниц, после
чего предпринимается попытка разместить его на текущей собираемой странице.
Если удается сделать это с оценкой "отлично" или "хорошо", вставляемый бокс
оставляется на данной странице. Если не удается — вставляемый бокс переносится
на следующую страницу; эти действия будут выполняться вполне естественным
образом, объяснить который, однако, не очень просто. Эти действия выполняются
до тех пор, пока не будет удовлетворено требование о размещении вставляемого
бокса на той же самой странице, что и заданная строка (т.е. осуществляется
вставка бокса в горизонтальном режиме). Затем используется наименее плохое из
имеющихся допустимых решений.
Подстрочные примечания (сноски): на протяжении более чем 2000 страниц книги The
Art of Computer Programming я сделал лишь три подстрочных примечания. Мое личное
мнение -- использование сносок должно быть редким исключением, поэтому я не
предполагаю разрабатывать достаточно изощренный механизм формирования подстрочных
примечаний (в частности, разделение длинных сносок между несколькими страницами,
или маркировку первой сноски на данной странице звездочкой, а второй — крестиком
и т.п.). Тем не менее, сносками можно вполне удовлетворительно управлять с помощью
команды \botinsert, как определено здесь. Пользователь может получить
возможность формировать и более причудливые сноски, если только он не против
того, чтобы переписать несколько ТЕХ'овских программ.
Программа формирования абзацев производит сборку горизонтального списка hlist
способом, описанным выше. Она должна разделить этот список на строки шириной
\hsize для передачи их в программу формирования страниц. (Примечание: имеется
лишь единственная программа формирования страниц, несмотря на то, что ТЕХ большей
частью работает рекурсивно, так же, как и единственная программа формирования
абзацев. Однако в активном состоянии одновременно может быть произвольно много
программ \hjust, осуществляющих горизонтальное выравнивание до длины <length>,
это в значительной мере аналогично тому, что имеет место для программы формирования
абзацев, поскольку она также должна разбивать списки hlist ка строки текста
формируемого документа. Обсуждение механизма разрыва строк имеет отношение также
и к этим программам, но для удобства я буду писать об этом процессе так, как если
бы за него отвечала только программа формирования абзацев.)
Элементы списка hlist, с которыми работает программа формирования абзацев,
обычно представляют собой последовательности текстовых символов или фрагментов
математических формул, однако возможен также случай, когда они будут неделимыми
боксами, созданными ТЕХ'овскими высокоуровневыми операторами работы с боксами.
В моих шрифтах предусмотрено небольшое количество переменного клея между
отдельными текстовыми символами (между буквами а и Ъ, например, можно было
бы использовать клей, полученный как сумма "правого клея" для а и "левого
клея" для Ъ, как это указано в шрифтовых таблицах); более того, пробелы между
словами имеют более эластичный клей, как это уже объяснялось ранее. ТЕХ дает
двойной у-клей первому пробелу (однако не будет изменять х-клей), который
идет после точки или двоеточия, восклицательного или вопросительного
знака, если только перед этим пробелом не вклинятся буквы, цифры, запятые, точки
с запятой или боксы. Точка с запятой и запятая обрабатываются аналогичным способом,
только значения компоненты у клея для них устанавливаются равными 1.5 и 1.25
соответственно.
Основная задача, которую решает программа формирования абзацев, состоит в том,
чтобы определить, каким образом разделить длинный список hlist. И опять здесь
ТЕХ опирается на концепцию "плохости", обсуждавшуюся выше применительно к
программе формирования страниц, но здесь данная концепция используется в
несколько усовершенствованном виде за счет введения средства "просмотра вперед"
Глава 25. ТЕХ.ONE
533
(lookahead), с помощью которого ситуация в последующих строках абзаца может
оказывать влияние на разрывы строк в его предыдущих строках. На практике это
часто приводит к получению существенно более высокого качества выходного текста,
чем это могут обеспечить другие программы.
Перед тем как начать обсуждение средств просмотра вперед, надо определить все
места допустимых переносов слов. Каждая команда \hskip, для которой компоненты
х или у клея превышают ширину пробела для текущего шрифта, является допустимым
местом для разрыва строки (и для того, чтобы удалить горизонтальный клей) без
наложения штрафа. Смежные команды \hskips объединяются, в данном случае — путем
добавления трех компонент клея. Еще одно такое допустимое место для разрыва без
штрафа — после явного знака переноса слова или тире. (Некоторые команды \hskip,
используемые для уменьшения пробела (backspacing), имеют отрицательное значение х;
они, конечно, недопустимы для организации разрыва строки.) Программа формирования
математических формул, обрабатывающая последовательность литер, заключенную
внутри пары символов $...$, разрешает разрывы строк сразу после знаков бинарных
операторов и отношений на верхнем уровне; для знаков отношений типа =, <, =
и т.п. устанавливается совсем небольшой штраф, например, 10; для операторов типа
+ ,-,x,/,mod этот штраф будет несколько больше, причем для - и mod он будет
больше, чем для остальных из этого перечня (например, 30, 70, 30, 40, 80
соответственно). Верхние и нижние индексы, аргументы функций и тому подобные
элементы должны присоединяться к своим боксам неразрывно.
Имеется четыре вида символов типа "discretionary", используемых для того, чтобы
обеспечить или запретить разрывы. Первый из них — это команда \penalty <number>,
которая указывает, что разрыв строки будет допустимым, если не будет превышено
установленное значение штрафа. Три других вида этих символов включают:
\- данное слово можно перенести в этом месте (штраф 30 единиц);
\+ перенос в этом месте не выполнять;
\* в этом месте можно выполнить перенос (штраф 30 единиц), но
вместо знака переноса вставить знак умножения.
Последний из показанных выше трех вариантов может понадобиться для длинных
произведений наподобие $(n+l)\*(n+2)\*(n+3)\*(n+4)$.
Теперь я расскажу о подходе, принятом в ТЕХ'е для выполнения автоматической
расстановки переносов. Но перед этим представим на минуту, что все подходящие
места для разбиения строк уже известны; каким образом тогда сделать так, чтобы
расстановка переносов была наилучшей с точки зрения абзаца в целом? Я думаю, что
наиболее приемлемым определением понятия "наилучший" здесь будет такое, при
котором минимизируется сумма квадратов плохостей всех выполненных индивидуальных
разбиений. Это должно привести к минимизации максимальной плохости, а также к
аналогичному поведению плохостей порядка второго, третьего и т.д. Как и до сих
пор, понятие плохости базируется здесь на количественной мере растяжения или
сжатия строки, плюс штрафные "очки".
Чтобы найти наилучшие точки разбиения по этому критерию, нам не надо решать задачу
экспоненциальной сложности. Для нахождения абсолютно наилучшего способа разбиения
за время 0(п~2), где п -- число разрешенных точек разбиения строки, можно
использовать алгоритм динамического программирования. А именно, пусть f(m) --
минимум суммы квадратов плохостей для абзаца вплоть до точки разбиения т, тогда
f(m) — минимальная при всех k<m при f(к) плюс квадрат плохости разбиения строк
текста из диапазона (k,m].
Для этого квадратичного алгоритма можно построить удовлетворительную
аппроксимацию, близкую к линейной. Пусть даны три лучшие точки разбиения для
к-й строки абзаца. Используем их для нахождения трех лучших точек разбиения для
534
Компьютерная типография
(к+1)-й строки. После того как достигнут конец абзаца, или же если абзац
настолько длинный, что не хватает объема буфера для его размещения (например,
если он будет длиной более 15 строк), очистим буферные области памяти с помощью
операции backtracking посредством вычисления f(m), чтобы найти лучшую из известных
последовательностей разбиения. В режиме \ragged (выравнивание по правому краю
выключено) строки не растягивают и не сжимают, чтобы подогнать их под размер
\hsize, но в режиме \justified (выравнивание по правому краю включено) эти
операции проводиться будут.
Встроенные переносы.
Помимо использования разрешенных разбиений строк, ТЕХ предпринимает также попытки
переноса слов. Он будет проделывать это только с последовательностями, состоящими
из букв в нижнем регистре (строчных букв), за ними может следовать (и им может
предшествовать) символ, отличный от буквы, цифры, знака - или символ типа
discretionary. Заметим что, например, составные слова с дефисом не будут
разрываться. Если обнаружено разбиение, допустимое с точки зрения переноса
слова, будет назначен штраф примерно в 30 единиц плохости, однако такой вариант
может оказаться более предпочтительным, чем без использования переноса вообще.
В рассматриваемом случае будут добавлены еще 20 единиц плохости, если переносимое
слово или формула находятся в последней строке абзаца (точнее, в строке, за которой
остается меньше, чем 0.5(\hsize) строк абзаца).
Нет способа найти все возможные варианты переносов. Насколько трудна эта задача,
можно увидеть на примере слова "record", для которого предполагается, что оно
будет разбито как "rec-ord", если оно является существительным, но "re-cord" —
если оно будет глаголом. В качестве еще одного примера рассмотрим само слово
"hyphenation", которое скорее будет исключением:
hy-phen-a-tion vs. co-or-di-na-tion
Почему в одном из этих двух случаев буква п идет вместе с буквой а, а во
втором -- нет? Если начать с буквы "а" в словаре и попытаться найти четкие
правила переноса слов, не опираясь при этом на слишком большой объем знаний,
получим такие пары слов, как a-part vs. ap-er-ture, aph-o-rism vs. a-pha-sia,
и т.д. После всех этих примеров становится ясно, что едва ли нас устроит
программа переносов, точная, но громоздкая и медленная в работе, занимающая
много памяти и процессорного времени. Лучше вместо этого располагать набором
правил переноса, которые были бы:
a) простыми;
b) почти всегда безопасными;
c) достаточно мощными для того, чтобы найти, к примеру, порядка 80'/,
переносов из тех, что есть в имеющемся издании книги The Art
of Computer Programming.
Анализируя условия, предъявляемые пунктом (с), я обнаружил, что имеют место
примерно 2 слова с переносами в них на страницу указанных книг. При этом
оказалось, что подготовленные правила переноса лишь в очень редких случаях
приводят к действительно плохому разрыву. Время, которое необходимо затратить,
чтобы указать способ обработки обнаруженных исключений из правил (т.е. слов, не
подчиняющихся имеющимся правилам), совершенно несущественно в сопоставлении
с общим временем, затрачиваемым на чтение гранок.
(В этом месте файла ТЕХ. ONE было пять страниц текста, посвященного
правилам расстановки переносов для текстов на английском языке. Эти страницы
опущены, поскольку не представляют особого интереса и, кроме того, могут быть
найдены в руководстве пользователя по ТЁХ'у издания 1979 г. Впоследствии Фрэнк
Глава 25. ТЕХ.ONE
535
Лианг построил существенно более эффективную процедуру решения данной задачи,
нашедшую применение и в других языках помимо английского.)
Чтобы завершить этот меморандум, следовало бы объяснить, как ТЕХ обращается
с математическими формулами. Сейчас я могу дать по крайней мере набросок
этого материала.
Основные операторы, которые надо обсудить, это I, t, \over, \groupxy и \sqrt;
остальные с незначительными изменениями сводятся к перечисленным (например,
команды \int и \surn преобразуются в нечто подобное командам i и t, команда
\atop представляет собой вариант команды \over без линейки, команда \imderline
подобна команде \group, а команда \vinc (формирование горизонтальной черты
над формулой) напоминает команду \sqrt). Для каждой из математических
формул вначале строится дерево синтаксического анализа; фактически формула
представляет собой модифицированный горизонтальный список hlist, который я буду
называть далее списком tlist (от tree-list, т.е. древовидный список). Список
tlist представляет собой список деревьев, возможно разделенных горизонтальным
клеем, а дерево определяется как объект в одной из следующих форм:
некоторый бокс (если это не символьный бокс, то он был построен при выключенном
математическом режиме);
узел \sub с деревом в качестве левого потомка и списком tlist в качестве
правого потомка;
узел \sup с деревом в качестве левого потомка и списком tlist в качестве
правого потомка;
узел \subsup с деревом в качестве левого потомка и списком tlist в качестве
среднего и правого потомков;
узел \over со списком tlist в качестве левого и правого потомков;
узел \sqrt со списком tlist в качестве единственного потомка;
узел \group с символами квадратных скобок в качестве левого и
среднего потомков, списком tlist в качестве правого потомка;
Наилучшие результаты будут получены, если использовать семейство из трех шрифтов
изменяющихся размеров. Определение
\fntfam <char><char><char>
задает такое семейство, упорядоченное по убыванию размера шрифта. Например, ТЕХ
первоначально настроен на работу со следующим набором шрифтовых операций:
\fntfam
\deffnt a cmlO \deffnt g cmilO
\deffnt Ъ cm9 \deffnt h cmi9
\deffnt с cm8 \deffnt i cmi8
\deffnt d cm7 \deffnt j cmi7
\deffnt e cm6 \deffnt k cmi6
\deffnt f cm5 \deffnt 1 cmi5
i adf \fntfam bef \fntfam gjl \fntfam hkl
\deffnt u cmathlO
\deffnt v cmath9
\deffnt ¥ cmath8
\deffnt x cmath7
\deffnt у cmath6
\deffnt z cmath5
\fntfam uxz \fntfam vyz
\mathrm a \mathit g \mathsy u (в тексте)
\mathrm Ъ \mathit h \mathsy v (в упражнениях)
Это шрифты семейств "Computer Modern" и "Computer Modern Italic" размера
от 10 pt до 5 pt; шрифт размера 8 pt фактически в формулах не используется,
только в нижней части титульных страниц и в указателе.
Если текущий шрифт появляется как первый (самый большой) в некотором объявленном
семействе шрифтов, то символы, используемые в математических формулах, будут
скорректированы так, чтобы использовать подходящий для каждого конкретного случая
шрифт из данного семейства; если же имеется только единственный шрифт, то он
будет трактоваться как "семейство" из трех идентичных шрифтов (т.е. одни и те же
размеры будут использоваться в нижних индексах и других элементах формул).
536
Компьютерная типография
После того как выполнен синтаксический разбор математической формулы и
представление ее в виде списка tlist, ТЕХ идет по этому списку сверху вниз,
присваивая каждому из индивидуальных деревьев пометку режима его обработки:
А режим выключных формул
В текстовый режим
С текстовый режим с уменьшенными верхними индексами
D режим индекса
Е режим индекса у индекса
При этом в режимах ABC будет использоваться размер первого шрифта из семейства,
в то время как в режимах D и Е — размеры второго и третьего шрифтов
соответственно. В следующей ниже таблице показано, как ТЕХ определяет режимы для
потомков корневого узла дерева в зависимости от того, в каком режиме находится
корневой узел (father):
father
А
В "
С
D
Е
\sub
AD
BD
CD
DE
ЕЕ
\sup
AD
BD
CD
DE
ЕЕ
\subsup
ADD
BDD
CDD
DEE
EEE
\over
ВС
DD
DD
ЕЕ
ЕЕ
\sqrt
С
С
С
D
Е
\gr<
А
В
С
D
Е
Большие знаки суммы, интеграла и т.д. используются только в режиме А.
После того как завершено приписывание режимов деревьям, ТЕХ делает по дереву
tlist проход снизу вверх, преобразуя все деревья в боксы путем добавления клея
везде, кроме списка tlist самого верхнего уровня, который становится
горизонтальным списком hlist (передаваемым в программу формирования абзацев или
куда-либо еще). Теперь, если вы хотите понять, почему ТЕХ делает сначала проход
сверху вниз, а затем снизу вверх, заметьте, что, например, для числителя в дроби
\over поначалу нельзя сказать, что это именно числитель; рассмотрим конструкцию
"1 \over 1", где для "1" предполагается, что этому элементу приписан режим D.
Более того, узлы \subsup могут порождаться из записи
...I...T... или ...T...I...
поскольку я обнаружил, что некоторые наборщики ставят первыми нижние индексы,
а другие наборщики -- верхние индексы. В данном случае, когда ТЕХ выполняет
синтаксический разбор формулы, операции I и t имеют наивысшее старшинство, затем
\sqrt, затем \over;
х I у I z и xtytz
трактуется как
х 1{у 1 z} и х t{y t z},
тогда конструкции типа
х 1 у t z 1 i
будут недопустимыми.
Первый из шрифтов семейства должен обладать таблицами, которые сообщают ТЕХ'у,
насколько надо поднять линию шрифта для размещения верхнего индекса, насколько
опустить ее для размещения нижнего индекса, позиции различных линий шрифта
в конструкции \over. Все эти данные должны формулироваться как функция от режима
и узла. Например, в шрифтах, которые я сейчас разрабатываю, верхний индекс,
набираемый шрифтом кегля 7 pt для бокса размера 10 pt без нижнего индекса,
будет иметь линию шрифта на высоте 11/3 pt в режиме В и 26/9 pt в режиме С;
нижний индекс для такого же бокса без верхнего индекса будет иметь линию
шрифта на глубине 3/2 pt как в режиме В, так и в режиме С; когда же у бокса
имеются оба индекса, нижний и верхний, нижний индекс будет иметь линию шрифта
на глубине 11/4 pt, а верхний индекс — на высоте 11/3 pt или 26/9 pt (или больше,
если это окажется необходимым для размещения над сложным нижним индексом).
Нижние и верхние индексы для более сложных боксов (например, для групп)
Глава 25. ТЕХ.ONE
537
позиционируются относительно нижней и верхней границы рассматриваемого бокса,
соответственно.
Выключные формулы никогда не разбиваются ТЕХ'ом на отдельные строки;
предполагается, что пользователь сам подберет место для разрыва формулы так,
чтобы она смотрелась наиболее приемлемым образом. Поскольку ТЕХ умеет работать
с отрицательными компонентами клея, вполне возможно ужать длинноватые формулы
так, чтобы втиснуть их в строку. Если с помощью команд \halign или \eqalign
формируется набор из нескольких выключных формул, их надо отделять друг от друга
с помощью команды \сг.
(конец файла ТЕХ. ONE)
И с тех пор жили все они счастливо...
Примечания переводчика
1. Перечень соответствий между номерами строк в примере на ее. 510-513 и
отвечающими им фрагментами книги АСР 2 и ее перевода см. в примечании 1 переводчика
на с. 502.)
2. Примечание к с. 520. См. примечание 2 переводчика на с. 503.
3. Перевод дневниковых записей.
30 июня:
В среду до поздней ночи в течении восьми часов опять пытался закончить букву «s».
Самочувствие неважное, не надо больше работать по такому дурацкому графику.
1 июля:
После 4 часов вычислений добился, наконец, успеха с «ess» (в 4:30 утра).
Почувствовал себя лучше. Сделал прививки от тифа и холеры для поездки в Китай.
2 июля:
Вычищал шрифтовую программу, добавил знаки препинания, после чего отложил ее
пока в сторону. Спал и спал.
3 июля:
Читал руководства по системам PUB и III.
4 июля:
К Видерхольдам на прощальный ужин с Виртом. Потом смотрел фейерверк у
особняка Дрейпера. День такого необходимого отдыха!
5 июля:
Спал допоздна, потом размышлял о структурах данных для ТЕХ'а.
6 июля:
Сформирован способ обработки формул. Прием в особняке Вридена, встретил
интересных людей.
7 июля:
Сделал много по спецификациям ТЕХ'овских структур данных. Переделал язык и
на 3/4 переписал черновик MS.
538
Компьютерная типография
8 июля:
Ходили с Джил за покупками. Работал над отчетом о ТЕХ'е.
9 июля:
Закончил писать ТЕХ.ONE, ходил в лабораторию AI, чтобы отпечатать первые 8
страниц.
10 июля:
Джон выступал в команде лучших игроков лиги юниоров, забил два гола. К двум
часам ночи завершил набор файла ТЕХ.ONE.
11 июля:
Корреспонденция за две недели — не так уж и плохо, справился за два-три часа.
Начал писать программу преобразования документов из белфастского формата в
формат, близкий к ТЕХ'овскому.
12 июля:
Долгое совещание с Майком и Фрэнком, обсуждали планы реализации ТЕХ'а.
Редактировал черновик ТЕХ.ONE, вносил различные усовершенствования в язык.
ТЁХ'овские инкунабулы
[Первоначально опубликовано в TUGboat 5 (1984), 4-11.]
Меня постоянно спрашивают о списке «первых» книг1, набранных с помощью
ТЁХ'а. Библиофилы, наверное, были бы довольны, если бы им была
предоставлена возможность проследить раннюю историю данного вида книгопечатания.
Вот почему я решил попытаться составить список таких публикаций,
известных мне, пока еще не изгладилась память об этих волнующих событиях.
Предлагаемый ниже перечень ограничивается только действительно вышедшими в
свет (опубликованными) работами, хотя среди моих файлов содержится также
еще и несколько десятков концертных и церковных программ,
информационных бюллетеней и тому подобных вещей, которые мы с женой готовили, даже
еще когда не было полноценного рабочего варианта Т^Х'а.
Первое издание руководства по ТеХ'у является сейчас уже раритетом,
хотя, как я полагаю, и было отпечатано несколько сотен его экземпляров. Оно
называлось «Тау Эпсилон Хи, система для подготовки технических текстов» и
было выпущено как технический отчет «Таи Epsilon Chi, a system for technical
text», Stanford Computer Science Report STAN-CS-78-675 = Artificial Intelligence
Laboratory Memo AIM-317 (September 1978), 198 pp. В июне 1979 г.
Американским математическим обществом AMS было выпущено исправленное издание
этого руководства. Моя жена Джил разработала для него оформление
обложки; было продано порядка 1000 экземпляров данной книги. Если у вас
имеется достаточно «чистый» экземпляр этого издания, то на его обложке можно
разглядеть легкий рисунок ТЁХтуры, очень похожей на ту, что приведена в
упр. 21.8 книги The T^Kbook.
Значительное число пользователей знакомилось с возможностями
экспериментальной версии (прототипа) TfeX'a, используя третье издание
вышеупомянутого руководства, которое было выпущено в качестве части 2 книги « Т^С
and METRFONT», подготовленной совместно Американским математическим
обществом и издательством Digital Press в конце 1979 г. Тираж этой книги
составил около 15000 экземпляров.
Печать всех этих трех изданий была выполнена с помощью
экспериментального некоммерческого оборудования с невысокой разрешающей способно-
1 Инкунабулы — первопечатные книги, т. е. книги, относящиеся к начальной поре
книгопечатания, до 1501 г.— Прим. перев.
540
*
,•*•■
Компьютерная типография
—«fc'r
LENA BERNICE
*
Her Christmas in Wood County, 1895
Lena Bernice was our grandmother.
She told us about her first Christmas
tree. She told us many things while
the snow fell.
Elizabeth Ann and Jill
Christmas 1978
Рис. 1. Титульный лист первой ГЩХ'овской книги
стью. При подготовке первого издания использовался графический принтер
Xerox Graphics Printer (XGP) фирмы Xerox, подаренный Лаборатории
искусственного интеллекта Станфордского университета; второе издание печаталось
на уникальном принтере «Colorado» на фирме Xerox Electro-Optical Systems
в Пасадене, шт.Калифорния; наконец, для третьего издания был
использован принтер «Penguin» Исследовательской группы фирмы Xerox по
перспективным системам в Пало Альто (Advanced Systems Development Group). Эти
устройства имели переменную разрешающую способность, установленную
равной 200 пикселей на дюйм у принтера XGP и 384 пикселей на дюйм у остальных
двух принтеров. Техническую поддержку печати второго и третьего изданий
осуществляли Дейл Грин и Лео Гуиба.
Руководство по METRFONT'y имеет сходную историю его публикации.
Первоначально оно было распечатано на принтере XGP под названием «МЕТА-
Глава 26. ТЁХ'овские инкунабулы
541
•*#
#
Elizabeth Ann wrote the
story for this book, and Jill
designed the pages and drew
the pictures. The book was
typeset by Don Knuth using
the T^JC system, and printed
by Homer Weathers at THE
RAINSHINE PRESS.
*
28
Рис. 2. Выходные данные в конце первой ТЁХ'овской книги
FONT, a system for alphabet design», Stanford Computer Science Report STAN-
CS-79-762 = Artificial Intelligence Laboratory Memo AIM-332 (September 1979),
105 pp.); затем данное руководство было перепечатано с небольшими
изменениями на принтере Penguin как часть упоминавшейся выше книги,
подготовленной издательством Digital Press.
Конечно, руководства пользователей вряд ли можно считать
существенными достижениями в области книгопечатания. По моему мнению первой
настоящей книгой, отпечатанной с помощью Т^Х'а, можно считать 28-страничное
сувенирное издание, подготовленное для родственников моей жены к
Рождеству 1978 г. В этой книге было 18 оригинальных линогравюр с
впечатанным с помощью принтера XGP текстом, набранным с использованием
расширенного варианта опытного шрифта Computer Modern, размера 14pt.
Чтобы компенсировать ограниченную разрешающую способность принтера
542
Компьютерная типография
■*»*
»
I he snow began around three o'clock. Aunt Sally
had the little ones turn to the window and recite their
lesson.
"See the snow softly fall
over barns and churches tall."
Gussie was trying to teach Horace at home, so she
copied it down. She wanted Horace to be a member of
the state legislature, like Ben James who was her uncle
and the greatest orator in Wood County.
Lena Bernice thought about little Jimmy Reed in
the lesson book and how he wondered if the snow tasted
of sugar. She thought about the brave dog, Caesar, who
had protected his mistress during the blizzard in Old
Kentucky. She thought about the layer of ice on Rock
Pond.
Aunt Sally took up the Illustrated Geography and
showed The Entire Class a picture of the Alps and of
the dear Saint Bernards who saved many a folk from
certain death.
*
*
Рис. З. Начальные страницы первой ТеХ'овской книги
XGP, подготавливался увеличенный вариант требуемой страницы, которая
затем печаталась с уменьшением до 70% от первоначального размера;
эффективная разрешающая способность при этом составляла 286 пикселей на
дюйм. Титульный лист, первые страницы и страница с выходными
данными книги приведены здесь в качестве иллюстраций (уменьшение до 61%
от реального размера). Было отпечатано около 100 экземпляров книги, из
которых примерно 25 было продано, а остальные 75 использовались в
качестве подарков. Полное библиографическое описание данной книги
имеет вид: «Lena Bernice: Her Christmas in Wood County, 1895. By Elizabeth
Ann James, with illustrations by Jill Carter Knuth. Columbus, Ohio: Rainshine
Press, 1978».
Довольно необычным способом T^jX и METflFONT были использованы
Дэвидом Уоллом при подготовке диссертации (Ph. D. thesis, «Mechanisms for
Глава 26. ТЁХ'овские инкунабулы
543
broadcast and selective broadcast», Stanford Computer Science Report STAN-
CS-82-919 = Stanford Computer Systems Laboratory Technical Report No. 190
(June 1980), 120 pp.) Он рассматривал каждую иллюстрацию как некий
«символ» некоторого нового «начертания», каждый из этих больших символов был
нарисован с помощью METflFONT'a, после чего с помощью Т^Х'а
производилось наложение одних текстовых фрагментов на другие. Такой подход
позволил бы «победить» существовавшую программную реализацию METflFONT'a,
если бы рисунки выполнялись с достаточно высоким разрешением, однако он
не оправдал себя при использовании принтера XGP. (См. приводимые ниже
примеры, уменьшенные до 65% от их исходного размера.) Дэвид сказал: «Я
боялся, что открыл ящик Пандоры, ведь это не совсем то, для чего создавался
METRFONT».
544
Компьютерная типография
On the other hand, if w looks at its own
fragment state and finds a better edge than the one
v selected, then w must know about a vertex in
the fragment of v and w that v did not know was
present. Thus as soon as w merged its fragment
state with that of v it had a larger fragment state
than v. Its fragment state may even have been
larger than t/'s beforehand.
We observe that x precedes у on this path p.
For if x = у then this single vertex is on both
path q\ and path (72, which are represented by
edges without a common endpoint. This violates
Lemma 4. Similarly, if x follows у then у is on the
portion of path p from m to z and so by Lemma
2 it must also be on the portion of path q\ from
mtoi. Thus у is on both q\ and 92, which again
contradicts Lemma 4. So x precedes y.
Рис.4. Фрагменты диссертации Дэвида Уолла.
В течение всего описываемого периода у нас не было возможности
воспользоваться фотонаборным устройством с высокой разрешающей
способностью, но после нескольких месяцев работы в течение зимы и весны 1980 г.
Дэвид Фукс и я разработали интерфейс для фотонаборной машины Alpha-
type CRS. (Большая часть наших усилий была направлена на то, чтобы
произвести полный пересмотр микрокода, используемого в CRS, поскольку память
для хранения шрифтов, имеющаяся в данном устройстве, была весьма
ограниченной.) Из моих записей видно, что первые вполне приличные по качеству
текстовые страницы были отпечатаны 1 апреля 1980 г., а первой
отпечатанной страницей, предназначавшейся для публикации, была моя одностраничная
поэма, озаглавленная «Disappearances» (Исчезновения), помещенная на с. 264
книги The Mathematical Gardner', edited by David Klarner (Belmont, California:
Wadsworth, 1981). В мае я отправил более длинную статью «The Letter S» в
журнал The Mathematical Intelligencer 2 (1980), 114-122. Эта статья
воспроизводится в качестве гл. 13 настоящей книги.
Большую часть своего времени в апреле, мае, июне и июле 1980 г. я
потратил на подготовку окончательной редакции большой книги, представлявшей
собой ТЁХ'овский raison d'etre1 > той самой книги, которая и побудила меня
первоначально заняться ЧЩХ'ом и METRFONT'om. Текст этого тома был уже
набран в 1976 г. в издательстве The Universities Press, Belfast, с использованием
Monophoto-систем типа Cora и Maths, результаты, однако, были неудовлетво-
Endpoint Disagrees with v
Replacing {m, n} with p
Смысл существования, причина бытия (франц.). — Прим. перев.
Глава 26. ТЁХ'овские инкунабулы
545
рительными. Я получил бумажные перфоленты из Белфаста и конвертировал
их в псевдо-ТЁХ так, чтобы упростить повторный набор текста. (На самом
деле совсем не очевидно, сэкономил ли я какое-то время с помощью такого
маневра!) Все 700 страниц данной книги в конце концов встали на свои
места и оригинал-макет книги Seminumerical Algorithms, Volume 2 of The Art
of Computer Programming, second edition; Reading, Massachusetts: Addison—
Wesley, 1981, был завершен в 2 часа ночи, во вторник 29 июня 1980 г. 22
октября я переделал страницу iv (она содержит информацию Библиотеки Конгресса
США). Сигнальный экземпляр этой книги я держал в руках уже 4 января
1981 г. Представляется, что именно с фактом появления этой книги наиболее
уместно связывать дату первого использования ЧЩХ'а в реальном
книгоиздании. Мои издатели подготовили ограниченный тираж данной книги (256
экземпляров) в кожаном переплете ручной работы. Я думаю, что
обладателями этих специальных экземпляров стало совсем немного людей, поскольку у
компьютерных специалистов едва ли возникло желание заплатить за кожаный
переплет, тогда как ценители типографского искусства не питали особо
нежных чувств к компьютерам. В то же время, в течение 1981 г. было продано
около 11 000 экземпляров «Seminumerical Algorithms» в обычном переплете.
А тем временем и другие люди в Станфорде при подготовке книг к
публикации стали использовать Т^Х и Alphatype в нашей лаборатории. Первой из
них была закончена книга KAREL the ROBOT: A Gentle Introduction to the
Art of Programming by Richard E. Pattis; New York: Wiley, 1981,120 pp. Многие
иллюстрации в этой книге были набраны при участии Дэвида Уолла с
использованием специальных символов METflFONT'a. Следующей книгой такого рода
стала Practical Optimization by Philip E. Gill, Walter Murray, and Margaret H.
Wright; New York: Academic Press, 1981, 417 pp. Говоря об оптимизации,
следует упомянуть еще статью: Bengt Aspvall and Yossi Shiloach, «A polynomial
time algorithm for solving systems of linear inequalities with two variables per
inequality», SIAM Journal of Computing 9 (1980), 827-845, которая также была
отпечатана с помощью устройства Alphatype в нашей лаборатории в этом же
году.
Скотт Ким был первым, кто использовал наш Alphatype вместе с Т^Х'ом,
чтобы выполнить печать с помощью шрифтов, полученных помимо
METflFONT'a (речь идет о его книге Inversions: A Catalog of Calligraphic Cartwheels
by Scott Kim; Peterborough, New Hampshire: Byte Books, 1981, 124 pp.)
Впоследствии он подготовил с помощью METflFONT'a ряд специальных символов,
использованных при издании книги по программированию на Паскале (Arthur
Keller. A First Course in Computer Programming using PASCAL; New York:
McGraw-Hill, 1982, 319 pp.) Интересно отметить, что итальянский перевод
этой книги {Programmare in PASCAL; Bologna: Zanichelli, 1983, 303 pp.) был
одним из первых в Италии, для набора которого использовался Т^Х.
Итальянские переводчики (G. Canzii, A. Pilenga, A. Consolandi) работали независимо от
американских авторов и подготовили оригинал-макет книги в Милане с
помощью наборной машины Versatec —к сожалению, без символов, подготовленных
Скоттом.
546
Компьютерная типография
Терри Виноград был одним из первых пользователей TgX'a и,
соответственно, одним из первых стал жаловаться на ограничения, присущие его
первоначальному варианту. Например, именно по его просьбе от 28 ноября
1978 г. я добавил команду \xdef. Он начинал писать книгу, используя систему
PUB [Larry Tesler, «PUB, The Document Compiler», Stanford Artificial Intelligence
Project Operating Note 70 (March 1973), 84 pp.], затем все имеющиеся файлы
конвертировал в формат системы BRAVO [Butler W. Lampson, «Bravo Manual»,
in Alto User's Handbook, Xerox Palo Alto Research Center (1978), 32-62], после
чего опять преобразовал их, на этот раз в ТЁХ'овский формат. Виноград
разработал макрокоманды индексации для первого выпуска журнала TUGboat, a
его борьба с ранней версией TgX'a увенчалась в конце концов книгой Language
as a Cognitive Process, Volume 1: Syntax; Reading, Massachusetts: Addison—
Wesley, 1983, 654 pp. Он пользовался шрифтами семейства Computer Modern,
но вместо применявшихся мною в то время (ужасных) шрифтов без засечек
(sans-serifs) подставлял шрифт Optima.
Гио Видерхольд модифицировал файлы ACME, созданные им при
подготовке первого издания его книги по базам данных, так что второе ее издание
он смог подготовить уже с помощью Т^Х'а. Как он говорил, процесс
окончательного форматирования текста второго издания занял около шести месяцев
(включая печать пробного экземпляра, чтобы убедиться, что все разрывы
страниц находятся на положенных им местах). Том, получившийся в итоге,
поставил рекорд того времени по объему книги, когда-либо печатавшейся в нашей
лаборатории: Database Design, second edition; New York: McGraw-Hill, 1983,
767 pp.
Еще один мой коллега-преподаватель, Джеффри Ульман, преобразовал
имевшиеся у него £ro/f-файлы первого издания его книги в ТЁХ'овские
файлы, на основе которых было получено второе издание этой книги (Principles
of Database Systems, second edition, Rockville, Maryland: Computer Science
Press, 1982, 491 pp.). После этого он воспользовался ТЁХ'ом уже напрямую для
написания книги Computational Aspects of VLSI; Rockville, Maryland: Computer
Science Press, 1984, 505 pp. Питер, 13-летний сын Джеффа, помог ему в
создании с помощью METflFONT'a специальных шрифтов для набора шаблонов из
повторяющихся элементов, используемых при разработке СБИС.
Мой соавтор Дэниел Грин перевел в ТЁХ'овскую среду нашу книгу
Mathematics for the Analysis of Algorithms', Boston: Birkhauser, 1981, 107pp»f
Интересно сравнить первое издание со вторым (1982 г., 123 с), поскольку в течение
года, прошедшего между первым и вторым изданием, были существенно
откорректированы шрифты, использовавшиеся в наборе. [Третье и «окончательное»
издание,(1990 г., 132 с.) демонстрирует дальнейшее улучшение
полиграфического уровня издания].
Книги и статьи, упоминавшиеся выше, были все подготовлены к
изданию их авторами, как было принято на кафедре Computer Science. Но бы-
1 Имеется русский перевод второго издания: Грин Д.., Кнут Д. Математические методы
анализа алгоритмов. — М.: Мир, 1987, но тогда «русский» Т^Х еще только зарождался.—
Прим. ред.
Глава 26. ТЁХ'овские инкунабулы
547
ло и несколько случаев, когда работа организовывалась более традиционным
образом, при котором ТЕХ'овскую подготовку текста осуществляли люди,
привычные к клавиатуре, но не слишком знакомые с предметом, о котором шла
речь в подготавливаемом издании. Мне кажется, первыми из книг,
подготовленными в нашей лаборатории по этой технологии, были Handbook of
Artificial Intelligence, Volume 2, edited by Avron Barr and Edward A. Feigenbaum;
Los Altos, California: William Kaufman, 1982, 441 pp.; Handbook of Artificial
Intelligence, Volume 3, edited by Paul R. Cohen and Edward A. Feigenbaum; Los
Altos, California: William Kaufman, 1982, 652 pp.; Introduction to Arithmetic for
Digital Systems Designers by Shlomo Waser and Michael J. Flynn; New York:
Holt, Rinehart and Winston, 1982, 326 pp.; Introduction to Stochastic Integration
by Kai Lai Chung and Ruth J. Williams; Boston: Birkhauser, 1983, 204 pp.;
серия практических руководств по языку программирования Basic для
компьютеров различных типов: Hands-on Basic: For the IBM Personal Computer,
by Herbert Peckham, New York: McGraw-Hill, 1983, 320 pp.; Hands-on Basic:
For the Apple II, by Herbert Peckham with Wade Ellis, Jr., and Ed Lodi,
New York: McGraw-Hill, 1983, 332 pp.; Hands-on Basic: For the TRS-80 Color
Computer, by Herbert Peckham with Wade Ellis, Jr., and Ed Lodi, New York:
McGraw-Hill, 1983, 354 pp.; Hands-on Basic: For the Atari 400/800/1200XL,
by Herbert Peckham with Wade Ellis, Jr., and Ed Lodi, New York: McGraw-
Hill, 1983, 319 pp.; Probability in Social Science by Samuel Goldberg, Boston:
Birkhauser, 1983, 131 pp. Между прочим, набор последней из перечисленных
книг был выполнен моим сыном Джоном летом 1982 г., еще до того, как он
узнал хоть что-нибудь о компьютерах. Я помог ему с несколькими
конструкциями \halign, но в остальном он работал вполне самостоятельно. В это время он
был старшеклассником; я знал еще по крайней мере троих ребят из их школы,
которые также занимались набором книг в ТЁХ'е. [Introduction to Commutative
Algebra and Algebraic Geometry by Ernst Kunz (Boston: Birkhauser, 1985),
237 pp., набрано Ами и Майклом Вангами; Social Dynamics by Nancy Brandon
Tuma and Michael T. Hannan (Orlando, Florida: Academic Press, 1984), 578 pp.,
набрано Кэти Тума.]
Небезынтересно отметить, что первый том Handbook of Artificial
Intelligence, 1981, был реализован с помощью ранней версии шрифтов
Computer Modern на нашей наборной машине Alphatype, однако подготовка текста
осуществлялась не в ТЁХ'е, а с помощью пакета PUB. В частности, все переносы
слов в этой книге были расставлены вручную.
Сотрудники Лаборатории космического пространства, телекоммуникаций
и радионаук (Space, Telecommunications and Radioscience Laboratory) Стан-
фордского университета начали использовать Т^Х для набора статей, которые
они печатали на Alphatype и публиковали затем в журналах и в сборниках
трудов конференций. Я думаю, первыми из таких статей были следующие: S.B.
Mende, P.M. Banks, «Photographic observations of earth's airglow from space»;
R. Nobles, О. К. Garriott, and J. Hoffman, Geophysical Research Letters 10 (1983),
1108-1111; С Robert Clauer, Robert L. McPherron, and Craig Searls, «Solar
wind control of the low-latitude asymmetric magnetic disturbance field», Journal
of Geophysical Research 88 (1983), 2123-2130; Robert A. Helliwell, «VLF wave
548
Компьютерная типография
injections from the ground», in Active Experiments in Space (Paris: European Space
Agency, 1983), 3-9; P.M. Banks, P.R. Williamson, J. Raitt, S.D. Shawhan, and
G. Murphy, «Electron beam experiments aboard the space shuttle», ibid., 171-175.
Несколько десятков других статей к настоящему времени (1983 г.) находятся
в печати.
Тем студентам, кто был уже достаточно подготовлен, разрешалось
использовать наш Alphatype по их усмотрению, не ставя меня об этом в известность.
Например, помню, как был удивлен однажды вечером, увидев свои шрифты
Computer Modern в рекламе «Earth Shoes», в программе музыкальной комедии,
поставленной станфордскими студентами. Разумеется, наиболее
поразительной вещью, вышедшей из нашей лаборатории, а в дальнейшем и наиболее
значительной в финансовом отношении, была аппаратная часть первой рабочей
станции Sun (или, по крайней мере, некоей ключевой частью ее): Андреас фон
Бехтольсхайм «набрал текст» печатной платы для первого изделия фирмы
Sun Microsystems и вывел его на наш Alphatype в 1981 г., используя
специализированные шрифты, созданные с помощью METflFONT'a.
Программное обеспечение, которое мы разработали для обеспечения
интерфейса между Т^Х'ом и машиной Alphatype CRS, использовалось также еще в
трех местах: в Американском математическом обществе (Провиденс, Род Ай-
ленд), в Королевском технологическом институте (Стокгольм, Швеция) и на
фирме Bell Northern Research (Маунтин Вью, шт. Калифорния). Я
располагаю только отрывочной информацией о том, какие книги были подготовлены
с помощью ЧЩХ'а в этих и других местах. Тем не менее, я привожу список,
заведомо неполный, чтобы те, кто был причастен к соответствующим работам,
дополнили и уточнили его.
Первым примером применения TfejX'a и Alphatype в Американском
математическом обществе (AMS), имеющимся в моей коллекции, является статья
«1980 Wiener & Steele Prizes Awarded», Notices of the American Mathematical
Society 27 (1980), 528-533. С тех пор с помощью ТЩХ'а готовится все большая
доля материалов, появляющаяся в «Notices...». Объединенный список
членов обществ SIAM, AMS и МАА за 1981-82 гг. (SIAM-AMS-MAA Combined
Membership List for 1981-1982) представляет собой еще один из ранних
примеров использования lEX'a, так же как и Каталог публикаций AMS за 1981-82 гг.
(AMS Catalog of Publications for 1981-1982.) Американское математическое
общество впервые испытало математические способности ТЕХ'а, подготовив
черновой вариант предварительной редакции книги (Michael Spivak. The Joy
of ТЁК, 134 pp.1, распространявшийся среди участников конференции AMS в
Сан-Франциско в январе 1981 г. Имеется много случаев использования Т^К'а
в «Трудах AMS» (Proceedings [Volume 85 (1982), pp. 141-488, 567-595, 643-665,
673-674; Volume 86 (1982), pp. 12-14,19-86,103-125,133-142,148-150,153-183,
186-188, 253-274, 305-306, 321-327, 363-374, 391, 459-490, 511-524, 574-598,
609-624, 632-637, 641-648, 679-684]). В Memoirs of the American Mathematical
Society 33, number 247, September 1981, 54 pp. была опубликована диссерта-
1 Имеется русский перевод: Спивак М. Восхитительный ТЕХ. — М.: Мир, 1993. Это одно
из первых изданий на русском языке, подготовленных в Т^Х'е. — Прим. ред.
Глава 26. ТЁХ'овские инкунабулы
549
ция Дэвида Экка (David J. Eck. «Gauge-natural bundles and generalized gauge
theories»); этот выпуск «Memoirs... » содержит интересное предисловие
Ричарда Пале, из которого следует, что Дэвид имел удовольствие быть «подопытным
кроликом», впервые испытавшим при наборе своей диссертации ЛА/(5-ТЁХ.
До того как издательская группа AMS стала применять машину Alpha-
type, она подготовила ряд вещей, используя выход наборной машины Varian,
уменьшенный фотоспособом. Указатели к отдельным выпускам журнала
Mathematical Reviews готовились с помощью ТЁХ'а после ноября 1979 г.
(Volume 58, #5); объединенный список членства Combined Membership List
за 1980-81 гг. также был получен с помощью машины Varian.
На оборудовании AMS был подготовлен также ряд книг, написанных в
других местах. Среди них: Oregon Software's PASCAL-2: Version 2.0 for RSX-11
(1981), 186 pp.; Turtle Geometry by Harold Abelson and Andrea diSessa
(Cambridge, Massachusetts: M. I. T. Press, 1981), 497 pp.; and History of Ophthalmology
by George Gorin (Wilmington, Delaware: Publish or Perish, 1982), 646 pp.
В Bell Northern, как я думаю, TgK использовался большей частью для
подготовки внутрифирменных отчетов. Однако мне доводилось видеть несколько
прекрасных публикаций из Шведского Королевского технологического
института, в частности, 46-страничную монографию Non-linear Inverse Problems by
Gerd Eriksson, Report TR17A-NA-8209, 1983, —и мне хотелось бы знать
больше относительно опыта, полученного при использовании Т^Х'а в этой
организации.
Издательство Висконсинского университета (The University of Wisconsin
Press) прислало мне экземпляр их каталога на осень 1981 г. (1981 Fall Catalog),
который, по их словам, был подготовлен с помощью Т^Х'а. Я не знаю, правда,
помог ли TgX подготовить какую-либо из книг, перечисленных в этом каталоге.
Когда шрифты Computer Modern еще не применялись, сказать,
использовался или нет Т^Х при подготовке той или иной публикации, было весьма
непросто. Однако я точно знаю, что книга Guide to International Commerce
Law by Paul H. Vishny; Colorado Springs, Colorado: Shepard's/McGraw—
Hill, 1981, 782 pp., была целиком набрана с помощью "ЩХ'а и распечатана на
IBM 370/3081 с использованием фотонаборной машины APS 5.
Некоторые из книг, изданных в Станфорде, печатались напрямую с
помощью устройства Xerox Dover (с разрешающей способностью 384 точки на
дюйм). В частности, первоначальное издание в твердом переплете книги Joseph
Deken. The Electronic Cottage] New York: William Morrow, 1982, 334 pp., было
осуществлено именно таким способом, вследствие очень жестких сроков
публикации. Аналогично обстояло дело и с книгами Arithmetic and Geometry: Papers
Dedicated to I. R. Shafarevich on the Occasion of His Sixtieth Birthday, edited
by Michael Artin and John Tate (Boston: Birkhauser, 1983); Volume 1, 359 pp.,
Volume 2, 481 pp.)
Макс Дьяс выполнил работы по установке TfejX'a в Институте
прикладных математических исследований Автономного национального университета
в Мехико (Instituto de Investigaciones en Matematicas Aplicadas у en Sistemas
of the Universidad Nacional Autonoma de Mexico (IIMAS-UNAM)). Первой
книгой, подготовка которой в ТЁХ'е была целиком осуществлена в Мехико, была
550
Компьютерная типография
книга Nonlinear Phenomena, edited by Kurt Bernardo Wolf, Lecture Notes in
Physics 189, 1983, 464 pp. Основой этой работы, которая была получена с
использованием фотоуменьшения выхода устройства с невысокой разрешающей
способностью, были, разумеется, подготовленные Максом ТЁХ'овские макро
Facil [TUGboat 2, 2 (July 1981), A-l-A-91].
Я начал работу над ЧЩХ'ом вскоре после того, как увидел гранки
книги P. Winston Artificial Intelligence; Reading, Massachusetts: Addison—Wesley,
1977, 444 pp., которая была первой научно-технической книгой, набранной с
помощью фотонаборной машины с высокой разрешающей способностью.
Только недавно я узнал, что новое издание этой книги (Patrick Henry Winston,
Artificial Intelligence, second edition (Reading, Massachusetts: Addison—Wesley,
1984), 527 pp.) готовится с помощью ТЁХ'а, так что КРУГ замкнулся.
Журнал AI Magazine (официальный орган Американской ассоциации
искусственного интеллекта) набирается в нашей лаборатории с помощью ТЁХ'а
после второго номера из тома 3 (весна 1982 г.). Я ничего не знал об этом до
16 июня 1983 г., когда получил следующее довольно неожиданное письмо от
главного редактора Claudia С. Mazzetti: «Время подготовки нашего
журнала сократилось почти наполовину при использовании ТЁХ'а. Мы хотели бы
выразить нашу признательность за создание такой замечательной системы!»
Сейчас, к 1983 г. я никак не могу понять, почему некоторые думают, что
старая версия TfeX'a была простой в использовании, ведь я потратил два года
на устранение сотен недостатков в ней. (Все публикации, о которых
говорилось выше, были подготовлены с помощью старого «прото-ТЁХ'а»). Более
того, я до сих пор не удовлетворен полностью качеством шрифтов Computer
Modern, хотя версия «Almost Computer Modern» от июля 1983 г. уже
много лучше, чем шрифты, которые мы использовали в 1980 г. Я предполагаю
сделать дальнейшие усовершенствования в шрифтах в течение следующих
двух лет, когда будут завершены мои исследования по издательскому делу.
Моя цель — разработать новый METAFONT к 1984 г. и новые шрифты
Computer Modern к 1985 г. Тем временем, в 1983 г. мы получили новую
постоянную редакцию ТЁХ'а, и я завершаю этот список упоминанием трех первых
публикаций, подготовленных с помощью этого нового ТЁХ'а и нашего
нового фотонаборного устройства APS Micro-5: книга The T^Kbook (Reading,
Massachusetts: Addison—Wesley, 1983), 496 pp.} была первой из них, она
была отправлена издателю 12 октября. Книга Coordinated Computing: Tools and
Techniques for Distributed Software by Robert E. Filman and Daniel P. Friedman
(New York: McGraw-Hill, 1984), 390 pp., была второй, а моя статья «Literate
Programming» (15 pp.)—третьей. В этой статье, в которой обсуждается WEB,
вместе со шрифтами Computer Modern используются также шрифты Times
Roman и Univers. Она будет опубликована в томе 27 журнала The
Computer Journal.
Мне хочется думать, что использование ТЁХ'а не только позволяет
готовить отлично отформатированные книги. Как представляется, ТЕХ также
1 Имеется русский перевод: Кнут Д. Е. Все про Т^Х. — Протвино: RDTEX, 1993, —еще
одно из первых русскоязычных ТЁХ'овских изданий. — Прим. перев.
Глава 26. ГЩХ'овские инкунабулы
551
помогает писать книги, которые и по содержанию лучше тех, что готовятся
по-старинке. Часть этих возможностей обусловлена просто преимуществами
использования текстовых процессоров и компьютерного редактирования, что
существенно облегчает работу. Однако другая часть предоставляемых
возможностей вытекает из того факта, что авторы теперь могут выбирать систему
обозначений и форму представления материала такими, какие они считают
наиболее подходящими; теперь они свободны от тревог, связанных со
взаимодействием через несколько уровней с людьми, для которых обозначения,
примененные автором, незнакомы и непривычны. Мне кажется, что
значительное число книг, перечисленных выше, демонстрируют такого рода улучшения в
части изложения материалов научного характера. К примеру, мои собственные
книги существенно улучшились, так как я теперь в состоянии управлять
процессом набора. Я с большим уважением относился и отношусь к советам
профессиональных редакторов и оформителей книг, однако теперь в значительно
большей степени, чем раньше, я могу быть уверен в конечном результате,
поскольку осталось сравнительно немного источников возможных
недоразумений между участниками издательского процесса, порождающих различные
ошибки. Таков, на мой взгляд, некий «итог», основной практический результат
моих работ по ТЁ^'у-
Добавление
Дополнительная информация, относящаяся к ранним этапам использования
ТЕХ'а в Королевском технологическом институте (Royal Institute of Technology)
была опубликована уже после опубликования данной статьи в TUGboat: Hans
Riesel, «Report on experience with ТЁХ80», TUGboat 6 (1985), 76-79.
НЁШ1111
Пиктограммы для TJjjX'a и
METflFONT'a
[Первоначально опубликовано в TUGboat 14 (1993), 387-389.]
Пользователи компьютеров Macintosh уже давно привыкли видеть их файлы
отображаемыми в оглавлениях графически, в «пиктограммной» (iconic)
форме. Я получил недавно в свое распоряжение рабочую станцию с графической
многооконной оболочкой и системой управления файлами (диспетчером
файлов), которые предоставляют аналогичные возможности по визуализации моих
собственных файлов для системы UNIX. Естественно, мне захотелось, чтобы
ТЁХ'овский материал представляли отвечающие ему по духу пиктограммы.
Цель этих заметок — предоставить разработанные мною пиктограммы в
распоряжение других пользователей: может быть они захотят ими воспользоваться
и/или улучшить их.
Диспетчер файлов моей новой машины (Sun SPARCstation) имеет в своем
составе «средства классификации», которые анализируют имя файла и/или
его содержимое, чтобы решить, к какому виду принадлежит данный файл.
Каждому из видов файлов поставлено в соответствие растровое изображение
размера 32 х 32 точки (пикселя), называемое пиктограммой, совместно с
другим растровым изображением (также размера 32 х 32 пикселя), именуемым
маской для данной пиктограммы. В точке пиктограммы, где бит маски
принимает значение 1, диспетчер файлов отображает один или два пиксельных
цвета, называемых цветом переднего плана и цветом фона, в зависимости от
того, имеет ли бит пиктограммы в этой позиции значение 1 или 0. (Цвета
переднего плана и фона могут быть различными для каждого из типов файлов.)
В прочих позициях растрового изображения, где биты маски имеют значение
0, диспетчер файлов отображает его собственный цвет фона.
Например, каждому из файлов, имена которых заканчиваются на .tex или
.mf, на моей машине сейчас поставлены в соответствие следующие растровые
изображения
или
Глава 27. Пиктограммы для Т^Х'а и METflFONT'a
553
соответственно. Это совместимо с существующей схемой, согласно которой у
исходных файлов с текстами для программ на языке С имена будут с
расширением .с, а у заголовочных файлов для них —с расширением .h, что
отображается в виде таких пиктограмм:
Аналогично этому, файлам с расширением *. ltx соответствует пиктограмма
Все, что я должен был сделать —это указать классифицирующей программе,
как идентифицировать ТЁХ'овские и METAFONT'oBCKne файлы, а также
подготовить растровые изображения для пиктограмм и их масок. В каждом из
упомянутых выше случаев в качестве соответствующей маски, требуемой для
формирования пиктограммы, указывалась встроенная маска, используемая
диспетчером файлов, для которой установлено имя Generic_Doc_glyph_mask:
Более интересной задачей стала разработка масок и пиктограмм для
протокольных файлов, выдаваемых ТЁХ'ом и METAFONT'om. Проблема здесь
заключалась в том, что оба этих протокольных файла в моей системе имеют одно
и то же расширение *. log, так что просто по имени различить их нельзя. Я
решил, что любой файл, первые 12 байтов которого содержат ASCII-символы
554
Компьютерная типография
'ThisuisuTeX', должен рассматриваться как 1ЁХ'овский протокольный файл, а
файл, начинающийся со строки 'ThisuisuMETAFONT — как METflFONT'OBCKmi.
Одно удовольствие было подготовить соответствующие пиктограммы; я
сделал их на основе иллюстраций Дуэйна Бибби из руководства пользователя по
ТЁХ'у и METflFONT'y:
Маски, отвечающие этим пиктограммам для 1ЁХ'а и METflFONT'a,
соответственно имеют вид:
Основным выходным файлом IgK'a является, безусловно, аппаратно-
независимый (DeVice-Independent) DVI-файл, а для METflFONT'a —типовой
шрифт в виде GF-файла. Я решил, что пиктограммы для этих двух видов
файлов должны иметь такой вид:
Глава 27. Пиктограммы для IgX'a и METflFONT'a
555
соответственно, поскольку они аналогичны, в известной степени,
фотографическим «негативам», которые требуют «проявки» их другими программами.
Когда GF-файл упаковывается в РК-файл, его пиктограмма меняется на такую:
Аналогичным образом представляются файлы виртуальных шрифтов
Эти файлы вполне идентифицируются их именами (расширения *.dvi, *gf,
*pk, *. vf), но их можно также опознавать и по их содержимому. Первый байт
в них всегда имеет десятичное значение 247 (восьмеричное 367), тогда как
следующий байт принимает значение 2, 131, 89, 202 (восьмеричное 002, 203,
131, 312) для dvi-, gf-, pk-, or vf-файлов, соответственно.
Еще один важный выходной файл METflFONT'a —это метрический файл
шрифта, который можно узнать по расширению .tfm в его имени. Этим
файлам я поставил в соответствие такие пиктограмму и ее маску:
Все программирование я выполняю с помощью языка CWEB [1, 2, 3, 4],
поэтому у меня накопилось много файлов двух дополнительных видов. Исходный
556
Компьютерная типография
текст CWEB-программ хранится в файлах с расширением . w, CWEB-файлы
изменений — в файлах с расширением . ch; были сформированы соответствующие
пиктограммы
хорошо соотносящиеся с существующими соглашениями относительно файлов
исходного текста (.с) и заголовочных файлов (.h) для языка С.
Какие цвета переднего плана и фона должны быть присвоены этим
пиктограммам? Я этого точно не знаю. В то время, когда я делал эти пиктограммы,
в моем распоряжении был монохромный монитор, а не цветной, так что у
меня просто нет достаточного опыта, чтобы рекомендовать какой-либо выбор.
Прекрасно работает установка всех цветов переднего плана равными
основному черному (RGB-значения для него (0,0,0)), но я не хотел бы
устанавливать их все равными базовому белому (RGB-значения (255,255,255)). Пока
я временно, использую чисто белый цвет в качестве фонового для
«негативных» пиктограмм (dvi, gf, pk, vf), и не совсем белый (off-white) цвет (RGB
(230,230,230)) в качестве фонового для пиктограмм протокольных файлов.
Пиктограммы для ТЁХ'овских и METRFONT'obckhx файлов исходного
текста имеют фоновые RGB-значения (200,200,255), в цветном варианте
отвечающие светло-голубому; пиктограммы для шрифтовых метрических файлов
и для ГАТеХ'овских файлов с исходным текстом — фоновые RGB-значения
(255,200,200), т.е. соответствующие светло-красному при цветном
воспроизведении. Для METRFONT'obckhx файлов с исходным текстом мне придется,
наверное, выбрать один из оттенков оранжевого цвета, что будет
соответствовать обложке книги The METRFONTbook. На моем полутоновом монохромном
мониторе мне пришлось несколько осветлить фоновый цвет, присвоенный
системным программным обеспечением объектным файлам языка С, а также
файлам дампа ядра (*.о и core*); кроме того, на моем полутоновом мониторе
невозможно разглядеть детали системных пиктограмм
Глава 27. Пиктограммы для TEJX'a и METRFONT'a
557
По-видимому, другим пользователям придется подстроить цвета переднего
плана и фона, чтобы они гармонировали с общим стилем оформления их
«рабочего стола».
Первый опыт общения с персональной графической станцией я приобрел
в 1989 г., после чего сразу же решил сделать растровые пиктограммы размера
64x64 бита для IgX'a и METRFONT'a —для самих этих систем, не для файлов, с
которыми они работают. Однако мне всегда казалось более удобным запускать
Т^Х и METflFONT из командного процессора операционной системы UNIX, так
что эти ранние пиктограммы так никогда и не использовались. Вот они, все
еще ожидающие подходящего оправдания своему raison d'etre1:
Смысл существования (франц.). — Прим. перев.
558
Компьютерная типография
Все пиктограммы, показанные выше, за исключением уже
имеющихся в каталоге /usr/openwin/share/include/images дистрибутива системы
Open Windows фирмы Sun Microsystems, можно получить с анонимного ftp-
сервера из каталога ~ftp/pub/tex/icons в labrea.stanford.edu по
Интернету. Этот каталог содержит также файл с именем cetex.ascii,
который можно использовать для установки рассматриваемых пиктограмм в
Open Windows. Данная операция может быть выполнена, если исполнить
команду 'ce_db_merge system -from_ascii cetex.ascii'.
Литература
[1] CWEB, свободно распростаняем, доступен по анонимному ftp в директории
~ftp/pub/cweb at labrea.stanford.edu.
[2] Donald E. Knuth, Literate Programming, CSLI Lecture Notes 27 (Stanford,
California: Center for the Study of Language and Information, 1992).
Distributed by Cambridge University Press.
[3] Donald E. Knuth, The Stanford GraphBase: A Platform for Combinatorial
Computing (New York: ACM Press, 1993).
[4] Donald E. Knuth and Silvio Levy, The CWEB System of Structured
Documentation, Version 3.0 (Reading, Massachusetts: Addison—Wesley, 1993).
Обновленная версия доступна в [1].
Добавление
Пиктограммы, разработанные для Open Windows, усилиями ряда
добровольных помощников к настоящему времени адаптированы и для других
«оконных систем» (window systems). Их можно найти, например, в каталоге
support /icons/ архива CTAN.
Компьютеры
и книгоиздание
[Заметки, представленные 21 мая 1986 г. Музею компьютеров в Бостоне,
шт. Массачуссетс, как часть «выпускного вечера» в честь завершения ТЁХ'а.
Первоначально опубликовано в TUGboat 7 (1986), 95-98.]
Заглавие книг, послуживших поводом для сегодняшнего торжества, —
Computers & Typesetting (Компьютеры и книгоиздание). И поскольку наша встреча
происходит в Музее компьютеров, вполне уместно вспомнить, мне думается,
что компьютеры были непосредственно связаны с типографским набором с
самого их зарождения.
Всякий, кто начинает изучать историю компьютеров, очень скоро
обнаруживает, что многие ключевые идеи в этой области восходят к Англии XIX в.,
где Чарльз Беббидж разработал так называемую «разностную машину» и
занимался разработкой «аналитической машины». Машины Беббиджа так
никогда и не были построены, однако шведский писатель и издатель Георг
Шойц, прочитав об этих работах, настолько заинтересовался ими, что вместе
со своим сыном изготовил действующий образец разностной машины. Именно
этот прибор был первым настоящим вычислительным устройством,
построенным в Швеции. Здесь самое интересное, для меня по крайней мере, что
машина Шойца выдавала результат не в виде перфокарт или чего-нибудь еще
в этом роде, а изготавливала фактически печатные формы для стереотипии,
с которых можно было печатать книги!1
1 Беббидж все время собирался осуществить типографский набор результатов,
выдаваемых его «разностной машиной». С этой целью он экспериментировал с подвижным шрифтом,
стереотипией и медными штампами, но никогда не обнародовал результаты этих
экспериментов. Его «аналитическая машина», которая должна была управляться с помощью перфокарт,
должна была располагать, по-видимому, как средствами выдачи получаемых результатов на
печать, так и возможностью их перфорации на специальных картах. См. Charles Babbage,
Passages From the Life of a Philosopher (London: Longman, Green, Longman, Roberts, &; Green,
1864), гл. 5 и 8; перепечатано в Charles Babbage and His Calculating Engines, edited by Philip
and Emily Morrison (New York: Dover, 1961), 35-37, 61.
Значительно раньше И. Мюллер планировал добавить печатающее устройство к
изобретенному им механическому калькулятору: «Если калькулятор будет пользоваться спросом, я
сделаю машину для печати на бумаге с помощью чернил произвольных арифметических
прогрессий, последовательностей простых чисел или чисел с аргументами, отделенными линией;
эта машина будет останавливаться самостоятельно, когда лист бумаги отпечатан
полностью». См. его письмо от 9 сентября 1784 г. в Georg Christoph Lichtenberg Briefwechsel 2,
edited by Ulrich Joost and Albert Schone (Munich: С. Н. Beck, 1985), 905.
560
Компьютерная типография
И в самом деле, при помощи этой ранней шведской машины было
напечатано несколько книг. Они демонстрировались на Всемирной выставке в Париже
в 1856 г. Сувенирный альбом этой выставки содержал такой пассаж: «Эта
почти интеллектуальная машина не только может в течение секунд выполнить
вычисления, на которые обычно нужны часы, она печатает также
полученные результаты, соединяя достоинства четкой каллиграфии с преимуществами
безошибочных вычислений»} Я скопировал небольшую часть страницы из
самой первой книги, подготовленной с помощью компьютера — отпечатанной в
1857 г. — и можно увидеть воочию, как далеко мы ушли с тех пор:2
2405
2400
2407
2408
2100
38112
38130
38148
38166
38184
Насколько я знаю, таблицы в этой книге представляют собой первый
дошедший до наших дней образец вывода результатов из автоматического
вычислительного устройства?
1 Leon Brisse, Alburn de VExposition Universelle (Paris, 1857), 194. (Цитируется в Uta С.
Merzbach, Georg Scheutz and the First Printing Calculator [Washington: Smithsonian Institution
Press, 1977].)
2 George and Edward Scheutz, Specimens of Tables, Calculated, Sterecrnouldcd, and Printed
by Machinery (London: Longman, Brown, Green, Longmans, &: Roberts, 1857), 50 pp. Пример,
воспроизводимый здесь, взят из главной таблицы на с. 13-42, которая содержит логарифмы
целых чисел от 1 до 10000. В книгу включены также еще 14 таблиц, чтобы подтвердить
разносторонний характер возможностей такого рода машин, выдающих результаты расчетов
со скоростью 120 чисел в час. Публичная библиотека в Бостоне располагает двумя
экземплярами данной книги, посланной первоначально Эдвардом Шойцем Бенджамину Гоулду —
датировано 1 мая 1857 г., и в библиотеку Nathaniel Bowditch Library (датировано 11 мая).
3 Это не так. Позднее я обнаружил, что Георг Шойц опубликовал до того момента
короткую таблицу, которая была рассчитана и отпечатана стереотипическим способом на первой
машине, которую они с сыном сделали совместно. Страница 74 его книги Nytt och Enkelt
Satt att Losa Nummereqvationer afHogre och Lagre Grader (Stockholm: J. L. Brudins, 1849),
содержит значения полинома х3 —Зх2 +90037.Т для 1 < х < 25; начало этой таблицы выглядит
следующим образом:
1
2
3
4
5
90035
180070
270111
360164
450235
Самый первый пример автоматически отпечатанной таблицы был предложен вниманию
историков вычислительной техники Майклом Линдгреном, книга которого Glory and Failure
(Stockholm: Royal Institute of Technology Library, 1987) содержит очаровательные
подробности, касающиеся всех аспектов машин Шойца. В частности, на с. 150 книги Линдгрена
приведена фотография подлинной стереотипной пластины, которая использовалась для печати
Глава 28. Компьютеры и книгоиздание
561
Я бы хотел также сказать несколько слов об истории моей собственной
работы в области применения компьютеров для выполнения допечатных
операций издательского процесса. На прошлой неделе я просматривал свой дневник
за 1977 г. В записи за 5 мая (это был четверг) сказано: «Начата разработка
ТЕХ'а». Из моего дневника1 следует, что в четверг, пятницу и субботу я
интенсивно работал над проектом TfejX'a, потом для разрядки сходил в кино. В
записи за следующий четверг говорится: «Писал черновой вариант отчета по
ТЕХ'у, до 5 часов утра вгонял его в машину». В выходные на той неделе мы
с женой отправились в поездку в район Сакраменто по линии Станфордской
библиотечной ассоциации. Во время этой поездки нам удалось увидеть много
примеров прекрасной печати, именно этот опыт побудил меня просмотреть на
следующей неделе гору книг, посвященных разработке шрифтов. Запись в
моем дневнике за субботу, 21 мая 1977 г.— ровно за девять лет до сегодняшнего
дня — говорит, что к пяти часам утра я завершил «предварительную
разработку строчных и прописных латинских букв в прямом и курсивном начертаниях,
а также цифр 0-9». После нескольких часов сна я провел остаток субботы за
написанием компьютерных программ для растрового вычерчивания кривых.
О, как мало я знал тогда про то, насколько трудно будет завершить работу,
основные контуры которой я набросал в упомянутые две недели!
Почему я начал работать над Т^Х'ом в 1977 году? Вся эта история
началась намного раньше, связана она была с моими книгами The Art of
Computer Programming. Я подготовил второе издание-тома 2, но когда я получил
его гранки, они выглядели ужасающе — из-за того что за прошедшие со
времени выхода первого издания годы технология книгопечатания изменилась
радикально. Книги готовились теперь с помощью фотонабора, вместо
машин Monotype с горячей отливкой строк; и (увы!) они теперь набирались не
вручную, а с помощью компьютера. Результатом была совершенно
неудовлетворительная расстановка пробелов, особенно в математических формулах, а
шрифты, использовавшиеся для набора, по сравнению с тем, что было
раньше, выглядели просто кошмарно. Я был совершенно обескуражен этим и не
знал, что предпринять. Издательство Addison—Wesley предлагало перенабрать
все заново с использованием старого метода, на котором основана машина
Monotype. Я, однако, понимал, что старый подход долго не проживет, т. е. к
моменту, когда я должен буду завершить работу над томом 4, эта же проблема
возникнет опять, но у меня не было никакого желания писать книгу, которая
будет выглядеть так, как те самые гранки, о которых я уже упоминал.
И тут произошло одно замечательное событие. Я состоял в комиссии по
пересмотру набора экзаменационных вопросов и задач по профилю нашей
кафедры. Одно из дел, которые надо было выполнить в ходе работы комиссии,
демонстрационной таблицы в 1849 г.; головные нули в этой таблице удалялись (стирались)
вручную! (В 1857 г. уже было не так). Отметим, что индивидуальные цифры в распечатке
Шойца 1849 г. выровнены гораздо лучше, чем в распечатке 1857 г. Можно предположить,
что с короткой демонстрационной таблицей машина справлялась намного успешнее, чем с
длинной таблицей, требующей многочасовых расчетов.
1 См. гл. 24 настоящей книги.
562
Компьютерная типография
заключалось в оценке книги Пэта Уинстона по искусственному интеллекту.
Мы получили гранки этой книги и суть произошедшего события заключалась
в том, что эти гранки были подготовлены с помощью новой машины (в Южной
Калифорнии, на фирме Information Internation, Inc.) с высокой разрешающей
способностью. Похоже, что один из студентов Уинстона в М. I. Т. слетал в Лос-
Анджелес, имея при себе текст книги на магнитной ленте, и результатом были
как раз те самые гранки, которые попали к нам в руки. Я, конечно, имел
значительный опыт растровой печати, но только на устройствах с невысокой
разрешающей способностью. Поэтому мне казалось, что печать с помощью
растровых представлений была чем-то вроде забавной аппроксимации
«настоящего» типографского набора. Когда же я увидел гранки книги Уинстона,
то был поражен высоким качеством печати: «цифровая» (дискретная)
природа ее была совершенно неразличима. Фактически, цифровой набор выглядел
несравненно лучше, чем то, что я мог наблюдать в гранках моей собственной
книги.
Цифровой типографский набор означает работу с объектами, состоящими
из нулей и единиц, и вообще вся вычислительная наука может трактоваться
как наука об изучении такого рода объектов, элементами которых являются
только 0 и 1. И здесь я впервые понял, что как специалист в области
программирования и информатики вполне в состоянии помочь решить проблему
высококачественной печати, так сильно беспокоившую меня. Мне не надо
знать металлургию, оптику,.химию или еще что-нибудь такое же «страшное»;
все, что мне надо сделать, — сконструировать правильный объект из нулей
и единиц, после чего послать его на исполнение на цифровую печатающую
машину с высокой разрешающей способностью, наподобие той машины из
Южной Калифорнии. Тогда я смогу получать свои книги в таком виде, в
каком захочу. Другими словами, проблема высококачественной печати свелась к
проблеме манипулирования с нулями и единицами. Значит, для специалиста по
вычислительным наукам вроде меня это почти что долг — тщательно изучить
данную проблему.
В течение недели с того момента, как я увидел гранки книги Уинстона, я
решил бросить все остальное и работать над проблемой цифровой типографии.
К сожалению, профессор Уинстон не смог присутствовать здесь сегодня, но я
должен сказать: Пэт, я не знаю как тебя и благодарить за то, что ты написал
ту книгу!
Т^Х'овский исследовательский проект сразу же после его начала в 1977
году преследовал две основные цели. Первой из этих целей было качество:
мы хотели получить документы не просто высокого, но высшего качества.
Были времена, когда компьютеры имели дело только с числами; несколько лет
прошло, прежде чем к цифрам прибавились прописные (заглавные) буквы;
через какое-то время им стали доступны также и строчные (малые) буквы; затем
компьютеры освоили буквы переменной ширины (пропорциональные шрифты)
и к 1977 году уже существовал ряд систем, позволявших получать радующие
глаз документы. Моей целью было сделать завершающий шаг на пути к
формированию печатных документов наивысшего качества.
Глава 28. Компьютеры и книгоиздание
563
Оказалось, что достичь этого уровня качества в смысле форматирования
текста не так уж и сложно: сделать это удалось после двух лет работы. К
примеру, мы экспериментировали с журналом Time, пытаясь показать, что Time
мог бы выглядеть намного лучше, если бы набирался с помощью Т^Х'а. Но
оказалось также, что разработка подходящих семейств шрифтов
существенно сложнее, чем я ожидал, —прошло семь лет, прежде чем удалось получить
формы букв, удовлетворявшие меня.
Вторая главная цель проекта— «архивная»: она состояла в том, чтобы
создать комплекс систем, которые были бы в максимальной степени
независимыми от изменений в технологии книгопечатания. Когда придет следующее
поколение печатающих устройств, я хотел бы быть в состоянии удержать
достигнутый уровень качества, вместо того чтобы решать все проблемы заново»
Я хотел создать нечто такое, что будет пригодно к употреблению и через 100
лет. Другими словами, моя цель была так поставить дело, чтобы по
спецификациям книги, зафиксированным сейчас, наши потомки смогли бы отпечатать
точно такую же книгу и в 2086 году. Хотя я и ожидаю непрерывного
развития средств «препроцессорного характера» для TfejX'a и METAFONT'a, равно
как и средств «постпроцессорного характера» или драйверов устройств,
работающих с выходом этих систем, сами системы T^jX и METAFONT не должны
изменяться вообще — они должны быть островками стабильности между
теми и другими, которым можно с полным основанием доверять и строить на их
основе требуемые системы.
Сегодня я уже вполне могу похвастаться и сказать, что цели высшего
качества и технологической независимости, на мой взгляд, достигнуты, а тома А,
В, С, D, Е рассказывают всем о том, как это было сделано. Сегодня я вижу
эти книги впервые и счастлив, что все вы здесь собрались, чтобы отметить со
мной это событие. Эти книги не совсем обычны —они описывают самих себя,
рассказывают в точности о том, как они были набраны. Все форматирование
было выполнено системой ТЕХ, описанной в томах А и В. Далее, каждая буква
и каждый символ, появляющиеся в этих пяти томах, а также на обложках и
суперобложках, были подготовлены с помощью системы METAFONT, описанной
в томах С и D. Том Е повествует, как я, образно говоря, «расставил все точки
над i и нарисовал все палочки у t». Если бы экземпляры этих книг послать на
Марс, марсиане смогли бы использовать их, чтобы воссоздать объекты из
нулей и единиц, использовавшиеся при издании книги. В этих книгах содержится
все существенное, чему я научился за последние девять лет.
Все методы, описанные в этих книгах, относятся к классу
общедоступных (public domain), т. е. идеями, изложенными в них, может воспользоваться
любой, у кого возникнет такая потребность. Единственное, что я оставил за
собой — контроль за использованием имен TgX и METAFONT: программные
продукты, выходящие под любым из этих имен, обязаны отвечать
соответствующему стандарту. Я не буду возражать против любых изменений, если
только измененные системы не будут именоваться TgX или METAFONT.
Тома А и С представляют собой руководства пользователя
рассматриваемых систем. Я пытался так написать эти руководства, чтобы они отвечали
потребностям пользователя на всех ступенях его роста по мере освоения систем.
564
Компьютерная типография
И я очень тщательно отбирал цитаты из работ других авторов, содержащиеся
в конце каждой главы.
Тома В и D содержат полные листинги TgX'a и METflFONT'a. Эти
книги ориентированы, в основном, на профессиональных программистов, а не на
случайных пользователей, и я особенно доволен тем, что эти книги все-таки
появились, поскольку они представляют собой «побочный продукт» моих
исследований. Я и не помышлял о нем, когда девять лет назад начинал свою
работу. Приступив к написанию программ для ТЁХ'а и METflFONT'a, я
захотел разработать системы, которые отвечали бы современному уровню
развития компьютерного программирования. Попытки достичь эту цель привели
к созданию системы WEB, реализующей концепцию структурированного
документирования. Я думаю, что WEB может оказаться наиболее важным
достижением всего проекта — более важным в долгосрочной перспективе, чем ТЕХ и
METRFONT сами по себе, — поскольку WEB реализует новый подход к созданию
программного обеспечения, и я полагаю, что этот путь и в самом деле
лучше любого другого. Использование WEB дало возможность писать программы
настолько удобочитаемые, что есть уже довольно много людей, понимающих
намного лучше внутренние механизмы ТЁХ'а, чем других программных систем
сопоставимых размеров. Более того, мне кажется, что имеются все
основания утверждать — мобильность, удобство сопровождения, надежность TgX'a
и METflFONT'a обеспечены именно применением WEB-подхода, причем на
таком уровне, какого нет сейчас ни у какого другого программного комплекса.
Программы TgX'a и METflFONT'a работают и дают практически идентичные
результаты почти на всех больших компьютерах; есть уже тысячи
пользователей, и несмотря на столь массовое «тестирование», число обнаруживаемых
ошибок не превышает одной в два года. Я думаю, что по крайней мере еще-то
одна ошибка в ТЁХ'е есть, и намерен заплатить $20.48 первому из лиц,
обнаруживших ее. (В следующем году вознаграждение будет удвоено и составит
$40.96 и т. д.)1
Тома В и D содержат также и другие новшества, улучшающие ранее
созданную систему WEB. Каждый разворот книги снабжен мини-указателем,
размещенным на правой странице разворота. Наличие таких мини-указателей
позволяет упростить работу с перекрестными ссылками на другие страницы
книги, это экономит много времени, которое пришлось бы потратить в
противном случае, обращаясь к главному указателю в конце книги.
В последние годы я развиваю точку зрения на программы, как на
своеобразный вид литературы. Хотя Пулитцеровскую премию за наилучшую
программу года все еще не присуждают, я попытался написать тома В и D таким
образом, как если бы ее в самом деле уже давали программистам! Говоря
более серьезно, я намеревался построить эти книги так, чтобы они были полезны
специалистам в области информатики и программирования для
самостоятельного изучения, а также для использования их в качестве учебных пособий на
1 Один из слушателей спросил, сколько денег должно будет пойти на оплату ошибок,
найденных в программах и книгах? Основываясь на имеющемся опыте, Дон сказал, что эта
сумма будет лежать в пределах от 2 до 5 тыс. долл. Едва ли на самом деле эта величина
поддается прогнозированию — Прим. ред. английского издания.
Глава 28. Компьютеры и книгоиздание
565
семинарских (практических) занятиях в колледжах. В частности, в томе D
имеется хороший материал для групп сильных студентов.
Пятый том, том Е, является наиболее привлекательным и интересным из
всех томов рассматриваемой серии. Я надеюсь, что все вы просматривали эти
тома, так что понимаете, что я имею в виду. METflFONT —это компьютерный
язык, не очень похожий на все остальные языки этого класса. По этой причине
мне пришлось подготовить и дать большое число примеров, поясняющих, как
можно использовать METflFONT для получения высококачественных
шрифтов. В томе Е содержится свыше 500 примеров, поясняющих практически все
буквы, цифры, знаки препинания и другие символы, использовавшиеся при
печатании книг рассматриваемой серии.
Шрифты, порождаемые этими программами, получили общее
наименование «Computer Modern». Мой коллега Чарльз Бигелоу написал для тома Е
введение, рассказывающее о шрифтах вида Modern вообще. В этой книге
объясняется, как можно вносить изменения в указанные шрифты, которые были
разработаны с большим числом варьируемых параметров, так что
возможности менять их практически безграничны. В конце книги даны страницы,
показывающие, как выглядят образцы литер из 75 стандартных шрифтовых
раскладок семейства Computer Modern. Можно осуществить и еще многие
тысячи дополнительных изменений, если возникнет такая необходимость, причем
делается это очень просто.
Если даже вы не будете читать METAFONT'obckhx программ в этой книге
(томе Е), я думаю, что она все равно привлечет ваше внимание
иллюстрациями, показывающими разработанные шрифты} а также осознанием того, что
программа на странице, посвященной какой-либо из букв, и есть именно та, с
помощью которой данная буква была «нарисована». В какой-то степени это
дает чувство удовлетворения от завершенности и упорядоченности полученных
результатов.
Еще одно важное обстоятельство, о котором я хотел бы сказать в это
утро — ПОМОЩЬ. Мне очень и очень много помогали — буквально сотни людей,
добровольно участвовавших в этом проекте самыми разнообразными
способами—начиная с Ганса Вольфа из издательства Addison—Wesley, обучившего
меня тонкостям работы с системами Monotype, которые использовались при
подготовке первого издания книги The Art of Computer Programming в 60-х
гг. Мне особенно повезло в работе над шрифтами, где я имел весьма
ощутимую поддержку от таких признанных авторитетов в этой области, как Герман
Цапф и Мэтью Картер.
Важнейшую роль сыграло и то, что в реализации проекта принимали
участие такие выдающиеся научные сотрудники, как Дэвид Фукс, Джон Хобби и
ряд других. Далее, мой исследовательский проект, реализовывавшийся в Стан-
форде, имел солидную финансовую поддержку. Наиболее заметна она была от
Национального научного фонда США (National Science Foundation) и Фонда
1 Иллюстрации, о которых идет речь, формировались отдельно от текста примеров и
затем вставлялись в них. Для одновременного формирования растровых изображений и текста
возможностей вычислительных машин, существовавших в то время (1985 г.) было
недостаточно. — Прим. ред. английского издания.
566
Компьютерная типография
развития систем (System Development Foundation). С такой внушительной
поддержкой провалить проект было просто невозможно. Очень большую помощь
и поддержку я получил также от моей жены Джил. (В следующем месяце мы
празднуем 25-летие со дня нашей свадьбы!)
И еще одно заключительное замечание. Меня часто спрашивают, почему
в качестве символов для ЧЩХ'а и METflFONT'a выбраны, соответственно, лев и
львица. Когда художник Дуэйн Бибби в первый раз пришел ко мне с «львиной
идеей», я инстинктивно почувствовал, что идея эта правильная, хотя и не мог
понять точно, почему же именно, пока спустя месяц не оказался в Бостонской
публичной библиотеке. Я прошел мимо величественных каменных львов,
сидящих* у главной лестницы, и подумал: «Вот оно! ТЕХ и METRFONT попытаются
стать, подобно этим львам, «опорой» великой библиотеки? Я люблю книги,
и львы символизируют книги!» Не удивительно, что я счастлив от того, что
IgX и METRFONT уже приняли участие в подготовке нескольких десятков книг
великолепного качества. Мне чрезвычайно приятно ощущать, что этот
исследовательский проект, по-видимому, еще не раз будет способствовать созданию
в грядущем многих и многих прекрасных книг.
1 Можно также упомянуть львов, величественно стерегущих вход в Нью-Йоркскую
публичную библиотеку, которая на той же неделе отмечала свое 75-летие. — Прим. ред.
английского издания.
Новые версии
TfjX'aH METAFONT'a
[Первоначально опубликовано в TUGboat 10 (1989), 325-328; 11 (1990), 12.]
Более пяти лет я пребывал в убеждении, что стабильная система —это много
лучше, чем система, продолжающая развиваться. Однако во время
конференции TUG в Станфорде (в августе 1989 г.) я был поставлен перед
необходимостью внести в эти системы последнюю серию изменений, чтобы довести TgX и
METAFONT до степени завершенности, отвечающей заявленным для них фи^
лософии и целям.
Основной побудительной причиной, заставлявшей меня пойти на
доработки, был тот факт, что я неверно оценил сравнительные перспективы 7-битовых
и 8-битовых наборов символов. Я считал, что стандартный текстовый ввод
будет по-прежнему основан на использовании максимум 128 символов, поскольку
клавиатура с 256 различными выводами едва ли будет действительно
эффективной. Нечего и говорить, что я оказался неправ, особенно для разработок
в Европе и Азии. Как только я понял, что программы форматирования
текста с 7-битовым вводом быстро станут казаться архаичными, как до того уже
было с 6-битовыми, то пришел к выводу, что основательной переработки не
избежать.
Однако «7-битовая догма» распространилась повсюду, так что пришлось
взять существующие программы и заняться тщательной их переработкой в
8-битовом стиле. Это привело T^jX «под нож» на мой «операционный стол»
впервые после 1984 г., и я получил последнюю возможность включить в'него
несколько нововведений, которые пришли мне в голову, либо были подсказаны
пользователями после указанной даты.
Требуемые расширения должны были вводиться в ТЕХ и METflFONT таким
образом, чтобы сохранилась совместимость старой и новой версий снизу вверх
(с несколькими небольшими исключениями, о которых упоминается ниже).
Это значит, что свободный от ошибок входной файл для старых Т^Х'а и
METAFONT'a таковым же должен оставаться и для их новых вариантов, причем
получаемые результаты в обоих случаях должны быть идентичными.
В то же время любой, кто отважится использовать вновь введенные
расширения TgX'a и METAFONT'a, теряет возможность получить требуемые
результаты с помощью старых версий этих систем. По этой причине я настоя-
568
Компьютерная типография
тельно прошу ТЁХ'овское сообщество обновить все имеющиеся в употреблении
системы возможно быстрее. Надо выкорчевать и уничтожить их устаревшие
7-битовые версии, несмотря на то, что мы успели сделать с их помощью много
прекрасных вещей.
В этих заметках я собираюсь обсудить последовательно те изменения,
которые были внесены в TgX и METflFONT. После этого я опишу имеющиеся
исключения и совместимость версий систем снизу вверх.
Набор символов
Для записи входных файлов теперь разрешается использовать символы,
взятые из набора, в который могут входить до 256 различных символов. Коды
символов, которые ранее ограничивались диапазоном 0.. 127, теперь можно
брать из диапазона 0.. 255. Все символы равноправны; вы можете свободно
использовать в ТЁХ'е любой символ для любой цели, задавая для него
соответствующие значения \catcode, \mathcode, \lccode, \uccode, \sfcode и
\delcode. Plain TfeX инициализирует эти кодовые значения для символов с
кодами больше 127 точно таким же образом, как и коды для обыкновенных
знаков препинания наподобие '!'.
Введены новые соглашения для ввода произвольного 8-битового символа в
ТЕХ, когда нет возможности задать его с клавиатуры непосредственно. Четыре
последовательно идущих символа ~~а/?, где а и /3 —любые «шестнадцатерич-
ные цифры в нижнем регистре» (0, 1, 2, 3, 4, 5, б, 7, 8, 9, а, Ь, с, d, e, f),
интерпретируются Т^Х'ом при чтении входного файла так, как если бы они
были единым символом с кодом, задаваемым данными цифрами. Например,
~~80 дает десятичный код символа 128; весь символьный набор лежит в
диапазоне кодов от ~~00 до ~~f f. Согласно старым соглашениям, обсуждаемым в
приложении С, символ 0 кодируется как ~~@, символ 1 (control-А) — как ~~А,
..., а символ 127 —как ~~?. Эти соглашения по-прежнему остаются в силе
для первых 128 символьных кодов, за исключением того, что символ,
следующий за ~~, не должен быть шестнадцатеричной цифрой в нижнем регистре,
если сразу же идущий за ней символ опять представляет собой такого же рода
шестнадцатеричную цифру.
На METAFONT существование 8-битовых символов оказало меньшее
воздействие, чем на ТЁХ> поскольку METfl FONT'obckhc символьные классы
являются встроенными для каждого конкретного экземпляра системы.
Нормальный набор из 95 печатаемых символов, описанный на с. 51 книги The
METRFONTbook, может быть дополнен расширенными символами так, как это
описано на с. 282, однако делается это весьма редко, поскольку приводит к
возникновению ряда проблем с мобильностью текстов, использующих эти
символы. METflFONT'obckhu оператор char теперь переопределен, чтобы работать
с modulo 256 вместо modulo 128.
Глава 29. Новые версии TEJX'a и METRFONT'a
569
Таблицы переносов
В ТЁ^'е теперь допускается до 256 различных наборов правил переноса. Введен
новый целочисленный параметр \language, текущее значение которого
однозначно определяет используемую таблицу переносов. Если параметр \language
имеет значение отрицательное или большее 255, Т£Х действует так, как если
бы данный параметр был равным нулю.
Когда вы перечисляете с помощью ТЦХ'овской команды-примитива
\hyphenation исключения из правил переноса, то эти исключения относятся
только к текущему языку. Аналогично, примитив \patterns сообщает ТЁХ'у>
что надо запомнить новые образцы переносов для текущего языка; выполнение
этой операции допускается только в специальной программе «инициализации»,
именуемой INITEX. Исключения из правил переноса могут быть добавлены в
любой момент, однако новые образцы после того, как таблица переносов уже
сформирована, добавить нельзя.
Когда Т£Х читает текст абзаца, он автоматически вставляет «whatsit
nodes» (узлы типа «что такое») в горизонтальный список для данного
абзаца во всех случаях, когда для обрабатываемого символа значение параметра
\language будет не таким, как у его предшественника. Таким способом Т^Х
получает возможность знать, какие правила переноса следует применять для
каждого из слов данного абзаца, даже если вы часто выполняете переключения
между большим количеством различных языков.
Специальные узлы типа whatsit автоматически вставляются в
неограниченном горизонтальном режиме (т. е. когда вы задаете абзац, а не когда
задаете содержимое блока hbox). Вы можете вручную вставить специальный узел
whatsit в ограниченном горизонтальном режиме, если воспользуетесь командой
\set language (number). Это потребуется только в том случае, если вы
пытаетесь делать нечто замысловатое, вроде вывода из состава блока некоторых
элементов абзаца.
Управление уровнем фрагментации слов
при переносах
Т£Х имеет два новых параметра \lefthyphenmin и \righthyphenmin,
задающих длину наименьшего фрагмента слова в его начале (\lef thyphenmin) и
конце (\righthyphenmin), которые можно оставлять на предыдущей строке
или переносить на следующую строку, соответственно. Ранее значения этих
параметров \lef thyphenmin=2 и \righthyphenmin=3 были жестко встроены в
Т^Х и изменить их было нельзя. Теперь plain T^jX поддерживает указанные
старые значения, которые по-прежнему рекомендуются для большинства
публикаций в США, однако вы можете увеличить число переносов путем
уменьшения значений упомянутых выше параметров, точно так же как и сократить
число переносов увеличением значений этих параметров. Если сумма значений
параметров \lef thyphenmin и \righthyphenmin равна 63 или более, все
переносы подавляются. (Вы можете также отключить переносы, используя шрифт
570
Компьютерная типография
с \hyphenchar=-l или путем переключения с помощью команды \language
на язык, где не заданы образцы переносов или исключения из правил
переноса.)
Большее разнообразие лигатур
Теперь о наиболее значительном изменении. В предыдущих версиях TgX'a был
только один вид лигатур, для которого два символа, подобных Т и 'i',
преобразовывались в один символ наподобие 'fi', если указанные символы шли в
тексхе один за другим. Новый Т£Х понимает значительно более сложные
конструкции, с помощью которых, например, есть возможность изменить символ
'j', следующий за 'Г, на «бесточечный» символ 'j' и получить (при оставшемся
неизменным символе Т) символ 'fj'.
Как и прежде, лигатуры можно вводить только тогда, когда для них есть
соответствия в используемом шрифте. Перед тем как рассмотреть новые
средства METRFONT'a, позволяющие создавать улучшенные лигатуры, обратимся
к старым соглашениям. Программист, работающий с METRFONT'om, всегда
имеет возможность задать «программу лигатуры/кернинга» для любого
символа из создаваемого шрифта. Если, например, комбинация 'fi' появляется в
шрифтовой позиции 12, замена 'Г и 'Г на 'fi' задается включением следующего
оператора
"i" =: 12
в программе лигатуры/кернинга для "f"; это — существующее соглашение,
принятое в METRFONT'e.
Новые лигатуры позволяют сохранять один или оба исходных символа, а
также вставить новый символ. Вместо =: можно теперь написать | = :, если
требуется сохранить левый символ, или =: | —если правый, или | = : | —если
надо сохранить оба символа. Например, если бесточечная буква cj'
содержится в позиции 17 соответствующего шрифта, можно получить результат типа
описанного выше, поместив оператор
"j" |=: 17
в программу лигатуры/кернинга для символа 'f'.
Имеются еще четыре дополнительных оператора
1 = :>, =:1>, 1 = :1>, 1 = :1»,
где каждый из символов > сообщает TfeX'y, что надо сдвинуть его «фокус
внимания» на одну позицию вправо. Например, после замены f и j на f и
бесточечную j, как это было описано выше, Т£Х опять начинает исполнять программу
лигатуры/кернинга, вставляя, возможно, кернинг перед бесточечной буквой],
или, может быть, заменяя f совсем на другой символ и т. п. Но если вместо
Глава 29. Новые версии TEJX'a и METRFONT'a
571
этого будет выдана инструкция
"j" |=:> 17
ТЕХ немедленно перейдет к программе лигатуры/кернинга для символов,
следующих за символом 17 (бесточечная буква j); никаких изменений больше не
будет вноситься между f и j, даже если в шрифте и определено что-то
специфическое именно для этой комбинации.
Граничные лигатуры
Каждая строка из последовательно расположенных «символов», читаемых
ТЦХ'ом B горизонтальном режиме (после развертывания текста макрокоманд)
может быть названа «словом». В техническом плане в данном определении
«символом» мы считаем символ, для которого код категории \ cat code
соответствует буквам или «прочим символам», или командную последовательность,
которая устанавливается (с помощью команды \let) равной такого рода
символам, или командную последовательность, определяемую с помощью команды
\chardef, или конструкцию вида \ char (number). Новый TfeX теперь
полагает, что имеется некий невидимый «левый граничный символ» непосредственно
перед таким словом, а также «правый граничный символ» сразу после него.
Эти граничные символы будут как-то влиять на ситуацию, если разработчик
шрифта определил лигатуры и/или кернинг между ними и смежными с ними
буквами. Это значит, что теперь имеется возможность автоматически
воздействовать на начертание первого или последнего символа в слове.
Программа лигатуры/кернинга для левого граничного символа задается в
METAFONT'e с помощью специальной метки I I : в команде ligtable.
Лигатура или кернинг с правым граничным символом определяется присваиванием
значения новому METflFONT'oBCKOMy внутреннему параметру boundarychar, a
также заданием лигатуры или кернинга для сочетаний с этим символом.
Граничный символ может существовать, а может и не существовать как реально
имеющийся символ в данном шрифте.
Например, пусть требуется изменить первую букву в слове с Т' на 'fT, если
мы занимаемся подготовкой некоторого текста на староанглийском языке. При
разработке шрифта с помощью METRFONT'a можно было бы записать
ligtable I I: "F" | = : 11
если символ с десятичным номером 11 есть 'ff'. Точно такая же инструкция
ligtable должна появиться в программах для символов типа (, ', " и -, которые
могут предшествовать буквенным строкам; тогда вместо 'Bassington-French'
получим 'Bassington-ffrench'.
Если буква V в нашем шрифте —это s из текстов до начала XIX века,
которая выглядит подобно искалеченной Т (а именно, Т), и если в позиции 128
у нас современная буква V, в окончательном варианте можно преобразовать
572
Компьютерная типография
конечные буквы s так, как это сделал Бен Франклин, вводя такие инструкции
для лигатуры
boundarychar := 255;
55 =
м _
и _
>
)" =
) II —
1 128,
1 128,
1 128,
1 128,
1 128,
и т.'д. (Настоящий шрифт для текстов в старинном стиле будет также
содержать лигатуры для ss, si, si, ssi, ssl, sh и, возможно, для st; было бы интересно
разработать шрифт Computer Modern Oldftyle, может быть, для рекламных
профпектов к Рождефтву (Chriftmas newfletter.))
Неявный левый граничный символ опускается Т^Х'ом, если
непосредственно перед словом поставить команду \noboundary; точно так же можно убрать
неявный (подразумеваемый) правый граничный символ, 'записав эту команду
сразу после соответствующего слова.
Более компактные таблицы лигатур
Один и тот же общий код может теперь совместно использоваться двумя или
более таблицами лигатур. Чтобы воспользоваться этим в METflFONT'e, надо
сначала записать 'skipto (n)' в конце текста одной команды ligtable, а потом
указать '(п): :' внутри другой такой команды. Такие локальные метки могут
быть повторно используемыми, например, можно написать skipto 1 снова
после того, как появилась метка 1::, что вызовет пропуск следующего появления
этой метки 1: :. Имеется 256 локальных меток, перенумерованных от 0 до 255.
Ограничение: Между инструкцией skipto и отвечающей ей меткой может быть
помещено самое большее 128 команд лигатуры/кернинга.
Формат TFM-файла расширен (с учетом требования совместимости снизу
вверх) таким образом, чтобы допускать более 32500 команд лигатуры/кернинга
на каждый шрифт. (Ранее действовавшее ограничение составляло 256 команд.)
Улучшение управления видом абзацев
Теперь имеется более эффективный, чем это было раньше, способ,
позволяющий предотвращать появление переполненных боксов. Он рассчитан на
тех авторов, которые не хотят тщательно просматривать полученный
документ и исправлять вручную неудачные разбиения на строки. Подобные
авторы раньше пытались добиться этого установкой значения параметра
\tolerance=10000, но результат получался ужасный, поскольку ТЁ^ в этой
ситуации будет стараться объединить все плохости в одной действительно
кошмарной строке текста. (ТЕХ считает все плохости > 10000 бесконечно
плохими, причем все эти «бесконечности» равны между собой).
Глава 29. Новые версии TgX'a и METRFONT'a
573
Более приемлемый способ дает использование нового параметра-размера
\ emergency stretch. Если значение этого параметра положительно, и если у
Т^Х'а не получается набрать абзац, не выходя за границы установленных
допусков, будет предпринята повторная обработка данного абзаца, в ходе которой
ТЕХ попытается каждой строке дать дополнительную растяжимость, равную
значению параметра \ emergency stretch. Эта мера позволяет уменьшить все
плохости до уровня, когда ранее бесконечные значения станут конечными. T^jX
будет искать оптимальное решение задачи уменьшенного размера и оно обычно
будет достаточно хорошим с практической точки зрения. Избыточная
растяжимость здесь реально присутствовать не будет; следовательно, боксы с недо-
заполнением («жидкие боксы») будут вызывать появление предупреждающих
сообщений до тех пор, пока не будет увеличено значение параметра \hbadness.
Возможность проверить плохость
ТЕХ получил новый целочисленный параметр с именем \badness, в котором
содержится значение плохости для бокса, сформированного последним.
Если бокс оказался переполненным, значение данного параметра для него будет
1000000; в противном случае параметр \badness будет иметь значение между 0
и 10000.
Возможность проверить номер строки
TgX получил также новый внутренний целочисленный параметр с именем
\inputlineno, значением которого является номер строки, которую T^jX
показал бы в сообщении об ошибке, если бы какая-либо ошибка произошла
сейчас. Этот параметр и параметр \badness имеют статус «только для
чтения» аналогично параметру \lastpenalty: вы можете использовать его в
соответствующем контексте как проверяемое число, например в выражении
' if num\ input lineno >\badness ... \f i' или '\the\inputlineno', но
устанавливать им новые значения нельзя.
«
Возможность управления объемом контекста,
выдаваемого в сообщениях об ошибках
Имеется новый параметр с именем \errorcontextlines, имеющий
целочисленное значение и задающий максимальное число пар строк контекста,
выдаваемых ТЁХ'овскими сообщениями об ошибке (в дополнение к верхней и
нижней строкам, которые обычно появляются). В plain Т^Х'е сейчас
принято \ error context lines=5, но форматирующие пакеты более высокого уровня
могут предпочесть значение этого параметра \errorcontextlines=l или даже
\errorcontextlines=0. В последнем случае ошибка, которая вызывала ранее
выдачу двух или трех пар строк контекста, будет теперь выдаваться в следу-
574
Компьютерная типография
ющей форме:
! Error.
<somewhere> The \top
line
1.123 \The
bottom line.
Если \errorcontextlines<0, вы не увидите здесь даже и строки '...'.
Возможность
повторного использования страниц
Еще один новый целочисленный параметр, получивший наименование
\holdinginserts, завершает рассматриваемый набор вновь введенных
параметров. Если \holdinginserts>0, то Т^Х помещает текущую страницу в
бокс \box255, который будет использоваться программой \output. Никакие из
вставляемых узлов ТеХ перемещать в соответствующие боксы не будет, все
такие узлы останутся на своих местах. Разработчики программ вывода могут
использовать это средство, когда им понадобится поместить содержимое бокса
255 опять на текущую страницу, чтобы ее восстановить (так как могло
потребоваться изменить вертикальный размер страницы \vsize или что-нибудь еще
в этом роде).
Исключения из совместимости снизу вверх
Вследствие новых свойств, появившихся у ЧЩХ'а и METAFONT'a, некоторые
средства этих систем работают несколько по-другому по сравнению с тем, что
было раньше. Я попробую перечислить здесь все случаи подобного рода (за
исключением случаев, когда T^jX или METflFONT раньше работали некорректно
вследствие тех или иных ошибок, присутствовавших в них). Мне неизвестны
какие-либо случаи реального влияния этих изменений на деятельность
пользователей, поскольку все они, пожалуй, таковы, что понятны лишь посвященным.
• TgX использовал преобразование символьных строк ~~0, ~~1, ..., ~~9,
~~а, ~~Ъ, ~~с, ~~d, ~~e, AAf в соответствующие одиночные символы р, q, ..., у,
!,",#,$, У,, &. Эта операция больше не выполняется, если следующий символ
представляет собой одну из шестнадцатеричных цифр 0123456789abcdef.
• TgX не вставлял никакого символа в конце входной строки, если
\endlinechar>127. Теперь он выполняет эту операцию до тех пор, пока
не станет истинным условие \endlinechar>255. Как и раньше, значение
\endlinechar<0 подавляет символ-конца-строки (end-of-line character).
Обычно это символ с десятичным номером 13 = ~~М = ASCII control-M = carriage
return (символ возврата каретки).
Глава 29. Новые версии TgX'a и METRFONT'a
575
• Некоторые из ТЁХ'овских диагностических сообщений использовали
обозначения [м80] .. ["FF], когда ссылались на символы с кодами в диапазоне
128 .. 255 (например, когда отображали содержимое переполнившегося блока,
использовались шрифты с такими символами). Вместо этого теперь
используется обозначение ~~80 .. ~~f f.
• Выражения char 128 и char 0 использовались в METAFONT'e как
эквивалентные; взамен этого теперь char определен как modulo 256. Следовательно,
char — 1 = char 255 и т. д.
• INITEX забывал все предыдущие образцы переносов каждый раз, когда
выдавалась команда \patterns. Теперь все образцы переносов используются
кумулятивно, т. е. их спецификации накапливаются и уже нельзя использовать
\patterns после того, как абзац обработан INITEX'om с точки зрения
расстановки переносов.
• Т^К действовал немного по-разному при попытках набрать
несуществующие символы шрифта. Пропущенный символ рассматривается теперь как
граница слова, так что вы получите диагностическое сообщение немного другое,
чем в случае, когда \tracingcommands>0.
• TgX и METflFONT будут выдавать различную статистику в конце прогона,
поскольку они теперь имеют разное число примитивов.
• Программы, использующие средства работы с буфером строк системы
TANGLE, без внесения в них изменений теперь работать не будут, так как
новый вариант TANGLE начинает нумеровать многосимвольные строки с 256
вместо 128.
• Чтобы программы INITEX вели себя аналогично тому, как это было в
старой версии ТЁХ'а, надо теперь устанавливать значения \lef thyphenmin=2
и \righthyphenmin=3.
Будущее TfjX'a
и METflFONT'a
[Первоначально опубликовано в TUGboat 11 (1990), 489.]
Моя работа по созданию TfeX'a, METflFONT'a и семейства шрифтов
Computer Modern подходит к концу. Я не буду вносить в них больше никаких
изменений, кроме случаев, когда обнаружатся особо серьезные ошибки.
Я сделал эти системы общедоступными с тем, чтобы люди в любой точке
мира могли свободно воспользоваться ими, если пожелают. Я потратил также
тысячи часов, чтобы обеспечить возможность получения одного и того же
результата на любых компьютерах. Я очень верю в то, что стабильная система,
не подвергающаяся изменениям, представляет собой большую ценность, хотя,
конечно, любую сложную систему можно улучшить. По этой причине я
полагаю, что было бы неразумным вносить дальнейшие «усовершенствования» в
системы, именуемые ТЕХ и METAFONT. Давайте будем рассматривать эти
системы как некие зафиксированные сущности, которые и через 100 лет должны
выдавать тот же самый результат, что они дают и сейчас.
Номером текущей версии для TgK'a является 3.1, а для METflFONT'a —2.7.
Если потребуется внесение каких-либо изменений, следующие версии TgX'a
должны иметь номера 3.14, потом 3.141, затем 3.1415, ..., т.е. они должны
сходиться к значению отношения длины окружности к ее диаметру. Для
METflFONT'a соответствующая последовательность будет иметь такой вид: 2.71,
2.718, ..., т.е. она должна сходиться к основанию натуральных логарифмов.
Я намереваюсь нести полную ответственность за все изменения, вносимые в
эти системы, до конца моих дней. Я буду периодически изучать отчеты о
выявленных ошибках и по результатам этого анализа буду решать, требуется ли
осуществить какие-либо изменения. Тем, кто первыми обнаружит те или иные
действительно существующие на мой взгляд ошибки, получат
вознаграждение, однако я не имею более возможности удваивать ежегодно сумму этого
вознаграждения. При разработке любой новой версии я буду передавать ее в
главный официальный ТЁХ'овский архив, который в настоящий момент
размещается в Станфордском университете. Мой замысел состоит в том, чтобы после
моей смерти существующие на тот момент текущие версии TgX'a и
METflFONT'a были заморожены и оставались бы с тех пор и навсегда неизменными
Глава 30. Будущее ТвХ'а и METRFONT'a
577
за исключением того, что номера версий систем, в заголовочных строках
соответствующих программ должны принять вид:
ТеХ, Version $\pi$
и
METAFONT, Version $e$
соответственно. С этого момента все «ошибки» в системах следует считать их
неотъемлемыми «свойствами».
Как следует из страниц томов В, D и Е, содержащих информацию об
авторских правах, любой может свободно использовать мои программы по своему
усмотрению, однако аналогичным образом пользоваться именами ТеХ,
METAFONT или Computer Modern нельзя. В частности, любое лицо или группа лиц,
кто захочет создать программу, которая будет превосходить то, что создано
мной, имеет полное право сделать это. Никто, однако, не имеет права
назвать вновь разработанную систему T^jX или METflFONT, если только она не
согласуется на 100% с моими собственными программами, как я определил
эту согласованность в руководствах по соответствующим системам через
тесты TRIP и TRAP. Никому также не разрешается использовать имена шрифтов
семейства Computer Modern из тома Е для любых других шрифтов, не
порождающих идентичных tf m-файлов. Этот запрет распространяется на всех людей
и машины, которые действуют как в рамках TUG, так и любых других
организаций. У меня нет намерения передавать ответственность за эксплуатацию
ТЁХ'а, METRFONT'a или шрифтов семейства Computer Modern кому бы то ни
было.
Конечно, я не утверждаю, что мне удалось найти наилучшие решения
для каждой из проблем. Я считаю лишь, что это большое преимущество —
располагать в качестве строительного блока некоторым зафиксированным
результатом. Со «входной стороны» можно добавлять улучшенные макропакеты,
с «выходной стороны» —усовершенствованные драйверы устройств. Я
приветствую продолжение исследований, направленных на создание альтернативных
систем, которые смогут решать задачи типографского набора и верстки
лучше, чем это умеет делать Т^Х. Но авторы таких систем должны подумать и о
других именах для них.
Это все, о чем я прошу, после того, как посвятил существенную часть
моей жизни созданию этих систем и тому, чтобы сделать их доступными всем. Я
искренне надеюсь, что члены TUG помогут мне провести в жизнь
высказанные пожелания, оказывая жесткое давление на любое лицо или группу лиц,
которые выпустили бы системы, несовместимые с Т^К'ом, METRFONT'om или
шрифты, несовместимые с семейством Computer Modern, но воспользовались
соответствующими именами. При этом совершенно не имеет значения,
насколько мала или велика эта несовместимость.
Вопросы и ответы, I
[Заседание ежегодной конференции TUG 25 июля 1995 года в Санкт-
Петербурге, Флорида. Впервые опубликовано в TUGboat 17, (1996), 7-22, под
редакцией Кристины Тиле на основе магнитофонных записей, сделанных
Келвином У. Джексоном и Джереми Гиббонсом. Заседание открыла Барбара
Битой.]
Барбара: Я имею удовольствие знать Дона довольно давно. Хочу начать с
первого вопроса ... очевидного, а не о том, что написано на футболке. Как
идет работа над четвертым томом? [ Смех. ]
Дон Кнут: Большое спасибо, Барбара. Ты сказала, что большинство
присутствующих находятся здесь из-за меня. Я думаю, что #, так же как и любой
другой, нахожусь здесь в большой мере из-за Барбары. Она проделала
замечательную работу за те годы, когда была редактором журнала TUGboat и
координатором многих других дел.
Как вы знаете, я приехал на эту конференцию, потому что после десятой
конференции TUG пообещал, что приеду на шестнадцатую, так как это самое
Глава 31. Вопросы и ответы, I
579
важное число для ученого-компьютерщика. 16 —это не только степень числа 2,
это 2 в степени числа 2:
22"°°
16 = 22* .
[ Смех. ] Примерно так можно получить бинарное представление числа, вплоть
до 65 536. Числа играют в моей жизни большую роль. Так что это важная
встреча для всего проекта ТЕХ'а.
Я задумался о том, что я делал ровно 16 лет назад в этот день.
Оказывается, помимо всего прочего, я работал с Барбарой Битон, которая приехала в
Станфорд на 2 или 3 недели как представитель Американского
математического общества. Она и несколько ее коллег продемонстрировали мне трудности, с
которыми они столкнулись при подготовке указателя к Math Reviews. Поэтому
25 июля 1979 г. мы с Барбарой пытались понять, как делать указатель к Math
Reviews. Наша работа привела к созданию более мощных средств для отточий
и подобных вещей, так как в указателе к Math Reviews немало проблем
связано с расположением точек определенным образом в зависимости от количества
ссылок. Это было очень интересно, потому что в тот день я нашел две ошибки
в ТЁХ'е — под номерами 413 и 414 за всю историю развития ТЁХ'а. Порой,
работая над тем или иным сообщением об ошибке, которое вы получаете в конце
файла, вы можете обнаружить нечто в середине ... Думаю, это была такого
рода ошибка. Это было ровно 16 лет назад.
Барбара спросила, почему я надел эту футболку. На футболке написано:
хп + уп = zn ... Not!
Это математическая формула, и я могу показать, как набирать ее в ТЁХ'е, если
вас это интересует ... [ Смех. ]
Я ношу эту майку, потому что месяц назад столкнулся с сенсацией.
Меня постоянно волнует то, какую пользу люди всего мира извлекают из Т^Х'а.
Очень волнует. Одним из самых главных событий прошлого месяца было то,
что я пошел в библиотеку и увидел решение последней теоремы Ферма,
сделанное Эндрю Уайлсом. Думаю, многие из вас знают, что это была новость
первой полосы} Некоторое время были небольшие сомнения относительно
того, нет ли в доказательстве какой-нибудь погрешности, но затем этот результат
был зафиксирован. Это самый выдающийся математический результат. Тфчно
так же, как люди помнят, где они находились в тот момент, когда услышали об
убийстве президента Кеннеди, я знаю, что все математики могут вспомнить,
где они были, когда впервые услышали о том, что большая теорема Ферма
доказана. Статья появилась в прошлом месяце в журнале Annals of Mathematics2;
журнал пришел в нашу библиотеку, и, сидя там, я ознакомился со статьей, и
она казалась мне замечательной, потому что была сделана в ЧЩХ'е и
выглядела блестяще! [ Смех. ] Я чувствовал себя так, как будто сам помог доказать
1 Уайлс доказал, что уравнение хп -\-уп = zn не имеет целочисленных решений, если п > 2
и xyz > 0.
2 Andrew Willes, «Modular elliptic curves and Fermat's Last Theorem», Annals of
Mathematics 142 (1995), 443-551.
580
Компьютерная типография
эту теорему! [ Смех усиливается.] Я также рад сообщить, что на этой неделе
здесь присутствуют люди, которые за это отвечали. В последнем ряду сидит
редактор Annals of Mathematics1, а также наборщица Джеральдин Печт. Это
тоже радость для меня. Давайте пожмем им руки. [Аплодисменты.]
Но мне бы не хотелось сегодня говорить на заранее подготовленные темы,
я хочу отвечать на вопросы.
Итак, Барбара задала первый вопрос: «Что слышно о четвертом томе The
Art of Computer Programming?» Обычно я отвечаю на этот вопрос только в
особых случаях. [ Смех. ] В настоящий момент я все время пишу и очень
усердно работаю над этой книгой. Минуточку, я посмотрю, смогу ли я найти свою
записку ... [ идет к проектору, отображающему экран с редактором Emacs с
компьютера, который работает в Станфорде и связан с Флоридой через
Интернет. ] Это чтобы я вспомнил, о чем мне говорить ...
В настоящее время для сокращения названия The Art of Computer
Programming принята аббревиатура АСР. Но кто-то предложил сокращение
ТАОСР. Поэтому теперь используется новая аббревиатура— ТА О СР. Это
работа всей моей жизни, это то, за что я взялся в 1962 г., и я думаю, что мне
понадобится еще 20 лет для работы, а когда я закончу, мне уже будет 77.
Теперь вы понимаете, почему я рано ушел на пенсию: чтобы иметь возможность
посвятить себя этой работе.
Барт Чайлдс: Здесь имеется в виду ТАОСР? (на экране опечатка— 'ТОАСР')
Дон: Да. Вы хотите, чтобы я увеличил шрифт? У меня только три или четыре
экранных шрифта ... О! [Замечает опечатку.]
Барт: Значит ли это, что я получу чек на сумму пять долларов и двенадцать
центов? [ Смех. ]
Дон: Ни в коем случае! [ Смех. ] ... Я сделал это нарочно, чтобы проверить,
смотрит ли кто-нибудь на экран. [ Смех. ] Ну ладно ... Итак, эта другая книга,
над которой я работаю, называется The Art of Computer Programming [ смех. ]
... Ax, да ... Надо же, я волнуюсь. [ Смех. ]
Итак, чтобы закончить этот проект, я должен работать очень напряженно,
потому что ученые-компьютерщики продолжают открывать новые
возможности. Первоначально моя идея состояла в том, чтобы подытожить все, что
происходит в области компьютерной науки, но сейчас я должен сказать, что
мне придется приложить много усилий, чтобы подытожить хотя бы все то, что
уже стало классикой. Особенно я работаю над тем, чтобы все было верно с
исторической точки зрения и чтобы заложить правильную основу для
специальных вещей. Но я не могу дать исчерпывающее представление, как я мог
это в шестидесятых годах, когда приступал к работе. Думаю, что в целом я
работал над ЧЩХ'ом около десяти лет, и я надеюсь, что эти десять лет
сэкономят мне б или 7 лет работы над ТАОСР, так как теперь я могу работать более
эффективно.
The Art of Computer Programming— это самая значительная вещь, которую
я могу сделать в жизни. Сейчас я чувствую себя очень здоровым и счастли-
Морин Шупски, ведущий редактор, Princeton University Press.
Глава 31. Вопросы и ответы, I
581
вым, и мне кажется, что я успеваю за неделю сделать больше, чем когда-либо.
Надеюсь, что так будет продолжаться достаточно долго. Но я знаю, что мне
потребуется много времени. Поэтому я ушел на пенсию и все свое время отдаю
этой работе.
Прошлый год я посвятил разработке основ проекта, что означало создание
больших компьютерных файлов из того, что накопилось у меня дома. Так что
теперь у меня тысячи и тысячи пунктов, которые я упорядочил и расставил
по местам, и теперь я знаю, как искать информацию.
Сейчас мой текущий план состоит в том, чтобы закончить отвечать на
почту, касающуюся The Art of Computer Programming, которая приходила в
тот период, когда я работал над ЧЩХ'ом. Как вы знаете, каждому, кто находил
ошибки в книге The TfeXbooic, я в итоге отвечал, платил за ошибки и т. д. Люди
также получали вознаграждение за найденные ошибки в The Art of Computer
Programming. Но на самом деле последний раз я выписал чек в июле 1981 г.
[ Смех. ] В августе 1981 г. моя секретарша начала рассылать стандартную
форму, выполненную в ТЁХ'е, где говорилось: «Я вам скоро отвечу». [Смех.] Я
начал складывать эти письма в маленькую кучку. Потом эта кучка стала
расти, перемешалась с другими документами, которые я получал, и в результате
выросла до 260 дюймов в высоту. Если перевести это в сантиметры ... ну, в
общем, это много! [ Смех. ] Там было около семи—восьми метров материала. Я
погрузился в это и теперь отвечаю на эти письма. Количество писем, на
которые я еще не ответил, меньше 500 —примерно 450 писем —и теперь я отвечаю
на них и надеюсь, что чеки дойдут до людей по тем адресам, с которых они
посылали мне свои комментарии.
von Neumann, John [=Margittai Neumann
Janos], 18, 225, 456.
Wadler, Philip Lee, 594.
Wall, Hubert Stanley, 481.
Wallis, John, product, 50, 112, 480.
. Wang, Hao(iJg), 382-384
Wang, Paul Shyh-Horng (ЗЕ±ЗД),
436, 631.
Watson, Dan Caldwell, 248.
Wedderburn, Joseph Henry Maclagan, 583.
Wegbreit,.Eliot Ben, 603.
Weierstrass, Karl Theodor Wilhelm, 381.
Wiles, Andrew John, 465.
Wilf, Herbert Saul, 92, 483.
Windley, Peter F., 518.
Wise, David Stephen, 420, 434, 595.
Wiseman, Neil Ernest, 420.
Yao, Andrew Chi-chih (l|f), 538.
Young Tanner, Rosalind Cecilia
Hildegard, 75.
Zave, Derek Alan, 90, 603.
Zeilberger, Doron, 64.
Рис. 1. Фрагмент последней страницы списка ошибок к тому 1.
Я покажу вам эти ошибки, потому что я сейчас над ними работаю. Вот
только один пример (рис. 1), так что вы поймете, о чем я говорю. [На дисплее
582
Компьютерная типография
вместо Emacs появляется вывод в xdvi.] Это часть ошибок к указателю к
тому if На самом деле это шрифт 8-го кегля, здесь слегка увеличенный. Я хочу
показать вам одну из тех вещей, над которыми сейчас работаю ... Для всех
авторов, упоминаемых в The Art of Computer Programming, если их фамилии не
западноевропейские, я построил большую базу данных из фамилий,
написанных на их родном языке, например, китайском или японском. (Я еще не
поместил туда индийские фамилии, но работаю со специалистами из Индии, чтобы
решить и этот вопрос.) ... Только что я практически обновил всю китайскую
часть базы ... У меня есть растровые изображения всех литер из Unicode — и
китайских иероглифов в частности — так что теперь у меня, надеюсь,
образовалась неплохая база таких вещей. Через несколько лет программный продукт
Unicode будет готов и доступен, и тогда я смогу правильно набирать любые
фамилии,
Я создал несколько интересных макро для Emacs, при помощи которых
обращаюсь с литерами Unicode, несмотря на то что пока не имею
соответствующего программного обеспечения. Я могу набирать в шестнадцатеричной
системе и затем написать в Emacs M-x unic; как по мановению волшебной
палочки шестиадцатеричные числа превращаются в растровые изображения
китайских иероглифов и вставляются в документ. [Показывает, набирая 59daM-x
unic] Вот как выглядит фамилия Энди Яо на китайском языке:
\Unil.08:24:24:-1:207. Unicode char "59da
<lc077018066018066018066018066019466effb66c339e78'/.
331670330660330660330660630е7066366с66е6667646660/.
6e06600c06600e0c601b0c6219986231b06360607i80803e>°/.
Пока у меня есть только растровые шрифты размера 24 на 24, но для
корректур этого достаточно. Мой компьютер настроен должным образом, поэтому
получить эти растровые изображения очень легко. Макро unic дает
команду Emacs запустить небольшую программу, которая ищет шестнадцатеричный
код в файле, находит растровое изображение и вставляет его в Т^Х-файл. То,
что находится между угловыми скобками, посылается с помощью TgX'a в
PostScript при помощи макро
\def\Uni#l:#2:#3:#4:#5<#6>7.
У, \Uni ems: cols:rows:-hof f :rows+vof f <hexbitmap>
{\leavevmode \hbox to#l\unicodeptsize
{\special{M 0 0 moveto currentpoint translate
\unicOdeptsize \unicOdeptsize scale #2 #3 true
[24 0 0 -24 #4 #5] {<#6>} imagemas*k}\hss}}
В конце года я планирую опубликовать этот список ошибок, который к
тому времени будет завершен. Сейчас у меня набралось около 180 страниц из
1 Файлы этих ошибок в формате PostScript сейчас находятся где-то внизу Web-страницы
http://vvv-cs-facuity.stanford.edu/~knuth/taocp.html. (Позже я неожиданно обнаружил,
что фамилия Paul Wang относится к ошибкам 2-го тома.)
Глава 31. Вопросы и ответы, I
583
всех трех томов, и я продолжаю пополнять этот список, отвечая на старые
письма.
Мои издатели собираются издавать 4-й том отдельными выпусками, в
каждом должно быть около 128 страниц. Предполагается делать это примерно
дважды в год в течение ближайших десяти лет. Я считаю, что буду готовить
около 256 страниц в год. Мы планируем иметь в наличии 3-4 выпуска, прежде
чем начать издание. Один из четырех первых выпусков будет большего объема
из-за обновленного списка ошибок, содержащихся в томах 1, 2 и 3; во втором
выпуске будет представлен гипотетический компьютер под названием MMIX,
который придет на смену компьютеру MIX. MMIX— это машина RISC, очень
похожая на компьютеры, которыми мы все сейчас пользуемся. Это 64-битный
RISC-компьютер, который я когда-нибудь даже смогу иметь, если
найдется кто-то, кто захочет его сконструировать. В его разработке мне помогают
несколько экспертов в этой области. Дик Сайте, создатель процессора Alpha и
один из моих студентов, пообещал работать над всей заключительной частью
разработки. Мне также помогает Джон Хеннеси, который создал процессор
MIPS, и несколько человек из SPARC. Поэтому MMIX должен быть хорошим
RISC-компьютером, и он поможет нам в экспериментах с алгоритмами, цель
которых — понять, насколько хорошо различные запасные схемы управления
работают с различными алгоритмами сортировки и т. д.
Второй выпуск заменит MIX на MMIX, и я надеюсь, что всякий раз, когда в
The Art of Computer Programming встретится программа MIX, она будет
заменена программой MMIX. Я не собираюсь делать это, пока не закончу тома 4 и 5.
Но надеюсь, что многие к тому моменту уже проделают эту работу.
Некоторые уже пообещали мне, что в следующем году у них будет С-компилятор для
MMIX, и мы пытаемся получить написанные для него операционные системы.
Что сказать о двух других начальных выпусках? Один из них будет
представлять собой первую часть 4-го тома, где говорится о вещах, не
поддающихся систематизации. В этом разделе обсуждаются технологии, почерпнутые, в
основном, из фольклора об эффективных методах для компьютеров при
проведении побитовых логических операций, таких как исключение и дополнение,
а также сложение, вычитание, умножение и деление, для достижения
наилучших результатов. Этот материал уже написан. На самом деле, это то, что я
запланировал еще до того, как начал работать над Т^Х'ом, — я написал первый
план для не вошедшего в первые три тома материала в начале 1977 г.
Затем я погружаюсь в изучение грубых перечислительных методов.
Четвертый том посвящен комбинаторным алгоритмам, т. е. методам, которые были
разработаны для разрешения проблем, где возможно несметное количество
вариантов. Для ускорения процедуры были выдвинуты самые разнообразные
идеи наравне с очевидными методами обработки важных комбинаторных
случаев. Я начал с рассказа о вещах, не поддающихся систематизации, далее
говорится о быстрых методах составления списков всех перестановок, всех
подмножеств множества и тому подобных вещах. По этому вопросу есть большое
количество литературы. Как ни странно, о создании перестановок написано
гораздо больше, чем о сортировке. Сортировка — это расположение по порядку,
584
Компьютерная типография
тогда как создание перестановок — это нечто вроде беспорядочного
расположения. Авторы чаще объясняют, как располагать вещи в беспорядке, а не как
упорядочить их. [ Смех. ] Большая часть этих трудов содержит повторы и
общие места и не так интересна, как то, что написано о сортировке, так что
основная трудность для меня заключается в том, чтобы ознакомиться с этой
литературой и собрать ее вместе. Большинство тех, кто писал о перестановках,
не знало о том, что много других людей работало над той же самой темой.
Ну ладно. Я думаю, что этого более чем достаточно для ответа на ваш
вопрос о томе 4. Я стараюсь делать одну страницу в день и думаю, что буду
работать в том же темпе.
Page xi replacement for exercise 3 25 Mar 1995
3. [34] Leonhard Euler conjectured in 1772 that the equation w4 -f x4 -f y4 = z4 has
no solution in positive integers, but Noam Elkies proved in 1987 that infinitely many
solutions exist [see Math. Сотр. 51 (1988), 825-835]. Find all integer solutions such
that 0 <w <x <y <z < 106.
4. [M50] Prove that when n is an integer, n > 4, the equation wn -f xn -f yn = zn
has no solution in positive integers w, x, y, z.
Рис. 2. Фрагмент списка ошибок для введения из тома 2.
Пока я пытаюсь вывести это на экран ... давайте перелистнем пару
страниц ... Я хочу взглянуть на это уравнение (рис. 2). Обычно в начале книги я
помещаю теорему Ферма как исследовательскую проблему. [ Смех. ] В списке
ошибок теперь говорится: «Докажите, что если п — целое число, большее 4,
то уравнение wn + хп + уп = zn не имеет решений для положительных
целых чисел. Таким образом, я просто добавил другой вариант этого уравнения,
и мы получили другую хорошую исследовательскую проблему. Оказывается,
для п = 4 существует много решений. Доказательство теоремы Ферма стало
для меня личным кризисом, но таким вот способом я из него вышел. [ Смех. ]
Рис. 3. Иллюстрация на METflPOST'e к списку ошибок тома 1.
Глава 31. Вопросы и ответы, I
585
Я также хотел бы взглянуть на с. 61 списка ошибок как на пример нового
материала (рис. 3). На этой странице показаны очень симпатичные
конструкции, которые получаются при изучении деревьев. Я привел эту иллюстрацию
в качестве примера: все иллюстрации для книги сделаны в METAPOST'e, и на
этой странице показан один такой рисунок, который попал в список ошибок.
Мне нравится METAPOST, и сегодня утром Джон [Хобби] покажет вам свою
систему. Она выполняет технические иллюстрации гораздо лучше других
систем. С моей точки зрения, огромное преимущество METAPOST'a состоит в
том, что если мне нужно модифицировать иллюстрации позже, например,
через год, то в коде METflPOST я могу увидеть точно, что я имел в виду при
создании оригинала. МЕТАР05Т —это декларативный язык, с помощью
которого вы устанавливаете характеристики для вашей иллюстрации, а затем
рисуете диаграмму. В списке ошибок сейчас содержится пять-шесть примеров
того, как я либо перерисовывал старый рисунок, либо, как в этом случае,
создавал новый. Многие другие примеры, которые я подготовил при работе над
книгой Stanford GraphBase убедили меня в том, что МЕТАР05Т действительно
идеально подходит для технических иллюстраций. Вряд ли можно придумать
что-нибудь лучше этого.
МЕТАР05Т не годится для таких видов иллюстраций как, например,
реклама. Но когда вы пишете техническую книгу (вчера Себастиан [Ратц] говорил то
же самое в отношении PSTricks), вам нужно сделать диаграмму,
удовлетворяющую определенным математическим правилам. Программа Super MacDraw-
type едва ли предоставит вам такую возможность, тогда как МЕТА POST делает
это с легкостью, и при этом все выполнено правильно с математической точки
зрения. Это позор, что до недавнего времени ни в одной книге по
математическому анализу не было хорошего изображения кардиоиды. Вчера на экране мы
увидели настоящую кардиоиду [слайд Дени Жиру]. Никто даже не знал, как
выглядит кардиоида, потому что рисунки были сделаны художниками,
пытавшимися скопировать работы своих предшественников и никогда не видевшими
самого предмета.
Ну ладно, я слишком много говорю об этом. Задавайте следующий вопрос.
Роберт Макгаффи: Считаете ли вы, что алгоритм RSA будет взломан?
Дон: Думаю ли я, что алгоритм RSA когда-нибудь будет взломан?
Алгоритм RSA — это схема Райвеста—Шамира—Адлемана для шифрования. Уже
найден ключ к подлинному шифру, разработанному в 1977 г. Это было число
из 140 разрядов, которое являлось очень слабой версией их общей идеи. Но
Райвест вместе с остальными сказал: «Вот наше секретное сообщение.
Можете ли вы расшифровать его?» К тому моменту, когда кто-то в прошлом году
сумел это сделать, Рон [Райвест] потерял свой ответ и забыл, о чем шла речь.
Оказалось, что после расшифровки сообщение выглядело так: «Секретное
слово-squeamish ossifrage (привередливая скопа)». Таким было решение. Чтобы
разгадать этот шифр, пришлось разложить на множители число из 140
разрядов, и в прошлом году на это были затрачены тысячи часов компьютерного
времени. Дело в том, что если вместо числа из 140 разрядов взять число из 141
586
Компьютерная типография
разряда, то проблема значительно возрастет. Поэтому если говорить о числе из
300 разрядов, то, насколько мне известно, работающие компьютеры всего мира
не смогут решить эту задачу. Однако могут быть преимущества при
разложении на множители, и сам Райвест считает, что кодирование с помощью числа
из 300 разрядов займет около 30 лет. А что касается числа из 500 разрядов, то
тут понадобится сто лет — он с уверенностью заявляет, что это правда.
Мы сомневаемся в том, что в ближайшее время кто-нибудь откроет
волшебный способ разложения чисел на множители. Однако большая проблема
заключается в том, что использовать RSA на полную мощность незаконно. Я
хочу сказать, что правительство хочет быть уверено в том, что оно сможет
при» необходимости прочитать секретные материалы, так как не желает,
чтобы у мафии были секреты. Таким образом, сложилась своеобразная ситуация,
когда противозаконно решать с помощью компьютера какое-нибудь
математическое равенство или формулу. Ладно, я не люблю конфронтации. [ Смех. ]
Мне не нравится вести секретный образ жизни Я имею в виду, что я не
засекреченный человек. Я целый год занимался криптанализом и работал со
многими замечательными людьми, но понял, что эта жизнь не для меня. Я
хочу быть профессором колледжа и рассказывать о том, что знаю. Поэтому
я плохой консультант по этому вопросу. Однако можно отправить надежную
информацию о том, что никто не умеет раскладывать числа на множители.
Это либо благодеяние, либо угроза, в зависимости от вашей точки зрения. Что
касается меня, то я могу смотреть на это с обеих позиций.
Кто еще?
Майкл Софка: Справедливо ли равенство Р = NP, и если нет, то насколько
далеки мы от доказательства?
Дон: Равенство Р = NP —это самая большая нерешенная задача в
компьютерной науке, подобная теореме Ферма, хотя этой задаче всего около 25-30 лет.
В контексте комбинаторных алгоритмов она звучит так: сможем ли мы решать
задачи, которые требуют применения 2П случаев? Можем ли мы сделать это в
п10, если бы мы знали лучший способ? Если Р = NP, то мы должны ответить
«да»: мы можем преобразовать все эти экспоненциальные задачи в задачи с
многочленами. Если равенство неверно, то следует ответить «нет», мы никогда
не сможем их преобразовать.
Я подозреваю, что мбжно решить эту задачу следующим способом. Кто-
нибудь докажет, что Р равно NP, потому что количество препятствий для того,
чтобы Р не равнялось NP, конечно. [ Смех. ] В результате окажется, что
существует некий многочлен, и с его помощью мы сможем решить все задачи NP.
Однако мы не узнаем, что это за многочлен, мы только будем знать, что он
существует. Таким образом, сложность может заключаться в том, будет ли п
равняться триллиону или чему-нибудь еще в этом роде, но это будет
многочлен. В таком случае мы никогда не сможем произвести вычисления, так как
потребуется слишком много времени, чтобы узнать, что это за многочлен. Но
он должен существовать. И это означает, что постановка вопроса Р = NP была
неверной. [Смех.] Получится что-то в этом роде. Даже когда вы используете
Глава 31. Вопросы и ответы, I
587
метод, требующий 2П шагов, и сравниваете его с методом, требующим п100
шагов, то в случае 2П степень п должна быть не больше 20-30. Но
воспользоваться методом с п100 вы не можете даже для п = 2. Поэтому очень важна
степень многочлена. Существует так много алгоритмов, что задача доказать
отсутствие алгоритмов для многочленов является очень сложной. Я
действительно полагаю, что теорема Ферма — аналогичное явление, когда более важно
сформулировать задачу, а не решить ее. Поэтому относительно теоремы Уайл-
са я думаю, что он проделал огромную замечательную работу, но я желаю ему
решить какую-нибудь другую задачу. [ Смех. ]
Многие думают, что если задача относится к классу NP, то ее можно не
решать, так как это означает, что ее нельзя решить с помощью многочленов. Но
пока мы не стали изучать NP, мы имели дело с неразрешимыми задачами, т. е.
с такими, для которых вообще не существует никаких алгоритмов. И неважно,
сколько вы работали, —вы никогда не могли решить задачу. Учитывая, что
данная машина Тьюринга когда-нибудь остановится, эту задачу нельзя решить
при помощи каких-либо алгоритмов, независимо от того, сколько времени вы
этому посвятили. Пока NP не стал популярным, никто не брался за решение
подобных задач, так как было доказано, что их нельзя решить в принципе.
Но это был неправильный подход, потому что почти все задачи, которые мы
когда-либо решали, являются специфическим случаем какой-нибудь задачи,
не имеющей решений.
Возьмем, например, дифференциальное исчисление — задачу, в которой
берется формула, функция от п, и ставится вопрос: «Равен ли нулю предел при
п, стремящемся к бесконечности?» Это неразрешимая задача. Однако это не
означает, что мы не должны изучать дифференциальное исчисление. Пределы
многих функций стремятся к нулю, и это позволило развить
дифференциальное исчисление. Но в общем виде эту задачу решить нельзя. Я хочу сказать,
что вы можете определить / от п — потребуется всего несколько строчек для
формулы, равной нулю, если данная машина Тьюринга остановлена в момент
п, и она будет равна 1, если машина Тьюринга все еще будет работать в
момент п. Таким образом, предел равен нулю тогда и только тогда, когда машина
Тьюринга прекращает работу. Это неразрешимая задача.
Подобные вещи происходят с NP. Есть множество задач, которые трудно
эффективно решить с помощью NP; если мы знаем, что какие-то задачи не
подходят для NP, то это еще не значит, что нужно отказаться от их решения
или перестать думать над хорошими эвристическими методами.
А не хотите ли вы задать вопросы о ТЁХ'е?! [ Смех. ] А?
Т. В. Раман: Одним из преимуществ TfejX'a является то, что это гибкая
система, позволяющая авторам определять макро, которые классифицируют
шифровку семантики. Таким образом, если вы пишете статью о перестановках,
вы можете ввести определение \permute и использовать его затем в своем
документе-. Я часто прибегаю к этому в своей системе A^IfeR- Я хотел бы знать —
Дон: Простите, вы потом будете выступать ... ?
Раман: Да, я буду выступать завтра днем.
588
Компьютерная типография
Дон: Значит, в вашей системе используются возможности TgX'a как часть
семантики документа, тогда как автор думает, в основном, об удобстве в
написании.
Раман: Да. На самом деле, все идет на пользу дела. Поэтому чем больше
семантики в разметке, тем лучше. Обычно в документах можно использовать
либо основной уровень разметки, когда автор просто пишет 'x\over у',
если ему нужно изобразить дробь '|', либо авторское определение, например,
\inference — макро, который берет 2 символа и затем помещает х над у и
ставит между ними горизонтальную линейку. В последнем случае я выигрываю,
а в первом проигрываю. У меня такое ощущение, что если вы посмотрите на
большую книгу, то вы увидите, что она выглядит как большая компьютерная
программа, и мне кажется, что из соображений здравого смысла лучше читать
ее таким образом.
Дон: Все ли поняли, в чем заключался вопрос? Он говорит, что если вы
слепой или неполноценный, вы можете изучить ТЁХ'овский исходник. Если он
сделан должным образом, это может быть даже лучше, чем иметь печатную
копию, потому что должен быть написан по схеме очень логичной разметки. В
тексте книги мы стараемся показать структуру с помощью полиграфических
средств. Но на самом деле мы знаем даже больше о структуре, когда
создаем наши исходные файлы. Поэтому в исходных файлах такого автора будет
больше информации, чем в том, что вы увидите впоследствии.
Когда вы пишете, не забывайте о тех, для кого это предназначается. Если
вы заглянете в любую книгу о том, как нужно писать, или прослушаете любой
курс на эту тему, вы поймете, что правило номер один всегда гласит:
Помните о своем читателе. Если авторы понимают, что они пишут гипертекст, они
построят свои объяснения таким образом, чтобы извлечь максимум из
гипертекста. Когда я написал свою первую статью на иностранном языке1, она была
опубликована в Канаде, где слово «color» пишется через «и». [Смех.] Моя
вторая статья на иностранном языке2 была написана по-норвежски, поэтому
когда я говорил о вариантах обозначения «left» и «right», я использовал буквы
V и 'Л,' вместо Т и V. Я хочу сказать, что обдумывая то, что вы будете
писать, вы делаете это для читателя. Это очень простые примеры. Поэтому если
вы предполагаете, что кто-то будет смотреть ваш исходный ТЁХ'овский файл
или сможет посмотреть часть вашего документа, вы должны построить весь
процесс объяснений по-другому, и у вас будет больше читателей. Поэтому я
попытаюсь... Я могу показать вам макро, сделанные для The Art of Computer
Programming в новом стиле, но...
Раман: Я хотел бы взглянуть на них, потому что следующее, что я собираюсь
сделать, — это запустить систему ...
Дон: [демонстрирует на экране; см. рис. 4.] Давайте посмотрим на файл. Он
все еще в незавершенном состоянии, да? [ Смех.] Я загрузил различные файлы
1 «Another enumeration of trees», Canadian Journal of Mathematics 20 (1968), 1077-1086.
2 «S0king etter noe i en EDB-maskin», Forskningsnytt 18,4 (Norges Almenvitenskapelige
Forskningsrad, 1973), 39-42.
Глава 31. Вопросы и ответы, I
589
7, Macros .for The Art of Computer Programming
7. (STILL UNDER CONSTRUCTION!
7. I started with manmac.tex and am letting this evolve)
\input epsf
\input rotate
\input picmac
\input Unicode
\catcode'@=ll 7. borrow the private macros of PLAIN (with care)
\font\ninerm=cmr9
Рис. 4. Начало файла acpmac.tex.
с макро: файл 'epsf —для того, чтобы получить рисунки METRP05T; файл
'rotate' позволяет PostScript'y вращать изображение; файл 'picmac' —это моя
подсистема той части ГАТ^К'а, которая делает рисунки; файл 'uni code ' — это
то, о чем я вам говорил, когда рассказывал о наборе китайских фамилий. Итак,
давайте посмотрим на некоторые моменты форматирования... [показывает
различные коды для форматирования. ]
Вот мои составные макро (рис. 5) ... как видите, я поместил сюда
несколько исключений, касающихся переносов. Уравнения нумеруются цифрами
старого стиля. Управляющая последовательность \star применяется для
обозначения раздела, помеченного звездочкой; \slug используется в конце
доказательства— мне нужно изменить его, чтобы он не был таким черным, а то люди
видят так много боксов при переполнении, что не хотят больше видеть черных
«марашек». [Смех.] Я переопределяю точку с бэкслэшем — \: вместо \. для
шрифта пишущей машинки в середине математического режима. Это
важная система обозначения согласно Иверсону, где вы можете заключить любую
формулу в квадратные скобки, что позволит вычислить ее в 0 или 1 —вы
можете поместить это в середину уравнения, это очень полезно. Вот макро для
обозначения A.D. или B.C. А вот то, что я использую для специальных
выделений. Я не пользуюсь этим для того, чтобы выделить курсив, для этого
существует команда \it. А \еш#1: —это специальный формат, который я
часто применяю для примечаний или чего-нибудь в этом роде. [Просматривает
макро, комментируя наиболее интересные из них. ] ... Это числа Эйлера ...
с угловыми скобками вместо круглых скобок, используемых для двучленных
коэффициентов.
Раман: Есть ли здесь макро \euler?
Дон: Да, вот здесь числа Эйлера. ... \Euler — это похожее обозначение, где
используются 2 ограничителя и есть достаточное количество отрицательного
пространства между ними, что позволяет поместить 2 угловые скобки после
каждой из них; точно так же \Choose заключает двучленные коэффициенты
590
Компьютерная типография
У. Composition macros
\hyphenation{logical Mac-Mahon hyper-geo-metric
hyper-geo-met-rics Ber-noulli Greg-ory dis-trib-uted}
{\obeyspaces\gdef {\ }}
\def\hang{\hangindent\parindent}
\def\dash {\ifdim\lastskip>Opt\unskip\fi\ \cdash }
\def\eq(#l){{\rm({\oldsty#l})}}
.\let\EQN0=\eqno \def\eqno(#l){\EQNO\hbox{\eq(#l)}}
\def\star{\llap{*}}
\def\slug{\hbox{\kernl.5pt\vrule width2.5pt
height6pt depthl.5pt\kernl.5pt}}
\let\:=\. У, preserve a way to get the dot accent
\def\.#l{\leavevmode\hbox{\tt#l}}
\def\[#1]{[\hbox{$\mskiplmu\thickmuskip =
\thinmuskip#l\mskiplmu$}]} '/, Iverson brackets
\def\bigi [#1]{\bigl[\begingroup\mskiplmu
\thickmuskip=\thinmuskip #l\mskiplmu\endgroup\bigr]}
\def\AD{{\adbcfont A.D.}}
\def\BC{{\adbcfont B.C.}}
\def\og#l{\leavevmode\vtop{\baselineskip\z@skip
\lineskip-.2ex \lineskiplimit\zQ
\ialign{##\cr\relax#l\cr
\hidewidth\kern.3em\shGft{40}'\hidewidth\cr}
\kern-lex}} '/, ogonek
\def\em#l:{{\it#l:\/}} % \em Hint: or \em Caution: etc
\def\euler{\atopwithdelims<>}
\def\Euler#l#2{\mathchoice{\biggl<\mskip-7mu
{#l\euler#2}\mskip-7mu\biggr>}'/,
{\left<\!{#l\euler#2}\!\right>}{}{}}
\def\Choose#l#2{\mathchoice{\biggl(\mskip-7mu
{#l\choose#2}\mskip-7mu\biggr)}7,
{\left(\!{#l\choose#2}\!\right)}{}{}}
\def\smsum{\mathop{\vcenter{\hbox{\tenrm\char6}}}}
'/, small summation sign
\def\phihrat{{\mkern5mu\hat{\vrule widthOpt
height1.2ex\smash{\mkern-5mu\phi}}}}
\def\umod{\nonscript\mskip-\medmuskip\mkern5mu
\mathbin{\underline{\rm mod}}\penalty900\mkern5mu
\nonscript\mskip-\medmuskip} У, least remainder
Рис. 5. Выдержки из файла acpmac.tex.
Глава 31. Вопросы и ответы, I
591
в круглые скобки. А это \smsum для маленького знака суммы —не помню, где
я им пользовался. А вот специальный символ \phihat — для буквы ф,
которая справа должна иметь «шляпку», потому что 1ф'— это то, с чем вы
всегда сталкиваетесь, изучая числа Фибоначчи. ... А здесь у меня формат для
алгоритма... целая куча макро для набора программ на Ассемблере,
подчеркивания текста в комментариях и т. д. [ остальные примеры сюда не включены. ]
Мои ТЁХ'овские файлы списка ошибок частично отражают структуру,
принятую в ТАОСР. Как я уже сказал, я ежедневно работаю над новыми
исправлениями. Есть 4 типа ошибок: первый называется исправлением, что означает
нечто новое, о чем мы не знали раньше; второй называется неисправностью и
должен быть отлажен; третий называется планом и означает, что детали
нуждаются в дальнейшей доработке, но я хочу отметить в файле, что помню о
том, что нужно внести изменения; и наконец, четвертый называется
улучшением, и это достаточно тривиально, но пока я над этим размышляю и хочу
использовать, когда мы придем к завершению книги.
\amendpage 1.189 insert quotation before the exercises (95.07.13)
{\quoteformat
\vskip-3pt
Up to a point it is better to let the snags [bugs]
be there than to spend such time in design that there are none
(how many decades would this course take?).
\author A. M. TURING, Proposals for ACE (1945)
У. pl8, quoted in Comp J 20(1977)273
}
\endchange
Рис. 6. Последние дополнения к списку ошибок.
Например (рис. 6), вот цитата из Тьюринга, которая мне нравится; она
относится к 1945 г., когда компьютеры еще не были изобретены, но он долго
думал о компьютерах: «Лучше оставить все огрехи как есть, чем тратить
время на такую переделку, чтобы их не осталось совсем. Представляете, сколько
недель на это уйдет?» Эта цитата исправлена 12 дней назад в томе 1.
\amendpage 2.ix replacement for exercise 3 (95.03.25)
\ехЗ. [34] Leonhard Euler conjectured in 1772 that the equation
$w~4+x~4+y~4=z~4$ has no solution in positive integers,
Umprovepage 2.27 line 2 (81.08.13)
random, they \becomes random; they
\endchange
Рис. 7. Другие примеры ошибок.
592
Компьютерная типография
А вот здесь (рис. 7) мы видим ТЁХ'овский исходный файл, с помощью
которого получен рис. 2. В этом примере я поменял запятую на точку с запятой.
Я сделал это, потому что обычные улучшения, как правило, не перечислены
в печатном экземпляре, если только вы не работаете сверх меры. Здесь
представлен особый способ получения всех \improvepage, но обычно они только
появляются в файле.
Вот чем я занимаюсь. Между прочим, улучшение было сделано в 1981 г. В
течение 20 лет я просматривал экземпляры The Art of Computer Programming,
сидя в своем кабинете, и делал пометки на полях, отмечая то, что нуждалось
в улучшении. Все это вы теперь видите в этих файлах.
Еще вопросы?
Сильвио Леви: Как получилось, что вы не пользуетесь IM^jX'om? [ Смех. ]
Дон: Как получилось, что я не пользуюсь ЕЧЩХ'ом? [ Смех. ] Я боюсь
больших систем! [ Смех усиливается.] Барт?
Барт Чайлдс: Ваша статья «The Errors of T^jX» — это великий труд. Не
собираетесь ли вы написать статью «Mistakes of Т^Х»?
Дон: «The Mistakes of ТЕХ»?? [ Смех. ]
Барт: Я имею в виду те изменения, которые вы сделали, когда пришли к 3
версии Т^Х'а. 7 и 8 битов и то, что могло считаться ошибкой (?). Есть ли еще
что-нибудь в этом роде?
Дон: Думаю, что в статье «The Errors of ТеХ»1 я перечислил все, что можно
считать ошибкой. Думаю, что я заметил бы неправильное предвычисление of
7-bit versus 8-bit input(?), если бы написал статью на год позже, но я написал
ее до выхода версии Т^ХЗ. Я пообещал поместить этот результат в статье,
когда все успокоится, и вы будете знать, что последняя ошибка Т^Х'а найдена.
[ Смех.] Итак, вот что мы имеем на сегодняшний день, [на экране появляется
файл errorlog.tex2; см. рис. 8.]
Последнее изменение было сделано 19 марта. Хотя нет, это день, когда
была замечена ошибка. Ее обнаружил Петер Брайтенлонер, который сегодня
находится здесь, и звучит она так: «Исключаются ложные подсчеты ссылок в
форматных файлах». Это вызвало некоторые проблемы. Он обнаружил, что
можно нарушить работу Т^Х'а, если сохранять форматные файлы и потом
опять загружать, потом опять сохранять и опять загружать, и так сотни раз;
вы исчерпаете память, потому что подсчет ссылок станет больше, чем общий
объем памяти. Эта ошибка была зафиксирована, и он получил за нее $327.68 —
215 пенни.
1 «The errors of Т]еХ», Software—Practice and Experience 19 (1989), 607-685; переиздана с
дополнениями и исправлениями как главы 10 и 11 Literate Programming. См. также «Notes
on the errors of T^X», TUGboat 10 (1989), 529-531; это был основной мотив выступления на
10 ежегодной конференции TUG, которая проходила в Станфорде в июле 1989 г.
2 Файл errorlog.tex находится в архиве CTAN в директории systems/knuth/errata/.
Другие файлы, упомянутые ниже, например, tex82.bug, также можно найти в этой
директории.
Глава 31. Вопросы и ответы, I
593
* 26 June 1993
R928\>668. Avoid potential future bug (Peter Breitenlohner). 0628,637
* 17 December 1993
S929\>881. Boundary character representation shouldn't depend on font
memory size (Berthold Horn). 0549,1323
* 10 March 1994
R930. Huge font parameter number may exceed array bound (CET). 0549
* 4 September 1994
F931\>926. Math kerns are explicit (Walter Carlip). 0717
R932. Avoid overflow on huge real-to-integer conversion. 0625,634
* 19 March 1995
R933. Avoid spurious reference counts in format files (PB). 01335
\relax
\bye
Рис. 8. Конец файла errorlog.tex.
Каковы другие самые последние изменения? Номер 932: «Исключаются
переполнения при преобразовании действительных чисел в целые». Номер 931:
«Математические керны являются явными» —это была ошибка, порожденная
изменением 926. Номер 930: «При большом числе параметров шрифта границы
массива могут быть нарушены» — это то место, где не было полной ясности.
Номер 929: «Границы представления символов не должны зависеть от
размера памяти шрифта»—это очень серьезное изменение, которое было сделано
вскоре после предыдущего обновления в 1993 г.
Перечисленные здесь даты этих ошибок — это даты их обнаружения. Я
зафиксировал их в марте этого года [1995]. Я планирую вернуться к ним опять
в 1997 году, затем в 2000, затем в 2004 и 2009, надеясь каждый раз потратить
на это один день. Множество добровольцев, которых сейчас здесь нет,
обрабатывает и исследует эти ошибки. Вчера, когда мы тестировали программы в
Станфорде, кто-то заметил, что мы до сих пор пользуемся очень старой
версией Т^Х'а, а проблем вроде бы и не возникает. [ Смех.] Надеюсь, что ошибки
начинают сходить на нет. Оставшиеся ошибки могут разрушить систему; но
только если вы очень постараетесь.
Есть одна серьезная ошибка в дизайне, которая должна остаться как
характерная, и она возникает, когда речь идет о наборе на нескольких языках.
Кажется, я не поместил ее в файл errorlog, но она есть в конце другого
файла под названием tex82.bug (рис. 9). Взгляните сюда ... Этот файл содержит
все подробности о каждом изменении, начиная с 1982 года. Видите вот это?
Это «самое последнее изменение в ТЕХ'6* которое должно быть сделано после
моей смерти». Номером версии станет 7Г. Это нечто вроде моей последней воли
и завещания. [Смех.] Таким образом, я никогда не узнаю, что это изменение
сделано. В TfejX'e версии 7Г ошибок не будет. Все, что носит имя TfejX, должно
быть полностью совместимым друг с другом.
594
Компьютерная типография
415. The absolutely final change (to be made after my death)
Ox module 2
Qd banner=='This is TeX, Version 3.14159' {printed when \TeX\ starts}
Qy
Qd baimer=='This is TeX, Version $\pi$' {printed when \TeX\ starts}
Qz
When this change is made, the corresponding line should be changed
in Volume B, and also on page 23 of The TeXbook. My last will and
testament for TeX is that no further changes be made under any
circumstances. Improved systems should not be called simply 'TeX';
that name, unqualified, should refer only to the program for which
I have taken personal responsibility. — Don Knuth
* Possibly nice ideas that will not be implemented
. classes of marks analogous to classes of insertions
* Design errors that are too late to fix
. additional parameters should be in symbol fonts to govern the
space between rules and text in \over, \sqrt, etc.
. multilingual typesetting doesn't work properly when the \lccode
changes within a paragraph
* Bad ideas that will not be implemented
. several people want to be able to remove arbitrary elements of
lists, but that must never be done because some of those elements
(e.g. kerns for accents) depend on floating point arithmetic
. if anybody wants letter spacing desperately they should put it in
their own private version (e.g. generalize the hpack routine)
and NOT call it TeX.
Рис. 9. Конец файла tex82.bug.
После последнего изменения в этом файле перечислены «неплохие идеи,
которые я хотел бы осуществить», а затем две «ошибки дизайна, которые
слишком поздно фиксировать». Самая серьезная касается случая
многоязычных текстов. Если вы используете несколько языков в одном абзаце, я забыл
сохранить часть информации —я не помню точно, что там используется1, но
это серьезная оплошность, и я должен над ней подумать. Сейчас это делать
слишком поздно; это единственная оставшаяся помеха.
Единственное, над чем я хотел бы поработать усерднее, — это
расположение квадратных корней и линеек в дробях. У меня нет достаточного количества
параметров, чтобы контролировать величину пробела между линейкой и
текстом. Я совершил ошибку, решив проблему, требующую двух параметров, с
помощью только одного параметра: я получил величину пробела, подсчитав
ее как кратную толщине линейки, тогда как пробел нужно рассматривать как
Для всех языков в абзаце должна использоваться одна и та же таблица \lccode.
Глава 31. Вопросы и ответы, I
595
независимый параметр. Теперь я обнаружил это, так как пишу статью и вижу,
что квадратный корень выглядит неправильно. Поэтому я должен помещать в
показатель степени скрытые распорки, чтобы пробел был больше. Я хотел бы,
чтобы это было сделано лучше, но учитывая неизбежные компромиссы моей
большой системы, я доволен тем, как все происходит.
Когда я читаю статьи, набранные в ТЁХ'е, меня больше всего беспокоит (не
считая набора квадратных корней) то, что люди не используют обновленные и
улучшенные шрифты Computer Modern, которые я выложил 3-4 года назад?
До сих пор применяются старые шрифты, и я не знаю, сколько еще времени
должно пройти, прежде чем люди их поменяют. Примерно 2-3 месяца назад
Эберхард [Маттес] внес изменения в свою широко распространенную систему
етТЁХ.
Изменение шрифтов особенно хорошо видно на примере греческой
строчной дельты. Около четырех или пяти лет назад, работая над статьей, я
обнаружил, что избегаю использования буквы S. Я стал думать, почему я стараюсь
обходиться без этой буквы, и понял, что я ее подсознательно ненавижу, потому
что мне не нравится, как она выглядит. Но в этой статье мне действительно
была необходима дельта, поэтому я взял выходной и переделал эту букву, в
результате чего получилась по-настоящему красивая дельта. Я думаю, что
теперь у нас есть самая лучшая дельта из всех, которые когда-либо видело
человечество. [Смех.] Это было давным-давно. И теперь, когда я вижу, что
люди пользуются старой дельтой, меня коробит.
Я также изменил несколько других букв, например, некоторые
рукописные прописные буквы. Я выдвинул горизонтальный штрих буквы 1'Н\ а кроме
того мне не нравилось основание буквы 'Т'5 и я поменял эту букву на "Г'.
Я вижу, что голландская группа использует в своем логотипе старую букву Т
... однако я надеюсь, что все будут пользоваться шрифтами cmr. Файлы TFM не
изменились. Да, я еще сделал все стрелки более мощными ('—>' превратилась в
'-»'). При ксерокопировании стрелки пропадали, поэтому теперь острие стало
больше и ярче.
Камерон Смит: А на какую дату или номер версии мы должны
ориентироваться?
Дон: Исходный файл должен быть датирован 93 или последующими годами,
и тогда все будет нормально.
Сильвио: Нет! Нужно поменять cm на dm! Пока вы этого не сделаете,
никакого обновления не произойдет.
Дон: Да, это происходит в большинстве случаев, но это те пакеты, где не
обновлены старые файлы. Если вы используете DVIPS, то все, что вам нужно
сделать,— это удалить файлы РК, и новые шрифты установятся
автоматически.
Сильвио: Если у вас есть новая версия исходников.
Дон: Все исходники здесь.
1 См. http://vvv-cs-facuity.Stanford.edu/~knuth/cm.html.
596
Компьютерная типография
Сильвио: Да, но очень трудно ...
Дон: Пожалуйста, найдите способ решить эту проблему, а то меня это
расстраивает. Каждый раз, когда я получаю письмо от кого-то, кто
пользуется старой дельтой, я пишу ему, что надо попросить программистов обновить
шрифты, и тогда он присылает мне новый вариант статьи и говорит, что да,
теперь все нормально. [ Смех.] Поскольку люди знают об этом. Не так уж много
нужно менять. Если мы сообщим об этом дистрибьюторам и математическим
журналам, то изменения не займут много времени.
Робин Фэрбэрнз: Можно я это прокомментирую? Эберхард Маттес
является автором версии, которой пользуется наибольшее число людей, и он уже все
обновил, а месяц назад разработал новый комплект шрифтов. В списке
рассылки мы сталкиваемся с постоянным нытьем типа «нам не нужны проблемы
с обновлением наших шрифтовых файлов». Я не устаю повторять: «Но вам
действительно необходимо это сделать». Несмотря на это, люди говорят, что
компьютерное время на их PC стоит дорого.
Дон: Через 5 лет у них будут новые PC. [Смех.] Все равно это произойдет.
Я только надеюсь, что ждать придется не очень долго.
Сильвио: Я послал копию в Австралию. Хочу сказать вам, что ради дельты
никто не будет делать обновлений. А вот если вы выпустите новую версию с
собственным номером и новым названием и если вы сделаете ее обязательной,
тогда ...
Дон: От того, что она будет обязательной, ничего не изменится.
Джереми Гиббоне: Если вы измените название, старые файлы DVI не будут
работать при печати, так как будет много недостающих шрифтов.
Дон: Правильно. Но это не самое главное. Видимо, я большой педант: я
просто рассказываю вам о том, что меня раздражает, но, очевидно, это не
раздражает остальных. [ Смех. ]
Сильвио: Меня это тоже раздражает!
Дон: Ну хорошо. Как бы там ни было, я не хочу менять названия моих
шрифтов, [пауза.] Нельсон?
Нельсон Бийби: Дон, с 1978 года мир сильно изменился —
Дон: Да, и это подтверждает великолепная цитата Билла Гейтса, которую я
привел в этом году в начале списка ошибок ... (рис. 10).
Нельсон: Если бы вы были на 25 лет моложе и приступили бы к разработке
TfejX'a сейчас, когда рынок полон процессоров, лазерных принтеров PostScript
и прочих вещей, что бы вы сделали по-другому?
Дон: Думаю, что я все сделал бы так же. Я бы оставил все, что вам не
нравится! [ Смех.] Так уж я устроен ...
Камерон: Я хотел задать вам один вопрос, связанный вот с чем. Вы
проделали большую работу при создании алгоритма разбиения текста на строки
внутри абзаца, и кажется, что существует масса возможностей для
оптимального разбиения. Но в книге The T^Kbook я прочел, что памяти компьютера
Глава 31. Вопросы и ответы, I
597
\vfill
{\quoteformat
Things have changed in the past two decades.
\author BILL GATES (1995)
7. "You, too, can start a software firm"
7. International Herald Tribune 5 Jan 1995, pages 9 and 11
\bigskip
In addition to the errors listed here,
about half of the occurrences of 'which' in volumes one and three
should be changed to 'that'.
\author DONALD E. KNUTH ({\sl The Art of Computer Programming 7.
Errata et Addenda}, 1981)
\eject
}
Рис. 10. Фрагмент из списка ошибок ТАОСР.
недостаточно для того чтобы разбить подобным образом несколько страниц
текста. Выходит, что между алгоритмом разбиения на строки и алгоритмом
разбиения на страницы нет достаточной связи. Если, например, вы пишете
письмо, и на первой странице у вас есть шапка, то у вас должна быть
другая ширина страницы и вам может понадобиться другое разбиение строк в
середине абзацев. Это можно было бы упростить, если бы была возможность
работать с частью страницы и если связь между алгоритмами разбиения на
строки и на страницы была бы лучше. Собираетесь ли вы переделывать что-
нибудь сейчас, когда компьютеры обладают мощной памятью?
Дон: Да, конечно, возможности памяти сейчас совсем другие.
Удивительно, как сильно изменилась память, — больше, чем что-либо другое. Мы долго
накапливали опыт и теперь мы понимаем многое из того, что не понимали
раньше. Когда я работал над ЧЩХ'ом, многие вещи были на уровне
эксперимента, и это давало возможность учиться. Когда вы создаете систему нового
поколения, то оказывается, что вы поняли систему предыдущего поколения и
привели ее в порядок, а затем вы будете ставить новые эксперименты,
которые будут приведены в порядок следующим поколением. Так обычно растет
уровень понимания, и так устроен мир.
Сейчас начинает проясняться то, какая связь лучше. Основная идея TgX'a
заключается (и я думаю, всегда будет заключаться) в том, чтобы найти
наименьшее количество примитивов для создания большинства главных вещей. В
результате 99% работы выполняется с помощью этих примитивов, а остальная
часть делается вручную. Я не ставил цели создать систему, которая выполняла
бы 100% работы, но я ожидал, что ручная работа сведется к минимуму.
Наведение лоска занимает ничтожный процент времени, потраченного мною на
другие части работы. Конечно, в понятие минимума разные люди вкладывают
разный смысл.
598
Компьютерная типография
Например, я работал над книгой о Библии1, где помещено много
иллюстраций. На каждую я потратил 6-7 часов: я возился с ними, занимался
цветоделением, чистил, высветлял, в общем, всячески их совершенствовал. С моей точки
зрения, это работа на уровне помех, потому что на написание главы с
иллюстрациями я уже потратил 40 часов. Так что эти 6 часов — небольшой процент
работы.
Но если я нахожусь в коммерческом учреждении, где нужно заниматься
графикой, и эта работа оплачивается, и если я должен сделать 60
иллюстраций и потратить на каждую по б часов, то это совсем другое дело. Поэтому
я думаю, что у разных пользователей есть разные представления о том, что
нуж^но автоматизировать. Автору сравнительно легко потратить немного
лишнего времени на какие-то детали, потому что он уже потратил гораздо больше
времени на написание книги. Но те люди, которые работают с авторами,
наверняка захотят, чтобы все это было автоматизировано и чтобы это было частью
волшебной системы, на изучение которой авторы не желают тратить времени.
Итак, если я должен выполнить некую полиграфическую работу в 2 или
3 прохода, я просто пробую пару раз, прогоняю ее через машину, смотрю
через визуализатор и привожу все в порядок. Неделю или две назад мы с
женой выпустили информационные бюллетени для нашей семьи. Мы делаем
это ежегодно; дело в том, что у наших четырех бабушек и дедушек есть
куча родственников, примерно по 60 или 80 человек. Мы пишем им письма с
просьбой прислать новости за последний год, а затем собираем всю
информацию в маленькие буклеты и рассылаем их по четырем направлениям. Каждый
год я вожусь с этим материалом б или 8 часов, как редактор
информационного бюллетеня, чтобы все выглядело красиво. ... Вы затрачиваете какое-то
время на то, чтобы навести глянец. Те инструменты, которые есть в вашем
распоряжении, всегда меняют ваши ожидания.
Я считаю, что следующее поколение систем будет обладать множеством
более сложных механизмов для выполнения общих задач, т. е. тех, которые я
причислил к 99%. В процессе набора книги могут возникнуть любые
осложнения—возможно, вам потребуется в качестве точки отсчета взять середину
знака, а не левое поле, когда вы двигаетесь налево и направо, используете при
этом цвет, поворот или несколько столбцов и т. д. Теперь мы лучше понимаем,
как создать такие общие механизмы.
Что касается памяти ... я думаю, что разбивка на страницы не так уж
сильно ограничена памятью — вам потребуется сделать это в 2 прохода, но
машины теперь обладают достаточной скоростью. В общем, люди будут работать
на компьютерах следующего поколения с учетом опыта работы на предыдущих
системах.
Пожалуйста, Пьер.
Пьер Макей: Я хотел бы вернуться к вопросу обновления шрифтов. Я
думаю, что нужно нечто такое, что не приводило бы к сбоям. Чтобы иденти-
1 Donald E. Knuth, 3:16 Bible Tetits Illuminated (Madison, Wisconsin: A—R Editions, 1990);
см. обзор в TUGboat 12 (1991), 233-235.
Глава 31. Вопросы и ответы, I
599
фицировать версию шрифтов, вы вставляете в METRFONT команду special.
Так как люди обновляют свои драйверы гораздо чаще, чем шрифты, нужно
только, чтобы драйвер распознал команду' special и сказал: «Нет-нет! Вы не
можете пользоваться этим шрифтом!» [Смех.]
Фред Бартлетт: Я думаю, что все, что выступавший ранее хочет сделать с
разбивкой на строки и на страницы, можно было бы достаточно легко
осуществить с помощью умеренно сложных макро и новой программы вывода, если
бы была возможность сохранять элементы, которые выбрасываются в конце
каждой страницы. Вы хотите сохранить эти выброшенные элементы, когда
Т^Х вызывает программу вывода. Меня интересует, почему, когда вы
писали ТЕХ, вы сделали так, что все это выбрасывается, и нет возможности это
сохранить?
Дон: Программа вывода может поместить их в бокс — скопируйте их в бокс —
Фред: —но нельзя сохранить выброшенный пробел между строками.
Дон: Разве выброшенный пробел не является значением одного из
параметров, которые сохраняются в программе вывода?
Петер Брайтенлонер: Штраф сохраняется, но пробел выбрасывается
после того как страница напечатана. А если ничего не возвращается, то он не
выбрасывается.
Дон: Где-то в книге The ТЁКЬоок приводится нулевая программа вывода,
которая предполагает, что все сохраняется. Разве она не работает?
Питер: Работает. Потому что в этом случае пробел находится не наверху.
Фред: Но вы не можете упрятать страницу, вы не можете поместить
страницу в бокс и вернуться назад, создать новую страницу и поместить ее во второй
бокс, как при расположении текста в 2 колонки, а затем соединить оба бокса
вместе, чтобы все выглядело гладко, поскольку пробел между ними будет
потерян. А это значит, что если вы хотите расположить сложный текст в 2 колонки
(я делал пару таких книг), то вы столкнетесь с проблемами при создании
таблиц, рисунков и тому подобных вещей. Я бился над этим б или 7 лет, и лучшее,
что я смог сделать, —это добиться, чтобы Т^Х выдавал мне предупреждение,
когда он приступает к выравниванию колонок, начиная с правой, потому что
у меня нет там нужного пробела. Почти все в TgX'e вписывается в параметры:
вы можете делать что-то, сохранять, просматривать результат, тестировать, —
все, кроме элементов и пробелов, которые уничтожаются. Я просто хочу знать,
почему это так.
Дон: Видимо, потому что я не подумал об этом. [ Смех.] Программа вывода
была в наибольшей степени экспериментальной частью ТЁХ'а. У нае не было
моделей, которым мы могли бы следовать. Нам нужно было разрешить 4 или
5 проблем, и мы пытались сделать это с помощью минимального количества
примитивов. Настал момент, когда мы смогли внести ясность в решение этих
проблем. Но мы знали, что все это было на уровне эксперимента. Жаль, что
ваша проблема не возникла до появления версии Tg^ 3.0, потому что она могла
бы меня соблазнить ... [ Смех. ]
600
Компьютерная типография
Фред: Вы, кажется, сказали, что предполагаете, что люди будут шире
использовать ТЕХ, чем раньше.
Дон: Да, безусловно. Я думаю, что T^jX будет использоваться в специальных
изданиях, таких как Encyclopedia Britanica или арабско-китайский словарь,
либо в крупных проектах. Я никогда не считал, что какой-нибудь экзотический
проект можно выполнить с помощью одного инструмента. Поэтому я встроил
в код множество специальных приемов (hooks), и благодаря этому специалист
за неделю сможет достаточно легко установить новую программу для особых
случаев. Таков был мой план. Но я не думаю, что люди будут этим очень часто
пользоваться.
Мне обязательно нужно это сделать. Если бы я выпускал Библию или
что-нибудь в этом роде, или если бы я был издателем, стремящимся
выполнить какую-то работу особенно хорошо, то мне был бы нужен специальный
инструмент для набора. Переписать систему набора достаточно легко. [ Смех. ]
Я полагаю, что многие люди не делают этого, потому что они боятся что-
нибудь нарушить. Думаю, они и не станут этого делать. Мне кажется, это
лишняя предосторожность. Я пытался показать, как это делать, с помощью
некоторых особенностей Т^Х'а, как если бы они были добавлены потом. Но
это их не убедило. Множество людей продолжает работать в TgK'e на уровне
макро. Конечно, большое преимущество заключается в том, что вы можете
совместить вашу программу вывода с другими — ваши исходники будут
работать на любых системах. Однако я считаю, что специальные проекты требуют
большого количества пользовательских версий программы. Но это пока не
случилось.
Джереми: В связи с этим такой вопрос ... Если разобрать вертикальный
бокс на составные части, поиграть с ними и снова его собрать, то есть одна
вещь, которая у вас не получится. Если бокс сдвинуть влево или вправо, когда
вы его разбираете, то вы потеряете эту информацию. [Дон: Ну да?] Вы можете
задать команду \lastbox и получить бокс, но эта команда не скажет вам, был
ли он перемещен. По-моему, я видел в вашем списке плохих идей, с которыми
непонятно что делать, что-то связанное с разбиранием на части. Это так?
Дон: Я не уверен что действительно упоминал о чем-то подобном. Нельзя
быть уверенным в том, что ни у одного пользователя не будет доступа к
результатам с округлением погрешностей, которые на разных машинах разные.
Поэтому мне надо быть очень осторожным с Т^Х'ом, чтобы он оставался
мобильным—каждый раз, когда производится подсчет клея. Хотя я не думаю,
что это произойдет при сдвиге влево и вправо. Одним из последних изменений
в ТЁХ'е в недавнем прошлом было ... не помню что. Может быть, кто-нибудь
вспомнит ... например, Петер [Брайтенлонер]. По-моему, это именно вы
предложили: было что-то в подпрограммах hlist.out и vlisLout, что контролировало
величину сдвига бокса и ... ?
Петер: Это было в отточиях. Для боксов отточий нужно следить за
величиной сдвига, но в структуре данных это значение всегда было равно нулю ...
Глава 31. Вопросы и ответы, I
601
Т^Х брал величину сдвига, прибавлял ее и снова вычитал или что-то в этом
роде.
Дон: Да, дело в том, что у меня там есть некий код —это не ошибка, потому
что от него никогда никакого вреда не бывает — но я всегда добавлял к чему-
нибудь ноль. Мы убрали это, чтобы никого не смущать. Величина, на которую
сдвигается бокс, заложена в боксе. Если текст расположен вертикально, то это
величина сдвига вправо, а если горизонтально, то это величина сдвига вверх и
вниз. Величина сдвига в боксах отточий никогда не может быть ненулевой. В
общем, это значение не установлено должным образом, возможно, это ошибка
и в 1997 году вы получите за нее большие деньги. [ Смех. ]
Джереми: Я не считаю это ошибкой, я думаю, что это просто проблема, с
которой вы не смогли справиться, и она касается разбирания и собирания на
части Ведь это было сделано не нарочно?
Дон: Вообще-то количество подобных вещей было слишком большим, чтобы
все их предвидеть, и я рад, что их не оказалось еще больше. Простите, если
что не так.
Камерон: Здесь задавалось много вопросов типа «почему вы сделали то-то
и то-то?», но я думаю, что на самом деле надо спросить вот о чем: если бы
вы делали это снова, как это пытаются сделать некоторые люди, могли бы вы
что-то этим людям посоветовать? Важно не то, почему вы сделали это 20 лет
назад именно так, а не иначе. Но если кто-то займется этим снова, скажете ли
вы им, о чем нужно подумать в первую очередь?
Дон: Я просто рекомендую обратить особое внимание на дизайн и
тестирование, а также привлечь для помощи большое количество пользователей, чтобы
они показали вам, с какими проблемами они столкнулись, и посмотрели как
можно больше примеров. Конечно, это уже делается. Нужно расставить все
точки над i, и для этого придется много работать в течение длительного
времени. Чем больше вы делаете открытий или осознаете, как много вам предстоит
решить, тем больше времени уходит на полное решение всех проблем.
Самыми тяжелыми являются усилия, направленные на конвергенцию
вместо дивергенции. Вам требуется загрузить множество разных исходников, но
при этом нужно избежать синдрома коллектива ... вам понадобится
небольшое количество людей, которые могут сделать так, что все сходится. Иначе
во всех коллективных проектах вы столкнетесь с большой проблемой,
которая заключается в том, что каждый член коллектива доволен только своей
частью конечного результата. Кроме того, у вас будет много несовместимого
материала, в основном, по политическим причинам. Очень трудно произвести
детальную проверку как можно большего количества вещей на предмет
согласованности и конвергенции. Проблема управления была самым тяжелым
аспектом развития TgK'a.
Если вы изучите статью «Ошибки I^X'a», вы увидите, как шел процесс.
Вначале существовал один пользователь, и я потратил много времени,
чтобы удовлетворить свои запросы. Затем у меня появилось 10 пользователей, и
возник целый уровень новых трудностей. Затем появилось 100 пользователей,
602
Компьютерная типография
а с ними и другой уровень проблем. Потом было 1000 пользователей, йотом
10 000, и все это были необходимые специальные фазы развития. Я не мог
заниматься с 10 000 человек, пока я не разобрался с тысячью. Но каждый
раз, когда проходила новая волна изменений, возникала идея улучшить 1EJK, а
не разнообразить его для выполнения новых задач. Поэтому когда я говорил,
что в основном я все делаю так же, как и раньше, я имел в виду, что у меня
по-прежнему есть горизонтальные и вертикальные списки, боксы, клей и т. д.
Эти основные структурные принципы позволяют максимально использовать
небольшое количество концепций и иметь дело с разными видами набора. Но
я не говорил, что поступил бы точно так же с величиной сдвига. Все эти вещи
чрезвычайно важны, но я буду сохранять ту же основную структуру.
Барбара: Нам пора заканчивать. Я хочу поблагодарить Дона за то, что он
нашел время ответить на все вопросы. Позволю себе задать последний вопрос:
сможете ли вы сделать это снова в 2011 году, через 16 лет?
Дон: Вполне вероятно. [ Смех.] 32 — это не так захватывающе, но тоже
ничего. Большое спасибо. [Бурные аплодисменты.]
Рис. 11. Президенты TUG'a, присутствовавшие на 16 ежегодной конференции: Пьер
Макей (1983-1985), Барт Чайлдс (1985-1989), Дон Кнут (1977-1980), Нельсон Бийби
(1989-1991), Кристина Тиле (1993-1995), Мишель Гуссенс (1995-1997). Фото Люции
Дитше.
Примечания переводчика
1. Перевод текста на рис. 2:
Страница xi замена для упражнения 3 25 марта 1995
3. [34] Леонард Эйлер предположил в 1772 г., что уравнение w4 + х4 + у4 = z4
не имеет решений для положительных целых чисел, но в 1987 г. Ноам Элкис
доказал, что существует бесконечно много решений [см. Math. Сотр. 51 (1988), 825-835].
Найдите все целые решения, такие, что 0<w<x<y<z< 106.
4. [М50] Докажите, что если п — целое число и п > 4, уравнение wn + xn + yn = z11
не имеет решений для положительных целых чисел w, x, у, z.
Глава 31. Вопросы и ответы, I
2. Перевод текста на рис. 9 (завещание Д. Кнута):
415. Самое последнее изменение (должно быть сделано после моей смерти
Ox module 2
Qd banner=='This is TeX, Version 3.14159' {printed when \TeX\ starts}
Gy
Qd banner=='This is TeX, Version $\pi$' {printed when \TeX\ starts}
Qz
Когда это изменение будет сделано, должны быть изменены и
соответствующие строки в томе В, а также на с. 23 The TeXbook.
Моей последней волей по отношению к ТеХ'у будет запрет на любые
изменения при каких бы то ни было обстоятельствах.
Усовершенствованные системы не должны носить имя ТеХ; это имя
должно относиться только к моей программе, за которую я несу
персональную ответственность. — Дон Кнут
* Возможно неплохие идеи, которые не будут внедрены:
. классы пометок, аналогичные классам вставок
* Ошибки дизайна, обнаруженные слишком поздно
и потому не зафиксированные:
. в символьных шрифтах должны быть дополнительные параметры
для управления расстоянием между линейками и текстом
в \over, \sqrt, и т.п.
. когда внутри абзаца меняется \lccode, многоязычный набор
работает некорректно
* Плохие идеи, которые не будут внедрены:
. некоторые хотят иметь возможность удалять произвольные
элементы списков, но это никогда не будет работать, потому что
некоторые из таких элементов (керны или акценты, например)
зависят от арифметики с плавающей точкой
. если кто-то остро нуждается в разрядке, он может сделать это в
своей собственной версии (например, обобщить подпрограмму hpack),
но НЕ называть это ТеХ.
'«&*$< ^^/Л^^ЩЩгЩ
Вопросы и ответы, II
[Заседание, посвященное ответам на вопросы в Карловом университете в Праге
9 марта 1996 г. Впервые опубликовано в журнале TUGboat 17, (1996, 355-367)
под редакцией Кристины Тиле и Барбары Битон.]
Карел Горак: [Вступительное слово на чешском, затем на английском
языке.]
Я очень рад, что у меня есть возможность представить вас, профессор
Кнут, нашей аудитории, которая в основном состоит из членов чехословацкой
группы пользователей TgX'a CsTUG, а также из нескольких академиков из
Праги, так как это заседание организовано группой CsTUG и математическим
факультетом Карлова университета. Мы очень рады видеть вас здесь, и я буду
счастлив вручить вам от имени Карлова университета специальную медаль.
[ Бурные аплодисменты. ]
Дон Кнут: [Удивленно.] Большое спасибо.
Профессор Иван Нетука: Профессор Кнут, дорогие коллеги, дорогие
друзья, леди и джентльмены. Я горжусь тем, что мне выпала честь приветствовать
профессора Дональда Кнута, так же, как большинство из вас гордится тем, что
находится в этом зале, благодаря декану физико-математического факультета
Карлова университета профессору Бедрику Седляку.
Насколько я знаю, профессор Кнут приехал в Прагу первый раз.
Несмотря на это, он здесь очень известен, и не только среди всех математиков и всех
специалистов по информатике, но и среди многих физиков и даже среди тех,
кто не имеет отношения к этим наукам. Здесь понимают значение
монографии Дональда Кнута The Art of Computer Programming. Многие из нас имели
возможность прочитать прекрасную брошюру Surreal Numbers. Мы знаем, что
любимый способ Дональда Кнута описать информатику — это сказать, что она
является изучением алгоритмов. Мы разделяем точку зрения, что изучение
алгоритмов открыло множество новых интересных математических проблем и
что оно дает стимул многим областям математики, страдающим от недостатка
новых идей.
Мой личный опыт — опыт математика — показывает, что для каждого
математика существует такая личность, вклад которой в его область чрезвычайно
Глава 32. Вопросы и ответы, II 605
Вогнутая сторона памятной медали (в натуральную величину).
велик. Здесь мы видим редкий случай, когда в этом утверждении порядок
может быть обратным: существует такая личность, вклад которой для каждого
математика велик, чрезвычайно велик. И вот мое краткое доказательство:
Дональд Кнут — TfeX.
Профессор Кнут, в знак признания ваших достижений в информатике,
математике, а также в компьютерной полиграфии, которая дала обществу
отличный инструмент для представления научных результатов, факультет
математики и физики Карлова университета постановил наградить вас памятной
медалью факультета. Я счастлив вручить ее вам. [Бурные продолжительные
аплодисменты. ]
Дон: Ну что же, очень красивая медаль и приятный сюрприз. Думаю, что
все могут подойти и посмотреть на нее.
«Universitas Carolina Pragensis» — значит, тут все знают латынь, наверное,
и мне придется сегодня говорить на латыни. [ Смех. ]
Мои познания, касающиеся чешского языка, невелики, но кое-что я
пытался выучить. На этой неделе на многих дверях я видел слово «Sem». [Смех.]
А когда я сегодня пришел в эту аудиторию, я видел много надписей «TgX».
[ Смех.] Поэтому я подумал, что надо бы создать особо мощную версию TgX'a
[пишет на доске «SemT^jK».]; [смех усиливается.] но кто знает, не опасно ли
это ...1
1 «Sem» — чешское слово, означающее «здесь, в этом месте»; надпись на двери означает
«от себя». «Semtex» — мощное пластиковое взрывчатое вещество, разработанное и
выпускаемое в Чешской республике (а также название нескольких компьютерных вирусов).
Компьютерная типография
Выпуклая сторона с изображением печати Карлова университета в центре.
Сегодня я не подготовил лекции, но хочу поговорить о том, что вам
интересно, т. е. ответить на ваши вопросы. Это традиция, которой я придерживался
в Калифорнии: самое последнее занятие в Станфорде я посвящал ответам на
вопросы. Я говорил студентам, что они могут не приходить на это занятие,
но если придут, то я отвечу на любые их вопросы. Эту традицию я перенял у
профессора [Ричарда] Фейнмана в Caltech. И сегодня я решил поступить так
же. Это очень хорошая идея, и я рекомендую всем преподавателям отводить
последние занятия на вопросы и ответы.
Недавно я сделал в Интернете несколько страничек, которые вы
можете посмотреть по адресу http://www-cs-facuity.Stanford.edu/~knuth. Там
я поместил ответы на все часто задаваемые вопросы. Но сегодня вы можете
задавать мне печасто задаваемые вопросы. [ Смех. ] Кстати, расскажу вам
еще одну шутку, а потом мы начнем. Вы знаете, как выглядит сайт OJ —
О. J. Simpson-—в США? Вот так: «http colon slash slash slash backslash
slash escape». [Смех.]
А теперь задавайте, пожалуйста, вопросы, [пауза.]
Ну что же, если вопросов больше нет ... [ Смех.) Вы можете говорить
по-чешски, а кто-нибудь потом переведет.
X: Может быть, начнем с такого вопроса? Я тщательно изучил Т^Х и
столкнулся с проблемой, когда меня попросили взять интеграл с тильдой. Я
обнаружил, что, видимо, в ЧЩХ'е такого нет, потому что мы не можем определить
поправку на курсив к боксам.
Глава 32. Вопросы и ответы, II
607
Дон: Поправка на курсив — это ... С каждым символом связано
ограниченное количество информации, относящейся к структуре символа; [рисует на
доске] у нас есть высота, глубина, ширина и поправка на курсив.
высота
глубина
ширина
Вот и все предусмотренные числа. А в математическом режиме поправка на
курсив используется по-другому. В математическом режиме поправка на
курсив часто используется для нижних индексов. Это та величина, на которую вы
должны сдвинуть нижний индекс влево. Без поправки на курсив Tg^
напечатает «Р sub n» (Рп) вот так: Рп.
Поправка на курсив к знаку интеграла —это, видимо, другой случай,
потому что в больших операторах поправка на курсив используется для того,
чтобы компенсировать смещение между нижним и верхним пределами. В
любом случае, здесь есть только одно число. Если вам нужна особая
конструкция, требующая большего количества чисел, то единственный известный мне
способ — создать для этого специальный макро. Я бы поместил информацию
где-нибудь на уровне ТЁХ'а, но не внутри и не в символе. Вам потребуется
создать такую структуру, где будет присутствовать эта информация. Я не знаю
сейчас общего решения, но, безусловно, если вы нацишете ... я даже не могу
сейчас вспомнить названия ... в общем, это тот же самый механизм, с
ПОМОЕТ def
щью которого можно поместить что-либо над знаком равенства, например = .
Это определено в plain ТЁ^'е с помощью макро1 ... Я бы построил это вне
таких примитивов, но если у вас другие интегралы, вам нужно, чтобы тот, кто
разработал шрифты ...
X: Я нашел решение, но не с помощью ТЁХ'а. Для создания специальных
символов я использовал METflFONT ...
Дон: Да, использование METfl FONT — это идеальный способ достичь нужного
результата, но тогда всем придется иметь ваш код METflFONT'a и
компилировать ваш шрифт. Просто комбинируя боксы и клей, вы можете должнцм
образом расставлять имеющиеся символы. Вы можете просто создать \vbox
или \vcenter чего-нибудь, а затем поместить какой-нибудь \hbox с керном,
затем тильду и т. д. Я не знаю другого простого способа все точно выполнить,
кроме балансировки, так как в случае со знаками интеграла все усложняется
видимыми пропорциями — очень сложно учесть все случаи.
поправка на курсив
1\buildrel.
608
Компьютерная типография
Моя философия относительно Т^Х'а заключалась в том, что я хотел
получить систему, которая с легкостью справлялась бы с 99% всех случаев, и я
знал, что всегда что-то еще останется. Но я понимал, что этот остаток
понадобится только тем, кто очень заботится о своих статьях, и если они потратят на
это только 1% своего времени, то смогут радоваться своему вкладу и их будет
согревать мысль, что они смогли добавить что-то свое. Поэтому я не пытался
все автоматизировать. Я считаю, что следует подумать о том, что еще
можно автоматизировать, но я не верю, что когда-нибудь будет автоматизировано
абсолютно все.
Карел Горак: Мне очень интересен ход ваших мыслей: когда вы начали
думать о создании Т^Х'а и системы для набора книг, то в какой момент вы
поняли, что вот также понадобятся и некоторые буквы, т. е. нужен не только ТЕХ,
но и METflFONT? Я не слишком много знаю о всех шрифтах, используемых в
компьютерном наборе, но думаю, что не так уж много шрифтов подошло бы
для ЧЩХ'а. Так может быть, вы с самого начала стали думать о METAFONT'e?
Дон: Именно так.
Давайте вернемся в май 1977 года. Я сел перед компьютером и начал
писать для себя меморандум, в котором формулировал свои представления о
хорошем языке для набора. Через две недели я начал работать над
шрифтами. У меня намечался годичный отпуск для научной работы, и с конца 1977
по начало 1978 года я не должен был вести занятия. Я думал, что напишу
систему для набора только для себя и своего секретаря. [ Смех. ] Я не
предполагал когда-нибудь увидеть ЧЩХ на щитах на трамвайных остановках в Брно
[смех] или на афишах в знаменитых соборах. ТЕХ предназначался для моих
личных целей, и у меня был год на его создание. И я думал, что это будет
легко. Итак, в мае 1977 года я отправился в Xerox PARC, место, где
зародились и внедрялись идеи мышей, окон, интерфейсов и тому подобных вещей. Я
знал, что там имеют дело со сплайнами и графической формой букв. Я увидел
за компьютером Батлера Лэмпсона, который подбирал сплайны для контуров
увеличенных букв, и подумал: «Пожалуй, я заключу на этот год трудовое
соглашение с фирмой Xerox PARC и буду пользоваться их техникой для создания
шрифтов».
Я с самого начала знал, что хочу иметь шрифт, облеченный в чисто
математическую форму; я хотел иметь нечто такое, что могло бы быть
приспособлено к технологии по мере ее изменения, и поэтому мне нужно было иметь
математическое описание букв. К сожалению, в фирме Xerox мне сказали:
«Пользуйтесь, пожалуйста, нашим оборудованием, но учтите, что все ваши
разработки станут собственностью нашей фирмы». Я не хотел, чтобы какая-
то часть моей работы стала чьей-то собственностью, и не хотел, чтобы люди
платили деньги за пользование моей системой ... Математическая формула —
это просто числа, так почему кто-то должен владеть этими числами?
Поэтому я работал только в Станфорде в лаборатории искусственного
интеллекта, где было очень примитивное оборудование. У нас были телекамеры,
и мое издательство Addison—Wesley очень мне помогло: оттуда мне прислали
Глава 32. Вопросы и ответы, II
609
контрольные оттиски моей книги The Art of Computer Programming. Этот
процесс 60-х годов, которому я собирался подражать, был весьма любопытным:
один экземпляр печатался на монотипе на хорошей бумаге, затем этот
экземпляр фотографировали и делали распечатки уже с фотографии. Издательство
Addison—Wesley предоставило мне тот самый экземпляр, с которого делались
фотографии. Я наводил на него телекамеру и шел от телекамеры к экрану
компьютера, чтобы скопировать формы буквы. В то же время мы могли соединить
наши дисплеи с телевизором и подключаться к телефильмам; люди смотрели
на названия фильмов, брали кадры из фильмов и затем делали шрифт. Нужно
было ждать большего количества серий фильма Star Trek или чего-нибудь в
этом роде, чтобы получить весь алфавит; в конце концов нам встретилось
название с буквой «х». Так в то время мы пытались получить шрифт с помощью
телевидения.
Я думал, что это будет легко, но я сразу же заметил, что стоит мне чуть-
чуть убавить яркость, как буквы становятся более жирными. Существовало
огромное количество вариантов, и я видел на своем экране, что между
буквами, которые я сделал в понедельник и во вторник, нет абсолютно никакого
сходства. Одна буква была толстой, другая тонкой, а между тем это была
одна и та же буква, просто яркость была сильно увеличена. Это и сейчас так:
если вы сканируете страницу текста и меняете порог между черным и белым,
то даже небольшие изменения совершенно преображают букву. Поэтому я не
смог использовать телевидение.
Следующая попытка состояла в том, что моя жена сфотографировала
страницы, а затем мы принесли домой наш проектор и спроецировали
страницы в длинном коридоре. Я пытался скопировать буквы со стены. Но тут
я понял, что разработчики этих шрифтов руководствовались вполне
определенными идеями. Между буквами была некая логическая связь. Возьмем,
например, буквы 'т', 'п', Т и Т. Я заметил, что ширина 'т' равна 15
единицам, ширина 'п' —10 единицам, а ширина Т — 5 единицам. Ага! Существует
какой-то шаблон! Ширина Т равнялась 5 единицам, ширина 'Р — 6 единицам,
а ширина лигатуры 'fi' —10 единицам. Итак, если срезать верхушки
некоторых букв, то можно увидеть четкую ритмичность 5 единиц между основными
штрихами букв. Здорово —в дизайне были правила! И тогда мне пришло в
голову, что, может быть, нужно не копировать формы буквы, а попытаться
понять логику. И я смогу сделать полужирный шрифт по тем же правилам,
что и светлый прямой шрифт.
Таким образом, правда заключалась в том, что вначале я не знал, что
делать со шрифтами. В конце мая 1977 года я начал думать о создании METfl-
FONT'a.
Я провел лето 1977 года в Китае, оставив моих студентов в Калифорнии и
велев им за время моего отсутствия разработать ТЕХ. [ Смех. ] Я думал, что это
будет очень легко: к моему возвращению T^jX будет готов, и я смогу взяться за
шрифты. Но когда я вернулся, то понял, что задал им неразрешимую задачу.
Они, несомненно, много потрудились над тем, чтобы T^jX печатал по одному
символу на одной странице, и это было великим достижением, поскольку мои
610
Компьютерная типография
инструкции были весьма туманными} Я считал инструкции четкими, однако
никто не понимал, насколько они расплывчаты, пока не была сделана попытка
разъяснить их компьютеру. И написать программу.
В тот период, когда я не был в Китае, т. е. в июне, в первой половине июля,
в сентябре, октябре и ноябре, я большую часть времени занимался
созданием шрифтов. И я должен был это делать, потому что тогда не было способа
получить шрифт, который выглядел бы точно так же на другой технике.
Существовало много хороших шрифтов, но каждый из них был разработан для
какого-то конкретного устройства. Не было такого шрифта, который подходил
бы двум устройствам. А сотрудники фирмы Xerox PARC, в первую очередь,
Дж*он Уорнок, все еще разрабатывали свои идеи; в конце концов, в 1982 году
они основали фирму Adobe Systems. И теперь с помощью многих выдающихся
разработчиков они создали множество красивых шрифтов. Но это произошло
позже, более чем через 5 лет после того, как мне потребовались не зависящие
от платформы шрифты.
Моя лекция в Американском математическом обществе была
запланирована на январь 1978 года. В стенограмме этой лекции2 отражена работа над
шрифтами, которую я проделал в 1977 году. Эта работа потребовала гораздо
больше времени, чем я мог себе представить. Я думал, что будет несложно
получить нечто привлекательное, но это было лет за шесть до того как я получил
то, что выглядело удовлетворительно.
Итак, первая важная идея состояла в том, чтобы с помощью
математических определений разработать шрифты, которые могли бы использоваться
на разных компьютерах и наборных машинах, включая будущие устройства,
к тому моменту еще не изобретенные. Вторая идея заключалась в постижении
замысла. Я не просто копировал рисунок букв, но пытался постичь их логику.
Моя цель заключалась в том, чтобы понять замысел разработчика, а не просто
скопировать результат этого замысла.
До мая 1978 года я не работал в ТЁ^'е; сначала я сделал шрифты. Для
статьи «Математическая типография», в которой было отражено мое
выступление в Американском математическом обществе в январе 1978 года, я сделал
специальные буквы высотой около 4 см. Каждую из них я поместил на большой
лист бумаги и сфотографировал.
Вот такой длинный ответ. Надеюсь, я ответил на ваш вопрос.
Карел: У меня еще один вопрос относительно вашей системы: когда вы
начали изучать полиграфию, у вас уже были какие-то знания или вы овладевали
ими постепенно в процессе изучения? У меня сложилось впечатление, что в
книге The ТЁКЬоок очень много написано о типографском наборе. Вы сумели
очень глубоко изучить полиграфию, гораздо глубже, чем некоторые
профессиональные наборщики, использующие системы с окнами и мышками. По
книгам, которые прилагаются к этим системам, никогда не изучишь полиграфию
на таком уровне.
См. гл. 25 данной книги.
См. гл. 2 данной книги.
Глава 32. Вопросы и ответы, II
611
Дон: Спасибо. Итак, каким был мой багаж знаний до 1977 года? Когда я
учился в средней школе —это такой американский вариант европейской
гимназии—я подрабатывал набором на мимеографической машине. Я не знаю, с
чем это можно сравнить. На мимеографе у вас есть нечто вроде синего
желатинового материала. Литера печатной машинки бьет по нему и получается
отверстие. Я также использовал освещенный стол и специальные карандаши
и пытался писать ноты и делать рисунки на трафаретке мимеографа. Летом
я печатал, а потом использовал мой резец для вырезания картинок на геле.
Поэтому у меня есть некоторые сведения о полиграфии. Конечно, качество
печати было не бог весть каким, все выглядело очень непрофессионально,
однако я понял, что могу постичь этот процесс. После изготовления трафаретов
я работал на мимеографе, резал бумагу и т. д. Я делал это в качестве ученика.
Позже в подвале нашего дома появился печатный станок, на котором мой
отец выполнял работу для нескольких школ Милуоки; делалось это в целях
экономии денег, поскольку школы не могли позволить себе иметь
профессионального печатника. Он также делал работу для некоторых наших друзей-
архитекторов. Школам были нужны программки концертов или выпускных
вечеров, билеты на футбольные матчи, и мой отец все это делал в нашем
подвале. Он начал с мимеографа, затем стал пользоваться машиной под названием
VariTyper, которая была чудесной, потому что на ней получались
пропорциональные пробелы —одни буквы были шире других. Шрифты были ужасными,
но у нас была эта машина, и я научился с ней обращаться.
Еще позже я начал писать The Art Of Computer Programming. Поэтому
к 1977 году я прочитал тысячи гранок. Безусловно, я обращал внимание на
типографский набор. Можно сказать, что типографская краска была у меня в
крови.
Но я также знаю, что инженеры часто делают ошибку, не обращая
внимания на традиции прошлого. Они думают, что начинают все на голом месте,
и я считаю ужасным такое отношение к делу. Поэтому в мае 1977 года, когда
я только собирался уйти в отпуск на год и посвятить его созданию системы
для набора книг, я совершил поездку вместе с членами Станфордской
библиотеки—группой любителей книг из Станфорда* Мы посетили Сакраменто
и Калифорнию, где жили другие библиофилы. Мы остановились в музее
типографского дела, где была страница из Библии Гутенберга и тому подобные
экспонаты. У одного человека, живущего в горах, был собственный ручной
станок, и я имел возможность попробовать поработать на нем. Всюду, где мы
путешествовали, я внимательно смотрел на буквы, представляя себе, как
компьютер сможет их нарисовать. И я также видел коллекции самых лучших
образцов печати.
В Станфордской библиотеке есть замечательная коллекция типографского
материала, переданная в дар Морганом и Элин Гунст, которые всю жизнь
собирали образцы красивой печати. Как только я вернулся из поездки, я узнал
о коллекции Гунстов, поэтому провел май и июнь за чтением работ Гауди и
1 См. записи, завершающие гл. 24 данной книги.
612
Компьютерная типография
Цапфа, а также других книг по истории предмета, которые я смог найти. Это
было замечательно, но я хотел быть уверенным в том, что смогу отразить в
компьютерной форме опыт предыдущих поколений.
Главная моя идея тогда заключалась в следующем. Во времена моей
молодости компьютеры могли иметь дело только с числами. Потом появились
компьютеры, которые помимо чисел, имели дело с прописными буквами. При
этом возможности самовыражения сильно возросли. Но даже при подготовке
1-го тома The Art of Computer Programming, в котором я описал мой
компьютер MIX я не ожидал, что компьютеры смогут обрабатывать строчные буквы.
[ Смех. ] Язык Pascal был разработан в 1970 году, и там использовались только
прописные буквы, а также скобки, запятые, цифры, всего 64 символа.
Позже, в начале 70-х годов появились и строчные буквы, и появилась
возможность готовить на компьютере документы, выглядевшие почти так же,
как те, которые были набраны типографским способом. Затем появилось
программное обеспечение, такое как юниксовская система eqn, с помощью которой
можно было готовить документы к печати. Вы, вероятно, знаете, что системы
troff и eqn, предназначенные для математиков, были разработаны в
лабораториях Bell. Фактически эти системы были разработаны как расширение
программы, которая началась в M.I.T. в 1961 году. Она прошла около 5 стадий
усовершенствования, и в 1975 году появилась система eqn.
Таким образом, я знал, что есть возможность готовить на компьютерах
документы все более высокого качества, которые выглядели бы почти как книги.
Обдумывая ТЁ^, я сказал: «Пришло время пройти весь этот путь. Не надо
пытаться приблизиться к лучшим книгам, а надо пройти весь путь до конца и
сделать эти книги!» Моя цель заключалась в создании системы, которая бы
делала лучшие книги из всех, которые когда-либо были выпущены, за
исключением, конечно, дополнений, сделанных вручную, вроде золотого листика и
тому подобных вещей. [ Смех. ] А почему бы и нет? Пора было найти
стандартное решение для всех проблем и получить самый лучший результат, а не
просто пытаться делать лучше и лучше то, что уже есть. Вот почему я
прочитал все другие работы, какие только смог найти —я хотел, чтобы от меня
не ускользнула ни одна мысль. Когда я читал книги из коллекции Гунстов,
чтобы увидеть, что эти книги могут рассказать мне о типографском наборе
и очертаниях букв, я пытался понять, как все это соотносится с сегодняшним
днем и как я могу обучить этому компьютер. Конечно, я не во всем преуспел,
но я попытался найти мощные примитивы для воплощения большинства идей,
которые формировались на протяжении сотен лет.
Безусловно, сейчас у нас есть многолетний опыт, и мы знаем, что
возможностей тонких усовершенствований гораздо больше, чем я мог предположить
в 1980 году. Работа над проектом заняла больше года, и в результате
пользователей стало больше одного. Последующая эволюция описана в моей статье
«The errors of TfejX», в ней же рассказано обо всем, что было после 1978 года?
1 Software — Practice and Experience 19 (1989), 607-681. Перепечатано с дополнениями в
Literate Programming (1992), 243-339.
Глава 32. Вопросы и ответы, II
613
В 1980 году мне посчастливилось встретиться со многими мировыми
лидерами полиграфии. Они смогли многому меня научить, заполнить пробелы в
моих познаниях. Мастера обычно не записывают то, что они знают. Они
просто делают это. Поэтому в книгах нельзя найти все, и мне пришлось учиться у
разных людей. Что касается шрифтов, то интересным было то, что там было
2 уровня: существовал дизайнер шрифтов, который рисовал форму знака, и
пуансонист, который вырезал шрифт. Дизайнер мог написать книгу, но пуан-
сонист этого не делал. Я узнал об оптическом обмане — наш глаз видит не то,
что на самом деле есть на странице. Поэтому пуансонист не следовал рисунку
строго, а искажал его таким образом, что после того, как все было напечатано
и вы смотрели на букву в правильном размере, вы видели то, что нарисовал
дизайнер. Пуансонист знал, как делать правильные искажения.
Некоторые из этих трюков уже не применяются на наших лазерных
принтерах, поскольку они предназначались только для старых видов шрифтов. Но
другие трюки по-прежнему необходимы, так как они позволяют избегать клякс
и тому подобных вещей. После того как я проделал первоначальную работу над
METRFONT'om, я пригласил Ричарда Саутолла в Станфорд; он работал в
университете в Рединге с людьми, которые, по существу, являются пуансонистами
наших дней. От него я получил необходимые мне дополнительные знания.
Например, когда штрихи должны выглядеть совершенно одинаково, некоторые
из них на самом деле чуть тоньше, как внутренняя часть буквы Р — вы
хотите, чтобы она была не такая толстая, а немного тоньше; затем, когда у вас
будет остальная часть буквы, тонкий штрих будет выглядеть как правильный.
Ричард рассказал мне о таком способе улучшения. Подобным вещам я
научился у Чака Бигелоу, Мэтью Картера, Криса Холмса, Герарда Унгера, Германа
Цапфа и других.
Однако в те времена у нас было очень примитивное оборудование, поэтому
шрифты, которые мы могли генерировать с низким разрешением, выглядели
непрофессионально. Они были всего лишь дешевым подобием хороших
шрифтов. Тогда Станфорд не мог позволить себе иметь дорогие наборные машины,
с помощью которых мы могли бы осуществить свои замыслы. И теперь я очень
счастлив, что у нас есть такие машины, как LaserJet 4, с помощью которых
мой шрифт выглядит так, как мне всегда хотелось, на недорогой машине.
X: Теперь, когда PostScript начинает так широко использоваться, считаете
ли вы, что он может успешно заменить METflFONT? Сейчас мы можем
использовать Т^Х и PostScript ...
Дон: Вопрос заключается в том, является ли PostScript достаточно
хорошей заменой METflFONT'y? Я думаю, что у имеющихся PostScript-шрифтов
отличное качество, несмотря на то, что они не используют всех улучшений в
METflFONT'e. Они отличаются дизайном высокого качества. Шрифты Multiple
Master имеют только 2 или 3 параметра, тогда как шрифты Computer Modern
имеют более 60 параметров, но даже только с двумя или тремя шрифты Myriad
и Minion выглядят отлично.
614
Компьютерная типография
Сейчас я работаю с сотрудниками фирмы Adobe, поэтому стало проще
заменить шрифты Multiple Master на шрифты из ТЁХ'овских документов. Цель
заключается в том, чтобы сделать файлы PDF меньше. В системе Acrobat
файлы PDF раз в десять больше файлов DVI, но если вам не надо было скачивать
шрифты, то они были бы больше только в три раза. В формате Acrobat
можно искать команды и достаточно хорошие электронные документы. Поэтому
я пытаюсь упростить процесс замены шрифтов Multiple Master. Пока еще они
носят не вполне общий характер, хотя, безусловно, мне нравится их качество.
Авторы шрифтов из фирмы Adobe, такие как Кэрол Твамбли и Роберт
Слимбах, — это мастера высокого класса; я же был просто любителем. Дизайн
моих шрифтов вполне устраивает меня в том отношении, что я могу их
использовать в своих собственных книгах, но я бы не осмелился предложить их
остальным. Мне очень нравятся шрифты, которые делают другие дизайнеры.
Просить художника шрифтов стать до такой степени математиком, чтобы
создать шрифт с 60 параметрами, — это уж чересчур. Специалисты в области
информатики понимают, что такое параметры, остальная же часть
человечества не имеет об этом понятия. Лет пять назад большинство людей не знало
даже самого слова «параметры», и до сих пор это слово остается загадочным.
Для человека, занимающегося информатикой, при автоматизации чего-нибудь
наиболее естественным является попытаться показать, как будет изменена
программа в соответствии с разными спецификациями. Однако для большинства
людей это вовсе не является естественным. Большинство привыкло в работе
отталкиваться от поставленных задач и давать ответ на конкретную
дизайнерскую проблему. Они не хотят давать ответ на все возможные дизайнерские
задачи и объяснять, как приспособить решение к каждой задаче. С другой
стороны, специалисту в области информатики легко понять связь между
вариацией параметров и вариацией программ.
Кто еще?
Ладя Льготка: У меня к вам вопрос: как вы решили написать программу
для ТЁХ'а и документировать ее?
Дон: Я разговаривал с Тони Хоаром, который был редактором серии книг,
издававшихся в Oxford University Press. Наша беседа состоялась примерно в ...
1980 году; я пытаюсь вспомнить точно, может быть, в 1979 году, да, наверное,
в 1979, когда я был в Ньюкасле. Не помню точно. Он сказал мне, что я должен
опубликовать мою программу для Т^Х'а*
В процессе написания Т^Х'а я второй раз в жизни пользовался системой
под названием «структурное программирование», которая произвела
революционный переворот в способе программирования, принятом в середине 70-х
годов. Я занимался преподаванием и знал, что люди пользуются структурным
программированием, но с 1971 года я не писал больших компьютерных
программ. В 1976 году я написал свою первую структурную программу, которая
1 Впоследствии я посмотрел запись и обнаружил, что моя память сильно меня подвела.
До Хоара дошли слухи о моей работе, и он написал мне в Станфорд письмо с предложением
об издании. Я ответил на это письмо 16 ноября 1977 года —гораздо раньше, чем я думал.
Глава 32. Вопросы и ответы, II
615
была довольно большого размера —что-то около 50000 строк кода, точно не
знаю. (Это уже другая история, и когда-нибудь я могу вам ее рассказать.)
Это дало мне некоторый опыт написания легко читаемых программ.
Несколько позже, когда я начал писать Т^Х (я начал работу над Т^Х'ом в октябре
1977 года и закончил в мае 78), я сознательно использовал идеи структурного
программирования.
Профессор Хоар искал примеры программ достаточно большого размера,
которые можно прочесть. Вообще-то для профессора информатики это очень
рискованно —показать кому-нибудь большую программу. В лучшем случае он
может опубликовать маленькие подпрограммы в качестве примера того, как
писать программы. И мы можем наводить лоск, пока ... ну, в общем,
каждый пример в литературе о таких программах содержит ошибки. Тони Хоар
был пионером в области испытания программ на корректность. Но если бы
вы посмотрели на детали ... читая некоторые статьи, я обнаружил, что могу
найти три ошибки в программе, которая была признана правильной. [Смех.]
А ведь это были маленькие программы. И вот он говорит: «Возьми мою
большую программу и обнародуй ее со всеми ее рискованными местами». Конечно,
я разработал ТеХ таким образом, что он мог продолжить многовековую
историю разных идей. Там должны были быть погрешности. Поэтому перспектива
показать кому-нибудь свою программу меня испугала. Но потом я осознал всю
необходимость примеров больших программ, которые можно рассматривать
как образцы хорошей практики, а не просто маленькие программы.
Некоторые ценные идеи я почерпнул у одного бельгийца, чья система
описана в моей статье по документированному программированию. Он прислал
мне отчет о своей системе на 150 страницах1, на который, по-видимому, его
вдохновил труд «The spirit in the machine». Первые 99 страниц этого отчета
представляли собой философский трактат, а сотая страница начиналась с
примера. И этот пример открыл мне глаза на то, что программа должна выглядеть
как гипертекст (как мы видели сегодня). Он предложил разбивать сложную
программу на маленькие части. Чтобы понять сложное в целом, нужно просто
понять маленькие части и связь между каждой частью и соседней с ней.
В феврале 1979 года я разработал систему под названием D0C и UND0C ...
нечто вроде системы WEB, которая появилась позже. D0C была похожа на WEAVE,
a UND0C — на TANGLE. Я поиграл с D0C и UNDOC и сделал а макет из маленькой
части TgX'a. я не использовал D0C целиком, а взял внутреннюю часть, которая
называется getnext, самую сложную часть Т^Х'овской программы загрузки,
и конвертировал ее в D0C. Получилась маленькая 20-страничная программа,
которая показывала ТЦХ'овскую часть getnext, написанную в DOC'e. Я показал
ее Тони Хоару и некоторым другим, а главное —Луи Трабб Пардо, и получил
от них кое-какой материал, связанный с идеями и форматом.
Потом у нас в Станфорде был студент Забала — испанец с двумя
фамилиями. Мы звали его Иньяки, а вообще его звали Игнасио. Он взял весь ТЕХ,
который я написал на языке под названием SAIL (Stanford Artificial Intelligence
1 Pierre Arnoul de Marneffe, Holon Programming (Universite de Liege, Service d'Informatique:
December 1973).
616
Компьютерная типография
Language — Станфордский Язык Искусственного Интеллекта), и
конвертировал его в Pascal в формате D0C. Эта версия Т^Х'а распространилась по миру
к 1981 году. Позже, в 1982 году, когда я писал ТЦХ82, я смог использовать
его опыт и все материалы, которые он получил от пользователей, и создал
систему, которая стала системой WEB. Это был двухнедельный период, когда мы
подбирали разные названия для D0C и UND0C, и победителями стали TANGLE и
WEAVE. В те времена в Станфорде каждую пятницу собиралось около 25 человек
для обсуждения компьютерной полиграфии. У нас был для обсуждения целый
ворох идей, и в этом, в основном, заключается успех Т^Х'а и METflFONT'a.
Другая программа, которую я писал в то время, называлась Blaise, потому
что это был препроцессор к Pascal. [ Смех. ]
Петр Олыпак: У меня два вопроса. Что вы думаете о ГДТ^Х'е с точки зрения
расширения TfejX'a на уровне макрокоманд? Я думаю, что ТЕХ был создан в
соответствии с философией plain ТЁХ'а, что означает, что пользователь прочитал
книгу The ТЁКЬоок ... [ Смех.], тогда как IAT^X создан с помощью
макрокоманд на основе plain ЧЩХ'а. И второй вопрос: почему ТЁ^ не используется в
коммерческих фирмах? Там пользуются только мышкой и программами,
построенными по принципу WYSIWYG.
Дон: Сначала вы спросили, что я думаю о lATEX'e. Мне всегда хотелось,
чтобы было много разных пакетов макрокоманд, предназначенных для
разных групп пользователей, a IAT^X, безусловно, является лучшим примером
такого пакета макрокоманд. Раньше было и много других. Но Лесли Лэм-
порт лучше всех понял, как сделать эту работу хорошо. Существует также
Лд/^-ТЁХ, и многие математики используют макро Макса Дьяса, известные
первоначально как MaxTgX и позже официально названные Facil ТЕХ — это
было до появления ГМ^Х'а. Майкл Спивак и Лесли Лэмпорт предоставили мне
очень важные материалы, связанные с тем, как я могу улучшить ТЁХ> чтобы
поддерживать такие пакеты. Я не хотел форсировать ... мне близка идея
системы макро, которую можно приспособить к специальным случаям. Сам я
не использую IAT^X, потому что у меня нет времени на чтение руководства.
[ Смех.] В iM^jX'e больше возможностей, чем это нужно мне. И кроме того, я,
конечно, достаточно хорошо понимаю ТЕХ, и дЛЯ меня легче не пользоваться
конструкциями высокого уровня, если это вне моего контроля.
Однако для многих людей IAT^X является более простой системой, в нем
автоматизированы те вещи, которые люди всегда хотят автоматизировать. На
мой взгляд, автоматизация касается в основном тех случаев, которые я считаю
небольшой частью работы в целом. Задача ручной настройки библиографии
не угнетает меня, однако других это очень раздражает. Я могу понять, почему
многие люди предпочитают такой стиль работы.
Кроме того, когда вы пишете в такой системе, как 1АТЁХ, вам проще
следовать правилам, которые позволяют другим программам понять структуру
вашего документа. Если вы работаете в plain ТЦХ'е, вас не связывает никакая
структура и вы можете вмешаться в любой процесс автоматизации
библиографии и тому подобных вещей в вашем документе. Если вы ограничите себя
Глава 32. Вопросы и ответы, II
617
одним видом основной структуры, тогда станут возможными другие процессы.
Таким образом, дисциплинированное использование ТЁХ'а может быть вполне
ценным. Оно допускает перевод в другие структуры, на другие языки и т. д.
Но я пользуюсь Т^Х'ом для большого количества разных случаев, где
гораздо труднее запастись впрок программами. ГАТ^Х находится на более
высоком уровне, и приспособить его к новым задачам непросто. Очень часто я
просыпаюсь утром и думаю, как сделать те или иные вещи ... или моя жена
приходит ко мне и спрашивает: «Дон, не мог бы ты сделать для меня то-то и
то-то?» Поэтому я создал 10 строк ТЁХ'овских макро, и вдруг получился новый
язык специально для такого рода документов. Многие из моих электронных
документов выглядят так, как будто в них нет никакой разметки.
Теперь, что касается вашего второго вопроса о том, почему T^jX
недостаточно используется в коммерческих публикациях. На самом деле я был
приятно удивлен, когда увидел, как много коммерческих изданий в Чехии
сделано в Т^Х'е. В четверг вечером я видел три или четыре чешско-английских
словаря, подготовленных в Т^Х'е, и, как вы знаете, ТеХ используется для
издания новой чешской энциклопедии. А Петр Сойка показал мне авангардный
роман, изданный в Т^Х'е, с некоторыми симпатичными фокусами,
касающимися новаторского вывода страниц. В Америке I^X используется исключительно
в легальных изданиях, а за кулисами —во многих крупных проектах.
У меня никогда не было намерения создать систему, которая была бы
универсальной и использовалась бы всеми. Я всегда хотел написать систему,
которая использовалась бы только для самых лучших книг. [ Смех. ] Я имею
в виду издания со сложным набором, либо такие, авторы которых согласны
были затратить дополнительные усилия для достижения отличного качества
полиграфии. Я никогда не рассчитывал на то, что T^jX будет конкурировать с
системами, созданными для массового пользователя.
В сущности, дух конкуренции мне чужд. Я чувствовал себя очень
счастливым от того, что работал над системой, предназначенной прежде всего
математикам. Насколько я знаю, ни один человек на свете не обиделся на меня за
то, что я упростил набор математических текстов. Наборщики считали
математические книги сущим наказанием и брались за них крайне неохотно.
Они воспринимали как штраф ужасную дополнительную работу по набору
математических текстов. Я никогда не ждал, что Т£Х вытеснит системы,
используемые в газетном издательстве и тому подобных учреждениях. Так
получилось, что после того, как T^jX стал использоваться, мы обнаружили, что
можно кое-что улучшить и в тех текстах, которые не связаны с математикой.
Например, в качестве эксперимента мы набрали заново страницу из журнала
Time, чтобы показать, насколько лучше она будет выглядеть, если применять
хороший алгоритм разбиения на строки} Но я вовсе не рассчитывал на то, что
такие журналы когда-нибудь будут пользоваться моей системой, потому что
это была индустрия, связанная с миллиардами долларов, и я не хотел оставить
кого-нибудь без работы или причинить другие неприятности.
См. рис. 28 и 29 из гл. 3 данной книги
618
Компьютерная типография
Поэтому мне было очень неприятно, когда я в начале 80-х годов
обнаружил, что существует человек, который очень расстроен тем, что я изобрел
ТЕХ. Он много трудился над созданием коммерческой системы набора
математических текстов, и теперь стал терять клиентов. Поэтому он написал в
фонд National Science Foundation письмо, в котором говорилось: «Я являюсь
налогоплательщиком, а вы пользуетесь выплаченными мною налогами, чтобы
помешать моему бизнесу». Это сильно меня огорчило. Я думал, что все, что
я делаю, направлено на общее благо, а оказалось, что есть человек, которому
я определенно навредил. Но я также подумал, что я все равно должен
сделать T^jX доступным всем, несмотря на то, что он был разработан с некоторой
помощью правительства. Я не думаю, что правительство должно было давать
финансовую поддержку только чисто академическим и бесполезным проектам.
Пожалуйста, ваш вопрос.
X: Мой вопрос связан с применением ваших типографских программ в
коммерческих учреждениях вроде мастерских DTP. Я бы хотел узнать об
использовании частей ТеХ'овского исходника. Вы объяснили, что программисты
могли свободно включать части ТЁХ'овского исходника в свои собственные
программы. Не могли бы вы привести несколько ярких примеров?
Дон: Этот же вопрос мне задавали прошлым летом на заседании TUG во
Флориде, которое было посвящено вопросам и ответам} Я думал, что будет
вполне обычным делом иметь специальные версии Т^Х'а. Я разработал Т^Х
таким образом, что у него внутри имеется много специальных приемов, и вы
можете писать дополнения и получать более мощную систему, которая уже
приспособлена к работе.
По-видимому, я думал, что в каждом издательстве, пользующемся ТЁХ'ом,
будет свой программист, который будет разрабатывать специальную версию
Т^Х'а, если понадобится издать Библию или арабско-китайский словарь или
еще что-нибудь специфическое. Если они будут издавать энциклопедию, у них
будет собственная версия Т^Х'а, применяемая для этой цели.
Макроязык полон по Тьюрингу — он может сделать все, но зачем нам
пытаться делать все на языке высокого уровня, если некоторые вещи можно легко
сделать на более низком уровне? Поэтому я встроил в Т^Х специальные
приемы и сделал эти части Т^Х'а демонстрационными, чтобы человек, который
читает код, мог видеть, как расширить ТЕХ для других целей. Мы
предусмотрели некоторого рода приемы для химических формул или для замены
горизонтальных штрихов, которые должны были быть сделаны в машинном
языке для специальных приложений.
Конечно, если бы я сам занимался издательским бизнесом, я бы имел
десять разных версий Т^Х'а для десяти разных сложных проектов. Все они
выглядели бы почти так же, как ТЕХ, но больше ни у кого не было бы точно
такой же программы — это было бы не нужно, поскольку никто бы не выпускал
книги точно так же, как мое издательство.
См. гл. 1 данного издания, слайд 21.
Глава 32. Вопросы и ответы, II
619
Я считал, что появится много таких специальных версий. И конечно, в
середине 80-х годов настал такой момент, когда более тысячи человек поняли
устройство ТЁХ'а. Они достаточно хорошо разобрались в сложностях
программы, они прочитали ее и если бы захотели, то могли бы создать много видов
дополнений. Но сейчас я должен сказать, что количество людей с рабочим
знанием устройства ТЁХ'а, больше ста, разумеется, но меньше тысячи. Моя идея
не получила такого развития, какого я ожидал.
Одним из наиболее крупных исправлений является то, что я видел на этой
неделе в Брно —студент по имени Тан1 создал систему, которая практически
выводит текст в формате PDF вместо DVI. Если вы введете \PDFon, то вывод
будет представлен в виде файла, который тут же может быть прочитан
системой Acrobat Reader. Десять лет назад я также считал, что пользователи будут
обращаться непосредственно к PostScript'y, но насколько я знаю, этого до сих
пор не произошло.
Никто пока еще не выпустил в Т^Х'е специальное издание Библии в том
виде, как я это предполагал. Некоторые расширения были сделаны в Исландии.
Я не помню, делали ли они это на более высоком уровне, но думаю, что в
основном они работали на уровне макрокоманд, а может быть, только в них.
В любом случае, я сделал возможным набор очень сложных вещей. Я
всегда считал, что если вы имеете дело со специальным приложением, то захотите
иметь специально настроенную программу, потому что так легче всего делать
подобные сложные вещи.
X: Я хочу узнать, какие особенности TgX'a существовали в первой версии.
Например, были ли в первой версии разбиение на строки, переносы и
использование макрокоманд?
Дон: Самая первая версия была разработана в апреле 1977 года. Там были
макро и алгоритм разбиения на строки. Он был еще недоработан; в то время
у меня еще не было всех этих штучек вроде \parshape, но с самого начала, с
1977 года, я знал, что буду обрабатывать абзац целиком, а не просто строчку
за строчкой. Алгоритм переносов у нас тогда был не тот, который мы
используем сейчас. Он был основан на перемещении приставок и суффиксов; это был
очень своеобразный метод, но он охватывал около 80% случаев. Я работал над
ним, просто заглядывая в словарь. Например, если слово начинается с «anti-»,
то после «i» ставится перенос; те же правила действуют в конце слова. -Или
если в середине слова появляется определенная комбинация букв, то там будут
переносы. Этот подход мне нравился больше, чем метод troff, опубликованный
ранее. Старый ТЁХ'овский алгоритм переносов описан в старом руководстве по
ТЦХ'у* которое можно найти в библиотеках?
Итак, вы спросили о разбиении на строки, переносах, макро и тому
подобных вещах. Я разработал язык макрокоманд следующим образом. Я
просмотрел 2-й том The Art of Computer Programming и выбрал из него наиболее
1 Han The Thanh; см. Petr Sojka, Han The Thanh, and Jiff Zlatuska, «The Joy of TEX2PDF —
Acrobatics with an alternative to DVI format», TUGboat 17 (1996), 244-251.
2 TjgX and METflFONT: New Directions in Typesetting (Bedford, Massachusetts: Digital Press,
1979).
620
Компьютерная типография
характерные части. Я сделал макет примерно из 5 страниц этой книги и
спросил себя, как бы мне хотелось, чтобы это выглядело в компьютерном файле.
И это был полный исходник дизайна?
Однажды вечером я задержался и сделал ТЕХ. Я прошелся по 2-му тому
и придумал инструкции, которые выглядели естественно —«Здесь я скажу:
'begin an algorithm', а затем —'Algorithm К', а затем —'algstep КГ». Так
получился небольшой файл, в котором представлен способ, которым я бы хотел
вводить текст книги The Art of Computer Programming. Файл также
содержал некоторые математические формулы. Формулы были созданы на основе
идей eqn\ язык troff демонстрировал способ представить математику так,
чтобы секретарши могли легко это выучить. В этом заключался дизайн. Затем
для поддержки этих возможностей я должен был создать макроязык.
Макроязык разрабатывался в течение 1978 года под влиянием Терри
Винограда. Терри писал книгу по лингвистике, по грамматике английского языка?
Он хотел использовать макро гораздо интенсивнее, чем я, поэтому я добавил
для него \xdef и экзотические параметры.
Алгоритм переносов, которым мы сейчас пользуемся, появился
благодаря исследованиям Фрэнка Лианга. Мы работали вместе с ним над методом
переносов, и его опыт позволил ему открыть лучший путь, который можно
приспособить ко всем языкам, т. е. ко всем западным языкам, в которых есть
переносы.
Чтобы разработать правила для правильных пробелов в математике, я
выбрал 3 стандарта качественного набора математических книг. Во-первых, это
были книги, выпущенные издательством Addison—Wesley, в частности, The Art
of Computer Programming. Сотрудники Addison—Wesley, особенно Ганс Вольф,
(именно он подавал идеи внутреннего оформления), создали стиль, который
в учебниках мне всегда нравился больше всех, когда я был студентом
колледжа. Во-вторых, я взял Acta Mathematica выпуска примерно 1910 года; это
такой шведский журнал ... его редактором был Миттаг-Леффлер. Его
жена была очень богата, и у них были большие возможности для качественной
печати математических текстов, поэтому в Acta Mathematica полиграфия
особенно хорошая. И третьим источником был экземпляр голландского журнала
Indagationes Mathematicae. В Нидерландах существует давняя традиция
качественной печати, и я выбрал выпуск 1950 года или около того, в котором
опять-таки особенно хорошо были выполнены математические тексты.
Я взял эти три стандарта и внимательно изучил все математические
формулы. Я измерил их с помощью телевизионной камеры Станфордского
университета, чтобы понять, насколько опущены подстрочные и подняты
надстрочные индексы, какие использованы шрифты, как сбалансированы дроби и т. д.
Я произвел подробные измерения и спросил себя, каким должно быть
наименьшее количество правил, чтобы я смог сделать все то, что сделали они. Я
1 См. этот отрывок в гл. 24 данного издания.
2 Language as a Cognitive Process, Volume 1: Syntax (Reading, Massachusetts: Addison—
Wesley, 1983).
Глава 32. Вопросы и ответы, II
621
понял, что могу свести все к рекурсивной конструкции, которая использует
только 7 типов объектов в формулах.
Я рад сообщить вам, что 3 года назад Acta Mathematica стала
использовать ТЕХ. Таким образом, круг замкнулся. Addison—Wesley, безусловно, тоже
пользуется Т^Х'ом, вот только не знаю насчет голландцев —я собираюсь к
ним на следующей неделе. [ Смех. ] Но в любом случае я надеюсь продолжить
хорошие полиграфические традиции.
Я должен дать слово тем, кто еще не выступал. Джордж?
Иржи Весели: У меня такой вопрос. Вас все время просят внимательно
рассматривать все предложения, касающиеся всяких усовершенствований.
Однажды меня спросили, есть ли возможность поместить в книге список всех
слов, в которых были сделаны переносы. В вашей книге я не смог найти
способа сделать это. Я бы хотел узнать вашу точку зрения относительно того, что
должно быть включено, а что нет. Что должно быть в специальном пакете, а
что в самом ТЁХ'е?
Дон: Вопрос заключается в том, что, по моему мнению, должно быть
основной частью ЧЩХ'а, а что — специальной или что-то в этом роде. Конечно, все
эти решения являются произвольными. Я думаю, было важно, чтобы все эти
решения были сделаны одним человеком, хотя ... Безусловно, я делаю много
ошибок. Я обращался к лучшим образцам, чтобы получить данные из многих
источников, но в конце концов я взял всю ответственность на себя, чтобы
сохранить некое единство. Всякий раз, когда вы работаете с группой людей над
созданием системы, каждый член группы вправе гордиться своим вкладом в
конечный продукт. Но потом вы получите гораздо менее унифицированный
результат, потому что в нем нашли отражение определенные веши,
удовлетворяющие вкусу того или иного человека. Я хотел угодить как можно большему
количеству людей, но при этом сохранить единство. Поэтому на протяжении
многих лет у нас было каждую пятницу двухчасовое заседание, на котором
присутствовали гости со всего мира. Я слушал их комментарии и пытался
включить в Т^Х лучшие идеи.
Теперь что касается вашего вопроса о том, почему нет простого способа
составить список всех переносов, сделанных в документе. Это очень интересное
предложение, и я не помню, чтобы кто-то задавал этот вопрос во время наших
еженедельных заседаний. Нас интересуют слова, которые действительно
перенесены. Решение сделать это осуществляется программой hpack, являющейся
частью алгоритма разбиения на строки. Но тот факт, что переносы
сделаны программой hpack, не означает, что это появится в последнем документе,
потому что вы могли выбросить бокс, в котором был сделан этот перенос.
В TgX'e очень легко набрать что-нибудь несколько раз, а потом выбрать
только один вариант для вывода текста. Поэтому, чтобы получить
определенные характерные примеры переносов, вам нужно зафиксировать их в
программе вывода по вашему усмотрению. Сейчас это несложно сделать в модуле,
специально написанном для Т^Х'а. Я бы сказал, что на самом деле вы сейчас
можете получить почти в точности то, что хотите, написав фильтр, который
622
Компьютерная типография
приказывает ТЁК'у включить все отслеживающие опции, которые помещают
что-либо в оглавление. Затем маленькая программа-фильтр будет отслеживать
информацию через UNIX и выдаст вам слова с переносами. Чтобы написать
такую программу, понадобится один вечер, ну может быть, два ... и одно утро.
[ Смех. ] Вы можете получить ее сейчас, но я не помню, обсуждали ли мы во
время наших еженедельных дискуссий по TEJX'y> должен ли я сделать такую
программу.
Моя статья «The errors of Ij^X» содержит полную запись всех изменений,
которые были сделаны с 1979 года, с датами и ссылками на код, когда точно
появилось каждое изменение. И вы можете видеть, каким путем шла эволюция.
Изменения часто появлялись в процессе написания книги The Т^КЬсюк, когда
я понимал, что мне очень трудно объяснить некоторые вещи. Я менял язык,
чтобы было проще объяснить, как им пользоваться. Это было тогда, когда
наши встречи с пользователями и другими подававшими идеи людьми были
наиболее массовыми; часть языка, о которой я писал, была частью, которая
менялась мгновенно.
В течение 1978 года я собственноручно набирал 2-й том, и это
способствовало усовершенствованиям, поскольку я имел дело с клавиатурой. На самом
деле, усовершенствования появлялись четко через 500 страниц. После каждых
четырех страниц у меня возникала очередная идея, как сделать I^X немножко
лучше. Но количество способов улучшить любую сложную систему
бесконечно, и аксиома заключается в том, что нет системы, которую нельзя было бы
усовершенствовать. Поэтому в конце концов я понял, что лучшее, что я
могу сделать, —это перестать совершенствовать систему. Это лучше, чем иметь
систему, которая все время совершенствуется.
Позвольте мне объяснить. Когда я занимался разработкой IgX'a в
лаборатории искусственного интеллекта Станфордского университета, там была
операционная система под названием WAITS, которую я считаю лучшей в
мире. Четыре программиста в течение всего рабочего дня совершенствовали эту
систему. Каждый день операционная система становилась все лучше и лучше.
И каждый день она ломалась, и ею долго нельзя было пользоваться.
На самом деле я написал первые наброски книги The T^Kbook
исключительно во время этих простоев в работе. По утрам я приносил в лабораторию
искусственного интеллекта большую порцию бумаги и сидел за компьютером
столько, сколько мог. Затем машина ломалась, и я садился писать очередную
главу. Потом машину налаживали, и я опять мог немного поработать. Потом
она опять зависала, и наступало время писать следующую главу. Наша
операционная система все время становилась лучше, но при этом я не мог долго
работать за машиной.
Через некоторое время деньги иссякли, и трое из четырех
программистов перешли в лабораторию Лоренса Ливермора и стали работать там над
новой операционной системой. Остался только один сотрудник, который
поддерживал систему, но больше не совершенствовал ее. И это было великолепно!
[ Смех.] В тот год моя работа была продуктивной, как никогда.
Глава 32. Вопросы и ответы, II
623
Поэтому я знал, что в конце концов надо будет где-то поставить точку и
больше не совершенствовать Т^Х. Это будет устойчивая и надежная система,
и пользователи поймут, какие у нее есть недостатки и чего она не сможет
сделать.
Я по-прежнему считаю, что лучше иметь систему, которая не является
движущейся мишенью. Людям в какой-то момент потребуется нечто стабильное
и не меняющееся. Конечно, если вдруг окажется, что может случиться нечто
катастрофическое, а мы не хотим, чтобы это случилось, то я внесу изменения
в ТЕХ, чтобы избежать потенциального бедствия. Но я больше не внедряю в
него новые заманчивые идеи.
Другие люди работают над расширениями ТЁ^'а, которые пригодятся
следующему поколению. И я бы им тоже настоятельно посоветовал в какой-то
момент сказать себе: «Вот здесь мы остановимся и больше ничего в нашей
системе менять не будем». Потом такая возможность будет у тех, кто придет им
на смену.
Карел: Я бы хотел спросить вас об идее курсивного шрифта в
математических текстах. Я никогда не видел в других учебниках, чтобы в текстах и в
формулах использовались бы разные курсивные шрифты, поэтому мне
хочется знать, принадлежит ли эта идея вам или вы позаимствовали ее из этих трех
источников?
Дон: Ни в каких других книгах я не сталкивался с идеей курсива для
текстов и математического курсива. Мне хотелось, чтобы математический курсив
выглядел как можно лучше, поэтому я начал с него. Но затем я обнаружил,
что текстовый курсив не так хорош, как математический, а поскольку у меня
был METflFONT, то мне ничего не стоило получить курсивный шрифт, который
выглядел бы лучше. Если бы я улучшил текстовый курсив, то подстрочные и
надстрочные индексы не могли бы быть расставлены так же.
Частично это объясняется тем, о чем я говорил раньше, —в ЧЩХ'е с
каждым символом имеют дело только 4 числа. У принтеров раньше было только
3 числа, и не было поправки на курсив. Поэтому они не могли автоматически
воспроизводить ТЕХ'овские пробелы; лучшие принтеры допускали
расстановку математических пробелов вручную. Однако сейчас курсивные шрифты всех
дизайнеров гораздо лучше, чем были раньше. За последние 10-15 лет
курсивные шрифты значительно усовершенствовались. Читая старые книги, вы
иногда думаете: «Неужели кто-то может прочесть этот курсив?» или
«Почему тут стоят такие странные пробелы?» Старые шрифты были основаны на
ограничениях типографского сплава. Понятие поправки на курсив в книгах
отсутствовало, но я считал необходимым получить нужный пробел.
Когда я показываю математические формулы дизайнерам шрифтов, они
не могут понять, для чего нужен математикам курсивный шрифт в
уравнениях. Например, нужно скомбинировать прямую двойку с курсивным х. И они
спрашивают: «А не станет ли этот процесс гораздо проще, если в
математике будет шрифт без наклона?» Дизайнер шрифтов Ян ван Кримпен однажды
работал в нидерландском городе Харлеме с известным физиком; я не помню,
624
Компьютерная типография
как его звали1. Кажется, это был второй человек, получивший нобелевскую
премию по физике. Он умер в двадцатых годах. В общем, они с ван Крим-
пеном собирались создать в Нидерландах новый математический шрифт, при
этом не предполагалось создавать математический курсив. Они хотели
унифицировать греческие буквы и другие математические символы. Но работа
остановилась из-за смерти физика, а ван Кримпен закончил только греческие
буквы, которые стали пользоваться заслуженной популярностью.
Несколько других дизайнеров шрифтов посетили Станфорд. Увидев
математический шрифт, они спросили: «А почему вы не используете шрифт без
наклона?» Герман Цапф предложил Американскому математическому обществу
создать новый математический шрифт, в который войдут готический шрифт,
специальные символы, греческие, рукописные и обычные буквы. Ключевая
идея состояла в том, чтобы не использовать наклонных символов, и таким
образом, х мог несколько смещаться вниз и вверх. Тогда было бы проще
расставлять символы и достигать равновесия. Герман создал серию разработок, и
комитет, состоящий из большого числа математиков, изучал эти разработки,
вносил свои замечания и занимался их настройкой?
Однако для математиков этот шрифт оказался слишком радикальным
изменением. Я знаю математиков, которые в своих работах пишут х с двойным
наклоном, чтобы он выглядел очень курсивным — только тогда они
воспринимают его как математический символ. Так что после того как в течение 300
лет математика печаталась курсивом, многие люди не могут от этого
отвыкнуть. Существует, наверное, всего два десятка книг, ну может быть, больше,
около сотни, где вместо курсива используется шрифт AMS Euler, но
большинство математиков считают, что он слишком отличается от курсива. С другой
стороны, я сейчас вижу, что шрифт Euler Fraktur используется практически
всеми.
В Брно я видел, что шрифт Euler Roman используется в
замечательной книге — чешском переводе Дюреровского «Апокалипсиса»? Я также видел
Euler Roman несколько дней назад в некоторых учебных записях. Однажды,
когда я был в Норвегии, я заметил, что на каждом компьютере был
наклеен ярлык с названием компьютера, набранным шрифтом AMS Euler, так как
он нравился людям. Это красивый шрифт, но им набрано не так уж много
математических книг.
Карел: Если вопросов больше нет, давайте поблагодарим профессора Кнута
за эту встречу. [ Бурные продолжительные аплодисменты. ]
Дон: Спасибо всем за прекрасные вопросы.
Карел: [ Заключительное слово на чешском языке. ]
1 Это был X. А. Лоренц. См. John Dreyfus, The Work of Jan van Krimpen (London: Sylvan
Press, Museum House, 1952), с 28.
2 AMS Euler—A new typeface for mathematics, Scholarly Publishing 20 (1989), 131-157;
вошло в данное издание как глава 17.
3 См. гл. 1 данного издания.
Вопросы и ответы, III
[6 января 1996 года Кес ван дер Лан оповестил NTG, голландскоговорящую
Группу пользователей TtfK'a о том, что Дональд Кнут в марте будет в
Голландии. Центр математики Mathematisch Centrum (MC, теперь он называется
Centrum voor Wiskunde en Informatica, CWI) пригласил Кнута произнести речь
на пятидесятилетии CWL Группа NTG посчитала это весьма удачной
возможностью организовать специальное собрание для всех голландских
пользователей TfeX'a и METRFONVa, кто хотел бы встретиться с самим Великим гуру.
К счастью, Кнут принял приглашение NTG, и встреча была организована 13
марта в «De Rode Hoed» в Амстердаме. В этом событии приняли участие около
35 человек со всей страны и даже из Бельгии. Все было записано на видео- и
аудиопленку Герардом ван Несом. Кристина Тиле добровольно вызвалась
сделать расшифровку, текст которой первоначально был опубликован в журнале
NTG: MAPS (Minutes and APpendiceS) 16 (1996), 38-49.]
Эрик Фрамбах: Приветствую всех на этом особом
собрании по случаю визита г-на Дональда Кнута в Голландию.
NTG посчитала, что было бы замечательно воспользоваться
предоставившимся шансом и попросить г-на Кнута ответить
на вопросы о ТЁХ'е, METflFONT'e и многом другом,
связанном с использованием Т^Х'а. К счастью, он согласился.
Итак, мы рады приветствовать здесь г-на Дональда Кнута —
спасибо за ваш приезд.
Сегодня у нас есть время задать ему все те вопросы, которыми мы
давно хотели его озадачить. [Смех.] Я уверен, что у каждого из вас имеется
несметное множество вопросов, мнение Великого гуру о которых вы хотели бы
узнать. Итак, давайте приступим к ним.
Дон Кнут: Я тоже начинаю задавать вопросы! [ Смех.]
В прошлую субботу я был в Праге и там было похожее собрание чешских и
словацких пользователей ТЁХ'а. Вам будет приятно узнать, что на той встрече
я видел довольно много экземпляров 4^Ё^ CDROM'ob1.
1 Популярный 4Т^Х-дистрибутив ТЁХ'а для ПК-совместимых компьютеров был
результатом коллективной работы членов NTG
626 Компьютерная типография
Это путешествие не первый мой визит в Амстердам: я был в Амстердаме
в 1961 году. Так что прошло всего лишь 35 лет, и, возможно, следующего раза
придется ждать меньше 35 лет. Я думаю, люди записывают на пленку эти
вопросы и ответы, чтобы я оставался честным, потому что в Праге они делали
то же самое. Так что если тот же вопрос будет задан снова, вам нужно будет
взять среднее от двух ответов. [ Смех. ]
Вице Дол: А вы знаете, что это из-за Барбары Битон? Она посылает тебе
письмо и говорит: «Записывайте все на пленку».
Дон: Да, в Праге они говорили то же самое! [ Смех. ] Я думаю, у нее
отчаянная нехватка материалов для публикации или, может быть, у нее просто
много вопросов. Но перед тем как вы начнете задавать вопросы, позвольте
сказать, что один из самых интересных вопросов, заданных мне в Праге,
прозвучал уже после собрания, и мне бы хотелось, чтобы он тоже был записан.
Вот этот вопрос: как я встретился с Дуэйном Бибби, который иллюстрировал
The T^Kbook и The METRFONTbook? Мне почему-то всегда хотелось, чтобы
люди узнали об этом.
Вот как это было. У меня была идея после многолетнего издания
математических книг сделать книгу с более причудливыми — ну, в любом случае, с
другими — иллюстрациями. А тут я писал книгу про книги, а в книгах бывают
иллюстрации, так почему бы и мне не обзавестись иллюстрациями? Поэтому
я написал художнику по имени Эдвард Гори. Кто-нибудь знает ...
Франс Годдейн: Да. Amphigorey1. Замечательно.
Дон: Да, Эдвард Гори. Amphigorey2. Его рисунки отличаются болезненным
воображением, но и прекрасным чувством юмора. Некоторые из его книг я
1 Amphi (гре-ч.) —с обеих сторон, Gorey — Гори — фамилия художника. — Прим. перев.
2 Amphigorey: Fifteen Books by Edward Gorey (New York: G. P. Putnam, 1972). Amphigorey
Too (New York: G. P. Putnam, 1975). Amphigorey Also (New York: Congdon & Weed, 1983).
Глава 33. Вопросы и ответы, III
627
давал своим детям. Мне казалось, что он бы вполне подошел. Я написал ему
два письма, но он так и не ответил. Потом я написал японскому художнику
Анно, Мацумасе Анно, который на самом деле является логическим
последователем Эшера1. Анно делает то же, что делал Эшер, только в цвете; поэтому
я спросил, не сможет ли он проиллюстрировать мою книгу. В ответ он прислал
очень милое письмо со словами: «К сожалению, у меня недостаточно времени
из-за других моих многочисленных занятий, но вот пять моих книг, полных
рисунков, и если вы хотите использовать какие-нибудь из них, то не
стесняйтесь». Очень мило, но я хотел, чтобы рисунки были сделаны специально для
меня.
Потом я пошел на вечеринку в Станфорде, где встретил даму,
пробовавшую свои силы в издательском бизнесе. Она только недавно познакомилась с
блестящим молодым художником и начала с ним работать. Я пригласил его к
себе домой, и мы провели вместе некоторое время — он замечательный
человек. Дуэйн сейчас живет в северной Калифорнии, примерно в четырех часах
езды от моего дома, так что я только один раз выбрался туда навестить его.
Он иногда бывает в районе Сан-Франциско по делам. Сначала мы обсудили
книгу, а потом он прислал мне ворох рисунков и самых разных своих эскизов.
Изначально предполагалось, что ТЕХ будет римским2 гражданином, и Дуэйн
нарисовал этого человека в тоге с оливковыми ветвями на голове — вот почему
сейчас оливковые ветви украшают льва. Но вдруг ни с того ни с сего он начал
делать эскизы своего кота, что вроде бы вполне подошло, и вскорости он
набросал все 37 рисунков, изобразив на них льва. Большинство из них в конце
концов вошли в книгу, а еще с полдюжины мы переделали. Когда я приехал
к нему в гости, я встретил кота Т^Х'а, очень похожего на изображенного в
книге. Вот и вся история про Дуэйна Бибби.
Эрик: Спасибо. Кто хотел бы задать первый вопрос? Пожалуйста, задавая
вопрос, представляйтесь.
Пит ван Острюм: Меня зовут Пит ван Острюм. У вас есть замечательный
лев в книге The T^Kbook, львица — в The METRFONTbook. А как насчет львят?
Дон: А, я понимаю ... [смех.] Дуэйн все еще делает иллюстрации в особых
случаях. Он сделал новые иллюстрации к японским переводам The T^Kbook
и The METRFONTbook, где Т^Х и МЕТЯ одеты в японскую одежду. Так что
теперь, если откуда-нибудь появится потомство, я полагаю, он с радостью
поможет его нарисовать. Но возможно, это будет в какой-то степени
незаконнорожденный ребенок, с моей точки зрения. [Смех.] Я имею в виду, что не
взял бы на себя ответственность за все, что делают эти персонажи. [ Смех.]
Пит: Так что вы думаете о потомках Т^Х'а и METflFONT'a?
Дон: Что ж, мне кажется, независимо от имеющейся у вас системы, будет
способ ее улучшить. Если кто-то захочет потратить время на серьезную, ак-
1 Мауриц Эшер (1898-1972) —голландский график, мастер ксилографии и литографии в
духе «фантастического реализма». — Прим. перев.
2 Игра слов: roman (англ.) —римский и в то же время прямой светлый шрифт. — Прим.
перев.
628
Компьютерная типография
куратную работу, то постольку, поскольку мы больше узнаем о типографском
деле, обязательно появится нечто новое. Лично я надеюсь, что мне не
придется тратить время на изучение новой системы, потому что мне для моих нужд
достаточно и старой. Но я, безусловно, никогда не намеревался сделать мою
систему единственным инструментом, который когда-либо может
понадобиться для книгопечатания. Я пытался сделать ее насколько возможно общей, но с
тем, чтобы размер программы не превосходил некоторых разумных пределов,
и с учетом того, что мы тогда знали о книгопечатании. Поэтому разные
другие проекты —я не считаю, что они мне угрожают или что-то в этом роде. Я
надеюсь, что будет некоторая совместимость, так чтобы —я хочу сказать, мне
бы -хотелось обрести бессмертие — так чтобы написанные мною книги все еще
можно было напечатать через 50 лет, не залезая для этого в файлы и не
редактируя содержимое. Мне особенно нравятся в Т^Х'е архивность и независимость
от платформы, я попытался разработать модель, минимальный стандарт
качества, которому могли бы следовать другие люди.
Ханс Хаген: Но если посмотреть в будущее, ... вы
считаете, что сегодня программирование для многих
людей —это искусство, что ж, многие произведения
искусства только через сотни лет были признаны
таковыми. Через сто лет компьютеры будут довольно сильно
отличаться от нынешних, языки программирования
изменятся, носители, на которые мы записываем все эти
вещи, изменятся. Собственно программы и все, к ним
относящееся, —будет ли у них шанс на бессмертие, как кажется вам?
Дон: А вы назвали ваше имя? [Смех.]
Ханс: Меня зовут Ханс Хаген.
Дон: Вы говорите: это довольно самонадеянно —предполагать, что наши
сегодняшние творения проживут хоть сколько-нибудь долго. Технология
меняется так быстро, что мы не имеем ни малейшего понятия о том, что люди
выдумают завтра. Сто лет назад физики говорили, что в физике уже все
сделано, осталось только получить еще один десятичный знак —пятый десятичный
знак после запятой в фундаментальных константах, — и это станет
завершением физики. Конечно, такие вещи невозможно предугадать. Но я действительно
верю, что, как только мы переводим вещи в электронную форму и у нас
имеются их зеркала, это дает достаточную долю бессмертия — в то время как бумага
горит.
Вы слышали о проекте под названием «The Clock», разрабатываемом
Стьюартом Брэндом и его коллегами? Он опубликовал каталог Whole Earth
Catalog. У них группа людей размышляет о том, можно ли построить что-
нибудь, что простоит тысячу лет ... Я не хочу углубляться в этот вопрос. Я
действительно надеюсь, что стабильность Т^Х'а позволит впоследствии
воспроизводить вещи, которые мы делаем сейчас. А так как сделать это
довольно легко, я думаю, это и произойдет — разве что наступит ядерный холокост.
Некоторые математики дискутируют о взглядах Платона ... существуют ли
Глава 33. Вопросы и ответы, III
629
все математические объекты, а мы просто открываем их, или мы на самом
деле их создаем? В некотором смысле, когда что-то переводят в биты, это
становится математическим объектом и поэтому будет существовать вечно, даже
если человеческая раса вымрет —оно останется, и что из этого?
Эрик: Кто следующий?
Марк ван Леувен: Мне хотелось бы продолжить
затронутую предыдущими вопросами тему. Стабильность самого
ТЕХ'а, в моем представлении, может быть камнем
преткновения для разработки новых вещей именно потому, что он
столь стабилен и все уже им пользуются. Так что если
появится что-то, что хоть чуточку лучше, то люди не станут
этим пользоваться, потому что оно не везде доступно и нет
никакого резона отказываться от старого.
Дон: Мне кажется, во Флориде я рассказывал, что люди все еще
пытаются использовать старые шрифты, которые я стараюсь искоренить. Четыре
года назад я переделал греческую строчную дельта и сделал концы
стрелок темнее. Я не менял ничего, могущего повлиять на работу Т^Х'а: все
размеры, высота и ширина всех символов остались неизменными. Я всего
лишь подправил некоторые символы. И до сих пор многие математические
журналы все еще пользуются старыми символами четырехлетней давности,
и я получаю от людей письма и препринты со старыми дельтами. Я внес
эти изменения, потому что больше смотреть не мог на старые варианты.
[ Смех. ] Теперь у меня есть свой Web-сайт — если у меня появляются какие-
нибудь исправления к ТЁХ'у или ДРУгие новости, я выкладываю их туда:
http://www-cs-faculty.stanford.edu/~knuth. Этот адрес приведет на мой
Web-сайт; там есть ссылка, озаглавленная «Важные замечания для всех
пользователей Т^Х'а», а в ней сказано: «Посмотри на строчную дельта и, если у
тебя не такая, тебя ожидает смерть!» [Смех.]
Я понимаю, что люди неохотно отказываются от вещей, к которым они
успели привыкнуть. Я знаю про две основных надстройки над Т^Х'ом: одна —
это £-ТЁХ, а другая — M'jS. £-ТЁХ должен быть, очевидно, на 100% совместим
с Т^Х'ом, так что если не пользоваться возможностями, не поддерживаемыми
исходной системой, то новая будет работать точно так же, как старая. Это
позволит осуществить постепенную замену. Конечно, потребуется дополнительное
место на компьютере, но в наше время это не проблема. Люди, работающие
над е-Т^Х'ом, всегда присылали мне очень точные комментарии про ТЕХ,
когда находили ошибки в моих программах, так что, как мне кажется, они
будут работать аккуратно. Таким образом, одна из этих вещей будет
поставляться вместе с произвольной установкой UNIX'а или еще чего-нибудь, и там
по умолчанию есть е-Т^Х и по-прежнему имеется Т^Х. Тогда можно также
использовать некоторые другие возможности, которые могут оказаться очень
полезными для конкретных нужд.
Иоханнес Брамс: Вы упомянули £-ТЁХ и M'jS. А знаете ли вы также о
проекте Омега?
630
Компьютерная типография
Дон: Конечно, проект П! Да, я сам собираюсь использовать его для имен и
фамилий авторов в The Art of Computer Programming. Я собираю китайских,
японских, индийских, еврейских, греческих, русских, арабских авторов и хочу
напечатать их имена правильно, [смех] а не просто в виде транслитерации.
У меня есть некое рудиментарное оборудование, которое можно использовать
для черновых распечаток, для поддержания моей базы данных и для
написания людям писем с вопросом: «Это ваше имя?» Система П, я надеюсь, будет
укомплектована хорошими шрифтами, которые позволят мне делать все это
без особых затрат. Сейчас, чтобы получить арабские имена, мне приходится
использовать Arabl^X; чтобы получить еврейские имена ... Две недели назад
я попал в ужасное положение, пытаясь найти шрифты для иврита в CTAN —
если вы хотите, я могу рассказать всю историю ... Я тыкался в разные места,
а там были ссылки на несуществующие файлы и README-файлы,
противоречивые и устаревшие на четыре года; мне так и не удалось найти ни одного
шрифта для иврита. Может быть он есть у вас на CD ...
Иоханнес: Я заведомо могу указать кое-кого, кто может помочь со
шрифтами для иврита: я знаю человека в Израиле, который пытается осуществить
поддержку иврита в рамках системы Babel. И в Израиле тоже печатают книги,
используя Т^Х.
Дон: Мой израильский друг — книгоиздатель Ден Берри, но он, к
сожалению, сильно привязан к troff'y. [ Смех.] Я уверен, что могу получить хороший
иврит через Янниса [Хараламбуса] и П. Я действительно надеюсь, что Unicode
появится скорее раньше, чем позже; он намного лучше всех альтернатив, во
многом по причинам, упомянутым Марком [ван Леувеном].
Я не увидел большого энтузиазма в отношении Unicode в Японии, потому
что у них есть работающая система, которая им прекрасно подходит, так
зачем что-то менять. Каждый раз, когда я спрашивал японцев об их именах в
Unicode, они говорили: «Что такое Unicode? Вот мое имя в JIS». Но символы
JIS включают не все китайские коды, и, на самом деле, мое собственное имя —
у меня есть китайское имя —нельзя написать при помощи JIS, не изменив его
немного. Имеются два разных символа Unicode: один для японской версии и
один —для китайской.
Кто-то позади? Кес?
Кес ван дер Лан: У меня, конечно, много вопросов. Но начать мне хотелось
бы с некоторых вопросов про METflFONT. Первый из них: как получилось, что
написания макро в Т^Х'е и METflFONT'e настолько различаются?
Дон: Почему макро в Т^Х'е и METflFONT'e так различаются? Я не решился
сделать TgX столь экстремальным, как METflFONT. Эти языки имеют
совершенно различную структуру. METflFONT в некоторых отношениях
невероятный язык программирования — он базируется на объектно-ориентированных
макро. Макро могут встретиться посередине структуры данных.
Довольно просто объяснить, как я создавал эти языки. Возьмем ТЕХ.
Однажды ночью я записал то, что, по моему мнению, было бы хорошим
исходником для The Art of Computer Programming. Я взглянул на второй том, который
Глава 33. Вопросы и ответы, III
631
должен был напечатать. Начал я с первой страницы, и, когда встречал любой
фрагмент, достаточно похожий на то, что я уже делал, то пропускал его. В
результате я получил примеры всех видов правил набора текста, которые
присутствуют во втором томе. Всего получилось пять напечатанных страниц; вы
даже можете увидеть эти страницы — в точности так выглядела моя
первоначальная тестовая программа—в нашей с Дейвидом Фуксом статье, где мы
обсуждаем оптимальное кэширование для шрифтов} Там мы привели пример
и показываем эти пять страниц, иллюстрирующих то, чему я хотел научить
ТЁК. Я записал то, что, как мне казалось, мне бы хотелось набрать —как
должен выглядеть мой электронный файл. И потом я сказал: «О'кей, это у меня
на входе, а вот что будет на выходе — как осуществить переход? А для этого,
что ж, для этого, кажется, мне нужны макро». [ Смех.]
То же самое и с METAFONT'om. Я просмотрел мои первые наброски всех
тех шрифтов, которые потом стали семейством Computer Modern. На самом
деле я писал на SAIL'e, языке-компиляторе типа ALGOL'a; но в SAIL'e
предусматривается возможность написания макро, так что я разработал несколько
примитивных макро, с помощью которых можно было сказать: «взять
широкое перо», «соединить точку 1 с точкой 2» и т. п. Компилятор SAIL'а переводил
эти макро в машинный код, который затем рисовал буквы. Я прошелся по
всему алфавиту, и к концу года у меня было около 300 небольших программок,
каждая из которых рисовала одну букву. Затем я понял, какого типа языком
мне хотелось бы пользоваться для описания букв. Так что однажды, во время
туристической поездки с семьей — я с женой и детьми был в Гранд-Каньоке2 —
я на час отвлекся от всего, сел под дерево и написал программу для буквы А на
языке, который, как мне казалось, будет хорошим алгебраическим языком, на
высоком уровне отражающим то, что я делал при помощи довольно
примитивных низкоуровневых инструкций в моих программах на SAIL'e. Я сделал также
букву В; прописные А и В. И потом я возвратился к туристической поездке.
Эти листки с моими первыми программами сейчас находятся в архивах Стан-
форда — программа для буквы В была напечатана в издании Станфордской
1 «Optimal prepaging and font caching», ACM Transactions on Programming Languages and
Systems 7 (1985), 62-79. См. также ее. 481-484 этой книги, где имеется первый набросок
исходного кода ТЕХ'а.
2 Гранд-Каньон — национальный парк неподалеку от Большого Каньона. — Прим. перев.
632
Компьютерная типография
библиотеки в прошлом году. Библиотекарь, занимающаяся в Станфорде
редкими книгами и собраниями рукописей, серьезно интересуется METRFONT'om,
поэтому она написала небольшую статью о том, что у них есть}
Та программа снова предполагала, что я хочу использовать какие-то мак-
ро. Но они должны были иметь гораздо более четкую структуру, чем макро
ЧЩХ'а. Когда я говорил zl', это на самом деле должно было быть эквивалентно
(xl' ,yl'); и я хотел иметь возможность писать zl' без всяких ограничителей.
Оказалось, что, если я хотел получить язык высокого уровня, который был бы
для меня естественным при написании программ, он должен был быть
совершенно отличен от ТЁХ'а. Поэтому у ТЁХ'а и METAFONT'a одинаковый формат
сообщений об ошибках и некоторые общие структуры данных внутри, но в
остальном это совершенно разные системы. В хорошем языке высокого уровня
для шрифтов я не хотел тратить время на написание круглых и квадратных
скобок, запятых и других ограничителей.
Кес: Это хорошее вступление к моему второму вопросу: [смех] относительно
будущего системы METflPOST, которая позволяет делать рисунки с конечным
результатом в виде инкапсулированного PostScript'а: что вы думаете о данных
с большим числом измерений для METflPOST'a и METAFONT'a? Например, о
добавлении тройки по аналогии со структурой данных pair?
Дон: В METflPOST'e уже есть структура данных для троек из-за color. Так
что выражения RGB на самом деле тройки чисел.
Кес: Да, но тройка для хранения точки в пространстве?
Дон: А, я понял. Я действительно писал METflFONT таким образом, чтобы
оставались специальные средства (hooks) и его можно было легко расширить;
например, вы можете захотеть рисовать трехмерные картинки с
использованием аксонометрии и проективной геометрии, вместо аффинной геометрии.
Сама программа для METAFONT'a была написана так, чтобы люди, желающие
иметь систему, идущую дальше основ, могли легко ее изменить. Я всегда хотел,
чтобы системы, которые я делаю для всеобщего употребления, были
способны справиться с 99% всех задач, известных мне. Но я всегда чувствовал, что
должны быть особые задачи, для выполнения которых будет легче поменять
программу, чем написать макро.
Я пытался писать программы так, чтобы у них была логическая структура
и было легко добавлять в них новые возможности. Это происходит не так
часто, как я думал, потому что люди оказались более заинтересованы, видимо, в
переносимости того, что они делают; если у тебя своя собственная программа,
то у других ее уже нет. Все же, если бы я был крупным издателем и мне нужно
было осуществить особый проект: что-нибудь вроде энциклопедии или нового
издания Библии и т. п., я бы непременно посчитал, что правильней всего будет
нанять хорошего программиста и сделать специальную компьютерную систему
именно под этот проект. По крайней мере, таково мое видение того, как это
стоит делать. Кажется, это случается нечасто, хотя в Брно я встретил студента,
который довольно далеко продвинулся, пытаясь получать формат Acrobat'a
1 Robin E. Rider, «Back to the future: High-tech history», Imprint 14,1 (Fall 1994), 9-18.
Глава 33. Вопросы и ответы, III
633
прямо из Т^Х'а, путем прямого изменения кода. А система ft, которую
упомянул Йоханнес, это 150 000 строк измененных файлов. [ Смех. ] Я встроил
спецсредства так, что каждый раз, когда Т£Х выдает страницу, он может
наткнуться на whatsit, a whatsit в разных версиях Т^Х'а может выражать самые
разные вещи. Поэтому, когда основная программа видит whatsit, она
вызывает специальную подпрограмму, спрашивая: «Как мне печатать этот whatsit?»
Эта специальная подпрограмма смотрит на подтип (subtype), а подтип может
оказаться другим подтипом, вставленным для демонстрации, или совершенно
новым подтипом.
Похожие спецсредтва имеются в программе METflFONT. Если у людей есть
лишнее время, когда они не бродят в Интернете [смех], я рекомендую
замечательное развлечение —читать программу METflFONT'a. Некоторые ее части
перевариваются с трудом, и я надеюсь, никто и никогда не найдет там
ошибку, потому что я не переживу, если мне придется туда еще раз заглядывать.
[Смех.] Но это — подпрограммы растеризации, то, что собственно заполняет
пиксели. В этой программе много других вещей: блок для решения линейных
уравнений и механизмы для структур данных ... там много чудесных
алгоритмов: найти квадратный корень в фиксированной точке, найти пересечение двух
кривых и т. д. METfl FONT полон маленьких программок, которые писались с
огромным удовольствием и которые кажутся мне полезными и интересными
сами по себе. Я думаю, когда Джон Хобби писал METflPOST, он тоже
получил удовольствие от того, что мог добавить свои собственные замечательные
программки к тем, что уже имелись.
Я —большой поклонник METflPOST'a для технических иллюстраций. Я не
знаю ни одной другой системы, которая хотя бы приближалась к нему,
поэтому все рисунки к The Art of Computer Programming я делаю в METflPOST'e.
Также технические статьи, написанные мною, Cambridge University Press
собирается издать в серии из восьми томов, и все рисунки, кроме фотографий
будут переведены в METfl POST. Первым из этих восьми томов была книга
Literate Programming; второй том должен выйти этим летом и должен
называться Selected Papers in Computer Science. В нем перепечатаны 12 или 15
статей, которые я написал для широкой публики, для неспециалистов в
информатике и программировании: статьи в журналах Scientific American или
Science и т. п. Третий том будет о компьютерной типографии, и в нем будут
перепечатаны все мои статьи в TUGboat и вещи, касающиеся TfnjX'a. Как,
кстати, вы думаете, стоит мне публиковать в этом третьем томе памятку, которую
я себе написал в первую ночь, когда создавал ТЕХ? Я записал ее в
компьютерный файл, и она хранится в архивах Станфорда, но я никогда и никому ее
не показывал. [Крики «конечно!», «обязательно» и смех аудитории.] Может
быть, это увеличит продажи. [ Снова смех.]
Франс: Вам нужно положить ее на ваш Web-сайт, и тогда мы сможем
решить—
Дон: Нет, нет. Так мы никогда не продадим книги. [Смех.] Не то, чтобы
я был очень корыстолюбив, конечно. Она находится в файле под названием
634
Компьютерная типография
tex.one—«текс точка уан», на самом деле. Должен признаться, что с месяц
или два я произносил название как «текс»: я имел в виду «технические
тексты». Файл назывался tex.one, и когда-нибудь его, возможно, будет интересно
почитать.
А ваше имя?
Ян Карман: В этой компании я, может быть, задам весьма еретический
вопрос, но немного ереси добавит интереса — разговор идет о METflFONT'e.
Сейчас, вероятно, многие словолитни производят много высококачественных
шрифтов и таблиц кернинга. Неясно, выживет ли PostScript или True Type.
Думаете ли вы, что METflFONT для текстовых шрифтов выживет? Не касаясь
математических шрифтов.
Дон: Я не думаю, что дополнительные возможности METflFONT'a оказались
необходимыми для создания шрифтов хорошего качества, хотя я все же думаю,
что с его помощью можно делать шрифты лучшего качества. Специалисту по
шрифтам сложно думать так, как думает компьютерщик, в том смысле, что,
когда люди, занимающиеся компьютерами, что-то автоматизируют, пытаясь
заставить компьютер сделать то или иное, для нас естественно ввести
параметры и сказать, что мы хотим решать не одну задачу, а сразу несколько. Мы
пытаемся решить целый спектр задач, зависящих от параметров, задаваемых
людьми. Но было бы гораздо проще, если бы люди требовали от нас решения
только одной задачи с одним набором значений параметров, тогда мы смогли
бы заставить компьютер сделать в точности то, что требуется.
Компьютерщики давно привыкли размышлять о том, как бы изменилось поведение при
изменении параметров, но для шрифтовиков это довольно непривычно. Они
чувствуют себя гораздо лучше, если сначала босс говорит: «Сделай мне
прямой шрифт средней насыщенности», а через месяц: «Сделай мне полужирный
прямой шрифт». Намного сложнее, если босс говорит: «Покажи мне, как бы ты
рисовал прямой шрифт, независимо от того, какой насыщенности я хочу
сделать буквы». METAFONT позволяет решить эту проблему и рисовать символы,
задаваемые параметрически, но далеко не каждый специалист по шрифтам
может свободно оперировать такими понятиями. Они могут сделать шаблоны,
начертив несколько рисунков, а затем отождествляя точки на разных рисунках
и заставляя компьютер интерполировать. Шаблоны в PostScripts позволяют
ввести до четырех параметров, а у большинства из них —только один или два
параметра. У большинства из известных мне —два; возможно, у других число
параметров достигает даже четырех. Но тогда им приходится делать рисунки
для всех граничных значений этих параметров.
Несмотря на такое ограниченное использование параметров, то, что
сейчас продается, обеспечивает вполне приличную удобочитаемость текста, хотя
все-таки не дает того качества, которое у вас в Нидерландах было в XVII веке.
Как имя того человека, великого пуансониста из Харлема — он сделал шрифты
кеглей 4.5, 5 и дальше до 16, и для каждого размера каждая буква делалась
отдельно, и его шрифты отличались замечательной общностью начертания. С
современными шрифтами Typel ситуация совсем другая. Были два парня, пу-
Глава 33. Вопросы и ответы, III
635
ансонисты, которые делали большую часть работы для Энсхеде и остальных
в XVIII веке: один из них, Флайшман, был гением по части очень красивых
букв; другой, Розар, просто хорошо делал очень много разных букв^ [Смех.]
Они были замечательны. Розар делал самые разные каллиграфические
алфавиты и т. п. У меня есть такая большая книжка с образцами всех шрифтов
Энсхеде, переведенная на английский язык отцом Мэтью Картера. Посмотрев
на все шрифты в этой книге, Typefoundries in the Netherlands, вам остается
лишь обливаться горючими слезами?
Тем не менее, на лазерных принтерах мы сейчас получаем достаточно
хорошие шрифты, и поэтому, наверное, не так много специалистов по шрифтам
будут пользоваться METRFONT'om. Pandora была хорошим метапроектом
настоящего художника? Оказалось, что METRFONT замечательно подходит для
создания контурных рисунков и специальных вещей, связанных с геометрией.
Сейчас в Польше есть очень изящная система, в которой 1^Х и METRFONT
связаны воедино: Tf^X выдает что-либо, и затем METRFONT рисует символ, и,
если он не подходит, Т^Х говорит: «возвратись назад и попробуй еще раз».
Яцковский и Рыцько понимают Т^Х и METRFONT, а программы хорошо
документированы и могут это делать. Таким образом, METRFONT не исчезнет; но
его и никогда не будут изучать в средней школе.
Франс: Меня зовут Франс Годдейн, и у меня есть один
вопрос с некоторыми подвопросами. [ Смех. ] Сначала я бы хотел
задать подвопросы. Меня интересует —и об этом, возможно,
уже много раз спрашивали раньше, — считаете ли вы,
оглядываясь назад, ваше творение — [это] произведение искусства или
инструмент? А причина такого вопроса — когда я слышу, как
вы с такой страстью говорите о шрифтах и прекрасных
алгоритмах, примененных вами в METRFONT'e, на которые вы
хотели бы указать людям, и одобрение со стороны тех людей, которые это
понимают,—но есть подавляющее большинство пользователей, которые просто
скачали TgX c какого-то сервера, так и не узнали, кто его создал, и
используют его для набора не всегда очень хороших текстов. [Смех.] Они делают
это достаточно грубо, и ничуть этим не озабочены. Вы заморозили Т^Х на
определенном уровне, позволив другим людям делать над ним надстройки.
Меня интересовало, что при этом должен испытывать отец — отец ли вы
произведения искусства, которое другие люди используют как инструмент, или
это ребенок, замороженный вами в развитии, который никогда не вырастет
... вопросов так много ... если бы вы просто вернулись к идее искусство или
инструмент, и вашим мыслям на этот счет.
1 Иоганн Михель Флайшман, 1701-1768; Жак-Франсуа Розар, 1714-1777.
2 Typefoundries in the Netherlands from the Fifteenth to the Nineteenth Centuries, by Charles
Enschede, translated by Harry Carter (Haarlem: Stichting Museum Enschede, 1978), 477 pp. Эта
замечательная книга была набрана вручную и напечатана высокой печатью, в честь 275-
летия Йоханнеса Энсхеде эн Зонена.
3 Neenie Billawala, Metamarks: Preliminary Studies for a Pandora's Box of Shapes, Stanford
Computer Science report STAN-CS-89-1256 (Stanford, California: July 1989), 132 pp.
636
Компьютерная типография
Дон: Конечно, если я пишу что-либо достаточно мощное, чтобы делать много
разных вещей, то можно будет заставить его делать и отвратительные вещи. Я
только недавно был в Рейксмюсеуме1, там есть выставка под названием «Эпоха
уродства», представляющая целый набор фантастических серебряных сосудов
конца XIX столетия... Когда вы говорите «искусство», я не уверен, что
правильно понимаю, что вы имеете в виду. Для меня «искусство» употребляется
в двух совершенно различных смыслах: сегодня чаще всего в смысле высокого
искусства, в то время как когда-то искусство (изначально Kunst) означало все,
не являющееся натуральным — поэтому у нас есть слово искусственный,
сделанный людьми, а не природой. Греческое слово — тех^)- [Смех.] Но затем вы
описываете инструмент, как нечто, что, возможно, просто приспособление для
быстрейшего получения нужного из имеющегося, но, может быть, при этом вы
не заботитесь об изяществе... Мне кажется, говоря об искусстве, люди имеют
в виду эстетику — нечто, связанное с красотой и несущее в себе частицу
любви. Касательно Tj^X'a, я хотел дать возможность людям делать работу, которой
можно гордиться; я полагал, что люди могут получить настоящее удовольствие,
затрачивая немного больше времени на то, чтобы улучшить результат. Я не
ожидал, что этим будет заниматься весь мир.[ Смех. ]
Между прочим, я не могу понять, о чем
думают люди, рисующие граффити на красивом здании,
хотя могу понять, почему им нравится рисовать.
Зачем что-то выцарапывать — по-моему, за это может
быть ответствен какой-то животный инстинкт —
пометить территорию, но для меня совершенно
невозможно постичь эти действия.
Когда дело касается эстетики, нельзя
навязывать свой вкус. Нельзя сказать, что твое понимание
красоты будет соответствовать пониманию красоты
у всех остальных. Но я действительно хотел иметь
инструмент, помогающий нам достигать высших
ступеней красоты согласно нашим собственным
вкусам. Я сделал изменение межбуквенных
пробелов не очень простым, но все остальное я постарался
сделать доступным для всех. [ Смех. ] Конечно,
изначально я делал Т£Х только для себя, для The
Art of Computer Programming; я думал, что мой
секретарь и я будем единственными
пользователями. И далеко не сразу меня убедили, что мне нужно
сделать ТеХ более общим и т. д. Но мне нужен был
такой инструмент, с помощью которого я мог бы
делать книги, вызывающие у меня чувство
удовлетворения после того, как почти всю жизнь я эти
книги писал.
1 Рейксмюсеум —государственный музей в Амстердаме. — Прим. перев.
Глава 33. Вопросы и ответы, III
637
Я начал писать The Art of Computer Programming в 24 года и мне еще
предстоит лет 20 работы. Это довольно много времени. Я не хочу писать
книги, которые будут отвратительно выглядеть. Я хотел найти способ
научиться делать высококачественные в полиграфическом отношении книги.
Вначале, когда компьютеры только появились, они понимали только числа,
цифры. Компьютеры XIX века могли печатать таблицы. Потом появились
компьютеры, которые могли работать с числами и буквами, но только на
телетайпе; так что были некоторые прописные буквы и всего было 32 символа.
Но затем, когда я закончил колледж, у нас появились ... дайте подумать, это
было, наверное, через десять лет после колледжа, когда мы смогли работать со
строчными буквами на компьютере. Вы знаете, язык Pascal, когда он
появился, использовал только прописные буквы: никто никогда не рассчитывал, что
в репертуаре компьютера будет более 64 символов. Наконец в середине 70-х
годов мы начали понимать, что компьютеры действительно могут работать
и со строчными буквами, и делать что-то, что можно было как-то читать,
что-то, похожее на книги. Здорово! [ Смех.]
Одновременно происходило развитие типографских программ, начавшееся
в M.I.T. в 1961 году и прошедшее через четыре или пять поколений, приведших
к системам troff и eqn, с помощью которых можно было печатать даже
математику. В результате в 1977 году я знал теорему существования: печатать что-то,
выглядящее почти как хорошая математика, возможно. Полученные при
помощи системы eqn тексты появлялись в физических журналах, и опыт показывал,
что секретари могли научиться их набирать. Поэтому я подумал: «Почему бы
не пройти весь путь до конца, до предела?» С Т^Х'ом я хотел не улучшить
немного troff и другие системы; я говорил себе: «Попробуем добиться лучшего
типографского качества за всю историю человечества». Не считая
золоченного тиснения с цветными рисунками, я хотел —по крайней мере что касается
черно-белой печати —я хотел достигнуть наилучшего возможного качества.
Компьютерная типография прошла такой долгий путь развития, понемногу
становясь все лучше и лучше. Пришло время сказать: «О'кей, давайте
перейдем к пределу». Конечно, я не думал, что этим захотят заниматься все. Но
было достаточно людей, которые хотели бы попытаться достичь наилучшего
возможного качества, которые могли бы — что ж, поэтому я в конце концов и
сделал TfeX более доступным. Главы Американского матобщества были
первыми, почти первыми, убедившими меня научить систему делать больше, чем я
планировал вначале.
Ленстра: Почему же вы не начали с troff'а,? Он совсем не подходил?
Дон: Да-да. Вы понимаете, troff был «заплатой» на вершине ... Я имею в
виду, это была целая система, это было пятое поколение, каждое из которых
было «заплатой» на предыдущем. Так что пришло время сдать все на слом и
начать все заново: «Вот каким должен быть язык, так что давайте придумаем
для него подходящие структуры данных». А не «Давайте попробуем добиться
совместимости». У меня было преимущество — я работал не в Bell Labs, так
что я не задевал ничьих чувств, если бы сказал: «Давайте все это выбросим».
638
Компьютерная типография
[ Смех. ] Для людей в Bell Labs сделать такое было, естественно,
невозможно—это было бы некрасиво. Но мне пришло в голову, что теперь у нас есть
доказательство достижимости более высоких целей, так что пришло время
начать заново и перепридумать, как получить конечный результат из исходного
файла. Таким образом программа могла быть гораздо более единообразной,
более компактной, а также могла бы работать. Я имею в виду, что troff все
время зависал. Многие самые первые пользователи TgX'a были разочарованы
troff''ом, падающим от раза к разу, потому что он стал неуклюжим. Но troff
также доказал, что есть свет в конце туннеля.
Знаете ли вы, что мне также пришлось выбросить на слом ТЕХ и начать
заново; после пяти лет я решил, что лучше всего вернуться назад и переделать
программу. Но мне было бы очень сложно сделать это, если бы ее написал
мой друг из соседнего отдела. [ Смех. ] Итак, я просто придерживался той
философии, что всегда найдутся люди, более заинтересованные в качестве,
чем остальные, и я хотел сделать T^jX удобным для них.
Я не знаю ни одного хорошего способа, как сделать невозможным создание
плохого документа, если только в вашей системе набор опций существенно не
сужен. Маленького набора опций, конечно, вполне достаточно для большого
класса пользователей — сделать систему такой простой, чтобы в ней
невозможно было сделать ничего уродливого.
Эрик: Я думаю, пришло время для перерыва на кофе — он займет пять-
десять минут.
Дон: Йоханнес, у вас был вопрос, который вы должны были задать, так что
давайте покончим с этим. [ Смех. ]
Йоханнес: Он про набор текста. Что вы думаете о применении при наборе
модели плавающего горизонта? В ТЁХ'е говорят о боксах: каждая буква
находится внутри бокса, и мы склеиваем боксы вместе, чтобы получить строку, и
каждая строка рассматривается как бокс, и боксы прилаживают друг к
другу, формируя абзац. В модели плавающего горизонта пытаются пойти немного
дальше строгого следования боксам и строкам, и пытаются учитывать, что
некоторые нижние выносные элементы верхней и выступающие части
нижней строк не перекрываются, так что на самом деле можно размещать строки
ближе друг к другу — особенные преимущества это может дать при наборе
математических формул.
Дон: Хммм, насколько я понимаю, вы говорите об общих принципах
компьютерной графики, когда на картинке присутствуют произвольные
прямоугольники, а не только прямоугольники, правильно расположенные внутри других
прямоугольников. ... Это, безусловно, привело бы к серьезным изменениям
во всех структурах данных ТЁХ'а. Можно обратиться к квадратным деревьям
или чему-то в этом роде. Все, что применяется для решения проблемы
невидимых линий и вывода изображений, для определения, что находится впереди,
и все алгоритмы, которые используются в производстве мультфильмов вро-
Глава 33. Вопросы и ответы, III
639
де Toy Story. В моем представлении, это будет очень полезно при обработке
необычных случаев в математических формулах.
У меня имеется два соображения на этот счет. Первое состоит в том, что
мне нравится наблюдать, как люди расширяют круг проблем, решаемых
компьютерами автоматически. Люди многому учатся, когда пытаются это сделать.
Вся область искусственного интеллекта была одним из разделов, оказавших
огромное влияние на компьютерные науки, потому что они пытались решать
очень трудные проблемы. Особенно в первое время у них возникали методы,
оказавшиеся полезными во многих других разделах компьютерных наук. Так
что по-моему, когда люди ставят себе более претенциозные задачи, они
разрабатывают мощные методы, у которых часто находятся самые неожиданные и
весьма полезные применения. Даже в том случае, когда задача уже решена,
они будут думать о чем-то другом, о еще одном усовершенствовании и т. д. —
у них никогда не возникнет ситуации, в которой они будут создавать самый
лучший документ автоматически. Придет время, когда вы посмотрите на
получившийся результат и увидите, что его все еще можно улучшить.
Создателям большинства автоматических систем можно дать хороший совет: оставить
пользователям по крайней мере возможность двигать что-нибудь вверх и вниз
и обжуливать автоматический алгоритм.
Философия, которой я придерживался, создавая ТЕХ, заключалась в том,
чтобы попытаться сделать систему, которая на 99% все делает
автоматически; затем я бы посмотрел на то, что получилось, и подчистил остаток. Но
«подчистить» —только один способ описания этого подхода; это можно
выразить по-другому: «привести все в порядок» или «расставить все точки над i».
Я чувствую, что неавтоматическая часть дает мне лишний повод гордиться,
потому что я знаю, что я придал продукту окончательную форму. Если этой
дополнительной работы слишком много, это неудобно, и я теряю время. Но
если мне действительно удается ограничить ее 1% —если я потратил 30 часов
на написание статьи, а на ее подчистку у меня уйдет всего лишь 15 лишних
минут,— тогда я с радостью потрачу в конце еще 15 минут. Этот небольшой
добавок дает мне возможность отметить тот факт, что я закончил статью.
Пробелы, которые T^jX сейчас делает хуже всего —это, на мой взгляд,
слишком маленькие пробелы около знаков квадратного корня: или операнд
слишком близок к знаку радикала, или слишком близок к горизонтальной
черте, или и то и другое; чаще всего мне хочется поиграть с этим. В книге
Concrete Math, а также теперь в The Art of Computer Programming, я принял
правило, согласно которому я вставляю знак @ в математическую формулу
там, где хочу сделать дополнительный пробел в одну математическую
единицу. Знак @ в таком случае определяется как имеющий математический код,
равный в шестнадцатеричной системе 8000, и я ввел определение
{\catcode'\@=\active \gdef@{\mkernlmu}};
в результате, в математическом режиме @ считается макро, добавляющим
пробел в одну математическую единицу. Например, я набираю
\sqrt{@\log n}
640
Компьютерная типография
потому что иначе пробел перед буквой Т немного маловат. [ Смех.] Теперь,
может быть, эта модель плавающего горизонта не будет знать, что эта Т слишком
близко, а может быть, будет. Но в случаях вроде этого ...
На самом деле, самый распространенный случай, где требуется
подправить пробелы, — это места вроде 'а;2//3', с простым индексом сверху, за которым
следует косая черта, а затем знаменатель. Почти всегда перед косой чертой
слишком большой пробел. И, как я обнаружил, то же относится ко всем книгам,
которые я привык считать идеально набранными вручную [смех], но теперь я
чувствителен к таким вещам. В последнее время я просматриваю мои книги
и статьи, как правило при помощи Emacs'a, и ищу все места, где
встречается односимвольная степень с последующей косой чертой, и большинство этих
мест лучше выглядят с отрицательным тонким пробелом перед косой чертой:
$х~{2\!/3}$ дает а;2//3. Было бы приятней, если бы мне не приходилось этого
делать. Но тем не менее, для меня это мелочь.
Сможет ли мне в этом помочь модель с плавающим горизонтом? Иногда
я попадаю в ситуации, когда я добавляю лишнее слово в ответ к
упражнению, чтобы избежать наползания строк друг на друга. На самом деле, строки
не расходятся слишком далеко, а расположены так близко друг к другу, что
нижний предел вроде '/с < п' наползает на скобку в следующей строке. И мне
совсем не хочется, чтобы там печать была очень плотной. Теперь, если бы я
был умнее, я бы сделал мой знак < с диагональной чертой под знаком <,
вместо горизонтальной, а именно '/с ^ п\ и я бы избавился от этих наползаний —
сейчас для этого слишком поздно. [ Смех. ]
Кес?
Кес ван дер Лан: Позвольте вас спросить о вашем
отношении к разметке вообще? Мне бы хотелось проиллюстрировать
этот вопрос, рассказав сначала следующую историю. Когда
мы начали использовать T^jX и т. д., на самом деле имеется в
виду, мы начали использовать IAT^X —я хочу сказать, такова
ситуация в Голландии. И тогда я посмотрел, что получается в
результате разметки, и мне это не понравилось. И тогда я
задумался, как вы к этому относитесь. С сожалением признаю,
что я пролистал исходный файл texbook.tex книги The T^Kbook и взглянул
на то, что есть там, и тогда подумал: «Ну, я немного понимаю, что вы думаете
про разметку». А когда вы объясняли про METRFONT и те вещи, которых там
нет, которые вы сделали неявными, — ошибусь ли я, если суммируя, скажу, что
вы придерживаетесь чего-то вроде минимальной разметки?
Дон: Да. Например, если я читаю книгу Эдсгера Дейкстры, каждый раз,
когда я дохожу до раздела, где сказано «Конец замечания», это бросается мне в
глаза своей избыточностью. И я всегда думаю: «А, да, это в стиле Эдсгера».
Когда я писал статью к его 60-летию, я сказал в конце: «Благодарности, я хочу
поблагодарить Эдсгера за то-то и то-то» и «Конец благодарностей». [Смех.]1
Но это был единственный раз в моей жизни, больше я так никогда делать не
Beauty is Our Business (Springer, 1990), 242.
Глава 33. Вопросы и ответы, III
641
буду. Может быть, я не логичен; но очевидно половина людей,
пользующихся сейчас HTML, набирают только <р> в начале абзаца, а другая половина —
только </р> в конце абзаца. [ Смех. ] Как донесла разведка, редко кто-нибудь
использует и то и другое. И я не знаю, способны ли эти системы вообще хоть
что-то делать с не заключенным в скобки материалом.
Когда я пишу на HTML, я делаю разметку скрупулезно. Загляните на мой
Web-сайт —я заплачу вам $2.56, если вы хоть где-нибудь обнаружите, что я
открыл что-то и не закрыл его меткой справа. Я старался быть к этому очень
внимательным, расставлять везде отступы и т. п. Но для меня это оказалось
весьма неприятно, потому что думаю я по-другому.
Язык высокого уровня, по-моему, должен каким-то образом визуально
отражать свою структуру, но не обязательно явно; так что, если я знаком с
правилами, можно кое-что опускать. Скобки —одно из таких правил, и
математика далеко продвинулась, когда были изобретены другие способы записи
вроде предшествующих операторов, которые позволяют нам видеть структуру,
не выписывая ее чересчур подробно. Математик много времени проводит,
выбирая тот или иной способ записи, и одна из вещей, которых мы в математике
стараемся избегать, это двойные нижние индексы. Я читал одну французскую
кандидатскую диссертацию, в которой автор дошел до пятого уровня нижних
индексов [смех.] — он последовательно загонял себя в угол. Начал он с
множества {#1,..., £п}, поэтому, когда ему понадобилось подмножество, оно должно
было выглядеть как {xix,..., Xim }, а потом он захотел взять его подмножество;
в конце концов он дошел до теоремы, использующей lX{d ... Х{. '. [ Смех. ] Я
стараюсь выбирать способы записи, позволяющие мне экономно мыслить на
высоком уровне.
Возможно поэтому я не придавал большого значения обилию разметки в
The ТЁХЬоок. Я бы начинал раздел, имитирующий пишущую машинку, и
заканчивал его, говоря \begintt и \endtt. Я бы также отделял строки,
представляющие части макрокоманд plain Т^Х'а, говоря \beginlines и \endlines —эти
макро присутствуют в файле, потому что мне очень важно видеть структуру.
Но в остальных случаях я оставил вещи сколь возможно простыми, настолько,
чтобы я мог отчетливо представлять себе, где здесь начало и где конец.
Похожая вещь получалась, когда я выполнял административную работу
в Станфорде. Иногда, решив проблему, я переставал о ней беспокоиться, так
что забывал воплотить решение в жизнь! Я всегда был очень плохим
председателем комитета потому, я полагаю, что никогда не умел заканчивать эту
последнюю строку. Тем не менее, что касается HTML, документы были
небольшими и я решил, что мой Web-сайт будет просматриваться самыми разными
типами браузеров, так что лучше соблюдать строгость.
Когда я разрабатывал ТЁ^, я посетил одно из заседаний комитета,
создавшего SGML, и у меня была очень интересная дискуссия с Чарли Голдфарбом
и другими членами комитета — только это заседание было рядом со Станфор-
дом. Конечно, я принимаю во внимание то, что благодаря строгой разметке
становится возможным надстраивать другие программы вокруг той, что есть
у тебя. Чем больше документ структурирован, тем легче сделать базу данных,
642
Компьютерная типография
содержащую сведения о нем и отслеживающую изменения. Я никогда не
возражал против SGML; я просто всегда чувствовал, что для максимизации моей
эффективности я не хотел возиться с полной разметкой, если без этого можно
обойтись.
X: SGML позволяет минимизацию; вот почему концы абзаца не являются
необходимыми. Так что это —одна из причин, почему он иногда так труден.
Нужно минимизировать формализацию.
Дон: Но iATfeX этого не позволяет.
Иоханнес: У нас, тем не менее, имеются некие спецприемы, разрешающие
опускать закрывающие метки, в ГАТ^ХЗ, но это еще далеко до завершения.
Дон: Ну что ж, Кесу стоит поговорить с Йоханнесом. [ Смех. ]
Так случилось, что я не ощущаю нужды в специальном редакторе для
написания исходников HTML —люди рекламируют чудные вещи, когда можно
нажать на инструмент (tool), и будут вставлены начальная и конечная метки
вместе. Но когда я писал свои файлы, я в Emacs'e написал небольшой макро,
работающий по нажатию клавиши, который берет любую только что
набранную мной метку и создает конечную метку. Все, что этот макро должен был
сделать, это найти предыдущий знак меньше, и затем сделать вторую копию
той строки, и добавить перед ней слэш; так что я все время этим пользовался —
это было нетрудно.
Иоханнес: Теперь вопрос совершенно из другой области, от человека,
который хотел бы быть здесь, он пишет, цитирую: «Почему высота знака минус в
символьном шрифте cm такая же, как высота знака плюс из cmr?»
Дон: А-а. Этому многие удивляются. Там, где у вас встречается 'а — с', или
1х-\ или что-то в этом роде, почему высота и глубина больше реальных
размеров знака минус? На самом деле, здесь не только + и —, то же самое относится и
к ±, =j=, ф, ©, ®, 0, х и -;—если вы посмотрите на их METflFONT-код, там есть
макро beginarithchar, начинающий любой арифметический символ шрифта
и обеспечивающий одинаковый размер для них всех.
Иоханнес: Но это не объясняет почему.
Дон: Это правда —это не объясняет почему. А причина в том, что в самом
начале я хотел, чтобы некоторые вещи располагались одинаково. Например, в
формуле
у/х + у + у/х - у
я хотел, чтобы знаки квадратного корня были одинаковыми. Иначе вы бы
получили
у/х + у + у/х - у.
И во множестве других случаев в одной части формулы есть плюс, в другой —
минус; чтобы пробелы были одинаковыми, эти части должны выглядеть
симметрично. Я охотно признаю, что во многих других случаях есть только минус
безо всякого дублирующего плюса, и вы удивляетесь, почему там сделан
такой большой отступ. Поэтому я говорю '\smash-' [размазать] [смех.] в таких
случаях.
Глава 33. Вопросы и ответы, III
643
Йоханнес: Конкретный случай, из-за которого этот вопрос был задан —
Майкл Даунз из Американского математического общества—
Дон: Да, Майкл Даунз, у него больше опыта, чем у кого бы то ни было
из присутствующих; он заведует выпуском в печать большей части мировой
математики.
Йоханнес: У него проблема с надписью над \rightarrowf ill ...
Дон: Команда \rightarrowf ill? О'кей ... Команда \rightarrowf ill —это
штука, которая делает стрелку вправо любой нужной длины, а потом он
хочет сделать над ней надпись. Какой макро нужен для этой конструкции? Я не
пользовался этой страницей уже давно ... [Смех.]1 \rightarrowf ill сделан
из минусов, так что, может быть, знай я о том, что Майкл ... знай я о
сложностях Майкла в то время, я бы изменил макро plain Т^Х'а так, чтобы высота
минуса не использовалась в операторе \rightarrowf ill? Как бы то ни было,
я теперь объяснил вам причины, почему это нужно в других случаях.
Йоханнес: Еще один вопрос, он про поддержку многих языков. Возникают
проблемы, когда в одном абзаце присутствуют разные языки.
Дон: Да, изменения \lccode. Это ...
Йоханнес: И мне говорили, что внутри одного абзаца можно использовать
только одну таблицу переносов, а именно ту, которая активна в конце абзаца.
Так что переключение таблиц переносов становится проблемой. Предположим,
например, что у вас есть абзац с английским текстом, внутри которого имеется
цитата на немецком языке длиной в несколько строк.
Дон: Нет, я знаю, что ТЕХ правильно отслеживает, какую таблицу переносов
использовать. Сбой, ошибка, которой я не предусмотрел, появляется, только
если у двух языков разные функции \1 с code —так что в каждом из них по-
разному решается вопрос, какие буквы строчные. Когда вы делаете перенос,
вы должны переносить слово из прописных букв так же, как слово из строчных
букв, поэтому TfjX использует \lccode символа для перевода каждой буквы в
такую же строчную букву. Я не предусмотрел, что в разных языках могут быть
разные функции перехода от прописных букв к строчным. Именно эта функция
в конце абзаца применяется ко всем языкам в этом абзаце. Но в остальном Т^Х
аккуратно отслеживает, какой язык является текущим в каждый конкретный
момент.
Кстати, есть файл, называющийся tex82.bug. Зайдите в архивы CTAN и
найдите поддиректорию systems/, а в ней knuth/, а в ней errata/, именно
там лежит tex82 .bug. В конце tex82 .bug эта конкретная ошибка, касающаяся
\lccode упомянута в качестве недосмотра, который слишком поздно
исправлять.
Марк ван Леувен: Почему слишком поздно исправлять? Это войдет в
конфликт с чем-то другим?
1 Макро называется \buildrel; см. The TJgXboole, с. 437. [См. также в русском издании
«Всё про ГЩХ», с. 426. — Перев.]
2 На самом деле, теперь, в plain.tex версии 3.14159 (март 1995 года), < и ►
действительно пренебрегают высотой и глубиной минуса.
644
Компьютерная типография
Дон: Да. Люди уже используют эти вещи во многих документах, и это очень
сложно изменить. На самом деле, я не вижу, как это можно исправить. [ Смех. ]
Я бы сказал, что, когда вы сталкиваетесь с ситуацией, в которой вам требуется
много разных языков с разными вариантами \lccode, это хорошая причина
написать свою собственную версию Т^Х'а.
Андрис Ленстра: Могу я задать вопрос? К счастью, я не
первым упомянул здесь ГАТ^Х, так что я могу упомянуть его
и сейчас. Часто, когда люди пытаются написать кандидатскую
диссертацию, возникает ситуация, в которой им бы хотелось
изменить код iATEX'a, потому что им кажется, они лучше
знают, что такое красота или как правильно печатать текст, но, к
большому сожалению, они не эксперты в rATjTJX'e, поэтому они
не достигают успеха или достигают весьма относительного.
Вообще, люди, сведущие в полиграфии, не могут написать хороший ГАТ^Х-код
или другие виды кода, и наоборот —люди, знающие, как писать эти виды
кода, не смыслят в типографии. Что вы думаете о прошлых попытках совместить
оба мира, так, например, как Виктор Эйкаут попытался сделать при помощи
своего формата lollipop1, механизма для создания других форматов. Я
полагал, что это должно было стать серьезным успехом, но кажется случилось
обратное. Что вы думаете об этом?
Дон: Я не знаком с системой lollipop близко. Я полагаю, она основана на
известной цитате из Элана Пер лиса, сказавшего: «Если кто-то говорит, что ему
нужен язык программирования, который все будет делать только правильно,
дайте ему леденец (lollipop)».
Андрис: Да.
Дон: Я уверен, что опыт с системой lollipop был поучительным и стоил
затраченных усилий, но я не знаю подробностей, так что не могу подробно ответить
на вопрос. Может быть, создателям шрифтов показалось, что язык слишком
сложно выучить. Я все-таки думаю, что сейчас, с каждым месяцем, общение
между людьми, сведущими в шрифтах, и людьми, сведущими в макро,
становится все активнее и активнее. Это всего лишь вопрос времени, а пока эти
волны продолжают двигаться — мы еще очень далеко от предельного
состояния, когда ТЕХ достигнет своих естественных границ и создатели шрифтов
достигнут своих естественных границ. Границы все еще сближаются. Я не
думаю, что получится как в гиперболической геометрии, где они никогда не
сойдутся.
Главная сложность, конечно, в том, что Т£Х распространяется бесплатно, и
поэтому многие люди скажут: «Что же может быть в нем хорошего, если вы не
получаете за это денег?» Многие из сообщества шрифтовиков будут работать
только над тем, за чем стоят деньги; деньги для них доказательство, что с
людьми стоит разговаривать. Так что должно пройти некоторое время, прежде
Lollipop (англ.) —леденец на палочке. — Прим. перев.
Глава 33. Вопросы и ответы, III
645
чем они увидят какие-нибудь удачные примеры и станут более расположены
к общению. И это все время происходит в разных странах.
В Чешской Республике я был очень обрадован, узнав, что новая чешская
энциклопедия, первая за много лет, делается в ТЁХ'е. И помимо этого у нее
очень высокий бюджет. Издатели пришли к такому решению, потому что они
перепробовали все остальные системы и те им не понравились. T^jX же их
вполне удовлетворил. Многие другие коммерческие издательства тоже
используют его, потому что общаются со своими друзьями из больших издательских
домов. Я думаю, этот вопрос со временем решится. А продукты вроде системы
lollipop пока что очень ценны для упрощения этого процесса. На то, чтобы
объединить два сообщества, требуется время. Я думаю, финансовый фактор
является определяющим для многих людей.
Пит ван Острюм: Я не знаю, смотрели ли вы, как устроен код iAT^X'a
изнутри, но если вы заглянете туда, у вас возникнет впечатление, что *ТЁХ
не самый подходящий язык программирования для создания таких больших
систем. Думали ли вы когда-либо, что T^jX будет использован для этого, и,
если нет, не приходило ли вам в голову придумать для этого язык получше?
Дон: В каком-то смысле, многие возможности ТЕХ'а, связанные с
программированием, появились только после долгих дебатов; поэтому я попробую
описать подоплеку. Я знаю, как Лесли [Лэмпорт] работал над ГАТ^Х'ом —
сначала он записывал алгоритмы на языке программирования высокого уровня, с
циклами while и ветвлениями if-then и пр.; потом он довольно механически
переводил высокоуровневый код в макро Т^Х'а. Если бы я предвидел, что это
будет самым распространенным способом использования Т^Х'а, я бы,
возможно, в те дни серьезно волновался об эффективности. Теперь компьютеры стали
настолько мощными, что я уже не беспокоюсь так сильно о времени работы,
потому что программа по-прежнему кажется работающей мгновенно!
В 70-е годы у меня сложилось отрицательное отношение к программам,
которые пытались делать все для всех. Каждая из виденных мной систем имела
свою собственную, каким-то образом встроенную машину Тьюринга, и
каждая такая машина немного отличалась от любой другой машины. Поэтому я
думал: «Ну, я-то не собираюсь создавать язык программирования; мне нужен
просто язык для печати текстов». Мало-помалу, тем не менее, мне требовались
все новые возможности, и поэтому программистские конструкции множились.
Гай Стил начал заблаговременно проталкивать еще больше возможностей, и
многие такие вещи я включил во вторую версию ТЁК'а —1^X82 —по его
настоянию. Это позволило находить простые числа, а также делать сложные
вещи, связанные с версткой страниц и расположением рисунков. Но причина,
по которой я не включил возможности программирования с самого начала,
заключалась в том, что как программист я устал от необходимости учить еще
один почти-такой-же язык программирования для каждой системы, которая
меня интересовала; я хотел попытаться избежать этого. Потом я понял, что
это в некотором роде неизбежно, но старался оставаться по возможности
верным образцу TgX'a как посимвольного макроязыка. Как я уже сказал раньше,
646
Компьютерная типография
я считал, что самые хитрые приложения будут делаться за счет изменения
скомпилированного кода. Но люди этого делать не стали; они хотели делать
низкоуровневые вещи на высоком уровне.
Пит: Что вы думаете, например, о том, чтобы в некотором смысле встроить
язык программирования, который с точки зрения разработки программного
обеспечения будет легче использовать?
Дон: Было бы неплохо, если бы существовал всем понятный стандарт
внутреннего языка-интерпретатора для произвольного приложения. Возьмите
регулярные выражения — UNIX я определяю как «30 определений регулярных
выражений, живущих под одной крышей». [Смех.] В каждой части UNIX'a
немного другие регулярные выражения. Теперь, если бы существовал
универсальный простой язык-интерпретатор, общий с другими системами, я бы,
естественно, немедленно на него перешел.
Пит: The Free Software Foundation пытается сделать его, и Sun пытается
сделать его, и Microsoft пытается ...
Дон: The Free Software Foundation на самом деле пытается включить также
решения Sun и Microsoft. Другими словами, заставить, насколько это
возможно, работать все правила вместе. А это не согласуется с моим собственным
стилем, для которого характерно достигнуть скорее единообразия, а не
разнообразия ... я не стремился предоставить возможность делать одну и ту же
вещь десятью способами. То же самое с C++ — каждый раз, когда члены
комитета по C++ говорили: «Ну, это можно сделать так или вот так», они делали и
так и так. В своих системах я не пошел по этому пути, потому что он ведет к
полной неразберихе. Но я согласен, что эта неразбериха —лучшее из того, что
на данный момент может быть реализовано на практике.
Марк: У меня вопрос о документированном программировании. Я знаю, оно
должно вам очень нравиться, если я правильно понимаю ваши интервью —
Дон: Да, оно мне так нравится, что я мог бы ... ну ... О'кей. [ Смех. ] Вы
знаете, мне действительно очень нравится документированное программирование,
это одна из величайших радостей в моей жизни —просто им заниматься.
Марк: Мой вопрос заключался в том, что, очевидно, оно не так популярно,
как ТЕХ, и кроме того в мире документированного программирования не
хватает согласованности. Используется около дюжины разных систем —одни люди
предпочитают этот путь, другие предпочитают другой, — и это меня несколько
беспокоит. Мне тоже очень нравится этот стиль программирования, но мне бы
хотелось, чтобы им чаще пользовались.
Дон: Документированное программирование настолько превосходит все
другие стили программирования, что трудно понять, почему им уже не пользуется
весь мир. Но мне кажется, Ион Бентли попал в точку, когда сказал, что
причина состоит примерно вот в чем: в мире не так много хороших программистов
и в мире не так много хороших писателей, а здесь мы ожидаем, что человек
окажется и тем и другим. Это некоторое преувеличение, но оно вскрывает суть
Глава 33. Вопросы и ответы, III
647
вопроса. Я думаю, каждый, кто занимался документированным
программированием, согласится, что это действительно стоящая вещь, но они не уверены,
что оно доступно обычному студенту. Некоторые эксперименты в Texas A&M
доказывают обратное, и у меня был подобный опыт в меньшем масштабе в
Станфорде. Это путь программирования через гипертекст; и я полагаю, что
с лучшим гипертекстом, вроде имеющегося теперь, и с людьми, все более и
более привыкающими к Сети, мы получим набор новых несовместимых
систем, поддерживающих документированное программирование. Надеюсь, кто-
нибудь, обладающий временем, и талантом, и вкусом, соберет воедино систему
документированного программирования, настолько очаровательную, что она
привлечет множество народа. Я верю, что там есть потенциал, он ждет только
нужного человека, который бы его раскрыл.
Марк: Я думаю, одна из проблем заключается в том, что, если вы сравните
ваши программы со средними программами из тех, что пишутся другими
людьми, в средней программе и близко нет стольких интересных алгоритмов, так
что документированное программирование не много добавляет к программе,
которая сама по себе скучна.
Дон: Что ж, спасибо за ваше замечание. Но, может быть, иногда я делаю
неинтересный алгоритм интересным, просто вставляя туда шутку. Я взял,
например, программы, полученные от Sun Microsystems, и в качестве упражнения
потратил день на перевод их в документированную форму. Там не было
никаких сногсшибательных алгоритмов, но, тем не менее, можно посмотреть на
получившуюся программу, и она была лучше — у нее была лучше диагностика
ошибок, она была лучше структурирована, в ней были исправлены некоторые
недочеты. У меня нет времени пойти в Sun, показать им это и сказать:
«Почему бы вам не переделать вашу операционную систему?» [ Смех.] Но я знаю,
что она стала бы намного лучше. Так что все, что я опубликовал, это очень
простая переделка программы wc подсчета слов в UNIX'e. Ничего особенного в
этом алгоритме нет, но это демонстрация того, как можно сделать качественное
системное программирование приятным занятием.1
Мой подход к документированному программированию, конечно, не
единственный. В недавно вышедшей книге группы авторов из Принстона А
Retargetable С Compiler Крис Фрейзер и Хансон использовали разные
документированные программы для описания их компилятора С. Выходят другие
книги, использующие другие особенности документированного
программирования. Я разговаривал с человеком из Microsoft, и он сказал, что, по его
мнению, документированное программирование на подъеме, а я сказал: «Значит
ли это, что следующая версия Windows будет сделана при помощи
документированного программирования?» ... «Ну, нет, не то чтобы». [Смех.]
Люди, вкусившие документированного программирования, никогда не вернутся
к старому, и возможно, они постепенно приобретут влияние. Компании,
использующие его, будут продавать больше продукции, чем их конкуренты, так
1 D. E. Knuth, Literate Programming (1992), 341-348; эта программа wc основана на
прототипе Клауса Гунтерманна и Иоахима Шрода, TUGboat 7 (1986), 135-137.
648
Компьютерная типография
что довольно скоро это случится. Я полагаю, что пользователей
документированного программирования около десяти тысяч, а пользователей ТЁХ'а около
миллиона, так что соотношение 1 к 100.
Марк: Не думаете ли Вы, что ему еще надо развиваться? У меня такое
впечатление, что, со столькими инструментами вокруг, оно еще не созрело. Идея
уже созрела, но воплощение еще нужно ...
Дон: Да, это правда. Имеется огромная потребность в программных средах,
основанных на этой идее. Это вовсе не просто — создать эти среды и иметь
достаточно влияния для их распространения и, может быть, средств, чтобы
сделать их установку не слишком дорогой и не слишком трудной. Идеально
было бы, если бы the Free Software Foundation приняла эту идею, или кто-то
вроде них, или люди, с ними работающие. На самом деле, [Ричард] Столлман
[из the Free Software Foundation] создал для себя вариант документированного
программирования, и у него оно хорошо интегрировано с ТЦХ'ом, в его
собственной манере. Не слишком много программ, в которые он его вставил, но
он к этому идет. Это одна из вещей, которым, как Вы говорите, нужно еще
дозреть.
Марк: Считаете ли вы, что документированное программирование должно
развиваться в сторону интегрированных систем, где у вас действительно
имеются все необходимые возможности в одной системе? Потому что, мне кажется,
современная тенденция больше склоняется к самым минимальным системам,
которые не позволяют сделать красивую распечатку, потому что это приводит
к слишком большим неприятностям, когда вы переключаетесь между
языками программирования. Так что в реальности это выливается во что-то очень
гибкое, но не очень удобное в использовании.
Дон: Для меня лично одного языка программирования вполне достаточно,
так что я не тот, кого стоит об этом спрашивать. Что касается моих
собственных потребностей, я собираюсь писать The Art of Computer Programming в
течение следующих двадцати лет, и вполне уверен, что CWEB будет полностью
удовлетворять всем моим запросам. Я буду писать программы для системы
Mathematica™ и буду иногда писать программы для МЕТАРОЕГГ'а; я мог бы
разработать или использовать документированное программирование для этих
систем, но не думаю, что осуществлю это. Я пишу не так много строк кода,
чтобы получить серьезный выигрыш ... хотя впоследствии я бы получил
лучшие программы. Если только кто-нибудь не подарит мне уже сейчас хорошую
систему для них, я не буду пользоваться MathWeb'oM или MPWeb'oM. Но на CWEB'e
в обозримом будущем я собираюсь писать в среднем пять программ в неделю,
моя продуктивность бесконечно больше, когда я делаю это, используя
документированное программирование.
Еще одна мысль промелькнула у меня в голове во время моих
предыдущих слов ... Я написал статью, это было, по-моему, в прошлом году, о
мини-указателях для документированных программ1, и пытался представить,
1 Software — Concepts and Tools 15 (1994), 2-11; перепечатано в главе 11 этой книги.
Глава 33. Вопросы и ответы, III
649
какого сорта программная среда мне бы помогла. В листингах в Т$£: The
Program и METRFONT: The Program, а также в The Stanford GraphBase
справа на каждом двухстраничном развороте имеется предметный указатель всех
идентификаторов, встречающихся на этих двух страницах, с указанием
места их объявления. В моей статье рассказывается о системе, использованной
мною для получения этих указателей, и такого типа деятельность потребуется
также в любой гипертекстовой системе. Такие минимальные системы
привлекательны в первую очередь тем, что хороший программист может написать их
за пару дней, понимать и использовать их и извлекать из них много пользы.
Как только будет написана хорошая гипертекстовая система для
документированного программирования, я думаю это привлечет очень многих. Нам нужна
крепкая система, которая не падает и имеет знакомый пользовательский
интерфейс, потому что похожа на другие гипертекстовые системы, которыми мы
уже пользуемся. Время для этого наступит примерно через два года.
Эрик: Сейчас уже половина десятого, и я думаю, нам стоит остановиться
на этом. Я хочу поблагодарить нашего особого гостя, Дональда Кнута, за эту
встречу. Я думаю, мы все многое узнали. Мы очень рады, что вы смогли
присутствовать здесь. Благодарим вас.
Дон: Я очень ценю всю проделанную вами работу по подготовке помещения
для этой встречи за довольно короткий срок. [ Аплодисменты. ]
Эрик: Также благодарим издательство Elsevier Science, оказавшее помощь в
лице Саймона Пеппинга, и нашего английского коллегу Себастиана Ратца,
которого здесь нет, хотя я его и ждал. Но он оплатил кофе и чай, так что спасибо.
У нас, конечно, есть небольшой подарок для вас. Надеюсь, он вам понравится!
[ Он дарит книгу о голландском искусстве, называющуюся De Stijl}. ]
Дон: А, да ... голландский создатель шрифтов, Ге-
рард Унгер, приезжал в Станфорд на три недели, он и
его жена Марьян, и они говорили о подобных вещах с
нашими создателями шрифтов. Они также связывали
моду в одежде, и мебели, и архитектуре еще и со
стилями печати. Это замечательная книга. Она сделана
вТЁХ'е?
Эрик: Я не думаю ... поскольку мы сейчас в
Голландии ... [ смех.} [ Он дарит также пару деревянных
тюльпанов. ]
Дон: Прекрасный подарок моей жене.
Эрик: И, конечно, экземпляр трудов конференции
ЕшоТЁХ'95? [ он дарит труды конференции. ]
1 Carel Blotkamp et al., De Stijl: The Formative Years (M.I.T. Press, 1986); перевод книги
De Beginjaren van De Stijl (Utrecht: Uitgeverij Reflex, 1982).
2 Wietse Dol, editor, Proceedings of the Ninth European TtfK Conference, September 4-8,
1995, Arnhem, The Netherlands, 441 pp.
650
Компьютерная типография
Дон: О!! Я думал, вы никогда ... [смех]. Да, я видел их на прошлой неделе
в Чешской Республике, так что спасибо всем.
Эрик: Что вы думаете об использованных шрифтах?
Дон: Я думаю ... о, вы использовали Computer Modern Brights. Да,
единственная жалоба, которая у меня была, — кернинг в самом слове 'T^jX' можно
было немного подправить} В целом печать вполне привлекательна — большое
спасибо.
1 The IgX logo in various fonts, TUGboat 7 (1986), 101; перепечатано в главе б данной
книги.
Последние ошибки TfjjX'a
[Эта глава была написана в августе 1998 года.]
Когда я завершил мою статью про «Ошибки Tf^K'a» в сентябре 1988 года [2],
я сказал, что «собираюсь опубликовать через десять лет короткую заметку,
которая окончательно завершит список». Вот эта обещанная короткая заметка.
В сентябре 1988 года журнал ошибок TfejX'a заканчивался пунктом номер
865. Шестнадцать пунктов добавились в журнал с мая 1987 года, так что у
меня не было никаких причин считать, что ЧЩХ вскоре достигнет абсолютной
стабильности. Впрочем с уверенностью могу сказать, что ожидал в конечном
итоге иметь менее 900 ошибок.
Но эти надежды были перечеркнуты в 1989 году, когда я понял, что
изменения в технологии свели на нет одно из моих ранних предположений. Я
считал, что ввод 7-битных символов будет по-прежнему оставаться нормой; но
быстрое развитие компьютерных систем, основанных на байтах из 8 битов, и
рабочих станций, использующих 8-битные символы для букв с акцентами,
ясно показало, что пристойную систему ТЕХ, предназначенную для всемирного
сообщества, придется снабдить новыми средствами для более адекватной
обработки неанглийских языков. Поэтому после серьезных обсуждений, пик
которых пришелся на 10-е ежегодное собрание сообщества пользователей ТЁХ'а,
я решил встроить несколько существенных новых возможностей в версию 3
ТЁХ'а и версию 2 METRFONT'a [4].
Естественно, новые расширения вызвали всплеск активности в журнале
ошибок ТЁХ'а, достигшем 900 пунктов уже в январе 1990 года. Сводка всех
записей журнала на конец 1991 года была опубликована в [3], составив в сумме
916 пунктов. И это всё еще был не конец истории; запись в моем дневнике от
9 января 1992 года говорит: «Увы, плохие новости от Т^Хогетов: ТрИ новые
ошибки в Т^Х'е, одна —в METRFONT'e».
Сегодня, как бы то ни было, я рад сообщить, что программа ТЁХ'а
сохраняла стабильность последние три года, так что, может быть, процесс наконец-
то сошелся. Оставшиеся записи журнала, с 1992 года по настоящий момент,
показаны на рис. 1; полностью подробное описание всех, изменений в форме
листингов строчек кода, этими изменениями затронутых, в состоянии до и
652
Компьютерная типография
10 January 1992
881 »-> 917 Also avoid producing a double kern at boundary (CET). §897 S
918 Disallow \setbox where it doesn't work (Robert Hunt). §1241,1270 S
919 Robustify \mskip and \mkern in presence of negative quad (WGS). §716, 717 S
679 »-> 920 Defend against 'H' in \read (Michael Downes). §483 S
798 »-> 921 Save string memory if font occurs repeatedly (Boguslaw Jackowski). §1260 E
784 »-> 922 Don't let \newlinechar interrupt unprintable expansion (Bernd Raichle). §59,60 S
7 February 1992
881 »-> 923 Restore cur.l properly when boundary character doesn't exist (Mattes and
Raichle). §1036 D
17 July 1992
892 »-> 924 Use current language at beginning of horizontal mode (Rainer Schopf and
CET). §1091,1200 С
17 December 1992
879 »-> 925 Avoid (harmless) range errors (Philip Taylor and CET). §934,960 R
25 February 1993
881 »-> 926 Protect kerns inserted by boundary characters (William Baxter). §837,866 С
917 i—»' 927 Don't let boundary kern disappear after hyphenation. §897 S
26 June 1993
668 »-> 928 Avoid potential future bug (Peter Breitenlohner). §628,637 R
17 December 1993
881 »-> 929 Boundary character representation shouldn't depend on the font memory size
(Berthold Horn). §549,1323 S
10 March 1994
930 Huge font parameter number may exceed array bound (CET). §549 R
4 September 1994
926 »-> 931 Math kerns are explicit (Walter Car lip). §717 F
932 Avoid overflow on huge real-to-integer conversion. §625,634 R
19 March 1995
933 Avoid spurious reference counts in format files (PB). §1335 R
Рис. 1.Журнал ошибок TfejX'a (1992-1998).
после внесения изменений можно найти в файле, называющемся tex82.bug,
являющемся частью архивов CTAN в Интернете.
Гистограмма на рис. 2 показывает, с какой интенсивностью журнал
ошибок пополнялся 68 пунктами после сентября 1988 года, пик интенсивности
приходится на первую половину 1989 года, а впоследствии она падает, за
исключением случайных всплесков активности, когда новые типы пользователей
наталкивались на новые типы ошибок. Затененные прямоугольники
обозначают пункты, порожденные предыдущими записями в журнале; если бы я на
должном уровне сделал предыдущие исправления, эти 34 пункта не
понадобились бы.
Некоторые записи в журнале представляют собой серьезные, коренные
изменения в программе. Например, изменение номер 878 — приводящее
программы 7-битного ввода/вывода к новым 8-битным правилам — заменило 195 строк
WEB-Паскаля на 213 новых строк кода. Изменение 881, вводящее «умные
лигатуры», потребовало замены 78 строк на 856 новых строк. А изменения 879-880,
необходимые для многоязыкового переноса, заменили 155 строк на 329.
Но такие коренные изменения возникали только при добавлении основных
новых возможностей версии 3.0. На самом деле, около 57% всех изменений с
Глава 34. Последние ошибки ТЩХ'а
653
К
JZL
fb i*P
-Р-
1993 1994 1995 1996 ' 1997 ' 1998
1988 1989 1990 1991 1992
Рис. 2. Когда делались изменения.
1988 года потребовали замены менее 10 строк кода на Паскале менее чем 10
новыми строками.
Если использовать пятнадцать категорий из [2] для классификации 68
записей в журнале за последнее десятилетие, мы получим следующие суммы:
• Тип А (алгоритмические аномалии), 0.
• Тип В (бывший бедлам или брак), 0.
• Тип С (чистка для членораздельности или четкости), 4.
• Тип D (дезорганизация структуры данных), 6.
• Тип Е (эскалация эффективности), 2.
• Тип F (факультативная функциональность), 3.
• Тип G (генерализация или глрбализация), 11.
• Тип I (интерактивная интенсификация), 2.
• Тип L (лаконичность лексикона), 0.
• Тип М (модуленесовместимость), 1.
• Тип Р (продвижение переносимости), 2.
• Тип Q (копилка качества), 1.
• Тип R (укрепление усиления), 10.
• Тип S (ситуация-сюрприз), 24.
• Тип Т (тривиальный тип), 0.
Ни для кого не сюрприз, что в списке доминируют сюрпризы.
Были ли какие-нибудь из этих изменений особенно поучительными или
заслуживающими особого внимания? Большинство уроков, извлеченных после
1988 года, были сходны с уже перечисленными в [2], только их стало больше.
Опыт еще десяти лет подтверждает, что, если мы хотим полностью избавить
от ошибок сложную программу, следует быть готовыми приложить к этому
значительные усилия.
Последняя ошибка?
Самая интересная из недавних ошибок вполне может оказаться и последней,
номер 933 —я действительно надеюсь, что она окажется «исторической»
последней ошибкой в TgX'e. Эта ошибка, обнаруженная в 1995 году Петером
Брайтенлонером, довольно эзотерична и в обычной работе никак не проявля-
654
Компьютерная типография
ется; всё же мне кажется, он честно заслужил награду в $327.68, которую я
выплатил ему 20 марта 1995 года.
Ситуация такова: I^X борется с накоплением мусора, используя счетчики
ссылок в ключевых местах структур данных. Предполагается, что для
хранения счетчика ссылок требуется не больше памяти, чем для указателя, потому
что число ссылок на узел не может превышать общего числа узлов, если
соблюдаются правила ТЁХ'а.
Брайтенлонер обнаружил пробел в этой непогрешимой логике,
используя специальную версию ТЁХ'а под названием INITEX. Системные мастера
установки инсталлируют макропакеты для INITEX'а, вызывая команду \dump
[сбрссить], которая сохраняет текущее содержимое структур данных в так
называемом форматном файле; \dump запрещена в обычных версиях Т^Х'а. Всё
время используемые шрифты и макро могут быть быстро подгружены Т^Х'ом
или INITEX'ом, если до этого они были сброшены в форматный файл.
Когда команда \dump возникает в процессе раскрытия макро и/или
посередине условного выражения, структуры данных, контролирующие состояние
ввода INITEX'а, не сохраняются как часть форматного файла, потому что
такие вещи безразличны для конечного пользователя. К несчастью, тем не менее,
эти структуры данных могут ссылаться на объекты, которые сохраняются —
и тут-то вся загвоздка. До того как было сделано изменение номер 933, INITEX
мог сбрасывать счетчики ссылок, включающие ссылки из узлов, которые
впоследствии не будут загружены. Поэтому пользователь с преднамеренным злым
умыслом мог всё время просить INITEX загружать такие файлы и сбрасывать
новые, еще худшие; счетчики ссылок могли расти до тех пор, пока они не
станут сколь угодно велики.
Изменение 933 добавило инструкции к программе TgX'a finaLcleanup, так
чтобы все ссылки из невосстановленных указателей удалялись перед
сбрасыванием. Аналогичное изменение, конечно, было сделано в METflFONT'e.
Не ошибки, но близко к этому
Я зарезервировал для себя правило решать относительно любого
подозрительного места, является ли это ошибкой ТЕХ'а, которую надо исправить.
Некоторые люди считают, что Т^Х некорректен, только потому, что
пользователи легко могут заставить его зациклиться. Но на самом деле T^jX и должен
зацикливаться, если ему даются команды, требующие бесконечной
деятельности. Например,
\def\x{\x}\x
приводит к бесконечному раскрытию макро. Более интересный пример
\let\par=\relax \noindent\vfill
говорит TfejX'y, чтобы он продолжал выполнять \relax, пока не перейдет в
вертикальный режим —а этого никогда не произойдет! (См. правила на с. 286
в книге The Т££Ъоок [1]})
1 См. также в русском издании «Всё про ТЕХ» на ее. 340-341. — Прим. перев.
Глава 34. Последние ошибки ТЕХ'а
655
Обобщая, я бы сказал, что ТеХ не должен выдавать сообщение об ошибке
«Это не может произойти», если только ранее он не выдал какого-нибудь
другого сообщения об ошибке. Но это определение ошибочного поведения тоже
имеет исключения, потому что программа TgX'a явно признает, что
определенные типы ошибок при выполнении возможны, но тем не менее абсурдны
(так как они не возникнут при нормальном использовании).
Например, §798 программы вызывает фатальное сообщение «это не может
произойти», когда пользователь пытается сделать \span [выделение] 256 или
более колонок таблицы. Программа §798 содержит комментарий
{это может произойти, но не произойдет}
— ясно признающее тот факт, что сообщение ЧЩХ'а в этом отдаленно
возможном случае ложно. Вы можете называть это примером моего извращенного
чувства юмора; или вы можете подумать, что я не хотел выдавать ошибку
«переполнения», потому что максимальное число выделяемых колонок не так
легко увеличить, как другие величины, перечисленные на с. 300 в книге The
ТЁКЬоок1 и выдаваемые по команде \tracingstats; но нельзя назвать это
ошибкой, заслуживающей $327.68. Разработчики, не согласные с этим, вольны
изменять поведение ТЁХ'а в этом случае, так как тест TRIP не имеет
предписаний, как нужно действовать при фатальных ошибках. Например, они могли бы
заменить сообщение по аналогии со случаем «дискреционный список слишком
велик» в §1120, если они действительно считают, что честный пользователь
будет введен в заблуждение при такой обработке Т^Х'ом попыток создания
слишком больших таблиц. Но я не думаю, что это выход. Между прочим,
в 1996 году Дейвид Каструп нашел потрясающе хитрый способ добиться от
Т^К'а такого лживого поведения с помощью следующей замечательно
короткой программы:
\def\x#l{\if#lm\span\expandafter\x\fi}
\halign{&#\cr\expandafter\x\romannumeral256001\cr}
Еще один пример аномального поведения, про которое точно известно, что
с ним можно столкнуться в экстремальных условиях, возникает, когда числа
становятся достаточно большими, чтобы вызвать арифметическое
переполнение. ТЁК пытается отловить целочисленное переполнение до того, как оно
произойдет, в ситуациях, которые предположительно будут возникать на практике
(см., например, §104, §445 и §1236); но в §104 указывается, что я не взял на
себя труд сделать программу совершенно непробиваемой для вражеских атак.
Например, ЧЩХ'овский код
\hbox{\romannumeral\maxdimen}
создает блок, содержащий 1073 741 букву т, за которыми следует 'dcccxxiii'.
В обычном шрифте cmrlO этот блок будет иметь ширину, в точности
равную 586410016845 пунктам; это около 1.954 мили (3.145 километра). Что-
то да произойдет. В этом случае строка сообщений ТЕХ'а, где
формируются римские числа, будет переполнена, но в меньших примерах вместо
1 См. также в русском издании «Всё про ТЕХ» н& ее. 358-359. — Прим. перев.
656
Компьютерная типография
этого даст сбой целочисленная арифметика. Хотя флаги компилятора в
§9 указывают, что целочисленное переполнение должно отлавливаться
аппаратными средствами, современные реализации I^X'a часто
пренебрегают этой рекомендацией; например, типичная для UNIX'a установка
сообщит, что \hbox{\romannumeral3932000} имеет ширину 32766.7666 пункта, в
то время как ширина в пунктах \hbox{\romannumeral3932001} составляет
-32766.45555!
Целочисленное переполнение можно получить многими способами, если
приложить достаточные усилия для преодоления имеющихся установок.
Например, можно состряпать абзацы, имеющие более 231 дефектов, при
некоторых выполнимых последовательностях разрывов строк. Но я не считаю такие
конструкции доказательством ошибок в ТЁХ'е, если только меня не убедят,
что разумный пользователь может столкнуться с таким поведением. (Или
если, как с ошибкой 933, не нарушено одно из фундаментальных предположений
в замысле ТЁХ'а.)
По причинам, связанным с независимостью от платформы, я не считаю,
ни что максимальное число выделяемых колонок в таблице нужно
увеличить, сделав больше 255, ни что максимальный размер целочисленной
константы на компьютерах с 64-битной арифметикой должен превышать 231 — 1 =
2147483647. В конце концов, Т^Х —это язык для печати текстов. Кому нужны
такие гигантские числа?
Просчеты проекта
Проект Т^Х'а был заморожен с 1990 года; поэтому больше никто не может
сказать, что в замысле Т^Х'а есть какая-нибудь ошибка. В настоящее время я
всё же знаю три вещи, которые я бы изменил, если бы задумался о них перед
тем, как решил заморозить проект в окончательной форме:
(1) Дополнительные параметры в символьных шрифтах могли бы влиять
на минимальное расстояние между линейками в дробях, \sqrt, \overline и
\underline; в настоящее время это минимальное расстояние зависит только
от толщины линии.
(2) Только один набор значений внутренних кодов, переводящих
прописные буквы в строчные, используется в абзаце для переноса, даже если в
абзаце присутствуют несколько языков с разными переводящими функциями. В
расширениях ТЕ^'а, в которых эту проблему захочется преодолеть, возможно
нужно будет предусмотреть новые типы whatsit'oB, записывающих изменения
значений \lccode.
Проблем можно избежать, не расширяя ТЕХ, если использовать следующее
окружение: макро \hyphenate, определяемый как
\newbox\hyfbox \def\hyphenate#l{{\everyvbox{}\setboxO=
\vbox{\pretolerance=-l\parfillskip=Opt\hsize=\maxdimen
\rightskip=0pt\hbadness=10000\everypar{}
\noindent\hskip-\leftskip #l\endgraf
\global\setbox\hyfbox=\lastbox}}\unhbox\hyfbox}
Глава 34. Последние ошибки Т^Х'а
657
перенесет всё, что ему будет поступать, используя правила переносов из
текущего языка, возвращая горизонтальный список, включающий мягкие
переносы.
(3) Правило 12 в приложении G в книге The T^Kbook не позволяет в
математическом режиме ставить большие акценты (скажем, из шрифта cmrl7)
близко к маленьким буквам из-за формулы 6 <— min(/i(a;),x)- Эта формула
не позволяет опустить акцент ниже высоты блока под ним, поэтому акцент не
опустится ниже своего первоначального положения в шрифте.
На проблему (3) мое внимание обратил Воан Пратт в марте 1998 года; он
спросил, как напечатать '?' (с акцентом, большим нормального 'г',
полученным из $\check r$), и мое лучшее решение в plain 1ЁХ'е было некрасивым:
\font\bigacc=cmrl7 \textfont"F=\bigacc
\def\CHECK{\mathaccent"7F14 }
\setbox2=\hbox{$r$}\setbox4=\hbox{\raise3pt\copy2}\ht4=\ht2
\def\CHECKr{\lower3pt\hbox{$\CHECK{\copy4}$}}
Я не вполне уверен, что бы я сделал, если бы он задал мне тот же вопрос в
1988 году; в то время я бы посчитал это ошибкой в "ЩХ'е. Теперь это лишь
неудачное свойство.
Заключение
Любую сложную систему можно улучшить; поэтому достичь абсолютного
совершенства и оптимальности невозможно. Всё же я думаю, можно сказать,
что ТЕХ достиг вполне удовлетворительного состояния, при условии, что
стабильность сама по себе тоже очень важна. Я глубоко признателен многим
добровольцам по всему миру, помогавшим мне формулировать многие
изменения, приведшие Т£Х к его нынешнему состоянию, известному как «версия
3.14159».
Литература
[1] Donald E. Knuth, The TfiKbook, Volume A of Computers к Typesetting
(Reading, Massachusetts: Addison—Wesley and American Mathematical
Society, 1984). [Имеется русский перевод: Дональд Е. Кнут. Всё про ТЕХ. —
Протвино: АО RDT£X, 1993.]
[2] Donald E. Knuth, "The errors of ТЕХ," Software—Practice and Experience 19
(1989), 607-685; перепечатано с дополнениями и исправлениями в главе 10
книги Literate Programming. См. также [3].
[3] Donald E. Knuth, "The error log of T£X (1978-1991)," глава 11 книги Literate
Programming, CSLI Lecture Notes 27 (Stanford, California: Center for the
Study of Language and Information, 1992), 293-339.
658
Компьютерная типография
[4] Donald E. Knuth, "The new versions of T^X and METRFONT," TUGboat
10 (1989), 325-328; 11 (1990), 12. Перепечатано в Die TjEXnische Komodie
2,1 (March 1990), 16-22. Перевод на французский Алена Куске (Alain
Cousquer), '"IfeK 3.0 ou le IgX nouveau va arriver," Cahiers GUTenberg, № 4
(December 1989), 39-45. Также перепечатано в главе 29 этой книги.
Добавление (декабрь 2002 г.)
В 1998 г. ТеХ стал успешно печатать текущий год с 4 цифрами вместо 2, таким
образом решив «проблему 2000 года».
В 1999 г. была обнаружена погрешность в \xleaders, в 2001 г. устранена
отмена выравнивания Т^Х'а; округление клея было улучшено в 2002 г. Но,
оставаясь оптимистом, я продолжаю думать, что больше никаких изменений
не понадобится.
Примечание переводчика
Перевод текста, представленного на рис. 1.
10 января 1992 года
881 н-> 917 Избежать также двойного керна на границе (СЕТ). §897 S
918 Запретить \setbox там, где он не работает (Роберт Хант). §1241,1270 S
919 Усилить \mskip и \mkern в присутствии негативного quad (WGS). §716,717 S
679 н-> 920 Защититься от 'К' в \read (Майкл Даунз). §483 S
798 н-> 921 Сохранять строковую память, если шрифт появляется неоднократно (Богуслав
Яцковский). §1260 Е
784 н-» 922 Запретить команде \newlinechar прерывать не отражаемое на печати раскрытие
(Бернд Райхле). §59,60 S
7 февраля 1992 года
881 н-> 923 Правильно восстанавливать сиг_1, когда граничного символа нет (Маттес и
Райхле). §1036 D
17 июля 1992 года
892 н-» 924 Использовать текущий язык в начале горизонтального режима (Райнер Шёпф и
СЕТ). §1091,1200 С
17 декабря 1992 года
879 н-> 925 Избежать (безобидных) ошибок диапазона (Филип Тейлор и СЕТ). §934,960 R
25 февраля 1993 года
881 н-> 926 Защитить керны, вставляемые граничными символами (Уильям Бакстер). §837,866 С
917 н-> 927 Предотвратить исчезание граничного керна после переноса. §897 S
26 июня 1993 года
668 н-> 928 Избежать потенциальной будущей ошибки (Петер Брайтенлонер). §628,637 R
17 декабря 1993 года
881 н-> 929 Представление граничного символа не должно зависеть от размера памяти
шрифта (Бертольд Хорн). §549,1323 S
10 марта 1994 года
930 Большое значение параметра шрифта может превысить размер массива (СЕТ). §549 R
4 сентября 1994 года
926 н-» 931 Математические керны точно определены (Уолтер Карлип). §717 F
932 Избежать переполнения при переводе больших действительных чисел в целые. §625,634 R
19 марта 1995 года
933 Избежать фальсификации счетчиков ссылок в форматных файлах (ПБ). §1335 R
Именной указатель
Адлеман (Adleman, Leonard Max)
585
Алжи (Algie, Stephen H.) 466, 467
Анастассиу (Anastasiou, Dimitris)
466
Аристотель (Aristotle of Stagira) 296
Бакстер (Baxter, William Erik) 658
Барнетт (Barnett, Michael Peter) 43, 75,
149, 163
Бартелс (Bartels, Samuel A.) 148,
163
Бартлетт (Bartlett, Fred) 599
Бафур (Bafour, Georges P.) 148, 163
Беббидж (Babbage, Charles) 559
Безье (Bezier, Pierre Etienne) 78
Бентли (Bentley, Jon Louis) 646
Берри (Berry, Daniel Martin) 630
Бехтольсхайм, фон (Bechtolsheim,
Andreas von) 548
Бибби (Bibby, Duane Robert) 554, 566,
626, 627
Бигелоу (Bigelow, Charles Andrew) 314,
315, 318, 333, 362, 381, 391, 565,
613
Бийби (Beebe, Nelson H. F.) 596, 602
Бил Дарт (Byl Dart, Renata Maria)
392
Биллавала (Billawala, Nazneen Noorudin
= Neenie) 392, 635
Биллот-Хоффманн (Billotet-Hoffmann,
Claudia) 460, 467
Битон (Beeton, Barbara Ann Neuhaus
Friend Smith) 162, 344, 356, 578, 604,
626
Бланшар (Blanchard, Andre R.)) 148,
163
Боас (Boas, Ralph Philip) 356, 358
Воден (Baudin, Fernand) 318
Бонтен (Bonnetain, Jean-Luc) 392
Ботнер (Bothner, Per Magnus Alfred)
390, 392
Брайтенлонер (Breitenlohner, Peter) 600,
653, 658
Брамс (Braams, Johannes Laurens)
629
Браун, Малкольм (Brown, Malcolm)
392
Браун, Рой Говард (Brown, Roy Howard)
363, 371
Брокар, де (Brocar, Arnao Guillen, de)
141
Бронсар (Bronsard, Henri-Paul) 318
Брэнд (Brand, Stewart) 628
Брюнгдал (Bryngdahl, Olof) 460,
467
Вайзенберг (Weisenberg, Michael)
392
Вайсман (Wiseman, Neil Ernest) 162,
315
Валлис (Wallis, John) 349, 368
Ван Вик (Van Wyk, Christopher John)
469, 476
Ванг, Ами (Wang, Amy Ming-te) 547
Ванг, Майкл (Wang, Michael Ming-kai)
547
Вейерштрасс (Weierstrass, Karl Theodor
Wilhelm) 366
Вельтюи (Velthuis, Frans Jozef) 295
660
Компьютерная типография
Весели (Vesely, Jiff = George) 621
Видден (Whidden, Samuel Blackwell)
356
Видерхольд (Wiederhold, Giovanni
Corrado Melchiore = Gio) 546
Виноград (Winograd, Terry Allen) 546,
620
Винчи, Леонардо, да (Vinci, Leonardo
da) 169, 171, 172
Вольф (Wolf, Hans) 73, 565, 620
Вулф (Woolf, William Blauvelt) 356
Гайдн (Haydn, Franz Joseph) 317
Галилей, Галилео (Galilei, Galileo)
124
Гард (Gard, Robert L.) 445, 466, 467
Гауди (Goudy, Frederic William) 52-54,
75, 612
Гиббоне (Gibbons, Jeremy) 578, 596
Го-Ань, Гу (Guoan, Gu, 11$) 31, 32,
35, 330, 343
Годдейн (Goddijn, Franciscus Theodorus
Hendrik) 626, 635
Голдфарб (Goldfarb, Charles Frederick)
641
Гопинат (Gopinath, Kanchi) 392
Гор (Gore, Gary) 318
Горак (Horak, Karel) 604, 608
Гори (Gorey, Edward Saint John) 626
Госпер (Gosper, Ralph William, Jr.)
64
Гоулд (Gould, Benjamin Apthorp)
560
Гош (Ghosh, Pijush Kanti Ppj^;fw Z'-J
294
Гранжан (Grandjean, Phillipe) 54
Гримм, Вильгельм Карл (Grimm,
Wilhelm Karl) 86, 136, 157, 164
Гримм, Якоб Людвиг Карл (Grimm,
Jakob Ludwig Karl) 86, 136, 157,
164
Грин, Дейл (Green, L. Dale) 540
Грин, Дэниел (Greene, Daniel Hill)
546
Грэхем (Graham, Ronald Lewis) 367,
369, 379
Гуиба (Guibas, Leonidas John) 73,
540
Гуммель (Hummel, Johann Julius)
317
Гунст, Морган (Gunst, Morgan Arthur)
611, 612
Гунст, Элин (Gunst, Aline Dreyfus) 611,
612
Гунтерманн (Guntermann, Klaus)
647
Гуссенс (Goossens, Michel) 602
Гутенберг (Gutenberg, Johannes =
Johann Gensfleish) 24, 51
Даунз (Downes, Michael John) 643,
658
Де Винн (De Vinne, Theodore Low) 43,
75, 138, 153, 163, 164
Дезарменьен (Desarmenien, Jacques
Robert Jean) 392
Дейкстра (Dijkstra, Edsger Wijbe)
640
Декарт (Descartes, Rene) 276
Джексон (Jackson, Calvin William, Jr.)
578
Джустиниани (Giustiniani, Agostino)
142, 143, 145, 146, 163
Дисней (Disney, Walter Elias) 297
Дитше (Dietsche, Luzia) 602
Дол (Dol, Wietse) 626, 649
Долби (Dolby, James Louis) 151, 163
Дрейфус (Dreyfus, John) 367, 368,
624
Дуглас (Douglass, Scott Alan) 226
Дункан (Duncan, Christopher John) 81,
90, 136, 150-152, 163
Дьяс (Diaz de la Pena, Maximiliano
Antonio Temfstocles) 549, 616
Дэрст (Durst, Lincoln Kearny) 356
Дюрер (Diirer, Albrecht) 35, 53, 75, 78,
624
Енест (Earnest, Lester Donald) 73
Жамм (Jammes, Andre)) 73, 76
Жиру (Girou, Denis) 585
Зигель (Siegel, David Rudolph = New
Wave Dave) 362, 368, 380, 391, 392
Зонен (Zonen. Joh. Enschede en) 635
Ив (Eve, James) 162, 163
Именной указатель
661
Капр (Карг, Albert) 318
Карагезян (Karagueuzian, Dikran =
^шршЩоцйши, SJiqpuiu) 392
Карлип (Carlip (= C3arlip), Walter
Bruce) 658
Карман (Karman, Willem Jan) 634
Каров (Karow, Peter) 318
Картер, Гарри (Carter, Harry Graham)
165, 367, 635
Картер, Мэтью (Carter, Matthew) 293,
295, 314, 315, 322, 333, 565, 613,
635
Картер, Уайлда Бэйтс (Carter, Wilda
Ernestine, урожденная Bates) 201
Кастейжо (Casteljau, Paul de Faget de)
78
Каструп (Kastrup, David Friedrich)
655
Кеннеди (Kennedy, John Fitzgerald)
579
Керниган (Kernighan, Brian Wilson) 76,
469, 500
Кертис (Curtis, Pavel) 392
Ким (Kim, Scott Edward) 323, 352, 354,
357, 359-361, 367, 545
Кнут, Джил (Knuth, Nancy Jill,
урожденная Carter) 7, 73, 196, 314,
392, 539, 566
Кнут, Дональд (Knuth, Donald Ervin
ИШ) 7, 76, 163, 164, 184, 250, 291,
316, 343, 367, 368, 379, 380, 392, 414,
445, 467, 468, 476, 558, 657, 658
Кресчи (Cresci Milanese, Giovanni
Francesco) 54, 55, 75
Кримпен, вал (Krimpen, Jan van) 347,
367, 368, 623, 624
Купер (Cooper, P. I.) 150, 151, 154, 162,
163
Лан, вал дер (Laan, Cornelis Gerardus
van der = Kees) 625, 630, 640
Лантц (Lantz, Kieth Allen) 390
Лапко Ольга Георгиевна 380
Ле Век (LeVeque, William Judson) 352,
354, 356-358, 360
Леви (Levy, Silvio Vieira Ferreira)
592
Лейбниц, фон (Leibniz, Gottfried
Wilhelm, Freiherr von) 63
Ленстра (Lenstra, Andries Johannes)
637, 644
Леувен, ван (Leeuwen, Marcus Aurelius
Augustinus van) 629, 630, 643
Лианг (Liang, Franklin Mark) 73, 506,
535, 620
Либан (Leban, Bruce Philip) 392
Ливермор (Livermore, Lawrence) 622
Линдгрен (Lindgren, Michael) 560
Лисина Марина Владиленовна 35
Лич (Lyche, Tom John Wiberg) 73
Лоренц (Lorentz, Hendrik Antoon) 347,
624
Льготка (Lhotka, LacPa) 614
Лэмпорт (Lamport, Leslie B.) 616,
645
Лэмпсон (Lampson, Butler Wright)
608
МакКиллин (McQuillin, Richard) 42
Макгаффи (McGaffey, Robert) 585
Маккей (МасКау, Pierre Anthony) 167,
184, 598, 602
Малкольм (Malcolm, Michael Alexander)
71, 76
Маннинг (Manning, J. R.) 59, 76,
317
Маттес (Mattes, Eberhard) 595, 596,
658
Маховая Ирина Анатольевна 10
Мейер (Meyer, Albert Ronald da Silva)
73
Мехлум (Mehlum, Even) 71, 76
Миллс (Mills, Daniel Bradford) 362,
391
Миттаг-Леффлер (Mittag-Leffler)
620
Мицумаса (Mitsumasa, Anno 5c Ц? T^ Jfit)
627
Моксон (Moxon, Joseph) 54, 77, 146, 147,
164
Моцарт (Mozart, Johann Chrysostom
Wolfgang Gottlieb) 310, 317
Мэрдок (Murdock, Phoebe/Phoebe
James) 356
Мюллер (Mtiller, Johann Helfrich)
559
662
Компьютерная типография
Нес, ван (Nes, Gerard van) 625
Несбитт (Nesbitt, Alexander) 318
Нетука (Netuka, Ivan) 604
Нойвирт (Neuwirth, Erich) 291, 292
Норден (Norden, Hugo Svan) 317
Ньютон (Newton, Isaac) 63, 350
Олдс (Olds, Arnold Elbert) 392
Ольшак (Olsak, Petr) 616
Оппенгеймер (Oppenheimer. Julius
Robert) 348
Оруэлл (Orwell, George = Blair, Eric
Arthur) 329
Осборн (Osborne, Stanley) 392
Острюм (Oostrum, Pieter van) 627,
645
Палатино (Palatino, Giovanbattista) 53,
63, 77
Пале (Palais, Richard Sheldon) 344, 345,
352, 354, 356, 357, 549
Парией (Parisi, Paul A.) 42, 77
Парк Куань-Чун (Park, Kwang-Chun)
392
Паркер (Parker, Michael Russell) 314
Парке (Parks, Herman D.) 152, 165
Паскаль (Pascal, Blaise) 124
Паташник (Patashnik, Oren) 367, 369,
379
Патерсон (Paterson, Michael Stewart)
71-73
Пачиоли (Pacioli, Fra Luca) 53, 63, 76,
77, 291
Пейнтер (Painter, Charles) 348
Пенингтон (Penington, Keith S.) 466
Пеппинг (Pepping, Simon) 649
Перлис (Perlis, Alan Jay) 280, 644
Печт (Pecht, Geraldine) 580
Пикассо (Picasso, Pablo Ruiz y) 398,
414
Плантен (Plantin, Christophe = Plantijn,
Christoffel) 144-146
Плэсс (Plass, Michael Frederick) 73, 79,
154, 165, 506
Пойа (Polya, Gyorgy = George) 36,
78
Пратт (Pratt, Vaughan Ronald) 468, 500,
657
Прингль (Pringle, Alison M.) 151,
165
Приор (Pryor, Roger Welton) 466,
468
Раглес (Ruggles, Lynn Elizabeth)
391
Райвест (Rivest, Ronald Linn) 585,
586
Раймон (Raymond, Frangois H.) 148,
163
Райт (Wright, William) 184
Райхле (Raichle, Bernd) 658
Раман (Raman, Thiruvilwamalai
Venkatraman) 587
Рамануджан (Ramanujan Iyengar,
Srinivasa) 350
Рамшоу (Ramshaw, Lyle Harold) 73,
505
Ратц (Rahtz, Sebastian Patrick Quintus)
585, 649
Ренц (Renz, Peter Lewis) 345, 356
Ригер (Rieger, Georg Johann) 291,
292
Роберте (Roberts, Charles Sheldon) 453,
467
Роджерс (Rodgers, David) 257
Роже (Rogers, Bruce) 153, 165
Розар (Rosart, Jacques-Frangois) 351,
635
Ройкрофт (Roycroft, Thomas) 145,
165
Рокицки (Rokicki, Tom) 257
Рондталер (Rondthaler, Edward)
318
Рубинштайн (Rubenstein, Arthur) 466,
468
Рыцько (Rycko, Marek) 635
Сайте (Sites, Richard Lee) 583
Саме (Samet, Hanan) 151, 165
Саутолл (Southall, Richard Francis) 319,
333, 381, 391, 392, 613
Cbohcoh (Swanson, Ellen Esther) 77,
356
Седляк (Sedlak, Bedfich) 604
Синк (Cinque, Gregory M.) 466, 468
Сиснерос, де (Ximenes = Jimenez de
Cisneros, Francisco) 141, 164
Именной указатель
663
Сифкес (Siefkes, Dirk) 73
Слимбах (Slimbach, Robert) 614
Смит, Джон Дэниэл (Smith, John
Daniel) 414
Смит, Камерон (Smith, Cameron))
595
Смит, Леланд (Smith, Leland Clayton)
153
Сноу (Snow, Charles Percy) 322, 347
Софка (Sofka, Michael) 586
Спивак (Spivak, Michael David) 548,
616
Спрулл (Sproull, Robert Fletcher) 73
Спрэдженс (Spragens, Alan) 392
Стейнберг (Steinberg, Louis Ira) 445,
447, 467
Стил (Steele, Guy Lewis, Jr.) 645
Столлман (Stallman, Richard Matthew)
648
Стоун (Stone, Sumner Robert) 335, 342,
343
Сэмюэль (Samuel, Arthur Lee) 391
Тан (Thanh, Han The) 619
Таттл (Tuttle, Joey) 392
Тауберт (Taubert, Karl Heinz) 317
Тейлор, Джин (Taylor, Jean Ellen)
73
Тейлор, Филип (Taylor, Philip) 658
Тиле (Thiele, Christina Anna Louisa)
578, 602, 604, 625
Токусу (Tokusue, Nori) 392
Тори (Tory, Geofroy) 54, 77
Торниелло да Новара (Torniello da
Novara, Francesco) 53, 54, 63, 76,
274-276, 278-280, 291, 292
Трабб Пардо (Trabb Pardo, Luis Isidoro)
104, 615
Трэйси (Tracy, Walter) 318
Тума (Tuma, Kathryn) 547
Туомбли (Twombly, Carol) 362, 614
Тьюринг (Turing, Alan Mathison) 587,
591, 618, 645
Уайлс (Wiles, Andrew John) 579
Уининг (Weening, Joseph Simon) 236,
250
Уинстон (Winston, Patrick Henry) 550,
562
Ульман (Ullman, Jeffrey David) 74,
546
Унгер (Unger, Gerard)) 318, 393, 400,
613, 649
Унгер (Unger, Marjan) 393, 400
Уолкер (Walker, Gordon Loftis) 73
Уолл (Wall, David Wayne) 542
Уорнок (Warnock, John Edward) 25,
610
Фейнман (Feynman, Richard Phillips)
606
Феличиано Веронезе (Feliciano Veronese,
Felice) 53, 63, 75
Ферма, де (Fermat, Pierre de) 579, 584,
586, 587
Филман (Filman, Robert Elliot) 326,
550
Фистед (Thisted, Ronald Aaron) 366
Фишер, Майкл (Fischer, Michael John)
73
Фишер, мл., Эд (Fisher, Ed, Jr.) 318
Флайшман (Fleischman, Johann Michael)
635
Флойд (Floyd, Robert W.) 445, 447,
467
Фляйшер (Fleischer, Bruce) 392
Форд (Ford, David) 318
Форсайт (Forsythe, George Elmer) 298,
318
Фрамбах (Frambach, Erik Hubertus
Martinus) 625
Франкел (Fraenkel, Abraham Adolf)
185
Франклин (Franklin, Benjamin) 572
Фрейзер (Eraser, Christopher Warwick)
647
Фри (Frey, A.) 106, 163
Фукс (Fuchs, David Raymond) 391, 392,
544, 565, 631
Фэрбэрнз (Fairbairns, Robin) 596
Хаген (Hagen, Johannes) 628
Хансен (Hansen, Wilfred James) 249,
250
Хансон (Hanson, David Roy) 647
Хант (Hunt, Robert) 658
Хараламбус (Haralambous, Yannis) 258,
630
664
Компьютерная типография
Хейн (Hein, Piet) 33, 303, 308
Хеннеси (Hennessy, John LeRoy) 583
Хенрикс (Henrichs, Marshall) 372
Хершбергер (Hershberger, John Edward)
392
Хики (Hickey, Thomas Butler) 324,
343
Xoap (Hoare, Charles Antony Richard)
614, 615
Хобби (Hobby, John Douglas) 31, 32, 35,
78, 330, 343, 362, 392, 419, 472, 476,
565, 585, 633
Ходулёв Андрей Борисович 380
Хокинсон (Hawkinson, Lowell) 42
Холладей (Holladay, Thomas Melvin)
452, 467
Холмс (Holmes, Kris Ann) 333, 613
Хорн (Horn, Berthold Klaus Paul) 466,
658
Хорстман (Horstman, Helen) 194
Хофштадтер (Hofstadter, Douglas
Richard) 314, 318
Хьюсон (Hewson, Rachel) 392
Хёниг (Hoenig, Alan) 206
Цапф (Zapf, Hermann) 52, 78, 314, 318,
333, 335, 344-346, 348-359, 361, 362,
368, 369, 371, 377, 380, 565, 612, 613,
624
Чайлдс (Childs, Selma Bart) 580, 592,
602
Черитон (Cheriton, David Ross) 390
Черри (Cherry, Lorinda Landgraf) 76,
500
Шамир (Shamir, Adi) 585
Шапплер (Schappler, John) 318
Шёпф (Schopf, Rainer Maria) 658
Шерхен (Scherchen, Hermann) 317
Шиллингер (Schillinger, Joseph) 317
Шойц (Scheutz, Edvard Georg Raphael)
559, 560
Шоу (Shaw, George Bernard) 139,
165
Шредер (Schroeder, Manfred Robert)
448, 468
Шрод (Schrod, Joachim) 647
Шупски (Schupsky, Maureen) 580
Эйкаут (Eijkhout, Victor Lambert)
644
Эйлер (Euler, Leonhard) 349, 351, 363,
367, 369
Эйнштейн (Einstein, Albert) 350
Энсхеде (Enschede, Charles) 635
Эриксон (Erichson, Knut) 368
Эшер (Escher, Maurits Cornelis) 627
Яо (Yao, Andrew Chi-Chih) 582
Ярвис (Jarvis, John Frederick) 445, 453,
467
Ясперт (Jaspert, W. Pincus) 318
Яцковский (Jackowski, Boguslaw) 635,
658
Оглавление
Предисловие редактора перевода 5
Предисловие 11
Ссылки на источники 16
Глава 1. Компьютерная типография 19
Источники иллюстраций 34
Глава 2. Математическая типография 36
Аннотация 36
Введение 37
Предварительные примеры 38
Набор при помощи компьютера 43
Т^Х как язык описания ввода 45
Разбиение на строки 47
Антракт 49
«Третье поколение» наборного оборудования 50
Полуфилософские заметки 51
Математический дизайн шрифта 53
Определение новых кривых 55
Практическая аппроксимация 58
Приложение к шрифтовому дизайну 61
Семейства шрифтов 64
От непрерывности к дискретности 66
Иные подходы 70
Рандомизация 72
Заключение 73
Благодарности 73
Литература, не упомянутая в тексте 73
Литература 74
Добавление 78
Глава 3. Верстка абзацев 79
Введение 79
Формулировка задачи 82
Компьютерная типография
Критерий желательности 89
Король-лягушонок, или Железный Генрих 98
Другие приложения 101
Состыковка абзацев 102
«Заплатки» 102
Висячая пунктуация 102
Как избежать «психологически плохих» разрывов 102
Строки с информацией об авторах 106
Рваный правый край 107
Центрированный текст 109
АЛГОЛо-подобные языки 110
Сложный указатель 113
Алгебраический подход 116
Введение в алгоритм 118
Дальнейшие подробности 125
Алгоритм 127
Вычислительный эксперимент 135
Исторический обзор 140
Проблемы и усовершенствования 155
Приложение: алгоритм расщепления на части 15Т
Благодарности 162
Литература 163
Добавление 165
Глава 4. Сочетание текстов, читаемых справа налево и слева направо 167
Термины и правила 168
Простейший случай 168
Тексты с чередованием 169
Один из путей реализации 170
Ликвидируем недочеты 171
L-шовинизм 171
Многоуровневое сочетание 173
Заключение 175
Приложение 175
Заключительные важные замечания 183
Литература 184
Примеры из типографской практики 184
Глава 5. Рецепты и дроби 187
Глава 6. Логотип системы Т[й}Х в различных шрифтах 192
Глава 7. Генерирование избранных страниц 194
Макрокоманды для генерирования избранных страниц 195
Глава 8. Макро, написанные для Джил 196
Глава 9. Задача на субботнее утро 205
Глава 10. Упражнения к книге ТеХ: The Program 207
Задачи 207
Оглавление 667
Ответы к задачам 216
Приложение 232
Благодарности 234
Глава 11. Мини-указатели для самодокументированных программ 235
Введение 235
Пример 237
Работа программы CTWILL 239
Обработка TfejX'oM 244
Заключительные замечания 249
Литература 250
Глава 12. Виртуальные шрифты. Развлечение для настоящих мастеров 256
Фрагменты файла VFtoVP. web 259
А здесь— фрагменты файла VPtoVF. web 261
Новости из издательства St. Anford Press 272
Глава 13. Буква S 273
Приложение 288
Литература 291
Дополнение 291
Глава 14. Мое первое знакомство с индийской письменностью 293
Дополнение 295
Глава 15. Концепция меташрифта 296
Благодарности и извинения 314
Аннотированный список литературы 315
Дополнение 318
Глава 16. Уроки METRFONT'a 321
Приложение 337
Добавление 342
Литература 343
Глава 17. AMS Euler— новый математический шрифт 344
Литература 367
Дополнение 368
Глава 18. Набор книги Concrete Mathematics 369
Литература 379
Добавление 380
Глава 19. Из опыта преподавания программирования на METflFONT'e 381
Примечание переводчика 392
Глава 20. Меташрифт Punk 393
Литература 414
Добавление 414
Глава 21. Шрифты для дискретных полутонов 415
Приложение 1. Препроцессор-для изобразительного материала ... 433
Приложение 2. Пиксельная оптимизация 439
Литература 445
668
Компьютерная типография
Глава 22. Оцифровка полутонов посредством диффузии точки 447
Диффузия ошибки 447
Упорядоченное размывание 448
Диффузия точки 448
Границы ошибки 450
Выделение краев 453
Примеры 453
Проблемы 458
Гладкая диффузия ошибки 460
Сравнение с другими методами 463
Благодарности 466
Литература 467
Глава 23. Заметки об оцифровке углов 469
Благодарности 475
Литература 476
Глава 24. TEXDR.AFT 477
Примечания переводчика 502
Глава 25. ТЕХ. ONE 506
Примечания переводчика 537
Глава 26. ТЁХ'овские инкунабулы 539
Добавление 551
Глава 27. Пиктограммы для TEJX'a и METflFONT'a 552
Литература 558
Добавление 558
Глава 28. Компьютеры и книгоиздание 559
Глава 29. Новые версии IgX'a и METRFONT'a 567
Набор символов 568
Таблицы переносов 569
Управление уровнем фрагментации слов при переносах 569
Большее разнообразие лигатур 570
Граничные лигатуры 571
Более компактные таблицы лигатур 572
Улучшение управления видом абзацев 572
Возможность проверить плохость 573
Возможность проверить номер строки 573
Возможность управления объемом контекста, выдаваемого в
сообщениях об ошибках 573
Возможность повторного использования страниц 574
Исключения из совместимости снизу вверх 574
Глава 30. Будущее IgX'a и METRFONT'a 576
Глава 31. Вопросы и ответы, I 578
Примечания переводчика 602
Оглавление
669
Глава 32. Вопросы и ответы, II 604
Глава 33. Вопросы и ответы, III 625
Глава 34. Последние ошибки Т^Х'а 651
Последняя ошибка? 653
Не ошибки, но близко к этому 654
Просчеты проекта 656
Заключение 657
Литература 657
Добавление 658
Примечание переводчика 658
Предметный указатель 659
Научное издание
Дональд Эрвин Кнут
КОМПЬЮТЕРНАЯ ТИПОГРАФИЯ
Ведущий редактор И. А. Маховая
Художник И. И. Куликова
Оригинал-макет подготовлен О. Г. Лапко в пакете Т^Х
с использованием семейства шрифтов Computer Modern
с кириллическим расширением LH
Санитарно- эпидемиологическое заключение
№77.99.02.953.Д.008286.12.02 от 09.12.2002 г.
Лицензия ЛР JVi 010174 от 20.05.97 г.
Подписано к печати с готовых диапозитивов 23.02.03.
Формат 70 х 1001/1в« Печать офсетная. Объем 21,00 бум. л.
Усл. печ. л. 54,60. Уч.-изд. л. 51,79. Изд. № 20/9724.
Тираж 5 000 экз. (1-й завод 3 000 экз.). Заказ № 122.
Издательство «Мир»
Министерства РФ по делам печати,
телерадиовещания и средств массовых коммуникаций
107996, ГСП-6, Москва, 1-й Рижский пер., 2.
ООО 4Издательство ACT»
667000, Республика Тыва, г. Кызыл, ул. Кочетова, д. 28
Наши электронные адреса:
WWW.AST.RU
E-mail: astpub@aha.ru
Диапозитивы изготовлены в издательстве «Мир»
Отпечатано с готовых диапозитивов в
ОАО «Санкт-Петербургская типография № 6».
191144, Санкт-Петербург, ул. Моисеенко, 10.
Телефон отдела маркетинга 271-35-42.