/



















































































































































































































































Текст
МАТЕМАТИЧЕСКОЕ
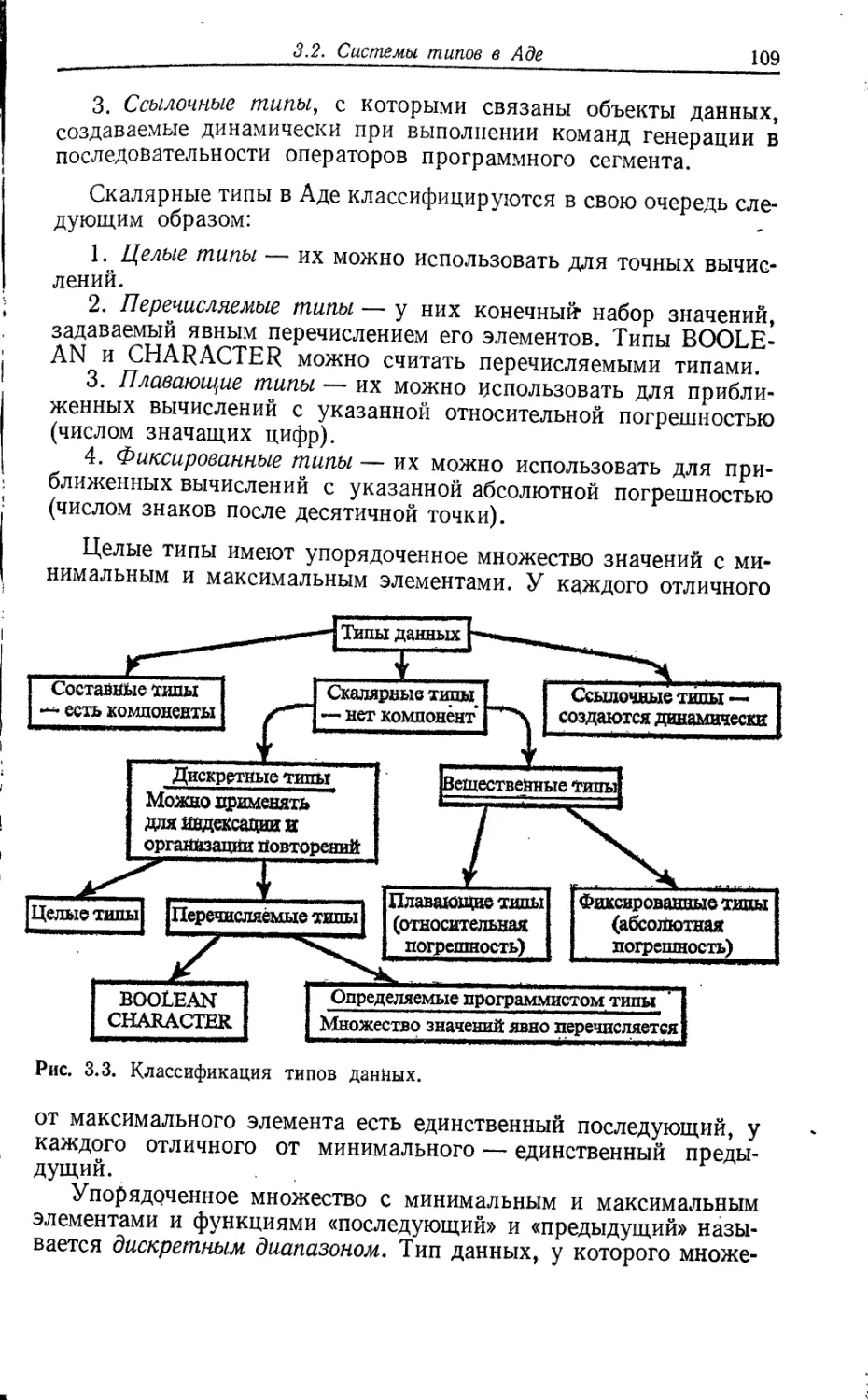
ОБЕСПЕЧЕНИЕ
ЭВМ
П.Вегнер
ПРОГРАММИРОВАНИЕ
НА ЯЗЫКЕ АДА
I
**>***<
«*♦****<
PROGRAMMING WITH ADA
AN INTRODUCTION
BY MEANS OF GRADUATED EXAMPLES
PETER WEGNER
Department of Computer Science
Brown University
PRENTICE-HALL, INC., ENGLEWOOD CLIFFS»
NEW JERSEY 07632
1980
МАТЕМАТИЧЕСКОЕ
ОБЕСПЕЧЕНИЕ
ЭВМ
П.Вегнер
ПРОГРАММИРОВАНИЕ
НА ЯЗЫКЕ АЛА
Перевод с английского
Ю. Ю. Галимова и Э. М, Киуру
под редакцией
В, Ш, Кауфмана
Москва
«Мир»
1983
ББК 32.973
В 26
УДК 681.3
В 26 Вегнер П. Программирование на языке Ада: Пер. с
англ./Под ред. В. Ш. Кауфмана.— М.: Мир, 1983.
240 с., ил.
Введение в новый язык программирования Ада, ориентированный на со-
временную технологию программирования, Он содержит выразительные
средства, ранее не встречавшиеся в языках такого класса,— абстрактные
типы данных, пакеты, управление видимостью и др. Книга богато снабжена
характерными примерами, показывающими возможности этого языка.
Для программистов, для всех, кто преподает и изучает программиро-
вание.
2405000000-004
В 041(01)—83
34—83, ч,
ББК 32.973
6Ф,7
Редакция литературы по математическим наукам
© 1980 by Prentice-Hall, Inc.,
Englewood Cliffs, N. J. 07632.
© Перевод на русский Язык,
«Мир», 1983,
ПРЕДИСЛОВИЕ РЕДАКТОРА ПЕРЕВОДА
Перед вами введение в язык программирования Ада, предва-
рительное описание п, а также обоснование l) 2) которого были !
опубликованы летом 1979 г. и сразу вызвали огромный интерес
у специалистов, В середине 1980 г,, после широкого междуна-
родного обсуждения (обработано свыше 900 отзывов из более
чем 50 стран) была выработана так называемая окончательная
версия языка 3), претендующая на роль не только национальное»
стандарта США, но и международного (стандарта ИСО).
Книга профессора Вегнера, принимавшего участие в работ»
над языком, появилась почти одновременно с предварительным
описанием, и поэтому в ней не отражены особенности окончатель-
ной версии. Несмотря на это мы считаем, что книга имеет ряд
преимуществ по сравнению с вышедшими позже нее учебниками \
И. Пайла 4) и Г, Ледгара опирающимися на версию 1980 г. \
Эту книгу следует рассматривать прежде всего как введени»
в систему понятий нового языка. С этой точки зрения версии
языка отличаются незначительно, и окончательную можно счи-
тать скорее уточнением, чем переработкой старой.
Особую ценность книге придает педагогическое мастерстве
автора. Понятия, призванные обеспечить языковую поддержку
современной технологии программирования и поэтому ва>Кнйе
даже независимо от языка Ада, автор объясняет с помощью тща-
тельно подобранных содержательных примеров, хорошо иллюст-
рирующих назначение и смысл выразительных средств.
Есть все основания считать, что язык Ада станет одним из
самых распространенных языков программирования. Многие
его концепции, отражающие последние достижения методологии
программирования (определяемые типы, раздельная компиляция,
пакеты, задачи, родовые сегменты, рандеву и др.), отличаются
от концепций самых известных у нас в стране языков (ПЛ/1,
Фортран, Алгол 60, Кобол), и поэтому крайне необходимо воз-
l) Preliminary ADA Reference Manual.— SIGPLAN Notices, 1979, v, 14,
№ 6, part А. (Имеется перевод: Язык программирования АДА (предваритель-
ное описание).— М.: Финансы и статистика, 1982.)
?> Rationale for Design of the ADA programming language.— SIGPLAN
Notices, 1979, v. 14, № 6, part B.
3) Ada Reference Manual (July 1980), Springer-Verlag, 1981.
4) Pyle I. C. The ADA Programming Language, Prentice Hall, 1981.
Ledgard H. ADA: An Introduction, Springer-Verlag, 1981 (издано в
одном томе с документом ®,— Прим. ред.).
6
Предисловие редактора перевода
можно скорее познакомить наших программистов с этими пер-
спективными концепциями.
В настоящее время среди языков программирования (как
и среди языков естественных) выделился довольно узкий и кон-
сервативный круг «мировых» языков. Ими владеют миллионы
людей, накоплена колоссальных объемов литература, сформиро-
вались поддерживающие их жизнеспособность организационные
структуры, эти языки приобретают официальный статус нацио-
нальных и международных стандартов. Стало ясно, что языки
программирования — это явления не столько научного, сколько
социального характера, судьбу которых определяют отнюдь не
только эстетические или логические критерии. Показательно,
что ни Алгол 60, ни Алгол 68, в свое время исключительно высоко
оцененные специалистами, так и не стандартизованы ИСО, в от-
личие от таких менее «красивых» языков, как Фортран, Кобол,
Бейсик и ПЛ/1. Таким образом, говорить о перспективах нового
языка программирования — задача исключительно трудная.
И тем не менее можно ожидать, что в ближайшем будущем
язык Ада станет «мировым» языком программирования. Предпо-
сылок для этого достаточно. К участию в работе над языком
в той или иной форме были привлечены лучшие специалисты из
многих стран мира, в результате чего он впитал в себя все наи-
более значимые идеи в области конструирования языков програм-
мирования. На основе языка Ада создается единая система про-
граммирования, обеспечивающая полный цикл производства,
аттестации и сопровождения программных продуктов. Предпри-
нимаются серьезные усилия по сохранению «чистоты» языка и
обеспечению высокого качества его реализаций прежде всего
с точки зрения соответствия единому стандарту. Для этого,
в частности, разработаны процедура аттестации трансляторов и
соответствующая система тестов.
Сказанное позволяет надеяться, что книга будет полезна и
преподавателям, и всем желающим ознакомиться с современ-
ными тенденциями развития средств программирования.
При переводе книги использовалась терминология из упомя-
нутого ранее перевода книги «Язык программирования Ада
(предварительное описание)», выполненного В. М. Курочкиным
и Д. Б. Подшиваловым. Мы старались без нужды не откло-
няться от принятой там терминологии, однако некоторые раз-
личия все-таки имеются.
Перевод предисловия и глав 1, 3 выполнен Э. М. Киуру,
глав 2, 4, 5 и приложения — Ю. Ю. Галимовым.
В. Ш. Кауфман
ПРЕДИСЛОВИЕ
Ада — это язык программирования для задач вычислитель-
ного характера, для системного программирования, систем реаль-
ного времени и параллельной обработки. Он назван в честь Ады
Августы, леди Лавлейс — первой в мире программистки, сот-
рудницы Чарльза Бэббиджа и дочери лорда Байрона. Язык раз-
работан в Париже группой авторов под руководством Жана
Ишбиа, в которую входили Б. Криг-Брукнер, Б. А. Уичман,
Г. Ф. Ледгар, Ж--К. Гельяр, Ж--К. Абриаль, Дж. Барнс и
О. Рубин.
Язык Ада был создан-по инициативе Министерства обороны
США. Цель, которую оно при этом преследовало,— разработка
языка программирования, пригодного в равной мере для армии,
флота и ВВС. Работа по созданию языка началась в 1975 году,
когда при Министерстве обороны была организована Рабочая
группа по языкам высокого уровня, которой было поручено
предложить единый язык высокого уровня, пригодный для про-
граммирования встроенных вычислительных систем Министерства
обороны США.
Первый шаг — определить требования, которые предъявляют
к единому языку программирования три названных военных ве-
домства, а также промышленность и университеты. Эту работу
умело координировал Дэвид Фишер, и ее результатом была по-
следовательность версий, в которых эти требования постепенно
уточнялись: «соломенные» (1975), «деревянные» (1975), «оло-
вянные» (1976), «железные» (1978) и, наконец, «стальные» (1979).
Идея начинать разработку языка программирования с опреде-
ления требований к нему была новой, и было не очень ясно, как
такие требования должны формулироваться. Окончательная
версия содержит около сотни требований, описывающих свойст-
ва, которыми должны обладать включаемые в язык конструкции,
и охватывающих такие области, как типы данных, управляющие
структуры, модули, задачи (процессы) и исключительные си-
туации. Есть среди них и глобальные требования: «легкость чте-
8
Предисловие
ния», «отсутствие чрезмерной общности», «простота» и «верифи-
цируемость».
Затем нужно было выяснить, удовлетворяет ли этим требова-
ниям какой-либо из существующих языков, и если нет, то ре-
комендовать процедуру проектирования и разработки нужного
языка. После тщательного изучения 26 существующих языков
в начале 1977 года был сделан вывод, что ни один из них не со-
гласуется полностью с требованиями оловянной версии и что
следует организовать конкурс по созданию нового языка. В ка-
честве отправной точки при конструировании нового языка было
рекомендовано взять один из следующих трех языков: Паскаль,
Алгол 68 или ПЛ/1.
Подготовка к проектированию языка в соответствии с этими
рекомендациями была закончена в мае 1977 года — было полу-
чено 16 эскизных проектов языка, только четыре из которых
были отобраны для шестимесячного этапа предварительного
проектирования (август 1977 — февраль 1978), финансировав-
щегося Министерством обороны США. Эти четыре проекта-побе-
дителя представили фирмы CII-Honeywell-Bull, Intermetrics,
SRI International и SofTech. Чтобы обеспечить беспристраст-
ность при оценке языков, конкурс был закрытым: языки полу-
чили условные названия Зеленого, Красного, Желтого и Синего.
Все четыре группы проектировщиков предложили в качестве
отправной точки Паскаль. Это обстоятельство, а также тот
факт, что проекты должны были соответствовать сформулиро-
ванным требованиям, существенно ограничивали создателей язы-
ков. Это облегчило им определенные глобальные решения и даже
некоторые частные, существенно уменьшило объем и длитель-
ность работы и позволило завершить предварительный проект
за шесть месяцев. Однако эти ограничения оставляли большую
свободу вариаций, так что четыре группы проектировщиков
подготовили удивительно - разные предварительные проекты.
Эти четыре предварительных проекта были закончены, как
и было запланировано, к 15 февраля 1978 года, и в период с фев-
раля по март 1978 года оценивались примерно 80 различными
экспертами из университетов, промышленности и правительст-
венных органов. В результате два из четырех языков были отоб-
раны для дальнейшей доработки в течение года до завершения
проектирования (апрель 1978 — март 1979). Это были Зеленый
(CII-Honeywell-Bull) и Красный (Intermetrics) языки.
Законченные проекты были сданы согласно плану к 15 марта
1979 года и подвергнуты тщательному анализу более чем пятью-
десятью экспертными группами. Результаты анализа были оце-
нены на четырехдневном совещании в Вашингтоне в конце апреля
1979 г. На совещании Рабочей группы второго мая 1979 г. Зеленый
язык был признан победителем и назван Адой в честь Ады Лав-
Предисловие
9
лейс. Руководство по языку Ада и его обоснование были опуб-
ликованы в июньском номере журнала SIGPLAN Notices за
1979 г. и стали широко доступны.
В том, что предпочтение было отдано Зеленому языку, сыг-
рали решающую роль следующие факторы:
1. Представлялось, что выбор Зеленого языка менее рискован
как потому, что его конструкции казались лучше отражающими
современное состояние и легче реализуемыми, так и потому, что
его проект оставался стабильным на протяжении нескольких
месяцев, в то время как Красный проект изменялся до послед-
ней минуты.
2. Зеленый язык содержал цельный подход к спецификации
и раздельной компиляции компонент программы, который до-
пускает эффективную проверку сопряжения компилятором, а
также обеспечивает языковую поддержку современной методо-
логии программирования. В Красном языке проблема языковой
поддержки создания больших систем, содержащих много взаимо-
действующих модулей, решена неадекватно.
С мая 1979 года язык Ада проходил тщательную техническую
проверку и оценку в процессе программирования прикладнйх
программ из более чем ста областей. Результаты этого экспери-
ментального программирования будут оценены на четырехднев-
ном совещании в октябре 1979 года, и на этой основе будут вы-
работаны рекомендации для авторов языка по его изменению.
Исправленная и, как предполагается, окончательная версия
языка, учитывающая эти рекомендации, должна появиться по
плану к апрелю 1980 года п.
Контролирующий транслятор, осуществляющий полный син-
таксический контроль программ на Аде и выполняющий доста-'
точно представительное их подмножество, доступен с 15 августа
1979 года. Ведутся работы еще над несколькими реализациями
и ожидается, что новые контролирующие трансляторы станут
доступны к концу 1979 года. Обеспечение Ады промышленным
компилятором остается пока проблемой. Самый ранний срок его
появления — лето 1981 года.
Назначение этой книги — служить введением в программи-
рование на Аде для программистов, хотя бы год поработавших
с языком высокого уровня, подобным Фортрану. Степень по-
нимания и освоения языка зависит не только от его технических
характеристик, но и от изложения материала. В этой книге мж
стремились дать легко читаемое, постепенное введение в язик
на самой ранней стадии его развития, чтобы ускорить процесс
его освоения.
1) Эта версия стала стандартом Министерства обороны США.— Прим. ptO.
10
Предисловие
Метод изложения — посредством примеров, начиная с от-
носительно тривиальных иллюстраций основных идей языка и
кончая нетривиальным конструированием «настоящих» про-
грамм — насколько известно автору, ранее в таком масштабе
не применялся. Автор уже несколько лет мечтал написать вве-
дение в язык программирования таким методом, и наконец,
представился подходящий случай.
Эта книга неполна в нескольких отношениях. Она посвящена
языку, который еще только создается. Она не касается таких
«сверхновых» возможностей языка, как спецификация представ-
ления. Ее назначение — не заменить руководство по программи-
рованию на Аде, а скорее дополнить его.
Автор планирует летом 1980 года подготовить новую редак-
цию этой книги, учитывающую изменения языка, которые
должны последовать за его испытаниями. Однако и настоящая
редакция может сослужить хорошую службу многим програм-
мистам, которые интересуются Адой уже сейчас. Хотя настоя-
щему изданию книги, по всей вероятности, суждена короткая
жизнь (если только оно не станет библиографической редко-
стью), оно может в этот промежуточный период сыграть важную
образовательную роль, подготовив почву для скорейшего освое-
ния Ады.
Книга состоит из пяти глав. Первая — подробный обзор Ады,
достаточный для того, чтобы программист смог читать и пони-
мать большинство программ на этом языке. Материал главы ес-
тественно делится на три части. Разделы с 1.1 по 1.6 освещают
«классические» возможности языка, имеющиеся в любом языке
типа Паскаль. Разделы с 1.7 по 1.12 посвящены «новым» возмож-
ностям, обеспечивающим модульное и параллельное програм-
мирование. Разделы 1.13—1.18 описывают структуру программы
и вопросы компиляции, необходимые для понимания способов
сборки больших программ. Эта глава может считаться также
введением в язык методом «сверху — вниз», который позволяет
читателю как бы охватить картину в целом, прежде чем рас-
сматривать отдельные детали.
Оставшиеся главы содержат более подробное изложение ме-
тодом «снизу — вверх» на уровне детализации, достаточном
для написания программ на Аде. Между материалом главы 1 и
более подробным изложением тех же самых идей в последую-
щих главах имеются неизбежные перекрытия. Насколько это
возможно, второй раз о том же самом рассказывается с другой
точки зрения, так что педагогически это оправдано.
Во второй главе рассматриваются выражения, операторы,
управляющие структуры, простые объявления, процедуры и
функции. Все эти понятия имеются и в предшественниках Ады,
например в Паскале, однако в Аде была сделана попытка учесть
Предисловие
И
ошибки языков-предшественников и поэтому набор операторов,
управляющих структур и подпрограмм языка спроектирован
очень тщательно. Ряд примеров программ для вычисления
простых чисел служит иллюстрацией того, как следует пользо-
ваться управляющими структурами, подобными циклам пока
(while), операторам выхода (exit), операторам перехода (go to)
и флажкам.
Глава 3 — об описании данных. Речь идет о средствах Ады
для определения числовых типов, перечисляемых типов, регу-
лярных и комбинированных типов. Способ описания типов в Аде
близок к паскалевскому, но в Аде устранены проблемы с вариан-
тными записями и проверкой типов при компиляции. И здесь
Ада — искусный синтез конструкций, проверенных в языках-
предшественниках.
Глава 4 — о структуре программы и модульности. Здесь
центральное понятие — пакет, который позволяет рассматривать
как одно целое логически связанный набор ресурсов, определять
совокупность общих данных, совокупность связанных подпро-
грамм и абстрактных типов данных. Приводится несколько при-
меров пакетов, в том числе для комплексных чисел, для управ-
ления доступом, управления таблицей символов и обработки
списков. Затем анализируются обширные средства Ады для уп-
равления видимостью имен и для раздельной компиляции. Эта
глава посвящена системе средств Ады, предназначенной для
создания больших программ из модулей. Наличие этих средств
было одной из причин победы Ады над конкурентами.
В пятой главе речь идет о параллельном программировании.
После первоначального ознакомления с такими понятиями, как
разделяемые переменные и передача сообщений, разбираются
примеры, иллюстрирующие запуск, выполнение, синхронизацию
и связь задач. Описаны средства Ады для семейств задач, родо-
вых задач и семафоров. Для известных задач о почтовых ящи-
ках и о читателе — писателе рассмотрено несколько различных
решений, чтобы показать разные способы применения соответ-
ствующих примитивов. Чтобы механизм взаимодействия задач
был понят глубже, обсуждается оптимизация определенных ви-
дов задач (обслуживающих задач) за счет разделения выполняе-
мого кода между обслуживаемыми задачами.
Задачи в Аде — это параллельно выполняемые модули, бо-
лее похожие на пакеты, чем на подпрограммы. Каждая задача
может снабжать некоторым набором ресурсов другие задачи в со-
ответствии со спецификацией задачи, которая в Аде отделена от
ее реализации. Процесс построения больших программ из па-
раллельно выполняемых модулей обеспечивается в Аде за счет
языковых средств, аналогичных тем, которые обслуживают по-
следовательное модульное программирование.
12
Предисловие
Автору приятно поблагодарить многих лиц, которые прочли ,
рукопись и внесли предложения по ее улучшению. Автор особо •
признателен Жану Ишбиа, который проявлял глубокий интерес
к написанию этой книги, терпеливо исправлял ошибки в приме- 1
рах и высказал много ценных замечаний. Брайен Керниган был '
исключительно полезен как рецензент от Prentice Hall, Дональд
Кнут и Роберт Седжевик помогли улучшить некоторые алго-
рцтмы. Стивен Райс внес свой вклад в улучшение глав 1—4. 1
Томасу Дупнеру принадлежит множество идей главы 5. Марк »
Девис и Стивен Фейнер очень тщаТельно выверили рукопись и
цомогли устранить формальные и существенные ошибки. Слуша-
та^й' моего курса по языкам программирования (CS 273) также
дряняди участие в проверке рукописи. Катрина Эйвери была
ц£заь)енима при перепечатке рукописи, и благодаря ее усилиям
б^д значительно сокращен период подготовки рукописи к изда- 1
нйю. И наконец, мне бы очень хотелось поблагодарить сотруд- ।
ников лаборатории в Монтрей (Жана Ишбиа, Джона Барнса, Ро-
берта Фирта и Джона Гудинафа), чьи замечания помогли лучше
изложить материал и которые разрешили мне использовать
в книге некоторые из придуманных ими примеров.
Петер Вегнер i
Университет Брауна !
Сентябрь 1979
ОГЛАВЛЕНИЕ
Предисловие редактора перевода . ............................ * • 5
Предисловие ............7
Глава 1. Обзор языка Ада ....................................« < « • 15
1.1. Простая программа на Аде ..........................* • 15
1.2. Примеры программирования на Аде ................. • 17
1.3. Объявление типа и объекта ........................... 22
1.4. Структура программы ............................. > . 28
1.5. Подпрограммы .................................. ♦ ♦ • ♦ 30
1.6. Параметры подпрограмм .......................... • • • 31
1.7. Родовые подпрограммы ................................ 34
1.8. Пакеты ................................................35
1.9. Абстрактные типы данных .......................,**♦» 38
1.10. Задачи............................................. 41
1.11. Отбор среди входов 45
1.12. Родовые модули 47
1.13. Блоки . . . 49
1.14. Раздельная компиляция................. 52
1.15. Область действия идентификаторов ...•..«•«»< 54
1.16. Ограниченные сегменты программы.............. ♦ < ♦ • 55
1.17. Ограниченные сегменты компиляции и библиотеки » « « , 57
1.18. Исключения 59
Глава 2. Основные черты языка
2.1. Введение . • . ..............
2.2. Множество символов и лексемы............. • * ,
2.3. Простые выражения и оператор присваивания » , • »
2.4. Условные операторы (операторы 11 и case)
2.5. Операторы повторения
2.6. Переход и выход .........
2.7. Примеры программ. Вычисление простых чисел » ♦ •
2.8. Объявления идентификаторов
2.9. Сегменты программы и блочная структура ♦
2.10. Процедуры и параметры . .
2.11. Виды связи параметров ..........♦................
2.12. Функции и вырабатывающие значения процедуры , •
2.13. Операторы контроля .
63
63
66
69
71
74
77
83
85
89
93
94
97
14
Оглавление
Глава 3. Описание данных « • • • *............................. 99
3.1. Объекты и действия . .....................*........... 99
3.2. Система типов в Аде ............................... 100
3.2.1. Предопределенные типы.......................... 100
3.2.2. Производные типы............................. 101
3.2.3. Уточнения...................................... 104
3.2.4. Определения анонимных типов и эквивалентность типов 101
3.2.5. Подтипы................................. . . . 106
3.2.6. Предопределенные атрибуты . _.................. 108
3.2.7. Классификация типов............................ 108
3.3. Числовые типы......................................... ПО
3.3.1. Целые типы...................................... ПО
3.3.2. Плавающие типы................................. 113
3.3.3. Фиксированные типы............................. 115
3.4. Перечисляемые типы................................... 117
3.5. Логические и символьные типы данных............ . , . 122
3.6. Регулярные типы........................................... 123
3.7. Регулярные типы с неуточненными границами 127
3.8. Строки ....................................... . . . . 130
3.9. Комбинированные типы (записи) ................. . . . . 131
3.10. Вариантные записи............................»♦♦... 135
3.11. Дискриминанты и параметры типа .............. . , . , 139
- 3.12ч Ссылочные типы . . ........................У • • • • 141
3.13. Обработка списков................ Ч • * • « 147
3.14. Древовидная таблица символов 149
Глава 4. Модульность и структура программы 155
4,1. Пакеты: данные и подпрограммы........................ 155
4.2. Синтаксис объявления пакета .............................. 160
4.3. Пакет для работы с комплексными числами ....... 161
4.4. Создание ключей «защиты»...................... . 165
4.5. Пакет для работы с таблицей имен ....... . . . , 166
4.6. Пакет для обработки списков.................. 167
4.7. Перечень используемых модулей ........................... 172
4.8. Ограничение видимости.................................... 176
4.9. Родовые программные структуры ........................... 179
4.10. Родовые пакеты........................................... 183
4.11. Структура программы и изменение пространства имен . . 186
4.12. Восходящая и нисходящая разработки программы . , , . 190
Глава 5. Задачи.................................................... 194
5.1. Введение................................................. 194
5.2. Запуск и выполнение задачи.......................'. . 196
5.3. Синхронизация и взаимодействие задач ..................... 198
5.4. Оператор отбора...................................... 204
5.5. Родовые задачи....................................... 208
5.6. Семейства задач, семейства входов и приоритеты задач . , . 211
5:7. Окончание задачи........................................ 214
5.8. Проблема чтения-записи............................... 215
5.9. Раздельная синхронизация и защита ........................ 219
5.10. Эффективность многозадачной работы . ..................... 224
ЙриЛоЖение. Сводка синтаксических правил................... • • • 230
ГЛАВА 1
ОБЗОР ЯЗЫКА АДА
1.1. Простая программа на Аде
Первая глава представляет обзор языка Ада в целом, чтобы
читатель мог, так сказать, представить себе весь лес, прежде
чем рассматривать отдельные деревья. Важнейшие понятия и
особенности языка вводятся с помощью тщательно подобранных
примеров, уровень подробности которых приемлем для чтения
и понимания большинства программ на Аде. Более подробные
сведения, необходимые для написания программ на этом языке,
изложены в последующих главах.
Наш первый пример — процедура с именем SIMPLE_ADD,
которая читает два числа, вычисляет их сумму и печатает ре-
зультат. Каждая строка заканчивается примечанием, оформ-
ленным по правилам Ады («-», за которыми следует текст при-
мечания).
Пример 1.1. Очень простая программа
procedure sim₽LE_add is,
X,Y,Zs INTEGER/ '
begin
GET(X) ?
GET(X)?
Z j=s X+Z;
TUT (Z) ?
end SIMPLE ADD?
- - процедура с именем SIMPLE ADD
- - -в которойобъявлено три переменных X, Y, Z
» последоЙ^ельность ее операторов — это
« « оператор GET, читающий значение X
• • ’оператЙр GET, читающий значение У
» оператор присваивания переменной Z
• оператор PUT, печатающий значение Z
- - и которая заканчивается ключевым:
• - словом end, за которым может следовать
- - имя процедуры
Самая первая строчка указывает на то, что программа — это
процедура с именем SIMPLE.ADD. Во второй строчке объявлены
три «идентификатора» X, Y, Z в качестве целых переменных.
Две эти строчки вместе составляют совокупность объявлений
процедуры 1), за которой расположена последовательность опе-
11 Неточность. По синтаксису Ады совокупность объявлений — это вторая
строчка. Первая — это спецификация подпрограммы (см. стр. 237).— Прим,
ред.
16
Гл. 1 Обзор языка Ада
раторов, ограниченная ключевыми словами begin .. end. Эта
последовательность содержит два оператора ввода, читающие ?
данные с внешнего носителя в X и Y; оператор присваивания, 5
вычисляющий сумму, и оператор вывода, печатающий результат. J
Структура этой программы такова: *
Пример 1.2. Структура программы
procedure name is
объявление переменных
begin
операторы, которые могут
использовать переменные
end;
совокупность объявлений
(описывающих данные)
совокупность операторов
(описывающих действия)
Эта структура — прототип структуры любой программы на
Аде. Каждая программа содержит совокупность объявлений,
которые называют и описывают переменные и другие програм-
мные объекты, и последовательность операторов, указывающих
действия над объектами, введенными в объявлениях. Ниже в
разд. 1.2 подробнее говорится о конструкциях, встречающихся
в совокупности операторов программ на Аде, а в разд. 1.3 —
о конструкциях, которые могут появляться в совокупности
объявлений.
Имена, вводимые программистом с помощью объявлений,
называются идентификаторами. Каждое объявление вводит
один или несколько идентификаторов и связывает с каждым из
них набор атрибутов. Так, объявление для X, Y, Z указывает
атрибуты X, Y, Z через тип данных INTEGER. В данном слу-
чае эти атрибуты включают множество значений, которые могут ’
иметь переменные X, Y, Z и операции, применимые к X, Y, Z.
Ада — язык с обязательными объявлениями в том смысле,
что каждый используемый в программе идентификатор должен
быть объявлен с помощью некоторого объявления. Это объявле-
ние накладывает ограничения на способ использования данного
идентификатора в программе, которые могут быть проверены
во время компиляции. Такие проверки позволяют выявить мно-
гие программистские ошибки гораздо быстрее, чем в случае от-
сутствия объявлений.
При описании выполняемых программой действий будем го-
ворить, что объявления обрабатываются, операторы выполнят?
ются, а выражения вычисляются. Таким образом, процедура*
SIMPLE_ADD начинается с обработки объявлений X, Y, Z,
затем выполняются четыре оператора тела процедуры. Выполне-
ние третьего оператора «Z := X+Y;» включает вычисление вы-
ражения ХЧ-Y и присваивание результата переменной Z.
L2. Примеры программирования на Аде
17
1.2. Примеры программирования на Аде
Всякая программа содержит управляющие структуры, кото-
рые управляют порядком выполнения операторов программы.
Два наиболее важных вида управляющих операторов в Аде —
это условные операторы, (которые выбирают альтернативные
действия) и операторы цикла (которые предписывают управляе-
мое повторение некоторого действия).
Условные операторы иллюстрируются следующим операто-
ром если (if), находящим абсолютную величину X.
Пример 1.3. Простой оператор если
if X < О then ' если X меньше нуля, то
X := -X; --заменить Хна—X
end if? - “ иначе ничего не дедать
Операторы цикла иллюстрируются следующим оператором
для, который суммирует первые десять элементов вектора V.
Пример 1.4. Простой оператор цикла
sum := 0; »-задать начальное значение переменной SUM,
for х in 1..10 loop •" положив егоравнымиулк»
sum := SUM +•¥(!); - жкл для последовательных значений I
end loop; - - прибавить I-й элемент вектора V к SUM
-- конец цикла' '
Следующий фрагмент программы находит максимум первых
десяти элементов V. В нем оператор если вложен в оператор для.
Пример 1.5. Цикл с внутренним оператором если
МАХ := У(1);
- - задать начальное значение МАХ, положив ею
--равным первому элементу V
• - цикл для последовательных значений I
• - еслииовое Уф > максимума, то
- - У(1) становится новым текупдам максимумом
- - конец оператора если
- - конец цикла.
for I in 2..10 loop
if V(I) > MAX then
MAX := V(X)7
end if;
end loop;
Операторы, вложенные в другие операторы, типичны для
структуры программ на Аде. Структура вложенности в приве-
денном выше фрагменте такова:
Пример 1.6. Вложенные управляющие структуры
оператор присваивания
оператор для (частный случай оператора цикла)
; оператор если, вложенный в этот оператор для
оператор присваивания, вложенный в этот оператор если
конец вложенного оператора если
конец оператора для ~
18
Гл. 1 Обзор языка Ада
Этот фрагмент программы служит для вполне определенной
функции (а именно для нахождения максимального значения из
некоторого вектора значений). Возможность находить максимум
вектора можно предоставить произвольному числу пользователей,
оформив фрагмент для нахождения максимума модульным об-
разом в виде определения функции.
Пример 1.7. Определение функции для нахождения максимума
function MAX TEN(V: VECTOR) return INTEGER is -- функция с именем
- - MAX—TEN с одним параметром типа VECTOR
- - и результатом типа INTEGER
MAX: INTEGER; •- имеет локальную переменную МАХ
begin
MAX : = 7(1);
for I in 2,.10 loop
if V(I) > MAX then
MAX 7(1);
end if;
end loop;
return MAX;
end MAXJTEN;
- - и последовательность операторов
• - в которой V(I) присваивается МАХ
- - затем в цикле
- - проверяется условие V(I) > МАХ
- - и если да, то V(I) становится максимумом
* - если V(I) < МАХ,ничего не делать
- - конец цикла
- - после завершения цикла возврат со значением МАХ
- - конец определения функции MAX—TEN
Определенная выше функция предоставляет пользователю
некоторый вычислительный ресурс (для нахождения максимума
вектора из десяти элементов). Следующий оператор находит
сумму максимумов десятиэлементного вектора А и десятиэле-
ментного вектора В и присваивает результат переменной Y.
Пример 1.8. Вызов функции
X ;= MAXJTEN (А) + MAXJTEN(В);
Вызовы функций, подобных MAX _TEN, могут появляться
в выражениях, в правой части оператора присваивания—везде,
где допустимы константы или переменные.
Функция MAX_TEN иллюстрирует основную идею опреде-
ления вычислительного ресурса и последующего его использо-
вания. Но функция MAX _TEN несовершенна в следующих от-
ношениях:
1. Ограничение длины вектора в точности числом десять не-
практично. Ресурс, находящий максимум, должен работать для
векторов произвольного «разумного» размера.
2. Иногда требуется знать не только значение максимального
элемента, но и его место (индекс) в векторе, чтобы с ним было
возможно работать в дальнейшем.
Следующая функция MAX .INDEX находит индекс макси-
мального элемента вектора произвольной длины. У нее есть пара-
1.2. Примеры программирования на Аде
19
метр V типа VECTOR. Считается, что этот тип предваритель-
но определен программистом как одномерный массив целых
(разд. 1.3). В ней использованы «вызовы атрибута» V’FIRST и
V’LAST, вычисляющие индексы первого и псследнего элементов
вектора V. В ней использованы также средства Ады для объявле-
ний с инициализацией.
Пример 1.9. Определение функции для нахождения индекса мак-
симума
function MAX INDEX(V: VECTOR) return INTEGER is —функция
' ’ -MAX—INDEX
MAX: INTEGER := V(V'FIRST); --установка начального значения
INDEX: INTEGER := V1 FIRST} - - локальной переменной MAX н INDEX
begin - - тело функции
for I in V’FIRST..V'LAST loop
if V(I) > MAX then
MAX s= V(I) ;
INDEX ;= I;
end if;
end loop;
return INDEX;
end MAX_INDEX;
• - цикл по элементам вектора
- -если V(I) > MAX
- - если да, то положить МАХ равным V(I)
- • и запомнить значение индекса
• - если V(D < МАХ, ничего не делать
< * - закончить цикл
- - и вернуться с индексом
«- максимального элемента
Вызов ”MAX_INDEX(A)” возвращает индекс максималь-
ного элемента. Поэтому сам максимальный элемент находится
как ”A(MAX_INDEX(A))”. Разность максимумов двух векторов
(возможно, разной длины) можно найти следующим образом:
Пример 1.10. Вызов функции МАХ _INDEX
CIFF S= A (MAX—INDEX (А)) - В (MAX_INDEX (В))'?
Выгода нахождения индекса максимального элемента по
сравнению с нахождением его значения иллюстрируется следую-
щим фрагментом программы, в которой меняются местами пер-
вый и максимальный элементы вектора.
Пример 1.11. Использование MAX .INDEX
К sa MAX-INDEX (А)»
JTEMP := А (К) ;
А(К) :«А(1);
А(1) := IEMF;
Этими средствами можно воспользоваться как основой для
сортировки нахождением последовательных максимумов под-
векторов, что иллюстрируется следующим примером для век-
тора из пяти элементов 3, 1,7, 6, 4.
20
Гл. 1. Обзор языка Ада
Пример 1.12. Пример сортировки методом последовательных мак-
симумов
3
б
4
мах — а(з)
SWAP А(3)
И А(1)
7 (7
II б
3 МАХ — А(4) 3
6 SWAP А (4) * 1
4J и А (2) 4
МАХ — А (5}
SWAP А(5)^
ж А(3)
7
б
4
11 МАХ — А(5)
3j SWAP А(5}*
и А (4)
7
6
4
3
Чтобы сортировать методом последовательных максимумов
с помощью подпрограммы МАХ_INDEX, нужно иметь возмож-
ность указывать в качестве параметров подмассивы (вырезки)
соседних элементов сортируемого массива. Ада допускает вырезки
(подмассивы) соседних элементов, указываемые обозначением
A (I. .J),4to значит «подмассив, состоящий из соседних элементов
массива от А(1) до A(J)».
В следующем примере вызов ”MAX_INDEX(A(I. .N))”
дает индекс максимального элемента вырезки A(I. .N). Предпо-
лагается, что для сортируемого вектора A’FIRST=1.
Пример 1.13. Сортировка последовательными максимумами
N ta A’LAST; « - присвоить N размер массива
for I in 1. .N loop " • ж повторять
К :я MAX-INDEX (A (I. .N)); найти МАХ_____INDEX вырезки A(I..N)
TEMP := А (К); - поменять местами максимальный элемент А(Ю
А (к) :=А(1); •« с первым элементом А(1)
А(1) := ТЕМ?; --вырезки A(LN)
end loop; - - и то же для следующего I
Сортировка — это вполне определенная задача, которую
удобно оформить как процедуру. Процедуры, подобно функциям,
вводятся с помощью определения, которое описывает подлежащую
выполнению задачу, и впоследствии могут быть вызваны с по-
мощью вызова процедуры. Й отличие от функций процедуры не
возвращают результат, а изменяют значения переменных, имена
которых доступны пользователю процедуры. Следующая про-
цедура SORT модифицирует (сортирует) значение своего пара-
метра типа VECTOR.
Пример 1.14. Процедура сортировки
1'2. Примеры программирования на Аде
21
procedure SORT(A: in out VECTOR) is
N; constant INTEGER := A’LAST;
K, TEMPS INTEGERS
begin
• for. I in l.,M loop
*~K := MMC_INDEX(A(I..N))f
TEMP := A(K);
A(K) := A(I)s
A(I) := VEHBf
end loop;
end SORT;
В программе SORT используются два не встречавшихся нам
ранее языковых средства:
1. Объявление постоянной. Локальный идентификатор N
получает начальное значение (равное длине вектора А), и при
работе процедуры его значение остается неизменным. Поэтому
он вводится объявлением постоянной. Постоянная N может об-
ладать разными значениями при различных активизациях про-
цедуры, но в течение одной активизации ее значение неизменно.
2. Входные и выходные параметры. Векторный параметр А
процедуры SORT доступен как для чтения, так и для обновления
при выполнении этой процедуры, и поэтому должен быть объяв-
лен с видом связи in out (входной-выходной). Этим он отли-
чается от параметра V функции MAX.INDEX, который ис-
пользуется только для чтения (т. е. как входной параметр) и
никогда не обновляется. Вид входных параметров в Аде специ-
фицировать не обязательно, так что ”V : VECTOR”— допусти-
мая спецификация параметра V, хотя более полной была бы
спецификация ”V: in VECTOR”, в которой явно указано, что
V — входной параметр. Для .универсальных (т. е. входных-
выходных) параметров вид связи специфицировать обязательно.
Процедуру SORT можно вызвать следующим оператором
вызова процедуры.
Пример 1.15. Вызов процедуры SORT
SORT(INTVECT);
Заметим, что вызов процедуры SORT воздействует на окру-
жающую среду, изменяя порядок . тементов своего векторного
параметра, в то время как функция MAX_INDEX не может
воздействовать на среду изменением значений своих парамет-
ров — она лишь возвращает в свою среду результат. Это верно
и в общем случае: функции имеют только входные параметры и
могут воздействовать на среду, только возвращая результат, а
процедуры не возвращают результата и должны воздействовать
па среду только изменением значений своих параметров.
22
Гл. 1 Обзор языка Ада
Процедуру SORT можно использовать, ничего не зная о том4"
как осуществляется сортировка. Если эту процедуру заменить
любой функционально эквивалентной процедурой, выполняю*^
щей сортировку совершенно другим способом, это не окажет!
влияния на пользователя.
Сортировка — одна из наиболее изученных проблем, и из*
вестны буквально сотни различных способов рассортировать
вектор. Сортировка последовательными максимумами была вы* ‘
брана только для иллюстрации, так как она одна из простейших
и позволяет проявить некоторые интересные средства Ады.
1.3. Объявление типа и объекта I
.с
Теперь, когда мы рассмотрели некоторые примеры программ
на Аде, займемся более подробным изучением возможностей,’
предоставляемых этим языком для описания данных. Ключевым?
для описания данных служит понятие типа данных. Тип данных;
определяет множество значений, которыми могут обладать иден-
тификаторы, объявленные как объекты этого типа данных, И;
множество операций, применимых к объектам этого типа данных?
В Аде имеются предопределенные типы данных INTEGER,'
FLOAT, BOOLEAN и CHARACTER. Однако мощь языка Ада
опирается на предоставленную программисту возможность са-'
мому вводить необходимые для конкретных приложений опре-
деляемые типы данных с помощью определений типа.
Новые типы данных разумно вводить просто для того, чтобы
предотвратить смешение операций над логически различными ви-
дами объектов. Например, если мы хотим считать яблоки и
апельсины, не смешивая их между собой, мы можем ввести два
определяемых целых типа APPLES (яблоки) и ORANGES
(апельсины), как показано в следующем примере.
Пример 1.16. Совместимость и преобразование типов
procedure DERIVED_TYPES is
type APPLES is new- INTEGER;
type ORANGES is new INTEGER;.
A: APPLES';-
B:« ORANGES;
T; INTEGER;
begin "
A 0;
В :== 0;
A := A+A;
I := A+B;
I := INTEGER(A) + INTEGER(B) ;
end DERIVED JCYPES;
- процедура, которая
- определяет новый тип APPLES
- и новый тип ORANGES
- объект типа APPLES
- объект типа ORANGES
- и объект типа INTEGER
* * объекту типа APPLES присвоена целая константа 0
- - та же константа присвоена объекту типа ORANGES
* * яблоки можно складывать между собой
- - но яблоки нельзя складывать с апельсинами
* - (неправильный оператор)
- не преобразовав их предварительно^
- к целому типу ,
1.3. Объявление типа и объекта 23
Типы APPLES и ORANGES в приведенном примере назы-
п-’ются производными типами, так как они образуются из уже
существующего типа INTEGER. Производные типы наследуют
константы из своих исходных типов. Поэтому оператор ”А:=0;”,
поисвапвающий константу «О» переменной типа APPLES, со-
вершенно правилен. Они наследуют также операции из исход-
ных типов. Поэтому выражение ”А+А”, в котором операция
«+» применяется к переменным типа APPLES, также правильно.
То же можно сказать и о выражении ”А+1”. Однако операция
сложения требует операндов одного и того же типа (поэтому
»д_|-В” и ”А+1” неправильны). Оператор присваивания требует,
чтобы выражение в его правой-части имело тот же тип, что и имя
в левой части (так что ”1: =А;” недопустимо). Однако допустимы
явные преобразования между производным и исходным ти-
пами (INTEGER(A) типа INTEGER, в то время как APPLES(I)
будет типа APPLES). Таким образом, ”1 := INTEGER(A)+IN-
TEGER(B);” — правильный оператор, поскольку оба операнда
операции сложения имеют тип INTEGER, сумма также имеет
тип INTEGER и тип значения правой части согласован с типом
переменной в левой части.
Объявление производного типа APPLES автоматически рас-
ширяет смысл операции «+», поэтому ею можно пользоваться
для сложения не только целых чисел, но и яблок. Расширение
смысла операции на операнды нового типа называется перекры-
тием операции. Ада позволяет перекрывать операции как
неявно, определяя производный тип из такого исходного типа,
для которого эта операция уже имеет смысл, так и явно с по-
мощью определения функции (разд. 1.8).
Операция «+» всегда перекрыта, потому что сложение опре-
делено и для операндов с фиксированной точкой, и для операн-
дов с плавающей точкой (сложение с фиксированной и с плаваю-
щей точкой на самом деле реализовано различными командами
на большинстве машин). Объявления типов APPLES и ORAN-
GES придают операции «+» дополнительный смысл, определен-
ный программистом. Смысл конкретного вхождения операции
«+» зависит от типов ее операндов. Так как типы операндов про-
извольной операции всегда известны в период компиляции,
компилятор всегда может определить, какой именно смысл опера-
ции «+» имеется в виду, и может выписать фрагмент объектной
программы, выражающий нужный смысл.
Предопределенный тип данных INTEGER обладает неявным
(определяемым реализацией) диапазоном значений. Явное управ-
ление диапазоном значений целых переменных возможно по-
средством явного уточнения диапазона, указываемого в
конце определения типа, как это сделано в следующем при-
мере.
24
Гл. 1 Обзор языка Ада
Пример 1.17. Целый тип, определенный программистом
procedure FIBONACCI is
type SHORTJTNT is range -
J: SIIORTJCNT 0;
K: SHORTINT s* 1; --
begin ** --
while К < 10000 loop,
PUT(K);
К J+K;
K-J;
end loop;
end FIBONACCI;
процедура нахождения чисел Фибоначчи
32768. .32767; --с типом SHORT ЦЗтр
две инициализированные переменные *** *
для порождения чисел Фибоначчи
и последовательность операторов
если число < 10000
вывести текущее число Фибоначчи
поместить в К следующее число Фибоначчи
поместить в J предыдущее значение К
и повторить этот процесс
В этом примере объявлен определяемый тип SHORT^INT
и два объекта J, К этого типа. У типа SHORT_INT явно ука-
зан диапазон, что повышает мобильность программы. Более
того, такой диапазон можно эффективно реализовать на маши-
нах с 16-битовым словом.
Имеется фундаментальное различие между объявлением типа
SHORT.INT, которое вводит новый тип, на основе которого
можно строить произвольное количество последующих объяв-
лений, и объявлением объекта J, К, которое вводит новые объек-
ты конкретного типа данных с тем, чтобы эти объекты можно
было использовать в последующих операторах.
Типы данных INTEGER и SHORT.INT называются ска-
лярными типами, потому что объекты этих типов не имеют ком-
понент. Другой важный класс скалярных типов образуют пере-
числяемые типы. С ними связано конечное множество значений,
которое задается явным перечислением, как показано в следую-
щем примере.
Пример 1.18. Перечисляемые типы
procedure ENUMERATION JTYPES is
type COLOR is (RED,GREEN,YELLOW,BLUE); ••
ADA:. COLOR; • - ADA — i
begin Q
ADA GREEN;
end ENUMERATION_TYPES;
• - значение GREEN (зелень:
- - присвоено объекту ADA
Перечисляемые типы очень полезны для определения конеч-
ных множеств объектов, с которыми приходится иметь дело
в реальной жизни: цветов радуги, дней недели (MON, TUE, . .),
направлений (N, Е, S, W), цифр (0, 1,2,.. .), кодов машин-
ных операций (ADD, MULT, . .) и т. д. Язык Ада позволяет
удобно записывать циклы по перечисляемым типам и использо-
вать последние в качестве индексных множеств для массивов.
1.3. Объявление типа и объекта
25
Скалярные типы не имеют компонент, и этим они отличаются
от структурных типов, например массивов^ чьи компоненты
выбираются по индексам. В следующем примере объявлен ре-
гулярный тип (тип массивов) VECTOR, два объекта V, W этого
типа и показано присваивание компонентам векторов и целым
векторам.
Пример 1.19. Регулярные типы
procedure ARRAY_TYJ?ES is - - процедура с именем ARRAY_TYPES
*~-type VECTOR is array (1.. 5) of INTEGER; --объявлением типа VECTOR
V,W: VECTOR; " ...........
begin
””v(5) :« 8;
W (2,4/6,8,10)
V :=» W;
end TYPES;
- и объявлением объектов V, W
- и последовательностью операторов
- которая присваивает элементу вектора
- присваивает агрегат целому вектору
- присваивает V значение вектора W
- и на этом завершает работу
Объявление типа VECTOR определяет образец, по которому
можно завести нужное количество векторных объектов посредст-
вом объявления объекта. Массивы состоят из компонент (эле-
ментов), к каждой из которых можно обратиться по индексу
(V(5), W(l)), или можно заполнить массив с помощью агрегата
(W := (2, 4, 6, 8, 10);), или присвоить значение совместимой
переменной регулярного типа (V := W;). Поэтому регулярные
структуры данных (массивы) можно рассматривать как абстракт-
ные сущности, обладающие как агрегатом значений, так и набо-
ром индивидуальных значений.
При определении регулярного типа границы индексов могут
быть оставлены неуточненными, если для указания типа индек-
сов массива применяется определение типа (как INDEX в сле-
дующем примере), а не указание диапазона (1. . 5). Для регу-
лярных типов, в которых границы не уточнены, нужно указы-
вать границы при объявлении объектов этих типов.
Пример 1.20. Векторы с неуточненными границами
INDEX is ranga 1. ,1000} • • тип INDEX, нужный да определения типа
Sfie VECTOR is, arra^(INDEX) p£ INTEGER; « - с неуточненными границами
V» VECTOR (1,, 20); •• 20-элементные векторы
w; VECTORCl. .10); ••> 10-элементный вектор
У типа VECTOR границы не уточнены, и это позволяет вво-
дить векторы любой длины от 1 до 1000. Вообще говоря, в ка-
26
Гл. 1 Обзор языка Ада
честве уточнения границ может фигурировать любой поддиа-
пазон диапазона для типа индексов из рассматриваемого опреде-
ления типа.
Регулярные типы с неуточненными границами особенно
важны в подпрограммах с параметрами регулярного типа, подоб-
ных процедуре SORT и функции МАХ _INDEX из предыдущего
раздела. В этих подпрограммах тип параметра VECTOR должен
иметь неуточненные границы, чтобы допускать вызовы с векто-
рами различных размеров. Еще один пример подпрограммы, тре-
бующей векторных параметров с неуточненными границами,—
следующая функция, выполняющая умножение векторов (на-
ходящая их скалярное произведение).
Пример 1.21. Умножение векторов
function VECMULT (X, Y: VECTOR) return INTEGER is -- RESULT получает
RESULT: INTEGER ;= 0; — начальное значение 0 |
begin
assert X ‘FIRST » Y'FIRST; - - два оператора контроля,
assert X'LAST « Y'LAST; -- проверяющих совместимость векторов
for I in X'FIRST.. X • LAST loop - - цикл по элементам вектора
RESULT RESULT+X (I) *Y (I) ; - - накопление скалярного произведения
end loop; * - повторение для следующих элементов;
return RESULT; *• и возврат результата
end VECMULT;
В функции VECMULT, как и в подпрограммах SORT и
MAXjINDEX, для выяснения границ векторного аргумента
использован вызов атрибута. Вызовы атрибутов X’FIRST и >
X’LAST доставляют индекс первой и последней, компонент
вектора и применяются для управления циклом. |
В этом примере показано также применение оператора конт- ?
роля (assert). По своему смыслу он должен выполняться в обыч- »
ном порядке, хотя иногда его истинность может быть проверена •
в период компиляции оптимизирующим компилятором. Если 1
указанное в нем условие истинно, то работу можно продолжать. I
Если же оно ложно, необходимо обработать ошибку. |
Компоненты регулярного типа должны иметь один и тот же •
тип. Доступ к ним осуществляется по индексам. Ада обеспечивает
возможность работать и со вторым важным классом определяе-
мых структур данных — записями, чьи компоненты могут иметь
различные типы. Эти компоненты доступны по именам селекто- ’
ров, связанным с именем записи. i
Пример 1.22. Комбинированные типы данных (типы записей) I
1.3. Объявление типа и объекта
27
procedure RECORD_TYPES is
type COMPLEX is - - определяемый тип COMPLEX
record - - запись с
RE: INTEGER; •- - компонентой RE типа INTEGER
IM: INTEGER; - - и компонентой IM типа INTEGER
end record; - - конец определения комбинированного типа
C,C1: COMPLEX; - - два объекта С, С1 типа COMPLEX
begin
C.RE :=2; * - присваивание RE-компоненте С
C.IM := C.RE+1; - - присваивание IM-компоненте С
Cl := (0,0); - - присваивание агрегата всей записи Cf
Cl := C; - - присваивание значения С всей записи CI
С := (C.RE*C1.RE-C.IM*C1.IM,C.RE*C1.IM+C.IM*C1.RE); --С*С1
end RECORD_TYPES;
Имея дело с записями, можно, подобно массивам, работать
не только с отдельными компонентами записи (например, C.RE),
но можно также присваивать комбинированные агрегаты комби-
нированным переменным (С1 := (0, 0);) и целиком присваивать
совместимые комбинированные переменные (С1 := С;).
У записи COMPLEX в предыдущем примере есть две компо-
ненты типа INTEGER. Комбинированные типы в Аде могут
иметь компоненты неопределенного размера и (или) типа. В сле-
дующем комбинированном типе есть динамическая компонента
регулярного типа, размер которой определен значением другой
компоненты, которая в свою очередь является постоянной, опре-
деляемой при создании конкретного экземпляра этого комби-
нированного типа.
Пример 1.23. Комбинированный тип изменяемого размера
type BUFFER is
record
SIZE: constant INTEGER range 1. -N; - - дискриминант
BLOCK: array (1, .SIZE) of INTEGER? . -- массив, размер которого
end record; ' --зависит от дискриминанта
Комбинированные типы, имеющие компоненты изменяемого
размера или типа, называются вариантными комбинированными
типами. Они должны содержать постоянную компоненту, по-
средством которой этот размер явно указывается при размеще-
нии конкретной записи. Эта постоянная компонента называется
дискриминантом, потому что она различает записи различных
размеров.
В Аде разрешены вариантные комбинированные типы, имена
и типы;компонент которых различаются для разных объектов
такого типа. У нижеследующего типа PERSON (ЧЕЛОВЕК)
имя и тип второй компоненты зависят от того, мужского или
Женского пола конкретный человек.
88
Гл. 1 Обзор языка Ада
Пример 1.24. Компоненты вариантного типа
type PERSON is
record
sex: constant - - дисгримянант (задержанная постояняая)
case sex of - - компонента, чье имя и тип зависят от дискриминант!
when И о BEARDED: BOOLEAN; --бородатый?
•when F <=> CHILDREN: INTEGER range 0..10Q; — СКОЛЬКО детей?
end case;
, end record;
Запись PERSON содержит дискриминант SEX (ПОЛ) пере-
числяемого типа, у которого может быть одно из двух значений
М (МУЖЧИНА) или F (ЖЕНЩИНА). Дискриминант называют
задержанной постоянной, потому что присваивание ему значе-
ния задерживается от момента объявления типа до момента
присваивания значения переменной этого комбинированного
типа. Присваивание дискриминанту допустимо только одновре-
менно с присваиванием значения всей записи целиком.
Дискриминанты в некотором смысле избыточны, потому что
содержащуюся в них информацию всегда можно извлечь из за-
висящих от них компонент. Однако дискриминанты проявляют
характер изменения записей в такой форме, которая позволяет
проверять допустимость и безопасность операций над записями.
С другой точки зрения дискриминант можно считать пара-
метром, значение которого задается в момент заведения объекта,
а не в момент определения типа. Ада позволяет указывать ди-
скриминанты вариантных записей с помощью «параметриче-
ской» нотации.
Пример 1.25. Параметризованные типы
В: EUFFER(N);
В; PERSON (М);
Записи изменяемого размера, подобные BUFFER, могут
иметь «динамические» параметры, значения которых определя-
ются в процессе обработки объявлений. В записях с изменяемым
типом компонент параметр должен быть определен статически,
так что совместимость типов может проверяться при компиля-
ции.
1.4. Структура программы
Теперь, когда введены операторы и объявления данных, мы
можем перейти к рассмотрению общей структуры программы на
Аде.
1.4. Структура программы
Описывая строение программы, мы будем выделять следую-
щие уровни программной структуры:
Символы — атомарные составляющие самого низкого уровня;
Лексемы — минимальные составляющие, имеющие смысл (се-
мантические атомы);
Выражения, которые указывают способ вычисления «значе-
ния»;
Операторы присваивания, которые присваивают переменной
значение, вычисленное выражением;
Управляющие структуры, которые управляют последова-
тельностью выполнения операторов присваивания и дру-
гих операторов;
Объявления, которые определяют атрибуты идентификаторов,
используемых в операторах программы;
Сегмент программы, который связывает объявления, опре-
деляющие атрибуты идентификаторов, с операторами, ко-
торые этими идентификаторами пользуются;
Сегмент компиляции — компонента программы, отдельно раз-
рабатываемая и компилируемая.
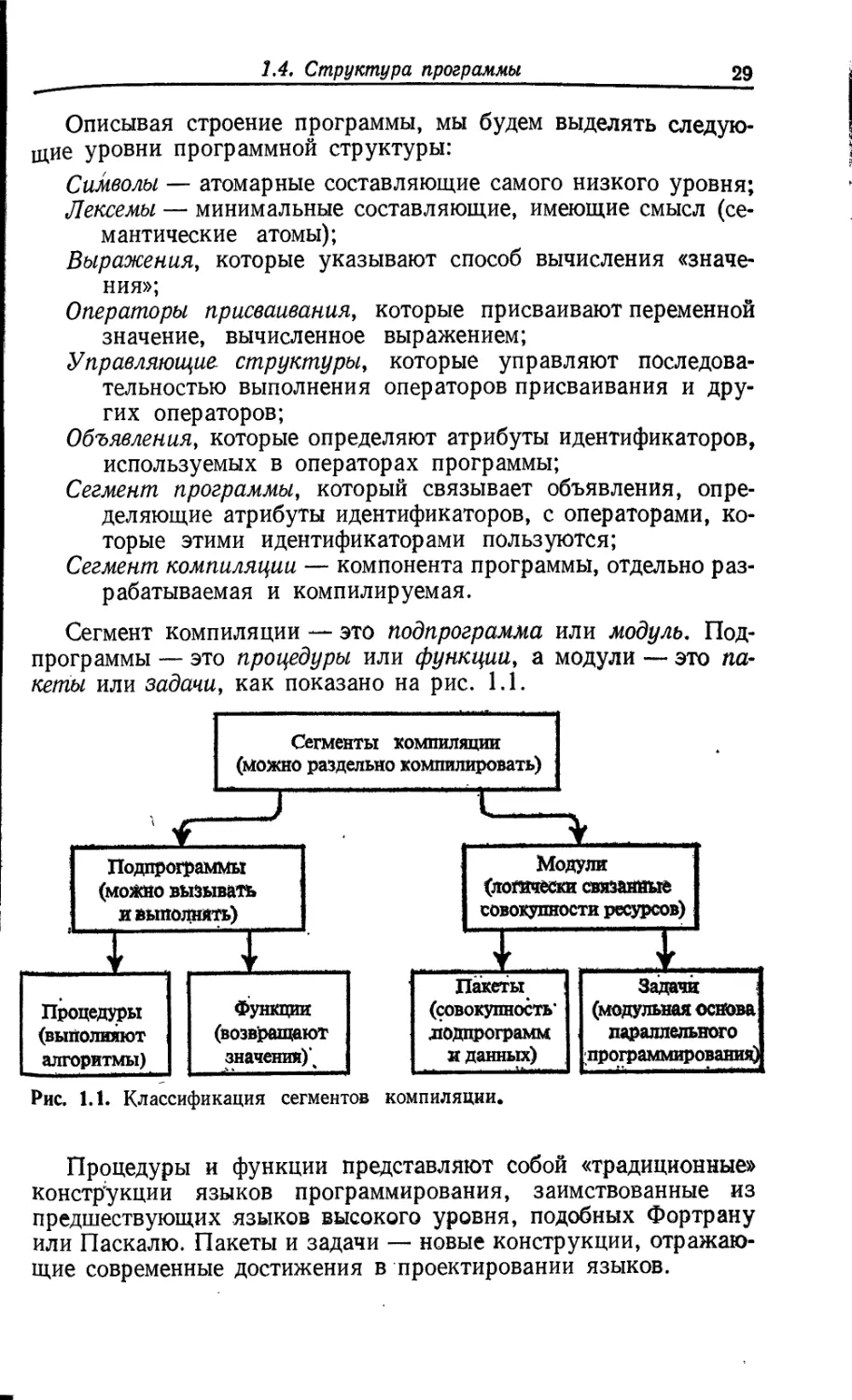
Сегмент компиляции — это подпрограмма или модуль. Под-
программы — это процедуры или функции, а модули — это па-
кеты или задачи, как показано на рис. 1.1.
Рис. 1.1. Классификация сегментов компиляции.
Процедуры и функции представляют собой «традиционные»
конструкции языков программирования, заимствованные из
предшествующих языков высокого уровня, подобных Фортрану
или Паскалю. Пакеты и задачи — новые конструкции, отражаю-
щие современные достижения в проектировании языков.
30
Гл. 1 Обзор языка Ада
Пакеты позволяют определить в качестве модуля логически
связанную совокупность вычислительных ресурсов. Например,
пакет матричной алгебры предоставляет логически связанную
совокупность ресурсов для действий над матрицами, пакет ввода-
вывода предоставляет логически связанную совокупность ресур-
сов для осуществления ввода-вывода. Задачи — это модульная
основа параллельного программирования. Связь между парал-
лельно выполняемыми задачами обеспечивается новым механиз-
мом рандеву, который требует синхронизации между вызываю-
щей и вызываемой задачами при всякой передаче сообщений
между ними.
Подпрограммы и модули могут быть как сегментами компи-
ляции (их можно компилировать раздельно), так и сегментами
программы (они связывают объявления идентификаторов с опе-
раторами, которые их используют). На самом деле всякий сег-
мент компиляции автоматически является сегментом программы.
Однако не каждый сегмент программы — сегмент компиляции.
В частности, подпрограммы и модули, определенные в совокуп-
ности объявлений объемлющего сегмента компиляции, не яв-
ляются сегментами компиляции. С определениями подпрограмм,
вложенными в объемлющий сегмент компиляции, мы познако-
мимся в следующем разделе.
1.5. Подпрограммы
О подпрограммах уже шла речь в разд. 1.2. В этом и следую-
щем разделах мы более подробно рассмотрим вложенные объяв-
ления подпрограмм и особенности их параметров.
Подпрограмма определяется с помощью объявления подпро-
граммы, в котором указываются имя подпрограммы, ее парамет-
ры, локальные объявления и последовательность операторов.
Подпрограмма активизируется вызовом подпрограммы, в кото-
ром указывается ее имя и аргументы, которые следует подста-
вить вместо параметров при данной активизации. В объявлении
функции, возвращающей результат, дополнительно указывается
тип этого результата.
У следующей функции F есть целый входной параметр, одна
локальная переменная с именем LOCAL и целый результат.
Пример 1.26. Объявление функции
function Г (N: INTEGER) return INTEGER is - - целый параметр и результат
LOCAL: INTEGER; - - локальная переменная типа INTEGER
begin - - и два оператора, которые используют
.LOCAL := N**2+N+l; •- ее для промежуточного результата
" return LOCAL; - - и возвращают значение типа INTEGER
end. F;
1.6. Параметры подпрограмм
31
Первая строчка этого объявления функции указывает ее имя,
параметр и тип результата, определяя тем самым полностью ее
характеристики, необходимые пользователю (ее внешнее сопря-
жение). Вторая строчка определяет внутреннюю локальную
переменную (недоступную пользователю функции F). Следую-
щие два оператора используют эту переменную и параметр для
вычисления функции F(N)=N2+N+1.
Эту функцию можно вызвать с помощью вызова функции,
имеющего тот же синтаксический статус, что и некоторая пере-
менная, появляющаяся в правой части оператора присваивания.
Пример 1.27. Вызовы функции
I .=: F (3)г *•- значение 13 присваивается I
J :=5 Г (3) +F (4) ? —• значение 34 (13 + 21) присваивается J
Объявления функций и их вызовы можно объединить в одну
программу, где в одной совокупности объявлений объемлющей
процедуры объявлены и целые переменные I, J, и функция F.
Пример 1.28. Вложенное объявление функции
procedure FUNCTIONS .is
I,J: INTEGER;
function F(N: INTEGER) return INTEGER;•
LOCAL: INTEGER;
begin
• LOCAL N**2+N+l;
return LOCAL;
end;
begin
I :* F (3); - - значение — 13
j F (3) +F (4); * - значение — 34‘
end FUNCTIONS;
I
*
$
s
g
Этот пример иллюстрирует вложенность объявлений подпро-
грамм в совокупность объявлений других подпрограмм, что ти-
пично для программ на Аде. Объявления целых I, J и процедуры
F вложены в совокупность объявлений процедуры FUNCTIONS.
В свою очередь в совокупности объявлений функции F объявлены
параметр N и целая переменная LOCAL. Функция F также мог-
ла бы иметь вложенные объявления функций, т. е. допустима
вложенность произвольного уровня.
1.6. Параметры подпрограмм
Параметры в определении подпрограммы называются фор-
мальными параметрами, так как это «фиктивные» идентифика-
торы (связанные переменные), которые можно заменить любыми
32
Гл. 1 Обзор языка Ада
другими без изменения смысла подпрограммы, лишь бы эти по-
следние не конфликтовали с идентификаторами внутри подпро-
граммы. (Формальные параметры будем для краткости называть,
просто параметрами.) Например, параметр N из F в приведенном
выше примере может быть заменен на М или X (но не на LOCAL)
во всех его трех вхождениях в F без изменения смысла функ-
ции F.
Параметры, входящие в вызов подпрограммы, называются
фактическими параметрами, так как они определяют те значения,
которые фактически используются при выполнении данного вы-
зова подпрограммы. При вызове подпрограммы фактические па-
раметры данного вызова «подставляются» вместо формальных
параметров ее определения в соответствии с видом связи каждого
параметра. Фактические параметры будем для краткости называть
аргументами.
Вид связи параметра определяет, предназначен ли соответ-
ствующий аргумент только для чтения, только для записи или
как для чтения, так и для записи. Эти три вида связи указываются
соответственно ключевыми словами in, out, in out.
Когда не указан никакой вид связи, по умолчанию подразу-
мевается in. Поэтому параметр N функции F имеет вид связи in.
У функций параметры могут быть только вида in, так как их
внешний эффект ограничен возвратом результата. Процедуры
в общем случае имеют хотя бы один параметр вида out или in
out, через который они и влияют на внешнюю среду своего вы-
зова 1).
Использование параметров in out иллюстрируется следующей
процедурой для обмена (перестановки) значений двух ее целых
параметров.
Пример 1.29. Параметры процедуры вида in out '
procedure SWAP (X,Y: in out INTEGER) is - - У SWAP два параметра in on
• и локальная переменная
- и три оператора,
- которые используют LOCAL как промежуточна
- память дрн обмене значениями X Я X
, LOCAL: INTEGER:
begin
LOCAL := X;
X := Y?
Y := LOCAL;
end.?
х> Процедуры могут также влиять на свою среду через нелокальные пере-
менные или посредством операторов вывода, по существу играющих роль
присваиваний нелокальной памяти на внешних носителях. Однако пара-
метры процедуры — более предпочтительный механизм для управляемой Я
гибкой передачи информации между вызываемой и вызывающей средами, t
хороший стиль программирования предполагает использование нелокальны:
переменных с большой осторожностью.
1.6. Параметры подпрограмм
33
У параметров X, Y вид связи in out, так как эта процедура
как использует значения соответствующих аргументов (X, Y
встречаются в правой части оператора присваивания), так и из-
меняет их значения (X, Y встречаются в левой части оператора
присваивания).
Параметры вида in ведут себя (в теле процедуры) подобно
локальным постоянным, чьи значения поставляются соответст-
вующими аргументами в точке вызова. Аргументы могут быть
константами, переменными или выражениями. Поэтому к функ-
ции F из примера 1.8 можно обращаться посредством вызовов
F(3), F(l), F(I+J) и т. д.
Аргументы для параметров вида out или in out должны быть
переменными. Параметр вида out действует как локальная пере-
менная, значение которой присваивается аргументу в резуль-
тате выполнения подпрограммы. Параметр вида in out действует
как локальная переменная, значение которой извлекается из
аргумента в момент вызова и присваивается аргументу в резуль-
тате выполнения подпрограммы.
Вызов ”SWAP(A, В);” процедуры SWAP заставляет пара-
метры X, Y из объявления процедуры действовать как локаль-
ные переменные, начальные значения которых извлекаются
из А и В в момент вызова. Окончательные значения X, Y в конце
выполнения этой процедуры будут присвоены А, В как резуль-
тат выполнения процедуры.
Применение процедуры SWAP можно проиллюстрировать
следующей процедурой SORT. Предполагается, что процедура
SWAP, функция MAX-INDEX и тип данных VECTOR опреде-
лены вне процедуры SORT так, что все эти объекты доступны
внутри этой процедуры.
Пример 1.30. Процедура сортировки
procedure SORT (Д': in out VECTOR) is - - процедура сортировки
K j INTEGER; - - с локальной переменной К
£egin . " - и последовательность^) операторов,
for X in l..A*LENGTH loop -- находящей максимум
К := MAX_INDEX (Д (I,. A 'LENGTH)); - - последовательных подмассивов Д
SWAP (А(1),А(К))? --обменивающей первый и максимальный
gn<3 loop? - - элементы для сортировки вектора А
?nd SORT?
Приведенная процедура пригодна только для сортировки
целых. Во многих приложениях для задач, подобных переста-
новке или сортировке, целесообразно иметь такие подпрограммы,
Которые были бы пригодны не только для одного какого-либо
типа (например, целого), а для широкого набора типов. В Аде
этого можно добиться с помощью родовых подпрограмм.
2 № 56
34
Гл. 1 Обзор языка Ада
1.7. Родовые подпрограммы I
Подпрограммы могут иметь параметры, представляющие со-1
бой переменные любого определенного типа данных, но пара- .
метры, значения которых — процедуры или определения типа, |
недопустимы. Родовой заголовок обеспечивает возможность па-
раметризации подпрограмм в период трансляции, допускающей
в качестве «родовых» параметров подпрограммы как типы, так
и подпрограммы. Родовая процедура SWAP иллюстрирует при-
менение родовых заголовков при определении операций, устроен-
ных аналогично для самых разных типов данных. Примером та-
кой операции может служить обмен значениями между двумя
переменными.
Пример 1.31. Родовая процедура обмена (перестановки значе-
ний)
generic (type Т) --родовой заголовок с параметром-типом Т —
procedure SWAP(X,Y; in out T) is --родовым параметром SWAP
TEMP: T ; = constant X; - - у TEMP тип T, начальное значение X
begin . . эти два оператора обменивают значения двух объектов <
X : = Y; - - типа Т, используя объект TEMP типа Т
Y s = TEMP; - - объектный код может быть разным
end SWAP; .. для разных типов
Родовые процедуры нельзя вызывать непосредственно. Их
можно рассматривать как макроопределения, к которым необ-
ходимо обратиться с конкретными значениями родовых парамет-
ров и в период компиляции построить соответствующие этим
параметрам обычные процедуры, прежде чем последние можно
будет выполнить. Этот происходящий в период компиляции
процесс построения называется конкретизацией, а построенные
в результате процедуры называются потомками соответствую-
щей родовой процедуры. Следующий пример иллюстрирует кон-
кретизацию родовой процедуры SWAP. Два потомка SWAP,
названные SWAP_INT и SWAP_VECT, можно использовать
для обмена целых и векторных объектов соответственно.
Пример 1.32. Конкретизация родовых процедур
procedure SWAPJLNT is new SWAP(INTEGER)?
procedure SWAP_VECT is new SWAP(VECTOR);
Процедура SWAP для векторов будет запрограммирована
совершенно не так, как для целых. Конкретизация родовых
процедур может порождать разный объектный код для разных
потомков и может рассматриваться как процесс периода компи-
ляции, а не периода выполнения. Родовые процедуры следует
1.8. Пакеты
35
рассматривать как макроопределения, а конкретизации — как
макровызовы, обеспечивающие генерацию соответствующего
объектного кода.
Связь между конкретизацией с заданными значениями родо-
вых параметров (происходящей в период компиляции при вы-
полнении операции new) и осуществляемой в период выполнения
подстановкой заданных значений аргументов (при выполнении
вызова процедуры) иллюстрируется рис. 1.2.
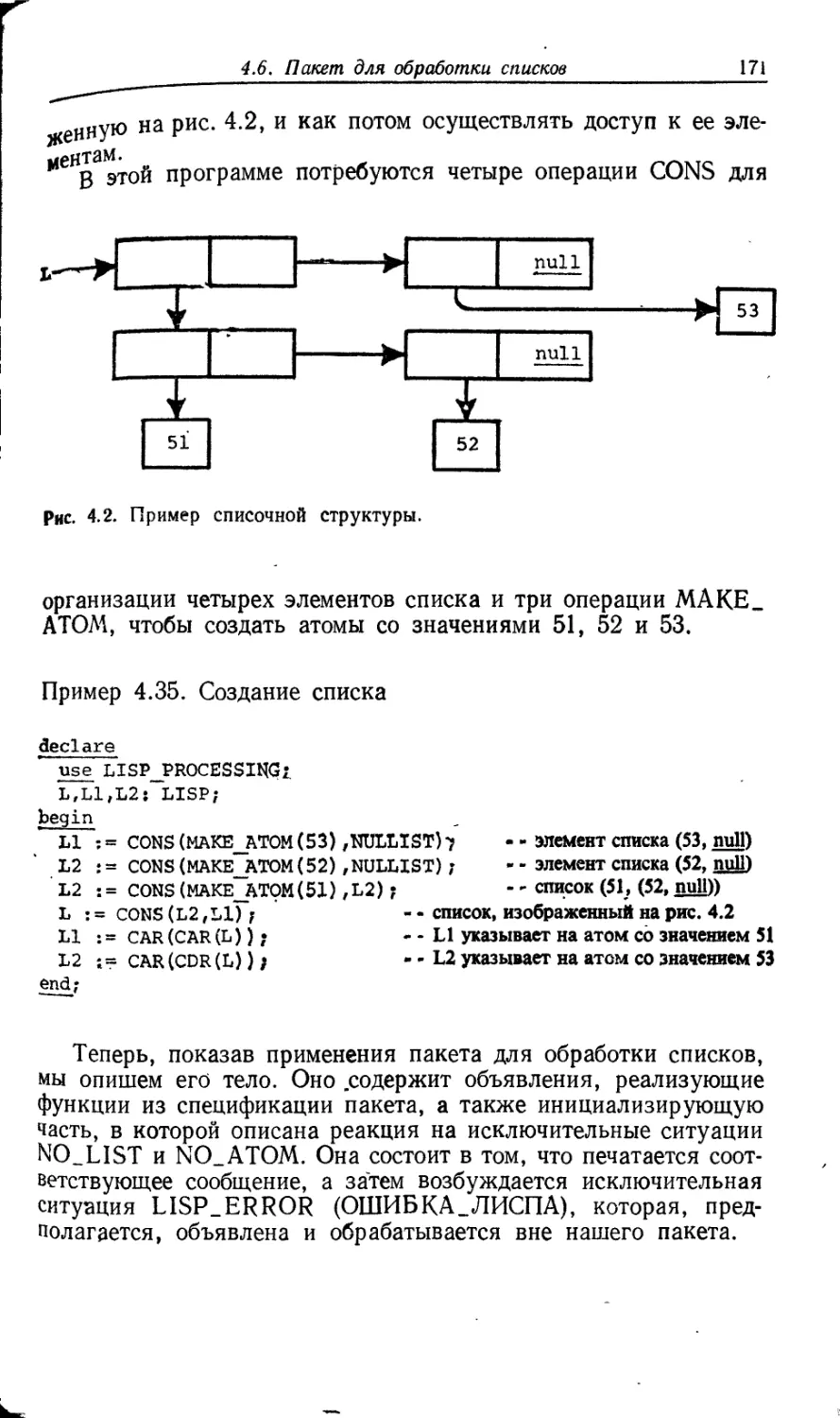
Рис. 1.2. Связь между родовой конкретизацией и вызовом процедуры.
Среди параметров могут быть и подпрограммы, и типы. Такие
параметры должны иметь статически (т. е. в период компиляции)
определенные значения, так как они влияют на создаваемый
компилятором объектный код в момент, когда в период компи-
ляции происходит конкретизация родовой подпрограммы.
1.8. Пакеты
Пакеты — это средство для предоставления совокупности
логически связанных вычислительных ресурсов. Следующий па-
кет DATA (ДАННЫЕ) предоставляет пользователю два целых
объекта, тип данных VECTOR и два векторных объекта.
Пример 1.33. Пакет данных
package DATA is
I,J: INTEGER;
type VECTOR is array (1..100) of INTEGER;
V,W: VECTOR;
; end;
Пакеты определяются в совокупности объявлений сегмента
программы. На компоненты пакета DATA можно ссылаться
с помощью составных имен (DATA.I, DATA.V(K)). Компоненты
2*
36
Гл. 1 Обзор языка Ада
пакета можно сделать и непосредственно доступными с помощью
перечня используемых сегментов и ссылаться на них затем по-
средством простых имен.
Пример 1.34. Перечень используемых сегментов
procedure USE_DATA is
use DATA?
begin
I x- 5;
V(K) S= 3f
end USE_DATA>
Перечень используемых сегментов может быть только пер-
вым предложением в совокупности объявлений (чтобы гаранти-
ровать единые соглашения об использовании имен во всем свя-
занном с этим перечнем сегменте программы). В совокупности
объявлений перечень используемых сегментов может быть только
один, но в нем можно перечислить имена нескольких пакетов.
Пакеты, предоставляющие объекты и типы данных, подобны
именованным общим блокам данных в языках, подобных Форт-
рану, однако они мощнее, поскольку могут обеспечить пользо-
вателю возможность работы не только с объектами, но и с ти-
пами данных. Кроме того, в общем случае пакет может предо-
ставлять в качестве ресурсов не только данные, но и программы.
Следующая спецификация пакета для действий с рациональными
числами включает комбинированный тип, позволяющий вводить
рациональные числа (представленные парами целых), операцию
«=», проверяющую равенство рациональных чисел, и две опе-
рации «+» и «*» для сложения и умножения рациональных чи-
сел.
Пример 1.35. Спецификация пакета для рациональных чисел
package RATIONALJTOMBfiRS is
type RATIONAL' is
record.
NUMERATOR: INTEGER;
DENOMINATOR: INTEGER range 1..INTEGER* LAST;
end record;
function "=" (X,Y: RATIONAL) return BOOLEAN;
function "+" (X,Y: RATIONAL) return RATIONAL;
function (X,Ys RATIONAL) return RATIONAL;
end;
Эта спецификация не полна, так как она задает лишь внеш-
нюю характеристику, а не семантику операций «=», «+» и
«*». Однако она снабжает пользователя всей информацией, ка-
сающейся способа доступа к ресурсам, предоставляемым паке-
1.8. Пакеты
37
том, и снабжает компилятор информацией, достаточной для тран-
сляции вызовов функций, для проверки типов и выделения па-
мяти объявляемым в таком окружении объектам.
Программные ресурсы, предоставляемые рассматриваемым
пакетом, реализованы в теле пакета, строение которого скрыто
от пользователя. Тело пакета для действий с рациональными
числами, приведенное ниже, содержит скрытую процедуру
SAME.DENOMINATOR (невидимую для пользователя пакета),
которая приводит операнды X и Y операций «=» и «+» к одному
знаменателю, так что (3, 4) и (6, 8) равны, а (3, 2) + (1,4) дает
(7, 4).
Пример 1.36. Тело пакета для рациональных чисел
package body, RATIONALJTOMBERS Is
procedure SAMEJDENOMINATOR (X,Ys in out RATIONAL) is
begin
- приводит X и Y к одному знаменатели
end?
function (X,Y: RATIONAL) return BOOLEAN is
U,Vs RATIONAL; ' '
begin
U 4» X;
V := Y;
SAME_DENOMINATOR (tT,V) ?
return (U.NUMERATOR - V. NUMERATOR)>
end
function ”4-" (X,Y: RATIONAL) return RATIONAL is ... end
function (X,Y: RATIONAL) return RATIONAL is' ... end
end RATIONAL-NUMBERS;
Следующий пример • иллюстрирует создание пользователем
объектов типа RATIONAL, а также применение равенства, сло-
жения, умножения и присваивания рациональных чисел.
Пример 1.37. Применение пакета для рациональных чисел
procedure USE_RATIONALS is
уде RATIONAL-NUMBERS;
X,Y,Zs RATIONAL 8= (1,1);
begin
X s= (3,4);
Y (6,8);
if X = Y then
Z tF X*X;
else
Z t- X+Y;
end if;
end;
- - пакет для рациональных должен быть
- - видимым
- * можно просто ссылаться на +,
* три рациональных объекта с начальным
- - значением
- - присваивание рационального числа
- - равенство таково, что (6,8) = (3,4)
- - проверка равенства рациональных’
< - умножение и присваивание рациональных
- - сложение и присваивание рациональных
38
Гл. 1 Обзор языка Ада
Выше в операторе ”Z := X+Y;” операция + интерпрети-
руется как сложение рациональных чисел, потому что ее one- ,
ранды — рациональные числа, а := интерпретируется как при-
сваивание рациональных чисел. Когда вводится новый тип,
например RATIONAL, присваивание и равенство автоматически
определены для объектов этого типа, но все другие операции
(такие, как +, *) должны быть определены явно. В пакете для
рациональных чисел равенство переопределяется так, чтобы
(3, 4) и (6, 8) были равны. Явно определенный смысл равенства
заменяет автоматически определенный смыслх).
Пример с пакетом для рациональных чисел показывает, что
пакеты могут содержать объявления типа и что объекты этого
типа можно создавать и работать с ними, применяя операции,
определенные для данного типа внутри этого модуля.
1,9. Абстрактные типы данных
Пакет для рациональных чисел предоставляет ресурсы для
создания объектов типа RATIONAL, для сложения и умноже-
ния рациональных чисел. Однако способ работы с объектами
типа RATIONAL может быть совершенно не связан с тем фактом,
что они являются рациональными числами.
Пример 1.38. Прямые операции над компонентами типа
procedure COMPONENTS is
use RATIONAL-NUMBERS;
X,Y,Zs RATIONAL (1,2);
begin
X.NUMERATOR X.NUMERATOR+5; --X становится равным (6,2)
X.NUMERATOR Y.DENOMINATOR; -- X становится равным (2,2)
end;
Здесь рациональные числа трактуются как записи с двумя
компонентами, а не как абстрактные объекты, над которыми
должны выполняться операции для рациональных чисел. В Аде
имеется возможность скрыть представление рациональных чисел
как записей с тем, чтобы сделать их доступными только внутри
пакета для действий над рациональными числами.
Если бы равенство не было явно определено в этом пакете, то X=Y
для рациональных операндов было бы истинно только для идентичных пар
целых и ложно для Х=(3,4) и Y=(6,8). Каждое определение равенства авто-
матически делает определенной двойственную операцию /=. Однако другие
операции над рациональными числами, например <, остаются неопределен-
ными для новых типов и должны быть явно определены подобно + и *.
1.9. Абстрактные типы данных
39
Пример 1.39. Приватные типы данных
package RATIONAL-NUMBERS is
"^IType RATlONAL is private; - - скрывает представление объектов
function (X,Y: RATIONAL) return BOOLEAN;
function "+" (X,Y: RATIONAL) return RATIONAL;
function (X,Y: RATIONAL) return RATIONAL;
function ,,/M (X,Y: INTEGER) return RATIONAL;
private
^type RATIONAL is
record
NUMERATOR: INTEGER;
DENOMINATOR: INTEGER range 1..INTEGER»LAST;
end record;
end;
Такая спецификация пакета скрывает представление объектов
типа RATIONAL, компоненты его объектов становятся недоступ-
ными и с ними можно манипулировать только с помощью опера-
ций, определенных для рациональных чисел внутри пакета.
В результате становится невозможным явно представлять рацио-
нальные постоянные в виде упорядоченных пар целых чисел.
Таким образом, ”Х := (3, 4);” становится неправильным опера-
тором, потому что пользователь не имеет теперь права считать,
что (3, 4) — это константа типа RATIONAL.
Эту трудность можно преодолеть, введя в теле пакета функ-
цию для создания рациональных чисел из пар целых.
Пример 1.40. Функция создания объектов приватного типа
function "/" (X,Ys INTEGER) return RATIONAL is •
begin
return (X,Y);
end ”/”;
Если «/» включена в тело пакета (где представление RATIO-
NAL известно), а спецификация этой функции (первая строка из
только что приведенного примера) включена в открытую часть
спецификации пакета, то «/» можно применять для превращения
пар целых в рациональные числа, ничего не зная о представле-
нии рациональных.
Пример 1.41. Применение функции создания объектов
х := 3/4; • - создается рациональное число и присваиваетсяX
В полученном пакете рациональные числа трактуются как
истинно абстрактные типы данных. Это значит, что рациональ-
ные числа можно создавать из пар целых, присваивать их пере-
40
Гл. 1 Обзор языка Ада
менным, проверять на равенство, складывать и перемножать,
но их целостность не может быть нарушена путем изменения их
компонент.
Операция «/», определенная выше для целых аргументов и
рациональных результатов, перекрывает предопределенную опе-
рацию «/» для целых (и плавающих) аргументов и результатов.
Этот пример показывает, что Ада допускает перекрытие опера-
ций, у которых одинаковые типы аргументов, но разные типы ре-
зультатов. Когда компилятор встречает оператор "X := 3/4;”,
то «/» интерпретируется как деление целых, если X целого типа,
и как функция создания рациональных чисел, если X типа RA-
TIONAL. Поскольку тип каждой переменной и константы из-;
вестей в период компиляции, компилятор в состоянии одно-
значно выбрать одну из перекрывающихся операций и правильно
перевести ее на машинный язык. В пакет для рациональных чи-
сел можно было бы включить еще и такую операцию «/» для де-
ления рациональных чисел, которая бы применялась к рацио- i
нальным аргументам и давала рациональный результат.
Чтобы сделать этот пакет действительно полезным инстру-
ментом, требуется добавить еще средства для печати рациональ-
ных чисел и, возможно, для обратного преобразования рацио-
нальных в пару целых. Никаких проблем при добавлении таких
функций не возникает.
Проиллюстрируем абстрактные типы данных еще и на при-,
мере пакета для реализации стека с операциями PUSH (ПРОТОЛ-
КНУТЬ) и POP (ВЫТОЛКНУТЬ) и скрытым представлением
структуры стека. Так как операции присваивания переменным
типа стек и сравнения их на равенство не требуются, желательно,
запретить автоматическое создание этих операций для нового
типа данных. Это делается посредством ключевого слова rest-
ricted.
Пример 1.42. Пример стека J
package ALL_AB0OT_STACKS is
restricted typ'e~STACK is private?
procedure BOSH (E: in ELEMENT; S: in out STACK)1
procedure' BOP (Es out ELEMENT; Ss jn out STACK)s
private ’ • '
type STACK is
record
TOP: INTEGER range 0..1000 := 0;
SPACE; array(1..1000) ELEMENT;
end record; '
end;
В приведенном выше примере запись содержит целое (указа-
тель вершины ,стека) и массив, в котором может разместиться-
L10, Задачи
41
1000 объектов тина ELEMENT. Операции PUSH и POP должны
быть Определены в теле пакета в терминах операций над этим
массивом (здесь они не приведены).
’Реализации стеков массивами скрыта от пользователя. Ее
можно заменить реализацией стеков списками без какого-либо
влияния на пользователя. Однако такое изменение представле-
ния стеков повлияет на структуры данных, создаваемых в моду-
лях пользователя при обработке объявлений объектов типа стек.
Именно по этой причине приватная часть модуля (выделяемая
словом private) рассматривается как часть спецификации па-
кета, а не как часть его тела.
Ада различает логическое сопряжение пакета, определенное
видимой частью модуля, и физическое сопряжение-, последнее со-
держит полную спецификацию пакета, т. е. и видимую, и при-
ватную часть. Логическое сопряжение содержит все, что поль-
зователю необходимо знать при использовании модуля, а физи-
ческое сопряжение включает дополнительную информацию, не-
обходимую компилятору, чтобы обеспечить пользование этим
модулем. Приватная часть рассматривается как часть физиче-
ского сопряжения, потому что компилятору необходима эта ин-
формация для выделения памяти под объекты приватных типов,
создаваемые в программах пользователя (в контексте пользо-
вателя).
1.10. Задачи
Задачи — это программные сегменты для параллельного
программирования. Связанные с задачами средства Ады покажем
на примере задачи, играющей роль «почтового ящика» (почты),
si
S2
Задача MAILBOX
Способна принимать вызовы'
входа SEND от отправителей
и вызовы RECEIVE'
от получателей
R1
R2
Задачиотправители Задачи-получатели
Рис. 1.3. Почта с многими отправителями и получателями.
принимающего сообщения от некоторого количества задач-«от-
правителей» SI, S2, . . ., SM и передающего сообщения несколь-
ким задачам-«получателям» Rl, R2, ..., RN, как показано на
рис. 1.3.
Мы рассмотрим спецификацию и реализацию этой задачи, а
Также средства, необходимые отправителям и получателям для
42
Гл. 1 Обзор языка Ада
связи с почтой. В первом нашем примере предполагается, что
почта в состоянии иметь дело в данный момент времени только
с одним сообщением, которое необходимо передать получателю,
прежде чем станет возможным принять другое сообщение. Во
втором примере рассматривается случай, когда у почты есть
буфер для конечного числа сообщений.
У задач, как и.у пакетов, есть спецификация, которая опре-
деляет ресурсы, доступные пользователю задачи, и тело, кото-
рое определяет реализацию этих ресурсов. К таким ресурсам
относятся входы (entry), позволяющие другим задачам связы- ,
ваться с данной задачей. Следующая спецификация задачи MAIL- j
BOX (ПОЧТА) определяет вход с именем SEND (ПОСЛАТЬ), |
позволяющий другим задачам посылать сообщения данной за- |
даче, и вход с именем RECEIVE (ПОЛУЧИТЬ), позволяющий |
другим задачам получать сообщения от данной задачи.
Пример 1.43. Спецификация задачи MAILBOX |
fcask mailbox is • » вход для посылки данной задаче-
entry SEND (INMAIL: in MESSAGE) ; -- вход для получения ИЗ 4
* entry RECEIVE (OUTMAIL; out MESSAGE)a -- данной задачи I
end s |
i
Входы некоторой задачи можно вызывать из других задач ’
с помощью вызовов входов, синтаксически неотличимых от вызо-
вов процедур. Однако вызовы входов требуют для своего выпол-
нения синхронизации между вызывающей и вызываемой зада-
чами. Вызов входа может быть выполнен в вызывающей задаче
только при условии, что в вызываемой задаче имеется оператор j
приема (accept), готовый принять этот вызов.
Покажем этот механизм синхронизации вызова входа вызы-
вающей задачи и оператора приема вызываемой задачи на при-,
мере тела задачи MAILBOX.
Пример 1.44. Тело задачи
task body MAILBOX is
BUFFER: MESSAGE; -- локальный буфер, может хранить одно сообщение
begin
loop
accept SEND (INMAIL: in MESSAGE) do --принять вызов SEND
- - из другой задачи
BUFFER INMAIL; -- запомнить принятое сообщение
end;
accept RECEIVE (OUTMAIL: out MESSAGE) do -- принять вызов RECEly
OUTMAIL := BUFFER; -- передать сообщение задаче-получателе
end;
end loop;
end MAILBOX;
1.10. Задачи
43
У задачи MAILBOX есть буфер, в котором можно сохранить
сообщения, когда вход SEND принимает вызов из задач-отправи-
телей, и который служит источником сообщения, когда вход
RECEIVE принимает вызов из задач-получателей. Так как со-
общения нужно послать на почту раньше, чем они будут пере-
даны, и так как на почте есть место только для одного сообще-
ния, входы SEND и RECEIVE должны принимать вызовы в стро-
го предписанном взаимоисключающем порядке.
Задачу MAILBOX можно запустить командой ’’initiate MA-
ILBOX;”. В результате эта задача начнет выполняться парал-
лельно с другими задачами. Будет создана локальная перемен-
ная BUFFER, и задача войдет в бесконечный цикл, в котором бу-
дет последовательно принимать вызовы входов SEND и RECEI-
VE из других задач.
Структура программы, которая определяет и запускает за-
дачу MAILBOX, а также несколько отправителей и получате-
лей,. показана ниже.
Пример 1.45. Запуск задач
procedure TASK,EXAMPLE is
спецификации S1,S2..SM
спецификации Rl, R2..RN
•спецификации задачи MAILBOX
begin
initiate SI, S2..SM;
initiate R1,R2..RN;
initiate MAILBOX;
end;
Спецификации задач должны быть расположены в совокуп-
ности объявлений, текстуально доступной из точки запуска
этих задач. Тела задач можно компилировать раздельно (т. е.
они могут быть сегментами компиляции).
Задачи, объявленные в программном сегменте, должны быть
закончены прежде, чем управление покинет этот сегмент. По-
этому, если вызвана процедура TASK-EXAMPLE, выход из
этой процедуры должен ожидать, пока все M+N+Г задач,
объявленных и запущенных в этой процедуре, не закончатся.
Изучим подробнее механизм связи задачи MAILBOX с от-
правителями и получателями.
Выполнение в задаче-отправителе вызова входа SEND из
задачи MAILBOX требует, чтобы как вызывающая задача ожи-
дала выполнения вызова этого входа, так и вызываемая задача
(MAILBOX) ожидала выполнения оператора приема вызова
этого входа, как показано на рис. 1.4.
Если вызов входа появляется рашше, чем вызываемая задача
готова принять его, то вызывающая задача вынуждена ожидать,
44
Гл. 1 Обзор языка Ада
пока в вызываемой задаче управление не достигнет оператора
приема; Если оператор приема достигнут раньше, чем появился s
вызов нужного входа, то этот вызов при его появлении можно
будет обработать немедленно, но пока вызов не появится, вы-
зываемая задача будет ждать на своем операторе приема. Прием
этого вызова требует синхронизации между вызывающей и вы- ' .
зываемой задачами. Когда такая синхронизация достигается,
I I
эызов входа SEND прием входа SEND
-У'-
вызывающая задача* вызываемая задай
Рис. 1.4. Рандеву отправителей и получателей.
говорят, что имеет место рандеву. Рандеву состоит в выполнении
операторов между ключевыми словами do и end в операторе
приема. Эти операторы могут включать передачу информации
между вызывающей и вызываемой задачами, и поэтому, пока они
выполняются, вызывающая задача должна быть приостановлена.
Когда эти операторы выполнены, рандеву считается закончен-
ным и обе задачи могут продолжать выполняться независимо.
Таким образом, некоторый вызов входа SEND приведет к ран-
деву, во время которого исходное сообщение, переданное из
вызывающей задачи через параметр INMAIL, будет запомнено
в локальном буфере. Вызов входа RECEIVE приведет к рандеву,
во время которого это сообщение из буфера будет передано вы-
зывающей задаче через параметр OUTMAIL,
Если вызовы входа SEND возникают чаще, чем они могут
быть приняты, то они помещаются в очередь и принимаются
в порядке «первым пришел — первым обслужен». В общем слу'
чае у каждого входа каждой задачи должна быть очередь для
ожидающих обслуживания вызовов.
Механизм рандеву — основное средство Ады для синхрони-
зации параллельно выполняемых процессов. По сравнению с низ-
коуровневыми механизмами, подобными семафорам, это струк-
турный механизм высокого уровня. Он навязывает дисциплину
взаимодействия между задачами, которая сродни дисциплине
структурного программирования. Это естественный механизм
взаимодействия, хотя прибегать к средствам низкого уровня
иногда может оказаться необходимым, так же как применение опе-
ратора goto иногда необходимо в структурном программировании.
1.11. Отбор среди входов
45
1.11. Отбор среди входов
Оператор приема можно рассматривать как средство, позво-
ляющее задаче ожидать заранее определенного события, о на-
ступлении которого сообщает вызов одного из входов. Однако
во многих приложениях параллельного программирования не-
возможно предсказать порядок, в котором будут возникать
входы, так что желательно позволить задаче отбирать в качестве
своего следующего действия прием одного из нескольких вызо-
вов различных входов.
Рассмотрим, например, задачу ПОЧТА с буфером для п
сообщений, которые можно писать в буфер, если он не полон, и
можно читать с буфера, если он не пуст.
При реализации такой задачи мы хотим выполнять входы
SEND и RECEIVE в порядке их поступления при условии, что
при приеме SEND буфер не полон, а при приеме RECEIVE —
не пуст. Такое'условное выполнение входов можно описать сле-
дующими условными (защищенными) операторами приема.
Пример 1.46. Защищенные операторы приема
Vhen NOT_FULL => accept SEND - - SEND только, когда буфер
- - не полон ч
when NOT_EMPTY => accept RECEIVE - - RECEIVE только, когда буфер
- - не пуст
Мы не можем предсказать порядок, в котором будут возни-
кать вызовы входов SEND и RECEIVE задачи ПОЧТА (с буфе-
ром). Если язык должен обеспечить выполнение входов SEND
и RECEIVE в порядке их возникновения, то’ он нуждается в
средстве для отбора альтернативных операторов приема в за-
висимости от порядка возникновения вызовов входов. Таким
средством служит оператор отбора (select). Выбор между
приемом вызова SEND (при гарантии, что буфер не полон) и
приемом вызова RECEIVE (при гарантии, что буфер не пуст)
можно записать следующим образом.
Пример 1.47. Отбор защищенных 'операторов приема
select
when NOTJFUL-L => accept SEND (,.) . <
or
when NOT-EMPTY => accept RECEIVE
end select;
Выполнение оператора отбора начинается с вычисления пред-
условий (NOT _ EMPTY и NOT_FULL), чтобы определить
множество операторов приема — кандидатов на выполнение
(называемых открытыми операторами приема). Затем прове-
ряется, имеются ли для открытых операторов приема ожидаю-
46
Гл. 1 Обзор языка Ада
щие вызовы входов. Если для одного или более открытых опе-
раторов приема ожидающие вызовы есть, то один из таких опе-
раторов отбирается для выполнения недетерминированноп.
Если же ожидающих вызовов для открытых операторов не ока-
залось, то выполнение приостанавливается до возникновения
вызова входа для одного из открытых операторов.
Следующее ниже тело задачи ПОЧТА (с буфером), по сущест-
ву, представляет собой бесконечный цикл, в котором повто-
ряется выполнение оператора отбора такого же вида, как в пре-
дыдущем примере. Локальные переменные SIZE и COUNT ука-
зывают соответственно размер буфера и число элементов в нем,
а локальные переменные NEXTIN, NEXTOUT указывают ин-
декс буфера для следующего посылаемого (SEND) и получае-
мого (RECEIVE) сообщений.
Пример 1.48. Буферизованная почта
task body MAILBOX is
SIZE: constant INTEGER 20; *-размер буфера
BUFFER: array(1».SIZE) of. MESSAGE;
NEXTIN, NEXTOUT: INTEGER range l-.SIZE := 1;
COUNT: INTEGER range O..SIZE := 0; -число сообщений в буфере
begin
loop
select
when COUNT < SIZE => - - защита, проверяющая, что буфер не полон
accept SEND (INMAIL: in MESSAGE) do - - до приема сообщения
BUFFER (NEXTIN) := INMAIL; - ч критическая секция; должна быть
end; " - - выполнена до возобновления вызывающей задачи
NEXTIN := NEXTIN mod SIZE + 1; -- операторы вне критической
COUNT ;= COUNTtl; --секции; можно выполнять параллельно
- - вызывающей задаче
or
when COUNT > о => - - защита, проверяющая, что буфер не пуст
accept RECEIVE (OUTMAIL: out MESSAGE) do - - до передачи
• • сообщения
OUTMAIL BUFFER (NEXTOUT);
end;
NEXTOUT := NEXTOUT mod SIZE +’ I; операторы, отмечающие,
count ;= COUNT ~ 1; -- что сообщение передано
end select;
end loop;
end MAILBOX;
X) Отбор вызовов входов для открытых операторов приема недетермини-
рован в том смысле, что программы пользователей не должны зависеть от
конкретной стратегии отбора. Однако отбор не обязан быть случайным. Любая
разумная стратегия пригодна; например, система может применять «круговую»
стратегию для реализации недетерминированного отбора вызовов входов для
открытых операторов приема.
1.12. Родовые модули
47
Это тело задачи показывает, что задачи представляют собой
ресурсы, у которых могут быть локально объявленные иденти-
фикаторы (буфера, счетчики и т. п.), йеобходимые для реали-
зации обслуживания, обеспечиваемого этой задачей для своих
пользователей. Когда буфер не пуст и не полон (что является
обычным для буфера размера 20), оба защищенных оператора
приема будут открыты и вызовы SEND и RECEIVE смогут при-
ниматься по правилу «первым пришел — первым обслужен».
Текст программы между do и end в операторе приема иногда
называют критической секцией. Вызывающая задача не может
возобновить выполнение, пока не закончено выполнение крити-
ческой секции соответствующего оператора приема вызываемой
задачи, поэтому критические секции должны быть как можно
короче. Этот пример иллюстрирует также то, что операторы, вы-
полняемые в вызываемой задаче в результате рандеву, могут
включать и операторы критической секции (передающие инфор-
мацию между вызывающей и вызываемой задачами), и операторы
вне критической секции, которые могут выполняться параллельно
с вызывающей задачей.
1.12. Родовые модули
Модули, подобно процедурам, могут быть родовыми. Такие
модули могут иметь параметры и для различных значений ар-
гументов могут при конкретизации давать разных потомков
данного родового модуля.
Излюбленный пример родового модуля — пакет стековых
операций п. В следующем примере как размер стека, так и
тип его элементов — родовые параметры.
Пример 1.49. Родовой пакет
generic (SIZE: INTEGER; type ELEMENT)
package STACK is
procedure PUSH(IN_ELEM:-in ELEMENT);
procedure POP(OUT_ELEM; out ELEMENT);
FULL, EMPTY; exception;
end STACK;
11 Стек — это структура данных, в которой можно запоминать элементы
посредством операций ”push” (протолкнуть) и извлекать их последующими
операциями ”рор” (вытолкнуть). Операция pop извлекает элемент, который
был запомнен в стеке последним, так что информация извлекается в порядке
«последним пришел — первым ушел». Неродовые стековые пакеты требуют
элементов конкретного типа (например, целого) в заранее ограниченном коли-
честве. Родовое определение позволяет ввести сколько угодно стеков, каждый
со своим собственным размером и собственным типом элементов.
48
Гл. 1 Обзор языка Ада
Такое родовое определение служит образцом (заготовкой).
Экземпляры стеков фиксированного размера и типа можно со-
здать с помощью конкретизации.
Пример 1.50. Конкретизация родового пакета
package STACKI is new STACK(100, INTEGER)f
package STACK2 is new STACK(50, INTEGER);
.package STACK3 is new STACK(75, CHARACTER);
package STACK4 is new STACK(W, RATIONAL);
Родовые модули будут полезны для многократного создания
экземпляров пакетов (или задач) даже при отсутствии парамет-
ров. Предыдущий пример показывает, что можно не только
варьировать атрибуты стека, но и создавать много стеков с оди-
наковыми атрибутами.
Возможность создавать множество экземпляров модуля осо-
бенно важна для задач. Немало приложений параллельной об-
работки включают моделирование ситуаций, когда имеется много
экземпляров данного объекта (кораблей, самолетов, радаров).
В таком случае естественно создать в качестве прототипа родо-
вую задачу для всего класса объектов и ввести ее объявлением
следующего вида.
Пример 1.51. Родовая задача без параметров
generic task SHIP is
спецификация ресурсов,
образующих корабль
end SHIP;
Потомков этой родовой задачи можно определить с помощью
операторов конкретизации, например ’’task QE2 is new SHIP;”*
Множество экземпляров задачи можно создать или конкре-
тизацией родовой задачи, как сделано выше, или спецификацией
одномерного массива задач данного типа, называемого семейством
задач. Одномерный массив кораблей можно ввести следующим
образом.
Пример 1.52. Сёмейство задач
_ task SHIP(1**1000) jg
спецификация ресурсов,
образующих корабль
end SHIP;
Такая спецификация дает пользователю возможность ссы-
латься на конкретную задачу, как на SHIP(55) или SHIP(I).
1.13. Блоки
49
Семейство, задач следует рассматривать, в целях экономии
памяти, как потенциальную, а не актуальную совокупность
задач. Выполнение оператора запуска для заданного члена
этого семейства, например initiate SHIP(55), можно рассматри-
вать как команду не только запуска, НО и создания некоторого
экземпляра этой задачи.
Родовой механизм для подпрограмм и модулей в основе своей
одинаков. И в том, й в другом случае Он обеспечивает возмож-
ности как для параметрического варьирования заготовок, так
и Для создания многих Конкретизаций одной заготовки. Однако
способ использования родовых возможностей для модулей и
подпрограмм будет, по всей вероятности, различным.
У процедур и так имеются параметры. Более того, вызов
процедуры — это средство конкретизации этой процедуры для
конкретных значений аргументов. Таким образом, родовые воз-
можности для процедур повторяют (дублируют) многие возмож-
ности, и так обеспечиваемые процедурами. Поэтому полезны
они прежде всего из-за более мощной параметризации (для типов
и подпрограмм), которая может потребовать генерации различ-
ного кода для различных потомков.
У модулей нет параметров и нет другого средства для созда-
ния многих экземпляров, чем родовой механизм. Поэтому в слу-
чае модулей наблюдается гораздо меньше дублирования обычных
возможностей. Применение родовых модулей без параметров для
создания многих потомков модуля-прототипа найдет, вероятно,
широкое применение в больших системах.
1.13. Блоки
Мы завершаем обзор важнейших свойств языка Ада. В остав-
шихся разделах рассмотрим вопросы структуры программ и дру-
гие подробности, необходимые для понимания того, как большая
программа составлена из своих сегментов. Читателю может
показаться элементарным содержание этих разделов и странным,
что они не предшествуют разделам о пакетах, задачах и родовых
средствах. Однако этот материал сознательно помещен в конце
общего обзора языка, чтобы создать минимум сложностей для
тех, кто желает как можно быстрее добраться до его сути. Чита-
тель, интересующийся только особенностями языка, может про-
пустить оставшиеся разделы этого обзора. Их назначение —по-
мочь лучше понять структуру языка, а не вводить в рассмотре-
ние его новые свойства.
В данном разделе вводится понятие блока и рассматриваются
связи между блоками и другими сегментами программы. Это при-
водит к обсуждению раздельной компиляции и правил, опреде-
50
Гл. 1 Обзор языка Ада
ляющих области текстуальной доступности объявленных иден-
тификаторов.
В Аде имеются три вида программных сегментов — подпро-
граммы, модули и блоки. Подпрограммы и модули довольно
подробно были рассмотрены в предыдущих разделах. Они имеют
имена и либо представляют собой отдельные сегменты компиля-
ции без текстуального окружения, либо входят в совокупность
объявлений некоторого объемлющего сегмента программы. В от-
личие от них блоки — это анонимные сегменты программы, об-
ладающие синтаксическим статусом оператора и обязанные по-
являться в одном ряду с операторами некоторого сегмента про-
граммы. Совокупность объявлений блока начинается ключевым
словом declare, а последовательность операторов блока заклю-
чается в скобки из ключевых слов begin . . . end
Пример 1.53. Синтаксис блоков
[declare
последовательность объявлений]
begin
последовательность операторов
end?
- в блоке может быть совокупность
~ объявлений
- и последовательность операторов,
- заключенная в скобки из ключевых
- слов begin, ., end
Блоки можно использовать для связи локальных объектов
с определенной последовательностью операторов. Однако име-
ются еще две причины для помещения последовательности опера-
торов в блок, не относящиеся непосредственно к локальным объ-
ектам.
1. Из блоков, как и из других сегментов программы, нельзя
выйти до тех пор, пока не будут закончены все задачи, объяв-
ленные в этом блоке. Поэтому операторы запуска логически
связанных задач можно поместить в некоторый блок, чтобы быть
уверенным в том, что все эти задачи закончатся до начала ис-
полнения следующих за блоком операторов.
2. С блоками, как и с другими сегментами программы, можно
связать реакцию на исключительные ситуации, или исключе-
ния (см. разд. 1.18).
Таким образом, блоки — это сегменты программы, которые
служат не только для введения локальных объектов, но и для
управления окончанием задач и реакциями на исключительные
ситуации.
Чтобы показать связь между блоками и другими сегментами
программы, рассмотрим сначала следующий простой блок для
обмена значениями X и Y.
1.13, Блоки
51
Пример 1.54. Блоки
declare
•^LOCAL: INTEGER;.
begin
LOCAL := X;
X Y;
Y :=* LOCAL;
end;
- - совокупность объявлений блока,
- - с локальной переменной
* - и последовательностью операторов,
- - которые используют эту переменную
- - и нелокальные переменные X и Y
- - обменивают значения X и Y
* - затем следует выход из блока
Этот блок использует в своем теле и локальную переменную
LOCAL, и нелокальные переменные X и Y. Такие нелокальные
переменные нужно объявить в текстуально объемлющей совокуп-
ности объявлений (точнее, в совокупности объявлений тексту-
ально объемлющего сегмента), как показано в следующем при-
мере.
Пример 1.55. Блок, вложенный в тело процедуры
procedure BLOCKS is.
X,Y; INTEGER; •
begin
X :== 5;
Y :« 7;
declare
LOCAL: INTEGER;
begin
LOCAL := X;
X Y;
Y := LOCAL;
end;
- - затем делается что-то полезное
end BLOCKS;
- - процедура с именем BLOCKS
- - с локальными переменными X, Y
- - и последовательностью операторов
- - которая инициализирует X
- - затем инициализирует Y
- - затем вход во вложенный блок
- - с локальной переменной
- - и последовательностью операторов,
• - которая использует LOCAL
- - и нелокальные переменные X и Y
• - чтобы обменять значения X и Y
- - затем выход из блока
- - и, наконец, выход из процедуры
Такое непосредственное (in-line) вхождение блоков с локаль-
ными переменными в тело процедуры затрудняет понимание
этого тела. По этой и по другим причинам часто использовать
такие вхождения блоков в процедуры нежелательно. Блок,
обменивающий значения двух переменных, можно заменить про-
цедурой с параметрами X и Y, как показано в следующем при-
мере.
52
Гл. 1 Обзор языка Ада
procedure NO_BLOCKS is
I/Js INTEGER;
procedure SWAP(X,Y: in
LOCAL; INTEGER;
begin
LOCAL := X;
X :« Y;
Y := LOCAL;
’ end SWAP;
begin
I ;=» S;
•J :=> 7;
SWAP(I,J);
— делает что-то полезное
end;
Пример 1.56. Замена блока процедурой
- - процедура с именем NO__BLOCfcj
- - с локальными переменными
out. integer) is... . и вложенным объявление.
' - процедуры с локальной переменной ж
- - и* последовательностью операторов
- - которая использует LOCAL
- - и параметры X, Y
• - чтобы обменять значения X и Y
- - затем выход из процедуры SWAP
- - это тело процедуры NO_BLOCKS
• - инициализирует переменные I, J
- - вызывает процедуру для обмена I, J
-« затем окончательный выход
Тело процедуры NO.BLOCKS читать намного легче, чем -
тело процедуры BLOCKS. Более того, процедуру S.WAP можно
вызывать из разных точек этого тела с разными аргументами..
Таким образом замена блока процедурой облегчает чтение и
повышает гибкость программы.
Замена -явно выписанного блока вызовом процедуры приво-
дит к дополнительным накладным расходам, которые в опреде-
ленных критических ситуациях могут оказаться неприемлемыми.
Устранить эти расходы можно с помощью указания (pragma),
что подпрограмма должна быть открытой (in-line).
Пример 1.57. Указание INLINE
pragma INLINE;
Указания не влияют на смысл программы, но сообщают не-
которую информацию компилятору. Указание INLINE, появ-
ляясь в совокупности объявлений некоторого определения под-
программы, предлагает компилятору заменять- каждый вызов
этой подпрограммы на ее расширенное (т. е. настроенное на
значения аргументов вызова) тело. Истинный эффект указания
зависит от оптимизационных возможностей компилятора. Он
может полностью игнорировать это указание, и все останется
правильным.
1.14. Раздельная компиляция
Читатели могут возразить, что тело процедуры NO_ BLOCKS
было сделано легче читаемым за счет усложнения ее совокуп-
ности объявлений. Можно еще больше облегчить чтение этой
1.14. Раздельная компиляция
53
поцедуры, объявив процедуру SWAP раздельно компилируе-
мом сегментом (separate compilation unit).
МЫ-’*
Пример 1-58. Раздельно компилируемое объявление процедуры
procedure SEPARATE_SWAP is,
•"JZjs INTEGER;
procedure SWAP(X,Y: in out INTEGER) is separate; -- SWAP
begin" ' ' - • компилируется раздельно
~l7= 5;
J := 7;
swap (i, J);
- - делается что-то полезное
end;
Текст процедуры, объявленной в контексте некоторого про-
граммного сегмента раздельно компилируемой, должен начи-
наться ограничением видимости (restricted clause), в котором
указывается тот программный сегмент, в который эта процедура
считается текстуально встроенной, а затем ключевое слово se-
parate. В телах таких процедур можно пользоваться идентифи- ~
катерами, объявленными в текстуальном окружении объявления
процедуры (скажем, I и J в приведенном выше примере). Эти
процедуры должны компилироваться после программных сег-
ментов, в которых они объявлены, и заново компилироваться
при каждом изменении ^объемлющего программного сегмента.
Такие процедуры зависят от своего текстуального окружения
и этим резко отличаются от рассматриваемых в последующих
разд. 1.16 и 1.17 независимых раздельно компилируемых про-
граммных сегментов.
Пример 1.59. Реализация раздельно компилируемой процедуры
restricted (SEPARATE_SWAP)
separate..procedure SWAP(X,Y: in out INTEGER) JLs
temps Integer;
begin
TEMP s* X;
X s« Y;
Y := TEMP.;
end SWAP;
Объявление, завершаемое ключевыми словами is separate
(’’раздельно компилируемая”), сообщает всю информацию, каса-
ющуюся синтаксической правильности вызовов этой процедуры,
и позволяет компилятору проверять правильность таких вызо-
вов. Программам, использующим раздельно компилируемые
процедуры, не нужно учитывать их реализацию. Более того,
изменения в реализации, не влияющие на внешнюю специфика-
цию, наверняка не потребуют изменений в программных сегмен-
54
Гл. 1 Обзор языка Ада
тах, использующих раздельно компилируемую процедуру. Тот
факт, что изменения в реализации, не влияющие на специфика-
цию, оказываются локализованными, очень облегчает сопровож-
дение больших программ. Реализацию процедуры можно изме-
нять даже во время работы использующей ее программы без
какого-либо влияния на другие части последней. Таким образом
можно модульно вносить в программу изменения, учитывающие
преимущества новой конфигурации аппаратуры или оптимиза-
ции машинного языка.
1.15. Область действия идентификаторов
Область действия идентификаторов — это часть текста, где
сказывается влияние объявления этого идентификатора. Для
идентификатора, объявленного в совокупности объявлений дан-
ного программного сегмента, область действия распростра-
няется от места объявления до конца этого сегмента. В проце-
дуре OUTER из следующего примера имеются две локальные
цёлые переменные А и В, а также вложенная процедура INNER
с повторным объявлением В.
Пример 1.60. Область действия идентификаторов
процедура с именем OUTER
с целой переменной А
и целой переменной В
и вложенной процедурой INNER
где В переобьявлена как логическая
у INNER последовательность операторов
присваивающая А целое значение
и логическое внутренней В
ссылающаяся иа внешнюю В через OUTER.B
у OUTER последовательность операторов,
которая присваивает А целое значение
неправильное присваиваний4—
может быть Обнаружено компилятором
и присваивание внешней В
procedure OUTER is
1 к At INTEGER := 0} * -
B: INTEGER := A+l; - •
i 1 procedure INNER is - -
B; BOOLEAN; - -
begin - -
кв A := 1; В TRUE; - -
§ S л OUTER.В Ml; - «
1 end;
о ь begin *• -
g A := 2} « —
ID О В s== TRUE;
В s« A+l; » -
' 1 r en^;
В этом примере В объявлена как целая переменная во внеш-
ней процедуре и как логическая переменная во внутренней про-
цедуре. Неуточненная ссылка на В во внутренней процедуре
связывается с внутренним объявлением В, так что ”В = TRUE”
— допустимый во внутренней процедуре оператор. Вместе с тем
на целую переменную В можно ссылаться во внутреннем блоке
посредством уточненного (составного) имени OUTER.В, так что
оператор 'XDUTER.B :=== А+1” допустим. Область действия
1.15. Область действия идентификаторов
55
внутреннего объявления В не распространяется на последова-
тельность операторов внешней процедуры, поэтому оператор
„В ;= TRUE;” во внешней процедуре недопустим.
Из этого примера также видно, что внешнее объявление В,
находясь в области действия А, может пользоваться значением А
для инициализации В. Перестановка объявлений А и В была бы
недопустимой, так как объявление В оказалось бы вне области
действия нужного объявления переменной А и нельзя было бы
воспользоваться значением А для инициализации В.
1.16. Ограниченные сегменты программы
Обычно границы программного сегмента действуют подобно
мембране: идентификаторы, объявленные в объемлющих про-
граммных сегментах, известны внутри этого сегмента, но иденти-
фикаторы, объявленные внутри, не известны вне сегмента. По
этой причине глубоко вложенные программные сегменты имеют
доступ к нескольким текстуально объемлющим слоям своего
окружения, что в некоторых случаях может приводить к непри-
ятностям.
Такого рода свободный доступ к текстуально объемлющему
окружению можно запретить с помощью ограничения види-
мости (restricted clause). Употребленное непосредственно перед
программным сегментом ключевое слово restricted делает тек-
стуальное окружение недоступным из этого сегмента.
Пример 1.61. Совершенно недоступное текстуальное окружение
restricted procedure Р (parameters) is,
- - объявления и операторы, в которых нельзя ссылаться ни на какие
. >• - идентификаторы, объявленные в текстуальном окружении Р
end Р;
В общем случае ограничение видимости данного программного
сегмента может содержать список видимости нелокальных про-
граммных сегментов, доступных внутри ограниченного програм-
много сегмента. Правила, определяющие, какая часть окруже-
ния становится видимой, когда некоторый сегмент появляется
в списке видимости, зависят от взаимного расположения в тексте
программы ограниченного сегмента и сегмента из списка види-
мости.
Рис. 1.5 иллюстрирует три варианта возможного расположе-
ния сегмента из списка видимости и ограниченного сегмента.
Сегмент'из списка может быть текстуально объемлющим для Р
(подобно Р1), может входить в его текстуальное окружение, но
не быть объемлющим (как М) и может быть независимым раз-
дельно компилируемым модулем (как Q).
56
Гл. 1 Обзор языка Ада
Если Р текстуально вложена в Р1, то появление Р1 в списке
видимости Р открывает доступ к текстуальному окружению?
до Р1, но не дальше. Можно представлять себе Р как бы погру-
женной в туман, Позволяющий все видеть в пределах Р1, но до-
статочно густой, чтобы вне Р1 ничего не было видно.
Если М входит в текстуальное окружение Р, но не объемлет
Р, ТО появление М в списке видимости Р обеспечивает доступ к
Программный сегмент OUTER
объемлет Pl, М, Р, но не Q
Модуль М
доступен из Р, но не объемлет Р
. пррграммнь1й сегмент Р1
текстуально объемлет Р
“restricted (Р1/м,Q)
PEQgedure ₽(•«’)•*
программный сегмент Р
СО СПИСКОМ видимости
шХ<2
модуль Q
независимый раздельно '
компилируемый
библиотечный модуль,
ВИДИМЫЙ из Р
Рис. 1.5. Взаимное расположение программных сегментов.
вычислительным ресурсам М, но не к другим идентификаторам из
текстуального окружения М.
Если Q — независимый раздельно компилируемый модуль,
то его появление в списке видимости Р обеспечивает для Р до-
ступ к вычислительным ресурсам Q.
Самое первое имя в списке видимости может, но не обязано
быть именем объемлющего программного сегмента. Остальные
имена (если они есть) должны быть именами модулей, располо-
женных вне ограничиваемого сегмента и вне объемлющего его
сегмента (если самый первый элемент списка — объемлющий сег-
мент). Таким образом, сегменты, которые становятся доступ-
ными (видимыми) за счет списка видимости,— это в сущности та-
кие модули, которые определяют скорее совокупность ресурсов,
чем отдельные ресурсы.
Это правило иллюстрируется следующим примером ограни-
ченной процедуры Р, вложенной в процедуру Р1, которая в свою
очередь вложена в процедуру OUTER, содержащую пакет М.
1Л7. Ограниченные сегменты компиляции и библиотеки
57
Пример 1-62. Объемлющие и
менты
procedure OOTER is
Is INTEGER;
package M is
• спецификация g тэдо M
procedure Pl is
J: 'INTEGER;
restricted (P1,M)’
procedure P is
feegjn
J : = 5;
Щ;
I 5;
end;
операторы Pl
операторы процедуры OUTER
необъемлющие программные сег-
- - I не доступно в Р
- - М доступно в Р
- - Р1 текстуально объемлет Р
- - J доступнд р Р-
- - ограничение видимости для Р
- - видимость из Р ограничена Р1 и М
- - правильно, можно видеть в Р1
- - правильный рекурсивный вызов Р1
- - неправильно: видно М, ио не I
В этом примере переменная J объявлена в Р1 и видима в Р,
а переменная I объявлена в OUTER, но не в М и поэтому неви»
дима в Р.
1.17. Ограниченные сегменты компиляции
и библиотеки
У сегментов компиляции нет явного текстуального окруже-
ния, так что для них не имеют смысла ограничения видимости,
связанные е таким окружением. Однако имеется неявное окру,
жениё, связываемое с сегментом компиляции, и видимостью
в этом окружении также можно управлять с помощью ограниче-
ний видимости. В это окружение входят:
1. Предопределенное окружение, включая предопределенные
типы и другие идентификаторы, перечисленные в пакете STAN-
DARD в приложении С руководства по языку Ада.
2. «Библиотечное» окружение сегмента компиляции, которое
в общем случае содержит пакет ввода-вывода, пакет математи-
ческих подпрограмм и другие стандартные библиотечные сред-
ства.
3. Набор независимых сегментов компиляции, определенных
пользователем для решения его текущих задач.
Ограничения видимости не влияют на видимость идентифика-
торов из предопределенного окружения. Идентификаторы, по-
добные JNTEGER, могут быть переопределены, например "type
INTEGER is SHORT_INTEGER;”. Однако и в этом случае
можно использовать идентификатор в исходном смысле посредст-
вом составного имени STANDARD.INTEGER.
58
Гл. 1 Обзор языка Ада
Чтобы сделать видимыми в определяемом пользователем сег-
менте компиляции библиотечные сегменты или другие сегменты
пользователя, нужно поместить их в список видимости этого
сегмента. Так, функции ввода-вывода GET и PUT на самом деле
определены в библиотечном пакете ТЕХТ_Ю, поэтому исполь-
зующие их сегменты должны содержать имя этого пакета в своем
списке видимости.
Пример 1.63. Связь сегментов компиляции
restricted (ТЕХТ_Ю) - - библиотечный пакет TEXT_____10 доступен в
procedure SIMPLE_ADD is - - процедуре SIMPLE__ADD
use4TEXT_IO; * - его ресурсы доступны по простым именам
X,Y,Z: INTEGER;
begin
GET (X); - - процедуры GET и PUT объявлены в ТЕХТ_ДО *
GET(Y);
Z := X+Y;
PUT(Z) ;
end;
Пример 1.1в начале этой главы на самом деле был неполной
программой, которая могла бы вызвать сообщение компилятора
о том, что GET и PUT не объявлены. Только что приведенная
программа — полная версия этого примера; имея подходящие
данные, ее можно выполнить.
Определенные пользователем сегменты компиляции имеют
в неявном окружении точно такой же статус, что и библиотечные
Рис. 1.6. Эффект компиляции сегмента.
сегменты. Поддерживающая язык операционная система должна,
вообще говоря, содержать для каждого пользователя свой биб-
лиотечный файл и обновлять его при каждой компиляции сег-
мента. Поэтому при каждой компиляции такого сегмента тре-
1.18. Исключения
59
буется иметь на входе его текст и соответствующий библиотеч-
ный файл, а на выходе получается оттранслированный сегмент
и обновленный файл (рис. 1.6).
Чтобы обеспечить связь сегментов компиляции в программе
пользователя, нужно помещать используемые сегменты в списки
видимости использующих сегментов.
Если имя сегмента С1 входит в список видимости сегмента С,
то в период компиляции С спецификация сегмента С1 уже должна
быть скомпилирована. Зависимость, связанная с ограничениями
видимости, должна определять последовательную (т. е. без цик-
лов) иерархию, и компилировать следует в таком порядке, чтобы
используемые сегменты компилировались раньше использую-
щих.
Однако эта зависимость касается только спецификаций про-
граммных сегментов. Так что если С1 — пакет, то специфика-
цию С1 следует компилировать раньше любого сегмента компи-
ляции, в список видимости которого входит С1, но тело этого
пакета можно компилировать и компилировать заново когда
угодно, не оказывая влияния на компиляцию использующих
С1 сегментов.
1.18. Исключения
Исключения (exceptions) — это средство для необычного за-
вершения (окончания) программных сегментов. Обычно блоки
и процедуры заканчиваются выполнением последнего оператора
их тела, а функции — выполнением оператора возврата. Исклю-
чения — это динамическое средство для выхода из программного
сегмента, позволяющее обходить механизм нормального завер-
шения.
Исключения могут быть предопределенными или опреде-
ляться пользователем. Примером предопределенного исключе-
ния может служить исключение INDEX_ERROR (НЕПРА-
ВИЛЬНЫЙ ИНДЕКС, т. е. индекс вышел за границы массива).
Так как это исключение — предопределенное, то предусмотрены
выполняемые системой «по умолчанию» действия в случае непра-
вильного индекса. Однако эти системные действия могут быть
заменены определяемыми пользователем действиями по обра-
ботке ошибки в индексе в конкретном месте его программы.
Ниже показано, как исключения можно объявлять, возбуж-
дать и «обрабатывать» (с помощью реакции на исключения).
Объявление исключений напоминает объявление переменной
некоторого типа.
60 Гл, 1 Обзор языка Ада
Пример 1.64. Объявление исключений
OVERFLOW г UNDERFLOW: exception; ' - - объявлено два идентификатора
- - исключений
SINGULAR: exception; - - и еще один
Возбуждать исключения можно с помощью ключевого слова
raise.
Пример 1.65. Возбуждение исключений
determinant « о then -- если детерминант нулевой, то
SINGULAR; " • - возбуждается исключение SINGULAR
end if;
Возникающие исключения обрабатываются реакцией на иск-
лючения. Определение этих реакций можно располагать только
после всех операторов подпрограммы, модуля или блока за клю-
чевым словом exception (исключение). Каждая конкретная ре-
акция вводится ключевым словом when (когда), за которым сле-
дует название исключения, а затем последовательность обраба-
тывающих это исключение операторов.
Пример 1.66. Обработка исключений
exception - - реакция на исключение SINGULAR
when SINGULAR => - - должна быть в самом Коцце
РОТ' ("MATRIX IS SIMGUIAR"); --блока, подпрограммы или модуля
Возбуждение исключений подобно вызову процедуры без
параметров, а определение реакции на исключение подобно спе-
цификации процедуры без параметров. Однако способ связи
реакции с возбужденным исключением отличается от соответст-
вующего способа для процедур.
Когда некоторое исключение возбуждается во время выпол-
нения некоторой подпрограммы, то определение соответствую-
щей реакции ищется сначала внутри этой подпрограммы, затем
в окружении вызова этой подпрограммы, затем в последователь-
ных динамически предшествующих программных сегментах. Та-
кой динамический критерий поиска принципиально отличается оТ
критерия для процедур, опирающегося на статическую связь
процедуры с ее вызовом.
Динамический способ связи реакций с исключениями иллЮ*
стрйруется следующей процедурой Р, у которой есть одна реак-
ция (первая реакция) в теле главной процедуры Р, и другая
реакция в теле процедуры R.
Пример 1.67. Динамический поиск реакции на исключение
1.18. Исключения
61
,rocedure & is
"SINGULARS exception;
procedure £ is
begin
.. объявление исключения SINGULAR в P
if DETERMINANT « 0 then
raise SINGULAR;
end if;
* - место в Q, где возбуждался
• - исключение SINGULAR
etid 2'
procedure R is,
begin
exception
when SINGULAR
— second handles for SINGULAR
end r;
begin. -- J?
exception
when, SINGULAR *> -
— first hahdler for SINGULAR
end P;
-» вызов Q внутри R
- - если исключение возникает прж
«- этом вызове, то выбирается
- - вторая реакция для SINGULAR
вызов QB теле самой Р
*- если исключение возникает прк
* - этом вызове Q, то выбирается
-- первая реакция
Если в этом примере исключение SINGULAR возбуждается
при вызове Q внутри R, то поиск производится сначала внутри
Q, затем реакция ищется внутри R, так что будет найдена вто-
рая реакция. Если же SINGULAR возникает при вызове Q
в теле сам&й Р, то выбирается первая реакция.
Обработка исключений полностью отличается от исполнения
процедур в части, касающейся возврата к месту вызова. Исклю-
чение трактуется как ошибка. Поэтому обычно покидается как
место, где Ойо возникло, так и место, где оно обработано. Реак-
ция на исключение—это средство необычного окончания той под-
программы, где исключение обработано. Поэтому в приведенном
выше примере, если исключение SINGULAR возникло бы внут-
ри Q (внутри R), это привело бы к поиску реакции на это исклю-
чение, чтобы закончить Q, а затем к выполнению реакции на
SINGULAR внутри R вместо нормальной последовательности
Действий, заканчивающих R. Только после окончания реакции
на исключение управление смогло бы вернуться в программу,
вызвавшую R.
Такой процесс окончания подпрограммы из-за невозмож-
ности найти в ней реакцию на исключение и возбуждение этого
Исключения заново в вызвавшей программе называется распро-
странением исключения. Таким образом, возникшее в данной
подпрограмме исключение распространяется назад по динамиче-
ской цепи вызовов до подпрограммы, в которой найдется реак-
62
Гл. 1 Обзор языка Ада
ция на возникшее исключение. Это исключение затем обрабаты-
вается в программном окружении найденной реакции, что со-
ставляет необычное окончание этой подпрограммы и приводит
к возврату в точку ее вызова.
Кроме исключений, определяемых пользователем, имеются.
предопределенные исключения, реакции на которые заранее
определены в системе. Некоторые предопределенные исключе-
ния, например DIVIDE_ERROR или INDEX_ERROR, воз-
никают в системе автоматически (когда делается попытка де-
лить на нуль или получить доступ к несуществующему элементу
массива). Другие предопределенные исключения (например,
FAILURE, возникающее в задаче Т1 при ошибке задачи Т2)
должны явно возбуждаться пользователем, чтобы активизи-
ровать системную реакцию. Полный список предопределенных
исключений приведен в руководстве по языку (разд. II).
Возникновение исключений можно подавить. Например, если
при особо быстрых (требующих минимума времени) расчетах
желательно не тратить время на проверку ошибок в индексах
в данном программном сегменте, то этого можно достигнуть,
поместив среди объявлений сегмента следующее указание.
Пример 1.68. Подавление неявных исключений
Pragma SUPPRESS (INDEX.EBKOR);
Это указание позволяет компилятору опустить при компиля-
ции этого сегмента части объектной программы, выполняющие
проверку индексов, однако компилятор не обязан следовать та-
кому указанию. И указание SUPPRESS, и рассматривавшееся
ранее указание INLINE лишь предлагают компилятору приме-
нить некоторую оптимизацию, но он может их игнорировать.
Указание SUPPRESS следует применять с осторожностью как
потому, что оно может привести к неуправляемому поведению
программы при возникновении подавленного исключения, так
и потому, что программа с подавленными исключениями может
вести себя по-разному для разных компиляторов.
ГЛАВА 2
ОСНОВНЫЕ ЧЕРТЫ ЯЗЫКА
2.1. Введение
Теперь, имея обзор Ады в целом, мы готовы к более деталь-
ному исследованию отдельных черт языка. В этой главе рас-
сматриваются выражения, операторы, управляющие структуры
и подпрограммы Ады. В гл. 3 мы исследуем средства описания
данных. В гл. 4 рассматриваются пакеты, а гл. 5 будет посвя-
щена задачам.
В начале главы мы кратко рассмотрим составляющие про-
граммы «низкого уровня» — множество символов и лексемы
Ады, затем перейдем к выражениям, операторам и управляю-
щим структурам и в заключение обсудим составляющие «высо-
кого уровня» (функции и процедуры).
2.2. Множество символов и лексемы
Основное множество символов Ады состоит из 55 символов,
включающих 26 букв, 10 цифр, пробел и следующие специальные
символы:
" # & ’ ( ) * + , J
Имеется также расширенное множество символов, включаю-
щее помимо перечисленных знаков строчные буквы латинского
алфавита и следующие специальные символы:
1 $ % ? @ [ \ ] ~ - { } л,
Всякая реализация Ады гарантирует наличие основного
множества символов. Расширенное множество обеспечивает боль-
шие выразительные возможности, но его наличие не гаранти-
руется. Определены стандартные правила транслитерации для
представления символов расширенного множества средствами
основного набора.
64
Гл. 2. Основные черты языка
Элементы программы низшего уровня, имеющие лингвисти-
ческий смысл, называются лексемами. В число лексем Ады вхо-
дят идентификаторы (такие, как ALPHA,А), числа (например,
365, 3.65, 3.65Е2), строки (например, ”1 AM A STRING”), огра-
ничители (такие, как ;, > =) и зарезервированные слова (на-
пример, for, task и begin).
Идентификаторы должны начинаться с буквы и могут содер-
жать буквы, цифры и символ подчеркивания (как, например,
в 1_53_52_6). Числа могут быть целыми (они не содержат
десятичной точки) или приближенными (такие числа содержат
десятичную точку и (или) символ порядка, или экспоненты, Е).
Числа могут для наглядности включать символ подчеркивания
(например, 1_000_000_000). Строки символов заключаются
в кавычки. Ограничители представляют собой отдельные сим-
волы, такие, как 4-, или пары символов, как знак присваива-
ния := .
Зарезервированные слова не могут использоваться в про-
грамме на языке Ада в качестве идентификаторов, поэтому при
написании программы их не нужно как-то специально отмечать.
Одндко для наглядности в этой книге зарезервированные слова
всюду выделены жирным шрифтом. м Шестьдесят два зарезерви-
рованных слова Ады перечислены в табл. 1.
Таблица 1
Список зарезервированных слов.
abort digits. 2 initiate pragma type
accept do is. private
access procedure use
ш."' <01 se j-OQP
and els i f raise
array end mod range , while
assert entry record
at exception new* renames xor
exit not restricted
begin null ' Return
body, ’ for - reverse
function of ‘
case dr select
constant generic others separate
gotb out subtype
declare
delay if package task
delta in packing then
1> В текстах программ зарезервированные слова подчеркнуты.— ПриМ<
перев.
2.2. Множество символов и лексемы
65
Пробелы не могут употребляться внутри лексем, но между
лексемами они используются свободно, не оказывая никакого
влияния на смысл. По крайней мере один пробел должен разде-
лять такие лексемы, как идентификаторы и числа, в случаях,
когда отсутствие пробела может вызвать неоднозначность. Од-
нако, если неоднозначности не возникает, использование пробе-
лов необязательно (например, в случае 3+4*5).
Комментарии начинаются с двух знаков минус подряд и за-
канчиваются вместе с концом строки. Они не оказывают влияния
на смысл программы.
Пример 2.1. Комментарии
- - коментарий может помещаться на любой строке
• * - после любой лексемы
* - они могут также появляться как самостоятельные
- - примечания, занимающие целую строку
Заметьте, что в приведенных выше примерах буквы — строч-
ные (для удобства чтения), так что комментарии написаны в рас-
ширенном, а не в основном множестве символов. Как правило,
мы будем пользоваться символами основного множества, но в слу-
чаях, когда это может облегчить чтение, без колебаний будем
употреблять символы расширенного набора.
Указания служат для того, чтобы передавать некоторую ин-
формацию компилятору. Они подобны комментариям в том от-
ношении, что, вообще говоря, не влияют на действия, выполняе-
мые программой. Однако указания могут существенно влиять
на информацию, выдаваемую пользователю при компиляции или
выполнении программы.
Пример 2.2. Указание, обеспечивающее дополнительную
информацию
£ragnta LIST (ON); - - обеспечивает распечатку программы для пользователя
Некоторые указания, такие, как приведенное выше, опреде-
ляют обязательные для компилятора действия. Другие, как
в следующем примере, являются советами компилятору, которые
могут быть, а могут и не быть реализованы.
Пример 2.3. Указания об оптимизации
Pragma TNLINE? - - заменять вызовы подпрограммы макрорасширением
pragma OPTIMIZE (SPACE); * - реализовать, минимизируя объем
- - используемой памяти
3
Ns 56
66 Гл. 2. Основные черты языка
Оба этих указания предлагают приемы оптимизации, не из-
меняющие функциональных свойств программы, их реальный
эффект в значительной степени определяется сложностью ком-
пилятора.
Следующие указания вызывают действия, которые выпол-
няются во время компиляции и могут повлиять на функциональ-
ные свойства программы.
Пример 2.4. Указания, изменяющие функциональные свой-
ства
pragma INCLUDE ("name”); * - текстовый файл с заданным именем
') - - вставить в программу на место указания
pragma SUPPRESS (имена исключительных ситуаций); - - проверки
- - перечисленных исключительных ситуаций при выполнении
- - данной компоненты программы могут быть (хотя и
>- - не обязательно) заблокированы
Более полное описание доступных в языке указаний приве-
дено в приложении В к справочному руководству по языку.
2.3. Простые выражения и оператор присваивания
В число лексем, которые могут встретиться в выражении,
входят константы, переменные, знаки операций и ограничители.
Например, выражение ”2* (1+3)” содержит константы 2 и 3, пере-
менную I, знаки операций * и + и ограничители ( и ).
При вычислении выражения вырабатывается значение, ко-
торое может быть присвоено переменной оператором присваи-
вания.
Пример 2.5. Операторы присваивания
I : - 3; - - присвоить значение константы 3 переменной I
J := 2* (1+3); --вычислить 2* (1+3) и присвоить результат J
К ;= J*I**2; - - если I = 3 и J = 12, то ~ 12*9 = 108’
С каждой константой, переменной, с каждым выражением
в Аде связан тип, который может быть определен во время ком-
пиляции. Все выражения в приведенном примере — целого типа,
точно так же целый тип имеют и переменные, которым присваи-
ваются их значения. В последующем примере эти операторы вхо-
дят в процедуру, в которой явно указано, что переменные I, J
и К — целые.
Пример 2.6. Операторы и описания
2.3. Простые выражения и оператор присваивания
67
procedure INTEGERS is - - процедура, названная INTEGERS,
I, J /К: INTEGER; - - с тремя описанными целыми переменными
begin * - и последовательностью операторов,
I Т= 3; - - присваивающая этим переменным значения
j := 1+1;
К := J*I**2;
end INTEGERS;
Константы плавающего типа можно отличить от целых благо-
даря тому, что они содержат десятичную точку и (или) символ Е.
Пример 2.7. Константы плавающего типа
3.65 - - константа плавающего типа *
3.65Е2 - - константа плавающего типа со значением 365.0
IE-2 v * - константа плавающего типа со значением .01
Следующая процедура иллюстрирует объявление и исполь-
зование переменных плавающего типа.
Пример 2.8. Переменные плавающего типа
х
У
Z
end
- - процедура, названная FLOATING,
с тремя объявленными переменными плавающего типа
и последовательностью операторов,
присваивающая этим переменным значения
значение Y становится равным 3.66
- - вы добираетесь и до значения Z
procedure FLOATING,is
X,Y,Z: FLOAT;
begin
3.65;
:= X+1E-2
: = X*Y**2
FLOATING;
Такие операции, как + и *, требуют, чтобы оба операнда
были одинакового типа, так что выражения с операндами одно-
временно и целого, и плавающего типов вроде ”1+3.5” ошибочны.
Точно так же оператор присваивания требует, чтобы выражение
справа имело тот же тип, что и переменная слева.
Пример 2.9. Употребление целого и плавающего типов в
одном выражении
procedure MIXEDJTYPES is *- - процедура иллюстрирует смешение типов
1,J: INTEGER; - - описание целых
xzY: ГЬО2$Г; - - и плавающих переменных
begin'
I := 3.5; - - ошибка: присваивание целой переменной значения
- - плавающего типа
. X := 1+1; - - ошибка: присваивание переменной плавающего типа
- - значения выражения целого типа
X х+1; - - ошибка: смешение типов в выражении
X := X+FLOAT(1); г* правильное преобразование целой
- - константы к плавающему типу
X ;= FLOAT (I+J) ; - - правильное преобразование значения
* - - выражения к плавающему типу
I : = INTEGER (3.65); - - при преобразовании отбрасывается дробная
- - часть; I получает значение 3
MIXED TYPES;
3*
68
Гл. 2. Основные черты языка
Этот пример показывает, что имена типов INTEGER и FLOAT
могут использоваться как функции преобразования, которые пре-
образуют значения к целому и плавающему типу соответственно.
К числовым операндам в Аде могут применяться не только
арифметические операции, которые получают аргументы некото-
рого числового типа и вырабатывают значение того же типа, но
также операции отношения (такие, как «<»), получающие аргу-
менты числового типа и вырабатывающие значение TRUE или
FALSE.
Пример 2.10. Отношения в выражениях
3 <4 * - значение выражения TRUE
4.5 < 3.5 г - значение выражения FALSE
3<4.5 - - ошибка: нельзя использовать одновременно целые
— и плавающие операнды
Х< У - - TRUE, если X и Y одного типа и если значение X
- - меньше значения Y
TRUE и FALSE являются константами логического типа
(BOOLEAN) и могут быть значениями переменных логического
типа. Логические операции and (И), or (ИЛИ), хог (исключающее
ИЛИ) и not (НЕ) имеют операнды и вырабатывают результат
логического типа.
Пример 2.11. Логические выражения
TRUE, FALSE - - две логические константы
А : = TRUE; * - присваивание логической переменной
В := X<Y; '• - логическое значение отношения X < Y присваивается В
С :=* A-and В; * “ TRUE, если таковы же значения и А, и В
Имеется шесть уровней старшинства операций, которые могут
встретиться в арифметических или логических выражениях; они
изображены в табл. 2.
Эти шесть уровней старшинства отражают обычные соглаше-
ния при записи математических выражений, за исключением
Таблица 2
Арифметические и логические операции и операции отношения.
Возведение в степень:
Мультипликативные операции:
Унарные операции:
Аддитивные операции:
Операции отношения:
Логические операции:
* % - - высшее старшинство
« / mod
-)-not
+ -
= /=<<=>>=
and, ’ or, хог - - низшее старшинство
2.4. Условные операторы
69
некоторых тонкостей использования арифметических и логиче-
ских операций в одном выражении.
Пример 2.12. Смешение арифметических и логических выра-
жений
Х+1 > X - - означает (X + 1) > Y
Х+1 > Y or X = 0 - - означает <(Х + 1) > Y) or (X = 0)
X > V or not (X = 0) - - not старше, чем =, поэтому запись такова
В последнем примере было бы ошибкой опустить скобки, по-
скольку notX=0 интерпретировалось бы как (notXj=0.
Мы не рассмотрели лишь одну операцию из табл. 2 — опера-
цию mod, которая получает целые операнды и вырабатывает в
качестве значения остаток от деления первого операнда на вто-
рой. Так, значение 20 mod 7 равно 6, а значение 14 mod 7 рав-
но 0.
2.4. Условные операторы (операторы if и case)
Оператор присваивания — это основной механизм низкого
уровня для выполнения вычислений. Всякое вычисление обычно
требует выполнения последовательности операторов присваива-
ния. Порядок и число выполняемых операторов регулируются с
помощью управляющих структур.
Условные операторы позволяют динамически, в процессе вы-
полнения, осуществлять выбор между альтернативными вариан-
тами действий. Например, следующий оператор if, присваиваю-
щий переменной Z большее из значений X или Y, вызывает
динамический выбор между выполнением двух операторов при-
сваивания в зависимости от значений X и Y.
Пример 2.13. Условный оператор с двумя ветвями
if X < У then
Z := Y;'
else
Z : = X;
end if;
> - если условие X < Y выполняется,
•- - то присвоить Z значение Y
- иначе
* - присвоить Z значение X
* • - явное завершение оператора
Этот условный оператор имеет две ветви, которые можно на-
звать «часть then» и «часть else». Возможны также и «части elsif»,
как в следующем примере.
Пример 2.14. Условный оператор с несколькими ветвями
70
Гл. 2. Основные черты языка
if X < 0 then
Y := -1;
elsif X = 0 then
Y ;= 0;
else
Y := 1}
end if;
- - если это условие выполняется,
- - то выполнить такой оператор
*• - иначе если выполняется это условие,
* - то выполнить такой оператор
- - во всех остальных случаях
- - выполнить следующее действие
* - и завершить оператор
В общем случае каждая ветвь оператора If может содержать
последовательность операторов, а у самого оператора может
быть сколько угодно частей elsif, причем у каждой из них — свое
условие выполнения соответствующей последовательности опера-
торов. Общий вид п оператора if таков:
Пример 2.15. Синтаксис оператора if
if условие then - - оператор имеет часть tf с условием
’ последовательность операторов - - и часть then, состоящую из
- - последовательности операторов
{ elsif условие ’then - - и произвольное число (возможно, ни одной)
последовательность операторов} -- частей elsif
[else - - и, возможно, часть else со своей
последовательность операторов] • последовательностью операторов
end if; ' - - и явный признак завершения оператора
Оператор if обязательно должен иметь часть then. Частей
elsif или else может не быть; если они есть, истинность условия
в части then приводит к тому, что их операторы пропускаются.
Каждая часть elsif в свою очередь определяет множество опера-
торов, которые могут быть выполнены в зависимости от некото-
рого условия. Часть else, если она имеется, указывает, что делать
в случаях, не предусмотренных последовательностью условий в
предшествующих частях.
Оператор выбора case, как и условный оператор if, имеет
несколько ветвей, выполнение которых регулируют связанные с
ними условия. Однако эти условия для оператора выбора имеют
специальную форму. Более того, гарантируется, что только одно
из условий может быть истинно, так что порядок, в котором усло-
вия задаются и проверяются, может быть изменен без изменения
смысла прогр аммы.
Следующий оператор выбора имеет управляющую перемен-
ную и три ветви. Первая выполняется в случае, если значение Y
Следуя соглашениям, принятым в руководстве по языку, мы заключаем
конструкции, которые могут входить несколько (в том числе и нуль) раз (как,
например, части elsif), в фигурные скобки, а те, что могут входить, а могут
и не входить (как, например, часть else), в квадратные скобки. Вообще говоря,
мы не будем описывать синтаксис конструкций языка, но включим специфи-
кации в нескольких случаях, там, где это представляется особенно полезным.
2.5. Операторы повторения
71
равно —'1. Вторая ветвь выполняется, если Y=0 или Y = l.
Третья — для всех других значений Y.
Пример 2.16. Оператор выбора с управляющей переменной
case Y of - - Y — управляющая переменная
^hen -1 => -NEGATIVE-ACTION; -- действия при Y = -1
when 011 => NON-NEGATIVE—ACTION; - - действия при Y = 0 или Y = 1
when others => ERROR__ACTION; * - действия для остальных значений Y
end case;
Выражения, следующие за ключевым словом when, называют-
ся выбирающими выражениями-, они задают множества значений,
которые должны быть вычислимы статически, во время компи-
ляции. Множества значений разных выбирающих выражений не
должны пересекаться, вместе они должны охватывать все возмож-
ные значения управляющей переменной. Альтернатива others
аналогична части else условного оператора в том отношении, что
она описывает «все остальные», не охваченные выбирающими вы-
ражениями возможные значения управляющей переменной.
2.5. Операторы повторения
Условные операторы и операторы выбора осуществляют выбор
среди возможных вариантов составляющих их операторов. В от-
личие от них операторы повторения описывают правила повто-
рения своих составляющих.
Основной конструкцией в Аде, описывающей повторение,
является оператор цикла loop. В своей простейшей форме этот
оператор задает безусловное повторение выполнения тела цикла.
Пример 2.17. Безусловный оператор повторения
loop - - начало цикла
X : = Х+1; - - его тело из двух операторов; один из них —•
exit when X = 1000; - - оператор выхода, см. разд. 2.6
end loop; - - конец цикла
В приведенном выше примере выход из цикла, т. е. прекраще-
ние повторения, определяется условием внутри цикла. В других
случаях оператор повторения может быть снабжен условием,
которое определяет правила повторения и ситуацию, в которой
повторение должно быть завершено. Операторы повторения ДЛЯ
(for) и ПОКА (while) представляют собой два варианта сочетания
правил повторения с оператором цикла.
Пример 2.18. Простой оператор повторения ДЛЯ
72
Гл. 2. Основные черты языка
SUM 0;
for I in 1.. 10 loop
SUM := SUM+I;
end loop;
- - подготовиться к циклу
* - значения управляющей переменной 1. .10
- - в теле цикла к СУММА прибавляется 1
* - при каждом повторении
Управляющая переменная часто используется в качестве ин-
декса массива, как в следующем примере, где складываются зна-:
чения десяти первых элементов массива А.
Пример 2.19. Повторение с перебором элементов массива
SUM :=* 0;
for I in 1«* 10 loop^
SUM :== SUM+A(I) ;
end loop;
Управляющая переменная цикла ДЛЯ доступна только вну-
три этого цикла. Поэтому в следующем примере поиска в массиве
А элемента со значением V индекс найденного элемента должен
быть присвоен нелокальной переменной К перед выходом из
цикла.
Пример 2.20. Цикл поиска с выходом
К : - 0; - - значение К для неудачного поиска
X in 1* loop, - - повторять для последовательных значений
- - управляющей переменной I
if A(I) ~ V then -- если А(1) равно V,
К I; -- присвоить К соответствующий индекс
exit; >-И выйти
532 * - если A(I) & V, не делать ничего
й повторить цикл со следующим значением I
Множеством значений, принимаемых управляющей перемен
ной (оно описывается между зарезервированными словами in
и loop), может быть любое упорядоченное множество, в котором
определены минимальный и максимальный элементы и функция
«следующий»,, вырабатывающая для каждого элемента (кроме
максимального) следующий за ним. Такое множество называется
дискретным диапазоном. Множество 1 . . N, очевидно, является
дискретным диапазоном: в нем есть максимальный и минимальный
элементы и функция «следующий». Множество N . . 1 — еще один
пример дискретного диапазона, оно может быть описано как
reverse 1 . .N. В следующем цикле ДЛЯ факториал числа N вы-
числяется как произведение сомножителей в порядке N*(N—1)*
(N—2)*...#2*1.
Пример 2.21. Повторение с указанием reverse
2.5. Операторы повторения
73
FACT. .
for I in reverse 1..N loop
FACT I * FACT;
end loop;
Операторы ДЛЯ полезны в случае, когда число и последова-
тельность повторений заранее определены и соответствуют после-
довательным значениям управляющей переменной. В тех, одна-
ко, случаях, когда повторение управляется условием, наклады-
ваемым на вычисляемые данные, таким, как сходимость функции
к фиксированному значению, цикл ДЛЯ не вполне удобен. Сле-
дующий фрагмент программы вычисления квадратного корня
иллюстрирует использование оператора повторения ПОКА.
Пример 2.22. Оператор ПОКА
FOOT != 1.0;
while ABS(ROQT*ROOT-X) > .0001 loop
ROOT := 0.5 *(ROOT + X / ROOT); ,
end loop;
r - пока выполняется это условие,
- - выполнять присваивание
- - и повторять снова
Тело этого цикла содержит единственный оператор присваи-
вания, в котором по старому приближению к значению квадрат-
ного корня вычисляется новое. Процесс заканчивается, когда
квадрат вычисленного приближения отличается от значения X
не более чем на 0.0001.
Еще один пример использования оператора ПОКА находим
в следующей программе моделирования деления вычитаниями.
Пример 2.23. Оператор ПОКА
QUOTIENT := 0; --ЧАСТНОЕ
while NUMBER >— DIVISOR loop «. - деление с помощью
NUMBER. NUMBER — DIVISOR; последовательных вычитаний
QUOTIENT QUOTIENT + 1; считаем количество вычитаний
end loop;
В операторе ДЛЯ количество повторений — это число эле-
ментов в диапазоне, оно известно до начала выполнения операто-
ра. В последнем примере мы не знаем его заранее. Фактически
наша цель в том и состоит, чтобы его (т. е. окончательное значе-
ние переменной ЧАСТНОЕ) определить. Очевидно, что сделать
это с помощью оператора ДЛЯ было бы нелегко и что в этом слу-
чае более общий оператор ПОКА предоставляет более подходящее
средство.'
Последний пример использования оператора ПОКА — чтение
из входного файла и обработка произвольного числа элементов
Данных до появления признака конца файла.
74
Гл. 2. Основные черты языка
Пример 2.24. Цикл ввода данных из файла
прочитать следующий элемент данных
•while данные хорошие loop
обработать элемент данных
прочитать следующий элемент данных
end loop;
Такое повторение может быть выполнено с помощью операто-
ра ДЛЯ, если число элементов данных известно заранее. Если же
признак конца потока данных находится в самом потоке, более
подходит оператор ПОКА.
Условный оператор, операторы выбора и повторения являют-
ся составными операторами, они управляют последовательностью
выполнения входящих в них операторов. В следующем разделе
мы рассмотрим две более простые управляющие структуры —
операторы выхода и перехода, которые просто передают управле-
ние из одной точки программы в другую.
2.6. Переход и выход
Управление последовательностью выполнения операторов
программы может быть описано либо с помощью составных опера-
торов, определяющих порядок, в котором должны выполняться
входящие в них операторы, таких, как повторение, выбор, услов-
ный оператор, либо с помощью простых операторов передачи уп-
равления, указывающих метку, по которой управление должно
быть передано.
Метка изображается таким образом: Передача управле-
ния на помеченный оператор может быть выполнена с помощью
оператора перехода goto. Его использование иллюстрирует сле-
дующий пример поиска в массиве элемента со значением V.
Пример 2.25. Оператор перехода
К := 0;
for I in 1..N loop
if A(I) « V then
К := I;
, go to FOUND;
'end“if7
end loop;
«FOUND»
if К = 0 then
выполнить действия, когда нет К, такого, что А(К) = V
else
выполнить действия для А(К) « V
end if;
2,6. Переход и выход
75
Поскольку на практике переход к первому оператору вне
цикла встречается часто, имеется специальный оператор — он
называется оператором выхода (exit) — для выполнения таких
переходов. Приведенный пример можно переписать с использо-
ванием оператора выхода следующим образом.
Пример 2.26. Оператор выхода
К := 0;
for I in 1..N loop
i_f A (I) » V then
К := I; *
exit;
end if;
end loop;
if К » 0 then
В этой программе осуществляется выход из самого внутрен-
него цикла, содержащего оператор exit, и выполнение продолжа-
ется со следующего за циклом оператора.
В общем случае с помощью этого оператора можно проходить
сквозь несколько уровней вложенных один в другой циклов, для
этого используется оператор выхода в форме «exit L», где L —
метка оператора цикла, выполнение которого следует завершить.
Оператор выхода может быть условным, как в следующем фраг-
менте программы поиска.
Пример 2.27. Условный оператор выхода
for I in 1..N loop
К := I;
exit when A(I) = V;
end loop;
Этот вариант программы проще предыдущего, поскольку нам
Удалось избавиться от условного оператора ЕСЛИ, описав усло-
вие как часть оператора выхода. Это, однако, немного замед-
ляет выполнение, так как текущее значение I присваивается К
при каждом повторении, в то время как в прежней версии это де-
лалось только в конце успешного поиска. Более того, в этом вари-
анте случай, когда поиск неудачен, обрабатывается неправильно
(он не отличается от ситуации, когда искомый элемент — послед-
ний).
Возможны, таким образом, следующие формы оператора вы-
хода.
76
Гл. 2. Основные черты языка
Пример 2.28. Формы оператора выхода
exit; - - без уточнений, выходлз самого внутреннего
- - цикла, содержащего этот оператор
exit L; -- выход из цикла, помеченного L
exit when condition; - - выход из самого внутреннего цикла
• - при выполнении условия
exit L yhen condition; - - выход из цикла L при выполнении условия
Оператор выхода обеспечивает значительную часть пере-
дач управления, которые иначе потребовали бы оператора пере-
хода. В следующем примере программы сортировки по методу
пузырька, однако, необходим переход к началу цикла всякий раз,
когда два элемента не удовлетворяют отношению порядка. Такой
переход удобнее описывать оператором перехода, а не выхода.
Пример 2.29. Сортировка по методу пузырька с оператором
перехода
«SORT» for I in 1..N-X loop
цикл выполняется раз каждой
перестановки
if A(I) < А (1+1) then проверяем, нужна ли перестановка
TEMP : =s А (I) ; - - число перестановок пропорционально N7
А (I) : = А (1+1);- число сравнений для одной перестановки
- - пропорционально N
А (1+1) : = TEMP; - - общее число сравнений пропорционально N*
go to SORT; - - после перестановки начать цикл снова
end if; * - если цикл закончен без единой перестановки
id loop. SORT; * - значит, вектор отсортирован
Приведенная программа сортировки очень неэффективна.
Для сортировки N элементов она требует времени п, пропорци-
онального N3, тогда как лучшим программам сортировки доста-
точно N log N. Она, однако, приведена здесь, чтобы проиллюст-
рировать ситуацию, когда оператор перехода нелегко заменить
оператором выхода. Одновременно она показывает, что програм-
мы, в которых переходы кажутся необходимыми, часто благода-
ря решительной перестройке могут быть заменены более эффек-
тивными или лучше структурированными программами без них.
Число перестановок пропорционально N2, а число сравнений для каж-
дой перестановки пропорционально N. Поэтому общее число сравнений про*
порционально N3,
2.7. Примеры программ. Вычисление простых чисел 77
Операторы перехода могут осуществлять выход из составных
операторов, но не из подпрограмм или модулей. Таким образом,
«правила видимости» для меток несколько отличаются от анало-
гичных правил для идентификаторов. Подпрограммам и модулям
доступны нелокальные идентификаторы, объявленные в тексту-
ально объемлющих конструкциях, но переход к меткам этих
конструкций не разрешен.
Следующий пример показывает, как можно комбинировать
операторы выхода и повторения для проверки окончания цикла
внутри его.
Пример 2.30. Обработка файла с оператором выхода
loop
получить элемент данных
exit when (конец файла)
обработать элемент данных
end loop;
Оператор повторения ПОКА может быть смоделирован с по-
мощью цикла, тело которого начинается с конструкции ’’exit
when условие”. Другая управляющая структура — оператор
Паскаля ”do . . until условие” реализуется безусловным циклом,
последний оператор которого — ’’exit when условие”. Таким об-
разом, комбинация операторов повторения и выхода обеспечива-
ет большую гибкость в моделировании управляющих структур,
соответствующих различным конкретным ситуациям.
2.7. Примеры программ. Вычисление простых чисел
В этом разделе мы построим серию программ для работы с про-
стыми числами. Эта область достаточно богата, чтобы можно было
проиллюстрировать некоторые интересные управляющие струк-
туры, и в то же время достаточно знакома, чтобы не требовать
Длинных объяснений. Мы сначала рассмотрим программу провер-
ки того, является ли N простым числом, затем перейдем к про-
грамме построения последовательности простых чисел, исполь-
зуя при этом проверку на «простоту» всех чисел, не превосходя-
щих квадратного корня из N, и, наконец, напишем программу
печати простых множителей последовательных целых чисел.
В следующем фрагменте выполняется проверка, простое ли
число N. При этом сначала мы исследуем делимость N на 2, а
78
Гл. 2. Основные черты языка
затем — на последовательные нечетные числа вплоть до квадрат-
ного корня из N. Фрагмент состоит из условного оператора, одна
из ветвей которого (ветвь then) — простой оператор присваива-
ния, а другая содержит оператор повторения, внутри которого
также условный оператор. Предполагается, что N — целое и
больше двух.
Пример 2.31. Вложенные условные операторы
if N mod 2 = 0 then PRIME := FALSE; - - проверить четность - - если да, положить ПРОСТОЕ равным FALSE - - и закончить проверку
else FACTOR := 3; loop if FACTOR**2 > N then PRIME ;= TRUE; exit; elsif N mod FACTOR = 0 - - если же N не делится на 2, - - положить МНОЖИТЕЛЬ равным 3 - и повторять: - - проверить МНОЖИТЕЛЬ > SQRT(N)? - - если так, положить ПРОСТОЕ равным TRUE - - и выйти then - - проверить, делится ли К на — МНОЖИТЕЛЬ
PRIME := FALSE; exit; end if; FACTOR := FACTOR+2; - - если так, положить ПРОСТОЕ равным FALSE -- и выйти - - конец внутреннего условного оператора - - следующий множитель для проверки
end loop; - end if; - - конец оператора повторения - - конец внешнего условного оператора
Оператор повторения в этой программе имеет интересную
структуру. Он содержит условный оператор, в котором прове-
ряется окончание цикла; условный оператор имеет ветвь elseif,
но не имеет ветви else. Поэтому, если не удовлетворено ни усло-
вие if, ни условие elseif, ни одна из ветвей не выполняется, значе-
ние FACTOR увеличивается и можно проверять следующее не-
четное число. Отметим, что в нашем случае присваивание FAC-
TOR := FACTOR+2 можно было бы включить в ветвь if услов-
ного оператора.
Внутренний условный оператор можно было бы заменить дву-
мя операторами выхода с условиями. Полученная в результате
этого программа менее эффективна, поскольку в ней выполняется
лишнее присваивание переменной PRIME во внутреннем цик-
ле, но мы приводим ее здесь для иллюстрации возможного вари-
анта управляющей структуры.
2.7. Примеры программ. Вычисление простых чисел 79
Пример 2.32. Проверка простоты с флажком и условными
выходами
If ы mod 2 = 0 then.
PRIME !:= FALSE;
- - если N делится на 2,
- - положить ПРОСТОЕ равным FALSE и выйти
е15е - - в противном случае
"“factor := 3; - положить МНОЖИТЕЛЬ равным 3
loop - и повторять:
PRIME := TRUE; --выйти, имея ПРОСТОЕ»-= TRUE
exit when FACTOR**2 > N; если МНОЖИТЕЛЬ > SQRT(N)
PRIME : = FALSE; “ - ВЫЙТИ, имея ПРОСТОЕJ = FALSE
exit when.N mod FACTOR =0; - если N делится на МНОЖИТЕЛЬ
FACTOR := FACTOR+2;--подготовить для проверки следующий множитель
end loop; - - конец цикла
end Tf; • “ конец условного оператора
Показанный ниже еще один метод проверки числа на простоту
использует для проверки окончания составные логические усло-
вия и оператор ПОКА. Здесь выполняется в среднем на одну
треть меньше проверок типа N mod FACTOR—0, чем в прежних
программах, благодаря тому, что используется такой факт: каж-
дое третье нечетное число делится на 3.
Пример 2.33. Более эффективная проверка простоты
if N mod 2 = 0 or. N mod 3 = 0 then - - если N делится на 2 или 3,
- - положить ПРОСТОЕ
PRIME := (N <4); - - равным TRUE при N = 2 или N = 3 и FALSE при N > 3
else - - и выйти; в противном случае
PRIME : = TRUE; - - заранее положить ПРОСТОЕ равным TRUE
FACTOR : = 5; - - и МНОЖИТЕЛЬ равным 5;
while FACTOR**2 <= N loop -- повторять, пока МНОЖИТЕЛЬ < SQRT(N)
if N mod FACTOR = 0 or N mod (FACTOR+2) = 0 - - если N делится на
PRIME := FALSE; — МНОЖИТЕЛЬ ИЛИ МНОЖИТЕЛЬ + 2,
- - положить ПРОСТОЕ равным FALSE и выйти
end if; - - МНОЖИТЕЛЬ + 4 делится на 3
FACTOR := FACTOR+б; --и может быть пропущен
end loop; - - значение ПРОСТОЕ равно TRUE при
end if; - - нормальном выходе и FALSE при ненормальном
Сравнение трех приведенных версий проверки числа на про-
стоту одновременно иллюстрирует многообразие путей решения
вычислительной, задачи и богатство и гибкость управляющих
структур Ады, обеспечивающих различные методы организации
решения даже относительно простых задач.
Рассмотренные фрагменты программы могут быть включены в
функцию с целым входным параметром N, простота которого
должна быть проверена, и логическим результатом: TRUE, если
N — простое, и FALSE в противном случае»
80
Гл. 2. Основные черты языка
Пример 2.34. Функция, проверяющая простоту
function ISPRIME (N: INTEGER) return BOOLEAN is - - функция С Целым
-- параметром,
FACTOR: integer; * - логическим результатом, двумя локальными
PRIME: BOOLEAN; — - Перинными,* МНОЖИТЕЛЬ и ПРОСТОЕ,
begin - - и последЬвательностью операторов:
* - любой из трех приведенных фрагментов программы
- - проверки числа на простоту
return prime; - - и затем оператор возврата
end ISPRIME; - - и конец.
Вызов функции ISPRIME (ЧИСЛО-ПРОСТОЕ) может встре-
титься всюду, где допустимо логическое значение. В следующем
примере он входит в условие оператора if, в котором подсчиты-
вается количество простых чисел в диапазоне от М до N.
Пример 2.35. Вызов функции ISPRIME
COUNT ;= 0;
for I in .2. .1000 loop
if ISPRlW(I) then
COUNT := COUNT+1;.
end if;
end loop;
- - подсчитать количество простых чисел
- - проверить, простое ли 1-е число
- - если это так, увеличить счетчик на 1
Функция ISPRIME предоставляет пользователю ресурс, реа-
лизация которого скрыта от него. В частности, изменения в реали-
зации, не меняющие внешнего вычислительного эффекта функ-
ции, не видны пользователю. Поэтому пользователь нашей про-
граммы не должен интересоваться тем, какой из трех вариантов
действительно входит в тело процедуры, так как функциональный
эффект их одинаков.
Если мы хотим не только проверить, является ли данное число
простым, а и перенумеровать все простые числа, мы можем сэко-
номить время, исследуя делимость только на уже найденные про-
стые числа (до квадратного корня из рассматриваемого числа).
В следующей программе первые 100 найденных простых чисел
сохраняются в векторе PRIMES (ПРОСТЫЕ). Так, 3 будет значе-
нием PRIMES(l), 5 — значением PRIMES(2), а 547 —PRI-
MES(100); программа может вычислить все простые числа ДО
5572 =310 249, поскольку все целые числа до 310 249 имеют сво-
ими множителями простые числа до 547.
Пример 2.36. Вычисление последовательности простых чисел
2.7. Примеры программ. Вычисление простых чисел
81
PUT(2)/-
PUT(3);
р rimes (1) 3;
N :== 1?
К := 5;
* - сообщить, что 2 — простое
* - и что 3 — также простое
* * поместить 3 в вектор ПРОСТЫЕ
* - число известных первоначально равно 1
* - начальное значение проверяемого числа
while К < 300J500 loop • * повторять, пока К < 300000
J :=г 1; начальное значение индекса вектора ПРОСТЫЕ
while PRIMES (I) **2<- К loop • - внутренний цикл по известным
простым
if К mod PRIMES (I) - 0 then * - проверка очередного простого
4 множителя
go to L;
end if;
I := 1+1;
end loop?
PUT(K);.
if N < 100 then
U N+l;
PRIMES (N) ;-K;
end if;
«I» К := K+2;
end loop?
- - выход, если найден
- - если К не делится на него,
* • взять следующий элемент ПРОСТЫЕ
* - и проверить
* - напечатать К, если оно простое
* - и если это — одно из первых 100 простых
- увеличить длину вектора
« - и запомнить новое простое число
-- увеличить К на 2
* - и проверить простоту следующего нечетного
Структура управления этой программы представляет собой
цикл ПОКА, содержащий внутренний цикл ПОКА с оператором
перехода из внутреннего оператора ПОКА в середину последова-
тельности операторов тела внешнего цикла. После нормального
выхода из внутреннего цикла (когда число — простое) выпол-
няется несколько операторов, необходимых для кое-каких
внутренних действий (запоминания простых чисел). Затем ветви
нормального и «ненормального» выходов объединяются, а для
указания этой точки слияния ветвей используется переход из
внутреннего оператора ПОКА для «ненормальной» ветви. Опера-
тор перехода — это естественный механизм передачи управления
из «ненормальной» ветви обратно в любую точку нормальной.
Другой способ достичь того же эффекта — при возникновении
необычного события установить флажок, а затем, когда необхо-
димо различать обычный и необычный случаи, проверять его.
Следующий пример, в котором печатаются простые множите-
ли последовательных целых чисел, по общей своей структуре по-
добен предыдущему. Он отличается только тем, что в нем имеется
внутренний цикл для обработки кратных простых множителей —
ситуаций, когда одно простое число входит множителем несколь-
ко раз. Вместо перехода используется флажок FLAG, который
устанавливается в положение FALSE, если множитель найден, и
затем проверяется. Эта программа является типичным примером
программы с многоуровневой структурой управления, она иллю-
стрирует взаимодействие операторов повторения ДЛЯ и ПОКА,
Выхода и условных операторов.
82
Гл. 2. Основные черты языка
Пример 2.37. Получить таблицу простых множителей после-
довательных чисел
procedure PRIME FACTORS(MAXNUM: INTEGER) is
N: integer : = q ; - - количеств простых в векторе .ПРОСТЫВ
I: integer; н - индекс в векторе ПРОСТЫЕ
FLAG: boolean; - - признак простоты рассматриваемого числя
М: INTEGER; --частично разделенное целое
PRIMES; array(1< >100) of INTEGER; v для хранения уже найденных
— простых
begin
PRIMES (1) := 2; - - первый элемент ПРОСТЫЕ
for К in 2. .MAXNUM loop- * - цикл по последовательным целым
FLAG := TRUE;
И К; w ш запомнить К в «рабочей ячейке»
1 •= 1 г - - начальное значение индекса вектора ПРОСТЫЕ
while PRIMES (l) **2 <= м loop - - цикл по последовательным простым
-- множителям
while М mod PRIMES (l) =0 and PRIMES (I)/НИ loop ЦИКЛ ДЛЯ
PUT (PRIMES (I)) ; И := M/PRIMES(I); FLAG :« FALSE; end loop; - - данного простого множителя * - напечатать .простой множитель - - разделить Мна него • - установить флажок * - и попробовать с этим множителем снова
I Ill; *- попробовать следующее простое
end loop; - - конец цикла поиска всех простых множителей
if FLAG and N < 100 then - - условие пересылки простого числа
в ПРОСТЫЕ
К Nil; *- еслиЫ < 100
PRIMES (N) : = К; - - добавить К в ПРОСТЫЕ
end if;
PUT (м) - - напечатать последний простой множитель
PUT (NEWLINE); * - и перейти на новую строку
end loop; * * конец цикла ДЛЯ, взять новое целое4
end PRIME_FACTORS;
Процедура ' PRIME-FACTORS (ПРОСТЫЕ.МНОЖИТЕ-
ЛИ) — самая крупная программа из рассмотренных до сих пор,
она содержит не только операторы, в которых выполняются вы-
числения, но также объявления, определяющие используемые в
вычислениях переменные и параметры процедуры. В оставшихся
разделах этой главы мы более детально займемся структурой объ-
явлений, процедур, функций, параметров. Мы будем использовать
главным образом «игрушечные» примеры, чтобы проиллюстрир<>
вать особенности языка в несложной обстановке. До конца этой
главы читатель уже не встретится с такими крупными програм-
мами, как ПРОСТЫЕ .МНОЖИТЕЛИ, но в следующих главах
появятся иллюстративные программы и побольше.
2.8. Объявления идентификаторов
83
2.8. Объявления идентификаторов
Используемые в процедуре ПРОСТЫЕ_МНОЖИТЕЛИ иден-
тификаторы могут быть разбиты на следующие группы:
1. Зарезервированные слова, которые в этой программе для
наглядности подчеркнуты, но в реальной ситуации могли бы вы-
глядеть как идентификаторы. Зарезервированные слова нельзя
объявлять в программе повторно.
2. Идентификаторы, определенные системой, например IN-
TEGER, BOOLEAN, TRUE. В принципе эти идентификаторы
можно было бы переобъявить, придав им другой смысл, но так
делать нежелательно.
3. Идентификаторы, объявленные в других программных сег-
ментах, например PUT или NEWLINE, которые предполагаются
объявленными в доступном библиотечном пакете ввода-вывода.
4. Идентификаторы, объявленные в данном сегменте про-
граммы. Они в свою очередь могут быть разбиты на группы
следующим образом:
а) Объявления простых переменных и постоянных, например
целых переменных N, I, М, логической переменной FLAG (ФЛА-
ЖОК).
Ь) Объявления структурных переменных, например массива
PRIMES.
с) Объявления параметров подпрограммы, например целого
параметра MAX NUM.
d) Объявление идентификатора процедуры, например иденти-
фикатора PRIME_FACTORS.
Ада — язык со строгой типизацией, т. е. в нем всякий иден-
тификатор должен иметь смысл, предопределенный в языке, опре-
деленный в другом сегменте программы или явно определенный
объявлением этого идентификатора в данном сегменте. Мы изучим
подробнее механизм явного объявления идентификаторов. Объ-
явление простых переменных и постоянных более подробно рас-
сматривается ниже в этом разделе. Механизмом объявления под-
программ и параметров мы займемся в следующих разделах дан-
ной главы. Объявлениям структурных типов данных и других
типов, определяемых программистом, посвящена следующая
глава.
Переменные и постоянные в Аде называют объектами. Объяв-
ления переменных и постоянных называют соответственно объяв-
лениями объектов, чтобы отличить от объявлений подпрограмм
и типов. В общем случае объявления объектов имеют такой вид:
список _ идентификаторов: [constant] спецификация _типа
[:= выражение];
84
Гл. 2. Основные черты языка
Таким образом, в нем можно выделить следующие компо-
ненты:
1. Список идентификаторов, содержащий хотя бы один эле-
мент. Идентификаторы — это имена объявляемых объектов. За-
вершает список двоеточие.
2. Необязательное зарезервированное слово constant. Если
оно присутствует, то объявляемые идентификаторы — постоян-
ные, их значение должно быть определено инициализирующим
(т. е. определяющим начальное значение) выражением. В против-
ном случае объявляемые идентификаторы — переменные, и ини-
циализирующее выражение необязательно.
3. Обязательная спецификация типа, указывающая тип объ-
являемых идентификаторов. Тип определяет множество значе-
ний, которые может принимать идентификатор, и применимые
к нему операции.
4. Знак присваивания и необязательное инициализирующее
выражение. Тип его должен соответствовать спецификации типа.
Объявления с указанием начального значения, вообще говоря,
обязательны для постоянных (за исключением случая задержан-
ной постоянной, см. примеры 1.23, 1.24, 3.80, 3.82).
5. Точка с запятой, завершающая объявление объекта.
В предыдущих примерах было уже много объявлений объек-
тов. Дадим тем не менее еще несколько примеров.
Пример 2.38. Объявления объектов
I,д- integer; - - две целые переменные I и J
COUNT; INTEGER := 0; -- целая переменная с начальным значением
FLAG: BOOLEAN ;= TRUE; -- логическая переменная с начальным значаще*
LENGTH: FLOAT : = 4.5; * - плавающая переменная с начальным значение*
SQUARE; FLOAT := LENGT.H*LENGTH; • - инициализирующее выражение
Объявления в любой данной совокупности объявлений обраба-
тываются последовательно. Последнее объявление в примере 2.38
показывает, что переменные, такие, как LENGTH (ДЛИНА),
объявленные с начальным значением, могут тотчас же исполь-
зоваться в последующих объявлениях. Однако такие переменные
(или постоянные) всегда должны быть объявлены до их исполь-
зования. Поэтому если два последних объявления поменять ме<>
тами, программа в результате станет неправильной, потому
переменная LENGTH не будет иметь начального значения в w
момент, когда оно потребуется для присваивания начальн
значения переменной SQUARE (ПЛОЩАДЬ). я3(
Постоянные должны быть инициализированы в момент
объявления, их значения не могут быть изменены присва ।
нием.
2.9. Сегменты программы и блочная структура
85
Пример 2.39. Объявления постоянных
- LIMIT: constant INTEGER : = 1000?
PI: constant FLOAT := 3.1416;
MAX_AREA: constant FLOAT :=> PI*FLOAT (LIMIT) **2‘;
В последнем примере целая постоянная LIMIT (ПРЕДЕЛ)
преобразуется к плавающему типу, чтобы ее можно было исполь-
зовать при вычислении выражения этого типа. Это выражение
можно было бы написать и так: PI*FLOAT(LIMIT#*2), здесь це-
лая переменная LIMIT возводится в квадрат перед преобразова-
нием результата к плавающему типу.
В рассмотренных примерах типы всех объявляемых объектов
были предопределены в языке, множества их значений и приме-
нимые операции определены системой. Объявление объектов оп-
ределенных программистом типов будет рассматриваться в сле-
дующей главе.
2.9. Сегменты программы и блочная структура
Разбиение программы на сегменты служит для связи объявле-
ний, определяющих атрибуты идентификаторов, с предложения-
ми, в которых эти идентификаторы используются.
Сегмент программы состоит из описательной части, или сово-
купности объявлений, где вводятся локальные идентификаторы
сегмента, и императивной части (последовательности операторов),
в которой могут использоваться как объявленные локальные
идентификаторы, так и доступные нелокальные. Удобно разли-
чать три типа сегментов программы.
1. Подпрограммы. Вводятся объявлениями подпрограмм в со-
вокупности объявлений некоторого сегмента программы и выпол-
няются при вызовах подпрограмм.
2. Модули. Объявляются в совокупности объявлений некото-
рого сегмента программы. Каждый модуль имеет спецификацию,
Которой описываются ресурсы, предоставляемые им пользова-
ЗДю. Эти ресурсы могут использоваться всюду, где данный мо-
Удь текстуально доступен.
tgк Блоки. Должны входить в последовательность операторов
^"гуально объемлющего сегмента программы, имеют синтакси-
Ии статус предложения.
««д^^енты программы определяют часть текста (область дейст-
’ в которой доступны локальные идентификаторы. Вопросы,
86
Гл. 2. Основные черты языка
связанные с понятием области действия, сначала рассмотрим на
примере блоков, а затем на примере других сегментов про-
граммы.
Синтаксис блока таков:
[declare
последовательность объявлений локальных идентификато-
ров]
begin
последовательность операторов, в которых могут исполь-
зоваться как локальные, так и нелокальные идентифика-
торы
end;
Таким образом, в блоке может быть совокупность объявле-
ний, в которой вводятся локальные идентификаторы, а за ней —
последовательность операторов, содержащих как объявленные
чуть выше локальные идентификаторы, так и доступные нело-
кальные.
Разницу между локальными и нелокальными идентификато-
рами можно проиллюстрировать на следующем примере блока, в
котором обмениваются значениями две переменные.
Пример 2.40. Снова обмен
declare
TEMP; constant INTEGER X;
begin
X s= Y;
Y TEMP;
end;
- - ВРЕМ — целая постоянная с начальным
значением
- - X и Y —• нелокальные переменные
* * ВРЕМ —• локальная переменная
В этом примере локальный идентификатор TEMP представ-
ляет собой инициализированную постоянную, значение которой
остается постоянным в течение всякого конкретного выполнения
блока, но при разных выполнениях этого блока ее значения мо-
гут различаться. X и Y — нелокальные переменные, которые
должны быть определены в доступных объявлениях текстуально
охватывающей компоненты программы.
Область действия объявленного идентификатора простирает-
ся от точки его объявления до конца сегмента программы, в кото-
ром он объявлен. Всякая попытка использовать идентификатор
вне его области действия незаконна.
2.9. Сегменты программы и блочная структура 87
Следующий пример иллюстрирует «внутренний блок» с ло-
кальной переменной Y и нелокальной X, вложенный во «внешний
блок», в котором X объявлена. Во внутреннем блоке известны
и могут использоваться и X, и Y. Во внешнем блоке известна
только переменная X, использовать Y нельзя.
Пример 2.41. Вложенные блоки
declare
X: INTEGER;
begin
X := 2;
declare
Y: INTEGER;
begin
Y := 4;
X :== X+Y;
end;
PUT(X+1);
PUT(X+Y);
end;
- - внешний блок
- - X локальна для внешнего блока
- - тело внешнего блока
- - присваивание а
- - внутренний блок
г - Y локальна для внутреннего блока
- - тело внутреннего блока
- - присваивание Y
г - X можно использовать
* - - выход из внутреннего блока, Y больше нет
- - вывести значение 7
- - нельзя: Y неизвестна во внешнем блоке
выход из внешнего блока; X больше нет
Приведенный пример показывает, что сегменты программы
обычно действуют как мембраны, позволяя употреблять нело-
кальные имена текстуально объемлющей среды внутри сегмента,
но не разрешая пользоваться локально объявляемыми именами
вне его.
Рассмотрим теперь случай конфликта между именами объяв-
ленных идентификаторов. Правила разрешения таких конфлик-
тов различны в случаях идентификаторов подпрограмм (которые
могут быть перекрыты, а «неоднозначность» снимается во время
компиляции, см. разд. 3.1) и других идентификаторов (для кото-
рых эти конфликты просто запрещены).
Нельзя иметь несколько объявлений одного и того же иденти-
фикатора (кроме идентификаторов подпрограмм) в одной сово-
купности объявлений. Однако в различных совокупностях объяв-
лений один и тот же идентификатор объявлять повторно можно.
Ниже мы подробнее рассмотрим случай повторного объявления
идентификатора во вложенной совокупности объявлений.
Когда идентификатор, объявленный во внешнем сегменте про-
граммы, повторно объявляется во внутреннем, внутреннее объ-
явление заслоняет одноименный идентификатор внешнего сегмен-
та, как показывает следующий пример.
Пример 2.42. Вложенное повторное объявление идентифика-
тора
88
Гл. 2. Основные черты языка
declare
ХД: INTEGER;
begin
X :=» 2;
У := 3;
declare
Y: INTEGER;
begin
Y 15;
PUT(X+Y);
end;
PUT(X+Y);
end;
* - объявить X и внешний Y
- - присвоить X
- - присвоить внешнему Y
- - объявить внутренний Y
- - присвоить внутреннему Y
• - используется внутренний Y, вывести 17
» - уничтожить внутренний Y при выходе из блока
« * используется внешний Y, вывести 5
Недоступность внешнего объявления идентификатора во вну-
треннем блоке, где он объявлен повторно,— следствие того, что
каждое объявление приводит к созданию нового объекта при
входе в блок, в котором это объявление сделано. Таким образом,
вход во внутренний блок означает в нашем примере создание но-
вого объекта Y, и во время выполнения этого блока упоминания
Y означают ссылку на этот самый новый объект. «Внутренний»
экземпляр Y уничтожается по выходе из внутреннего блока, и
тогда ”Y” снова относится к внешнему объекту.
Идентификатор, объявленный в блоке, может рассматривать-
ся как связанная переменная в том смысле, что замена всех его
вхождений некоторым другим, не используемым в программе
идентификатором не изменяет действия программы. Следующий
пример получен из предыдущего заменой вхождений Y во внут-
реннем блоке на Т.
Пример 2.43. Переименование локальных идентификаторов
declare
X,Y: INTEGER;
begin
X := 2;
Y 3;
declare
T: INTEGER;
begin
T := 4;
PUT(X-bT) ;
end;
PUT(X+Y);
end;
Эта программа нагляднее той, что дана в примере 2.42, по-
скольку различные объекты, имеющие по недоразумению в 2.42
одинаковые имена, в последнем примере различаются и по имени.
- - внешний блок
- - внутренний блок
- - замена Y идентификатором Т
* • замена всех упоминаний Y на Т
- во внешнем блоке замен нет
2.10. Процедуры и параметры
89
Хорошее правило — по возможности избегать употребления од-
ного и того же объявляемого имени для разных объектов во вло-
женной структуре.
Для именованных сегментов программы, таких, как процеду-
ры, повторное объявление идентификатора во внутреннем сег-
менте не заслоняет полностью его внешнее объявление, по-
скольку на внешний идентификатор можно ссылаться, уточняя
его именем сегмента.
Пример 2.44. Нелокальный доступ с уточнением имени
procedure OUTER is
X,Y: INTEGER; '
begin
X := 2;
Y := 3;
declare
Y: INTEGER;
begin
Y := OUTER.Y+Z;
PUT(Y+OUTER.Y) ;
end;
PUT(X+Y) ;
end;
-- объявление X и Y
*• - повторное объявление Y
- - уточненное имя означает внешнее Y
- - печатается 8
- - печатается 5
Сегменты программы могут входить друг в друга на любую
глубину уровней статической вложенности. Определить, к како-
му объявлению относится данное употребление идентификатора,
можно, если последовательно рассматривать совокупности объяв-
лений текстуально охватывающих это вхождение уровней вло-
женности, начиная с самого внутреннего, и остановиться на пер-
вом же объявлении данного идентификатора. Таким образом, объ-
явление, связанное с данным употреблением идентификатора,—
это самое внутреннее его объявление из некоторого сегмента,
объемлющего это употребление идентификатора.
2.10. Процедуры и параметры
Общий формат спецификации процедуры таков:
procedure имя [спецификация параметров] is
[локальные объявления!
begin
[последовательность операторов]
end [имя!;
Открывает спецификацию зарезервированное слово procedure,
за которым идет имя процедуры, за ним — спецификация пара-
метров (она опускается, если параметров нет). Это составляет
90
Гл. 2. Основные черты языка
спецификацию процедуры, а за ней идут объявления локальных
идентификаторов (если таковые есть) и последовательность опе-
раторов, описывающих выполнение процедуры.
Процедура PRINT_CUBES (ПЕЧАТЬ.КУБОВ) не имеет
параметров, а следовательно, и спецификации параметров, в ней
одна локальная переменная CUBE (КУБ) и три оператора.
Пример 2.45. Процедура без параметров
procedure PRINT_CUBES is
CUBE: INTEGER;
begin
for I in 1..100 loop
CUBE := 1**3;
PUT(CUBE);
end loop;
end CUBE;
Первые две строки составляют описательную часть этой про-
цедуры, в них объявляются PRINT.CUBES как имя процедуры
и CUBE — локальная для процедуры переменная. Тело про-
цедуры составляет оператор повторения, в котором вычисляются
и печатаются кубы последовательных целых чисел.
Параметры процедуры имеют тип, а также вид связи — ука-
зание на то, как информация передается через параметр между
средой вызова и средой выполнения процедуры.
Следующая простая процедура сложения двух целых чисел
имеет два входных параметра (слагаемые) и один выходной (ре-
зультат).
Пример 2.46. Объявление процедуры с входными и выход-
ными параметрами
procedure ADD(I,J : in INTEGER; К: out INTEGER) is
begin
К := I+J;
efid;
Текст между зарезервированными словами procedure и is
составляет спецификацию процедуры и задает ее имя, а также
тип и вид связи каждого параметра. Спецификация процедуры
представляет собой сопряжение между теми, кто реализует про-
цедуру, и теми, кто ее использует. В ней имеется вся информа-
ция, необходимая пользователю для правильной работы с этой
процедурой. В частности, там есть имя процедуры, количество
параметров, тип и вид связи каждого параметра. Чтобы напи-
сать вызов процедуры ADD (СЛОЖИТЬ), пользователю нужно
знать только имя процедуры и типы ее параметров.
2.10. Процедуры и параметры
91
Пример 2.47. Вызов процедуры ADD
ADD(X,Y,Z);
- - сложить значения X и Y и поместить результат в Z
При этом вызове переменные X, Y и Z (объявленные в среде
вызова как целые переменные) ассоциируются с параметрами I,
J и К объявления процедуры. Вычисляется значение X+Y, ко-
торое затем сохраняется в среде вызова'как значение переменной-
результата Z.
Параметры I, J и К описания процедуры — связанные пере-
менные в том смысле, что систематическая их замена другими
неконфликтующими именами в описании процедуры не изменяет
ее смысла. Они безразличны пользователю и потому называются
формальными параметрами, или просто параметрами. Исполь-
зуемые при вызове идентификаторы называются фактическими
параметрами или аргументами', они определяют значения, ис-
пользуемые как аргументы для входных параметров, а для вы-
ходных указывают, куда следует вернуть результат.
Пользователю не нужно знать имена параметров, но знание
типа и вида связи необходимо. Соответствие типов параметров
и аргументов может быть проверено во время компиляции. Вид
связи также существен для пользователя, поскольку входные
аргументы могут задаваться выражениями (например, X-j-5),
в то время как выходные должны быть переменными. Перед ис-
пользованием вызова входным аргументам должны быть при-
своены какие-то значения, хотя в общем случае это нельзя
проверить при компиляции.
В следующем примере мы видим процедуру ADD (СЛОЖИТЬ),
в которой параметры I, J и К заменены неконфликтующими име-
нами FIRST, SECOND и RESULT, а также ее вызов с аргумен-
тами-выражениями. .
Пример 2.48. Аргументы-выражения
procedure USE__ADD is.
X,z: INTEGER; - - локальные переменные — аргументы СЛОЖИТЬ
procedure ADD(FIRSTzSECOND: in. INTEGER; RESULT: out INTEGER) is
- - переименованные формальные параметры
begin
RESULT FIRST-HSECOND;
• end ADD;’
begin,
X := 7;-
ADD (4,X+5,Z); * - входные аргументы могут быть выражениями
Рит (z); 1 * - выходные аргументы должны быть переменными
gnd USEJWD;
92
Гл. 2. Основные черты языка
Соответствие аргументов параметрам определяется в этом при-
мере их позицией, порядком перечисления при вызове. В Аде мож-
но также задавать это соответствие, указывая имена параметров,
как в следующем примере.
Пример 2.49. Поименованные аргументы
ADD(SECOND г= Х+5, FIRST 4f RESULT =: Z) ;
Когда имена параметров указываются явно, порядок аргу-
ментов не зависит от порядка параметров в объявлении процеду-
ры. Более того, имена параметров могут служить полезным напо-
минанием об их роли в этой процедуре, особенно для тех, кто не
знаком с программой. Поскольку, однако, такое явное именова-
ние означает, что изменение имен параметров внутри процедуры
может потребовать их изменения там, где процедура использует-
ся, оно несколько ослабляет модульность.
Явное наименование параметров позволяет опускать аргу-
менты, когда это семантически осмысленно. Рассмотрим, напри-
мер, следующий вариант процедуры ADD, в котором у обоих
входных параметров задано начальное значение 1.
Пример 2.50. Параметры с начальными значениями
procedure NEW ADD(FIRST,SECONDг in INTEGER := 1;
RESULT: out INTEGER) is
begin
RESULT s= FIRST+SECONDf
end;
Новая процедура может, как и прежняя, использоваться для
суммирования двух входных аргументов с выдачей результата.
Если, однако, один из них опущен, вместо него по умолчанию
используется значение 1, и мы получаем функцию «следующий».
Пример 2.51. Подразумеваемое значение отсутствующего ар-
гумента
ADD (FIRST :« 4; RESULT »s Z)-- значение отсутствующего
• - аргумента равно 1, получаем Z s ’
При явном именовании требуется указать не только имена,
но и виды связи параметров. Вид связи входных и выходных па-
раметров обозначается при вызове символами «:=» и «=:» соот-
ветственно. Есть также третий вид, универсальный (in out), оя
обозначается
2,11. Виды связи параметров 93
2.11. Виды связи параметров
Семантика трех допустимых в Аде видов параметров опреде-
лена в руководстве по языку следующим образом:
in Параметр рассматривается как локальная постоянная,
значение которой определяется соответствующим ар-
гументом.
out Параметр рассматривается как локальная переменная,
значение которой после выполнения подпрограммы
присваивается соответствующему аргументу.
in out Параметр рассматривается как локальная переменная.
Имеется возможность использовать значение соответст-
вующего аргумента и присваивать ему новые, значения.
Семантика каждого вида определена независимо от того, реа-
лизована ли передача параметров с копированием значений аргу-
ментов или с доступом непосредственно в среду вызова. Поэтому
передача входных аргументов-переменных может быть реализо-
вана либо через доступ только для чтения к их локальным ко-
пиям, созданным в момент входа в процедуру, либо через доступ
только для чтения к самим этим нелокальным переменным в сре-
де вызова. Выходные параметры могут быть реализованы как ло-
кальные переменные, значение которых при выходе присваивается
переменным-аргументам, либо как прямые ссылки на эти нело-
кальные аргументы. Универсальные параметры можно реализо-
вать как локальные переменные с копированием значений при
входе и выходе либо как ссылки на нелокальные переменные-
аргументы.
Такая семантика обеспечивает независимость передачи пара-
метров от реализации в том смысле, что она не фиксирует кон-
кретный механизм — копирование или совместное использова-
ние. Она позволяет компилятору оптимизировать время или
память в зависимости от того, что эффективнее. Пользователю
предоставляется простая реализация — независимая абстракт-
ная модель передачи параметров.
Однако такой подход требует считать неопределенными про-
граммы, результат которых зависит от реализации передачи пара-
метров копированием или совместным использованием. Тем самым
объявляется незаконным целый класс процедур, которые в языке,
где копирование и совместное использование параметров проце-
дуры различаются, были бы совершенно законными; естественно,
что описываемые этими процедурами действия должны быть
описанье как-то иначе. Более того, компилятор, вообще говоря,
не в состоянии проверить законность передачи параметров. Про-
блема, зависит ли результат программы от той или иной реализа-
ции механизма связи параметров, в общем случае неразрешима.
94
Гл. 2. Основные черты языка
Компилятор должен либо считать незаконными некоторые нор-
мальные программы, либо считать нормальными некоторые
незаконные, создавая тем самым проблему их мобильности при
разных реализациях.
Серьезность отмеченных проблем отчасти зависит от того, в
какой мере семантика исключает действительно полезные про-
граммы, а отчасти от того, в какой мере невозможность точно
реализовать такую семантику — практический, а не теоретиче-
ский вопрос. Для ответа на эти вопросы требуется больший опыт
программирования на языке и работы с реальными промышлен-
ными компиляторами.
Раньше мы приводили примеры входных и выходных пара-
метров, а сейчас рассмотрим использование универсальных па-
раметров в вызовах описанных ранее процедур.
Пример 2.52. Вызовы процедур с универсальными парамет-
рами
SWAP(X ;=: А, Г :=s в);
SORT(VECT);
Наш старый знакомый, процедура SWAP(OBMEH), имеет два
универсальных параметра (скажем, X и Y), значения которых и
используются, и изменяются. У процедуры SORT (СОРТИРОВ-
КА) из гл. 1 один параметр — вектор, элементы которого выби-
раются для определения соотношения их величин и изменяются
(присваиванием), чтобы в результате вектор оказался отсорти-
рованным.
В обоих случаях параметр действует как локальная перемен-
ная, которая обеспечивает доступ к соответствующему аргументу
и присваивание ему. Семантика не зависит от того, выполняются
ли действия над локальной копией аргумента или в той области
памяти вызывающей программы, где хранятся аргументы. В обеих
процедурах, и SWAP, и SORT, не делается ничего, что выявило
бы различия между копированием и совместным использованием.
Однако в случае многозадачной работы, когда некоторая другая
задача имеет доступ к области памяти, содержащей фактические
параметры, такие различия были бы возможны. Поэтому закон-
ность процедур SWAP и SORT зависит не только от их опреде-
лений, но также от выполнения некоторых ограничений на среду
вызова.
2.12. Функции и вырабатывающие значение процедуры
В общем случае процедуры имеют побочные эффекты в том
смысле, что они изменяют значения нелокальных переменных.
Например, побочный эффект вызова ’’SWAP (А, В)” состоит в
2.12. Функции и вырабатывающие значения процедуры
95
том, что нелокальные переменные А и В обмениваются значе-
ниями.
В Аде различаются процедуры, которые изменяют внешнюю
среду за счет побочных эффектов, и функции, для которых по-
бочные эффекты запрещены, их единственное воздействие на сре-
ду — возврат результата, который может быть использован как
операнд в выражении. Приведенная выше процедура ADD
(СЛОЖИТЬ) может быть описана как функция следующим об-
разом.
Пример 2.53. Функция ADD
function ADD(X,Y: in INTEGER) return INTEGER IS
begin
return (X+Y); - - возвращает целый результат
end;
У приведенной функции ADD меньше параметров, чем у соот-
ветствующей процедуры, но зато она возвращает результат, ко-
торый синтаксически должен быть операндом выражения.
Пример 2.54. Вызов функции ADD
Z := 2*ADD(A,B) + 1?
*• - удвоенная сумма А и В плюс!
Функция может иметь только входные параметры, присваи-
вания глобальным переменным недопустимы, и единственное
законное воздействие на среду — возвращаемый результат. Эти
ограничения позволяют выполнять оптимизации, например
F(X)+F(X)=2*F(X), что может существенно сократить работу
по выполнению выражений.
Функции могут рекурсивно вызывать себя, как в следующем
примере.
Пример 2.55. Рекурсивная функция
function FACT(I: INTEGER) return INTEGER is
begin
if I ® 1 then
return 1;
else
return l*FACT (I-X); , -• рекурсивный вызов ФАКТ
end if;
end FACTj
Этот пример показывает, что может быть больше одной точки
возврата из функции в вызывающую программу. Вызов FACT(I)
Для 1=5^1 приводит к рекурсивному выполнению I*FACT(I—1)
96
Гл. 2. Основные черты языка
при попытке вычислить подлежащее возврату значение и к воз-'
врату I для 1 = 1. Таким образом, вызов FACT(3) приводит к ре-
курсивным вызовам FACT(2) и FACT(l), вычислению FACT(l)
и раскручиванию рекурсии.
Пример 2.56. Вызов функции факториал
ГАСТ(З) = 3*FACT(2) - - перввтВуровень рекурсии
s 3*2*FACT(1) - - второй уровень рекурсии
= 3*2*1 --третий уровень рекурсии
Общий вид спецификации функции таков:
function имя [спецификация параметров] return
спецификация типа is
[объявления локальных переменных]
begin
последовательность операторов, содержащая предложение
возврата
end [имя];
Отметим, что как спецификации параметров, так и объявле-
ния локальных переменных могут отсутствовать в спецификации
функции точно так же, как и в спецификации процедуры. Однако
тип значения, возвращаемого функцией, должен быть известен
всегда.
Есть ситуации, когда удобно допустить функцию с глобаль-
ными переменными, например когда желательно подсчитать,
сколько раз некоторая функция выполнялась. Такие функции
реализованы в Аде в виде вырабатывающих значение процедур.
Следующая процедура, вырабатывающая значение, вычисляет
факториал числа N и увеличивает глобальную переменную
СЧЕТЧИК, с помощью которой подсчитывается количество вы-
полнений функции.
Пример 2.57. Факториал в виде вырабатывающей значение
процедуры
procedure FACT(I; INTEGER) returri INTEGER ig
begin f
count :=: COUNT+1; *- увеличить значение глобальной переменной
if 1 = 0 then
return 1;
else
return X*FACT(l-l)?
end
end FACT?
Чтобы свести к минимуму взаимные влияния глобальных пе-
ременных, возвращающих значение процедур и вызовов этих
2.13. Операторы контроля
97
процедур, накладывается ограничение: вырабатывающие значе-
ние процедуры могут вызываться только там, где их глобальные
переменные недоступны.
Такие процедуры внешне ведут себя как функции, но порядок
выполнения их вызовов оптимизировать нельзя. Такие опти-
мизации, как F(X)4-F(X)=2* F(X), недопустимы (в случае
FACT это привело бы к тому, что значение переменной COUNT
(СЧЕТЧИК) оказалось бы меньше, чем должно быть, что в опре-
деленном контексте могло бы критическим образом повлиять на
ход вычислений).
Если F — функция, а Р — вырабатывающая значение про-
цедура, тогда F(X)4-F(X)+P(X) можно преобразовать в 2*F(X)+
+Р(Х), в то время как F(X)+P(X)-f-F(X) так преобразовать
нельзя. Вырабатывающие значение процедуры, входящие в вы-
ражение, разбивают его на подвыражения, внутри которых вы-
полнять оптимизацию можно, но выходить за границы подвыра-
жений нельзя.
Приведенные примеры показывают, что синтаксически функ-
ции, процедуры и блоки имеют общую структуру. Они имеют
тело, состоящее из последовательности операторов, и совокуп-
ность объявлений локальных идентификаторов. Они могут со-
держать нелокальные идентификаторы, введенные в совокупно-
сти объявлений текстуально объемлющего сегмента. Блоки опи-
сываются и выполняются непосредственно в теле некоторого дру-
гого программного сегмента. Процедуры и функции описываются
в совокупности объявлений (либо мк раздельно компилируемые
сегменты программы) и в дальнейшем вызываются в теле, где до-
ступно это объявление.
Функции могут вызываться также при задании начальных
значений в совокупности объявлений сегмента' программы. На-
значение совокупности объявлений принципиально отличается
от назначения тела соответствующего программного сегмента, и
для всех сегментов эти части жестко синтаксически разграниче-
ны. Однако тот факт, что вычисления при инициализации в мо-
мент объявления в принципе так же мощны, как н вычисления в
теле сегмента, ослабляет это различие.
2.13. Операторы контроля
Оператор контроля состоит из зарезервированного слова
assert (утверждать), за которым следует условие. Эти операторы
выполняются непосредственно в точке, где они стоят, и вызывают
вычисление значения соответствующего условия. Если оно рав-
но TRUE, продолжается нормальное выполнение следующего
оператора. В противном случае могут быть начаты действия по
< »5в
Гл. 2. Основные черты языка
£
обработке ошибки (определенные исключительной ситуацией
ASSERT.ERROR).
Оператор контроля требует, чтобы связанное с ним условие
было истинно при всяком его выполнении. Он дает программисту
возможность явно использовать обеспечиваемые системой средст-
ва динамического контроля. Ниже даны примеры некоторых си-
туаций, в которых такие операторы могли бы быть полезными.
Пример 2.58. Возможные операторы контроля
aggertXAOj .. проверить X перед делением на вего
agjiert LENGTH1 LENGTHS j • - проверить равенство длин двух векторов
I _in 1.. 100; . - проверить принадлежность индекса диапазону
В последнем операторе используется новая форма отношения,
которое истинно, если значение слева принадлежит множеству,
указанному справа от in, и ложно в противном случае,.
Оператор контроля можно рассматривать динамически как
средство условного прекращения вычислений. Полезно, однако,
смотреть на него также как на задание статического инварианта,
Который должен быть истинным всегда, если программа правиль-
на. Если имеется верификатор программ, иногда можно дока-
зать, что данное условие всегда будет выполняться в данной
точке. В таком случае утверждение проверено статически, и ди-
намическая его проверка не нужна.
Операторы контроля могут использоваться как помощь вери-
фикатору в доказательстве правильности программы; они обес-
печивают промежуточные утверждения, из истинности которых,
будь она доказана, следует доказательство правильности про-
граммы. Если мы можем найти утверждения, не только необхо-
димые, но и достаточные для правильной работы программы,
полезно включать их в тестовые версии программы, даже если их
невозможно доказать, поскольку динамическая проверка пра-
вильности такого утверждения даже для небольшого числа тестов
поможет увеличить степень нашего доверия к правильности про-
граммы.
Можно заблокировать выполнение операторов контроля, за-
блокировав обработку исключительной ситуации ASSERT.ER-
ROR. Таким образом, проверку утверждений можно использо-
вать как отладочное средство и отключать при работе в реальных
условиях или только для вычислений, критичных в отношений
времени.
ГЛАВА 3
ОПИСАНИЕ ДАННЫХ
3.1. Объекты и действия
Программы определяют последовательность действий на сово-
купности объектов данных. Действия определяются выражения-
ми и операторами. Объекты данных определяются в Аде объяв-
лениями.
При написании программ можно принять точку зрения, со-
гласно которой самым важным считается описание алгоритма,
а описание данных, которыми оперирует этот алгоритм, пред-
ставляется менее существенным. Эту точку зрения назовем ориен-
тированной на действия. Альтернативной является точка зре-
ния, ориентированная на объекты, при которой важнейшим счи-
тается описание объектов вычислений, а алгоритмы рассматри-
ваются как вспомогательные сущности, нужные для описанйя
поведения объектов.
Ориентированная на действия точка зрения пригодна прежде
всего для научных расчетов, где вся сложность заключается в
алгоритме, а структуры данных относительно просты. Ориенти-
рованная на объекты точка зрения лучше соответствует систем-
ному программированию и созданию встроенного программного
обеспечения, где структуры данных представляют состояния
системы, изменяющейся во времени.
Ранние языки, подобные Фортрану, были ориентированными
на действия (что отражается термином «алгоритмические языки»).
Однако новые сферы применения вычислительных машин все
более требовали ориентированной на объекты точки зрения, прй
которой начинают с описания объектов реального мира (кораблей,
самолетов, банков или городов) некоторыми структурами данных,
а лишь затем переходят к алгоритмам для работы с этими объек-
тами.
В Аде имеются мощные средства описания как алгоритмов, так
и данных. Однако выразительные средства для описания алго-
ритмов были достаточно хорошо развиты уже в ранних языках,
подобных Фортрану. Ада отличается от таких языков прежде
всего в области описания данных.
В настоящей главе будут описаны имеющиеся в Аде среДствд
определения типов, в частности числовых типов, перечисляемых
100
Гл. 3. Описание данных
типов, регулярных, комбинированных и ссылочных типов. Но
прежде обсудим общие свойства системы типов в Аде:
1. Предопределенные типы — для которых предопределено
множество значений и применимых операций.
2. Производные типы — которые определяются через ранее
определенные типы.
3. Уточнения — которые уточняют множество значений не-
которого типа, но не влияют на набор применимых операций.
4. Анонимные определения типов — которые определяют
типы через их атрибуты, а не через ранее определенные типы. Для
таких типов будут рассмотрены правила эквивалентности.
5. Подтипы — учитывающие ограничения на исходный (ро-
дительский) тип, но считающиеся тем же типом, что и исходный.
6. Запрос атрибута — который позволяет программисту уз-
навать атрибуты типа.
7. Классификация типов на скалярные, структурные и ссы-
лочные.
3.2. Система типов в Аде
3.2.1. Предопределенные типы
Тип данных определяет множество значений, которые могут
принимать объекты данных этого типа, и множество операций,
применимых к этим объектам.
В Аде есть несколько предопределенных типов данных, чьи
множества значений и операций определены в системе заранее.
К предопределенным относятся типы INTEGER, FLOAT и
BOOLEAN. Эти типы данных уже многократно нами использо-
вались, но все-таки проиллюстрируем их следующим примером.
Пример 3.1
ртосеЗиге EREDEEINEDjm>ES is .
j,jj integer 1= 1;«-целые переменные, инициализированные константой*
, FLOAT := 1.0; -- плавающие переменные, инициализированные
i -- константой 1.0
А,В,Ct BOOLEAN TRUE; -- логические переменные, инициализирований»
-- константой TRUE
begin
i := 2*J+5; - целые константы, переменные и операнда
X 3.5+У72. 5 ; г - плавающие константы, переменные и опЧР»1**
с (not в) or А; --логические’переменные к операция
епЗ;
С каждым предопределенным типом связано множество кон-
стант, которыми можно пользоваться для представления зиаче^
ний этого типа данных. Целые константы — это последователь-
ности цифр. Плавающие константы содержат десятичную точку
3.2. Системы типов в Аде
101
или символ Е. Логический тип данных представлен двумя кон-
стантами TRUE и FALSE. Константы всех предопределенных
типов синтаксически различны.
Множество операций каждого типа данных логически (но не
обязательно синтаксически) отличается от операций любого
другого типа. Символ «-Ь» используется для обозначения опера-
ции сложения как типа FLOAT, так й типа INTEGER-. Но опера-
ция «+» для целых операндов отличается по смыслу от операции
«+» для плавающих операндов. Эта неоднозначность, вызванная
синтаксическим перекрытием символов операций, может быть
устранена в период компиляции за счет проверки типов операн-
дов каждой операции. Поэтому компилятор в состоянии понять,
что символ «+» между двумя операндами целого типа обозначает
целое сложение, а между двумя операндами плавающего типа —
плавающее сложение, в то время как «+» между операндами
другого типа — ошибка программиста. Так как целое и плаваю-
щее сложение обычно реализуются различными машинными
командами, то скорее всего компилятор будет по-разному про-
граммировать целое и плавающее сложение как на промежуточ-
ном, так и на объектном языке.
3.2.2. Производные типы
В Аде можно определять производные типы, которым соответ-
ствуют те же множества значений и операций, что и исходным
типам, но которые представляют логически отличающиеся классы
объектов. В следующем примере введен производный тип
WEIGHT, у которого то же множество значений, что и у типа
INTEGER, и то же множество операций. Язык требует тракто-
вать веса и целые как логически различные объекты данных и
запрещает складывать веса с целыми и (или) присваивать веса
целым переменным.
Пример 3.2. Производные типы
Eroceflure DERIVED TTPES is
WEIGHT is new INTEGER; - - WEIGHT - НОВЫЙ тип, ПРОИЗВОДНЫЙ
— ОТ INTEGER
i: integer ss 0; — инициализированная целая переменна*
W: WEIGHT te 0; ~ ~ переменная типа WEIGHT, яницналитарлввпя^
. — целой константой
fiegin к
w — правильно, потому что WEIGHT наследует 1 и операцию +
— йепразильно, так как W и I разных типов
” ; --неправильно, WHlpa3Hbixтипов
WEIGHT (I); » - правильно, WEIGHT (I) ТШИ WEIGHT
sa integer (W) +1; - - правильно, INTEGER (W) тип* INTEGER
4 ;aw*W; умножать веса можно, так как* наследуется
102
Гл. 3. Описание данных
Этот пример показывает, что производный тип WEIGHT на-
следует и константы, и операции исходного типа INTEGER.
Константа 1 в выражении «W+1» понимается по контексту как
константа типа WEIGHT, а операция «+» понимается как опе-
рация сложения объектов типа WEIGHT, потому что ее операн-
ды типа WEIGHT. Поэтому определение производного типа
WEIGHT приводит к перекрытию констант и операций целого
INTEGER
✓“I WEIGHT^
HEIGHT
TRUCKWEIGHT
Рис. 3.1. Древовидная структура производных типов.
типа. Однако в этом случае реализация сложения весов на ма-
шинном языке скорее всего не будет отличаться от реализации
сложения целых. Компилятор должен лишь проверять правиль-
ность программ на исходном языке. Программа на объектном
языке скорее всего не будет отличаться от той, которая получи-
лась бы для программы с W, объявленной целой переменной.
Механизм производных типов можно применить для построе-
ния древовидной структуры связанных типов, как показано на
рис. 3.1.
Функции преобразования типов автоматически считаются оп-
ределенными для соседних вершин такой древовидной структу-
ры, но ими нельзя пользоваться для прямого преобразования
между отдаленными вершинами.
Пример 3.3. Преобразования для производных типов
procedura RECONVERSION is
type, WEIGHT is new INTEGER; . - новый ТИП (ВЕС)
> tyee HEIGHT is new INTEGER; . . новый тип (ВЫСОТА) •
TRUCK_WEIGHT is new WEIGHT; - - НОВЫЙ ТИП (ВЕС-ТОВАРА)
I: INTEGER ;=« 0;
Ws WEIGHT 0;
Hs HEIGHT := 0;
TWs TRUCK WEIGHT :« 0;
begin
н s« INteger(i) ; --правильное преобразование ме»(пу «соседями»
Н height (w); -« неправильное преобразование —- это не «соседи»
Н ; = HEIGHT (INTEGER (W)); - - правильно
ИГ :я TRUCK_WEIGHT (WEIGHT(I)); --правильно
Н := HEIGHT (INTEGER (WEIGHT (TW) И; --правильно
end TY₽E_CONVERSION;
3.2. Системы типов в Аде
103
Производные типы позволяют пользователю различать логи-
чески разные классы объектов. Однако правило наследования из
исходного типа всех констант и операций позволяет чересчур
много. Например, бессмысленно перемножать веса и присваивать
результат переменной типа WEIGHT, как в операторе ”W : =
W*W;”. Механизм наследования для производных типов недо-
статочно точен для работы с именованными величинами (едини-
цами измерения физических величин). Это показано в следу-
ющем примере.
Пример 3.4. Преобразование единиц измерения
procedure UNITS is --процедура ЕДИНИЦЫ
type LENGTH is new FLOAT; - - длина — основная единица
type area is new float • - произведение дайн должно было бы давать
-- площадь
type TIME is new FLOAT; . - время — основная единица
type VELOCITY is newFLOAT; - . даина/время ДОЛЖНО было бы дать СКОРОСТЬ
LlzL2s LENGTH :== 0.0;
А1,А2: AREA := 0.0;
Tl,T2s TIME s« JO.’O;
Vs VELOCITY;
begin
LI := L1+L2; -- правильное сложение длин
LI := L1*L2; • - произведение длин оказывается данной
Al := L1*L2; •» неправильно, ведь результат —• дайна
V :== L1/T1; «•- неправильно смешаны типы
end UNITS;
Два последних неправильных оператора этого примера мож-
но сделать правильными, если определить функции, перекрываю-
щие операции * и /, как показано ниже.
Пример 3.5. Функции для преобразования единиц измерения
procedure OVERLOAD is . - процедура ПЕРЕКРЫТИЕ
function "*u (X,Ys LENGTH) return AREA is
begin
return AREA (FLOAtT (X*X));
end
function "/“ (Ls LENGTH; T: TIME) return VELOCITY is
begin
x return VELOCITY(FLOAT(L)/FLOAT(T));
end
begin
Al := L1*L2; • « перемножение длин дает площадь
V := Ll/Tl; «• деление дайны на время дает скорость
end OVERLOAD;
Преимуществом свободного правила наследования для про-
8зВодных типов является его простота, и, по всей вероятности,
104
Гл. 3. Описание данных
программист-прикладник предпочтет это правило более сложно-
му набору правил наследования, позволяющему корректно рабо-
тать с единицами измерения.
Однако если пользователь захочет определить производные
типы с более тонкими правилами наследования, ему придется
проделать немного больше работы: он должен Поместить функ-
ции, подобные приведенным выше, в Некоторый библиотечный
пакет, как описано в гл. 4.
3.2.3. Уточнения
Множество значений некоторого типа может быть ограничено
посредством уточнений, связанных с определением типа. Напри-
мер, множество значений типа WEIGHT (ВЕС) можно ограни-
чить одним из следующих уточнений диапазона.
Пример 3.6. Определения производных типов с уточнениями
1
type weight is new INTEGER range 0.. 1000} - • целые в диапазоне 0..1000
•type WEIGHT is new INTEGER range 0, .MAXWEIGHT? -- величина диапазона
, -- будет меняться при исполнении
type WEIGHT is new INTEGER range O..INTEGER'LAST; --любое
**7— .—.—. . --неотрицательное целее
Уточнения показаны выше на примере целых типов, но они
могут применяться к самым разнообразным типам. Об этом мы
будем говорить впоследствии при рассмотрении каждого вводи-
мого типа.
3.2.4. Определения анонимных типов
и эквивалентность типов
Общий синтаксис объявлений типа выгляди? так»
type имятипа is определение-типа;
Определение типа может быть или определением производного
типа, или определением анонимного типа. Первое определяет но-
вый тип через старый именованный тип с возможным уточнением
в соответствии со следующим синтаксисом:
new имятипа [уточнение];
Второе определяет новый тип непосредственно через атрибу*
ты этого нового типа. Например, определение производного
типа ’’new INTEGER range 1 . . 1000” Может быть заменено опр®*
делением анонимного типа ’’range 1.. 1ОО0”, не использующим на-
звание типа INTEGER. Три объявления производных типов из
предыдущего примера можно заменить следующими опреДОЛ®"
ниями анонимных типов.
3.2. Системы типов в Аде
105
Пример 3.7. Объявления типов с определениями анонимных ти-
пов
type WEIGHT is range 0,.1000?
type WEIGHT is range 0. .MAXWEIGHT?4
type WEIGHT is range 0,.INTEGER'LAST?
Определения анонимных типов были применены выше для
объявления имен новых типов. Но их можно использовать и в
объявлениях объектов непосредственно для объявления типа
некоторого объекта.
Пример 3.8. Объявление объекта анонимного типа
11 range 0..1000? » «I — делая.переменная анонимного типа
A; array (1.. 1000) of INTEGER? -- массив анонимного типа <
SEX: (м,Е)? < . • - объект анонимного комбинированного типа
Каждое определение типа в Аде вводит отдельный новый тип.
Следовательно, каждое объявление анонимного типа следует рас-
сматривать как вводящее некоторый отдельный тип. Поэтому А и
В в следующем примере одного типа, а тип С считается отличным
от типа объектов А и В, так как он введен другим определением
типа.
Пример 3.9. Эквивалентность типов для анонимных типов
A,B; array (1.. 100) of INTEGER? -• у А и В один и тот же тип >
С; array (1..100) of integer? • - тип С отличается от типа А и В
Анонимные типы иногда полезны для сокращения записи и
помогают устранить избыточные имена типов. Однако исполь-
зовать их следует с осторожностью, так как из-за них возможна
непредвиденная несовместимость типов. В частности, анонимные
типы не следует применять в параметрах процедуры, потому что
у такого параметра будет уникальный анонимный тип и никак
не удастся вызвать эту процедуру с совместимым по типу аргу-
ментом.
Пример 3,10. Проблема параметров анонимного типа
&: аггау(1. .100) of INTEGER? ' »« А анонимного типа
procedure Т(Х: array/1. .100) of INTEGER) ? --тип X отличен от А
Т (А) ; - - неправильный вызов, тип А несовместим с X, >
• . так хак У X он анонимный и нельзя привести А к типу X
Так как спецификация анонимного типа для параметров про-
цедуры бессмысленна, то это считается синтаксически недопусти-
мым (ошибкой периода компиляции). Типы параметров процедуры
следует всегда указывать с помощью имен типов подобно тому,
Как в следующем примере это сделано с помощью имени «VEC-
106
Гл. 3, Описание данных
Пример 3.11. Эквивалентность для именованных типов
type VECTOR is array(1..100) of INTEGER;
A,BS vector; -- А'и В типа VECTOR
C t vector; - - С того же типа, что,и А, В
procedure T(X; VECTOR); -- X того же отца, что и А, В, С
т (А); - • правильный вызов; А и X одного типа
Итак, два идентификатора переменных имеют в Аде один и тот
же тип, если они объявлены с помощью одного и того же имено-
ванного типа или если они объявлены в одном объявлении объ-
ектов с помощью одного и того же анонимного определения типа.
3.2.5. Подтипы
Подтипы в Аде — это сокращения для названия типа и свя-
занного с ним уточнения. Они вводятся объявлением подтипа,
похожим по форме на объявление производного типа. Однако
переменные различных подтипов некоторого заданного типа
можно свободно комбинировать между собой и с переменными и
константами исходного типа.
Пример 3.12. Подтипы и проверка диапазона
procedure SUBTYPES is
subtype SMALL is INTEGER range -100..100; - - объявление подтипа
SMALL
S ,T; SMALL s« 0; •• - S, T — переменные подтипа SMALL
I, J: INTEGER :« 0; — INTEGER — исходный тип
begin
S := 50; -- правильность может проверить компилятор
S := S+10; >> может потребоваться проверка диапазона при исполнении
X ;= S; -- правильное присваивание
S := I; «> может потребоваться проверка при исполнении
I := S+J; переменные типа и подтипа можно комбинировать
S := s*s-T*T; -- при вычислении выражения нарушения ограничений
end SUBTYPES; ~ - подтипа допустимы; проверка нужна при присваивании
Этот пример показывает, что уточнения иногда можно прове-
рить при компиляции (в случае ”S := 50”), но может потребовать-
ся и проверка при исполнении (в случае ”S := S+10;”). Сочета-
ние разных подтипов при присваивании допустимо, но может по-
требоваться проверка диапазона. Выражения (подобные ”S*S—
Т*Т”) вычисляются как для переменных исходного типа, но при
последующем присваивании требуется проверка диапазона.
Преобразования типа и необходимость проверки диапазона
для типа, его подтипов и производных типов показаны на рис. 3.2.
3.2. Системы типов в Аде
107
Заметим, что объявление подтипа, в котором исходный тип
I указан без уточнения,— это способ переименования исходного
типа.
Пример 3.13. Переименование типа
spbtype INT is integer; - - INT — новое название для INTEGER
Синтаксис объявления подтипа таков:
subtype новоеимя is имятипа [уточнение];
Таким образом, новое имя (подтипа) следует определять через
название некоторого типа. Поэтому следующее определение под-
типа неправильное.
исходный тип
никакой >
проверки
диапазона
ненужно
никакое смешение недопустимо
без явного преобразования типа
проверка при
выполнении
присваивания
производный
тип
j
I
j Рис. 3.2. Проверка диапазона и явное преобразование типа.
i Пример 3.14. Подтип следует определять через именованный
; тип
subtype WEIGHT is range ’0. • 1QQ0; * “ неправильно, так каклодтип нужно
‘ • • *- определять через название типа
i
; Определение WEIGHT как уточненного (ограниченного) це-
i лого типа (или подтипа) более точно характеризует реальные
I значения возможных весов и позволяет некоторые ошибки (ска-
> жем, отрицательный вес) находить автоматически. Однако, вооб-
ще говоря, нарушения диапазона нельзя проверить при компи-
ляции. Может потребоваться вставлять в объектную программу
j дополнительные команды для проверки диапазонов при испол-
нении программы. Вычисления с уточненными переменными во
внутренних циклах могут существенно замедлить счет. Поэтому
в языке имеется возможность отключать проверку диапазона
i (см. разд. 1.18).
| Уточнения были показаны только для целых типов, но на
самом деле они применимы к самым разнообразным типам данных
и по-разному записываются для различных категорий типов.
Это будет показано по мере введения в рассмотрение каждой из
таких категорий.
108
Гл. 3. Описание данных
3.2.6. Предопределенные атрибуты
Типы данных определяют набор атрибутов, которыми об-
ладают объекты данного типа. Когда эти атрибуты требуются в
процессе вычислений, их можно получить с помощью запроса
атрибута.
Запрос атрибута — это составное имя специального вида. Оно
состоит из имени типа объекта, за которым следуют кавычка
и имя атрибута.
Пример 3.15. Запросы атрибутов
INTEGER'EIRST
INTEGER'LAST
WEIGHT'LAST
VECTOR'FIRST
VECTOR'LENGTH
V'LENGTH
- . первое (наибольшее по модулю трвцааяыюф ЦООЛ
- - последнее (наибольшее) целое
- - последнее значение типа WEIGHT
• - первый индекс (нижняя граница индексов) типа VECTOR
» - длина объекте» типа VECTOR
- - длина объекта V типа VECTOR
Запросы атрибутов — это переменные, доступные только для
чтения (т. е. на самом деле это постоянные). Их значениями мож-
но пользоваться для управления процессом вычислений. Напри-
мер, атрибуты V’FIRST, V’LAST можно применять для управ-
ления переменной цикла for в цикле по элементам вектора V.
Пример 3.16. Применение атрибутов для управления циклом
fog X in у'FIRST. .V'LAST loop •• от первого ДО ПОСЛШЯйЙВДОСа
SUM := SUM+V(I)j
- - или более сложные
f вычисления над V
end loop?
Каждая категория объектов имеет свои атрибуты. О них пой-
дет речь при рассмотрении этих категорий. Список, включаю-
щий 45 предопределенных атрибутов, приведен в приложении А
руководства по языку.
3.2.7. Классификация типов
Типы данных в Аде можно разбить на три категории;
1. Скалярные типы, с которыми связаны объекты данных без
компонент. Это числовые, логические, символьные и перечисляе-
мые типы.
2. Составные типы — регулярные и комбинированные — с
ними связаны объекты данных с компонентами, доступными по
селекторам.
3.2. Системы типов в Аде
109
3, Ссылочные типы, с которыми связаны объекты данных,
создаваемые динамически при выполнении команд генерации в
последовательности операторов программного сегмента.
Скалярные типы в Аде классифицируются в свою очередь сле-
дующим образом:
1. Целые типы — их можно использовать для точных вычис-
лений.
2. Перечисляемые типы — у них конечный набор значений,
задаваемый явным перечислением его элементов. Типы BOOLE-
AN и CHARACTER можно считать перечисляемыми типами.
3. Плавающие типы — их можно использовать для прибли-
женных вычислений с указанной относительной погрешностью
(числом значащих цифр).
4. Фиксированные типы — их можно использовать для при-
ближенных вычислений с указанной абсолютной погрешностью
(числом знаков после десятичной точки).
Целые типы имеют упорядоченное множество значений с ми-
нимальным и максимальным элементами. У каждого отличного
Рис. 3.3. Классификация типов данных.
от максимального элемента есть единственный последующий, у
каждого отличного от минимального — единственный преды-
дущий.
Упорядоченное множество с минимальным и максимальным
элементами и функциями «последующий» и «предыдущий» назы-
вается дискретным диапазоном. Тип данных, у которого множе-
Гл. 3. Описание данных
сТвр значений — дискретный диапазон, называется дискретным
типом.
В Аде и целые, и перечисляемые типы имеют дискретные
диапазоны. У плавающих и фиксированных типов множество
значений упорядочено, но это не дискретные типы, потому что
для их множеств значений не определены функции «последующий»
и «предыдущий». Плавающие и фиксированные типы называются
вещественными типами.
Дискретные диапазоны можно использовать как множества
индексов массивов и как область изменения переменной цикла.
В Аде как целыми, так и перечисляемыми типами можно поль-
зоваться для индексирования и организации повторений, а ве-
щественными типами — нельзя.
Скалярные типы удобно разделять на дискретные и веществен-
ные типы в соответствии с рис. 3.3.
В оставшихся разделах этой главы пойдет речь сначала об оп-
ределении различных категорий скалярных типов, а затем — об
определении составных и ссылочных типов.
3.3. Числовые типы
При определении числовых типов мы исходим из понятия чис-
ла как абстрактного математического объекта, над которым мож-
но выполнять абстрактные алгебраические операции. Однако
конечность вычислительных машин требует ограничить диапазон
значений числовых типов. В случае плавающих и фиксированных
типов кроме этого требуется еще и ограничить точность пред-
ставления значений чисел.
В Аде есть предопределенные целые и плавающие типы с диа-
пазонами и ограничениями точности, зависящими, вообще го-
воря, от размера машинного слова в реализации. Предопреде-
ленных фиксированных типов нет.
Необходимость в числовых типах, определяемых программи-
стом, возникает частично из желания обеспечить мобильность
Программ относительно разных реализаций языка, частично из
Потребности различать в приложениях объекты с тем же самым
множеством значений и, наконец, из потребности гарантировать
диапазон и точность для числовых значений.
3.3.1. Целые типы
Предопределенный тип INTEGER обладает определяемым
реализацией диапазоном, наименьшее (наибольшее по модулю
отрицательное) значение которого доступно посредством запроса
атрибута INTEGER’FIRST, а наибольшее значение — INTE-
GER’LAST. Реализация может обеспечить также предопреде-
3.3. Числовые типы
111
ленный тип LONG_ INTEGER с диапазоном, большим, чем у
INTEGER, и SHORT_1NTEGER с диапазоном, меньшим, чем
у INTEGER.
Программист не может управлять диапазоном предопреде-
ленных целых типов данных. Содержащие их программы могут
оказаться немобильными по отношению к разным реализациям
языка. Программист может пожелать определить целые типы дан-
ных с явными уточнениями диапазона как в интересах мобиль-
ности, так и потому, что эти уточнения (например, неотрицатель»
ность) могут естественно возникнуть в его задачах. В следующем
примере тип INDEX с уточнением диапазона можно использо-
вать для ограничения размеров массивов, тип NATURAL с яв-
ным уточнением диапазона требует, чтобы переменные этого тина
были натуральными числами, а тип SHORT_INT с уточнением
диапазона позволяет размещать переменные этого типа в 16-раз-
рядном машинном слове.
Пример 3.17. Объявление и использование целых типов
procedure INTEGER_TYPES is
type INDEX is range 1.. 100; - « диапазон индексов
type NATURAL is range 1. .INTEGER’LAST; -» положительные целые
type SHORT_INT Is range -32768. ,32767; »• короткие (16-разрядные)
~ - --целые
I, J: INDEX; - - две индексные переменные
N1 ,N2 s NATURAL; - - две переменные с натуральными значениями
- - две короткие целые переменные
« - присваивание индексной переменной
> « нужна проверка диапазона при исполнении
- - для целых предопределены функции
- - PRED — предыдущий, SUCC — последующий
- - нужна проверка диапазона при исполнении
- - недопустимая комбинация типов
.S1,S2: SHORTJNT;
begin
I 80;
I 1+1;
I :=» INTEGER'SUCC(I)
SI := S2*S2;
N1 := I;
end INTEGER TYRES;
Назовем целым типом такой тип данных, множество значений
которого — поддиапазон целых и операции которого — целые
операции. Целые типы можно определять как производные от
предопределенных типов (разд. 3.2.2) или как анонимные типы
(разд. 3.2.4). Наименьшее и наибольшее значения произвольного
целого типа Т доступны с помощью запросов атрибутов T’FIRST,
T’LAST. Таким образом LONG_INTEGER’LAST дает значе-
ние наибольшего длинного целого.
Целые константы — это строки цифр, разделенных, возмож-
но, символом подчеркивания (например, 1_234_567). Общий
синтаксис целых таков:
цифра {[подчеркивание] цифра}
112
Гл. 3. Описание данных
В Аде допустимы целые константы с основанием, которое мо-
жет быть любым от 2 до 16. Синтаксис целых констант с основа-
нием таков:
основание # обобщенная-цифра {[подчеркивание] обобщен-
ная-цифра}
где обобщенная цифра для оснований больше 10 — это цифра
или символы А, В, С, D, Е, F для представления 10, 11, 12, 13,
14, 15 соответственно.
Пример 3.18. Целые константы с основанием
2#1101 --представляет 13
2#11Ь1 ЗОН ’ * представляет 219
- -~ я - представляет 13
16#DB я - представляет 219
Операции, применимые к объектам целых типов, перечислены
в табл. 3.1 в порядке убывания приоритетов.
Таблица 3.1
Приоритеты целых операций
Возведение в степень:
. Мультипликативные операции:
Унарные операции:
Аддитивные операции:
Операции отношения:
* * —высшее старшинство 4
❖ / mod
ч—
ч—
= / = < < = >> = - - низшее старшин-
ство
В общем это совершенно обычные операции. Несколько нестан-
дартны возведение в степень, деление и mod, о чем подробнее го-
ворится ниже.
У операции возведения в степень целых первый операнд дол-
жен быть целым, а второй — неотрицательным целым.
Пример 3.19
2**3 --даст 8
2**3.5 “ - неправильно — показатель степени не целый
2**-3 " • неправильно — отрицательный показатель недопустим
2**1 • “ может потребоваться проверка при исполнении
Операция деления предполагает усечение в сторону нуля.
Пример 3.20. Особенности целого деления
7/4
-7/4
7/4 + 7/4
- - дает 1
«•- дает —1
—- дает 2
3.3. Числовые типы 113
Операции деления и взятия остатка по модулю (mod) связаны
тождеством
А=(А/В)*В+А mod В
Поэтому если А есть —7 и В есть 4, то
_7=(—7/4)*4+(—7 mod 4)
так что —7 mod 4=—3, а остаток A mod В есть, вообще говоря,
отрицательное число, когда A/В отрицательно.
Это означает, что mod, вообще говоря, не удовлетворяет ра-
венству
A mod В=(А—B)mod В
Пример 3.21. Особенности операции mod
3 mod А « - дает 3
(3-4) mod 4 --дает—1
(I-J) mod 4 --значение зависит от знака I—J
Поэтому функцией mod следует пользоваться с осторожностью
там, где A/В может быть отрицательным, так как результат мо-
жет показаться неожиданным.
3.3.2. Плавающие типы
Плавающие типы характеризуются точностью и диапазоном,
как видно- из следующего определения типа.
Пример 3.22. Определение плавающего типа
digits 8 range -1Е30..IE30;
Определения типа можно использовать для объявления име-
нованных типов с атрибутами, указываемыми этим определе-
нием, как сделано в следующем примере.
Пример 3.23. Объявление плавающего типа
type MY_FbOAT is digits 8 range -1ЕЗО,,1ЕЗО;
Точность и диапазон из спецификации некоторого типа опре-
деляют минимальные требования к реализации. Реальные точ-
ность и диапазон зависят от характеристик объектной машины
и могут превосходить эти требования. Например, спецификация
’’digits 8 range —1Е30 . . 1ЕЗО” требует не менее 28 битов для ман-
тиссы^ 8 битов для порядка. Это можно эффективно реализовать
на машине с 36-разрядным словом. Однако если машина с 32-раз-
рядным словом, то реализация такого типа потребовала бы двух
слов, так что мантисса, например, могла бы занять 32 разряда
114
Гл, 3. Описание данных
(точность более 9 цифр), порядок — 8 разрядов и еще 24 битов
остались бы неиспользованными.
Предопределенный тип FLOAT характеризуется определяе-
мыми системой диапазоном и точностью, которые, вообще говоря,
зависят от аппаратуры. Эти характеристики можно уточнить,
написав, скажем, FLOAT digits 8 range — 1Е30 . . 1Е30. Новые
уточненные типы можно определять через старые именованные
типы с помощью объявлений производных типов.
Пример 3.24. Немобильное объявление производного типа
'type MY_FLT is new FLOAT digits 8 range -1ЕЗО..1ЕЗО;
У этого объявления тот же смысл, что и у объявления типа
из предыдущего примера, при условии, что предопределенный
тип FLOAT имеет точность и диапазон, не меньшие, чем указано
в уточнении. Однако если точность FLOAT менее восьми цифр,
то объявление MY_FLT станет неправильным. Из этого приме-
ра видно, что программа с уточненными предопределенными ти-
пами может оказаться немобильной.
Следующий пример показывает наверняка мобильное объяв-
ление производного типа, так как оно определено через новый
тип (MY_FLOAT), диапазон и точность которого явно опреде-
лены и превосходят указанные в уточнении.
Пример 3.25. Мобильное объявление производного типа
type MY~FLT is new MYJFLOAT digits 6 range -1ЕЗО. ЛЕЗО;
В следующем примере приведены оба варианта объявлений,
а также некоторые правильные и неправильные операторы при-
сваивания.
Пример 3.26. Объявление и использование плавающих типов
procedure FLOATJCYPES is
type MY__FLOAT is digits 8 range -1E3O« ЛЕ30;
type MY_FLT is new MY_FLOAT digits 6 range -1ЕЗО.<1E3O;
x r y t z: my-Float : = 0.0; - * точность и диапазон заданы пользователем
F,Q,R: MY_FLT; е
begin
X 1,53+2,53Е-1;--
Y := 2.0*X**2;
Y :== X**3.51;
R :== 2*P+1;
Z R;
end FLOATJTYPES;
постоянное выражение, вычисленное при компиляции
умножение и возведение в степень
неправильно, степень только целая
неправильно, целые константы недопустимы
неправильно, нельзя смешивать типы
3.3. Числовые типы
115
Итак, синтаксис плавающих констант таков:
[знак] целое.целое [Е порядок] - - 3.5, 3.5Е —1
[знак] целое Е порядок - - 1Е2, 1Е —2
Таким образом, плавающие константы — это числовые кон-
станты с десятичной точкой, за которыми, возможно, следует
порядок, или целые, за которыми следует порядок. Перед поряд-
ком обязателен символ Е, а перед целым возможен знак + или —.
Множество операций над плавающими числами включает все
операции над целыми, кроме mod. Приоритет операций сохра-
няется.
Операция возведения в степень плавающих чисел допускает
в качестве второго операнда как отрицательные, так и неотрица-
тельные целые, но только не плавающие числа.
Синтаксис объявлений плавающего типа таков:
type имятипа is digits Р [range L..R];
type имятипа is new старыйтип digits P [range L..R];
где P — это статическое целое выражение, указывающее число
цифр, a L и R — статические плавающие выражения, указываю-
щие''минимальное (наибольшее по модулю отрицательное) и мак-
симальное’ значения диапазона.
Заметим, что диапазон (который определяет число разрядов,
необходимых для размещения порядка) в объявлении типа мож-
но не указывать. Точность указывать обязательно (она опреде-
ляет число разрядов для мантиссы).
Если Т — некоторый плавающий тип, то запросы атрибутов
T’DIGITS, T’SMALL и T’LARGE указывают точность, наимень-
ший положительный элемент и максимальный элемент типа Т.
Таким образом FLOAT’DIGITS указывает точность предопреде-
ленного типа FLOAT.
Предопределенные типы LONG_FLOAT с точностью, боль-
шей точности FLOAT, и SHORT_FLOAT с точностью, меньшей
FLOAT, являются необязательными. Их реальную точность
можно узнать с помощью соответствующего запроса атрибута;
она может оказаться и такой же, как у FLOAT в реализациях,
которые не поддерживают эти типы по существу.
3.3.3. Фиксированные типы
Фиксированным типам соответствует то же множество кон-
стант и’операций, что и плавающим типам. Однако точность фик-
сированных типов абсолютна, а не относительна. Будем называть
ее словом дельта (delta).
116
Гл. 3. Описание данных
Пример 3.27. Определение фиксированного типа
'Itа .01 range -1QQ.0.,100*0;
- >
Это определение можно использовать в объявлении типа, свя-
зывающем имя с этим определением.
Пример 3.28. Объявление фиксированного типа
type МУ FIXED is delta .01 range -100.0..lOO/O;
Пример 3.29. Определение фиксированного производного типа
type МУ_ЕХХ is new MX_FIXED delta \1-
Так как уточнение диапазона отсутствует, он считается тем
же, что и у исходного типа.
Фиксированные типы гарантируют, что числа будут представ-
лены с точностью, не меньшей дельты. Однако они не гаранти-
руют, что числа хранятся (представлены) точно. Следующий
пример иллюстрирует накопление ошибок из-за неточного пред-
ставления чисел.
Пример 3.30. Объявление и использование фиксированных типов
procedure FIXED_TYPES is
type My_EIXED is delta *1 range -100;
X,XS M_FIXED;
begin
X ;« 1.1;
X := 1.1+2.1+3.1;
eut (x); - - Значение 1.1 гарантируется
put (у); - - значение 6.3 негарантдруетея
end ElXEDjm?ES;
Объявление типа MY_FIXED гарантирует, что числа, та-
кие, как 1.1, будут представлены с точностью дельта=.1, так что
PUT(X) напечатает правильное значение. Однако дробная часть,
соответствующая дельте .1, может быть, например, представлена
четырьмя двоичными разрядами. В этом случае .1 было бы пред-
ставлено как 2/16=.125, .2 — как 3/16=.1875, .3 — как 5/16=
=.3125ит. д. Сумма 1.14-2.1+3.1 была бы вычислена как 1.125+
+2.125+3.125=6.375 и отпечатана как 6.4. С другой стороны,
если представить дробную часть пятью или более разрядами, то
отдельные числа будут храниться с большей точностью и приве-
денная последовательность сложений даст правильное значе-
ние 6.3.
Этот пример показывает, что фиксированные типы данных
нельзя применять для точных вычислений, подобных расчетам
3.4. Перечисляемые типы
117
платежей, где, скажем, сумма по столбцам ведомости должна
быть точной.
Допустимы умножение и деление фиксированных выражений
на целые.
Пример 3.31. Умножение на целые
2*Х+Х/3 * правильно, если X фиксированное,
“ но неправильно, если плавающее
Довольно легко потерять точность фиксированных вычисле-
ний, если числа меньше ожидаемых, или выйти на переполнение,
если они больше ожидаемых. Плавающие типы обеспечивают
большую гибкость, чем фиксированные, для большинства число-
вых расчетов. Фиксированная арифметика — это существенно
обедненная плавающая арифметика для машин, аппаратура кото-
рых не поддерживает плавающей арифметики или память кото-
рых настолько ограниченна, что порядок хранить невыгодно.
3.4. Перечисляемые типы
Перечисляемые типы имеют конечный набор значений, кото-
рые можно явно перечислить в определении типа. Так, тип DI-
RECTION (НАПРАВЛЕНИЕ) с четырьмя значениями можно
определить следующим образом.
Пример 3.32. Объявление перечисляемого типа
type DIKECTIOK is (NORTH,SOUTH,EAST,WEST) ; - - Сввер, ЮГ, 80СТ0Ж, Запад
Применение перечисляемых типов можно показать на следую-
щей функции TURN_LEFT (ПОВОРОТ НАЛЕВО) с парамет-
ром типа DIRECTION и результатом того же типа.
Пример 3.33. Функция с параметром и результатом перечисляе-
мого типа
function тавд.ДЕЮ(Р> DIRECTION)
begin
case D of
when NORTH «=> return WEST;
when SOUTH => return EAST;
when EAST return NORTH;
when WEST «=> return SOUTH;
end case;
end TURNJLEET;
return DIRECTION is
• - если СЕВЕР, на ЗАПАД
-- если ЮГ, на ВОСТОК
-- если ВОСТОК, на СЕВЕР
-• если ЗАПАД, на ЮГ
Этот пример показывает, что функция, выполняющая разные
действия для каждого значения некоторого перечисляемого типа,
118
Гл. 3. Описание данных
обычно выражается с помощью оператора выбора. Вместе с тем
пример демонстрирует легкость, с которой Ада позволяет опреде-
лить и использовать такое абстрактное понятие, как направле-
ние.
Разовьем этот пример несколько дальше и определим функ-
цию CHANGE-COURSE (ИЗМЕНЕНИЕ. КУРСА), которая по
направлению и повороту TURN как параметрам вырабатывает
в качестве результата новое направление. Удобно предваритель-
но определить следующий тип данных.
Пример 3.34. Еще один перечисляемый тип
type TURN is (LEFT, RIGHT, STRAIGHT,REVERSE) -- ТИП ПОВОРОТ
• - co значениями НАЛЕВО, НАПРАВО, ВПЕРЕД, НАЗАД
Функцию CHANGE-COURSE теперь несложно определить
через типы DIRECTION и TURN.
Пример 3.35. Функция с двумя параметрами перечисляемого
типа
function CHANGE COURSE (D: DIRECTION: Т: TURN) return DIRECTION is
begin
case T of
when LEFT -> return TURNJLEFT (D) ;
when RIGHT «=> return TURN_RIGHT(D)
when STRAIGHT return D;
when REVERSE return TURNJWBOUT (D);
end case;
end CHANGEJ3OURSEI
Использованная в CHANGE_COURSE функция TURN-
LEFT уже была определена выше. Функции TURN-RIGHT и
TURN-ABOUT (ПОВОРОТ-НАПРАВО и ПОВОРОТ .НАЗАД)
нетрудно определить через оператор выбора аналогично TURN-
LEFT.
Проиллюстрируем применение типов DIRECTION и TURN
еще и на примере функции MANEUVER (МАНЕВР), восприни-
мающей старое и новое направления как аргументы и вырабаты-
вающей значение поворота, необходимое для изменения курса.
Пример 3.36. Построение «навигационного» словаря
3.4. Перечисляемые типы
119
function MANEUVER(OLD,NEW: DIRECTION) return TURN is
begin
' if NEW = TURNLEFT(OLD) then
return LEFT?
elsif NEW = TURNRIGHT(OLD) then
return RIGHT;' ~
elsif NEW = TURN_ABOUT(OLD) then
return REVERSE;
elsif NEW - OLD then
return STRAIGHT;
end if;
end MANEUVER;
Этот пример написан с помощью условного оператора с че-
тырьмя ветвями, соответствующими четырем вариантам связи
между старым (OLD) и новым (NEW) направлениями. Нельзя
было использовать оператор выбора, так как в нем ветви могут
соответствовать только статически вычисляемому набору значе-
ний, а не условиям, проверяемым при исполнении программы.
Приведенные примеры показывают, как можно использовать
объявления типов и подпрограмм для построения набора абст-
рактных понятий некоторой прикладной области (в данном слу-
чае «навигации»).
В последующих примерах применения перечисляемых типов
мы расстанемся с навигацией и рассмотрим перечисляемый тип
DAY (ДЕНЬ) с семью днями недели в качестве его значений.
Пример 3.37. Дни недели*
type DAY is (MONZTUE,WED,THU,FRI,SAT,SUN) ;
Применение типа DAY можно продемонстрировать функцией
HOURS.WORKED (РАБОЧЕЕ .ВРЕМЯ), которая восприни-
мает день недели в качестве параметра и выдает число рабочих
часов в этот день в качестве результата.
Пример 3.38. Функция HOURS.WORKED
function HOURS WORKED(D: DAY) return INTEGER is
begin
case D of
*" when MON|TUe]WED[tHu|fRI => return 8;:
when SAT SUN «> return 0;
end case;
end HOURSJWORKED;
Последовательность значений перечисляемого типа считается
упорядоченной («TUECSAT» имеет значение TRUE). Функцию
HOURS-WORKED можно было бы определить и так:
120
Гл. 3. Описание данных
Пример 3.39. Реализация с использованием отношения порядка
function HOURS WORKED(D; DAY) return INTEGER is
begin '
if D < SAT then
return 8;
else
return 0;
end if;
end HOURSWORKED;
Заметим, что такой способ определения этой функции исклю-
чает применение оператора выбора. Оборот «when D<SAT=>
return 8;» неправилен, потому что следующее за when условие
должно быть статически определяемым, а условие D < SAT
можно проверить только в период выполнения.
Множество элементов перечисляемого типа — это дискретный
диапазон с верхней и нижней границами и линейным порядком.
Дискретные диапазоны перечисляемых типов обладают многими
свойствами дискретных диапазонов целых (чисел). Например,
запись MON . . FRI можно использовать для обозначения под-
диапазона типа DAY так же, как 1 . . 10 применяется для обо-
значения поддиапазона целых. Поддиапазоны перечисляемых
типов можно применять для управления повторениями в опера-
торах цикла, как это сделано в следующем примере.
Пример 3.40. Повторения в пределах перечисляемого диапазона
for I in M0N..ERI loop
•A(I). := A(I)+1;
enfl loop?
Этот пример показывает также, что типом индексов массива
может быть перечисляемый тип, как в следующем объявлении
анонимного типа для А.
Пример 3.41. Массив с индексами перечисляемого типа
A: array(DAY) of INTEGER;
Поддиапазоны перечисляемого типа можно использовать в
качестве уточнений в определении производного типа или уточне-
ний диапазона непосредственно определяемого типа аналогично
целым.
Пример 3.42. Поддиапазоны перечисляемого типа
type WEEKDAY is new DAV range MON. .FRI; тип ДЕНЬ НЕДЕЛИ
subtype WEEKDAY is DAY range MOW,.FRI;
3.4. Перечисляемые типы
121
У перечисляемых типов много предопределенных атрибутов,
которые можно узнавать с помощью соответствующих запросов.
Некоторые из допустимых запросов показаны в следующем
примере.
Пример 3.43. Перечисляемые типы
procedure ENUMERATION TYPES is
t'ype DAY is (MONjTUE/W£D/TSU;FRI,SAT,SUN)j
D1,D2; DAY? - - Dl, D2 — объекты типа DAY
begin
DI := MON;
DI := DAY'FIRST;
D2 := DAY'SUCC(Dl);
if Dl /- DAY'FIRST then
DI !» DAY'FRED (Dl);
end if;
end ENUMERATION TYPES;
- . присваивание Dl константы MON
- - эквивалентно предыдущему
«- функция «следующий» для типа DAY
- > проверка для корректного применения
- - функщШ «предыдущий»
Этот пример Показывает, что первый элемент перечисляемого
типа Т можно присвоить переменной V этого типа с помощью за*
проса атрибута T’FIRST (например, DAY’FIRST). Последний
элемент можно аналогично Найти как T’LAST. Показано также
применение к переменным Перечисляемого типа атрибутных функ-
ций «следующий» T’SUCC и «предыдущий» T’PRED.
Среди других запросов атрибутов укажем T’ORD(X), дающий
номер позиции X в перечисляемом типе (DAY’ORD(TUE)=2),
и T’VAL(I), дающий значение I-й константы в диапазоне типа
Т (DAY’VAL(2)=TUE). Функции ORD И VAL взаимно обратны:
T’VAL(T’ORD(X))=X и T’ORD(T’VAL(I))=I.
Элементы перечисляемого типа (называемые перечисляемыми
константами) могут быть идентификаторами или символьными
константами. В следующем примере множество значений типа
HEX_LETTER (ШЕСТЬ.БУКВ) отличается от множества кон-
стант типа GRADE (КЛАСС).
Пример 3.44. Перечисляемые константы
type HEX_LETTER is ("A","B",,'C","D","E"/"F");
type GRADE is (A,B,C,D,E,F);
Однако перечисляемые типы с теми же самыми константами
определять можно, что и показано в следующем примере.
Пример 3.45. Перекрытие перечисляемых констант
type COLOR is (RED^LOS/WilTE^IACK); - - дает (красный, голубой, белый,
-- черный) ’
t^E® ИбНТ is, (RED,AMBER,GREEN); »- свет (красный, Янтарный, зеленый)
type LANGUAGE is (RED,GREEN,YELLOW,BLUE); - - язык (красный. аепепыйэ
. --желтый,голубой)
122
Гл, 3, Описание данных
Константы RED, GREEN и BLUE в этом примере являются
перекрывающимися. В большинстве случаев неоднозначность,
вызываемая таким перекрытием, может быть разрешена за счет
контекста, требующего определенный тип. Если же это не так
(как в обороте for I in RED . . GREEN loop), тип постоянной мож-
но указать с помощью явного преобразования.
Пример 3.46. Обеспечение однозначности при перекрывающихся
константах
for I in LANGUAGE(КЕР)..LANGUAGE(GREEN) loop
3.5. Логические и символьные типы данных
Предопределенный тип данных BOOLEAN можно рассмат-
ривать как перечисляемый тип с двумя константами FALSE,
TRUE. У предопределенных логических операций not, and, or,
хог (не, и, или, исключающее или) и операнды, и результат
типа BOOLEAN. Набор его значений, как и у других перечисляе-
мых типов, образует дискретный диапазон, так что FALSE<
TRUE, BOOLEAN’FIRST дает значение FALSE и BOOLE-
AN’SUCC(FALSE) дает TRUE. Примеры выражений и операто-
ров с объектами типа BOOLEAN приводились в гл. 2.
Предопределенный тип CHARACTER можно рассматривать
как перечисляемый тип со стандартными упорядоченными 128
символьными константами кода ASCII. Набор символов и их
порядок определены в руководстве по языку (приложение С)
с помощью определения типа.
Пример 3.47. Перечисляемый тип CHARACTER
type CHARACTER Is
(NUL, SOH, STX, ETX, EOT, ENQ, ACK, BEL,
BS, HT, IF, VT, FF, CR, SO, Si,
DLE, .DC1, DC2, • DC3, DC4, NAK, SYN, ETB,
CAN, EM’, SUB, ESC, FS, GS, RS, US,
* H . T, мини •
t.' T, *+*, H ‘w ft n
"0", *2*, *7*
*8”, • 9*,. • t *?%
"A", *b*, *C', *E*, *F", *G*,
*r, ‘ *K', *M“, *0*,
"CT, *R*, •S', *U*,
*YV "l“. •\< T, ft*tt — •
*a*t *bH, "c*. •d’. "e", t'
*h". • > "K’, T, *пГ; *n”,
v. V; '•s', *t". "iT, *v*, . *w*.
V. t. T, /V a DEL);
3.6, Регулярные типы
123
В соответствии с этим упорядочением буквы следуют за циф-
пами (но не непосредственно). Цифра «О» — это 49-й элемент
диапазона (CHARACTER’ORD («0»)=49), в то время как буква
«д» __ это 66-й элемент диапазона (CHARACTER’ORD («А»)=
=66). Арифметические операции предшествуют буквам и цифрам,
малые буквы следуют за заглавными. Для символов, не входя-
щих в расширенный набор символов языка, предусмотрены мне-
моничные идентификаторы.
Тип данных STRING (СТРОКА), обозначающий массив сим-
волов,— это предопределенный тип, о котором мы подробнее
поговорим после рассмотрения регулярных типов данных.
Предопределенная бинарная операция & (конкатенация)
применима к аргументам типа CHARACTER или STRING и вы-
дает результат типа STRING.
3.6. Регулярные типы
Массив — это структура данных с множеством компонент
одинакового типа, которые можно указывать с помощью индек-
сации. Регулярные типы можно построить из типа компонент и
типа индексов с помощью конструктора типа с ключевым словом
array (массив).
Пример 3.48. Определение регулярного типа
array (1. ЛОО) of integer -- тин компонент INTEGER, индексов -1. .100
Объявление и доступ к регулярным типам показаны в следую-
щем примере.
Пример 3.49.
procedure ARRAYS is
tZES. vector is array (i. лоо) of integer? - - поддиапазон вдвое хак
... . --тип индексов
MATRIX is array.и) o£ INTEGER?»- Двумерный .массив
Vs vector? --объект типа VECTOR
M : matrix? объект типа MATRIX
begin
v(3) »sa 7- • » присваивание элементу вектора
s= V(3)+l? *-присваивание элементу матрицы
ARRAYS j
В- Аде можно работать с массивом либо посредством доступа
к его компонентам, как в предыдущем примере, либо посредством
операций над полным массивом. Можно определить обозначаю-
щую некоторый массив константу (называемую составным значе-
124
Гл. 3. Описание данных
наем, или агрегатом), присвоить составное значение переменной
регулярного типа (регулярной переменной) и присвоить значение
такой переменной массиву подходящего размера.
Пример 3.50. Позиционные регулярные составные значения
declare ’* ’ " '
type VECTOR is array(1..5) of INTEGER?
V,W; VECTOR ;= (o,o,o,o,o); ' • - ИНИДиаЛИЗаДВЯ регулярно» КОИСТЯЛТОМ ’
begin
v := (1,2,3,4,5)? присвоитьV регулярную коиетагпу
w ’® V? •« присвоить W значение массива V
end?
Присваивание полного массива, подобное ”W :=V;”, счи-
тается правильным только для W и V с совпадающими типами
и числом элементов.
Константы из этого примера называются позиционными со-
ставными значениями, потому что компоненты массива сопостав-
ляются своим значениям по позициям в некотором списке. Ада
допускает и непозиционные регулярные составные значения, в
которых связь между именами и значениями указана явно.
Пример 3.51. Непозиционные регулярные составные значения
(1..3 => 1, 4,.5 => 0) эквивалентно(1,1,1,0,0)
(1.. 3 .=> 1? others , в > о) • - еще одно представление того же значения .
(Х]3[3 1, others е=> 0) эквивалентно(1,0,1,ОД)
(MON. .FRI =* 8, others ~> 0) «-константа (8,8,8,8,8,0,0) для
• ’ "array (DAY) of INTEGER”
(N «=> W, S => E, E «> N, W «=> S) - - инициализация для "array (DIRECTION)
• - of DIRECTION”, соотв'етствуйщая повороту налево
Применение непозиционных составных значений можно про-
демонстрировать на следующей реализации функции TURN_
LEFT с помощью инициализированного массива, чьи индексы
и значения компонент — направления (DIRECTIONS).
Пример 3.52. Применение непозиционных регулярных значений
function TORN LEFT(D: DIRECTION) return DIRECTION is
NEW_D: constant array(DIRECTION) of DIRECTION
:== (N => * * присвоить начальные значения компонентам
S Е/ - - постоянного массива NEW D с помощью
E ~> N, - - непозиционного составного значения,
w «> S) ; begin • независимого от порядка компонент
return NEW D(D)? - - новое направление находится просмотром
end TORN_LEFT? - - таблицы, представленной; массивом NEW_P
L
3.6, Регулярные типы 125
В этом примере предлагается реализовывать таблицы симво-
лов массивами с индексами и значениями перечисляемых типов.
Множество индексов соответствует множеству «ключей» таблицы
символов. Просмотр обеспечивается индексацией идентификато-
ра, обозначающего соответствующий массив, тем элементом ин-
дексного множества, который соответствует ключу, а обновление
конкретного входа таблицы символов обеспечивается присваива-
нием нового значения заданному входу.
Пример 3.53. Индексы перечисляемого типа и таблицы символов
TABLE: ахуау (INPEX SET) off WUE SET; -- объявление таблицы
” аннонимного типа
function TABLE LOOK TO (KEY: IliDEX_SET) return VALUE SET is,
просмотр таблицы
begin
return TABLE(KEY)?
end TABLE LOOK TO;'
procedure TODATE(KEY: in INDEXJSET; VALUE: in VALUE_SET) is
- обновление таблицы
begin
Table(key) :« value?
end UPDATE;
Приведенные выше операции над таблицей символов и проще
определять, и можно эффективней выполнять. Индексы перечис-
ляемого типа позволяют ссылаться на объекты из прикладной
области непосредственно по их именам, без кодирования этих
имен целыми числами, необходимого в случае, если бы индексами
были только целые. __
Массив TABLE (ТАБЛИЦА) — это нелокальная структура
данных, доступная как в функции TABLE_LOOK_UP (про-
смотр таблицы), так и в процедуре UPDATE (обновление). В сле-
дующей главе мы покажем, как группировать использующие об-
щие данные подпрограммы в пакеты, которые скрывают общие
структуры, но предоставляют пользователю процедуры, работаю-
щие с этими структурами данных.
В приведенном примере показано присваивание отдельным
элементам массива и полным массивам. Но можно выполнять при-
сваивание и непрерывным подпоследовательностям элементов
массйва. Такие подпоследовательности называются вырезками
(slices).
Пример 3.54. Вырезки массивов
126
Гл. S. Описание данных
procedure SLICES is Vs array(1. .100) of INTEGER?. begin V(5..9) (0,0,0,0,0)? VC15..19) :=V(5..9); V(6..1O) s«V(5..9); * • у V анонимный тип ~ « присвоить вырезке составное значение - - присвоить вырезке вырезку * - неправильно, присваивание * * пересекающихся вырезок запрещено
V(6..1O) :«V(I...ff)? «> - чтобы проверить правильность, - • нужна проверка при исполнении
end SLICES?
Вырезки векторов обозначаются именем вектора, за которым
следует дискретный диапазон, который должен быть поддиапа-
зоном этого вектора. Составные значения и вырезки подходящего
размера можно присваивать вырезкам, но пересекающиеся вырез-
ки присваивать нельзя.
Запросы атрибутов для одномерных регулярных типов и объ-
ектов этих типов касаются первого индекса, последнего индекса
и длины.
Пример 3.55. Запросы атрибутов для векторов
VECTOR*FIRST
VECTOR*LAST
VECTOR’LENGTH
V’FIRST
V’LAST .
V'LENGTH
- - нижняя граница для типа VECTOR
- - верхняя граница индекса
- - число компонент в объектах типа VECTOR
« " нижняя граница индекса для объекта V
• » верхняя граница индекса для объекта V
» » число компонент в объекте V
Применение таких запросов покажем на программном фраг-
менте, вычисляющем скалярное произведение двух векторов.
Пример 3.56. Скалярное произведение двух векторов
assert; V'FIRST о W'FIRST? - - у векторов должны совпадать длины
assert V'LENGTH « WLENGTH? « » и нижние границы индекса
PRODUCT S= О?
for I in V'FIRST..V’LAST loop
PRODUCT ?« FRODUCT+V(I)*W(I)?
end loop?
В случае многомерных массивов к запросу атрибута дописы-
вается номер индексной позиции.
Пример 3.57. Запросы атрибутов для матриц
MATRIX’FIRST(I)
MATRIX'LAST(I)
MATMX'LENGTH(I)
И’FIRST(X)
M'LAST(I)
M*LENGTH(I)
« » нижняя граница I-го индекса для типа MATRIX
. . верхняя граница I-го индекса
« длина по I-му индексу для типа MATRIX
« • нижняя граница I-го индекса для матрицы М
- - верхняя граница I-го индекса для матрицы М
- - длина по I-му индексу для матрицы М
3.7. Регулярные типы с неуточненными границами
127
Применение таких запросов покажем на программном фраг-
менте, умножающем I-ю строку матрицы Ml па J-й столбец мат-
рицы М2 при условии, что число столбцов в Ml равно числу строк
в М2.
Пример 3.58. Умножение I-й строки Ml на J-й столбец М2
assert Ml'LENGTH(2) = М2'LENGTH(I)-; --число столбцов Ml должно
PRODUCT := 0; • совпадать с числом строк М2
for К in M1'J,IRST(2) ..M1’IAST(2) loop -- повторить столько раз,
"product :=s PRODUCT+M1(I,K)*M2(K,J) --сколько столбцов В Ml
end loop?
Ада позволяет вырезать одномерные подмассивы многомер-
ных массивов. Следующий пример показывает присваивание
вырезке вектора V вырезки из второй строки матрицы М.
Пример 3.59. Вырезки одномерных подматриц
V(59) := М (2) (6.. 16) ; - • 5-элементная вырезка 2-й строки М
В этом примере М(2) обозначает вторую строку М, а М(2)(6 . .
10) — вырезку из этой строки. Вырезки из столбцов указать
нельзя. В случае трех измерений можно обозначить одномерную
вырезку, зафиксировав два первых индекса и указав поддиапазон
для третьего индекса. Так что если M3D — это трехмерная мат-
рица, то следующий оператор присваивает вырезке вектора V
вырезку из подмассива (5,2) массива M3D.
Пример 3.60. Вырезки многомерных матриц
V(5.,9) := M3D(5,2) (б..10); г - вырезка из подмассива (5,2)
» - массива M3D
В общем случае можно определять подмассивы многомерных
массивов, фиксируя первые индексы и оставляя переменными
последние индексы. Из получаемых таким образом одномерных
массивов можно делать вырезки, а из других одномерных подмас-
сивов многомерных массивов — нельзя.
3.7. Регулярные типы с неуточненными границами
Определение регулярного типа имеет следующий синтаксис:
array (тип-индекса), тип-индекса}) of имятипа [уточнение];
где каждый тип индекса можно указывать или именем, или диск-
ретным диапазоном (скажем, 1 . . 10).
Если тип индекса указан диапазоном, то границы массива оп-
ределены к моменту обработки объявления этого типа.
128
Гл. 3. Описание данных
Пример 3.61. Типы индексов, указанные дискретными диапазо-
нами
type VECT is array (1. .10) of INTEGER; -- границы известны врв
--'КОМПИЛЯЦИИ
type VECTl is array(1..N) -of INTEGER; --динамические границы,
--известные при обработке
VI: VECT; , «» все объекты типа VECT одного размера
V2: vect 1; - - при объявлении объекта границы не уточнены
Если тип индексов указан именем типа, то соответствующий регу-
лярный тип называется типом с неуточненными границами (но
они должны входить в некоторый поддиапазон типа индексов).
Границы для таких массивов должны быть указаны в каждом
объявлении объекта.
Пример 3.62. Регулярные типы с неуточненными границами
type INDEX is range 1..100;
type VECTOR is array(INDEX) of INTEGER;
vis vector(1. .100); - - VI имеет 100 элементов
V2s VECTOR (1. .10); -- V2 Имеет 10 элементов
V 3: vector(1. .200); --неправильно *- границы вышли из диапазона
V 4: vector; - - неправильно — не указаны границы
V 5: vector(I. .о); - - возможно потребуется проверка при исполнении
Необходимые сведения* о границах при объявлении объекта
можно извлекать из констант, задающих начальное значение это-
го объекта.
Пример 3.63. Границы, указываемые при инициализации
V6; VECTOR ;в (2,4,6,8,10); - границы указаны в начальном значении
- — V(I) « 2, V(5) « 10
Регулярные типы с неуточненными границами особенно по-
лезны в подпрограммах с регулярными параметрами, принимаю-
щими разные значения при разных вызовах. Параметр VECTOR
следующей суммирующей функции обладает неуточненными гра-
ницами и позволяет суммировать векторы-аргументы с разными
границами.
Пример 3.64. Регулярные параметры с неуточненными граница-
ми
function SUM(A: in VECTOR) return WEQer is
X: INTEGER 0; *
begin
for I in A,eirst..A,iast loop •• границы берутся из аргумента
X Х+А(Х);
.end loop ;
return X;
end SUM;
3.7. Регулярные типы с неуточненными границами
129
Границы A’FIRST, A’LAST вычисляются при входе в цикл
во время выполнения этой функции; они извлекаются из подле-
жащего суммированию вектора-аргумента. Поэтому в следующем
примере цикл будет выполнен 100 раз при первом вызове SUM и
10 раз при ее втором вызове (если считать VI и V2 объявленными,
как в предыдущих примерах).
Пример 3.65. Вызов функции с регулярным параметром
value s» SUM (VI) + 2*SUM(V2)VI имеет 100 элемеитрв, V2 —10 элементов
Чтобы правильно работали такие вызовы, необходимо при
вызове процедуры передавать вызывающей подпрограмме не
только имя массива, но и его границы. Во многих ранних языках
(скажем, в Алголе 60) нужно было передавать информацию о гра-
ницах с помощью дополнительных параметров, из-за чего вызов
приобретал вид SUM(A.N). Ада рассматривает информаций о
границах массивов как неявно передаваемую часть аргумента и
тем самым обеспечивает взгляд на регулярный параметр как на
абстрактный объект, передаваемый подпрограмме точно так же,
как скалярный объект.
Передачу информации о границах многомерных массивов по-
кажем на процедуре MATMULT перемножения матриц, состоя-
щих из объектов плавающего типа; в ней два входных параметра
и один выходной типа MATRIX.
Пример 3.66. Процедура перемножения матриц
procedure MATMULT(А,В: in MATRIX; С: out MATRIX) is
TEMP: FLOAT;
begin
assert A’LENGTH (2) « В ’LENGTH (1) - ЧИСЛО столбцов A 5= число строк В
for м in A’FIRST(l)..A’LAST(l) loop »- внешний цикл по строкам А
for N in B’FIRST(2) . .B’LAST(2) loop -- средний ЦИКЛ ПО столбцам В
TEMP ; = 0.0;
for К in A’FIRST(2). .A’LAST(2J loop - - внутренний цикл, скалярное
TEMP ;= ТЕМР+А(М,К) *B(KfN); - - произведение М-й строки А
— на N-й столбец В
end loop; - - конец внутреннего цикла
C(M,N) : = TEMP; •»- присваивание элементу С
end loop; " - - конец среднего цикла
end loop; - - конец внешнего цикла
end, MATMULT;
Ниже показаны объявление типа MATRIX и вызов процеду-
ры MATMULT с матричными аргументами подходящих типов.
Пример 3.67. Вызов процедуры перемножения матриц
5 № 56
130
Гл. 3. Описание данных
procedure MATMULT_CALL is
type NATURAL is range 1.. INTEGER'LAST;
type MATRIX is array(NATURAL,NATURAL) of FLOAT?
X: MATRIX(1..20,1..30) ;
Y: MATRIX(1.. 30,1.. 10) ;
Z; MATRIX(1..20,1..10) ;
procedure MATMULT(A,В: in MATRIX; C: out MATRIX) is separate,
begin
— присвоить начальные значения X и Y
MATMULT(X,Y,Z);
— напечатать или иначе использовать матрицу Z
end MATMULT_CALL;
3.8. Строки
Строки описаны в предопределенном окружении как массивы
с неуточненными границами с помощью следующих объявлений.
Пример 3.68. Предопределенные объявления строк
type NATURAL is INTEGER range 1..INTEGER’LAST;
subtype STRING is. array(NATURAL) of CHARACTER;
Конкатенация строк также описана в предопределенном ок-
ружении как функция со следующим эффектом.
Пример 3.69. Конкатенация строк
function "&"(X,Y: STRING) return STRING is
RESULT; STRING(1..X'LENGTH+Y’LENGTH);
begin .
RESULT (1.. X' LENGTH) : = X; - - присвоить X вырезке из RESULT,
RESULT (X1LENGTH+1.. RESULT' LAST) := Y; - a Y - соседней вырезке
return RESULT;
end
Хотя конкатенация — предопределенная функция, этот при-
мер показывает, как она могла бы быть реализована средствами
языка Ада.
Применение строчных типов данных и конкатенации иллю-
стрирует следующий пример. .
Пример 3.70. Некоторые действия над строками
3.9. Комбинированные типы
131
erocedure-OSBJ5IRIH6S is
^LiNETsTRlNG(1..100) ;
TEXT: STRING(1..1000);
STR: STRING(1.* 10);
VI,V2; STRING S= "AECDE";
begin.
STR :s VI & V2;
LINE(1..V1’LAST) := VI,-
L ;= VI'LENGTH + V2'LENGTH;
EINE(I..I+L-1) := VI & V2;
end USE_STRINGS»
«> длина определена инициализацией
- - длина STR должна точно
- - соответствовать сумме длин VI, V2
- • присвоить VI вырезке длинной строка
- - сложить длины строк
- - еще одно присваивание вырезке
Константа «ABCDE» — это составное регулярное .значение
(длины 5) типа STRING, определяющее не только значение,
но и длину строк VI, V2. Длина строки STR, которой присваи-
вается конкатенация V1&V2, должна быть точной суммой длин
VI и V2. Часто удобнее присваивать вычисленную строку вы-
резке (подстроке) длинной строки — это иллюстрируется двумя
присваиваниями вырезкам строки LINE.
Метод присваивания строк вырезкам строчных массивов
соответствует средствам работы с подстроками в языках, подоб-
ных ПЛ/1.
3.9. Комбинированные типы (записи)
Комбинированные типы определяют структуру данных, ком-
поненты которых можно указывать с помощью селекторов. Объ-
явленный ниже комбинированный тип данных DATE (ДАТА)
содержит объекты с тремя компонентами, указываемыми се-
лекторами DAY (ДЕНЬ), MONTH (МЕСЯЦ), YEAR (ГОД).
Пример 3.71. Объявление записи
type DATE is
record
DAY: INTEGER range 1..31';
MONTH: (JAN,FEB,MAR,APR,MAY,JUNfJULzAUG,SEP,OCT;NOV,DEC))
YEAR: INTEGER range 0..2000;
end record;
Объявление записи определяет «образец структуры», по
Которому создаются объекты комбинированного типа (т. е.
отдельные записи) при обработке объявления объекта. Объяв-
ление таких объектов, доступ к ним и присваивание иллюстри-
руются следующим примером.
Пример 3.72. Создание и инициализация записей
5*
132
Гл. 3. Описание данных
procedure USE_RECORDS is |
X: date; - - неинициализированный объект типа DAT|
Y: date := (15, JUN, 1979); --инициализированный объект типа DATE 3
begin ‘
' 3gday := 15; --присвоить компоненте записи число 15
X.MONTH := JUN;
X.YEAR := 1979;
X »и У; присвоить значение Y полной записи X
X := (15,JUN,1979); --присвоить позиционное составное значение
X := (MONTH=>JUN,DAY=>15,YEAR=>1979); -- присвоить непозиционное
-- составное значение
enfl XJSE_RECORPS;
Этот пример иллюстрирует несколько способов присваивания
комбинированной переменной некоторого значения: инициала*
зацию при объявлении, присваивание индивидуальным компо-.
нентам, присваивание значения, взятого из комбинированной
переменной подобного типа, присваивание позиционных состав-
ных значений (где соответствие между значениями и компонен-
тами устанавливается по позиции в списке) и непозиционных
составных значений (где соответствие между значениями и име-
нами полей указано явно).
Применение записей можно показать на процедуре TOMOR-
ROW (ЗАВТРА) с параметром типа DATE, вычисляющей «завт-
рашнюю» дату (если задана в качестве аргумента правильная
дата). Спецификация этой процедуры такова:
Пример 3.73. Спецификация процедуры TOMORROW
proceflure TOMORROW(Р; in out Pate);
Чтобы определить TOMORROW, нужна функция VALID
для проверки правильности заданной даты. Эта функция В
свою очередь использует функцию DAYS_IN_MONTH, вычис-
ляющую число дней в заданном месяце, а эта последняя Приме-
няет функцию LEAP, чтобы выяснить, является ли год високос-
ным. Спецификации VALID, DAYS_IN_MONTH и LEAP сле-
дуют ниже.
Пример 3.74. Спецификация вспомогательных процедур
function VALIP(P; DATE) return BOOLEAN;
function DAYS_IN_MONTH(M: MONTH, IS_LEAPS BOOLEAN) return DAY;
function LEAP(Y; YEAR) return BOOLEAN;
Идентификаторы DAY, MONTH, YEAR (ДЕНЬ, МЕСЯЦ.
ГОД) использованы выше как Имена типов, содержательно
соответствующих типам компонент записи DATE (ДАТА).
3.9. Комбинированные типы
133
Каждое из этих имен следует теперь ввести явно соответствую-
щими объявлениями типа, a DATE следует переопределить,
чтобы у нее были компоненты названных выше, а не анонимных
типов.
Пример 3.75. Исправленные спецификации типов данных для
DATE
tyge DAY is range 1..31;
MONTH is (JAN^FEB^MARrAPR^MAY/CrUNrJUL^AUGzSEP/OCT^NOV^DEC) ;
type YEAR is range 0..2000;
type DATE is.
record
D: DAY;
M: MONTH;
Y: YEAR;
end record;
TODAY: DATE; • - TODAY (СЕГОДНЯ) — объект типа DATE
Применение именованных типов вместо анонимных при объ-
явлении компонент имеет то преимущество, что такие компо-
ненты можно передавать в качестве аргументов процедурам с
параметрами соответствующего типа.
Правило определения високосного года состоит в том, что
такой год делится на 4, но не делится на 100. Функцию LEAP
можно определить так:
Пример 3.76. Определение високосного года
function LEAP(Y: YEAR) return BOOLEAN is
begin
return (Y mod 4 « 0) and not (Y mod 100 ~ 0) ;
end; • '
Функцию DAYS_IN_MONTH (ЧИСЛО_ДНЕЙ_В_МЕСЯ-
ЦЕ) можно реализовать оператором выбора с тремя вариантами,
соответствующими 30-дневному месяцу, 31-дневному и февралю.
Пример 3.77. Вычисление числа дней в месяце
junction DAYS IN MONTH (Mt MONTH? IS__LEAJ?t BOODEAN) return DAY is
begin. '
case M of
When SEpIaPrIjUNInov => return 30|
when FEB
if ISJLEAP then
return 29;
else
return 28;
end if;
when others return 31f
feud case;
end DAYS IN MONTH?
134
Гл. 3. Описание данных
Функция VALID получает в качестве аргумента объект типа
DATE, про компоненты которого уже известно, что они удов-
летворяют ограничениям, связанным с типами компонент DAY,
MONTH, YEAR. Требуется лишь проверить, что значение ком-
поненты типа DAY не выходит за пределы, устанавливаемые
Компонентой типа MONTH.
Пример 3.78. Допустимость сегодняшней даты
function VALID(TODAY: DATE) return BOOLEAN ig
begin
return TODAY.D <~ DAYS jCNJtoNTH (TODAY. M, LEAP(TODAY.Y));
end VALID; '
Теперь, когда все вспомогательные ^функции определены,
можно следующим образом определить процедуру TOMORROW.
Пример 3.79. Предсказание завтрашней даты
procedure TOMORROW(TODAY: in out DATE) is
LY: constant BOOLEAN := LEAP(TODAY.Y);
begin
if not VALID (TODAY) then
PUT("INVALID DATE")
elsif TODAY.D < DAYS_IN_MONTH(TODAY.M, LY) then
TODAY. D : = today . D+1; - - не последний день в месяце
elsif TODAY.М < DEC then
TODAY. D : = 1; . - - последний день в месяце
TODAY.М := MpNTH’SUCC (TODAY.M) ; - - но не последний месяц в году
elsif TODAY*. Y < YEAR*MAX then-
TODAY' : = (1, JAN t TODAY. YEAR+1) ; - - последний день В ГОДУ
else
put ("beyond the end of TIME")* -- выход за границу лет
end if;
end TOMORROW;
В этих примерах показаны подпрограммы с параметрами
комбинированных типов (записями) и показано, как типы, и
значения компонент можно использовать в таких подпрограм-
мах. Комбинированные типы позволяют пользователю пред-
ставлять записи как абстрактные целостные объекты и вместе
с тем при необходимости манипулировать с компонентами этих
записей. В приведенных примерах реализатор процедуры, по-
добной TOMORROW, должен знать все о структуре дат, но
пользователь этой процедуры может представлять себе пара-
метр типа DATE; как абстрактный объект.
У комбинированных типов могут быть постоянные компо-
ненты, как в следующем примере.
Пример 3.80. Записи с задержанными постоянными
3.10. Вариантные записи
135
tvpe CONST_YEAR is*
'рдУ: INTEGER range 1..31;
MONTH: MONTH_NAME; . - - перечисляемый тип (НАЗВАНИЕ МЕСЯЦА)
YEAR: constant INTEGER range 1..200&; -- задержанная постоянная
end record;
Постоянная компонента, подобная YEAR, не заданная
явным присваиванием при определении типа, называется за-
держанной постоянной. Значения задержанным постоянным
можно присваивать только одновременно с присваиванием
значения полной записи.
Пример 3.81. Присваивание задержанной постоянной
declare
—X: CONST YEAR; - - неинициализированная запись
Y: constTyear ;== ’(201 JUL, 1980); - - инициализированная запись
begin
’’'"xTdAY X.DAY+1;'
X.MONTH := OCT;
X.YEAR 1984;
X :== Y;
- правильно, компонента целого подтипа
- правильно, компонента перечисляемого типа
- неправильно, постоянную обновлять нельзя
- правильное присваивание полной записи
end;
3.10. Вариантные записи
Комбинированные типы, которые мы рассматривали в пре-
дыдущих разделах, имели компоненты фиксированного типа и
структуры. Непостоянные компоненты можно было изменять
компонентным присваиванием, а с помощью присваивания
полным записям можно было менять и постоянные, и непостоян-
ные компоненты.
Ада допускает и такие комбинированные типы, в которых
можно менять не только размер, но и структуру компонент.
Такие типы называются вариантными комбинированными ти-
пами (вариантными записями). В таких типах допускаются
два существенно разных вида вариаций.
1. Вариация размера. Компоненты могут быть динамиче-
скими массивами, размер которых может меняться за счет при-
сваиваний полным записям.
2. Вариация типа. Типы компонент и селекторы могут ме-
няться за счет присваиваний полным записям.
Записи варьируемого размера покажем на примере типа
VARYING.ARRAY (ВАРЬИРУЕМЫЙ.МАССИВ) с компонентой
SIZE (РАЗМЕР), представляющей собой задержанную постоян-
ную, и компонентой BUFFER (БУФЕР), размер которой за-
висит от значения первой компоненты.
136
Гл. 3. Описание данных
Пример 3.82. Комбинированный тип варьируемого размера
type VARYING^ARRAY is
record
SIZE: constant integer range 1..N; ** задержанная постоянная
" "" * * - (дискриминант)
BUFFER: array(1..SIZE) of INTEGER; - - массив, размер которого
ond record; ** зависит от дискриминанта
Объекты типа VARYING.ARRAY можно инициировать
при объявлении, но это не обязательно.
Пример 3.83. Объявление объектов варьируемого размера. ' .
VA1: VARYING ARRAY; --неинициированный варьируемый массив
VA2; varyingJ\RRAY t= (3, (1,2,3)); - - позиционная инициализация
VA3: VARYING_ARRAY s- (SIZE => 4,EUFFER=> (0,0,0,0));
. - непозиционная инициализация
VA4: VARYTNGJARRAY (2,, (1,2,3) ); --неправильно,несовместимые
- - значения
Размер любого заданного объекта типа VARYING.ARRAY
можно изменить присваиванием полной записи при выполнении
программы. Размер компоненты BUFFER нельзя менять ком-
понентным присваиванием, но допустимы компонентные при-
сваивания, не меняющие размера, как элементам массива BUF-
FER, так и всему массиву.
Пример 3.84. Присваивание записям варьируемого размера
VA1 := (4, (2,4,6,8)) ;
VAI ;= VA2;
VAI.BUFFER := (0,0,0)?
VAl.BUFFER(l) s» 7?
VAI.SIZE := 4;
for I in l«<10 loop
VAI (I,(1.*I Q));
end loop;
- - присваивание полной записи константы
-* присваивание полной записи леременной
*• - правильно, если VA1.SIZE » 3
* - присваивание первой компоненте буфера
*• - ведравидьно —* это достоянная
* - присваивание VA1 последовательности
* - записей разных размеров
Компонента SIZE называется дискриминантом — с ее по-
мощью различаются записи разных размеров. Значение диск-
риминанта полностью определяет структуру записи. В общем
случае вариантные записи имеют один или несколько дискри-
минантов, в совокупности полностью определяющих структуру
записи.
Можно создать и ограниченные вариантные записи, размеры
которых нельзя менять даже присваиванием полной записи;
для этого при объявлении объекта нужно наложить ограничения
на дискриминант.
3.10. Вариантные записи
137
Пример 3.85. Ограничения дискриминанта
V: varying_arr.ay(20); -- это фиксирует размер объектаV
W j VARVING_ARRAY (И) ; --это ограничение вычисляется при исполнягаи
Дискриминант SIZE можно считать «параметром» типа VA-
RYING.ARRAY, управляющим вариацией структуры его объ-
ектов. Вариантные записи — эго средство определения парамет-
рических типов. Такая точка зрения получит развитие в сле-
дующем разделе после рассмотрения записей с вариацией типа
компонент.
Записи с компонентами варьируемого типа должны иметь
дискриминант перечисляемого типа, значения из которого ис-
пользуются для распознавания альтернативных вариантов в
операторе выбора. В рассматриваемом ниже комбинированном
типе PERSON (ЧЕЛОВЕК) у дискриминанта SEX (ПОЛ) два
возможных значения М (МУЖСКОЙ) и F (ЖЕНСКИЙ), в за-
висимости от которых у записей этого типа будет либо поле
HEIGHT (РОСТ) типа INTEGER для мужского пола, либо
поле PREGNANT (БЕРЕМЕННА) типа BOOLEAN для жен-
ского пола.
Пример 3.86. Записи варьируемого типа
type PERSON is
record
SEX'i constant (M,F) ; «-дискриминант
case SEX* of
when M => HEIGHT sINTEGER range 1..1000;
when E => PREGNANT: BOOLEAN;
end;
Множество значений дискриминанта должно быть известно
статически (при компиляции). Компонента-дискриминант должна
появляться раньше варьируемых компонент, использующих
этот дискриминант. В общем случае вариантные записи могут
иметь несколько дискриминантов, а также несколько регуляр-
ных компонент.
Пример 3.87. Объявление и использование записей варьиру-
емого типа
138
Гл. 3. Описание данных
procedure USE_PERSON is
man : person : = (m , 70); - - инициализированная запись типа PERSON
woman : person (f) ; - - ограниченная запись с неизменяемы^ дискримии^у^
anyone: person; • - неинициализированная запись w
begin
anyone :=* (f,true); -* присваивание полной записи
ANYONE.PREGNANT := FALSE;
ANYONE.HEIGHT := 68;
ANYONE.SEX := M;
MAN := (F,FALSE);
- - присваивание совместимого значат^
неправильно, несовместимые значения
недопустимое присваивание дискриминанту
правильное изменение пола
MAN := ANYONE;
WOMAN (F,TRITE) ;
WOMAN :« (M,70);
end USE_PERSON;
- - правильно присвоена полная запись
* - правильно
- - неправильно, у этого объекта
- - пол фиксирован
Требование, чтобы дискриминант вариантной записи нельзя
было менять без изменения всей записи, обеспечивает соответ-
ствие типа варианта и типа дискриминанта. Однако для надежной
работы с вариантными записями необходимо проверять при
обращении к варьируемым компонентам, того ли они типа, ко-
торый ожидается. Такую проверку можно программировать
посредством оператора выбора, структура которого подобна
структуре проверяемой вариантной записи.
Пример 3.88. Проверка дискриминанта
case X.SEX
when м => действия для мужского варианта
when г => действия для женского варианта
end case;
Когда такая проверка не запрограммирована явно автором
программы, она может быть вставлена в программу компиля-
тором.
Пример 3.89. Неявная проверка дискриминанта при исполнении
X.HEIGHT $= X.HEIGHT+1; --может потребоваться проверка,
- - что X.SEX = М
Проверка при исполнении программы может добавляться
системой даже тогда, когда и самим автором программы преду-
смотрена некоторая проверка.
Пример 3.90. Побочный эффект, который может сделать недоста- .
точной авторскую проверку
3.11. Дискриминанты и параметры типа
139
case X.SEX
*"'^hen м => X.HEIGHT := 65; - - проверки при исполнении не нужно
„^процедура с потенциальным побочным эффектом, возможно, меняющая X
X.HEIGHT := 75; • - нужна проверка при исполнении
when F => X«PBEGNANT :== TRUE; •« проверки не нужно
end case;
Этот пример показывает, что, когда между проверкой ди-
скриминанта и использованием варианта возможен неконтроли-
руемый побочный эффект, необходимо перепроверить дискри-
минант.
Надежность работы с вариантной записью не гарантирована,
если эта запись разделена между задачами А и В, причем ей
присваивается значение в задаче В, а используется запись в
задаче А. Надежность вариантных записей, разделенных между
параллельными задачами, нельзя обеспечить проверками ди-
скриминанта при исполнении — она требует применения про-
граммистом адекватных средств защиты данных и исключения
одновременного доступа на основе имеющихся в его распоря-
жении примитивов для параллельного программирования.
3.11. Дискриминанты и параметры типа
Дискриминантные компоненты записи в некотором смысле
являются избыточными, потому что содержащаяся в них ин-
формация содержится и в самих варьируемых компонентах; в
принципе эта информация могла бы быть сделана доступной
через запросы атрибутов.
Однако дискриминанты проявляют структуру, вариаций за-
писи в такой форме, в которой становится удобным проверять
корректность и безопасность действий до их реального выпол-
нения.
Дискриминанты записи служат также для «параметризации»
ее структуры.
Пример 3.91. Ограниченные типы
Z; VARYING_ARRAY(SIZE => 20);
Г; PERSON (SEX => М, FAMILY_SIZE 5);
Эти ограниченные типы указывают ограничения дискрими-
нантов, явно называя соответствующие атрибуты. Такая нотация
очень похожа на принятую для параметров процедуры и под-
черкивает параметрическую природу сообщаемой информации.
В общем случае у вариантных записей бывает по одному
Дискриминанту на'каждую варьируемую компоненту. Во втором
из указанных выше ограниченных типов предполагается, что
140
Гл. 3. Описание данных
запись PERSON имеет дискриминант SEX для управления
вариацией типа, а дискриминант FAMILY_SIZE для управления
размером.
Можно провести некоторые аналогии между ограничиваю-
щими параметрами записей и параметрами подпрограмм.
У подпрограммы имеются параметры, и' ее можно вызвать с
несколькими разными наборами аргументов. Дискриминанты
вариантных записей служат неявными параметрами. Объявления
объектов в виде ограниченных записей поставляют аргументы
для таких дискриминантов-параметров.
Связь между объявлением подпрограммы и ее вызовом можно
сопоставить со связью между объявлением типа и объявлением
объекта. Объявление подпрограммы, как и объявление типа,
можно рассматривать как образец, позволяющий создавать
много вызовов при исполнении программы совершенно так же,
как и объявление типа позволяет создавать при исполнении
много объектов. И вызовы процедур, и объявления объектов
реализуются размещением в памяти структур данных, которые
могут различаться для разных экземпляров вызовов или объ-
явлений.
Естественно поэтому иметь параметры для определений типа,
значения которых поставляются объявлениями объектов, по
аналогии с процедурами. Ада не обеспечивает средств для самой
общей параметризации, но дискриминанты вариантных запи-
сей — это эффективная параметризация для специального случая.
Отличие между процедурами и типами заключается в том,
что у процедур есть скрытое от пользователя тело, в то время
как компоненты комбинированных типов автоматически до-
ступны, если доступно имя записи. Ада предоставляет средства
для закрытия в типах внутренних структур данных и доступа к
компонентам таких структур только, через определенные поль-
зователем операции. Об этих средствах будет идти речь в гл. 4.
Массивы с неуточненными границами — это также рудимен-
тарное средство параметризации типов, где аргументом служит
поддиапазон.
Пример 3.92. Аргументы-размеры для регулярных типов
LINE: STRING(1..80); *•-1..80 —это аргумент-диапазон
S: STRING (1. .N); > - - N вычисляется при обработке объявлений
И: MATRIX (X.. 20/1.. 20); -- двумерный массив требует двух
• - аргументов-диапазонов
Таким образом, всякий раз, когда язык Ада допускает типы,
чья структура не определена полностью при компиляции, он
пытается обеспечить «параметр структуры», который позволяет
«заморозить» эту структуру при обработке объявления объекта.
3.12. Ссылочные типы
141
3.12. Ссылочные типы
Ссылочные типы дают возможность создавать объекты и
труктуры данных динамически, при исполнении операторов
программы. Подобно другим определяемым программистом типам
данных, они вводятся объявлениями типа. Синтаксис объявлений
ссылочных типов тдков:
type Т is access спецификация-типа; - - объявляет Т как ссы-
лочный тип для объектов типа, заданного спецификацией.
Пример 3.93. Объявления ссылочных типов
type INT_POINTER is access INTEGER;- - ССЫЛОЧНЫЙ ТИП ДЛЯ Целых объектов
^уре ARRAY—POINTER is access array (1. .5) of INTEGER; - - ССЫЛОЧНЫЙ
' -• тип для регулярных объектов'
Ссылочные типы отличаются от других типов способом объ-
явления объектов данных. Объявление объекта нессылочного
типа (скажем, ”Х; INTEGER;”) служит для двух целей:
1. Определяет идентификатор X как имя целых значений;
2. Создает (размещает) целый объект (выделяет ячейку па-
мяти) и связывает его с идентификатором X.
Эти функции для ссылочных типов реализуются разными
(отдельными) языковыми средствами. Имена для ссылочных
переменных вводятся объявлениями, которые очень похожи
на объявления объектов.
Пример 3.94. Объявление ссылочных переменных
ptri ,PTR2: int pointer; - - две ссылочные переменные для именования целых
Al, А2 s array_pointer; - - две ссылочные. переменные для именования массивов
Объявления ссылочных переменных создают имена для объ-
ектов заданного типа, не создавая самих этих объектов. Объ-
екты данных ссылочного типа (называемые ссылочными объек-
тами) создаются другой языковой конструкцией — генератором,
который имеет следующий синтаксис:
new имя-ссылочного-типа (инициализирующее-выражение)
Ссылочные объекты двух определенных выше типов можно
определить следующим образом.
Пример 3.95. Создание анонимных ссылочных объектов
Sgw.-JNTJ’ODffERp) »-создает ссылочный объект типа INT_POINTER
- - в инициализирует его целым значением 3
ARRAX-POiNTfR 10,0,0,0,0) - .-создает ссылочный регулярный
--объект е начальным значением (0,0,0,0,0)
142
Гл. 3. Описание данных
Генератор ’’new INT_POINTER(3)” создает анонимный ини-
диализированный ссылочный целый объект и возвращает в
качестве его значения ссылку на этот объект, которую можно
присвоить ссылочной переменной подходящего типа оператором
присваивания.
Пример 3.96. Присваивание ссылочного объекта ссылочной
переменной.
PTR1 := hew Int Pointer(3) ? . . присвоить PTR1 целый ссылочный объект
Alps ARRAY_POINTER( (0/0,0,6z0));«« присвоить Al ССЫЛОЧНЫЙ МЯССЦ
Генерацию объектов и присваивание начальных значений
ссылочным переменным можно совмещать с объявлением.
Пример 3.97. Инициализированные при объявлении ссылочные
переменные
RTRl: INTjPOINTER new INI_POINTER(3); м. инициализированное
’ “ ' -- объявление
Al: ARRAY-POINTER := new ARRAY POINTER((0,0,0,0,0)):
Объявление ”Xi INTEGER;” устанавливает жесткую связь
между идентификатором X и некоторым целым объектом, не
изменяющуюся за все время действия X. Объявление ’’PTR1:
INT.POINTER;” создает только имя и позволяет связывать с
именем PTR1 последовательно разные целые объекты за счет
выполнения некоторой последовательности операторов при-
сваивания.
«
Пример 3.98. Динамическое присваивание ссылочных объектов
PTR1 :=* new INTJPOINTER(.3);. - - создать ссылочный целый объект» связать
> • ’* его с PTR1
2TR2 new-INI POINTER (57); *-СОЗдать^ПрИ$ВОИГЬ ВТОРОЙ
--ссылочный объект
RTR1 PTR2; -- irpHCBOHTb.PTRl ссылку на второй объект, '
- - /гак что РТИГи PTR2 теперь «разделяют» этот объект
Al new ARRAY POINTER. ((6,0,0‘, 0,0)) ? --создать и присвоить
j-- ссылочный массив
А2 new ARRAY_POINTER( (1,2,3,4,5) ) ; ТО же ДЛЯ ВТОРОГО массива
Al А2; - - А1 получает ссылку на второй массив
А1 и А2 теперь «разделяют» один и тот же массив
Выполнение этой последовательности из шести присваиваний
приводит к связи между ссылочными переменными и ссылочными
объектами, показанной на рис. 3.4.
Рисунок 3.4 иллюстрирует следующие свойства ссылочных
объектов:
3.12. Ссылочные типы
143
1 Несколько ссылочных переменных могут разделять один
ссылочный объект.
2 . Ссылочные объекты могут оказаться недоступными, когда
на них не ссылается ни одна ссылочная переменная.
Ссылочные объекты позволяют ссылаться на объект по не-
скольким именам. Возникающая в результате синонимия
(aliasing) мешает следить за значением этого объекта, потому что
ссылочные переменные ссылочные объекты
Рис. 3.4. Связь между ссылочными переменными и ссылочными объектами.
его обновление возможно через любое его имя. Однако синонимия
важна для приложений, где играет существенную роль возмож-
ность ссылаться на объект с помощью его атрибутов несколькими
разными способами. Об этом мы еще поговорим позднее.
Недоступные объекты представляют некоторую проблему,
так как это «мусор», который никак нельзя использовать в
вычислениях, хотя он продолжает занимать память. Реализация
языков, допускающих ссылочные переменные, требует механизма
сборки мусора, очищающего память от недоступных объектов.
Ссылочные переменные всегда создаются при входе в про-
граммный сегмент, в котором они объявлены, и ликвидируются
при выходе из области этого сегмента. Создание и ликвидация
ссылочных переменных подчиняются правилу ’’последним при-
шел — первым ушел” и могут быть реализованы в стеке вместе
с обработкой объявлений нессылочных переменных.
Однако ссылочные объекты создаются динамически и не
подчиняются стековой дисциплине. Для их размещения и сборки
мусора выделяется отдельная область памяти, иногда называемая
кучей.
Ссылочные объекты имеют два вида значений:
1. Ссылочное значение (ссылка) — с точки зрения реализа-
ции это указатель на область памяти, представляющую ссылоч-
ный объект.
2. Содержимое — с точки зрения реализации это состояние
144
Гл. 3. Описание данных
области памяти, представляющей ссылочный объект. Ада по-
зволяет обозначать содержимое объекта Y через Y.all.
Различие между присваиванием ссылки и содержимого видно
из следующего примера.
Пример 3.99. Ссылка и содержимое
PTR2 := PTR1; --PTR2 присваивается ссылка на объект, связанный С PTR1
- - PTR2 и PTR1 разделяют один и тот же объект
PTR2.all РТЫ.all? - - PTR2 присваивается новое содержимое —
- - копия1 содержимого PTR1
Обозначение ’’.all” (все) мотивировано тем, что ссылочные
объекты часто бывают структурированными объектами данных
(массивами или записями),— в этом случае «А.а11» позволяет
сослаться на все компоненты объекта А.
Пример 3.100. Ссылка и содержимое для массива
Al := new ARRAY_POINTER((0,0,0;0,0)); -- присвоитьинипиалйзивопантл^
' объект переменной А1
Al.all ;= (1,2,3,4,5); • обновить все компоненты Al
А2 ;= Al? --обновить ссылку А2
А2 := new ARRAY POINTER(Al.all) ;-- А2получает НОВЫЙ объект,
- • инициализированный содержимым А1
A2.all := Al.all; -- содержимоеА1 присваиваетсяА2
Операцию ’’.all” иногда называют разыменованием, так как
она преобразует имя (ссылку) в содержимое.
Для структурных объектов нужно иметь доступ не только
ко всей структуре, но и к отдельным ее компонентам. Строго
говоря, следовало бы обозначать I-ю компоненту ссылочного
массива А1 через ”А1 .all(I)”. Однако при выборе Компоненты
операция разыменования «.all» не указывается явно, а подразу-
мевается, так что обозначение компоненты ссылочного массива
А1 в точности совпадает с обозначением компоненты непосред-
ственно объявленного (нессылочного) массива с тем же именем.
Пример 3.101. Доступ к компонентам ссылочного массива
А1 ;= new ARRAY POINTER((0,0,0,0,0));
Al(3) ‘:= 17; --ненужно писать Al.all(3)i = 17;
for I in 1..5 loop
A (I) := 2*X; * - ирисваиваййе ссыйбадому ШССЙйУ
end loop ; - - выглядит как обычное продаже
Ссылочные массивы могут сами иметь компоненты ссылоч-
ного типа, как в следующем объявлении типа.
3.12. Ссылочные типы 145
Пример 3.102
type POINTERARRAY is access array (INTEGER) of INT_ROINTER;.
^TpOINTERJNsSraY,
Создать инициализированный ссылочный объект для массива
указателей А можно следующим образом.
Пример 3.103. Инициализация ссылочного массива и ссылочного
значения
А new POINTER-ARRAY(1..20 => new INT POINTER(O));
Этот оператор присваивания включает два уровня генерации,
соответствующие двум вхождениям ключевого слова new:
1. Генерация регулярного ссылочного объекта с 20 компо-
нентами, каждая из которых — некоторое имя целого (ссылка
на объект целого типа), и присваивание ссылки на этот объект-
массив переменной А.
2. Генерация целого ссылочного объекта и присваивание
ссылки на этот объект каждой из 20 компонент массива.
Выделено специальное ссылочное значение null, которое
можно присвоить ссылочному значению любого типа; в резуль-
тате это последнее не будет указывать ни на какой объект. Ини-
циализация компонент массива А значением null позволяет
создать массив имен целых, вначале не указывающих на какие-
либо целые объекты. Затем компоненты этого массива можно
отдельными компонентными присваиваниями избирательно свя-
зывать с целыми объектами.
Пример 3.104. Избирательная инициализация ссылочных зна-
чений
А := new'TWO_LEVEIr_ACCESS (1. .JLOO => null) ; »-создать массив имен
:= new INT—POINTER (3)создать некоторые целью ссылочные объекты
(5) s=a(1)« --или связать с ранее созданными объектами
£2£_ I in 1.. 100 loop - - или избирательно инициализировать полный
•-массив
if Р (l) then - « создать объект А(1) ц
А(1) := new INi^POINTERCFfl)) ; -- инициализировать егозначением
end if; - - И1)» но все это иря истинности Р(П
loop;
Теперь, когда введены ссылочные массивы с компонентами
ссылочных типов, рассмотрим ссылочные записи с компонентами
146
Гл. 3. Описание данных
ссылочных типов. Следующее объявление ссылочного комбине,
рованного типа описывает некоторого человека (PERSON) с
помощью его имени (NAME) (варьируемой длины), а также отца.
(FATHER), матери (MOTHER) и супруги(а) (SPOUSE), кото-
рыми являются, естественно, также некоторые люди.
Пример З.ГО5. Запись с рекурсивно определенными ссылочными
типами
type PERSON Is - - тип ЧЕЛОВЕК
access record
SIZE: constant INTEGER; .. задержанная постоянная
NAME: string (1: .size) ; -. имя варьируемого размера
father; person; - . три рекурсивно определенные компонента
MOTHER: PERSON;
SPOUSE: PERSON;
end record;
Конкретный объект такого типа можно создать и инициали- '
зировать следующим образом.
Пример 3.106. ADA — пример рекурсивного имени
ADA AUGUSTA: PERSON := (3, "ADA",
LORDJBYRON,
LADY_BYRON,
LORD_LOVELACE) J.
Лорд Байрон, леди Байрон и лорд Лавлейс считаются ранее
созданными людьми. В связи с этим возникает некоторая про-
блема, так как полное определение объекта ADA_AUGUSTA
потребовало бы бесконечно много предков. К счастью, спасает
нас библия своим постулатом о «первом человеке» без отца, без
матери и без супруги.
Пример 3.107. Пустая ссылка как заменитель динамически со-
здаваемых данных
ADAM: PERSON new PERSON (4,"ADAM",null,null,null);
EVE: PERSON := new PERSON (3, "EVE11,null,null,ADAM) ;
Это не только обеспечивает базис для определения предков
Ады Августы (точнее, объекта ADA_AUGUSTA), но и иллю-
стрирует полезное применение пустой ссылки null как замени-
теля сведений, которые могут, но не обязаны возникнуть позднее.
Ссылочный тип называется рекурсивно определенным, если
он определен через самого себя. Тип PERSON — это пример ре-
курсивно определенного ссылочного типа с тремя рекурсивно
определенными компонентами. Всякий рекурсивно определенный
3.13. Обработка списков
147
сылочный тип потенциально содержит бесконечную цепь ссылок
на ранее определенные объекты, но его можно определить ко-
нечным способом, инициализируя отсутствующие компоненты
значением null.
Компоненты ссылочных записей можно указывать обычным
для записей способом.
Пример 3.108. Доступ к записям и связанная с этим синонимия
ADA_AUGUSTA. FATHER имеет значение LORD_BYRON
EVE.SPOUSE имеет значениеj ADAM
EVE.SPOUSE однозначно указывает на объект ADAM и
можно считать его таким синонимом имени ADAM, который
указывает на тот же объект не прямо, а через его связь с объ-
ектом EVE. Записи с рекурсивно определенными ссылочными
компонентами особенно полезны в приложениях, имеющих дело
с отношениями на совокупностях объектов (людей, городов,
самолетов и т. п.). Каждый из таких объектов можно определить
как ссылочную запись, а отношение (связь) между объектом А
и объектом В указывается определенной компонентой объекта
А, которая ссылается на В.
3.13. Обработка списков
Списковые структуры — важный класс структур данных,
которые можно определять как записи со ссылочными компонен-
тами рекурсивного типа. Элемент списка с полем значения и
полем указателя, ссылающимся на следующий элемент или
имеющим значение null, можно определить следующим образом.
Пример 3.109. Объявление элемента списка
type ELEMENT is access
record
VALUE: INTEGER; ' - - Поле значения
NEXT: ELEMENT; указывает на следующий элемент или пусто
end record;
Обработку списков средствами Ады покажем на программе,
строящей список из N таких элементов. Используем две вспо-
могательные ссылочные переменные HEAD (ГОЛОВА) и CUR"-
RENT (ТЕКУЩИЙ) для ссылок соответственно на первый и
текущий элемент списка. Список, который мы хотим построить,
показан на рис. 3.5.
Обе ссылочные переменные HEAD и CURRENT имеют тип
ELEMENT. Определить их можно следующим образом.
148
Гл. 3. Описание данных.
память для статических
объектов (стек)
память для динамических
объектов (куча)
Рис. 3.5. Список с переменным числом элементов. Доступ к элементам этого
списка обеспечивается ссылочными переменными HEAD и
CURRENT.
Пример 3.110. Два имени элементов списка
HEAD/ CURRENT: ELEMENT null)
Такое состояние переменных представляет список без эле-
ментов, Список с одним элементом можно создать, если сгенери-
ровать элемент списка и присвоить ссылку на этот элемент
как переменной HEAD, так и переменной CURRENT.
Пример 3.111. Одноэлементный список
head := new element(1 .null); - - создать элемент, присвоить HEAD
CURRENT := HEAD; - - CURRENT также должен ссылаться на этот элемент
Создать остальные N—1 элементов списка можно посред-
ством цикла, в котором создается очередной элемент, ссылка
на него присваивается полю NEXT предыдущего элемента, а
также обновляется значение переменной CURRENT.
Пример 3.112. Двухэлементный список
for I in 2.. N loop
current.next := new element (I .null); -- создать следующий элемент
, - - обновить поле NEXT предыдущего элемента
CURRENT : = CURRENT. NEXT; - - обновить указатель на текущий элемент
end loop;
В этом примере используются две статически созданные
переменные HEAD и CURRENT для управления списком про-
извольной длины из динамически создаваемых элементов. Па-
мять для переменных HEAD и CURRENT выделяется в момент
обработки их объявлений при входе в тот блок, где они объяв-
лены, ' а память для элементов списка выделяется динамически
в динамической области (куче).
Ликвидация ссылочных переменных HEAP и CURRENT
происходит при выходе из области того программного сегмента,
где они объявлены. Динамически создаваемые элементы списка
3.14. Древовидная таблица символов
149
,.,ируются сборщиком мусора (после того, как они станут
доступными).
н Однако сборка мусора может оказаться слишком дорогой
времени формой управления памятью (особенно для вычис-
П° пй где время является критическим ресурсом). Поэтому
Та предоставляет средство, позволяющее избежать сборки
,сОра за счет указания пользователем максимально возможного
м'сла объектов данного типа (размера коллекции таких объектов).
Для коллекции требуется фиксированный объем памяти, и ее
можно размещать в стеке как часть записи, с которой связан
Объявляемый ссылочный тип. Однако, предопределяя макси-
мальное число создаваемых объектов некоторого ссылочного
типа, мы жертвуем и возможностью узнать этот максимум ди-
намически, исходя из требований реализации, и возможностями
сборки мусора по ликвидации ставших недоступными объектов.
Поэтому степень применяемости коллекций на практике будет
зависеть, в частности, от эффективности механизма сборки
мусора.
3.14. Древовидная таблица символов
В качестве еще одного примера программирования с помощью
ссылочных типов рассмотрим программу поиска и обновления
для «упорядоченных» деревьев, вершинам которых сопоставлены
целые значения. У каждой вершины может быть левая дуга к
Рис. 3.6. Таблица символов с целыми ключами.
вершине с меньшим целым значением и правая дуга к вершине
с большим целым значением, как это показано на рис. 3.6.
Вершину дерева можно представить ссылочной записью с
одним целым полем и двумя полями-указателями.
Пример 3.113. Объявление вершины дерева
type NODE is access - - тип ВЕРШИНА
record
KEY; INTEGER; --КЛЮЧ
LEFT, RIGHT: NODE; -- ПРАВАЯ, ЛЕВАЯ
end record;
ROOT: NODE := null; -- КОРЕНЬ ДЕРЕВА
Гл. 3. Описание данных
150
Напишем функцию FIND (НАЙТИ), которая по задан»
целому аргументу выдает значение TRUE, когда это
найдено в дереве, и FALSE в противном случае. Спецификой
нашей функции такова:
Пример 3.114. Спецификация функции поиска в дереве
- function FIND(It -INTEGER) return BOOLEAN;
Приведенная ниже реализация FIND основана на предпо.
ложении, что тип данных NODE (ВЕРШИНА) и объект ROOT
(КОРЕНЬ) типа NODE определены в окружении FIND и до.
ступны как нелокальные переменные.
Пример 3.115. Реализация функции поиска в дереве
function FIND(It INTEGER) return BOOLEAN is
N: NODE ; = root ; - - N инициализировано глобальной переменной ROOT
begin
while N /= null loop - - пока имеются текущие вершины
if I < N.KEY then -- если номер меньше ключа,
, N‘ := ’N.LEFT; --то по левой дуге
elsif I > N.KEY then -- если номер больше ключа,*
N. := N.RIGHT; --то по правой дуге
else - - если номер равен ключу,
return TRUE? --выдатьTRUE
end if;
end loop;
return FALSE; - - если I нет в дереве, выдать FALSE
end FIND;
Если исходными данными служат изображенное на рис. 3.6
дерево и целое 41, то эта программа проверит 55 и выполнит
”N:=N.LEFT;”, проверит 37 и выполнит ”N := N.RIGHT;”;
проверит 44 и выполнит ”N := N.LEFT;”, а затем выйдет' из
цикла и выдаст значение FALSE.
Рассмотрим следующую вычисляющую значение процедуру
UPDATE (ОБНОВИТЬ), которая делает в точности то же, что
и FIND, когда аргумент имеется в дереве, но когда он отсутст-
вует, она добавляет новую вершину. Так что вызов UPDATE
с аргументом 41 включил бы в дерево новую вершину, связанную
с вершиной 44 левой дугой.
У процедуры UPDATE те же аргументы, что и у FIND, И
проверяет она ту же последовательность вершин, чтобы опре-
делить наличие аргумента в дереве. Но чтобы обновить дерево;
3.14. Древовидная таблица символов
151
н доступ к его листьям, так что она работает с ними более
образ»»-
Пример З.П6. Процедура обновления дерева
jtirA UPDATE (I: INTEGER) return BOOLEAN is
__________ ___________________
|Tnode^= r00T;
Heel in
= null then
—ROOT := new NODE(I,null,null);
return FALSE;
else
loop
i < N.KEY then
if N.LEFT := null then
N.LEFT ------
return FALSE;
else
N := N.LEFT;
end if;
elsif I > N.KEY then
if N.RIGHT = null then
N.RIGHT
return FALSE
else
N := N.RIGHT
end if;
else
return TRUE;
end if;
end loop;
end if;
end UPDATE;
- если дерево пустое
- вставить первую вершину
- и выдать FALSE
- иначе (если есть вершины)
- основной поисковый цикл
- 1 < N.KEY, левая дуга
- если пусто, то лист
new node (I, null f null); - - вставить новую вершину
- - и выдать FALSE
- - иначе (если у N есть левая дуга)
- - подготовить просмотр следующей вершины
-1 > N.KEY, правая дуга
- если пусто, то лист
new NODE (I/null, null) ; - - вставить новую вершину
- - и выдать FALSE
- - иначе (если у N есть правая дуга)
- - подготовить просмотр следующей вершины
I = N.KEY, найдено
выдать TRUE без обновления
Процедуру UPDATE можно применять и для построения
Дерева, и для поиска в нем. Это прототип функции, выполняю-
щей построение таблицы символов и поиск в ней.
Однако обычно в таблице символов имеются и поле ключа,
и поле значения. Поэтому модифицируем предыдущий пример
так, чтобы можно было работать с таблицей символов, ключи
Которой — строки литер, а значения — целые.
Будем допускать в качестве ключей строки литер варьиру-
емой длины. Поэтому вершины дерева следует реализовать как
вариантные записи с дискриминантом, указывающим размер
Поля ключа.
Пример 3.117. Вершины с ключами варьируемого размера
152
Гл. 3. Описание данных,
type NODE is access
record
SIZE: constant INTEGER; - - дискриминант поля ключа
KEY: STRING (1. «SIZE}; * - поле ключа варьируемого размера
VALUE: INTEGER; •- поле значения
LEFT, RIGHT: NODE :« null; -- левая или правая последующая вершив
end record;
ROOT: NODE null;
Таблицы символов, построенные из таких вершин, будут
лексикографически упорядоченными по варьируемому полю
ключа, как показано на рис. 3.7.
Определим для таких таблиц функцию FIND, которая по
заданной в качестве аргумента строке литер (ключевому слову)
Рис. 3.7. Таблица символов с ключами и значениями.
выдает или указатель на вершину, содержащую эту строку,
если такая есть^ или значение null в противном случае.
Пример 3.118. Функция поиска по ключевым словам
function FIND(S: STRING) return NODE is.
N: NODE := ROOT;
begin
while N /= null Idop
if S < N.KEY thdn
N := N.LEFT
elsif S > N.KEY then
N := N.RIGHT; •
£lse
return N; - - выдать К, если S = N.KEY
vend if;
end loop;
return null; - выдать пусто, если S нет в таблице
end FIND;
Заметим, что, когда вершина с ключом S содержится в таб-
лице, на самом деле могло оказаться более удобным получить
значение типа INTEGER. Однако это не так просто, потому что
функция должна выдавать значения некоторого фиксированного
4
3.14. Древовидная таблица символов
153
па т. е. тип выдаваемого значения при наличии вершины
тИ ж’еН быть таким же, как и при ее отсутствии в таблице. Име-
ется и Другие решения этой проблемы, например выделение
Гениального делого значения (скажем, 0) или использование
сеХанизма исключений при отсутствии ключа.
* О ДРУГ°Й версии этой программы поговорим в гл. 4.
Процедуру обновления реальной таблицы символов можно
было бы реализовать с минимальными изменениями до срав-
неНию с предыдущей процедурой UPDATE. Однако, желая
познакомить читателя е различными вариантами структуры
этой программы, мы в следующей ниже ее версии отделили этап
поиска в дереве от создания и присоединения новой вершины.
Пример 3.119. Исправленная процедура обновления
procedure UPDATE(S: STRING; V: INTEGER) is
Mz№ NODE s- ROOT;
ROUND: BOOLEAN FALSE;
TEMP: NODE;
begin
" while N /== null loofi
M := N;
if S < N.KEY then
N :=; N.LEFT;
elsif S > N.KEY then
N N.RIGHT;
elsif S = N.KEY then
FOUND TRUE;
N.VALUE V;
exit;
end if;
end loop;
if not FOUND then
TEMP r
if M r-
ROOT := TEMP;,
elsif S < N.KEY then .
N.LEFT := TEMP;
elsif S > N.KEY then
M.RIGHT :« TEMP;
end if;
end if;
Sjd UPDATE;
- « дока вершина есть
- - запомнить текущую вершину
- - если меньше ключа
по левой дуге
- . если больше ключа
- - по правой дуге
- - если совпадает с ключом
- - положить FOUND (НАЙДЕНО) равным TRUE
- - обновить значение в найденной вершине
- - и выйти
_________ * - если не найдено, создать новую вершину
new (NODE (VALUE -> V, SIZE S ’LENGTH, KEY => S) ;
null then
- - если дерево пустое
- - присвоить новую вершину корню
- - если меньше» чем ключ листа
- - создать новую левую дугу
- - если больше, чем ключ листа
- - создать новую правую дугу
Подпрограммы FIND и UPDATE используют тип данных
node и переменную ROOT типа NODE. Эти переменные — об-
1Цие для подпрограмм FIND и UPDATE, потому что функция
FIND должна иметь доступ к таблице символов, созданной UP-
154
Гл. 3. Описание данных
DATE, чтобы пользоваться информацией, включаемой в таблицу
при обновлении. у
Однако никаким другим подпрограммам не нужно ничего
знать о представлении таблицы символов, поэтому вершины и
корень дерева следует определить в окружении, доступном
только FIND и UPDATE, но недоступном другим подпрограмм
мам.
Такая защита общей для нескольких подпрограмм инфор.
мации обеспечивается механизмом пакетов, изложенным в гл. 4.
В разд. 4.5 мы определим пакет, скрывающий представление
таблицы символов, но предоставляющий пользователю подпро-
граммы FIND и UPDATE в качестве вычислительных ресурсов.
ГЛАВА 4
МОДУЛЬНОСТЬ
И СТРУКТУРА ПРОГРАММЫ
4,1. Пакеты: данные и подпрограммы
Модули позволяют пользователю отделить спецификацию
вычислительных ресурсов от их реализации. В Аде имеются
два типа модулей: пакеты и задачи. Задачи — это компоненты
параллельных вычислений, они будут рассматриваться в гл. 5.
Пакеты позволяют определять логически связанные наборы
ресурсов для последовательных вычислений. О них пойдет речь
в данной главе.
Пакет может состоять из двух текстуально различных ча-
стей, возможно написанных разными программистами и раз-
дельно скомпилированных.
1. Спецификация пакета. Определяет ресурсы, предостав-
ляемые пакетом пользователю. Спецификация пакета должна
быть написана раньше использующих его программ и скомпили-
рована раньше их сегментов (или одновременно с ними).
2. Тело пакета. «Реализует» обеспечиваемые пакетом ресур-
сы. Может содержать зависящие от реализации ресурсы, скры-
тые от пользователя; может быть написано и скомпилировано
независимо от его спецификации; может быть заменено «функ-
ционально эквивалентным» телом без перекомпиляции программ,
использующих пакет.
Отношение между спецификацией и телом пакета иллюстри-
рует рис. 4.1.
Если пакет содержит только объявления типов и объектов,
ему не нужно тело, поскольку нет деталей реализации, которые
следовало бы скрывать; мы сначала рассмотрим именно такие
пакеты. Простейшие пакеты содержат только объявления объ-
ектов.
пример 4.1. Пакет с объявлениями только объектов
package COMMON is,
X: INTEGER;
Ys INTEGER;
Vs array (1. .100), of INTEGER;
end;
Гл. 4. Модульность и структура программы
156
Пакеты, содержащие только объявления типов и объект*»
подобны именованным блокам COMMON Фортрана. Они п
нако, в некоторых отношениях более гибки, чем последив*
Блоки COMMON Фортрана глобальны для программы, для
Спецификация пакета: видимая часть Пользователь может «видеть» специфика». Достаточно информации, чтобы “иа использовать ресурсы: объявлять и использовать типы данных* вызывать процедуры и т.д. Должна компилироваться прежде сегментов, использующих пакет (иди одновременно С ними)
Может содержать: объявления типов данных объявления объектов спецификации подпрограмм «приватные» типы данных спецификации вложенных пакетов
-
Тело пакета: скрытая часть Может компилироваться отдельно Может быть написано и скомпилировано значительно позже спецификаций Замена «эквивалентной» реализацией не потребует перепрограммирования или перекомпиляции других сегментов Пакеты, содержащие только объявления типов и объектов* не имеют тела
Может содержать: реализацию подпрограмм, определенных в видимой части объявления локальных переменных и вспомогательных подпрограмм* необходимых для реализации подпрограмм пользователя w определение начальных значений
Рис. 4.1. Разделение спецификации и тела пакета.
во время загрузки выделяется непрерывный блок памяти, все
их компоненты нужно перечислять в каждом'использующем
модуле. Пакеты могут быть объявлены локальными для любого
сегмента программы, память для них выделяется только в мо-
мент входа в соответствующий сегмент, и их можно использовать
в любой точке области действия объявления, не перечисляя
всех компонент.
Ресурсы, поименованные в пакете, в области действия его
объявления доступны с помощью точечной нотации, подобной
той, что использовалась при доступе к компоненте комбиниро-
ванного типа.
Пример 4.2. Доступ к объектам пакета
COMMON.X := Of
COMMON.Y :« COMMON. X+•'COMMON. Y;
• COMMON. V(l> »«= 37;
Сходство обозначений, связанных с доступом к пакету и
записи, отражает тот факт, что и объявление пакета, и объяв'
4.1. Паке/ры: данные и Подпрограммы
157
ление записи — это способ группировки логически связанных
ресурсов- Есть, однако, несколько различий между специфи-
кацией пакета и объявлением комбинированного типа.
Первое важное различие — следствие того, что комбиниро-
ванный тип — это образец, по которому с помощью объявления
объекта можно создавать экземпляры объектов, в то время как
спецификацией пакета прямо объявляется группа объектов, к
которым возможен доступ. Поэтому COMMON.Х:=53; присваи-
вает значение компоненте X пакета COMMON, а чтобы при-
своить компоненте X комбинированного типа, сначала нужно
создать конкретный объект — запись.
Пример 4.3. Сравнение комбинированных типов и пакетов
recore components is
type VULGAR Хв - - комбинированный тип — образец
‘record * - обмяты этого типа должны быть созданы
X: INTEGER; --прежде чем их компоненты будут доступны
Y: INTEGER;
Z: array(1..100) of INTEGER;
end record;
ME, you: vulgar; -- объявление двух объектов типа VULGAR
begin
ME.x := 53; --допустимое присваивание значения объекту
VULGAR.X :« 53; --недопустимая попытка присваивания типу
end;
Другое различие между компонентами пакета и комбиниро-
ванного типа состоит в том, что точечная нотация для компонент
пакета не обязательна, если в совокупности объявлений сег-
мента программы указан перечень используемых сегментов
(фраза use),
Пример 4.4. Перечень используемых сегментов
declare;.
йВё-СЙММоК;
begin
X ;я 0; --.вместо COMMON.Xможно писать X
X :=« Y+X; --вместо COMMON. Y можно писать Y
V(l) :=* 37; --вместо COMMON. V(l) можно писать V(l)
end;
Механизма, позволяющего отказаться от точечной нотации
при доступе к объекту комбинированного типа, в Аде нет. Веро-
ятно, самое важное различие между компонентами пакета и
комбинированного типа •— в том, что первые не обязательно
Должны быть объектами данных. Следующая спецификация
пакета содержит наравне с объявлениями объектов объявления
типов.
158
Гл. 4. Модульность и структура программы
Пример 4.5. Пакет с объявлениями типов
package WORK DATA is
type DAY is (MON,TUE,WEDZTTO,FRI,SAT,SUN);
type TIME is delta 0.01 range 0.0».24.0;
type WORK WEEK is array (MON. .SUN) of TIME;
fiORMAL HOURS: constant WORK WEEK :=* (MON..FRI «> 8.0r
~ SAMSUN «> 0.0);
end?
Пакет WORK-DATA (РАБОЧЕЕ_ВРЕМЯ) предоставляет 1
пользователю не .только объект данных NORMAL_ HOURS
(НОМИНАЛЬНОЕ_РАБОЧЕЕ_ВРЕМЯ), но и типы данных
DAY (ДЕНЬ), TIME (ВРЕМЯ), WORK.WEEK (РАБ.НЕДЕЛЯ).
Приведенная ниже функция OVERTIME (СВЕРХУРОЧНЫЕ),
которая должна быть объявлена в области действия пакета
WORK-DATA, имеет параметр типа WORK-WEEK и исполь-
зует типы данных DAY и TIME, а также нелокальный объект
данных NORMAL-HOURS.
Пример 4.6., Функция, использующая пакет
use WORK_DATA;
function OVERTIME(ACTUAL: WORK_WEEK) return FLOAT is
OVER; FLOAT := 0.0;
begin
for I in DAY loop
OVER := OVER + FLOAT (ACTUAL (I)) - FLOAT (NORflALJIOURS (I)) ;
end loop; '
return OVER;
end OVERTIME;
Эта функция в свою очередь могла бы использоваться функ-
цией SALARY (ОПЛАТА) для вычисления полной оплаты по
данному почасовому тарифу и количеству отработанных часов.
Пример 4.7. Использование объявления пакета несколькими
функциями
function SALARY(RATE; FLOAT; HOURS: WORKJSEEK) return FLOAT is I
PAY, EXCESS: FLOAT; ' ~
begin
EXCESS := OVERTIME(HOURS);
if EXCESS <0.0 then - - если EXCESS (ИЗБЫТОК) отрицателей, i
PAY := ’(40.0+excess) * RATE; -> оплата по тарифу
else
PAY 40.0*RATE + 2.0*EXCESS*RATE; --оплата СверхурОЧНЫХ ЯД**
end if; ~~
return PAY?
end SALARY;
4.1. Пакеты: данные и подпрограммы 159
Пакет WORK-DATA можно расширить, включив в него
функции OVERTIME и SALARY, в результате чего он будет
предоставлять более богатый набор ресурсов.
Пример 4.8. Пакет со спецификациями подпрограмм
-ackage WORK_PROGRAMS is
£-^g~DAY i£ (MON,TUE,WED,THU,FRI,SAT,SUN);
type TIME is delta 0.01 range 0,0..24.0;
WORK-WEEK is array (MON. .SUM) of TIME;
Formal hours; constant workweek ;'= (mon..fri => 8.0,
SAT I SUN => 0.0);
function OVERTIME(ACTUAL: WORK_WEEK) return FLOAT;
function SALARY(RATE; FLOAT, ACTUAL: WORK_WEEK) return FLOAT?
end;
Эта спецификация пакета WORK-PROGRAMS (РАБОЧИЕ-
ПРОГРАММЫ) содержит объявления типов, объектов и под-
программ и является примером пакета-подпрограммы. Тело
такого пакета содержит реализации специфицированных под-
программ (таких, как OVERTIME и SALARY), а также любые
дополнительные локальные переменные и подпрограммы, ко-
торые для них понадобятся. Тело пакета WORK-PROGRAMS
могло бы иметь следующий вид.
Пример 4.9. Тело пакета с реализацией подпрограмм
package body WORKJPROGRAMS is_
- объявление функции, реализующей OVERTIME (пример 4.6)
' - объявление функции, реализующей SALARY (пример 4.7)
end WORK_PROGRAMS;
В программу можно включить и заранее подготовленный
текст, если оформить его как текстовый файл, а в программе'
использовать указание INCLUDE (включить).
Пример 4.10. Указание INCLUDE
package body WORK_PROGRAMS is
pragma INCLUDE(OVERTIMEJFILE);
pragma INCLUDE(SALARY_FILE);
end WORK PROGRAMS; ~
В этом примере предполагается, что тексты подпрограмм
OVERTIME и SALARY оформлены как файлы с именами
OVERTIME_FILE и SALARY-FILE соответственно с помощью
средств, определенных в гл. 14 руководства по языку. Это, по
существу, средства редактирования текстов, а не программи-
рования, и мы не будем их далее рассматривать.
160
Гл, 4. Модульность и структура программы
4.2. Синтаксис объявления пакета
Спецификация пакета имеет следующий синтаксис.
Пример 4.11. Синтаксис спецификации пакета
package имя is
объявления видимых ресурсов
(private
объявления приватных типов данных]
end {имя};
Приватная (private) часть может содержать спецификации
«закрытых» типов данных, имена которых видны пользователю,
а внутренняя структура скрыта от него. В этом же пакете можно
определить операции над приватным типом, так что пользова-
тель имеет возможность работать с данными приватного типа,
но не имеет доступа к его внутренней реализации.
Тело пакета, среди специфицированных ресурсов которого
есть подпрограммы, имеет следующий синтаксис.
Пример 4.12. Синтаксис пакета
package body имя is
[объявления локальных ресурсов]
объявления, реализующие видимые подпрограммы
[begin
инициализирующая часть]
end [имя]7
Спецификация пакета может располагаться в совокупности
объявлений объемлющего сегмента программы либо представ-
лять собой отдельный библиотечный пакет. Результатом обра-
ботки спецификации пакета является создание и инициализация
переменных, объявленных в видимой части. Кроме того, созда-
ются локальные переменные тела пакета и выполняются дей-
ствия, описанные в инициализирующей части. Локальные пере-
менные продолжают существовать до выхода из области дей-
ствия спецификации пакета и ведут себя как «собственные пере-
менные» тела пакета. Другими словами, они сохраняются в
промежутках между выполнениями видимых подпрограмм па-
кета и могут использоваться для запоминания состояния инфор-
мации в этих промежутках.
Тело пакета можно компилировать отдельно от его специ-,
фикации. Поскольку вся информация, необходимая для исполь-
зования пакета, содержится в спецификации, тело пакета можно
писать независимо от модулей, работающих с ним, а также пере-
писывать и заменять его даже после того, как система начала
применяться, не воздействуя при этом на другие модули. Однако
4.3. Пакет для работы с комплексными числами
161
к моменту применения пакета его скомпилированное тело должно
быть готово, поскольку обработка спецификации пакета пред-
полагает обработку его тела и инициализацию.
4.3. Пакет для работы с комплексными числами
Связь спецификации пакета и его тела можно проиллюст-
рировать на примере пакета, содержащего операции для сложе-
ния и умножения комплексных чисел. Спецификация пакета,
приведенная ниже, содержит тип данных COMPLEX (КОМПЛ),
внутренняя структура которого видна пользователю, функции
сложения и умножения с комплексными аргументами и резуль-
татами и функцию умножения комплексного числа на скаляр.
Пример 4.13. Спецификация пакета для работы с комплексными
числами
package COMPLEXJJUMBERS is
type COMPLEX’ is
record.
RE: FLOAT t* 0.0;
IM: FLOAT 0.0»
end record?
function "+"(X,Y: COMPLEX) return COMPLEX»
function "*"(X,Y: COMPLEX) return COMPLEX;
function (X: FLOAT; Y; COMPLEX)- return COMPLEX;
end COMPLEX_NUMBERS;
Прежде, чем переходить к телу этого пакета, покажем, как
могут использоваться его ресурсы.
Пример 4.14. Использование комплексных чисел
declare
use । COMPbSX_NUMBERS;
X,Y,' Z: COMPLEX;
begin X ; = (1.5,2.5); •* - присваивание X комплексной константы
Y !=x X*X; - - умножение комплексных чисел
Z X+Y; * - сложение комплексных чисел
Z : = 2.7*Z; - - умножение на плавающее число
Z : = 2*Z; - - нельзя: умножение на целое не определено
Z : = Z*2.7; - - нельзя: умножение на,скаляр справа не определено
end;
Ошибочные выражения 2*Z и Z*2.7 можно было бы сделать
правильными, дополнив пакет еще двумя процедурами.
Пример 4.15. Перекрытие операции умножения
4 № 56
162 Гл. 4, Модульность и структура программы
function "*"(X; INTEGER; Y: COMPLEX) return COMPLEX;
function "*"(X; COMPLEX; Ys FLOAT) return COMPLEX;
Это не покрывает все «разумные» комбинации умножения
действительных и комплексных чисел, поскольку ”Z+2” по
прежнему недопустимо. Однако приведенный пример показывает,
что попытка охватить все разумные типы может в определенном
контексте привести к экспоненциальному росту количества
подпрограмм.
Наша спецификация пакета позволяет пользователю рабо
тать с компонентами комплексных чисел независимо, например
так, как в следующем примере.
Пример 4.16. Доступ к компонентам абстрактных объектов
declare
use COMPLEX-NUMBERS;
X,Y: COMPLEX;
begin
x.re 53.7; * • произвольные манипуляции с компонентам!
Y.IM X.RE*36.9; --допустимое умножение плавающих чисел
end;
Пакет для работы с комплексными числами, рассматриваю-
щий их как абстрактные объекты, не должен допускать произ-
вольные манипуляции с компонентами. Этого можно достичь,
объявив тип данных COMPLEX приватным и включив функ-
цию МАКЕ_СОМР (НОВ_КОМПЛ), которая по двум плаваю-
щим аргументам создает значение типа COMPLEX.
Пример 4.17. Комплексные числа и приватные типы данных
package COMPLEX_TYPE is
type COMPLEX is private;
function (X,Ys COMPLEX) return COMPLEX;
function "*"(X,Ys COMPLEX) return COMPLEX;
function "*" (Xs FLOAT; Y: COMPLEX) return COMPLEX;
function MAKE COMP(X, Y: FLOAT) return COMPLEX;
private
type COMPLEX is
record
RE: FLOAT :== 0.0;
IM: FLOAT 0.0;
end record;
end COMPLEX JTYPE;
Объявление COMPLEX приватным типом позволяет пользу
вателю объявлять комплексные переменные и работать с яиМ
с помощью операций, имеющихся в пакете, но не дает ему *
4.3. Пакет для работы с комплексными числами
163
сТупа к компонентам этих переменных. Пользователь не знает,
каково представление комплексного числа, и поэтому не может
писать комплексных констант. Поэтому в спецификации пакета
имеется функция, строящая комплексное значение по плавающим
компонентам.
Поскольку приватные типы данных скрыты от пользователя,
а подобные объекты обычно описываются как часть тела пакета,
может вызвать удивление тот факт, что структура приватного
типа данных в Аде должна быть дана в спецификации, а не в
теле пакета. Причина в том, что компилятору необходимо знать
эту структуру при размещении в памяти объектов приватных
типов, созданных пользователем. Поэтому в следующем примере
компилятор, имея доступ к структуре типа COMPLEX, может
сразу выделить память для комплексных объектов X, Y, Z °.
Пример 4.18. Использование пакета абстрактных комплексных
I чисе|
declare
~~use COMPLEXJTYPES ;
X z Y: COMPLEX; - - разместить 2 комплексных объекта скрытой структуры
z• COMPLEX :« МАКЕ_СОМР (1.5,2.5); - - начальное значение Z
begin - - выработано функцией
х МАКЕ_СОМР (2.5,3,5); - - присваивание значения
Y : = X+Z; -- комплексное сложение
X. re : = Y. RE; ’ “ незаконная попытка доступа К компоненте
11 у я у 4-ирп - - равенство определено
'—X • = Y+£; ”" комплексное сложение
else
х •.== Y*Z; *" комплексное умножение
end if;
end;
Присваивание и проверка на равенство и неравенство обычно
автоматически определены для всех новых типов (в том числе и
приватных), объявленных в пакете. Поэтому можно писать ”Х
Если бы спецификация типа COMPLEX была в отдельно компилиру-
емом теле пакета, компилятор не мог бы учитывать представление данных
Этого типа при компиляции модулей, использующих тип COMPLEX, Эти
м°ДУли пришлось бы компилировать в предположении, что данные приватных
типов будут размещены во время загрузки. Это потребовало бы более сложных
^грузчиков, хотя не обязательно привело бы к снижению эффективности
^ьектной программы.
Включение приватных типов в спецификацию означает, что при изме-
™-нии в их представлении нужно будет заново компилировать сегмент про-
Раммы, содержащий их спецификацию; тем самым нарушается принцип:
перекомпилировать спецификацию пакета только в том случае, когда изме-
ни ее внешний эффект. Это, похоже, слишком дорогая цена за упрощение
Эпиляции и загрузки.
6*
Гл. 4. Модульность и структура программы
I» Y”, ”Х=У” и ”X/=Y” для переменных приватных тип
например COMPLEX, как у нас. ЯОв»
Мы проиллюстрировали два разных стиля специфика^,
пакета для работы с комплексными числами, но все еще не
сматривали его тело с реализацией функций, обещанных nojnl
зователю в спецификации. Вообще говоря, тело пакета не пор»
ставляет интереса для его пользователя, и мы испытываем
блазн под этим предлогом покончить с нашим пакетом. Однако
хотя программисту и не нужно знать детали тел пакетов, подг</
товленных другими, каждый программист, вероятно, будет
создавать свои собственные прикладные пакеты и поэтому должен
быть знаком с конструированием тела пакета.
Тело пакета можно определить следующим образом.
Пример 4.19. Тело пакета для работы с комплексными числами
package body COMPLEXJTYPES is
function ”+”(X/Yt COMPLEX) return COMPLEX is --функция
begin - - комплексного сложения
\ return (X.RE+Y.RE, X.IM+Y.IM); --складываются действительны»
end; - - и мнимые компоненты
function (X,Y: COMPLEX) return COMPLEX is --комплексное
“ - - умножение
R: FLOAT : = X.RE*Y.RE - X.IM*Y.IM; --действительная компонента
I: FLOAT :« X.RE*Y.IM + X.IM*Y.RE; -- мнимая компонента
begin
return (й, I) 7 - - возвращает комплексное число с компонентами RhI
end;
function ”*”(X: FLOAT; Y: COMPLEX) return COMPLEX is
TEMP: COMPLEX; - - умножение на скаляр
begin
temp : = (x*Y. RE f x* Y. IM); - - умножить на скаляр каждую компоненту
return TEMP;
end;
function MAKE COMP(X,Y: FLOAT) return COMPLEX is -- создание
^ед in — комплексного числа
return (XrY); - возвращает комплексное число
end ? - - с данными компонентами
endToMPLEX TYPES;
Тело этого пакета содержит только реализации видимых
процедур, здесь нет никаких дополнительных локальных объ-
явлений. Как видимая, так и приватная части спецификации
пакета доступны из тела, так что функции «+» и «#» могут об-
ращаться к компонентам, например X.RE или X.IM, а функция
MAKE.COMPLEX может построить комплексное значение по
плавающим компонентам.
•4.4, Создание ключей «защиты»165
^4 Создание ключей «защиты»
Приватные типы МОГУТ употребляться также в ситуациях,
е необходима защита данных. Рассмотрим, например, систему
ашиты, основанную на использовании «ключей», поставляемых
пакетом управления ключами. Этот пакет должен уметь выда-
вать ключи уникальные и не поддающиеся подделке. Этого
можно добиться, объявив KEY (КЛЮЧ) приватным типом
данных.
Пример 4.20. Спецификация управления ключами
гсКа£е KEY_MANAGER is
KEY is private;
.procedure GET—KEY (K: out KEY); - - выдать уникальный ключ
' function ”<” (X, Y: KEY) return BOOLEAN; - - определить <«» для
private - - ключей
jjypiTkEY is new INTEGER range 0, .INTEGER ’LAST;
end KEY—MANAGER;
Функция GET.KEY (НОВ„КЛЮЧ) обеспечивает пользо-
' вателя уникальным ключом, который невозможно подделать.
Уникальность ключа может быть обеспечена включением в
тело пакета переменной этого типа, которой присваивается
начальное значение 1, увеличивающееся на 1 при каждом со-
здании нового ключа. Подлинность гарантируется благодаря
тому, что преобразования типов между объектами приватного
типа KEY -и другими, например целыми, незаконны вне тела
пакета. Поэтому единственный способ создавать объекты типа
КЛЮЧ — с помощью процедуры GET. KEY.
Хотя преобразования между ключами и целыми запрещены
вне тела пакета, они допустимы внутри его благодаря тому, что
там известно: тип KEY — производный от целого типа. Функция
«<» над объектами типа KEY содержит оператор, в котором
ключи преобразуются в значения целого типа, так что эта опе-
рация может быть определена через соответствующую операцию
над целыми.
Пример 4.21. Тело пакета
Декаде body KEY—MANAGER jLa
nextjkey: key := 1; •- собственнаяпеременная — существует
Kocedure GET-KEY (К: out KEY) is - - между вызовами процедуры
besin
К NEXT—KEY; -- присвоить значение ключа
NEXT—KEY := NEXT—KEY+l; *-выходному параметру, увеличить
GET—key ; *" значение уникального ключа
Sa^tion ”<” (X,Y; KEY) return BOOLEAN is
£^in '
£sturn INTEGER (X) <INTEGER (Y); - - преобразование ключей в целые,
SS. ; - - так что «<» для ключей определено
Key MANAGER; - - через «< » для целых
166
Гл. 4. Модульность и структура программы
Хотя ключи, создаваемые этим пакетом, уникальны и
поддаются подделке, их можно копировать присваиваний
переменной типа KEY. Поэтому в программе (возможно, пакете}*
использующей создаваемые таким образом ключи,, должны бык
приняты дополнительные меры безопасности для контроля за
доступом к другим ресурсам.
4.5. Пакет для работы с таблицей имен
Программы FIND (НАЙТИ) и UPDATE (ОБНОВИТЬ)
предназначенные для работы с таблицей имен и рассмотренные
в гл. 3, можно собрать в один пакет со следующей специфи-
нацией.
Пример 4.22. Спецификация пакета для работы с таблицей имен
package SYMTAB is
function FIND (S • STRING) return INTEGER; * • по ключу S возвращк;
- - значение
procedure UPDATE (S» STRING; V: .INTEGER);. • • по ключу S обновляет
end SYMTAB; --значение
Функция FIND будет определена таким образом, чтобы она
возвращала значение, ассоциированное с ключом S, если S
имеется в таблице имен, и специальное значение INTEGER’
FIRST, если его там нет. Это можно сделать, слегка модифици-
ровав процедуру FIND из гл. 3.
Пример 4.23. Подпрограмма FIND
function FIND (S -. STRING) return INTEGER; - найти ключ S, вернуть цшк
N: NODE ;= ROOT; --ROOT не локально для FIND,
begin - - но локально для пакета
while N /« null loop - - пока узел — не пустой,
if S < N.KEY then -- если аргумент меньше узла,
N ; = N. LEFT; - - спускаться по левой ветви
elsif S > N.KEY then -- если аргумент больше узла,
N := N.RIGHT; --спускаться по правой ветви
else - - если равны,
return N .VALUE; - - вернуть значение в узле
end if;
end loop; - - конец цикла
return INTEGER'FIRST; - - если ключ не найден на дереве,
end FIND; - - вернуть особое значение
Текст приведенной программы FIND может быть включен
в тело пакета, в котором есть объявление типа NODE (УЗЕЛ)
и переменной ROOT (КОРЕНЬ) и текст программы UPDATE-
В следующем пакете предполагается, что функции FIND и
4.6. Пакет для обработки списков
167
UPDATE уже созданы и хранятся в файлах с именами FIND.
FILE и UPDATE.FILE соответственно.
Пример 4.24. Тело пакета для работы с таблицей имен
package body SYMTAB is
e"type~NODE is access - - NODE — вариантная запись
record
SIZE: constant INTEGER range 1. .INTEGER’LAST;
KEY: STRING(1..SIZE);
VALUE: INTEGER;
LEFT, RIGHT: NODE := null;
end record;
ROOT: NODE := null;
pragma INCLUDE(FIND_FILE);
- см. предыдущий пример
pr»gpa INCLUDE(UPDATE_FILE)t
- - очень похоже на пример в конце гя. 3
end SYMTAB;
Сравнение пакетов SYMTAB (ТАБЛ.ИМЕН) и COMPLEX.
NUMBERS (КОМПЛ.ЧИСЛА) иллюстрирует два уровня «уп-
рятывания», которые можно связать с типом данных. В пакете
COMPLEX-NUMBERS тип COMPLEX был приватным, но его
имя известно пользователю. В пакете SYMTAB нам удалось
скрыть и структуру, и имя типа NODE.
Эти два уровня служат двум весьма различающимся целям.
Механизм private удобен для абстрактных типов данных, когда
разрешаются только специфицированные операции над объек-
тами некоторого типа, и для защиты данных в случае, когда их
структура — «личная» или «конфиденциальная» информация,
но имя должно быть доступно. Обе эти ситуации налицо в при-
мерах с комплексными числами и управлением ключами. Когда
же структура не интересует пользователя и является лишь
средством реализации, как в примере с таблицей имен, то свя-
занная с ней информация скрывается полностью.
4.6. Пакет для обработки списков
В качестве заключительного примера пакета рассмотрим
реализацию примитивов Лиспа для работы со списками. В языке
Лисп.два типа первичных объектов: атомы и списки. Элемент
списка имеет две ссылочные компоненты, каждая из которых
может указывать на атом или на список. Нужные свойства
элементов списка Могут быть реализованы так.
168
Гл. 4. Модульность и структура программы
Пример 4.25. Тип данных LISP
type LISP is access - - тип данных LISP — вариантный комбинированные
yecord '
CHOICE: constant(LIST t ATOM); • • два значения дискриминанта
qase CHOICE of
when LIST => CAR: LISP; - - у варианта LIST — два поля,
CDR: LISP ; * - CAR и CDR, оба типа LISP ’
! wnen ATOM => VALUE: INTEGER; у варианта ATOM —
end case; * - одно целочисленное поле
end record;
Мы хотим определить пакет со следующими операциями
Лиспа.
Пример 4.26. Операции над структурами данных Лиспа
function CAR(X: LISP) return LISP;
function CDR(X: LISP) return LISP;
function CQNS(X,Y: LISP) return LISP;
function ATOM(X: LISP) return BOOLEAN;
function EQ(X,Y: LISP) return, BOOLEAN;
Функция CAR получает аргумент X типа LISP (ЛИСП). Если
компонента CHOICE (ВАРИАНТ) имеет значение LIST (СПИ-
СОК), результат имеет значение X.CAR. Если ее значение
АТОМ, возникает исключительная ситуация NO_LIST (НЕ_
СПИСОК), объявленная и обрабатываемая вне подпрограммы.
Пример 4.27. Функция CAR
function CAR(X: LISP) return LI6P is •• функция CAR
&egin
if X.CHOICE ~ LIST then * - если аргумент — список,
return x.CAR; - - возвращает значение компоненты CAR
else
raise NO_L±ST; - - и возбуждает исключение,
. end if; * - если аргумент — ATOM
♦end CAR;
Функция CDR возвращает значениеX.CDR, если X.CHOICE==
LIST, и возбуждает исключительную ситуацию при X.CHOI-
CE =АТОМ. Реализована она аналогично функции CAR.
Пример 4.28. Функция CDR
function CDR(X: LISP) return LISP is --функция CDR
begin
if X.CHOICE = LIST then -- если аргумент — список,
return X. CDR; - - возвращает значение компоненты CDR
else
raise NO_LIST; - • и возбуждает исключение,
end if ; • * - если аргумент — ATOM
end CDR;
_______4.6. Пакет для обработки списков 169
Функция CONS получает два аргумента типа LISP и создает
новый объект того же типа со значением дискриминанта LIST.
Пример 4.29. Функция CONS
function CONS(X,Y: LISP) return LISP is
begin
return new LISP (CHOICE => LIST, CAR’=> X; CDR Y) ;
end;
функция ATOM возвращает значение TRUE, если X.CHOI-
CE-ATOM, и FALSE, если X.CHOICE-LIST.
Пример 4.30. Функция ATOM
function ATOM(X: LISP) return BOOLEAN is - - функция ATOM
begin
if X.CHOICE =» ATOM then -- возвращает значение TRUE,
return TRUE; * - если аргумент — ATOM
else
return FALSE; - - и значение FALSE,
end if; * - если аргумент — LIST
end ATOM;
Функция EQ возвращает значение TRUE, если оба ее аргу-
мента — атомы с одинаковыми значениями, значение FALSE,
если X и Y — неодинаковые атомы, и возбуждает исключение,
если X и/или Y не атом.
Пример 4.31. Функция EQ
function EQ(X,Y; LISP) return BOOLEAN is -- функция EQ
begin
if X.CHOICE « ATOM and Y.CHOICE « ATOM *then -- возвращает
- - значение TRUE,
return X. VALUE=Y,VALUE; - - если аргументы — одинаковые атомы
else - - FALSE,если неодинаковые атомы
raise NO_ATOM; * - и возбуждает исключение,
end if; • - если один аргумент или оба —
end EQ; -- не атомы
Все эти примитивы для обработки списков имеют аргументы
типа LISP, некоторые возвращают результат того же типа..
Пользователю должно быть разрешено создавать переменные
типа LISP, но доступ к представлению элементов для него должен
быть закрыт. Поэтому тип LISP будет объявлен в спецификации
Пакета приватным типом данных.
Пример 4.32. Спецификация пакета LISP_PROCESSING (ОБ-
РАБОТКА.СПИСКОВ)
170
Гд. 4. Модульность и структура программы
package LISP_PROCESSING is
type LISP is private;
NULLIST: constant LISP;
function CAR(X: LISP) return LISP
function CDR(X: LISP) return LISP
function CONS(X,Y: LISP) return LISP;
function ATOM(X: LISP) return BOOLEAN;
function EQ(X,Y: LISP) return BOOLEAN;
function MAKE ATOM(X: INTEGER) return LISP?
private
- спецификация пакета
- с приватным типом
- начальное значение констадпж
- определено в приватной част^
- - в пакете - б фунхадг
- - работающих с этой
- - структурой данных
-type bISP jis access - . приватный тип
» - это вариантный комбинированный тшг
CHOICE; constant (LIST/АТОМ) := LI ST; l - у дискриминанта —
сале CHOICE df - - 2 возможных значения
when LIST => CAR: LISP :« nullвариант LIST имеет два поля,
CDR: lisp := null;» - CAR и CDR, оба типа LISP
when ATOM => VALUE: INTEGER; - - вариант ATOM имеет одно по»
end case ; * - VALUE, целого типа.
end record;
NULLIST: constant LISP ;== null; -- представлениеNULLIST
• - известно в приватной части
end lisp_processing?
Эта спецификация содержит, кроме описания примитивов,
функцию МАКЕ-АТОМ (СОЗД-АТОМ). Она может быть оп-
ределена следующим образом.
Пример 4.33. Функция СОЗД-АТОМ.
function MAKE АТОМ(Х: INTEGER) return LISP is
begin
return new LISP (CHOICE ATOM, VALUE => X)? -- возвращает новы!
end; - - объект типа LISP с дискриминантом ATOM
Функция MAKE-LIST (СОЗД-СПИСОК) не нужна, потому
что пользователь может с помощью операции CONS добавлять
новые элементы к аргументу NULLIST (ПУСТ-СП).
Пример 4.34. Создание списка
declare
use LISP_PROCESSING;- - LI — переменная типа LISP со значением NULLIST
Liz LISP NULLIST;--L2иL3— переменныетипа LISP
L2 ,L3: LISP; - - начальные значения не заданы
begin ~ - - L2 — список из двух элементов NULLIST
L2 := CONS (LI ,L1) ? - - L3 — список с компонентам#
L3 CONS (MAKE-ATOM (53) ,NULLIST) ; - - ATOM И NULLIST
Для иллюстрации работы функций CONS, CAR и CDR мы
покажем, как можно построить списочную структуру, изобрз-
4.6. Пакет для обработки списков
171
ценную на рис. 4.2, и как потом осуществлять доступ к ее эле-
•^этой программе потребуются четыре операции CONS для
Рис. 4.2. Пример списочной структуры.
организации четырех элементов списка и три операции МАКЕ
АТОМ, чтобы создать атомы со значениями 51, 52 и 53.
Пример 4.35. Создание списка
declare
use LISP_PROCESSING;
L,L1,L2; LISP;
begin
LI ;= CONS(MAKE_ATOM(53),NULLIST)y
L2 := CONS(MAKE JVTOMf52),NULLIST);
L2 := CONS(MAKE_ATOM(51),L2);
L := CONS(L2,LI) ;
LI := CAR(CAR(L));
L2 := CAR(CDR(L));
end;
элемент списка (53, null)
элемент списка (52, null)
список (51, (52, null))
- список, изображенный на рис. 4.2
- L1 указывает на атом со значением 51
- L2 указывает на атом со значением 53
Теперь, показав применения пакета для обработки списков,
мы опишем его тело. Оно .содержит объявления, реализующие
функции из спецификации пакета, а также инициализирующую
часть, в которой описана реакция на исключительные ситуации
NO.LIST и NO_ATOM. Она состоит в том, что печатается соот-
ветствующее сообщение, а затем возбуждается исключительная
ситуация LISP_ERROR (ОШИБКА_ЛИСПА), которая, пред-
полагается, объявлена и обрабатывается вне нашего пакета.
172
Гл. 4. Модульность и структура программы
Пример 4.36. Тело пакета
package bpdy LISP—PROCESSING is - . тело пакета
текст, реализующий CAR
* - текст CDR
- - текст CONS
- - текст АТОМ
* - текст EQ
- - текст МАКЕ—АТОМ
end LISP_PROCESSING;
Приведенный пакет LISP_PROCESSING — типичный при-
мер пакета, в котором определяется группа общих операций над
абстрактным типом данных. Тип данных абстрактен в том смы-
сле, что над ним можно выполнять только операции из пакета
и никакие другие. Пакет LISP^PROCESSING иллюстрирует
случай, когда пользователь имеет доступ к имени типа, но пред-
ставление типа от него скрыто.
Поучительно сравнить пакет для работы с таблицей имен,
структура данных которого полностью скрыта в спецификации
пакета, с пакетом для работы со списками с приватной струк-
турой данных. В первом случае пользователь заботится только
о правильном поиске и обновлении ранее записанной инфор-
мации.
Структура данных, используемая для этого, его совер-
шенно не интересует и может оставаться полностью скрытой.
Во втором случае обработка списков — суть всего дела, и здесь
важно, чтобы пользователь мог явно именовать и перебирать
списочные структуры. Лисп — это как раз язык высокого уровня
для обработки списков, *он обеспечивает пользователя абстракт-
ными операциями, не зависящими от представления элементов
списка. Приведенный пакет для обработки списков очень на-
глядно иллюстрирует механизмы, с помощью которых такая
абстракция может быть достигнута.
4.7. Перечень используемых модулей
Теперь, проиллюстрировав понятие пакета на ряде приме-
ров, мы рассмотрим некоторые вопросы, которые возникают
При объединении пакетов и других компонент программ в за-
конченную программу. В частности, мы рассмотрим механизмы
сопряжения сегмента программы с окружающей его средой,
изменяющие множество идентификаторов (имен), которые можно
использовать в сегменте. Начнехм мы с перечня используемых
сегментов. Перечень используемых модулей может рассматри-
ваться как механизм переименования внешних, объявленных
4,7, Перечень используемых модулей
173
не сегмента, идентификаторов. Этот перечень расширяет про-
странство имен того сегмента, в который входит, позволяя при-
менять сокращенные (неуточненные) формы для некоторых уже
доступных имен. В ряде случаев это делает программы более
лаконичными и наглядными. В других случаях как раз уточ-
нение снимает неоднозначность имен и помогает читать и сопро-
вождать программы за счет полезной мнемоники.
Пакеты HEIGHT (РОСТ) и WEIGHT (ВЕС) с одинаковыми
именами компонент — это, вероятно, крайний случай. Пере-
чень используемых модулей в процедуре INNER (ВНУТР)
фактически не дает ровным счетом ничего, поскольку употреб-
ление имен ID (ИД) и VALUE (ЗНАЧ) без уточнения приводит
к неразрешимым неоднозначностям.
Пример 4.37. Перечень модулей, создающий неоднозначность
имен
procedure OUTER ’is
package HEIGHT is - - пакет HEIGHT с переменными ID и VALUE
'ID: INTEGER;
value : float ; - - компонента VALUE пакета HEIGHT
end'HEIGHT;
package WEIGHT is
ID: INTEGER;
VALUE;. FLOAT; - - компонента VALUE пакета WEIGHT
end WEIGHT;
procedure INNER is
use HEIGHT, WEIGHT; -- пополнить пространство имен
begin - - неуточненными именами компонент пакетов
HEIGHT.VALUE 65.3; - - уточненные имена по-прежнему разрешены
WEIGHT.VALUE :« HEIGHT.VALUE ; --без всякой неоднозначности
VALUE: «63.5; - - нельзя: без уточнения неоднозначно
end INNER; - - это может обнаружить компилятор
be^in - - начало последовательности операторов OUTER
VALUE •» 63.5; - - нельзя, но по иной причине: вне области
£nd OUTER; - - действия use разрешены только уточненные имена
Следующий пример поможет глубже понять действие перечня
модулей, в этом примере повторно объявляется VALUE во
внутренней процедуре. Тем самым внешние неоднозначные
идентификаторы VALUE оказываются скрытыми, и ссылки на
VALUE в процедуре INNER будут означать ссылки на внутренний
объект целого типа.
Внешний идентификатор ID виден в процедуре, поэтому
неуточненные ссылки на ID неоднозначны и, следовательно,
запрещены. Однако уточненные ссылки на внешние идентифи-
174 Гл. 4. Модульность и структура программы
каторы — например, HEIGHT.VALUE (РОСТ.ЗНАЧ)
HEIGHT.ID (РОСТ.ИД) — разрешены. “
Пример 4.38. Повторное объявление имен, видимых благодаря
перечню модулей
package OUTER is
package HEIGHT is
ID: INTEGER;
VALUE: FLOAT;
end HEIGHT;
package WEIGHT is
ID: INTEGER;
VALUE: FLOAT;
end WEIGHT;
procedure INNER is
use HEIGHT, WEIGHT;
VALUE: INTEGER;
begin
HEIGHT.VALUE :«= 65.3;
VALUE :« 65;
VALltfE := 65.3;
OUTER.VALUE :« 65.3;
ID := 2365.7;
end INNER;
end OUTER;
- - переменная VALUE пакета НЕ1ОВД
- - переменная VALUE пакета WEIGHT
- - внутреннее объявление VALUE
- - переменная VALUE пакета HEIGHT
- - внутренняя переменная VALUE
- - нельзя: справа должно быть целое
- - нельзя: неодноэначность имени
- - нельзя: неоднозначность имени
В следующем примере идентификатор WEIGHT объявлен во
внутренней совокупности объявлений, так что по обычным
правилам действия имен для блочной структуры VALUE можно
было бы без всякой неоднозначности использовать в процедуре
INNER.
Однако, согласно описанию языка (разд. 8.4), «перечень
используемых модулей делает идентификатор видимым, если
он определен в видимой части одного и только одного модуля,
видимого благодаря доступному перечню модулей»; поэтому
VALUE, в соответствии с нынешним определением языка,—
переменная, невидимая в процедуре INNER.
4.7. Перечень используемых модулей
175
-Ап 4.39. Мнемоника уточненных имен
oCedure HEIGHTJ>ROC is
HEIGHT is
*HEIGHT__ID: INTEGER;
VALUE: FLOAT;
end HEIGHT;’ .
^Jocedure WEIGHT_PROC is
*pZckage WEIGHT is
WEIGHT-ID: INTEGER;
VALUE: FLOAT;
end WEIGHT;
procedure INNER is
use HEIGHT,WEIGHT;
begin
VALUE 96.5
WEIGHT.VALUE
HEIGHT.VALUE
WEIGHT—ID := :
HEIGHT_ID := ;
end INNER;
begin ....
begin ...
end WEIGHT_PROC;
end HEIGHT PROC;
>; - - нельзя: VALUE невидимо,есть в HEIGHT и в WEIGHT
: = 96.5; - - эффект тот же
* = WEIGHT.VALUE/2.О;
28537; - - психологически эффект мнемонических имен
28537; - - тот же, что и у уточненных имен
- - последовательность операторов HEIGHT__PROC
- - последовательность операторов WEIGHT—PROC
В этом примере компоненты ID пакетов HEIGHT (РОСТ)
и WEIGHT (ВЕС) имеют уникальные имена HEIGHT.ID
и WEIGHT. ID. Эти неуточненные имена производят такое же
впечатление, как HEIGHT.ID и WEIGHT.ID.
Таким образом, в случае контекстной неоднозначности уточ-
нение имен можно рассматривать как полезный мнемонический
прием.
Эти примеры показывают, что перечень используемых мо-
дулей — относительно «пассивное» средство, которое просто
вводит сокращенные «синонимы» для объектов, доступных и
без такого перечня. Он не вносит ничего радикального, например
не расширяет множество доступных объектов.
Ограничение видимости restricted, рассматриваемое в сле-
дующем разделе,— в двух отношениях более мощный аппарат
изменения пространства имен, чем перечень используемых
сегментов:
1. Оно может как ограничивать, так и расширять множество
имен, доступных в программном сегменте, к которому соот-
ветствующая фраза restricted относится.
176
Гл. 4. Модульность и структура программы
2. Оно изменяет не только множество доступных имен
и множество доступных объектов и вычислительных ресу
сов.
4.8. Ограничение видимости
Сегмент программы в Аде обычно действует как мембрана
давая доступ из программного сегмента к идентификаторам*
объявленным в текстуально объемлющем сегменте, но закрывая
доступ извне к идентификаторам, объявленным в нем.
Ограничение видимости позволяет программисту сузить мно-
жество нелокальных идентификаторов, доступных изнутри сег-
мента программы. Зарезервированное слово restricted, непо-
средственно предшествующее объявлению подпрограммы или
модуля, исключает всякий доступ из него к нелокальным иден-
тификаторам.
Пример 4.40. Полное отсутствие видимости нелокальных иден-
тификаторов
restricted procedure Р(Х: in out INTEGER) is
- - изнутри процедуры P запрещен всякий доступ
- - к нелокальным идентификаторам, объявленным программистом
- - предопределенные идентификаторы, такие как INTEGER, INTEGER1 LAST
- - при этом доступны
- - связь между Р и внешней средой
- - ограничена параметром X
end Р;
В общем случае за зарезервированным словом restricted
может следовать перечень видимых сегментов (список видимости),
в котором перечисляются именованные сегменты программы.
Пример 4.41. Ограниченная видимость
restricted (Q) - - список видимости содержит Q, которое должно быть-
procedure Р is - - именем объемлющего сегмента или не объемлющего МОДУЛ*
- - доступность нелокальных идентификаторов ограничена
- - нелокальным сегментом Q
- - если Q — пакет, доступны все его видимые идентификаторы
- - если Q текстуально объемлет Р, видимы все идентификаторы,
- - объявленные в сегментах, объемлющих Р, но вложенных в Q
end Р;
NWWWt <
4.8. Ограничение видимости
177
программы ч
Должны быть
от ограничения доступа из Р нелокальным сегментом
зависит от текстуальных взаимосвязей Р и Q.
рассмотрены два варианта.
j, Q текстуально объемлет ограниченную программу Р.
р этом случае все идентификаторы, объявленные в сегментах,
содержащихся в Q, но объемлющих Р, доступны из Р. Но
идентификаторы, которые объявлены в текстуально объемлющих
q сегментах, остаются невидимыми.
2. Q не содержит Р, но объявлен в текстуально объемлющем
сегменте и при отсутствии ограничения видимости был бы до-
ступен. В таком случае сегмент Q должен быть модулем и не
может быть подпрограммой.
Благодаря наличию Q в списке видимости, все ресурсы,
объявленные в видимой части Q, доступны в Р, но остальные
нелокальные объявления текстуально объемлющей среды оста-
ются недоступными.
В общем случае список видимости ограниченного сегмента
программы может содержать один текстуально объемлющий сег-
мент, удовлетворяющий условию 1, и несколько модулей, удов-
летворяющих условию 2.
Общий вид ограничения видимости таков: ’’restricted (Р, Ml,
М2.....МК)”, где первый параметр Р может (но не обязательно
должен) быть именем объемлющего сегмента программы, а ос-
тальные — имена модулей. Каждое имя в списке видимости
обеспечивает доступ к набору ресурсов (среде). Первое имя может
предоставлять доступ к множеству «объемлющих» ресурсов,
в то время как остальные имена — к ресурсам не объемлющих
модулей.
В следующем примере, взятом из руководства, имеется ог-
раниченная процедура R со списком видимости (Q, Е), содер-
жащим объемлющую процедуру R и пакет Е, объявленный вне Q.
В результате все нелокальные идентификаторы и параметры в
пределах Q, а также видимые компоненты пакета Е видимы в R.
Но внешняя процедура Р и содержащиеся в этой процедуре
объявления, не входящие в Q или в видимую часть Е, не вид-
ны в R. .
Пример 4.42. Видимость для объемлющих и не объемлющих
сегментов
7
№ 56
178
Гл. 4. Модульность и структура программы
procedure Р (X: INTEGER) is.
LP: BOOLEAN;
package E is,
LE: BOOLEAN
end Е;
package body Е is
LBE: BOOLEAN;
- . P и X не видны в R
* - LP не виден в R
• * Б видим в R
Q текстуально объемлет R
- - ограничение видимости
- - для процедуры R
end Е;
procedure Q(Y: INTEGER) is
LQ: BOOLEAN;
restricted (Q,E)
procedure R(Z: INTEGER) is
begin
- - видимые локальные идентификаторы Q:
- - сама процедура Q
- параметр Y
я - локальная переменная LQ
• » - сама процедура R
- - параметр Z процедуры R
• - видимо имя пакета Б:
- - можно использовать такие имена, как E.LE
* - допустим перечень модулей “use Е;”
- ~ как обычно, LBE не видимо
* * имена Р, X и LP не видимы
end R;
begin
end 2;
begin
end P;
Ограничение видимости можно использовать не только для
того, чтобы сузить набор обычно доступных идентификаторов
внешней среды. Оно позволяет также расширить множество
доступных идентификаторов за счет включения в список види-
мости отдельно компилируемых сегментов. Например, проце-
дура QUADRATIC-EQUATIONS (КВАДРАТНЫЕ.УРАВНЕ-
НИЯ) использует для ввода-вывода пакет ТЕХТ-Ю, а для из-
влечения квадратного корня — пакет MATH-LIB. Ограничение
видимости дополняет пространство имен процедуры идентифи-
каторами, объявленными в видимых частях пакетов MATH-LIB
и ТЕХТ-Ю. В такой ситуации зарезервированное слово rest-
ricted (ограниченный), очевидно, недоразумение. Представляется,
однако, разумным использовать в языке один и тот же механизм
и для ограничения, и для расширения пространства имен.
4.9. Родовые программные структуры
179
Пример 4.43. Процедура решения квадратных уравнений
„dieted (MATHJLIB, TEXT_IO)- - делает доступными MATH_LIB TEXT_IO
J^^^QUADRATI^EQUATIONS is
Е^^ГтЁХТ_1О; - - PUT, GET, NEWLINE определены в TEXT—IO
5fB,C,Ds FLOAT;
^=T(A); GET(B); GET(C);
D .= B**2 - 4.0*A*C;
,if D < 0.0 then
~~PUT ("IMAGINARY ROOTS");
else
"""declare
use MATHJLIB; .. SQRT определен в MATH—LIB
begin
PUT("REAL ROOTS:");
PUT((B - SQRT(D))/(2.0*A));
RUT((B + SQRT(D))/(2.0*A));
PUT (NEWLINE) }
end;
end if;
end QUADRATIC_EQUATIONS;
Спецификации модулей и подпрограмм, от которых зависит
отдельно компилируемый сегмент программы, должны быть
скомпилированы раньше него. Поэтому спецификации МАТН_
LIB и ТЕХТ_Ю в последнем примере должны компилироваться
до процедуры QUADRATIC_EQUATIONS. Процедура для
решения квадратных уравнений должна быть перекомпилиро-
вана, если изменятся спецификации MATH_LIB или ТЕХТ_Ю,
однако этого не требуется при изменении лишь реализации этих
пакетов. Таким образом, разделение спецификации и реализации
не только разграничивает информацию, нужную пользователю,
и информацию для реализации желаемых ресурсов, но также
облегчает сопровождение, явно показывая, когда изменения
Данного модуля могут потребовать изменения других модулей.
49. Родовые программные структура
Родовые программные структуры, точно так же как пакеты,
представляют собой средство описания абстрактного вычисли-
тельного процесса. Пакеты обеспечивают абстракцию, «упряты-
вая» несущественную информацию о реализации, и позволяя
пользователю «видеть» только вычислительные ресурсы высокого
Уровня. Родовые программные структуры обеспечивают абст-
ракцию, воплощая общие для группы вычислительных задач
свойства в единой программной структуре и описывая их раз-
личия с помощью параметров.
7»
180 _________Гл. 4. Модульность и структура программы
Параметризация чуть ли не с самого начала рассматривав
как основной механизм абстрагирования. Этот механизм леж?
и в основе понятия подпрограммы. Однако параметризави >
подпрограмм в Аде ограничивается переменными. То <^7?
что может быть воплощено таким образом, выражается измени
нием значения переменной на множестве значений ее типа.
Родовые программные сегменты обеспечивают более мощную
форму параметризации. Они позволяют использовать в чаче-
стве параметров не только переменные, но также типы и проце-
дуры. Следующая родовая процедура SWAP (ОБМЕН), у^
рассматривавшаяся в гл. 1, показывает, как абстрактное поня-
тие обмена, не зависящее от типа обмениваемых объектов, может
быть реализовано с помощью родовой процедуры.
Пример 4.44. Два типа параметризации
generic (type Т)
procedure SWAP(X,Y: in out I) is
TEMP; I; . '
begin
TEMP ;== X;
X := Y;
Y := TEMP?
end SWAP;
Это объявление процедуры показывает, что родовые проце-
дуры имеют два уровня параметризации:
1. Параметры процедуры (они должны быть переменными).
Фактические параметры (аргументы) , подставляются вместо
формальных параметров при выполнении в момент вызова
процедуры.
2. Родовые параметры, указанные в фразе generic, которые
могут быть переменными, типами или подпрограммами. Под-
становка фактических параметров вместо формальных должна
быть выполнена при компиляции.
В то время как обычные процедуры вызываются во время
выполнения, «вызов» родовых процедур происходит при компи-
ляции. Такие «вызовы» родовых процедур в период компиляции
называются созданием потомков, или конкретизацией проце-
дуры. Конкретизация родовой процедуры цожет означать гене-
рацию фрагмента текста программы во многом аналогично тому,
как в случае макроассемблера макровызов означает макрорас-
ширение текста.
Два потомка процедуры SWAP для обмена отдельными зна-
чениями целого типа (и векторами соответственно) могут быть
созданы следующим образом.
4.9. Родовые программные структуры 181
4.45. Конкретизация родовой процедуры
procedure SWAP_INT is new SWAP(INTEGER);
procedure SWAP^VECT is new SWAP (VECTOR) ?
Поскольку объектный код для обмена векторами совершенно
яеПохож на код для обмена целыми значениями, может пока-
яться разумным генерировать два различных программных
текста для SWAPJNT (ОБМЕН.ЦЕЛ) и SWAP_VECT (ОБ-
МЕН_ВЕКТ). Концептуально каждый' потомок родового про-
граммного сегмента воплощен в виде отдельного текста. Однако
часто такие потомки достаточно похожи, так что оказывается
целесообразной оптимизация — воплощение их одним текстом.
У родовых программных структур родовыми параметрами
могут быть подпрограммы. В следующем примере интегрируемая
функция служит родовым параметром родовой функции INTE-
GRATE (ИНТЕГР), а границы отрезка интегрирования служат
параметрами функции.
Пример 4.46. Подпрограммы в качестве родовых параметров
generic (-function F(X: FLOAT) retu'rn FLOAT)
function.INTEGRATE(LOW,HIGH; FLOAT) return FLOAT is
- - текст функции численного интегрирования,
- - вычисляющей определенный интеграл
। - - функции F(x), задаваемой при конкретизации,
- - на отрезке от LOW до HIGH, значения которых
“ - задаются при вызове функции INTEGRATE
end INTEGRATE;
Родовая функция INTEGRATE может быть частью пакета
математических подпрограмм. Прежде чем использовать INTE-
GRATE для интегрирования конкретной функции, нужно соз-
дать соответствующий ее потомок.
Пример 4.47. Потомки в случае родовых параметров-подпро-
грамм *
function INTEGRATE_SIN is'new INTEGRATE(SIN)У
function INT_FOP is' new INTEGRATE(USERF)у
При конкретизации в качестве параметра передается инте-
грируемая функция, которая в этот момент должна быть опре-
делена и доступна и должна иметь типы параметров и результата,
совместимые с объявленными в родовом заголовке (SIN должна
иметь параметр и результат плавающего типа).
В результате конкретизации создается функция с двумя
Параметрами и результатом того же типа, что и INTEGRATE.
(INTEGRATE_SIN имеет два параметра, LOW (НИЖН) и
182 Гл. 4. Модульность и структура программы
HIGH (ВЕРХИ) типа FLOAT, и вырабатывает результат тип
FLOAT.) иа
Пример 4.48. Вызов потомка родовой функции
declare
X,Y: FLOAT7
begin
X := INTEGRATEJ5IN(O.5,1,0);
У := INT_FOO(-1.0,1.0);
end;
Когда родовые программные структуры имеют параметром
тип, часто бывает необходимо обеспечить в качестве дополни-
тельных параметров подпрограммы для работы с объектами
этого типа. Так, следующая родовая функция возведения в
квадрат объектов произвольного типа Т требует операции умно-
жения для объектов типа Т в качестве второго родового пара-
метра.
Пример 4.49. Зависимость параметров-подпрограмм от парамет-
ров-типов
generic (type Т; function "*"(U,V: Т) return Т)
function SQUARING(X: T) return T is
pragma INLINE;
begin
return X*X;
end SQUARING;
Потомков этой функции для объектов типа INTEGER, COMPLEX
и MATRIX можно создать следующим образом.
Пример 4.50. Потомки с параметрами — типами и подпрограм-
мами
function SQUARE is new SQUARING(INTEGER,"*");
function SQUARE is new SQUARING(COMPLEX,"*");
function SQUARE is new SQUARING(MATRIX,MATMULT);
Этот пример показывает, что не обязательно давать новое
имя функции для каждого типа аргументов SQUARE (КВАДР),
разрешены перекрытия во многом такие же, как перекрытия
функций «+» или «*».
При каждой конкретизации задается как имя типа, которое
должно быть подставлено вместо родового параметра-типа, так
и имя процедуры для подстановки вместо родового параметра-
процедуры. Имя «*» для возведения в квадрат целых обозначит
предопределенную операцию умножения целых, а в случае ком-
плексных нужно сначала определить операцию умножения
комплексных, например как в разд. 3.3. Чтобы была законной.
4.10, Родовые
пакеты
183
конкретизация возведения в квадрат матриц, нужно предвари-
тельно определить функцию умножения матриц MATMULT
родовые аргументы, как и обычные, могут передаваться
посредством явного указания имени формального параметра и
значения аргумента.
Пример 4.51. Явное именование родовых параметров
function SQUARE is new SQUARING(T is COMPLEX, "*"• is COMPLEX."*");
Можно задавать значения родовых параметров по умолчанию.
Так, в следующем примере для функции «*» (U, V:T) return Т
по умолчанию определено значение Т.”«”.
Пример 4.52. Задания значений родовых параметров по умол-
чанию
generic (type Т; "*"(U,V: I) return T is T."*")
function SQUARING (X:. • !) return T;
- - текст процедуры
Это позволяет опускать второй аргумент при конкретизации
родовой процедуры, если его значение для типа Т есть Т.”*”.
Пример 4.53. Умолчание параметра при конкретизации
function SQUARE is new. SQUARING (T is INTEGER) ; • - 2 параметр
—по умолчанию INTEGER."*"
function SQUARE is new SQUARING (COMPLEX); - - 2 параметр по умолчанию
--COMPLEX.”*"
function SQUARE is new SQUARING (MATRIX,MATMULT) ; - - требует явного
- - задания второго параметра
Таким образом, значение второго параметра может быть опу-
щено для возведения в квадрат целых и комплексных значений,
но должно быть указано для матриц, если операцией умножения
матриц является MATMULT/ Если бы операция эта называлась
«*», тогда и для возведения в квадрат матриц второй параметр
можно было бы опустить.
4.10. Родовые пакеты
Между подпрограммой и модулем есть два различия, благо-
даря которым концепция рода для модулей оказывается еще
более полезной, чем для подпрограмм.
1. Подпрограммы имеют параметры, а модули—нет. Поэтому
Родовые параметры подпрограмм — лишь более мощная версия
Уже существующего механизма, в то время как для модулей —
это нечто совершенно новое.
184
Гл. 4. Модульность и структура программы
2. Экземпляр подпрограммы создается по ее объявление
по существу, при каждом ее вызове, спецификация же моду’
не позволяет создавать несколько его экземпляров.
образом, конкретизация родовой подпрограммы — это вариа»!
периода компиляции для средства, и без того доступного
период выполнения через механизм вызова подпрограмму *
то время как конкретизация родового модуля — совершен^
новая возможность.
В качестве примера родового пакета рассмотрим пакет ддя
работы с таблицей имен из разд. 4.5. Его можно сделать более
гибким, если оформить тип элементов таблицы как родовой
параметр, и ввести новый параметр — максимальную ее длину.
Пример 4.54. Родовой пакет для работы с таблицей имен
generic (type Т; SIZE: INTEGER);
package SYMTAB is
function FIND(S: STRING) return T;
procedure UPDATE(S: STRING; V: T);
end SYMTAB;
Такой родовой пакет позволяет создавать таблицы имен раз-
ной длины и с разными типами значений.
Пример 4.55. Потомки для разных типов значений
. package INT_TABLE is new SYMTAB(INTEGER, 100)?
package FLOAT_TABLE is new SYMTAB(FLOAT, 100);
package PERSON TABLE is new SYMTAB(PERSON, 50);
/ -rj • " J
Можно определять значения, присваиваемые параметрам по
умолчанию. В следующем примере для параметра SIZE (ДЛИНА)
таким будет значение 100, в дальнейшем этот параметр надо
указывать явно, только если требуется другое значение.
Пример 4.56. Задание значения оДного из параметров по умол-
чанию
generic (type Т; SIZE: INTEGER := 100)
package SYMTAB is
,» - текст спецификации SYMTAB
package INT_TABLE is new SYMTAB(INTEGER);
package PERSON TABLE is new SYMTAB (PERSON, 50) ;
В следующем примере задаются умалчиваемые значения
обоих параметров — и типа, И длины.
Пример 4.57. Указание умалчиваемых значений обоих пара*
метров
4,10, Родовые пакеты
185
generic (type Т is INTEGER; SIZE; INTEGER Юм
package SYMTAB is '
- - текст спецификации SYMTAB
Это позволяет создать потомка родового пакета SYMTAB
л-дБЛ.ИМЕН), указывая один или два параметра или не ука-
зывая их вовсе.
Пример 4.58. Указание разного числа параметров
„ackage. INT_TABLE is new SYMTAB- - умолчание типа и длины
T^kage FLOAT_TABLE is new SYMTAB (FLOAT) ; - - умолчание ДЛИНЫ, ТИП
~ указан
package PERSON_TABLE is new SYMTAB (PERSON, 50); - - указаны явно и тип,
- --и длина
Аппарат умолчания позволяет сочетать гибкость варьиро-
вания в необходимых случаях и простоту в стандартных ситуа-
циях.
Механизм родовых программных структур можно использо-
вать для создания нескольких копий модуля без параметров.
Например, если нам нужны таблицы имен только длиной в
100 строк и только с целыми значениями, можно эти параметры
в спецификации опустить и работать с таким родовым пакетом
без параметров.
Пример 4.59. Родовые пакеты без параметров
generic, package SYMTAB is - - родовой пакет без Параметров SYMTAB
- - текст спецификации пакета
package Т1 is new SYMTAB; . - можно работать с T1.FIND* Т1 .UPDATE
package Т2 is new SYMTAB; - - и T2.FIND, T2.UPDATE
Родовой пакет без параметров можно сравнить с объявлением
комбинированного типа. Это — трафарет, по которому могут
создаваться копии во многом так же, как объявления объектов
создают копии записей. Доступ к компонентам экземпляров
пакета похож на доступ к компоненте объекта комбинированного
типа. Однако компоненты записи могут быть только объектами,
а компоненты родовых пакетов — и типами, и процедурами.
Потребность в нескольких экземплярах одного модуля часто
возникает в больших прикладных программах. Рассмотрим,
например, модель флота с большим количеством кораблей, каж-
дый из которых характеризуется одинаковым набором вычис-
лительных ресурсов. В таком случае удобно определить родовой
пакет SHIP (КОРАБЛЬ) со спецификацией этих ресурсов, по-
зволяющий создавать столько экземпляров кораблей, сколько
потребует модель.
186
Гл. 4. Модульность и структура программы
Пример 4.60. Несколько экземпляров пакета
generic package SHIP -is
- •* спецификация ресурсов,
- - определяющих корабль
- - родовой пакет без параметра»
end;
package S is new SHIP;
package T is new SHIP;
- - несколько экземпляров с одинаковыми
- - атрибутами (скорость, вооружение),
- - но, возможно, с разными их значениями
Такие объекты, как корабли,—это источник асинхронных
вычислений и событий. Более адекватно их можно моделировать-
с помощью параллельных процессов (называемых в Аде зада-
чами), а не пакетов.
Пример 4.61. Родовая задача без параметров
generic, task SHIP is
— спецификация ресурсов»
— определяющих корабль
end;
Задачи в Аде — это модули, представляющие пользователю
вычислительные ресурсы аналогично пакетам, но с одним до-
полнительным свойством: они могут выполняться параллельно
с другими модулями. Подробно задачи будут рассмотрены в
гл. 5.
4.11. Структура программы
и изменение пространства имен
' В языках программирования механизмы изменения совокуп-
ности доступных имен — основа понимания структуры про-
граммы. В Аде основной конструкцией для такого изменения
является сегмент программы.
Первоначально пространство имен программы включает мно-
жество зарезервированных слов (таких, как begin, for, proce-
dure) и предопределенных идентификаторов (таких, как INTE-
GER, INTEGER’LAST, TRUE, INLINE). Это изначальное про-
странство изменяется при входе в сегменты выполняемой про-
граммы, так что множество доступных имен в данный момент
выполнения программы состоит из первоначального пространства
имен плюс все его изменения сегментами, вход в которые уже
осуществлен, а выхода еще не было. Множество доступных
в данной точке выполнения программы имен будем называть
окружением.
Средства изменения окружения при сопряжении сегментов
программы таковы:
4.11. Структура программы и изменение пространства имен 187
1. Объявление локальных идентификаторов в совокупности
пбъя'влений сегмента программы.
00 2. Спецификации параметров, а именно формальных пара-
,еТров, связываемых с фактическими при вызовах подпрограмм,
’ родовых параметров подпрограмм и модулей, связываемых с
фактическими при компиляции.
v 3. Ограничение видимости restricted, сужающее доступ к
текстуально объемлющим объявлениям, но позволяющее и
расширить множество доступных имен за счет видимых иденти-
фикаторов отдельно компилируемых сегментов и библиотечных
модулей.
4. Перечень используемых модулей, который позволяет
сокращать некоторые нелокальные доступные имена.
Синтаксические средства изменения окружения при входе
в сегмент иллюстрирует следующий пример. Шесть различных
приемов модификации пространства имен показывают, что Ада
обладает большими синтаксическими возможностями управления
пространством имен, чем предшествующие языки, такие, как
Алгол 68, Паскаль или даже ПЛ/1. Разные средства предназна-
чены для разных целей, хотя есть и некоторое дублирование.
Пример 4.62. Изменение окружения при входе в сегмент
[ограничение видимости] * - определяет доступность нелокальных сегментов
[родовой заголовок] - - уровень локальной терминологии (связанные
переменные периода компиляции)
.procedure имя-процедуры - - можно использовать внутри и вне процедуры
[спецификация параметров] - - уровень локальной терминологии
- - (связанные переменные периода выполнения)
[перечень используемых сегментов] - - сокращения нелокальных имен
[локальные объявления] - - еще один уровень локальной терминологии
begin
последовательность операторов - - операторы выполняются в новом окружении,
[реакция в исключительных ситуациях] - - полученном изменением старого
end ; - - с помощью шести перечисленных средств
Ограничение видимости и перечень сегментов управляют
видом доступа к определенным вовне нелокальным именам. Эти
конструкции получают в качестве аргументов сегменты про-
граммы и. вводят в пространство имен ресурсы с именами и
типами, не указанными явно. Спецификации соответствующих
сегментов должны быть скомпилированы заранее так, чтобы
компилятор имел доступ в момент обработки данного сегмента
программы к таким именам.
Тот факт, что ограничения видимости вводят имена неявно,
означает, что синтаксическая правильность сегмента не может
быть определена только по тексту самого сегмента. Это может
188
Гл. 4. Модульность и структура программы
усложнить задачу чтения и сопровождения программы челове-
ком. Однако компилятор всегда может определить синтаксис
скую правильность, поскольку все сегменты, используемые
в данном, должны иметь уже скомпилированные спецификации
Более того, административная система языка будет хранить
запись зависимостей сегментов программы, поэтому всегда буд^
точно известно, какие сегменты следует скомпилировать заново
при изменении спецификаций некоторого данного сегмента.
Таким образом, программист может полагаться на админист-
ративную систему в вопросах проверки сопряжения взаимоза-
висимых сегментов.
В то время как ограничение видимости и перечень исполь-
зуемых сегментов относятся к сопряжению с нелокальными
именами, остальные механизмы изменения пространства имен
имеют дело с созданием новых локальных имен. Родовой заго-
ловок вводит уровень локальных имен периода компиляции,
исчезающий при конкретизации, а имя процедуры, спецификация
параметров и локальные объявления определяют локальное
окружение периода выполнения.
Все создаваемые локально имена требуют полной специфи-
кации типа. Корректность использования локальных объектов
может быть проверена пользователем и компилятором — до-
статочно обратиться к этим спецификациям.
Интересно проследить за сходством и различием между
спецификациями параметров и объявлениями локальных имен.
В обоих случаях используются похожие соглашения для ука-
зания типа и начальных значений. Однако параметры — это
часть сопряжения процедуры с окружением, они могут исполь-
зоваться для передачи информации между окружением вызова
и окружением выполнения, в то время как локальные объяв-
ления — это временные локальные ресурсы, необходимые для
выполнения процедуры, но полностью скрытые от пользователя.
Имеется возможность задать начальные значения как па-
раметров, так и локальных переменных явным присваиванием.
Однако при отсутствии таких явных указаний начальные зна-
чения параметров определяются значениями аргументов из ок-
ружения вызова, в то время как инициализация локальных пе-
ременных в таком случае не производится, и их значения должны
быть заданы оператором присваивания, прежде чем можно будет
их использовать.
Таким образом, принципиальное различие между парамет-
рами и локальными переменными — в степени их локальности
и в способе инициализации.
Кратко сравним средства изменения пространства имен про-
цедур и пакетов. Последние можно охарактеризовать следую-
щим образом.
4.11- Структура программы и изменение пространства имен 189
Пример 4.63. Изменение окружения при входе в пакет
Гограиичение видимости] - - определяет доступность нелокальных сегментов
Ьдовой заголовок] I - - уровень параметров периода компиляции
декаде имя-пакета is - - имя используется вне, но не внутри пакета
*ркречень используемых сегментов] - - сокращения нелокальных имен
[спецификация видимых ресурсов] - - доступные извне (экспортируемые) имена
end; - - несовершенная аналогия с параметрами процедуры
<gkage body имя-пакета is
^""[локальные объявления] * . локальное пространство, (как для процедур)
реализация видимых ресурсов
соответствует совокупности предложений процедуры
[beain
действия по инициализации]
end;
Ограничение видимости и перечень используемых сегментов
определяют множество доступных нелокальных имен в точности,
как и для процедур. Родовой заголовок задает уровень ло-
кального окружения, но может быть более полезным для па-
кетов, чем для процедур, ибо, как отмечено в предыдущем разделе,
только он обеспечивает механизм параметризации и создания
потомка родовой программной структуры.
Хотя между параметрами процедуры и видимыми идентифи-
каторами пакета — огромная разница, их роль в обеспечении
сопряжения с пользователем обнаруживает определенное сход-
ство. Видимые идентификаторы пакета — не формальные пара-
метры, они скорее подобны аргументам. Они представляют «фак-
тические ресурсы», совместно используемые всеми пользовате-
лями пакета, а не «формальные .ресурсы», вместо которых в
момент вызова подставляются фактические.
Что касается тела пакета, видимые ресурсы пакета пред-
ставляют собой слой пространства имен, составляющий часть
сопряжения сегмента, в то время как локальные объявления
тела пакета — слой, полностью скрытый от пользователя. Таким
образом, с точки зрения изменения пространства имен, имеется
шесть возможных механизмов, каждый из которых аналогичен
соответствующему механизму для процедур.
Есть еще одно важное различие между окружением, опре-
деленным пакетом, и процедурой. В случае процедуры время
существования объектов, соответствующих параметрам и ло-
кальным объявлениям, ограничено временем выполнения про-
цедуры, локальные объекты не сохраняются между вызовами.
Что касается пакета, то время существования его локальных объ-
ектов — это время существования его объявления, а не вызовов.
Поэтому как видимые, так и скрытые структуры данных созда-
ются в момент объявления пакета и сохраняются между вызо-
190
Гл. 4. Модульность и структура программы
вами его видимых процедур. Это позволяет представлять базы
данных и другие вычислительные структуры, требующие ло-
кальной памяти, сохраняющейся между активациями пакета.
4.12. Восходящая и нисходящая разработки программы
Возможность отделить в Аде спецификацию модуля от его
реализации обеспечивает поддержку методологии программи-
рования на уровне языка. В частности, Ада способствует как
нисходящей, так и восходящей разработке программ.
Восходящая разработка предполагает реализацию сначала
сегментов программы низкого уровня, а затем последовательную
реализацию все более высоких уровней в терминах уже раз-
работанных сегментов более низкого уровня.
Восходящая разработка возможна на любом языке, сегменты
программы которого имеют хорошо определенные сопряжения,
скрывающие детали реализации. Подпрограммы ранних языков
программирования и восходящее программирование с помощью
библиотек подпрограмм — все это было общеизвестно еще в
50-е годы.
Модули Ады (пакеты и задачи) — это, в сущности, другой
механизм обеспечения модульности вычислительных ресурсов. •
Они позволяют независимо разрабатывать и использовать как
компоненты больших программ не только алгоритмы, но и объ-
екты данных со связанными с ними операциями. Это решитель-
ным образом расширяет класс понятий, допускающих пред-
ставление в виде модульных сегментов, и может существенно
повлиять на способ организации задачи.
При нисходящем программировании начинают со специфи-
каций проблемы высокого уровня, а затем «детализируют» их
последовательными спецификациями все более низкого уровня,
пока, наконец, все спецификации не будут выражены на самом
«низком уровне» — на языке программирования. Такой подход
более соответствует задачам, выполняемым системным аналити-
ком по сведению поставленных пользователем задач к вычисли-
тельным проблемам. Однако работа со спецификациями, реали-
зация которых еще не существует,— процесс более абстрактный,
чем конструирование из уже готовых, реализованных специфи-
каций. Нисходящий подход недоступен инженерам, создающим
здания или мосты, поскольку невозможно построить верхние
этажи раньше нижних. «Концептуальная инженерия», которой
занимаются программисты, дает гораздо большую свободу в
выборе порядка выполнения задачи.
Обеспечение нисходящего программирования требует более
мощных языковых средств, чем для восходящего. В частности,
необходима возможность работать со спецификациями сегмен-
4.12. Восходящая и нисходящая разработки программы
191
тов программы как с независимыми объектами. Ада позволяет
рассматривать спецификации подпрограммы и модуля как
отдельные языковые объекты, которые могут прилагаться к сег-
менту независимо от реализации. Разделение спецификации и
реализации подпрограммы или модуля отмечается зарезервиро-
ванным словом separate.
Пример 4.64. Раздельные подсегменты компилируемой компо-
ненты
function F(X: FLOAT) return, FLOAT is separate; •<« реализация
; * - прилагается отдельно
package body D is separate; - - тело пакета прилагается отдельно
Нисходящее программирование будет проиллюстрировано
примером из описания языка. Пример состоит из процедуры ТОР
(ВЕРХ), содержащей пакет D и процедуру Q с «раздельными»
реализациями.
Пример 4.65. Пример нисходящего программирования
procedure TOP is
type REAL is digits 10;
R,S: REAL;
D is спецификация пакета
PI: constant REAL := 3.14159_26536;
function F(X: REAL) return REAL;
procedure G(Y,Z: REAL);
end D;
package body D -is separate; .. начало D
procedure Q (U: in out REAL) is separate; - - начало Q
—g-1- ' - - последовательность предложений TOP
2(R);
D.G(R,S);
end TOP.;
Тела пакета D и процедуры Q представлены в процедуре
ТОР заглушками, тексты которых компилируются отдельно.
Такие тексты, соответствующие заглушкам, называются под-
сегментами того компилируемого сегмента, в котором имеется
заглушка; говорят, что они заключены в этот компилируемый
сегмент. Текст подсегмента должен иметь ограничение види-
мости со списком видимости, первый элемент которого — имя
заключающего компилируемого сегмента. Таким образом, под-
сегмент, соответствующий приведенной выше процедуре Q,
должен быть оформлен следующим образом.
192
Гл. 4. Модульность и структура программы
Пример 4.66. Раздельный подсегмент-процедура
restricted (ТОР)
separate procedure Q(Us in out REAL) is
use D;
begin
U F(U)r
end Q;
Заметим,, что благодаря фразе restricted пакет ,D и тип D •
оказываются видимыми в Q — точно так же, как было бы, если
бы Q физически помещалась вместо своей заглушки. Пере-
чень видимых сегментов в процедуре Q позволяет ссылаться на
ресурсы D, такие, как F, не прибегая к уточнению.
Подсегмент, соответствующий заглушке тела пакета, дол-
жен быть оформлен следующим образом. .
Пример 4.67. Раздельный сегмент-модуль
restricted (ТОР)
separate package body D is.
м - локальные объявления
function 3?(X: REAL) return REAL is
begin
* - w последовательность операторов F
end F;
procedure G(Y,Z: REAL) is separate; --заглушка G, иерархическая
end? ' “ “ нисходящая разработка
Приведенное тело пакета — подсегмент ТОР и потому может
использовать сделанные в ТОР объявления, например REAL.
Отметим, что тела пакетов могут также компилироваться раз-
дельно как отдельные независимые компилируемые сегменты.
В этом случае они имеют доступ только к спецификации пакета,
но не к остальным объявлениям из окружения спецификации.
В теле пакета спецификация процедуры G содержит ука-
зание separate, иллюстрирующее иерархическую нисходящую
разработку. Тело G можно оформить следующим образом.
Пример 4.68. Иерархическая нисходящая разработка
restricted (TOPZ INPUT_OUTPUT)
separate procedure G(Y,Z: REAL) is
- begin
* * * последовательность операторов G
* - в том числе операторы ввода-вывода
end;
Отдельно компилируемая процедура G — подсегмент па-
кета D и транзитивно подсегмент ТОР. Ограничение видимости
4.12. Восходящая и нисходящая разработки программы
193
лчволяет внутри G использовать локальные объявления ТОР,
^пример REAL. л .
Приведенные примеры показывают, что в Аде и специфика-
ции модуля, и спецификации подпрограммы могут рассматри-
ваться как отдельные языковые объекты. С этой целью необхо-
димо ясно определить, что же такое понимается под специфи-
кацией. Спецификации Ады не' описывают поведение подпро-
грамм или модулей полностью. Их функция гораздо уже: ука-
зание имен и типов параметров, которые пользователю необхо-
димо знать, чтобы использовать обеспечиваемые сегментом
ресурсы.
Понятие «спецификация», использовавшееся выше,— поня-
тие скорее синтаксическое, чем семантическое, оно преднаме-
ренно неадекватно как основа для проверки (доказательства)
правильности программы или определения того, что же про-
грамма должна делать. Оно просто позволяет программисту при
нисходящей разработке задавать синтаксические сопряжения,
ограничиваясь обещанием, что о семантических сопряжениях
позаботятся отдельно. Оно позволяет также компилятору кон-
тролировать синтаксические сопряжения. Использование сла-
бых синтаксических спецификаций как языкового механизма
определения отношений между сегментами программы пред-
ставляет собой компромисс, основанный на понимании того, что
работа с более полными формами спецификаций неосуществима.
Систематическое использование синтаксических специфи-
каций как независимых лингвистических конструкций представ-
ляет собой значительное новшество в разработке языка, которое
может вполне повести к значительному прогрессу в обеспечении
методологии программирования на уровне языка — более серь-
езному, чем могут обеспечить отдельные пакеты разработки
программ. Слабость понятия спецификации может в дейст-
вительности обернуться одним из наиболее мощных источников,
обеспечивая язык средствами для работы с сопряжениями
между взаимно зависимыми модулями.
ГЛАВА 5
ЗАДАЧИ
5.1. Введение
Средства параллельного программирования важны по двум
причинам:
1. Они могут ускорить работу за счет параллельного выпол-
нения операций, которые иначе выполнялись бы последовательно.
Так, умножение двух матриц NxN, требующее № умножений
при использовании обычного последовательного алгоритма,
может быть выполнено за время, необходимое для одного ум-
ножения и log N сложений, если имеется N3 параллельных про-
цессоров.
2. Вторая, более фундаментальная причина — в том, что
такие предметные области, как резервирование авиабилетов,
банки, корабли, порты и города, естественно моделируются си-
стемами параллельно выполняемых задач.
В случае перемножения матриц параллелизм не является
внутренним, присущим самой структуре задачи свойством, он
вводится просто ради эффективности. Подлинная выгода от
параллельного подхода обеспечивается не искусственным вне-
сением параллелизма, позволяющего ускорить обработку, а
тем фактом, что реальный мир ведет себя как совокупность
параллельных процессов. Много предметных областей более
естественно моделируется параллельными, а не последователь-
ными процессами, их следует описывать системами параллельно
выполняемых задач, даже если программа будет выполняться
на машине с единственным процессором.
Такой подход избавляет программиста от необходимости за-
ботиться о порядке выполнения в случаях, когда это является
лишь «подробностями реализации».
Механизм задач в Аде проектировался с учетом реализация
в условиях двух совершенно различных вариантов архитек-
туры:
а) Архитектура с общей памятью, когда один или несколько
физических процессоров совместно работают над общей обла-
5.1. Введение
195
_ь10 памяти. При таком подходе физические процессоры обычно
являются наиболее дефицитным, критическим ресурсом, плани-
рование задач должно обеспечить оптимальное использование
процессоров, а эффективность многозадачной работы зависит
от методов планирования задач, времени переключения процес-
соров и других деталей реализации.
б) Архитектура распределенных процессов, когда есть мно-
жество процессоров со своей локальной памятью, но без сов-
местного использования общей памяти. В таком случае разные
задачи назначаются разным процессорам, и можно предполо-
жить, что имеется достаточно процессоров для всех задач, но
для связи между задачами больше нельзя рассчитывать на об-
щую память, необходимо использовать механизм сообщений.
Чтобы осознать следствия принятого в языке механизма
многозадачной работы, следует сопоставить концепции, поло-
женные в основу каждой из моделей — как основанной на об-
щей памяти', так и на распределенных процессах. Модель с сов-
местным использованием памяти отражает современную архи-
тектуру больших машин, все первые реализации Ады основаны
исключительно на ней. Однако громадное сокращение стоимости
процессоров, которое сейчас наблюдается, появление микро-
компьютеров и сама природа предметных областей, в которых
Ада, вероятно, будет применяться, вполне могут уже на раннем
этапе жизни языка вызвать реализации, основанные на распре-
делении процессов.
Параллельное выполнение легко моделируется, если выпол-
няемые параллельно задачи полностью независимы друг от
друга. Однако в большинстве ситуаций множество параллельных
задач совместно работает над некоторой более крупной задачей
и требует как взаимодействия, так и синхронизации в опреде-
ленные моменты работы. Ада обеспечивает две формы взаимо-
действия между задачами, соответствующие концепциям общей
памяти и передачи сообщений:
1. Взаимодействие посредством общих нелокальных пере-
менных.
2. Взаимодействие посредством передачи сообщений.
Взаимодействие посредством общих нелокальных перемен-
ных может представлять некоторую проблему как потому, что
во избежание конфликтов при доступе разных задач к совместно
используемой переменной необходима самая тщательная син-
хронизация, так и потому, что эта модель предлагает использо-
вание общей памяти,' что не просто моделируется при реализа-
ции с помощью распределенных процессов.
Однако в некоторых случаях общие переменные более ес-
тественны и эффективны, чем передача сообщений. Таким об-
196
Гл. 5. Задачи
разом, общая память, вероятно, на аппаратном уровне остаиегс
важным ресурсом, а общие переменные — существенным меха?
низмом межмодульного взаимодействия даже тогда, когда рас.
пределенная обработка станет сегодняшним днем. и
Рассматривая параллельную работу, мы будем обращу,
особое внимание на средства языка, предназначенные для взаимо.
действия посредством передачи сообщений. Однако, прежде чем
переходить к этим возможностям, мы рассмотрим случай под.
ностью независимых задач, не требующих никакого взаимо*
действия или синхронизации. Он позволит нам проиллюстри-
ровать основные средства запуска и выполнения параллельных
задач в условиях, не осложненных взаимодействием и синхро,
низацией.
5.2. Запуск и выполнение задачи
Для каждой задачи в программе должно быть соответствую-
щее объявление задачи; запускаются задачи с помощью операто-
ров запуска (initiate). Объявление задачи состоит из совокуп-
ности спецификаций, в которых описываются ресурсы, предо-
ставляемые задачей пользователю, и тела задачи, в которой
задается последовательность операторов, подлежащих выпол-
нению после запуска задачи.
Когда задачи выполняют полностью независимые действия,
их совокупности объявлений могут быть пустыми (вырожден-
ными). Приведенная ниже процедура ARRIVE_AT_AIRPORT
(ПРИБЫТИЕ_В_АЭРОПОРТ) содержит три независимые за-
дачи: CLAIM BAGGAGE (ПОЛУЧИТЬ.БАГАЖ), RENT.
A.CAR (ЗАКАЗАТЬ.МАШИНУ) и BOOK-HOTEL (ЗАКА-
ЗАТЬ_НОМЕР_В_ОТЕЛЕ) — тела которых и (вырожденные)
спецификации объявлены в процедуре.
Пример 5.1. Независимые задачи с вырожденными совокупнос-
тями объявлений
procedure ARRIVE_AT_AIRPORT is
- task CLA1MJRAGGAGE ;
task body CLAIM_BAGGAGE is
* - операторы, моделирующие
-- получение багажа
end CLAIM BAGGAGE;
task RENTJL.CAR? ’
task body RENT_A_CAR is
- вырожденная спецификация
- - задачи получения багажа
- - тело задачи, где описаны действия»
- - начинаемые по оператору запуская
- - выполняемые параллельно с друг®®
- - вырожденная спецификация
• - задачи по заказу машины
- - тело задачи по заказу машины
- - операторы, моделирующие заказ машины
end RENT_A_CAR?
task book^hotel; - - вырожденная совокупность специфика!®*
5.2. Запуск и выполнение задачи
197
к faddy BOOK_HOTEL is - - тело задачи
5^77 операторы, моделирующие заказ номера в отеле
end BOOKHOTEL;
7^ - - операторы процедуры ARR1VE_AT_AIRPORT
Vitiate CLAIM_BAGGAGE, RENT_A_CAjR, BOOKJIOTEL - —это оператор
•— • — запуска
^faRiyE^ATJYIRPORT; - - все задачи должны быть завершены до выхода
2й --из сегмента
Задачи могут быть завершены «нормально», когда выпол-
няется последний оператор тела задачи. Например, задача
CLAIM-BAGGAGE заканчивается после выполнения ее по-
следнего оператора. Однако, выход из сегмента, содержащего
локальныё объявления задач, не происходит до тех пор, пока
активна (не завершена) хотя бы одна из его локальных задач.
Поэтому нельзя выйти из процедуры ARRIVE_AT_AIRPORT,
пока все три задачи, объявленные и запущенные в ней, не за-
кончат свое выполнение.
Эти три задачи независимы в том смысле, что при выполнении
они не взаимодействую! друг с другом. Как только они запу-
щены, эти задачи не требуют ни синхронизации, ни общения
между собой, и поэтому их совокупности спецификаций могут
быть вырожденными. Однако задачи — активные модули, ко-
торые могут воздействовать на свое окружение и осуществлять
вывод, даже если они не предоставляют другим задачам никаких
ресурсов. В этом отношении они отличаются от пакетов, которые
пассивно «дремлют», если их ресурсы не используются. Пакет
с вырожденной совокупностью спецификаций не имел бы ни-
какого смысла, поскольку такой пакет никак не может воздей-
ствовать на остальную программу.
Каждая задача Т имеет атрибут T’ACTIVE, значение кото-
рого равно TRUE, если Т запущена, но еще не завершена, и
FALSE в противном случае. Попытка запустить уже активную
задачу (т. е. такую, для которой T’ACTIVE =TRUE) приводит
к ошибке запуска задачи (возникает исключительная ситуация
INITIATE_ERROR (ОШИБКА_ЗАПУСКА)). Таким обра-
зом, можно сказать, что задачи подобны пакетам в том отноше-
нии, что они существуют не более чем в одном экземпляре в лю-
бой момент выполнения программы, и отличаются от процедур,
которые могут существовать в нескольких динамических экземп-
лярах, как в результате рекурсивного вызова, так и при парал-
лельном их выполнении несколькими задачами.
Родитель задачи Т — это задача, при выполнении которой
обрабатывается объявление Т. В связи с этим главная программа
Рассматривается как задача. Если главная программа вызывает
Процедуру ARRIVE_AT_AIRPORT, то в результате этого
198
Гл. 5. Задачи
вызова обрабатывается объявление задачи CLAIM-BAGQAp
и та будет иметь своим родителем главную программу. В
тате вызова ARRIVE-AT.AIRPORT некоторой другой э*
чей Т будет создана задача CLAIM-BAGGAGE, родителем^*
торой будет Т. Таким образом, объявленная в процедуре зада
может иметь разных родителей в зависимости от вызова проц
дуры.
5.3. Синхронизация и взаимодействие задач
В общем случае совокупность спецификаций задачи может
содержать спецификации типов, подпрограмм, исключительных
ситуаций и входов, что иллюстрирует рис. 5.1.
Спецификации типа, подпрограммы и исключительной ситуа-
ции могут встретиться в совокупности спецификаций кятг L
Спецификация задачи
Может содержать:
спецификации типов
спецификации подпрограмм
спецификации исключений
спецификации входов
но не может содержать:
спецификации переменных
спецификации модулей
Тело задачи’
содержит скрытые локальные
объявления,
обрабатываемые при запуске задачи,
последовательность операторов,
выполняемых при запуске задачи,
и операторы приема,
которые должны выполняться
для приема вызовов
входов из других задач
Рис. 5.1. Спецификация и тело задачи.
дачи, так и пакета. Спецификации входа могут
в спецификации задачи, но не пакета, а спецификации перемен
ной и модуля — только в спецификации пакета.
Спецификация входа — основное средство взаимодействие
и синхронизации задач. Оно уже иллюстрировалось в гл. 1 йа
задаче о почтовом ящике: вход SEND (ПОСЛАТЬ) служил №
5.3. Синхронизация и взаимодействие задач
199
иилки сообщений от задач пользователя в почтовый яшик
RECEIVE (ПОЛУЧИТЬ) позволял зада,™ вольS
а а получать сообщения. Ниже этот же механизм иллюстоиоует
ЛХача LINE.TO.CHAR (СТРОКА_СИМВ), у которой вход
qEND LINE (ПОСЛАТЬ.СТРОКУ) позволяет другим зада-
ям посылать ей строки текста, а вход GET.CHAR (ПОЛУ-
ЙТЬ_СИМВ) — получать у нее символы. Спецификация
„a4H-LlNE_TO_CHAR содержит также спецификацию типа
LINE (СТРОКА), с тем чтобы все задачи, снабжающие ее стро-
ками текста, имели доступ к этому типу.
Пример 5.2. Спецификация типа и входа
task LINE_TO_CHAR is >
type LINE is array(1..80) of CHARACTER;
entry SEND_LINE(L: in LINE);
entry GET_CHAR(C: out CHARACTER);
end;
Спецификации входов синтаксически подобны специфика-
циям процедур. Они могут иметь параметры с такими же видами
связи, как и параметры процедур, и могут вызываться из дру-
гих 'задач с помощью вызовов входов, синтаксически неотличи-
мых от вызовов процедур. Однако, в то время как вызов проце-
дуры немедленно приводит к ее выполнению, вызов входа
требует синхронизации с оператором приема accept в теле за-
дачи, прежде чем вход начнет выполняться.
Тело задачи, соответствующее приведенной выше специфи-
кации, содержит для каждого объявления входа по оператору
приема, что позволяет этой задаче принимать из других задач
вызовы SEND.LINE и GET.CHAR.
Пример 5.3. Тело задачи с операторами приема
- - буфер для строки в 80 символов
task body LINEJTO_CHAK is
BUFFER: LINE;
begin
loop * - бесконечный цикл, принимающий
accept SENDJLINE (L: in LINE) do* - - вызов ПОСЛАТЬ_СТРОКУ
BUFFER : =. L; * - запомнить строку в буфере
end SEND_LINE;
for I in 1.. 80 loop - - теперь нужно принять 80 вызовов
accept GET_CHAR(С; out CHARACTER) do -- входа
- - ПОЛУЧИТЬ—СИМВ,
- - читающих по символу из буфера
С;:= BUFFER(I);
end'GET CHAR;
end loop;
£nd loop;
LINE TO CHAR;
- - когда это сделано,
- - мы готовы получить новую строку
200
Гл. 5. Задачи
Задачу можно запустить оператором запуска (initiate)
Пример 5.4. Запуск задачи
initiate LINE_TO_CHAR;
Мы рассмотрим выполнение задачи LINE_TO_CHAR, og.
ращая особое внимание на синхронизацию этой задачи и всех
вызывающих ее задач, необходимую при выполнении оператора
приема. Процесс синхронизации вызова входа в вызывающей
задаче с оператором приема в вызываемой называют рандеву,
В результате выполнения оператора запуска тело запускае-
мой задачи начинает выполняться параллельно с задачей, за-
пустившей ее. В нашем случае запуск задачи приведет к созда-
нию буфера для строки, а затем начнет выполняться бесконечный
цикл, в котором поочередно принимается вызов входа SEND.
LINE из другой задачи, а после этого — восемьдесят вызовов
GET_CHAR одной или несколькими другими задачами.
Когда выполнение дойдет до оператора accept SEND.LINE,
прежде чем можно будет продолжать, должно состояться ран-
деву задачи LINE_TO_CHAR с вызовом этого входа другой
задачей. На время рандеву, пока выполняется последователь-
ность операторов между do и end в вызванной задаче, выполне-
ние вызвавшей задачи приостанавливается. По окончании вы-
полнения этой последовательности рандеву завершено, и можно
дальше выполнять вызвавшую задачу параллельно с вызванной.
В нашем случае во время рандеву будет выполнен единствен-
ный оператор BUFFER := L; . В нем вызвавшая задача пере-
дает вызванной текст L. Выполняемые во время рандеву опера-
торы обычно и связаны с передачей информации между вызываю-
щей и вызываемой задачами.
Как отмечалось в гл. 1, последовательность операторов
между do и end, следующая за оператором приема, называется
критической секцией, поскольку вызывающая задача не может
выполняться дальше, пока эта последовательность не выпол-
нена. В нашем случае ясно, что выполнение вызывающей задачи
во время передачи строки на буфер может вызвать изменение
этой строки в процессе пересылки и потому должно быть запре-
щено. Критические секции позволяют выполнять критичные
действия, связанные с оператором приема, без помех со стороны
вызывающей задачи. '
В общем случае синтаксис оператора приема таков.
5.3. Синхронизация и взаимодействие задач 201
Пример 5.5. Синтаксис оператора приема
a;=ept имя-входа [список формальных параметров] do - • формальные
-^юслёд°вательность операторов (критическая секция) - - параметры '
end [имя-входа]; —локальны для критической секции
Выполнение операторов приема требует синхронизации между
содержащей их задачей и задачей, в которой имеется вызов входа
с именем, связанным с оператором приема. Если нет вызовов
входа, уже ожидающих приема, задача сама должна подождать
такой вызов. Если вызов входа уже ждет, происходит рандеву
с задачей, содержащей этот вызов, выполняется критическая
секция, причем вызвавшая задача тем временем остается при-
остановленной, а затем вызвавшая и вызванная задачи продол-
жают выполняться независимо друг от друга.
Вызовы некоторого данного имени входа могут возникать
быстрее, чем они обрабатываются операторами приема. В таком
случае они становятся в очередь, связанную с именем входа, и
обрабатываются операторами приема вызванной задачи в по-
рядке поступления. В общем случае задача может иметь более
одного оператора приема для данного имени входа, но очередь
ожидающих вызовов для каждого имени входа всегда одна.
Между вызовом входа и его исполнением может пройти значи-
тельное время. Весь этот период вызывающая задача остается
приостановленной. Но значения параметров вызывающей задачи
могут быть изменены другими выполняемыми задачами. В дейст-
вительности передаются те значения параметров, которые имеют
место в момент рандеву при выполнении критической секции
оператора приема. Такая интерпретации, однако, опирается на
предположение, что фактические параметры, являющиеся пере-
менными, копируются вызванной задачей лишь в момент ран-
деву. Это предположение разумно, если исходить из архитек-
туры с общей, совместно используемой памятью. Но при рас-
пределенной обработке есть соблазн копировать значения пара-
метров для передачи в очередь, физически связанную со входом
вызываемой задачи, в момент вызова, а не ждать до рандеву.
Параметры вызова входа, очевидно, не должны изменяться
между вызовом и рандеву. Возможно, было бы желательно сде-
лать это требованием языка. Однако проверка такого требова-
ния в общей случае требует динамического контроля во время
выполнения и может оказаться дорогой. Программисты могли бы
обеспечивать безопасность программ, локализуя параметры вы-
зова входа в вызывающей задаче, но это потребует иногда до-
полнительного уровня вложенности областей действия.
Механизм рандеву — основное средство синхронизации вза-
имозависимых задач. Синхронизированное взаимодействие осу-
ществляется через передачу параметров при рандеву. Если тре-
202
Гл. 5. Задачи
буется синхронизация без взаимодействия, можно испздьал
вызов входа без параметров. ЬЗовать
В следующей задаче реализации семафоров главная цел
синхронизация, а не передача значений, поэтому здесь поч1Г'
йены входы без параметров. ₽ИМе'
Пример 5.6. Задача SEMAPHORE (СЕМАФОР)
task SEMAPHORE is
entry P;
entry V;
end;
task body SEMAPHORE is
begin
loop
accept P;
accept V;
end loop;
ends
- - задача имеет
• - два входа: P и V
* - тело задачи
- - составляет
* * бесконечный цикл,
- - в котором поочередно
• - выполняются операторы
- - приема входов Р и V
Семафор может применяться для обеспечения взаимной)
исключения при доступе к совместно используемой переменной.
Если X — такая переменная, доступная нескольким различным
задачам, взаимное исключение доступа к ней может быть обес-
печено требованием, чтобы перед всяким фрагментом программы,
в котором осуществляется доступ к X, располагался вызов
входа Р, а после фрагмента — вызов входа V.
Пример 5.7. Использование семафора для взаимного исключения
Г; - - вызов Р перед монопольным доступом
- * фрагмент, в котором
- * осуществляется монопольный
- - доступ к общей переменной X
V- - вызов V после монопольного доступа
Задача СЕМАФОР гарантирует, что во всякий момент вре-
мени выполняется не более одного фрагмента такого типа, по-
скольку вызов V должен следовать за вызовом Р прежде, чем
можно будет выполнить второй вызов Р. Таким образом, если
в каждой задаче, осуществляющей доступ к X, соответствующий
фрагмент будет помещен между вызовами входов Р и V, взаимное
исключение доступа к X гарантируется.
Семафоры — это примитивы синхронизации «низкого уров-
ня», используемые во многих языках параллельного программа-
5.3. Синхронизация и взаимодействие задач 203
пвяния как отправной пункт для построения примитивов более
Сокого уровня. Напротив, вызовы входов и операторы прие-
примитивы высокого уровня, они позволяют легко опре-
лять средства более низкого уровня, например семафоры, и
ясе время обеспечивают более прямой механизм синхрониза-
9 й и взаимодействия задач.
По существу, вызовы входов и операторы приема — это при-
ливы передачи сообщений. Появление вызова входа требует,
тобы вызванной задаче был послан сигнал о том, что сообщение
«о для пересылки, а завершение рандеву — чтобы вызвав-
шей задаче был послан сигнал об окончании пересылки сообще-
ния. Собственно пересылка сообщения происходит при выпол-
нении критической секции оператора приема.
Протокол передачи сообщения определен независимо от того,
используется ли архитектура с общей памятью или распреде-
ленных процессов; он разработан так, чтобы была возможность
оеализовать его при обоих подходах.
F Задача MAILBOX (ПОЧТОВЫЙ .ЯЩИК) из первой гла-
вы — классический пример передачи сообщений. Мы вернемся
к этому примеру как для того, чтобы еще более явно показать
связь между ресурсами-входами и передачей сообщений, так и
с целью использовать далее эту задачу как «дежурный» пример
для иллюстрации операторов отбора и родовых задач в после-
дующих разделах.
Задача ПОЧТОВЫЙ.ЯЩИК имеет вход SEND (ПОСЛАТЬ),
позволяющий другим задачам посылать сообщения в почтовый
ящик, и вход RECEIVE (ПОЛУЧИТЬ), с помощью которого
задачи получают сообщения из почтового ящика.
Пример 5.8. Спецификация задачи MAILBOX
task MAILBOX is
entry SEND (INMAIL: in MESSAGE) ; --ВХОД ПОСЛАТЬ
entry RECEIVE (OUTMAIL: out MESSAGE); - - ВХОД ПОЛУЧИТЬ
end;
Когда буфер вмещает только одно сообщение, тело задачи
состоит из буфера, попеременно принимающего входы SEND,
через который другие задачи посылают в буфер свои сообщения,
и RECEIVE, через который некоторая другая задача получает
сообщение, хранящееся в буфере в результате выполнения пред-
шествующего входа SEND.
Пример 5.9. Почтовый ящик с буфером для одного сообщения
204
Гл. 5. Задачи
task body MAILBOX is
BUFFERS MESSAGE; - * локальный буфер, может хранить одно
begin
loop - - бесконечный цикл поочередной посылки и получения сопл»^
agcegt SEND (INMAIL: in MESSAGE) do > - принять вызов . *****•
*" ТЮСЛАТЬ от другом _
BUFFER inmail; * запомнить сообщение331*'*
ac^gt RECEIVE (OUTMAIL: out MESSAGE) do - принять вызов
* ” ПОЛУЧИТЬ
ena^™AIL != BUFFERj - - передать сообщение полум^
end loop?
end MAILBOX?
Входы SEND и RECEIVE задачи MAILBOX служат как ддя
синхронизации вызывающей и вызываемой задач в момент
приема или передачи сообщения-, так и для обмена сообщениями !
между ними. В точности так же, как и в примере 5.3, оператор 5
приема имеет критическую секцию, в которой осуществляется
связь между задачами, пока вызвавшая задача остается приос-
тановленной, после чего возобновляется параллельное выпол-
нение обеих задач.
Задача MAILBOX может обрабатывать одновременно только
одно сообщение. Если скорость, с которой сообщения поед-
лаются в почтовый ящик, выше скорости их обработки получаю-
щими задачами, входы ПОСЛАТЬ помещаются в очередь и каж-
дая посылающая задача, вход которой еще не обработан, будет
приостановлена до тех пор, пока задача MAILBOX не примет
этот вход.
Такие задержки можно предотвратить, если буфер почтового
ящика будет вмещать более одного сообщения. Это, однако,
требует серьезной перестройки тела задачи MAILBOX. В част-
ности, теперь нельзя фиксировать порядок, в котором входы
SEND и RECEIVE принимаются задачей, и в языке необходимо
средство для описания того, что вход ПОСЛАТЬ должен быть
немедленно принят всякий раз, когда буфер не полон, а вход
ПОЛУЧИТЬ — когда буфер не пуст. Такое средство, позволяю-
щее описывать подобные ситуации, называется оператором от-
бора select и рассматривается в следующем разделе.
S.4. Оператор отбора
Оператор приема позволяет задаче ожидать заранее опре-
деленного события, отмечаемого вызовом входа. Однако во мно-
гих случаях мы не можем предсказать, в каком порядке вызовы
входов будут возникать, и хотели бы поэтому позволить задаче
5.4. Оператор отбора
205
оиТь свои действия в зависимости от того, какие вызовы вхо-
ов (если таковые вообще есть) ожидают приема.
* Отбор одного из нескольких вызовов входа осуществляется
оператором отбора, имеющим следующий синтаксис.
Пример 5.10. Синтаксис оператора отбора
elect “ • начинается зарезервированным словом,
£-[when условие «=>] - - за ним — последовательность «защищаемых»
"отбираемая-альтернатива - - альтернатив отбора, далее — возможно,
? [последовательность операторов] - - последовательность операторов,
{or [when условие ->] *- выполняющихся по окончании
отбираемая-альтернатива --действий (рандеву),
[последовательность операторов] * - связанных с альтернативой;
felSe - - за последовательностью альтернатив может идти
~ последовательность операторов] - - последовательность операторов,
end select; - - выполняемых, если в данный момент ни одна альтернатива
- - не может быть отобрана
Отбираемой альтернативой может быть оператор приема
(синтаксис его рассматривался в предыдущем разделе) или за-
держки с описанным ниже синтаксисом. В операторе отбора,
содержащем оператор задержки, альтернатива else недопус-
тима.
Пример 5.11. Синтаксис оператора задержки
delay выражение-указывающее-времЯ'задержки
Выполнение оператора отбора начинается с обработки свя-
занных с отбираемыми альтернативами условий (называемых
«предохранителями»), чтобы определить множество приемлемых
в данный момент альтернатив (называемых открытыми альтер-
нативами). Если с открытым оператором приема связан ровно
один ожидающий вызов входа, он и будет немедленно принят.
Если таких вызовов несколько, будет сделан «недетерминиро-
ванный» выбор одного из них. Если же ожидающих вызовов входа
нет, должны быть рассмотрены следующие случаи:
1. Если нет ни открытых операторов задержки, ни фразы
else, задача будет неопределенно долго ожидать вызова входа,
связанного с открытым оператором приема, и выполнит первый
поступивший вызов.
2. Если имеется открытый оператор задержки, задача будет
ожидать открытого вызова входа в течение интервала времени,
определенного оператором задержки, а затем выполнит соответ-
ствующую альтернативу.
206
Гл. 5. Задачи
3. Если нет открытого оператора задержки, но есть фраза
else, задача немедленно приступит к выполнению части else.
4. Если нет ни открытых альтернатив, ни фразы else, возни-
кает исключительная ситуация SELECT-ERROR.
Оператор отбора имеет, таким образом, богатый ассортимент
возможностей, но главная его идея — в том, чтобы обеспечить
два уровня отбора альтернатив:
1. Отбор подмножества «открытых» альтернатив с помощью
обработки предохранителей на входе оператора отбора.
2. Отбор конкретной открытой альтернативы, соответствую-
щей вызову входа, подлежащему обработке.
' Эти два уровня отбора могут быть проиллюстрированы на
задаче о почтовом ящике с буферизацией. В этом случае вызовы
входов SEND могут выполняться всякий раз, когда буфер не
полон, a RECEIVE — когда буфер не пуст, так что в результате
имеем оператор отбора следующей структуры.
Пример 5.12. Пример оператора отбора
select
When NOT_FULL е=> » - если буфер Иб ПОЛОН
accept SEND (..) do.
- - запомнить сообщение в буфере
end;
- > отметить для себя, что сообщение запомнили
or - • если буфер не пуст
when NOT_EMPTY е>
accept RECEIVE (..) do
- - переслать сообщение получателю
end;
- отметить для себя, что сообщение переслали
end select;
В случае когда размер буфера больше единицы, может быть
истинно NOT-FULL (НЕ_ПОЛОН) и NONEMPTY (НЕ-
ПУСТ) одновременно, так что оба оператора приема могут быть
открытыми, и будет отобран первый пришедший вызов входа
SEND или RECEIVE.
Поскольку буфер не может быть и полон, и пуст одновре-
менно, по крайней мере один оператор приема всегда будет от-
крыт. Если он пуст, открыта только альтернатива ПОСЛАТЬ,
и вызовы входа ПОЛУЧИТЬ должны ожидать в очереди, по-
скольку сообщений, которые они могли бы получить, нет. Если
буфер полон, открыта только альтернатива ПОЛУЧИТЬ, а
входы ПОСЛАТЬ должны ожидать в очереди, поскольку буфер
не может вместить больше сообщений, пока накопленные сооб-
щения не будут пересланы получателям.
5.4. Оператор отбора
207
Показанное ниже полное тело задачи, моделирующей почто-
вый ящик с буферизацией, имеет переменные, необходимые для
ее внутренних нужд, они специфицированы как локальные,
g частности, SIZE — это размер буфера, NEXTIN и NEXTOUT
задают соответственно индексы следующего поступления (ко-
торое будет послано в буфер) и следующего отправления (кото-
рое будет переслано из буфера), a COUNT указывает число эле-
ментов в буфере. Условие NOT .FULL соответствует отношению
”COUNT<SIZE”, а условие NOT. EMPTY — отношению
”COUNT>0”.
Пример 5.13. Почтовый ящик с буфером
task body MAILBOX is
SIZE: constant INTEGER •:= 20; — размер буфера
'BUFFER: array(1..SIZE) of MESSAGE:
NEXTIN, NEXTOUT: INTEGER range 1..SIZE 1;
COUNT: INTEGER range 0. .SIZE s= 0; —-.число элементов в буфере
begin
loop
select
when COUNT < SIZE => — предохранитель: буфер не полон?
.accept SEND(INMAIL: in MESSAGE) do
BUFFER (NEXTIN) : = INMAIL; - - критическая секция
^2^.' ' “ выполняется до возобновления вызвавшей задачи
NEXTIN :» NEXTIN mod SIZE + 1; .. операторы вне
COUNT := COUNT+1; _ .. критической секции могут
2Е - выполняться параллельно с вызвавшей задачей
when COUNT > 0 => - - предохранитель: буфер не пуст?
. _accept RECEIVE (OUTMAIL: out MESSAGE) do '
OUTMAIL := BUFFER(NEXTOUT);
end;
NEXTOUT := NEXTOUT K>d SIZE + 1; - - регистрация
COUNT := COUNT -1; »- пересылки сообщения
end select;
end loop; ‘
№d MAILBOX;
Приведенное тело задачи может заменить тело задачи из
Предыдущего раздела, и при этом не потребуется никаких изме-
нений в ее спецификации. Такая замена не сказывается на функ-
циональном эффекте последовательности вызовов SEND и RE-
CEIVE, поскольку вызовы входов обслуживаются в порядке их
поступления как в случае, когда они ожидают обработки в оче-
реди у входа, так и в случае ожидания сообщений, связанных
с вызовами, в буфере почтового ящика. Однако такая замена
Может на несколько порядков изменить скорость обработки
сообщений.
208
Гл. 5. Задачи
Этот пример демонстрирует разумность определения ая
как модулей, допускающих разделение спецификации и па34
зации. В языках, где задачи моделируются посредством
сов, а не модулей, почтовый ящик пришлось бы предст»»*
с помощью процессов ПОСЛАТЬ и ПОЛУЧИТЬ, а
ящик с приватным буфером, над которым можно работать тшл*
с помощью операций ПОСЛАТЬ и ПОЛУЧИТЬ, пришлось*^
определить через механизм абстрагирования данных (наприм»
как пакет). В Аде нужная абстракция может быть достигнута^
всяких усилий с помощью модулей. 489
5.5. Родовые задачи
Задачи, как и пакеты, могут быть специфицированы как ро.
довые с помощью родового заголовка. Родовые задачи полезны
и как средство параметризации задач, вводящее такие парамет-
ры, как тип или процедура, и как средство создания нескольких
экземпляров задачи без параметров.
Задача MAILBOX неплохо подходит для иллюстрации родо-
вых параметров. Предположим, что нужно определить почтовые
ящики разных размеров и с различными типами сообщений. Это
можно осуществить, определив размер и тип сообщения как
параметры родовой задачи.
Пример 5.14. Родовая задача MAILBOX
generic(SIZE; INTEGER; type MESSAGE)
task MAILBOX is
entry SEND(INMAIL; in MESSAGE);
entry RECEIVE(OUTMAIL: out MESSAGE);
end;
Потомок родовой задачи MAILBOX может быть создан и
использован следующим образом.
Пример 5.15. Конкретизация родовой задачи MAILBOX
procedure MAILBOXES is .
•task Ml is new MAILBOX (50, INTEGER) ; « « почтовый ящик,
его размер равен 50, тип сообщений—INTEGER
); --размер 100,
тип сообщений—PERSON (ЧЕЛОВЕК)
запуск задач
послать задаче Ml сообщение типа INTEGER
значаще JONES — типа PERSON
значение К—типа INTEGER
•task М2 is -new MAILBOX (100 .PERSON)
begin
initiate Ml,М2;
Ml.SEND(15);
М2.SEND(JONES);
Ml.RECEIVE (K);
end;
Можно определить и значения параметров родовой задачи,
используемые по умолчанию.
5-5, Родовые задачи
209
Пример 5.16. Инициализация родовых параметров
generic (SIZE: INTEGER ;=s 20; type MESSAGE is INTEGER)
Определенные таким способом значения можно при конкре-
тизации явно не задавать, а отличные от них необходимо указы-
вать явно.
Пример 5.17. Неявное задание значений по умолчанию
task Ml is new MAILBOX (50); - - 50 сообщений типа INTEGER
tasfc М2 is new MAILBOX (100., PERSON)- - 100 сообщений типа PERSON
М3 is new MAILBOX; . - - 20 сообщений типа INTEGER
task M4 is new MAILBOX (MESSAGE is PERSON); - - 20 сообщений типа
--- -- PERSON
task M5 is new MAILBOX (SIZE := 50); -- 50 сообщений типа INTEGER
Отметим, что при задании значения первого параметра SIZE
может использоваться как позиционная нотация (АН), так и не-
позиционная (М5), в то время как при задании только одного
второго параметра необходима непозиционная нотация с явным
указанием имени параметра (М4).
Родовые заголовки без параметров полезны при создании
нескольких экземпляров задачи, устроенных совершенно оди-
наково. Так, в ряде приложений вполне может потребоваться
несколько почтовых ящиков одинаковых размеров с сообще-
ниями одного типа.
Пример 5.18. Родовая задача без параметров
generic task MAILBOX is
entry SEND/
entry RECEIVE 1
end;
'task Ml is new MAILBOX?
task М2 is new MAILBOX;
Таким образом, родовые заголовки для задач, в точности так
же, как и для пакетов, полезны и как способ параметризации,
и как способ создания нескольких одинаково устроенных эк-
земпляров.
Можно следующим образом определить родовую задачу без
параметров SEMAPHORE (СЕМАФОР).
Пример 5.19. Родовая задача SEMAPHORE
8 й 66
210 Гл- 5* Задачи
generic task SEMAPHORE is
entry P;
entry V;
end ;
task bbdy SEMAPHORE is
begin
loop
accept P;
accept V;
end loop;
end SEMAPHORE;
Другой вариант задачи SEMAPHORE рассматривался в пре-
дыдущем разделе. Наш новый вариант позволяет создавать
много семафоров.
Пример 5.20. Создание семафоров
procedure SEMAPHORES is - - СЕМАФОРЫ
task SI is new SEMAPHORE;
task S2 is new SEMAPHORE;
begin
initiate SI, S2;
SI.p; - - вызов входа P задачи SI
- - выполняется фрагмент, требующий взаимного исключения
Si. V; - - должно быть выполнено прежде,
end; - - чем другая задача сможет выполнить SLP
Семафоры — это примитивы низкого уровня для реализации
взаимного исключения, они легко могут быть смоделированы
с помощью входов и операторов приема. В интересах эффектив-
ности семафоры в языке Ада предопределены, так что их реали-
зация не потребует дополнительных накладных расходов и мо-
жет опираться на приемы оптимизации, зависящие от системы
и машины.
С другой стороны, так как спецификация и реализация раз-
делены, программы пользователя не зависят от того, реализова-
ны ли тела таких задач, как семафоры, на уровне языка или на
уровне системы. Это позволяет проектировщикам системы улуч-
шать эффективность критических для системы модулей, реали-
зуя их как часть системного программного или аппаратного
обеспечения. Решения такого рода не обязательно принимать
еще во время разработки поддерживающей язык системы, изме-
нения могут быть осуществлены в любой момент жизненного
цикла программы.
5.6. Семейства задач, входов и приоритеты, задач
211
Если, например, будет решено, что почтовый ящик — кри-
тический модуль, можно изменить систему таким образом, что
uaJLBOX будет идентификатором предопределенной родовой
Чдачи, тело которой реализовано системой, а вызовы входов
зарабатываются эффективно, не требуя переключения контек-
«тов. Все это может быть сделано без всяких изменений програм-
мы пользователя (кроме, может быть, удаления из нее описан-
ноГо на языке Ада тела задачи MAILBOX).
5,6. Семейства задач, семейства входов
и приоритеты задач
Семейства задач полезны при моделировании систем, имею-
щих несколько параллельно работающих подсистем с аналогич-
ными спецификациями. Рассмотрим, например, вычислительную
машину с шестнадцатью АЦПУ, работающими параллельно.
Набор из 16 АЦПУ можно смоделировать следующим семейст-
вом 16 задач.
Пример 5.21. Спецификация семейства задач
task PRINTER(1..16) is
type LINE is STRING(1..80);
entry PRINT(Ls LINE);
entry STOP;
end?
- - семейство PRINTER (АЦПУ)
- - из 16 задач, использующих
• - тип LINE (СТРОКА) и имеющих
- - входы PRINT (ПЕЧАТЬ)
* - и 'STOP (СТОП) каждая
Оператор запуска для семейства задач может запустить от-
дельную задачу семейства или целый непрерывный поддиапазон.
Пример 5.22. Запуск задач в семействах
initiate PRINTER(5);
initiate PRINTER(5..9) ?
- - запустить АЦПУ с индексом 5
* - запустить АЦПУ с индексами от 5 до 9
Тело задачи PRINTER реализовано ниже с использованием
атрибута PRINT’COUNT, значение которого равно количеству
вызовов входа PRINT, ожидающих в данный момент в очереди
этого входа.
Пример 5.23. Тело, выполняемое каждой задачей семейства
8*
212
Гл. 5. Задачи
task body PRINTER is
BUFFER; LINE;
begin
loo£
select
accept PRINT (L: LINE) do
BUFFER :=> L;
end;
- - печать строки из буфера
or
when PRINT’COUNT 0 =>
accept STOP;
exit;
end select;
end loop;
end PRINTER;
- - тело задачи PRINTER
- - прием входа PRINT
- - строка запоминается
- - и затем печатается
- - прием входа STOP:
• * если очередь входа
* - PRINT пуста, то выход
Все задачи семейства используют одну спецификацию и одно
тело. Однако запуск задач концептуально соответствует выпол-
нению различных копий, тела задачи. Если бы было запущено
16 задач PRINTER, параллельно выполнялось бы 16 задач, каж*
дая из которых имела бы свою собственную копию буфера и всей
остальной локальной информации периода выполнения. Вызовы
входов для задачи с индексом 5 можно было бы задавать следую-
щим образом.
Пример 5.24. Вызовы входов одной из задач семейства
PRINTER (5) .PRINT (TEXTLINE); - - вызов входа PRINT 5-ГО АЦПУ
PRINTER (5) .STOP; - - ВЫЗОВ ВХОДЯ STOP 5-ГО АЦПУ
В то время как при вызове входов нужно указывать индекс
конкретной задачи семейства, спецификации типов являются
общими для всех задач семейства, так что при объявлении объек-
та нужного типа индекс указывать не следует.
Пример 5.25. Объекты типа, объявленного в семействе
X: PRINTER. LINE} • - объект X ТИЙЯ LINE
* X: line? *-перечень используемых модулей
- - позволяет не указывать имя семейств»
Обобщая, можно сказать, что типы, константы и исключи-
тельные ситуации, объявленные в видимой части задачи^ при-
надлежат семейству в целом; для доступа к ним достаточно
имени семейства, в то время как входы и процедуры принадле-
жат конкретным задачам и доступны только с указанием индекса
этих конкретных задач.
5.6. Семейства задач, входов и приоритеты задач 213
Семейства входов в Аде позволяют с одним входом связать
только очередей и таким образом организовать приоритетное
^служивание. Например, в следующей задаче вход REQUEST
лдПРОС) — это семейство входов, индекс здесь задает уровень
Прочности запроса, а параметры —.необходимые для запроса
данные.
Пример 5.26. Задача с семейством входов
task PRIORITIES is -- ПРИОРИТЕТЫ
type LEVEL is (LOW,MEDIUM,URGENT) ,• - - уровень приоритета
- - НИЗКИЙ, СРЕДНИЙ, СРОЧНО
entry REQUEST (LOW. .URGENT) (D: DATA)'; - - семейство входов
end; - - с параметром типа ДАТА (ДАННЫЕ)
Вызов входа REQUEST требует указания индекса, иденти-
фицирующего конкретный вход семейства, и значения аргумента.
Пример 5.27. Вызов члена семейства входов
REQUEST (URGENT) (X) ;
Каждый член семейства входов связан со своей очередью.
Тело задачи может использовать это обстоятельство для плани-
рования вызовов входа REQUEST.
Пример 5.28. Приоритетное обслуживание входов семейства
task ЬоЗу PRIORITIES is
begin
loop
accept REQUEST(URGENT)(D; DATA) cto
• • •
end;
or
when REQUEST (URGENT) ’COUNT = 0 =>
accept REQUEST(MEDIUM)(D: DATA) do
end;
or •
when REQUEST(URGENT)’COUNT « 0 and
REQUEST(MEDIUM)'COUNT = 0 =>
accept REQUEST(LOW)(D: DATA) do
end;
end select;
end loop;
end PRIORITIES;
214
Гл. 5. Задачи
Тело задачи обеспечивает обслуживание запросов среднего
приоритета только в отсутствие запросов срочных, а запросы
низкого приоритета обрабатываются только тогда, когда нет за-
просов высших приоритетов.
С каждой задачей связан приоритет, определяющий стратегию
планирования в ситуации, когда на обслуживание претендует
несколько задач. Множество допустимых приоритетов предопре-
делено и составляет следующий подтип целого типа.
Пример 5.29. Определенный системой подтип PRIORITY (ПРИ-
ОРИТЕТ)
subtype PRIORITY is INTEGER range SYSTEM'MIN_PRIORITY..
SYSTEM'MAXJPRIORITX
Главная программа запускается с приоритетом, определен-
ным реализацией. Запущенная задача обычно получает приори-
тет задачи, запустившей ее. Задача может установить свой собст-
венный приоритет, вызвав предопределенную процедуру SET
PRIORITY (УСТАНОВИТЬ_ПРИОРИТЕТ).
Пример 5.30. Установка приоритета задачи
SET PRIORITY (Р); - - установить приоритет выполняемой
— - - задачи равным значению Р
Планировщик задач обрабатывает задачи с более высоким
приоритетом прежде других. Задачи одного приоритета обраба-
тываются по правилу «первым пришел — первым ушел», причем
здесь допускается квантование времени, чтобы избежать «голод-
ной смерти» для задач одного приоритета.
Однако задачи более низкого приоритета могут оказаться
в состоянии «голодания», если задачи с высоким приоритетом
требуют всей вычислительной мощности системы.
5.7. Окончание задачи
Нормальное окончание задачи происходит в том случае,
когда достигается конец тела этой задачи, причем все локальные
ее задачи (если таковые есть) также завершены.
Ненормальное окончание задачи Т возможно в двух ситуа-
циях:
1. В одной из выполняемых в данный момент задач возникает
исключительная ситуация T’FAILURE. Результатом этого яв-
ляется возбуждение исключительной ситуации FAILURE в вы-
полняемой в данный момент точке задачи Т и распространение
5.8. Проблема чтения-записи
215
ее по описанным в руководстве по языку правилам распростра-
нения исключительных ситуаций.
2. Выполняется оператор ’’abort Т;”, безусловно прекращаю-
щий выполнение задачи Т.
i Обоими средствами окончания задач следует пользоваться,
i соблюдая осторожность, поскольку в результате могут возник-
‘ путь аварийные ситуации в тех задачах, с которыми Т в настоя-
j щее время взаимодействует.
। 5,8. Проблема чтения-записи
Теперь, когда основные примитивы многозадачной работы
описаны, мы рассмотрим примеры, которые позволят нам глубже
вникнуть в их суть, понять, как можно использовать возмож-
ность многозадачной работы в Аде. В частности, мы исследуем
несколько различных решений проблемы чтения-записи.
Проблема чтения-записи — это проблема обеспечения такой
[ работы с защищенной базой данных, чтобы писатель не мог из-
менять информацию, которую в данный момент кто-то пытается
читать. В частности, при отсутствии попыток писать любому
количеству задач разрешено читать данные, но писатель обла-
дает монопольным доступом.
Простое, но неэффективное решение — позволить в каждый
момент времени выполнять только одну операцию — чтение или
запись, как в следующем примере задачи PPOTECTED.VARI-
ABLE (ЗАЩИЩЕННАЯ-ПЕРЕМЕННАЯ).
Пример 5.31. Защищенные переменные
task PROTECTED_VARIABLE is entry READ(V: out ELEM); entry WRITE(E: in ELEM); end ; task body PROTECTEDJ7ARTABLE is VARIABLE: ELEM; begin loop select accept READ(V: out ELEM) do V := VARIABLE? ' - - end; or accept WRITE(E: in ELEM) do VARIABLE E; end; end select; end loop; >. end PROTECTED VARIABLE; спецификация задачи имеет входы ЧИТАТЬ и ПИСАТЬ тело задачи с локальной защищенной переменной и циклом, в котором отбирается вход ЧИТАТЬ: чтение из защищенной переменной или вход ПИСАТЬ: запись в защищенную переменную цикл повторяется бесконечно
216
Гл. 5. Задачи
Поучительно сравнить задачу PROTECTED_VARIABLEca».
дачей MAILBOX из примера 5.9. В этом примере операции SFMn
(ПОСЛАТЬ) и RECEIVE (ПОЛУЧИТЬ) выполняются строго
по очереди, поскольку считается, что получение сообщения*^
провождается его изъятием из почтового ящика. Здесь же у нар
аналогичные операции WRITE (ПИСАТЬ) и READ (ЧИТАТЬ)
отбираются оператором select, поскольку в результате чтения
извлекается не само значение, а лишь его копия. Поэтому можно
повторно выполнять чтение защищенной переменной. Однако
такое решение позволяет в каждый момент времени только.одной
операции чтения (или записи) иметь доступ к переменной V.
В следующей версии разрешается одновременно выполнять
несколько операций чтения переменной V при условии, что
записи не производятся. Это может быть достигнуто, если в спе-
цификации задачи оформить READ как процедуру, а не как
вход.
Пример 5.32. Спецификация первой задачи чтение-запись
task READER WRITER, is
procedure READ (V: out ELEM); . - процедура ЧИТАТЬ
entry WRITE (Ё: in ELEM) ; - - вход ПИСАТЬ
end;
Следует отметить, что, поскольку синтаксически вызовы
входов и процедур идентичны, подобная замена входа процеду-
рой не потребует никаких изменений программ пользователя.
Процедура READ — это ресурс, определенный в теле задачи
READER_WRITER, который может быть вызван другими за-
дачами и выполнен без всякой необходимости в рандеву. Эта
процедура входит в совокупность объявлений тела задачи и не
является частью выполняемой параллельно последовательности
операторов этой задачи.
Пример 5.33. Тело первой задачи чтение-запись
task body READER_WRXTER is - - тело задачи
variable: ELEM; -- имеет защищенную переменную,
READERS: INTEGER s= О; -- счетчик числа читателей
entry START_READ; - - и два локальных входа
entry STOP READ; --для синхронизации внутри
«- процедуры READ
procedure READ (Vs out ELEM) is - - процедура в совокупности
begin - - объявлений, не среди параллельно выполняемых операторов
START_READ; - - вход START_READ (НАЧАЛО_ЧТЕНИЯ)
V := VARIABLE; --блокирует запись на время
STOP-READ; - - чтения, так как он увеличивает число
end; ~ - - читателей (READERS), а запись требует READERS*"
5.8. Проблема чтения-записи
217
WRITE (Е: in ELEM} do
•^VARIABLE := E;
end;
1222
select
accept START_READ;
READERS := READERS+1; ► .
or
accept STOP READ;
READERS :» READERS-l; - -
• * здесь начинаются параллельно
* • выполняемые операторы; сначала —
запись в защищаемую переменную?
* - затем — цикл
• - отбор:
- - если принят вход START__READ,
увеличить значение READERS,
что запирает предохранитель входа WRITE,
пока STOP___READ не уменьшит
значение READERS до нуля
or
when READERS « О
accept WRITE (Е: in ELEM)
VARIABLE := E;
end;
end select;
end loop;
end READERWRITER;
- - когда READERS = 0,
do - - можно принять вход WRITE
- - и присвоить новое значение,
- - но если читателей слишком много,
* - они могут монополизировать доступ
- - и совсем заблокировать запись
Процедуры из спецификаций некоторой задачи могут парал-
лельно вызываться из нескольких других задач, при этом они
как бы становятся частью последовательности операторов вы-
звавшей их задачи, которая ее и выполняет. Спецификации про-
цедур (таких, как READ) включаются в тело задачи (как в слу-
чае задачи READER-WRITER) не потому, что они составляют
часть параллельно выполняемой последовательности его опера-
торов, а из-за того, что им нужен доступ к локальным объектам
тела задачи.
Хотя процедура READ может параллельно выполняться из
нескольких различных задач, при каждом вызове непосредст-
венно перед чтением должна быть выполнена проверка, не про-
исходит ли в это время запись. В теле задачи это осуществляется
с помощью двух локальных входов START^READ и STOP-
READ, которые используются внутри процедуры как для син-
хронизации с задачей READER .WRITER, так и для подсчета
числа читателей. Таким образом, в теле этой задачи мы имеем
любопытную ситуацию, когда запись и подсчет числа читателей
выполняются как часть параллельно выполняемой последова-
тельности операторов задачи READER-WRITER, в то время
как специфицированная в этой же задаче процедура чтения после
соответствующей синхронизации выполняется как часть последо-
вательности операторов каждой из вызывающих задач, желаю-
щих прочитать значение защищаемой переменной.
Описанный механизм, позволяющий нескольким вызываюн
щим задачам параллельно выполнять операторы вызываемой
задачи за счет оформления их в виде процедуры, следует внима-
218
Гл. 5. Задачи
тельно изучить. Наши предшествующие примеры иллюстрипп
вали параллельное выполнение разных задач. В задаче о чтении"
записи дополнительно требуется, чтобы параллельно выполня-
лись операторы одной и той же задачи, и это осуществлено с по^
мощью процедуры READ.
Наша реализация проблемы чтения-записи эффективно об-
рабатывает одновременно произвольное число читателей, но
может привести к неопределенно долгой блокировке записи
когда наплыв читателей, постоянно увеличивающих счетчик
READERS, не позволяет ему стать нулевым. Такую бесконеч-
ную блокировку вызова входа называют «голодной смертью».
Удовлетворительное решение проблемы чтения-записи должно
гарантировать, что как чтение, так и запись будут осуществлены
в «разумное» время. Один из способов — такое планирование,
при котором писатель может писать сразу после того, как за-
кончат читать все читатели, прибывшие раньше писателя. Когда-
возникает очередь писателей, стратегия модифицируется таким
образом, чтобы все читатели, прибывшие прежде, чем писатель
достигнет головы очереди, обслуживались раньше него.
Этот подход реализован с помощью атрибута WRITE’COUNT,
значение которого равно числу элементов в очереди ко входу
WRITE.
Пример 5.34. Второй вариант задачи чтение-запись
loop
select
when WRITE1 COUNT = 0 =>
accept STARTJREAD;
READERS := READERS+1;
or
accept STOREAD ;
READERS': = READERS-1;.
or
when READERS = 0 ~ >
accept WRITE(E: in ELEM)
VARIABLE := E;
end;
loop
select
accept START_READ;
READERS := READERS+1
else
.exit;
end select;
end loop;
end»select;
do
- - если очередь на запись пуста,
- - можно начать чтение
- - но если она непуста,
- - читатели больше не принимаются
- - они оканчивают чтение
- - все до одного
- - когда дочитает последний,
- - можно принять запись
- - в монопольном режиме
- - по окончании записи — цикл
- - оператор отбора,
- - принимает всех ожидающих
- - чтения
- - имеется фраза else
- - выход, если читателей нет,
- - и возврат управления внешнему
- оператору отбора:
- если чтение начато, оно будет закончено,
- после чего снова можно писать
5.9. Раздельная синхронизация и защита
219
Такое решение существенно уменьшает возможность для чита-
телей заблокировать запись. Но она все-таки остается в случае,
* кОгда читатели прибывают быстрее, чем принимаются (внутрен-
1 ним) входом START_READ. Поскольку выполнение задачи
j производится под управлением системы и возможны прерывания
в любой точке программы в реальном времени, имеется возмож-
ность, что в напряженной операционной обстановке запись будет
блокирована на неопределенное время даже при работе на одном
процессоре из-за прерываний задачи READER-WRITER в
реальном времени, позволяющих другим задачам генерировать
запросы на чтение чаще, чем START-READ сможет принимать
их.
5.9. Раздельная синхронизация и защита
Другое решение этой задачи, предложенное Томом Дэппне-
ром, состоит в том, чтобы разделить защиту и синхронизацию.
Пример 5.35. Пакет PROTECT
package PROTECT is * * пакет реализует защиту' с помощью
procedure READ (V: out ELEM); - - процедур READ и WRITE,
procedure WRITE (E: in ELEM) ; - содержащих вызовы входов
end; - - REQUEST и FIN для синхронизации
package body PROTECT is
use READER—WRITER;
VARIABLE: ELEM;
procedure READ(V: out ELEM)
begin
REQUEST(R);
V := VARIABLE;
FIN;
end;
procedure WRITE(E: in ELEM)
begin
REQUEST(E);
VARIABLE :== V;
FIN;
end;
end PROTECT;
- - в теле пакета используется
- - задача READER__WRITER
- - и содержится защищаемая переменная
is - - процедура READ
- - просит разрешения читать
- - перед тем, как выполнить чтение
- - и сообщает о его конце
is - - процедура WRITE
- - просит разрешения писать
- перед записью
• - и сигнализирует о ее конце
Защита реализуется пакетом, содержащим защищаемую пере-
менную и — в совокупности спецификаций — процедуры чте-
ния (READ) и записи (WRITE) этой переменной. Синхрониза-
220
Гл. 5. Задачи
ция выполняется задачей, которая может принимать запросы
на чтение или запись и позволяет нескольким читателям ож
временно читать, не заставляя «голодать» писателей. Процедупи
READ и WRITE содержат вызовы входа REQUEST (ЗАПРОС?
перед операцией чтения или записи и входа FIN (КОНЕЦ) до
ее окончании.
Спецификация и тело пакета PROTECT (ЗАЩИТА) имеют
следующий вид (см. пример 5.35. Пакет PROTECT на пре-
дыдущей странице).
В этой реализации защищенных переменных как. READ
так и WRITE реализованы как процедуры. Но с точки зрения
пользователя, доступ к этим процедурам пакета точно такой же
как к входам задачи.
Программы пользователя не требуют изменения даже после
замены в реализации задач на пакеты.
Пакет PROTECT может параллельно использоваться несколь-
кими задачами, осуществляющими чтение или запись, и должен
быть объявлен в окружении, доступном всем нуждающимся
в нем задачам.
В свою очередь задача READER.WRITER должна быть
объявлена в окружении, доступном пакету. В ее совокупности
спецификаций должны быть указаны входы REQUEST и FIN и
перечисляемый тип со значениями R и W, используемыми при
вызовах входа REQUEST для указания того, требуется ли чте-
ние или запись.
Пример 5.36. Спецификация синхронизирующей задачи
task READER ^WRITER is
type READ~OR WRITE is (R,W) ; - - тип ЧТЕНИЕ_ИЛИ_ЗАПИСЬ
entry REQUEST(REQTYPE: in READ_OR_WRITE);
entry FIN ;
end;
Тело этой задачи отбирает вызов входа REQUEST или FIN.
Для вызовов REQUEST запоминается значение параметра (чтобы
можно было использовать его позднее вне критической секции
оператора приема).
Для вызова WRITE внутри критической секции умень-
шается до нуля число ожидающих обслуживания читателей,
затем критическая секция заканчивается, что позволяет проце-
дуре WRITE записать новое значение, а затем от нее принимается
вызов входа FIN.
5,9t Раздельная синхронизация и защита 221
Пример 5.37. Тело синхронизирующей задачи
body READERJWRITER is
read ORWRITE ; - - признак запросов на чтение или запись
READERS? INTEGER := 0; -- счетник текущего числа читателей
begin?
select .
accept REQUEST (REQTYPE: in READ_OR_WRITE) do - - ВХОД ЗАПРОС
- T := REQTYPE; - - запоминание типа запроса .
if REQTYPE a W then - * если запрос на запись,
while READERS>0 loop _ - - уменьшаем число читателей до 0,
accept FIN;- * - принимая от активных сейчас
readers :«* READERS*!; читателей вызовы FIN
end loop?
end if;
end ; - * при выходе из критической секции вызвавшая
- - задача может быть продолжена
if Т = W then accept FIN; - - если запрос на запись, дождаться FIN
else READERS := READERS+1;' --если на чтение,
end if; - - увеличить счетчик READERS
or
accept FIN; - - заметим, что для FIN не нужен критический
READERS ;ж READERS-!; -- раздел, счетчик уменьшается
end select; - - параллельно с вызвавшей задачей
end loop;
end READERJWRITER;
При использовании описанного выше механизма запросы на
чтение и запись ставятся в одну очередь (ко входу REQUEST)
и обрабатываются по правилу «первым пришел — первым ушел».
Запросы на чтение могут обслуживаться параллельно. Даже
увеличение значения счетчика числа читателей может произво-
диться параллельно с читающей задачей. Однако для записи сна-
чала требуется довести до нуля число читателей в критической
секции оператора приема, чтобы запись не могла начаться рань-
ше, чем завершатся все уже начатые чтения. После этого вне
критической секции должен быть выполнен вызов FIN прежде,
чем может быть принят какой-либо другой запрос.
Новая версия задач PROTECT и READER_WRITER по
своей структуре довольно серьезно отличается от прежних. Она
показывает, как можно сделать так, что вызовы двух различных
входов будут совместно работать с одной очередью за счет ис-
222
Гл. 5. Задачи
пользования «служебных» вызовов входа REQUEST, параметр
которого и используется для определения того, какой из входов
нас в данный момент интересует (R, W). Здесь показана также
критическая секция оператора приема, в которой содержится
другой оператор приема. Из этого примера видно, что критиче-
ские секции полезны не только для передачи информации, но
также для того, чтобы задержать вызвавшую задачу-писателя
до окончания некоторых действий (завершения задач-читате-
лей).
Таким образом, показанная выше проработка нескольких
вариантов решения проблемы чтения-записи полезна не только
благодаря тому, что всесторонне освещена именно эта проблема,
но.также и потому, что различные решения показывают различ-
ные способы применения примитивов многозадачной обработки.
Прежде чем оставить эту тему, посмотрим на взаимосвязь
окончательной версии задачи READER_WRITER и пакета
PROTECT. Если задача используется только для защиты пере-
менной V, она может быть объявлена локальной для тела пакета
PROTECT. В таком случае перечень используемых модулей
(use) в теле пакета может быть заменен либо всей этой задачей,
либо ее спецификацией и раздельно компилируемым телом.
Пример 5.38. Пакет PROTECT с локальной задачей READER.
WRITER
package body PROTECT is — версия пакета PROTECT
task READER_WRITER is —- с локальной задачей READER_WRITER
type READ_OR_WRITE is (R,W);
entry REQUEST(REOTYPE: in READJ3RJJRITE);
entry FIN;
end;
task body READER_WRITER is separate; — тело задачи компилируется
— отдельно
VARIABLE: ELEM; — защищаемая переменная
procedure READ end READ; — процедуры READ и WRITE
procedure WRITE (..).... end WRITE— были описаны выше
end PROTECT;
Этот пакет PROTECT можно было бы использовать для за-
щиты нескольких переменных, если бы сделать переменную и ее
тип родовыми параметрами пакета.
Пример 5.39. Родовой пакет PROTECT
generic (type is ELEM; VARIABLE: ELEM)
package PROTECT is
procedure READ(V: out ELEM);
procedure WRITE(E: in ELEM);
end;
i 5.9. Раздельная синхронизация и защита
223
Потомки такого пакета могут создаваться, например, следую-
щим образом.
Пример 5.40. Конкретизация пакета PROTECT
package PROTECT_X is new PROTECT (INTEGER, X); -- защищается целая
-- переменная X
package PROTECT_Y is new PROTECT (FLOAT, Y); - - защищается переменная'
- - плавающего типа Y
package PROTECT_VECT is new PROTECT (VECTOR, Z); - - защищается
- - переменная Z типа VECTOR
Каждый потомок этого пакета будет иметь свою локальную
задачу для синхронизации. Внутренние имена задач будут раз-
личными, так что при параллельном выполнении задач разных
потомков ошибки запуска не возникнет.
Теперь, зная, что мы можем делать с локальной для тела
пакета задачей READER_WRITER, рассмотрим вариант с не-
локальной задачей, доступной нескольким разным сегментам
программы.
В случае когда задача нелокальна, можно явно объявить не-
сколько (неродовых) пакетов PROTECT_X и PROTECT-Y
с различными локальными переменными. Эти пакеты будут
отличаться от потомков одного родового пакета в нескольких
отношениях:
1. Все защищаемые переменные будут одинакового типа, по-
скольку параметр-тип не предусмотрен.
2. Все будут совместно использовать одну и ту же задачу
READER_WRITER и одну очередь запросов. Запись значения
любой из защищаемых переменных потребует прекращения чте-
ния любой из них.
При таком решении параллельное чтение защищаемых пере-
менных ставится в невыгодное положение всякий раз, когда
записывается значение хотя бы одной из них, поэтому оно не
может быть рекомендовано. Однако этот недостаток можно лик-
видировать, если оформить READER_WRITER как родовую
задачу без параметров и в разных пакетах создавать разных ее
потомков.
Пример 5.41. Родовая задача READER_WRITER
generic task READER_WRITER is_
; type READ_OR_WRITE is (R,W);
entry REQUEST(REQTYPE: in READ_OR_WRITE);
entry FIN;
end;
224
Гл. 5. Задачи
Тело пакета PROTECT можно тогда переписать так.
Пример 5.42. Пакет PROTECT с конкретизацией родовой задачи
package body PROTECT_X is - - тело пакета
task RWX is new READERWRITER; - - С локальным ПОТОМКОМ
X: ELEM; - - родовой задачи READER^WRITER
• procedure READXend;
procedure READYend;
end PROTECT;
Задача READER_WRITER фактически не имеет никакого
отношения к защите и'даже к чтению или записи. С абстрактной
точки зрения это просто планирование работы устройства, до-
пускающего два вида обращения с разными ограничениями на
параллельное выполнение и одной очередью запросов. Вполне
возможны и другие, совершенно иные приложения, где требуется
точно такая же дисциплина синхронизации, как при защите
переменной. В них мог бы использоваться механизм синхрони-
зации, обеспечиваемый родовой задачей READER_WRITER, ,
если для каждого приложения будет создан потомок этой задачи,
так что у всех потомков будут свои очереди запросов с двумя
классами вызовов входов, один из которых допускает параллель-
ное выполнение, а другой требует монопольного доступа.
Приведенный анализ показывает, что многозадачная работа
открывает совершенно новое измерение в проектировании про-
грамм, требующее исследования гораздо более богатого диапазо-'
на возможностей, чем в случае последовательной работы. Мы
в какой-то мере познакомились с таким диапазоном возмож-
ностей для задачи чтения-записи, чтобы получить представление
о духе этих исследований.
б.Ю. Эффективность многозадачной работы
Строго говоря, эффективность языковых средств—это не тема
для обсуждения во вводном курсе. Анализ эффективности много-
задачной работы все-таки включен в эту главу с целью помочь
еще глубже понять природу соответствующих языковых прими-
тивов, а вовсе не для того, чтобы убедить читателя в том, что они
эффективны. Показав, как операторы некоторой задачи могут
быть распределены между использующими ее задачами, мы на-
деемся помочь читателю лучше понять динамику параллельно
работающих задач.
Эффективность многозадачной работы может рассматриваться
на трех уровнях:
1. Уровень пользователя. Может ли пользователь описать
параллельную работу, исходя непосредственно из требований.
______,______5-/0. Эффективность многозадачной работы___ 225
к ней и не вводя чуждые конструкции, навязываемые природой
языковых примитивов?
2. Уровень планирования. Может ли эта работа быть выпол-
нена без «лишнего» ожидания сверх ограничений аппаратуры и
исходных требований приложения? В частности, могут ли такие
ситуации, как «пробуксовка» или «смертельное объятие», или
другие потенциальные проблемы планирования быть легко
опознаны и предупреждены?
3. Уровень реализации. Могут ли примитивы многозадачной
работы быть эффективно реализованы в рамках архитектуры (а)
с общей областью памяти, (б) с распределенной обработкой?
В частности, можно ли избежать задержек на переключение
контекстов при переходе от задачи к задаче в случае критичных
по времени вычислений, а также выполнить оптимизации, по-
зволяющие встраивать операторы вызываемой задачи прямо
в вызывающую, чтобы исключить переключение контекстов
вовсе?
С конкретными утверждениями относительно эффективности
многозадачной работы следует подождать, пока накопится до-
статочный опыт как в использовании языка, так и в его реали-
зации. Однако некоторые идеи уже сейчас представляют интерес
не только потому, что они могут нам сказать что-то об эффектив-
ности, но и благодаря возможности с их помощью лучше понять
конструкции языка.
Вызовы входов и операторы приема обеспечивают механизм
высокого уровня, который кажется «естественным» для описания
взаимодействия и синхронизации на уровне пользователя. Как
и в случае других механизмов высокого уровня, здесь будут
ситуации, когда примитивы более низкого уровня были бы
более удобны, и для таких случаев предусмотрены семафоры
(«многозадачные» аналоги операторов goto).
На уровне планирования удобно различать случаи «быстрого
производства», когда вызовы входов возникают более часто,
чем оператор приема способен их обработать, и «быстрого по-
требления», когда операторы приема вызываемой задачи готовы
«проглотить» вызов входа в тот же момент, как только он по-
явится.
С точки зрения того, кто вызывает, быстрое потребление,
очевидно, предпочтительнее, чем быстрое производство. Ведь
быстрое производство может вызвать значительные задержки
вызывающих процессов.
Возможное решение — ввести между производителем и по-
требителем процессы-посредники (обслуживающие процессы, по-
добные почтовому ящику), которые могут хранить сообщения,
вырабатываемые быстрым производителем, до тех пор, пока они
не станут нужны потребителю.
226
Гл. 5. Задаяи
Процессы-посредники сокращают время ожидания быстрых
процессов-производителей, но вводят дополнительную задачу
между производителем и потребителем. Дополнительные затраты
времени на переключение контекстов между задачами могут ока-
заться неприемлемыми в некоторых критических ситуациях.
Накладные расходы на создание задач-посредников зависят
от используемой архитектуры. Следует рассмотреть три случая:
1. Архитектура распределенных процессов, когда задача-
посредник (почтовый ящик) имеет свой собственный процессор
и свою локальную память.
2. Архитектура с общей памятью, когда имеется множество
параллельно работающих процессоров и задаче-посреднику вы-
деляется свой собственный процессор.
3. Однопроцессорная архитектура с общей памятью, когда
имеется единственный процессор, и переключение задач требует
запоминания состояния выполняемой задачи и восстановления
состояния следующей подлежащей выполнению задачи.
Поскольку последний случай на современных машинах наи-
более типичен, мы рассмотрим способы повышения его эффектив-
ности. В частности, мы посмотрим, как вызовы входов некоторых
типов задач-посредников можно заменить вызовами процедур,
чтобы избавиться от накладных расходов на синхронизацию,
а в случае однопроцессорной работы — от расходов и на пере-
ключение контекстов.
Рассмотрим задачу-посредник Т, операторы которой пред-
ставляют собой цикл, содержащий оператор отбора, все альтер-
нативы которого — охраняемые операторы приема входов сле-
дующего вида.
Пример 5.43. Ограничения, позволяющие оптимизировать опе-
раторы отбора
task body Т is
- - локальные объявления
begin
ISPP
select
when предохр! => accept вход’1 (.»)do. .end; операторы
or when пред охр \2 => accept вход 2 (..) do.. end; операторы
or when предохр n=> accept ВХОДП («*) do..end; операторы
end select;
end loop;
end;
От задачи T можно избавиться, а ее операторы распределить
между теми, кто ее вызывает, обеспечив при этом, чтобы все вы-
5.10. Эффективность многозадачной работы 227
ЗОВЫ входов выполнялись в монопольном режиме а охознярмыр
вызовы входов, условия отбора для которых не выполняются
ожидали выполнения этих условий В чяДнХЛ выполняются,
входа, соответствующий альтернативе каждаи вызов
when предохранитель=>ассер! вход (. . .) do end- опе-
раторы ' ‘ ‘ ’ пе"
может в вызывающей программе быть заменен следующей после-
довательностью операторов.
Пример 5.44. Оптимизация вызова входа
p(TJLOCK); * - семафор для взаимного исключения вызовов входов
if guard then - - если значение предохранителя —• TRUE, можно «выполнить»
. - - моделируемый вход
- - выполнить операторы критической секции оператора приема
- - выполнить следующие за ними операторы
V (TJLOCK), - - снять блокировку по окончании моделирования
exit; - - выйти из цикла, закончив моделировать вызов
end if;
* V (т LOCK); - - снять блокировку, чтобы дать работать с другими входами
- - ждать сигнала (вероятно, о завершении некоторого другого вызова входа)
end loop;
Эту замену мы проиллюстрируем на задаче MAILBOX.
Задача имеет как раз ту структуру, которая требуется: есть две
альтернативы отбора, SEND (ПОСЛАТЬ) и RECEIVE (ПОЛУ-
ЧИТЬ). Сначала мы покажем, какими операторами должны быть
заменены вызовы входа SEND, а затем — RECEIVE.
Для входов SEND мы сначала выполняем операцию Р над
семафором для взаимного исключения при работе с почтовым
ящиком, скажем M_LOCK. Затем проверяем предохранитель
для входов SEND. Если буфер не полон и посылка разрешена,
мы выполняем как операторы из критической секции, так и сле-
дующие за ним операторы и затем операцию V на M_LOCK,
чтобы можно было выполнить какой-нибудь другой вызов входа.
Следует также послать сигнал, разрешающий перепроверку
ожидающих предохранителей. Если буфер полон, немедленно
выполняется операция V, чтобы разблокировать M.LOCK, и
задача должна дождаться сигнала от завершенного вызова RE-
CEIVE^ чтобы можно было снова обработать этот вход.
Пример 5.45. Оптимизированный вход SEND
228
Гл. 5. Задачи
loop
рГм LOCK) t - - семафор для взаимного исключения входов почтового ящиед
if COUNT<SIZE then -- если буфер не полон,
BUFFER(NEXTIN) := INMAIL; -- прочитать сообщение в буфер
NEXTIN := NEXTIN mod SIZE + 1; -- и скорректировать значение
COUNT := COUNT+1; -- NEXTIN (СЛЕДУЮЩЕЕ-ПОСТУПЛЕНИЕ)
. - и COUNT,
V (м LOCK); - - затем разблокировать семафор
сообщить об окончании обработки входа SEND
exit; • - выйти из цикла, закончив моделировать выполнение входа SEND
end if; - - если буфер полон,
V (м lock) ; - - немед ленко открыть семафор
- - ждать сигнала завершения от входа RECEIVE
end loop;
Аналогичным образом вызовы входов RECEIVE можно за-
менить следующими операторами;.
Пример 5.46. Оптимизированный вход RECEIVE
loop
Р (M_LOCK);
if COUNT>0 then
OUTMAIL := BUFFER(NEXTOUT);
NEXTOUT NEXTOUT mod SIZE + If
COUNT := COUNT-1;
V(M_LOCK);
— сигнализировать об окончании обработки входа RECEIVE
exit;
end if;
V (M_LOCK);
- - ждать сигнала завершения от входа SEND
end loop;
Замена операторов задачи, аналогичная продемонстрирован-
ной выше, представляет собой один из оптимизирующих прие-
мов, применимых в компиляторе и оправданных в случае, если
соблюдаются следующие условия;
1. Обычно при вызове входа предохранители истинны, ложны
они лишь изредка. В частности, очередь невыполненных вызовов
входов, ожидающих сигнала, не слишком велика.
2. Если предохранитель данного вызова входа ложен, вызов
некоторого другого входа сделает его истинным. В частности,
повторная проверка предохранителей заблокированных входов
по окончании вызова незаблокированного входа разблокирует
один или несколько вызовов.
3. Выполнение операторов, следующих за критической сек-
цией, не требует слишком много времени.
5.10. Эффективность многозадачной работы
229
Задача MAILBOX удовлетворяет первому требованию, если
буфер достаточно велик, чтобы справиться с потоком сообщений.
Она удовлетворяет и второму требованию, поскольку заверше-
ние входа RECEIVE, когда есть очередь ко входу SEND, раз-
блокирует по крайней мере один вход SEND, и наоборот.
Таким образом, для определенной программистом задачи
MAILBOX, приведенной в разд. 5.4, описанный только что способ
оптимизации будет оправданным. Однако, если бы задача MAIL-
BOX была предопределенной, система могла бы выполнить еще
более изощренную оптимизацию, основываясь на том факте, что
выполнение входа RECEIVE при полном буфере всегда осво-
бождает ровно одно место в буфере сообщений для вызова входа
SEND.
Хотя описанный метод оптимизации в определенных случаях
может значительно ускорить параллельное выполнение про-
грамм, он может также привести и к замедлению, понижению
эффективности, если предохранители часто ложны или опера-
торы вне критических секций операторов приема требуют зна-
чительного времени, поскольку до оптимизации они выпол-
няются в параллель, а после оптимизации — в монопольном
режиме.
Прежде, чем включать описанный прием оптимизации в ре-
альные компиляторы, необходимы дополнительные исследова-
ния. Однако цель наша в данном разделе не в том, чтобы предло-
жить этот метод создателям компиляторов, а скорее в том, чтобы
выдвинуть для пользователей языка некоторые заманчивые идеи
относительно компромиссов между последовательной и парал-
лельной работой.
ПРИЛОЖЕНИЕ
СВОДКА СИНТАКСИЧЕСКИХ ПРАВИЛ
Здесь представлен полный синтаксис языка Ада. Номера раз-
делов в синтаксических определениях относятся к руководству
по языку. Разд. 2, 3, 4 и 5 посвящены литералам, типам, выра-
жениям и операторам соответственно. В разд. 6, 7, 8 и 9 рас-
сматриваются подпрограммы, пакеты, правила видимости и за-
дачи. Разд. 10—14 касаются вопросов структуры программы,
исключительных ситуаций, родовых программных сегментов,
спецификации представления и ввода-вывода.
Стиль определений мы объясним, кратко прокомментировав
первое определение:
идентификатор ::= буква {[подчеркивание]буква-или-цифра}
В этом определении имеются знак «:;=», который можно чи-
тать «определяется как», квадратные скобки, обозначающие
возможное, но не обязательное вхождение заключенной в них
конструкции, и фигурные скобки, которые означают, что заклю-
ченная в них конструкция может входить произвольное число
раз (в том числе и нуль). Таким образом, это определение можно
прочесть так:
«идентификатор» определяется как «буква», за которой может
идти произвольное число «букв или цифр», причем перед каждой
из них может стоять «подчеркивание».
Мы покажем, как пользоваться этой сводкой синтаксических
правил, проверив, например, что задачи с вырожденной сово-
купностью спецификаций (пример 5.1 в настоящей книге) яв-
ляются допустимыми синтаксическими конструкциями.
Поскольку задачи — это модули, первый шаг — проверить
синтаксис спецификации модуля из разд. 7.1 приложения (но-
мера разделов соответствуют номерам разделов руководства по
языку, в которых соответствующие конструкции вводятся):
спецификация .модуля ::= [родовой.заголовок]
природа.модуля идентификатор [(дискретный.диапазон)]
Приложение. Сводка синтаксических правил
231
[is совокупность_объявлений
[private совокупность.объявлений] end [идентификатор]];
Если отсутствуют необязательные вхождения родового заго-
ловка, дискретного диапазона, закрытой части и завершающего
идентификатора, а вместо «природа.модуля» указано task, ос-
тается
task идентификатор [is совокупность.объявлений end];
Если совокупность объявлений пуста, синтаксические компо-
ненты «is совокупность.объявлений end» можно отбросить, в ре-
зультате чего имеем «task идентификатор;», как в примере 5.1.
Эта проверка соответствия конкретного примера общему син-
таксическому определению — типичный образец того, как про-
граммист может использовать описание синтаксиса языка, чтобы
проверить синтаксическую правильность программы.
СВОДКА
2.3
идентификатор
буква {[подчеркивание] буква.или-цифра}
буква.или_цифра буква | цифра
буква ::= прописная-буква | строчная-буква
2.4
число целое «число | приближенное-число
целое-число ::= целое | целое _с_ основанием
целое ::= цифра {[подчеркивание] цифра}
целое_С-основанием =
основание # обобщенная-цифра {[подчеркивание] обобщенная-цифра}
основание ::== целое
обобщенная «цифра ::= цифра | буква
приближенное»число целое.целое [ Е порядок]
| целое Е порядок
порядок [+] целое | —целое
2.5
строка .символов ::= ’’{символ}”
2.7
указание pragma идентификатор [(аргумент.указания
{, аргумент.указания})];
аргумент .указания идентификатор | строка .символов | число
232
Приложение. Сводка синтаксических правил
3.1
объявление ::=
объявление «объекта | объявление «типа
| объявление «подтип а | объявление-приватного «типа
| объявление «подпрограммы | объявление .модуля
( объявление - входа | объявление - исключения
| объявление.переименования
3.2
объявление «объекта :
список-идентификаторов : [constant] тип [:±= выражение];
список «идентификаторов ::== идентификатор {, идентификатор}
3,3
тип ::= определение «типа | обозначение «типа [уточнение]
определение «типа ::=
определение - перечисляемого - типа
определение - целого - тип а
определение _ вещественного - типа
определение - регулярного _типа
определение _ комбинированного _ типа
определение _ ссылочного _ типа
определение - производного _ типа
обозначение «типа имя.тшш | имя „подтипа
уточнение ::=
уточнение «диапазона | уточнение-погрешности
| уточнение «индекса | уточнение «дискриминанта
объявление «тип а ::= type идентификатор [is определение «типа];
объявление «подтипа
subtype идентификатор is обозначение «типа [уточнение];
3.4
определение_производного_типа new обозначение «типа [уточнение]
3.5
уточнение-диапазона ::=» range диапазон
диапазон ::== простое «выражение .. простое «выражение
3.5.1
определение-перечисляемого «тип а ::=
(перечисляемая «константа {, перечисляемая .константа})
перечисляемая «константа идентификатор | символьная «константа
3.5.4
определение «целого «типа ::= уточнение-диапазона
Приложение. Сводка синтаксических правил____________233
3.5.5
определение „вещественного .типа уточнение „погрешности
уточнение-погрешности :: =
digits простое „выражение [уточнение-диапазона]
delta простое «выражение [уточнение-Диапазон а]
3.6
определение_регулярного-типа :: =
array (индекс {, индекс} of обозначение-типа [уточнение]
индекс ::= дискретный-диапазон | обозначение-типа
дискретный-диапазон ::== [обозначение-типа range] диапазон
уточнение-индекса ::=*= (дискретный-диапазон {, дискретный-диапазон})
3.6.2
составное «значение (соответствие„компонент
{, соответствие-компонент})
соответствие-компонент [вариант { | вариант} =>] выражение
вариант простое-выражение | дискретный „диапазон | others
3.7
определение-комбинированного «типа ::^=
record
список _ компонент
end record
список-компонент ::= {объявление-объекта} [описание - вариантов] | null
описание-вариантов :: =
case дискриминант of
when вариант { | вариант} =>
список _ компонент}
end case;
дискриминант имя»постоянной-компоненты
3.7.3
уточнение-дискриминанта ::=*= составное-значение
3.8
определение-ссылочного-типа ::= access тип
4.1
имя ::= идентификатор | индексированная „компонента
| поименованная-компонента ] предопределенный „атрибут
индексированная „компонента имя (выражение {^выражение})
поименованная «компонента ::== имя.идентификатор
предопределенный - атрибут ::= имя'идентифякатор
234
Приложение. Сводка синтаксических правил
4.2
постоянная :: = число | перечисляемая-константа | символьная-строка | null
4.3
переменная ::= имя [ (дискретный-диапазон)] | имя.all
4.4
выражение ::= отношение {and отношение}
| отношение {ог отношение}
I отношение {хог отношение}
отношение ::
простое .выражение [операция-отношения простое-выражение]
| простое-выражение [not] in диапазон
| простое-выражение [not] in обозначение-типа [уточнение]
простое-выражение =
[одноместная-операция] слагаемое {операция-типа-сложения слагаемое}
слагаемое ::= множитель {операция-типа-умножения множитель}
множитель первичное [** первичное]
первичное ::= постоянная | составное-значение | переменная
| генератор | вызов-подпрограммы | квалифицированное-выражение
| (выражение)
4.5
логическая «операция ::= and ] or | хог
операция «отношения = | / = | < j < = | > | > =
операция-типа-сложения ::= + | — | &
одноместная-операция ::= + | — | not
операция-типа-умножения ::= * | / | mod
возведение-в-степень ::=**
4.6
квалифицирован ное-выражение
обозначение _типа (выражение) | обозначение-типа составное-значение
4.7
генератор ::= new квалифицированное-выражение
5
последовательность-операторов {оператор}
оператор простой-оператор | составной-оператор
| «идентификатор» оператор
простой «оператор ::==
оператор _ присваивания
оператор _ выхода
оператор - перехода
оператор - запуска
оператор _ исключения
кодированный - оператор
оператор - вызова _ подпрограммы
оператор - возврата
оператор - контроля
оператор - задержки
оператор - прекращения
Приложение. Сводка синтаксических правил
составной «оператор ::= условный _ оператор | оператор .цикла | оператор .отбора | оператор, выбор а | оператор .приема | блок
5.1 оператор-присваивания переменная := выражение:
5.2
оператор _вызова« подпрограммы ::= вызов-подпрограммы;
вызов _ подпрограммы :: = имя - подпрограммы [(соответствие - параметра
{, соответствие .параметра})]
соответствие-параметра —
параметр :=] аргумент
| [параметр =:] аргумент
| [параметр :=:] аргумент
параметр ::= идентификатор
аргумент выражение
5.3
оператор-возврата ::= return [выражение];
5.4
условный-оператор
if условие then
последов ате льность _ опер аторов
{elsif условие then
последовательность _ операторов}
[else последовательность - операторов]
end if;
условие выражение {and then выражение}
] выражение {or else выражение}
5.5
оператор-выбора
case выражение of
{when вариант { | вариант} = > последовательность-операторов}
end case;
5.6
оператор «цикла ::= [спецификация .повторения] основной .цикл
основной .цикл =
loop
последовательность _ операторов
end loop [идентификатор];
спецификация .повторения :: =
for параметр .цикла in [reverse] дискретный .диапазон
(while условие
параметр .цикла идентификатор
236 Приложение. Сводка синтаксических правил
5.7
оператор-выхода ::= exit [идентификатор) [when условие]
5.8
оператор-перехода ::= goto идентификатор;
5.9 .
оператор-контроля ::= assert условие;
6.1
совокупность «объявлений ::«= [перечень-используемых-сегментов]
{объявление} {спецификация-представления} {тело}
тело [ограничение.видимости] тело.сегменТа | Заглушка
тело сегмента тело .подпрограммы | спецификация-модуля
| тело-модуля
6.2
объявление-подпрограммы спецификация .подпрограммы;
| природа.подпрограммы обозначение is конкретизация;
спецификация-подпрограммы [родовой .заголовок]
природа .подпрограммы обозначение [совокупность-параметров]
[return обозначение .типа [уточнение]]
природа-подпрограммы ::= function | procedure
обозначение идентификатор | строка «символов
совокупность-параметров ::=
(объявление-параметра {; объявление «параметр а})
объявление «параметр а
список «идентификаторов : вид«связи обозначение-типа
[уточнение] [:= выражение]
вид.связи [in] | out | in out
6.4
тело.подпрограммы ::=
спецификация .подпрограммы is
совокупность .объявлений
begin
последовательность .‘операторов
[exception
{реакция _ на . исключение}]
end [обозначение];
6.7
блок
[declare
совокупность _ объявлений
begin
последовательность _ операторов
[exception
{реакция _ на _ исключение}]
end [идентификатор];
Приложения. Сводка синтаксических правил 237
7.1
объявление «модуля —
[ограничение_ видимости] спецификация «модуля
| природа «модуля идентификатор [(дискретный «диапазон)]
is конкретизация;
спецификация «модуля :: =
[родовой «заголовок]
природа «модуля идентификатор [(дискретный «диапазон)] [is
совокупность « объявлений
[private
совокупность «объявлений]
end [идентификатор]];
природа «модуля ::= package | task
тело «модуля :: =
природа «модуля body идентификатор is
совокупность « объявлений
[begin
последовательность _ операторов]
[exception
(реакция «на «исключение}]
end [идентификатор];
7.4
объявление_приватного«типа ::=& [restricted] type идентификатор
is private;
8.3
ограничение «видимости restricted [перечень «Видимых «сегментов]
перечень «видимых «сегментов (имя-сегмента {, имя -сегмента})
8.4
перечень «используемых «сегментов ::«« use имя-модуля {, имя.модуля};
8.5
объявление «переименования
идентификатор : обозначение «типа renames имя;
идентификатор : exception renames имя;
природа «подпрограммы обозначение renames [имя.] обозначение
природа «модуля обозначение renames имя;
9.3
оператор «запуска initiate обозначение «задачи {, обозначение «задачи);
обозначение «задачи ::= имя-задачи [(дискретный «диапазон)]
9.5 '
объявление «входа :: =
entry идентификатор [(дискретный«диапазон)]
[совокупность ^параметров];.
238
Приложение. Сводка синтаксических правил
оператор-Приема :: =
accept имя_входа [совокупность«параметров] do
последовательность « операторов
end [идентификатор];
9.6
оператор «задержки delay простое-выражение;
9.7
оператор-отбора
select
[when условие =>]
отбираемая _ альтернатива
{or [when условие =>]
отбираемая « альтернатива
else
последовательность - операторов
end selert;
отбираемая «альтернатива ::=
оператор - приема [последовательность - операторов]
| оператор «задержки [последовательность .опер аторов]
9.10
оператор-прекращения abort обозначение-задачи
{, обозначение «задачи};
10.1
компиляция ::= {сегмент«компиляции}
сегмент «компиляции [ограничение «видимости] [separate] тело-сегмента
10.2
заглушка
спецификация «подпрограммы is separate;
| природа «модуля body идентификатор is separate;
11.1
объявление-исключения список «идентификаторов: exception;
11.2
реакция «на «исключение :: =
when вариант «исключения { | вариант» исключения} =>
последовательность _ операторов
вариант»исключения ::= ыя. .исключения | others
11.3
оператор-исключения v.= raise [имя .исключения}*,
12.1
родовой «заголовок ::=
generic [(родовой параметр {; родовой „параметр})]
239
Приложение. Сводка синтаксических правил
родовой-параметр ::=
объ яв ле н ие _ п ар аметр а
| спецификация «подпрограммы [is [имя.] обозначение]
| [restricted] type идентификатор
12.2
конкретизация ::= new имя [(родовое«соответствие
{, родовое «соответствие})]
родовое - соответствие :: =
соответствие - параметр ов
I [параметр is] [имя.] обозначение
I [параметр is] обозначение.типа
13
спецификация «представления
спецификация _ упаковки
спецификация длины
представление, комбинированного «типа
спецификация «адреса
представление _ перечисляемого «типа
13.1
спецификация-упаковки ::= for имя-типа use packing;
13.2
спецификация «длины for имя use статическое «выражение;
— >
13.3
представление _ перечисляемого «типа ::=
for имя .типа use составное «значение;
13.4
представление _ комбинированного - типа ::=
for имя «типа use
record [выравнивание;]
{имя-компоненты положение;}
end record;
положение ::=at статическое -выражение range диапазон
выравнивание at mot статическое «выражение;
13.5
спецификация _ адреса for имя use at статическое «выражение;
13.8
кодированный «оператор квалифицированное «выражение]
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги, ее
оформлении, качестве перевода и другие просим
присылать по адресу: 129820, Москва, И-110, ГСП^
1-й Рижский пер., д. 2, издательство «Мир».
Петер Вегнер
ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ АДА
Научн. рсд. Л. Н. Бабынина
Мл. научн. ред. Р. И. Пяткина
Художник В. М. Новоселова
Художественный редактор В. И. Шаповалов
Технический редактор Е. С. Потапенкова
Корректор А. Я. Шехтер
ИБ 3091
Сдано в набор 04.03.82. Подписано к печати 05.07.82. Формат бОХЭО1/^. Бумага
типографская № 2. Гарнитура литературная. Печать высокая. Объем 7,5 бум. л.
Усл. печ. л. 15,00. Усл. кр.-отт. 15,48. Уч.-изд. л. 12,98. Изд. № 1/1744.
Тираж 45 000 (2*й >д 20 001—45 000) экз. Заказ № 56. Цена 95 коп.
ИЗДАТЕЛЬСТВО «МИР» Москва, 1-й Рижский пер., 2.
Ордена Октябрьской Революции и ордена Трудового Красного Знамени
Первая Образцовая типография имени А. А. Жданова
Союзполиграфпрома при Государственном комитете СССР
по делам издательств, полиграфии и книжной торговли.
Москва, М-54, Валовая, 28.